
Ce blog n'a d'autre prétention que de me permettre de mettre à la disposition de tous des petits textes que j'écris. On y parle surtout d'informatique mais d'autres sujets apparaissent parfois.
Noël à UltraDNS
Première rédaction de cet article le 25 décembre 2009
Les services du fournisseur d'hébergement DNS UltraDNS, filiale de NeuStar, ont été complètement interrompus mercredi 23, apparemment suite à une attaque par déni de service. Avec UltraDNS, est tombé le service DNS de plusieurs gros clients notamment Amazon et Walmart.
Comme d'habitude, il n'y a pas beaucoup de détails techniques disponibles. Et tout ce qui est publié n'est pas forcément correct. Il semble bien que l'attaque était une DoS contre les serveurs DNS d'UltraDNS et, si c'est bien le cas, il pourrait s'agir de la première attaque DoS réussie contre un service DNS complètement anycasté. En l'absence d'autres informations, il est toutefois difficile d'en déduire quelle technique exacte a été utilisée. Le marketing ultra-agressif d'UltraDNS, et notamment leur habitude détestable d'appeler directement les Directions Générales, en crachant sur le logiciel libre et en expliquant au Directeur que son équipe technique utilise des logiciels gratuits d'amateurs, fait que beaucoup de gens ne pleureront pas sur les malheurs de ce fournisseur. Les concurrents directs d'UltraDNS ne se sont pas privés de rappeller cette attaque réussie. Mais il faut quand même se rappeler que les attaques par déni de service sont les plus difficiles à contrer, qu'il existe une offre assez vaste de mercenaires prêts à travailler pour n'importe qui et que personne n'a encore la solution miracle contre cette vulnérabilité.
Quelles étaient les motivations de l'attaque ? Certains se sont étonnés que les attaquants ne soient pas sensibles à la magie de Noël. Mais c'est sans doute justement la proximité de cette date qui est responsable. Noël est depuis longtemps une opération commerciale et non plus la célébration de la naissance du barbu palestinien qui voulait que tout le monde s'aime. Des entreprises comme Amazon font une bonne part de leur chiffre d'affaires dans les jours précédant Noël. C'est donc logiquement à ce moment que les extorsions se font, de même que les sites Web de paris en ligne reçoivent ces demandes au moment du Super Bowl. Le plus probable est donc qu'Amazon a refusé de payer et que les gangsters ont attaqué l'entreprise par son point le plus faible (Amazon n'a, bien à tort, qu'un seul fournisseur DNS en tout et pour tout).
Quelques articles sur le sujet :
L'article seul
RFC 2777: Publicly Verifiable Nomcom Random Selection
Date de publication du RFC : Février 2000
Auteur(s) du RFC : Donald E. Eastlake, 3rd (Motorola)
Pour information
Première rédaction de cet article le 22 décembre 2009
Ce curieux RFC répond à une question apparemment paradoxale : comment tirer au hasard de manière publiquement vérifiable ? Par exemple, les membres d'un des comités de l'IETF, le Nomcom, sont choisis au hasard. Comment permettre à tous les participants à l'IETF de vérifier que le tirage était bien aléatoire, alors que l'opération se fait sur l'Internet, sans qu'on puisse vérifier le dé ou la roulette ?
Une solution traditionnelle est de désigner une autorité arbitraire, considérée comme digne de confiance, et dont on n'a pas le droit de remettre l'honnêteté en doute. C'est ce que font toutes les loteries qui se déroulent « sous contrôle d'huissier ». Une telle méthode, basée sur la confiance aveugle en une entité particulière, ne colle pas avec la culture IETF.
Une autre méthode est proposée par notre RFC 2777. Utiliser un certain nombre de sources d'entropie, publiquement consultables, et les passer à travers une fonction de hachage qui garantira la dispersion des résultats, rendant ainsi très difficile d'influencer ceux-ci. Et chacun pourra faire tourner l'algorithme chez lui, vérifiant ainsi que le résultat est honnête.
La section 1 du RFC rappelle le problème original, la désignation du Nomcom (Nominating Committee, cf. RFC 2727) de l'IETF. Mais, depuis, la méthode de ce RFC a été utilisée dans bien d'autres cas.
La section 2 décrit les étapes à suivre :
- Identifier les candidats possibles (le RFC décrit le cas du Nomcom mais cette étape existe pour toute désignation),
- Publication de l'algorithme et des sources d'entropie utilisées, pour permettre la future vérification. Cette étape est indispensable car la possibilité de tous les participants de contrôler eux-même l'honnêteté du processus est vitale. (À noter que c'est justement cette possibilité qui est retirée au citoyen dans le cas de mesures anti-démocratiques comme le vote électronique.)
- Faire tourner l'algorithme et publier le résultat.
Ça, c'était le principe général. Maintenant, le gros problème est évidemment le choix de bonnes sources aléatoires. Toute la section 3 est vouée à cette question. La source doit produire un résultat qui ne peut pas être facilement influencé et qui doit être accessible publiquement. (La section 6 détaille les problèmes de sécurité.)
La section 3.1 analyse les sources possibles et en identifie trois :
- Les loteries sérieusement organisées, notamment celles faites par l'État. Notez qu'une loterie particulière peut être truquée mais, d'une part, l'algorithme repose sur plusieurs sources, d'autre part les gens qui sont prêts à truquer une loterie le feront plutôt pour des gains financiers, pas pour perturber l'IETF.
- Les résultats financiers comme le prix de vente d'une action à la clôture de la Bourse ou le volume d'actions échangée en une journée. Ce ne sont pas des nombres aléatoires mais leur valeur dépend des actes de beaucoup d'opérateurs séparés, en pratique, le résultat exact sera imprévisible.
- Les événements sportifs mais ils posent pas mal de problèmes pratiques comme les risques d'annulation ou de retard.
Attention à ne pas mettre les plus mauvaises sources en dernier, car, avec la connaissance des autres sources, publiées avant, un attaquant qui peut influencer la dernière source aurait un pouvoir excessif.
On pourrait penser qu'il faut multiplier le nombre de sources, pour limiter le pouvoir de nuisance d'une source manipulée. Mais le RFC note que le mieux est l'ennemi du bien : chaque source supplémentaire est également une source de problème, par exemple si elle ne produit aucun résultat (évenement annulé, par exemple). Il recommande environ trois sources.
Aucun des types de source cités plus haut ne produit une distribution uniforme. C'est une des raisons pour lesquelles on doit les faire passer à travers une fonction de hachage (cf. RFC 4086) pour obtenir cette uniformité. Une autre raison est que, pour certaines sources, leur valeur approximative peut être influencée (le cours en Bourse d'une action peut grimper ou descendre selon la volonté d'un gros opérateur) mais pas la totalité des chiffres. Le hachage empêchera donc ledit influenceur d'obtenir le résultat qu'il désire (section 3.2).
La section 3.3 calcule la quantité d'entropie nécessaire pour sélectionner P vainqueurs parmi N possibilités. Par exemple, pour 100 candidats et 10 places, il faut 44 bits d'entropie. (À noter que la fonction de hachage MD5, utilisée par notre RFC en suivant le RFC 1321 ne fournit « que » 128 bits d'entropie.)
Un algorithme détaillé est ensuite présenté en section 4. Les valeurs obtenues des diverses sources sont transformées en chaînes de caractères (en les séparant par des barres obliques). Ce sont ces chaînes qui sont ensuite condensées par MD5. Un exemple complet figure dans la section 5. Notez la précision avec laquelle les sources sont définies !
Une mise en œuvre de référence figure en section 7. Je l'ai rassemblée dans une archive tar. On la compile ainsi :
% make cc -c -o rfc2777.o rfc2777.c cc -c -o MD5.o MD5.c cc -lm -o rfc2777 rfc2777.o MD5.o rfc2777.o: In function `main': rfc2777.c:(.text+0x16a): warning: the `gets' function is dangerous and should not be used.
et on l'utilise ainsi (sur l'exemple de la section 5) :
% ./rfc2777 Type size of pool: (or 'exit' to exit) 25 Type number of items to be selected: (or 'exit' to exit) 10 Approximately 21.7 bits of entropy needed. Type #1 randomness or 'end' followed by new line. Up to 16 integers or the word 'float' followed by up to 16 x.y format reals. 9 18 26 34 41 45 9 18 26 34 41 45 Type #2 randomness or 'end' followed by new line. Up to 16 integers or the word 'float' followed by up to 16 x.y format reals. 2 5 12 8 10 2 5 8 10 12 Type #3 randomness or 'end' followed by new line. Up to 16 integers or the word 'float' followed by up to 16 x.y format reals. 9319 9319 Type #4 randomness or 'end' followed by new line. Up to 16 integers or the word 'float' followed by up to 16 x.y format reals. float 13.6875 13.6875 Type #5 randomness or 'end' followed by new line. Up to 16 integers or the word 'float' followed by up to 16 x.y format reals. end Key is: 9.18.26.34.41.45./2.5.8.10.12./9319./13.6875/ index hex value of MD5 div selected 1 746612D0A75D2A2A39C0A957CF825F8D 25 -> 12 <- 2 95E31A4429ED5AAF7377A15A8E10CD9D 24 -> 6 <- 3 AFB2B3FD30E82AD6DC35B4D2F1CFC77A 23 -> 8 <- 4 06821016C2A2EA14A6452F4A769ED1CC 22 -> 3 <- 5 94DA30E11CA7F9D05C66D0FD3C75D6F7 21 -> 2 <- 6 2FAE3964D5B1DEDD33FDA80F4B8EF45E 20 -> 24 <- 7 F1E7AB6753A773EFE46393515FDA8AF8 19 -> 11 <- 8 700B81738E07DECB4470879BEC6E0286 18 -> 19 <- 9 1F23F8F8F8E5638A29D332BC418E0689 17 -> 15 <- 10 61A789BA86BF412B550A5A05E821E0ED 16 -> 22 <- Done, type any character to exit.
On note l'affichage de la clé (les valeurs séparées par des barres obliques) et celui du nombre de bits d'entropie nécessaires.
Outre les exemples de sélection du Nomcom qu'on trouve dans le
RFC, cette méthode a été utilisé pour sélectionner le préfixe
xn-- des IDN. Voici la
description
de la méthode et l'annonce
du résultat.
Un autre exemple intéressant sera l'utilisation de ce RFC 2777 pour sélectionner les /8 à donner aux RIR lors de l'épuisement final des adresses IPv4.
L'article seul
Ethnologue, le livre, la liste de toutes les langues vivantes
Première rédaction de cet article le 18 décembre 2009
L'organisation missionnaire SIL International publie un excellent livre,
« Ethnologue, languages of the world », qui tient
à jour une liste de toutes les langues vivantes
avec leur(s) nom(s), leur nombre de locuteurs, et plein d'autres
renseignements. Le livre papier étant très cher (cent dollars
états-uniens), on peut se contenter de ce qui existe en ligne, sur
http://www.ethnologue.com/.
Ethnologue est le site de référence sur les langues vivantes, toujours le premier cité dans toutes les discussions. Pour avoir une idée de son contenu, on peut lire l'Introduction to the Printed Volume, disponible en ligne. Elle indique la méthodologie, les informations collectées, etc. Parmi les plus originales, l'attitude des locuteurs par rapport à leur propre langue. En sont-ils fiers ou pas ? Ce n'est pas la même chose que l'usage. En France, aujourd'hui, les langues régionales comme le breton bénéficient d'une image de marque très favorable (après des siècles de répression) mais ont très peu de locuteurs (et en nombre décroissant). Au contraire, des langues amérindiennes très vivantes et très parlées sont mal perçues par leurs locuteurs, qui s'excusent parfois de ne pas bien parler espagnol. Ethnologue affiche donc, quand elle est connu, cette attitude. On peut ainsi trouver que le kurde du nord ou le lisu font l'objet d'une appréciation positive de la part de ses locuteurs alors que ceux du créole anglais guyanais sont plus partagés et ceux du qiang du nord plutôt critiques...
L'article seul
RFC 5744: Procedures for Rights Handling in the RFC Independent Stream
Date de publication du RFC : Décembre 2009
Auteur(s) du RFC : R. Braden (ISI), J. Halpern (Ericsson)
Pour information
Première rédaction de cet article le 18 décembre 2009
L'infrastructure juridique des « nouveaux » RFC, désormais répartis en plusieurs voies selon leur source, continue à se mettre en place. Ce RFC 5744 décrit les procédures pour les droits liés aux RFC soumis par la voie « indépendante » (RFC soumis par un individu, ni l'IAB, ni un groupe de travail de l'IETF). Actuellement, il existe des dizaines de documents approuvés techniquement, qui attendent dans la file du RFC Editor car ils ont été soumis par cette voie et son statut n'a pas été clarifié depuis le déploiement des « nouveaux » RFC (RFC 5620). Sans doute vont-ils enfin être publiés mais on ne sait pas encore quand.
C'est que la publication d'un RFC, acte essentiellement technique au début, est devenue une grosse affaire juridico-politique. Des centaines de pages de discussions juridiques ont été noircies sur les problèmes de droits donnés par les auteurs (incoming rights, cf. RFC 5378) et les droits (forcément inférieurs ou égaux) que reçoivent les lecteurs (outgoing rights, cf.RFC 5377). Ces deux derniers RFC ne concernaient que les documents produits par l'IETF et, depuis, les documents produits par des individus languissaient sans statut et ne pouvaient être publiés.
Après tant de débats, il est ironique de constater que la procédure pour les RFC « indépendants » est finalement très proche de celle des RFC « IETF ».
Pour se saisir du contexte, la section 2 de notre RFC 5744 rappelle que le systèmes des voies (streams) a été défini dans les RFC 4844 (et RFC 4846, spécifiquement pour la voie indépendante). Cette dernière est une vieille tradition, et permet de publier des RFC qui sont proposés par des individus isolés, ou bien qui ont rencontré le veto de certaines parties à l'IETF (comme le RFC 4408). Tout RFC n'est donc pas le produit d'un groupe de travail IETF.
Depuis le RFC 5620, qui « éclatait » l'ancienne fonction de RFC Editor, la responsabilité des RFC soumis par voie indépendante revient au Independent Stream Editor, qui ne sera finalement désigné qu'en février 2010.
La section 3 pose les buts des nouvelles règles. Reprenant la politique traditionnelle, suivie informellement depuis l'époque de Jon Postel, elle pose comme principe que l'utilisation des RFC doit être la plus libre possible (« Unlimited derivative works »). Toutefois, tous les RFC de la voie indépendante ne sont pas équivalents. Certains sont des republications de documents édités ailleurs (par exemple par d'autres SDO) et les auteurs ont donc la possibilité de demander des restrictions supplémentaires. À noter que ces principes s'appliquent également au code inclus dans les RFC.
Enfin, les règles formelles elle-mêmes, en section 4. La procédure est proche de celle des autres RFC, l'auteur devant donner certains droits pour permettre la publication (par défaut, il donne presque tous les droits, en gardant évidemment l'attribution de son travail). Les termes exacts (le boilerplate) seront fixés par l'IETF Trust.
Le respect de la procédure par l'auteur ne préjuge pas de l'adoption du RFC. L'éditeur de la voie indépendante, l'ISE, reste seul juge de l'intérêt de publier le RFC. Le choix d'un auteur de ne pas permettre la réutilisation du RFC (« no derivative worlks ») peut, par exemple, être motif de rejet.
L'implémentation de cette politique nécessite une action de la part de l'IETF Trust, décrite en section 5. Celui-ci devra accepter la responsabilité de la gestion des droits de propriété intellectuelle pour ces RFC « indépendants » et devra écrire les termes exacts qui seront inclus dans chaque RFC.
Quant aux questions de brevets et de marques déposées, elles sont réglées dans la section 6. Les règles des RFC 2026 et RFC 8179 s'appliquent aux RFC de la voie indépendante comme aux autres : toute prétention de propriété intellectuelle doit être déclarée, de façon à ce que l'ISE puisse décider en toute connaissance de cause (notez bien qu'en pratique, cette règle est parfois violée). Comme d'habitude à l'IETF, il n'y a pas d'a priori sur les conditions de licence des brevets (tout est théoriquement possible) mais notre RFC précise que les termes de licence les plus favorables possibles seront privilégiés, notamment des licenses gratuites, voire implicites.
L'article seul
RFC 5656: Elliptic-Curve Algorithm Integration in the Secure Shell Transport Layer
Date de publication du RFC : Décembre 2009
Auteur(s) du RFC : D. Stebila (Queensland University of
Technology), J. Green (Queen's
University)
Chemin des normes
Première rédaction de cet article le 15 décembre 2009
Les algorithmes de cryptographie de la famille des courbes elliptiques prennent de plus en plus d'importance, concurrençant les traditionnels RSA et DSA. Ce RFC spécifie l'utilisation de certains de ces algorithmes dans le protocole SSH.
Il y a déjà plusieurs RFC qui utilisent les courbes elliptiques : les RFC 4050, RFC 4492, RFC 5349, etc. SSH n'est donc pas, et de loin, le premier protocole IETF à en bénéficier. Mais il est plus répandu et l'intégration des courbes elliptiques leur donnera donc une bien meilleure exposition.
Outre des avantages techniques comme des clés de faible taille (voir la section 1 du RFC pour des chiffres précis), l'intérêt des courbes elliptiques est que, compte-tenu du risque toujours existant de percées soudaines en cryptanalyse, il est prudent de garder « plusieurs fers au feu ». Si une nouvelle méthode de factorisation en nombres premiers apparait, menaçant RSA, la disponibilité d'algorithmes utilisant les courbes elliptiques fournira une solution de repli.
Notre RFC 5656 étend donc SSH, tel qu'il est spécifié dans les RFC 4251 et RFC 4253. Pour davantage d'information sur les courbes elliptiques, il renvoie à « SEC 1: Elliptic Curve Cryptography » et « SEC 2: Recommended Elliptic Curve Domain Parameters ».
La section 3 de notre RFC attaque les détails pratiques de l'algorithme ECC. Le format des clés (section 3.1), l'algorithme utilisé pour la signature (nommé ECDSA), avec la fonction de hachage SHA-2 et l'encodage de la signature y sont normalisés.
Un protocole d'échange de clés utilisant les courbes elliptiques, ECDH, occupe la section 4. Un autre, ECMQV, figure en section 5 (mais seul ECDH est obligatoire dans SSH).
Le tout est enregistré dans le registre
des paramètres SSH, tel que décrit en section 6. Comme le terme
de « courbes elliptiques » désigne une famille, pas un seul
algorithme, il faut ensuite préciser l'algorithme exact utilisé.
Trois courbes elliptiques
sont ainsi mise en avant, nommées nistp256,
nistp384 et nistp521. Un
mécanisme utilisant l'OID de la courbe est
prévu pour celles sans nom (section 6.1). Ces courbes peuvent être
utilisées pour ECDSA (section 6.2), ECDH (section 6.3) et ECMQV
(section 6.4). Ainsi, le nom complet de l'algorithme utilisé pour
ECDSA avec la courbe nistp256 est ecdsa-sha2-nistp256.
Comment vont faire les mises en œuvres de SSH avec ces nouveaux algorithmes et interopéreront-elles avec les anciennes ? Oui, répond la section 8 : le protocole SSH a toujours prévu un mécanisme de négociation des algorithmes utilisés et les programmes ignorent simplement les algorithmes inconnus (section 8.2). La section 8 couvre d'autres problèmes concrets comme les performances des nouveaux algorithmes (en général meilleure que celle de RSA ou DSA, en raison de la taille plus faible des clés).
Une très riche section 9 analyse en détail les caractéristiques de sécurité des courbes elliptiques et leur résistance à la cryptanalyse. D'abord, il faut bien retenir que « courbes elliptiques » désigne une famille, pas un seul algorithme. Certains membres de la famille sont plus vulnérables que d'autres, par exemple à des attaques comme la descente de Weil. Il faut donc considérer avec prudence une courbe qui n'est pas listée dans la section 10 (qui résume la liste des courbes utilisées pour SSH).
Ppur les courbes ainsi spécifiées, il n'existe pas actuellement d'autres attaques que la force brute. Les seules exceptions concernent les algorithmes pour ordinateurs quantiques (comme celui de Shor). Or, ces ordinateurs ont déjà le plus grand mal, à l'heure actuelle, à additionner 2 + 2 et le RFC note qu'il est peu probable qu'ils deviennent une menace réelle dans les prochaines années. Les lois de la physique et celle de l'ingéniérie ne sont pas faciles à faire plier !
La section 10 rassemble les caractéristiques des courbes
obligatoires (section 10.1) et
recommandées (section 10.2), donnant pour chacune l'OID
attribué. Toutes sont dérivées de normes NIST. Ainsi, nistp256 a l'OID
1.2.840.10045.3.1.7. Tous ces algorithmes sont
enregistrés dans le registre SSH,
suivant le RFC 4250.
La mise en œuvre la plus répandue de SSH,
OpenSSH, a intégré ces
algorithmes à courbes elliptiques sa version 5.7, livrée en janvier 2011 (voir un résumé en http://pthree.org/2011/02/17/elliptic-curve-cryptography-in-openssh/). Il y a quelques années, un interview d'un des
développeurs indiquait qu'un des problèmes était celui des
brevets logiciels (il parlait aussi de
l'absence de normalisation, ce qui n'est plus vrai avec la sortie de
notre RFC).
L'article seul
Google peut même prévoir nos recherches
Première rédaction de cet article le 14 décembre 2009
On savait déjà que Google pouvait prévoir les épidémies de grippe, rien qu'en examinant les recherches pour des termes liés aux symptômes de cette maladie. Maintenant, on peut en apprendre bien davantage sur la prédictabilité des recherches en lisant « On the Predictability of Search Trends ».
Cet article d'août 2009 est une publication de chercheurs de Google étudiant quelles recherches dans le moteur sont prévisibles et lesquelles ne le sont pas. Ainsi, la moitié des requêtes les plus populaires sont prédictibles un an à l'avance, avec une prédictabilité particulièrement forte pour les catégories comme Santé ou Voyage... Au contraire, des catégories comme Distractions sont peu prévisibles, trop liées à des modes très changeantes. (Et, si vous vous demandez quelle est la définition formelle de « prédictabilité », elle figure dans l'article, avec toutes les mathématiques nécessaires.)
Pourquoi Santé ou Voyage sont-elles prévisibles ? Parce que les requêtes dans ces deux catégories obéissent à des logiques saisonnières. De même que Shopping a une pointe parfaitement prévisible avant Noël... C'est une information utile pour les gens du marketing et les annonceurs.
Mais il est plus instructif de regarder les requêtes qui étaient en théorie prévisibles mais qui ont dévié par rapport aux prédictions. Ainsi, la catégorie Chômage a nettement grimpé au dessus des prévisions de Google à l'été 2008, marquant la crise financière que tous les experts et ministres niaient. Si on veut de l'information exacte, il faut regarder les requêtes Google plutôt que les médias...
En revanche, les requêtes au moteur de recherche portant sur des vacances au Mexique ont été en dessous des prévisions à partir d'avril 2009, sans que les requêtes pour d'autres destinations de vacances ne subissent le même sort. C'est sans doute le résultat de l'épidémie de grippe.
Bref, Google fournit une vision de notre société bien plus riche que les simples et amusantes tendances.
L'article seul
RFC 5731: Extensible Provisioning Protocol (EPP) Domain Name Mapping
Date de publication du RFC : Août 2009
Auteur(s) du RFC : S. Hollenbeck (Verisign)
Chemin des normes
Première rédaction de cet article le 14 décembre 2009
Le protocole d'avitaillement EPP ne spécifie pas comment représenter les objets qu'on crée, détruit, modifie, etc. Cette tâche est déléguée à des RFC auxiliaires comme le nôtre, consacré aux noms de domaine.
EPP permet à un client de créer, détruire et modifier des objets de types différents. En pratique, EPP n'est utilisé que dans l'industrie des noms de domaine mais, en théorie, il pourrait être utilisé pour n'importe quel type d'objets.
Le type n'est donc pas spécifié dans le protocole EPP de base, normalisé dans le RFC 5730, mais dans des RFC supplémentaires. Par exemple, celui qui fait l'objet de cet article spécifie le type (EPP dit le mapping, on pourrait aussi l'appeler une classe) pour les noms de domaine.
Ce type est spécifié (section 4 du RFC) dans le langage W3C XML Schema.
On note que ce schéma, se voulant adaptable à de nombreux
registres différents, ne colle parfaitement à
la politique d'aucun. Par exemple,
<infData> est spécifié ainsi :
<sequence>
<element name="registrant" type="eppcom:clIDType"
minOccurs="0"/>
<element name="contact" type="domain:contactType"
minOccurs="0" maxOccurs="unbounded"/>
<element name="ns" type="domain:nsType"
minOccurs="0"/>
ce qui veut dire que des « règles métier » très courantes comme « un titulaire et un seul » ou bien « au moins deux serveurs de noms » ne sont pas respectés avec le schéma EPP seul.
Ce RFC remplace son prédécesseur, le RFC 4931 mais ce ne sont que des modifications de détail, résumées en annexe A. Elles vont en général dans le sens d'une plus grande latitude laissée aux implémenteurs.
Voici un exemple d'une réponse à une requête
<epp:info> (section 3.1.2) pour le domaine
example.com (comme avec whois
mais, typiquement, non public) :
<response>
<result code="1000">
<msg>Command completed successfully</msg>
</result>
<resData>
<domain:infData
xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
<domain:name>example.com</domain:name>
<domain:roid>EXAMPLE1-REP</domain:roid>
<domain:status s="ok"/>
<domain:registrant>jd1234</domain:registrant>
<domain:contact type="admin">sh8013</domain:contact>
<domain:contact type="tech">sh8013</domain:contact>
<domain:ns>
<domain:hostObj>ns1.example.com</domain:hostObj>
<domain:hostObj>ns1.example.net</domain:hostObj>
</domain:ns>
<domain:host>ns1.example.com</domain:host>
<domain:host>ns2.example.com</domain:host>
<domain:clID>ClientX</domain:clID>
<domain:crID>ClientY</domain:crID>
<domain:crDate>1999-04-03T22:00:00.0Z</domain:crDate>
<domain:upID>ClientX</domain:upID>
<domain:upDate>1999-12-03T09:00:00.0Z</domain:upDate>
<domain:exDate>2005-04-03T22:00:00.0Z</domain:exDate>
<domain:trDate>2000-04-08T09:00:00.0Z</domain:trDate>
<domain:authInfo>
<domain:pw>2fooBAR</domain:pw>
</domain:authInfo>
</domain:infData>
</resData>
...
On y voit les serveurs de noms du domaine,
ns1.example.com et
ns1.example.net, son titulaire, identifié par un
code, ici
jd1234, sa date de création, le 3 avril 1999, etc.
De même, pour créer un domaine, on appele
<epp:create> (section 3.2.1) avec des éléments de l'espace
de nom urn:ietf:params:xml:ns:domain-1.0, par
exemple :
<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
<command>
<create>
<domain:create
xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
<domain:name>example.com</domain:name>
<domain:period unit="y">2</domain:period>
<domain:ns>
<domain:hostObj>ns1.example.com</domain:hostObj>
<domain:hostObj>ns1.example.net</domain:hostObj>
</domain:ns>
<domain:registrant>jd1234</domain:registrant>
...
La liste complète des commandes EPP utilisables pour ce type « domaine » figure dans la section 3.
La syntaxe utilisable pour un nom de domaine est celle du RFC 1123, bien plus restrictive que celle utilisée dans le DNS (section 2.1). Ce type « domaine » ne peut donc pas être utilisé pour tout nom de domaine légal.
Chaque domaine a un « statut », ceux mis par le client (typiquement
un registrar) étant préfixés
par client (section 2.3). Par exemple,
clientHold indique que, à la demande du
registrar, ce nom, quoique enregistré, ne doit pas
être publié dans le DNS.
L'article seul
Publication des sites Web qui refusent les adresses de courrier légales
Première rédaction de cet article le 13 décembre 2009
J'ai prévenu (ou tenté de prévenir) un certain nombre de gérants de sites Web que leurs formulaires refusaient des adresses de courrier légales : « Arrêter d'interdire des adresses de courrier légales ». Mais je ne gère pas de listes des sites qui sont dans ce cas (il y en a hélas, trop). Inspiré par l'effort de Thierry Stoehr, pour les sites qui refusent les liens entrants, je publie désormais les messages d'erreur de ces sites en microblogging, sur Twitter et identi.ca.
Dans les deux cas, j'utilise le
hashtag
#ral pour « Refus d'Adresses Légales ». C'est
joli et puis il est libre.
J'essaie de prévenir le webmestre avant, pour qu'il puisse corriger. Mais, la plupart du temps, il n'y a pas de mécanisme de réponse. Et, lorsqu'il y en a un, il est exceptionnel que le problème soit résolu.
- Messages sur Twitter
- Messages sur identi.ca
L'article seul
Sélectionner les « commits » Subversion d'un auteur particulier
Première rédaction de cet article le 13 décembre 2009
Un des gros avantages de Subversion par rapport à CVS est de disposer d'une API qui évite analyser la sortie texte des commandes. Voici un petit utilitaire qui se sert de cette API pour n'afficher que les commits d'un certain auteur.
Il s'utilise ainsi :
% svnlog.py smith 2009-June-29 13:29 (8761): "Log message 1" 2009-June-29 13:28 (8760): "Log message 2" ... % svnlog.py jones 2009-July-10 14:34 (8789): "Log message 3" 2009-July-07 11:49 (8781): "Log message 4" ...
Il est écrit en Python, avec la bibliothèque
pysvn. Le code est svnlogbyauthor.py.
L'article seul
Mon premier vrai programme en Go
Première rédaction de cet article le 8 décembre 2009
Go, créé par Google, est surtout intéressant comme langage de programmation « système ». Il est donc concurrent de C et C++, sur un créneau où il y a relativement peu de candidats (certains, comme D, n'ont eu aucun succès). Certains commentateurs s'étaient étonné que Google crée encore un nouveau langage de programmation lors qu'il y en a déjà des milliers mais, contrairement aux langages fonctionnels, les langages « système » sont bien plus rares.
Le code de mon client whois est en whois.go. Mon
point de départ avait été socketgo. (Un autre
programme de niveau de complexité analogue est un client pour l'entrepôt de données
de Rennes, gostar.go.) Quelques points qui
m'ont interpellé pendant le développement du client whois :
- Le compilateur qui a un nom différent selon le type du
processeur (très énervant, pour écrire des
Makefile portables, ce n'est qu'après que j'ai appris à mettre
include $(GOROOT)/src/Make.$(GOARCH)), - La très bonne documentation des paquetages standard,
- La conversion obligatoire des
stringen[]byte, les premières étant nécessaires pour l'affichage et les seconds servant aux entrées/sorties (j'ai créé unBufferpour cela, y avait-il une meilleure solution ?), - La séparation entre la création d'une variable (où on peut lui
donner une valeur avec
:=) et sa mutation ultérieure (où on doit utiliser=), - L'absence d'exceptions, probablement le plus gros manque du langage,
- La déclaration automatique d'une variable, avec inférence de types, ce qui m'a rappelé Haskell,
- Et, bien sûr, comme tous les débutants en Go, le fait qu'une variable déclarée doive être utilisée, sous peine du désormais célèbre message XXX declared and not used.
Mon deuxième programme, pour illustrer le parallélisme en Go est un serveur du protocole echo, NoNewContent. Plus perfectionné et tout aussi parallèle, un serveur de noms en Go.
J'ai aussi fait un exposé en français sur Go.
Je stocke mes liens vers des ressources Go en http://delicious.com/bortzmeyer/golang.
L'article seul
RFC 5706: Guidelines for Considering Operations and Management of New Protocols and Protocol Extensions
Date de publication du RFC : Novembre 2009
Auteur(s) du RFC : D. Harrington (Huwaei / Symantec)
Pour information
Première rédaction de cet article le 8 décembre 2009
Ce n'est pas tout de normaliser des protocoles. Pour qu'ils ne rendent pas la vie impossible aux administrateurs réseaux, il faut encore qu'ils soient faciles à administrer. Cela peut être plus facile si ces questions opérationnelles ont été prises en compte dès le début. Ce RFC 5706 demande donc que tout nouveau protocole fait à l'IETF reçoive, dès le début, une sérieuse attention pour ses problèmes de gestion. Le faire a posteriori est en effet souvent moins efficace.
Ce RFC est essentiellement composé d'une liste de recommandations (très détaillées) aux auteurs de nouveaux protocoles, expliquant les étapes qu'ils doivent suivre pour que leur protocole soit « gérable ». Cette liste est résumé dans l'annexe A, qu'il suffit normalement de suivre pas-à-pas pour que le protocole soit complet.
La section 1.1 resitue la question : cela fait longtemps que l'IETF demande aux auteurs de protocole de prévoir les mécanismes de gestion pratique dès le début. Un cadre existe pour cela, autour du SMI (modèle décrivant les variables du protocole) du RFC 2578 (et du protocole qui lui est le plus souvent associé, SNMP ; voir le RFC 3410). Mais ce modèle est trop étroit et ne couvre pas l'intégralité de ce qu'il faut savoir pour le déploiement et l'administration d'un protocole. Sans aller jusqu'à formellement imposer une section Management Considerations dans les RFC (comme il existe une Security Considerations obligatoire), notre RFC 5706 demande une attention sérieuse portée, dès le début, aux questions de gestion et d'opération des réseaux.
La différence entre « gestion » (management) et « opération » (operation) est décrite en section 1.2. Les opérations, c'est faire fonctionner le réseau, même sans mécanisme de gestion. La gestion, c'est utiliser des mécanismes qui ont été créés dans le but d'améliorer les opérations.
Contrairement à l'idée dominante à l'IETF depuis quinze ans, et
depuis les grandes luttes entre SNMP et
CMIP, il n'est plus envisagé (section 1.3) d'atteindre le
Graal du mécanisme unique. Toutes les solutions
sont désormais acceptables, pourvu qu'elles marchent. (Parmi les
échecs du SMI, on peut noter celui décrit par le RFC 3197. Aujourd'hui encore, les serveurs DNS sont gérés par des
mécanismes non-standard comme la commande rndc de
BIND.)
Le RFC 5706 va donc donner des lignes directrices et des conseils, plutôt que des obligations. C'est donc un assouplissement par rapport à l'ancienne politique de l'IESG qui exigeait une MIB (description des variables en suivant le SMI) pour tout protocole, au grand désespoir de certains auteurs.
Les sections 1.4 et 1.5 rappellent l'histoire tourmentée des mécanismes de gestion des réseaux TCP/IP. Par exemple, une date importante avait été le RFC 1052 en 1988, qui séparait le langage de modélisation (celui qui sert à écrire la MIB) du protocole d'accès aux données (aujourd'hui SNMP). Une autre avait été le RFC 3139 en 2001, qui listait les obligations d'un mécanisme de gestion. Le RFC 3535 en 2003, faisait le bilan des mécanismes utilisés et critiquait notamment la dépendance vis-à-vis d'un format binaire, celui de SNMP.
La première grande section de notre RFC 5706 est donc la section 2, consacrée aux opérations : comment le nouveau protocole va t-il fonctionner ? Il ne suffit pas pour cela que le protocole soit lui-même bien conçu. Il doit aussi s'insérer dans l'environnement humain et technique existant. Ses concepteurs doivent donc réflechir au débogage, à la configuration, à la mise à jour depuis une précédente version...
Comme exemple de mauvaise interaction avec l'existant, le RFC cite l'exemple du damping de BGP (RFC 2439). Lorsqu'une route annoncée en BGP change trop souvent, les routeurs BGP commencent à ignorer cette route. Mais cette technique n'avait pas pris en compte l'interaction avec d'autres techniques comme la path exploration et avait donc créé autant de problèmes qu'elle en avait résolu, menant certains administrateurs à couper le damping.
Avant même que le protocole ne fonctionne, il faut le configurer. C'est le but de la section 2.2 qui commence en rappelant un sage principe du RFC 1958 : « tout ce qui peut être configuré peut être mal configuré ». Ce RFC (et son lointain successeur, le RFC 5505) recommandait de préférer les configurations automatiques. Pour les cas où une valeur par défaut a un sens, il faut éviter toute configuration (mais permettre de connaitre les valeurs effectivement configurées).
Parfois, il y avait déjà une version plus ancienne du protocole qui tournait (ou bien un ancien protocole jouant le même rôle). La norme doit alors prévoir un mécanisme de migration, dit la section 2.3. D'autres principes de ce genre forment le reste de la section 2.
La section 3, elle, s'occupe de la gestion de réseaux. Il ne s'agit plus uniquement de faire marcher le réseau, il faut encore le faire marcher bien. Cela passe par l'identification des entités à gérer, puis de la méthode à utiliser. L'ancienne approche qui répondait à toutes ses questions par « il faut écrire une MIB » a montré ses limites. Un ensemble de variables n'est pas un protocole, d'autant plus qu'elle ne concerne en général qu'une des deux extrémités de la communication. Comme le dit le RFC 3535, « une MIB est souvent une liste d'ingrédients sans une recette ». L'introduction de la section 3 donne des pistes pour améliorer les choses.
Un des credos principaux de l'IETF est l'interopérabilité, couverte dans la section 3.1. Appliquée à la gestion du réseau, l'interopérabilité veut dire qu'on devrait pouvoir choisir librement le programme utilisé pour gérer un équipement, et l'utiliser quel que soit l'équipement réseau qu'on gère. Cela implique un protocole standard de gestion.
Beaucoup d'équipements réseau peuvent être gérés via une page Web (elle-même souvent très peu standard, avec abus de fonctions qui ne marchent que sur certains navigateurs, même si le RFC ne mentionne pas ce point), ou parfois via la ligne de commande. Mais cela ne suffit pas. Si on gère des dizaines d'équipements différents, ce qui est courant dans un réseau de taille moyenne, la complexité devient vite unsupportable. Pour que la gestion du réseau soit simplifiée et soit automatisable, une normalisation de ces interfaces est nécessaire.
Historiquement, tout le monde était d'accord sur le papier avec une telle approche. Mais, en pratique, ces interfaces, même celles en ligne de commande, plus faciles à spécifier, n'ont jamais été standardisées. L'IETF n'a pas aidé, en se focalisant sur un seul schéma de données (le SMIv2 du RFC 2578) et un seul protocole (SNMP, du RFC 3410). Ces mécanismes ne convenaient pas à tous et les « autres » interfaces, ignorées de l'IETF, étaient développées mais sans norme unificatrice. Désormais, l'IETF a une vision plus ouverte, et considère d'autres langages de schéma (comme les W3C Schema) ou d'autres protocoles (comme Netconf, dans le RFC 6241, ou syslog, dans le RFC 5424).
La normalisation est plus facile à dire qu'à faire. Normaliser au niveau de la syntaxe est déjà délicat mais, idéalement, il faudrait aussi normaliser la sémantique, pour qu'un même nom décrive bien le même concept partout. Cela impose de développer des modèles, aussi bien des modèles d'information que des modèles de données. (La différence est expliquée dans le RFC 3444 et la section 3.2 couvre les modèles d'information.)
Un protocole ne fonctionne jamais sans pannes. La très riche section 3.3 se
penche sur la gestion des pannes. Bien sûr, les mécanismes de gestion
du réseau ne vont pas réparer la panne tout seuls. Mais ils peuvent
aider à la diagnostiquer. Par exemple, tout protocole devrait avoir
un mécanisme de détection de la vie d'un élément du réseau, pour
pouvoir répondre à la question simple « Est-il encore en
marche ? ». C'est le but de protocoles aussi variés que
l'ICMP echo du RFC 792, du protocole echo de
TCP ou
UDP (RFC 862, mis en œuvre dans des programmes comme echoping et
malheureusement presque abandonné aujourd'hui), les appels
NULL dans Sun-RPC (section
11.1 du RFC 1831),
etc.
Dans un ordre surprenant, la section 3 passe ensuite à la gestion de la configuration (sous-section 3.4). Quels paramètres de configuration, lesquels survivent au redémarrage, que dit le RFC 3139, etc. Cette section, comme le reste du RFC, est trés détaillée, abordant même le problème de l'internationalisation (et, oui, il faut permettre l'UTF-8 dans les fichiers de configuration). D'autre part, le RFC demande également qu'on puisse vérifier la configuration avant de la charger dans l'équipement réseau, pour éviter de laisser celui-ci dans un état invalide, voire de gêner le bon fonctionnement du réseau.
Pour beaucoup d'opérateurs, notamment dans les réseaux traditionnels de téléphonie, il n'y a pas de gestion de réseau sans comptabilisation du trafic. C'est le sujet de la section 3.5, qui renvoie au RFC 2975, et qui dit bien que la comptabilisation n'est nullement obligatoire, qu'elle doit faire l'objet d'un choix réfléchi.
Plus importante est la gestion des performances : tout le monde veut que le réseau aille vite. Pour cela, le point de départ (section 3.6) est de mesurer les performances, pour déterminer, par exemple, si un changement les améliore ou bien les dégrade. Deux groupes de travail de l'IETF se consacrent à ce sujet, BMWG pour les mesures en laboratoire et IPPM pour celles dans la nature.
La sécurité est un gros sujet en soi, lors de la configuration d'un système, et est traitée dans la section 3.7. Par exemple, un nouveau protocole devrait comporter une analyse des menaces et des solutions possibles. Certains protocoles prévus pour la gestion de réseau ont une utilisation directe en sécurité. Par exemple, les traps SNMP et syslog sont couramment utilisés pour alerter les administrateurs sur des phénomènes qui peuvent être une attaque.
Une fois les problèmes des opérations (section 2) et de la gestion (section 3) ainsi décrits, qu'en faire, lorsqu'on définit un nouveau protocole ? Documenter, dit la section 4. Il devrait idéalement y avoir une section Manageability Considerations dans les RFC, juste avant les Security Considerations, et contenant les informations essentielles pour ceux qui auront à opérer et à gérer le nouveau protocole. Si le ou les concepteur(s) du protocole estiment que cette section n'a pas lieu d'être pour leur création, alors ils devraient l'indiquer explicitement (ce qui garantit que l'absence d'une Manageability Considerations n'est pas un oubli). Le premier RFC à avoir suivi cette règle (avant même qu'elle soit formalisée) est apparemment le RFC 5440 (dans sa section 8).
L'article seul
Guerre à la Terre
Première rédaction de cet article le 7 décembre 2009
Sortant tout juste de la seconde guerre mondiale, la France et ses voisins devaient s'ennuyer car plusieurs œuvres d'un genre récent, la science-fiction, mettaient en scène des conflits à côté desquels la récente guerre semblait une suite de simples escarmouches. Si E. P. Jacobs, dans Le Secret de l'Espadon imagine comme ennemi de mystérieux « jaunes » tapis au fond de l'Asie, Marijac, dans le magnifique Guerre à la Terre, enrôle des envahisseurs extra-terrestres (aidés toutefois par des collabos jaunes).
Cette BD avait d'abord été publié dans Le Coq Hardi en 1946 et 1947. Elle doit l'essentiel de sa diffusion d'ajourd'hui à sa réédition par Glénat en 1975. Si le tome 1 se trouve assez souvent chez les bouquinistes, le tome 2 est bien plus rare. Moins tiré à l'époque ?
Sur la forme, on y trouve les caractéristiques de la BD de l'époque, notamment les très longs textes, y compris pour expliquer ce que tout lecteur voit bien sur l'image (« L'avion pique à travers la masse de nuages »). La récente guerre fournit plein d'idées de scénarios, les progrès techniques et l'imagination font le reste (notez les progrès considérables de l'aviation terrestre d'un tome à l'autre : d'avions classiques dans le tome 1, les terriens sont passés à des engins dignes de Flash Gordon dans le tome 2). Par contre, le scénariste n'est pas toujours d'une grande rigueur : la Tour Eiffel, détruite dans le tome 1, a subitement ressuscité dans le tome 2 (pour être à nouveau jeté à bas)
Le fond politique est nettement conservateur, souvent raciste (les fusées ennemies qui « sèment la panique dans les quartiers indigènes » ou bien la « race jaune fanatique »). La seconde guerre mondiale étant à peine terminée dans le tome 1, tous les Alliés le sont encore (français, états-uniens et soviétiques). La guerre froide se déclenchant rapidement, les gentils soviétiques ont disparu du tome 2, où les combats ne sont plus menés que par les franco-états-uniens. Le contraste avec Les Pionniers de l'Espérance est net.
Les dessins (deux dessinateurs différents, pour les deux tomes) sont splendides. La peinture de la guerre est saisissante, souvent brutale. Les deux tomes sont pleins de magnifiques morceaux de bravoure, comme la panique dans le métro lors de l'évasion des prisonniers extra-terrestres. Il y a aussi une étonnante description, dans le tome 2, des affrontements entre partisans de la poursuite de la lutte et ceux de la capitulation, écho de juin 1940. Ils culminent dans une scène de conflit armé, sur une base militaire française entre ceux qui veulent rejoindre les États-Unis toujours en guerre et les capitulards.
En tout cas, l'auteur a du souffle et l'apocalypse du tome 2, lorsque les extra-terrestres utilisent leur nouvelle arme, n'a rien à envier à celle du récent film « 2012 ».
L'article seul
Tout le monde parle de Google DNS...
Première rédaction de cet article le 4 décembre 2009
Dernière mise à jour le 8 décembre 2009
Alors, je vais en faire autant. Après Google Mail, Google Docs, Google Talk, Google Wave, Google DNS est la dernière vedette de la blogosphère, en attendant Google Power (pour distribuer l'électricité) et Google Airlines (gratuit, évidemment, pour battre les compagnies low cost).
Google
DNS est un résolveur DNS ouvert, accessible à tous gratuitement. On
peut l'utiliser à la place des résolveurs fournis par le service
informatique du réseau local, ou par le
FAI. Les instructions pour cela sont
disponibles chez Google (en gros, sur Unix, il
suffit d'éditer son /etc/resolv.conf).
L'adresse à
indiquer, 8.8.8.8, sera certainement dans très
peu de temps une des plus connues de
l'Internet. C'était une idée marketing géniale
que d'utiliser une adresse simple à mémoriser (avec son alternative,
8.8.4.4, et ses équivalents IPv6, moins sexys, 2001:4860:4860::8888 et 2001:4860:4860::8844) même s'il n'est pas sûr que faire de
l'anycast sur cette plage
normalement allouée à Level 3 soit parfaitement
conforme aux règles de l'ARIN. Mais ne
chipotons pas.
Quel intérêt y a t-il à utiliser un résolveur DNS distinct du résolveur habituel qu'on trouve sur n'importe quel réseau ? La seule raison valable, à mon avis, est le cas où ledit résolveur soit inexistant ou très lent (cela arrive avec certains FAI).
Mais Google met en avant d'autres raisons. En résumant : vitesse, sécurité et honnêteté. Commençons par la fin : contrairement à ses trois concurrents plus anciens (dont le plus connu, en raison de leur marketing agressif, est OpenDNS), les résolveurs de Google ne sont en effet pas des menteurs. Remarquons qu'on est tombés très bas : ne pas mentir devient si rare que c'est désormais cité comme argument commercial.
% dig @8.8.8.8 MX doesnotexist.fr ... ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 3712
On obtient bien le NXDOMAIN (No Such
Domain), le DNS fonctionne normalement.
Et la vitesse ? A priori, l'essentiel du temps de réponse étant dû à la latence jusqu'au résolveur, Google DNS a peu de chances d'être plus rapide. À l'heure actuelle, Google DNS n'a apparemment pas d'instance en France et le serveur semble à Francfort. Mais mesurons, ne devinons pas. En utilisant qtest, voyons, pour une machine française, trois résolveurs de son réseau local, les deux résolveurs d'OpenDNS et les deux de Google DNS :
% qtest -n3 "A a.gtld-servers.net" 127.0.0.1 192.134.7.248 192.134.4.162 208.67.222.222 208.67.220.220 8.8.8.8 8.8.4.4 0 127.0.0.1/127.0.0.1 0 192.134.4.162/192.134.4.162 0 192.134.7.248/192.134.7.248
Les résolveurs locaux gagnent nettement, comme prévu. Et si on compare les trois services de résolveur extérieurs :
% qtest -n3 "A a.gtld-servers.net" 208.67.222.222 208.67.220.220 8.8.8.8 8.8.4.4 156.154.70.1 156.154.71.1 11 8.8.4.4/8.8.4.4 11 8.8.8.8/8.8.8.8 17 208.67.220.220/208.67.220.220
Google l'emporte sur OpenDNS, non seulement en honnêteté mais aussi en vitesse. Il n'y a donc vraiment aucune raison pratique d'utiliser OpenDNS. (Il y a d'autres mesures sérieuses, avec le même résultat, par exemple Google DNS vs OpenDNS: Google Rocks for International Users ou Divers Resolver DNS Services. Un autre outil de mesure, certes écrit par Google mais dont le source est disponible, si vous n'avez pas confiance, est l'excellent Namebench. Voyez aussi Domain Name Speed Benchmark (ce dernier étant spécifique à Windows).
Et la sécurité ? Google promet que ses résolveurs mettent en œuvre toutes les bonnes pratiques actuelles, ce qui est la moindre des choses. La seule stratégie qui aurait été différenciatrice aurait été de faire la validation DNSSEC mais Google DNS ne le fait pas. Par rapport aux résolveurs locaux utilisant les logiciels libres actuels, à jour, comme Unbound ou BIND, Google DNS n'a qu'un avantage, l'utilisation de la variation de la casse, un hack amusant mais marginal.
Parlant de sécurité, notons un petit problème : il n'y a aucune authentification entre le client sur son poste de travail et Google DNS. Rien ne garantit qu'on parle bien aux machines de Google. D'habitude, cette sécurisation du dernier kilomètre n'était pas un problème car le résolveur DNS était proche : sur le même réseau local ou en tout cas sur le même FAI. Avec Google DNS, cela cesse d'être vrai et on pourrait imaginer de nombreux détournements possibles, par attaque sur le système de routage. Ces attaques pourraient être faites par un intermédiaire, ou bien par un FAI malhonnête, peu soucieux de voir ses clients partir chez Google. Pour s'en protéger, il existe plusieurs solutions techniques mais aucune ne semble réaliste. Les seules solutions DNS (j'exclus IPsec et compagnie) possibles sont TSIG (RFC 8945), qui repose sur un secret partagé, et est donc inutilisable pour un service public comme Google DNS, et SIG(0) (RFC 2931), que personne n'a jamais déployé). Dans les deux cas, je ne crois pas qu'aucun stub resolver existant (par exemple la GNU libc) ne le gère, ce qui les rend complètement irréalistes et explique pourquoi Google n'offre pas ce service de sécurité.
Bref, il n'y a de raisons d'utiliser un service de résolveurs externe que si le « sien » est dramatiquement défaillant. Mais, dans ce cas, quelles sont les conséquences ? D'abord, il y a un problème spécifique à Google : l'existence d'une offre très vaste couvrant à peu près tout les services Internet. Si malhonnête que soit OpenDNS, quoi qu'ils fassent des données recueillies sur les utilisateurs, le fait qu'ils ne gèrent qu'un unique service limite les corréalations qu'ils peuvent établir et donc le mal qu'ils peuvent faire.
Au contraire, Google, ayant une offre complète, peut établir des relations, mettre en connexion des données, et représente donc un danger potentiel plus important. Externaliser son courrier à Gmail (ou son DNS à Google DNS), est une chose. Externaliser tous ses services en est une autre. Cela revient à avoir la même entreprise qui serait à la fois votre banque, votre médecin, votre épicier et votre garagiste...
Comment Google peut-il exploiter Google DNS, service gratuit ? Ici, je spécule, je n'ai pas d'informations précises. Google peut gagner de l'argent :
- en exploitant l'information recueillie pour améliorer le moteur de recherche,
- en vendant cette information (les noms les plus populaires,
par exemple, une information qui intéressera les
domainers, surtout si la
réponse est
NXDOMAIN, indiquant que le domaine est libre), - en hébergeant, dans le futur (ce service n'existe pas aujourd'hui), moyennant finances, des serveurs faisant autorité, qui profiteront de la proximité du résolveur pour de meilleures performances. Google, futur hébergeur de TLD ?
- Reconstituer la totalité d'un TLD, même lorsque celui-ci ne publie pas cette information, en comptant les noms dans les requêtes et les réponses obtenues.
- Ou, tout simplement, s'assurer que l'Internet fonctionne bien, pour que les clients puissent aller voir les autres services de Google (chez certains FAI, les résolveurs DNS marchent mal, ce qui gêne sans doute Google dans son cœur de métier).
L'article seul
Exposé DNSSEC à JRES
Première rédaction de cet article le 4 décembre 2009
Le 4 décembre, à Nantes, j'ai eu le plaisir de faire un exposé lors des JRES sur le sujet « Sécurité du DNS et DNSSEC ».
Voici les documents produits à cette occasion :
- L'article, en format PDF ou son original en format OpenOffice.
- Les transparents en PDF. Et leur source en format OpenOffice. Il s'agit d'une version réduite et mise à jour de ceux que j'avais présentés à SARSSI.
L'article est sous GFDL (JRES n'ajoute pas de contraintes). Pour les transparents, leur licence est dans l'avant-dernier (transparents issus d'un projet collectif et ayant eu une longue histoire).
PS : l'exemple NSEC est faux (merci à Rani Zaidi) car
ftp.nic.example n'est pas entre
ns2 et www.
L'article seul
L'OARC, un exemple d'ISAC
Première rédaction de cet article le 3 décembre 2009
Si vous aimez les acronymes de quatre lettres, en voici un dont je viens d'apprendre l'existence alors qu'il n'est même pas dans Wikipédia : ISAC pour Information Sharing and Analysis Center. L'OARC est un exemple d'ISAC, pour le DNS.
Ce terme générique d'ISAC recouvre toutes les organisations qui font du partage de données et d'expériences, en général dans les secteurs d'activité considérés comme critiques (devant fonctionner sans panne). Quelques exemples :
- IT-ISAC, pour l'informatique, plutôt tendance grosses entreprises sérieuses (leur site Web ne me convainc pas),
- Multi-State Information Sharing and Analysis Center, pour l'informatique aussi,
- Financial Services ISAC,
- Une ISAC pour le transport terrestre.
Donc, l'OARC (DNS Operations Analysis and Research Center) est une ISAC. Dire que j'ai été élu au CA sans savoir cela.
Par contre, je sais ce que fais l'OARC : recevoir des informations de ses membres et leur rendre accessible ces informations. En pratique, le gros du travail aujourd'hui est de gérer les fichiers pcap envoyés par des opérateurs de serveurs de noms et de les analyser. Cela peut mener à la publication de rapports comme celui sur les conséquences de l'augmentation de taille de la racine. Il y a aussi de très intéressantes réunions (la prochaine est à Prague en mai 2010) et des outils très pratiques.
L'article seul
Le rejet des règles de sécurité peut être raisonnable
Première rédaction de cet article le 2 décembre 2009
Si les utilisateurs s'obstinent à violer les règles de sécurité que les spécialistes de sécurité leur imposent, est-ce parce qu'ils sont bêtes et obstinés ? Ou bien parce qu'il font un calcul plus raisonnable qu'on ne pourrait le penser ? Un économiste tente de répondre à la question.
Cormac Herley, dans son article « So Long, And No Thanks for the Externalities: The Rational Rejection of Security Advice by Users » étudie le comportement des utilisateurs, lors de questions de sécurité informatique, à la lumière de calculs économiques rationnels. Excellent article, très provoquant. Sa thèse est que l'insistance des responsables de sécurité informatique, ou des informaticiens, à exiger des utilisateurs qu'ils appliquent des règles de sécurité contraignantes est non seulement sans espoir (ce que tout informaticien a déjà pu constater) mais également inappropriée. Les mesures de sécurité coûtent cher et il n'y a quasiment jamais d'analyse coût/bénéfice de celles-ci. On demande aux utilisateurs de passer du temps, donc de l'argent, pour résoudre des problèmes qui ne se posent finalement que rarement.
Un des meilleurs exemples de Cormac Herley concerne les certificats X.509. Lorsqu'une alerte de sécurité survient, il s'agit dans la quasi-totalité des cas d'une fausse alerte (certificat signé par une CA qui n'est pas dans le magasin, magasin qui est rempli assez arbitrairement, ou bien certificat expiré). Les vraies attaques sont très rares. Une analyse coût/bénéfice rationnelle comparerait le produit de cette probabilité d'attaque par le coût d'une attaque réussie, avec le coût des mesures de sécurité (ne pas pouvoir accomplir la tâche souhaitée). Et cette analyse dirait probablement que l'utilisateur qui s'obstine à passer outre l'avertissement et le parcours du combattant qu'impose Firefox 3 pour ignorer l'alarme, cet utilisateur est raisonnable.
Même chose avec l'analyse des URL dans le navigateur pour tenter de détecter une tentative de hameçonnage. Même si cette analyse ne prend que dix secondes par utilisateur, multipliée par le nombre d'utilisateurs et leur salaire horaire, cette vérification coûterait plus cher que le hameçonnage (l'article comprend un calcul détaillé, dans le cas des États-Unis). C'est bien la raison pour laquelle toutes les études sur le hameçonnage montrent qu'il n'y a pas d'utilisation de noms de domaines « confondables » (contrairement à ce qu'on lit souvent pour s'opposer aux noms de domaine en Unicode).
Je ne dis pas que je suis d'accord avec l'auteur en tout. Il oublie de prendre en compte les effets rebonds (certaines attaques sont très rares mais, si on baisse la garde en pensant que les précautions coûtent trop cher, le nombre d'attaques va augmenter). Et les utilisateurs ne sont pas forcément rationnels car ils sous-estiment (souvent) ou sur-estiment (plus rarement) certains risques techniques. Mais Cormac Herley a le mérite de poser enfin le problème : dans certains cas (mots de passe par exemple), on n'a presque pas de données sur les attaques réussies par suite d'une trop faible sécurité. Alors, faut-il continuer à prôner aveuglément des mesures de sécurité, sans aucune mesure de leur rentabilité ?
L'article seul
Fin du groupe de travail LTRU
Première rédaction de cet article le 30 novembre 2009
Le groupe de travail LTRU (Language Tag Registry Update) de l'IETF vient d'être dissous, après un long travail, finalement couronné de succès.
À l'IETF, les groupes de travail ne sont pas éternels (à quelques exceptions près). Ils sont créés pour une tâche spécifique, décrite dans leur charte, et sont dissous dès qu'elle est accomplie, pour éviter la création de bureaucraties qui s'auto-entretiennent. C'est ce qui vient d'arriver au groupe de travail LTRU.
LTRU était chargé de mettre à jour le vieux RFC 3066 sur
les étiquettes de langue, ces courts
identificateurs qui permettent d'indiquer la langue d'un document ou
la langue souhaitée par un utilisateur (par exemple
br pour le breton ou
mn-Latn pour le mongol en
alphabet latin). Cela a été fait en deux temps, avec la création du
RFC 4646 en septembre 2006 (ce RFC introduisait
la notion de sous-étiquette, à partir de laquelle on pouvait génerer
les étiquettes de son choix), puis avec celle du RFC 5646 en septembre 2009 (qui intégrait les nouveautés de
ISO 639-3). Les discussions ont été
longues et souvent
acharnées mais le résultat est là.
Une particularité curieuse de LTRU : il fut un des rares groupes de travail de l'IETF à ne jamais avoir de rencontre physique. Ses membres n'ont interagi que par le biais de la liste de diffusion.
Aujourd'hui, il reste de ce groupe la liste (toujours ouverte), le site Web et, bien sûr, les RFC produits...
L'article seul
RFC 5536: Netnews Article Format
Date de publication du RFC : Novembre 2009
Auteur(s) du RFC : K. Murchison (Carnegie Mellon
University), C. Lindsey (University of
Manchester), D. Kohn (FlyDash)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF usefor
Première rédaction de cet article le 29 novembre 2009
Malgré la concurrence de la messagerie instantanée, du courrier, du Web avec la syndication, Usenet / Netnews, un des plus anciens outils numériques de communication et de distribution d'information continue à vivre. Plus ancien que l'Internet sur beaucoup de sites (Usenet était souvent distribué via UUCP), ce dinosaure continue à faire la joie et le désespoir de millions d'utilisateurs. Mais ses normes avaient un peu vieilli et pas subi de mise à jour depuis longtemps. C'est heureusement ce qui vient de leur arriver, dans une série de RFC dont les premiers publiés sont le RFC 5537 et notre RFC 5536, qui normalise le format des messages. Ces documents ont pris plus de huit ans à être élaborés et approuvés.
Notre RFC 5536 est le successeur du célèbre RFC 1036, publié en décembre 1987, et qui spécifiait avant lui le format des messages (comme ce que fait le RFC 5322 pour le courrier). Depuis des années, les mises en œuvres existantes de Usenet utilisaient un sur-ensemble du RFC 1036, sur-ensemble qui vient d'être normalisé. (Avant cela, ces améliorations étaient contenues dans un document informel, « Son of RFC 1036 », qui a finalement été publié en RFC 1849.)
Les news comprennent plusieurs parties : le protocole de transport des messages, aujourd'hui essentiellement NNTP (RFC 3977), le format des messages (notre RFC 5536) et des conventions plus ou moins formelles entre les sites qui s'envoient des messages NetNews, ces sites formant le réseau Usenet (ou des réseaux privés).
Que contient concrètement notre RFC ? La section résume les concepts de base. « NetNews » est composé d'un ensemble de protocoles pour stocker, transmettre et lire des articles, organisés en groupes (newsgroups). Ces articles sont typiquement distribués au sein d'Usenet par un algorithme d'inondation. Pour retrouver facilement un article, et déterminer s'il est déjà présent localement, le serveur Usenet utilise un Message ID (section 3.1.3) qui est présent dans chaque article, et est unique. Le format NetNews est très proche de celui du courrier, tel que décrit dans les RFC 5322 et RFC 2045. La définition de la syntaxe d'un article (section 1.4) emprunte également beaucoup au RFC 5322 (voir annexe C, qui développe les différences entre les deux formats ; notre RFC 5536 a une syntaxe plus stricte).
La section 2 décrit en détail ce format, en partant du RFC 5322, mais en ajoutant des restrictions (section 2.2). L'internationalisation, comme pour le courrier, est assurée par MIME (section 2.3) et notamment les RFC 2049 et RFC 2231 (voir aussi la section 4).
Une fois les principes de base du format posés dans la section 2,
la section suivante décrit chaque en-tête possible. Certains sont
obligatoires dans tout article (section 3.1) comme
Date: (section 3.1.1) ou
From: (3.1.2). Est également obligatoire
Message-ID: (section 3.1.3) qui est un
identifiant unique de l'article, sur lequel les serveurs se basent
pour mettre en œuvre l'algorithme d'inondation. Les
identificateurs d'articles
sont transmis à tous les serveurs voisins, ceux-ci pouvant alors dire
s'ils acceptent ou refusent (car ils ont déjà un article de même
Message-ID:). (Le Message-ID: sert également aux recherches d'un article, par exemple, via GoogleGroups.)
Dans les en-têtes obligatoires, on trouve également
Newsgroups: (section 3.1.4) qui donne la liste des groupes dans
lequel l'article a été envoyé et Path: (3.1.5),
qui est la séquence des serveurs par lesquels est passé l'article,
séparés par des !. Cet en-tête vise à empêcher
les boucles dans l'algorithme d'inondation : même si la détection d'un
Message-ID: connu ne marche pas, le fait que le
serveur apercevra son nom dans le path: lui
indiquera qu'il doit rejeter l'article.
L'ancienneté des NetNews fait que beaucoup de points de la norme
s'expliquent par des raisons historiques. Ainsi, le fait de mettre le
nom de l'expéditeur au début du Path: et la ressemblance d'un
Path: avec une adresse
UUCP avec route explicite ne sont pas un
hasard. Dans les réseaux UUCP, le Path: pouvait
être utilisé comme adresse de courrier, pour écrire à l'expéditeur
(cet usage s'est perdu et notre RFC recommande de mettre
not-for-mail comme adresse d'expéditeur).
Bien sûr, il y a aussi des en-têtes facultatifs, décrits dans la
section 3.2 : c'est le cas par exemple de
Archive: (section 3.2.2) qui indique si
l'expéditeur veut que son message puisse être archivé
(Google permet de chercher dans tous les
articles échangés sur Usenet depuis
1981).
Expires: (section 3.2.5) sert à indiquer au
bout de combien de temps l'article peut être supprimé d'un serveur qui
veut faire de la place (en l'absence de cet en-tête, le serveur décide
seul de la date d'expiration).
Et il y a bien d'autres en-têtes possibles dans cette section 3.2.
Quelle est la sécurité offerte par Usenet ? Nulle, rappelle la section 5. Les articles ne sont pas confidentiels et leur intégrité n'est pas garantie.
La liste complète des changements depuis le RFC 1036
apparait en annexe B. MIME est désormais
formellement reconnu (la plupart des logiciels le géraient depuis
longtemps mais il n'existait pas à l'époque du RFC 1036). Certains en-têtes largement acceptés par les logiciels
deviennent officiels, comme Archive:. Autrement, les changements sont surtout du toilettage
de syntaxe.
Voici, tel qu'il passe sur le réseau (affiché dans un logiciel de lecture, cela peut évidemment être très différent) un article à ce format :
Path: news.free.fr!xref-2.proxad.net!spooler1c-1.proxad.net!cleanfeed2-a.proxad.net!nnrp3-2.free.fr!not-for-mail From: Stephane Acounis <panews@free.fr> Subject: =?iso-8859-1?b?wA==?= donner: Sun(s) SS20 sur Nantes Date: Mon, 09 Jun 2008 19:24:17 +0200 User-Agent: Pan/0.14.2 (This is not a psychotic episode. It's a cleansing moment of clarity.) Message-Id: <pan.2008.06.09.17.24.16.590396@free.fr> Newsgroups: fr.comp.ordinosaures MIME-Version: 1.0 Content-Type: text/plain; charset=ISO-8859-15 Content-Transfer-Encoding: 8bit Bonsoir, J'ai deux stations Sun SS20, une bi-pro (SM75), l'autre mono-pro (SM75), à donner sur Nantes (ou Nançay mercredi/jeudi ou Brest vendredi). 256Mo de mémoire vive, disque 9Go, carte vidéo. Je doit avoir des claviers, des câbles divers, des cartes SBus en plus. ...
Notez l'en-tête Subject: encodé selon le RFC 2047.
NetNews est mis en œuvre dans de nombreux logiciels aujourd'hui, souvent dans les logiciels de courrier, vu la ressemblance des formats. C'est ainsi que le célèbre MUA Thunderbird est également un bon lecteur de News.
L'article seul
RFC 5537: Netnews Architecture and Protocols
Date de publication du RFC : Novembre 2009
Auteur(s) du RFC : R. Allbery (Stanford)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF usefor
Première rédaction de cet article le 29 novembre 2009
L'antique RFC 1036 qui, pendant les vingt dernières années, était la seule norme gouvernant le système de news, vient d'être remplacé par une série de RFC dont celui qui fait l'objet de cet article, le RFC 5537 qui décrit l'architecture générale des news.
Les news (ou Netnews, dit le RFC) sont un extraordinaire système de distribution de messages, organisés en groupes de discussion (newsgroups). Chacun de ces groupes peut être un vecteur d'annonces ou bien un forum de discussion, où la vigueur de ces discussions sont une caractéristique fréquente des news. Les news existaient avant que l'Internet ne se répande et, jusqu'à très récemment, était souvent distribuées avec des protocoles non-TCP/IP tel qu'UUCP. Mille fois, la fin des news a été annoncée, au profit de gadgets récents accessibles via le Web et à chaque fois, elles ont continué à inonder les serveurs et à passionner des dizaines de milliers de participants. À l'époque où n'importe quel système de communication via le Web fait immédaitement l'objet de l'attention des médias et des experts, les news reste un outil « invisible » (en tout cas invisible aux chefs, aux experts, aux ministres et aux journalistes), ce qui fait une bonne partie de leur charme.
Maintenant, place à la technique. Comment les news
fonctionnent-elles (section 1 de notre RFC) ? Les serveurs de news s'échangent des articles,
dans un format normalisé. Les articles sont regroupés en groupes comme
fr.reseaux.internet.hebergement ou soc.culture.belgium. Les
groupes qui partagent un préfixe commun comme fr
forment une hiérarchie. Chaque
serveur transmet ses articles à ses voisins qui, à leur tour, le
transmettent à leurs voisins, un protocole dit
d'inondation (il existe d'autres protocoles fondés sur le bavardage de proche en proche dans l'Internet). Un ensemble de serveurs ainsi
reliés est un réseau et le principal se nomme
Usenet (il existe aussi des réseaux privés,
bien plus petits). Lorsque les gens disent qu'ils lisent les news
ils font en général allusion à celles d'Usenet.
Les deux principaux RFC de la nouvelle série, celle qui remplace le RFC 1036, sont le RFC 5536, qui normalise le format des messages, un format très inspiré de celui du courrier électronique, et notre RFC 5537 qui décrit le cadre général. L'annexe A est consacrée aux changements depuis le RFC 1036. Le développement de cette nouvelle série de RFC a finalement pris près de dix ans. (Une documentation du premier effort se trouve dans le RFC 1849, « Son of RFC 1036 ».)
Parmi les serveurs de news, la section 1.2 fait la distinction entre :
- injecting agent le premier serveur qui reçoit un article, article à qui il manquera peut-être quelques caractéristiques pour être tout à fait conforme à la norme,
- relaying agent un serveur qui recevra et transmettra un article, typiquement sans le modifier,
- serving agent, un serveur qui permettra la lecture par les clients finaux,
- user agent, le logiciel qui tourne sur le bureau de l'utilisateur final, lui-même séparé en posting agent qui permet d'écrire et reading agent qui permet de lire,
- et les passerelles, qui connectent le monde des news à d'autres systèmes, comme le courrier électronique ou le Web
mais, en pratique, beaucoup de logiciels assurent plusieurs fonctions à la fois. Par exemple, INN est injecting agent, relaying agent et serving agent.
Les devoirs des différents logiciels sont résumés dans la section 3. Il y a des grands principes (section 3.1), comme le Principe de Robustesse « Soyez restrictif dans ce que vous envoyez et ouvert pour ce que vous recevez » ou bien comme le principe d'Hippocrate, « Avant tout, ne pas nuire », c'est-à-dire que, en cas de doute, le logiciel doit s'abstenir d'intervenir. D'autant plus que le RFC rappelle que tous les lecteurs doivent voir le même article, ce qui interdit les modifications qui ne soient pas purement techniques.
Et il y a des règles plus pratiques. Par exemple, la section 3.2
est consacrée au champ Path: des en-têtes. Il
sert à indiquer le chemin parcouru par le message entre les
relaying agent et donc à éviter les boucles. Tout
serveur doit donc indiquer son identité dans ce champ (section 3.1.5
du RFC 5536, l'identité est en général le
nom de domaine du serveur). Les sections 3.2.1
et 3.2.2 détaillent le processus de formation du champ
Path:, bien plus riche que dans le RFC 1036. Un Path: peut être aussi complexe
que :
Path: foo.isp.example!.SEEN.isp.example!!foo-news
!.MISMATCH.2001:DB:0:0:8:800:200C:417A!bar.isp.example
!!old.site.example!barbaz!!baz.isp.example
!.POSTED.dialup123.baz.isp.example!not-for-mail
qui utilise la plupart des possibilités comme celle de noter que la
machine 2001:DB::8:800:200C:417A n'avait
peut-être pas le droit de se prétendre
bar.isp.example.
Tout aussi important que Path: qui permet
d'éviter les boucles et de détecter les problèmes, par exemple les
injections de spam, est l'en-tête
Message-ID: (section 3.1.3 du RFC 5536) qui sert à assurer l'unicité des articles et à garantir que
l'algorithme d'inondation se termine : un serveur refuse les articles
qu'il a déjà. Pour s'en souvenir, il doit donc stocker les
Message-ID: dans une base de données, souvent
nommée history (section 3.3).
La section 3.4 se penche ensuite sur le cas des posting
agents, le logiciel avec lequel l'utilisateur va interagir
pour écrire sur les news. Parmi leurs nombreuses tâches figure
celles liées aux réponses à des messages existants (sections 3.4.3 et
3.4.4). Le logiciel doit
notamment construire un champ References: qui
citera le Message-ID: du message auquel on répond,
permettant ainsi au lecteur de news de reconstituer les fils de
discussion (même s'il y aura toujours des ignorants pour voler les fils, comme avec le
courrier). Voici la partie de l'en-tête qui montre une réponse au
message
<l_CdnfgkWe7PWyLUnZ2dnUVZ8viWnZ2d@giganews.com> :
Newsgroups: fr.comp.reseaux.ethernet References: <l_CdnfgkWe7PWyLUnZ2dnUVZ8viWnZ2d@giganews.com> Subject: =?iso-8859-1?Q?Re:_Debogage_d'une_panne_r=E9seau?= Message-ID: <49bfceec$0$2734$ba4acef3@news.orange.fr>
Les news ne sont pas seulement une technique mais avant tout un réseau social (même si le mot n'était pas encore à la mode lors de leur création). Certains groupes sont donc modérés et il faut donc aussi spécifier les règles techniques que doivent observer les modérateurs (section 3.9).
Il n'y a pas que les news dans la vie et certains groupes peuvent
intéresser des gens qui ne veulent ou ne peuvent pas accéder aux
news. Le rôle des passerelles est donc de convertir les articles
depuis, ou vers le monde des news. Par exemple, une passerelle peut
traduire les news d'un groupe en HTML et les mettre sur
une page Web (voyez par exemple l'archive de
comp.os.research). Mais les passerelles les plus répandues sont
celles entre les news et le courrier
électronique, permettant aux utilisateurs du courrier
d'écrire sur les news ou bien de recevoir des news par
courrier. Historiquement, les passerelles ont souvent été responsables
de problèmes sur les news, par exemple de boucles sans fin (article
transmis du réseau A au réseau B puis retransmis vers A et ainsi de
suite éternellement) et la section 3.10 normalise donc ce
qu'elles doivent faire et ne pas faire. Les passerelles doivent
notamment conserver le Message-ID:, principale
protection contre les boucles, puisque permettant de voir qu'un
message est déjà passé. La section 3.10.4 donne un exemple complet
pour le cas d'une passerelle bidirectionnelle avec le courrier.
Aujourd'hui, la plupart des news sont transportées par le protocole NNTP, dont le RFC 3977 date d'un peu plus de deux ans. Mais, historiquement, UUCP (RFC 976) avait été très utilisé. La section 2 du RFC détaille les obligations de ces protocoles de transport, notamment le fait de pouvoir faire passer des caractères codés sur 8 bits (permettant ainsi des encodages comme Latin-1). Cette obligation, nécessaire à l'internationalisation a fait l'objet de longues luttes, depuis l'époque où les logiciels devaient encoder les messages écrits en français avec le Quoted-Printable. L'obligation s'applique aussi aux en-têtes des messages et un logiciel de news a donc davantage d'obligations ici qu'un logiciel de messagerie.
Une des particularités des news est que les messages de contrôle
(comme ceux demandant la création ou la suppression d'un groupe) sont
des messages comme les autres, distribués par le même mécanisme
d'inondation. La section 5 normalise ces messages. Le principe de base
est que le message de contrôle se reconnait par la présence d'un
champ Control: (section 3.2.3 du RFC 5536). Dans l'ancien RFC 1036, les messages de contrôle
pouvaient aussi se reconnaitre par un sujet spécial, commençant par
cmsg mais cet usage est désormais officiellement
abandonné.
Il n'y a aucune sécurité dans les news en général. Certains réseaux peuvent ajouter leurs propres mécanismes mais Usenet, par exemple, n'a pas de mécanisme général. Les messages de contrôle peuvent donc facilement être imités, même s'il existe des méthodes non officielles pour les authentifier (section 5.1). Usenet étant un réseau très animé et très peu policé, cette absence de sécurité a donc entrainé souvent des surprises. Le RFC rappelle donc l'importance de tenter de s'assurer de l'authenticité d'un message de contrôle (les méthodes pour cela ne sont pas normalisées mais, par exemple, INN peut vérifier les signatures PGP).
Les messages de contrôle permettent, par exemple, d'annuler un
message, de stopper sa diffusion (section 5.3). Comme on s'en doute,
ce sont parmi les messages les plus souvent usurpés. Le RFC 1036 demandait, dans l'espoir de renforcer la sécurité, que
l'expéditeur (tel qu'indiqué par le champ From:)
soit le même dans le message de contrôle et dans le message
initial. Comme il est trivial d'usurper cette identité, cela ne
faisait que diminuer la traçabilité, en décourageant les
« annulateurs » de s'identifier. Cette règle est donc supprimée par
notre RFC.
Les messages de contrôle liés à la gestion des groupes sont
décrits dans la section 5.2. Par exemple,
newgroup (section 5.2.1) permet de créer un
nouveau groupe. Il ressemble à :
From: "example.* Administrator" <admin@noc.example> Newsgroups: example.admin.info Control: newgroup example.admin.info moderated ...
Parlant de sécurité, la section 6 lui est entièrement consacrée. Elle résume dès le début la situation : NetNews avait été conçu pour la diffusion large de l'information, et la sécurité en est presque totalement absente. Des grosses erreurs de mise en œuvre avaient en outre aggravé les choses comme le fait que certains logiciels appliquaient (il y a longtemps) les messages de contrôle... en les passant, verbatim, au shell !
Avant de participer aux news il faut donc bien être conscient ce
ces problèmes : vulnérabilité aux dénis de
service (section 6.2), non-authentification de
l'expéditeur (attention donc si un message semble particulièrement
outrancier, son vrai expéditeur n'est peut-être pas celui affiché dans
le champ From:) et diffusion très large, parfois
au delà de ce qui était prévu (section 6.3).
Les articles de news étaient traditionnellement marqués, dans le
système MIME comme
message/news. Ce type n'a jamais été un grand
succès et notre RFC 5537 le remplace par trois nouveaux
types, décrits en section 4,
application/news-transmission pour un articles en
route vers un injecting agent ou bien un modérateur
et deux types pour les messages de contrôle,
application/news-groupinfo et application/news-checkgroups.
L'annexe A résume les changements depuis le RFC 1036. Parmi eux :
- Un format beaucoup plus riche du champ
Path:, permettant de mettre davantage d'informations comme la notification de suspicions sur l'origine d'un message, - Les nouveaux types MIME de la section 4,
- Les nouvelles règles pour le format des messages de contrôle,
notamment la suppression de la règle du sujet commençant par
cmsg, - La suppression de la règle de pseudo-authentification des
messages d'annulation (qui obligeait à ce que le champ
From:du message et de l'annulation correspondent), - Et de nombreuses précisions ou des normalisations de pratiques que tout le monde faisait mais qui n'étaient pas dans le précédent RFC.
Il existe aujourd'hui de nombreuses mises en œuvre des news en logiciel libre. Par example, parmi les logiciels client (lecture et écriture), xrn ou Thunderbird (ce dernier ne sert donc pas qu'au courrier). Parmi les serveurs, INN. Personnellement, je regrette que mon lecteur de courrier habituel, mutt, n'aie pas de fonction de lecture des news, même si plusieurs modifications non officielles ont déjà été proposées.
En 2001, l'achat par Google de la société DejaNews a mis à la disposition du géant de la recherche sur Internet une archive de tous les messages Usenet depuis 1981. Cette archive est désormais cherchable par date sur Google Groups. Si vous voulez chercher mon premier article envoyé sur les news... (Avec une double signature, une erreur de débutant.) Ou bien une discussion en 1993 sur le DNS...
L'article seul
Combien y a t-il vraiment de serveurs DNS racine ?
Première rédaction de cet article le 27 novembre 2009
Dernière mise à jour le 13 janvier 2010
La question resurgit régulièrement dans les discussions sur la gouvernance de l'Internet : combien le DNS a t-il de serveurs racine ?
Comme souvent avec les chiffres, tout dépend de ce qu'on mesure. La marionette du gouvernement états-unien se contredit même dans sa propre propagande. En 2007, l'ICANN criait bien fort qu'il n'y en avait pas que treize serveurs racine, pour se moquer des critiques de son concurrent, l'UIT. En 2009, dans les publications officielles de la même organisation, ils sont redevenus treize.
En fait, les deux textes ont raison, car ils ne mesurent pas la même chose. Ce qui est drôle est que le texte de 2007 est très agressif, très arrogant, laissant entendre que les gens qui parlent des « treize serveurs » sont des ignorants, alors que la même organisation reprend ce compte deux ans après.
Donc, si on veut les chiffres authentiques, il faut passer un peu de temps et mieux comprendre ce qu'il y a derrière les chiffres. On peut trouver tous les détails sur le site (non officiel) de certains des opérateurs des serveurs racine. Le résultat :
- Il y a onze organisations qui gèrent un serveur racine (VeriSign, ISI, Cogent, université du Maryland, NASA, ISC, armée US, Autonomica, RIPE-NCC, ICANN et WIDE). Seulement deux sont européennes et une japonaise, toutes les autres sont états-uniennes. Changer cette liste est à peu près impossible pour des raisons politiciennes. Il n'y a aucun processus pour recruter un gérant de serveur racine et aucun pour en licencier un, quelles que soient les choses étranges qu'il fasse. En l'absence d'autorité (au sens moral et politique du terme) qui puisse dire qu'on va remplacer telle organisation, qui ne rend pas un service génial, par telle autre (les bons ne manquent pas), la liste n'a jamais connu une seule modification depuis quinze ans, cas unique de stabilité dans l'Internet. Le statu quo semble la seule solution.
- Il y a treize noms dans la racine (treize
enregistrements NS pour « Name Server »), de
A.root-servers.netàM.root-servers.net. Avec dig, la commandedig NS .vous les affichera. Déduire de ce nombre une insuffisance de la résistance de la racine aux pannes (« Il n'y a que treize pauvres machines (et là on imagine un vieux serveur Dell sur son rack) ») serait donc erroné, ces treize serveurs ne sont pas treize machines. À noter que le nombre de treize vient de vieilles considérations sur l'ancienne taille des paquets DNS, limitée à 512 octets autrefois. La limite a été étendue il y a dix ans et a été effectivement dépassée lors de l'introduction des adresses IPv6 dans la racine en 2008 mais personne n'ose prendre la responsabilité de remettre en cause ce nombre magique de treize. - Il y a vingt et une adresses IP de serveurs de noms de la racine (certains n'ont pas encore une adresse IPv6).
- Grâce à l'anycast, il y a cent quatre vingt neuf sites physiques différents où se trouve un serveur racine, comme celui de Prague, annoncé dans le communiqué de l'ICANN d'octobre 2009. Un bon nombre de ces sites sont purement locaux, leurs annonces BGP ne sont pas propagées en dehors d'un cercle limité et ces sites ne sont donc pas accessibles de l'extérieur (par exemple, ils sont souvent limités aux opérateurs connectés à un même point d'échange). Ce nombre varie souvent et dépend uniquement des décisions de chaque organisation gérant un serveur. Certaines, les plus dynamiques comme l'ISC, ouvrent des sites à un rythme soutenu.
- Il y a un nombre inconnu de machines qui assurent ce service, certainement nettement plus de deux cents, la plupart des sites hébergeant plus qu'une machine, derrière un répartiteur de charge.
Si on va analyser la résistance de la racine aux pannes, le chiffre à prendre en considération dépend de la panne envisagée. Si c'est la panne d'un composant électronique dans un ordinateur, c'est bien le nombre de machines physiques qui est le paramètre important. Si la panne est un incendie ou un tremblement de terre, c'est plutôt le nombre de sites qui compte car la panne affectera tous les serveurs situés sur le site. Enfin, si la panne est de nature organisationnelle (cas de certains serveurs racines où l'organisation qui les héberge ne fait guère d'efforts et ne déploie guère de moyens, voire connait des conflits internes), c'est bien le chiffre de onze, le nombre d'organisations, qu'il faut prendre en compte pour évaluer la fiabilité de la racine.
Autres lectures sur ce sujet : un article technique très détaillé sur « pourquoi 13 et pas 14 » et une discussion sur certains points historiques.
L'article seul
Le musée d'histoire naturelle de Rouen n'a pas subi le sort imaginé par le romancier
Première rédaction de cet article le 27 novembre 2009
En 1996, Philippe Delerm publiait un court roman pour jeunes, « Sortilège au muséum ». Le cadre était le musée d'Histoire Naturelle de Rouen. Dans le roman, le musée va être fermé et certaines des collections vénérables déplacées vers un musée plus moderne, au grand déplaisir du jeune héros... et de certains fantômes.
C'est un très joli livre, hymne aux vieux musées poussiéreux de province et aux trésors improbables qu'ils renferment. Au moment où il a été écrit, le musée était un archétype de la muséologie du 19ème siècle, avec ses calmars dans le formol, ses animaux empaillés, ses têtes de « cannibales » prélevées par l'armée coloniale française (non exposées au public) et son parquet qui craque. Et il était effectivement question de le rénover de fond en comble.
Mais l'histoire a suivi un autre cours : le musée a simplement été nettoyé, dépoussiéré et mis aux normes de sécurité modernes. Le musée a rouvert en 2007. En 2009, il est quasiment dans l'état où il était avant sa longue fermeture.
Contrairement à la grande galerie de l'évolution à Paris, qui, après une incroyablement longue fermeture, a été refaite complètement et n'a plus rien à voir avec l'ancienne muséologie, le musée d'histoire naturelle de Rouen reste un « musée de musée ».
L'article seul
RFC 3207: SMTP Service Extension for Secure SMTP over Transport Layer Security
Date de publication du RFC : Février 2002
Auteur(s) du RFC : P. Hoffman (Internet Mail Consortium)
Chemin des normes
Première rédaction de cet article le 26 novembre 2009
Le courrier électronique, on le sait, n'offre guère de sécurité, que cela soit contre la lecture illégitime des messages ou bien contre l'injection de faux messages. Vue la complexité de son architecture (cf. RFC 5598), fruit d'une histoire longue et agitée, il ne faut pas espérer trouver la solution parfaite à tous les problèmes de sécurité du courrier. Aussi, ce RFC 3207 se contente d'apporter juste une brique à l'édifice, l'utilisation de TLS pour protéger le canal de communication entre deux MTA.
La communication normale entre deux de ces serveurs de messagerie se fait, avec le protocole SMTP, en clair. Aucune protection contre l'écoute ou la modification de données (section 1). Il n'y a pas non plus de moyen d'être sûr de l'authenticité du serveur en face. TLS, normalisé aujourd'hui dans le RFC 5246, fournit ces services de confidentialité (via le chiffrement) et d'authentification (via les certificats). Il faut noter que TLS ne sécurise ici que le canal entre deux serveurs, pas le message qui est transporté. Un message passe typiquement par plusieurs serveurs et toutes les communications ne seront pas forcément protégées par TLS. Même si elles le sont, si un des serveurs intermédiaires est malhonnête, TLS ne protégera pas (voir la section 6 du RFC qui détaille ce point de manière très complète). Au contraire, les solutions de sécurité de bout en bout comme PGP protégeront le message (mais sont peut-être plus difficiles à déployer).
Donc, le principe de ce RFC est de faire tourner SMTP au dessus de
TLS. Cela se fait par le biais d'une nouvelle extension SMTP,
STARTTLS, décrite en section 2 (contrairement à
HTTP, il n'y a pas de
port spécial où on utiliserait toujours
TLS).
Cette extension est composée d'une option qu'annonce le serveur
distant, STARTTLS :
220 mail.generic-nic.net ESMTP Postfix (Debian/GNU) EHLO chezmoi.example.net 250-mail.generic-nic.net 250-PIPELINING 250-SIZE 10240000 250-VRFY 250-ETRN 250-STARTTLS 250-ENHANCEDSTATUSCODES 250-8BITMIME 250 DSN ...
et d'une nouvelle commande, également nommée
STARTTLS, décrite en section 4 :
STARTTLS 220 2.0.0 Ready to start TLS ...
À cette commande, le serveur distant peut parfois répondre 454
(TLS not available due to temporary reason) auquel
cas l'initiateur de la connexion devra décider s'il continue sans TLS
(et est donc vulnérable à une attaque par repli,
où un attaquant actif essaie de faire croire que la sécurisation n'est
pas possible, voir la section 6 du RFC) ou de renoncer. Voir par
exemple l'option smtp_tls_security_level
= encrypt" de Postfix. Le RFC suggère (section 6) d'enregistrer le fait qu'un pair
donné utilise TLS et de refuser les connexions ultérieures si TLS a
été abandonné mais je ne connais aucune mise en œuvre de SMTP
sur TLS qui fasse cela.
Pour que le courrier puisse continuer à fonctionner dans l'Internet, le RFC impose qu'un serveur annoncé publiquement (par exemple, placé en partie droite d'un enregistrement MX) accepte les connexions sans TLS. En revanche, l'option TLS est particulièrement intéressante (section 4.3) si l'utilisateur humain est authentifié et donc si on utilise le port de soumission (RFC 4409).
Si la commande STARTTLS est un succès (code
220), la négociation TLS habituelle commence. Les deux parties
examinent ensuite ses résultats (par exemple l'algorithme de
cryptographie négocié, ou bien le certificat du
pair distant) et décident de continuer
ou pas (section 4.1).
Parlant du certificat, faut-il vérifier celui du voisin ? En pratique, quasiment personne ne le fait, en raison du prix des certificats et de la difficulté à les obtenir et les gérer. De nos jours, SMTP sur TLS procure donc la confidentialité par rapport à des écoutants passifs mais aucune authentification. À la rigueur, on peut toujours regarder les en-têtes du message pour avoir quelques informations supplémentaires :
Received: from mail.bortzmeyer.org (unknown [IPv6:2001:4b98:41::d946:bee8:232])
(using TLSv1 with cipher DHE-RSA-AES256-SHA (256/256 bits))
(Client CN "mail.bortzmeyer.org", Issuer "ca.bortzmeyer.org" (not verified))
by mx1.nic.fr (Postfix) with ESMTP id 964A71714088
for <echo@nic.fr>; Thu, 26 Nov 2009 12:08:08 +0100 (CET)
Si le MTA vérifie l'authenticité de son partenaire, le RFC lui laisse le choix des détails, recommandant seulement d'accepter un serveur situé dans le même domaine que celui qu'on cherche à contacter.
Une fois TLS négocié avec auccès, les machines doivent ignorer tout
ce qui a été tapé avant et reprendre la négociation SMTP
(EHLO et la suite), puisque l'information obtenue
sans TLS n'est pas fiable (section 4.2).
Ce RFC est une mise à jour de la première norme, le RFC 2487, en bien plus détaillé, notamment sur les attaques possibles (une annexe résume les changements).
La plupart des MTA aujourd'hui ont la capacité de faire du TLS, comme décrit pour Postfix dans mon article. Parmi les auto-répondeurs de test, certains acceptent TLS.
L'article seul
Une approche d'économiste sur le prix des routes BGP
Première rédaction de cet article le 25 novembre 2009
D'innombrables électrons ont déjà été agités pour discuter de l'architecture actuelle du routage sur l'Internet et des conséquences du multi-homing. La plupart de ces discussions portaient plutôt sur l'aspect technique. Voici un article de mai 2009 qui discute de l'aspect économique.
L'article « Internet Multi-Homing Problems: Explanations from Economics », de Richard Clayton (université de Cambridge) prend la question du multi-homing (qu'il appelle le « problème » du multi-homing, ce qui montre qu'il avait déjà une idée derrière la tête) en évaluant le coût, pour l'infrastructure globale de l'Internet, d'une annonce BGP supplémentaire, due au fait qu'un réseau devient multi-homé. L'article expose d'abord en détail et de maniètre très claire et très correcte le fonctionnement du routage (il cite des documents utiles comme le RFC 4116 ou le RFC 3582). Puis il passe aux applications numériques.
L'auteur (je résume son calcul) arrive à un coût total de l'infrastructure de routage de 23 milliards de dollars US (en additionnant le coût de tous les routeurs de tous les opérateurs). En divisant par le nombre de préfixes annoncés en BGP (près de 300 000), il arrive à 77 000 $ par préfixe. Ce coût est porté par tous les opérateurs de l'Internet et pas par le réseau multi-homé. Une décision locale, par les administrateurs du réseau multi-homé aura donc eu des conséquences globales. L'auteur ne fait donc pas preuve d'originalité en citant pour la millionième fois l'article de Hardin sur la tragédie des biens communs (article presque toujours cité à tort).
En économiste traditionnel, l'auteur demande donc la mise à l'étude d'un mécanisme de paiement permettant de récupérer cet argent auprès du réseau multi-homé. Il ne mentionne guère une autre approche, qui serait de modifier l'architecture de l'Internet (par exemple par une séparation de l'identificateur et du localisateur) pour rendre le multi-homing moins coûteux (seul SHIM6 (RFC 5533) est sérieusement cité, HIP (RFC 7401) est éliminé sans explication).
Une autre idée originale est de demander que l'IETF aie une section Economic Considerations obligatoire dans ses RFC comme c'est déjà le cas pour la sécurité, avec les obligations du RFC 3552. Mais l'IETF, bien qu'ayant souvent discuté de cette approche, a toujours refusé de prendre en compte les questions économiques. Deux raisons à cela : l'IETF n'a pas de compétence particulière dans ce domaine et les questions économiques sont très différentes des questions techniques. On ne peut pas changer la vitesse de la lumière alors que les « lois » économiques sont le résultat de décisions politiques, qui peuvent changer.
L'article seul
RFC 4310: Domain Name System (DNS) Security Extensions Mapping for the Extensible Provisioning Protocol (EPP)
Date de publication du RFC : Décembre 2005
Auteur(s) du RFC : S. Hollenbeck (Verisign)
Chemin des normes
Première rédaction de cet article le 25 novembre 2009
Le protocole EPP d'avitaillement d'un registre (par exemple un registre de noms de domaine), normalisé dans le RFC 5730, manipule des objets qui sont des instances d'une classe (nommée mapping). Par exemple, il existe une classe (un mapping) pour les noms de domaine, décrite dans le RFC 5731. Notre RFC 4310 (remplacé depuis par le RFC 5910) décrit, lui, une extension EPP à ce mapping permettant de spécifier les données nécessaires à DNSSEC, notamment la clé publique d'une zone signée.
DNSSEC, normalisé dans le RFC 4033, utilise la même délégation que le DNS. La zone parente d'une zone signée délègue en indiquant la clé publique de sa zone fille. Plus exactement, la zone parente publie un condensat cryptographique de la clé publique de la zone fille, l'enregistrement DS (pour Delegation Signer), normalisé dans la section 5 du RFC 4034 (voir aussi le rappel en section 2.1 de notre RFC 4310).
Lorsqu'un bureau d'enregistrement crée un nom de domaine signé, ou bien informe le registre qu'un domaine est désormais signé, comment indique t-il ce DS ? Il y a plusieurs façons, et notre RFC propose d'utiliser EPP.
L'extension nécessaire est résumée en section 2. Elle fonctionne en ajoutant des éléments à la classe Domaine du RFC 5731. Un élément obligatoire est le condensat cryptographique de la clé (alors qu'il n'est pas forcément unique : cette erreur a été corrigée dans le RFC 5910). Mais le client EPP peut aussi fournir la clé elle-même (le RFC 6781 explique pourquoi le condensat, le futur DS, est obligatoire alors que la clé est facultative). Le RFC prévoit également que le registre de la zone parente peut également récupérer la clé dans le DNS (enregistrement DNSKEY) pour tester si le condensat reçu est correct (et il est donc recommandé que ladite DNSKEY soit publiée avant de prévenir le parent par EPP). La clé transmise au registre doit être une clé de confiance, c'est-à-dire avoir le bit SEP à 1 (cf. RFC 3757). En terminologie moderne, cette clé doit être une KSK (Key Signing Key).
Les commandes EPP pour gérer cette information font l'objet de la
section 3. Ainsi, les réponses à <info>
doivent désormais contenir un élément
<secDNS:infData>, qui contient lui-même des
éléments comme <secDNS:dsData> qui a son
tour contient les champs qu'on trouve dans un enregistrement DS comme
<secDNS:keyTag> (l'identificateur de la
clé), <secDNS:alg> (l'algorithme utilisé),
etc. L'espace de noms
urn:ietf:params:xml:ns:secDNS-1.0 (ici avec le
préfixe secDNS) est enregistré dans le registre IANA (voir section 6). (C'est désormais secDNS-1.1, depuis le RFC 5910.) Voici un exemple de réponse à
<info> sur le domaine
example.com :
<resData>
...
<domain:name>example.com</domain:name>
...
<extension>
<secDNS:infData
xmlns:secDNS="urn:ietf:params:xml:ns:secDNS-1.0"
xsi:schemaLocation="urn:ietf:params:xml:ns:secDNS-1.0 secDNS-1.0.xsd">
<secDNS:dsData>
<secDNS:keyTag>12345</secDNS:keyTag>
<secDNS:alg>3</secDNS:alg>
<secDNS:digestType>1</secDNS:digestType>
<secDNS:digest>49FD46E6C4B45C55D4AC</secDNS:digest>
</secDNS:dsData>
</secDNS:infData>
</extension>
Le condensat est de type SHA1
(<digestType>1</digestType>), la clé
elle-même étant DSA/SHA1
(<alg>3</alg>).
L'extension DNSEC permet évidemment de créer un domaine signé, avec <create> (section 3.2.1) :
<domain:create>
<domain:name>example.com</domain:name>
...
<extension>
<secDNS:create xmlns:secDNS="urn:ietf:params:xml:ns:secDNS-1.0"
xsi:schemaLocation="urn:ietf:params:xml:ns:secDNS-1.0 secDNS-1.0.xsd">
<secDNS:dsData>
<secDNS:keyTag>12345</secDNS:keyTag>
<secDNS:alg>3</secDNS:alg>
<secDNS:digestType>1</secDNS:digestType>
<secDNS:digest>49FD46E6C4B45C55D4AC</secDNS:digest>
<!-- <secDNS:keyData>, la clé elle-même, est *facultatif* -->
</secDNS:dsData>
</secDNS:create>
...
Une fois le domaine ainsi créé, le registre publiera typiquement un enregistrement DS comme :
example.com. IN DS 12345 3 1 49FD46E6C4B45C55D4AC
Bien sûr, on peut aussi ajouter DNSSEC à un domaine existant, ou
bien changer une clé existante. Cela se fait avec
<update> :
<domain:update>
<domain:name>example.com</domain:name>
...
<extension>
<secDNS:update
xmlns:secDNS="urn:ietf:params:xml:ns:secDNS-1.0"
xsi:schemaLocation="urn:ietf:params:xml:ns:secDNS-1.0 secDNS-1.0.xsd">
<secDNS:add>
<secDNS:dsData>
<secDNS:keyTag>12346</secDNS:keyTag>
<secDNS:alg>3</secDNS:alg>
<secDNS:digestType>1</secDNS:digestType>
<secDNS:digest>38EC35D5B3A34B44C39B</secDNS:digest>
<!-- <secDNS:keyData>, la clé elle-même, est *facultatif* -->
</secDNS:dsData>
</secDNS:add>
</secDNS:update>
...
Et, en utilisant <secDNS:rem> au
lieu de <secDNS:add>, on peut retirer une
délégation sécurisée (« dé-signer » le domaine).
Comme la grande majorité des extensions et mappings d'EPP, celle-ci est spécifiée en utilisant la syntaxe formelle des W3C schemas, ici en section 4.
L'article seul
Des numéros d'AS attribués deux fois à des organismes différents
Première rédaction de cet article le 24 novembre 2009
Dernière mise à jour le 21 décembre 2009
Il existe un certain nombre de ressources virtuelles sur l'Internet qui doivent être uniques. Les noms de domaine, par exemple. Pour cela, toute une infrastructure est mise en place, en partant de l'IANA, pour s'assurer de cette unicité. Mais cette infrastructure peut cafouiller, comme en août dernier où des numéros d'AS ont été attribués deux fois...
Le numéro d'AS est utilisé dans des protocoles comme BGP. Il identifie de manière (normalement) unique un système autonome qui est une collection de réseaux gérés par la même entité (typiquement, un opérateur réseau). C'est ainsi que PCH, par exemple, a le numéro 42. On peut trouver des informations liées à un numéro d'AS avec whois, par exemple, pour un AS de mon employeur :
% whois -h whois.ripe.net AS2486 ... aut-num: AS2486 as-name: NIC-FR-DNS-TH2 descr: AFNIC remarks: Peering: peering@nic.fr remarks: NOC: noc@nic.fr ...
Normalement, pour que BGP fonctionne, un numéro d'AS doit être unique au niveau mondial. L'IANA alloue des plages de numéros contigus à des RIR qui les affecte ensuite à leurs membres et aux clients de ceux-ci. L'AS 2486, cité plus haut, a ainsi été délégué par le RIPE-NCC à l'AFNIC.
Mais cette unicité suppose un minimum d'attention de la part des
RIR et il vient d'y avoir un gros cafouillage. Toute une plage (de
l'AS 1708 au 1726), avait été transférée du RIPE-NCC à
l'ARIN sans faire attention aux faits qu'ils
étaient déjà alloués (voir https://www.iana.org/assignments/as-numbers/).
En août 2009, l'ARIN a commencé à les affecter
et des collisions se sont déjà produites. Ansi, l'AS 1712
« appartient » désormais à la fois à Télécom Paris
Tech et à un opérateur texan :
% whois -h whois.ripe.net AS1712 aut-num: AS1712 as-name: FR-RENATER-ENST descr: Ecole Nationale Superieure des Telecommunications, descr: Paris, France. descr: FR % whois -h whois.arin.net AS1712 OrgName: Twilight Communications City: Wallis StateProv: TX Country: US
Et le 1715 est à la fois à REMIP et chez un new-yorkais qui fait des placements dans les paradis fiscaux :
% whois -h whois.ripe.net AS1715 aut-num: AS1715 as-name: FR-REMIP2000 descr: REMIP 2000 Autonomous System descr: Metropolitan Network descr: Toulouse City France descr: FR % whois -h whois.arin.net AS1715 OrgName: Harrier Hawk Management LLC City: New York StateProv: NY Country: US
Une telle erreur est grave dans son principe et indique un sérieux cafouillage du système des RIR. Quelles sont ses conséquences pratiques ? Les deux AS jumeaux ne peuvent pas se voir l'un l'autre, car les annonces BGP entrantes de l'« autre » sont refusées, BGP interprétant la présence de son propre AS dans le chemin comme le signe d'une boucle. Par contre, les autres AS peuvent voir les deux annonces, qui portent sur des préfixes d'adresses IP différents. Voici un préfixe de Twilight et un de Télécom Paris Tech / ENST, depuis un site tiers (rappel : les chemins d'AS se lisent de droite à gauche, comme les mangas, l'AS d'origine est donc le plus à droite) :
% bgproute 74.118.148.1 AS path: 3277 3267 174 701 1712 Route: 74.118.148.0/22 % bgproute 137.194.2.1 AS path: 293 20965 2200 2422 1712 Route: 137.194.0.0/16
La solution adoptée (et annoncée officiellement le 26 novembre) a été d'annuler les allocations faites par ARIN, les plus récentes. Au 21 décembre, cela n'était réalisé que pour 5 AS sur 19 (ce qui n'est pas étonnant, les clients d'ARIN qui ont reçu ces numéros ne sont évidemment pas enthousiastes à l'idée de renuméroter).
Pour les prochaines fois, les RIR se sont engagés à faire ce que n'a pas fait ARIN : tester, avant d'affecter un numéro d'AS, s'il est dans les bases des autres RIR, et s'il est utilisé dans la table de routage BGP globale (s'il est annoncé, ce qui n'est pas le cas de tous les AS).
Merci à Jean-Louis Rougier, Éric Elena et Pierre Beyssac pour le diagnostic et l'analyse. Un article ultérieur de Renesys montre qu'il existe d'autres problèmes de conflit de numéro d'AS, en général bien moins graves et plutôt dus à des problèmes internes aux entreprises, liés aux divers rachats et fusions..
L'article seul
Le koala n'est pas vraiment karmique pour moi
Première rédaction de cet article le 24 novembre 2009
Je viens de passer un portable Ubuntu dans la dernière version de ce système d'exploitation et j'ai bien galéré autour de gdm.
Ubuntu a de jolis noms pour ses versions. Je viens
de passer du Bouquetin Intrépide au Koala Karmique (en sautant l'étape
intermédiaire du Jackalope Enjoué, ce qui
ajoutait un élément de risque). En gros, ça s'est bien passé, sauf que
gdm (Gnome Display Manager)
ne se lançait plus normalement. Lancé à la main par sudo
gdm, tout allait bien. Lancé par le système lui-même au
démarrage, ou bien par la commande officielle sudo service
gdm start,
X se lance mais gdm plante presque aussitôt et me laisse avec un écran
X tout noir (l'écran reste vraiment noir, sans clignoter).
Des commandes comme aptitude dist-upgrade
(pour être sûr que tout soit à jour) ou
aptitude install ubuntu-desktop (pour être sûr
qu'il ne manque rien) n'aident pas (merci à gabe, à ce sujet).
Après pas mal de temps passé, la solution est de retourner à l'ancien gdm, comme expliqué en
http://richardsantoro.wordpress.com/2009/11/02/ubuntu-9-10-karmic-koala-reinstaller-lancien-gdm/
ou en http://www.ubuntugeek.com/how-to-downgrade-gnome-display-manager-2-28-to-2-20-in-ubuntu-9-10-karmic.html. Cela
nécessite un peu de sed (s#X11R6/##) mais ça
marche. On peut trouver des détails dans la documentation d'Ubuntu en
français (merci à Antonio Kin-Foo pour son aide).
Bref, Ubuntu a parfois des bogues qui le rendent difficile pour les utilisateurs normaux.
L'article seul
RFC 5694: Peer-to-peer (P2P) Architectures
Date de publication du RFC : Novembre 2009
Auteur(s) du RFC : G. Camarillo
Pour information
Première rédaction de cet article le 24 novembre 2009
Il existe un très grand nombre de systèmes pair-à-pair et leur succès est un témoignage de la capacité de l'Internet à accepter des applications complètement imprévues à l'origine. Cette variété est telle qu'il est difficile de s'y retrouver, par exemple pour d'éventuels travaux de normalisation sur les protocoles pair-à-pair. D'où ce document de l'IAB, qui définit ce qu'est un système pair-à-pair, et propose une taxonomie de ceux-ci. Ce RFC propose également des méthodes pour analyser si un système pair-à-pair est adapté à un problème donné.
Pourtant, on ne manque pas de textes sur les systèmes pair-à-pair. Il y a eu de très nombreuses publications scientifiques, plusieurs conférences uniquement consacrées à ce sujet, et un groupe de travail de l'IRTF lui est entièrement voué. Et, bien sûr, il existe de nombreuses applications pair-à-pair, certaines avec un code source disponible, et parmi lesquelles se trouvent des applications parmi les plus populaires sur l'Internet.
Mais il n'existe pas encore de compréhension commune de ce qu'est le pair-à-pair et, pire, beaucoup de gens, de bonne ou de mauvaise foi, assimilent « pair-à-pair » aux seules activités illégales de transfert de fichiers (section 1 du RFC).
Le but de de document est donc d'aider à la construction de cette compréhension commune et de montrer que le pair-à-pair est largement utilisé pour des activités tout à fait légitimes.
La section 2 du RFC s'attaque à la définition du pair-à-pair. Il existe plusieurs définitions, qui ne sont pas forcément équivalentes, d'autant plus que le marketing s'en mêle et que « pair-à-pair » est souvent un terme vendeur. En outre, la section 2 prévient aussi que certains systèmes souvent qualifiés de « pair-à-pair » ne correspondront que partiellement à cette définition et ne pourront donc pas être considérés comme complètement « pair-à-pair ». Ce n'est pas forcément un défaut : le but est de bâtir le meilleur système possible, pas de coller à la définition du « pair-à-pair ». Bien des systèmes réussis sont « mixtes », mélangeant « pair-à-pair » et « centralisé ».
La définition de ce RFC 5694 est donc : « Est pair-à-pair un système où les éléments qui le composent partagent leurs ressources pour fournir le service pour lequel le système est prévu. Chaque élément du système fournit des services et en reçoit. » En théorie, cette définition impose que tous les éléments partagent leurs ressources mais, en pratique, il existe des systèmes où certains éléments sont des clients purs, ne fournissant aucune ressource. Le RFC considère qu'un système où les clients seraient nettement plus nombreux que les pairs ne serait pas réellement pair-à-pair. Par contre, le RFC note explicitement que le fait que certaines parties du système soient centralisées ne l'empêche pas d'être pair-à-pair. L'exemple cité est celui d'un système où il y aurait un serveur central pour enregistrer les nouveaux pairs. Un tel système serait pair-à-pair, selon la définition proposée.
On peut ensuite faire varier cette définition à l'infini, en ajoutant que les pairs doivent participer à des transactions qui ne leur bénéficient pas directement, ou que les pairs doivent pouvoir communiquer sans passage par un intermédiaire, ou que le contrôle doit être entièrement distribué (sans aucun serveur central, contrairement à ce qu'accepte la définition du RFC 5694).
Il est d'autant plus difficile de classer les systèmes pair-à-pair que beaucoup sont composites, faits de plusieurs services, pas forcément pair-à-pairs. Ainsi, si j'utilise un moteur de recherche BitTorrent accessible par le Web, comme btjunkie, pour récupérer ensuite un fichier avec le protocole BitTorrent, suis-je en pair-à-pair ou pas, le Web étant client/serveur ?
Notre définition étant posée, le reste de la section 2 va l'appliquer à divers systèmes existants, pour voir s'ils peuvent être considérés pair-à-pair ou pas.
La section 2.1 commence ces applications avec le DNS. Les résolveurs DNS étant des clients purs, qui ne fournissent aucun service, le DNS ne peut pas être considéré comme pair-à-pair selon la définition de notre RFC.
Et SIP (RFC 3261) ? La section 2.2 en rappelle les principes, notamment le fait que les user agents sont à la fois client et serveurs. Mais un user agent ne participe qu'aux transactions qui ont un intérêt pour lui (parce qu'il appelle ou bien qu'il est appelé) et le SIP traditionnel ne peut pas être considéré comme pair-à-pair. En revanche, P2PSIP, décrit en section 2.3, est différent : les user agents ne s'enregistrent plus auprès d'un serveur mais entre eux et la fonction de rendez-vous nécessite donc la participation d'autres pairs, qui n'y tirent pas de bénéfice personnel. P2PSIP est donc bien pair-à-pair.
L'un des protocoles pair-à-pair les plus connus est BitTorrent. La section 2.4 examine son cas. Comme un pair BitTorrent, non seulement récupère des fichiers pour son usage personnel, mais en outre en envoie à d'autres, sans que cela ne présente d'interêt pour eux, BitTorrent est bien pair-à-pair. Toutefois, le monde réel est toujours plus compliqué que cela et le RFC note que, si la majorité de l'essaim (l'ensemble des pairs), est composée de pairs ayant récupéré tous leurs fichiers et ne faisant plus que les distribuer (des seeders dans la terminologie BitTorrent), alors, l'essaim ne fonctionne plus vraiment en pair-à-pair.
Après ces études de cas, le RFC se penche, dans sa section 3, sur les fonctions qu'il faut assurer pour qu'un système pair-à-pair fonctionne. Au minimum, et quel que soit le service fourni par ce système, il faut assurer :
- Le recrutement, c'est-à-dire le mécanisme d'authentification et d'autorisation auxquels sont soumis les nouveaux pairs,
- La découverte des pairs : le nouveau nœud du réseau doit trouver un ou plusieurs pairs pour commencer la communication.
Dans certains systèmes pair-à-pairs (par exemple eDonkey), ces fonctions sont centralisées. Un serveur de recrutement (dit parfois bootstrap server) est contacté par les nouveaux venus, et il peut, après les avoir autorisés, les mettre en contact avec les autres pairs. Ce serveur est évidemment un point vulnérable du réseau mais notre RFC 5694 ne considère pas que son existence empêche le système d'être authentiquement pair-à-pair. En effet, les fonctions considérées comme significatives sont celles qui ont un rapport direct avec le service fourni.
À noter que ces fonctions peuvent avoir été programmées une fois pour toutes dans un ensemble logiciel qui sert de base pour la construction d'un système pair-à-pair (cf. section 5.4). C'est le cas par exemple de JXTA.
Celles-ci dépendent du service et ne sont donc pas présentes systématiquement. On trouve parmi elles :
- L'indexation des données présentes dans le système.
- Le stockage des données présentes dans le système.
- Les calculs que doit faire le système.
- L'acheminement de messages d'un pair à l'autre, acheminement qui peut impliquer plus de deux pairs.
Il reste à classer les différents systèmes pair-à-pair. La section de taxonomie est la numéro 4. Le problème n'est pas simple puisqu'il existe déjà plusieurs classifications incompatibles des systèmes pair-à-pair. Pire, le vocabulaire n'est même pas identique entre les auteurs (par exemple pour des termes comme « première génération » ou « deuxième génération »). Notre RFC propose de partir de la fonction d'indexation. Un index peut être centralisé, local ou distribué (cf. RFC 4981). Dans le premier cas, une seule machine garde trace de toutes les données (Napster fonctionnait ainsi). Dans le second, chaque machine se souvient des données qui l'intéressent (les premières versions de Gnutella fonctionnaient ainsi). Avec un index distribué, les références aux données se trouvent sur plusieurs machines. Les DHT sont un bon exemple d'un tel système.
On peut aussi classer les index entre ceux avec ou sans sémantique. Les premiers contiennent des informations sur les relations entre les données et les métadonnées mais pas les seconds. Les index avec sémantique permettent donc des recherches plus riches mais ne trouvent pas forcément toutes les données présentes.
D'autres auteurs ont classé les systèmes pair-à-pair entre systèmes hybrides (pas complètement pair-à-pair, par exemple parce qu'ils ont un index centralisé) et purs. Les systèmes purement pair-à-pair peuvent continuer à fonctionner même quand n'importe laquelle des machines qui les composent est en panne ou arrêtée.
Une autre classification est selon la structure. Les systèmes non structurés sont ceux où un nouveau pair peut se connecter à n'importe quel pair existant. Les systèmes structurés imposent au pair arrivant de ne se connecter qu'à certains pairs bien définis, en fonction de leur identité (c'est par exemple le cas des DHT, où les pairs sont en général organisés en un anneau virtuel dans l'ordre des identificateurs). Mais, là encore, la distinction n'est pas absolue et on trouve, par exemple, des systèmes non structurés où certains pairs ont des rôles particuliers.
Une autre classification qui a eu un relatif succès médiatique est par « génération ». Certains auteurs ont classé les systèmes à index centralisé dans une « première génération du pair-à-pair », ceux à index local dans la seconde génération et ceux utilisant une DHT dans la troisième. Cette classification a plusieurs problèmes, l'un des principaux étant qu'elle laisse entendre que chaque génération est supérieure à la précédente.
Aucune de ces classifications ne prend en compte les fonctions de recrutement et de découverte : un système peut donc être pair-à-pair même si un des ces fonctions, ou les deux, est effectuée par un mécanisme centralisé.
Si on développe des systèmes pair-à-pair, c'est parce qu'ils ont une utilité concrète. La section 5 décrit les principaux domaines d'application des systèmes pair-à-pair. Le plus connu est évidemment la distribution de contenu, qui fait l'objet de la section 5.1. Parfois, ce contenu est composé de fichiers illégalement distribués, par exemple parce que ledit contenu n'est pas encore monté dans le domaine public dans tous les pays. Mais le pair-à-pair va bien au delà des utilisations illégales. La distribution de contenu sur Internet se fait par de nombreux moyens, HTTP, RFC 7230 et FTP, RFC 959 étant les plus traditionnels, et personne ne prétend que HTTP est néfaste parce que du contenu illégal est parfois distribué par HTTP.
Parmi les exemples importants de distribution de contenu légal par le pair-à-pair, il y a les systèmes d'exploitation dont les images ISO sont distribués en BitTorrent (comme Debian ou NetBSD), soulageant ainsi les serveurs de l'organisation, qui n'a pas en général de grands moyens financiers pour leur fournir une capacité réseau suffisante. Il y a aussi les mises à jour de logiciel commerciaux comme World of Warcraft et bien d'autres.
Le gros avantage du pair-à-pair, pour ce genre d'applications, est le passage à l'échelle. Lorsqu'une nouvelle version de NetBSD est publiée, tout le monde la veut en même temps. Un serveur FTP ou HTTP central, même avec l'aide de dix ou vingt miroirs, s'écroulerait sous la charge, tout en restant très sous-utilisé le reste du temps. Au contraire, un protocole comme BitTorrent marche d'autant mieux qu'il y a beaucoup de téléchargeurs (les leechers dans la terminologie BitTorrent). L'effet est équivalent à celui de milliers de miroirs, sans que l'utilisateur n'aie à les choisir explicitement.
Cette question de la sélection du pair d'où on télécharge le fichier est centrale pour l'efficacité d'un système pair-à-pair. L'un des problèmes que pose cette sélection est que les intérêts des différentes parties peuvent être contradictoires. Les utilisateurs veulent le pair le plus rapide, les gérants du système de distribution du contenu voudraient que les pairs possédant les parties les plus rares soient sélectionnés en premier (pour augmenter la fiabilité globale de la distribution), les FAI voudraient que les pairs situés sur leur propre réseau soient privilégiés. Il n'est pas étonnant que la sélection du pair aie été tant discuté au IETF workshop on P2P Infrastructure de 2008 (dont un compte-rendu figure dans le RFC 5594). Le groupe de travail Alto de l'IETF est chargé de travailler sur ce point.
La section 5.1 se termine sur un exemple original, Zebranet, un système de collecte de données sur les zèbres en liberté. Chaque animal porte un collier qui collecte des informations et les transmet aux stations qui se déplacent dans la savane. Mais il arrive souvent qu'un zèbre ne passe jamais près d'une station ! Zebranet permet alors la transmission de données de collier à collier. Chaque zèbre rassemble ainsi les données de plusieurs autres animaux, et le passage d'un seul zèbre près de la station permet de récolter toutes ces données d'un coup. Le RFC note toutefois que Zebranet n'est pas vraiment pair-à-pair puisque le collier ne fait que donner et la station que recevoir.
Une autre utilisation courante du pair-à-pair est le calcul distribué (section 5.2). Une tâche de calcul y est divisée en plusieurs sous-tâches, chacune confiée à une machine différente. Il est général bien moins coûteux d'avoir beaucoup de machines bon marché et relativement lentes plutôt qu'un seul supercalculateur. Contrairement à une grappe, les pairs sont typiquement très éloignés les uns des autres. Il existe aujourd'hui bien des systèmes de calcul distribué (comme Boinc) mais la plupart ne peuvent pas être considérés comme pair-à-pair et seraient mieux qualifiées de « maître-esclave ». En effet, en général, il existe un nœud central, qui décide des calculs à effectuer et les différentes machines lui obéissent, sans tirer elle-mêmes profit du calcul fait (un exemple typique est SETI@home). Tous les systèmes compris sous l'appelation marketing de grille sont dans ce cas.
C'est également la même chose pour l'une des plus grosses applications du calcul distribué, les botnets. Même lorsqu'ils reposent sur une technique pair-à-pair comme Storm, qui dépend d'une DHT, le zombie ne tire pas de profit des actions du botnet, que ce soit l'envoi de spam ou bien la dDoS. Il ne fait qu'obéir aveuglément au C&C (Command and Control Center, la ou les machines qui dirigent le botnet.
La troisième grande catégorie, les applications de collaration, fait l'objet de la section 5.3. Les plus connues de ces applications sont celles de voix sur IP et de messagerie instantanée. Si la conversation elle-même se fait entre deux machines, le rendez-vous initial peut être réalisé en pair-à-pair, comme ce que permet P2PSIP (cf. section 2.3).
Bien, il y a donc de nombreuses applications qui utilisent le pair-à-pair. Mais est-ce à juste titre ? Dans quels domaines le pair-à-pair est-il fort et dans quels domaines vaut-il mieux s'en méfier ? C'est l'objet de la section 6 qui donne des critères d'évaluation des avantages et inconvénients du pair-à-pair. Notre RFC note qu'il n'existe pas de règle simple, la réponse à la question « Vaut-il mieux utiliser le pair-à-pair ? » dépend de beaucoup de choses. Parmi les points importants, le RFC note que les systèmes pair-à-pair sont particulièrement adaptés aux cas où il n'existe pas d'infrastructure existante et où il serait difficile de l'installer, ce qui est le cas des réseaux ad hoc.
Autre point fort du pair-à-pair, le passage à l'échelle. Avec lui, augmenter les ressources du système se fait simplement en ajoutant de nouveaux pairs. Si l'application envisagée doit pouvoir grossir jusqu'à la taille de l'Internet, le pair-à-pair est souvent une option à regarder sérieusement. (En fait, tout n'est pas toujours si simple et la fin d'OpenDHT a montré que le pair-à-pair ne se fait pas forcément tout seul.)
Si on est désireux d'avoir une application fiable (cf. RFC 4981), les systèmes pair-à-pair sont également intéressants. Si chaque pair individuel est en général considéré comme peu fiable, le système complet est conçu pour fonctionner alors même que les pairs individuels arrivent ou repartent du groupe en permanence. Il peut donc être très robuste.
Et les performances ? Il est difficile de dire si le pair-à-pair est plus rapide ou pas, cela dépend de nombreuses choses. Des « pique-assiettes » (free riders), qui profitent du système mais ne lui fournissent rien, peuvent sérieusement dégrader ces performances. D'où la recherche permanente de bons mécanismes d'incitation pour que les pairs ne se conduisent pas en parasites.
Un système pair-à-pair réel doit parfois choisir entre toutes ces caractéristiques. Le RFC cite l'exemple d'une base de données pair-à-pair : si toutes les données sont dupliquées sur tous les pairs, elle serait très robuste face aux pannes et très rapide en lecture. Mais l'arrivée d'un nouveau pair serait très lente parce qu'il devrait commencer par tout recopier. Et les écritures prendraient un temps fou.
Et les questions de sécurité ? Lorsque des tas de machines, parfois placées sous des administrations différentes, travaillent ensemble, ces problèmes de sécurité prennent une autre ampleur. La section 7 leur est consacrée. D'abord, toutes les machines du système sont-elles de confiance ? Certains systèmes pair-à-pair n'enrôlent pas n'importe qui mais uniquement des machines appartenant à la même entité. Dans ces conditions, le problème est plus facile à résoudre. Par contre, avec un système pair-à-pair ouvert à tout l'Internet, que n'importe quelle machine peut joindre quand elle veut, le problème devient un défi...
Dans tous les cas, la liste des problèmes de sécurité potentiels posés par les systèmes pair-à-pair est longue. Par exemple :
- Pour les systèmes qui ont un composant centralisé, une DoS réussie contre ce composant stoppe tout service,
- Pour les (nombreux) systèmes pair-à-pair où les messages ne sont pas transmis directement mais routés d'un pair à un autre jusqu'à la destination finale (cas de DHT comme Chord par exemple), les pairs intermédiaires ont des capacités de nuisance très importantes. Une attaque Sybil peut aboutir à ce qu'une grande partie des intermédiaires ne soient pas dignes de confiance,
- Si le protocole utilisé ne chiffre pas les messages, ceux-ci peuvent être écoutés par les routeurs IP mais aussi par les pairs intermédiaires (si on chiffre, il faut quand même laisser ceux-ci déchiffrer ce qui concerne le routage),
- Pour les systèmes pair-à-pair qui permettent le stockage des données, comme les DHT, un attaquant peut essayer d'épuiser les ressources. Un quota peut donc être nécessaire (ou une politique de nettoyage, comme le faisait OpenDHT),
- Si l'attaquant ne réussit pas à faire enrôler des machines à lui pour s'insérer dans le système, il peut, dans certains cas, subvertir le routage pour arriver à recevoir quand même les messages (attaque Eclipse, voir « Eclipse Attacks on Overlay Networks: Threats and Defenses).
L'article seul
RIM cache ses brevets à l'IETF
Première rédaction de cet article le 23 novembre 2009
Les brevets logiciels, légaux dans certains pays, sont une source d'ennuis sans fin pour les organisations de normalisation. En effet, l'intérêt évident du détenteur du brevet est d'obtenir que des normes fassent référence audit brevet, obligeant ainsi tous ceux qui déploient cette norme à lui acheter une licence. L'intérêt des utilisateurs étant au contraire que la norme ne soit pas plombée par des brevets, les SDO déploient diverses mesures pour limiter les dégâts. Pour les titulaires de brevet, la tentation est donc forte de tricher comme vient de le faire RIM auprès de l'IETF.
Les politiques des SDO sur les brevets varient beaucoup. Certaines, comme OASIS, laissent même chaque groupe de travail décider de sa politique. Les attitudes possibles vont du refus absolu de normaliser une technique encombrée par des brevets à leur acceptation moyennant publication. L'inconvénient de la position dure est que, appliquée strictement, il ne resterait plus rien de normalisable. La quantité de brevets futiles est telle que toute technique un peu sophistiquée est forcément couverte par des milliers de brevets, tous plus ridicules les uns que les autres, mais qui sont quand même acceptés par les offices de brevets, à la fois par incompétence et aussi parce que ces organismes n'ont aucun intérêt à limiter le nombre de brevets, bien au contraire.
L'IETF a donc une politique de brevets fondée sur la divulgation (disclosure). Cette politique, originellement spécifiée dans le RFC 2026, est aujourd'hui exposée en détail dans le RFC 8179 mais, en deux mots, elle consiste à accepter les technologies plombées par un brevet, tout en imposant à tout participant à l'IETF de divulguer les brevets dont il a connaissance, concernant tout sujet sur lequel se penche le ou les groupes de travail auxquels il participe. Ces divulgations sont ensuite publiées sur le site Web de l'IETF.
Le but de cette politique est d'éviter les brevets sous-marins. Il s'agit de brevets qu'une entreprise détient mais dont elle n'informe pas la SDO, dans l'espoir que celle-ci normalisera une technique brevetée... découvrant ensuite, mais trop tard, que tous les utilisateurs devront payer une licence.
Cette politique est présentée à chaque inscription dans une liste de diffusion de l'IETF et répétée systématiquement lors des réunions physiques, sous le nom de Note Well. On peut donc difficilement l'ignorer.
Néanmoins, une telle tricherie vient d'être découverte à l'IETF. RIM, entreprise connue pour son gadget pour cadres sup', le Blackberry, avait déposé une demande de brevet, tout en travaillant à l'IETF à normaliser une technologie qui en dépendait. Et cela sans divulgation, en violation directe de la Note Well.
Pris la main dans le sac, les employés de RIM ont essayé de prétendre que le réglement intérieur de leur entreprise ne leur avait pas permis de communiquer sur ces demandes de brevet. Défense tout à fait inappropriée puisque les règles de l'IETF sont claires et que la participation à cette organisation est volontaire. Si on ne peut pas en respecter les règles, on ne doit pas participer. Le président de l'IETF, Russ Housley et l'avocat, Jorge Contreras, l'ont rappelé nettement.
Mais il est vrai que le capitalisme n'est pas la démocratie. Dans l'entreprise, il n'existe pas de liberté d'expression, un employé ne peut raconter quelque chose à l'extérieur qu'après avoir eu l'aval de trois juristes et cinq vice-présidents. Cela a mené à des situations cocasses comme les messages rigoureusement identiques envoyés par tous les employés de RIM à l'IETF. Tristes manifestations d'unanimisme brejnevien.
Notez que, deux ans plus tard, Huawei a fait la même chose que RIM dans le processus qui a mené au RFC 6468. Cette seconde violation grossière des règles a mené à la publication de deux RFC, le RFC 6701, qui décrit les sanctions possibles contre les tricheurs, et le RFC 6702, qui rappelle comment encourager le respect des règles.
Ce n'est pas la première fois qu'il y a une collision entre les règles de l'IETF et les principes de la communication corporate. Par exemple, l'IETF avait déjà dû refuser les ridicules ajouts juridiques aux courriers que certaines entreprises mettent systématiquement. Comme, selon le mot de John Levine, les juristes recommanderont toujours n'importe quoi, quel que soit son coût, pour se prémunir contre n'importe quel risque, de tels ajouts sont aujourd'hui fréquents. Il a donc fallu que l'IETF développe une politique de refus de ces textes.
L'article seul
RFC 5730: Extensible Provisioning Protocol (EPP)
Date de publication du RFC : Août 2009
Auteur(s) du RFC : S. Hollenbeck (Verisign)
Chemin des normes
Première rédaction de cet article le 23 novembre 2009
Les registres, par exemple les registres de noms de domaine fonctionnent parfois sur un modèle registry/registrar c'est-à-dire où le client final doit passer par un intermédiaire, le bureau d'enregistrement (registrar) pour enregistrer son nom de domaine. Le registrar souhaite en général avoir un protocole de communication avec le registre afin d'automatiser ses opérations, dans son langage de programmation favori. EPP, décrit dans ce RFC, est un de ces protocoles d'avitaillement (provisioning, et merci à Olivier Perret pour la traduction). (EPP n'emploie pas le terme de registrar mais celui de sponsoring client, plus neutre. EPP peut donc en théorie être utilisé en cas de vente directe.)
Notre RFC remplace le second RFC sur EPP, le RFC 4930, mais les changements sont mineurs (cf. annexe C, le principal étant que le RFC rend plus clair le fait que la liste des codes de retour est limitative : un registre ne peut pas créer les siens, ce qui est une des plus grosses limitations de EPP). EPP est désormais une norme complète (Full Standard).
EPP a été réalisé sur la base du cahier des charges dans le RFC 3375. Au lieu de s'appuyer sur les protocoles classiques de communication comme XML-RPC ou SOAP, ou même sur l'architecture REST, EPP crée un protocole tout nouveau, consistant en l'établissement d'une connexion (authentifiée) puis sur l'échange d'éléments XML, spécifiés dans le langage W3C Schemas.
Par exemple, l'ouverture de la connexion se fait en envoyant
l'élément XML <login> (section 2.9.1.1) :
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<epp xmlns="urn:ietf:params:xml:ns:epp-1.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="urn:ietf:params:xml:ns:epp-1.0
epp-1.0.xsd">
<command>
<login>
<clID>ClientX</clID>
<pw>foo-BAR2</pw>
<newPW>bar-FOO2</newPW>
<options>
<version>1.0</version>
<lang>fr-CA</lang>
</options>
<svcs>
<objURI>urn:ietf:params:xml:ns:obj1</objURI>
<objURI>urn:ietf:params:xml:ns:obj2</objURI>
<objURI>urn:ietf:params:xml:ns:obj3</objURI>
</svcs>
</login>
<clTRID>ABC-12345</clTRID>
</command>
</epp>
Les espaces de noms utilisés, comme
urn:ietf:params:xml:ns:epp-1.0 sont enregistrés
dans le registre IANA (cf. section 6).
Le <clTRID> est un identifiant de
transaction (celui-ci est choisi par le client) et il facilite la traçabilité des opérations EPP.
L'exécution de ces éléments doit être atomique
(section 2 du RFC).
Chaque commande EPP entraîne une réponse (section 2.6) qui inclus notamment un code numérique à quatre chiffres (section 3) résumant si la commande a été un succès ou un échec (reprenant le schéma expliqué dans la section 4.2.1 du RFC 5321). Le premier chiffre indique le succès (1) ou l'échec (2) et le second la catégorie (syntaxe, sécurité, etc). Par exemple 1000 est un succès complet, 1001 un succès mais où l'action n'a pas encore été complètement effectuée (par exemple parce qu'une validation asynchrone est nécessaire), 2003, une erreur syntaxique due à l'absence d'un paramètre obligatoire, 2104 une erreur liée à la facturation (crédit expiré, par exemple), 2302, l'objet qu'on essaie de créer existe déjà, etc.
EPP est donc typiquement un protocole synchrone. Toutefois, il
dispose également d'un mécanisme de notification asynchrone. La
commande EPP <poll> (section 2.9.2.3) permet d'accéder à des
messages qui avaient été mis en attente pour un client, et lui
donnaient l'état des traitements asynchrones.
Le RFC 5730 spécifie une dizaine de commandes EPP comme
<check>, qui permet de s'assurer qu'un
objet peut être créé, <info>, qui permet
d'accéder aux informations disponibles à propos d'un objet existant
(comme whois sauf que whois est typiquement
public et EPP typiquement réservé aux bureaux d'enregistrement),
<create> pour créer de nouveaux objets (par
exemple réserver un nom de domaine), etc.
Comme tout objet géré par
EPP a un « sponsoring client », l'entité qui le
gère (dans le cas d'un registre de noms de domaine, il s'agit
typiquement du bureau d'enregistrement), EPP fournit une commande pour
changer ce client, <transfer> (section
2.9.3.4). Des options de cette commande permettent d'initier le
transfert, d'annuler une demande en cours, de l'approuver
explicitement (pour le client sortant), etc.
La syntaxe formelle des éléments XML possibles est décrite dans la section 4, en utilisant le langage W3C schema.
Le transport de ces éléments XML sur le réseau peut se faire avec différents protocoles, s'ils respectent les caractéristiques listées en section 2.1. Par exemple, le RFC 5734 normalise EPP reposant directement sur TCP.
Un des points délicats de la conception d'un tel protocole est que
chaque registre a sa propre politique d'enregistrement et ses propres
règles. Quoi que dise ou fasse l'ICANN, cette
variété va persister. Par exemple, l'expiration automatique d'un
domaine existe dans .com
mais pas dans .eu ou
.fr. Le protocole EPP ne
prévoit donc pas d'éléments pour gérer telle ou telle catégorie
d'objets (les domaines mais aussi les serveurs de noms ou les
contacts). Il doit être complété par des mappings,
des schémas définissant une classe d'objets. Certains de ces
mappings sont spécifiés pas
l'IETF comme le domain
mapping (gestion des domaines) dans le RFC 5731. L'annexe A fournit un exemple de
mapping. Plusieurs registres utilisent des
mappings non-standard, pour s'adapter à leurs
propres règles d'enregistrement, ce qui limite la portabilité des
programmes EPP (le cadre d'extension de EPP fait l'objet de la section
2.7). C'est ce qu'ont fait les
français, les
brésiliens ou les
polonais.
Dans tous les cas, chaque objet manipulé avec EPP reçoit un
identificateur unique (par exemple
SB68-EXAMPLEREP),
dont les caractéristiques sont normalisées dans
la section 2.8. Les dépôts possibles sont enregistrés dans un registre IANA.
Complexe, EPP n'a pas été reçu avec enthousiasme chez les registres existants,
sauf ceux qui refaisaient complètement leur logiciel comme
.be. On notera que certains gros TLD comme .de n'utilisent pas
EPP (Denic utilise son
protocole MRI/RRI). Il existe d'autres protocoles d'avitaillement
comme :
- Le registre Adams' Names a son protocole au dessus de XML-RPC,
- Le registrar Gandi utilise son protocole, au dessus de XML-RPC pour ses revendeurs,
- Le registrar BookMyName utilise son protocole, au dessus de SOAP pour ses revendeurs,
- OVH a aussi une API SOAP très riche,
et beaucoup d'autres qui ne semblent pas forcément documentés publiquement.
Il existe plusieurs mises en œuvres d'EPP en
logiciel libre par exemple le serveur EPP OpenReg de
l'ISC, le logiciel Fred du registre de .cz ou
bien le client EPP Net::DRI de
Patrick Mevzek. Si vous voulez expérimenter avec EPP, vous devez
installer votre propre serveur, il n'existe pas de serveur public pour
tester.
L'article seul
Avoir sa base de données hébergée sur l'Internet : rdbhost
Première rédaction de cet article le 20 novembre 2009
Dernière mise à jour le 22 novembre 2009
Si on veut avoir sa base de données hébergée quelque part sur l'Internet et accessible depuis des applications qui peuvent tourner à divers endroits, on a bien sûr plusieurs solutions. Je présente ici un hébergement chez rdbhost.
Si on est administrateur système de profession, ou simplement si on a besoin d'applications très spécifiques, qu'on a peu de chances de trouver dans une offre standard, la meilleure solution est sans doute de louer une machine dédiée, par exemple chez Slicehost. Mais si on est un programmeur ordinaire, qui n'a ni le temps, ni l'envie de faire de l'administration système, un service hébergé peut être intéressant. Le public typique visé par rdbhost est le client de Google App Engine qui veut une autre base de données que celle fournie par Google.
Que fournit rdbhost ? Un service gratuit (pour les usages raisonnables) de base de données, vous donnant accès à une base SQL (en l'occurrence, PostgreSQL). L'interface avec la base n'utilise pas le protocole réseau habituel de PostgreSQL, mais un protocole spécifique à rdbhost, au dessus de HTTP (et qui a donc de fortes chances de passer les pare-feux). Pour les programmeurs Python, rdbhost fournit une bibliothèque conforme au standard « Python DB » (PEP 249).
Voici donc un exemple en Python :
from rdbhdb import rdbhdb
import sys
role = 'r0000000837'
authcode = 'trop secret'
conn = rdbhdb.connect (role, authcode)
conn.https = True
cur = conn.cursor()
cur.execute("INSERT INTO Test (data) VALUES ('%s')" % sys.argv[1])
cur.execute("SELECT * FROM Test")
for tuple in cur.fetchall():
print tuple
conn.close()
On note le conn.https = True. Par défaut, la
connexion n'est pas chiffrée
et le mot de passe circule donc en clair. Un exemple de script plus
riche est celui de chargement
de la base de StackOverflow.
Pour créer les tables et les modifier, on peut utiliser des
requêtes SQL DDL comme CREATE TABLE mais aussi une interface Web
pratique, fournie par rdbhost.
Le service est gratuit, mais il vient avec un certain nombre de
limites, comme un maximum de cent tuples en réponse à un
SELECT. Si on veut stocker de grosses quantités
de données, récupérer davantage de tuples, etc, il faut s'abonner au
service payant. Et, naturellement, comme avec toute base de données
hébergée, on n'a pas de garantie sur la confidentialité des données ou
sur leur pérennité.
Il est donc indispensable de pouvoir sauvegarder ses données. Pour cela, rdbhost fournit un service de récupération du contenu de ses bases.
Le service est encore assez récent et on peut donc donner son avis sur Uservoice.
Il existe un certain nombre de services ayant des caractéristiques similaires (merci à Fil et à David Larlet pour leurs informations) :
- SimpleDB d'Amazon ne fournit pas d'interface SQL, et la documentation se moque du monde en prétendant qu'avec des bases de données relationnelles, on ne peut pas ajouter de colonnes a posteriori.
- RDS, d'Amazon, est par contre une vraie base relationnelle (mise en œuvre avec MySQL). Contrairement à rdbhost, on peut apparemment utiliser n'importe quel client MySQL, le protocole d'accès est celui du SGBD. RDS est payant, même pour les petites bases.
- FathomDB utilise aussi MySQL. Il n'y a guère de détails sur le site Web et le service est actuellement en beta et je n'ai pas d'invitation.
Connaissez-vous d'autres services équivalents ?
L'article seul
Combiner DNSSEC avec les mises à jour dynamiques
Première rédaction de cet article le 18 novembre 2009
Un certain nombre de zones DNS sont mises à jour par le protocole Dynamic Update du RFC 2136. Peut-on encore signer les données ainsi avitaillées, pour DNSSEC ? Même avec NSEC3 ? Même avec l'opt-out ? La réponse est oui.
Le fonctionnement le plus courant de DNSSEC
est de signer la zone d'un coup, avec un outil comme
dnssec-signzone de BIND ou
comme ldns-signzone de
ldns. Mais un tel mode n'est pas compatible
avec les mises à jour dynamiques (dynamic updates)
du RFC 2136).
Une solution est mise en œuvre par BIND, sous le nom de online key (cf. RFC 3007). Si le serveur a accès à la clé privée, il peut signer les nouveaux enregistrements qui arrivent. Les exemples suivants ont été testés avec la version beta de BIND 9.7. Ils marcheraient sans doute avec des versions antérieures mais la 9.7 apporte suffisamment de choses du point de vue de DNSSEC pour que cela vaille la peine.
Voici la configuration de BIND :
zone "example" {
type master;
allow-update {
localhost; // Cette ACL est définie par défaut dans BIND
};
file "example.db.signed";
};
On est parti d'une zone ordinaire, qu'on a signé avec une clé de type NSEC3RSASHA1 (NSEC3 est normalisé dans le RFC 5155 et rend le recalcul des signatures plus délicat). La suite de l'évolution de la zone se fera uniquement par mise à jour dynamique.
Un exemple de script de mise à jour est :
#!/bin/sh NUM=$(date +%s) PID=$$ nsupdate -d <<EOF server ::1 8053 zone example update add created-dyn-$NUM-$PID.example 3600 NS ns1.nic.example send EOF
Il contacte le serveur local (adresse ::1), sur
le port 8053 et lui demande d'ajouter un enregistrement pour le nom
created-dyn-$NUM-$PID.example (qui n'existait pas
avant). Ce genre d'ajout est typique de l'activité d'un
TLD (une zone DNS ordinaire utiliserait plutôt
des enregistrements de type A ou AAAA).
La mise à jour se passe bien :
% ./dynupdate Sending update to ::1#8053 ... ;; UPDATE SECTION: created-dyn-1258541343-2833.example. 3600 IN NS ns1.nic.example. ... Reply from update query: ;; ->>HEADER<<- opcode: UPDATE, status: NOERROR, id: 1926 ;; flags: qr ; ZONE: 0, PREREQ: 0, UPDATE: 0, ADDITIONAL: 0
Et le serveur de noms note :
18-Nov-2009 11:27:47.327 client ::1#46234: updating zone 'fr/IN': adding an RR at 'created-dyn-1258541343-2833.example' NS 18-Nov-2009 11:27:47.708 zone fr/IN: sending notifies (serial 2222229958)
Et on peut vérifier que le serveur connait bien le nouvel enregistrement :
% dig +dnssec -p 8053 @::1 ANY created-dyn-1258541343-2833.example. ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 1019 ... ;; AUTHORITY SECTION: created-dyn-1258541343-2833.example. 3600 IN NS ns1.nic.example. DE3SCFLTLOBRFQAAO85TGISFO23QDLO5.example. 5400 IN NSEC3 1 1 10 F00DCAFE FU8ND8DK3QVMR9JNDR9LIM31K0RPAS43 NS SOA TXT RRSIG DNSKEY NSEC3PARAM ...
Comme les enregistrements de délégation, les NS, ne font pas autorité, la réponse ne figure pas dans la section Réponse mais dans la section Autorité. Les enregistrements NSEC3 sont inclus dans la réponse mais ils ne sont pas modifiés par les ajouts dynamiques puisqu'on est en opt-out, on ne modifie pas les chaînes NSEC3 pour des enregistrements ne faisant pas autorité. (BIND découvre tout seul que la zone avait été signée avec opt-out, en regardant le champ Flags de l'enregistrement NSEC3 précédent, cf. section 3.1.2 du RFC 5155. L'enregistrement NSEC3PARAM ne peut pas être utilisé, car son champ opt-out est toujours à zéro, cf. section 4.1.2 du RFC 5155, cet enregistrement ne servant qu'à informer les serveurs secondaires.)
Passons maintenant à l'enregistrement d'un domaine signé, ayant un enregistrement DS, qui fera donc autorité. On modifie le script :
#!/bin/sh NUM=$(date +%s) PID=$$ nsupdate -d <<EOF server ::1 8053 zone fr update add created-dyn-$NUM-$PID.example 3600 NS ns1.nic.example update add created-dyn-$NUM-$PID.example 3600 DS 24045 7 1 c5746... send EOF
Et, cette fois, le nombre d'enregistrements NSEC3 dans la zone change, BIND en a ajouté automatiquement un.
Toutes ces signatures nécessitent évidemment que BIND aie accès à
la clé privée (c'est-à-dire le fichier
Kexample.+007+39888.private où 39888 est
l'identicateur de la clé). BIND la cherche dans le répertoire indiqué
par l'option directory. (BIND peut aussi utiliser
PKCS #11 pour parler à un équipement qui garde
la clé.)
Si
jamais on a « retiré le tapis » de sous les pieds du serveur de noms,
par exemple en déplaçant les clés (les fichiers
Kexample...), logiquement, BIND n'arrive plus à
signer :
18-Nov-2009 11:05:03.162 client ::1#32072: updating zone 'example/IN': found no private keys, unable to generate any signatures 18-Nov-2009 11:05:03.162 client ::1#32072: updating zone 'example/IN': RRSIG/NSEC/NSEC3 update failed: not found
et il renvoie donc SERVFAIL au client.
Enfin, on peut noter que, bien que le RFC 3007 le permettre, il n'est pas actuellement possible de calculer la signature dans le client avant de l'envoyer au serveur :
18-Nov-2009 12:29:36.777 client ::1#36479: updating zone 'example/IN': update failed: \
explicit RRSIG updates are currently not supported in secure zones \
except at the apex (REFUSED)
Un bon article sur le même sujet, allant jusqu'à la création d'un service de DNS dynamique, est « How-To: Create your own 'DynDNS' Service ».
L'article seul
Quelques pensées sur la faille de renégociation de TLS
Première rédaction de cet article le 18 novembre 2009
Dernière mise à jour le 25 novembre 2009
Beaucoup d'électrons ont déjà été secoués pour communiquer des informations sur la faille de sécurité de renégociation de TLS. Je ne vais pas martyriser davantage ces pauvres leptons, uniquement faire partager quelques réflexions que m'a inspiré cette faille.
J'ai d'autant moins l'intention d'expliquer en détail la faille que je ne suis pas un expert TLS. D'accord, j'ai lu la norme, le RFC 5246, mais cela ne suffit pas. Et, de toute façon, les articles de Marsh Ray, le découvreur (« Renegotiating TLS » ou d'Eric Rescorla, le gourou TLS de l'IETF (« Understanding the TLS renegotiation attack ») sont très clairs.
Non, je voudrais plutôt gloser sur quelques points liés à cette faille. D'abord, il faut se rappeler qu'il s'agit d'une faille du protocole, pas d'une mise en œuvre particulière. Les protocoles, comme les programmes, ont des bogues. L'utilisation (parfois) de méthodes formelles pour les spécifier n'a pas diminué le nombre de bogues. (Après tout, les programmes sont tous écrits dans un langage formel et ont quand même plein de bogues.) Néanmoins, certains choix d'implémentation peuvent aggraver la faille. Ainsi, OpenSSL, par défaut, permet la renégociation, même si l'application qui utilise cette bibliothèque n'a rien demandé. GnuTLS, au contraire, ne la permet que si l'application l'a explicitement demandée, ce qui rend ses utilisateurs moins vulnérables.
Ensuite, pourquoi y a t-il des failles dans le protocole TLS ? Une des raisons est sa complexité, le pire ennemi de la sécurité. La norme (RFC 5246) fait plus de cent pages et offre plein d'options et de choix, dont cette fameuse renégociation. Simplifier la norme, retirer des options non indispensables comme la renégociation, aurait probablement diminué le nombre de failles dans TLS.
Évidemment, dans le monde réel, les choses ne sont jamais aussi
simples. Un protocole offrant moins de possibilités aurait peut-être
eu moins de succès. Par exemple, avec HTTPS, si
on n'a pas de possibilité de renégociation, la seule façon
d'authentifier un
client avec un certificat est d'exiger
systématiquement le certificat au début de la session TLS. Il ne
serait plus possible d'attendre la requête du client, puis de
renégocier si cette requête s'avère nécessiter une
authentification. Avoir deux serveurs,
www.example.org et
auth.example.org est bien sûr possible, mais pas
forcément pratique (rendre public un document signifierait un
changement d'URL, ce qui est presque toujours une mauvaise idée.
En relisant la liste des failles de sécurité qui ont affecté TLS et son prédécesseur SSL, on voit que la faille de renégociation n'est pas la première à reposer sur un problème de liaison (binding) entre deux élements du protocole. Les oublis de liaison sont une des erreurs les plus fréquentes dans les protocoles de sécurité. Supposons un protocole au dessus de TCP qui authentifie, mettons par cryptographie, au début de la connexion. On se croit en sécurité par la suite ? Erreur. Si les paquets TCP suivant l'authentification ne sont pas liés à la session qui a été authentifiée (par exemple par une MAC), l'attaquant pourra attendre l'authentification, puis injecter des paquets TCP mensongers qui seront acceptés. De même, dans la faille de renégociation, il n'y avait pas de liaison entre l'« ancienne » session (avant la renégociation) et la « nouvelle », ce qui permettait l'injection de trafic.
Ce qui nous amène aux solutions. Le correctif apporté par OpenSSL supprime simplement la renégociation (ce qui va dans la sens de mes remarques sur le danger des protocoles trop riches en fonctions). Mais cela va empêcher certaines applications de fonctionner. C'est donc un contournement, avec effets de bord désagréables, pas une vraie solution.
Une solution à plus long terme a été élaborée à
l'IETF dans le groupe de travail TLS. Elle
est décrite dans le RFC 5746. Son
principe est de créer une liaison entre l'« ancienne » session et la
nouvelle, par le biais d'une nouvelle extension TLS, nommée
renegotiation_info. Le problème est que les
clients TLS ne peuvent pas l'utiliser contre les anciens serveurs (qui
ne connaissent pas cette extension) et que le déploiement risque donc
d'être laborieux. Pendant un certain temps, les clients TLS auront
donc le choix entre exiger cette extension (au risque de ne pas
pouvoir se connecter) ou bien accepter le risque de tomber sur un
serveur vulnérable à la faille de renégociation. (Il existe un projet
concurrent, draft-mrex-tls-secure-renegotiation,
qui inclus une bonne description de la faille.)
Et pour finir sur une note pratique, un bon moyen (merci à Kim-Minh Kaplan) pour tester si un serveur permet la renégociation (et est donc peut-être vulnérable) :
% openssl s_client -connect www.example.org:443 CONNECTED(00000003) ... R <--- Tapez cette unique lettre pour commencer la renégociation RENEGOTIATING depth=2 /C=ES/ST=BARCELONA/L=BARCELONA/O=IPS Seguridad CA/OU=Certificaciones/CN=IPS SERVIDORES/emailAddress=ips@mail.ips.es verify error:num=19:self signed certificate in certificate chain verify return:0
Ici, le serveur était vulnérable, il a accepté la renégociation. Sinon, il aurait juste affiché :
RENEGOTIATING [Puis plus rien]
Une exploitation publique de la vulnérabilité existe, en http://www.redteam-pentesting.de/en/publications/tls-renegotiation/-tls-renegotiation-vulnerability-proof-of-concept-code.
L'article seul
Faudra t-il désormais noter l'adresse IP et le port ?
Première rédaction de cet article le 12 novembre 2009
Les serveurs réseau qui tournent aujourd'hui enregistrent leur activité dans un journal où ils notent, en général, l'adresse IP de leur client. Vue l'évolution de l'Internet va t-il falloir également enregistrer le port dudit client ?
N'importe quel serveur réseau aujourd'hui, qu'il fasse du HTTP, du SMTP ou bien d'autres protocoles reposant sur TCP, note chaque connexion dans son journal. Par exemple, pour Apache, les entrées dans le journal ressemblent à :
192.0.2.235 - - [12/Nov/2009:15:38:31 +0100] "GET /feed.atom HTTP/1.0" 304 - "-" "Liferea/1.4.23 (Linux; fr_FR.UTF-8; http://liferea.sf.net/)" www.bortzmeyer.org 2001:db8:2f58:ce40:216:3eff:feb0:452f - - [12/Nov/2009:15:38:36 +0100] "GET /xml-to-csv.html HTTP/1.1" 200 18011 "http://www.google.fr/search?q=transformer+fichier+xml+en+csv" "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; .NET CLR 1.1.4322; InfoPath.1)" www.bortzmeyer.org
où 192.0.2.235 et
2001:db8:2f58:ce40:216:3eff:feb0:452f sont les
adresses IP de deux
clients. On enregistre l'adresse IP car elle permet, normalement,
d'identifier de manière unique une machine. C'est en tout cas
l'architecture originale de l'Internet.
Cette idée qu'une adresse IP est unique est largement répandue, y compris chez les non-techniciens. Par exemple, Cédric Manara attire mon attention sur un arrêt d'un tribunal, le 7 octobre 2009 à Paris, qui dit « les numéros IP étant attribués par l'IANA (Internet Assigned Numbers Agency [sic]), deux ordinateurs ne peuvent pas avoir la même adresse IP ».
L'affirmation n'est pas 100 % fausse mais elle est très simpliste et ne correspond plus à la réalité de l'Internet d'aujourd'hui.
D'abord, il faudrait préciser « deux ordinateurs ne peuvent pas avoir la même adresse IP en même temps » car les adresses IP sont couramment réaffectées. C'est probablement ce que fait Verizon (gérant de l'adresse citée dans le jugement).
Ensuite, l'IANA n'a pas de force de police et ne peut donc pas empêcher des gens de prendre sauvagement des adresses IP. À une époque, un opérateur européen s'était ainsi arrogé un préfixe IP qui fut finalement officiellement alloué à un opérateur kenyan. Avec l'épuisement des adresses IPv4, ce genre de squattage sera de plus en plus fréquent.
Un problème analogue est que l'architecture de l'Internet ne permet pas de s'assurer facilement de l'authenticité d'une adresse IP, vieux problème de sécurité bien connu (voir le RFC 2827). Avec UDP, utiliser une fausse adresse est trivial. C'est toutefois plus compliqué en TCP, qui est utilisé pour le courrier, ce qui affaiblit l'argument de la défense qui laissait entendre que n'importe qui pouvait facilement usurper une adresse.
Tout ceci est bien connu. Mais il y a un autre problème, plus récent. Le principe d'un espace d'adressage unique, commun à tout l'Internet, ne correspond plus à la réalité d'aujourd'hui. Avec les adresses IP privées du RFC 1918, (ce qui n'est pas le cas de celle citée, attention), des milliers d'ordinateurs ont la même adresse et utilisent ensuite le NAT. En Europe ou aux États-Unis, le partage ne concerne en général qu'un foyer ou qu'une entreprise (et donc tous les ordinateurs partageant cette adresse sont sous la même responsabilité). Mais, avec l'épuisement rapide des adresses IPv4, cela va changer et des NAT au niveau d'un opérateur entier, déjà courants en Asie ou en Afrique, vont se répandre.
Ce partage intensif d'adresses IP est tellement répandu que
l'IETF, à sa réunion d'Hiroshima, s'est
penchée sérieusement sur une normalisation du fait que
l'identificateur, aujourd'hui, n'est plus l'adresse seule mais le
couple adresse+port
(merci à Rémi Desprès pour la discussion sur ce sujet). Un des
documents qui discutent la question est
l'Internet-Draft draft-ford-shared-addressing-issues (devenu depuis RFC 6269). Mais
il y en a d'autres comme
draft-ietf-geopriv-held-identity-extensions qui
note « However, widespread use of
network address translation (NAT) means that some Devices cannot be
uniquely identified by IP address alone. ».
Revenons à notre journal. Tout cela veut dire que cela sera de moins en moins utile d'enregistrer uniquement l'adresse IP. Il faudra bientôt enregistrer également le port source utilisé par le client, et, si on veut de la traçabilité, que le routeur NAT conserve trace des correspondances entre une adresse IP interne et le couple {adresse IP publique, port} qu'il avait attribué à cette adresse interne. (Cette recommandation est devenue RFC deux ans après, avec le RFC 6302.) Verra t-on Apache écrire :
192.0.2.235:13174 - - [12/Nov/2009:15:38:31 +0100] "GET /feed.atom HTTP/1.0" 304 - "-" "Liferea/1.4.23 (Linux; fr_FR.UTF-8; http://liferea.sf.net/)" www.bortzmeyer.org [2001:db8:2f58:ce40:216:3eff:feb0:452f]:48221 - - [12/Nov/2009:15:38:36 +0100] "GET /xml-to-csv.html HTTP/1.1" 200 18011 "http://www.google.fr/search?q=transformer+fichier+xml+en+csv" "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; .NET CLR 1.1.4322; InfoPath.1)" www.bortzmeyer.org
où 13174 et 48221 sont les ports source ? Apache ne savait
pas autrefois enregistrer le port mais c'est possible désormais
(merci à Tony Finch)
en mettant dans le format %{remote}p
(%p étant le port local au serveur). Les
applications Web, elles, peuvent utiliser la variable CGI
REMOTE_PORT.
L'article seul
Vélos en libre service à Hiroshima
Première rédaction de cet article le 8 novembre 2009
Il existe désormais de nombreuses villes dans le monde avec un système de vélos en libre-service. Hiroshima est en train de beta-tester le sien, baptisé E-cycle. J'ai pu le tester à l'occasion de la réunion IETF dans cette ville.
L'article complet
Festival Dreamination à Hiroshima
Première rédaction de cet article le 8 novembre 2009
Quelques photos du festival Dreamination, festival de sculptures lumineuses, qui se tient en ce moment à Hiroshima.
L'article complet
Noms de domaines IDN dans la racine
Première rédaction de cet article le 6 novembre 2009
L'annonce par l'ICANN le 30 octobre de la proche possibilité de demander l'introduction d'IDN dans la racine du DNS a suscité beaucoup d'articles, la plupart d'un niveau de désinformation consternant. Ce n'est pas étonnant de la part de médias professionnels, dont les contributeurs ne connaissent jamais leur sujet et ne cherchent jamais, mais cela a aussi été le cas de la part de sites d'information d'habitude plus sérieux comme LinuxFr.
Certes, c'est l'ICANN qui a commencé. Leur communiqué officiel contient des affirmations comme quoi par exemple les IDN représenteraient « The biggest technical change to the Internet since it was created four decades ago ». Pour voir le caractère ridicule de cette phrase, il suffit de se rappeler que, quarante ans auparavant :
- Le DNS n'existait pas,
- BGP n'existait pas et l'Internet (enfin, son ancêtre) était un réseau mono-opérateur (alors que sa principale caractéristique d'aujourd'hui est de ne pas dépendre d'un opérateur particulier),
- IPv4 n'existait même pas.
Alors, de dire que les IDN sont un changement plus important que le DNS (vers 1985), BGP (1989) ou IPv4 (1983), c'est franchement grotesque.
Autre affirmation trompeuse de l'ICANN, prétendre que cette
organisation aurait fourni un travail quelconque dans le domaine des
IDN. La réalité est que la norme technique (le RFC 3490, aujourd'hui le RFC 5891) a été fait par l'IETF, les
logiciels (comme la GNU libidn) développés par
diverses équipes et les premiers déploiements, réalisés par des
registres de noms de domaines comme ceux de
.cn ou
.jp. Malgré ces énormités,
la plupart des articles ont repris le communiqué de l'ICANN tel
quel.
Très peu ont expliqué ce qu'il y avait de nouveau dans l'annonce ICANN, le fait que le domaine de tête puisse désormais être en IDN, alors que, jusqu'à présent, en raison du blocage de l'ICANN, il restait en caractères latins.
Et les articles publiés ont même souvent rajouté des erreurs au communiqué ICANN. Quelques exemples :
- «
Internet : L'Icann s'ouvre à d'autres alphabets » qui prétend la décision de
l'ICANN permettra d'avoir des noms de domaine Unicode dans
.fralors que la politique d'enregistrement dans ce TLD ne dépend pas de l'ICANN, - « L'Icann introduit les alphabets arabe et chinois dans les adresses web [sic] qui introduit l'argument comme quoi le délai est dû au « temps de mettre à niveau l'infrastructure technique » alors que les IDN ne nécessitent aucun changement dans les serveurs DNS,
- « Le Web, nouvelle tour de Babel ? » qui annonce que l'ICANN a conçu un nouveau système de traduction,
- « L'internationalisation des adresses internet » qui affirme que les IDN n'étaient pas « officiels » (le RFC 3490 date de six ans déjà...),
- Et, naturellement, tous les articles qui prétendent que les IDN vont augmenter le risque de hameçonnage.
L'article seul
La grande panne DNS de Chine de mai 2009
Première rédaction de cet article le 6 novembre 2009
Le 19 mai 2009, la Chine a connu sa plus grande panne de l'Internet. Sur le moment, de nombreux articles ont été publiés, sans détails pratiques la plupart du temps, à part le fait qu'il s'agirait d'un problème lié au DNS. Le 5 novembre, à la réunion OARC à Pékin, Ziqian Lu, de China Telecom, a fait un remarquable exposé détaillant les causes de la panne.
C'est un bel exercice de transparence, avec plein de détails techniques. Je ne suis pas sûr que les opérateurs Internet français en fassent autant, si une telle panne frappait la France.
Donc, le 19 mai vers 21 h, heure locale, les téléphones se mettent à sonner : « l'Internet est en panne ». China Telecom, mais également d'autres FAI, constate à la fois que les utilisateurs se plaignent mais que le trafic a chuté considérablement. Les « tuyaux » ne sont donc pas surchargés, bien au contraire. En outre, le service n'est pas complètement interrompu : parfois, cela marche encore un peu. En raison de la baisse du trafic, on soupçonne un problème dans le routage. Il faut un certain temps pour que quelqu'un remarque ces lignes dans le journal des serveurs de noms récursifs du FAI :
19-May-2009 22:21:13.186 client: warning: client 218.77.186.180#51939: recursive-clients soft limit exceeded, aborting oldest query 19-May-2009 22:21:13.213 client: warning: client 59.50.182.161#1151: recursive-clients soft limit exceeded, aborting oldest query
Et la vérité se fait jour : le problème est dans le service DNS récursif. La majorité des requêtes DNS échouent. Quelques unes passent, ce qui explique que l'Internet ne semble pas complètement en panne à certains utilisateurs. Comme presque toutes les activités Internet dépendent du DNS, le trafic réseau chute.
Pour résumer la panne, il y avait bien une attaque
DoS mais, comme au
billard, l'attaque n'a pas frappé directement
les serveurs DNS. L'attaque a touché un service très populaire,
Baofeng, qui distribue de la vidéo et de la
musique. Les attaquants frappent un serveur de jeux en ligne et
l'arrêtent. Rien d'extraordinaire, ce genre de choses arrive tous les
jours sur l'Internet. Sauf que l'attaque stoppe également certains des
serveurs du domaine baofeng.com, qui partagent la
même infrastructure. Et que les logiciels clients de Baofeng, devant
la panne, réagissent en faisant encore plus de requêtes DNS, qui
restent sans réponse. Le logiciel résolveur utilisé par tous les FAI
chinois, BIND, a une
limite sur le nombre de requêtes DNS récursives en attente, 1000 par
défaut. En temps normal, c'est largement suffisant mais, ici elle était
vite remplie par les innombrables requêtes en attente des serveurs de baofeng.com.
Si vous gérez un récurseur BIND, vous pouvez voir l'état des
requêtes en cours avec rndc :
% rndc status ... recursive clients: 13/1900/2000
Le dernier chiffre est la limite dure au nombre de requêtes en attente
(il se règle avec l'option recursive-clients dans
named.conf). L'avant-dernier est la limite
« douce » à partir de laquelle BIND commencera à laisser tomber des
requêtes, provoquant le message ci-dessus. Le premier chiffre est le
nombre de requêtes actuellement en attente.
En raison du nombre de clients attendant
baofeng.com,
cette limite a été vite
dépassée, supprimant toute résolution DNS, même pour les domaines
n'ayant rien à voir avec Baofeng. Pour votre récurseur, faites le
calcul : prenez la différence entre la limite douce et le nombre de
clients en temps normal (ici, c'est 1900 - 13, mettons 1900) et
divisez là par le taux de requêtes : cela vous donnera une idée du
nombre de secondes que vous pourrez tenir en cas de panne. Ici, si le
taux de requêtes est de 100 par seconde (ce qui est une valeur pour un
petit FAI), vous avez droit à seulement dix-neuf secondes de marge en
cas de panne d'un gros domaine très populaire... La plupart des
récurseurs ont probablement une valeur de
recursive-clients trop basse.
Conclusion : si quelqu'un réussit à planter tous les serveurs DNS de
google.com ou ebay.com, il
peut théoriquement planter tout le DNS et donc tout l'Internet.
Dans le cas chinois, tous les résolveurs étaient des BIND (comme c'est probablement le cas dans la plupart des pays). Il n'a pas été possible de tester avec d'autres résolveurs comme Unbound mais rien n'indique qu'ils auraient fait mieux. Le choix des développeurs de BIND était d'avoir un tableau de taille limitée pour les requêtes en attente. Si ce tableau était par contre dynamique, le récurseur aurait, à la place, avalé toute la mémoire du serveur.
Quelques-uns des articles les moins mal informés qui ont été publiés sur cette panne :
- « DNS Attack Downs Internet in Parts of China »
- « A month after web chaos, Baofeng issues new media player »
- « Internet attack 'organized' says Ministry »
Merci à Ziqian Lu pour ses explications détaillées.
L'article seul
Le hameçonnage n'a pas de rapport avec les IDN
Première rédaction de cet article le 3 novembre 2009
L'annonce par l'ICANN, le 30 octobre, de la possibilité d'avoir bientôt des IDN dans la racine, c'est-à-dire des domaines de tête en Unicode, a suscité la marée attendue de réactions provinciales et étroites de tous ceux qui regrettent qu'on ne puisse pas forcer ces insupportables chinois ou russes à utiliser la même écriture que nous. Un record dans ce domaine a été établi par l'ultra-nostalgique « ICANN Approves Domain Names We Can't Type ». Un des arguments avancés, très classique mais complètement faux, serait que les IDN favorisent le hameçonnage. Qu'en est-il ?
L'argument est que IDN permet des
noms de domaine
homographes, c'est-à-dire qui s'écrivent de
manière visuellement identique (ou très proche). On risque alors de ne
pas pouvoir distinguer PAYPAL.com et
PΑYPAL.com (dans le second, il y a un
alpha grec).
Les homographes existent bien, et ils n'ont pas attendu les
IDN. Par exemple, google.com et
goog1e.com sont quasi-homographes (regardez
bien). Unicode multiplie leur nombre car les
écritures humaines n'ont pas été conçues par des technocrates
rationnels mais sont issues d'une longue évolution distribuée sur
toute la planète. Unicode est donc complexe, car le monde est
complexe.
Mais le problème n'est pas dans l'existence d'homographes. Il est
dans le fait que ce problème n'a rien à voir avec le hameçonnage. Je
reçois beaucoup de rapports de hameçonnage au bureau et aucun ne
dépend jamais d'homographes. La plupart du temps, le hameçonneur ne
fait aucun effort pour que l'URL soit
vraisemblable : il utilise un nom comme
durand.monfai.net, voire une adresse
IP. Et pour cause, très peu d'utilisateurs vérifient la
barre d'adresse de leur navigateur, ne
serait-ce que parce qu'ils ne comprennent pas ce qu'elle contient et
qu'ils n'ont eu aucune formation sur les noms de domaines. Le
hameçonneur, escroc rationnel, ne se fatigue donc pas.
Parfois, il faut quand même un petit effort. On voit des noms comme
secure-societegenerale.com pour tromper sur
societegenerale.com. À part les spécialistes du
DNS, qui comprennent sa nature arborescente et
le rôle de chaque label du nom, qui verra que
secure-societegenerale.com n'a aucun rapport avec
societegenerale.com ?
Si vous ne faites pas confiance à mon vécu, regardez les nombreux articles de psychologie qui ont été consacrés au hameçonnage. Comme cette activité coûte cher aux banques, de nombreuses études scientifiques ont été faites pour mieux comprendre ce phénomène et pourquoi les utilisateurs se font avoir. Toutes concluent que le nom de domaine ne joue aucun rôle (et que donc l'argument d'homographie contre les IDN est du FUD). Voici une petite bibliographie (avec mes remerciements à Mike Beltzner de Mozilla) :
- « Decision Strategies and Susceptibility to Phishing » de Downs, Holbrook & Cranor,
- « Why Phishing Works » de Dhamija, Tygar & Hearst (lien alternatif),
- « Do Security Toolbars Actually Prevent Phishing Attacks » de, Wu, Miller & Garfinkel,
- « Phishing Tips and Techniques » de Gutmann.
On peut aussi citer, sur une problématique proche, « So Long, And No Thanks for the Externalities: The Rational Rejection of Security Advice by Users » de Cormac Herley, dont la section 4 parle de l'analyse d'URL. Et le rapport 2010 de l'Anti-Phishing Working Group dont la page 16 parle des IDN.
Mais, si toutes les études scientifiques montrent qu'il n'y a pas de connexion entre IDN et hameçonnage, pourquoi trouve t-on tant d'articles faisant ce lien ? La principale raison est l'ignorance : les journalistes ne connaissent pas leur sujet, ne cherchent pas (pas le temps) et se recopient donc les uns les autres, sans questionner l'« information » originale. Ce phénomène n'est d'ailleurs pas réservé aux journalistes professionnels et s'étend aux blogueurs, aux twitteurs, etc.
Mais il y a une autre raison : beaucoup, parmi les « élites mondialisées », qui parlent anglais, regrettent, plus ou moins explicitement, qu'il ne soit pas possible de faire rentrer toutes les langues humaines dans le lit de Procuste d'une seule langue. Les vagues accusations d'hameçonnage contre les IDN, jamais étayées, ne sont donc que l'expression en douceur de leur refus de l'internationalisation.
L'article seul
OpenDNSSEC, ou comment faciliter l'utilisation de DNSSEC
Première rédaction de cet article le 31 octobre 2009
Le fait que le DNS soit très vulnérable aux attaques d'empoisonnement (comme l'attaque Kaminsky) est désormais bien connu. On sait aussi que la seule solution à moyen terme est DNSSEC (mais des solutions à court terme, plus faciles à déployer, existent). Seulement, DNSSEC est un protocole complexe et les erreurs se paient cher, par une impossibilité d'accèder aux informations DNS. Il y a donc en ce moment plusieurs efforts visant à rendre DNSSEC plus digeste, comme par exemple OpenDNSSEC.
En quoi DNSSEC, tel que normalisé dans le RFC 4034 et suivants est-il complexe ? Certes, le protocole n'est pas pour ceux qui ont du jus de navet dans les veines (le RFC 5155 étant certainement le pire). Mais, après tout, cela ne concerne que les implémenteurs, les auteurs de logiciels comme BIND ou nsd. Les simples administrateurs système peuvent-ils, eux, ignorer la complexité de DNSSEC ? Pas complètement : en effet, une bonne part de la complexité réside dans les procédures qu'il faut suivre pour configurer correctement sa zone et surtout pour qu'elle le reste. En effet, le DNS classique était une statue de chat : une fois une zone configurée (et testée avec des outils comme Zonecheck), elle restait configurée. DNSSEC est un chat vivant : il faut aspirer ses poils, le nourrir et changer sa litière. (J'ai oublié qui m'a enseigné cette parabole la première fois. S'il se reconnait...) Quelles sont les tâches récurrentes avec DNSSEC ? Essentiellement la gestion des clés cryptographiques. Il est recommandé de changer ces clés régulièrement (la discussion exacte du pourquoi de cette recommandation a déjà fait bouger beaucoup d'électrons, je ne la reprends pas ici). Ce changement est très délicat car, à tout moment, la zone doit être validable. Or, la propagation des informations dans le DNS n'est pas instantanée. Par exemple, en raison des caches chez les résolveurs, notamment des FAI, une signature faite il y a des heures peut être encore disponible... et la clé qui a servi à cette signature doit l'être également. Changer une clé DNSSEC est une opération qui nécessite, soit des procédures manuelles très rigoureuses et parfaitement suivies, soit une automatisation par un logiciel. Et c'est le rôle d'OpenDNSSEC.
Il existe diverses solutions d'automatisation des procédures de changement de clés de DNSSEC. La plupart sont embryonnaires, les problèmes concrets de déploiement de DNSSEC sont assez récents (le RFC 6781 en donne une idée). Il y a des solutions sous forme d'un boîtier fermé (comme Secure64) ou bien en logiciel libre comme OpenDNSSEC. Ce dernier est encore en version béta et je préviens donc tout de suite il faut être prêt à bricoler un peu.
J'ai rédigé cet article en travaillant sur une machine Debian. OpenDNSSEC nécessite plusieurs programmes tiers et voici une liste non-exhaustive de ce qu'il faudra installer :
% sudo aptitude install libxml2-dev rubygems libopenssl-ruby \
libsqlite3-dev libldns-dev libdns-ruby
Ensuite, il faut choisir le mécanisme de stockage des clés. La méthode la plus sûre est d'utiliser un HSM (Hardware Security Module), un boîtier qui génère les clés, les stocke, et fait les signatures cryptographiques. Certains HSM (à partir de la certification FIPS 140-3) sont en outre résistants aux attaques physiques : si vous essayez de les ouvrir, la clé privée est détruite. Vos clés sont ainsi parfaitement en sécurité.
Il existe une API standard pour accéder à ces HSM, PKCS #11 et la plupart des logiciels DNSSEC (comme, par exemple, le signeur de BIND) la gèrent. En pratique, toutefois, il semble que cela ne soit pas toujours aussi simple et on peut trouver facilement sur le Web beaucoup de récits désabusés...
En outre, ces HSM sont des engins relativements chers (apparemment à partir de 1 000 € en France) et difficiles à obtenir. Faites l'expérience avec des vendeurs nationaux de HSM comme Thales ou Bull en France : les commerciaux ne vous rappellent pas. Pour commencer, on va donc utiliser un stockage logiciel des clés, dans le système appelé SoftHSM (oui, c'est un oxymore), dû aux même auteurs que OpenDNSSEC. SoftHSM permet de stocker les clés en local, dans une base SQLite (qu'il faudra évidemment protéger avec soin, le matériel ne le faisant pas pour vous).
Bref, on installe SoftHSM, on n'oublie pas, comme la documentation l'indique, le ldconfig pour que les nouvelles bibliothèques soient trouvées, on initialise notre « HSM » :
% softhsm --init-token --slot 0 --label "OpenDNSSEC"
On devra alors, comme avec un vrai HSM, indiquer un « PIN », un mot de passe.
Le HSM étant prêt, on peut compiler et installer OpenDNSSEC. On édite
son /etc/opendnssec/conf.xml pour indiquer le
PIN :
<Repository name="softHSM">
<Module>/usr/local/lib/libsofthsm.so</Module>
<TokenLabel>OpenDNSSEC</TokenLabel>
<PIN>cestressecret</PIN>
</Repository>
OpenDNSSEC est alors prêt à utiliser ce « HSM ». Il connait le nom de
la bibliothèque à charger pour lui parler
(/usr/local/lib/libsofthsm.so) et le PIN. Testons
qu'il apparait bien dans la liste des HSM :
% sudo hsmutil list hsm_session_init(): Incorrect PIN for repository softHSM
OK, faute de frappe en tapant le PIN, on recommence :
% sudo hsmutil list Listing keys in all repositories. 0 key found. Repository ID Type ---------- -- ----
C'est parfait. (Dans les versions d'OpenDNSSEC ultérieures, toutes les
commandes sont préfixées de ods- donc on aurait
écrit sudo ods-hsmutil list.) Il n'y a pas de clé mais, à ce stade, c'est normal
(OpenDNSSEC les créera tout seul).
Maintenant, on configure OpenDNSSEC : quelles zones doit-il gérer,
avec quels paramètres, etc. Les fichiers de configuration livrés
contiennent déjà des paramètres par défaut (par exemple, clé RSA de
2048 bits pour la KSK, la Key Signing Key, périodes
avant le renouvellement des clés, en suivant la syntaxe décrite en
http://trac.opendnssec.org/wiki/Signer/Using/Configuration,
etc). Je ne
touche pas tout de suite à
/etc/opendnssec/kasp.xml, qui contient les
politiques de définition de ces paramètres et j'édite
/etc/opendnssec/zonelist.xml qui contient la
liste de mes zones :
<Zone name="bortzmeyer.fr">
<Policy>default</Policy>
...
<Adapters>
<Input>
<File>/var/opendnssec/unsigned/bortzmeyer.fr</File>
</Input>
<Output>
<File>/var/opendnssec/signed/bortzmeyer.fr</File>
</Output>
...
Cette zone sera signée avec les paramètres par défaut (définis dans
kasp.xml) et je dois mettre le fichier de zone
non signé dans
/var/opendnssec/unsigned/bortzmeyer.fr. (Attention
pour ceux qui ont déjà utilisé le signeur
dnssec-signzone de BIND : ici, on ne doit
pas inclure les DNSKEY, OpenDNSSEC fait cela tout
seul.)
Je compile les politiques (sudo ksmutil
setup la première fois, sudo ksmutil update
all ensuite ; comme indiqué plus haut, c'est
ods-ksmutil dans les OpenDNSSEC récents). Je démarre alors les démons OpenDNSSEC :
% sudo ./ods-signerd % sudo ./ods-enforcerd
Le premier est le signeur. Écrit avec la bibliothèque ldns, il réalise les opérations de signature (avec un vrai HSM, elles seraient largement déléguées au matériel). Le second démon, le policeur, fait respecter les politiques de remplacement des clés qu'on a définies.
Normalement, le policeur doit alors noter qu'il n'a pas de clés, et les générer. Vérifions :
% sudo hsmutil list Listing keys in all repositories. 4 keys found. Repository ID Type ---------- -- ---- softHSM cc59d2b16e421c57eec35ed4ceae0099 RSA/1024 softHSM e17b1d0465e6976536119c872a353911 RSA/1024 softHSM fa8cdfc8da319311283b66fe55839212 RSA/2048 softHSM 60b57dff6604cc35ec6fdd8aef7710a2 RSA/2048
C'est parfait, on a deux ZSK (1024 bits par défaut) et deux KSK (2048 bits par défaut), une active et une prête à assurer le remplacement futur. On la publie en avance, pour être sûr qu'elle soit disponible dans les caches DNS.
De la même façon, la zone a dû être signée et le résultat mis en
/var/opendnssec/signed/bortzmeyer.fr. Sinon, il
faut regarder le journal pour savoir ce qui
s'est passé. On peut aussi forcer OpenDNSSEC à signer tout de suite
avec ods-signer sign bortzmeyer.fr. Par défaut,
OpenDNSSEC ne fait pas le travail si la zone n'a pas changé pour on
peut le convaincre de signer quand même avec ods-signer
clear bortzmeyer.fr qui précède le ods-signer sign bortzmeyer.fr.
OpenDNSSEC permet de gérer plusieurs zones DNS donc si je veux voir
uniquement les clés d'une zone, je me sers de
--zone :
% sudo ksmutil key list --zone bortzmeyer.fr SQLite database set to: /var/opendnssec/kasp.db Keys: Zone: Keytype: State: Date of next transition: bortzmeyer.fr KSK active 2010-10-27 13:14:39 bortzmeyer.fr KSK ready next rollover bortzmeyer.fr ZSK active 2009-11-26 13:14:39 bortzmeyer.fr ZSK ready next rollover
Je vois ainsi les clés, et le moment où elles seront remplacées (par
la clé qui est dans l'état
ready). --verbose affiche
également le key tag (annexe B du RFC 4034), également mis par le signeur dans le fichier de zones
et qu'affiche aussi
dig avec l'option +multi,
ce qui est pratique pour déboguer les zones une fois chargées :
% sudo ksmutil key list --zone bortzmeyer.fr --verbose
SQLite database set to: /var/opendnssec/kasp.db
Keys:
Zone: Keytype: State: ... Keytag:
bortzmeyer.fr KSK active ... 24045
bortzmeyer.fr KSK ready ... 36168
...
% dig @192.0.2.1 +dnssec +multi DNSKEY bortzmeyer.fr
bortzmeyer.fr. 3600 IN DNSKEY 257 3 7 (
...
) ; key id = 24045
24045 étant le key tag de la KSK active.
OpenDNSSEC ne permet pas de mettre à jour automatiquement la clé dans la zone parente (en partie parce qu'il existe plusieurs protocoles différents pour cela, comme celui du RFC 4310). Mais il aide, en indiquant ce qu'il faut transmettre au parent, un enregistrement DS :
% sudo ksmutil key export --ds SQLite database set to: /var/opendnssec/kasp.db ;active KSK DS record (SHA1): bortzmeyer.fr. 3600 IN DS 24045 7 1 c57467e055adde7fcad11... ;active KSK DS record (SHA256): bortzmeyer.fr. 3600 IN DS 24045 7 2 2d47e39d7f04237292760...
Seule la KSK actuellement active, la 24045, est ainsi « exportée » (avec deux algorithmes de hachage possibles).
OpenDNSSEC n'a pas de problèmes avec les petites zones. Si on
essaie de signer des zones de plus d'un million d'enregistrements, il
vaut mieux supprimé l'auditeur, encore trop bogué. L'auditeur a pour
but de vérifier l'intégrité du fichier signé et sa conformité aux
politiques décrites dans kasp.xml. S'il échoue,
la zone signée n'est donc pas publiée. Comme il échoue souvent, je
l'ai pour l'instant débrayé : suppression de
<Auditor> dans
conf.xml, de <Audit>
dans kasp.xml et ods-ksmutil
update pour prévenir les démons qui sont en cours
d'exécution. Les signatures se dérouleront alors normalement.
Prochaines étapes, chers lecteurs :
- Voir si on peut utiliser OpenDNSSEC avec les mises à jour DNS dynamiques (il semble que non),
- Tester avec un vrai HSM,
- Faire marcher l'auditeur.
L'article seul
NKM fait l'éloge des crapauds fous
Première rédaction de cet article le 30 octobre 2009
Dernière mise à jour le 1 novembre 2009
Cela fait longtemps que je n'avais pas lu le livre d'une politique en activité. Vous savez, ces livres écrits par des nègres qui s'intitulent « Ma vision », « Mon ambition pour la France » voire « Désir d'avenir ». Je viens d'acheter, le jour de sa parution en fanfare, « Tu viens ? », de Nathalie Kosciusko-Morizet.
Hélas, pas de surprises. Pour 12 € 90, le contenu est très limité en quantité (175 pages), et surtout en idées. Bon, je veux bien passer sur le nombre de pages, après tout l'auteure est une cumularde (maire et ministre en même temps et je ne mentionne pas ses activités familiales, car si elle était un homme, personne ne le ferait) et manquait donc de temps.
Mais le manque d'idées est plus sérieux. Si Nathalie Kosciusko-Morizet n'arrête pas de déplorer le manque d'élan de la politique, l'absence de grands rêves, et le caractère bien terre-à-terre de nos ambitions, elle ne propose rien. Aucun grand projet exaltant ne semble suggéré. Elle appelle à écouter les « prophètes » et les « crapauds fous » (ceux qui ne se dirigent pas aveuglément vers la même mare que tous les autres) mais elle-même prend bien soin de ne pas se placer dans cette catégorie. Elle a quelques idées (sur l'écologie, le rôle de l'argent, la consommation, d'ailleurs, on se dit de temps en temps en lisant le livre qu'il faudrait qu'une âme charitable la prévienne qu'elle est dans un gouvernement de droite, elle semble l'oublier souvent). Mais pas de propositions.
Sur la forme, je trouve le ton et les références à Thoreau ou Saint Augustin assez pédantes mais, bon, chacun écrit comme il veut.
La campagne médiatique organisée par les communiquants fait référence à ce livre comme le « premier livre politique 2.0 », car on peut envoyer des commentaires via un site Web. J'ai essayé mais c'est davantage « Web 1.0.1 » que « Web 2.0 ». Les commentaires sont limités à mille caractères, modérés a priori, et la liste des menaces légales à lire avant d'écrire a de quoi sérieusement décourager le crapaud pas trop fou. C'est néanmoins sur le site officiel que j'ai trouvé la meilleure analyse du livre, « Non, je ne viens pas ». Sylvius Aeneas s'y moque à juste titre d'une « ministre de l'Internet » qui n'a rien à dire sur Hadopi. Le gouvernement dont elle fait partie multiplie les mesures liberticides contre Internet pendant Nathalie Kosciusko-Morizet relit Saint-Augustin. (Depuis que cet article a été écrit, Nathalie Kosciusko-Morizet a explicitement pris position en faveur de la loi répressive Loppsi.)
J'ai personnellement tenté deux contributions, en essayant de suivre lesdites règles. Une a été affichée, l'autre (qui me semblait bien plus modérée, et purement factuelle) rejetée, sans explications : « Nous sommes au regret de vous dire que votre contribution, parce qu'elle contrevient à la charte de notre site ou bien qu'elle ne répond pas à l'une des six questions posées, ne sera pas publiée sur le site www.tuviens.fr. [...] Merci de ne pas répondre à cet email, votre réponse ne sera pas traitée. »
Sur la politique de Nathalie Kosciusko-Morizet, j'approuve complètement l'article de bluetouff, « À quoi sert Nathalie Kosciusko-Morizet ? » (vous vous doutez de la réponse...)
L'article seul
Le prix Nobel d'Économie pour étudier les biens communs
Première rédaction de cet article le 30 octobre 2009
Effet amusant de la crise financière, le prix Nobel d'Économie, auparavant attribué uniquement aux économistes les plus ultra-capitalistes, partisans d'un marché à outrance, a retourné sa veste. Désormais, finies les modélisations mathématiques irréalistes, ayant pour seul but de justifier les réductions de salaire ou d'avantages sociaux. Maintenant, priorité aux économistes qui étudient le monde réel.
En 2009, le prix Nobel d'Économie est revenu à Elinor Ostrom et Oliver Williamson. La première est surtout connue pour son étude du fonctionnement des biens communs.
Dans un article du 12 octobre, Hervé Le Crosnier se félicite de cette décision du comité Nobel et estime que l'un des mérites d'Ostrom est d'avoir tordu le cou à la théorie simpliste de la tragédie des biens communs.
Cette théorie, formalisée dans un article célèbre de Garrett Hardin en 1968 part du cas d'un pré communal où chaque berger peut faire paître ses moutons. Rapidement, selon Hardin, le pré, qui n'est à personne puisqu'il est à tout le monde, est complètement dévasté et plus rien n'y pousse. L'article (court, seulement six pages, et où l'auteur nous inflige ses opinions sur à peu près tous les sujets, de la surpopulation à la publicité en passant par une réflexion quasi-eugéniste) ne détaille pas longuement ce cas. Mais l'exemple de la « tragédie des biens communs » est en général cité à l'appui de la propagande pro-privatisation : la solution est tout simplement de donner le pré à un ou plusieurs hommes riches qui vont s'en occuper... et taxer les bergers.
Je vous laisse lire l'excellent article d'Hervé Le Crosnier pour une explication de l'argument d'Ostrom contre cette théorie. Mais il y a un point qui me tient à cœur dans le problème de la tragédie des biens communs qui est rarement mentionné : c'est que le problème est artificiellement déséquilibré. Dans la description classique du problème, le pré est public mais les moutons sont privés. Donc, les dépenses (d'entretien et de régénération du pré) sont partagées entre tous alors que les bénéfices reviennent à 100 % au berger. Pas besoin d'être prix Nobel d'Économie pour voir que, dans ce cas, l'intérêt rationnel de chaque berger est d'épuiser le pré le plus vite possible. En effet, s'il y a N bergers et qu'ils sont en même temps, en tant que membres de la communauté, responsables équitablement du pré, les dépenses D provoquées par le surpâturage seront de D/N par berger, alors que le bénéfice dû à ce surpâturage, même s'il est très inférieur à D, est entièrement pour le berger. Le choix rationnel individuel est vite fait et, comme souvent, il mène à la ruine de tous. On voit ce genre de phénomènes tous les jours ; par exemple, dans le transport routier, le patron d'une entreprise de transport ne paie qu'une partie de l'usure de la route due à ses camions, via ses impôts, alors qu'il garde tous les bénéfices : les moyens de transport collectifs comme le train ne peuvent donc pas lutter.
Comme tous les articles célèbres, « Tragedy of the commons » est souvent cité et jamais lu. Car ces deux points sont centraux dans l'article d'Hardin (avec la pollution à la place du transport routier), beaucoup plus riche et nuancé que l'ultra-résumé qu'on cite tout le temps.
Et pas besoin d'avoir un doctorat en mathématiques pour se dire que le problème peut être résolu d'un côté (privatiser la terre commune) ou de l'autre (remettre en cause la propriété privée des moutons) : c'est la contradiction entre les deux modes de propriété - dépenses publiques et bénéfices privés - qui est la source du problème. (Là, par contre, Hardin s'est arrêté avant ce point.)
Pour une critique analogue de l'article d'Hardin, cf. « La tragédie des communs était un mythe ».
L'argument d'Ostrom est différent (mais pas incompatible) en insistant sur le fait que les biens communs ne sont pas seulement une ressource passive qu'on exploite mais aussi un espace politique, régulé par la communauté. Ce point a été traité, par exemple, par Eva Hemmungs Wirten dans ses études sur les glaneuses. Pour éviter qu'une glaneuse individuelle ne ramasse tout, un certain nombre de règles ont été élaborées par les glaneuses, ainsi qu'une méta-règle, glaner uniquement en plein jour, pour garantir la transparence du processus.
L'article seul
RFC 5692: Transmission of IP over Ethernet over IEEE 802.16 networks
Date de publication du RFC : Octobre 2009
Auteur(s) du RFC : H. Jeon (ETRI), M. Riegel (NSN), S. Jeong (ETRI)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF 16ng
Première rédaction de cet article le 28 octobre 2009
Le système de transmission radio par micro-ondes Wimax, normalisé par l'IEEE sous le numéro de 802.16, offre une interface Ethernet aux protocoles de couche réseau comme IP. À première vue, on pourrait penser qu'il n'y a donc rien de spécial à faire pour faire fonctionner IP sur Wimax. En fait, ce système offre suffisamment de particularités par rapport à l'Ethernet filaire pour que ce RFC soit nécessaire, pour normaliser les points de détails où il faut s'écarter de l'usage classique d'Ethernet.
Parmi les points importants de Wimax, système conçu pour fonctionner à grande distance, contrairement au Wifi :
- Il n'est pas pair-à-pair. Les machines connectées (nommées SS pour Subscriber Station) ne peuvent pas se parler directement, elles doivent passer par la station de base (BS pour Base Station).
- Wimax est orienté connexion et non pas datagramme : la machine ne peut pas transmettre avant une négociation avec la station de base, qui lui alloue un canal et des ressourecs.
- Il n'y a pas de vraie diffusion : une machine qui veut parler à toutes les autres doit transmettre à la station de base, qui diffusera.
- Comme souvent avec les transmissions radio, les machines qui l'utilisent peuvent avoir des ressources limitées, notamment en électricité, et il faut éviter de les activer pour un oui ou pour un non.
- Wimax offre, entre autres, une interface (un convergence layer, dans la terminologie IEEE) Ethernet. Mais Ethernet avait été prévu pour un bus, un média partagé, alors que Wimax est point-à-multipoint.
La norme IEEE 802.16 est très riche et complexe et beaucoup d'options qu'elle présente peuvent avoir une influence sur IP.
Le défi de ce RFC 5692 (section 1) est donc de profiter de l'interface Ethernet de Wimax, tout en l'optimisant pour l'usage d'IPv4 et IPv6, sans abandonner les principes de base de l'IP sur Ethernet. Le cahier des charges détaillé avait fait l'objet du RFC 5154.
La section 4 décrit le modèle d'IEEE 802.16. Chaque connexion entre la SS (la machine qui se connecte) et la BS (la station de base) reçoit un identificateur sur 16 bits, le CID (Connection Identifier). Il peut y avoir plusieurs connexions entre une BS et une SS. L'acheminement des paquets se fait avec le CID, pas avec l'adresse MAC de l'interface Ethernet.
La section 4.2 couvre les subtilités de l'adressage 802.16. Chaque SS a une adresse MAC sur 48 bits, comme avec Ethernet. Mais la commutation des paquets par la BS se fait uniquement sur la base des CID, les identificateurs des connexions SS<->BS. L'adresse MAC sources des paquets sur un lien radio n'est donc pas forcément celle d'une des deux stations, puisque la BS peut relayer des messages, jouant le rôle d'un pont.
Contrairement au vrai Ethernet, il n'y a pas de diffusion (globale ou restreinte) avec Wimax. La BS peut diffuser à toutes les SS mais si une SS veut en faire autant, elle doit transmettre à la BS, qui reflétera le paquet vers toutes les stations (section 4.3 et annexe A).
Les concepteurs de 802.16, conscients de l'importance d'Ethernet dans le monde des réseaux, avaient prévu dans la norme un mécanisme (et même deux) pour la transmission de paquets au format Ethernet. Comme l'explique la section 4.4, le premier de ces mécanismes, Packet Convergence Sublayer permet d'affecter différents protocoles au dessus d'Ethernet à des connexions différentes (et donc d'avoir des QoS différentes).
Ethernet n'est pas seulement un format de paquets, c'est aussi un modèle de réseau où toute station d'un même Ethernet peut parler directement à n'importe quelle autre. Ce n'est pas le cas, on l'a vu, pour 802.16, et il a donc fallu introduire un pont, rôle joué par la station de base, la BS (section 5). Ce mécanisme n'est pas très différent de celui de l'Ethernet filaire commuté (section 5.1). Comme un commutateur, la BS transmet aveuglément les paquets d'une station d'abonné, une SS, à une autre.
Il reste à réaliser la diffusion (broadcast). Comme indiqué plus haut, et précisé en section 5.2, la BS réalise une diffusion en dupliquant les paquets, un exemplaire par SS destinataire.
Bien, maintenant que le modèle de la liaison et celui de l'émulation Ethernet sont clairs, comment faire passer IP là-dessus ? C'est le rôle des techniques exposées en section 6. Les sections 6.1 et 6.2 font un rappel de la méthode habituelle de transmission d'IP sur Ethernet. Décrite dans les RFC 894 pour IPv4 et RFC 2464 pour IPv6, cette méthode décrit l'encapsulation d'IP dans Ethernet, et la résolution d'adresses IP en adresses MAC par les protocoles ARP (RFC 826, pour IPv4) et NDP (RFC 4861, pour IPv6). IP sur Wimax continue dans la même veine et utilise les mêmes techniques.
C'est ici que se nichent les subtiles différences entre IP sur Ethernet et IP sur 802.16. Par exemple, la section 6.2.2.1 recommande des valeurs particulières pour certaines variables comme l'écart maximum entre deux annonces par un routeur. Comme les machines connectées en Wimax peuvent dépendre d'une batterie, qu'il faut économiser, les valeurs recommandées sont plus importantes que pour un réseau où la majorité des machines est connectée au secteur.
La section 7 détaille ces améliorations qui doivent être apportées à « IP sur Wimax ». Par exemple, la mise en œuvre de la diffusion restreinte Ethernet par les BS consiste à répéter la trame sur tous les liens virtuels, réveillant ainsi même les machines qui n'étaient pas membres du groupe multicast considéré. La section 7.1.1 demande donc que l'information sur qui est membre ou pas soit traitée par la BS, de façon à ce qu'elle sache sur quels liens transmettre la trame. Pour cela, la BS doit donc écouter le trafic lié à la diffusion restreinte, comme expliqué dans le RFC 4541.
Et la diffusion générale (broadcast) ? Elle est encore plus gourmande en électricité. La section 7.1.2 demande donc que la station de base procède intelligement et ne transmette pas les trames de diffusion des protocoles comme ARP, DHCP ou IGMP, qu'elle doit plutôt intercepter et traiter elle-même. La section 7.2 explique comment assurer ce traitement pour DHCP et la 7.3 pour ARP. Dans ce dernier cas, la BS, connaissant toutes les stations des clients et donc leurs adresses MAC, doit assurer un rôle de relais ARP. À noter que l'équivalent d'ARP pour IPv6, NDP, ne fonctionne pas de la même manière (les trames sont transmises en diffusion restreinte) et peut donc être traitée par le mécanisme général de la diffusion restreinte.
La section 10 clôt le RFC avec les questions de sécurité. Comme IP sur Wimax est très proche de IP sur Ethernet, les problèmes de sécurité liés à Ethernet sont souvent les mêmes, et les solutions aussi. Ainsi, les paquets NDP (Neighbor Discovery Protocol) peuvent être mensongers et les techniques de sécurité comme SEND peuvent être utilisées.
Deux annexes reviennent sur des choix qui ont été faits lors de l'adaptation d'IP à 802.16. L'annexe A discute la possibilité d'utiliser des CID (Connection Identifier) pour la diffusion restreinte, mais la rejette car la diffusion restreinte de 802.16 ne fonctionne que dans un seul sens, de la BS vers les SS. De plus, elle nécessite un traitement par toutes les machines à qui la BS a envoyé la trame, les forçant ainsi à se réveiller et à consommer du courant.
L'annexe B discute pour sa part les avantages et les inconvénients d'un pont centralisé entre les SS, par rapport à un ensemble de ponts connectés entre eux.
L'article seul
RFC 5702: Use of SHA-2 algorithms with RSA in DNSKEY and RRSIG Resource Records for DNSSEC
Date de publication du RFC : Octobre 2009
Auteur(s) du RFC : J. Jansen (NLnet Labs)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsext
Première rédaction de cet article le 28 octobre 2009
Dernière mise à jour le 28 juin 2010
La cryptanalyse progresse sans cesse et, comme aiment le répéter les experts, « Les attaques ne deviennent jamais pires, elles ne font que s'améliorer ». Les menaces contre la fonction de hachage SHA-1 devenant de plus en plus précises, cet algorithme est petit à petit remplacé par la famille SHA-2. Ce RFC 5702 spécifie ce futur remplacement pour le protocole DNSSEC.
Normalisé dans le RFC 4033 et suivants, DNSSEC, qui vise à garantir l'authenticité des ressources DNS par le biais d'une signature numérique, n'est pas lié à un algorithme particulier. Aussi bien l'algorithme asymétrique utilisé pour les signatures que celui de hachage qui sert à créer un condensat des données à signer ne sont pas fixés en dur dans le protocole. SHA-1 avait été spécifié dans le RFC 3110. Un registre IANA des algorithmes possibles existe et notre RFC 5702 marque l'entrée de la famille SHA-2 dans ce registre.
Il n'est pas évident de savoir si SHA-1 est vraiment vulnérable dès aujourd'hui. Plusieurs attaques ont été publiées dans la littérature ouverte (et il y en a donc sans doute bien d'autres, gardées secrètes) mais elles ne semblent pas facilement exploitables, surtout dans le cas de l'utilisation particulière qu'en fait DNSSEC. Néanmoins, le remplacement de SHA-1 était une nécessité, compte-tenu du fait que les attaques ne peuvent que s'améliorer (voir la section 8 pour un exposé plus détaillé), et parce qu'un tel remplacement prend du temps (par exemple, l'élaboration de ce RFC a été très longue).
Le remplaçant, SHA-2, décrit dans la norme FIPS 180-3 de 2008, n'est pas vraiment un algorithme unique mais une famille d'algorithmes. DNSSEC n'en retient que deux, SHA-256 (code 8) et SHA-512 (code 10). Voir la section 1 du RFC pour ces rappels.
SHA-2 est utilisable dans les enregistrements de type
DNSKEY (clés cryptographiques distribuées par le
domaine) et RRSIG (signature
cryptographiques). Le RFC 4034 décrit tous ces
types d'enregistrement.
La section 2 décrit les enregistrements DNSKEY. Comme la clé
publique ne dépend pas de l'algorithme de hachage utilisé
ultérieurement, on pourrait penser qu'ils ne sont pas modifiés. Mais
il est important d'indiquer au résolveur cet algorithme de hachage car
tous les résolveurs ne connaissent pas SHA-2 du jour au lendemain. Il
faut donc qu'ils sachent tout de suite, en examinant la clé, s'ils
pourront valider la zone ou pas. (Sinon, ils considéreront la zone
comme étant non signée.) Les DNSKEY avec RSA + SHA-256 sont donc
stockés avec le même format qu'avant, mais avec le numéro d'algorithme
8. Les DNSKEY avec RSA + SHA-512 auront, eux, le numéro
d'algorithme 10.
Les signatures (enregistrements RRSIG) sont,
elles, plus largement modifiées. La section 3 décrit ces
modifications. Elle indique la représentation à suivre pour les
RRSIG, suivant le standard
PKCS #1 (RFC 3447).
Les signatures faites avec RSA + SHA-256 seront stockées avec le numéro d'algorithme 8 et leur codage aura un préfixe spécifique, pour les distinguer des signatures faites avec d'autres fonctions (section 3.1). Idem pour celles faites avec RSA + SHA-512 (section 3.2).
Et les problèmes pratiques du déploiement ? Pas de panique, ils sont dans la section 4. La taille des clés elle-mêmes n'est pas couverte (section 4.1) mais déferrée aux recommendations du NIST. La taille des signatures dépend de celle de la clé, pas de l'algorithme de hachage et ne changera donc pas (section 4.2).
Quels logiciels peuvent aujourd'hui utiliser ces algorithmes ? Pour
BIND, ce sera à partir de la version 9.7 (actuellement en béta
publique, mais sans SHA-2). Pour ldns, c'est déjà
disponible dans la version actuelle, la 1.6.1 (mais tous les
paquetages binaires de ldns n'ont pas forcément été compilés avec
l'option --enable-sha2). La section 5 donne
quelques détails pour les programmeurs, notamment sur la raison pour
laquelle il n'y a plus de version spécifique à NSEC3 (section 5.2 et
RFC 5155).
Voici un exemple d'utilisation du programme
ldns-keygen (livré avec ldns) pour générer des
clés utilisant SHA-256 pour la zone vachement-secure.example :
% ldns-keygen -a RSASHA256 vachement-secure.example
Kvachement-secure.example.+008+23094
% cat Kvachement-secure.example.+008+23094.key
vachement-secure.example. 3600 IN DNSKEY 256 3 8 \
AwEAAc87fkhQ3RehZ9AWUtataphm6Ku+DLKgtUPp/Zi0mwhtDN36oWBhzUt5a82Zeat4zsbC6WjIDWWqOx33cWh3ISMKDK0cOu1kMRCZTXS98WoSA0TgfMBdGdaK/Z+yLX+COq8HL72gBDG/RuDqIOwdtCBhbDluIwafzPAw3l2rIEiR \
;{id = 23094 (zsk), size = 1024b}
Et lorsqu'on la signe :
% ldns-signzone vachement-secure.example.zone Kvachement-secure.example.+008+23094
% cat vachement-secure.example.zone.signed
...
. 3600 IN SOA localhost. root.localhost. 1 604800 86400 2419200 604800
. 3600 IN RRSIG SOA 8 0 3600 \
20091125150944 20091028150944 23094 . nvIldICQaBpHR/Fn264gL
7bl5RCzzM6h3S5o6k/yq9cFRhYpOO4FQGfozP2q8A7whoHfymCg1D6harOt7b0ffO+TA1iBddpF1DJLQ/DKPhfS2REqXbXjpveU3uQNK
g0jOdj7G6hrSQl9wXg3Co5yL84jG33oSlDWQM9QhKUyAUk= \
;{id = 23094}
Comme il y a déjà eu des attaques de cryptanalyse contre SHA-1 publiées, la section 8, qui synthétise les questions de sécurité, recommande donc d'utiliser SHA-2 pour les futurs déploiement de DNSSEC.
Enfin, la section 8.2 explique pourquoi SHA-2 n'est pas vulnérable aux attaques par repli : si une zone a deux clés, utilisant SHA-1 et SHA-2, un méchant ne peut pas forcer l'utilisation de l'algorithme le plus faible car les enregistrements DNSSEC doivent être signés avec toutes les clés présentes.
Si on veut voir des signatures en vrai, la racine, et des TLD comme
.pm sont signés (au 28 juin 2010) avec
SHA-256, tandis que .cat
est signé avec SHA-512. Sinon, on peut trouver des exemples de
DNSKEY et de RRSIG utilisant
SHA-2 dans la section 6 du RFC, ou bien les générer soi-même comme dans l'exemple ci-dessus.
L'article seul
RFC 5693: Application-Layer Traffic Optimization (ALTO) Problem Statement
Date de publication du RFC : Octobre 2009
Auteur(s) du RFC : J. Seedorf (NEC), E. Burger (Neustar)
Pour information
Réalisé dans le cadre du groupe de travail IETF alto
Première rédaction de cet article le 28 octobre 2009
Le groupe de travail Alto de l'IETF est chargé de développer un protocole permettant aux participants d'un réseau pair-à-pair de trouver le pair le plus « proche », pour améliorer la communication ultérieure et consommer moins de ressources réseau. Ce premier RFC officiel du groupe décrit le problème à résoudre.
Le fond du problème est que les pairs ne connaissent pas la topologie du réseau. Disposant de trop peu d'informations, ils risquent de choisir, parmi les pairs potentiels, un pair situé très loin d'eux, ce qui se traduira par une capacité réseau inférieure, et une utilisation exagérée des lignes à longue distance, alors que des réseaux à courte distance, moins chargés, étaient disponibles. Le but d'Alto est donc de donner aux pairs le moyen de faire des choix meilleurs que le simple hasard.
Le problème n'est d'ailleurs pas limité aux applications
pair-à-pair. Comme le rappelle la section 1, les applications
client/serveur traditionnelles ont également
parfois à choisir entre plusieurs sources, pour une même ressource (« vais-je télécharger mon
image ISO de NetBSD
depuis ftp.nl.netbsd.org ou bien
ftp.de.netbsd.org ? »). L'Internet
est actuellement exploitée de manière très peu « développement
durable ». Les applications gourmandes comme le chargement de vidéos
ou l'échange de fichiers multimédia consomment beaucoup de capacité du
réseau, sans faire d'effort pour minimiser cette consommation.
Comme dans l'exemple de la distribution de NetBSD ci-dessus, la ressource convoitée est aujourd'hui souvent disponible depuis plusieurs sources, chacune ayant une réplique de la ressource (section 1.1). Mais les applications ne disposent pas d'éléments suffisants pour choisir la réplique la plus proche. Des heuristiques comme le pays (dans l'exemple de NetBSD ci-dessus) sont très insuffisantes car la connectivité n'épouse pas les frontières nationales. Les mesures comme celle du RTT (mises en œuvre par un logiciel comme netselect) ne donnent pas d'informations sur la capacité du réseau (cf. RFC 5136), ni sur le coût des différentes lignes (par exemple entre transit et peering). Voici un exemple avec netselect, où il affiche le serveur ayant le plus faible RTT (l'algorithme exact de netselect est plus riche, voir la documentation) :
% netselect ftp.be.netbsd.org ftp.nl.netbsd.org ftp.de.netbsd.org ftp.es.netbsd.org 25 ftp.be.netbsd.org
et, en plus détaillé :
% netselect -vv ftp.be.netbsd.org ftp.nl.netbsd.org ftp.de.netbsd.org ftp.es.netbsd.org Running netselect to choose 1 out of 5 addresses. .................................... ftp.be.netbsd.org 11 ms 11 hops 100% ok (10/10) [ 23] 192.87.102.43 9999 ms 30 hops 0% ok 192.87.102.42 9999 ms 30 hops 0% ok ftp.de.netbsd.org 24 ms 10 hops 100% ok (10/10) [ 48] ftp.es.netbsd.org 17 ms 10 hops 100% ok (10/10) [ 34] 23 ftp.be.netbsd.org
Face à ce problème, plusieurs groupes ont expérimenté des solutions visant à donner davantage d'information aux applications (cf. par exemple le RFC 5632, et le RFC 6029 pour une étude détaillée des propositions techniques existantes). Si cela viole un peu le modèle en couches (pour lequel l'application devrait être totalement ignorante du réseau sous-jacent), cela permet en général une nette augmentation des performances et une diminution de la consommation de ressources.
L'état de l'art est résumé dans la section 1.2 du RFC. Outre le RFC 5632, on peut consulter les références données dans le RFC comme « P4P: Explicit Communications for Cooperative Control Between P2P and Network Providers ». Ces solutions ont en commun de fournir un mécanisme de découverte de la source d'information et, une fois qu'on a trouvé celle-ci, un mécanisme d'interrogation de la source, pour récupérer les informations qui permettront de prendre une bonne décision.
La section 2 définit les (nombreux) termes utilisés par Alto. Le schéma des protocoles est particulièrement recommandé, il illustre notamment le fait qu'Alto n'est concerné que par la récupération de l'information depuis les serveurs Alto, pas par la manière dont cette information a été récoltée par les serveurs.
Enfin, le problème qu'Alto veut résoudre est défini rigoureusement dans la section 3. Dans un environnement où on veut une ressource (un fichier MP3, par exemple), pas une machine spécifique, il s'agit de trouver la meilleure machine pour la communication, parmi un ensemble de machines qui hébergent la même ressource. « Meilleure » peut signifier plusieurs choses, débit, coût ou même d'autres critères comme la volonté de ne pas concentrer tous les « clients » sur un seul « serveur ». En tout cas, « meilleur » doit être simplement « meilleur qu'en tirant au hasard », ce choix aléatoire étant la référence de base.
Dans quels cas un protocole de type Alto serait-il utile ? La section 4 donne des exemples de scénarios. Par exemple, le partage de fichiers (section 4.1) est une application courante et très gourmande, les fichiers en question étant souvent du gros multimédia. Si je veux télécharger un film, la quantité de données à faire passer par le réseau justifie certainement de passer quelques secondes à choisir la ou les meilleures machines d'où le charger.
Même chose lorsqu'il faut choisir, dans un protocole client/serveur traditionnel comme HTTP (section 4.2), le meilleur « miroir » d'un site donné (comme dans l'exemple de NetBSD plus haut).
Il existe encore plusieurs exemples comme l'utilisation d'Alto pour aider à construire une DHT (section 4.5).
Alto soulève plein de questions (comme l'avait montré la réunion animée à Dublin). La section 5 tente d'y répondre. D'abord, quelle information doit être distribuée par Alto (section 5.1) ? Pour éviter de surcharger le protocole, il faut développer des critères permettant de dire ce qu'on distribue et ce qu'on ne distribue pas. On ne distribue certainement pas avec Alto de l'information très temporaire comme la congestion. Alto devrait servir à transporter de l'information relativement stable et, surtout, que l'application ne peut pas obtenir facilement elle-même. La mesure du RTT, par exemple, n'a pas besoin d'Alto. Mais séparer les liens Internet chers de ceux bon marché ne peut jamais être découvert par l'application et doit donc être fourni par Alto. Même chose pour toutes les notions « comptables » comme le quota restant, dans le cas d'une connexion Internet facturée à l'usage (notez que la plupart des offres Internet sur mobile sont dans ce cas, même si la publicité mensongère des opérateurs les nomme « Internet illimité ».
Et qui va rassembler l'information que les serveurs Alto distribueront (section 5.2) ? A priori, on pourrait imaginer que cela soit fait par les opérateurs (qui connaissent leur réseau), des tiers qui bénéficient de certaines informations fournies par les opérateurs (un bon exemple est Akamai) ou bien, en style davantage « 2.0 », des communautés d'utilisateurs travaillant de manière décentralisée.
Le service Alto pourra donc être présenté de manière différente (section 5.3). Il pourrait être un service centralisé ou bien être lui-même pair-à-pair. Il faudra donc prévoir un mécanisme de découverte, pour savoir où s'adresser.
Évidemment, les applications utilisée peuvent manipuler des données privées. Si j'utilise une application pair-à-pair pour récupérer des films pornos, je n'ai pas forcément envie que mon FAI soit au courant, même si c'est une activité parfaitement légale. La section 5.4 explore donc la question de la protection de la vie privée. Le serveur Alto souhaiterait avoir le plus d'informations possibles pour prendre la meilleure décision, mais l'utilisateur doit avoir un moyen de ne pas trop en dire. Un problème analogue est celui de la protection des données confidentielles de l'opérateur réseau. Celui-ci ne souhaite pas forcément que ses clients soient au courant de la topologie du réseau (section 5.5).
Enfin, le problème de la coexistence avec les caches fait l'objet de la section 5.6.
Alto pose aussi des questions liées à la sécurité (section 6). Si les problèmes de mise en œuvre du contrôle des contenus sont explicitement exclus, d'autres questions restent posées. Par exemple, comme le serveur Alto peut influencer le processus de choix d'un pair (c'est son but), Alto introduit une tierce partie dans le dialogue pair-à-pair et donc un composant de plus pour l'analyse de la securité.
Ainsi, si le serveur Alto est géré par le FAI, certains utilisateurs peuvent ne pas avoir envie de l'utiliser car ils craignent (à juste titre quand on voit le comportement de certains FAI) que le FAI ne se serve d'Alto pour imposer les quatre volontés de Warner ou de Disney, ou bien pour espionner l'activité de certains utilisateurs, ou encore pour appliquer des politiques de sélection qui sont dans l'intérêt du FAI mais pas dans celui des utilisateurs (faire passer par des routes lentes mais moins chères, par exemple).
Toutefois, il n'est pas envisagé de rendre Alto obligatoire. Si certains serveurs Alto n'agissent plus dans l'intérêt des utilisateurs, le plus simple sera de ne pas les utiliser.
L'article seul
RFC 5668: Four-octet AS Specific BGP Extended Community
Date de publication du RFC : Octobre 2009
Auteur(s) du RFC : Y. Rekhter (Juniper Networks), S. Sangli (Cisco Systems), D. Tappan
Chemin des normes
Première rédaction de cet article le 28 octobre 2009
Depuis le RFC 1997 en août 1996, les annonces BGP effectuées par un routeur sont fréquemment marquées par une communauté, un nombre qui identifie des caractéristiques particulières d'une route, comme, par exemple, le fait qu'elle ne doive pas être réexportée vers d'autres AS. Ces communautés étaient traditionnellement encodées sous la forme { numéro d'AS : valeur de la communauté } en profitant du fait que les communautés du RFC 1997 faisaient quatre octets (deux pour l'AS et deux pour la valeur spécifique à l'AS). Avec l'arrivée des AS sur quatre octets, il fallait un nouveau type de communauté.
Le RFC 1997 recommandait ce type d'encodage, qu'on
retrouve dans la documentation des politiques de routage de nombreux
AS. Par exemple, whois -h whois.ripe.net AS3356
nous montre :
remarks: -------------------------------------------------------- remarks: prefix type communities remarks: -------------------------------------------------------- remarks: 3356:123 - Customer route remarks: 3356:666 - Peer route remarks: -------------------------------------------------------- remarks: error type communities remarks: -------------------------------------------------------- remarks: 3356:911 - "internal use" communities received from peer remarks: -------------------------------------------------------- remarks: city communities (some cities not listed as they home off remarks: one of the below) remarks: -------------------------------------------------------- remarks: 3356:2001 - CHI1 - Chicago remarks: 3356:2002 - SDG1 - San Diego remarks: 3356:2003 - LAX1 - Los Angeles remarks: 3356:2004 - DEN1 - Denver ...
où on voit une communauté encodée sous forme de numéro d'AS
(3356), d'un deux-points et d'une valeur.
Mais, depuis le RFC 4893, en mai 2007, les numéros d'AS peuvent faire quatre octets et, à partir du 1er janvier 2010, ce sera même la taille par défaut, distribuée par les RIR. L'ancien encodage ne convenait pas.
Notre RFC 5668 propose donc un nouveau mécanisme. Il s'appuie sur les « communautés étendues » du RFC 4360, qui normalisait un type de communauté n'ayant plus la limitation des quatre octets et où les deux premiers octets indiquaient le type de communauté.
Notre RFC 5668 déclare donc un nouveau type de communauté étendue, pour les AS à quatre octets. Sa structure est détaillé dans la section 2. Le premier octet du champ Type du RFC 4360 vaut 0x02 pour les communautés transitives et 0x42 pour les autres (le tout est enregistré dans le registre IANA). Le champ Valeur de la communauté étendue, pour qui le RFC 4360 réserve six octets est séparé en deux, la partie Global Administrator, qui stocke l'AS sur quatre octets, et la partie Local Administrator, qui stocke une valeur spécifique à l'AS, sur les deux octets restants.
Petit piège mentionné en section 3, bien que ces communautés étendues pour AS 4-octets permettent de représenter les anciens AS 2-octets (en ajoutant des zéros devant), cela ne doit pas être fait, pour éviter qu'une communauté puisse être codée de deux façons différentes (ce qui compliquerait les comparaisons).
Il n'y a pas de nouvelle représentation texte standard de ces communautés, on reprend l'existante, comme dans l'exemple de l'AS 3356 plus haut.
L'article seul
Qu'est-ce que Google Wave ?
Première rédaction de cet article le 26 octobre 2009
Dernière mise à jour le 25 août 2010
Tout le monde a parlé de Google Wave au moment de sa sortie, alors, pourquoi pas moi ? je vais expliquer ce que j'y ai compris, en commençant par des choses qui peuvent intéresser tous les utilisateurs de l'Internet, puis en passant à une analyse un peu plus technique.
L'article complet
RFC 5644: IP Performance Metrics (IPPM) for spatial and multicast
Date de publication du RFC : Octobre 2009
Auteur(s) du RFC : E. Stephan (France Telecom R&D), L. Liang (University of Surrey), A. Morton (AT&T Labs)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF ippm
Première rédaction de cet article le 24 octobre 2009
Deux jeux de métriques (grandeur à mesurer, définies de façon formelle) sont normalisés dans ce RFC, l'un pour des mesures « spatiales », l'autre pour la diffusion de groupe.
Dans le cadre du RFC 2330, il existe plusieurs métriques pour mesurer des « performances » d'un réseau de bout en bout. On peut ainsi mesurer le temps de trajet (RFC 7679), le taux de perte (RFC 7680), les changements d'ordre des paquets (RFC 4737), etc. Notre RFC 5644 étend ces métriques :
- aux cas où on ne mesure pas seulement de bout en bout mais également aux routeurs intermédiaires,
- aux cas où il y a plusieurs destinations pour un paquet (multicast).
Ici, je parlerais surtout des premières, les métriques dites « spatiales » (voir les sections 7 et 8 pour les autres).
Comme les précédentes, ces nouvelles métriques sont enregistrées dans le registre créé par le RFC 4148. Les définitions nécessaires figurent dans la section 2. Ainsi, métrique multipartite (multiparty metric) est définie (section 2.4) comme le cas où il existe plusieurs points de mesure, une métrique spatiale (spatial metric) est (section 2.5) celle où certains des points de mesure ne sont ni la source, ni une destination du paquet (mais des routeurs situés sur le trajet). Et la métrique de groupe est (section 2.6) celle où il existe plusieurs destinations.
La section 2.7 introduit la notion de points intéressés (points of interest). Ce sont les machines où se fait la mesure. Pour les métriques spatiales, c'est un sous-ensemble des routeurs du chemin suivi par le paquet. Pour les métriques de groupe, ce sont les machines de destination.
Autre terme important, celui de vecteur (vector), défini en section 2.9. C'est simplement une liste de valeurs obtenues en différents points. Par exemple, si on mesure le temps que met un paquet multicast pour aller de la source à N destinations, le résultat de la mesure est un vecteur dont chaque composante est le temps qu'a pris le trajet de la source à un des récepteurs.
Une fois qu'on a les vecteurs, les matrices ne sont pas loin (section 2.10). Une matrice est simplement une liste de vecteurs. Dans le contexte de notre RFC, la matrice a une dimension d'espace (mesures effectuées à différents points, comme dans le vecteur cité en exemple ci-dessus) et une dimension de temps (mesures répétées dans le temps). Si on met le temps horizontalement et l'espace verticalement, une colonne est un vecteur (mesures à différents points, d'un même paquet) et une ligne est un échantillon (mesures de paquets successifs au même point).
Les métriques elles-mêmes sont introduites dans la section 3, en reprenant les concepts des RFC 2330, RFC 2679, RFC 2680, RFC 3393 et RFC 3432. Petit rappel : Type-P indique le type du paquet (TCP ou UDP, taille du paquet, etc) car les performances peuvent en dépendre. Par exemple, Type-P-Spatial-One-way-Delay-Vector reprend la métrique Type-P-One-way-Delay du RFC 2679 et l'étend en vecteur. Elle désigne donc le temps de trajet mesuré à différents points successifs du chemin (différents routeurs).
Pourquoi avoir créé ces nouvelles métriques ? La section 4 reprend les motivations du travail du groupe ippm. Pour les métriques spatiales (section 4.1), il y avait le souhait de comprendre la contribution de chaque étape du chemin au temps total (ce que fait l'ingénieur réseaux lorsqu'il regarde ce qu'affichent traceroute ou mtr avant de dire « Ça coince à tel endroit »).
Venons-en maintenant aux définitions formelles. La section 5 le fait pour les métriques spatiales. Il faut avoir bien lu avant les définitions pour les métriques de bout en bout, les métriques spatiales étant simplement une généralisation. Type-P-Spatial-One-way-Delay-Vector est définie en section 5.1 et, comme indiquée plus haut, c'est simplement l'ensemble des délais d'acheminement d'un paquet, mesuré à plusieurs points du trajet. Je ne recopie pas ici la définition détaillée et très précise du RFC mais je dis juste un mot sur la discussion en section 5.1.5. Cette métrique peut rencontrer des cas pathologiques par exemple si le temps au point N+1 est supérieur au temps au point N. Cela peut être dû à plusieurs choses comme une désynchronisation des horloges (section 3.7.1 du RFC 2679) ou bien un changement dans le routage. Entre le moment où on a déterminé l'ordre des points de mesure (par exemple en faisant un traceroute) et le moment de la mesure, le routage a pu changer et le routeur N+1 passer avant le N.
De même qu'on peut définir Type-P-Spatial-One-way-Delay-Vector en « vectorisant » Type-P-One-way-Delay, la section 5.2 crée Type-P-Spatial-Packet-loss-Vector en vectorisant Type-P-Packet-loss, le taux de perte de paquets du RFC 2680. Et la section 5.3 crée Type-P-Spatial-One-way-ipdv-vector à partir de l'IPDV (Inter-Packet Delay Variation) du RFC 5481.
Les mesures « spatiales » posent des problèmes de méthodologie particuliers qui font l'objet de la section 5.4. Ainsi, la perte d'un paquet est définie par le RFC 2680 comme la non-arrivée de ce paquet au bout d'un temps fini. Si deux points de mesure n'utilisent pas la même valeur pour ce temps, un paquet peut être considéré comme perdu à un point de mesure... mais pas à un point situé en aval, qui utilise un délai maximum plus élevé (section 5.4.1). Il est donc important que tous les points de mesure utilisent des valeurs cohérentes.
Les vecteurs de notre RFC 5644 sont ordonnés : chaque point mesure a une place, qui est l'ordre dans lequel ils voient passer le paquet. Toutes les métriques spatiales dépendent donc de cet ordre. Or, celui-ci n'est pas constant sur l'Internet. Par exemple, une instabilité temporaire du routage peut entraîner une micro-boucle où le paquet passe plusieurs fois par le même routeur et est donc observé plusieurs fois (section 5.4.2). Les points de mesure doivent donc pouvoir détecter de pareils cas, pour les éliminer des statistiques. (La section 10.2.1 mentionne aussi l'importance d'indiquer le chemin suivi par le paquet dans les publications.)
Un vecteur désigne des mesures qui varient dans l'espace, une mesure par point d'observation. Les mesures varient aussi dans le temps, ce qui mène aux métriques de la section 6. Type-P-Segment-One-way-Delay-Stream (section 6.1) est ainsi l'observation dans le temps du délai d'acheminement entre deux routeurs.
Les vecteurs étant évidemment plus gros que les scalaires, les métriques de notre RFC posent des problèmes techniques liés à l'espace de stockage nécessaire et à la capacité du réseau pour les transporter. La section 9 discute de ces détails pratiques. Par exemple, la section 9.3 expose deux méthodes de réduction des matrices avant de les envoyer, réduction sur le temps (agréger les mesures faites à des moments différents) ou bien sur l'espace (agréger les mesures de tous les routeurs). Comme seule la première méthode de réduction peut être effectuée localement, sur chaque point de mesure, c'est elle qui permet de minimiser le trafic réseau lié à ces mesures.
L'article seul
L'Internet IPv6 coupé en deux
Première rédaction de cet article le 23 octobre 2009
Depuis au moins le 12 octobre, l'Internet IPv6 est coupé en deux et les paquets ne passent plus entre les deux moitiés.
À ma connaissance, le problème a été signalé pour la première fois
à
NANOG. Depuis certains sites IPv6, on peut
joindre www.cogentco.com (ici depuis Renater) :
% traceroute6 www.cogentco.com traceroute to cogentco.com (2001:550:1::cc01) from 2001:660:3003:8::4:69, 30 hops max, 16 byte packets ... 13 2001:550:1::1 (2001:550:1::1) 101.526 ms 92.821 ms * 14 cogentco.com (2001:550:1::cc01) 92.261 ms 92.558 ms 92.294 ms
et pas depuis d'autres (ici Hexago mais c'est pareil depuis Hurricane Electric) :
% traceroute6 www.cogentco.com traceroute to cogentco.com (2001:550:1::cc01) from 2001:5c0:1000:b::219, 30 hops max, 24 byte packets 1 2001:5c0:1000:b::218 (2001:5c0:1000:b::218) 31.998 ms 27.998 ms 31.998 ms 2 ix-5-0-1.6bb1.MTT-Montreal.ipv6.as6453.net (2001:5a0:300::5) 31.998 ms !N 31.998 ms !N 31.998 ms !N
Que s'est-il passé ? Un problème non-technique, qui arrive parfois dans le monde IPv4 (mais qui est en général réglé rapidement car la perte de connectivité est trop grave) et qui fait ici ses débuts dans le monde IPv6 : le depeering, en l'occurrence celui de Hurricane Electric par Cogent.
Pour que l'Internet fonctionne, il faut que des opérateurs réseau concurrents échangent du trafic. Ils peuvent le faire sur la base d'une relation client/fournisseur, où le client paie le fournisseur (on dit qu'il « achète du transit ») ou bien sur la base d'une égalité approximative entre les deux opérateurs (on dit qu'ils « peerent »). Évidemment, les gros n'aiment pas peerer avec les petits et saisissent toute occasion de « dépeerer », les forçant à passer par les liens de transit, plus coûteux. Dans le monde IPv4, ce genre de bras de fer peut se traduire par des coûts plus élevés mais ne met pas en péril la connectivité, sauf cas extrêmes, car les opérateurs ont en général plusieurs solutions de rechange pour acheminer les paquets.
Mais la connectivité IPv6 est bien plus pauvre, avec moins de redondance. En outre, comme IPv6 n'est encore largement utilisé que pour des essais, les coupures suscitent nettement moins d'intérêt de peuvent durer bien plus longtemps.
Voici le point de vue de Hurricane Electric. Je ne peux pas pointer vers celui de Cogent, cette entreprise n'informe jamais les utilisateurs. Mais voici un bon article de synthèse de l'affaire, avec la photo du gâteau que Hurricane Electric a réalisé...
L'article seul
RFC 5011: Automated Updates of DNS Security (DNSSEC) Trust Anchors
Date de publication du RFC : Septembre 2007
Auteur(s) du RFC : M. StJohns
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsext
Première rédaction de cet article le 23 octobre 2009
Dernière mise à jour le 2 juillet 2015
La plaie de DNSSEC, comme celle de tous les systèmes de cryptographie, est la gestion des clés. Avec DNSSEC, la clé de signature des autres clés, la KSK (Key Signing Key) est censée être remplacée (rolled over) régulièrement. Si un résolveur a une KSK dans sa configuration, cela oblige l'administrateur du résolveur à effectuer le remplacement à la main, ce qui peut être contraignant. Notre RFC 5011 propose une autre solution : le domaine signe la nouvelle KSK avec l'ancienne et le résolveur accepte alors automatiquement cette nouvelle clé.
Le résolveur peut ainsi construire une chaîne de confiance menant de la première clé pour laquelle il a été configuré, jusqu'à la clé actuelle. Cela implique que ledit résolveur ait un espace où écrire les clés successives qu'il a authentifié et décidé de garder.
La méthode de notre RFC présente des risques (cf. section 8.3) mais pas plus que la situation actuelle où les clés sont entièrement gérées à la main.
Ce RFC 5011 fournit donc un moyen de ne configurer la clé d'un domaine qu'une seule fois (cette configuration initiale reste manuelle), même si elle est remplacée par la suite. Le principe est simple (et le RFC est donc très court). La section 2 le décrit : quand une clé est configurée pour une zone du DNS (cette clé est dite un « trust anchor ») et qu'une nouvelle KSK apparait dans la zone, signée par l'ancienne, le résolveur accepte cette nouvelle KSK comme trust anchor et l'enregistre dans sa configuration. Une machine à états complète figure en section 4.
Le principal piège avec cette méthode est que, si une clé privée
est volée, l'attaquant pourra continuer à générer une chaîne de
confiance : le retrait de la clé compromise par le gérant de la zone
ne suffira pas à annuler son usage. Il faut donc un mécanisme de
révocation (section 2.1). Lorsqu'une KSK est publiée, signée mais que
le nouveau bit REVOKE est mis, alors le résolveur
doit retirer cette clé de sa configuration.
Un autre risque est que la clé privée soit volée sans que le gérant de la zone ne s'en rende compte immédiatement. Pour éviter que l'attaquant ne fasse accepter une nouvelle clé, le résolveur est supposé attendre lorsqu'une clé apparait (section 2.2). La durée d'attente est typiquement de 30 jours (section 2.4.1).
Le résolveur qui met en œuvre ce RFC 5011 doit périodiquement vérifier que la clé est toujours en service. La section 2.3 expose les règles à suivre pour cette vérification (il faut demander souvent pour détecter les nouvelles clés, sans attendre l'expiration du TTL mais pas trop pour ne pas surcharger les serveurs).
On l'a vu, ce RFC crée un nouveau booléen dans les enregistrement
DNSKEY, pour indiquer la révocation. Le format
est donc légèrement modifié, comme spécifié en section 3. C'est le bit
n° 8 du champ DNSKEY Flags (voir section 2.1.1 du
RFC 4034) qui servira à cet
effet.
Si toutes les clés d'une zone sont révoquées, la zone devient non-validable (section 5), ce qui signifie qu'elle sera traitée comme si elle n'était pas signée du tout (insecure en terminologie DNSSEC).
Le bon fonctionnement de l'algorithme nécessite que la zone signée procède au remplacement des clés d'une manière particulière, décrite en section 6. Ainsi, le remplacement (rollover) va nécessiter la révocation de l'ancienne clé.
Le logiciel BIND a introduit le système de ce
RFC dans sa version 9.7. (Voir le fichier README.rfc5011 dans le code
source.) Cela se configure avec la directive
managed-keys, qui ressemble beaucoup à
trusted-keys (sauf l'ajout d'un mécanisme pour
trouver la première clé, ici avec le paramètre initial-key), par exemple ainsi :
managed-keys {
"example.com." initial-key 257 3 5
"AwEAAeeGE5unuosN3c8tBcj1/q4TQEwzfNY0GK6kxMVZ
1wcTkypSExLCBPMS0wWkrA1n7t5hcM86VD94L8oEd9jn
HdjxreguOZYEBWkckajU0tBWwEPMoEwepknpB14la1wy
3xR95PMt9zWceiqaYOLEujFAqe6F3tQ14lP6FdFL9wyC
flV06K1ww+gQxYRDo6h+Wejguvpeg33KRzFtlwvbF3Aa
pH2GXCi4Ok2+PO2ckzfKoikIe9ZOXfrCbG9ml2iQrRNS
M4q3zGhuly4NrF/t9s9jakbWzd4PM1Q551XIEphRGyqc
bA2JTU3/mcUVKfgrH7nxaPz5DoUB7TKYyQgsTlc=";
// key id = 8779
};
Une fois que BIND démarre, il crée un journal pour une zone bidon,
managed-keys.bind et commence le processus décrit
dans le RFC :
23-Oct-2009 10:55:10.152 zone managed-keys.bind/IN/_meta: loaded serial 0 23-Oct-2009 10:55:10.169 zone managed-keys.bind/IN/_meta: Initializing automatic trust anchor management for zone 'example.com'; \ DNSKEY ID 49678 is now trusted, waiving the normal 30-day waiting period.
On voit que example.com a déjà une nouvelle clé,
49678, signée avec l'ancienne (celle que j'ai configurée dans
manage-keys) et que BIND commence la période
d'attente. Voici, avec une zone différente, le contenu de managed-keys.bind
au moment où une deuxième clé vient d'être publiée :
$ORIGIN . $TTL 0 ; 0 seconds @ IN SOA . . ( 2 ; serial 0 ; refresh (0 seconds) 0 ; retry (0 seconds) 0 ; expire (0 seconds) 0 ; minimum (0 seconds) ) KEYDATA 20150703040258 20150702160258 19700101000000 257 3 8 ( AwEAAaP3gGQ4db0tAiDEky0dcUNGeI1aTDYP5NFxzhbd pD60ZhKLVV4KyxPmoSNUpq5Fv5M0iBwK1Tyswsyq/9sM SoZ8zx8aT3ho1YnPsSqQeJfjTT1WsX6YZ5Kw6B2QkjRN a6OMGZ96Kn8AI/slqsw+z8hY49Sn3baeo9iJxHPzloNc 2dQkW4aLqzNEYxnuoJsthCfGrPSAXlUjY9m3YKIaEWR5 WFYQk770fT+gGWLk/54Vp0sG+Lw75JZnwhDhixPFaToT DNqbHQmkEylq1XJLO15uZ/+RZNRfTXZKO4fVR0tMEbMA ITqRmyP8xLXY4RXbS4J32gnenQbzABX8sQmwO7s= ) ; KSK; alg = RSASHA256; key id = 55954 KEYDATA 20150703040258 20150702160258 19700101000000 257 3 8 ( AwEAAchb6LrHCdz9Yo55u1id/b+X1FqVDF66xNrhbgnV +vtpiq7pDsT8KgzSijNuGs4GLGsMhVE/9H0wOtmVRUQq Q50PHZsiqg8gqB6i5zLortjpaCLZS7Oke1xP+6LzVRgT 4c8NXlRBg3m/gDjzijBD0BMACjVGZNv0gReAg2OCr9dB rweE6DnM6twG7D2NyuGjpWzKeJfNd3Hek39V9NGHuABG kmYG16XCao37IWcP/s/57HuBom5U3SNfuzfVDppokatu L6dXp9ktuuVXsESc/rUERU/GPleuNfRuPHFr3URmrRud 4DYbRWNVIsxqkSLrCldDjP1Hicf3S8NgVHJTSRE= ) ; KSK; alg = RSASHA256; key id = 24439
Pour Unbound, la configuration de ce RFC se
fait en préfixant les directives par
auto-. Ainsi, au lieu d'avoir une clé statique et
qui ne bougera pas :
trust-anchor-file: "root.key"
On aura une clé modifiable :
auto-trust-anchor-file: "autokey/root.key"
Il faut bien sûr veiller à ce que le répertoire (ici
autokey/) soit accessible à Unbound en
écriture. Voici un fichier pour les mêmes clés que l'exemple BIND plus
haut :
; autotrust trust anchor file
;;id: . 1
;;last_queried: 1435856265 ;;Thu Jul 2 16:57:45 2015
;;last_success: 1435856265 ;;Thu Jul 2 16:57:45 2015
;;next_probe_time: 1435899044 ;;Fri Jul 3 04:50:44 2015
;;query_failed: 0
;;query_interval: 43200
;;retry_time: 8640
. 86400 IN DNSKEY 257 3 8 AwEAAaP3gGQ4db0tAiDEky0dcUNGeI1aTDYP5NFxzhbdpD60ZhKLVV4KyxPmoSNUpq5Fv5M0iBwK1Tyswsyq/9sMSoZ8zx8aT3ho1YnPsSqQeJfjTT1WsX6YZ5Kw6B2QkjRNa6OMGZ96Kn8AI/slqsw+z8hY49Sn3baeo9iJxHPzloNc2dQkW4aLqzNEYxnuoJsthCfGrPSAXlUjY9m3YKIaEWR5WFYQk770fT+gGWLk/54Vp0sG+Lw75JZnwhDhixPFaToTDNqbHQmkEylq1XJLO15uZ/+RZNRfTXZKO4fVR0tMEbMAITqRmyP8xLXY4RXbS4J32gnenQbzABX8sQmwO7s= ;{id = 55954 (ksk), size = 2048b} ;;state=1 [ ADDPEND ] ;;count=2 ;;lastchange=1435813814 ;;Thu Jul 2 05:10:14 2015
. 85667 IN DNSKEY 257 3 8 AwEAAchb6LrHCdz9Yo55u1id/b+X1FqVDF66xNrhbgnV+vtpiq7pDsT8KgzSijNuGs4GLGsMhVE/9H0wOtmVRUQqQ50PHZsiqg8gqB6i5zLortjpaCLZS7Oke1xP+6LzVRgT4c8NXlRBg3m/gDjzijBD0BMACjVGZNv0gReAg2OCr9dBrweE6DnM6twG7D2NyuGjpWzKeJfNd3Hek39V9NGHuABGkmYG16XCao37IWcP/s/57HuBom5U3SNfuzfVDppokatuL6dXp9ktuuVXsESc/rUERU/GPleuNfRuPHFr3URmrRud4DYbRWNVIsxqkSLrCldDjP1Hicf3S8NgVHJTSRE= ;{id = 24439 (ksk), size = 2048b} ;;state=2 [ VALID ] ;;count=0 ;;lastchange=1434990786 ;;Mon Jun 22 16:33:06 2015
Notez qu'Unbound, lui, écrit l'état des clés, VALID pour celle en cours d'utilisation et
ADDPEND (Add, Pending) pour
celle qui la remplacera.
Un très bon article de test de notre RFC, avec OpenDNSSEC, BIND et Unbound, par Jan-Piet Mens.
L'article seul
RFC 5734: Extensible Provisioning Protocol (EPP) Transport over TCP
Date de publication du RFC : Août 2009
Auteur(s) du RFC : S. Hollenbeck (Verisign)
Chemin des normes
Première rédaction de cet article le 22 octobre 2009
Dernière mise à jour le 30 octobre 2009
Ce court RFC spécifie comment utiliser le protocole d'avitaillement EPP au dessus d'une simple connexion TCP.
EPP, décrit dans le RFC 5730 est à sa base uniquement un format XML pour les requêtes d'avitaillement (création, mise à jour et destruction d'objets) et leurs réponses. Ces éléments XML peuvent être transmis de différence façon (au dessus de HTTP, de BEEP, par courrier électronique, etc), et notre RFC normalise la plus commune aujourd'hui, une simple connexion TCP. Il remplace le RFC 4934, avec uniquement des modifications de détail, portant notamment sur l'utilisation de TLS (section 9).
Le RFC est court car il n'y a pas grand'chose à dire, juste
l'utilisation des primitives de TCP (ouverture et fermeture de
connexion, section 2 du RFC), l'ordre des messages (section 3), le
port utilisé (700, 3121 ayant été abandonné,
section 7) et le fait que chaque élément EPP soit précédé d'un entier
qui indique sa taille (section 4). Sans cet entier (qui joue le même rôle que
l'en-tête Content-Length de HTTP), il faudrait,
avec la plupart des implémentations, lire les données
octet par octet (sans compter que la plupart des analyseurs XML ne
savent pas analyser de manière incrémentale, il leur faut tout
l'élément). En outre, sa présence permet de s'assurer que toutes les données ont été reçues (voir l'excellent article The ultimate SO_LINGER page, or: why is my tcp not reliable).
L'entier en question est fixé à 32 bits. Si on programme un client EPP en Python, l'utilisation brutale du module struct ne suffit pas forcément. En effet :
struct.pack("I", length)
force un entier (int) mais pas forcément un
entier de 32 bits. Pour forcer la taille, il faut utiliser également,
comme précisé dans la documentation, les opérateurs < et >, qui servent aussi à forcer la
boutianité (merci à Kim-Minh Kaplan pour son
aide sur ce point).
Voici une démonstration (un "l" standard fait 4
octets alors que le type long de C peut faire 4 ou 8 octets) :
# Machine 32 bits :
Python 2.4.4 (#2, Apr 5 2007, 20:11:18)
[GCC 4.1.2 20061115 (prerelease) (Debian 4.1.1-21)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import struct
>>> print struct.calcsize("l")
4
>>> print struct.calcsize(">l")
4
# Machine 64 bits :
Python 2.4.5 (#2, Mar 11 2008, 23:38:15)
[GCC 4.2.3 (Debian 4.2.3-2)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import struct
>>> print struct.calcsize("l")
8
>>> print struct.calcsize(">l")
4
Si on a quand même un doute, on peut tester la taille obtenue mais ce code est probablement inutile (merci à David Douard pour son aide ici) :
# Get the size of C integers. We need 32 bits unsigned.
format_32 = ">I"
if struct.calcsize(format_32) < 4:
format_32 = ">L"
if struct.calcsize(format_32) != 4:
raise Exception("Cannot find a 32 bits integer")
elif struct.calcsize(format_32) > 4:
format_32 = ">H"
if struct.calcsize(format_32) != 4:
raise Exception("Cannot find a 32 bits integer")
else:
pass
...
def int_from_net(data):
return struct.unpack(format_32, data)[0]
def int_to_net(value):
return struct.pack(format_32, value)
L'algorithme complet d'envoi est :
epp_as_string = ElementTree.tostring(epp, encoding="UTF-8") # +4 for the length field itself (section 4 mandates that) # +2 for the CRLF at the end length = int_to_net(len(epp_as_string) + 4 + 2) self._socket.send(length) self._socket.send(epp_as_string + "\r\n")
et la lecture :
data = self._socket.recv(4) # RFC 5734, section 4, the length
# field is 4 bytes long
length = int_from_net(data)
data = self._socket.recv(length-4)
epp = ElementTree.fromstring(data)
if epp.tag != "{%s}epp" % EPP.NS:
raise EPP_Exception("Not an EPP instance: %s" % epp.tag)
xml = epp[0]
Le code Python complet (qui ne met en œuvre qu'une petite
partie de EPP, le but était juste de tester ce RFC 5734),
utilisant la bibliothèque ElementTree, est
disponible en ligne. Le code
ci-dessus comporte
une grosse faiblesse (mais classique) : rien ne garantit que
recv(n) retournera autant
d'octets que réclamé. Il en renverra au plus n
mais peut-être moins. Pour de la programmation sérieuse, il faut donc
le réécrire avec une fonction du genre :
def safe_recv(s, n):
data = ''
while (n > 0):
tmp = s.recv(n)
data += tmp
n -= len(tmp)
return data
(Merci à Kim-Minh Kaplan pour son aide sur ce point.)
Pour Perl, ce code ressemblerait (merci à
Vincent Levigneron), pour envoyer un élément EPP stocké dans la variable $out, à :
print pack('N', length($out) + 4).$out;
et pour lire un élément EPP :
my $length = unpack "N", $buf; ... $rc = read STDIN, $buf, $length;
Puisque le format N désigne un entier non signé
gros boutien (cf. http://perldoc.perl.org/functions/pack.html).
À noter que cette lecture du champ longueur présente un risque de sécurité : si le serveur malloque aveuglément la taille indiquée dans ce champ, comme il fait quatre octets, le serveur naïf risque de consommer quatre giga-octets de mémoire.
La section 8, consacrée à la sécurité, et surtout la nouvelle section 9, consacrée à TLS, détaillent le processus d'authentification du client et du serveur. L'utilisation de TLS (RFC 5246) est obligatoire, ne serait-ce que pour protéger les mots de passe qui circulent en clair dans les éléments EPP. TLS permet également au client d'authentifier le serveur et au serveur d'authentifier le client, par la présentation de certificats X.509. Leur présentation et leur usage sont désormais obligatoires dans EPP. Notons que, comme toujours avec X.509, la difficulté est de déterminer ce qu'on vérifie. La section 9 détaille le cas où on vérifie un nom et celui où on vérifie une adresse IP. Il serait intéressant de savoir quels registres et quels bureaux d'enregistrement effectuent réellement ces validations...
La liste des changements par rapport au RFC 4934 se trouve dans l'annexe A. Le principal changement consiste en une meilleure spécification des règles de vérification du certificat X.509 lorsque TLS est utilisé (cf. la nouvelle section 9).
L'article seul
Regarder les films débiles de YouTube avec uniquement du logiciel libre
Première rédaction de cet article le 21 octobre 2009
Dernière mise à jour le 4 novembre 2010
Aujourd'hui, l'Internet sert presque uniquement à regarder les vidéos publiées sur YouTube. Mais le mode de publication par défaut est sous forme d'animation Flash, une technologie fermée, contrôlée par un seul acteur, Adobe. Peut-on voir les mêmes films débiles que tout le monde avec uniquement du logiciel libre ?
Si on utilise une machine qui ne fait tourner que du logiciel libre, dans mon cas une Debian, version « lenny » qui n'a que la section « main », celle qui ne contient que du logiciel libre, et donc pas celui de la section « non-free », que voit-on sur YouTube ? « Hello, you either have JavaScript turned off or an old version of Adobe's Flash Player. Get the latest Flash player. » Eh oui, YouTube impose l'utilisation de la technologie fermée et privatrice Flash.
Peut-on utiliser un autre logiciel pour voir ses animations ? Gnash, équivalent d'Adobe Flash en logiciel libre n'a jamais vraiment atteint un niveau suffisant pour être utilisé couramment.
Mais il existe une autre solution. La page renvoyée par YouTube contient le nom du film (au format FLV). On peut donc récupérer celui-ci avec un logiciel comme wget ou curl. Il y a toutefois plus pratique, utiliser l'excellent logiciel youtube-dl qui automatise tout cela. Il analyse le source HTML de la page pour vous et récupère le film. Une fois celui-ci stocké sur votre disque, vous pourrez le regarder à loisir avec des logiciels comme mplayer ou vlc (FLV est lisible par beaucoup de logiciel libres, il n'y a même pas besoin de codecs non-libres).
Voici un exemple d'utilisation :
% youtube-dl -t 'http://www.youtube.com/watch?v=ro6sTexFQbU' [youtube] Setting language [youtube] ro6sTexFQbU: Downloading video info webpage [youtube] ro6sTexFQbU: Extracting video information [download] Destination: A_la_belle_viiiie-ro6sTexFQbU.flv [download] 100.0% of 6.24M at 65.24k/s ETA 00:00 % mplayer A_la_belle_viiiie-ro6sTexFQbU.flv ...
Les apostrophes autour de l'URL sont là parce que le point
d'interrogation est un caractère spécial pour le shell. L'option -t est là pour que le fichier prenne
comme nom le titre du film (autrement, le fichier a un nom inhumain,
l'identifiant YouTube du film.)
youtube-dl fonctionne par
scraping de la page Web. Une
telle technique est très fragile : il suffit que YouTube change son
format et tout est à recommencer. En pratique, lorsque cela arrive,
une nouvelle version de youtube-dl sort en
général rapidement.
Enfin, pour venir, quelques bons films choisis tout à fait subjectivement et arbitrairement sur YouTube :
- Une bonne représentation de la fracture numérique sous forme d'une course de voitures entre les
RIR :
http://www.youtube.com/watch?v=-g-TOkMqufI. - Tous les épisodes de « Avez-vous déjà vu..?, par exemple
http://www.youtube.com/watch?v=n8twu3hpILs. - L'immortel éléphant sur le trampoline :
http://www.youtube.com/watch?v=TK27aknWVI4. - Le formidable Food fight ou la
seconde guerre mondiale où les camps en
présence sont de la nourriture :
http://www.youtube.com/watch?v=e-yldqNkGfo.
Je trouve personnellement que youtube-dl
manque de quelques options pratiques comme la possibilité de lancer un
programme de visualisation une fois le chargement terminé. Le petit
script shell suivant répond à ce problème. On
l'utilise ainsi :
% yt 'http://www.youtube.com/watch?v=7sjlX8ueFfU' [youtube] Setting language [youtube] 7sjlX8ueFfU: Downloading video info webpage [youtube] 7sjlX8ueFfU: Extracting video information [download] Destination: UN_VILLAGE_FRANCAIS_SAISON_2-7sjlX8ueFfU.flv [download] 100.0% of 1.19M at 284.76k/s ETA 00:00 MPlayer 1.0rc2-4.3.2-DFSG-free (C) 2000-2007 MPlayer Team CPU: Intel(R) Pentium(R) Dual CPU E2140 @ 1.60GHz (Family: 6, Model: 15, Stepping: 13) ... Playing UN_VILLAGE_FRANCAIS_SAISON_2-7sjlX8ueFfU.flv.
et on a à la fois le film enregistré en un endroit précis et sa visualisation tout de suite. Le script est simplement :
#!/bin/sh
if [ -z "$1" ]; then
echo "Usage: $0 YouTube-URL" >&2
exit 1
fi
url=$1
LOGFILE=youtube-dl-$$.log
set -e
cd ~/tmp
youtube-dl -t $url | tee $LOGFILE
file=$(awk '/Destination:/ {print $3}' < $LOGFILE)
if [ -z $file ]; then
echo "$url: invalid YouTube URL" >&2
exit 1
fi
mplayer $file
rm -f $LOGFILE
Comme youtube-dl n'a apparemment pas d'option
pour indiquer simplement le nom du fichier enregistré sur la sortie
standard (les options -g et
-e n'affichent pas exactement ce nom, et elles
inhibent le téléchargement), il faut utiliser
awk pour analyser le résultat de youtube-dl.
Bien sûr, comme le fait de pouvoir regarder YouTube fait partie des
droits de l'homme fondamentaux, plein de gens ont développé d'autres
mécanismes pour le faire avec du logiciel libre. Ainsi, Yannick
Roehlly, me signale get-flash-videos,
quasiment l'équivalent de youtube-dl mais écrit
en Perl (et qui gère
d'autres services que YouTube). Christophe Narbonne me recommande
YouTube
Perfect, un script Greasemonkey pour
voir YouTube. Marc Hertzog suggère un truc
pour obtenir de YouTube un fichier
MP4. Et Yannick Palanque préfère utiliser cclive (il existe aussi
un clive).
Et pour
Dailymotion ? Pas de problème, youtube-dl
le gère depuis peu mais, apparemment, clive et cclive le font aussi. Notez que Dailymotion, contrairement à son
concurrent, a en test une distribution de vidéos ne dépendant pas de
logiciel non-libre : http://openvideo.dailymotion.com/. (Voir le communiqué de la
FSF,
« Dailymotion's
support for Ogg is a big deal ».) Pour le service
Vimeo, en revanche, il y a http://gist.github.com/146789 (suggestion de Marc Hertzog).
L'article seul
District 9
Première rédaction de cet article le 18 octobre 2009
Bon, comme tout les lecteurs de ce blog, je suis allé voir ce film. Je n'ai pas été déçu par les qualités cinématographiques (très bon film, très « coup de poing », fait avec un budget raisonnable pour un film de SF moderne), j'ai apprécié un film en anglais où tout le monde a un accent inhabituel mais...
J'ai été un peu gêné par le rôle des noirs : tous les rôles importants (que ce soient des bons ou des méchants) sont tenus par des blancs (ou des aliens). Par contre, les excités anti-aliens qui répondent au micro-trottoir sont tous noirs, ainsi que les pogromistes ou les gangsters nigérians (noirs et nigérians, ils sont bien plus aliens que les aliens).
Ce film est censé, en tout cas c'est ce que dit tout le monde, dénoncer le racisme. Comme il est fait par un sud-africain, on pense forcément à l'apartheid. Mais, dans le film, j'ai eu plutôt l'impression que l'auteur essayait de faire oublier l'apartheid au profit d'un discours comme quoi tous les humains sont des racistes.
En tout cas, le film est plus conçu pour nous émouvoir sur le sort des aliens (surtout le mignon enfant) que sur celui des humains qui peuplent, encore aujourd'hui, les bidonvilles de Johannesburg.
Finalement, la meilleure critique, dans ce film, est celle des médias : tout est vu à travers des reportages à la télévision et le héros, lorsqu'il s'aventure dans le bidonville des aliens, est bien plus attentif à la caméra qui le filme en permanence, qu'aux aliens auxquels il s'adresse.
Voir, sur le même sujet, l'article de Thomas Quinot, plutôt critique du film et celui de Goon, très favorable.
L'article seul
Je ne veux pas de liens vers mon site Web !
Première rédaction de cet article le 18 octobre 2009
Aujourd'hui, la plupart des gérants de sites Web veulent attirer du trafic par n'importe quel moyen. Ils paient très chers des rebouteux (pardon, des consultants) en SEO qui leur promettent une « optimisation du référencement ». Ils ne se demandant pas si leur site est intéressant ou utile, uniquement comment avoir davantage de visiteurs. Donc, logiquement, ils devraient chercher à tout prix à avoir des liens entrants, des liens hypertexte qui pointent vers leur site ? Eh bien non, beaucoup de gros sites Web interdisent explicitement qu'on mette des liens vers eux...
Thierry Stœhr, auteur de l'excellent blog Formats Ouverts, a commencé une liste de tels sites (elle est actualisée régulièrement sur identi.ca, sous l'étiquette #pdlsa, « Pas De Lien Sans Autorisation »). La liste est étonnament longue, et regroupe des sites Web d'origines très variées, grosses entreprises capitalistes, syndicats, ONG, services publics, etc.
Qu'est-ce qui leur a pris ? Pourquoi ces webmestres ne veulent-ils pas de liens entrants, alors que, par exemple, le nombre de ces liens est un des principaux critères utilisés par Google pour déterminer la popularité d'un site ? Ils sont devenus fous ?
Difficile d'obtenir des gérants de ces sites la moindre explication. Il semble que la motivation la plus fréquente (mais on ne la met jamais par écrit, par peur du ridicule) soit juridique. Le raisonnement est le suivant : comme, de nos jours, on peut être trainé en justice pour absolument n'importe quoi, surtout si ça a un rapport avec l'Internet, la possibilité d'une procédure judiciaire pour un lien entrant n'est pas nulle. Un groupe néo-nazi fait un lien vers vous et paf, vous pouvez être accusé de complicité. Bien sûr, c'est absurde, bien sûr, il n'y a pratiquement aucune chance d'être condamné mais, pour pas mal d'organisations, qui pilotent leur site Web l'œil fixé sur le trouillomètre, il vaut mieux surréagir et stériliser le Web, plutôt que de courir le moindre risque.
Si, en outre, vous demandez un avis juridique à des professionnels, vous êtes pratiquement sûrs d'obtenir une réponse du type « Il y a un risque, il vaut mieux interdire » (car, en effet, toute activité présente un risque). Le risque de procès est tel désormais que l'avis du juriste passera toujours devant celui du responsable de la communication, qui voudrait bien avoir davantage de liens. La mention « Pas De Lien Sans Autorisation » reflète donc, pour un site Web, l'importance relative donnée aux critères juridiques par rapport au but normal d'un site Web : être lu et connu.
Si vous travaillez dans un organisme qui met de telles mentions anti-Web sur son site, vous pouvez toujours essayer l'argumentaire « Votre site Web demande une autorisation pour faire un lien vers lui : les 10 questions à vous poser » ou bien le texte de synthèse « Texte destiné aux Services juridique, marketing, commercial (ou autres) et la Direction de votre site Web ». Il n'est pas sûr que cela marche, car l'argument « C'est pour des raisons juridiques » (jamais explicitées) est en général définitif et indiscutable.
Inutile de dire que les liens entrants vers ce site http://www.bortzmeyer.org/ sont les bienvenus et que je donne
d'avance mon autorisation enthousiaste !
Quelques articles sur la campagne qui a suivi l'étude de Thierry Stœhr :
- « Peut-on interdire les liens hypertextes vers un site ? » dans le Monde,
- « Fini les liens HTML vers les sites M6, Bouygues ou TF1 ? » dans PC Inpact,
- « Les liens hypertextes ou quand les juristes verrouillent le web », dans Numérama,
- « Aucun lien », dans Écrans.fr.
L'article seul
Un domaine de tête entier, le suédois, disparait temporairement
Première rédaction de cet article le 14 octobre 2009
Lundi 12 octobre, vers 20h00 UTC, le
domaine de tête
.se a chargé la zone
DNS de
numéro de série 2009101210 qui comprenait une énorme erreur. Pendant
une heure, plus aucun nom de domaine se terminant par .se ne
fonctionnait.
Très vite, Twitter a vu des tweets sur le sujet, puis des rapports et des discussions ont commencé sur les listes de diffusion d'opérateurs comme Nanog.
La cause immédiate était le manque d'un point
dans le fichier de zone, les enregistrement NS de la zone avaient tous
un .se en trop à la fin, par exemple
h.ns.se.se. En effet, dans le format standard
des fichiers de zone DNS, tel qu'il est défini
en section 5 du RFC 1035, un nom qui ne se
termine pas par un point est complété par la nom de la zone, ici
.se. Pendant la panne, on a donc pu voir :
% dig +cd NS se. ... ;; ANSWER SECTION: se. 172540 IN NS h.ns.se.se. se. 172540 IN NS g.ns.se.se. ...
Vous avez remarqué ? (Moi, je ne l'avais pas vu.) Un
.se de trop à la fin, les noms des serveurs de
noms étaient donc tous considérés comme
inexistants. .se avait
donc disparu de l'Internet, plus de Web, plus
de courrier, plus
de XMPP, etc. Comme quasiment toutes les
interactions sur l'Internet commencent par une
requête DNS, plus
rien ne marchait.
Selon la façon dont les résolveurs remplaçaient la délégation venue de
la racine (qui était correcte) par celle faisant autorité (car publiée
par le domaine .se lui-même), ils
arrivaient encore à résoudre les noms en .se ou pas (BIND se
débrouillait mieux qu'Unbound, l'inverse aurait été vrai si l'erreur
avait été à la racine).
Le problème ne concernait pas que les enregistrement NS du TLD mais aussi ceux de toutes les zones déléguées :
ballou.se. 42617 NS ns1.ballou.se.se.
42617 NS ns2.ballou.se.se.
45098 NS ns3.aname.se.se.
Vers 21h00 UTC, .se a chargé la zone 2009101211 qui corrigeait
l'erreur... et en introduisait d'autres, notamment des signatures
DNSSEC invalides pour le SOA. (Ce problème a
été reconnu
par le registre.)
Tout a finalement été réparé mais la mauvaise
information pouvait encore
se trouver dans des caches. Pendant un certain temps, les sites en
.se restaient injoignables, sauf à obtenir de
votre FAI qu'il redémarre son résolveur (comme
conseillé
par le registre, command rndc flush pour
BIND). Pendant quelle durée exactement ? Le TTL
est de deux jours, donc j'avais pensé que ce serait la durée de la
panne (et c'est aussi ce qu'annonce
le registre) mais Jay Daley me fait remarquer à juste titre
que, les noms n'existant pas, c'est le cache négatif (RFC 2308) qui compte et que
celui-ci est de seulement deux heures pour .se.
Cette panne est une des plus graves qui aient jamais affecté un domaine de tête sérieux. Aurait-elle pu être évitée ? Il est évident qu'il faut faire tourner des tests de validité avant de publier la zone. Mais aucun test ne détecte tous les problèmes possibles. Par exemple, un outil de vérification livré avec BIND aurait pu détecter le problème :
% named-checkzone example example.zone zone example/IN: NS 'ns1.nic.example.example' has no address records (A or AAAA)
Mais named-checkzone a aussi des limites. Il ne
positionne pas le code de retour dans le cas ci-dessus, par exemple
(et, non, -n fail ne change rien). Et il ne
marche pas si la zone est mise à jour par dynamic
update (RFC 2136).
Quelques leçons à en tirer :
- Les problèmes surviennent, donc une détection et correction rapide est primordiale,
- DNSSEC, pour lequel le registre suédois était pionnier, n'a pas aidé. Si les données sont fausses, DNSSEC ne va pas les corriger. Garbage In, Garbage Out.
Quelques articles sur le sujet :
- Sweden's Internet broken by DNS mistake, analyse détaillée par Pingdom,
- I Don't Want to Say "I Told You So"..., l'avis d'un expert,
- Crisis information in the modern society..., et d'un autre expert,
- Tech glitch darkens Swedish websites , des nouvelles par un journal suédois anglophone,
- Stora internetproblem för Sverige et des nouvelles pour ceux qui parlent la langue de Henning Mankell et Stieg Larsson.
- Le registre de
.sea publié quelques mois après une étude très détaillée en anglais.
Je dois aussi des remerciements à Jay Daley, David Blacka, Gilles Massen, Jakob Schlyter, Jelte Jansen et Olaf Kolkman pour leurs analyses et le partage d'information.
L'article seul
RFC 5733: Extensible Provisioning Protocol (EPP) Contact Mapping
Date de publication du RFC : Août 2009
Auteur(s) du RFC : S. Hollenbeck (Verisign)
Chemin des normes
Première rédaction de cet article le 14 octobre 2009
Le protocole d'avitaillement EPP ne spécifie pas comment représenter les objets qu'on crée, détruit, modifie, etc. Cette tâche est déléguée à des RFC auxiliaires comme le nôtre, consacré aux contacts, c'est-à-dire aux personnes physiques ou morales responsables d'un objet de la base et qui peuvent être contactées à son sujet. (L'objet étant typiquement un nom de domaine ou bien un préfixe IP.)
EPP permet à un client de créer, détruire et modifier des objets de types différents. En pratique, EPP n'est utilisé que dans l'industrie des noms de domaine mais, en théorie, il pourrait être utilisé pour n'importe quel type d'objets.
Le type n'est donc pas spécifié dans le protocole EPP de base, normalisé dans le RFC 5730, mais dans des RFC supplémentaires. Par exemple, celui qui fait l'objet de cet article spécifie le type, la classe (EPP dit le mapping) pour les contacts. Il remplace le RFC 4933, avec très peu de changement, et marque l'arrivée de cette norme au statut de « norme complète », la dernière étape du chemin des normes de l'IETF.
Ce type est spécifié (section 4 du RFC) dans le langage W3C XML Schema.
Un contact est donc composé d'un
identificateur (type
clIDType du RFC 5730). Cet
identificateur (on l'appelait traditionnellement le
handle) est, par exemple,
SB68-GANDI (section 2.1).
Les contacts ont également un statut (section 2.2) qui est toujours mis par le client EPP, typiquement le bureau d'enregistrement. Ce mapping ne permet pas aux contacts d'être maîtres de leur propre information et de la changer directement (ce qui est cohérent avec l'approche d'EPP où un intermédiaire, le bureau d'enregistrement, a l'exclusivité des changements).
Les contacts ont aussi évidemment des moyens d'être contactés, via
numéro de téléphone, adresse postale, etc. Par exemple, l'adresse de
courrier du
contact est spécifiée en section 2.6. La syntaxe formelle est celle du
RFC 5322, par exemple
joe.o'reilly+verisign@example.com. (Mais le
schéma XML a une syntaxe plus bien laxiste, presque tout est accepté.)
Les contacts pouvant être des personnes physiques, pour protéger
leur vie privée, la section 2.9 du RFC décrit aussi un format pour
spécifier si ces informations doivent être publiées ou
pas. Insuffisant pour tous les cas, ce format est en général remplacé,
chez les registres européens, par un mapping
spécifique (par exemple, EPP
parameters for .pl ccTLD pour les polonais qui
utilisent un élément <individual> pour
indiquer si le contact est une personne physique, et a donc droit à la
protection des lois européennes sur les données personnelles).
La section 3 normalise ensuite l'usage des commandes standards
d'EPP (comme <create>) pour les objets de
notre classe « contact ».
À titre d'exemple, voici la réponse d'un serveur EPP à une requête
<epp:info> (section 3.1.2) pour le contact
SB68-GANDI :
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
<response>
<result code="1000">
<msg>Command completed successfully</msg>
</result>
<resData>
<contact:infData
xmlns:contact="urn:ietf:params:xml:ns:contact-1.0">
<contact:id>SB68-GANDI</contact:id>
<contact:roid>SH8013-REP</contact:roid>
<contact:status s="clientDeleteProhibited"/>
<contact:postalInfo type="int">
<contact:name>John Doe</contact:name>
<contact:org>Exemple SA</contact:org>
<contact:addr>
<contact:street>123 rue de l'Exemple</contact:street>
<contact:city>Trifouillis-les-Oies</contact:city>
<contact:cc>FR</contact:cc>
</contact:addr>
</contact:postalInfo>
<contact:voice x="1234">+33.7035555555</contact:voice>
<contact:fax>+33.7035555556</contact:fax>
<contact:email>jdoe@example.com</contact:email>
<contact:crDate>1997-04-03T22:00:00.0Z</contact:crDate>
<contact:upDate>1999-12-03T09:00:00.0Z</contact:upDate>
<contact:trDate>2000-04-08T09:00:00.0Z</contact:trDate>
<contact:authInfo>
<contact:pw>2fooBAR</contact:pw>
</contact:authInfo>
<contact:disclose flag="0">
<contact:voice/>
<contact:email/>
</contact:disclose>
</contact:infData>
</resData>
</response>
</epp>
L'espace de noms XML pour les contacts est
urn:ietf:params:xml:ns:contact-1.0.
Comme rappelé par la section 5, EPP utilise XML dont le modèle de caractères est Unicode depuis le début. Logiquement, on devrait donc pouvoir enregistrer des noms et prénoms comportant des accents (comme « Stéphane ») mais je ne suis pas sûr que cela marche avec tous les registres : c'est une chose de transporter la chaîne de caractères Unicode jusqu'au registre et une autre de la stocker dans la base et de la ressortir proprement.
La
classe « Contact » permet de représenter certains éléments (comme
l'adresse postale) sous deux formes, une en Unicode complet (en
indiquant type="loc" et l'autre sous une version
restreinte à l'ASCII (en indiquant
type="int", notez que ces labels doivent être lus
à l'envers, la forme restreinte en labelisée int
pour « internationale » et la forme complète loc
pour « locale » alors que le contraire aurait été plus logique.)
Ce RFC remplace son prédécesseur, le RFC 4933 mais ce ne sont que des modifications légères, détaillées dans l'annexe A.
L'article seul
RFC 5732: Extensible Provisioning Protocol (EPP) Host Mapping
Date de publication du RFC : Août 2009
Auteur(s) du RFC : S. Hollenbeck (Verisign)
Chemin des normes
Première rédaction de cet article le 13 octobre 2009
La représentation des serveurs de noms (host, dans ce contexte) dans un registre de noms de domaine a toujours été une source de confusion et de désaccords. Le protocole EPP d'avitaillement (provisioning) d'un registre a tranché arbitrairement et décidé que la bonne méthode était d'avoir des objets « serveur de noms » (host) explicitement mis dans le registre. C'est ce que normalise notre RFC, successeur du RFC 4932, qui lui-même succédait au RFC 3732.
Un registre de noms de domaine stocke en
effet au moins deux classes d'objets : les domaines, bien sûr, et les contacts, les entités
(personnes physiques ou organisations) qui gèrent les domaines. Mais
cela laisse ouverte la question des serveurs de noms. Pour pouvoir
déléguer un domaine, le registre a besoin de ces serveurs, qui se
retrouveront en partie droite des enregistrements de type
NS, comme ici, dans le registre de .org :
example.org. IN NS ns1.example.org.
IN NS galadriel.lothlorien.net.
Comme souvent lors de l'élaboration d'un schéma de données, on peut se poser la question : objet ou attribut ? Les serveurs de noms doivent-ils être des objets « de première classe », gérés en tant que tels, accessibles via whois ou bien doivent-ils être de simples attributs des objets de la classe domaine ?
Les deux approches sont
possibles. .com utilise la première. Un serveur de noms est
un objet de première classe, vous pouvez le voir avec whois :
% whois ns.kimsufi.com ... Server Name: NS.KIMSUFI.COM IP Address: 213.186.33.199 Registrar: OVH
D'autres registres ont choisi de faire des serveurs de noms de simples attributs. Quelle approche fallait-il retenir pour le protocole d'avitaillement EPP, normalisé dans le RFC 5730 ? Celui-ci sépare le protocole proprement dit de la définition des classes d'objets (classes nommées, dans EPP, mappings. Il existe une classe (un mapping) pour les domaines (RFC 5731), une pour les contacts (RFC 5733) et notre RFC 5732 pour les serveurs de noms. Toutes sont optionnelles. Un registre n'est pas obligé de mettre en œuvre tous ces mappings et peut donc, s'il ne gère pas les objets hosts, ignorer le RFC 5732.
Si un registre choisit, par contre, de gérer des objets « serveur
de noms » comme dans ce RFC, la section 1
décrit les relations entre ces objets et les domaines. Ainsi, tout
serveur de noms est subordonné à un domaine (le parent) :
ns1.example.org est subordonné à
example.org et la relation doit être conservée
par EPP (par exemple, l'objet host ne peut être
créé que par le client EPP qui gère l'objet domaine parent). À noter
que le parent peut être externe au registre (par exemple
galadriel.lothlorien.net pour le registre de
.org).
La section 2 de ce RFC énumère ensuite les attributs de l'objet
« serveur de noms ». Le serveur a un nom (par
exemple ns2.example.net), conforme aux règles
syntaxiques du RFC 1123. Comme tous les objets
manipulés avec EPP, il a un identificateur unique spécifique à EPP, le
client identifier (voir le RFC 5730). Il a
aussi un état (status), qui peut être une combinaison par
exemple ok combiné avec
linked (qui indique qu'il est utilisé dans au
moins un domaine).
Il a enfin une adresse IP facultative. Le RFC recommande de ne la stocker que si elle est nécessaire pour publier la colle, les enregistrements qui permettent de trouver l'adresse IP d'un serveur de noms qui sert la zone dont il fait lui-même partie par exemple dans :
example.org. IN NS ns1.example.org.
IN NS galadriel.lothlorien.net.
Ici, ns1.example.org est dans la zone qu'il sert
(example.org), il faut donc transmettre au
registre son adresse IP, pour qu'il puisse publier la colle :
ns1.example.org. IN AAAA 2001:db8:314::1:53
alors que cela n'est pas nécessaire pour
galadriel.lothlorien.net. Les RFC 2874 et RFC 3596 contiennent des détails sur cette
question. La section 3.2.1 de notre RFC, sur la commande
<create> revient également sur ce point en
insistant que cette commande n'impose pas de transmettre des adresses
IP, bien au contraire.
Le cœur d'EPP est décrit dans le RFC 5730, qui
inclus une description des commandes possibles (comme
<create> ou <delete>). Toutes ne s'appliquent
pas à tous les objets et chaque norme d'un mapping
doit donc décrire quelles commandes ont un sens pour lui. C'est ici
l'objet de la section 3. Par exemple (section 3.1.3), le passage d'un
registrar à un autre
(transfer) n'a pas de sens pour un objet
« serveur de noms » et n'est donc pas défini. L'espace de noms XML
du host mapping, de notre classe « serveur de
noms » est urn:ietf:params:xml:ns:host-1.0 (voir
section 6).
Les commandes
<check> et
<info> ont leur sens habituel (section
3.1), celui de récupérer des informations sur un objet, ici en donnant
son nom. Voici l'exemple donné par le RFC pour la réponse à une
commande <info> pour le serveur ns1.example.com :
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
<response>
<result code="1000">
<msg>Command completed successfully</msg>
</result>
<resData>
<host:infData
xmlns:host="urn:ietf:params:xml:ns:host-1.0">
<host:name>ns1.example.com</host:name>
<host:roid>NS1_EXAMPLE1-REP</host:roid>
<host:status s="linked"/>
<host:status s="clientUpdateProhibited"/>
<host:addr ip="v4">192.0.2.2</host:addr>
<host:addr ip="v4">192.0.2.29</host:addr>
<host:addr ip="v6">1080:0:0:0:8:800:200C:417A</host:addr>
<host:clID>ClientY</host:clID>
<host:crID>ClientX</host:crID>
<host:crDate>1999-04-03T22:00:00.0Z</host:crDate>
<host:upID>ClientX</host:upID>
<host:upDate>1999-12-03T09:00:00.0Z</host:upDate>
<host:trDate>2000-04-08T09:00:00.0Z</host:trDate>
</host:infData>
</resData>
<trID>
<clTRID>ABC-12345</clTRID>
<svTRID>54322-XYZ</svTRID>
</trID>
</response>
</epp>
Les informations spécifiques à notre classe sont dans l'espace de noms
urn:ietf:params:xml:ns:host-1.0 dont le préfixe
est ici host.
La syntaxe formelle complète de cette classe figure dans la section 4, sous la forme d'un schéma W3C.
L'annexe A rassemble les changements depuis le RFC 4932. Les changements, à part la mise à jour des RFC cités en référence, consistent surtout en une nouvelle licence pour le schéma XML et une précision sur le code de retour 2201 (permission refusée).
L'article seul
Michael Crichton essaie de calmer nos peurs
Première rédaction de cet article le 11 octobre 2009
Dernière mise à jour le 12 octobre 2009
Finalement, ce n'est pas avant la mort de l'auteur que j'ai lu State of Fear de Michael Crichton. Je n'avais rien perdu en fait. Outre la forme, dont je parle plus tard, l'auteur utilise des méthodes rhétoriques peu honorables pour nier le changement climatique.
Tout au long du roman, tous les personnages sérieux ou attachants expliquent longuement que le changement climatique n'est qu'une vue de l'esprit (et, pour faire bonne mesure, qu'il aurait fallu continuer à utiliser le DDT et les CFC). Puis, dans une annexe au roman, Crichton explique que ce n'est qu'un roman, donne quelques détails sur ses opinions personnelles et explique que tout ça est bien compliqué et qu'il faut écouter les deux parties (y compris, donc, les négationnistes).
En effet, un roman n'est qu'un roman. Je ne vais pas fonder mon opinion sur l'Opus Dei, ou mon analyse de la cryptographie, sur les livres de Dan Brown. Mais tous les auteurs de romans ne sont pas, comme Dan Brown, uniquement occupés à essayer de distraire leurs lecteurs. Certains sont des militants, qui se servent du roman pour faire passer des opinions. Victor Hugo n'a pas écrit les Misérables uniquement pour passionner les lecteurs mais aussi pour dénoncer la situation des femmes, des bagnards ou des pauvres. Hugo a passé vingt ans en exil pour ses idées. Crichton n'avait pas envie de s'éloigner des MacDo et de l'air conditionné sans lesquels (comme l'explique sérieusement un personnage du livre), on ne peut pas vivre. Il prétend donc ne pas faire un livre militant et donner la parole à tous les points de vue, au travers des divers personnages. Bref, il veut le beurre et l'argent du beurre.
Mais il n'y a pas d'égalité dans le traitement des deux camps dans le roman. Les personnages importants et sérieux sont tous négationnistes. Tous ceux qui considèrent le réchauffement planétaire comme une menace sérieuse, sans exception, sont au contraire de ridicules exemplaires de la « gauche Hollywood », des avocats véreux ou des politiciens malhonnêtes.
Même si l'auteur tentait de tenir une égale balance entre les deux camps (ce qui est très loin d'être le cas), cela serait injuste. Bien sûr, certaines organisations environnementalistes sont devenues de grosses bureaucraties, dépensant des millions en frais d'avocat, et gérées comme des entreprises, avec des directeurs payés au succès. Mais cela ne change rien à l'énorme inégalité de moyens entre les environnementalistes et les grandes entreprises qui promeuvent les OGM, la production de dioxyde de carbone ou le nucléaire. Ce sont les secondes qui ont les budgets de propagande (pardon, on doit dire « communication », aujourd'hui) les plus élevés, et même chose pour les cabinets d'avocats qu'elles peuvent déployer. Prétendre tirer un trait d'égalité entre les unes et les autres est intellectuellement malhonnête, comme lorsque Crichton présente les grandes entreprises comme de malheureuses victimes innocentes de méchants environnementalistes fanatiques.
Enfin, sa rage anti-écologiste a au moins un avantage pour le lecteur : lui donner un roman écrit après le 11 septembre où les terroristes ne sont pas musulmans...
Crichton a bien d'autres malhonnêtetés à sa disposition. Par exemple, l'un des personnages essaie à plusieurs reprises de faire pleurer le lecteur sur les malheurs du Tiers-Monde en expliquant que les écologistes sont les ennemis du progrès et veulent donc maintenir les pauvres dans leur misère. Mais ces diatribes prétendument pro-Tiers-Monde seraient plus convaincantes si le livre comptait un seul personnage issu du monde non industrialisé. À part un groupe de cannibales sortis tout droit d'un film de série B des années 1930, il n'y a, bons ou méchants, que des ressortissants des pays riches, dans ce livre qui veut avoir une perspective mondiale...
Peut-être est-ce dû au bâclage général du roman ? L'auteur semble ne pas avoir pris de notes sur son travail, des personnages changent de rôle en cours de route, comme la juriste écologiste qui est présentée comme s'interrogeant sincèrement sur la réalité du changement global, avant d'être présentée comme une policière infiltrée (ce qui explique ses exploits commando lorsqu'elle est capturée par les cannibales), piste qui sera finalement abandonnée en rase campagne... Les invraisemblances ne font pas non plus peur à l'auteur comme le milliardaire âgé qui tient seul dans la jungle pendant une semaine, à surveiller le camp des terroristes.
Même sans vérifier les références données, la partie scientifique du roman comporte aussi des énormités. Par exemple, un personnage critique des prévisions des climatologues leur reprochent des erreurs dans les prévisions numériques et compare l'écart entre la prévision et le résultat à ce qu'on obtiendrai dans d'autres domaines, comme le temps de voyage d'un avion. C'est une méthode absurde : le degré de précision obtenu dans une prédiction dépend énormément du domaine considéré. En physique atomique, on n'est pas satisfait à moins de douze chiffres significatifs alors que bien d'autres domaines des sciences dures (comme l'astrophysique) sont très contents quand l'erreur n'est que d'un facteur deux.
Comme dans son roman suivant, Next, Crichton semble avoir perdu tout talent et tout sérieux d'écrivain. Le conseil le plus charitable qu'on puisse donner est de laisser tomber ses romans tardifs, écrits lorsqu'il luttait contre le cancer, et de relire Jurassic Park et surtout Eaters of the Dead, son chef d'œuvre.
Ou bien, si on veut s'instruire, on peut s'amuser à analyser les erreurs techniques du roman, en s'aidant d'un bon article comme « Crichton's Thriller State of Fear: Separating Fact from Fiction ». En français, on peut aussi lire « Commentaire de lecture : Etat d'Urgence » ou, sur la question du DDT, « Revanche du DDT ».
L'article seul
Exposé DNSmezzo à RIPE 59 (Lisbonne)
Première rédaction de cet article le 8 octobre 2009
Le 8 octobre, à Lisbonne, j'ai eu le plaisir de faire un exposé lors de RIPE 59, l'une des réunions RIPE, réunions rassemblant les acteurs de l'Internet européen (comme vous pouvez le voir, l'Europe du RIPE s'étend assez loin...) L'exposé portait sur DNSmezzo, la partie passive de DNSwitness, le logiciel de mesures des données DNS que j'ai développé à l'AFNIC. Cet exposé a été fait au sein du groupe de travail DNS.
Voici les documents produits à cette occasion :
- Les transparents en PDF, en mode présentation
- Les mêmes en mode adapté à l'impression.
- Leur source en format LaTeX/Beamer.
L'article seul
Interface de configuration du futur BIND 10
Première rédaction de cet article le 8 octobre 2009
Le développement de la prochaine version du serveur DNS BIND continue à suivre son petit bonhomme de chemin. Cette semaine, la discussion portait surtout sur l'interface de configuration, posant quelques problèmes intéressants, notamment pour les cas où BIND sert un très grand nombre de zones.
BIND est utilisé dans des cas très
variés. Du serveur de noms de la racine, avec
très peu de données mais énormément de trafic et un rôle critique, au
serveur d'un fournisseur de services Internet, qui héberge 100 000
zones pour ses clients, en passant par le petit résolveur du petit
réseau local de la petite entreprise. Il est difficile de concevoir
une interface qui convient à tous les cas. Aujourd'hui, BIND version 9
se configure essentiellement via le fichier
named.conf où on indique à la fois des
informations de contrôle (comme
recursion no; ou listen-on { 127.0.0.1;
};) et des données comme la liste des
zones servies. Dans la plupart des cas, ces données sont de taille
raisonnable mais, pour un gros hébergeur DNS, il peut y avoir des
centaines de milliers de zones servies (soit comme serveur maître,
soit comme esclave), et la lecture du fichier de configuration, au
démarrage comme au rechargement, prend un temps fou :
zone "example.net" IN {
type master;
file "pri/example.net.zone";
};
zone "example.org" IN {
type master;
file "pri/example.org.zone";
};
zone "example.com" IN {
type master;
file "pri/example.com.zone";
};
...
La configuration via un fichier, traditionnelle sur Unix, surtout pour un démon, a d'autres défauts. Tout changement doit se faire par la modification d'un fichier, puis un rechargement (opération, on l'a vu, parfois assez lente et pendant laquelle le serveur ne répond pas, ou plus lentement). Cela n'est pas pratique par rapport à une configuration interactive, comme celle des routeurs Cisco utilisant IOS.
La proposition des développeurs de BIND 10 était donc de remplacer
le traditionnel named.conf par une telle
interface interactive. L'administrateur système aurait alors tapé des
requêtes de configuration, que BIND aurait sauvegardé sous un format
non texte, par exemple une base de données
SQLite.
Ce projet, présenté dans des réunions physiques en marge de la réunion RIPE à Lisbonne, a suscité, c'est le moins qu'on puisse dire, des réserves. Outre le fait qu'un tel projet heurtait des habitudes ancestrales, outre le fait qu'il mettait BIND à part de tous les autres démons Unix, ce mécanisme avait d'autres inconvénients comme de rendre impossible l'échange de fichiers de configuration (par exemple pour signaler une bogue ou un problème sur une liste de diffusion). Et les gérants de grands parcs de serveurs BIND craignaient la perspective de ne plus pouvoir générer un fichier de configuration avant de le pousser sur toutes les machines.
Des tas d'approches alternatives ont été discutées : par exemple s'inspirer de JunOS plutôt que de IOS, pour une interface interactive (avec navigation hiérarchique) ou bien permettre une exportation de la base de données sous forme texte pour les sauvegardes ou l'échange d'informations.
Mais l'idée qui est revenue le plus souvent était de regarder ce que font les autres démons Unix qui gèrent des milliers de domaines. En général, ils gardent le principe du fichier de configuration pour le contrôle et y renoncent pour les données.
Ainsi, Apache a plusieurs méthodes pour configurer divers domaines. La méthode de base est de les mettre dans les fichiers de configuration :
NameVirtualHost 198.51.100.44 <VirtualHost 198.51.100.44> ServerName www.customer-1.com DocumentRoot /www/hosts/www.customer-1.com/docs </VirtualHost> <VirtualHost 198.51.100.44> ServerName www.customer-2.com DocumentRoot /www/hosts/www.customer-2.com/docs </VirtualHost> # ... <VirtualHost 198.51.100.44> ServerName www.customer-N.com DocumentRoot /www/hosts/www.customer-N.com/docs </VirtualHost>
Mais il en existe d'autres, très bien
décrites dans la
documentation. Avec le module Apache
mod_vhost_alias, on utilise le système de fichiers comme base de données : la présence d'un
répertoire indique la gestion d'un domaine de même nom, sans avoir
besoin d'éditer un fichier ou de recharger Apache :
VirtualDocumentRoot /www/hosts/%0/docs # Et il n'y a plus qu'à créer /www/hosts/www.customer-1.com, # /www/hosts/www.customer-1.com, etc
Pour le serveur de courrier Postfix, il existe également plusieurs méthodes, décrites dans la documentation. Toutes reposent sur l'usage des maps, des tables qui associent une clé (typiquement une adresse de courrier) à une valeur, par exemple :
virtual_alias_domains = example.com ... virtual_alias_maps = hash:/etc/postfix/virtual ... # /etc/postfix/virtual postmaster@example.com postmaster info@example.com joe sales@example.com jane
Ces tables peuvent être des fichiers texte, ou bien distribuées par des SGBD, LDAP, etc.
Bref, il en existe des méthodes pour configurer un serveur Internet.
L'article seul
Signature DNSSEC de la racine du DNS en 2010
Première rédaction de cet article le 7 octobre 2009
Dernière mise à jour le 16 décembre 2009
À la réunion RIPE du 6 octobre, l'ICANN et Verisign ont conjointement annoncé la signature DNSSEC de la racine du DNS pour le 1er juillet 2010. (Le processus pratique a commencé en janvier 2010.)
Cette annonce spectaculaire, quoique attendue, comportait notamment un calendrier pour la signature :
- signature (non publiée) le 1er décembre 2009,
- publication des signatures (mais pas de la clé) : de janvier-juin 2010, et de manière différenciée selon les serveurs racine,
- publication officielle de la clé (et donc vrai lancement, puisque cela permettra aux résolveurs de valider) : 1er juillet 2010,
- ajout des délégations vers les TLD
(enregistrements DS) : non spécifié et c'est là le point le plus
noir. Comme (malgré ce qu'écrivent les journalistes au sujet d'une
soi-disant indépendance que l'ICANN aurait récemment gagné)
tout changement dans la racine du DNS, même
purement technique, doit être approuvé par écrit et à l'avance par le
gouvernement états-unien, ce point va sérieusement handicaper le
déploiement de DNSSEC. Les TLD déjà signés comme
.seou.orgne sont donc pas près de pouvoir être validés.
L'annonce a été faite à deux voix (Joe Abley pour l'ICANN et Matt Larson pour Verisign) car, si la grande majorité des acteurs de l'Internet voulaient confier la responsabilité de la signature à l'ICANN, Washington a finalement préféré renouveler sa confiance à une société privée à but lucratif, Verisign. L'ICANN gérera donc la clé de signature de clé (KSK pour Key Signing Key) et Verisign la clé de signature de zone (ZSK pour Zone Signing Key).
Le délai entre la signature et la publication officielle de la clé,
via un canal sécurisé à déterminer, s'explique par le fait que, tant
qu'on ne publie pas la clé officiellement (on peut toujours la
prendre dans le DNS avec dig DNSKEY .), les gens sérieux ne valident pas les signatures
et, donc, rien ne peut aller vraiment mal. Quand on publie la clé,
les gens s'en servent et, là, ça peut portentiellemnt aller mal.
Il est donc prudent de prévoir une marge. Avant que la clé soit
publiée officiellement, on peux toujours arrêter de signer (.gov
l'avait fait pendant leurs essais). Après, ce n'est plus possible, les
résolveurs validateurs casseraient.
Quelques décisions techniques ont également été annoncées hier :
- KSK RSA de 2048 bits,
- changée tous les 2-5 ans (avec cérémonie solenelle de génération de la nouvelle clé),
- condensats de la famille SHA2 (SHA-256).
Les transparents de l'annonce sont en
ligne. Un site officiel d'informations sur le processus a été
créé en http://www.root-dnssec.org/.
La signature de la racine soulève quelques problèmes techniques spécifiques liés à l'augmentation de taille des réponses, problèmes discutés en Preparing K-root for a Signed Root Zone.
L'article seul
Le projet Net4D d'utilisation des classes DNS
Première rédaction de cet article le 6 octobre 2009
Le projet Net4D vise à utiliser un champ peu connu du DNS, la classe, pour permettre de créer autant d'« espaces de noms » distincts que de classes, afin de démocratiser la gestion des noms de domaine, actuellement verrouillée par le gouvernement états-unien. Ce n'est pas forcément une bonne idée que de « casser » les projets rigolos et originaux mais, comme les promoteurs de Net4D ont manifestement l'oreille des médias, je vais y aller quand même.
D'abord, désolé, mais je ne peux pas m'empêcher d'un petit retour
technique. Le DNS
distribue des enregistrements, dont la
clé est un nom de domaine. Chaque enregistrement a un
type (par exemple AAAA pour
les adresses IP,
MX pour les relais de courrier, etc). Il a aussi une
valeur, qui dépend du type (par exemple, la
valeur d'un enregistrement de type LOC est une
latitude et une
longitude). Il a aussi une durée de vie et,
surtout, ce qui nous intéresse ici, une
classe. Le champ class était
quasiment oublié car il a toujours la même valeur,
IN (pour Internet). Mais
il est toujours là et figure également dans la
question que pose un client DNS (champ
QCLASS pour Query Class). Tout
ceci est précisé dans le RFC 1034, notamment sections 3.6
et 3.7.1.
À la fin de cet article, je donne quelques exemples techniques. Mais, avant cela, revenons à la proposition de Net4D. Aujourd'hui, seules trois classes sont enregistrées à l'IANA :
Registry: Decimal Hexadecimal Name Reference ------------- ------------------------------ --------- 0 Reserved [RFC5395] 1 Internet (IN) [RFC1035] 2 Unassigned 3 Chaos (CH) [Moon1981] 4 Hesiod (HS) [Dyer1987] 5-253 Unassigned 254 QCLASS NONE [RFC2136] 255 QCLASS * (ANY) [RFC1035] 256-65279 Unassigned 65280-65534 Reserved for Private Use [RFC5395] 65535 Reserved [RFC5395]
J'ai déjà parlé de la classe IN pour Internet,
numéro 1. Chaos
(classe numéro 3) était un protocole réseau qui n'a guère eu de succès
mais qui utilisait le DNS. Et Hesiod (numéro 4) était un mécanisme de
distribution d'information sur les utilisateurs via le DNS (je l'avais
déployé au CNAM mais, aujourd'hui, tout le
monde utilise LDAP ou le vieux
NIS).
Aujourd'hui, un nom comme
www.carlabrunisarkozy.org est donc quasiment
toujours de la classe IN. C'est tellement le cas
qu'on ne pense plus en général à l'indiquer. Il n'existe pas de
mécanisme standard dans les URL (comme
http://www.carlabrunisarkozy.org/) pour indiquer
une classe, des fonctions pour les programmeurs comme
getaddrinfo() n'ont pas de paramètre
pour la classe, etc.
L'idée de base de Net4D est d'allouer un certain nombre de classes,
actuellement libres, et d'y créer des racines du DNS, avec des
noms qui auraient une signification différente. Par exemple, supposons
qu'on alloue la classe numéro 2 sous le nom UN,
on pourrait, dans la configuration des serveurs de noms, créer un
www.carlabrunisarkozy.org qui n'aurait rien à
voir avec celui cité précédemment et qui pourrait avoir un
enregistrement de type adresse qui pointe vers un tout autre service. (La procédure d'allocation de nouvelles classes, relativement souple, figure dans la section 3.2 du RFC 6195.)
La motivation est politique : il s'agit, comme l'indique le titre
du publi-reportage
du Monde, d'avoir plein de nouvelles
ICANN, pour que d'autres puissent jouer aux
jeux politiciens qui occupent les fréquentes réunions de cette
organisation. Un autre
.com pourrait donc voir le
jour, où sex.com pourrait être vendu à un autre,
un autre .fr serait alloué
à une autre organisation que l'AFNIC,
etc. C'est pour cela que l'UIT, qui souffre
d'être tenue à l'écart de la gouvernance d'Internet par le gouvernement états-unien, finance
Net4D.
Maintenant, quels sont les problèmes de cette approche ? Il y en a trois, un technique, un politique et un de méthode.
Le problème technique est le suivant : bien sûr, les classes
fonctionnent, le logiciel est déjà là et tout est déjà
normalisé. Mais, sur l'Internet, il y a ce qui marche en théorie et ce
qui marche en pratique : l'Internet est hélas très ossifié
aujourd'hui. Des tas de programmes mal écrits avec les pieds sont
fermement installés et ne laissent pas passer des choses parfaitement
légales. D'innombrables boitiers intermédiaires sont sur le chemin des
paquets et filtrent ce qu'ils ne comprennent
pas. Comme l'ont fort bien expliqué Avri Doria
et Karl Auerbach lors des discussions sur la
liste governance@lists.cpsr.org, le manque
flagrant de robustesse de beaucoup de composants de l'Internet, leur
incapacité à gérer des situations légales mais inattendues, ne laisse
pas beaucoup d'espoir (voir le message
d'Auerbach et celui
de Doria ; notez qu'aucun des deux n'est un défenseur de
l'ICANN, bien au contraire). Entre deux logiciels sérieux situés sur deux
machines du même réseau, les classes vont marcher. Sur l'Internet en
général, c'est bien plus difficile (il suffit de voir le temps qu'il a
fallu pour que des types légaux comme
SRV, passent à peu près partout).
Ce problème technique est d'autant plus sérieux que les
promoteurs de Net4D traitent avec une désinvolture inquiétante les
points sur lesquels il faudra déployer du code
nouveau (comme un remplaçant de
getaddrinfo()).
Bref, déployer les classes serait sans doute quasiment autant de travail que de déployer un système de nommage et de résolution complètement nouveau (DNS 2.0 ?).
Le problème politique est qu'utiliser un truc technique astucieux (comme les classes) pour résoudre un problème politique (la mainmise du gouvernement états-unien et des titulaires de propriété intellectuelle sur l'ICANN) est en général une mauvaise idée. Le problème de fond est politique, et aucune astuce technique ne permettra de le contourner. Évidemment, il est plus facile de rêver à se créer son monde idéal, plutôt qu'à s'attacher à changer celui qui existe...
Enfin, il y a un problème de méthode. L'UIT, on l'a vu, finance,
avec l'argent public, la technique des classes. Ce n'est pas très
compliqué que de configurer un serveur comme
NSD pour charger une racine composée de
plusieurs classes (par exemple la numéro 65280, prévue pour les essais), tester la délégation, les logiciels clients DNS
courants, une version modifiée de getaddrinfo(),
un site Web accessible via une classe autre que
IN,
etc. Ce serait un bon exercice dans un cours sur les réseaux à
l'Université. Une entreprise sérieuse pourrait réaliser une telle
étude en un temps, et pour une somme très raisonnable. Mais rien ne semble avoir été fait en ce sens (en tout cas rien
n'a été publié). Tout le temps et
l'argent ont été dépensés en relations publiques, dont l'article du
Monde, qui ne donne la parole qu'à un seul point de vue, est un bon
exemple. Cela n'augure pas bien du sérieux de la démarche.
Terminons avec un peu de technique. Une des rares utilisations
aujourd'hui des classes autres que IN est pour
détecter la version d'un serveur de noms (il existe désormais une
autre méthode, dans le RFC 5001, mais elle est
encore peu utilisée). Cela se fait en interrogeant le serveur pour le
type TXT, la classe CH, et
le nom version.bind :
% dig +short @f.root-servers.net CH TXT version.bind. "9.5.1-P3"
Le domaine de tête .bind
n'existe pas dans la classe IN.
Enfin, pour ceux qui s'intéressent aux bits sur le câble, pour décoder les paquets DNS, la classe figure dans la question, juste après le nom et le type. En C, le décodage ressemble donc à :
struct dns_packet {
...
uint16_t qtype, qclass;
...
/* sectionptr indicates the next byte in the packet */
decoded->qtype = ntohs(*((uint16_t *) sectionptr));
sectionptr += 2; /* Two bytes for the type */
CHECK_SECTIONPTR(2); /* Two bytes for the class */
decoded->qclass = ntohs(*((uint16_t *) sectionptr));
L'article seul
Un « Internet-Draft » résumant ce que peut faire un FAI contre les zombies
Première rédaction de cet article le 5 octobre 2009
Une des plus grosses menaces sur la sécurité de l'Internet réside dans les zombies, ces machines Windows contaminées par du logiciel malveillant et qui obéissent désormais à un maître qui leur ordonne, selon sa volonté, de lancer une dDoS, d'envoyer du spam, etc.
Il n'existe pas de solution miracle contre les zombies. C'est comme cela que je lis
l'Internet-Draft, draft-oreirdan-mody-bot-remediation,
intitulé « Remediation of bots in ISP networks »
mais qui, malgré son nom, propose peu de
remèdes. (Bot est l'abrévation de
robot et désigne un zombie.)
Cet Internet-Draft, qui est devenu un RFC de « bonnes pratiques » quelques années plus tard (RFC 6561), est écrit par des employés de Comcast et résume l'état actuel de l'art, vu du point de vue du FAI. Celui-ci, étant donné sa position, est bien placé pour identifier les machines de ses clients qui sont devenues des zombies. Mais que peut-il faire ?
Le document explique bien le problème, ainsi que la manière de détecter les zombies (par l'analyse passive du trafic, ou bien par les plaintes, même si peu de FAI les traitent ; le document évoque aussi la possibilité de recherches actives, comme le permet un outil comme nmap, bien que de telles recherches ne soient pas forcément légales). Il insiste sur la nécessité de détecter vite, si nécessaire au détriment de la justesse des résultats (tirer d'abord, réflechir ensuite...)
Parmi les techniques disponibles, le document cite Netflow (RFC 3954) ou bien les méthodes à base de DNS, très à la mode en ce moment, notamment grâce au travail des chercheurs de Georgia Tech (voir par exemple David Dagon, Wenke Lee, « Global Internet Monitoring Using Passive DNS », Cybersecurity Applications & Technology Conference for Homeland Security, 2009). Mais combien de FAI, qui n'arrivent déjà pas à fournir un service correct à leurs utilisateurs, ont les moyens, la compétence et le temps de mener ce genre d'études ?
Le document rend aussi un hommage obligatoire à la nécessite de préserver la vie privée des utilisateurs, sans trop s'attarder sur comment concilier surveillance rapprochée et respect de la vie privée.
La partie la plus intéressante du document concerne la notification
des utilisateurs. Comment les prévenir que leur machine, infectée, est
devenue un zombie ? Et le faire de façon à ce qu'ils comprennent et
agissent ? Le problème est d'autant plus complexe que les méchants
peuvent essayer d'envoyer de faux messages pour brouiller les pistes
(du genre « Nous avons reçu notification d'une alerte de sécurité sur
votre compte, connectez-vous à
http://igotyou.biz/phishing.asp pour indiquer vos
coordonnées »...)
Toutes les techniques de communication possibles avec les utilisateurs sont soigneusement passées en revue, mais aucune ne semble parfaite. Les appels téléphoniques coûtent cher (le courrier papier encore plus), les messages peuvent être ignorés, couper l'accès pour que l'utilisateur appele est violent, quoique efficace, etc. Cette discussion des difficultés à attirer l'attention de ses propres clients sur un problème sérieux est la plus concrète et certainement la plus intéressante du document. Le RFC 6108, publié plus tard, présente une solution possible.
La seule section qui aie un rapport direct avec le titre, sur les remèdes est, par contre, très courte, peut-être à juste titre, étant donné la difficulté à traiter les zombies : « Réinstallez votre système d'exploitation » est un remède assez radical et donc peu susceptible d'être suivi...
L'article seul
Une organisation hacker en France ?
Première rédaction de cet article le 4 octobre 2009
Un « Manifeste pour la création d'une organisation hacker » circule en ce moment (le site original - craqué ? - ne semble plus accessible mais on peut trouver des copies ici ou bien là). Comme son nom l'indique, il plaide pour la mise sur pied d'une organisation qui regrouperait les hackers, en citant des exemples comme le fameux Chaos Computer Club allemand.
Pour les lecteurs de ce blog qui ne seraient pas familiers avec le terme, il faut préciser que le Manifeste fait évidemment référence au sens premier du mot hacker : un passionné qui veut savoir comment ça marche, regarde à l'intérieur et ne se contente pas du mode d'emploi et des livres « Pour les nuls ». Ce genre de personnes est bien antérieure à l'invention de l'informatique (Galilée était un hacker). Ce n'est que bien après que des journalistes ignorants ont commencé à utiliser ce terme comme synonyme de délinquant informatique.
Seulement, c'est aussi sur ce point que le Manifeste a un gros manque : il transforme une méthode (être un hacker) en une idéologie (la liberté et la résistance aux oppresseurs). Il y a des gentils et des méchants chez les hackers, des gens qui utilisent leurs compétences pour aider l'humanité à progresser et des gens qui les utilisent pour se faire un maximum de fric et de gloire en écrasant les autres. Hacker n'est pas une opinion politique et ne peut pas servir à fonder une organisation politique ; c'est un état d'esprit, une technique de pensée, une compétence, c'est tout. Il y a des hackers dans les organisations liberticides, où leurs compétences servent à aider Big Brother. (Au passage, le Manifeste cite à ce sujet, Jean-Bernard Condat mais en lui prêtant des pouvoirs qu'il n'a probablement jamais eu : c'était davantage un habitué des médias, plutôt qu'un super-méchant au service des forces du mal.)
Objection, dirons certains, le Manifeste parle de « vrais » hackers, ceux qui partagent la connaissance et la diffusent à tous, ce qui est incompatible avec un travail pour la DST ou la NSA. Certes, mais, alors, pourquoi ce terme de hacker ? On pourrait aussi bien dire « partisan de la liberté de l'information et de la connaissance » et revenir à des classifications politiques traditionnelles... (Cela serait évidemment moins chic que de citer Hakim Bey... Allez, moi aussi, je vais faire du littéraire, « Le guerrier de la lumière partage avec les autres sa connaissance du chemin. Celui qui aide est toujours aidé ; et il a besoin d'enseigner ce qu'il a appris. » - Paulo Coelho, « Manuel du guerrier de la lumière »)
Cette distinction entre bons et méchants est essentielle, bien plus que celle entre les gens compétents et les autres (cf. la grotesque citation dans le Manifeste « Mon crime est de vous surpasser »). C'est la différence entre le voleur individuel, capitaliste parfait, pour qui seul compte le profit, et celui qui viole les lois dans l'intérêt général, pas pour son profit personnel. Si le partisan de l'Ordre les mettra tous les deux dans le même sac des « actions illégales », le Guerrier de la Lumière :-) fera la différence. Le Manifeste cite la loi Godfrain comme loi répressive, l'assimilant à des lois purement répressives comme Hadopi, alors que, s'il est vrai qu'elle interdit qu'on pénètre dans le système informatique d'une multinationale pour découvrir ses méfaits, elle empêche aussi le petit con qui se prend pour un hacker de jouer avec les machines de citoyens moins compétents que lui, mais qui ont tout autant droit à la tranquillité.
Le Manifeste contient aussi une erreur fréquente mais que je ne peux pas laisser passer : une peinture d'un « monde anglo-saxon » mythique où régnerait une liberté d'expression totale et sans limites (le Manifeste cite explicitement le droit à nier la Shoah). Il y a deux erreurs énormes ici : l'une est de voir le « monde anglo-saxon » comme un bloc homogène de défense de la liberté d'expression totale (alors que des pays comme l'Australie et la Grande-Bretagne sont très en pointe, parmi les démocraties, dans la censure d'Internet). L'autre est de croire sur parole à la légende comme quoi, aux États-Unis, la liberté d'expression serait totale. Essayez de porter un T-shirt « J'aime Fidel Castro » à Miami ou un badge « L'avortement est une liberté fondamentale pour les femmes » en Alabama et vous mesurerez physiquement les limites de la liberté d'expression...
Pour conclure positivement, j'encourage les hackers attachés à des valeurs comme la liberté d'expression, le droit à la connaissance, et la transparence, à rejoindre les organisations qui, aujourd'hui, et depuis des années, se battent pour ces causes :
L'article seul
Le modem US Robotics Courier
Première rédaction de cet article le 1 octobre 2009
Je viens de ressortir du placard un vieux modem analogique, un US Robotics Courier V.34. Ce n'est pas que j'en avais besoin, mais, à une époque, je travaillai souvent avec de tels engins, donc c'était l'occasion de voir s'il marchait toujours, et de prendre quelques photos.
Le Courier était (enfin, est, car il est toujours en vente même si, en France, les modems analogiques ne sont plus guère utilisés) la Rolls-Royce des modems. Doté d'une alimentation électrique sérieuse (alors que la plupart des modems avaient une alimentation de train électrique et supportaient mal les réseaux électriques de mauvaise qualité, par exemple en Afrique), d'un processeur DSP hors du commun, le Courier arrivait en général à accrocher avec le modem d'en face, même sur les plus mauvaise lignes téléphoniques. Il était en outre très fiable. J'ai vu il y a six mois des Courier toujours en service à Nouakchott, malgré la poussière et le sable qui s'infiltraient partout.
(À noter que le Sportster, du même constructeur, n'avait pas du tout les mêmes caractéristiques.)
Voici un Courier, vu de devant. Il est connecté à un ordinateur (diodes TR - Terminal Ready et RS
- Request To Send). 
Une fois en ligne, il allume en outre les diodes CD
- Carrier Detect (porteuse détectée), HS
- High Speed (ce qui veut simplement dire >
2 400 b/s...) et ARQ (la correction d'erreurs
V.42).
 .
.
À noter que la seconde photo a été prise lors d'une connexion via le réseau téléphonique de Free, le modem étant branché sur le port téléphonique de la Freebox. Bien que les CGV disent « Du fait de la technologie utilisée, ce Service ne permet pas de garantir le raccordement d'équipements DATA (télécopieurs, modems, minitel, équipements de télésurveillance...) ainsi que l'accessibilité des services afférents », le modem accroche quand même avec certains services RTC.
On peut trouver d'autres photos sur Wikimedia Commons.
Pour me connecter au modem depuis une machine
Debian, j'utilise un convertisseur
USB<->RS-232
puisque peu de PC de nos jours ont encore des
ports série. Le logiciel est
minicom et voici le contenu du fichier de
configuration /etc/minicom/minirc.modem :
pu port /dev/ttyUSB0 pu rtscts Yes
Le résultat, lorsqu'on envoie les commandes Hayes et que le modem se connecte :
AT S7=45 S0=0 L1 V1 X4 &c1 E1 Q0 OK ATDT 0x xx xx xx xx CONNECT 28800/ARQ/V34/LAPM/V42BIS ### Access restricted to authorized users ### foobar login:
Merci à Pascal Courtois et Marc Baudoin pour le coup de main.
L'article seul
RFC 5657: Guidance on Interoperation and Implementation Reports for Advancement to Draft Standard
Date de publication du RFC : Septembre 2009
Auteur(s) du RFC : L. Dusseault (Messaging Architects), R. Sparks (Tekelec)
Première rédaction de cet article le 1 octobre 2009
Dans son processus de normalisation, l'IETF a toujours accordé une grande importance au caractère réaliste et pratique de ses normes. Contrairement à d'autres SDO, qui n'hésitent pas à publier comme norme des pavés incompréhensible et inimplémentables, l'IETF veille à ce que l'avancement d'une norme sur le chemin des normes s'accompagne d'une vérification que cette norme peut être mise en œuvre et que les différents programmeurs ont bien compris la même chose. Cette vérification se traduit par des rapports analysant l'état actuel des implémentations d'une norme et le but de ce RFC est de guider les auteurs de ces rapports.
Le processus du chemin des normes est décrit dans le RFC 2026 (cf. section 1 de notre RFC 5657). Il comprenait trois étapes, proposition de norme (Proposed Standard), projet de norme (Draft Standard) et enfin norme tout court (Standard). Leur nombre a toutefois été réduit à deux par le RFC 6410. Lors du passage de la première à la deuxième étape, pour devenir projet de norme, un RFC doit (section 4.1.2 du RFC 2026) avoir été mis en œuvre au moins deux fois, par des équipes indépendantes, et ces deux mises en œuvre doivent interopérer (pouvoir travailler ensemble).
Le dossier présenté à l'IESG pour l'avancement d'une norme au statut de projet de norme doit comprendre un rapport (même section 4.1.2 du RFC 2026) décrivant les tests effectués entre ces mises en œuvre, leurs résultats, etc. Historiquement, ces rapports, dont la forme n'était spécifiée nulle part, ont été de qualité très variable ; certains étaient très courts, se contentant de dire « On a testé et ça marche ». D'autres détaillaient à l'extrême un aspect particulier des tests mais oubliaient les résultats. Le but de ce RFC 5657 est de limiter cette variation. Il met donc à jour légèrement le RFC 2026. Lui-même a été amendé par le RFC 6410, qui a rendu ce rapport facultatif.
L'espoir est que ce RFC contribuera également à clarifier les tâches à accomplir pour faire avancer une norme : aujourd'hui, peu de gens s'y retrouvent et bien des normes stables et très utilisées sont restées au début du chemin des normes car personne n'avait eu le courage de lancer le processus d'avancement.
La section 2 définit donc ce que doit contenir le rapport d'interopérabilité. Sur certains points, il est moins strict que le RFC 2026. Par exemple, il n'est plus obligatoire de nommer les implémentations testées (cela défrisait certains vendeurs). Si seulement une partie des implémentations existantes est testée, le rapport doit dire comment la sélection s'est faite.
Le RFC 2026 parlait d'implémentations « indépendantes » sans définir ce que voulait dire ce terme. Notre RFC 5657 précise que cela veut dire qu'elles ont été écrites par des personnes différentes, dans des organisations différentes et qu'elles n'aient pas de code en commun (il est fréquent que plusieurs logiciels dérivent de la même souche et n'aient donc guère de mérite à interopérer correctement).
La section 3 décrit le format du rapport d'interopérabilité. C'est le même que celui des RFC. La section indique aussi les parties obligatoires et leur contenu. Un résumé doit préciser les points importants. La méthodologie de test doit être décrite. Les éventuelles exceptions (points de la norme sur lesquels l'interopérabilité échoue) doivent être précisement listées.
Un point délicat des rapports d'interopérabilité est la question des fonctions qu'on teste. Faut-il tout tester dans le moindre détail ou bien a t-on le droit d'omettre des fonctions qui sont dans la norme ? La section 4 analyse la question. En gros, si on teste seulement des grandes fonctions, on ne pousse pas les implémentations dans leurs limites mais si on teste tous les détails et leurs combinaisons, la matrice des tests explose, notamment pour les protocoles ayant beaucoup d'options. Il faut donc trouver un niveau intermédiaire raisonnable. Le RFC cite en exemple le rapport sur RTP qui liste les fonctions testées sous forme de services importants, et non pas sous la forme, trop détaillée, de chaque bit possible de l'en-tête.
Le pragmatisme reste nécessaire. La section 5 explique comment gérer des cas particuliers. Par exemple, si le protocole est déjà largement déployé, on peut (section 5.1) privilégier l'analyse de son fonctionnement réel plutôt que des tests en laboratoire. Une étude ou un questionnaire sont donc sans doute la meilleure méthode. Par contre, si le protocole n'a pas encore connu de déploiement significatif (section 5.2), les tests sont la meilleure approche. Le RFC insiste quand même sur le fait qu'il faut essayer d'anticiper les problèmes opérationnels comme la congestion ou la gestion.
Un autre cas particulier est celui des RFC qui normalisent des formats et pas des protocoles, traité dans la section 5.3. Par exemple, le RFC 5234 normalise les grammaires ABNF et le RFC 4287 le format de syndication Atom. L'interopérabilité, dans ce cas, se juge notamment à la capacité des différentes implémentations à considérer comme corrects les mêmes fichiers (et même chose pour les incorrects). ABNF a ainsi fait l'objet d'un rapport de mise en œuvre.
Parmi les autres cas couverts par notre RFC, celui des protocoles pour lesquels il existe une suite de tests comme WebDAV, avec Litmus. Cette suite ne permet pas forcément de tester l'interopérabilité (section 5.5) car elle ne teste pas des vraies mises en œuvre les unes contre les autres. Avec Litmus, par exemple, le client WebDAV est un client artificiel, qui n'est pas forcément représentatif des vrais clients.
Tous les rapports de mise en œuvre existants sont disponibles en ligne. La section 6 de notre RFC 5657 cite quelques exemples particulièrement instructifs comme le rapport sur PPP-LCP pour sa concision ou celui sur OSPF (publié également dans le RFC 2329), jugé trop long mais quand même de qualité. Celui sur le « pipelining » SMTP est jugé très court, à la limite de la taille minimale.
L'article seul
Nominum, une entreprise à éviter de loin
Première rédaction de cet article le 23 septembre 2009
Dernière mise à jour le 4 octobre 2009
La société Nominum, qui vend des logiciels DNS, s'était déjà fait connaître par des discours marketing douteux sur ses concurrents, notamment ceux utilisant du logiciel libre. Elle franchit un nouveau pas, avec l'interview / publireportage de son marketroïde Jon Shalowitz en Why open-source DNS is 'internet's dirty little secret' .
Aujourd'hui que Microsoft proteste de son amitié pour le monde du logiciel libre, et qu'Apple la ferme prudemment, Nominum prend le relais de SCO en assumant le rôle du méchant, qui crache son venin sur le principe même du logiciel libre, comparé au malware.
Bien sûr, comme tant de commerciaux, Jon Shalowitz est un ignorant complet et n'a même pas pensé que tout le monde testerait immédiatement les serveurs de Nominum pour voir quels logiciels ils utilisent :
% dig +short NS nominum.com ns1.nominum.com. ns2.nominum.net. ns3.nominum.com. % dig +short @ns1.nominum.com CH TXT version.bind. "Nominum ANS 3.0.1.0" % fpdns ns1.nominum.com fingerprint (ns1.nominum.com, 64.89.228.10): Nominum ANS % dig +short @ns2.nominum.net CH TXT version.bind. "9.3.5-P2" % fpdns ns2.nominum.net fingerprint (ns2.nominum.net, 81.200.68.218): ISC BIND 9.2.3rc1 -- 9.4.0a0
Eh oui, un des serveurs DNS de Nominum utilise BIND, archétype du serveur DNS en logiciel libre. (Les deux autres utilisent ANS, Authoritative Name Server, l'un des principaux produits de Nominum.)
Depuis que cette information a été publiée, le serveur a
changé. Difficile de dire s'il a vraiment été remplacé ou bien si un
technicien de Nominum a utilisé la directive
version du bloc options pour
changer le nom sous lequel BIND s'annonce...
Autre cas où Nominum dépend de logiciel libre, son site Web :
% telnet www.nominum.com http Trying 67.192.49.178... Connected to www.nominum.com. Escape character is '^]'. HEAD / HTTP/1.0 Host: www.nominum.com HTTP/1.1 200 OK Date: Wed, 23 Sep 2009 10:20:28 GMT Server: Apache/2.0.52 (Red Hat) X-Powered-By: PHP/4.3.9 ...
Pour une société qui prétend que son logiciel est sécurisé, utilisable industriellement, etc, cela fait drôle d'utiliser PHP, dont on n'avait jamais entendu dire qu'il était spécialement durci... (En outre, si le numéro de version est correct, la version de PHP date de 2004, ce qui montre un certain sens du conservatisme.)
On pourrait continuer à l'infini à se moquer de Nominum et de la nullité de ses équipes commerciales, dont l'aggresivité essaie de masquer la perte de part de marché actuelle. Mais il est probable que le discours de Nominum ne vise pas à convaincre les lecteurs de ce blog, ni les habitués du logiciel libre, ni même d'ailleurs aucun technicien connaissant ne serait-ce qu'un tout petit peu le DNS. Leur propagande est conçue pour une population de PHB, qui ignorent tout du logiciel libre, qui les inquiète. Ceux-ci sont rassurés que quelqu'un ose tenir un discours de guerre froide, avec la reprise d'arguments moyen-âgeux, comme le fait que la non-distribution du code source permettrait à Nominum de mettre en œuvre des protections originales contre les vulnérabilités du DNS.
Tiens, à propos de cet argument (Nominum cite la faille Kaminsky, en oubliant qu'elle les avait obligé, eux aussi, à mettre à jour en urgence leur logiciel), est-il vrai ? Beaucoup pensent que Nominum ne fait que bluffer, qu'il n'existe aucune protection particulière contre l'empoisonnement de cache dans CNS (Caching Name Server, l'autre produit de Nominum). Mais il y en a bien une (merci à Paul Vixie pour son rappel à ce sujet), CNS essaie de se connecter en TCP s'il reçoit des réponses dont le Query ID ne correspond pas (ce qui peut indiquer une tentative d'empoisonnement). Cela n'a évidemment rien de « secret » contrairement à ce que raconte le menteur en chef de Nominum, puisque n'importe quel gérant de zone peut voir (par exemple avec tcpdump) les machines CNS essayer en TCP, simplement en tentant d'empoisonner sa propre zone.
Les serveurs de Nominum, à part qu'ils sont privateurs, sont-ils meilleurs ou au moins comparables aux serveurs en logiciel libre comme Unbound, NSD ou PowerDNS ? Impossible de le dire : lorsqu'il y a des tests comparatifs de logiciels DNS, Nominum refuse systématiquement de prêter une copie d'ANS ou de CNS pour les essais. Ou alors, ils imposent des contraintes comme l'impossibilité de rendre compte publiquement des résultats sans leur autorisation expresse. Donc, on ne peut rien dire, Nominum n'a pas assez confiance dans ses logiciels pour les comparer aux autres.
Devant la pluie de critiques qui s'est abattue sur Nominum à cette occasion, un chef plus haut placé a fini par comprendre l'erreur commise et a opéré un tournant à 180° dans un article sur CircleID où il abandonne toutes les attaques contre le logiciel libre. Voilà des gens qui n'ont pas de fierté : on attaque méchamment puis, lorsque les victimes font trop de bruit, on s'enfuie en prétendant n'avoir jamais voulu cela.
Mais il y a bien plus grave que ces attaques anti-pingouins. Nominum, on l'a vu, ne cherche pas à convaincre les porteurs de T-shirts IETF. Nominum vise les messieurs sérieux, ceux qui sont haut placés dans les entreprises ou les gouvernements. Et, à ceux-ci, Nominum ne se présente pas simplement comme un fournisseur de logiciels DNS, mais comme une entreprise de filtrage et de censure: « Since the first step of any Internet request is a DNS look-up, the name service is a natural position to deploy technology asserting manageable controls over the complexities and threats of today's Internet. ».
Pas étonnant, donc, que Nominum cherche en ce moment à convaincre le gouvernement français de l'intérêt de ses produits, au moment où l'une des pistes suivies pour la loi LOPPSI est l'installation obligatoire de serveurs DNS censeurs chez les FAI.
D'autres bons articles sur Nominum :
L'article seul
Que se passe-t-il vraiment quand vous consultez un site Web avec votre navigateur ?
Première rédaction de cet article le 21 septembre 2009
Sur l'excellent site de Q&A Super User, une question « What exactly happens when you browse a website in your browser? » a suscité une excellente réponse de Ilari Kajaste. Comme elle est à la fois correcte et drôle, cela valait la peine de la traduire en français. Traduction et adaptation par Ève Demazière.
Navigateur : Bon, j'ai un utilisateur qui me demande cette adresse :
www.telerama.fr. Comme il n'y a pas de
barre oblique, ni rien d'autre,
j'imagine qu'il s'agit de la page d'accueil. Pas de protocole ni de
port ? Ce doit être du HTTP et le port 80... Mais commençons par le
commencement. Hello, DNS ! Réveille-toi ! Où se cache ce
www.telerama.fr ?
DNS : Attends... Je demande aux serveurs du
fournisseur d'accès. Bon, il semble que ce soit le 212.95.67.146.
Navigateur : Merci. Internet Protocol, c'est à toi ! Appelle le
212.95.67.146, s'il te plaît. Envoie-leur cet en-tête HTTP. On
demande la structure basique et la page d'accueil... Mais c'est vrai,
tu t'en fiches !
TCP/IP : Comment ça, « c'est à moi » ? Comme si je ne bossais pas déjà comme un malade pour le DNS !... Pas moyen d'être un peu reconnu, par ici...
Navigateur : ...
TCP/IP : ça va, ça va, je me connecte... Je vais demander au routeur de le transmettre. Vous savez, ça n'est pas si simple que ça, je vais devoir diviser votre demande en plusieurs morceaux pour qu'elle aille jusqu'au bout, et rassembler les milliers d'infos que je reçois en retour... Ah oui, vous vous en fichez...
[Entretemps, au quartier général de Télérama, un message finit par arriver à la porte du serveur Web.]
Le serveur Web de Télérama : Tchôôô ! Un client ! Il veut des infos ! La page d'accueil ! On peut ?
Logiciel de gestion du contenu : Oui, c'est bon. La page d'accueil, c'est ça ?
Le serveur de la base de données de Télérama : Ouïe, du travail pour moi ! Vous voulez quoi, comme contenu ?
Logiciel de gestion du contenu : euh... désolé, la base de données ! En fait, j'ai déjà une copie de la page d'accueil, dans mon cache, pas besoin de rassembler les infos. Mais récupère donc l'identité de cet utilisateur et garde-le en réserve, comme ça on saura à qui on parle, plus tard. Je renvoie un cookie à l'utilisateur !
Le serveur de la base de données de Télérama : OK !
[Revenons à l'ordinateur de l'utilisateur...]
TCP/IP : Oooookay, voilà la réponse. Oulà, j'ai comme l'impression que c'en est une grosse...
Navigateur : Waouh, il y a toutes sortes de
Javascript... Et des images, et des formulaires... Bon, ça va prendre
un peu de temps, pour l'affichage. Je m'y mets. Hé, IP, il
faut que tu ailles m'en chercher un peu plus. Il y a des feuilles de
style chez statique.telerama.fr. Passe par le HTTP et demande
/css/styles_2009.css. Et regarde aussi les scripts dans /scripts/, dans
/uz/ et dans /scriptaculous_beta/, j'en trouve 60 pour le moment.
Il y a même un iframe qui va chez
pubm.lemonde.fr.
TCP/IP : je vois le genre... Donne-moi l'adresse du serveur et le reste. Les infos sur les fichiers, mets-les toi-même dans la demande HTTP, je ne veux pas avoir à m'en occuper.
DNS : c'est bon, je cherche le serveur
statique.telerama.fr... Ouah, facile, en fait il s'appelle statique-telerama.sdv.fr et son
numéro IP est le 212.95.67.146.
Navigateur : ouais, ouais... Attends ! ça va prendre quelques nanosecondes, j'essaie de comprendre tous ces scripts...
TCP/IP : tiens, voilà la CSS que tu demandais. Ah... et encore des scripts qui viennent juste d'arriver.
Navigateur : hey, il y a une publicité en Flash, aussi !
TCP/IP : oh mec, ça a l'air super marrant...
Navigateur : il y a plein d'images, aussi. Et cette CSS est un peu bizarre... Alors, si ce bout va ici, avec cette ligne tout en haut... Et ça, où est-ce que je le mets, il n'y a plus de place... Bon, il faut que je déplace tout pour que ça tienne... Ah, mais l'autre CSS remplace cette règle... Bon, ça ne va pas être facile à afficher, c'est sûr !
TCP/IP : hé, arrête de me distraire, j'ai encore plein de choses à faire, de mon côté !
Navigateur : hé, l'utilisateur, voici une petite barre de progression pour toi, pendant que tu attends. Désolé, mais ça va prendre quelques secondes, il doit y avoir 245 éléments différents à télécharger, et j'en ai 16, pour le moment !
[Une ou deux secondes plus tard...]
TCP/IP : Bon, je crois que j'ai tout. Désolé si je t'ai aboyé dessus tout à l'heure... Tu t'en sors ? C'est un sacré boulot, pour toi...
Navigateur : Ouf, c'est sûr... Tous ces sites Web, de nos jours, ne nous rendent pas la tâche facile. Bon, je m'en sortirai, après tout c'est à ça que je sers...
TCP/IP : c'est difficile pour nous tous, en ce moment... Eh, arrête de faire des demandes DNS pendant ce temps !
Navigateur : Ouh ouh, l'utilisateur ! Ton site Web est prêt, tu peux lire tes infos !
L'article seul
Mes débuts avec Twitter
Première rédaction de cet article le 21 septembre 2009
Dernière mise à jour le 23 septembre 2009
Bon, on ne peut pas dire que je sois un pionnier : j'ai ouvert un
compte Twitter (http://twitter.com/bortzmeyer) pour la première fois il y a
quelques jours seulement, alors que toute la planète utilise ce
service depuis longtemps et qu'il a largement été commenté dans les
médias. Je peux maintenant informer la planète entière de ce que j'ai
mangé à midi ou bien demander des
conseils littéraires. Et j'apprends à grand pas les règles
et les usages, le rôle du @ et celui du #.
Néanmoins, je peux toujours dire qu'arriver tard a quelques
avantages, notamment la grande disponibilité d'outils divers, déjà
développés. Par exemple, j'aime beaucoup http://foller.me/ qui affiche plein de statistiques inutiles
sur un abonné Twitter (voir les miennes).
J'ai beaucoup hésité avant de sauter le pas mais, en matière d'outils de communication, la règle est simple : la valeur d'un outil provient du nombre de gens qui y sont connectés (loi de Metcalfe). Un outil de communication génial mais que personne n'utilise n'a guère d'intérêt. Or, je constate que des tas de gens très bien utilisent Twitter et que beaucoup d'informations utiles y circulent (pour les informations inutiles, voir un bon résumé dans l'excellent « Le top 10 des relous sur twitter ».)
Twitter est aussi utilisé désormais par des entreprises « sérieuses » pour diffuser de l'information urgente (c'est le cas de la RATP). Des discussions vives ont déjà eu lieu sur des forums comme Nanog au sujet de l'intérêt de communiquer sur Twitter. Pour un acteur de l'Internet, l'un des intérêts est que l'infrastructure de Twitter ne tombera peut-être pas en panne au même moment que celle dont on veut annoncer la défaillance. En revanche, un des problèmes est que les modes passent vite : si une entreprise investit dans la communication via Twitter, elle est raisonnablement sûre de devoir investir dans un gadget plus récent dans un an ou deux, accumulant petit à petit les canaux de communication, ce qui risque de brouiller celle-ci.
Twitter a quelques particularités qui sont rarement évoquées :
- C'est un service centralisé, où tout passe par un acteur unique. Techniquement, Twitter est un grand recul par rapport à XMPP.
- Il n'est pas seulement centralisé techniquement mais aussi organisationnellement : une seule société contrôle tout et, comme avec la plupart des services « 2.0 », vos données ne vous appartiennent plus (quel utilisateur de Twitter a lu les règles d'utilisation ?).
- Twitter est accessible par de très nombreux moyens techniques. J'ai lu des gens qui refusaient d'utiliser Twitter avec des arguments du genre « Pas question de passer par un navigateur Web pour suivre les nouvelles » mais cet argument ne tient pas, le navigateur n'est qu'une des innombrables options possibles.
Pour cette dernière raison, des discussions sur « Le meilleur outil de veille, RSS ou Twitter » sont un peu à côté de la plaque, puisqu'on peut suivre Twitter en RSS... (Et probablement l'inverse.)
Twitter étant un grand succès, il n'est pas étonnant que les identificateurs Twitter deviennent désormais aussi convoités que dans d'autres domaines. Ainsi, la SNCF a déjà vu son nom lui échapper (c'est une violation directe des règles d'utilisation mais cela se fait quand même.)
Personnellement, pour tout ce qui ressemble de près ou de loin à la messagerie instantanée, ce qui est le cas de Twitter, j'utilise l'excellent logiciel Pidgin. Il a deux greffons pour faire du Twitter, pidgin-twitter et microblog-purple, qui est celui que j'utilise. On en trouve une bonne documentation en How to Add Twitter in Pidgin (Windows/Linux).
Son installation, sur une machine Debian, consiste simplement en :
wget http://microblog-purple.googlecode.com/files/mbpurple-0.2.3.tar.gz tar ... sudo aptitude install libpurple-dev pidgin-dev make sudo make install
Et le résultat ressemble à :
S'il y a tant de clients Twitter différents, c'est en bonne partie parce que Twitter dispose d'une API très simple. Elle permet le développement de plein de gadgets rigolos comme par exemple l'envoi des messages de commits de Subversion (pour lequel il existe même plusieurs méthodes).
Pour le programmeur Python qui veut utiliser cette API, le plus simple est d'installer le paquetage python-twitter. On peut ensuite faire des choses comme :
>>> import twitter >>> api = twitter.Api(username='MONNOM', password='MONMOTDEPASSE') >>> status = api.PostUpdate(u"Envoyé grâce à l'API de Twitter et python-twitter")
(La lettre u devant la chaîne de caractères est pour bien expliquer qu'on veut de l'Unicode, la chaîne comptant des caractères composés.) On peut ensuite lire cette passionnante information.
Un exemple plus sophistiqué est celui que j'utilise pour prévenir, sur Twitter, des nouveautés de mon blog. Le programme Python est très simple, il extrait automatiquement le titre à partir du source XML et essaie juste de faire tenir le titre et l'URL dans la limite de Twitter, les fameux 140 caractères :
max_twitter = 140
...
rest = max_twitter - len(url) + 1
if len(title) > rest:
shorttitle = title[:rest-3] + "..."
else:
shorttitle = title
message = u"%s %s" % (shorttitle, url)
Il existe bien d'autres outils pour faire du Twitter depuis la ligne de commande, par exemple, toujours en Python, Twyt.
Bien sûr, Twitter n'est pas le seul outil centralisé de microblogging et on me recommande souvent Identi.ca, qui travaille uniquement avec du logiciel libre et s'engage à ne pas abuser des données personnelles. J'ai aussi un compte sur identi.ca mais, pour l'instant, je n'ai pas l'impression qu'il y aie autant de monde que sur Twitter. Et je n'ai pas encore testé l'API. (Il en existe une version compatible avec Twitter.)
L'article seul
Accéder aux ports série d'une Sparc
Première rédaction de cet article le 20 septembre 2009
Dernière mise à jour le 2 avril 2011
Je sais, il n'y a plus grand'monde qui a des Sparc ou des UltraSparc en production mais c'était de bonnes machines et j'ai passé tellement de temps à essayer d'accéder à la console d'une Sparc par son port série qu'il me semble que ce serait dommage de ne pas rédiger cet article. Qui sait, je pourrais avoir demain besoin de cette petite documentation...
Pourquoi a t-on besoin du port série ? Parce que la Sparc n'a pas forcément une carte graphique et, même si elle en a, on n'a pas toujours le clavier et l'écran spéciaux qu'elle réclame. Si on a acheté sa Sparc sur eBay ou bien lors d'un vide-grenier, par exemple pour jouer avec Debian ou NetBSD sur une machine originale, on n'a souvent pas tout le matériel. En raison de cette utilisation « Unix libre », courante sur les vieilles Sparc, les meilleures documentations se trouvent en relation avec ces Unix (par exemple, la FAQ de NetBSD ou celle spécifique aux UltraSparc). Mais je n'ai jamais trouvé de documentation qui mentionne tous les points exposés ici. Si vous venez donc de toucher une vieille Sparc et que vous voulez y installer un Unix libre, voici quelques trucs utiles au démarrage.
Le principe de base est simple : la Sparc, dans sa configuration de sortie d'usine, démarre sur son clavier et son écran (spécifiques de Sun). Si elle ne trouve pas de clavier (et pas d'écran), elle bascule sur son premier port série, nommé A. Si on veut utiliser le second port série, nommé B, il faudra la configurer explicitement. Donc, même si on n'a pas de clavier Sun, le port série devrait être utilisé automatiquement. Néanmoins, il y a parfois des imprévus et, d'une manière générale, la solution la plus simple est d'essayer de mettre la main sur un clavier Sun.
Lorsque la machine démarre, si on veut prendre la main pour, par
exemple, changer les options de démarrage, avec le clavier Sun, on
doit taper STOP-A (les deux touches en même
temps). Si on n'a pas de clavier Sun et qu'on passe par le port série,
cela dépend du logiciel utilisé. Avec Minicom,
c'est Ctrl-A F (qui envoie un
BREAK) Avec
cu, c'est ~#.
Note sur Minicom en passant : voici un fichier de configuration
(/etc/minicom/minirc.$NOM_CONFIG) qui permet de
se connecter au port série d'une Sparc, depuis un PC
Linux moderne, qui n'a donc pas de port série
et utilise un câble USB<->série (le câble
série étant un « zéro modem »). Une fois
le module noyau usbserial
chargé, on se connecte donc à /dev/ttyUSB0 (ce
serait plutôt /dev/ttyS0 pour un vieux PC, équipé
d'un port série) :
# Connection to the serial port, for managing a machine such as a Sparc pu port /dev/ttyUSB0 pu baudrate 9600 pu bits 8 pu parity N pu stopbits 1 pu minit pu mreset pu mhangup pu rtscts No
Fin de la digression minicom, retournons à la Sparc. Si on utilise
un clavier Sun et que le clavier est un Azerty, il faut faire un
STOP-Q et non pas STOP-A. Ce
n'est qu'après que la Sparc reconnait son clavier correctement. Les
autres commandes sont donc à taper normalement.
Cela, c'est pour la configuration d'usine. Mais, si on a récupéré
une Sparc d'occasion, une autre configuration, en général inconnue, a parfois été stockée
dans la NVRAM. Cette configuration peut, par exemple, débrayer la
sélection du port série et on est alors bien démuni si on n'a pas le
clavier et l'écran Sun. Remettre à zéro la NVRAM nécessite, avec un
clavier Sun, un STOP-N (les deux touches en même temps) au démarrage
(presser bien avant d'allumer, et bien attendre longtemps). Si on n'a
même pas de clavier Sun, même emprunté pour cinq minutes, je ne sais
hélas pas quoi faire.
L'UltraSparc 10 a deux ports série, un DB25 femelle (le port A) et un DB9 mâle (le port B). Que faire si le premier, le seul choisi automatiquement avec la configuration d'usine, ne marche pas, ce qui m'est arrivé sur une Sparc récupérée ? Le mieux est d'emprunter un clavier Sun (l'écran n'est pas nécessaire) et de taper en aveugle les commandes qui forcent l'usage du port B :
setenv output-device ttyb setenv input-device ttyb reset
On peut aussi utiliser le clavier Sun en entrée et la console série seulement en sortie mais l'installeur de Debian n'aime pas (« Inconsistent console »).
Sur la photo ci-dessous, on voit un câble série branché dans le port B :
 et sur celle-ci, les deux ports sont libres. A est le 25-broches à gauche, B est étiqueté par son nom :
et sur celle-ci, les deux ports sont libres. A est le 25-broches à gauche, B est étiqueté par son nom :

L'article seul
Fiche de lecture : Dictionnaire amoureux des langues
Auteur(s) du livre :
Claude Hagège
Éditeur : Plon / Odile Jacob
978-2-259-20409-5
Publié en 2009
Première rédaction de cet article le 20 septembre 2009
Comme son titre l'indique, ce livre est pour l'amoureux des langues, celui qui est prêt à se pencher sur la néologie en islandais (article « Islandais ») ou sur les risques pesant sur le qawasqar (article « Danger (langues en) »). Si, au contraire, vous voulez annuler Babel et pensez qu'il vaudrait mieux que tout le monde ne parle qu'une seule langue, il vaudrait mieux trouver une autre lecture.
Claude Hagège est connu pour ses travaux de linguiste que, dans ce livre, il essaie de faire partager à tous. La forme est celle d'un dictionnaire mais, en fait, chaque article est plutôt encyclopédique, détaillant un des points qui touchent particulièrement l'auteur.
Ainsi, l'article « Témoignages » explique qu'en français, les conditions dans lesquelles on a appris une information (« Jean n'est pas allé travailler aujourd'hui ») doivent être exprimées en plus (« Irène m'a dit que Jean n'était pas allé travailler aujurd'hui ») alors qu'en turc, il y a deux verbes différents selon qu'on sait l'information de première main, ou bien indirectement. (Et le tuyuca a cinq niveaux différents, selon qu'on est témoin immédiat, ou plus ou moins éloigné de la source originale.) Ainsi, on ne peut pas être ambigu en turc lorsqu'on rapporte une information : la grammaire oblige à dire si on était vraiment là pour la constater.
« Composés et dérivés » explique, lui, comment former des nouvaux mots, selon les langues, certaines, comme le chinois, privilégiant la composition (faire un mot avec deux), d'autres, comme les langues sémites, la dérivation (ajouter des affixes à un radical).
Autre article passionnant, « Hybridation » explique les mécanismes par lesquelles les langues se mélangent. L'emprunt massif de vocabulaire est l'exemple le plus connu mais il y a aussi des mélanges bien plus intimes comme dans le cas du maltais où l'hybridation avec l'italien et l'anglais rend parfois difficile de détecter le fond arabe. (Il y a aussi un article « Emprunt », sur le même sujet.)
L'article « Traduire » est évidemment un des plus longs car cette activité a une longue histoire d'auto-introspection. Comment traduire le chinois « une moustache en huit » sans savoir que l'expression fait allusion à la forme du caractère représentant ce chiffre en chinois ? Et si un français parlait de « moustache à la gauloise », le traducteur en chinois aurait sans doute besoin de se renseigner sur l'histoire de France...
Mon principal regret est que beaucoup d'articles passionnants (comme « Difficiles (langues) ») soient assez gâchés par l'anglophobie militante de l'auteur qui passe beaucoup trop de temps à cracher son venin contre le rôle excessif de la langue d'Obama et de Ballmer, en dérapant souvent sérieusement.
Le livre est très technique, et nécessite, si on n'a pas de connaissances préalables en linguistique, une attention soutenue. Mais l'auteur a fait de gros efforts pour tout expliquer et rendre ces concepts accessibles et il y est bien arrivé.
L'article seul
OpenDNS, surtout pas
Première rédaction de cet article le 17 septembre 2009
Dernière mise à jour le 11 mai 2015
Quand survient un problème avec les résolveurs DNS d'un FAI, la réponse courante dans les forums bas de gamme est « il faut utiliser les résolveurs d'OpenDNS ».
Un exemple courant de problème est lorsque le FAI déploie des DNS menteurs pour diriger ses utilisateurs vers des sites Web de publicité. Par exemple, lorsque SFR a rétabli ses DNS menteurs en août 2009, des tas de blogueurs ont conseillé sur leur site d'utiliser OpenDNS. Même chose lorsqu'une faille de sécurité touchant au DNS est publiée (par exemple lors de l'attaque contre Eircom).
Dans le premier cas, l'idée est mauvaise : les résolveurs d'OpenDNS sont également des menteurs. Si OpenDNS a supprimé les mensonges en cas de noms non existants, ils continuent à changer les réponses « pour des raisons de sécurité ».
Donc, utiliser OpenDNS pour échapper aux résolveurs menteurs de son FAI, c'est comme plonger dans le lac lorsqu'il pleut, pour éviter d'être mouillé. Le seul avantage, c'est qu'on est mouillé volontairement... (Je plaisante mais j'ai vu l'argument « Oui, mais OpenDNS, on n'est pas obligé de l'utiliser ». Justement, puisqu'on n'est pas obligé, ne l'utilisons pas.)
À noter que ces mécanismes de mensonge sur les réponses DNS sont également débrayables si on se crée un compte (gratuit) chez OpenDNS avant d'indiquer ses adresses IP et de décocher la case qui va bien.
La publicité d'OpenDNS repose sur plusieurs arguments, la plupart fallacieux. Un des plus courants est la vitesse. Cet argument est très souvent répété sur les forums, par des gens qui n'ont jamais mesuré eux-mêmes, et n'est pas très différent de tous les arguments marketing « X est plus rapide que Y », argument qui ne s'impose que par la répétition. Si tout le monde le dit, c'est que ça doit être vrai, non ? Eh bien non, si on mesure soi-même au lieu de répéter ce que disent les moutons, on s'aperçoit qu'OpenDNS est toujours plus lent que les serveurs DNS de votre réseau local ou de votre FAI. Comme le note seizurebattlerobot lors d'une discussion sur Slashdot, c'est logique, « Despite their claims to the contrary, OpenDNS's servers are likely farther away from you than your local ISP's. ».
D'autre part, OpenDNS affirme protéger l'utilisateur de la pornographie et du malware en mentant sur les réponses DNS, même lorsque le nom de domaine existe. (Ce qui entraîne de sérieux risques de surblocage.)
Enfin, il y a ce qu'OpenDNS ne dit pas : puisque l'usage de leurs résolveurs est gratuit, quel est leur modèle d'affaires ? Simplement vendre l'information qu'ils ont récolté sur vous. Comme le note encore seizurebattlerobot sur Slashdot, en juillet 2009 : « They also keep permanent logs of all queries, which could be subpoenaed by a government entity. Their joke of a privacy policy allows them to sell your logs to "Affiliated Businesses", which pretty much means anybody. Not that it really matters - they could amend their privacy policy tomorrow morning and be selling your info by the afternoon. ». Un résolveur DNS reçoit énormément d'informations sur ce que font ses clients (et je sais de quoi je parle, grâce à des systèmes comme DNSmezzo).
Donc, pour l'utilisateur typique, il n'existe aucune raison valable d'utiliser OpenDNS. Y a t-il des cas où on n'a pas le choix ? Sur certains réseaux (par exemple chez beaucoup de FAI africains, sur un hotspot mal géré, dans beaucoup d'hôtels), les serveurs DNS sont souvent en panne ou très lents. Si on est coincé sur un tel réseau, on a bien besoin de résolveurs DNS quand même. Autrefois, tous les résolveurs DNS étaient ouverts à tous et il suffisait d'en prendre un au hasard. Aujourd'hui, pour diverses raisons (voir par exemple le RFC 5358), de tels serveurs récursifs ouverts sont de plus en plus rares et ceux qui restent ne sont pas forcément dignes de confiance. Une des solutions est de les utiliser quand même, et d'être prêt à changer lorsqu'ils tombent en panne ou bien se sécurisent.
Une autre solution est d'avoir un résolveur DNS local sur sa
machine ou son réseau. Cela peut sembler une solution très
geek mais c'est plus simple
que ça n'en a l'air. Sur Debian ou
Ubuntu, un simple aptitude install
unbound et le résolveur Unbound est
prêt à l'emploi (il faut modifier
/etc/resolv.conf pour indiquer comme serveur de
noms 127.0.0.1, la machine locale, ou bien
changer les réglages DHCP si c'est
possible). Unbound est probablement plus sûr que
BIND car moins chargé en fonctions. Mais, bien
sûr, on peut utiliser BIND aussi. Pour les amateurs de MS-Windows, Gils
Gayraud me recommande TreeWalk.
Certaines personnes peuvent s'inquiéter à cette idée d'un résolveur sur chaque machine (ou en tout cas sur chaque petit réseau), en raison de la charge supplémentaire que cela imposera aux serveurs de la racine ainsi qu'à ceux des domaines de tête. Sans le partage des informations dans les grands caches des résolveurs DNS des FAI, les serveurs de la racine tiendront-ils le coup ? C'est en raison de cette question que je ne conseille pas d'installer son résolveur à soi sans une bonne raison. Dans le futur, il est possible qu'on n'ait plus le choix, si on veut un service DNS correct. Et, à ce moment, on verra bien. Lors de réunions d'experts comme à l'OARC, les opérateurs des serveurs racine ont toujours déclaré qu'ils n'étaient pas inquiets sur ce point.
Reste le cas des documentations dont l'auteur ne sait pas sur quel
réseau tournera la machine et où il préfère indiquer les serveurs
d'OpenDNS pour permettre un copier-coller des instructions (voir par
exemple http://wiki.openmoko.org/wiki/Android_usage). Une meilleure
solution serait de recommander d'utiliser DHCP, pour récupérer les serveurs du réseau local.
La dernière solution est d'utiliser un concurrent d'OpenDNS. La
plupart utilisent les mêmes méthodes et ont des résolveurs tout aussi
menteurs. C'est le cas de Comodo, de Scrubit ou de Neustar/Advantage. À défaut
de tout, les utiliser permet d'éviter la constitution d'un monopole
d'OpenDNS. Mais il existe aujourd'hui un service de résolveur ouvert
honnête, c'est Google DNS et c'est
donc une possibilité intéressante. Pour une liste plus complète (trop
complète, on y trouve de tout mais, heureusement, avec tous les
détails pratiques), voir l'excellent resolv.conf
de Chris Hills.
Je laisse la conclusion à, à nouveau, seizurebattlerobot : « I think many people read the "Open" part of the OpenDNS name and turn their brains off. »
L'article seul
RFC 3971: SEcure Neighbor Discovery (SEND)
Date de publication du RFC : Mars 2005
Auteur(s) du RFC : J. Arkko, J. Kempf, B. Zill, P. Nikander
Chemin des normes
Première rédaction de cet article le 15 septembre 2009
Pour trouver l'adresse MAC d'un voisin, une machine IPv6 utilise le protocole NDP (Neighbor Discovery Protocol), normalisé dans le RFC 4861. Ce protocole ressemble beaucoup au traditionnel ARP (RFC 826) d'IPv4 et il partage notamment sa principale vulnérabilité : une machine peut tout à fait se faire passer pour une autre et recevoir ainsi les paquets qui ne lui sont pas destinés. En outre, NDP dispose d'autres fonctions qu'ARP, comme la découverte des routeurs, fonctions qui sont tout aussi critiques et tout aussi vulnérables. Au début d'IPv6, l'enthousiasme pour IPsec était sans limite et il était donc censé résoudre ce problème, comme beaucoup d'autres. En réalité, IPsec a été peu implémenté et encore moins déployé et il a donc fallu trouver une autre solution, SEND (SEcure Neighbor Discovery) qui fait l'objet de ce RFC.
Les détails sur les vulnérabilités de NDP figurent dans le RFC 3756. Ils sont aussi résumés dans la section 11.1 du RFC 4861 et rappelés dans la section 1 de notre RFC 3971. Exemple ironique, à chaque réunion physique de l'IETF, certains portables sont configurés pour créer des réseaux ad hoc et envoient des annonces RA (Router Advertisement) concurrents de ceux du routeur légitime. La seule solution est de donner au micro les adresses MAC des routeurs « pirates » pour les filtrer.
Cette section 1 explique aussi, en plus des problèmes généraux d'IPsec, pourquoi il ne peut pas être utilisé pour sécuriser un protocole de découverte des voisins et du réseau, en raison des limites du bootstrap (on a besoin du réseau pour IKE mais on a besoin d'IPsec pour initialiser le réseau..).
Sur un réseau local qui n'offre pas de sécurité physique (Ethernet sans 802.1x ou bien WiFi), NDP est très vulnérable et c'est la raison d'être de SEND.
Résumé brièvement, SEND consiste à utiliser des adresses CGA (adresses auto-signées) sur les machines non-routeuses et des signatures cryptographiques avec certificat pour authentifier les annonces des routeurs.
La section 3 résume les fonctions de NDP :
- Découverte automatique des routeurs (une autre solution étant d'utiliser DHCP),
- Auto-configuration, sans état, des adresses IP des machines (RFC 4862),
- Détection des conflits d'adresses (lorsque deux machines ont reçues la même adresse IP),
- Résolution d'adresses IP en adresses MAC (section 7.2 du RFC 4861).
Toutes ces fonctions sont mises en œuvre par des messages portés sur ICMP (RFC 4443) qui contiennent des données et des options encodées en TLV. (Voir la liste dans le registre IANA.)
Comment fonctionne SEND ? C'est l'objet du reste du RFC, à commencer par la section 4 qui décrit le fonctionnement général. SEND comprend :
- Un système de certificats, permettant de valider les annonces d'un routeur, en suivant un chemin de certificats signés (l'annonce du routeur n'a pas besoin d'inclure tous les certificats du chemin, des nouveaux messages NDP permettent au récepteur de demander les certificats qui lui manquent).
- Des adresses cryptographiques, les CGA du RFC 3972, permettent de s'assurer que la machine qui répond aux requêtes Neighbor Discovery est bien la « propriétaire » de l'adresse. (Donc, contrairement aux annonces des routeurs, SEND n'utilise pas de certificat pour authentifier les simples machines. Cette possibilité est uniquement mentionnée pour un usage possible dans le futur.)
- Une nouvelle option NDP,
RSA signature, permet de vérifier l'intégrité du message. La clé publique utilisée pour la signature est récupérée, soit par les certificats, si l'émetteur est un routeur, soit, pour le cas de CGA par une autre option qui permet d'inclure cette clé dans les messages. À noter que RSA est le seul algorithme normalisé, pour garantir l'interopérabilité (puisque SEND tourne dans des environnements où il ne serait pas réaliste de se lancer dans des négociations entre émetteur et récepteur). S'il fallait changer d'algorithme, par exemple suite aux progrès de la cryptanalyse, il faudrait alors développer une nouvelle version de SEND (ce qui est précisement en cours). - Et enfin un mécanisme de nonce contre les attaques par rejeu.
Le détail de ces nouvelles options et de leur format figure en
section 5. Par exemple, l'option CGA (section 5.1) permet au répondeur
qui utilise des adresses IP CGA d'inclure la clé publique utilisée
dans la réponse.
La
section 5.1.1 détaille comment l'émetteur doit remplir cette option et
la 5.1.2 comment le récepteur peut l'utiliser pour vérifier que le détenteur de la clé est bien celui de l'adresse
La section 5.2, elle, normalise l'option CGA
signature, où le message SEND contient une signature au format
PKCS#1. Là encore, la section décrit en détail
ce que doit faire l'émetteur pour remplir cette option et le récepteur
pour la vérifier. Toute aussi indispensable, la section 5.2.3 traite
de la configuration de l'option par l'administrateur système et note
qu'une mise en œuvre de SEND doit pouvoir être configurée pour
vérifier cette signature par différents moyens, comme une
trust anchor, une clé publique de départ, à
laquelle on fait confiance et qui peut à son tour signer d'autres
clés.
Un enjeu de sécurité important de SEND est la protection contre le
rejeu. Pour cela, les options
Timestamp et Nonce, décrites
en section 5.3 sont indispensables. Timestamp
indique le temps de l'émetteur et permet, si les horloges de
l'émetteur et du récepteur sont raisonnablement synchronisées (la
section 5.3.4.2 précise les tolérances admises),
d'empêcher qu'un méchant n'enregistre une réponse tout à fait légitime
et ne la réutilise plus tard, alors qu'elle n'est plus
valable. Nonce, elle, stocke un nombre aléatoire
(de taille variable, au moins 48 bits)
envoyé par le solliciteur et retourné par le répondant. Ainsi, on peut
être sûr que le paquet SEND est bien une réponse à une question qu'on
avait posé. Les règles de génération imposent l'usage de ces deux
options (et les récepteurs doivent considérer les messages SEND sans
une de ces options comme étant non-SEND donc non sûrs).
La section 6 entreprend de résoudre le difficile problème de la validation des certificats des routeurs. La méthode normale, si on n'a pas déjà l'information dans son magasin de certificats, est d'aller la chercher sur l'Internet. Mais, ici, comme il s'agit de découvrir le routeur, cette solution n'est pas possible puisque, justement, on n'a pas encore de routeur pour aller sur l'Internet. Comment SEND traite t-il ce problème ?
Le modèle général est celui de X.509, comme l'utilisent, par exemple, les navigateurs Web. Chaque machine doit avoir un magasin de certificats (qui ne sont pas forcément les mêmes que ceux utilisés, après la configuration d'IP, pour des activités comme le Web) et se sert de ce ou ces certificats comme trust anchors, comme points de départ de la validation (sections 6.1 et 6.5). La machine terminale n'a pas de certificats à elle (à part avec CGA, elle ne s'authentifie pas, seul le routeur le fait). Le routeur, lui, reçoit son certificat et sa clé privée. Le certificat l'autorise non seulement à agir comme routeur mais également à annoncer certains préfixes IP et pas les autres.
Qui attribue ces certificats ? La section 6.2 mentionne une autorité de certification mondiale unique pour les routeurs... qui n'existe pas (et n'est sans doute pas près d'exister). Elle pourrait émaner de l'IANA ou bien d'un consortium formé par les RIR.
Une autre solution mentionnée par le RFC (nommée dans le RFC le « modèle décentralisé », un terme incorrect), et la seule possible aujourd'hui, est celle d'un nuage de diverses autorités de certification, chacune reconnue par certains sites mais pas par d'autres. Cela rend très difficile la mobilité (un portable en visite sur un autre site n'a aucun moyen de valider les annonces SEND du routeur local).
Le format des certificats, lui, est expliqué en section 6.3. C'est du X.509 v3, avec le profil des RFC 3779 et RFC 5280, RFC qui permet de décrire dans le certificat les ressources Internet qu'on peut annoncer (les adresses IP, par exemple, section 4.2.1.6 du RFC 5280).
Enfin, pour permettre la réception de certificats non contenus
dans le magasin, mais nécessaires pour boucler la chaîne de
validation, la section 6.4 prévoit des types de messages ICMP Certificat
Path Solicitation et Certification Path
Advertisement. Avec elles, on peut construire des messages
pour demander ou obtenir des certificats.
L'usage des adresses IP par SEND fait l'objet de la section 7. Une machine SEND est censée n'utiliser que CGA (section 7.1) et donc pas les adresses IP temporaires du RFC 4941. Sécurité ou vie privée, il faut choisir ! Pour travailler avec d'autres adresses, rien n'est encore trop précisé, à part l'API du RFC 5014. Autre exemple (section 7.4), SEND ne fournit aucun moyen d'authentifier les messages NDP pour les adresses IPv6 statiques, ou bien les adresses autoconfigurées à partir de l'adresse MAC.
SEND est aujourd'hui très peu déployé. Comme tous les protocoles récents (il date quand même de plus de quatre ans), il fait face à des problèmes de transition avec l'ancienne méthode (qui est de ne pas sécuriser du tout). La section 8 expose ces problèmes. Comme, en pratique, une machine SEND va certainement rencontrer des réseaux non-SEND, le RFC demande que les messages non sécurisés soient également acceptés. La machine SEND qui reçoit deux sortes de messages doit évidemment donner la priorité à ceux qui sont sécurisés. Le RFC recommande également une option de configuration « paranoïaque » où seuls les messages NDP sécurisés soient acceptés (à condition qu'elle ne soit pas active par défaut). Inversement, le RFC admet une option de ne pas envoyer de messages SEND (au cas où ils perturbent le réseau mais, si tout le monde suit la norme IPv6 correctement, cela ne devrait pas arriver, les options SEND des messages NDP devraient simplement être ignorées) mais cette option doit être activée explicitement.
La cohabitation de réseaux SEND (sécurisés) et non-SEND (non
sécurisés) peut avoir pour conséquence la réception d'un message non
sécurisé qui essaie de remplacer l'information issue d'un message
sécurisé. Notre RFC 3971 impose que les caches (comme celui
des voisins qui, sur Linux, peut être affiché
avec ip -f inet6 neighbour show) doivent garder
trace du caractère sûr ou non sûr de l'information et ne doivent pas
remplacer une information sûre par une non sûre.
SEND est entièrement voué à la sécurité donc l'obligatoire section Sécurité pourrait être inutile mais, ici, la section 9.1 couvre un problème utile : les menaces que SEND ne résout pas. Ainsi, SEND ne protège pas la confidentialité des échanges NDP. SEND ne rend pas complètement sûr un réseau physique non sûr (par exemple, une machine malveillante peut toujours envoyer des paquets avec une adresse MAC source mensongère).
À l'heure actuelle, un groupe de travail de l'IETF, csi, travaille à améliorer SEND. Par exemple, SEND est limité à SHA1 et RSA alors que le groupe de travail explore la meilleure façon d'utiliser de nouveaux algorithmes cryptographiques.
Quells mises en œuvres de SEND sont disponibles ? DoCoMo en avait une mais qui n'est plus maintenue. On trouve quelques bouts de code par ci par là, quelques projets pas finis, mais apparemment pas d'implémentation libre complète qui marche sur des systèmes comme Linux ou FreeBSD. Donc, je ne crois pas que je pourrai activer SEND sur ma Freebox. En revanche, Cisco a une mise en œuvre de SEND sur ses routeurs (mais pas, semble t-il, Juniper).
Pourquoi SEND n'est-il pratiquement pas déployé ? Il y a sans doute plusieurs raisons : le déploiement est difficile puisqu'il faut mettre la clé publique des routeurs dans chaque machine et la sécurité du protocole NDP n'est pas vraiment un problème aujourd'hui (à part sur le réseau de Defcon, les attaques réelles sont rares).
L'article seul
Acheter légalement de la musique sur Internet, est-ce possible ?
Première rédaction de cet article le 13 septembre 2009
Dernière mise à jour le 20 septembre 2009
Les défenseurs des lois liberticides comme Hadopi mettent souvent en avant l'argument comme quoi les amateurs de musique désireux d'acheter sur l'Internet peuvent simplement recourir au téléchargement légal, en achetant en ligne à un commerçant qui reversera une part à l'industrie du divertissement. Par exemple, l'Hadopi mentionne cette offre légale sur son site (en ne donnant pas un seul exemple). Je me suis toujours méfié de cet argument mais, après tout, peut-être faut-il essayer ?
Je ne connais rien à ces mythiques « plate-formes de téléchargement légal » qui sont régulièrement vantées comme la solution légale aux désirs des internautes musicophiles, sans jamais fournir de liste. J'ai donc commencé par me dresser une petite liste des critères qui sont importants pour moi :
- Accessible via du logiciel libre, sans devoir installer un logiciel privateur et probablement très indiscret comme iTunes,
- Disponible dans un format raisonnablement ouvert comme Ogg/Vorbis ou, à la rigueur (parce que je ne veux pas être sectaire) MP3,
- Évidemment sans menottes numériques (un excellent article de Korben détaille leur nocivité, pour le cas des e-books).
Bien sûr, je souhaiterai aussi qu'on puisse acheter sans devoir s'inscrire (je n'ai pas besoin de remplir un questionnaire pour acheter dans un magasin physique !) et que cela ne soit pas trop cher (puisqu'il est moins coûteux de déplacer des bits que des atomes).
Je ne sais pas trop où chercher des vendeurs qui corrspondent à ces critères alors j'ai demandé des idées à un moteur de recherche. Il m'a trouvé Starzik qui, parait-il, colle à mon cahier des charges. Mais, apparemment, il est impossible de télécharger sans s'inscrire et Starzik ne semble pas vouloir de moi comme client, répondant systématiquement que « L'adresse email ne semble pas valide ». (D'autres personnes y arrivent donc cela semble indiquer que Starzik accepte arbitrairement certains clients et pas d'autres.) Le support de Starzik, prévenu, ne répond évidemment pas. Mais, en désactivant Javascript dans le navigateur, il est possible de passer outre : on le voit, acheter de la musique légalement nécessite d'être motivé ! En prime, les messages de Starzik sont systématiquement marqués comme spam par leur propre serveur de messagerie !
En tout cas, avec Starzik, j'ai enfin réussi par obtenir un fichier Ogg que je peux écouter avec mplayer. Avec le temps et les efforts que ça a pris, j'aurais certainement pu télécharger vingt morceaux illégalement...
Le même moteur de recherche suggère alors Amazon, une entreprise connue et sérieuse, dont je suis déjà client. Curieusement, Amazon recommande l'installation d'un logiciel privateur livré sans code source, Amazon MP3 Downloader. Certes, son utilisation ne semble pas obligatoire (« Si vous préférez ne pas installer l'application Amazon MP3 Downloader, vous pouvez quand même acheter des titres individuels. ») mais, en pratique, le lien qui suit cette affirmation ne fait rien et ramène toujours au texte de publicité en faveur de Amazon MP3 Downloader. C'est d'autant plus frappant que les bogues sont extrêmement rares sur le site Web d'Amazon, conçu avec un autre sérieux que les bricolages de tant de cyber-commerçants.
Lucas Nussbaum, qui a courageusement testé, me dit qu'il faut sans doute cocher la case « j'accepte les conditions d'utilisation de de MP3 Downloader » même si on ne veut pas l'utiliser. Très intuitif.
Enfin, au moins, le logiciel en question tourne sur Unix, ce qui est suffisamment rare pour être signalé. Mais, ne voulant pas l'installer, je suis également privé d'Amazon.
Depuis la première version de cet article, Amazon a changé la procédure et, désormais (novembre 2010), lorsque j'essaie d'acheter de la musique, j'ai : « We could not process your order. The sale of MP3 Downloads is currently available only to US customers located in the 48 contiguous states, Alaska, Hawaii, and the District of Columbia. ». Acheter légalement de la musique reste un parcours du combattant...
Bon, en lisant cet article, des gentils lecteurs m'ont fait d'autres recommandations.
Par exemple, Deezer, qui m'insulte en disant que ma version de Flash est trop ancienne. Sympa avec les clients, d'autant plus que je n'ai pas Flash du tout.
Il reste Spotify mais qui n'est pas encore complètement ouvert au public (il me demande un code d'invitation, que je n'ai pas). Apparemment, Spotify a été ouvert à un moment, puis refermé, mais un formulaire « sans invitation » reste ouvert. Il ne semble pas fonctionner, me ramenant à chaque fois au formulaire lorsque je clique « Create account and proceed ».
Bref, acheter légalement n'est pas de la tarte. Quelqu'un a t-il de meilleurs commerçants à me recommander ?
PS: le même gentil moteur de recherche m'a fait découvrir http://www.dilandau.com/ où on peut télécharger plein de
MP3 sans payer, en très peu de temps, sans installer de logiciel sur
sa machine, sans se faire insulter
(« You must install Flash Player, you obsolete dinosaur! »). Sans doute pas légal mais il
est frappant de constater que l'expérience utilisateur est bien
meilleure avec un système illégal qu'avec un légal.
Merci à Pierre Beyssac et Kevin Hinault pour leurs suggestions. Un exemple d'article (médiocre) présentant les offres légales est « Quels sites conseiller aux ados pour écouter de la musique légalement sur Internet ? » : peu de recherches (Amazon et Starzik ne sont même pas mentionnés) et aucun effort pour indiquer les sites qui vendent du contenu DRMisé ou bien imposant un logiciel non-libre.
L'article seul
Un logiciel pour se créer sa page d'accueil, sans dépendre d'un service hébergé ?
Première rédaction de cet article le 12 septembre 2009
Dernière mise à jour le 18 octobre 2009
Je suis de plus en plus content des services hébergés comme iGoogle ou Netvibes qui vous permettent de créer une page d'accueil, de la modifier souvent, en y mettant plein de données dynamiques, via les gadgets, et du contenu régulièrement mis à jour via la syndication. Je configurerai bien désormais mon navigateur pour avoir comme page par défaut un service de ce genre. Mais ces services ne tournent pas avec du logiciel libre et, surtout, on est entièrement dépendant d'une entreprise extérieure, qui peut faire ce qu'elle veut avec les données ainsi récoltées. Pourquoi pas un logiciel libre qui me permette de mettre un Netvibes ou un iGoogle chez moi ?
Pour des services comme les moteurs de recherche, cela parait difficile, puisque mettre sur pied un tel service nécessite des moyens humains et financiers colossaux. Mais, pour un service comme iGoogle, presque rien n'est fourni par Google. Ce dernier se contente de publier le code Javascript qui permet de modifier la page (des bibliothèques comme Prototype ou jQuery rendent aujourd'hui bien plus facile l'écriture de tels programmes Javascript), et d'héberger les préférences de l'utilisateur, la liste de ses gadgets (j'aime beaucoup celui qui me permet de voir les vélos libres dans les stations Vélib), etc. Il semble que cela soit faisable avec relativement peu de moyens. Mon cahier des charges :
- Tourne sur Unix (de préférence sur Debian),
- Logiciel libre.
En logiciel libre, il n'y a apparemment que trois candidats :
- Le plus perfectionné semble être dropthings mais, paradoxe, il ne tourne que sur MS-Windows.
- Le second est liferay, tourne sur Unix mais il dépend de bien des usines à gaz comme Tomcat et je n'ai jamais réussi à l'installer.
- Enfin, Posh de la société Portaneo (à ne pas confondre avec le shell du même nom). Écrit en PHP.
Posh correspond au cahier des charges. Cela aurait été bien de
pouvoir le retenir. Malheureusement, il a deux points faibles. L'un
est la sécurité, question traditionnellement ignorée des développeurs
PHP. J'étais déjà assez inquiet à la pensée d'installer une grosse
application PHP sur mes machines. Mais Posh demande en plus de
débrayer les protections qui existent, par exemple en mettant la
variable magic_quotes_gpc à OFF et la variable
allow_url_fopen à ON (et pas question de passer
outre, le script d'installation le vérifie).
Mais, surtout, Posh est encore trop bogué. L'Unicode est mal géré (bogue sur la syndication, notamment). Pas moyen de l'utiliser depuis Konqueror. La présentation est très contestable. Bref, c'est encore un outil expérimental.
Bref, si un lecteur de ce blog a une solution géniale, ça m'intéresse. Si un programmeur s'ennuie en ce moment, et cherche un bon sujet pour développer un logiciel libre, c'est également l'occasion.
J'avais posé la question sur Server Fault mais sans trop de résultats pour l'instant. Merci à Cyril Fait et Christian Fauré pour leurs suggestions.
L'article seul
Mystère sur l'œil de Londres
Première rédaction de cet article le 12 septembre 2009
Aujourd'hui, les romans pour grands enfants et pour adolescents sont souvent d'une qualité telle que les adultes peuvent aussi les lire, sans trop avoir l'impression de régresser. Cela vaut donc la peine de passer faire un tour à des librairies spécialisées (comme le Divan Jeunesse à Paris) pour chercher ce genre de livres (si on a des enfants, c'est encore mieux, on peut partager les livres). Par exemple, The London Eye Mystery de Siobhan Dowd.
La traduction en français est très bonne mais sous un titre publicitaire, « L'étonnante disparition de mon cousin Salim », qui n'a rien à voir avec le titre original et sert seulement à faire penser au chef d'œuvre de Mark Haddon, « Le bizarre incident du chien pendant la nuit » dont le héros, comme celui du London Eye Mystery, est atteint du syndrome d'Asperger (mais c'est la seule ressemblance entre les deux livres).
Assez digressé, revenons au livre : un roman policier sans crime, mais avec un mystère, sans violence (alors que les livres visant un public adulte sont lancés dans une surenchère de meurtres atroces, de tortures décrites avec les détails, et de longues autopsies) autour d'un lieu unique, l'œil de Londres. Par des méthodes... non-standard... et de curieuses croyances (par exemple dans la combustion spontanée) , le héros, Ted, est-il vraiment le mieux placé pour retrouver Salim ? Avant de le savoir, on aura un peu visité Londres et surtout beaucoup voyagé dans un cerveau déroutant.
L'article seul
Cafouillage entre .PR et le registre DLV de l'ISC
Première rédaction de cet article le 11 septembre 2009
DNSSEC, technologie chargée d'améliorer la
sécurité du DNS, est
une source de distractions sans fin pour l'administrateur
système. Depuis que j'ai activé la validation DNSSEC sur le résolveur
de ma machine au bureau, je vois des problèmes qui sont évidemment
complètement invisibles si on ne vérifie pas les signatures DNSSEC. Ce fut le
cas cette semaine avec la panne de
.pr.
Comme toute technique cryptographique, DNSSEC (normalisé dans le RFC 4033 et suivants), produit des faux positifs, des cas où la vérification échoue, sans qu'il y aie eu de tentative de fraude, simplement parce que la cryptographie est compliquée et que les erreurs opérationnelles sont fréquentes. Avant d'améliorer la sécurité, la cryptographie sert donc souvent à casser des choses qui marchaient très bien avant qu'on ne l'utilise.
Le registre DNS de
.pr a tenu à être un des
premiers domaines de tête à signer avec
DNSSEC. Mais leurs moyens humains ne semblent pas à la hauteur de
leurs ambitions et il y a déjà eu plusieurs cafouillages, par exemple
des signatures expirées ou, en dehors de DNSSEC, des attaques par injection SQL. Ce mois-ci, .pr a
procédé à un changement de sa clé, certainement
l'opération la plus dangereuse de DNSSEC. Cette opération a été assez
mal faite, notamment parce que les administrateurs du domaine
continuent à laisser l'ancienne clé sur
leur site Web mais aussi parce qu'ils n'ont attendu que deux
jours entre l'ajout de leur clé dans ITAR et le retrait de l'ancienne. Or, la
racine du DNS n'étant pas signée, et le suivi à la main de toutes les
clés de tous ceux qui signent n'étant pas réaliste, les très rares
personnes qui, comme moi, utilisent un résolveur DNSSEC validant, se
servent en général du registre DLV de
l'ISC. DLV (DNSSEC Lookaside Validation), normalisé dans le RFC 5074, permet de ne gérer qu'une seule clé, celle du registre
DLV, qui contient les autres clés. Heureusement que, grâce à l'ISC, ce
registre DLV existe. Mais, problème,
dlv.isc.org,
ne se mettait apparemment à jour à partir d'ITAR que toutes les
semaines. Résultat, l'ancienne clé de .pr a été
retirée de la zone alors qu'elle était encore dans DLV (et, on l'a vu,
sur le site Web du registre de .pr, donc le
problème ne concerne pas que DLV).
Résultat, un beau SERVFAIL (Server
Failure) à chaque tentative de résolution d'un nom en
.pr. Gageons que cela n'encouragera pas les
administrateurs de serveurs DNS récursifs à activer la validation DNSSEC.
L'incident a également réanimé tous ceux qui n'avaient pas apprécié le travail de l'ISC pour la mise en place du registre DLV. Pas mal de noms d'oiseaux ont été échangé sur des listes de diffusion comme celle du groupe de travail dnsop de l'IETF. Après tout, ce sont toujours ceux qui font le travail concret qui attirent les reproches...
L'article seul
RFC 5681: TCP Congestion Control
Date de publication du RFC : Septembre 2009
Auteur(s) du RFC : M. Allman, V. Paxton (ICSI), E. Blanton (Purdue University)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tcpm
Première rédaction de cet article le 11 septembre 2009
Successeur du souvent cité RFC 2581, ce RFC 5681 présente les algorithmes que doivent utiliser les mises en œuvres de TCP pour limiter les risques de congestion sur l'Internet. Comme TCP (RFC 793) est, de très loin, le principal protocole de transport de l'Internet, ces quatre algorithmes sont donc la principale ligne de défense contre la congestion.
Leurs noms en anglais sont tellement répandus qu'il n'est pas facile de concevoir une traduction. Essayons :
- Démarrage en douceur (slow start),
- Évitement de la congestion (congestion avoidance),
- Retransmission rapide (fast retransmit),
- Récupération rapide (fast recovery).
Mis au point à l'origine par Van Jacobson, ces algorithmes ont d'abord été normalisés dans le RFC 1122 (avant les RFC 2001, une lecture très recommandée, et RFC 2581). Des RFC comme le RFC 3390 ont également contribué. Richard Stevens décrit ces algorithmes dans son livre TCP/IP Illustrated (explications dans le premier volume et code source dans le deuxième). Ce livre est de très loin le meilleur pour quiconque veut apprendre le délicat fonctionnement de TCP.
Si TCP envoyait des données à la vitesse maximale que permet la carte réseau et la machine, l'Internet s'écroulerait rapidement. Le but de ces algorithmes est donc de freiner TCP et la section 3 note qu'une mise en œuvre de TCP est autorisée à être plus prudente que ces algorithmes (à envoyer moins de données) mais pas à être plus violente.
La section 3.1 décrit le Démarrage en douceur. Le principe est, au
démarrage d'une connexion TCP, de ne pas envoyer trop de données sans
avoir vu qu'elles pouvaient arriver au même rythme. L'envoyeur garde
une variable, cwnd, la fenêtre de congestion, qui
indique combien de données il peut envoyer sans recevoir d'accusé de
réception (ACK). TCP commence avec une fenêtre assez petite (la section 3.1
donne la méthode de calcul, un exposé complet figure dans le RFC 3390) et l'ouvre au fur et à mesure de l'arrivée
des accusés de réception (là encore, les valeurs précises figurent
dans le RFC).
Si vous lisez le code source du
noyau Linux 2.6, ces
variables supplémentaires sont déclarées dans
include/linux/tcp.h. Tous les noms de fichiers
donnés plus loin concernent ce noyau.
Quant la fenêtre de congestion a été augmentée au delà d'un certain
seuil, noté ssthresh, le second algorithme,
l'Évitement de congestion prend le relais. Cet algorithme augmente
différemment, de manière plus rapide, la fenêtre de congestion (quand
tout va bien) et réagit à la
congestion (détectée par l'expiration d'un délai de garde) en
réduisant ssthresh, voire la fenêtre de congestion (ce qui peut la faire tomber en
dessous de ssthresh, réactivant le démarrage en
douceur). Ce second algorithme est décrit en détail dans la même
section 3.1. Pour la mise en œuvre sur Linux, voir le très joli net/ipv4/tcp_cong.c.
Attention, comme l'ont montré plusieurs alertes de sécurité (la dernière datant de quelques jours après la publication du RFC), le fait de réagir aux messages de l'hôte distant présente toujours un risque, si celui-ci essaie de vous tromper. Diverses contre-mesures sont citées (cf. RFC 3465).
Les deux autres algorithmes, la Retransmission rapide et la
Récupération rapide, sont décrits dans la section 3.2. Tous les deux
reposent sur les accusés de réception dupliqués. Ceux-ci (définis
formellement en section 2) sont des accusés de réception pour des
données qui ont déjà fait l'objet d'un tel accusé. Notre RFC 5681 recommande que le TCP récepteur envoie un accusé de
réception immédiatement lorsqu'il reçoit des données qui ne sont pas
dans l'ordre des numéros de séquence (fonction
__tcp_ack_snd_check dans
net/ipv4/tcp_input.c). Cet accusé, considéré
comme « dupliqué », permet à l'envoyeur de voir tout de suite que des
données ont probablement été perdues (rappelez-vous que les accusés de
réception, pour TCP, indiquent simplement le rang du dernier octet
reçu avec succès, pas une plage ; les données hors-séquence ne
suscitent normalement pas d'accusé de réception immédiat, TCP attend
plutôt que les données manquantes arrivent).
La Retransmission rapide est utilisée lorsque TCP reçoit des accusés de réception dupliqués. Dans ce cas, TCP doit retransmettre tout de suite les données non encore acceptées par son pair, sans attendre que le délai de garde expire. La Récupération rapide consiste à ne pas utiliser le Démarrage en douceur lorsqu'on détecte des accusés de réception dupliqués. Elle a fait depuis l'objet de perfectionnements, décrits plus longuement dans le RFC 6582.
Après ces quatre algorithmes à utiliser, le RFC, dans sa section 4.1,
couvre aussi le problème du redémarrage des sessions qui ont été
longtemps inactives. Dans ce cas, TCP ne peut plus compter sur
l'arrivée des accusés de réception pour calibrer le réseau (tous les
ACK sont arrivés depuis longtemps) et son calcul de la fenêtre de
congestion peut être désormais dépassé. Il risque donc d'envoyer un
brusque flux de données. Le RFC recommande donc une variante du
Démarrage en douceur, lorsque la session a été inactive pendant
longtemps.
La section 4.2 revient sur le problème de l'envoi des accusés de
réception. Le RFC 1122 (dans sa section 4.2.3.2) spécifie un algorithme
pour cet envoi, dont le principe de base est d'attendre un peu avant
d'envoyer l'ACK (dans l'espoir que d'autres
données arriveront, permettant de se contenter d'un seul
ACK), mais sans attendre trop pour éviter que
l'émetteur ne s'impatiente et ne réemette. Notre RFC 5681
précise simplement les règles (ambigües) du RFC 1122.
En prime de la Retransmission rapide et du Redémarrage rapide,
certains algorithmes ont été proposés et parfois déployés, pour
récupérer des pertes de données. La section 4.3 les énumère, sans
forcément prendre position sur leur opportunité. Certains,
comme celui du RFC 3517, dépendent de l'option
SACK (Selective Acknowledgment)
du RFC 2018, d'autres, comme celui
du RFC 3782 n'en dépendent pas.
Il est important de noter que le bon fonctionnement de l'Internet dépend de la mise en œuvre correcte de tous ces principes, par chaque implémentation de TCP. Deux machines « inciviles » qui désireraient envoyer le plus de données possibles, et tant pis pour la congestion, peuvent techniquement le faire (section 5, consacrée à la sécurité). C'est un des aspects les plus étonnants de l'Internet que peu de vendeurs aient eu l'idée de promouvoir un TCP « optimisé », c'est-à-dire égoïste. On trouve toutefois des cas limites comme Fast TCP.
Enfin, les changements par rapport au RFC 2581 sont présentés dans la section 7. Les principaux sont :
- Une définition rigoureuse de la notion d'accusé de réception dupliqué (en section 2),
- La recommandation d'utiliser le RFC 3465 pendant le Démarrage en douceur,
- La recommandation d'utiliser le RFC 3042 pendant les Retransmission rapide et Récupération rapide.
(Je trouve personnellement que le RFC 2001 était le plus clair de tous et que la précision des mises à jour suivantes a plutôt brouillé les explications.)
L'article seul
RFC 5632: Comcast's ISP Experiences in a Proactive Network Provider Participation for P2P (P4P) Technical Trial
Date de publication du RFC : Septembre 2009
Auteur(s) du RFC :
C. Griffiths, J. Livingood (Comcast), L. Popkin (Pando), R. Woundy (Comcast), Y. Yang (Yale)
Pour information
Première rédaction de cet article le 11 septembre 2009
Beaucoup de FAI se demandent comment limiter la charge qui provient de l'intense activité pair-à-pair de leurs clients. Les plus bas de front tentent l'interdiction (comme dans les conditions générales d'utilisation de SFR pour certaines de ses offres Internet mobile, où le pair-à-pair est explicitement interdit), d'autres cherchent des solutions techniques. L'une de ces solutions, P4P, qui permet au FAI d'informer les logiciels pair-à-pair de la topologie de son réseau, dans l'espoir qu'ils choisiront des pairs plus proches, est activement promue par certaines entreprises comme Pando. Comcast, un gros FAI, a testé P4P pour nous et en fait le compte-rendu dans ce RFC.
Ce gros FAI états-unien connecte essentiellement des particuliers, par le câble. Comcast est un des participants au groupe de travail qui élabore P4P. Le principe du système P4P (Proactive network Provider Participation for P2P) est de déployer des iTrackers qui sont des serveurs informant les clients pair-à-pair de la topologie du réseau, quels sont les liens recommandés, quelles adresses IP sont externes ou internes au dit réseau, etc (section 1 du RFC). Le logiciel peut alors choisir le pair le plus proche, économisant ainsi les ressources.
P4P a été discuté dans des forums comme le IETF workshop on P2P Infrastructure (raconté dans le RFC 5594) ou à la BoF Alto de l'IETF. Le test en vrai grandeur dont notre RFC 5632 rend compte a eu lieu en juillet 2008.
La section 2 du RFC résume le principe du test. Cinq essaims de machines, avec des iTrackers programmés différemment à chaque fois, participaient. Les statistiques étaient enregistrées par chaque client puis rassemblées. Témoignage de la puissance du pair-à-pair, le seeder (la machine qui avait le contenu original) n'a envoyé que dix copies alors qu'il y a eu un million de téléchargements.
Quels étaient les différents types de iTrackers utilisé ? Si, dans le premier essaim, les pairs étaient choisis au hasard, les autres utilisaient les politiques suivantes :
- Grain fin (section 3.1). De loin le plus complexe à configurer, ce iTracker avait toute l'information sur le réseau de Comcast, incluant tous les liens avec l'extérieur. Non seulement l'élaboration et la mise à jour de sa configuration étaient très complexes (le fichier faisait plus de cent mille lignes) mais cet iTracker est très indiscret, permettant aux clients de récupérer une information que le FAI n'a pas forcément envie de livrer.
- Gros grain (section 3.2). Présentant une vue moins précise du réseau (notamment de ses connexions externes), cet iTracker ne faisait plus que mille lignes et surtout (du point de vue de Comcast) était plus discret.
- Pondéré génériquement (section 3.3). Identique au iTracker à gros grain, sauf que les poids attribués aux différents liens étaient définis par une autre équipe.
Qu'est-ce que ça a donné ? La section 4 résume les résultats (mais il faut aussi lire la section 5, qui détaille les pièges d'interprétation possibles) : chaque essaim de machines a réalisé environ 25 000 téléchargements par jour. Le plus gros essaim a atteint une taille de 11 700 machines. Les iTrackers à grain fin ou à gros grain ont vu leur débit de téléchargement (section 4.2) augmenter de 13 % (en moyenne) mais de 57 à 82 % pour les machines de Comcast, qui avaient le plus d'informations. Et la politique à gros grain s'est montrée plus efficace que celle à grain fin, contrairement à ce qu'on aurait pu attendre.
La section 4.2 donnait les résultats individuels, l'amélioration pour une machine qui télécharge. Mais pour le FAI, quel était le résultat ? La section 4.3 les résume : le trafic sortant de Comcast a diminué de 34 %, l'entrant vers Comcast de 80 %. À noter également qu'il y a d'avantage d'annulations (l'utilisateur s'impatiente et arrête le téléchargement) avec le premier essaim, celui qui n'utilisait pas P4P. Il est possible que les débits plus faibles entrainent davantage de découragement et donc d'annulation. En tout cas, le trafic à l'intérieur de Comcast augmente avec P4P : quand ça marche, les utilisateurs s'en servent plus.
La section 6 formule donc une conclusion relativement optimiste et recommande que l'IETF considère sérieusement P4P dans le cadre du groupe de travail Alto.
L'article seul
RFC 5646: Tags for Identifying Languages
Date de publication du RFC : Septembre 2009
Auteur(s) du RFC : A. Philipps (Lab126), M. Davis (Google)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF ltru
Première rédaction de cet article le 7 septembre 2009
Successeur du RFC 4646 (qui lui-même succédait au RFC 3066), notre RFC décrit les noms des langues (langues humaines, pas langages informatiques). Toute application qui a besoin d'indiquer une langue doit s'en servir.
Le protocole HTTP par exemple permet à un navigateur
Web d'indiquer au serveur quelle langue il
préfère (en-tête Accept-Language: dans le RFC 7231, section 5.3.5), au cas où le
serveur aie plusieurs versions d'une page et soit correctement
configuré (ce que Apache
permet). Cela marche très bien avec des sites comme http://www.debian.org/.
Les noms des langues ont deux ou trois lettres et sont tirés de la norme ISO 639. Par exemple :
- "fr" pour le français (à ne pas confondre avec le TLD ".fr", qui désigne la France),
- "ar" pour l'arabe,
- "br" pour le breton,
- "en" pour l'anglais,
- etc.
La norme complète est plus complexe : par exemple, l'anglais parlé aux
États-Unis n'est pas tout à fait le même que celui parlé en
Grande-Bretagne. Aussi, notre RFC permet de décrire la langue de
manière plus fine par exemple fr-CH désigne le français tel qu'il est parlé en Suisse.
Il y a d'autres caractéristiques que la langue ou le pays. Ainsi, sr-Latn-CS
représente le serbe
(sr) écrit dans l'alphabet latin (Latn)
tel qu'il s'utilise en Serbie (CS).
La question étant sensible (le croate est-il une langue différente du serbe, par exemple ?) l'IETF a évité les problèmes en s'appuyant sur des normes existantes (ISO 639 pour les langues comme le RFC 1591 s'appuie sur ISO 3166 pour éviter l'épineuse question de « qu'est-ce qui est un pays »). Néanmoins, le RFC confie un rôle de registre à l'IANA pour garantir une stabilité des noms (l'ISO ne la garantit pas, ne s'intéressant qu'au présent, alors que l'Internet a besoin de stabilité sur le long terme, cf. la section 3.4 pour la politique de stabilité du registre des langues).
ISO 639-1 et 2 reflétaient plutôt les besoins des bibliothécaires, soucieux de simplifier la classification en évitant la multiplication des langues. ISO 639-3 adopte plutôt le point de vue des linguistes, qui tendent à voir bien plus de langues. Ce débat entre mergers (les bibliothécaires) et splitters (les linguistes) ne cessera pas de sitôt. L'intégration de ISO 639-3 fait que le registre des étiquettes de langues passe plutôt du côté des splitters.
Les étiquettes de langue sont donc composées de
sous-étiquettes, et les diverses restrictions qui
existent sur leur longueur et leur place font qu'il est possible
d'analyser une étiquette, de déterminer où est la langue, où est le
pays, etc, sans avoir d'accès au registre (section 2.2). Une étiquette peut être
bien formée (obéir à la syntaxe) même si ses
sous-étiquettes ne sont pas enregistrées (section 2.2.9 pour la
définition de la conformance à cette norme, et la notion de « bien
formée » et de « valide »). Le registre stocke des
sous-étiquettes, pas des étiquettes entières, et ces sous-étiquettes
peuvent être combinées librement, même si le résultat n'est pas
forcément sensé. Par exemple, ar-Cyrl-AQ est à la
fois bien formée - elle obéit à la grammaire, valide (toutes ses
sous-étiquettes sont enregistrées) et néanmoins inutile car désignant
l'arabe en écriture cyrillique tel que pratiqué en Antarctique.
Les différentes parties d'une étiquette sont décrites en section 2.2. Par exemple, l'écriture est complètement traitée en section 2.2.3 est dérive d'ISO 15924.
La section 2.2.6, sur les extensions (qu'il ne faut pas confondre avec les extlangs) n'est pas encore utilisée ; pour l'instant, aucune extension n'a été enregistrée.
Le format et la maintenance du registre sont décrits en section 3. Le registre est au format record-jar (section 3.1.1, ce format est décrit dans le livre The Art of Unix programming) et, par exemple, l'enregistrement du français est :
Type: language Subtag: fr Description: French Added: 2005-10-16 Suppress-Script: Latn
et celui du cantonais est :
Type: language Subtag: yue Description: Yue Chinese Added: 2009-07-29 Macrolanguage: zh
et cet enregistrement comporte la mention de la macrolangue (le chinois).
Désormais, le registre est en UTF-8 ce qui permet des choses comme :
Type: language Subtag: pro Description: Old Provençal (to 1500) Description: Old Occitan (to 1500) Added: 2005-10-16
L'ajout d'éléments au registre est possible, via une procédure
décrite en sections 3.5 et 3.6.
Si vous voulez enregistrer une sous-étiquette, la lecture
recommandée est « How to register a new subtag ». La procédure inclus un examen par un
Language Subtag Reviewer (section 3.2),
actuellement Michael Everson. Je préviens tout
de suite : comme indiqué en section 3.6, la probabilité qu'une demande
refusée par l'ISO soit acceptée dans le
registre IANA est très faible (malgré cela, des demandes sont
régulièrement reçues pour des « langues » que seuls certains radicaux
considèrent comme telles).
Une liste
complète des demandes d'enregistrement effectuées est archivée en
https://www.iana.org/assignments/lang-subtags-templates. Un exemple réel
est décrit dans « Enregistrement
de l'alsacien dans le registre IETF/IANA ».
Lorsqu'on est occupé à étiqueter des textes, par exemple à mettre
des attributs xml:lang dans un document
XML, on se pose parfois des questions comme
« Dois-je étiqueter ce texte comme fr ou bien
fr-FR, lorsque les deux sont légaux ? » La
réponse figure dans la section 4.1, qui est résumée dans
« Tag wisely » (la réponse,
ici, est « En général, fr tout court, sauf s'il
est important de le distinguer des dialectes étrangers à la France »).
Les changements les plus importants par rapport au RFC 4646 (section 8) sont :
- Intégration des normes ISO 639-3 et 5 (section 2.2.1) ce qui fait passer le nombre de langues de 500 à 7000.
- L'arrivée de ISO 639-3 a apporté les extlangs (Extended Language Subtag, section 2.2.2) et 639-5 les collections, groupes de langues reliées entre elles.
- Meilleure description du rôle de l'IANA, surtout pour l'archivage des requêtes.
- Quelques changements pour les implémenteurs : grammaire différente mais meilleure (section 2.1) (notamment par une meilleure séparation des aspects syntaxiques et sémantiques) et registre désormais en UTF-8 et plus en ASCII.
- Et plein de petits détails.
Le changement de grammaire ne change pas grand'chose aux étiquettes bien formées ou pas mais il facilitera la tâche des implémenteurs. Les étiquettes patrimoniales (grandfathered) sont ainsi séparées en deux catégories, selon qu'elles obéissent quand même à la syntaxe standard ou pas.
L'augmentation importante de la taille du registre fait que, encore
plus qu'avant, la récupération automatique du registre nécessite donc
de faire attention pour ne pas charger les serveurs de l'IANA (la
méthode recommandée est le GET conditionnel de
HTTP RFC 7232 (If-Modified-Since, section 3.3), par exemple, avec
curl, curl --time-cond "20090702" https://www.iana.org/assignments/language-subtag-registry
)
Les extlangs ont été une question particulièrement délicate. Parmi les macrolangues (une collection de langues qui, dans certaines cicronstances, peuvent être vues comme une langue unique), le piège spécifique à l'arabe et au chinois est que le mot « chinois » désigne à la fois une macrolangue et une langue particulière couverte par cette macrolangue (le mandarin). Pire, dans les deux cas (chinois et arabe), les communautés locales ont du mal à admettre le verdict des linguistes. Ceux-ci disent que l'« arabe » n'est pas une langue, et que le marocain et le syrien sont des langues distinctes. Les arabophones ne sont pas tous d'accord avec l'analyse scientifique.
Les autres macrolangues n'ont pas de « langue de référence » et elles sont typiquement pratiquées par des communautés ayant moins de poids que le gouvernement de Pékin.
L'IETF a tranché que, pour certaines langues, l'extlang serait PERMIS, la forme sans extlang RECOMMANDÉE (voir notamment la section 4.1.2 sur l'usage des extlangs). Les vainqueurs sont donc : 'ar' (Arabe), 'kok' (Konkanî), 'ms' (Malais), 'sw' (Swahili), 'uz' (Ouzbèke), et 'zh' (Chinois).
Donc :
Les transparents d'un exposé sur ces language
tags sont disponibles. Ils ne parlent que de la
version précédente, celle du RFC 4646. Le site
Web officiel sur les étiquettes de langues est http://www.langtag.net/.
Un analyseur de language tags en
logiciel libre existe, GaBuZoMeu et gère cette
nouvelle norme. On peut trouver d'autres mises en œuvre en
http://www.langtag.net/.
L'article seul
RFC 5645: Update to the Language Subtag Registry
Date de publication du RFC : Septembre 2009
Auteur(s) du RFC : D. Ewell
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF ltru
Première rédaction de cet article le 7 septembre 2009
Ce RFC, compagnon du RFC 5646, décrit le nouvel état du registre des langues de l'IANA. Comme son prédécesseur, le RFC 4645 avait servi à initialiser le registre des langues, notre RFC 5645 servira à la grande mise à jour qu'est l'intégration des normes ISO-639-3 et ISO 639-5. Le nombre de langues enregistrées passe de 500 à plus de 7 000.
Le registre est écrit dans le format dit record-jar, décrit dans le livre The Art of Unix programming.
Il sert juste à lister l'état du nouveau registre IANA avec des affectations comme ici pour le Nandi ou l'écriture du Bamum :
%% Description d'une langue, ici le Nandi (niq) Type: language Subtag: niq Description: Nandi Added: 2009-07-29 Macrolanguage: kln %% %% Description d'une écriture, ici le Bamum Type: script Subtag: Bamu Description: Bamum Added: 2009-07-30 %%
Le registre va ensuite vivre sa vie et accepter de nouveaux
enregistrements, suivant les procédures du RFC 5646. Une des façons de suivre ces futures évolution est de
s'abonner au flux de syndication http://www.langtag.net/registries/lsr.atom.
Comment a été construit le nouveau registre ? La section 2 répond à cette question. Le point de départ était le registre existant, celui qui avait été créé par le RFC 4646. Les fichiers d'ISO 639-3 (disponibles chez SIL car l'ISO ne distribue quasiment jamais ses normes) et ISO 639-5 ont ensuite été intégrés, mais pas aveuglément :
- Les langues qui n'avaient pas déjà de code dans le registre
(comme l'ankave - code
aak- ou le ghotuo - codeaaa) ont été ajoutées. A contrario, celles qui avaient déjà un code ont été ignorées. - Les langues qui avaient une macrolangue
(une nouveauté d'ISO 639-3, la macrolangue est une catégorie
regroupant des langues qui sont parfois considérées comme distinctes
et parfois comme une seule langue) ont été traitées comme les autres à
l'exception de six langues pour lesquelles le groupe de travail LTRU
de l'IETF a estimé qu'elles présentaient des
caractéristiques particulières, notamment le fait que la macrolangue
était souvent utilisée. Ces six exceptions sont
l'arabe (
ar), le konkani (kok), le malais (ms), le swahili (sw), l'ouzbèque (uz) et le chinois (zh). Pour les six exceptions, un extended language subtag a été créé dans le registre, pour indiquer la macrolangue et cela permettra d'écrire des étiquettes commezh-yue(le cantonais, dont l'étiquette canonique est justeyue) pour le cas où l'ajout de la macrolangue semble important. Les autres langues ayant une macrolangue voient juste cette macrolangue ajoutée comme un champ de l'enregistrement. - Les descriptions présentes dans le registre ont parfois été
complétées ou modifiées pour avoir une présentation cohérente. Cela aboutit parfois à élargir la portée d'un code. Ainsi,
la collection
afa« Autres langues afro-asiatiques » est devenue « Langues afro-asiatiques » ce qui est bien plus large. - Le RFC 5646 a inclus dans les codes de pays
les éléments de ISO 3166 qui étaient marqués
comme « exceptionellement réservés ». Cela a permis l'arrivée de
EU, on peut donc désormais utiliser l'étiquetteen-EUpour l'anglais parlé à Bruxelles. D'autres codes étaient déjà présents pour d'autres raisons comme l'amusantFX(France Métropolitaine).
L'article seul
Efficacité du stockage dans un VCS
Première rédaction de cet article le 4 septembre 2009
Un intéressant article d'Eric Sink, « Time and Space Tradeoffs in Version Control Storage », expose de manière très simple et très compréhensible (même par un programmeur peu expérimenté), les choix à faire lors de la conception du stockage des fichiers d'un VCS.
L'auteur décrit et met en œuvre successivement plusieurs systèmes pour stocker les différentes versions d'un fichier dans un VCS. La plus évidente est de garder chaque version complète : cela rend la récupération d'une version donnée très rapide, mais consomme beaucoup de disque. Plus sophistiqué, le stockage des différences uniquement (par exemple en suivant le RFC 3284). On occupe moins de place mais on est plus lent. Bref, il n'y a pas de méthode idéale, juste des compromis.
L'intérêt de l'article est de tester systématiquement chaque approche et les résultats ne sont pas forcément conformes à l'intuition. Par exemple, l'une des solutions qui prennent le moins de place est... de stocker chaque version complète mais en la comprimant. Plusieurs algorithmes très astucieux que teste l'auteur sont moins bons, à la fois en espace et en temps, que le bon vieux zlib. Cela illustre bien le fait, qu'en matière d'optimisation, il faut tester et ne pas se fier à des impressions.
(Par contre, l'auteur, après avoir très justement noté que la première qualité d'un VCS était de ne pas perdre les données qu'on lui a confié, oublie ce critère par la suite et ne prend pas en compte la fragilité de chacune des solutions testées. Par exemple, la chaîne des différences - on stocke la première version, puis la différence entre la version 1 et la 2, puis celle entre la 2 et la 3, etc - est très fragile car la perte d'une des différences fait perdre toutes les versions ultérieures.)
L'article seul
Fiche de lecture : Paris - quinze promenades sociologiques
Auteur(s) du livre : Michel Pinçon, Monique Pinçon-Charlot
Éditeur : Payot
978-2-228-90411-7
Publié en 2009
Première rédaction de cet article le 3 septembre 2009
Toujours soucieux d'explorer l'espace et de voir comment les sociétés l'occupent et le transforment, les auteurs des « Ghettos du Gotha » ont écrit un guide touristique original de Paris : quinze promenades sociologiques dans quinze quartiers différents.
Guide en main, on suit les auteurs, rue par rue, dans ces quinze quartiers, visitant à chaque fois, non seulement les bâtiments, mais surtout ce qu'ils nous disent du quartier, qui y habite, quelles évolutions il a connu.
Les Pinçon, ce qui n'étonnera pas les lecteurs de leurs précédents ouvrages, traitent en connaisseurs les quartiers des ultra-riches (la villa Montmorency dans le chapitre XI consacré aux « villas de Paris ») mais aussi les quartiers populaires comme la Goutte d'Or (chapitre XII).
Ils travaillent aussi sur des espaces négligés mais où beaucoup de parisiens (et de banlieusards) passent une bonne partie de leur journée : les transports en commun avec le chapitre VI sur la gare Saint-Lazare et le chapitre V sur un « quartier » un peu spécial, le métro. Dans ce dernier chapitre, la visite de la ligne 13 permet d'analyser les quartiers traversés et aussi ce quartier virtuel qu'est le métro, l'un des rares endroits où se croisent, au moins physiquement, toutes les classes sociales.
Même dans la capitale où tout changement s'opère sous l'œil de beaucoup d'autorités, les urbanistes ne peuvent pas changer la ville simplement en construisant : les quartiers échappent parfois à leur destin prévu comme le 13ème arrondissement dont une partie avait été semée de tours (à la grande époque du gaullisme immobilier) pour jeunes cadres dynamiques, tours dont les destinataires n'ont pas voulu (elles faisaient trop HLM) et qui ont finalement été recupérées par les immigrés du Sud-Est asiatique (chapitre IX, Chinatown).
Paris a été pendant longtemps une ville dangereuse pour les pouvoirs en place, pleine d'artisans et d'ouvriers prompts à la barricade. Aujourd'hui, beaucoup d'anciens quartiers populaires ont été « gentrifiés » et les chapitres VII (la reprise de la Bastille) et VIII (un nouveau quartier nocturne : la rue Oberkampf) étudient en détail ce phénomène en cours de réalisation.
Les conquêtes ne sont pas forcément éternelles. Si le monde du luxe a réussi à mettre la main sur Saint-Germain-des-Prés, chassant les fantômes de Sartre et Beauvoir (chapitre III), les Champs-Élysées, eux, semblent petit-à-petit être abandonnés par la bourgeoisie riche (chapitre IV).
Pour tous ceux qui sont rentrés de vacances et habitent à Paris ou dans les environs, voici donc quinze idées de promenades intelligentes pour le week-end, le guide à la main.
(Cette deuxième édition est la réédition et mise à jour d'un livre de 2001.)
L'article seul
RFC 3339: Date and Time on the Internet: Timestamps
Date de publication du RFC : Juillet 2002
Auteur(s) du RFC : Graham Klyne (Clearswift Corporation), Chris Newman (Sun Microsystems)
Chemin des normes
Première rédaction de cet article le 30 août 2009
Comment représente-t-on une date sur l'Internet ? Il existe beaucoup de RFC qui ont besoin d'un format de date et, si certaine restent fidèles à des vieux formats, la plupart des RFC modernes se réfèrent à ce RFC 3339 qui définit un sous-ensemble d'ISO 8601 pour la représentation des dates.
Un des exemples les plus connus des vieux formats est le RFC 5322 qui garde, pour le courrier électronique, l'ancien format (initialement normalisé dans
le RFC 724) difficile à analyser, et qui ressemble à
Date: Thu, 27 Aug 2009 08:34:30 +0200. Ce format n'a
été gardé que parce qu'on ne peut plus changer la norme du courrier
sur un point aussi fondamental. Mais les RFC récents définissent un
autre format, celui de notre RFC 3339. C'est, par exemple, le
cas du RFC 4287 qui dit que les éléments
XML d'un flux de syndication
Atom doivent utiliser ce format, par exemple <published>2009-08-25T00:00:00Z</published>.
Pourquoi un RFC sur ce sujet et ne pas simplement se référer à la norme ISO 8601 ? Il y a plusieurs raisons. L'une est politique, c'est le fait que l'ISO ne distribue pas librement le texte de la plupart de ses normes (une version provisoire non redistribuable traine sur le serveur de l'ISO). L'autre est que ISO 8601, comme beaucoup de normes ISO, est mal spécifiée, très complexe et pleine de détails inutiles (cf. section 5.5). L'IETF a donc choisi la voie d'un sous-ensemble de ISO 8601, le format du RFC 3339.
La section 1 du RFC résume le problème général de la transmission et de l'affichage des dates. Beaucoup de programmes se sont cassés le nez sur ce sujet (je me souviens d'un logiciel commercial de gestion de tickets, très cher, qui envoyait des messages avec des dates invalides, ce qui décidait un autre logiciel commercial très cher, chargé de la lutte contre le spam, à les jeter).
Le RFC est bâti sur quelques principes, exposés dans cette section 1. On utilise évidemment le calendrier grégorien. Comme le but est de dater des événements Internet, on se limite aux dates de l'ère actuelle (i.e. après Jésus-Christ), on suppose que le décalage entre l'horloge locale et UTC est connu, etc.
Le problème de l'heure locale fait l'objet de la section 4. Les règles définissant l'heure légale étant très compliquées et changeantes (en raison de la stupide heure d'été), le choix est de s'appuyer sur UTC (section 4.1). Puisque le décalage entre l'heure locale et UTC est supposé connu, il est prévu de permettre d'indiquer ce décalage (section 4.2). Cela se fait toujours sous forme numérique, les noms alphabétiques des fuseaux horaires n'étant pas normalisés. Enfin, la section 4.4 réenfonce le clou au sujet des horloges qui ne connaissent que l'heure locale et pas son décalage avec UTC : de telles horloges sont inutilisables sur l'Internet puisqu'elles les indications temporelles transmises à partir d'elles sont fausses 23 fois sur 24 (dès qu'on n'est pas dans le même fuseau horaire).
Les historiens notent que c'était le cas des systèmes d'exploitation Microsoft pendant longtemps : l'horloge du PC ne stockait que l'heure locale, ce qui a créé d'innombrables problèmes lorsque Windows a dû se résigner à accepter les connexions avec l'Internet.
Voici pour le concept de temps. Et le format ? Quel est le cahier
des charges précis ? La section 5 commence par énumérer les
caractéristiques souhaitées. Les temps doivent pouvoir être comparées
lexicographiquement (section 5.1), par exemple
avec strcmp() en
C ou sort
avec le shell Unix. Contrairement à une idée
répandue, ISO 8601 ne garantit pas cette possibilité (voir la section
5.1 pour une liste des règles à observer pour qu'une telle comparaison
soit possible).
Autre critère important, le format doit être compréhensible par un humain (section 5.2). C'est une caractéristique fréquente des protocoles Internet ; les formats binaires sont relativement rares. Ceci dit, un format trop lisible peut mener à des erreurs. Par exemple, le format de date du RFC 5322 a mené certains programmeurs à croire qu'ils pouvaient traduire les noms de jour et de mois, puisque ceux-ci apparaissent sous une forme non-numérique (c'était l'erreur du logiciel commercial dont je parlais plus tôt). Le format de notre RFC est donc compréhensible mais pas forcément familier à tout être humain et les logiciels doivent donc se préparer à l'afficher sous une forme plus conforme aux habitudes locales.
Autre erreur du format du RFC 5322, la redondance de l'information (section 5.4). Inclure le nom du jour est redondant (puisqu'on peut le calculer à partir de la date, l'annexe B donne un exemple de code) et augmente donc les risques d'erreur (que faire si ce jour n'est pas correct, qui croire ?).
Assez de préliminaires, quel format utiliser, maintenant ? La section 5.6 va le décrire rigoureusement, en utilisant le langage ABNF (RFC 5234). Il existe quelque options comme le fait que le temps peut être écrit en heure locale, si le décalage avec UTC est indiqué. La section 5.8 donne quelques exemples de temps corrects. Voici comment les produire avec GNU date (le fait de séparer la date et le temps par un espace et pas par la lettre T est une violation de la grammaire mais le RFC est ambigu sur ce point) :
% date --rfc-3339='ns' 2009-07-12 11:03:08.434344377+02:00 % date --rfc-3339='seconds' 2009-07-12 11:03:12+02:00 % date --rfc-3339='date' 2009-07-12
et voici un programme Python qui affiche la
date actuelle en UTC (donc avec le Z à la fin, Z étant l'équivalent de
+00:00) :
import time
# date+time but no fractional seconds
rfc_3339_nosecfrac = "%Y-%m-%dT%H:%M:%SZ"
# gmtime = UTC (old name)
print time.strftime(rfc_3339_nosecfrac,
time.gmtime(time.time()))
Et, en C, voici un exemple possible :
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <sys/time.h>
#define MAX_SIZE 256
#define RFC_3339_NOFRAC_UTC "%Y-%m-%dT%H:%M:%SZ"
int
main()
{
char *result = malloc(MAX_SIZE);
struct timeval tv;
struct tm *time;
size_t result_len;
(void) gettimeofday(&tv, NULL);
time = gmtime(&tv.tv_sec);
result_len = strftime(result, MAX_SIZE, RFC_3339_NOFRAC_UTC, time);
if (result_len != 0) {
printf("%s\n", result);
exit(0);
} else {
printf("Error in strftime\n");
exit(1);
}
}
Y a t-il des problèmes de sécurité cachés derrière l'affichage de la date ? Oui, la section 7 en cite un : la connaissance de l'heure locale d'un système peut permettre à un attaquant de déterminer les heures où le système est le plus suceptible d'être surveillé et le paranoïaque peut donc avoir intérêt à n'émettre que des temps en UTC…
Notre RFC compte plusieurs annexes intéressantes. Par exemple, l'annexe A est une rétro-ingénierie de la norme ISO 8601. Comme celle-ci ne spécifie pas formellement de grammaire pour le format des dates, ce sont les auteurs du RFC qui en ont établi une, à partir de la norme. Elle est bien plus riche (avec beaucoup plus d'options) que celle de la section 5.6. L'annexe D donne les détails sur la gestion des secondes intercalaires, qu'on peut trouver en ligne.
L'article seul
Repartir de zéro pour construire un meilleur Internet
Première rédaction de cet article le 29 août 2009
Un interview récent de John Doyle, « When the Internet breaks, who ya gonna call? », montre que le mème « l'Internet est vraiment trop nul, il faut le refaire complètement en partant de zéro » se porte toujours aussi bien (voir aussi mes articles sur John Day et sur Sciences & Vie). (Un exemple d'article Web en français sur le même sujet, sensationnaliste, bourré d'erreurs et souvent ridicule est « Histoire d'Internet : l'espoir - épisode 3 ».) Pourtant, aucun progrès n'a été effectué en ce sens et cela ne changera probablement pas tant que les « reparteurs à zéro » ne traiteront pas leurs trois faiblesses.
D'abord, il y a une faiblesse de positionnement. Dans le monde réel, on n'a pas souvent le luxe de repartir de zéro. D'énormes investissements ont été faits, des millions de gens ont été formés, personne ne va jeter tout cela uniquement parce que Doyle dit dans un interview qu'il faut arrêter de mettre des rustines et qu'il faut repartir de zéro. Faire un réseau informatique meilleur, en partant de zéro, est de la recherche fondamentale, avec peu de perspectives de déploiement. C'est une activité noble et utile mais qui, dans un pays où lire la Princesse de Clèves est considéré inutile, ne rapporte rien. Alors, les promoteurs du redépart à zéro prétendent que leur activité pourrait avoir des applications concrètes, ce qui est franchement malhonnête.
Ensuite, ce n'est pas tout de critiquer, il faut proposer. Les reparteurs à zéro sont intarissables sur les défauts de l'Internet et complètement muets sur leur futur réseau « bien meilleur ». Ils ne citent de ce futur réseau que des vagues promesses (« sécurisé », « rapide », « fiable »), jamais de principes architecturaux concrets, encore moins de descriptions techniques, de prototypes, etc. Ils font penser à un apprenti médecin qui, notant avec gourmandise et un grand luxe de détails les nombreuses et sérieuses limites de la médecine moderne, proposerait de refaire la médecine en partant de zéro, sans expliquer le moins du monde pourquoi il fera mieux.
Mais la troisième faiblesse est la plus sérieuse : le cahier des charges. Quels sont les principes qu'ils veulent mettre en œuvre ? Actuellement, l'Internet permet à n'importe quelle entreprise ou association de fournir des services, que ce soit de connectivité ou de contenu. La plupart des reparteurs de zéro sont des nostalgiques de la téléphonie ou de la télévision d'autrefois, où ces possibilités étaient réservées à un petit cartel. Dans un tel contexte, résoudre certains problèmes, par exemple de sécurité, est relativement facile. Mais cela supprimerait complètement l'intérêt de l'Internet. Dans le fond, ce qu'ils reprochent à ce réseau, n'est-ce pas simplement qu'il est trop ouvert et trop libre pour eux ?
L'article seul
RFC 5635: Remote Triggered Black Hole filtering with uRPF
Date de publication du RFC : Août 2009
Auteur(s) du RFC : W. Kumari (Google), D. McPherson (Arbor Networks)
Pour information
Réalisé dans le cadre du groupe de travail IETF opsec
Première rédaction de cet article le 29 août 2009
Un des ennuis les plus fréquents sur l'Internet est l'attaque par déni de service. Répondre à ce genre d'attaques ne peut pas se faire par une mise à jour logicielle ou par un changement de configuration ; d'une manière ou d'une autre, il faut éliminer le trafic anormal qui constitue la DoS. Notre RFC 5635 présente une technique permettant de déclencher le filtrage à distance, et en le faisant en fonction de l'adresse source des paquets IP de l'attaquant.
Plusieurs techniques ont déjà été développées pour faire face aux
DoS, résumées dans la section 1 du RFC. Filtrer le trafic
sur son propre routeur ou
pare-feu est souvent inefficace : le trafic
anormal a déjà transité sur votre liaison Internet et cela suffit
souvent à la rendre inutilisable. Le mieux est en général de filtrer
chez le FAI. Filtrer par le biais
d'ACL marche bien mais les routeurs sont en général bien plus rapides
à router qu'à filtrer à l'aide d'ACL. Il est donc préférable
d'utiliser le routage en créant des routes « bidon », qui aboutissent
dans le vide (Null0 sur
IOS, par exemple, ou bien route
... discard sur JunOS), et à qui on envoie le trafic indésirable. L'élimination
des paquets sera ainsi faite à la vitesse maximale du routeur.
Autre problème avec le filtrage chez le FAI : le faire à la main, après échange de coups de téléphone, n'est pas très pratique, et impose des détails alors que l'attaque est déjà en cours. D'où l'utilité de pouvoir déclencher le filtrage à distance, selon la technique dite RTBH (Remote Triggered Black Hole), qui est décrite dans le RFC 3882. Dans ce RFC, on se sert de BGP pour annoncer le filtrage à un autre routeur, en marquant les annonces en question avec une communauté BGP particulière (une communauté est une sorte d'étiquette numérique attachée à l'annonce BGP).
C'était l'état de l'art documenté avant la sortie de ce RFC 5635. Le problème de cette méthode du RFC 3882 est que les routes, dans le protocole IP, sont en fonction de la destination. On va par exemple filtrer tout le trafic à destination du serveur victime d'une attaque. On empêche ainsi les dommages collatéraux sur les autres machines mais on rend le serveur attaqué complètement inaccessible (section 1 du RFC). Lors d'une attaque, on préférerait parfois filtrer selon la source.
Le principe est donc de combiner le RTBH (Remote Triggered Black Hole) classique avec les techniques RPF du RFC 3704. C'est là l'apport de notre RFC, détaillé en section 4.
Avant cela, le RFC rappelle, dans sa section 3, le fonctionnement du RTBH par destination tel que décrit dans le RFC 3882, en fournissant des détails nouveaux. Le principe du RTBH est que l'annonce BGP indique comme routeur suivant (next hop) une route vers un trou noir, où tous les paquets sont détruits. Les détails pratiques sont en section 3.2. Parmi eux, attention aux importants filtres de sortie, qui empêcheront les annonces BGP de destruction de fuir en dehors du réseau de l'opérateur.
Le déclenchement du filtrage par le client nécessite que celui-ci puisse communiquer ses desiderata. Il le fait en général en marquant ses annonces par une communauté BGP, choisie par l'opérateur. Celui-ci a même intérêt à prévoir plusieurs communautés, pour un filtrage plus fin.
La section 4 présente la nouvelle technique. Le principe est de réutiliser le mécanisme uRPF (unicast Reverse Path Forwarding) du RFC 3704. uRPF vérifie qu'il existe une route légitime pour l'adresse source du paquet entrant, afin d'éliminer des paquets dont l'adresse source est fausse. Si le routeur sait qu'une route vers un trou noir n'est pas légitime, alors, il peut filtrer en fonction de la source, si des routes vers ces adresses sources ont été installées par RTBH. Pour l'instant, aucun routeur ne fournit apparemment la possibilité de refuser uniquement les adresses pour lesquelles la route va dans un trou noir, mais elle devrait apparaitre bientôt.
La section 4.1 fournit les étapes exactes à suivre lorsqu'on met en
œuvre ce filtrage. Lorsqu'on veut bloquer les paquets venant de
192.0.2.66, on doit :
- Activer RPF sur les routeurs du FAI,
- Annoncer, depuis le client, une route vers
192.0.2.66/32, marquée avec la communauté BGP de filtrage indiquée par le FAI. (Attention, cela veut dire que le client va annoncer des réseaux qui ne lui appartiennent pas : le FAI devra accepter ces annonces mais faire très attention à ce qu'elles ne se propagent pas au delà de son réseau.) - La route sera alors installée dans les routeurs du FAI, pointant vers un trou noir. Les tests RPF échoueront alors pour les paquets émis par l'attaquant et les paquets seront rejetés.
Permettre à n'importe quel client de vouer ainsi n'importe quelle adresse source au trou noir est évidemment dangereux et le RFC conseille de ne pas activer cette possibilité par défaut (contrairement à ce qu'on peut faire pour le filtrage selon la destination). Le RTBH reste utile même s'il n'est utilisé que dans le réseau de l'opérateur, car il évite de configurer manuellement tous les routeurs de ce dernier. La section 5 détaille les risques de cette technique et les précautions à prendre.
L'annexe A détaille la configuration des routeurs pour cette famille de techniques, avec des exemples concrets pour IOS et JunOS.
Un bon article sur RTBH est « Mitigating DoS/DDoS attacks with Real Time Black Hole (RTBH) filtering », avec exemples pour Cisco IOS.
L'article seul
RFC 5672: RFC 4871 DomainKeys Identified Mail (DKIM) Signatures -- Update
Date de publication du RFC : Août 2009
Auteur(s) du RFC : D. Crocker (Brandenburg InternetWorking)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dkim
Première rédaction de cet article le 27 août 2009
Depuis sa publication, le RFC 4871, qui normalise DKIM, le mécanisme d'authentification du courrier électronique, le RFC, donc, a connu un certain nombre d'implémentations et de déploiements. Ceux-ci ont mis en évidence des problèmes dans la norme. D'où ce nouveau RFC, un erratum, qui corrige la norme sur quelques points. Une nouvelle version de DKIM, dans le RFC 6376, a ensuite été adoptée, rendant ce RFC 5672 inutile.
Quel était le principal problème ? Comme l'explique la section 1 de notre
RFC 5672, DKIM sert à prouver une
identité, sous la forme d'un
identificateur, typiquement un nom de domaine. Quelle est la sémantique de cet identificateur ?
C'est justement ce qui n'était pas clair dans le RFC 4871. Celui-ci spécifiait deux identités, indiquées par les
marques d= et i= de la
signature. Un exemple de signature est :
DKIM-Signature: v=1; a=rsa-sha256; s=brisbane; d=example.com;
c=simple/simple; q=dns/txt; i=joe@football.example.com;
...
et on y voit deux identités légèrement différentes,
example.com et
joe@football.example.com. Je ne maintiens pas le
suspense : la bonne, celle à indiquer l'utilisateur, est bien celle
marquée par d=, ici
example.com, ce qui n'était pas évident dans le
RFC 4871. C'est ce nom qui devrait être affiché
par le MUA comme ayant été authentifié
(cf. section 15).
Les sections suivantes du RFC mettent chacune à jour une partie du
RFC 4871 original, sous la forme « texte
original / nouveau texte ». Certaines sections sont entièrement
nouvelles, notamment pour introduire beaucoup de nouveau vocabulaire. C'est ainsi qu'est introduit, dans la
section 6, le terme de SDID (Signing Domain IDentifier), qui
désigne la « vraie » identité de l'émetteur du message. Le SDID de
l'exemple précédent est donc example.com. La
section 9 de notre RFC corrige la section 3.5 du RFC original en remplaçant le vague terme
« domaine » par SDID. Et la section 10 de notre RFC, pour parler du
nom qui figure après la marque i=, emploie
désormais AUID (Agent or User Identifier) à la
place du trop imprécis « identité ». (Le RFC 5672 précise
aussi la sémantique de ce champ, insistant notamment sur le fait que
sa ressemblance syntaxique avec une adresse de courrier électronique
ne doit pas être prise trop au sérieux : le AUID n'est
pas une adresse.)
L'article seul
Machan, ou l'équipe nationale de handball du Sri Lanka
Première rédaction de cet article le 26 août 2009
Il y a désormais eu plusieurs films sur le difficile parcours du combattant du candidat au voyage venu du Tiers-Monde et qui veut migrer vers un pays riche mais Machan (Sri Lanka National Handball Team)) est spécial. Réalisé par un italien, avec des moyens allemands, il est entièrement situé du côté des immigrés, les européens n'étant que des figurants. Il montre la misère au Sri Lanka sans être misérabiliste (les pires horreurs comme la vente de reins ne sont qu'évoquées, pas montrées). Et, surtout, il montre le courage et l'intelligence dont il faut faire preuve pour arriver à rejoindre les brillantes lumières de l'Europe.
Ce n'est pas une comédie, même si la presse l'a parfois présenté ainsi, et qu'il y a souvent des moments drôles. C'est un film d'aventure, d'amitié (« machan »), de tristesse et d'espoir.
Un bon résumé (mais attention, qui raconte presque tout le film, ne le lisez pas avant de la voir) figure dans « Machan - The Movie (2008) » de Jazon Bourne, avec un résumé de l'affaire original de 2004, dont le film s'est inspiré (là encore, je suggère de le lire après avoir vu le film). Et, si vous lisez le cinghalais, ce qui n'est pas mon cas, voyez cet article.
L'article seul
RFC 5625: DNS Proxy Implementation Guidelines
Date de publication du RFC : Août 2009
Auteur(s) du RFC : R. Bellis (Nominet UK)
Réalisé dans le cadre du groupe de travail IETF dnsext
Première rédaction de cet article le 26 août 2009
La connexion à l'Internet typique du particulier ou de la petite entreprise passe aujourd'hui par une boîte aux fonctions mal définies. Parfois, celle-ci assure, parmi ses autres tâches, le rôle d'un relais DNS. Et ces relais, programmés en général avec les pieds par un stagiaire en Chine, violent souvent les règles du protocole DNS, et causent d'innombrables problèmes. Ce RFC dresse la liste des problèmes potentiels et formule les règles que doivent suivre les relais pour ne pas trop casser le DNS. Cela servira, pour le cas improbable où les bricoleurs qui écrivent le logiciel de ces boîtes lisent les RFC...
Ces « boîtes » sont parfois nommées box (en anglais, ça fait plus sérieux) parfois « décodeurs » (en souvenir de Canal+, première entreprise qui a réussi à mettre des boîtes chez ses clients), parfois « modem », parfois « routeur », ce qui est techniquement souvent correct, mais insuffisant, vue la variété des fonctions qu'elles assurent. Au minimum, la « boîte » devrait faire passer les paquets IP d'un côté à l'autre (du réseau local vers celui du FAI et réciproquement). Mais, pour des raisons comme celles expliquées par le RFC dans sa section 5.3, beaucoup de boîtes s'arrogent des rôles comme celui de relais DNS, rôle qu'elles remplissent mal.
La section 1 du RFC rappelle l'excellente étude qu'avait fait le même
auteur, Ray Bellis, employé du registre de
.uk, pour le compte du SSAC de l'ICANN : cette étude, et
celle du
registre DNS suédois, montraient
que la grande majorité des boîtes existantes, dans leur configuration
par défaut) violaient largement le
protocole DNS et qu'elles contribuaient ainsi à
l'ossification de
l'Internet (le fait qu'on ne puisse plus
déployer de nouveaux services car les boîtes intermédiaires abusent de
leur rôle et bloquent ce qu'elles ne comprennent pas). Des nouveaux
services comme DNSSEC risquent donc d'être très
difficiles à installer.
La boîte qui fait relais DNS (et pas simplement routeur IP, comme elle le devrait) n'a en général pas un vrai serveur DNS, avec capacités de cache et gestion complète du protocole. Elle est un être intermédiaire, ni chair, ni poisson, violant le modèle en couches, et dépend des résolveurs du FAI auquel elle transmet les requêtes. Le RFC commence donc par recommander de ne pas utiliser de tels relais. Néanmoins, s'ils existent, il faudrait au minimum qu'ils suivent les recommandations du document.
La section 3 remet ces recommandations dans le contexte du principe de transparence. Un relais DNS ne peut espérer mettre en œuvre toutes les fonctions du DNS, surtout celles qui n'existent pas encore. En effet, la boîte a en général des ressources matérielles assez limitées, elle n'a souvent pas de mécanisme de mise à jour simple, ce qui veut dire qu'elle tournera toute sa vie avec le même code, et son interface de configuration doit idéalement être simple.
Alors, le relais, puisqu'il ne peut pas gérer complètement le DNS, devrait le laisser en paix. L'étude du SSAC montrait que, plus la boîte joue un rôle actif dans le protocole DNS, plus elle fait de bêtises. Le relais devrait donc juste prendre les paquets d'un côté et les envoyer de l''autre, sans jouer à les interpréter, ce qu'il fait toujours mal. Et, dans tous les cas, le RFC recommande que les machines du réseau local puissent écrire directement au résolveur DNS de leur choix, si celui de la boîte est vraiment trop mauvais (ce n'est pas toujours possible, par exemple dans les hôtels où le port 53, celui du DNS, est souvent filtré).
Dans le cadre de ce principe de transparence, la section 4 du RFC détaille ensuite point par point toutes les règles à respecter particulièrement. Ainsi, la section 4.1 rappelle que les relais ne doivent pas jeter un paquet DNS simplement parce que des options inconnues apparaissent dans celui-ci. Beaucoup de boîtes jettent les paquets où les bits AD (Authentic Data) ou CD (Checking Disabled) sont à un, simplement parce qu'ils n'existaient pas à l'époque du RFC 1035 (section 4.1), le seul que le stagiaire qui a programmé la boîte a lu (quand il en a lu un). (Ces bits sont dans la plage Reserved for future use, notée Z.)
De même, certaines boîtes ne laissent pas passer les types d'enregistrement inconnus, la section 4.3 rappelle donc, suivant le RFC 3597 qu'une mise en œuvre correcte du DNS doit laisser passer les types inconnus, sinon il sera impossible de déployer un nouveau type.
Un autre point sur lequel les logiciels des boîtes (mais aussi beaucoup de pare-feux) sont en général défaillants est celui de la taille des paquets DNS. Là encore, si le programmeur a lu un RFC (ce qui est rare), il s'est arrêté au RFC 1035, sans penser que, depuis vingt-deux ans qu'il existe, des mises à jour ont peut-être été faites et que la taille maximum de 512 octets n'est donc plus qu'un souvenir. La section 4.4 doit donc rappeler que les paquets DNS ne sont pas limités à 512 octets et que des réponses de plus grande taille sont fréquentes en pratique. Le relais doit donc gérer TCP correctement (section 4.4.1), et accepter EDNS0 (section 4.4.2, voir aussi le RFC 6891..
Les boîtes maladroites peuvent aussi interférer avec la sécurité. La section 4.5 rappelle que TSIG (RFC 8945) peut être invalidé si la boîte modifie certains bits des paquets (ce qui existe) ou bien retourne des réponses non signées à des requêtes signées (ce qui est courant sur les points chauds Wifi).
Une autre section, la 5, couvre les questions de l'interaction avec DHCP. La plupart du temps, la machine de M. Toutlemonde obtient l'adresse IP du résolveur DNS via DHCP (option 6, Domain Name Server, RFC 2132, section 3.8). La plupart des boîtes indiquent leur propre adresse IP ici. Et, en général, il n'est pas possible de modifier ce paramètre (par exemple, la Freebox ne permet pas d'indiquer un autre serveur DNS, choisi par le client ; même chose chez SFR). La seule solution pour court-circuiter le service DNS par défaut est donc d'indiquer en dur les résolveurs souhaités, dans la configuration de chaque machine. La section 5.1 appelle donc à une option de la boîte permettant de changer les serveurs DNS annoncés.
DHCP permet également une option indiquant le nom de domaine du réseau (option 15, section 3.17 du RFC 2132) et la section 5.2 du RFC 5625 demande qu'elle soit vide par défaut, en l'absence d'un domaine local normalisé.
La section 5.3 est consacrée à une discussion sur la durée du bail DHCP. Une des raisons pour lesquelles beaucoup de boîtes indiquent leur propre adresse IP comme résolveur DNS est que, au démarrage, la boîte ne connait pas forcément les adresses des résolveurs DNS du FAI. Mais cette technique oblige ensuite la boîte à agir comme relais DNS, ce qui est précisément la source de beaucoup de problèmes. Une solution possible, suggérée par notre RFC, est d'annoncer l'adresse IP de la boîte avec une durée de bail ultra-courte, tant que la boîte n'est pas connectée à l'Internet, puis d'annoncer les résolveurs du FAI ensuite, avec une durée de bail normale.
Les interférences provoquées par les boîtes mal conçues peuvent aussi avoir un impact sur la sécurité. C'est l'objet de la section 6. Il y a des boîtes qui, ignorant le RFC 5452, réécrivent le Query ID, rendant ainsi les utilisateurs davantage vulnérables à la faille Kaminsky (section 6.1). Il y en a qui répondent aussi aux requêtes DNS venues du WAN, permettant ainsi les attaques décrites dans le RFC 5358 (section 6.2).
Bref, les relais DNS des boîtes sont souvent plus dangereux qu'utiles. Le principe d'ingéniérie simple « si vous voyez un système inconnu, bas les pattes » est malheureusement très largement ignoré dans l'Internet. Pourquoi ? Pour les boîtes, il y a plusieurs raisons, typiquement liées à l'isolement complet dans lequel vivent les programmeurs anonymes de ces machines. Au contraire des logiciels libres comme Unbound ou BIND, dont les auteurs participent régulièrement à la communauté DNS, les programmeurs des boîtes sont inconnus, ne fournissent pas d'adresse pour leur envoyer des rapports de bogue ou de remarques. Pas étonnant, dans ces conditions, que le logiciel soit de mauvaise qualité.
Les abonnés à Free noteront que la Freebox n'a pas les problèmes mentionnés dans le RFC puisqu'elle est purement routeur, elle ne sert pas de relais DNS. Les serveurs DNS qu'elle indique en DHCP sont situés derrière elle, dans les salles de Free.
L'article seul
« Dette technique » lors de l'écriture de logiciels
Première rédaction de cet article le 25 août 2009
Dernière mise à jour le 9 mai 2012
Les développeurs de logiciels, lorsqu'ils suivent les cours d'un établissement d'enseignement sérieux, apprennent un certain nombre de bonnes pratiques qui, si elles étaient systématiquement utilisées lorsqu'ils programment plus tard, dans le monde réel, mènerait à du logiciel de bien meilleure qualité. Au lieu de cela, les logiciels contiennent des bogues, parfois énormes, des failles de sécurité et sont souvent très difficiles à maintenir par les successeurs des premiers programmeurs.
Pourquoi les bonnes pratiques ne sont-elles pas davantage utilisées ? Les programmeurs mettent souvent en avant le manque de temps : à l'Université, on a des heures ou des jours pour programmer un crible d'Ératosthène ou une suite de Fibonacci avec tous ses détails, alors que, dans le monde réel, le temps manque, le chef réclame que le logiciel soit livré à temps, on prend donc des raccourcis et tant pis pour la qualité.
Ont-ils raison ou tort de « bâcler » le travail ? Le débat se focalise souvent en des termes binaires, le camp des « vrais programmeurs qui codent » accuse celui des experts d'irréalisme, celui des experts accuse les « bricoleurs » de mal faire le travail. Par exemple, dans une excellente discussion sur Server Fault, Laura Thomas écrit, en défense de l'approche « vite fait et pas parfaitement fait », « Another of my favorite mottos is "Don't let perfect get in the way of better." Sometimes people struggling for elegance, simplicity, or the "right way" will refuse improvement because it isn't good enough. » alors que Ben Dunlap répond « Filthy scripts have a tendency to punish your co-workers and successors, and to fail when unexpected circumstances arise, which they always do. So do get the job done, but find the right balance between expedience and ideals. Those ideals exist for a reason. ;-) ».
L'article de Martin Fowler, Technical debt (« dette technique »), évite au contraire de parler en terme de mal ou de bien, juste de compromis. Ne pas suivre complètement les pratiques idéales équivaut à s'endetter : il faudra payer un jour (rien n'est gratuit) mais, dans certains cas, s'endetter reste quand même une approche raisonnable. Il faut juste en être conscient.
Un autre excellent article sur ce même thème est celui de Anthony Ferrara, The Power of Technical Debt, où il compare la dette technique du programmeur à divers types de dettes qu'on trouve dans le monde financier (attention, les exemples sont plutôt empruntés au monde états-unien, les dettes ne fonctionnent pas forcément pareil dans les autres pays), analysant à chaque fois si cela peut être une bonne ou une mauvaise dette.
L'article seul
RFC 5594: Report from the IETF workshop on P2P Infrastructure, May 28, 2008
Date de publication du RFC : Juillet 2009
Auteur(s) du RFC : J. Peterson (Neustar), A. Cooper (Center for Democracy & Technology
Pour information
Première rédaction de cet article le 24 août 2009
Le développement très rapide et très spectaculaire du pair-à-pair soulève plein de questions. Parmi elles, celle de la charge que font peser ces services sur les réseaux des opérateurs, et les points sur lesquels un travail de normalisation de l'IETF pourrait aider. C'étaient les deux thèmes du colloque organisé au MIT en mai 2008 et dont ce RFC est le compte-rendu.
La principale application du pair-à-pair aujourd'hui est le transfert de fichiers. Il n'y a pas de limite à la taille des contenus, notamment vidéo et les logiciels de pair-à-pair, comme le rappelle la section 1 du RFC, sont conçus pour utiliser le réseau à fond. C'était le point de départ du colloque : peut-on améliorer les choses ? Avant cela, il faut comprendre le phénomène et donc étudier les caractéristiques des réseaux pair-à-pair existants. Puis trois propositions ont émergé du colloque, un protocole de contrôle de congestion mieux adapté aux transfert de fichiers massifs, une étude des applications qui ouvrent plusieurs connexions simultanées, et une solution qui permettrait d'améliorer la sélection des pairs avant de commencer le transfert du fichier convoité.
Pour mieux comprendre le phénomène, le colloque a vu des exposés par des opérateurs (section 3). Par exemple, deux employés de Comcast ont décrit successivement les problèmes spécifiques aux réseaux câblés utilisant la norme DOCSIS, où chaque modem a accès à son tour. Par exemple, lorsque le CMTS donne accès au câble à un modem, celui-ci peut alors envoyer autant de données qu'il veut. Une machine en train d'envoyer un gros fichier pourra alors, à nombre de transferts égaux, prendre nettement plus de capacité que les autres.
Pour éviter les problèmes, outre les évolutions de la norme DOCSIS, certains opérateurs cherchent à mesurer en temps réel l'activité réseau des clients, pour ensuite limiter dans le CMTS leur accès au réseau. Outre qu'elle pose la question de la transparence du réseau, on peut noter que l'utilisateur n'est pas informé de cette situation (communiquer vers les clients des informations concrètes n'est jamais la priorité des opérateurs).
Autre point de vue, celui des développeurs de logiciels pair-à-pair (section 4). Stanislas Shalunov, de BitTorrent, a expliqué les défis auxquels étaient confrontés les développeurs et proposé des solutions. Là encore, les réseaux où beaucoup de ressources sont partagées, comme ceux fondés sur le câble TV, sont particulièrement affectés puisqu'un seul abonné peut en gêner beaucoup d'autres.
Les solutions possibles font l'objet de la section 5. La plus évidente est d'améliorer la sélection des pairs (section 5.1). Lorsqu'un client BitTorrent veut télécharger un fichier, il peut choisir n'importe lequel (ou lesquels) dans un essaim qui comporte souvent des centaines ou des milliers de machines. En général, il ne tient aucun compte de la topologie du réseau ou des informations contenues dans le système de routage. L'algorithme de sélection du pair varie selon les logiciels mais aboutit souvent à choisir une machine à l'autre bout du monde, alors qu'un pair volontaire était plus « proche ». Cela induit un délai supplémentaire pour l'utilisateur, et une charge plus grande du réseau pour l'opérateur.
Une solution serait donc d'avoir quelque part un service qui pourrait informer les pairs des conditions topologiques et les aider à choisir de meilleurs pairs.
Il n'est pas certain qu'il existe une solution idéale. Par exemple, si BitTorrent utilise une part d'aléatoire dans la sélection d'un pair, c'est aussi parce que cela évite la concentration des requêtes sur les machines les mieux placées, et permet de trouver ceux qui ont des parties rares d'un fichier.
En outre, les intérêts de l'opérateur et de l'utilisateur ne sont pas identiques. On pourrait imaginer des cas où la sélection qui soit optimale pour l'opérateur ne le serait pas pour l'utilisateur... qui risquerait donc de ne plus utiliser le système de sélection. Il est donc important que le système d'aide à la sélection ne soit donc qu'une indication parmi d'autres.
Compte-tenu de tout ceci, quelles sont les solutions techniques possibles ? Par exemple, le RFC cite :
- Tenir compte des AS. Des études ont montré que, avec des essaims typiques (de 2 000 à 10 000 pairs), on pouvait obtenir la majorité des fichiers uniquement en demandant à l'intérieur de l'AS. (En revanche, un niveau de détail plus grand, par exemple chercher les pairs connectés au même DSLAM, ne rapporte quère de bénéfice, la probabilité de tout trouver dans le voisinage devient trop faible.)
- Utiliser P4P, un système où l'opérateur met à la disposition de ses clients un service leur permettant de trouver les pairs les plus proches en communiquant des informations sur la topologie du réseau et le coût des différents liens.
- Un système « multi-niveaux » où plusieurs services d'information coexisteraient, certains pour le contenu global, d'autres uniquement pour un contenu local, avec redirection des premiers vers les seconds. Comme le contenu peut être, dans certains cas, illégal, la question de la responsabilité de l'opérateur qui gère le service pourrait être engagée.
- Créer un système de sélection du pair assisté par l'opérateur. Après tout, le FAI connait plein de choses sur son propre réseau, les liens de transit et ceux de « peering », les métriques OSPF ou BGP, la capacité des différents liens, etc. Cette information permettrait sûrement au logiciel de mieux choisir ses pairs. Dans cette optique, le FAI installerait un « oracle » qui serait un service d'information qui, contrairement à P4P, ne distribuerait pas cette connaissance (beaucoup d'opérateurs la considèrent comme confidentielle) mais qui recevrait une liste d'adresses IP de pairs potentiels et la renverrait triée, les « meilleurs » en premier. Cela pose évidemment un grand problème de passage à l'échelle. Pour un essaim de 10 000 pairs, la quantité d'information à transmettre à l'oracle est impressionnante. Pour les essaims du futur, qui pourraient compter des centaines de milliers de pairs, il faudra renoncer à tout transmettre. Mais le gros avantage de cette méthode est que l'opérateur ne voit que des adresses IP, et ne connait rien du contenu transféré, ce qui décharge complètement sa responsabilité juridique.
- En informatique, des tas de problèmes de performance se résolvent en mettant des caches, des mémoires intermédiaires, rapides, entre le demandeur d'information et le lieu de stockage de cette information. Un FAI pourrait donc installer des caches pair-à-pair sur son réseau. Les risques juridiques sont alors à l'opposé de la solution précédente : le FAI garderait en effet sur ses propres machines un contenu dont une partie est considérée comme illégale par certains.
Une fois ces solutions énumérées, que peut faire l'IETF ? Vouloir normaliser un système pair-à-pair complet (un « BitTorrent IETF ») est clairement prématuré, dans l'état actuel de l'expérience avec le pair-à-pair, domaine très bouillonant. À la place, le RFC 5594 n'envisage que de la spécification de quelques composants ponctuels d'un tel système. Une longue section 5.1.6 énumère les actions possibles pour chacune des solutions citées plus haut :
- Pour trouver le numéro d'AS d'une machine, il n'existe actuellement pas d'interface standard. L'IETF pourrait en développer une.
- Pour interroger un « oracle », un protocole standard d'interrogation (qui ne préjugerait pas de comment l'oracle prend sa décision) serait également souhaitable.
- Pour découvrir l'oracle, un moyen normalisé
(même si ce n'est qu'une simple convention de nommage comme
oracle.example.net) aurait bien des avantages. DHCP est un moyen possible, l'anycast un autre, un enregistrement SRV dans le DNS un troisième. - On l'a vu plus haut, lorsque le service que vend un FAI est limité, par exemple à une certaine quantité d'octets par mois, ou bien par shaping automatique, l'approche de la limite n'est pas communiquée à l'utilisateur, ou uniquement par des mécanismes non-standard et souvent peu adaptés à une récupération automatique (par exemple via une page Web). Un protocole standard de communication aiderait les utilisateurs à mieux surveiller leur consommation. Ce ne serait évidemment pas facile de développer un tel protocole, compte-tenu de la variété des offres commerciales (pensez au côté incompréhensible des offres dans la téléphonie mobile).
- Si plusieurs services d'information sont possibles, avec redirection entre eux, un mécanisme standard pour cette redirection serait bienvenu.
Après une meilleure sélection des pairs, l'autre grand chantier que
pose le pair-à-pair est le contrôle de
congestion (section 5.2). La plupart des
applications cherchent à transférer leurs données le plus vite
possible. Avec l'abondance de contenu disponible en pair-à-pair, cela
peut signifier une occupation permanente du réseau. Si les logiciels de
pair-à-pair étaient plus modérés dans leur usage de la capacité réseau
disponible, les choses iraient mieux. (Certains logiciels offrent des
possibilités d'auto-limitation, par exemple, avec
mldonkey, on peut mettre
max_hard_upload_rate = 10 dans
downloads.ini et on limite alors la consommation
« montante » à 10 ko/s.)
Un exemple d'un meilleur comportement est le client BitTorrent officiel qui mesure en permanence le délai de transmission et cherche à le minimiser, ce qui laisse de la capacité pour les applications qui veulent une faible latence (comme la VoIP).
Une autre approche serait un contrôle de congestion pondéré, pour que TCP sur la machine laisse davantage de ressources à certaines applications (actuellement, depuis l'échec de TOS dans IP, l'application n'a pas de moyen standard d'indiquer ce genre de préférences, DiffServ (RFC 2474) est plutôt prévu pour être géré par le réseau (section 5.2.2 pour un traitement plus détaillé de la pondération).
Un autre endroit où mettre en œuvre une telle inégalité de traitement est bien sûr dans le réseau lui-même. Ainsi, un FAI peut déployer une architecture souvent appelée du terme marketing de qualité de service (alors que le but est au contraire de dégrader la qualité du service de certaines applications, au profit d'autres). Pour classer les données qui circulent dans son réseau, il peut utiliser les numéros de port (443 indique de l'HTTPS, 22 du SSH, etc) ou la DPI. Comme cette classification vise à diminuer la qualité de service de certains usages, les logiciels tentent en permanence d'y échapper et, de même que le numéro de port est devenu peu à peu inutile, tous les logiciels changeant de numéro ou détournant un numéro de port comme 443, la DPI motive les auteurs de logiciel à utiliser de plus en plus la cryptographie pour éviter à leur trafic d'être reconnu (section 5.3).
Autre question de justice : le cas des applications qui ouvrent plusieurs connexions TCP simultanées (section 6). La tendance avait été lancée par Netscape pour imposer son navigateur contre Mosaic. En effet, TCP essayant d'attribuer des parts identiques à toutes les connexions, avoir plusieurs connexions permet une part plus grosse. Il est donc nécessaire d'étudier plus attentivement la question.
Il y a bien longtemps que l'Internet ne vit plus exclusivement des subventions de l'armée états-unienne et tous les débats techniques du monde pèsent donc peu à côté des histoires de gros sous. La section 7 détaille donc les discussions autour du coût du pair-à-pair. Les chiffres rigoureux manquent dans ce domaine car, s'il est facile de connaître le prix d'un câble, celui de la congestion est bien plus dur à fixer. Il existe des estimations allant de 10 cents à 2 dollars US pour un gigaoctet transféré. La consommation qu'entraine le pair-à-pair pousse certains à réclamer le retour au tarif au volume.
Traditionnellement, l'IETF ne travaille pas sur les questions économiques, qui sont difficiles, vue la variété des modèles d'affaires, et de toute façon pas forcément de sa compétence. Mais il faudrait peut-être que l'IRTF commence un travail sur ce sujet.
Assez parlé, il faut maintenant agir. Quelles sont les prochaines étapes ? La section 8 cite les suivantes :
- Travailler à un protocole de contrôle de congestion permettant aux applications pair-à-pair de réduire leur propre impact. À ma connaissance, ce travail n'a pas encore commencé.
- Documenter précisement les effets de l'ouverture de connexions TCP multiples (section 6). Là non plus, je ne crois pas que ce travail aie déjà démarré.
- Améliorer la séclection des pairs, par un nouveau protocole d'information (section 5.1). C'est désormais le travail du groupe Alto.
Les exposés faits lors du colloque peuvent être téléchargés en http://trac.tools.ietf.org/area/rai/trac/wiki/PeerToPeerInfrastructure.
L'article seul
RFC 5620: RFC Editor Model (Version 1)
Date de publication du RFC : Août 2009
Auteur(s) du RFC : O. Kolkman (IAB)
Pour information
Première rédaction de cet article le 24 août 2009
L'articulation compliquée entre l'IETF qui produit les normes TCP/IP et le RFC Editor qui les publie, n'a jamais cessé de faire couler de l'encre (ou d'agiter des électrons). Dans ce document, l'IAB décrit un modèle pour le RFC Editor, modèle où les fonctions de ce dernier sont éclatées en plusieurs fonctions logiques. Aujourd'hui effectuées par la même organisation, elles pourraient demain être réparties entre plusieurs groupes. Ce RFC était un premier essai (« version 1 ») et il a ensuite été remplacé par le RFC 6635.
Le document de référence actuel est le RFC 4844. Comme le rappelle la section 1, il décrit les tâches du RFC Editor de manière globale, comme si c'était forcément une seule entité (c'était, à l'origine, une seule personne, Jon Postel). La section 2 note que la tâche de RFC Editor est actuellement une partie de l'IASA et financée par son budget.
La section 3 s'attaque à la définition du rôle du RFC Editor sous forme de fonctions séparées. L'IAB voit quatre fonctions :
- Éditeur des RFC,
- Éditeur des contributions indépendantes,
- Producteur des RFC,
- Publieur des RFC.
Chaque section va ensuite détailler ces tâches.
L'Éditeur de la série des RFC (RFC Series Editor) est décrit en premier, en section 3.1. Il est responsable du travail à long terme, définir les principes qui assurent la pérennité des RFC, garder à jour les errata, développer le guide de style des RFC (ce qui inclus la délicate question du format), etc. Notre RFC décrit les compétences nécessaires, qui comprennent une expérience des RFC en tant qu'auteur.
L'Éditeur des contributions indépendantes (Independent Submission Editor) fait l'objet de la section 3.2. Les contributions indépendantes sont celles qui sont envoyées directement au RFC Editor, sans passer par l'IETF. Le RFC Editor doit donc jouer un rôle bien plus actif avec elles, notamment pour juger de leur valeur technique. Le responsable de cette tâche doit donc avoir une solide compétence technique et jouir d'une bonne réputation auprès des participants à l'IETF. (Le premier a été nommé en février 2010.) Son rôle est désormais décrit par le RFC 6548.
Le travail quotidien est, lui, assuré par le Producteur des RFC (RFC Production Center) dont parle la section 3.3. Il reçoit les documents bruts, les corrige, en discute avec les auteurs, s'arrange avec l'IANA pour l'allocation des numéros de protocoles, attribue le numéro au RFC, etc.
Les RFC n'étant publiés que sous forme numérique, il n'y a pas d'imprimeur mais le numérique a aussi ses exigences de publication et il faut donc un Publieur des RFC (RFC Publisher), détaillé en section 3.4. Celui-ci s'occupe de... publier, de mettre le RFC dans le dépôt où on les trouve tous, d'annoncer sa disponibilité, et de s'assurer que les RFC restent disponibles, parfois pendant de nombreuses années.
Chacune de ces fonctions pourra faire l'objet d'une attribution spécifique (à l'heure actuelle, elles sont toutes effectuées par le même groupe à l'ISI). L'annexe A décrit le mécanisme de sélection actuellement en cours.
L'article seul
RFC 5612: Enterprise Number for Documentation Use
Date de publication du RFC : Août 2009
Auteur(s) du RFC : P. Eronen (Nokia), D. Harrington (Huawei)
Pour information
Première rédaction de cet article le 24 août 2009
L'arborescence de nommage de gestion, décrite dans le RFC 1155 puis dans le RFC 2578, prévoit un sous-arbre
pour les organisations privées, 1.3.6.1.4.1. Ce
RFC ajoute un numéro d'entreprise à ce
sous-arbre, pour les exemples et la documentation.
Autrefois, ces noms et numéros réservés pour la documentation n'existaient pas, on utilisait des valeurs prises au hasard, ou bien qui reflétaient l'entreprise de l'auteur du RFC. Malheureusement, ces valeurs se retrouvaient parfois utilisées par des administrateurs réseau distraits, d'où la tendance actuelle à réserver des valeurs uniquement pour les cours, tutoriels, modes d'emploi, etc. C'est ce que font le RFC 5737 pour les adresses IPv4, le RFC 3849 pour les adresses IPv6, le RFC 2606 pour les noms de domaines, etc. Notre RFC le fait pour les numéros d'organisation (enterprise numbers) de l'arborescence de gestion, qui est utilisée notamment par SNMP mais également par Radius (les attributs vendor-specific) ou par Syslog (les structured data).
Ainsi, l'entreprise Netaktiv a t-elle obtenu en avril
2001 le numéro 9319 et son sous-arbre est donc
1.3.6.1.4.1.9319. Pour la documentation et les
exemples, le nombre réservé est 32473 (sections 2
et 3 du RFC) donc le
sous-arbre 1.3.6.1.4.1.32473. Le registre IANA contient désormais ce numéro.
Il se reflète également dans le domaine
enterprise-numbers.org qu'on peut interroger via
le DNS :
% dig +short TXT 32473.enterprise-numbers.org "Example Enterprise Number for Documentation Use"
L'article seul
RFC 5617: DomainKeys Identified Mail (DKIM) Author Domain Signing Practices (ADSP)
Date de publication du RFC : Août 2009
Auteur(s) du RFC : E. Allman (Sendmail), J. Fenton (Cisco), M. Delany (Yahoo), J. Levine (Taughannock Networks)
Intérêt historique uniquement
Réalisé dans le cadre du groupe de travail IETF dkim
Première rédaction de cet article le 24 août 2009
Dernière mise à jour le 26 novembre 2013
Le protocole de signature des messages électroniques DKIM, normalisé dans le RFC 6376, a un petit défaut : si un message ne porte pas de signature, comment savoir si c'est parce que le domaine émetteur ne signe pas ou bien si c'est parce qu'un attaquant a modifié le message et retiré la signature ? (À noter que la solution proposée par ce RFC a finalement été officiellement abandonnée par l'IETF en novembre 2013.)
La solution qui avait été choisie par le groupe de travail DKIM de l'IETF était, comme documenté dans ce RFC 5617, de permettre à un domaine de publier ses pratiques de signature. Désormais, un domaine va pouvoir annoncer dans le DNS qu'il signe tous ses messages (et donc qu'un message sans signature est suspect) ou bien qu'il ne signe pas systématiquement et qu'il faut donc être indulgent à la vérification.
Dans le futur, il est théoriquement possible que DKIM soit tellement largement déployé que cette publication soit inutile, et qu'on puisse considérer que tout message doit être signé. Mais on en est très loin (section 1 du RFC).
Le RFC 5016 avait défini le cahier des charges pour un tel mécanisme de publication des pratiques. Voici donc sa réalisation.
La section 3 du RFC définit les grandes lignes du mécanisme :
- Publication par l'émetteur, dans le DNS, d'un enregistrement à
_adsp._domainkey.mydomain.example, indiquant les pratiques de signature demydomain.example(mais pas celles des domaines fils commechild.mydomain.example, cf. section 3.1). - Consultation par le destinataire de cet enregistrement, le nom de domaine utilisé étant celui qui apparait dans le champ
From:du message (l'Auteur, en terminologie DKIM). À noter que le message peut avoir des signatures pour d'autres domaines que celui de l'Auteur, par exemple s'il a été transmis via une liste de diffusion qui signe (cf. section 3.2). - Décision par le destinataire du sort du message, en fonction de ce qu'il a trouvé dans ADSP et de la présence ou pas d'une signature. Par exemple, si un message ne porte aucune signature mais que l'enregistrement ADSP indique que le domaine de l'auteur signe systématiquement, le message est très suspect. Par défaut, la situation actuelle est « pas de signature, pas d'enregistrement ADSP » (cf. section 3.3).
Place maintenant à la description détaillée du protocole, en
section 4. Les enregistrements ADSP sont publiés sous forme
d'enregistrements TXT. Les objections du RFC 5507 ne s'appliquent pas ici puisque l'enregistrement n'est
pas immédiatement dans le domaine, mais dans
_adsp._domainkey.LEDOMAINE. Dans le texte de
l'enregistrement, la syntaxe habituelle de DKIM,
clé=valeur est utilisée. Actuellement, seule la
clé dkim est définie (section 4.2.1) et elle peut
prendre les valeurs :
unknown: on ne sait pas (c'est la valeur par défaut, s'il n'y a pas d'enregistrement ADSP),all: tout le courrier venant de ce domaine est signé,discardable: tout le courrier venant de ce domaine est signé et peut être jeté à la poubelle sans remords s'il ne l'est pas.
Des futures valeurs pourront apparaitre plus tard dans le registre IANA (section 5).
On retrouve, dans le choix d'une valeur pour la clé
dkim, un problème classique de
l'authentification : que faire lorsqu'elle échoue ? Si on met
unknown, ADSP ne sert à rien puisque le récepteur
n'a aucune idée de s'il peut agir ou non. Si on met
discardable, on fait courir un grand risque à son
courrier puisque une bête erreur comme l'expédition d'un message
depuis un site qui ne signe pas pourra entrainer la destruction du
message. Je fais le pronostic que, par prudence, les émetteurs
n'utiliseront que unknown ou
all et les récepteurs ne jetteront le message que
lorsqu'un discardable apparait. En pratique, il
est donc probable qu'aucun message abusif ne sera éliminé par ADSP.
Les tests faits suite à des requêtes ADSP peuvent donc fournir des
informations sur l'authenticité d'un message et ces informations
peuvent être publiées dans un en-tête
Authentication-Results: du RFC 8601. La méthode dkim-adsp s'ajoute
donc aux méthodes
d'authentification utilisables (section 5.4).
La section 6, les questions de sécurité, explore les risques et les problèmes associés à ADSP. Elle note par exemple, ce qui est plutôt amusant, que puisque des MUA très courants comme Outlook n'affichent pas l'adresse de courrier de l'expéditeur, authentifier le domaine de celle-ci (tout le but de ADSP) n'apporte pas grand'chose avec ces MUA.
Comme ADSP dépend du DNS, il en partage les vulnérabilités, et l'usage de DNSSEC peut donc être nécessaire.
Voici un exemple de requête dig pour trouver l'enregistrement ADSP de formattype.fr :
% dig +short TXT _adsp._domainkey.formattype.fr "dkim=unknown"
D'autres exemples, très détaillés figurent en annexe A, couvrant les différents cas.
L'annexe B est très intéressante et couvre plusieurs scénarios
d'utilisation typiques, où l'usage d'ADSP n'est pas complètement
évident. Le cas des listes de
diffusion n'y apparait pas, alors qu'elles sont souvent un
des plus gros casse-têtes avec DKIM. Si une liste de diffusion
respecte le message original et ne le modifie pas, pas de
problème. Elle peut laisser l'éventuelle signature DKIM originale (et,
si elle le souhaite, ajouter sa propre signature, mais qui ne pourra
pas utiliser ADSP puisque le domaine de l'auteur n'est pas celui de la
liste). Mais si la liste modifie les messages, par exemple pour
ajouter de la publicité à la fin, ou pour ajouter une étiquette dans
le sujet, alors la signature DKIM originale ne correspondra plus. Le
message sera alors jugé comme étant de la triche (ce qu'il est,
puisque le message originel a été changé). Si le programme
gestionnaire de listes supprime la signature et que le domaine de
l'auteur publiait avec ADSP dkim=discard, ce
n'est pas mieux, le message sera également considéré comme faux.
À l'heure de la publication du RFC, les mesures faites par DNSdelve montrent qu'il n'existe
quasiment aucun domaine publiant de l'ADSP sous
.fr. Si on veut tester,
les domaines catinthebox.net,
isdg.net ou wildcatblog.com
publient de l'ADSP.
En novembre 2013, l'IESG a officiellement annoncé la fin d'ADSP et la reclassification de ce RFC comme « intérêt historique seulement ». Il y a certes eu des mises en œuvre d'ADSP mais peu de déploiements. Et parfois, ils se sont mal passés par exemple avec des politiques trop strictes qui faisaient rejeter les messages de certains utilisateurs. Pour connaître la politique DKIM d'un domaine, il faut désormais recourir à des méthodes autres.
L'article seul
Faille BIND permettant une DoS via les mises à jour dynamiques
Première rédaction de cet article le 29 juillet 2009
La mise à jour, lors d'urgences frénétiques, de logiciels critiques, est une occupation courante sur l'Internet. Aujourd'hui, c'est BIND, un habitué de ce genre de distractions, qui nous offre une telle émotion, avec la faille de sécurité CVE-2009-0696, alias VU#725188, la possibilité de planter BIND à distance par le biais d'une requête DNS de mise à jour dynamique, même si la configuration du serveur n'autorise pas de telles mises à jour.
Annoncée le 28 juillet par
l'ISC, cette faille, spécifique à BIND (contrairement à la
faille Kaminsky), vient
d'une mauvaise analyse des requêtes de mise à jour dynamique
(dynamic update, normalisé dans le RFC 2136). Lorsqu'il reçoit une requête DNS spécialement
fabriquée, où le pré-requis à la mise à jour, dans le paquet, a
le type ANY (normalement jamais utilisé), le
serveur plante immédiatement et écrit dans son
journal :
Jul 29 09:10:57 lilith named[2428]: db.c:619: \
REQUIRE(type != ((dns_rdatatype_t)dns_rdatatype_any)) failed
Jul 29 09:10:57 lilith named[2428]: exiting (due to assertion failure)
(On note que l'adresse IP de l'attaquant n'apparait pas dans ce message et que, de toute façon, un seul paquet UDP suffit et que son adresse source peut être mensongère.) Il n'y a plus qu'à redémarrer BIND et, entre temps, on n'a pas de résolution de noms. Si le domaine n'utilise que BIND (ce qui est hélas courant) et que l'attaquant vise tous les serveurs du domaine, il peut faire disparaitre le domaine de l'Internet. C'est d'ailleurs en raison de ce genre de risques qu'il faut que les serveurs Internet soient de diverses origines. Par exemple, il ne faut pas utiliser que BIND, il est important d'avoir également d'autres logiciels comme NSD.
Pour que le serveur soit vulnérable, il faut aussi qu'il fasse
autorité pour au
moins une zone DNS de type master
(slave ne suffit pas). Comme BIND, par défaut,
est master pour localhost et
0.0.127.in-addr.arpa, cela explique que la grande
majorité des serveurs BIND sont vulnérables.
L'exploitation de cette faille a été rendue publique et peut-être
aussi simple que ce programme écrit
en Perl. Voici, vue par
tshark, le paquet d'attaque
(utilisant la zone localhost pour laquelle tous
les BIND font autorité par défaut) :
Domain Name System (query)
Transaction ID: 0x6142
Flags: 0x2800 (Dynamic update)
0... .... .... .... = Response: Message is a query
.010 1... .... .... = Opcode: Dynamic update (5)
.... ..0. .... .... = Truncated: Message is not truncated
.... ...0 .... .... = Recursion desired: Don't do query recursively
.... .... .0.. .... = Z: reserved (0)
.... .... ...0 .... = Non-authenticated data OK: Non-authenticated data is unacceptable
Zones: 1
Prerequisites: 1
Updates: 1
Additional RRs: 0
Zone
localhost: type SOA, class IN
Name: localhost
Type: SOA (Start of zone of authority)
Class: IN (0x0001)
Prerequisites
localhost: type ANY, class IN
Name: localhost
Type: ANY (Request for all records)
Class: IN (0x0001)
Time to live: 0 time
Data length: 0
Updates
localhost: type ANY, class ANY
Name: localhost
Type: ANY (Request for all records)
Class: ANY (0x00ff)
Time to live: 0 time
Data length: 0
On peut examiner le paquet complet sur pcapr.net.
La solution la plus propre est de mettre à jour BIND vers une version sûre, et d'urgence, en suivant la liste donnée par l'ISC. Avec les versions officielles de l'ISC, vous pouvez voir si un serveur est à jour avec :
% dig @ns1.EXAMPLE.net CH TXT version.bind.
et vous obtenez le numéro de version que vous pouvez comparer à la liste des versions sûres. Attention : avec beaucoup de paquetages BIND de différents systèmes d'exploitation, le numéro de version n'est pas forcément modifié lors de l'application de mises à jour de sécurité.
Si cette mise à jour est
difficile, pour une raison ou pour une autre,
le plus simple est de « démasteriser », c'est-à-dire de supprimer les
zones de type master de la configuration
(named.conf). Sur un serveur qui est uniquement à
autorité, cela n'est pas un problème. Sur un serveur récursif, cela
entrainera quelques disfonctionnements mais qui ne sont probablement
pas trop graves, par rapport aux risques de la faille.
Une des raisons pour lesquelles on n'a pas toujours la possibilité de faire une mise à jour est que les fournisseurs réagissent plus ou moins rapidement. À l'heure où j'écris, Debian a fait une mise à jour mais pas RHEL, pourtant bien plus cher.
Une dernière solution pour protéger votre serveur est de demander au pare-feu, si vous n'utilisez pas les mises à jour dynamiques, de les bloquer. Avec Netfilter, on peut bloquer une partie de ces requêtes et donc les attaques du script cité plus haut avec :
iptables -A INPUT -p udp --dport 53 -j DROP -m u32 --u32 '30>>27&0xF=5'
Mais cela n'empêche pas tout : comme le filtre ci-dessus travaille avec des offsets fixes, il peut être contourné, par exemple, si l'attaquant rajoute des options dans le paquet. (La difficulté à écrire des règles u32 pour le DNS a été abordée dans un autre article.)
Si vous voulez capturer les requêtes DNS de mise à jour dynamique, pour analyse ultérieure, et que vous utiliser dnscap, une requête comme :
# dnscap -w updates -mu -i eth0
conviendra (-mu ne garde que les requêtes
d'opcode UPDATE). Si vous
voulez juste les voir et pas les enregistrer sur disque, remplacez
-w updates par -g.
L'article seul
L'AS 13214 perd à nouveau la boussole
Première rédaction de cet article le 28 juillet 2009
Le protocole BGP est une source de distraction sans fin pour les administrateurs réseaux de l'Internet. Comme n'importe lequel des dizaines de milliers d'opérateurs Internet de la planète peut annoncer les routes qu'il veut, des incidents se produisent régulièrement. La plupart du temps, les différents filtres limitant la casse, puis les systèmes immunitaires de l'Internet empêchent ces incidents de faire la une des journaux. Ce matin, c'est l'AS 13214 qui se signale à l'attention de tous, pour la deuxième fois en trois mois.
Vers 08h30 UTC, les utilisateurs du système d'alarme BGP Cyclops reçoivent des messages inquiétants annonçant qu'un autre AS que leur leur annonce leurs préfixes IP :
Alert ID: 5078076 Alert type: origin change Monitored ASN,prefix: 192.134.4.0/22 Date: 2009-07-28 08:30:26 UTC No. monitors: 1 Announced prefix: 192.134.4.0/22 Announced ASPATH: 48285 13214
En clair, l'AS 13214 (DCP,
en Suède) annonce des préfixes IP qui ne lui
appartiennent pas, et ce en mettant son propre numéro d'AS dans le
chemin BGP (ASPATH, qu'il faut lire de droite à
gauche, le premier AS est le plus à droite). La lecture de la liste
de diffusion Nanog montre vite que le problème est mondial :
l'AS 13214 est en train d'annoncer toute la table de routage de
l'Internet !
Le plus drôle est que le même AS avait fait la même bétise deux mois plus tôt.
Mais, pas de panique : un seul des moniteurs de Cyclops a vu le
problème (la ligne No. monitors: 1). Cela veut
donc dire qu'il ne s'est pas propagé loin. Les autres systèmes
d'alarme comme BGPmon n'ont rien
vu. Probablement, les filtres ont fonctionné dans la plupart des
endroits.
Normalement, lorsqu'on échange en BGP avec quelqu'un, on n'accepte pas n'importe quoi de lui (sauf s'il s'agit de son fournisseur de transit). Au minimum, on limite le nombre de préfixes. Si on peut, on liste les préfixes que le pair BGP est autorisé à annoncer. Pourquoi Robtex, l'AS 48285 qui a relayé l'annonce erronée, ne le faisait-il pas, surtout après l'incident de Mai ? Parce que ce n'est pas facile : DCP est le fournisseur de transit de Robtex et on ne peut pas filtrer les annonces de son fournisseur, on est obligés de lui faire confiance.
L'article seul
Cryptographie en Python
Première rédaction de cet article le 27 juillet 2009
Dernière mise à jour le 30 juillet 2009
Quant on fait de la programmation réseau, on a souvent besoin d'utiliser de la cryptographie. En effet, par défaut, les méchants qui sont situés entre les deux machines qui communiquent peuvent écouter tout le trafic et apprendre ainsi des secrets qu'on aurait préféré garder pour soi. Comment fait-on de la cryptographie en Python ?
L'article complet
« Courriel » n'est pas un bon mot pour désigner le courrier électronique
Première rédaction de cet article le 22 juillet 2009
Pour désigner le courrier électronique, le terme « officiel » en France qui doit, par exemple, être systématiquement employé dans les appels d'offres publics, est « courriel » (JO du 20 juin 2003). Ce terme est rejeté par ceux qui préfèrent utilisent des mots anglais comme mail ou email, mais aussi par ceux qui trouvent ce néologisme inutile et même néfaste.
Quel est le problème avec « courriel » ? C'est qu'il rend le medium explicite, au lieu de se concentrer sur le message. Si je dis « Jeanne m'a envoyé un message », quelle importance que celui-ci ait été un message papier ou numérique ? C'est le contenu qui compte. La plupart du temps, écrire « Jeanne m'a envoyé un courriel » surspécifie en donnant des détails inutiles.
Pour les rares cas où le medium utilisé est important (par exemple « PGP permet de sécuriser le courrier électronique »), autant utiliser le terme complet. Vouloir utiliser la forme condensée « courriel » ne vaut pas mieux que de le dire en anglais puisque ce mode de construction des mots, très courant aux États-Unis, ne l'est pas en France.
Si on veut être tout à fait précis, on peut aussi noter que « courrier électronique » n'est pas tout à fait rigoureux, c'est la numérisation qui compte, pas le fait qu'elle se fasse aujourd'hui surtout avec des électrons. Mais parler de « courrier numérique » serait sans doute déroutant pour beaucoup. La langue n'est pas toujours rigoureuse en matière d'étymologie.
Je continuerai donc à dire « Le RFC 6532 normalise un moyen de mettre des caractères Unicode dans les adresses de courrier électronique » ou bien « Pour l'activité professionnelle, le courrier est en général plus efficace que le téléphone car il laisse une trace et oblige à réfléchir ».
Merci à Fil pour ses pertinentes remarques.
L'article seul
Install Ubuntu / Linux on a HP / Compaq CQ71 - 103EF
First publication of this article on 21 July 2009
Last update on of 17 September 2010
I installed the operating system Ubuntu on a Compaq Presario CQ71 - 103EF laptop machine. This article is to share the information that I obtained during the process.
While the basic functions are OK, there are problems. As often with laptops, especially very recent machines, a lot of things do not work, or do not work out of the box.
L'article complet
Extraire une partie d'un dépôt Subversion alors qu'il y a eu un renommage
Première rédaction de cet article le 21 juillet 2009
Le VCS Subversion
offre la possibilité d'exporter une partie d'un
dépôt (avec svndumpfilter)
mais il offre aussi la possibilité de renommer,
de déplacer un sous-arbre d'un point du dépôt à un autre, et ces deux
fonctions s'entendent parfois mal.
Le mécanisme normal de filtrage, avec
svndumpfilter, est bien
documenté. On exporte le dépôt avec svnadmin
dump, on le filtre avec svndumpfilter
et hop :
% svnadmin dump /my/repository | svndumpfilter include /quizzie > quizzie.svn
et on a un dump quizzie.svn
qui ne contient que le sous-arbre /quizzie. Mais
la documentation prévient bien que cela peut entraîner des problèmes :
« It is possible that at some point in the lifetime of your
repository, you might have copied a file or directory from some
location that svndumpfilter is excluding, to a location that it is
including. In order to make the dump data self-sufficient,
svndumpfilter needs to still show the addition of the new
path - including the contents of any files created by the copy - and not
represent that addition as a copy from a source that won't exist in
your filtered dump data stream. » Bref, le filtrage peut
aboutir à exclure des moments de l'histoire, sans lesquels on ne peut
pas reconstituer un fil cohérent. Au moment de la restauration, on
aura des problèmes comme :
% svnadmin load /my/new-repository < quizzie.svn
<<< Started new transaction, based on original revision 7
svnadmin: File not found: transaction '8-8', path 'quizzie/new-name/bar/myfile'
* editing path : quizzie/new-name/bar/myfile ...
Prenons l'exemple suivant, tiré d'une expérience réelle : un
répertoire a été déplacé de /foo/old-name en
/other/new-name. On veut exporter le dépôt pour
le passer à quelqu'un mais, comme le dépôt contient à la fois des
choses privées et des choses publiques, on veut filtrer et ne garder
que /other/new-name/bar (et son ancien nom,
/foo/old-name/bar). Ce faisant, la révision où a
été faite le renommage sera exclue (car située plus haut dans
l'arbre). Cela produira l'erreur
ci-dessus à la restauration (vous pouvez essayer, avec le script subversion-filtering-problem.sh).
Il existe plusieurs solutions à ce problème. Par exemple, il semble
que des alternatives à svndumpfilter comme svndumpfilter2
ou svndumpfilter3
permettent d'éviter ce problème. Je n'ai pas eu de succès avec ces
programmes (et je note que, dans les deux cas, passer un nom de
répertoire inexistant ne produit aucune erreur, ce qui semble indiquer
que le programmeur ne teste pas ce que fait son programme).
Ma solution a donc été de trouver la révision où est faite le
renommage, de dumper (en filtrant) jusqu'à cette
révision (exclue), de dumper (avec l'option
--incremental) à partir de cette révision
(également exclue) et, au rechargement, de faire un svn
rename moi-même. La version modifiée du script, subversion-filtering-solution.sh, fait cela.
À noter que cette question a été discutée sur Server Fault. Vous y trouverez peut-être davantage de détails.
L'article seul
De la Lune à Arpanet
Première rédaction de cet article le 21 juillet 2009
Hier, c'était le quarantième anniversaire du premier débarquement humain sur la Lune, un gigantesque projet états-unien, formidablement mis en scène, entre autre pour faire oublier la guerre du Viêt Nam. Quatre mois plus tard, et bien plus discrètement, le réseau Arpanet, le futur Internet faisait ses débuts, il comptait alors quatre ordinateurs.
Par rapport au formidable déploiement de moyens de communication qui avait été mis en place pour la mission Apollo 11, Arpanet a eu des débuts très discrets. Pourtant, c'était aussi un projet à forte composante militaire, il avait également nécessité des dépenses étatiques massives. Mais il n'y avait pas de jolies images à filmer...
Aujourd'hui, les missions Apollo n'ont laissé aucune trace. On n'est jamais revenu sur la Lune et on n'a pas fait un pas supplémentaire vers Mars. Les navettes spatiales, autobus de l'espace, ont remplacé les Saturn V puis ont disparu à leur tour. Le voyage de Collins, Aldrin et Armstrong n'a eu aucune influence sur la vie quotidienne quarante ans après.
Arpanet a connu un sort très différent : quarante ans après, et pas mal de milliards de dollars plus tard, son descendant direct, l'Internet, est dans la vie de tous. Des grands-mères de l'Iowa aux ingénieurs de Shanghai en passant par les associations de Salvador de Bahia, toute la planète l'utilise, tous les jours et en dépend désormais beaucoup.
Quel meilleur exemple de la difficulté de la prospective et de la nécessité de se méfier du cirque médiatique ? Quel journaliste ou politicien avait prévu le succès du réseau ?
L'article seul
RFC 5598: Internet Mail Architecture
Date de publication du RFC : Juillet 2009
Auteur(s) du RFC : D. Crocker (Brandenburg Internetworking)
Pour information
Première rédaction de cet article le 20 juillet 2009
Le courrier électronique est aujourd'hui une des principales applications de l'Internet. Mais, bien qu'il existe plusieurs RFC normalisant ses composantes techniques (comme les RFC 5321 et RFC 5322), aucun document « officiel » ne décrivait l'architecture du courrier, ses principales composantes, leurs relations, et les termes à utiliser pour les désigner. C'est le rôle de ce nouveau RFC, dont le développement souvent douloureux a pris près de cinq ans.
Depuis bientôt trente ans qu'il existe, le courrier électronique a connu des hauts et des bas dans les médias. Très souvent, sa fin proche a été proclamée, au profit, par exemple, de la messagerie instantanée. On a même vu des discours à la limite du racisme, affirmant que le courrier électronique n'avait pas de sens en dehors de l'Europe parce que les africains seraient éternellement voués à la culture orale. Mais, malgré la concurrence de nouveaux gadgets qui brillent (le plus récent étant Google Wave), malgré les assauts du spam, malgré les réglements intérieurs décourageant l'usage du courrier électronique (comme je l'ai vu récemment dans une entreprise dont 100 % de l'activité concerne l'Internet), le traditionnel courrier marche encore très bien. Ce n'était donc pas inutile de documenter son architecture, tâche à laquelle s'est attelée un vétéran, Dave Crocker.
Le courrier s'étant développé de manière relativement informelle, sans architecture pré-définie (au contraire du défunt X.400, qui avait tenté une approche de haut en bas), même le vocabulaire n'est pas normalisé. La différence entre forwarding et redirecting n'a jamais ainsi été clairement expliquée, et c'est encore pire si on veut écrire en français. Résultat, les noms des menus dans les logiciels ne sont pas cohérents d'un logiciel à l'autre, et les discussions techniques sont souvent lentes et pénibles car il n'y a pas d'accord sur les concepts de base. C'est ainsi que le groupe de travail Marid avait perdu beaucoup de temps dans des débats byzantins.
Le RFC 5598 va donc souvent créer un vocabulaire nouveau, qui déroutera tout le monde.
Autre problème lorsqu'il faut décrire l'architecture du courrier : il a beaucoup évolué depuis le début. Comme un service de messagerie sans utilisateurs ne sert à rien, chaque changement s'est fait en maintenant la compatibilité et le résultat n'est donc pas toujours très organisé.
Ce RFC 5598 ne vise pas à améliorer le courrier, uniquement à décrire comment il fonctionne actuellement. Il résume le fonctionnement du courrier (section 1). Celui-ci repose sur trois séries de normes :
- Le protocole SMTP (aujourd'hui normalisé dans le RFC 5321) qui décrit le moyen de faire circuler un message sur l'Internet,
- Le format des messages, dit souvent « RFC 822 » (aujourd'hui normalisé dans le RFC 5322) et que notre RFC nomme IMF (Internet Message Format),
- Une extension à ce format, MIME (aujourd'hui normalisé dans le RFC 2045), qui permet de gérer du texte dans différents jeux de caractères et des contenus multimédias.
La connaissance de l'histoire est souvent utile pour comprendre l'existant, d'autant plus que l'Internet repose largement sur le respect de la base installée : pas question de supprimer tout à coup un service utile. La section 1.1 retrace donc les (très) grandes lignes de l'évolution du courrier. Celui-ci a eu son premier document d'architecture avec le RFC 1506, qui empruntait à X.400 le vocabulaire de MUA et MTA. L'ensemble des MTA formait le MHS (Message Handling System). Mais les piliers que sont le protocole SMTP, le format IMF des messages, et le format des adresses avec le fameux @, sont restés très constants. Autre constante, la séparation entre le contenu du message et les informations de contrôle, qui permettent son acheminement.
Sont également restés les principes suivants :
- Adressage global
(
stephane+blog@bortzmeyer.orgfonctionne partout et désigne toujours la même boîte aux lettres), - Échange asynchrone, la grosse différence entre le courrier et la plupart des autres modes de communication,
- Absence d'accord préalable entre les acteurs. Un étudiant chilien peut écrire à un chercheur d'une entreprise indienne, sans qu'aucun contrat n'aie été signé, ou aucun contact pris précédemment. (C'est un des points les plus attaqués par ceux qui, comme le MAAWG, voudraient limiter le courrier à un cartel de gros opérateurs.) Mais le RFC note que ce point est le principal facteur de succès du courrier électronique et qu'il doit être maintenu.
Autre méta-question, quel est le rôle d'une architecture ? La section 1.2 la voit comme la connexion entre un service rendu à l'utilisateur et le(s) protocole(s) qui mettent en œuvre ce service. C'est l'architecture qui permet de s'y retrouver dans les protocoles utilisés. Elle est donc d'un plus haut niveau que les protocoles. Mais attention, le protocole ne respecte pas forcément complètement l'architecture (surtout comme lorsque, comme ici, il a été développé bien avant...) et ce n'est pas forcément un défaut, l'architecture doit être une aide, pas un réglement à respecter aveuglément.
Bien, maintenant que les bases sont posées, chaque section va parler d'une classe d'objets différente. La section 2 commence avec les rôles des différents acteurs (actor roles). Quels sont les rôles joués ici ?
D'abord, il y a les utilisateurs (user actors), expliqués en section 2.1. Ce ne sont pas forcément des humains, il existe aussi des programmes qui écrivent, traitent et lisent les messages. Il y a quatre sortes d'utilisateurs (le RFC contient un diagramme de leurs interactions, en page 10) :
- les auteurs,
- les destinataires,
- les répondeurs (return handlers),
- les intermédiaires (mediators).
L'auteur est responsable du contenu du message, qu'il confie au MHS pour que celui-ci l'achemine au destinataire. Celui-ci lit le message. S'il y répond, créant un nouveau message, il devient Auteur et le précédent auteur devient Destinataire de ce nouveau message. Les répondeurs se chargent de générer des réponses lors d'évènements comme une adresse de destination inexistante (dans ce cas, l'auteur reçoit une réponse qui ne vient pas du destinataire).
Plus complexe, l'intermédiaire (section 2.1.4) va recevoir le message et le réémettre à des destinataires différents, parfois après modification. Un intermédiaire typique est un gestionnaire de liste de diffusion. Le RFC suggère une bonne définition pour un intermédiaire : il envoie des messages donc il est Auteur, mais les Destinataires de ces messages ne le considèrent pas comme tel.
Le second rôle est celui des serveurs (MHS actors), vus en section 2.2. Ce sont les programmes qui vont, collectivement, mettre en œuvre ce que les utilisateurs perçoivent comme une entité unique, le MHS (Message Handling System). La page 13 contient un joli diagramme de leurs interactions. Il y a :
- l'origine (originator), le premier serveur qui reçoit le message, et a notamment pour travail de s'assurer de sa validité,
- le relais (relay) qui reçoit le message d'un
serveur et le transmet à un autre (un message passe souvent par
plusieurs relais, le courrier n'étant pas implémenté directement entre
deux machines). Suivant le RFC 2505, le relais ajoutera une
trace dans les en-têtes des messages (l'en-tête
Received:). Le relais travaille à un niveau en dessous de l'Intermédiaire, mais un niveau au dessus des routeurs IP, - le récepteur (receiver), le dernier serveur à traiter le message,
- la passerelle (gateway), un serveur un peu particulier, qui tient de l'Intermédiaire et du Relais (section 2.2.3). Son travail est de faire passer le courrier vers des mondes utilisant d'autres types de courrier, par exemple un autre format que l'IMF du RFC 5322.
Après les Utilisateurs et les Serveurs, un autre rôle important est celui des Organisations (administrative actors, section 2.3). Plus formellement, on les nomme ADMD (ADministrative Management Domain). C'est au sein d'un ADMD que se prennent les décisions et que sont appliquées des politiques, par exemple des choix en terme de lutte anti-spam. Au niveau de l'ensemble de l'Internet, il n'y a pas unité de décision, il n'est pas envisageable de demander, par exemple, un déploiement généralisé de telle ou telle technique. En revanche, au sein d'un ADMD, de telles décisions sont possibles (c'est donc au courrier ce qu'un AS est au routage.) Beaucoup de décisions, par exemple en matière de filtrage, dépendent de si le message est interne à l'ADMD ou pas.
Le RFC 5598 discerne plusieurs sortes d'ADMD :
- Ceux du bord (Edge),
- Les consommateurs (Consumer),
- Ceux de transit (Transit).
Un dessin page 17 illustre leurs relations. Lors de l'envoi d'un message, la transmission se fait en général entre les deux ADMD de bord, directement (à ce niveau d'analyse ; à un niveau plus bas, il y a plusieurs MTA). Parfois, un ou plusieurs ADMD de transit traitent le message. Parfois encore, l'ADMD du bord garde le message pour l'ADMD consommateur, comme lorsqu'il s'agit d'un accès Web aux boîtes aux lettres. (Voir aussi le RFC 5068.)
Pour désigner toutes les entités qui apparaissent dans le courrier, il faut des identificateurs. Il existe plusieurs identités possibles, exposées en section 3 :
- Les boîtes aux lettres, identifiées par une adresse de courrier
comme
Jean.Durand@comptabilite.monentreprise.example. La partie à gauche du @ doit être considérée comme opaque par la plupart des programmes qui manipulent le courrier, surtout lorsqu'ils n'ont pas lu la norme. Elle ne doit être interprétée qu'à la destination finale. Les conventions comme les adresses incluant un + sont purement locales et ne doivent pas être utilisées par les autres acteurs. (Un autre exemple de telles conventions est le RFC 3192 avec ses adresses de fax commeFAX=+12027653000/T33S=1387@fax.example.org.) Aujourd'hui, ces adresses sont utilisées bien au delà du courrier, par exemple, bien des sites Web utilisent ces adresses comme identifiants pour leurs clients enregistrés (c'est le cas d'Amazon, par exemple). - Une autre identité est le nom de domaine, la partie à droite du @ dans une adresse. Il suit les règles générales des noms de domaine (plusieurs composants séparés par des points, etc).
- L'identificateur du message (section 3.4.1). Chaque message a un
identificateur unique, stocké dans le champ
Message-ID:et dont la forme syntaxique ressemble à une adresse de courrier (mais ne l'est pas). Il est fixé par l'origine. Un exemple est<alpine.BSF.2.00.0907081901140.79224@in1.dns-oarc.net>. Cet identificateur sert à désigner un message sans ambiguité. C'est par exemple lui qui est utilisé comme référence dans les fils de discussion. Une question intéressante est de savoir à partir de quand affecter un nouvel identificateur lorsque le message est modifié. Le RFC ne fournit pas de règles strictes mais suggère que, si le changement ne met en jeu que la forme (par exemple un nouvel encodage), alors, il ne s'agit pas d'un nouveau message et on ne devrait pas mettre un nouvel identificateur. Mais il y a bien d'autres cas plus douteux. Le problème est analogue à celui qui se pose pour d'autres identificateurs comme les ISBN. Avec ces derniers, on constate en pratique que les éditeurs ont des pratiques très différentes quant à la réutilisation d'un ISBN.
Notre RFC se déplace ensuite vers des entités plus concrètes, les
programmes serveurs (section 4). Illustrés page 24, leur présentation
nécessite d'abord un petit détour sur le format des messages (section 4.1). Il y a
le message proprement dit, normalisé dans le RFC 5322. Et il y a des métadonnées,
couramment appelées l'enveloppe (section 4.1.1) et qui servent au
MHS pour assurer une distribution correcte. Les informations de
l'enveloppe sont souvent enregistrées dans le message, pour analyse et
débogage a posteriori (c'est le cas
des champs Received:).
Dans le message lui-même, il y a deux parties, les
en-têtes (section 4.1.2) et le
corps (section 4.1.3). Les
en-têtes (comme From:, Date: ou
Subject:) sont structurées, pour permettre un
traitement automatique, par exemple par
Sieve. La liste des champs est décrite dans le
RFC 4021 et on peut la modifier suivant les procédures du
RFC 3864. Le corps du message n'est pas normalement structuré (mais
la norme MIME lui a donné un certaine
structure). Les informations de l'en-tête ne coïncident pas forcément
avec celles de l'enveloppe (par exemple, si un message est envoyé à
une liste de diffusion, le champ To: de l'en-tête
indique la liste, le paramètre RCPT TO de
l'enveloppe indiquera un destinataire individuel).
Enfin, il existe aussi des « méta-messages », automatiquement générés et analysables par un programme comme les MSN (Message Disposition Notification) des RFC 3297 et RFC 8098, ou comme les DSN (Delivery Status Notification) du RFC 3461, qui sont typiquement utilisés comme avis de non-remise d'un message.
Pour toutes ces parties d'un message, il existe des identités différentes. Une question aussi simple que « Quel est l'auteur du message ? » a ainsi plusieurs réponses possibles, toutes légitimes. Ce point est souvent mal compris par les utilisateurs, par exemple lorsqu'une technique d'authentification est utilisée. Qu'authentifie t-elle exactement ? Pas forcément ce que l'utilisateur croit...
La section 4.1.4 fait la liste de ces identités, en indiquant qui
la met dans le message. Par exemple, RFC5322.From
est le champ From: de l'en-tête, et est mis par
l'Auteur. RFC5321.EHLO est le nom qu'annonce un
serveur SMTP à ses pairs et est mis par
l'Origine (MSA ou MTA). RFC2919.ListID est
l'identité d'une liste de diffusion (cf. RFC 2919) et est
mise par l'Intermédiaire. Dernier exemple (mais la liste du RFC est bien
plus longue) : RFC791.SourceAddr est l'adresse
IPv4 de la machine cliente (certains
protocoles, comme SPF - RFC 7208, l'utilisent).
Après cela, la section 4.2 peut commencer à lister les programmes serveurs de courrier. On y trouve le MUA (Mail User Agent), celui qui interagit directement avec l'utilisateur (Outlook, mutt, Thunderbird, etc), le MSA (Message Submission Agent, le premier serveur à recevoir le courrier), le MTA (Mail Transfer Agent), ce que l'utilisateur ne voit pas, Courier, Exchange, Postfix, etc)... Pour chacun d'eux, le RFC indique les identités qui sont pertinentes pour ce serveur. Par exemple, le MSA et le MTA manipulent des identités du RFC 5321, ce qui n'est pas le cas du MUA.
Cette section couvre en détail leurs fonctions. Par exemple, le MTA a droit à une section 4.3.2 qui précise son fonctionnement de « routeur de niveau 7 ». Comme tous les routeurs, il a besoin de recevoir l'information sur les routes existantes et, sur l'Internet, cela se fait essentiellement via les enregistrements MX du DNS.
Moins connu que le MUA et le MTA, le MDA
fait l'objet de la section 4.3.3. Le Mail Delivery
Agent est chargé du passage du message depuis le MHS jusqu'à
la boîte aux lettres de l'utilisateur. Le courrier est reçu via le
protocole LMTP (RFC 2033) ou bien par
un mécanisme non normalisé (par exemple, sur Unix, via un appel d'un
exécutable et transmission du courrier sur l'entrée standard de
celui-ci). Parmi les plus connus, dans le monde
Unix, procmail ou le
local de Postfix.
L'acheminement du courrier suit en général un modèle de push où l'emetteur envoie le message vers un destinataire supposé toujours prêt. Mais le modèle du courrier permet également un fonctionnement en pull, avec des protocoles comme ceux du RFC 1985 ou du RFC 2645. (Les protocoles comme UUCP étant traités via un système de passerelle, cf. section 5.4). De même, une fois le message délivré, le destinataire peut y accéder selon un mode pull, avec POP (RFC 1939) ou IMAP (RFC 9051).
Comme tout ce RFC 5598, cette section parle d'architecture, pas de mise en œuvre. Dans la pratique, une implémentation donnée de cette architecture peut répartir ses serveurs de façon assez différente (section 4.5). Par exemple, il est fréquent que les fonctions de MSA et de MTA soient fusionnées dans le même serveur (et, avec Postfix, il est même difficile de séparer les deux fonctions).
La complexité des fonctions assurées par les intermédiaires (mediators) méritait bien une section entière, la 5. Contrairement au MTA, transporteur neutre, qui doit transmettre un message avec le minimum d'altérations, l'intermédiaire a le droit de réécrire partiellement le message. Par contre, contrairement au MUA, l'intermédiaire n'est pas censé composer de messages nouveaux, et doit toujours partir d'un message existant dont il préserve le sens général. Le RFC cite plusieurs exemples d'intermédiaires :
- Les alias (comme gérés par les fichiers
~/.forwardde Postfix et sendmail). Le destinataire décide alors de renvoyer le message à une nouvelle adresse (section 5.1). La fonction est typiquement mise en œuvre par le MDA. Le message est inchangé mais l'enveloppe indique désormais un nouveau destinataire (donc, l'identitéRFC5322.Tone change pas maisRFC5321.RcptTooui.) À noter que l'émetteur (RFC522.Fromou bienRFC5321.MailFrom) n'est pas affecté donc les messages d'erreur n'iront pas au responsable de l'alias, ce qui en rend le débogage très difficile. On peut contester ce classement des alias parmi les intermédiaires, puisque le message n'est pas modifié, mais notre RFC décide que le changement de destinataire est un changement de sémantique suffisant pour que cette fonction ne soit pas considérée comme faisant partie du MTA. - Les listes de
diffusion sont sans doute l'exemple le plus connu
d'intermédiaire. Elles font l'objet de la section 5.3. Recevant un
message, elles le retransmettent à plusieurs destinataires, souvent
après de légères modifications (comme l'ajout d'instructions de
désabonnement ou la suppression de certaines pièces jointes). Les RFC 2369 et RFC 2919 créent des identités spécifiques aux
listes de diffusion, qu'on retrouve dans les en-têtes (comme
List-Id: IETF IP Performance Metrics Working Group <ippm.ietf.org>). Beaucoup de listes de diffusion ajoutent également un champReply-To:, ce qui est en général une très mauvaise idée. - Un autre type d'intermédiaire est devenu plus rare avec le temps. À une époque, il y avait plusieurs systèmes de courrier, en général reposant sur des protocoles privés, et que certaines entreprises déployaient. C'était bien sûr ridicule (imagine t-on, sauf pour les militaires, de déployer un système de téléphonie fermé, reposant sur des protocoles spécifiques ?) mais, de la fin des années 1970 au début des années 1990, la pression idéologique était forte pour rejeter les protocoles Internet, gratuitement accessibles donc pas sérieux. Comme l'intérêt de tout système de courrier est dans le fait qu'on peut joindre des personnes différentes, il a donc fallu développer des passerelles (gateways). À une époque, la seule façon d'envoyer du courrier entre les deux systèmes de messagerie privés d'IBM était via une passerelle Internet... Les passerelles sont exposées en section 5.4. Comme, par définition, elles communiquement avec un monde non-Internet, une réécriture du message, parfois avec perte d'informations, est inévitable. Tout l'art de la conception d'une passerelle est donc de minimiser ces pertes. Il est amusant de noter qu'il existe des passerelles normalisées pour des protocoles comme le fax (RFC 4143) ou la voix (RFC 3801), ce que fait aujourd'hui, par exemple, la fonction répondeur téléphonique de la Freebox).
- Un autre cas intéressant d'intermédiaire est le filtre (section 5.5), qui supprime des parties du message, par exemple parce qu'elles contiennent un virus MS-Windows (un logiciel comme Amavis permet de créer de tels filtres).
Par rapport aux débuts du courrier électronique, un des grands changements a concerné la sécurité, un sujet devenu bien plus important aujourd'hui. D'où la section 6.1, qui lui est consacrée. Elle rappelle que le MHS n'est pas obligatoirement sécurisé. Son but est en effet de permettre l'échange de courrier avec le moins d'embêtements possibles. Sans cette propriété, le courrier électronique n'aurait jamais décollé. Mais elle a aussi été exploitée par des méchants comme les spammeurs. Cependant, il existe de nombreuses techniques pour sécuriser le courrier, par exemple TLS (RFC 3207) pour sécuriser la communication entre deux serveurs, l'authentification SMTP (RFC 4954) pour s'assurer de l'identité d'un utilisateur ou encore PGP (RFC 4880) pour protéger le message de bout en bout.
Enfin, dernier gros morceau, l'internationalisation, en section 6.2. Si les RFC de base du courrier supposent uniquement l'utilisation d'ASCII, plusieurs extensions ont permis d'avoir aujourd'hui un courrier complètement internationalisé :
- MIME (RFC 2045, RFC 2046, RFC 2047 et RFC 2049) a permis d'utiliser d'autres caractères que ceux d'ASCII dans le corps des messages et, via un surencodage, dans les en-têtes.
- Le RFC 1652 a permis de transmettre des caractères de 8
bits (extension SMTP
8BITMIME). - Une série de RFC a permis l'utilisation d'adresses de courrier non limitées à l'ASCII.
Merci à Olivier Miakinen pour ses nombreuses corrections.
L'article seul
Super User, un site de Q&A pour utilisateurs
Première rédaction de cet article le 18 juillet 2009
Jeff Atwood a annoncé le 14 juillet le lancement de la version « beta publique » de Super User, le troisième site de Q&A de la trilogie commencée par les fameux Stack Overflow et Server Fault. Super User est un site Web de questions & réponses pour utilisateurs des systèmes informatiques, avec système de réputation.
Comme pour ses deux prédécesseurs, Super User repose sur le principe que toute personne qui veut
écrire doit s'authentifier (en OpenID, donc,
http://www.bortzmeyer.org/ pour moi) et que les actions de cette personne (poser une question,
proposer une réponse) lui vaudront petit à petit une
réputation, déterminée par les votes des autres
utilisateurs. Les simples lecteurs peuvent, eux, être
anonymes.
Les réponses aux questions sont classées, non pas dans l'ordre chronologique comme sur un blog mais dans l'ordre décroissant des votes, ce qui permet à l'information la plus reconnue d'émerger hors du bruit. C'est un gros avantage, par exemple par rapport aux traditionnelles listes de diffusion où il faut faire un gros effort de synthèse lorsqu'on lit un fil riche, rempli de messages parfois incomplets ou contradictoires.
Pour ceux que ça intéresse, ma réputation est de 131 ce qui me permet, par exemple, de voter contre une contribution (il faut une réputation de 15 pour voter pour). À 250, je pourrai voter sur la fermeture ou la réouverture de mes propres questions et à 500, je pourrais réétiqueter les questions des autres.
Quels genres de sujet sont traités ? Tout ce qui concerne l'usage des ordinateurs et des logiciels. On y trouve des questions comme :
- How many computer does it take at home to be an "addict" ?
- What do you do to stay healthy and active while using the computer for several hours a day?
- How do I make Firefox remember its window size?
- View attachment size in Gmail without opening the mail
- Can a torrent with zero seeders download?
- Verify whether a Facebook user is a real human before accepting their friend request
Comme il est peu probable qu'un lecteur soit intéressé par tous les
logiciels possibles, Super User
permet d'étiquetter les questions et
chercher ensuite selon ces étiquettes. Ainsi, http://superuser.com/questions/tagged/bittorrent donnera accès
aux questions sur le système de partage de fichiers pair-à-pair BitTorrent et http://superuser.com/questions/tagged/firefox aux
questions sur le navigateur Web Firefox.
Super User sera t-il un succès ? Ce n'est pas évident à prévoir. Stack Overflow a été un rapide succès car les programmeurs étaient très demandeurs d'informations (et que les créateurs de ce site étaient eux-même des gourous connus dans ce monde). Server Fault semble avoir pris moins vite, peut-être parce que c'est une autre communauté, ou bien parce que les administrateurs système avaient d'autres sources d'informations. Les utilisateurs ordinaires sont-ils prêts à se lancer dans un site sérieux et de qualité ? Contrairement aux programmeurs et aux administrateurs système, ce ne sont pas forcément des professionnels passionnés.
L'article seul
github, un nouveau site d'hébergement pour le développement logiciel
Première rédaction de cet article le 17 juillet 2009
Dernière mise à jour le 20 juillet 2009
github est un hébergeur de projets logiciels, comme SourceForge, mais bâti autour du VCS git (celui écrit par Linus Torvalds et utilisé pour le noyau Linux). Il permet d'avoir un compte gratuitement (pour les « petits » projets) et héberge, outre le VCS, un Wiki et quelques autres outils comme un système de veille permettant de surveiller d'autres projets.
Très perfectionné et très populaire, github a attiré beaucoup de projets libres en peu de temps. Par exemple, je viens de passer le développement du petit programme query-loc sur ce site.
Pour l'importation originale d'un projet, on peut utiliser son propre dépôt git (puisque git est un VCS distribué). S'il est public, github sait aller le chercher (pull) et le cloner. Sinon, on peut le faire soi-même (push) :
git remote add origin git@github.com:MYNAME/MYPROJECT.git git push origin master
Si le dépôt était originellement géré par Subversion, deux solutions :
- Le convertir soi-même (
git-svn clone svn+ssh://svn.example.org/MYPROJECT, git-svn est distribué avec git) et, ensuite, on a un dépôt git que github peut tirer ou qu'on peut pousser. - Demander à github de le faire lui-même, si le dépôt Subversion est public. Attention, c'est fait de manière asynchrone et cela peut prendre du temps (un courrier vous prévient à la fin). Ça a bien marché à partir du dépôt d'echoping à Sourceforge pour faire un dépôt git expérimental. Attention toutefois, l'importation n'est que dans un seul sens, si on veut continuer à maintenir synchrones les dépôts, il faut le faire soi-même.
La plupart des projets hébergés par github sont libres mais pas tous. Le logiciel de github lui-même n'est pas libre aussi certains préfèrent utiliser Gitorious (que je n'ai pas testé).
Merci à Pablo Rauzy pour ses corrections et remarques. Quelques articles intéressants : « De subversion à git », « Subversion to Git » ou « GitHub issues ».
L'article seul
Le déploiement des résolveurs DNS menteurs
Première rédaction de cet article le 16 juillet 2009
L'annonce récente par Comcast du début du déploiement de résolveurs DNS menteurs pour ses clients a remis sur le devant de la scène une technique que, malheureusement, beaucoup de FAI déploient. Mais, d'abord, il faut bien comprendre de quoi il s'agit.
Comme à chaque nouvelle publication, il y a de nombreux débats sur
cette mesure, par exemple sur
Slashdot, sur
DSLreports, ou sur la
liste NNsquad. Mais ces débats ne sont pas toujours bien
informés et mélangent parfois plusieurs choses. D'abord, qu'est-ce
qu'un résolveur DNS
menteur ? L'abonné typique d'un FAI utilise les
résolveurs DNS de son FAI. Il connait leurs adresses IP via des protocoles comme
DHCP. En général, à l'heure actuelle, la
plupart des FAI laissent l'utilisateur libre d'utiliser d'autres
résolveurs (dans le futur, cela pourrait changer, avec le blocage du
port 53). Mais,
évidemment, l'écrasante majorité des utilisateurs ne connait pas le
DNS et n'ose pas changer les réglages et tombe donc sur les résolveurs
du FAI. Il est donc tentant pour celui-ci de violer la
neutralité du réseau et d'utiliser ces
résolveurs pour rabattre du trafic vers ses serveurs, par exemple pour
y installer de la publicité. (Certains FAI prétendent mettre en place
des DNS menteurs pour « le bien des clients » alors qu'en réalité, ils
sont poussés par des intermédiaires qui leur proposent de
« monétiser » l'audience du site Web ainsi pointé, comme l'a bien
expliqué
le directeur technique de Free). C'est le rôle du résolveur DNS menteur,
qui est typiquement chargé, lorsqu'il reçoit un code
NXDOMAIN (No Such Domain, ce
nom n'existe pas) de le remplacer par le code
NOERROR et d'ajouter une adresse IP où écoute un
serveur HTTP qui sert de la publicité.
Comcast n'est pas, et de loin, le seul FAI à
faire cela. Aux États-Unis, RoadRunner le fait
déjà (et plusieurs autres) et, en France, cela est apparemment fait
par SFR. Je dis
« apparemment » car, contrairement à Comcast, la plupart des FAI ne
s'en vantent pas et n'annoncent jamais qu'ils procèdent à de telles
manœuvres. Il est donc difficile de vérifier ces informations. Ignorant le RFC 4084, ils
n'informent ni leurs clients, ni leurs potentiels futurs clients
(essayez, avant de choisir un FAI, de connaitre leur politique en
matière de réécriture DNS. Vous n'y arriverez pas.) Une fois que vous
avez signé, vous pouvez toujours tester avec un client DNS comme
dig. Si dig A
nexistesurementpas.bortzmeyer.org affiche autre chose que
status: NXDOMAIN, c'est que votre résolveur vous ment.
Cette pratique pose de nombreux problèmes techniques et politiques. Je ne les cite pas tous ici (un bon nombre ont été déjà notés, par exemple dans le document 32 du SSAC). Mais les principaux problèmes techniques sont :
- Cette réécriture est conçue uniquement pour un client final qui utilise un navigateur Web. Les autres protocoles, ou bien les clients HTTP non-Web (par exemple les clients REST) récupèrent des adresses qui, au mieux ne leur servent à rien, au pire les déroutent.
- Ce mensonge empêche le déploiement de toutes les techniques de sécurité du DNS de bout en bout comme DNSSEC (RFC 4033).
- Les applications qui testent si une entrée est présente dans le DNS (par exemple les listes noires DNS ou simplement les programmes de détection de liens Web morts) ne peuvent plus fonctionner.
Mais les principaux problèmes que pose cette technique sont politiques :
- Le titulaire d'un domaine en perd le contrôle puisque le
résolveur menteur va prétendre que
xxxxx.wikipedia.orgexiste, malgré le fait que le gérant dewikipedia.orgne l'ai pas créé. C'est donc un coup de force du gérant du résolveur DNS (le FAI) contre celui du domaine. - Le fait qu'un intermédiaire technique, le FAI, se permette de modifier les données en transit par son système est une violation de la neutralité du réseau, qui en appelle d'autres. Si on abandonne le principe du « transporteur neutre », qui relaie mécaniquement les paquets de ses clients, demain, on assistera à des ingérences encore plus nettes.
Ces résolveurs DNS menteurs ont des points communs, mais aussi des
grosses différences, avec les jokers que
mettent certains gérants de domaines dans leur zone (comme l'avait
fait Verisign dans
.com en
2003). Il y a notamment une différence technique : les jokers dans un domaine respectent le protocole DNS,
les résolveurs menteurs non, donc seuls les premiers sont
compatibles avec DNSSEC et une différence politique, les jokers dans un domaine sont mis par le titulaire du
domaine, alors que le résolveur menteur est un tiers qui se permet de modifier
les domaines qui ne sont pas à lui. À tout point de vue, les jokers
dans un domaine, quoique une mauvaise idée, sont donc « moins
graves ». Néanmoins, il est normal de ne pas les déployer, comme s'y
est engagée, par exemple, l'AFNIC.
La confusion entre les deux techniques persiste trop souvent. Par exemple, le rapport 32 du SSAC, Preliminary Report on DNS Response Modification est très bien fait techniquement, comme d'habitude avec le SSAC, et fait bien le tour de la question. Mais il mélange trop les jokers dans un domaine (par exemple un TLD) et le mensonge par un résolveur, un serveur de noms récursif. (Probablement pour que l'ICANN puisse exercer une pression sur les TLD en leur interdisant les jokers, comme proposé à la réunion ICANN de Sydney.)
Comcast, en annonçant son début de déploiement de résolveurs DNS
menteurs, a également tenu à citer l'IETF en
affirmant que sa technique avait été présentée à la dite IETF. C'est
exact (document draft-livingood-dns-redirect)
mais cela oublie deux choses. L'une est que n'importe qui peut
présenter n'importe quoi à l'IETF, il n'y a pas de barrière à
l'entrée. Si l'approbation d'un RFC, surtout
sur le chemin des normes, est une affaire sérieuse, la publication
d'un Internet-Draft est entièrement automatique et
ne vaut donc pas approbation du document. Ensuite, le document a bien
été discuté au sein du groupe de travail DNSOP
mais il a été très largement rejeté par tous les participants et a peu
de chances de devenir un RFC un jour (ce qui n'empêchera pas Comcast
ou les autres de
continuer leurs pratiques, d'ailleurs). Au contraire, le RFC 4924 rappelle bien, dans sa section 2.5.2, que
cette pratique est fortement déconseillée.
D'autres articles sur le sujet : Comcast Unleashes Trial DNS Redirection in Select States et Comcast Finally Launches DNS Redirection.
L'article seul
Votre serveur DNS peut-il faire passer des paquets de toutes les tailles ?
Première rédaction de cet article le 13 juillet 2009
Dernière mise à jour le 27 janvier 2010
Il y a très longtemps, lorsque les ministres ne parlaient pas de l'Internet à la télévision, la taille des paquets DNS était limitée à 512 octets (RFC 1035, section 2.3.4). Cette limite a été supprimée par le RFC 2671 en 1999. Mais dix ans sont une durée très courte pour le conservatisme de certains et beaucoup d'administrateurs réseaux qui mettent à jour leur version de Flash toutes les deux semaines n'ont jamais vérifié la configuration de leur pare-feux. L'OARC vient donc de publier un excellent outil qui permet de tester facilement si votre environnement DNS est correct.
L'outil en question consiste simplement en un serveur DNS
spécifique, qu'on peut interroger (le nom est
rs.dns-oarc.net et le type est TXT) avec n'importe quel client
DNS. Voici un exemple avec dig :
% dig +short rs.dns-oarc.net txt rst.x4001.rs.dns-oarc.net. rst.x3985.x4001.rs.dns-oarc.net. rst.x4023.x3985.x4001.rs.dns-oarc.net. "192.168.1.1 sent EDNS buffer size 4096" "192.168.1.1 DNS reply size limit is at least 4023 bytes"
Ici, on voit que les réponses DNS de 4023 octets peuvent arriver.
Avec des résolveurs DNS mal configurés ou mal connectés (ici, ceux d'Alice, via une AliceBox) :
% dig +short rs.dns-oarc.net txt rst.x486.rs.dns-oarc.net. rst.x454.x486.rs.dns-oarc.net. rst.x384.x454.x486.rs.dns-oarc.net. "213.228.63.58 lacks EDNS, defaults to 512" "213.228.63.58 DNS reply size limit is at least 486 bytes"
486 octets arrivent à passer, ce qui est insuffisant dans de nombreux cas.
Malheureusement, les environnements DNS bogués sont fréquents. Ce n'est pas forcément à cause du serveur de noms : cela peut être à cause d'un pare-feu stupidement configuré pour refuser les paquets DNS de plus de 512 octets ou bien par la faute d'une middlebox programmée avec les pieds en Chine. D'où l'importance un tel système de test.
Vous pouvez le tester sur votre machine habituelle, au bureau et à la maison. Si vous obtenez moins de 2048 octets, danger : DNSSEC, pour ne citer que lui, va vous causer des problèmes. La plupart des technologies vieilles de moins de dix ans (comme IPv6) auront également des problèmes.
Si
les paquets de plus de 512 passent, mais pas ceux de plus de 1500, il
s'agit probablement d'un problème de MTU (avec
filtrage stupide de l'ICMP) ou bien d'un pare-feu qui ne gère pas les
fragments. Par exemple, sur un Cisco, il faut
penser à mettre ip virtual-reassembly
avant le passage par un pare-feu (il y en a
beaucoup) qui ne gère pas les fragments.
Le même logiciel a aussi été installé par le RIPE-NCC sur ses serveurs donc on peut aussi comparer avec :
% dig +short test.rs.ripe.net txt rst.x3828.rs.ripe.net. rst.x3833.x3828.rs.ripe.net. rst.x3839.x3833.x3828.rs.ripe.net. "192.134.4.162 sent EDNS buffer size 4096" "192.134.4.162 summary bs=4096,rs=3839,edns=1,do=1" "192.134.4.162 DNS reply size limit is at least 3839 bytes"
Si on est sur une machine qui n'a pas dig mais qui a nslookup (cas du logiciel privateur MS-Windows, on peut probablement tester (je n'ai pas regardé en détail donc je ne garantis rien) :
% nslookup -q=txt rs.dns-oarc.net Server: ::1 Address: ::1#53 Non-authoritative answer: rs.dns-oarc.net canonical name = rst.x3827.rs.dns-oarc.net. rst.x3827.rs.dns-oarc.net canonical name = rst.x3837.x3827.rs.dns-oarc.net. rst.x3837.x3827.rs.dns-oarc.net canonical name = rst.x3843.x3837.x3827.rs.dns-oarc.net. rst.x3843.x3837.x3827.rs.dns-oarc.net text = "192.134.4.69 DNS reply size limit is at least 3843" rst.x3843.x3837.x3827.rs.dns-oarc.net text = "192.134.4.69 sent EDNS buffer size 4096" rst.x3843.x3837.x3827.rs.dns-oarc.net text = "Tested at 2010-01-27 10:20:02 UTC" Authoritative answers can be found from: x3843.x3837.x3827.rs.dns-oarc.net nameserver = ns00.x3843.x3837.x3827.rs.dns-oarc.net. ns00.x3843.x3837.x3827.rs.dns-oarc.net internet address = 149.20.58.136
D'autres outils pour faire ce genre de test existent mais plus complexes :
- Une application à télécharger en local, qui nécessite Sun Java,
- Un autre outil qui dépend d'un simple nom de domaine et est donc
utilisable par dig est
pathtest.isc.org: tapezdig $RECORDSIZE.pathtest.isc.org TXT +bufsize=$YOURBUFFERSIZEet le serveur faisant autorité générera pour vous un enregistrement de type TXT et de taille$RECORDSIZE. Vous verrez bien si vous arrivez à le récupérer... - L'outil Netalyzr, qui nécessite Sun Java,
- Des instructions détaillées, uniquement avec dig, par Mark Andrews (le mainteneur de BIND), sur la liste des utilisateurs BIND et une variante plus synthétique sur la liste Nanog.
La racine du DNS devant être complètement signée en mai 2010, cette question de taille :-) se posera donc souvent, comme dans l'article « Preparing K-root for a Signed Root Zone » ou dans les excellentes mesures de « Measuring DNS Transfer Sizes - First Results ».
Si le test montre que les paquets de plus de 1500 octets (voire les paquets de plus de 512 octets) ne peuvent pas passer, faut-il paniquer ? Oui et non. Le fait qu'ils ne peuvent pas passer est inquiétant, dix ans après que la vieille limite de 512 octets aie été supprimée. Mais cela n'entrainera pas forcément une catastrophe. Cela dépend de beaucoup de choses. Par exemple, si le résolveur ne gère pas du tout EDNS (ici, Google DNS) :
% dig @8.8.8.8 +short test.rs.ripe.net txt rst.x477.rs.ripe.net. rst.x481.x477.rs.ripe.net. rst.x486.x481.x477.rs.ripe.net. "209.85.228.94 DNS reply size limit is at least 486 bytes" "209.85.228.94 lacks EDNS, defaults to 512" "209.85.228.94 summary bs=512,rs=486,edns=0,do=0"
Certes, c'est une limite anormale en 2010 mais cela ne cassera sans doute pas lors de la signature de la racine : si le résolveur n'émet pas de paquets EDNS, il ne pourra pas mettre le bit DO à 1 (RFC 3225, section 3) et ne recevra donc pas les grosses signatures DNSSEC.
Autre cas intéressant, celui de Free Les
clients de ce FAI ont des résultats apparemment incohérents, un coup
ça marche, un coup ça ne marche pas. C'est parce que derrière chaque
résolveur de Free (par exemple 212.27.40.241), il
y a plusieurs machines (c'est banal), qui ont des configurations
différentes (c'est assez étonnant, et je ne vois pas de raison valable
de faire cela).
Notez bien que l'adresse IP dans la réponse du test
est différente à chaque fois, montrant bien que plusieurs machines se
partagent le travail.
L'article seul
RFC 2679: A One-way Delay Metric for IPPM
Date de publication du RFC : Septembre 1999
Auteur(s) du RFC : Guy Almes (Advanced Network & Services, Inc.), Sunil Kalidindi (Advanced Network & Services, Inc.), Matthew J. Zekauskas (Advanced Network & Services, Inc.)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF ippm
Première rédaction de cet article le 12 juillet 2009
Ce RFC définissait une métrique, une grandeur à mesurer, en l'occurrence le délai d'acheminement d'un paquet d'un point à un autre du réseau. Cela semble trivial, mais la définition rigoureuse de la métrique, permettant des mesures scientifiques et leur comparaison, prend vingt pages... (Il a depuis été remplacé par le RFC 7679.)
Comme tous les RFC du groupe de travail ippm, celui-ci s'appuie sur les définitions et le vocabulaire du RFC 2330, notamment la notion de Type-P (paquets IP ayant la même « signature », c'est-à-dire même protocole de couche 4, même numéro de port, etc, car certains équipements réseaux traitent différemment les paquets selon ces variables).
Commençons par le commencement, c'est-à-dire l'introduction, en section 2. Le RFC définit une métrique pour une mesure unique (un singleton) nommé Type-P-One-way-Delay, ainsi qu'un échantillonnage, pour le cas où la mesure est répétée, et enfin diverses statistiques agrégeant les résultats de plusieurs mesures. Pourquoi une telle métrique ? Comme le rappelle la section 2.1, celle-ci est utile dans des cas comme, par exemple :
- Estimer le débit maximal qu'on obtiendra (avec certains protocoles comme TCP, il est limité par le RTT).
- La valeur minimale de ce délai d'acheminement nous donne une idée du délai dû uniquement à la propagation (qui est limitée par la vitesse de la lumière) et à la transmission. (Voir aussi la section 5.3.)
- Par contre, son augmentation nous permet de détecter la présence de congestion.
Mais pourquoi un délai d'acheminement « aller-simple » et pas « aller-retour », comme le fait ping, ou bien comme le normalise le RFC 2681 ? Après tout, le délai aller-retour est bien plus simple à mesurer. Mais il a aussi des défauts :
- Une bonne partie des routes sur l'Internet sont asymétriques. Le délai aller-retour dépend donc de deux délais aller-simple, qui peuvent être très différents.
- Même si le chemin est symétrique, les politiques de gestion de la file d'attente par les routeurs peuvent être très différentes dans les deux sens.
- Certains protocoles s'intéressent surtout aux performances dans une direction. C'est le cas du transfert d'un gros fichier, où la direction des données est plus importante que celle des accusés de réception.
Le RFC ne le mentionne apparemment pas, mais on peut aussi dire que la mesure d'un délai aller-retour dépend aussi du temps de réflexion par la machine distante (avec ping, si la machine visée est très chargée, la génération du paquet ICMP de réponse peut prendre un temps non négligeable ; c'est encore pire avec des protocoles applicatifs, où la réflexion n'est pas faite dans le noyau, et est donc vulnérable à par exemple, le swapping).
Comme avec tout système de mesure, les horloges et leurs imperfections jouent un rôle crucial. La section 2.2 rappelle des concepts (voir le RFC 2330) comme la synchronisation (le fait que deux horloges indiquent la même valeur) ou le décalage (le fait qu'une horloge aille plus ou moins vite qu'une autre).
Enfin, après tous ces préliminaires, le RFC en arrive à la définition de la métrique, en section 3. Type-P-One-way-Delay est définie comme une fonction de divers paramètres comme les adresses IP des deux parties et l'instant de la mesure. La mesure dépend aussi du Type-P (par exemple parce que certains ports sont favorisés par la QoS). Elle est en secondes. Et sa définition (section 3.4) est « Le temps entre l'envoi du premier bit du paquet sur le câble et la réception du dernier bit du paquet depuis le câble ». Si le paquet n'arrive pas, le délai est dit « indéfini » et, en pratique, pris comme étant infini.
Ce n'est pas tout de définir une métrique, il faut aussi la mesurer. Dans le monde réel, cela soulève quelques problèmes, couverts par la section 3.5. Le principal étant évidemment la synchronisation des horloges. Si le paquet part à 1247389451,578306110 (en secondes depuis le 1er janvier 1970) et arrive à 1247389453,018393817, le délai a t-il réellement été de 1,44 secondes ou bien seulement de 1,32 secondes mais les horloges différaient de 0,12 secondes ? Comme des délais peuvent être aussi bas que 100 µs, une synchronisation précise est nécessaire. Le GPS est une bonne solution pour cela, NTP une moins bonne, car sa résolution est plus faible et il dépend du réseau qu'on veut mesurer.
IL faut aussi tenir compte de problèmes comme les paquets perdus (si le délai de garde est de cinq secondes, un paquet perdu ne doit pas compter pour un délai d'acheminement de cinq secondes, ou bien des agrégats comme la moyenne seront complètement faussés) ou comme la duplication de paquets (dans ce cas, le RFC précise que c'est la première occurrence qui compte).
Enfin, pour celui qui voudrait concevoir un protocole de mesure de cette métrique, le RFC suggère une méthodologie, en section 3.6 :
- S'assurer de la synchronisation des horloges,
- Former le paquet et y mettre l'instant de départ sur le câble (sur une machine non temps réel, cela peut être délicat de mettre cet instant exact) ,
- À la réception, mesurer l'instant et calculer la différence avec ce qui est indiqué dans le paquet,
- Évaluer l'erreur (il y en aura forcément) et, éventuellement, corriger.
Cette question de l'analyse d'erreur fait l'objet de la section
3.7. Les deux principales sources d'erreur seront liées aux horloges
(qui ne sont jamais parfaites) et à la différence entre le temps de
départ ou d'arrivée mesuré et le temps réel. Sur un système d'exploitation multi-tâches et non
temps réel comme Unix,
le temps entre le moment où le paquet arrive dans la carte
Ethernet et celui où l'application peut appeler
gettimeofday() est souvent
significatif (section 3.7.2) et, pire, variable et imprévisible (car
on dépend de l'ordonnanceur). Parmi les
mécanismes pour déterminer l'erreur, de façon à pouvoir effectuer les
corrections, le RFC suggère la calibration
(section 3.7.3).
Une fois qu'on a bien travaillé et soigneusement fait ses mesures, il est temps de les communiquer à l'utilisateur. C'est l'objet de la section 3.8. Elle insiste sur l'importance d'indiquer le Type-P, les paramètres, la métode de calibration, etc. Si possible, le chemin suivi par les paquets dans le réseau devrait également être indiqué.
Maintenant, la métrique pour une mesure isolée, un singleton, est définie. On peut donc bâtir sur elle. C'est ce que fait la section 4, qui définit une mesure répétée, effectuée selon une distribution de Poisson, Type-P-One-way-Delay-Poisson-Stream.
Une fois cette métrique définie, on peut créer des fonctions d'agrégation des données, comme en section 5. Par exemple, la section 5.1 définit Type-P-One-way-Delay-Percentile qui définit le délai d'acheminement sous lequel se trouvent X % des mesures (les mesures indéfinies étant comptées comme de délai infini). Ainsi, le 95ème percentile indique le délai pour lequel 95 % des délais seront plus courts (donc une sorte de « délai maximum en écartant les cas pathologiques »). Attention en regardant l'exemple, le RFC comporte une erreur. La section 5.2 définit Type-P-One-way-Delay-Median qui est la médiane (équivalente au 50ème percentile, si le nombre de mesures est impair). La moyenne, moins utile, n'apparait pas dans ce RFC.
Au moins un protocole a été défini sur la base de cette métrique, OWAMP, normalisé dans le RFC 4656 et mis en œuvre notamment dans le programme de même nom. Depuis, cette métrique a été légèrement modifiée dans le RFC 7679.
L'article seul
RFC 1: Host Software
Date de publication du RFC : Avril 1969
Auteur(s) du RFC : Steve Crocker (University California Los Angeles (UCLA))
Statut inconnu, probablement trop ancien
Première rédaction de cet article le 10 juillet 2009
Un document historique, le premier des RFC. Cette série de documents, qui forme l'ossature de la normalisation de l'Internet a désormais un peu plus de quarante ans. L'auteur de ce RFC 1, Steve Crocker, a d'ailleurs publié un excellent article dans le New York Times pour célébrer cet anniversaire, How the Internet Got Its Rules, révélant que le RFC 1 avait été écrit dans une salle de bains.
Évidemment, le temps a passé. Techniquement, le RFC 1 n'a plus beaucoup d'utilité. Mais, outre son rang dans la série, il reste une lecture fascinante pour l'ingénieur, le souvenir d'une époque où une bande d'universitaires mettaient en place les fondations de ce qui allait devenir l'Internet.
Pour l'anecdote, notons que le dernier RFC écrit par Steve Crocker, le RFC 4986 sur DNSSEC, a été publié en août 2007, trente-huit ans après le premier. (Ne pas confondre avec les RFC, plus récents, de son frère Dave Crocker).
Le prédécesseur de l'Internet, l'Arpanet, existait déjà lorsque le RFC a été écrit. Suivant une tradition courante sur l'Internet, la documentation suit le déploiement. Ce réseau était composé de deux sortes de machines bien distinctes, les IMP (on dirait aujourd'hui les routeurs) et les machines terminales, les hosts. Les IMP étant fermés et contrôlés par une entreprise privée, BB&N, les étudiants comme Crocker étaient laissés avec le host software. Le RFC 1, contrairement aux RFC récents, méritait bien son nom d'« Appel à commentaires ». Il contient autant de questions que de réponses.
Donc, à l'époque, les données circulaient dans des messages (les termes comme paquet n'existaient pas encore). L'en-tête de ces messages faisait seulement 16 bits dont cinq (!) étaient réservés à l'adresse de destination. Il ne pouvait donc y avoir que 32 machines sur le premier Arpanet (IPv4 passera à 32 bits en 1981 et IPv6 à 128 en 1995). Parmi les autres champs de l'en-tête, un bit Trace qui indiquait à l'IMP d'envoyer une copie du message au Network Measurement Center, pour débogage...
Plus étonnant, l'en-tête comporte un champ nommé Link qui indique une connexion entre deux machines. Ces connexions n'étaient pas établies ou coupées à la demande mais fixes. (Le fait que les ressources soient allouées statiquement était courant dans les systèmes d'exploitation de l'époque.) Les connexions étaient au nombre de 32, maximum, et le RFC se demande à juste titre pourquoi le champ Link fait huit bits (il semble que personne ne se souvienne de la raison).
Après cette description très sommaire du logiciel, le RFC liste les usages prévus, et les exigences que doit suivre ce logiciel. Ainsi, le principal usage envisagé est la connexion à distance (dans le style du futur telnet).
La question de la latence du réseau revient souvent dans le RFC. Avec le temps que prend un message pour aller et venir (environ une seconde à l'époque), des problèmes comme l'écho des caractères tapés localement allaient être pénibles.
Si certains problèmes ont disparu avec le temps (ou bien ont diminué d'acuité comme la question de la latence), d'autres restent d'actualité. Ainsi, le RFC 1 insiste sur le fait que la machine doit mettre en œuvre de la correction d'erreurs, même si BB&N jure que l'IMP le fait déjà (« nous les croyons mais nous vérifions »). Une question qui préfigure les futurs débats sur le principe de bout en bout.
Si les connexions entre machines sont permanentes, à bord de chaque machine, les programmes n'ont pas d'accès au lien avant de l'avoir demandé explicitement. Chaque système d'exploitation d'une machine Arpanet doit donc fournir des fonctions de gestion de la connexion (et, bien sûr, d'envoi et de réception des données via la connexion). La fonction doit indiquer si la connexion sera plutôt utilisée pour l'accès à distance ou plutôt pour le transfert de fichiers (auquel cas la gestion des tampons est différente et il n'y a pas d'échappement des caractères de contrôle).
L'accès à distance étant de loin la principale application envisagée, et le problème étant très riche, une section entière du RFC discute des besoins particuliers de ce service. Par exemple, compte-tenu des problèmes de latence, le RFC recommande que la gestion de certains caractères comme le caractère de suppression soit effectuée localement. Mais le RFC allait plus loin en proposant un langage entier de description des terminaux, nommé DEL.
Sinon, voyez une bonne lecture de ce RFC par Darius Kazemi.
L'article seul
Exposé IETF aux RMLL
Première rédaction de cet article le 8 juillet 2009
Le 8 juillet, à Nantes, j'ai eu le plaisir de faire un exposé lors des RMLL sur le sujet « Développement de protocoles à l'IETF ; les RFC ».
Voici les documents produits à cette occasion les transparents en PDF, en mode présentation ou bien en mode adapté à l'impression. Et leur source en format LaTeX/Beamer.
(C'est une version un peu étendue de l'exposé que j'avais fait à JRES 2007.)
L'article seul
Fais-moi plaisir !
Première rédaction de cet article le 8 juillet 2009
Un film gai, intellectuel, drôle, sentimental d'Emmanuel Mouret. Les acteurs sont tous extra, quelle que soit l'importance de leur rôle. Les dialogues sont bavards, drôles, entraînants.
Ma préférence personnelle, subjective et irrationnelle, parmi les acteurs, va à Deborah François, dans le rôle de la soubrette discrète mais indispensable.
À quel autre film ressemble t-il ? « After Hours » de Martin Scorsese (pour la soirée qui ne se passe pas comme prévu), « Diva » de Jean-Jacques Beineix (pour les décors et les personnages curieux) et « Chacun cherche son chat » de Cédric Klapisch (pour la légéreté et le marivaudage).
L'article seul
RFC 5585: DomainKeys Identified Mail (DKIM) Service Overview
Date de publication du RFC : Juillet 2009
Auteur(s) du RFC : T. Hansen (AT&T Laboratories), D. Crocker (Brandenburg Internetworking), P. Hallam-Baker
Pour information
Réalisé dans le cadre du groupe de travail IETF dkim
Première rédaction de cet article le 8 juillet 2009
Le système DKIM de signature numérique du courrier électronique est normalisé dans le RFC 6376. Ce n'est pas une norme simple et, comme le domaine dans lequel elle se situe est traditionnellement très délicat et voué aux polémiques vigoureuses, un effort d'explication était nécessaire. C'est ainsi qu'est né ce RFC 5585, qui donne une description de haut niveau de DKIM, en se focalisant sur le protocole (les aspects opérationnels ne sont pas évoqués).
Le principe de DKIM est de signer cryptographiquement les messages, en utilisant le DNS comme serveur de clés. La signature permet de lier, de manière fiable, un message à une organisation, celle qui gère le nom de domaine où a été trouvé la clé publique. Il y a très loin de cette liaison à la lutte contre le spam : DKIM n'est qu'une technique d'authentification, il ne peut donc pas résoudre tous les problèmes posés par les usages malveillants du courrier. Pour citer le RFC, « DKIM est une seule arme, dans ce qui doit être un vaste arsenal ».
La section 1 du RFC résume les principes de base de DKIM. Les attaques auxquelles DKIM permet de répondre ont été documentées dans le RFC 4686.
Une notion centrale est celle d'identité. Une personne ou une organisation a une identité et le but de DKIM est d'associer le message à une telle identité. Notons bien que, en soi, cela ne signifie pas que le message soit meilleur ou davantage valable, uniquement qu'il peut être rattaché à une personne ou une organisation. DKIM ne dit rien des qualités ou des défauts de cette personne ou de cette organisation, c'est une technique d'authentification, pas d'autorisation.
Pour DKIM, l'identité est un nom de domaine
comme pape.va, enron.com, ministere-de-l-harmonie.cn ou
enlargeyourpenis.biz. Ce nom de domaine est
désigné par le sigle SDID (Signing Domain
IDentifier). De même que BGP transmet
des informations entre AS, la confiance ne régnant qu'à l'intérieur
d'un AS, DKIM signe du courrier entre ADMD
(ADministrative Management Domain), un ADMD étant
une organisation (parfois informelle) à l'intérieur de laquelle la
confiance règne - alors qu'il n'y a évidemment pas, a priori, de confiance entre deux ADMD (annexe A.2).
La section 1.1 rappelle ce que DKIM ne fait pas :
- DKIM ne garantit pas tout le message, uniquement ce qui est signé (ce qui peut ne pas inclure certaines en-têtes, ou une partie du corps),
- DKIM ne dit rien sur le caractère du signataire. Si un message
proposant des modifications de l'anatomie prétend être émis par
enlargeyourpenis.biz, DKIM permet de vérifier cette prétention, il ne teste pas l'efficacité du médicament promu, - DKIM n'impose pas de politique quant au traitement à faire subir au message, après la vérification.
DKIM n'est pas, et de loin, la première technique mise au point pour augmenter la sécurité du courrier électronique. La section 1.2 examine les autres candidats (inutile de dire que la comparaison faite par les auteurs de DKIM est systématiquement défavorable à ces malheureux concurrents). Par exemple, SPF (RFC 7208) a des points communs avec DKIM, utilise également le nom de domaine comme identité (contrairement à ce que prétend ce RFC 5585) mais est également lié à l'adresse IP de l'émetteur, rendant difficile certaines délégations (par exemple, faire suivre un message).
Pas moins de quatre autres normes IETF utilisent une signature du message, l'ancêtre PEM (RFC 989), PGP (RFC 4880), MOSS (RFC 1848) et S/MIME (RFC 3851). Seuls PGP (plutôt apprécié dans le monde technique) et S/MIME (plutôt apprécié dans l'entreprise sérieuse et cravatée) ont connu un déploiement significatif mais qui, dans les deux cas, reste très loin du niveau de généralité qui serait nécessaire.
Outre le fait que la base installée était bien mince, le choix de DKIM de partir de zéro s'appuyait sur des arguments techniques. Ainsi, DKIM ne dépend pas, pour juger d'une clé, de signatures de cette clé (contrairement aux certificats X.509 de S/MIME ou au réseau de confiance de PGP) mais uniquement de sa disponibilité dans la DNS. DKIM n'a ainsi pas besoin d'une nouvelle infrastructure (comme le sont les serveurs de clés pour PGP).
Après ce tour d'horizon, le RFC expose les services que rend DKIM, en section 2. Il y a deux services importants, vérifier une identité et l'évaluer, juger de sa crédibilité et de son sérieux. DKIM fournit le premier service (section 2.1) et permet le second, dont il est un pré-requis.
Cette évaluation (section 2.2) n'est pas directement faite par
DKIM. Ce dernier ne peut pas répondre à la question « Est-ce qu'un
message venu de enron.com ou
france-soir.fr mérite d'être délivré ? ». Tout ce
que DKIM pourra faire est de garantir que cette identité est
authentique et que le message n'a pas été modifié en route (section
2.3). Mais, comme le dit le RFC, « si le message était mensonger au
début, il le sera toujours après la signature, et DKIM permettra de
garantir que le mensonge a été transmis fidèlement ».
À noter que l'absence d'une signature DKIM peut aussi bien signifier que le domaine (le SDID) en question ne signe pas, que d'indiquer une attaque active où le méchant a retiré la signature. La protection contre ces attaques sera assurée par la future norme sur les règles de signature (Signing Practices), qui permettra aux gérants d'un domaine d'indiquer dans le DNS si les messages émis par leur organisation sont systématiquement signés ou pas.
La section 3 résume le cahier des charges que suivait DKIM. Parmi les buts de ce dernier, pour ce qui concerne le protocole (section 3.1) :
- Une vérification du seul nom de domaine, pas de l'adresse entière (comme le fait PGP),
- La possibilité de signer à n'importe quel endroit de la chaîne, pas uniquement dans le MUA (pour tous ces termes techniques, l'annexe A du RFC rappelle leur sens) de l'émetteur (là encore, contrairement à PGP),
- Permettre de déléguer la signature à des tiers.
Et parmi les buts plus opérationnels (section 3.2) :
- Ne pas être intrusif pour les lecteurs qui ne gèrent pas DKIM : concentrée dans les en-têtes, la signature n'est guère visible pour eux,
- Permettre un déploiement progressif, sans exiger de tout le monde qu'il adopte le nouveau gadget immédiatement.
Comment DKIM atteint-il ces buts ? La section 4 expose les
fonctions qu'il assure. Le principe de base est que le signeur choisit
le SDID (le nom de domaine qui identifie l'origine du message), un
sélecteur (une chaîne de caractères arbitraire) et
signe le message, mettant la signature dans un en-tête
DKIM-Signature:. Le récepteur du message trouve
la clé publique en interrogeant le DNS pour un nom de domaine qui est formé par
l'ajout du sélecteur au SDID. Il peut alors vérifier la signature.
Ainsi, si je reçois un message d'un utilisateur de Google Mail contenant :
DKIM-Signature: v=1; a=rsa-sha256; c=relaxed/relaxed;
d=gmail.com; s=gamma;
...
je sais que ce message vient de gmail.com (quoi
que puissent dire les autres en-têtes) et que, comme le sélecteur est
gamma, je peux trouver la clé publique en
interrogeant gamma._domainkey.gmail.com.
Pour mieux comprendre où se situent ces différentes fonctions, on peut regarder le joli diagramme de la section 5, qui représente graphiquement l'architecture de DKIM (il vaut la peine de lire également l'annexe A, qui résume l'architecture du courrier électronique). Un autre point important de cette section est qu'actuellement, l'absence d'une signature dans un message ne prouve rien. Elle peut indiquer que l'émetteur ne signe pas, mais aussi qu'un méchant a modifié un message (ou inséré un faux). Dans l'état actuel du déploiement de DKIM, il est donc difficile de prendre des décisions lorsqu'un message n'est pas signé. Le problème sera traité par le futur RFC sur les règles de signature (Signing Practices), qui permettra à un domaine de publier les règles qu'il a choisi et qu'il suit en matière de signature DKIM. Un domaine pourra ainsi annoncer au monde qu'il signe systématiquement, ce qui permettra de rejeter les messages non signés mais prétendant venir de ce domaine.
Un article récent de Cisco sur le déploiement de DKIM indiquait une croissance rapide de son utilisation. Enfin, on peut trouver davantage d'informations sur le site officiel.
L'article seul
Améliorer les temps de réponse des requêtes PostgreSQL avec EXPLAIN
Première rédaction de cet article le 2 juillet 2009
Un des pièges de SQL est que c'est un
langage de haut niveau. Le rapport entre la
commande qu'on tape et le travail que doit faire la machine est
beaucoup moins direct et beaucoup plus dur à saisir qu'avec
l'assembleur. Il est donc fréquent qu'une
requête SQL qui n'aie pas l'air bien méchante prenne des heures à
s'exécuter. Heureusement, PostgreSQL dispose
d'une excellent commande EXPLAIN
qui explique, avant même qu'on exécute la commande, ce qu'elle va
faire et ce qui va prendre du temps.
Un excellent exposé d'introduction est Explaining
EXPLAIN mais, uniquement avec les transparents, c'est
un peu court. Voyons des exemples d'utilisation
d'EXPLAIN sur la base de données de
StackOverflow.
Je commence par une requête triviale, SELECT * FROM
Votes et je la fais précéder de
EXPLAIN pour demander à PostgreSQL de m'expliquer :
so=> EXPLAIN SELECT * FROM Votes;
QUERY PLAN
----------------------------------------------------------------
Seq Scan on votes (cost=0.00..36658.37 rows=2379537 width=16)
(1 row)
On apprend que PostgreSQL va faire une recherche séquentielle
(Seq Scan), ce qui est normal, puisqu'il faudra
tout trouver, que 2379537 tuples (lignes de la table SQL) sont à
examiner. Et que le coût sera entre... zéro et 36658,37. Pourquoi
zéro ? Parce que PostgreSQL affiche le coût de récupérer le
premier tuple (important si on traite les données
au fur et à mesure, ce qui est souvent le cas en
OLTP) et celui de récupérer tous les
tuples. (Utiliser LIMIT ne change rien,
PostgreSQL calcule les coûts comme si LIMIT
n'était pas là.)
Et le 36658,37 ? C'est 36658,37 quoi ? Pommes, bananes, euros, bons points ? Ce coût est exprimé dans une unité arbitraire qui dépend notamment de la puissance de la machine. Avant de lire toute la documentation sur le calcul des coûts, faisons une autre requête :
so=> EXPLAIN SELECT count(*) FROM Votes;
QUERY PLAN
---------------------------------------------------------------------
Aggregate (cost=42607.21..42607.22 rows=1 width=0)
-> Seq Scan on votes (cost=0.00..36658.37 rows=2379537 width=0)
(2 rows)
Cette fois, le coût du premier tuple est le même que le coût total, ce
qui est logique, puisque les fonctions d'agrégation comme
count() nécessitent de récupérer toutes les
données.
Les coûts qu'affiche EXPLAIN ne sont que des
coûts estimés, sans faire effectivement tourner
la requête (donc, EXPLAIN est en général très
rapide). Si on veut les temps réels, on peut ajouter le mot-clé
ANALYZE :
so=> EXPLAIN ANALYZE SELECT * FROM Votes;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------
Seq Scan on votes (cost=0.00..36658.37 rows=2379537 width=16) (actual time=0.042..3036.302 rows=2379537 loops=1)
Total runtime: 5973.786 ms
(2 rows)
Cette fois, on a le temps effectif, trois secondes. On peut en déduire que, sur cette machine, l'unité de coût de PostgreSQL vaut environ 0,08 milli-secondes (3036,302 / 36658,37). Sur un serveur identique, mais avec des disques de modèle différent et un autre système de fichiers, on arrive à une valeur quasiment identique. Mais sur un simple portable, je mesure un facteur de 0,5 milli-secondes par unité de coût.
De toute façon, il faut faire attention : ce facteur d'échelle dépend de beaucoup de choses, à commencer par les réglages du SGBD. Est-ce que ce ratio de 0,08 milli-secondes peut nous aider à prévoir le temps d'exécution d'une requête ? Voyons une requête plus compliquée qui compte le nombre de votes ayant eu lieu dans les 24 heures ayant suivi le message :
so=> EXPLAIN SELECT count(votes.id) FROM votes, posts WHERE votes.post = posts.id AND
so-> votes.creation <= posts.creation + interval '1 day';
QUERY PLAN
---------------------------------------------------------------------------------
Aggregate (cost=147911.94..147911.95 rows=1 width=4)
-> Hash Join (cost=31161.46..145928.99 rows=793179 width=4)
Hash Cond: (votes.post = posts.id)
Join Filter: (votes.creation <= (posts.creation + '1 day'::interval))
-> Seq Scan on votes (cost=0.00..36658.37 rows=2379537 width=12)
-> Hash (cost=15834.65..15834.65 rows=881665 width=12)
-> Seq Scan on posts (cost=0.00..15834.65 rows=881665 width=12)
(7 rows)
PostgreSQL affiche un coût de 147911,95 soit 11,8 secondes. Et le résultat effectif est :
so=> EXPLAIN ANALYZE SELECT count(votes.id) FROM votes, posts WHERE votes.post = posts.id AND
votes.creation <= posts.creation + interval '1 day';
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=147911.94..147911.95 rows=1 width=4) (actual time=15125.455..15125.456 rows=1 loops=1)
...
soit 15 secondes au lieu des 11 prévues, ce qui n'est pas trop mal, pour une fonction de coût qui agrège beaucoup de choses différentes.
Si on trouve le résultat de EXPLAIN ANALYZE un peu dur à lire, on peut
le copier-coller dans http://explain-analyze.info/ et on a alors une présentation plus jolie.
Que voit-on d'autre sur la sortie de EXPLAIN
pour cette requête ? Que les coûts s'additionnent (regardez bien
l'indentation des lignes commençant par -> pour voir comment faire l'addition). La recherche
séquentielle la plus interne (sur la table Posts) coûte 15834,65, le
hachage coûte le même prix (il n'a rien
ajouté), l'autre recherche séquentielle (sur la table Votes) a un coût de 36658,37 et ces
deux coûts vont s'ajouter, ainsi que le filtrage et le test de
jointure, pour donner 145928,99, le coût de la
jointure. Ensuite, un petit coût supplémentaire restera à payer pour
l'agrégat (count()) nous emmenant à
147911,95.
L'addition des coûts se voit encore mieux sur cette requête :
so=> EXPLAIN SELECT count(votes.id)*100/(SELECT count(votes.id) FROM Posts, Votes
so(> WHERE Votes.post = Posts.id) AS percent
so-> FROM votes, posts WHERE
so-> votes.post = posts.id AND
so-> votes.creation > (posts.creation + interval '1 day')::date;
QUERY PLAN
----------------------------------------------------------------------------------------------------
Aggregate (cost=287472.95..287472.97 rows=1 width=4)
InitPlan
-> Aggregate (cost=133612.15..133612.16 rows=1 width=4)
-> Hash Join (cost=30300.46..127663.31 rows=2379537 width=4)
Hash Cond: (public.votes.post = public.posts.id)
-> Seq Scan on votes (cost=0.00..36658.37 rows=2379537 width=8)
-> Hash (cost=15834.65..15834.65 rows=881665 width=4)
-> Seq Scan on posts (cost=0.00..15834.65 rows=881665 width=4)
-> Hash Join (cost=31161.46..151877.84 rows=793179 width=4)
Hash Cond: (public.votes.post = public.posts.id)
Join Filter: (public.votes.creation > ((public.posts.creation + '1 day'::interval))::date)
-> Seq Scan on votes (cost=0.00..36658.37 rows=2379537 width=12)
-> Hash (cost=15834.65..15834.65 rows=881665 width=12)
-> Seq Scan on posts (cost=0.00..15834.65 rows=881665 width=12)
(14 rows)
dont le temps d'exécution effectif est de 30 secondes, très proche des 23 secondes calculées en multipliant le coût total de 287472,97 par le facteur d'échelle de 0,08 millisecondes.
Plusieurs essais avec des bases très différentes montrent que le facteur d'échelle (la valeur en milli-secondes d'une unité de coût) est plutôt stable. Voici un résultat avec la base de DNSmezzo :
dnsmezzo2=> EXPLAIN ANALYZE SELECT DISTINCT substr(registered_domain,1,43) AS domain,count(registered_domain) AS num FROM DNS_packets WHERE file=3 AND NOT query AND rcode= 3 GROUP BY registered_domain ORDER BY count(registered_domain) DESC;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------------------------
Unique (cost=496460.23..496460.31 rows=10 width=12) (actual time=41233.482..42472.861 rows=234779 loops=1)
-> Sort (cost=496460.23..496460.26 rows=10 width=12) (actual time=41233.478..41867.259 rows=234780 loops=1)
Sort Key: (count(registered_domain)), (substr(registered_domain, 1, 43))
Sort Method: external merge Disk: 11352kB
-> HashAggregate (cost=496459.91..496460.06 rows=10 width=12) (actual time=38954.395..39462.324 rows=234780 loops=1)
-> Bitmap Heap Scan on dns_packets (cost=197782.55..496245.34 rows=42914 width=12) (actual time=34594.268..38306.833 rows=250006 loops=1)
Recheck Cond: ((rcode = 3) AND (file = 3))
Filter: (NOT query)
-> BitmapAnd (cost=197782.55..197782.55 rows=87519 width=0) (actual time=34590.468..34590.468 rows=0 loops=1)
-> Bitmap Index Scan on rcode_idx (cost=0.00..74228.75 rows=1250275 width=0) (actual time=28144.654..28144.654 rows=1290694 loops=1)
Index Cond: (rcode = 3)
-> Bitmap Index Scan on pcap_idx (cost=0.00..123532.10 rows=2083791 width=0) (actual time=6393.187..6393.187 rows=2233781 loops=1)
Index Cond: (file = 3)
Total runtime: 42788.863 ms
(14 rows)
Quelques ressources intéressantes si on veut accelérer ses requêtes PostgreSQL :
- Performance Tips dans la documentation officielle.
- Performance Optimization sur le Wiki officiel.
- A Quick Look at How To Optimize PostgreSQL Queries.
L'article seul
RFC 1498: On the Naming and Binding of Network Destinations
Date de publication du RFC : Août 1993
Auteur(s) du RFC : Jerome H. Saltzer (MIT, Laboratory for Computer Science)
Statut inconnu, probablement trop ancien
Première rédaction de cet article le 2 juillet 2009
Les discussions d'architecture des réseaux à l'IETF ou
dans d'autres communautés techniques achoppent souvent sur le
vocabulaire. Qu'est-ce que le nom d'une machine ?
Qu'identifie t-il réellement ? La clé publique
SSH d'une machine est-elle un nom ? D'ailleurs,
faut-il identifier les machines ? Pourquoi pas les
processus ? Ou les utilisateurs ? Et l'adresse ?
Quel est son statut ?
http://www.foo.example:8080/toto est-il une
adresse bien qu'il inclus un nom ? Il ne s'agit pas uniquement de
pinaillage philosophique. C'est en partie à cause du flou sur les
concepts que les discussions d'architecture tournent en rond et
s'éternisent.
D'innombrables documents, dont ce RFC, ont été produits pour tenter de clarifier la situation. Mais aucune terminologie cohérente n'a été adoptée. Notre RFC 1498 est donc une étape, une des plus souvent citées, dans cette longue liste. Quels sont ses points essentiels ? (Attention si vous distribuez ce document, c'est un des rares RFC qui a une licence qui n'autorise pas une distribution libre.)
Le RFC essaie d'appliquer les principes des systèmes d'exploitation aux réseaux. Les systèmes d'exploitation, eux aussi, doivent identifier les fichiers, les utilisateurs, les disques, les partitions, les parties de la mémoire, etc. Le RFC reprend la terminologie classique (mais très peu appliquée en pratique) de John Shoch, que tous les étudiants des années 1980 et 1990 ont apprise par cœur (Shoch, « A note on Inter-Network Naming, Addressing, and Routing », une copie est disponible sous le nom d'IEN 19 ) :
- Un nom identifie ce qu'on veut,
- Une adresse identifie où cela se trouve,
- Une route identifie comment y aller.
À noter que cette terminologie, dans notre RFC, ne ne fait pas référence à la forme des identificateurs. Ainsi, un nom peut aussi bien être une suite de lettres ayant un sens qu'une série de chiffres opaques (contrairement à une vision trop simpliste selon laquelle les noms sont juste une forme conviviale des adresses). La terminologie de ce RFC ne sépare donc pas les identificateurs qu'un humain peut traiter et ceux qu'une machine peut traiter.
On peut voir tout de suite (ce point ne figure pas dans le RFC) que cette terminologie ne s'applique pas du tout à l'Internet. Une adresse IP, par exemple, n'identifie pas une position dans la topologie de l'Internet, puisqu'il existe des adresses PI, il y a l'anycast, etc. Un URL est un mélange de nom (la ressource que je veux) et d'adresse (puisqu'il indique où trouver la ressource, avec pas mal de détails de bas niveau comme le numéro de port).
J. Saltzer, donc, procède autrement. Il distingue quatre types d'objets qu'on peut avoir envie d'identifier :
- Les services et les utilisateurs. Les services sont, par exemple, un service de synchronisation d'horloge.
- Les nœuds du réseau (en gros, les machines).
- Les points d'attachement au réseau. Ce sont les endroits où une machine se connecte et, dans la terminologie de Shoch, ce sont les adresses. Une machine IP multihomée aura ainsi plusieurs points d'attachement au réseau.
- Les chemins (ou routes) entre points d'attachement.
Et Saltzer insiste sur le fait qu'un nom peut prendre plusieurs formes (par exemple une binaire sur le câble et une lisible pour les documentations et les fichiers de configuration), sa nature ne dépend pas de sa forme.
Là encore, même si ce point n'est pas abordé dans le RFC, on peut s'amuser à chercher une correspondance entre ces types et les identificateurs utilisés sur l'Internet :
- Les services ou utilisateurs sont typiquement identifiés par un
URI (ou parfois par une forme dégénérée,
uniquement le nom de domaine, comme lorsqu'on
dit
fr.wikipedia.orgau lieu dehttp://fr.wikipedia.org/), - Les nœuds n'ont pas vraiment d'identificateurs, à part dans certains protocoles comme SSH et HIP,
- Les points d'attachement sont vaguement identifiés par les adresses IP mais des techniques comme l'anycast ou des mécanismes d'allocation comme les adresses PI brouillent sérieusement les choses (avec l'anycast, l'adresse IP est plutôt un identificateur de service),
- Les chemins sont la liste des adresses IP des routeurs traversés, celle qu'affiche traceroute.
Pour notre RFC, les quatre types d'objets cités ci-dessus ont chacun une identité. Cette identité se maintient même si l'objet change ses liaisons avec les autres objets. Ainsi, un service ne devrait pas changer de nom lorsqu'il migre d'une machine à une autre, une machine (un nœud) ne devrait pas changer de nom lorsqu'il migre d'un point d'attachement à un autre, etc.
L'essentiel, donc, dit le RFC, est la liaison (binding) qui est faite entre un type d'objets et un autre. Ainsi, il doit exister un mécanisme de découverte qui permet de faire la liaison entre un service et la machine sur laquelle il opère. Un autre mécanisme de liaison permet de passer de la machine au point d'attachement. Un dernier fait passer du point d'attachement au chemin. Chacun de ces mécanismes doit également effectuer un choix, car il existe souvent plusieurs réponses.
Dans l'Internet actuel, en l'absence de vrai identificateur de machine, il y a plutôt un mécanisme unique, le DNS, qui sert aux deux premiers rôles. BGP, lui, prend en charge le dernier. (Ils ne sont pas cités dans le RFC.)
Il existe aussi parfois un autre mécanisme préalable aux autres, celui qui permet de trouver l'identificateur du service, c'est par exemple un moteur de recherche. La question est discutée dans le RFC, qui note qu'il n'y a pas toujours une liaison explicite, dans une table, entre l'idée humaine d'un service et son nom formel. Ainsi, changer un nom formel est très difficile (voir l'excellent article Cool URIs don't change).
Le RFC discute ensuite quelques cas de réseaux réels, en tenant de les mettre en correspondance avec les notions de types d'objets et de liaisons. Dans le cas d'Ethernet, l'adresse MAC est très mal nommée puisqu'elle est constante et ne dépend pas de la localisation. C'est en fait plutôt un nom et elle est utilisée comme telle par certains logiciels, par exemple pour le contrôle de la licence d'utilisation. Le cas est en fait plus complexe, par exemple parce qu'une machine a deux cartes Ethernet et peut se connecter à un réseau Ethernet en deux points. Les réseaux réels n'ont pas été conçus selon une architecture propre...
Un autre exemple est le vieux NCP où l'identificateur appelé « nom » était en fait dépendant de la position de la machine. En l'absence de mécanisme de résolution commun, la liaison entre un nom et un point d'attachement était câblée en dur dans toutes les machines du réseau. Changer une machine de place imposait donc de changer son nom... ou de mettre à jour toutes les machines du réseau, ce qui n'est pas mieux. Saltzer argumente donc que la nature d'un identificateur dépend de l'existence ou nom d'un mécanisme de résolution, et donc de l'existence d'une vraie liaison avec les identificateurs des autres types d'objet (Un autre exemple aurait pu être Fidonet.)
Donc, pour résumer ce brillant document :
- Il existe plusieurs types d'objet à identifier,
- Un mécanisme de liaison est nécessaire pour passer des identificateurs d'un type aux identificateurs d'un autre type,
- Les réseaux réels comme l'Internet ne collent jamais parfaitement aux modèles.
L'article seul
RFC 1122: Requirements for Internet Hosts - Communication Layers
Date de publication du RFC : Octobre 1989
Auteur(s) du RFC : Robert Braden (University of Southern California (USC)/ Information Sciences Institute (ISI))
Chemin des normes
Première rédaction de cet article le 2 juillet 2009
Compagnon du RFC 1123, ce document normalise ce que toute machine terminale (host, par opposition à routeur) connectée à l'Internet devrait savoir. Le RFC 1123 fixait les règles des « couches hautes » (notamment la couche application), notre RFC s'attaque aux « couches basses », notamment réseau et transport). Il a depuis été partiellement mis à jour par le RFC 9293.
Le résultat est un document épais (116 pages), décrivant en détail tout ce qu'IP et TCP doivent faire sur une machine terminale (les routeurs sont, eux, traités dans le RFC 1812). La section 1.4 note que les discussions sur ce RFC avaient duré dix-huit mois et généré trois méga-octets de courrier, ce qui était considérable à l'époque mais est moins qu'un document MS-Word d'une page d'aujourd'hui.
Ce RFC n'avait pas pour but de changer les normes existantes (comme le RFC 791 pour IPv4 ou RFC 793 pour TCP) mais de les résumer et les préciser. Comme le note la section 1, « une mise en œuvre de bonne foi des protocoles TCP/IP, faite en lisant les normes, ne doit différer de ce RFC 1122 que par des détails ».
Aujourd'hui, plusieurs de ses sections sont bien dépassées mais il reste la norme officielle, personne n'a eu le courage de mettre ce travail à jour.
Il n'est donc pas possible de résumer tout le RFC et j'ai donc sélectionné arbitrairement quelques points qui me semblaient intéressants.
La section 1.1 rappelle l'architecture de l'Internet et la section 1.1.1 revient sur la notion de machine terminale (host dans le RFC). La section 1.1.2 note notamment que :
- L'Internet est un réseau de réseaux. Une machine terminale ne se connecte donc pas réellement à l'Internet, elle se connecte à un réseau connecté à Internet. Cette connexion se fait avec les mêmes protocoles, qu'on communique avec des machines du même réseau ou bien avec des machines lointaines. (La section 1.1.3 en donne une liste partielle, du protocole IPv4 pour les couches basses aux protocoles d'application comme telnet ou SMTP.)
- Les routeurs (le RFC utilise encore souvent le vieux terme de « passerelle » - gateway - qui n'est plus utilisé aujourd'hui que pour les engins travaillant dans la couche 7) n'ont pas de mémoire, ils routent chaque paquet indépendamment des autres. Les machines terminales ont donc à faire tout le travail d'établissement et de maintien des connexions.
- Le routage, par contre, ne doit être fait que par les routeurs. Il doit y avoir une stricte séparation entre machines terminales et routeurs. (Certains systèmes d'exploitation comme les Unix BSD routaient autrefois automatiquement dès qu'ils étaient connectés à deux réseaux. La section 1.1.4 explique pourquoi c'est une mauvaise idée. Voir aussi la discussion à la fin de la 3.3.4.2)
La section 1.2 pose les grands principes comme le célébrissime Principe de Robustesse (section 1.2.2), « Soyez tolérant pour ce que vous recevez et exigeant pour ce que vous envoyez », principe qu'on trouve dans plusieurs autres RFC. Ainsi, un programmeur doit résister à la tentation d'exploiter les cas spécifiques d'une norme, pour éviter de perturber les autres implémentations.
La section 1.2.4 détaille la configuration des machines terminales. Elle se faisait entièrement à la main à l'époque. Aujourd'hui, avec la disponibilité fréquente de DHCP (RFC 2131), il vaut mieux oublier cette section et lire le dernier document sur la configuration, le RFC 5505.
Ensuite, le RFC suit le modèle en couches (section 1.3.1), ainsi que le vocabulaire spécifique de chaque couche pour désigner une unité de transmission de données sur le réseau (frame pour la couche 2, packet ou datagram - selon que la fragmentation aie eu lieu ou pas - pour la couche 3, message - segment pour TCP - pour la couche 4).
La section 2 concerne donc la couche de même rang. C'est ici que se trouve ARP (section 2.3.2, qui insiste que l'expiration des entrées du cache ARP est obligatoire, ce qui n'était pas assez clair dans le RFC 826). C'est aussi dans cette section (en 2.3.3) que l'on rappelle que l'encapsulation normale des paquets IP sur Ethernet est celle du RFC 894, où le troisième champ de l'en-tête Ethernet est le type du protocole de couche 3 (0x800 pour IPv4) pas celle, bien plus complexe, du RFC 1042, où la longueur de la trame se trouve à cet endroit.
Évidemment, la section 3, consacrée à la couche équivalente, est bien plus longue. Elle porte aussi son âge, par exemple en consacrant une section 3.2.1.3 aux classes d'adresse, supprimées depuis.
Parmi les nombreux points abordés, le choix du
TTL à mettre dans les paquets (section
3.2.1.7). Une machine terminale ne doit pas émettre un paquet avec un
TTL déjà à zéro. La mise en œuvre d'IP doit permettre aux
applications de fixer
le TTL (sur une machine Posix, cela se fait
normalement avec setsockopt(), voir
« Tester quels bits de l'en-tête IP on
peut changer »).
Mais il y a aussi des exigences du RFC qui ne sont plus du tout suivies aujourd'hui. La section 3.2.1.8 obligeait toute mise en œuvre d'IP à permettre le routage par la source alors que, pour des raisons de sécurité, quasiment plus aucun routeur ne l'accepte.
ICMP (RFC 792) faisant conceptuellement partie de la couche 3, il a droit à une sous-section de la section 3. Elle rappelle par exemple qu'un paquet ICMP d'erreur ne doit jamais être envoyé lorsque le paquet original était lui-même un paquet ICMP d'erreur, pour éviter les boucles. (On lit souvent cette règle énoncée comme « Un paquet ICMP ne doit jamais être envoyé en réponse à un paquet ICMP », ce qui est complètement faux, voir par exemple ping avec les ICMP echo, revus en section 3.2.2.6.)
Parmi les autres sujets abordés, la détection d'un routeur mort, qui ne transmet plus les paquets. Comme les machines terminales n'ont pas (ou plus) de protocole de routage (comme, par exemple, RIP), comment savent-elles que le routeur, en panne, est devenu un trou noir ? La méthode recommandée est, formellement, une violation du modèle en couches, mais c'est la seule qui marche dans tous les cas : les couches hautes doivent informer IP qu'elles ne reçoivent plus rien. (La section 3.3.1.4 est une passionnante discussion des autres options possibles. À lire par tout ingénieur qui s'intéresse aux réseaux.)
Le multihoming, la connexion d'une machine (ou
d'un réseau) à plusieurs réseaux, a toujours été un problème difficile
pour IP. La section 3.3.4 tente de fixer certaines règles. Par
exemple, lors d'une réponse, l'adresse IP source de la réponse doit
être l'adresse IP de destination où a été envoyée la question. Ou
encore, une application cliente doit avoir la possibilité de choisir son
adresse IP source (directive BindAddress de
OpenSSH ou bien
tcp_outgoing_address de
Squid). Et que faire en l'absence de telles
directives ? C'est l'objet de la section 3.3.4.3 qui demande de
privilégier, si possible, une adresse source située dans le même
réseau physique que l'adresse de destination (notez que le RFC 3684 a depuis fourni une solution plus générale à cette
question de sélection d'adresse source, pour le protocole
IPv6). Par exemple, une machine choisira comme
adresse IP source 127.0.0.1 si elle doit
contacter localhost et son adresse globale si
elle doit contacter une autre machine.
Au sommet de la couche
3 se trouve l'interface avec la couche 4. La section 3.4 détaille les services
que doit rendre cette interface. Par exemple, la couche 3
doit fournir un moyen de fixer (pour un paquet
émis) et d'interroger (pour un paquet reçu) des paramètres comme le
TTL ou le TOS (depuis
rebaptisé DSCP par le RFC 2474). Cette section
est rédigée sous forme d'une API virtuelle (les
API de programmation réseau réelles ont suivi un autre modèle, mais
fournissent les mêmes services, cf. le livre de Stevens). Cette API comporte
des méthodes comme SEND(src, dst, prot, TOS,
TTL, BufPTR, len, Id, DF, opt) (envoi d'un paquet en fixant
chaque paramètre).
Finalement, un tableau synthétique, en section 3.5, résume tout ce que doit implémenter le programmeur qui réalise une mise en œuvre d'IP.
La couche 4 est ensuite traitée dans la section 4. Suivant le modèle en sablier, une machine connectée à Internet a un grand choix de couches 2 et de supports physiques, une seule couche 3, IP, et à nouveau un choix en couche 4. À l'époque de notre RFC, il n'y avait qu'UDP (RFC 768) et TCP (RFC 793). Depuis, plusieurs autres ont rejoint ces deux pionniers.
Parmi les exigences pour UDP, le RFC cite une forte recommandation d'activer la somme de contrôle (section 4.1.3.4). Celle-ci est en effet facultative en UDP et plusieurs protocoles ont souffert d'avoir cru qu'ils pouvaient s'en passer (notamment NFS et le DNS pour lequel la version 1 de Zonecheck testait que cette somme de contrôle était bien activée).
TCP est bien plus riche et fait donc l'option d'une section nettement plus longue, la 4.2. À l'époque comme aujourd'hui, il est le protocole de transport le plus utilisé.
Le RFC commence (section 4.2.2) par une discussions sur le rôle des ports, en rappelant que la seule distinction normalisée entre les ports est celle entre ceux inférieurs à 255 (services normalisés) et les autres. La distinction entre les ports privilégiés (inférieurs à 1024) et les autres n'est pas normalisée, en pratique, elle est spécifique à Unix. Le RFC ne s'oppose pas à cette distinction mais note à juste titre qu'elle ne vaut pas grand'chose en matière de sécurité puisque rien ne dit que la machine avec qui on correspond applique les mêmes règles. En outre, depuis la publication du RFC 1122, la vaste diffusion des ordinateurs fait qu'un éventuel attaquant a probablement sa propre machine, sur laquelle il est root. La très relative protection sur laquelle comptaient rlogin (en vérifiant que le port source était 513) et le DNS (qui utilisait à une époque lointaine un port source fixe, 53), ne vaut donc plus rien.
Il y a plein d'autres détails intéressants à couvrir comme l'option PUSH (section 4.2.2.2) dont le RFC rappelle qu'elle ne fournit pas un marquer de fin de message mais qu'elle indique juste un souhait que les données soient transmises « le plus vite possible » (TCP attend normalement un peu pour voir si d'autres données n'arrivent pas, cette optimisation, l'algorithme de Nagle est à nouveau discutée en section 4.2.3.4).
Finalement, un tableau synthétique, en section 4.2.5, résume tout ce que doit implémenter le programmeur qui réalise une mise en œuvre de TCP.
L'article seul
La version 10 de BIND avance
Première rédaction de cet article le 30 juin 2009
La prochaine version de BIND, le serveur de noms le plus répandu sur l'Internet, est désormais en phase active de développement, financée par des organisations comme l'AFNIC. Cette version sera marquée par plusieurs changements majeurs, notamment un mode de développement nettement plus ouvert (BIND 9 avait toujours été géré de manière très privée).
Une liste résumée
des principaux changements est en ligne. La nouvelle version sera écrite en C++, avec Python pour les extensions et les scripts. Il existe aussi déjà
un Trac public, en https://bind10.isc.org/. Pour l'instant, il contient surtout
du remue-méninges. Et il existe une liste de
diffusion des développeurs et personnes intéressées.
L'article seul
Pourquoi le DNS, qu'est-ce qu'il apporte par rapport aux adresses IP ?
Première rédaction de cet article le 30 juin 2009
Le DNS est souvent présenté comme utile, car permettant d'utiliser des identificateurs « conviviaux » (les noms de domaine) plutôt que des suites de chiffres (les adresses IP). Cette explication n'est pas fausse mais elle est très incomplète.
On trouve une justification du DNS analogue à celle-ci en beaucoup
d'endroits. L'article de
Wikipédia dit « Il n'est pas évident pour un humain de
retenir ce numéro lorsque l'on désire accéder à un ordinateur
d'Internet. C'est pourquoi un mécanisme a été mis en place pour
permettre d'associer à une adresse IP un nom intelligible, humainement
plus simple à retenir, appelé nom de domaine. ». Sur le site de l'AFNIC, on
trouve « Sans le DNS, il faudrait mémoriser l'adresse d'un site ou une
adresse électronique sous la forme de l'adresse IP du domaine (qui est
une suite de chiffres. Exemple :
mon-correspondant@[192.134.4.35]) ! ». Et, en anglais, on voit sur le
site de
l'ICANN « Because IP addresses (which are strings of
numbers) are hard to remember, the DNS allows a familiar string of
letters (the "domain name") to be used instead. So rather than typing
"192.0.34.163," you can type "www.icann.org." ». Mais ce
n'est pas parce que tout le monde répète quelque chose que c'est
complètement vrai. D'abord, le fait que des identificateurs composés
uniquement de chiffres soient moins pratiques n'est pas si évident que
cela. Ainsi, les numéros de téléphone restent
largement utilisés et n'ont (malheureusement) pas été remplacés par
les URL SIP
comme sip:helpdesk@voip.apnic.net. (Curiosité : il existe
même une proposition de remplacer les noms de domaine par des numéros
de téléphone, ENUM.)
Personnellement, je pense que les noms de domaine sont plus simples, car plus mémorisables et plus porteurs d'identité mais, manifestement, tout le monde n'est pas d'accord, sinon les numéros de téléphone auraient disparu depuis longtemps (supprimant également le problème de la portabilité).
Les noms « conviviaux » ont un autre problème : comme ils ont une
sémantique, ils font l'objet de conflits. Tout le monde veut
sex.com et la
multinationale Kraft Foods peut empêcher Mme
Milka de garder son nom de domaine s'il
correspond à une marque déposée de ladite multinationale.
Néanmoins, le DNS est le système d'identificateur le plus fréquent
sur l'Internet. Quasiment toutes les
transactions sur le réseau passent par lui, et le trafic sur les
serveurs de noms ne cesse pas d'augmenter. C'est parce que les noms de
domaine fournissent un service bien plus utile que la « convivialité »
des noms : ils fournissent de la stabilité. La
plupart des sites Internet reçoivent des adresses IP liées au
fournisseur d'accès ou à un
hébergeur. Ce sont des adresses
PA, dont il faut changer si on change de
prestataire. Si je fait de la publicité pour mon blog en annonçant
http://208.75.84.80/, son adresse IP actuelle,
ce n'est pas seulement « moins joli » et « moins mémorisable » que
http://www.bortzmeyer.org/, c'est surtout moins
stable. L'adresse IP 208.75.84.80 est liée à l'hébergeur
actuel, Slicehost, et devra
changer si je passe à un autre hébergeur comme
OVH. Et je devrais prévenir tous mes lecteurs,
faire corriger tous les articles qui parlaient de ce blog, demander à
Google de changer l'URL
(tout en gardant mon PageRank), etc.
Bien sûr, il existe des adresses IP indépendantes du fournisseur, les adresses PI. Mais elles ne sont pas forcément faciles à obtenir et, surtout, elles ne résolvent pas complètement la question de la stabilité. Si deux services sont sur la même machine, et ont donc la même adresse IP, et que j'en déménage un seul, il devra bien changer d'adresse, même si l'ancienne et la nouvelle étaient indépendantes du prestataire. En application du principe « Cool URIs don't change », les noms de domaine permettent la permanence des identificateurs.
Et ne parlons même pas de la transition d'adresses IPv4 aux adresses IPv6. Sans l'intermédiaire des noms de domaine, cette transition serait encore plus pénible qu'elle ne l'est.
(Certaines personnes relativisent l'importance de la stabilité des URL en affirmant que les moteurs de recherche permettent de toute façon de retrouver la page Web. D'abord, les noms de domaine ne servent pas qu'au Web. Ensuite, le moteur de recherche ne permet justement aucune stabilité : un jour, taper « hôtel luchon » dans Google mènera à l'hôtel Majestic, un jour à un autre hôtel...)
L'article seul
strlen et l'optimisation
Première rédaction de cet article le 25 juin 2009
Dernière mise à jour le 30 juin 2009
Comme le savent les lecteurs de ce blog, je suis en général très méfiant vis-à-vis de l'optimisation prématurée des programmes. Pas seulement parce que la plupart des programmeurs qui parlent de performance tout de suite ne mesurent pas le résultat de leurs bricolages mais aussi parce que cette « optimisation » est souvent un prétexte pour faire du code imbittable et inmaintenable. Mais, comme avec toute règle, il y a des exceptions.
Par exemple, si une fonction donnée est appelée très souvent, elle
est évidemment une bonne candidate pour des optimisations très
poussées. C'est le cas de strlen,
fonction de la libc
qui mesure la longueur d'une chaîne de caractères en
C. Les programmes écrits en C (ce qui inclue
les implémentations des langages comme Ruby ou
Perl) appellent strlen
tout le temps. On peut donc, une fois une mise en œuvre correcte
de strlen produite, chercher des
optimisations de bas niveau.
Il est par exemple amusant de comparer les deux versions produites par OpenBSD :
- La version portable, triviale,
- et la version optimisée pour les processeurs i386, en assembleur.
La GNU libc dispose également d'une telle
version optimisée sur les i386 (version en
assembleur pour i586 et plus). Voir aussi un bon article sur l'écriture
en assembleur de strlen. Évidemment,
strcmp serait encore plus
intéressante à étudier, car plus complexe (les deux chaînes n'ont pas
forcément la même longueur).
Une autre curiosité pour les amateurs d'optimisation est la discussion sur un strlen() rapide pour UTF-8.
Merci à Victor Stinner pour ses intéressants ajouts.
L'article seul
Tutoriel DNSSEC à la conférence SARSSI
Première rédaction de cet article le 22 juin 2009
SARSSI est une petite conférence scientifique qui se déroule dans un cadre magnifique (surtout qu'il fait beau). Les sessions ont lieu dans le superbe « Pavillon Normand » qui avait été construit à Paris pour une Exposition Universelle et démonté ensuite pour être remonté à Luchon.
Les transparents du
tutoriel DNSSEC sont le résultat du travail de plusieurs ingénieurs successifs à
l'AFNIC. Voici leur source au format
OpenOffice : dnssec-tutorial-sarssi.odp.
Une jolie vue de Luchon depuis l'hôtel de la conférence : 
L'article seul
Fiche de lecture : Freakonomics
Auteur(s) du livre : Steven Levitt, Stephen Dubner
Éditeur : Penguin Books
978-0-14-103008-1
Publié en 2005
Première rédaction de cet article le 22 juin 2009
Ce livre a déjà fait l'objet de plein de mentions sur beaucoup de blogs différents donc je n'étais pas sûr qu'il fallait ajouter le mien. Mais, bon, le livre m'a énormément intéressé donc j'avais envie, d'une part d'en recommander la lecture, d'autre part d'ajouter quelques bémols.
Steven Levitt est économiste. Comme beaucoup d'économistes, il voit le monde uniquement à travers des lunettes d'économiste et analyse tous les comportements humains en terme de calculs rationnels visant à maximiser les gains matériels. Contrairement à beaucoup d'économistes, il ne fait pas trop de mathématiques et il ne s'intéresse guère aux politiques financières des banques centrales ou à la politique fiscale de l'État. Non, il se penche plutôt sur des sujets peu ou pas étudiés par l'économie et parfois pas étudiés du tout. Ses exemples pittoresques ont déjà fait la joie de beaucoup de commentateurs et facilité la tâche de l'éditeur qui cherche des choses amusantes à mettre sur le quatrième de couverture : les enseignants de Chicago et les joueurs de sumo trichent-ils ? Pourquoi la baisse de la criminalité aux États-Unis au début des années 1990 ? Peut-on déterminer l'efficacité de l'éducation que les parents donnent à leurs enfants ?
Bien que Levitt joue les modestes en prétendant qu'il est nul en maths, une bonne partie de ses méthodes emprunte aux statistiques. Par exemple, aussi bien pour les matchs de sumo que pour les examens scolaires à Chicago, il peut démontrer la triche uniquement en regardant les données, sans enquêter sur le terrain. (On comprend pourquoi tant d'organismes refusent de distribuer leurs données brutes sous une forme numérique : cela révèle plein de choses.) Pas besoin de parler japonais, mais il faut bien connaitre les règles de ce jeu. Si deux joueurs de sumo à peu près de force égale (à en juger par leurs matches précédents) se rencontrent, la probabilité de victoire de chacun est d'à peu près 50 %. Or, si le match en question est décisif pour l'un mais pas pour l'autre (par exemple parce qu'il est déjà qualifié), celui pour lequel le match est décisif gagne nettement plus souvent que ne le voudrait le calcul des probabilités. Est-ce simplement parce qu'il est plus motivé, à cause de l'importance de l'enjeu ? Mais, aux rencontres suivantes des deux mêmes adversaires, le joueur qui a gagné perd nettement plus souvent qu'il ne le devrait. Difficile de penser qu'il n'y a pas eu accord et renvoi d'ascenseur...
Même chose pour les enseignants de Chicago. Depuis qu'un PHB local s'est mis en tête d'évaluer les enseignants sur les résultats de leurs élèves, la motivation pour tricher, qui n'existait que pour les cancres, s'est étendue à leurs professeurs. Par une excellente analyse statistique, Levitt montre la réalité de cette fraude. À noter qu'il ne se demande pas une seconde si la décision d'augmenter le salaire des profs en fonction des notes des élèves n'était pas, peut-être, une stupide idée. Il se contente de laisser entendre que, si on ne licencie pas davantage de tricheurs, c'est à cause des syndicats trop puissants.
Les tricheurs ne sont en effet pas très forts en statistiques : les plus stupides changent toujours les réponses des mêmes questions. Les plus malins essaient de changer des questions au hasard mais l'être humain est un mauvais générateur de nombres aléatoires et l'impitoyable statistique montre facilement le côté invraisemblable de certaines notes. (Levitt revient sur la difficulté que nous avons à comprendre l'aléatoire en étudiant les scores d'une équipe de base-ball, les Kansas City Royals, et leur longue série de matches perdus en montrant que, si peu intuitif que cela soit, cette série peut être due au hasard.)
Le tricheur moyen est loin de posséder la maîtrise mathématique et le goût du travail parfait qui animent l'un des personnages de Cryptonomicon, lorsqu'il calcule la quantité de faux indices qu'il doit semer pour que les statisticiens de l'armée allemande considèrent le pourcentage de pertes mystérieuses de leurs navires comme étant « statistiquement vraisemblable », au lieu de conclure que leur code a été cassé.
(Maintenant que Stack Overflow a publié ses données, il serait intéressant de voir ce que Levitt peut déduire d'une telle masse d'informations.)
Levitt professe un culte des données : il se présente comme esprit libre, qui déduit des affirmations à partir des données, sans idées préconçues. Ainsi, il montre facilement qu'une piscine est bien plus dangereuse qu'une arme à feu lorsqu'on a des enfants en bas âge à la maison (Bruce Schneier a déjà longuement écrit sur le thème de notre difficulté à apprécier correctement l'ampleur relative des risques.) Mais, évidemment, dans le contexte des États-Unis, rien de ce qui concerne les armes à feu ne peut être vu commme neutre...
Levitt peut d'autant moins se réclamer d'une approche neutre qu'il répète à plusieurs reprises des énormités non prouvées, comme celle d'une hérédité du QI. En dépit de ses propres principes, il ne cite cette fois aucune référence (et pour cause, la plus connue était une fraude). Il reprend même la légende des N % de l'intelligence qui serait due à l'hérédité, montrant ainsi que son ignorance proclamée des maths n'est pas de la fausse modestie : il n'a effectivement pas compris que toutes les grandeurs ne sont pas additives.
Une autre polémique avait fait rage autour de Freakonomics, celle autour de l'avortement. Levitt montre que la criminalité baisse juste au moment où la légalisation de l'IVG a produit ses effets, lorsque les enfants non désirés qui seraient nés sans cette légalisation arrivent à l'âge où on commence une carrière criminelle. Mais simplement poser comme principe le droit des femmes à disposer de leur corps n'est pas acceptable pour un économiste digne de ce nom et Levitt se sent donc obligé de passer du temps à des calculs compliqués et sans base objective sur la « valeur » comparée d'un fœtus et d'un nouveau-né.
Beaucoup plus ethnologique est son étude des prénoms comparés des noirs et des blancs aux États-Unis. J'y ai appris que la ségrégation reste toujours très forte. Noirs et blancs vivent dans le même pays, mais pas dans la même nation. Leurs goûts en matière de feuilletons télévisés débiles ne sont pas les mêmes (et la différence est statistiquement très nette), de même que leurs choix des prénoms. Aujourd'hui, les blancs nomment leurs garçons Jake, Connor, Tanner, Wyatt ou Cody, les noirs DeShawn, DeAndre, Marquis, Darnell ou Terrell. Est-ce que ce prénom va influencer l'avenir de l'enfant ? Si oui, cette influence est difficile à démêler au milieu de tous les autres et Levitt, qui croit fermement à la réussite individuelle aurait sans doute noté, si on livre avait été publié plus tard, que s'appeler Barack plutôt que John n'était pas forcément un handicap...
Pour synthétiser, Levitt est-il de gauche ? Globalement non, notamment en raison de sa croyance aveugle dans les beautés du marché. Mais la comparaison des gangs de vendeurs de drogue avec McDonald's est très pertinente (dans les deux cas, l'entreprise est florissante et gagne beaucoup d'argent mais l'employé de base est payé des clopinettes et fait un travail très pénible, le tout s'appuyant sur une des rares études des finances d'un gang).
L'auteur et quelques personnes qui se réclament des mêmes méthodes, s'exprime aujourd'hui sur le blog Freakonomics.
L'article seul
DNSCurve, la sécurité pour le DNS ?
Première rédaction de cet article le 20 juin 2009
Dernière mise à jour le 31 août 2009
Tout le monde sait que le DNS n'est pas sûr. Si quelqu'un n'est pas au courant, il suffit de l'envoyer lire le RFC 3833. En 2008, la faille Kaminsky avait encore remis le dossier de la sécurité DNS sur le dessus de la pile. Les risques étant de natures très variées, il n'y a certainement pas de solution miracle à tous les problèmes de sécurité du DNS. Mais comme l'analyse sérieuse des problèmes de sécurité est difficile, comme la « balle d'argent » est une histoire plus vendeuse que la longue liste des mesures à prendre, on voit souvent une technologie particulière présentée comme la solution à tout. Vu l'expérience avec d'autres créations de Daniel Bernstein, il est probable que DNSCurve sera ainsi promu.
Avant de regarder DNSCurve et ses différences avec le protocole DNSSEC, revenons en arrière sur la sécurité du DNS. Lorsqu'un serveur DNS faisant autorité pour une zone envoie une réponse à un résolveur, un serveur DNS récursif, un méchant peut répondre avant le bon serveur et voir sa réponse acceptée par le résolveur, qui sera alors empoisonné (le RFC 5452 contient une explication plus détaillée et des calculs de la probabilité de réussite). C'est l'une des principales vulnérabilités du DNS.
Pour résoudre ce problème, il y a deux approches. Pour reprendre le vocabulaire du RFC 3552, on peut choisir de sécuriser le canal (vérifier qu'on parle bien à la machine à qui on voulait parler) ou de sécuriser le message (vérifier que le message vient bien de l'autorité et qu'il n'a pas été modifié en route). Les deux méthodes ne sont d'ailleurs pas contradictoires, on peut aussi choisir une défense en profondeur en adoptant les deux approches. En général, la sécurisation du message offre le maximum de sécurité (même si des intermédiaires ne sont pas dignes de confiance, on peut s'assurer de l'authenticité du message, ce qui est une propriété essentielle pour le DNS, qui dépend de tels intermédiaires, les serveurs cache) mais la sécurisation du canal est souvent plus facile à déployer.
Le débat existe pour tous les protocoles Internet. Par exemple, pour le courrier électronique, PGP sécurise le message, SMTP sur TLS (RFC 3207) sécurise le canal.
Dans le monde du DNS, la première solution, sécuriser le canal, est possible grâce à de nombreuses technologies :
- TSIG (RFC 8945), une signature de la transaction grâce à une clé secrète partagée entre les deux serveurs,
- SIG(0) (RFC 2931), une signature de la transaction utilisant des clés publiques,
- Diverses techniques de résistance à la fraude, comme le choix au hasard du port source (RFC 5452),
- Puisqu'une grande partie de la vulnérabilité du DNS vient de la
taille trop petite du Query ID, il y a des
propositions de l'étendre comme les DNS cookies
(Internet-Draft
draft-eastlake-dnsext-cookies) ou EDNS ping (Internet-Draftdraft-hubert-ulevitch-edns-ping), - IPsec (RFC 3401), si seulement il était déployé,
- Un protocole de transport résistant naturellement aux tricheries, comme TCP ou SCTP,
- Et pourquoi pas des datagrammes protégés par TLS comme avec DTLS (RFC 6347),
- Et enfin DNSCurve.
Toutes ces techniques ont leurs avantages et leurs inconvénients, certaines (comme celles du RFC 5452) ont eu de grands succès (comme de rendre peu exploitable la faille Kaminsky) mais toutes ont en commun de ne sécuriser que le canal entre deux serveurs. Si un serveur esclave d'une zone est contrôlé par un méchant et modifie les données, s'assurer qu'on parle bien à ce serveur ne servira à rien. Idem dans le cas, beaucoup plus fréquent, où un résolveur/cache d'un FAI ment à ses propres clients (cf. RFC 4924, section 2.5.2).
Pour la sécurisation du message, il n'existe à l'heure actuelle qu'une seule méthode, DNSSEC (RFC 4033 et suivants).
Revenons donc à DNSCurve. Cette technique n'est pas normalisée à
l'heure actuelle. Il existe une présentation sommaire sur le site officiel et un
Internet-Draft,
draft-dempsky-dnscurve. Pour la cryptographie
sous-jacente, le mieux est de regarder le site Web de NaCl. Le
principe de DNSCurve est que le dialogue entre deux serveurs est
chiffré (par un algorithme de la famille des courbes
elliptiques, Curve25519) et authentifié. La clé publique
du serveur auquel on parle est obtenue dans le DNS, c'est le nom du
serveur. Si le TLD .example est délégué à
uz5xgm1kx1zj8xsh51zp315k0rw7dcsgyxqh2sl7g8tjg25ltcvhyw.nic.example,
le résolveur peut, en examinant ce nom, voir que la délégation est
sécurisée par DNSCurve, trouver la clé publique, et interroger le
serveur de manière sûre, grâce au chiffrement
asymétrique. Seule la communication entre deux serveurs
est protégée. Si un des serveurs est une machine pirate, DNSCurve ne
sert à rien.
Donc, DNSCurve n'est pas réellement un concurrent de DNSSEC, il traite un problème assez différent. Un exposé de l'auteur de DNSCurve compare DNSCurve avec DNSSEC et est intellectuellement très malhonnête, comme presque toujours avec Daniel Bernstein, avec notamment une utilisation intensive du FUD.
Que peut-on dire encore en comparant ces deux protocoles ? D'abord que DNSSEC a été soigneusement conçu pour que le serveur n'aie aucune opération de cryptographie à faire « par requête » (à l'exception de NSEC3 et encore il ne s'agit que de hachage, pas de chiffrement asymétrique). Toutes les opérations de signature peuvent être faites hors-ligne, une fois pour toute, sur la zone. Au contraire, DNSCurve exige des opérations de signature à chaque requête. Il ne convient donc pas à de gros serveurs.
Il est amusant de noter que la page officielle de DNSCurve reproche à DNSSEC que « DNSSEC reduces existing confidentiality by publishing the complete list of "secured" DNS records. This publication is integrated into the DNSSEC protocol; » alors que cette publication est inhérente au fait de signer la zone et pas chaque requête. Si on est prêt à faire des opérations de cryptographie à chaque requête, les solutions des RFC 4470 et RFC 5155 résolvent le problème de la confidentialité des données.
On peut terminer par un point amusant : avec DNSCurve, la clé publique est encodée dans le nom de la machine. C'est astucieux. Mais les clés de la cryptographie asymétrique sont très longues et les composants d'un nom de domaine sont limités à 63 octets. Cela a deux conséquences :
- Pour les zones qui limitent la taille d'une délégation à 512 octets, comme la racine du DNS, on ne peut utiliser qu'un maximum de trois serveurs avec DNSCurve (car il faut aussi laisser de la place pour la question, et pour la colle).
- DNSCurve n'utilise donc pas les courbes elliptiques parce qu'elles sont meilleures que les algorithmes basés sur la factorisation des nombres premiers (comme RSA) mais simplement parce qu'elles permettent des clés plus courtes. Le fait de les mettre dans les noms de domaine va sérieusement contraindre l'évolution ultérieure de DNSCurve. Il sera par exemple impossible d'augmenter la taille des clés.
Il n'existe guère de textes d'analyse de DNScurve, ce système est très marginal. Notons toutefois un article d'Eric Rescorla, qui se concentre sur les questions de performance, « Some notes on DNSCurve » et une très bonne synthèse de Paul Vixie, « Whither DNSCurve? », qui se focalise sur le fait que DNScurve résout le problème facile que personne n'a, DNSSEC préférant attaquer le problème important.
Merci à Kim Minh Kaplan pour ses nombreuses et pertinentes remarques sur DNSCurve. Un autre bon article sur DNScurve est celui de Sam.
L'article seul
RFC 5533: Shim6: Level 3 Multihoming Shim Protocol for IPv6
Date de publication du RFC : Juin 2009
Auteur(s) du RFC : E. Nordmark ((Sun), M. Bagnulo (UC3M)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF shim6
Première rédaction de cet article le 18 juin 2009
Quelles sont les méthodes disponibles dans l'Internet d'aujourd'hui pour assurer une plus grande fiabilité à un site ? On peut payer plus cher son FAI mais cela ne garantit pas une meilleure fiabilité. Aujourd'hui, la seule méthode réaliste est d'avoir plusieurs FAI, le multihoming. Mais cela implique d'avoir ses adresses IP à soi et de faire du BGP avec ses FAI. Si on utilise en effet des adresses « appartenant » à un des FAI, la panne de celui-ci empêchera de les utiliser, même si l'autre connexion est intacte. Comme les protocoles de transport comme TCP sont liés aux adresses IP utilisées, cela veut dire que toutes les sessions TCP existantes seront cassées. Ce n'est pas forcément génant pour HTTP, aux connexions souvent courtes, mais bien plus grave pour, par exemple, SSH. Le multihoming sans BGP permet donc d'établir de nouvelles connexions, mais pas de faire vivre les anciennes.
Il faut donc faire du BGP. Mais c'est complexe et, surtout, cela impose de mettre ses adresses IP dans la table de routage globale, qui est déjà bien chargée. Shim6, objet de ce RFC, propose une autre solution, lier les connexions à un groupe d'adresses IP, pas à une seule comme actuellement. On pourrait alors changer l'adresse utilisée en couche 3 sans dommage pour la couche 4. Shim6 dispense donc d'utiliser BGP.
Ce nouveau protocole dépend d'IPv6, comme son nom l'indique, car sa sécurité et même son fonctionnement de base nécessitent des mécanismes propres à IPv6. Shim6 se situe conceptuellement entre la couche 3 et la couche 4, d'où son nom de shim (mince couche entre deux vraies couches). On peut noter que SCTP (RFC 3286) part d'une idée proche (le groupe d'adresses IP) mais fonctionne, lui, dans la couche 4. Shim6, au contraire, est accessible à tous les protocoles de transport comme, par exemple, le TCP traditionnel.
Une autre façon de s'attaquer au même problème est de séparer complètement l'identificateur du localisateur comme le fait HIP, ce qui permet de traiter des problèmes supplémentaires comme la mobilité. Cette séparation est explicitement marquée comme « non-but » dans Shim6, qui ne manipule que des « localisateurs » même si l'un d'eux, baptisé « identificateur » sans l'être vraiment, a un rôle particulier dans l'association (section 1.3, qui définit les ULID - Upper-Layer Identifier).
Il existe donc désormais un grand choix de protocoles, tous prometteurs mais tous aussi marginaux les uns que les autres.
La gestation de ce protocole a été longue et difficile. Au final, Shim6 est un protocole très complexe, avec un RFC de plus de 130 pages (sans la détection de panne, qui fait l'objet d'un document séparé, le RFC 5534).
La section 1 expose les principes de base de Shim6. Le protocole est mis en œuvre complètement dans les machines finales, il ne nécessite aucune participation des routeurs. Chaque machine a un jeu d'adresses IP possibles, a priori toutes liées à un FAI (Shim6, contrairement à BGP, n'impose pas d'utiliser des adresses PI - Provider Independant). À un moment donné, une paire d'adresses (source et destination) est utilisée pour la communication effective et les machines peuvent changer de paire par la suite (le mécanisme de détection des pannes, ou des autres raisons qui qui déclencheraient un changement de paire, sera spécifié dans un autre document). Pour assurer qu'une machine ne puisse pas prétendre être utilisatrice d'une adresse IP quelconque, des adresses HBA (Hash Based Addresses) ou CGA (signées par la cryptographie) sont utilisées.
La section 1.1 détaille le cahier des charges et la 1.2 l'anti-cahier des charges, les questions qui étaient hors-sujet pour Shim6. Dans le cahier des charges, cette section 1 insiste notamment sur le côté « opportuniste » de Shim6 : contrairement à HIP, une association Shim6 peut commencer sans échange particulier et être établie bien après la connexion TCP. D'autre part, outre la résistance aux pannes, Shim6 doit permettre la répartition de charge, selon des paires d'adresses IP différentes. Dans l'anti-cahier des charges, se trouve la question de la rénumérotation, suite à des changements de FAI. Shim6 ne la traite pas (section 1.5) : l'ensemble des adresses IP disponibles doit être fixe, ou, en tout cas, changer lentement. Shim6 ne permet donc pas le nomadisme, même si celui-ci pourra être traité dans le futur. En attendant, au début de l'association Shim6, toutes les adresses IP possibles doivent être connues.
Shim6 est un protocole de couche « 3,5 », entre la couche de réseau et la couche de transport (section 1.6). Les protocoles situés au dessus de Shim6, comme TCP ou UDP utilisent des adresses IP habituelles, les ULID (Upper-Layer Identifier, voir la section 2.1 pour une terminologie complète). En dessous d'eux, Shim6 va fabriquer des paquets IP dont les adresses sources ou destination pourront être des ULID (puisque Shim6 ne sépare pas localisateurs et identificateurs) ou bien des purs localisateurs, différents des ULID que continue à utiliser le protocole de transport. Shim6 maintient, pour chaque paire d'ULID, la liste des localisateurs possibles (les adresses IP utilisables pour la communication).
Après une section 2 de terminologie et de notations, puis une section 3 sur les pré-supposés de Shim6, voici venir le protocole lui-même en section 4. L'essentiel du fonctionnement de Shim6 peut être résumé dans les étapes suivantes :
- Une machine A en contacte une autre, B, par les moyens classiques, sans Shim6. Par exemple, elle établit une connexion TCP.
- Une des deux machines, ou les deux, décide que ce serait une bonne idée de faire du Shim6. Par exemple, plus de N paquets ont été échangés et il semble donc bien que la connexion va durer, ce qui rend intéressant de la faire résister aux pannes. Un contexte Shim6 (une association entre les deux machines) est alors mis en place.
- Les échanges continuent comme avant. À ce stade, bien que le contexte Shim6 aie été configuré, rien n'apparait dans les paquets échangés.
- Une panne survient, rendant impossible d'utiliser les localisateurs actuels (les adresses IP de A et B). C'est là que Shim6 sert à quelque chose, une nouvelle paire de localisateurs est choisie et un en-tête d'extension est ajouté désormais à chaque paquet, pour indiquer le contexte utilisé (section 4.1). Ce contexte servira à trouver les ULID (les identificateurs) utilisés. Shim6 réécrira alors les paquets avant de les transmettre à TCP... qui ne se sera rendu compte de rien, il utilisera les mêmes adresses IP tout le temps (section 12 pour les détails sur la réception des paquets).
Donc, on ne peut pas, en observant le réseau, savoir si un contexte Shim6 est disponible car les paquets ne sont modifiés (par l'ajout de l'en-tête d'extension Shim6) que si la première paire de localisateurs devient inutilisable.
Ces en-têtes d'extension sont une nouveauté d'IPv6 (RFC 2460, section 4). Leur présence dans les paquets IPv6 est rare aujourd'hui mais des techniques comme Shim6 pourrait la rendre plus fréquente (si les différents pare-feux acceptent de les laisser passer). La section 4.6 décrit le placement de l'en-tête Shim6.
Les informations mémorisées par chaque machine (ULID de la connexion, localisateurs possibles, contextes, etc) sont décrites dans la section 6.
Comme toute technique d'indirection,
c'est-à-dire comme toutes les techniques qui découplent, si peu que ce
soit, l'identificateur et le localisateur, Shim6 est vulnérable aux
attaques portant sur la correspondance entre utilisateur et
localisateur. Qu'est-ce qui empêche un méchant, par exemple, d'ajouter
une adresse IP qu'il ne contrôle pas légitimement, au jeu des
localisateurs, pour que son partenaire Shim6 y envoie des paquets ? La
section 4.4 résume les techniques utilisées pour empêcher cela, qui
tournent autour d'adresses cryptographiques (RFC 3972 et RFC 5535) et de tests
de la connectivité effective (voir si le pair répond avant de le noyer
sous les paquets, cf. section 5.13 pour le message Probe).
Comment se fait l'établissement du contexte Shim6 ? Par un échange de quatre paquets (comme dans HIP) et non pas de trois paquets comme avec TCP. La section 4.5 résume ces quatre paquets, I1, R1, I2 et R2, pour lesquels l'explication complète est en section 7 (et la machine à états dans la section 20). La liste des localisateurs connus est envoyée dans ces paquets mais elle peut être modifiée par la suite, Shim6 ayant d'autres messages de contrôle que ces quatre-ci (section 10).
Le format des messages sur le câble est normalisé dans la section 5. Les messages de contrôle de Shim6 ne circulent ni sur UDP, ni sur TCP mais dans son propre protocole, de numéro 140 (section 17). Le début du paquet est le même pour tous les messages Shim6 (section 5.1). Les messages de la communication en cours ont le 16ème bit à 1 et sont décrits dans la section 5.2. Les messages de contrôle ont ce 16ème bit à zéro et font l'objet de la section 5.3.
Comment se fait le premier contact ? La procédure est synthétisée
dans la section 13. La méthode recommandée est d'essayer toutes les
adresses disponibles, de ne pas renoncer simplement parce qu'une paire
d'adresses émetteur-récepteur ne fonctionne pas. Le problème de cette
méthode est que, mise en œuvre directement (boucler sur toutes
les adresses de la liste de struct addrinfo
renvoyée par getaddrinfo() et tenter
un connect() sur chacune) va mener à
de longs délais puisqu'il faudra attendre l'expiration du délai de garde.
Idéalement, il faudrait donc tenter des connexions non-bloquantes simultanément.
Comment est établi un contexte Shim6 ? La section 7 fournit toutes les informations nécessaires. L'échange nécessite quatre paquets (section 7.3), ce qui permet (contrairement à l'échange à trois paquets de TCP) de ne pas garder d'état dès le premier paquet, tout en permettant l'usage d'options. Cette section couvre également la vérification des adresses utilisées (section 7.2), vérification, par la cryptographie, que le « propriétaire » d'un ULID a le « droit » d'utiliser ces localisateurs et vérification que ces localisateurs fonctionnent.
Un problème classique de toute séparation, même partielle, entre l'identificateur et le localisateur, est le traitement des erreurs envoyées par ICMP. L'émetteur de ces erreurs ne connait pas forcément Shim6 et gère simplement des adresses IP. Il faut donc, sur réception d'un message ICMP, retrouver le contexte Shim6 (section 8) et transmettre le message ICMP à la couche de transport puisque, dans la plupart des cas, c'est elle qui doit être informée des erreurs. Cela nécessite de réécrire le message pour remplacer les adresses IP par des ULID, les seules adresses que connaisse la couche 4.
Arrivé à ce point du RFC, il est temps de voir quelques contraintes d'implémentation. Elles sont regroupées dans la section 15. D'abord, si Shim6 change la paire de localisateurs utilisée, les paquets IP passeront probablement par un chemin bien différent, et Shim6 devrait donc (section 15.1) prévenir la couche de transport que la congestion sera probablement différente.
Tout nouveau protocole qu'on tente de déployer sur l'Internet doit se battre contre les middleboxes, les équipements intermédiaires qui refusent fréquemment les paquets inconnus. La section 15.2 soulève le problème. Par exemple, quoique que Shim6 soit une technique entièrement « machine », qui est gérée uniquement aux extrémités du réseau (section 15.3), il est toujours possible qu'un pare-feu bloque les paquets Shim6. Cela apparaitra à chacune des machines comme une absence de Shim6 chez le pair. Outre cette paranoïa générale des pare-feux, Shim6 soulève des questions particulières puisque l'autorisation ou l'interdiction des paquets devraient, idéalement, prendre en compte les ULID, pas les adresses IP du paquet. Shim6 aura donc les mêmes difficultés que HIP ou SCTP à s'installer dans un Internet très ossifié.
Enfin, certaines applications passent des adresses IP à leurs pairs (par exemple les téléphones SIP) et elles devraient donc s'assurer (section 15.4) qu'elles n'envoient pas uniquement l'ULID mais un nom de domaine ou bien le jeu complet de localisateurs.
Et la sécurité ? La section 16 résume les problèmes spécifiques à Shim6 (cf. RFC 4218) et les solutions possibles. Contre le risque d'usurpation d'adresses IP, les adresses cryptographiques, HBA (RFC 5535) et CGA (RFC 3972). Contre les attaques par inondation (en redirigeant du trafic vers une machine innocente), les tests d'atteignabilité (vérifier que la machine répond positivement avant de lui transmettre des gigaoctets).
En parlant d'implémentations, quelle est la situation de Shim6 de
ce côté ? Une équipe coréenne avait mis en œuvre Shim6 pour le
noyau Linux. Leur travail avait été décrit dans
l'Internet-Draft
draft-park-shim6-implementation mais le travail
semble ne pas être allé plus loin. Plus récemment, une autre équipe, belge, avait
réalisé LinShim6, sur le même système et
documenté dans l'Internet-Draft
draft-barre-shim6-impl. Il existe aussi une autre
implémentation Linux dans l'OpenHIP. Une
liste à jour des tentatives se
trouve sur le site « officiel ».
Terminons ce résumé du RFC 5533 avec les annexes. La section 19 décrit de possibles extensions futures du protocole. Celui-ci est déjà bien assez compliqué comme cela et beaucoup d'idées ont été laissées à de futures nouvelles versions, comme la pré-vérification d'une paire de localisateurs de secours, l'interaction avec Mobile IP ou encore la normalisation d'une API. À l'heure actuelle, il n'existe pas d'API standard pour l'application qui voudrait être consciente de Shim6 et, par exemple, forcer ou, au contraire, interdire son utilisation (section 4.3).
L'excellente section 22 intéressera les étudiants en réseaux informatiques et tous les curieux qui se demandent « mais pourquoi les choses sont-elles comme elles sont ? ». Elle est en effet consacrée aux choix alternatifs, à ce qui aurait pu être. Parmi les idées envisagées et finalement abandonnées, on trouve d'autres solutions de sécurité (section 22.4) comme l'utilisation de cookies lors de l'établissement de l'association. La connaissance du cookie prouvait qu'on était toujours le même pair. Mais le cookie aurait été vulnérable lors d'une écoute du réseau. D'où le choix final des adresses cryptographiques. Dans le cas de HBA (RFC 5535), tous les localisateurs (toutes les adresses IP) sont liées et on peut donc vérifier que deux adresses appartiennent au même ensemble HBA. Par contre, HBA ne permet pas d'ajouter ou de supprimer des localisateurs. Dans le cas de CGA (RFC 3972), l'ULID est une clé publique (plus rigoureusement, un résumé d'une clé publique) et signe les localisateurs, ce qui autorisde l'ajout de localisateurs. Mais CGA dépend donc de la cryptographie à clé publique, plus coûteuse.
La création d'un contexte Shim6 (ce que j'ai baptisé association) se fait avec quatre paquets. On aurait pu en utiliser moins (section 2.5), pour accélerer l'association mais le choix a finalement été de privilégier la protection contre les attaques DoS. Une des raisons du choix est que, de toute façon, l'établissement de l'association ne bloque pas la connexion qui utilise Shim6, puisque les premiers paquets peuvent passer avant que Shim6 ne crée son contexte. Ce n'est donc pas trop grave si l'association prend du temps.
L'article seul
RFC 5535: Hash Based Addresses (HBA)
Date de publication du RFC : Juin 2009
Auteur(s) du RFC : M. Bagnulo (UC3M)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF shim6
Première rédaction de cet article le 18 juin 2009
Les HBA (Hash Based Addresse) de ce RFC sont des adresses IPv6 fondées sur un résumé cryptographique d'un certain nombre de valeurs, permettant de garantir que toutes les adresses HBA d'un groupe donné sont liées. Elles sont notamment utilisées par le protocole SHIM6 (RFC 5533). Contrairement aux adresses CGA du RFC 3972, dont elles sont proches, les HBA ne nécessitent pas de cryptographie asymétrique. Par contre, elles ne permettent pas de prouver le lien entre une machine et une adresse IP, juste de prouver que les adresses d'un groupe ont été générées par la même machine.
Quel problème essaient de résoudre les HBA (section 1 du RFC) ? Dans les protocoles conçus pour le multihoming comme SHIM6 (RFC 5533), une machine annonce à ses pairs qu'elle a plusieurs adresses IP. Qu'est-ce qui l'empêche d'annoncer des adresses qui ne sont pas « à elle », soit pour capter le trafic d'un tiers, soit pour réaliser une DoS contre ce tiers en provoquant l'envoi de nombreux paquets vers lui ? SHIM6 utilise deux mécanismes proches, les CGA et les HBA. Dans les deux cas, les adresses IP annoncées peuvent être vérifiées cryptographiquement. CGA signe les adresses avec une clé asymétrique donc le pair peut vérifier qu'une adresse « appartient » bien au pair. HBA procède différemment : une adresse HBA est composée de deux parties, un préfixe de 64 bits et un identificateur local (également de 64 bits) qui est un résumé de l'ensemble des préfixes IP de la machine (puisque HBA est fait pour les machines multihomées, il y a plus qu'un préfixe) et d'un nombre aléatoire. HBA ne permet donc pas de prouver l'appartenance d'une adresse IP à une machine, uniquement le fait que toutes les adresses HBA d'un même groupe sont liées. Une machine SHIM6 qui utilise HBA ne pourra donc pas ajouter ou retirer des adresses IP au jeu d'adresses annoncé (elle le pourrait avec CGA) et HBA ne convient donc pas à des problèmes comme la renumérotation d'un réseau ou comme la mobilité. Mais le pair pourra vérifier, lors de l'établissement de l'association SHIM6, que ces adresses sont toutes liées à la même machine et sans les calculs longs et compliqués de la cryptographie asymétrique. HBA est donc plus économe. (Voir la section 3.3 pour une discussion plus détaillée du cahier des charges de HBA.)
Autrement, HBA et CGA sont très proches, utilisent les mêmes formats et ont également en commun de ne pas nécessiter de PKI.
Les risques de sécurité que les HBA traitent sont résumés en section 3.1, suivant le RFC 4218 (et traités en détail dans la section 11). En gros, les deux attaques possibles sont le détournement (un méchant va essayer d'obtenir des paquets qui n'étaient pas normalement pour lui) et l'inondation (un méchant va essayer de noyer une victime sous un flot de paquets). HBA protège uniquement contre les premier risque, d'autres protocoles doivent gérer le second, par exemple en testant si le pair est joignable (ce que fait SHIM6).
La section 3.2 donne le principe de base de HBA : si une machine a trois préfixes IPv6, mettons A, B et C, elle choisit un nombre M au hasard puis génère trois adresses, une par préfixe. Pour A, elle concatène au préfixe le résumé cryptographique de la concaténation de M, de A et la la liste des préfixes (A, B et C). Même principe pour les autres préfixes. Étant donné une liste de préfixes (rappelez-vous que, avec HBA, elle doit être stable), un préfixe et le nombre M, on peut donc vérifier qu'une adresse fait bien partie du groupe, en recalculant le résumé.
Une particularité des HBA est qu'elles sont normalisées comme étant une variante des CGA du RFC 3972. La section 4 de notre RFC est donc dédiée à l'étude de la compatibilité exacte entre HBA et CGA. Cette compatibilité permet d'avoir des adresses qui sont à la fois HBA et CGA. On peut donc les utiliser dans des protocoles comme SEND (RFC 3971), qui impose des CGA. Il y a donc trois types d'adresses :
- Les CGA pures, normalisées dans le RFC 3972, qui n'incluent donc pas la nouvelle extension « multi-préfixe » (section 5),
- Les HBA pures qui n'utilisent pas du tout de clé publique,
- Les mixtes qui sont liées à la fois à une clé publique (CGA) et à un jeu de préfixes.
Quelle est cette extension « multi-préfixe » ? Décrite dans la section 5 de notre RFC, elle permet de représenter l'ensemble des préfixes liés par HBA. C'est cet ensemble qui servira d'entrée au hachage cryptographique.
Le mécanisme exact de génération est en section 6. Il est dérivé de celui de CGA, en section 4 du RFC 3972. La plus grande différence avec CGA est que l'adresse ne peut pas être fabriquée sans connaître les préfixes. Toutes les adresses doivent donc être générées ensemble. L'entrée des fonctions cryptographiques comporte donc l'extension multi-préfixe, qui indique les préfixes, une clé publique (si l'adresse est une mixte CGA/HBA) ou une initialisation aléatoire (nonce) - encodée comme si c'était une clé publique CGA - si l'adresse est une HBA pure et les autres paramètres de CGA.
À ce stade, on a donc un ensemble d'adresses disponible pour la machine. Si une autre machine veut vérifier ces adresses, elle doit utiliser les techniques de la section 7. Par exemple, 7.2 expose comment vérifier qu'une adresse donnée fait bien partie d'un ensemble HBA. (On vérifie que le préfixe de l'adresse est dans l'ensemble indiqué dans l'extension multi-préfixe puis on refait le hachage et on vérifie que l'identificateur local, les 64 bits les plus à droite, sont bien les mêmes.)
La publication des adresses HBA dans le DNS fait l'objet de la section 9. La recommandation est que « ça dépend ». Selon que la machine a uniquement des adresses HBA ou pas, selon que les préfixes soient des ULA ou pas, il peut être raisonnable ou pas de publier ces adresses HBA dans les DNS. Puisqu'une adresse HBA ressemble à n'importe quelle autre adresse IPv6, le client qui les trouve dans le DNS ne sait pas s'il a affaire à une HBA ou pas et il doit donc déduire cela d'un autre mécanisme.
Une mise en œuvre de HBA en C
se trouve en
http://ops.ietf.org/multi6/francis-hba.tar.gz.
L'article seul
Le Péril bleu
Première rédaction de cet article le 17 juin 2009
Parmi les écrivains français d'aventure de la « Belle Époque », Maurice Renard est nettement moins connu que Jules Verne ou J.-H. Rosny aîné. On cite souvent uniquement son livre « Les Mains d'Orlac ». Mais il est aussi l'auteur d'un fantastique roman, « Le Péril bleu ».
Le livre n'a pas été réédité depuis trente ans. Il s'inscrit clairement dans le courant du roman « pré-science-fiction » français. Je ne peux absolument pas raconter l'histoire, car beaucoup repose sur les surprises successives (et ne lisez donc pas l'article de Wikipédia avant le livre !). Dans une petite région tranquille de France, le Bugey, deux années avant la première guerre mondiale, dans un monde qui se croit stable, où les ouvriers restent à leur place, où les bourgeois républicains rêvent de marier leur fille avec un noble, où les allemands sont des méchants militaristes, où les policiers ont forcément d'épaisses moustaches et où les paysans sont assez abrutis, mais fidèles, de mystérieuses disparitions d'objets se produisent. Drôles au début, elles vont vite devenir plus dramatiques. Pour retrouver les mystérieux « Sarvants », comme les gens du pays appellent leurs persécuteurs, sur quoi peut-on compter ? Sur la science de l'astronome Le Tellier ou de son assistant Robert Collin ? Sur la fougue sportive du jeune, beau et riche duc d'Agnès ? Sur les capacités de déduction du détective amateur Tiburce ?
Le livre passe du tragique au très drôle (excellente caricature du concurrent des romains anglais, Sherlock Holmes, bien plus drôle que celle de Maurice Leblanc). Il y a d'innombrables pistes à suivre et toutes ne sont pas fausses...
À l'heure où on recommande les lectures de vacances, voici mon conseil : allez enquêter au Bugey. Et voyez si vous déduirez mieux que Tiburce.
Les érudits peuvent aussi emporter à la plage « La science-fiction française au XXe siècle (1900-1968) » de Jean-Marc Gouanvic (éditions Rodopi), qui détaille longuement le Péril bleu.
L'article seul
abuse@BIGISP.net ne répond pas
Première rédaction de cet article le 16 juin 2009
Comment signale-t-on un problème sur
l'Internet ? Si un ver fait des requêtes HTTP
répétées à la recherche d'une vulnérabilité ? Si un autre ver se
connecte en SSH en permanence à votre
Kimsufi en tentant le compte guest ? Si un script utilise automatiquement
votre service en dépit des conditions d'utilisation ? Si vous recevez
du spam depuis telle ou telle machine ? En
théorie, il existe une adresse de courrier standard pour cela. Spécifiée dans
le RFC 2142, c'est abuse@DOMAIN.EXAMPLE
où DOMAIN.EXAMPLE est le domaine en cause. Mais
le courrier envoyé à abuse n'obtient jamais de
réponse et, souvent, n'est même pas lu. Pourquoi ?
Au cours de ma carrière, j'ai été des deux côtés de la barrière, du
côté de ceux qui reçoivent les messages envoyés à
abuse et du côté de ceux qui les envoient. Du
côté du simple utilisateur, qui voudrait signaler un problème, le
bilan n'est pas très glorieux. Les réponses reçues sont rarissimes. La
plupart du temps, c'est le silence complet. Parfois, on reçoit un avis
de non-remise « il n'y a pas de compte abuse à
l'adresse indiquée ». Parfois une réponse standard inutile.
Est-ce qu'au moins les messages sont lus, même si
abuse ne peut pas répondre à tous ceux qui lui
écrivent ? Même pas. La plupart du temps, les messages atterissent
directement dans
/dev/null, ou bien, à la
rigueur, dans la boîte d'un stagiaire embauché pour faire le
support utilisateur, qui n'y connait rien et
n'est pas assez payé pour qu'on
puisse lui demander de travailler sérieusement.
Même si certains gros FAI s'obstinent à nier
et affirment, contre toute évidence, que les messages sont lus
soigneusement, la triste réalité est qu'écrire à
abuse ou bien jouer à World of Warcraft donneront le même résultat (et, dans
le second cas, au moins, on voit les monstres qu'on combat).
Est-ce de la paresse ou de la méchanceté de la part des FAI ? En
partie oui, bien sûr, c'est vrai qu'ils se moquent totalement de ce
que leurs propres utilisateurs peuvent raconter. Alors, quand il
s'agit d'inconnus... Mais il faut aussi remarquer que le problème
n'est pas simple. D'abord, sur l'Internet, il y a tout le temps des
problèmes. Si on héberge un parc de dix mille machines
Unix dédiées et louées à des clients, il y en a
forcément toujours un bon nombre qui se lancent dans des attaques,
soit parce que le locataire est un méchant, soit parce qu'il a laissé
un script PHP vulnérable sur sa machine. Si
on connecte des dizaines de milliers de foyers où se trouvent des
machines MS-Windows, c'est encore pire, un bon
nombre a été transformé en zombies et les attaques qu'elles lancent
vaudront certainement à abuse pas mal de
courrier.
Mais il y a un autre problème : la très grande majorité des
rapports envoyés à abuse sont
inutilisables. Aucun détail, aucune précision, l'heure de l'attaque
n'est pas indiquée (ou alors en heure locale, sans indication du
fuseau horaire), les messages sont résumés et
mal traduits au lieu d'être cités littéralement, etc. Le message
typique reçu par abuse (rappelez-vous qu'un gros
hébergeur peut avoir des dizaines de milliers de machines, voire
davantage pour les très gros) est simplement « Mon firewall [sic] me
dit que votre machine m'attaque, arrêtez tout de suite » (et encore,
je n'ai pas respecté l'orthographe). Il est même fréquent que le
message soit 100 % erroné et qu'il n'y ait pas d'attaque du tout
(comme le voit fréquemment l'IANA).
Plus drôle, les messages à abuse sont parfois des tentatives d'attaque.
Analyser de tels messages sérieusement nécessiterait du temps et
une main d'œuvre qualifiée, alors qu'en général on met au
« support de premier niveau » les gens les
moins payés de l'entreprise. Il faudrait demander des précisions,
faire preuve de patience, suivre le dossier, tout ce que fait un
avocat d'affaires payé très cher de l'heure, mais pas ce que peut
faire le Marocain ou l'Indien qui travaille dans un
call center. Pour des
simples raisons économiques, les messages à abuse
sont donc traités vite et mal.
abuse est d'autant moins enclin à lire ses
messages qu'un certain nombre d'utilisateurs spamment à tout vent et
écrivent, lors de n'importe quel problème, à toutes les adresses de
courrier qu'ils peuvent trouver en interrogeant whois.
Et les messages de qualité ? En général, vu l'afflux de messages inutilisables, les rares messages corrects, précis et complets sont traités comme les autres, perdus au milieu du flot.
Une bonne introduction au rôle (théorique) d'un service « abuse » est « Le service abuse des hébergeurs : comment ça fonctionne ? ».
L'article seul
RFC 4347: Datagram Transport Layer Security
Date de publication du RFC : Avril 2006
Auteur(s) du RFC : E. Rescorla (RTFM), N. Modadugu
(Stanford University)
Intérêt historique uniquement
Première rédaction de cet article le 16 juin 2009
Le protocole de cryptographie TLS, normalisé dans le RFC 5246, ne s'appliquait traditionnellement qu'à TCP. Les applications utilisant UDP, comme le fait souvent la téléphonie sur IP ne pouvaient pas utiliser TLS pour protéger leur trafic contre l'écoute ou la modification des données. Mais, désormais, cette limitation disparait, DTLS permet de protéger du trafic UDP. Ce RFC était le premier sur DTLS, il a été remplacé depuis par le RFC 6347 et l'ancienne version de DTLS décrite dans notre RFC est maintenant abandonnée.
TLS ne tournait que sur TCP car il avait besoin d'un transport fiable, garantissant que les données arrivent toutes, et dans l'ordre. Le grand succès de TLS (notamment utilisé pour HTTP et IMAP) vient de sa simplicité pour le programmeur : rendre une application capable de faire du TLS ne nécessite que très peu de code, exécuté juste avant l'envoi des données. Par contre, cela laissait les applications UDP comme SIP non protégées (section 1 de notre RFC). Les solutions existantes comme IPsec ne sont pas satisfaisantes, notamment parce qu'elles n'offrent pas la même facilité de déploiement que TLS, qui tourne typiquement dans l'application et pas dans le noyau.
DTLS a été conçu pour fournir TLS aux applications UDP. Il offre les mêmes services que TLS : garantie de l'intégrité des données et confidentialité.
La section 3 explique les principes de DTLS : protégé ou pas par DTLS, UDP a la même sémantique, celle d'un service de datagrammes non fiable. DTLS est une légère modification de TLS : il en garde les principales propriétés, bonnes ou mauvaises.
Mais pourquoi ne peut-on pas faire du TLS normal sur UDP ? Parce que TLS n'a pas été conçu pour tourner au dessus d'un protocole non fiable. TLS organise les données en enregistrements (records) et il ne permet pas de déchiffrer indépendamment les enregistrements. Si l'enregistrement N est perdu, le N+1 ne peut pas être déchiffré. De même, la procédure d'association initiale de TLS (handshake) ne prévoit pas de perte de messages et ne se termine pas si un message est perdu.
Le premier problème fait l'objet de la section 3.1. La dépendance des enregistrements TLS vis-à-vis de leurs prédécesseurs vient du chaînage cryptographique (chiffrement par blocs) et de fonctions anti-rejeu qui utilisent un numéro de séquence, qui est implicitement le rang de l'enregistrement. DTLS résout le problème en indiquant explicitement le rang dans les enregistrements.
Et la question de l'association initiale est vue dans la section 3.2. Pour la perte de paquets lors de l'association, DTLS utilise un système de retransmission (section 3.2.1) et pour l'éventuelle réorganisation des paquets, DTLS introduit un numéro de séquence (section 3.2.2). En prime, DTLS doit gérer la taille importante des messages TLS (souvent plusieurs kilo-octets), qui peut être supérieure à la MTU. DTLS permet donc une fragmentation des paquets au niveau applicatif, un message pouvant être réparti dans plusieurs enregistrements (section 3.2.3).
Enfin, l'anti-rejeu a été modifié pour tenir compte du fait que la duplication de paquets, en UDP, n'est pas forcément malveillante (sections 3.3 et 4.1.2.5).
La définition formelle du nouveau protocole est en section 4. DTLS étant une légère évolution de TLS, la définition se fait uniquement en listant les différences avec TLS, dont il faut donc garder le RFC 5246 sous la main.
Au niveau du Record Protocol de TLS, l'enregistrement spécifié dans la section 6.2.1 du RFC 5246 gagne deux champs (section 4.1) :
struct {
ContentType type;
ProtocolVersion version;
uint16 epoch; // NOUVEAU
uint48 sequence_number; // NOUVEAU
uint16 length;
opaque fragment[DTLSPlaintext.length];
} DTLSPlaintext;
notamment le numéro de séquence sequence_number
(qui était implicite dans TLS, puisque TCP garantissait l'ordre des
messages). Pour éviter la fragmentation et les
ennuis associés, les mises en œuvre de DTLS doivent déterminer
la MTU du chemin et n'envoyer que des
enregistrements plus petits que cette MTU (section 4.1.1).
Contrairement à IPsec, DTLS n'a pas la notion d'identificateur d'association. Une machine qui reçoit du TLS doit trouver l'association toute seule, typiquement en utilisant le tuple (adresse IP, port).
En toute rigueur, DTLS n'est pas spécifique à UDP, il peut marcher sur n'importe quel protocole de transport ayant une sémantique « datagrammes ». Certains de ces protocoles, comme DCCP (cf. RFC 5238), ont leur propres numéros de séquence et ils font donc double emploi avec ceux de DTLS. Petite inefficacité pas trop grave.
Au niveau du Hanshake protocol, les modifications que DTLS apporte à TLS font l'objet de la section 4.2. Les trois principales sont :
- L'ajout d'un gâteau pour limiter les risques de DoS,
- Modification des en-têtes pour gérer les pertes ou réordonnancements des paquets (section 4.2.2),
- Ajouts de minuteries pour détecter les pertes de paquets (section 4.2.4).
Les gâteaux de DTLS sont analogues à ceux de
Photuris ou
IKE (section
4.2.1). Le message ClientHello de la section
7.4.1.2 du RFC 5246 y gagne un champ :
opaque cookie<0..32>; // NOUVEAU
OpenSSL gère DTLS depuis la version 0.9.8
(on peut aussi consulter le site Web du
développeur). Un exemple d'utilisation se trouve dans http://linux.softpedia.com/get/Security/DTLS-Client-Server-Example-19026.shtml. Il
me reste à inclure ce protocole dans echoping. GnuTLS
n'a pas de support DTLS (et aucun développement n'est en cours, les
volontaires sont les bienvenus).
Une très bonne description de la conception de Datagram TLS et des choix qui ont été faits lors de sa mise au point, se trouve dans l'article The Design and Implementation of Datagram TLS, écrit par les auteurs du RFC. C'est une lecture très recommandée.
L'article seul
StackOverflow data to PostgreSQL
First publication of this article on 14 June 2009
The great social site Stack Overflow just announced the publication of its entire database under a Creative Commons free licence. I believe it is the first time such an important social networking site publishes its data, so it is a great day for data miners. In this small article, I will explain how I entered these data into a PostgreSQL database for easier mining. (The work was done on a Debian machine but it should work on any Unix.)
The original file is huge (200 megabytes today, and growing). To
avoid killing the Stack Overflow servers, it is distributed in a
peer-to-peer fashion with
BitTorrent. I just downloaded the torrent file
http://blog.stackoverflow.com/wp-content/uploads/so-export-2009-06.7z.torrent
to my download directory and BitTorrent does the rest. I then
extract the XML files with
p7zip. Each XML file store a class of Stack
Overflow objects:
- Users, today 88,558 (but many of them registered once but never came back afterwards),
- Posts, today 182,742 questions and 698,923 answers,
- Comments, today 705,085,
- Votes,
- Badges.
I then created one SQL table for each
class. The complete DDL instructions are in
file so-create.sql. I can then create the database and
its schema:
% createdb --encoding=UTF-8 so % psql -f so-create.sql so
I am normally a fan of integrity constraints in
databases. But, in the case of Stack Overflow, there are many obvious
integrity constraints that I did not include
because they are violated at least one, especially in old data
(presumably during beta testing of the site). For instance, 18,239
users (20 %) has no name (see for instance http://stackoverflow.com/users/57428, the one with the highest
reputation) and
therefore I cannot write name TEXT NOT NULL.
Same problem with the accepted answer, some posts reference an answer which is not available (for instance post #202271 has an accepted answer in the XML file, #202526, which does not exist).
Once the database is set up, we just have to parse the XML files
and to load them in the database. I choose the Python
programming language and the ElementTree XML
library. I produce SQL files which uses the COPY instruction.
The Python program is available as so-so2postgresql.py. To execute it, you just indicate the
directory where the Stack Overflow XML files have been
extracted. Then, you run PostgreSQL with the name of the produced SQL
COPY file, and with the name of the database:
% python so-so2postgresql.py /where/the/files/are > so.sql % psql -f so.sql so
This so-so2postgresql.py program requires a
lot of memory, because it keeps the entire XML
tree in memory (that is a weakness of the XML library used). Do not
attempt to run it on a machine with less than eight gigabytes of
physical RAM, swapping will make it awfully
slow. You may also have to increase the available memory with
ulimit.
Once the program is over, you can start studying the data:
so=> SELECT avg(reputation)::INTEGER FROM Users; avg ----- 183 (1 row) so=> SELECT avg(reputation)::INTEGER FROM Users WHERE reputation > 1; avg ----- 348 (1 row)
The first analysis produced with this database was an exploration
of the "fastest gun in West" syndrome (available at stack-overflow-short-tail.html, in
French).
Many people already posted on the subject of the Stack Overflow database. For instance:
- Data Mining the StackOverflow Database (SQL server, only as a video in this article but other articles are more text-friendly),
- What interesting stats can I obtain from the Stack Overflow data-dump?, with many interesting statistics,
- Stack Overflow: Up and Down Voting Pattern Analysis,
- Statistics about tags, users and questions at StackOverflow, ServerFault and SuperUser,
- How to Import the StackOverflow XML into SQL Server, which focuses on the import into a database, like this article,
- A Python script to load StackOverflow data in the rdbhost system. Unlike my script, it uses SAX and not DOM and therefore can run with much less memory,
- StackOverflow question statistics (nice graphs).
- Franck Piochaud made a much improved version (specially performance-wise) of my code.
L'article seul
Les participants à Stack Overflow travaillent-ils sur le long terme ?
Première rédaction de cet article le 14 juin 2009
Le site social Stack Overflow ayant désormais rendu publique sa base de données, il est possible de l'analyser et d'étudier les comportements des participants à ce site. Par exemple, les votes et les réponses se poursuivent-ils pendant des mois ou bien sont-ils concentrés dans les heures qui suivent la publication d'une question ?
Regardons d'abord l'évolution des votes dans le temps. Combien de temps s'écoule t-il entre un message (question ou réponse) et les votes sur ce message ?
so=> SELECT DISTINCT (votes.creation - posts.creation::date) AS interval,
so-> to_char(count(votes.id)*100.0/
so(> (SELECT count(votes.id) FROM Posts, Votes
so(> WHERE Votes.post = Posts.id), '99.99') AS
so-> percent
so-> FROM Votes, Posts
so-> WHERE Votes.post = Posts.id
so-> GROUP BY interval ORDER BY interval;
interval | percent
----------+---------
0 | 54.75
1 | 10.33
2 | 2.62
3 | 1.74
4 | 1.26
5 | 1.01
6 | .87
7 | .70
8 | .57
9 | .49
10 | .44
11 | .42
12 | .38
13 | .39
14 | .39
15 | .33
16 | .30
...
La majorité absolue des votes ont lieu le jour de publication de l'article. Dès le cinquième jour, on passe en dessous d'un pour cent des votes pour la journée. Bref, il semble que le syndrôme connu à Stack Overflow sous le nom de fastest gun in West joue à plein. N'importe quel contributeur peut le voir : si on arrête d'écrire, la réputation ne bouge plus guère, les votes tardifs étant rares.
Cela se voit très bien sur le graphique, produit par gnuplot avec ces instructions :
set xrange [:150] set format y "%.0f" plot "votes-per-day.dat" using 1:2 with lines title ""
et en extrayant les données avec psql --file
votes-per-day.sql --field-separator ' ' --tuples-only --no-align so >
votes-per-day.dat, on obtient :
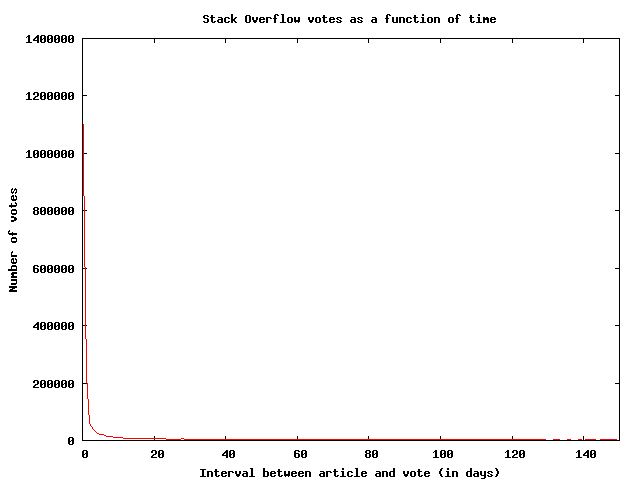
Mais la traîne est tellement longue qu'elle contribue quand même. Ainsi, 27 % des votes ont lieu plus d'une semaine après l'article et 19 % des votes plus d'un mois après :
so=> SELECT count(votes.id)*100/(SELECT count(votes.id) FROM Posts, Votes
WHERE Votes.post = Posts.id) AS percent
FROM votes, posts WHERE
votes.post = posts.id AND
votes.creation >= (posts.creation + interval '7 day')::date;
percent
---------
27
(1 row)
so=> SELECT count(votes.id)*100/(SELECT count(votes.id) FROM Posts, Votes
WHERE Votes.post = Posts.id) AS percent
FROM votes, posts WHERE
votes.post = posts.id AND
votes.creation >= (posts.creation + interval '30 day')::date;
percent
---------
19
(1 row)
Graphiquement, en mettant l'axe des Y en logarithmique, on voit mieux la longue traîne. Les instructions gnuplot sont :
set xrange [:150] set logscale y set format y "%.0f" plot "votes-per-day.dat" using 1:2 with lines title ""
et le résultat est :
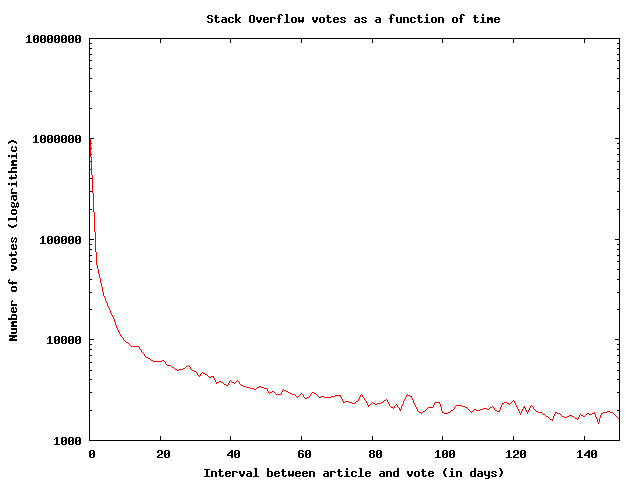
Et l'intervalle entre la question et une réponse acceptée (dans Stack Overflow, l'auteur d'une question peut marquer une question et une seule comme acceptée) ?
so=> SELECT DISTINCT(answers.creation::date - questions.creation::date) AS interval,
so-> to_char((count(questions.id)*100.0/(SELECT count(answers.id)
so(> FROM Posts questions, Posts answers
so(> WHERE answers.id = questions.accepted_answer AND
so(> questions.type = 1 AND
so(> answers.type = 2)), '999.9') AS percent
so-> FROM Posts questions, Posts answers
so-> WHERE answers.id = questions.accepted_answer AND questions.type = 1 AND
so-> answers.type = 2
so-> GROUP BY interval ORDER by interval;
interval | percent
----------+---------
0 | 83.9
1 | 7.3
2 | 1.5
3 | 1.0
4 | .7
5 | .5
6 | .4
7 | .4
8 | .3
...
La courbe est encore plus brutale. On pourrait résumer en disant que, si on ne répond pas le premier jour, on n'a que peu de chances d'être accepté... Mais il faut garder espoir. 4 % des réponses acceptées ont été écrites plus d'une semaine après l'article et 1 % après un mois.
so=> SELECT count(answers.id)*100/(SELECT count(answers.id)
FROM Posts questions, Posts answers
WHERE answers.id = questions.accepted_answer AND
questions.type = 1 AND
answers.type = 2) AS percent
FROM Posts questions, Posts answers
WHERE answers.id = questions.accepted_answer AND
questions.type = 1 AND answers.type = 2 AND
answers.creation > (questions.creation + interval '7 day')::date;
percent
---------
4
(1 row)
so=> SELECT count(answers.id)*100/(SELECT count(answers.id)
FROM Posts questions, Posts answers
WHERE answers.id = questions.accepted_answer AND
questions.type = 1 AND
answers.type = 2) AS percent
FROM Posts questions, Posts answers
WHERE answers.id = questions.accepted_answer AND
questions.type = 1 AND answers.type = 2 AND
answers.creation > (questions.creation + interval '30 day')::date;
percent
---------
1
(1 row)
L'article seul
Internet est-il de gauche ?
Première rédaction de cet article le 10 juin 2009
On pourrait se dire que oui. Après tout, ceux qui tapent le plus sur l'Internet, Sarkozy, Allègre, Val ou Lefebvre, sont tous des gens de droite (même si certains sont parfois, en raison d'une très ancienne adhésion à un parti de gauche, étiquetés différemment par les médias). Mais ces discours anti-Internet, méfiants, voire franchement hostiles, face à la liberté que procure ce nouvel outil, se retrouvent bien au-delà de la droite. Et ceux qui ont construit Internet, étaient-ils de gauche ?
L'ancêtre d'Internet, l'Arpanet, a été développé, pendant des années, à 100 % sur fonds publics, les capitalistes n'aimant pas prendre des risques. Mais ces fonds n'étaient pas distribués pour la culture ou la recherche puisqu'ils venaient en totalité de l'armée états-unienne, via son agence de recherche, nommée à l'époque ARPA. Revoyons le contexte. C'était en pleine guerre du Viêt Nam. Sur les campus états-uniens en ébullition, il n'était pas toujours facile de trouver des chercheurs qui acceptaient de travailler pour l'armée. Aujourd'hui, la plupart des chercheurs ne prennent plus en compte des considérations politiques ou morales avant d'accepter un budget : l'argent n'a pas d'odeur. Mais, à l'époque, la prise de conscience était bien plus forte et tout un courant existait chez les scientifiques pour dire qu'on ne pouvait pas faire n'importe quelle recherche en éludant ses responsabilités. (Pour une bonne édition en français des textes de ce courant, voir le livre de Jean-Marc Lévy-Leblond et Alain Jaubert, « (Auto)critique de la science », publié au Seuil en 1973.)
Ceux qui ont créé Arpanet puis l'Internet étaient donc les moins hostiles à l'armée et à sa guerre en Asie du Sud-Est. Ce fut au point que d'autres réseaux, concurrents de l'Arpanet, refusaient tout simplement d'utiliser des techniques marquées comme « militaires ». Ce fut le cas de Fidonet, par exemple, très utilisé par les ONG, notamment en Afrique parmi les ONG d'aide au développement et qui prenait soin de développer ses propres protocoles.
Comme rien n'est jamais aussi simple, l'argument que l'Internet était un protocole de l'armée états-unienne avait aussi été utilisé de manière protectionniste (par exemple en France), pour travailler sur des protocoles spécifiques aux entreprises françaises, en rejetant le « protocole du DoD » comme TCP/IP était qualifié dans les livres de cours comme le Pujolle.
En fait, la complexité de la question vient d'un problème plus fondamental, la neutralité des objets techniques. Est-ce que le téléphone est de gauche ou de droite ? Est-ce que IPv6 est plus ou moins à gauche qu'IPv4 ? Ce genre de questions parait absurde et cela permet au chercheur de travailler sur n'importe quel sujet en disant qu'il est neutre, que ce sont les applications qui sont bonnes ou mauvaises mais certainement pas le sujet de recherche pour lequel il touche des subventions.
Or, s'il est vrai que le téléphone ou l'Internet peuvent être utilisés par tous, il est également vrai que de tels réseaux complexes et très coûteux à déployer ne naissent pas dans un garage : leur mise au point et, encore plus, leur sortie dans le monde réel nécessite que la société mette d'énormes moyens en jeu et elle ne le fera que s'il y a un intérêt (c'est la différence entre l'invention, phénomène individuel qui peut se faire dans un garage, et l'innovation qui est un phénomène social.). Un objet technique ne réussit pas sur ses propres mérites, mais parce que des gens riches et puissants y voient un intérêt.
Et, en même temps, il a toujours une ambiguité. Les objets techniques peuvent partiellement échapper à leur créateur, ils peuvent avoir des résultats inattendus et un réseau conçu pour l'armée de l'Empire peut servir à diffuser plein d'informations d'une manière qui était difficile et chère avant, peut servir à bâtir une encyclopédie libre et peut servir à bien d'autres choses qui auraient sans doute surpris les généraux de 1969...
L'article seul
Synchroniser deux dépôts darcs par courrier
Première rédaction de cet article le 9 juin 2009
darcs est un excellent VCS décentralisé. Il est par exemple utilisé pour gérer les fichiers de ce blog. Permet-il de travailler sur plusieurs machines sans qu'aucun des dépôts ne soit connecté en permanence ? Oui, en échangeant des patches par courrier, patches qu'on applique ensuite localement.
D'abord, il faut demander à darcs de
produire un patch. On peut utiliser pour cela la
fonction shell darcsdiff, que présentait mon article sur les fonctions shell.
darscdiff prend comme argument l'ID du
dernier message du dépôt qui est en retard de
synchronisation. (Ou, dit autrement, l'ID immédiatement
précédent celui à partir duquel on veut envoyer
les patches.) Si on prend un ID trop lointain dans
le passé, ce n'est pas très grave (le message sera simplement trop
gros), darcs n'appliquera que les patches nouveaux.
Donc, par exemple :
% darcsdiff 'Manque de scalabilite du Wifi' What is the target email address? stephane+darcs@bortzmeyer.org Successfully sent patch bundle to: stephane+darcs@bortzmeyer.org.
(Attention, par défaut, darcsdiff envoie tout le
dépôt s'il ne trouve pas l'ID donc lisez bien les avertissements avant
de taper sur la touche Entrée.)
Et le destinataire reçoit un message du genre :
Subject: darcs patch: Article NetBSD format fini (and 26 more) From: bortzmeyer@batilda.nic.fr To: stephane+darcs@bortzmeyer.org Date: Tue, 9 Jun 2009 09:04:00 +0200 (CEST) X-Mail-Originator: Darcs Version Control System X-Darcs-Version: 2.0.2 (release) DarcsURL: CONTEXT [-- Attachment #1 --] [-- Type: text/plain, Encoding: quoted-printable, Size: 2.4K --] Wed Jun 3 11:37:53 CEST 2009 stephane@ludwigVII.sources.org * Article NetBSD format fini Wed Jun 3 13:25:43 CEST 2009 stephane@ludwigVII.sources.org * TODO: strlen et l'optimisation ...
Il doit alors sauvegarder le message (par défaut, l'attachement porte comme nom l'ID du premier patch qui était manquant) puis demander à darcs d'appliquer ces patches (il peut y en avoir plusieurs, comme dans l'exemple ci-dessus) :
% darcs apply article-netbsd-format-fini.dpatch
Si on le fait deux fois, par erreur :
% darcs apply article-netbsd-format-fini.dpatch All these patches have already been applied. Nothing to do.
On trouve de nombreux détails, notamment l'intégration avec mutt dans la documentation de darcs.
(Les utilisateurs de git peuvent sans doute
faire à peu près pareil avec git bundle create
/tmp/project.gitbundle HEAD, puis en envoyant le
/tmp/project.gitbundle par courrier.)
L'article seul
Format pour transmettre des données structurées sur le réseau
Première rédaction de cet article le 8 juin 2009
La question du meilleur format pour transmettre des données structurées d'une machine du réseau à une autre a toujours suscité bien des discussions. Ce n'est peut-être pas aussi passionnel que le choix du langage de programmation mais cela fait toujours largement débat.
Le débat n'est pas toujours très informé. Sur les forums, on voit souvent, lorsque quelqu'un s'enquiert du « meilleur » format pour transmettre des données structurées, des réponses aussi idiotes que « XML est nul [sans autre explication], utilises JSON » ou bien « Il faut utiliser les Protocol Buffers [là aussi, sans explication, à part que c'est le protocole de Google et que Google a forcément raison] ». (Données « structurées » signifie qu'elles ne sont pas simplement des listes de tuples, donc un format comme CSV (RFC 4180) ne compte pas.)
Une discussion bien meilleure s'est déroulée récemment sur une
liste de diffusion de l'IETF,
apps-discuss, la liste du secteur Applications de l'IETF. On
trouve son point de départ dans un
article de Patrik Fältström. L'IETF n'a pas de format standard pour
ses applications, SNMP (RFC 1157)
utilise ASN.1, EPP (RFC 4930) et
Netconf (RFC 6241) XML, etc.
Pour ceux qui n'ont pas participé aux N discussions précédentes sur le même sujet, voici une liste (que je crois exhaustive) des candidats au rôle de format idéal, ainsi que quelques notes personnelles, et qui assument leur subjectivité, sur chacun. Tous disposent d'une documentation, parfois d'une vraie norme ouverte, et tous ont des mises en œuvre en logiciel libre :
- XML, normalisé (par le W3C), très répandu, beaucoup de mises en œuvres en logiciel libre dans tous les langages, beaucoup d'experts disponibles, gère proprement Unicode depuis le début.
- JSON, le seul, semble t-il, qui aie fait l'objet d'un RFC, le RFC 7159. Assez répandu dans le monde Web 2.0.
- YAML, plus répandu pour des fichiers (par exemple des fichiers de configuration) locaux, je ne crois pas l'avoir souvent rencontré sur le réseau.
- Les S-expressions, popularisées par le langage Lisp et donc appréciées par les fans de ce langage.
- ASN.1, d'origine ISO et donc, à juste titre, mal aimé dans le monde Internet. ASN.1 permet de décrire les données, l'encodage exact sur le câble étant laissé à des formats compagnons comme BER ou DER.
- Les netstrings, conçu par l'inénarrable djb et qui plait donc à ses fans.
- Les Protocol Buffers, un des plus récents, mais qui a derrière lui tout le poids du géant Google.
- Le système BERT, introduit par Github et basé sur Erlang (mais utilisable depuis d'autres langages).
- On peut citer aussi les formats spécifiques à un langage de
programmation donné, qui permettent de
sérialiser des objets du langage pour les
transporter sur le réseau comme
picklepour Python oujava.io.Serializablepour Java. - Et, enfin, les informaticiens étant ce qu'ils sont, il y a toute la cohorte des formats conçus et mis en œuvre localement par un programmeur ou bien une petite équipe...
L'article seul
Les protocoles réseaux de bavardage
Première rédaction de cet article le 7 juin 2009
Il existe une classe de protocoles réseaux nommés protocoles de bavardage (gossip protocol) qui résout élegamment un problème classique dans les réseaux : informer tout le monde sans utiliser de mass media centralisé. Ils utilisent pour cela un principe simple : tout pair du réseau transmet l'information aux pairs qu'il connait (un sous-ensemble du total) et ceux-ci, à leur tour, transmettent aux pairs qu'ils connaissent, et ainsi de suite (on appelle parfois cette procédure l'indondation - flooding). Au bout d'un moment, la totalité du réseau est au courant, sans qu'on aie eu besoin d'un système centralisé.
L'Internet utilise un certain nombre de protocoles de bavardage. C'est ainsi que le routage global, avec le protocole BGP (RFC 4271), dépend d'un protocole de bavardage. Aucun routeur BGP ne connait tous les autres routeurs BGP de la DFZ, l'Internet n'a pas de centre, pas de chaîne de télévision unique qui informerait tous les routeurs de l'arrivée d'un nouveau réseau. Pourtant, de fil en aiguille, l'information sur un nouveau préfixe d'adresses IP touche tout l'Internet en quelques minutes.
Avant BGP, les protocoles de bavardage ont été surtout popularisés
par les News (RFC 5537 et RFC 3977), où un article était diffusé à chaque
pair (par opposition au Web qui est d'avantage
centralisé : si le serveur de www.playboy.fr
tombe en panne ou bien est victime d'une attaque, l'information (?)
sur le site n'est plus accessible du tout). Au contraire, avec BGP ou
les News, il faut détruire beaucoup de machines
pour réellement supprimer certaines informations ! (Avec les
protocoles de bavardage, l'information cesse d'être accessible à tous
dès que le réseau cesse d'être connecté, lorsqu'il est
partitionné en deux - ou plus - morceaux.)
Donc, les principales forces des protocoles de bavardage sont la résistance aux pannes et le fait qu'aucun nœud ne joue de rôle essentiel, y compris pour l'injection initiale (alors que le terme d'« inondation » n'implique pas d'égalité, l'inondation peut aussi servir lorsqu'un des nœuds est le seul à pouvoir initier une information).
Pour fonctionner correctement, les protocoles de bavardage ont
besoin que chaque pair maintienne un historique :
quels messages a t-il reçus, a qui les a t-il envoyés,
etc. Autrement, on perdrait du temps et des ressources à retransmettre
un message déjà connu et on risquerait même de faire des boucles sans
fin. Dans les News, chaque serveur retient les
messages reçus (identifiés par leur Message-ID:,
et « oubliés » au bout d'une durée réglable, pour éviter de remplir le
disque dur). BGP a en outre d'autres mesures pour limiter l'inondation
comme le fait de ne transmettre comme toutes que celles qu'il utilise
lui-même, éliminant ainsi d'une propagation ultérieure les
« mauvaises » routes.
Une propriété intéressante des architectures fondées sur le bavardage est qu'il n'est pas nécessaire que la transmission des messages entre les pairs utilise toujours le même protocole. Par exemple, dans les News, le protocole NNTP (RFC 3977) est le plus courant mais pas le seul (pendant longtemps, UUCP était plus utilisé).
Pour illustrer le fonctionnement d'un protocole de bavardage, voici
une petite implémentation en Python, avec la bibliothèque standard socket : gossiper.py. Les
fils sont utilisés pour éviter
d'être bloqué, chaque pair pouvant évidemment être en panne,
injoignable, etc. Dans l'implémentation actuelle, on réessaie un nombre limité de fois
si un pair n'est pas joignable. Il ne faut évidemment pas comparer cette petite implémentation
aux vraies qui tournent sur le vrai Internet, notamment parce qu'elle
manque sérieusement de robustesse, par exemple lors de la lecture des
messages des autres pairs.
Dans cet exemple simple, le protocole entre deux pairs est fixé (comme avec BGP, mais contrairement aux News). Chaque pair a un numéro unique, l'ID, fixé à la main au démarrage (si on n'a pas de serveur central pour attribuer des numéros uniques, le mieux est de tirer ces ID au hasard dans un espace très grand, limitant ainsi les risques de collision, ou bien de prendre le résumé cryptographique d'une phrase, unique pour chaque pair.) Le « serveur » (le pair qui répond aux demandes de connexion) envoie son ID (suivi d'une virgule). Le « client » (le pair qui lance la connexion) envoie son ID, suivi d'une virgule et suivi du message (sur une seule ligne). Si l'ID est l'identificateur du pair, pour s'y connecter effectivement sur l'Internet, il faut un localisateur, un tuple (adresse IP, port). Dans cette simple implémentation, il n'y a qu'un de ces tuples par pair mais ce n'est pas imposé par le protocole (de toute façon, les pairs sont identifiés par leur ID, pas par leur adresse IP, donc une connexion du pair N peut venir d'une autre adresse IP que celle connue pour N, si la machine cliente a plusieurs adresses).
Au démarrage, on indique donc au programme gossiper.py le port sur lequel il doit écouter (30480 par
défaut) et les identificateurs et localisateurs de ses pairs. À noter
que la relation entre pair n'est pas symétrique : 1 peut savoir
comment joindre 2 sans que le contraire soit vrai. Le nombre de pairs
est quelconque mais il faut juste que l'ensemble des pairs soit
connecté sinon certains
messages n'arriveront pas partout.
Les pairs se souviennent des messagers qu'ils ont vu (dans l'historique global) et de ceux qu'ils ont envoyés à chaque pair (dans un historique spécifique au pair).
Le mode d'emploi est simple. Supposons qu'on veuille lancer le pair
d'ID 42, écoutant sur le port 22000, et pouvant parler aux pairs d'ID 261
(2001:DB8:1::bad:dcaf, port par défaut) et d'ID 4231
(2001:DB8:2::dead:beef, port 443), on tapera :
% python gossiper.py -i 42 -p 22000 \
261,\[2001:DB8:1::bad:dcaf\] 4231,\[2001:DB8:2::dead:beef\]:443
La syntaxe (adresse IP, port) utilisée est celle du RFC 3986, section 3.2.2. Les barres obliques inverses devant les crochets sont imposés par certains shells Unix.
Le programme affichera alors les communications avec ses pairs. Pour amorcer la pompe et injecter des messages facilement, on peut utiliser netcat (ici, l'injecteur original a indiqué un ID de 0) :
% echo 0,"Les sanglots longs des violons de l'automne" | nc 127.0.0.1 22000
Avec des messages inspirés de Radio Londres, on obtiendra des dialogues comme suit (un délai artificiel a été ajouté pour mieux simuler la durée de propagation dans un réseau). Ici, le pair d'ID 5 :
2009-06-05 17:30:13 - ::ffff:127.0.0.1 - 30 bytes (NEW message received from peer 0: "Jean a de longues moustaches...") 2009-06-05 17:30:29 - - 0 bytes (Sender task Thread-1 received "Jean a de longues moustaches" from 0, connecting to 2 (192.134.7.253:30480))
Et ici le 2 :
2009-06-05 17:31:30 - ::ffff:192.134.4.69 - 30 bytes (NEW message received from peer 5: "Jean a de longues moustaches...") 2009-06-05 17:32:01 - - 0 bytes (Sender task Thread-3 received "Jean a de longues moustaches" from 5, connecting to 6 (192.134.7.248:4242))
Et ici, un pair, le 3, reçoit un message deux fois, de 6, puis de 2. il ignore le second. Cette précaution est ce qui permet aux protocoles de bavardage de ne pas boucler éternellement.
2009-06-06 22:56:35 2a01:e35:8bd9:8bb0:21c:23ff:fe00:6b7f - 30 bytes - NEW message received from peer 6: "Jean a de longues moustaches..." 2009-06-06 22:56:49 2a01:e35:8bd9:8bb0:21c:23ff:fe00:6b7f - 30 bytes - Ignoring known message from peer 2: "Jean a de longues moustaches..." ... 2009-06-06 22:58:08 2a01:e35:8bd9:8bb0:21c:23ff:fe00:6b7f - 35 bytes - NEW message received from peer 6: "Les lapins s'ennuient le dimanche..." 2009-06-06 22:58:28 2a01:e35:8bd9:8bb0:21c:23ff:fe00:6b7f - 35 bytes - Ignoring known message from peer 2: "Les lapins s'ennuient le dimanche..."
Pour approfondir le concept, on peut lire le bon article du Wikipédia anglophone.
L'article seul
Claude Allègre pulvérise le record de Frédéric Lefebvre
Première rédaction de cet article le 5 juin 2009
Il était déjà célèbre pour ses poussées négationnistes concernant le réchauffement planétaire mais Claude Allègre, qui tient vraiment à devenir ministre dans le prochain gouvernement Sarkozy, a fait encore plus fort, battant nettement l'ancien record détenu par Frédéric Lefebvre : « Non à la commercialisation du gratuit ».
Il veut devenir ministre. Or, pour cela, il faut démontrer à Sarkozy qu'on est vraiment prêt à tout pour le servir. Les députés UMP regardent leurs chaussures et essaient de se faire porter pâle lorsqu'on parle de la loi Hadopi ? La ministre fantôme de l'économie numérique est aux abonnés absents dès qu'il s'agit de cette loi ? Allègre, lui, n'a pas peur de défendre Hadopi et écrit tout un article pour en arriver à la conclusion qu'Hadopi est le début de la civilisation contre la barbarie, tout en faisant un détour par la nécessité que la gratuité soit un monopole de l'État (comme la violence et la monnaie).
Difficile de dresser la liste complète des mensonges de cet article. Le plus énorme est la réactivation d'une vieille légende, celle comme quoi il n'y aurait pas de lois sur Internet (« [...] engager enfin la démarche de régulation d'Internet : faire entrer ce merveilleux outil dans les règles »). Mais je laisse Jean-Michel Planche et Laurent Chemla répondre, ils le font bien mieux que moi. Pour le reste, l'article d'Allègre est logique : il est de droite, il veut rentrer dans un gouvernement de droite, il tient des propos de droite. Cela ne surprendra que les naïfs qui le croyaient de gauche car il avait vaguement été membre d'un parti rose pâle il y a de nombreuses années.
L'article seul
RFC 5581: The Camellia Cipher in OpenPGP
Date de publication du RFC : Juin 2009
Auteur(s) du RFC : D. Shaw
Pour information
Première rédaction de cet article le 4 juin 2009
La cryptographie évoluant sans cesse, il est nécessaire, pour tous les protocoles Internet qui en dépendent, de prévoir la possibilité d'utiliser plusieurs algorithmes de cryptrographie, au fur et à mesure que les anciens craquent sous les coups de la cryptanalyse. Le format PGP, normalisé dans le RFC 4880 peut ainsi désormais utiliser l'algorithme de chiffrement symétrique Camellia.
Le RFC est très court car il n'y a pas grand'chose à dire. Camellia, un algorithme symétrique à blocs, d'origine japonaise, est décrit dans le RFC 3713. Notre RFC 5581 se contente de l'ajouter à la liste officielle des algorithmes PGP, aux côtés de protocoles comme AES et Twofish.
L'article seul
NetBSD formate un disque pour Linux
Première rédaction de cet article le 3 juin 2009
Quand on installe NetBSD, le programme d'installation s'occupe en général des détails comme le partitionnement et le formatage du disque et on a juste à suivre les indications d'un menu. Mais si on veut ajouter un disque ensuite ? C'est bien documenté. Et si ce disque est pour un autre système, par exemple Linux, parce qu'on veut héberger des machines virtuelles Xen ou bien simplement partager un disque entre deux systèmes d'exploitation qui alternent ? Alors, on trouve moins de documentation et voici donc quelques notes qui peuvent aider.
Sur un PC, le partitionnement est fait avec fdisk. Mais fdisk ne gère que les partitions dites « MBR », celles du monde PC. NetBSD (qui ne tourne pas que sur PC, bien au contraire), se fie, lui, aux disklabels, les tables qu'il a mises sur le disque. Une partition « PC » peut contenir une ou plusieurs partitions NetBSD. Avec fdisk, on découpe donc le disque du PC, c'est un découpage standard que n'importe quel système d'exploitation de PC va reconnaître. Puis, on utilise disklabel pour créer d'autres partitions dans ces partitions, ou bien simplement pour faire enregistrer les partitions de manière à ce que NetBSD les voit. Donc, pour résumer, fdisk s'occupe des partitions PC et disklabel des partitions NetBSD.
Pour fdisk, la méthode que je trouve le plus simple est la méthode
interactive avec l'option -u. On donne le nom de
partition qu'on veut éditer (de 1 à 4 pour les quatre partitions
primaires et en partant de E0 pour les partitions étendues) et sa
taille.
Ensuite, on utilise disklabel. La méthode que je préfère est
l'édition avec l'option -e qui lance un éditeur. On indique les
partitions NetBSD identifiées par une lettre (ici, de i à l pour mes
partitions étendues), le type (disklabel -l pour
afficher les types possibles) et les points de départ et taille des
partitions (si on fait une partition NetBSD de chaque partition MBR,
il suffit de recopier les valeurs qu'affiche fdisk).
Après le partitionnement, le disque vu avec fdisk wd0 :
Partition table:
0: NetBSD (sysid 169)
start 63, size 24386607 (11908 MB, Cyls 0-1517), Active
1: Ext. partition - LBA (sysid 15)
start 24386670, size 15745833 (7688 MB, Cyls 1518-2498/33/54)
2: <UNUSED>
3: <UNUSED>
Extended partition table:
E0: Linux native (sysid 131)
start 24386733, size 7164927 (3498 MB, Cyls 1518-1963)
PBR is not bootable: All bytes are identical (0x00)
E1: Linux swap or Prime or Solaris (sysid 130)
start 31551723, size 530082 (259 MB, Cyls 1964-1996)
PBR is not bootable: Bad magic number (0x666f)
E2: Linux native (sysid 131)
start 32081868, size 7164927 (3498 MB, Cyls 1997-2442)
PBR is not bootable: All bytes are identical (0x00)
E3: Linux swap or Prime or Solaris (sysid 130)
start 39246858, size 885645 (432 MB, Cyls 2443-2498/33/54)
PBR is not bootable: All bytes are identical (0x00)
Et le même, vu avec disklabel wd0 après l'édition
du disklabel (disklabel -e
lance un éditeur avec un contenu qui est très proche de celui-ci) :
16 partitions: # size offset fstype [fsize bsize cpg/sgs] a: 1043280 63 4.2BSD 1024 8192 0 # (Cyl. 0*- 1035*) b: 639072 1043343 swap # (Cyl. 1035*- 1669*) c: 24386607 63 unused 0 0 # (Cyl. 0*- 24193*) d: 40132503 0 unused 0 0 # (Cyl. 0 - 39813*) e: 6144768 1682415 4.2BSD 2048 16384 0 # (Cyl. 1669*- 7765*) f: 2458512 7827183 4.2BSD 2048 16384 0 # (Cyl. 7765*- 10204*) g: 13893138 10285695 4.2BSD 2048 16384 0 # (Cyl. 10204*- 23986*) i: 7164927 24386733 Linux Ext2 0 0 # (Cyl. 24193*- 31301*) j: 530082 31551723 swap # (Cyl. 31301*- 31827*) k: 7164927 32081868 Linux Ext2 0 0 # (Cyl. 31827*- 38935*) l: 885645 39246858 swap # (Cyl. 38935*- 39813*)
Et je peux formater ces partitions Linux avec mke2fs
(attention, pour que NetBSD puisse les monter, il faut apparemment
augmenter la taille des
inodes, par exemple avec mke2fs -I 128 /dev/wd0i), les
monter avec mount, etc.
Voici à quoi ressemble le partitionnement avec fdisk
-u. Ici, on va créer la quatrième partition, E3, en
indiquant son type (130 = Linux, fdisk -l pour
avoir la liste), le bloc où elle démarre, et sa taille (ici, on prend
les valeurs par défaut) :
1: Ext. partition - LBA (sysid 15)
start 24386670, size 15745833 (7688 MB, Cyls 1518-2498/33/54)
2: <UNUSED>
3: <UNUSED>
Extended partition table:
E0: Linux native (sysid 131)
start 24386733, size 7164927 (3498 MB, Cyls 1518-1963)
PBR is not bootable: All bytes are identical (0x00)
E1: Linux swap or Prime or Solaris (sysid 130)
start 31551723, size 530082 (259 MB, Cyls 1964-1996)
PBR is not bootable: Bad magic number (0x666f)
E2: Linux native (sysid 131)
start 32081868, size 7164927 (3498 MB, Cyls 1997-2442)
PBR is not bootable: Bad magic number (0x8fe6)
First active partition: 0
Drive serial number: 1054424792 (0x3ed93ed8)
Which partition do you want to change?: [none] E3
sysid: [0..255 default: 169] 130
start: [1518..2498cyl default: 39246858, 2443cyl, 19164MB]
size: [0..55cyl default: 885645, 55cyl, 432MB]
bootmenu: []
Question documentation, on peut noter que la documentation de NetBSD sur Cobalt, quoique touchant à un système différent est, en pratique, très bien faite.
Tous mes remerciements à Thierry Laronde pour m'avoir guidé dans cette tâche.
L'article seul
Générateurs en Python, un exemple réel
Première rédaction de cet article le 2 juin 2009
Les fanas du langage de programmation Python citent souvent parmi les merveilles de ce langage la possibilité d'écrire des générateurs, c'est-à-dire des fonctions qui gardent automatiquement un état d'un appel sur l'autre et peuvent servir à énumérer à loisir une structure de données. Beaucoup d'exemples de générateurs qu'on trouve dans les tutoriels sont plutôt artificiels et, en les lisant, on se dit « C'est une idée amusante mais à quoi peut-elle servir en vrai ? ». Voici donc un exemple de générateur tiré d'un programme réel.
Le problème était d'analyser le journal d'un serveur whois. Pour chaque requête d'un client whois, on va mettre une information dans une base de données. Ce motif de conception est courant en administration système et, sans les générateurs, se programme en général ainsi (en pseudo-code) :
for each line in log
entry = parse(line)
do something for the entry
avec mélange de l'analyse syntaxique
(parse(line)) et de l'action effectuée
(do something for the entry). Or, ces deux calculs n'ont rien à voir
et n'ont aucune raison d'être imbriqués dans la même boucle, d'autant plus qu'on pourrait
parfaitement vouloir les utiliser séparement. Les générateurs
permettent de séparer les deux calculs dans des endroits bien
distincts du programme :
# Le générateur
def whois_entry
for each line in log
entry = parse(line)
yield entry
for each entry in whois_entry()
do something for the entry
En Python, le mot-clé yield renvoie une valeur
(comme return) mais la fonction ne se termine
pas. Le prochain appel continuera à l'instruction suivant
yield et la boucle sur le journal reprendra au
point où elle s'était arrêtée.
Les générateurs ont été, à ma connaissance, introduits par le langage CLU et très bien présentés dans le livre de Liskov, « Abstraction and Specification in Program Development ». Ce livre date des années 1980, ce qui donne une idée du temps qu'il faut en informatique pour qu'une idée devienne banale. Pour les générateurs Python, une très bonne introduction existe dans Wikipédia.
Enfin, voici le code presque complet qui analyse le journal du serveur whois et met le résultat dans une base de données :
#!/usr/bin/python
import re
import sys
import psycopg2
db = "dbname=essais"
def parse_whois(filename):
ifile = open(filename)
for line in ifile:
match = whois_request.search(line)
if not match:
print >>sys.stderr, "Warning: invalid line \"%s\"" % line
continue
time = match.group(2) + ":" + match.group(3) + ":" + match.group(4)
source = match.group(6)
request = match.group(8)
if request.find(' ') == -1:
domain = request
else:
args = request.split(' ')
domain = args[len(args)-1]
yield (time, source, unicode(domain.lower(), "latin-1"))
whois_request = re.compile("^\[(\d+)-(\d+)H(\d+):(\d+)\]\s+Request from \[([\da-f\.:/]+)\] +\[([\da-f\.:]+)/(\d+)\] +=> +\[(.*)\]$")
if __name__ == '__main__':
filename = sys.argv[1]
...
conn = psycopg2.connect(db)
cursor = conn.cursor()
cursor.execute("BEGIN;")
...
for (time, source, request) in parse_whois(filename):
date = day + ":" + time
cursor.execute("""INSERT INTO whois_requests (file, seen, source, domain)
VALUES (%(file_id)s, %(date)s,
%(source)s, %(request)s);", locals())
cursor.execute("COMMIT;")
L'article seul
Taille des bases PostgreSQL
Première rédaction de cet article le 28 mai 2009
Quand on apprend les SGBD et SQL (par exemple en lisant la Guide des bases de données en manga), on ne travaille qu'avec des bases minuscules et on ne remplit jamais le disque. Mais les SGBD sont typiquement utiisés pour stocker de grandes quantités de données et, là, de nouveaux problèmes surgissent pour le programmeur et le DBA. Le développement du système DNSmezzo est l'occasion de tester PostgreSQL avec de grandes bases.
Pour l'instant, les chiffres n'ont pas de quoi impressionner, la base commence juste à se remplir. On y reviendra dans quelques temps. Mais on peut déjà de se préparer.
Les fonctions utiles au DBA sont bien documentées. Par exemple, pour connaître la taille d'une base, on ne peut pas utiliser df ou ls car la base n'est pas stockée dans un fichier unique. Mais PostgreSQL fournit ce qu'il faut :
dnsmezzo2=> SELECT pg_database_size('dnsmezzo2');
pg_database_size
------------------
34512910768
(1 row)
C'est une taille en octets. Pas très lisible. Mais il y a des fonctions plus jolies :
dnsmezzo2=> SELECT pg_size_pretty(pg_database_size('dnsmezzo2'));
pg_size_pretty
----------------
32 GB
(1 row)
C'est mieux. Et si on veut voir la taille par table et non plus pour une base entière ? PostgreSQL le permet aussi :
dnsmezzo2=> SELECT pg_size_pretty(pg_relation_size('DNS_packets'));
pg_size_pretty
----------------
3537 MB
(1 row)
Cette taille n'inclus pas les index et autres données auxiliaires. Pour les voir :
dnsmezzo2=> SELECT pg_size_pretty(pg_total_relation_size('DNS_packets'));
pg_size_pretty
----------------
8219 MB
(1 row)
Si on a une base qui se remplit automatiquement, il est prudent de surveiller automatiquement les disques, ce que permettent tous les moniteurs (par exemple mon). Mais le script check_postgres, écrit par Greg Sabino Mullane, permet de faire mieux en surveillant divers paramètres comme la taille des tables :
% sudo -u postgres /usr/local/sbin/check_postgres.pl --action disk_space POSTGRES_DISK_SPACE OK: FS /dev/sda2 mounted on /var is using 53.97 GB of 73.61 GB (78%) * FS /dev/sda4 mounted on /home is using 116.25 GB of 157.69 GB (78%) * FS /dev/sdb1 mounted on /databases is using 8.17 GB of 1.09 TB (1%) | time=0.05 /dev/sda2=57950318592 * time=0.05 /dev/sda4=124827308032 * time=0.05 /dev/sdb1=8776122368
Son format de sortie n'est pas conçu pour les humains mais pour des programmes comme Nagios ou Munin. Ici, la surveillance des tables :
% check_postgres.pl -c 10G --dbname=dnsmezzo2 --action table_size POSTGRES_TABLE_SIZE OK: DB "dnsmezzo2" largest table is "public.dns_packets": 3537 MB | time=0.09 information_schema.sql_features=40960 information_schema.sql_implementation_info=8192 pg_catalog.pg_statistic=122880 [...] public.dns_types=8192 public.pcap_files=8192 public.dns_packets=3708461056 frzone.nameservers=2375680
On indique la taille maximale de la table (ici, dix gigaoctets) avec l'option
-c. Le programme alertera si une table dépasse
cette taille et un programme comme mon ou Nagios pourra alors agir :
% check_postgres.pl -c 3G --dbname=dnsmezzo2 --action table_size POSTGRES_TABLE_SIZE CRITICAL: DB "dnsmezzo2" largest table is "public.dns_packets": 3537 MB [...]
Examiner la taille des tables et des bases, ou bien l'occupation disque
avec la commande df, peut parfois donner un résultat
surprenant : si on détruit des tuples avec la commande SQL
DELETE, la taille des tables ne diminue pas. Ce
point est bien
expliqué dans la documentation : le SGBD ne récupère pas
automatiquement l'espace libre, car celui-ci peut resservir pour de
nouvelles données. Si on veut vraiment retrouver ses gigaoctets, on
peut se servir de VACUUM et VACUUM
FULL :
dnsmezzo2=# SELECT pg_size_pretty(pg_total_relation_size('DNS_packets'));
pg_size_pretty
----------------
8219 MB
(1 row)
dnsmezzo2=# vacuum full;
VACUUM
dnsmezzo2=# SELECT pg_size_pretty(pg_total_relation_size('DNS_packets'));
pg_size_pretty
----------------
8020 MB
(1 row)
Dans ce cas, le gain a été très faible car peu de suppressions ont eu
lieu. Sur une base très vivante, le gain peut être bien plus
spectaculaire. Mais attention ! VACUUM FULL
bloque complètement la base, parfois pendant de longues périodes (voir
la documentation
de Postgresql pour des solutions alternatives).
Bon, une fois qu'on peut voir quelle place prennent les données,
peut-on les mettre à un autre endroit, sur un autre disque ? Par
défaut, PostgreSQL crée ses bases dans un répertoire qui dépend des
options de lancement du serveur (sur Debian,
par défaut, c'est
/var/lib/postgresql/$VERSION/main/base) mais on
peut demander à ce qu'elles soient mises ailleurs (et cela peut être
intéressant de répartir les bases sur plusieurs contrôleurs
disque, pour des raisons de performance). Cela se fait
avec les tablespaces. On
crée une tablespace sur le disque de son choix :
% psql -c "CREATE tablespace Compta location '/big/disk/compta/db'"
et on peut l'utiliser, par exemple au moment de la création de la base :
% createdb --tablespace compta comptabilite
On peut ensuite voir les tablespaces et les bases qui les utilisent avec le catalogue de PostgreSQL :
=> SELECT datname AS database, spcname AS tablespace, spclocation AS directory
FROM pg_database INNER JOIN pg_tablespace
ON pg_tablespace.oid = pg_database.dattablespace;
database | tablespace | directory
-------------------+--------------------+---------------
template1 | pg_default |
essais | pg_default |
ucd | pg_default |
dnswitness-ipv6 | pg_default |
dnsmezzo2 | databasespartition | /databases/db
comptabilite | compta | /big/disk/compta/db
Avec ce système, une base de données est toute entière dans un
répertoire Unix, celui du tablespace. Si
on veut répartir une base, c'est possible avec les
tablespaces, puisque des commandes comme
CREATE TABLE peuvent prendre un
tablespace comme argument. Si on veut par contre
répartir une table sur plusieurs endroits,
il faut utiliser le partitionnement
mais c'est nettement plus compliqué et je n'ai pas encore d'expérience pratique avec.
Si vous voulez la liste des table/index par taille, ainsi que des informations sur le tablespace utilisé, voyez ce joli code. Si on a mis une base sur un tablespace qui, à l'expérience, ne convient pas, on peut changer ensuite.
L'article seul
Pourquoi l'Union Européenne est-elle moins démocratique que les États membres ?
Première rédaction de cet article le 28 mai 2009
Dans les débats sur l'avenir de l'Union Européenne, un argument fréquent de ceux qui se présentent comme « pro-européens » et qui ont voté Oui au traité de Maastricht et à la constitution européenne est que l'Union est un État comme un autre, aussi démocratique que les pays traditionnels et qu'il n'y a donc pas de raison d'être « euro-sceptique » ou « anti-européen », sauf si on est un chauvin rétrograde.
À première vue, cette remarque est de simple bon sens. Les hommes politiques sont les mêmes au niveau européen qu'au niveau national traditionnel et il n'y a pas de raison que celui qui est un démocrate à Paris ou à Berlin cesse de l'être à Bruxelles.
Mais il existe une grande différence : ce qui assure le caractère relativement démocratique du régime à Paris ou à Berlin, ce n'est pas la « vertu » des hommes politiques. C'est l'existence d'une « société civile », c'est-à-dire de toute un ensemble de contre-pouvoirs, associations, syndicats, journaux, etc, qui gardent un œil sur le gouvernement, le contestent, le combattent et le font rester à peu près sur les rails de la démocratie.
À Bruxelles, rien de tel : il y a des hommes politiques et des lobbyistes mais pas d'associations européennes, pas de syndicats européens (uniquement de lourdes confédérations qui n'ont pas de réelle activité multinationale), pas de médias européens.
La société civile européenne n'existe pas (pas encore ?). Tant que ce sera le cas, l'Europe sera moins démocratique que les états traditionnels.
L'article seul
Server Fault, un site de Q&A pour administrateurs systèmes et réseaux
Première rédaction de cet article le 27 mai 2009
Jeff Atwood a annoncé le 25 mai le lancement de la version « beta publique » de Server Fault, un compagnon du fameux site Stack Overflow. Server Fault est un site Web de questions & réponses pour administrateurs systèmes et réseaux, avec système de réputation.
Comme pour son célèbre parent, Server Fault repose sur le principe que toute personne qui veut
écrire doit s'authentifier (en OpenID, donc,
http://www.bortzmeyer.org/ pour moi) et que les actions de cette personne (poser une question,
proposer une réponse) lui vaudront petit à petit une
réputation, déterminée par les votes des autres
utilisateurs. Les simples lecteurs peuvent, eux, être
anonymes.
Les réponses aux questions sont classées, non pas dans l'ordre chronologique comme sur un blog mais dans l'ordre décroissant des votes, ce qui permet à l'information la plus reconnue d'émerger hors du bruit. C'est un gros avantage, par exemple par rapport aux traditionnelles listes de diffusion où il faut faire un gros effort de synthèse lorsqu'on lit un fil riche, rempli de messages parfois incomplets ou contradictoires.
Pour ceux que ça intéresse, ma réputation est de 214 ce qui me permet, par exemple, de voter contre une contribution (il faut une réputation de 15 pour voter pour) et d'avoir moins de publicité. À 250, je pourrai voter sur la fermeture ou la réouverture de mes propres questions et à 500, je pourrais réétiqueter les questions des autres.
Quels genres de sujet sont traités ? Tout ce qui concerne l'administration systèmes et réseaux. On y trouve des questions comme :
Comme il est peu probable qu'un lecteur soit intéressé par tous les
systèmes d'exploitation possibles, Server Fault
permet d'étiquetter les questions et
chercher ensuite selon ces étiquettes. Ainsi, http://serverfault.com/questions/tagged/netbsd donnera accès
aux questions sur le système d'exploitation NetBSD (pour l'instant aucune) et http://serverfault.com/questions/tagged/bind aux
questions sur le serveur de noms BIND.
Ouvert en version beta avant l'annonce officielle, Server Fault n'est pas encore aussi riche que son grand cousin Stack Overflow mais je pense qu'il va le rattraper rapidement.
Principaux bémols : comme son prédécesseur, il n'est qu'en anglais et le (excellent) logiciel n'est pas distribué (même pas sous une licence restrictive) donc on ne peut pas facilement essaimer cette idée.
Ce genre d'outils est l'exemple de ce qu'on peut produire de mieux avec le Web, la mise en commun de la connaissance et son organisation.
L'article seul
RFC 3552: Guidelines for Writing RFC Text on Security Considerations
Date de publication du RFC : Juillet 2003
Auteur(s) du RFC : E. Rescorla, B. Korver
Première rédaction de cet article le 27 mai 2009
La sécurité est désormais devenue une préoccupation constante de tous les administrateurs réseau et système. Elle concerne également les auteurs de logiciels. Mais les concepteurs de protocoles ne sont pas épargnés. L'IETF demande désormais à tout protocole conçu pour un déploiement sur l'Internet d'être impeccable, sur le plan de la sécurité, d'avoir prévu les attaques possibles, et les parades à utiliser. Pour éviter tout oubli, il est obligatoire, dans tout RFC, d'avoir une section Security considerations, qui contient l'analyse des questions de sécurité du protocole normalisé par ce RFC. Que mettre dans cette section ? C'est le but de ce RFC 3552 que de l'expliquer.
Ce RFC est donc une lecture indispensable pour l'auteur de RFC. Il porte toute l'autorité de l'IAB. Mais il est aussi un excellent tutoriel sur la sécurité sur l'Internet, notamment par son exposé des différents types d'attaques, et il est donc une lecture recommandée pour toute personne qui débute sur ce sujet. Elle y apprendra le vocabulaire et les concepts de base de la sécurité, qui font défaut à tant d'administrateurs aujourd'hui.
À quoi sert la section Sécurité des RFC, obligatoire depuis le RFC 2223 (section 9) ? Comme le rappelle la section 1 de notre RFC 3552, cette section Sécurité sert à s'assurer que les auteurs du protocole ont procédé à une analyse sérieuse de la sécurité de leur œuvre, et à informer les lecteurs des résultats de ladite analyse.
Bon, mais avant de prendre des mesures de sécurité, il faut mieux définir ce qu'est la sécurité. En avant pour la section 2, qui introduit la partie « tutoriel » du RFC. La sécurité est en fait un ensemble de propriétés diverses. On peut identifier deux catégories, la sécurité des communications et celles des systèmes qui communiquent.
La sécurité des communications est détaillée en section 2.1. Elle se subdivise entre trois sous-catégories, la confidentialité, l'intégrité des données et l'authentification du partenaire. La confidentialité est le fait que vos secrets restent secrets : personne ne doit pouvoir écouter vos communications. L'intégrité des données est le fait qu'on reçoit bien ce qui a été envoyé, aucun méchant n'a modifié ces données (un objectif très difficile à atteindre dans le monde numérique : contrairement au papier, les changements ne laissent pas de trace). Et l'authentification est le fait de s'assurer qu'on parle bien avec celui qu'on croit.
Ces trois propriétés sont liées : par exemple, sans authentification, la confidentialité est difficile à assurer (si Alice sécurise ses communications contre l'écoute, mais n'authentifie pas, qui sait si elle n'écrit pas à Ève en pensant écrire à Bob ? Auquel cas, ses précautions ne serviraient à rien.)
Une autre propriété qui ne rentre pas dans cette classification est la non-répudiation (section 2.2) qui est le fait de pouvoir prouver que le message a bien été émis.
La sécurité des systèmes est en section 2.3. Elle comprend entre autres :
- La protection contre l'usage non autorisé du système,
- La protection contre les usages inappropriés (les petites lettres dans les contrats qui limitent ce que vous avez le droit de faire),
- La protection contre les dénis de service, les attaques qui visent à empêcher tout usage de la machine.
Avec la section 3, on étudie cette fois les méchants, les agresseurs. Elle est consacrée à la modélisation des menaces. L'idée est qu'on ne peut pas se protéger contre tout (les meilleures protections contre le déni de service, par exemple, ne serviront pas si l'attaquant coupe physiquement le câble). La modélisation des menaces la plus courante sur l'Internet consiste à considérer que l'attaquant :
- N'a pas pris le contrôle d'une des deux machines qui communique (autrement, la défense devient quasi-impossible),
- Mais, en revanche, a un contrôle total du réseau qui les relie. Il peut lire n'importe quel paquet, en modifier et en fabriquer, y compris avec une adresse IP source qui n'est pas la sienne.
Il existe aussi des modèles de menaces plus limités (section 3.1) par exemple où l'attaquant est strictement passif : s'il peut lire n'importe quel paquet, il n'a pas la possibilité d'en créer ou d'en modifier. De telles attaques représentent une proportion non négligeable, dans le monde réel. (En sécurité des réseaux, Ève est un attaquant passif, Mallory un attaquant actif.)
La section 3.2 détaille donc ce que peut faire un attaquant passif. Les attaques passives nécessitent d'être quelque part sur le chemin entre les deux partenaires (section 3.5 pour cette notion d'« être sur le chemin »), par exemple parce qu'on est sur le même réseau Wifi (réseau partagé, voir aussi section 3.6) qu'une des deux machines qui communiquent, ou bien parce qu'on contrôle un routeur sur le chemin (beaucoup de routeurs sont mal protégés). Dans ces conditions, l'attaquant passif peut :
- Écouter les communications,
- Capturer des mots de passe (par exemple avec l'excellent outil dsniff),
- Faire, avec les données capturées, des attaques hors-ligne, par exemple en cryptanalysant.
Passons aux attaques actives. La section 3.3 leur est consacrée. Un attaquant actif peut fabriquer des paquets IP quelconques (en théorie, les FAI ne devraient pas laisser passer les paquets ayant une adresse IP source usurpée, mais le RFC 2827 est bien peu déployé). Il ne peut pas toujours recevoir la réponse (qui ira à celui dont il a usurpé l'adresse) mais certaines attaques, dites aveugles, sont malgré tout possibles dans ce cas.
Parmi les autres attaques possibles, il y a le rejeu (section 3.3.1) où l'attaquant réemet un paquet qu'il a déjà vu (sans même le comprendre, par exemple si le message déclenche un retrait bancaire, et que le protocole n'a pas de protection contre le rejeu, on voit ce qu'il peut advenir), la modification de message (section 3.3.4) ou l'homme du milieu où Janus, se plaçant entre Alice et Bob, se fait passer pour Bob auprès d'Alice et pour Alice auprès de Bob (et relaie les messages, pour qu'Alice et Bob ne s'aperçoivent de rien).
Maintenant, arrivé à ce stade, on connait les agresseurs et leurs capacités. Il existe évidemment de nombreuses défenses possibles mais toutes ne sont pas bonnes, loin de là. La section 4 doit donc lister des questions fréquentes, communes à beaucoup de protocoles. Par exemple, pour l'authentification des utilisateurs (section 4.1), notre RFC rappelle les forces et les faiblesses des différents mécanismes, comme le traditionnel mot de passe (désormais interdit dans les protocoles IETF, sauf si le canal est protégé par la cryptographie, le risque de sniffing étant trop élevé autrement) ou les certificats (RFC 5280), qui peuvent être également utilisés pour authentifier une machine.
En fait, concevoir un protocole sûr est une tâche tellement complexe, avec tellement de possibilités d'erreur (et, en sécurité, les erreurs ne se voient pas, avant qu'elles ne soient exploitées), que la meilleure solution est souvent... de ne pas le faire, mais de compter sur un cadre générique (section 4.2) comme SASL (RFC 2222) pour l'authentification. En disant simplement « Pour l'authentification, on utilise SASL », l'auteur de protocole prudent peut ainsi s'appuyer sur un cadre solide et prouvé. Ceci dit, rien n'est jamais simple en sécurité et le RFC 3552 rappelle que ces cadres génériques ont souvent une faiblesse, ils peuvent être victimes d'une attaque par repli, où un attaquant actif va essayer de faire en sorte qu'Alice et Bob n'utilisent pas la sécurité maximale, si d'autres sont disponibles. Bien sûr, tout protocole de sécurité où les paramètres sont négociables court ce risque mais il est plus élevé pour les cadres génériques car ils encouragent le développeur du protocole à ne pas trop réfléchir aux détails.
La section 4.4 rappelle la différence entre authentifier et autoriser (le premier permet de vérifier une identité, le second de déterminer si une entité donnée a le droit de faire telle action).
Comment fournir des communications sécurisées entre deux machines ? Un protocole donné a deux solutions, fournir lui-même cette sécurité ou bien s'appuyer sur un protocole de sécurité généraliste. Ainsi, le DNS se protège contre les modifications en transit par la signature des enregistrements (DNSSEC, RFC 4033), la première solution, celle d'une sécurité fournie par le protocole. Par contre, HTTP délègue en général sa sécurité à un protocole générique, TLS (RFC 5246 et RFC 2818 pour l'adaptation spécifique à HTTP), ce qui est la deuxième solution. La section 4.5 de notre RFC discute ces deux solutions et donne des exemples.
Par exemple, le mécanisme le plus générique est IPsec (RFC 4301). Cette solution protège toute communication IP. Mais IPsec est peu déployé, et en général sous forme de VPN. Un inconvénient de la méthode VPN est qu'elle est invisible aux applications, ce qui rend difficile pour celles-ci de savoir si leurs communications sont protégées (et donc si elles peuvent employer un mot de passe classique). Le RFC demande donc que les auteurs de protocole ne tiennent pas pour acquise la disponibilité d'IPsec (une violation de cette règle se trouve dans le RFC 5340, qui a supprimé les possibilités d'authentification qui existaient dans les précédentes versions d'OSPF, pour imposer IPsec). Pourtant, le RFC rappelle qu'IPsec est obligatoire pour IPv6 (ce qui est de la pure réthorique, la plupart des implémentations d'IPv6 n'ont pas IPsec et, même quand il est implémenté, son activation reste facultative... et compliquée).
L'autre grand mécanisme générique de protection des communications
est TLS (RFC 5246) qui
travaille, lui, juste en dessous de la couche
7. Il ne protège donc pas contre, par exemple, des paquets
TCP RST (ReSeT) faux. Notre
RFC note qu'il existe deux façons d'utiliser TLS, avec un port spécial
dédié (ce que fait HTTPS, avec son port 443) ou
bien avec un démarrage de TLS une fois la connexion établie. À part
HTTP, où le RFC 2817 n'a eu aucun succès, cette seconde
méthode est la plus employée parmi les protocoles TCP/IP, sous le nom
de STARTTLS. Son avantage est qu'elle permet de
n'utiliser qu'un seul port et de négocier certains paramètres avant de
lancer TLS et donc de choisir le certificat en fonction de critères
comme le nom demandé (ce qui est utile en HTTP, autrement, avoir
plusieurs certificats sur une même machine est complexe, cf. section 4.5.2.1). Son
inconvénient principal est qu'elle peut ouvrir la voie à des attaques
par repli, où Mallory essaie de convaincre Alice et Bob que TLS n'est
pas possible, les amenant à ne pas sécuriser leur communication.
Les attaques par déni de service forment une classe entière d'attaques, très difficiles à combattre. Très fréquentes sur l'Internet aujourd'hui (un exemple est l'attaque contre les serveurs racine du DNS en février 2007), elles n'ont pas de solution générale, contrairement à la plupart des autres attaques où la cryptographie résout tous les problèmes techniques. La section 4.6 étudie cette menace et les approches possibles. Certaines attaques par déni de service sont brutales et sans subtilité, d'autres plus avancées comme les attaques SYN flood contre TCP. Il est parfois possible de modifier les protocoles pour les rendre moins vulnérables aux attaques subtiles. Par contre, pour les attaques par force brute, les seules protections restent le surdimensionnement des infrastructures (si c'est économiquement raisonnable) et la réaction a posteriori.
Parmi les variétés de DoS, le RFC signale l'attaque aveugle (comme le TCP SYN flood cité plus haut), où l'attaquant n'a même pas besoin de pouvoir recevoir les réponses. Mais il y a aussi la DoS distribuée où des dizaines ou des centaines de milliers de machine MS-Windows, devenues des zombies, coopèrent pour l'attaque.
Quant aux protections, elles reposent sur les principes suivants :
- Faire en sorte que l'attaquant aie plus de travail que vous (section 4.6.3.1) par exemple en demandant au client de résoudre des puzzles cryptographiques comme le fait HIP (RFC 5201). Cela ne protège pas contre les attaques distribuées, où l'ennemi a une énorme puissance de calcul à sa disposition.
- Obliger l'attaquant à montrer qu'il peut recevoir les réponses par exemple en générant aléatoirement un petit gâteau, un ensemble de bits que le partenaire va devoir transmettre verbatim, prouvant ainsi qu'il reçoit les réponses. Cela empêche les attaques aveugles et valide ainsi l'adresse IP source de l'attaquant. (Photuris, RFC 2522 utilise cette technique.)
Il y a une autre façon de voir les techniques de sécurité, c'est de séparer celles qui protègent le message et celles qui protègent le canal. Dans le premier cas, le message est protégé de bout en bout, quels que soient les intermédiaires. Dans le second, on ne protège qu'un échange entre deux machines, mais des intermédiaires ont pu lire et/ou modifier le message avant ou après le canal sécurisé. Par exemple, pour le DNS, DNSSEC fournit une protection de bout en bout, il protège le message. Même si un des serveurs de noms secondaires du domaine ou un serveur de noms récursif est sous le contrôle d'un attaquant, DNSSEC permettra de détecter une modification. Au contraire, DNSCurve ne protège que le canal. Si un serveur de noms récursif triche, DNSCurve ne protège pas (le point n'est pas mentionné sur le site Web de DNSCurve, ce qui n'est pas étonnant, l'honnêteté intellectuelle n'ayant jamais été le fort de djb). Autre exemple, avec le courrier électronique, PGP (RFC 4880) sécurise le message (et il est donc protégé contre la lecture non autorisée ou la modification, quels que soient le comportement des serveurs intermédiaires) alors que SMTP + TLS (RFC 3207) ne protège qu'un canal (alors que le courrier est relayé, stocké, etc). Le RFC note que la distinction entre protection du message et protection du canal dépend de la couche qu'on regarde. Au niveau IP, chaque paquet est un message et donc IPsec peut dire que, au niveau 3, il sécurise le message alors que, au niveau 7, les applications considèrent qu'IPsec ne sécurise que le canal. Et il y a des cas encore plus compliqués comme une page Web dont les différents composants ont été récupérés par des canaux différents.
Enfin, après toutes ses considérations sur la sécurité des réseaux en général et de l'Internet en particulier, on arrive avec la section 5 aux prescriptions sur la section Security considerations des futurs RFC. Que faut-il y mettre ? Les auteurs doivent indiquer :
- quelles attaques sont exclues par l'analyse de sécurité (et pourquoi !)
- quelles attaques sont inclues dans l'analyse et, pour chacune, si le protocole est protégé contre cette attaque ou pas.
Le RFC doit également inclure un modèle des menaces, s'appliquant à
l'Internet entier (pas uniquement à un réseau local déconnecté du
reste du monde). Un exemple que donne le RFC concerne
l'authentification traditionnelle Unix via le
mot de passe et les fichiers /etc/passwd et
/etc/shadow et un texte possible serait quelque
chose du genre « La sécurité du système repose sur la difficulté à
deviner le mot de passe et à écouter le réseau lorsque le mot de passe
circule. La divination du mot de passe est possible
hors-ligne avec des programmes comme Crack
(surtout si la longueur du mot est limitée à huit caractères) et
l'écoute est possible dès que le mot de passe est utilisé en clair,
par exemple par telnet. »
Enfin, la section 6 fournit des exemples de « bonnes » sections Sécurité, tirées de RFC réels comme le RFC 2821 (avec des ajouts mis par le RFC 3552 pour traiter des problèmes que le RFC 2821 avait négligé) ou comme le RFC 2338, là encore avec quelques ajouts (le RFC 2338 oubliait de dire explicitement que la confidentialité n'était pas un but).
L'article seul
Un modèle économique pour le pair-à-pair ?
Première rédaction de cet article le 22 mai 2009
Le pair-à-pair reste un sujet de recherche bouillonant sur Internet. Tous les jours, de nouveaux articles sont publiés, de nouveaux logiciels sont testés. Mais certains aspects ont été peu étudiés, par exemple le « modèle économique », c'est-à-dire comment motiver les pairs en leur promettant une récompense pour leur participation.
Il y a des tas de façons de faire participer les gens à un réseau pair-à-pair. On peut les enrôler sans leur demander leur avis (cas de Skype qui se sert des machines ayant installé leur logiciel ultra-fermé comme relais, sans les prévenir), on peut faire appel aux valeurs les plus hautes (participer à une aventure dénuée de modèle économique), on peut les appâter avec un chantage « seuls ceux qui donnent recevront ». C'est ce dernier mécanisme qu'utilisent beaucoup de réseaux d'échange de fichiers en pair-à-pair comme eDonkey.
Mais ce système a un gros défaut. Si on veut le faire respecter (à part en dénigrant les leechers et en espérant que cela leur fasse honte), si on veut compter ce que chacun apporte, il faut un mécanisme centralisé, auquel tout le monde doit faire confiance.
Le réseau GNUnet n'a pas de tel mécanisme puisqu'il est entièrement bâti sur une architecture intégralement pair-à-pair. Aucun serveur central n'y est admis. Comment faire pour récompenser les bons, dans un tel système ? C'est le problème auquel s'attaque un article de 2003, An Excess-Based Economic Model for Resource Allocation in P2P Networks.
Je ne prétendrai pas avoir tout compris, et je n'essaierai donc pas de résumer cet article ici. Mais j'apprécie que certains se penchent sur les problèmes difficiles (la plupart des autres tentatives de créer un système de récompense dans le pair-à-pair se contentaient d'ajouter un serveur centralisé pour la comptabilité.)
L'article seul
Interdire l'accès à un site Mason à certains
Première rédaction de cet article le 20 mai 2009
J'assure la maintenance d'un service Web dynamique écrit en Mason. Plusieurs machines se sont mises récemment à l'utiliser en boucle, violant ses règles d'usage. Comment leur interdire l'accès ?
Mason est un environnement de développement en Perl pour faire des sites Web dynamiques. Il est utilisé notamment pour amazon.com. Il s'appuie sur l'intégration de Perl dans Apache, mod_perl. Comme il tourne sur Apache, on peut bloquer l'accès à certaines adresses IP via les mécanismes Apache normaux. Mais j'ai finalement choisi une solution complètement « Masonienne ». L'un de ses intérêts est qu'on a toute la puissance de Perl à sa disposition pour imaginer des règles d'accès aussi baroques qu'on veut (même si cette possibilité n'est pas utilisée ici).
Le service en question est une interface Web à whois, protocole normalisé dans le RFC 3912 pour l'accès aux base de données des registres. Comme une des grosses faiblesses de whois est le fait qu'il faut désigner explicitement le serveur requis, ce service Web essaie de trouver automatiquement le bon serveur (il existe plusieurs méthodes pour cela, le site documente celles utilisées).
Un tel service est relativement rare sur le Web et il est donc logique que certains « petits malins » se mettent à utiliser des robots pour récolter des données via ce site. C'est gênant car, comme le service effectue les requêtes whois pour le compte de ses clients Web, c'est lui qui risque de se faire mettre en liste noire par les serveurs whois, en cas de requêtes trop fréquentes. Je préviens donc le responsable de l'adresse IP « coupable » puis, en cas de non-réponse, je coupe.
Par exemple, 212.27.63.204, alias
pperso.free.fr fait de telles requêtes. La base
du RIPE-NCC, interrogée en whois, nous apprend
que les protestations doivent être envoyées à
abuse@proxad.net qui, comme la très grande
majorité des services abuse@, ne répond jamais et
ne lit probablement pas son
courrier. Place donc aux mesures fascistes.
Le code Mason a été modifié ainsi :
<%once>
my %blacklist = (
'212.27.63.204' => 1, # Proxad pperso.free.fr 2009-05-12
'69.59.186.12' => 1, # Unknown robot 2009-05-12
'2001:660:3003:8::4:69' => 1, # Test only 2009-05-12
);
</%once>
La section <%once> est exécutée une seule
fois au chargement de la page. Ici, elle ne fait qu'initialiser le
dictionnaire %blacklist qui indique les adresses
IP des méchants et la date
d'entrée dans la liste noire.
Ensuite, il faut, pour chaque requête (donc dans la section <%init>), tester l'appartenance du
client HTTP à cette liste :
<%init>
if (exists $blacklist{$ENV{'REMOTE_ADDR'}} ) {
$m->clear_and_abort(403);
}
...
Mason, comme CGI, rend accessible un certain
nombre d'informations sur le client, via des variables d'environnement
(dictionnaire Perl
%ENV). REMOTE_ADDR est
l'adresse IP du client. Si elle est dans la liste noire, on appelle la
méthode clean_and_abort (dont le nom indique bien
ce qu'elle fait) de l'objet $m (qui identifie la
requête Mason, et qui est une variable « magique », créée
automatiquement par Mason).
Le paramètre passé à clean_and_abort, 403, est
le code de statut HTTP. 403, défini dans le RFC 2616, section 10.4.4, signifie « Accès interdit ».
Et voici le rejet d'une connexion, vue dans le journal d'Apache :
212.27.63.204 - - [20/May/2009:09:18:52 +0200] "GET /dyn/whois/ask?query=82.230.221.96 HTTP/1.0" 403 403 "-" "-" www.generic-nic.net
Voilà, solution rapide et simple, prochaine étape, mettre les adresses IP dans un fichier de configuration plutôt que dans le code Mason, mais, bon, c'est une solution vite fait.
Merci à Éric Redon pour ses idées, son aide et son débogage.
L'article seul
RFC 5505: Principles of Internet Host Configuration
Date de publication du RFC : Mai 2009
Auteur(s) du RFC : B. Aboba, D. Thaler, Loa Andersson, Stuart Cheshire
Pour information
Première rédaction de cet article le 20 mai 2009
Comment est-ce qu'une machine arrive à se connecter à Internet alors que tant de paramètres doivent être configurés, comme l'adresse IP, la longueur du préfixe de celle-ci, les résolveurs DNS à utiliser, etc ? Ces réglages qui se faisaient autrefois à la main sont maintenant souvent automatisés. Ce RFC de l'IAB explique les principes de la configuration IP et les meilleures façons de la faire.
Commençons par la section 1.2 qui explique les paramètres en jeu. Ils sont séparés en deux parties, les paramètres de couche 3 (section 1.2.1) et ceux des couches supérieures (section 1.2.2). Parmi les paramètres de la couche réseau, il y a bien sûr l'adresse IP, dont dépend tout le reste. Souvent configurée autrefois avec le protocole RARP, elle est désormais souvent fixée par DHCP sur IPv4 et par DHCPv6 et l'auto-configuration sur IPv6. Ces protocoles ont en effet en commun de fonctionner entièrement sur IP, contrairement à RARP. La configuration d'IP est donc auto-suffisante.
Les autres paramètres sont souvent configurables par DHCP, le routeur par défaut, le fichier à charger si la machine charge son système d'exploitation via le réseau, la MTU du lien, etc.
Bien sûr, on peut toujours configurer ces paramètres manuellement,
ce qui est souvent fait pour des serveurs, qui changent rarement de
paramètres, et n'aiment pas dépendre de mécanismes externes comme
DHCP. Par exemple, sur une machine Debian, on
configurera ces paramètres dans le fichier
/etc/network/interfaces :
# Configurer l'interface eth0 avec une adresse fixe
iface eth0 inet static
# Adresse IPv4
address 80.67.170.53
# Longueur du préfixe, ici 26 bits, sur les 32 d'une adresse v4
netmask 255.255.255.192
# Routeur par défaut
gateway 80.67.170.1
...
Les paramètres des couches supérieures incluent les adresses des serveurs de noms (DNS la plupart du temps mais il y a aussi des mécanismes de résolution de noms comme LLMNR qui ne nécessitent pas de configuration), service de synchronisation d'horloge (typiquement NTP), etc.
Quels sont les bons principes pour la configuration de ces paramètres ? La section 2 tente de répondre à ces questions. Premier principe, posé en section 2.1 : « Tout ce qui peut être configuré peut être configuré de travers ». Notre RFC rappelle donc le RFC 1958 qui disait « Évitez les options et les paramètres autant que possible. Les options et les paramètres devraient être configurés ou négociés dynamiquement, plutôt qu'à la main ». L'idée est qu'on éviterait bien des erreurs en découvrant les paramètres automatiquement plutôt qu'en demandant à l'administrateur système de les fixer. Par exemple, la MTU peut être découverte par les techniques du RFC 4821. Tout protocole devrait donc avoir le moins de réglages possible ou, en tout cas, ceux-ci devraient pouvoir être obtenus automatiquement.
En outre, le processus de configuration devrait, même s'il est automatique, être simple. C'est ce que détaille la section 2.2 qui cite encore le RFC 1958 : « Que cela reste simple. En cas de doute lors de la conception d'un protocole, choisir la solution la plus simple. » Une des raisons de ce choix est qu'IP tourne sur un très grand nombre de machines, du téléphone portable au super-calculateur et ceux-ci ont des capacités très variables. Le code IP doit donc pouvoir tenir dans une machine de bas de gamme. Un exemple typique concerne les machines qui doivent charger le noyau de leur système d'exploitation depuis le réseau (PXE). Puisque, par définition, le système n'est pas en route lors de ce chargement, le code qui l'effectue doit pouvoir tenir dans une ROM et donc être très petit (cela exclut TCP, par exemple, et c'est une raison de plus de n'embarquer qu'IP, sans protocoles de configuration additionnels).
Et le choix des mécanismes de configuration ? La section 2.3 demande de le minimiser : un vaste ensemble de tels mécanismes augmenterait la taille du code, le temps de configuration (il faudrait essayer successivement plusieurs méthodes) et l'interopérabilité (au cas où deux machines du même réseau ne mettent pas en œuvre les mêmes mécanismes).
Moins évidente est la nécessité de ne pas dépendre des couches basses (typiquement la couche 2) pour la configuration. Ce point fait l'objet de la section 2.4. Une implémentation d'IP va typiquement tourner sur plusieurs types de réseaux et ne peut pas compter sur une technique qui serait disponible sur tous. La méthode recommandée est donc qu'IP se débrouille seul.
Il existe des contre-exemples dans la famille IP. Avec PPP, le protocole IPv4CP du RFC 1332 assurait la configuration IP et une extension à PPP (RFC 1877) configurait les serveurs de noms. Cette erreur (compréhensible à l'époque, où DHCP était très rare) a été corrigée dans son équivalent IPv6, IPv6CP (RFC 5072, mais il y a aussi d'autres mécanismes de configuration en IPv6). Le RFC 3818 a ainsi sérieusement limité la possibilité de rajouter des mécanismes de configuration dans PPP.
En outre, la couche 2, en croyant bien faire, peut en fait limiter les possibilités des machines IP. Ainsi, si l'adresse IPv6 était configurée par la couche 2, des services comme les adresses temporaires de protection de la vie privée (RFC 4941) ou comme les adresses cryptographiques du RFC 3972 ne pourraient pas être utilisées.
Enfin, la section 2 se clôt sur un point important : la configuration n'est pas le contrôle d'accès et devrait en être complètement séparée (section 2.5). De toute façon, l'administrateur d'une machine peut toujours la configurer à la main et vouloir limiter l'accès au mécanisme de configuration n'a donc guère de sens. Si on veut limiter l'accès au lien de niveau 2, il vaut mieux utiliser une technique spécifique telle que 802.1X.
Une fois ces bons principes posés, le RFC discute dans la section 3 quelques questions supplémentaires. 3.1 estime que l'ensemble des mécanismes de configuration existants suffit et qu'il n'est sans doute pas opportun d'en développer d'autres. Cette section rappelle également que l'Internet n'est pas qu'une affaire de machines mais aussi d'humains qui les gèrent et que les considérations organisationnelles doivent être prises en compte lors du choix d'un mécanisme de configuration. Ainsi, routeurs et serveur de noms sont en général sous la responsabilité de deux équipes différentes et qu'il faut veiller à ce que la configuration du routeur ne dépende pas inutilement d'une autre équipe.
La frontière est floue entre configuration et « découverte d'un service » comme le fait SLP (RFC 2608). La section 3.2 explore cette frontière et explique que les deux ont leur place, les mécanismes de découverte de service ayant des capacités plus étendues.
Cela mène le RFC à la question du « destin commun » (fate sharing, section 3.2.1). On parle de destin commun quand deux services ont intérêt à être liés (la panne de l'un entraîne celle de l'autre) car ils n'ont pas de sens séparément. Ainsi, apprendre le routeur par défaut par des RA (router advertisement, RFC 4861) émis par le routeur lui-même est un excellent exemple de destin commun. Si le routeur est en panne, il n'émettra plus de RA et les machines n'apprendront donc pas son adresse. En revanche, si le routeur est appris par DHCP, la panne du routeur ne sera pas forcément détectée par le serveur DHCP et les machines apprendront l'adresse d'un routeur inutilisable.
Le destin commun est donc en général souhaitable pour les protocoles de configuration mais il n'est pas toujours possible.
La section 4 est consacrée à la sécurité, problème toujours difficile d'autant plus qu'une machine pas encore configurée, par définition, ne sait pas encore grand'chose du réseau auquel elle est attachée et est donc très vulnérable à toutes les impostures. Si l'attaquant réussit à convaincre la machine qui se configure d'utiliser tel serveur de noms, que l'attaquant contrôle, alors presque toute l'activité Internet de cette machine est dirigée par l'attaquant. C'est encore pire si l'attaquant convainc une machine sans disque local de charger comme système d'exploitation un programme choisi par l'attaquant.
La section 4.1 explore les solutions possibles. Disons tout de suite qu'il n'y a pas de miracle : la simplicité et la souplesse de la configuration d'IP s'opposent à la sécurité. La plupart des solutions au problème de la sécurité de la configuration dépendent d'une configuration manuelle de chaque machine, ce qui ne réjouira pas l'administrateur système débordé. On peut parfois compter sur la protection apportée par les couches basses (un réseau Ethernet dont les commutateurs protègent l'accès aux différents ports, par exempe). Autrement, il existe plusieurs techniques d'authentification comme SEND (RFC 3971) mais qui, comme le note le RFC, dépend d'une configuration d'une clé sur chaque machine, ce qui n'est pas pratique, surtout lorsque la machine visite plusieurs réseaux.
L'article seul
Schéma de données adapté, avec Docbook
Première rédaction de cet article le 19 mai 2009
Le format Docbook est un des plus utilisés pour la documentation technique, notamment dans la secteur informatique. La très grande majorité des grands logiciels libres utilisent Docbook. Ce format est très riche, avec plusieurs centaines d'éléments possibles. Malgré cette richesse, on a parfois besoin d'ajouter des élements ou bien d'effectuer d'autres adaptations locales à une organisation ou un projet. Comment faire avec Docbook ?
Les avantages de Docbook sont évidents : format ouvert, indépendant de tout vendeur, exprimé sous forme de schéma XML pour profiter des outils XML existants et pouvoir être traité par des outils divers comme les VCS (contrairement aux formats binaires), Docbook s'est largement imposé. Mais chaque projet ou chaque organisation ressent parfois le besoin d'adapter le format standard et cet article expose la façon de le faire, pour le Docbook fondé sur les DTD (jusqu'à la version 4 incluse ; ensuite, à partir de la version 5 - publiée en 2008, Docbook utilise un langage de schéma bien plus perfectionné, RelaxNG, qui change nettement les choses).
Bien sûr, Docbook est un format ouvert, on peut tout simplement prendre les sources du schéma et les éditer. Mais, en procédant ainsi, on sort vraiment de Docbook et on aura du mal, par exemple, à intégrer les modifications futures. Il vaut donc mieux étendre Docbook de la manière « prévue pour ».
Pour prendre un exemple concret, on veut citer souvent, dans son
document écrit en Docbook, les RFC. XML n'offrant hélas pas de macros, la méthode correcte est
d'ajouter un élément
<rfc>. Pour cela, on écrit une DTD qui
définit cet élément :
<!ELEMENT rfc EMPTY> <!ATTLIST rfc num CDATA #IMPLIED>
Ici, l'élément est défini comme n'ayant pas de contenu
(EMPTY) et prenant un attribut obligatoire,
num, le numéro du RFC. Cela permet d'écrire
<rfc num="5514"/> (mais pas
<rfc>IPv6 over social networks</rfc>,
puisque dans ce cas, num manque et le contenu
n'est pas vide).
Il reste à dire à Docbook que cet élément est acceptable et où on
peut le trouver. Pour faciliter cela, Docbook est réalisé de manière
modulaire et beaucoup de termes DTD ont été définis comme vide, leur
définition permettant de les remplir éventuellement avec des éléments
locaux. C'est le cas du terme local.para.char.mix
qui indique quels éléments supplémentaires peuvent apparaître dans un
paragraphe (<para>). Par défaut, il est
vide, remplissons-le avec notre nouvel élément :
<!ENTITY % local.para.char.mix
"|rfc">
Désormais, comme local.para.char.mix est
ajouté à la définition des éléments acceptables dans un
<para>, <rfc> est
acceptable (la barre verticale signifie OU BIEN).
Le document doit ensuite indiquer qu'il utilise, non pas le Docbook standard mais la version étendue. Si l'en-tête avec la version standard ressemble à :
<?xml version="1.0" encoding="iso-8859-1"?>
<!DOCTYPE article PUBLIC "-//OASIS//DTD DocBook XML V4.3//EN"
"dtd/xml/4.3/docbookx.dtd">
<article>...
celui d'un document utilisant notre Docbook adapté à nos besoins sera :
<?xml version="1.0" encoding="iso-8859-1"?> <!DOCTYPE article PUBLIC "-//OASIS//DTD DocBook XML V4.3//EN" "dtd/xml/4.3/docbookx.dtd"[ <!ENTITY % dtd_custom SYSTEM "myschema.dtd"> %dtd_custom; ]> <article>...
Maintenant, on peut écrire des documents complets correspondant au schéma « amélioré » par exemple :
<article> <para>Ceci est un exemple de document <ulink url="http://www.docbook.org"> Docbook</ulink> avec une référence à un <rfc num="5241"/> (<foreignphrase>Naming Rights in IETF Protocols</foreignphrase>).</para> </article>
et ils sont validables (ici avec xmllint) :
% xmllint --noout --valid example.db %
Maintenant, comment les traiter, par exemple pour une transformation en HTML afin de les servir sur le Web ? Essayons d'abord avec XSLT. Les programmes standard ne connaissent évidemment que les éléments officiels de Docbook et pas notre addition. Mais XSLT étant modulaire, il est très facile de rajouter un traitement pour nous :
<xsl:template match="rfc">
<xsl:variable name="href">
<xsl:text>http://www.ietf.org/rfc/rfc</xsl:text><xsl:value-of select="@num"/><xsl:text>.txt</xsl:text>
</xsl:variable>
<a href="{$href}"><xsl:text>RFC </xsl:text><xsl:value-of
select="@num"/><xsl:text></xsl:text></a><xsl:if
test="not(preceding::rfc)"> (RFC signifie Request For
Comments. Ce sont les textes fondamentaux de
l'Internet. Toutes les normes Internet sont des RFC, l'inverse
n'est pas forcément vrai. Tous les RFC sont
librement disponibles en ligne sur le <a
href="http://www.ietf.org/">serveur de l'IETF</a>, l'organisme
qui les édite. Plus de détails sont accessibles sur le <a
href="http://www.rfc-editor.org/">serveur de l'éditeur des RFC</a>.)</xsl:if>
</xsl:template>
Ce gabarit XSLT traite tout élément nommé
<rfc> et produit de l'HTML avec un lien
vers le serveur Web de l'IETF et, si l'élément
<rfc> est le premier du document (not(preceding::rfc)), un petit
texte explicatif.
Pour les traditionnalistes qui préfèrent DSSSL, une version très simplifiée du code XSLT ci-dessus (elle est prévue pour l'impression uniquement, sans lien hypertexte) est :
(element rfc
(let (
(num (attribute-string "num"))
)
(if num
(literal (string-append
"RFC "
num
))
(literal "RFC UNKNOWN")
)))
Un exemple plus complexe vient lorsqu'on essaie d'utiliser XInclude avec Docbook, par exemple pour inclure une bibliographie. La DTD complète pour faire cela est :
<!-- http://www.sagehill.net/docbookxsl/ModularDoc.html#UsingXinclude -->
<!ELEMENT xi:include (xi:fallback?) >
<!ATTLIST xi:include
xmlns:xi CDATA #FIXED "http://www.w3.org/2001/XInclude"
href CDATA #REQUIRED
parse (xml|text) "xml"
encoding CDATA #IMPLIED >
<!ELEMENT xi:fallback ANY>
<!ATTLIST xi:fallback
xmlns:xi CDATA #FIXED "http://www.w3.org/2001/XInclude" >
<!-- Where are they allowed? -->
<!ENTITY % local.divcomponent.mix "| xi:include"> <!-- inside chapter or section elements -->
<!ENTITY % local.para.char.mix "| xi:include"> <!-- inside para, programlisting, literallayout, etc. -->
<!ENTITY % local.info.class "| xi:include"> <!-- inside bookinfo, chapterinfo, etc. -->
<!ATTLIST book
xmlns:xi CDATA #FIXED "http://www.w3.org/2001/XInclude">
<!ATTLIST article
xmlns:xi CDATA #FIXED "http://www.w3.org/2001/XInclude">
<!ATTLIST chapter
xmlns:xi CDATA #FIXED "http://www.w3.org/2001/XInclude">
<!ATTLIST section
xmlns:xi CDATA #FIXED "http://www.w3.org/2001/XInclude">
Et un éditeur sensible à la syntaxe comme psgml
peut alors éditer le document Docbook contenant les
<xi:include> sans problème.
La documentation de référence sur les adaptations locales de Docbook est DocBook: The Definitive Guide.
L'article seul
Injection SQL, quelques exemples
Première rédaction de cet article le 19 mai 2009
L'injection SQL est une technique d'attaque utilisée contre les bases de données SQL dès lors qu'elles sont accessibles de l'extérieur, via une interface qui ne permet normalement pas de taper des commandes SQL quelconques. Cette technique est ancienne, banale, et largement utilisée. Je ne vais pas faire un tutoriel complet sur l'injection SQL, il en existe plusieurs en ligne. Je veux juste montrer quelques exemples.
L'article complet
Attaque sur plusieurs systèmes d'enregistrement de noms de domaines
Première rédaction de cet article le 18 mai 2009
Vous avez sans doute vu un des nombreux articles publiés depuis deux semaines, sur les attaques portant sur les systèmes d'enregistrement de noms de domaines : les ccTLD de la Nouvelle-Zélande, de Porto-Rico et du Maroc ont été touchés.
Le rythme semble s'accélerer et d'autres attaques sont signalées (Tunisie, Ouganda, Équateur). Comme le domaine de Google était souvent visé, Google a publié un texte expliquant que c'était la faute du DNS.
C'est donc l'occasion de faire un petit point. Je n'ai pas d'informations « de l'intérieur » sur ces attaques, je relaie simplement des informations publiques. La plupart des articles cités ci-dessus étant « garantis 0 % information », il faut prendre tout cela avec beaucoup de pincettes. Pour la même raison, ce message n'est pas officiel, il n'a pas été validé par le Ministère de l'Intérieur, etc.
- il n'est pas certain qu'il s'agisse d'une attaque coordonnée. C'est évidemment tentant que penser que les Illuminati visent tous les registres de ccTLD en même temps mais ce n'est pas prouvé, il peut s'agir d'un simple effet de mode (un peu comme les voitures qui brûlent en banlieue).
- sauf peut-être dans le cas d'un FAI kenyan, qui pourrait avoir été victime d'une attaque de style Kaminsky, aucune de ces attaques ne semble mériter le nom d'attaque DNS. Toutes ont porté sur le système d'enregistrement, en amont du DNS. Le modus operandi le plus fréquent semble la traditionnelle injection SQL, qui marche toujours très bien contre des sites Web écrits en PHP ou en VB.net par un stagiaire. Une fois l'injection réussie, le craqueur insère de fausses données dans la base et le DNS publie aveuglément ces données.
- pour la même raison, les techniques de signature cryptographiques comme DNSSEC n'auraient servi à rien, contrairement à ce que raconte bêtement le marketing de PIR. En effet, DNSSEC signe les données de la base ; si celle-ci est corrompue, DNSSEC signe des données fausses.
- l'attaque a parfois porté sur le registre (cas de .PR), parfois sur un bureau d'enregistrement (« registrar », cas de .MA).
Tout ceci forme une leçon très classique en sécurité : les experts se focalisent sur les attaques de haute technologie, rigolotes, comme la faille Kaminsky et ignorent les attaques bêtes, simples et classiques comme l'injection SQL (voire l'ingéniérie sociale).
Terminons en rendant hommage aux malawites qui sont les premiers à avoir publié un rapport technique sur les attaques. Deux ans après, les porto-ricains ont à leur tour rendu publiques les informations. Un rapport détaillé sur les problèmes d'attaques sur les systèmes d'enregistrement des registres de noms est le SAC 40: Measures to Protect Domain Registration Services Against Exploitation or Misuse.
L'article seul
A Study of the ARPANET TCP/IP Digest
Première rédaction de cet article le 14 mai 2009
La date du 1er janvier 1983 a souvent été citée dans les articles et livres traitant de l'histoire de l'Internet. Séparation de l'Arpanet « public » et du Milnet, passage à TCP/IP, dernier flag day qu'aie connu l'Internet... Tout ceci s'est-il réellement passé le 1er janvier ?
L'article de Ronda Hauben, « From the ARPANET to the Internet; A Study of the ARPANET TCP/IP Digest and of the Role of Online Communication in the Transition from the ARPANET to the Internet » fait le point sur cette date devenue mythique, notamment à travers l'histoire de la liste de diffusion « TCP/IP digest », créée en octobre 1981 pour discuter de la transition.
Au début, il n'y avait qu'un seul réseau, l'Arpanet. Il lui manquait une des propriétés les plus essentielles de l'Internet d'aujourd'hui, le fait d'être multi-organisations et sans chef. Arpanet dépendait entièrement de l'ARPA qui pouvait donc édicter des oukases comme « Au premier janvier 1983, on arrête NCP ». Au début des années 1980, Arpanet vivait encore avec le vieux protocole NCP (RFC 36 et RFC 54), qui mélangeait couche 3 et couche 4. C'est en 1982 qu'a été achevé le déploiement de la nouvelle étoile du réseau, la famille TCP/IP (les protocoles applicatifs, eux, n'ont pas changé, SMTP, telnet et FTP étaient déjà là). TCP/IP a eu des débuts difficiles, trois versions d'IP ont été testées avant le déploiement en grand de la version 4, normalisée dans le RFC 791 et qui est encore aujourd'hui, malgré les timides tentatives d'IPv6, le protocole dominant de l'Internet.
Sa mise en œuvre n'est pas non plus allé sans mal et l'article de Hauben cite de nombreux exemples savoureux de discussions sur des listes de diffusion où des ingénieurs réseaux inquiets de l'approche du flag day demandent « Quelqu'un a t-il une bonne implémentation de ce truc, ce TCP/IP, pour TOPS-20 ? ». Ou bien « Et pour mon Vax, que dois-je mettre pour faire du TCP/IP dans les meilleures conditions ? VMS ou Unix BSD ? ». Certains systèmes d'exploitation, sans bonne mise en œuvre de TCP/IP, ont ainsi été achevés par la transition, comme Tenex.
Arpanet n'était pas complètement déconnecté des autres réseaux de
l'époque (par exemple de ceux utilisant
UUCP). Il existait des passerelles, au moins
pour le courrier (cf. RFC 754). La liste était ainsi accessible depuis le monde UUCP avec l'adresse ...!duke!bmd70!tcp-ip... C'est d'ailleurs via une
passerelle vers Usenet que la liste a été archivée.
Le 14 décembre 1981, un article de ComputerWorld s'inquiétait du risque de perturbations massives d'Arpanet début 1983 et notait que le réseau était devenu un outil de travail indispensable, avec lequel on ne pouvait plus jouer comme avant.
Alors, y a t-il eu un flag day le 1er janvier, un jour où tout le monde bascule ses systèmes exactement au même moment, selon un plan bien établi à l'avance ? Pas tout à fait, dit Hauben, le 1er janvier était plutôt un cutoff day, un jour où le support pour l'ancien système stoppe. Le plan de transition était détaillé dans le RFC 801. L'ARPA avait décidé depuis des mois que NCP devait avoir disparu le 1er janvier 1983. Comme toujours, certains ont attendu le dernier moment, certains ont réclamé une prolongation mais, impitoyable, l'ARPA a coupé NCP dans les IMP (les routeurs de l'époque) à la date prévue. C'était la dernière fois dans l'histoire de l'Internet qu'une décision globale, s'appliquant à tous les nœuds du réseau pouvait être prise et appliquée. Depuis, le changement de structure sociale du réseau a rendu impossible de telles « dates magiques », au détriment du déploiement de nouveaux protocoles, comme IPv6.
L'article seul
Un nouveau raseur de table veut faire un meilleur Internet
Première rédaction de cet article le 12 mai 2009
C'est en train de devenir une tendance, la refonte complète de l'Internet pour faire « mieux ». Les promoteurs (peu nombreux mais très bruyants) de cette approche se réclament en général de l'idée de « table rase » : Internet serait vraiment trop mal fichu, il faut le remplacer complètement. J'apprécie l'ambition de ces projets et les idées techniques, souvent très bonnes, de leurs participants. J'apprécie moins leur mélange systématique (et probablement volontaire) de la recherche fondamentale (pour la liberté qu'elle procure au chercheur) avec les applications pratiques (qui rapportent des sous). Les secondes nécessitent de tenir compte de l'existant (ne serait-ce que pour déployer la nouvelle technologie) et se marient mal avec l'idée de repartir de zéro. John Day vient de rejoindre les rangs des raseurs de table, avec un livre et une nouvelle organisation.
Celle-ci, la Pouzin Society a tenu sa première réunion à Boston le 7 mai. Je n'y étais pas et je n'ai pas trouvé de compte-rendu sur le Web mais certains documents sont distribués (l'adresse est bizarre mais c'est parce que le site original ne permet pas de faire des liens directs vers une page, en raison de leur utilisation des frames ; comme quoi, on peut parfaitement vouloir refaire le mécanisme de nommage et d'adressage de l'Internet et être complètement ignorant de l'utilisation pratique des URL, les adresses Web...).
Plusieurs noms connus apparaissent dans l'annuaire de la Pouzin Society comme Louis Pouzin ou Mike O'Dell (auteur du RFC 2374 et de quelques autres) mais seul John Day (auteur des RFC 520, RFC 732 et quelques autres) semble réellement actif (les autres n'ont rien publié de technique depuis longtemps).
Parmi les papiers de Day que j'ai lus (je ne me suis pas encore attaqué à son récent livre, Patterns in Network Architecture: A Return to Fundamentals), le plus intéressant est "Networking is IPC": A Guiding Principle to a Better Internet qui explique les bases de ses idées.
Elles sont très intéressantes. Par exemple, sa proposition sur le nommage et l'adressage n'utilise que des noms (les adresses sont reléguées à des couches très basses) et donc « son » Internet dépendrait du DNS encore plus que l'actuel. Cette proposition que les applications ne manipulent que les noms a déjà été faite dans le contexte de la migration vers IPv6 (il est en effet tout à fait anormal qu'il faille « porter » les applications vers IPv6 alors que l'écrasante majorité des applications se moque pas mal du protocole de couche 3 qui est utilisé ; cette obligation du portage est un effet néfaste de l'API « sockets »).
Mais le problème n'est pas dans l'architecture qu'il propose (on repartirait vraiment de zéro, elle serait certainement à considérer) mais dans le fait qu'il fait de la recherche fondamentale (idées novatrices, pas de souci de l'existant, pas de plan de transition) tout en prétendant, pour les journalistes et les financeurs, faire de la recherche appliquée, ayant des chances d'être déployée relativement rapidement. Day est très radical car il ne veut pas seulement refaire l'Internet en partant de zéro, mais il impose aussi de réécrire toutes les applications réseau.
Mais il y a aussi d'autres problèmes comme les conséquences politiques de ses choix. L'Internet de Day est un Internet à autorisation préalable indispensable, pour toute fonction. Albanel va adorer ! En outre, Day se vante (section 6.6 de son article) d'empêcher toute transparence du réseau et de permettre aux FAI de s'insérer dans les communications.
Enfin, comme pas mal de chercheurs en recherche... de subventions, Day utilise des procédés à la limite de l'honnêteté intellectuelle. Par exemple, il explique dans la section 6.5 de « Networking is IPC » que sa proposition supprime le « kludge of NAT » alors que ce n'est qu'un changement de terminologie, sa proposition est au contraire de généraliser le NAT en faisant de toutes les adresses des adresses privées. Il utilise la même rhétorique pour expliquer que sa proposition supprime le kludge des firewalls.
Parmi les autres papiers, Why Loc/Id Split Isn't the Answer est supposé être une critique de la technique de la séparation du localisateur et de l'identificateur. Mais il n'a pratiquement aucun contenu technique. Présenté sous forme d'un dialogue entre Day et un utilisateur naïf, c'est juste une longue complainte contre le monde injuste qui n'a pas voulu reconnaitre les qualités de Day. Comme le découvre petit à petit l'utilisateur, Day avait toujours raison sur tout depuis les débuts de l'Arpanet mais ni l'ISO, ni l'IETF n'ont voulu l'écouter. Pathétique.
Quant à The Fundamentals of Naming, c'est un essai intéressant de mettre au point une terminologie solide pour parler des réseaux (« A name is a unique string, N, in some alphabet, A, that unambiguously denotes some object... »). Effort louable (combien d'électrons ont été secoués en vain pour faire circuler des messages polémiques sur des notions comme les noms et les adresses sans que ceux-ci aient été définis d'une manière standard ?) mais probablement irréaliste, le vocabulaire suit en général la technique qui l'utilise, pas le contraire. Au moins, contrairement au précédent, ce texte est dénué d'affirmations cassantes comme quoi le reste du monde serait composé uniquement de crétins.
Est-ce que l'innovation dans les réseaux informatiques est vraiment condamnée à n'être utilisée que par des vieilles gloires qui cherchent à se recaser, des trolls, ou des journalistes en mal de sensationnel ? Évidemment non, et une telle innovation demeure toujours aussi nécessaire. L'Internet d'aujourd'hui n'est pas la réalisation ultime de l'humanité et des percées formidables se produiront certainement un jour. Mais les vrais chercheurs, ceux qui inventent les réseaux de demain, sont trop occupés à spécifier des protocoles et à les mettre en œuvre pour s'occuper de leur promotion...
L'article seul
Fiche de lecture : Adventures in the bone trade
Auteur(s) du livre : Jon Kalb
Éditeur : Copernicus books
0-387-98742-8
Publié en 2001
Première rédaction de cet article le 12 mai 2009
Si vous aimez la science, l'aventure et la vie au grand air, précipitez vous sur ce pavé (380 pages) où Jon Kalb raconte ses recherches en Éthiopie, à fouiller la dépression de l'Afar, à la recherche de fossiles. Si vous voulez garder de la science l'image d'une activité pure et désintéressée, par contre, passez votre chemin, car vous aurez droit dans ce livre à pas mal de réglements de compte entre les différents camps qui se sont violemment affrontés en Afrique orientale, pour la découverte de fossiles humains (car personne ne s'intéresse aux autres).
Commençons par la science : la dépression de l'Afar est située en plein sur le rift africain et est très riche en fossiles. Dans les années 1970, de nombreux chercheurs s'y sont précipités, pour dresser la carte de son originale géologie et pour trouver des fossiles humains car l'âge des terrains qui émergent est à peu près celle de l'apparition de l'homme. Cette course a culminé dans la découverte de la fameuse Lucy en 1974. Outre les australopithèques, l'Afar, aujourd'hui très stérile, recèle des fossiles d'innombrables animaux dont beaucoup d'éléphants, bien pratiques car leurs dents sont de grande taille, se conservent bien, et sont très différentes d'une espèce à l'autre. On peut donc facilement dater un terrain dès qu'on y trouve des molaires d'éléphant. L'Afar est donc, malgré les conditions climatiqus qui y règnent, un paradis pour les paléontologues.
Continuons avec l'aventure : les conditions de travail sont évidemment mauvaises. Il faut se déplacer dans des régions peu cartographiées, arides, au milieu des nomades turbulents et prompts à considérer (souvent à juste titre) l'arrivée des blancs comme prémisse de gros problèmes. Les Land Rover tombent souvent en panne, les voleurs attaquent le camp la nuit, les rivières sont à sec quand on a soif et débordent soudainement en pleine nuit.
L'aventure serait belle si elle se déroulait dans un climat de fraternité entre tous ces hommes de science attirés uniquement par le désir de connaitre. Mais ce n'est pas le cas : les rivalités professionnelles, l'influence d'un pays où le fusil est souvent la seule loi, et la dureté des conditions de vie, finissent par corrompre les meilleurs, et les ramener souvent à la mentalité de la jungle. Les affrontements sont fréquents, les haines se développent. Après avoir travaillé ensemble, Kalb et Johanson (le découvreur de Lucy) sont devenus ennemis et aucune mesquinerie de leurs conflits ne sera épargnée au lecteur. Personnages secondaires dans le livre, les français Maurice Taïeb et Yves Coppens en prennent également pour leur grade, surtout le premier. Il doit être intéressant de comparer leurs livres avec celui de Kalb... La dynastique famille Leakey est par contre traitée plus favorablement.
Et la politique ? Deux fils s'entrecroisent dans le livre, la fin de l'empire éthiopien, avec les dernières années du règne d'Hailé Sélassié, puis la chute de l'ancien régime, puis la prise du pouvoir par le dictateur Mengistu, et, second fil, les utilisations de la politique locale, ou de celle des organismes de recherche aux États-Unis, pour mettre des bâtons dans les roues des concurrents. Le tout se terminera, comme souvent aux États-Unis, par un procès en bonne et due forme de Kalb contre la NSF, qui avait refusé de financer ses fouilles, après une campagne de Johanson. Dans des pays comme l'Éthiopie ou le Kenya, qui ne sont pas des états de droit, il est bien tentant d'utiliser les autorités locales pour bloquer les demandes de permis de fouille des autres, voire les faire expulser du pays.
J'apprécie le récit très détaillé des fouilles, des subtiles difficultés techniques de l'identification d'un squelette, du problème de faire fonctionner des équipes multinationales ou de mener une vie de famille à Addis-Abeba. Quant à la violence des relations entre chercheurs, je la préfère dans la fiction, comme dans l'excellente nouvelle The gift, du même auteur.
L'article seul
RFC 4395: Guidelines and Registration Procedures for New URI Schemes
Date de publication du RFC : Février 2006
Auteur(s) du RFC : T. Hansen, T. Hardie, L. Masinter
Première rédaction de cet article le 11 mai 2009
Les URI, ces identificateurs normalisés dans le RFC 3986 commencent tous par un plan (scheme), la partie de l'URI avant le premier deux-points. Ce RFC explique les anciennes procédures d'enregistrement dans le registre des plans (remplacées depuis par celles du RFC 7595).
Il existe de nombreux plans, du très connu
http: au moins fréquent tag:
(RFC 4151) en passant par bien d'autres, souvent
assez confidentiels comme le dns: du RFC 4501
ou le dict: du RFC 2229. Le RFC 3986 décrit seulement la syntaxe générique des
URI, celle commune à tous les URI et qui se
limite largement à « un plan, deux points, puis du texte » (par
exemple, http://www.bortzmeyer.org/608.html ou tag:bortzmeyer.org,2006-02:Blog/608). La
grande majorité du contenu de l'URI a une signification qui dépend du
plan et un logiciel d'usage très général doit donc connaître ces plans et
leurs particularités. Et si
j'ai une idée géniale de nouveaux URI et que je
veux réserver un plan, je fais comment ? Je lis ce RFC 4395. Que me dit-il ?
La section 2 du RFC fournit des critères pour déterminer si un nouveau plan d'URI est une bonne idée. Ainsi, pour que son enregistrement soit accepté, le plan doit présenter une utilité à long terme (section 2.1). Cette restriction est justifiée par le fait que tout nouveau plan peut nécessiter une modification de tous les logiciels qui traitent des URI et agissent différemment selon le plan. (Le RFC note également que, bien que l'espace de nommage des plans soit infini, en pratique, il pourrait y avoir une concurrence trop forte pour les noms courts et facilement mémorisables et que cela justifie donc de ne pas accepter toutes les candidatures.)
Il y a aussi des contraintes plus techniques. Ainsi, la section 2.2
impose que le nouveau plan respecte les règles syntaxiques
existantes. Ainsi, le // a une signification bien
précise dans un URI, il précède le nom de la machine qui sert d'autorité de
nommage, pour attribuer le reste de l'URI (section 3.2 du
RFC 3986). En l'absence d'une
telle machine de référence, le // ne doit donc
pas être utilisé. (c'est pour cela que
dict://dict.example.org/d:chocolate: a un
//, car il contient le nom d'un serveur, ici
dict.example.org alors que
mailto:echo@generic-nic.net n'en a pas, car les
adresses de courrier sont globales, elles ne dépendent pas d'un
serveur particulier).
Il faut bien sûr que le plan soit correctement et complètement défini
(sections 2.3 et 2.4). Par exemple, si l'URI est résolvable, sa
description doit expliquer comment. Autre exemple, la description doit
expliquer ce qu'on peut faire de l'URI. Accéder (et parfois modifier) à une ressource (cas
du http:) ? À une machine (cas de
telnet:) ?
Enfin, le plan doit recevoir un nom (section 2.8), qui soit à la
fois assez court pour être pratique et assez long pour être
descriptif. Pire, comme ces plans sont visibles (des URI sont souvent
affichés dans les publications, sur les cartes de visite, sur les
publicités), le nom du plan ne doit pas interférer avec des marques
déposées défendues par des bataillons d'avocats. Il vaut donc mieux ne
pas essayer de normaliser le plan coca-cola: (qui
permettrait d'écrire des choses utiles comme
coca-cola:light)... Le RFC recommande aussi
d'éviter des noms trop marketing comme tout ce qui contient
« universal » ou
« standard ».
Ces règles de la section 2 sont obligatoires pour les plans enregistrés de manière permanente. Mais le registre contient aussi des plans enregistrés à titre provisoire et les règles en question ne sont qu'indicatives pour eux (section 3).
Bref, une fois qu'on a bien lu toutes ces considérations, on peut
passer à l'enregistrement proprement dit. Pour cela, il faut suivre la
procédure exposée en section 5 (qui utilise les termes du RFC 5226). On remplit un formulaire (section 5.4), il est
examiné (dans la plupart des cas) sur une liste de diffusion comme uri@w3.org,
puis par un expert (section 5.2).
C'est par exemple le processus qu'a suivi le plan geo, qui permet des URI comme
geo:48.208333,16.372778 (la cathédrale
Saint-Étienne à Vienne).La section
3 de la norme sur geo:,
le RFC 5870, contient le
formulaire d'enregistrement :
3. IANA Registration of the 'geo' URI Scheme
This section contains the fields required for the URI scheme
registration, following the guidelines in Section 5.4 of [RFC4395].
3.1. URI Scheme Name
geo
3.2. Status
permanent
3.3. URI Scheme Syntax
The syntax of the 'geo' URI scheme is specified below in Augmented
Backus-Naur Form (ABNF) [RFC5234]:
geo-URI = geo-scheme ":" geo-path
geo-scheme = "geo"
geo-path = coordinates p
coordinates = coord-a "," coord-b [ "," coord-c ]
coord-a = num...
À noter que, bien qu'il existe une norme pour les URI en Unicode (le RFC 3987, sur les IRI), il n'y a pas de plan en caractères non-ASCII.
Ce RFC remplaçait les anciens RFC 2717 et RFC 2718, et a lui-même été remplacé par le RFC 7595. Ces deux anciens RFC avaient été écrits avec l'idée d'une
stricte séparation entre localisateurs (les
URL) et noms
(les URN). À l'usage, cette distinction est
apparemment bien moins claire qu'on ne le pensait, beaucoup de gens
ont utilisé, à juste titre, des URL (par exemple des URI http:)
comme noms et, inversement, ont développé des mécanismes pour accéder
à une ressource à partir d'un nom. Notre RFC 4395 ne parle
donc plus que d'URI. Un autre changement est que le RFC 2717
avait tenté d'organiser hiérarchiquement les plans alors que nous
sommes revenus à un espace de nommage plat.
Un récit très vivant (mais très subjectif)
d'un enregistrement difficile : http://lists.w3.org/Archives/Public/uri/2011May/0001.html.
L'article seul
Fiche de lecture : Les chemins de la peste
Auteur(s) du livre : Frédérique Audouin-Rouzeau
Éditeur : Texto
978-2-84734-426-4
Publié en 2007
Première rédaction de cet article le 9 mai 2009
Peu de maladies ont suscité autant de livres, et aussi variés, que la peste. D'érudits traités aux romans comme le célèbre texte de Camus, il y a de tout. Il est donc difficile d'apporter quelque chose de nouveau. Frédérique Audouin-Rouzeau y arrive en se concentrant sur l'angle archéozoologique. Contrairement à la variole, la peste ne vit pas que chez les humains. Quel est le rôle de ses hôtes animaux et notamment du rat ?
On est loin des romans de Fred Vargas comme le magnifique « Pars vite et reviens tard » (mais les lecteurs pourront s'amuser à trouver les intersections entre les deux livres comme l'épisode de la peste des chiffoniers de Paris). « Les chemins de la peste » est un livre scientifique épais, détaillé, et voué à une cause, revenir au rôle primordial de la puce du rat dans la propagation de la maladie, rôle qui avait été contesté dans la deuxième moitié du vingtième siècle.
Pas de repos pour la puce et le rat, au long des six cents pages. Les deux animaux, ou plus exactement les différentes espèces que le profane regroupe souvent sous ces deux mots, sont traqués, étudiés, disséqués et analysés même longtemps après leur mort, comme lorsque l'auteur passe au tamis des poubelles du Haut Moyen Âge pour prouver que le rat existait déjà en Europe à cette époque.
C'est que tout le monde n'est pas d'accord sur le principal mécanisme de propagation de la peste. La puce du rat a tenu la vedette au dix-neuvième siècle, mais a vu son rôle très contesté plus tard, au profit de la puce de l'homme. Frédérique Audouin-Rouzeau se consacre à rétablir le rôle essentiel de la puce du rat, tout au long d'une enquête scientifico-historique qui va de la Constantinople de Justinien aux douars marocains misérables, en passant par l'arrivée de navires chargés de tissus orientaux dans le port de Marseille.
Parfois, le ton monte, l'auteur n'apprécie pas le discours des partisans de la puce de l'homme, comme leur rhétorique consistant à se présenter comme luttant contre un « dogme ». Le monde scientifique n'a pas la sérénité du commissaire Adamsberg, flânant à la recherche d'une solution. Ici, l'argumentaire et les expériences des partisans de la puce de l'homme sont soigneusement démontés et réduits en poudre.
Je ne vous résumerai pas la liste des arguments qui permettent de voir en Xenopsylla cheopis la principale coupable, bien plus redoutable que la peu dangereuse Pulex irritans. À vous de lire. Vous ne le regretterez pas.
L'article seul
Surveiller ses annonces BGP avec les systèmes d'alarme
Première rédaction de cet article le 8 mai 2009
Dernière mise à jour le 18 mai 2009
La sécurité du protocole BGP suscite régulièrement de l'intérêt. En l'absence de mécanisme de signature cryptographique des annonces BGP (mécanisme très difficile à concevoir puisque les routeurs BGP, les préfixes IP et les AS ne forment pas un arbre mais un graphe très touffu), la seule protection contre les détournements est la vigilance. Il existe plusieurs moyens automatiques d'être prévenus d'un changement d'annonces BGP et j'en teste ici quatre, RIPE IS, BGPmon, Cyclops et IAR.
L'article complet
Jointures en SQL, quelques notes
Première rédaction de cet article le 6 mai 2009
Je ne vais pas faire le Nième tutoriel sur les jointures SQL (pour cela, je recommande l'excellent article du Wikipédia anglophone), j'essaie juste de documenter deux ou trois choses de base sur elles, pour m'en souvenir la prochaine fois. Si ça peut servir à d'autres...
Une jointure, c'est... joindre deux tables, en général avec un critère de sélection. L'idée de base est de générer des tuples qui combinent les tuples des deux bases. Ce n'est donc pas une opération ensembliste, contrairement à ce qu'à écrit Jeff Atwood.
Avant de commencer, je crée quelques tables pour illustrer la question, une table de personnes et une de livres (le code SQL complet, testé avec PostgreSQL est disponible en ligne) :
CREATE TABLE Authors ( id SERIAL UNIQUE NOT NULL, name TEXT NOT NULL); CREATE TABLE Books ( id SERIAL UNIQUE NOT NULL, title TEXT NOT NULL, author INTEGER REFERENCES Authors(id));
Bien sûr, ce schéma de données est ultra-simplifié. Par exemple, il ne
permet pas de représenter un livre qui a plusieurs auteurs. Mais peu
importe, c'est pour faire des exemples. Le point important à noter est
qu'un « auteur » n'est pas forcément référencé par un livre et qu'un
livre peut ne pas avoir d'auteur connu (la colonne
author peut être
NULL).
Voici les données, avec des livres que j'ai apprécie (comme « La horde du contrevent » ou les livres de Fred Vargas) :
essais=> SELECT * FROM Authors; id | name ----+--------------------- 1 | Stéphane Bortzmeyer 2 | Fred Vargas 3 | Ève Demazière 4 | Alain Damasio (4 rows) essais=> SELECT * FROM Books; id | title | author ----+-----------------------------------------+-------- 1 | Les cultures noires d'Amérique Centrale | 3 2 | La horde du contrevent | 4 3 | Pars vite et reviens tard | 2 4 | L'homme à l'envers | 2 5 | Bible | (5 rows)
(Cherchez le livre sans auteur connu et la personne qui n'a pas écrit de livre.)
Il existe deux grands types de jointures, la jointure interne
(INNER JOIN) et l'externe (OUTER
JOIN). S'il existe toujours un lien entre les deux tables
(si tous les livres ont un auteur et si tous les auteurs sont
référencés depuis au moins un livre), il n'existe pas de différence
entre les deux types. Mais ce n'est pas le cas en général.
La jointure interne s'écrit avec le mot-clé INNER
JOIN et la condition ON (l'ensemble des requêtes de jointure
est disponible en ligne, tous les tests
ont été faits avec PostgreSQL 8.3) :
essais=> SELECT name, title FROM Books INNER JOIN Authors
ON Books.author = Authors.id;
name | title
---------------+-----------------------------------------
Ève Demazière | Les cultures noires d'Amérique Centrale
Alain Damasio | La horde du contrevent
Fred Vargas | Pars vite et reviens tard
Fred Vargas | L'homme à l'envers
(4 rows)
(Le INNER est facultatif, la jointure interne est
la jointure par défaut.) Si les deux colonnes sur lesquelles se fait
la jointure ont le même nom, on peut utiliser
USING au lieu de ON.
Les jointures internes s'écrivent plus fréquemment (mais c'est une question de goût) avec l'ancienne syntaxe :
essais=> SELECT name, title FROM Books, Authors
WHERE Books.author = Authors.id;
name | title
---------------+-----------------------------------------
Ève Demazière | Les cultures noires d'Amérique Centrale
Alain Damasio | La horde du contrevent
Fred Vargas | Pars vite et reviens tard
Fred Vargas | L'homme à l'envers
(4 rows)
Dans les deux cas (c'était juste une différence de syntaxe), le
résultat est le même et n'inclus pas les livres sans auteur connu, ni
les « auteurs » qui n'ont pas écrit de livre. Une jointure interne
ne sélectionne que les tuples qui répondent à la condition de jointure
(le ON, dans la nouvelle syntaxe).
Et les jointures externes ? Au contraire des internes, elles
produisent également des tuples où la condition de jointure n'est pas
remplie. Un mot clé LEFT ou
RIGHT est obligatoire. Une jointure gauche garde
les tuples de la table indiquée à gauche et vous vous doutez de ce que
fera une jointure droite. On peut facilement transformer l'une en
l'autre, A LEFT OUTER JOIN B est la même chose
que B RIGHT OUTER JOIN A. Je ne montrerai donc que les
jointures externes à gauche :
essais=> SELECT name, title FROM Books LEFT OUTER JOIN Authors
ON Books.author = Authors.id;
name | title
---------------+-----------------------------------------
Ève Demazière | Les cultures noires d'Amérique Centrale
Alain Damasio | La horde du contrevent
Fred Vargas | Pars vite et reviens tard
Fred Vargas | L'homme à l'envers
| Bible
(5 rows)
On voit désormais le livre sans auteur. Si la colonne
name vide gène :
essais=> SELECT CASE WHEN name IS NULL THEN 'Unknown author' ELSE name END,
title FROM Books LEFT OUTER JOIN Authors
ON Books.author = Authors.id;
name | title
----------------+-----------------------------------------
Ève Demazière | Les cultures noires d'Amérique Centrale
Alain Damasio | La horde du contrevent
Fred Vargas | Pars vite et reviens tard
Fred Vargas | L'homme à l'envers
Unknown author | Bible
(5 rows)
Et si on veut garder, non pas les livres sans auteur mais les personnes sans livres, on utilise une jointure externe à droite ou bien, tout simplement, on inverse les tables :
essais=> SELECT name, title FROM Authors LEFT OUTER JOIN Books
ON Books.author = Authors.id;
name | title
---------------------+-----------------------------------------
Stéphane Bortzmeyer |
Fred Vargas | Pars vite et reviens tard
Fred Vargas | L'homme à l'envers
Ève Demazière | Les cultures noires d'Amérique Centrale
Alain Damasio | La horde du contrevent
(5 rows)
Donc, contrairement à ce que présente l'article d'Atwood déjà cité,
INNER JOIN n'est pas une
intersection et OUTER JOIN n'est pas une
union (SQL a des
opérateurs pour ces opérations ensemblistes mais je ne les utilise pas
ici). Les jointures créent des nouveaux tuples, elles ne sélectionnent
pas des tuples existants.
Et si on veut aussi bien les livres sans auteurs que les gens qui
n'ont pas écrit de livre ? C'est le rôle de la jointure externe
complète, FULL OUTER JOIN :
essais=> SELECT name, title FROM Books FULL OUTER JOIN Authors ON Books.author = Authors.id;
name | title
---------------------+-----------------------------------------
Stéphane Bortzmeyer |
Fred Vargas | Pars vite et reviens tard
Fred Vargas | L'homme à l'envers
Ève Demazière | Les cultures noires d'Amérique Centrale
Alain Damasio | La horde du contrevent
| Bible
(6 rows)
Et enfin, pour un exemple réel, emprunté à DNSmezzo, une jointure externe
un peu plus compliquée. La table DNS_packets
contient des paquets DNS, la table DNS_types, la
correspondance entre le numéro de type d'enregistrement, contenu dans
la requête, et des chaînes de caractères mnémoniques comme NAPTR ou SRV. On fait une sous-requête
SQL pour ne garder que les paquets utiles, puis une jointure externe
(car certains paquets contiennent des requêtes pour des types qui ne
sont pas enregistrés dans la base IANA et
sont donc absents de la table DNS_types) :
dnsmezzo=> SELECT (CASE WHEN type IS NULL THEN qtype::TEXT ELSE type END),
meaning,
count(Results.id) AS requests
FROM (SELECT id, qtype FROM dns_packets WHERE
(file=5 or file=13) AND query) AS
Results
LEFT OUTER JOIN DNS_types ON qtype = value
GROUP BY qtype, type, meaning ORDER BY requests desc;
type | meaning | requests
--------+----------------------------------------+----------
MX | mail exchange | 983180
A | a host address | 847228
AAAA | IP6 Address | 129656
NS | an authoritative name server | 13583
SOA | marks the start of a zone of authority | 10562
TXT | text strings | 10348
255 | | 9125
38 | | 8440
SRV | Server Selection | 3300
SPF | | 677
PTR | a domain name pointer | 384
CNAME | the canonical name for an alias | 351
DNSKEY | DNSKEY | 323
0 | | 39
26226 | | 11
NAPTR | Naming Authority Pointer | 11
HINFO | host information | 7
NSEC | NSEC | 7
8808 | | 1
14184 | | 1
3840 | | 1
54312 | | 1
13203 | | 1
(23 rows)
L'article seul
Le greylisting marche toujours très bien, malgré les critiques
Première rédaction de cet article le 5 mai 2009
Sur tous les serveurs de messagerie que je gère, j'active le greylisting, une technique simple mais géniale, qui élimine la moitié des spams avant qu'ils ne soient envoyés. Depuis des années que je m'en sers, les critiques n'ont pas manqué, tournant en général autour de la remarque que « Les spammeurs peuvent s'adapter facilement, en gérant une file d'attente, et donc le greylisting ne servira plus à rien. ».
Ce raisonnement semble raisonnable mais il a comme gros défaut... de n'être qu'un raisonnement. La réalité le dément régulièrement. Le greylisting est quasiment aussi efficace qu'au premier jour. (Ce qui n'arrête pas les critiques, qui en général n'ont jamais l'idée de mesurer les techniques anti-spam au lieu de supposer.)
Pourquoi les spammeurs, en général très prompts à s'ajuster à toutes les techniques anti-spam, n'ont-ils rien fait contre le greylisting ? Je ne voudrais pas me mettre à faire de la supposition hasardeuse mais je pense qu'une des raisons est que peu de gens utilisent le greylisting. Tant que la majorité des serveurs ne sont pas protégés, les spammeurs n'ont pas de raison de se fatiguer à contourner cette protection, qui reste donc la plus rentables des techniques anti-spam.
C'est l'illustration parfaite d'un vieux principe de sécurité : « Il n'est pas nécessaire de courir plus vite que l'ours, il suffit de courir plus vite que les autres randonneurs. » Maintenant, peut-être qu'en lisant cet article, des millions de gens vont activer le greylisting, changeant ainsi l'équation ⌣.
Petite note technique : j'utilise en général Postfix et le logiciel de greylisting est, soit postgrey, soit l'excellent greyfix. Le premier se configure ainsi :
# postfix/main.cf
smtpd_recipient_restrictions = permit_mynetworks, [...]
check_policy_service inet:127.0.0.1:60000
postgrey étant lancé par /usr/sbin/postgrey
--pidfile=/var/run/postgrey.pid --daemonize
--inet=127.0.0.1:60000. Le second se configure avec :
smtpd_recipient_restrictions = permit_mynetworks, [...]
check_policy_service unix:private/greyfix
greyfix n'est pas lancé séparement mais par Postfix et doit donc être
configuré dans le master.cf :
greyfix unix - n n - - spawn user=nobody argv=/usr/local/sbin/greyfix --greylist-delay 300 --network-prefix 28
On voit alors dans le journal de nombreux rejets de spam, qui ne réessaient qu'exceptionnellement :
May 5 23:45:23 aetius postfix/smtpd[31070]: NOQUEUE: reject: RCPT from unknown[200.121.246.20]: 450 4.7.1 <blog@bortzmeyer.org>: Recipient address rejected: Greylisted by greyfix 0.3.8, try again in 300 seconds. See http://www.kim-minh.com/pub/greyfix/ for more information.; from=<bookkeeper@sport-weiss.com> to=<blog@bortzmeyer.org> proto=ESMTP helo=<dsldevice.lan>
Le greylisting est désormais officiellement documenté dans le RFC 6647.
L'article seul
RFC 5511: Routing Backus-Naur Form (RBNF) : A Syntax Used to Form Encoding Rules in Various Routing Protocol Specifications
Date de publication du RFC : Avril 2009
Auteur(s) du RFC : A. Farrel (Old Dog Consulting)
Chemin des normes
Première rédaction de cet article le 3 mai 2009
Contrairement à d'autres SDO, l'IETF utilise relativement peu de langages formels dans ses normes. Beaucoup de protocoles réseaux sont normalisés uniquement en langage naturel. Malgré les efforts des chercheurs qui ont développé de nombreux langages de spécification comme Lotos ou le désormais abandoné Estelle, malgré l'exemple de SDO qui dépendent de langages comme SDL/Z100, l'IETF reste fidèle aux langues humaines. Parfois, un langage formel est quand même utilisé pour une partie d'une norme. Souhaitons donc la bienvenue à RBNF (Routing Backus-Naur Form), nouveau venu dans cette famille.
Les langages formels n'étaient pas du tout utilisés au début des RFC. Petit à petit, certains sont arrivés comme ROHC-FN (RFC 4997) mais ils sont loin d'avoir pénétré partout. L'IETF n'a ainsi toujours pas de langage formel standard pour les machines à états, ni pour le format des paquets, toujours spécifiés par de l'art ASCII. Il y a plusieurs raisons à cet état de fait, l'une étant que les langages formels existants sont souvent de grosses usines à gaz assez irréalistes (l'apprentissage du langage devient une contrainte et plus une aide) et n'ont souvent même pas une seule mise en œuvre en logiciel libre.
Mais un des grands succès IETF en matière de langage formel est un langage pour écrire des grammaires, ABNF (RFC 5234). Il est utilisé pour de très nombreux RFC. Comme souvent à l'IETF, son utilisation n'est toutefois pas obligatoire et on peut constater que plusieurs RFC dans le domaine du routage ont choisi une autre forme de BNF, qui n'était pas normalisée jusque là. C'est ainsi que (section 1.2) les RFC 2205, RFC 3473, RFC 4204, RFC 5440 et bien d'autres utilisent un dialecte désormais nommé RBNF pour Routing Backus-Naur Form. Ce dialecte vient d'être normalisé dans notre RFC 5511. Son usage est conseillé pour des RFC reprenant et étendant les techniques décrites dans les RFC cités plus haut. Mais, pour des projets complètement nouveaux, il est plutôt conseillé de regarder ABNF (section 1.3).
La définition complète du langage figure en section 2. Il est plus
proche de la BNF classique qu'ABNF ; par
exemple, la définition d'une règle utilise ::= et
pas = comme en ABNF (section 2.2.1). Les noms
des règles sont systématiquement entre chevrons (section 2.1.1), par exemple (tous les exemples
sont tirés du RFC 5440)
<request-list> ou bien
<Keepalive Message>. Les définitions
terminales sont typiquement écrites en majuscules et sans espaces
(section 2.1.2)
comme <BANDWIDTH> ou
<NO-PATH>. Les règles peuvent être
combinées par des opérateurs par exemple la concaténation (section
2.2.2) notée simplement en mettant les noms des règles à la
queue-leu-leu ou bien le choix (section 2.2.4) noté
|. La répétition peut se
faire par récursion par exemple
<request-list> ::= <request>
[<request-list>] (section 2.2.5).
Avec uniquement ces opérateurs, il pourrait y avoir un risque de
confusion avec des règles comme celle, hypothétique,
<truc> ::= <machin> | <chose>
<bidule>. Est-ce que
<machin> seul est légal ? Tout dépend de la
précédence entre le choix et la
concaténation. Les règles exactes de précédences sont normalisées dans
la section 2.4 mais tous les lecteurs ne les connaissent pas forcément
sur le bout des doigts et il est donc demandé de groupe explicitement
les règles avec des parenthèses (section 2.2.6). La concaténation lie plus fortement que l'alternative
et, donc, la bonne interprétation de la règle ci-dessus est <truc> ::= <machin> | (<chose>
<bidule>).
Selon la section 3, consacrée à la validation automatique des grammaires, il n'y a malheureusement pas encore d'outil automatique pour RBNF comme il en existe pour ABNF. Un jour où j'aurai le temps, je modifierai Eustathius pour cela...
L'article seul
Création du groupe de travail IETF sur LISP
Première rédaction de cet article le 28 avril 2009
Non, ce nouveau groupe de travail de l'IETF, créé officiellement aujourd'hui, ne concerne pas le fameux langage de programmation. Il est chargé de travailler sur un nouveau protocole réseau qui, sur le long terme, permettra peut-être de résoudre le problème de passage à l'échelle du routage sur l'Internet.
Le problème auquel s'attaque le nouveau groupe de travail est un grand classique de l'Internet : comme les adresses IP servent à la fois d'identificateurs, que leurs titulaires souhaitent stables et indépendants de leur fournisseur d'accès, et de localisateurs, servant au routage entre opérateurs et devant donc être, autant que possible, agrégés pour limiter la croissance des tables BGP, personne n'est content. Ni les utilisateurs forcés de renuméroter lorsqu'ils changent de fournisseur, ni les opérateurs qui voient la table de routage par défaut, la DFZ, grossir plus vite que l'Internet. Ce problème est bien discuté dans le RFC 4984 et la solution qui a la faveur du plus grand nombre est la séparation de l'identificateur et du localisateur. L'adresse IP qui sert à tout aurait alors fait son temps.
De nombreuses propositions pour une telle séparation ont déjà été
faites et certaines sont déjà normalisées comme HIP dans le RFC 7401. Parmi les protocoles expérimentaux,
LISP (Locator/ID Separation
Protocol) est un des plus avancés et a donc gagné de haute
lutte son groupe de travail à lui. Celui-ci est donc chargé, avant fin
2010, d'écrire et de faire adopter les futurs
RFC sur LISP (actuellement en
Internet-Draft individuels), le protocole
draft-farinacci-lisp, le système d'annuaire ALT
(mapping) qui permettra de trouver les
localisateurs pour un identificateur donné
(draft-fuller-lisp-alt) et quelques autres. LISP
quitte donc les voies de la recherche pour passer en mode ingéniérie
même si la charte du nouveau groupe, prudente, précise bien que les
futurs RFC auront uniquement le statut « Expérimental ».
Comment fonctionne LISP ? Il appartient à la famille des protocole map-and-encap (RFC 1955). Les paquets sont tunnelés entre une minorité de routeurs, ceux qui participent à LISP (il ne sera donc pas nécessaire de mettre à jour tous les routeurs de l'Internet). En dehors des tunnels, on utilise les identificateurs (EID pour Endpoint IDentifier), à l'intérieur des tunnels, ce sont les localisateurs, les RLOC (Routing LOCator) qui sont utilisés, le routeur d'entrée du tunnel étant chargé de trouver les localisateurs (map, grâce à ALT ou à un autre système) et d'encapsuler les paqets (and encap). Les EID ne seront pas publiés via BGP, uniquement via ALT (ou un autre système de mapping). Et les RLOC seront fortement agrégés.
Contrairement à HIP, qui fonctionne entièrement dans les machines finales, ou bien à IPv6, qui nécessite la mise à jour de tous les routeurs, le déploiement effectif de LISP dépend donc seulement d'une minorité de routeurs, ceux qui seront désignés comme ITR (Ingress Tunnel Router, le point d'entrée des paquets) ou ETR (Egress Tunnel Router, le point de sortie).
L'article seul
Tests de performances de systèmes de fichiers pour une application PostgreSQL
Première rédaction de cet article le 27 avril 2009
À chaque fois qu'on installe et configure des machines pour une application spécifique, on se pose la question des meilleurs réglages pour tirer les performances maximales du matériel disponible. On peut lire alors plein de pages Web et de blogs remplis d'avis péremptoires mais, au bout du compte, il faut toujours faire des mesures, ne serait-ce que parce que les réglages idéaux dépendent de l'application. Ce qui accélère une application peut en ralentir une autre. L'informatique est une science expérimentale. Ici, je devais installer une machine pour une application faisant un usage intensif du SGBD PostgreSQL mais avec peu de concurrence (presque toujours un seule client), sur Linux.
Le matériel utilisé est un serveur Dell PowerEdge un peu vieux, un 2970 équipé de deux processeurs Opteron dual-core et de huit gigas de RAM. Le contrôleur des disques est un PERC 5/i. Les disques sont des Dell ST9300603SS, configurés en RAID 5. Le noyau du système est un Linux 2.6.26. Le système est Debian 5.0 « lenny ». PostgreSQL est en version 8.3.7.
Je teste avec plusieurs systèmes de fichiers différents et plusieurs algorithmes d'ordonnancement des requêtes d'E/S. Les systèmes de fichiers testés sont ext2, ext3 (ext4 ne semble pas encore présent dans le noyau livré par Debian), JFS et XFS.
Pour les tests génériques des disques, j'utilise l'excellent programme bonnie qui teste de nombreuses fonctions du système de fichiers, comme la création d'un grand nombre de fichiers (ce qui ne reflète pas vraiment ce que fait un SGBD).
Pour les tests spécifiques de PostgreSQL, j'utilise pgbench, qui permet de mesurer le nombre de transactions faisables par seconde, et dispose de plusieurs options pour essayer de reproduire le mieux possible la charge réelle.
Pour effectuer le test plus facilement et surtout pour le rendre reproductible, j'ai fait un petit programme qui effectue les tests Bonnie et pgbench pour les différents systèmes de fichiers. Attention, ce programme ne mesure que la performance et il y a bien d'autres critères pour évaluer un système de fichiers comme la sécurité (ne pas perdre de données). L'utilisation prévue ne demandait pas une grande fiabilité, donc je me suis focalisé sur la vitesse.
D'autre part, faire tourner le programme deux fois avec les mêmes paramètres montre des différences allant jusqu'à 5 % (la machine était peu chargée mais néanmoins active pour d'autres tâches, ce qui est en général déconseillé pour des mesures) donc il ne faut pas prendre trop au sérieux les petites variations.
Testons d'abord avec l'algorithme d'ordonnancement des E/S par défaut, CFQ :
% cat /sys/block/sdb/queue/scheduler noop anticipatory deadline [cfq]
Les résultats complets sont disponibles dans test-disk-linux-postgresql-results-cfq.txt. Que voit-on ?
Pour les tests génériques avec bonnie, en quantité de données, ext2 et
XFS (quasiment ex-aequo) gagnent de peu devant JFS, mais ext2 consomme bien
plus de CPU. En quantité de fichiers, XFS
gagne. Pour ext3,
pour des raisons que j'ignore, bonnie a sauté les tests sur les
fichiers.
Pour les tests spécifiques de PostgreSQL, avec pgbench, JFS l'emporte
(mais les différences sont faibles).
Les différences sont plus marquées si on augmente le nombre de clients PostgreSQL concurrents mais cela reflèterait moins notre usage réel. (Avec 15 « clients », on a typiquement deux fois plus de transactions par seconde, sauf pour ext3 qui est plus lent dans ces conditions.)
Le principe des algorithmes d'ordonnancement comme CFQ est de
réarranger les requêtes dans un ordre qui minimise le travail pour le
disque. Mais, si une machine virtuelle tourne
sur la machine physique, elle aura déjà fait cette optimisation et la
machine physique, qui ne sait pas ce qui se passe dans la machine
virtuelle, a peu de chances de pouvoir améliorer les choises. C'est
pourquoi on dit souvent que le meilleur algorithme dans la machine
physique est noop, l'algorithme qui ne fait rien et passe les requêtes
inchangées (FIFO). Même chose pour le cas où on utilise un
SGBD, celui-ci ayant déjà ordonné ses requêtes
d'E/S intelligemment (voir par exemple une intéressante
discussion sur ce sujet sur la liste postgresql-performance et
une autre également
portée sur l'algorithme deadline). Est-ce vrai qu'on peut
améliorer les performances ainsi ? Testons d'abord avec
noop :
# echo noop > /sys/block/sdb/queue/scheduler
Pour ces tests, les résultats ne sont pas probants. Seul ext2 voit une nette augmentation des performances.
Et avec l'ordonnanceur deadline ? pgbench va
en fait moins vite. Il est probable que le changement d'ordonnanceur
serait plus efficace dans le cas de nombreux accès concurrents non synchronisés.
Merci à Malek Shabou pour son aide et ses suggestions.
Des articles intéressants sur le sujet de l'ordonnancement des E/S sur Linux :
- elevator=noop et VMware Server Tips'n'Tricks, explorent les conséquences de la virtualisation sur l'ordonnancement des E/S,
- Choosing an I/O Scheduler for Red Hat® Enterprise Linux® 4 and the 2.6 Kernel, article détaillé, et pas spécifique à RedHat,
- Linux Change The I/O Scheduler For A Hard Disk, court résumé des instructions de base, et LinuxIoScheduler, bonne documentation générale.
- Dans les sources du noyau Linux, répertoire
Documentation/, les documents (très pointus !)block/as-iosched.txt,kernel-parameters.txtetblock/switching-sched.txt. - A Tweaker's Guide to Solid State Drives (SSDs) and Linux est surtout consacré aux SSD mais plusieurs leçons peuvent être appliquables à tous les disques.
- Spécifiquement sur PostgreSQL, on peut lire Performance Optimization, liste de liens vers des articles sur l'optimisation de ce SGBD, avec une section Disk and hardware setup qui nous concerne directement. Dans cette section, j'ai notamment utilisé Is that performance I smell? Ext2 vs Ext3 on 50 spindles, testing for PostgreSQL.
- Le livre sur Oracle, Pro Oracle database 10g RAC on Linux, bien que consacré à un autre SGBD, contient des informations intéressantes.
Pour les tests avec PostgreSQL, Erwan Azur me suggère aussi Sysbench. Mais il ne compile pas sur mes machines Debian :
% ./configure --with-pgsql --without-mysql % make ... /bin/sh ../libtool --tag=CC --mode=link gcc -pthread -g -O2 -o sysbench sysbench.o sb_timer.o sb_options.o sb_logger.o db_driver.o tests/fileio/libsbfileio.a tests/threads/libsbthreads.a tests/memory/libsbmemory.a tests/cpu/libsbcpu.a tests/oltp/libsboltp.a tests/mutex/libsbmutex.a drivers/pgsql/libsbpgsql.a -L/usr/lib -lpq -lrt -lm ../libtool: line 838: X--tag=CC: command not found ../libtool: line 871: libtool: ignoring unknown tag : command not found ../libtool: line 838: X--mode=link: command not found ../libtool: line 1004: *** Warning: inferring the mode of operation is deprecated.: command not found ../libtool: line 1005: *** Future versions of Libtool will require --mode=MODE be specified.: command not found ../libtool: line 2231: X-g: command not found ...
L'article seul
Gérer son contrôleur RAID PERC sur un Dell PowerEdge sous Debian
Première rédaction de cet article le 24 avril 2009
Dernière mise à jour le 28 avril 2009
Faire fonctionner un PC, qu'il soit machine de bureau ou serveur sans écran, avec du logiciel libre n'a jamais été facile. Même si les fabricants affirment tous « supporter (sic) Linux », dans la réalité, un tel « support » nécessite en général de n'utiliser qu'un seul système d'exploitation, en général d'origine commerciale, de charger des pilotes non-libres et de renoncer à certaines fonctions du matériel.
Prenons l'exemple des contrôleurs RAID PERC, livrés sur les serveurs PowerEdge de Dell (tous les essais ici ont été effectués avec un PowerEdge 2970, muni d'un PERC 5/i). Officiellement, il ne marche qu'avec Red Hat. Essayons quand même avec Debian.
Le contrôleur est bien géré par le pilote
megaraid_sas. Si on configure le RAID dans le
BIOS et qu'on charge ledit pilote, tout va
bien. le noyau affiche :
[ 4.226361] scsi0 : LSI SAS based MegaRAID driver [ 4.226361] scsi 0:0:0:0: Direct-Access SEAGATE ST9146802SS S206 PQ: 0 ANSI: 5 [ 4.226361] scsi 0:0:1:0: Direct-Access SEAGATE ST9146802SS S206 PQ: 0 ANSI: 5 [ 4.226361] scsi 0:0:2:0: Direct-Access SEAGATE ST9146802SS S206 PQ: 0 ANSI: 5 [ 4.356866] scsi 0:0:8:0: Enclosure DP BACKPLANE 1.05 PQ: 0 ANSI: 5 [ 4.368366] scsi 0:2:0:0: Direct-Access DELL PERC 5/i 1.03 PQ: 0 ANSI: 5 [ 4.427331] Driver 'sd' needs updating - please use bus_type methods [ 4.430358] sd 0:2:0:0: [sda] 570949632 512-byte hardware sectors (292326 MB)
et lspci -vvv :
08:0e.0 RAID bus controller: Dell PowerEdge Expandable RAID controller 5
Subsystem: Dell PERC 5/i Integrated RAID Controller
Control: I/O- Mem+ BusMaster+ SpecCycle- MemWINV+ VGASnoop- ParErr+ Stepping+ SERR+ FastB2B- DisINTx-
Status: Cap+ 66MHz+ UDF- FastB2B- ParErr- DEVSEL=medium >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx-
Latency: 32 (32000ns min), Cache Line Size: 64 bytes
Interrupt: pin A routed to IRQ 37
Region 0: Memory at e00f0000 (32-bit, prefetchable) [size=64K]
Region 2: Memory at e9fe0000 (32-bit, non-prefetchable) [size=128K]
Expansion ROM at e9e00000 [disabled] [size=32K]
Capabilities: <access denied>
Kernel driver in use: megaraid_sas
Kernel modules: megaraid_sas
Mais utiliser le contrôleur n'est qu'une partie. On voudrait
aussi connaître l'état des disques (pour savoir ceux qu'on doit
remplacer), créer des nouveaux disques virtuels sans repasser sous le
BIOS, etc. Dell fournit pour cela un logiciel, OMSA. Pour l'installer,
on va chercher sur ftp://ftp.sara.nl/pub/outgoing/dell/ :
% wget ftp://ftp.sara.nl/pub/outgoing/dell/binary-amd64/dellomsa_5.4.0-1_amd64.deb % sudo aptitude install openipmi ia32-libs lib32ncurses5 % sudo dpkg -i dellomsa_5.4.0-1_amd64.deb
Mais l'authentification ne marche pas ensuite. OMSA authentifie
normalement via PAM mais le stagiaire qui en un
été a développé le cliquodrome chez Dell ne savait pas qu'il existe
des machines 64-bits. Il faut donc installer à la main des
bibliothèques PAM 32-bits comme bien expliqué en
http://blog.zztopping.com/2008/04/29/dell-omsa-debian-64bit/. Je
résume le contenu ce cette page Web :
... télécharger les ".deb" ... % dpkg -x libselinux1_1.32-3_i386.deb ./pam-omsa ... idem pour les autres ... % sudo cp pam-omsa/lib/libsepol.so.1 /lib32 % sudo cp pam-omsa/lib/libselinux.so.1 /lib32 % sudo cp pam-omsa/lib/security/pam_unix.so /lib32/security % sudo cp pam-omsa/lib/security/pam_nologin.so /lib32/security % sudo ldconfig % sudo emacs /etc/pam.d/omauth
et, dans ce dernier fichier :
auth required /lib32/security/pam_unix.so nullok auth required /lib32/security/pam_nologin.so account required /lib32/security/pam_unix.so nullok
Je suppose que ça doit aussi marcher avec LDAP mais je n'ai pas encore testé.
L'application de gestion du contrôleur RAID est alors accessible
depuis la machine en https://127.0.0.1:1311/
(HTTPS seulement). Il faut
accepter le certificat bidon. Un
navigateur très riche est nécessaire, vue la surutilisation de gadgets
divers. En
raison d'une bogue SSL, le serveur HTTPS ne marche
pas avec Konqueror
(20930:error:140773F2:lib(20):func(119):reason(1010):s23_clnt.c:578:).
Si on veut se connecter depuis une autre machine, je suppose qu'on
peut demander au serveur HTTP d'écouter sur d'autres adresses IP mais c'est peu sûr. La solution que
je préfère est de faire un tunnel avec
SSH en tapant ssh -L
1311:127.0.0.1:1311 MONSERVEURPOWEREDGE -N et d'utiliser
ensuite un Firefox local qui se connecte à
https://127.0.0.1:1311/ (j'ai utilisé le même port).
N'importe quel utilisateur PAM peut alors se loguer. root a tous les droits, mais on peut aussi se loguer avec un autre compte (et, je crois, configurer ses autres comptes pour avoir des privilèges particuliers sur le contrôleur RAID).
OMSA vient aussi avec des programmes en ligne de commande comme
omreport :
% omreport chassis Health Main System Chassis SEVERITY : COMPONENT Ok : Fans Ok : Intrusion Ok : Memory Ok : Power Supplies Ok : Processors Ok : Temperatures Ok : Voltages Ok : Hardware Log Ok : Batteries
ou :
% omreport storage vdisk controller=0 List of Virtual Disks on Controller PERC 5/i Integrated (Embedded) Controller PERC 5/i Integrated (Embedded) ID : 0 Status : Ok Name : Virtual Disk 0 State : Ready Progress : Not Applicable Layout : RAID-5 Size : 272.25 GB (292326211584 bytes) Device Name : /dev/sda Type : SAS Read Policy : No Read Ahead Write Policy : Write Back Cache Policy : Not Applicable Stripe Element Size : 64 KB Disk Cache Policy : Disabled ID : 1 Status : Ok Name : Databases State : Ready Progress : Not Applicable Layout : RAID-5 Size : 1,115.50 GB (1197759004672 bytes) Device Name : /dev/sdb Type : SAS Read Policy : No Read Ahead Write Policy : Write Back Cache Policy : Not Applicable Stripe Element Size : 64 KB Disk Cache Policy : Disabled
Avec l'interface Web, je peux maintenant voir l'état des disques, créer un nouveau disque virtuel, etc.
D'autre part, Dell fournit un autre programme en ligne de commande, MegaCli, pour interroger le contrôleur RAID. On peut le trouver en ligne sous forme d'un RPM. alien ne peut convertir ce RPM :
dpkg-gencontrol: error: current host architecture 'amd64' does not appear in package's architecture list (i386) dh_gencontrol: command returned error code 65280
mais, comme indiqué dans l'article Some useful MegaCli commands/quick debian howto, on peut tout simplement extraire les exécutables :
% rpm2cpio MegaCli-1.01.39-0.i386.rpm | cpio -idmv # cp ./opt/MegaRAID/MegaCli/MegaCli64 /usr/local/sbin/MegaCli
Outre l'article cité ci-dessus, on peut trouver une documentation très sommaire sur MegaCli.
Une fois MegaCli installé, on peut s'en servir, par exemple pour du monitoring régulier comme le fait ce script Perl qui teste l'état de la batterie et envoie un message en cas de problème.
Quelques articles sur ce sujet :
- Repository/OMSA, la page officielle de Dell,
- Installation of openmanage, article très détaillé sur la configuration des alarmes et, en prime, leur récupération via SNMP,
- How To Manage Dell Servers using OMSA - OpenManage Server Administrator On Linux, des copies d'écran,
- Ubuntu-Server (Debian) and DELL RAID Monitoring over OMSA .
Merci à Jean-Édouard Babin pour ses suggestions.
L'article seul
Vente forcée : pourquoi nous oblige t-on à acheter du « triple play » ?
Première rédaction de cet article le 23 avril 2009
Le protocole IP est la base de l'Internet, celle au dessus de laquelle on peut tout construire. Les services comme la téléphonie ou la distribution de la télévision pourraient être simplement fournies au dessus d'IP, pas forcément par le fournisseur d'accès à l'Internet. Alors, pourquoi tant de FAI s'obstinent-ils à nous forcer à acheter du triple play même si nous n'en voulons pas ?
Pour moi, le FAI idéal ne devrait pas me contraindre à acheter du téléphone, de la télé ou autres multimédiaries. Je veux du IP, point. Je peux déjà recevoir la télé par un autre canal et je peux me débrouiller avec Asterisk (et les blaireauphones comme backup) pour la téléphonie.
Est-ce que ça existe en France, un FAI qui ne cherche pas à nous vendre en plus d'autres services qu'on n'a pas demandé ? Qui fasse du « IP pur » en dégroupage total ?
Je vois bien les obstacles à cela, notamment le fait que gérer plusieurs offres soit, pour le FAI, compliqué commercialement et techniquement, et que vendre la même chose à tous les clients soit plus simple : Henry Ford n'est pas mort. De même, les lois et autres réglements, conçus pour un paysage complètement différent, sont inadaptés aujourd'hui (par exemple, ce sont deux lois et deux organismes de régulation complètement différents qui jugent d'un clip vidéo selon que celui-ci est diffusé à la télévision ou via l'Internet). Absurde, mais c'est comme ça et un dinosaure du passé comme le CSA va se cramponner à son rôle jusqu'au bout.
Résultat, pour l'instant, peu de fournisseurs tiers apparaissent et certains essaient et se plantent, comme Wengo qui a arrêté de faire de la téléphonie. Le cercle vicieux marche à plein : les clients potentiels, via la vente forcée, ont déjà un abonnement téléphonique, pourquoi achèteraient-ils un service en plus ?
Ma vision est que l'Internet doit être un service de base et que d'autres acteurs doivent pouvoir vendre par dessus d'autres services à ceux qui veulent. Le triple play me semble incompatible avec l'idée de concurrence libre et non faussée.
En français, voir également l'article « Vente liée ». Et Patrik Falström a dit la même chose en anglais dans What is wrong in triple play offerings?.
L'article seul
RFC 5507: Design Choices When Expanding DNS
Date de publication du RFC : Avril 2009
Auteur(s) du RFC : P. Faltstrom (IAB), R. Austein (IAB), P. Koch (IAB)
Pour information
Première rédaction de cet article le 23 avril 2009
Le DNS est au cœur de la plupart des transactions sur l'Internet. Bien connu, très fiable et largement déployé, il est un service très tentant, lorsqu'on veut déployer un nouveau service d'information sur l'Internet. Bien des protocoles ont ainsi délégué la récupérations de données au DNS. Parfois, ils ne l'ont pas fait de manière optimum et ce RFC de l'IAB veut « redresser la barre » en précisant les bonnes (et les mauvaises) façons de stocker et de récupérer de l'information dans le DNS.
Dès le résumé, notre RFC pointe le problème le plus fréquent : abuser des enregistrements de type TXT (texte), le type le plus tentant pour distribuer de l'information. Par exemple, SPF à l'origine utilisait exclusivement ce type pour distribuer des politiques d'autorisation de MTA, exprimées en un mini-langage (la version finalement normalisée, dans le RFC 4408, a créé un type spécifique, nommé SPF mais, en pratique, le TXT reste le plus utilisé, le SPF ayant même été abandonné dans le RFC 7208). La principale conclusion du RFC est donc qu'il vaut mieux, en général, créer un nouveau type d'enregistrement.
À l'origine, le DNS stockait surtout deux sortes de données : celles liées à l'infrastructure DNS elle-même comme les enregistrements SOA ou NS et celles liées à la résolution de noms en adresses IP (enregistrement A) ou inversement (PTR). Le succès du DNS, sa disponibilité universelle, ont mené à bien d'autres utilisations, soit spécifiques à une application comme les enregistrement MX, soit génériques comme les enregistrements SRV du RFC 2782. Beaucoup d'autres, plus récents, s'y sont ajoutés comme les SSHFP du RFC 4255 ou les HIP du RFC 8005. (Les sections 1 et 2 du RFC rappellent les bases du DNS, nécessaires pour comprendre la question.)
Quels sont les moyens disponibles aujourd'hui pour « étendre » le DNS, pour stocker de nouveaux types de données dans cette base ? La section 3 les liste successivement.
Il y a la possibilité (section 3.1) de stocker les données dans un enregistrement
générique comme TXT ou le défunt SINK ou NAPTR et d'ajouter dans
ses données un sélecteur qui indique à
l'application si ce sont bien ces données. SPF
fonctionne ainsi, la présence de la chaîne v=spf1
au début de l'enregistrement TXT indiquant qu'il s'agit bien de
SPF. Les utilisateurs des NAPTR (RFC 6116) font souvent
pareil. Cette méthode (nommée subtyping) a un gros inconvénient. Comme les requêtes DNS
se font par clé (la question posée, le QNAME) et
pas par valeur, il n'y a aucun moyen de ne récupérer que les
enregistrements intéressants. On les obtient tous et on trie
après. Ainsi, si je veux les enregistrements SPF de
sources.org, je dois récupérer deux
enregistrements :
% dig TXT sources.org ... sources.org. 86400 IN TXT "v=spf1 mx a:uucp.bortzmeyer.org a:central.sources.org ?all" sources.org. 86400 IN TXT "Sources" ...
et trier ensuite. Cela peut poser des problèmes si le nombre d'enregistrements de ce type (le RRset) est gros.
La section 3.2 propose une autre méthode : ajouter un préfixe au
nom de domaine (le QNAME). C'est, par exemple, ce que fait
DKIM (RFC 6376) qui utilise des enregistrements TXT mais
des noms de domaine qui lui sont propres. Si je reçois un message
signé par DKIM qui indique le domaine example.net
et le sélecteur beta, je fais une requête DNS pour le type TXT et le nom beta._domainkey.example.net. XMPP a un mécanisme analogue.
La principale limite de cette méthode vient des
jokers (wildcards). Les jokers
ne peuvent apparaitre que tout à fait à gauche d'un nom de
domaine. Donc, si on a un joker dans example.net,
il ne sera pas facile d'en faire un pour
_prefixe.*.example.net (cf. RFC 4592). Cela concerne particulièrement le courrier
électronique car c'est la principale utilisation des jokers.
Continuons les méthodes possibles. Puisque le préfixe a des
limites, pourquoi pas un suffixe ? (Section 3.3.) Le principal
problème est alors de s'assurer que example.net
et example.net._suffixe sont synchrones, alors
qu'ils sont désormais dans deux sous-arbres du DNS complètement
distincts.
Plus astucieuse est l'idée de jouer sur la classe. La question DNS ne comporte pas uniquement un nom de domaine (QNAME) mais aussi un type (QTYPE) et une classe (QCLASS). On a tendance à oublier cette dernière car elle vaut quasiment toujours IN (pour INternet) mais d'autres classes sont possibles et certaines sont déjà enregistrées. Mais, si certaines applications comme Hesiod (j'avais déployé Hesiod dans les salles de classe du CNAM il y a longtemps...) utilisaient ces autres classes, il parait difficile aujourd'hui de s'en servir, beaucoup de logiciels, de serveurs intermédiaires et de pare-feux n'acceptant pas les classes autres que IN. Et, du point de vue administratif, cela représente une nouvelle arborescence à mettre en place, puisque l'arbre du DNS dans une autre classe ne correspond pas forcément à celui de IN.
Alors, un nouveau type ? Je trahis le suspense mais c'est en effet la solution privilégiée par l'IAB. La section 3.5 explique les avantages de ce mécanisme mais aussi ses limites. Pour insérer des données du nouveau type, et pour pouvoir les utiliser, il faut que beaucoup d'acteurs mettent à jour quelque chose :
- les auteurs de serveurs faisant autorité (serveur primaire, qui charge les données et qui doit donc pouvoir les lire, la section 6 revient sur ce problème de l'avitaillement), et serveurs secondaires, qui les copient ; historiquement, on a déjà vu des secondaires qui ne pouvaient pas recharger une zone qu'ils avaient transféré car elle contenait des types inconnus ; normalement, c'est devenu un problème très rare, cf. RFC 3597).
- les auteurs de résolveurs (normalement, ceux-ci doivent être transparents aux divers types, voir encore le RFC 3597).
- les auteurs d'applications, qui doivent pouvoir lire ces données (toutes les bibliothèques d'accès au DNS ne le permettent pas forcément, notamment dans le monde Microsoft) et les comprendre.
En plus de ces difficultés techniques, l'enregistrement d'un nouveau type utilisable dans le DNS a toujours été un processus très long et très complexe. L'IAB le reconnait dans ce RFC (après l'avoir nié pendant longtemps) mais ce n'est que depuis la sortie du RFC 5395 en novembre 2008 que le processus est devenu raisonnable. (Obtenir un nouveau type demeure un certain travail car l'espace disponible est sur 16 bits seulement, donc pas infini et il faut justifier sa demande.)
Maintenant que les différentes solutions ont été présentées, il
faut fournir les éléments permettant de choisir. Avant cela, la
section 4 fait un petit détour sur un problème sur lequel les
débutants en DNS se cassent souvent le nez, le fait que les frontières
des zones DNS soient invisibles aux applications. En effet, le
découpage d'un nom de domaine en sous-domaines qui est, lui, visible (les
éléments sont séparées par des points), n'indique pas où sont les
frontières de zones, encore moins quelles sont les frontières
administratives et politiques. Si je vois le nom
www.durand.free.fr, est-ce un nom contrôlé par
Free ou bien Free a t-il délégué à M. Durand,
son client ? Rien dans le DNS ne permet de le savoir et une
application qui se baserait sur cette connaissance aurait de grandes
chances de se tromper. Ainsi, on a vu des applications, lorsqu'elles
ne trouvaient pas un nom dans un domaine, chercher dans le domaine
parent. C'est très dangereux, car rien n'indique si le domaine parent
est sous le contrôle des mêmes personnes (ce mécanisme, dit de
tree climbing, fut la base de la faille
de sécurité WPAD). La seule solution serait de
connaitre la politique de tous les registres, y
compris ceux qui ne sont pas des TLD comme
eu.org, ce qui est évidemment irréaliste. Voir
aussi le RFC 1535 sur ce point.
La section 5 synthétise tous ces points en recommandant fortement la création d'un nouveau type d'enregistrement DNS, lorsqu'on a besoin de stocker des données dans le DNS. Cette section exprime une certaine compréhension pour le développeur qui n'utilise pas le DNS pour le plaisir, mais parce qu'il a besoin de stocker ses données et d'y accéder, et qui n'est donc pas un expert DNS, et qui file donc droit vers la solution la plus évidente, les enregistrements TXT.
Mais cela ne change rien aux problèmes posés par les TXT notamment le manque de structure interne. Chaque application qui utilise les TXT doit donc définir son mini-langage, rendant ainsi difficile la cohabitation d'enregistrements TXT d'applications différentes. En pratique, le TXT est donc plutôt un enregistrement privé, dont la signification est laissé à chacun.
La cohabitation est rendue encore plus difficile par l'absence d'un
sélecteur standard (le RFC 1464 avait essayé d'en définir un
mais avait été un échec). Chaque application doit donc avoir son
mécanisme pour « reconnaître ses petits » (comme le
v=spf1 de SPF).
Les enregistrements TXT avec un préfixe spécifique dans le nom de domaine, comme ceux de DKIM, sont meilleurs mais souffrent d'autres problèmes comme la difficile cohabitation avec les jokers.
Il reste donc, et la section 6 conclut le RFC sur ce point, à lire le RFC 5395 et à remplir un dossier pour avoir un nouveau type d'enregistrement. C'était très difficile autrefois, aussi bien à obtenir qu'à déployer ensuite, mais c'est désormais plus facile.
L'article seul
Les moteurs de recherche de code source
Première rédaction de cet article le 21 avril 2009
Dernière mise à jour le 20 octobre 2011
Pour le programmeur, la présence
d'énormes quantités de codes
source librement disponibles sur l'Internet est une
bénédiction. Si la documentation n'est pas claire et qu'on cherche à trouver un exemple d'utilisation de la
fonction C gpgme_get_engine_info ou la définition
de la classe Java
BufferedReader, on a tout sous la main.
Quels outils sont disponibles pour ces recherches ? Il y a les
moteurs de recherche
classique comme Yahoo ou
Exalead. Mais ils ne sont pas spécialisés dans
le code source : ils gèrent mal des chaînes de caractères comme
PERL_DL_NONLAZY (Exalead croit que ce sont trois
mots séparés), ils ne peuvent pas restreindre la recherche à un
langage particulier, ils n'indexent pas les
archives, par exemple tar, etc.
C'est pour cela qu'il existe des moteurs de recherche spécialisés
dans le code source. J'en présente quelques uns, en maintenant une
liste que je crois complète en http://delicious.com/bortzmeyer/codesearch.
La « méthodologie » que je suis pour leur évaluation est la suivante :
- Voir si les codes qui ne sont pas dans une
archive ou un dépôt d'un VCS sont également
indexés. Par exemple, ces moteurs voient-ils
traceroute-nanog-xml.cougpgme-sign.c? - Voir si on peut trouver des choses qui apparaissent dans des relativement « petits » programmes, des logiciels libres pas trop connus (j'ai choisi echoping, xmldiff et darcs).
Le premier moteur de recherche spécialisé dans le code source est Krugle. Parfois, il ne répond plus et toutes les adresses de courrier de contact échouent. Quand il marche, il ne connait pas les fichiers publiés sur mon blog, il ne connait pas echoping, ni xmldiff, ni darcs. Krugle a une interface simple, qui permet de chercher uniquement dans certaines parties du code (par exemple uniquement dans les commentaires ou, pour les fonctions, de ne chercher que les définitions ou que les appels, ce qui est très pratique).
Le géant de la recherche, Google, avait aussi son moteur de recherche spécialisé
dans le code source, dont la fin a été récemment annoncée. Il dispose d'un langage de
requête perfectionné qui permet, par exemple, de spécifier le langage
de programmation choisi (avec le qualificateur
lang:) et de nombreux langages sont reconnus,
même parmi les plus exotiques. S'il indexe d'innombrables archives, il
ne connait pas les fichiers publiés sur mon blog (alors que mon blog
lui-même est très bien indexé par Google).
Outre le qualificateur lang:, Google Code
Search disposait
du très pratique function: permet de trouver la
définition d'une fonction. Mais il n'existe pas de moyen de trouver
l'usage d'une fonction. Plus ennuyeux, si on cherche les usages de la
définition IPV6_UNICAST_HOPS, on est noyés sous
les définitions mais je n'ai pas trouvé de moyen simple de voir les
appels de fonctions utilisant ce paramètre.
Google connait les programmes testés, echoping, xmldiff et darcs. Enfin, il dispose d'une API (je ne l'ai pas testée).
Continuous la tournée des moteurs de recherche. Si intéressant qu'il soit, et en logiciel libre, je n'ai pas cherché longtemps avec Gonzui car il fonctionne uniquement en local, avec les archives qu'on lui fournit. Cela peut être pratique dans un environnement fermé mais, pour les logiciels librement accessibles, il indexera donc toujours moins que Google.
Enfin, place à Codase, le plus récent. Parmi ses propriétés intéressantes, une possibilité de chercher, par le nom d'une fonction, son utilisation (option Method Name) ou sa définition (option Method Definition). Encore mieux, l'option Smart Query tient compte de la syntaxe du langage pour proposer le bon résultat. C'est ainsi qu'on peut chercher des fonctions par signature, ce qui est pratique si deux fonctions portent le même nom.
Par contre, le choix des langages est bien plus restreint qu'avec Google : uniquement C, C++ et Java. Et le nombre de programmes indexé est également beaucoup plus faible : ni echoping, ni xmldiff, ni darcs ne sont archivés. C'est logique qu'il ne connaisse pas beaucoup de programmes. Lorsqu'on utilise son interface pour signaler un nouveau projet, on obtient « Bad Gateway The proxy server received an invalid response from an upstream server. Apache/2.0.54 (Fedora) Server at www.codase.com Port 80 ». Même message lorsqu'on essaie d'utiliser leur formulaire de feedback.
Le dernier que j'ai rencontré est Koders. Il ne connait pas non plus
mes fichiers, ni les trois programmes d'exemple (malgré sa prétention
à indexer « 2,099,323,932 lines of open source
code »). Il est le seul moteur testé ici qui ne reconnait
pas la convention du _ comme partie d'un
identificateur et il croit donc que KEYRING_DIR
est composé de deux mots !
Bref, comme souvent avec les moteurs de recherche, l'écart des capacités techniques entre Google et ses lointains suivants est énorme. La fin brutale de Google Code Search début 2012 devrait donc dégager un espace pour les concurrents. Un de ces jours, je re-testerai tous ceux de ma liste.
Mes remerciements à Sébastien Tanguy, Hervé Agnoux et à Kim-Minh Kaplan pour leurs suggestions.
L'article seul
Abysses, de Frank Schätzing
Première rédaction de cet article le 18 avril 2009
Vous aimez les romans catastrophico-scientifiques ? « Abysses », de Frank Schätzing (Der Schwarm en allemand) est un livre passionnant sur une catastrophe écologique provoquée par... lisez le livre, vous verrez bien. Je dis juste que cela se passe dans la mer et un peu partout dans le monde, notamment en Norvège et au Canada.
Contrairement aux livres-catastrophes états-uniens, il n'y a pas qu'un seul héros mais plusieurs, avec des places équivalentes, et rien ne garantit que cela se terminera bien. Je peux même déjà dire qu'il y a beaucoup de morts, même parmi les « gentils ». Si vous n'avez pas peur d'aller à l'eau, commencez ce livre...
L'article seul
Utiliser une bibliographie avec Docbook
Première rédaction de cet article le 17 avril 2009
Le schéma XML de documentation Docbook
contient un élément <bibliography>
qui permet d'indiquer une bibliographie. Gérer
le contenu de cette bibliographie à la main dans chaque document
Docbook n'est pas pratique : après tout, beaucoup d'éléments de la
bibliographie sont certainement partagés entre tous les documents
qu'on édite dans son travail. Je présente ici une méthode qui permet
de gérer la bibliographie à part, sous forme d'un fichier XML unique,
et d'inclure dans les documents Docbook seulement les références
effectivement citées.
Le principe est donc d'avoir un seul fichier XML contenant les
références bibliographiques utilisées par une personne ou un
groupe. Il existe peut-être un schéma standard simple et pratique pour
décrire ce fichier mais je ne l'ai pas trouvé et j'ai donc fait un
schéma, écrit en DTD et publié en docbook-biblio-resources.dtd. Ce schéma permet d'écrire des
documents comme :
<!DOCTYPE bibliography SYSTEM "internet.dtd">
<bibliography>
<netresource id="xml-rpc">
<author>
<lastname>UserLand Software</lastname>
</author>
<title>XML-RPC Home Page</title>
<year>2003</year>
<url>http://www.xml-rpc.com/</url>
</netresource>
<netresource id="honeynet.knowyourenemy">
<author><lastname>The Honeynet Project & Research Alliance</lastname></author>
<title>Know your Enemy: Tracking Botnets</title>
<year>2005</year>
<url>http://www.honeynet.org/papers/bots/</url>
</netresource>
<book id="iteanu.identite">
<author><firstname>Olivier</firstname><lastname>Iteanu</lastname></author>
<title>L'identité numérique en question</title>
<year>2008</year>
<number>978-2-212-12255-8</number>
<publisher>Eyrolles</publisher>
</book>
...
</bibliography>
Ce fichier XML peut être écrit et modifié avec les éditeurs de son choix et géré dans un VCS.
On pourrait bien sûr inclure le fichier entier dans le document Docbook (pas par copier-coller, ce qui empêcherait de profiter des mises à jour, mais par un mécanisme d'inclusion automatique comme XInclude) mais la bibliographie complète peut être énorme. On va donc chercher à extraire l'information utile.
Cela se fait par un programme XSLT, docbook-biblio-extract.xsl, qui
extrait les élément comme <netresource> si leur identité
(l'attribut id) est celle indiquée (via le paramètre refs). Pour ne pas avoir à
indiquer toutes les identités à la main, un autre programme XSLT, docbook-biblio-find.xsl,
permet de les extraire automatiquement du document Docbook, en
regardant les références comme <xref>.
Voici comment utiliser ces deux programmes en même temps avec le
processeur xsltproc et le
shell Unix
($(COMMAND) signifie « exécuter la commande
COMMAND et inclure son résultat à cet endroit ») :
xsltproc -o SPECIFICBIBLIO.xml \
--stringparam refs "$(xsltproc docbook-biblio-find.xsl MYDOCUMENT.db)" \
docbook-biblio-extract.xsl MYBIBLIO.xml
La commande est longue à taper mais, personnellement, j'automatise cela avec un Makefile.
docbook-biblio-extract ne fait qu'extraire les
éléments XML, qui sont toujours au format de ma DTD. Pour les traduire
en Docbook, un dernier programme XSLT est nécessaire, docbook-biblio-resources2docbook.xsl. Il s'utilise ainsi :
xsltproc -o SPECIFICBIBLIO.db resources2docbook.xsl SPECIFICBIBLIO.xml
Il ne reste plus qu'à mettre ce fichier dans le document Docbook qu'on est en train d'écrire, par exemple via XInclude. Dans ce dernier cas, le document Docbook qu'on écrit contiendra :
<xi:include href="SPECIFICBIBLIO.db"/>
pourra être traité, par exemple, par xmllint :
xmllint --xinclude MYDOCUMENT.db > MYDOCUMENT-COMPLET.db
Parmi les documents cités dans des articles, les
RFC posent un cas particulier. En effet, il
existe déjà une liste des RFC en XML (au format décrit dans le RFC 7749), il n'y a pas besoin de maintenir
cette liste à la main avec les autres. Je crée donc une DTD qui étend
la précédente pour les RFC, docbook-biblio-rfc.dtd, et
un programme pour traduire la liste officielle vers mon format, docbook-biblio-2629toresources.xsl. La liste officielle est
automatiquement récupérée par wget
http://xml.resource.org/public/rfc/bibxml/index.xml et
traduite dans mon format.
Ensuite, pour finir de traiter les RFC, j'ai des programmes
spécifiques, docbook-biblio-findrfc.xsl qui trouve les
références de type RFCnnn où NNN est le numéro
d'un RFC, et docbook-biblio-extractrfc.xsl qui extrait
les RFC de la liste officielle.
Toutes ces commandes sont complexes à taper, alors
make arrive à la rescousse. Voici le
Makefile qui automatise tout cela :
rfc-MONDOCUMENT-automatic.xml: rfc.xml MONDOCUMENT.db
xsltproc -o $@ --stringparam rfcs "`xsltproc docbook-biblio-findrfc.xsl MONDOCUMENT.db`" docbook-biblio-extractrfc.xsl $<
biblio-MONDOCUMENT-automatic.xml: bibliocommune.xml MONDOCUMENT.db
xsltproc -o $@ --stringparam refs "`xsltproc docbook-biblio-find.xsl MONDOCUMENT.db`" docbook-biblio-extract.xsl $<
MONDOCUMENT-COMPLET.db: MONDOCUMENT.db rfc-MONDOCUMENT-automatic.db biblio-MONDOCUMENT-automatic.db
xmllint --xinclude $< > $@
%.db: %.xml
xsltproc -o $@ docbook-biblio-resources2docbook.xsl $<
Taper make MONDOCUMENT-COMPLET.db suffit
alors à tout faire en cascade.
Comme tout le processus dépend de plusieurs fichiers, le script
docbook-biblio-create-links.sh
L'article seul
RFC 5451: Message Header Field for Indicating Message Authentication Status
Date de publication du RFC : Avril 2009
Auteur(s) du RFC : M. Kucherawy (Sendmail)
Chemin des normes
Première rédaction de cet article le 17 avril 2009
Il existe désormais plusieurs techniques pour authentifier les courriers
électroniques. Certaines peuvent nécessiter des calculs un
peu compliqués et on voudrait souvent les centraliser sur une machine
de puissance raisonnable, dotée de tous les logiciels
nécessaires. Dans cette hypothèse, le MUA ne
recevra qu'une synthèse (« Ce message vient bien de
example.com ») et pourra alors prendre une
décision, basée sur cette synthèse. C'est le but du nouvel en-tête
Authentication-Results: que normalisait notre
RFC (depuis remplacé par le RFC 7001).
Avec des techniques d'authentification comme
DKIM (RFC 6376) ou
SPF (RFC 7208), les
calculs à faire pour déterminer si un message est authentique peuvent
être complexes (DKIM utilise la cryptographie) et nécessiter la
présence de bibliothèques non-standard. Les installer et
les maintenir à jour sur chaque machine, surtout en présence
d'éventuelles failles de sécurité qu'il faudra boucher en urgence,
peut être trop pénible pour l'administrateur système. L'idée de ce RFC
est donc de séparer l'opération en deux :
l'authentification est faite sur un serveur,
typiquement le premier MTA du site (cf. annexe
D pour une discussion de ce choix), celui-ci
ajoute au message un en-tête indiquant le résultat de ladite
authentification et le MUA (ou bien le MDA,
voir la section 1.5.3 pour un bon rappel sur ces concepts) peut ensuite, par exemple par un langage de
filtrage comme procmail ou
Sieve, agir sur la base de ce résultat. Cet
en-tête marche pour tous les protocoles d'authentification et surpasse
donc les en-têtes spécifiques comme le
Received-SPF: de SPF (section
1 du RFC et notamment section 1.4 pour le filtrage, qui n'est
pas obligatoire).
J'ai utilisé le terme de « site » pour désigner un ensemble de
machines gérées par la même organisation mais le RFC a un terme plus
rigoureux, ADMD (ADministrative Management
Domain). La frontière d'un ADMD est la « frontière de confiance » (trust boundary),
définie en section 1.2. Un domaine administratif de gestion est un
groupe de machines entre lesquelles il existe une relation de
confiance, notamment du fait que, à l'intérieur de l'ADMD, l'en-tête
Authentication-Results: ne sera pas modifié ou
ajouté à tort (section 1.6 : l'en-tête n'est pas protégé, notamment il
n'est pas signé). Un ADMD inclus typiquement une organisation (ou un
département de celle-ci) et d'éventuels sous-traitants. Il a un nom,
l'authserv-id, défini en section 2.2.
L'en-tête Authentication-Results: lui-même est formellement défini en section 2. Il
appartient à la catégorie des en-têtes de « trace » (RFC 5322, section 3.6.7 et RFC 5321, section 4.4) comme
Received: qui doivent être ajoutés en haut des
en-têtes et jamais modifiés. La syntaxe de Authentication-Results: est en section
2.2. L'en-tête est composé du authserv-id, le nom
de l'ADMD et d'une série de doublets (méthode, résultat), chacun
indiquant une méthode d'authentification et le résultat obtenu. Par
exemple (tiré de l'annexe C.3), une authentification SPF réussie, au
sein de l'ADMD example.com, donnera :
Authentication-Results: example.com;
spf=pass smtp.mailfrom=example.net
Received: from dialup-1-2-3-4.example.net
(dialup-1-2-3-4.example.net [192.0.2.200])
by mail-router.example.com (8.11.6/8.11.6)
with ESMTP id g1G0r1kA003489;
Wed, Mar 14 2009 17:19:07 -0800
From: sender@example.net
Date: Wed, Mar 14 2009 16:54:30 -0800
To: receiver@example.com
La liste complète des méthodes figure dans un registre IANA (section 6).
La section 2.3 détaille l'authserv-id. C'est
un texte qui identifie le domaine, l'ADMD. Il doit donc être unique
dans tout l'Internet. En général, c'est un
nom de domaine comme
laposte.net. (Il est possible d'être plus
spécifique et d'indiquer le nom d'une machine particulière mais cette
même section du RFC explique pourquoi c'est en général une mauvaise
idée : comme les MUA du domaine n'agissent que sur les Authentication-Results: dont ils
reconnaissent l'authserv-id, avoir un tel
identificateur qui soit lié au nom d'une machine, et qui change donc
trop souvent, complique l'administration système.)
La section 2.4 explique les résultats possibles pour les méthodes
d'authentification (en rappelant que la liste à jour des méthodes et
des résultats est dans le registre IANA). Ainsi, DKIM (section 2.4.1)
permet des résultats comme pass (authentification
réussie) ou temperror (erreur temporaire au cours
de l'authentification, par exemple liée au DNS). Des résultats similaires sont possibles
pour SPF (section 2.4.3).
Notons la normalisation d'une méthode traditionnelle
d'authentification faible, le test DNS du chemin « adresse IP du
serveur -> nom » et retour. Baptisée iprev, cette
méthode, bien que bâtie sur la pure superstition (cf. section 7.11) est utilisée
couramment. Très injuste (car l'arbre des résolutions inverses du DNS,
in-addr.arpa et ip6.arpa,
n'est pas sous le contrôle du domaine qui envoie le courrier), cette
méthode discrimine les petits FAI, ce qui est sans doute un avantage
pour les gros, comme AOL qui
l'utilisent. Attention aux implémenteurs : aussi bien la résolution
inverse d'adresse IP en nom que la résolution droite de nom en adresse
IP peuvent renvoyer plusieurs résultats et il faut donc comparer des
ensembles. (Cette méthode qui, contrairement aux autres, n'avait
jamais été exposée dans un RFC, est décrite en détail dans la section
3, avec ses sérieuses limites.)
Dernière méthode mentionnée, auth (section
2.4.5) qui repose sur l'authentification SMTP
du RFC 4954. Si un MTA (ou plutôt MSA) a
authentifié un utilisateur, il peut le noter ici.
Une fois le code d'authentification exécuté, où mettre le Authentication-Results: ?
La section 4 fournit tous les détails, indiquant notamment que le MTA
doit placer l'en-tête en haut du message, ce qui facilite le repérage
des Authentication-Results: à qui on peut faire confiance (en examinant les en-têtes
Received: ; en l'absence de signature, un Authentication-Results:
très ancien, situé au début du trajet, donc en bas des en-têtes, ne
signifie pas grand'chose). On se fie a priori aux en-têtes mis par les
MTA de l'ADMD, du domaine de confiance. L'ordre est donc
important. (La section 7 revient en détail sur les en-têtes Authentication-Results: usurpés.)
Ce n'est pas tout de mettre un Authentication-Results:, encore faut-il l'utiliser. La
section 4.1 s'attaque à ce problème. Principe essentiel pour le MUA :
ne pas agir sur la base d'un Authentication-Results:, même si ce n'est que pour
l'afficher, sans l'avoir validé un minimum. Comme le Authentication-Results: n'est pas
signé, n'importe qui a pu en insérer un sur le trajet. Le RFC précise
donc que les MUA doivent, par défaut, ne rien faire. Et qu'ils doivent ne
regarder les Authentication-Results: qu'après que cela aie été activé par
l'administrateur de la machine, qui indiquera quel
authserv-id est acceptable.
Naturellement, le MTA d'entrée du domaine devrait supprimer les
Authentication-Results: portant son propre authserv-id qu'il trouve
dans les messages entrants : ils sont forcément frauduleux (section
5). (Le RFC accepte aussi une solution plus simpliste, qui est de
supprimer tous les Authentication-Results: des messages entrants, quel que soit leur
authserv-id.)
Arrivé à ce stade de cet article, le lecteur doit normalement se
poser bien des questions sur la valeur du Authentication-Results:. Quel poids lui
accorder alors que n'importe quel méchant sur le trajet a pu ajouter
des Authentication-Results: bidons ? La section 7, consacrée à l'analyse générale de la
sécurité, répond à ces inquiétudes. 7.1 détaille le cas des en-têtes
usurpés. Les principales lignes de défense ici sont le fait que le MUA
ne doit faire confiance aux Authentication-Results: que s'ils portent le
authserv-id de son ADMD et
le fait que le MTA entrant doit filtrer les Authentication-Results: avec son
authserv-id. Comme l'intérieur de l'ADMD, par
définition, est sûr, cela garantit en théorie contre les Authentication-Results:
usurpés. Le RFC liste néanmoins d'autres méthodes possibles comme le
fait de ne faire confiance qu'au premier Authentication-Results:
(le plus récent), si on sait que le MTA en ajoute systématiquement un
(les éventuels Authentication-Results: usurpés apparaîtront après ; mais certains
serveurs les réordonnent, cf. section 7.3).
Comme toujours en sécurité, il faut bien faire la différence entre
authentification et
autorisation. Un spammeur a
pu insérer un Authentication-Results: légitime pour son
authserv-id. Même authentifié, il ne doit pas
être considéré comme une autorisation (section 7.2).
Plusieurs mises en œuvre de ce système existent déjà comme dans Mdaemon, sendmail, etc. De même, Gmail met désormais systématiquement cet en-tête, par exemple :
Authentication-Results: mx.google.com; spf=pass \
(google.com: domain of stephane@sources.org designates 217.70.190.232 \
as permitted sender) smtp.mail=stephane@sources.org
Comme indiqué plus haut, le RFC désormais officiel pour cet en-tête est, depuis septembre 2013, le RFC 7001. Il ne contient que peu de changements.
L'article seul
Programmation réseau avec des prises brutes, en IPv4 et en IPv6
Première rédaction de cet article le 16 avril 2009
Dernière mise à jour le 20 avril 2009
De nombreuses applications réseau nécessitent de contrôler
étroitement le contenu du paquet IP, y compris les parties qui ne
sont normalement pas accessibles aux applications. Cela peut se faire
en C
avec des appels adéquats à
setsockopt() mais, si on veut
vraiment changer la plus grande partie du paquet, il peut être plus
simple de fabriquer un paquet IP entièrement « à la main » en
utilisant des prises
brutes (en anglais raw
sockets). Voyons comment on fait en IPv4 et si c'est
possible en IPv6.
Un petit avertissement, cher lecteur, ce qui suit est d'assez bas
niveau, au sens de « proche de la
machine ». L'API des prises offre des mécanismes de programmation bien
plus simples que les prises brutes. Même si on veut changer une partie
de l'en-tête, par exemple le champ TTL, il existe des techniques
plus simples à base de
setsockopt(). Avec les prises
brutes, au contraire, le noyau ne fera plus
grand'chose pour vous, vous allez devoir vous débrouiller seul
(prononcer le tout avec une voix sépulcrale). Considérez vous mis en
garde.
D'abord, le principe, tel qu'illustré depuis de nombreuses années
par les applications qui ont besoin d'accéder à ces fonctions de bas
niveau, comme traceroute. On déclare la prise
de type SOCK_RAW, de protocole
IPPROTO_RAW et, pour bien dire au
noyau qu'on se charge de tout, on utilise
l'option IP_HDRINCL de setsockopt :
int on = 1; ... sd = socket(result->ai_family, SOCK_RAW, IPPROTO_RAW); setsockopt(sd, IPPROTO_IP, IP_HDRINCL, (char *) &on, sizeof(on));
Ensuite, on crée une structure pour représenter le paquet IP (ici, on utilisera UDP) :
struct opacket4 {
struct ip ip; /* 'struct ip' est une représentation en C
d'un paquet IP, déclarée dans <netinet/ip.h> */
struct udphdr udp;
char payload[MSGSIZE];
} __attribute__ ((packed)); /* La directive 'packed' s'assure que le
compilateur ne laissera pas d'espace entre les champs */
...
struct opacket4 op4; /* Output Packet of IP version 4 */
/* S'assurer que tout est à zéro au début */
memset(&op4.ip, '\0', sizeof(op4.ip));
Enfin, on peuple cette structure à sa guise, en lisant le RFC 791 pour savoir ce qu'il faut mettre :
op4.ip.ip_v = 4; /* Version */
op4.ip.ip_hl = sizeof(op4.ip) >> 2; /* Taille des en-têtes (en IPv4,
elle est variable) */
op4.ip.ip_dst = ... (un champ sin_addr...)
/* Sur Linux, l'adresse source, op4.ip.ip_src, est mise
automatiquement, même pour une prise brute */
op4.ip.ip_p = SOL_UDP; /* Protocole de transport utilisé */
op4.ip.ip_ttl = 1; /* Limite à un seul saut */
headersize = sizeof(op4.ip) + sizeof(op4.udp);
packetsize = headersize + strlen(message);
op4.ip.ip_len = htons(packetsize);
On fait pareil pour la partie UDP et on peut alors envoyer le paquet :
sendto(sd, &op4, packetsize, 0, result->ai_addr,
result->ai_addrlen);
Le programme complet qui met en œuvre cette technique s'utilise ainsi :
# ./send-udp -v --port 5354 192.168.2.1 Connecting to 192.168.2.1... Sending 42 bytes (28 for the headers)...
et, vu avec tcpdump, cela donne bien le résultat attendu :
13:55:12.241391 IP (tos 0x0, ttl 1, id 44977, offset 0, flags [none], \
proto UDP (17), length 42) 192.168.2.2.5354 > 192.168.2.1.5354: \
[no cksum] UDP, length 14
L'adresse source a été mise seule mais le programme a une option pour la forcer :
# ./send-udp -v --port 5354 --source 192.0.2.1 192.168.2.1 Connecting to 192.168.2.1... Sending 42 bytes (28 for the headers)...
qui donne :
13:55:24.815620 IP (tos 0x0, ttl 23, id 45015, offset 0, flags [none], \
proto UDP (17), length 42) 192.0.2.1.5354 > 192.168.2.1.5354: \
[no cksum] UDP, length 14
Il existe quelques pièges, par exemple le fait que la somme de contrôle de l'en-tête IP (cf. RFC 791) n'est pas forcément remplie automatiquement (ça dépend du noyau utilisé) et qu'il peut donc être nécessaire de la calculer soi-même. Je l'ai dit, avec les prises brutes, il faut penser à tout.
OK, ça, c'était pour IPv4. Et en
IPv6 ? Eh bien, c'est plus compliqué. Pour des
raisons exposées dans la section 1 du RFC 3542, l'option
IP_HDRINCL n'est pas garantie en IPv6. La
démarche « normale » est d'utiliser les techniques dudit RFC, à base
de setsockopt et de renoncer aux prises brutes
(attention, le RFC utilise, en sa section 3, le terme de raw sockets
quand même, pour désigner les prises où un appel à
setsockopt a permis de modifier certains
champs). (La section 5 du RFC 3542 propose une autre approche
dite d'ancillary data.)
Si on veut quand même faire de la prise brute en IPv6, il n'y a que
des solutions non portables. On peut se servir du
BPF (où on peut modifier tout ce qui est au
dessus de la couche 2, option PF_PACKET de
socket(), cf. packet(7)) ou bien utiliser les prises brutes comme en IPv4, sur les systèmes où ça marche,
typiquement Linux.
(Mathieu Peresse me fait remarquer que, sur Linux, « après examen du code du noyau, pour IPv4, créer une RAW socket IPv4 avec IPPROTO_RAW comme protocole équivaut exactement à créer une socket RAW IPv4 et mettre l'option IP_HDRINCL à 1 (la fonctionnalité d'inclure le header est en fait activée en mettant le membre "hdrincl" de la structure "inet_sock" à 1)... ».)
Sur FreeBSD et
NetBSD, IP_HDRINCL ne
marche tout simplement pas (cf. http://lists.freebsd.org/pipermail/freebsd-pf/2006-May/002174.html).
Le programme indiqué plus
haut marche donc également en IPv6 mais sur Linux
uniquement. La prise est créée avec exactement les mêmes options qu'en
v4, la
configuration en vraie prise brute est légèrement différente, on n'utilise pas IP_HDRINCL, juste le type IPPROTO_RAW.
Et les structures de données sont proches :
struct opacket6 {
struct ip6_hdr ip;
struct udphdr udp;
char payload[MSGSIZE];
} __attribute__ ((packed));
struct opacket6 op6;
sauf que cette fois, il faut lire le RFC 2460 en les remplissant (des champs comme Protocol ou TTL n'ont pas le même nom, car leur sémantique est légèrement différente) :
memset(&op6.ip, '\0', sizeof(op6.ip));
op6.ip.ip6_vfc = 6 << 4; /* Les quatre premiers bits stockent la
version, ici 6 */
op6.ip.ip6_dst = sockaddr6->sin6_addr;
op6.ip.ip6_nxt = SOL_UDP;
op6.ip.ip6_hlim = TTL;
headersize = sizeof(op6.ip) + sizeof(op6.udp);
packetsize = headersize + strlen(message);
op6.ip.ip6_plen = htons((uint16_t) packetsize);
Par défaut, si la machine visée a des adresses v4 et v6,
il utilise la politique de préférence du système (celle qui, sur
Linux, se règle dans /etc/gai.conf) , mais on
peut la forcer avec les options -4 et
-6. tcpdump voit :
14:07:52.030339 ::.5354 > 2a01:e35:8bd9:8bb0:a00:20ff:fe99:faf4.5354: \
UDP, length: 14 (len 62, hlim 1)
On note que l'adresse source n'a pas été mise automatiquement, en
IPv6. Elle reste donc à zéro (::, qui veut dire
« adresse indéfinie »). Si on la force :
14:08:29.745203 2001:db8::1.5354 > 2a01:e35:8bd9:8bb0:a00:20ff:fe99:faf4.5354: \
UDP, length: 14 (len 62, hlim 1)
Merci à Mathieu Peresse et à Yves Legrand-Gérard pour leur aide. Outre le RFC, on peut aussi trouver une bonne explication en français de l'API dans le livre de Gisèle Cizault.
L'article seul
Pourquoi pas d'attributs booléens dans les normes du W3C ?
Première rédaction de cet article le 16 avril 2009
Dernière mise à jour le 17 avril 2009
Une question me titille : dans plusieurs (toutes ?) normes du
W3C, un attribut prend une valeur qui est le
nom de l'attribut, plutôt qu'un booléen. Deux
exemples : en CSS, l'attribut
border-collapse (pour fusionner les bordures de
deux cellules contiguës d'un tableau) s'utilise :
border-collapse: collapse;
alors que :
border-collapse: true;
me semblerait plus logique. De même, en XHTML, on indique le bouton radio sélectionné avec :
<input checked="checked" type="radio" name="operator" value="OR" />
alors que j'aurai préféré :
<input checked="true" type="radio" name="operator" value="OR" />
Existe t-il une raison à cette absence de booléens ?
Daniel Dardailler me signale que les booléens ont un défaut : ils
ne sont pas extensibles. Si on a un type booléen, on ne pourra pas
rajouter de troisième valeur par exemple une apparence spéciale pour
dire que le bouton est délibérement désactivé. Donc, plutôt que
true et false, il vaudrait
peut-être mieux :
<input checked="on" type="radio" name="operator" value="OR" />
où on et off n'empêcheraient
pas d'ajouter disabled par la suite.
Bert Bos ajoute que, si un jour on décide de combiner plusieurs
propriétés dans un super-propriété (ce qui est courant en CSS sous le
nom de shorthand, par exemple
background intègre plusieurs propriétés comme
background-color,
background-image, etc), on risque moins
d'ambiguïté. Par exemple, si un jour on veut une propriété
table-handling comme abréviation pour
table-layout, empty-cells et
border-collapse, on peut sans problème écrire
table-handling: fixed collapse (qui implique donc
aussi show) mais pas table-handling:
true false ce qui serait peu clair.
Sur le cas de XHTML (mais cela n'explique pas celui de CSS), Éric
van der Vlist note que la valeur checked était
déjà là du temps de HTML / SGML. En effet,
avant XHTML, on aurait écrit :
<INPUT CHECKED TYPE=radio ...>
où CHECKED n'est pas le nom de l'attribut mais sa
valeur (oui, c'est déroutant mais c'est vrai, cf. l'article
du W3C sur les liens entre HTML et SGML, le
livre de Martin Bryan qui explique SGML et HTML et
une
longue discussion sur ce problème des boutons radio).
Merci à Éric van der Vlist, Bert Bos et Daniel Dardailler pour leurs intéressantes informations.
L'article seul
Pour tester, il faut utiliser une commande d'une ligne, rappelable
Première rédaction de cet article le 15 avril 2009
À chaque fois que je donne des cours d'administration système et réseaux sur Unix (par exemple pour les FFTI), je suis surpris de voir que beaucoup d'étudiants, pour tester leur serveur de messagerie qu'ils viennent de configurer, utilisent un MUA interactif et graphique (comme Thunderbird) où beaucoup de clics sont nécessaires avant d'avoir pu envoyer le message. En fait, le test leur prend plus de temps que le changement de configuration qu'ils voulaient tester. Utiliser une commande d'une ligne, facilement rappelable avec la flèche vers le haut, ce que permettent tous les shells, leur faciliterait pourtant beaucoup la vie.
Autre exemple, pris sur une liste de diffusion, un conseil donné à quelqu'un qui devait tester son Postfix : utiliser, certes, la traditionnelle commande Unix mail mais en tapant un contenu du message (terminé par un point) à chaque fois. C'est presque aussi compliqué que d'utiliser un MUA graphique. Comme le courrier ne va pas marcher du premier coup, il faudra sans doute refaire le test plusieurs fois, ce qui est peu compatible avec ce mode interactif.
La bonne méthode est de fabriquer une commande d'une seule ligne, qu'on pourra rappeler avec la fonction de rappel du shell (typiquement la flèche vers le haut), autant de fois qu'il faut. Ici, par exemple, on peut utiliser :
echo Test | mail -s "Essai" user@example.org
Cette méthode simplifie la vie du testeur : il n'a que deux touches
à taper (flèche vers le haut et <Entrée>)
pour refaire un test. Elle permet en outre d'utiliser des variables
qui peuvent être bien pratiques lors de l'examen du courrier envoyé,
par exemple :
echo Test | \
mail -s "Essai depuis le processus $$, utilisateur $(id -u)" \
user@example.org
Autre avantage : si on demande de l'aide sur une liste de diffusion ou un forum Web, il sera plus facile d'indiquer la commande réellement effectuée pour le test (beaucoup de messages sur de tels forums sont inutilisables car le questionneur a juste dit « Ça ne marche pas » au lieu de reproduire littéralement et intégralement la commande tapée et le résultat obtenu).
Mais il y a une autre raison pour laquelle la technique de la commande sur une ligne est préférable, une raison sans doute plus importante que la seule facilité de frappe. Les actions menées interactivement sont difficiles à reproduire. Si on est lancé dans un cycle essai -> modification des paramètres -> nouvel essai, il est primordial que les essais soient absolument identiques, pour qu'on ne fasse pas varier à la fois la configuration et le test. C'est un principe de base de la méthode scientifique. L'informatique étant une science expérimentale, suivre cette méthode est nécessaire.
J'ai vu souvent des stagiaires croire que la modification qu'ils venaient d'appliquer à leurs fichiers de configuration avait provoqué un changement, alors qu'ils s'étaient simplement trompés en essayant de reproduire le test. Avec une commande d'une seule ligne, qu'on rappelle à l'identique, on a la garantie que le test ne change que si on le veut explicitement.
Bien sûr, ce conseil ne s'applique pas qu'à la mise au point des serveurs de messagerie. Les serveurs Web sont également concernés. Il ne faut évidemment pas les tester avec un navigateur (je parle bien de la configuration du serveur HTTP, pour le contenu de la page, HTML et CSS, c'est évidemment différent), outil lent, lourd et qui fait bien des choses sans le dire, rendant le test plus difficile à interpréter. Les meilleurs outils de mise au point sont des programmes en ligne de commande comme curl et wget. Par exemple, avec wget :
wget -O /dev/null http://www.example.org/
teste http://www.example.org/ sans sauvegarder la
page (option -O ou, en version longue, --output-document). Parmi les choses qu'affiche
wget par défaut, le code de statut HTTP (200 si tout va bien) tel que
normalisé dans le RFC 7231. Si on veut
davantage de détails, on peut utiliser l'option
-S (ou, en version longue,
--server-response) qui affiche tous les en-têtes
HTTP. Mais attention : un test trop bavard n'est pas une bonne idée
car l'information importante risque d'être noyée au milieu de tout ce qui est affiché.
Autre logiciel de test de serveurs HTTP, curl :
curl http://www.example.org/ > /dev/null
Cette commande n'affiche pas le code de retour mais on peut changer cela :
curl --write-out 'HTTP status: %{http_code}\n%{size_download} bytes downloaded\n' \
http://www.example.org/ >
curl va alors écrire le code de statut HTTP et le nombre d'octets transférés.
L'article seul
Meridian, un mécanisme pour trouver le pair le plus proche
Première rédaction de cet article le 14 avril 2009
Le développement formidable des techniques pair-à-pair a apporté d'immenses possibilités et des défis nouveaux. Par exemple, si une machine peut potentiellement demander un service à 10 000 pairs, lequel utiliser ? Le plus proche, évidemment mais comment définir « le plus proche » ? Certainement pas par la proximité géographique qui, sur l'Internet, n'est qu'un indicateur très grossier. Et, une fois cette notion de proximité définie, comment la mesurer de manière qui supporte le passage à l'échelle ? Utiliser ping avec chacun des 10 000 pairs prendrait un temps fou et serait très coûteux en ressources réseau.
Meridian intervient ici. Ce protocole, mis au point par Bernard Wong, Aleksandrs Slivkins et Emin Gün Sirer de l'université Cornell, est une approche du problème de la mesure par le biais de requêtes qui sont transmises à des machines de plus en plus proches de la « cible » jusqu'à localiser la plus proche. Il est décrit dans Meridian: A Lightweight Network Location Service without Virtual Coordinates. Meridian est un concurrent des systèmes de coordonnées Internet. Il est moins général mais est censé être moins coûteux en ressources.
Le principe est que chaque nœud Meridian :
- Organise ses pairs, les autres nœuds Meridian qu'il connait, en un ensemble d'anneaux concentriques, selon leur distance. Les plus proches sont dans l'anneau interne, les plus éloignés sont dans le dernier anneau, qui englobe tout l'« univers » restant.
- Lorsqu'il reçoit une requête, la fait suivre aux pairs dont la distance à l'objectif est « proche » (le facteur de proximité, noté β dans l'article, est réglable) de celle qu'il mesure lui-même. La requête sera ensuite formellement transférée au pair qui signalera la plus faible distance avec l'objectif. Celui-ci fera de même et on arrivera donc rapidement dans un anneau interne, plus peuplé et donc plus précis. On « zoomera » ainsi vers une précision de plus en plus grande, un peu comme le font des DHT comme Chord.
Contrairement aux systèmes de coordonnées euclidiennes, Meridian n'a donc pas besoin d'amers fixes.
Pour échanger avec ses pairs l'information qui va permettre de maintenir le réseau de machines Meridian, chaque nœud va utiliser un protocole de bavardage.
L'article original ne semble pas donner beaucoup de détail sur la faon dont Meridian mesure la distance entre pairs. Il utilise probablement une simple mesure de RTT, une métrique imparfaite mais simple.
Une mise
en œuvre de Meridian écrite en C++
est disponible sous une licence libre. Une des applications pratiques de Meridian est
ClosestNode, une passerelle entre le DNS et Meridian. Les services
accessibles sur Internet via un nom de domaine peuvent s'enregistrer
auprès de ClosestNode et celui-ci renverra au client DNS
l'adresse IP du serveur le plus proche de
lui. Testez avec dig en cherchant l'adresse IP
de proxy.cob-web.org pour un exemple de
ClosestNode en action. ClosestNode est décrit dans le bref
article ClosestNode.com: An
Open-Access, Scalable, Shared Geocast Service for Distributed
Systems. Reposant sur le DNS, il évite donc aux
clients d'avoir à parler le protocole Meridian.
L'article seul
Fiche de lecture : Dictionnaire des mots nés de la mer
Auteur(s) du livre : Pol Corvez
Éditeur : Chasse-marée/Glénat
978.2.3535.7007.2
Publié en 2007
Première rédaction de cet article le 13 avril 2009
Dernière mise à jour le 3 juillet 2009
J'aime l'étymologie, savoir d'où viennent les mots et quels voyages ils ont fait avant d'arriver en français. Et, à propos de voyages, j'aime la mer et la voile. Alors, je recommande fortement le dictionnaire de Pol Corvez, qui porte sur l'étymologie des termes marins et sur le parcours qui a amené beaucoup d'entre eux à passer dans le vocabulaire non-marin.
Chaque définition est un voyage et on peut lire tout ce dictionnaire à la suite. Ainsi, le catamaran vient du tamoul et le trimaran... a combiné une racine latine et une partie du mot tamoul. Gare est un terme fluvial à l'origine. Et le préfixe cyber, mis aujourd'hui à toutes les sauces, a une origine maritime (après avoir été originellement un terme de politique), celle du mot grec qui a donné gouvernail. (Beaucoup d'usages en informatique de termes d'origine maritime sont cités dans ce dictionnaire comme pilote ou sémaphore.)
Continuons les voyages : récif vient de l'arabe, hauban d'un mot scandinave, orient du latin et s'orienter vient de l'ancienne habitude de mettre l'Est en haut sur les cartes. Les noms propres ont également contribués et martinet vient d'un officier de marine renommé pour sa dureté.
La France maritime n'a pas été unifiée pendant la plus grande partie de son histoire et les entrées du dictionnaire font souvent la différence entre les vocabulaire de l'Atlantique et celui de la Méditerranée. Ainsi, on rame en Méditerranée quand on nage en Atlantique. Le bateau rencontre des vagues en Méditerranée et des lames en Atlantique.
L'auteur, grand défenseur du breton tend à voir des racines celtiques à beaucoup d'endroits. Mais n'est-ce pas normal pour la région qui a fourni tant de marins ?
P.S. (cela vient du latin) : Pol Corvez m'envoie les commentaires suivants avec autorisation de les publier. « Deux petites remarques : 1/ je ne suis pas "grand défenseur du breton", même si je suis Breton. En tant que linguiste, je défends toutes les langues ; 2/ je ne pense pas outrepasser les données étymologiques sérieuses quand je pense qu'un terme vient du breton ou d'une autre langue celtique. Il est évident que si vous en croyez Alain Rey, seuls une trentaine de termes proviennent du celtique. Cela est une aberration totale : comment un substrat linguistique tel que le celte aurait pu s'effacer de la sorte après des siècles d'usage courant ? Il s'agit pour certains étymologistes d'une idéologie romaniste, qui est de plus en plus contestée par les chercheurs, qui s'accordent de plus en plus à dire que le français est un métissage de roman, de germanique et de celtique mâtiné d'arabe (et de grec pour le lexique savant). Je pense avoir eu l'honnêteté intellectuelle d'avouer mes doutes quand j'en avais du point de vue étymologique ou historique. »
L'article seul
RFC 1305: Network Time Protocol (Version 3) Specification, Implementation
Date de publication du RFC : Mars 1992
Auteur(s) du RFC : David L. Mills (University of Delaware, Electrical Engineering Department)
Chemin des normes
Première rédaction de cet article le 10 avril 2009
Dans tout système technique complexe, comme l'Internet, on a besoin d'horloges correctes. À tout moment, on lit l'heure et on en tient compte. Par exemple, l'ingénieur système qui lit les journaux d'un serveur a besoin d'être sûr de l'heure qu'ils indiquent. De même, le chercheur qui mesure le temps de propogation d'un paquet IP entre deux machines en soustrayant le temps de départ de celui d'arrivée (cf. RFC 7679) doit être sûr des horloges des deux machines, sinon la mesure sera fausse. Pour synchroniser des horloges, on pourrait munir chaque ordinateur connecté à Internet d'un récepteur GPS ou équivalent. Mais de tels récepteurs sont relativement chers (surtout pour les engins les moins puissants comme les PC bas de gamme ou les téléphones portables) et ne marchent pas dans toutes les circonstances (le GPS ne fonctionne bien qu'en plein air). Le mécanisme privilégié sur l'Internet est donc que seules certaines machines sont connectées à une horloge physique correcte et que les autres d'ajustent sur celles-ci, par le biais du protocole NTP, objet de ce RFC.
A priori, synchroniser une machine C sur une autre, nommée S, est simple : C demande l'heure à S et S lui donne. C'est ainsi que fonctionnait le protocole Time du RFC 868. Mais ce mécanisme a un gros défaut : il ne tient pas compte du temps de propagation dans le réseau. Lorsque C reçoit la réponse, elle n'est déjà plus correcte... La résolution d'horloge qu'on peut obtenir est donc limitée par ce temps de propagation. En outre, les algorithmes tels que celui du RFC 868 ne permettent pas de tirer profit de multiples serveurs de temps puisqu'ils ne fournissent aucun moyen de décider quel est le « meilleur » serveur.
Pour expliquer la synchronisation d'horloge, tout un vocabulaire
spécifique est nécessaire. Il n'y a pas de glossaire
dans le RFC mais des mots come delay et offset sont définis en section
2 : pour résumer, une horloge peut avoir
un écart (offset) avec le
« vrai » temps, UTC (ou bien avec une autre
horloge, si on s'intéresse juste au fait qu'elles soient
synchronisées, ce qui n'est pas le cas de NTP). Si cet écart est
inférieur à une certaine valeur, on dit que l'horloge est
correcte (accurate). Et
l'horloge peut avoir un décalage
(skew), elle peut avancer plus ou moins vite qu'une autre
(ce qui entrainera l'apparition ou l'aggravation d'un écart). Pire, la
dérive peut être variable, auquel cas on mesure la dérivée seconde du
décalage sous le nom de dérive
(drift, mais NTP ignore ce facteur). Enfin, l'horloge a une certaine
résolution (precision), la
plus petite unité de temps qu'elle peut mesurer.
Des problèmes de mesure de temps analogues sont présents dans bien
d'autres RFC notamment le RFC 2330 mais aussi
les RFC 4656 ou RFC 5481. Pour obtenir le temps d'un
autre serveur, alors que le délai de propagation est non-nul, NTP
utilise des estampilles temporelles, des valeurs
de la mesure de l'horloge, mises dans le paquet. Après plusieurs
paquets échangés, chaque serveur NTP connait le délai de propagation
avec un autre serveur (ainsi que, au bout d'un temps un peu plus long,
la gigue, la variation de ce délai, suite aux
hoquets du réseau) et peut donc déduire ce délai des temps mesurés par
son pair. Sur une machine Unix, voyons ce que cela donne avec la commande ntpq -c peers :
% ntpq -c peers
remote refid st t when poll reach delay offset jitter
==============================================================================
+relay1.nic.fr 192.134.4.11 3 u 998 1024 377 0.297 -1.554 0.163
gw.prod-ext.pri .INIT. 16 u - 1024 0 0.000 0.000 0.000
+obelix.gegeweb. 145.238.203.10 3 u 695 1024 377 5.226 0.586 1.768
-ntp.univ-poitie 224.22.30.230 3 u 498 1024 377 6.885 -4.565 0.267
*ns1.azuria.net 193.67.79.202 2 u 56 1024 377 2.739 -1.411 0.305
-rps.samk.be 193.190.198.10 3 u 984 1024 377 5.293 5.930 0.317
Lorsque plusieurs serveurs NTP sont accessibles, NTP sélectionne le meilleur (en tenant compte de divers paramètres comme justement la gigue). Il n'y a pas de vote entre serveurs, NTP est une dictature où le meilleur serveur a toujours raison.
Comme norme, NTP est très stable, et n'avait pas bougé entre cette
version 3 et la version 4, apparue dix-huit ans plus tard dans le RFC 5905. La version 2 était décrite dans le RFC 1119 et les différences (aucune n'est essentielle) entre les
deux versions sont décrites dans l'annexe D. La version 3 a surtout
amélioré les divers algorithmes de traitement des données, sans
changer le modèle, et en changeant à peine le protocole. (La première
version de NTP était dans le RFC 958.) NTP n'était pas le
premier protocole de synchronisation d'horloge, loin de là. Il a été
précédé par daytime (RFC 867) ou
time
(RFC 868), ainsi que par des options d'ICMP comme celle
du RFC 781. Il y a également eu des mises en œuvre non
normalisées comme le démon
timed sur Berkeley Unix. NTP a aussi été inspiré par
le protocole DTS, partie du système DCE mais,
contrairement à DTS, il n'impose pas que toutes les machines
participantes dépendent du même administrateur. Enfin, il y a eu
d'innombrables projets de recherche sur des thèmes bien plus ambitieux
comme la détermination de la justesse ou de la fausseté d'une horloge,
problèmes que NTP n'essaie pas de traiter. Voir la section 1.1 pour
plus de détails sur ces autres techniques. Enfin, la version 4 de NTP,
on l'a dit, a été publiée en juin 2010 dans le RFC 5905, sans qu'elle change fondamentalement les principes du
protocole.
Le problème de la synchronisation d'horloges est très complexe et plein de détails difficiles. Le RFC 1305 est donc un des plus gros RFC qui soit (plus de cent pages). En outre, l'abondance des formules mathématiques, rares dans les RFC mais nécessaires ici à cause des calculs d'erreur, fait que notre RFC n'est pas uniquement disponible en texte brut. S'il y a bien une version dans ce format, l'auteur prévient qu'il est recommandé de lire la version PDF, disponible au même endroit. Elle est la seule à disposer des équations mais aussi de la pagination. Enfin, le caractère plus « scientifique » de ce RFC fait que la section 7, les références, est spécialement longue et évoque plus un article de physique qu'une norme TCP/IP. Le lecteur pressé a sans doute intérêt à lire plutôt l'article de David Mills (l'auteur du RFC), Internet Time Synchronization: the Network Time Protocol qui reprend le plan du RFC mais en omettant les détails (attention, cet article ne décrit que la version 2 de NTP mais les différences ne sont pas vitales). Autrement, la page Web dudit auteur, propose plein d'informations sur NTP.
La section 2 décrit le modèle utilisé. NTP considère que certaines machines ont l'information correcte (par exemple parce qu'elles l'ont obtenu d'une horloge sûre) et que le seul problème est de transmettre cette information aux autres machines. NTP ne s'essaie pas à déterminer si les serveurs ont raison ou tort, il leur fait confiance, il n'existe pas de système de vote, NTP n'est pas une démocratie. Certaines machines ont raison et les autres s'alignent.
Communiquant avec un serveur, un client NTP détermine l'écart (clock offset) avec ce serveur, le RTT (roundtrip delay) et la dispersion, qui est l'écart maximal avec l'autre horloge.
Pour cette communication, il existe plusieurs mécanismes (section 2.1), le plus courant étant un mécanisme client/serveur où le client NTP demande au serveur le temps. Celui-ci répond et l'information contenue dans le paquet permettra au client de déterminer les valeurs ci-dessus, notamment l'écart. En fait, NTP est plus compliqué que cela car il existe plusieurs niveaux de serveurs et chaque client utilise plusieurs serveurs, pour se prémunir contre une panne. La proximité d'un serveur avec une « vraie » horloge est mesurée par un nombre, la strate (section 2.2), qui vaut 1 lorsque le serveur est directement connecté à l'horloge et N+1 lorsque le serveur est coordonné avec un serveur de strate N.
Le serveur calcule ensuite (par une variante de l'algorithme de Bellman-Ford), le chemin le plus court (en utilisant comme métrique le nombre d'étapes et la strate), et c'est par celui-ci que sera transmise la valeur correcte de l'horloge (je le répète, NTP ne fait pas de pondération entre les serveurs possibles, sauf dans le cas particulier décrit dans l'annexe F, une nouveauté de la version 3 de NTP).
La section 3 décrit le protocole. La plus importante information transportée par NTP est évidemment le temps, exprimé sous forme d'un doublet. La première partie du doublet est un nombre sur 32 bits qui indique le nombre entier de secondes depuis le 1er janvier 1900 (section 3.1). La seconde est la partie fractionnaire de cette même valeur. Cela assure donc une précision d'environ 200 picosecondes. Comme tout le fonctionnement de NTP dépend de la précision de ces estampilles temporelles, le RFC recommande que leur écriture dans les paquets soit, autant que possible, fait dans les couches les plus basses, par exemple juste au dessus du pilote de la carte réseau.
32 bits n'est pas énorme et la valeur maximale sera atteinte en 2036. Les programmes devront donc s'adapter et faire preuve d'intelligence en considérant qu'un nombre de secondes très faible signifie « un peu après 2036 » et pas « un peu après 1900 ». Plus drôle, comme la valeur zéro est spéciale (elle signifie que le temps n'est pas connu), pendant 200 picosecondes, au moment de la transition, NTP ne marchera plus.
Pour son bon fonctionnement, NTP dépend de certaines variables, décrites en section 3.2. Il y par exemple l'adresse IP du pair mais aussi :
- leap indicator qui indique si une seconde intercalaire est imminente,
- la strate (1 si le serveur a une horloge, de 2 à 255 autrement),
- la précision de son horloge,
- un identifiant sur quatre octets, typiquement une chaîne de caractères pour un serveur de strate un, par exemple GPS pour le GPS, ATOM pour une horloge atomique ou LORC pour le bon vieux LORAN,
- temps d'aller-retour lors de la communication avec le pair,
- etc.
L'identifiant du type d'horloge est indiqué dans la sortie de
ntpq -c peers si le pair est de strate 1, ou bien
par la commande ntptrace sous le nom
de refid. Par exemple, ici,
clock.xmission.com est synchronisé au GPS :
% ntptrace localhost: stratum 3, offset 0.000175, synch distance 0.072555 tock.slicehost.net: stratum 2, offset 0.000658, synch distance 0.057252 clock.xmission.com: stratum 1, offset 0.000010, synch distance 0.000274, refid 'GPS'
NTP peut fonctionner selon plusieurs modes (section 3.3), en client ou en serveur
mais aussi en mode diffusion (un serveur qui
envoie ses données que quelqu'un écoute ou pas). Ainsi, avec le
programme ntpd (voir http://support.ntp.org/) d'Unix, si on
configure dans /etc/ntp.conf :
broadcast 224.0.0.1
(où l'adresse est celle de diffusion) ntpd va diffuser ses informations à tout le réseau local. Si on met :
broadcastclient
il écoutera passivement les annonces des serveurs qui diffusent. Si enfin, on écrit :
server ntp1.example.net server ntp2.example.net
il cherchera activement à se connecter aux serveurs
ntp1.example.net et
ntp2.example.net pour obtenir d'eux des
informations sur l'heure qu'il est. Les deux serveurs établiront alors
une association entre eux.
NTP peut se défendre contre un pair qui enverrait des informations aberrantes mais il ne contient pas de système de vote qui pourrait protéger contre des pairs malveillants. Même avec un tel système, si tous les pairs participaient d'un commun accord à l'attaque, NTP serait alors trompé. Il faut donc s'assurer que les pairs sont bien ceux qu'on croit. La section 3.6 (et l'annexe C) décrit les contrôles d'accès qu'on peu utiliser. En pratique, cette sécurité est peu pratiquée ; bien que fausser l'horloge d'une machine puisse avoir de sérieuses conséquences pour la sécurité (journaux avec une heure fausse, par exemple), les attaques sur NTP semblent rares. La principale protection reste le filtrage au niveau du pare-feu.
La section 4 décrit les algorithmes de correction qui permettent de réparer dans une certaine mesure les erreurs des horloges, ou bien celles introduites par la propagation dans le réseau. NTP peut aussi bien filtrer les mesures d'une horloge donnée (en ne gardant que les meilleures) que garder les bonnes horloges parmi l'ensemble des pairs accessibles. C'est une des parties les plus mathématiques du RFC, et qui justifie de lire la version PDF.
La précision obtenue avec NTP dépend évidemment de la précision de l'horloge locale. La section 5 décrit la conception d'une horloge telle qu'utilisée dans le système Fuzzball et permettant d'atteindre les objectifs de NTP.
Le format effectif des paquets apparait dans l'annexe A. Les paquets NTP sont transportés sur UDP, port 123. Chaque message indique le mode de l'émetteur (par exemple client, serveur ou autre), les différentes estampilles temporelles (heure de réception du paquet précédent Receive Timestamp, heure d'émission de celui-ci Transmit Timestamp, etc), précision de l'horloge locale, etc. Les estampilles temporelles sont indiquées dans le format à 64 bits décrit plus haut. Leur usage est décrit en section 3.4. Du fait que chaque paquet contienne toutes les estampilles nécessaires, les paquets sont auto-suffisants. Il n'est pas nécessaire qu'ils arrivent dans l'ordre, ni qu'ils soient tous délivrés (d'où le choix d'UDP comme protocole de transport).
Pour observer NTP en action, on peut utiliser tcpdump :
# tcpdump -vvv udp and port 123
tcpdump: listening on eth0, link-type EN10MB (Ethernet), capture size 96 bytes
17:11:46.950459 IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], proto UDP (17), length 76) munzer.bortzmeyer.org.ntp > tock.slicehost.net.ntp: [udp sum ok] NTPv4, length 48
Client, Leap indicator: (0), Stratum 3, poll 10s, precision -20
Root Delay: 0.037567, Root dispersion: 0.082321, Reference-ID: tock.slicehost.net
Reference Timestamp: 3448017458.952901899 (2009/04/06 16:37:38)
Originator Timestamp: 3448018483.951783001 (2009/04/06 16:54:43)
Receive Timestamp: 3448018483.951863646 (2009/04/06 16:54:43)
Transmit Timestamp: 3448019506.950407564 (2009/04/06 17:11:46)
Originator - Receive Timestamp: +0.000080633
Originator - Transmit Timestamp: +1022.998624563
17:11:46.950946 IP (tos 0x10, ttl 63, id 0, offset 0, flags [DF], proto UDP (17), length 76) tock.slicehost.net.ntp > munzer.bortzmeyer.org.ntp: [udp sum ok] NTPv4, length 48
Server, Leap indicator: (0), Stratum 2, poll 10s, precision -20
Root Delay: 0.036941, Root dispersion: 0.012893, Reference-ID: clock.xmission.com
Reference Timestamp: 3448019415.234667003 (2009/04/06 17:10:15)
Originator Timestamp: 3448019506.950407564 (2009/04/06 17:11:46)
Receive Timestamp: 3448019506.951188027 (2009/04/06 17:11:46)
Transmit Timestamp: 3448019506.951214015 (2009/04/06 17:11:46)
Originator - Receive Timestamp: +0.000780425
Originator - Transmit Timestamp: +0.000806425
On voit ici que munzer.bortzmeyer.org, machine
chez Slicehost a contacté le
serveur de temps, tock.slicehost.net (le second
serveur NTP de cet hébergeur se nomme
tick.slicehost.net) en indiquant que le paquet
était émis (Transmit Timestamp à
3448019506.950407564 (soit le six avril 2009 vers
17:11:46). tock.slicehost.net répond, renvoie
cette estampille dans le champ Originator
Timestamp, indique qu'il l'a reçue à 3448019506.951188027,
soit 780 microsecondes plus tard et qu'il a répondu à
3448019506.951214015, 26 microsecondes après la réception. munzer.bortzmeyer.org, en
regardant à quelle heure il a reçu le paquet, peut en déduire le
délai d'acheminement et le décalage des deux horloges. Si le serveur venait de démarrer, toutes les estampilles sont à zéro, sauf celle de transmission :
22:39:26.203121 IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], proto UDP (17), length 76) munzer.bortzmeyer.org.ntp > tick.slicehost.net.ntp: [udp sum ok] NTPv4, length 48
Client, Leap indicator: clock unsynchronized (192), Stratum 0, poll 6s, precision -20
Root Delay: 0.000000, Root dispersion: 0.000000, Reference-ID: (unspec)
Reference Timestamp: 0.000000000
Originator Timestamp: 0.000000000
Receive Timestamp: 0.000000000
Transmit Timestamp: 3448384766.203066617 (2009/04/10 22:39:26)
Originator - Receive Timestamp: 0.000000000
Originator - Transmit Timestamp: 3448384766.203066617 (2009/04/10 22:39:26)
L'annexe E contient des passionnants détails sur les calculs de temps. Par exemple, l'annexe E.3 est consacrée à un exposé plus détaillé des divers services de synchronisation d'horloges publics, par exemples ceux du NIST, le LORAN ou le DCF77 allemand. Notez que, à l'époque de la publication du RFC, le GPS était encore en cours de déploiement.
L'annexe E.4 parle de l'organisation du temps, les calculs calendaires. (Je me permets de placer ici une petite publicité pour le livre de Reingold & Dershowitz Calendrical calculations.)
L'annexe G, chargée en mathématiques et en physique, décrit la
modélisation des horloges. En G.1.2, l'informaticien intéressé par
Unix trouvera un exposé très détaillé de
l'application de ce modèle aux horloges Unix. Les appels système
settimeofday() et
adjtime() permettent de modifier
l'horloge système, brutalement dans le premier cas et progressivement
dans le second (celui utilisé par NTP). adjtime()
prend bien soit que l'horloge ne recule jamais (si elle est en avance,
on la ralentit, mais on ne la fait pas aller en arrière).
L'annexe H est une analyse fouillée des causes d'erreurs dans la synchronisation d'horloges, aussi bien celles dues à l'horloge elle-même que celles dues à la propagation des messages dans le réseau. Ces dernières erreurs sont difficiles à caractériser car elles sont tout sauf aléatoires. (En effet, elles dépendent surtout de la taille des files d'attente dans les routeurs, puisque le temps de propagation, lui, est peu variable, cf. H.4. Les variations de taille de ces files sont assez chaotiques.)
L'annexe I plaira aux programmeurs car elle est la seule qui contient du code source, en C, mettant en œuvre certains des algorithmes décrits dans le RFC.
La mise en œuvre la plus courante de NTP, sur Unix, est celle
du serveur ntpd. Il se configure
dans le fichier /etc/ntp.conf et la documentation
complète figure en ligne sur http://doc.ntp.org/. La commande ntpdate permet une mise à jour sommaire, sans faire tourner de serveur :
# ntpdate pool.ntp.org 23 Feb 01:34:10 ntpdate[3335]: step time server 192.83.249.31 offset 2.155783 sec
Mais pour une meilleure précision, il faut un serveur tournant en
permanence (autrement, il existe une version simplifiée de NTP,
SNTP,
décrite dans le RFC 4330). Voici par exemple une station de
travail ordinaire, synchronisée au serveur NTP de son réseau,
ntp.example.org :
server ntp.example.org server 127.127.1.0 fudge 127.127.1.0 stratum 13
Les deux dernières lignes sont là pour dire à ntpd que l'horloge locale est raisonnablement stable et qu'on peut la considérer comme de strate 13. Comme on ne veut pas forcément que tout l'Internet aille ensuite noyer cette machine sous le trafic NTP et, pire, changer son horloge, on restreint souvent les possibilités de NTP à certaines actions. Par exemple :
# Exchange time with everybody, but don't allow configuration. restrict default kod notrap nomodify nopeer noquery # Local users may interrogate the ntp server more closely. restrict 127.0.0.1 nomodify
Une fois cette machine synchronisée, les commandes
ntpq et
ntptrace permettront de regarder
l'état de NTP :
% ntptrace localhost: stratum 3, offset 0.000116, synch distance 0.015000 fuzzer.example.org: stratum 2, offset 0.000149, synch distance 0.009868 192.0.2.77: timed out, nothing received ***Request timed out
Ici, le serveur de strate 1, 192.0.2.77 n'accepte pas des interrogation directes
de la part des stations, il ne répond donc pas à ntptrace.
On peut avoir plus de détails sur les pairs avec
ntpq, par exemple :
ntpq> peers
remote refid st t when poll reach delay offset jitter
==============================================================================
*fuzzer.ex 192.0.2.176 2 u 50 64 377 0.304 0.107 0.064
LOCAL(0) .LOCL. 13 l 1 64 377 0.000 0.000 0.001
ntpq> clocklist
assID=0 status=0000 clk_okay, last_clk_okay,
device="Undisciplined local clock", timecode=, poll=33834, noreply=0,
badformat=0, baddata=0, fudgetime1=0.000, stratum=13, refid=76.79.67.76,
flags=0
qui permet de voir le délai de la communication avec le serveur de strate 2 (ce délai est logiquement de zéro avec l'horloge locale, de strate 13). On peut aussi voir qu'il y a eu association :
ntpq> associations ind assID status conf reach auth condition last_event cnt =========================================================== 1 16199 9614 yes yes none sys.peer reachable 1 2 16200 9014 yes yes none reject reachable 1 ntpq> pstatus 16199 assID=16199 status=9614 reach, conf, sel_sys.peer, 1 event, event_reach, srcadr=fuzzer.example.org, srcport=123, dstadr=192.0.2.1, dstport=123, leap=00, stratum=2, precision=-20, rootdelay=1.999, rootdispersion=7.858, refid=192.0.2.176, reach=377, unreach=0, hmode=3, pmode=4, hpoll=6, ppoll=6, flash=00 ok, keyid=0, ttl=0, offset=0.116, delay=0.305, dispersion=3.077, jitter=0.015, reftime=cd848978.4d74dea3 Mon, Apr 6 2009 16:00:24.302, org=cd848a03.2ce4faea Mon, Apr 6 2009 16:02:43.175, rec=cd848a03.2ce6b9ee Mon, Apr 6 2009 16:02:43.175, xmt=cd848a03.2cd129e9 Mon, Apr 6 2009 16:02:43.175, filtdelay= 0.31 0.32 0.32 0.32 0.32 0.31 0.37 0.34, filtoffset= 0.13 0.13 0.13 0.13 0.13 0.12 0.15 0.12, filtdisp= 0.00 0.99 1.94 2.93 3.90 4.88 5.85 6.80
Ici, il n'y avait qu'une seule vraie association, de numéro 16199, avec le serveur NTP de strate 2.
Et sur un routeur Cisco ? Configurer NTP en client est simplement :
Router#config terminal Enter configuration commands, one per line. End with CNTL/Z. Router(config)#ntp server 129.237.32.2 Router(config)#^Z
Le configurer en serveur pour d'autres machines, ici en strate 10 par défaut :
Router#config terminal Enter configuration commands, one per line. End with CNTL/Z. Router(config)#ntp master 10 Router(config)#^Z
On peut alors vérifier l'état de NTP :
Router#show ntp status
Clock is synchronized, stratum 3, reference is 128.249.2.2
nominal freq is 250.0000 Hz, actual freq is 249.9961 Hz, precision is 2**16
reference time is BF454660.7CCA9683 (22:37:36.487 EDT Sat Sep 8 2001)
clock offset is 4.3323 msec, root delay is 136.28 msec
root dispersion is 37.69 msec, peer dispersion is 1.14 msec
Router#show ntp associations
address ref clock st when poll reach delay offset disp
*~128.249.2.2 192.5.41.40 2 4 64 377 76.9 5.49 0.4
-~130.218.100.5 198.72.72.10 3 33 128 377 7.1 13.13 0.6
+~129.237.32.2 192.43.244.18 2 16 64 377 44.8 3.05 0.9
+~128.118.25.3 128.118.25.12 2 48 64 377 39.7 5.50 1.4
* master (synced), # master (unsynced), + selected, - candidate, ~ configured
Tout le monde n'a pas forcément un serveur NTP chez lui, ni un
fournisseur qui lui en procure un de qualité. Il est donc pratique de
faire appel à des serveurs publics. Pour cela, le projet
pool.ntp.org
enregistre dans le DNS l'adresse IP des volontaires qui participent au
service ntp.pool.org. Il suffit au client de
mettre dans sa configuration :
server pool.ntp.org server pool.ntp.org server pool.ntp.org server pool.ntp.org
pour se synchroniser à quatre serveurs, pris au hasard parmi les volontaires. Notez bien que le fait de répéter la même ligne quatre fois n'est pas une erreur. Chacune de ces lignes va déclencher une requête DNS qui donnera à chaque fois une liste d'adresses IP dans un ordre différent :
% dig +short A pool.ntp.org 91.208.102.2 195.83.66.158 81.19.16.225 87.98.147.31 88.191.77.246 % dig +short A pool.ntp.org 88.191.77.246 91.208.102.2 195.83.66.158 81.19.16.225 87.98.147.31 % dig +short A pool.ntp.org 87.98.147.31 88.191.77.246 91.208.102.2 195.83.66.158 81.19.16.225
Pour être sûr d'avoir des adresses différentes, il suffit de préfixer les noms par un chiffre :
server 1.pool.ntp.org server 2.pool.ntp.org server 3.pool.ntp.org server 4.pool.ntp.org
Vu avec ntpq, on pourra avoir, par exemple :
% ntpq
ntpq> peers
remote refid st t when poll reach delay offset jitter
==============================================================================
ks34176.kimsufi 193.52.184.106 2 u 25d 1024 0 1.116 -4.039 0.000
*ns1.azuria.net 193.67.79.202 2 u 116 256 377 1.412 -1.931 0.647
+mail1.vetienne. 129.240.64.3 3 u 208 256 377 1.657 -18.063 3.348
+ntp1.adviseo.ne 209.81.9.7 2 u 114 256 377 1.001 -3.440 1.622
ntpq>
où des machines d'hébergeurs très différents sont utilisées, NTP
choisissant le meilleur (atteignable, proche, faible gigue, etc).
Bien sûr, pool.ntp.org n'offre aucune sécurité,
puisque rien ne dit qu'un méchant ne s'est pas glissé dans le lot dans
le but de perturber vos horloges. Mais c'est un service gratuit,
fourni par la communauté et
globalement de très bonne qualité. À noter que ceux qui réalisent un système d'xploitation peuvent demander un sous-domaine, pour y mettre par défaut leur machine. C'est ce que fait, par exemple, Debian et une machine Debian sera configurée par défaut avec quelque chose du genre :
server 0.debian.pool.ntp.org server 1.debian.pool.ntp.org server 2.debian.pool.ntp.org server 3.debian.pool.ntp.org
L'article seul
État du routage sur Internet par rapport aux registres de routes
Première rédaction de cet article le 8 avril 2009
Il n'y a quasiment que des articles intéressants sur le blog de Renesys et toute personne intéressée par BGP ou, plus généralement, par l'état de l'Internet devrait le lire régulièrement. Le dernier article, Route Hygiene: The Dirt on the Internet analyse l'état réel de la table de routage BGP globale par rapport à ce que contiennent les registres de route.
Un des charmes du routage sur l'Internet est que n'importe quel routeur BGP peut annoncer n'importe quelle route et cela permet des attaques intéressantes. Une des difficultés pour sécuriser BGP est de déterminer quel est l'état normal. Renesys reçoit la totalité des annonces BGP, les met dans une grande base de données. Ne peuvent-ils pas détecter les annonces anormales comme celle de Pakistan Telecom ? Si, ils le pourraient, s'ils savaient quelles sont les annonces normales...
En théorie, celles-ci sont stockées dans les registres de route, au format RPSL, décrit dans le RFC 2622. Mais les différents IRR sont de qualité très variables et aucun n'est 100 % correct.
L'approche de Renesys décrite dans Route Hygiene est donc de faire une moyenne des variations entre les annonces réelles et les différents IRR. Les détails figurent dans leur article mais la principale analyse est un résumé par pays. Les « pires » (ceux qui ont le plus grand écart entre les annonces réelles et celles des registres) sont la Malaisie, le Niger et la Guinée équatoriale. La Malaisie est d'autant plus mal située qu'elle a beaucoup de routes (pour les deux pays africains, qui ont peu de routes, il peut y avoir un biais statistique). Par contre, l'article félicite les « meilleurs », les îles Féroé, l'Islande et la Slovénie.
L'article seul
RFC 5540: 40 Years of RFCs
Date de publication du RFC : Avril 2009
Auteur(s) du RFC : RFC Editor
Pour information
Première rédaction de cet article le 8 avril 2009
Ce mois d'avril marque le quarantième anniversaire du premier RFC, le RFC 1, Host software, publié le 7 avril 1969.
Le RFC 5540 célèbre cet anniversaire en notant (section 1) que les 5400 RFC publiés (il y a des trous dans la numérotation) comportent 160 000 pages. Les RFC existaient donc longtemps avant l'IETF. Leur succès est celui de l'Internet : simple, librement accessible, fondé sur des normes ouvertes. La série des RFC a donc largement mérité son succès.
Pendant vingt-neuf ans, le RFC Editor était Jon Postel. Ce rôle est désormais assuré par une équipe de l'ISI, dirigée par Bob Braden. L'ISI a récemment publié un bilan de son action, à la veille du transfert de la fonction de RFC Editor à une autre organisation, pas encore choisie.
L'auteur du RFC 1 a également écrit un excellent article résumant la signification de ce travail, How the Internet Got Its Rules, où il rappelle que le RFC 1 a été terminé dans une salle de bains mais aussi que l'Internet n'aurait jamais existé si les requins de la propriété intellectuelle avaient pu donner leur avis. Le RFC 2555 avait, pour le trentième anniversaire, rassemblé les souvenirs de nombreux pionniers. Et le RFC 8700 avait continué la tradition, pour parler du cinquantième anniversaire.
L'article seul
RFC 5518: Vouch By Reference
Date de publication du RFC : Avril 2009
Auteur(s) du RFC : P. Hoffman (Domain Assurance Council), John Levine (Domain Assurance Council)
Chemin des normes
Première rédaction de cet article le 7 avril 2009
Le courrier électronique ne fournit pas assez de garanties pour un certain nombre d'utilisations, notamment celles exigeantes en matière de sécurité. Il y a donc beaucoup de propositions pour améliorer les choses, dont ce RFC qui propose un mécanisme par lequel un message électronique peut annoncer le nom d'un certificateur, qui se portera garant (to vouch for) de son sérieux.
La section 1 résume le principe : un en-tête
VBR-Info: est ajouté au message par l'émetteur, et le receveur
qui veut vérifier le message va demander aux tiers certificateurs,
listés dans cet en-tête, leur
opinion. Il y a plusieurs points importants pour que cela améliore
réellement la sécurité comme le fait que le receveur doit d'abord
authentifier le domaine
émetteur ou comme l'importance pour le receveur de ne consulter que
des certificateurs qu'il connait et apprécie (autrement, l'émetteur pourrait
toujours ne mettre que les noms de ses copains à
lui dans le VBR-Info:, cf. section 8).
Vouch By Reference est donc une technique d'autorisation, pas d'authentification, et la différence est essentielle.
La section 2 explique l'utilisation de l'en-tête VBR-Info: (ou des
en-têtes ; ils peuvent être plusieurs). Il contient le nom du domaine
émetteur (celui qu'il faut authentifier avant de contacter les
certificateurs), le type du message (un même émetteur peut avoir des
messages de types différents par exemple « publicité » et «
opérationnel ») et enfin la liste des certificateurs qui peuvent se
porter garant, sur le thème de « Oui, nous connaissons
example.com et tous ses messages de type
opérationnel sont utiles ». La syntaxe formelle est en section 4 et un exemple de VBR-Info: est :
VBR-Info: md=example.com; mc=operation;
mv=certifier.example;
où example.com est l'émetteur du message et certifier.example le certificateur qui peut se porter garant.
Le processus exact de validation d'un message entrant fait l'objet de la section 3. En gros, le récepteur :
C'est la section 5 qui fournit les détails sur cette requête
DNS. Elle utilisera le type d'enregistrement TXT sur le nom de domaine
du certificateur, préfixé par le nom de domaine à certifier et la
chaîne de caractères _vouch. Ainsi, dans
l'exemple ci-dessus, la requête DNS sera pour
example.com._vouch.certifier.example. S'il y a
une réponse, c'est que certifier.example se porte
garant et le texte de la réponse contient une liste des types garantis
(par exemple « operational security » garantit
les messages opérationnels et de sécurité et ne dit rien sur les
message de type advertisement). Les types sont
décrits plus en détail en section 6. Notez bien qu'ils sont gérés par
l'émetteur et ne « prouvent » donc rien, ils ne sont là que pour la
traçabilité. Il existe certains types standards comme
transaction (message envoyé en réponse à une
action spécifique de l'utilisateur).
Enfin, la section 7 revient en détail sur l'authentification du nom
de domaine de l'émetteur. Sans précaution particulière, un VBR-Info: ne
vaudrait rien puisque le méchant pourrait toujours mettre un autre
domaine que le sien dans le VBR-Info:. Notre RFC recommande donc de
vérifier ce nom avec DKIM (RFC 6376), présenté en section 7.1 mais il permet également
d'autres techniques comme SPF (RFC 7208 et section 7.3).
L'article seul
Python, TLS et les délais de garde
Première rédaction de cet article le 6 avril 2009
J'ai besoin de munir un client HTTP existant, écrit en Python, de TLS. Je ne veux pas seulement faire des connexions chiffrées mais aussi accéder à des informations sur le certificat du serveur, notamment le nom de la CA qui l'a signé. Comme le but du projet est d'interroger pas mal de serveurs HTTP, souvent non répondants (il est fréquent qu'un serveur réponde en HTTP et timeoute en HTTPS et on ne peut pas le savoir avant d'essayer), il faut pouvoir mettre des délais de garde sur la connexion.
Il y a plusieurs solutions en Python (en dépit de la règle There should be one-- and preferably only one --obvious way to do it. du PEP 20) mais aucune parfaite pour ce besoin. Voyons les solutions.
python-gnutls : pratiquement pas documenté, peut-être pas maintenu,
ne permet pas de mettre un délai maximum (car il fonctionne avec des
prises
non-bloquantes, on récupère un gnutls.errors.OperationWouldBlock: Function was interrupted).
Python
OpenSSL. Pas mieux : si on met un timeout, il plante également tout de suite
avec un OpenSSL.SSL.WantReadError.
Le module SSL de la bibliothèque standard. Il nécessite Python 2.6 et je voudrais bien que mon code marche en 2.5. Il ne semble pas permettre de récupérer les métadonnées du certificat.
TLSlite. Ne semble pas capable de récupérer le nom du signataire.
Donc, toujours pas de solution pour faire du TLS avec timeout. Le programme qui l'appelera étant multi-threadé, je ne peux pas utiliser les signaux Unix. Je suis donc toujours à la recherche de la solution géniale. Pour les utilisateurs de Stack Overflow, j'ai lancé une récompense de 100 points sur cette question.
L'article seul
La compagnie Emporte-Voix au Kibélé (le Horla)
Première rédaction de cet article le 2 avril 2009
La compagnie Emporte-Voix présente ses spectacles en ce moment au Kibélé à Paris. Hier, c'était Raphaël d'Olce dans une adaptation de la nouvelle de Maupassant, le Horla.
Excellente interpétation d'un acteur seul, comme l'est le héros de Maupassant, face à sa folie. Dans une petite pièce dont il sort de temps en temps, mais sans pouvoir s'empêcher de revenir vers son mal, Raphaël d'Olce angoisse le spectacteur et le laisse plutôt inquiet. C'est donc si fragile, un cerveau ? (Et, non, contrairement à ce que dit le programme, ce n'est pas du tout un « spectacle humoristique ».)
La compagnie Emporte-Voix continue ses spectacles au même endroit. Consultez le programme et n'oubliez pas de réserver et d'arriver tôt : la salle est minuscule, et on ne voit vraiment pas grand'chose depuis les derniers rangs.
L'article seul
RFC 5474: A Framework for Packet Selection and Reporting
Date de publication du RFC : Mars 2009
Auteur(s) du RFC : Nick Duffield (AT&T Labs)
Pour information
Réalisé dans le cadre du groupe de travail IETF psamp
Première rédaction de cet article le 1 avril 2009
L'échantillonnage est une opération qui consiste à ne sélectionner qu'une partie des objets qu'on mesure. Par exemple, lors de l'étude des paquets passant par un réseau, on ne capture qu'une partie des paquets, afin de ne pas faire exploser le disque et que le temps d'analyse reste raisonnable. Le groupe de travail PSAMP de l'IETF met au point des normes sur l'échantillonnage de paquets, afin de garantir une certaine cohérence dans les mesures. Ce RFC présente le cadre général de PSAMP.
Les travaux de PSAMP partent dans plusieurs directions, aussi bien la définition des opérations d'échantillonnage que le protocole permettant de transmettre à une autre machine les paquets capturés (de la même façon qu'IPFIX transmet des informations sur les flux). Notre RFC 5474 est le cadre général, le RFC 5475 décrit les mécanismes d'échantillonnage, le RFC 5476 normalise le protocole qui permet d'exporter le résultat de l'échantillonnage et le RFC 5477 décrit le schéma de données utilisé pour cette exportation.
Attaquons cette famille avec la section 3 du RFC, qui décrit les généralités. À un endroit du réseau (par exemple sur le port d'un routeur), on observe les paquets, un processus les sélectionne (c'est l'échantillonnage), un autre construit des données en utilisant les paquets sélectionnés et un dernier les exporte vers un point de collecte, où se fera l'analyse finale (selon un mécanisme proche de celui d'IPFIX, RFC 7011). Les paquets sélectionnés n'ont pas forcément quelque chose en commun et c'est pour cela que le RFC utilise pour l'exportation le terme de stream et pas celui de flow (RFC 3917).
Je m'intéresse particulièrement ici au processus de sélection, décrit en section 3.3. La sélection peut se faire sur divers critères, et elle peut mettre dépendre d'un état du processus du sélection (le RFC cite plusieurs exemples de tels états comme le numéro d'ordre du paquet, comme l'état d'un générateur pseudo-aléatoire, etc).
Les protocoles qui mettent en œuvre ce système obéissent à des exigences décrites en section 4. Les mécanismes de sélection (section 4.1) doivent être :
- assez simples pour être déployés facilement en des endroits où il faut aller vite. L'idée est de pouvoir traiter les paquets au rythme où ils passent (line-rate). La section 10 revient plus en détail sur cette exigence de performance et sur la complexité des opérations de sélection de paquets. La sous-section 10.2 plaira aux passionnées des couches basses, puisqu'elle décrit les implémentations possibles dans le matériel, notamment les ASIC.
- mais aussi assez riches pour couvrir tous les cas d'usage.
- et extensibles car tout n'aura pas été prévu.
Les sélecteurs obéissant à ces critères figurent en section 5 et surtout dans le RFC 5475.
Il y a aussi des exigences pour le système de mesure (capacité à indiquer que de l'information a été perdue, respect de la vie privée des utilisateurs, selon le RFC 2804, etc), et pour le système d'exportation (proches de celles d'IPFIX, cf. RFC 3917).
Les sélecteurs sont décrits en section 5. Ils sont de deux modèles,
ceux qui filtrent et ceux qui échantillonent. Les premiers
sélectionnent certains paquets selon les caractéristiques du
paquet. Par exemple, si on dit à tcpdump, en
langage BPF, tcp and dst port
443, il va filtrer selon ce critère et ne garder que les
paquets TCP à destination du port 443
(HTTPS). Les seconds, ceux qui échantillonent,
sont tous les autres, ceux qui n'utilisent pas uniquement le contenu du paquet
mais un critère extérieur, par exemple un tirage aléatoire. Les
sélecteurs qui échantillonent se divisent à leur tour en deux
sous-groupes, ceux où la sélection ne dépend pas du tout du contenu du
paquet et ceux où ce contenu est utilisé, par exemple pour réaliser
une distribution non
uniforme. Donc, si j'utilise
pcapdump et que je le lance avec l'option
-S, j'utilise un sélecteur qui n'est pas un
filtre, et qui ne dépend pas du tout du contenu du paquet (cette
option garde un paquet sur N, où N est l'argument de l'option).
La section 5.2 résume les sélecteurs importants :
- Échantillonnage fondé sur le comptage des paquets. C'est l'option
-Sde pcapdump mentionnée plus haut. À ma connaissance, ni tcpdump, ni Wireshark n'ont une option équivalente. - Échantillonnage fondé sur le temps. Je ne connais pas de progiciel de capture de paquets qui aie une telle possibilité, il faut le développer soi-même avec la libpcap.
- Diverses formes d'échantillonnage aléatoire. Même remarque que ci-dessus quant à la (non-)disponibilité d'une tellee option dans l'offre logicielle actuelle.
- Filtrage sur le contenu, comme avec le langage BPF cité plus haut dont disposent tous les outils de capture sur Unix. Selon le langage disponible, on pourra utiliser plus ou moins de critères (le RFC 7012 en donne une idée).
- Filtrage selon la valeur d'une fonction de hachage du paquet. C'est une technique que les répartiteurs de charge utilisent souvent.
Les sélecteurs peuvent naturellement être combinés (section 5.5), par exemple en faisant un filtrage suivi d'un échantillonnage.
Mais, au fait, quelle est l'utilité de ce travail ? La section 11 donne des exemples d'applications de l'échantillonnage.
Enfin, l'inévitable section sur la sécurité est la numéro 12, qui pointe, entre autres, un problème général de toutes les mesures passives, le risque d'atteintes à la vie privée (section 12.2) et un risque spécifique de l'échantillonnage, celui qu'un méchant tente d'échapper à la détection en se débrouillant pour que ses paquets ne soient pas ceux sélectionnés (section 12.3).
L'article seul
RFC 5504: Downgrading mechanism for Email Address Internationalization
Date de publication du RFC : Mars 2009
Auteur(s) du RFC : K. Fujiwara (JPRS), Y. Yoneya (JPRS)
Expérimental
Première rédaction de cet article le 1 avril 2009
Complétant l'ancienne série de RFC sur l'internationalisation du
courrier électronique, ce document normalise la procédure de
repli (downgrade) que doivent
utiliser les MTA lorsqu'ils essaient de
transmettre un message RFC 5335 à un autre MTA
si ce dernier ne gère pas l'extension UTF8SMTP du
RFC 5336. Ce mécanisme de repli a finalement été
complètement supprimé lors de la parution des normes définitives,
autour du RFC 6530, et n'a désormais qu'un
intérêt historique.
Écrit par des employés de JPRS, le registre
du .jp, c'est un document
plutôt simple malgré la complexité du sujet. En effet, lorsque les
autres RFC sur l'internationalisation complète du courrier (comme les
RFC 5335 ou RFC 5336)
seront déployés, ils ne le seront pas instantanément sur toute la
planète. Si on se fie au lent déploiement des extensions précédentes
(comme la transparence aux caractères « 8 bits » du RFC 2045), on peut prévoir d'importants délais, de l'ordre de dix
ans ou plus, avant que tous les MTA suivent le nouveau mécanisme. Que
faire en attendant si un MTA veut transmettre un message complètement
internationalisé à un MTA ancien, qui ne sait pas quoi en faire ? Tous
les MTA écrits avant le RFC 5336 n'acceptent en
effet que les enveloppes et les en-têtes en ASCII.
La solution choisie (introduite par le RFC 5336, sections 3.1 à 3.4, résumée en section 1 de notre RFC) est, soit de renoncer à délivrer le message, la plus simple mais évidemment pas satisfaisante, soit de mettre en œuvre le mécanisme de repli (downgrade) que normalise notre RFC 5504. Ce mécanisme consiste à convertir l'enveloppe SMTP et les en-têtes du message pour être acceptable par le vieux serveur. Elle n'est pas complètement réversible et donc aucun upgrade ne correspond à ce downgrade.
Pour permettre de se souvenir d'une partie de ce qui a été fait, des nouveaux
en-têtes apparaissent, préfixés de Downgraded- et
qui indiquent l'ancienne valeur. Ils sont encodés en
UTF-8 et surencodés avec la méthode du RFC 2047 (Mon
=?UTF-8?Q?h=C3=B4tel_et_mes_horaires?= pour « Mon hôtel et
mes horaires »).
La section 3 décrit ces en-têtes Downgraded:. 3.1 couvre
le repli de l'enveloppe (paramètres des commandes
SMTP MAIL FROM et
RCPT TO, voir aussi la section 4). Les adresses qu'elle contient se
replient sur le paramètre ALT-ADDRESS s'il est
présente (sinon, ce destinataire est abandonné).
3.2 et 3.3 couvrent le repli des en-têtes du message comme
From:.
La section 4 revient sur le repli de l'enveloppe : celui-ci ne peut
se faire que si l'adresse a un paramètre
ALT-ADDRESS (cf. RFC 5336).
La section 5, elle, analyse en détail les problèmes que peuvent
poser certains en-têtes lors du repli. Ainsi,
Received: peut contenir des adresses de
courrier :
Received: from fallback1.mel.teaser.net (fallback1.mel.teaser.net [213.162.54.52])
by mail.bortzmeyer.org (Postfix) with ESMTP id 146B5941E4
for <stéphane+blog@bortzmeyer.org>; Tue, 14 Oct 2008 22:29:11 +0200 (CEST)
et ces adresses doivent également se replier en ASCII.
Quant à la partie 6, elle traite le cas où le corps est structuré
selon MIME (RFC 2045) et
comprend donc des pseudo en-têtes comme
Content-Description: qui devront peut-être
également se replier. À propos de MIME, il faut noter que le repli ne
considère pas le corps des messages. Si le serveur SMTP suivant, non
seulement ne gère pas UTF8SMTP mais ne gère pas
non plus le transport « huit bits », il faudra également modifier le
corps du message pour le passer en un encodage qui tient en sept bits
(cf. section 8.2).
La section obligatoire sur la sécurité (section 7) couvre notamment le fait que le repli, comme n'importe quel processus qui modifie le message en cours de route, a de fortes chances d'invalider toute signature apposée à ce message, par exemple avec DKIM (RFC 6376). Les autres méthodes de signature comme PGP (RFC 4880) peuvent également être affectées.
Voyons un exemple (non testé par manque d'implémentations), tiré de l'annexe A.1. Si le message original était :
# Enveloppe SMTP
MAIL FROM: <stéphane@bortzmeyer.org>
ALT-ADDRESS=stephane@bortzmeyer.org
RCPT TO: <françoise@example.org>
ALT-ADDRESS=francoise@example.net
RCPT TO: <rené@example.org>
# Message proprement dit
Mime-Version: 1.0
Content-Type: text/plain; charset="UTF-8"
Content-Transfer-Encoding: 8bit
Subject: C'est bien de pouvoir écrire en français
# La syntaxe ci-dessous a été introduite par le RFC 5335, section 4.4, pour
# représenter les ALT-ADDRESS
From: Stéphane Bortzmeyer <stéphane@bortzmeyer.org
<stephane@bortzmeyer.org>>
To: Françoise Durand <françoise@example.org
<francoise@example.net>>
Cc: René Dupont <rené@example.org>
# Corps du message
la version de repli sera :
# Enveloppe SMTP
MAIL FROM: <stephane@bortzmeyer.org>
RCPT TO: <francoise@example.net>
# René a disparu, il n'avait pas d'adresse de repli
# Message proprement dit
Downgraded-Mail-From: =?UTF-8?Q?<st=C3=A9phane@bortzmeyer.org>_?=
=?UTF-8?Q?<stephane@bortzmeyer.org>?=
Downgraded-Rcpt-To: =?UTF-8?Q?<fran=C3=A7oise@example.org>_?=
=?UTF-8?Q?<francoise@example.net>?=
Mime-Version: 1.0
Content-Type: text/plain; charset="UTF-8"
Content-Transfer-Encoding: 8bit
Subject: =?UTF-8?Q?C'est bien de pouvoir =C3=A9crire en fran=C3=A7ais?=
From: =?UTF-8?Q?St=C3=A9phane Bortzmeyer?= <stephane@bortzmeyer.org>
Downgraded-From: =?UTF-8?Q?St=C3=A9phane Bortzmeyer_<st=C3=A9phane@bortzmeyer.org_?=
=?UTF-8?Q?<stephane@bortzmeyer.org>>?=
To: =?UTF-8?Q?Fran=C3=A7oise Durand?= <francoise@example.net>
Downgraded-To: =?UTF-8?Q?_Fran=C3=A7oise Durand?=
=?UTF-8?Q?<fran=C3=A7oise@example.org>_<francoise@example.net>>?=
Cc: =?UTF-8?Q?Ren=C3=A9 Dupont?= Internationalized address
=?UTF-8?Q?ren=C3=A9@example.org?= removed:;
Downgraded-Cc: =?UTF-8?Q?Ren=C3=A9 Dupont_?=
=?UTF-8?Q?<ren=C3=A9@example.org?>=
# Corps du message
L'article seul
RFC 5475: Sampling and Filtering Techniques for IP Packet Selection
Date de publication du RFC : Mars 2009
Auteur(s) du RFC : T. Zseby, M. Molina, N. Duffield, S. Niccolini, F. Raspall
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF psamp
Première rédaction de cet article le 1 avril 2009
Ce RFC fait partie de la série des normes produites par le groupe de travail psamp sur l'échantillonage (ou, plus exactement, la sélection) des paquets IP. Les explications générales sur ce mécanisme figurent dans le RFC 5474 et notre RFC 5475, lui, détaille les techniques de sélection des paquets.
Il est donc très recommandé de lire le RFC 5474 avant puisque ce RFC 5475 en reprend les concepts et le vocabulaire (sections 2 et 3, ainsi que la section 4, qui reprend la classification des techniques de sélection en filtrage (où on sélectionne certains paquets selon leurs propriétés, par exemple tous les paquets UDP) et échantillonage où on veut juste sélectionner un sous-ensemble représentatif des paquets. L'échantillonage peut se faire via une fonction de hachage (avec certaines de ces fonctions, cela peut faire un échantillonage quasi-aléatoire) mais, à part ce cas, le contenu du paquet n'est pas pris en compte. La même section 4 rappelle les différentes techniques de sélection, déjà présentées dans le RFC 5474 comme par exemple l'échantillonnage fondé sur le comptage des paquets ou celui fondé sur le temps.
La section 5 est consacrée à l'étude détaillée des techniques d'échantillonage. En fonction du phénomène qu'on veut étudier, on utilisera telle ou telle technique. Par exemple, l'échantillonage systématique (section 5.1) est déterministe et se décline en échantillonage systématique fondé sur le rang des paquets (on sélectionne un paquet sur N) et en échantillonage systématique fondé sur le temps (on prend tous les paquets, mais pendant une courte période).
L'échantillonage aléatoire est décrit dans la section 5.2 et lui aussi se décline en de nombreuses variantes, par exemple selon la distribution utilisée.
La section 6 parle, elle, du filtrage. Contrairement à l'échantillonage, le filtrage considère que le contenu du paquet est important, mais pas sa place dans le temps. Dans le cas du filtrage fondé sur les propriétés (section 6.1), le RFC 5475 permet d'utiliser comme critères de filtrage les attributs d'IPFIX (RFC 7012). Ces attributs (un sous-ensemble de ce qui est disponible, par exemple dans le BPF) sont combinables avec un opérateur ET (pas de OU en standard, par contre). Dans le filtrage fondé sur une fonction de hachage (section 6.2), le contenu du paquet n'est pas utilisé directement mais via cette fonction. Un des buts est, par exemple, de coordonner la sélection des mêmes paquets en différents points d'observation. Le RFC détaille ce filtrage, les différentes utilisations possibles et les propriétés souhaitables pour ls fonctions de hachage (comme la vitesse). Les programmeurs noteront avec plaisir que l'annexe A contient plusieurs mises en œuvre d'une « bonne » fonction de hachage, dont une optimisée pour IPv4, où le résultat n'a pas de lien évident avec le contenu du paquet. (Il existe aussi une étude comparative de ces fonctions dans A Comparative Experimental Study of Hash Functions Applied to Packet Sampling.)
Les différentes techniques de sélection sont résumées par un tableau synthétique dans la section 7.
Notez, hélas, que certains prétendent avoir breveté certaines de ces techniques. Il s'agit probablement de brevets futiles, comme 99,9 % des brevets logiciels mais on ne sait jamais...
L'article seul
RFC 5470: Architecture for IP Flow Information Export
Date de publication du RFC : Mars 2009
Auteur(s) du RFC : G. Sadasivan (Cisco), N. Brownlee (CAIDA / University of Auckland), B. Claise (Cisco), J. Quittek (NEC Europe)
Pour information
Première rédaction de cet article le 1 avril 2009
Voici donc les RFC décrivant le protocole IPFIX, le successeur normalisé de Netflow. Ce RFC particulier décrit l'architecture d'IPFIX.
Ces RFC sont bâtis sur le travail du groupe "ipfix" de l'IETF qui avait formalisé son cahier des charges dans le RFC 3917. Il s'agissait de remplacer le protocole privé Netflow par un mécanisme ouvert et normalisé.
La section 2 du RFC décrit la terminologie utilisée. L'un des principaux termes est évidemment celui de flot (flow) et on notera la définition très large choisie : en gros, un flot est n'importe quel ensemble de paquets pour lequel il existe un critère automatique permettant de tester leur appartenance au flot. Cela peut donc être l'adresse source, l'adresse destination, ou même des données qui n'apparaissent pas dans le paquet (comme l'adresse du routeur suivant).
Les autres concepts importants sont ceux d'exporteur (exporter, nommé probe dans Netflow) et de récolteur (collector). Le premier (en général un routeur mais ce n'est pas obligé, le logiciel libre Ntop peut aussi servir d'exporteur) exporte des flots sous forme agrégée, le second les récolte et les traite.
On notera que le format des flots n'est pas complètement spécifié dans les RFC. En effet, chaque exporteur peut définir des gabarits (template) décrivant les données transmises par le flot (section 5.6 du RFC).
L'article seul
Ajout d'un attribut HTML indiquant la langue du document lié
Première rédaction de cet article le 31 mars 2009
J'ai souvent lu qu'il était de bonne pratique d'ajouter un
attribut hreflang
aux liens hypertexte lorsqu'ils pointent vers
un document d'une langue différente. Cela permet à l'utilisateur de ne
pas être surpris désagréablement en changeant soudain de domaine
linguistique.
J'ai donc modifié les feuilles de style de ce blog pour produire un tel attribut lorsque le lien est marqué comme d'une autre langue. Par exemple :
<a url="http://www.ofis-bzh.org/bzh/langue_bretonne/index.php" hreflang="br">Site en breton</a> (avec un code de langue erroné dans l'URL).
(Toutes les pages ne sont pas encore modifiées, patience.)
Mais cela semble ne produire aucun effet visuel, que ce soit avec Firefox ou avec Konqueror. Apparemment, pour que l'utilisateur soit effectivement prévenu, il faut aussi prévoir une CSS spéciale ce qui diminue beaucoup l'intérêt de cette manipulation.
L'article seul
Faire passer ssh à travers un relais qui ne permet que HTTP
Première rédaction de cet article le 28 mars 2009
Parfois, en voyage, on est coincé sur un réseau qui ne permet que HTTP. Pour se connecter à sa machine distante avec SSH, il « suffit » d'avoir un serveur SSH qui écoute sur le port 443, celui normalement dédié à HTTPS. Mais, si le réseau en question oblige à passer explicitement par un relais, comme cela vient de m'arriver ?
Avant d'aller plus loin, un rappel : les règles techniques sont probablement là pour mettre en œuvre une politique, des conditions d'utilisation, etc. Les violer peut avoir des conséquences pour vous et donc, renseignez-vous avant de tester la technique présentée ici.
Son principe est également d'avoir un serveur SSH qui écoute sur le
port 443, ce qui est de toute façon très souvent utile. Ensuite, il
faut dire au SSH client de passer par le
relais. OpenSSH lui-même ne sait pas parler
HTTP mais il sait lancer des commandes arbitraires et il existe des
programmes conçus pour relayer des protocoles quelconques au dessus de
HTTP. J'utilise corkscrew («
tire-bouchon »). Une fois qu'il est installé, il suffit de configuer
le ~/.ssh/config ainsi (je suppose ici que le
relais est proxy.example.com, port 80) :
ProxyCommand corkscrew proxy.example.com 80 %h %p
%h et %p seront remplacés par le nom et le port du serveur SSH. corkscrew utilisera la commande HTTP CONNECT (RFC 7231, section 4.3.6) pour se connecter au serveur SSH. Le trafic sur le port 443 étant supposé être chiffré, le relais n'a pas de moyen technique de savoir que ce qui circule est en fait du SSH (mais attention, un relais intelligent pourrait le déduire de certaines caractéristiques du trafic, comme sa relative symétrie).
Le fait qu'il écoute sur le port 443 est important avec certains relais, qui n'acceptent pas de relayer vers un port quelconque et produisent un message comme : Proxy could not open connnection to mymachine.example.org: Proxy Error ( The specified Secure Sockets Layer (SSL) port is not allowed. ISA Server is not configured to allow SSL requests from this port. Most Web browsers use port 443 for SSL requests. ) .
Avec certains relais, les connexions SSH coupent au bout d'un moment, car le relais impose une durée maximale aux connexions HTTP. Pas d'autre solution que de se reconnecter.
L'article seul
Exposé sur les normes techniques au colloque IG3T à Milan
Première rédaction de cet article le 27 mars 2009
Dernière mise à jour le 30 mars 2009
Aujourd'hui, à l'université du Sacré-Cœur à Milan, j'ai eu le plaisir de faire un exposé sur les normes techniques au colloque de l'IG3T, Internet Governance : Transparency, Trust and Tools. Cette session milanaise de l'IG3T portait sur Technical norms and Internet governance : socio-technical et socio-ethical dimensions.
Voici les transparents de cet exposé, au format PDF. Il portait sur le caractère des normes techniques et la façon dont elles façonnent la politique :
- Format adapté à la lecture sur écran,
- Format adapté à l'impression.
D'autres participants ont publié leurs transparents ou leurs impressions :
L'article seul
Avoir un TLD à soi, d'accord, mais s'en servir ?
Première rédaction de cet article le 25 mars 2009
L'ICANN avait annoncé à l'occasion de sa réunion de Paris en juin 2008, un assouplissement important des conditions de création de nouveaux TLD. Si l'assouplissement n'est pas aussi important que ce que la presse avait prétendu à l'époque (et il semble en outre actuellement très ralenti par l'opposition active des titulaires de marques déposées), le dossier reste néanmoins ouvert. Mais il semble qu'un petit aspect technique est passé relativement inaperçu, la difficulté à utiliser des noms de domaines composés d'un seul élément.
Contrairement à ce qu'a toujours prétendu l'ICANN pour justifier son immobilisme, il n'existe aucune raison technique pour ne pas créer des milliers ou des dizaines de milliers de TLD. La racine du DNS est une zone comme une autre et, même en créant dix TLD par jour, en vingt ans, la racine resterait loin derrière la majorité des zones des TLD.
Mais la discussion s'était toujours focalisée sur des TLD
à délégation comme
.fr ou
.com, où personne
n'exploite le TLD lui-même, tout se fait dans des sous-domaines comme
example.com ou bortzmeyer.fr. Avec le nouveau plan de
libéralisation des TLD, au contraire, on pourrait voir des TLD pour
une seule entreprise, sans délégation de sous-domaines. On suppose que
certaines des entreprises intéressées envisagent d'utiliser des
noms de domaines composés
d'un seul élément. Si l'entreprise se nomme Example,
Inc., elle va vouloir le TLD example et
probablement espère t-elle communiquer sur des adresses de courrier
comme president@example ou des adresses Web
http://example. Mais cela a peu de chances de
marcher.
Comment, de telles adresses ne sont pas légales ? Elles violeraient un RFC ? Pas du tout, elles sont tout à fait légales mais il y a la norme technique et la pratique. Dans l'Internet tel qu'il est aujourd'hui, ces adresses ne marcheront que partiellement.
Un nom de domaine est en effet composé de plusieurs
éléments (labels en anglais,
voir le RFC 1034). Ainsi,
munzer.bortzmeyer.org a trois éléments,
munzer, bortzmeyer et enfin
org, qui est le TLD. En représentation textuelle, par
exemple sur une carte de visite, les éléments sont séparés par des
points. Un nom de domaine à un seul élément est légal, il ne comprend
dans ce cas aucun point. example ou
dk sont ainsi des noms de domaine (seul le second
existe réellement, c'est le TLD du
Danemark). Ces noms, à un, deux, trois ou
davantage d'éléments, sont tous égaux pour le DNS et fonctionnent
tous aussi bien.
Mais il n'y a pas que le DNS, les titulaires achètent des noms de
domaine pour des applications. Commençons par le
courrier électronique. L'écrasante majorité des
serveurs de courrier sont configurés (et c'est
l'option par défaut, dans bien des cas) pour regarder si le nom de
domaine (ce qui est à droite du @ dans une
adresse de courrier) comporte un point ou pas. S'il n'en a pas, ils
ajoutent en général le nom de domaine de leur organisation. Si je
travaille sur une machine du domaine
bortzmeyer.org et que je tente d'écrire à
president@example, le serveur de messagerie (dans
l'exemple ici, un Postfix tout à fait
standard), réécrit l'adresse puis me dit :
<president@example.munzer.bortzmeyer.org> (expanded from <president@example>):
Host or domain name not found. Name service error for
name=example.munzer.bortzmeyer.org type=AAAA: Host not found
On peut argumenter que je suis en tort et que je devrais régler mon
serveur mieux que ça. Sans doute. Mais comme je suis loin d'être le
seul dans ce cas, la conclusion est claire : si le Président met
uniquement sur sa carte de visite
president@example, il ne recevra pas beaucoup de
courrier. Et il ne pourra pas s'inscrire sur beaucoup de sites Web qui
demandent une adresse de courrier et souvent, exigent que le nom de
domaine de l'adresse comporte au moins un point.
Et pour le Web ? Il souffre d'un problème
analogue. Beaucoup de navigateurs (ou bien de relais) ajoutent un TLD (souvent
.com) après les noms de domaine composés d'un
seul élément. Firefox est un peu plus
intelligent, il teste d'abord si le nom de domaine a une
adresse IP. Ainsi, http://dk/
fonctionne (les danois ont mis une adresse à leur TLD) mais http://fr ne donne pas le résultat attendu. Comme il n'y a
pas d'adresse IP associée, le navigateur ajoute
.com d'autorité et on va ensuite visiter le site
Web d'un cabinet d'avocats états-uniens. Subtilité Firefoxienne : http://fr/ donne le résultat correct. Avez-vous remarqué quel
est le caractère qui diffère ? Avant de tester vous-même, n'oubliez
pas que le résultat exact dépend de beaucoup de choses : version
exacte de Firefox, utilisation ou non d'un
relais, etc.
En conclusion, qu'une entreprise (je n'ai parlé que des entreprises car les tarifs de l'ICANN - plus de 180 000 dollars US uniquement pour déposer le dossier - excluent les associations, les particuliers étant de toute façon explicitement interdits de candidature) veuille son TLD, pourquoi pas, cela ne gêne personne. Mais qu'elle n'espère pas trop pouvoir utiliser des adresses où le nom de domaine serait uniquement le TLD.
Une discussion amusante sur Stack Overflow sur ce sujet : Pourquoi mon nom composé d'un seul composant ne marche pas ?. Un article très récent sur ce sujet est « Domain Names Without Dots » de Paul Vixie. Une autre étude (assez bien faite techniquement mais très orientée vers la sur-régulation ICANNienne) est le rapport 053 du SSAC. Un exemple de faille de sécurité amusante dans les produits Microsoft, avec des domaines d'un seul composant, est l'article « Top-Level Universal XSS ».
Dans ses règles finales, l'ICANN a finalement interdit de mettre des adresses au sommet de la zone (sans justification technique, comme d'habitude avec l'ICANN).
L'article seul
Fiche de lecture : The manga guide to databases
Auteur(s) du livre : Mana Takahashi, Shoko Azuma
Éditeur : Omhsha
978-1-59327-190-9
Publié en 2009
Première rédaction de cet article le 25 mars 2009
Finis, les livres d'informatiques « pour les nuls ». Place aux mangas. No Starch Press et O'Reilly ont lancé il y a quelques mois les traductions en anglais de la série « Le guide Manga de XXX » avec déjà des titres où XXX = électricité, statistiques et bases de données avec The manga guide to databases.
J'aime bien les dessins, les textes sont rigolos, ce n'est pas toujours très rigoureux mais cela change des livres de Date. C'est plutôt court, il faudra donc compléter avec d'autres ressources mais ça donne une bonne idée de départ des bases de données relationnelles. Surtout, contrairement à pas mal de livres « pour les débiles mentaux », ce livre ne parle pas que de SQL mais n'hésite pas à aborder la conception d'un schéma, la normalisation, etc.
L'explication de la première forme normale est moins stricte que celle de la deuxième mais le problème pédagogique qu'elles posent est telle que je ne ferai pas de reproches à l'auteur.
Et, en plus, il y a des exercices, pour les courageux qui veulent empêcher leurs collègues de se moquer d'eux « Tu lis des mangas au bureau ? »
L'article seul
RFC editor à l'ISI, un bilan
Première rédaction de cet article le 24 mars 2009
Ce texte était à l'origine la réponse de l'ISI à la candidature pour le renouvellement du poste de RFC editor en 1996, où l'ISI avait été reconduite facilement. Il vient d'être republié et mis à jour, pour servir cette fois de bilan puisque l'ISI a annoncé qu'elle ne serait pas candidate à sa succession. Cela mettra fin à une époque : la fonction de RFC editor a toujours été à l'ISI...
Que fait le RFC editor (RFC 4844) ? C'est tout simplement l'organisation qui est responsable de publier et de conserver les RFC, les textes sacrés de l'Internet, normes (RFC 2026), analyses, et même plaisanteries (cf. RFC 527, RFC 1149 ou RFC 5241). Cette tâche a toujours été effectuée à l'ISI, au début par Jon Postel et désormais par Bob Braden (et quelques autres).
L'ISOC a annoncé un nouvel appel d'offres pour la fonction de RFC editor en 2009 et l'ISI ne sera pas candidate (c'est finalement AMS qui a été choisi). Au précédent appel d'offres, l'ISI avait écrit un texte qui présentait la fonction de RFC editor et comment elle était assurée. Ce texte servait de base à leur réponse. Mis à jour et allégé de la plupart des considérations budgétaires, ce document est désormais public, The RFC Editor at ISI. C'est un excellent document (bien que, évidemment, assez pro domo) sur une fonction peu connue de l'Internet.
Vu de l'extérieur, la fonction semble simple (attribuer un numéro aux textes qui entrent et les mettre sur un serveur FTP) mais le plaidoyer du RFC editor explique les subtilités et les complications. Le RFC editor doit être conservateur, très conservateur puisque les normes peuvent rester en service des dizaines d'années, parfois trop conservateur. Il doit corriger les fautes d'anglais, les fautes techniques (alors que les RFC sont de plus en plus complexes et que l'époque où le seul Jon Postel pouvait les avoir tous lu et compris est bien lointaine) et gérer la liste des erreurs (un domaine où, pendant longtemps, le travail du RFC editor avait été en dessous de tout).
L'article seul
Science & Vie et la table rase
Première rédaction de cet article le 23 mars 2009
Le numéro de Science & Vie de décembre 2008. contient un article intitulé « Internet au bord de l'explosion ». L'article explique que ce n'est que par miracle que l'Internet continue de fonctionner et qu'il est nécessaire de faire table rase de tout ce qui existe pour bâtir, en partant de zéro, un réseau « meilleur ».
La principal caractéristique de l'article est le ton sensationnaliste, traditionnel avec le Paris-Match de la science. « Une naïveté confondante », « Déjà un quart des ordinateurs dans le monde serait détourné par des hackers [sic] », « Le Net est une démo inachevée qui ne survit que grâce à des rustines », voici quelque uns des sous-titres de cet article. Ces titres devraient suffire, même aux gens qui ne connaissent pas Internet, pour juger du sérieux de l'article.
Si, en plus, on connaît le sujet, c'est plutôt pire. L'article est bourré d'erreurs, comme sur la taille du botnet Storm, estimée à plus de quinze millions de machines (bien au delà des estimations les plus larges, pourtant elles-mêmes très souvent gonflées), ou sur la faille BGP de Kapela & Pilosov, illustrée par un dessin... faux (si le premier routeur a été « reprogrammé », il n'y a nul besoin de faille BGP pour rediriger le trafic, le danger de l'attaque Kapela & Pilosov est justement qu'elle marche avec des routeurs non piratés). Les connaissances de l'auteur ne sont pas meilleures sur les sujets non techniques. Ainsi, un encadré explique doctement que, à l'IETF, on vote à mains levées (non, il n'y a pas de votes à l'IETF).
Toutes ces énormités se comprennent mieux lorsqu'on voit apparaître la conclusion de l'article : il faut tout refaire, recommencer en partant de zéro. Ce thème de la table rase est un thème qui bénéficie d'un certain écho, suite à l'activité intense de plusieurs groupes de chercheurs, comme ceux du projet Clean Slate aux États-Unis. Cherchant à obtenir crédits et soutiens médiatiques, l'un n'allant pas sans l'autre, plusieurs groupes se sont lancées dans des campagnes actives autour de l'idée qu'il faut arrêter de corriger un problème de l'Internet après l'autre et refaire le réseau en partant de zéro. L'article de Science & Vie est simplement un élément de cette campagne de presse, seuls deux opposants ont été invités à s'exprimer en quelques lignes.
Où est le problème avec les projets de table rase ? A priori, l'idée est raisonnable. Un bon ingénieur ne va pas corriger sans cesse un objet technique mal conçu, il va le refaire. Mais il y a deux failles dans ce raisonnement. Le premier est que l'Internet n'est pas un objet isolé qu'on peut jeter à la poubelle et remplacer. C'est un système très grand et très complexe qu'on ne peut pas plus remplacer qu'on ne pourrait remplacer les autres grands systèmes complexes sur lesquels repose notre société. On peut refaire la peinture de son appartement, pas raser Paris pour la refaire en mieux. C'est un phantasme d'ingénieur que de croire qu'on peut tout jeter et repartir de zéro. Dans la réalité, de tels changements nécessitent des grands moyens, des très grands moyens. (Cette idée de la modestie par rapport aux changements nécessaires est défendue dans l'article de Science & Vie par Christian Huitema et, dans un excellent article, There are no "do overs" in history , par Milton Mueller.)
Mais il y a une deuxième faille chez nos révolutionnaires. En mettant le paquet, on peut toujours changer ce qu'on veut. Mais encore faut-il pouvoir créer mieux après. Et c'est là que le bât blesse le plus. Que veulent les tenants de la table rase et comment comptent-ils l'obtenir ? Ce qu'ils veulent n'est pas toujours clair, on trouve des textes appelant à un réseau plus sûr, avec des contrôles systématiques à tous les niveaux (car l'Internet n'est pas assez sécurisé) tout en réclamant une possibilité de communications anonymes (car l'Internet sait trop de choses). La plupart des partisans du retour à la case Départ sont plutôt du côté du maximum de contrôle, comme le dénonce à juste titre Bernard Benhamou dans l'article de Science & Vie.
Il n'y a pas que sur le cahier des charges que les raseurs de table sont en désaccord. Ils sont typiquement très flous sur les moyens à mettre en œuvre. Par exemple, tout le monde déteste le spam. Les remiseurs à zéro ont donc la partie facile en expliquant qu'il est difficile de mettre en place des mécanismes anti-spam sur le courrier électronique existant (vrai) et en annonçant qu'avec « leur » réseau, il n'y aura pas de spam. Promesse facile ! Comment comptent-ils faire ? Aucun détail n'est jamais fourni. Et, pour cause, soit les réseaux sont très utilisés, comme l'Internet, et ils attirent alors, entre autre, les escrocs et les bandits, soit personne ne s'en sert (comme le défunt X.400 que certains promoteurs de la table rase, en France, avaient défendu) et, en effet, les délinquants n'y vont pas...
Comme les journalistes professionnels ne font que se recopier les uns les autres, Libération s'y est mis le 15 avril avec un article identique, « Internet est limité ».
Terminons par quelques attaques personnelles. L'article de Science & Vie est complètement unilatéral. Le « journaliste » a simplement transcrit le dossier de presse qui lui a été présenté par quelques équipes de recherche en demande de subventions et quelques anciens des réseaux (comme un professeur d'université français qui écrivait dans son livre, dans les années 1980, que TCP/IP était une expérimentation sans avenir).
Par contre, il ne cite pas une seule fois les jeunes chercheurs et étudiants qui travaillent effectivement sur le futur. En effet, les gens qu'il faut interroger sur l'avenir des communications numériques ne sont pas ceux qui ont des titres ronflants de Directeur de ceci ou de Président de cela, ou ceux qui exhibent leur Légon d'Honneur. Ceux qu'il faut interroger, ce sont des chercheurs et des étudiants peu connus, les Vint Cerf de demain...
L'article seul
Sécurité des logiciels peu utilisés
Première rédaction de cet article le 23 mars 2009
La publication récente de deux failles de sécurité dans le logiciel djbdns met l'accent sur un problème particulier de la sécurité, la question des logiciels peu utilisés, qui intéressent peu de monde et n'ont donc guère de revues de sécurité, laissant ainsi leurs utilisateurs dans le noir, quant aux risques de leur logiciel.
Le serveur DNS djbdns avait connu une petite période de popularité il y a pas mal d'années, lorsque BIND semblait la seule alternative. Aujourd'hui, il est bien dépassé (surtout par rapport à des logiciels modernes comme nsd ou Unbound) et ne bénéficie donc pas de l'attention des experts en sécurité, qui travaillent sur des cibles qui leur apporteront davantage de gloire.
Néanmoins, il existe de temps en temps des analyses de sécurité de djbdns et deux ont été publiées coup sur coup, djbdns<=1.05 lets AXFRed subdomains overwrite domains et la plus sérieuse djbdns has two weaknesses that allow an attacker to poison its cache in very short amounts of time. Elles ont montré que djbdns, en dépit de l'aggressivité de son auteur, avait sa part des failles de sécurité. Mais, par rapport à la longue liste des failles de sécurité de BIND, djbdns assure plutôt bien. Pourquoi ?
Le record du plus grand nombre de bogues publiées va t-il toujours au logiciel plus utilisé ? Microsoft a largement utilisé cet argument pour justifier leur catastrophique bilan en matière de sécurité. Mais il n'est pas forcément correct. Après tout, IIS (cf. le moteur de recherche de Microsoft) a beaucoup plus d'alertes de sécurité qu'Apache (cf. Apache Security Vulnerabilities), bien que nettement moins utilisé.
En fait, la principale différence n'est pas entre les logiciels très utilisés et ceux moins courants (il y a suffisamment de chercheurs en sécurité pour s'occuper également des challengers comme IIS pour les serveurs HTTP ou KDE pour le bureau). Mais certains logiciels sont tellement « en dessous du radar » qu'ils n'ont quasiment jamais de revues de sécurité. Si echoping n'a jamais eu d'alerte de sécurité depuis le début, je ne me fais pas d'illusion, ce n'est pas qu'il est particulièrement robuste, c'est parce que c'est un programme très peu connu.
Donc, pour résumer, si l'argument de Microsoft est mensonger, cela ne veut pas dire pour autant que tous les logiciels bénéficient de la même attention de la part des experts. Avant de vous vanter « mon logiciel n'a aucune faille de sécurité », cherchez d'abord s'il a été audité...
L'article seul
Utilisation de carte Ethernet Realtek 8168 sur Debian
Première rédaction de cet article le 23 mars 2009
Dernière mise à jour le 3 avril 2009
Contrairement à ce que racontent des optimistes invétérés, l'installation et la configuration du matériel sur Linux sont souvent très pénibles. Je documente ici mes aventures avec une carte Ethernet Realtek RTL8168, pour en garder trace pour la prochaine fois et pour que cela puisse servir à d'autres.
La carte venait installée dans un PC Compaq acheté chez Darty. lspci la voit comme :
02:00.0 Ethernet controller [0200]: Realtek Semiconductor Co., Ltd. RTL8111/8168B PCI Express Gigabit Ethernet controller [10ec:8168] (rev 02)
J'ai eu à deux reprises à passer du temps pour la configurer, lors de l'installation initiale de Debian (version « etch ») et lors de la mise à jour en Debian « lenny ».
Pour l'installation, rien ne marchait et, sans réseau, je ne pouvais donc même pas facilement copier des fichiers, ou installer les sources du noyau pour recompiler. Ce que j'ai fini par faire :
- Mettre une vieille carte Ethernet 3com 3C905 dans l'unique fente PCI libre.
- Installation Debian netinst classique.
- Installer de quoi compiler et les sources du noyau actuel :
aptitude install build-essential linux-headers-$(uname -r). - Récupérer le pilote Realtek en
http://www.realtek.com.tw/downloads/downloadsView.aspx?Langid=1&PNid=13&PFid=5&Level=5&Conn=4&DownTypeID=3&GetDown=false(Aucune idée de sa licence, je ne trouve rien dans la distribution.) - Compilation et installation du pilote :
make install. - Mise à jour de la liste des modules :
depmod -a.
Là, j'ai testé avec modprobe, ça a marché. dmesg affiche :
eth1394: eth0: IEEE-1394 IPv4 over 1394 Ethernet (fw-host0) eth1: Identified chip type is 'RTL8168C/8111C'. eth1: RTL8168B/8111B at 0xf8934000, 00:1e:8c:76:29:b6, IRQ 177
Et j'ai configuré la machine ainsi pour que ce soit permanent :
- Empêcher le chargement du (mauvais) module livré avec Debian en
éditant
/etc/modprobe.d/blacklistpour y mettreblacklist r8169. update-initramfs -u(Pas sûr que ce soit vraiment nécessaire.)
Le fichier de configuration du réseau,
/etc/network/interfaces est ainsi :
allow-hotplug eth1 iface eth1 inet dhcp # Le module qui marche pre-up modprobe r8168
et tout est bon au redémarrage. Merci à Jacques L'helgoualc'h pour son aide ici.
Mais il a fallu recommencer après la mise à jour en Debian « lenny ». J'étais retourné à la carte 3com puis, voulant repasser en Ethernet gigabit, je me suis remis à la carte Realtek, avec exactement les mêmes réglages. Mais, entre temps, le noyau Linux avait changé et le pilote Realtek ne compilait plus :
% make ... CC [M] /local/src/Realtek-RTL8168C/src/r8168_n.o /local/src/Realtek-RTL8168C/src/r8168_n.c: In function 'rtl8168_init_board': /local/src/Realtek-RTL8168C/src/r8168_n.c:2270: error: implicit declaration of function 'SET_MODULE_OWNER' /local/src/Realtek-RTL8168C/src/r8168_n.c: In function 'rtl8168_init_one': /local/src/Realtek-RTL8168C/src/r8168_n.c:2570: error: 'struct net_device' has no member named 'poll' /local/src/Realtek-RTL8168C/src/r8168_n.c:2571: error: 'struct net_device' has no member named 'weight' ...
Et le pilote livré avec Debian ? Il marchait nettement mieux en IPv4 mais, en IPv6, le fonctionnement était assez aléatoire : la carte met plusieurs minutes à configurer son adresse globale (je vois bien les Router Advertisement - RFC 4862 - avec tcpdump mais on dirait que la carte ne les voit pas tout de suite). Une fois l'adresse globale (et les routes) configurées, la carte marche une heure ou deux puis la route par défaut disparait et avec elle mes espoirs de faire de l'IPv6.
Utiliser tcpdump ou un autre logiciel de
sniffing rétablit la
situation. On a donc un cas classique
d'Heisenbug où observer la bogue la fait
disparaître. La raison est probablement que tcpdump met l'interface
réseau en mode indiscret (promiscuous), ce qui fait
qu'elle reçoit alors tous les paquets
multicast de la RA
IPv6. Un contournement posssible serait donc de forcer le passage en
mode indiscret avec ip link set eth0 promisc on. (Merci à Kim Minh Kaplan pour sa suggestion ici.)
Donc, la solution, trouvée sur https://bugs.launchpad.net/ubuntu/+source/linux-source-2.6.24/+bug/141343/comments/21
a été de télécharger un patch
du pilote, de l'appliquer avec cd src; patch -p1 <
../r8168-8.005.00.hardy.diff.txt et de recompiler le
pilote. (Le patch est pour la
version 005 du pilote RealTtek, version que j'avais gardée des
manipulations précédentes, pas la toute dernière qui est la 011
mais je suppose que l'adaptation n'est pas trop difficile.) Avec certaines versions
du noyau, les Makefile ne sont pas corrects et il faut faire un lien symbolique
depuis /src (!) vers le répertoire de compilation avec
ln -s $(pwd)/src /src.
Après cela, tout semble marcher. dmesg affiche :
[ 9.028941] eth0: Identified chip type is 'RTL8168C/8111C'. [ 9.028941] eth0: RTL8168B/8111B at 0xf897e000, 00:1e:8c:76:29:b6, IRQ 18
et IPv4 et IPv6 marchent. Remerciements à Goldy, cette fois. (Kim Minh Kaplan signale que le noyau Linux 2.6.28 est une autre solution, il sembel résoudre le problème.)
L'article seul
The gift, de Jon Kalb
Première rédaction de cet article le 19 mars 2009
Tiens, l'art de la nouvelle n'est pas complètement perdu aux États-Unis ? On peut encore y faire des œuvre de moins de huit cents pages ? C'est ce qu'a fait Jon Kalb, connu pour son livre d'histoire sur les découvertes de fossiles humains en Afrique de l'Est, Adventures in the Bone Trade. Il a également commis un excellent livre de fiction, The Gift, court roman sur le thème des relations très violentes dans le milieu des chercheurs en paléoanthropologie. Très recommandé, passionnante histoire, et très bons personnages.
L'article seul
RFC 4366: Transport Layer Security (TLS) Extensions
Date de publication du RFC : Avril 2006
Auteur(s) du RFC : S. Blake-Wilson, M. Nystrom, D. Hopwood, J. Mikkelsen, T. Wright
Chemin des normes
Première rédaction de cet article le 19 mars 2009
Ce RFC décrivait les premières extensions au protocole cryptographique TLS. Il décrit le mécanisme général d'extension (qui a depuis été déplacé dans le RFC 5246) puis certaines extensions spécifiques (résumées en section 1). Il est désormais remplacé par le RFC 6066.
Ces extensions ne changent pas le protocole : un client ou un
serveur TLS qui ne les comprend pas pourra
toujours interagir avec ceux qui les comprennent. Le serveur doit en
effet ignorer les informations contenues dans le Hello
Client qu'il ne connait pas (section 7.4.1.2 du RFC 5246).
La section 2 décrit le mécanisme général des extensions. Elle
a été remplacée par le RFC 5246,
notamment la section 7 de ce dernier (voir la structure en 7.4.1.2). En gros, le principe est
d'ajouter des données à la fin du paquet Hello,
qui marque le début de la négociation TLS. Dans le langage de
spécification propre à TLS, la liste des extensions possibles est un
enum (section 2.3) mais elle est désormais en
ligne à l'IANA.
Les premières extensions normalisées sont décrites dans la section 3. J'en cite seulement certaines. Leur description officielle est désormais dans le nouveau RFC 6066.
SNI (Server Name Indication, section 3.1) permet au client TLS d'indiquer au serveur le nom sous lequel il l'a trouvé. Cela autorise le serveur à présenter des certificats différents selon le nom sous lequel on y accède, fournissant ainsi une solution au problème récurrent de l'authentification avec TLS lorsqu'un serveur a plusieurs noms. À noter que SNI fonctionne avec les IDN, le RFC décrivant le mécanisme à suivre.
Maximum Fragment Length, section 3.2, permet au client d'indiquer qu'il souhaiterait des fragments de données de taille plus réduite. Cela peut être utile pour un client contraint en mémoire ou en capacité réseau, par exemple un téléphone portable. Certains de ces clients contraints apprécieront également Truncated HMAC (section 3.5) qui autorise à réduire la taille du MAC utilisé pour protéger l'intégrité des paquets.
La section 3.6 décrit (Certificate Status Request), une extension qui permet d'indiquer la volonté d'utiliser OSCP, un protocole d'interrogation de certificats X.509 (plus léger que l'habituelle liste de certificats révoqués).
Qui dit nouvelles extensions, dit nouvelles erreurs. La section 4
est donc consacrée aux nouveaux codes d'erreur, pour toutes les
extensions décrites. La plus évidente étant
unsupported_extension où le client TLS
reçoit une extension qu'il n'avait pas demandé (mise dans son
Hello).
Enfin, la section 5 décrit la procédure pour l'enregistrement des nouvelles extensions mais, comme elle a été assouplie par le RFC 5246, il vaut mieux consulter la section 12 de ce dernier.
Notre RFC annule le RFC 3546 (le principal changement est un léger assouplissment des règles d'enregistrement de nouvelles extensions) et est lui-même remplacé par les RFC 5246 et RFC 6066.
L'article seul
Toujours apprendre, ici sur Python
Première rédaction de cet article le 18 mars 2009
C'est quand on croit bien connaître quelque chose qu'il faut retourner apprendre du nouveau sur celle-ci. Par exemple, parmi les outils du programmeur, connaissez-vous vraiment tout sur votre langage de programmation, même si vous l'utilisez depuis des années ? Probablement pas, vous avez appris un certain nombre de choses au début et pas tellement après ? J'ai raison ? Si oui, il est temps de lire Code Like a Pythonista: Idiomatic Python.
Cet article ne s'adresse par aux débutants en Python mais à ceux qui utilisent le langage depuis plusieurs années et ne se sont pas tenus assez au courant de ce qu'il permet. Personnellement, j'y ai découvert (ou redécouvert) :
- Que la fonction
locals()renvoie un dictionnaire avec toutes les variables locales et que cela simplifiait beaucoup l'interpolation dans les chaînes de caractères, par exemple pour écrireprint("Vous avez %(num_messages) messages", locals()), ce qui affiche le contenu de la variablenum_messages. - L'argument
keyde la méthodesortqui permet de spécifier une fonction de canonicalisation de la variable, par exemplestring.lowerpour trier indépendemment de la casse ouint(conversion en entier) pour trier numériquement.
Et il me reste encore à me mettre enfin aux générateurs...
Suivant la même démarche, voir aussi Hidden features of Python sur Stack Overflow qui liste des techniques peu connues ou très récentes.
L'article seul
Qui achète du porno en ligne ?
Première rédaction de cet article le 17 mars 2009
Les économistes peuvent tout étudier, comme l'a montré Steven Levitt dans son célèbre livre Freakonomics. Donc, les ventes de pornographie en ligne sont aussi un sujet d'étude. Quel jour de la semaine y a t-il le plus d'abonnements ? Dans quel état des États-Unis ? Ces achats sont-ils corrélés à la pratique religieuse ? Au niveau de diplôme ?
Benjamin Edelman, professeur à la Harvard Business School répond à toutes ces questions dans son article Red light states: who buys online adult entertainment?. La pornographie est un des principaux moteurs du développement des NTIC. C'est une industrie dynamique, très ancienne et qui a toujours su tirer profit des nouveaux médias, comme le livre, la photographie ou, aujourd'hui, l'Internet. Il est donc normal que les économistes l'étudient de près. L'article d'Edelman est notamment très intéressant par sa description de l'organisation de cette industrie aux États-Unis, les relations entre les acteurs, les mécanismes de commercialisation, les défis auxquels les entreprises sont confrontées (comme la copie illégale qui, comme dirait Christine Albanel, nuit gravement aux créateurs, et qui a motivé beaucoup de développements marketing intéressants pour récompenser les clients légaux).
Je ne donne pas toutes les réponses ici, à vous de voir l'article mais le point le plus intéressant est que, lors d'études nationales aux États-Unis, les différences d'un état à l'autre sont souvent énormes (Edelman cite l'exemple de la densité de population ou bien du taux de possession d'un camion). Ici, au contraire, le sujet est consensuel, les différences entre états sont, par rapport à la plupart des études, relativement faibles.
N'espérez pas des photos coquines, c'est un article d'économie, il est plein de chiffres et les seules courbes ne sont pas celles du corps humain.
Sur le même sujet, on peut lire en français « Le dimanche, jour du seigneur... et du porno ».
L'article seul
La Dame à la Licorne, de Tracy Chevalier
Première rédaction de cet article le 17 mars 2009
Si vous avez visité Paris, il y a des chances que vous ayez vu le Musée du Moyen-Âge à Cluny. Le chef d'œuvre de ce musée est un ensemble de six grandes tapisseries, la Dame à la Licorne. Si vous avez lu les textes, vous savez... qu'on ne sait pas grand'chose de cette tapisserie, qui l'a dessinée, où elle a été réalisée, et quelle est la symbolique derrière ces curieuses scènes. C'est donc un terrain parfait pour la romancière Tracy Chevalier qui s'est lancée dans la tâche d'imaginer les auteurs de la Dame à la Licorne.
Tracy Chevalier, également auteur de La Jeune fille à la Perle, autre roman portant sur une œuvre célèbre, décrit une fin de Moyen-Âge très vivante, où les riches bourgeois récemment ennoblis, comme le commanditaire de la tapisserie (un des rares personnages du roman qui aie vraiment existé), ont beaucoup d'argent à dépenser, un statut social à tenir, et nourissent de nombreux artistes... qui ont un message à faire passer et vont utiliser la tapisserie pour cela.
Le chemin est long de l'idée à l'œuvre accrochée au mur, nécessite bien des acteurs différents (la tapisserie, contrairement à la peinture, est un sport d'équipe), et le résultat ne sera pas forcément celui prévu.
L'article seul
RFC 5482: TCP User Timeout Option
Date de publication du RFC : Mars 2009
Auteur(s) du RFC : L. Eggert (Nokia), F. Gont (UTN/FRH)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tcpm
Première rédaction de cet article le 17 mars 2009
Le RFC 793, qui normalise TCP, prévoit un paramètre local user timeout qui permet de régler la « patience » de TCP. S'il n'arrive pas à échanger des données avec son partenaire avant l'expiration de ce délai, TCP renonce et coupe la connexion. Notre RFC étend l'utilité de ce paramètre, en permettant de le communiquer au partenaire, pour qu'il soit prévenu de la patience ou de l'impatience de celui avec qui il communique. On augmente ainsi les chances des connexion TCP de survivre aux longues coupures ou, au contraire, de détecter plus rapidement la coupure du réseau.
Ce paramètre user timeout peut être spécifié par l'application qui utilise TCP (ceci-dit, je ne trouve pas l'option de setsockopt qui permettrait de le faire sur tout Unix ; d'après le RFC, Solaris a une telle option). Il vaut cinq minutes par défaut (section 3.8 du RFC 793). Mais il n'était jamais connu de l'autre machine avec laquelle on est connecté en TCP. C'est ce que change notre RFC qui permet de communiquer ce paramètre.
Cette communication se fait via le mécanisme d'option de TCP, décrit dans la section 3.1 du RFC 793. La nouvelle option porte le nom d'UTO (User Timeout Option) et est strictement indicative : le TCP qui la reçoit peut parfaitement l'ignorer. S'il l'accepte, il va ajuster son propre user timeout à la valeur indiquée. Ainsi, TCP pourra, par exemple, survivre à de longues périodes de déconnexion, sans que le partenaire ne raccroche.
La section 1 fournit d'autres cas où cette option UTO est utile : pour des mobiles utilisant une technique qui conserve l'identificateur comme HIP (RFC 9063) ou Mobile-IP (RFC 3344), les périodes pendant lesquelles le mobile n'a pas de connexion risquent d'être longues. Le fait de garder l'identificateur (adresse IP ou Host Identity) constant permet en théorie de garder les sessions TCP lorsqu'on se déconnecte et se reconnecte mais, avant l'option UTO, cela ne servait à rien puisque TCP coupait la connexion qui lui semblait en panne.
De même, l'application peut dans certains cas connaître la durée d'une déconnexion et utiliser UTO pour prévenir son partenaire (le RFC cite l'exemple amusant d'une sonde spatiale qui sait, grâce aux lois de la mécanique céleste, qu'elle ne sera pas en vue de sa base pendant une longue période).
La section 3 définit rigoureusement la nouvelle option. Quatre
paramètres définissent le comportement du TCP local :
USER_TIMEOUT, qui existe déjà (mais n'est pas
réglable sur tous les systèmes d'exploitation, cf. sections 3.1 et 5),
ADV_UTO, la valeur de l'UTO communiquée au pair
(typiquement identique à USER_TIMEOUT), ENABLED qui indique si le pair doit être notifié
par la nouvelle option UTO et CHANGEABLE qui
indique si USER_TIMEOUT doit être ajusté en
fonction des notifications du pair (ou bien s'il doit être ignoré, ce
qui est permis).
La section 3.1 contient une discussion détaillée des « bonnes »
valeurs pour USER_TIMEOUT (notons que ce ne sera
pas forcément le même pour les deux pâirs). Le RFC 1122
donnait quelques recommandations à ce sujet (par exemple, les valeurs
inférieures à 100 s sont découragées). La 3.2 discute de la fiabilité
de la transmisson d'UTO (inexistante, comme toutes les options TCP ;
il ne faut donc pas tenir pour acquis qu'elle a été reçue par le
pair). Et 3.3 décrit le format concret de l'option : numéro 28
(enregistré dans le registre IANA), un
bit qui indique l'unité utilisée (minutes ou secondes) et 15 bits qui
contiennent la valeur elle-même.
La section 4 passe aux problèmes pratiques que peut rencontrer le déploiement de l'option. Le RFC rappelle en section 3 que l'espace des options dans TCP est limité (40 octets) et que l'ajout d'UTO peut nécessiter de renoncer à certaines options. Il faut aussi dire que beaucoup de pare-feux bogués rejettent tout paquet TCP ayant des options (cf. Probing the viability of TCP extensions) et que celles-ci sont donc difficiles à utiliser en pratique. En théorie, une implémentation de TCP qui ne connait pas cette option devrait l'ignorer (RFC 1122) et le RFC décrète que, bien qu'il y aie quelques violations de cette règle (cf. Measuring interactions between transport protocols and middleboxes), elles ne méritent pas qu'on renonce à une option utile (section 4.1). Notez aussi qu'un pare-feu à état a typiquement ses propres délais de garde et peut donc couper une connexion sans tenir compte de l'UTO annoncée (les pare-feux futurs tiendront peut-être compte de cette option).
J'ai déjà mentionné la difficulté qu'il y a à changer la valeur de
USER_TIMEOUT. La section 5 revient sur cette
question de l'API mais ne fournit pas de
proposition de normalisation de l'API des prises.
Bien sûr, l'UTO introduit des problèmes de sécurité nouveaux, discutés en section 6. Par exemple, un méchant pourrait spécifier de très longs délais de garde, puis s'en aller pendant que sa victime serait forcée de garder une connexion ouverte pendant de longues minutes, malgré l'absence de trafic. Notre RFC propose des mécanismes pour limiter les risques comme n'accepter les UTO qu'après authentification IP (par exemple par IPsec), ou bien seulement après que l'application aie indiqué à TCP qu'elle avait réussi une authentification à son niveau, par exemple par TLS. Sans authentification, TCP pourrait aussi mettre des limites au délai de garde total d'un pair (s'il a ouvert plusieurs connexions) et au délai de garde total (pour limiter les risques dus aux dDoS).
Je n'ai pas trouvé tout de suite de trace de mises en œuvre de TCP qui incluent cette option UTO mais, depuis, il y a cet article expérimental.
L'article seul
WSGI, une technique pour des applications Web en Python
Première rédaction de cet article le 16 mars 2009
Dernière mise à jour le 11 juin 2011
Pour créer une application Web en Python, il existe plusieurs solutions. La plus ancienne est d'utiliser le standard CGI qui permet de créer très simplement des applications Web sommaires. La plus à la mode est d'installer un des innombrables environnements de développement et d'exécution, comme Django. Il existe encore une autre solution, développer des applications en WSGI.
D'abord, qu'est-ce qui ne va pas avec les CGI ? Cette méthode, la plus ancienne du Web, est ultra-simple (n'importe quel programmeur, n'ayant jamais fait de Web, peut écrire un CGI en cinq minutes, et ceci quel que soit le langage de programmation utilisé), robuste, ne nécessite pas d'installer quoi que ce soit de particulier, fonctionne avec tous les serveurs HTTP. En Python, l'excellent module cgi de la bibliothèque standard rend cela encore plus facile.
Mais les CGI ont des défauts, liés au fait que tout (machine virtuelle Python, connexion aux bases de données, etc) est initialisé à chaque requête HTTP. Les CGI sont donc en général lents. Mais ils restent imbattables pour les petites applications développées vite fait.
Les développeurs Python modernes vont alors crier en anglais framework! (environnement de développement et d'exécution). Ces environnements, mis à la mode par Ruby on Rails, sont innombrables dans le monde Python (le premier ayant été Zope, le plus populaire aujourd'hui étant Django). On en compte des dizaines activement maintenus et le nombre augmente tous les jours. Le simple choix d'un environnement peut prendre des jours, l'installation et l'administration système sont loin d'être simples et la pérennité des applications développées dans un environnement est loin d'être assurée, puisque les applications sont dépendantes d'un environnement. En outre, certains environnements imposent (ou, en tout cas, poussent fortement) à utiliser des choses dont je me méfie comme les ORM. Enfin, personnellement, j'ai du mal à me plonger dans ces usines à gaz complexes, qui utilise chacune son vocabulaire particulier. Je ne suis pas développeur d'applications Web à temps plein donc le temps que je passerai à apprendre un gros machin comme Django ne pourra pas être amorti sur de nombreux projets.
Pour une petite (toute petite) application Python sur un site Web, le moteur de recherche de ce blog, je cherchais s'il n'y avait pas mieux ou plus récent dans la catégorie « trucs ultra-simple pour le programmeur, qui permet de faire une application Web en trente secondes sans se prendre la tête ». Je cherchais à retrouver la simplicité et la rapidité de développement des CGI avec un truc qui aie moins de problèmes de performance et de passage à l'échelle.
Il existe plusieurs solutions dans cette catégorie. Par exemple, mod_python est un module Apache qui permet d'embarquer la machine virtuelle Python dans le serveur HTTP Apache et donc de démarrer bien plus rapidement. Porter une application CGI en mod_python n'est pas trivial (le mode de fonctionnement est assez différent) et mod_python semble moins maintenu de nos jours (mais il reste la meilleure solution lorsqu'on veut accéder aux fonctions d'Apache, pour modifier le comportement de ce serveur). En outre, mod_python est spécifique à Apache.
Une autre solution envisageable est WSGI. Décrit dans le PEP 333, indépendant du serveur HTTP, WSGI est un standard d'interface entre le serveur HTTP et Python. Il est plutôt prévu pour fournir aux développeurs d'environnements une interface sur laquelle s'appuyer, afin de garantir que leur environnement tournera sur tous les serveurs HTTP. WSGI n'est typiquement jamais promu comme interface pour le développeur d'applications finales.
C'est bien dommage, car WSGI a plusieurs propriétés intéressantes :
- Rapide (pour mon application, qui utilise un SGBD, mesuré avec echoping, le gain de performance est net, la médiane passe de 0,4 s (CGI) à 0,1 s (WSGI), sur la machine locale).
- Une mise en œuvre de WSGI pour Apache, mod_wsgi, a un mode « démon » où les processus qui exécutent le code Python ne sont pas dans le serveur HTTP mais sont des démons séparés, comme avec FastCGI. Ainsi, une bogue dans le code Python (par exemple une fuite de mémoire) n'affectera pas le processus Apache (l'un des problèmes récurrents de mod_python ou de mod_perl).
- Modèle de programmation suffisamment simple pour que les applications CGI puissent être portées très vite.
(Et quelles sont les différences avec FastCGI ? Dans les deux cas, le serveur HTTP envoie la requête à un processus externe qui tourne en permanence, ce qui évite de payer le coût du démarrage pour chaque requête. Mais les deux solutions sont distinctes : FastCGI spécifie le protocole entre le serveur HTTP et le serveur d'application. WSGI normalise l'API utilisée par le serveur HTTP pour parler au serveur d'application - et celle utilisée par le serveur d'application pour parler à l'application. WSGI est donc spécifique à un langage - Python - mais de plus haut niveau. On peut donc implémenter WSGI sur FastCGI.)
À quoi ressemble une application WSGI ? Un exemple trivial, qui affiche les variables d'environnement est :
import os
def application(environ, start_response):
status = '200 OK'
output = str(environ.keys()) + "\n"
response_headers = [('Content-Type', 'text/plain'),
('Content-Length', str(len(output)))]
start_response(status, response_headers)
return [output]
On y voit les points importants : WSGI appelle un sous-programme nommé
application, il lui passe un objet qui contient
les variables d'environnement, ici nommé environ
et une fonction à appeler avec le code de retour HTTP (ici 200) et les
en-têtes HTTP (comme le type MIME
Content-Type).
Pour comparer, le programme qui affiche les variables d'environnement ressemblerait à ceci en CGI :
import os print "Content-Type: text/plain" print "" print os.environ.keys()
Bien sûr, WSGI est beaucoup plus riche que cela et on peut faire
bien d'autre choses. Par exemple, pour répartir les requêtes selon
l'URI indiqué, on regarde la variable
PATH_INFO et cela donne :
def application(environ, start_response):
if environ['PATH_INFO'] == "/toto":
return toto(start_response)
if environ['PATH_INFO'] == "/shadok":
return shadok(start_response)
else:
return default(start_response, environ['PATH_INFO'])
...
def shadok(start_response):
status = '200 OK'
output = "<h1>Ga Bu Zo Meu</h1>\n"
response_headers = [('Content-type', 'text/html'),
('Content-Length', str(len(output)))]
start_response(status, response_headers)
return [output]
...
[Idem pour les autres fonctions]
Ainsi, on peut bâtir des applications arbitrairement complexes. Aujourd'hui, la plupart des environnements de développement et d'exécution Web pour Python sont développés en utilisant WSGI.
Sans aller jusque là, un exemple réel est le moteur de recherche de ce blog.
En pratique, comment installe t-on des WSGI sur
Apache ? (Mais rappelez-vous qu'un gros
avantage de WSGI est la capacité à fonctionner sur tous les serveurs
HTTP.) Il faut installer le logiciel (sur
Debian, aptitude install
libapache2-mod-wsgi, sur Gentoo
emerge mod_wsgi, etc). On configure ensuite Apache,
par exemple ainsi :
WSGIScriptAlias /search /var/www/www.bortzmeyer.org/wsgis/search.py
WSGIDaemonProcess bortzmeyer.org processes=3 threads=10 display-name=%{GROUP}
WSGIProcessGroup bortzmeyer.org
<Directory /var/www/www.bortzmeyer.org/wsgis>
Options -Indexes -Multiviews +ExecCGI
Order allow,deny
Allow from all
</Directory>
Cette configuration fait fonctionner WSGI en mode démon, avec trois démons.
Du fait que le démon tourne en permanence, ses variables sont conservées d'une requête sur l'autre. Par exemple, voici une démonstration qui incrémente un compteur et affiche le PID et l'adresse IP d'origine. Le PID indique le démon qui a exécuté le programme et le compteur s'incrémente à chaque requête. Attention, il n'y a pas de mémoire partagée, chaque démon a son compteur. Voici le code :
# Ces variables seront initialisées au lancement du démon
# et tarderont leur valeur d'une requête HTTP sur l'autre.
calls = 0
pid = os.getpid()
...
def counter(start_response, client):
status = '200 OK'
output = """
<html><head><title>WSGI works</title></head>
<body>
<h1>WSGI works</h1>
<p>You are the %i th visitor for this WSGI daemon (Process ID %i).
Reload the page to see the changes.</p>
<p>You arrived from machine %s.</p>
</body>
</html>""" % (calls, pid, client)
response_headers = [('Content-type', 'text/html'),
('Content-Length', str(len(output)))]
start_response(status, response_headers)
return [output]
...
def application(environ, start_response):
global calls
calls += 1
if environ['PATH_INFO'] == "/counter":
return counter(start_response, environ['REMOTE_ADDR'])
else:
return default(start_response, environ['PATH_INFO'])
Dans les exemples ci-dessus, le code WSGI doit gérer tout un tas de problèmes de bas niveau, comme d'envoyer correctement des en-têtes HTTP. Le programmeur paresseux pourra aussi faire du WSGI en utilisant des bibliothèques comme webob ou wsgiref. Je ne les ai pas encore testées mais cela peut simplifier le développement.
Puisqu'on parle de simplifier le développement, existe t-il un
moyen plus simple de tester ses applications WSGI en local, sans avoir à
installer un Apache sur sa machine ? Oui, on peut utiliser, là
encore, la bibliothèque wsgiref, elle contient un serveur HTTP
minimum, très pratique pour les tests locaux. Supposons que
l'application « compteur » citée plus haut soit dans un fichier
myapps.py. Le programme Python suivant va
l'importer, puis lancer un serveur HTTP sur le port indiqué :
import wsgiref.simple_server as server
import myapps
port = 8080
httpd = server.make_server('', port, myapps.application)
print "Serving HTTP on port %i..." % port
# Respond to requests until process is killed
httpd.serve_forever()
En regardant avec un navigateur
http://localhost:8080/counter, on appelera
l'application qu'on veut déboguer, avec le même contexte (puisque WSGI
est une norme, il n'est pas spécifique à Apache, il marchera aussi
bien, avec simple_server).
Enfin, un autre bon truc pour déboguer des applications WSGI en local, sans passer du tout par un serveur HTTP. Écrire ce code dans le programme principal :
# Si et seulement si ce code est lancé interactivement
if __name__ == '__main__':
def local_debug(status, headers):
print status
print headers
import os
print "".join(application(os.environ, local_debug))
Le script WSGI sera alors exécuté et affichera ses résultats.
Les idées exposées dans cet article viennent en bonne partie de Writing Blazing Fast, Infinitely Scalable, Pure-WSGI Utilities.
L'article seul
Mise en œuvre du moteur de recherche de ce blog
Première rédaction de cet article le 16 mars 2009
Le tout nouveau moteur de recherche de ce blog repose sur plusieurs techniques que j'apprécie, notamment WSGI, TAL et la recherche texte de PostgreSQL.
Les données sont à l'origine dans des fichiers
XML (voir l'article « Mise en œuvre de ce
blog »). Ces données sont, chaque nuit, lues par un programme
Python, blog2db.py, qui
traduit le XML en texte et met ledit texte dans une base de données
PostgreSQL. Cette base est configurée (script
de création en create.sql) pour
faire de la recherche plein
texte. Je peux y accéder depuis la ligne de commande
Unix ainsi :
% search-blog médiane
filename | title
-----------------------------------+---------------------------------------------------
mediane-et-moyenne.entry_xml | Médiane et moyenne
2681.rfc_xml | A Round-trip Delay Metric for IPPM
le-plus-rapide-dns.entry_xml | Quel est le plus rapide serveur DNS d'un groupe ?
echoping-6-fini.entry_xml | Version 6 d'echoping
...
où le script search-blog fait simplement une
requête SQL
psql -c "SELECT filename,trim(replace(substr(title,1,63),E'\n','')) \
AS title \
FROM Blog.search('$query') LIMIT 13;" \
blog
Et pour le Web ?
WSGI est utilisé comme plate-forme de
développement et d'exécution du script Python qui anime l'interface Web du moteur de recherche. Le langage
de gabarit utilisé est TAL (alors que le reste du blog
est en Cheetah, je sais, ce n'est pas très cohérent). Le gabarit est nommé search.xhtml et le programme WSGI est search.py.
Le programme se connecte à la base de données, la connexion reste ouverte tant que le démon WSGI tourne. On ne se connecte donc pas à chaque requête. Mais la base de donnés posait un autre problème. Une fois qu'un a configuré PostgreSQL pour faire de la recherche plein texte, on a le choix entre deux syntaxes pour exprimer les requêtes :
- La syntaxe normale à base de & pour ET, de | pour OU, par exemple
'postgresql&python' pour trouver les articles qui parlent du SGBD et
du langage de programmation. C'est celle qu'on a avec
to_tsquery(). - La syntaxe sans opérateurs explicites par exemple 'postgresql
python' pour la même requête. C'est celle qu'on a avec
plainto_tsquery().
Aucune des deux ne me convenait tout à fait. Je voulais une syntaxe sans
opérateurs mais où l'opérateur implicite soit OU et pas ET comme avec
plainto_tsquery().
Le code du programme essaie donc
to_tsquery() :
try:
cursor.execute("SELECT to_tsquery('french', '%(query)s')" % \
{'query' : query})
except psycopg2.ProgrammingError:
# Not PostgreSQL FTS syntax, convert it
query = to_postgresql(query, default_is_or)
cursor.execute("ROLLBACK;")
et, si cela échoue, il traduit la requête en PostgreSQL avec l'opérateur par défaut sélectionné (via un bouton radio) :
def to_postgresql(q, default_or = True):
""" Converts query q (typically an human-entered string with funny
characters to PostgreSQL FTS engine syntax. By default, the connector is OR.
"""
q = separators.sub(" ", q)
q = q.strip()
if default_or:
connector = "|"
else:
connector = "&" # AND
return re.sub(" +", connector, q)
Le système n'est pas parfait : PostgreSQL accepte des requêtes non documentées (par exemple « foo;bar » est accepté et équivalent à « foo&bar ») mais il permet de satisfaire l'utilisateur avancé (qui veut contrôler précisément la recherche grâce au langage de requête de PostgreSQL) et les autres, qui veulent simplement taper une liste de mots.
Tous les fichiers nécessaires sont distribués dans l'archive des programmes qui animent ce blog.
L'article seul
Moteur de recherche sur mon blog
Première rédaction de cet article le 16 mars 2009
Dernière mise à jour le 28 mai 2011
Cela fait longtemps que je voulais avoir un moteur de recherche sur mon blog. Il y a deux solutions, installer un logiciel sur le serveur, ou bien utiliser un des moteurs de recherche publics. J'ai exploré la deuxième possibilité mais avec des résultats peu satisfaisants, notamment du point de vue des licences d'utilisation. Je suis donc repassé à ma première idée, un logiciel installé sur le serveur. Il est désormais disponible depuis chaque page.
J'aurai pu utiliser un logiciel libre existant comme mnogosearch. Mais aucun ne m'enthousiasmait et j'avais envie de tester quelques techniques nouvelles. J'ai donc développé un outil. Voici le résultat.
Quelques mots sur son utilisation : on peut taper une série de mots séparés par des espaces. Par défaut, il va chercher les articles comportant au moins un mot mais un bouton radio permet de demander uniquement les articles comportant tous les mots. (On peut aussi utiliser directement la syntaxe de PostgreSQL.) On ne peut pas chercher une phrase entière (comme « Cannot allocate resource for EISA slot 1 »). Il n'y a pas de recherche par expressions rationnelles.
Les résultats sont ensuite présentés par ordre de pertinence. On peut les demander au format HTML (pour affichage dans le navigateur) ou Atom (pour lire depuis un logiciel de syndication afin de, par exemple, suivre l'actualité des articles sur un certain sujet). Pour avoir accès aux autres formats, il faut aller sur la page principale du moteur.
Ce n'est qu'un logiciel, il ne vous comprend pas.
Une description OpenSearch de ce moteur est disponible en /others/add-search-engine.xml.
L'article seul
Nouvelle version de Conficker, avec une utilisation plus intensive du DNS
Première rédaction de cet article le 14 mars 2009
Dernière mise à jour le 30 mars 2009
L'une des originalités du ver Conficker est qu'il utilise des noms de domaine et pas des adresses IP pour contacter son maître, afin de lui demander des mises à jour, des listes d'actions à effectuer, etc. Mais la nouvelle version, analysée il y a quelques jours, pousse cette logique encore plus loin.
L'ancienne version avait été bien analysée dans des articles comme
Detecting
Conficker in your Network ou
An Analysis of Conficker's Logic and Rendezvous
Points. Une mise en œuvre complète se trouve en
http://mhl-malware-scripts.googlecode.com/files/downatool.zip. Dans
cette ancienne version, Conficker se connecte à son maître via un nom
de domaine, dans huit domaines de
tête possibles comme
.com ou org. Ce n'était pas assez pour le ver : dès que
son code a été analysé, plusieurs registres ont
bloqué les noms en question, empêchant leur utilisation.
Mais cette version n'est plus complètement d'actualité : Conficker nouvelle mouture, analysé dans W32.Downadup.C Digs in Deeper et dans Conficker Call-home Protocol v2, fait mieux en générant de très longues listes de noms de domaines, dans presque tous les domaines de tête, rendant ainsi plus difficile le blocage. Un rapport encore plus complet a été publié (avertissement : c'est très technique), Conficker C Analysis, avec presque tous les détails.
Il ne semble pas que ces nouveaux noms aient été activés. L'ICANN a demandé à tous les TLD de les bloquer. Certains se sont exécutés comme l'ACEI qui l'a annoncé dans un communiqué.
Sur Conficker C, on peut aussi consulter :
- Le site du groupe de travail Conficker, organisation privée qui regroupe Microsoft et des éditeurs d'anti-virus,
- L'avis lancé par le CERT états_unien,
- L'article de Microsoft (attention, Microsoft appele D la version C),
- Detecting and Containing Conficker - Management Overview.
L'article seul
Filtrage maladroit dans les bibliothèques parisiennes
Première rédaction de cet article le 13 mars 2009
Il existe plein d'endroits au monde où l'accès à l'Internet est filtré, par exemple par le passage obligatoire des requêtes HTTP à travers un relais qui va tenter de déterminer si la page Web qu'on veut voir est légitime ou pas. Ces relais fonctionnent en général en combinant une liste noire d'URL interdits et une liste blanche d'URL autorisés. Ces listes sont maintenues au petit bonheur la chance et sont une grande source d'agacement pour les utilisateurs, comme le montre le filtrage dans les bibliothèques parisiennes.
On croit souvent que ce filtrage n'existe que chez les sauvages, par exemple à Dubaï ou bien au fin fond du Texas. Mais on le trouve dans beaucoup d'endroits et des exaltés comme Frédéric Lefebvre voudraient le généraliser (« Combien faudra-t-il de jeunes filles violées pour que les autorités réagissent ? »).
La Mairie de Paris, qui gère un excellent
réseau de bibliothèques municipales, munies d'accès Internet, l'a
entendu. Un filtrage automatique est en place et il n'est pas très
subtil. Le site de tagging
del.icio.us, ayant récemment changé son
nom de domaine de
del.icio.us en delicious.com
en a fait l'expérience et s'est retrouvé classé dans la rubrique
Pornographie (le message du filtre ne donne pas
la raison mais elle apparrait dans l'URL, paramètre
CAT, par exemple http://195.154.158.97:81/public/stop.htmopt?CAT=[art-lg|pornographie-ac]&RULE=[General]&DATETIME=[13/Mar/2009:17:41:01]&FILE=-&CODE=06dc8bf5cf7f7f496d71a83eba063d3ffbdbf69ee9f246546bf8b3237503f730a902db232a8b86f9d577b9f62db0c7d5d767f0ed91f98f8b4408d4c824db1f8f63e19a6cbba131e108be8f63c32211bd39275e99f61120df&LANG=fra&URL=http://en.wikipedia.org/wiki/Hustler).
Après, c'est une page du Wikipédia anglophone,
http://en.wikipedia.org/wiki/Discover_(magazine). Pourquoi
celle-ci (le reste du Wikipédia anglophone est accessible) ? Qu'est-ce
que ce malheureux magazine scientifique peut avoir fait de mal ? La
page Wikipédia consacrée à Hustler est dans la même situation (on peut
par contre lire l'article sur le Wikipédia francophone : bravo pour la
cohérence). C'est
absurde car, même si on trouve le journal original contestable,
l'article encyclopédique sur le journal devrait être accessible. Mais,
si je vois bien le problème que les puritains peuvent avoir avec
Playboy, qu'est-ce qui ne va pas avec Discover ? Qui a décidé de le
ranger dans « Pornographie » ? (La page de Wikipédia sur
Hitler est accessible, alors qu'il a
certainement fait bien plus de mal que Playboy...)
À chaque fois, en utilisant le formulaire de signalement d'un URL mal filtré, l'accès a été décoincé. Mais quelle perte de temps. Les bibliothécaires n'ont rien d'autre à faire que de maintenir à jour une liste d'URL ?
L'article seul
Fiche de lecture : The world without us
Auteur(s) du livre : Alan Weisman
Éditeur : Picador
978-0-312-42790-0
Publié en 2008
Première rédaction de cet article le 13 mars 2009
Qu'adviendrait-il du monde, des animaux et végétaux qui le peuplent, des choses que nous avions construites, si l'humanité disparaissait, victime d'une épidémie, d'un enlèvement comme dans le roman Left Behind, ou bien de n'importe quelle autre cause ? La nature reconquérerait-elle son territoire ? Les futurs visiteurs extraterrestres retrouveront-ils quelque chose de nous ? C'est le point de départ de ce livre (ou, plus exactement, de cette série d'articles) scientifico-journalistique.
Le thème « Après l'humanité » a inspiré beaucoup d'auteurs de science-fiction mais Alan Weisman l'aborde sous l'angle du « reportage scientifique ». Il y a plusieurs études de cas. Par exemple, un reportage dans la forêt de Białowieża permet de se demander si les bisons qui l'occupent pourraient repeupler l'Europe en cas de disparition de l'homme. Une étude de la situation à Chypre, où une part de l'île est interdite à tout humain depuis la guerre de 1974 donne une idée de ce qui arrivera à certains de nos bâtiments (les constructions bon marché du vingtième siècle disparaitront vite, voir les chapitres 2 et 3 pour les détails). En Corée, c'est la nature qui a bien profité de la guerre et de la zone démilitarisée qui s'étend entre les deux moitiés du pays.
Conclusion : la nature, si mal en point qu'elle soit, n'a pas encore été éradiquée. À partir de zones sauvegardés comme Tchernobyl (où les radiations sont moins dangereuses que les chasseurs), elle reprendra vite sa place sur les terrains autrefois occupés par nous et la plupart des artefacts humains disparaitront vite et laisseront les archéologues extra-terrestres du futur bien démunis. Parmi les exceptions, les statues en bronze (chapitre 18), les déchets radioactifs (chapitre 15) et les plastiques (chapitre 9), sans doute l'héritage le plus durable que nous laisserons sur Terre.
Le livre, qui a grossi à partir d'un article de Discover, est plutôt éclaté et les différents chapitres n'ont pas vraiment de lien. Il faut plutôt le lire en s'arrêtant entre chaque chapitre. Mais le ton est sympa, on voyage beaucoup et on ne voit pas le temps passer. Reste la question que l'auteur ne pose que par à-côtés : faudra t-il éliminer l'espèce humaine pour que la nature ne disparaisse pas complètement ?
L'article seul
RFC 2645: ON-DEMAND MAIL RELAY (ODMR) ; SMTP with Dynamic IP Addresses
Date de publication du RFC : Août 1999
Auteur(s) du RFC : R. Gellens (Qualcomm)
Chemin des normes
Première rédaction de cet article le 11 mars 2009
Le protocole de transfert de courrier électronique SMTP, normalisé dans le RFC 5321, est prévu pour des cas où la connexion est la règle et l'absence de connexion une exception. S'il ne peut joindre le serveur suivant, le MTA SMTP réessaie de temps en temps, pendant trois à cinq jours puis renonce. Ce mécanisme ne marche pas lorsque le serveur suivant n'a pas d'adresse IP fixe, ce qui est fréquent, ou bien lorsqu'il est fréquemment déconnecté (tellement fréquemment que les périodes où l'envoyeur essaie ont de fortes chances de ne pas coïncider avec celles où le receveur est connecté). Il existe plusieurs solutions à ce problème et notre RFC normalisait ODMR (On-demand mail relay), également appelé ATRN (Authenticated TURN). Il n'a pas été un succès et reste très peu déployé aujourd'hui.
Parmi les concurrents de ODMR, une autre
extension de SMTP, ETRN,
normalisée dans le RFC 1985. Mais ETRN nécessitait une
adresse IP fixe. Au contraire, le principe de
ODMR, une extension de SMTP, est simple : le receveur contacte
l'envoyeur en SMTP, sur le port 366, à son
choix, à l'heure qu'il veut,
s'authentifie, et envoie une commande SMTP, ATRN
qui prend en paramètre un ou plusieurs noms de domaine. L'envoyeur
expédie alors, toujours en SMTP, le courrier de ce domaine (section 4 du RFC). Voici un
exemple, pris dans la section 6, où le receveur est example.org et son
fournisseur de courrier, qui lui garde en attendant la connexion de
son client, est example.net :
P: 220 EXAMPLE.NET on-demand mail relay server ready C: EHLO example.org P: 250-EXAMPLE.NET P: 250-AUTH CRAM-MD5 EXTERNAL P: 250 ATRN C: AUTH CRAM-MD5 P: 334 MTg5Ni42OTcxNzA5NTJASVNQLkNPTQo= C: Zm9vYmFyLm5ldCBiOTEzYTYwMmM3ZWRhN2E0OTViNGU2ZTczMzRkMzg5MAo= P: 235 now authenticated as example.org C: ATRN example.org,example.com P: 250 OK now reversing the connection C: 220 example.org ready to receive email P: EHLO EXAMPLE.NET C: 250-example.org C: 250 SIZE P: MAIL FROM: <Lester.Tester@dot.foo.bar> C: 250 OK P: RCPT TO: <l.eva.msg@example.com> C: 250 OK, recipient accepted ... P: QUIT C: 221 example.org closing connection
La machine à états complète d'ODMR est
présentée en section 5. Notez que
l'authentification est obligatoire (section 5.1.2). Pour
réclamer le courrier de example.org, il faut
prouver qui on est ! Dans l'exemple ci-dessus, l'authentification se
fait en CRAM-MD5, la seule méthode que tous les
clients et serveurs ODMR doivent mettre en
œuvre. ATRN lui-même est décrit en section
5.2.1. Comme dans l'exemple ci-dessus, il peut prendre plusieurs noms
de domaine comme paramètre. Le « retournement » de la session SMTP est
dans la section 5.3 (le serveur ODMR devient client SMTP et
réciproquement). Les codes de réponse ODMR sont en section 7. Par
exemple, un ATRN lorsqu'il n'y a pas eu
authentification renvoie 530 Authentication required.
Comme indiqué plus haut, ODMR nécessite un accord préalable avec un
fournisseur de messagerie (qui peut être n'importe où sur
l'Internet et n'est pas forcé d'être le
FAI). Les enregistrements MX du domaine du récepteur, mettons
example.org, sont alors pointés vers le serveur
ODMR du fournisseur. Je ne trouve pas de liste de fournisseurs gérant
ODMR, probablement parce que cette technique n'est quasiment plus utilisée.
Le fournisseur, outre l'exigence d'authentification, peut prendre d'autres précautions comme de restreindre l'accès au port 366 à certaines adresses IP (section 8).
J'ai indiqué qu'ODMR semble abandonné. Quelles sont les alternatives ? On trouve des solutions spécifiques d'un fournisseur, avec un protocole privé tournant sur un port donné, sur lequel le client est censé se connecter pour annoncer sa disponibilité. Aujourd'hui, comme hier, UUCP semble nettement dominer ce domaine d'application.
Il ne semble pas exister beaucoup d'implémentations activement maintenues de ODMR. Le démon odmr semble fonctionner avec le MTA Postfix. Brian Candler avait écrit un odmrd pour Courier, démon qui ne semble plus exister. Un plan détaillé de mise en œuvre dans Postfix avait été écrit mais ne semble pas avoir été mené à bout.
Côté client (le receveur de courrier), fetchmail gère ODMR, on peut utiliser l'option --protocol ODMR.
L'article seul
La loi Hadopi à l'Assemblée Nationale
Première rédaction de cet article le 10 mars 2009
Dernière mise à jour le 10 avril 2009

{kind=link}
L'Assemblée Nationale commence aujourd'hui l'examen du projet de loi Hadopi. Si elle est adoptée, cette loi innovera en droit pénal en permettant des sanctions sans aucune procédure judiciaire.
En effet, aux sanctions existantes et qui ne sont pas modifiées (et qui vont déjà très loin), Hadopi ajouterait la possibilité de couper l'accès Internet d'un citoyen qui serait accusé par les majors des médias de copie illégale de fichiers. Le tout sans aucune protection contre des dénonciations abusives.
Il y a d'autant plus de raisons d'être inquiet de ces dénonciations que la protection des gros éditeurs et de quelques ultra-vedettes comme Johnny Hallyday ou Luc Besson mène en général à des envolées de propagande particulièrement outrancières. Des fameuses sauterelles aux accusation grand-guignolesques de Frédéric Lefebvre, rien n'est trop beau lorsqu'il s'agit de protéger les amis bling-bling du président.
Heureusement, le 10 mai, la loi liberticide a été rejetée par l'Assemblée. Le gouvernement, fidèle aux principes de la Cinquième République, a déjà annoncé qu'il ne tiendrait pas compte de ce vote et représenterait le texte de loi jusqu'à ce qu'il soit enregistré par la Chambre d'Enregistrement.
Quelques articles intéressants sur Hadopi : Projet de Loi « création et internet » : mort de la création, mort de l'internet, requiem des libertés, HADOPI, mon amie, qui es-tu ? (notez un conseil juridique pratique : « Surtout, n'acceptez pas de signer le récépissé (rien ne vous y oblige dans la loi), et si vous recevez une lettre recommandée de la CPD [Commission de Protection des Droits], ne l'acceptez pas. ») et le dossier de l'APRIL.
L'article seul
RFC 5424: The syslog Protocol
Date de publication du RFC : Mars 2009
Auteur(s) du RFC : R. Gerhards (Adiscon)
Chemin des normes
Première rédaction de cet article le 10 mars 2009
Mettant à jour l'ancienne description, voici la nouvelle spécification du protocole syslog, protocole de transmission d'informations sur les événements observés par un système.
syslog est un très ancien protocole, qui,
comme souvent sur l'Internet,
n'avait pas été normalisé pendant longtemps. Seul l'examen des sources
du programme syslogd ou bien l'étude des paquets
passant sur le réseau, permettaient de décrire le protocole. Le
premier RFC à formaliser syslog était le RFC 3164, qui vient d'être remplacé par notre RFC. Au contraire de
son prédécesseur, qui décrivait l'existant, ce nouvel RFC et ses
compagnons normalisent un nouveau
protocole, en étendant l'ancien syslog, le BSD
syslog (l'annexe A.1 discute des différences entre les deux protocoles). Parmi les changements du nouveau protocole, notons une description
modulaire, qui sépare le format utilisé (qui fait l'objet de notre
RFC) du protocole utilisé pour le transport des données (voir par
exemple le RFC 5426).
syslog sert à transmettre des rapports sur des événements survenus
dans un système. Le programme client (originator) qui signale les événements
transmet à un serveur syslog (collector), situé sur la même machine ou bien
ailleurs sur le réseau. Le serveur syslog, typiquement configuré sur
Unix via le fichier
/etc/syslog.conf va ensuite enregistrer ces
événements, par exemple dans un fichier comme
/var/log/mail.log. Ces fichiers, véritables
journaux de bord du système, permettent à
l'ingénieur de suivre tout ce qui se passe. On y trouvera des informations
telles que la date, le nom de la machine où à été noté l'événement, un
court texte décrivant celui-ci, etc. Par exemple :
Nov 29 21:18:11 ludwigVI dhcpd: DHCPREQUEST for 172.19.1.25 from 00:1c:23:00:6b:7f via eth0
où le serveur DHCP a signalé une requête pour une adresse IP, ou bien :
Nov 29 21:06:17 foobar named[2418]: lame server resolving 'oasc08a.247realmedia.com' (in 'oasc08a.247realmedia.com'?): 64.191.219.251#53
où le serveur de noms BIND note un problème avec un domaine.
syslog est un immense succès. Non seulement tous les
démons Unix l'utilisent pour signaler les
événements qu'ils observent (tournant en permanence, sans console,
sans utilisateur qui les suit, ils n'ont que ce canal pour
communiquer) mais tout routeur, tout
commutateur réseau a aussi un client syslog,
qu'on peut configurer pour envoyer les messages à un serveur, souvent
Unix, qui écoute sur le réseau et note tout. (Avec
IOS, par exemple, cela se fait avec les commandes logging facility local3 - ou un autre service que local3 - et
logging 192.0.2.84 pour indiquer l'adresse IP du serveur syslog.)
On peut aussi utiliser syslog pour noter manuellement des événements qu'on détecte.
L'architecture complète peut être plus complexe qu'un simple client/serveur, la section 4.1 donnant plusieurs exemples.
Rien ne garantit la bonne délivrance des messages, syslog est typiquement unidirectionnel (les sections 5.1 et 8.5 discutent plus en détail cette question).
La section 6 discute en détail du format des messages syslog,
format conçu pour rester compatible avec le précédent, tout en
permettant davantage de structuration (l'ancien format avait très peu
de structure et il était donc difficile d'en extraire automatiquement
des informations, par exemple pour le filtrage des événements avec un
programme comme Swatch). Le premier champ d'un
en-tête syslog, nommé PRI est écrit entre < et
> et code le service
(facility) et la gravité
(severity) du message. Le service indique quelle
partie du système a noté l'événements (2, le sous-système de courrier, 4,
la sécurité, etc). Notons que ce système est très rigide et ne permet
pas une grande finesse dans le classement. La gravité permet, elle, de distinguer les messages de
débogage (gravité 7), de simple information (gravité 6) et ainsi de
suite jusqu'aux
extrêmes urgences (gravité 0). Service et gravité sont encodés dans un
seul nombre en multipliant le premier par 8, donc, si j'émets un
message du service 16 (« usage local 0 ») avec une gravité de 3
(erreur), ici avec la commande logger :
% logger -p local0.error "Test syslog"
Le message sur le réseau commencerait par <131>
(16 * 8 + 3).
L'en-tête permet ensuite d'indiquer le numéro de version de syslog, la date, le nom de la machine émettrice, le nom de l'application (logger, cité plus haut, met par défaut le nom de l'utilisateur), un numéro qui peut identifier une instance de l'application (sur Unix, c'est typiquement le numéro de processus mais le RFC note à juste titre que ce champ ne peut pas avoir de signification standard)...
Une nouveauté de ce RFC est la présence de données structurées,
après l'en-tête et avant le message. Ces données sont formatées de
telle façon qu'un serveur syslog de l'ancien protocol peut toujours
les traiter comme du texte. Elles s'écrivent sous forme de doublets
attribut-valeur placés entre crochets. Les noms d'attributs possibles
sont décrits dans la section 7 et font l'objet d'un registre IANA (section 9.2). Un exemple est [meta
language="fr"] pour indiquer que le texte est en français
ou bien [timeQuality tzKnown="1" isSynced="1"]
pour indiquer que la machine qui a émis le message connait son fuseau
horaire et que son horloge est synchronisée, par exemple par
NTP.
Enfin, le message se termine par du texte libre, encodé en UTF-8. Le RFC cite ainsi comme exemple un message complet avec son en-tête :
<34>1 2003-10-11T22:14:15.003Z mymachine.example.com su - ID47 - BOM'su root' failed for lonvick on /dev/pts/8
syslog étant un protocole assez primitif, fonctionnant souvent sur le simple UDP, il n'est pas étonnant qu'il aie connu quelques problèmes de sécurité et que la section 8, consacrée à ce sujet, soit très détaillée. Parmi les nombreuses questions discutées, on peut citer par exemple le rejeu (section 8.4), contre lequel syslog n'a pas de protection, l'absence de garantie de délivrance des messages (section 8.5, qui note qu'on peut avoir de bonnes raisons de ne pas vouloir cette garantie), l'absence de contrôle de congestion, qui rend possible une noyade d'une machine sous les messages syslog (section 8.6), etc.
Une mise en œuvre comme rsyslog gère les principales nouveautés de ce RFC (comme le transport sur TCP, avec ou sans TLS).
L'article seul
RFC 5425: TLS Transport Mapping for Syslog
Date de publication du RFC : Mars 2009
Auteur(s) du RFC : F. Miao (Huawei), Y. Ma (Huawei), J. Salowey (Cisco)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF syslog
Première rédaction de cet article le 10 mars 2009
Le protocole syslog, de transport des données de journalisation entre deux machines TCP/IP, a toujours souffert de son absence de sécurité. Ce RFC normalise un transport des données authentifié et chiffré, grâce au protocole TLS, et permet donc de combler une des failles de sécurité de syslog.
Les sections 8.5, 8.7 et 8.8 du RFC 5424 et la section 2 de notre RFC 5425 notent bien que de nombreuses attaques sont possibles contre le syslog traditionnel. Notamment, deux nous intéressent particulièrempent ici :
- La possibilité d'écouter les données, souvent sensibles, qui circulent sur le réseau,
- La possibilité pour un tiers d'intercepter des données à la place du vrai récepteur.
Il faut aussi se rappeler qu'un message syslog peut être relayé par des machines intermédiaires, augmentant ainsi les risques. TLS (RFC 5246) traite ces deux problèmes pour bien d'autres protocoles. Il utilise la cryptographie pour protéger les communications des indiscrets et des usurpateurs. Son utilisation pour syslog allait donc de soi.
La section 2 expose par contre que certains risques ne sont pas pris en compte, par exemple celui de déni de service. TLS augmente plutôt ce risque, en exigeant davantage de ressources disponibles de la part des deux machines. (Le transport UDP du RFC 5426 est plus léger mais bien moins sûr.) La section 3 fait remarquer que l'usage de TLS ne protège pas non plus contre un faux message : si on veut signer ses messages syslog, il faut utiliser un autre mécanisme, actuellement en cours de développement.
Enfin, la section 4 décrit en détail le protocole. Il utilise le port 6514. Il se sert des certificats du RFC 5280 pour l'authentification de l'autre machine (sections 4.2 et 5, la seconde sur les politiques d'authentification). Les données sont ensuite simplement encapsulées dans TLS (section 4.3).
Je ne connais pas encore de mise en œuvre du protocole syslog qui aie ce transport sécurisé.
L'article seul
RFC 5426: Transmission of syslog messages over UDP
Date de publication du RFC : Mars 2009
Auteur(s) du RFC : A. Okmianski (Cisco)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF syslog
Première rédaction de cet article le 10 mars 2009
La nouvelle version du protocole syslog offre désormais le choix du protocole de transport. Il y aura un RFC par transport et celui-ci normalise le transport sur UDP.
Le RFC 5424, qui définit la nouvelle version du protocole syslog comporte une innovation : le protocole de transport peut être choisi séparément du format des données transmises. Historiquement, syslog a toujours été transporté sur UDP et notre RFC normalise cette pratique. Le transport UDP est même rendu obligatoire, pour assurer l'interopérabilité.
Le RFC est court, car il y a peu de détails à préciser. Parmi ceux-ci, notons les questions de taille des paquets (section 3.2), où un minimum est imposé (480 octets en IPv4) et où il est recommandé de se tenir à la MTU du lien comme maximum (le maximum théorique étant celui d'UDP, 65535 octets).
Le RFC normalise également le port utilisé (c'est le port historique, 514).
La section 4 détaille les conséquences pour syslog de la nature non-fiable d'UDP. Les paquets syslog transmis sur UDP peuvent donc être perdus et l'application doit en tenir compte. De même, UDP ne fournissant pas de contrôle de congestion, un émetteur syslog doit donc prendre soin de ne pas émettre de messages au maximum de ses capacités.
Enfin, la section 5, consacrée à la sécurité, rappelle l'absence presque complète de sécurité du transport UDP, qui ne protège contre rien, rendant son utilisation à l'extérieur du réseau local très dangereuse.
L'article seul
RFC 4001: Textual Conventions for Internet Network Addresses
Date de publication du RFC : Février 2005
Auteur(s) du RFC : M. Daniele, B. Haberman, S. Routhier, J. Schoenwaelder
Chemin des normes
Première rédaction de cet article le 9 mars 2009
Il y a plein de normes Internet dans lesquelles il faut représenter sous forme texte des adresses IP. Parmi elles, les MIB, normalisées dans le RFC 2578 pour la gestion des réseaux (cf. section 2 du RFC et le RFC 3410). Comment représenter une adresse ? La question est un peu plus difficile que cela ne parait et méritait une norme.
Notre RFC spécifie donc à quoi doit ressembler une adresse IP dans
une MIB. Par exemple, le RFC 4292 normalise une MIB pour le
routage des paquets IP et doit donc indiquer des adresses, par exemple
pour les objets inetCidrRouteNextHop qui
indiquent l'adresse du « routeur suivant ». Notez que notre RFC 4001 peut même être utilisé en dehors du monde des MIB comme
dans le RFC 5388 qui décrit un schéma XML pour
les résultats d'un traceroute et qui doit donc
également contenir des adresses IP.
Contrairement à une croyance répandue, il n'existe pas de norme
générale pour la représentation des adresses
IPv4. Le RFC 791 est muet
à ce sujet et, bien qu'il y ait une représentation courante
(192.0.2.134), d'autres représentations sont possibles. Pour
IPv6, en revanche, il existe une représentation
texte normalisée, dans le RFC 5952.
Notez bien que le RFC 4001 ne normalise que la représentation d'adresses IP « pures » sans les informations liées à la couche transport comme le port. Pour des adresses généralisées, voir le RFC 3419.
C'est la section 3 qui contient les définitions des représentations des adresses IP en ASN.1. On note que les noms de domaine sont inclus comme alternative :
InetAddressType ::= TEXTUAL-CONVENTION
...
ipv4(1) An IPv4 address as defined by the
InetAddressIPv4 textual convention.
ipv6(2) An IPv6 address as defined by the
InetAddressIPv6 textual convention.
...
dns(16) A DNS domain name as defined by the
InetAddressDNS textual convention.
...
InetAddressIPv4 ::= TEXTUAL-CONVENTION
DISPLAY-HINT "1d.1d.1d.1d"
STATUS current
DESCRIPTION
"Represents an IPv4 network address:
Octets Contents Encoding
1-4 IPv4 address network-byte order
...
InetAddressIPv6 ::= TEXTUAL-CONVENTION
DISPLAY-HINT "2x:2x:2x:2x:2x:2x:2x:2x"
STATUS current
DESCRIPTION
"Represents an IPv6 network address:
Octets Contents Encoding
1-16 IPv6 address network-byte order
The corresponding InetAddressType value is ipv6(2).
...
SYNTAX OCTET STRING (SIZE (16))
La section 4, quant à elle, donnant des indications sur l'usage de ces variables. On trouve aussi des adresses munies d'un zone index, qui indique le réseau auquel elles appartiennent, pour le cas d'adresses locales au lien par exemple celles du RFC 3927 pour IPv4 ou du RFC 4007 pour IPv6 (section 4.2).
Enfin, le RFC se conclus sur un exemple d'utilisation (section 5)
pour une MIB imaginaire de peerAddress :
peerTable OBJECT-TYPE
SYNTAX SEQUENCE OF PeerEntry
...
::= { somewhere 1 }
peerEntry OBJECT-TYPE
SYNTAX PeerEntry
...
INDEX { peerAddressType, peerAddress }
::= { peerTable 1 }
PeerEntry ::= SEQUENCE {
peerAddressType InetAddressType,
peerAddress InetAddress,
...
}
peerAddressType OBJECT-TYPE
SYNTAX InetAddressType
...
::= { peerEntry 1 }
peerAddress OBJECT-TYPE
SYNTAX InetAddress (SIZE (1..64))
...
DESCRIPTION
"The Internet address for the peer. The type of this
address is determined by the value of the peerAddressType
object. ...
::= { peerEntry 2 }
Ce RFC remplace le RFC 3291 avec peu de changements (détaillés en section 8).
L'article seul
RFC 5485: Digital Signatures on Internet-Draft Documents
Date de publication du RFC : Mars 2009
Auteur(s) du RFC : R. Housley (Vigil Security)
Pour information
Première rédaction de cet article le 6 mars 2009
Dernière mise à jour le 13 décembre 2010
Lorsqu'un document, par exemple un Internet-Draft est publié et distribué via l'Internet, il peut être difficile de prouver qu'il est bien « authentique », qu'il a été validé et pas modifié ensuite. La technique la plus courante pour cela est la signature cryptographique et ce nouveau RFC explique comment elle s'applique aux Internet-Drafts.
Le principe est le suivant : lors de la réception d'un nouvel Internet-Draft le secrétariat de l'IETF le signe au format CMS (RFC 3852), en utilisant un certificat X.509 (qui reste apparemment à publier). La signature, détachée de l'Internet-Draft, au format PKCS#7, est publiée avec les Internet-Drafts.
Pourquoi CMS et pas PGP tel que normalisé dans le RFC 4880 ? Je l'ignore mais c'est sans doute lié au fait que les défenseurs de X.509 sont plus bruyants, beaucoup d'argent est en jeu pour eux, avec les coûteuses AC.
Les détails, maintenant. CMS utilise ASN.1 (section 1.2) et ASN.1 a certains encodages qui permettent plusieurs représentations de la même donnée. C'est évidemment gênant pour la signature et notre RFC impose donc l'encodage DER qui n'a pas ce défaut.
Le texte de l'Internet-Draft devra être canonicalisé. Pour les Internet-Drafts au format texte seul, il faut notamment avoir une forme unique pour les fins de lignes, la forme standard CRLF (cf. annexe B du RFC 5198, la seule norme de cette forme standard). Pour ceux en XML (section 2.3), suivant la norme XML, ce sera LF qui marquera la fin de ligne. Les autres formats seront simplement traités comme du binaire.
CMS est une norme très complexe et la
section 3 est consacrée à définir un profil de CMS pour nos
signatures. C'est aussi l'occasion de spécifier quelques points
pratiques comme l'importance pour le secrétariat qui publie les Internet-Drafts
d'avoir des ordinateurs à l'heure, pour que l'attribut
Signing-Time (section 3.2.3.3) soit correct.
Enfin, comme le but de toute l'affaire est la sécurité, le RFC se termine sur des Security Considerations (sections 5 et 6) qui recommandent l'usage de HSM pour stocker la clé privée de l'IETF.
Les signatures détachées portent l'extension
p7s (section 2 et cf. RFC 3851). Les
signatures peuvent être vérifiées avec OpenSSL
(version 0.9.9 minimum car il faut la commande
cms, et version 1.0 maximum, en raison d'un
problème avec la 1.1, vous pouvez taper openssl
version pour tester votre version). En attendant que
j'installe cette version, j'ai fait les essais suivants avec la
commande smime, puisque
S/MIME et CMS ont
beaucoup en commun.
Si je suis un simple lecteur d'Internet-Drafts et que je veux vérifier une signature (annexe A) :
% openssl smime -verify -CAfile $CERT -content ${id} \
-inform DER -in ${id}.p7s -out /dev/null
où id est le nom de l'Internet-Draft et
CERT celui du fichier .pem
contenant le certificat de l'IETF. Si tout se passe bien, OpenSSL
répondra :
Verification successful
et si un seul caractère de l'Internet-Draft a été modifié :
Verification failure 14024:error:04077068:rsa routines:RSA_verify:bad signature:rsa_sign.c:235: 14024:error:21071069:PKCS7 routines:PKCS7_signatureVerify:signature failure:pk7_doit.c:981: 14024:error:21075069:PKCS7 routines:PKCS7_verify:signature failure:pk7_smime.c:312:
Si je veux juste regarder le certificat contenu dans la signature :
% openssl pkcs7 -print_certs -inform DER -in ${id}.p7s
subject=/C=FR/L=Paris/O=Bidon/CN=Ca essai
issuer=/C=FR/L=Paris/O=Bidon/CN=CA essai
Si je suis le secrétariat de l'IETF et que je veux signer un Internet-Draft (bien sûr, dans la réalité, cela ne sera pas fait à la main avec la ligne de commande) :
% openssl smime -sign -in $id -inkey privkey.pem -outform DER -binary \
-signer mycacert.pem -out ${id}.p7s -noattr
Si vous voulez faire l'essai complet, le moyen le plus rapide de créer
l'infrastructure du secrétariat (les fichiers
privkey.pem et mycacert.pem)
est :
% openssl genrsa -out privkey.pem 1024 % openssl req -sha1 -new -x509 -key privkey.pem -out mycacert.pem -days 1095
À noter que cette technique ne s'applique qu'aux Internet-Draft, pas aux RFC eux-même (et cela sera sans doute difficile en raison de l'extrême prudence du RFC editor).
La mise en service de ce système a eu lieu (avec retard) en décembre 2010 et son mode d'emploi est désormais documenté.
Ce RFC a été légèrement mis à jour par la suite avec le RFC 8358.
L'article seul
Les structures de données IP en C
Première rédaction de cet article le 5 mars 2009
Dernière mise à jour le 6 mars 2009
Comme je ne programme pas en C tous les jours, à chaque fois que je m'y remets (et c'est en général pour un programme réseau), j'ai du mal avec les structures de données qui servent à IP. Alors, pour garder trace de ce que j'ai compris la dernière fois, le plus simple est encore d'en faire profiter l'univers en mettant quelques notes sur ce blog.
Les structures de données qui stockent les adresses IP, les métadonnées sur ces adresses comme leur famille (IPv4 ou IPv6), les prises, etc, sont complexes. Mais c'est le résultat d'un choix de faire assez général, notamment pour permettre au même programme de gérer IPv4 et IPv6, avec le minimum de modifications.
Donc, la structure de données la plus importante est la
struct addrinfo. Elle stocke tout ce qu'il faut
pour se connecter à une machine, notamment son adresse
IP. Pour pouvoir être chaînée à d'autres struct
addrinfo, elle se termine par un pointeur vers la structure
suivante. Sa définition officielle est dans le RFC 3493 et on trouve le code (un peu plus complexe qu'ici) dans
/usr/include/netdb.h :
struct addrinfo {
int ai_flags; /* AI_PASSIVE, AI_CANONNAME */
int ai_family; /* PF_xxx */
int ai_socktype; /* SOCK_xxx */
int ai_protocol; /* 0 or IPPROTO_xxx for IPv4 and IPv6 */
socklen_t ai_addrlen; /* length of ai_addr */
char *ai_canonname; /* canonical name for hostname */
struct sockaddr *ai_addr; /* binary address */
struct addrinfo *ai_next; /* next structure in linked list */
};
On voit donc que les adresses sont de type struct
sockaddr. Ce type est défini dans
/usr/include/sys/socket.h (parfois via une
inclusion d'un autre fichier) et vaut :
struct sockaddr {
uint8_t sa_len; /* total length */
sa_family_t sa_family; /* address family */
char sa_data[14]; /* address value */
};
Le point important est que c'est une structure générique, qui
marche aussi bien pour IPv4 que pour IPv6. Pour extraire des
informations pertinentes à ces deux protocoles, il faut convertir les
struct sockaddr génériques en struct
sockaddr_in et struct sockaddr_in6
spécifiques. Cela se fait en général en convertissant les pointeurs (exemple ci-dessous lors de l'utilisation de inet_ntop()).. La
structure pour IPv6 vaut (/usr/include/netinet/in.h) :
struct sockaddr_in6 {
uint8_t sin6_len; /* length of this struct */
sa_family_t sin6_family; /* AF_INET6 */
in_port_t sin6_port; /* transport layer port # */
uint32_t sin6_flowinfo; /* IPv6 flow information */
struct in6_addr sin6_addr; /* IPv6 address */
uint32_t sin6_scope_id; /* set of interfaces for a scope */
};
et celle pour IPv4 :
struct sockaddr_in {
uint8_t sin_len;
sa_family_t sin_family;
in_port_t sin_port;
struct in_addr sin_addr;
__int8_t sin_zero[8];
};
Notez la padding de
huit octets à la
fin, qui lui permet d'avoir exactement la même taille que son
équivalente IPv6. Normalement, ce n'est pas garanti, si on veut une
structure de données qui puisse réellement contenir les deux familles
d'adresses, on devrait utiliser struct
sockaddr_storage (RFC 3493, section
3.10).
Nous nous approchons désormais sérieusement des adresses IP tout
court. Il reste une étape, regarder le champ
sin_addr ou sin6_addr. Il
est de type struct in_addr ou struct
in6_addr. La définition de ces structures est également
dans /usr/include/netinet/in.h
(in6_addr est présentée à la section 3.2 du RFC 3493) :
struct in_addr {
uint32_t s_addr;
};
...
struct in6_addr {
uint8_t s6_addr[16];
};
Les deux structures stockent la représentation binaire des adresses
IP, celle qui circule sur le câble : quatre octets pour IPv4 et 16
pour IPv6. Si vous regardez le fichier .h, vous verrez que
in6_addr est souvent représentée sous forme d'une
union, pour faciliter l'alignement.
Maintenant qu'on a ces structures de données, comment les utilise
t-on ? Pour remplir les struct addrinfo, on
utilise getaddrinfo() qui a remplacé
gethostbyname() il y a de très nombreuses
années. Par exemple, si le nom de la machine qu'on cherche est dans
server (un simple char *) :
/* hints and res are "struct addrinfo", the first one is an IN parameter, the second an OUT one. */ memset(&hints, 0, sizeof(hints)); hints.ai_family = PF_UNSPEC; /* v4 or v6, I don't care */ hints.ai_socktype = SOCK_STREAM; getaddrinfo(server, port_name, &hints, &res); /* Now, "res" contains the IP addresses of "server" */ /* We can now do other things such as creating a socket: */ sockfd = socket(res->ai_family, res->ai_socktype, protocol); /* And connecting to it, since connect() takes a "struct sockaddr" as input: */ connect(sockfd, res->ai_addr, res->ai_addrlen);
Notez que le code ci-dessus ne parcourt par la liste des adresses
renvoyée par getaddrinfo(), seule la première est
utilisée (ai_next est ignorée).
Dans la struct addrinfo passée en premier
paramètre à getaddrinfo(), une option est
particulièrement intéressante, AI_NUMERICHOST qui
permet de s'assurer qu'une chaîne de caractères, donnée par
l'utilisateur, a bien la syntaxe d'une adresse IP :
hints_numeric.ai_flags = AI_NUMERICHOST;
error = getaddrinfo(server, port_name, &hints_numeric, &res);
if (error && error == EAI_NONAME) { /* It may be a name, but
it is certainly not an address */
... /* Handle it as a name */
Et pour afficher des adresses à l'utilisateur humain ? Les
structures in_addr et
in6_addr stockent la forme binaire de l'adresse
mais, ici, on veut la forme
texte. Pour cela, deux fonctions sont fournies,
inet_ntop() pour traduire l'adresse
en texte et inet_pton() pour le
contraire. Supposons que la variable myaddrinfo
soit une struct addrinfo, afficher la première
adresse IP nécessite d'extraire ai_addr, de le
convertir dans la struct sockaddr du bon type
(struct sockaddr_in6 pour IPv6) et
d'appeler inet_ntop() avec les bons paramètres,
qui dépendent de la famille :
struct addrinfo *myaddrinfo;
struct sockaddr *addr;
struct sockaddr_in6 *addr6;
addr = myaddrinfo->ai_addr;
char *address_text;
...
if (myaddrinfo->ai_family == AF_INET6) {
address_text = malloc(INET6_ADDRSTRLEN);
addr = myaddrinfo->ai_addr;
addr6 = (struct sockaddr_in6 *) addr; /* Conversion between the
various struct sockaddr* is always possible,
since they have the same layout */
inet_ntop (AF_INET6, &addr6->sin6_addr, address_text,
INET6_ADDRSTRLEN);
}
else /* IPv4... */
Un descripteur de prise, lui, est très simple, c'est un bête entier :
int sockfd; ... sockfd = socket(...);
Il pointe, via la table des descripteurs (que vous ne manipulez jamais) vers la vraie prise. C'est toujours le descripteur qu'on passera comme paramètre pour agir sur la prise, par exemple pour la lier à une adresse donnée :
bind(sockfd, ...);
L'article IP
Addresses, structs, and Data Munging m'a beaucoup
aidé et fournit une excellente introduction. Pour tout connaître en
détail, la référence est bien sûr le livre de
Stevens, Unix Network
Programming. Merci à Samuel Tardieu pour ses
remarques sur la conversion des struct sockaddr.
L'article seul
RFC 5481: Packet Delay Variation Applicability Statement
Date de publication du RFC : Mars 2009
Auteur(s) du RFC : A. Morton (AT&T labs), B. Claise (Cisco)
Pour information
Réalisé dans le cadre du groupe de travail IETF ippm
Première rédaction de cet article le 4 mars 2009
Le RFC 3393 normalise une métrique de variation du délai d'acheminement des paquets. Cette métrique est assez souple pour que, en pratique, plusieurs formules aient été utilisées. Ce RFC en discute deux et précise leur usage.
Souvent, le délai moyen d'acheminement d'un paquet (ce que peut mesurer, dans une certaine mesure, la commande ping) n'est pas la seule métrique de délai intéressante. Il est souvent utile de connaître la variation de ce délai d'acheminement. Les applications « temps-réel » par exemple en vidéo sont en effet très sensible à la gigue, c'est-à-dire à cette variation, par exemple parce qu'elle va nécessiter de stocker les données dans un tampon, avant de commencer leur affichage, pour garantir que celui-ci reste lisse pendant toute la session (voir le RFC 3550 et la section 3 de notre RFC 5481). Outre le RFC 3393, cette gigue fait l'objet de la norme ITU Y.1540. En anglais, le mot jitter (gigue) est souvent utilisé mais le RFC préfère « variation de délai ».
Cette variation se mesure par rapport au délai d'acheminement d'un paquet (métrique définie dans le RFC 7679). Comme le rappelle la section 1, il y a deux grandes formulations possibles pour la variation de délai :
- Variation entre paquets ou IPDV (Inter-Packet Delay Variation), où on mesure par rapport au paquet précédent. C'est celle qui est utilisée dans le RFC 3550.
- Variation par rapport à un paquet ou PDV (Packet Delay Variation), où on mesure par rapport à un paquet donné, en général celui avec le plus petit délai de voyage.
Toutes les deux sont compatibles avec le RFC 3393.
La section 3 détaille les usages qui sont raisonnables pour cette métrique. Par exemple, la section 3.2 discute des « tampons de suppression de gigue », ces structures de données où les applications audio et vidéo gardent les données, pour compenser les variations du réseau. Les formules pour calculer leur taille optimale dépendent de la variation de délai d'acheminement. Ou bien la section 3.4 explique que cette variation peut être pertinente pour comparer les offres de deux opérateurs et qu'elle peut même faire l'objet d'un SLA.
Enfin la section 4 donne les définitions exactes pour les deux formules, IPDV et PDV. IPDV est en 4.1 et se définit simplement comme la différence entre le délai d'acheminement du paquet i et celui du paquet i-1 (l'IPDV peut donc être négatif). PDV, en section 4.2, est défini comme la différence entre le délai d'acheminement du paquet i et celui du paquet au délai le plus faible. Il est donc toujours positif (ou nul). (La section 12 revient sur le calcul de ce délai minimum, par rapport auquel tout est mesuré.)
Pour les érudits, la section 5 détaille la littérature existante sur la question et les comparaisons déjà faites entre IPDV et PDV. Ces comparaisons ont utiles pour estimer la « meilleure » formule pour un problème donné.
Le point de vue des auteurs du RFC est en section 7, consacrée à l'étude de l'applicabilité de chaque formule à divers problèmes. Ainsi, la question de la taille des tampons de suppression de gigue, en section 7.1.2 est tranchée en faveur de PDV, car le tampon est calculé pour que le paquet de délai maximum n'attende pas et que le paquet de délai minimum attende pendant toute la longueur du tampon. Même chose si on est en présence de nombreuses pertes de paquets (section 7.2.3) : IPDV se comporte mal dans ce cas car chaque perte fait aussi perdre la mesure qui aurait pu être faite au paquet suivant. Par contre, si on désire utiliser la variation de délai pour mesurer des changements de route sur le réseau, IPDV est préféré, pour les raisons expliquées en section 7.2.2 (meilleure isolation des effets de chaque changement).
La section 8 couvre les problèmes pratiques que pose la mesure. Par exemple, comme notre métrique est dérivée d'une métrique uni-directionnelle, la synchronisation des horloges des machines est cruciale. C'est ce qu'explique la section 8.5, qui recommande le GPS et déconseille NTP.
Pour mesurer la gigue avec du logiciel libre, voir le bon article de NicoLargo.
L'article seul
Décoder les paquets DNS capturés avec pcap
Première rédaction de cet article le 3 mars 2009
Dernière mise à jour le 5 mars 2009
Une fois capturés et stockés sur disque, au format pcap, les paquets doivent être disséqués pour trouver les éléments intéressants. Quels sont les particularités de la dissection de paquets DNS ?
L'article complet
Des certificats pour prouver qu'on est titulaire d'une ressource Internet
Première rédaction de cet article le 2 mars 2009
On le sait bien, le système de routage de l'Internet est très peu fiable, comme l'a montré par exemple le détournement du trafic de YouTube par Pakistan Telecom. Pourquoi ne pas sécuriser les annonces BGP par des signatures cryptographiques, comme on authentifie le DNS avec DNSSEC ? Il y a plusieurs raisons à cela, mais l'une est souvent oubliée : il n'y a pas de moyen facile de « prouver » qu'on est bien le titulaire d'une ressource Internet, par exemple une adresse IP.
Avant donc de vouloir transformer BGP en protocole utilisant la cryptographie, il faut donc d'abord distribuer aux titulaires de ressources numériques (adresses IP, numéros de systèmes autonomes, etc). Fin 2008, l'APNIC a été le premier RIR à avancer dans cette direction, en annonçant un logiciel de gestion de PKI de ressources, rpki-engine, et en prévoyant de commencer la distribution de certificats. Les extensions à X.509 pour ces ressources sont normalisées dans le RFC 3779.
Notons tout de suite que le déploiement ne survient pas maintenant par hasard : les adresses IPv4 s'épuisent et tout le monde s'attend à un développement du marché de ces adresses. Une pré-condition d'un tel marchéb étant l'équivalent des titres de propriété du monde physique, on voit que BGP ne sera pas le seul client de ces nouveaux certificats...
Un résumé du projet figure dans l'article Detecting Internet routing "lies". Un article très détaillé est Resource Certificates.
En février 2012, une nouvelle étape a été franchie, dans la voie de l'utilisation de ces certificats, avec la sortie des RFC spécifiant leur utilisation pour sécuriser le routage.
L'article seul
RFC 2046: Multipurpose Internet Mail Extensions (MIME) Part Two: Media Types
Date de publication du RFC : Novembre 1996
Auteur(s) du RFC : Ned Freed (Innosoft International, Inc.), Nathaniel S. Borenstein (First Virtual Holdings)
Chemin des normes
Première rédaction de cet article le 1 mars 2009
La norme MIME permettant de distribuer du contenu multimédia par courrier électronique est composée de plusieurs RFC dont le plus connu est le RFC 2045 qui décrit la syntaxe des messages MIME. Mais notre RFC 2046 est tout aussi important car il traite d'un concept central de MIME, le type des données. En effet, MIME attribue un type à chaque groupe de données qu'il gère. Cela permet d'identifier du premier coup telle suite de bits comme étant une image PNG ou une chanson codée en Vorbis. Ces types ont eu un tel succès qu'ils ont été repris par bien d'autres systèmes que MIME par exemple dans HTTP pour indiquer le type de la ressource envoyée au navigateur Web (avec Firefox, on peut l'afficher via le menu Tools, option Page info), ou même par certains systèmes d'exploitation comme BeOS qui, dans les métadonnées du système de fichiers, stocke le type de chaque fichier sous forme d'un type de média. Logiquement, le nom officiel a donc changé et on ne devrait plus dire type MIME mais « type du média ».
Ces types, conçus à l'origine pour être codés dans le message et
jamais vus par les utilisateurs ont finalement été diffusés largement
et presque tout auteur de contenu sur l'Internet a déjà vu des codes
comme text/html (une page
HTML), image/jpg (une
image JPEG) ou bien
application/octet-stream (un fichier binaire au
contenu inconnu). Si on veut voir la liste complète, ils sont
enregistrés dans un
registre à l'IANA, géré selon les règles du RFC 6838.
Quelle est la structure des types de média ? Chacun est composé de
deux parties (section 1 du RFC), le type de premier niveau comme
text ou audio qui identifie
le genre de fichiers auquel on a affaire (section 2) et le
sous-type qui identifie le format utilisé. Un
type est donc composé d'un type de premier niveau et d'un sous-type,
séparés par une barre oblique. Ainsi,
text/plain désigne des données au format
« texte seul » (type text
et format plain, c'est-à-dire sans aucun
balisage). application/msword
est un fichier lisible uniquement par un certain programme ou
catégorie de programmes (d'où le type de premier niveau
application) et au format
msword, c'est-à-dire le traitement de textes de Microsoft. Notez aussi le
type multipart, utile lorsqu'on transporte en
même temps des données de types différents (chaque partie sera alors
marquée avec son propre type de média).
Les types de média sont ensuite indiqués selon une méthode qui
dépend du protocole. Dans le courrier électronique, cela se fait avec
l'en-tête Content-Type par exemple pour un
message en texte seul :
Content-Type: text/plain;
charset="utf-8"
(Notez un paramètre supplémentaire, la mention de l'encodage, appelé par MIME charset, car un texte brut peut être en ASCII, en Latin-1, en UTF-32, etc. Voir section 4.1.2.)
Dans le monde du Web, voici un exemple affiché par le client HTTP wget :
% wget http://upload.wikimedia.org/wikipedia/commons/e/ec/En-us-type.ogg ... Length: 12635 (12K) [application/ogg] ...
Ici, un fichier Ogg (la prononciation
de « type » en anglais) a été chargé et le serveur
HTTP avait annoncé le type MIME application/ogg
(depuis le RFC 5334, cela devrait être
audio/ogg mais le changement est lent sur l'Internet).
La définition complète des types de premier niveau figure dans la
section 2. pour chaque type, on trouve sa description, les paramètres
qui ont du sens pour lui (comme charset dans
l'exemple plus haut), la manière de gérer les sous-types inconnus,
etc.
La section 3 décrit les sept types de premier niveau de l'époque (ils sont dix, début 2017). Il y a deux types composites et cinq qui ne le sont pas, détaillés en section 4.
Le plus simple, text est... du texte
et qu'on puisse visualiser sans logiciel particulier. L'idée est
également qu'on peut toujours montrer de telles données à un
utilisateur humain, même si le sous-type est inconnu (règle simple
mais pas toujours d'application simple, comme l'ont montré les
polémiques sur text/xml). Cela fait donc de
text un excellent format stable et lisible par
tous (et qui est donc utilisé pour les RFC eux-même). Les formats
illisibles sans logiciel particulier ne sont donc pas du
text au sens MIME. Des exemples de formats
text ? Évidement plain cité
plus haut, le texte brut mais aussi :
troff(RFC 4263),enrichedaliasrichtext, qui avait été créé spécialement pour MIME (RFC 1896) mais qui n'a jamais eu beaucoup de succès.csv(RFC 4180) pour des données au populaire format CSV.
En théorie, les formats de balisage légers modernes comme reST ou comme ceux des Wiki par exemple le langage de MediaWiki pourraient rentrer ici mais, en pratique, aucun sous-type n'a encore été enregistré.
La section sur les encodages, 4.1.2, recommande que le paramètre
charset soit le PGCD des
encodages possibles. Par exemple, si le texte ne comprend que des
carractères ASCII, charset="UTF-8" est correct
(puisque UTF-8 est un sur-ensemble d'ASCII)
mais déconseillé. mutt met en œuvre
automatiquement cette règle. Si on écrit dans sa configuration,
set send_charset=us-ascii:iso-8859-15:utf-8, mutt
marquera le message comme ASCII s'il ne comprend que des caractères
ASCII, sinon ISO-8859-15 s'il ne comprend que
du Latin-9 et UTF-8 autrement.
image (section 4.2), audio (section 4.3) et
video (section 4.4) sont décrits ensuite.
application (section 4.5) est plus difficile à saisir. Ce
type de premier niveau est conçu pour le cas où les données sont
définies par une application (ou un groupe d'applications puisque, par
exemple, de nombreuses applications peuvent lire le format
PDF, que le RFC 3778 a enregistré sous
le nom de application/pdf). Le RFC détaille
l'exemple de application/postscript pour le
langage Postscript (section 4.5.2). Ce type
application est souvent associé à des problèmes
de sécurité car charger un fichier sans précaution peut être dangereux
avec certains types de fichier ! Le RFC cite des exemples comme
l'opérateur deletefile de Postscript mais
beaucoup d'autres formats ont des contenus potentiellement « actifs ».
Il y a un certain recouvrement entre les domaines de
text et de application,
parfaitement illustré par le vieux débat sur le statut de
HTML : est-ce du texte ou pas ?
La section 3 couvre aussi le cas des types de premier niveau
composés comme multipart et
message, détaillés en section 5. Le premier
(section 5.1) permet de traiter des
messages comportant plusieurs parties, chaque partie ayant son propre
type. Par exemple, un message comportant du texte brut et une musique
en Vorbis sera
de type multipart/mixed et comportera deux
parties de type text/plain et
audio/ogg (ou, plus précisément, audio/ogg; codecs="vorbis"). On peut aussi avoir plusieurs
parties équivalentes (par exemple le même texte en texte brut et en
HTML) et utiliser alors le type
multipart/alternative. (Mais attention à bien
synchroniser les deux parties.)
Le second type composé, message (section 5.2) sert à
encapsuler des messages électroniques dans d'autres messages, par
exemple pour les faire suivre ou bien pour un avis de non-remise. Un
message au format du RFC 5322 sera ainsi marqué
comme message/rfc822 (le RFC 822 étant
l'ancienne version de la norme).
On peut aussi avoir des types de premier niveau et des sous-types
privés (section 6), attribués par simple décision
locale. Pour éviter toute confusion avec les identificateurs
enregistrés, ces identificateurs privés doivent commencer par
x- comme par exemple
application/x-monformat.
À noter qu'il n'existe pas de types MIME pour les
langages de programmation. Quasiment tous sont
du texte brut et devraient être servis en
text/plain. Leur donner un type n'aurait
d'intérêt que si on voulait déclencher automatiquement une action sur
ces textes... ce qui n'est en général pas une bonne idée, pour des
raisons de sécurité. C'est ainsi que seuls les langages
sandboxables
comme Javascript (RFC 9239) ont leur
type MIME. Résultat, on voit souvent les types privés utilisés,
par exemple le fichier /etc/mime.types qui, sur
beaucoup d'Unix, contient la correspondance
entre une extension et un type MIME, inclus,
sur une Debian,
text/x-python pour les fichiers
.py (code Python). Par
contre, pour C, le type est
text/x-csrc et pas simplement
text/x-c, sans doute pour être plus
explicite. Autre curiosité, je n'y trouve pas de type MIME pour les
sources en Lisp...
Ce RFC a remplacé l'ancien RFC 1522, les changements, importants sur la forme mais peu sur le fond, étant décrits dans l'annexe B du RFC 2049.
L'article seul
RFC 4251: The Secure Shell (SSH) Protocol Architecture
Date de publication du RFC : Janvier 2006
Auteur(s) du RFC : T. Ylonen (SSH communications security), C. Lonvick (Cisco)
Chemin des normes
Première rédaction de cet article le 27 février 2009
Pendant longtemps, les connexions interactives à une machine distante, via l'Internet, se faisaient par un protocole (telnet ou rlogin) qui ne chiffrait pas les communications et notamment le mot de passe échangé pour s'authentifier. D'innombrables sniffers ont ainsi capturés des mots de passe et les ont ensuite transmis à Eve, pour qu'elle en fasse un mauvais usage. L'arrivée de SSH, en 1995, a donc bouleversé la sécurité sur Internet. Sa simplicité d'usage, la possibilité de résoudre enfin la majorité des problèmes de sécurité de X11, et la sécurité qu'il offre lui ont permis de l'emporter facilement contre des concurrents compliqués à déployer et à utiliser comme Kerberos telnet.
SSH est désormais un des protocoles de base de l'infrastructure d'Internet. Il a plusieurs mises en œuvre dont une en logiciel libre, OpenSSH. Longtemps spécifié uniquement dans les documents liés à une mise en œuvre particulière, SSH est aujourd'hui normalisé dans une série de RFC dont ce RFC 4251 est le point de départ. Il décrit l'architecture générale, le RFC 4252 décrit le protocole d'authentification, le RFC 4253 le protocole de transport, le RFC 4254 le protocole de connexion et le RFC 4250 les différents identificateurs utilisés par SSH.
Les différents protocoles sont résumés dans la section 1 :
- Tout en bas, le protocole de transport (RFC 4253), authentifie le serveur et chiffre les communications avec lui.
- Un cran au dessus, le protocole d'authentification (RFC 4252) permet au client de s'authentifier auprès du serveur.
- Enfin, tout en haut, le protocole de connexion (RFC 4254) multiplexe plusieurs canaux (par exemple une session interactive de type shell et une session X11) sur un seul transport chiffré.
Quels sont les composants essentiels de SSH ? La section 4 les énumère. D'abord, il y a la notion de clé de machine (section 4.1). Il n'existe pas sur Internet de mécanisme général d'identité des machines. Ce manque est parfois gênant, par exemple dans un réseau pair-à-pair où on essaie de garder trace des services que rend un pair, ou bien dans des modèles de sécurité comme la Same Origin Policy de Javascript où le navigateur Web ne peut se connecter qu'à « la même machine » que celle d'où vient le code Javascript, sans que « la même machine » soit une notion définie rigoureusement, ce qui permet les changements d'adresse IP.
SSH fonctionne donc en donnant à chaque machine une identité qui
est sa clé publique (stockée, avec OpenSSH, en
/etc/ssh/ssh_host_dsa_key.pub). Cette clé
permettra de s'assurer qu'on parle bien à la machine attendue. Quel
modèle de confiance utiliser ? Le RFC en cite deux, une base locale
des clés publiques des machines connues, qui a l'avantage de ne pas
nécessiter de lourdes et chères PKI, ou bien
une PKI, avec une CA qui signe les clés. SSH
n'impose pas un modèle particulier mais encourage la première
méthode. En effet, le RFC insiste beaucoup sur la nécessité pour le
protocole d'être facile à utiliser et facilement déployable. Les PKI
en sont tout l'opposé et, si SSH avait imposé l'usage d'une PKI, il
n'aurait probablement jamais connu de succès (le RFC 5218 discute ce point). (Depuis, le RFC 4255 a fourni un mécanisme permettant de récupérer la clé
dans le DNS ; sans
DNSSEC, ce mécanisme ne vaut pas grand'chose.)
Pour peupler cette base locale, la même section 4.1 conseille un modèle dit TOFU (Trust On First Use) ou encore (mais ce terme est moins précis) leap of faith (acte de foi), où la clé est vérifiée systématiquement, sauf à la première connexion, où on demande juste à l'utilisateur son accord pour enregistrer la nouvelle machine, en lui indiquant l'empreinte de la clé publique :
% ssh susanna The authenticity of host 'susanna (2001:660:3003:3::1:3)' can't be established. DSA key fingerprint is 56:b7:62:30:11:d3:6d:b6:d5:ec:5d:1e:7e:3c:42:1e. Are you sure you want to continue connecting (yes/no)?
Si ce modèle rencontre l'opposition de certains experts en sécurité (car il rend SSH vulnérables aux attaques de l'homme du milieu lors de la première connexion), c'est aussi lui qui a permis le succès du déploiement de SSH, d'autant plus qu'il n'existe aucune PKI largement déployée sur l'Internet. Ici, le mieux était clairement l'ennemi du bien si on avait attendu une telle PKI, on utiliserait toujours des connexions non chiffrées et bien plus vulnérables. (La section 9.3.4 revient en grand détail sur le risque d'attaque par l'homme du milieu et sur la vérification des clés des machines auxquelles on se connecte.)
(À noter qu'aujourd'hui, des techniques comme Perspectives tentent d'améliorer le système TOFU.)
Les clés SSH sont donc en général non signées. On peut aussi, outre
les clés des machines, avoir des clés liées à un utilisateur. Celui-ci
les génère, avec OpenSSH, en tapant ssh-keygen,
et peut les utiliser pour s'authentifier, ce qui est plus sûr qu'un
mot de passe, car cela évite de transmettre un secret réutilisable (le
mot de passe) à une machine pas forcément fiable (le serveur). Les
sections 9.4.4 et 9.4.5 discutent les forces et les faiblesses des
deux mécanismes d'authentification : la clé publique ne nécessite pas
de transmettre un secret au serveur mais sa compromission sur la
machine client est toujours possible, et le serveur ne peut pas
contrôler si la machine client applique de bonnes politiques de sécurité.
Comme précisé dans la section 4.5, SSH peut utiliser plusieurs
algorithmes. La cryptographie et la
cryptanalyse évoluent en effet sans cesse et il
peut être nécessaire de changer les algorithmes de cryptographie
utilisés, sans changer le protocole (cf. section 9.3.1). Pour cela, chaque algorithme a un
nom (la section 6 détaille les règles de nommage) et peut être négocié
à l'établissement de la connexion (avec OpenSSH, option
-c en ligne de commande
et mot-clé Ciphers dans sshd_config). Les algorithmes officiels sont
enregistrés dans un registre IANA et les
non-officiels ont un nom qui inclus un @, par exemple
mon-algo@leroidelacrypto.fr.
La section 9, consacrée à l'étude détaillée des questions de sécurité est évidemment particulièrement longue. C'est une lecture indispensable pour qui veut évaluer la sécurité de SSH. 9.1 rappelle l'importance cruciale de bons algorithmes de génération de nombres aléatoires, une faiblesse classique en cryptographie (bien illustrée, par exemple, par la faille Debian/OpenSSL, qui a affecté OpenSSH sur Debian). Il est donc nécessaire de suivre les consignes du RFC 4086.
La section 9.3.1 discute le choix des algorithmes de cryptographie, en recommandant de s'appuyer sur l'état actuel de la science, en utilisant des algorithmes reconnus comme AES.
Certaines fonctions de SSH sont débrayables. La section 9.3.2
rappelle que le contrôle d'intégrité par MAC
peut être ainsi coupé (option -m de OpenSSH) et
insiste que cela doit être fait uniquement pour le débogage.
Tous les systèmes utilisant la cryptographie sont vulnérables à des
attaques DoS où l'attaquant va déclencher chez
sa victime de lourds calculs... sans aller jusqu'à s'authentifier. La
section 9.3.5 recommande donc de permettre de limiter les tentatives
depuis certaines machines (avec OpenSSH, on utilise en général les
tcpwrappers pour cela et on met quelque chose
comme sshd: [2001:DB8:0:1::]/64 dans
/etc/hosts.allow et pour arrêter les machines en
dehors de 2001:DB8:0:1::/64, on a sshd:
ALL dans /etc/hosts.deny.
Pour illustrer un certain nombre de points de SSH, voici le résultat d'un ssh -v depuis une machine OpenSSH (Debian) depuis une autre (Gentoo) :
OpenSSH_5.1p1 Debian-5, OpenSSL 0.9.8g 19 Oct 2007 ... debug1: Connecting to munzer.bortzmeyer.org [10.75.84.80] port 6622. debug1: Connection established.
La connexion TCP a été établie.
... debug1: Checking blacklist file /usr/share/ssh/blacklist.DSA-1024 debug1: Checking blacklist file /etc/ssh/blacklist.DSA-1024
Le test ci-dessus est spécifique à Debian et correspond à la faille Debian 1571.
debug1: Remote protocol version 2.0, remote software version OpenSSH_5.1 ... debug1: kex: server->client aes128-cbc hmac-md5 none debug1: kex: client->server aes128-cbc hmac-md5 none
Ici, les algorithmes de cryptographie acceptés ont été transmis (section 4.5 du RFC). Le premier est AES.
debug1: SSH2_MSG_KEX_DH_GEX_REQUEST(1024<1024<8192) sent debug1: expecting SSH2_MSG_KEX_DH_GEX_GROUP debug1: SSH2_MSG_KEX_DH_GEX_INIT sent debug1: expecting SSH2_MSG_KEX_DH_GEX_REPLY debug1: checking without port identifier debug1: Host 'munzer.bortzmeyer.org' is known and matches the RSA host key. debug1: Found key in /home/stephane/.ssh/known_hosts:24 debug1: ssh_rsa_verify: signature correct
Ici, la vérification de la machine distante, munzer.bortzmeyer.org, a été faite. Déjà connue, sa clé a été acceptée.
debug1: SSH2_MSG_NEWKEYS sent debug1: expecting SSH2_MSG_NEWKEYS debug1: SSH2_MSG_NEWKEYS received debug1: SSH2_MSG_SERVICE_REQUEST sent debug1: SSH2_MSG_SERVICE_ACCEPT received debug1: Authentications that can continue: publickey,keyboard-interactive debug1: Next authentication method: publickey debug1: Offering public key: /home/stephane/.ssh/id_dsa debug1: Server accepts key: pkalg ssh-dss blen 433 debug1: Authentication succeeded (publickey).
Une authentification de l'utilisateur par la clé publique DSA qu'il a présentée a marché.
debug1: Entering interactive session.
Et le reste n'est plus que formalité...
Si, par contre, une machine s'était glissée au milieu, devant le serveur attendu, on aurait obtenu le fameux message :
The authenticity of host '[munzer.bortzmeyer.org]:6622 ([10.75.84.80]:6622)' can't be established. RSA key fingerprint is ac:73:5e:34:59:29:7f:4a:a0:9f:56:d4:00:21:fe:c6. Are you sure you want to continue connecting (yes/no)?
SSH est aujourd'hui présent sur pratiquement, toutes les machines, du téléphone portable au commutateur Ethernet. Malgré cela, les mauvaises habitudes ont la vie dure et le rapport 2008 d'Arbor Network sur la sécurité remarquait que 24 % des opérateurs utilisaient toujours telnet (et ce rapport est basé uniquement sur les déclarations des acteurs, qui n'ont pas intérêt à avouer de telles faiblesses ; le chiffre réel est donc probablement supérieur.).
L'article seul
Ressources en ligne pour ceux qui écrivent en français
Première rédaction de cet article le 26 février 2009
Dernière mise à jour le 13 mars 2009
Il me semble qu'il y a bien davantage de ressources en ligne (dictionnaires, guides de conjugaison, etc) pour l'anglais que pour le français. Les francophones préfèrent en général organiser de coûteux colloques et subventionner des éléphants blancs sans lendemain, plutôt que de mettre gratuitement des ressources à la disposition de tous (les principales ressources sont en effet des projets issus de la base, comme le wiktionnaire, pas des projets officiels). Mais peut-être y a t-il des ressources pour le français que je ne connais pas ?
Je ne fais pas allusion au cas des gens qui veulent apprendre le français mais à ceux qui écrivent dans cette langue et qui se demandent soudain « Mais comment s'écrit hydillique ? Idilique ? Idyllique ? » ou bien « Quel est l'impératif présent singulier de marcher ? ». J'ai notamment besoin de ressources qui peuvent :
- Être accédées depuis n'importe quel navigateur Web, sans imposer Javascript ou, pire, Flash.
- Être téléchargées en local pour ne pas dépendre du réseau et pouvoir travailler dans l'avion.
- Être accédées par des protocoles standard permettant l'intégration facile dans n'importe quel logiciel, notamment le protocole DICT (RFC 2229).
- Être disponibles sous forme de données brutes, pour ne pas dépendre d'un logiciel particulier, surtout s'il est non-libre, ce qui est malheureusement de loin le cas le plus fréquent avec les ressources francophones.
- Une extension Firefox (comme celle du Conjugueur) serait un gros plus.
Je maintiens une liste à jour sur
del.icio.us en http://delicious.com/bortzmeyer/français (si votre navigateur
ne comprend pas les IRI du RFC 3987, allez en http://delicious.com/bortzmeyer/fran%C3%A7ais.) Si vous
connaissez des ressources non listées, n'hésitez pas à me
prévenir.
Pour l'instant, ce qui me manque le plus :
- Un dictionnaire français accessible avec le protocole
DICT, pour l'utiliser depuis
emacs avec l'excellent mode
dictionary.el(certains préfèrent le mode dictem). - Un correcteur orthographique équivalent à celui de Google. ATILF ne sait pas corriger « hydillique » en « idyllique » alors que Google propose la bonne orthographe : « Essayez avec cette orthographe : idyllique 2 premiers résultats affichés ».
Terminons avec quelques logiciels locaux : sans être « en ligne »
(ce qui peut être un avantage si on n'est pas connecté), ils peuvent
néanmoins aider le francophone à rédiger. acheck est un programme
qui aide les traducteurs de logiciel à trouver les erreurs dans leurs
traductions. Il semble qu'il aie été écrit spécialement pour
Debian mais il devrait pouvoir tourner sur
d'autres Unix. Il permet d'insérer des annotations sur les
corrections effectuées. Le traditionnel aspell
est également toujours disponible. Il permet d'avoir différents modes en fonction
du contexte (courrier, écriture de HTML, ...).
On peut bien sûr l'utiliser dans emacs ((setq-default
ispell-program-name "aspell"))
et dans mutt (set
ispell="LC_ALL=fr_FR /usr/bin/aspell -e -c"). Question
dictionnaire, le Littré
est téléchargeable et consultable avec stardict (un paquetage Debian du Littré existe
déjà, stardict-xmlittre).
Merci à Marc Hertzog pour ses suggestions et à Vishaal Golam pour ses nombreuses idées.
L'article seul
RFC 5492: Capabilities Advertisement with BGP-4
Date de publication du RFC : Février 2009
Auteur(s) du RFC : J. Scudder (Juniper), R. Chandra (Sonoa)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF idr
Première rédaction de cet article le 26 février 2009
Cette norme modifie le protocole BGP (RFC 4271) pour ajouter une nouvelle option, qui est plutôt une méta-option, permettant de décrire des capacités optionnelles d'un pair BGP.
Sans ce système de capacités (Capabilities), deux routeurs BGP peuvent
annoncer des options lors de la négociation de la session mais tous
ces paramètres bien mal nommés « optionnels » sont obligatoires. Si un
seul d'entre eux n'est pas reconnu par le pair, celui-ci doit refuser
la session (RFC 4271, section 6.2). Cela
rendrait très difficile de déployer de nouvelles options. D'où le
paramètre optionnel CAPABILITIES que décrit notre
RFC et qui est le seul que les routeurs doivent connaitre. Il permet
de décrire des options qui sont réellement facultatives (section
1).
La section 3 explique comment utiliser ce paramètre. En gros, une
capacité peut être utilisée si les deux pairs l'ont publiée dans un
paramètre CAPABILITIES. Si ce paramètre lui-même
n'est pas géré, notre RFC conseille de réessayer sans
lui. Naturellement, un routeur BGP est toujours libre de ne pas
établir de session s'il manque une capacité qu'il juge indispensable
(le RFC cite l'exemple des extensions multiprotocole du RFC 4760, section 8, indispensables pour un routeur
IPv6). La section 5 revient sur ce sujet en
spécifiant les comportements possibles en cas d'erreur.
Et la section 4 décrit précisement le paramètre
CAPABILITIES, qui porte le numéro 2 parmi les
paramètres optionnels de BGP. Les
capacités sont encodées en TLV par un code (1 pour les extensions
multiprotocoles du RFC 4760, ou 65 pour les AS sur quatre octets du RFC 6793), une longueur et une valeur. Les codes sont
enregistrés
à l'IANA. (Leur procédure d'enregistrement a été modifiée par
la suite, dans le RFC 8810.)
Ce RFC remplace son prédécesseur, le RFC 3392. Les
changements, décrits dans l'annexe B, sont peu nombreux et consistent
surtout en un durcissement de certaines règles, maintenant que tous les
routeurs BGP gèrent CAPABILITIES.
L'article seul
RFC 5461: TCP's Reaction to Soft Errors
Date de publication du RFC : Février 2009
Auteur(s) du RFC : F. Gont (UTN/FRH)
Pour information
Réalisé dans le cadre du groupe de travail IETF tcpm
Première rédaction de cet article le 26 février 2009
Que doit faire une implémentation de TCP lorsqu'une erreur est signalée par le réseau, par exemple lorsqu'un paquet ICMP indique une route inaccessible ? La norme traditionnelle est peu respectée et ce RFC explique pourquoi et documente la réaction la plus courante des mises en œuvre de TCP.
Soit une machine qui a une connexion TCP (RFC 793) avec une autre (ou bien qui est en train de tenter d'établir cette connexion). Arrive un paquet ICMP (RFC 792) qui dit, par exemple Network unreachable. Que doit faire TCP ? Abandonner la connexion ? Ignorer le message ?
Les exigences pour les machines Internet, le RFC 1122, sont claires. Il existe deux sortes d'erreur ICMP, les « douces » (soft errors, qui sont en général temporaires, c'est le cas du type 3, Destination unreachable, pour ses codes 0, Network unreachable, 1, Host unreachable et 5 Source route failed) et les « dures » (hard errors, en général de longue durée, comme le type 3 pour le code 3, Port unreachable, dû en général à l'action délibérée d'un pare-feu). Le RFC 1122 dit que TCP ne doit pas interrompre une connexion pour une erreur douce. En effet, celles-ci étant souvent transitoires, une telle interruption immédiate empêcherait de tirer profit de la résilience de l'Internet, où le réseau se reconfigure pour contourner un problème (voir aussi la section 2.2).
Pourtant, la plupart des mises en œuvre de TCP ignorent cette règle, afin d'éviter une longue attente au cas où une machine ne soit pas joignable sur certaines adresses (cas courant, notamment avec IPv6). Notre RFC 5461, sans changer la norme officielle, documente le comportement non-officiel, explique ses raisons et indique ses limites.
D'abord, le cas couvert par ce nouveau RFC est uniquement celui de
l'établissement de la connexion (quand TCP est
dans l'état SYN_RECEIVED ou
SYN_SENT). Celui des connexions déjà établies
n'est pas traité.
Le RFC 816 séparait le traitement des pannes réseaux en deux : leur détection et leur réparation. ICMP est un outil de détection. Il permet de voir qu'il y a un problème. Mais quelle réparation utiliser ? (section 1 du RFC).
Le RFC 1122, section 4.3.2.9, dit que TCP ne doit pas couper la connexion pour les erreurs douces (et, par contre, y mettre fin en cas d'erreur dure). La section 2 de notre RFC revient sur cette règle en notant qu'elle n'est absolument pas respectée en pratique.
Pourquoi ? C'est l'objet de la section 3. En gros, si on suit le RFC 1122 au pied de la lettre, et qu'on essaie de se connecter à une machine qui a plusieurs adresses IP (ce qui est courant avec IPv6), l'algorithme typique de l'application est séquentiel : on essaie toutes les adresses l'une après l'autre. Si la réception d'une erreur ICMP n'entraine pas l'échec immédiat d'une tentative sur une adresse, il faudra attendre l'expiration du délai de garde (trois minutes, dit le RFC 1122 !) pour renoncer à cette adresse et essayer la suivante (section 3.1). Le cas fréquent d'une adresse IPv4 et d'une IPv6 sur la même machine est discuté en section 3.2.
Alors, que font les mises en œuvre actuelles de TCP ? La section 4 décrit deux stratégies courantes. Le RFC se sent obligé de rappeler que ces statégies sont, formellement, une violation de la norme mais changer celle-ci semble difficile, alors autant documenter les écarts...
La première stratégie (section 4.1), est de réagir différemment selon que l'erreur est reçue pendant la phase d'établissement de la connexion ou bien après. Le noyau Linux, depuis la version 2.0.0, renonce immédiatement à l'établissement d'une connexion TCP lorsqu'il reçoit le paquet ICMP pendant ledit établissement. L'application peut alors immédiatement passer à l'adresse suivante.
La seconde stratégie (section 4.2) est plus méfiante. Elle consiste à ne renoncer à l'établissement de la connexion qu'après N erreurs ICMP, avec N > 1 (il vaut exactement un dans la stratégie précédente). C'est la méthode utilisée par FreeBSD. (Par contre, je ne trouve pas comment régler N sur FreeBSD 7.0.)
Évidemment, violer la norme n'est pas innocent. La section 5 détaille donc les conséquences qui attendent le violeur. Par exemple, 5.1 explique qu'un problème temporaire qui affecte toutes les adresses de destination risque d'empêcher complètement la création d'une nouvelle connexion, alors qu'un TCP conforme à la norme aurait patienté et serait finalement passé. Il y a ici clairement un compromis entre l'attente, dans l'espoir de finalement réussir (parfait pour les connexions non-interactives comme un transfert de fichier nocturne avec rsync lancé par cron) et l'abandon rapide (sans doute préférable pour les applications interactives, où il ne faut pas bloquer l'utilisateur humain).
L'article seul
RFC 5466: IMAP4 Extension for Named Searches (Filters)
Date de publication du RFC : Février 2009
Auteur(s) du RFC : A. Melinkov (Isode), C. King (Isode)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF lemonade
Première rédaction de cet article le 25 février 2009
La déjà très longue série des RFC sur IMAP s'agrandit avec cette norme pour le nommage de filtres IMAP. On peut désormais stocker ses filtres sous un nom et les réutiliser plus tard.
Le protocole d'accès au courrier IMAP permet
de filtrer le courrier selon des filtres définis dans le RFC 3501. Ces filtres devaient être stockés côté client et
réenvoyés au serveur à chaque fois. Désormais, on peut leur donner un
nom, les stocker de manière permanente sur le serveur IMAP et les
utiliser dans des commandes IMAP comme SEARCH
(section 2 du RFC pour une introduction).
Un serveur IMAP qui connait cette nouvelle extension l'annonce en
réponse à la commande CAPABILITY par le mot-clé
FILTERS (l'ensemble des mots-clés possibles étant
dans le registre IANA). La commande SEARCH
d'IMAP peut alors prendre un critère FILTER qui
indique le nom du filtre (section 3.1). Par exemple :
mytag1 SEARCH FILTER mon-filtre
Un filtre nommé peut lui-même être défini en termes d'autres filtres nommés.
Les filtres nommées étant un cas particulier des métadonnées
d'IMAP, créer et détruire les filtres nécessite un serveur IMAP qui
comprend les métadonnées (RFC 5464). On peut alors utiliser
les commandes comme SETMETADATA dans
l'arborescence normalisée /private/filters/values, par exemple :
mytag2 SETMETADATA "" "/private/filters/values/mon-filtre" "FROM \"moi@example.org\" "
Les noms des filtres étant restreints à
US-ASCII, l'arborescence
/private/filters/descriptions est réservée pour
stocker des descriptions en UTF-8, donc plus
présentables pour l'utilisateur.
Je ne sais pas encore quels serveurs IMAP gèrent cette extension.
L'article seul
ITAR est officiellement publié, pour aider au déploiement de DNSSEC
Première rédaction de cet article le 24 février 2009
Dernière mise à jour le 22 décembre 2010
Un problème classique de DNSSEC est qu'il faut connaître au moins une clé publique pour commencer la validation. Si la racine du DNS est signée, on configure logiquement dans son résolveur DNS la clé publique de la racine, largement diffusée. Mais, aujourd'hui, la racine n'est pas signée (cela a été fait en juillet 2010) et cette signature, qui dépend du gouvernement états-unien, est bloquée par des considérations essentiellement politiciennes. Alors, en attendant, une nouvelle méthode est disponible, ITAR. Elle a finalement servi deux ans, avant sa suppression en novembre 2010.
DNSSEC, normalisé dans les RFC 4033 et suivants, permet de résoudre certaines failles de sécurité du DNS comme l'empoisonnement de caches. Pour cela, les enregistrements DNS sont signés avec une clé cryptographique privée. Si on connait la clé publique correspondante, on peut alors valider la signature. Il existait deux méthodes pour connaître les clés publiques :
- Les rassembler à la main en cherchant sur les sites Web des
titulaires comme
https://www.ripe.net/projects/disi/keys/. C'est long et pénible, d'autant plus que les clés sont régulièrement remplacées. - Utiliser DLV (DNSSEC Lookaside Validation, RFC 5074), bien plus simple.
Une troisième méthode a été annoncée le 17 février par l'IANA : ITAR. C'est un dépôt des clés publiques de TLD, vérifiées par l'IANA. Il est distribué sous différents formats et on peut le récupérer et le valider, par exemple ainsi :
% wget https://itar.iana.org/anchors/anchors.mf % wget https://itar.iana.org/anchors/anchors.mf.sig % gpg anchors.mf.sig
(La dernière étape, vérifier avec GPG, est probablement sans intérêt puisque la clé PGP de l'IANA n'est pas signée et qu'il n'y a aucun moyen de la valider.) Une fois cela fait, ce fichier peut être utilisé pour configurer son résolveur, par exemple pour Unbound :
trust-anchor-file: "anchors.mf"
En fait, cette annonce n'est pas si importante que cela : d'abord,
ITAR ne stocke que les clés des TLD. On n'y trouvera donc pas celles
de ripe.net ou des
in-addr.arpa, citées plus haut, ni celles des
nombreux domaines signés dans des TLD non signés comme
sources.org. Mais, surtout, le registre DLV de l'ISC
copie automatiquement ITAR toutes les nuits et l'intègre dans leur
base. utiliser DLV suffit donc. La publication d'ITAR est donc plutôt
un geste politique de la part de l'ICANN, qui
tient à affirmer sa candidature à la signature de la racine. ITAR a été officiellement fermée en 2010.
L'article seul
RFC 5453: Reserved IPv6 Interface Identifiers
Date de publication du RFC : Février 2009
Auteur(s) du RFC : S. Krishnan (Ericsson)
Chemin des normes
Première rédaction de cet article le 11 février 2009
Une machine IPv6 doit évidemment avoir une adresse IP unique mais il existe une autre contrainte, c'est que les 64 bits de plus faible poids de cette adresses, l'interface identifier (RFC 4291, section 2.5.1), doivent être uniques sur le lien auquel la machine est attachée. Or, certains interface identifier sont réservés et ne doivent pas être utilisés. Lorsque l'interface identifier est attribuée manuellement par l'administrateur système, pas de problème. Mais s'il est attribué par autoconfiguration (RFC 4862) ? Ou par des une des autres méthodes citées dans l'annexe A du RFC ? Dans ce cas, le logiciel doit prendre garde à ne pas utiliser ces identificateurs notre RFC que réserve.
C'étaient plusieurs RFC qui réservaient ces identificateurs et ils n'avaient pas encore été rassemblés en un seul endroit, ce qui est désormais fait. Les identificateurs réservés seront dans le futur placés dans le registre IANA.
Notre RFC 5453 est assez court : la section 2 fait
quelques rappels sur les interface identifiers, la
section 3 explique toutes les horribles choses qui arriveront s'ils ne
sont pas uniques (par exemple, une machine qui a pris
l'interface identifier
FDFF:FFFF:FFFF:FFFE va « capturer » tout le
trafic normalement envoyé au Home agent des
machines mobiles, décrit dans le RFC 2526).
Et la section 4 donne le contenu initial du registre, la liste des interface
identifiers réservés, qui comprend
0000:0000:0000:0000 et la plage qui va de
FDFF:FFFFFFFF:FF80 à FDFF:FFFF:FFFF:FFFF.
L'article seul
RFC 4301: Security Architecture for the Internet Protocol
Date de publication du RFC : Décembre 2005
Auteur(s) du RFC : S. Kent, K. Seo (BBN Technologies)
Chemin des normes
Première rédaction de cet article le 9 février 2009
L'Internet n'est pas sûr, on le sait bien. Un méchant peut lire les paquets IP qui circulent, il peut injecter de faux paquets, avec une fausse adresse IP source, etc. Il existe des tas de façons d'aborder ce problème et ce RFC décrit une des plus ambitieuses, une complète architecture de sécurité pour IP, IPsec.
Actuellement, le problème est en général traité au niveau des applications. Par exemple, SSH va complètement sécuriser une session, quelles que soient les vulnérabilités de la couche réseau sous-jacente. Un attaquant ne pourra pas faire passer sa machine pour une autre, même s'il peut envoyer de faux paquets IP.
Cette approche est relativement simple, assez facile à déployer et
règle une grande partie des problèmes. Elle a deux limites : il faut
modifier chaque application. Lorsque leur nombre augmente, cela
devient vite pénible. Et elle ne protège pas contre certaines
attaques. Par exemple, des faux paquets TCP
RST (ReSeT, c'est-à-dire
remise à zéro de la connexion TCP) peuvent couper une session SSH
puisque la couche transport n'est pas
authentifiée. De tels faux paquets RST se trouvent dans le monde réel, par exemple, envoyés par la censure chinoise.
D'où l'idée de IPsec : sécuriser au niveau IP afin que toutes les applications soient automatiquement protégées, contre toutes les attaques. Ce RFC décrit l'architecture générale d'IPsec. Ce protocole est réputé très complexe à comprendre (et à déployer) et le RFC est gros et complexe (alors même qu'une partie des détails figure dans d'autres RFC comme le RFC 4303 ou le RFC 4305, ce dernier normalisant les algorithmes de cryptographie obligatoires).
Comme le rappelle bien la section 1.1, IPsec est une architecture de sécurité pour IP, pas pour l'Internet. La securisation complète d'un réseau comme l'Internet dépend de bien d'autres choses.
La section 2.1 décrit le cahier des charges d'IPsec : fournir des services d'authentification, d'intégrité et de confidentialité à IP (IPv4 ou IPv6).
Commençons par quelques généralités (section 3) : IPsec crée une barrière entre une zone non protégée et une zone protégée (section 3.1). Au passage de la barrière, IPsec traduit les paquets, d'une forme protégée vers une non-protégée, ou bien le contraire.
IPsec peut sécuriser la communication de deux façons : en authentifiant les paquets, sans chercher à assurer leur confidentialité, c'est le protocole AH, Authentication Header (section 3.2 et RFC 4302). Ou bien authentifier tout en chiffrant pour empêcher les méchants de lire le contenu, c'est le protocole ESP, Encapsulating Security Payload (section 3.2 et RFC 4303). Le second est de loin le plus utilisé, entre autre parce que AH ne passe pas à travers les routeurs NAT.
Pour ces deux protocoles, AH et ESP, IPsec dispose de deux modes, tunnel et transport. Dans le mode transport, la connexion est sécurisée de bout en bout entre les deux machines. Ce mode est donc le plus sûr mais nécessite IPsec sur les deux engins. Le mode tunnel, crée un VPN entre deux routeurs et les machines des deux réseaux locaux ainsi connectés sont protégées dans leurs communications entre ces deux réseaux, sans qu'elles aient besoin d'IPsec elles-mêmes.
Comment IPsec place ses informations dans le paquet ? Avec AH, le mode transport et IPv4, le champ Protocole de l'en-tête IPv4 indique non pas le protocole de la couche transport (typiquement TCP) mais AH (valeur 51 dans le registre IANA). On trouve donc un second en-tête après l'en-tête IP normal, contenant les données notamment :
- Le SPI, Security Parameter Index, un nombre qui permet à la machine de retrouver les paramètres de la session, par exemple l'algorithme cryptographique utilisé (plusieurs algorithmes sont possibles, puisque la technologie en ce domaine ne cesse pas d'évoluer),
- Le résumé cryptographique des données qu'on veut authentifier, notamment l'adresse IP source,
- L'indication du « protocole suivant », c'est-à-dire le protocole de la couche transport.
Pour un routeur IP, un paquet protégé par AH est donc un paquet IP comme un autre, le champ Protocole d'IP n'étant lu qu'à l'arrivée.
En mode tunnel, le « protocole suivant » de l'en-tête AH sera IP, tout simplement, et c'est un paquet IP complet qui sera encapsulé.
L'un des principaux problèmes avec AH concerne les routeurs NAT. Comme AH vise à garantir l'intégrité du paquet et donc l'absence de modifications, il rentre directement en conflit avec le NAT qui modifie au moins l'adresse source. Le RFC 3715 discute plus en détail ce problème. À noter que AH n'est plus désormais obligatoire dans IPsec (section 3.2), ESP le remplaçant en mieux dans presque tous les cas.
Et ESP ? Cette fois, le paquet est chiffré et l'indication du protocole suivant indique comment analyser le contenu, après déchiffrement. Le SPI joue le même rôle qu'avec AH, il indique le contexte dans lequel a été fait le chiffrement et donc notamment l'algorithme utilisé. À noter que l'en-tête IP circule donc en clair et peut, à lui seul, fournir des indications à un indiscret : qui communique avec qui et même quel genre d'applications (par les bits DSCP).
Contrairement à AH, ESP ne garantit pas l'intégrité de l'en-tête IP mais celui lui permet de passer le NAT.
Comme AH, ESP peut fonctionner en mode tunnel ou en mode transport.
En pratique, aujourd'hui, rares sont les utilisateurs de AH, la grande majorité des sessions IPsec sont protégées par ESP.
Je reviens maintenant un peu sur le SPI (Security Parameter Index). Il fait partie d'un contexte plus large, la SA (Security Association, section 4). Ce contexte est ce qui permet de retrouver les paramètres d'une session IPsec notamment l'algorithme de chiffrement. Stocké dans une SAD (Security Associations Database, section 4.4.2), la SA est indexée par le SPI et, selon les cas, également par les adresses IP et le protocole (AH ou ESP). À chaque arrivée d'un paquet IP entrant, c'est le SPI dans ce paquet qui servira à trouver la politique à appliquer (section 5.2).
Puisque j'ai mentionné la SAD, c'est l'occasion de revenir sur les bases de données d'IPsec (section 4.4). Leur forme exacte dépend évidemment de l'implémentation mais, conceptuellement, toute mise en œuvre d'IPsec doit avoir les bases suivantes :
- SPD (Security Policy Database) qui stockera
les préférences de l'administrateur réseau : quels paquets doivent
être protégés par IPsec, notamment, en fonction de
sélecteurs qui sont en général des adresses IP et
numéros de port. Une politique sera par exemple, « Protéger avec ESP
tous les paquets échangés avec
2001:DB8:1:27::/64et laisser passer le reste non protégé ». - SAD (Security Association Database), qui indique les SA en cours.
- PAD (Peer Authorization Database), liée à la gestion des clés.
La SPD est présentée en détail dans la section 4.4.1. Sur FreeBSD, on la
trouve typiquement dans /etc/ipsec.conf et elle
contient des appels à setkey. Les politiques possibles sont
PROTECT (protéger le trafic avec IPsec),
BYPASS (laisser passer, même non protégé) et
DISCARD (ne pas laisser passer). Les sélecteurs
possibles sont décrits en section 4.4.1.1. Toute mise en œuvre
d'IPsec doit au moins accepter les adresses IP source et destination
comme sélecteurs. Les sélecteurs pouvant se recouvrir
partiellement, l'ordre des directives dans cette base est crucial
(voir l'annexe B pour un algorithme permettant de supprimer ce
recouvrement).
Une fois la SPD configurée, elle sera consultée à chaque paquet IP, pour déterminer l'action à entreprendre (section 5 pour le traitement des paquets IP). Par défaut, en l'absence d'une mention dans la SPD, le paquet sera mis à la poubelle.
La SAD est décrite en section 4.4.2. Elle garde mémoire des options de chaque association de sécurité, comme l'algorithme cryptographique utilisé (la section 4.4.2.1 détaille le contenu des entrées de cette base). Pour les paquets sortants, IPsec utilise typiquement un cache associant une prise réseau à une association de sécurité présente dans la SAD. Pour les paquets entrants, le SPI (Security Parameter Index) dans le paquet sert d'index dans la SAD.
La gestion des clés est traitée dans la section 4.5. C'est de loin la partie la plus complexe d'IPsec (comme de beaucoup d'autres protocols de sécurité). En pratique, la grande majorité des utilisateurs d'IPsec ne comptent que sur des clés gérés manuellement (section 4.5.1), IKE (RFC 4306) étant très peu déployé.
Comme souvent en sécurité, le diable est dans les détails. Par exemple, la section 6 couvre le traitement des paquets ICMP. Que faire d'eux ? Les ignorer lorsqu'ils ne sont pas protégés par IPsec ? Du point de vue sécurité, cela serait cohérent mais, dans l'état actuel du déploiement d'IPsec, presque tous les paquets ICMP émis par des routeurs intermédiaires seraient alors ignorés, bien qu'ils apportent des informations essentielles. Notre RFC recommande donc (section 6.1.1) de laisser le choix à l'administrateur réseau de les accepter ou pas.
Si la section 7 traite un autre détail délicat, la gestion de la fragmentation, la section 8 parle des problèmes de MTU, une des plaies de l'Internet. AH et ESP ajoutent tous les deux des octets au paquet qu'ils protègent, et ces octets peuvent faire que le paquet dépasse la MTU du lien. Le problème est donc similaire à celui de tous les autres tunnels. Aux autres difficultés de déploiement d'IPsec s'ajoute donc le problème de MTU.
Le déploiement réel d'IPsec est très faible. Conçu pour sécuriser peu ou prou toutes les communications sur Internet, sa principale utilisation aujourd'hui est pour faire des tunnels entre deux réseaux de la même organisation. Comme un protocole normalisé est moins vital dans ce cas, IPsec est concurrencé par d'autres protocoles de tunnel (comme celui d'OpenVPN).
Quelles sont les implémentations pour les systèmes d'exploitation Unix ? Sur Linux, la plus répandue est
Openswan mais il y a aussi StrongSwan (les deux dérivant
du même code). Sur NetBSD, IPsec est inclus dans le système et bien
documenté dans la NetBSD IPsec
FAQ. Avec NetBSD, la SPD peut être par prise : Per-socket: configured via
setsockopt(2) for a certain socket. You can specify like "encrypt
outgoing packets from this socket". This works well when you would
like to run IPsec-aware server program. . Sinon, elle est par paquet, la SPD se configure (c'est pareil sur FreeBSD par exemple dans /etc/ipsec.conf) avec setkey(8) :
#! /bin/sh # # packet will look like this: IPv4 ESP payload # the node is on 10.1.1.1, peer is on 20.1.1.1 setkey -c <<EOF add 10.1.1.1 20.1.1.1 esp 9876 -E 3des-cbc "hogehogehogehogehogehoge"; add 20.1.1.1 10.1.1.1 esp 10000 -E 3des-cbc 0xdeadbeefdeadbeefdeadbeefdeadbeefdeadbeefdeadbeef; spdadd 10.1.1.1 20.1.1.1 any -P out ipsec esp/transport//use; EOF
9876 et 10000 sont le SPI.
Ce RFC décrit « IPsec version 3 » (le RFC 2401 étant la version 2), même si ces numéros de version ne sont pas mentionnés dans le RFC (mais ils apparaissent dans d'autres documents). La section 13 liste les différences avec la version 2, notamment le fait qu'AH n'est plus obligatoire (ce qui reflète son faible usage), des SPD plus souples, etc.
Pour une excellente introduction à IPsec, je recommande l'article de Steve Friedl « An illustrated guide to IPsec », qui contient notamment de bons schémas des paquets tels qu'ils sont présents sur le câble. Parfait si on veut comprendre comment IPsec marche.
IPsec a toujours suscité des passions. Une des critiques les plus fouillées a été écrite par Niels Ferguson et Bruce Schneier dans un article très vivant et très pédagogique, A Cryptographic Evaluation of IPsec. Ferguson et Schneier font remarquer que IPsec semble avoir été conçu par un comité, où l'important était de faire plaisir à tout le monde plutôt que de produire un protocole sûr. Ainsi, ils reprochent à IPsec d'avoir deux protocoles (AH et ESP) alors qu'ESP seul suffirait. De même, ils contestent les deux modes, tunnel et transport, puisque le mode transport assurerait l'équivalent des fonctions des deux modes. La sécurité d'un protocole dépendant largement de sa simplicité, IPsec, pour eux, ne peut pas être vraiment sûr. Cette critique couvre la version 2 mais la plupart des remarques s'appliquent encore à la version actuelle. (Notez tout de même que le RFC actuel reconnait que AH n'est pas vraiment indispensable.)
L'article seul
RFC 3148: A Framework for Defining Empirical Bulk Transfer Capacity Metrics
Date de publication du RFC : Juillet 2001
Auteur(s) du RFC : M. Mathis (Pittsburgh supercomputing center), M. Allman (BBN/NASA)
Pour information
Réalisé dans le cadre du groupe de travail IETF ippm
Première rédaction de cet article le 8 février 2009
Parmi les différentes métriques qu'on peut définir sur l'Internet, une est particulièrement intéressante pour les utilisateurs, c'est le débit possible lors d'un transfert de fichiers. Si l'administrateur système tend à regarder plutôt le RTT avec ping, l'utilisateur préférerait savoir le temps qu'il lui reste avant l'arrivée des copies de la dernière saison de Desperate Housewives. D'où la définition formelle de ce débit, dans ce RFC.
Bulk Transfer Capacity (Capacité de Transfert en Gros) est donc définie comme la capacité du réseau à transporter des données en quantité importante lors d'une seule connexion (typiquement TCP). Il s'agit des données utiles, excluant les en-têtes des paquets, et intégrant la retransmission de données en cas de perte de paquets. La section 1 dit que la BTC peut tout simplement être définie comme la division de la quantité de données effectivement transmise par le temps écoulé. C'est typiquement elle qu'affichent des outils comme ncftp ou netpipe.
Toute implémentation de TCP, ou d'un protocole équivalent, devrait donc, dans le cas idéal, afficher la même BTC, puisque tous doivent suivre les mêmes principes de contrôle de la congestion (RFC 5681). Ce n'est pas forcément le cas en pratique, certaines mises en œuvre de TCP affichant des résultats non-linéaires dans certaines plages de fonctionnement.
La question des algorithmes utilisés en cas de congestion est détaillée en section 2. Les définitions habituelles de ces algorithmes laissent pas mal de latitude au programmeur qui les met en œuvre et la définition d'une métrique nécessite donc de rajouter quelques contraintes. Par exemple, en cas d'utilisation d'algorithmes « avancés » comme NewReno (RFC 2582), ceux-ci doivent être complètement spécifiés dans la définition de la métrique. Même chose avec les détails de l'algorithme de retransmission (RFC 2988).
La section 3 couvre ensuite certaines métriques secondaires qui peuvent aider à comprendre le comportement du réseau. Par exemple 3.6 explique la séparation entre le chemin aller et le chemin retour, beaucoup de liens sur Internet étant asymétriques.
L'article seul
RFC 5411: A Hitchhiker's Guide to the Session Initiation Protocol (SIP)
Date de publication du RFC : Février 2009
Auteur(s) du RFC : J. Rosenberg (Cisco)
Pour information
Réalisé dans le cadre du groupe de travail IETF sip
Première rédaction de cet article le 4 février 2009
La quantité de RFC sur le protocole SIP est colossale et s'accroit tous les jours. Depuis la norme originale, le RFC 3261, ce sont des dizaines de RFC que devrait lire l'implémenteur de SIP consciencieux. Pour lui faciliter la vie, ce RFC résume les RFC pertinents sur SIP et les classe en catégories.
C'est un travail analogue à celui du RFC 7414 pour TCP : ne pas créer de nouvelles normes mais lister celles qui existent, en indiquant leur importance et leur place dans la famille. C'est donc essentiellement une liste commentée de RFC qui compose notre RFC 5411. La liste est longue, vue la taille du zoo SIP. D'autant plus que certains RFC ont connu un succès très limité.
Un petit avertissement : comme son titre l'indique, il vaut mieux faire précéder la lecture de ce RFC par celle du livre de Douglas Adams, « The hitchiker's guide to the galaxy » (en français « Le Guide du Routard Galactique »). Cela permettra d'apprécier les allusions, comme le rappel récurrent à ne pas s'affoler.
Commençons bien sûr par le cœur de SIP (section 3), les normes indispensables à tout logiciel SIP. Le RFC de référence est le RFC 3261, le « président de la galaxie » (et une première référence à Douglas Adams, une). Mais les RFC 3263 (trouver un serveur SIP), RFC 3264 (utiliser SDP pour décrire les paramètres d'une session SIP), ou RFC 3265 (le modèle de notification d'évènements en SIP, évènements auxquels on peut s'abonner) sont également centraux.
Le cœur contient également d'autres RFC comme (au hasard), le RFC 4474 qui permet de définir une véritable identité numérique dans SIP, avec authentification, ou bien le RFC 4566 qui normalise SDP.
Plusieurs catégories sont ensuite détaillées dans le RFC. Contrairement au cœur, elles ne sont utiles que pour certains logiciels. Ainsi, la section 4 décrit les normes qui ont un rapport avec l'interconnexion de SIP et du PSTN. La section 5 décrit les extensions à SIP qui, sans être utilisées systématiquement, ont une audience générale. C'est le cas, par exemple, du RFC 3323, qui permet de configurer la protection de la vie privée offerte par les logiciels SIP.
La section 6 est consacrée à un problème douloureux qui a beaucoup handicapé SIP par rapport à certains concurrents commerciaux et fermés comme le protocole de Skype : la traversée des NAT. Peu d'utilisateurs aujourd'hui ont la possibilité d'avoir, en IPv4, une véritable liaison Internet de bout en bout. Ils doivent en général passer par des traducteurs NAT, dont la présence complique beaucoup le travail des applications. Un groupe de travail entier de l'IETF, Behave, travaille aux solutions « passe-NAT ». C'est ainsi que deux Internet-Drafts sont listés ici : bien que pas terminés, les protocoles ICE et SIP outbound seront probablement nécessaires dans toute mise en œuvre de SIP.
Plusieurs autres catégories sont traitées dans les sections suivantes : établissement de l'appel (section 7), gestion d'évènement (sections 8 et 9), QoS (section 10), problèmes opérationnels (section 11), compression (section 12), URI SIP (section 13), téléconférences (section 16) messagerie instantanée (section 17), services d'urgence (section 18) et extensions diverses (section 14). Pointons du doigt un RFC au hasard dans cette liste : le RFC 5079 fournit un moyen à l'appelé de dire qu'il refuse un appel parce que l'appelant est anonyme (au lieu de lui raccrocher au nez sans explication).
SIP a fait l'objet d'analyse critiques sur sa sécurité. La section 15 est donc dédiée aux RFC ayant un rapport avec la sécurité. Le RFC 4916 complète le mécanisme d'identité numérique du RFC 4474. Le RFC 5360 normalise un mécanisme d'expression du consentement (à une communication).
L'article seul
RFC 5434: Considerations for Having a Successful Birds-of-a-Feather (BOF) Session
Date de publication du RFC : Février 2009
Auteur(s) du RFC : Thomas Narten (IBM)
Pour information
Première rédaction de cet article le 2 février 2009
Le travail de normalisation au sein de l'IETF se fait dans des groupes de travail (Working Groups) dont la constitution nécessite un grand formalisme. L'écart est tel entre des discussions informelles dans un bistrot et la création d'un groupe de travail que des états intermédiaires se sont développés comme les BoF (Birds of a Feather, d'une expression anglophone intraduisible). Les BoF sont actives depuis de nombreuses années et le premier RFC qui les avait mentionnées était le RFC 2418, dans sa section 2.4.
L'idée est qu'un groupe de gens qui estiment que tel travail de normalisation peut et doit être fait vont se rassembler et approfondir leurs accords, avant de demander à l'IESG la création d'un vrai groupe de travail. Alors que les BoF étaient au début une réponse à la formalisation de plus en plus grande des groupes de travail (qui n'ont plus rien du rassemblement spontané et informel des débuts), les voici à leur tour normalisées. Ce RFC est bâti sur l'excellent exposé que fait Thomas Narten à chaque réunion IETF, à l'usage des débutants dans cet organisme.
Pour illustrer le RFC, je prendrais des exemples de la seule BoF où j'étais impliqué, celle sur le langage Cosmogol à l'IETF de Prague en mars 2007.
La section 1 commence par « Pourquoi une BoF ? » Il peut y avoir des tas de raisons, par exemple une présentation sur un problème particulier, qui ne rentre dans aucun groupe de travail précis. Mais la motivation la plus fréquente est la création future d'un groupe de travail, c'était clairement le but de la BoF sur Cosmogol (qui a échoué) ou de celle d'Alto à Dublin en juillet 2008, qui, elle, a finalement réussi.
L'IETF est très focalisée sur le résultat : le but n'est pas de parler, quoique ce soit sympa, c'est de produire des normes. Le RFC recommande donc fortement de s'assurer que le problème est bien défini, très focalisé, est soluble (« supprimer le spam » n'est donc pas un bon problème), que l'IETF est le bon endroit pour le traiter, et que des gens sont prêts à travailler concrètement en ce sens (car il existe beaucoup d'idées qui rassemblent un large soutien... mais peu de travailleurs).
Alors, quelles sont les étapes nécessaires ? La section 2 les détaille :
- Le groupe fondateur (le terme officiel est design
team) se rencontre (physiquement ou bien en ligne)
pour discuter le problème. Il cherche s'il n'existe pas déjà un groupe
de travail sur ce sujet. Il discute avec des groupes existants. Si
aucun groupe de travail ne correspond mais qu'il existe une zone
(regroupement de plusieurs groupes) sur ce sujet, il en parle sur la
liste de diffusion de la zone, etc. Et, surtout, il produit les
premiers Internet-Drafts,
pour aider à la discussion. (Pour Cosmogol, le groupe fondateur se
limitait à une personne, ce qui était son principal handicap. Le
premier Internet-Draft,
draft-bortzmeyer-language-state-machinesa été publié en septembre 2006.) - Le groupe va ensuite approcher les directeurs de la zone envisagée, pour leur proposer la BoF. (Pour Cosmogol, la zone était l'Application Area et c'est Lisa Dusseault qui a géré la discussion du côté de l'IESG.)
- Le projet est alors rendu public et une liste de diffusion créée. (Pour Cosmogol, cela avait été fait le 27 décembre 2006.) Les inscriptions à cette liste et les discussions qui suivent permettent de jauger de l'intérêt du travail.
- Enfin, si le groupe fondateur n'est pas encore dérouragé, il peut faire une demande formelle d'une BoF. Si acceptée, la BoF peut alors être convoquée.
- Il reste à profiter du temps qui reste avant la prochaine réunion physique de l'IETF pour continuer la discussion, commencer à parler de la charte du futur groupe de travail, préparer la liste des questions qui devront être résolues par la BoF (« Avons-nous besoin d'un langage formel pour décrire les machines à états ? » « Si oui, faut-il le normaliser ? » « Si oui, peut-on utiliser les langages existants ? » « Est-ce que Cosmogol est un bon candidat ? »).
Les projets de BoF échouent souvent, non pas sur les solutions au problème, mais sur la définition du problème. C'est contre cet écueil que met en garde la section 3. Ainsi, le groupe de travail MARID, qui a connu une vie agitée et une fin brutale, était censé travailler uniquement sur l'authentification des serveurs de messagerie, un problème bien délimité, mais beaucoup de gens s'obstinaient à essayer de le tirer vers une solution générale au problème du spam, un bon moyen de n'aller nulle part, vue la taille et la complexité du problème.
Le risque est d'autant plus élevé que les ingénieurs ont une nette tendance à préférer les discussions sur les solutions aux discussions sur la définition du problème ! Ces discussions prématurées sont souvent une cause de perte de temps. Ainsi, alors même qu'une bonne partie de l'IETF n'était pas convaincue de la nécessité d'avoir un langage standard pour les machines à état, la plupart des messages sur la liste Cosmogol portaient sur des points subtils de l'ABNF du langage ou bien sur la question de savoir s'il fallait autoriser Unicode dans les identificateurs.
Enfin, si on a passé tous ces obstacles, la BoF elle-même commence (section 4). Parfois, c'est un échec et il n'y a que le groupe fondateur dans la salle. Parfois, c'est un succès quantitatif, comme les Bof d'Alto ou de Cosmogol où plus de cent personnes se serraient dans une salle trop petite. Comme les participants à l'IETF adorent discuter, le RFC conseille de rester focalisé : « Quel est le but de la BoF ? » « Qu'attend t-on comme résultat ? »
Un bon compte-rendu de la BoF sur Cosmogol (officiellement nommée Finite State Machines BOF) peut être lu sur le blog de Barry Leiba.
Après, on peut passer à la suite : compte-tenu de ce qui s'est passé à la BoF, quelle est l'étape suivante ? Si la BoF a été un succès, et si l'IESG a semblé favorable, on peut faire une demande formelle de création d'un groupe de travail. (Pour Cosmogol, l'IESG avait clairement manifesté que la création du groupe semblait lointaine, vu le manque de consensus sur le problème de base.)
Comme on apprend davantage des échecs que des réussites, la section 6 décrit les pièges les plus fréquemment observés :
- S'y prendre au dernier moment (les débutants sous-estiment la lenteur de toute SDO),
- Trop parler des solutions, avant d'être sûr d'avoir bien compris le problème,
- Mauvaise communication avec les potentiels participants. Les membres du groupe fondateur sont tellement pris par leur projet qu'ils en oublient d'expliquer clairement aux non-membres pourquoi le projet est nécessaire et pourquoi il faut venir à la BoF.
On le voit, créer une BoF est compliqué et long et ne réussit pas toujours. D'où la demande pour des réunions plus informelles comme les Bar BoF où les participants se rencontrent au bar. Trois ans après, un RFC a formalisé les Bar BoF.... (RFC 6771)
L'article seul
RFC 5435: Sieve Email Filtering: Notifications
Date de publication du RFC : Janvier 2009
Auteur(s) du RFC : A. Melnikov (Isode Limited), B. Leiba, W. Segmuller (IBM T.J. Watson Research Center), T. Martin (BeThereBeSquare)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF sieve
Première rédaction de cet article le 1 février 2009
Le langage de filtrage du courrier Sieve se voit désormais doté d'une nouvelle fonction, la possibilité de prévenir lors de l'arrivée de certains messages. Cette notification pourra se faire via plusieurs protocoles, spécifiés dans d'autres RFC.
Certains utilisateurs du courrier veulent être prévenus tout de suite lorsqu'un message a certaines caractéristiques (par exemple un message du chef comportant « URGENT » dans le sujet). Cette demande va même parfois au delà du raisonnable, lorsqu'ils rejettent, par exemple, des méthodes anti-spam très efficaces comme le greylisting (RFC 6647) parce qu'ils ne supportent pas l'idée que leur courrier soit retardé de quelques minutes. La méthode classique pour être prévenu est de type pull : interroger le serveur de messagerie regulièrement, ce qui le fait travailler, la plupart du temps pour rien. Notre RFC 5435 propose donc une méthode de type push où l'utilisateur est notifié lorsqu'un message obéit à certaines caractéristiques.
Voyons tout de suite un exemple :
if allof (header :contains "from" "chef@example.com",
header :contains "subject" "URGENT")
{
notify
:importance "1"
:message "This is probably very important"
"tel:123456";
}
Cette règle appelera le numéro de téléphone 123456 dès qu'un message du chef comportant le mot-clé arrivera.
D'autres RFC décriront les mécanismes de notification. Le RFC 5436 décrit mailto: (envoi de la
notification par courrier), le seul mécanisme obligatoire. Le RFC 5437 décrit, lui, la notification par le protocole de
messagerie instantanée
XMPP. La section 3.8 détaille les limites que
doivent suivre ces mécanismes (par exemple sur la taille des messages
de notification). La liste complète des mécanismes figure dans le registre IANA.
Le RFC est court, le gros de la définition se trouvant dans la
section 3, qui précise la syntaxe de la nouvelle action
notify, syntaxe illustrée dans l'exemple
ci-dessus. Les options les plus importantes sont :
- La méthode de notification, un URI (par
exemple
xmpp:bortzmeyer@gmail.comou bienmailto:stephane+alert@bortzmeyer.org, le support de cette dernière méthode étant obligatoire). - L'expéditeur à utiliser pour la notification
(
:from), - L'importance du message de notification, utilisée par certaines méthodes pour le prioritiser,
- Et bien sûr le message de notification lui-même,
:message.
Voici un exemple plus élaboré que le précédent, utilisant les variables Sieve du RFC 5229 :
require ["enotify", "fileinto", "variables"];
if header :contains "to" "sievemailinglist@example.org" {
# :matches is used to get the value of the Subject header
if header :matches "Subject" "*" {
set "subject" "${1}";
}
# :matches is used to get the value of the From header
if header :matches "From" "*" {
set "from" "${1}";
}
notify :importance "3"
:message "[SIEVE] ${from}: ${subject}"
"mailto:alm@example.com";
fileinto "INBOX.sieve";
}
Les sections 4 et 5 décrivent des tests Sieve permettant à un script de savoir quelles méthodes de notification sont disponibles sur le site.
La section 8, très détaillée, est consacrée aux questions de sécurité. En effet,
comme le note le RFC, la notification est potentiellement très
dangereuse. Elle peut entraîner des boucles (si un courrier de
notification déclenche à son tour une notification), « spammer » des
destinataires, aboutir à la sortie involontaire d'informations
confidentielles, etc. Combinée avec des extensions comme les variables
(qui permettent de fabriquer dynamiquement des composants de la
notification, comme le message ou le destinataire), l'action
notify peut mener à des résultats très
surprenants. Les programmeurs sont donc invités à la prudence,
notamment pour éviter les boucles.
Je ne connais pas encore d'implémentation de Sieve qui mette en œuvre ce mécanisme de notification.
L'article seul
RFC 5437: Sieve Notification Mechanism: xmpp
Date de publication du RFC : Janvier 2009
Auteur(s) du RFC : P. Saint-Andre (XMPP Standards
Foundation), A. Melnikov (Isode)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF sieve
Première rédaction de cet article le 1 février 2009
Le langage de description de filtres de courrier Sieve dispose d'une possibilité de notification. Avec ce RFC la notification peut utiliser le protocole XMPP, ce qui intéressera surtout les utilisateurs de la messagerie instantanée.
XMPP (également connu sous son ancien nom de Jabber) est un protocole qui sert notamment à la messagerie instantanée. Le langage Sieve (RFC 5228) dispose d'une extension de notification (RFC 5435) qui permet de signaler, par exemple, l'arrivée d'un message important. Notre RFC relie ces deux services en permettant l'envoi de notifications Sieve en XMPP.
Voici un exemple (section 3.3) d'une action dans un script Sieve, qui notifie via XMPP :
notify :importance "1"
:message "Contact Juliet immediately!"
"xmpp:romeo@im.example.com"
Qu'y trouve t'on ? Le paramètre :importance
(section 2.4 du RFC, la valeur 1 indiquant un message urgent), le paramètre :message
(section 2.5) et l'URI du destinataire XMPP,
URI conforme au RFC 5122.
La stanza XMPP émise aura à peu près cet aspect :
<message from='notify.example.com'
to='romeo@im.example.com'
type='headline'
xml:lang='en'>
<body>Contact Juliet immediately!</body>
<headers xmlns='http://jabber.org/protocol/shim'>
<header name='Urgency'>high</header>
</headers>
<x xmlns='jabber:x:oob'>
<url>
imap://romeo@example.com/INBOX;UIDVALIDITY=385759045/;UID=20
</url>
</x>
</message>
L'article seul
RFC 5436: Sieve Notification Mechanism: mailto
Date de publication du RFC : Janvier 2009
Auteur(s) du RFC : B. Leiba, M. Haardt
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF sieve
Première rédaction de cet article le 1 février 2009
Le système de notification du langage de filtrage de courrier Sieve est normalisé dans le RFC 5435. Il se décline en plusieurs mécanismes, pour envoyer des SMS, des coups de téléphone, ou bien même, avec notre RFC 5436, du courrier.
Pourquoi envoyer un message lorsqu'on vient d'en recevoir un ? L'idée est typiquement de filtrer son courrier avec la puissance des règles de Sieve (RFC 5228) et de notifier une autre adresse dans certains cas. Cette autre adresses est probablement lue plus souvent, par exemple parce qu'elle est transmise à un Blackberry ou un gadget analogue.
Évidemment, une des inquiétudes que peut générer un tel mécanisme est la création de boucles, le message de notification déclenchant lui-même une notification et ainsi de suite. Aussi, à de nombreux endroits dans le RFC, se trouvent des règles pour minimiser cet effet (et une discussion complète se trouve dans la section 5). Les discussions à l'IESG sur le risque de « bombardement » entraînés par ce mécanisme de notification ont d'ailleurs considérablement retardé la sortie de ce RFC.
Sinon, le principe est simple : le script Sieve peut envoyer un
courrier si le paramètre method de l'action
notify est un URI de plan
mailto: (RFC 6068). D'autres options
sont possibles, détaillées dans la section 2. Voici un exemple (un
autre se trouve dans la section 3) :
if allof (header :contains "from" "chef@example.com",
header :contains "subject" "URGENT")
{
notify
:importance "1"
:message "This is probably very important <http://www.paulgraham.com/boss.html>"
"mailto:poor-employee@example.com";
}
L'importante section 2.7 revient sur la génération du message de
notification, notamment les précautions à prendre pour éviter les
boucles, par
exemple, l'ajout de l'en-tête Auto-submitted:,
suivant les recommandations de la section 5 du RFC 3834, avec une
valeur de auto-notified, section 2.7.1. Cet ajout
est obligatoire. Notre RFC étend même le RFC 3834 en définissant formellement (section 6) le registre IANA des
mots-clés de Auto-submitted:.
L'article seul
Measurement Lab, pour savoir si votre FAI vous ment
Première rédaction de cet article le 31 janvier 2009
Google lance un énorme pavé dans la mare avec Measurement Lab, une plate-forme distribuée de mesures sur Internet, avec un système de rapport qui permet à tout utilisateur de tester sa connectivité, son débit mais aussi d'éventuelles violations de la transparence du réseau, par exemple de la limitation de trafic BitTorrent.
Comme les FAI qui bloquent ou ralentissent certains usages ne communiquement jamais et n'informent jamais leurs utilisateurs (voire leur mentent), beaucoup ne vont pas aimer d'autant plus que Google ne prend pas de gants en annonçant que good data is the bedrock of sound policy.
Actuellement, c'est plus alpha que beta et ça plante souvent. Mais je pense que cela va sérieusement secouer le cocotier une fois au point.
Voire l'annonce de Google.
L'article seul
pcapr.net, pour explorer des paquets réseau
Première rédaction de cet article le 30 janvier 2009
Dernière mise à jour le 31 juillet 2013
Examiner en détail, au niveau des champs qui le composent et même des bits sous-jacents, des paquets capturés sur le réseau est une occupation essentielle pour l'étudiant en réseaux informatiques, pour le programmeur réseau, pour l'administrateur réseaux... et pour celui qui s'intéresse à la sécurité des réseaux. Des outils pour programmeur comme Scapy ou des outils graphiques très riches comme Wireshark permettent de rendre cette tâche bien plus efficace, pour les paquets qu'on a capturé soi-même. Mais il peut être instructif d'explorer les paquets capturés sur des réseaux différents du sien, par exemple pour apprendre des protocoles dont on n'a pas de mise en œuvre disponible. C'était l'un des buts de pcapr, le Flickr des paquets. Ce service semble malheureusement mort aujourd'hui.
Le principe est simple : vous vous enregistrez (gratuit mais obligatoire) et vous pouvez ensuite envoyer vos propres traces et/ou regarder celles envoyées par les autres membres. Du fait de l'inscription obligatoire, certains liens dans cet article ne seront pas accessibles tant que vous n'aurez pas un compte pcapr (actuellement, un visiteur anonyme peut avoir une idée des paquets mais pas les examiner en détail).
Vous pouvez chercher une trace (un ensemble de paquets) par date ou
par mot-clé (des étiquettes - tags -, comme dans
del.icio.us). Si je m'intéresse à
BGP et que le RFC 4271
ne me suffit pas, je peux chercher http://www.pcapr.net/browse?proto=bgp. Si je
préfère LDAP, j'ai http://www.pcapr.net/browse?proto=ldap.
Une fois la trace trouvée, je peux regarder les paquets, voir leur représentation binaire, ou bien voir une dissection des paquets (apparemment faite par tshark).
Cela permet déjà d'innombrables possibilités. On ne peut pas déployer tous les protocoles chez soi pour les essayer mais pcapr permet d'accéder à des tas de protocoles différents. On peut aussi télécharger les traces chez soi au format Pcap pour les étudier plus à loisir, par exemple avec ses propres programmes en C ou en Python.
Mais pcapr a une autre possibilité : on peut modifier les paquets, via l'interface Web et copier ensuite la version modifiée (une sorte de Scapy sur le Web).
Terminons sur un avertissement : les traces Pcap peuvent contenir des informations confidentielles. Par exemple, les adresses IP permettent de retrouver une personne, celle qui utilisait cette adresse et sont donc considérées à juste titre par la CNIL comme des données personnelles, relevant de la loi Informatique & Libertés. Pcapr étant situé aux États-Unis, qui n'ont pratiquement aucune protection légale de la vie privée, il faut donc n'envoyer que des traces :
- Anonymisées, par exemple par un programme d'anonymisation comme
pktanon,
comme le plus riche et plus complexe Flaim, comme CoralReef,
ranonymize,
Anontools
ou encore IP::Anonymous. Ces
programmes remplacent chaque adresse IP par une valeur prise dans
192.0.2.0/24ou2001:DB8::/32, voire la suppriment totalement. Notez aussi l'option-hde dnscap si on l'a utilisé pour la capture. Attention, en utilisant les autres informations, il est parfois possible de retrouver quand même les identificateurs qui avaient été anonymisés. C'est pour rendre cette « désanonymisation » plus difficile que la plupart des programmes cités ci-dessus mettent en œuvre des algorithmes complexes. - Ou des traces ne montrant que des adresses IP « à vous »,
locales à votre réseau. (Ou encore, ce qui est fréquent lors des
attaques, des adresses IP que l'on sait usurpées, et qui sont bien
indiquées comme telles dans les commentaires de la trace. Voir par exemple
http://www.pcapr.net/view/bortzmeyer+pcapr/2009/0/4/13/dns-ns-dot-attack-january-2009.pcap.html.)
Grâce à François Ropert, voici les adresses de services similaires :
- OpenPacket
- EvilFingers (sur ce dernier, il semble qu'on ne puisse pas envoyer ses propres traces, c'est moins Web 2.0...)
Sinon, l'idée de pcapr était séduisante mais, en pratique, le site semble avoir été abandonné en 2011-2012 (plus de nouveautés, dernier message automatique du site en août 2012). En juillet 2013, même le téléversement de nouveaux pcap ne marchait plus (« We are unable to process this pcap. Please see the faq for common upload problems. » et aucun moyen de contacter un administrateur).
L'article seul
RFC 5452: Measures for making DNS more resilient against forged answers
Date de publication du RFC : Janvier 2009
Auteur(s) du RFC : A. Hubert (Netherlabs Computer Consulting), R. van Mook (Equinix)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsext
Première rédaction de cet article le 29 janvier 2009
Le système de résolution de noms DNS est indispensable à la grande majorité des sessions sur l'Internet et pourtant il est très peu fiable. « Empoisonner » un résolveur DNS, lui faire avaler de fausses informations, est relativement facile, et ce problème est connu depuis longtemps (et documenté dans le RFC 3833, notamment les sections 2.2 et 2.3). Il existe une solution à long terme, DNSSEC, mais il n'est pas évident qu'elle puisse un jour être déployée suffisamment pour fournir une réelle protection. Alors, que faire en attendant ? Ce RFC documente les mesures que devrait prendre un résolveur pour ne pas se faire empoisonner.
Le résolveur DNS est le logiciel qui se charge
de poser les questions, pour le compte des applications
(client, pour ce RFC). Il en existe
plusieurs possibles (en ne comptant que le logiciel libre et que les logiciels sérieux : BIND,
Unbound et
PowerDNS
Recursor). Il utilise typiquement
UDP pour poser la question aux serveurs DNS
faisant autorité. UDP ne reposant pas sur une connexion, un attaquant
qui essaie d'empoisonner le résolveur peut, juste après que la
question aie été posée, envoyer une réponse fabriquée de toute pièce
et, dans certains cas, la faire accepter. Bien que le DNS aie été
amélioré au cours du temps (voir notamment le RFC 2181), il
reste trop fragile. Pire, comme la plupart des résolveurs sont
également des caches, une fausse réponse, une
fois acceptée, sera resservie à chaque requête d'un client. Heureusement, le résolveur
peut rendre cet empoisonnement bien plus difficile, en utilisant
quelques techniques décrites par notre RFC. Celui-ci ne concerne que
les résolveurs, les serveurs faisant autorité (par exemple ceux de
l'AFNIC pour
.fr) ne sont pas
concernés. Les résolveurs sont typiquement gérés par le
FAI ou les administrateurs du réseau local de l'organisation.
La publication de la faille Kaminsky en août 2008 a mis sous le feu des projecteurs cette vulnérabilité des résolveurs DNS. Mais elle était connue depuis des années, et le travail sur ce RFC avait commencé à l'IETF bien avant que la faille Kaminsky soit découverte. La première version officiellement adoptée par l'IETF date en effet de janvier 2007 et la première version tout court remonte à août 2006. Hélas, bien que plus agile que la plupart des autres organismes de normalisation, l'IETF est parfois un mammouth difficile à faire bouger. Pour diverses raisons, comme le fait que les auteurs du futur RFC (parmi lesquels Bert Hubert, le père de PowerDNS) étaient des nouveaux venus, le processus a pris plus longtemps qu'il n'aurait dû.
Oublions les retards. Que contient ce RFC ? La section 2 rappele le problème et la cible visée, les programmeurs qui écrivent les résolveurs et, dans une moindre mesure, les administrateurs de ceux-ci.
La section 3 décrit le mécanisme d'empoisonnement. L'idée, présente dans la section 5.3.3 du RFC 1034 est que, ne pouvant compter sur la protection qu'apportent les connexions TCP, les résolveurs DNS doivent se méfier des réponses UDP et vérifier que la réponse corresponde à une question actuellement en cours. Cela implique :
- Que la question (qui est rappelée dans la réponse DNS) soit une
question en attente. Le truc
0x20, expliqué plus loin, pousse encore plus loin cette idée. - Que le Query ID (RFC 1035, section 4.1.1) de la réponse soit celui de la question en cours. Notons que ce Query ID ne fait que 16 bits, ce qui est très insuffisant.
- Que la réponse soit adressée à la bonne adresse IP (si le résolveur en a plusieurs) et au bon port (c'est surtout sur la question du port que ce RFC apporte une nouveauté, voir plus loin).
Comme prévu par ce RFC (et d'autres documents antérieurs comme le RFC 3833) et comme l'a montré la faille Kaminsky, en 2008, il était trop facile, avec la plupart des résolveurs, de prévoir les informations à fournir, seul le Query ID était imprévisible et devait être essayé par force brute. Mais il n'a que 65536 valeurs possibles.
La section 4 détaille cette attaque. En effet, il existe une
certaine différence entre la théorie et la pratique, et cette
différence avait protégé le DNS jusqu'à présent. D'abord (section
4.1), il faut que le résolveur fasse une requête pour qu'on puisse
tenter de fournir une fausse réponse. Si le résolveur est ouvert (ce
qui est très dangereux, voir RFC 5358), c'est
trivial. S'il ne l'est pas, l'attaque est restreinte aux clients
légitimes du résolveur (c'est le cas de l'attaque Kaminsky mais ce
n'est pas une grosse limitation car beaucoup d'attaquants ont déjà un
zombie à leur service sur le réseau attaqué) ou à ceux
qui attendent une requête spontanée. (On peut aussi indirectement
provoquer une requête par exemple en envoyant un message dont la
lecture déclenchera la requête DNS.) Il existe des méthodes pour
prévoir le moment où se déclenchera la prochaine requête. Par exemple,
certains résolveurs, sans permettre l'accès au service complet,
permettent l'accès au cache (avec BIND, l'option
allow-recursion <MYNETWORKS> ne suffit donc
pas à protéger le résolveur, il faut aussi un
allow-query-cache <MYNETWORKS>). Dans ce
cas, l'attaquant peut voir le TTL et prévoir
lorsqu'il atteindra zéro, menant à une requête.
Une section est ensuite consacrée à chaque élément de la réponse, que l'attaquant doit connaître ou deviner (RFC 1035, section 7.3). La section 4.3 détaille la protection qu'offre le Query ID, un nonce de seulement 16 bits (et encore plus faible dans certaines implémentations comme le résolveur de Microsoft qui, pendant longtemps, n'utilisait que 14 bits). Si l'attaquant peut générer plusieurs requêtes simultanées (ce que permet l'attaque Kaminsky), le paradoxe de l'anniversaire lui offre de grandes chances de tomber juste. PLus loin, la section 5 détaille ce paradoxe de l'anniversaire. Il doit son nom à une observation simple. Dans un groupe de personnes (par exemple des étudiants dans un amphi), quelle doit être la taille du groupe pour avoir au moins 50 % de chances que deux aient la même date d'anniversaire ? La plupart des gens pensent au premier abord que ce nombre est de l'ordre de 180 (les 365 jours de l'année divisés par 2 puisqu'on veut une chance sur deux) alors qu'il est bien plus bas, environ 23. Appliqué au DNS, ce paradoxe veut dire que, certes, trouver un Query ID particulier est difficile mais que trouver un Query ID identique à un autre, à n'importe quel autre, est beaucoup plus facile.
La section 4.4 rappelle que l'adresse IP source de la réponse doit correspondre à celle à qui a été envoyée la question et que le succès de l'attaque dépend donc de la possibilité, pour l'attaquant, de tricher sur son adresse IP. En dépit des RFC 2827 et RFC 3704, la plupart des opérateurs permettent en effet à leurs clients d'indiquer n'importe quelle adresse IP source.
La section 4.5 étudie le rôle du port source de la requête, port où doit être renvoyé la réponse. La principale originalité de ce RFC est en effet de recommander l'utilisation des 16 bits du numéro de port comme source additionnelle d'entropie, en renfort des sources existantes comme le Query ID.
Enfin, la section 4.6 rappelle que l'attaquant n'a qu'un temps limité devant lui. Il doit répondre avant le vrai serveur soit, typiquement, en moins de 50 à 100 ms. Toutefois, l'attaquant peut améliorer ses chances en ralentissant le vrai serveur, par exemple par une attaque DoS.
Une dernière ligne de protection du résolveur (section 6) est de
n'accepter que des réponses « dans la
bailliage », c'est-à-dire des réponses dans le
domaine de la question posée. Si un résolveur interroge les serveurs
de demaziere.fr sur l'adresse IP de
www.demaziere.fr, les réponses, notamment dans la
section additionelle, devraient être ignorées si elles portent sur
d'autres domaines. L'absence de ce test permettait l'attaque dite
Kashpureff et cette vérification du bailliage
est recommandée depuis le RFC 2181.
D'accord, il existe une vulnérabilité. Mais, en pratique, quel est le risque réel ? Peut-on le quantifier ? C'est l'objet des sections 7 et 8, qui vont faire un peu de mathématiques pour estimer la difficulté réelle d'empoisonnement d'un résolveur. Par exemple, si le port source est constant (ce qui était fréquent au début de la rédaction du RFC), il fallait injecter de fausses réponses au rythme de 416 Mb/s pour avoir une chance sur deux de gagner. Si le serveur réel était ralenti ou stoppé par une attaque, on pouvait se contenter de nettement moins, soit 42 Mb/s. Les calculs détaillés figurent en section 7.1 et 7.2. La conclusion est que, avec un port source fixe, l'empoisonnement est assez accessible. Avec un port variable, il faut un débit de 285 Gb/s ce qui explique que les résolveurs d'aujourd'hui sont encore protégés pour quelque temps. Augmenter le TTL favorise le défenseur, sauf si les requêtes sont pour des domaines inexistants, ce qui est le cas de l'attaque Kaminsky (discutée plus en détail en section 8.1).
Après ces calculs inquiétants, quelles sont les contre-mesures possibles, exposées en section 9 ? D'abord, le résolveur doit déjà utiliser la totalité des mesures recommandées par les RFC 1035 et RFC 2181, ce qui n'est pas encore le cas pour tous aujourd'hui. Ensuite, la plus importante contre-mesure nouvelle est l'aléatoirisation du port source (SPR pour Source Port Randomization), c'est-à-dire le fait d'utiliser peu ou prou les 65536 valeurs théoriquement possibles comme source des requêtes (section 9.2, qui recommande aussi de faire varier l'adresse IP si possible, ce qui n'est guère réaliste qu'avec IPv6). C'est cette technique qui est mise en œuvre dans BIND depuis 2008 et un peu avant dans Unbound et PowerDNS. En pratique, ces résolveurs, suivant la recommandation du RFC, utilisent les ports de 1024 à 65536.
À noter (section 10) que cette aléatoirisation du port source (voire de l'adresse) peut entrainer des problèmes avec certains routeurs NAT dont la table des flux en cours va vite déborder.
À noter aussi que la tâche de compliquer l'empoisonnement ne se termine
pas avec ce RFC. Par exemple, l'IETF travaille sur un truc nommé
0x20 (voire la section 4.2 de notre RFC) qui
consiste à faire varier la casse du nom de
domaine dans la question pour ajouter un peu d'entropie supplémentaire.
Une autre raison importante des délais qu'a subi ce RFC est la controverse autour de DNSSEC (RFC 4033). Le raisonnement des « ultras » de DNSSEC est le suivant : comme les mesures anti-empoisonnement de notre RFC 5452 ne font que le rendre plus difficile, sans l'empêcher totalement, pourquoi perdre du temps à retarder l'attaquant lorsqu'on peut le stopper complètement avec DNSSEC ? En outre, DNSSEC protège contre d'autres attaques comme une trahison par un serveur secondaire faisant autorité. Bref, selon ce courant, très fortement représenté à l'IETF, travailler sur la résistance à l'empoisonnement est une perte de temps, voire une diversion par rapport aux seules tâches qui comptent, le déploiement de DNSSEC. Le RFC a donc eu du mal à passer face à une telle opposition (voir par exemple le compte-rendu de la réunion de Minneapolis en 2008). C'est ce qui explique le « lip service » qu'on trouve au début du RFC, avec l'affirmation que notre RFC ne décrit que des mesures temporaires, en attendant la « vraie » solution, DNSSEC. En réalité, le déploiement de DNSSEC, chez tous les acteurs (serveurs faisant autorité et distribuant des zones signées, résolveurs validant et/ou applications testant DNSSEC) va prendre de nombreuses années et ne sera peut-être jamais suffisamment effectif pour gêner réellement les empoisonneurs. Des mesures rendant leur tâche plus difficile sont donc essentielles.
L'article seul
Attaque DNS par amplification en demandant "NS ."
Première rédaction de cet article le 24 janvier 2009
Depuis au moins le 7 janvier, une série d'attaques DoS utilisant le DNS a lieu. Parfois nommée ISPrime, du nom de la première victime, cette attaque utilise une variante originale des attaques par amplification.
Le principe est que le DNS repose essentiellement sur UDP, protocole sans connexion et très vulnérable aux usurpations d'adresses IP. Tirant partie de l'absence de filtrage à la source par la grande majorité des FAI, l'attaquant envoie des paquets avec une fausse adresse source. Il est donc absurde de bloquer complètement ces adresses, ce sont celles des victimes, pas celles des attaquants.
L'attaque par amplification originale visait des serveurs récursifs ouverts, comme le détaille le RFC 5358. Cette variante actuelle, compte-tenu de la diminution du nombre de récursifs ouverts, utilise des serveurs qui n'acceptent pas de faire des requêtes récursives mais acceptent de répondre à la question "NS .", c'est à dire à une demande de la liste des serveurs de noms de la racine. La liste étant assez longue, l'attaquant réussit ainsi une amplification (la réponse, envoyée à la victime, est bien plus grosse que la requête, envoyée par l'attaquant).
Un bon article de l'OARC, Upward Referrals Considered Harmful explique pourquoi il faut configurer ses résolveurs pour éviter de répondre à ces questions "NS ." (et comment le faire pour BIND).
Vous pouvez vérifier que votre résolveur est sûr en lui demandant, depuis une machine à l'extérieur de votre réseau :
% dig @votre-machine NS .
et vous ne devez pas avoir de réponse (ou bien une réponse courte
comme REFUSED ou
SERVFAIL). Vous pouvez aussi tester depuis un site Web.
La plupart des utilisateurs de BIND voient ces requêtes dans leurs journaux :
/var/log/daemon.log:Jan 24 09:23:30 lilith named[31908]: client 63.217.28.226#28124: view external: query (cache) './NS/IN' denied /var/log/daemon.log:Jan 24 09:23:31 lilith named[31908]: client 63.217.28.226#53227: view external: query (cache) './NS/IN' denied /var/log/daemon.log:Jan 24 09:23:32 lilith named[31908]: client 66.230.160.1#1601: view external: query (cache) './NS/IN' denied
mais, si on utilise l'excellent outil de capture DNS dnscap, on peut aussi les voir en demandant les requêtes concernant la racine :
% sudo dnscap -i eth0 -w ~/tmp/isprime -g -s i -x '^\.$'
...
[45] 2009-01-24 22:22:41.094184 [#1300 eth0 0] \
[206.71.158.30].27234 [192.0.2.1].53 \
dns QUERY,NOERROR,23839,rd \
1 .,IN,NS 0 0 0
[45] 2009-01-24 22:22:42.251658 [#1301 eth0 0] \
[206.71.158.30].2960 [192.0.2.1].53 \
dns QUERY,NOERROR,41966,rd \
1 .,IN,NS 0 0 0
[45] 2009-01-24 22:22:42.553856 [#1302 eth0 0] \
[206.71.158.30].2204 [192.0.2.1].53 \
dns QUERY,NOERROR,7922,rd \
1 .,IN,NS 0 0 0
Un autre moyen de suivre ces attaques est d'utiliser une version
récente de l'excellent dnstop. Avec
l'option -f, on peut regarder, en temps réel, uniquement les
requêtes refusées :
Replies: 1 new, 499 total Thu Jan 29 16:53:34 2009 Destinations Count % -------------- --------- ------ 72.249.127.168 201 40.3 69.64.87.156 146 29.3 72.20.3.82 129 25.9 ...
ncaptool peut également filtre ces paquets :
% ncaptool -i eth0 -mg - dns qname=. qtype=ns flags\#qr
[17 pcap if eth0] 2009-01-30 14:54:34.757562000 [00000000 00000000] \
[76.9.16.171].6448 [208.75.84.80].53 udp \
dns QUERY,NOERROR,56008,rd \
1 .,IN,NS 0 0 0
[17 pcap if eth0] 2009-01-30 14:55:37.391382000 [00000000 00000000] \
[76.9.16.171].53139 [208.75.84.80].53 udp \
dns QUERY,NOERROR,56607,rd \
1 .,IN,NS 0 0 0
Dernière méthode pour regarder si une attaque est en cours, la plus geek, due à Geoffrey Sisson, et implémentée uniquement avec tcpdump :
tcpdump -n -s 0 -vvv '
udp dst port 53 and
(udp[10:2] & 0x8000 = 0) and
udp[12:2] = 1 and
udp[20] = 0 and
udp[21:2] = 2 and
udp[23:2] = 1
'
# Ici, les explications de chaque ligne (sauf "udp dst port 53" qui est triviale)
# QR = 0
# QDCOUNT = 1
# QNAME = '.'
# QTYPE = NS (code 2) https://www.iana.org/assignments/dns-parameters
# QCLASS = IN (code 1)
Un autre logiciel qui peut être utile est en http://www.smtps.net/pub/dns-amp-watch.pl. C'est un petit
script Perl qui analyse
le journal de BIND pour dresser une liste des attaques qui ont laissé
une trace dans le fichier, si votre BIND est correctement configuré
pour les refuser :
% perl dns-amp-watch.pl Queries for root (probable DNS amplification attacks AGAINST these IPs 3564 206.71.158.30 148 66.230.160.1 98 63.217.28.226 51 76.9.16.171
Ici, on voit que la principale victime de la
journée est 206.71.158.30.
Enfin, vous pouvez aider la recherche sur cette attaque en utilisant ce programme qui fait tourner tcpdump sur votre serveur et transmet les résultats intéressants à l'OARC.
Voir aussi l'article DNS queries for. Et merci à Samuel Tardieu pour être le premier à m'avoir signalé cette atttaque.
L'article seul
RFC 5408: Identity-based Encryption Architecture and Supporting Data Structures
Date de publication du RFC : Janvier 2009
Auteur(s) du RFC : G. Appenzeller (Stanford
University), L. Martin (Voltage
Security), M. Schertler (Tumbleweed Communications)
Pour information
Réalisé dans le cadre du groupe de travail IETF smime
Première rédaction de cet article le 24 janvier 2009
L'IBE (Identity-Based Encryption) est une technique d'identité numérique où les clés cryptographiques sont dérivées de l'identité (par exemple d'une adresse de courrier). Ce RFC normalise son utilisation, notamment dans S/MIME.
C'est fou
ce qu'on fait avec les identités numériques. Il y avait des cas où l'identité était elle-même une clé publique
(HIP, cf. RFC 7401 et
CGA, cf. RFC 3972) mais,
avec IBE, les
clés cryptographiques dérivent de l'identité. Si je prends comme
identité une adresse de courrier comme
stephane+ibe@bortzmeyer.fr, divers algorithmes
comme celui de Boneh-Franklin (cf. RFC 5409) permettent de fabriquer une
clé publique, que mes correspondants peuvent utiliser pour chiffrer
des messages qui me sont destinés.
La clé privée, dans les systèmes d'IBE, est générée par un serveur dédié, dont la sécurité devient donc vitale (la section 7 du RFC le discute en détail). IBE est donc un système avec une bonne dose de centralisation. Ce serveur utilise les mêmes paramètres que pour le calcul de la clé publique, plus un secret.
La section 2.1 du RFC résume l'essentiel sur les IBE. Comme indiqué plus haut, il faut disposer d'un PPS (Public Parameter Server) qui distribuera les paramètres publics nécessaires au calcul des clés et d'un PKG (Private Key Generator) qui générera les clés privées. Il y a typiquement un PPS et un PKG par « domaine », un domaine étant un groupe d'identités ayant les mêmes paramètres. Comme une identité comprend souvent un nom de domaine (c'est le cas des identités basées sur l'adresse de courrier), la distribution des PPS et PKG suit typiquement celle du DNS.
Le RFC ne discute absolument pas des problèmes politiques que posent les IBE, problèmes qui avaient pourtant été soulevés dans le groupe de travail S/MIME de l'IETF, mais ignorés. Le principal problème est qu'IBE est typiquement soutenu par des gens qui veulent garder le contrôle des clés privées des utilisateurs, gouvernements dictatoriaux ou entreprises paranoïaques. L'argument principal est de simplifier la gestion des clés (celle-ci est la faiblesse courante des autres techniques de cryptographie car peu d'utilisateurs ont la compétence et l'envie de gérer leurs clés correctement). Un autre argument est le désir de mettre en œuvre des techniques de menottes numériques, par exemple pour empêcher la lecture d'un message après une certaine date. Ces points, absents du RFC, sont à garder en tête lorsqu'on évalue les IBE.
Le format de chiffrement et de signature des messages S/MIME (RFC 3851) est moins utilisé que son concurrent PGP (RFC 4880) mais il est le premier à permettre d'utiliser les IBE.
La section 2.2 explique le fonctionnement des IBE. Un client IBE doit récupérer les paramètres publics de génération de la clé publique (section 2.2.1) à un URI « bien connu ». Il peut ensuite fabriquer la clé publique et chiffrer (section 2.2.2). Pour lire un message ainsi chiffré (section 2.3), le destinataire doit obtenir les mêmes paramètres publics puis contacter le PKG (section 2.3.2). Il doit évidemment s'authentifier auprès de ce dernier.
Maintenant, place aux détails. La section 3 définit le format des identités en ASN.1. Elles seront typiquement encodées en DER. L'identité elle-même est une chaîne de caractères. La structure qui la contient contient aussi un domaine district, qui est l'URI du PPS.
La section 4 donne le protocole d'interrogation du PPS, le serveur
qui donnera les paramètres publics. Il s'agit d'un simple
GET HTTP (RFC 7231, section 4.3.1) sur l'URI du domaine (section 4.1). Les
paramètres seront encodés en DER et surencodés en
Base64 et marqués comme du type
application/ibe-pp-data (section 4.3).
Et pour les paramètres privés ? La section 5 s'en occupe. Le
récepteur d'un message IBE contacte son PKG en HTTP (qui doit être
chiffré et authentifié) et envoie une
requête POST (RFC 2616, section 9.5). Dans le corps de cette requête, il enverra du
XML (section 5.3) qui codera son identité et
des paramètres optionnels (curieusement, il n'existe aucun
schéma pour définir le XML acceptable). La réponse, de type application/ibe-pkg-reply+xml, sera également en XML (section
5.6), contenant entre autres un code de réponse et la clé privée en
DER. Le code sera par exemple IBE100 (succès) ou
IBE301 (clé inconnue ou irrécupérable).
L'article seul
Tables de hachage pour le programmeur C
Première rédaction de cet article le 23 janvier 2009
Dernière mise à jour le 9 février 2009
Les tables de hachages, appelées, selon les
langages de programmations, hashes (Perl), dictionnaires (Python),
HashTable (Java), sont une des structures de données les
plus courantes en programmation, en partie à cause de leur
simplicité. Sont-elles réservées aux langages de haut niveau ? Et en
C ?
Ce langage est parfois nécessaire par exemple pour des raisons de performance. Ayant eu à traiter de grandes quantités de données, j'ai tenté un essai en C. Mais le problème se prêtait bien aux tables de hachage et je n'en avais jamais fait en C. Allait-il falloir que je les code moi-même ? Non, il existe plusieurs bibliothèqus de qualité déjà existantes, et en logiciel libre.
Voici une liste, non exhaustive (et je n'ai pas eu le temps de tout tester) :
- La GLib fournit une énorme quantité de structure de données, dont les tables de hachage. Très répandue, elle est bien documentée et, je trouve, très facile à utiliser. C'est de loin celle qui m'a permis de terminer le plus vite.
- HamsterDB est surtout connu pour sa
capacité à sauvegarder les tables sur disque. Mais, pour des tables
temporaires, il peut aussi fonctionner en mémoire, avec l'option
HAM_IN_MEMORY_DB. Je le trouve moins bien documenté que la GLib mais la photo sur la page d'accueil du site Web est trop mignonne. Par contre, l'absence d'un mécanisme de tri pratique m'a fait perdre du temps. - Judy est utilisée dans un certain nombre de programmes et semblait prometteuse. Mais la documentation est horrible et la bibliothèque est donc d'un abord difficile (sans compter les noms incompréhensibles de ses macros).
- HashIt semble intéressant mais j'ai manqué de temps pour le tester.
- Comme HamsterDB, Berkeley DB est surtout conçu pour garder les tables sur disque mais il a apparemment une option pour rester en mémoire, décrite ainsi : « In-memory databases never intended to be preserved on disk may be created by setting the file parameter to NULL. »
- Enfin, en s'éloignant des tables de hachage, il faut aussi
signaler que SQLite a aussi un mode « en
mémoire » (
base ":memory:"). On a alors toute la puissance de SQL (pour faire une simple table de hachage, ça peut être beaucoup).
Pour comparer trois de ces bibliothèques, je suis parti d'un
programme qui analyse des requêtes faites à un serveur DNS faisant autorité. On veut
savoir quels domaines déclenchent le plus souvent une réponse NXDOMAIN
(indiquant que le domaine n'existe pas). Pour cela, on ouvre le
fichier au format pcap, on analyse le contenu et, pour chaque réponse
NXDOMAIN, on regarde la table de hachage. Si le domaine y est déjà, on
incrémente le compteur. Sinon, on crée une entrée avec un compteur
initialisé à 1. À la fin, on affiche le résultat. Trivial avec un
langage comme Perl, voici le
programme en C (et son fichier d'en-tête). Pour le compiler, le plus simple est d'utiliser
un Makefile du genre de :
#HASHTABLE=HASHTABLE_JUDY
#HASHTABLE=HASHTABLE_GLIB
HASHTABLE=HASHTABLE_HAMSTERDB
ifeq (${HASHTABLE},HASHTABLE_GLIB)
HASHTABLE_CFLAGS=$(shell pkg-config --cflags glib-2.0)
else ifeq (${HASHTABLE},HASHTABLE_JUDY)
HASHTABLE_CFLAGS=
else ifeq (${HASHTABLE},HASHTABLE_HAMSTERDB)
HASHTABLE_CFLAGS=
else
HASHTABLE_CFLAGS=
endif
ifeq (${HASHTABLE},HASHTABLE_GLIB)
HASHTABLE_LDFLAGS=$(shell pkg-config --libs glib-2.0)
else ifeq (${HASHTABLE},HASHTABLE_JUDY)
HASHTABLE_LDFLAGS=-lJudy
else ifeq (${HASHTABLE},HASHTABLE_HAMSTERDB)
HASHTABLE_LDFLAGS=-lhamsterdb
else
HASHTABLE_LDFLAGS=
endif
CFLAGS=-D${HASHTABLE} ${DEBUG} -Wall ${HASHTABLE_CFLAGS}
LDFLAGS=-lpcap ${HASHTABLE_LDFLAGS}
...
En faisant varier HASHTABLE, on peut tester le
programme avec quatre bibliothèques différentes et vérifier que tout
marche bien.
Et leurs performances ? Avec un fichier pcap de 55 millions de paquets DNS (7,6 Go), dont 3,7 millions renvoient NXDOMAIN, ce qui fait 310 000 domaines à mettre dans la table de hachage, sur un PC muni d'un Pentium à 2,66 Ghz et de 2 Go de RAM, avec Debian, HamsterDB l'emporte haut la main en 4 minutes et 10 secondes. GLib est loin derrière avec 14 minutes et 55 secondes.
Merci à Kim-Minh Kaplan pour le support de BerkeleyDB dans le programme.
L'article seul
Unbound, un autre résolveur DNS
Première rédaction de cet article le 21 janvier 2009
Le résolveur DNS le plus courant, dans le monde du logiciel libre, est BIND. Mais il est toujours bon qu'il existe des alternatives sérieuses, pour faire face à toute éventualité. Le deuxième résolveur DNS le plus utilisé est sans doute Unbound.
Le résolveur est le logiciel serveur qui va répondre aux requêtes
des clients DNS (ces
clients sont typiquement des programmes ayant appelé
getaddrinfo), en utilisant les
informations qu'il va trouver chez les serveurs faisant autorité. Le
résolveur est également typiquement un cache,
pour éviter de refaire ces requêtes trop souvent.
Pendant de nombreuses années, seul BIND assurait cette fonction (il existait aussi quelques expériences peu fiables). Désormais, il est concurencé par PowerDNS Recursor et Unbound. Ce dernier, après un prototype en Java est désormais, dans sa version de production, écrit en C.
Je teste Unbound sur une Debian 5.0 "lenny". Il existe un paquetage tout fait, mais d'une version un peu trop ancienne, à qui manque notamment le support de DLV (RFC 5074). Je vais donc créer un paquetage local en partant de celui de la version de développement de Debian, "sid") :
# Récupérer le source Debian. À faire sur une machine sid, puis à copier % apt-get source unbound # Récupérer la dernière version d'Unbound % wget http://unbound.net/downloads/unbound-1.3.2.tar.gz # La détarer % tar xzvf unbound-1.3.2.tar.gz % cd unbound-1.3.2 # Copier le répertoire "debian", depuis le paquetage Debian % cp -a -r ../unbound-sid/debian . # Paquetages nécessaires pour compiler unbound (indiqués dans le champ # Build-Depends: de debian/control) % sudo aptitude install doxygen automake libldns-dev quilt # Éditer le debian/changelog % dch -i # On y mettra: # unbound (1.3.2-0.99) unstable; urgency=low # # * Local package of 1.3, to get DLV # # -- Stephane Bortzmeyer <bortzmeyer@nic.fr> Wed, 21 Jan 2009 15:31:23 +0100 # Créer le paquetage binaire % dpkg-buildpackage -rfakeroot # Voilà, le paquetage est prêt, on l'installe % sudo dpkg -i ../unbound-host_1.3.2-0.99_i386.deb ../libunbound1_1.3.2-0.99_i386.deb ../unbound_1.3.2-0.99_i386.deb
Notez que le démon ne démarre pas automatiquement en raison de la bogue #500176 :
Starting recursive DNS server: unbound[1232549330] unbound[25036:0] error: bind: address already in use [1232549330] unbound[25036:0] fatal error: could not open ports failed!
Je reconfigure BIND (dont j'ai besoin pour autre chose) pour ne pas écouter sur le réseau :
options {
listen-on-v6 { };
listen-on { };
...
et on reconfigure les paquetages :
% sudo dpkg --configure -a Setting up unbound (1.3.2-0.99) ... Starting recursive DNS server: unbound.
et tout est bon, comme on peut le vérifier dans le journal
/var/log/daemon.log :
Jan 21 15:52:05 batilda unbound: [26056:0] notice: init module 0: validator Jan 21 15:52:05 batilda unbound: [26056:0] notice: init module 1: iterator Jan 21 15:52:05 batilda unbound: [26056:0] info: start of service (unbound 1.3.2).
ainsi qu'avec dig, en demandant à
::1 (la machine locale) :
% dig @::1 SOA af. ... ;; ANSWER SECTION: af. 86400 IN SOA ns1.nic.af. hostmaster.nic.af. 2009012100 43200 3600 604800 86400
Tout va bien, le résolveur est allé chercher l'information sur
.af. On peut alors éditer
/etc/resolv.conf et mettre :
% cat /etc/resolv.conf ... # unbound local avec DLV 2009-01-21 nameserver ::1
Un des intérêts de Unbound (et d'un résolveur DNS sur sa propre
machine) est de pouvoir valider les réponses DNS avec
DNSSEC (RFC 4033 et
suivants). J'édite /etc/unbound/unbound.conf pour activer
la validation.
server:
...
dlv-anchor-file: "dlv.isc.org.key"
trust-anchor-file: "itar-trusted-anchors"
Où obtient-on ces fichiers ? Le premier est la clé publique du registre DLV, trouvée sur le site de l'ISC et vérifiée par PGP :
% sudo wget http://ftp.isc.org/www/dlv/dlv.isc.org.key % sudo wget http://ftp.isc.org/www/dlv/dlv.isc.org.key.asc % gpg --verify dlv.isc.org.key.asc gpg: Signature made Sun Sep 21 06:30:51 2008 CEST using RSA key ID 1BC91E6C gpg: Good signature from "Internet Systems Consortium, Inc. (Signing key, 2006) <pgpkey2006@isc.org>" ...
Le second est un fichier de KSK (Key Signing Key) comme on en trouve sur le site Web des registres qui utilisent DNSSEC. Pour éviter de toutes les récupérer une par une, on va télécharger l'ITAR (Interim Trust Anchor Repository) de l'IANA :
% sudo wget https://itar.iana.org/anchors/anchors.mf # On ne télécharge pas la signature PGP, on fait confiance à TLS % sudo mv anchors.mf itar-trusted-anchors
Et on recharge Unbound :
% sudo /etc/init.d/unbound force-reload
Est-ce que tout marche ? Testons avec un nom dans un TLD non signé :
% dig +dnssec SOA com. ... ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 13, ADDITIONAL: 1 ... ;; ANSWER SECTION: com. 900 IN SOA a.gtld-servers.net. nstld.verisign-grs.com. 1232550840 1800 900 604800 900
On a une réponse mais pas de flag AD (Authentic Data). En l'absence de signature, Unbound n'a rien pu vérifier.
Maintenant, testons avec un domain signé mais pour lequel ni le registre DLV de l'ISC ni l'ITAR ne contient de trusted anchor (ou secure entry point), de clé publique :
% dig +dnssec SOA ripe.net ... ;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 5, ADDITIONAL: 5 ... ;; ANSWER SECTION: ripe.net. 172419 IN SOA ns-pri.ripe.net. dns-help.ripe.net. 2009012101 3600 7200 1209600 7200 ripe.net. 172419 IN RRSIG SOA 5 2 172800 20090220060006 20090121060006 13992 ripe.net. BMAf2Ft7hEcaW0OyMluelgeUSLbfeC5Wok+7l0ZjK3Ui2boiDMBQxDcX gSqmIqIeRizi9tmTVnzNigBNHkrqe8z9fNkxl5GoTLtjXU4iwqmiSiVH 1AbWL7eyJwcIMzFdU84zj3jPadLjnbQa59x465GoFVviJgEd7+/SYZAK y5jaKyIlGB0/KZoeKAV29o1h9DcBn3ZE
Il y a bien une signature (enregistrement RRSIG) mais aucun moyen de la valider.
Maintenant, prenons un domaine qui est signé et existe dans le registre DLV de l'ISC :
% dig +dnssec SOA mondomaineamoi.fr ... ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 2, AUTHORITY: 3, ADDITIONAL: 5 ... ;; ANSWER SECTION: mondomaineamoi.fr. 21600 IN SOA ns.mondomaineamoi.fr. postmaster.mondomaineamoi.fr. 2009010701 7200 3600 2419200 3600
C'est parfait, on a le flag AD (Authentic Data), la signature a pu être vérifiée. On est désormais protégé contre un empoisonnement DNS de ce domaine.
Et avec ITAR ? Le TLD suédois n'est pas dans le registre DLV mais sa clé est dans ITAR :
% dig +dnssec SOA iis.se ... ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 2, AUTHORITY: 4, ADDITIONAL: 1 ... ;; ANSWER SECTION: iis.se. 3600 IN SOA ns.nic.se. hostmaster.iis.se. 1232358302 10800 3600 1814400 14400
Ça marche aussi.
Un dernier test, que se passe t-il si les données sont invalides,
par exemple parce qu'un méchant a essayé d'empoisonner notre cache
DNS ? Utilisons le service de test test.dnssec-tools.org. Je
mets leurs clés dans un autre fichier de clés (Unbound peut en gérer
plusieurs, ce qui est très pratique pour les mises à jour) :
trust-anchor-file: "manual-trusted-anchors"
et je teste :
% dig +dnssec A baddata-A.test.dnssec-tools.org ... ;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 20526
et Unbound, fort logiquement, refuse de me donner ces données
incorrectes et répond SERVFAIL (Server Failure). Si
on trouve ce comportement trop sévère, on peut l'adoucir avec
l'option val-permissive-mode.
Unbound n'est pas intéressant que pour DNSSEC. Il a plein d'autres
options. Par exemple, supposons que votre entreprise utilise des
TLD bidons comme .local
(c'est une violation des RFC 2606 et RFC 2826 mais c'est une autre histoire). Pour résoudre
les noms dans ces TLD, vous devez vous adresser à un serveur qui les
connaisse. Mettons que cela soit 192.0.2.129 et
2001:DB8:63::1. On écrit dans
unbound.conf :
forward-zone:
name: "local"
forward-addr: 192.0.2.129
forward-addr: 2001:DB8:63::1
et on peut alors résoudre les noms en .local. (La
configuration ci-dessus suppose que 192.0.2.129 et
2001:DB8:63::1 soient récursifs, sinon il
faudrait utiliser la directive stub-zone.)
L'article seul
Fiche de lecture : The World's Writing Systems
Auteur(s) du livre : Peter Daniels, William Bright
Éditeur : Oxford University Press
978-0-19-507993-7
Publié en 1996
Première rédaction de cet article le 19 janvier 2009
Depuis l'invention de l'écriture il y a cinq mille ans, du côté de Sumer ou d'Uruk (section 3 du livre, une des plus longues, en hommage à l'écriture première), d'innombrables systèmes d'écriture ont été inventés par l'homme. Bien que moins nombreux que les langues puisqu'un même système d'écriture peut servir à de nombreuses langues, on compte néanmoins pas moins de 131 entrées dans la norme ISO 15924, qui normalise la liste des écritures... sans compter celles qui ne sont pas connues. La thèse de Peter Daniels, exposée dans la section 1, est que l'écriture mérite une science à elle, qu'il nomme grammatologie, distincte de la linguistique.
Si aujourd'hui, l'alphabet latin a une place particulière dans le monde (avec des évolutions, comme le décrit bien la section 59), l'écriture arabe (section 50) ou la chinoise (section 15) ne donnent aucun signe de prochaine disparition. L'humanité va donc continuer à vivre avec plusieurs écritures, en dépit des espoirs de certains uniformisateurs qui auraient trouvé que l'adoption généralisée de leur alphabet aurait bien simplifié certains problèmes techniques sur l'Internet (comme les noms de domaines internationalisés du RFC 3490). Certains pays comme l'Inde ont même plusieurs écritures en usage officiel (c'est aussi le cas de l'Union Européenne, passée à trois écritures depuis l'intégration de la Bulgarie).
Pour apprécier cette variété, vous pouvez regarder la célèbre page Web « Tout le monde peut avoir une mentalité de provincial » qui liste la phrase « Pourquoi ne peuvent-ils pas tout simplement parler français ? » en de nombreuses langues et de nombreuses écritures.
Il fallait donc un gros livre pour traiter de toutes les écritures du monde. Cet ouvrage collectif de près de mille pages a réussi, en faisant appel à de nombreux spécialistes. Malgré tout, la place manque et, par exemple, les hiéroglyphes égyptiens (section 4) sont expédiés en onze pages. Mais cette écriture est bien connue et les éditeurs ont préféré passer du temps sur des systèmes moins connus tels le syriaque et sa famille araméenne (sections 46 à 49) ou des écritures d'Asie comme la tangoute (section 18).
Ce livre est donc très souvent cité dans les forums où se préparent
les normes techniques pour un Internet
accessible à tous, par exemple la liste unicode@unicode.org où se discutent les
progrès de la norme Unicode.
La section 1 explique la classification adoptée (mais pas par tous les auteurs du livre : c'est l'inconvénient des ouvrages collectifs, plusieurs ne reprennent pas le vocabulaire de la section 1). Il y a six types d'écriture différents, les logosyllabaires, où les caractères notent un mot (logogramme) ou bien une syllabe, les syllabaires où les caractères notent exclusivement des syllabes comme l'antique cunéiforme, les abjad où on ne note que les consonnes (cas des écritures arabe et hébreu), les alphabétiques, où on note consonnes et voyelles, dont la plus connue est l'écriture latine que vous lisez en ce moment, les abugidas où les caractères notent une consonne et une voyelle associée, l'utilisation d'une autre voyelle se faisant par un caractère diacritique (les abugidas sont notamment communs en Inde), et enfin les écritures à caractéristiques (featural) comme le hangeul où les formes des caractères sont liées aux caractéristiques de la langue.
En revanche, un système purement logographique, où chaque caractère représenterait un mot, n'est pas possible, car il faut bien noter les mots nouveaux et les mots étrangers. Les hiéroglyphes égyptiens, par exemple, ne sont pas purement logographiques (une image ne vaut pas forcément un mot) mais plutôt logosyllabaires.
Ce classement, qui est loin de faire consensus, a suscité d'autant plus de passions que les analyses des différentes écritures étaient traditionnellement obscurcies par des jugements de valeur. Par exemple, aux dix-neuvième et vingtième siècles, la plupart des linguistes occidentaux considéraient comme acquis que les écritures syllabaires étaient inférieures aux abjads, eux-même inférieurs aux alphabets. Ainsi, la supériorité de l'Occident se manifestait même dans son alphabet !
Depuis qu'il existe des systèmes d'écriture, il y a des théories sur leur origine. Souvent, il s'agit d'une origine divine comme le dieu Thot enseignant les hiéroglyphes aux Égyptiens. Dans le cas d'écritures plus récentes comme la cherokee (section 53), l'invention est présentée comme survenue en rêve. Parfois, le récit est plus concret, par exemple les Grecs de l'Antiquité furent les premiers à donner à leur écriture une origine humaine, une importation depuis la Phénicie (cette histoire est décrite en section 21, qui raconte le voyage de l'écriture phénicienne vers l'Ouest). Puisque l'écriture grecque dérive de celle des Phéniciens, c'est l'occasion de se demander combien d'inventions complètement indépendantes de l'écriture ont eu lieu ? Au moins trois (Mésopotamie, Amérique Centrale et Chine) mais jusqu'à sept selon certains auteurs, qui considèrent que les écritures de l'Inde ou de l'Égypte ont été créées sans aucune influence moyen-orientale.
Pendant que le phénicien voyageait vers l'Ouest et créait les alphabets grecs puis ses descendants latin et cyrillique, les écritures araméennes, issues de la même souche mésopotamienne, partaient vers l'Est, donnaient naissance à de nombreuses écritures asiatiques. La boucle sera bouclée à Manille (section 45), en 1593 avec la publication de Doctrina Christiana, livre bilingue et bi-écriture, en espagnol, avec une écriture latine qui avait fait le demi-tour du monde par l'Ouest et en tagalog avec l'écriture baybayin, qui avait fait le demi-tour du monde par l'Est.
Contrairement aux langues, en permanente évolution et qu'il n'y a aucune raison de figer, les écritures sont forcément assez conservatrices, un de leurs buts étant de permettre le voyage dans le temps, de faire voyager des textes vers le futur. Si on réforme trop radicalement, on ne pourra plus lire les textes du passé. Ces problèmes sont d'autant plus sensibles que l'écriture est souvent valorisée et que toute réforme suscite des passions (voir l'excellente section 63 sur les politiques d'écriture en Allemagne et, par exemple, les hésitations du régime nazi sur le gothique).
Chaque écriture ou famille d'écritures fait l'objet d'une section séparée, écrite par un expert du domaine et systématiquement complétée d'une reproduction d'un texte dans cette écriture, avec sa transcription en alphabet latin, et sa traduction en anglais. Il n'a pas été facile de composer de tels textes, les chaînes de production éditoriale n'étaient pas vraiment armées pour un livre utilisant à peu près la totalité d'Unicode. La préface remercie donc Apple pour le Macintosh II et ses logiciels. (Un système comme LaTeX, très utilisé dans le monde académique, et réputé pour la qualité du résultat, n'aurait pas convenu car il gérait fort mal Unicode. Il faudrait tester aujourd'hui avec XeTeX pour voir si un tel livre serait possible en TeX.)
Ces exemples de texte sont variés et choisis dans des domaines très divers. « Ce monument a été construit par Siderija, fils de Parmna, pour lui, sa femme et son fils Pubele. » (lycien) ou bien « Les armes ne tuent pas l'âme, le feu ne la brûle pas » (sanskrit, en devanāgarī, extrait de la Bhagavad-Gîtâ) mais aussi « Erreur due à la gueule de bois » (irlandais, en ogham).
Le déchiffrement des écritures mortes n'est pas forcément une partie de plaisir. C'est une activité proche de la cryptanalyse (section 9) et le livre de David Kahn, The Codebreakers, contient d'ailleurs une section sur le travail des paléo-linguistes. Les amateurs sont d'ailleurs informés que le linéaire A attend toujours son Champollion.
L'invention de nouvelles écritures ne s'est pas arrêtée à l'Antiquité. On invente toujours de nouvelles écritures, parfois pour de bonnes raisons, parfois par simple souci de se distinguer. Une section décrit certaines de ces écritures « modernes » comme le Vai (section 54) ou le Cri (section 55).
J'ai appris aussi qu'il existe des systèmes d'écriture non linguistiques comme la notation phonétique en section 71, la musique en section 72 ou, plus étonnant, les mouvements du corps en section 73, par exemple avec le système Beauchamp-Feuillet.
Un ouvrage pour les longues journées d'hiver, à lire avec une table solide, vu son poids, et qui nécessite de prendre des notes au passage. Et encore, je n'ai pas lu une seule des références bibliographies citées... Bonne lecture et bon voyage dans le monde extrêmement riche des écritures humaines.
L'article seul
RFC 3757: Domain Name System KEY (DNSKEY) Resource Record (RR) Secure Entry Point (SEP) Flag
Date de publication du RFC : Avril 2004
Auteur(s) du RFC : O. Kolkman (RIPE-NCC), J. Schlyter
(NIC SE), E. Lewis (ARIN)
Chemin des normes
Première rédaction de cet article le 17 janvier 2009
Le protocole DNSSEC de signature des enregistrements DNS par des signatures cryptographiques repose sur des clés dont la partie publique est distribuée dans le DNS lui-même. La partie privée sert à signer les enregistrements ou d'autres clés. Certaines de ces clés ne servent qu'à signer des clés, afin d'être moins exposées que les autres. Pour permettre de distinguer ces clés, un bit spécial est réservé par ce RFC.
DNSSEC est normalisé dans les RFC 4033 et suivants. Ces documents ont intégré une distinction, qui n'existait pas dans le protocole originel, et qui a été introduite par notre RFC 3757, entre les clés servant à signer les enregistrements, les ZSK (Zone Signing Key) et les clés servant à signer d'autres clés, les KSK (Key Signing Key). Depuis la publication du RFC 4034, notre RFC 3757 est donc dépassé mais il garde son intérêt historique.
Faire cette distinction entre ZSK et KSK n'est pas obligatoire. On peut parfaitement faire du DNSSEC avec une seule clé, à la fois ZSK (servant à signer la zone) et KSK (mise dans les résolveurs validateurs, ou bien envoyée au registre de la zone parente pour qu'il la publie sous forme d'enregistrement DS). Pour le protocole de validation des enregistrements (RFC 4035), ZSK et KSK sont identiques (voir section 3).
Mais cette simplification présente un inconvénient : comme la clé va servir à signer des enregistrements, qui peuvent être très nombreux, et que les signatures sont renouvelées souvent (par défaut, un mois, avec BIND), et que les données DNS sont publiques, on va fournir à un cryptanalyste beaucoup de matériel. Et, en cryptographie, plus on a de matériel signé à analyser, plus on a de chances.
Il est donc recommandé de changer de clé souvent. Mais, si cette
clé a été publiée, que ce soit via une page Web (comme le fait IIS, le registre
de .se) ou bien via une
zone parente, changer cette clé est pénible et le risque que certains
continuent à utiliser l'ancienne clé est non négligeable.
D'où l'idée, qui est au cœur de notre RFC, d'avoir deux genres de clé. Comme le note la section 1, en pastichant La ferme des animaux, « toutes les clés sont égales mais certaines sont plus égales que d'autres ».
Il y a donc désormais deux sortes de clé, différenciées par un bit dans le champ Flags de l'enregistrement DNSKEY (RFC 4034, section 2.1) :
- Les ZSK (Zone Signing Key), où ce bit vaut zéro, et qui servent à signer les enregistrements. Elles ne sont pas publiées « officiellement » et ne doivent donc jamais se retrouver dans un fichier de configuration. Pour les raisons expliquées plus haut, elles doivent être changées relativement souvent (par exemple tous les six mois).
- Les KSK (Key Signing Key), où ce bit vaut un, et qui servent uniquement à signer les ZSK. Utilisées pour un plus petit nombre d'enregistrements, elles peuvent être de longueur plus grande, et sont changées moins souvent (par exemple tous les deux ans). Elles sont typiquement publiées par la zone parente, ou bien sur une page Web sécurisée (comme au RIPE-NCC). (Comme le rappelle la section 5, l'existence du bit SEP ne suffit pas en elle-même, car un attaquant a pu le définir. Il faut donc récupérer la KSK par un canal sûr.) Les KSK peuvent alors être mises dans la configuration d'un résolveur validateur, d'où le nom de SEP (Secure Entry Point) que leur donne ce RFC.
(La section 1 du RFC détaille tous ces points.)
La section 2 normalise le format du bit SEP. C'est le quinzième du
champ Flags de l'enregistrement DNSKEY donc celui
du plus faible poids (il est enregistré dans le registre
IANA). Si la valeur du champ Flags
est paire, c'est une ZSK, si elle est impaire, c'est une KSK. Si je
demande les DNSKEY du domaine generic-nic.net,
j'obtiens :
% dig DNSKEY generic-nic.net. ... generic-nic.net. 64800 IN DNSKEY 256 3 5 AwEAAbLKp5/pZ+5E8nZgxRiUzr1hxV8Y64/63JUqttROZKqkvnAs4kFW 7qq6DTWBPW/m0n+CwPjVuwWm8xRMFugRKemOFsgyFICkunqQKWrHVmFn JwBFXDO9n82fXwCK+oU5XTiINKQzCg6pMgIrrVPJPSvuuxaVefxWJT7o pwBQZX9v generic-nic.net. 64800 IN DNSKEY 256 3 5 AwEAAfNNMrML2opUMF4ImMpy8fr90YCb/czyb3ASxMys1FlbbQRSlQ5v 1+9IC2R26Ow0ymHlFBugsrtEdFAqO/wkUgRxDrb3GzhUWvZBL0hMsykM QIJlsm6DXzTxDwhxetUhsjZa6EnQvGSMExei4PLc6+Jrz8rqVtS+rLQd LfgrWIat generic-nic.net. 64800 IN DNSKEY 257 3 5 AwEAAd+KNrUQaor2JiLB/oodx9HrUjiGBjn5WpsZHiu2a7oTQYTiVV19 hyWkQL6kwINyaWrkFKS2DJiMQHz7UQoti/J6j26gkQ5XUWviOGrA8g/S xWTVEEQ1FcmyLjBOgLDlUJyWDGO/T8B9lsObuYS1uMkZD6y8BOmRAGeg JtPyASRK5xA9pA20a2XLVWlBqfrvNZ2frXuCkEXaGOgSRTWIm0quYd7/ 2nhVcjiF3+gj4PvVPqVa2jb4iKdlQ1s1Mgx5JqKLPD6wqzHdMTIL+F3U /k/iuEi1olluyEUXM3uMIEgISh6AwHTghGX/ChIVRCz5TzHMXiO45fIk 9gVxwgbqVVBNmy4ZXQwegvMx33afKH27hx1VbiilwGjiaEeoZppXcZ/1 A+hfixRcdNoyvjMgjppDc42hFPCYYY+NFez9BLM8Xac/oq6F/a+4POZP ZV6aaqTmvQLY1wmeKvnhRwKXBtLFkSB7d7RipVVKXsLIA/qQnLTle21H U1azUy3WV5F5S+Vm/cZVv5d1X4/xcdqA+KvAnNAT4rv563Cw1sUhwdzX T1mDdw6UA62wnaZ8KWxqD1ilrk+b8pw+Ri0DXzxmclNlbUduv7UnI6px Y3OGV6K9hkt9IJbHyc02M5JhkeUUSg+AVQjX5OaRzFrPz8pwFZrBPeHf Npln89ofvqcOo9Jp
Le champ Flags est le premier après le type
DNSKEY. Les deux premières clés sont des ZSK (bit de plus faible poids
à zéro), la troisième une KSK (notez aussi sa longueur plus importante, elle
fait 4096 bits, contre 1024 pour les ZSK, c'est l'option
-b du dnssec-keygen de BIND). (Il
y a deux ZSK car l'une est la future clé de signature, publiée en
avance, RFC 6781, section 4.1.1.1.) -f KSK
La section 4 rappelle un mode d'emploi des différentes clés, mais le RFC 6781, plus récent, est une meilleure source.
Avec les outils de gestion de clés de BIND, la génération d'une KSK
se fait simplement en ajoutant l'option -f KSK.
L'article seul
Analyser les en-têtes IPv6 avec pcap
Première rédaction de cet article le 15 janvier 2009
Comme expliqué dans mon article sur l'analyse des paquets réseau en C, il est relativement facile d'analyser des paquets capturés sur le réseau au format pcap, depuis un programme écrit en C. Mais la plupart des exemples qu'on trouve en ligne ne concernent qu'IPv4. Son possible successeur, IPv6, est-il plus ou moins difficile à analyser ?
Le code d'analyse de l'en-tête IPv4 est compliqué par le fait que la taille de cet en-tête est variable. Comme l'explique la norme, le RFC 791 (section 3.1), « The option field is variable in length. There may be zero or more options. ». Le code d'analyse doit donc lire le champ Longueur de l'en-tête (Total Length) et est donc en général du genre :
#define IP_HL(ip) (((ip)->ip_vhl) & 0x0f) ... size_ip = IP_HL(ip) * 4; transport_header = ip_header + size_ip; /* Puis on analyse les données situées à partir de transport_header */
En IPv6, l'en-tête est de taille fixe, ce qui simplifie notamment la tâche des routeurs. Pour les programmes d'analyse, on pourrait donc se dire que ce code suffit :
transport_header = ip_header + SIZE_IP; /* Puis on analyse les données situées à partir de transport_header */
Avec SIZE_IP étant cette fois une constante (40, cf. RFC 8200, section 3).
Mais ce serait trop simple. L'en-tête IPv6 est de taille fixe mais IPv6 permet d'insérer, entre l'en-tête IP et celui de la couche transport un nombre quelconque d'en-têtes dits Extension Headers (cf. RFC 8200, section 4 et une très bonne explication chez Cisco, avec dessins).
Notons d'abord qu'à l'heure actuelle, ces en-têtes supplémentaires sont rares en pratique, en tout cas sur l'Internet public. Ainsi, en analysant aujourd'hui les requêtes IPv6 envoyées à un gros serveur DNS (mesure faite à l'AFNIC), on ne trouve pas un seul Extension Header sur des dizaines de milliers de paquets IPv6. Il est d'ailleurs possible que la présence de middleboxes trop zélées diminue les chances de tels paquets de pouvoir circuler un jour (un problème qui existe déjà pour IPv4).
Mais l'analyseur ne peut quand même pas complètement ignorer cette possibilité. D'abord, les clients du serveur DNS ne sont pas forcément représentatifs (ce sont souvent de gros serveurs Unix, et il existe bien d'autres machines dans le monde) ensuite, il y a au moins un en-tête, celui de fragmentation, qui sera sans doute plus répandu dans le futur, au fur et à mesure de l'augmentation de la taille des réponses DNS.
Comment faire le plus simplement possible ? Le type de l'en-tête
est indiqué dans le champ Next header de l'en-tête
précédent. Les valeurs possibles sont enregistrées à l'IANA mais rien n'indique si une valeur
donnée est celle d'un protocole de la couche
transport ou bien celle d'un extension
header. Il faut donc traiter les valeurs qu'on connait... et
ignorer les autres, il n'y a pas de moyen de « sauter » un en-tête
qu'on ne connait pas. Si la plupart des en-têtes ont un format qui
permet ce saut (au tout début, un octet pour le type du prochain en-tête et un octet
pour la longueur de l'en-tête), ce n'est pas le cas de tous. Heureusement, le RFC 6564 a simplifié le problème, en limitant les variations des en-têtes futurs. Le problème est très bien expliqué dans les
commentaires du sources du module Perl Net::Pcap : Since this module isn't a v6 capable end-host it doesn't implement TCP or UDP or any other `upper-layer' protocol. How do we decide when to stop looking ahead to the next header (and return some data to the caller)? We stop when we find a `next header' which isn't a known Extension Header [...] This means this will fail to deal with any subsequently added
Extension Headers, which is sucky, but the alternative is to
list all the other `next header' values and then break when a
new one of them is defined . Les en-têtes existants comme
Destination Options, avec son format
TLV, offrent déjà beaucoup de possibilités.
Un autre exemple de description de cet algorithme est la section 4.4.1.1 du RFC 4301 sur IPsec, qui explique comment trouver la partie « couche transport » d'un paquet IP, pour accéder au numéro de port et donc déterminer s'il faut le protéger ou pas), et qui donne la liste des en-têtes à sauter.
L'analyse du paquet IPv6 suit donc la méthode
décrite par l'auteur de Net::Pcap (également
suivie par Wireshark dans la fonction
capture_ipv6() du fichier
epan/dissectors/packet-ipv6.c ; la bogue
#2713 montre d'ailleurs que ce n'est pas facile à faire
correctement) :
while (!end_of_headers) {
where_am_i = where_am_i + size_header;
/* Extension headers defined in RFC 8200, section 4 */
if (next == 0 ||
next == 43 || next == 50 || next == 51 || next == 60) {
eh = (struct sniff_eh *) (where_am_i);
next = eh->eh_next;
size_header = (eh->eh_length + 1) * 8;
options++;
}
/* Shim6, RFC 5533 */
else if (next == 140) {
eh = (struct sniff_eh *) (where_am_i);
next = eh->eh_next;
size_header = (eh->eh_length + 1) * 8;
options++;
}
/* Fragment */
else if (next == 44) {
fragmented = 1;
frag = (struct sniff_frag *) (where_am_i);
next = frag->frag_next;
size_header = SIZE_FRAGMENT_HDR;
} else {
/* Unknown extension header or transport
protocol header */
end_of_headers = 1;
}
}
Le code complet figure dans explore-paquets-v6.c et
explore-paquets-v6.h. Sur les traces d'un serveur de
noms de .fr, on trouve :
% ./explore eth1.2009-01-* 30447 IPv6 packets processed 0 TCP packets found 30447 UDP packets found 0 ICMP packets found 0 unknown packets found (other transports or new extension headers) 0 non-initial fragments found 0 options found (some packets may have several)
Sur une autre machine, en réduisant délibérement la MTU avec ifconfig pour obliger à la fragmentation, on peut voir le résultat :
% ./explore fragments.pcap 10 IPv6 packets processed 0 TCP packets found 6 UDP packets found 0 ICMP packets found 0 unknown packets found (other transports or new extension headers) 4 non-initial fragments found 0 options found (some packets may have several)
L'article seul
La taille du botnet Storm est-elle surestimée ?
Première rédaction de cet article le 14 janvier 2009
Quelle est la taille du plus célèbre des botnets, Storm ? Selon un article de chercheurs à l'UCSD, elle serait moins importante qu'annoncée.
Les botnets inquiètent beaucoup, et à juste titre, les praticiens de la sécurité des réseaux informatiques et notamment de l'Internet. Ces réseaux pirates de dizaines ou de centaines de milliers de machines Windows enrôlées de force sont responsables de la très grande majorité du spam, ainsi que de beaucoup d'attaques DoS. Il y a donc une activité de recherche intense sur les botnets, notamment pour évaluer leur taille.
Comme les gérants de botnets ne publient évidemment pas de statistiques fiables, les chercheurs ne doivent donc compter que sur des heuristiques diverses. Le plus célèbre botnet actuel, Storm, est normalement facilement mesurable puisqu'il utilise, pour enregistrer ses machines, une DHT, avec protocole connu, Kademlia, au sein du réseau Overnet. Plusieurs études ont donc annoncé des chiffres sur la taille de Storm, estimée quelque part entre 100 000 machines et bien plus d'un million.
L'article de Kanich, Levchenko, Enright, Voelker et Savage, The heisenbot uncertainty problem: challenges in separating bots from chaff a un point de vue plus nuancé. Selon eux, Storm serait en fait plus petit qu'annoncé, en raison d'un certain nombre d'erreurs systématiques commises dans la mesure. D'abord, Storm partage le réseau Overnet avec des applications légitimes comme mldonkey et toutes les machines enregistrées dans la DHT ne sont donc pas forcément des zombies.
Ensuite, les botnets attirent justement beaucoup de monde : chercheurs en sécurité, concurrents (puisque les botnets sont surtout utilisés dans le cadre d'une économie criminelle) et « justiciers » qui essaient de perturber le botnet. Une partie des machines recensées comme faisant partie de Storm sont donc en fait des parasites qui infectent le botnet pour l'étudier ou l'attaquer (un autre article des mêmes chercheurs, plus facile d'accès, When researchers collide, détaille ce problème).
En résumé, excellent article, très détaillé sur le fonctionnement du botnet, un domaine bien plus riche qu'on ne pouvait le penser au début.
Donc, sans relativiser la considérable menace que représentent les botnets, il vaut se rappeler que la mesure d'un phénomène clandestin est difficile et que la plupart des chiffres publics sont fournis par... des vendeurs de solutions de sécurité, qui ont tout intérêt à gonfler les chiffres. Le phénomène est donc le même que pour la délinquance classique.
Un bon article sur ce problème de comptage est « Lies, Damn Lies, and Botnet Size ».
L'article seul
Exposé sur les identités numériques à la réunion FULBI
Première rédaction de cet article le 13 janvier 2009
Dernière mise à jour le 16 janvier 2009
Le 13 janvier, à Paris, j'ai eu le plaisir de faire un exposé lors de la réunion FULBI consacrée à « Identification, identifiant, identité... individu ». La FULBI est la Fédération des Utilisateurs de Logiciels pour Bibliothèque, Documentation et Information, regroupement d'associations de bibliothécaires et de documentalistes. Environ 150 personnes étaient présentes. La sociologie de ce métier étant ce qu'elle est, une grande majorité était des femmes, ce qui change des réunions d'informaticiens. La plupart venaient du monde Enseignement supérieure / Recherche. Mon exposé portait sur « Qu'est-ce qu'un service d'identité ».
Voici les documents produits à cette occasion :
- Les transparents en PDF, en mode présentation
- Les mêmes en mode adapté à l'impression.
- Leur source en format LaTeX/Beamer.
Les exposés des autres intervenants sont disponibles sur le site Web de FULBI. Celui que j'ai trouvé le plus intéressant était celui de Carine Garcia et Claire Leblond sur « Former les étudiants à la maîtrise de leur identité numérique », ou comment expliquer à de grands gamins accros à Facebook qu'il peut y avoir une utilisation professionnelle du Web, passant entre autres par un minimum de réflexion sur l'identité numérique qu'on présente au monde. Les transparents de la formation sont disponibles (Flash nécessaire, malheureusement). Ne manquez pas de visiter le blog des dynamiques documentalistes de l'ESC.
Outre cet article, on trouve le compte-rendu de Claire Scopsi, avec les supports des intervenants et l'article de Claire Leblond.
Merci à Claire Scopsi pour l'organisation.
L'article seul
C'est vraiment bien d'indiquer la date dans les commentaires des fichiers de configuration
Première rédaction de cet article le 12 janvier 2009
Souvent, je regarde les fichiers de configuration d'une machine qui a plusieurs administrateurs système et je vois un commentaire du genre :
# Modification temporaire, tant qu'on n'a pas davantage d'espace disque do_something=false
et, là, je suis perplexe. Depuis combien de temps est-ce « temporaire » ? Des années, peut-être. La date du fichier ne me renseigne pas car il a pu être modifié à d'autres endroits. Pourquoi tout le monde ne met-il pas la date de la modification lorsqu'il ajoute un tel commentaire ?
C'est un des mes conseils favoris aux administrateurs système. Lorsqu'on modifie la configuration du système et que cette modification est de nature temporaire, il faudrait toujours mettre une date. Par exemple :
# Modification temporaire (2004-05-23), tant qu'on n'a pas d'avantage # d'espace disque do_something=false
Cette fois, plus aucun doute, on sait ce qu'il en est et on peut apprécier si le problème est encore d'actualité.
Un cas où les modifications sont fréquemment temporaires est celui
des pare-feux. On doit souvent les modifier en
urgence, pour répondre à une menace spécifique, et il est important de
ne pas laisser trainer de telles règles éternellement. Un exemple dans
un fichier de configuration Shorewall, blacklist, est le blocage
complet d'une machine qui attaque notre système :
# Accès SSH répétés 2009-01-12 192.0.2.6
Les adresses IP étant
réaffectés relativement souvent, il ne faut pas laisser trainer une
telle configuration, sous peine de bloquer le malheureux qui a
récupéré 192.0.2.6. D'où l'importance de la
date.
Sous quel format mettre la date ? Sur les machines ayant des
administrateurs système de diverses nationalités, il vaut mieux
utiliser la norme internationale, ISO 8601 (ou plutôt
son sous-ensemble plus simple défini dans le RFC 3339). On
écrira donc 2008-04-09 et pas
09-04-2008 (ou, bien pire, la notation
états-unienne 04-09-2008 qui est ambigüe : parle
t-on du 4 septembre ou du 9 avril ?).
Regarder sa montre et taper la date est un peu pénible et surtout
sujet aux erreurs. Pour faciliter sa tâche, l'administrateur système peut compter sur
des outils comme Emacs. J'ai par exemple ce
code dans mon ~/.emacs :
(defun today ()
"Insert the current date"
(interactive "*")
(insert (format-time-string
"%Y-%m-%d" ; ISO format
(current-time))))
(global-set-key [f7] 'today)
et il suffit alors, en éditant un fichier de configuration, de taper F7 pour avoir la date exacte et correctement formatée.
Et si on gère ses fichiers de configuration dans un VCS ? Ceux-ci gardent trace de la date, après tout. En effet, on n'a alors pas besoin de l'indiquer, à condition que le VCS fournisse des outils de voyage dans le temps simples et puissants.
L'article seul
Repli d'une langue vers ou autre, ou demander son chemin à Helsinki
Première rédaction de cet article le 12 janvier 2009
Chaque fois que quelqu'un qui n'a pas encore étudié la question se penche sur le choix des langues pour un logiciel, en fonction des demandes d'un utilisateur, il se dit « Mais pourquoi, lorsque la langue demandée n'est pas disponible, ne pas lui en fournir une autre, assez proche ? ». Pour comprendre pourquoi c'est une idée difficile à appliquer, prenons le cas d'un étranger qui demande son chemin à Helsinki.
Si l'étranger parle finnois, pas de problème, il peut utiliser cette langue, officielle et majoritaire en Finlande. Et sinon ? Selon la vision qu'on adopte, la meilleure seconde langue pourra être :
- Le suédois, dira celui qui a une vision politique ou administrative des langues. C'est la seconde langue officielle du pays (et un des finlandais les plus célèbres, Linus Torvalds l'a comme langue maternelle).
- L'estonien, dira le linguiste, c'est la langue la plus proche du finnois, au sein de cette famille des langues finno-ougriennes (le hongrois en fait également partie mais il est bien plus éloigné).
- l'anglais (ou peut-être l'allemand ou même le russe), dira le pragmatique. C'est ce qui multiplie les chances de se faire comprendre, en pratique.
Toutes ces visions sont correctes, bien que parfois peu réalistes. Toutes sont implémentables (des bases comme CLDR nous donnent les langues officielles et des normes comme ISO 639-5 nous donnent une partie du classement linguistique). Mais si on a une vision pragmatique, il faut se faire à l'idée que le choix est complexe et ne peut pas être résolu par des algorithmes simples comme ceux du RFC 4647, qui se limite aux cas où on distribue une autre variante de la même langue, un problème un peu plus simple.
Ainsi, un site Web où l'utilisateur, via la configuration de son navigateur, demande des pages en breton choisira plutôt de lui servir du français puisque tous les locuteurs du breton, aujourd'hui, parlent français. Mais ce genre d'information ne peut pas être déduite algorithmiquement, elle nécessite une base assez riche et toujours changeante. Question subsidaire : quelle base publique existant stocke cette information sur le breton ?
(On la trouve indirectement dans CLDR, qui note le breton comme parlé en France et dans aucun autre paysou bien sur Ethnologue.com mais qui brouille l'information en notant que le breton est également parlé aux USA.)
L'article seul
Faire des schémas avec un langage et pas avec la souris
Première rédaction de cet article le 9 janvier 2009
On dit qu'une image vaut mille mots. C'est vrai qu'il est souvent bien plus facile d'expliquer avec un dessin qu'avec de la prose. Dans le monde physique, je le fais souvent. Alors, lorsqu'on communique via des ordinateurs ? Pourquoi n'y a t-il pas davantage de dessins sur ce blog ? Une des raisons est que je dessine très mal à la souris, je préfère utiliser un langage de description de schémas, comme Graphviz.
L'article complet
RFC 768: User Datagram Protocol
Date de publication du RFC : Août 1980
Auteur(s) du RFC : J. Postel (University of Southern California (USC)/Information Sciences Institute)
Chemin des normes
Première rédaction de cet article le 8 janvier 2009
Le protocole IP, situé dans la couche 3, fournit un service de datagrammes où presque rien n'est garanti. Les datagrammes peuvent arriver dans le désordre, être dupliqués ou, plus couramment, ne pas arriver du tout. IP ne fournit pas non plus de mécanisme permettant d'identifier un processus particulier sur la machine de destination. Quasiment toutes les applications utilisent un protocole de transport au dessus d'IP. TCP (RFC 793) est le plus connu. Il fournit, lui, fiabilité de la transmission mais au prix de délais parfois importants. En effet, tout octet devant être acheminé à bon port, TCP doit souvent attendre les retardataires... ou demander leur rééxpédition. De plus, le fonctionnement de TCP nécessite l'établissement préalable d'une connexion et cela prend du temps (trois trajets sont nécessaires, donc la latence est parfois importante).
Il existe des applications pour qui cette stricte sémantique est excessive ou, plus exactement, pour lesquels on n'a pas envie de payer son prix. Ainsi, si on transmet un flux vidéo avec RTSP (RFC 7826), et qu'un paquet de données se perd, on préfère en général afficher à l'écran un petit carré noir plutôt que de geler l'affichage en attendant une retransmission.
UDP fournit donc un service minimum, peu coûteux. Si l'application n'a pas besoin de fiabilité, UDP lui permet un débit maximum. Si elle a besoin d'une sémantique plus forte, elle doit la mettre en œuvre elle-même.
Un autre service important fourni par TCP ou ses homologues comme SCTP est le contrôle de congestion. Une application qui utilise UDP bêtement, en envoyant autant de données qu'elle le peut, risque de saturer le réseau, au détriment d'autres applications plus raisonnables. Si on utilise UDP pour des données en quantité importante, on doit assurer ce contrôle de congestion soi-même (RFC 3714, RFC 5348 et RFC 8085).
UDP n'apporte donc presque rien par rapport à IP seul. Son principal ajout est la notion de ports. Le paquet UDP indique deux nombres, le port de source et le port de destination, qui, avec les adresses IP, servent à identifier les deux processus qui communiquent. L'application a typiquement indiqué le port souhaité en appelant bind.
Le RFC est ultra-court, seulement trois pages, reflet d'une époque où les protocoles étaient spécifiés avec quelques grands principes plutôt qu'avec un luxe de détails, qui évoque désormais plutôt des textes juridiques. Les RFC d'il y a vingt-huit ans ne ressemblent guère à ceux d'aujourd'hui... Mais il faut aussi noter que la taille du RFC est le reflet de la simplicité d'UDP. Le RFC se contente essentiellement de spécifier le format (simple) de l'en-tête des paquets UDP. Si on analyse UDP avec pcap, il suffit (page 1 du RFC), pour le décoder, de :
/* UDP header */
struct sniff_udp {
uint16_t sport; /* source port */
uint16_t dport; /* destination port */
uint16_t udp_length;
uint16_t udp_sum; /* checksum */
};
...
const struct sniff_dns *dns;
...
udp = (struct sniff_udp *) (packet + SIZE_ETHERNET + size_ip);
source_port = ntohs(udp->sport);
dest_port = ntohs(udp->dport);
...
Quels protocoles d'application utilisent UDP ? Le plus connu est le DNS, dont l'essentiel du trafic se fait en UDP. Le mode principal du DNS, « une requête / une réponse », chacune tenant souvent dans un paquet, correspond en effet bien à UDP. Au moment de la sortie de notre RFC 768, l'un des principaux utilisateurs d'UDP était d'ailleurs un ancêtre du DNS, Internet Name Service (IEN 116). Mais il y a aussi NTP (RFC 5905) et, depuis moins longtemps, les protocoles « multimédia » comme RTP (RFC 3550) qui ont typiquement des grandes quantités de données à faire passer, sans exigence qu'elles arrivent toutes (une trame vidéo en retard n'a plus aucun intérêt). Aujourd'hui, les protocoles de transmission de contenu multimédia (par exemple SIP, RFC 3261 pour la téléphonie sur IP) utilisent en général TCP pour le canal de contrôle et UDP pour les données, pour lesquelles l'acheminement de tous les paquets n'est pas vital.
On peut bien sûr utiliser aussi UDP pour les transferts de fichiers, qui ont besoin d'être parfaitement fiables. Cela suppose de gérer, au dessus d'UDP (qui n'assure pas ce service), un mécanisme permettant de s'assurer que tout a été bien transmis. C'est ce que fait le client BitTorrent de référence depuis fin 2008, une décision qui a suscité pas mal de remous (souvent exagérés).
Vu avec tcpdump, commande tcpdump
-vvv -n udp, voici d'ailleurs un exemple de paquet UDP, en
l'occurrence pour le DNS (une question et une réponse) :
16:03:11.436076 IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], proto UDP (17), length 78) 192.134.7.248.15301 > 199.6.1.30.53: [bad udp cksum eaea!] 31425% [1au] Type32769? doleh.com.dlv.isc.org. ar: . OPT UDPsize=4096 OK (50) 16:03:11.451313 IP (tos 0x0, ttl 54, id 0, offset 0, flags [DF], proto UDP (17), length 775) 199.6.1.30.53 > 192.134.7.248.15301: 31425 NXDomain*- q: Type32769? doleh.com.dlv.isc.org. 0/6/1 ns: dlv.isc.org. SOA[|domain]
Les champs spécifiques d'UDP (protocole 17) sont le champ Longueur et les ports (ici, 53 et 15301).
UDP a aujourd'hui plusieurs camarades / concurrents dans la catégorie « protocole de transport sans connexion et non fiable ». C'est le cas de DCCP (RFC 4340). Il a aussi des ajouts ou des variantes comme DTLS (RFC 5238) pour la sécurité ou UDP-Lite (RFC 3828) pour encore moins de vérifications.
Et pour le programmeur ? Utiliser UDP n'est pas plus difficile que
d'utiliser TCP, sauf si on veut assurer les mêmes services que TCP et
qu'on met en œuvre la fiabilité des transferts. Sinon, un client
UDP a
« juste » à créer les prises avec
l'option SOCK_DGRAM (au lieu de
SOCK_STREAM), à appeler
bind pour obtenir un port et à
envoyer les paquets, par exemple avec sendto.
Un intéressant article historique de David Reed décrit l'histoire d'UDP.
L'article seul
Homelink, pour échanger ses maisons pour les vacances
Première rédaction de cet article le 6 janvier 2009
Vous voulez une maison de trois étages à Londres ? Plutôt au Canada, près d'un lac ou en Norvège dans la montagne ? Ou bien un appartement dans le centre de Barcelone ? Vous pouvez avoir tout cela gratuitement en adhérant à un système d'échange de maisons comme Homelink.
Outre l'économie que cela représente par rapport à l'hôtel, ce système a d'autres avantages. On est dans une maison, pas dans une chambre impersonnelle, on a de la place, on cuisine ce qu'on veut quand on veut. Et on vit un peu plus comme les habitants et un peu moins comme un touriste.
Le principe est simple : ils viennent chez vous et vous venez chez eux. Chacun laisse un trousseau de clés, un peu à manger dans le frigo et va découvrir une autre maison.
Il existe plusieurs associations d'échange de maisons. Je suis membre de Homelink, une des plus anciennes. Avant l'Internet, Homelink éditait un gros catalogue papier annuel, regroupant toutes les offres des membres, catalogue distribué à grands frais et plus à jour dès sa parution. Aujourd'hui, c'est plus simplement un site Web, avec un moteur de recherche pour pouvoir passer ses soirées à rêver devant des villas californiennes ou des cabanes en Estonie. Une fois les maisons choisies, on écrit à l'autre membre et on essaie de le convaincre de faire un échange. Bien sûr, il faut souvent écrire des dizaines de messages pour un échange effectif mais on reçoit aussi des propositions spontanées, souvent exotiques.
Il faut donc « se vendre ». Si on habite, comme moi, à Paris, tout est plus simple, beaucoup de gens veulent aller à Paris. Si, comme dans une proposition que j'ai reçu, on est dans une maison perdue au milieu du Hainaut belge, il faut argumenter davantage. Notez que les villes sont plus représentées que les campagnes et que le Nord l'est beaucoup plus que le Sud. Si vous pouvez encore trouver une maison à Rome, à partir de la Sicile, cela devient bien plus difficile.
Outre le fossé géographique, il y a aussi un fossé social, on croise surtout des CSP+ (en partie à cause du coût de l'adhésion à Homelink, en partie parce qu'il faut être bien logé pour avoir ses chances de faire un bon échange).
Lorsque j'explique le système à des personnes qui ne le connaissent pas, la réaction immédiate est souvent de crainte : « Mais ils vont tout voler chez moi ! » ou, plus psychologique, « Jamais je ne laisserai des gens que je ne connais pas chez moi ! ». Je ne peux rien dire contre l'argument psychologique mais, sur celui de sécurité, il faut relativiser. La plupart des échanges se passent bien et, lorsqu'il y a des problèmes, c'est moins grave qu'un vol, ce sont plutôt des désaccords sur la quantité de ménage à faire avant de partir. Alors, des risques, oui, il y en a certainement (à l'hôtel aussi) mais, si on n'a pas 100 000 € en liquide chez soi, le risque de vol est nettement plus faible que celui de perte d'une assiette ou deux, suite à une vaisselle trop énergique.
Conçu longtemps avant la mode du Web 2.0 et des réseaux sociaux, le site Web d'Homelink n'a pas de ces mécanismes de vote, de notation ou de réputation qui déclenchent tant de passions et de crises sur eBay ou sur Stack Overflow. C'est reposant. Les seuls critères de sélection sont la maison elle-même, l'accord de l'autre, et le nombre d'échanges qu'il a déjà fait.
L'article seul
RFC 2385: Protection of BGP Sessions via the TCP MD5 Signature Option
Date de publication du RFC : Août 1998
Auteur(s) du RFC : Andy Heffernan (cisco Systems)
Chemin des normes
Première rédaction de cet article le 6 janvier 2009
Le protocole TCP est vulnérable à plusieurs attaques fondées sur l'envoi de paquets prétendant venir d'un correspondant légitime, alors qu'ils sont injectés dans le réseau par le méchant. La communauté des opérateurs Internet est depuis longtemps particulièrement soucieuse de ces risques pour les sessions BGP entre ses membres et a donc développé ce bricolage qui consiste à insérer une option TCP validant très partiellement les paquets. (Bien que cette vulnérabilité de TCP soit très générale, cette solution n'a été utilisée que pour BGP. Le résultat est un très court RFC, traitant - assez mal - un problème très particulier.)
Une attaque typique contre BGP est une DoS où le méchant envoie un paquet TCP RST (ReSeT, sections 3.1 et 3.4 du RFC 793) qui va couper brutalement la session. Les techniques récentes comme TLS ne protègent pas contre ce genre d'attaques car elle opèrent juste en dessous de la couche application, et ne peuvent pas authentifier les paquets TCP (section 1). Même chose si on avait une solution purement BGP.
La solution de ce RFC est donc (section 2) d'insérer dans chaque segment TCP un résumé cryptographique MD5 portant sur une partie des en-têtes IP et TCP, les données, et un secret partagé entre les deux routeurs. L'attaquant ne connaissant pas ce mot de passe, il ne peut pas fabriquer de faux paquets.
À noter que, bien qu'enregistrée dans le registre IANA des options, ce n'est pas une « vraie » option TCP : les options TCP (section 3.1 du RFC 793) ne sont pas, comme leur nom l'indique, obligatoires. Chacun des deux pairs peut les refuser. Ici, pour éviter toute attaque par repli, la signature TCP MD5 est à prendre ou à laisser.
Passons aux bits sur le câble, avec la section 3 qui décrit le format dans le paquet. Puis aux considérations pratiques avec la section 4 qui détaille les problèmes qui peuvent se produire avec les signatures MD5, comme les soucis qui peuvent provenir car des paquets TCP légitimes peuvent être refusés (section 4.1 mais qui ne mentionne pas le fait que des paquets ICMP, non validés par la signature MD5, peuvent par contre être acceptés alors qu'ils sont faux), le coût en performance à cause des opérations cryptographiques (section 4.2 mais il faut relativiser : lorsque le RFC a été écrit, l'exemple de processeur de routeur était le MIPS R4600, à 100 Mhz) ou l'augmentation de la taille des paquets (section 4.3).
Plus sérieux est le problème de la vulnérabilité de MD5. Elle était déjà bien connue à l'époque (section 4.4) et ça ne s'est évidemment pas arrangé. (En décembre 2008, une attaque réussie contre MD5 a permis de générer de faux certificats X.509). À noter que le RFC ne prévoit pas de moyen d'indiquer un autre algorithme cryptographique que MD5, pour les raisons expliquées dans cette section 4.4. De l'avis de certains, dans le cas de BGP, MD5 reste encore relativement raisonnable. Néanmoins, cela ne pouvait pas durer éternellement et c'est l'une des motivations qui ont finalement mené au remplacement de ce protocole (cf. RFC 5926).
Presque tous les routeurs dédiés savent utiliser cette option MD5 TCP. Ainsi, sur IOS, c'est le mot-clé password :
router bgp 64542 neighbor 192.0.2.108 password g2KlR43Ag
La situation est plus délicate sur les routeurs non-dédiés, par
exemple fondés sur
Unix. Linux ou
FreeBSD n'ont pas eu pendant longtemps le support du RFC 2385 en série (il existait des patches comme http://hasso.linux.ee/doku.php/english:network:rfc2385), en partie pour une question de principe (cette
option viole le modèle en couches avec ses aller-retours entre
l'application et TCP). (Pour Quagga, voir
certains liens en http://wiki.quagga.net/index.php/Main/AddRes.) Aujourd'hui, le
noyau Linux (par exemple en version 2.6.26) a cette fonction (au
moment de la compilation, activer TCP: MD5 Signature Option
support (RFC2385) (EXPERIMENTAL), ce qui est le cas sur
Debian par défaut).
En pratique, l'exigence de sessions « TCP MD5 » a souvent servi à éliminer ceux qui utilisent Quagga sur Unix et n'avaient pas de moyen facile de configurer leurs routeurs selon cette option.
Une autre objection fréquente faite à ce RFC 2385 est qu'il aurait mieux valu utiliser IPsec, qui a l'avantage de couvrir les autres protocoles (comme ICMP) et d'être plus générique. Mais IPsec, notamment en raison de sa complexité, a connu peu de déploiements.
Le groupe de travail tcpm de l'IETF a donc finalement développé un meilleur protocole, TCP Authentication Option (TCP-AO), normalisé dans le RFC 5925.
Un bon exposé technique en français sur ce RFC est dans l'article « Les signatures MD5 des segments TCP ».
L'article seul
RFC 2330: Framework for IP Performance Metrics
Date de publication du RFC : Mai 1998
Auteur(s) du RFC : Vern Paxson (MS 50B/2239), Guy Almes (Advanced Network & Services, Inc.), Jamshid Mahdavi (Pittsburgh Supercomputing Center), Matt Mathis (Pittsburgh Supercomputing Center)
Pour information
Réalisé dans le cadre du groupe de travail IETF ippm
Première rédaction de cet article le 4 janvier 2009
La mesure des performances sur Internet est un vaste sujet, rendu plus difficile par l'utilisation massive de mots mal définis ou, pire, utilisés à contre sens (« débit », « bande passante » ou, pire, « vitesse » étant de bons exemples). C'est pour cela que le travail du groupe IPPM (IP Performance Metrics) a commencé par ce RFC 2330 qui essaie de définir un cadre solide pour parler de mesures de performances.
Prenons l'exemple d'un cas qui semble trivial : un liaison Internet est saturée et on n'arrive plus à y faire passer tous les films qu'on veut regarder. Pour la remplacer, on hésite entre deux liaisons dont on voudrait bien mesurer la capacité, afin de choisir la « meilleure ». Mais que veut dire exactement « cette liaison permet un débit de 20 Mb/s » ? Ce chiffre est mesuré dans quelle couche ? Est-il valable en permanence ou bien est-ce une moyenne ? Dépend-il de la taille (ou d'autres caractéristiques) des paquets ? Sans réponse claire à ces questions, le chiffre de 20 Mb/s ne signifie pas grand'chose. D'autant plus que les vendeurs ont tout intérêt à brouiller les pistes. (Au fait, cette notion, nommée « capacité », est définie dans le RFC 5136.)
La section 3 du RFC résume les buts : définir des métriques, c'est-à-dire des grandeurs mesurables et définies de manière rigoureuse. Pour cela, notre RFC spécifie le cadre commun à toutes les métriques, qui seront développées dans des RFC ultérieurs (comme le RFC 2678 pour la métrique de connectivité ou bien le RFC 2681 pour la métrique de temps d'aller-retour entre deux points).
Quels sont les critères pour une « bonne » métrique ? C'est la question que traite la section 4. Parmi ces critères :
- Pouvoir être définie rigoureusement,
- Pouvoir être mesurée de façon reproductible,
- Être utile en pratique, pour les utilisateurs ou les administrateurs du réseau.
On voit que les questions de vocabulaire vont être cruciales. Pour rompre avec le flou des données, il faut que les grandeurs mesurées soient définies d'une manière rigoureuse et précise. Ainsi, la section 5 donne des définitions pour un certain nombre d'éléments qui seront utilisés dans les métriques. Par exemple, host, machine connectée au réseau, inclus explicitement les routeurs, link est un lien de couche 2, path un ensemble contigu de links, etc.
Une fois ces bases de langage établies, le RFC s'attaque aux concepts (section 6). Il s'attache à bien établir la différence entre la définition d'une métrique (qui doit avant tout être complète et rigoureuse) et la mesure effective (qui n'est pas toujours facile, comme illustré plus loin par la discussion sur la mesure du wire time).
Cette section est aussi l'occasion de poser certaines conventions comme le fait que les temps se mesurent toujours en UTC et que les kilos valent toujours 1000 (suivant la règle des télécommunications, celle du stockage informatique étant plutôt qu'un kilo vaut 1024).
Une fois une métrique définie, il faut la mesurer : c'est l'objet de la section 6.2. On peut le faire directement en mesurant la grandeur qui nous intéresse ou indirectement, par exemple en calculant ou en déduisant cette grandeur d'autres mesures. Les particularités de la mesure doivent être soigneusement étudiées et publiées avec les résultats. Par exemple, certaines mesures modifient la grandeur mesurée (des pings répétés chargent le réseau et modifient donc le temps d'aller-retour que ping est censé mesurer). La science de la mesure est aussi ancienne que la physique et ces problèmes, tout comme ceux des erreurs ou incertitudes (section 6.3) sont bien connus, mais souvent oubliés lorsqu'il s'agit de réseaux informatiques. Le RFC a donc raison de les rappeler et d'insister sur l'importance de les documenter lorsqu'on publie.
Les métriques ne vivent pas seules : il est souvent utile de les composer, ce que traite la section 9. Elle décrit en 9.1 les compositions spatiales où les mesures sur des sous-chemins (subpath) s'additionnent. Par exemple, le délai de propagation d'un paquet le long d'un chemin (path) est proche de la somme des délais de propagation sur les sous-chemins. En 9.2, on trouve les compositions temporelles, où le passé permet de prédire le futur. Par example, si on a mesuré le débit sur un lien depuis vingt-quatre heures, et que sa variation selon l'heure est bien comprise, on va pouvoir déduire le débit futur pendant les prochaines vingt-quatre heures.
La plupart des mesures, en matière de réseau, font intervenir le temps. Le concept est souvent mal compris et une section entière, la 10, est dédiée à Chronos. Certes, l'Internet dispose depuis longtemps d'un protocole standard pour la gestion d'horloges, NTP (RFC 5905). Mais ses buts sont différents : il vise à garder des horloges synchronisées sur une longue période. Pour la mesure, on s'intéresse à des périodes plus courtes pour lesquelles NTP n'est pas forcément la solution.
Quels sont les problèmes avec les horloges ? Une horloge peut avoir un écart (offset) avec le « vrai » temps, UTC (ou bien avec une autre horloge, si on s'intéresse juste au fait qu'elles soient synchronisées). Si cet écart est inférieur à une certaine valeur, on dit que l'horloge est correcte (accurate). Et l'horloge peut avoir un décalage (skew), elle peut avancer plus ou moins vite que la normale (et donc cesser au bout d'un moment d'être correcte). Pire, la dérive peut être variable, auquel cas on mesure la dérivée seconde du décalage sous le nom de dérive (drift). Enfin, l'horloge a une certaine résolution (resolution), la plus petite unité de temps qu'elle peut mesurer.
Pour minimiser l'effet de ces limites sur la mesure, le RFC recommande donc que les horloges des différentes machines impliquées soient synchronisées, idéalement à partir d'une source extérieure commune (comme le GPS). Le RFC illustre l'importance de la synchronisation par un simple exemple. Si on mesure le délai de transmission d'un paquet sur un lien transaméricain, une valeur de 50 ms est raisonnable. Si le décalage est de 0,01 %, après seulement dix minutes, l'écart atteindra 60 ms soit davantage que ce qu'on veut mesurer.
NTP n'est pas forcément la bonne solution car son exactitude dépend des liens Internet, exactement ceux dont on veut mesurer les caractéristiques. D'autre part, NTP donne la priorité à la correction, pas à la limitation du décalage. NTP peut délibèrément accélérer ou ralentir une horloge (augmenter ou diminuer le décalage) pour la rapprocher du temps correct. On n'a pas envie que cela survienne pendant une mesure !
Un autre problème de mesure lié au temps est celui du wire time (section 10.2). Les mesures sont souvent effectuées sur les machines elle-mêmes, et pas via un équipement spécial connecté au câble. Les machines ne sont pas forcément optimisées pour la mesure et n'ont pas forcément un noyau temps réel. Elles peuvent donc introduire leurs propres inexactitudes. Pour séparer les délais internes à la machine des délais du réseau, le RFC recommande d'utiliser dans les métriques le « temps du câble » (wire time), pas le temps de la machine. Le premier reflète le moment où le paquet est effectivement présent sur le câble. Plus rigoureux, il est par contre plus difficile à mesurer. Ainsi, pour un programme comme ping, le temps de la machine (host time) est facilement connu grâce à gettimeofday alors qu'il n'y a pas de moyen de mesurer le temps du câble, depuis une application Unix ordinaire. C'est donc une instance particulière du problème discuté plus haut, où le souci de donner une définition correcte de la métrique a priorité sur la facilité de mesure.
Pour réaliser une mesure du temps du câble, le RFC recommande d'utiliser un filtre à paquets comme le BPF qui associe à chaque paquet une estampille temporelle en général proche du temps du câble. Il recommande également de ne pas faire tourner ce filtre sur la machine qu'on veut observer, pour limiter les perturbations.
Les mesures impliquent des statistiques et la section 11 quitte les rivages de la physique pour revenir à ceux de la mathématique. Elle est consacrée à la différence entre les mesures uniques (singleton) et les échantillons (samples), ensembles de mesures uniques. Par exemple, un échantillon de mesures consiste en « une heure de mesures uniques, chacune prise à intervalles de Poisson avec un écart moyen d'une seconde entre les mesures ». L'échantillonnage est un art délicat et la section 11.1 expose différents moyens de le réaliser. Par exemple, le plus simple est la mesure périodique, à intervalles fixes. Mais elle a des défauts :
- Si la grandeur mesurée est elle-même périodique, la mesure risque de se faire toujours au même moment, par rapport à la période du phénomène observé. On peut alors ne pas percevoir la périodicité de celui-ci.
- Si la mesure est active, l'injection de données à intervalles périodiques entraîne parfois des effets de synchronisation non désirés (cf. un article fameux, S. Floyd et V. Jacobson, The Synchronization of Periodic Routing Messages, IEEE/ACM Transactions on Networking, avril 1994).
- Enfin, l'échantillonage périodique est prévisible, ce qui peut être gênant si un malhonnête essaie d'influencer le résultat.
Le RFC recommande donc d'échantilloner à intervalles aléatoires, suivant une certaine distribution. Quelques exemples de telles distributions suivent comme celle de Poisson en section 11.1.1.
Autre piège de la mathématique, les probabilités (section 12). Le RFC met en garde contre leur abus lors de la définition d'une métrique. Dire que 34 paquets sur 100 ont été perdus (ce que ping affiche sous l'étiquette packet loss) est un fait, dire que « la probabilité de perte d'un paquet est de 0,34 » est une interprétation, qui suppose que le phénomène soit aléatoire (ce qui est faux, la perte des paquets, contrairement à la désintégration d'un atome radioactif est très déterministe).
Outre les questions physiques et mathématiques, la mesure cache des
pièges liés à l'informatique. Pour plusieurs raisons, les différents
paquets ne reçoivent pas le même traitement. Par exemple, certains
FAI ralentissent délibérement les paquets
considérés comme liés à un protocole pair à pair. La mesure dépend donc du type de paquets, ce que la
section 13 formalise avec la notion de « paquets de type
P ». Lorsqu'on dit « la machine
2001:db8:42::bad:cafe est joignable », cela n'est
pas toujours vrai pour tous les protocoles, en raison notamment des
coupe-feux. Il faut donc dire « la machine
2001:db8:42::bad:cafe est joignable pour un
certain type P », où P est défini comme, mettons « paquets
TCP à destination du
port 80 ».
L'article seul
Peut-on vraiment mettre des utilisateurs ordinaires sur Ubuntu ?
Première rédaction de cet article le 2 janvier 2009
Le système d'exploitation Ubuntu est souvent présenté comme la solution idéale pour mettre sur le bureau de l'utilisateur ordinaire, non technicien. Fondé sur essentiellement du logiciel libre, Ubuntu bénéficie d'un marketing très dynamique, à base de photos d'utilisateurs multiraciaux et souriants. La promesse : qu'Ubuntu, contrairement aux autres Unix, est utilisable par tous. Quelle est la réalité ?
Ce n'est pas parce qu'on répète quelque chose que c'est
vrai. Pourtant, dans le marketing de l'informatique, c'est une méthode
très fréquente. « Ubuntu, c'est convivial » ou bien « Avec Ubuntu,
Unix est aussi facile qu'avec le système XXXXX » sont des phrases
répétées tellement souvent qu'on finit par y croire. Je gère donc
plusieurs machines Ubuntu, destinées à des utilisateurs exigeants mais
pas du tout techniciens (voir des descriptions plus techniques en
dell-latitude-d430-linux.html, dell-inspiron-7500.html et packard-bell-mx37.html).
Et que constater ? D'abord, l'administration système n'est pas du « tout cuit ». Bien qu'Ubuntu cède partiellement aux pressions de l'industrie du matériel et accepte d'incorporer des pilotes non libres dans son système, le matériel ne fonctionne pas forcément du premier coup. Obtenir des meilleurs résultats nécessite des manipulations qui ne sont certes pas à la portée de l'utilisateur ordinaire comme de compiler une version plus récente du pilote. La lecture de forums comme la liste de diffusion des utilisateurs francophones d'Ubuntu montre bien que ce problème est fréquent. Il est récurrent avec tous les Unix libres et n'est souvent pas de la responsabilité des programmeurs Unix, mais de celle des fabricants de matériel. Néanmoins, nier ou minimiser ce problème, comme le font trop souvent les promoteurs du logiciel libre est contre-productif. L'utilisateur naïf qui a pris ce discours au pied de la lettre risque, de dépit, de s'enfuir bien vite au premier problème.
Mais il y a pire : les problèmes ne s'arrangent pas forcément avec le temps. Parfois, une mise à jour du système résout soudain un problème matériel qui trainait depuis des mois. Parfois, au contraire, il y a régression (en passant de Ubuntu Heron à Ubuntu Ibex, la fonction de mise en hibernation de mon Dell D430 marche moins bien).
Ces problèmes, je le sais bien, sont largement dus à l'attitude de l'industrie du matériel, qui refuse de publier des documentations correctes, réservant les informations à ceux qui écrivent des pilots pour Windows. Les autres Unix libres ne font pas forcément mieux qu'Ubuntu sur ce point et ils sont parfois bien plus complexes.
Mais il existe aussi des
problèmes purement logiciels. L'environnement graphique par défaut
d'Ubuntu, Gnome, vise explicitement à copier
MS-Windows. Comme son modèle, la priorité est
aux gadgets qui brillent et pas à la stabilité et à la
fiabilité. Certaines bogues indiquent un mépris de la robustesse qui
est assez étonnant. Ainsi, les nombreuses
bogues de gnome-appearance-properties, le programme lancé
lorsqu'on clique sur Système -> Préférences -> Apparence montrent une
absence totale de contrôle
qualité. gnome-appearance-properties fait des
erreurs de segmentation dès
qu'il rencontre un petit problème, sans qu'aucun message d'erreur ne
signale rien.
Une bogue que j'ai rencontrée personnellement (et qui est
enregistrée sous le numéro
312931) est particulièrement « réussie » : si un fichier avec
une extension .jpg (normalement une image JPEG)
contient en fait un autre format, le programme crashe sans aucun message d'erreur. Le programmeur n'a
pas eu l'idée qu'un fichier pouvait ne pas être au bon format !
Produire un message « Fichier invalide ou inconnu » avec le nom du
fichier n'aurait-il pas été la moindre des choses ? Ce genre de
programmation, dite « défensive » est pourtant enseigné dans les écoles
depuis de nombreuses années.
Pour contourner cette bogue particulière et permettre de lancer le
programme, il a fallu trouver son nom (Système -> Préférences -> Menu
principal puis Choix de la catégorie (par exemple Accessoires) puis
Clic droit sur le nom de l'application (par exemple Calculatrice) puis
Clic sur Propriétés, le champ commande contient... ce nom, merci à
Bernardo pour la méthode, que je ne trouvais nulle part). Ensuite, il
faut faire tourner le programme sous strace pour afficher
les appels systèmes effectués. On voit alors
qu'immédiatement avec le SIGSEGV, il ouvrait un
fichier, fichier qu'il suffit ensuite de supprimer pour que
gnome-appearance-properties fonctionne à nouveau.
Une autre solution aurait été de faire tourner le programme sous un débogueur comme gdb. Dans les deux cas, on ne peut pas dire que cela soit accessible à l'utilisateur typique.
Je suis politiquement attaché au logiciel libre et je suis bien conscient que MS-Windows est lui aussi très loin d'être facile et sans douleur pour l'utilisateur non informaticien. Mais j'aimerais des fois que le marketing du logiciel libre soit un peu moins optimiste et un peu plus réaliste.
L'article seul
Articles des différentes années : 2024 2023 2022 2021 2020 2019 2018 Précédentes années
Syndication : Flux Atom avec seulement les résumés et Flux Atom avec tout le contenu.
{kind=link}