
Ce blog n'a d'autre prétention que de me permettre de mettre à la disposition de tous des petits textes que j'écris. On y parle surtout d'informatique mais d'autres sujets apparaissent parfois.
RFC 7422: Deterministic Address Mapping to Reduce Logging in Carrier Grade NAT Deployments
Date de publication du RFC : Décembre 2014
Auteur(s) du RFC : C. Donley (CableLabs), C. Grundemann (Internet Society), V. Sarawat, K. Sundaresan (CableLabs), O. Vautrin (Juniper Networks)
Pour information
Première rédaction de cet article le 26 décembre 2014
Un nouveau RFC pour Big Brother : quand un FAI veut savoir quel abonné utilisait telle adresse IP à tel moment, c'est simple, non, il lui suffit de regarder les journaux du système d'allocation d'adresses ? En fait, non, c'est simple en théorie, mais cela a beaucoup été compliqué par le développement du partage d'adresses, dont l'exemple le plus connu est le CGN. Si la police ou les ayants-droit disent à un FAI « on voudrait savoir qui utilisait 192.0.2.199 le mercredi 24 décembre à 08:20 », le FAI va se rendre compte que des dizaines d'abonnés utilisaient cette adresse IP à ce moment. Trouver l'abonné exact va nécessiter d'examiner d'énormes journaux. Ce RFC propose donc une méthode pour réduire la taille de ces journaux, en attribuant les ports du CGN de manière partiellement déterministe. L'examen des journaux pourra donc être plus efficace et on trouvera plus vite le méchant abonné qui a osé commettre des délits impardonnables, comme de partager des œuvres culturelles.
Le problème de l'identification d'un abonné précis, en présence de partage d'adresses IP est difficile. (Cela concerne IPv4 seulement car IPv6 n'a pas ce problème et son déploiement natif complet résoudrait le problème pour moins cher - cf. RFC 7021 ; mais, comme disaient les Shadoks, « pourquoi faire simple quand on peut faire compliqué ? ») Je recommande fortement la lecture du RFC 6269 pour en saisir tous les aspects. Notez déjà un point important : si on n'a pas noté, au moment de l'observation du comportement illégal, non seulement l'adresse IP source, mais également le port source, on n'a guère de chance de remonter jusqu'à un abonné individuel, dès qu'il y a utilisation du CGN. Un premier pré-requis est donc que les serveurs journalisent le port source (comme demandé par le RFC 6302) et que les systèmes d'observation du réseau enregistrent ce port. Ensuite, muni de l'adresse IP source, du port source, et d'une heure exacte (ce qui suppose que tout le monde utilise NTP ou équivalent, cf. RFC 6269, section 12), on peut aller voir le FAI et lui poser la question « on voudrait savoir qui utilisait 192.0.2.199:5347 le mercredi 24 décembre à 08:20 » (notez la nouveauté, la mention du port, ici 5347). Si le FAI alloue dynamiquement adresses et ports en sortie, et journalise ces allocations, il lui « suffira » de faire un grep dans les journaux pour donner la réponse. Mais, et ce mais est à l'origine de notre nouveau RFC, ces journaux peuvent être de très grande taille.
Le partage massif d'adresses, tel que pratiqué dans les CGN, est motivé par l'épuisement des stocks d'adresses IPv4. Plusieurs RFC décrivent des variantes du concept de CGN (RFC 6264, RFC 6333...) mais tous ont un point commun : une adresse IP est partagée, non pas seulement entre les membres d'un même foyer, mais entre des abonnés d'un même FAI, abonnés qui ne se connaissent pas, et ne forment pas légalement une entité unique. Pas question donc, dans un état de droit, de punir tous les utilisateurs de 192.0.2.199 parce que l'un d'entre eux a fait quelque chose d'illégal, comme de distribuer des fichiers pris dans l'entreprise qui pirate les ordinateurs de ses clients.
A priori, l'information sur qui utilisait quel couple {adresse, port} à un moment donné est connue du CGN. Il l'enregistre, quelque chose du genre (syntaxe imaginaire) :
2014-12-24T08:20:00 Outgoing connection from 10.4.8.2:6234, allocate 192.0.2.199:5347 2014-12-24T08:21:15 192.0.2.199:5347 is now free (used for 10.4.8.2:6234)
Le FAI sait donc que l'adresse interne correspondant à 192.0.2.199:5347 était 10.4.8.2 et il peut alors consulter son plan d'adressage interne pour savoir de quel abonné il s'agit (ou bien consulter un autre journal si ces adresses internes sont elle-mêmes dynamiques). Au fait, si vous voulez un exemple réel des journaux d'un routeur CGN, voici un extrait de la documentation de Juniper :
Jun 28 15:29:20 cypher (FPC Slot 5, PIC Slot 0) {sset2}[FWNAT]: ASP_SFW_CREATE_ACCEPT_FLOW: proto 6 (TCP) application: any, ge-1/3/5.0:10.0.0.1:8856 -> 128.0.0.2:80, creating forward or watch flow ; source address and port translate to 129.0.0.1:1028
Jun 28 15:29:23 cypher (FPC Slot 5, PIC Slot 0) {sset2}[FWNAT]:ASP_NAT_POOL_RELEASE: natpool release 129.0.0.1:1028[1]
Comme dans mon exemple imaginaire, on y voit que deux entrées sont
enregistrées, pour l'allocation du port et pour sa libération (sur les
routeurs A10, on peut configurer séparement les
formats de journalisation pour ces deux événements, avec les mots-clés
fixed-nat-allocated et fixed-nat-freed).
Mais quelle est la taille de ces journaux de ces CGN ? L'expérience montre des tailles de 150 à 175 octets par entrée, ce qui est la taille de mon exemple imaginaire ci-dessus, qui journalise en mode texte (cela peut bien sûr se faire de manière structurée dans une base de données, ou bien cela peut se comprimer, les journaux texte se réduisent facilement d'un facteur 2 ou 3 à la compression). Mais à quelle rythme les entrées sont-elles créées ? Il ne semble pas y avoir beaucoup d'études précises sur ce sujet mais des observations chez des FAI états-uniens indiquent des moyennes par abonné autour de 33 000 connexions par jour. Cela ferait plus de 5 mégaoctets par jour et par abonné. Avec un million d'abonnés, le FAI devrait stocker 150 téraoctets par mois. Et il faut la capacité d'acheminer ces journaux : avec seulement 50 000 abonnés, il faut dédier 23 Mb/s entre le routeur CGN et le serveur de journalisation.
Et, une fois stockées les données, il reste à les fouiller. Il faut trouver deux évenements (le début de l'allocation et sa fin) au milieu de ces énormes fichiers, ce qui va prendre du temps.
Une solution élégante, préconisée par notre RFC, est d'avoir un mécanisme déterministe d'allocation des ports en sortie, de manière à ne pas avoir à journaliser l'allocation. Il suffira alors de faire tourner l'algorithme à l'envers pour savoir qui avait tel couple {adresse IP publique, port}.
Quelle est la dynamique d'allocation des ports ? Même si un abonné utilise des milliers de connexions par jour, à un instant donné, sa consommation est bien plus faible. Si le rapport entre le nombre d'abonnés et le nombre d'adresses IP publiques est faible (mettons de l'ordre de 10), chaque abonné pourra utiliser des milliers de ports sans gêner les autres. On peut donc allouer des intervalles entiers de ports, sans avoir besoin de journaliser chaque allocation d'un port donné. Il « suffit » donc d'avoir une fonction déterministe, qui associe à chaque adresse IP interne une adresse IP externe et un intervalle de ports externes. Un exemple trivial d'une telle fonction serait l'allocation de l'intervalle 1024-2999 au premier (dans l'ordre des adresses IP internes) abonné, de 3000-4999 au deuxième, etc. Lorsqu'on a épuisé les numéros de port, on passe à la deuxième adresse IP publique et on recommence. En sens inverse, lorsqu'on recevra la requête « qui utiisait 192.0.2.1:4219 le mercredi 24 décembre à 08:20 ? », on saura, sans consulter le journal, que c'était le deuxième de nos abonnés (deuxième intervalle de ports de la première adresse publique). Cette fonction n'est qu'un exemple, la décision d'utiliser telle ou telle méthode est une décision purement locale. (Attention à ne pas allouer les ports séquentiellement dans l'intervalle donné, afin de limiter les risques pour la vie privée de l'abonné. La section 5 du RFC détaille ce risque pour la vie privée, et suggère des mesures.)
Pour cela, le routeur CGN a besoin de connaitre la liste des adresses internes (avec certains CGN comme DS-Lite, technique de coexistence temporaire IPv4/IPv6, ce seront des adresses IPv6, cf. la section 4 de notre RFC), celles des adresses externes disponibles pour sa fonction de CGN, le nombre total d'abonnés (pour calculer le rapport avec le nombre d'adresses publiques), le nombre de ports par utilisateur, la liste des ports à ne pas utiliser, et, bien sûr, la fonction déterministe de correspondance entre une adresse interne et un couple {adresse externe, port externe}. Parmi les fonctions possibles :
- Allocation séquentielle (comme dans l'exemple proposée plus haut, ou dans l'exemple plus détaillé de la section 2.3 du RFC),
- Entrelacement : si on a un facteur de 10 entre le nombre d'abonnés et le nombre d'adresses publiques, on alloue à chaque abonné un port sur dix. Le premier abonné a les ports 1024, 1034, 1044, etc,le deuxième 1025, 1035, etc,
- Alternance sur l'adresse : un abonné utilise toujours le même port externe mais avec une adresse IP publique différente par connexion. Cela ne marche que si on a autant d'adresses IP publiques que de connexions par abonné mais cela simplifie beaucoup la recherche,
- Méthode cryptographique, inspirée de la section 2.2 du RFC 6431 : on chiffre une concaténation d'une clé et d'autres informations et le résultat chiffré nous donne le port externe à utiliser. Attention, il faudra la clé pour inverser la fonction et donc retrouver l'abonné, il ne faut pas la jeter si on veut pouvoir répondre à des demandes concernant un passé un peu lointain, alors que les clés ont été changées.
Outre les ports « système » (RFC 6335), exclus de l'allocation, il est prudent de garder en réserve un intervalle de ports pour des allocations dynamiques traditionnelles, avec journalisation de l'allocation. Cela permet, par exemple, de gérer les utilisateurs avancés qui utilisent tellement de connexions sortantes qu'ils épuisent l'intervalle des ports. Avec cette réserve, on pourra toujours les satisfaire. Il faudra certes enregistrer ces allocations mais on aura quand même gagné en taille, en ne journalisant que moins d'information.
Comme on n'a rien sans rien, la plupart des méthodes d'allocation déterministe sont moins « efficaces » qu'une allocation purement dynamique, au sens où elles sous-utilisent les ports (pour les utilisateurs peu gourmands). En outre, elles imposent davantage de travail aux équipes opérationnelles (choix d'un algorithme, réglage de ses paramètres...). D'autre part, il ne faut pas s'imaginer qu'un CGN dissimule sérieusement l'abonné final, l'algorithme d'allocation des ports peut toujours être rétroingénierié (cf. section 6, sur la sécurité).
À noter qu'il faut aussi, pour que tout se passe bien, noter la configuration du CGN et ses éventuels changements. Pas question d'appliquer l'algorithme d'aujourd'hui à une requête judiciaire qui concernerait le mois précédent, si l'algorithme ou ses paramètres ont changé. Il faut donc que le routeur CGN journalise également les changements de paramètres (comme le nombre de ports par abonné).
L'article seul
RFC 7405: Case-Sensitive String Support in ABNF
Date de publication du RFC : Décembre 2014
Auteur(s) du RFC : P. Kyzivat
Chemin des normes
Première rédaction de cet article le 24 décembre 2014
La plupart des RFC contenant une grammaire formelle pour un format ou un protocole, utilisent le langage ABNF, normalisé dans le RFC 5234. Une des particularités d'ABNF, qui agace beaucoup de monde depuis le début, est le fait que les chaînes de caractères sont forcément insensibles à la casse. Si on veut les rendre sensibles à la casse, ce qui est une demande assez fréquente, il faut utiliser des trucs plus ou moins propres. D'où ce nouveau RFC qui fait sauter l'obstacle en permettant enfin d'indiquer qu'une chaîne de caractères est sensible à la casse.
Voici un exemple tiré du RFC 7208, qui décrit SPF :
mx = "mx" [ ":" domain-spec ] [ dual-cidr-length ]
Du fait de l'insensibilité à la casse, un enregistrement SPF peut
inclure mx:example.net/26 mais aussi
mX:example.net/26,
MX:example.net/26 ou
Mx:example.net/26. Ce comportement est souvent
raisonnable mais, dans certains cas, il ne convient pas et on ne peut
plus alors utiliser des chaînes de caractères, il faut (RFC 5234, section 2.3), indiquer explicitement les
valeurs numériques de chaque caractère. Par exemple, dans le RFC 4997, les identificateurs sont forcément en
majuscule et le littéral THIS doit donc être
défini par :
THIS = %d84.72.73.83
Si on l'avait défini :
THIS = "THIS"
alors, il aurait pu être écrit en minuscules ou en mixte.
Donc, désormais, la règle est que les chaînes de caractères en ABNF
peuvent être précédées de %i pour indiquer
qu'elles sont insensibles à la casse ou %s pour
dire qu'elles ne le sont pas. Comme %i est la
valeur par défaut (pour préserver la compatibilité), elle sera souvent
omise. La définition du RFC 4997 plus haut
aurait donc pu être :
THIS = %s"THIS"
À ma connaissance, les différents outils ABNF en http://tools.ietf.org/ n'ont pas encore fait l'objet d'un
examen systématique pour déterminer s'ils intégraient la nouvelle norme.
L'article seul
RFC 7413: TCP Fast Open
Date de publication du RFC : Décembre 2014
Auteur(s) du RFC : Y. Cheng, J. Chu, S. Radhakrishnan, A. Jain
(Google)
Expérimental
Réalisé dans le cadre du groupe de travail IETF tcpm
Première rédaction de cet article le 19 décembre 2014
Quand on parle de performances sur l'Internet, on se focalise souvent exclusivement sur la capacité du réseau. C'est, par exemple, l'argument quasi-exclusif des FAI : « Avec la fibre Machin, passez à la vitesse supérieure, XXX Mb/s ». Mais un autre facteur de la qualité de l'expérience utilisateur est la latence, à savoir le temps qu'il faut attendre pour recevoir une réponse. Par exemple, pour accéder à une page Web, avant même d'envoyer le premier octet « utile », il faut réaliser une « triple poignée de mains » (RFC 793, section 3.4) avec le serveur, pour établir la connexion, et cette poignée de mains nécessite pas moins de trois paquets, donc il faudra attendre trois fois le temps d'un aller simple, avant de pouvoir foncer et envoyer les images de chats (ou de loutres). Ce nouveau RFC, encore officiellement expérimental, mais déjà largement déployé, vise à raccourcir ce délai d'ouverture d'une connexion avec le serveur.
L'idée est ancienne (on la trouve par exemple dans le système T/TCP
du RFC 1644, et dans les autres systèmes résumés
en section 8) mais le problème est plus difficile
à résoudre qu'il n'en a l'air, notamment si on veut garder un bon
niveau de sécurité (le problème qui a tué T/TCP). L'idée est ancienne, car devoir
attendre trois voyages avant de pouvoir envoyer les données contribue
sérieusement à la latence d'applications comme le Web. Si le serveur
est à 100 ms de distance, on attendra au moins 300 ms avant que des
données ne commencent le voyage. Et, contrairement à la capacité, la
latence ne s'améliore pas avec le temps et les progrès de l'électronique. Des mesures faites sur
Chrome montre que la triple poignée de mains de TCP
est responsable de 25 % de la latence moyenne des requêtes HTTP. Il existe des solutions pour
certaines applications. Par exemple, pour HTTP,
on peut utiliser les connexions persistantes (RFC 7230, section 6.3). L'établissement de ces connexions
prendra autant de temps qu'avant mais ce « coût » ne sera payé qu'une
fois : les requêtes/réponses ultérieures avec le même serveur HTTP
réutiliseront la connexion TCP existante (et, si elles ne viennent
pas, la connexion finit par être coupée, par exemple au bout de cinq
minutes pour Chrome). Le problème est que ces
connexions persistantes ne sont pas assez répandues. Les mesures des
auteurs du RFC (Radhakrishnan, S., Cheng, Y., Chu, J., Jain, A.,
Raghavan, B., « TCP Fast
Open », Proceedings of 7th ACM CoNEXT Conference,
2011) montrent que 35 % des requêtes nécessitent la création d'une
nouvelle connexion TCP. Il serait agréable de pouvoir accélérer ces
créations. La triple poignée de mains prend trois paquets,
SYN (du client vers le serveur), SYN +
ACK (du serveur vers le client) et ACK
(du client vers le serveur). Les données ne voyagent qu'après. L'idée
de base de TCP Fast Open (TFO), technique venant de chez Google, est de mettre les données dès le premier paquet
SYN du client.
Le plus drôle est que le TCP original
n'interdit pas de mettre des données dans le paquet
SYN (section 2 de notre RFC). Bien au contraire, c'est explicitement
autorisé par la section 3.4 du RFC 793 (« Although these
examples do not show connection synchronization using data-carrying
segments, this is perfectly legitimate [...] »). Mais avec
une grosse restriction, que les données ne soient délivrées au serveur
d'applications qu'une fois la triple poignée de mains terminée, ce qui
en supprime l'intérêt. Cette règle a pour but d'éviter que des données
soient envoyées deux fois (le paquet SYN peut
être perdu et retransmis). Les variantes de TCP qui ont essayé
d'optimiser le temps d'ouverture de connexion ont en général choisi de sacrifier
de la sécurité, afin de maintenir la sémantique de TCP, ce qui n'est en général pas considéré comme acceptable
de nos jours (RFC 7414). TCP Fast Open sacrifie,
lui, la non-duplication des données : un serveur Fast Open peut, dans
certains cas (par exemple si le serveur a redémarré entre les deux SYN), recevoir deux fois les mêmes données envoyées dans un
paquet SYN. Ce n'est pas toujours si dramatique que ça en
a l'air. Pour HTTP, le premier paquet de données du client sera sans
doute un GET /something HTTP/1.1 et cette requête
peut être effectuée deux fois sans conséquences graves. Première chose
à retenir, donc, sur Fast Open : il ne convient pas à toutes les
applications. TCP Fast Open est juste un compromis. Les systèmes ne doivent donc pas
l'activer par défaut (les exemples plus loin montrent comment
un programme Unix peut activer explicitement
Fast Open). La section 4.2 insistera sur ce point.
Et la sécurité ? Le TCP normal présente une vulnérabilité : les
paquets SYN n'ayant aucune forme
d'authentification, un attaquant peut, en trichant sur son adresse IP,
envoyer des paquets SYN sans révéler son identité et ces paquets,
s'ils sont assez abondants, peuvent remplir la file d'attente du
serveur (attaque dite « SYN
flood »). C'est encore pire avec Fast Open
puisque ces requêtes en attente comprennent des données, et peuvent
déclencher l'exécution de commandes complexes (GET
/horrible-page-dont-la-génération-nécessite-10000-lignes-de-Java-ou-de-PHP
HTTP/1.1...) Les techniques du RFC 4987 ne sont en général pas appliquables à Fast Open. C'est pour cela que Fast Open ajoute un composant essentiel : un petit gâteau (cookie) généré par le serveur et que le client devra transmettre pour bénéficier du Fast Open.
La section 3 décrit en termes généraux le protocole. À la première
connexion Fast Open d'une machine vers une autre, le client envoie
l'option TCP (pour les options TCP, voir la section 3.1 du RFC 793) 34
TCP Fast Open Cookie (désormais dans le registre IANA mais attention, les
mises en œuvre actuelles utilisent souvent la valeur expérimentale précédente) avec un contenu vide. Si le serveur gère
Fast Open, il répondra (dans le SYN + ACK) avec un gâteau (cookie),
généré par lui et imprévisible. Dans les connexions TCP ultérieures,
le client renverra l'option Fast Open Cookie avec le même
gâteau. Le serveur le reconnaitra alors. Les requêtes
SYN comportant ce gâteau pourront inclure des
données, elles seront transmises tout de suite aux applications qui le
demandent (et on aura alors du beau TCP Fast Open) et le premier
paquet de réponse pourra inclure des données (dans les limites données
par le RFC 5681). On voit donc que
la première connexion entre deux machines ne bénéficiera pas de Fast
Open. Mais toutes les suivantes, oui (sur
Linux, le noyau se
souviendra du gâteau). Si le serveur ne gère pas cette option, il
répond par un SYN + ACK sans l'option, informant
ainsi le client qu'il ne doit pas compter sur Fast Open.
Voici, vu avec tcpdump, un exemple d'une session TCP Fast Open d'une machine
Debian/Linux (version
jessie) vers Google. Le
gâteau (32a8b7612cb5ea57) est en mémoire chez le
client (les options TCP sont affichées entre
crochets, la « nôtre » est exp-tfo) :
20:10:39.920892 IP (tos 0x0, ttl 64, id 6594, offset 0, flags [DF], proto TCP (6), length 158)
106.186.29.14.53598 > 173.194.38.98.80: Flags [S], cksum 0x5c7d (incorrect -> 0x9bd5), seq 1779163941:1779164027, win 29200, options [mss 1460,sackOK,TS val 114031335 ecr 0,nop,wscale 7,exp-tfo cookie 32a8b7612cb5ea57], length 86
20:10:39.923005 IP (tos 0x0, ttl 57, id 3023, offset 0, flags [none], proto TCP (6), length 52)
173.194.38.98.80 > 106.186.29.14.53598: Flags [S.], cksum 0xae4c (correct), seq 1775907905, ack 1779164028, win 42900, options [mss 1430,nop,nop,sackOK,nop,wscale 6], length 0
20:10:39.923034 IP (tos 0x0, ttl 64, id 6595, offset 0, flags [DF], proto TCP (6), length 40)
106.186.29.14.53598 > 173.194.38.98.80: Flags [.], cksum 0x5c07 (incorrect -> 0x95af), ack 1, win 229, length 0
20:10:39.923462 IP (tos 0x0, ttl 57, id 3024, offset 0, flags [none], proto TCP (6), length 589)
173.194.38.98.80 > 106.186.29.14.53598: Flags [P.], cksum 0xcdd1 (correct), seq 1:550, ack 1, win 670, length 549
20:10:39.923475 IP (tos 0x0, ttl 57, id 3025, offset 0, flags [none], proto TCP (6), length 40)
173.194.38.98.80 > 106.186.29.14.53598: Flags [F.], cksum 0x91d0 (correct), seq 550, ack 1, win 670, length 0
20:10:39.923492 IP (tos 0x0, ttl 64, id 6596, offset 0, flags [DF], proto TCP (6), length 40)
106.186.29.14.53598 > 173.194.38.98.80: Flags [.], cksum 0x5c07 (incorrect -> 0x9382), ack 550, win 237, length 0
20:10:39.923690 IP (tos 0x0, ttl 64, id 6597, offset 0, flags [DF], proto TCP (6), length 40)
106.186.29.14.53598 > 173.194.38.98.80: Flags [R.], cksum 0x5c07 (incorrect -> 0x937d), seq 1, ack 551, win 237, length
Notez la longueur du premier paquet, 86 octets (une requête HTTP), alors qu'elle est normalement nulle, sans Fast Open.
Il y a en tout sept paquets. Sans Fast Open, la même requête HTTP aurait pris deux paquets de plus :
20:11:13.403762 IP (tos 0x0, ttl 64, id 55763, offset 0, flags [DF], proto TCP (6), length 60)
106.186.29.14.42067 > 173.194.38.96.80: Flags [S], cksum 0x5c19 (incorrect -> 0x858c), seq 720239607, win 29200, options [mss 1460,sackOK,TS val 114041380 ecr 0,nop,wscale 7], length 0
20:11:13.405827 IP (tos 0x0, ttl 57, id 7042, offset 0, flags [none], proto TCP (6), length 52)
173.194.38.96.80 > 106.186.29.14.42067: Flags [S.], cksum 0x5792 (correct), seq 687808390, ack 720239608, win 42900, options [mss 1430,nop,nop,sackOK,nop,wscale 6], length 0
20:11:13.405857 IP (tos 0x0, ttl 64, id 55764, offset 0, flags [DF], proto TCP (6), length 40)
106.186.29.14.42067 > 173.194.38.96.80: Flags [.], cksum 0x5c05 (incorrect -> 0x3ef5), ack 1, win 229, length 0
20:11:13.405915 IP (tos 0x0, ttl 64, id 55765, offset 0, flags [DF], proto TCP (6), length 126)
106.186.29.14.42067 > 173.194.38.96.80: Flags [P.], cksum 0x5c5b (incorrect -> 0xaa0c), seq 1:87, ack 1, win 229, length 86
20:11:13.407979 IP (tos 0x0, ttl 57, id 7043, offset 0, flags [none], proto TCP (6), length 40)
173.194.38.96.80 > 106.186.29.14.42067: Flags [.], cksum 0x3ce6 (correct), ack 87, win 670, length 0
20:11:13.408456 IP (tos 0x0, ttl 57, id 7044, offset 0, flags [none], proto TCP (6), length 589)
173.194.38.96.80 > 106.186.29.14.42067: Flags [P.], cksum 0x9cce (correct), seq 1:550, ack 87, win 670, length 549
20:11:13.408469 IP (tos 0x0, ttl 57, id 7045, offset 0, flags [none], proto TCP (6), length 40)
173.194.38.96.80 > 106.186.29.14.42067: Flags [F.], cksum 0x3ac0 (correct), seq 550, ack 87, win 670, length 0
20:11:13.408498 IP (tos 0x0, ttl 64, id 55766, offset 0, flags [DF], proto TCP (6), length 40)
106.186.29.14.42067 > 173.194.38.96.80: Flags [.], cksum 0x5c05 (incorrect -> 0x3c72), ack 550, win 237, length 0
20:11:13.408720 IP (tos 0x0, ttl 64, id 55767, offset 0, flags [DF], proto TCP (6), length 40)
106.186.29.14.42067 > 173.194.38.96.80: Flags [R.], cksum 0x5c05 (incorrect -> 0x3c6d), seq 87, ack 551, win 237, length ...
Dans cet exemple, le gâteau envoyé par Google était en mémoire. Si ce n'est pas le cas (la machine vient de redémarrer, par exemple), la première requête Fast Open va être une triple poignée de mains classique, les bénéfices de Fast Open ne venant qu'après :
16:53:26.120293 IP (tos 0x0, ttl 64, id 55402, offset 0, flags [DF], proto TCP (6), length 64)
106.186.29.14.57657 > 74.125.226.86.80: Flags [S], cksum 0x07de (incorrect -> 0xc67b), seq 3854071484, win 29200, options [mss 1460,sackOK,TS val 325168854 ecr 0,nop,wscale 6,exp-tfo cookiereq], length 0
16:53:26.121734 IP (tos 0x0, ttl 57, id 16732, offset 0, flags [none], proto TCP (6), length 72)
74.125.226.86.80 > 106.186.29.14.57657: Flags [S.], cksum 0xb913 (correct), seq 2213928284, ack 3854071485, win 42540, options [mss 1430,sackOK,TS val 2264123457 ecr 325168854,nop,wscale 7,exp-tfo cookie 234720af40598470], length 0
Ici, le client, n'ayant pas de gâteau pour
74.125.226.86, a dû envoyer une option Fast Open
vide (et donc pas de données : la longueur de son paquet
SYN est nulle). À la deuxième connexion, on a un
gâteau, on s'en sert :
16:54:30.200055 IP (tos 0x0, ttl 64, id 351, offset 0, flags [DF], proto TCP (6), length 161)
106.186.29.14.57659 > 74.125.226.86.80: Flags [S], cksum 0x083f (incorrect -> 0x651d), seq 1662839861:1662839950, win 29200, options [mss 1460,sackOK,TS val 325184874 ecr 0,nop,wscale 6,exp-tfo cookie 234720af40598470], length 89
16:54:30.201529 IP (tos 0x0, ttl 57, id 52873, offset 0, flags [none], proto TCP (6), length 60)
74.125.226.86.80 > 106.186.29.14.57659: Flags [S.], cksum 0x67e3 (correct), seq 2010131453, ack 1662839951, win 42540, options [mss 1430,sackOK,TS val 2264192396 ecr 325184874,nop,wscale 7], length 0
La section 4 de notre RFC plonge ensuite dans les détails compliqués de TCP Fast Open. Le gâteau est un MAC généré par le serveur et est donc opaque au client. Ce dernier ne fait que le stocker et le renvoyer. L'option Fast Open est simple : juste le code 34, une longueur (qui peut être nulle, par exemple pour un client qui ne s'est pas encore connecté à ce serveur, et qui demande donc un gâteau), et éventuellement le gâteau. Le serveur, lors de la génération du gâteau, va typiquement devoir suivre ces règles :
- Lier le gâteau à l'adresse IP source (pour éviter qu'un attaquant ayant espionné le réseau n'utilise le gâteau d'un autre),
- Utiliser un algorithme de génération imprévisible de l'extérieur (par exemple un générateur aléatoire),
- Aller vite (le but de Fast Open est de diminuer la latence : pas question de faire des heures de calcul cryptographiques compliqués),
- Imposer une date d'expiration au gâteau (soit en changer la clé privée utilisée lors de la génération, soit en incluant une estampille temporelle dans les données qui servent à générer le gâteau).
Un exemple d'algorithme valable (mais rappelez-vous que le gâteau est opaque, le serveur peut donc utiliser l'algorithme qu'il veut) est de chiffrer avec AES l'adresse IP et de changer la clé AES de temps en temps (invalidant ainsi automatiquement les vieux gâteaux). AES étant très rapide, cet algorithme a toutes les propriétés listées plus haut. Pour vérifier un gâteau entrant, le serveur a tout simplement à refaire tourner l'algorithme et voir s'il obtient le même résultat.
Et côté client ? Comme indiqué plus haut, le client doit stocker
les gâteaux reçus (sans les comprendre : ils sont opaques pour lui) et
les renvoyer lors des connexions suivantes vers le même
serveur. Puisqu'on mémorise le gâteau de chaque serveur, on peut en
profiter pour mémoriser également le MSS,
ce qui indiquera la taille des données qu'on pourra envoyer dans le
prochain paquet SYN. (Rappelez-vous que le
serveur indique normalement sa MSS dans le SYN +
ACK, donc trop tard pour Fast Open.) Mais attention : même
si le MSS ainsi mémorisé est grand (supérieur à la
MTU, par exemple), ce n'est pas forcément une
bonne idée d'envoyer autant de données dans le paquet
SYN. Des problèmes comme la
fragmentation ou comme les
middleboxes ne s'attendant
pas à des SYN s'étalant sur plusieurs paquets
IP, risquent de diminuer les performances, voire
d'empêcher TCP de marcher.
Ah, et si on ne connait pas
le MSS, on doit se limiter à 536 octets en IPv4
et 1240 en IPv6.
Comme toujours sur l'Internet, lorsqu'on déploie une nouvelle
technique, il faut aussi tenir compte des trucs bogués. Si le serveur
ne répond pas aux SYN comportant l'option Fast
Open, cela peut être parce qu'une stupide
middlebox a décidé de jeter
ces paquets, qui passeraient sans l'option. Même chose au cas où le
serveur n'accuse pas réception des données qui étaient dans le
SYN : le client Fast Open doit être prêt à
réessayer sans cette option, et à mémoriser que le serveur ne doit pas
être utilisé avec Fast Open. (Notez, car le RFC ne le fait pas, que
ces incompatibilités, étant typiquement causées par une
middlebox et pas par le serveur lui-même, peuvent
changer dans le temps, si le routage fait soudain passer par un autre chemin.)
Autre point important lorsqu'on met en œuvre Fast Open : le serveur
doit garder une trace en mémoire du nombre de connexions qui ont
demandé Fast Open mais n'ont pas encore terminé la triple poignée de
mains. Et, au delà d'une certaine limite, le serveur doit refuser de
nouvelles connexions Fast Open (en ne renvoyant pas d'option Fast Open
dans le SYN + ACK), n'acceptant que le TCP
traditionnel. Cette précaution permet de résister à certaines attaques
par déni de service.
En parlant d'attaques, la section 5 du RFC se concentre sur la
sécurité. L'obligation d'envoyer un gâteau authentique arrête
certaines attaques triviales (envoyer paquets SYN
avec des données qui vont faire travailler le serveur). Mais d'autres
attaques restent possibles. Accrochez-vous, nous allons étudier ce
qu'un méchant peut faire contre des serveurs TCP Fast Open.
D'abord, il peut tenter d'épuiser les ressources du serveur en utilisant des gâteaux valides. Où les obtient-il ? Cela peut être en utilisant plein de machines (un botnet). Bien sûr, vous allez me dire, on peut faire des tas d'attaques par déni de service avec un botnet mais, avec Fast Open, les zombies peuvent faire plus de dégâts pour moins cher (ils ne sont pas obligés d'écouter les réponses ni même de les attendre). D'où l'importance de la variable « nombre de connexions Fast Open pas complètement ouvertes » citée plus haut.
On ne peut pas normalement voler des gâteaux à une machine et les utiliser ensuite soi-même puisque le gâteau est (si le serveur a bien fait son boulot) lié à l'adresse IP. Mais ce vol reste possible si plusieurs machines partagent une adresse IP publique (cas du CGN par exemple). Une solution possible serait d'inclure dans le calcul du gâteau, non seulement l'adresse IP mais aussi la valeur d'une option TCP Timestamp.
Fast Open peut aussi en théorie être utilisé dans des attaques par réflexion. Par exemple (mais le RFC indique aussi d'autres méthodes), si l'attaquant contrôle une machine dans le réseau de sa victime, il peut obtenir des gâteaux valables et ensuite, lancer depuis un botnet des tas de connexions Fast Open en usurpant l'adresse IP source de sa victime. Les serveurs Fast Open vont alors renvoyer des données (potentiellement plus grosses que les requêtes, donc fournissant une amplification, chose bien utile pour une attaque par déni de service) à la victime. C'est idiot de la part de l'attaquant de s'en prendre à une machine qu'il contrôle déjà ? Non, car sa vraie victime peut être le réseau qui héberge la machine compromise. Les réponses des serveurs Fast Open arriveront peut-être à saturer la liaison utilisée par ce réseau, et cela en contrôlant juste une machine (soit par piratage, soit par location normale d'une machine chez l'hébergeur qu'on veut attaquer). La seule protection envisagée pour l'instant est de décourager les serveurs d'envoyer les réponses au-delà d'une certaine taille, tant que la triple poignée de mains n'a pas été terminée. Mais cela diminue une partie de l'intérêt de TCP Fast Open.
Bon, fini avec ces tristes questions de sécurité, revenons à la
question de l'applicabilité de Fast Open. On a bien dit que Fast Open
ne convient pas à tous les cas. Si je suis développeur, dans quels cas
mon application a-t-elle raison d'utiliser Fast Open ? D'abord, on a
vu que Fast Open fait courir le risque d'une duplication du
SYN si le paquet est dupliqué
et que le second arrive après que le serveur ait
détruit le début de connexion. En pratique, la probabilité d'une telle
malchance semble faible. Le RFC ne fournit pas de chiffres précis
(voir Jaiswal, S., Iannaccone, G., Diot, C., Kurose, J.,
Towsley, D., « Measurement and classification of
out-of-sequence packets in a tier-1 IP backbone »
dans IEEE/ACM Transactions on Networking
(TON)). Dans le doute, une application qui ne pourrait pas
gérer le cas de données dupliquées ne doit donc
pas activer Fast Open (rappelez-vous qu'il ne
doit pas non plus l'être par défaut). Comme indiqué plus haut, pour
HTTP, un GET ne pose pas
de problèmes (les navigateurs Web impatients causent déjà souvent des
GET dupliqués, qu'on retrouve dans ses
journaux) mais un POST non protégé (par
exemple par les requêtes conditionnelles du RFC 7232) a davantage de chances
de créer des histoires.
Autre cas où il n'y a pas de problèmes à attendre, celui de
TLS. Si le client met le
TLS_CLIENT_HELLO dès le SYN,
cela n'entraine pas de conséquences fâcheuses si le
SYN est dupliqué, et cela fait gagner un
RTT sur la poignée de mains de TLS.
Ensuite, même s'il n'a pas de conséquences néfastes, TCP Fast Open n'a pas non plus d'avantages si le temps d'établissement de la connexion est négligeable devant la durée totale de la connexion. Une requête HTTP pour un fichier de petite taille peut sans doute profiter de Fast Open, mais pas le transfert d'une énorme vidéo.
On a parlé plus haut des connexions HTTP persistantes (RFC 7230). TCP Fast Open est-il utile lorsqu'on a ces connexions persistantes ? Oui, répond notre RFC. L'étude de Radhakrishnan, S., Cheng, Y., Chu, J., Jain, A. et Raghavan, B. citée plus haut, ainsi que celle d'Al-Fares, M., Elmeleegy, K., Reed, B. et Gashinsky, I., « Overclocking the Yahoo! CDN for Faster Web Page Loads » (dans Proceedings of Internet Measurement Conference , novembre 2011), montrent que le nombre moyen de transactions HTTP par connexion TCP n'est que de 2 à 4, alors même que ces connexions restent ouvertes plusieurs minutes, ce qui dépasse normalement le temps de réflexion d'un être humain. Les mesures effectuées sur Chrome (qui garde les connexions de 5 à 10 minutes) ne voyaient que 3,3 requêtes HTTP par connexion. Faudrait-il allonger cette durée pendant laquelle les connexions persistent ? Cela entrainerait d'autres problèmes, par exemple avec les routeurs NAT qui, en violation du RFC 5382, coupent automatiquement les connexions bien avant la limite de deux heures demandée par le RFC (voir les études de Haetoenen, S., Nyrhinen, A., Eggert, L., Strowes, S., Sarolahti, P. et Kojo., M., « An Experimental Study of Home Gateway Characteristics » dans les Proceedings of Internet Measurement Conference, octobre 2010 ainsi que de Wang, Z., Qian, Z., Xu, Q., Mao, Z. et Zhang, M., « An Untold Story of Middleboxes in Cellular Networks » dans Proceedings of SIGCOMM, août 2011). Envoyer des keepalives TCP résoudrait ce problème mais serait une sérieuse source de consommation électrique pour les machines fonctionnant sur batteries. On voit même le phénomène inverse, les navigateurs Web conçus pour les équipements mobiles qui se mettent à couper les connexions HTTP persistantes plus tôt (Souders, S., « Making A Mobile Connection »).
Ce RFC sur TCP Fast Open a le statut « expérimental ». Qu'est-ce qu'on doit encore étudier et mesurer pour être sûr que Fast Open marche bien ? D'abord, quel est le pourcentage exact de chemins sur l'Internet où les paquets TCP ayant des options inconnues sont jetés ? Pas mal de middleboxes stoppent stupidement tout ce qu'elles ne comprennent pas (Medina, A., Allman, M., and S. Floyd, « Measuring Interactions Between Transport Protocols and Middleboxes » dans Proceedings of Internet Measurement Conference en octobre 2004). Une option nouvelle, comme Fast Open, pourrait donc avoir du mal à percer. Des mesures semblent indiquer que 6 % des chemins Internet seraient dans ce cas (Langley, A, « Probing the viability of TCP extensions » ou bien Honda, M., Nishida, Y., Raiciu, C., Greenhalgh, A., Handley, M. et Tokuda, H., « Is it Still Possible to Extend TCP? » dans Proceedings of Internet Measurement Conference en novembre 2011). TCP Fast Open réagit à ce problème en réessayant sans l'option (comme le font les résolveurs DNS quand ils n'obtiennent pas de réponse lorsque les requêtes sont envoyées avec EDNS).
Autre sujet de recherche intéressant, les liens avec la congestion. Normalement, Fast Open ne modifie pas les algorithmes qui tentent d'éviter la congestion mais il peut y avoir des cas subtils où Fast Open ne peut pas suivre ces algorithmes (données déjà envoyées avant que les pertes ne soient détectées).
TCP Fast Open impose actuellement l'usage d'un gâteau pour détecter les méchants qui tricheraient sur leur adresse IP source. Mais pour certains serveurs qui n'assurent que des tâches simples et idempotentes (le RFC prend l'exemple d'un serveur HTTP qui ne ferait que des redirections), la protection fournie par le gâteau est peut-être inutile et on pourrait faire des économies en s'en passant (l'expérience du DNS, qui est aussi requête/réponse, me rend personnellement sceptique sur ce point). Ou bien le serveur pourrait s'en passer par défaut, et basculer en Fast Open avec gâteau s'il détecte une attaque par déni de service en cours ? Bref, il y a encore des sujets ouverts.
La section 8 rappelle les travaux qui avaient précédé Fast Open. Il y a bien sûr T/TCP, déjà cité, qui avait trébuché sur les problèmes de sécurité. Une autre solution pour TCP est le TCPCT du RFC 6013 (désormais abandonné, cf. RFC 7805). Mais il y a aussi les solutions dans les applications comme « preconnect ».
Sinon, si vous voulez de la lecture sur Fast Open, il y a une bonne explication dans Linux Weekly News, avec des détails sur son utilisation dans les programmes.
À propos de programmes, et les mises en œuvre ? TCP Fast Open existe dans le navigateur
Chrome, ainsi que dans le noyau
Linux, depuis la version 3.7 (3.16 seulement pour
IPv6). Une Debian en
version « jessie » permet donc de tester.
Une API possible figure en annexe A du RFC. Du
côté serveur, il faut, après avoir créé une
socket :
setsockopt(sfd, SOL_TCP, TCP_FASTOPEN, &qlen, sizeof(qlen));
C'est plus compliqué sur le client (il faudrait envoyer des données
dans le connect() ou bien
utiliser sendto() ou encore une
option de la socket). Le programme client-http-tcp-fastopen.c montre un simple client HTTP
utilisant Fast Open. C'est avec lui qu'ont été obtenues les traces
montrées plus haut (le pcap complet est sur pcapr ; il utilise une valeur expérimentale pour l'option et pas la valeur standard de 34).
Une lecture pour finir : la présentation « Network Support for TCP Fast Open (NANOG 67) ».
Merci à Alexis La Goutte pour ses remarques.
L'article seul
RFC 7378: Trustworthy Location
Date de publication du RFC : Décembre 2014
Auteur(s) du RFC : H. Tschofenig
(Independent), H. Schulzrinne (Columbia
University), B. Aboba (Microsoft )
Pour information
Réalisé dans le cadre du groupe de travail IETF ecrit
Première rédaction de cet article le 18 décembre 2014
Il existe des applications de communication (de téléphonie, par exemple), qui indiquent la localisation de l'appelant, et cette localisation est cruciale lorsque il s'agit d'appels d'urgence, par exemple aux pompiers ou à la police, ou, moins dramatique, d'assistance routière (« ma voiture est en panne et je ne sais pas exactement où je suis », comme cela m'est arrivé sur la N 1 ce mois d'août). Ce nouveau RFC décrit le problème de la sécurité et de la fiabilité de la localisation, ainsi que des solutions pour améliorer cette sécurité et cette fiabilité.
Pour envoyer sa localisation à son correspondant, il y a deux sous-problèmes : 1) déterminer la localisation 2) la transmettre de manière sûre. Pour la téléphonie traditionnelle, la localisation est déterminée par le récepteur à partir du numéro de téléphone présenté. Cela veut dire notamment qu'un faux numéro peut entraîner une mauvaise localisation (cf. RFC 7340 et les autres documents du groupe STIR). Il y a plusieurs mécanismes pour s'assurer du numéro de téléphone comme le rappel (qui permet aussi de confirmer l'urgence, cf. RFC 7090). Mais quand l'appelant est mobile, même lorsqu'on est sûr du numéro de téléphone présenté, le problème n'est pas résolu. Ce RFC se focalise sur les cas où le numéro de téléphone de l'appelant est raisonnablement authentifié mais où il reste des doutes sur la localisation physique de la cible (oui, c'est comme cela qu'on désigne la personne ou l'objet dont on cherche à connaître la localisation). Le mode normal d'obtention de la localisation est de faire appel à un LIS (Location Information Server) qui, connaissant les caractéristiques du réseau utilisé, va l'indiquer à son client. Un malveillant peut faire en sorte qu'une mauvaise localisation soit indiquée de trois façons :
- Changement d'endroit (place shifting), lorsque l'attaquant arrive à placer un faux objet PIDF-LO ( Presence Information Data Format Location Object, voir le RFC 4119). Dans certains cas, il y a une limite à la triche, par exemple l'attaquant peut indiquer une fausse position mais qui doit rester dans la zone couverte par un relais donné.
- Changement de moment (time shifting), où l'attaquant réussit à ré-utiliser une information de localisation qui était vraie dans le passé, mais ne l'est plus.
- Vol de localisation (location theft), lorsque on présente un objet de localisation qui est correct et valide mais concerne une autre personne.
La première façon est la plus puissante, mais n'est pas toujours accessible aux attaquants.
Pour comprendre complètement le problème, il faut aussi connaître
l'architecture des services d'urgence (section 1.2) sur
l'Internet. Son cadre général figure dans le RFC 6443. Les
bonnes pratiques à suivre pour faire un service d'urgence qui marche
sont dans le RFC 6881. Ces services d'urgence nécessitent des
informations sur l'appelant (comme sa localisation, qu'il n'a pas
toujours le temps ou la possibilité de donner, lorsqu'il est en
situation d'urgence). Lorsqu'un service d'urgence reçoit l'appel, il
doit donc déterminer la localisation, en déduire à qui transmettre
l'appel (ce qu'on nomme un PSAP pour Public Safety Answering
Point) et router l'appel (en SIP,
transmettre un INVITE, contenant la localisation,
cf. RFC 6442).
Le problème de tout service d'urgence, ce sont les faux appels. Ils existent depuis bien avant l'Internet. Comme ils détournent les services d'urgence des vrais appels, ils peuvent littéralement tuer, si quelqu'un qui avait besoin d'un secours urgent ne l'obtient pas car tous les services sont occupés à traiter des canulars. (Il est recommandé de consulter le document EENA sur les faux appels.) Parmi les faux appels, l'un est particulièrement dangereux, le swatting. Il doit son nom au SWAT états-unien et consiste à appeler les services de police en prétendant qu'il y a une situation d'extrême danger nécessitant de faire appel à la force (prise d'otages, par exemple). Cet appel amènera à un déploiement policier intense, style cow-boys, chez la victime. Le FBI a documenté ce phénomène. De telles actions étant sévèrement punies, les attaquants vont toujours essayer de cacher leur identité, par exemple en indiquant un faux numéro de téléphone, si leur fournisseur de services téléphoniques le permet. Plusieurs études ont montré que les faux appels étaient particulièrement nombreux si on ne pouvait pas authentifier l'appelant (cf. « Emergency services seek SIM-less calls block » ou « Rapper makes thousands of prank 999 emergency calls to UK police »).
Place maintenant aux menaces sur la localisation. Le RFC 6280 décrit une architecture pour des services de localisation intégrant la notion de vie privée. D'autres RFC décrivent les exigences de tout service de localisation (RFC 3693), les menaces contre eux (RFC 3694), le cas particulier des services d'urgence (RFC 5069), et l'usurpation des numéros de téléphone (RFC 7375).
Notre RFC s'attaque aux menaces en distinguant d'abord trois classes d'attaquants :
- Les attaquants externes, ne disposant d'aucun privilège particulier,
- Les attaquants situés dans l'infrastructure de téléphonie, et qui en contrôlent une partie, par exemple le LIS (Location Information Server),
- Les attaquants situés sur la machine de l'utilisateur.
Évidemment, les deux dernières classes peuvent faire des dégats plus facilement.
Outre la tricherie sur son numéro de téléphone, un attaquant peut aussi tricher sur sa localisation, soit en en inventant une de toutes pièces, soit en « rejouant » une localisation authentique, mais dans le passé ou encore en « volant » une localisation authentique mais d'un autre utilisateur. Ce RFC se focalise sur ces risques liés à la localisation mais la tricherie sur l'identité n'est pas à oublier. En effet, l'auteur des faux appels cherche en général à éviter les représailles, et donc à dissimuler son identité, par exemple en appelant d'une cabine téléphonique.
Maintenant, que peut-on faire pour limiter les risques (section 3) ? Il y a trois mécanismes principaux :
- Signer les informations de localisation (les fichiers PIDF-LO décrits dans le RFC 4119) au départ de l'appel. Aucune norme n'existe pour cela.
- Obtention de la localisation, non pas via l'émetteur mais depuis le récepteur, via le RFC 6753, en utilisant le protocole HELD (HTTP-Enabled Location Delivery) RFC 5985. Dans ce cas, le destinataire de l'appel, le PSAP (le service d'urgence), contacte le serveur de localisation, le LIS.
- Obtention de la localisation, non pas via l'émetteur mais via le réseau (plus exactement un mandataire dans le réseau), en utilisant le RFC 6442. Cette dernière technique, elle, impose la participation du FAI (qui connait la localisation physique de ses abonnés, même si c'est avec une précision limitée, surtout pour les mobiles).
Une fois obtenue la localisation, encore faut-il en évaluer la fiabilité. Ce niveau de fiabilité est une information cruciale pour le processus de décision. Par exemple, un appel d'urgence où la localisation est marquée comme « absolument sûre » peut être traité instantanément, alors qu'on passera un peu plus de temps à vérifier un appel depuis une localisation douteuse (section 4). La localisation dépend d'un certain nombre de partenaires, et cette fiabilité va donc varier selon la confiance qu'on accorde à ces partenaires. Par exemple, dans le deuxième mécanisme cité plus haut (le PSAP interroge le LIS), si le LIS est connu, de confiance, et qu'on l'utilise depuis longtemps avec succès, on se fiera facilement à lui. À l'inverse, dans le cas du troisième mécanisme (interrogation d'un mandataire géré par le FAI), s'il y a eu peu d'appels d'urgence depuis ce FAI et qu'on n'a jamais pu vérifier la fiabilité de ses informations, la localisation sera marquée comme douteuse.
Pour déterminer la validité des informations de localisation, on
peut aussi faire des vérifications croisées. Lors d'un appel SIP, une
fois qu'on a reçu une localisation physique de l'émetteur, on peut
comparer avec la localisation qu'indique l'adresse
IP dans les champs Via: ou
Contact:, ou celle dans les paquets de
données. Si les deux localisations coïncident, on est rassuré. Sinon,
on note la localisation comme étant douteuse.
La section 5 résume tous les problèmes de sécurité liés à la localisation fiable. Il faut notamment se rappeler que cette fiabilité peut être en opposition avec d'autres critères de sécurité, comme la protection de la vie privée (la section 6 détaille ce problème). D'autre part, toutes les mesures envisagées ne sont guère efficaces face au problème spécifique de l'attaque par déni de service : un attaquant qui effectuerait un très grand nombre d'appels pourrait toujours perturber le PSAP (le service d'urgence), ne serait-ce que via les vérifications faites. Effectuer un tel nombre d'appels est évidemment plus facile avec la téléphonie sur IP qu'avec le téléphone traditionnel. Et cela permet plus facilement de franchir les frontières, pour attaquer les services d'urgence d'un autre pays.
Ces appels en masse peuvent être faits par des zombies mais aussi par du code non sécurisé, par exemple un malware JavaScript, chargé automatiquement par le navigateur Web, et qui ferait des appels via WebRTC (RFC 8825). Il peut donc être prudent d'empêcher ce genre de code non sécurisé d'appeler les services d'urgence.
Pour analyser la résistance d'un service d'urgence aux attaques par déni de service, il faut séparer les cas des trois ressources finies dont disposent ces services : l'infrastructure informatique (réseaux et serveurs), les humains qui répondent à l'appel, et les services de secours eux-mêmes (police, pompiers, etc). Par exemple, si le réseau marche bien et que les preneurs d'appel répondent bien, mais qu'il n'y a plus aucun pompier disponible car tous sont partis combattre des incendies imaginaires, l'attaque par déni de service a malheureusement réussi. Les contre-mesures doivent donc veiller à traiter les cas d'abus de ces trois ressources. Par exemple, faire des vérifications automatiques poussées sur la vraisemblance de l'information de localisation va stresser la première ressource (l'infrastructure informatique) mais cela préservera les deux autres (qui sont souvent limitées : on n'a pas des ressources humaines abondantes et qualifiées).
Apparemment, il n'existe pas encore de mise en œuvre de ce système.
L'article seul
Un Raspberry Pi en fonctionnement permanent, ça tient ?
Première rédaction de cet article le 16 décembre 2014
Comme le savent mes lecteurs les plus attentifs (ceux et celles qui lisent tous les articles, et plusieurs fois, afin de les retenir), j'utilise un Raspberry Pi pour superviser les machines et services Internet auxquels je tiens. Après quelques mois, la machine a-t-elle tenue ? Quelle charge peut supporter le petit Raspberry Pi ?
Mon expérience avec la fiabilité du matériel est variable. Il y a clairement des problèmes avec les cartes SD. Souvent, le problème se manifeste dès le départ : certaines cartes ont tout le temps des problèmes (on redémarre, le système de fichiers est corrompu, on fait tourner fsck, il massacre tout). D'autres tiennent le coup longtemps (c'est le cas de celle qui est située dans le Raspberry Pi « de production »). Je n'ai pas trouvé de règles simples, du genre « telle marque est pourrie ». Je teste désormais les cartes avec deux ou trois démarrages sur un Pi, et je jette immédiatement celles qui ont une défaillance. Avec ce principe, j'ai nettement moins d'ennuis.
Parfois, le problème semble lié au Pi. J'en ai un qui est nettement plus pénible que les autres, et qui corrompt son système de fichiers, quelle que soit la carte SD utilisée.
Par contre, une fois éliminés les matériels défaillants, tout peut très bien marcher. Mon Pi de supervision est allumé 24 heures sur 24, sans alimentation électrique sécurisée (les coupures sont parfois violentes, par exemple quand on débranche le Pi pour brancher l'aspirateur...) et il tourne depuis plus de deux ans sans histoires. Voici ses records d'uptime :
% uprecords
# Uptime | System Boot up
----------------------------+---------------------------------------------------
1 74 days, 17:15:35 | Linux 3.12.20-1-ARCH Wed Jun 4 18:39:08 2014
-> 2 59 days, 05:25:39 | Linux 3.12.29-1-ARCH Sat Oct 18 16:14:03 2014
3 47 days, 16:41:18 | Linux 3.10.25-1-ARCH Sun Jan 5 23:05:17 2014
4 45 days, 20:48:04 | Linux 3.10.30-1-ARCH Sat Feb 22 15:47:14 2014
5 45 days, 06:08:27 | Linux 3.6.11-8-ARCH+ Thu Mar 14 14:02:38 2013
6 40 days, 20:29:03 | Linux 3.6.11-14-ARCH+ Mon Jul 22 21:46:41 2013
7 40 days, 07:29:16 | Linux 3.6.11-12-ARCH+ Wed Jun 12 14:17:05 2013
8 26 days, 23:52:42 | Linux 3.12.26-1-ARCH Thu Aug 21 14:35:08 2014
9 26 days, 18:26:10 | Linux 3.6.11-17-ARCH+ Mon Sep 23 20:18:13 2013
10 26 days, 14:52:31 | Linux 3.6.11-11-ARCH+ Thu May 16 23:23:45 2013
----------------------------+---------------------------------------------------
no1 in 15 days, 11:49:57 | at Thu Jan 1 08:29:37 2015
up 770 days, 00:12:50 | since Wed Oct 3 21:50:46 2012
down 33 days, 23:36:06 | since Wed Oct 3 21:50:46 2012
%up 95.773 | since Wed Oct 3 21:50:46 2012
Certes, il n'a jamais fonctionné six mois de suite, contrairement à d'autres machines Unix mais rappelez-vous qu'il est installé à la maison, pas dans un centre de données professionnel, et qu'il fait tourner Arch Linux, qui change le noyau Linux souvent, nécessitant un redémarrage.
Les services qui tournent dessus ? Icinga pour la surveillance et
Cacti pour les statistiques d'activité,
essentiellement. Cacti est très gourmand en ressources lorsqu'on
affiche les graphes mais, en fonctionnement normal, la charge est très
modérée (de l'ordre de 1, en moyenne), comme l'affiche xload : 
Il est vrai que le travail lié à une telle activité est
relativement faible. Icinga surveille 47 machines et 152 services. Les
programmes exécutés pour les tests sont en C,
Perl, Python, etc. Rien
d'extraordinaire pour une machine Unix mais cela illustre qu'un
Raspberry Pi a exactement les mêmes capacités qu'un « vrai »
ordinateur. Je me connecte souvent en SSH sur
cette machine, pour mesurer depuis mon réseau local, et la réactivité
du shell est parfaite.
Cacti affiche 6
machines, avec environ 4 graphes par machine. En bits/seconde, cela
fait : 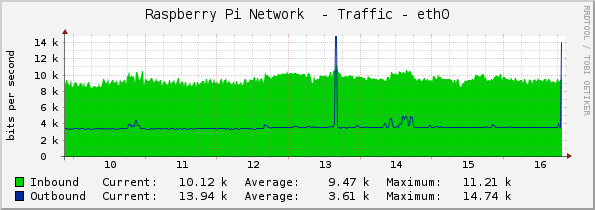 Et en paquets/seconde :
Et en paquets/seconde : 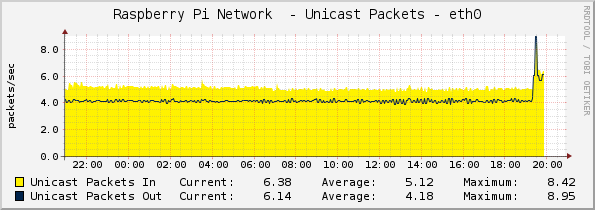
Et les entrées/sorties sur la carte SD ? Voici ce qu'affiche vmstat :
% vmstat 300 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 54976 28184 10432 50084 0 0 4 1 7 8 25 4 70 0 0 0 0 55056 33576 9892 49228 0 0 4 19 375 220 26 4 69 0 0 0 0 55168 45464 4304 43656 0 0 6 19 385 243 27 4 68 0 0
L'article seul
RFC 7418: An IRTF Primer for IETF Participants
Date de publication du RFC : Décembre 2014
Auteur(s) du RFC : S. Dawkins (Huawei)
Pour information
Première rédaction de cet article le 13 décembre 2014
Ce court RFC est une introduction à une entité peu connue du monde de l'Internet, l'IRTF, Internet Research Task Force. Tellement peu connue qu'elle n'a même pas de page dans le Wikipédia francophone, c'est dire. L'IRTF est censée travailler sur des projets à long terme (proches de la recherche), pendant que l'IETF travaille sur des sujets bien maîtrisés techniquement, et qu'on peut normaliser relativement rapidement. Cette introduction vise essentiellement les gens qui participent déjà à l'IETF et se demandent si leur prochain projet ne serait pas plus adapté à l'IRTF.
Disons-le franchement tout de suite, l'IRTF n'est pas toujours le truc le plus intéressant dans la vaste galaxie des entités dont le nom commence par un I. La plus grande partie de la recherche concernant l'Internet n'est pas faite là. L'IRTF, très peu connue, et vivant dans l'ombre de l'IETF, n'a pas une activité débordante.
Un des problèmes de l'IRTF, et auquel ce RFC voudrait remédier, est que beaucoup de participants potentiels à l'IRTF croient acquis que ses pratiques sont les mêmes qu'à l'IETF. Ils présentent leurs idées d'une manière qui serait appropriée à l'IETF mais qui ne marche pas pour l'IRTF. D'abord, il faut comprendre la différence entre recherche et ingéniérie. Deux citations l'illustrent, une de Fred Baker qui estime que « le résultat de la recherche, c'est la compréhension, le résultat de l'ingéniérie, c'est un produit ». Et la seconde, de Dave Clark, affirme que « si ça doit marcher à la fin du projet, ce n'est pas de la recherche, c'est de l'ingéniérie ». Le RFC résume en disant que « la recherche, c'est un voyage, l'ingéniérie, c'est une destination ». Un chercheur qui ouvre plus de questions qu'il n'en a fermé dans sa recherche peut être satisfait. Un ingénieur qui ne termine pas ne l'est pas.
Cela entraine des différences entre l'organisation de l'IETF et celle de l'IRTF (section 2 du RFC). Par exemple, les unités de base de l'IETF, les groupes de travail, sont très focalisés, avec une charte précise, des buts à atteindre, et un calendrier. Les unités de base de l'IRTF, les groupes de recherche, sont au contraire larges, traitant plusieurs sujets assez différents en même temps, et avec une charte bien plus large.
De même, les délais ne sont pas les mêmes. L'IRTF, travaillant sur des problèmes difficiles, voit typiquement à trois ou cinq ans, alors que les calendriers (très théoriques...) des groupes de travail IETF visent des échéances plus courtes.
Autre différence, alors que l'IETF est supposé arriver à un consensus (approximatif) entre les membres du groupe de travail (RFC 7282), l'IRTF n'a pas de telles obligations et peut parfaitement, par exemple, suivre plusieurs lièvres à la fois.
L'IRTF n'est pas non plus obligée de suivre les politiques de l'IETF relatives aux brevets (RFC 8179).
Et sur le résultat du groupe de recherche ? En quoi doit-il consister ? Un groupe de travail IETF produit des RFC, c'est son but. Mais un groupe de recherche IRTF ne le fait pas forcément. Il peut aussi publier par d'autres moyens (rapports, articles académiques...), voire se contenter d'Internet-Drafts qui ne deviendront pas de RFC. Le critère du succès, pour un groupe IRTF, c'est de faire avancer la science, pas de faire des RFC.
Maintenant que la section 2 a surtout expliqué ce que l'IRTF n'est pas, la section 3 donne des conseils sur ce qu'il faut faire quand on veut travailler à l'IRTF. L'actuel président de l'IRTF, Lars Eggert, le résume en disant « comportez-vous comme un groupe de recherche IRTF pendant un an, et on verra bien si vous en êtes un ». Et comment est un groupe de recherches IRTF ? Le RFC 4440 donne quelques pistes, purement indicatives :
- Rassemblez des chercheurs, en nombre suffisant, qui veulent travailler sur ce sujet,
- Analysez bien ce qui se fait ailleurs, en vous demandant ce que le futur groupe de recherche IRTF apporterait, par rapport à ces activités externes,
- Organisez un premier atelier pour voir ce que cela donne,
- Si vous estimez que cette recherche peut déboucher sur des techniques normalisables, trouvez quelques ingénieurs pour jeter un coup d'œil et voir si c'est faisable.
Si vous vous intéressez plutôt aux règles et procédures de fonctionnement de l'IRTF, plutôt qu'à la vision « haut niveau » exposée ici, voyez le RFC 2014. Si vous voulez lire mes articles sur des RFC issus de l'IRTF, demandez au moteur de recherche.
L'article seul
RFC 7397: Report from the Smart Object Security Workshop
Date de publication du RFC : Décembre 2014
Auteur(s) du RFC : J. Gilger, H. Tschofenig
Pour information
Première rédaction de cet article le 13 décembre 2014
Le 23 mars 2012, à Paris, a eu lieu un atelier sur la sécurité des objets « intelligents ». Ce RFC résume (bien après...) ce qui s'est dit pendant cet atelier.
Cela fait plusieurs années que les organisations de la galaxie IETF travaillent sur la question de l'« Internet des Objets », son architecture, sa sécurité, etc. Ainsi, en 2011, l'IAB avait fait un atelier à Prague sur ce sujet, dont le RFC 6574 avait donné un compte-rendu. Plusieurs groupes de travail de l'IETF se sont attelés à des tâches liées à l'Internet des Objets, c'est le cas par exemple de LWIG (qui a produit le RFC 7228). L'atelier du 23 mars 2012 à Paris était plus ciblé, ne concernant que la sécurité. (« Smart Object Security » fait « SOS », au fait...)
Trente-six articles avaient été acceptés pour cet atelier, répartis en quatre catégories, « Exigences de sécurité et scénarios », « Expériences de mise en œuvre », « Autorisation » et « Fourniture des informations de créance ».
La première catégorie, « Exigences de sécurité et scénarios », découle de l'obligation de mettre, dans les RFC, une section « Security considerations » (RFC 3552 et RFC 4101), analysant les problèmes éventuels de sécurité de la technologie décrite. Mais l'idée est de généraliser cette préoccupation à un écosystème plus large, au lieu d'avoir le nez sur chaque protocole indépendamment. Quelques exemples de questions posées dans cette catégorie :
- Quels sont les acteurs impliqués ? Dans le cas des compteurs intelligents, par exemple, cela fait beaucoup de monde, c'est un écosystème complexe (cf. RFC 6272).
- Qui fait l'avitaillement en informations de créance (credentials) ? Le fabricant des objets ? L'utilisateur ?
- À ce sujet, justement, qu'attend-on de l'utilisateur final ? Entrer un PIN à la première utilisation ? Appuyer sur deux boutons simultanément pour appairer deux objets ? Se connecter à l'objet via un navigateur Web pour le configurer ? Le problème est d'autant plus aigu que la sécurité trébuche en général sur les problèmes liés aux utilisateurs.
Ainsi, à l'atelier, Paul Chilton avait (cf. son article) parlé de l'éclairage : les coûts d'une ampoule sont réduits et on ne peut pas doter chaque interrupteur d'un processeur 32 bits avec puce crypto ! À bien des égards, l'éclairage représente le cas idéal pour évaluer les solutions de sécurité : si une solution est réaliste dans le cas de l'éclairage, elle le sera pour beaucoup de cas d'objets connectés. (Et cela permettra de faire des blagues sur le thème « Combien d'experts en sécurité faut-il pour changer une ampoule ? »)
Rudolf van der Berg avait, lui, parlé d'objets plus complexes, capables d'utiliser une SIM et donc d'être authentifiés par ce biais. Pour le cas où on n'utilise pas un réseau d'opéateur mobile mais, par exemple, le WiFi, on peut utiliser l'EAP-SIM du RFC 4186.
Un problème récurrent des réseaux d'objets « intelligents » est celui de l'interface utilisateur. Où va t-on taper le mot de passe, dans une ampoule ou un interrupteur ? Pour l'authentification via une SIM, on peut tout sous-traiter à l'opérateur mais, si on change d'opérateur, comment reconfigurer les SIM ?
Pour le marché grand public, on sacrifiera probablement la sécurité, pour éviter de compliquer la tâche de l'utilisateur. On n'a donc pas fini de voir des photos nues des utilisateurs, prises par leur réfrigérateur et volées ensuite par un pirate. (Après tout, tout le monde se fiche de la sécurité de M. Michu, surtout si elle diminue les ventes d'objets jugés trop complexes par le consommateur. Quelques affirmations fortes « nos objets sont sécurisés et cryptés », sous la plume du service Communication, suffiront.) Pour les déploiements d'objets en entreprise, par exemple dans une usine ou un entrepôt, les exigences de sécurité seront sans doute plus fortes, ainsi que la possibilité d'avoir du personnel formé.
Actuellement, on l'a vu, la sécurité de ces objets est faible. Il
est très fréquent que, lorsqu'ils sont protégés par un mot
de passe, ce mot de passe soit défini en usine, et identique
pour tous les objets d'un même modèle. La grande majorité des
utilisateurs ne changeant pas les mots de passe (d'autant plus que
cela peut être difficile à faire), le pirate n'aura qu'à essayer le
mot de passe usine pour craquer la majorité des objets. (Souvenir
personnel : en 1986, les
VAX/VMS de Digital, engins horriblement coûteux, étaient vendus avec un mot
de passe du compte d'administration, SYSTEM,
identique pour tous les systèmes - c'était
manager. Mais ils étaient gérés par des
professionnels qui, en général, savaient qu'il fallait changer
immédiatement les mots de passe. Ce qui ne veut pas dire que tout le
monde le faisait... Le RFC note que beaucoup d'images logicielles pour
les Raspberry Pi ont la même faiblesse. Bien
des Pi sont sans doute vulnérables...) Globalement, la sécurité des objets est restée à
un stade pré-Internet. Tant qu'on ne les connecte pas, ça va à peu
près.
Enfin, en analysant la sécurité des objets connectés, il ne faut pas prendre en compte seulement la sécurité d'une maison ou d'une usine mais aussi les risques plus globaux. Si tout le monde a des compteurs électriques intelligents vulnérables, un attaquant peut couper le courant chez M. Michu et M. Michu, réduit à la bougie, est alors bien embêté. Mais, si l'exploitation de la faille peut être automatisée et faite depuis l'Internet, on peut envisager des scénarios où l'attaquant couperait une ville entière (style Watch Dogs).
Les solutions ne manquent pas, bien sûr, mais elles se heurtent souvent à des problèmes concrets. Si on trouve une faille logicielle dans tous les compteurs intelligents, peut-on les mettre à jour automatiquement et à distance (cf. section 4 du RFC pour les recommandations sur ce point) ? Et cette possibilité de mise à jour ne peut-elle pas être elle-même un vecteur d'attaque ? Un objet non intelligent peut être vendu ou donné à un nouveau propriétaire. Est-ce que ce sera toujours le cas s'il est sécurisé (mot de passe changé, oublié et non resettable) ? La solution de sécurité sera-t-elle ouverte ou bien verrouillera-t-elle l'utilisateur auprès d'un fournisseur unique ? Outre les coûts du matériel pour mettre en œuvre la solution de sécurité, y aura-t-il des coûts de licence, par exemple à cause de brevets ? La sécurité ne travaille pas en isolation, elle doit tenir compte de ce genre de questions.
La deuxième catégorie, trois retours d'expérience, portait sur des points comme les résultats de la mise en œuvre de CoAP. À chaque fois, la conclusion était que le déploiement de solutions de sécurité dans des objets très contraints en ressources était faisable. Souvent, cela nécessitait une adaptation, en laissant tomber des options qui auraient été trop coûteuses. La plupart des protocoles IETF permettent cette adaptation (par exemple, pour TLS, il n'est pas nécessaire de gérer tous les algorithmes de cryptographie du monde). Les développeurs ne signalent pas de cas de protocoles IETF impossibles à ajuster aux exigences des objets connectés. L'idée de concevoir des protocoles de sécurité spécialement faits pour les objets connectés n'a pas eu beaucoup de succès : il n'y a pas de raison de croire que ces protocoles, une fois toutes les fonctions souhaitées mises en œuvre, soient moins gourmands. Mohit Sethi a remarqué que, par exemple, les opérations cryptographiques nécessaires sont à la portée d'un Arduino UNO. En fait, si on veut faire des économies, ce n'est pas la cryptographie, même asymétrique, qu'il faut viser en premier mais plutôt la transmission de données : émettre des ondes radio vide la batterie très vite.
Est-ce que la loi de Moore va aider ? Non. Comme déjà noté dans le RFC 6574, les développeurs sont d'avis que cette loi sera utilisée pour baisser les prix, pas pour augmenter les capacités des objets.
Troisième catégorie, les histoires d'autorisation. Richard Barnes a expliqué que le modèle de sécurité dominant, authentifier une entité puis lui donner tous les droits, était particulièrement peu adapté aux objets communiquants, et il propose d'utiliser plutôt des capacités, comme le permet OAuth (RFC 6749). Cela donne une meilleure granularité aux autorisations.
Enfin, la quatrième et dernière catégorie est celle de la création et de la distribution aux objets des informations de créance. Prenons un nouvel objet qui arrive dans un réseau. Il va falloir qu'il connaisse l'information par laquelle il va être accepté par les autres membres du réseau. Faut-il la mettre dans l'objet à sa fabrication ? En tout cas, la faire rentrer par l'utilisateur de l'objet n'est pas une perspective bien tentante : ces objets ont des interfaces utilisateur très limitées, vraiment pas idéales pour, par exemple, rentrer une longue phrase de passe.
Johannes Gilger (cf. son article) a fait le tour des solutions d'appairage, qui permettent d'introduire deux objets l'un à l'autre, de manière à ce qu'ils ne communiquent qu'entre eux après. Par exemple, un humain se tient à côté des deux objets, qui affichent tous les deux un code numérique, et l'humain vérifie que ces codes coïncident.
Cullen Jennings proposait de faire appel à un tiers : l'objet contacte un serveur qui va faire l'enrôlement dans le réseau (mais le RFC oublie de mentionner les graves problèmes de vie privée que cela pose).
La fin de la section 4 de notre RFC résume quelques groupes de travail IETF qui sont impliqués dans la solution des problèmes qui avaient été identifiés dans cet atelier : LWIG (conseil aux implémenteurs de TCP/IP sur des objets limités), DICE (adapter DTLS à ces objets limités), ACE (authentification et autorisation chez les objets connectés), etc.
Une liste complète des papiers présentés figure dans l'annexe C du RFC. Comme l'indique l'annexe B du RFC, les articles présentés pour l'atelier sont tous en ligne (avec une copie ici). Pour la minorité des orateurs qui ont utilisé des supports de présentation, ceux-ci sont également en ligne.
L'article seul
Introduction à IPv6 à Lolut/UTBM
Première rédaction de cet article le 12 décembre 2014
Dernière mise à jour le 13 décembre 2014
Le 11 décembre à l'UTBM à Belfort, j'ai eu le plaisir d'être invité par l'association libriste Lolut à parler d'IPv6. L'idée était une introduction à cette technique, avec notamment les aspects « stratégiques » (pourquoi IPv6 n'est-il pas plus déployé ? Quels sont vraiment les obstacles ?)
Le public de cette conférence était composée d'environ 50 personnes, en majorité d'étudiants en informatique de l'UTBM. C'était donc très mâle. (Mais merci à l'étudiante assez courageuse pour avoir posé des questions sur des sujets qu'elle ne comprenait pas, alors que d'autres ne comprenaient pas plus mais n'osaient pas demander.)
Voici les supports de cet exposé :
- Version adaptée à la vue sur écran,
- Version adaptée à l'impression,
- Version source.
La vidéo est disponible chez Lolut (tout en bas de la page). Vous trouverez au même endroit un récit détaillé de la conférence et des difficultés à la diffuser en temps réel :-)
Et merci à Jérome Boursier pour l'idée, l'organisation et
l'accueil. 
L'article seul
RFC 7410: A Property Types Registry for the Authentication-Results Header Field
Date de publication du RFC : Novembre 2014
Auteur(s) du RFC : M. Kucherawy
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF appsawg
Première rédaction de cet article le 5 décembre 2014
Le RFC 7001 avait créé l'en-tête de courrier
Authentication-Results: qui permettait de
signaler à un logiciel de courrier les résultats de tests
d'authenticité faits par un serveur. Cet en-tête pouvait inclure un
type de propriété (property type ou ptype) qui
indiquait d'où venait la propriété testée : la session
SMTP, l'en-tête du message, son corps, ou bien
une politique locale. Le jeu de valeurs pour les types possibles était
fixe et, depuis, certains ont trouvé ce jeu trop restreint. Ce nouveau
et très court
RFC remplace donc la liste fixe du RFC 7001 par un registre en
ligne à l'IANA. (Depuis, le RFC 7601, a
remplacé ces deux RFC.)
Le principe de base du RFC 7001 est de séparer l'exécution des tests d'authenticité de l'utilisation de leurs résultats. Par exemple, les tests sont effectués sur un serveur de messagerie de l'organisation, et leur utilisation est décidée sur le poste de travail de l'utilisateur. Voici un exemple de résultat transmis au logiciel, utilisant les types de propriétés :
Authentication-Results: example.com;
spf=pass smtp.mailfrom=example.net
^^^^^^^^^^^^^
Type et propriété
Ici, le test SPF a été fait lors de la session
SMTP (le type est smtp et
il est suivi d'un point et de la commande SMTP - la propriété -
testée). Autre exemple :
Authentication-Results: example.com;
dkim=fail reason="bad signature"
header.i=@newyork.example.com
^^^^^^^^
Type et propriété
Ici, le test était du DKIM, le type était
l'en-tête du message (header) et la propriété le
champ i de la signature DKIM (notez que le RFC 7001 dit que la propriété après
header doit être un en-tête du message, ce qui
n'est pas le cas ici, mais c'est un exemple officiel, je n'y peux
rien, voir la bogue
du RFC 7001).
Dans ces deux exemples, on a vu les types de propriétés
smtp et header. Deux autres
sont définis par le RFC 7001, section 2.2,
body et policy. Cette liste
était fixe et c'est ce point que change notre nouveau RFC.
Désormais, le type de propriété peut être n'importe quel mot-clé enregistré à l'IANA. Ce registre démarre avec les quatre types du RFC 7001. L'enregistrement d'une nouvelle valeur se fait selon la procédure « Examen par un expert » du RFC 5226.
Il est recommandé d'ignorer les types de propriété inconnus (ceux qui viennent d'être enregistrés et ne sont pas encore connus du logiciel). Autrement, déployer un nouveau type serait quasi-impossible.
Comme indiqué plus haut, ce RFC a été fusionné avec le RFC 7001 pour donner le texte qu'il faut consulter aujourd'hui, le RFC 7601.
L'article seul
Nommer les différentes parties d'un nom de domaine
Première rédaction de cet article le 30 novembre 2014
Je vois souvent des explications sur le système des noms de domaine qui tentent de
donner des noms aux différentes parties d'un nom. Par exemple, pour
www.example.com, on voit parfois des explications
du genre « www est un sous-domaine,
example est le nom de domaine et
com est l'extension ». Ces explications sont
toutes fausses et je vais essayer d'expliquer pourquoi.
En prime, je vais essayer de ne pas parler du DNS, juste de rester à la partie visible de tout le monde, le nom. Donc, normalement, cet article est accessible à tous.
Depuis qu'on les trouve sur les côtés des autobus et sur les
paquets de lessive, tout le monde sait ce qu'est un nom de
domaine. Tout le monde sait que amazon.com ou
potamochère.fr sont des noms de domaine. Tout le
monde sait également qu'ils sont hiérarchiques : on a un nom plus
général en dernier (à droite quand on écrit en français) et plus
spécifique en premier (à gauche). Mais cela ne suffit pas
à l'être humain : ce dernier veut absolument des explications
supplémentaires et c'est là que les choses se gâtent, et qu'on trouve
dans les médias et les forums du n'importe quoi. Rectifions donc le
tir : signal.eu.org,
www.bortzmeyer.org,
www.phy.cam.ac.uk,
impots.gouv.fr, af, 亨氏宝宝.中国,
b14-sigbermes.apps.paris.fr, яндекс.рф,
pizza ou
_xmpp-server._tcp.jabber.lqdn.fr sont
tous des noms de domaine (même si tous ne sont
pas promus sur les paquets de lessive...). Le fait qu'ils aient un
nombre différent de composants (la partie entre
les points) ne change rien. Beaucoup de gens croient qu'un nom de
domaine comporte forcément deux (ou trois, selon les sources)
composants mais c'est tout à fait faux. (On trouve cette erreur, par
exemple, dans le Wikipédia
francophone.) Le nombre de composants
(labels, en anglais) est
quelconque. (Au passage, le terme technique pour ce nom complet est
FQDN pour Fully Qualified Domain
Name.)
On entend parfois le terme de « sous-domaine ». Malheureusement,
il est souvent utilisé en supposant qu'il y a des domaines qui sont
des sous-domaines et d'autres qui seraient des « vrais »
domaines. Mais ce n'est pas le cas. Tous les domaines sont des
sous-domaines d'un autre (à part le cas particulier de la racine, le
début des domaines). Ainsi, signal.eu.org est un
sous-domaine de eu.org, lui-même un sous-domaine
de org, lui-même sous-domaine de la racine.
Souvent, les gens sont intéressés par le domaine
enregistré, le nom de domaine qui a été
loué auprès d'un registre de noms de
domaine, le nom pour lequel on a acquis un droit d'usage
(droit qui inclut la possibilité de créer des noms plus spécifiques). Par exemple, dans
www.toyota.co.jp, le nom qui a été enregistré (à
JPNIC) était
toyota.co.jp. Certains croient que le nom
enregistré est composé des deux derniers composants mais c'est inexact
(voyez l'exemple japonais plus haut). Une autre légende est
qu'on ne peut créer des noms que sous un domaine d'enregistrement à un
seul composant
comme fr ou com mais non :
tout titulaire d'un nom peut créer des noms sous ce nom. Si je suis
titulaire de example.com, je peux créer, mettons compta.paris.example.com.
Comment connaître le domaine enregistré, dans un nom comme
www.paca.drjscs.gouv.fr ? Rien ne l'indique dans
le nom, il n'y a pas de syntaxe particulière. Il faut donc connaître
les règles d'enregistrement utilisées (ici, il faut savoir que
gouv.fr est un domaine d'enregistrement). Le domaine d'enregistrement est également parfois nommé « suffixe
public » (et Mozilla publie une liste - très
incomplète - de ces domaines : on voit qu'elle ne comporte pas
que des noms d'un seul composant). L'avantage du terme « suffixe » est
qu'il ne présuppose pas un nombre donné de composants. Puisque
« suffixe » décrit raisonnablement bien une réalité, on pourrait (bien
que ce soit très rare en pratique) utiliser « préfixe » pour, par exemple,
la partie avant le domaine d'enregistrement.
Un autre terme utilisé, et qui recouvre parfois une réalité
importante, par exemple pour déterminer la loi nationale applicable en
cas de conflit, est TLD (Top-Level
Domain) qui désigne le composant le plus général (le
dernier, le plus à
droite). fr,
net et
pizza sont
tous les trois des TLD. (On note parfois le TLD avec un point devant,
pour bien montrer que c'est un nom de domaine.) Formé de la même
façon, on rencontre parfois le sigle SLD, pour Second-Level
Domain comme gouv.fr ou ovh.com.
On voit parfois le terme d'« extension » être utilisé, mais sans qu'il soit jamais défini. Parfois, c'est un synonyme de TLD (mais en moins clair, car on peut confondre avec l'extension du nom de fichier), parfois un synonyme de domaine d'enregistrement. Un terme aussi flou est donc à fuir. Si on ne veut pas utiliser de sigle pour les TLD, on peut dire, comme au Québec, « domaine de tête ».
Ah, et une dernière remarque :
https://www.laquadrature.net/fr/TAFTA n'est pas
un nom de domaine mais un URL (une adresse
Web). Il comprend un nom de domaine
(www.laquadrature.net) mais pas seulement.
L'article seul
RFC 7404: Using Only Link-Local Addressing Inside an IPv6 Network
Date de publication du RFC : Novembre 2014
Auteur(s) du RFC : M. Behringer, E. Vyncke (Cisco)
Pour information
Réalisé dans le cadre du groupe de travail IETF opsec
Première rédaction de cet article le 19 novembre 2014
L'utilisation du protocole IPv6 fait que chaque machine a une adresse dite « locale au lien » (link-local) qui n'est pas unique mondialement mais seulement unique sur le lien. Est-ce qu'on peut se contenter de ces adresses, et, par exemple, configurer ses routeurs pour les utiliser ? Ce RFC discute les avantages et les inconvénients. (Attention, le sujet est brûlant à l'IETF.)
Imaginons deux routeurs connectés et qui échangent des routes, via un protocole de routage. On les a configurés avec l'adresse du voisin. Cette adresse peut être une adresse « normale », mondialement unique. Mais elle peut aussi être locale au lien et cela présente quelques avantages. Par exemple, les adresses des routeurs ne sont pas présentes dans la table de routage (car elles n'ont de signification que locale), rendant ces tables plus petites. Et le routeur est plus dur à attaquer, puisqu'il faut être sur le lien pour lui parler. Par contre, cela peut rendre des outils de tests habituels comme ping ou traceroute difficiles ou impossibles à utiliser.
L'un dans l'autre, l'IETF ne tranche pas : cette possibilité marche, elle est documentée dans ce RFC mais chacun doit ensuite décider s'il va l'utiliser ou pas. Comme le dit le RFC avec un sens aigu du lavage de mains « The deployment of this technique is appropriate where it is found to be necessary ».
La section 2 forme le gros de ce RFC : exposer l'approche, ses
avantages, et ses risques. Les adresses locales au lien sont désignées
par le sigle LLA (link-local addresses). Voici un
exemple sur une machine Linux (les LLA
sont dans le préfixe fe80::/10) :
% ip -6 addr show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qlen 1000
inet6 fe80::ba27:ebff:feba:9094/64 scope link
valid_lft forever preferred_lft forever
Le principe de base de leur utilisation est que, lorsqu'une machine n'a pas besoin de parler au monde extérieur sur cette adresse (ce qui est typiquement le cas d'un routeur), on peut ne mettre qu'une LLA sur une interface.
Attention, ce n'est vrai que pour une interface. Pas question de n'avoir que des LLA sur l'ensemble du routeur car celui-ci doit pouvoir émettre des paquets ICMP du genre Message too big ou bien Time exceeded. Il faut donc qu'au moins une interface du routeur ait une adresse globale, qui sera utilisée comme adresse source lors de l'émission de ces paquets ICMP (cf. RFC 6724). Cette adresse devra être routée, pour éviter tout filtrage en raison du RFC 3704. Dans le monde des routeurs, on appelle cela en général une loopback interface mais attention, c'est un sens différent de celui du mot loopback sur les machines Unix ordinaires. (Au fait, si quelqu'un sait comment modifier l’interface source des erreurs ICMP sur IOS... Ça existe en NX-OS, mais c'est introuvable en IOS et IOS-XE.)
Les protocoles de routage (OSPF, BGP, RIPng) fonctionnent déjà avec des LLA naturellement, ou peuvent être configurés pour le faire (pour BGP, Francis Dupont me souffle qu'il faut faire attention au RFC 2545, qui n'est pas cité). La découverte des voisins par NDP se fait toujours avec des LLA donc n'est pas affectée. Pour les protocoles de gestion du routeur, comme SSH ou SNMP (le RFC s'amuse aussi à citer Telnet...) devront, eux, utiliser l'adresse globale mentionnée plus haut.
Ah, et, évidemment, le gros du trafic du routeur, ce ne sont pas les protocoles de routage ou de gestion du routeur, c'est le trafic des autres, qu'il transmet. Ce dernier a des adresses source et destination qui ne sont pas celles du routeur et, donc, l'utilisation par ce dernier de LLA ou pas ne change rien. Bref, ça devrait marcher. Mais quels sont les avantages à une configuration uniquement avec des LLA ?
D'abord, comme indiqué plus haut, les tables de routage sont plus petites, puisqu'on n'y met pas les LLA, seulement les adresses globales, moins nombreuses (une seule par routeur, dans le cas le plus économe). Ensuite, on simplifie le plan d'adressage : pas besoin d'attribuer des préfixes aux liens entre routeurs. On a également moins de complexité dans la configuration, les LLA étant attribuées automatiquement. Et on a moins de configuration DNS à maintenir, puisqu'on ne met pas les LLA dans le DNS (évidemment, on n'est pas forcé d'y mettre les adresses globales non plus).
Surtout, on réduit les possibilités d'attaque puisque l'envoi de paquets au routeur, depuis l'extérieur du lien, ne pourra se faire que via l'adresse globale (par exemple pour les attaques du RFC 4987). Il n'y aura donc que celle-ci à protéger (par exemple via des ACL).
Le monde où nous vivons n'étant pas un monde idéal, depuis
l'expulsion hors du jardin d'Éden, il y a aussi
des problèmes associés aux LLA. On peut encore pinguer une interface spécifique depuis le
lien (ping $lla%$if-name) mais plus depuis un autre
réseau. Le débogage peut donc devenir plus difficile. (Notez que,
contrairement à ce qu'on lit souvent dans les articles sur
TCP/IP, lorsqu'on pingue une adresse IP associée à une
interface, une réponse positive ne garantit pas du tout qu'on est
passé par cette interface.) Bien sûr, on peut toujours pinguer
l'adresse globale du routeur depuis n'importe où, mais cela fournit
moins d'informations. Pour déterminer si une interface marche ou pas,
il faudra donc utiliser d'autres méthodes par exemple en se loguant
sur le routeur et en examinant l'état des interfaces. (Notez que, là
encore, en dépit des légendes, avec certains systèmes d'exploitation,
on peut pinguer avec succès une adresse IP associée à cette interface
même lorsque cette interface est débranchée.) Le RFC 5837, lorsqu'il est
mis en œuvre, peut aider au débogage, en mettant de l'information sur l'interface
dans la réponse ICMP.
Même problème, évidemment, avec traceroute. Non seulement on ne peut pas tracerouter vers une interface spécifique, mais le paquet ICMP de réponse viendra de l'adresse IP globale et ne nous renseignera donc pas sur l'interface précise qui l'a émis (sauf si le routeur utilise le RFC 5837 et si le traceroute utilisé exploite cette option). Notez que cela peut être vu comme un avantage : tous les traceroutes passant par ce routeur verront la même adresse de réponse, aidant à repérer le routeur (alors que, autrement, il aurait fallu corréler les différentes adresses, par exemple via les enregistrements PTR associés, ce qui dépend d'heuristiques peu fiables).
Et, bien sûr, cela concerne aussi les systèmes de gestion de réseau : si un gérant SNMP, par exemple, veut parler à un routeur, il devra probablement utiliser son adresse globale.
Autre problème, les adresses LLA automatiquement attribuées vont
dépendre du matériel, puisqu'elles seront en général dérivées de
l'adresse MAC (via EUI-64). Si on change une carte
Ethernet du routeur, on change de LLA, ce qui
peut nécessiter une reconfiguration manuelle si ces LLA étaient
utilisées statiquement, par exemple dans une configuration
BGP. (Matthieu
Herrb me fait remarquer qu'on peut parfaitement créer des LLA
statiques, genre fe80::31, ce que mentionne
d'ailleurs le RFC.) Pendant qu'on est aux configurations
statiques, il faut aussi rappeler que les LLA sont moins pratiques à
manier puisqu'elles n'ont pas de signification globale. Il faut donc
toujours indiquer le lien utilisé. Par exemple, une configuration BGP
sera bgp neighbor fe80::21e:8cff:fe76:29b6%eth2 (le
%eth2 indiquant l'interface réseau, cf. RFC 4007).
Un cas particulier est celui des points d'échange. Ils connectent beaucoup de monde et représentent une part significative du trafic Internet. Une attaque ou une panne peut sérieusement perturber le trafic. Le préfixe d'adresses IP qui est utilisé pour numéroter les routeurs sur le LAN du point d'échange est donc sensible. Pour réduire les risques, on peut soit ne pas le publier dans la table de routage globale, soit filtrer le trafic entrant vers ce préfixe. Dans le premier cas, les paquets émis depuis l'interface du routeur avec le point d'échange, ayant une adresse source non routée, seront jetés par les réseaux qui font des tests uRPF. Cela perturbe traceroute, mais, surtout la découverte de la MTU du chemin, ce qui est inacceptable. La deuxième méthode ne marche que si tous les opérateurs connectés au point d'échange la mettent en œuvre, ce qui est peu vraisemblable.
Une meilleure solution serait donc de numéroter les routeurs au point d'échange avec des LLA. Chaque routeur aurait toujours son adresse globale, prise dans l'espace d'adressage de l'opérateur propriétaire, mais une attaque globale contre tout le point d'échange serait plus difficile. Par contre, cela pourrait poser des problèmes avec certaines méthodes d'ingénierie du trafic, si l'opérateur veut transporter le préfixe du point d'échange dans son IGP. Ces opérateurs devront trouver une autre méthode.
En synthèse, la conclusion de notre RFC est que l'utilisation des LLA a des avantages et des inconvénients, et que chaque acteur doit faire son évaluation, le RFC ne recommandant spécialement aucune des deux méthodes. Cette conclusion a été chaudement discutée à l'IETF, ceux qui pensaient que les LLA étaient une mauvaise idée n'ayant pas envie que cette utilisation soit documentée, craignant que cela n'apparaisse comme une approbation.
L'article seul
RFC 7286: ALTO Server Discovery
Date de publication du RFC : Novembre 2014
Auteur(s) du RFC : S. Kiesel (University of Stuttgart), M. Stiemerling (NEC Europe), N. Schwan (Stuttgart, Germany), M. Scharf (Alcatel-Lucent Bell Labs), H. Song (Huawei)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF alto
Première rédaction de cet article le 14 novembre 2014
Le protocole ALTO (Application-Layer Traffic Optimization), normalisé dans le RFC 7285, permet à une machine qui communique avec des pairs, de déterminer quel pair utiliser lorsqu'ils fournissent le même service (par exemple, dans un système de partage de fichiers pair-à-pair, lorsque les membres d'un même essaim ont le fichier convoité). La machine, un client ALTO, demande à un serveur ALTO quel est le « meilleur » pair, optimisant ainsi son utilisation du réseau. Oui, mais comment est-ce que le client trouve le serveur à utiliser ?
Le RFC 6708, le cahier des charges d'ALTO, disait dans son exigence AR-32 qu'il fallait un mécanisme pour trouver le serveur. ALTO reposant sur HTTP, trouver un serveur, c'est trouver l'URI qui le désigne. Le protocole de découverte va partir d'un nom de domaine (obtenu, par exemple, via DHCP, ou bien via une configuration manuelle), faire une requête DNS sur ce nom, en demandant le type U-NAPTR (RFC 4848, mais ne paniquez pas, j'explique le U-NAPTR plus loin). La réponse sera l'URI désiré.
Donc, première étape (section 3.1), récupérer le nom de
domaine. Pour la machine typique de M. Michu, cela se fait en
DHCP, le serveur DHCP donnant, parmi d'autres
informations, le nom de domaine de référence du réseau local (options
DHCP 213 - OPTION_V4_ACCESS_DOMAIN - et 57 -
OPTION_V6_ACCESS_DOMAIN - de la section
3 du RFC 5986, ou bien, si elle n'est pas
présente, et en IPv4 seulement, l'option 15 de la section 3.17 du RFC 2132). Le nom
sera alors celui du FAI ou celui de
l'organisation où M. Michu se connecte. Mais le RFC demande aussi que
les mises en œuvre de la découverte de serveurs ALTO puisse aussi se
faire à partir d'un nom de domaine rentré manuellement par
l'utilisateur. Cela permet, par exemple, de traiter le cas où un
utilisateur n'a pas confiance dans le serveur ALTO de son FAI et
souhaite utiliser le serveur ALTO d'une organisation tierce. (Tiens,
peut-être verrons-nous apparaître un Google Alto ?)
Une fois qu'on a le nom de domaine, on passe à la deuxième étape de
la procédure de découverte du serveur (section 3.2). Pour cela, on va demander un
enregistrement de type U-NAPTR. Ce type de données, normalisé dans le
RFC 4848, est très complexe. Disons simplement
qu'il permet de découvrir des services en
utilisant un enregistrement DNS qui comprend une étiquette de service,
et une expression rationnelle de remplacement dont le résultat
sera l'URI recherché (la procédure de découverte de serveur d'ALTO
simplifie les choses en n'utilisant pas la partie gauche de
l'expression, seulement le résultat). Les U-NAPTR sont plus riches que
les S-NAPTR du RFC 3958 mais moins que les NAPTR
originels (RFC 3403). À noter que la différence
entre NAPTR, S-NAPTR et U-NAPTR ne se voit pas dans le DNS : tous
utilisent le même type, NAPTR. Voici un exemple d'un enregistrement
DNS pour la découverte du serveur ALTO de
example.net :
example.net. IN NAPTR 100 10 "u" "ALTO:https" "!.*!https://alto1.example.net/ird!" ""
L'étiquette de service est ALTO:https (désormais
enregistrée à l'IANA). En
filtrant sur cette étiquette, on pourra récupérer uniquement les
enregistrements ALTO. Ici, l'URI de résultat sera https://alto1.example.net/ird.
Il peut y avoir plusieurs NAPTR, pour fournir des serveurs alternatifs, et on pourrait donc avoir :
example.net. IN NAPTR 100 10 "u" "ALTO:https" "!.*!https://alto1.example.net/ird!" ""
IN NAPTR 100 20 "u" "ALTO:https" "!.*!https://alto2.example.net/ird!" ""
Dans ce cas, le champ « Préférence » du second serveur (le second URI, plutôt) étant plus élevé, il ne sera choisi que si le premier ne répond pas (oui, une préférence plus élevée veut dire qu'on sera moins considéré, comme pour les enregistrements MX).
Au fait, pourquoi un U-NAPTR et pas un simple S-NAPTR (puisqu'on ne se sert pas de la partie gauche de l'expression rationnelle) ? Parce que les S-NAPTR ne fournissent comme résultat qu'un couple {serveur, port}, pas un URI comme le protocole ALTO en a besoin.
En pratique, quelles questions posera le déploiement de cette
procédure (section 4) ? Elle dépend d'une bonne réception du nom de
domaine. Les options du RFC 5986 ne sont pas
forcément gérées par tous les serveurs DHCP. Ensuite, dans le cas
d'une connexion typique à la maison via un petit routeur
CPE, il faudra que le routeur passe fidèlement
en DHCP les noms de domaine qu'il a lui-même obtenu. Si, à la place du
example.net, il transmet aux clients un nom comme,
mettons, .local, la recherche de serveur ALTO
échouera.
Cette procédure de découverte du serveur, comme le note la section 6 de notre RFC, n'est pas très sécurisée. Si un méchant arrive à diriger les clients vers un mauvais serveur ALTO, celui-ci pourra donner de l'information fausse, menant les clients à choisir un pair particulièrement lent. Pour cela, le méchant peut s'attaquer à l'échange DHCP. DHCP n'est pas sécurisé du tout mais, bon, si le méchant peut envoyer des fausses réponses DHCP, il pourra faire des choses bien pires que de donner un mauvais serveur ALTO. Donc, cette méthode d'attaque n'est pas très inquiétante. Une autre méthode pour l'attaquant serait de convaincre l'utilisateur de rentrer manuellement un nom de domaine menant au serveur ALTO malveillant, un problème qui ressemble à celui du hameçonnage (et qui, comme lui, n'a pas de solution technique).
Une dernière attaque possible serait de compromettre la résolution DNS. La procédure de découverte du serveur ALTO n'impose pas l'usage de DNSSEC et, sans lui, le DNS n'est pas vraiment sûr. Enfin, l'attaque pourrait porter, après la découverte du serveur correct, sur la communication HTTP avec le serveur (surtout si on n'utilise pas HTTPS). Personnellement, je ne suis pas trop inquiet : on a des problèmes de sécurité bien plus sérieux sur l'Internet.
À noter que d'autres mécanismes de découverte du serveur ALTO ont été proposés à l'IETF et qu'ils feront peut-être l'objet d'une spécification officielle plus tard.
L'article seul
RFC 7403: A Media-based Traceroute Function for the Session Initiation Protocol (SIP)
Date de publication du RFC : Novembre 2014
Auteur(s) du RFC : H. Kaplan (Oracle)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF straw
Première rédaction de cet article le 11 novembre 2014
Le protocole de téléphonie sur IP SIP est séparé en deux parties, la signalisation (appeler, raccrocher, etc) qui se fait avec SIP lui-même, et les données qui sont envoyées par un autre mécanisme, mais contrôlé par SIP. Pour la signalisation, SIP avait déjà une fonction de genre traceroute, permettant de visualiser le chemin suivi par les messages SIP. Mais il n'y avait pas l'équivalent pour les données, ce qui est fait désormais.
SIP est normalisé dans le RFC 3261, dont la section 20.22 décrit l'utilisation de
l'en-tête Max-Forwards: pour tracer la route
entre l'appelant et l'appelé. C'est que les appels SIP ne voyagent que
très rarement directement d'un appelant (par exemple un
softphone) vers un appelé
(entre autres parce que l'appelé n'est pas forcément joignable
directement, coincé qu'il est derrière le
NAT). Il est courant que l'appel passe par au
moins deux intermédiaires (le relais du fournisseur SIP de l'appelant
et celui de l'appelé), d'où l'importance de pouvoir faire des
« traceroute ». Un traceroute SIP fonctionne
donc en envoyant des requêtes avec un
Max-Forwards: à 0, puis à 1, et ainsi de suite
(comme le traceroute IP utilise le champ TTL),
en recevant les messages de code 483 (Too many
hops), on identifie les intermédiaires.
Même problème pour les données, elles ne vont pas forcément directement d'un client SIP à un autre, elles peuvent passer par des intermédiaires qui ajoutent des fonctions comme la musique d'attente (RFC 7088), la traversée des NAT, le réencodage du flux audio dans un autre format, etc. Bref, pour les données aussi, on a besoin d'un équivalent de traceroute, afin de pouvoir déboguer tout problème qui surgirait.
Justement, le RFC 6849 fournit un mécanisme, dit media loopback, sur lequel bâtir ce traceroute. Le service de « bouclage » du RFC 6849 permet de renvoyer le flux de données vers l'émetteur, afin que celui-ci puisse contrôler en quel état est ce flux à une étape donnée. Mettons que notre sympathique Alice veuille appeler Bob. Bob n'entend rien à ce que raconte Alice. Il va falloir déboguer. Alice va donc devoir demander à chaque intermédiaire (les B2BUA, back-to-back user agent) de lui envoyer une copie du flux de données, suivant le RFC 6849. Mais Alice ne les connait pas, ces intermédiaires, et n'a pas de moyen de leur parler directement. D'où notre nouveau RFC.
Le principe est d'envoyer une requête SIP
INVITE vers Bob, avec des
Max-Forwards: partant de zéro et croissant,
et d'y joindre un SDP qui
demande le bouclage des données (suivant la syntaxe du RFC 6849). Un intermédiaire SIP classique va
rejeter l'appel avec le code 483 mais, s'il suit ce nouveau RFC (et le
RFC 7332, qui le complète), il va
accepter l'appel et renvoyer les données à Alice. Sa réponse sera une
réponse positive au INVITE, donc avec le code
200, et, pour indiquer que ce n'est pas la « vraie » réponse de Bob,
il indiquera une raison (RFC 3326) Traceroute
response.
Attention à la sécurité, ce mécanisme peut finir par envoyer pas mal de données à Alice et imposer du travail aux intermédiaires. Ceux-ci doivent donc avoir un mécanisme pour activer/désactiver ce service, ainsi qu'une limitation automatique du nombre de réponses envoyées (comme les routeurs IP ont une telle limitation pour le traceroute classique).
L'article seul
RFC 7393: Using Port Control Protocol (PCP) to update dynamic DNS
Date de publication du RFC : Novembre 2014
Auteur(s) du RFC : X. Deng, M. Boucadair (France Telecom), Q. Zhao (Beijing University of Posts and Telecommunications), J. Huang, C. Zhou (Huawei Technologies)
Pour information
Première rédaction de cet article le 8 novembre 2014
Lorsqu'on a une machine avec une adresse IP variable, et qu'on veut la joindre depuis l'extérieur (pour se connecter à sa webcam, ou bien à un serveur HTTP qu'elle héberge ou bien pour tout autre raison), il est courant d'utiliser une mise à jour dynamique du DNS. Après tout, c'est bien le but principal du DNS, fournir un identificateur stable, le nom de domaine. Ce RFC explique les pièges et les problèmes lorsqu'on est connecté via un système à fort partage d'adresses IP (comme DS-Lite), et comment on peut utiliser PCP dans ce contexte.
Il existe plusieurs fournisseurs qui hébergent votre nom de domaine et acceptent des requêtes de mise à jour dynamiques, via un formulaire Web ou bien via une API. On peut avoir une idée du nombre de tels fournisseurs en regardant la liste de DNSlookup. Il n'y a pas à proprement parler de norme pour cette demande de mise à jour, à part le RFC 2136 qui ne semble guère utilisé par ces fournisseurs (comme le note à juste titre le Wikipédia anglophone, « DNS dynamique » désigne en fait deux choses différentes, la mise à jour par le RFC 2136 et le fait de mettre à jour la base sans édition manuelle). Le fournisseur doit avoir une interface qui assure en outre un minimum de sécurité (cf. la section 4 de notre RFC) par exemple en utilisant HTTPS + une authentification du client. Une utilisation courante est que le routeur ou l'ordinateur de l'utilisateur détecte une nouvelle adresse IP, et il notifie l'hébergeur de cette nouvelle adresse. Ce dernier met alors à jour le DNS (via le RFC 2136 ou via toute autre méthode).
Mais, aujourd'hui, de plus en plus d'utilisateurs sont coincés derrière un système à partage d'adresses massif (cf. RFC 6888), où on n'a plus une seule adresse IP publique à la maison. Pour être joint de l'extérieur, il faut communiquer non seulement son adresse IP mais également un port. Plus question de faire tourner son serveur Web sur le port 80, celui-ci ne peut pas être partagé. En outre, il faudra évidemment indiquer au réseau que le port en question devra être connecté au port sur lequel écoute le serveur de l'utilisateur (ce qui se fait en UPnP ou, plus récemment, en PCP, ce dernier étant normalisé dans le RFC 6887).
Les nombreux problèmes posés par le partage d'adresses sont bien connus (RFC 6269). Parmi eux :
- On ne peut plus compter sur les ports « bien connus » (comme 80 pour HTTP), il faut pouvoir indiquer aux clients un port explicite,
- Il faut un mécanisme pour configurer les connexions entrantes (justement ce que fait PCP),
- Il faut pouvoir détecter des changements d'adresses IP qui se passent très loin de l'utilisateur, dans l'AFTR de DS-Lite (RFC 6333) ou dans le routeur CGN pour NAT444.
À noter que, pour prévenir le monde extérieur du couple {adresse, port} à contacter (problème connu sous le nom de « problème du rendez-vous »), on utilise souvent aujourd'hui des techniques non-standard, spécifiques à une application particulière (cela se fait souvent dans le monde du jeu en ligne) ou spécifiques à un protocole donné (SIP va utiliser un SIP proxy, section 16 du RFC 3261).
Voyons donc les trois problèmes à résoudre et les solutions possibles (section 2 du RFC) :
- Pour indiquer le port, deux méthodes, utiliser des
URI qui permettent d'inclure le port, comme le
permet HTTP
(
http://www.example.net:5318/foo/bar), ou utiliser des enregistrement DNS SRV (RFC 2782). La seconde méthode est plus propre, car invisible à l'utilisateur (et elle offre d'autres possibilités), et elle n'oblige pas les applications à utiliser des URI. Malheureusement, elle est anormalement peu déployée dans les applications (par exemple les navigateurs Web). - Pour configurer les connexions entrantes, on se sert de PCP (RFC 6887), dont c'est justement le but principal.
- Pour détecter les changements d'adresses, on va encore se servir
de PCP. Une des solutions est
de faire des requêtes PCP de type
MAPrégulièrement, demandant une correspondance {adresse externe -> adresse interne} de courte durée et de voir quelle est l'adresse IP retournée. Une autre solution, moins bavarde, est de juste vérifier la table locale du client PCP, notant les changements d'adresses, et de ne faire une requêteMAPque s'il n'y a pas de correspondance dans la table locale. Dans les deux cas, lorsqu'on détecte un changement d'adresse, on met à jour le DNS par les moyens classiques (le client PCP, routeur ou ordinateur, est également client du service de DNS dynamique).
La section 3 couvre quelques détails pratiques de déploiement. Par exemple, le RFC couvre le cas où le service de « DNS dynamique » ne fait pas de DNS du tout mais publie sa propre adresse dans le DNS, redirigeant ensuite les clients vers le bon serveur (via une réponse 301 en HTTP, ce qui se nomme parfois URL forwarding). Ces serveurs devront modifier leur API pour que le client puisse indiquer le port en plus de l'adresse IP (aujourd'hui, ils ont souvent 80 câblé en dur). Dans un contexte différent (protocole ne permettant pas les redirections), on peut envisager d'utiliser la technique de découverte du RFC 6763.
Pour résumer par des remarques personnelles, tout cela est plutôt embrouillé, et on n'est pas tiré d'affaire, d'autant plus que PCP n'est pas tellement déployé aujourd'hui.
L'article seul
Fiche de lecture : La France espionne le monde (1914-1918)
Auteur(s) du livre : Jean-Claude Delhez
Éditeur : Economica
978-2-7178-6694-0
Publié en 2014
Première rédaction de cet article le 6 novembre 2014
En ce centenaire du déclenchement de la boucherie inutile de la Première Guerre mondiale, on voit évidemment apparaître un grand nombre de livres sur cette période. Celui-ci a un angle original, l'activité d'écoute des communications par les services d'espionnage français, à l'époque où ceux-ci étaient les meilleurs du monde (selon l'auteur, qui est parfois un peu cocardier).
Les choses ont bien changé depuis. À l'époque, les communications interceptées étaient chiffrées et déchiffrées à la main, avec papier et crayon (on voit passer à un moment dans le livre une machine à chiffrer autrichienne, précurseuse de la future Enigma), ce qui entrainait plein de délais et d'erreurs (comme le savent tous les gens qui ont suivi les ateliers d'Amaelle Guiton et Aeris), et encourageait à utiliser des algorithmes de chiffrement trop simples et donc trop cassables. Les divers services secrets français maitrisaient cet art difficile de la cryptanalyse et pouvait donc casser les codes allemands, autrichiens, turcs, bulgares et, apprend-on au détour d'une page, monégasques...
Attention si vous êtes fana de cryptographie et de mathématiques : ce livre est très pauvre en détails techniques. Il décrit certains des algorithmes de chiffrement, mais ne dit rien des techniques de cryptanalyse utilisées, ou tout simplement du travail quotidien des cryptographes. C'est plutôt un livre d'histoire, de personnages (on croise Marie Curie, Wilhelm Canaris, qui n'est encore qu'un jeune officier de marine, et bien d'autres), et de stratégie. La première partie couvre un pan bien connu de l'histoire de la Première Guerre mondiale, l'affrontement en Europe entre la France et l'Allemagne, où les Français écoutent systématiquement les communications radio de l'ennemi et arrivent ainsi à connaître ses intentions. Mais pas forcément à agir : l'offensive contre Verdun était apparemment connue, mais les mesures prises n'ont pas forcément été à la hauteur. Et, lorsque les écoutes radio et le déchiffrement permettent de connaître à l'avance un passage de Guillaume II près des lignes françaises, une erreur dans l'interprétation fait que les avions français chargés d'aller l'assassiner le ratent.
La seconde partie du livre concerne un champ de bataille nettement moins connu, l'Espagne. Pendant la guerre, l'Espagne est neutre et est donc investie par de nombreux agents secrets des deux camps. Madrid est un « nid d'espions ». Les Allemands, qui bénéficient de la sympathie d'une armée espagnole ultra-réactionnaire et qui voit dans les Français de dangereux subversifs mangeurs de curés, cherchent surtout à provoquer des révoltes dans le Maroc, partagé entre une colonie française et une espagnole. Mais, séparés de leur patrie par la France, ils doivent communiquer essentiellement par radio et font une confiance trop grande à leur chiffrement (et n'accordent pas assez d'importance aux alarmes des experts). Les Français apprennent ainsi tous leurs plans, par exemple les tentatives de faire revenir le souverain exilé en Espagne Moulay Hafid. Toutes ces tentatives échoueront finalement, grâce aux décrypteurs.
Ah, et pour un livre aussi riche en noms de personnes et de lieux, il manque vraiment un index.
L'article seul
PassiveDNS.cn, une autre base d'histoire du DNS
Première rédaction de cet article le 4 novembre 2014
Il existe plusieurs services « historique
DNS » ou « passive DNS » qui
permettent de remonter dans le temps et de consulter les données qui
étaient associées à un nom de domaine. J'ai
déjà parlé ici de DNSDB, voici un nouveau,
https://PassiveDNS.cn.
Tous ces services reposent sur le même principe : un ensemble de sondes écoute passivement le trafic DNS près de gros résolveurs, et stocke les réponses, avec leurs dates, dans une base de données, qu'il n'y a plus qu'à interroger. En ne stockant que le contenu des réponses (pas les requêtes, pas les adresses IP du requêtant), on évite pas mal de problèmes liés à la vie privée. Ces services se différencient par leurs conditions d'utilisation (aucun n'est public), par la quantité de données (qui dépend entre autres de la position des sondes), la géographie de leurs sondes (DNSDB a l'air d'avoir surtout des sondes aux États-Unis) et leurs qualités logicielles. Ils sont des outils essentiels aux chercheurs et aux professionnels de la sécurité.
Ce https://PassiveDNS.cn a l'originalité d'être basé
en Chine. Il faut demander un compte, après
avoir expliqué pourquoi on le voulait et ce qu'on en ferait et, si le
gestionnaire du service est d'accord, vous recevez de quoi vous
connecter. Comme pour DNSDB, les recherches
peuvent être faites par la partie gauche de la réponse DNS
(owner name) ou par la partie droite
(resource record data). On peut ainsi demander
quelles ont été les adresses IPv6 successives de
www.bortzmeyer.org :
2001:4b98:dc0:41:216:3eff:fece:1902 2605:4500:2:245b::42 Time begin: 2014-08-12 21:05:56 Time end: 2014-11-04 08:02:40 Count: 793
Le Time begin indique quand PassiveDNS.cn a
commencé à stocker ses données (ce nom a une adresse IPv6 depuis des
années).
Et on peut chercher par la partie droite, par le contenu. Qui a
utilisé le serveur de noms ns2.nic.fr :
... polytechnique.fr press.ma supelec.fr telecom-bretagne.eu u-bordeaux.fr u-nancy.fr ...
(Notez que press.ma est une lame
delegation, une délégation faite à un serveur qui n'est pas
au courant, comme le sont plusieurs délégations de cette zone.)
Il existe bien sûr une API. Curieusement, il faut demander une clé manuellement (on ne peut pas le faire depuis le site Web). Une fois obtenue, on a du REST classique. Une requête avec curl est un peu compliquée à faire (il faut ajouter deux en-têtes HTTP dont l'un est un condensat de l'URL demandé et de la clé). À défaut de curl en direct, on peut se programmer ça, ou bien on peut utiliser l'outil flint.
% flint rrset www.bortzmeyer.org AAAA www.bortzmeyer.org AAAA In rrset ------- Record times: 2014-08-12 15:05:56 -- 2014-11-04 01:02:40 Count: 793 www.bortzmeyer.org AAAA 2001:4b98:dc0:41:216:3eff:fece:1902 www.bortzmeyer.org AAAA 2605:4500:2:245b::42
Et si on préfère le JSON, pour analyse ultérieure :
% flint -j rrset www.elysee.fr CNAME
[
{
"count": 1882,
"time_first": 1407251470,
"rrtype": "CNAME",
"rrname": "www.elysee.fr",
"rdata": "cdn.cdn-tech.com.c.footprint.net;",
"time_last": 1415128869
}
]
(Notez le curieux point-virgule à la fin du rdata.)
Bon, si vous tenez à le programmer vous-même, ce script shell
marche (il faut lui passer rrset/keyword/$DOMAIN/
en paramètre) :
#!/bin/sh
KEY='secret.key.for.you.only'
ID='guest.test'
# No / at the end
URL=https://www.passivedns.cn
query=/api/$1
hash=$(echo -n "$query$KEY" | md5sum | cut -d " " -f1)
curl -v -H "Accept: application/json" \
-H "X-BashTokid: $ID" -H "X-BashToken: $hash" $URL$query
Comme tous les outils de ce genre, PassiveDNS.cn permet d'analyser des
attaques. Ici, par exemple, on voit de fausses réponses pour le
TLD .us :
% flint rrset us NS us NS In rrset ------- Record times: 2014-08-20 09:17:03 -- 2014-11-04 01:29:31 Count: 102064 us NS a.cctld.us us NS b.cctld.us us NS c.cctld.us us NS e.cctld.us us NS f.cctld.us us NS k.cctld.us Record times: 2014-08-25 12:45:11 -- 2014-09-09 21:49:09 Count: 252 us NS ns1.360dns.cc us NS ns1.360dns.net us NS ns2.360dns.cc us NS ns2.360dns.net Record times: 2014-08-25 12:03:07 -- 2014-09-09 21:29:54 Count: 388 us NS ns1.unidns.x us NS ns2.unidns.x ...
Le premier enregistrement est correct, les autres (notez leur durée plus courte) sont des empoisonnements de cache ou d'autres manipulations du DNS, dont la Chine est coutumière (on ne voit pas ces réponses anormales depuis DNSDB).
Ah, un dernier point, PassiveDNS.cn n'est pas très rapide ; soyez patient.
L'article seul
RFC 7396: JSON Merge Patch
Date de publication du RFC : Octobre 2014
Auteur(s) du RFC : P. Hoffman (VPN
Consortium), J. Snell
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF appsawg
Première rédaction de cet article le 1 novembre 2014
La commande HTTP PATCH
permet d'envoyer à un serveur HTTP un document représentant les
différences entre l'état d'une ressource sur le serveur et l'état
souhaité par le client HTTP. Cette liste de différences peut prendre
plusieurs formats et ce RFC en spécifie un nouveau, JSON
merge patch, un format de
patch conçu pour
JSON.
À noter que ce RFC remplace le RFC 7386, publié deux semaines avant, mais qui comportait une erreur technique.
Le format normalisé par ce RFC n'est en fait pas spécifique à HTTP
et pourra même servir avec d'autres protocoles. Mais la commande
PATCH du RFC 5789 sera sans
doute sa principale utilisation. Une ressource au format JSON
merge patch est un objet JSON elle-même. Pour chaque clé, si la
ressource cible a également cette clé, la valeur est remplacée par
celle du patch. Si elle ne l'a pas, on ajoute le
couple clé/valeur. Et si la valeur dans le patch
est null, on supprime le couple clé/valeur de la
ressource cible. Ainsi, si on a ce document JSON sur le serveur :
{
"a": "b",
"c": {
"d": "e",
"f": "g"
}
}
et qu'on envoie le patch suivant en HTTP (notez le type MIME de notre nouveau format) :
PATCH /target HTTP/1.1
Host: example.org
Content-Type: application/merge-patch+json
{
"a":"z",
"c": {
"f": null
}
}
On obtiendra :
{
"a": "z",
"c": {
"d": "e"
}
}
(La valeur de a a été changée, et le couple
indexé par c / f a été supprimé.)
Ce format, centré sur le résultat plutôt que sur les opérations, suit donc des principes assez différents de son homologue XML du RFC 5261.
On notera donc que tous les contenus
JSON ne sont pas patchables ou, en tout cas, pas de
manière propre et facile, avec ce format. Par
exemple, si des null sont effectivement utilisés,
ou bien si la structure du texte JSON n'est pas celle d'un
objet. Mais, bon, ce format est très simple, est lui-même en JSON, et
le RFC est très court et facile à comprendre (ce qui n'aurait pas été
le cas si on avait voulu tout prévoir), on ne peut pas tout avoir.
La section 2 du RFC précise les règles à suivre lors du traitement des patches. Elle est rédigée en pseudo-code (c'est une erreur dans l'indentation de ce pseudo-code qui avait rendu nécessaire le remplacement du RFC 7386 par notre RFC) et est assez simple pour être citée ici :
define MergePatch(Target, Patch):
if Patch is an Object:
if Target is not an Object:
Target = {} # Ignore the contents and set it to an empty Object
for each Name/Value pair in Patch:
if Value is null:
if Name exists in Target:
remove the Name/Value pair from Target
else:
Target[Name] = MergePatch(Target[Name], Value)
return Target
else:
return Patch
Parmi les points à noter, le fait qu'un patch qui n'est pas un objet JSON (par exemple un tableau) va toujours remplacer l'intégralité de la ressource cible, ou le fait qu'on ne peut pas modifier une partie d'une ressource cible qui n'est pas elle-même un objet (il faut la changer complètement).
Le patch va agir sur les valeurs, pas sur leur représentation. Ainsi, on n'a aucune garantie qu'il préservera l'indentation du texte JSON ou la précision des nombres. De même, si la ressource cible tire profit des faiblesses de la norme JSON, elle peut ne pas sortir intacte : par exemple, si la ressource cible a plusieurs membres qui ont la même clé (ce qui n'est pas formellement interdit en JSON mais donne des résultats imprévisibles).
Un exemple plus détaillé de patch JSON se trouve en section 3. On part de ce document :
{
"title": "Goodbye!",
"author" : {
"givenName" : "John",
"familyName" : "Doe"
},
"tags":[ "example", "sample" ],
"content": "This will be unchanged"
}
Et on veut changer le titre, ajouter un numéro de téléphone, retirer
le nom de famille de l'auteur, et retirer l'élément
sample du tableau tags.
On envoie cette requête :
PATCH /my/resource HTTP/1.1
Host: example.org
Content-Type: application/merge-patch+json
{
"title": "Hello!",
"phoneNumber": "+01-123-456-7890",
"author": {
"familyName": null
},
"tags": [ "example" ]
}
Et on obtient ce document :
{
"title": "Hello!",
"author" : {
"givenName" : "John"
},
"tags": [ "example" ],
"content": "This will be unchanged",
"phoneNumber": "+01-123-456-7890"
}
Notez qu'il a fallu remplacer complètement le tableau
tags : il n'y a pas de mécanisme pour retirer
juste un élément du tableau (comme expliqué au début). Des tas d'exemples figurent dans l'annexe
A, si vous voulez écrire une suite de tests.
Le type MIME
application/merge-patch+json figure désormais
dans le registre IANA (cf. section 4 du
RFC), aux côtés de l'équivalent XML décrit dans
le RFC 7351, application/xml-patch+xml.
L'article seul
RFC 7368: IPv6 Home Networking Architecture Principles
Date de publication du RFC : Octobre 2014
Auteur(s) du RFC : T. Chown (University of
Southampton), J. Arkko
(Ericsson), A. Brandt (Sigma
Designs), O. Troan (Cisco
Systems), J. Weil (Time Warner
Cable)
Pour information
Réalisé dans le cadre du groupe de travail IETF homenet
Première rédaction de cet article le 1 novembre 2014
Le projet Homenet de l'IETF est très ambitieux. Il s'agit de définir une architecture et des protocoles pour des réseaux IPv6 à la maison. Non seulement tout doit marcher « tout seul » (on ne peut pas demander à M. Michu de lire le RFC, ou même la documentation) mais en outre le groupe de travail Homenet prévoit deux innovations principales par rapport aux réseaux IPv4 des maisons actuelles : un inter-réseau à la maison (plusieurs réseaux séparés par des routeurs) et pas de NAT, la plaie des communications actuelles. Ce premier RFC du groupe de travail Homenet décrit l'architecture générale envisagée.
La tendance générale dans les maisons modernes est à la prolifération des équipements électroniques. Si toutes les maisons ne connaissent pas encore la situation de la célèbre Maison qui tweete, il n'y a pas de doute que les vingt dernières années ont vu un changement de modèle avec le passage de « à la maison, un ordinateur et un seul, connecté au réseau » à « deux ou trois dizaines d'équipements électroniques dont beaucoup sont connectés au réseau, au moins de temps en temps ». Entre les smartphones, les compteurs intelligents, l'Arduino qui arrose les plantes, la box, le PC du joueur de jeu vidéo, les tablettes de tout le monde, et la télé connectée, on atteint vite un nombre de machines connectées bien supérieur à la totalité de l'Arpanet du début. Il y a bien longtemps qu'il n'y a plus assez d'adresses IPv4 pour tout ce monde. L'architecture typique aujourd'hui (pas réellement documentée, car jamais vraiment réfléchie et étudiée) est d'un réseau à plat (pas de séparation des machines, tout le monde est sur la même couche 2), avec numérotation des équipements avec les adresses IPv4 privées du RFC 1918 et connexion à l'Internet via un unique FAI. Homenet vise au contraire des réseaux IPv6 (IPv4 peut continuer à tourner sur un réseau Homenet mais à côté, car Homenet ne prévoit rien de particulier pour lui), non gérés (M. Michu...) et connectés à plusieurs FAI, pour la résilience, pour compenser les faiblesses ou manques d'un FAI par un autre (bridage de YouTube, par exemple...) ou tout simplement parce que des tas d'offres de connectivité sont disponibles (pensez au smartphone qui a le choix entre la 3G et le WiFi).
Homenet ne sera pas un protocole unique. L'idée du projet est d'analyser ce qui existe, de réutiliser autant que possible les protocoles existants et testés, et d'identifier ce qui manque, pour pouvoir ensuite l'ajouter. Homenet se focalise sur la couche 3 et quelques services indispensables, comme la résolution de noms. Les protocoles physiques sous-jacents sont tous acceptés, du moment qu'IPv6 peut tourner dessus.
L'explosion du nombre d'équipements connectés est déjà largement une réalité (donnant naissance à des slogans plus ou moins pipeau comme « Internet des objets »). Le routage interne (plusieurs réseaux à la maison, séparés par des routeurs) est par contre encore embryonnaire. Mais Homenet vise le futur (ce qui explique aussi pourquoi les questions liées à IPv4 ne sont pas abordées, cf. section 3.2.3). À noter qu'il existe déjà une description du routeur IPv6 idéal pour la maison, dans le RFC 7084.
Comme tout document d'architecture, le RFC Homenet commence avec de la terminologie (section 1.1). Ainsi, la frontière (border) est l'endroit où on change de domaine administratif et où on applique donc les règles de sécurité (filtrage, par exemple). Chaque réseau derrière une frontière se nomme un royaume (realm). Le CER (Customer Edge Router) est le routeur qui est à la frontière. Il peut y en avoir plusieurs (un point important de Homenet, qui avait été chaudement discuté, est que Homenet doit gérer le cas où il y a plusieurs FAI). Homenet prévoit plusieurs routeurs à la maison et le réseau des invités (guest network) est un réseau interne conçu pour les visiteurs et n'ayant pas forcément accès à tous les services du réseau de la maison (pour pouvoir fournir un accès WiFi à vos invités sans qu'ils puissent fureter dans votre collection de sex tapes sur le NAS). Si FQDN est bien connu, Homenet utilise aussi le sigle LQDN (Locally Qualified Domain Name, un nom qui n'a de signification que local).
Attaquons maintenant le problème de créer des homenets. La section 2 fait le point des différences entre IPv4 et IPv6 qui vont avoir un impact sur le réseau à la maison (ou dans le petit bureau d'une petite organisation). Premièrement (section 2.1), IPv6 permet d'avoir plusieurs réseaux à la maison. C'est possible également en IPv4, mais uniquement avec des adresses privées, on a rarement des préfixes IPv4 assez grands pour les découper finement. En revanche, IPv6 permettrait de faire plus facilement des réseaux multiples, par exemple pour séparer le réseau des invités, ou bien pour avoir un réseau de l'employeur, étendu à la maison via un VPN, mais séparé du réseau personnel. Une autre raison pour le multi-réseaux est que les technologies de couche 1 et de couche 2 deviennent de plus en plus hétérogènes, notamment en raison de l'apparition de techniques dédiées aux objets limités (peu de puissance électrique, peu de capacités de calcul, etc). Des écarts de trois ordres de grandeur (de 1 Mb/s à 1 Gb/s) sont courants aujourd'hui et tendent à s'élargir. Pour éviter d'aligner Ethernet sur le plus grand dénominateur commun de ces réseaux limités (RFC 7102), il faut bien partitionner en plusieurs réseaux IP et router entre eux.
Cela implique d'avoir un préfixe IPv6 plus général qu'un /64. Le /64 permet un nombre colossal d'adresses mais ne permet qu'un seul préfixe, donc qu'un seul réseau, en tout cas tant qu'on garde l'auto-configuration sans état du RFC 4862. C'est pour cela que le RFC 6177 recommande d'allouer à M. Michu des préfixes suffisants pour tous ses usages, y compris futurs.
Donc, avoir plusieurs réseaux IP à la maison serait très bien. Mais ce n'est pas trivial. Il faut allouer ces préfixes (rappelons que le réseau à la maison n'est pas géré, M. Toutlemonde ne va pas installer un logiciel d'IPAM et concevoir un plan d'adressage). Et les mécanismes existants pour le réseau sans configuration (comme le mDNS du RFC 6762) ne fonctionnent pas en multi-réseaux (ils dépendent de la diffusion, qui s'arrête au premier routeur rencontré).
Deuxième propriété importante d'IPv6, la possibilité d'avoir des adresses uniques au niveau mondial et donc l'élimination du NAT (section 2.2). C'est à la fois une chance formidable de retrouver la communication directe de bout en bout qui a fait le succès de l'Internet, et aussi un risque car tout trafic sur l'Internet n'est pas souhaitable, et beaucoup d'engins connectés ont une sécurité... abyssale (imprimantes ou caméras avec des mots de passe par défaut, et jamais changés). Une connectivité de bout en bout nécessite une meilleure sécurité des machines, ou alors des pare-feux IPv6 protégeant le réseau. S'agissant de ces pare-feux, notre RFC Homenet note qu'il faut distinguer adressabilité et joignabilité. IPv6 fournit l'adressabilité (toute machine, si humble soit-elle, a une adresse IP unique) mais on ne souhaite pas forcément la joignabilité (je ne veux pas que le voisin se connecte à ma caméra IP).
À noter qu'il existe un débat très chaud à l'IETF concernant les recommandations à faire pour la politique de sécurité par défaut d'un pare-feu à la maison. Les RFC 4864 et RFC 6092 discutent des mérites comparés des politiques « bloquer tout par défaut, sauf quelques exceptions » et « autoriser tout par défaut, avec quelques exceptions ».
Bien sûr, une des nouveautés les plus spectaculaires d'IPv6 est la disponibilité d'un grand nombre d'adresses. Mais on oublie souvent une autre nouveauté, le fait qu'avoir plusieurs adresses IP n'est plus un bricolage spécial, mais devient la norme (section 2.3). Cela entraine des questions nouvelles comme « quelle adresse IP source choisir pour les connexions sortantes ? » (RFC 6724).
IPv6 permet de disposer d'adresses purement locales (section 2.4 de notre RFC), attribuées sans référence à un registre central, les ULA (Unique Local Addresses, RFC 4193 et RFC 7084 pour leur usage dans les CER). Comme M. Michu n'a typiquement pas d'adresses IP à lui, les adresses externes de sa maison ou de sa petite association seront sans doute des adresses attribuées par le FAI. Pour la stabilité, il est donc recommandé d'y ajouter des ULA, qui permettront aux machines locales de se parler en utilisant toujours les mêmes adresses, même en cas de changement de FAI. Comme toutes les adresses privées, les ULA isolent des changements extérieurs. Par contre, elles n'impliquent pas de faire du NAT, même pas du NAT IPv6 (RFC 6296). La machine est censée utiliser son ULA lorsqu'elle communique avec le réseau local et une adresse publique lorsqu'elle communique avec l'extérieur (c'est le comportement par défaut si le RFC 6724 a été implémenté correctement sur la machine). Homenet déconseille donc toute forme de NAT IPv6, même celle du RFC 6296 (pourtant bien meilleure techniquement que le NAT d'IPv4).
Un autre avantage des ULA est que les machines qui n'ont pas besoin de communiquer avec l'extérieur (une imprimante, par exemple), n'ont pas besoin d'adresse publique et peuvent donc se contenter de l'ULA.
Dans les réseaux IPv4, on voit parfois des équipements exposer leur adresse IPv4 à l'utilisateur, par exemple pour pouvoir la changer manuellement. Les adresses IPv6 étant plus longues, plus difficiles à mémoriser et plus aléatoires d'apparence, cette pratique est déconseillée pour Homenet (section 2.5). Pas touche aux adresses !
Enfin, dernier point spécifique à IPv6, le fait que certains réseaux seront peut-être seulement en IPv6. Si on part de zéro aujourd'hui (déploiement greenfield en anglais), il n'y a guère de raison de mettre de l'IPv4. Ne faire que de l'IPv6 simplifie le réseau et sa gestion, par contre cela implique que chaque machine sache tout faire en IPv6 (par exemple, il existe des systèmes qui ont une gestion d'IPv6 complète, sauf pour les résolveurs DNS qui doivent être accessibles en IPv4). Évidemment, même si le réseau local peut être entièrement IPv6, il faudra encore, pendant un certain temps, communiquer avec des machines purement IPv4 et donc déployer des solutions de coexistence comme celle du RFC 6144.
Sur ce, la section 2 du RFC Homenet est terminée. Vous savez désormais ce qu'il faut savoir d'important sur IPv6, place aux principes d'architecture de Homenet en section 3. Comment construire des réseaux IPv6 à la maison avec les techniques IPv6 ? Et ce avec des engins variés, connectés en une topologie quelconque, sans configuration manuelle ou, en tout cas, sans qu'elle soit obligatoire ? La section 3.1 pose les principes de base :
- Autant que possible, réutiliser des protocoles existants. Homenet est ambitieux mais conservateur.
- Imposer le moins de changements possibles aux machines, routeurs ou machines terminales.
Les topologies (façons dont les réseaux qui forment le homenet sont connectés) doivent pouvoir être quelconques (section 3.2). Les utilisateurs vont sans doute connecter sans réfléchir et on ne veut pas leur imposer des règles comme « ne pas faire de boucles » ou « le réseau doit avoir une topologie strictement arborescente ». Le réseau doit continuer à fonctionner tant qu'il n'est pas physiquement partitionné. Par exemple, si deux commutateurs sont connectés en une boucle, le commutateur doit le détecter (en voyant son adresse MAC à l'extérieur) et réparer tout seul. Le réseau doit pouvoir être dynamique : il doit accepter non seulement l'ajout ou le retrait de machines mais également les changements dans la connectivité. Le RFC 7084 donne des idées de configurations qui doivent fonctionner. Parmi les propriétés d'un réseau qui ont une particulière importance :
- La présence ou non de routeurs internes (très rare à l'heure actuelle),
- Présence de plusieurs réseaux physiques interconnectés uniquement via l'Internet,
- Gestion du CER (Customer Edge Router) par l'utilisateur ou par le FAI (le RFC ne mentionne pas le cas plus compliqué où l'utilisateur doit utiliser le CER du FAI mais peut configurer certains aspects),
- Nombre de FAI (presque toujours un seul aujourd'hui mais cela pourrait changer, notamment pour avoir davantage de résilience),
- Et nombre de CER (il n'y en a pas forcément qu'un seul par FAI).
Le cas le plus commun aujourd'hui est un seul FAI, un seul CER, pas de routeurs internes. Le cas le plus simple dans le RFC est celui de la section 3.2.2.1 : un seul FAI, un seul CER mais des routeurs internes. (Les sections suivantes présentent des cas plus compliqués.)
Le multi-homing présente des défis spécifiques. Une partie du groupe de travail Homenet aurait préféré travailler sur des réseaux ayant un seul FAI, où la plus grande partie des services permettant de faire fonctionner le homenet aurait été fournie par le FAI. Cela simplifiait nettement le problème mais au prix d'une grosse perte d'indépendance pour l'utilisateur. Sans surprise, cette position était surtout défendue par les gens qui travaillent pour les FAI, ceux qui travaillent pour les fabriquants de routeurs préférant du multi-homing, avec plein de routeurs partout. Le multi-homing reste relativement simple s'il n'y a qu'un seul CER, connecté aux différents FAI. Des fonctions comme la sélection d'un FAI en fonction de l'adresse IP source peuvent être entièrement gérées dans le CER. S'il y a plusieurs CER, il faut que chaque machine choisisse le bon CER de sortie. « Bon » au sens qu'il doit être cohérent avec l'adresse IP source (utilisation des adresses du préfixe du FAI) pour éviter le filtrage par les techniques anti-usurpation dites BCP 38 (RFC 2827 et RFC 3704). La question du multi-homing est récurrente à l'IETF et mène souvent à des solutions assez complexes, peut-être trop pour le homenet. Par exemple, une solution possible serait de faire tourner les protocoles de routage sur toutes les machines, de façon à ce que même les machines terminales apprennent les routes et sachent quel routeur contrôle quel réseau. Le RFC 7157 décrit une solution plus simple (qui évite la traduction d'adresses du RFC 6296, déconseillée pour le projet Homenet). Il y a aussi d'utiles techniques qui sont entièrement dans les machines terminales, sans mettre en jeu le réseau, comme SHIM6 (RFC 5553), MPTCP (RFC 6824) ou les globes oculaires heureux du RFC 6555.
Parmi les pièges du multi-homing, le RFC note que certains des FAI peuvent ne pas fournir une connectivité complète. Un exemple est celui du télé-travailleur où le réseau local est multihomé vers l'Internet et vers le réseau de l'employeur, via un VPN, et où le réseau de l'employeur ne donne pas accès à tout l'Internet. Homenet ne fournit pas de solutions à ce sous-problème. (Un autre cas où il se pose, plus polémique et non cité par le RFC, est celui où l'un des FAI bride, filtre ou censure, en violation de la neutralité.)
Le réseau à la maison doit évidemment être entièrement auto-configuré, puisqu'on ne souhaite pas que M. Toutlemonde soit obligé de devenir administrateur réseaux (section 3.3). C'est plus facile à dire qu'à faire. Par exemple, il faut éviter que n'importe quelle machine qui se trouve passer dans les environs puisse rejoindre le réseau alors que sa présence n'est pas souhaitée. L'utilisateur doit donc avoir un moyen simple de tenir à distance les importuns et donc de dire « cette machine est bienvenue ». Il y a d'intéressants problèmes d'interface utilisateur ici... Un exemple d'un moyen simple est la pression quasi-simultanée de deux boutons, un sur la nouvelle machine qui arrive et un sur le routeur.
En parlant de sécurité et de « eux » et « nous », il faudra bien que le homenet soit conscient de l'étendue de son royaume afin, par exemple, d'appliquer des politiques de sécurité différentes entre les communications internes et externes. Sans compter les frontières à l'intérieur même de la maison, comme entre le réseau des enfants et l'extension virtuelle du réseau de l'entreprise de Maman. Comme souvent, le RFC demande que cela soit automatique, mais avec possibilité de changement manuel si on a une configuration très spéciale.
Et l'adressage (section 3.4) ? Ah, c'est une question compliquée. D'abord, le homenet sera dépendant de ce que lui aura alloué le ou les FAI. Espérons qu'ils suivent les politiques du RFC 6177 et lui donnent donc assez d'adresses et en tout cas plus que le pauvre /64 que certains FAI distribuent aujourd'hui à leurs abonnés, et qui ne leur permet pas d'avoir facilement plusieurs réseaux à la maison. Le RFC 6177 n'imposant plus une longueur unique aux allocations, le homenet récupérera peut-être un /60, un /56 ou un /48 (notre RFC recommande un /56 ou plus général). Le protocole de récupération du préfixe sera sans doute celui du RFC 3633. Il permet au homenet de solliciter une certaine longueur de préfixe, mais sans garantie que le FAI ne lui enverra pas un préfixe plus spécifique. Là encore, la délégation de préfixe peut échouer (si la liaison avec le FAI est coupée) et le homenet doit donc pouvoir fonctionner seul, y compris pour son adressage. Une nouvelle raison d'utiliser les ULA. Rappelez-vous que ce RFC est juste une architecture, il ne définit pas en détail les protocoles utilisés, mais il note ici qu'il faudra sans doute une et une seule méthode de délégation de préfixe, pour que tous les routeurs du réseau local soient d'accord sur les adresses à utiliser.
Il est préférable que les préfixes utilisés en interne soient stables, et notamment survivent au redémarrage des routeurs. Cela implique un mécanisme de stockage permanent des données sur les routeurs, ainsi que, de préférence, un moyen de tout remettre à zéro s'il y a une reconfiguration significative.
À propos de stabilité, il faut noter que, bien qu'elle facilite nettement le fonctionnement du réseau, elle a aussi des inconvénients en terme de vie privée. Si le préfixe alloué à un client du FAI reste stable, il aura à peu près le même effet qu'une adresse IPv4 fixe : les machines avec qui communique le client pourront voir que plusieurs requêtes viennent de la même maison. Le NAT (en IPv4) ou les extensions de vie privée (en IPv6, cf. RFC 8981) n'aident pas contre cette indiscrétion.
La section 3.5 discute ensuite de la question du routage interne. En effet, une des nouveautés du projet Homenet est de considérer qu'il y aura des routeurs internes et donc du routage à faire entre les différents réseaux de la maison. Là encore, tout doit se configurer tout seul donc il faudra problablement choisir un protocole de routage dynamique, de préférence un protocole existant et déjà testé, mais qui tient compte des exigences particulières de Homenet (par exemple le peu de ressources matérielles des routeurs internes).
Que des gros problèmes compliqués, non ? Chacun d'entre eux a déjà de quoi distraire une équipe d'ingénieurs pendant un certain temps. Mais ce n'est pas fini. La section 3.6 s'attaque à la sécurité. Le problème est difficile car on ne veut évidemment pas que les voisins récupèrent les selfies qu'on a laissés sur l'appareil photo connecté, mais on veut également une grande simplicité de configuration (voire zéro configuration), ce qui va généralement mal avec la sécurité. La disparition souhaitée du NAT ajoute en outre une nouvelle composante au problème. Il sera difficile d'éviter une réflexion sur la sécurité des machines (abyssalement basse, aujourd'hui), la protection offerte par le réseau ayant ses limites (surtout si on veut que chaque brosse à dents puisse communiquer sur l'Internet). L'un des buts d'Homenet est de rétablir le principe des communications de bout en bout (RFC 2775). Mais cela ne signifie pas open bar pour tout le trafic et notre RFC distingue donc bien le fait d'être mondialement adressable (adresse IPv6 unique) et celui d'être mondialement joignable (n'importe quel script kiddie peut tenter une attaque sur la brosse à dents IP). Le RFC 4864 proposait un modèle de sécurité fondé sur un pare-feu protégeant le périmètre, considérant qu'on ne pouvait pas espérer que toutes les machines soient sécurisées. La polémique se concentre évidemment sur la politique par défaut de ce pare-feu. On sait bien que très peu de gens changeront cette politique donc elle a une importance cruciale. Un blocage par défaut (default deny) ferait retomber dans les problèmes du NAT où des tas d'applications (serveur auto-hébergé, pair-à-pair) sont interdites, sauf à déployer des techniques d'ouverture de pare-feu comme UPnP ou le PCP du RFC 6887. Le RFC 6092 ne suivait donc pas cette approche du « interdit par défaut », et recommandait que, même si elle était choisie, il soit facile de revenir à un mode d'autorisation par défaut, celui qui permet l'innovation et le déploiement de nouveaux services. La question continue à susciter d'innombrables discussions à l'IETF et il est clair qu'il n'existe pas de consensus entre les partisans du « interdit par défaut » et ceux du « autorisé par défaut ».
Par contre, il est certain que, comme indiqué plus haut, tout trafic n'est pas souhaitable. Le principe fondateur de connectivité de bout en bout, c'est « deux machines qui le souhaitent doivent pouvoir communiquer directement », pas « je dois supporter n'importe quel trafic qu'un crétin quelconque veut m'envoyer ». Par exemple, comme indiqué plus haut, on peut souhaiter isoler le trafic du réseau des invités. Filtrer à la frontière sera donc toujours nécessaire.
Est-ce que le NAT ou les pare-feux actuels assurent cette fonction de manière satisfaisante ? Pour le NAT, clairement non. Pour les pare-feux, la religion actuelle des pare-feux (auditeurs ignorants qui vous reprochent de ne pas avoir de pare-feu devant un serveur Internet public, managers qui croient qu'ils ont traité les problèmes de sécurité en installant une boîte noire très chère marquée en gros Firewall...) ne peut pas masquer les innombrables problèmes de sécurité qui affectent les utilisateurs pourtant situés derrière un pare-feu (distribution de malware par le courrier, par exemple). Une des plus grosses faiblesses de la religion du pare-feu est qu'elle suppose que les méchants sont uniquement à l'extérieur : résultat, la compromission d'une seule machine à l'intérieur suffit à annuler l'effet du pare-feu. Donc, la situation actuelle n'est pas satisfaisante. Néanmoins, pour un réseau typique, on peut difficilement se passer aujourd'hui du pare-feu. Autant on peut sécuriser un serveur Internet sérieux, géré par des professionnels, autant on ne peut pas compter sur les innombrables objets connectés : la plupart d'entre eux ont zéro sécurité (serveur Web d'administration activé par défaut, avec un mot de passe identique pour toutes les machines et jamais changé, et un CGI écrit en bash pour faire bonne mesure). Il est donc nécessaire que la sécurité soit assurée en dehors de ces machines, par un pare-feu. Donc, avoir cette fonction de protection, ainsi que la politique « tout interdit sauf ce qui est autorisé » (même si elle n'est pas activée par défaut) est utile, comme demandé par le RFC 7084. Cela ne doit pas faire oublier qu'il faut aussi pouvoir permettre aux machines du réseau de communiquer, lorsqu'elles en ont besoin.
Autre grande question des systèmes répartis, le nommage (section 3.7). Il ne fait pas de doute que Jean-Michu Toutlemonde préférera des noms parlants et surtout stables, aux adresses IPv6. À chaque changement de FAI, le préfixe IPv6, et donc les adresses, changera, alors que les noms resteront. Il faut donc des noms et, comme toujours dans le projet Homenet, que ces noms puissent être attribués sans administration explicite (à part éventuellement la saisie du nom dans une interface simple ; les autres machines devront s'attribuer un nom unique automatiquement). D'autre part, il faudra pouvoir découvrir des services (par exemple, une imprimante, ou bien un NAS), typiquement via une interface graphique qui affichera tous les services trouvés dans le réseau. Les protocoles existants à cette fin (comme celui du RFC 6763) sont typiquement mono-réseau et fonctionnent en criant à la cantonade « Y a-t-il une imprimante dans la salle ? » Avec les homenets composés de plusieurs réseaux, il faudra une autre approche.
En parlant de découverte de service, il est important de faire une distinction entre résolution (lookup) et découverte (discovery). La première consiste à trouver les informations (comme l'adresse IP) à partir d'un nom connu et existant. La seconde à trouver des noms (s'il y en a) correspondant à un certain critère. Homenet va avoir besoin d'un service de noms fournissant ces deux fonctions. Il est évidemment souhaitable, en application du principe qu'Homenet doit réutiliser autant que possible les protocoles existants, que cela soit le DNS (ou une variante comme celle du RFC 6762). Notre RFC voudrait même en plus qu'on puisse utiliser DNSSEC (RFC 4033) ce qui est très souhaitable pour la sécurité, mais tout en gardant cette absence de configuration, ce qui va être difficile.
D'autre part, on voudrait
pouvoir utiliser un espace de nommage public, celui des noms de domaine, mais tout en
gardant l'aspect « zéro configuration ». La question « un espace de
noms ou plusieurs » n'est pas tranchée par ce RFC. Si on veut accéder
aux engins de la maison depuis l'extérieur, il faudra bien utiliser
l'espace public et unique (celui d'aujourd'hui, là où se trouvent les
noms comme www.potamochère.fr, qui marchent sur
toute la planète). Si les noms dans
cet espace public dépendent du FAI (par exemple
jean-jacques.michu.free.fr), l'utilisateur
dépendra de son FAI. Le RFC souhaite donc qu'Homenet fonctionne avec
des noms de domaine personnels, qui assurent à l'utilisateur son
indépendance. Même dans le cas où on a des noms mondiaux, le RFC
demande qu'on puisse avoir en plus un espace de noms purement local,
qui ne fonctionne que sur le homenet (de la même
façon qu'il recommande des adresses IPv6 publiques
et des ULA). Le TLD
.local ne convient pas
forcément à cet usage car il est lié à un protocole particulier (le
mDNS du RFC 6762). Il faudra donc un nouveau TLD
pour les homenets multi-réseaux (ou bien attendre
une éventuelle extension de mDNS, dont le RFC ne parle pas). Une fois
le nouveau TLD défini (.sitelocal ? .home ?), les noms
dans ce TLD
seront des ALQDN (Ambiguous
Local Qualified Domain Name), des noms ambigus car plusieurs
réseaux pourront utiliser le même (par exemple Jean-Jacques Michu et
Jennifer Michu auront tous les deux un
michu.sitelocal). Ces noms sont casse-gueule car
on ne peut jamais exclure qu'un utiliseur ne mémorise un tel nom
lorsqu'il est sur un des réseaux et l'utilise après sur un autre
réseau où cela ne marchera pas ou, pire, où cela l'entrainera sur un
autre service que celui attendu. Une façon de résoudre le problème est
d'avoir des ULQDN (Unique Locally Qualified Domain
Name) où le deuxième composant du nom (avant
.sitelocal) serait une chaîne de caractères
unique, par exemple en condensant l'ULA. Cela peut être généré
automatiquement, et survivre aux redémarrages. Ainsi, on peut obtenir
un nom unique, avec quasiment aucun risque de collisions, sans faire
appel à un registre central. Cela
résoudrait le problème de l'accès depuis l'extérieur. Mais le
RFC oublie de dire que ces noms ne seront pas très
conviviaux... (04619d3973addefca2be3.sitelocal ?). Et
si on ne faisait pas appel à un TLD comme
.sitelocal mais qu'on utilisait simplement des
noms courts comme pc-jean-jacques ou
printer ? Le problème de ces noms est le risque
de collision avec, par exemple, un TLD délégué (que se passe-t-il si
l'ICANN délègue .printer ?)
Enfin, parmi les autres innombrables détails qui compliquent le déploiement d'un joli système de nommage pour le homenet, le RFC note que ce système doit continuer à fonctionner même si le réseau est déconnecté de l'Internet (et ne peut donc pas joindre les serveurs racine du DNS). Cela va à l'opposé de l'approche de la plupart des « objets intelligents » qu'on vend au gogo aujourd'hui et qui sont presque tous dépendants d'un cloud lointain à qui ils envoient systématiquement toutes les données. Et il y a le problème des engins mobiles qui peuvent être connectés à un homenet puis se déplacer pour un autre. On voudrait évidemment qu'ils gardent le même nom, mais ce n'est pas évident (DNS dynamique du RFC 2136 ?).
Pour terminer cette longue liste de problèmes à résoudre, la section 3.8 du RFC traite des problèmes divers. Par exemple, la gestion opérationnelle du réseau. Comme on veut un réseau sans administrateur et qui s'organise tout seul, cette activité de gestion doit être facultative. Mais il peut y avoir des tâches optionnelles, par exemple pour l'utilisateur avancé, ou pour celui qui a des exigences de sécurité fortes et veut donc durcir la configuration par défaut. Au minimum, même si l'utilisateur ne change rien, il aura peut-être envie de regarder (en mode « lecture seule ») son réseau, voir les machines connectées, le trafic (un seul ado abonné à Netflix à la maison peut sérieusement stresser le réseau, croyez-moi), les pannes, l'état de certains services (« NAS plein à 98 % », merci BitTorrent).
Enfin, pour clore le RFC, la section 3.9 revient sur les problèmes qui sont déjà résolus par IPv6 et sur ceux qu'il faudra résoudre. Le principe d'Homenet est de réutiliser, autant que possible, les protocoles existants de la famille IPv6. Mais il faudra bien développer de nouveaux protocoles pour les cas qui sortent du possible actuel. Le routage de base est, selon le RFC, bien traité à l'heure actuelle (bientôt OSPF à la maison...) Le cas du multi-homing avec plusieurs routeurs de sortie est plus compliqué, et nécessitera sans doute des extensions aux protocoles de routage.
À noter que Homenet a un futur protocole de distribution d'information, HNCP (Home Networking Control Protocol, pas encore de RFC publié), qui pourra servir de base à des mécanismes de distribution des routes.
Autre problème pas vraiment résolu, les protocoles de résolution (RFC 6762) et de découverte de services (RFC 6763) ne fonctionnent que sur un réseau où la diffusion à tous est possible. Dans un environnement multi-réseaux comme Homenet, il faudra utiliser leurs extensions, actuellement en cours de développement.
Dernier problème ouvert, pour les ambitieux qui ont des idées : découvrir automatiquement les frontières du réseau, où se termine la maison et où commence le monde extérieur. On l'a dit, Homenet est un projet très ambitieux, régulièrement critiqué comme trop ambitieux et traitant trop de choses à la fois.
Quelques bons articles à lire :
- Sur l'automatisation de la maison, les excellents et très concrets exposés de Nathalie Trenaman comme IPv6 at Home.
- Un article généraliste sur la maison qui tweete et l'exposé de son architecte à la Journée du Conseil Scientifique de l'AFNIC.
- Un article de synthèse très bien fait et très rigolo.
- Un très bon interview stratégique de Mark Townsley, président du groupe de travail Homenet. « The homenet working group focuses on home networks with IPv6. The task of the working group includes producing an architecture document that outlines how to construct home networks involving multiple routers and subnets, i.e. multi-homing with IPv6. » Il insiste sur les oppositions à Homenet et sur les contestations dans le groupe de travail, entre ceux qui voulaient que le réseau à la maison soit une simple extension de celui du FAI et ceux qui voulaient un réseau autonome « The limit from the operator’s perspective seems to be that the user can have one two or maybe three routers with one ISP connection and a backup or VPN connection, and thats about it. [...] There has always been this tug-of-war between what the operator will provide as a supported configuration and what the users will make happen on their own if the ISP doesn’t provide it. We’re seeing a bit of that in the Working Group now. ».
- Une excellente présentation générale, du même auteur.
Et, côté mise en œuvre, le projet Hnet.
L'article seul
RFC 7395: An XMPP Sub-protocol for WebSocket
Date de publication du RFC : Octobre 2014
Auteur(s) du RFC : L. Stout (&yet), J. Moffitt
(Mozilla), E. Cestari (cstar
industries)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF xmpp
Première rédaction de cet article le 1 novembre 2014
Le protocole XMPP (surtout connu par son utilisation dans la messagerie instantanée) peut fonctionner directement au-dessus de TCP. Mais pas mal de middleboxes se permettent de bloquer les protocoles inconnus et leur liste de protocoles connus est bien courte. XMPP a donc une adaptation à HTTP, lui permettant de tourner sur ce protocole. Mais la sémantique de HTTP, requête/réponse, ne convient guère à XMPP et les performances ne sont donc pas géniales. D'où ce nouveau RFC, qui adapte XMPP à WebSocket, lui permettant de tourner sur un protocole peu filtré, avec des meilleurs résultats que HTTP. La technique date de plusieurs années mais elle est maintenant normalisée.
XMPP est normalisé dans les RFC 6120 et RFC 6121. L'adaptation à HTTP, connue sous le nom de BOSH (Bidirectional-streams Over Synchronous HTTP) est décrite dans XEP-0124 et XEP-0206. Cette approche a fait l'objet de critiques (RFC 6202) notamment pour ses performances, comparées au XMPP natif (directement sur TCP).
Outre le problème des innombrables boîtiers situés sur le chemin et qui se permettent de bloquer certains protocoles, une limite de ce XMPP natif est liée au modèle « tout dans le navigateur Web ». Ces navigateurs peuvent exécuter du code récupéré sur le Web (code typiquement écrit en JavaScript) mais ce code a des tas de restrictions, notamment pour l'utilisation directe de TCP. Un client de messagerie instantanée écrit en JavaScript a donc du mal à faire du XMPP « normal ». D'où l'utilisation, peu satisfaisante, de HTTP. Mais, plutôt que d'utiliser le HTTP habituel, comme le faisait BOSH, on va utiliser WebSocket (RFC 6455). WebSocket fournit un service simple d'acheminement de messages, bi-directionnel, pour toutes les applications tournant dans un navigateur Web. Ce service est donc proche de celui de TCP (à part qu'il est orienté messages, au lieu d'acheminer un flux d'octets continu). XMPP sur WebSocket sera du XMPP normal, ayant les mêmes capacités que du XMPP sur TCP.
Attention à la terminologie : le mot anglais
message n'a pas le même sens en WebSocket (où il
désigne les unités de base de la transmission, équivalent des segments
TCP) et en XMPP (où il désigne un type particulier de strophe, celles
qui commencent par <message>). Dans ce RFC,
« message » a le sens WebSocket.
WebSocket permet de définir des sous-protocoles (qui devraient
plutôt être nommés sur-protocoles puisqu'ils fonctionnent au-dessus de
WebSocket) pour chaque application.
La définition formelle du sous-protocole XMPP est dans la section 3 de
notre RFC. Le client doit inclure xmpp dans
l'en-tête Sec-WebSocket-Protocol: lors du passage
du HTTP ordinaire à WebSocket. Si le serveur renvoit
xmpp dans sa réponse, c'est bon (ce
xmpp est désormais dans le registre
IANA des sous-protocoles WebSocket). Voici un exemple
où tout va bien, le serveur est d'accord, le client fait donc du XMPP
juste après :
Client:
GET /xmpp-websocket HTTP/1.1
Host: example.com
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Key: dGhlIHNhbXBsZSBub25jZQ==
Origin: http://example.com
Sec-WebSocket-Protocol: xmpp
Sec-WebSocket-Version: 13
Server:
HTTP/1.1 101 Switching Protocols
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Accept: s3pPLMBiTxaQ9kYGzzhZRbK+xOo=
Sec-WebSocket-Protocol: xmpp
Client:
<open xmlns="urn:ietf:params:xml:ns:xmpp-framing"
to="example.com"
version="1.0" />
Server:
<open xmlns="urn:ietf:params:xml:ns:xmpp-framing"
from="example.com"
id="++TR84Sm6A3hnt3Q065SnAbbk3Y="
xml:lang="en"
version="1.0" />
Chaque message WebSocket doit contenir un et un seul document XML complet (pas question de le répartir sur plusieurs messages), par exemple :
<message xmlns="jabber:client" xml:lang="en">
<body>Every WebSocket message is parsable by itself.</body>
</message>
Ce point était un de ceux qui avaient fait l'objet du plus grand nombre de discussions à l'IETF. L'avantage de cette exigence est qu'elle simplifie le travail des programmeurs. Autrement, c'est très proche de ce que fait XMPP sur TCP, à quelques détails près, dans le reste de la section 3.
Du fait de la règle « uniquement des documents XML complets et bien formés », les clients XMPP sur WebSocket ne peuvent plus utiliser le truc traditionnel qui consistait à envoyer des espaces entre les strophes pour garder la connexion ouverte (section 4.6.1 du RFC 6120). À la place, ils doivent utiliser un mécanisme comme le ping XMPP de XEP 0199 ou la gestion de flots du XEP 0198. Pourquoi ne pas utiliser les services de ping de WebSocket lui-même (section 5.5.2 du RFC 6455) ? On en a le droit mais ce n'est pas obligatoire, en reconnaissance du fait que les navigateurs Web ne donnent en général pas accès à ce service aux programmes JavaScript.
Autre conséquence de cette règle « uniquement des documents XML complets et bien
formés », on ne peut pas utiliser du XMPP chiffré avec TLS
(cela serait vu comme du binaire, pas comme du XML bien formé). Si on
veut sécuriser XMPP sur WebSocket, il faut lancer TLS avant, dans la
session WebSocket (URI
wss:, section 10.6 du RFC 6455).
Mais, au fait, comment un client sait-il qu'un service XMPP donné,
mettons jabber.lqdn.fr,
fournit du XMPP sur WebSocket ou pas ? Cette question fait l'objet de
la section 4. L'idéal serait d'avoir l'information dans le
DNS, de la même façon que le client XMPP
classique découvre, dans le DNS, que pour communiquer avec
bortzmeyer@jabber.lqdn.fr, il faut passer par le
serveur iota.lqdn.fr :
% dig SRV _xmpp-server._tcp.jabber.lqdn.fr ... ;; ANSWER SECTION: _xmpp-server._tcp.jabber.lqdn.fr. 3600 IN SRV 0 5 5269 iota.lqdn.fr.
Mais les pauvres scripts tournant dans les navigateurs n'ont hélas pas le
droit de faire directement des requêtes DNS. Il faut donc une autre
méthode d'indirection. La méthode officielle est d'utiliser les métadonnées du RFC 6415, avec les liens du RFC 8288. La relation à utiliser se nomme
urn:xmpp:alt-connections:websocket et elle est
décrite dans le XEP 0156. Pour l'adresse XMPP
bortzmeyer@jabber.lqdn.fr, on va 1) envoyer une
requête HTTP
http://jabber.lqdn.fr/.well-known/host-meta 2)
chercher dans le document récupéré un lien pour
urn:xmpp:alt-connections:websocket. Si on
trouve (c'est un exemple imaginaire) :
<XRD xmlns='http://docs.oasis-open.org/ns/xri/xrd-1.0'>
<Link rel="urn:xmpp:alt-connections:websocket"
href="wss://im.example.org:443/ws" />
</XRD>
C'est qu'il faut se connecter en WebSocket (avec TLS) à
im.example.org.
Quelques petits mots sur la sécurité : la méthode de découverte repose sur le DNS, comme pour la méthode originale de XMPP, puisqu'on doit se connecter en HTTP donc faire une requête DNS pour le nom du service XMPP. On peut (et on devrait) sécuriser le tout avec TLS. Mais attention, les applications qui tournent dans un navigateur Web n'ont pas toujours les moyens de faire leur vérification du certificat et notamment la correspondance entre le sujet du certificat et le nom de service souhaité. Si le nom est le même pour WebSocket et XMPP (ce qui n'est pas le cas de l'exemple de découverte cité plus haut, et ne sera pas le cas si on sous-traite son service XMPP), le navigateur a déjà fait la vérification lors de la connexion TLS WebSocket et il faut lui faire confiance. Sinon, il faut faire confiance à la délégation citée plus haut (le XRD).
Pour le reste, c'est toujours du XMPP et les mécanismes de sécurité classiques de XMPP, comme l'authentification des utilisateurs avec SASL, suivent les mêmes règles.
Il existe déjà plusieurs mises en œuvre de XMPP sur WebSocket (reflétant la relative ancienneté du protocole). Côté serveur, elles peuvent être dans le serveur lui-même (Node-XMPP-Bosh qui, en dépit de son nom, fait aussi des WebSockets, un module pour ejabberd ou un autre pour Openfire) ou bien sous forme d'une passerelle qui reçoit le XMPP sur WebSocket et le transmet au-dessus de TCP vers le vrai serveur (comme celle de Kaazing ou wxg). Côté client, il y a les bibliothèques JavaScript Strophe, Stanza.io et JSJaC. Question documentation, il y a un livre que je n'ai pas lu.
L'article seul
RFC 7384: Security Requirements of Time Protocols in Packet Switched Networks
Date de publication du RFC : Octobre 2014
Auteur(s) du RFC : T. Mizrahi (Marvell)
Pour information
Réalisé dans le cadre du groupe de travail IETF tictoc
Première rédaction de cet article le 30 octobre 2014
De plus en plus de protocoles sur l'Internet dépendent d'une horloge correcte. L'époque où les machines étaient vaguement mises à une heure approximative, de façon purement manuelle, est révolue. Aujourd'hui, il est essentiel de connaître l'heure exacte, et cela implique des dispositifs automatiques comme NTP. C'est encore plus essentiel quand il s'agit de protocoles de sécurité, comme DNSSEC (pour déterminer si une signature a expiré) ou X.509 (pour savoir si un certificat est encore valable). Mais cette utilisation du temps comme donnée dans un protocole de sécurité pose elle-même des problèmes de sécurité : si un attaquant perturbe NTP, ne risque-t-il pas d'imposer une fausse heure, et donc de subvertir des protocoles de sécurité ? D'où le groupe de travail TICTOC de l'IETF, dont voici le premier RFC : le cahier des charges des solutions de sécurité pour les protocoles de synchronisation d'horloges, comme NTP. (Une solution pour NTP a ensuite été normalisée dans le RFC 8915.)
Deux de ces protocoles sont largement déployés aujourd'hui : un protocole IETF, NTP (RFC 5905) et PTP, alias IEEE 1588 (pas disponible en ligne, comme toutes les normes du dinosaure IEEE). NTP inclut des mécanismes de sécurité, une authentification par secret partagé (RFC 5905, notamment section 7.3) et une autre par clé publique (Autokey, RFC 5906). Par contre, si PTP a un mécanisme d'authentification expérimental (annexe K de la norme), celui-ci ne semble pas avoir été formalisé complètement. Les déploiements de PTP sont donc non sécurisés.
On ne part donc pas de zéro, en tout cas pour NTP, qui a déjà une bonne partie des mécanismes demandés par ce cahier des charges. Ce RFC vise (section 1) un public composé des auteurs de logiciels de synchronisation (pour s'assurer qu'ils mettent en œuvre correctement les mécanismes de sécurité normalisés) et des auteurs de normes (qui vont devoir ajouter des mécanismes de sécurité là où ils manquent). Il peut aussi être utile aux opérationnels, lorsqu'ils révisent ou auditent la sécurité de leur système de synchronisation d'horloges. À partir de questions simples, « quelles sont les menaces ? », « quels sont les coûts de la sécurité ? », « quelles sont les dépendances croisées (par exemple une authentification des serveurs de temps via un certificat dont l'usage dépend d'une horloge correcte) ? », le RFC va poser une liste d'exigences pour les solutions de sécurité.
Un petit mot sur la terminologie au passage : PTP et NTP n'ont pas le même vocabulaire mais l'analyse de notre RFC traite ensemble les deux protocoles et utilise donc un vocabulaire commun. Ainsi, les termes « maître » (master) et « esclave » (slave) servent pour PTP et NTP (bien qu'en NTP, on dise plutôt « serveur » et « client »). Un « grand-maître » (grandmaster) est une machine qui a un accès direct à une horloge, sans passer par le protocole réseau.
Donc, commençons par l'analyse des menaces (section 3). On se base surtout sur l'article de l'auteur du RFC, T. Mizrahi, « Time synchronization security using IPsec and MACsec » (ISPCS 2011). Mais le RFC contient d'autres références à lire.
D'abord, une distinction entre attaquants internes et externes. Les externes sont juste connectés au même Internet que leurs victimes, ils n'ont aucun privilège particulier. Les internes, par contre, soit ont accès à une partie des clés cryptographiques utilisées, soit ont un accès au réseau sur lequel se trouvent leurs victimes et peuvent donc mener certaines attaques. Ils peuvent par exemple générer du faux trafic qui a plus de chances se sembler authentique. Se défendre contre ces Byzantins sera donc plus difficile. Si aucun mécanisme de sécurité n'est déployé, les attaquants internes et externes ont les mêmes possibilités.
Autre distinction importante entre les attaquants, ceux capables d'être Homme du Milieu et les autres. Un homme du milieu est placé de telle façon qu'il peut intercepter les paquets et les modifier. Les autres peuvent injecter des paquets (y compris en rejouant des paquets qu'ils ont lu) mais pas modifier le trafic existant.
Maintenant, quelles sont les attaques possibles ? La section 3.2 en fournit une longue liste. Rappelez-vous que ce sont des attaques théoriques : beaucoup sont déjà empêchées par les techniques de sécurité existant dans NTP (si elles sont activées...) Un homme du milieu peut modifier les paquets, en changeant les informations sur le temps, donnant ainsi de fausses informations. Tout va sembler OK mais les ordinateurs vont s'éloigner de l'heure réelle. Un attaquant actif peut aussi fabriquer, en partant de zéro, un faux paquet, contenant ces fausses informations. Il peut se faire passer pour le maître, trompant ainsi les esclaves, ou pour un esclave, donnant des informations au maître qui vont lui faire envoyer une réponse erronée au vrai esclave. Là aussi, tout semblera marcher, les horloges seront synchronisées, mais l'information sera fausse. Si l'attaquant a du mal à modifier des paquets ou à les générer (par exemple en raison d'une mesure de sécurité), il peut aussi tenter de rejouer des paquets du passé qu'il aura copiés. Cela permet potentiellement de faire reculer les horloges des victimes.
Un autre moyen de se faire accepter comme le maître, au lieu d'usurper l'identité du vrai maître, est de tricher dans le processus de choix du maître. Par exemple, en PTP, le maître est choisi par un algorithme nommé BMCA (Best Master Clock Algorithm) et le tricheur peut donc arriver à se faire désigner comme maître (rappelez-vous que PTP n'a guère de sécurité).
Un attaquant homme du milieu peut aussi jeter les paquets (faisant croire qu'un maître n'est pas joignable) ou les retarder délibérement : ce retard peut permettre de modifier l'horloge, puisque les participants au protocole NTP utilisent le temps d'aller-retour pour calculer l'heure chez le pair. Certaines protections anti-rejeu (comme le fait de vérifier qu'on ne reçoit pas de copie d'un paquet déjà reçu) ne marchent pas contre cette attaque.
Certaines de ces attaques peuvent se faire par des moyens très divers, situés dans la couche 2 ou dans la couche 3 : ARP spoofing, par exemple.
Une solution évidente à bien des problèmes de sécurité est la cryptographie. Mais attention, elle ouvre la voie à de nouvelles attaques comme l'envoi de paquets mal formés qui mènent à des calculs cryptographiques très longs, réalisant ainsi une attaque par déni de service. Une autre attaque par déni de service moins sophistiquée serait de noyer la machine sous un volume énorme de paquets NTP ou PTP.
L'attaquant peut aussi viser le grand-maître : si ce dernier utilise le GPS, un attaquant qui peut envoyer des faux signaux GPS peut tromper le grand-maître, trompant en cascade tous les autres participants. Aucune défense située dans le protocole de synchronisation ne sera alors effective, puisque l'attaque a lieu en dehors de ce protocole. Elle échappe donc au groupe de travail TICTOC.
Bien sûr, il y a aussi des menaces exploitant une faille des programmes qui mettent en œuvre les protocoles, plutôt que des protocoles eux-mêmes, par exemple les attaques par réflexion utilisant NTP, lorsque le serveur accepte trop facilement des requêtes normalement utiles uniquement pour le débogage.
Plus sophistiquées (peut-être trop pour être utilisées en vrai), les reconnaissances d'un réseau conduites grâce aux protocoles de synchronisation d'horloge. Un attaquant, pour préparer de futures attaques, commence par reconnaître sa cible, chercher les machines, etc. Avec la synchronisation d'horloges, il peut, passivement, collecter des informations qui, par leur fréquence et leur contenu, permettent, entre autres, de fingerprinter des machines spécifiques.
Les attaques possibles sont résumées en section 3.3, avec un tableau qui indique pour chaque attaque l'impact (horloges complètement faussées, précision diminuée - mais l'horloge reste proche du temps réel, ou déni de service) et le type d'attaquant qui peut les effectuer (interne ou externe, devant être homme du milieu ou pas).
De cette liste d'attaques et de leurs caractéristiques, notre RFC va tirer un certain nombre d'exigences auxquelles devront se conformer les solutions de sécurité. Chacune de ces exigences aura un niveau d'impérativité (les MUST et SHOULD du RFC 2119) selon l'impact et selon le type d'attaquant. Par exemple, les attaques qui peuvent être faites par un attaquant externe sont plus graves (le nombre d'attaquants potentiels est plus élevé) et ont donc plus souvent un MUST (section 4 pour la discussion sur les niveaux). Notez que la solution n'est pas forcément interne au protocole de synchronisation d'horloges : utiliser IPsec ou IEEE 802.1AE est souvent une bonne solution.
La section 5 donne la liste des exigences elle-mêmes. La première est l'authentification : il FAUT un mécanisme d'authentification (vérifier que la machine est bien ce qu'elle prétend être) et d'autorisation (vérifier que la machine qui annonce être un maître en a le droit). Notamment, les esclaves doivent pouvoir vérifier les maîtres. Ces mécanismes doivent être récursifs, car les protocoles de synchronisation d'horloges passent souvent par des relais intermédiaires (en NTP, une machine de strate 3 ne reçoit pas directement l'horloge, mais le fait via la machine de strate 2 - le RFC 5906 avait inventé le terme de proventication, contraction de provenance et authentication pour décrire cette question). Cette authentification permet de répondre aux attaques par usurpation d'identité. Sans cela, des attaques triviales sont possibles.
Par contre, l'authentification des esclaves par les maîtres est facultative (MAY) car un esclave malveillant ne peut pas tellement faire de mal à un maître (à part peut-être le déni de service par l'afflux d'esclaves non autorisés) et qu'un esclave a peu de maîtres alors qu'un maître a beaucoup d'esclaves, dont l'authentification pourrait nécessiter trop de travail.
Le RFC impose aussi l'existence d'un mode « fermé » où seuls des pairs authentifiés peuvent participer (il existe sur l'Internet beaucoup de serveurs NTP publics, acceptant des connexions de la part d'inconnus).
Le RFC exige un mécanisme de protection contre les attaques d'un homme du milieu essayant de diminuer la qualité des données, par exemple en retardant délibérement des paquets. En NTP, c'est par exemple le fait d'avoir plusieurs maîtres.
Après l'authentification (et l'autorisation), l'intégrité des paquets : notre RFC exige un mécanisme d'intégrité, permettant de s'assurer qu'un méchant n'a pas modifié les paquets en cours de route. Cela se fait typiquement par un ICV (Integrity Check Value). La vérification de l'intégrité peut se faire à chaque relais (ce qui est plus simple), ou bien de bout en bout (ce qui protège si un des relais est un vilain Byzantin).
L'usurpation d'identité est ensuite couverte : le RFC exige (MUST) un mécanisme permettant d'empêcher un attaquant de se faire passer pour le maître. Comme son nom l'indique, le maître peut modifier les horloges des autres machines à volonté et empêcher une usurpation est donc critique. Le RFC impose en outre un mécanisme contre le rejeu (car ce sont des attaques triviales à monter) et un moyen de changer les clés cryptographiques utilisées (cela a l'air évident mais certains protocoles - comme OSPF, cf. RFC 6039 - sont très pénibles pour cela, et en pratique les clés ne sont pas changées).
Les demandes suivantes sont moins fortes, car concernant des attaques moins graves ou plus difficiles à faire. Par exemple, il faudrait, si possible (SHOULD), fournir des mécanismes contre les attaques par déni de service.
Enfin viennent les simples suggestions, comme de prévoir un mécanisme assurant la confidentialité des paquets. Comme aucune information vraiment secrète ne circule dans les messages de synchronisation d'horloges, cette suggestion est un simple MAY.
Ces exigences sont résumées dans la section 6, sous la forme d'un tableau synthétique.
La section 7 rassemble un ensemble de questions diverses sur la sécurité des protocoles de synchronisation d'horloge. Par exemple, la section 7.4 se penche sur les interactions entre cette synchronisation et des protocoles extérieurs de sécurité comme IPsec. La 7.5 expose un cas plus embêtant, le problème d'œuf et de poule entre la synchronisation d'horloges et des protocoles qui utilisent l'heure dans leurs mécanismes de sécurité. Par exemple, si on utilise TLS avec authentification X.509 à un moment quelconque pour se connecter, une horloge correcte est nécessaire (vérification de la non-expiration du certificat), alors que NTP n'est pas forcément déjà disponible. Il faut donc une horloge stable, pour ne pas trop dériver en attendant que NTP prenne le relais.
Enfin, la section 8 rappelle que le problème difficile de la distribution des clés n'est pas encore traité, que ce soit dans ce RFC ou dans les protocoles.
Voici un court exemple de sécurisation avec NTP. Je n'ai pas utilisé la technique Autokey du RFC 5906 mais la plus ancienne (voire archaïque), qui utilise des clés privées. L'un des avantages est la portabilité, on sait que cela va marcher sur tous les clients et serveurs NTP. Sur le serveur, je crée les clés :
% sudo ntp-keygen -M Built against OpenSSL OpenSSL 1.0.1i 6 Aug 2014, using version OpenSSL 1.0.1j 15 Oct 2014 Generating new md5 file and link ntpkey_md5_alarmpi->ntpkey_MD5key_alarmpi.3623647899 % sudo ln -s ntpkey_md5_alarmpi ntp.keys % cat ntp.keys ... 11 SHA1 2db9278081f6b410cfb826317b87cf95d5b90689 # SHA1 key 12 SHA1 cc52f97bc43b6c43a4cbe446813f0c6c3bd54f7c # SHA1 key
Et j'indique dans la configuration que je n'autorise
(notrust) que les clients du réseau local, et
s'ils s'authentifient avec la clé n° 11 :
keys /etc/ntp/ntp.keys trustedkey 11 ... restrict default noquery nopeer nomodify notrap ... restrict 2a01:e35:8bd9:8bb0:: mask ffff:ffff:ffff:ffff:: notrust
Avec une telle restriction, les clients qui ne s'authentifient pas ne reçoivent pas de réponse (même pas une réponse négative), ce qui rend les problèmes d'authentification difficiles à déboguer, d'autant plus que Wireshark n'indique apparemment nulle part si les paquets sont authentifiés ou pas. Côté client, il faut donc montrer patte blanche, d'abord copier les clés puis :
keys /etc/ntp/ntp.keys trustedkey 11 server my-favorite-server key 11
Et, cette fois, le serveur répond et tout se passe bien.
Si vous voulez faire de l'Autokey (cryptographie à clé publique), vous pouvez consulter la documentation officielle ou bien, en français, l'article de Laurent Archambault (ou, en général, son cours NTP). Si, au lieu d'être sur Unix avec la mise en œuvre de référence ntpd, vous gérez un routeur Cisco, voyez en français cet article. Si vous utilisez le programme des gens d'OpenBSD, OpenNTPD, tant pis pour vous, il n'a aucun mécanisme de sécurité. Je n'ai pas trouvé de documents ANSSI sur la sécurisation des protocoles de synchronisation d'horloge. Le NIST a un service NTP authentifié (notez la complexité des procédures d'inscription !). Pendant longtemps, la référence en français était l'excellent article d'Alain Thivillon mais il est trop ancien aujourd'hui.
L'article seul
RFC 7381: Enterprise IPv6 Deployment Guidelines
Date de publication du RFC : Octobre 2014
Auteur(s) du RFC : K. Chittimaneni (Dropbox), T. Chown
(University of Southampton), L. Howard (Time Warner
Cable), V. Kuarsingh (Dyn), Y. Pouffary
(Hewlett Packard), E. Vyncke (Cisco)
Pour information
Réalisé dans le cadre du groupe de travail IETF v6ops
Première rédaction de cet article le 26 octobre 2014
Le déploiement d'IPv6 continue, trop lentement, mais il continue et de plus en plus d'organisations font désormais fonctionner ce protocole. Ce document est une série de conseils sur le passage à IPv6 au sein d'une organisation (le RFC dit « enterprise » mais je ne vois pas de raison de traduire par « entreprise », ce qui limiterait arbitrairement aux organisations privées prévues pour faire gagner de l'argent à leurs actionnaires). Les précédents RFC de conseils sur le déploiement d'IPv6 ciblaient des organisations spécifiques (comme les opérateurs réseaux dans le RFC 6036), celui-ci s'adresse à toute organisation qui dispose d'un réseau et d'administrateurs pour s'en occuper (les particuliers, ou toutes petites organisations sans administrateurs réseaux, ne sont pas traités).
Bref, vous êtes l'heureux titulaire du titre d'administrateur réseaux dans une organisation qui est pour l'instant encore attardée et qui n'utilise que le protocole du siècle dernier, IPv4. Votre mission, que vous l'acceptiez ou pas, est de passer à IPv6, sachant en outre que vous n'avez probablement pas le droit d'abandonner complètement IPv4. Que faire ? Le RFC 4057 décrivait ces réseaux d'organisation, qui se distinguent du réseau SOHO par la présence d'administrateurs réseaux compétents et dévoués. Il s'agit donc de réseaux gérés, contrairement au réseau de la maison de M. Toutlemonde. Le, la ou les administrateurs réseau doivent gérer un réseau interne, comprenant des serveurs, des postes de travail, des imprimantes, et parfois des routeurs internes. Ce réseau est connecté à l'Internet via au moins un routeur. Plusieurs serveurs sont prévus pour être accessibles de l'extérieur, par exemple le serveur de courrier. Donc, pour résumer le cahier des charges :
- Déployer IPv6 sans casser IPv4, qui doit continuer à fonctionner,
- Perturber le moins possible le service. L'utilisateur professionnel veut que ça continue à marcher, les changements techniques indispensables (comme le passage à IPv6) doivent pouvoir être ignorés dans le cadre de son travail.
La pénurie d'adresses IPv4 a des conséquences même sur ceux qui s'obstinent à ne pas déployer IPv6. Par exemple, comme le note le RFC 6302, les serveurs Internet, face au déploiement de techniques comme le CGN, ne peuvent plus se contenter de journaliser l'adresse IP source de leurs clients, ils doivent aussi noter le port source. D'autre part, même si on croit pouvoir se passer d'IPv6, certains réseaux ont déjà de l'IPv6 sans le savoir (parce qu'il est activé par défaut sur beaucoup de systèmes) et cela a des conséquences de sécurité (cf. RFC 6104 pour un exemple et le RFC 7123 pour une vision plus générale de ce problème).
Notre RFC propose trois phases pour l'opération de déploiement :
- Préparation et détermination,
- Phase interne,
- Phase externe.
Les deux dernières ne sont pas forcément exécutées dans cet ordre. Par exemple, si on gère un site Web et que beaucoup de clients potentiels ont déjà IPv6, il est logique de commencer par la phase externe, doter ce site d'une connectivité IPv6. En outre, bien des applications de gestion, comme celles de comptabilité sont affreusement archaïques et n'auront pas IPv6 de si tôt, ce qui relativise l'urgence de la phase interne. D'un autre côté, bien des systèmes d'exploitation ont IPv6 par défaut, et le RFC 7123 note que cela pose des problèmes de sécurité qui mériteraient peut-être une attention immédiate, et donc une priorité à la phase interne. Autre cas où la phase interne doit sans doute passer en premier : si l'espace d'adressage du RFC 1918 commence à ne plus suffire ou bien si une fusion/acquisition a mené à assembler deux réseaux qui utilisaient les mêmes préfixes, entraînant un grand désordre et l'envie, chez l'administrateur réseaux, de se reconvertir comme affineur de fromage dans l'Hérault, ou de déployer IPv6. Comme le notait le RFC 6879, la fusion/acquisition de deux organisations est souvent une bonne occasion pour passer à IPv6, car fusionner deux réseaux IPv4 en adressage privé est toujours long et compliqué. Bref, chaque organisation va devoir déterminer ses priorités et décider de commencer, après la première phase de préparation, par la phase interne ou par l'externe. Autrefois, il y avait aussi la catégorie « c'est bien compliqué tout cela, est-ce que ça en vaut la peine ? » mais sa taille diminue. Certaines objections techniques qui étaient valables à une époque (RFC 1687) ont depuis été traitées.
Donc, maintenant, au travail, avec la première phase, Préparation & Détermination (section 2 du RFC). Le RFC recommande de nommer un « chef de projet professionnel ». Ce qui est sûr est qu'il faut gérer le projet sérieusement, car c'est après tout un changement important dans l'infrastructure, avec plein d'interdépendances. La phase de Préparation & Détermination va, entre autres, servir à décider si on priorise la Phase Interne ou la Phase Externe. La première phase découvrira sans doute des problèmes inattendus et elle se fera donc en plusieurs itérations (« zut, ce plan ne marchera pas, il faut en trouver un autre »).
D'abord, l'inventaire de l'existant. Il faut faire la liste des matériels en déterminant pour chacun s'il est prêt pour IPv6. Il y aura du matériel déjà prêt (au sens où il fait déjà tourner un système capable d'IPv6), du matériel qui pourra recevoir une mise à jour logicielle, et du matériel qu'il faudra remplacer car aucun système avec IPv6 n'existe pour ce matériel. Par exemple, les routeurs (sauf le bas de gamme) sont probablement prêts, mais les objets connectés (genre caméras ou imprimantes) ne le sont souvent pas.
Après le matériel, le logiciel. Il faut faire le tour des applications pour déterminer lesquelles passeront en IPv6 sans problèmes. Si certains logiciels ne sont pas prêts, il faut demander au vendeur. Je suis toujours surpris que les vendeurs expliquent leur manque d'IPv6 par l'argument « aucun client ne l'a demandé ». Parfois, bien sûr, le vendeur ment mais, parfois, les clients semblent effectivement d'une timidité maladive et n'osent pas dire aux vendeurs, même gentiment « excusez-nous de vous demander pardon, mais pourrions-nous avoir de l'IPv6 un jour, s'il vous plait ? »
Lorsque l'application est développée/maintenue en interne, c'est l'occasion de se pencher sur les pratiques de codage. Est-ce que les applications ne sont pas d'un trop bas niveau, intégrant des détails non pertinents comme la taille de l'adresse IP ? Parmi les RFC dont la lecture peut être utile aux programmeurs à ce stade, citons le RFC 4038 sur le rapport entre les applications et IPv6, le RFC 6724 sur la sélection de l'adresse IP source, et le RFC 6555, sur l'algorithme des globes oculaires heureux, si utile lorsqu'on a à la fois IPv4 et IPv6. Un autre point important, mais non mentionné par ce RFC, est que le cycle de vie d'un logiciel développé en interne est long : ce qui est programmé aujourd'hui sera toujours en service dans de nombreuses années. Il faut donc adopter des bonnes pratiques de programmation (programmation réseau de haut niveau, valable aussi bien pour IPv4 que pour IPv6) aujourd'hui, même si la migration vers IPv6 semble lointaine.
C'est l'occasion d'aborder la question cruciale de la formation. Aujourd'hui, il existe encore des écoles ou universités qui enseignent IP sans parler d'IPv6, ou en le réduisant à deux heures de cours à la fin de l'année, dans un fourre-tout « divers sujets ». C'est consternant et cela veut dire que la formation à IPv6 dépendra surtout du technicien lui-même, ou bien de son employeur (section 2.3 du RFC).
Autre gros morceau dans la phase de préparation et détermination, la question de la sécurité. Évidemment, on veut que le réseau soit aussi sûr en IPv6 qu'en IPv4. Au passage, j'ai fait un long exposé à ce sujet. Je ne suis pas d'accord avec l'approche du RFC. Le RFC note qu'IPv6 n'est pas intrinsèquement plus sûr qu'IPv4 juste parce qu'il est plus récent, ce qui est du bon sens. Mais il prend ensuite une approche unilatérale, en notant qu'il existe beaucoup de failles de sécurité dans le code IPv6 car il n'a guère été testé au feu. C'est exact mais le RFC oublie de dire que c'est la même chose pour les attaquants : leurs programmes sont rarement adaptés à IPv6. Mon expérience est que les attaquants et les défenseurs sont aussi peu préparés à IPv6 et que, en pratique, la sécurité des deux protocoles est à peu près équivalente. Le RFC, comme le font souvent les professionnels de la sécurité, pessimistes par profession, ne voit que les faiblesses de la défense. En tout cas, tout le monde est d'accord pour dire que la formation (paragraphe précédent...) est essentielle.
Le RFC tord le cou à quelques mythes comme quoi la sécurité d'IPv6 serait meilleure (il oublie les mythes inverses, tout aussi répandus). Par exemple, IPv6 ne rend pas impossible le balayage d'un réseau, juste parce qu'il a davantage d'adresses. Le RFC 7707 décrit plusieurs techniques de balayage qui sont faisables avec IPv6 (et qui sont effectivement mises en œuvre dans des outils existants). Mais s'il est vrai qu'IPv6 n'empêche pas le balayage, ce nouveau RFC, dans son analyse trop rapide, oublie de dire que le balayage est bien plus facile et rapide en IPv4, comme le montre la disponibilité d'outils (comme massscan) qui balaient tout l'Internet IPv4 en quelques heures ! De même, notre nouveau RFC rappelle qu'IPv6 n'a pas de sécurité cryptographique par défaut (contrairement à une légende répandue par des zélotes d'IPv6 au début, cf. RFC 6434 pour l'enterrement de cette légende). Pire (et, là, ce RFC 7381 est gravement en tort) : la section 2.4.1 explique que c'est une bonne chose pour la sécurité qu'il n'y ait pas de chiffrement car il faut pouvoir espionner le trafic de ses utilisateurs, un argument vraiment incroyable à l'ère post-Snowden.
Le RFC est plus raisonnable par la suite en notant que certaines pratiques de sécurité relèvent plus de la magie que de la raison. Par exemple, les ULA en IPv6 (RFC 4193) ou les adresses privées en IPv4 (RFC 1918) n'apportent aucune sécurité en elles-même, contrairement à ce que croient naïvement certains administrateurs réseau.
Notre RFC fait le point sur les failles de sécurité qui sont spécifiques à IPv6 :
- Les adresses de protection de la vie
privée (RFC 8981) ne la protègent
que partiellement mais, surtout, compliquent la vie de
l'administrateur réseaux, en limitant la traçabilité des machines. Si
un journal montre que
2001:db8:1:1:c144:67bd:5559:be9fs'est connecté au serveur LDAP, comment savoir quelle machine était2001:db8:1:1:c144:67bd:5559:be9fpuisque, s'il utilisait le RFC 8981, il a pu changer d'adresse souvent, sans que cela soit enregistré quelque part ? Une solution possible est d'utiliser un logiciel qui écoute le réseau et stocke dans une base de données les correspondances entre adresses MAC et adresses IPv6 (un logiciel comme ndpmon, donc). Si on contrôle complètement les machines terminales, on peut aussi interdire les extensions « vie privée ». On peut enfin forcer l'usage de DHCP en demandant au routeur d'envoyer toutes les annonces avec le bit M (qui indique que DHCP est disponible, RFC 4861, section 4.2) et qu'aucun préfixe ne comporte le bit A (ce qui interdira l'auto-configuration sans état, RFC 4861, section 4.6.2). Cela suppose que toutes les machines ont un client DHCP v6, ce qui n'est pas gagné aujourd'hui. Pire : on sait qu'aujourd'hui le comportement des différents système en présence des bits M et A varie énormément. - Et les en-têtes d'extension ? Leur analyse est difficile et, résultat, certains systèmes de sécurité ne savent pas les traiter, permettant ainsi au méchant d'échapper à la détection ou au filtrage, simplement en ajoutant des en-têtes au paquet IPv6 (RFC 7113 pour un exemple).
- La fragmentation est une source classique de casse-tête. Elle existe aussi en IPv4 mais IPv6 la restreint à la source, les routeurs intermédiaires ne peuvent pas fragmenter. Du point de vue sécurité, la principale question liée à la fragmentation est le fait que, au nom d'une sécurité mal comprise, certains réseaux bloquent le protocole ICMP, malgré le RFC 4890, gênant ainsi la détection de MTU et empêchant donc de facto la fragmentation. Autres problèmes liés à la fragmentation, mais qui ne sont pas spécifiques à IPv6, le risque d'utilisation de fragments pour échapper à la détection (RFC 6105 pour un exemple), et le réassemblage de fragments qui se recouvrent (RFC 5722).
- Pour la résolution d'adresses IP en adresses MAC, IPv6 utilise NDP et plus ARP. Le RFC classe cela comme « une importante différence » mais, en fait, du point de vue de la sécurité, les deux protocoles sont très proches. Ils fonctionnent en diffusant à tous l'adresse convoitée, et ils font une confiance absolue à la première réponse reçue. Aucune authentification n'existe (IPv6 a des solutions, mais très peu déployées, cf. RFC 3971 et RFC 3972).
- Enfin, dernier problème qu'on n'avait pas avec de l'IPv4 pur, un réseau double-pile, IPv4 et IPv6, augmente la surface d'attaque en offrant davantage de possibilités au méchant. Au minimum, il faut faire attention à ce que les politiques de sécurité soient les mêmes en IPv4 et en IPv6 afin d'éviter (je l'ai déjà vu), un pare-feu strict en IPv4 mais très laxiste en IPv6.
Maintenant, le routage. Un grand réseau interne va probablement utiliser un IGP. Lequel ? Plusieurs protocoles gèrent IPv6 (RIPng, IS-IS, OSPF). A priori, pour faciliter la vie des techniciens, il est logique d'utiliser le même protocole de routage en IPv4 et en IPv6. Petit piège dans le cas d'OSPF : OSPF v2 (pour IPv4) et OSPF v3 (pour IPv6) sont proches mais ne sont pas exactement le même protocole (le RFC oublie qu'OPSF v3 peut désormais gérer IPv4, cf. RFC 5838, mais il est vrai que c'est très peu fréquent).
Et l'adressage (section 2.6) ? Il est évidemment radicalement différent en IPv4 et en IPv6. En IPv4, l'essentiel du travail sur l'adressage a pour but d'économiser les quelques adresses qu'on détient, pour tout faire fonctionner malgré la pénurie. En IPv6, ce problème disparait et on peut donc se concentrer sur un plan d'adressage propre. Le document à lire pour faire de jolis plans d'adressage en IPv6 est le RFC 5375.
L'une des décisions à prendre sera d'utiliser des adresses PA ou PI. Les premières sont attribuées par l'opérateur réseau qui nous connecte à l'Internet. Pas de formalités particulières à remplir, elles sont typiquement allouées en même temps que la connectivité est mise en place. Leur inconvénient est qu'on dépend de l'opérateur : le multi-homing va être plus difficile, et, si on change d'opérateur, on est parti pour une pénible renumérotation (RFC 5887). En outre, il peut être difficile d'obtenir la taille de préfixe souhaitée, malgré le RFC 6177 : certains opérateurs ne fileront qu'un /56, voire un /60. Les secondes adresses, les adresses PI, résolvent ces problèmes mais les obtenir nécessite d'affronter la bureaucratie des RIR. Pour les réseaux internes, notre RFC recommande un /64 pour les réseaux des utilisateurs, et un /127 pour les interconnexions point-à-point, comme dit dans le RFC 6164. IPv6 ne nécessite pas les masques de longueur variable, très communs en IPv4 pour essayer de grappigner quelques malheureuses adresses. Utiliser, par exemple, un /80 pour un Ethernet de plusieurs machines utilisateur empêcherait d'utiliser l'auto-configuration (RFC 4862) sans gain utile, et au risque de perturber les futures réorganisations du réseau.
Une fois le plan d'adressage fini, il reste à distribuer les adresses aux machines. Autrefois, on n'utiliisait que SLAAC, parce que c'était la seule possibilité. Le RFC note, avec un très grand optimisme, que DHCP est désormais une alternative mûre (en fait, bien des machines clientes n'ont pas encore de client DHCP, voilà pourquoi je trouve le RFC trop optimiste). Pour le réseau fermement administré, DHCP a l'avantage de garder trace de la correspondance entre adresse MAC et adresse IP, en un point central. Pour faire l'équivalent avec SLAAC, il faudrait un logiciel de supervision comme ndpmon cité plus haut. Autre avantage de DHCP, le serveur DHCP est l'endroit logique où faire des mises à jour dynamiques du DNS pour refléter les changements d'adresses IP. Dernier mot sur le DNS : il est déconseillé de mettre des données pour les ULA dans le DNS mondial.
La phase de Préparation et de Détermination se termine avec une analyse des outils disponibles pour l'administrateur réseaux. Il arrive en effet trop souvent que l'outil utilisé, par exemple, pour le déploiement de nouvelles versions de logiciels, ne soit finalement pas compatible IPv6. S'il a été écrit dans les dix dernières années, cela montre une grande incompétence de la part de son auteur mais ça arrive. Parmi les erreurs faites par les programmeurs, le manque de place pour la représentation des adresses, que ce soit en forme texte (RFC 5952) ou sous leur forme binaire. Ceci dit, tant que le réseau est en double-pile, certaines fonctions (par exemple l'interrogation des agents SNMP) peuvent continuer à se faire en IPv4.
S'il est logique de commencer par la phase Préparation & Détermination, le choix de la phase suivante dépend, comme on l'a vu, des caractéristiques propres à l'organisation dont on gère le réseau. Le RFC commence par la phase externe (section 3) mais ce n'est que l'ordre de présentation, pas forcément l'ordre recommandé.
Donc, la phase externe : il s'agit de migrer en IPv6 les composants du réseau visibles de l'extérieur. Il va évidemment falloir obtenir une connectivité IPv6 d'un opérateur réseau. Il est fortement recommandé d'utiliser de l'IPv6 natif, plus simple à déboguer et évitant les problèmes comme la taille de MTU. Mais, si cela n'est pas possible (dans certaines régions du monde, il est très difficile de trouver un opérateur qui sache faire de l'IPv6), il faudra se résigner à utiliser un tunnel, par exemple vers Hurricane Electric, qui fournit un service stable et pro. Si les adresses utilisées sont des adresses PA, ledit opérateur s'occupera du routage externe. Si ce sont des PI, l'opérateur pourra parfois les router pour le compte du client, et le client devra parfois faire du BGP lui-même. Évidemment, l'obtention d'un préfixe PI va dépendre des règles du RIR local. Par exemple, en Europe, le RIPE-NCC n'impose plus d'être multihomé pour avoir un préfixe PI.
Notre RFC ne traite pas des problèmes spécifiques à chaque
service. Par exemple, cela aurait pu être l'occasion d'expliquer que,
si annoncer une adresse IPv6 pour un serveur
HTTP peut présenter un risque (pour les clients
qui croient avoir une connectivité IPv6 alors qu'elle est imparfaite,
cf. RFC 6556), en revanche, mettre des adresses
IPv6 à ses serveurs DNS n'en présente aucun,
puisque les clients DNS mettent en œuvre depuis longtemps un
algorithme de test et de sélection des différents serveurs d'une
zone. Cela explique sans doute que, selon le
rapport ODRIF, il y ait beaucoup plus de zone sous
.fr avec du DNS IPv6 que
de zones avec un serveur Web IPv6. (Notez que
Google fait, curieusement, le contraire : leurs
sites Web sont IPv6 depuis longtemps mais leurs zones DNS non.)
Il faudra évidemment penser à la sécurité. Le RFC rappelle que, si on filtre, il ne faut surtout pas bloquer stupidement tout ICMP, indispensable à certaines fonctions d'IPv6 (voir le RFC 4890 pour une discussion détaillée, que notre RFC résume en donnant la liste minimale des types de messages ICMP qui doivent être autorisés).
Il y a des règles de sécurité générales, qui s'appliquent à IPv6 aussi bien qu'à IPv4 : attention aux applications (pensez à mettre bash à jour, par exemple...), mettez en place des mécanismes contre l'usurpation d'adresses (RFC 2827), protégez les routeurs (RFC 6192), etc. Et il y a quelques règles spécifiques d'IPv6 comme les attaques contre le cache NDP (RFC 6583) : il est recommandé de limiter le rythme des requêtes NDP et de bloquer le trafic entrant sauf vers les adresses publiques.
La supervision doit aussi faire l'objet d'une grande attention. Notre RFC recommande de surveiller séparément IPv4 et IPv6, pour être averti si un des deux protocoles défaille. Prenons l'exemple d'un serveur HTTP. Si vous testez son bon fonctionnement avec curl ou wget, vous ne serez pas prévenu si IPv4 ou IPv6 est en panne. En effet, ces deux programmes passent automatiquement aux adresses IP suivantes si l'une d'elles ne fonctionne pas. Il faut donc un test explicitement limité à IPv4 et un limité explicitement à IPv6. Avec Icinga et le check_http des monitoring plugins, cela peut être :
define service{
use generic-service
hostgroup_name WebServers
service_description HTTP4
check_command check_http!-4
}
define service{
use generic-service
hostgroup_name WebServers
service_description HTTP6
check_command check_http!-6
}
Il reste la phase interne (section 4) qui, rappelez-vous, peut être faite avant, après ou en même temps que la phase externe, selon les caractéristiques de votre réseau et vos choix. Il s'agit cette fois de migrer en IPv6 le réseau interne, ses applications métier, ses commutateurs, ses postes de travail... A priori, comme il y a peu de chances que toutes les applications et systèmes IPv4 soient prêts demain à migrer, le réseau interne va rester mixte pendant longtemps. Pour la connectivité, la règle habituelle s'applique : « double-pile quand on peut, tunnel quand on n'a pas le choix ». La double-pile (IPv4 et IPv6 sur tous les équipements) est la solution la plus simple pour la gestion du réseau. Le tunnel, fragile et faisant dépendre IPv6 d'IPv4, sert pour les cas où on est coincé à n'utiliser que des systèmes antédiluviens.
En interne également, on va se poser la question de la
sécurité. Les gestionnaires de réseaux d'organisations sont souvent
peu satisfaits des adresses IP « vie privée » du RFC 8981, car elles rendent difficile la
traçabilité (« 2001:db8:1:1:c144:67bd:5559:be9f a fait des
accès répétés au serveur LDAP, c'est qui, déjà,
2001:db8:1:1:c144:67bd:5559:be9f ? ») Ou bien on force
l'utilisation de DHCP, ou bien on utilise un outil comme
ndpmon qui garde trace des correspondances
entre adresses MAC et adresses IP.
Comme pour les ARP et DHCP d'IPv4, les techniques de base du réseau IPv6 (les RA de NDP, et DHCP) n'offrent aucune sécurité et il est trivial, par exemple, d'envoyer des « RAcailles », des faux RA (RFC 6104). Il est donc très recommandé de déployer des techniques comme celles du RFC 6105. Vérifiez auprès de votre fournisseur de commutateurs qu'elles sont disponibles ! Dans le futur, les techniques issues du projet SAVI (Source Address Validation Improvement, cf. RFC 6959) aideront peut-être.
Pour assurer le bon fonctionnement du réseau interne, une des questions qui perturbent le plus les administrateurs d'un réseau IPv6 est le choix du mécanisme principal de configuration des machines terminales. SLAAC (RFC 4862) ou DHCP (RFC 8415) ? Il n'y a pas de réponse simple, chacune des deux solutions ayant ses avantages et ses inconvénients. SLAAC est certainement plus simple et plus rapide à déployer mais DHCP permet davantage de contrôle, ce qui est en général apprécié dans les réseaux d'organisations. En pratique, malheureusement, il faudra sans doute les deux car aucun des deux mécanismes ne permet de tout faire. Par exemple, DHCP n'a pas d'option pour indiquer les routeurs à utiliser (il faudra donc compter sur les RA de SLAAC, ou sur une configuration statique). Et SLAAC ne permet pas d'indiquer les serveurs NTP. Si les deux protocoles, DHCP et SLAAC, permettent désormais d'indiquer les résolveurs DNS, aucun des deux n'est encore suffisant pour tous les usages et, en pratique, il est difficile de choisir.
Autre question essentielle, la résilience face aux pannes. Cela passe par la redondance des équipements comme les routeurs. NDP permet aux machines de maintenir une liste de routeurs disponibles et de passer à un autre en cas de panne (RFC 4861, section 7.3). Par défaut, la bascule se fait en 38 secondes (RFC 4861, section 10), ce qui est bien trop long dans beaucoup de cas. Il est donc souvent préférable d'utiliser des techniques comme VRRP (RFC 5798).
Autre problème à regarder de près pendant la phase Interne, les machines terminales, de l'ordinateur de bureau à la machine à café connectée, en passant par l'imprimante et la caméra de vidéo-surveillance. Les ordinateurs ont quasiment tous IPv6 aujourd'hui (mais pas forcément activé par défaut). Mais certaines fonctions peuvent manquer (adresses privées du RFC 8981, client DHCPv6, client RA qui comprend les résolveurs DNS du RFC 8106...) Il est également possible que des algorithmes comme la bonne sélection de l'adresse source (RFC 6724) ou les globes oculaires heureux (RFC 6555) soient manquants ou désactivés. Or, sans eux, l'utilisation d'un système double-pile (IPv4 et IPv6) est bien plus pénible. Il faut donc s'assurer de bien connaître le comportement par défaut des systèmes qu'on utilise sur les réseaux locaux.
Quant aux autres engins, non considérés comme des ordinateurs, il est malheureusement fréquent, en 2014, qu'ils n'aient toujours pas IPv6 (alors même qu'ils sont souvent bâtis sur des systèmes, comme Linux, qui ont IPv6 depuis longtemps). Enfin, le dernier gros problème de la phase interne sera les systèmes utilisés dans l'infrastructure de l'organisation (le système de téléphonie, par exemple) qui ne sont pas toujours prêts pour IPv6. Là encore, il est essentiel que les clients se fassent entendre et tapent sérieusement sur les vendeurs les plus attardés.
On a parlé à plusieurs reprises de réseaux double-pile car c'est l'approche la plus réaliste aujourd'hui. Pourra-t-on un jour simplifier sérieusement le réseau en supprimant enfin le bon vieil IPv4 et en ayant à nouveau un réseau mono-protocole, entièrement IPv6 ? C'est bien le but à long terme, dit avec optimisme la section 5 de notre RFC. Atteindre ce but ne nécessite même pas que tout l'Internet soit entièrement passé en IPv6. Il existe des techniques permettant aux machines d'un réseau purement IPv6 de parler avec les derniers survivants de l'ère IPv4 (cf. par exemple RFC 6144). Au début, une bonne partie du trafic devra passer par ces relais ou des traducteurs NAT64. Mais au fur et à mesure que le reste de l'Internet devient accessible en IPv6 (RFC 6883), ces techniques deviennent naturellement de moins en moins utilisées.
Tous les conseils ci-dessus étaient génériques, s'appliquant à toutes sortes d'organisations. La section 6 traite maintenant des cas particuliers de certaines organisations. Par exemple, les gens dont le métier est de distribuer du contenu sur l'Internet (par exemple via un CDN) ont intérêt à lire les RFC 6883 et RFC 6589.
Un autre cas particulier, qui permettra de finir sur une note optimiste, est celui des campus universitaires. Ils sont aujourd'hui très souvent passés à IPv6. Les NREN ont en général IPv6 depuis le début des années 2000. L'intérêt pour les techniques nouvelles, et la mission de recherche et d'éducation, faisait des universités l'endroit logique pour les premiers déploiements. C'est évidemment souvent le département d'Informatique qui était le premier à migrer ses machines et ses services vers IPv6. Le réseau Eduroam est également accessible avec IPv6 puisqu'il repose sur 802.1x (qui est indifférent à la version du protocole IP utilisée) et non pas sur ces horribles portails captifs (dont un des inconvénients est d'être limité à un protocole).
La grande majorité des universités qui ont déployé IPv6 n'utilise pas d'ULA, ni traduction d'adresses. Presque toujours, elles utilisent des adresses PA fournies par le NREN.
L'article seul
RFC 7375: Secure Telephone Identity Threat Model
Date de publication du RFC : Octobre 2014
Auteur(s) du RFC : J. Peterson (NeuStar)
Pour information
Réalisé dans le cadre du groupe de travail IETF stir
Première rédaction de cet article le 26 octobre 2014
Elle est loin, l'époque où l'Internet et le téléphone étaient deux mondes complètement séparés. Aujourd'hui, le téléphone n'est qu'une application parmi toutes celles tournant sur l'Internet. et les problèmes de sécurité du téléphone sont donc des problèmes Internet. D'où ce RFC qui décrit les menaces d'usurpation d'identité qui planent sur la téléphonie sur IP (cf. SIP, RFC 3261).
La plupart des attaques utilisant le téléphone commencent en effet par un mensonge sur le numéro d'appel : l'attaquant va se débrouiller pour présenter un numéro d'appel qui n'est pas le sien. Souvent, en effet, le numéro de l'appelant est utilisé pour mettre en œuvre une politique de sécurité : on décroche parce qu'on connait le numéro, ou bien on prend au sérieux un appel d'urgence parce qu'on sait qu'on pourra retrouver l'éventuel mauvais plaisant via son numéro ou encore on donne accès à un répondeur en n'utilisant pour toute authentification que le numéro d'appel. Bien sûr, quelqu'un qui ne veut pas révéler son numéro peut toujours ne pas le présenter. Mais beaucoup de correspondants ne décrocheront pas s'ils reçoivent un appel sans numéro. C'est pour cela que les spammeurs du téléphone préfèrent présenter un numéro, n'importe lequel. D'où la création du groupe de travail STIR de l'IETF, groupe qui est chargé de travailler sur ce problème (une description du problème figure dans le RFC 7340). Le but de STIR est de faire en sorte que, quand on voit un numéro entrant s'afficher, on soit raisonnablement sûr que ce soit bien un numéro que l'appelant est autorisé à utiliser.
On ne peut pas traiter le problème à la source : l'attaquant contrôle son téléphone et peut lui faire faire ce qu'il veut. Il faut donc traiter le problème dans le réseau téléphonique, ou bien à l'arrivée, et pouvoir distinguer les numéros autorisés des autres. Une fois qu'on aura cette distinction, on pourra appliquer les politiques de sécurité de son choix (par exemple ne pas décrocher si le numéro présenté n'est pas vu comme sérieusement authentifié).
Ce RFC se focalise sur la triche lors de l'appel. Une fois la connexion établie, d'autres attaques sont possibles (écouter le trafic en cours de route, rediriger les paquets IP vers une autre destination ou, tout simplement utiliser les nombreuses possibilités de SIP pour transférer un appel) mais elles nécessitent typiquement plus de moyens que l'usurpation de numéro, qui peut souvent être faite en n'ayant pas d'autres outils que son téléphone.
Autre piège qui n'est pas traité par le groupe STIR : des téléphones ont des fonctions de carnet d'adresses ou d'annuaire et peuvent donc afficher, à la place du numéro d'appel, le nom de la personne appelante. Cela permet d'autres attaques : par exemple, si l'annuaire n'est pas bien sécurisé, on peut imaginer que l'attaquant glisse un nom d'apparence légitime pour son numéro d'appel, et que le destinataire sera alors trompé, sans qu'il y ait eu usurpation de numéro. C'est une vraie possibilité mais elle nécessite des solutions très différentes (sécurisation des carnets d'adresse et des annuaires).
La section 2 de notre RFC décrit les différents acteurs. Il y a les utilisateurs, aux extrémités, avec leurs téléphones, simples engins sans trop de complications ou au contraire smartphones très riches. Il y a les intermédiaires, par exemple les relais SIP (on ne fait pas de la téléphonie en direct, en général, ne serait-ce que parce que le destinataire n'est pas forcément joignable en ce moment), et il y a les attaquants. Les intermédiaires peuvent modifier les caractéristiques de l'appel en cours de route, par exemple en jetant le numéro d'appel ou en substituant un autre. Ainsi, une passerelle entre la téléphonie IP et le PSTN pourra substituer au numéro indiqué dans un paquet IP son propre numéro, pour une meilleure traçabilité. Quant aux attaquants, on suppose qu'ils ont un téléphone (!) et peuvent passer un appel depuis le lieu de leur choix. Comme indiqué plus haut, ils peuvent indiquer un faux numéro (les téléphones traditionnels ne permettaient pas cela mais c'est possible avec les engins modernes). Pire, ayant accès à l'Internet, on suppose qu'ils peuvent envoyer des paquets IP quelconques, sans passer par un téléphone ou un softphone. Enfin, notre RFC ne prend délibérement pas en compte le risque d'une trahison ou d'un piratage des intermédiaires. Certes, l'attaquant qui contrôlerait les serveurs intermédiaires pourrait faire beaucoup de dégâts mais ce n'est pas ce qui se fait aujourd'hui, dans la grande majorité des cas d'usurpation de numéro.
Après les acteurs, place aux attaques (section 3). L'attaquant peut chercher à usurper un numéro de téléphone donné (par exemple pour se faire passer pour une personne précise) ou bien il peut juste chercher à usurper n'importe quel numéro de téléphone valide (pour ne pas exposer le sien, qui permettrait de remonter jusqu'à lui). Un exemple du premier cas est celui de l'accès à une boîte vocale, lorsque l'authentification se fait uniquement sur la base du numéro présenté. Certes, il serait sans doute préférable d'utiliser (en plus, ou à la place du numéro présenté) une authentification plus forte mais, en pratique, un certain nombre de systèmes n'authentifient qu'avec le numéro appelant, surtout les services commerciaux comme la vidéoconférence où on ne souhaite pas trop embêter le client. Ajouter une authentification par, par exemple, un code numérique à taper, compliquerait les choses pour l'utilisateur. Si le système appelé pouvait savoir si le numéro de téléphone a été correctement authentifié, il pourrait, par exemple, n'imposer la frappe du code numérique que dans le cas où le numéro n'est pas fiable. Comme ces services sont souvent appelés de manière répétitive, on peut aussi compter sur l'historique, par exemple savoir s'il est normal ou pas que tel numéro entrant soit authentifié.
Et le spam, plaie du téléphone comme il l'est du courrier électronique ? Comment empêcher les appels automatiques (robocallers) ? Pour éviter les plaintes, et qu'on remonte jusqu'à eux, les spammeurs ne veulent pas présenter leur vrai numéro. Par exemple, Bouygues Telecom m'appele toujours depuis une ligne qui ne présente pas le numéro d'appelant. Résultat, je ne décroche plus pour de tels appels. Les spammeurs ont donc intérêt à présenter un numéro, mais qui ne soit pas le leur. Leur tâche est donc plus facile que dans le cas précédent, où ils devaient usurper un numéro précis. Par contre, cette fois, l'appelé ne peut pas compter sur l'historique pour évaluer l'appel.
Un des problèmes de l'authentification des appels entrants est le manque de temps. Si c'est une machine qui est appelée (comme dans le cas précédent, celui du répondeur), on peut la faire patienter, le temps qu'on vérifie. Si c'est un humain qu'il faut contacter, c'est plus délicat. Faut-il lui signaler un appel qu'on n'a pas encore eu le temps d'authentifier ? Cette nécessité d'agir en temps réel peut rendre certaines techniques (par exemple de longs calculs cryptographiques) difficiles à faire accepter. Les SMS n'ont pas ce problème : on peut retarder leur distribution sans conséquences sérieuses.
La téléphone connait aussi des attaques par déni de service. Un attaquant peut appeler simplement pour épuiser des ressources limitées, et déguiser alors son numéro pour éviter des représailles (ou tout simplement pour éviter d'être mis en liste noire). Il peut être capable d'utiliser plusieurs fournisseurs et plusieurs téléphones, pour faire une dDoS. Comme le robocaller, l'attaquant qui vise un déni de service n'a pas besoin d'usurper un numéro de téléphone particulier. Tout numéro qui n'est pas le sien conviendra (il voudra probablement le faire varier rapidement, pour éviter les contre-mesures fondées sur des listes noires). Une exception est le cas de l'attaque par réflexion, où l'attaquant veut faire croire à la culpabilité d'un tiers, et usurpe donc le numéro de ce tiers.
Les contre-mesures sont donc les mêmes que pour les appels automatiques des spammeurs : vérifier que les numéros présentés sont des numéros possibles (cela bloque les attaques les moins sophistiquées, celles où l'attaquant met n'importe quoi au hasard), et traiter différemment les appels où on peut être sûr que les numéros sont légitimes (dans le cas d'une attaque, jeter systématiquement les numéros non garantis, par exemple). Un tel traitement différencié n'est toutefois pas acceptable pour les appels d'urgence, qui ont l'obligation de répondre à tout.
Et, pour finir le RFC, les scénarios d'attaque possibles (section
4). Si l'attaquant et sa victime (l'appelant et l'appelé) sont tous
les deux en SIP, l'attaquant n'a qu'à mettre le
numéro qu'il veut dans le champ From: de la
requête SIP INVITE. Si les deux sont au
contraires connectés au PSTN (la téléphonie
traditionnelle), l'attaquant doit avoir le contrôle du
PABX qu'utilise son téléphone. Le PABX envoie une
requête Q.931 SETUP avec
le numéro de son choix qui va se retrouver dans l'appel
SS7, champ Calling Party
Number. Et si l'attaquant est en IP et la victime sur le
PSTN ? Comme dans le premier cas, il met le numéro qu'il veut dans le
message SIP et la passerelle IP<->PSTN va le transmettre à
l'appelé. Arrivé là, vous vous demandez sans doute quelles sont les
solutions possibles à ces attaques, qui semblent si simples à faire ?
Mais ce RFC ne fait que l'analyse des menaces, les solutions seront
dans des RFC futurs.
L'article seul
RFC 7386: JSON Merge Patch
Date de publication du RFC : Octobre 2014
Auteur(s) du RFC : P. Hoffman (VPN
Consortium), J. Snell
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF appsawg
Première rédaction de cet article le 15 octobre 2014
La commande HTTP PATCH
permet d'envoyer à un serveur HTTP un document représentant les
différences entre l'état d'une ressource sur le serveur et l'état
souhaité par le client HTTP. Cette liste de différences peut prendre
plusieurs formats et ce RFC en spécifie un nouveau, JSON
merge patch, un format de
patch conçu pour
JSON. Suite à une grosse erreur technique, ce RFC
a été remplacé très peu de temps après par le RFC 7396.
En fait, le format normalisé par ce RFC n'est pas spécifique à HTTP
et pourra même servir avec d'autres protocoles. Mais la commande
PATCH du RFC 5789 sera sans
doute sa principale utilisation. Une ressource au format JSON
merge patch est un objet JSON elle-même. Pour chaque clé, si la
ressource cible a également cette clé, la valeur est remplacée par
celle du patch. Si elle ne l'a pas, on ajoute le
couple clé/valeur. Et si la valeur dans le patch
est null, on supprime le couple clé/valeur de la
ressource cible. Ainsi, si on a ce document JSON sur le serveur :
{
"a": "b",
"c": {
"d": "e",
"f": "g"
}
}
et qu'on envoie le patch suivant en HTTP (notez le type MIME de notre nouveau format) :
PATCH /target HTTP/1.1
Host: example.org
Content-Type: application/merge-patch+json
{
"a":"z",
"c": {
"f": null
}
}
On obtiendra :
{
"a": "z",
"c": {
"d": "e"
}
}
(La valeur de a a été changée, et le couple
indexé par c / f a été supprimé.)
Ce format, centré sur le résultat plutôt que sur les opérations, suit donc des principes assez différents de son homologue XML du RFC 5261.
On notera donc que tous les contenus
JSON ne sont pas patchables ou, en tout cas, pas de
manière propre et facile, avec ce format. Par
exemple, si des null sont effectivement utilisés,
ou bien si la structure du texte JSON n'est pas celle d'un
objet. Mais, bon, ce format est très simple, est lui-même en JSON, et
le RFC est très court et facile à comprendre (ce qui n'aurait pas été
le cas si on avait voulu tout prévoir), on ne peut pas tout avoir.
La section 2 du RFC précise les règles à suivre lors du traitement des patches. Elle est rédigée en pseudo-code (attention, l'indentation dans le RFC est complètement ratée, cf. l'errata #4132, et c'est à cause de cela qu'il a fallu publier le RFC 7396) et est assez simple pour être citée ici :
define MergePatch(Target, Patch):
if Patch is an Object:
if Target is not an Object:
Target = {} # Ignore the contents and set it to an empty Object
for each Name/Value pair in Patch:
if Value is null:
if Name exists in Target:
remove the Name/Value pair from Target
else:
Target[Name] = MergePatch(Target[Name], Value)
return Target
else:
return Patch
Parmi les points à noter, le fait qu'un patch qui n'est pas un objet JSON (par exemple un tableau) va toujours remplacer l'intégralité de la ressource cible, ou le fait qu'on ne peut pas modifier une partie d'une ressource cible qui n'est pas elle-même un objet (il faut la changer complètement).
Le patch va agir sur les valeurs, pas sur leur représentation. Ainsi, on n'a aucune garantie qu'il préservera l'indentation du texte JSON ou la précision des nombres. De même, si la ressource cible tire profit des faiblesses de la norme JSON, elle peut ne pas sortir intacte : par exemple, si la ressource cible a plusieurs membres qui ont la même clé (ce qui n'est pas formellement interdit en JSON mais donne des résultats imprévisibles).
Un exemple plus détaillé de patch JSON se trouve en section 3. On part de ce document :
{
"title": "Goodbye!",
"author" : {
"givenName" : "John",
"familyName" : "Doe"
},
"tags":[ "example", "sample" ],
"content": "This will be unchanged"
}
Et on veut changer le titre, ajouter un numéro de téléphone, retirer
le nom de famille de l'auteur, et retirer l'élément
sample du tableau tags.
On envoie cette requête :
PATCH /my/resource HTTP/1.1
Host: example.org
Content-Type: application/merge-patch+json
{
"title": "Hello!",
"phoneNumber": "+01-123-456-7890",
"author": {
"familyName": null
},
"tags": [ "example" ]
}
Et on obtient ce document :
{
"title": "Hello!",
"author" : {
"givenName" : "John"
},
"tags": [ "example" ],
"content": "This will be unchanged",
"phoneNumber": "+01-123-456-7890"
}
Notez qu'il a fallu remplacer complètement le tableau
tags : il n'y a pas de mécanisme pour retirer
juste un élément du tableau (comme expliqué au début). Des tas d'exemples figurent dans l'annexe
A, si vous voulez écrire une suite de tests.
Le type MIME
application/merge-patch+json figure désormais
dans le registre IANA (cf. section 4 du
RFC), aux côtés de l'équivalent XML décrit dans
le RFC 7351, application/xml-patch+xml.
L'article seul
RFC 7377: IMAP4 Multimailbox SEARCH Extension
Date de publication du RFC : Octobre 2014
Auteur(s) du RFC : B. Leiba (Huawei
Technologies), A. Melnikov (Isode)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF appsawg
Première rédaction de cet article le 14 octobre 2014
Nouvelle extension IMAP normalisée, pour
effectuer une recherche dans plusieurs boîtes aux lettres
simultanément, avec la nouvelle commande ESEARCH. Proposée initialement par le RFC 6237, à titre expérimental, cette extension accède
désormais au statut de norme.
Par défaut, une recherche IMAP (commande
SEARCH, RFC 3501, sections
6.4.4 et 7.2.5, puis étendue par les RFC 4466
et RFC 4731) ne cherche que dans la boîte aux lettres courante. Si
on n'est pas sûr de la boîte où se trouve le ou les messages
intéressants, et qu'on veut chercher dans plusieurs boîtes, la seule
solution est de faire une boucle, effectuant séquentiellement des
SELECT pour changer de boîte et un
SEARCH à chaque fois. Ces commandes ne peuvent
pas être exécutées en parallèle car il n'y a pas de moyen de
distinguer leurs résultats (les réponses SEARCH
n'indiquent pas quelle était la boîte). La nouvelle commande permet au
serveur de faire les recherches en parallèle, s'il le peut, et évite des
allers-retours entre client et serveur.
Donc, la nouvelle commande ESEARCH (à ne pas
confondre avec la capacité ESEARCH du RFC 4731, même si les deux RFC ont des points
communs, comme le format des réponses), présentée en section 2. Sa disponibilité
est annoncée par la capacité MULTISEARCH dans la
bannière du serveur IMAP. (Cette capacité figure dans le registre
IANA.) Voici un exemple où on cherche des messages
parlant du Tchad dans les boîtes
folder1 et celles sous
folder2 (C = client, et S serveur IMAP) :
C: mytag ESEARCH IN (mailboxes "folder1" subtree-one "folder2") subject "chad" S: * ESEARCH (TAG "mytag" MAILBOX "folder1" UIDVALIDITY 1) UID ALL 3001:3004,3788 S: * ESEARCH (TAG "mytag" MAILBOX "folder2/salmon" UIDVALIDITY 1111111) UID ALL 50003,50006,50009,50012 S: mytag OK done
La syntaxe pour indiquer les boîtes aux lettres où on cherche est
celle de la section 6 du RFC 5465, avec l'ajout
de subtree-one (utilisé ci-dessus pour
folder2) qui, contrairement à
subtree, s'arrête au premier niveau (donc la
boîte folder2/tuna/red ne serait pas
cherchée). Avertissement du RFC au programmeur :
subtree peut aller très loin (pensez à une
hiérarchie de boîte aux lettres mise en œuvre avec un système de
fichiers hiérarchiques, et des liens symboliques qui vont se promener
ailleurs) et il faut donc prêter attention au risque d'écroulement du
serveur. Voir aussi la section 2.4, qui autorise le serveur à refuser
les recherches trop gourmandes, avec le code
LIMIT du RFC 5530, et la section 5, sur
la sécurité, qui note que cette extension multi-boîtes peut être
dangereuse pour le serveur. Un client méchant ou maladroit peut
demander un gros travail au serveur, avec juste une commande.
Le RFC note que le mot-clé personal est
le moyen le plus pratique de fouiller dans toutes les boîtes de
l'utilisateur. Si celui-ci désigne au contraire des boîtes par leur
nom, et que le serveur gère les ACL du RFC 4314, il faut avoir le droit de lecture sur ces boîtes (et
celui de découverte, si les boîtes ne sont pas explicitement nommées,
par exemple si on utilise subtree). Pas question
de retourner des résultats pour des boîtes que l'utilisateur n'est pas
censé lire.
À noter qu'un serveur qui accepte les recherches floues du RFC 6203 peut les accepter également pour les recherches dans des boîtes multiples.
La réponse est décrite dans la section 2.1 : elle consiste en
lignes ESEARCH (cf. RFC 4731). Les
messages doivent être identifiés par leur UID (RFC 3501, section 2.3.1.1) comme ci-dessus, pas par
leurs numéros (qui n'ont de sens que pour une boîte sélectionnée). Le
ALL (RFC 4731, section 3.1), indique
qu'on retourne la totalité des messages qui correspondent au critère
de recherche. Pour le premier dossier, le
folder1, ces messages sont ceux d'UID 3001 à 3004
(une séquence, définie dans la section 9 du RFC 3501) et le message d'UID 3788.
La section 3 du RFC donne un exemple plus complexe, avec deux recherches multi-boîtes en parallèle, chacune identifiée par une étiquette différente :
C: tag1 ESEARCH IN (mailboxes "folder1" subtree "folder2") unseen C: tag2 ESEARCH IN (mailboxes "folder1" subtree-one "folder2") subject "chad" S: * ESEARCH (TAG "tag1" MAILBOX "folder1" UIDVALIDITY 1) UID ALL 4001,4003,4005,4007,4009 S: * ESEARCH (TAG "tag2" MAILBOX "folder1" UIDVALIDITY 1) UID ALL 3001:3004,3788 S: * ESEARCH (TAG "tag1" MAILBOX "folder2/banana" UIDVALIDITY 503) UID ALL 3002,4004 S: * ESEARCH (TAG "tag1" MAILBOX "folder2/peach" UIDVALIDITY 3) UID ALL 921691 S: tag1 OK done S: * ESEARCH (TAG "tag2" MAILBOX "folder2/salmon" UIDVALIDITY 1111111) UID ALL 50003,50006,50009,50012 S: tag2 OK done
Des implémentations de cette norme ? Il y en a apparemment une, en
logiciel non-libre, chez
Oracle. Cette extension semble rare (et cela a
été noté dans les débats à l'IETF :
méritait-elle vraiment d'avancer sur le chemin des normes ?). J'ai testé quelques serveurs et je n'ai
pas vu la capacité MULTISEARCH dans un
Zimbra récent, ou dans la version de
Courier actuellement chez
Debian. Rien non plus dans des services en
ligne comme laposte.net ou Gmail.
Depuis le RFC 6237, qui décrivait cette extension pour la première fois, peu de changements, les principaux sont (section 7) :
- Passage au statut de norme,
- Recherches floues,
- Et quelques autres détails.
L'article seul
Un nouveau logiciel post-Snowden dans ma logithèque, TextSecure
Première rédaction de cet article le 12 octobre 2014
Dernière mise à jour le 1 novembre 2014
Je suis désormais, comme beaucoup de gens, l'heureux utilisateur de TextSecure qui a complètement remplacé, sur mon smartphone, l'application SMS par défaut.
À quoi sert TextSecure ? C'est un logiciel de messagerie instantanée, conçu pour être très simple d'usage, pour servir de remplaçant « tel quel » aux logiciels SMS actuels, tout en offrant une meilleure protection de la vie privée, dans certains cas. Remplaçant « tel quel », car l'idée de base est que les utilisateurs normaux (le célèbre M. Michu) ne devraient pas avoir à renoncer à quoi que ce soit pour avoir une meilleure sécurité, dans un monde post-Snowden. En effet, M. Michu peut mettre TextSecure, gérer tous ses SMS avec, et il ne verra guère de différence. Contrairement à bien d'autres outils de sécurisation, qui sont, au minimum, moins faciles à utiliser que les outils habituels, au pire, franchement hostiles aux utilisateurs, TextSecure peut être recommandé aux parents, aux ministres, et autres populations non-geeks, sans se dire qu'on leur joue un mauvais tour. Sans doute n'offre-t-il pas de sécurité en béton, mais il ne fait rien perdre à l'utilisateur non plus. On peut résumer TextSecure en disant qu'il offre un très bon compromis entre facilité d'usage et sécurité.
Bon, qu'est-ce que voit l'utilisateur, avec TextSecure ? Justement, rien de particulier : il s'en sert comme de l'outil SMS par défaut. Le principal changement est que certains messages vont être marqués d'un joli cadenas : si le correspondant utilise également TextSecure, les messages sont chiffrés automatiquement avec sa clé. Si on est simple utilisateur, on a donc un peu plus de vie privée, et on en aura de plus en plus au fur et à mesure que TextSecure se répand.
TextSecure peut utiliser deux transports différents (mais on peut débrayer l'un ou l'autre), le SMS et la liaison « données » du smartphone (ce second transport se nomme PUSH dans la terminologie TextSecure, et est utilisé par défaut pour les correspondants qui ont également TextSecure). Le mode PUSH peut être intéressant si on a un quota SMS limité mais pas en Internet, et le mode SMS dans le cas contraire. Les messages apparaissent en vert traditionnel quand ils ont été transportés en SMS et en bleu autrement (curieux choix de couleur : les messages en vert ne sont pas forcément les plus sûrs, puisqu'ils ne sont en général pas chiffrés, c'est peut-être une copie aveugle de ce que fait Apple, suggère Jean Champémont).
TextSecure peut aussi chiffrer toute la base des SMS reçus et stockés. Ainsi, même si on vole votre téléphone, vos communications resteront sûres. Attention : si vous oubliez la phrase de passe, tout est fichu. Pensez à sauvegarder.
Si maintenant on est un utilisateur pas simple, qui veut savoir comment ça marche, on se pose quelques questions. Voici celles que je me posais et les réponses que j'ai pu trouver. Notez que la société qui développe TextSecure, OpenWhisper, a aussi une bonne FAQ.
D'abord, on a dit que TextSecure trouvait automatiquement les contacts de l'utilisateur qui étaient également utilisateurs de TextSecure. Ouh là là, se dit le paranoïaque moyen, c'est pas bon pour la vie privée. Comment il fait ? Il envoie tout mon carnet d'adresses à la société qui gère TextSecure, pour comparaison ? Cela serait catastrophique pour la sécurité. Le problème est difficile : si on veut de la sécurité maximale, il faudrait envoyer zéro bit d'information à l'extérieur. Mais le cahier des charges de TextSecure n'est pas « la sécurité maximale et rien d'autre », c'est « la meilleure sécurité du monde ne sert à rien si elle n'est pas déployée, car trop complexe ou trop pénible ». Pas question, donc, de se passer d'un système de découverte automatique. Il existe des algorithmes complexes et très astucieux (décrits dans ce remarquable article), mais le problème reste largement ouvert.
L'expert en sécurité qui sommeille dans chacun de mes lecteurs a déjà compris que les métadonnées de la communication, elles, sont en clair et que des tiers peuvent donc savoir qui écrit à qui et quand, même si le contenu des messages est chiffré. Comme le note Alda Marteau-Hardi « les metadata sont connues d'OpenWhisper [si on utilise PUSH] ou de ton opérateur mobile [si on utilise le SMS traditionnel], au final ».
Au fait, toujours si je suis expert en sécurité paranoïaque, pourquoi ferais-je confiance à OpenWhisper plus qu'à la NSA ou à Orange ? La principale raison est que TextSecure est un logiciel libre : le code est disponible, et des experts en sécurité l'ont déjà lu et personne n'a encore trouvé de défaut significatif. Notez que le code du serveur utilisé par OpenWhisper est également disponible en ligne mais c'est moins utile puisque, de toute façon, on ne peut pas vérifier que le serveur effectif exécute bien ce code.
Et si je lis dix RFC le matin avant mon petit déjeuner et que je veux connaître le protocole exact utilisé ? Pas de problème, ce protocole est documenté.
OK, mais il reste le gros problème de la cryptographie, authentifier le type en face. C'est bien joli de tout chiffrer mais, si Alice croit parler à Bob alors qu'elle parle en fait à Mallory, le chiffrement ne sert pas à grand'chose. Comment TextSecure traite-t-il ce problème ? À la première communication, TextSecure fait confiance. C'est risqué, si un Homme du Milieu se trouvait là, mais ce système, dit TOFU (Trust On First Use) a l'avantage d'être trivial d'utilisation. Il correspond donc bien au cahier des charges de TextSecure, qui veut que le logiciel soit effectivement utilisé et, pour cela, qu'il ne rebute pas ses utilisateurs. Ce modèle est également utilisé par SSH et, comme le note le RFC 5218, est une des principales causes de son succès. Je n'ai pas encore testé ce qui se passait si le correspondant réinitialise sa clé mais, d'après la documentation, TextSecure vous prévient (puisque cela peut indiquer une attaque de l'Homme du Milieu).
Si on veut, on peut toujours vérifier, lors d'une rencontre
AFK, la clé de son correspondant, soit en la
lisant à l'écran (la mienne est
BdY73Lfk12kv9iTVUTGIL6VZrpbg+6V1q+ZsZMrpu2p3 en
Base64 ou bien 05 d6 3b dc b7 e4 d7
69 2f f6 24 d5 51 31 88 2f a5 59 ae 96 e0 fb a5 75 ab e6 6c 64 ca e9
bb 6a 77 en suite de chiffres hexadécimaux), soit via des codes QR. Voici d'ailleurs le
mien : 
Comme beaucoup de points de TextSecure, c'est bien documenté en ligne. Mais, et c'est à mon avis une des plus grosses faiblesses de TextSecure, je n'ai trouvé aucun moyen d'enregistrer le fait qu'on a vérifié, afin, par exemple, d'afficher les messages ultérieurs d'une couleur différente si le correspondant a ainsi été solidement authentifié. (La question est discutée dans la bogue #314 et la #689.)
X_cli (qui met aussi
son code QR TextSecure sur sa page
d'accueil) m'a suggéré une technique rigolote et, à ma
connaissance, jamais utilisée : mettre la clé TextSecure dans une
identité PGP, que les gens qui ont vérifié pourront signer. C'est fait
pour ma clé CCC66677 :
% gpg --list-keys CCC66677
...
uid TextSecure fingerprint (05 d6 3b dc b7 e4 d7 69 2f f6 24 d5 51 31 88 2f a5 59 ae 96 e0 \
fb a5 75 ab e6 6c 64 ca e9 bb 6a 77) \
<BdY73Lfk12kv9iTVUTGIL6VZrpbg+6V1q+ZsZMrpu2p3@base64>
...
Au passage, pour exporter la clé publique, le plus simple est
d'afficher le code QR, de partager par courrier
électronique, et le message contient la clé en Base64. Si
on la veut en liste de chiffres hexadécimaux, on peut se servir de ce
petit script Python base64-to-hexas.py.
Autre défaut, et une exception à la règle comme quoi installer TextSecure ne fait rien perdre par rapport à l'application par défaut, envoyer un message à plusieurs personnes n'est pas possible simplement (il faut d'abord créer un groupe statique, qui, si un membre n'a pas TextSecure, est converti en groupe MMS dont l'usage est franchement pénible - et donne de drôles de résultats sur les vieux téléphones). Il y a également un intéressant article sur les groupes. Autre problème, TextSecure affiche obligatoirement l'heure de réception du message et pas son heure de départ. Si le téléphone a été éteint longtemps, c'est pénible (on a accès à l'heure de départ en sélectionnant le message puis en choisissant l'option I comme Information, en haut).
À noter qu'il existe des logiciels concurrents. Le plus proche me semble être Telegram. Une discussion de comparaison entre TextSecure et Telegram a eu lieu sur Ycombinator.
Merci à Amaelle Guiton et Adrienne Charmet pour avoir servi de cobayes et pour les intéressantes discussions.
L'article seul
RFC 7364: Problem Statement: Overlays for Network Virtualization
Date de publication du RFC : Octobre 2014
Auteur(s) du RFC : T. Narten (IBM), E. Gray (Ericsson), D. Black (EMC), L. Fang, L. Kreeger (Cisco), M. Napierala (AT&T)
Pour information
Réalisé dans le cadre du groupe de travail IETF nvo3
Première rédaction de cet article le 11 octobre 2014
En informatique, depuis les débuts des temps, on a de plus en plus virtualisé. Le processeur, puis la mémoire, puis des machines entières. Désormais, il est donc logique qu'on cherche à virtualiser le réseau. Par exemple, est-il possible de fournir, dans un centre d'hébergement de données, plusieurs centres de données virtuels, chacun complètement isolé des autres, et permettant de déployer, non pas une seule machine mais tout un réseau ? Il n'y a pas encore de solution technique complète pour ce problème mais ce RFC fournit au moins une description détaillée du problème.
Les organisations qui géreront ces centres de données virtuels seront distinctes, peut-être concurrentes. Il est donc essentiel que les différents réseaux soient parfaitement isolés les uns des autres, avec des espaces d'adressage distincts et des communications uniquement faites de manière explicite (comme s'ils étaient deux réseaux physiques connectés par un routeur). Pas question, par exemple, qu'une de ces organisations puisse sniffer le trafic d'une autre.
Le but est de gagner en souplesse d'administration. Installer un « data center » coûte cher, prend du temps, et l'infrastructure physique ne peut pas être facilement modifiée ensuite. En virtualisant tout, on pourrait imaginer que le gérant du centre de données physique loue des centres de données virtuels à différents acteurs, qui à leur tour loueront des services hébergés dans ces centres virtuels. On aura ainsi du virtuel sur du virtuel sur...
Si la virtualisation est bien faite, le locataire n'aura même pas besoin de savoir quelle est la technique sous-jacente utilisée.
Bon, c'est très joli, comme projet, mais est-ce réaliste ? Notre RFC se concentre sur la première étape, cerner le problème et poser les questions auxquelles il va falloir répondre. C'est le rôle du groupe de travail IETF nommé NVO3, et ce RFC, avec le RFC 7365, est sa première publication. Le chiffre 3 dans le nom fait référence au fait que le groupe se concentre sur les solutions de virtualisation mises en œuvre dans la couche 3 (que ces solutions fournissent un service de couche 3 ou de couche 2). Un autre document, le RFC 7365, spécifie notamment le vocabulaire utilisé. Notre RFC y ajoute le concept de réseau supérieur (overlay network), qui désigne le réseau virtuel bâti au-dessus du réseau physique. Un exemple réalisé dans la couche 2 est 802.1Q qui fait de l'encapsulation de trames de niveau 2 dans d'autres trames.
Donc, quels sont les problèmes à résoudre, se demande la section 3 de notre RFC ? On s'attend à pouvoir déplacer les machines virtuelles d'un serveur à l'autre. En cas de virtualisation du réseau lui-même, cette mobilité doit être possible sans tenir compte de la position physique des serveurs. La machine virtuelle doit pouvoir garder son adresse IP (sinon, cela casserait les sessions TCP en cours, sans parler de la nécessité de mettre à jour le DNS, et autres informations), mais aussi son adresse MAC. En effet, des licences logicielles peuvent être liées à cette adresse MAC. En outre, d'autres perturbations pourraient surgir (système d'exploitation qui ne gère pas correctement un changement d'adresse MAC qu'il n'a pas décidé lui-même).
Dans le centre de données classique, l'adresse IP d'un serveur dépend de sa position. Par exemple, si on a un sous-réseau (et donc un routeur) pour une rangée d'armoires, préserver l'adresse IP impose de ne pas changer de rangée. Ce n'est pas une contrainte trop grave pour un serveur physique, qu'on déplace rarement. Mais ce serait très pénible pour des machines virtuelles, dont l'intérêt est justement la souplesse de placement.
Pour permettre un placement des machines à n'importe quel endroit, il est tentant d'avoir un réseau complètement plat, sans routeurs intermédiaires, ou bien en annonçant des routes spécifiques à une machine (/32 en IPv4) dans l'IGP. Mais cette absence de partitionnement, jointe à l'augmentation du nombre de machines que permet la virtualisation, met une sacrée contrainte sur les tables qu'utilisent les machines pour stocker les coordonnées de leurs voisins (ARP ou NDP en couche 2, l'IGP en couche 3). En couche 2, au lieu de stocker les adresses MAC de ses quelques voisines physiques, une machine devra stocker les milliers d'adresses MAC des machines virtuelles « voisines ». Sans compter le trafic ARP que cela représentera (cd. RFC 6820 ; un million de machines généreront plus de 468 240 ARP par seconde soit l'équivalent de 239 Mb/s).
L'exigence de souplesse et d'agilité, afin de permettre l'utilisation optimale du matériel, nécessite de séparer la configuration du réseau physique et celle du réseau logique. Le RFC donne l'exemple d'un centre de données virtuel qui serait mis en œuvre sur un petit groupe de machines physiques proches. Puis le client veut agrandir son centre et il n'y a pas de place aux alentours, on doit donc lui allouer des machines physiques situées relativement loin dans le centre physique. Cela doit pouvoir marcher, indépendamment du fait que le centre de données du client est désormais réparti en deux endroits.
Autre exigence, que les adresses utilisées sur un centre de données virtuel ne dépendent pas de celles utilisées sur un autre centre virtuel présent sur la même infrastructure physique. Dit autrement, deux clients doivent pouvoir numéroter leurs centres comme ils veulent, sans se coordonner entre eux, et sans tenir compte du plan d'adressage du réseau physique sous-jacent.
Ces exigences sont fort ambitieuses, surtout si on les combine avec la demande que la transmission des paquets suive un chemin optimal. Car la virtualisation, celle du réseau comme celle d'autres ressources, a toujours un coût en termes de performance. Par exemple, lorsqu'une machine virtuelle change de place, le meilleur routeur par défaut peut être différent, alors que cette machine n'est pas consciente de son déplacement et de la nécessité de changer. Autant que possible, l'infrastructure sous-jacente devrait faire cela pour elle. Et encore, un routeur IP classique ne garde pas d'état. Mais s'il y avait des middleboxes à état sur le trajet, comme des pare-feux ?
Pour résumer les services attendus du système de virtualisation : fournir un espace d'adressage isolé, et séparer les paquets de ceux des autres clients (on ne veut pas qu'un tcpdump sur une machine virtuelle montre les paquets d'un autre client). La section 4 décrit la classe de solutions envisagée, celle des réseaux virtuels bâtis au-dessus (d'où le terme d'overlay) des réseaux physiques. Chaque réseau virtuel (pour le centre de données virtuel d'un client) serait un réseau supérieur. Lorsqu'un paquet doit être transmis, il sera encapsulé et voyagera dans un tunnel à l'extrémité duquel il sera décapsulé (technique dit map and encap). Le point d'entrée du tunnel devra faire l'opération de recherche de correspondance (map), indiquant, pour une adresse de destination donnée, quel sera le point de sortie du tunnel. Ce point d'entrée encapsulera ensuite (encap) en mettant en adresse de destination de l'en-tête externe, l'adresse du point de sortie du tunnel. Comme le groupe de travail NVO3 ne considère que les réseaux virtuels mis en œuvre sur la couche 3, les adresses externes (celles de l'en-tête externe du paquet) seront forcément des adresses IP. Les adresses internes (celles du paquet avant encapsulation, ou après décapsulation) peuvent être de couche 2 ou de couche 3.
Il faudra aussi, dans bien des cas, connecter le réseau virtuel à l'extérieur (notamment à l'Internet). Cela nécessitera un routeur connecté à l'extérieur qui, après la décapsulation, transmettra le paquet par les procédés habituels (transmission IP normale, dans le cas d'une connexion à l'Internet). Même chose pour connecter deux réseaux virtuels entre eux. Si ces réseaux fournissent un service de couche 3, c'est de l'interconnexion IP classique, via un routeur.
D'un point de vue plus quantitatif, le RFC note (section 4.4) que ce système de réseaux virtuels devra fonctionner dans un environnement de grande taille (des milliers de commutateurs et des dizaines, voire des centaines de milliers de machines virtuelles) et devra donc bien passer à l'échelle. De plus, le réseau virtuel pourra être très dispersé au sein du réseau physique, avec ses fonctions mises en œuvre sur des tas de machines physiques relativement éloignées, qui travailleront aussi pour beaucoup d'autres réseaux virtuels. Le tout sera sans doute très mouvant (un des buts de la virtualisation est la souplesse, la capacité à changer souvent).
Dans le futur, on construira peut-être des centres de données physiques prévus depuis le début uniquement pour héberger des réseaux virtuels et conçus donc à cet effet. Mais, pour l'instant, ce n'est pas le cas et le RFC demande donc aussi que les solutions de virtualisation soient déployables de manière incrémentale, sans exiger une refonte complète de tout le réseau. Ainsi, les routeurs IP qui sont sur le trajet d'un tunnel ne devraient pas avoir à en être conscients. Pour eux, les paquets du tunnel sont des paquets IP comme les autres. De même, le multicast ne devrait pas être obligatoire (car il est peu déployé).
Le cahier des charges est donc gratiné. Heureusement, il n'est pas prévu que le réseau physique sous-jacent s'étende à tout l'Internet. On parle ici de virtualiser un centre de données, placé sous une administration unique.
Néanmoins, la réalisation de cette vision grandiose va nécessiter du travail. Le RFC envisage deux secteurs de travail : celui du contrôle et celui des données. Pour le contrôle, il faudra trouver des mécanismes efficaces pour créer, gérer et distribuer les tables de correspondance (celles qui permettent au point d'entrée de tunnel de trouver le point de sortie). Cela fera peut-être l'objet d'un tout nouveau protocole. Ce mécanisme devra permettre l'arrivée et le départ d'une machine virtuelle dans le réseau supérieur en mettant à jour ces tables rapidement et efficacement.
Pour les données, il existe déjà pas mal de formats d'encapsulation et, ici, il serait sans doute mieux de les réutiliser. Le RFC décourage donc ceux qui voudraient inventer encore un nouveau format.
La section 5 est justement consacrée aux systèmes existants et qui pourraient fournir des idées, voire des réalisations déjà opérationnelles. D'abord, on peut se servir de BGP et MPLS pour faire des réseaux virtuels IP, le RFC 4364 décrit comment. Cette solution est déjà déployée en production. Sa principale limite, selon notre RFC, est le manque de compétences BGP disponibles, alors que cette solution nécessite du BGP partout. Les mêmes protocoles permettent de faire des réseaux virtuels Ethernet (RFC en cours d'écriture).
Bon, alors, autre solution, utiliser les VLAN de 802.1. Ils fournissent une virtualisation en couche 2 en présentant plusieurs réseaux Ethernet virtuels sur un seul réseau physique. Mais ils ne reposent pas sur IP donc ne sont pas utilisables si on a, par exemple, un équipement comme un routeur sur le trajet. À l'origine, on était limité à 4 096 réseaux différents sur un seul réseau physique, mais cette limite est passée à 16 millions depuis IEEE 802.1aq.
Cette dernière technique, également nommée SPB, utilise IS-IS pour construire ses réseaux virtuels.
Et TRILL ? Il utilise lui aussi IS-IS pour fournir des réseaux de couche 2 différents. En France, cette technique est par exemple déployée chez Gandi.
Plus exotique est le cas de LISP (RFC 6830). Son but principal n'est pas de virtualiser le data center mais il pourrait contribuer, puisqu'il fournit des réseaux virtuels IP au-dessus d'IP (donc, service de couche 3, mis en œuvre avec la couche 3).
Enfin, bien que non cité par le RFC, il faudrait peut-être mentionner VXLAN, bien décrit en français par Vincent Bernat et en anglais par le Network Plumber.
À noter qu'un groupe de travail de l'IETF, ARMD, avait travaillé sur un problème proche, celui posé par la résolution d'adresses IP en adresses MAC (avec ARP ou NDP) dans les très grands centres de données où tout le monde était sur le même réseau de couche 2. Le résultat de leurs travaux avait été documenté dans le RFC 6820.
En résumé, notre RFC conclut (section 6) que le problème est complexe et va nécessiter encore du travail...
Merci à Nicolas Chipaux et Ahmed Amamou pour leur relecture.
L'article seul
RFC 7365: Framework for Data Center (DC) Network Virtualization
Date de publication du RFC : Octobre 2014
Auteur(s) du RFC : Marc Lasserre, Florin Balus
(Alcatel-Lucent), Thomas Morin (France Telecom
Orange), Nabil Bitar (Verizon), Yakov
Rekhter (Juniper)
Pour information
Réalisé dans le cadre du groupe de travail IETF nvo3
Première rédaction de cet article le 11 octobre 2014
Ce nouveau RFC décrit le cadre général de la virtualisation de réseaux en utilisant IP comme substrat. Il est issu du projet NVO3 de l'IETF, qui a produit une description du problème (dans le RFC 7364) et ce document. À ce stade, ce n'est pas encore un protocole concret, même s'il existe déjà des solutions techniques partielles pour ce problème.
La cible est constituée des grands centres de données, hébergeant des centaines de milliers de machines virtuelles, et qu'on souhaite pouvoir gérer de manière souple (par exemple en déplaçant facilement une machine virtuelle d'une machine physique à une autre, sans l'éteindre et sans la changer d'adresse IP). Le RFC 7364 décrit plus en détail le problème à résoudre (et il est donc recommandé de le lire d'abord), ce RFC 7365 étant le cadre de(s) la(les) solution(s). Comme on envisage des grands ensembles de machines, et qu'on cherche à être très dynamique (reconfigurations fréquentes), il faudra beaucoup d'automatisation (pas question de modifier des tables à la main parce qu'une machine s'est déplacée).
Il définit donc un vocabulaire et un modèle pour ces réseaux virtuels. Donc, on parle de réseaux NVO3 (NVO3 networks). Il s'agit de créer des réseaux virtuels (VN pour virtual networks, ou bien overlays) fonctionnant au-dessus d'un protocole de couche 3, IP. Ces réseaux virtuels fournissent aux clients (qui peuvent appartenir à des organisations distinctes, voire concurrentes) soit un service de couche 3, soit un service de couche 2 . Les réseaux virtuels sont créés au-dessus d'un substrat, l'underlay, qui est le « vrai » réseau sous-jacent. Le substrat est toujours de couche 3, comme le nom du projet NVO3 l'indique. Chaque VN aura un contexte, un identificateur qui figurera dans les paquets encapsulés et qui permettra à l'arrivée de distribuer le paquet au bon VN. Le réseau NVO3 utilisera des NVE (Network Virtualization Edge) qui seront les entités qui mettent en œuvre ce qui est nécessaire pour la virtualisation. Un NVE a au moins une patte vers le client (qui envoie des paquets sans savoir qu'il y a virtualisation) et une autre vers le réseau IP qui transporte le trafic entre les NVE. Un NVE n'est pas forcément un équipement physique, cela peut être, par exemple, le commutateur virtuel d'un hyperviseur.
Les sections 2 et 3 présentent le modèle de référence utilisant ce vocabulaire, et ses composants. Les systèmes des clients (tenant systems) sont connectés aux NVE, via un VAP (virtual access point, qui peut être une prise physique ou bien virtuelle, par exemple un VLAN ID). Un même NVE peut présenter aux clients plusieurs VNI (virtual network instance, une instance particulière de réseau virtuel). NVE et système du client peuvent être physiquement dans la même boîte, ou bien il peut s'agir de systèmes distants (le schéma 2 du RFC n'est pas une représentation physique, mais logique). Dans le premier cas, la communication de l'information peut se faire par une API locale, dans le second, par un protocole réseau. Les NVE échangent l'information entre eux (comme des routeurs avec un IGP) ou bien ils sont connectés à une NVA (Network Virtualization Authority) qui leur fournit les informations sur l'état du réseau (qui est membre, comment joindre les membres, etc). Il y aura donc un protocole entre NVE, ou bien entre NVE et NVA. Le NVA n'est évidemment pas forcément un serveur unique, cela peut être une grappe, pour la redondance. Les machines qui forment l'underlay font du routage IP normal et ne connaissent pas, a priori, les systèmes des clients. La gestion de ce réseau underlay se fait avec les mêmes outils OAM que n'importe quel réseau IP.
Le réseau virtuel (l'overlay) devra donc utiliser une forme ou l'autre d'encapsulation pour faire passer ses paquets sur l'underlay. Cela pourra être GRE, IPsec, L2TP, etc. Ce n'est pas tout de tunneler, il faut aussi un mécanisme de contrôle, rassemblant et distribuant l'information dans le réseau. Un tel mécanisme peut être centralisé (comme dans le cas de SDN) ou réparti (comme l'est traditionnellement le routage dans l'Internet).
Quant un NVE fournit un service de couche 2, les systèmes des clients ont l'impression de se connecter à un Ethernet normal (comme avec le RFC 4761 ou le RFC 4762). S'il fournit un service de couche 3, les systèmes des clients voient un réseau IP, comme avec le RFC 4364.
Autre service important, la possibilité de déplacer des VM à l'intérieur du centre de données. Permettre des déplacements à chaud, sans arrêter la VM, est évidemment très souhaitable, mais cela aura des conséquences sur des points comme les caches ARP (qu'il faut mettre à jour si une VM se déplace, alors qu'elle pense rester dans le même réseau de niveau 2).
La section 4 du RFC décrit quelques aspects essentiels dans les discussions sur les réseaux virtuels. D'abord, les avantages et inconvénients des réseaux virtuels. Sur le papier, ils offrent des tas d'avantages : les systèmes des clients n'ont à s'occuper de rien, ils bénéficient d'un réseau certes virtuel mais qui a les mêmes propriétés qu'un vrai, tout en étant plus souple, avec des changements plus rapides. Même les adresses (MAC et IP) sont séparées de celles de l'underlay donc les clients sont isolés les uns des autres. Malheureusement, il y a quelques problèmes en pratique : pas de contrôle sur le réseau sous-jacent et même pas d'information sur lui, par exemple sur son utilisation, ou sur des caractéristiques comme le taux de perte de paquets (RFC 7680). Il y a donc un risque de mauvaise utilisation des ressources réseaux. Et si plusieurs overlays partagent le même underlay, l'absence de coordination entre les réseaux virtuels, chacun ayant l'impression qu'il est tout seul (« each overlay is selfish by nature »), peut encore aggraver les choses. Mais, bon, des réseaux virtuels existent depuis de nombreuses années, et marchent.
Autre exemple, parmi ceux cités par le RFC, des difficultés à réaliser proprement ce projet, le cas de la diffusion. On veut pouvoir fournir des services qui existent sur les réseaux physiques, comme la capacité à diffuser à tous les membres du réseau, avec un seul paquet. Comment fournir le même service avec des réseaux virtuels ? Il va falloir automatiquement répliquer le paquet pour le transmettre ensuite à tous les réseaux physiques qui contribuent au réseau virtuel. Cela peut se faire de manière violente (dupliquer le paquet en autant d'exemplaires qu'il y a de machines et le transmettre à chacune en unicast) ou bien de manière plus subtile mais plus complexe avec le multicast. La première solution minimise l'état à conserver dans les routeurs, la seconde minimise la capacité réseau consommée.
La mise en œuvre concrète de la virtualisation va nécessiter des tunnels, connectant les différents réseaux physiques. Qui dit tunnel dit problèmes de MTU, en raison des octets consommés par les en-têtes du format de tunnel utilisé. Ces quelques octets en plus diminuent la MTU du réseau virtuel. En théorie, la fragmentation résout le problème mais elle a un prix élevé en performances (idem si fragmentation et réassemblage étaient faits dans le système de virtualisation et non pas, comme la fragmentation IP habituelle, par les machines terminales et - en IPv4 - les routeurs). La découverte de la MTU du chemin (RFC 1981 et RFC 4821) permet de se passer de fragmentation mais, en pratique, elle marche souvent mal. Il semble que la meilleure solution soit de faire en sorte que le réseau virtuel présente une MTU « habituelle » (1 500 octets, la MTU d'Ethernet) et, pour réaliser cela, que la MTU de l'underlay soit assez grande pour que les octets de l'encapsulation puissent être ajoutés sans problèmes (utilisation de jumbogrammes).
Enfin, les réseaux virtuels posent des problèmes de sécurité spécifiques (section 5). Un système client ne doit pas pouvoir attaquer le réseau sous-jacent (il ne doit même pas le voir), et un système client ne doit pas pouvoir attaquer un autre système client (par exemple, s'ils sont dans des réseaux virtuels séparés, il ne doit pas pouvoir lui envoyer directement de paquet, même si les deux systèmes clients se trouvent être sur la même machine physique).
Du point de vue du client, le critère est la capacité du réseau NVO3 à distribuer son trafic au bon endroit, et à séparer les trafics. Un tcpdump chez un client ne doit pas montrer les paquets d'un réseau virtuel d'un autre client (ce qui ne dispense évidemment pas d'utiliser le chiffrement, pour les attaques effectuées par le réseau sous-jacent). Et les machines doivent pouvoir faire confiance au VNI (identificateur du réseau virtuel) indiqué dans un paquet. Comme avec le RFC 2827, une machine client ne doit pas pouvoir injecter des paquets mentant sur le réseau virtuel auquel elle appartient.
Des futurs protocoles conformes à ce schéma sont en cours d'examen dans le groupe de travail, mais qui seront en concurrence avec des protocoles déjà existants qui ont les mêmes objectifs, comme celui du RFC 4364.
Merci à Thomas Morin et Marc Lasserre pour leur relecture.
L'article seul
Mon glossaire en informatique pour ce blog
Première rédaction de cet article le 7 octobre 2014
Ce blog comprend un certain nombre d'articles techniques en français sur l'informatique. J'essaie d'utiliser moins de mots anglais que la moyenne des informaticiens. Résultat, dans ce domaine où le vocabulaire est très anglicisé, des termes français perturbent les francophones, qui ne les comprennent pas car ils ne sont pas largement répandus. D'où une liste partielle des termes les moins classiques.
Mais d'abord, les principes que j'essaie de suivre dans l'écriture de ces articles :
- Quand l'article est en français (une minorité est en anglais), l'écrire en français correct. Cela veut dire pas trop de fautes de grammaire ou d'orthographe mais également pas de mots en anglais s'il existe un meilleur terme en français. Utiliser un terme en anglais est souvent un signe de paresse (ce qui peut être une bonne idée) ou de non-compréhension (ce qui est plus grave).
- Ne pas refuser par principe tout terme anglais. Le français, comme toutes les langues, récolte de temps en temps des termes étrangers et il serait ridicule de vouloir figer la langue dans un état donné. Dans la technique, le vocabulaire est en général défini par ceux qui inventent et maîtrisent la technique, comme l'a bien montré Pol Corvez à propos du vocabulaire de la marine.
- S'agissant de l'anglais, une difficulté supplémentaire est que bien des mots anglais viennent du français, ont franchi la Manche avec Guillaume le Conquérant et nous reviennent aujourd'hui à travers l'Atlantique. C'est le cas de termes comme challenge comme le note Henriette Walter dans son excellent livre.
- Je ne privilégie pas forcément les traductions officielles (celles qui sont publiées au Journal Officiel et qui doivent obligatoirement être employées par l'administration française, dont ce blog ne dépend heureusement pas). La plupart du temps, elles sont élaborées en comité fermé, sans tenir aucun compte des usages existants, et sans même comprendre le concept traduit. Ceux et celles qui cherchent ces termes officiels peuvent consulter FranceTerme. Ceux qui préfèrent suivre l'usage peuvent suivre Wikipédia mais cette encyclopédie utilise en général davantage de termes français que l'usage courant, surtout dans le langage parlé. (Il y a aussi le Bitoduc.)
Alors, embarquons-nous maintenant pour un pot-pourri de termes divers que j'ai eu besoin de citer dans mes articles. D'abord, un des plus difficiles, socket. Il y a eu des tentatives humoristiques de traduction (chaussette...) mais puisqu'une socket sert à se brancher sur le réseau, je préfère dire prise (c'est l'équivalent d'une prise électrique, mais pour le logiciel). Je n'ai jamais vu personne utiliser le « connecteur logiciel » officiel.
Et le très fréquent buffer ? Là aussi, j'ai vu des traductions amusantes qui essayaient de coller au mot anglais comme buffet (c'est vrai qu'on stocke des choses dans un buffet...) mais je préfère tampon (qui est aussi le terme officiel). Au lieu de mettre les données dans le buffet, je les tamponne.
Et le cache ? Je ne le traduis pas car je n'ai pas trouvé de bon terme (le terme officiel, antémémoire, est bien trop restrictif, le concept de cache en informatique est bien plus riche que celui d'antémémoire puisqu'on trouve par exemple des serveurs cache pour le Web). Mais comme le mot cache en français a un autre sens, cela peut faire des phrases très bizarres, comme « pour mieux accéder à la ressource, on la cache » ou « on la met dans une cache à proximité »...
Et le très répandu (le mot et la chose...) bug ? J'utilise bogue, le terme officiel, qui évoque les piquants de la châtaigne, et qui permet de les chasser avec un débogueur. Mais j'avais un professeur d'informatique qui appelait le défaut une bourde et gdb un débourdeur, termes qui fleuraient bon le terroir.
Terme plus rare mais qui était aussi difficile à traduire, le nonce (au fait, l'article du Wikipédia anglophone le réduit à un usage dans la cryptographie alors qu'il est courant dans les protocoles réseau, même quand il n'y a pas de cryptographie du tout). Utiliser le terme anglais entraîne des risques de confusion avec l'ambassadeur du pape. Il n'y a pas de traduction officielle. Cela a été un long débat, documenté dans un autre article, avant que je ne choisisse numnique.
Passons maintenant au streaming. La quantité énorme d'octets qui sont poussés chaque jour vers les temps de cerveau disponibles, grâce à cette technique, nécessite un terme. C'est la diffusion en flux pour le Journal Officiel, terme qui me semble bien lourd. Ou bien parler de « flux temps réel » ? Comme le terme anglais est construit pour évoquer la rivière, on pourrait parler de rivièrage ? De ruissellement (« Tu regardes YouTube sur ta Freebox en ruissellement ») ? Ou, toujours en filant la métaphore aquatique, de diffusion en flot ? en courant ? Je ne me suis pas vraiment décidé.
Le nom stream pose d'ailleurs les mêmes problèmes. La norme HTTP 2 (RFC 9113) utilise beaucoup stream, un concept très important pour ce protocole. Je l'ai traduit par « ruisseau ».
Et le flow, concept très utilisé dans les réseaux (rien à voir avec le streaming, traité plus haut), par exemple dans les protocoles comme IPFIX (RFC 3917) ? J'utilise en général flot dans le contexte de l'analyse du trafic réseau (cas d'IPFIX). Mais flux pourrait également convenir. Sauf que je l'utilise pour le terme suivant.
Toujours dans les choses qui coulent d'un point à un autre, les feeds de syndication. Je dis flux, qui est également le terme officiel, et apparemment le plus utilisé en pratique.
Passons au monde du routage maintenant. L'anglais a deux termes, routing, qui désigne la construction des tables de routage par les routeurs (on dit aussi control), et forwarding, qui est le passage d'un paquet d'un routeur à un autre, en suivant les tables de routage. En français, routing se traduit bien par routage mais forwarding n'a pas de traduction équivalente. Je propose simplement transmission.
Une des raisons pour lesquelles l'usage abusif de l'anglais me hérisse, c'est que c'est souvent le résultat d'une incompréhension. La proximité même des deux langues fait que les faux amis sont nombreux, et on voit souvent des gens utiliser un terme anglais (pourquoi pas) à contre-sens (c'est déjà plus embêtant). Un exemple fameux est le logiciel malveillant stupidement traduit par « logiciel malicieux », ce qui n'a rien à voir. Un autre exemple est regular expression traduit par « expression régulière » (elles n'ont rien de régulier, ces expression rationnelles). Attention donc à la paresse, elle peut cacher une absence de compréhension du concept.
Passons maintenant à un autre terme difficile : hash (et hashing), à savoir le résultat d'une fonction qui va produire une chaîne de bits, souvent de longueur constante mais surtout de taille réduite, donc plus facile à manipuler (notamment à signer), à partir d'un texte de longueur quelconque. Pour une fois, la traduction officielle et l'usage coïncident pour parler de hachage (pour traduire hashing ; je ne trouve pas de traduction officielle pour le hash, le résultat du hachage). Je n'aime guère ce terme qui donne l'impression que le résultat est une purée quelconque, ce qui fait perdre la principale caractéristiques des fonctions de « hachage », leur reproductibilité. Je préfère donc parler de condensation, ce qui a l'avantage de donner des termes dérivés comme condensat pour hash. À noter qu'il s'agit de condensation au sens de réduction, pas au sens de passage à l'état solide (passage qui, lui, est réversible)... (Je ne suis pas toujours cohérent dans mes articles : j'ai parfois utilisé le terme « résumé » à la place de « condensat ».)
Maintenant, prenons un terme plus rare et bien moins utilisé,
scheme,
au sens qu'il a dans les URI (RFC 3986, section 3.1). Par exemple, dans http://présumés-terroristes.fr/, le plan est http:. L'usage est souvent de le traduire par
schéma mais
je préfère personnellement plan (en français, un
schéma est plus approximatif qu'un plan, ce second terme convient donc
mieux au caractère très formalisé des plans d'URI). En tout cas, ce
n'est pas un « protocole » et il ne faut pas utiliser ce terme qui
montre qu'on n'a rien compris aux URI (un URI est un identificateur,
pas un localisateur,
il n'y a pas forcément de protocole utilisable dedans, même quand le
plan est http:).
Bon, sauf si on travaille au W3C, on n'utilise pas ce terme de « plan » tous les jours. Mais il y a aussi des termes qui sont très importants en informatique, des concepts essentiels, mais pour lesquels la traduction frustre toujours les terminologues les plus avertis. C'est le cas de la scalability, la capacité d'un système à garder ses propriétés essentielles lorsqu'on change sérieusement d'échelle (par exemple quand on passe de mille à un million d'utilisateurs). Le terme revient tout le temps dans les discussions à l'IETF (« The scalability of ARP is very poor since every machine on the link must process every ARP request ») et le traduire est difficile. La traduction officielle est « extensibilité », ce qui est à la limite du contre-sens. L'extensibilité est une autre propriété des systèmes, la capacité à recevoir de nouvelles fonctions. Ici, il ne s'agit pas d'étendre le protocole, par exemple en lui ajoutant des fonctions, mais d'étendre le nombre d'utilisateurs. Je parle donc de passage à l'échelle en sachant bien que c'est nettement moins percutant que le terme anglais.
Passons ensuite à la génération de textes (par exemple une page HTML) à partir d'un template. Mais comment on dit template en français ? La traduction officielle est « modèle », ce qui me semble curieux (un modèle est plutôt conçu pour être copié tel quel, alors que l'expansion d'un template va donner des résultats différents selon la valeur des variables utilisées). Wikipédia ne traduit pas, mais propose éventuellement « patron », ce qui est joli (ce terme vient de la couture) mais ne me semble pas meilleur (un patron est également appliqué tel quel, il n'y a pas l'idée qui est essentielle avec les templates, d'incarnation d'une entité spécifique, en combinant template et variables). Je préfère donc de loin le terme de gabarit au sens où il est utilisé par les maquettistes.
Bon, et puisque j'écris ce paragraphe au moment des manifestations de Hong-Kong, c'est le moment de traduire le terme de réseau mesh. Il n'y a, semble-t-il, pas de traduction officielle (peut-être que l'État français n'aime pas cette idée de citoyens se connectant directement entre eux ?) Réseau maillé semble le plus fréquent mais c'est un peu idiot, tous les réseaux sont maillés. Cette traduction ne rend pas compte de la propriété importante des réseaux mesh, leur auto-organisation, qui permet la résistance à la censure.
Et le log des connexions, comment l'appeler ? Je ne trouve pas de traduction officielle mais Wikipédia propose de parler d'historique, ce qui est raisonnable. Pour une fois, je préfère une traduction littérale : le log en anglais vient de la marine (pour parler du journal de bord) et je propose donc de parler tout simplement de journal (et, donc, loguer une information est l'écrire dans le journal ou la journaliser, quoique ce dernier terme entre en collision avec certains systèmes de fichiers).
Enfin, certains termes sont problématiques, non pas parce qu'ils viennent de l'anglais, mais tout simplement parce qu'ils sont techniquement incorrects. C'est ainsi que je ne parle pas de propagation DNS, ni de cryptage.
Mille mercis à tous ceux et toutes celles qui ont discuté avec moi de terminologie, notamment sur Twitter (pardon, Gazouilleur), à chaque fois que je demande « et vous, comment vous traduiriez ce terme ? ».
Et il y a plein d'autres termes pas évidents à traduire et sur lesquels je vous laisse réfléchir (merci à Bertrand Petit pour les suggestions) : closure (le terme venant des maths, il faut probablement chercher une traduction dans ce secteur), mixin, bytecode, tail-recursivity (récursivité terminale semble répandu ?), mapping (je suggère « correspondance »), garbage collector...
L'article seul
RFC 3646: DNS Configuration options for Dynamic Host Configuration Protocol for IPv6 (DHCPv6)
Date de publication du RFC : Décembre 2003
Auteur(s) du RFC : R. Droms
Chemin des normes
Première rédaction de cet article le 7 octobre 2014
Les options DHCP IPv6 normalisées dans ce RFC permettent au serveur DHCP d'envoyer au client la liste des résolveurs (serveurs récursifs) DNS (ainsi que les domaines à utiliser pour les fonctions de recherche).
Il existe trois moyens d'indiquer à une machine
IPv6 quels sont les résolveurs
DNS à interroger (ceux qui, sur
Unix, seront mis dans
/etc/resolv.conf). Le premier moyen est statique, c'est
la configuration manuelle de la machine. Les deux autres sont
dynamiques. L'un utilise les RA (Router Advertisement, RFC 4862), en y ajoutant les options normalisées dans
le RFC 6106. L'autre utilise
DHCP pour IPv6 (RFC 3315), plus les options de notre RFC 3646. Le choix
entre les deux derniers moyens dépend des capacités des clients IPv6
du réseau local et aussi de questions de goût.
La première option (section 3 du RFC) permet d'indiquer les résolveurs (ou serveurs récursifs). Elle a le code 23 (dans le registre IANA) et sa valeur est une liste d'adresses IPv6, sur lesquelles écoute un résolveur DNS.
La seconde option (section 4 du RFC) est une liste de domaines dans lesquels chercher le
nom indiqué par l'utilisateur (s'il tape ping
foobar et que la liste comprend
example.org et
internautique.fr, on essaiera
foobar.example.org, puis
foobar.internautique.fr). Son code est 24. À
noter que le comportement d'un résolveur en présence d'une telle liste
de recherche (option search dans
/etc/resolv.conf si on est sur Unix) est mal
spécifié et que des surprises sont fréquentes (cf. RFC 1535,
notamment sa section 6).
Comme avec toute utilisation de DHCP, il n'y a aucune sécurité (section 6) : un serveur DHCP malveillant peut diriger les pauvres clients vers des résolveurs menteurs, par exemple. Notre RFC conseille l'utilisation de l'authentification DHCP (RFC 3315, section 21), qui ne semble pas déployée, ni même mise en œuvre dans les clients et serveurs courants. (Elle a même été abandonnée, dans le RFC 8415.)
L'article seul
Suspendre l'exécution d'un programme Unix pendant un temps précis ?
Première rédaction de cet article le 30 septembre 2014
Dernière mise à jour le 2 octobre 2014
Supposons que vous développiez en C sur Unix et que vous deviez suspendre l'exécution du programme pendant exactement N μs. Par exemple, vous voulez envoyer des paquets sur le réseau à un rythme donné. La réaction immédiate est d'utiliser sleep. Mais il y a en fait plein de pièges derrière ce but a priori simple.
Le plus évident est que sleep prend en argument un nombre entier de secondes :
unsigned int sleep(unsigned int seconds);
Sa résolution est donc très limitée. Qu'à cela ne tienne, se dit le programmeur courageux, je vais passer à usleep :
int usleep(useconds_t usec);
Celui-ci
fournit une résolution exprimée en μs et, là, on va pouvoir attendre
pendant une durée très courte. Testons cela en lançant un chronomètre
avant l'appel à usleep() et en l'arrêtant après,
pour mesurer le temps réellement écoulé :
% ./usleep 1000000 1 seconds and 67 microseconds elapsed
OK, pour une attente d'une seconde, le résultat est à peu près ce qu'on attendait. Mais pas à la μs près. Le noyau est un Linux, système multitâche préemptif et des tas d'autres tâches tournaient sur la machine, le noyau a donc d'autres choses à faire et un programme ne peut pas espérer avoir une durée d'attente parfaitement contrôlée. Ici, l'erreur n'était que de 0,0067 %. Mais si je demande des durées plus courtes :
% ./usleep 100 0 seconds and 168 microseconds elapsed
J'ai cette fois 68 % d'erreur. La durée écoulée en trop (le temps que
l'ordonnanceur Linux remette mon programme en route) est la même mais
cela fait bien plus mal sur de courtes durées. Bref, si
usleep() a une résolution théorique de la
microseconde, on ne peut pas espérer avoir d'aussi courtes durées
d'attente :
% ./usleep 1 0 seconds and 65 microseconds elapsed
Avec une telle attente minimale, un programme qui, par exemple, enverrait à intervalles réguliers des paquets sur le réseau serait limité à environ 15 000 paquets par seconde. Pas assez pour certains usages.
Là, le programmeur va lire des choses sur le Web et se dire qu'il faut utiliser nanosleep :
struct timespec
{
__time_t tv_sec; /* Seconds. */
long int tv_nsec; /* Nanoseconds. */
};
int nanosleep(const struct timespec *req, struct timespec *rem);
Celui-ci permet d'exprimer des
durées en nanosecondes, cela doit vouloir dire qu'il peut faire mieux
que usleep(), non ?
% ./nsleep 1000 0 seconds and 67 microseconds elapsed
Eh bien non. Le problème n'est pas dans la résolution de la durée
passée en argument, il est dans l'ordonnanceur
de Linux. (À noter qu'il existe d'autres bonnes raisons d'utiliser
nanosleep() plutôt que
usleep(), liées au traitement des
signaux.) La seule solution est donc de changer
d'ordonnanceur. Il existe des tas
de mécanismes pour cela, allant jusqu'à la recompilation du noyau avec
des options davantage « temps réel ». Ici, on
se contentera d'appeler sched_setscheduler() qui
permet de choisir un nouvel ordonnanceur. Attention, cela implique
d'être root, d'où le changement
d'invite dans les exemples :
# ./nsleep-realtime 1000 0 seconds and 16 microseconds elapsed
Le noyau utilisé n'est pas réellement temps-réel mais, en utilisant
l'ordonnanceur SCHED_RR, on a gagné un peu et les
durées d'attente sont plus proches de ce qu'on demandait. (Les gens
qui veulent de la latence vraiment courte, par exemple pour le jeu
vidéo, utilisent des noyaux spéciaux.)
Ce très court article ne fait qu'effleurer le problème compliqué
de l'attente sur un système Unix. Il existe par exemple d'autres
façons d'attendre (attente
active, select sur aucun fichier, mais avec
délai d'attente maximal, dormir mais jusqu'à un certain moment comme illustré par ce programme,
etc).
Je vous conseille la lecture de
« High-resolution
timing » et de « Cyclictest »
ainsi évidemment que celle de StackOverflow. Le
code source des programmes utilisé ici est usleep.c et
nsleep.c. Plus compliqué, le programme test_rt4.c utilise des timers, des
signaux, bloque le programme sur un seul processeur, interdit le
swap et autres trucs pour
améliorer la précision.
Merci à Michal Toma pour l'idée, à Laurent Thomas pour son code et à Robert Edmonds pour plein de suggestions.
L'article seul
RFC 7322: RFC Style Guide
Date de publication du RFC : Septembre 2014
Auteur(s) du RFC : H. Flanagan (RFC Editor), S. Ginoza
(RFC Editor)
Pour information
Première rédaction de cet article le 27 septembre 2014
Comme pour toute série de documents, il vaut mieux que les RFC soient cohérents dans leur style. Si certains RFC mettent les références entre parenthèses et d'autres entre crochets, la tâche du lecteur qui doit lire plusieurs RFC sera plus pénible. D'où cette série de règles, que le RFC Editor impose aux auteurs de RFC.
Rappelons que les RFC et leur RFC Editor sont décrits dans le RFC 8729, et que l'organisation du travail dudit RFC Editor est décrite dans le RFC 6635. L'actuel éditeur est Heather Flanagan, une des auteures de ce RFC 7322.
Les auteurs de RFC sont typiquement des ingénieurs informaticiens, qui n'ont pas forcément eu une formation en écriture et ignorent souvent les règles de base. La section 1 leur rappelle d'abord que le guide de style n'est pas là pour les embêter, mais pour que les RFC soient clairs et cohérents, à la fois en interne et entre eux. Le premier RFC Editor, Jon Postel, avait défini des règles s'imposant à tous les auteurs. Elles sont, en moyenne, bien plus souples que celles qu'imposent les journaux scientifiques ou les conférences et ne devraient donc pas trop gêner les participants à l'IETF.
Ce RFC 7322 est prévu pour être plutôt stable (une des fonctions du système des RFC est de garder les documents disponibles pendant de nombreuses années) et ne contient donc que des règles très solides, qui ont peu de chances de bouger avant de nombreuses années. Il a un inséparable compagnon en ligne, qui le complète avec les règles tout aussi importantes mais peut-être moins stables ou plus récentes.
Les règles de style des RFC ne sont pas spécialement extraordinaires : elles suivent avant tout le CMOS, le Chicago Manual of Style, la référence largement reconnue chez les auteurs anglophones, notamment dans les domaines scientifiques et techniques (mais très traditionaliste, et pas disponible en ligne). Le guide complète le CMOS, notamment pour les questions que ce dernier traite mal, comme la présence de codes informatiques au milieu du texte en anglais.
Enfin, comme tous les RFC commencent comme Internet-Drafts, la lecture du guide d'écriture des ID est également nécessaire à l'auteur débutant.
Armé de ce guide et des bons principes, le (enfin, actuellement, la) RFC Editor va alors (section 2) relire le document, corriger les erreurs, signaler aux auteurs les problèmes que le RFC Editor ne peut pas corriger seul, réparer les incohérences... Le but est qu'il y ait une forte cohérence à l'intérieur du document, presque aussi forte entre les RFC d'un même cluster et un peu moindre entre tous les RFC. (Les clusters sont des groupes de RFC portant sur une norme technique commune, et publiés en même temps, comme par exemple le cluster HTTP/1.1. On trouve une discussion plus détaillée en ligne.)
Attention, le travail du RFC Editor n'est pas technique (au sens de l'informatique). Les problèmes techniques doivent être traités par les auteurs et l'exactitude technique doit toujours avoir le pas sur le style. En aucun cas, le RFC Editor ne doit changer le sens du texte. (En pratique, toute activité éditoriale implique des frictions entre auteurs et éditeurs. L'un des buts du guide est de les minimiser, en expliquant clairement les règles.)
Après la philosophie, les règles (section 3). La première est la langue : pas le choix, les RFC doivent être en anglais. Mais lequel ? Celui de quel côté de la mare ? Britannique ou états-unien ? Faut-il écrire minimisation ou minimization ? meter ou metre ? Sur ce point, comme sur pas mal d'autres, le guide est ouvert : l'auteur fait comme il veut mais doit être cohérent. S'il ne l'est pas, le RFC Editor passera tout en orthographe états-unienne.
Les règles de ponctuation sont celles du CMOS (deux espaces après le point, la virgule avant le dernier élément d'une énumération, etc).
Les noms de domaine utilisés doivent être
ceux du RFC 2606 pour éviter toute collision
avec des noms réels. Les URI doivent être entre
chevrons, comme le demande l'annexe C du RFC 3986. Notez bien que cette règle sur les URI ne
s'applique qu'au texte seul (ce qui est le cas
des RFC), et c'est pour cela que je ne l'applique pas sur ce blog (où
j'écris https://www.example.org/parici).
La capitalisation n'est pas imposée mais elle doit être cohérente, selon les règles de cohérence du document sur les termes. Les mots importants d'un titre ou d'une section sont tous capitalisés, donc on écrit Extension for Named Searches (RFC 5466) et pas Extension for named searches ou Extension For Named Searches.
Et les citations ? Là encore, contrairement à ce qu'on voit souvent dans les revues scientifiques ou les actes des colloques, pas de règle impérative, à part le fait que la citation est entre crochets. Autrement, on peut citer en indiquant un court identificateur, comme « [TRILL-OAM] » (exemple pris dans le RFC 7276), ou en indiquant un numéro comme « [2] » (ce que fait par exemple le RFC 6410).
Et les abréviations ? Elle doivent être détaillées à leur première occurrence (avec l'abréviation entre parenthèses), par exemple « JavaScript Object Notation (JSON) » (vu dans le RFC 7072). On a évidemment le droit à une exception pour les abréviations que tout participant à l'IETF connaît certainement comme TCP ou HTTP. En cas d'oubli, vous avez une liste d'abréviations en ligne.
Enfin, la section 4 de notre RFC décrit la structure normale d'un RFC. Un RFC comporte un certain nombre d'éléments, pas forcément obligatoires. La première page a un contenu obligatoire, avec les avertissements juridiques (« boilerplates ») normalisés par le RFC 7841 (voir aussi le site de l'IETF trust). Elle indique aussi le ou les auteurs et leur organisation. On répète souvent que les participants à l'IETF ne représentent qu'eux-mêmes et pas leur employeur. Mais c'est largement faux, sauf pour la minorité assez riche pour se payer elle-même le temps de participation (et les voyages aux réunions). D'ailleurs, justement, l'employeur de l'auteur est indiqué dans le RFC. À noter que, si plusieurs auteurs ont le même employeur, on ne mentionne parfois ce dernier qu'une fois. Cela rend le texte ambigu : dans le RFC 6382, D. McPherson et R. Donnelly sont-ils au chômage ou bien sont-ils, comme le troisième auteur F. Scalzo, des employés de Verisign ?
La première page indique aussi le numéro ISSN des RFC, 2070-1721 et quelques autres métadonnées.
Le RFC doit aussi contenir un résumé, pour les lecteurs paresseux ou pressés. Publié seul (par exemple dans les catalogues des RFC), il doit être lisible en lui-même, sans faire appel au RFC (donc, sans citations faisant référence à la bibliographie). Souvent, il est simplement fait avec un copier/coller des premiers paragraphes de l'introduction, ce qui est autorisé mais pas forcément optimum.
Il y a parfois aussi une note, qui n'a pas été écrite par les auteurs, mais ajoutée par une des autorités qui a examiné le RFC. Par exemple, le RFC 4408 avait une note de l'IESG exprimant sa prudence vis-à-vis du problème, alors très controversé, d'authentification du courrier électronique. On peut aussi citer le RFC 4776, qui contient une note du RFC Editor expliquant que ce RFC a été publié uniquement pour corriger une erreur dans la valeur du code d'une option DHCP.
Ensuite, le corps du RFC. Il y a des parties qui dépendent du sujet du RFC. Ainsi, les RFC décrivant une MIB incluent en général le texte standard présentant les MIB (voir par exemple le RFC 4898, section 2). Et il y a des parties qu'on trouve dans tous les RFC. Certains termes ont un sens particulier dans les RFC. Ainsi, le lecteur anglophone mais non habitué aux RFC s'étonnera peut-être des MUST ou SHOULD écrits en majuscules. Ils sont définis dans le RFC 2119, l'écriture en majuscules signifiant un sens plus spécifique que le sens vague qu'ils peuvent avoir en anglais.
Les auteurs envoient parfois au RFC Editor un document pas
complètement fini, notamment parce que les affectations de codes
spécifiques par l'IANA n'ont pas encore été
faites (RFC 5226). Par exemple, l'Internet-Draft sur le
protocole Babel,
draft-chroboczek-babel-routing-protocol,
contenait le texte « IANA has registered the UDP port number TBD, called "babel", for use
by the Babel protocol. » Une fois un
port réservé officiellement, le « TBD »
(To Be Done) a été remplacé et le RFC 6126 dit « IANA has registered the UDP port number 6697, called "babel", for use
by the Babel protocol. ».
À la fin du RFC, se trouvent des sections plus ou moins standardisées, comme la fameuse (et obligatoire) « Security Considerations » (RFC 3552), qui doit permettre de s'assurer que les auteurs du RFC ont pensé aux problèmes de sécurité éventuels. Facultative, en revanche, la section sur les questions liées à l'internationalisation du protocole (RFC 2277).
Reste la bibliographie : elle comporte deux parties, une avec les références normatives et une avec le reste. Une des conséquences est que, si une référence normative est un Internet-Draft pas encore publié, la publication du futur RFC devra attendre. Une référence non-normative, elle, peut être un Internet-Draft non publié. Dans ce cas, il est marqué comme « Work in Progress » pour bien indiquer son manque de stabilité. Quand un RFC est cité, c'est parfois via son numéro de norme ou de BCP (Best Current Practice) car une telle référence est plus stable. Les URI sont autorisés dans la bibliographie, à condition qu'ils soient raisonnablement stables. Ainsi, BCP47 désignait au début le RFC 4646 et le RFC 4647 (oui, un BCP peut correspondre à plusieurs RFC) et, lorsque le RFC 4646 a été remplacé par le RFC 5646, le numéro de BCP n'a pas changé, pointant toujours vers la version la plus récente des bonnes pratiques.
Le RFC se termine aussi par des remerciements aux contributeurs. Le guide note qu'il n'y a pas de règles précises concernant qui est noté comme contributeur. C'est à l'initiative des auteurs. Par exemple, je suis cité comme contributeur dans dix-sept RFC mais cela correspond à des niveaux de participation très différents, d'une vraie participation à juste quelques corrections de détail. Et certains auteurs ont choisi de régler le problème des contributeurs avec une formule attrape-tout comme dans le RFC 4408 « The authors would also like to thank the literally hundreds of individuals who have participated in the development of this design. They are far too numerous to name [...] ».
Un dernier détail, les adresses de courrier
électronique dans les RFC doivent être intactes (pas de
modification comme rfc-editor (at)
rfc-editor.org). Le but des adresses est de pouvoir
contacter les auteurs et cela implique de ne pas faire de modifications.
Voilà, c'est fini. Ah, que faire en cas de conflit insoluble entre un auteur et le RFC Editor ? Comme rappelé par l'annexe A, on suit les procédures du RFC 6635.
L'article seul
Remerciements à ceux qui m'aident pour ce blog
Première rédaction de cet article le 24 septembre 2014
Ce blog est signé de mon nom, car c'est moi qui écris tous les articles et qui ai le dernier mot avant publication. Mais il bénéficie de l'aide de plusieurs personnes.
Cela va être difficile de citer tout le monde. Pour les relectures techniques, avec corrections des innombrables bogues dans le texte, je mentionne dans l'article les contributeurs. Mais il y a aussi un énorme travail qui ne se voit pas, c'est la relecture littéraire, avec corrections des fautes de français. Pour cela, je dois un million de remerciements (et quelques chocolats) à André Sintzoff, qui relit tous les articles impitoyablement et trouve au moins une faute de français à chaque fois (parfois dans des cas très subtils qui nécessitent plusieurs lectures du Grevisse, mais parfois des erreurs grossières).
Et merci aussi à Yannick Palanque pour ses propres corrections orthographiques et grammaticales.
L'article seul
Faut-il changer la clé DNSSEC de la racine ?
Première rédaction de cet article le 24 septembre 2014
Voici le genre de question qui ne va pas angoisser le célèbre M. Michu, mais que se posent sérieusement des tas de techniciens de l'Internet. Cette question a suscité la création récente d'une liste de diffusion très animée, et fera l'objet d'une réunion à la rencontre ICANN de Los Angeles en octobre prochain.
De quoi s'agit-il et de quoi discute-t-on sur cette liste ksk-rollover ? Les informations diffusées par le DNS sont sécurisées par des signatures cryptographiques, un système connu sous le nom de DNSSEC. Comme le DNS, DNSSEC est décentralisé mais arborescent. Le résolveur DNS qui veut valider (vérifier ces signatures) trouve la clé publique de la zone dans la zone parente, et ainsi de suite jusqu'à la racine, le sommet du DNS, qui est un cas particulier, le résolveur doit en connaître la clé. Typiquement, elle est incluse dans la distribution du logiciel et installée automatiquement. Aujourd'hui, cette clé de la racine, clé de voute de l'authentification des données DNS, est une RSA, a l'identificateur 19036, et vaut :
. IN DNSKEY 257 3 8 (
AwEAAagAIKlVZrpC6Ia7gEzahOR+9W29euxhJhVVLOyQ
bSEW0O8gcCjFFVQUTf6v58fLjwBd0YI0EzrAcQqBGCzh
/RStIoO8g0NfnfL2MTJRkxoXbfDaUeVPQuYEhg37NZWA
JQ9VnMVDxP/VHL496M/QZxkjf5/Efucp2gaDX6RS6CXp
oY68LsvPVjR0ZSwzz1apAzvN9dlzEheX7ICJBBtuA6G3
LQpzW5hOA2hzCTMjJPJ8LbqF6dsV6DoBQzgul0sGIcGO
Yl7OyQdXfZ57relSQageu+ipAdTTJ25AsRTAoub8ONGc
LmqrAmRLKBP1dfwhYB4N7knNnulqQxA+Uk1ihz0=
) ; KSK; alg = RSASHA256; key id = 19036
(Il y a en fait plusieurs sortes de clés, celle qui est importante, le point de départ de la confiance - trust anchor - est la KSK, Key Signing Key.) Mais, si on la change, comment mettre à jour (en anglais to roll over) les dizaines de milliers (et demain les centaines de milliers) de résolveurs qui l'utilisent ?
Avant cela, demandons-nous pourquoi la changer ? Il peut y avoir au moins deux cas où nous serions obligés de la changer : si elle est compromise (si la clé privée est copiée par un méchant) ou si les progrès de la cryptanalyse la rendent trop peu sûre. Aujourd'hui, aucun de ces deux cas ne se présente. Mais, si cela arrivait (et, au moins pour le premier cas, cela peut arriver du jour au lendemain), nous serions bien embêtés car on n'a jamais essayé une opération aussi complexe.
C'est le principal argument des « changeurs », ceux qui veulent qu'on change de clé : cela n'est pas nécessaire maintenant mais cela permet de tester les procédures et de s'assurer qu'on sait faire, de manière à ne pas être pris au dépourvu en cas de problème. Ils ajoutent que, pour l'instant, seules 10 à 20 % des requêtes DNS passent par un résolveur validant mais que DNSSEC se répand et que donc, plus on attend, plus ce sera dur. Les « conserveurs », eux, disent que c'est déjà trop tard, et que c'est embêtant de changer une donnée aussi critique juste pour faire des tests. Le risque de tout casser (et de donner ainsi une mauvaise réputation à DNSSEC) est trop important.
Par exemple, sur la machine Ubuntu où je
tape cet article, il faudrait, si la décision de changer de clé est
prise, que je récupère la nouvelle clé (évidemment de manière
sécurisée, pas en copiant/collant depuis
Twitter) et que j'édite
/etc/unbound/root.key. Pas évident d'obtenir cela
de nombreux administrateurs système dispersés et qui ne lisent pas
forcément tous les jours la liste dns-operations...
Il existe en théorie des solutions qui éviteraient de mettre à jour
manuellement. Certaines sont dépendantes du
logiciel. Unbound a son programme
unbound-anchor qui récupère la clé sur le serveur
de l'IANA, en HTTPS, et
en vérifiant le certificat. Il y a aussi les
mises à jour automatiques ou semi-automatiques des logiciels : si on met à jour son
résolveur ainsi, on aura la nouvelle clé. Si on n'est pas trop pressé,
cela marchera. Et il y a la technique du RFC 5011 qui permet d'indiquer dans le
DNS que l'ancienne clé est révoquée et de
publier la nouvelle, signée avec l'ancienne (cela ne marche pas si
l'ancienne clé privée a été copiée par un attaquant ; comme le disait
l'auteur du RFC dans la discussion sur la
liste ksk-rollover « If you lose your last trust anchor,
you're screwed. »). Le gros problème du RFC 5011 est qu'il n'a jamais été testé au feu.
Et il y a aussi les questions bureaucratiques, qui prendront certainement dix fois plus de temps que les discussions techniques (pourtant déjà très bavardes), dans le marigot qu'est la gouvernance d'Internet. Pour l'instant, aucune décision n'a été prise. Les discussions se poursuivent...
Et mon opinion personnelle à moi ? Je crains qu'il ne soit effectivement trop tard pour changer la clé de manière propre. Elle est présente en trop d'endroits qu'on ne maitrise pas. Il faudrait mettre en place un vaste programme de mise à jour des logiciels, pour s'assurer que tous mettent en œuvre le RFC 5011 proprement. Quand ce sera fait, dans dix ou vingt ans, on pourra remettre sur le tapis la question du changement (rollover) de clé.
L'article seul
RFC 7343: An IPv6 Prefix for Overlay Routable Cryptographic Hash Identifiers Version 2 (ORCHIDv2)
Date de publication du RFC : Septembre 2014
Auteur(s) du RFC : J. Laganier (Luminate Wireless), F. Dupont (Internet Systems Consortium)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF hip
Première rédaction de cet article le 21 septembre 2014
Une nouvelle pierre dans la construction d'une éventuelle future
architecture Internet séparant identificateur et
localisateur, les ORCHID sont des identificateurs dont la forme est celle d'une
adresse IPv6 (afin de pouvoir être utilisés dans les API qui attendent des
adresses IP). Ils sont typiquement utilisés dans le cadre de
protocoles comme HIP (RFC 9063). Pour les distinguer, notre RFC réserve le préfixe
2001:20::/28. Si vous voyez une telle « adresse
IP », ne vous attendez pas à pouvoir forcément la
« pinguer », elle n'a pas vocation à être
routable, c'est un pur identificateur.
ORCHID signifie Overlay Routable Cryptographic
Hash Identifiers. L'adresse IP
traditionnelle joue un rôle double, localisateur d'une machine dans le
réseau et identificateur d'une machine. ORCHID
est prévu pour les protocoles qui séparent identificateur et
localisateur (comme HIP) et sert
d'identificateur. Leur forme physique est celle d'une adresse IPv6, afin
de ne pas changer les API et les applications
qui les utilisent (on peut publier des ORCHID dans le
DNS, faire un ssh 2001:20::1:42
si on est sur une machine HIP, etc). Bien sûr, il serait plus propre
de tout refaire de zéro, avec de nouvelles API, plus adaptées à cette
séparation identificateur/localisateur, mais c'est
irréaliste. (Dommage, cela
aurait permis d'utiliser tout le ::/0 pour ORCHID
au lieu de les limiter à un préfixe. Voir la section 4 à ce sujet.)
Voilà pourquoi vous ne trouverez
pas des adresses de ce préfixe dans les paquets IPv6 ordinaires
(l'identificateur est traduit en localisateur par HIP avant que le
paquet soit mis sur le câble). Les paquets ayant ces adresses sont
routables dans le réseau virtuel HIP, pas dans l'Internet actuel. Les
ORCHID sont donc utilisés « entre machines consentantes », dit le
RFC. Un préfixe spécial, le 2001:20::/28, est
réservé par l'IANA pour éviter les confusions avec les « vraies » adresses
IP. Il figure dans le registre des adresses
spéciales (RFC 6890). Cela permet aussi des choses comme une mise en œuvre de HIP sous
forme d'un programme extérieur au noyau du
système, utilisant le préfixe pour distinguer facilement les ORCHID,
et permettre au noyau de transmettre les paquets utilisant des ORCHID
à ce programme extérieur. Dans tous les cas, l'utilisation des ORCHID
nécessitera un programme (dans le noyau ou extérieur) qui fera la
correspondance entre les identificateurs maniés par les applications
(les ORCHID) et les localisateurs mis dans l'en-tête des paquets IPv6
envoyés sur le réseau.
Les ORCHID ont été normalisés pour la première fois dans le RFC 4843. Ce nouveau RFC est la version 2, très différente (nouveau préfixe, nouvel algorithme de construction, voir l'annexe B pour toutes les différences entre ORCHID v1 et ORCHID v2).
Les ORCHID ont les propriétés suivantes :
- Quasi-unicité (sauf malchance, voir l'annexe A),
- Sécurité, via une chaîne de bits utilisée pour leur construction (la plupart du temps, une clé cryptographique, qui servira à authentifier l'ORCHID),
- Limitation au préfixe
2001:20::/28, - Routabilité dans l'overlay, pas dans le réseau sous-jacent (l'Internet d'aujourd'hui).
Comme les adresses CGA (RFC 3972), les ORCHID
sont en général utilisés avec de la cryptographie, la section 2 de notre RFC détaillant
le mécanisme de construction d'un ORCHID. On part d'un certain nombre
de paramètres, un OGA ID (ORCHID Generation Algorithm
IDentifier) qui identifie la fonction de
hachage utilisée, un contexte qui identifie le protocole
qui utilise ORCHID (la liste possible est à
l'IANA), une chaîne de bits et quelques autres. La chaîne de
bits est censée être unique. En pratique, ce sera souvent une clé
publique. Il y aura un contexte pour HIP, et un pour les futurs autres
protocoles qui utiliseront ORCHID. On concatène chaîne de bits et contexte,
on les condense et
on a un identificateur de 96 bits de long. Il n'y a plus ensuite qu'à ajouter
le préfixe 2001:20::/28 et l'identificateur OGA
(4 bits) pour avoir l'ORCHID complet de 128 bits.
Maintenant qu'on a construit des ORCHID, comment s'en sert-on ? La section 3 décrit les questions de routage et de transmission. Les routeurs ne doivent pas traiter les ORCHID différemment des autres adresses IP par défaut (afin d'éviter de gêner le déploiement ultérieur de nouveaux usages des ORCHID). Par contre, ils peuvent être configurés pour les rejeter (on peut changer la configuration plus tard, mais c'est plus difficile pour le code), par exemple par une ACL.
La section 4 revient sur les décisions qui ont été prises pour la conception des ORCHID. La principale était la longueur du préfixe. Un préfixe plus court aurait laissé davantage de place pour le résultat de la fonction de condensation, résultat qu'on doit tronquer à 96 bits, au détriment de la sécurité. Mais cela aurait avalé une plus grande partie de l'espace d'adressage d'IPv6. Pour gagner des bits, le contexte (le protocole utilisé) n'est pas dans l'ORCHID lui-même mais dans les paramètres d'entrée qui seront condensés. On ne peut donc pas, en regardant un ORCHID, connaître le contexte (on peut connaitre la fonction de hachage utilisée, via l'OGA ID qui, lui, est dans l'ORCHID final). On ne peut que vérifier a posteriori que le contexte supposé était le bon. Cela comble un des principaux défauts d'ORCHID v1 (dans le RFC 4843), l'absence d'agilité cryptographique (la possibilité de changer d'algorithme suite aux progrès de la cryptanalyse). Par exemple, dans l'ancienne norme ORCHID, HIP était restreint à utiliser SHA-1.
Si vous vous lancez dans l'analyse sécurité d'ORCHID, regardez aussi la section 5. ORCHID dépend de la sécurité des fonctions de condensation (RFC 4270) pour garantir la liaison sécurisée entre une clé publique et l'ORCHID. La nécessité de tronquer leur résultat, pour tenir dans les 128 bits d'une adresse IPv6 (moins le préfixe et le OGA ID) a affaibli ces fonctions (le RFC 6920, quoique parlant d'un sujet très différent, discutait déjà des conséquences de cette troncation).
L'annexe A du RFC, elle, se penche sur les risques de collision. Après tout, chaque ORCHID est censé être unique. Or, il n'y a pas de registre central des ORCHID : chacun les génère de son côté. Il n'y a donc qu'une unicité statistique : il est très improbable que deux machines génèrent le même ORCHID.
Et l'annexe B résume les différences entre les ORCHID v1 du RFC 4843 et les v2 de ce RFC 7343 :
- Mécanisme d'agilité cryptographique en mettant l'identificateur de l'algorithme (OGA ID) dans l'ORCHID,
- Suppression de plusieurs discussions intéressantes mais pas indispensables pour créer des ORCHID (voir le RFC 4843 si vous êtes curieux),
- Nouveau préfixe IPv6,
2001:20::/28, remplaçant l'ancien2001:10::/28, désormais restitué à l'IANA et à nouveau libre. Les ORCHID v2 sont donc totalement incompatibles avec les v1.
Les programmeurs de HIP for Linux et OpenHIP ont déjà promis de modifier leur code pour s'adapter à ces nouveaux ORCHID (qui sont désrmais dans la v2 de la norme HIP, RFC 7401).
Merci aux deux auteurs du RFC pour leur relecture de cet article.
L'article seul
RFC 7323: TCP Extensions for High Performance
Date de publication du RFC : Septembre 2014
Auteur(s) du RFC : D. Borman (Quantum
Corporation), B. Braden (University of Southern
California), V. Jacobson
(Google), R. Scheffenegger (NetApp)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tcpm
Première rédaction de cet article le 21 septembre 2014
L'algorithme originel de TCP rendait ce protocole de transport trop prudent et n'utilisant pas assez les réseaux, notamment ceux à forte latence. Après quelques essais, le RFC 1323, publié en 1992, a permis à TCP de fonctionner correctement sur une bien plus grande variété de réseaux, et jusqu'à aujourd'hui. Il est désormais remplacé par ce nouveau RFC 7323 qui, après une longue genèse, représente l'état de l'art en matière de performances TCP. Ce nouveau RFC est une lecture indispensable pour les fans de TCP ou tout simplement pour ceux qui veulent comprendre en détail ce protocole.
Avant le RFC 1323, TCP (normalisé dans le RFC 793 en 1981) se comportait très bien sur les réseaux locaux, ainsi que sur les réseaux distants à faible débit, comme ce qu'on avait sur un modem. Mais il était beaucoup moins satisfaisant sur les réseaux à forte latence et forte capacité, les réseaux à fort BDP où BDP signifie Bandwitdh-Delay Product. Si la capacité est faible ou la latence faible, pas de problèmes. Si leur produit dépasse une certaine valeur, TCP n'était pas capable de remplir la fenêtre et ses performances restaient en deçà du maximum théorique du réseau.
La section 1 décrit ce problème. TCP avait été conçu (et avec succès) pour tourner sur des réseaux très disparates, et pour s'adapter automatiquement à leurs caractéristiques (taux de perte, latence, taux de duplication...) À l'époque du RFC 1323, TCP tournait en production sur des réseaux dont les capacités allaient de 100 b/s à 10 Mb/s et cette plage s'est nettement élargie depuis. Existe-t-il une limite au débit de TCP, au-delà de laquelle il ne servirait à rien d'accélérer encore les réseaux ? La question n'a pas de réponse simple.
La caractéristique importante du réseau n'est en effet pas la capacité mais le produit de la capacité et de la latence, le BDP cité plus haut. C'est cette caractéristique qui indique la taille du tuyau que TCP doit remplir, la capacité étant le « diamètre » du tuyau et la latence sa « longueur ». Si la capacité croît beaucoup, au rythme des progrès techniques, la latence est bloquée par la finitude de la vitesse de la lumière et la seule façon de l'améliorer est de raccourcir les câbles. Donc, un gros BDP oblige TCP à avoir davantage de données « en transit », envoyées, mais n'ayant pas encore fait l'objet d'un accusé de réception, ce qui implique des tampons d'entrée/sortie de grande taille mais qui implique aussi la possibilité de garder trace de grands nombres (par exemple le nombre d'octets en transit), donc d'avoir des compteurs de taille suffisante. Ces liaisons Internet avec un fort BDP sont parfois surnommées les « éléphants » de l'anglais LFN (Long Fat Network).
Un exemple typique d'éléphant est une liaison satellite, avec sa capacité souvent respectable mais sa latence terrible, due à la nécessite d'un aller-retour avec l'orbite géostationnaire. À l'époque du RFC 1123, le BDP de ces liaisons était d'environ 1 Mbit soit 100 segments TCP de 1 200 octets chacun. Si une mise en œuvre de TCP se limitait à 50 segments envoyés avant de recevoir un accusé de réception, elle n'utiliserait que la moitié de la capacité disponible. Et les liaisons terrestres peuvent être des éléphants aussi. Un lien transcontinental aux États-Unis a une latence de 30 ms, ce qui, à 45 Mb/s, fait également un BDP de 1 Mbit.
Qu'est-ce qui empêchait TCP de tirer profit de ces éléphants ? Trois points :
- La taille de la fenêtre n'est stockée par défaut que sur 16 bits, ne permettant pas de fenêtre plus grande que 65 535 octets. Ce problème est résolu par le RFC 1323 avec l'introduction du window scaling.
- La récupération était trop longue en cas de perte de paquets. Les premiers TCP, dès qu'un paquet était perdu, attendaient de vider complètement le pipeline, puis repartaient de zéro, comme pour une connexion TCP neuve. En 1990, l'algorithme de TCP avait été modifié pour permettre un redémarrage plus rapide, tant qu'on ne perdait qu'un seul paquet par fenêtre TCP. Mais, avec des fenêtres plus grandes, cette probabilité de perte augmente. Les accusés de réception de TCP étant cumulatifs, une perte de paquet survenant au début de la fenêtre peut faire tout perdre. La solution a été une option d'accusés de réception sélectifs (SACK pour Selective ACKnowledgment). Ce point n'a pas été traité dans le RFC 1323 mais dans le RFC 2018.
Un autre problème à considérer est la fiabilité. Si on utilise TCP, c'est pour avoir certaines garanties : que tous les octets émis seront reçus, dans le même ordre, etc. Est-ce que le passage à de plus hautes performances menace ces garanties ? Par exemple, avec des fenêtres plus grandes, la probabilité qu'un paquet ancien, appartenant à une précédente connexion, lorsqu'il finit par arriver, tombe dans la fenêtre courante, cette probabilité est plus élevée. Dans ces conditions, les données seraient corrompues. La principale protection de TCP contre cet accident est la notion de MSL (Maximum Segment Lifetime), le temps qu'un segment peut traîner sur l'Internet. Il ne faut pas réutiliser des numéros de séquence avant qu'une durée supérieure ou égale à la MSL se soit écoulée. Ce numéro ne faisant que 32 bits, cela peut être délicat, surtout aux débits élevés (même sans fenêtres agrandies). La MSL est généralement prise à deux minutes et, à seulement 1 Gb/s, les numéros de séquence ne durent que dix-sept secondes. Or, aucun mécanisme sur l'Internet ne garantit le respect de la MSL. Un vieux paquet ne sera pas jeté. D'où l'utilisation par notre RFC 7323 de l'option Timestamps pour détecter les segments trop anciens et se protéger donc contre la réutilisation des numéros de séquence TCP (solution PAWS, en section 5).
À noter que ces mécanismes sont conçus pour les réseaux à fort BDP. Sur des réseaux à faible BDP, il peut être intéressant de les débrayer, manuellement ou automatiquement.
Reste que les solutions proposées dans ce RFC dépendent des options TCP. Pour certains protocoles, par exemple IP, certaines options ont du mal à passer à travers le réseau (section 1.3 de notre RFC). TCP semble mieux placé de ce point de vue (il est mentionné à la fin de mon article sur les options IP). On peut consulter à ce sujet « Measuring Interactions Between Transport Protocols and Middleboxes » et « "Measuring the Evolution of Transport Protocols in the Internet ».
La section 2 de notre RFC présente la première option qui avait été normalisée pour améliorer les performances de TCP sur les liens à fort BDP (Bandwidth-Delay Product), le window scaling. L'idée de base est très simple : 16 bits pour indiquer la taille de la fenêtre, c'est trop peu, on va donc appliquer un facteur (indiqué dans une option TCP) au nombre décrit par ces 16 bits. À noter que, comme les options ne sont envoyées qu'au début de la connexion TCP, le facteur est constant (la fenêtre elle-même étant dynamique).
L'option Window Scale comprend trois champs : Type, Longueur et Valeur. Le type vaut 3 et est enregistré dans le registre des options, la longueur est forcément de 3 (trois octets en tout) et la valeur est un octet qui indique de combien de bits on va décaler la taille de la fenêtre. Une valeur de 0 indique pas de décalage, donc un facteur de 1 (une telle valeur n'est pas inutile car elle sert à indiquer au pair TCP qu'on sait gérer le window scaling). Une valeur de 1 indique qu'on double la taille de la fenêtre pour connaître la vraie valeur, etc. Voici un exemple vu par Wireshark :
Transmission Control Protocol, Src Port: 51336 (51336), Dst Port: 4332 (4332), Seq: 0, Len: 0
...
Options: (20 bytes), Maximum segment size, SACK permitted, Timestamps, No-Operation (NOP), Window scale
...
Window scale: 5 (multiply by 32)
Kind: Window Scale (3)
Length: 3
Shift count: 5
Et, quelques paquets plus loin, on voit bien le facteur d'échelle appliqué (32, soit 2^5). Le champ indiquant la longueur de la fenêtre vaut 728 octets mais il faut en fait lire 23 296 octets :
Window size value: 728
[Calculated window size: 23296]
[Window size scaling factor: 32]
(À noter que je parlais aussi de cette option à la fin de l'article
sur le RFC 793.) Sur
Linux, cette option peut s'activer ou se
désactiver avec le paramètre sysctl
net.ipv4.tcp_window_scaling (c'est parfois
nécessaire de la désactiver dans certains réseaux bogués qui bloquent
les paquets TCP contenant des options inconnues d'eux).
Autre option normalisée ici, la meilleure mesure du RTT par l'option Timestamps, en section 3. La mesure du RTT est cruciale pour TCP, pour éviter des accidents comme la congestion brutale décrite dans le RFC 896. Si TCP ne mesure qu'un seul paquet par fenêtre, les résultats seront mauvais pour les grandes fenêtres, par simple problème d'échantillonage (critère de Nyquist).
L'option Timestamps a le type 8, une longueur de
10, et deux champs de quatre octets, l'heure qu'il était au moment de
l'envoi et l'heure lue dans le paquet pour lequel on accuse réception
(cette valeur n'a donc de sens que si le paquet a le bit
ACK). L'« heure » n'est pas forcément celle de
l'horloge au mur (puisque, de toute façon, on n'utilisera que des
différences), l'important est qu'elle avance à peu près au même
rythme. En fait, il est même recommandé que l'horloge ne soit pas
directement celle de la machine, pour éviter de donner une information
(la machine est-elle à l'heure)
à un éventuel observateur indiscret. La section 7.1 recommande d'ajouter à
l'horloge de la machine un décalage spécifique à chaque connexion, et
tiré au hasard au début de la connexion.
Attention, il n'y a aucune raison qu'on ait le même nombre de paquets dans les deux sens. On peut voir un pair TCP envoyer deux paquets et le récepteur ne faire qu'un seul paquet d'accusé de réception. Dans ce cas, ledit récepteur devra renvoyer le temps du paquet le plus ancien. Toujours avec Wireshark, cela donne :
Transmission Control Protocol, Src Port: 4332 (4332), Dst Port: 51336 (51336), Seq: 0, Ack: 1, Len: 0
...
Options: (20 bytes), Maximum segment size, SACK permitted, Timestamps, No-Operation (NOP), Window scale
...
Timestamps: TSval 2830995292, TSecr 27654541
Kind: Timestamp (8)
Length: 10
Timestamp value: 2830995292
Timestamp echo reply: 27654541
Et, dans le paquet suivant de la même direction, les compteurs ont augmenté :
Timestamps: TSval 2830995566, TSecr 27654569
Kind: Timestamp (8)
Length: 10
Timestamp value: 2830995566
Timestamp echo reply: 27654569
Ici, il s'agissait d'une communication entre deux machines
Linux. La génération des estampilles
temporelles dans les options TCP est contrôlée par la variable
sysctl
net.ipv4.tcp_timestamps (documentée, comme les
autres, dans le fichier
Documentation/networking/ip-sysctl.txt des
sources du noyau). Par exemple :
% sysctl net.ipv4.tcp_timestamps net.ipv4.tcp_timestamps = 1
Cela signifie que cette option est activée sur cette machine (0 = désactivée).
Cette option d'estampillage temporel est utilisée dans PAWS (présenté plus loin) mais aussi dans d'autres systèmes comme ceux du RFC 3522 ou du RFC 4015.
La section 4 décrit l'utilisation des estampilles temporelles pour mesurer le RTT des paquets, ce qui sert à TCP à déterminer le RTO (Retransmission TimeOut), le délai au bout duquel TCP s'impatiente de ne pas avoir eu d'accusé de réception et réémet. Voir à ce sujet le RFC 6298, pour savoir tout de ce calcul du RTO, et aussi le papier « On Estimating End-to-End Network Path Properties ».
La section 5 présente le mécanisme PAWS (Protection Against Wrapped Sequence numbers), qui sert à lutter contre les vieux segments TCP qui arriveraient tard et avec, par malchance, un numéro de séquence qui a été réutilisé depuis et est donc considéré comme valide. Les numéros de séquence étant stockés sur 32 bits seulement, la probabilité d'un tel accident augmente avec la capacité des réseaux. PAWS se sert de la même option Timestamps qui a été présentée plus haut. L'idée est que si un segment TCP arrive avec une estampille temporelle trop ancienne, par rapport à celles reçues récemment, on peut le jeter sans remords. Comme pour tous les usages de l'option Timestamps, il ne nécessite pas de synchronisation d'horloges entre les deux pairs TCP car les comparaisons se font toujours entre les estampilles mises par une même machine.
Quels sont les changements depuis le RFC 1323 (voir l'annexe H) ? D'abord, une partie du texte a été supprimée, celle consacrée à la discussion des mérites des différentes options. Si on veut lire cette discussion, il faut reprendre le RFC 1323.
Ensuite, de nombreux changements importants ont été apportés. Je ne
vais pas les lister tous ici mais, par exemple, la section 3.2 a été
très enrichie pour mieux préciser l'utilisation des estampilles
temporelles (trop floue précédémment), l'algorithme de sélection de
l'estampille dans la section 3.4 du RFC 1323 a
été corrigé (deux cas n'étaient pas traités), le cas des paquets TCP
RST (ReSeT d'une connexion) a
été décrit, la discussion sur la MSS a été
déplacée dans le RFC 6691, etc.
Nouveauté de ce RFC (le RFC 1323 clamait qu'il ne se préoccupait pas du sujet), la section 7, sur la sécurité. Ouvrir la fenêtre TCP pour augmenter les performances, c'est bien. Mais cela ouvre également la voie à des attaques où un méchant tente de glisser un paquet dans la séquence des paquets TCP. Normalement, un attaquant situé en dehors du chemin des paquets, qui ne peut donc pas les observer, doit, s'il veut réussir cette injection, deviner le numéro de séquence (RFC 5961). Mais plus la fenêtre est grande et plus c'est facile (il n'a pas besoin de deviner le numéro exact, juste de deviner un numéro qui est dans la fenêtre). Il faut donc mettre en rapport le gain de performances avec le risque d'accepter de faux paquets. PAWS protège partiellement contre ces attaques mais en permet de nouvelles (par exemple l'injection d'un paquet ayant une estampille dans le futur permettrait, si ce paquet est accepté, de faire rejeter les vrais paquets comme étant trop anciens).
Les fanas de programmation et de placement des bits dans la mémoire
liront avec plaisir l'annexe A, qui recommande un certain arrangement
des options dans le paquet TCP : en mettant deux options vides
(NOP) avant l'option
Timestamp, on obtient le meilleur alignement en
mémoire pour une machine 32-bits.
L'article seul
RFC 7321: Cryptographic Algorithm Implementation Requirements and Usage Guidance for Encapsulating Security Payload (ESP) and Authentication Header (AH)
Date de publication du RFC : Août 2014
Auteur(s) du RFC : D. McGrew (Cisco Systems), P. Hoffman
(VPN Consortium)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF ipsecme
Première rédaction de cet article le 19 septembre 2014
Le protocole de cryptographie IPsec vient avec une liste d'obligations concernant les algorithmes cryptographiques qu'il faut inclure. Autrefois dans le RFC 4835, cette liste a été mise à jour dans ce RFC 7321, remplacé depuis par le RFC 8221. Ainsi, les différentes mises en œuvre d'IPsec sont sûres d'avoir un jeu d'algorithmes corrects en commun, assurant ainsi l'interopérabilité.
Plus précisément, ce nouveau RFC concerne les deux services d'IPsec, ESP (Encapsulating Security Payload, RFC 4303) et AH (Authentication Header, RFC 4302). Les RFC normatifs sur IPsec se veulent stables, alors que la cryptographie évolue. D'où le choix de mettre les algorithmes dans un RFC à part. Par exemple, la section 3.2 du RFC 4303 note « The mandatory-to-implement algorithms for use with ESP are described in a separate RFC, to facilitate updating the algorithm requirements independently from the protocol per se » (c'était à l'époque le RFC 4305, remplacé depuis par le RFC 4835, puis par notre RFC 7321, sept ans après son prédécesseur).
Ce RFC « extérieur » à IPsec spécifie les algorithmes obligatoires, ceux sur lesquels on peut toujours compter que le pair IPsec les comprenne, ceux qui ne sont pas encore obligatoires mais qu'il vaut mieux mettre en œuvre car ils vont sans doute le devenir dans le futur, et ceux qui sont au contraire déconseillés, en général suite aux progrès de la cryptanalyse, qui nécessitent de réviser régulièrement ce RFC (voir section 1). Cette subtilité (différence entre « obligatoire aujourd'hui » et « sans doute obligatoire demain ») mène à une légère adaptation des termes officiels du RFC 2119 : MUST- (avec le signe moins à la fin) est utilisé pour un algorithme obligatoire aujourd'hui mais qui ne le sera sans doute plus demain, en raison des avancées cryptanalytiques, et SHOULD+ est pour un algorithme qui n'est pas obligatoire maintenant mais le deviendra sans doute.
La section 2 donne la liste des algorithmes. Je ne la répète pas intégralement ici. Parmi les points à noter :
- ESP a un mode de chiffrement intègre (authenticated encryption qu'on peut aussi traduire par chiffrement vérifié ou chiffrement authentifié, que je n'aime pas trop parce qu'on peut confondre avec l'authentification, cf. RFC 5116). Ce mode n'a pas d'algorithme obligatoire mais un SHOULD+ qui sera peut-être donc obligatoire dans la prochaine version, AES-GCM (il était MAY dans le RFC 4835).
- Le mode le plus connu d'ESP, celui de chiffrement, a deux
algorithmes obligatoires, AES-CBC (RFC 3602) et le surprenant
NULL, c'est-à-dire l'absence de chiffrement (RFC 2410 ; on peut utiliser ESP pour l'authentification seule, d'où cet algorithme). Il y a aussi un algorithme noté MUST NOT, DES-CBC (RFC 2405) qui ne doit pas être mis en œuvre, afin d'être sûr qu'on ne s'en serve pas (il était seulement SHOULD NOT dans le RFC 4835). - Le mode d'authentification (enfin, intégrité serait peut-être un meilleur mot mais c'est subtil) d'ESP a un MUST, HMAC-SHA1 (RFC 2404) mais aussi un SHOULD+ qui pourra le rejoindre, AES-GMAC, GMAC étant une variante de GCM (et qui était en MAY dans le vieux RFC).
- Et AH, lui, a les mêmes algorithmes que ce mode d'authentification d'ESP.
La section 3 donne des conseils sur l'utilisation d'ESP et AH. AH
ne fournit que l'authentification, alors qu'ESP peut fournir également
le chiffrement. Bien sûr, le chiffrement sans l'authentification ne
sert pas à grand'chose, puisqu'on risque alors de parler à
l'homme du milieu sans le savoir (voir l'article de
Bellovin, S. « Problem areas for the IP security
protocols » dans les Proceedings of the Sixth Usenix Unix Security
Symposium en 1996). Certaines
combinaisons d'algorithmes ne sont pas sûres, par exemple, évidemment, ESP avec les algorithmes
de chiffrement et d'authentification tous les deux à NULL (voir par exemple l'article de
Paterson, K. et J. Degabriele, « On the (in)security of
IPsec in MAC-then-encrypt configurations » à l'ACM Conference
on Computer and Communications Security en 2010). Si on veut
de l'authentification/intégrité sans chiffrement, le RFC recommande d'utiliser
ESP avec le chiffrement NULL, plutôt que AH. En
fait, AH est rarement utile, puisque ESP en est presque un
sur-ensemble, et il y a même eu des propositions de le
supprimer. AH avait été prévu pour une époque où le chiffrement
était interdit d'utilisation ou d'exportation dans certains pays et un
logiciel n'ayant que AH posait donc moins de problèmes
légaux. Aujourd'hui, la seule raison d'utiliser encore AH est si on
veut protéger certains champs de l'en-tête IP,
qu'ESP ne défend pas.
La section 4 de notre RFC donne quelques explications à certains des choix d'algorithmes effectués. Le chiffrement intègre/authentifié d'un algorithme comme AES-GCM (RFC 5116 et RFC 4106) est la solution recommandée dans la plupart des cas. L'intégration du chiffrement et de la vérification d'intégrité est probablement la meilleure façon d'obtenir une forte sécurité. L'algorithme de chiffrement AES-CTR (auquel on doit ajouter un contrôle d'intégrité) n'a pas de faiblesses cryptographiques, mais il ne fournit aucun avantage par rapport à AES-GCM (ne tapez pas sur le messager : c'est ce que dit le RFC, je sais que tous les cryptographes ne sont pas d'accord, par exemple parce qu'ils trouvent GCM beaucoup plus complexe).
Par contre, Triple DES et DES, eux, ont des défauts connus et ne doivent plus être utilisés. Triple DES a une taille de bloc trop faible et, au-delà d'un gigaoctet de données chiffrées avec la même clé, il laisse fuiter des informations à un écoutant, qui peuvent l'aider dans son travail de décryptage. Comme, en prime, il est plus lent qu'AES, il n'y a vraiment aucune raison de l'utiliser. (DES est encore pire, avec sa clé bien trop courte. Il a été cassé avec du matériel dont les plans sont publics.)
Pour l'authentification/intégrité, on sait que MD5 a des vulnérabilités connues (RFC 6151), question résistance aux collisions. Mais cela ne gêne pas son utilisation dans HMAC-MD5 donc cet algorithme, quoique non listé pour IPsec, n'est pas forcément ridicule aujourd'hui. SHA-1 a des vulnérabilités analogues (quoique beaucoup moins sérieuses) mais qui ne concernent pas non plus son utilisation dans HMAC-SHA1, qui est donc toujours en MUST. Bien que les membres de la famille SHA-2 n'aient pas ces défauts, ils ne sont pas cités dans ce RFC, SHA-1 étant très répandu et largement suffisant.
Dans le précédent RFC, Triple DES était encore noté comme une alternative possible à AES. Ce n'est plus le cas aujourd'hui, où les vulnérabilités de Triple DES sont bien connues (sans compter ses performances bien inférieures). Triple DES est maintenu dans IPsec (il est en MAY) mais uniquement pour des raisons de compatibilité avec la base installée. Le problème est qu'il n'y a donc plus de solution de remplacement si un gros problème est découvert dans AES (section 5, sur la diversité des algorithmes). Il n'y a aucune indication qu'une telle vulnérabilité existe mais, si elle était découverte, l'absence d'alternative rendrait le problème très sérieux.
Voilà, c'est fini, la section 8 sur la sécurité rappelle juste quelques règles bien connues, notamment que la sécurité d'un système cryptographique dépend certes des algorithmes utilisés mais aussi de la qualité des clés, et de tout l'environnement (logiciels, humains).
Ce RFC se conclut en rappelant que, de même qu'il a remplacé ses prédécesseurs comme le RFC 4835, il sera probablement à son tour remplacé par d'autres RFC, au fur et à mesure des progrès de la recherche en cryptographie. (Ce fut fait avec le RFC 8221.)
Si vous voulez comparer avec un autre document sur les algorithmes cryptographiques à choisir, vous pouvez par exemple regarder l'annexe B1 du RGS, disponible en ligne.
Merci à Florian Maury pour sa relecture acharnée. Naturellement, comme c'est moi qui tiens le clavier, les erreurs et horreurs restantes viennent de ma seule décision. De toute façon, vous n'alliez pas vous lancer dans la programmation IPsec sur la base de ce seul article, non ?
L'article seul
RFC 7372: Email Authentication Status Codes
Date de publication du RFC : Septembre 2014
Auteur(s) du RFC : M. Kucherawy
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF appsawg
Première rédaction de cet article le 17 septembre 2014
Il existe désormais plusieurs techniques d'authentification du courrier électronique, comme SPF ou DKIM. Elles permettent à un serveur de messagerie, s'il le désire, d'accepter ou de rejeter le courrier entrant s'il échoue à ces tests d'authentification. Mais il n'existait pas jusqu'à présent de moyen standard de prévenir l'expéditeur, lors de la session SMTP, de la raison de ce rejet. C'est désormais fait, avec ce nouveau RFC, qui permet de renvoyer des codes de retour SMTP explicites, si on veut.
J'ai bien dit « si on veut » car tous les administrateurs de serveurs ne sont pas d'accord pour indiquer à l'expéditeur les raisons exactes du rejet. Après tout, si l'authentification échoue, c'est peut-être que l'expéditeur était un méchant, un spammeur, par exemple, et, dans ce cas, on ne souhaite pas lui donner de l'information. L'utilisation de ces nouveaux codes de retour est donc optionnelle.
Ces codes sont de type « codes étendus », normalisés par le RFC 3463 et dotés d'un registre IANA depuis le RFC 5248. Les codes « améliorés » du RFC 3463 comportent trois nombres, la classe (2 : tout va bien, 4 : erreur temporaire, 5 : erreur définitive, etc), le second le sujet (6 : problème avec le contenu du message, 7 : problème avec la politique de sécurité, etc) et le troisième le détail. Ils s'écrivent avec un point comme séparateur, contrairement aux codes de retour traditionnels, eux aussi à trois chiffres, mais sans séparateur.
La section 3 du RFC liste ces nouveaux codes. Ils figurent tous dans le registre IANA. Dans quasiment tous les cas, le code de base (non étendu) associé sera 550, le code étendu donnant les détails.
D'abord, pour
DKIM (RFC 6376). Il y a
deux cas de succès, passing, où la
signature DKIM est valide et
acceptable, où non seulement la signature est valide
mais où elle correspond aux règles locales du serveur récepteur (qui, par
exemple, impose que tel ou tel en-tête soit couvert par la
signature). Un cas particulier de acceptable (qui a
son code spécifique) est celui où le serveur de réception impose que
l'auteur du message (dans le champ From:)
corresponde à une des identités DKIM utilisées pour signer le
message. C'est donc la vérification la plus stricte.
Les codes sont respectivement :
- X.7.20 (où X indique la classe, qui sera 5 Permanent Failure dans la plupart des cas) : aucune signature DKIM passing.
- X.7.21 : aucune signature DKIM acceptable. Au moins une signature est valide (passing), autrement on utiliserait X.7.20 mais elle ne correspond pas aux exigences locales (rappelez-vous que la norme DKIM laisse une grande latitude à l'émetteur sur ce qu'il signe et notamment sur l'identité utilisée, voir entre autres la section 1.2 du RFC 6376).
- X.7.22 : il y a au moins une signature DKIM
passing mais elle n'est pas
acceptable car l'identité utilisée n'est pas celle
contenue dans le
champ
From:(un cas particulier de X.7.21, donc).
Notez que DKIM permet d'avoir des signatures valides et des invalides sur le même message. En effet, certains logiciels modifient le message en route, invalidant les signatures. Le principe de DKIM est donc qu'on ignore les signatures invalides. On n'envoie les codes de retour indiquant un rejet que lorsqu'on n'a aucune signature valable. À noter aussi que tous ces codes indiquent que le serveur SMTP de réception s'est assis sur l'avis de la section 6.3 (et non pas 6.1 contrairement à ce que dit le nouveau RFC) du RFC 6376. Cet avis dit en effet « In general, modules that consume DKIM verification output SHOULD NOT determine message acceptability based solely on a lack of any signature or on an unverifiable signature; such rejection would cause severe interoperability problems. » Le but est d'augmenter la robustesse de DKIM face à des intermédiaires qui massacreraient des signatures. Mais, bon, il y a des gens qui rejettent les messages juste pour une absence de signature valide, donc, autant leur fournir un code de retour adapté. (Voir aussi la section 4 qui discute ce point et insiste bien sur le fait que cela ne signifie pas une approbation de ce rejet violent par les auteurs du RFC. Cette question a été une des plus chaudement discutées dans le groupe de travail IETF.)
Ensuite, il y a des codes pour SPF (RFC 7208) :
- X.7.23 : message invalide selon SPF,
- X.7.24 : pas forcément invalide mais l'évaluation de SPF a entraîné une erreur (problème DNS, par exemple).
Voici à quoi pourrait ressembler une session SMTP avec rejet SPF :
% telnet mail.example.com smtp 220 myserver.example.com ESMTP Postfix (LibreBSD) ... MAIL FROM:<me@foobar.fr> 550 5.7.23 Your server is not authorized to send mail from foobar.fr
Enfin, il y a un code pour le test dit reverse DNS décrit dans la section 3 du RFC 8601, qui consiste à traduire l'adresse IP de l'émetteur SMTP en nom(s) puis ce(s) nom(s) en adresses IP pour voir si l'adresse originale se trouve dans cet ensemble d'adresses. Il peut conduire au code SMTP X.7.25 en cas d'échec.
La section 4 de notre RFC mentionne un certain nombre de considérations générales sur ces codes de retour. Par exemple, les autres techniques d'authentification développées ultérieurement devront ajouter leur propre code SMTP étendu, sur le modèle de ceux-ci.
Autre point, SMTP ne permet de renvoyer qu'un seul code de retour étendu. Si on a plusieurs techniques d'authentification qui ont échoué, on peut toujours utiliser le code général X.7.26 qui indique que plusieurs tests ont échoué. Mais si on a une erreur d'authentification et une erreur d'un autre type, il n'y a pas de solution propre : il faut choisir une des causes de rejet et renvoyer le code correspondant.
Et la section 5, sur la sécurité, rappelle que l'utilisation de ces codes de retour étendus est facultative. Si vous ne voulez pas révéler à vos correspondants pourquoi vous rejetez leurs messages, vous êtes libre.
L'article seul
RFC 7366: Encrypt-then-MAC for TLS and DTLS
Date de publication du RFC : Septembre 2014
Auteur(s) du RFC : P. Gutmann (University of Auckland)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 16 septembre 2014
Dernière mise à jour le 22 février 2015
Depuis ses débuts, le protocole de cryptographie TLS (héritier de SSL) protège l'intégrité des paquets transmis en calculant un MAC, qui est inclus dans les données avant le chiffrement, une technique qu'on nomme MAC-then-encrypt. Plusieurs failles de sécurité ont été depuis identifiées dans cette technique et ce nouveau RFC normalise une extension à TLS qui permet de faire l'inverse, chiffrer avant de calculer le MAC, ce qui est aujourd'hui considéré comme plus sûr. On nomme cette méthode, logiquement, encrypt-then-MAC. (Notez qu'il existe une méthode encore plus sûre, le chiffrement intègre, systématisé à partir de TLS 1.3.)
Lorsque le protocole SSL, ancêtre de TLS, avait été normalisé, au milieu des années 1990, le MAC-then-encrypt semblait tout à fait sûr. C'est ainsi que l'actuelle norme TLS, le RFC 5246 (section 6.2.3.1), continue à utiliser MAC-then-encrypt. Des études comme celle de M. Bellare et C. Namprempre, « Authenticated Encryption: Relations among notions and analysis of the generic composition paradigm » ou celle de H. Krawczyk, « The Order of Encryption and Authentication for Protecting Communications (or: How Secure Is SSL?) » ont depuis montré que MAC-then-encrypt est vulnérable à un certain nombre d'attaques cryptanalytiques, dans certaines conditions d'utilisation (je simplifie : la question de la vulnérabilité exacte de MAC-then-encrypt est plus compliquée que cela). Il est désormais recommandé d'utiliser plutôt encrypt-then-MAC (je simplifie encore : le RFC note par exemple que les algorithmes qui ne séparent pas chiffrement et calcul du MAC n'ont pas besoin de cette méthode).
Pour sélectionner la méthode recommandée, le groupe de travail
TLS de
l'IETF a choisi (section 2 de notre RFC) d'utiliser une extension à TLS
(RFC 5246, section 7.4.1.4). Le client ajoute
dans son message de bienvenue (client_hello)
l'extension encrypt_then_mac (le
extension_type de
encrypt_then_mac vaut 22 et est désormais
dans le registre IANA). Si le serveur TLS
est d'accord, il mettra cette extension dans son
server_hello.
Une autre solution (que d'utiliser le mécanisme d'extensions) aurait été de définir de nouveaux algorithmes de chiffrement et elle a fait l'objet de nombreux débats au sein du groupe de travail. Mais cela menait à une explosion du nombre d'algorithmes (ciphers), il aurait fallu presque doubler le nombre d'algorithmes concernés, pour avoir une version MAC-then-encrypt (l'actuelle) et une version encrypt-then-MAC. Encore une autre solution aurait été de créer une nouvelle version de TLS, la 1.3, où encrypt-then-MAC aurait été le comportement standard. Quand on sait que la version actuelle de TLS, la 1.2, est toujours minoritaire dans la nature, on voit qu'une telle solution aurait sérieusement retardé le déploiement. Au contraire, avec la solution choisie, il « suffira » de changer quelques dizaines de lignes de code dans les bibliothèques TLS actuelles. Un tel changement a des chances de se retrouver plus rapidement sur le terrain.
Comme le mécanisme d'extension est apparu avec TLS (il n'existait pas dans SSL, même dans sa dernière version, la 3), encrypt-then-MAC ne sera pas utilisable pour les logiciels qui utilisent encore SSL v3 (le cas principal semblant être la version 6 d'Internet Explorer). Comme SSL est abandonné depuis quinze ans, des logiciels aussi vieux ont probablement des tas d'autres failles de sécurité plus graves que l'utilisation de MAC-then-encrypt. (Au passage, c'est une des raisons pour lesquelles ce modeste blog n'accepte pas SSLv3.)
Arrêtons la discussion sur les alternatives qui auraient été
possibles et revenons à la nouvelle extension (section 3 de notre RFC). Une fois qu'elle est
acceptée par le client et le serveur, le traitement des paquets par
TLS passera de l'ancien comportement encrypt (data || MAC ||
pad) (où || désigne la concaténation) au
nouveau encrypt (data || pad) || MAC. Le MAC est calculé
comme avant, sauf qu'il part du texte chiffré
(TLSCiphertext) et plus du texte en clair
(TLSCompressedtext, cf. RFC 5246, section 6.2.3.1).
La structure de données TLS qui était (RFC 5246,
section 6.2.3) :
struct {
ContentType type;
ProtocolVersion version;
uint16 length;
GenericBlockCipher fragment; /* Après moultes discussions,
le groupe de travail a décidé de n'appliquer
encrypt-then-MAC qu'aux "block ciphers". */
} TLSCiphertext;
va devenir :
struct {
ContentType type;
ProtocolVersion version;
uint16 length;
GenericBlockCipher fragment;
opaque MAC; /* Ce champ supplémentaire est la seule
nouveauté */
} TLSCiphertext;
Pour le déchiffrement, on fait les opérations en sens inverse, on
vérifie le MAC d'abord, on jette immédiatement le paquet si le MAC est
incorrect (en renvoyant un message
bad_record_mac), sinon on déchiffre. Ainsi, un
attaquant qui modifie les données en vol ne peut rien apprendre sur
les clés cryptographiques utilisées : toute modification invalidera le
MAC et tous les calculs d'un MAC incorrect prendront le même temps, ne
permettant pas d'attaque par mesure du
temps.
À noter que TLS permet d'utiliser un MAC raccourci (RFC 6066) et cela reste possible avec encrypt-then-MAC, dans les mêmes conditions.
Comme avec toute extension qui améliore la sécurité, il y a un risque qu'un attaquant actif perturbe la négociation (section 4 du RFC) pour amener les deux parties à ne pas choisir la nouvelle extension (attaque par repli), par exemple en forçant une utilisation de vieilles versions du protocole, n'ayant pas d'extensions (et donc pas de encrypt-then-MAC). La seule protection est de refuser le repli, ce qui peut provoquer des problèmes d'interopérabilité avec certains vieux logiciels (voir par exemple le ticket #1084025 chez Mozilla).
Il y a un serveur TLS public qui gère cette extension, si vous
voulez tester votre code client : https://eid.vx4.net.
Au 14 septembre 2014, la gestion de cette extension ne figure pas
encore dans la version publiée d'OpenSSL, la
1.0.1i mais est dans la version de développement (voir le
commit). Par contre, encore rien dans
GnuTLS (la version publiée est la 3.3.7).
Merci à Florian Maury pour sa relecture et à Manuel Pégourié-Gonnard pour avoir corrigé une faute sur l'attaque par repli..
Une bonne explication technique de ces problèmes est celle de Moxie Marlinspike.
L'article seul
RFC 7352: Sieve Email Filtering: Detecting Duplicate Deliveries
Date de publication du RFC : Septembre 2014
Auteur(s) du RFC : S. Bosch
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF appsawg
Première rédaction de cet article le 16 septembre 2014
Voici un nouveau test pour le langage de filtrage du courrier
Sieve : duplicate permet
de tester si un message reçu est un double d'un message déjà arrivé
(en général en se fiant au Message-Id:)
et, par exemple, d'ignorer le doublon.
Tout le monde a déjà rencontré ce problème : on est inscrit à une
liste de diffusion et quelqu'un écrit à la
liste en vous mettant en copie. Résultat, on reçoit deux fois le même
message. La consommation de ressources réseau et système est
négligeable, mais c'est gênant pour le lecteur, qui se retrouve avec
deux messages à traiter au lieu d'un. Il serait bien plus pratique de
détecter automatiquement le duplicata et de le résorber. Même chose si
on est abonné à deux listes de diffusion (encore que, dans ce cas, des
informations spécifiques à la liste et ajoutées dans les messages,
comme le Archived-At: du RFC 5064, peuvent être utiles).
Beaucoup de gens traitent automatiquement leur courrier, avec des techniques comme Sieve ou procmail et la solution décrite dans ce RFC concerne Sieve (qui est normalisé dans le RFC 5228).
La section 3 de notre RFC décrit le nouveau test
duplicate. Il s'utilise ainsi :
require ["duplicate", "fileinto", "mailbox"];
if duplicate {
fileinto :create "Trash/Duplicate";
}
Ici, si le message est un doublon d'un message existant, il est mis
dans le dossier Trash/Duplicate. Mais comment le
test duplicate sait-il que le message est un
doublon ? Il fonctionne en déterminant, pour chaque message, un
identificateur unique. Lors du test, on
regarde si l'identificateur est présent dans une base de données et,
si ce n'est pas le cas, on l'y stocke. Contrairement à bien des
extensions à Sieve, celle-ci va donc nécessiter un mécanisme de
mémoire, permettant de garder trace des identificateurs de messages
déjà vus.
Notez bien que la base est mise
à jour lors du test duplicate, pas à la réception
de chaque message (le test duplicate peut ne pas
être exécuté dans tous les cas, par exemple s'il dépend d'un autre
test). De même, l'ajout de l'identificateur unique dans la base ne
doit être fait que si le script Sieve se termine normalement, pour
éviter de considérer les messages suivants comme des doublons si le
premier n'a pas pu être stocké correctement (disque plein ou autre
erreur). Dans certains cas (livraison en parallèle), cela mènera à la
distribution de deux copies mais le RFC considère qu'il faut éviter à
tout prix la perte accidentelle d'un message donc qu'il vaut mieux
quelques doublons en trop plutôt que le classement erroné d'un message
comme étant un doublon.
Mais comment est déterminé l'identificateur unique indispensable au
classement ? Il existe un en-tête prévu pour cela,
Message-ID:, dont la section 3.6.4 du RFC 5322 dit bien qu'il doit être unique (il est en
général formé d'une concaténation d'un grand nombre tiré au hasard et
du nom de domaine du serveur, par exemple
5400B19D.70904@hackersrepublic.org). Mais, en pratique, on voit parfois des
Message-ID: dupliqués et il faut donc prévoir des
solutions de secours.
C'est ce que contient la section 3.1 de notre RFC, avec les
arguments :header et
:uniqueid. Par défaut, l'identificateur unique
utilisé par le test duplicate est le
Message-ID:. Si on utilise le paramètre
:header, c'est le contenu de cet en-tête qui est
utilisé comme identificateur unique. Par exemple :
if duplicate :header "X-Event-ID" {
discard;
}
va jeter tous les messages dont l'en-tête (non standard)
X-Event-ID: a une valeur déjà vue (cas d'un
système de supervision envoyant ses
informations par courrier).
Si on utilise le paramètre :uniqueid, c'est la
valeur indiquée par le paramètre qui est l'identificateur unique. Cela
n'a d'intérêt, je crois, qu'en combinaison avec les variables Sieve du
RFC 5229 (l'exemple suivant utilise aussi les statuts
IMAP du RFC 5232) :
require ["duplicate", "variables", "imap4flags"]
if header :matches "subject" "ALERT: *" {
if duplicate :uniqueid "${1}" {
setflag "\\seen";
}
Ici, la valeur du paramètre :uniqueid vaut la
variable ${1}, c'est-à-dire le contenu du sujet
du message, après l'étiquette « ALERT: ».
Bien sûr, on utilise :header ou
:uniqueid mais jamais les deux en même temps.
Le test duplicate met tous les identificateurs
uniques dans une seule base. Si on souhaite avoir plusieurs bases, on
utilise le paramètre :handle (section 3.2) :
if duplicate :header "X-Event-ID" :handle "notifier" {
discard;
}
if duplicate :header "X-Ticket-ID" :handle "support" {
# Utilisation d'une base différente: un X-Ticket-ID peut être
# dans la base notifier mais pas dans la base support.
}
Pour mettre en œuvre le test duplicate, une façon
simple de ne pas se compliquer la vie avec plusieurs fichiers est de
garder dans un fichier unique un condensat de la
concaténation de :handle avec l'identificateur
unique.
On souhaite parfois que la mémorisation d'un identificateur unique
ne soit que provisoire : si un message arrive un mois après, même s'il
a un identificateur déjà vu, c'est probablement un nouveau message
qui, par erreur ou par bogue, a un identificateur déjà existant. Il
est peu probable que le même message, transmis par deux listes de
diffusion différentes, traine autant... Le RFC conseille de ne
mémoriser l'identificateur que pendant une semaine et fournit un
paramètre :seconds (section 3.3) pour contrôler cette durée :
if not duplicate :seconds 1800 {
notify :message "[SIEVE] New interesting message"
"xmpp:user@im.example.com";
La durée est en secondes : ici, on indique une expiration au bout de seulement une demi-heure, peut-être parce qu'on ne veut absolument pas perdre de messages et qu'on craint que les identificateurs ne soient réutilisés trop fréquemment. (L'extension pour une notification par XMPP est dans le RFC 5437.)
La durée indiquée par le paramètre :seconds se
compte à partir du premier message vu. Les messages ultérieurs portant
le même identificateur ne remettent pas le compteur à zéro. Si on utilise le paramètre
:last, par contre, la durée est comptée à partir
du dernier message vu : tant que des messages arrivent avec cet
identificateur, il n'y a pas d'expiration.
Comme toutes les extensions de Sieve,
duplicate doit être annoncée au début du script
Sieve (RFC 5228, section 6) :
require ["duplicate"]
Et la sécurité (section 6) ? Pour éviter de se faire DoSer, il faut imposer une limite à la taille de la base (en supprimant les identificateurs les plus anciens). Autrement, un flot important de messages avec chacun un identificateur unique pourrait faire exploser le disque dur.
Un autre problème de sécurité est le risque de faux positif :
typiquement, on jette les messages dupliqués. Or des identificateurs
censés être uniques, comme le Message-ID: ne le
sont pas toujours. On risque donc, avec le test
duplicate, de jeter à tort des messages. Il est
donc prudent de ne pas détruire les messages dupliqués (action
discard de Sieve) mais plutôt de les stocker dans
une boîte spéciale (avec fileinto).
Il peut y avoir aussi de légères conséquences pour la vie privée :
un utilisateur qui a détruit un message sur le serveur sera peut-être
surpris que la base des identificateurs uniques continue à stocker le
Message-ID: de ce message, qui peut être assez
révélateur. Ceci dit, ce n'est pas pire que les actuels
journaux (genre
/var/log/mail.log, qui contient aussi ce genre d'informations).
Il y a apparemment deux mises en œuvre de Sieve qui gèrent cette extension.
Sinon, en dehors du monde Sieve, voici la solution traditionnelle avec procmail pour obtenir le même résultat :
:0:/var/tmp/.duplicate.lock * ? formail -D 8192 $HOME/.duplicate.procmail-cache $HOME/.mail-duplicates
Qui se lit : si le Message-ID: est déjà
dans le fichier $HOME/.duplicate.procmail-cache
(qui garde les 8 192 dernières entrées), on ne le distribue pas dans
la boîte normale, mais dans $HOME/.mail-duplicates.
L'article seul
Mon blog plus à poil sur l'Internet, grâce à TLS
Première rédaction de cet article le 10 septembre 2014
Dernière mise à jour le 25 novembre 2018
Voilà, plus d'un an après les révélations de
Snowden, ce blog est enfin sécurisé par
HTTPS
et vous pouvez donc vous connecter à https://www.bortzmeyer.org/.
L'intérêt de TLS (et de son utilisation pour le Web, HTTPS) pour sécuriser un site ne se discute plus. C'est conseillé à la fois par l'ANSSI (dans ses « Recommandations pour la sécurisation des sites web » : « Le recourt [sic] à TLS, c’est à dire [re-sic] l’emploi du protocole HTTPS, est recommandé dès lors que les communications entre le client et le serveur doivent être protégées en confidentialité ou en intégrité »), mais également par tous les hackers, darknetteurs, cryptoterroristes, cipherpunks, etc. Depuis qu'Edward Snowden a courageusement publié plein de détails sur l'intensité de l'espionnage de masse sur le Web, c'est encore plus crucial. Sans TLS, n'importe qui peut savoir ce que vous regardez sur ce blog, quelles recherches vous faites, et un attaquant actif peut même modifier le contenu des pages avant qu'elles ne vous arrivent, me faisant dire encore plus n'importe quoi que d'habitude (voir un joli exemple avec Haka).
Lorsque HTTPS a été activé sur ce blog, j'avais fait le choix d'une
autorité de certification que votre
navigateur Web ne connait peut-être pas. Pour
comprendre, il faut revenir au modèle de TLS (et donc de
HTTPS). Client et serveur se mettent d'accord sur un mécanisme de
chiffrement et sur ses paramètres, comme la
clé. Une fois le chiffrement en route, un attaquant passif ne peut
plus comprendre le contenu des communications (mais il peut toujours
regarder qui communique, donc savoir que vous parlez à mon serveur) et
un attaquant actif ne peut plus le modifier sans que ce soit
détecté. Mais il reste un problème : comment le client peut-il savoir
qu'il parle au vrai serveur et pas à un homme du
milieu, un serveur qui se serait glissé au milieu de la
conversation ? (Il existe plusieurs techniques pour être homme du
milieu. Le domaine bortzmeyer.org étant signé
avec DNSSEC, cela en élimine une,
l'empoisonnement DNS, mais il en reste
d'autres.) Ce genre d'attaques est fréquent : beaucoup d'entreprises
font cela pour surveiller leurs employés, par exemple, et il existe
une offre commerciale pour cela (par exemple,
Blue Coat se vante d'être
capable de « visibility of SSL [sic] -encrypted traffic
(including the ability to stream decrypted content to an external
server with an Encrypted Tap license) ». C'est réalisé en
détournant le trafic dans le routeur de sortie
et en l'envoyant à un équipement qui déchiffre et rechiffre après,
pour l'envoyer au vrai serveur après examen. Cela se fait aussi au
niveau des États (en Iran, par exemple).
Comment est-ce que TLS se protège contre ce genre d'attaques ? En
authentifiant le
serveur : il existe plusieurs techniques pour cela mais la plus
courante, de loin, est d'utiliser un certificat
à la norme X.509 (souvent appelé, par très gros abus de langage, « certificat SSL »). Ce certificat est composé
d'une clé publique et de diverses métadonnées,
notamment un nom (en X.509, on dit un sujet) comme
www.bortzmeyer.org, et une signature de la clé publique par
une autorité de certification (AC). Le client TLS va
vérifier la signature des messages (prouvant que le serveur connait
bien la clé privée) et la signature du certificat (prouvant que l'AC a
validé que le certificat appartenait bien au titulaire légitime du
nom). Quelles sont les autorités de certification acceptées ? Eh bien,
c'est justement le piège : il n'existe pas de liste officielle, chacun
a la sienne, stockée dans son magasin de certificats, et un même site Web peut donc parfaitement être accepté
sans histoires par un navigateur et rejeté par un autre. En pratique,
la plupart des utilisateurs font une confiance aveugle aux auteurs de
leur navigateur Web (Mozilla,
Google, Microsoft, etc)
et utilisent sans se poser de questions les AC incluses par défauts
dans les navigateurs. Cela marche à peu près, tant qu'une AC ne trahit
pas (par exemple, au Ministère
des finances français).
Mais le problème est qu'on ne peut jamais être sûr que son certificat sera accepté partout. Pour limiter les risques, la plupart des webmestres ne prennent pas de risques et font appel à une des grosses AC connues partout. Ce n'est pas satisfaisant, ni du point de vue de la sécurité, ni du point de vue du business (il devient très difficile d'introduire une nouvelle AC, la concurrence reste donc assez théorique). J'ai choisi une AC qui est très simple à utiliser, rend un bon service, et est contrôlée par ses utilisateurs, CAcert (je suis depuis passé à Let's Encrypt). Mais CAcert est dans peu de magasins et, si vous visitez mon blog en HTTPS, il y a des chances que vous ayiez un message d'erreur du genre « Unknown issuer ». Ce n'est pas satisfaisant, je le sais mais, comme je ne fais pas de e-commerce sur ce blog et que je ne manipule pas de données personnelles, je trouve que c'est acceptable et que c'est l'occasion de faire de la publicité pour les AC « alternatives ». Je vous encourage donc à ajouter le certificat de CAcert à votre magasin (j'ai mis un lien HTTP ordinaire car, si vous n'avez pas déjà le certificat CAcert, le HTTPS vous donnera une erreur : vous devez vérifier l'empreinte du certificat par un autre moyen). Au fait, pour les utilisateurs d'Android, on me souffle que sur un téléphone non rooté, il faut passer par les paramètres Sécurité > Installer depuis stockage. En tout cas, ça a bien marché sur mon Fairphone rooté.
Un problème supplémentaire est la pauvreté des messages d'erreur
des navigateurs, qui ne permettent pas au visiteur de comprendre
clairement ce qui s'est passé. Félicitons Safari pour son bon message d'erreur : 
Bien sûr, il y a d'autres AC, plus traditionnelles et qui auraient créé moins de surprises à mes visiteurs. Certaines sont très chères et, surtout, l'obtention d'un certificat nécessite un processus compliqué (et pas forcément plus sûr). En revanche, on m'a souvent cité StartSSL comme bonne AC assez reconnue. J'ai réussi à m'y créer un compte (non sans difficultés car ils testent l'adresse de courrier, non pas par la bonne méthode - envoyer un courrier - mais en faisant une connexion SMTP directe, ce qui pose un problème avec le greylisting et génère un stupide message d'errreur « We were not able to verify your email address! Please provide us with a real email address! »). Je testerai plus loin un autre jour. À noter que ce débat « AC commerciales privées ou bien CAcert » agite tous les acteurs du libre, par exemple LinuxFr, qui utilise également CAcert (pour ces raisons), ce qui suscite de vigoureuses discussions (merci à Patrick Guignot pour les références).
En pratique, l'utilisation de CAcert a suscité trop de
problèmes. Chaque fois que j'envoyais un URL
avec https://, il y avait quelqu'un pour me dire
« ah, il y a une erreur de configuration », souvent avec un diagnostic
faux (« ton certificat est auto-signé »). Le matraquage marketing des seules AC
officielles fait qu'il est très difficile de proposer autre chose. Je
suis donc finalement passé à
let's Encrypt, AC qui, elle, est acceptée par les auteurs de logiciels.
En raison de cettte méconnaissance de CAcert par beaucoup de
magasins, je n'avais donc pas imposé HTTPS (par exemple, http://www.bortzmeyer.org/ ne redirigeait pas d'autorité vers
https://www.bortzmeyer.org/). Pour la même raison, je
n'avais pas mis d'en-tête HSTS (RFC 6797) car HSTS ne permet pas d'erreur : tout problème est
fatal. Depuis le passage à let's Encrypt, ces pratiques de sécurité
sont en place.
Pour les liens dans le flux de syndication, pour essayer de faire en sorte
qu'ils soient cohérents avec le protocole utilisé pour récupérer ce
flux, j'avais essayé de les faire commencer par // ce qui,
normalement (ce n'est pas très clair dans la norme des
URI, le RFC 3986), fait
du HTTP si le flux a été récupéré en HTTP et du HTTPS s'il l'a été en
HTTPS. En pratique, cela ne marche pas avec beaucoup de logiciels de
syndication et j'ai donc désormais plusieurs flux de syndication.
Bien sûr, une solution à ce problème des AC non connues est d'utiliser DANE (RFC 6698 et mon article à JRES). C'est sur ma liste des choses à faire (ceci dit, tant qu'aucun navigateur ne fait du DANE, cela limite l'intérêt).
Bon, assez parlé de ce problème des autorités de certification. Un
autre sujet de dispute quand on configure TLS est le choix des
algorithmes cryptographiques utilisés. TLS (RFC 5246) permet en effet un large choix, qui va être
présenté par le client, et parmi lequel le serveur choisira. Il est donc
important de ne pas proposer d'algorithmes qui
soient trop faibles. Les sélections par défaut des logiciels utilisés
pour faire du TLS sont en général bien trop larges. Cela convient au
webmestre (car cela augmente les chances d'accepter tous les clients,
même les plus anciens ou bogués) mais moins à l'auditeur de
sécurité. Celui-ci teste le serveur avec SSLlabs ou bien un outil comme
SSLyze ou encore https://testssl.sh/ et il
vous engueule en disant « quoi, mais vous proposez encore SSLv3, c'est
bien trop dangereux ». Pour éviter cette engueulade, on peut mettre
dans sa configuration TLS une liste complète des bons algorithmes (on
en trouve par exemple dans le document de
l'ANSSI cité plus haut et Mozilla en publie
une pour GnuTLS) mais cette méthode est
longue et pénible et difficile à maintenir car la liste change
évidemment dans le temps. Cela ne devrait pas être au webmestre de
devenir expert en crypto ! Pour arriver à un réglage raisonnable,
j'ai donc choisi une autre solution, en partant des jeux d'algorithmes
disponibles dans le logiciel utilisé. Dans mon cas, c'est GnuTLS. Il fournit
des identificateurs désignant des jeux d'algorithmes déterminés comme
ayant certaines propriétés. Ainsi, NORMAL est le
jeu par défaut. Il est très large. Pour le paranoïaque, il existe un
jeu SECURE qui est plus raisonnable. On peut donc
configurer son Apache ainsi :
GnuTLSPriorities SECURE
et c'est déjà mieux. Mais, tout l'intérêt de la méthode, est qu'on
peut partir d'un jeu prédéfini puis ajouter ou enlever protocoles ou
algorithmes. Par exemple, le jeu SECURE inclut
actuellement le protocole SSLv3, vieux et bogué, et qui n'est
apparement nécessaire que pour Internet
Explorer version 6. Comme il est peu probable que beaucoup
de visiteurs de mon blog utilisent cette horreur d'IE 6, je supprime
SSL :
GnuTLSPriorities SECURE:-VERS-SSL3.0
(Cette directive veut dire : partir de la liste
SECURE et retirer SSLv3.)
Maintenant, si je teste avec testssl, j'ai :
% ./testssl.sh https://www.bortzmeyer.org/ ... SSLv3 NOT offered (ok) TLSv1 offered (ok) TLSv1.1 offered (ok) TLSv1.2 offered (ok) SPDY/NPN not offered --> Testing standard cipher lists Null Cipher NOT offered (ok) Anonymous NULL Cipher NOT offered (ok) Anonymous DH Cipher NOT offered (ok) 40 Bit encryption NOT offered (ok) 56 Bit encryption Local problem: No 56 Bit encryption configured in /usr/bin/openssl Export Cipher (general) NOT offered (ok) ... --> Checking RC4 Ciphers RC4 seems generally available. Now testing specific ciphers... Hexcode Cipher Suite Name (OpenSSL) KeyExch. Encryption Bits Cipher Suite Name (RFC) -------------------------------------------------------------------------------------------------------------------- [0x05] RC4-SHA RSA RC4 128 TLS_RSA_WITH_RC4_128_SHA RC4 is kind of broken, for e.g. IE6 consider 0x13 or 0x0a ...
Pas mal. SSLv3 a bien été retiré, le seul gros problème restant est que RC4 est encore proposé alors que cet algorithme a de sérieuses failles. Un dernier effort, pour le supprimer :
GnuTLSPriorities SECURE:-VERS-SSL3.0:-ARCFOUR-128:-ARCFOUR-40
Et, cette fois, RC4 n'est plus proposé :
... --> Checking RC4 Ciphers No RC4 ciphers detected (OK)
Voilà, j'ai maintenant une configuration TLS raisonnable. Principal manque : augmenter la priorité des algorithmes offrant la forward secrecy, ce sera pour une prochaine fois.
Ah, question outils de test, j'ai bien sûr utilisé SSLlabs mais il a deux
inconvénients : stupidement, il teste également le nom sans
www (et échoue donc souvent), et il ne connait
pas CAcert donc la note globale reste à « T » (non documenté). Avec un
certificat qu'il connaitrait, https://www.ssllabs.com/ssltest/analyze.html?d=www.bortzmeyer.org
me donnerait une meilleure note (« If trust issues are ignored: A- »).
J'ai aussi testé le logiciel sslscan (qui est en paquetage sur ma
Debian) mais son ergonomie est vraiment
horrible, il sort juste une longue liste
de trucs testés, sans autre précision, hiérarchisation ou explication.
Quelques autres détails pratiques maintenant. Comme j'aime bien
regarder les journaux, j'ai voulu indiquer si
la connexion s'était faite en TLS ou pas (je rappelle que, pour
l'instant, TLS n'est pas obligatoire sur ce blog). Il existe une
variable HTTPS mais qui est spécifique
à OpenSSL (voir un
exemple de son utilisation). Pour GnuTLS, j'ai donc créé deux
directives LogFormat :
LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\" %v" complete
LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\" %v TLS" completetls
et j'utilise l'une ou l'autre selon le
VirtualHost :
<VirtualHost *:80>
CustomLog ${APACHE_LOG_DIR}/access.log complete
...
<VirtualHost *:443>
CustomLog ${APACHE_LOG_DIR}/access.log completetls
...
La visite de SSLlabs est ainsi correctement enregistrée :
64.41.200.103 - - [10/Sep/2014:08:43:13 +0000] "GET / HTTP/1.0" 200 285954 \
"-" "SSL Labs (https://www.ssllabs.com/about/assessment.html)" \
www.bortzmeyer.org TLS
Je n'ai pas encore changé la description OpenSearch de ce blog. Les recherches sont évidemment sensibles
(elles indiquent à un attaquant vos sujets d'intérêt) mais je ne sais
pas trop comment dire en OpenSearch « utilise HTTPS si tu peux et HTTP
sinon ». Si on met deux éléments url, je ne sais
pas lequel est choisi. Donc, il faut que je relise
la spécification.
Un piège classique avec X.509 est l'oubli du fait que les certificats ont, parmi leurs métadonnées, une date d'expiration. Comme le mécanisme théorique de révocation des certificats ne marche pas en pratique, cette expiration est la seule protection qui empêche un voleur de clé privée de s'en servir éternellement. Il faut donc superviser l'expiration des certificats, ce que je fais depuis Icinga :
# HTTPS
define service{
use generic-service
hostgroup_name Moi
service_description HTTPS
check_command check_http!-S -C 30,7
}
Cette directive indique de se connecter en HTTPS (option
-S), d'avertir s'il ne reste que 30 jours de
validité au certificat et de passer en mode panique s'il ne reste plus
que 7 jours. Bien sûr, CAcert prévient automatiquement par courrier
lorsqu'un certificat s'approche de l'expiration mais, renouveler le
certificat chez l'AC ne suffit pas, encore faut-il l'installer sur le
serveur, et c'est cela que teste Icinga.
Merci à Manuel Pégourié-Gonnard pour la correction d'une grosse erreur sur TLS.
L'article seul
RFC 7335: IPv4 Service Continuity Prefix
Date de publication du RFC : Août 2014
Auteur(s) du RFC : Cameron Byrne (T-Mobile US)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF v6ops
Première rédaction de cet article le 7 septembre 2014
Le RFC 6333, qui normalisait le protocole
DS-Lite, réservait un préfixe
IPv4, 192.0.0.0/29, pour
numéroter les entités impliquées dans le fonctionnement des tunnels
DS-Lite. Ce nouveau RFC 7335 généralise
ce préfixe en le rendant utilisable pour toutes les solutions
techniques liées à la migration vers IPv6.
En effet, ces adresses ne doivent jamais apparaître sur l'Internet. Dans DS-Lite, elles sont limitées aux communications entre les extrémités du tunnel DS-Lite. Il n'y a donc pas de risque de collision si on se sert de ces adresses pour une autre utilisation interne. Si un autre système de transition vers IPv6 a besoin d'adresses IPv4 internes, il peut désormais les prendre dans ce préfixe. C'est par exemple le cas (section 3) de 464XLAT (RFC 6877) où la machine de l'utilisateur (CLAT : client side translator) peut faire de la traduction d'adresses mais a besoin d'une adresse IPv4 (qui ne sortira pas de la machine) à présenter aux applications.
Plutôt que de réserver un préfixe IPv4 différent pour DS-Lite,
464XLAT et les zillions d'autres
mécanismes de transition, la section 4 de notre RFC pose donc
comme principe que toutes les solutions utilisant des adresses IPv4
internes se serviront du même préfixe, 192.0.0.0/29
.Ce préfixe est donc ainsi documenté dans le registre
des adresses spéciales.
L'article seul
RFC 7363: Self-tuning Distributed Hash Table (DHT) for REsource LOcation And Discovery (RELOAD)
Date de publication du RFC : Septembre 2014
Auteur(s) du RFC : J. Maenpaa, G. Camarillo (Ericsson)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF p2psip
Première rédaction de cet article le 7 septembre 2014
Le mécanisme RELOAD est un mécanisme pair-à-pair pour créer un réseau virtuel au-dessus des réseaux existants, notamment aux fins de téléphonie, messagerie instantanée et diffusion multimédia. Ce RFC étend le protocole Chord tel qu'utilisé par RELOAD de manière à permettre l'ajustement automatique de la DHT à des conditions changeantes (par exemple une augmentation ou diminution du taux de changement des pairs, le churn).
C'est le RFC 6940 qui normalise
RELOAD. RELOAD offre le choix de plusieurs algorithmes de gestion du
réseau virtuel mais, afin
de permettre l'interopérabilité de toutes les machines RELOAD, il
existe un algorithme obligatoire, que toute mise en œuvre de RELOAD
doit connaître. Les autres algorithmes ne pourront être utilisées que
si toutes les machines du réseau sont d'accord. Cet algorithme
obligatoire se nomme CHORD-RELOAD et repose sur
la DHT Chord. Comme
toutes les DHT, Chord s'organise tout seul (pas besoin de chef pour
créer le réseau virtuel), passe bien à
l'échelle et est très résilient. Pour maintenir la DHT,
les machines échangent des informations sur leur état et
reconfigurent le réseau virtuel si nécessaire. Pour être le plus optimisé possible,
afin de limiter le trafic réseau de gestion, ce travail dépend de
paramètres comme le taux de changement des pairs (le
churn), ou la taille du réseau. Souvent, ces
paramètres sont fixés à l'avance lors de l'initialisation de la
DHT. Ce n'est évidemment pas satisfaisant car ils peuvent varier dans
le temps. Ils servent à calculer des caractéristiques de la DHT comme
la taille de la liste des successeurs, ou comme la taille de la table
de routage. Ces caractéristiques devraient pouvoir changer dans le
temps, elles aussi. (Voir l'article de Mahajan, R., Castro, M., et A. Rowstron, « Controlling the
Cost of Reliability in Peer-to-Peer Overlays ».)
Ces mécanismes de stabilisation qui tournent pour maintenir la DHT sont de deux types, périodique ou bien réactif. Dans l'approche périodique, les informations sont régulièrement échangés entre pairs, qu'il y ait eu des changements ou pas. La DHT est ajustée s'il y a du changement. Dans l'approche réactive, les pairs transmettent la nouvelle information lorsqu'il y a un changement et la DHT s'ajuste alors. On voit que l'approche réactive permet des ajustements plus rapides mais qu'elle écroule vite le réseau si le nombre de changements est trop important, notamment parce qu'elle peut entraîner une boucle de rétroaction. (Voir l'article de Rhea, S., Geels, D., Roscoe, T., et J. Kubiatowicz, « Handling Churn in a DHT ».) Le Chord de RELOAD permet d'utiliser les deux approches, alors que la plupart des mises en œuvre d'une DHT n'utilisent que la stabilisation périodique. La période de diffusion des informations fait partie de ces paramètres qu'on voudrait voir évoluer dynamiquement.
La section 4 de notre RFC résume ce qu'il faut savoir de Chord pour comprendre les changements introduits (je ne la répète pas ici). Les sections 5 et 6 décrivent ces changements, qu'est-ce qui peut être modifié dynamiquement et quand.
Ces changements se traduisent par des nouveaux enregistrements
dans les
registres IANA RELOAD : nouvel algorithme de gestion du réseau
virtuel CHORD-SELF-TUNING, nouvelle extension
self_tuning_data, etc.
L'article seul
RFC 7326: Energy Management Framework
Date de publication du RFC : Septembre 2014
Auteur(s) du RFC : J. Parello, B. Claise (Cisco
Systems), B. Schoening (Independent
Consultant), J. Quittek (NEC Europe)
Pour information
Réalisé dans le cadre du groupe de travail IETF eman
Première rédaction de cet article le 6 septembre 2014
Ce nouveau RFC présente un cadre général pour la gestion de l'énergie dans les protocoles IETF. La préoccupation est assez récente. Pendant longtemps, les ordinateurs et routeurs connectés à l'Internet consommaient autant de courant qu'ils voulaient et personne ne regardait la facture. La montée des préoccupations écologiques, le prix de plus en plus élevé de l'électricité dans les centres de données, et le désir d'avoir des machines sans fil à la patte, alimentées uniquement par une batterie, font que la gestion de l'énergie est maintenant devenue une préoccupation à part entière de l'IETF. Ce cadre modélise les consommateurs d'électricité comme des objets énergétiques (energy objects) qui vont pouvoir être supervisés et contrôlés à distance. On pourra, par exemple, par des protocoles normalisés, suivre la consommation électrique d'un serveur, ou bien la quantité d'énergie restante dans une batterie mais aussi faire passer une machine dans un état à consommation énergétique réduite.
La gestion de réseaux informatiques est divisée par la norme X.700 en cinq parties, Panne, Configuration, Comptabilité, Performance et Sécurité. La gestion de l'énergie n'y figure pas. La norme ISO 50001 ajoute cette préoccupation aux textes. L'IETF a créé un groupe de travail sur la gestion de l'énergie, EMAN, qui avait déjà produit un premier RFC, le cahier des charges, le RFC 6988.
Notre nouveau RFC introduit le concept d'interface énergie, en s'inspirant de celui bien connu d'interface réseau. C'est par une interface énergie que la machine fournit ou consomme de l'énergie. Une machine ne sait pas forcément mesurer ce qu'elle consomme et c'est donc parfois en interrogeant le dispositif de fourniture d'énergie qu'on aura cette information. (L'interface énergie de sortie de l'un étant l'interface énergie d'entrée de l'autre.)
Autres termes définis par ce RFC (section 2) :
- Entrée (power inlet ou simplement inlet) : l'interface énergie par laquelle le courant arrive.
- Sortie (outlet) : l'interface énergie par laquelle le courant sort.
- Énergie : le nombre de kWh consommés ou produits, ou bien qu'on peut consommer ou produire.
- Puissance : énergie divisée par le temps (en watts ou en joules/seconde). Si l'énergie est une distance, la puissance est la vitesse.
- Demande : puissance moyennée sur un intervalle. Ces trois dernières définitions sont tirées de IEEE 100.
- Attributs du courant : la tension, la phase, la fréquence, etc.
- Qualité du courant : ses attributs par rapport à une référence. Comme le précédent, ce terme vient de IEC 60050.
La section 3 du RFC définit la notion de cible (target device). Ce sont tous les engins qui peuvent être supervisés ou contrôlés dans le cadre défini dans ce RFC : ordinateurs de bureau, serveurs, routeurs, imprimantes, commutateurs, points d'accès WiFi, batteries (lorsqu'elles sont autonomes et non pas enfermés dans un ordinateur), générateurs, fournisseurs PoE, compteurs, capteurs divers... Plusieurs de ces engins ne parleront pas IP et devront être interrogés / commandés via un relais.
Le cadre général défini par ce RFC concerne l'énergie, mais il ne couvre pas toutes les applications liées à l'énergie. La section 5 liste ce qui n'est pas l'objet du travail EMAN en cours : les engins non-électriques (si vous avez un routeur steampunk, propulsé par la vapeur, EMAN ne va pas vous aider) et la production électrique (seules sa distribution et sa consommation sont prises en compte).
La section 6 du RFC décrit le modèle utilisé pour la gestion de
l'énergie. Il suit une conception objets
classique : une classe Energy Object, avec trois
sous-classes, Device,
Component et Power
Interface. La super-classe Energy
Object modélise tout ce qui est relié au réseau et qui
l'utilise pour superviser ou commander sa gestion de l'énergie. La
classe Device modélise les équipements physiques
qui consomment, distribuent ou stockent de l'énergie, comme les ordinateurs.
Component sert à décrire les parties d'un objet
Device, et le nouveau concept, Power
Interface représente les interconnexions.

Tous les objets héritent de Energy Object qui
a comme attributs :
- Un identificateur unique, un UUID (RFC 4122),
- Un nom (relativement) lisible ; cela pourra être un nom de domaine (pour les ordinateurs et routeurs, c'est déjà le cas), ou d'autres conventions de nommage,
- Une importance, allant de 1 à 100, et qui sera utilisée pour prendre des décisions comme « les accumulateurs sont presque à plat, qui est-ce que je coupe en premier ? »,
- Une série d'étiquettes (tags) permettant de trouver et de manipuler facilement tous les objets ayant une caractéristique commune,
- Un rôle, qui indique le but principal de cet objet (routeur, lampe, réfrigérateur, etc),
- Et quelques autres attributs que je n'ai pas cité ici.
Les objets de la classe Energy Object ont
également des méthodes permettant la mesure de certaines grandeurs :
puissance, attributs du courant électrique, énergie et demande.
D'autres méthodes permettent le contrôle de l'objet et et changer
son état. Plusieurs normes donnent des listes d'état possibles pour un
objet. Par exemple, IEEE 1621 décrit trois
états : allumé, éteint et dormant. D'autres normes, comme
ACPI, vont avoir une liste
différente. DMTF décrit pas moins de quinze
états possibles, faisant par exemple la différence entre Sleep
Light et Sleep Deep. Le groupe de travail
EMAN, auteur de ce RFC, a produit sa propre liste, qui comprend douze
états (section 6.5.4 du RFC), chacun numéroté (pour faciliter
l'écriture des futures MIB, dont plusieurs sont
proches de la publication en RFC). Par exemple,
en cas de suspension, une machine est en sleep(3)
et high(11) est au contraire l'état d'une machine
complètement réveillée et qui ne cherche pas à faire des économies
d'électricité. Un tableau en section 6.5.5 donne des équivalences
entre ces normes. Par exemple, le sleep(3) d'EMAN
correspond à l'état dormant de IEEE 1621, au "G1, S3" d'ACPI, et au
Sleep Deep de DMTF. Ces états sont stockés dans un registre IANA (section 12 du RFC) et
cette liste pourra être modifiée par la suite.
Une description formelle du modèle, en UML, figure en section 7.
Pour connaître l'état des mises en œuvre de ce cadre de gestion de l'énergie, voir le Wiki du groupe de travail (plusieurs MIB ont déjà été définies selon ce cadre).
Maintenant, la sécurité (section 11). Sérieux sujet dès qu'on touche à un service aussi essentiel que l'alimentation électrique. Va-t-on éteindre toute l'électricité d'une ville avec son téléphone, comme dans Watch Dogs ? Non, c'est plus compliqué que cela. Néanmoins, la gestion d'énergie doit être mise en œuvre prudemment. Si on gère les machines avec SNMP, le RFC 3410 sur la sécurité de SNMP est une lecture indispensable. Les accès en écriture, permettant de modifier l'état d'unee machine, peuvent en effet permettre, s'ils ne sont pas bien sécurisés, d'éteindre un appareil critique à distance. Mais même les accès en lecture seule peuvent être dangereux, car révélant des choses qu'on aurait préféré garder pour soi.
On lire aussi avec intérêt le RFC 7603 qui précise le cadre d'utilisation.
L'article seul
RFC 7285: ALTO Protocol
Date de publication du RFC : Septembre 2014
Auteur(s) du RFC : R. Alimi (Google), R. Penno (Cisco
Systems), Y. Yang (Yale University)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF alto
Première rédaction de cet article le 5 septembre 2014
Couronnant un travail commencé six ans auparavant, avec un net ralentissement de l'enthousiasme vers la fin, ce nouvel RFC normalise enfin le protocole ALTO (Application-Layer Traffic Optimization). Ce protocole sert notamment dans le cas de transferts de fichiers en pair à pair. Lorsqu'une machine qui veut récupérer un fichier (disons, au hasard, un épisode de Game of Thrones) a le choix entre plusieurs pairs possibles, qui ont chacun les données convoitées, lequel choisir ? ALTO permet d'interroger un oracle, le serveur ALTO, qui va nous donner des informations guidant le choix.
Il existe déjà des tas de façons, pour une application, de mesurer ou de calculer le « meilleur » pair. Par exemple, l'information de routage (annonces BGP, notamment) est publique et une application peut y accéder, par exemple via un looking glass. Mais cela ne donne pas une vue complète et, surtout, cela ne donne pas la vision de l'opérateur réseau, qui pourrait souhaiter, par exemple, qu'on utilise plutôt un pair qui fasse passer par un lien de peering (gratuit), plutôt que par un lien de transit (payant). ALTO est donc avant tout un moyen de faire connaître les préférences du FAI, de manière à ce que l'application puisse faire un choix plus informé. Par exemple, ALTO permet de distribuer des cartes simplifiées du réseau, suffisantes pour que l'application repère les liens intéressants.
Le but est donc bien que les applications changent leur comportement, en utilisant l'information ALTO, afin de mieux utiliser les ressources du réseau (le transfert en pair à pair peut représenter une bonne part du trafic et il est dans l'intérêt de tous de l'optimiser). La même méthode et le même protocole ALTO peut aussi être utilisé pour optimiser l'accès à un CDN et le serveur ALTO peut donc être fourni par d'autres acteurs que le FAI (le protocole lui-même est neutre, au sens où il n'impose pas de critères de choix ; le coût financier, utilisé dans l'exemple précédent peering/transit, n'est qu'une possibilité parmi d'autres).
Le problème que résout ALTO est formellement décrit dans le RFC 5693. Pour le résumer : en raison du modèle en couches, les applications n'ont pas assez d'information sur le réseau sous-jacent et ne peuvent donc pas prendre de décisions « intelligentes ». Il s'agit donc de leur donner cette information. Ainsi, le réseau sera mieux utilisé, on aura moins de gaspillage (avantage collectif) et les applications auront de meilleures performances (temps de téléchargement plus courts, par exemple, un avantage individuel, cette fois).
Techniquement, ALTO est un protocole HTTP/REST, où requêtes et réponses sont en JSON (RFC 8259). Que du classique, donc, et qui utilisera l'infrastructure HTTP existante.
Un petit rappel de terminologie (s'appuyant sur le RFC 5693) est fait en section 2. On y trouve les termes d'extrémités (endpoint), ALTO information base (l'ensemble des informations connues d'un serveur ALTO), etc.
Place maintenant à l'architecture d'ALTO, en section 3. Le cas typique est celui d'un opérateur, ayant un AS et un serveur ALTO pour distribuer l'information sur cet AS (bien sûr, des tas d'autres cas sont possibles). L'ALTO information base de cet AS est composée d'une série de coûts entre extrémités du réseau. Une extrémité est exprimée sous forme d'un préfixe IP (ce n'est donc pas forcément une seule adresse IP). Dans le cas le plus simple, la base peut tout simplement contenir quelque chose du genre « nos préfixes ont un coût fixe et faible, le reste de l'Internet un coût fixe et deux fois plus élevé » ou bien des informations bien plus complexes. La base contient donc les coûts, vus de cet opérateur. Elle va être distribuée par un serveur ALTO, interrogé par des clients ALTO. Plus tard, d'autres moyens de désigner une extrémité existeront, un registre IANA a été créé pour stocker les types d'adresses (section 14.4 de notre RFC).
Et d'où la base vient-elle ? Le protocole ALTO ne spécifie pas de méthode particulière. La base a pu être remplie à la main par les employés de l'opérateur réseau, en fonction de leur politique. Ou générée automatiquement à partir des données de l'opérateur sur la topologie du réseau. Ou elle a pu être assemblée dynamiquement par le biais d'un système de mesure, ou à partir des informations d'un protocole de routage. Ou encore elle peut être l'agrégation de plusieurs sources. La base n'est donc pas statique, mais elle est prévue pour ne pas changer en temps réel, elle ne tient donc typiquement pas compte de la congestion, phénomène très transitoire. On peut aussi imaginer des serveurs ALTO dialoguant entre eux, pour échanger leurs informations, mais il n'existe pas de protocole standard pour cela (notre RFC concerne uniquement le protocole d'interrogation d'un serveur par un client).
L'information ALTO sera peut-être dans le futur également distribuée par d'autres moyens (une DHT ?) mais rien n'est normalisé pour l'instant. Cela nécessiterait sans doute des mécanismes permettant d'indiquer la fraîcheur de l'information (date d'expiration, par exemple) et des mécanismes de sécurité (signatures) qui n'existent pas actuellement. Pour l'instant, ces services sont fournis par le protocole de transport, HTTP.
ALTO distribue l'information sous la forme de tables (map), indiquant les caractéristiques du réseau, et les coûts associés. (Comme indiqué plus haut, ces tables peuvent être de simples fichiers, distribués comme tels.) Une utilisation directe des tables (ce qu'on nomme le Map Service) ferait beaucoup de travail pour le client : télécharger les tables (qui peuvent être très grosses), puis faire des calculs compliqués pour trouver le meilleur pair. ALTO fournit donc en plus des services auxiliaires pour les clients paresseux. Le premier est le service de filtrage (Map Filtering Service) : le client donne des informations supplémentaires et le serveur lui envoie des tables simplifiées, ne correspondant qu'à ce que le client a demandé. Le second service auxiliaire est le service d'information sur une extrémité (Endpoint Property Service) : le client demande des détails sur une extrémité, par exemple son type de connectivité (on préférera un pair connecté en FTTH à un pair ADSL). Enfin, le troisième service auxiliaire, Endpoint Cost Service permet d'obtenir directement les coûts d'une extrémité donnée. Mais, avant de détailler le protocole pour ces trois services, voyons le service de base, le Map Service, d'abord pour les tables, puis pour les coûts.
D'abord, l'accès aux informations sur le réseau, la Network Map (section 5). Elle part d'une observation : il est coûteux de distribuer l'information sur chaque machine connectée et c'est surtout inutile, les machines se groupant selon la topologie du réseau. Une Network Map est donc surtout une série de regroupements. Chaque regroupement est identifié par un PID (Provider-defined IDentifier) qui, comme son nom l'indique, n'a de sens que pour un opérateur donné. Chaque groupe désigné par un PID va comprendre un ou plusieurs préfixes d'adresses IP (d'autres identificateurs des extrémités sont possibles). Un PID peut désigner toute une ville, ou bien tout ce qui est connecté à un POP donné. On verra plus loin que les coûts sont indiqués par PID et pas par préfixe ou par adresse, de manière à diminuer la quantité d'information à manier. Dans le futur, des groupes pourront être identifiés par autre chose qu'un PID, par exemple un pays ou un AS. Un registre IANA a été créé pour stocker ces futurs propriétés des extrémités. À la réunion IETF de Toronto, en 2014, ont été ainsi discutées des propriétés comme « type d'accès » (ADSL ou 3G...), « volume limité » (pour les offres illimitées des opérateurs 3G/4G, etc.
Un exemple d'une table triviale serait :
- PID1 regroupe
192.0.2.0/24et198.51.100.0/25. - PID2 regroupe
198.51.100.128/25. - PID3 regroupe
0.0.0.0/0(c'est-à-dire tout le reste de l'Internet).
Ensuite, la table des coûts (Cost Map, section 6). Elle est souvent plus dynamique que la table du réseau (ce qui justifie leur séparation) et indique les coûts vus par l'opérateur. Un « type de coût » comprend une métrique (une définition de comment on mesure un coût) et un mode (comment comparer les coûts, notamment est-ce qu'on peut appliquer des opérations arithmétiques comme l'addition). Les métriques possibles sont enregistrées à l'IANA et l'enregistrement de nouvelles métriques requiert un RFC qui ne soit pas un document individuel.
Au moins une métrique doit être utilisée par le serveur,
routingcost, qui doit refléter le coût de
routage. Elle n'est pas davantage définie donc cela peut être un
nombre de kilomètres à vol d'oiseau, un nombre de
sauts IP, un calcul à partir des coûts indiqués par
l'IGP, etc. Quant aux modes, deux sont
obligatoires, numerical et
ordinal. Le premier utilise des nombres
en virgule flottante et permet toutes les opérations
arithmétiques classiques (comme l'addition de deux coûts), le second
utilise des entiers et
ne permet que les comparaisons. À la réunion
IETF de Toronto, en
juillet 2014, on a discuté de futures métriques comme par exemple le
taux de perte de paquets, la gigue...
Une table des coûts triviale serait :
- En partant de PID1, le coût d'aller à PID2 est de 2 et le coût vers tout l'Internet (PID3) est de 5,
- En partant de PID2, le coût pour aller à PID1 est de 1 (les coûts ne sont pas forcément symétriques) et le coût vers le reste de l'Internet (PID3) de 4.
Pour la plupart des exemples ci-dessous, je vais utiliser un des
rares
serveurs ALTO publics existants,
http://alto.alcatel-lucent.com:8000/. Le plus
simple est d'utiliser curl, combiné avec jsonlint pour
mieux afficher le JSON :
% curl -s http://alto.alcatel-lucent.com:8000/network/full | jsonlint -f
{
"meta" : { "vtag" : {
"resource-id" : "default-network",
"tag" : "192.11.155.88/f9d21e031e5cf58103d4687d65025cfb"
} },
"network-map" : {
"defaultpid" : {
"ipv4" : [ "0.0.0.0/0" ],
"ipv6" : [ "::/0" ]
},
"mypid1" : { "ipv4" : [
"15.0.0.0/8",
"10.0.0.0/8"
] },
"mypid2" : { "ipv4" : [ "192.168.0.0/16" ] },
"mypid3" : { "ipv4" : [ "192.168.10.0/24" ] },
"peeringpid1" : { "ipv4" : [ "128.0.0.0/16" ] },
"peeringpid2" : {
"ipv4" : [ "130.0.0.0/16" ],
"ipv6" : [ "2001:DB8::/32" ]
},
"transitpid1" : { "ipv4" : [ "132.0.0.0/16" ] },
"transitpid2" : { "ipv4" : [ "135.0.0.0/16" ] }
}
}
Et voilà, on a la table complète du réseau d'un FAI (fictif). La table contient des préfixes IP, avec le PID associé (par exemple,
128.0.0.0/16 a le PID peeringpid1).
La section 8 de notre RFC en vient au protocole : ALTO est un
protocole REST pour accéder à des ressources
(les tables) et à des annuaires de ressources, les IRD
(Information Resource Directory). Les ressources
sont récupérées en HTTP et ont donc un
type de média indiqué
(application/alto-networkmap+json pour la table
du réseau, et application/alto-costmap+json pour
la table des coûts). Ces types MIME ont été enregistrés dans le registre officiel. En général, les requêtes ALTO se font avec la
méthode HTTP GET. Comme tous les protocoles
s'appuyant sur HTTP, ALTO a à sa disposition toutes les fonctions
rigolotes de HTTP, comme la mise en cache (RFC 7234). De même, la sécurité est fournie par les mécanismes
HTTP habituels (HTTPS, authentification du RFC 7236, etc). Les codes de réponse habituels de HTTP
sont utilisés, comme 200 si tout s'est bien passé, 405 si la méthode
utilisée ne plait pas au serveur et 503 si le serveur
a un problème temporaire.
Si la requête HTTP s'est bien passée, mais qu'un problème
spécifique à ALTO est survenu, le serveur renvoie des données JSON de
type application/alto-error+json. Elles
comprennent au moins un champ code qui indiquera
le type d'erreur par exemple E_SYNTAX pour des
paramètres d'entrée incorrects, E_MISSING_FIELD
pour l'absence d'un champ obligatoire, etc. Testons avec le serveur
public, en envoyant du JSON incorrect (accolade
ouvrante sans la fermante) :
% curl -s -d '{' -H "Content-Type: application/alto-networkmapfilter+json" \
-X POST http://alto.alcatel-lucent.com:8000/network/filtered | jsonlint -f
{ "meta" : {
"code" : "E_SYNTAX",
"syntax-error" : "Premature EOF in JSON object; expecting key"
} }
Les erreurs possibles sont dans un registre IANA (section 14.5 de notre RFC).
La section 9 présente l'IRD, l'Information Resource
Base, le mécanisme de distribution de méta-information (où
trouver la Network Map, où trouver la Cost
Map, etc). Elle a aussi la forme de données JSON, servies
sous le type
application/alto-directory+json. Voici celle du
serveur ALTO public indiqué plus haut :
% curl -s http://alto.alcatel-lucent.com:8000/directory | jsonlint -f
{
"meta" : {
"cost-types" : {
"hop-num" : {
"cost-metric" : "hopcount",
"cost-mode" : "numerical",
"description" : "Simple hopcount"
},
...
"default-alto-network-map" : "default-network",
"priv:alu-server-info" : {
"Build-Date" : "2014-04-28 13:57:08 EDT",
"Build-OS" : "Mac OS X 10.9.2",
"Build-OS-Nodename" : "wdr-i7mbp2.mh.lucent.com",
"Build-User" : "wdr",
"Implementation-Title" : "ALTO Server Implementation",
"Implementation-Vendor" : "Alcatel-Lucent (Bell Labs/Murray Hill)",
"Implementation-Version" : "(2014-04-28 13:57:08 EDT)",
...
"resources" : {
"costs-end" : {
"accepts" : "application/alto-endpointcostparams+json",
"capabilities" : {
"cost-constraints" : true,
"cost-type-names" : [
"rtg-num",
"rtg-ord",
"hop-ord",
"hop-num"
]
},
"media-type" : "application/alto-endpointcost+json",
"uri" : "http://alto.alcatel-lucent.com:8000/costs/end"
},
...
"default-network" : {
"media-type" : "application/alto-networkmap+json",
"uri" : "http://alto.alcatel-lucent.com:8000/network/full"
},
...
}
}
On y voit, par exemple, que si je veux obtenir la table complète du
réseau, je dois demander
http://alto.alcatel-lucent.com:8000/network/full,
comme fait plus haut.
Bon, ce n'est pas tout, ça, il faut maintenant des données. La section 10 indique les types de base qui sont utilisés : les PID (identificateurs des réseaux) sont des chaînes de caractères ASCII, les ressources comme les Network Maps ont également un identificateur, le Resource ID (encore une chaîne ASCII), les extrémités sont en général identifiées par une adresse ou un préfixe IP, à la syntaxe traditionnelle, les mode et métriques des coûts sont des chaînes ASCII...
Avec ces types, on peut construire les données.
Quand un
client ALTO a l'adresse d'un pair potentiel, et cherche dans la table
le PID correspondant, il peut y avoir plusieurs préfixes qui
correspondent. Dans ce cas, c'est le plus spécifique qui gagne (règle
dite du « longest match », cf. RFC 1812). Pour éviter toute ambiguité, la table doit être
complète et sans recouvrement. Complète signifie que toutes les
adresses doivent être présentes. Dans le cas d'un opérateur ayant une
connectivité avec tout l'Internet, cela veut dire qu'il faut
représenter toutes les adresses de l'Internet. Une entrée pour le
réseau 0.0.0.0/0 en IPv4 et
::0/0 en IPv6 est le moyen le plus simple
d'atteindre ce but : cette entrée, attrapera toutes les adresses non
couvertes par un des préfixes plus spécifiques. Quant au
non-recouvrement, il signifie que la table ne doit pas avoir deux
préfixes identiques (il peut y avoir recouvrement mais uniquement
entre préfixes de longueurs différentes, la règle du longest
match permettra alors de sélectionner).
Par exemple, cette table est complète et sans recouvrement :
"network-map" : {
"PID0" : { "ipv6" : [ "::/0" ] },
"PID1" : { "ipv4" : [ "0.0.0.0/0" ] },
"PID2" : { "ipv4" : [ "192.0.2.0/24", "198.51.100.0/24" ] },
"PID3" : { "ipv4" : [ "192.0.2.0/25", "192.0.2.128/25" ] }
}
Avec cette table du réseau, 192.0.2.1 sera dans
PID3 (le préfixe dans PID2
est moins spécifique), 198.51.100.200 sera dans
PID2 et 203.0.113.156 sera
dans PID1, en raison de la règle attrape-tout qui
couvre tout l'Internet IPv4. Notez l'utilisation de la désagrégation :
192.0.2.0/24 a été représenté avec deux préfixes
dans PID3 car, autrement, la table aurait eu un
recouvrement.
Et la table des coûts ? Voici un exemple :
% curl -s http://alto.alcatel-lucent.com:8000/costs/full/routingcost/num | jsonlint -f
{
"cost-map" : {
"defaultpid" : {
"defaultpid" : 15.0,
"mypid1" : 15.0,
"mypid2" : 15.0,
"mypid3" : 15.0,
"peeringpid1" : 15.0,
"peeringpid2" : 15.0,
"transitpid1" : 15.0,
"transitpid2" : 15.0
},
"mypid1" : {
"defaultpid" : 4.0,
"mypid1" : 15.0,
"mypid2" : 15.0,
"mypid3" : 15.0,
"peeringpid1" : 15.0,
"peeringpid2" : 15.0,
"transitpid1" : 5.0,
"transitpid2" : 10.0
},
...
"peeringpid1" : {
"defaultpid" : 15.0,
"mypid1" : 15.0,
"mypid2" : 15.0,
"mypid3" : 15.0,
"peeringpid1" : 15.0,
"peeringpid2" : 15.0,
"transitpid1" : 15.0,
"transitpid2" : 15.0
},
...
},
"meta" : {
"cost-type" : {
"cost-metric" : "routingcost",
"cost-mode" : "numerical"
},
"dependent-vtags" : [ {
"resource-id" : "default-network",
"tag" : "192.11.155.88/f9d21e031e5cf58103d4687d65025cfb"
} ]
}
}
On y voit, par exemple, que le coût entre
mypid1
et
peeringpid1
est de 15 (en utilisant la métrique routingcost).
On l'a vu, le client ALTO peut ne demander qu'une partie d'une
table, pour réduire la consommation de ressources réseau et de temps
de calcul. Ici, un client envoie un objet JSON (de type
application/alto-networkmapfilter+json) qui indique quel(s)
PID l'intéresse(nt) :
POST /networkmap/filtered HTTP/1.1
Host: custom.alto.example.com
Content-Length: 33
Content-Type: application/alto-networkmapfilter+json
Accept: application/alto-networkmap+json,application/alto-error+json
{
"pids": [ "PID1", "PID2" ]
}
Notez qu'on utilise la méthode HTTP POST au lieu
de GET. On peut aussi filtrer les tables de
coûts, par exemple en n'acceptant qu'un seul mode.
Et voici une récupération des propriétés d'une extrémité, l'adresse
de l'extrémité étant indiquée dans l'objet JSON application/alto-endpointpropparams+json :
POST /endpointprop/lookup HTTP/1.1
Host: alto.example.com
Content-Length: 181
Content-Type: application/alto-endpointpropparams+json
Accept: application/alto-endpointprop+json,application/alto-error+json
{
"properties" : [ "my-default-networkmap.pid",
"priv:ietf-example-prop" ],
"endpoints" : [ "ipv4:192.0.2.34",
"ipv4:203.0.113.129" ]
}
HTTP/1.1 200 OK
Content-Length: 396
Content-Type: application/alto-endpointprop+json
...
"endpoint-properties": {
"ipv4:192.0.2.34" : { "my-default-network-map.pid": "PID1",
"priv:ietf-example-prop": "1" },
"ipv4:203.0.113.129" : { "my-default-network-map.pid": "PID3" }
}
}
Et ici une récupération des coûts associés à une extrémité. Par
exemple, on est un client BitTorrent qui hésite
entre trois pairs potentiels de l'essaim,
192.0.2.89, 198.51.100.34 et
132.0.113.45. On les envoie
au serveur (notez les conséquences pour la vie
privée : ce point est développé plus loin) :
# Les données JSON de la requête sont mises dans un fichier
% cat /tmp/select
{
"cost-type": {"cost-mode" : "ordinal",
"cost-metric" : "routingcost"},
"endpoints" : {
"srcs": [ "ipv4:10.0.2.2" ],
"dsts": [
"ipv4:192.0.2.89",
"ipv4:198.51.100.34",
"ipv4:132.0.113.45"
]
}
}
# On donne ce fichier à curl comme source des données à envoyer
# (option -d)
% curl -s -d '@/tmp/select' -H "Content-Type: application/alto-endpointcostparams+json" \
-X POST http://alto.alcatel-lucent.com:8000/costs/end | jsonlint -f
Et le serveur ALTO répond en indiquant des coûts :
{
"endpoint-cost-map" : { "ipv4:10.0.2.2" : {
"ipv4:132.0.113.45" : 2,
"ipv4:192.0.2.89" : 1,
"ipv4:198.51.100.34" : 1
} },
"meta" : { "cost-type" : {
"cost-metric" : "routingcost",
"cost-mode" : "ordinal"
} }
}
Ici, depuis la source 10.0.2.2, les meilleurs
pairs sont 192.0.2.89 et
198.51.100.34, ex-aequo.
Pour rendre les choses plus concrètes, la section 12 du RFC présente un certain nombre de scénarios d'usage. Le premier, et le plus « évident » est celui d'un client ALTO placé dans un tracker pair à pair, un de ces logiciels qui aiguillent les pairs vers un pair qui a le contenu convoité. Chaque tracker gère des essaims (ensemble de pairs qui téléchargent le même fichier et a la tâche délicate de choisir quels pairs sont annoncés à chaque machine connectée au tracker (sauf si l'essaim est petit, auquel cas la tâche est triviale, on envoie tout). Les trackers utilisent déjà un ensemble de mécanismes pour cela et ils peuvent y ajouter ALTO. Comme un tracker pour un contenu populaire (mettons le dernier épisode d'une série télévisée très populaire) peut avoir des dizaines, voire des centaines de milliers de machines connectées, la meilleure solution ALTO est sans doute de télécharger la table du réseau et la table des coûts complètes et de les analyser. Pour chaque membre de l'essaim, le tracker cherchera le PID dans la table du réseau, puis le coût dans la table des coûts. Il enverra les pairs de préférence vers un pair du même PID ou, sinon, vers le pair au coût le plus bas.
Mais, pour diverses raisons, les pairs peuvent souhaiter faire la sélection eux-même. Les trackers sont des cibles évidentes pour la répression du pair à pair (ou, tout simplement, des SPOF...) et on peut vouloir se débrouiller sans eux, utilisant un mécanisme de rendez-vous complètement pair à pair comme une DHT. Dans ce cas, le client ALTO doit forcément être dans le logiciel de partage pair à pair (par exemple rTorrent). La technique la plus coûteuse, mais aussi celle qui préserve le mieux la vie privée de l'utilisateur, est que le logiciel télécharge la table du réseau et la table des coûts, puis fasse les calculs lui-même. Ainsi, il ne donnera presque aucune information au serveur ALTO.
Troisième scénario d'usage proposé par notre RFC, la sous-traitance des calculs et du filtrage au serveur ALTO, en utilisant le Map Filtering Service. Le logiciel pair à pair, cette fois, ne télécharge pas les tables entières, il indique au serveur ALTO une liste de pairs potentiels (trouvée, par exemple, sur la DHT), des critères de choix, et le serveur ALTO choisit le « meilleur » selon ces critères.
Notre RFC comprend ensuite une section 13 de discussion sur divers points du protocole. Premier point : comment un client trouve-t-il le serveur ALTO ? La norme ne définit pas une méthode unique et obligatoire. Le serveur peut être trouvé par une configuration manuelle, ou bien par la technique DNS du RFC 7286 sur la découverte de serveurs ALTO.
Et le cas d'une machine qui a plusieurs adresses IP ? C'est d'autant plus compliqué qu'il y a une interaction entre l'adresse utilisée, le FAI par lequel on passe et l'adresse du pair distant. ALTO ne fournit pas de solution immédiate, uniquement un mécanisme de description des extrémités suffisamment souple pour qu'on puisse y intégrer d'autres identificateurs que les bêtes adresses IP (voir plus haut les registres IANA de types d'adresses).
Reste à régler la question du passage par les routeurs NAT, le cauchemar habituel du pair à pair. En raison de ces obstacles, un protocole devrait éviter de transporter des adresses IP dans ses données, justement ce que fait ALTO. On a vu que, dans certains cas, le client ALTO indique son adresse au serveur, pour lui permettre un bon choix du pair. En raison du NAT, cette méthode ne marche pas forcément et le RFC autorise donc le serveur ALTO à utiliser l'adresse IP source des paquets ALTO entrants (adresse traduite par le routeur NAT) plutôt que celle indiquée dans les données JSON. Si le client ALTO n'est pas satisfait et veut indiquer lui-même son adresse IP dans les données, il doit utiliser un service comme STUN (RFC 8489) pour découvrir son adresse publique.
Et la sécurité dans tout ça ? La section 15 du RFC explore en détail les questions de sécurité d'ALTO. Le RFC cahier des charges, le RFC 6708, reconnaissait le problème et demandait des solutions minimum. D'abord, l'authentification. En effet, un attaquant peut vouloir distribuer de la fausse information ALTO, pour tromper un pair et l'envoyer vers des pairs plus lents. Cela serait une attaque par déni de service sur le réseau pair à pair. ALTO s'appuyant sur HTTP, les solutions de sécurité à utiliser sont celles de HTTP, essentiellement TLS. Pour l'authentification via un certificat, les clients et serveurs ALTO doivent bien suivre le RFC 6125. Attention, cette authentification se fait en fonction du nom présent dans l'URL utilisé par le client ALTO. Si celui-ci utilise un mécanisme de découverte de l'URL qui n'est pas fiable, la protection de TLS arrivera trop tard. Aujourd'hui, il n'y a pas de protection des données ALTO (pas de signature des maps, par exemple), seulement du canal par lequel elles transitent.
C'est bien joli d'authentifier le serveur ALTO mais encore faut-il qu'il soit digne de confiance. Si un méchant serveur ALTO distribue de mauvaise informations, comment peut-on se protéger ? Le RFC 5693 pointait déjà ce risque. Si les serveurs ALTO sont gérés par les FAI, comme beaucoup d'entre eux ont affirmé leur goût pour les violations de la neutralité du réseau, pourquoi les clients leur feraient-ils confiance ? Deux approches sont possibles pour le client ALTO. La première est d'analyser les conséquences de son choix. Si un logiciel pair à pair utilise parfois ALTO et parfois choisit les pairs au hasard, en mesurant les débits obtenus, il peut savoir si l'utilisation d'ALTO est dans son intérêt. (Attention, le but d'ALTO n'est pas uniquement la satisfaction du client : un FAI peut légitimement envoyer les clients vers des pairs qui ne sont pas plus rapides mais qui lui coûtent moins cher, par exemple parce qu'ils sont accessibles par un lien de peering gratuit.) Une seconde approche pour le client est de ne pas utiliser les serveurs ALTO du FAI (qui n'a pas forcément les mêmes intérêts que lui) mais des serveurs ALTO « neutres » fournis par une tierce partie (les exigences AR-20 et AR-21 dans le RFC 6708). Rappelez-vous aussi qu'ALTO n'est qu'une source d'information parmi d'autres, le client l'utilise pour sa prise de décision mais ne lui obéit pas aveuglément.
Et la confidentialité ? Bien sûr, une bonne partie des informations distribuées par ALTO sont publiques ou presque. La network map peut être vue comme confidentielle par le FAI mais, si elle est distribuée à tous ses clients, elle ne peut pas rester trop longtemps secrète. Néanmoins, on ne souhaite pas forcément que n'importe quel espion lise tout le trafic ALTO. Après tout, en combinant la table du réseau et celle des coûts, un attaquant peut récolter plein d'information sur le réseau d'un opérateur, à des fins d'espionnage industriel, ou bien pour préparer une attaque par déni de service. Et les informations données par les clients (liste de pairs potentiels...) sont également très sensibles. Que peut-on faire contre l'espionnage ? D'abord, au moment de créer les tables qui seront utilisées par ALTO, il faut se rappeler qu'ALTO n'impose pas un niveau de détail particulier. Le FAI qui veut avant tout optimiser le trafic fournira un grand niveau de détails, celui qui craint l'espionnage économique donnera des tables plus grossières. Ensuite, pour éviter l'écoute par un tiers, ALTO utilise, comme pour l'authentification, les solutions habituelles de HTTP, en l'occurrence TLS.
Notre RFC se penche aussi sur la vie privée des clients ALTO. D'abord, en raison de l'utilisation de HTTP, certains des risques de vie privée de HTTP affectent ALTO (par exemple l'utilisation de cookies, pas obligatoire dans ALTO mais qui peuvent être activés par défaut par certains clients HTTP). Ensuite, il y a clairement des risques de confidentialité différents pour le client et pour le serveur ALTO. Le client soucieux de vie privée a tout intérêt à télécharger l'intégralité des tables (réseau et coûts) et à faire la sélection soi-même, ne transmettant ainsi aucune information au serveur. En revanche, le serveur soucieux de sa vie privée à lui va vouloir le contraire : ne pas envoyer les tables complètes mais demander au client de lui fournir des critères de filtrage, avec lesquels le serveur fera son choix. On peut donc s'attendre, si ALTO se répand, à des conflits entre utilisateurs et FAI, par exemple si un FAI décide de ne pas fournir le service « tables complètes » et impose l'utilisation des services avec filtrage.
Dernier risque de sécurité pour ALTO, le risque de panne. Si on est habitué à utiliser ALTO, on sera bien embêté si un attaquant trouve le moyen de planter le serveur ALTO. Cela peut servir à aggraver une attaque par déni de service. Ce risque est d'autant plus important qu'un serveur ALTO peut se trouver, si on lui demande de faire des filtrages, dans l'obligation de faire des gros calculs, décidés par son client. Un client malveillant peut ainsi générer facilement une table avec N origines et M destinations, forçant le serveur à calculer N*M chemins. Un serveur ALTO doit donc être prudent sur ce point et prévoir de la limitation de trafic, et sans doute de l'authentification des clients (par exemple, pour un FAI, restreindre l'accès à ses abonnés).
Reste la gestion d'ALTO (section 16). Suivant le RFC 5706, cette section va se pencher sur les problèmes concrets des pauvres ingénieurs système qui vont devoir déployer ALTO et le maintenir en état de marche. ALTO reposant sur HTTP, cela impose l'installation et le maintien d'un serveur HTTP, soit un serveur standard avec un module ALTO, soit un serveur ALTO incluant le protocole HTTP. Mais il y a des problèmes plus sérieux, notamment les choix des services rendus. Par exemple, quel niveau de détail envoie-t-on, quelles requêtes permet-on ? Si on refuse d'envoyer la table du réseau complète, que doit-on faire lorsqu'une requête avec filtrage arrive, avec un filtre vide (un client ALTO astucieux peut utiliser cela pour contourner les restrictions d'accès à la table complète) ? Il faut aussi décider d'un mécanisme pour distriber l'URL où trouver le serveur ALTO. Dans la documentation accessible aux utilisateurs ? Uniquement avec la méthode du futur RFC sur l'utilisation du DNS pour trouver le serveur ? ? (Le RFC n'en parle pas mais le faible nombre de clients ALTO existants n'aide pas à trancher sur ces points.) Heureusement, il n'y a pas encore de question de migration à assurer, puisque ALTO est un nouveau service.
Pour l'opérateur réseau, ALTO va, s'il est utilisé, mener à des déplacements du trafic vers d'autres lignes. C'est bien son but mais cela peut entraîner des surprises : le responsable du serveur ALTO a désormais les moyens d'influencer sur la localisation du trafic, autant que celui qui configurait MPLS ou OSPF.
Pour la journalisation, le RFC recommande que les serveurs ALTO utilisent le standard syslog (RFC 5424), ce que ne font typiquement pas les serveurs HTTP habituels.
ALTO ne fournit pas encore d'interface standard de communication entre serveurs ALTO (par exemple pour agréger de l'information provenant de diverses sources), ni de MIB, ni d'interface standard de configuration, style NETCONF.
Pour les passionnés d'histoire, l'annexe B rappelle tous les ancêtres d'ALTO, notamment P4P (voir « P4P: Provider Portal for (P2P) Applications », présenté à SIGCOMM en 2008.
Et les mises en œuvre existantes ? On a vu le serveur d'Alcatel-Lucent. Il existe aussi celui fait à partir d'un dessin fameux de XKCD. Trois mises en œuvre différentes ont été montrées à la réunion IETF 80 et bien plus ont été testées rigoureusement lors d'un test d'interopérabilité à l'IETF 81. Les résultats sont documentés en ligne. Un autre test a eu lieu à l'IETF 85 et est également documenté.
Merci à Wendy Roome pour le serveur ALTO public utilisé ici, et pour ses patientes explications.
L'article seul
RFC 7344: Automating DNSSEC Delegation Trust Maintenance
Date de publication du RFC : Septembre 2014
Auteur(s) du RFC : W. Kumari (Google), O. Gudmundsson (Shinkuro), G. Barwood
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 4 septembre 2014
Dernière mise à jour le 12 septembre 2014
Un des obstacles à un plus large déploiement de DNSSEC est la nécessité de faire mettre, par le gestionnaire de la zone parente, un enregistrement faisant le lien avec la clé de signature de la zone fille. Cet enregistrement, nommé DS (pour Delegation Signer) est indispensable pour établir la chaîne de confiance qui va de la racine du DNS à la zone qu'on veut sécuriser. Mais, autant signer sa zone ne nécessite que des actions locales, qu'on peut faire tout seul, mettre cet enregistrement DS dans la zone parente nécessite une interaction avec une autre organisation et d'autres personnes, ce qui est souvent compliqué et réalisé d'une manière non standardisée. Ce nouveau RFC propose une méthode complètement automatique, où la zone fille publie les enregistrements de clé localement, et où la zone parente va les chercher (via le DNS) et les recopier.
Faire passer de l'information de la zone fille à la zone parente se fait actuellement avec des mécanismes ad hoc, par exemple via un formulaire Web ou une API chez le BE (cf. section 2.2 du RFC). Un exemple de l'opération est décrit dans mon article sur le remplacement d'une clé. Il faut transmettre les clés (ou leur condensat, le futur enregistrement DS, cf. RFC 4034) à la zone parente pour que la zone soit vérifiable avec DNSSEC. Et il faut le refaire lorsqu'on change la clé. Comme pour tout processus qui franchit les frontières entre deux organisations humaines, bien des choses peuvent aller de travers, surtout lorsqu'il est partiellement effectué manuellement. Et l'absence de techniques normalisées rend difficile le changement de prestataire.
Notre nouveau RFC propose donc une autre méthode : le gestionnaire de la zone signée publie ses clés uniquement dans sa zone, et la zone parente l'interroge à la recherche de nouvelles clés à publier. La sécurité du processus est assurée par les signatures DNSSEC. Ce mécanisme ne marche donc que pour les mises à jour, pas pour la configuration initiale (puisque celle-ci ne peut pas être vérifiée par DNSSEC). Depuis, le RFC 8078 a présenté un moyen de faire la configuration initiale.
En attendant le déploiement du RFC 8078, ce mécanisme supprimera néanmoins une opération pénible et qui est apparemment mal maitrisée par bien des gérants de zones DNS. Naturellement, les anciennes solutions resteront disponibles pour ceux qui préfèrent, et pour le premier envoi des clés, lorsque la zone devient signée. À noter que cette solution est spécifique aux informations DNSSEC (clés de signature). Il y a d'autres informations qu'on pourrait vouloir transmettre automatiquement au parent (serveurs de noms, colle) mais cela dépendra d'autres RFC.
Un petit mot de terminologie : il existe plusieurs mécanismes de gestion (au sens organisationnel) de la relation entre une zone DNS parente et une zone fille. Cette relation peut être directe (par exemple, dans une université, entre l'administrateur de la zone du département de mathématiques et l'administrateur de la zone de l'université), indirecte (passage par un intermédiaire, le BE, imposé, celui-ci communiquant ensuite avec le registre, souvent via EPP) ou complexe (gestion de la racine où le gérant d'un TLD passe par l'ICANN pour un changement qui est fait par le NTIA et Verisign). Pour traiter tous ces cas, le RFC utilise le terme d'« agent du parent » (parental agent) pour désigner l'entité avec lequel le gestionnaire de la zone fille communique, que cette entité soit le gestionnaire de la zone parente ou pas. L'agent du parent est donc l'administrateur de la zone de l'université dans le premier cas, le BE dans le second et l'ICANN dans le troisième. L'annexe A de notre RFC revient en détail sur ces différents modèles et leurs conséquences.
À noter d'ailleurs une complication supplémentaire : le titulaire de la zone fille ne gère pas forcément ses serveurs DNS lui-même (section 2.2.1 du RFC). Il a pu les déléguer à un tiers, l'hébergeur DNS, ou à son agent du parent (il est fréquent que les gens qui louent un nom de domaine à un BE lui confient également l'hébergement DNS). Dans ce dernier cas, tout est simple, l'utilisateur active la signature DNSSEC (ça peut même être fait par défaut, pour épargner ce choix technique à l'utilisateur) et l'hébergeur DNS s'occupe de tout.
Autre point à garder en tête : on peut transmettre à la zone parente un enregistrement DS (le condensat d'une clé) ou bien DNSKEY. Certains gérants de zones demandent un DS, d'autres un DNSKEY, d'autres acceptent les deux. La solution technique de ce RFC marche dans tous les cas.
Voyons maintenant la solution technique choisie. Elle est décrite en section 3. Deux nouveaux enregistrements DNS sont créés, CDS et CDNSKEY, correspondant respectivement aux DS et DNSKEY. Ils sont publiés dans la zone fille (le C initial veut dire Child) et indiquent à la zone parente les informations que la zone fille veut lui transmettre. Le CDS, type 59, a le même format que le DS (RFC 4034, section 5) et le CDNSKEY, type 60, le même format que le DNSKEY (RFC 4034, section 2). Comme on l'a vu plus haut, certains parents demandent un DS, d'autre un DNSKEY. La fille peut publier juste le CDS ou juste le CDNSKEY, selon la parente, ou bien les deux.
L'utilisation de CDS et de CDNSKEY (section 4) est facultative. S'ils sont absents, tout continue comme aujourd'hui. S'ils sont présents, la zone parente qui les détecte peut les publier sous forme d'enregistrement DS (en copiant le CDS ou bien en calculant un DS à partir du CDNSKEY). CDS et CDNSKEY doivent évidemment être signés avec DNSSEC (autrement, on pourrait empoisonner la zone parente) et doivent correspondre à ce qui est réellement dans la zone fille (par exemple, le CDS doit correspondre à une DNSKEY réellement existante). Le mécanisme marche aussi pour les suppressions, la zone parente pouvant retirer les DS qui n'ont plus de CDS mais avec des précautions (section 4.1) : pas question de « dé-sécuriser » la zone en retirant tous les DS valides, par exemple (la possibilité de retrait de DS de la zone parente est, à mon avis, pas très clairement expliquée dans le RFC, mais le RFC 8078 a présenté une solution). La parente peut ensuite prévenir la fille que les nouveaux DS ont été pris en compte et les anciens retirés (par exemple par courrier). Une fois que c'est fait, la zone fille peut supprimer CDS et CDNSKEY. (Attention à bien les supprimer tous : si on en supprime certains, la zone parente va retirer les DS correspondants. Aucun CDS/CDNSKEY ne veut pas dire « supprimer tous les DS » mais « ne faire aucun changement .)
(Au passage, pourquoi avoir un CDNSKEY, pourquoi la zone parente ne regarde pas directement le DNSKEY ? Il y a deux raisons : la première est qu'en général, on ne veut pas publier le DS tout de suite, on souhaite d'abord tester la configuration DNSSEC pendant plus ou moins longtemps. La zone va donc rester signée mais pas rattachée de manière sécurisée à sa parente. Ce rattachement doit être volontaire et explicite car, à partir du moment où il est fait, les erreurs DNSSEC ne pardonnent plus. La deuxième raison est qu'il peut y avoir plusieurs clés dans la zone fille, dont certaines sont, par exemple, en cours de retrait et ne doivent pas être utilisées pour faire un DS.)
Comment l'agent du parent sait-il qu'une zone fille a publié de nouveaux CDS ou CDNSKEY ? Une possibilité est l'interrogation régulière des zones. C'est simple à faire et automatique pour le gérant de la zone fille mais cela peut poser des problèmes de performance pour, par exemple, un gros BE qui gérerait des centaines de milliers de zones (section 6.1). Une autre est de fournir aux clients un bouton à pousser sur un formulaire Web quelconque, indiquant qu'il y a du nouveau dans la zone. Cette deuxième possibilité peut aussi permettre, si le formulaire Web est authentifié et qu'on présente à l'utilisateur le DS pour vérification, de faire l'ajout initial du DS (cela suppose que l'utilisateur fasse une vérification sérieuse… voir à ce sujet le RFC 8078). On peut aussi envisager une API simple pour cela, mais rien n'est encore normalisé. (C'était l'une des plus grosses controverses lors du développement de ce RFC : la méthode décrite ici doit-elle être la méthode officielle ou bien juste une méthode parmi d'autres ? Pour l'instant, c'est la seule normalisée mais elle n'est nullement obligatoire.)
La section 9 du RFC est l'analyse de sécurité de ce système. En automatisant le plus possible la transmission des clés de la fille à la parente, on espère augmenter la sécurité, en diminuant les risques d'erreurs humaines (copier/coller maladroit d'une DS dans un formulaire Web, par exemple). Cette décroissance des incidents aiderait au déploiement de DNSSEC. Mais il n'y a pas de miracle : le gérant de la zone fille pourra toujours faire des bêtises comme de supprimer de sa zone toutes les DNSKEY correspondant aux DS dans la zone parente.
Si le système d'avitaillement de la zone fille est piraté, le pirate pourra évidemment créer des CDS et CDNSKEY signés. Bien sûr, aujourd'hui, il peut déjà créer des enregistrements mais, dans ce cas, cela permettra peut-être d'étendre la durée de l'attaque (il faudra republier les bons CDS/CDNSKEY et attendre la mise à jour de la parente).
Dans le cas où la la gestion de la zone fille est sous-traitée à un hébergeur DNS, cette nouvelle technique a l'avantage que l'hébergeur DNS peut publier les CDS/CDNSKEY lui-même et donc mettre à jour la zone parente sans qu'on ait besoin de lui confier le mot de passe du compte chez le BE.
On peut mettre facilement des CDS et des CDNSKEY dans
BIND depuis la version 9.10.1. Sinon,
quels « agents de parent » mettent en œuvre ce RFC ? Pour
l'instant, le serveur FRED, et
ça marche dans .cz. Et,
sinon, il existe un logiciel public qui fait ce
travail de récupération et validation des CDS et CDNSKEY, cds-monitor. Jan-Piet
Mens a fait un
récit de son utilisation avec PowerDNS et BIND et l'outil dnssec-cds.
L'article seul
RFC 7353: Security Requirements for BGP Path Validation
Date de publication du RFC : Août 2014
Auteur(s) du RFC : S. Bellovin (Columbia
University), R. Bush (Internet Initiative
Japan), D. Ward (Cisco Systems)
Pour information
Réalisé dans le cadre du groupe de travail IETF sidr
Première rédaction de cet article le 2 septembre 2014
La sécurité du routage BGP est un sujet de préoccupation sur l'Internet depuis de nombreuses années. Ce protocole ne dispose en effet par défaut d'aucune sécurité, n'importe quel opérateur (ou personne extérieure ayant piraté les routeurs d'un opérateur) pouvant annoncer une route vers n'importe quel préfixe, détournant, par exemple le trafic d'un service vital. Ce manque de sécurité ne vient pas d'une confiance naïve dans la nature humaine, mais plutôt de la nature même de l'Internet : il n'y a pas (heureusement !) de Haute Autorité Supérieure de l'Internet qui connaitrait tous les opérateurs et pourrait les autoriser et les surveiller. Un opérateur ne connait (et encore, pas toujours très bien) que ses voisins immédiats, et ne sait pas quelle confiance accorder aux autres. Dans ces conditions, la sécurisation de BGP est forcément un projet à long terme. La première grande étape avait été la normalisation et le déploiement de RPKI et ROA. L'étape suivante est la sécurisation du chemin entier (et pas uniquement de l'origine), dont ce nouveau RFC est le cahier des charges. En route donc vers BGPsec ! (Le nom PATHsec ne semble plus utilisé.)
Rappelons en effet qu'une annonce BGP (RFC 4271) comprend un chemin, la liste des AS par lesquels l'annonce est passée (et, dans la plupart des cas, celle, en sens inverse, dans lequel un paquet IP émis par le récepteur de l'annonce voyagera s'il veut atteindre l'AS d'origine). Voici un telle annonce, extraite du service de looking glass d'Hurricane Electric :
Prefix: 2001:678:c::/48, Status: E, Age: 31d9h14m31s
NEXT_HOP: 2001:7fa:0:1::ca28:a116, Metric: 0, Learned from Peer: 2001:7fa:0:1::ca28:a116 (1273)
LOCAL_PREF: 100, MED: 1, ORIGIN: igp, Weight: 0
AS_PATH: 1273 2200 2484
Le chemin comprend trois AS, et l'origine, l'AS émetteur de l'annonce, est 2484 (oui, tout à droite : un chemin d'AS se lit de droite à gauche).
Avec les certificats de la RPKI (RFC 6480) et avec le système des ROA (Route Origin Authorization, RFC 6482), on peut désormais (RFC 6811) valider l'origine d'une annonce. Cela protège contre les détournements accidentels (comme celui de YouTube par Pakistan Telecom cité plus tôt), où l'AS d'origine est en général celle du détourneur. Mais lors d'une attaque délibérée, l'attaquant peut tricher sur le chemin et envoyer une annonce avec un chemin d'AS qui semble correct, avec la bonne origine. RPKI+ROA ne protègent pas contre cet attaquant compétent. (Les RFC 4593 et RFC 7132 décrivent en détail les vulnérabilités de BGP.)
Maintenant, place aux exigences que devra satisfaire la nouvelle
solution de sécurisation. La section 3 du RFC liste les exigences
générales et la section 4 celles spécifiques au traitement effectué
lors de la réception d'une annonce BGP. Les exigences générales
d'abord, numérotées de 3.1 à... 3.23 (oui, une longue liste). D'abord,
3.1 et 3.2, qui résument le projet complet : le routeur BGP qui reçoit une
annonce doit pouvoir déterminer, avec un bon niveau de confiance, que
l'origine dans l'annonce (exigence 3.1), et
le chemin des AS (AS Path) dans l'annonce (exigence
3.2) sont
authentiques. On veut être sûr que l'AS d'origine avait bien le droit
d'annoncer ce préfixe, et que le chemin d'AS dans l'annonce reflète
bien le chemin suivi par l'annonce (dans l'exemple ci-dessus, que 2484
avait bien le droit d'annoncer le préfixe 2001:678:c::/48, et qu'il a bien transmis
l'annonce à 2200, qui l'a lui-même bien transmis à 1273). Attention,
il ne s'agit pas uniquement de montrer que le chemin d'AS est possible
(ces AS sont bien des pairs...) mais que c'est bien celui qui a
effectivement été utilisé. Les autres
attributs de l'annonce (comme le MED dans
l'exemple ci-dessus) ne sont pas protégés
(exigence 3.3) car ils ne sont utilisés que dans un AS ou ses voisins
immédiats. (Voir aussi l'exigence 3.10.)
Comme toute technologie nouvelle, BGPsec aura des difficultés de déploiement, dans un Internet très ossifié, et la nouvelle solution devra donc être déployable de manière incrémentale (exigences 3.4 et 3.5) : les routeurs BGPsec devront pouvoir travailler avec les routeurs actuels (exigence 3.13 ; la section 5 reconnait que cette exigence ouvre la voie aux attaques par repli, où un attaquant réussit à faire croire qu'un pair ne gère pas BGPsec et qu'il faut donc se replier sur un protocole non sécurisé). Au début, les routeurs BGPsec auront sans doute des pairs BGPsec et d'autres en BGP non sécurisé et BGPsec doit donc pouvoir être configuré pair par pair (exigence 3.12). La cryptographie peut coûter cher en ressources matérielles et un routeur BGP typique a un CPU moins puissant que celui d'une console de jeu de salon. L'exigence 3.6 autorise donc BGPsec à réclamer du matériel nouveau (par exemple des processeurs cryptographiques spécialisés). La compatibilité avec le matériel existant n'est donc pas exigée.
L'attaquant n'est pas forcément situé dans un garage à des milliers de kilomètres, comme dans le cas des détournements BGP spectaculaires connus. Il peut aussi être mieux placé, par exemple sur le lien entre deux routeurs (l'attaquant peut être sur le même point d'échange que ses victimes...) L'exigence 3.8 impose donc une solution qui marche même en cas d'ennemi sur le lien Ethernet (le RFC note que AO - RFC 5925 - ou TLS - RFC 5246 suffisent).
La cryptographie ne sert pas à grand'chose si on n'a pas de moyen de vérifier l'authenticité des clés utilisés. C'est bien joli de tester l'intégrité d'une signature mais il faut aussi que la clé de signature soit reliée aux ressources qu'on veut protéger (ici, les préfixes d'adresses IP et les numéros d'AS). L'exigence 3.9 dit donc que la solution technique a le droit de s'appuyer sur une infrastructure existante établissant ce lien, comme la RPKI (et qu'évidemment cette infrastructure doit être fiable, cf. section 5). 3.17 ajoute que cette infrastructure doit permettre le choix, par l'opérateur, des entités à qui faire confiance (toutes les mises en œuvre actuelles de la RPKI permettent cela, en éditant la liste des trust anchors).
L'exigence 3.14 concerne une question de gouvernance. Il a souvent été reproché aux projets de sécurisation de BGP de faire un déplacement de pouvoir, des opérateurs BGP aux RIR qui gèrent les points de départ de la RPKI. Avec le BGP traditionnel, le RIR a un pur rôle de registre, il ne prend aucune décision opérationnelle concernant le routage. Avec un BGP sécurisé, ce n'est plus le cas. Pour rassurer les opérateurs, 3.14 rappelle que, signature correcte ou pas, la décision d'accepter, de refuser, de prioriser ou de déprioriser une annonce doit rester locale au routeur et à son opérateur. La question « que doit faire un routeur BGPsec en recevant une annonce invalide ? » n'a donc pas de sens et les futurs RFC n'y répondront pas. BGPsec permettra de dire « cette annonce est invalide », il ne dira pas quelle politique adopter vis-à-vis de ces annonces.
Pas question de sacrifier le secret des affaires à la sécurité BGP : l'exigence 3.18 dit que BGPsec ne doit pas révéler au monde plus que ce que BGP diffuse déjà. On ne pourra donc pas exiger, par exemple, qu'un opérateur publie la liste de ses pairs privés ou de ses clients.
Bien sûr, la solution adoptée devra permettre (exigence 3.19) la journalisation des événements pertinents, notamment en matière de sécurité (c'est plus une exigence pour les mises en œuvre que pour les futurs RFC).
Rien n'étant éternel dans l'Internet, le BGP sécurisé devra ré-authentifier les informations de temps en temps, par exemple suite aux mises à jour de la RPKI (exigence 3.20), même s'il n'y a pas eu de changement BGP (ce protocole n'annonce en effet que les changements : une route qui n'a pas changé ne sera pas ré-annoncée périodiquement, et les sessions BGP peuvent durer des mois, l'annonce montrée au début de cet article était vieille de 31 jours).
Enfin, pour en finir avec les exigences générales, la 3.21 impose que la solution BGPsec permette de changer les algorithmes cryptographiques utilisés, pour faire face aux progrès de la cryptanalyse.
La section 4 décrit les exigences spécifiques au traitement des
messages BGP UPDATE qui annoncent une nouvelle
route ou bien en retirent une ancienne. C'est le moment où il faut
valider (exigences 4.1 et 4.2). L'exigence 4.3 dispense BGPsec d'une
protection générale contre les attaques par
rejeu, qui resteront donc possibles (retransmission d'une
annonce BGP qui était valide mais ne l'est plus, vu les changements
dans le graphe BGP). Plus difficile, 4.4 demande qu'on puisse se
protéger, au moins partiellement, contre le retrait par l'attaquant
d'un message BGP.
Pour terminer, la section 5, sur les problèmes généraux de sécurité, rappelle plusieurs choses importantes notamment le fait que la sécurité du routage ne garantit pas celle des paquets IP (« The data plane may not follow the control plane ») et le fait qu'une sécurité de bout en bout, assurée par les deux machines qui communiquent, reste nécessaire. (Il existe d'autres moyens de détourner le trafic que les attaques BGP.)
Le protocole n'est pas encore terminé (ce RFC n'est qu'un cahier des charges) et il n'existe donc pas encore de mise en œuvre de BGPsec dans du code livré aux opérateurs.
Merci à Bruno Decraene pour les corrections.
L'article seul
RFC 7351: A Media Type for XML Patch Operations
Date de publication du RFC : Août 2014
Auteur(s) du RFC : E. Wilde (UC Berkeley)
Pour information
Première rédaction de cet article le 31 août 2014
Vous voulez patcher des
documents XML, c'est-à-dire envoyer juste la
différence entre deux documents à un serveur pour qu'il applique les
opérations de transformation qui vont rendre les deux documents
identiques ? Le RFC 5261 fournissait un
format de description de ces patches. Il manquait
toutefois un type MIME décrivant ce
format. C'est désormais fait, avec la normalisation dans ce
RFC du type de média
application/xml-patch+xml.
Outre le RFC 5261, qui décrivait un format
pour les patches
XML, l'un des protocoles qui utilisent le plus
XML, HTTP, a une opération
PATCH qui permet de mettre à jour une ressource
Web distante (RFC 5789). HTTP, comme d'autres
protocoles de l'Internet, étiquette les ressources envoyées ou
récupérées avec un type de média (dit aussi
« type MIME », cf. RFC 6838), et pour utiliser le format du
RFC 5261 avec l'opération
PATCH du RFC 5789, il
fallait un tel type, désormais
application/xml-patch+xml. (Pour l'opération
PATCH, les serveurs HTTP choisissent librement
les formats de patch qu'ils gèrent, il n'existe pas
de format obligatoire. Ils peuvent accepter
diff, ce nouvel
application/xml-patch+xml et/ou bien
d'autres.)
Notez que le RFC 5261 définissait un type
MIME mais uniquement pour les messages d'erreur,
application/patch-ops-error+xml.
Outre l'enregistrement du type MIME
application/xml-patch+xml, ce nouveau RFC corrige
également les erreurs du RFC 5261,
liées à la complexité de la combinaison entre
XPath et les namespaces
XML.
Une des raisons pour lesquelles le RFC 5261
ne définissait pas de type MIME est qu'il ne définissait pas un format
complet mais juste les éléments XML indiquant l'ajout, la suppression
ou la modification d'éléments XML dans le document cible. Notre
nouveau RFC, lui, définit un format complet, où les éléments de
patch sont inclus dans un document dont l'élément
racine est <patch> (et qui sera donc servi
avec le type MIME
application/xml-patch+xml). Voici un exemple d'un
tel document :
<p:patch xmlns:p="urn:ietf:rfc:7351">
<p:add sel="/section"><para>Nouveau paragraphe, lorem, ipsum, dolor, etc</p:add>
</p:patch>
Notez que l'élément à la racine, <patch> et
les éléments du RFC 5261 comme
<add> sont dans le même espace
de noms urn:ietf:rfc:7351. À part ça, on peut reprendre les exemples du RFC 5261 tels quels (voir la section 2.2 de notre nouveau RFC).
L'annexe A contient un certain nombre de détails techniques. D'abord, une discussion détaillée du problème de la correspondance de deux espaces de noms en XML, problème difficile et où le RFC 5261 s'était planté. Ensuite, le problème des espaces de noms dans le document résultat, où les règles ne sont pas les mêmes en XML et en XPath.
Pour comprendre ce dernier problème, regardez ce document XML :
<x xmlns:a="tag:42">
<y/>
</x>
L'espace de noms est le même pour les deux éléments XML
(URI tag:42, qui utilise de manière inhabituelle le
RFC 4151). Mais dans ce document XML
quasi-identique :
<x xmlns:a="tag:42">
<y xmlns:a="tag:42"/>
</x>
Chaque élément a sa propre déclaration d'espace et de
noms et, si le patch
veut modifier /x/namespace::a, ce sélecteur XPath
ne désigne que le nœud <x>, et
<y> ne doit pas, lui, être modifié. Or, XPath ne
fournit pas assez d'informations pour cela, un logiciel de
patch XML doit donc trouver une autre façon de
déterminer où stopper sa récursion (par exemple en utilisant DOM). Une mise en œuvre naïve du RFC 5261 qui ne s'appuyerait que sur XPath échouerait
dans des cas comme celui indiqué dans ce paragraphe.
Enfin, l'annexe B contient une grammaire ABNF des expressions autorisées par le sous-ensemble de XPath du RFC 5261, pour ceux qui n'aiment pas le W3C Schema qu'utilisait le premier RFC.
Des mises en œuvre complètes de XML Patch+ ce nouveau RFC ? Il y en a apparemment une dans le xDB d'EMC.
L'article seul
Fiche de lecture : Hackers, au cœur de la résistance numérique
Auteur(s) du livre : Amaelle Guiton
Éditeur : Au Diable vauvert
9-782846-265010
Publié en 2013
Première rédaction de cet article le 31 août 2014
S'il y a un mot galvaudé, dans l'univers du numérique, c'est bien celui de « hacker ». Ce terme est utilisé aussi bien pour parler du méchant en cagoule dans son sous-sol et qui fait sauter des centrales nucléaires à distance, que pour le type qui se croit un génie parce qu'il a installé Yo sur son iPhone. Ici, dans le livre d'Amaelle Guiton, « hacker » retrouve son sens original : celui (ou celle) qui ne se contente pas de faire fonctionner des systèmes techniques existants, mais qui veut les comprendre, les modifier, voire les subvertir.
Un petit livre trop court pour couvrir tous les hackers intéressants : on rencontre WikiLeaks, Telecomix, des gens anonymes et d'autres très exposés, toute la galaxie de ceux qui pensent qu'on peut changer le monde, et en tout cas la technique. À lire et surtout à faire lire par ceux qui ne connaissent du hacker que les reportages de TF1.
À noter que le livre n'est pas facile à trouver dans les librairies, le mieux, comme je l'ai fait, est de le faire commander par sa librairie de quartier (vous n'allez pas le commander sur Amazon, quand même, vu le sujet.) Mais vous avez aussi d'autres solutions expliquées sur le site officiel (oui, je sais, le lien vers « version papier » ne marche plus. Comme je l'ai dit, demandez à votre libraire.)
Vous pouvez aussi regarder un interview de l'auteure ou un autre.
L'article seul
J'ai un téléphone Fairphone
Première rédaction de cet article le 29 août 2014
Dernière mise à jour le 20 octobre 2014
Voilà, il y a quelques jours, j'ai reçu mon téléphone « équitable » Fairphone. Qu'a-t-il d'équitable et que fournit-il ?
L'article complet
Les quatorze qui soi-disant contrôlent tout l'Internet
Première rédaction de cet article le 28 août 2014
Hier, le magazine GQ a cru bon de publier un article intitulé « Qui détient (vraiment) les clés d’Internet ? » et qui contient tellement d'erreurs, d'exagérations, et de sensationnalisme que c'était un exercice intéressant que de tenter de les lister toutes, de rectifier la vérité de manière (je l'espère) compréhensible par des gens qui ne sont pas des experts de l'infrastructure Internet, et d'en profiter pour regarder comment travaillent les médias auxquels tant de gens font confiance pour s'informer.
D'abord, il faut noter qu'il n'y a aucun travail d'enquête : cet article et d'autres qui l'ont précédé en français (comme celui de Paris-Match) sont juste de mauvaises traductions et adaptations d'un article du Guardian, qui était également pas mal sensationnaliste mais qui reposait au moins sur un reportage réel. Chaque adaptation successive de cet article a dégradé un peu plus le contenu. Mais, que voulez-vous, produire du contenu de qualité coûte cher, et adapter des articles déjà faits est plus rapide. Pour faire croire que le contenu est original, l'article doit prétendre qu'il va révéler « un des secrets les mieux gardés » alors que, on l'a vu, ce système a déjà été décrit dans plusieurs journaux.
Maintenant, reprenons l'article de GQ. Il use et abuse de termes
sensationnels (« L’histoire est digne d’un film de science-fiction. »)
pour faire du spectacle à partir d'une réalité nettement plus austère,
qui n'intéresse normalement que les ingénieurs réseau. Résumé
simplement, il s'agit de la technologie DNSSEC,
un mécanisme technique et organisationnel qui permet de sécuriser une
partie importante de l'infrastructure de l'Internet, le système des
noms de domaine. Sans
DNSSEC, il est relativement facile à un craqueur de subvertir ce système en
redirigeant un nom (mettons bortzmeyer.org qui
sert au courrier que je reçois) ailleurs que ce
que voulait le titulaire du nom. Il est amusant que l'article de GQ ne
mentionne pas une seule fois ce sigle DNSSEC. Une caractéristique
importante de DNSSEC est qu'il est optionnel : aujourd'hui, seule une
petite minorité des noms (bortzmeyer.org en fait
partie) est protégée par DNSSEC et seule une minorité des utilisateurs
se servent de serveurs de noms qui vérifient les
signatures que DNSSEC appose. Il est donc
ridicule de présenter ce système comme étant la
sécurité de l'Internet (« le cœur de la sécurité du Net »). Il existe
d'autres systèmes de sécurité qui jouent un rôle bien plus
important pour l'instant.
Ce n'est pas trop glamour, bien sûr, et donc un certain nombre de personnes ont choisi de gonfler les choses, en menant une politique de communication personnelle active. On l'a vu, produire des articles de qualité coûte cher. Alors que les journalistes sont bombardés de contenus tout prêts, déversés sur eux par des entreprises ou des personnes qui veulent se mettre en avant. Il suffit de reprendre leurs discours, sans contre-enquête, sans nuance critique, et hop, on a une jolie histoire. Sur Internet comme ailleurs, ceux qui communiquent le plus ne sont pas forcément ceux qui font le travail (de « plombiers »)...
Bon, on va être indulgent, on va dire que ces abus sensationnalistes sont un choix de récit, que cela n'affecte pas le fond de l'article.
Mais c'est qu'il y a plein d'erreurs dans l'article. Citons-les dans l'ordre. D'abord, il y a une confusion entre l'Internet et le Web (les deux articles de Wikipédia sur ces deux technologies expliquent bien la différence). Des phrases comme « [une] simple clé qui permet de sécuriser tout le web » sont donc fausses : DNSSEC n'est pas spécifique au Web.
Ensuite, l'article parle d'une « une clé centrale de chiffrement » alors que DNSSEC ne fait pas de chiffrement ! Le chiffrement sert à garantir la confidentialité des communications mais ce n'est pas le rôle de DNSSEC. Son rôle est d'assurer l'authenticité des données, via un mécanisme de signature.
Passons sur « des data centers aussi sécurisés qu’une centrale nucléaire ». Si c'était vrai, les riverains de Fessenheim pourraient s'inquiéter...
Plus embêtant, « Ce que contrôle cette clé centrale est le "serveur-racine" ». Non, non, non. D'abord, il n'existe pas un seul serveur racine mais plusieurs (leur nombre dépend de comment on compte) et, surtout, la clé en question est tout simplement la clé de signature des données situées à la racine des noms de domaine. Elle ne contrôle pas une machine mais des données.
Revenons maintenant à la propriété la plus importante de DNSSEC, le
fait qu'il soit optionnel. Ce point est complètement oublié dans
l'article, parce que cela obligerait à dire que cette fameuse clé
n'est pas si importante que cela, puisque seuls les gens qui utilisent
DNSSEC pourraient éventuellement être affectés par sa perte ou son
vol. Et l'infographie dans l'article cite un seul exemple de « nom de
domaine sécurisé »... gqmagazine.fr qui justement
ne l'est pas. Ce nom n'est pas signé avec DNSSEC
et la perte ou le vol des clés de la racine n'auraient donc
rigoureusement aucune influence sur la sécurité
de GQ.
La partie de l'article concernant la gouvernance n'est pas épargnée, avec une affirmation comme quoi l'ICANN « définit également les protocoles qui permettent aux machines de communiquer entre elles » (c'est faux, c'est le rôle de l'IETF).
L'article seul
RFC 7342: Practices for Scaling ARP and Neighbor Discovery (ND) in Large Data Centers
Date de publication du RFC : Août 2014
Auteur(s) du RFC : L. Dunbar (Huawei), W. Kumari (Google), I. Gashinsky (Yahoo)
Pour information
Première rédaction de cet article le 28 août 2014
Les protocoles de résolution d'adresse IP en
adresse MAC sur un réseau local,
ARP pour IPv4 et
ND pour IPv6,
fonctionnent par diffusion. Le client crie à tout le monde
« qui connaît 2001:db8:376:ab::23:c0f ? » et la
machine qui se reconnaît répond. L'inconvénient de ce mécanisme est
qu'il passe mal à l'échelle : lorsque des
centaines de milliers de machines virtuelles
sont sur le même réseau local dans un grand data
center, et crient toutes en même temps, le réseau
va souffrir. Ce nouveau RFC ne propose pas de
solution mais décrit les pratiques qui sont actuellement utilisées
pour limiter les dégâts.
Le problème des protocoles ARP (RFC 826) et ND (RFC 4861) dans les grands data centers a été décrit en détail dans le RFC 6820. Le problème a toujours existé mais est devenu bien plus sérieux depuis qu'on pratique massivement la virtualisation et que le nombre de machines qui font de l'ARP ou du ND a explosé. Le désir de souplesse dans la gestion de ces machines fait qu'il est difficile d'architecturer le réseau en fonction de ce problème. Par exemple, faire de chaque machine physique un réseau limiterait la diffusion des requêtes ARP ou ND mais obligerait à changer l'adresse IP des machines virtuelles lorsqu'elles passent d'une machine physique à une autre, annulant ainsi cette souplesse que fournit la virtualisation.
Les trois principales conséquences de cette augmentation du trafic ARP/ND :
- Consommation de capacité réseau au détriment du trafic « utile » (bien sûr, avec les liens modernes à 10 Gb/s, c'est moins grave qu'avant),
- Augmentation de la charge de travail des routeurs, sans doute la conséquence la plus gênante aujourd'hui (cf. une étude de Merit),
- En IPv4, augmentation de la charge de toutes les machines car la diffusion est totale (IPv6 utilise le multicast). Là encore, l'augmentation des ressources de calcul des équipements réseau peut aider : un test en laboratoire indique que 2 000 messages ARP par seconde consomment 2 % du CPU d'un serveur.
Comme expliqué dans la section 3, le réseau interne d'un grand data center a en général une de ces trois architectures :
- Connectivité au niveau 3 (L3), c'est-à-dire qu'on fait du routage IP dans le data center,
- Tout en niveau 2, le data center est un grand réseau L2,
- Virtualisation du réseau (overlay).
Pour chacune de ces architectures, une section de notre RFC décrit les pratiques actuelles pour limiter l'effet des protocoles de résolution.
Dans le premier cas (réseau L3), c'est la section 4. Les réseaux utilisant le routage mettent un routeur IP dans chaque baie, voire un pour chaque machine physique. Gros avantage : la diffusion des messages ARP ou ND, qui ne va pas au-delà du premier routeur, est très limitée. Le problème décrit dans le RFC 6820 disparaît donc complètement. Inconvénient : on n'a plus aucune souplesse. Changer une VM de baie, voire de serveur physique dans la même baie, oblige à la changer d'adresse IP, ce qui va casser les sessions en cours, nécessiter une reconfiguration, etc. Cette architecture ne convient donc que lorsque le data center est assez statique, ou bien lorsque les services qui y tournent peuvent supporter ces changements d'adresses IP.
Variante sur cette architecture (non mentionnée dans le RFC mais que j'emprunte à Vincent Bernat), annoncer dans le protocole de routage interne une route par machine (un préfixe /32 en IPv4 et /128 en IPv6). Cela résout ce problème et permet de tout faire en L3, mais, si on a des centaines de milliers de machines, le protocole de routage va souffrir.
Deuxième architecture possible (section 5), le grand réseau L2 où toute diffusion va frapper toutes les machines. Cette fois, le problème des messages de diffusion ARP ou ND va se poser en grand. Les routeurs qui vont faire communiquer ce réseau L2 avec l'extérieur vont souffrir. Comment diminuer cette souffrance ? D'abord, pour le cas où une machine cherche à communiquer avec une machine externe et doit donc résoudre l'adresse IP du routeur en adresse MAC. Si cette adresse MAC n'est pas dans le cache de la machine, elle envoie une requête, et le routeur doit la traiter, ce qui se fait en général via le CPU généraliste du routeur, pas dans les circuits spécialisés.
Première solution : pré-charger l'adresse MAC du routeur dans toutes
les machines (options -s et
-f de la commande arp sur
Unix). Deuxième solution, plus souple : que le routeur envoie des
réponses ARP ou ND spontanément, sans attendre les requêtes (cf. RFC 5227). Ainsi,
son adresse MAC sera quasiment toujours dans les caches. Cela marche
très bien pour IPv4. Mais cela ne
résout pas complètement le problème pour IPv6 : ce protocole impose
l'envoi de requêtes au routeur, pour valider que la liaison avec
celui-ci fonctionne (RFC 4861, section 7.3,
notamment « Receipt of other Neighbor Discovery messages, such as Router
Advertisements and Neighbor Advertisement with the Solicited flag set
to zero, MUST NOT be treated as a reachability confirmation. Receipt
of unsolicited messages only confirms the one-way path from the
sender to the recipient node. In contrast, Neighbor Unreachability
Detection requires that a node keep track of the reachability of the
forward path to a neighbor from its perspective, not the neighbor's
perspective. »). Malgré cela, notre RFC recommande que cette
pratique soit utilisée pour les réseaux IPv4 et que l'on travaille à
améliorer la situation pour IPv6, dans la ligne du RFC 7048.
Second cas dans ce grand réseau L2, celui du traitement du trafic entrant dans le réseau. Le routeur de bordure reçoit un paquet pour une machine interne. L'adresse MAC de cette dernière n'est pas dans le cache ARP ou ND du routeur. Il faut donc émettre une requête ARP ou ND, ce qui fait du travail pour le CPU et utilise de nombreux tampons d'attente. Première solution : limiter la quantité de requêtes par seconde. Celles en excès seront simplement abandonnées. Deuxième solution : en IPv4, le routeur peut également surveiller le trafic ARP des machines afin d'apprendre leurs adresses MAC et de remplir son cache à l'avance. En IPv6, le trafic ND n'est pas toujours diffusé et donc pas toujours écoutable, et cette solution n'aide donc pas tellement. Notre RFC recommande cette deuxième solution, au moins pour IPv4, en notant que, s'il est possible que beaucoup de paquets soient destinés à des machines éteintes ou injoignables (et qui n'émettent donc jamais), il vaut mieux trouver d'autres solutions.
De même qu'on peut pré-configurer statiquement l'adresse MAC du routeur dans toutes les machines, on peut aussi pré-configurer statiquement les adresses MAC de toutes les machines dans les routeurs. C'est évidemment un cauchemar à gérer (ceci dit, ce n'est pas fait à la main pour chaque VM, mais typiquement à l'intérieur du programme de création des VM) et il n'existe pas de mécanisme standard pour cela. Le RFC suggère que l'IETF regarde si on peut augmenter des protocoles comme NETCONF pour faire ce genre d'opérations.
Autre approche, rendre la résolution ARP hiérarchique (voir RFC 1027 et les travaux ultérieurs comme cette proposition). Au lieu de n'avoir que deux niveaux, le client et le serveur, on pourrait avoir un relais ARP spécialisé qui puisse répondre aux requêtes, garder en cache les résultats, etc. Le RFC 4903 déconseillait cette approche, notamment parce qu'elle peut gêner le déplacement rapide d'une machine (il faut alors invalider les caches) et parce qu'elle est incompatible avec SEND (que personne n'utilise, il est vrai, cf. RFC 3971). Même possibilité, au moins en théorie, avec ND (RFC 4389 décrit un relais mais qui ne réduit pas le nombre de messages). Au bout du compte, notre RFC ne recommande pas cette technique, bien qu'elle ait parfois été déployée.
Troisième architecture possible pour un grand data center, les réseaux virtuels (overlays, section 6). Il existe des normes pour cela (TRILL ou IEEE 802.1ah) et plusieurs projets. L'idée est que seul un petit nombre d'adresses MAC sont visibles dans les paquets qui circulent entre les baies, les paquets étant décapsulés (révélant l'adresse MAC interne) à un endroit très proche des VM. Les équipements qui font l'encapsulation et la décapsulation doivent être suffisamment dimensionnés puisqu'ils se taperont presque tout le trafic ARP et ND. L'intensité du travail peut être diminuée par des correspondances statiques (comme cité pour les autres architectures) ou bien en répartissant astucieusement la charge entre les machines d'encapsulation/décapsulation.
La section 7 du RFC résume les recommandations : pas de solution miracle qui conviendrait à tous les cas, plusieurs solutions mais aucune parfaite. Certaines améliorations nécessiteraient un changement des protocoles et cela fait donc du travail possible pour l'IETF :
- Atténuer certaines obligations de ND concernant la bidirectionnalité, obligations qui interdisent actuellement de profiter complètement des messages ND spontanés.
- Spécifier rigoureusement les sémantiques des mises à jour (lorsqu'on reçoit une réponse ARP ou ND alors qu'on a déjà l'information en cache).
- Développer des normes pour des relais/caches pouvant stocker les réponses ARP ou ND et les redistribuer largement. Le RFC 4389 peut donner des idées.
À l'heure actuelle, il n'y a plus de groupe de travail IETF sur ce sujet et ce développement de nouvelles solutions risque donc de ne pas être immédiat.
L'article seul
Sécurité, facilité d'usage, et les utilisateurs non-informaticiens
Première rédaction de cet article le 25 août 2014
La question de la facilité d'usage des solutions de sécurité informatique revient régulièrement sur le devant de la scène. S'il y a si peu d'utilisateurs de l'Internet qui se servent de la cryptographie ou d'autres mesures techniques qui les protégeraient, ne serait-ce pas parce que les techniques en question sont trop complexes, amenant les utilisateurs à préférer prendre des risques plutôt que de tenter de les maîtriser ?
La question revient souvent, mais elle est très ancienne. L'article qui avait été le premier à pointer ce problème de l'utilisabilité est « Why Johnny Can't Encrypt » d'Alma Whitten et J. D. Tygar1, en... 1999 Peu de progrès dans le débat depuis, à part une large reconnaissance, par la communauté des gens qui travaillent dans la sécurité informatique, que l'utilisabilité est en effet cruciale : la meilleure solution de sécurité du monde ne servira à rien si elle n'est pas utilisée car trop compliquée. Or, les révélations du héros Snowden ont rappelé l'importance de se protéger, face à l'espionnage massif qui a lieu sur l'Internet. La cryptographie fait donc l'objet d'un regain d'intérêt. Et il y a également une reprise du débat critique. Il y a deux semaines, Matthew Green avait écrit « What's the matter with PGP? » où il estimait que ce système devait disparaître (attention, son article contient bien des confusions, notamment entre le logiciel GPG et la norme OpenPGP, et des malhonnêtetés intellectuelles comme de comparer la longueur d'une clé avec celle d'un certificat).
Plus récemment, en France, Okhin à Pas Sage en Seine s'est attaqué aux informaticiens en critiquant vigoureusement « les barbus auto proclamés gourous des internets, cyber hactivistes, hackers, sysadmin et autre » et en annonçant que « Ce qui est cassé ce sont nos égos, nos réactions de sociopathes nihilistes face à un problème politique et social. » Ce thème a ensuite été repris par Barbayellow dans « Sécurité : pourquoi ça ne marche pas » et par Numendil en « Chers nous... » ainsi que par Tris Acatrinei dans « Une histoire de privilèges ».
Je vous laisse lire tous ces articles avant de voir le mien. Je ne vais pas essayer de réfuter la thèse « L'utilisabilité est essentielle pour la sécurité » car elle est exacte. La grande majorité des attaques réussies ne viennent pas d'une brillante réussite technique contre un algorithme de cryptographie, elles viennent d'erreurs commises par les utilisateurs. Mais je voudrais discuter un peu d'autres affirmations, comme de prétendre que la balle est à 100 % dans le camp des informaticiens/hackers/programmeurs, ou comme l'idée selon laquelle la difficulté d'utilisation des logiciels de sécurité est essentiellement due au manque d'intérêt des techniciens pour l'utilisabilité.
Alors, commençons par un problème pratique : clamer qu'il faut améliorer les logiciels, notamment du point de vue de l'ergonomie, c'est bien mais c'est vain. Encore faudrait-il dire en quoi on peut améliorer l'ergonomie existante. J'ai lu attentivement tous les articles cités plus haut et il y a beaucoup plus de temps passé à critiquer les développeurs (orgueilleux, autistes, méprisants, privilégiés) qu'à discuter de solutions concrètes. Il faut dire que le problème n'est pas trivial. Même un informaticien professionnel a du mal à configurer HTTPS sur son serveur Web, ou à utiliser PGP (et, plus encore, à l'utiliser tous les jours sans jamais faire d'erreur). C'est qu'il ne s'agit pas uniquement de compétences : même quand on a les compétences de base, on n'a pas forcément le temps. Donc, si on pouvait rendre ces logiciels plus faciles d'accès, ne nécessitant pas un week-end de travail pour générer une clé PGP conforme aux exigences de la cryptographie moderne, cela profiterait à tout le monde, de M. Michu au gourou informaticien. La question est « comment ? » Certaines améliorations sont assez évidentes (pour PGP, avoir des choix par défaut corrects, au lieu d'obliger les utilisateurs à demander à des experts en cryptographie comment les améliorer). D'autres le sont nettement moins. J'aimerai voir moins d'articles « les informaticiens sont méchants, ils font des logiciels peu utilisables » et plus d'articles « proposition concrète d'amélioration / de nouveau logiciel ». (Je ne suis pas exigeant, je ne demande pas de logiciel fini.) Donc, oui, les logiciels d'aujourd'hui peuvent et doivent être considérablement améliorés. Mais tout le monde en est convaincu ! Ce qu'il faudrait faire désormais, c'est avancer un peu et proposer des améliorations précises, et je n'en ai pas encore vu. Et c'est un problème difficile, loin des Yakafokon. L'article « Why Johnny Can't Encrypt », cité plus haut, explique bien pourquoi le problème des interfaces utilisateur en sécurité est différent des problèmes d'ergonomie habituels. (Il explique également bien pourquoi le manque d'interface graphique est un faux problème : « All this failure is despite the fact that PGP 5.0 is attractive, with basic operations neatly represented by buttons with labels and icons, and pull-down menus for the rest ».)
Comme exemple de difficulté à concevoir une interface utilisateur simple et efficace, prenons le gros problème de la cryptographie, la gestion des clés. Une des difficultés de PGP est qu'il faut récupérer la clé publique de son correspondant (typiquement via un serveur de clés), la valider (c'est l'opération essentielle, sans laquelle il n'y a plus guère de sécurité) et la stocker. Ces opérations compliquées sont difficiles à expliquer et une erreur est vite arrivée (par exemple d'accepter une clé sans l'avoir vraiment vérifiée). OTR fonctionne sur un principe proche : comme OTR, contrairement à PGP, est limité aux communications synchrones, on n'a pas à récupérer la clé de son correspondant, mais il faut toujours la vérifier. Peut-on faire mieux ? Tout dépend de ce qu'on est prêt à abandonner en échange. Dans une discussion sur Twitter, Okhin vantait le modèle de clés de X.509 (utilisé dans TLS et donc dans HTTPS) comme étant plus simple : l'utilisateur n'a aucune vérification à faire. Mais Okhin oublie de dire que le prix à payer est la sous-traitance complète de sa sécurité aux autorités de certification qui valent... ce qu'elles valent. Si on veut protéger sa vie privée, devoir faire confiance à ces entreprises n'est pas l'idée la plus géniale qui soit. Autre solution au problème de la gestion de clés, SSH et son principe TOFU (Trust On First Use). Il est amusant que SSH soit si rarement cité par ceux qui réclament des logiciels de sécurité plus faciles à utiliser. Car SSH est justement une réussite de l'interface utilisateur, puisqu'il est plus simple que ne l'était son concurrent non sécurisé, telnet. Si on veut un exemple de conception réussie, il ne faut pas regarder TLS ou OTR mais certainement plutôt le grand succès qu'est SSH (cf. annexe A.3 du RFC 5218). Mais, là encore, rien n'est parfait. SSH est facile grâce au TOFU : la première fois qu'on se connecte à un nouveau serveur, la clé est vérifiée (en théorie...) et elle est automatiquement mémorisée pour la suite. Ce principe est assez bon (c'est un compromis raisonnable entre utilisabilité et sécurité) mais il a aussi des inconvénients : vulnérabilité lors du premier usage, difficulté à changer les clés par la suite...
Outre la notion de compromis, essentielle en sécurité (mais trop rarement citée dans les articles réclamant des logiciels plus simples), il y a une autre notion essentielle, et souvent oubliée : l'éducation. En général, elle est balayée avec des phrases du genre « il n'y a pas besoin d'être ingénieur pour conduire une voiture ». Mais c'est une illusion : bien sûr qu'il faut apprendre beaucoup de choses pour conduire une voiture. Pas besoin d'être ingénieur, certes, mais n'importe quel conducteur a dû apprendre beaucoup, simplement, comme c'est aujourd'hui un savoir banalisé, il ne s'en rend pas compte (voir à ce sujet l'hilarant texte sur le support de General Motors). Dans une société où de plus en plus de choses dépendent de l'informatique, dire que les outils modernes doivent être accessibles sans aucune éducation, c'est illusoire. Il faut au contraire développer une littératie numérique, qui implique un minimum de choses sur la sécurité. L'apprentissage de cette littératie va nécessiter des efforts des deux côtés. Réclamer des systèmes informatiques qui soient utilisables sans aucune formation, ni effort de la part des utilisateurs, va entretenir des illusions.
Quand Barbayellow écrit « [Le métier des journalistes], ce n'est pas de savoir comment fonctionne un ordinateur, un serveur ou même Internet », il se trompe. Aujourd'hui, où une si grande partie des activités humaines (le journalisme, mais pas uniquement), se passe sur l'Internet, il faut y connaître quelque chose. Dire que les journalistes ne devraient pas connaître l'Internet, c'est comme s'il disait « connaître le droit n'est pas notre métier », alors que tant de métiers aujourd'hui nécessitent forcément une culture juridique minimale. Et dire qu'il n'est pas nécessaire d'apprendre l'Internet en 2014, c'est comme dire en 1450 qu'il n'est pas nécessaire d'apprendre à lire si on n'est pas un professionnel de l'édition...
A translation in english of this article was kindly done by Pete Dushenski (footnotes are not mine).
L'article seul
RFC 7336: Framework for Content Distribution Network Interconnection (CDNI)
Date de publication du RFC : Août 2014
Auteur(s) du RFC : L. Peterson (Akamai
Technologies), B. Davie (VMware), R. van
Brandenburg (TNO)
Pour information
Réalisé dans le cadre du groupe de travail IETF cdni
Première rédaction de cet article le 22 août 2014
Ce RFC est le nouveau cadre technique pour les solutions standard d'interconnexion de CDN. Après le document de description du problème (RFC 6707), une liste de scénarios d'usage (RFC 6770) et un cahier des charges formel (RFC 7337), voici une nouvelle étape du travail du groupe CDNI de l'IETF. Il remplace un ancien travail équivalent, qui n'avait pas débouché, dans le RFC 3466.
Personnellement, je trouve qu'il ne va pas très loin par rapport aux RFC 6707 et RFC 7337. Mais, bon, c'est la description officielle de l'architecture des futurs protocoles d'interconnexion de CDN donc, allons-y.
N'attendez pas de ce RFC des protocoles précis : les spécifications viendront plus tard, ce qui est décrit ici est une architecture de haut niveau, très proche de ce qui avait été écrit dans le RFC 6707. (Par contre, terminologie et architecture du vieil RFC 3466 sont abandonnés.) Le principal ajout est que l'interface de routage des requêtes (Request routing interface) est désormais découpée en deux, une interface de redirection (Request routing indirection Interface) et une interface d'échange d'informations (Footprint & Capabilities Interface). Autrement, je vous renvoie à mon article sur le RFC 6707. Outre la terminologie des RFC 6707 et RFC 7337, quelques concepts nouveaux apparaissent :
- [Rappel] « CDN amont » : celui sollicité par le client qui veut du contenu, mais qui n'a pas le contenu (ou bien, pour une raison ou pour une autre, qui ne peut pas / ne veut pas servir la requête) et doit donc utiliser les mécanismes CDNI pour déléguer ; le RFC écrit aussi uCDN pour upstream CDN,
- [Rappel] « CDN aval » : celui qui a le contenu et va donc servir le client ; le RFC écrit aussi dCDN pour downstream CDN,,
- « Domaine CDN » : le
nom de domaine dans
l'URL qui identifie le CDN. Par exemple, pour
le site Web de l'Élysée, qui utilise le CDN
de Level 3, c'est actuellement
cdn.cdn-tech.com.c.footprint.net. - « Redirection Itérative » : lorsque le CDN amont renvoie simplement au CDN aval, sans essayer de traiter la requête lui-même,
- « Redirection Récursive » : lorsque le CDN amont fait le travail de redirection lui-même, sans que le client qui accédait au contenu en soit même conscient.
La section 3 du RFC est un survol général du fonctionnement de CDN interconnectés. L'opérateur A gère le CDN amont, celui qui a un lien avec le fournisseur de contenu, qui a choisi A pour servir ses ressources. L'opérateur A a un accord avec l'opérateur B, qui gère un possible CDN aval, qui pourra servir des clients intéressés, par exemple sur une base de proximité géographique (mettons que A est en Europe et B aux États-Unis). Avant que le client n'arrive, A et B auront donc échangé des messages (via les interfaces MI et FCI, cf. RFC 7337) pour que B sache quoi servir (interface MI, envoi de métadonnées) et pour que A sache les capacités de B (interface FCI). Lorsque le client final envoie sa requête, elle est d'abord dirigée (par les techniques habituelles des CDN existants) vers A. Via l'interface RI, le client est redirigé vers B (voir plus loin les techniques de redirection). Le client envoie alors ses requêtes à B. Celui-ci doit contacter A pour obtenir le contenu lui-même (cette opération n'utilise pas les protocoles CDNI) et il sert ce contenu au client. Ensuite, il contactera A pour remplir les statistiques de ce dernier (interface LI).
La section 3 détaille ensuite les mécanismes de redirection récursifs et itératifs. La section 2 du RFC avait déjà résumé ces techniques de base utilisées par les CDN pour la redirection des requêtes. Dans le cas le plus simple, un client (par exemple un navigateur Web) va interroger un CDN qui, soit lui répondra, soit le renverra vers le CDN aval. Pour cette redirection, on peut utiliser le DNS ou bien des mécanismes de redirection du protocole applicatif (par exemple, en RTSP, un code de retour 302). D'abord, le DNS. Le principe est d'envoyer des réponses différentes selon le client. Ce dernier est situé en Europe et interroge un CDN amont qui ne sert de contenu qu'en Amérique ? Pas de problème, aux requêtes sur le domaine CDN, on renvoie l'adresse IP d'un CDN aval qui est présent en Europe. Il y a quelques précautions à prendre (se souvenir que les réponses DNS seront gardées en cache et qu'il faut donc choisir intelligemment le TTL, sans compter le fait que certains résolveurs trichent en gardant en cache plus longtemps, prêter attention à DNSSEC si on génère les redirections au vol, cf. section 3.4.1) mais cette méthode est simple et est déjà utilisée par les CDN actuels, non connectés entre eux. L'avantage de la technique DNS est qu'elle est complètement invisible à l'application, qui ne se rend même pas compte qu'elle a été servie par un autre CDN que celui demandé. L'un de ces inconvénients est que le serveur DNS qui fait autorité ne connait pas le client mais son résolveur DNS. Si le client utilise un résolveur DNS public (comme OpenDNS), le client du contenu et le résolveur peuvent être sur des continents différents et la redirection ne se fera pas vers le CDN optimal. Autre inconvénient, on ne pourra tenir compte, dans l'URL original, que du nom de domaine, le reste de l'URL n'étant pas connu du serveur DNS.
À noter qu'il existe une variante, où on ne renvoie pas directement l'adresse IP mais un nom (technique CNAME ou, mieux, DNAME). C'est le cas de l'Élysée citée plus haut :
% dig A www.elysee.fr ... ;; ANSWER SECTION: www.elysee.fr. 3600 IN CNAME cdn.cdn-tech.com.c.footprint.net.
Autre possibilité de redirection, la redirection
HTTP : cette fois, on se sert des codes de
retour 301 ou 302 qui indiquent au client HTTP qu'il doit aller
chercher ailleurs ce qu'il voulait. La nouvelle URL est donnée dans la
réponse (en-tête Location:). Cette fois, le
serveur peut changer tout l'URL, pas juste le nom de domaine, on
connait l'adresse IP du client original (le RFC oublie de mentionner
qu'il peut être un relais), ce qui peut permettre de mieux
choisir le serveur, et enfin on a plein d'autres informations qui
peuvent être utiles pour une redirection intelligente, comme la marque
du logiciel client utilisé.
Il y a par contre des inconvénients, le changement de domaine fait que les cookies ne suivront pas, et les caches ne gardent pas en mémoire les redirections (le RFC 7234 le permet mais ce n'est pas fréquemment mis en œuvre).
La section 4 du RFC donne quelques détails sur les différentes interfaces du système, interfaces qui avaient été présentées dans les RFC 6707 et RFC 7337. Dans certains cas, l'interconnexion des CDN se fait à l'intérieur du protocole de communication déjà utilisé (in-band). C'est le cas des redirections HTTP. Dans d'autres cas, on utilise un protocole externe (out-of-band). Il faut également noter, pour comprendre la complexe combinaison d'interfaces de CDNI que, bien que les interfaces soient largement indépendantes, elles reposent sur des conventions communes, par exemple pour le nommage des ressources.
Parmi les détails creusés dans ce RFC 7336 sur les interfaces :
- Une liste des éléments d'information qui peuvent être
intéressants pour l'interface de journalisation, LI
(Logging Interface). Conceptuellement, cette
interface peut être vue simplement comme une copie des fichiers
apache/access.logdu CDN aval vers l'amont... Attention, le champ indiquant le nom de domaine demandé (VirtualHostdans Apache) peut être différent de l'original, s'il y a eu redirection HTTP. - Certains services de l'interface de communication de métadonnées (MI pour Metadata Interface) peuvent être assurés par le mécanisme de redirection. Par exemple, si le fournisseur de contenu veut limiter l'accès aux utilisateurs européens, il suffit que le CDN amont ne redirige pas vers le CDN américain, pour les requêtes de ce contenu à accès limité. (Le RFC note toutefois que cela manque de souplesse : par exemple, il y a peu de chances que le CDN aval ait une couverture géographique qui coïncide parfaitement avec les exigences de géo-limitation du fournisseur de contenu.)
La section 5 du RFC décrit plusieurs scénarios d'usage de CDNI quand il sera terminé. Par exemple, bien que le modèle de référence (et les exemples que j'ai cités) soient unidirectionnels (le CDN A délègue au CDN B et jamais le contraire), on pourra se servir de CDNI pour les CDN maillés, avec des graphes arbitraires entre les différents CDN.
Déléguer ses fonctions soulève évidemment tout un tas de questions, comme toute sous-traitance. Le CDN amont peut-il faire confiance au CDN aval pour servir le contenu correctement ? Les statistiques de trafic qu'il remonte sont-elles correctes ou bien modifiées dans l'intérêt exclusif du CDN aval ? La section 6 explore le problème de la confiance dans un monde de CDN connectés. Notons que le fournisseur de contenu a déjà aujourd'hui le même problème avec son opérateur CDN : dès qu'on sous-traite, la question de la confiance surgit. Mais CDNI rend les choses un peu plus compliquées : un fournisseur de contenu qui a signé avec l'opérateur de CDN amont peut ne pas être conscient que celui-ci a un accord avec l'opérateur CDN aval. Et si un opérateur CDN modifiait les fichiers avant de les envoyer ? Il existe évidemment des solutions techniques, comme la signature cryptographique des fichiers. Mais, fondamentalement, il faut une combinaison de confiance et de quelques vérifications (par exemple des sondages aléatoires faits par divers clients pour vérifier que le contenu est bien là, et bien conforme à ce qui est demandé).
En parlant de confiance et de sécurité, la section 7
se demande quelles sont les conséquences de l'interconnexion de CDN
pour la vie privée (l'existence d'une section
nommée Privacy considerations est récente dans les
RFC et vient du RFC 6973). Un CDN est bien placé
pour observer beaucoup de choses dans le comportement de
l'utilisateur, par exemple à quels fichiers il accède, de
mécanique_quantique_pour_les_nuls.epub à
how_to_make_bombs.avi. L'utilisateur qui accède à
un site Web ne sait typiquement pas si celui-ci utilise un CDN (cela
se trouve relativement facilement mais tout le monde n'a pas les
compétences ou le temps nécessaire). Il fait confiance au site Web,
mais ne se rend pas compte qu'il fait également confiance à
l'opérateur CDN (qui peut avoir une autre éthique, ou être soumis à
d'autres lois : lorsqu'on visite http://www.elysee.fr/,
on croit faire confiance à un organisme public français, alors qu'il
est en fait servi par un CDN états-unien, soumis au
Patriot Act).
Certaines fonctions de CDNI sont justement conçues pour faire circuler de l'information sur l'activité des utilisateurs, notamment l'interface de journalisation (LI). Il faudra donc s'assurer qu'elles disposent de protections appropriées.
Et, toujours sur la sécurité, la section 8 note également d'autres points délicats, qui s'ajoute aux questions de sécurité déjà existantes pour les CDN actuels :
- Certaines exigences des fournisseurs de contenu (distribution limitée géorgraphiquement, ou bien limitée dans le temps) sont plus difficiles à satisfaire lorsqu'il y a interconnexion des CDN,
- Par contre, les menottes numériques ne sont pas affectées par CDNI puisqu'elles reposent typiquement sur des mécanismes présents dans le contenu lui-même,
- Les interfaces entre CDN doivent être protégées, contre l'écoute (cas des journaux d'activité dans la section précédente) mais aussi contre les modifications non autorisées (imaginez qu'un méchant modifie les contenus servis lorsqu'ils passent d'un CDN amont au CDN aval), même si l'interconnexion se fait en utilisant l'Internet public, non sécurisé.
Deux fournisseurs de solutions techniques, Cisco et Alcatel-Lucent, ont annoncé qu'ils travaillaient sur des prototypes d'interconnexion de CDN, utilisant le futur protocole qui sera la concrétisation de ce cadre.
L'article seul
RFC 7305: Report from the IAB Workshop on Internet Technology Adoption and Transition (ITAT)
Date de publication du RFC : Juillet 2014
Auteur(s) du RFC : E. Lear
Pour information
Première rédaction de cet article le 19 août 2014
En décembre 2013, à Cambridge, l'IAB a tenu un atelier sur l'adoption des nouvelles technologies dans l'Internet. Qu'est-ce qui fait que telle technologie réussit dans le monde réel et que telle autre reste éternellement sur le papier ? Sérieuse question pour l'IETF, qui a a normalisé aussi bien des succès fous que des échecs plus ou moins complets. (Par exemple, le déploiement de la grande œuvre de l'IETF, IPv6, est extrêmement lent.)
Ce RFC résume les contributions à l'atelier. Comme on s'en doute, il n'y a eu aucun consensus, à part sur l'importance d'étudier l'angle de l'économie, et sur la référence à Bitcoin, grande vedette de l'atelier et source de nombreux exemples. Attention, donc, ce RFC n'est pas une prise de position de l'IAB, mais le compte-rendu d'un colloque pluraliste, aussi bien dans ses participants que dans les opinions exprimées. (Le rôle de l'IAB n'est pas de faire des protocoles - c'est la tâche de l'IETF, sous la direction de l'IESG - mais de réfléchir sur le long terme et sur les questions les plus fondamentales.)
On représente souvent l'écosystème de l'Internet sous forme d'un sablier : le protocole standard d'interconnexion est forcément unique et occupe donc la « taille », le tuyau fin du sablier. Au contraire, les protocoles d'application, beaucoup plus nombreux, occupent le bulbe du haut, et les protocoles « physiques », pour lesquels il y a également un grand choix, sont le bulbe du bas. Dans la vision traditionnelle de l'Internet, la taille était IP.
Dans la biologie, c'est l'ATP qui joue ce rôle central, la brique de base sur laquelle tout le reste est bâti (papier de Meyer).
Aujourd'hui, en raison de l'ossification de l'Internet et de la prévalence de stupides middleboxes qui bloquent tout, la taille (ou faut-il l'appeler le cou ?) du sablier est plutôt HTTP... Il devient de plus en plus difficile pour un protocole de s'imposer, surtout s'il ne tourne pas sur HTTP. En prime, le poids de l'existant est bien plus important qu'aux débuts de l'Internet. Aujourd'hui, un nouveau protocole doit lutter contre des concurrents bien installés.
La section 2 de notre RFC résume les motivations de ce travail, et les travaux équivalents déjà réalisés. On constate souvent que des protocoles, développés soigneusement par l'IETF, ont peu ou pas de succès dans le monde réel et, quand ils se répandent, c'est à un rythme bien trop lent. Trois exemples sont cités par le RFC, IPv6 (RFC 2460), SCTP (RFC 4960) et DNSSEC (RFC 4034). Ce retard peut à son tour retarder d'autres déploiements. Ainsi, DNSSEC est indispensable à DANE (RFC 6698) et le déploiement trop lent de DNSSEC, goulet d'étranglement, affecte donc DANE. Par contre, si les protocoles nouveaux ont du mal, les protocoles existants continuent à évoluer (le RFC cite SMTP et IMAP, qui peuvent être vus comme des réfutations de la théorie comme quoi « HTTP est le nouvel IP, la taille du sablier »).
Un excellent RFC avait déjà étudié les causes du succès ou de l'échec des protocoles, le RFC 5218. Une conséquence de ce RFC 5218 est l'importance plus grande désormais donnée aux facteurs de réussite. Faire un bon protocole ne suffit plus. Les groupes de travail de l'IETF doivent désormais aussi réfléchir à la valeur ajoutée de leurs propositions : le nouveau protocole apporte-t-il suffisamment pour surmonter les barrières situées devant l'adoption ?
Ces barrières étant largement financières, il n'est pas étonnant que plusieurs des papiers présentés à l'atelier portaient sur l'économie (section 3). Le RFC en résume quelques uns. D'abord, la théorie de Weber, S., Guerin, R., et J. Oliveira, sur le couplage. Peut-on augmenter les chances de succès d'un protocole en le livrant avec d'autres ? Ou, au contraire, le couplage va-t-il ralentir le succès ? Comme cité précédemment, DANE dépend de DNSSEC. Cela simplifie son développement, permettant de s'appuyer sur les propriétés de sécurité de DNSSEC. Mais, du point de vue économique, cela fait dépendre DANE du succès de DNSSEC. Le couplage peut aider quand une technologie à succès en tire une autre, et ralentir si une technologie dépend d'une autre.
Autre exemple, très discuté à l'atelier (et c'est une nouveauté à l'IETF, puisque ce système a été développé en dehors de celle-ci), le succès de Bitcoin. Dans son papier, R. Boehme suggère que les protocoles Internet s'inspirent de Bitcoin, exemple de grand succès (section 3.2 de notre RFC). Bitcoin n'a pas eu la partie facile : des médias hostiles (parfois au point de la propagande, comme dans le mensonge souvent répété comme quoi Bitcoin était une pyramide de Ponzi), des incertitudes juridiques (est-ce bien légal ?), des failles techniques (immédiatement exploitées par des voleurs), plusieurs tentatives de « monnaies Internet » avaient déjà été des échecs, des attaques par des spéculateurs visant le gain à court terme, même au prix de l'existence même du système. Mais Bitcoin a survécu à ces campagnes de presse et à ces problèmes techniques et de sécurité. Selon l'auteur, les raisons principales sont :
- Un mécanisme de récompense des premiers qui adoptent le système. Au début de Bitcoin, miner (créer de nouveaux bitcoins) est relativement facile et cela se durcit par la suite. Les plus difficiles à convaincre, les premiers adoptants, sont donc récompensés davantage, ce qui est logique et efficace. (J'ajoute personnellement que c'est juste : il est normal que ceux qui ont pris des risques au début reçoivent plus que ceux qui attendaient passivement.)
- Bitcoin ne vit pas dans son coin, isolé. Dès le début, des mécanismes de conversion ont été mis en place de et vers les monnaies d'État. Ainsi, adopter Bitcoin ne signifiait pas s'enfermer dans un monde à part. Un autre exemple, cité par le RFC, est le succès du courrier électronique : dès le début, le courrier Internet a eu des passerelles de et vers les autres systèmes de courrier. Autrement, il n'aurait pas été choisi.
- Les bitcoins ont une valeur pour leurs possesseurs, ce n'est pas juste pour le bien de l'humanité qu'on demande aux utilisateurs d'adopter la nouvelle technologie : ils y trouvent un intérêt. (Une remarque personnelle : les discussions à l'atelier supposaient acquis un point de vue égoïste, où les gens n'agissent qu'en fonction d'un intérêt personnel à court terme. Le problème serait très différent si on se plaçait dans une perspective plus volontariste, où on considère que les humains peuvent changer leur mentalité.)
Bref, Bitcoin fournit des motivations à ses adopteurs. (Un problème bien connu des militants pro-IPv6 : lorsqu'on suggère aux gens de migrer vers IPv6, la question est souvent « qu'est-ce que ça m'apporte, à moi ? », et elle n'a guère de réponse.)
Troisième étude de cas, le déploiement de
DNSSEC (section 3.3) via le récit de A. Eklund
Lowinder et P. Wallstrom sur le déploiement de cette technique en
Suède, à commencer par le
TLD
.se. Le travail d'IIS pour encourager DNSSEC a pris la
forme d'une contribution au financement
d'OpenDNSSEC (pour abaisser les barrières
techniques), et d'incitations financières (auprès des bureaux d'enregistrement).
Une des conclusions de cette partie de l'atelier était qu'il faut éviter d'accrocher une technologie exclusivement à une autre. Le logiciel privateur Skype a été cité comme exemple : il teste plusieurs transports disponibles et choisit celui qui marche. De même, lier une application à SCTP serait probablement une erreur : si SCTP ne réussit pas à se répandre, cette application serait fichue). Il faudrait plutôt essayer plusieurs transports et garder le premier qui marche, un peu comme le fait l'algorithme des globes oculaires heureux dans le RFC 6555.
Et puisqu'on parlait d'économie, il y a eu évidemment des discussions sur le modèles de prix, comme suite au papier de S. Sen. Par exemple, certains protocoles pourraient bénéficier d'un prix dépendant de l'heure (pour encourager le trafic à se déplacer vers les heures creuses).
Ah, une question qui est dans la section 5 mais qui aurait eu sa place dans celle sur l'économie : celle des brevets. Leurs effets néfastes sont bien connus. Le papier de E. Lear et D. Mohlenhoff décrit leurs relations avec la normalisation. Le plus gros problème identifié est celui des « brevets sous-marins », brevets que l'IETF ne connait pas... jusqu'au moment où il est trop tard.
Mais l'économie ne peut pas tout résoudre. Les choix se font aussi, mais si ce n'est pas la seule motivation, sur la qualité technique. De ce point de vue-là, pour qu'un protocole réussisse, il faut aussi faire en sorte qu'il soit le « meilleur » possible. Par exemple, est-ce que le processus de normalisation de l'Internet est suffisamment bien connecté au monde de la recherche, où s'élaborent les idées du futur ? Normalement, l'IETF ne normalise que des technologies bien maîtrisées. L'interaction avec la recherche se fait via l'IRTF.
Les chercheurs suggèrent parfois que l'architecture actuelle de l'Internet n'est plus adaptée aux défis futurs, et qu'il faudrait la changer, par exemple dans la direction du Lowest Common Denominator Networking, idée qui a apparemment été mal reçue à l'atelier.
Un atelier n'est pas complet sans une rubrique « Divers » (section 6) et deux autres points ont donc été abordés. D'abord, la résilience de l'Internet, et notamment la sécurité du routage. Le papier d'A. Robachevsky l'abordait en partant de l'éculée référence à la tragédie des terres communales. L'Internet est composé d'un grand nombre de réseaux distincts, sans administration centrale (ce qui est une bonne chose). La tentation peut donc être forte de se servir des communs (comme la table de routage globale) sans souci de leur pérennité, sans gestion collective.
Et un deuxième point « Divers » concernait TLS. TLS est très largement adopté et ne souffre pas, a priori, du syndrome du protocole qu'on n'arrive pas à déployer. Mais la très grande majorité des clients et serveurs existants utilisent des vieilles versions du protocole TLS, ayant des vulnérabilités connues (comme Beast). La version la plus récente de TLS, la 1.2, est normalisée dans le RFC 5246. Comment faire en sorte qu'elle soit déployée partout ? Et le problème ne concerne pas que le protocole lui-même mais aussi les algorithmes de cryptographie utilisés. (Au cours de l'atelier, il a été noté qu'une grande partie du trafic est toujours chiffrée avec Triple DES, algorithme aux faiblesses connues.)
Maintenant, les actions (section 7). La conclusion de ce RFC reconnait l'importance de regarder le succès des systèmes comme Bitcoin, mentionné pour la première fois dans un RFC, et un exemple pour tout nouveau système. Autrement, l'idée la plus intéressante me semble être celle de pousser la collaboration avec le monde académique, par exemple en enrôlant des étudiants pour relire et critiquer les documents IETF. Cela fournirait à ces étudiants une excellente occasion d'apprendre, et à l'IETF plein de regards neufs.
L'article seul
RFC 7337: Content Distribution Network Interconnection (CDNI) Requirements
Date de publication du RFC : Août 2014
Auteur(s) du RFC : K. Leung (Cisco), Y. Lee (Comcast)
Pour information
Réalisé dans le cadre du groupe de travail IETF cdni
Première rédaction de cet article le 18 août 2014
Le projet IETF CDNI (Content Delivery Network Interconnection) vise à permettre l'interconnexion de CDN, ces réseaux de serveurs répartis dans le monde qui servent à amortir la charge des serveurs Internet les plus populaires. CDNI a été expliqué dans le RFC 6707 et trois études de cas ont fait l'objet du RFC 6770. Ce troisième RFC du projet décrit les exigences formelles, le cahier des charges du projet. (Le cadre général de la solution technique adoptée est dans le RFC 7336.)
Le projet est important car, aujourd'hui, les CDN ne coopèrent pas, en partie en raison du manque d'interfaces standards. Si un CDN très présent en Amérique veut s'associer avec un autre CDN fort en Europe, à la grande joie de leurs clients respectifs, qui auront ainsi un meilleur service dans les deux cas, ils doivent développer un système ad hoc. Le but de CDNI est de développer cette interface standard (RFC 7336), de manière à ce que plusieurs CDN puissent coopérer et apparaître à l'utilisateur comme un seul service. Dans le futur, une fois le projet complété, le CDN d'origine (« CDN amont ») pourra faire en sorte que le CDN qui l'aide (« CDN aval ») ait accès au même contenu et puisse le servir lui-même aux clients.
Les exigences listées par ce cahier des charges sont classées par priorité : « haute » signifie que cette exigence est impérative, même si elle est compliquée à réaliser, « moyenne » que l'exigence est importante, qu'elle doit être satisfaite sauf si, par sa complexité, elle entraîne un retard dans le projet et, enfin, « basse » est utilisé pour les exigences certes utiles mais pas nécessaires au projet.
Les exigences sont rangées selon l'interface à laquelle elles s'appliquent. Une interface (RFC 7336) est un ensemble de fonctions du CDN, qu'on peut appeler en utilisant des mécanismes normalisés, et qui correspondent à un ensemble de services proches. Par exemple, LI (Logging Interface) regroupe les services de journalisation, permettant à un CDN amont d'avoir des informations sur l'activité d'un CDN aval associé.
Je ne vais pas ici recopier les nombreuses exigences, me focalisant sur celles de niveau élevé, donc impératives à satisfaire.
D'abord, en section 3, les exigences générales, indépendantes de l'interface. La solution ne doit évidemment pas nécessiter de changer les clients (exigence GEN-2), par exemple les navigateurs Web. Elle ne doit pas nécessiter que le fournisseur de contenu change son système de publication (GEN-3) : si celui-ci permet de publier dans un CDN, il doit permettre de profiter de l'interconnexion. Elle doit être assez abstraite pour que chaque CDN soit une « boîte noire » pour les autres, sans avoir besoin de publier de l'information interne. Elle doit marcher au moins lorsque la délivrance au client est faite en HTTP (exigence GEN-5, il existe d'autres protocoles - voir GEN-7 - mais moins cruciaux), et elle doit éviter de créer des boucles entre CDN et elle doit fonctionner même quand les références à une tierce partie sont cassées (exigence GEN-12), par exemple à cause du NAT ou du split DNS.
Suivent en section 4 les exigences pour la CI. CI (Control Interface) est l'interface qui contrôle les autres interfaces, par exemple pour les opérations de démarrage (ce sera là qu'on indiquera le serveur de statistiques auquel il faudra indiquer l'ampleur du trafic, par exemple). Elle doit permettre au CDN amont de demander le nettoyage (la destruction de contenu, exigence CI-1), et elle doit fournir un mécanisme de rétroaction par lequel le CDN aval informe le CDN amont de ce qu'il a fait (CI-4).
En section 5, la RI (Request routing indirection Interface) est l'interface vers le système de routage des requêtes. Elle doit fonctionner rapidement quelle que soit la taille du contenu (exigence RI-1) ce qui veut dire qu'il faut un mécanisme de redirection ultra-léger pour les objets de petite taille (ceux où le temps de redirection risque de dépasser le temps de transfert des données), et qu'il faut pouvoir choisir le compromis entre fraîcheur des données et rapidité. Pour les gros objets (exigence RI-2) où le temps de transfert sera long, il faut bien choisir le CDN d'où il sera servi et il faut donc que la solution permette un choix précis, lié aux caractéristiques de la requête. Autrement dit, un mode où on passe du temps à sélectionner la source des données, pour que le transfert aille ensuite plus vite.
Il faut aussi que cette redirection puisse être récursive (exigence RI-3), c'est-à-dire que la cible d'une redirection va elle-même suivre les éventuelles nouvelles redirections, et itérative (RI-4), c'est-à-dire que l'initiateur suive lui même les redirections multiples. Cela implique que le CDN aval reçoive du CDN amont toutes les informations nécessaires (exigence RI-8), comme l'origine géographique de la requête, les en-têtes HTTP, etc, et à l'inverse que le CDN aval transmette la réponse complète dans le cas d'une redirection (l'URI complet en HTTP, exigence RI-10).
En section 6, la FCI (Footprint & Capabilities Interface). Elle permet l'échange d'informations entre CDN, de manière à permettre le routage des requêtes (leur transmission au CDN le plus approprié) par l'interface RI. Si on compare RRI (Request Routing Interface, une méta-interface qui regroupe FCI et RI) à IP, FCI est l'équivalent des protocoles d'échange de routes comme OSPF et RI est l'équivalent du lookup dans une table de routage.
La FCI doit au minimum permettre de communiquer au CDN amont que le CDN aval est prêt (exigence FCI-1). Idéalement (mais ces exigences sont seulement au niveau moyen, donc pas indispensables), il faudrait aussi qu'il puisse communiquer des méta-informations comme les formats et protocoles qu'il gère, son extension géographique, les protocoles de redirection, les capacités de journalisation, etc.
En section 7, l'interface MI (Metadata Interface), qui permet l'échange de métadonnées sur les contenus servis, comme les restrictions géographiques, les durées de vie des contenus, les limitations d'accès (par exemple, aux abonnés)... Pour cette interface, l'exigence de base (MI-1) est de permettre l'envoi d'informations depuis le CDN amont. Parmi ces informations, il y a évidemment l'endroit d'où le CDN aval doit tirer le contenu (exigences MI-5 et MI-6). Il faut pouvoir ajouter des métadonnées dans le CDN aval (exigence MI-7) et en retirer (MI-8). La granularité de ces métadonnées doit être au niveau d'un objet (MI-9) mais il faut aussi pouvoir regrouper les objets, de manière à gérer ces métadonnées plus facilement (MI-10), avec un système d'héritage entre les groupes d'objets (MI-11).
L'industrie du contenu étant ce qu'elle est, il n'est pas étonnant qu'une longue exigence MI-13 décrive toutes les conditions d'accès au contenu, filtrage selon les pays, selon les adresses IP, dans le temps, etc.
Enfin, en section 8, la LI (Logging Interface), qui permet de transmettre les informations sur l'activité du CDN, de manière à avoir des journaux d'activité. Le transports desinformations de journalisation doit être fiable (exigence LI-1, pas question de se contenter de syslog sur UDP), doit être exhaustif (le CDN amont veut connaître tous les téléchargements faits à partir du CDN aval, exigence LI-2), le transferts des journaux doit pouvoir se faire en batch (LI-4), et utiliser un format standard (LI-6) et un transport standard (LI-7).
Il n'y a plus qu'à normaliser la sécurité (section 9). Bien sûr, la première exigence, SEC-1, est que toutes les opérations entre CDN soient sécurisables, même quand elles s'effectuent au-dessus de l'Internet normal, non sécurisé. Il faut donc pouvoir fournir authentification, intégrité, et confidentialité. Mais il faut aussi se défendre contre les attaques par déni de service, dont les CDN sont souvent victimes (SEC-2).
L'article seul
RFC 7328: Writing I-Ds and RFCs using Pandoc and a bit of XML
Date de publication du RFC : Août 2014
Auteur(s) du RFC : R. Gieben (Google)
Pour information
Première rédaction de cet article le 13 août 2014
Vous voulez écrire un RFC ? Il faut commencer par faire un Internet-Draft (I-D) et il existe pour cela deux formats, en XML ou bien en Word. Ce RFC présente une troisième solution, utilisant Markdown, ou plutôt sa variante définie par Pandoc.
Le format d'écriture de RFC le plus répandu est sans doute XML, tel que décrit dans le RFC 7749. Le format Word est dans le RFC 5385. (Il existe aussi le format historique, utilisant nroff mais je ne suis pas sûr qu'il soit encore accepté aujourd'hui.) Certaines personnes trouvent que les tags XML les distraient pendant qu'ils écrivent leur Internet-Draft (I-D) et ils préfèrent donc utiliser un autre format « texte », avec les marquages de Markdown, jugés moins intrusifs. Markdown est très populaire et est utilisé à plein d'endroits différents (par exemple, dans les formulaires du système de suivi de bogues de GitHub). Markdown a plein de dialectes et de variantes et celle utilisée ici est celle du logiciel Pandoc, un sur-ensemble de Markdown. (Par abus de langage, j'écris ensuite « Pandoc » pour désigner ce format.)
(Au passage, vous pouvez regarder la page officielle de Markdown et celle de Pandoc.)
Le document en Pandoc peut ensuite être traduit dans d'autres formats, HTML, EPUB, DocBook, etc, d'où on peut ensuite tirer le futur RFC dans un format de publication officiel (comme le texte seul). L'outil Pandoc2rfc convertit le Pandoc en Docbook, qui est ensuite traduit en XML-RFC7749, puis ensuite dans les différents formats de publication souhaités (on passe donc d'un texte quasi-brut avec instructions de formatage, à XML, pour revenir à du texte brut...) Dans le futur, peut-être existera-t-il un chemin plus rapide, allant directement du Pandoc au RFC final. En attendant, ce chemin impose quelques contraintes, notamment qu'on ne peut pas complètement éviter d'éditer du XML. L'auteur doit éditer quatre documents :
- Un document Markdown
abstract.mkdcontenant le résumé, - Un document Markdown
middle.mkdcontenant le gros du RFC, - Un document Markdown facultatif
back.mkdcontenant les annexes, - Un document XML
template.xmlcontenant auteurs et références bibliographiques.
Un exemple du gabarit template.xml figure dans la
section 2 de notre RFC.
Pour installer l'outil Pandoc2rfc, vous allez avoir besoin du processeur XSLT xsltproc (la transformation du Docbook en XML-RFC7749 est faite avec XSLT) et bien sûr de Pandoc lui-même.
Pandoc2rfc contient un script shell qui fait les transformations nécessaires (voir la section 3 du RFC).
Pour apprendre la syntaxe de Pandoc, il faut regarder le
guide. Pandoc2rfc traduit via xml2rfc (l'outil du RFC 7749) et met en correspondance les concepts
Markdown avec ceux de XML-RFC7749. Par exemple, une énumération avec
* va être traduite en une liste
(<list> XML)
style="symbols" et une énumération avec des
numéros (comme "1.", "2.", etc) va être traduite en
style="numbers" (RFC 7749,
section 2.22.3). La section 4 de notre RFC donne
une liste complète des équivalences Pandoc<->XML, résumées sous
forme d'un tableau dans l'annexe B.
Il est d'ailleurs difficile de faire du Pandoc2rfc sans connaître
xml2rfc. Par exemple, pour afficher une table des matières, il faut
inclure l'invocation xml2rfc <?rfc toc="yes"?>.
La section 5 liste quelques limitations de Pandoc2rfc par rapport à Pandoc : pas de gestion des index, les commentaires doivent être faits avec des commentaires HTML dans le source Pandoc, les citations se font avec les références XML, le système de citation de Pandoc n'est pas utilisé, et enfin les auteurs doivent se résigner à voir apparaître des erreurs de xml2rfc, la traduction Pandoc vers Docbook ne gère pas toutes les erreurs possibles. De mon expérience, il faut pas mal bricoler pour faire marcher le tout. Écrire des RFC en Markdown est sympa mais on n'y arrive pas en cinq minutes.
Si vous voulez un exemple concret, la distribution de
Pandoc2rfc contient un répertoire test/
avec un exemple de RFC bidon utilisant toutes les fonctions de
Pandoc2rfc. J'ai un peu modifié le Makefile pour
faire des versions texte, XML et HTML du RFC :
% make all pandoc2rfc -t template.xml back.mkd middle.mkd pandoc2rfc -H -t template.xml back.mkd middle.mkd pandoc2rfc -X -t template.xml back.mkd middle.mkd
Et cela produit les trois versions, à partir du source Markdown
(essentiellement en middle.mkd) et du gabarit template.xml.
L'article seul
RFC 7194: Default Port for IRC via TLS/SSL
Date de publication du RFC : Août 2014
Auteur(s) du RFC : Richard Hartmann
Pour information
Première rédaction de cet article le 8 août 2014
Le protocole de messagerie instantanée IRC est toujours très utilisé, malgré la concurrence de XMPP. Il n'existait pas de port « officiel » pour les connexions IRC sécurisées par TLS, ce qui est fait avec ce RFC, qui décrit l'usage, déjà très répandu, du port 6697.
IRC est officiellement standardisé dans les RFC 1459, RFC 2810, RFC 2811, RFC 2812 et RFC 2813 mais il ne faut pas s'y fier : la pratique réelle est loin de ces RFC, qu'il faut plutôt utiliser comme point de départ d'une description du protocole que comme une « Bible » définitive. IRC avait depuis longtemps deux ports standards, 194 pour le trafic en clair et 994 pour le trafic chiffré avec TLS. Ces deux ports sont inférieurs à 1 024 et nécessitent donc que le serveur soit lancé par root sur une machine Unix. Comme ce n'est pas toujours possible, ou souhaitable, en pratique, les serveurs IRC écoutent en général sur 6667 en clair et 6697 en chiffré. Le port 6667 a été documenté pour cet usage mais ce n'était pas encore le cas du 6697. Les clients IRC n'avaient donc pas de moyen standard fiable de découvrir si un serveur gérait les connexions IRC sur TLS.
La section 2 du RFC décrit le fonctionnement d'IRC sur TLS : le client se connecte à un serveur IRC. Une fois la connexion établie, la négociation TLS a lieu. Le serveur est censé présenter un certificat d'une autorité reconnue, dont le nom est le nom du serveur. Le client peut s'authentifier, aussi comme décrit dans la documentation d'OFTC . Une fois la négociation terminée avec succès, les identités vérifiées et tout, le trafic passe alors par cette connexion protégée.
Le nouveau numéro est désormais dans le registre IANA :
ircs-u 6697 tcp Internet Relay Chat via TLS/SSL 2014-02-11
À noter que ce mécanisme ne protège que la liaison client<->serveur. IRC a aussi des communications serveur<->serveur (coordination non standardisée entre les différentes machines qui mettent en œuvre un service IRC) qui ne sont pas traitées ici, même si le RFC recommande aux opérateurs IRC de systématiquement chiffrer le trafic entre machines d'un même service. À noter aussi qu'IRC ne fait pas de liaison directe en pair à pair. Quand Alice et Bob se parlent en IRC, cela passe toujours par un serveur et, même si TLS sécurise la connexion avec le serveur, cela ne protège pas Alice et Bob d'un espionnage par le serveur (par exemple si celui-ci participe au programme PRISM), comme le rappelle la section 3 du RFC. Le chiffrement qui n'est pas de bout en bout a des pouvoirs de protection limités ! Seul OTR fournirait une protection de bout en bout (mais nécessite un peu plus d'action de la part d'Alice et Bob alors que TLS est largement invisible).
L'annexe A du RFC rappelle qu'en 2010, une étude avait montré que dix des vingt principaux services IRC géraient TLS.
La plupart des grands serveurs IRC aujourd'hui gèrent TLS. Parmi
les exceptions, j'ai trouvé ircnet.nerim.fr mais
aussi le serveur IRC du W3C qui n'est hélas
accessible en TLS que par les membres du W3C. Avec un serveur qui gère
TLS, et avec Pidgin comme client, il faut
cocher la case Use SSL
[sic] mais aussi changer manuellement le port, pour 6697 :
On verra alors des connexions TLS :
(09:00:20) gandalf.geeknode.org: (notice) *** You are connected to gandalf.geeknode.org with TLSv1-AES256-SHA-256bits
À noter que Geeknode est signé par CAcert comme beaucoup de serveurs IRC. Freenode, par contre, est signé par Gandi :
% openssl s_client -connect chat.freenode.net:6697 CONNECTED(00000003) depth=1 C = FR, O = GANDI SAS, CN = Gandi Standard SSL CA verify error:num=20:unable to get local issuer certificate verify return:0 --- Certificate chain 0 s:/OU=Domain Control Validated/OU=Gandi Standard Wildcard SSL/CN=*.freenode.net i:/C=FR/O=GANDI SAS/CN=Gandi Standard SSL CA 1 s:/C=FR/O=GANDI SAS/CN=Gandi Standard SSL CA i:/C=US/ST=UT/L=Salt Lake City/O=The USERTRUST Network/OU=http://www.usertrust.com/CN=UTN-USERFirst-Hardware --- ...
L'article seul
delv, le futur outil principal de débogage de DNSSEC ?
Première rédaction de cet article le 26 juillet 2014
La version 9.10 de BIND vient avec un nouvel outil de débogage en ligne de commande, delv. Qu'apporte-t-il par rapport à dig ? C'est surtout pour ce qui concerne DNSSEC qu'il est utile.
L'outil de base de celui qui débogue un problème
DNS, l'équivalent de ce que sont
ping et traceroute pour
l'ingénieur réseaux, c'est dig. Cet outil
permet de récupérer des données DNS et de les afficher. Avec le DNS
traditionnel, on n'avait pas besoin de plus. Mais avec
DNSSEC, un problème supplémentaire survient :
les données obtenues sont-elles vérifiées cryptographiquement ? dig avait bien
une option +sigchase pour tester cela mais, très
boguée, elle est restée peu connue. On n'avait donc pas d'outil
simple, en ligne de commande, pour valider du DNSSEC. On a bien sûr
drill (livré avec ldns)
mais son option -S est très bavarde.
Depuis la version 9.10 de BIND, est apparue avec ce logiciel un nouvel outil, nommé delv. delv permet de faire la même chose que dig (en moins bavard par défaut) :
% delv www.ssi.gouv.fr ; unsigned answer www.ssi.gouv.fr. 21600 IN A 86.65.182.120 % delv -t mx laposte.net ; unsigned answer laposte.net. 600 IN MX 10 smtp4.laposte.net.
Mais c'est surtout lorsque le domaine est signé que delv est utile. (Autrement, comme vous l'avez vu plus haut, il affiche un triste unsigned answer.) Testons avec un nom correctement signé :
% delv www.bortzmeyer.org ; fully validated www.bortzmeyer.org. 52712 IN A 204.62.14.153 www.bortzmeyer.org. 52712 IN RRSIG A 8 3 86400 20140813162126 20140724102037 37573 bortzmeyer.org. ZU9fgjc34O2xfBoN1crbGpMsw8Ov56Jex/6yuSHiAEUFSYTK1H4kBrcK H6MIoeUPrA6/4gmtPTBrc6+KWv765ioWgvHiGPPa8v85T2w0zLsX24NT 4Zz0XVsfybu1re/Nr6V//BOnVF3cZ2hFvdI1Yp9EiKLnRFfPrYX316Hx aJI=
Cette fois, il a procédé à une validation DNSSEC de la réponse (correcte, dans ce cas, fully validated).
Vous allez le dire « mais il suffit d'utiliser un résolveur DNS validant et on sait, via le bit AD (Authentic Data) que les données sont correctement signées ». Mais delv donne des informations supplémentaires. Par exemple, si le domaine est signé mais pointe vers un domaine non-signé :
% delv www.paypal.co.uk ; fully validated www.paypal.co.uk. 3600 IN CNAME www.intl-paypal.com.edgekey.net. www.paypal.co.uk. 3600 IN RRSIG CNAME 5 4 3600 20140816050243 20140717044122 22776 paypal.co.uk. TU8EubeTmR0NCU+bLlhWPTJL91fUkoExM/86ZIL6qr1kJU7g69lqRzLJ N33TzZdIOgj7g1O4eEyUUgBKxe8GpH5dLisXlHhi64aluT4DkL3PwqDi W9enJobC660aPSp0vebasOnJlCZ2rRwKKqmWUiRfXhhkKmu1U1l4IOMV wmY= ; unsigned answer www.intl-paypal.com.edgekey.net. 120 IN CNAME e493.a.akamaiedge.net. e493.a.akamaiedge.net. 20 IN A 23.58.178.37
Dans ce cas (aucun CDN ne gère aujourd'hui DNSSEC, hélas), delv indique bien quelle partie de la réponse est signée et laquelle ne l'est pas.
Et en cas de problème ? Si on teste avec des domaines délibérement cassés :
% delv -t mx servfail.nl ;; resolution failed: failure
Eh oui, on utilise un résolveur validant, il ne nous donne donc pas
les données liées à ce domaine. Il faut donc (paradoxalement !)
utiliser un résolveur non-validant ou bien, tout simplement, ajouter
l'option +cd, Checking
Disabled, à delv :
% delv +cd -t mx servfail.nl ;; validating servfail.nl/DNSKEY: verify failed due to bad signature (keyid=25594): RRSIG has expired ;; validating servfail.nl/DNSKEY: no valid signature found (DS) ;; no valid RRSIG resolving 'servfail.nl/DNSKEY/IN': 127.0.0.1#53 ;; validating R6K26LDO0GS7N66JPQALLM0JIDU6PHML.servfail.nl/NSEC3: bad cache hit (servfail.nl/DNSKEY) ;; broken trust chain resolving 'servfail.nl/MX/IN': 127.0.0.1#53 ;; resolution failed: broken trust chain
Voilà, on connait désormais la raison du problème, l'enregistrement
DNSKEY de servfail.nl a une
signature expirée. Avec un autre domaine, comportant une autre
erreur (une signature délibérement modifiée) :
% delv +cd -t mx dnssec-failed.org ;; validating dnssec-failed.org/DNSKEY: no valid signature found (DS) ;; no valid RRSIG resolving 'dnssec-failed.org/DNSKEY/IN': 127.0.0.1#53 ;; validating dnssec-failed.org/NSEC: bad cache hit (dnssec-failed.org/DNSKEY) ;; broken trust chain resolving 'dnssec-failed.org/MX/IN': 127.0.0.1#53 ;; resolution failed: broken trust chain
Et, ici, avec une date de signature dans le futur :
% delv +cd -t aaaa futuredate-aaaa.test.dnssec-tools.org ;; validating futuredate-aaaa.test.dnssec-tools.org/AAAA: verify failed due to bad signature (keyid=19442): RRSIG validity period has not begun ;; validating futuredate-aaaa.test.dnssec-tools.org/AAAA: no valid signature found ;; RRSIG validity period has not begun resolving 'futuredate-aaaa.test.dnssec-tools.org/AAAA/IN': 127.0.0.1#53 ;; resolution failed: RRSIG validity period has not begun
Comme vous avez vu, delv est parfait pour du premier débogage, donc, quitte à utiliser des outils plus complexes par la suite. Au fur et à mesure que les versions récentes de BIND se diffuseront, et que DNSSEC sera plus courant, dig sera sans doute souvent remplacé par delv.
Voir aussi l'article « Debugging dnssec with delv ».
L'article seul
RFC 7301: Transport Layer Security (TLS) Application-Layer Protocol Negotiation Extension
Date de publication du RFC : Juillet 2014
Auteur(s) du RFC : S. Friedl (Cisco Systems), A. Popov
(Microsoft), A. Langley
(Google), E. Stephan (Orange)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 24 juillet 2014
On le sait, désormais, tout l'Internet tourne sur le port 443 (et aussi sur 80 mais de moins en moins, en raison des révélations de Snowden). C'est en effet l'un des rares ports dont on peut être sûr qu'il est à peu près tout le temps ouvert, même sur les réseaux les plus affreux genre hôtel ou aéroport. En prime, les communications sur ce port sont chiffrées avec TLS (RFC 5246). Si seul HTTP se servait de ce port, cela marcherait mais de plus en plus de protocoles applicatifs se bousculent pour l'utiliser. Comment leur permettre de partager le port 443 sans émeutes ? En ajoutant une extension à TLS qui permet d'indiquer le protocole applicatif qui va utiliser ce port, une fois la session TLS démarrée.
Cette extension avait surtout été conçue pour les besoins de HTTP/2 (autrefois nommée SPDY), version qui est loin d'être terminée. ALPN (Application-Layer Protocol Negotiation), objet de notre RFC, sert à indiquer la version de HTTP, et aussi désigner les services qui vont tourner au dessus de HTTP, comme WebRTC (RFC 8833). Mais elle pourra servir à d'autres protocoles. Comme, par exemple, faire coexister IMAP et HTTP sur le même port. Vous allez peut-être me dire « mais pourquoi ne pas faire cela dans une couche entre TLS et l'application, de manière à éviter de complexifier TLS ? » et le RFC vous répond que le but est de performance (éviter les allers-retours entre client et serveur) et de souplesse (choisir un certificat différent selon le protocole d'application).
À noter qu'il s'agit d'une extension TLS : si on veut faire coexister sur un même port des applications TLS comme HTTP et non-TLS comme SSH, il faut une autre solution (par exemple sslh).
Comment fonctionne ALPN (section 3 de notre RFC) ? Le client envoie la liste des
applications qu'il gère dans son message TLS
ClientHello (section 7.4.1.2 du RFC 5246), le serveur en choisit une et la renvoie dans son
ServerHello. Tout se fait donc dans la poignée de
mains de TLS, sans imposer d'allers-retours supplémentaires. Si le
client ne veut qu'une seule application, il envoie un message avec une
liste ne comportant que cette application.
L'extension se nomme
application_layer_protocol_negotiation et a le
numéro 16 (désormais dans le registre IANA). Elle a un contenu (de type
ProtocolNameList) qui contient la liste des
protocoles applicatifs, en ordre de préférence décroissante. En termes TLS, cela s'écrit :
enum {
application_layer_protocol_negotiation(16), (65535)
} ExtensionType;
opaque ProtocolName<1..2^8-1>;
struct {
ProtocolName protocol_name_list<2..2^16-1>
} ProtocolNameList;
Les valeurs possibles pour les protocoles applicatifs sont dans un registre IANA. Des nouveaux protocoles pourront être ajoutés après un examen par un expert (RFC 5226, section 4.1). Pour l'instant, on y trouve le HTTP actuel, 1.1 (RFC 7230) et les variantes de SPDY. HTTP/2 sera placé dans ce registre après sa normalisation.
Cette extension sert aussi bien au client (liste des applications que
le client veut utiliser) qu'au serveur (application - au singulier -
choisie, après avoir ignoré
celles que le serveur ne connait pas). Si le serveur ne met pas cette
extension dans sa réponse, c'est ce qu'est un vieux serveur, qui ne la
connait pas. S'il répond avec une alerte
no_application_protocol, c'est que l'intersection
de la liste du client avec celle configurée dans le serveur est hélas vide.
Si vous utilisez une application qui peut attirer l'attention de la NSA, attention : la négociation ALPN est en clair, avant que le chiffrement ne démarre (sections 4 et 5). C'était un des points les plus controversés lors des discussions à l'IETF mais cela a été décidé pour être cohérent avec le modèle d'extension de TLS (un concurrent d'ALPN, NPN, n'avait pas ce défaut). Si vous tenez à cacher le protocole applicatif utilisé, vous devez faire une renégociation une fois le chiffrement commencé.
Des mises en œuvre de cette extension ? C'est apparemment fait pour NSS (voir #996250 et #959664). Et Wireshark va pouvoir le décoder. Pour les autres, voir le tableau synthétique.
L'article seul
RFC 7290: Test Plan and Results for Advancing RFC 2680 on the Standards Track
Date de publication du RFC : Juillet 2014
Auteur(s) du RFC : L. Ciavattone (AT&T Labs), R. Geib
(Deutsche Telekom), A. Morton (AT&T
Labs), M. Wieser (Technical University
Darmstadt)
Pour information
Réalisé dans le cadre du groupe de travail IETF ippm
Première rédaction de cet article le 23 juillet 2014
Le RFC 2680 normalisait une métrique utile à l'analyse des performances des réseaux informatiques, le taux de perte de paquets (mesuré sur un aller simple). Pour faire avancer ce RFC sur le chemin des normes, pour qu'il accède au statut de « norme tout court », il faut une évaluation : la description du RFC est-elle claire et complète ? Les mises en œuvre logicielles sont-elles équivalentes ? C'est ce travail d'évaluation que ce nouveau RFC documente, et qui a mené au RFC 7680.
Évaluer la norme d'une métrique est un peu plus compliqué qu'évaluer un protocole. La méthode traditionnelle à l'IETF pour évaluer un protocole est de regarder si deux mises en œuvre différentes peuvent interopérer. Pour une métrique, ce n'est pas possible et on utilise donc une autre méthode, regarder si deux mises en œuvre différentes d'une métrique, confrontées au même trafic, produisent des résultats compatibles (pas forcément identiques : les mesures ne sont jamais parfaitement précises).
Le groupe de travail IPPM de l'IETF travaille depuis longtemps sur ce problème d'avancement des métriques sur le chemin des normes. Les principes de l'évaluation d'une métrique ont été décrits dans le RFC 6576 et ont déjà été mis en pratique dans le RFC 6808, pour la métrique « délai d'acheminement d'un paquet (en aller simple) ». L'idée de base est que, si deux mesures, par des mises en œuvre différentes, donnent des résultats suffisamment proches, c'est que la métrique était correctement définie, claire et sans ambiguité. Cette évaluation permet aussi de voir quelles options de la métrique n'ont jamais été implémentées, et sont donc candidates à être supprimées dans une future révision de la norme.
En suivant le même plan que le RFC 6808, voici donc l'évaluation du RFC 2680 en pratique. La configuration de test est décrite en section 3 : les deux mises en œuvre testées étaient un NetProbe (ce qu'utilise WIPM), utilisant des paquets UDP avec une distribution périodique (RFC 3432) ou de Poisson (RFC 2330), et un Perfas+ (description en allemand), également avec UDP. Dans les deux cas, on passait par un tunnel L2TP (RFC 3931), pour dissimuler aux équipements intermédiaires les adresses IP et ports des équipements de tests (autrement, le trafic risquerait de passer par des chemins différents pour les deux tests). À l'extrémité du tunnel, le trafic est renvoyé donc cela permet d'avoir l'émetteur et le récepteur au même endroit, tout en faisant une mesure unidirectionnelle sur une longue distance. Pour introduire des phénomènes rigolos comme des pertes de paquet, un émulateur Netem est installé sur une machine Fedora, qui assure la communication entre le tunnel et un VLAN où se trouve l'équipement de test, via un lien FastEthernet. Les équipements testés ont envoyé des flots à 1 et 10 p/s, avec des centaines de paquets, de tailles variables (de 64 à 500 octets). Le type-P (cf. RFC 2680, section 2.8.1) des paquets était « UDP avec DSCP best effort » (de toute façon, l'encapsulation dans le tunnel L2TP fait que ces bits DSCP ont probablement été ignorés).
La section 4 de notre RFC décrit l'étalonnage (vérifier les horloges, par exemple).
On l'a dit, c'est bien joli de comparer deux programmes mais que doit être le résultat de la comparaison ? Une égalité rigoureuse ? Ce n'est pas possible. La section 5 indique les critères de comparaison : on fait de l'ADK avec un facteur de confiance à 0,95 (et de l'adéquation à la loi de distribution).
Enfin, après toutes ces précautions méthodologiques, la section 6 contient les résultats. Par exemple, en périodique, les deux systèmes mesurés donnent des résultats largement compatibles mais, en distribution de Poisson, les résultats sont tout juste acceptables. Les mesures ont bien résisté à des tests comme celui du délai maximal d'attente (avant de déclarer un paquet perdu) ou comme celui du désordonnement des paquets (lorsqu'un paquet est tellement en retard qu'il arrive après un paquet parti après).
Conclusions (section 7) : les deux mises en œuvre sont compatibles, ce qui indique que le RFC 2680 est suffisamment clair et précis. Le processus de test a toutefois noté quelques points où le RFC 2680 pouvait être rendu plus clair (sans compter les erreurs connues du RFC). Cela a été fait dans le RFC 7680.
Pour les fanas, la section 10 rassemble toutes les commandes de configuration des équipements qui ont été utilisées. Par exemple, Netem a été configuré avec tc (ici, pour ajouter un retard variable et en prime 10 % de perte de paquets) :
tc qdisc change dev eth1 root netem delay 2000ms 1000ms loss 10%
L'article seul
Un petit galop d'essai avec le système Haka (filtrage, sécurité, paquets, protocoles, etc)
Première rédaction de cet article le 20 juillet 2014
Le 10 juillet dernier, lors des RMLL à Montpellier, j'ai eu le plaisir de participer à l'« Atelier HAKA : un langage open source [sic] de sécurité réseau ». Haka est un langage permettant d'analyser les paquets, de réagir à certaines caractéristiques des paquets et de générer des réponses diverses. Cela permet entre autres de faire des pare-feux très souples car complètement programmables.
Haka est fondé sur Lua et il faut donc un peu réviser ses connaissances Lua avant de pratiquer l'atelier. (J'ai déjà écrit ici et là sur Lua et réalisé un tout petit programme avec.) Haka étend Lua en ajoutant au langage de base des extensions permettant de tripoter les paquets réseau facilement. Je ne vais pas vous faire un cours sur Haka (il y en a un en ligne et les transparents de l'atelier sont disponibles en ligne), juste documenter mon expérience.
L'atelier se faisait dans une machine
virtuelle Debian dans VirtualBox.
La machine virtuelle utilisée pouvait être téléchargée en https://hakasecurity.files.wordpress.com/2014/07/haka-live-iso.zip. (Je
n'ai pas encore essayé d'installer Haka moi-même.) Une machine plus
récente est, depuis, en http://www.haka-security.org/resources.html.
Une
fois la machine démarrée, il faut faire un
setxkbmap fr dans un terminal pour passer en
AZERTY, le clavier par défaut étant QWERTY. Si vous éditez les sources
Lua avec Emacs, notez qu'il n'y a pas de mode
Lua pour Emacs dans la machine virtuelle. Bon, on s'en passe, sinon,
on le télécharge avec apt-get. Les pcap
d'exemple sont livrés avec la machine virtuelle, dans
/opt/haka/share/haka/sample/hellopacket.
Premier exercice, s'entraîner aux bases de Haka et apprendre à afficher certains paquets. Allons-y en Lua :
-- On charge le dissecteur IPv4 (pas encore de dissecteur IPv6,
-- malheureusement ; un volontaire pour l'écrire ?)
local ip = require('protocol/ipv4')
-- Haka fonctionne en écrivant des *règles* qui réagissent à des
-- *évènements*, ici, l'évènement est le passage d'un paquet IPv4
haka.rule{
hook = ip.events.receive_packet,
-- Suit une série d'actions, qui reçoivent un paramètre qui dépend
-- du dissecteur. Le dissecteur IPv4 passe à l'évènement
-- receive_packet un paquet.
eval = function (pkt)
haka.log("Hello", "packet from %s to %s", pkt.src, pkt.dst)
end
}
Et comment on a trouvé que les champs de pkt qui
contenaient les adresses IP source et destination se nommaient
src et dst ? On a lu la
doc (également disponible dans la machine virtuelle en
/lib/live/mount/medium/haka/manual/modules/protocol/ipv4/doc/ipv4.html#dissector). Il
existe aussi un mode interactif de Haka, permettant d'explorer les
paquets, pas montré ici.
Si on lance ce script Haka sur un pcap existant, il affiche :
% hakapcap hellopacket.lua hellopcaket.pcap info core: load module 'packet/pcap.ho', Pcap Module info core: load module 'alert/file.ho', File alert info core: setting packet mode to pass-through info core: loading rule file 'hellopacket.lua' info core: initializing thread 0 info dissector: register new dissector 'raw' info pcap: opening file 'hellopacket.pcap' info dissector: register new dissector 'ipv4' info core: 1 rule(s) on event 'ipv4:receive_packet' info core: 1 rule(s) registered info core: starting single threaded processing info Hello: packet from 192.168.10.1 to 192.168.10.99 info Hello: packet from 192.168.10.99 to 192.168.10.1 info Hello: packet from 192.168.10.1 to 192.168.10.99 info Hello: packet from 192.168.10.1 to 192.168.10.99 info Hello: packet from 192.168.10.99 to 192.168.10.1 info Hello: packet from 192.168.10.1 to 192.168.10.99 info Hello: packet from 192.168.10.99 to 192.168.10.1 info Hello: packet from 192.168.10.1 to 192.168.10.99 info core: unload module 'Pcap Module' info core: unload module 'File alert'
Ça a bien marché, chaque paquet du pcap a été affiché.
Deuxième exercice, filtrage des paquets qui ne nous plaisent pas,
en l'occurrence, ceux qui viennent du méchant réseau
192.168.10.0/27 :
local ip = require('protocol/ipv4')
local bad_network = ip.network("192.168.10.0/27")
haka.rule{
hook = ip.events.receive_packet,
eval = function (pkt)
-- On teste si le paquet appartient au méchant réseau
if bad_network:contains(pkt.src) then
-- Si oui, on le jette et on journalise
haka.log("Dropped", "packet from %s to %s", pkt.src, pkt.dst)
pkt:drop()
-- Si non (pas de 'else') le paquet suit son cours
end
end
}
Une fois lancé le script sur un pcap, on obtient :
... info Dropped: packet from 192.168.10.1 to 192.168.10.99 info Dropped: packet from 192.168.10.1 to 192.168.10.99 info Dropped: packet from 192.168.10.1 to 192.168.10.99 info Dropped: packet from 192.168.10.1 to 192.168.10.99 info Dropped: packet from 192.168.10.10 to 192.168.10.99 info Dropped: packet from 192.168.10.10 to 192.168.10.99 info Dropped: packet from 192.168.10.10 to 192.168.10.99
Si vous regardez le pcap avec tcpdump, vous verrez qu'il y a d'autres paquets, en provenance de 192.168.10.99 qui n'ont pas été jetés, car pas envoyés depuis le méchant réseau :
14:49:27.076486 IP 192.168.10.1 > 192.168.10.99: ICMP echo request, id 26102, seq 1, length 64 14:49:27.076536 IP 192.168.10.99 > 192.168.10.1: ICMP echo reply, id 26102, seq 1, length 64 14:49:28.075844 IP 192.168.10.1 > 192.168.10.99: ICMP echo request, id 26102, seq 2, length 64 14:49:28.075900 IP 192.168.10.99 > 192.168.10.1: ICMP echo reply, id 26102, seq 2, length 64 14:49:31.966286 IP 192.168.10.1.37542 > 192.168.10.99.80: Flags [S], seq 3827050607, win 14600, options [mss 1460,sackOK,TS val 2224051087 ecr 0,nop,wscale 7], length 0 14:49:31.966356 IP 192.168.10.99.80 > 192.168.10.1.37542: Flags [R.], seq 0, ack 3827050608, win 0, length 0 14:49:36.014035 IP 192.168.10.1.47617 > 192.168.10.99.31337: Flags [S], seq 1811320530, win 14600, options [mss 1460,sackOK,TS val 2224052099 ecr 0,nop,wscale 7], length 0 14:49:36.014080 IP 192.168.10.99.31337 > 192.168.10.1.47617: Flags [R.], seq 0, ack 1811320531, win 0, length 0 14:49:46.837316 ARP, Request who-has 192.168.10.99 tell 192.168.10.10, length 46 14:49:46.837370 ARP, Reply 192.168.10.99 is-at 52:54:00:1a:34:60, length 28 14:49:46.837888 IP 192.168.10.10.35321 > 192.168.10.99.8000: Flags [S], seq 895344097, win 14600, options [mss 1460,sackOK,TS val 2224054805 ecr 0,nop,wscale 7], length 0 14:49:46.837939 IP 192.168.10.99.8000 > 192.168.10.10.35321: Flags [R.], seq 0, ack 895344098, win 0, length 0 14:49:50.668580 IP 192.168.10.10 > 192.168.10.99: ICMP echo request, id 26107, seq 1, length 64 14:49:50.668674 IP 192.168.10.99 > 192.168.10.10: ICMP echo reply, id 26107, seq 1, length 64 14:49:51.670446 IP 192.168.10.10 > 192.168.10.99: ICMP echo request, id 26107, seq 2, length 64 14:49:51.670492 IP 192.168.10.99 > 192.168.10.10: ICMP echo reply, id 26107, seq 2, length 64 14:49:51.841297 ARP, Request who-has 192.168.10.10 tell 192.168.10.99, length 28 14:49:51.841915 ARP, Reply 192.168.10.10 is-at 52:54:00:30:b0:bd, length 46
Bon, jusqu'à présent, on n'a rien fait d'extraordinaire,
Netfilter en
aurait fait autant. Mais le prochain exercice est plus intéressant. On
va faire du filtrage TCP. La documentation du dissecteur TCP nous apprend que le champ qui
indique le port de destination est
dstport :
local ip = require('protocol/ipv4')
-- On charge un nouveau dissecteur
local tcp = require ('protocol/tcp_connection')
haka.rule{
-- Et on utilise un nouvel évènement, qui signale un nouveau flot TCP
hook = tcp.events.new_connection,
eval = function (flow, pkt)
-- Si le port n'est ni 22, ni 80...
if flow.dstport ~= 22 and flow.dstport ~= 80 then
haka.log("Dropped", "flow from %s to %s:%s", pkt.ip.src, pkt.ip.dst, flow.dstport)
flow:drop()
else
haka.log("Accepted", "flow from %s to %s:%s", pkt.ip.src, pkt.ip.dst, flow.dstport)
end
end
}
Et on le teste sur un pcap :
info Accepted: flow from 192.168.10.1 to 192.168.10.99:80 info Dropped: flow from 192.168.10.1 to 192.168.10.99:31337 info Dropped: flow from 192.168.10.10 to 192.168.10.99:8000
Il y avait trois flots (trois connexions TCP) dans le pcap, une seule a été acceptée.
Maintenant, fini de jouer avec des pcap. Cela peut être intéressant (analyse de pcap compliqués en ayant toute la puissance d'un langage de Turing) mais je vous avais promis un pare-feu. On va donc filtrer des paquets et des flots vivants, en temps réel. On écrit d'abord le fichier de configuration du démon Haka :
[general] # Select the haka configuration file to use configuration = "tcpfilter.lua" # Optionally select the number of thread to use. #thread = 4 # Pass-through mode # If yes, haka will only inspect packet # If no, it means that haka can also modify and create packet pass-through = no [packet] # Select the capture model, nfqueue or pcap module = "packet/nfqueue" # Select the interfaces to listen to interfaces = "lo" #interfaces = "eth0" # Select packet dumping for nfqueue #dump = yes #dump_input = "/tmp/input.pcap" #dump_output = "/tmp/output.pcap" [log] # Select the log module module = "log/syslog" [alert] # Select the alert module module = "alert/syslog"
Le script est le même que dans l'essai précédent, il accepte uniquement les connexions TCP vers les ports 22 ou 80. On lance le démon (notez que celui-ci fera appel à Netfilter pour lui passer les paquets) :
% sudo haka -c haka.conf --no-daemon info core: load module 'log/syslog.ho', Syslog logger info core: load module 'alert/syslog.ho', Syslog alert info core: load module 'alert/file.ho', File alert info core: load module 'packet/nfqueue.ho', nfqueue info nfqueue: installing iptables rules for device(s) lo info core: loading rule file 'tcpfilter.lua' info core: initializing thread 0 info dissector: register new dissector 'raw' info dissector: register new dissector 'ipv4' info dissector: register new dissector 'tcp' info dissector: register new dissector 'tcp_connection' info core: 1 rule(s) on event 'tcp_connection:new_connection' info core: 1 rule(s) registered info core: starting single threaded processing
Et on tente quelques connexions (143 = IMAP) :
info Accepted: flow from 127.0.0.1 to 127.0.0.1:80 info Dropped: flow from 127.0.0.1 to 127.0.0.1:143 info Dropped: flow from 127.0.0.1 to 127.0.0.1:143 info Dropped: flow from 127.0.0.1 to 127.0.0.1:143
Et en effet, les clients IMAP vont désormais timeouter. Dès qu'on arrête le démon, avec un Control-C, IMAP remarche :
% telnet 127.0.0.1 imap2 Trying 127.0.0.1... Connected to 127.0.0.1. Escape character is '^]'. * OK [CAPABILITY IMAP4rev1 LITERAL+ SASL-IR LOGIN-REFERRALS ID ENABLE IDLE STARTTLS AUTH=PLAIN] Dovecot ready.
J'ai beaucoup aimé la possibilité de journaliser ou de jeter un flot TCP entier, pas en agissant paquet par paquet. Pour la partie IP au début de cet atelier, Haka a un concurrent évident, Scapy (mêmes concepts mais Python au lieu de Lua). Mais Scapy ne sait pas gérer les flots TCP, il ne travaille que par paquet.
Exercice suivant, le protocole du Web,
HTTP. On va modifier les pages
HTML en vol (et vous comprendrez pourquoi il
faut toujours utiliser HTTPS).
Il faut changer haka.conf pour indiquer le nouveau script, blurring-the-web.lua.
D'abord, on se contente d'afficher les requêtes HTTP :
local ip = require('protocol/ipv4')
-- On charge un nouveau dissecteur
local http = require ('protocol/http')
-- Pas d'indication du protocole supérieur dans TCP, seulement du
-- numéro de port, donc il faut être explicite
http.install_tcp_rule(80)
haka.rule{
-- Et on utilise un nouvel évènement
hook = http.events.request,
eval = function (connection, request)
haka.log("HTTP request", "%s %s", request.method, request.uri)
-- Il faut être sûr que les données ne soient pas comprimées,
-- pour que la modification ultérieure marche. On modifie donc
-- la requête.
request.headers['Accept-Encoding'] = nil
request.headers['Accept'] = "*/*"
end
}
Haka fait beaucoup de choses mais il ne décomprime pas les flots HTTP. Comme la compression est souvent utilisée sur le Web, on modifie les en-têtes de la requête pour prétendre qu'on n'accepte pas la compression (cf. RFC 7231, sections 5.3.4 et 5.3.2).
On lance maintenant le démon Haka avec ce nouveau script. Pour
tester que les requêtes du navigateur Web ont bien été modifiées, on
peut aller sur un site qui affiche les en-têtes de la requête comme
http://www.bortzmeyer.org/apps/env. Par défaut,
le Firefox de la machine virtuelle envoie :
HTTP_ACCEPT: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 HTTP_ACCEPT_ENCODING: gzip, deflate
alors qu'une fois le démon en route, on n'a plus que (mettre une
entrée de tableau à nil la détruit) :
HTTP_ACCEPT: */*
Attention au passage : Firefox peut maintenir des connexions TCP persistantes avec le serveur HTTP. Si vous lancez Firefox avant Haka, vous risquez de récupérer fréquemment des :
alert: id = 8
time = Sat Jul 19 16:31:32 2014
severity = low
description = no connection found for tcp packet
sources = {
address: 127.0.0.1
service: tcp/56042
}
targets = {
address: 127.0.0.1
service: tcp/80
}
C'est parce que Haka a vu passer des paquets d'une connexion TCP antérieure à son activation et qu'il ne sait donc pas rattacher à un flot qu'il suit. (C'est le problème de tous les filtres à état.)
Attention aussi, Haka ne gère pas IPv6. Si on se connecte à un serveur Web
en indiquant son nom, on peut utiliser IPv6 (c'est le cas de
http://localhost/ sur la Debian de la machine
virtuelle) et Haka ne verra alors rien. D'où l'option
-4 de wget, pour tester :
% wget -v -4 http://localhost/ ... # Haka affiche info HTTP request: GET /
Maintenant, on ne va pas se contenter d'observer, on modifie la réponse HTTP en ajoutant du CSS rigolo :
local ip = require('protocol/ipv4')
local http = require ('protocol/http')
local re = require('regexp/pcre')
-- Ce CSS rend tout flou
local css = '<style type="text/css" media="screen"> * { color: transparent !important; text-shadow: 0 0 3px black !important; } </style>'
http.install_tcp_rule(80)
-- Bien garder cette règle, pour couper la compression, qui est
-- activée par défaut sur beaucoup de serveurs
haka.rule{
hook = http.events.request,
eval = function (connection, request)
haka.log("HTTP request", "%s %s", request.method, request.uri)
request.headers['Accept-Encoding'] = nil
request.headers['Accept'] = "*/*"
end
}
-- Deuxième règle, pour changer la réponse
haka.rule{
hook = http.events.response_data,
options = {
streamed = true,
},
eval = function (flow, iter)
-- Chercher la fin de l'élément <head>
local regexp = re.re:compile("</head>", re.re.CASE_INSENSITIVE)
local result = regexp:match(iter, true)
-- Si on a bien trouvé un <head>
if result then
result:pos('begin'):insert(haka.vbuffer_from(css))
end
end
}
Et re-testons :
% wget -O - -v -4 http://localhost/
--2014-07-19 16:41:48-- http://localhost/
Resolving localhost (localhost)... 127.0.0.1, 127.0.0.1
Connecting to localhost (localhost)|127.0.0.1|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 190 [text/html]
Saving to: `STDOUT'
0% [ ] 0 --.-K/s <html><head><style type="text/css" media="screen"> * { color: transparent !important; text-shadow: 0 0 3px black !important; } </style></head><body><h1>It works!</h1>
100%[==============================================>] 190 --.-K/s in 0s
2014-07-19 16:41:48 (45.0 MB/s) - written to stdout [190/190]
Le CSS a bien été inséré ! Et, avec un vrai site Web, on voit bien l'effet :
Attention, le haka.conf indiqué ici n'écoute que
sur l'interface lo. Pour tester sur le Web en
grand, pensez à changer le haka.conf (et
rappelez-vous que Haka n'aura aucun effet sur les sites Web
accessibles en IPv6 comme http://www.ietf.org/, si la
machine virtuelle a une connectivité IPv6).
Voilà, sur ce truc spectaculaire, ce fut la fin de l'atelier. À noter que nous n'avons pas testé les performances de Haka, question évidemment cruciale pour des filtrages en temps réel. En première approximation, Haka semble bien plus rapide que Scapy pour les tâches d'analyse de pcap mais il faudra un jour mesurer sérieusement.
L'article seul
RFC 7314: Extension Mechanisms for DNS (EDNS) EXPIRE Option
Date de publication du RFC : Juillet 2014
Auteur(s) du RFC : M. Andrews (ISC)
Expérimental
Première rédaction de cet article le 18 juillet 2014
L'enregistrement DNS
SOA (Start Of Authority) a
un champ expire qui indique au bout de combien de
temps un serveur esclave qui ne réussit pas à contacter le maître peut
arrêter de servir la zone. Si l'esclave a eu les données, non pas
directement du maître, mais d'un autre esclave, la durée d'expiration
peut ne pas être correcte. C'est ce (rare) problème que règle l'option
EDNS EXPIRE.
En effet, il faut se rappeler que la distribution d'une zone DNS depuis un serveur maître (le RFC utilise l'ancien terme de « serveur primaire ») n'est pas forcément directe. On peut avoir un maître qui envoie des données à un esclave, qui à son tour les envoie à un autre esclave. Cela permet notamment davantage de robustesse (si le maître n'est temporairement pas joignable depuis certains esclaves). Notez que l'esclave ne sait même pas si la machine qui lui a envoyé les données était un maître ou pas.
Si la période de validité donnée par le champ
expire du SOA (RFC 1035,
section 3.3.13) vaut V et que le transfert de
l'esclave à un autre esclave prend place S secondes après le transfert
depuis le maître (les transferts ne sont pas forcément instantanés,
par exemple en cas de coupure réseau), la zone sera servie pendant V + S secondes et pas
seulement pendant V secondes. Pire, s'il existe une boucle dans le
graphe de distribution, la zone risque de ne jamais expirer, les
esclaves se rafraichissant mutuellement.
Personnellement, le problème me semble rare et de peu d'importance. Il y a des tas d'autres choses plus urgentes à régler dans le DNS. Mais, bon, c'est juste une expérience.
La nouvelle option de ce RFC dépend de
EDNS (RFC 6891). Elle a
le numéro 9. Mise dans une requête (a priori une requête de type
SOA, AXFR ou IXFR), elle indique que le client DNS connait cette
option et voudrait sa valeur. Un serveur qui ne connait pas l'option
EXPIRE ne mettra pas l'option dans sa
réponse.
Par contre, un serveur qui connait cette option répondra avec une
option EXPIRE dans sa réponse. Elle comporte
quatre octets de données (comme pour le champ
expire du SOA), indiquant le nombre de secondes
de la période de validité. Si le serveur est un maître, il met
toujours dans cette option la valeur du champ
expire du SOA. S'il est un esclave, il met la
valeur actuelle de son compteur d'expiration. Ainsi, si le champ
expire du SOA vaut 7 200 secondes (2 heures) et
que le serveur secondaire reçoit une demande 30 minutes après le
transfert depuis le maître, il mettra 5 400 dans l'option EDNS
EXPIRE (120 minutes de validité moins les 30
minutes écoulées). C'est ainsi qu'on évite l'accumulation des périodes
de validité en cas de transfert indirect.
Un serveur esclave (le RFC utilise l'ancien terme de « serveur
secondaire ») qui utilise l'option, et qui reçoit une réponse lors
d'un transfert initial de la zone, devrait utiliser comme durée de
validité la valeur de l'option EXPIRE (et pas le
champ expire du SOA, sauf si ce champ a une
valeur inférieure à celle de l'option
EXPIRE). Cette durée de validité est ensuite mise
dans un compteur d'expiration qui décroît avec le temps. Pour les rafraichissements ultérieurs,
le serveur esclave doit également
utiliser comme durée de validité la valeur de l'option, sauf si le
compteur actuel a une valeur plus élevée. Par exemple, si le compteur
du secondaire dit que la zone est encore valable pour 4 500 secondes,
et qu'une réponse IXFR (RFC 1995) contient une
option EXPIRE de valeur 9 300 secondes, alors le
compteur est mis à 9 300 secondes. Si l'option
EXPIRE avait valu 2 400 secondes, le compteur
n'aurait pas été modifié.
Une conséquence amusante de cette option est qu'elle permet de savoir quand a eu lieu le dernier transfert de zone réussi, juste en interrogeant un esclave. Cela peut être vu comme indiscret, mais cela peut aussi être un outil de supervision très pratique.
Cette option est utilisable depuis dig, à partir de la version 9.10. Wireshark a récemment été modifié pour reconnaître cette option.
L'article seul
RFC 7291: DHCP Options for the Port Control Protocol (PCP)
Date de publication du RFC : Juillet 2014
Auteur(s) du RFC : M. Boucadair (France
Telecom), R. Penno, D. Wing
(Cisco)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF pcp
Première rédaction de cet article le 15 juillet 2014
Le protocole PCP, normalisé dans le RFC 6887 permet à la machine de M. Michu de configurer un routeur/traducteur, par exemple pour lui demander de laisser passer le trafic entrant vers un port donné. La norme PCP ne précisait pas tellement comment le client était censé trouver le serveur PCP. Dans certains cas, c'est trivial, c'est le routeur par défaut. Dans d'autres, il faut d'autres mécanismes et c'est là que notre RFC 7291 est utile : il normalise un moyen de découvrir le serveur PCP grâce à une nouvelle option DHCP.
Le mécanisme est le même pour DHCP IPv6
(RFC 8415) ou DHCP IPv4
(RFC 2131). Pour DHCP IPv6, l'option est décrite
en section 3. Elle est nommée
OPTION_V6_PCP_SERVER et a le code 86 (mis dans
le registre IANA). Suit une
liste d'adresses IPv6, qui sont celles d'un serveur PCP. S'il y a
plusieurs serveurs PCP, on met plusieurs occurrences de l'option
OPTION_V6_PCP_SERVER.
On note que c'est une adresse IP et pas un nom de domaine qui est utilisée pour identifier le ou les serveur(s) PCP. Un nom de domaine aurait permis un niveau d'indirection supplémentaire. Le sujet a donc fait l'objet d'une certaine controverse au sein du groupe de travail PCP à l'IETF avant que le consensus se fasse sur l'adresse IP.
Pour obtenir cette liste d'adresses, le client DHCP doit mettre
l'option OPTION_V6_PCP_SERVER dans sa requête et,
si le serveur DHCP connait des serveurs PCP, il mettra leur(s)
adresse(s) dans sa réponse.
Le mécanisme est quasiment le même en IPv4 (section 4), avec
l'option OPTION_V4_PCP_SERVER de code 158 (registre IANA). La
principale différence est le mécanisme utilisé pour mettre plusieurs
serveurs PCP (pas juste plusieurs adresses IP pour un serveur,
mais plusieurs serveurs) : en IPv6, on répétait l'option. En IPv4, on
envoie plusieurs listes dans la même réponse.
Donc, attention, aussi bien côté client que côté serveur, ce RFC permet d'avoir plusieurs serveurs PCP, ayant chacun plusieurs adresses IP. Par exemple, côté serveur, le mécanisme de configuration du serveur (mettons son fichier de configuration) doit permettre de distinguer les deux cas, afin de choisir le bon encodage. Si le fichier de configuration permet de mettre un nom de domaine pour le serveur PCP, et que le serveur DHCP, en résolvant ce nom, trouve plusieurs adresses IP, il doit bien les mettre dans une seule option (en IPv6) ou une seule liste (IPv4).
Notez une différence entre IPv6 et IPv4 : un serveur DHCP IPv6 peut retourner des adresses IPv4 (encodées selon la section 2.5.5.2 du RFC 4291) dans sa réponse (cas d'un réseau purement IPv6 mais qui reçoit une connectivité IPv4 via un mécanisme spécifique), l'inverse n'étant pas vrai.
À noter que, dans le cas de multi-homing, on peut recevoir plusieurs serveurs PCP via des réponses DHCP différentes, sur des liens réseau différents (par exemple un lien WiFi et un 3G). Dans ce cas, la machine doit bien faire attention à associer chaque serveur PCP à son réseau, pour ne configurer que le bon serveur PCP correspondant à l'adresse qu'on veut utiliser.
Les praticiens noteront avec plaisir qu'il existe au moins une mise en œuvre documentée (sur Fedora).
L'article seul
RFC 7320: URI Design and Ownership
Date de publication du RFC : Juillet 2014
Auteur(s) du RFC : M. Nottingham
Réalisé dans le cadre du groupe de travail IETF appsawg
Première rédaction de cet article le 12 juillet 2014
Ah, les URI... Comme ces identificateurs
sont très souvent vus et manipulés par un grand nombre d'utilisateurs,
ils suscitent forcément des passions et des discussions sans fin. Ce
RFC de bonne pratique s'attaque à un problème
fréquent : les applications ou extensions qui imposent des contraintes sur l'URI,
sans que cela soit justifié par le format de ces URI. Par exemple, on
voit des CMS imposer, au moment de
l'installation, que le CMS soit accessible par un URI commençant par
le nom du logiciel. S'il s'appelle Foobar, on voit parfois des
logiciels qui ne marchent que si l'URI commence par
http://www.example.org/Foobar/. Pourquoi est-ce
une mauvaise idée et que faudrait-il faire à la place ? (Ce RFC a
depuis été remplacé par le RFC 8820, moins normatif.)
D'abord, l'argument d'autorité qui tue : la norme des
URI, le RFC 3986, dit
clairement que la structure d'un URI est déterminé par son
plan (scheme en anglais) et
que donc l'application n'a pas le droit d'imposer des règles
supplémentaires. Les deux seuls « propriétaires » sont la norme
décrivant le plan (qui impose une syntaxe, et certains éléments, par
exemple le nom du serveur avec le plan http://)
et l'organisation qui contrôle cet URI particulier (par exemple,
toujours pour http://, l'organisation qui
contrôle le domaine dans
l'URI). Imposer des règles, pour une application ou une extension, c'est violer ce
principe de propriété. (Il est formalisé dans une
recommandation du W3C, section 2.2.2.1.)
Un exemple de structure dans les URI est l'interprétation du
chemin (path en anglais) comme étant un endroit du
système de fichiers. Ainsi, bien des serveurs
HTTP, en voyant l'URI
http://www.example.org/foo/bar/toto.html,
chercheront le fichier en
$DOCUMENT_ROOT/foo/bar/toto.html. C'est une
particularité de la mise en œuvre de ce serveur, pas une obligation du
plan d'URI http://. Un autre exemple est
l'utilisation de l'extension du nom de fichier comme moyen de
trouver le type de média de la ressource. (« Ça
se termine en .png ? On envoie le type
image/png. ») Ces deux cas ne violent pas
forcément le principe de propriété des URI car l'utilisateur, après
tout, choisit son serveur.
Mais, dans certains cas, l'imposition d'une structure (autre que celle déjà imposée par la norme du plan d'URI) a des conséquences néfastes :
- Risque de collisions entre deux conventions différentes.
- Risque d'instabilité si on met trop d'informations dans l'URI (voir la section 3.5.1 du document « Architecture of the World Wide Web, Volume One », cité plus haut). Pour reprendre l'exemple de l'extension du fichier, si on change le format de l'image de PNG en JPEG, l'URI changera, ce qui est néfaste.
- Rigidité accrue. Si un logiciel impose d'être installé en
/Foobarcomme dans l'exemple au début, il contraint les choix pour l'administrateur système (et si je veux des URI avec un chemin vide, genrehttp://foobar.example.org/, je fais quoi ?) - Risque que le client fasse des suppositions injustifiées. Si une
spécification décrit le paramètre
sigcomme étant forcément une signature cryptographique, il y a une possibilité qu'un logiciel client croit, dès qu'il voit un paramètre de ce nom, que c'est une signature.
Donc, pour toutes ces raisons, notre RFC déconseille fortement de rajouter des règles de structure dans les URI. Ces règles diminuent la liberté du propriétaire de l'URI.
Qui risque de violer ce principe ? Les auteurs d'applications,
comme dans l'exemple Foobar plus haut, mais aussi des gens qui font
des extensions aux URI, par le biais de nouvelles spécifications (par
exemple pour mettre des signatures ou autres métadonnées dans
l'URI). En revanche, ce principe ne s'applique pas au propriétaire
lui-même, qui a évidemment le droit de définir ses règles pour la
gestion de ses URI (exemple : le webmestre qui
crée un schéma de nommage des URI de son site Web). Et cela
ne s'applique pas non plus au cas où le propriétaire de l'URI reçoit
lui-même une délégation pour gérer ce site (par exemple, un
RFC qui crée un registre
IANA et spécifie la structure des URI sous
https://www.iana.org/ est dans son droit, l'IANA
agissant sur délégation de l'IETF). Le principe
« bas les pattes » de ce RFC n'est pas technique : on n'interdit pas
de mettre de la structure dans les URI, on dit juste
qui a le droit de le faire.
Notre RFC reconnait que certaines normes IETF (non citées...) violent ce principe, et appelle à profiter de la prochaine révision pour les corriger.
La partie normative de notre RFC est la section 2. Elle explicite
le principe « bas les pattes » (« get off my lawn »
dans le nom original du document en anglais...) D'abord, éviter de
contraindre l'usage d'un plan particulier. Par exemple, imposer
http:// peut être trop contraignant, certaines
applications ou extensions pourraient marcher avec d'autres plans
d'URI comme par exemple file:// (RFC 8089).
D'autre part, si on veut une structure dans les URI d'un plan
particulier, cela doit être spécifié dans le document qui définit le
plan (RFC 7230 pour
http://, RFC 6920 pour
ni:, etc) pas dans une extension faite par
d'autres (« touche pas à mon plan »).
Les URI comprennent un champ « autorité » juste après le plan. Les
extensions ou applications ne doivent pas imposer
de contraintes particulières sur ce champ. Ainsi, pour
http://, l'autorité est un nom de
domaine et notre RFC ne permet pas qu'on lui mette des
contraintes (du genre « le premier composant du nom de domaine doit
commencer par foobar-, comme dans
foobar-www.example.org »).
Même chose pour le champ « chemin », qui vient après
l'autorité. Pas question de lui ajouter des contraintes (comme dans
l'exemple du CMS qui imposerait /Foobar comme
préfixe d'installation). La seule
exception est la définition des URI bien connus du RFC 8615. Le RFC 6415 donne un exemple
d'URI bien connus, avec une structure imposée.
Autre conséquence du principe « bas les pattes » et qui est, il me
semble, plus souvent violée en pratique, le champ « requête »
(query). Optionnel, il se trouve après le
point d'interrogation dans l'URI. Notre RFC
interdit aux applications d'imposer l'usage des requêtes, car cela
empêcherait le déploiement de l'application dans d'autres contextes
où, par exemple, on veut utiliser des URI sans requête (je dois dire
que mes propres applications Web violent souvent ce principe). Quant
aux extensions, elles ne doivent pas contraindre le format des
requêtes. L'exemple cité plus haut, d'une extension
hypothétique, qui fonctionnerait par l'ajout d'un paramètre
sig aux requêtes pour indiquer une signature est
donc une mauvaise idée. Une telle extension causerait des collisions
(applications ou autres extensions qui voudraient un paramètre de
requête nommé sig) et des risques de suppositions
injustifié (un logiciel qui se dirait « tiens, un paramètre
sig, je vais vérifier la signature, ah, elle est
invalide, cet URI est erroné »). Au passage, les préfixes n'aident
pas. Supposons qu'une extension, voulant limiter le risque de
collisions, décide que tous les paramètres qu'elle définit commencent
par myapp_ (donc, la signature serait
myapp_sig). Cela ne supprime pas le risque de
collisions puisque le préfixe lui-même ne serait pas enregistré.
Sauf erreur, Dotclear gère bien cela, en
permettant, via les « méthodes de lecture »
PATH_INFO ou QUERY_STRING
d'avoir les deux types d'URI (sans requête ou bien avec).
Pourtant, HTML lui-même fait cela, dans la norme 4.01, en restreignant la syntaxe lors de la soumission d'un formulaire. Mais c'était une mauvaise idée et les futures normes ne devraient pas l'imiter.
Comme précédemment, les URI bien connus ont, eux, droit à changer
la syntaxe ou contraindre les paramètres puisque, d'une certaine
façon, l'espace sous .well-known est délégué à
l'IETF et n'est plus « propriété » de l'autorité.
Dernier champ de l'URI à étudier, l'identificateur de fragment (ce qui est après le croisillon). Les définitions d'un type de média (RFC 6838) ont le droit de spécifier la syntaxe d'un identificateur de fragment spécifique à ce type de média (comme ceux du texte brut, dans le RFC 5147). Les autres extensions doivent s'en abstenir.
Bon, assez de négativité et d'interdiction. Après les « faites pas ci » et les « faites pas ça », la section 3 de notre RFC expose les alternatives, les bonnes pratiques pour remplacer celles qui sont interdites ici. D'abord, si le but est de faire des liens, il faut se rappeler qu'il existe un cadre complet pour cela, décrit dans le RFC 8288. Une application peut utiliser ce cadre pour donner la sémantique qu'elle veut à des liens. Autre technique rigolote et peu connue, les gabarits du RFC 6570, qui permettent de gérer facilement le cas de données spécifiques à l'application dans un URI.
Et, comme cité plusieurs fois, les URI bien connus du RFC 8615 sont un moyen de déclarer sa propre structure sur des URI. Par contre, ils sont censés avoir un usage limité (accéder à des métadonnées avant de récupérer une ressource) et ne sont pas un moyen générique d'échapper aux règles qui nous dérangent !
L'article seul
RFC 7303: XML Media Types
Date de publication du RFC : Juillet 2014
Auteur(s) du RFC : H. Thompson (University of Edinburgh), C. Lilley (W3C)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF appsawg
Première rédaction de cet article le 11 juillet 2014
Voici la nouvelle norme décrivant les types
MIME XML, comme
application/xml. Elle remplace le RFC 3023. Cette norme décrit aussi l'utilisation de
+xml comme suffixe pour des formats de données
fondés sur XML comme TEI, avec son
application/tei+xml.
XML est une norme du
W3C et n'est donc pas dans un
RFC mais dans un document du W3C. Lorsque des documents sont envoyés sur
l'Internet, ils sont souvent étiquetés avec un type de média, dit
aussi, pour des raisons historiques, type
MIME. Pour XML, il existe cinq types,
application/xml, text/xml,
application/xml-external-parsed-entity,
text/xml-external-parsed-entity et
application/xml-dtd. Il existe aussi une
convention, formalisée dans le RFC 6838, pour
les formats bâtis au-dessus de XML, comme Atom
(RFC 4287). On écrit les types de média pour ces
formats avec un +xml à la fin, indiquant ainsi
qu'un processeur XML généraliste pourra toujours en faire quelque
chose, même s'il ne connait pas ce format spécifique. Ainsi, Atom est
application/atom+xml. (Ces suffixes sont
désormais banals mais, à l'époque du RFC 3023, ils étaient
contestés et l'annexe A du RFC 3023 contient une
justification détaillée, qui n'a pas été reprise dans ce nouveau RFC 7303.)
Pour normaliser quelque chose à propos de XML, il faut d'abord se
pencher sur les problèmes d'encodage de
caractères. Le modèle de caractères de XML est forcément
Unicode.Les encodages de documents peuvent être
très divers, mais la norme Unicode n'en définit que trois,
UTF-8, UTF-16 et
UTF-32. UTF-8 (RFC 3629)
représente les caractères par une suite d'octets de longueur
variable. Il
n'a qu'une seule sérialisation en octets possible. UTF-16 en a deux,
car il représente les caractères (enfin, ceux du
PMB) par des seizets.
Selon qu'on mette l'octet de poids fort du seizet en premier ou en
dernier, on parle d'UTF-16 gros-boutien
(utf-16be dans une déclaration XML) ou d'UTF-16
petit-boutien (utf-16le). Quant à UTF-32, qui est
le plus simple des encodages, car le plus uniforme (tout caractère
Unicode est représenté par quatre octets, codant son point de code), il a
quatre sérialisations possibles en théorie mais deux seulement sont
définies, UTF-32BE, gros-boutien, et
UTF32-LE, petit-boutien. UTF-32
est malheureusement peu déployé (qu'on ne me dise pas que c'est parce
qu'il prend plus de place : quatre octets par caractère, à l'époque où
on s'échange des vidéos HD, ce n'est rien). Ce
RFC déconseille désormais son usage. (Une bonne discussion des problèmes avec UTF-32 est dans
ce rapport de bogue chez Mozilla.)
La section 3 du RFC décrit toutes les recommandations actuelles
pour l'encodage des documents XML envoyés sur l'Internet. UTF-8 est
recommandé (et sans BOM : il faut le retirer
si, par exemple, on convertit de l'UTF-16 en UTF-8). Les
producteurs/envoyeurs de XML devraient mettre un paramètre
charset (pour les protocoles qui ont ce
paramètre) et utiliser la déclaration XML (le truc qui commence
par <?xml version="1.0" encoding=...)
lorsqu'ils utilisent autre chose qu'UTF-8.
Cela suppose qu'ils sachent exactement quel est l'encodage. Si on
envoie de l'XML et qu'on ne peut pas déterminer son encodage, il vaut
mieux ne rien dire que de raconter n'importe quoi. Le RFC note que
c'est particulièrement important pour les serveurs Web : avoir un
paramètre global pour tout le site qui indique un encodage est
dangereux, à moins qu'on puisse être absolument sûr que tous les
documents du site auront cet encodage. Le RFC recommande que cet
étiquetage soit configurable par l'utilisateur, pour qu'il puisse
l'adapter à ses fichiers (AddDefaultCharset et
AddCharset dans
Apache.)
Quant aux consommateurs de documents XML, ils doivent considérer le
BOM comme faisant autorité, et utiliser le paramètre
charset si le BOM est absent. Les consommateurs
qui comprennent le XML peuvent, s'il n'y a ni BOM, ni
charset, utiliser les techniques purement XML,
exposées dans la norme de ce format (en gros, utiliser la déclaration
par exemple <?xml version="1.0"
encoding="ISO 8859-1"?>. Il y a plein d'exemples en
section 8 du RFC. Par exemple, ce cas-ci :
Content-Type: application/xml; charset=utf-8 ... <?xml version="1.0" encoding="utf-8"?>
est trivial : tout le monde est d'accord, le document est en UTF-8 et c'est explicite. En revanche, ce cas :
Content-Type: application/xml; charset=iso-8859-1 ... <?xml version="1.0" encoding="utf-8"?>
est pathologique : le type MIME dans l'en-tête HTTP et la déclaration
XML se contredisent. Ici, un logiciel respectueux des normes doit
traiter le document comme de l'ISO 8859-1, le
type MIME ayant priorité (il n'y a pas de BOM, qui aurait une priorité
supérieure). Mais, évidemment, l'envoyeur n'aurait pas dû
générer ces informations incohérentes. Il vaut mieux ne pas envoyer de
charset que d'envoyer un incorrect (voir aussi
annexe C.2). Ainsi, dans ce troisième exemple :
Content-Type: application/xml ... <?xml version="1.0"?>
il n'y a rien d'explicite : pas de BOM, pas de
charset dans le type MIME et pas d'encodage
indiqué dans la déclaration XML. Dans ce cas, puisque MIME ne dit
rien, on applique la règle XML : l'encodage par défaut en XML est UTF-8.
À noter que le transport le
plus utilisé pour XML, HTTP, avait un encodage de
caractères par défaut, ISO 8859-1 mais ce n'est
plus le cas depuis le RFC 7230. Voir aussi le
RFC 6657 pour l'encodage par défaut des types text/*.
Assez fait d'encodage, place aux types MIME, sujet principal de ce RFC. La section 4 donne leur liste :
- Les documents XML eux-mêmes auront le type
application/xmloutext/xml. Le RFC ne tranche pas entre les deux possibilités, alors que ce choix a fait se déplacer beaucoup d'électrons, lors des innombrables discussions sur le « meilleur » type. (Le prédécesseur, le RFC 3023 recommandaittext/xml.) - Les DTD auront le type
application/xml-dtd. - Les « entités externes analysées » (external parsed
entities), sont de type
application/xml-external-parsed-entityoutext/xml-external-parsed-entity. Si elles sont par ailleurs des documents XML bien formés (ce qui n'est pas toujours le cas), elles peuvent avoir les typesapplication/xmloutext/xml. - Les paramètres externes (external parameter
entities) ont le même type que les DTD,
application/xml-dtd.
Ils sont tous mis dans le registre IANA (cf. section 9 du RFC).
Il y a aussi le suffixe +xml (section 4.2),
utilisant la notion de suffixe du RFC 6839. Il a
vocation à être utilisé pour tous les formats XML. Si les concepteurs
de ce format ne veulent pas d'un traitement générique XML (un cas
probablement rare), ils doivent choisir un type MIME sans ce suffixe.
À noter que, si on envoie du XML en HTTP, le système de
négociation de contenu de HTTP ne prévoit pas de mécanisme pour dire
« j'accepte le XML, quel que soit le format ». Pas question de dire
Accept: text/*+xml, donc.
La section 5 décrit ensuite le cas des identificateurs de fragment
(le texte après le # dans un
URI, pour désigner une partie d'un
document). Ils sont décrits dans la section 3.5 du RFC 3986. Pour le cas particulier de XML, on se sert de la
syntaxe XPointer pour écrire ces
identificateurs (pas exemple, http://www.example.org/data.html#xpointer(/foo/bar)).
Le document XML envoyé peut utiliser l'attribut
xml:base (section 6) pour spécifier un URI de
référence, utilisé pour construire des URI absolus à partir des
relatifs qu'on peut trouver dans le document XML (par exemple, lors de
l'inclusion d'un autre document XML).
Et les versions de XML (il existe actuellement deux versions
normalisées, 1.0 et 1.1) ? Voyez la section 7, qui précise que les
types MIME sont exactement les mêmes pour toutes les versions : un
analyseur XML doit utiliser les techniques XML (le champ
version dans la déclaration) pour identifier les
versions, pas les types MIME.
Enfin, si vous vous intéressez à la sécurité, voyez la section 10
qui résume rapidement les grandes questions de sécurité de
XML. D'abord, les documents XML étant souvent modulaires (un document
déclenche le chargement de paramètres ou d'entités XML externes, ou
encore de feuilles de style), la sécurité doit
prendre en compte tous les documents extérieurs et leur technique de
chargement. Si un document XML est chargé en
HTTPS mais qu'il contient une référence HTTP à
une feuille de style CSS, la sécurité de HTTPS
ne protégera pas cette dernière, alors qu'elle pourrait, par exemple, faire
disparaître certains des éléments XML (display:
none;...) Ainsi, beaucoup de documents XML se réfèrent à des
entités XML qui sont sur les serveurs du W3C,
sans se préoccuper d'analyser la sécurité desdits serveurs. Si la
définition de l'entité mdash
est remplacée par le texte de Winnie l'ourson, de drôles de résultats peuvent
survenir.
Il y a aussi des attaques par déni de service : un document XML qui contient une référence à une entité qui contient à son tour de nombreuses autres références, qui contiennent chacune de nombreuses autres références, et ainsi de suite, jusqu'au dépassement de pile. (La forme la plus triviale de l'attaque, où l'entité se référence elle-même, est normalement empêchée par la prohibition de ces auto-références.)
Également d'un grand intérêt pratique, l'annexe C, sur les
questions opérationnelles. La situation actuelle, notamment pour
trouver l'encodage des caractères d'un document, n'est pas idéale. La
nouvelle règle sur les BOM (priorité sur le paramètre
charset) casse, en théorie, la compatibilité
mais, en pratique, n'aggrave pas la situation et devrait l'améliorer à
terme. Si on veut se simplifier la vie lors de l'envoi de XML, on le
met en UTF-8 : c'est l'encodage recommandé par défaut, et il se passe
de BOM. Si on n'utilise pas UTF-8, alors, il faut mettre un BOM.
Et le consommateur de XML ? Il lui suffit de regarder le BOM sinon
le charset sinon la déclaration XML. En suivant
ces règles simples, tout le monde devrait être heureux.
Depuis le RFC 3023, la précédente norme, que s'est-il
passé ? L'annexe D résume les nombreux et sérieux changements. Les sous-types de text comme
text/xml ont vu leur définition alignée avec
celle du sous-type
d'application. text/xml est
donc désormais un simple synonyme de
application/xml, ce qui reflète la réalité des
mises en œuvre logicielles de XML. Le BOM est désormais prioritaire
sur le charset. D'autre part,
XPointer est désormais intégré. Et
UTF-32 est maintenant officiellement
déconseillé, au nom de l'interopérabilité.
L'article seul
RFC 7300: Reservation of Last Autonomous System (AS) Numbers
Date de publication du RFC : Juillet 2014
Auteur(s) du RFC : J. Haas (Juniper
Networks), J. Mitchell (Microsoft
Corporation)
Réalisé dans le cadre du groupe de travail IETF idr
Première rédaction de cet article le 11 juillet 2014
Ce très court RFC réserve formellement deux numéros d'AS, 65535 et 4294967295, qui ne doivent donc pas être alloués à un opérateur réseau.
Ces deux AS étaient déjà réservés en pratique mais cela n'avait pas été documenté (au sens du RFC 6996). Ils sont les derniers de leur plage (65535 est le dernier des AS traditionnels sur 16 bits et 4294967295 le dernier des AS sur 32 bits du RFC 6793), d'où le titre de ce RFC.
Pourquoi les réserver ? Pour 65535, c'est parce qu'il est déjà
utilisé dans des communautés BGP bien connues
(RFC 1997 et registre
IANA, c'est le cas, par exemple, de NO_EXPORT, alias 65535:65281). Par contre, 4294967295 n'a pas de telles communautés
mais il est réservé au cas où on ait besoin d'un AS qui ne soit jamais
annoncé en BGP.
Donc, ces deux AS ne doivent pas être utilisés
sur l'Internet et ne seront donc jamais (si tout le monde respecte les
règles) dans un attribut BGP comme AS_PATH. Mais
ils peuvent servir à des usages pas encore définis et les programmes qui mettent en œuvre
BGP ne doivent donc pas interdire leur usage. Ils sont
désormais dans le registre IANA des
AS et dans celui
des AS spéciaux.
L'article seul
RFC 7304: A method for mitigating namespace collisions
Date de publication du RFC : Juillet 2014
Auteur(s) du RFC : W. Kumari (Google)
Pour information
Première rédaction de cet article le 7 juillet 2014
Il arrive parfois, lors de l'utilisation d'un nom de
domaine, qu'il y ait plusieurs noms qui correspondent à
l'intention exprimée par l'utilisateur humain (dans les milieux
ICANN, c'est souvent appelé une
collision, terme brutal conçu pour faire peur). Par exemple, si
l'utilisateur dans une entreprise example.com
tape « www.foobar » dans son
navigateur Web, peut-être comptait-il aller en
http://www.foobar.example.com/ en comptant sur
le fait que le logiciel complètera (ce qu'on nomme une search
list) mais peut-être aussi voulait-il aller en
http://www.foobar/ (le TLD
.foobar n'existe pas aujourd'hui mais, au rythme
où des TLD sont créés, cela pourrait arriver un jour). Dans ces
conditions, comment faire pour désambiguer ? Ce très court
RFC décrit une méthode... et explique pourquoi
elle est fortement déconseillée.
Ce problème n'est pas spécifique aux search lists. On peut aussi l'avoir lorsque plusieurs espaces de nommage sont utilisés, par exemple en cas de « racines alternatives ». Les partisans desdites racines écartent souvent le problème de « collision » entre deux racines en disant « il suffira de demander à l'utilisateur son choix ». Pourquoi est-ce une mauvaise idée (mon intention était d'écrire « une idée idiote » mais le RFC dont je rends compte est plus prudent) ?
La section 2 de notre RFC décrit la méthode et ses défauts : si le nom n'a qu'une
signification possible, on y va, sinon on présente à
l'utilisateur une liste des possibilités « vouliez-vous aller en
http://www.foobar.example.com/ ou en
http://www.foobar/ ? » et on lui demande de
choisir. On peut mémoriser ce choix, pour éviter de demander trop
souvent à l'utilisateur. Mes lecteurs techniques voient sans doute
immédiatement pourquoi cela ne peut pas marcher, mais ce RFC est conçu
à des fins pédagogiques, pour tordre le cou une bonne fois pour toutes
à cette fausse bonne idée, qui resurgit de temps en temps.
Quels sont les problèmes avec cette approche (si vous êtes enseignant en informatique, vous pouvez faire de cette question un sujet d'interrogation, pour voir si les étudiants ont bien compris les réseaux) ?
- Il n'y a pas toujours un humain disponible devant l'écran. Il y a des serveurs fonctionnant automatiquement, et des applications qui s'exécutent en arrière-plan (comme les mises à jour périodiques).
- L'humain peut ne pas savoir, notamment si le choix découle d'une tentative de hameçonnage ou autre tentative délibérée de l'induire en erreur.
- Le délai supplémentaire pendant lequel l'utilisateur réfléchit peut conduire l'application à renoncer.
- Ces demandes perpétuelles peuvent être pénibles pour l'utilisateur (songez qu'une seule page Web peut comporter des dizaines de noms de domaine).
- Mémoriser les choix résoudrait partiellement le problème
précédent, mais créerait d'autres ennuis, par exemple en cas de
déplacement (si l'utilisateur se servait d'un
portable et qu'il quitte les locaux de
example.com).
Bref, c'est une mauvaise solution et notre RFC la déconseille. Par contre, il ne propose pas d'alternative (il n'y en a pas de sérieuse).
Pous les informaticiens, notez que, question mise en œuvre technique d'une telle solution, on aurait
plusieurs possibilités : intercepter les requêtes de résolution de
noms dans un shim, une mince couche logicielle
entre l'application et la bibliothèque de résolution de noms (c'est
ainsi que sont souvent mis en œuvre des TLD
« alternatifs » comme .bit
ou .onion) ou bien en
remplaçant complètement la bibliothèque de résolution de noms. On
pourrait encore mettre ce service dans le navigateur Web (ignorant les
problèmes des applications non-Web), ou dans un
relais sur le trajet.
L'article seul
RFC 7252: Constrained Application Protocol (CoAP)
Date de publication du RFC : Juin 2014
Auteur(s) du RFC : Z. Shelby (Sensinode), K. Hartke, C. Bormann (Universitaet Bremen TZI)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF core
Première rédaction de cet article le 2 juillet 2014
Le protocole CoAP n'est pas destiné aux ordinateurs, ni même aux smartphones mais principalement aux petits engins, aux machines qui n'ont parfois qu'un microcontrôleur 8 bits pour tout processeur, très peu de mémoire (cf. RFC 6574) et qui, en prime, sont connectées par des liens radio lents et peu fiables (les « LowPAN » des RFC 4919 et RFC 4944), allant parfois à seulement quelques dizaines de kb/s. Pour de tels engins, les protocoles comme HTTP et TCP sont trop contraignants. CoAP est un « HTTP-like » (il reprend pas mal de termes et de concepts de HTTP, comme le modèle REST) mais spécialement conçu pour des applications M2M (machine-to-machine) dans des environnements à fortes limitations matérielles.
Le succès de HTTP et notamment de REST a
sérieusement influencé les concepteurs de CoAP. Le modèle de CoAP est celui de HTTP : protocole
requête/réponse, verbes GET,
POST, DELETE, etc, des
URI et des types de media comme sur le Web
(application/json...) Cette proximité facilitera
notamment le développement de passerelles entre le monde des objets CoAP et le Web
actuel (section 10). Une des pistes explorées
pour l'Internet des Objets (terme
essentiellement marketing mais répandu) avait été de prendre de l'HTTP
normal et de comprimer pour gagner des ressources réseau mais CoAP
suit une autre voie : définir un protocole qui est essentiellement un
sous-ensemble de HTTP. Si vous connaissez HTTP, vous ne serez pas trop
perdu avec CoAP.
CoAP tournera sur UDP (RFC 768), TCP étant trop consommateur de ressources, et, si on veut de la sécurité, on ajoutera DTLS (RFC 6347). CoAP fonctionne donc de manière asynchrone (on lance la requête et on espère une réponse un jour). On pourrait décrire CoAP comme composé de deux parties, un transport utilisant UDP avec des extensions optionnelles si on veut de la fiabilité (accusés de réception), et un langage des messages (requêtes et réponses en HTTP-like).
Et les messages ? L'en-tête CoAP (section 3 du RFC) a été conçu pour être facile à
analyser par des programmes tournant sur de petites machines. Au lieu du texte lisible de HTTP, l'en-tête de CoAP
commence par une partie fixe de quatre octets, qui comprend un
Message ID de deux octets. Ce Message
ID permet de détecter les duplicatas et d'associer un accusé
de réception à un message précis. À noter qu'avec ces deux octets, on
est limité à environ 250 messages par seconde (en raison du paramètre
EXCHANGE_LIFETIME qui est à 247 secondes par
défaut). Ce n'est pas une limite bien grave : les ressources
(en énergie, en capacité réseau, etc) des machines CoAP ne leur permettront pas
d'être trop bavardes, de toute façon.
Le message contient également un champ Token (utilisé pour mettre en correspondance les requêtes et les réponses, à un niveau supérieur à celui des messages, qui sont, eux, identifiés par le Message ID) et un code sur huit bits. Ce code s'écrit sous forme d'un groupe de trois chiffres, le premier indiquant la classe (2 : succès, 4 : erreur du client, 5 : erreur du serveur, etc) et suivi d'un point, et les deux autres chiffres fournissant des détails. Comme vous connaissez HTTP, vous ne serez pas étonné d'apprendre que le code 4.03 indique un problème de permission... Un registre de ces codes existe.
Notez bien que l'encodage, lui, est radicalement différent de celui de HTTP. Il est en binaire et le code 4.03 sera transmis sous forme d'un octet (10000011, avec 100 pour la classe et 11 pour le détail), pas sous forme de la chaîne de caractères qu'utilise HTTP.
Le message contient ensuite des options, qui jouent le rôle des
en-têtes de requête de HTTP (leur liste est également
dans un registre, on y trouve des trucs
connus comme If-Match - section 5.10.8.1,
Accept - section 5.10.4 - ou
ETag - section 5.10.6). Pour économiser
quelques bits, leur encodage est assez spécial. Le numéro de l'option,
normalement sur 16 bits, n'est pas transmis tel quel mais sous forme
d'une différence avec l'option précédente. Ainsi, si on utilise les
options 4 (ETag) et 5
(If-None-Match), la première option indiquera
bien 4 mais la seconde indiquera 1... De même, les valeurs de l'option
sont violemment comprimées. Si on veut envoyer un entier, on ne doit
transmettre que le nombre d'octets nécessaire (rien si l'entier vaut
zéro, un seul octet s'il est inférieur à 255, etc).
Le transport utilisé par CoAP, UDP, ne
fournit aucune garantie de remise : un paquet UDP peut être perdu, et
UDP ne s'en occupera pas, ce sera à l'application de gérer ce
cas. CoAP fournit un service pour faciliter la vie aux applications :
on peut marquer un message CoAP comme nécessitant un accusé de
réception (type CON pour
Confirmable). Si ce type est présent dans
l'en-tête CoAP, l'expéditeur recevra un accusé de réception
(type ACK) portant le Message ID du
message reçu. Le RFC fournit l'exemple d'un capteur de
température interrogé en CoAP :
Client -> Serveur: CON [0xbc90] "GET /temperature" Serveur -> Client: ACK [0xbc90] "2.05 Content" "22.5 °C"
Ici, le second message, la réponse du serveur, contient un accusé de
réception pour 0xbc90 (le Message ID). La requête
est un GET et la réponse a le code 2.05 (un
succès). Notez que, contrairement à HTTP, les codes sont écrits avec
un point entre le premier chiffre (la classe) et les deux autres (le
détail, cf. section 5.9). Ainsi, 4.04
a la classe 4 (erreur du client) et le détail 04 (ressource non
trouvée). Comme indiqué plus haut, les classes sont les mêmes qu'en HTTP : 2 pour un succès, 4 pour une erreur du client (qui devrait
changer sa requête avant de réessayer) et 5 pour une erreur du serveur
(réessayer à l'identique plus tard peut marcher).
Le Message ID et ces types
CON et NON (son contraire,
Non-confirmable) permettent de mettre en œuvre des
mécanismes simples de retransmission. L'émetteur envoie un message de
type CON, s'il ne reçoit pas de message de type
ACK à temps, il réessaie, avec
croissance exponentielle du délai. Le
Message-ID permet aussi de détecter les éventuels duplicatas.
On n'est pas obligé d'utiliser le type CON. Si
un message n'a pas besoin de fiabilité (par exemple les lectures
périodiques qu'envoie un capteur, que quelqu'un
écoute ou pas), il sera du type NON.
Le Message ID doit évidemment être unique,
pendant la durée de vie possible des échanges (variable
EXCHANGE_LIFETIME, quatre minutes par défaut). Il
peut être généré de manière incrémentale (l'émetteur garde un compteur
indiquant le dernier Message ID généré) mais, dans
ce cas, le RFC recommande (section 4.4) que la valeur initiale soit aléatoire, pour
limiter les possibilités d'attaque par un méchant non situé sur le
chemin des données (c'est un problème de sécurité analogue à celui des
identificateurs de fragments IP - voir l'option
--frag-id-policy de l'outil frag6 - ou celui des
numéros de séquences initiaux de TCP - voir le RFC 6528).
Autre problème pour l'émetteur CoAP : quelle taille de messages ? Les machines pour qui CoAP est conçu peuvent avoir du mal à gérer parfaitement la fragmentation. Et puis des gros paquets ont davantage de chances d'être corrompus que des petits, sur les liens radios typiques des machines CoAP. Le RFC recommande donc de ne pas dépasser la MTU et, si elle est inconnue, de ne pas dépasser 1 280 octets en IPv6. (C'est plus compliqué pour IPv4 où le RFC recommande 576 octets et le bit DF - Don't Fragment - en notant que, pour les usages typiques de CoAP, le chemin sera simple, avec peu de routeurs et pas de liens à grande distance, donc peu de chances que la fragmentation soit nécessaire.)
Comme CoAP repose sur UDP, il n'y a pas de mécanisme de contrôle de
la congestion par défaut. CoAP doit donc
s'auto-limiter : réémissions avec croissance
exponentielle des délais, et au maximum une requête en attente pour
chaque machine avec qui on communique (paramètre
NSTART). Ces règles sont pour le client. Si tous
les clients les respectent, tout ira bien. Mais un
serveur CoAP prudent doit considérer que certains clients seront
bogués ou malveillants. Les serveurs ont donc tout intérêt à avoir une forme ou
une autre de limitation de trafic.
La sémantique des requêtes et réponses CoAP figure en section 5. On l'a dit, elle ressemble à celle de HTTP, un client qui envoie une requête et un serveur qui transmet une réponse. L'une des plus grosses différences avec HTTP est le caractère asynchrone de l'échange.
Les requêtes sont les classiques (section 5.8) GET,
POST, PUT et
DELETE, agissant sur une ressource donnée
(identifiée par un URI), comportant des données
optionnelles (surtout utilisées pour POST et
PUT) et utilisant les types de
média. CoAP exige que GET,
PUT et DELETE soient
idempotents (une bonne pratique mais pas
toujours respectée sur le Web). Une requête non reconnue et la
réponse sera un 4.05. La liste des requêtes possibles est dans un registre IANA.
Du fait du caractère asynchrone de l'échange, mettre en correspondance une requête et une réponse est un peu plus compliqué qu'en HTTP, où toutes les deux empruntaient la même connexion TCP. Ici, la section 5.3.2 résume les règles de correspondance : une réponse correspond à une requête si l'adresse IP source de la réponse était l'adresse IP de destination de la requête et que le Message ID et le Token correspondent.
Comme HTTP, CoAP permet d'utiliser des relais. C'est d'autant plus important que les machines CoAP sont souvent indisponibles (hibernation pour économiser la batterie, par exemple) et un relais pourra donc répondre à la place d'une machine injoignable. Les relais sont traités plus en détail en section 5.7. Comme en HTTP, on pourra avoir des forward proxies sélectionnés par les clients ou des reverse proxies placés devant un serveur.
On l'a vu, CoAP, comme HTTP, utilise des
URI, détaillés en section 6. Ils commencent par
les plans coap: ou
coaps:. On verra ainsi, par exemple,
coap://example.com/~sensors/temp.xml ou
coaps://[2001:db8::2:1]/measure/temperature/. Attention,
tout le monde croit bien connaître les URI car ils sont massivement
utilisés pour le Web mais le RFC met en garde les programmeurs : il y
a plein de pièges dans le traitement des URI, notamment dans le
décodage des valeurs encodées en pour-cent.
Si le port n'est pas indiqué dans l'URI (ce
qui est le cas des deux exemples ci-dessus), le port par défaut est
5683 pour coap: et 5684 pour coaps:.
CoAP utilise, comme HTTP, la convention du
/.well-known/ (RFC 8615)
pour placer des ressources « bien connues », facilitant ainsi leur
découverte.
Justement, à propos de découverte, la section 7 détaille comment un
client CoAP va pouvoir trouver les URI des ressources
intéressantes. CoAP est conçu pour des communications de machine à
machine, où aucun humain n'est présent dans la boucle pour deviner,
faire une recherche Google, utiliser son
intuition, etc. La méthode privilégiée dans CoAP est celle du RFC 6690 : un fichier au format normalisé situé en
/.well-known/core.
Les section 9 et 11 sont consacrées à la sécurité de CoAP. Évidemment, vu les ressources très limitées des machines CoAP typiques, il ne faut pas s'attendre à une grande sécurité. Par exemple, une protection par DTLS (RFC 6347) est possible mais pas obligatoire, juste conseillée. En outre, les ressources matérielles limitées des machines CoAP compliquent la tâche du programmeur : des processeurs très lents qui facilitent les attaques par mesure du temps écoulé, et pas de bon générateur aléatoire. En l'absence d'un tel générateur, on ne peut donc pas générer des clés cryptographiques localement, il faut le faire en usine et les enregistrer sur la machine. Et pas question de mettre les mêmes clés à tout le monde : comme les machines CoAP seront souvent dispersées dans des endroits ayant peu de sécurité physique (capteurs placés un peu partout), et n'auront en général pas de protection contre les manipulations physiques, pour des raisons de coût, un attaquant pourra facilement ouvrir une machine et en extraire ses clés.
La complexité est l'une des ennemies principales de la sécurité. Le RFC rappelle que le traitement des URI (bien plus compliqué qu'il n'en a l'air) impose des analyseurs relativements complexes et donc augmente la probabilité de bogues, pouvant mener à des failles de sécurité. Même chose pour le format des liens du RFC 6690.
Question réseau, CoAP souffrira sans doute d'attaques rendues possibles par l'usurpation d'adresses IP. Comme UDP ne nécessite pas d'échange préalable, il est trivial d'envoyer un paquet depuis une adresse usurpée et de le voir accepté. Cela permet des tas d'attaques comme :
- Envoyer un
RST(Reset) aux demandes de connexion vers un serveur, rendant ainsi ce serveur inutilisable (déni de service), - Envoyer une fausse réponse à une requête
GET.
Pour cette deuxième attaque, il faut pouvoir deviner le Token utilisé. Si l'attaquant est aveugle (parce que situé en dehors du chemin des paquets), sa tâche sera difficile si le Token est bien aléatoire (mais ces machines contraintes en ressources n'ont souvent pas de vrai générateur aléatoire, au sens du RFC 4086).
En pratique, il est probable que les déploiements réels de CoAP aient lieu dans des réseaux fermés, ne contenant que des machines de confiance, et où l'accès à l'extérieur passera par une passerelle qui s'occupera de sécurité. Autrement, un simple ping à destination d'une machine CoAP pourrait suffir à vider sa batterie.
CoAP introduit aussi une autre menace, celle d'attaques par amplification (section 11.3). Comme SNMP et le DNS (tous les deux déjà utilisés pour ces attaques), CoAP a des réponses plus grandes que les questions (permettant l'amplification) et repose sur UDP et non pas TCP (permettant l'usurpation d'adresse IP).
La seule limite à ces attaques semble devoir être les faibles ressources des machines CoAP, qui devraient les rendre relativement peu intéressantes comme amplificateurs contre des serveurs Internet. En revanche, à l'intérieur d'un réseau de machines CoAP, le risque demeure élevé et le RFC ne propose aucune vraie solution.
CoAP est, d'une certaine façon, un vieux protocole (voir l'article « CoAP: An Application Protocol for Billions of Tiny Internet Nodes » de Carsten Bormann, Angelo Paolo Castellani et Zach Shelby publié en 2012 dans dans Internet Computing, IEEE (Volume:16 , Issue: 2) et malheureusement pas disponible en ligne, il faut demander une copie à l'auteur). Il existe déjà plusieurs mise en œuvre, qui ont été souvent testées dans des essais d'interopérabilité formels. Un exemple de mise en œuvre est celle du système Contiki.
Des exemples de requêtes CoAP décrites en détail figurent dans l'annexe A du RFC. Grâce à Renzo Navas, voici quelques traces CoAP au format pcap :
- Un simple GET du
fichier des services,
/.well-known/core, - Un autre GET,
- Un GET avec réponse,
- POST, PUT et DELETE.
Si tcpdump ne connait pas encore CoAP,
Wireshark, par contre, sait bien
l'analyser. Ici, une
la première requête GET du premier fichier pcap et sa réponse :
Constrained Application Protocol, TID: 27328, Length: 21
01.. .... = Version: 1
..00 .... = Type: Confirmable (0)
.... 0000 = Option Count: 0
Code: GET (1)
Transaction ID: 27328
Payload Content-Type: text/plain (default), Length: 17, offset: 4
Line-based text data: text/plain
\273.well-known\004core
Constrained Application Protocol, TID: 27328, Length: 521
01.. .... = Version: 1
..10 .... = Type: Acknowledgement (2)
.... 0000 = Option Count: 0
Code: 2.05 Content (69)
Transaction ID: 27328
Payload Content-Type: text/plain (default), Length: 517, offset: 4
Line-based text data: text/plain
\301(\261\r
[truncated] \377</careless>;rt="SepararateResponseTester";title="This resource will ACK anything, but never send a separate response",</helloWorld>;rt="HelloWorldDisplayer";title="GET a friendly greeting!",</image>;ct="21 22 23 24";rt="Ima
Merci à Laurent Toutain pour sa relecture attentive.
L'article seul
RFC 7288: Reflections On Host Firewalls
Date de publication du RFC : Juin 2014
Auteur(s) du RFC : D. Thaler (Microsoft)
Pour information
Première rédaction de cet article le 2 juillet 2014
Aujourd'hui, on met des pare-feux partout et leur présence est en général considérée, sans aucune réflexion supplémentaire, comme indispensable. Il existe des pare-feux qui se branchent sur le réseau et protègent ainsi toutes les machines du réseau (network firewall). Et il existe des pare-feux sur les machines terminales, des host firewalls, qui font l'objet de ce RFC. En présence d'un tel pare-feu, on peut avoir une application qui tourne, et donc consomme des ressources, mais ne peut pas communiquer avec l'extérieur puisqu'elle est bloquée par le pare-feu. Le même résultat de sécurité pourrait être atteint en ne faisant pas tourner l'application, ou en la configurant pour limiter ses possibilités. Cette approche ne serait-elle pas meilleure ?
Le RFC 2979 discutait des pare-feux sur l'Internet et des propriétés qu'on attendait d'eux (et les RFC 4949 et RFC 4948 discutaient de la terminologie). Le RFC 2979 pointait notamment le risque de « faux positif », lorsqu'un pare-feu bloque accidentellement une communication légitime. Les vendeurs de pare-feux oublient toujours de mentionner ce risque. Pourtant, nombreux sont les pare-feux qui bloquent stupidement des connexions parfaitement légitimes, par exemple parce que les paquets IP contiennent des options, ou des en-têtes IPv6 (cf. RFC 7045). Le RFC 4924 revient sur cette question des pare-feux en notant qu'ils sont largement responsables de l'ossification de l'Internet, et que de plus en plus d'applications consacrent beaucoup d'effort à contourner ces obstacles. En outre, les pare-feux contribuent souvent à un faux sentiment de sécurité, qui peut mener à baisser sa garde sur les machines supposées « protégées par le pare-feu » (section 6 de notre RFC). Enfin, la section 1.1 du RFC rappelle que le NAT n'est pas un vrai pare-feu.
Le problème des pare-feux est d'autant plus aigu que la réponse classique à la question de l'utilité d'un pare-feu est « bloquer le trafic non souhaité », mais que cette réponse ne dit pas « non souhaité par qui ». Par l'utilisateur final ? Par son employeur ? Par l'administrateur réseau ? Par le développeur ? Leurs intérêts sont souvent en conflit et on ne peut pas espérer un consensus simple entre tous ces acteurs (le RFC reprend l'excellent terme de « tussle »). Pas étonnant qu'on voit souvent des « courses aux armements » entre ceux qui bloquent et ceux qui contournent le blocage.
Le pare-feu typique est souvent configuré par des règles allow/deny où on indique que tel type de trafic est autorisé ou interdit (section 2 du RFC). Voici par exemple des règles Shorewall où tout est interdit par défaut mais où on accepte quelques services :
# SMTP ACCEPT net fw tcp 25 ACCEPT net fw tcp 587 # IMAP, IMAPS et POPS ACCEPT net fw tcp 143 ACCEPT net fw tcp 993 ACCEPT net fw tcp 995 # Nagios Remote Execution (NRPE) ACCEPT net:192.0.2.187 fw TCP 5767 # SNMP ACCEPT net:192.0.2.187,203.0.113.170 fw udp 161
Pour un pare-feu sur une machine terminale, l'utilisateur n'a pas le droit de modifier ces règles sauf dans le cas (fréquent avec les machines personnelles) où l'utilisateur est en même temps administrateur système. Par contre, des applications peuvent configurer le pare-feu, pour les systèmes où celui-ci fournit une API aux applications, ou bien s'il existe un protocole standard de changement de la configuration du pare-feu comme UPnP ou son successeur potentiel PCP (RFC 6887). Ces règles sont classées par notre RFC en deux catégories : réduction de la surface d'attaque (empêcher l'application de faire des choses que le développeur ne voulait pas qu'elle fasse) et politique de sécurité (empêcher l'application de faire des choses que l'administrateur système ne voulait pas qu'elle fasse).
La section 3 décrit la première catégorie, la réduction de la surface d'attaque. On peut se demander si cette catégorie est utile : après tout, si on ne veut pas qu'une application, par exemple, détruise des fichiers en réponse à une requête venue par le réseau, le mieux est de ne pas mettre en œuvre cette fonction. On sera alors bien plus en sécurité. Sauf qu'on n'a pas toujours le luxe d'avoir uniquement des applications bien conçues et bien écrites. Souvent, le développeur a fait des impasses (ou, en termes plus savants, a pris de la dette technique) et réécrire l'application serait trop coûteux. C'est par exemple le cas de beaucoup d'applications Web programmées à la va-vite sans souci de sécurité, en PHP ou VB.NET. Coller un pare-feu devant l'application est en général moins coûteux et plus efficace que de se plonger dans le plat de spaghettis.
Il y a aussi des cas où la dette prise par le développeur (reporter le problème à plus tard...) était justifiée par un manque de support de la part du système. Par exemple, une règle aussi simple et courante que « communication uniquement avec le lien local » est difficile à mettre en œuvre de façon portable, sur Unix, dans tous les langages de programmation. (Notez au passage que n'autoriser que les adresses IP source du même réseau que celui du serveur n'est pas suffisant, en raison de la possibilité d'usurpation d'adresse. Pour UDP, il faudrait aussi tester le TTL, cf. RFC 5082.) Il y a aussi le cas où la machine se déplace d'un réseau sûr à un réseau non-sûr. Le développeur est donc tenté de déléguer la mise en œuvre de cette politique à un pare-feu.
Même chose avec des politiques complexes, comme de ne communiquer que sur les liens les moins coûteux, sachant que l'application n'a pas forcément connaissance des coûts (sur Android, cette politique est en général purement binaire : on considère que la 3G est coûteuse et le Wifi gratuit, ce qui n'est pas toujours vrai.) Avoir une API permettant à l'application d'exprimer ses souhaits, que le système d'exploitation traduirait en règles de pare-feu concrètes, simplifierait beaucoup les choses.
Quelles sont donc les solutions pour l'utilisateur, qui se retrouve avec une application « imparfaite », pleine de failles de sécurité ? D'abord, réparer le logiciel en corrigeant ces failles. Les partisans des pare-feux feront évidemment remarquer qu'il est plus rapide et plus efficace d'utiliser un pare-feu : déboguer un logiciel mal écrit est long et coûteux et on n'est jamais sûr d'avoir bouché tous les trous de sécurité. Il y a d'ailleurs des cas où réparer le logiciel est quasi-impossible : pas les sources pour le faire ou bien pas de mécanisme de mise à jour pour les engins qui font tourner ce logiciel. En général, un changement des règles du pare-feu peut être déployé plus facilement qu'un patch.
Autre idée, ne pas utiliser le logiciel. Solution brutale mais qui résout tout. Notez que l'idée n'est pas si violente qu'elle en a l'air : certains systèmes font tourner par défaut des logiciels qui ne devraient pas tourner. Arrêter ce logiciel inutile est une solution réaliste.
Enfin, il y a le pare-feu, qui va protéger contre le logiciel mal fait. Le logiciel tournera toujours, consommant des ressources (personnellement, je ne trouve pas l'argument très convaincant : si le logiciel est juste en attente d'événements, il ne consomme pas grand'chose). Et, surtout, si un utilisateur tente de se servir du logiciel, il aura des surprises, car beaucoup de programmes ne sont pas conçus de manière robuste : ils réagissent mal quand, par exemple, certains services réseau ne leur sont pas accessibles. Parfois, cela aggrave la consommation de ressources (par exemple, le logiciel, n'ayant pas compris qu'il était bloqué par le pare-feu, réessaie en boucle). Autre problème avec les pare-feux : ils sont souvent surbloquants. Par exemple, ils bloquent tout ce qu'il ne connaissent pas et gênent donc considérablement l'innovation. Certains analysent les paquets de manière très sommaire (oubliant par exemple certaines fonctions avancées du protocole) et prennent donc de mauvaises décisions. C'est ainsi qu'ICMP est souvent bloqué, menant à des problèmes de découverte de la MTU du chemin (RFC 4890 et RFC 2979).
Deuxième catégorie de règles dans un pare-feu, celles qui visent à faire respecter une politique de sécurité. L'administrateur a décidé qu'on ne regarderait pas YouTube, les règles bloquent YouTube. Cette catégorie peut en théorie être mise en œuvre à trois endroits. D'abord, dans les applications elles-mêmes. Ça ne passe évidemment pas à l'échelle : il faudrait ajouter du code à toutes les applications (faites un peu une liste du nombre de clients HTTP sur votre machine, par exemple ; rappelez vous qu'il n'y a pas que les navigateurs Web) et les configurer. En pratique, il y aura toujours une application oubliée. Cette solution n'est donc pas réaliste.
Deuxième endroit possible, le pare-feu. Outre les problèmes discutés plus haut (application qui réagit mal au blocage de certains services), cela mène facilement à une course aux armements : comme les désirs de l'utilisateur final et de l'administrateur du pare-feu ne coïncident pas forcément, les applications, à la demande des utilisateurs, vont évoluer pour contourner le filtrage, qui va devenir de plus en plus intrusif et ainsi de suite jusqu'à ce que tout le monde, pris dans cette course, oublie le but originel de la politique de sécurité. Comme le disait la section 2.1 du RFC 4924, le filtrage sans le consentement (au moins passif) de l'utilisateur est difficile, et va mener à des solutions compliquées, coûteuses et fragiles, violant largement les bons principes d'architecture réseau (par exemple en faisant tout passer au-dessus de HTTP, seul protocole autorisé).
Reste le troisième endroit, qui a plutôt les faveurs du RFC : faire des politiques de sécurité un service auquel s'inscrivent les applications. L'application utilise une bibliothèque (comme les TCP wrappers) ou bien parle un protocole réseau (comme PCP, RFC 6887), décrit ce qu'elle veut, et apprend si c'est autorisé ou pas, de manière propre. Cela nécessite évidemment des standards (comme PCP, qui est pour l'instant très peu déployé, et qui est de toute façon sans doute insuffisant pour gérer toutes les politiques possibles) car on n'imagine pas chaque application ajouter du code pour l'API de chaque marque de pare-feu.
Cette technique est très originale par rapport à l'approche habituelle sur les pare-feux mais c'est celle recommandée par notre RFC. Pour le résumer en une phrase, on fait trop travailler les pare-feux et pas assez les applications.
L'article seul
RFC 7250: Using Raw Public Keys in Transport Layer Security (TLS) and Datagram Transport Layer Security (DTLS)
Date de publication du RFC : Juin 2014
Auteur(s) du RFC : P. Wouters (Red Hat), H. Tschofenig, J. Gilmore, S. Weiler (SPARTA), T. Kivinen (AuthenTec)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 1 juillet 2014
Le système de sécurité TLS, normalisé dans le RFC 5246 est souvent confondu avec la norme de certificats X.509. On lit souvent des choses comme « le serveur TLS envoie alors un certificat X.509 au client », voire, pire, on appelle ces certificats « certificats TLS » (ou, encore plus inexact, « certificats SSL »). Dans la réalité, les deux systèmes, TLS et X.509, sont indépendants. X.509 peut servir à autre chose qu'à TLS (et c'est pourquoi parler de « certificats SSL » est une grosse erreur), et TLS peut utiliser d'autres techniques d'authentification que X.509. Une de ces techniques était déjà spécifiée dans le RFC 6091, l'utilisation de clés PGP. Une autre vient d'être normalisée dans ce RFC, l'utilisation de « clés brutes » (raw keys), sans certificat autour. Comme une clé seule ne peut pas être authentifiée, ces clés brutes n'ont de sens que combinées avec un mécanisme d'authentification externe, comme DANE.
Rappelons en effet qu'un certificat, c'est une clé
publique (champ SubjectPublicKeyInfo
dans X.509) plus un certain nombre de métadonnées (comme la
date d'expiration) et une signature par une autorité qui certifie la clé. Pour la session
TLS, la seule partie indispensable est la clé (dans un certificat
« auto-signé », seule la clé a un sens, le reste du certificat ne
pouvant pas être vérifié). Mais, en pratique, le
chiffrement sans l'authentification est limité : il ne protège que
contre un attaquant purement passif. Dès que l'attaquant est actif
(pensons par exemple à un
hotspot Wifi tentant... mais tenu par
l'attaquant), il peut rediriger le client TLS vers un serveur intermédiaire qui va faire croire au client qu'il est le vrai serveur, avant
de retransmettre vers le serveur authentique. Pour contrer cette
attaque de l'homme du milieu, on
authentifie le serveur. Sur l'Internet, la
méthode la plus courante est l'utilisation de certificats
X.509, ou plus précisement de leur profil
PKIX (RFC 5280). Cette
méthode est d'une fiabilité très douteuse : des centaines
d'organisations dans le monde peuvent émettre
un faux certificat pour gmail.com et il ne peut donc pas y
avoir de confiance rationnelle dans ce système (cf. « New
Tricks for Defeating SSL in Practice »).
Il existe d'autres méthodes d'authentification que X.509, permettant de faire un lien entre le serveur qu'on veut contacter, et l'entité qui nous envoie une clé publique en TLS :
- Les certificats ou clés publiés dans le DNS et sécurisés par DNSSEC, à savoir la technique DANE du RFC 6698,
- Les certificats ou clés publiés dans un annuaire LDAP,
- Les certificats ou clés stockés en dur chez le client. Cela manque de souplesse (il est difficile de les changer) et ce n'est donc pas très recommandé pour l'Internet public mais c'est envisagé pour des déploiements plus fermés comme ceux du protocole CoAP (RFC 7252), où les objets peuvent sécuriser la communication avec DTLS. (Cette troisième méthode est sans doute la seule possible pour l'authentification du client TLS par le serveur, cf. section 4.3.)
La section 6 de notre RFC revient en détail sur l'authentification de ces clés brutes. Sans cette authentification, une session TLS utilisant ces clés est très vulnérable à l'homme du milieu.
La section 3 décrit les détails de format des clés brutes. Il faut
deux extensions au protocole TLS, client_certificate_type
et server_certificate_type (enregistrées
dans le
registre des extensions), qui permettent d'indiquer
(lors de la négociation TLS)
séparément le type de certificat utilisé par le serveur et par le
client. Par exemple, pour le serveur, cela s'écrit ainsi :
struct {
select(ClientOrServerExtension) {
case client:
CertificateType server_certificate_types<1..2^8-1>;
case server:
CertificateType server_certificate_type;
}
} ServerCertTypeExtension;
Lorsque ces extensions TLS sont utilisées, la structure
Certificate est modifiée ainsi :
struct {
select(certificate_type){
// certificate type defined in this document.
case RawPublicKey:
opaque ASN.1_subjectPublicKeyInfo<1..2^24-1>;
// X.509 certificate defined in RFC 5246
case X.509:
ASN.1Cert certificate_list<0..2^24-1>;
// Additional certificate type based on TLS
// Certificate Type Registry
// https://www.iana.org/assignments/tls-extensiontype-values/tls-extensiontype-values.xhtml#tls-extensiontype-values-3
// for instance PGP keys
};
} Certificate;
(On notera que le RFC 6091 utilisait un autre
mécanisme, l'extension cert_type, numéro 9, mais qui n'a pas été réutilisée ici, le RFC 6091 n'ayant pas le statut « Chemin des Normes » et le mécanisme cert_type ne permettant pas des types différents pour le client et le serveur.) Le champ
subjectPublicKeyInfo contient un encodage
DER de la clé et d'un identificateur
d'algorithme (un OID comme 1.2.840.10045.2.1
pour ECDSA) :
SubjectPublicKeyInfo ::= SEQUENCE {
algorithm AlgorithmIdentifier,
subjectPublicKey BIT STRING }
L'omission d'une grande partie du certificat permet de se contenter d'un analyseur ASN.1 plus réduit. Mais les clés brutes ne sont malheureusement pas réellement brutes, c'est quand même une structure décrite en ASN.1 et il faut donc un analyseur minimal.
La section 4 décrit les modifications à la négociation initiale de
TLS (les autres parties de la communication ne sont pas modifiées par
ce RFC). Le client ajoute une ou deux des extensions TLS (la plupart
du temps, en TLS, le client ne s'authentifie pas, et on n'aura donc
que l'extension server_certificate_type). La ou
les extensions indiquent les types de certificat reconnus par le pair
TLS (si l'extension est absente, seul X.509 est reconu). Ainsi, un
serveur nouveau, intégrant les clés brutes, sait tout de suite si un
client pourrait les traiter (si le client n'a pas mis
server_certificate_type, ou bien si son
server_certificate_type n'inclut pas les clés
brutes, ce n'est pas la peine d'en envoyer). Si c'est le client qui
est nouveau et le serveur ancien, la réponse du serveur ne contiendra
pas les extensions et le client saura donc qu'il ne faut pas
s'attendre aux clés brutes. Si le serveur reconnait l'extension, mais
aucun des types de certificats indiqués, il termine la session. À noter que
ces clés brutes marchent avec tous les algorithmes de
cryptographie déjà reconnus.
La section 5 du RFC fournit des exemples de sessions TLS avec cette
nouvelle possibilité. Par exemple, ce dialogue montre un client qui
gère les clés brutes du serveur (et uniquement celles-ci, ce n'est
donc pas un navigateur Web typique) et un serveur qui
accepte d'envoyer sa clé ainsi. Le client n'est pas authentifié (il
n'envoie pas sa clé ou son certificat et ne se sert donc pas de client_certificate_type) :
client_hello,
server_certificate_type=(RawPublicKey) // [1]
->
<- server_hello,
server_certificate_type=(RawPublicKey), // [2]
certificate, // [3]
server_key_exchange,
server_hello_done
client_key_exchange,
change_cipher_spec,
finished ->
<- change_cipher_spec,
finished
Application Data <-------> Application Data
Ce cas d'un client ne comprenant que les clés brutes est un cas qui peut se produire pour l'Internet des objets, par exemple avec CoAP. Mais un client différent, par exemple un navigateur Web, va accepter d'autres types de certificats. Le dialogue pourrait ressembler à :
client_hello,
server_certificate_type=(X.509, RawPublicKey)
client_certificate_type=(RawPublicKey) // [1]
->
<- server_hello,
server_certificate_type=(X.509)//[2]
certificate, // [3]
client_certificate_type=(RawPublicKey)//[4]
certificate_request, // [5]
server_key_exchange,
server_hello_done
certificate, // [6]
client_key_exchange,
change_cipher_spec,
finished ->
<- change_cipher_spec,
finished
Application Data <-------> Application Data
Ici, le serveur reconnait la nouvelle extension mais ne sait envoyer
que des certificats X.509 (ce qui est donc fait par la suite). Le
client, lui, s'authentifie en envoyant une clé brute (même si ce
message est marqué certificate dans le dialogue).
Il existe apparemment déjà plusieurs mises en œuvre de TLS qui utilisent ces extensions, par exemple GnuTLS.
L'article seul
RFC 7284: The Profile URI Registry
Date de publication du RFC : Juin 2014
Auteur(s) du RFC : M. Lanthaler
Pour information
Première rédaction de cet article le 1 juillet 2014
Le RFC 6906 définit la notion de profil, une variante (en général restrictive) d'un format. Les profils du RFC 6906 sont identifiés par un URI et ce nouveau RFC crée un registre de ces URI, afin de faciliter la tâche des développeurs.
Les conditions d'inscription dans le registre sont spécifiées dans
la section 2 : il faut indiquer l'URI qui sert d'identificateur, un nom
court pour le profil, la description et un lien vers une documentation stable du profil, accessible
publiquement. Ensuite (section 4), c'est du premier arrivé, premier servi
(politique décrite dans la section 4.1 du RFC 5226).
La section 3 donne un exemple en utilisant un profil
bidon, http://example.com/profiles/example.
Le registre est désormais en ligne et comprend au début cinq profils :
urn:example:profile-uri, prévu pour être utilisé dans les exemples, documentations, etc,- Dublin Core
http://dublincore.org/documents/2008/08/04/dc-html/, un moyen pour mettre les métadonnées en HTML, http://www.w3.org/ns/json-ld#expanded,http://www.w3.org/ns/json-ld#compactedethttp://www.w3.org/ns/json-ld#flattened, des profils du monde JSON décrits dans une norme du W3C.
L'article seul
RFC 7282: On Consensus and Humming in the IETF
Date de publication du RFC : Juin 2014
Auteur(s) du RFC : P. Resnick (Qualcomm)
Pour information
Première rédaction de cet article le 1 juillet 2014
L'IETF, organisme de normalisation des protocoles de l'Internet, fonctionne normalement par « consensus ». Il n'y a pas de vote formel, pas de majorité qui décide, on discute jusqu'à ce que presque tout le monde soit d'accord. À cause du « presque », on parle de « consensus approximatif » (rough consensus). Ça, c'est la théorie. En pratique, les évolutions récentes font que de plus en plus de décisions sont prises suite à des opérations qui ressemblent pas mal à des votes majoritaires, justement ce que les règles de l'IETF voulaient éviter. D'où ce RFC d'opinion, écrit pour défendre le principe du consensus approximatif, et pour appeler à se méfier de ces dérives.
Ce RFC a le statut « pour information » et représente le point de vue de son auteur : ce n'est pas un document officiel. En outre, il ne définit pas de nouvelles règles, il explique juste le fonctionnement idéal. Pour résumer ce RFC, revenons à la théorie. Le fonctionnement normal de l'IETF a été traduit par une percutante phrase de Dave Clark (dans « A Cloudy Crystal Ball - Visions of the Future »), que tous les participants à l'IETF connaissent par cœur : « We reject kings, presidents and voting. We believe in rough consensus and running code. ». Les décisions à l'IETF ne peuvent pas être prises par un seul individu (roi ou président), mais elles ne doivent pas non plus être prises par un vote, pour les raisons expliquées plus loin. Au contraire, elles doivent s'appuyer sur le consensus approximatif, lui-même nourri d'expérience concrète (le « running code », par opposition à des organisations comme l'ISO qui ont développé des usines à gaz impossibles à programmer). La pratique doit toujours l'emporter : le code qui marche a raison.
Notez que le consensus est approximatif : avoir un consensus tout court (tout le monde est d'accord ou, au moins, se tait) serait l'idéal mais ce n'est pas réaliste. Demander un consensus complet serait donner un droit de veto à n'importe quel individu négatif qui s'oppose à tout (l'IETF, comme toute organisation humaine, a quelques trolls de ce calibre...).
Comme il n'y a pas de vote, l'IETF a développé une autre pratique inhabituelle, le mmmmmmmm (humming). Lorsqu'on veut avoir une idée de l'opinion des gens, lors d'une réunion physique, on demande à chacun de se manifester par ce bruit produit en gardant la bouche fermée (ce qui assure un certain secret, contrairement aux mains levées). En faisant des mmmmmmmmm plus ou moins forts, on peut même avoir un vote non-binaire. Ce rituel est souvent pratiqué pendant les réunions IETF.
Mais tous les participants à l'IETF ne comprennent pas forcément ces subtilités, surtout lorsqu'ils viennent d'arriver. « Pourquoi un mmmmmm et pas un vote normal ? » ou « Il y avait une majorité de mmmmmm en faveur de la proposition B, pourquoi continue-t-on de discuter ? » Même quand le groupe de travail est arrivé à un résultat, bien des participants ne comprennent pas comment il a été obtenu et pensent que le processus a produit un mauvais résultat. Paradoxe : il n'y a pas de consensus à l'IETF sur l'importance du consensus. Ou plutôt, il y en a un en parole (la phrase de Clark est très souvent citée) mais pas dans la réalité du travail.
Donc, premier point expliqué par ce RFC, en section 2, l'important n'est pas que tout le monde soit d'accord, mais qu'il n'y ait pas trop de désaccord. Imaginons un groupe qui doit trancher entre deux formats pour un protocole (mettons JSON et XML, pour prendre un exemple réel...). Il y a des gens pour et des gens contre chacune des deux propositions. Cela veut-il dire qu'il n'y aura jamais de consensus ? Sauf que tout travail d'ingéniérie (et la création d'une norme technique en est un) nécessite des compromis. Si on demande un accord de tous, on ne l'aura jamais (surtout avec le goût des ingénieurs pour les discussions sur la couleur du garage à vélos). En revanche, si on demande qu'il n'y ait pas d'objections bloquantes, on peut arriver à un résultat. Les partisans de XML ne vont pas tout à coup préférer JSON. Par contre, ils peuvent considérer que JSON, sans être leur solution préférée, est acceptable, qu'il n'a pas de défaut qui mettrait vraiment en péril le nouveau protocole. Il ne faut donc pas demander aux participants « êtes-vous heureux avec ce choix ? » (il y aura forcément des râleurs) mais plutôt « ce choix a t-il un défaut rédhibitoire (et, si vous répondez oui, argumentez) ? » Bien sûr, il faut quand même qu'il y ait un certain nombre de gens qui soutiennent activement la proposition. Une solution technique qui ne rencontrerait aucune objection, mais pas non plus de soutien actif ne serait sans doute pas intéressante !
Autre point où il faut entrer dans les nuances, la différence entre compromis et compromission. Le mot « compromis » (en français, comme en anglais avec « compromise ») est utilisé dans deux sens différents. Le compromis est une bonne chose : en ingéniérie, on a rarement des solutions idéales. Il faut en général arbitrer et, par exemple, décider de sacrifier du temps CPU pour consommer moins de ressources réseau ou le contraire, ou bien mettre de la redondance pour assurer l'intégrité alors qu'elle va diminuer les performances, ou encore préférer un format texte qui facilite le débogage à un format binaire plus efficace mais plus dur à traiter par les humains. Ce genre de compromis est un travail normal et essentiel de l'ingénieur, et l'IETF le fait.
En revanche, les compromissions sont néfastes : une compromission est quand on tient compte des opinions et pas des principes d'ingéniérie. Par exemple qu'on accepte telle option, qui semble inutile, voire dangereuse, parce qu'une partie du groupe de travail trépigne et y tient absolument. On ajoute alors l'option pour obtenir leur accord (ou leur non-désaccord), faisant ainsi une compromission (ou un « design by committee », où le résultat n'enthousiasme personne, à force d'avoir intégré plein de demandes contradictoires). Ce genre de compromission (qu'il faudrait plutôt appeler capitulation) n'a pas réglé les problèmes techniques. Pire, on peut voir ce que le RFC désigne sous le nom de « horse trading » (comportement de maquignon ?) « Je ne suis pas d'accord avec ta proposition sur l'algorithme de traitement de la congestion, tu n'es pas d'accord avec ma proposition sur le format des données, mettons-nous d'accord pour chacun soutenir la proposition de l'autre. » Cela permet d'arriver à un accord mais au prix de la qualité : les objections contre les deux propositions ont été ignorées, alors qu'elles étaient peut-être sérieuses techniquement et devaient être traitées comme telles. Ce comportement donne l'apparence du consensus alors qu'il est de la pure magouille.
Deuxième point important, en section 3, le fait qu'il faut traiter toutes les questions mais pas forcément les résoudre. Parfois, une objection technique va être résolue à la satisfaction de tous : celui qui l'a soulevée est convaincu que son objection était erronée, ou bien le groupe de travail a été convaincu qu'elle était sérieuse et a modifié le protocole en cours de discussion. Mais, parfois, le groupe de travail ne change pas de direction et celui qui a soulevé l'objection est frustré. Est-ce un échec du consensus ? Non, car il y a toujours « consensus approximatif ». Celui-ci est une solution de repli : l'idéal est le consensus complet mais, comme le dit le conte « Le meunier, son fils et l'âne », on ne peut pas toujours plaire à tout le monde et, de toute façon, il y a des gens qui ne sont jamais contents. La notion de consensus approximatif est faite pour ces cas-là : l'objection n'a pas été ignorée, elle a été sérieusement étudiée et le groupe de travail a délibérement décidé de continuer dans la voie originale. Compte-tenu de la forte personnalité de pas mal de participants à l'IETF, le consensus seulement approximatif, qui devrait être une exception à la règle du consensus, est souvent la norme.
Notez que ce consensus approximatif vu comme un repli lorsque le consensus idéal n'est pas atteint est une description nouvelle. Le RFC 1603 voyait plutôt le consensus approximatif comme exprimant le « point de vue dominant » du groupe de travail IETF. Cette vision quantitative (exprimée de manière encore plus directe dans son successeur, le RFC 2418) n'est pas partagée par ce nouveau RFC 7282, qui met l'accent sur le fait que les 0,1 % qui sont en désaccord ont peut-être raison (comme le disait un de mes enseignants à la fac, « la science n'est pas une démocratie »).
Et le mmmmmmm ? La section 4 revient sur son rôle. D'abord, pourquoi ne vote-t-on pas, à l'IETF (certainement la première question que posent tous les nouveaux venus) ? D'abord, l'IETF n'a pas de membres : il n'existe aucun processus formel d'adhésion. On s'inscrit à la liste de diffusion d'un groupe de travail et, hop, on est un participant à l'IETF. Impossible donc, de compter le corps électoral. Ensuite, le vote peut être une mauvaise chose : comme indiqué plus haut (même si l'expression n'est pas dans le RFC), la technique n'est pas démocratique. 51 % ou même 99 % d'un groupe de travail peut toujours voter X, c'est peut-être quand même Y qui est justifié techniquement. Le vote pourrait être un moyen de glisser sous le tapis les problèmes gênants, qui doivent au contraire être traités en pleine lumière. Une des raisons de l'utilisation du mmmmmmm est donc, précisément par le caractère folkorique de la procédure, de rappeler qu'on ne vote pas, à l'IETF (par comparaison avec, disons, un vote à main levée).
Le mmmmmmm sert donc à jauger la situation et à ordonner la discussion. Par exemple, s'il y a beaucoup plus de mmmmmmm objectant contre X que contre Y, partir des objections contre Y peut permettre d'optimiser le temps de discussion (sans pour autant considérer que Y a « gagné »).
Malgré cela, un effet pervers s'est développé, avec des gens considérant le mmmmmmm comme une sorte de vote anonyme. Ce n'est pas son but, le mmmmmmm devrait être utilisé au début (pour avoir une idée des points de vue en présence) pas à la fin pour clore le bec aux minoritaires. Le mmmmmmm n'est pas une méthode magique, et, s'il est mal utilisé, il a souvent les mêmes inconvénients que le vote classique (par exemple une extrême sensibilité à la rédaction des questions, ou même simplement à leur ordre).
Donc, le but, c'est le consensus ? Pas du tout. La section 5 insiste sur le fait que le consensus est un moyen et pas une fin. Le consensus approximatif est un moyen d'obtenir la meilleure décision technique possible, en s'assurant qu'aucune objection, aucun problème, n'a été négligé. Au contraire, l'expérience des SDO qui votent a largement montré que cela mène à des mauvaises décisions, notamment suite à des compromissions pour obtenir une majorité, et suite au mépris des remarques parfaitement valides des minoritaires.
Alors, évidemment, la méthode IETF prend du temps et est souvent exaspérante, même pour les plus patients des participants. Et il ne faut donc pas se faire d'illusions : les magouilles politiciennes existent aussi à l'IETF. Simplement, passer à un système plus rapide comme le vote permettrait d'avoir plus vite des normes de moins bonne qualité.
La section 6 revient sur la notion de majorité et sur l'approche quantitative, qu'appuyait le RFC 2418 (« Note that 51% of the working group does not qualify as "rough consensus" and 99% is better than rough. ») S'il y a 100 participants dans un groupe qui trouvent la proposition en cours excellente, et la soutiennent activement, et 5 participants qui sont en désaccord, prédisant, par exemple, « ce protocole va créer de la congestion et n'a aucun mécanisme de réaction en cas de congestion » et que personne ne répond de manière argumentée à ce point, alors, il n'y a pas de consensus, même pas de consensus approximatif. Une objection a été ignorée, pas traitée, et pas rejetée. Le faible nombre d'opposants n'y change rien, on ne peut pas parler d'un consensus, même pas approximatif. (Le RFC note que c'est pareil si la ou les personnes qui ont soulevé l'objection ne sont pas des participants réguliers, et qu'ils n'insistent pas après avoir fait leurs remarques ; les remarques en question doivent quand même être traitées.)
En sens inverse, et même si cela peut sembler anti-intuitif, on peut avoir 5 personnes qui soutiennent un projet et 100 qui sont contre, et qu'il y ait quand même un consensus en faveur du projet (section 7). Comment est-ce possible ? Le RFC décrit une telle situation (et des cas analogues se sont effectivement produits) : un groupe de travail a peu de participants actifs. Ils sont arrivés à un consensus malgré les objections de l'un d'entre eux, objection qui a été étudiée et rejetée. Le « dissident » fait appel à une centaine de personnes, parfois des participants à d'autres groupes de travail mais souvent des employés de la même société que lui, qui ne connaissent rien au sujet mais font ce qu'on leur dit. Ils envoient tous un message sur la liste de diffusion, disant qu'ils soutiennent l'objection. Une bonne façon de traiter ces soutiens vides (sans contenu nouveau) est de leur demander « Nous avons déjà discuté de ce point et abouti à un consensus. Avez-vous des éléments techniques nouveaux qui justifieraient de rouvrir la discussion ? » En général, les commerciaux et marketeux qui avaient été recrutés pour faire masse dans la discussion ne répondent pas... Ils croyaient que l'IETF fonctionnait sur un système de vote et sont surpris de découvrir qu'on leur demande d'argumenter. Bien sûr, ce cas est un peu extrême mais la même méthode peut servir dans des cas moins dramatiques. Le principe du consensus sert à traiter une des plus grosses failles des systèmes de vote : le bourrage des urnes par des ignorants.
L'article seul
Exposé « Tous à poil » à Pas Sage en Seine
Première rédaction de cet article le 27 juin 2014
Dernière mise à jour le 30 juin 2014
Le 26 juin, j'ai eu le plaisir de livrer quelques réflexions sur l'utilisation de la transparence pour la sécurité des protocoles réseaux, à l'évènement « Pas Sage en Seine » à Paris, l'évènement qui rassemble tous les regards critiques et novateurs sur le numérique, l'Internet et bien d'autres choses. Sous le titre de « Tous à poil » (titre choisi pour des raisons de SEO), je parlais de bitcoin, de Namecoin, d'Usenet et même de BGP.
Voici les supports de cet exposé :
- Version adaptée à la lecture sur écran,
- Version adaptée à l'impression,
- Source,
- Et la vidéo (également ici en format libre, en BitTorrent ici, mais également sur YouTube, si on veut augmenter ses chances d'être suivi par la NSA, ou bien ).
Parmi les exemples de systèmes de sécurité fonctionnant sur la transparence, j'ai oublié de mentionner le Stamper. J'aurais dû. Pour les autres sujets que je mentionnais :
- La Certificate Transparency est décrite dans le RFC 6962.
- La transparence de BGP a été utilisée pour une analyse de panne, des systèmes d'alerte, un rapport sur la résilience de l'Internet, etc.
L'article seul
RFC 7276: An Overview of Operations, Administration, and Maintenance (OAM) Tools
Date de publication du RFC : Juin 2014
Auteur(s) du RFC : T. Mizrahi (Marvell), N. Sprecher (Nokia Solutions and Networks), E. Bellagamba (Ericsson), Y. Weingarten
Pour information
Réalisé dans le cadre du groupe de travail IETF opsawg
Première rédaction de cet article le 25 juin 2014
Ce RFC est entièrement consacré à la gestion de réseaux. Quels sont les outils existants dans les réseaux TCP/IP, notamment l'Internet ? Ce RFC est destiné aux opérateurs réseau, aux fournisseurs d'équipements et de logiciels réseau, et aux gens de la normalisation, pour s'assurer qu'ils ont une base d'information commune sur les outils existants.
La gestion de réseaux est ici désignée par le sigle OAM qui signifie Operations, Administration, and Maintenance. OAM est défini dans le RFC 6291. Les outils de l'OAM sont tous les dispositifs qui permettent de détecter un problème et de l'isoler, ou bien de mesurer les performances. (Les outils permettant de configurer les équipements réseaux ne sont pas traités ici.) Ce nouveau RFC couvre les outils utilisés dans des contextes très divers, d'IP à MPLS en passant par TRILL mais je ne vais parler que des outils IP, ceux que je connais.
Ce RFC décrit les outils, logiciels mettant en œuvre un protocole particulier. Une liste des protocoles normalisés par l'IETF pour l'OAM est dans le RFC 6632. Par exemple, OWAMP (RFC 4656) est un protocole, le programme distribué par Internet 2 est un outil mettant en œuvre ce protocole.
Tous les réseaux sont bien sûr gérés, et tous ont évidemment des dispositifs d'OAM, plus ou moins perfectionnés. On a donc :
- O (pour Operations) : tout ce qui contribue à ce que le réseau reste « up & running » en détectant les problèmes (et en les résolvant) avant même que l'utilisateur ne s'en aperçoive.
- A (pour Administration) : garder à jour la liste des ressources et surveiller leur utilisation.
- M (pour Maintenance) : permettre les réparations et les évolutions (mise à jour du logiciel du routeur, par exemple).
Parfois, ces dispositifs d'OAM ont été ajoutés après, en utilisant (souvent de manière créative) les fonctions disponibles. De nos jours, on tend à prévoir l'OAM dès le début, comme ce fut le cas pour l'ATM.
Notre RFC commence (section 2) par des rappels de concept et de terminologie (outre le RFC 6291, déjà cité, le RFC 7087 définit les termes spécifiques à MPLS). D'abord, données vs. contrôle : on distingue souvent dans un équipement réseau le sous-système des données (data plane ou user plane) et le sous-système de contrôle (control plane). Le premier désigne toutes les fonctions qui contribuent à transmettre les paquets (et donc les données) à l'équipement suivant. Le second, le sous-système de contrôle, comprend les fonctions qui permettent d'établir dynamiquement les informations dont le sous-système des données va avoir besoin. Par exemple, dans un routeur, le sous-système des données est composé des fonctions qui font passer le paquet d'une interface d'entrée à une interface de sortie (rôle de forwarding), alors que le sous-système de contrôle (rôle de routing) comprend notamment les fonctions de calcul de la table de routage (les mises en œuvre d'OSPF, de BGP, etc), table de routage qu'utilisera le sous-système des données lors de la transmission. Si le routeur est une machine Unix, le sous-système de données est mis en œuvre dans le noyau, alors que celui de contrôle l'est par un démon séparé, genre Quagga ou BIRD. La distinction entre sous-systèmes de contrôle et de données n'est pas seulement conceptuelle, ni limitée au logiciel. Dans un routeur Juniper ou Cisco moyen ou haut de gamme, c'est même du matériel différent (ASIC pour les données, CPU généraliste pour le contrôle). L'OAM, tel qu'utilisé ici, mesure et teste le sous-système de données, mais il peut utiliser des informations fournies par le sous-système de contrôle, et être piloté par lui. (On voit parfois, par exemple dans le RFC 6123, un troisième sous-système, le sous-système de gestion, le management plane. De toute façon, la différence entre ces sous-systèmes n'est pas forcément claire et nette dans tous les cas.)
Encore un peu de terminologie : les outils peuvent être « à la demande » ou bien « proactifs ». Les premiers sont déclenchés lorsqu'il y a un problème (c'est l'administrateur réseaux à qui on dit « le serveur ne marche pas » et qui lance ping tout de suite), les seconds tournent en permanence, par exemple pour détecter et signaler les pannes.
Quelle sont les fonctions précises d'un logiciel d'OAM ? Notre RFC cite le test de la connectivité, la découverte du chemin, la localisation d'un problème, et des mesures liées aux performances comme la mesure du taux de perte de paquets, ou comme la mesure des délais d'acheminement.
On entend parfois parler de « tests de continuité » et de « tests de connectivité ». Ces termes viennent de MPLS (RFC 5860) et désignent, dans le premier cas, un test que les paquets peuvent passer et, dans le second, que deux systèmes sont effectivement connectés, et par le chemin attendu (IP, étant sans connexion, n'a guère besoin de ces tests de connectivité).
En parlant de connexion, le monde TCP/IP comprend des protocoles avec connexion et des protocoles sans. L'OAM concerne ces deux groupes et les outils présentés dans ce RFC couvrent les deux. Un test utilisant un protocole sans connexion (ping est l'exemple archétypal) peut emprunter un autre chemin, d'autres ressources (et donc donner un autre résultat), qu'une utilisation réelle du réseau. Au contraire, en testant un protocole avec connexion (TCP, par exemple), on utilise les mêmes ressources que les vraies données. Notez aussi que des protocoles sans connexion peuvent être testés par des protocoles avec connexion, le RFC donnant l'exemple d'un test d'IP fait avec BFD (RFC 5880).
Enfin, dernier point de terminologie, les mots utilisés pour les problèmes. Il n'existe pas une norme unique et acceptée pour ces mots. Suivant la norme ITU-T G.806, notre RFC fait une différence entre défaillance (fault), qui est l'incapacité à effectuer une tâche, comme de livrer un paquet, interruption (defect), qui est un arrêt temporaire d'un service et panne (failure). Cette dernière, au contraire de l'interruption, n'est pas un accident ponctuel et elle peut durer longtemps.
Bien, après tous ces préliminaires, les outils eux-mêmes, présentés en section 4 du RFC. À tout seigneur, tout honneur, on va évidemment commence par l'outil emblématique de l'OAM, ping. Il envoie un paquet ICMP de type « demande d'écho » et la réception d'un paquet ICMP de réponse indiquera que la connectivité est complète. Il donnera également quelques indicateurs de performance comme le RTT, affiché après time= :
% ping -c 3 www.ietf.org PING www.ietf.org (4.31.198.44) 56(84) bytes of data. 64 bytes from mail.ietf.org (4.31.198.44): icmp_req=1 ttl=44 time=227 ms 64 bytes from mail.ietf.org (4.31.198.44): icmp_req=2 ttl=44 time=222 ms 64 bytes from mail.ietf.org (4.31.198.44): icmp_req=3 ttl=44 time=223 ms --- www.ietf.org ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2004ms rtt min/avg/max/mdev = 222.689/224.685/227.533/2.067 ms
Certaines versions de ping peuvent faire des tests avec UDP plutôt qu'ICMP. ping donne un point de vue unilatéral, celui du côté qui initie la connexion. Si on veut le point de vue du pair, il faut que celui-ci fasse un test de son côté (par exemple, s'il y a un pare-feu à état entre les deux machines, un des tests peut échouer même si l'autre réussit). Malheureusement, il arrive que ces paquets ICMP soient filtrés (par exemple, suite à l'incompétence de l'administrateur qui croit que l'attaque mal nommée ping of death a un rapport avec ping alors qu'elle n'en a pas).
Après ping, l'outil d'OAM le plus connu et le plus utilisé est sans doute traceroute. Comme ping, il n'y a pas de texte sacré de référence le décrivant. À l'époque, on codait d'abord, on documentait ensuite (parfois). Les textes les plus canoniques sur traceroute semblent être les RFC 1470 et RFC 2151.
traceroute sert à découvrir le chemin pris par les paquets entre
l'initiateur de la requête et une cible. Il envoie un paquet
UDP à destination du
port 33434 en mettant dans l'en-tête
IP un TTL inhabituel, de
1. Vu avec tcpdump, cela donne (notez le
ttl 1) :
22:10:20.369307 IP (tos 0x0, ttl 1, id 19164, offset 0, flags [none], proto UDP (17), length 60)
192.168.2.1.44024 > 213.154.224.1.33434: UDP, length 32
Le premier routeur rencontré va donc considérer ce paquet comme trop ancien, le jeter, et envoyer un paquet ICMP de type Time exceeded à la source, qui aura ainsi l'adresse IP du premier routeur :
22:17:46.359084 IP (tos 0xc0, ttl 64, id 64893, offset 0, flags [none], proto ICMP (1), length 88)
192.168.2.254 > 192.168.2.1: ICMP time exceeded in-transit, length 68
IP (tos 0x0, ttl 1, id 19239, offset 0, flags [none], proto UDP (17), length 60)
192.168.2.1.34315 > 213.154.224.1.33434: UDP, length 32
Ensuite, traceroute itère : il incrémente le numéro de port et le TTL et trouve ainsi le deuxième routeur. Le jeu s'arrête lorsque traceroute reçoit un paquet ICMP Port unreachable lorsque le paquet UDP atteint sa cible et que celle-ci, n'ayant pas de service sur ce port, répondra négativement :
22:19:20.648790 IP (tos 0x0, ttl 53, id 11453, offset 0, flags [none], proto ICMP (1), length 56)
213.136.31.102 > 192.168.2.1: ICMP 213.154.224.1 udp port 33445 unreachable, length 36
IP (tos 0x0, ttl 1, id 19325, offset 0, flags [none], proto UDP (17), length 60)
192.168.2.1.57471 > 213.154.224.1.33445: UDP, length 32
Utilisant toutes ces informations, traceroute peut alors afficher le chemin :
% traceroute -q 1 www.nlnetlabs.nl traceroute to www.nlnetlabs.nl (213.154.224.1), 30 hops max, 60 byte packets 1 freebox (192.168.2.254) 13.646 ms 2 88.189.152.254 (88.189.152.254) 37.136 ms 3 78.254.1.62 (78.254.1.62) 37.133 ms 4 rke75-1-v900.intf.nra.proxad.net (78.254.255.42) 46.845 ms 5 cev75-1-v902.intf.nra.proxad.net (78.254.255.46) 39.030 ms 6 p16-6k-1-po12.intf.nra.proxad.net (78.254.255.50) 43.658 ms 7 bzn-crs16-1-be1024.intf.routers.proxad.net (212.27.56.149) 43.662 ms 8 bzn-crs16-1-be1106.intf.routers.proxad.net (212.27.59.101) 43.637 ms 9 londres-6k-1-po101.intf.routers.proxad.net (212.27.51.186) 55.973 ms 10 * 11 amsix-501.xe-0-0-0.jun1.bit-1.network.bit.nl (195.69.144.200) 60.693 ms 12 nlnetlabs-bit-gw.nlnetlabs.nl (213.136.31.102) 62.287 ms
(On note que le routeur n° 10 a refusé de répondre, ce qui arrive, ou que sa réponse s'est perdue, ce qui arrive aussi.)
Sur une machine Unix d'aujourd'hui, il existe souvent plusieurs mises en œuvre différentes de traceroute. traceroute est une idée, pas un programme unique. Par exemple, Paris traceroute fait varier l'en-tête IP pour essayer de découvrir plusieurs chemins lorsqu'il y a de l'ECMP. Des traceroutes ont des options pour utiliser ICMP et pas UDP (c'est le cas des sondes Atlas). Il existe des extensions à ICMP pour rendre traceroute plus utile, comme celles du RFC 4950 ou RFC 5837.
Attention aux limites de traceroute : il ne montre que le chemin aller. Le routage sur l'Internet pouvant être asymétrique, rien ne dit que le chemin de retour sera le même.
Après, le RFC passe à des outils moins connus du grand public. D'abord, les outils BFD. Normalisé dans le RFC 5880, BFD permet de tester la connectivité dans le contexte d'IP (RFC 5881) mais aussi de MPLS (RFC 5884) et de bien d'autres. Il fonctionne en mode connecté : les deux machines établissent une session BFD. Ensuite, elles échangent des paquets BFD, soit périodiquement, soit à la demande. La bonne arrivée de ces paquets indique que la connexion avec le pair fonctionne. Il existe aussi un mode où BFD envoie des paquets « demande d'écho » et attend une réponse.
Il existe ensuite plusieurs outils d'OAM pour le monde MPLS, le plus important étant LSP-Ping, décrit dans le RFC 4379. S'il assure des fonctions analogues à ping, comme son nom l'indique, il en fait aussi qui sont équivalentes à traceroute. Répondre à une demande d'écho est moins trivial en MPLS qu'en IP. Par exemple, un chemin (un LSP, Label Switched Path) peut n'être établi que dans une seule direction, rendant impossible de répondre en MPLS à un LSP-Ping.
Les autres outils MPLS sont décrits en détail dans les sections 4.4 et 4.5 de notre RFC. Sinon, la problématique générale de l'OAM en environnement MPLS est dans les RFC 4377 et RFC 4378. (L'OAM de MPLS a d'ailleurs suscité un affrontement entre l'IETF et l'UIT, le point de vue de l'IETF étant exposé dans le RFC 5704.)
ping sur un réseau IP a plusieurs limites : il mesure un aller-retour (alors que les chemins peuvent être différents, avec des caractéristiques très différentes), et il n'est pas défini avec une grande précision donc la sémantique du RTT, par exemple, n'est pas rigoureuse. L'IETF, via son groupe de travail IPPM, a deux protocoles qui traitent ces limites, OWAMP et TWAMP. Outre des définitions rigoureuses de métriques comme le délai d'acheminement aller-simple (RFC 7679), ou comme la connectivité (RFC 2678), IPPM a produit ces deux protocoles qui établissent une session de contrôle entre deux points, sur TCP, avant de lancer une mesure précise avec UDP. OWAMP (RFC 4656) mesure un aller-simple alors que TWAMP (RFC 5357) mesure un aller-retour (comme ping).
À noter que, pour mesurer les performances, il existe bien d'autres outils comme les outils OAM d'Ethernet.
Enfin, la section 4 se termine par une section sur TRILL (RFC 6325). Trop récent, ce système n'a pas encore beaucoup d'outils OAM. Il existe un cahier des charges pour ces outils, le RFC 6905, qui demande des outils pour tester la connectivité, découvrir le chemin suivant et mesurer des indicateurs comme le temps d'acheminement d'un paquet.
La section 5 du RFC résume tous les outils décrits, sous forme d'un tableau donnant le nom des outils, un résumé de leur fonctionnement, et le protocole auquel ils s'appliquent (IP, MPLS, TRILL, etc). Pratique pour les lecteurs pressés.
Il reste enfin la classique section de sécurité, la section 6. Un système d'OAM soulève évidemment des enjeux de sécurité. Par exemple, un attaquant qui contrôle l'OAM pourrait créer l'illusion de pannes non-existantes, forçant les équipes du réseau à perdre du temps. Ou il pourrait empêcher la détection de pannes réelles, ce qui aggraverait le déni de service.
Certains des outils d'OAM présentés dans ce RFC ont des fonctions de sécurité, empêchant par exemple la modification des données par un tiers. BFD a un mécanisme d'authentification. OWAMP et TWAMP peuvent authentifier (via un HMAC) et/ou chiffrer leurs communications (en AES). Ceci dit, la confidentialité n'est pas en général considérée comme un problème pour l'OAM, seules l'authentification et l'intégrité le sont. D'autres outils n'ont aucune sécurité (traceroute peut facilement être trompé, comme l'avait montré The Pirate Bay).
Les outils d'OAM peuvent aussi être utilisés pour la
reconnaissance : par exemple, l'option -g de
fping ou la possibilité d'indiquer un préfixe
IP (et pas juste une adresse) à nmap,
permettent de découvrir les machines existant sur le réseau.
L'annexe A termine le RFC en énumérant une (longue) liste de documents de normalisation sur l'OAM, y compris des documents non-IETF.
L'article seul
RFC 7269: NAT64 Deployment Options and Experience
Date de publication du RFC : Juin 2014
Auteur(s) du RFC : G. Chen, Z. Cao (China
Mobile), C. Xie (China
Telecom), D. Binet (France
Telecom-Orange)
Pour information
Réalisé dans le cadre du groupe de travail IETF v6ops
Première rédaction de cet article le 20 juin 2014
L'épuisement des adresses IPv4 étant allé plus vite que le déploiement d'IPv6 (qui est freiné par la passivité de nombreux acteurs), il y a de plus en plus souvent le problème de connecter des réseaux modernes, entièrement en IPv6, à des machines anciennes restées en IPv4. La solution de l'IETF à ce problème est le déploiement de NAT64, normalisé dans le RFC 6144. Ce nouveau RFC documente l'expérience concrète de trois gros opérateurs avec NAT64. Qu'est-ce qui a marché, qu'est-ce qui a raté ?
Ces réseaux entièrement IPv6 ont l'avantage
de ne pas avoir de problème de manque d'adresses IP (même les préfixes du RFC 1918 peuvent être insuffisants pour un grand réseau) et de
permettre d'utiliser un plan d'adressage propre dès le début (pas de
contorsions pour faire durer les adresses) et une architecture unique
(un seul protocole à gérer). Pour les réseaux
mobiles, par exemple, cela signifie un seul contexte
PDP, ce qui simplifie les choses. Mais, comme vu plus haut, leur
inconvénient est qu'ils ne peuvent pas accéder aux services qui
restent archaïquement en IPv4 seul comme Twitter ou
impots.gouv.fr. Et, même si les
professionnels sérieux ont compris depuis longtemps l'importance de
migrer vers IPv6, les résistances des plus attardés vont sans doute
durer longtemps et on peut penser que des réseaux uniquement IPv4
seront encore en fonctionnement pendant de longues années. Au lieu du
plan de transition envisagé au début (« tout le monde en IPv4 » ->
« double-pile - IPv4 et IPv6 - déployée progressivement » -> « tout
le monde en IPv6 »), il faut maintenant travailler dans le cadre d'un
nouveau plan, « tout le monde en IPv4 » ->
« certains réseaux en v4 seul et certains en v6 seul » -> « tout
le monde en IPv6 ». L'étape intermédiaire a été décrite dans les RFC 6145 et
RFC 6146 et son composant le plus connu est
nommé NAT64. NAT64 effectue une traduction
d'adresses de IPv6 vers IPv4 en sortie du réseau moderne vers le
réseau archaïque et l'inverse lorsque la réponse arrive.
NAT64 a donc une partie des inconvénients du NAT IPv4 traditionnel (NAT44), comme le montre le compte-rendu d'expérience du RFC 6586 mais il parait incontournable, sauf si le déploiement d'IPv6 s'accélérait subitement dans l'Internet, ce qu'on ne voit pas venir.
30 % des opérateurs, selon un sondage signalé dans le RFC 6036 prévoient de déployer NAT64 ou un système équivalent. NAT64 est également systématiquement présent lors des réunions des organismes de normalisation ou de gestion des ressources réseau, comme l'IETF ou le RIPE. À chaque réunion, un des réseaux WiFi est « IPv6 seulement » et bénéficie d'une passerelle NAT64 vers l'extérieur. De nombreux experts peuvent ainsi tester en vrai les technologies modernes. Bref, NAT64 est désormais une technique importante et il est donc nécessaire d'étudier ses conséquences pratiques. C'est le rôle de ce nouveau RFC, qui ne décrit pas un nouveau protocole mais offre simplement un retour d'expérience.
À noter que NAT64 peut être déployé en deux endroits :
- Côté FAI, ce qu'on appelle le NAT64-CGN (pour Carrier-Grade NAT), sous forme d'un gros traducteur NAT dans le réseau du FAI,
- Ou bien côté fournisseur de services/contenus, ce qu'on appelle le NAT64-FE (pour Front End), sous forme d'un traducteur NAT dans le data center, devant les serveurs.
Le premier cas est celui du FAI tout en IPv6 mais qui veut permettre à ses clients d'accéder à des services IPv4. Le second est celui du fournisseur de services ou de contenus dont l'infrastructure est malheureusement entièrement ou partiellement en IPv4 mais qui veut fournir un accès IPv6, en ne gérant qu'un traducteur, au lieu de mettre à jour tous ses systèmes. (Le RFC ne discute pas la question de savoir si c'est une idée intelligente ou pas...)
À noter que le cas d'un NAT64 chez l'utilisateur (le célèbre M. Michu), dans son CPE, n'est pas mentionné. Un NAT64 dans le CPE imposerait un réseau du FAI qui soit en IPv4 jusqu'au client, justement ce qu'on voudrait éviter. Le RFC recommande plutôt de mettre les traducteurs NAT64 près de la sortie du FAI, de façon à permettre à celui-ci de conserver un réseau propre, entièrement IPv6 (section 3.1.3). Certes, cela va concentrer une bonne partie du trafic dans ces traducteurs mais NAT64 est fondé sur l'idée que la proportion de trafic IPv4 va diminuer avec le temps : les traducteurs n'auront pas besoin de grossir. Aujourd'hui, 43 des cent plus gros sites Web (selon Alexa) ont déjà un AAAA et court-circuitent donc complètement le NAT64.
Autre problème avec la centralisation, le risque de SPOF. Si le CPE de M. Michu plante, cela n'affecte que M. Michu. Si un gros traducteur NAT64, gérant des milliers de clients, plante, cela va faire mal. Il faut donc soigner la disponibilité (voir section 4).
Centraliser dans un petit nombre de traducteurs près de la sortie évite également d'avoir plusieurs équipements NAT64, avec les problèmes de traçabilité que cela poserait, par exemple s'ils ont des formats de journaux différents.
NAT64 nécessite un résolveur DNS spécial,
utilisant DNS64 (RFC 6147). En effet, les
clients, n'ayant qu'IPv6, ne demanderont que des enregistrements AAAA
(adresses IPv6) dans le DNS. Le résolveur DNS64 doit donc en
synthétiser si le site original (par exemple
twitter.com) n'en a pas. Dans certains cas,
par exemple une page Web où les liens contiennent des adresses IPv4
littérales (comme <a
href="http://192.0.2.80/">), la solution 464xlat du RFC 6877 permet de se passer de DNS64. Mais, dans la
plupart des déploiements NAT64, DNS64 sera indispensable.
NAT64 va probablement coexister avec NAT44 (le NAT majoritaire aujourd'hui), les réseaux locaux chez l'utilisateur gardant un certain nombre de machines IPv4. Si le RFC 6724 donne par défaut la priorité à IPv6, quelque soit le type de connectivité IPv6, les algorithmes comme celui des globes oculaires heureux (RFC 6555) peuvent mener à préférer IPv6 ou IPv4 et même à en changer d'un moment à l'autre, en fonction de leurs performances respectives. Ces changements ne seront pas forcément bons pour l'expérience utilisateur.
Pour le NAT64-FE (juste en face des serveurs), le RFC 6883 donnait quelques indications, qui peuvent s'appliquer à NAT64. Ici, DNS64 n'est pas forcément nécessaire, les adresses IPv6 servant à adresser les serveurs sont en nombre limité et peuvent être mises dans le DNS normal.
La section 4 de notre RFC revient sur l'exigence de haute disponibilité, essentielle si on veut que le passage de IPv4+IPv6 à IPv6+NAT64 ne diminue pas la fiabilité du service. Je me souviens d'une réunion RIPE où il n'y avait qu'un seul résolveur DNS64 et, un matin, il avait décidé de faire grève. DNS64 étant indispensable à NAT64, les clients étaient fort marris. Mais la redondance des résolveurs DNS est un problème connu, et relativement simple puisqu'ils n'ont pas d'état. Le RFC se focalise surtout sur la haute disponibilité des traducteurs NAT64 car eux peuvent avoir un état (comme les traducteurs NAT44 d'aujourd'hui). Il y a trois types de haute disponibilité : le remplaçant froid, qui est un traducteur NAT64 inactif en temps normal, et qui ne se synchronise pas avec le traducteur actif. Il est typiquement activé manuellement quand le traducteur actif tombe en panne. Comme il n'a pas de copie de l'état (la table des sessions en cours, aussi nommée BIB pour Binding Information Base), toutes les connexions casseront et devront être réétablies. Le second type est le remplaçant tiède. Il ne synchronise pas les sessions mais il remplace automatiquement le traducteur NAT64 principal, par exemple grâce à VRRP (RFC 5798). Au cours des tests faits par les auteurs du RFC, il fallait une minute pour que VRRP bascule et que les trente millions de sessions de la BIB soient établies à nouveau. Enfin, il y a le remplaçant chaud, qui synchronise en permanence l'état des sessions. Cette fois, la bascule vers le remplaçant est indétectable par les clients. Pour s'apercevoir rapidement de la panne du traducteur principal, le test a utilisé BFD (RFC 5880) en combinaison avec VRRP. Cette fois, la bascule des trente millions de sessions n'a pris que trente-cinq millisecondes, soit une quasi-continuité de service. Évidemment, cela nécessite du logiciel plus complexe dans les traducteurs, surtout vu l'ampleur de la tâche : avec 200 000 utilisateurs, il faut créer et détruire environ 800 000 sessions par seconde ! Un lien à 10 Gb/s entre les traducteurs n'est pas de trop, pour transporter les données nécessaires pendant les pics de trafic.
Alors, remplaçant froid, tiède ou chaud ? Notre RFC ne tranche pas définitivement, disant que cela dépend des applications. (L'annexe A du RFC contient des tests spécifiques à certaines applications.) Environ 90 % du trafic pendant les tests était dû à HTTP. Ce protocole n'a pas besoin de continuité de service, chaque requête HTTP étant indépendante. Le traducteur chaud n'est donc pas indispensable si HTTP continue à dominer (au passage, c'est pour une raison analogue que la mobilité IP n'a jamais été massivement utilisée). En revanche, le streaming souffrirait davantage en cas de coupure des sessions. (Curieusement, le RFC cite aussi le pair-à-pair comme intolérant aux coupures de session, alors que les clients BitTorrent, par exemple, s'en tirent très bien et réétablissent automatiquement des sessions.)
Le trafic d'un traducteur NAT64-CGN peut être intense et, même en l'absence de pannes, il est raisonnable de prévoir plusieurs traducteurs, afin de répartir la charge. Attention, si on fait du NAT64 avec état (le plus courant), il faut s'assurer que les paquets d'une session donnée arrivent toujours au même traducteur. Une façon de distribuer les requêtes entre les traducteurs, pour le NAT64-CGN, est de demander au serveur DNS64 de synthétiser des préfixes différents selon le client, et d'envoyer les différents préfixes à différents traducteurs, en utilisant le classique routage IP. Pour le NAT64-FE, les techniques classiques des répartiteurs de charge (condensation de certains paramètres puis répartition en fonction du condensat) conviennent.
La section 5 du RFC se penche ensuite sur le problème de l'adresse IP source. À partir du moment où on fait du NAT (quel que soit le NAT utilisé), l'adresse IP source vue par le destinataire n'est pas celle de l'émetteur mais celle du traducteur NAT. Cela entraine tout un tas de problèmes. D'abord, la traçabilité. Un serveur voit un comportement illégal ou asocial (par exemple, pour un serveur HTTP, des requêtes identiques coûteuses répétées, pour réaliser une attaque par déni de service). Son administrateur note l'adresse IP du coupable. Qu'en fait-il ? Pour pouvoir remonter de cette adresse IP au client individuel, il faut garder les journaux du traducteur NAT (et aussi, le RFC l'oublie, que le serveur note l'heure exacte et le port, comme rappelé par le RFC 6302). Les auteurs du RFC ont tenté l'expérience avec 200 000 clients humains pendant 60 jours. Les informations sur les sessions étaient transmises par syslog (RFC 5424) à une station d'archivage. Avec toutes les informations conservées (heure, protocole de transport, adresse IPv6 source originelle - et son port, adresse IPv4 source traduite - et son port), soit 125 octets, les 72 000 sessions par seconde ont produit pas moins de 29 téra-octets de données. La seule activité de journalisation, pour faire plaisir au CSA, nécessite donc une infrastructure dédiée (machines, disques et liens) et coûteuse.
Le système pourrait toutefois être amélioré. Au lieu de noter le port pour chaque session, on pourrait allouer une plage de ports à chaque client et réduire ainsi le volume à journaliser (seule l'allocation de la plage serait notée ; ceci dit, cela compliquera sérieusement le logiciel de recherche, qui aura moins de données à fouiller mais davantage de calculs à faire). On peut même statiquement allouer des plages de port à chaque client, supprimant ainsi une grande partie de la journalisation. Mais attention, ces méthodes d'optimisation ont deux gros défauts : elles diminuent l'efficacité du multiplexage (certains client vont tomber à court de ports alors que d'autres en auront des inutilisés) et elle est contraire aux recommandations de sécurité du RFC 6056, qui prescrit des ports sources difficiles à deviner, pour compliquer la tâche d'un attaquant.
Autre problème lié à la traduction d'adresses, la
géolocalisation. Un serveur qui géolocalise
en se fondant sur l'adresse IP source trouvera la position du
traducteur, pas celle de l'utilisateur. Parfois, cela peut être
gênant. Le RFC 6967 cite quelques solutions
possibles, mais aucune n'est parfaite : on peut par exemple se servir
d'informations applicatives comme l'en-tête
Forwarded: de HTTP (RFC 7239), ce qui ne marche évidemment qu'avec ce protocole.
La section 6 revient vers les problèmes de M. Michu, heureux
utilisateur, sans le savoir, d'un traducteur NAT64. Quelle va être la
qualité de son vécu d'utilisateur ? Ou, dit plus trivialement, est-ce
que ça va marcher ou planter ? Certaines applications fonctionnent
facilement et simplement à travers n'importe quel
NAT, comme HTTP ou SSH. D'autres
nécessitent un relais, une ALG. Les traducteurs
NAT64 fournissent en général une ALG pour FTP
(RFC 6384). Même pour les protocoles qui
marchent « tout seuls » à travers NAT64, une ALG peut être utile pour
la traçabilité, par exemple insérer des en-têtes
Via: dans une requête HTTP ou
Received: dans un message transmis en
SMTP.
En testant des applications réelles, comme l'avait fait le RFC 6586, les auteurs de ce RFC ont trouvé que plusieurs continuent à planter, ce qui plaiderait pour l'ajout à NAT64 des fonctions 464xlat du RFC 6877. Ainsi, SIP n'a pas réussi à appeler depuis la machine IPv6 pure vers un softphone en IPv4 pur (les adresses IP sont transmises dans la signalisation, et ne sont pas traduites par NAT64). Il faut donc, comme recommandé par le RFC 6157, que les clients SIP utilisent ICE (RFC 8445), qui a l'avantage de traiter également le problème des pare-feux.
Pour IPsec, le bilan est également mitigé : comme prévu, AH n'a pas fonctionné (puisque son but est d'empêcher toute modification des en-têtes, donc des adresses IP source et destination), mais ESP non plus, les paquets du protocole de couche 4 50, le protocole d'ESP, n'étant pas traduits. Utiliser ESP sur UDP, comme décrit dans le RFC 3947, aurait probablement résolu ce problème.
Le tableau de la section 6.1 résume les applications testées et les résultats :
- Web : pas de problème, sauf les rares cas où un URL inclut une adresse IPv4 littérale,
- Messagerie instantanée : la plupart des services testés ont échoué (mon expérience personnelle est que XMPP et IRC fonctionnent très bien à travers NAT64, donc je suppose qu'il s'agissait de protocoles fermés et de logiciels privateurs),
- Jeux : les jeux non-Web ont presque tous échoué,
- SIP : échec,
- IPsec : échec (vor ci-dessus),
- Partage de fichiers en pair-à-pair : échec, par exemple avec eMule,
- Courrier électronique : pas de problème,
- FTP : pas de problème.
L'annexe A décrit en outre les délais acceptables pour ces applications, lorsque le traducteur NAT64 tombe en panne et est remplacé. Les jeux interactifs, par exemple, ne supportent pas les longues interruptions.
Comme un traducteur NAT64 gène certains services, il serait utile de fournir aux clients un moyen de contrôler, par exemple, l'ouverture de ports entrants, les ports sortants affectés, etc. Il existe un protocole standard pour cela, PCP (RFC 6887), qui serait un ajout très utile aux traducteurs NAT64 mais, pour l'instant, aucun n'en dispose encore.
La section 7 du RFC se penche ensuite sur les problèmes de MTU. Certes, il n'y a pas de tunnel avec NAT64, mais il peut y avoir des liens IPv4 dont la MTU est inférieure à 1 280 octets, le minimum des liens IPv6. Il n'y a pas de moyen simple, en NAT64-CGN, de gérer ce problème.
Bon, et la sécurité ? La section 9 étudie la question. NAT64 fait du suivi des sessions TCP et est donc normalement à l'abri de pas mal de types d'attaques par déni de service. On peut renforcer sa sécurité en déployant RPF (RFC 3704), pour empêcher les usurpations d'adresses IPv6.
Pour NAT64-FE, une attaque possible serait de remplir la table des sessions en commençant plein de sessions vers les serveurs situés derrière le traducteur NAT64-FE. Celui-ci doit donc avoir un mécanisme de limitation de trafic.
Ah, et puis il faut rappeler qu'un résolveur DNS64, étant un résolveur menteur (pour la bonne cause, certes, mais menteur tout de même), s'entend mal avec DNSSEC. Le RFC 6147 contient de nombreuses notes à ce sujet.
Ce RFC est issu d'un processus qui a commencé par un exposé à l'IETF. Il y a eu quelques objections de principe (un certain nombre de participants à l'IETF estiment que toute traduction est une erreur, NAT64 comme les autres).
L'article seul
Version 7 d'Unicode
Première rédaction de cet article le 19 juin 2014
Le 16 juin a vu la sortie d'une nouvelle version du jeu de
caractères Unicode, la 7.0. On peut trouver une
description des principaux changements en http://www.unicode.org/versions/Unicode7.0.0/ mais voici ceux
qui m'ont intéressé particulièrement. (Il n'y a pas de changement radical.)
Pour explorer plus facilement la grande base Unicode, j'utilise un programme qui la convertit en SQL et permet ensuite de faire des analyses variées. Faisons quelques requêtes SQL :
ucd=> SELECT count(*) AS Total FROM Characters; total -------- 113021
Plus de 113 000 caractères. Lesquels ont été apportés par la version 7 ?
ucd=> SELECT version,count(version) FROM Characters GROUP BY version ORDER BY version; version | count ---------+------- ... 6.0 | 2088 6.1 | 732 6.2 | 1 6.3 | 5 7.0 | 2834
2 834 nouveaux. Lesquels ?
ucd=> SELECT To_U(codepoint) AS Codepoint, name FROM Characters WHERE version='7.0'; codepoint | name -----------+---------------------------------------------------------------------------- ... U+2B5E | BENT ARROW POINTING DOWNWARDS THEN NORTH EAST ... U+10350 | OLD PERMIC LETTER AN ... U+10500 | ELBASAN LETTER A ... U+10600 | LINEAR A SIGN AB001 ... U+10880 | NABATAEAN LETTER FINAL ALEPH ... U+1236F | CUNEIFORM SIGN KAP ELAMITE ... U+1F57D | RIGHT HAND TELEPHONE RECEIVER ... U+1F6F2 | DIESEL LOCOMOTIVE ...
Comme on le voit, c'est varié. On trouve vingt-trois nouveaux alphabets, ayant souvent cessés d'être utilisés, et intégrés à Unicode surtout pour les recherches historiques, comme par exemple le vieux permien, l'elbasan, le nabatéen ou le Linéaire A, toujours pas déchiffré (ce qui explique les noms des caractères, qui sont des chiffres sans sémantique). Il y a aussi l'ajout de plus de mille nouveaux caractères cunéiformes.
La partie la plus spectaculaire, mais pas forcément la plus utile, est l'ajout de nombreux symboles, comme les innombrables flèches (comme la U+2B5E ci-dessus), ou la locomotive Diesel U+1F6F2... À ceux qui disent « digital » pour numérique (comme les innombrables « agences digitales » qui font de la « stratégie digitale »), on pourra désormais répondre avec l'image du caractère U+1F595, « REVERSED HAND WITH MIDDLE FINGER EXTENDED »... Pour mieux apprécier ces nouveaux symboles (avec des représentations graphiques), vous pouvez regarder la liste de ceux de la série U+1F300 et suivants... Si vous avez les bonnes polices de caractères, voici les caractères pris en exemple plus haut : ⭞ 𐍐 𐔀 𐘀 𐢀 𒍯 🕽 🛲 🖕 ... Une autre solution est de se servir d'UniView qui a été mis à jour avec les données de la version 7. Quant aux noms officiels en français de tous ces caractères, ils sont en ligne.
L'article seul
RFC 7211: Operations Model for Router Keying
Date de publication du RFC : Juin 2014
Auteur(s) du RFC : S. Hartman (Painless Security), D. Zhang (Huawei)
Pour information
Réalisé dans le cadre du groupe de travail IETF karp
Première rédaction de cet article le 19 juin 2014
Il y a un gros travail en cours à l'IETF pour améliorer la sécurité du routage sur l'Internet. L'un des aspects de ce travail concerne la gestion des clés par les routeurs. Bien des solutions de sécurité nécessitent que les routeurs disposent de clés secrètes. Le groupe de travail KARP travaille sur les problèmes de gestion de ces clés (cf. RFC 6518). Ce nouveau RFC du groupe décrit les problèmes opérationnels et les pratiques actuelles de gestion des clés dans les routeurs.
KARP a déjà produit plusieurs RFC. Celui-ci se veut particulièrement terre-à-terre. Il existe des tas de techniques pour sécuriser la communication entre routeurs. Mais comment sont-elles effectivement déployées ? Pour le savoir, il faut disposer d'un modèle décrivant les opérations de gestion de clés. C'est d'autant plus crucial que la sécurisation du routage présente quelques défis spécifiques. Par exemple, comme il faut que le routage fonctionne pour pouvoir contacter d'autres machines du réseau, les solutions fondées sur un serveur d'authentification central ne conviennent pas.
D'abord, le modèle de configuration d'un routeur, en section 3. La configuration consiste à indiquer au routeur les clés qu'il utilisera pour s'authentifier, ainsi que divers paramètres. Cela peut se faire manuellement ou automatiquement. La configuration automatique étant encore un sujet d'étude, notre RFC se concentre sur la configuration manuelle, via une structure abstraite, la table des clés. Ce n'est déjà pas évident car certains protocoles nécessitent une clé commune à tous les routeurs, et d'autres pas. Il faut donc pouvoir configurer les clés par interface réseau et par pair. Prenons l'exemple d'OSPF (RFC 2328) : sur tout lien réseau, tous les routeurs doivent utiliser la même clé. En revanche, d'un lien à l'autre, un même routeur peut se trouver à utiliser plusieurs clés différentes. Mais ce n'est pas obligatoire et, dans certaines organisations, on aura peut-être une clé pour chaque zone (area) OSPF, avec seuls les ABR (Area Border Router) utilisant plusieurs clés. Bien sûr, avec une table de clés OSPF où les clés sont rangées par lien, on peut réaliser la politique « une clé par zone » en mettant la même clé pour tous les liens de la zone. Mais, si ce n'est pas vérifié par le système de gestion de la table de clés, il y a un risque de désynchronisation, par exemple parce qu'on change la clé d'un lien en oubliant les autres liens de la zone. Il serait donc souhaitable d'avoir un mécanisme d'héritage (« la clé du lien dépend de la zone ») permettant d'éviter cette désynchronisation accidentelle.
L'intégrité de la table des clés par rapport aux règles techniques des protocoles de routage est évidemment essentielle. Le routeur doit donc s'assurer que les algorithmes de cryptographie indiqués sont compatibles avec le protocole de routage, que la fonction de dérivation l'est également, etc. La table peut être modifiée via une quantité de méthodes (système de gestion de configuration, interface Web, CLI, etc) du moment que son intégrité est vérifiée.
Afin d'éviter les « clés éternelles », jamais changées (même lorsqu'un employé qui les connait quitte l'organisation), il faut aussi que le table prévoit un système d'expiration, pour pouvoir indiquer « cette clé est valable jusqu'au 15 avril 2014 » et qu'elle soit automatiquement marquée comme expirée après cette date.
Il existe des tas de façons d'utiliser des clés en cryptographie. La plus simple (et sans doute la plus courante aujourd'hui) est que les clés configurées dans le routeur soient partagées, et utilisées telles quelles dans le protocole de routage. Mais on peut aussi passer par une fonction de dérivation, qui va combiner la clé partagée avec des paramètres d'une session particulière, rendant ainsi la tâche plus difficile pour l'attaquant (même s'il a la clé, il ne pourra pas forcément s'insérer dans une session en cours). C'est par exemple ce que fait le protocole AO du RFC 5925 (dans sa section 5.2). Ou bien on peut se servir des clés préconfigurées pour s'authentifier le temps de générer des clés de session, par exemple avec Diffie-Hellman. Les clés sont parfois identifiées par un nombre court, parfois pas identifiées du tout et un routeur peut avoir à en essayer plusieurs avant de tomber sur la bonne.
Enfin, il y a le cas où les routeurs utilisent de la cryptographie asymétrique. La clé privée de chaque routeur ne quittera alors jamais le routeur, ce qui augmente la sécurité. (Ceci dit, cela empêchera de remplacer rapidement un routeur, ce qui est une opération souhaitable, et qui justifie donc une gestion centrale des clés.) L'authentification des autres routeurs pourra se faire via une PKI (ce qui peut être compliqué à mettre en place), ou bien en ajoutant la clé publique de chaque routeur à tous ses pairs (ce qui n'est pas pratique si on ajoute souvent de nouveaux routeurs). Pour identifier les clés, notre RFC recommande de se servir du RFC 4572 (section 5). Ensuite, les autorisations de tel ou tel routeur pair peuvent se faire en indiquant les clés (ce qui a l'inconvénient qu'il faut les refaire si un routeur change de clé) ou en indiquant une identité du routeur (ce qui nécessite, pour cette indirection supplémentaire, un moyen sécurisé de passer de l'identité du routeur à sa ou ses clés). Avec une PKI, le problème ne se posera évidemment pas.
On l'a vu, un problème spécifique à la sécurisation du routage est qu'il faut que le mécanisme marche sans dépendre du réseau puisque, avant que les routeurs soient authentifiés et échangent les routes, on n'aura peut-être pas de réseau. Cela limite sérieusement le rôle que peuvent jouer des serveurs centraux, genre RADIUS (RFC 2865). Pas question par exemple que le seul moyen d'obtenir les clés des pairs soit de demander à un serveur central. Cela ne veut pas dire que ces serveurs centraux soient inutiles. Ils peuvent aider à des opérations comme la diffusion de nouvelles clés en cas de préparation à un remplacement de clés ou comme la distribution de la clé d'un nouveau pair. Simplement, le réseau doit pouvoir démarrer et fonctionner sans eux.
La section 6 de notre RFC est consacrée au rôle de l'administrateur humain dans la gestion des clés. Deux exemples typiques où il est indispensable, l'arrivée d'un nouveau pair (il faut décider si on le laisse entrer ou pas) et la réparation en cas de problème. Si le réseau fonctionne déjà, l'arrivée d'un nouveau pair peut être simplifiée car il peut suffire d'inscrire ce routeur dans une base de données et toutes les informations nécessaires peuvent être propagées aux autres routeurs en utilisant le réseau. Le cas d'un réseau tout nouveau démarrant à froid est évidemment plus compliqué.
Naturellement, le nouveau routeur doit être proprement configuré
sur le plan de la sécurité ; il ne servirait à rien de protéger les
clés utilisées par les protocoles de routage si on pouvait se
connecter en SSH sur le routeur avec
login: admin password: admin !
Et les pannes ? C'est que la sécurité apporte ses propres causes de panne. Vouloir sécuriser un réseau peut l'empêcher de fonctionner. Ainsi, l'expiration d'un certificat entraîne son refus par les autres routeurs et le retrait du routeur au certificat trop vieux... Même si le RFC n'en parle pas, une des raisons du faible déploiement des solutions de sécurisation du routage est la crainte d'avoir davantage de pannes. Le déploiement de toute solution de sécurité nécessitera des pratiques plus rigoureuses, par exemple une supervision des dates d'expiration des certificats.
Et une fois qu'on a décidé de déployer une jolie sécurité toute neuve avec une meilleure gestion des lettres de créance des routeurs, comment on fait ? La section 7 fait remarquer que le passage du système actuel au nouveau ne va pas forcément être sans douleur. Si on conçoit un réseau tout neuf, on peut le faire proprement dès le début. Mais si on a un réseau existant et qu'on veut y introduire de nouvelles pratiques ? Et sans tout casser ? Aujourd'hui, si des clés comme celles d'OSPF ou bien celles utilisées entre routeurs BGP sont très rarement changées, c'est souvent par peur que ce changement coupe le routage. Pour deux routeurs BGP appartenant à des organisations différentes, le changement du mot de passe MD5 (RFC 2385) doit être soigneusement coordonné et il faut que le pair respecte rigoureusement la procédure qui a été définie, notamment le moment du changement. Comme on s'en doute, c'est rarement fait.
Prenons l'exemple du nouveau mécanisme AO (RFC 5925) qui remplace l'authentification MD5. Il n'existe pas de mécanisme automatique pour savoir si le pair BGP utilise MD5 ou AO. Il faut donc un changement coordonné (« le 11 mars à 13h37 UTC, on passe à AO »). Si le logiciel utilisé permet de grouper les configurations en traitant tout un ensemble de pairs de la même façon, il faut en prime faire cela pour tous les pairs à la fois. Vu cette difficulté, il n'est pas étonnant que peu de sessions BGP soient aujourd'hui protégées par AO.
Enfin, le rappelle la section 8, beaucoup de mécanismes de sécurité dépendent d'une horloge à l'heure. Il est donc crucial de s'assurer que l'heure sur les routeurs est correctement synchronisée.
L'article seul
RFC 7240: Prefer Header for HTTP
Date de publication du RFC : Juin 2014
Auteur(s) du RFC : J. Snell
Chemin des normes
Première rédaction de cet article le 18 juin 2014
Dans certains cas, la norme du protocole
HTTP laisse un serveur choisir entre plusieurs
comportements, tous légaux. Un client peut avoir une préférence
personnelle et ce nouvel en-tête Prefer:, dans la
requête HTTP, permet à ce client de la spécifier. Ce n'est pas un
ordre, le serveur peut ignorer cette préférence.
Un exemple de cette latitude laissée aux serveurs ? Lorsqu'un
client modifie une ressource Web avec la commande
PUT (cf. RFC 5023), le
serveur peut retourner la nouvelle ressource, complète, ou bien
seulement la modification faite. Le client pourrait dire « je ne vais
même pas lire ce texte, envoie le minimum » ou bien « je vais tout
vérifier soigneusement, envoie la ressource après modification, pour
m'éviter un GET ultérieur ». Le peut-il
aujourd'hui avec l'en-tête Expect: (section 14.20
du RFC 2616) ? Non, car
Expect: est impératif : tout serveur, ou même
tout intermédiaire (par exemple un relais) qui
ne le comprend pas, ou ne peut lui obéir, doit rejeter la
requête. Expect: ne convient donc pas pour le cas
où on veut dire « si tu arrives à le faire comme cela, ça
m'arrangerait mais ne te casse pas trop la tête ». Comme le dit le
RFC, dans un style très Jane Austen,
« preferences cannot be used as expectations ». C'est
d'autant plus important que certaines préférences peuvent avoir un
coût de traitement élevé pour le serveur et que, si celui-ci les
acceptait aveuglément, il pourrait se retrouver victime d'un
déni de service (cf. section 6).
La section 2 spécifie la syntaxe du nouvel en-tête
Prefer:. Sa sémantique, on l'a vu, est qu'il n'est
pas impératif. Le serveur qui ne comprend pas un
Prefer: ou ne peut pas ou ne veut pas le
respecter continue le traitement de la requête en ignorant cet
en-tête. Il peut y avoir plusieurs en-têtes
Prefer: ou bien un seul avec une liste de
préférences séparées par des virgules, comme ici :
GET /coffee HTTP/1.1 Prefer: no-sugar, no-milk, hot
Certaines préférences prennent une valeur, après un signe = :
GET /coffee HTTP/1.1 Prefer: sugar=2
Il peut aussi y avoir des paramètres à certaines préférences, après un ; comme :
GET /coffee HTTP/1.1 Prefer: milk; organic="true"
Vu le caractère optionnel de ce système de préférences, on ne
s'étonnera pas que le RFC demande aux serveurs HTTP d'ignorer les
préférences inconnues (ce qui est le cas de milk
ou sugar, qui ne sont pas dans le registre officiel...)
Que peut-on mettre dans un champ
Prefer: ? Uniquement des préférences enregistrées. La section 4 décrit les préférences
existant actuellement :
respond-asyncindique que le client n'aime pas attendre et préfère une réponse asynchrone plus tard. Le serveur qui acceptera enverra alors un code de retour 202, accompagné d'un champLocation:pour indiquer où récupérer la réponse lorsqu'elle sera prête. Cette préférence ne prend pas de valeur.- Par contre, la préférence
waitprend une valeur, le nombre de secondes qu'on est prêt à attendre, ce qui est utile en combinaison avecrespond-async. Ainsi,Prefer: respond-async, wait=30signifiera qu'on est prêt à attendre une demi-minute, puis qu'on préférerait une réponse asynchrone ensuite. returna aussi une valeur, indiquant si le client préfère recevoir la ressource entière ou bien une version allégée.Prefer: return=representationexprime le premier choix etPrefer: return=minimalle second (c'est sans doute ce que demanderont les clients connectés à un réseau très lent).- Enfin,
handlingindique où le client met le curseur entre le libéralisme et la rigidité.handling=lenientsignifie que le client préférerait que le serveur soit libéral, où cas où la requête contienne quelques erreurs mineures,handling=strict, que le client demande au serveur de n'accepter que des requêtes parfaites.
Comme le respect de Prefer: est facultatif,
attention à ne pas l'utiliser comme substitut de la
négociation de contenu. En effet, il peut être
ignoré par les caches,
qui pourraient mémoriser un contenu correspondant à certaines
préférences et le servir à d'autres clients qui auraient d'autres
préférences. Si le serveur sert des contenus différents selon les
préférences, il doit penser à mettre un Vary:
dans la réponse.
Si le serveur HTTP est sympa, il peut inclure dans la réponse un
en-tête Preference-Applied: qui indique quelles
préférences ont été effectivement appliquées. Un exemple avec la
commande PATCH du RFC 5789 et le format du RFC 6902 :
PATCH /my-document HTTP/1.1
Host: example.org
Content-Type: application/json-patch
Prefer: return=representation
[{"op": "add", "path": "/a", "value": 1}]
qui entraîne la réponse :
HTTP/1.1 200 OK
Content-Type: application/json
Preference-Applied: return=representation
Content-Location: /my-document
{"a": 1}
Les détails bureaucratiques sont en section 5, consacrée aux
registres IANA. Les en-têtes
Prefer: et
Preference-Applied: sont ajoutés au registre
des en-têtes. Un nouveau registre, pour stocker les
préférences, est créé. Les
enregistrements se feront selon la politique « Norme nécessaire » du
RFC 5226 : chaque préférence devra être décrite
dans un document stable, décrivant ses caractéristiques syntaxiques et
sémantiques. Le tout sera envoyé à la liste
ietf-http-wg@w3.org pour un premier examen, puis
approuvé ou rejeté par l'expert nommé par l'IANA.
Début 2013, il semble que cet en-tête Prefer:
soit déjà géré par Abdera. Le protocole
OData cite aussi cet en-tête. Mais on ne
s'attend pas à ce qu'il soit massivement utilisé par les
navigateurs : il est plutôt prévu pour des
clients automatiques, appelant une API REST.
L'article seul
RFC 7238: The Hypertext Transfer Protocol (HTTP) Status Code 308 (Permanent Redirect)
Date de publication du RFC : Juin 2014
Auteur(s) du RFC : J. Reschke (greenbyte)
Expérimental
Première rédaction de cet article le 17 juin 2014
Le protocole HTTP définit plusieurs codes de
retour pour une redirection (« la ressource que tu cherches n'est pas
ici, va voir là »). La section 6.4 du RFC 7231 classe ces trois codes de retour en notant que
deux désignent des redirections temporaires (302 et 307) et qu'un
désigne une redirection permanente (301). Deux codes permettent au
client HTTP de remplacer, pour la nouvelle requête, la méthode
POST par un GET (301 et 302), un
autre ne le permet pas (307). Si vous avez suivi, vous avez noté qu'il
manquait un code voulant dire « redirection permanente mais sans
changer la méthode HTTP ». C'est l'objet du nouveau code décrit dans
ce RFC, le 308 (depuis normalisé dans le RFC 7538).
Donc, 308 veut dire (section 3 de notre RFC) que la ressource Web
convoitée a changé de place, que c'est permanent et que le client HTTP
devrait donc aller chercher la ressource au nouvel endroit
et, s'il le peut, modifier sa base de données
(dans le cas d'un crawler,
par exemple, ou dans celui d'un navigateur qui modifie les
marque-pages). Où est indiqué « le nouvel endroit » ? Par
l'en-tête Location: de la réponse HTTP
(cf. section 7.1.2 du RFC 7231). Il est recommandé d'inclure un petit texte en
HTML fournissant un autre moyen de suivre la
redirection, si le client HTTP n'a pas compris le 308. Bref, le 308
est très proche du 301, à la seule exception près qu'un client n'a pas
le droit de changer la méthode HTTP (POST,
GET, etc) utilisée. Le nouveau code est désormais
dans le registre IANA.
Est-ce que l'information comme quoi il y a redirection peut être mémorisée dans les caches ? Il n'y a pas de mécanisme parfait pour cela mais lesdits caches sont invités à regarder le RFC 7234.
Ajouter un nouveau code HTTP peut provoquer des problèmes de
déploiement (section 4). En effet, la section 6 du RFC 7231 dit que les codes inconnus commençant par 3
doivent être traités comme le code 300 (qui annonce des choix
multiples, en cas de négociation de contenu). Au début, 308 va être
inconnu de tous les clients HTTP et sera donc mal interprété. (Vous pouvez tester votre navigateur ici.) Il n'y
aura pas de redirection automatique. En attendant que tous les clients
soient mis à jour, le webmestre prudent n'utilisera 308 que s'il
connait les clients utilisés, ou s'il sait que l'absence de
redirection automatique n'est pas trop grave. Le RFC déconseille
formellement de faire varier la réponse selon le client (ou selon ce
qu'on croit être le client, rappelez-vous que le champ
User-Agent: peut être trompeur), cela rend le Web
trop difficile à déboguer.
Une façon de s'en tirer pourrait être via le code HTML suggéré plus haut. Par exemple :
HTTP/1.1 308 Permanent Redirect
Content-Type: text/html; charset=UTF-8
Location: http://example.com/new
Content-Length: 454
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN"
"http://www.w3.org/TR/html4/strict.dtd">
<html>
<head>
<title>Permanent Redirect</title>
<meta http-equiv="refresh"
content="0; url=http://example.com/new">
</head>
<body>
<p>
The document has been moved to
<a href="http://example.com/new">
http://example.com/new</a>.
</p>
</body>
</html>
Ainsi, un navigateur Web qui ne comprend pas le
308 sera redirigé, via le <meta http-equiv="refresh" ....
Où en sont les mises en œuvre ? Vous pouvez tester sur le test de libcurl. Pour les navigateurs et autres clients :
- Pour Chrome, voir le ticket 109012.
- Pour libcurl, c'est apparemment déjà fait.
- Pour Firefox, ticket 714302 (intégré depuis la version 14).
Enfin, je signale deux bons articles sur le 308, un en français et un en anglais. Ce code était expérimental à l'époque et est désormais normalisé, depuis le RFC 7538.
L'article seul
RFC 7239: Forwarded HTTP Extension
Date de publication du RFC : Juin 2014
Auteur(s) du RFC : A. Petersson, M. Nilsson (Opera Software)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF appsawg
Première rédaction de cet article le 17 juin 2014
Lorsqu'un client HTTP se connecte
directement à un serveur HTTP, ce dernier voit
l'adresse IP du client et peut la
journaliser pour la traçabilité, faire du contrôle d'accès, des statistiques,
etc. Mais si le client est passé par un relais
(proxy) ? La solution proposée par notre
RFC est que le relais ajoute un en-tête,
Forwarded:, à la requête, reprenant l'information
que le passage par le relais a fait perdre. Il existait déjà des
en-têtes non standards pour ce rôle, ce RFC est le premier à
normaliser.
Notez que, non seulement les relais sont d'un usage très fréquent dans le Web d'aujourd'hui, mais qu'ils sont souvent inconnus du client, par exemple parce qu'ils s'insèrent automatiquement dans la requête HTTP, sans configuration explicite. Même s'il voulait indiquer son adresse IP, le client ne pourrait pas. Il est donc nécessaire que ce soit le relais qui le fasse. La plupart du temps, la perte d'information due au relais (on n'a plus accès à l'adresse IP du client) n'est pas le but principal du relais, ni même un effet souhaité. Le relais vise par exemple à diminuer l'usage de la liaison Internet en gardant les ressources Web dans son cache. Dans ce cas, la perte d'information est un effet de bord non désiré et on peut souhaiter que le relais répare le problème qu'il a causé.
À noter qu'il existe aussi souvent des relais situés, non pas à proximité du client, mais proche du serveur, par exemple pour lui ajouter une fonction de cache des données souvent accédées (le logiciel le plus connu pour cette tâche est Varnish). Ces relais (parfois appelés « relais inverses ») posent le même problème (de perte d'information) et peuvent utiliser la même solution.
Il existe déjà plusieurs en-têtes pour transporter l'information
jusqu'au serveur (comme X-Forwarded-For:) mais
aucun n'avait encore été normalisé, ce qui fait que l'interopérabilité
ne pouvait être garantie. Forwarded: est
désormais dans le registre des en-têtes
(section 9).
Parfois, le relais a au contraire pour but de dissimuler les
clients (par exemple pour permettre l'accès
anonyme au Web) et, dans ce cas, il ne va
évidemment pas utiliser la technique de ce RFC :
Forwarded: n'est pas obligatoire.
Notez que les mêmes problèmes de perte d'information (parfois souhaitée, parfois non) se produisent avec le NAT : voir le RFC 6269.
L'ancien système
non normalisé faisait en général appel à trois en-têtes, X-Forwarded-For:, X-Forwarded-By:, et
X-Forwarded-Proto:. Un des gros inconvénients de
ce système (et qui explique la décision de n'avoir plus qu'un
en-tête, avec plusieurs types d'information) était qu'on ne pouvait
pas savoir quels en-têtes étaient liés : rien n'indiquait si un
X-Forwarded-For: et un
X-Forwarded-By: avaient été mis par le même relais.
La section 4 donne la syntaxe complète de cet en-tête
Forwarded:. Il est bien sûr facultatif et doit
être débrayé par défaut (en raison des problèmes de protection de la
vie privée qu'il pose). Il
comporte une liste de couples {paramètre, valeur} qui permettent
d'indiquer les changements (par exemple d'adresse IP) au passage du
relais. Si plusieurs relais ont été
successivement utilisés, certains paramètres peuvent être répétés. Premier exemple, où seule l'adresse IP du « vrai » client est
indiquée :
Forwarded: For="[2001:db8:cafe::17]"
Autre exemple, où on met l'adresse IP et le port originels :
Forwarded: For="[2001:db8:cafe::17]:4711"
Bien plus bavard, un en-tête qui indique l'adresse IP du client mais aussi celle du relais, ainsi que le protocole original (un relais peut transformer du HTTP en HTTPS et réciproquement, par exemple si un relais termine les sessions TLS avant de passer au vrai serveur) :
Forwarded: for=192.0.2.60;proto=http;by=203.0.113.43
(Je vous laisse chercher pourquoi seules les adresses IPv6 sont entre guillemets. C'est expliqué plus loin.) Et enfin un exemple où deux relais ont été successivement traversés, ils sont alors séparés par des virgules :
Forwarded: for=192.0.2.43, for="[2001:db8:cafe::17]"
Ces paramètres (dans les exemples ci-dessus,
for, by et
proto) sont spécifiés en détail en section
5. by identifie le relais (utile, si on en a
plusieurs, ou simplement si un relais écoute sur plusieurs adresses IP
et veut indiquer laquelle a reçu la requête originale). Ce n'est pas
forcément une adresse IP. for identifie le client
original. Là encore, ce n'est pas forcément une adresse IP, cela peut
être un identificateur arbitraire.
Si ce n'est pas une adresse IP, qu'est-ce que c'est ? La section 6
décrit le concept d'identificateur, utilisé par les paramètres
for et by. Pour des raisons
de sécurité, mais aussi parce qu'ils peuvent être plus pratiques, un
relais peut toujours utiliser des identificateurs à lui pour désigner
le client (l'identificateur spécial unknown
indique que le relais ne sait pas). On peut donc avoir :
Forwarded: for=unknown;by=203.0.113.43
où le relais s'identifie mais ne veut pas ou ne peut pas dire qui est
son client (il pourrait aussi ne pas mettre for
du tout mais le unknown indique que c'est une décision
délibérée, pas un oubli).
Autre possibilité, utiliser des identificateurs attribués localement (précédés par un trait bas), qui ont un sens pour le relais mais pas forcément pour le serveur. Cela permet la traçabilité, sans trop révéler à l'extérieur. Exemple :
Forwarded: by=_eth1
ou bien :
Forwarded: for=_97470ea54d581fc676f6b781b811296e
Des nouveaux paramètres pourront être ajoutés dans le futur et seront stockés dans le nouveau registre des paramètres.
Enfin, les identificateurs peuvent être des adresses IP, comme dans les précédents exemples. Dans ce cas, les adresses IPv6 doivent être entre guillemets, car le deux-points a une signification particulière dans les en-têtes HTTP.
Petit point à garder en tête, l'en-tête Via:,
normalisé dans la section 5.7.1 du RFC 7230 ne donne, lui, d'informations que sur le
relais, pas sur le client originel. En général, on ne peut pas espérer
retrouver toute l'information en combinant Via:
et Forwarded: car certains relais mettront
uniquement un Via:, certains uniquement un
Forwarded: et d'autres les deux.
La section 8 couvre toutes les questions de sécurité liées à
l'en-tête Forwarded:. D'abord, il faut se
rappeler qu'il n'est absolument pas authentifié. Un client plaisantin
a pu en mettre un bidon au départ. Si la requête n'est pas en HTTPS,
quelqu'un sur le trajet a pu ajouter, retirer ou modifier cet en-tête
n'importe comment. Il faut donc traiter cette information avec
prudence, sauf si on est sûr que le précédent relais était une machine
de confiance.
Mais les plus gros problèmes de sécurité posés par ce mécanisme
concernent évidemment la fuite d'information. L'en-tête
Forwarded: peut révéler la structure interne d'un
réseau privé (Forwarded: for=192.168.33.165 et on
sait quelle plage du RFC 1918 est utilisée en
interne...). Plus drôle, si un serveur renvoie cet en-tête dans la
réponse (ce que le RFC interdit), il révèle au
client les relais éventuellement non connus de ce dernier (notez qu'il
existe des sites Web pour cela).
Mais le risque principal de cette fuite d'information est
évidemment celui de compromission de la vie privée : l'en-tête Forwarded:
transmet au serveur des informations que le client peut considérer
comme privées, notamment une donnée nominative,
l'adresse IP. D'où le rappel qu'un relais qui
vise l'anonymisation des requêtes ne doit évidemment pas utiliser cet
en-tête. (Le RFC 8165 cite d'ailleurs cet
en-tête Forwarded: comme un exemple de mauvaise pratique.)
Le RFC demande donc que, par défaut, les identificateurs utilisés
dans les paramètres for et
by soient opaques, et générés plus ou moins
aléatoirement, pour chaque requête. (Mon avis
personnel est que, dans ce cas, autant ne pas mettre de
Forwarded: du tout...)
Le RFC rappelle aussi que le problème de l'anonymat sur le Web est
bien plus vaste que cela : si on n'utilise pas de relais anonymisant,
on divulgue déjà son adresse IP, et il existe un million d'autres
moyens pour un serveur de suivre à la trace un client, comme le montre
le Panopticlick. Les gens qui se plaignent de la
menace que Forwarded: (ou ses prédécesseurs comme
X-Forwarded-For:) font courir à leur vie privée
ne sont pas toujours cohérents avec eux-mêmes (par exemple, il est
rare qu'ils débrayent les
cookies, bien plus efficaces
pour le suivi des visiteurs).
Question mises en œuvre, plusieurs logiciels HTTP géraient déjà les
en-têtes non officiels (par exemple, Squid
documente
comment le configurer, même chose avec
Varnish dans sa
FAQ). Pour le Forwarded:, il va falloir
attendre un peu.
L'article seul
Stocker son identité dans Namecoin ?
Première rédaction de cet article le 16 juin 2014
Le système Namecoin peut servir à beaucoup de choses. Pourquoi pas à avoir une identité stable, en ligne, sans dépendre d'aucune « plateforme » centralisée ?
J'ai déjà parlé de mon expérience avec
Namecoin. Je parlais surtout de la possibilité d'utiliser
Namecoin pour gérer des noms de
domaines. Mais on peut aussi s'en servir pour son
identité. C'est quoi, une identité numérique ? C'est un
identificateur stable et unique, qu'on peut
utiliser pour accéder à des informations sur une entité (cette entité
pouvant être une personne physique, une association, etc). Il existe
des tas de systèmes pouvant servir de support d'identité, des
classiques noms de
domaines résolus grâce au DNS, à
Persona en passant par une identité gérée par
des gros silos états-uniens centralisés comme
Facebook, ou bien des systèmes fédérant des
identités existantes comme l'intéressant Keybase. (Au passage, dans mon cas
personnel, je me sers des noms de domaine
- bortzmeyer.org, d'OpenID
- http://www.bortzmeyer.org/, de
Twitter - @bortzmeyer, de Keybase et de quelques
autres.)
Aucun de ces systèmes n'est parfait (quoi que puissent dire leurs promoteurs). Par exemple, utiliser Facebook pour son identité numérique (comme le font de plus en plus d'entreprises qui n'annoncent comme moyen de les trouver en ligne qu'un identificateur Facebook) vous met à la merci d'un gros silo capitaliste prompt à la censure.
Namecoin n'est pas plus parfait que les autres mais il a des
propriétés intéressantes : dépourvu de « centre » ou de « racine », il
ne vous fait dépendre d'aucune organisation. La syntaxe des
identificateurs est libre mais il existe des conventions de nommage
pour accéder aux différentes facettes de Namecoin. Pour le système
d'identité, documenté en
ligne, l'identificateur doit commencer par
id/ et le mien est donc
id/bortzmeyer. Vous pouvez regarder les
opérations sur cet identificateur dans le livre des
opérations.
Comment je l'ai créé ? Une fois un nœud Namecoin tournant sur la machine, trois commandes ont suffi :
% namecoind name_new id/bortzmeyer
[affiche un identificateur de transaction]
[Attendre que la transaction précédente apparaisse dans le livre des opérations]
% namecoind name_firstupdate id/bortzmeyer [identificateur de transaction précédent]
% namecoind name_update id/bortzmeyer '{"name": "Stéphane Bortzmeyer", "email": "stephane+namecoin@bortzmeyer.org", "hobby": "Internet", ...}
[Les champs déjà définis sont dans https://wiki.namecoin.info/?title=Identity ]
Désormais, le nom est enregistré, et contrôlé uniquement par moi. Pas de vol ou de détournement possible. On peut vérifier, sur sa copie locale validée, que tout est bien enregistré :
% namecoind name_filter id/bortzmeyer
[
{
"name" : "id/bortzmeyer",
"value" : "{\"name\": \"St\u00C3\u00A9phane Bortzmeyer\", \"email\": \"stephane+namecoin@bortzmeyer.org\", \"photo_url\": \"http://www.bortzmeyer.org/images/moi.jpg\", \"hobby\": \"Internet\", \"weblog\": \"http://www.bortzmeyer.org/\", \"namecoin\": \"Myw9PZkBDjjKpaCjSMnWNGrVd7AnDpQoBY\", \"bitcoin\": \"1FLmdwFvodSmyYShPBeSC86L2vNgCnjqLA\", \"xmpp\": \"bortzmeyer@dns-oarc.net\", \"gpg\": \"F42D 259A 35AD BDC8 5D9B FF3E 555F 5B15 CCC6 6677\"}",
"expires_in" : 35839
}
]
Mais est-ce que ça sert à quelque chose ? Quel logiciel est capable d'utiliser ces informations et d'en tirer profit ?
Eh bien, aucun, aujourd'hui, à ma connaissance. Tout ça en est encore
à ses débuts. Signalons le récent projet http://oneid.io qui vise à fournir un site Web de publication
(voyez ma page et notez
la bogue UTF-8) et un
logiciel permettant à chacun d'afficher les informations de Namecoin.
L'article seul
RFC 7236: Initial Hypertext Transfer Protocol (HTTP) Authentication Scheme Registrations
Date de publication du RFC : Juin 2014
Auteur(s) du RFC : J. Reschke (greenbytes)
Pour information
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 16 juin 2014
Une des nouveautés de la série de RFC sur le protocole HTTP 1.1 est l'introduction d'un registre des mécanismes d'authentification (RFC 7235). Ce registre commence avec les mécanismes pré-existants, comme Basic ou Digest, que ce RFC enregistre formellement.
Cinq mécanismes sont donc enregistrés à l'IANA :
L'article seul
RFC 7235: Hypertext Transfer Protocol (HTTP/1.1): Authentication
Date de publication du RFC : Juin 2014
Auteur(s) du RFC : R. Fielding (Adobe), J. Reschke
(greenbytes)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 16 juin 2014
Dans la série de RFC sur le protocole HTTP 1.1, ce nouveau document normalisait l'authentification faite en HTTP. Le RFC 9110 l'a remplacé depuis.
Le HTTP originel avait été conçu uniquement pour de l'accès à des documents publics. Toutefois, l'authentification a été assez vite ajoutée, afin de permettre de mettre en ligne des documents dont l'accès est restreint à une certaine catégorie d'utilisateurs. HTTP dispose aujourd'hui de plusieurs mécanismes d'authentification, décrits dans ce RFC. Il faut quand même noter que tous ont des limites et, qu'en pratique, l'authentification des utilisateurs humains se fait presque toujours par des mécanismes non-HTTP, et pas par ceux de ce RFC.
Le principe de base de l'authentification HTTP est le
défi/réponse. Un client cherche à accéder à une ressource
non-publique : le serveur lui envoie à la place un défi (code de
réponse 401 et en-tête WWW-Authenticate:), le client
fait une nouvelle demande, avec la réponse au défi (en-tête Authorization:). À noter qu'il n'y
a pas que les serveurs d'origine qui peuvent exiger une
authentification, les relais peuvent le faire
également (la réponse de défi est alors un 407 et la réponse du client
est dans un en-tête Proxy-Authorization:). Les
codes de retour liés à l'authentification (301 et 307) sont décrits en
détail dans la section 3 et stockés dans le registre
IANA des codes de retour. Voici un exemple, vu avec
curl, d'un site faisant une authentification
par mot de passe :
% curl -v https://icinga.example.org/icinga/ ... > GET /icinga/ HTTP/1.1 > Host: icinga.example.org > < HTTP/1.1 401 Unauthorized < WWW-Authenticate: Basic realm="Icinga Access" ...
Et, si on indique via curl le mot de passe (si on s'en sert souvent,
on peut aussi mettre le mot de passe dans ~/.netrc) :
% curl -u icinga:vachementsecret -v https://icinga.example.org/icinga/ ... > GET /icinga/ HTTP/1.1 > Authorization: Basic aWNpbmdhOnZhY2hlbWVudHNlY3JldA > Host: icinga.example.org ... < HTTP/1.1 200 OK
Notez que l'authentification se fait sur le canal HTTP (le mot de passe n'est pas chiffré, juste un peu brouillé) et que celui-ci a donc intérêt à être protégé (par exemple par TLS).
Un navigateur Web, recevant le défi (401),
va automatiquement demander à l'utilisateur le mot de passe  et le renverra, dans une seconde requête (et,
en général, il mémorisera ce mot de passe, pour éviter de le demander
à chaque requête HTTP ; HTTP est sans état, c'est le client qui
mémorise et donne l'illusion d'une « session »).
et le renverra, dans une seconde requête (et,
en général, il mémorisera ce mot de passe, pour éviter de le demander
à chaque requête HTTP ; HTTP est sans état, c'est le client qui
mémorise et donne l'illusion d'une « session »).
Une fois qu'on est authentifié, on n'est pas forcément autorisé : si un client reçoit un 403, c'est qu'il n'est pas autorisé, même si son authenticité ne fait pas de doute.
Un concept important de l'authentification HTTP est celui de
« royaume » (realm, section 2.2). Un royaume est un ensemble de
ressources sur le serveur qui ont la même base d'utilisateurs. Un
serveur peut partitionner ses ressources en plusieurs royaumes, par
exemple pour utiliser plusieurs sources d'authentification
différentes. Le royaume utilisé est transmis par le serveur dans le
défi (en-tête WWW-Authenticate:).
La section 4 décrit en détail les en-têtes liés à
l'authentification. Le WWW-Authenticate: contient
le défi. Il est composé d'une indication du type d'authentification,
avec le royaume utilisé, et d'éventuels paramètres. Par exemple, pour
le type le plus simple, Basic, où le défi est vide,
et où le client doit simplement envoyer identificateur et
mot de passe, l'en-tête ressemblera à (pour le
royaume Staff) :
WWW-Authenticate: Basic realm="Staff"
Quant au champ Authorization:, il est envoyé
par le client en réponse à un défi (ou préventivement si le client sait
que l'accès à la ressource est authentifié). Les informations qu'il
contient dépendent du type d'authentification. Avec
Basic, ce sont un identificateur et un mot de
passe, séparés par un deux-points et encodés en
Base64 (c'est normalisé dans le RFC 7617, section 2).
Au fait, la configuration du serveur Apache qui a servi pour les exemples plus haut :
<Directory> AuthName "Icinga Access" AuthType Basic AuthUserFile /etc/icinga/htpasswd.users Require valid-user ...
Et le fichier /etc/icinga/htpasswd.users est
géré avec la commande htpasswd.
L'authentification auprès d'un relais, est identique, avec
Proxy-Authenticate: et
Proxy-Authorization: au lieu de WWW-Authenticate: et
Authorization:.
Les différents mécanismes d'authentification (comme Basic) sont notés dans un registre IANA. Le registre inclut un lien vers la spécification de chaque mécanisme. Ainsi, le traditionnel Basic est dans le RFC 7617 et le récent Bearer dans le RFC 6750. Si vous voulez enregistrer un nouveau mécanisme, lisez aussi le RFC 7236 pour voir des exemples.
Tout nouveau mécanisme doit tenir compte des caractéristiques de HTTP. Par exemple, comme HTTP est sans état, le serveur ne doit pas avoir à se souvenir des requêtes précédentes : toutes les informations pour authentifier un client doivent être dans la requête.
La section 6 résume les problèmes de sécurité liés à l'authentification. Par exemple, le cadre général d'authentification de HTTP, spécifié dans ce RFC 7235, ne précise pas de mécanisme assurant la confidentialité des lettres de créance présentées. Ainsi, dans le cas du mécanisme Basic, le mot de passe est transmis en clair (on ne peut pas considérer Base64 comme un chiffrement...) Il faut donc prendre des précautions supplémentaires (TLS...) Notez qu'il n'y a pas que le mot de passe qui soit une donnée sensible : dans le cas de Basic, l'identificateur de l'utilisateur est également confidentiel.
Le mécanisme HTTP d'authentification, reposant sur un protocole sans état, ne fournit pas de durée de vie de l'authentification. Un client peut garder le mot de passe éternellement alors que le serveur voudrait, par exemple, obliger les clients qui avaient été absents longtemps à se ré-authentifier. Et si c'est le client qui veut annuler l'effet de son authentification, le mécanisme HTTP ne permet pas de fonction de « déconnexion ». C'est une des principales raisons pour lesquelles les applications qui authentifient les utilisateurs ne se servent pas souvent de l'authentification HTTP. Une autre raison est l'impossibilité d'adapter le dialogue de login, par exemple en mettant un lien vers une page de documentation. En pratique, la plupart des applications se servent donc d'un formulaire Web pour demander le mot de passe, puis d'un cookie (RFC 6265) pour chaque requête.
Les changements depuis les RFC 2616 et RFC 2617 ? Ils sont cités dans l'annexe A. Les deux
principaux sont la révision de la grammaire des
valeurs des en-têtes Authorization: et
l'introduction d'une procédure d'enregistrement des nouveaux
mécanismes d'authentification (un premier exemple est celui des
mécanismes existants, dans le RFC 7236).
L'article seul
RFC 7234: Hypertext Transfer Protocol (HTTP/1.1): Caching
Date de publication du RFC : Juin 2014
Auteur(s) du RFC : R. Fielding (Adobe), M. Nottingham
(Akamai), J. Reschke (greenbytes)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 15 juin 2014
Le protocole HTTP 1.1, désormais décrit dans une série de RFC, transporte énormément de données tous les jours et consomme donc à lui seul une bonne partie des ressources de l'Internet. D'où l'importance de l'optimiser. Une des méthodes les plus efficaces pour cela est le cache (terme anglais qui fait très bizarre en français : pour mieux accéder à une ressource, on la cache...). Ce RFC spécifie le modèle de cachage de HTTP et comment les clients et les serveurs peuvent l'utiliser. (Il a depuis été remplacé par le RFC 9111.)
Un cache Web est un espace de stockage local où on peut conserver la représentation d'une ressource qu'on a récupérée. Si la même ressource est à nouveau désirée, on pourra la récupérer depuis le cache, plus proche et donc plus rapide que le serveur d'origine. Outre le temps d'accès, le cachage a l'avantage de diminuer la consommation de capacité réseau. Un cache peut être partagé entre plusieurs utilisateurs, augmentant ainsi les chances qu'une ressource désirée soit présente, ce qui améliore l'efficacité. Comme tous les caches, les caches Web doivent gérer le stockage, l'accès et la place disponible, avec un mécanisme pour gérer le cas du cache plein. Comme tous les caches, les caches Web doivent aussi veiller à ne servir que de l'information fraîche. Cette fraîcheur peut être vérifiée de différentes façons, y compris par la validation (vérification auprès du serveur d'origine). Donc, même si l'information stockée dans le cache n'est pas garantie fraîche, on pourra quand même l'utiliser, si le serveur d'origine confirme qu'elle est toujours utilisable (dans ce cas, on aura quand même un accès réseau distant à faire, mais on évitera de transférer une ressource qui peut être de grande taille).
Le cache est optionnel pour HTTP, mais recommandé, et utiliser un cache devrait être le comportement par défaut, afin d'épargner le réseau, pour lequel HTTP représente une bonne part du trafic.
On peut garder en cache plusieurs sortes de réponses HTTP. Bien
sûr, le résultat d'une récupération après un GET
(code 200, cf. RFC 7231) est cachable et
représente l'utilisation la plus courante. Mais on
peut aussi conserver dans le cache le résultat de certaines
redirections, ou bien des résultats négatifs (un code 410, indiquant que la
ressource est définitivement partie), ou même le résultat de méthodes
autres que GET (bien que cela soit plus rare en
pratique).
Ici, un exemple où une page a été stockée par un cache
Squid, et récupérée ensuite. L'argument de
GET est l'URI complet, pas
juste le chemin :
% curl -v http://www.w3.org/WAI/
...
> GET http://www.w3.org/WAI/ HTTP/1.1
> User-Agent: curl/7.26.0
> Host: www.w3.org
...
< HTTP/1.0 200 OK
< Last-Modified: Thu, 12 Jun 2014 16:39:11 GMT
< ETag: "496a-4fba6335209c0"
< Cache-Control: max-age=21600
< Expires: Sun, 15 Jun 2014 15:39:30 GMT
< Content-Type: text/html; charset=utf-8
< Age: 118
< X-Cache: HIT from cache.example.org
< X-Cache-Lookup: HIT from cache.example.org:3128
< Via: 1.1 cache.example.org:3128 (squid/2.7.STABLE9)
...
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
Le client HTTP curl suit la
variable
d'environnement http_proxy et
contacte donc le relais/cache Squid en
cache.example.org en HTTP. À son tour, celui-ci
se connectera au serveur d'origine si nécessaire (ce ne l'était pas
ici, l'information a été trouvée dans le cache, comme l'indique la
mention HIT.)
Les données stockées dans le cache sont identifiées par une
clé (section 2 de notre RFC). Pour un cache
simple, qui ne gère que GET, la clé principale
est l'URI de la ressource convoitée. On verra
plus loin que la clé est en fait plus complexe que cela, en raison de
certaines fonctions du protocole HTTP, comme la négociation de
contenu, qui impose d'utiliser comme clé certains en-têtes de la requête.
La section 3 du RFC normalise les cas où le cache a le droit de stocker une réponse, pour réutilisation ultérieure. Le RFC définit ces cas négativement : le cache ne doit pas stocker une réponse sauf si toutes ces conditions sont vraies :
- La méthode est cachable (c'est notamment le cas de
GET), - Le code de retour est compris du cache (200 est le cas évident),
- Il n'y a pas de directive dans la réponse qui interdise le
cachage (en-tête
Cache-Control:, voir plus loin), - L'accès à la ressource n'était pas soumis à autorisation (cf. RFC 7235), dans le cas d'un cache partagé entre plusieurs utilisateurs,
- La réponse contient des indications permettant de calculer la
durée de vie pendant laquelle elle restera fraîche (comme l'en-tête
Expires:).
Un cache peut stocker des réponses partielles, résultat de requêtes avec intervalles (cf. RFC 7233), si lui-même comprend ces requêtes. Il peut concaténer des réponses partielles pour ensuite envoyer une ressource complète.
Une fois la ressource stockée, le cache ne doit pas la renvoyer sauf si (là encore, la norme est formulée de manière négative, ce qui est déroutant) toutes ces conditions sont vraies :
- Les URI correspondent,
- Les en-têtes désignés par l'en-tête
Vary:correspondent (cela concerne surtout le cas où il y a négociation du contenu), - La requête ne contient pas de directive interdisant de la servir avec des données stockées dans le cache,
- La ressource stockée est encore fraîche, ou bien a été re-validée avec succès.
L'exigence sur la clé secondaire (les en-têtes sur lesquels se fait la
négociation de contenu) est là pour s'assurer qu'on ne donnera pas à
un client une ressource variable et correspondant aux goûts d'un autre
client. Si le client dont la requête a déclenché la mise en cache
avait utilisé l'en-tête Accept-Language: fr
indiquant qu'il voulait du français, et que le second client du cache
demande la même ressource, mais avec Accept-Language:
en, il ne faut évidemment pas donner la copie du premier
client au second. Si la réponse avait l'en-tête Vary:
accept-language indiquant qu'elle dépend effectivement de
la langue, le cache ne doit la donner qu'aux clients ayant le même
Accept-Language:.
Et la fraîcheur, elle se définit comment (section 4.2, une des plus
importantes du RFC) ? Le cas le plus simple
est celui où le serveur d'origine envoie un en-tête
Expires (ou une directive
max-age), par exemple Expires: Mon, 15 Jun 2015 09:33:06 GMT (un an dans le futur). Dans ce cas, la ressource gardée en
cache est fraîche jusqu'à la date indiquée.
Attention : les formats de date de HTTP sont compliqués et il faut
être prudent en les analysant. Si le Expires:
indique une date syntaxiquement incorrecte, le cache doit supposer le
pire et considérer que la ressource a déjà expiré.
En pratique, bien des serveurs HTTP ne fournissent pas cet
en-tête Expires: et le cache doit donc compter
sur des heuristiques. La plus courante est d'utiliser le champ
Last-Modified: et de considérer que, plus le
document est ancien, plus il restera frais longtemps (section
4.2.2). (La FAQ
de Squid explique bien l'heuristique de ce
logiciel de cache.) Le RFC ne normalise pas une heuristique particulière mais met
des bornes à l'imagination des programmeurs : ces heuristiques ne
doivent être employées que s'il n'y a pas de date d'expiration
explicite, et la durée de fraîcheur doit être inférieure à l'âge du
document (et le RFC suggère qu'elle ne soit que 10 % de cet âge). Par
contre, l'ancienne restriction du RFC 2616
contre le fait de garder en cache des documents dont l'URL comprenait
des paramètres (après le point d'interrogation)
a été supprimée. Un serveur ne doit donc pas compter que ces documents
seront forcément re-demandés. Il doit être explicite quant à la durée
de vie de ces documents.
Dans sa réponse, le cache inclut un en-tête
Age:, qui peut donner au client une idée de la
durée depuis la dernière validation (auprès du serveur
d'origine). Par exemple, Age: 118, dans le
premier exemple, indiquait que la page était dans le cache depuis
presque deux minutes.
Une réponse qui n'est pas fraîche peut quand même être renvoyée au
client dans certains cas, notamment lorsqu'il est déconnecté du réseau
et ne peut pas donc valider que sa copie est toujours bonne. Le client peut empêcher cela avec
Cache-Control: must-revalidate.
Comment se fait cette validation dont on a déjà parlé plusieurs
fois ? Lorsque le serveur a une copie d'une ressource, mais que sa
date maximum de fraîcheur est dépassée, il peut demander au serveur
d'origine. Cela se fait typiquement par une requête conditionnelle
(cf. RFC 7232) : si le serveur a une copie plus
récente, il l'enverra, autrement, il répondra par un 304, indiquant
que la copie du cache est bonne. La requête conditionnelle peut se
faire avec un If-Modified-Since: en utilisant
comme date celle qui avait été donnée dans le
Last-Modified:. Ou bien elle peut se faire avec
l'entity tag et un
If-None-Match: :
% telnet cache 3128 ... GET http://www.w3.org/WAI/ HTTP/1.1 Host: www.w3.org If-None-Match: "496a-4fba6335209c0" HTTP/1.0 304 Not Modified Date: Sun, 15 Jun 2014 09:39:30 GMT Content-Type: text/html; charset=utf-8 Expires: Sun, 15 Jun 2014 15:39:30 GMT Last-Modified: Thu, 12 Jun 2014 16:39:11 GMT ETag: "496a-4fba6335209c0" Age: 418 X-Cache: HIT from cache.example.org X-Cache-Lookup: HIT from cache.example.org:3128 Via: 1.0 cache.example.org:3128 (squid/2.7.STABLE9) Connection: close
Le cache peut aussi
utiliser la méthode HEAD pour tester sa copie
locale auprès du serveur d'origine, par exemple pour invalider la
copie locale, sans pour autant transférer la ressource.
La section 5 liste tous les en-têtes des requêtes et des réponses
qui sont utilisés pour le bon fonctionnement des caches, comme
Age:, Expires:, etc. Ils
sont enregistrés à
l'IANA, dans le registre des en-têtes. Notons
parmi eux le peu connu (et peu mis en œuvre, au point que ce RFC
supprime plusieurs possibilités avancées de cet en-tête) Warning: qui permet de
transférer des informations utiles au cache mais qui ne tiennent pas
dans les autres en-têtes. Par exemple, un serveur peut indiquer qu'il
ne sera pas joignable (pour revalidation), avec le code
d'avertissement 112 (ces codes sont dans un registre
spécial) :
HTTP/1.1 200 OK Date: Sat, 25 Aug 2012 23:34:45 GMT Warning: 112 - "network down" "Sat, 25 Aug 2012 23:34:45 GMT"
Parmi ces en-têtes, Cache-Control: (autrefois
Pragma:) permet de
spécifier des directives concernant le cache. Un client d'un cache
peut spécifier l'âge maximum qu'il est prêt à accepter (directive
max-age), une fraîcheur minimum (directive
min-fresh), que la ressource ne doit pas être
stockée dans le cache
(directive no-store, qui est là pour des raisons
de vie privée mais, bien sûr, est loin de
suffire pour une véritable confidentialité), ou bien qu'elle peut être stockée mais ne
doit pas être servie à un client sans revalidation (directive
no-cache), etc. Les directives possibles sont
stockées dans un
registre IANA.
L'en-tête Cache-Control: peut aussi être
utilisé dans des réponses. Un serveur peut lui aussi indiquer
no-cache, typiquement parce que ce qu'il envoie
change fréquemment et doit donc être revalidé,
private s'il veut insister sur le fait que la
réponse n'était destinée qu'à un seul utilisateur et ne doit donc pas
être transmise à d'autres, etc.
À noter qu'un cache HTTP n'est pas forcément un serveur spécialisé. Tous les navigateurs Web ont des fonctions d'historique (comme le bouton Back). Est-ce que celles-ci nécessitent des précautions analogues à celles des caches, pour éviter que le navigateur ne serve des données dépassées ? Pas forcément, dit le RFC, qui autorise un navigateur à afficher une page peut-être plus à jour lorsqu'on utilise le retour en arrière dans l'historique.
La section 8 détaille les problèmes de sécurité qui peuvent affecter les caches. Un cache, par exemple, peut permettre d'accéder à une information qui n'est plus présente dans le serveur d'origine, et donc de rendre plus difficile la suppression d'une ressource. Un cache doit donc être géré en pensant à ces risques. Plus grave, l'empoisonnement de cache : si un malveillant parvient à stocker une fausse représentation d'une ressource dans un cache (avec une longue durée de fraîcheur), tous les utilisateurs du cache recevront cette information au lieu de la bonne. Un cache peut avoir des conséquences pour la vie privée : en demandant une ressource à un cache partagé, un utilisateur peut savoir, à partir du temps de chargement et d'autres informations envoyées par le cache, si un autre utilisateur avait déjà consulté cette page.
L'annexe A liste les différences depuis le texte précédent, celui du RFC 2616, section 13. Elles sont nombreuses (le texte a été réécrit) mais portent surtout sur des détails, par exemple des précisions sur les conditions exactes dans lesquelles on peut garder une information dans le cache. Depuis, un autre changement a eu lieu avec le remplacement de notre RFC par le RFC 9111.
Notez que le RFC 8246 a ajouté une
extension à Cache-Control:, pour indiquer
l'immuabilité d'une ressource.
L'article seul
RFC 7233: Hypertext Transfer Protocol (HTTP/1.1): Range Requests
Date de publication du RFC : Juin 2014
Auteur(s) du RFC : R. Fielding (Adobe), Y. Lafon (W3C), J. Reschke (greenbytes)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 15 juin 2014
Parmi les fonctions du protocole HTTP 1.1 qui ont eu droit à un RFC spécifique, les intervalles. C'est la possibilité de récupérer en HTTP, non pas la totalité d'une ressource mais une partie, un intervalle (range) de celle-ci. Ce RFC les décrivait mais a été ensuite supplanté par le RFC 9110.
Cette fonction est utile, par exemple, lorsqu'un transfert est interrompu en cours de route et qu'on voudrait pouvoir reprendre le téléchargement au point où il s'était arrêté, et non pas bêtement depuis le début. C'est possible avec le protocole rsync, comment faire avec HTTP ? Le client lit la partie déjà téléchargée, note sa taille, et demande au serveur le reste, en utilisant les intervalles. D'autres usages sont possibles comme de ne récupérer qu'une partie d'un document quand on n'a pas la possibilité de le traiter en entier. Attention, toutefois, ces intervalles sont optionnels pour les serveurs HTTP et un serveur qui ne les gère pas va vous envoyer toutes les données, même si vous n'aviez demandé qu'une partie.
Voici un exemple d'utilisation de ces intervalles avec le client
HTTP curl et son option -r
(--range en version longue). Ici, on récupère la fin du fichier,
à partir du 20 001 ème octet (on compte en partant de zéro), et jusqu'à la fin :
% curl -v --range "20000-" http://www.bortzmeyer.org/images/moi.jpg > moi-partiel.jpg > GET /images/moi.jpg HTTP/1.1 > Range: bytes=20000- < HTTP/1.1 206 Partial Content < Accept-Ranges: bytes < Content-Length: 34907 < Content-Range: bytes 20000-54906/54907 ...
Vous avez vu les en-têtes utilisés pour décrire les intervalles. Notez
qu'avec curl, on peut aussi mettre directement les en-têtes (par
exemple --header "Range: bytes=20000-" au lieu de
--range "20000-") mais c'est déconseillé car cela
ne corrige pas les erreurs de syntaxe.
Maintenant, comment cela fonctionne t-il sur le câble,
lorsqu'on examine le trafic HTTP ? D'abord, un mot sur les unités
utilisées. L'en-tête Range: peut indiquer
l'intervalle en octets, comme plus
haut, ou dans d'autres unités (pour l'instant, aucune n'a été
normalisée, lorsque ce sera le cas, elles seront ajoutées dans le registre IANA). L'avantage des octets est qu'ils conviennent à tous les
types de ressources, les représentations des ressources étant
transférées sous forme d'un flot d'octets. L'inconvénient est qu'ils
ne tiennent pas compte de la syntaxe sous-jacente de la ressource. Par
exemple, pour un fichier CSV, il serait sans
doute plus pratique d'indiquer l'intervalle en nombre de lignes, pour
permettre de récupérer un fichier non corrompu, mais cela supposerait
un serveur HTTP qui connaisse la syntaxe CSV. Autre exemple d'une
limite des octets : pour un fichier texte seul
dont le jeu de caractères est Unicode, le
nombre de caractères serait certainement une unité plus pertinente que
le nombre d'octets (avec des octets, on risque de récupérer un fichier
où certains caractères ne soient pas complets). Mais les serveurs HTTP
ne savent pas forcément analyser les encodages d'Unicode, comme UTF-8.
Les intervalles peuvent être ouverts ou fermés. Un exemple
d'intervalle fermé est bytes=500-999 qui spécifie
le deuxième groupe de 500 octets de la ressource, de l'octet 500
(inclus) à l'octet 999 (inclus aussi). Un intervalle ouvert
est bytes=-999 qui indique les 999 derniers
octets du fichier (notez que le 999 n'a donc pas du tout la même
signification selon qu'il y a un chiffre avant le
tiret ou pas). On peut indiquer plusieurs
intervalles discontinus, par exemple
bytes=500-600,601-999. Ces intervalles doivent
être dans l'ordre croissant et n'ont pas le droit de se recouvrir. Attention, un client
facétieux ou malveillant peut utiliser des chiffres très grands pour
un intervalle ou bien des intervalles qui se recoupent, ce qui, dans au moins un cas avec
Apache, a mené à une faille de sécurité (voir aussi la section 6.1 sur ce
problème de sécurité).
Le serveur peut indiquer quelles unités il accepte pour les
intervalles avec l'en-tête Accept-Ranges:, par
exemple :
Accept-Ranges: bytes
Le client, pour indiquer qu'il ne demande qu'une partie de la
représentation d'une ressource, utilise, on l'a vu dans l'exemple plus
haut, l'en-tête Range:. Combiné avec la requête
GET, cet en-tête indique que le serveur, s'il est
d'accord, s'il gère l'unité indiquée, et si la syntaxe est correcte,
peut n'envoyer que la partie demandée. Ces en-têtes spécifiques aux
requêtes avec intervalle sont stockés dans le
registre IANA des en-têtes.
Un cas un peu plus compliqué
est celui où le client a récupéré une partie d'une ressource, la
ressource a été modifiée sur le serveur, le client veut récupérer le
reste. Les intervalles demandées par le client ne signifient alors
plus rien. Un mécanisme peu connu existe pour traiter ce cas :
l'en-tête If-Range:, suivi d'un validateur
(cf. RFC 7232) dit au serveur « envoie-moi
seulement l'intervalle, s'il n'y a pas eu de changement depuis ce
validateur, ou bien tout le fichier sinon ».
Quelles sont les réponses spécifiques aux requêtes avec
intervalles ? La section 4 en donne la liste (elles ne sont que deux,
dans les autres cas, le code de retour est un classique, comme par
exemple 200 pour un transfert complet réussi, et sont dans le registre IANA). D'abord, il y a 206 qui
signifie un succès (classe = 2) mais qui prévient que, comme demandé,
seule une partie du contenu a été envoyé. Le serveur doit inclure un
en-tête Content-Range: dans la réponse, indiquant
ce qui a été réellement envoyé (regardez l'exemple curl au début). Si
plusieurs intervalles étaient spécifiés dans la requête, le résultat
est transporté dans une structure MIME de type
multipart/byteranges décrite dans l'annexe
A. Chaque partie de la réponse aura son propre
Content-Range: indiquant où elle se situe dans la
ressource originale.
L'autre code de retour possible est 416 qui indique une erreur
(classe = 4) car l'intervalle indiqué n'est pas admissible. Par
exemple, il y a recouvrement entre les intervalles, ou bien l'octet de
départ est situé après la fin du fichier. Attention, rappelez-vous que
les intervalles sont optionnels, un serveur peut ignorer l'en-tête
Range: et, dans ce cas, répondre systématiquement
avec un 200 en envoyant tout le contenu de la ressource.
Les changements depuis le RFC 2616 ? L'annexe
B en fait la liste mais elle est courte, notre nouveau RFC est surtout
une reformulation, avec peu de changements : insistance sur la liberté
du serveur à honorer ou pas les requêtes avec intervalles, précisions
sur les validateurs acceptables, création du registre des unités
- même s'il ne compte pour l'instant qu'une seule unité,
bytes...
L'article seul
La norme HTTP 1.1, nouvelle rédaction
Première rédaction de cet article le 14 juin 2014
Dernière mise à jour le 17 juin 2014
La norme HTTP est actuellement en version 1.1. Cette version était normalisée dans le RFC 2616, un document unique couvrant tous les aspects de HTTP. Ce protocole étant largement utilisé, dans des contextes très différents, des problèmes, voire des bogues dans la spécification sont apparus. Son côté monolithique rendait difficile une évolution. HTTP 1.1 est donc désormais normalisé dans huit RFC différents qui, tous ensemble, remplacent le RFC 2616. (Ils ont depuis été à leur tour remplacés par la série qui comprend notamment les RFC 9110 et RFC 9112.)
Cela a été une des deux tâches du groupe de travail httpbis de l'IETF, l'autre étant de développer la version 2 de HTTP (publiée depuis, dans le RFC 7540).
HTTP a eu plusieurs versions. La première, souvent nommée (après coup) 0.9, n'a pas fait l'objet d'une normalisation formelle. Le premier RFC spécifiant HTTP a été le RFC 1945 en 1996, remplacé ensuite par le RFC 2068 (qui a introduit la version 1.1) puis le RFC 2616. Le RFC 2145 décrit les versions de HTTP et comment les interpréter. À noter que cette dernière révision modifie aussi les RFC 2817 et RFC 2818 sur HTTPS.
La liste des questions ouvertes par le processus de révision était longue : voici celle maintenue par le W3C et celle de l'IETF. Le grand débat était le classique « Faut-il écrire un document en partant de zéro ou bien se contenter de corriger les erreurs les plus évidentes du RFC ? » et le choix a été de refaire les documents mais de garder le protocole.
La liste complète des RFC décrivant HTTP 1.1 est désormais :
- RFC 7230, qui décrit l'architecture, les URI, et la syntaxe des messages,
- RFC 7231, qui décrit la sémantique des messages, les codes de retour à trois chiffres, les en-têtes des requêtes et des réponses,
- RFC 7232, sur les requêtes conditionnelles,
- RFC 7233, normalise les requêtes demandant une portion d'un contenu, en spécifiant un intervalle,
- RFC 7234, décrit le fonctionnement des caches Web,
- RFC 7235, spécifie les mécanismes d'authentification de HTTP,
- RFC 7236, enregistre les anciens mécanismes d'authentification, qui avaient été spécifiés avant le RFC 7235,
- RFC 7237, enregistre les anciennes méthodes HTTP, pour initialiser le registre.
La sortie de cette nouvelle norme a aussi permis la publication
d'extensions à HTTP qui en dépendaient, comme le code de retour 308
dans le RFC 7238, comme l'en-tête
Forwarded: dans le RFC 7239 ou encore comme l'en-tête Prefer:
du RFC 7240.
Les changements ? Le protocole ne change pas, c'est toujours HTTP 1.1. Les changements sont de forme, de précision, de correction de bogues dans la spécification. Parmi les changements transversaux, qui affectent l'ensemble des huit RFC, le passage à l'ABNF standard du RFC 5234, au lieu d'un langage de description de grammaire spécifique à HTTP. La révision de HTTP a été un énorme travail, vu la nécessité de rester compatible avec le comportement de tous les logiciels existants, tout en étant plus rigoureux.
Un bon article résumant le projet est celui de Mark Nottingham, un des présidents du groupe de travail httpbis. (Il y a aussi celui d'Evert Pot.)
L'article seul
RFC 7232: Hypertext Transfer Protocol (HTTP/1.1): Conditional Requests
Date de publication du RFC : Juin 2014
Auteur(s) du RFC : R. Fielding (Adobe), J. Reschke
(greenbytes)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 14 juin 2014
Dans la longue série des RFC sur le protocole HTTP 1.1, ce document relativement court se consacre aux requêtes HTTP conditionnelles : quand un client dit à un serveur « envoie-moi le contenu de cette ressource mais seulement si telle ou telle condition est vraie ». La principale utilité de ces requêtes conditionnelles est d'économiser la capacité réseau si le client a déjà une copie du contenu. Une autre utilité est de permettre la mise à jour d'un document si et seulement si il n'a pas été modifié depuis que le client a commencé à travailler dessus, évitant ainsi le problème de la « mise à jour perdue ». Il est maintenant dépassé par le RFC 9110.
Pour indiquer ces conditions, le client ajoute un ou plusieurs en-têtes (RFC 7231) à sa requête. Quels sont les éléments dont dispose le client pour indiquer les conditions ? On les nomme les validateurs. Deux validateurs sont très répandus, la date de dernière modification d'une ressource et l'étiquette de ressource (entity tag ou ETag). D'autres peuvent être définis, par exemple par WebDAV (RFC 4918). Un validateur est fort ou faible. Un validateur fort est un validateur dont la valeur change à chaque changement, même trivial, du contenu d'une ressource (les étiquettes sont dans ce cas, comme le sont les identifiants de commits d'un VCS comme git ou Subversion). Avec du contenu Web statique, et s'il n'y a pas de négociation du contenu, une façon simple de générer un validateur fort est de condenser le contenu de la ressource, et d'utiliser le condensat comme étiquette. Les validateurs forts sont idéaux (ils identifient précisement un état d'une ressource) mais souvent difficiles, voire impossibles, à générer. Au contraire, les validateurs faibles sont moins précis (plusieurs états d'une ressource peuvent correspondre à la même valeur du validateur) mais simples à générer. Par exemple, une date de dernière modification est un validateur faible : si sa résolution est d'une seconde, et que deux changements de la ressource sont faits dans la même seconde, le validateur ne changera pas. HTTP permet les deux, chacun ayant son utilité. Mais le développeur qui se sert des validateurs pour son application a fortement intérêt à connaître la différence ! Le RFC donne l'exemple de rapports météorologiques : pour éviter qu'un rapport reste dans un cache Web (RFC 7234) alors qu'une version plus récente existe sur le serveur d'origine, le gérant de cette base de rapports doit veiller à ce que les validateurs changent quand le contenu change. D'une manière générale, les validateurs faibles sont acceptables quand on veut juste optimiser les coûts (cas des caches) mais lorsqu'on veut modifier un contenu et éviter l'effet « perte de mise à jour », il faut utiliser un validateur fort.
Comment un serveur HTTP communique-t-il un validateur au client ? Via les en-têtes de la réponse (section 2.2 du RFC). Il y a deux en-têtes possibles :
Last-Modified:qui indique la date de dernière modification de la ressource,ETag:qui indique une étiquette identifiant une version spécifique de la ressource.
Le RFC prescrit à tout serveur HTTP d'envoyer systématiquement un
Last-Modified: dès lors qu'il peut déterminer la
date de modification (si la ressource est assemblée à partir de
plusieurs éléments, c'est le plus récent qui compte). Cela permettra d'utiliser plus souvent les
caches et donc de diminuer la consommation de capacité réseau. Un exemple de cet en-tête (la dernière ligne) :
% curl -v http://verite/ > GET / HTTP/1.1 ... < HTTP/1.1 200 OK < Server: nginx/1.6.0 < Date: Thu, 29 May 2014 19:45:17 GMT < Content-Type: text/html < Content-Length: 612 < Last-Modified: Thu, 24 Apr 2014 14:14:52 GMT
Dans la grande majorité des cas, le
Last-Modified: est un validateur faible. (Ne
serait-ce que parce que la ressource peut changer deux fois en une
seconde, ce qui ne changera pas le
Last-Modified:.)
Le ETag:, lui, est un identificateur
opaque. Il est en général plus difficile à
générer pour le serveur mais bien plus fiable (il évite notamment le
problème des « deux changements dans la même seconde »). En général,
c'est un validateur fort. Un exemple :
% curl -v http://verite/toto.txt ... > GET /toto.txt HTTP/1.1 ... < HTTP/1.1 200 OK < Server: nginx/1.6.0 ... < ETag: "53878f56-5"
Comme c'est un identificateur opaque, seul le serveur sait comment il a été généré. Premier critère avant de choisir une méthode de génération : garantir que deux versions différentes d'une ressource auront deux ETag différents. Deux méthodes courantes pour le générer sont l'utilisation d'un numéro de révision interne (par exemple si les ressources sont stockées dans un VCS) ou bien l'utilisation d'une fonction de condensation. Là encore, le RFC demande que le serveur envoie une étiquette si possible, sauf s'il y a de bonnes raisons, par exemple de performance. Donc, un serveur qui suit le RFC de près enverra les deux validateurs, la date et l'étiquette, en réponse à chaque requête.
Comment le client utilise-t-il ce validateur (section 3) ? Il
dispose d'un choix d'en-têtes à mettre dans la requête permettant de
dire au serveur « agis sur la ressource si et seulement si telle
condition portant sur les validateurs est vraie ». Par exemple,
l'en-tête If-Match: indique une condition portant
sur l'étiquette :
If-Match: "4149d-88-4b1795d0af140"
La condition ci-dessus, dans une requête GET,
POST ou autre, signifie au serveur de n'agir que
si la ressource correspond à l'étiquette indiquée. Pour une méthode
modifiant l'état de la ressource (comme POST ou
PUT), cela permet d'éviter le syndrome de la mise
à jour perdue. Voici un exemple, n'utilisant pas
les requêtes conditionnelles :
- Le client récupère avec
GETune ressource, - Il la modifie localement,
- Pendant ce temps, la ressource a été modifiée sur le serveur, peut-être par un autre client,
- Le client veut enregistrer sa version et fait un
PUT. Les modifications de l'étape précédente sont donc perdues.
Avec les requêtes conditionnelles, on aurait eu :
- Le client récupère avec
GETune ressource, et obtient un validateur fort, l'étiquettee68bd4cc10e12c79ff830b0ec820ef6b, - Il la modifie localement,
- Pendant ce temps, la ressource a été modifiée sur le serveur, peut-être par un autre client,
- Le client veut enregistrer sa version et fait un
PUTen ajoutant unIf-Match: "e68bd4cc10e12c79ff830b0ec820ef6b". Le serveur calcule l'étiquette (ici, c'est un condensat MD5), voit qu'elle ne correspond pas, et refuse lePUTavec un code 412. Les modifications de l'étape précédente ne sont pas perdues.
If-Match: est surtout utile dans les
opérations modifiant la ressource comme PUT. Son
opposé If-None-Match: sert plutôt pour les
GET lorsqu'un cache dit à un serveur
« envoie-moi une copie si elle est différente de celle que j'ai
déjà ». Notez que If-None-Match: peut prendre
comme valeur une liste de ETags.
Il y a aussi des pré-conditions qui portent sur la date de
modification et non plus sur l'étiquette. Ce sont
If-Modified-Since: et
If-Unmodified-Since:. Si on envoie :
If-Modified-Since: Mon, 26 May 2014 19:43:31 GMT
dans une requête GET, on ne recevra le contenu de
la ressource que s'il est plus récent que le 26 mai 2014. Autrement,
on aura un 304, indiquant que le contenu n'a pas été changé
depuis. C'est ainsi qu'un cache peut s'assurer que la copie qu'il
détient est toujours valable, sans pour autant consommer de la
capacité réseau. C'est également utile pour un
crawler, par exemple celui
d'un moteur de recherche qui ne veut pas
récupérer et indexer un contenu qu'il connait déjà. Le cache qui a
reçu un Last-Modified: au dernier
GET conserve la valeur de ce
Last-Modified: et la renvoie dans un
If-Modified-Since: la fois
suivante. curl a des options pour cela. Ici, un
script de téléchargement qui trouve dans un fichier la date de
dernière modification, et ne télécharge que si le fichier est plus récent :
ltr_date=`head -n 1 ${LTR_LOCAL} | cut -d" " -f2`
# Allow time to elapse. The date of the file at IANA is often the day after
# the date written in the LTR. Heuristically, we add one day and a few hours.
current_date=`date +"%Y%m%d %H:%M:%S" --date="${ltr_date} +1 day +4 hour"`
...
curl --time-cond "${current_date}" ...
Ces en-têtes sont enregistrés à l'IANA. Leur usage est facultatif pour le serveur HTTP et, par exemple, nginx ignore ces en-têtes, limite signalée depuis pas mal de temps.
La section 4 liste les deux codes de retour HTTP en rapport avec
ces requêtes conditionnelles. 304 indique que le contenu n'a pas été modifié
depuis la date donnée et le serveur redirige (d'où le 3xx) le client
vers sa copie locale pré-existante. 412 indique qu'une pré-condition nécessaire n'est pas vraie. C'est
en général le résultat d'une requête avec
If-Match: lorsque l'étiquette ne correspond plus
au contenu de la ressource. Ces deux codes sont dans le
registre IANA.
Les sections 5 et 6 précisent l'ordre d'évaluation des pré-conditions, entre elles, et par rapport aux autres critères de recherche. Notamment, les pré-conditions ne sont pas utilisées si la ressource n'existe pas ou si son accès est interdit. Si on a un 404 (ressource non trouvée) sans pré-conditions, on aura le même 404 avec pré-conditions, l'existence de la ressource est testée avant les pré-conditions.
Et les pré-conditions entre elles, puisqu'on peut en avoir plusieurs dans une requête ? Le serveur doit évaluer dans cet ordre (en supposant à chaque fois que l'en-tête en question soit présent ; sinon, on saute au test suivant) :
- D'abord,
If-Match:, car il faut avant tout éviter la mise à jour perdue, - Ensuite
If-Unmodified-Since:(qui passe après car les dates sont moins fiables que les étiquettes), - Ensuite
If-None-Match:(il sert à la validation des caches, ce qui est moins crucial que d'empêcher la mise à jour perdue), - Et enfin
If-Modified-Since:.
Et, pour finir, quelques considérations de sécurité, en section
8. D'abord, les validateurs ne sont pas des mécanismes de contrôle
d'intégrité, comme peut l'être une signature
numérique (le serveur peut mentir, ou un tiers situé sur
le trajet a pu modifier les en-têtes en vol). Ensuite, les étiquettes,
les ETag peuvent poser des problèmes de protection
de la vie privée : un serveur méchant peut
générer une étiquette unique pour un client donné ce qui, lorsque le
client reviendra et enverra des If-Match: ou
If-None-Match: permettra de le reconnaître. Une
sorte de cookie caché,
donc. Un navigateur Web doit donc les traiter comme tel (oublier les
étiquettes lorsque l'utilisateur vide le stock des
cookies, par exemple).
L'annexe A dresse une liste des différences par rapport aux sections correspondantes du RFC 2616. Rien de fondamental mais la définition de la force et de la faiblesse des validateurs a été étendue et précisée, et une définition de l'ordre d'évaluation des pré-conditions a été ajoutée.
L'article seul
RFC 7231: Hypertext Transfer Protocol (HTTP/1.1): Semantics and Content
Date de publication du RFC : Juin 2014
Auteur(s) du RFC : R. Fielding (Adobe), J. Reschke (greenbytes)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 14 juin 2014
Ce RFC est le deuxième plus important de la longue série des nouveaux RFC décrivant le protocole HTTP 1.1. Le premier, le RFC 7230 décrivait les principes généraux, les URI et la syntaxe des messages. Ce second RFC fournit la sémantique desdits messages. Il est donc assez long, mais facile à comprendre car il consiste surtout en une liste détaillée de champs d'en-têtes, de codes de retour, etc. Il a depuis été remplacé par le RFC 9110.
Si on veut comprendre HTTP 1.1 en détail, il faut donc commencer
par le RFC 7230. Ensuite, on peut lire ce RFC 7231 mais la plupart des gens l'utiliseront sans doute uniquement
comme référence, pour vérifier un point particulier de la
norme. Rappelons juste qu'un message HTTP est soit une requête, soit
une réponse, et que requête ou réponse sont composées d'une première
ligne, puis d'une série de champs (formant l'en-tête de la requête ou
de la réponse) et éventuellement d'un corps. La première ligne d'une
requête est une méthode (comme GET), qui donne le
sens principal de la requête (l'en-tête pouvant légèrement modifier
cette sémantique) et ses
paramètres, la première ligne d'une réponse est surtout composée d'un
code de retour, les fameux trois chiffres.
Les méthodes des requêtes (comme GET ou
POST) agissent sur des
ressources (section 2 de notre RFC). Les ressources peuvent être n'importe
quoi. Au début du Web, c'étaient forcément des
fichiers mais cela a évolué par la suite et
c'est désormais un concept bien plus abstrait. Une ressource est
identifiée par un URI (RFC 3986 et section 2.7 du RFC 7230). Notez donc qu'on spécifie indépendemment méthode et
ressource (contrairement à d'autres systèmes hypertextes où c'était
l'identificateur qui indiquait l'action souhaitée).
La ressource, vous l'avez vu, est une notion assez abstraite. On ne peut interagir avec elle que via l'étroite interface de HTTP, sans savoir comment le serveur à l'autre bout gère les ressources (fichier ? extraction dynamique d'une base de données ? autre processus ?) Cette abstraction est à la base du principe « REST ». Mais la ressource a une représentation (section 3 de notre RFC), qui est une suite d'octets, quelque chose de concret, donc. Une même ressource peut avoir plusieurs représentations. Un exemple simple est celui où la ressource est une image et où il y a une représentation en JPEG, une en PNG, etc. Les différentes représentations seront des suites d'octets complètement différentes les unes des autres alors qu'elles représenteront « la même » image.
Le choix de la représentation est fait par le mécanisme dit de « négociation du contenu ».
Les représentations sont étiquetées avec un type de média (dit
aussi type MIME) à la syntaxe bien connue
« type/sous-type » comme image/png. En plus du
type et du sous-type, ils peuvent contenir des paramètres comme le
charset (terme impropre car c'est en fait un
encodage), charsets qui sont
enregistrés à l'IANA, suivant le RFC 2978. Le tout est mis dans le champ
Content-type: comme, par exemple :
Content-Type: text/html; charset=UTF-8
Malheureusement, les serveurs HTTP ne sont pas toujours correctement configurés et les étiquettes de type/sous-type peuvent être incorrectes. Certains navigateurs Web tentent de résoudre le problème en analysant la représentation (ce qu'on nomme le « content sniffing ») mais cette pratique, peu fiable, est déconseillée par notre RFC, notamment pour des raisons de sécurité (il existe des logiciels malveillants encodés de façon à sembler une image GIF pour certains logiciels et un exécutable Windows pour d'autres).
Outre ce type/sous-type, la représentation a d'autres
métadonnées. Par exemple, on peut indiquer une
langue, soit dans la requête (la langue qu'on
veut), soit dans la réponse (la langue obtenue). La langue est codée
par une étiquette de langue (RFC 5646) comme fr, az-Arab ou
en-AU. En pratique, demander des langues
spécifiques n'a guère d'intérêt car la qualité de la traduction n'est
pas prise en compte. Si je préfère le français, mais que je peux lire
l'anglais, une demande dans cet ordre me donnera surtout des pages Web
mal traduites en français.
Les méthodes de HTTP font l'objet de la section 4 de notre RFC. Certaines méthodes sont sûres, c'est-à-dire qu'elles sont en lecture seule : elles ne modifient pas les ressources sur le serveur. On peut donc les utiliser sans modération. Les méthodes peuvent être idempotentes, c'est-à-dire que leur application répétée produit un résultat identique à une application unique. Toute méthode sûre est idempotente (puisqu'elle ne change pas la ressource) mais l'inverse n'est pas vrai. Enfin, certaines méthodes sont qualifiées de « cachables » (désolé pour l'affreux terme, et qui est faux en plus car il ne s'agit pas de dissimuler quoi que ce soit, c'est une allusion aux caches dans les réseaux). Les réponses peuvent potentiellement être gardées en mémoire pour resservir. Toutes les méthodes sûres sont cachables.
La reine des méthodes, la première définie, la plus courante est
évidemment GET. C'est la méthode par défaut de la
plupart des clients (par exemple, avec curl,
c'est celle qui sera utilisée si on ne met pas l'option -X/--request). Elle demande au serveur d'envoyer une
représentation de la ressource indiquée. Dans le cas du serveur HTTP
le plus simple, les URI sont traduits en noms de fichiers locaux (et
la syntaxe des URI reflète la syntaxe des noms de fichiers
Unix) et
ces fichiers sont alors simplement envoyés au client. Mais on peut
mettre en œuvre GET de bien d'autres
façons. GET est sûre et donc idempotente et
cachable.
Utilisée surtout pour le débogage, la méthode
HEAD ne transfère pas la représentation, mais
uniquement le code de retour et les en-têtes de la réponse. Cela
permet de tester un serveur sans épuiser la capacité réseau, par exemple dans un programme
de vérification de liens. HEAD est sûre et donc idempotente et
cachable. (Attention, certaines applications Web
boguées renvoient un code de succès alors même qu'elles ont un
problème ; pour vérifier le bon fonctionnement d'une telle
application, il faut faire un GET et analyser le
contenu, comme avec les options -r ou -s du
check_http des plugins Nagios.)
Au contraire, POST n'est pas sûre : elle
demande qu'on traite le contenu de la requête (avec
GET, la requête n'a pas de contenu, juste
l'en-tête) dans le cadre d'une ressource donnée. Son utilisation la
plus connue est le cas où la ressource visée est un
formulaire et où la requête contient les
valeurs qui vont être placées dans les champs. Dans certains cas,
POST est cachable (mais, en pratique, peu de
logiciels de cache en profitent).
Plus radical, PUT remplace la ressource par le
contenu de la requête (ou bien crée une ressource si elle n'existait
pas déjà). Elle n'est évidemment pas sûre mais elle est idempotente
(le résultat, qu'on applique la requête une fois ou N fois, sera
toujours une ressource dont la représentation est le contenu de la
requête). Le code de retour (voir la section 6 de notre RFC) sera
différent selon que la ressource a été créée ou simplement
remplacée. Dans le premier cas, le client récupérera un 201, dans le
second un 200. PUT et POST
sont souvent confondus et on voit souvent des
API REST qui utilisent
POST (plus courant et plus connu des
développeurs) pour ce qui devrait être fait avec
PUT. La différence est pourtant claire : avec un
PUT, la ressource sur le serveur est remplacée
(PUT est donc idempotente),
alors qu'avec POST elle est modifiée pour
intégrer les données envoyées dans le corps du POST.
Voici un exemple de PUT avec l'option
-T de curl (qui indique le fichier à charger) :
% curl -v -T test.txt http://www.example.net/data/test.txt > PUT /data/test.txt HTTP/1.1 > User-Agent: curl/7.37.0 > Host: www.example.net > Accept: */* > Content-Length: 7731 ... < HTTP/1.1 201 Created < Server: nginx/1.6.0 < Date: Fri, 30 May 2014 20:38:36 GMT < Content-Length: 0 < Location: http://www.example.net/data/test.txt
(Le serveur nginx était configuré avec dav_methods PUT;.)
La méthode DELETE permet de supprimer une
ressource stockée sur le serveur, comme le ferait le rm
sur Unix.
La méthode CONNECT est un peu particulière car
elle n'agit pas réellement sur une ressource distante : elle dit au
serveur de créer un tunnel vers une destination
indiquée en paramètre et de relayer ensuite les données vers cette
destination. Elle sert lorsqu'on parle à un relais Web et qu'on veut
chiffrer le trafic de bout
en bout avec TLS. Par exemple :
CONNECT server.example.com:443 HTTP/1.1 Host: server.example.com:443
va se connecter au port 443 de server.example.com.
Restent les méthodes OPTIONS et
TRACE qui servent pour l'auto-découverte et le
débogage. Rarement mises en œuvre et encore plus rarement activées,
vous trouverez peu de serveurs HTTP qui les gèrent.
Une fois les méthodes étudiées, dans la section 4, place aux en-têtes envoyés après la ligne qui contient la méthode. C'est l'objet de la section 5 du RFC. Ces en-têtes permettent au client HTTP d'envoyer plus de détails au serveur, précisant la requête.
D'abord (section 5.1), les en-têtes de
contrôle. Ce sont ceux qui permettent de diriger
le traitement de la requête par le serveur. Le plus connu est
Host:, défini dans le RFC 7230. Mais il y a aussi
Expect:, qui permet de réclamer de la part du serveur
qu'il mette en œuvre certaines fonctions. Si ce n'est pas le cas, le
serveur peut répondre 417 (« I'm sorry,
Dave »). La seule valeur actuellement définie
pour Expect:
est 100-continue qui indique que le client va
envoyer de grandes quantités de données et veut recevoir une réponse
intérimaire (code de réponse 100).
Les autres en-têtes de contrôle sont définis dans d'autres RFC de
la famille. Ceux relatifs aux caches, comme
Cache-Control: ou Pragma:, sont dans le RFC 7234. Range:, lui, figure dans le RFC 7233.
Après les en-têtes de contrôle, il y a ceux liés aux
requêtes conditionnelles, comme
If-Match: ou If-Modified-Since:. Ils sont décrits dans
le RFC 7232.
Troisième catégorie d'en-têtes transmis lors des requêtes, ceux
liés à la négociation de
contenu (section 5.3), comme
Accept:. Ils vont permettre d'indiquer le genre
de contenu que le client préfère. Comme ces choix ne sont pas binaires
(« je gère PNG et JPEG,
ex-aequo, et je peux me débrouiller avec GIF
s'il n'y a vraiment pas le choix »), les en-têtes de cette catégorie
prennent un paramètre indiquant la qualité. Le paramètre se nomme
q et sa valeur est le poids attribué à une
certaine préférence, exprimée sous forme d'un nombre
réel entre 0 et 1. Ainsi, lorsqu'une requête
GET vient avec cet en-tête
Accept: :
Accept: audio/*; q=0.2, audio/basic
elle indique que le client préfère audio/basic
(pas de qualité indiquée donc on prend celle par défaut, 1). Pour
l'exemple cité plus haut avec les formats d'image, cela pourrait
être :
Accept: image/bmp; q=0.5, image/jpeg, image/gif; q=0.8, image/png
indiquant une préférence pour JPEG et
PNG (pas de qualité indiquée, donc 1 pour tous
les deux), avec un repli vers GIF et, dans les cas vraiment où il n'y
a rien d'autre, BMP (notez que le type
image/bmp n'est pas enregistré mais on le
rencontre quand même souvent).
Même principe pour sélectionner un encodage des caractères
avec Accept-Charset: (rappelez-vous que le terme
charset utilisé à l'IETF est
incorrect, il désigne plus que le jeu de caractères). Et l'encodage
des données ? Il peut se sélectionner avec
Accept-Encoding: :
Accept-Encoding: gzip;q=1.0, identity; q=0.5, *;q=0
(identity signifie « aucune transformation ». La
qualité zéro indiquée à la fin signifie qu'en aucun cas on n'acceptera
cette solution.)
Il existe enfin un en-tête Accept-Language:
pour indiquer les langues préférées mais, en
pratique, il ne sert pas à
grand'chose.
Catégorie suivante d'en-têtes, ceux
d'authentification. C'est le cas de
Authorization: défini dans le RFC 7235.
Une dernière catégorie d'en-têtes est représentée par les en-têtes
de contexte (section 5.5), qui donnent au serveur
quelques informations sur son client. Ils sont trois,
From: qui contient l'adresse de
courrier électronique de l'utilisateur. Il
n'est guère utilisé que par les robots, pour indiquer une adresse à laquelle se
plaindre si le robot se comporte mal. En effet, son envoi systématique
poserait des gros problèmes de protection de la vie
privée. Le deuxième en-tête de cette catégorie est
Referer: qui indique l'URI
où le client a obtenu les coordonnées de la ressource qu'il demande. (À
noter que le nom est une coquille ; en anglais, on écrit
referrer.) Si je visite l'article de Wikipédia sur
le Chaperon Rouge et que j'y trouve un lien vers
http://www.example.org/tales/redridinghood.html, lors de la connexion au serveur
www.example.org, le navigateur enverra :
Referer: http://fr.wikipedia.org/wiki/Le_Petit_Chaperon_rouge
Cet en-tête pose lui aussi des problèmes de vie privée. Il peut
renseigner le serveur sur l'historique de navigation, les requêtes
effectuées dans un moteur de recherche,
etc. Notamment, le navigateur ne doit pas envoyer cet en-tête si l'URI
de départ était local, par exemple de plan
file:.
Enfin, User-Agent:, le troisième en-tête de
contexte, permet d'indiquer le logiciel du client et son numéro de
version. Comme certains sites Web, stupidement, lisent cet en-tête et
adaptent leur contenu au navigateur (une violation hérétique des
principes du Web), les navigateurs se sont mis à mentir de plus en
plus, comme le raconte une jolie
histoire. Par exemple, le
navigateur que j'utilise en ce moment envoie :
User-Agent: Mozilla/5.0 (X11; Linux i686; rv:29.0) Gecko/20100101 Firefox/29.0 Iceweasel/29.0.1
(Au passage, si vous voulez voir tout ce que votre navigateur envoie, vous pouvez essayer ce service.)
Si vous utilisez Apache, et que vous voulez conserver, dans le journal, la valeur de certains en-têtes rigolos, Apache permet de le faire pour n'importe quel en-tête. Ainsi :
LogFormat "[%h]:%{remote}p %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\" %v" combinedv6
va enregistrer le Referer: et le
User-Agent: ce qui donnera :
[2001:db8:22::864:89]:37127 - - [12/Jun/2014:10:09:17 +0200] "GET /greylisting.html HTTP/1.1" 200 3642 "http://fr.wikipedia.org/wiki/Greylisting" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.152 Safari/537.36" www.bortzmeyer.org
J'ai déjà parlé du code de retour HTTP, les fameux trois chiffres qui indiquent si la requête a réussi ou pas. La section 6 le décrit plus en profondeur. Ce code est composé d'une classe, indiquée par le premier chiffre, et d'un code particulier dans les deux chiffres suivants. Des nouveaux codes sont régulièrement créés et un client HTTP doit donc se préparer à rencontrer de temps en temps des codes inconnus. En revanche, le nombre de classes est fixe. Ce sont :
- 1xx : codes informatifs indiquant que la requête a été reçue mais le travail demandé n'est pas encore terminé (par exemple 100 qui signifie « patientez deux secondes, ça arrive » ou 101 lorsqu'on utilise WebSocket).
- 2xx : la requête est un succès (le code le plus fréquent est 200
« tout va bien, voici ta réponse » mais il y en a plusieurs autres
comme 201 indiquant que la ressource n'existait pas mais a été créée
avec succès, par exemple par un
PUT). - 3xx : codes de redirection, indiquant que le client va devoir
aller voir ailleurs pour terminer sa requête (300 pour indiquer qu'il
y a plusieurs choix possibles et que le client doit se décider). 301
et 302 permettent désormais de changer la méthode utilisée
(
POSTenGETpar exemple) 307 et 308 ne le permettent pas. 301 et 308 sont des redirections permanentes (le navigateur Web peut changer ses signets), les autres sont temporaires. Si vous utilisez Apache, la directiveRedirectpermet de faire des 301 (Redirect temp) ou des 302 (Redirect permanent), pour les autres, il faut indiquer explicitement le code (cf. la documentation). Attention à bien détecter les boucles (redirection vers un site qui redirige...) - 4xx : erreur située du côté du client, qui doit donc changer sa
requête avant de réessayer. C'est par exemple le fameux 404,
« ressource non trouvée » ou le non moins célèbre 403 « accès
interdit ». À noter que, si vous êtes administrateur d'un serveur et
que vous savez que la ressource a définitivement disparu, vous pouvez
envoyer un 410, qui indique une absence définitive (
Redirect gone /PATHdans Apache, au lieu d'un simpleRedirectmais ce n'est pas forcément respecté.) Ah, et si vous voyez un 402, sortez vos bitcoins, cela veut dire Payment required. - 5xx : erreur située du côté du serveur, le client peut donc essayer une requête identique un peu plus tard (c'est par exemple le 500, « erreur générique dans le serveur » lorsque le programme qui produisait les données s'est planté pour une raison ou l'autre).
La liste complète des codes enregistrés (rappelez-vous qu'elle est parfois allongée) est stockée à l'IANA mais c'est plus rigolo de regarder la fameuse page des codes HTTP représentés par des chats, où les images ont été très bien choisies (ce sont des images de cette collection qui sont affichées par ce blog en cas d'erreur). Il existe aussi une page équivalente avec des chiens.
Derrière la première ligne de la réponse, celle qui contient ce
code de retour en trois chiffres, les en-têtes de réponse. La section
7 du RFC les décrit en détail. Là encore, plusieurs catégories. La
première est celle du contrôle. C'est le cas de
Date: qui indique date et heure du serveur. Le
format de cette information est un sous-ensemble de celui du RFC 5322 (et, hélas, pas du RFC 3339, bien plus simple et lisible). À noter qu'on trouve
parfois des serveurs utilisant d'autres formats : c'était mal spécifié
au début de HTTP. Un exemple avec le format recommandé :
% curl -v http://www.hackersrepublic.org/ ... < HTTP/1.0 200 OK < Server: Apache/2.4.6 < Date: Sat, 14 Jun 2014 12:11:19 GMT
Location: sert en cas
de redirection à indiquer le nouvel URI. Par exemple :
% curl -v http://www.bortzmeyer.org/eusthatius-test-grammars.html ... > GET http://www.bortzmeyer.org/eusthatius-test-grammars.html HTTP/1.1 ... < HTTP/1.0 301 Moved Permanently < Date: Sat, 14 Jun 2014 12:13:21 GMT < Location: http://www.bortzmeyer.org/eustathius-test-grammars.html
(Redirection mise en place suite à une coquille dans le lien depuis un site important.)
Le champ Vary: est plus subtil. Il indique de
quels paramètres de la requête dépend le résultat obtenu. C'est
indispensable pour les caches : si une réponse varie selon, mettons,
la langue demandée, un autre client qui demande
une autre langue ne doit pas recevoir le même contenu, même si l'URL
est identique. Un cache Web doit donc utiliser comme clé d'une
ressource, non pas l'URL seul mais la combinaison de l'URL et du
contenu de Vary:. Voici un exemple sur ce blog,
où le format d'image peut être négocié :
% curl -v http://www.bortzmeyer.org/images/nat66 ... > GET /images/nat66 HTTP/1.1 > Accept: */* ... < HTTP/1.1 200 OK < Content-Location: nat66.gif < Vary: negotiate,accept ...
C'est la version GIF qui a été choisie et le
Vary: indique bien que cela dépendait de
l'en-tête Accept:.
Troisième catégorie de réponses, les
validateurs, comme
Last-Modified:. Leur utilisation principale est
pour des requêtes conditionnelles ultérieures (RFC 7232). Ainsi, une réponse avec un
Last-Modified:, indiquant la date de dernier
changement, permettra au client de demander plus tard « cette
ressource, si elle n'a pas changé depuis telle date », limitant ainsi
le débit réseau si la ressource est inchangée. Autre en-tête
validateur, Etag:, dont la valeur est une
étiquette (entity tag) identifiant de manière
unique une version donnée d'une ressource. Ainsi :
% curl -v https://www.laquadrature.net/fr/snowden-terminator-et-nous ... < HTTP/1.1 200 OK < ETag: "da6e32e8d35ff7cf11f9c83d814b9328" ...
La ressource snowden-terminator-et-nous de ce
serveur est identifiée par l'étiquette
da6e32e8d35ff7cf11f9c83d814b9328 (probablement un
condensat MD5).
Il y a deux autres catégories pour les en-têtes de réponse, la
troisième comprend les en-têtes utilisées pour l'authentification
(RFC 7235) comme
WWW-Authenticate:. Et la quatrième est composée
des en-têtes indiquant le contexte. La plus connue est
Server: qui indique le(s) logiciel(s) utilisé(s) par le
serveur. Par exemple, dans le cas de ce blog (et changeons un peu,
utilisons wget au lieu de curl) :
% wget --server-response --output-document /dev/null http://www.bortzmeyer.org/ ... HTTP/1.1 200 OK Server: Apache/2.2.22 (Debian) ...
La section 9.6 rappelle que, contrairement à une idée reçue, les indications sur la version du logiciel que transporte cet en-tête ne posent guère de problèmes de sécurité. Les attaquants ne s'y fient pas (ils savent que cet en-tête peut être modifié par l'administrateur du serveur et que, de toute façon, la vulnérabilité n'est pas liée à une version, certains systèmes patchent le logiciel mais sans changer le numéro de version) et essaient donc toutes les attaques possibles (le serveur HTTP qui héberge ce blog reçoit souvent des tentatives d'attaques exploitant des failles d'IIS, alors que c'est un Apache et qu'il l'annonce).
Toutes ces listes de codes, en-têtes, etc, ne sont pas figées. Régulièrement, de nouveaux RFC les mettent à jour et la version faisant autorité est donc stockée dans un registre à l'IANA. La section 8 rappelle la liste de ces registres :
- Un nouveau registre
pour les méthodes
(
GET,PUT, etc, le RFC 7237 enregistre formellement les anciennes méthodes). Les éventuelles nouvelles méthodes doivent être génériques, c'est-à-dire s'appliquer à tous les genres de ressources. Lors de l'enregistrement, il faudra bien préciser si la méthode est idempotente, sûre, etc. - Un autre registre pour les codes de retour comme 200 ou 404. L'ajout d'un nouveau code nécessite le processus IETF review décrit dans le RFC 5226, section 4.1.
- Encore un autre pour les en-têtes, qu'ils soient dans les
requêtes ou dans les réponses. Ce registre est partagé avec d'autres
protocoles qui utilisent un format similaire, notamment le
courrier électronique. Les procédures sont
celles du RFC 3864. Autrefois, il était
fréquent de définir des en-têtes sans les enregistrer, en les
préfixant d'un
X-. Cette pratique a été abandonnée par le RFC 6648. - Et enfin un dernier registre pour le codage du contenu (en fait pas tout à fait le dernier, j'en ai omis certains).
Reste le gros morceau de la sécurité, en section 9. Notre RFC étudie successivement plusieurs points qui peuvent poser problème. D'abord, l'attaque basée sur le nom de fichier. Si un serveur HTTP imprudent transforme directement le chemin dans l'URL en un nom de fichier du système de fichiers local, il peut sans s'en douter donner accès à des endroits non prévus. Par exemple, sur un serveur Unix, lorsque la requête est :
GET /../../../../../../../../etc/passwd HTTP/1.1
un serveur mal programmé donnerait accès au fichier (normalement non
distribué /etc/passwd), car
.., sur Unix, désigne le répertoire situé un cran
au dessus (et le répertoire courant, si c'est la racine, donc
l'attaquant a intérêt à mettre beaucoup de ..
pour être sûr d'atteindre la racine avant de redescendre vers
/etc).
Autre attaque possible, l'injection de commandes ou de code. Le
contenu du chemin dans l'URL, ou celui des autres paramètres de la requête, ne mérite aucune confiance : il est
complètement sous le contrôle du client, qui peut être un attaquant,
et qui peut donc inclure des caractères spéciaux, interprétés par un
des logiciels qui manipulent ce contenu. Imaginons par exemple que le
contenu de l'en-tête Referer: soit mis dans une
base de données relationnelle et que le client
ait envoyé un en-tête :
Referer: http://www.google.com/' ; DROP TABLE Statistics; SELECT'
Comme l'apostrophe et le point-virgule sont des caractères spéciaux pour le langage SQL, on pourrait réussir ici une injection SQL : le code SQL situé entre les deux apostrophes (ici, une destruction de table) sera exécuté. Ces attaques par injection sont bien connues, relativement faciles à empêcher (les données issues de l'extérieur ne doivent pas être passées à un autre logiciel avant désinfection), mais encore fréquentes.
L'actualité (les révélations de Snowden)
poussent évidemment à se préoccuper des questions de vie
privée. Un client HTTP peut envoyer plein d'informations
révélatrices (comme la localisation physique de l'utilisateur, son
adresse de courrier électronique, des
mots de passe...) Le
logiciel, qui connait ces informations, doit donc faire attention à ne
pas les divulguer inutilement. Certaines personnes utilisent l'URI
comme un mot de passe (en y incluant des données secrètes et en
comptant que l'URI ne sera pas publié) ce qui est une très mauvaise
idée. En effet, les URI sont partagés, par les systèmes de
synchronisation de signets, par les navigateurs qui consultent des
listes noires d'URI, par des utilisateurs qui n'étaient pas conscients
que c'était un secret, par l'en-tête
Referer:... Bref, il ne faut pas compter sur le
secret de l'URI. Créer un site Web confidentiel et compter sur le fait
qu'on n'a envoyé l'URI qu'à un petit groupe restreint de personnes est
une très mauvaise stratégie de sécurité. Autre piège pour la vie
privée, les informations apparemment purement techniques et non
personnelles transmises par le navigateur Web, comme le
User-Agent:, les en-têtes de négociation de
contenu (comme Accept-Language:), mais aussi la liste des
polices ou bien d'autres
caractéristiques. Prises ensemble, ces informations permettent le
fingerprinting, l'identification d'un navigateur
unique au milieu de millions d'autres, grâce à ses caractéristiques uniques. Le
fingerprinting marche bien car, en pratique, la
combinaison de toutes ces informations techniques est souvent
unique. Vous ne me croyez pas ? Regardez le Panopticlick.
Voilà, le gros du RFC est passé, il était long mais c'est parce que
HTTP est riche et plus complexe qu'il n'en a l'air. Les annexes de ce
RFC fournissent encore quelques informations intéressantes. Ainsi,
l'annexe A explique les différences entre HTTP et
MIME. HTTP se sert de beaucoup de pièces
empruntées au courrier électronique et à MIME et, à première vue, lire
le RFC 2045 suffit pour les utiliser. Mais HTTP
ayant des caractéristiques différentes de celles du courrier, ce n'est
pas tout à fait vrai. Par exemple, l'en-tête
MIME-Version: n'est pas obligatoire et les formats
de date sont plus stricts. Plus gênant, HTTP n'a pas les limites de
longueur de ligne de MIME et ne replie donc pas les lignes trop
longues.
La liste des changements entre le précédent RFC, le RFC 2616 et ce RFC figure dans l'annexe B. Rappelez-vous que le protocole est le même, HTTP 1.1 et qu'il n'y a donc pas normalement, sauf bogue dans la spécification, d'incompatibilité entre les deux RFC. Les changements sont normalement uniquement dans la rédaction de la norme. Parmi les changements qui peuvent quand même avoir des conséquences pratiques :
- Les méthodes possibles sont désormais dans un registre IANA.
- ISO 8859-1 n'est plus le jeu de caractères par défaut des en-têtes (on trouvait très peu d'en-têtes qui tiraient profit de cette règle : mon blog en avait un et plusieurs personnes m'avaient fait remarquer, bien à tort, que c'était illégal). Même chose pour les contenus de type texte.
- Les codes de retour de redirection 301 et 302 autorisent
explicitement le changement de méthode (de
POSTenGET, par exemple), alignant la norme avec la réalité du comportement des logiciels.
L'article seul
RFC 7230: Hypertext Transfer Protocol (HTTP/1.1): Message Syntax and Routing
Date de publication du RFC : Juin 2014
Auteur(s) du RFC : R. Fielding (Adobe), J. Reschke (greenbytes)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 14 juin 2014
Grande révision de la norme HTTP 1.1, désormais éclatée en huit RFC différents. Celui-ci décrit
l'architecture générale du principal protocole du
Web, HTTP, le format des URI
http: et https:, et la
syntaxe générale des messages. (Il a depuis été largement remplacé par les RFC 9110 et RFC 9112.)
HTTP, un des protocoles les plus célèbres de l'Internet, permet à des clients d'accéder à des ressources situées sur des serveurs. (Le terme de « ressource » a été choisi car il est abstrait : les ressources peuvent être des fichiers mais ce n'est pas forcément le cas.) HTTP est sans état, chaque requête est indépendante des autres et un serveur peut répondre à une requête sans forcément connaître la séquence des requêtes précédentes. Comme il est très générique, et ne suppose pas grand'chose sur les clients et les serveurs, HTTP peut être utilisé dans un grand nombre de contextes différents. Son utilisation par les navigateurs Web n'est donc qu'une seule possibilité. HTTP est utilisé, côté client, par des appliances, des programmes non-interactifs (mise à jour du logiciel, par exemple), des applications tournant sur mobile et récupérant des données sans que l'utilisateur le voit, etc. De même, le modèle du serveur HTTP Apache tournant sur un serveur Unix dans un data center n'est qu'un seul modèle de serveur HTTP. On trouve de tels serveurs dans les caméras de vidéo-surveillance, les imprimantes, et bien d'autres systèmes. Il faut notamment se souvenir qu'il n'y a pas forcément un humain dans la boucle. C'est pourquoi certaines propositions d'évolution de HTTP qui nécessitaient une interaction avec un utilisateur humain, par exemple pour désambiguïser des noms de domaine, sont absurdes. Même chose pour les décisions de sécurité.
Il existe de nombreuses passerelles vers d'autres systèmes d'information. Un client HTTP peut donc, via une passerelle, accéder à des sources non-HTTP. D'une manière générale, HTTP étant un protocole, et pas une implémentation, le client ne sait pas comment le serveur a obtenu la ressource et où. Au tout début du Web, le seul mécanisme pour le serveur était de lire un fichier, mais ce n'est plus le cas depuis bien longtemps (d'où l'utilisation du terme « ressource » et pas « fichier » dans la norme). HTTP spécifie donc un comportement extérieur, pas ce qui se passe à l'intérieur de chaque machine.
La section 2 de notre RFC décrit l'architecture du
World-Wide Web et notamment de HTTP. Ce
dernier, on l'a vu, est un protocole requête/réponse, sans état. Un
client interroge un serveur, au-dessus d'un protocole de transport fiable,
TCP. Comme dans tout protocole client/serveur,
le serveur attend passivement des requêtes et les traite lorsqu'elles
arrivent. Les ressources sont identifiées par un
URI (normalisés dans le RFC 3986). Le format des messages HTTP est du texte, comme avec
bien d'autres protocoles TCP/IP, par exemple
SMTP. Cela facilite l'écriture des programmes,
et surtout leur débogage (messages tapés à la main, lecture des
communications). À noter que la prochaine version de HTTP, HTTP 2,
utilisera au contraire un encodage binaire. Ce format texte ressemble
à bien des égards à l'IMF du RFC 5322, notamment pour la syntaxe des en-têtes
(Name: value). HTTP emprunte aussi à
MIME par exemple pour indiquer le type des
ressources (texte, image, etc).
Le cas le plus simple en HTTP est la récupération d'une ressource
par une requête GET. En voici un exemple, affiché
par le client HTTP curl dont l'option
-v permet de visualiser les requêtes et les
réponses. Le client envoie la ligne GET suivie du
chemin de la ressource sur le serveur, le serveur répond par une ligne
de statut, commençant par le fameux code à trois chiffres (ici, 200). Client et
serveur peuvent et, dans certains cas, doivent, ajouter des en-têtes
précisant leur message :
% curl -v http://www.bortzmeyer.org/files/exemple-de-contenu.txt
...
> GET /files/exemple-de-contenu.txt HTTP/1.1
> User-Agent: curl/7.26.0
> Host: www.bortzmeyer.org
> Accept: */*
>
[Fin de la requête. La réponse suit]
< HTTP/1.1 200 OK
< Date: Thu, 29 May 2014 16:35:44 GMT
< Server: Apache/2.2.22 (Debian)
< Last-Modified: Fri, 11 Nov 2011 18:05:17 GMT
< ETag: "4149d-88-4b1795d0af140"
< Accept-Ranges: bytes
< Content-Length: 136
< Vary: Accept-Encoding
< Link: rel="license"; title="GFDL"; href="http://www.gnu.org/copyleft/fdl.html"
< Content-Type: text/plain; charset=UTF-8
[Fin des en-têtes, le contenu de la ressource suit]
C'est juste un exemple de texte ("contenu"), rien de particulier. Il
est uniquement en ASCII, pour contourner les histoires d'encodage.
Ceci était le cas le plus simple : HTTP permet des choses bien plus compliquées. Ici, pour une page en HTML avec davantage de champs dans la réponse :
% curl -v http://www.hackersrepublic.org/ ... > GET / HTTP/1.1 > User-Agent: curl/7.26.0 > Host: www.hackersrepublic.org > Accept: */* > < HTTP/1.1 200 OK < Server: Apache/2.4.6 < X-Powered-By: PHP/5.4.4-14+deb7u9 < X-Drupal-Cache: HIT < Content-Language: french < X-Generator: Drupal 7 (http://drupal.org) < Cache-Control: public, max-age=0 < Expires: Sun, 19 Nov 1978 05:00:00 GMT < Etag: "1401374100-0-gzip" < Last-Modified: Thu, 29 May 2014 14:35:00 GMT < Content-Type: text/html; charset=utf-8 < Vary: Cookie,Accept-Encoding < Transfer-Encoding: chunked < Date: Thu, 29 May 2014 16:37:15 GMT < Connection: keep-alive < Via: 1.1 varnish < Age: 0 < ... <!DOCTYPE html> <head> <meta http-equiv="X-UA-Compatible" content="IE=Edge" /> <meta charset="utf-8" /> <link rel="apple-touch-icon-precomposed" href="http://www.hackersrepublic.org/sites/all/modules/touch_icons/apple-touch-icon-precomposed.png" type="image/png" /> <link rel="apple-touch-icon" href="http://www.hackersrepublic.org/sites/all/modules/touch_icons/apple-touch-icon.png" type="image/png" /> <meta name="viewport" content="width=device-width" /> <meta name="Generator" content="Drupal 7 (http://drupal.org)" /> ...
Une des complications possibles est la présence
d'intermédiaires. HTTP permet des relais des
passerelles et des
tunnels. Le relais (proxy) est du côté du client,
souvent choisi par lui, et transmet les requêtes, après avoir appliqué
certains traitements, comme le filtrage de la publicité, la censure,
ou bien la mise en cache (cf. RFC 7234) des ressources souvent
demandées, pour accélérer les requêtes suivantes (c'est par exemple la
principale fonction de l'excellent logiciel
Squid et c'est un excellent moyen d'économiser
de la capacité réseau, particulièrement lorsqu'on est connecté par des
lignes lentes). Lorsque le relais n'est pas
explicitement choisi par le client, on parle de transparent
proxy (RFC 1919 et RFC 3040). Ils servent
typiquement à restreindre les services auquel un utilisateur captif
peut accéder.
La passerelle (gateway, également nommée reverse proxy, et
qu'il ne faut pas confondre avec celle décrite plus haut qui fait la
conversion entre HTTP et un autre protocole) est, au contraire, proche
du serveur, choisie par lui, et fournit des services comme la
répartition de charge ou comme la mémorisation
des réponses, pour aller plus vite la prochaine fois (c'est par
exemple le rôle du logiciel Varnish dont vous avez vu la présence signalée par l'en-tête Via: dans l'exemple précédent).
Enfin, le tunnel assure juste une transmission des octets d'un point à
un autre. Il est surtout utilisé pour le cas où la communication est
chiffrée par
TLS mais que le client et le serveur ne peuvent
pas se parler directement. Pour tout intermédiaire, il est important
de se rappeler que HTTP est sans état : deux
requêtes, même venant de la même adresse IP, ne sont pas forcément
liées (le RFC 4559 faisait l'erreur de violer cette règle).
Un point important pour les logiciels HTTP : la norme ne met pas de limites quantitatives dans bien des cas. C'est le cas par exemple de la longueur des URI. Il y a donc potentiellement problèmes d'interopérabilité. Au minimum, notre RFC demande qu'une mise en œuvre de HTTP sache lire des éléments aussi longs que ceux qu'elle génère elle-même, ce qui semble du bon sens.
On l'a dit, cette version de HTTP est la même que celle du RFC 2616 (et, avant, celle du RFC 2068), la version 1.1. L'idée est que la syntaxe des messages échangés dépend du numéro majeur (1, ici). C'est pour cela que le passage à un encodage binaire (et non plus texte) des messages va nécessiter un passage à la version majeure numéro 2. Par contre, des nouveaux messages ou des extensions des messages précédents peuvent être ajoutés en incrémentant juste le numéro mineur (1, à l'heure actuelle). En général, clients et serveurs HTTP 1.1 et HTTP 1.0 (normalisé dans le RFC 1945) peuvent ainsi interagir.
Le World-Wide Web repose sur trois piliers,
le protocole HTTP, présenté ici, le langage
HTML, et les adresses des ressources, les
URI, normalisées dans le RFC 3986. HTTP utilise deux plans (scheme)
d'URI, http: et
https:. http: est spécifique
à TCP, bien que HTTP ait juste besoin d'un
canal fiable et ne se serve pas des autres fonctions de TCP. Porter
HTTP sur, par exemple, SCTP, serait trivial,
mais nécessiterait des URI différents (autrement un client bilingue
ne saurait pas a priori s'il doit essayer d'établir la connexion en
TCP ou en SCTP). Le plan est suivi des deux barres obliques et du
champ « nom de machine ». L'adresse IP de la
(ou des) machine(s) est typiquement trouvée dans le
DNS. Ainsi, ce blog est en
http://www.bortzmeyer.org/ ce qui veut dire qu'il
faudra faire une requête DNS pour le nom
www.bortzmeyer.org
(http://www.bortzmeyer.org/ est un URI,
www.bortzmeyer.org est un nom de
domaine). Le port par défaut est le
bien connu 80.
Malheureusement, HTTP n'utilise pas de mécanisme
d'indirection comme les MX du
courrier électronique ou comme les plus
modernes SRV du RFC 2782,
utilisés par presque tous les autres protocoles Internet. Résultat, il
n'est pas trivial de mettre un nom de domaine « court » (juste le nom enregistré, comme example.org, sans préfixe devant) dans un URI.
Cela ne peut se faire qu'en mettant directement une adresse IP au nom enregistré,
empêchant ainsi d'autres services sur le nom court. Cela rend également très difficile
la répartition de charge côté client. C'est un
des manques les plus sérieux de HTTP.
Le plan https: est pour les connexions HTTP
sécurisées avec TLS (le petit cadenas du
navigateur Web...) Le port est alors le 443. TLS est normalisé dans le RFC 5246.
La section 3 de notre RFC décrit le format des messages. Bon, HTTP est bien connu, il faut vraiment que je le répète ? Une ligne de départ, puis une syntaxe inspirée de l'IMF du RFC 5322, avec ses champs « Nom: valeur », puis une ligne vide puis un corps optionnel. Le récepteur va en général lire la ligne de départ, puis lire les en-têtes en les mettant dans un dictionnaire, puis, si l'analyse de ces données montre qu'un corps peut être présent, le récepteur va lire le corps pour la quantité d'octets indiquée, ou bien jusqu'à la coupure de la connexion. La ligne de départ est la seule dont la syntaxe est différente entre les requêtes et les réponses. Pour une requête, on trouve une méthode (la liste des méthodes possibles est dans le RFC 7231), une cible, puis la version HTTP. Pour la réponse, on a la version HTTP, le code de retour (les fameux trois chiffres), et une raison exprimée en langue naturelle. Voici un exemple avec curl, où on récupère une ressource existante, avec la méthode GET et on a le code de retour 200 (succès) :
% curl -v http://www.afnic.fr/ ... > GET / HTTP/1.1 > User-Agent: curl/7.32.0 > Host: www.afnic.fr > Accept: */* > < HTTP/1.1 200 OK < Date: Tue, 22 Apr 2014 16:47:34 GMT < Server: Apache/2.2.3 (Red Hat) DAV/2 mod_ssl/2.2.3 OpenSSL/0.9.8e-fips-rhel5 < Expires: Thu, 19 Nov 1981 08:52:00 GMT < Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0 < Pragma: no-cache < Content-Type: text/html; charset=utf-8 < Set-Cookie: afnic-prod=m3nc4r1oivltbdkd9qbh6emvr5; path=/ < Transfer-Encoding: chunked < <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1 -transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en"> ...
Ici, par contre, on essaie de détruire (méthode DELETE) une ressource qui n'existe pas. On a le code de retour 404 (ressource inexistante) :
% curl -v -X DELETE http://www.afnic.fr/test ... > DELETE /test HTTP/1.1 > User-Agent: curl/7.32.0 > Host: www.afnic.fr > Accept: */* > < HTTP/1.1 404 Not Found < Date: Tue, 22 Apr 2014 16:50:16 GMT < Server: Apache/2.2.3 (Red Hat) DAV/2 mod_ssl/2.2.3 OpenSSL/0.9.8e-fips-rhel5 < Expires: Thu, 19 Nov 1981 08:52:00 GMT < Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0 < Pragma: no-cache ...
Les codes de retour possibles sont décrits en détail dans le RFC 7231. En attendant, vous trouvez des jolies photos de chats illustrant ces codes chez les HTTP status cats et, pour les chiens, voyez par ici.
Il n'y a pas de limite imposée par la norme pour des choses comme la longueur des lignes de début ou comme la longueur d'un champ dans l'en-tête. En pratique, il est recommandé aux logiciels HTTP d'accepter au moins 8 000 octets.
Les en-têtes des requêtes et réponses comprennent un nom de champ
(comme User-Agent ou
Expires), deux-points et
la valeur de l'en-tête. Des nouveaux champs sont introduits
régulièrement, HTTP n'impose pas un jeu fixe de noms de champs. Ils
sont enregistrés dans un registre IANA
qui est le même que pour les champs du courrier
électronique (certains en-têtes, comme
Date:, sont communs à plusieurs
protocoles/formats.)
L'ordre des champs n'est pas significatif. Normalement, les champs
sont présents une seule fois au maximum. Mais il y a des exceptions,
si le contenu d'un champ est une liste, on peut avoir plusieurs
occurrences du champ, la valeur étant alors la concaténation de toutes
les valeurs en une liste. Au moins un champ,
Set-Cookie: (RFC 6265),
n'obéit pas à cette règle, pour des raisons historiques, et doit donc
être traité à part.
Important changement par rapport à la norme précédente, le RFC 2616, la grammaire des en-têtes. Il n'y a plus une règle spécifique par champ mais une grammaire générique pour les champs, avec une partie spécifique pour la valeur.
Il n'y a pas d'espace entre le nom de champ et le deux-points et le RFC impose, principe de robustesse ou pas, de rejeter les messages ayant de tels espaces. (Autrement, cela permettrait d'intéressantes attaques.)
Autre changement important depuis le précédent RFC, l'encodage par défaut. La norme autorisait explicitement ISO 8859-1 dans les en-têtes, les autres encodages devaient passer par la technique du RFC 2047. Cette règle est désormais abandonnée, les valeurs des en-têtes devant rester en ASCII, ou bien être traitées comme du binaire, sans être interprété comme du ISO 8859-1.
Au cours de son transfert, la ressource à laquelle on accède en HTTP peut subir des transformations, par exemple pour en réduire la taille. La section 4 de notre RFC décrit ces « codages pendant le transfert » : compression mais aussi transfert en plusieurs morceaux.
Maintenant, en section 5 du RFC, un autre point important de HTTP,
le routage des requêtes. Lorsqu'un client HTTP reçoit un URL, qu'en
fait-il ? Il va regarder si la ressource correspondant à cet URL est
déjà dans sa mémoire et est réutilisable. Si non, il va regarder s'il
doit faire appel à un relais (cela dépend de la
configuration dudit client). Si oui, il se
connecte au relais et fait une requête HTTP où l'identificateur de
ressource est l'URL complet (absolute form dans le RFC). Si non, il extrait le nom du serveur HTTP
de l'URL, se connecte à ce serveur, et fait une requête HTTP où
l'identificateur de ressource est juste la partie « chemin ». Le champ
Host: de l'en-tête HTTP vaut le nom du serveur. Le
port par défaut (s'il n'est pas indiqué dans
l'URL) est, comme chacun le sait, 80 (et 443 pour
HTTPS). Le nom de serveur donné dans l'URL est
directement utilisé pour une requête de résolution de noms pour avoir
l'adresse. Malheureusement, comme indiqué plus haut, HTTP n'utilise pas les
SRV du RFC 2782, d'où le
fait qu'on voit souvent des adresses IP mises directement à l'apex du
domaine enregistré.
À noter que ce RFC ne couvre pas l'autre partie du « routage », le
fait, pour le serveur, de trouver, pour une cible donnée,
la localisation de la ressource demandée. Les premiers serveurs HTTP
avaient un routage très simple : la cible était préfixée par un nom de
répertoire configuré dans le serveur, et le tout était interprété
comme le chemin d'un fichier sur le serveur. Ainsi, GET
/toto.html sur un serveur où le nom de départ était
/var/web, servait le fichier
/var/web/toto.html. Aujourd'hui, ce mécanisme
de routage existe toujours mais il est accompagné de nombreux
autres. À noter que, depuis la création du concept de virtual
host, le serveur HTTP commence par chercher le
virtual host, en utilisant le champ
Host: pour le routage.
La section 6 de notre RFC couvre la gestion des connexions. HTTP
n'a pas besoin de grand'chose de la part du protocole de transport sous-jacent : juste une
connexion fiable, où les octets sont reçus dans l'ordre
envoyé. TCP convient à ce cahier des charges et
c'est le protocole de transport utilisé lorsque l'URL est de plan
http: ou https:. On pourrait
parfaitement faire du HTTP sur, par exemple,
SCTP (RFC 4960), mais il
faudrait un nouveau plan d'URL. HTTP, pour l'instant, utilise
forcément TCP, et le client HTTP doit gérer les connexions TCP
nécessaires (les créer, les supprimer, etc).
Le modèle le plus simple (et le modèle historique de HTTP mais qui
n'est plus celui par défaut) est celui où chaque couple requête/réponse
HTTP se fait sur une connexion TCP différente, établie avant l'envoi
de la requête, et fermée une fois la réponse reçue. Mais d'autres
modèles sont possibles. Pour indiquer ses préferences, le client
utilise l'en-tête Connection:. Par défaut, une
connexion TCP persiste après la fin de l'échange, et peut servir à
envoyer d'autres requêtes. Si le client veut fermer la connexion TCP
immédiatement, il envoie :
Connection: close
L'établissement d'une connexion TCP prenant un certain temps (la fameuse triple poignée de mains), il est logique que les connexions soient persistentes et réutilisables.
Un client HTTP peut aussi avoir plusieurs connexions TCP ouvertes simultanément vers le même serveur mais le RFC lui impose de limiter leur nombre. (Ce parallélisme est utile pour éviter qu'une courte requête, par exemple pour une feuille de style soit bloquée par un gros téléchargement.) Les versions précédentes de la norme donnaient des valeurs précises (deux, dans le RFC 2616) mais notre nouveau RFC ne donne plus de chiffre, demandant simplement aux clients d'être raisonnables.
La section 9 est l'obligatoire section de sécurité. D'abord la question de l'autorité que fait (ou pas) la réponse. Les problèmes de sécurité surviennent souvent lorsque l'idée que se fait l'utilisateur ne correspond pas à la réalité : c'est le cas par exemple du hameçonnage où la réponse qui fait autorité, pour HTTP, n'est pas celle que croit l'utilisateur. Le RFC donne quelques conseils comme de permettre aux utilisateurs d'inspecter facilement l'URI (ce que ne font pas les utilisateurs et que les navigateurs Web ne facilitent pas, trop occupés à noyer la barre d'adresses, jugée trop technique, au milieu d'autres fonctions). Mais il peut aussi y avoir des cas où HTTP lui-même est trompé, par exemple si un empoisonnement DNS ou bien une attaque contre le routage IP a envoyé le navigateur vers un autre serveur que celui demandé. HTTPS vise à résoudre ces problèmes mais, avec l'expérience qu'on a maintenant de ce service, on peut voir que ce n'est pas si simple en pratique (attaques contre les AC, bogues dans les mises en œuvre de TLS, etc). Et cela ne résout pas le problème de l'utilisateur qui suit aveuglément un lien dans un courrier reçu... À noter que HTTP n'a aucun mécanisme d'intégrité, pour se protéger contre une modification du message. Il dépend entièrement des services sous-jacents, TLS dans le cas de HTTPS. Ces services protègent le canal de communication mais pas les messages eux-mêmes, pour lesquels il n'y a pas de sécurité de bout en bout, encore une sérieuse limite de HTTPS. Même chose pour la confidentialité (le groupe de travail, après de longues discussions n'a pas réussi à se mettre d'accord sur un texte à inclure au sujet de l'interception des communications HTTP.)
HTTP soulève aussi plein de questions liées à la vie privée. On sait que le journal d'un serveur HTTP peut révéler beaucoup de choses. Un serveur cache d'un réseau local, notamment, voit tout le trafic et peut le relier à des utilisateurs individuels. Bref, il faut traiter les journaux sérieusement : ils sont souvent soumis à des lois de protection de la vie privée (ils contiennent des informations qui sont souvent nominatives comme l'adresse IP du client HTTP), et ils doivent donc être gérés en accord avec les bonnes pratiques de sécurité (par exemple, lisibles seulement par les administrateurs système). Le RFC recommande qu'on ne journalise pas tout ou que, si on le fait, on « nettoie » les journaux au bout d'un moment (par exemple en retirant l'adresse IP du client ou, tout simplement, en supprimant le journal).
La section 8 de notre RFC résume les enregistrements faits à l'IANA pour HTTP :
- Les champs d'en-tête comme
Connection:ouDate:sont dans le registre des en-têtes (qui est partagé avec d'autres services, notamment le courrier électronique), - Les plans d'URI comme
http:sont dans le registre des plans, - Les types des ressources manipulés, dits aussi « types
MIME », comme
text/htmlsont dans le registre des types, - Les codages des données transférées (comme
gzip) sont dans un registre adhoc, - etc.
Le travail de développement de HTTP a mobilisé énormément de monde,
ce qui reflète l'extrême importance de ce protocole sur l'Internet. La
section 10 liste des centaines de noms de personnes ayant participé à
ce protocole (dont votre serviteur).
L'annexe A résume la longue histoire de HTTP depuis sa création en
1990. HTTP/0.9 (qui n'avait pas encore de
numéro de version officiel, il l'a reçu après) était un protocole
ultra-simple (d'où son succès, alors que les gourous de
l'hypertexte travaillaient tous sur des choses
bien plus complexes, et regardaient de haut ce service trop simple)
qui n'avait qu'une méthode, GET. Sa spécification était minimale. Les numéros de
versions sont officiellement apparus avec HTTP/1.0, le premier décrit
dans un RFC, le RFC 1945. HTTP/1.0 introduisait les en-têtes permettant de
varier les requêtes et les réponses, et notamment d'indiquer le type
de la ressource récupérée. Son principal manque était l'absence de
toute gestion des virtual hosts, puisqu'il n'avait
pas l'en-tête Host:. Il fallait donc une adresse
IP par site servi...
HTTP/1.1, décrit pour la première fois dans le RFC 2068, introduisait notamment le virtual hosting et les connexions TCP persistantes. Le RFC 2068 a été remplacé ensuite par le RFC 2616, puis par notre RFC 7230 puis encore, mais partiellement, par le RFC 9112, mais sans changement du numéro de version. Si les changements apportés depuis le RFC 2616 sont très nombreux, ils ne changent pas le protocole. Parmi les principaux changements qu'apporte notre RFC 7230 :
- L'indication du nom de l'utilisateur (et, dans certains cas, du mot de passe !) dans l'URI est abandonnée.
- Les URI
https:sont désormais officiellement définis dans le RFC HTTP et plus dans un RFC à part (le RFC 2818). - Les en-têtes s'étendant sur plusieurs lignes sont maintenant découragés.
- Et plein d'autres détails, indispensables au programmeur d'un client ou d'un serveur HTTP mais qui ennuieraient probablement très vite la plupart des lecteurs.
L'article seul
RFC 7237: Initial Hypertext Transfer Protocol (HTTP) Method Registrations
Date de publication du RFC : Juin 2014
Auteur(s) du RFC : J. Reschke (greenbytes)
Pour information
Première rédaction de cet article le 14 juin 2014
Une des nouveautés de la série de RFC
sur le protocole HTTP 1.1 est l'introduction d'un registre des
méthodes HTTP (GET,
POST, etc), permettant
de voir du premier coup d'œil les méthodes existantes. Ce registre
commence avec les méthodes pré-existantes que ce purement bureaucratique RFC 7237 enregistre formellement.
Les procédures pour spécifier une nouvelle méthode (et donc être publié dans le registre) sont décrites dans la section 8.1 du RFC 7231.
Sont donc ajoutés, dans la version initiale du registre
IANA, outre les méthodes du RFC 7231
comme les classiques GET ou
PUT pas moins de trente-quatre méthodes, la
plupart venues de WebDAV (RFC 4918). Parmi elles, ACL (RFC 3744), LABEL (RFC 3253),
SEARCH (RFC 5323), mais aussi certaines
sans lien avec WebDAV comme PATCH (RFC 5789).
L'article seul
Neutralité des plateformes : les gros silos actuels sont-ils incontournables ?
Première rédaction de cet article le 13 juin 2014
Aujourd'hui, le Conseil National du Numérique a publié un rapport sur « la neutralité des plateformes ». Quel est le plus gros manque de ce rapport ?
D'abord, il faut voir l'origine du concept de « neutralité des plateformes ». Depuis plusieurs années, les utilisateurs de l'Internet se battent pour défendre le principe de la neutralité de l'Internet, c'est-à-dire l'idée que les intermédiaires (les FAI, par exemple) doivent être de simples tuyaux et ne doivent pas profiter du fait qu'ils sont un passage obligé pour discriminer contre telle ou telle utilisation du réseau. Ce combat gêne évidemment un certain nombre d'intermédiaires, qui luttent donc contre la neutralité. Ou plutôt, car il est désormais difficile politiquement de se dire « contre la neutralité », ils essaient de relativiser ce principe (comme le PDG d'Alcatel-Lucent qui dit qu'il faut « revoir les règles de net-neutralité en faisant preuve de pragmatisme »). Ou encore ils essaient de noyer le poisson en faisant surgir tout un tas de sujets annexes baptisés du terme de « neutralité » pour créer de la confusion. Ce fut le cas il y a deux ou trois ans de l'idée de « neutralité des terminaux ». Aujourd'hui, la diversion à la mode est la « neutralité des plateformes ». L'idée des défenseurs de cette notion est que les gros silos (comme les GAFA : Google, Apple, Facebook et Amazon) sont des intermédiaires obligés et doivent donc être soumis eux aussi à une obligation de neutralité. Notons que les plateformes citées sont toujours états-uniennes et que l'accent sur la neutralité des plateformes plutôt que sur celui de neutralité de l'Internet recouvre donc souvent du classique protectionnisme. (En France, les FAI, par contre, sont en général français.)
Que contient le rapport du CNN ? Il plonge dans l'erreur dès le début en affirmant « Le Conseil relevait à cette occasion que la société numérique n’est pas seulement mise en action par des réseaux physiques mais aussi par un ensemble de services, parmi lesquels les plateformes occupent une place centrale. » C'est le plus gros problème avec ce rapport : il affirme que les gros silos comme Google sont incontournables. Mais ce n'est pas vrai. Autant le FAI est un intermédiaire obligé (à part les projets très expérimentaux et très limités de réseaux « mesh »), autant l'usage de Gmail n'est pas obligatoire. On peut envoyer et recevoir du courrier sans Gmail, on peut louer des machines virtuelles ailleurs que sur Amazon, on peut stocker et distribuer des fichiers sans Dropbox. Cela fait une énorme différence entre les FAI et les gros silos : s'il est légitime de protéger la neutralité de l'Internet contre les abus des intermédiaires, rien ne dit que cela doive forcément être le cas pour des « plateformes » qu'on n'est pas obligés d'utiliser.
Mais, vont se dire mes lecteurs, qui sont intelligents et subtils (et détectent immédiatement les tentatives de flatterie), s'il est vrai qu'on peut faire du courrier sans Gmail, en pratique, N,n % des M. Michu (avec N grand) se servent de Gmail. Ce n'est peut-être pas un passage obligé, mais c'est un quasi-monopole et la régulation s'impose donc. Mais le problème avec cette attitude est qu'elle est de résignation. Je suis d'accord que la place excessive prise par les GAFA dans les services sur l'Internet est dangereuse : ces silos stockent des données personnelles sans vergogne, savent tout de vous (alors que vous ne savez rien d'eux), et transmettent les informations à la NSA (programme PRISM, entre autres). Ils représentent des SPOF : si Facebook fait une crise de bigoterie et de puritanisme, ils peuvent vous censurer et leur importance fait que les victimes de la censure hésiteront à aller ailleurs.
Mais la solution est-elle d'imposer à ces silos des règles protégeant (sans doute fort mal) leurs victimes ? On entrera alors dans une logique dangereuse, où on laisse ces entreprises vous exploiter, en mettant simplement quelques garde-fous (l'expression, révélatrice, est du CNN : « Il est donc crucial de développer des garde-fous adaptés aux dynamiques de plateformes afin de protéger les usagers et l’innovation lorsque le passage d’une logique ouverte à une logique fermée se produit »). Pour reprendre les termes de Bruce Schneier, les silos sont des seigneurs féodaux : on obtient d'eux quelques services et, en échange, ils sont vos maîtres. Faut-il limiter les excès des seigneurs, leur imposer des garde-fous ? Ou bien faut-il plutôt passer à un régime post-féodal ?
Car il est une chose que les ministres ne savent pas : l'Internet existe sans les GAFA. Ils n'ont pas toujours été là et ils ne seront pas toujours là. Il existe des alternatives, comme le développement du pair-à-pair et comme l'auto-hébergement. Il est absurde que, pour partager des fichiers, on les mette à des milliers de kilomètres de là, sur Dropbox, alors qu'on pourrait partager directement entre utilisateurs. Pourquoi est-ce que cela ne se fait pas déjà ? Il y a plusieurs raisons. Certaines sont techniques (l'auto-hébergement reste trop compliqué, Caliopen est très loin d'être prêt à concurrencer Gmail, etc). D'autres sont marketing : les GAFA ont bien réussi à faire croire à tout le monde (à commencer par le CNN) qu'ils étaient incontournables. Comme le note Pierre Beyssac « c'est triste de voir les gens s'enchaîner volontairement puis pleurer de l'être ». Mais il y a aussi des raisons politiques : le pair-à-pair a été activement persécuté et diabolisé, sur ordre de l'industrie du divertissement, jetant ainsi des millions d'utilisateurs dans les bras des silos centralisés. Et puis, les ministres aiment bien râler contre Google mais, au fond, ils sont très contents de sa domination. Ils sont bien plus à l'aise avec quelques grosses entreprises privées qu'avec des millions d'internautes libres.
Est-ce tout simplement irréaliste de croire qu'on pourrait remplacer Google et Facebook ? Le rapport du CNN dit pourtant que constituer ces services n'a nécessité qu'un « faible niveau d’investissement initial ». C'est évidemment faux (le rapport du CNN oscille entre l'irréalisme - vouloir faire céder Google depuis Paris - et la résignation - croire que les GAFA sont indéboulonnables), mais, à ceux qui croient que Google est tout-puissant, rappelez-vous les telcos attardés des années 90, essayant de stopper le déploiement de l'Internet. Ils avaient de l'argent, les médias à leur service, et des soutiens politiques en quantité et ont quand même dû céder.
Sinon, quelques autres points dans le rapport du CNN. La proposition qui a fait le plus de buzz était « Développer des agences de notation de la neutralité pour révéler les pratiques des plateformes et éclairer les usagers et partenaires dans leurs choix. » Pourquoi pas ? Ce serait toujours ça. Mais pourquoi le réserver aux GAFA ? Des tas d'autres entreprises gagneraient à être ainsi évaluées, et leurs pratiques révélées (les grosses violations de la neutralité de l'Internet ont toujours été faites clandestinement). On peut dire la même chose pour une autre proposition du CNN, « Définir également des standards de lisibilité, de compréhension, d’ergonomie et de simplicité de l’accès au droit dans la relation à la plateforme, pour rendre plus effectifs les droits des usagers. » Excellent, mais pourquoi se limiter aux silos Web ? Les conditions d'utilisation de mon abonnement 3G méritent certainement tout autant d'être rendues lisibles et compréhensibles.
Il y a aussi de très bonnes idées dans le rapport du CNN comme « Pour que les fruits de ces efforts bénéficient à l’ensemble de la société, il importe qu’ils s’accompagnent d’une politique ambitieuse de littératie numérique des citoyens et des organisations. » et « Informer les citoyens sur le fonctionnement des plateformes en introduisant les principes techniques qui sous-tendent leurs fonctionnalités essentielles dans les différents référentiels de littératie numérique. Mettre à disposition les assortiments d’outils nécessaires pour en permettre une expérimentation accessible au plus grand nombre. » Cette question de la « littératie » (ne pas être un consommateur balloté par la pub mais un citoyen, actif et comprenant) est en effet cruciale.
En résumé, l'effort essentiel ne devrait pas être consacré à essayer de mettre quelques pauvres garde-fous à la voracité des GAFA, mais a encourager leur relativisation. Le rapport du CNN parle un peu de « Soutenir activement les initiatives de constitution de modèles d’affaires alternatifs. Par exemple, soutenir les solutions « cross-platforms » qui facilitent l’utilisation simultanée de services concurrents complémentaires, ou celles qui apportent une diversification des voies de la chaîne de valeur entre les services et leurs utilisateurs et le développement d’applications nouvelles dans l’économie sociale. » mais ce n'est guère développé et cela se limite apparemment à la création de quelques entreprises privées concurrentes (mais françaises) au lieu de chercher à limiter l'usage des silos centralisés.
Quelques autres articles sur le rapport du CNN :
L'article seul
RFC 7279: An Acceptable Use Policy for New ICMP Types and Codes
Date de publication du RFC : Mai 2014
Auteur(s) du RFC : M. Shore (No Mountain Software), C. Pignataro (Cisco Systems)
Première rédaction de cet article le 13 juin 2014
Voici un court RFC sur un protocole peu connu mais indispensable au bon fonctionnement de l'Internet : ICMP. Plus précisément, ce RFC se penche sur la création de nouveaux types et codes ICMP : quand est-ce une bonne idée ?
ICMP est normalisé dans le RFC 792 pour IPv4 et dans le RFC 4443 pour IPv6. Il sert de protocole de signalisation pour IP, transportant des informations sur l'état du réseau et les éventuels problèmes rencontrés. Les messages ICMP ont un champ nommé Type qui indique la catégorie du message et, lorsque le message nécessite davantage d'analyse, un champ Code. Ainsi, pour IPv6, un paquet ICMP dont le champ Type vaut 1 indique que la destination souhaitée n'est pas joignable, et le Code indique la raison (par exemple, 0 indique que le routeur ne connait pas de route vers cette destination). La liste de ces types et codes n'est pas figée et on pouvait toujours en ajouter des nouveaux (par exemple celui du RFC 6743) ou en retirer (cf. RFC 6633). Un registre IANA donne la liste actuelle (pour IPv4 et pour IPv6).
Il n'existait pas de politique formelle quant à l'enregistrement de nouveaux types et codes. Chaque demande était évaluée sans référence à une règle commune. La section 2 de notre RFC introduit une politique. Deux cas sont estimés acceptables :
- Le nouveau type sert à indiquer à l'émetteur du paquet qu'un problème dans la transmission est survenu en aval. L'examen du message ICMP doit permettre à l'émetteur de savoir si le paquet a été transmis ou pas. C'est par exemple le cas, pour les types existants, de Destination unreachable (type 3 en IPv4 et 1 en IPv6), de Time exceeded (utilisé par traceroute, type 11 en IPv4 et 3 en IPv6), de Packet too big (type 2 en IPv6, malheureusement trop souvent filtré, ce qui explique les problèmes de Path MTU discovery fréquents avec IPv6).
- Le nouveau type sert à obtenir ou à transmettre des informations sur un nœud du réseau, obtenir ou transmettre des paramètres du réseau, ou découvrir des machines situées sur le lien. C'est par exemple le cas, pour les types existants, de Echo (request or reply) (dont dépend la commande ping, types 0 et 8 en IPv4, 128 et 129 en IPv6), des messages de sollicitation ou d'annonce du routeur (types 9 et 10 en IPv4, 133 et 134 en IPv6), des messages de résolution d'adresse IP en adresse MAC (types 135 et 136 en IPv6, cf. RFC 4861).
La section 2.1 de notre RFC classe tous les types existants en indiquant de quel cas ils relèvent. Attention, cette classification couvre aussi les types abandonnés et qui ne doivent plus être utilisés (RFC 6918).
Ces cas limitatifs excluent donc l'usage d'ICMP pour faire un protocole de routage complet. D'abord, du point de vue architecture, ICMP n'a pas été prévu pour cela. Ensuite, il n'a aucun mécanisme d'authentification et il permet des usurpations triviales. D'autre part, et malheureusement, il est souvent filtré.
Il existe au moins un protocole de routage mis en œuvre sur ICMP : RPL (RFC 6550). C'est une exception et elle ne devrait pas être généralisée (RPL ne fonctionne pas au niveau de tout l'Internet mais uniquement dans des réseaux locaux).
Certaines applications utilisent ICMP de manière créative, par exemple en provoquant délibérement des conditions d'erreur, pour récolter, via les messages ICMP d'erreur, des informations sur le réseau. C'est notamment le cas de traceroute, qui envoie des paquets avec un TTL délibérement trop bas, pour provoquer l'envoi de messages Time exceeded. Cela ne pose pas de problème philosophique : ces applications utilisent les types ICMP existants, elles ne changent pas le protocole.
Notre RFC note également que, si on veut étendre ICMP parce qu'il est actuellement trop limité, il existe un mécanisme standard pour mettre de l'information structurée dans les messages ICMP, mécanisme décrit dans le RFC 4884. Par exemple, ce mécanisme permet d'indiquer dans les messages ICMP des informations sur les interfaces réseaux utilisées par le paquet d'origine (RFC 5837).
La section 3 résume les choses importantes à savoir sur la place d'ICMP : originellement prévu pour signaler les erreurs, il a été vite étendu pour faire des diagnostics (style ping). Il fait partie intégrante d'IP (ce n'est pas une option : une machine IP doit gérer ICMP). Bien que ses messages soient encapsulés dans IP, il n'est pas considéré comme un protocole au-dessus d'IP mais comme un composant d'IP. Et le RFC rappelle que son nom est trompeur : le « Protocole des Messages de Contrôle de l'Internet » ne contrôle nullement l'Internet, son rôle est plus modeste mais indispensable.
L'article seul
RFC 7265: jCal: The JSON format for iCalendar
Date de publication du RFC : Mai 2014
Auteur(s) du RFC : P. Kewisch (Mozilla), C. Daboo (Apple), M. Douglass (RPI)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF jcardcal
Première rédaction de cet article le 1 juin 2014
Le format iCalendar permet de décrire de manière standard, compréhensible par tous les logiciels de gestion d'agenda, les événements, rendez-vous, tâches à accomplir, etc. Très connu et largement déployé, il est présent à de nombreux endroits. iCalendar est à la fois un modèle de données (décrivant ce qu'on stocke) et une syntaxe particulière. Des syntaxes alternatives sont possibles et ce nouveau RFC en propose une, fondée sur JSON. Elle se nomme donc jCal.
Il y avait déjà une autre syntaxe alternative, fondée sur XML, dans le RFC 6321. Celle-ci s'inscrit dans la mode JSON actuelle (RFC 8259) et promet de rendre le vieux format iCalendar plus accessible pour les applications Web, notamment celles écrites en JavaScript. Notez qu'il existe un autre format en JSON, le jsCalendar du RFC 8984, qui repose sur un modèle de données différent.
iCalendar est normalisé dans le RFC 5545. Il a plusieurs points techniques en commun avec le format vCard de description de « cartes de visite » virtuelles, normalisé dans le RFC 6350 et c'est pour cela que le même groupe de travail à l'IETF a normalisé la version JSON de iCalendar (dans ce RFC 7265) et la version JSON de vCard (RFC 7095). Cette dernière, jCard, a essuyé les plâtres et jCal lui doit beaucoup et lui ressemble énormément.
La section 1 du RFC résume le cahier des charges du projet jCal (identique à celui du RFC 6321 pour xCal) :
- Possibilité de conversion iCalendar -> jCal et retour, sans perte sémantique,
- Pas d'impératif de préservation de l'ordre des éléments,
- Maintien du modèle de données de iCalendar,
- Les futures extensions de iCalendar devront pouvoir être intégrées naturellement, sans nécessiter un nouveau RFC jCal.
La section 3 est le gros morceau du RFC, indiquant comment convertir les iCalendar actuels en jCal. iCalendar a quelques particularités syntaxiques. Par exemple, les lignes trop longues peuvent être repliées, et certaines valeurs ont besoin d'échappement. Pour passer à jCal, on déplie toutes les lignes et on retire les échappements. Puis on applique les échappements de JSON.
Un document iCalendar est une suite d'objets iCalendar (a iCalendar stream) qu'on transforme en un tableau JSON, dont chaque élément est un objet iCalendar. Ce simple objet iCalendar, qui définit un événement Planning meeting :
BEGIN:VCALENDAR CALSCALE:GREGORIAN PRODID:-//Example Inc.//Example Calendar//EN VERSION:2.0 BEGIN:VEVENT DTSTAMP:20080205T191224Z DTSTART:20081006 SUMMARY:Planning meeting UID:4088E990AD89CB3DBB484909 END:VEVENT END:VCALENDAR
va être traduit ainsi en jCal (exemple tiré de l'annexe B du RFC) :
["vcalendar",
[
["calscale", {}, "text", "GREGORIAN"],
["prodid", {}, "text", "-//Example Inc.//Example Calendar//EN"],
["version", {}, "text", "2.0"]
],
[
["vevent",
[
["dtstamp", {}, "date-time", "2008-02-05T19:12:24Z"],
["dtstart", {}, "date", "2008-10-06"],
["summary", {}, "text", "Planning meeting"],
["uid", {}, "text", "4088E990AD89CB3DBB484909"]
],
[]
]
]
]
La section 4 explique, elle, les détails de l'opération inverse, convertir du jCal en iCalendar.
Ce nouveau format jCal a désormais son propre type
MIME,
application/calendar+json (et pas
jcal+json, attention).
Parmi les mises en œuvre de jCal, on note :
L'article seul
RFC 7254: A Uniform Resource Name Namespace for the Global System for Mobile communications Association (GSMA) and the International Mobile station Equipment Identity (IMEI)
Date de publication du RFC : Mai 2014
Auteur(s) du RFC : M. Montemurro, A. Allen (Blackberry), D. McDonald (Eircom), P. Gosden (GSM Association)
Pour information
Première rédaction de cet article le 22 mai 2014
Ce RFC normalise un nouvel espace de nommage
dans la famille des URN. Cet espace sera géré
par l'association des fabriquants de matériel
GSM, GSMA. Il permettra notamment d'écrire les
IMEI, ces identifiants des téléphones mobiles,
sous forme d'un URN, par exemple urn:gsma:imei:35465101-163629-9.
L'utilité de ces URN ne s'arrêtera pas au
GSM puisque les mêmes identificateurs sont
utilisés pour UMTS ou la
3G. Outre l'IMEI
(identifié par la chaîne de caractères imei), ils
pourront dans le futur
exprimer d'autres identificateurs. Le mécanisme pour définir des espaces
de noms dans les URN est spécifié dans le RFC 8141. Un URN
est un URI qui
commence par urn: suivi d'un espace de noms (ou
NID pour Namespace IDentifier), ici
gsma. Donc, le début des URN de ce RFC sera
toujours urn:gsma:.
Ensuite, l'IMEI. Ce numéro de série unique à
chaque téléphone figure en général sur l'appareil, ou son emballage,
ou bien peut être lu via le logiciel du téléphone. Ici, sous la batterie d'un téléphone 
L'usage le plus connu de l'IMEI est en cas de perte ou de vol du téléphone : on indique l'IMEI à la police ou au service des objets trouvés, et ils pourront ainsi savoir si le téléphone récupéré est le bon. L'IMEI comporte 15 chiffres, organisés en trois groupes qu'on sépare parfois par un trait d'union : 8 chiffres pour le TAC (Type Allocation Code), 6 chiffres pour le SNR (Serial NumbeR) et le Spare, un chiffre de contrôle. Le TAC identifie le modèle chez le constructeur et le SNR indique une machine particulière de ce modèle. Tous les deux sont câblés en dur dans le matériel du téléphone. L'IMEISV (SV pour Software Version) inclut en plus un numéro de version du logiciel du téléphone. Si vous voulez plus de détails, il faudra lire le standard TS 23.003.
Les IMEI sont alloués hiérarchiquement (de GSMA au constructeur). GSMA est une association privée d'opérateurs de la téléphonie et ses politiques d'allocation sont documentées sur son site Web.
Donc, place aux nouveaux URN, leur structure est définie en section
3. Ils ne comptent que des caractères ASCII
(dans une communication GSM, l'IMEI est transmis en binaire - section
4.2.4 de notre RFC, l'URN est
une représentation texte) et,
pour l'instant, qu'un seul sous-espace,
imei. Après l'IMEI lui-même, il y a des
paramètres optionnels. Par exemple, cet URN :
urn:gsma:imei:90420156-025763-0;svn=42
a le paramètre indiquant le numéro de version du logiciel
(IMEISV), ici 42. Le NID
gsma est désormais dans le registre des NID.
Normalement, les URN ont une obligation de persistence (section 1 du RFC 8141). Ici, elle est garantie par l'engagement de GSMA à maintenir les IMEI.
À noter que les URN ne sont pas, dans le cas général, résolvables
automatiquement (pas de service équivalent au DNS) et que rien ne garantit donc qu'on puisse utiliser ces
URN gsma: pour autre chose que des comparaisons
entre eux. Leur utilité (alors que les IMEI existent et sont utilisés
depuis longtemps) est de pouvoir être mis là où un protocole ou un
format attend des URI (section 5 du RFC).
La section 8, sur la sécurité, est plus détaillé que ce n'est le cas habituellement pour les URN. Mais c'est parce qu'il y a parfois des erreurs sur la sémantique des IMEI. Comme ils sont souvent écrits sur le téléphone lui-même, ou facilement consultables une fois le téléphone allumé, ils ne sont pas confidentiels. Il ne faut donc pas s'en servir comme capacité (un identifiant dont la seule connaissance fournit un accès à une ressource). Par exemple, certains help desks d'opérateurs utilisent la connaissance de l'IMEI comme une preuve que la personne qui appelle est le titulaire légitime du téléphone. C'est une sérieuse erreur de sécurité.
L'IMEI est un identifiant personnel, puisqu'il est attaché à un
téléphone mobile individuel que le propriétaire trimballera partout
avec lui. Il soulève donc des problèmes de protection de la
vie privée. Les IMEI (et les URN
urn:gsma:imei:...) ne doivent donc pas être
transmis aveuglément, ce qui risquerait de permettre de suivre
l'utilisateur à la trace. Il est recommandé de chiffrer les communications où un IMEI
est échangé.
Mais il n'est pas remis à zéro lorsque le téléphone change de propriétaire, et il ne faut donc pas l'utiliser pour router des appels vers une personne, ces appels pourraient en effet être envoyés au mauvais endroit. (L'IMEI est dans le matériel, réinstaller complètement le logiciel ne le change pas.)
L'article seul
RFC 7133: Information Elements for Data Link Layer Traffic Measurement
Date de publication du RFC : Mai 2014
Auteur(s) du RFC : S. Kashima (NTT), A. Kobayashi (NTT East), P. Aitken (Cisco Systems)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF ipfix
Première rédaction de cet article le 22 mai 2014
Le protocole IPFIX permet de transmettre des informations statistiques d'un point de mesure à un dispositif d'analyse. Quelles informations ? Cela dépend des éléments d'information normalisés et utilisés par le dispositif de mesure. La plupart des éléments d'information décrits au début d'IPFIX concernaient la couche 3, mais ce nouveau RFC étend IPFIX vers la couche 2, en permettant de transmettre des informations sur des choses comme le nombre total d'octets transportés par tous les paquets du lien (pas seulement les paquets IP).
C'est que les opérateurs de réseaux à longue distance, pas seulement les administrateurs de LAN, doivent désormais produire des chiffres sur le comportement de la couche « liaison de données ». Si Ethernet et les VLAN n'étaient autrefois utilisés qu'en local, on a désormais plein d'offres de services de couche 2 sur une plus grande distance (IEEE 802.1Q). IPFIX, normalisé dans le RFC 7011, a bien un modèle de données pour l'échantillonnage de paquets (RFC 5477) mais pas directement assez d'éléments d'information pour la couche 2. Les éléments d'information normalisés sont tous rangés dans un registre IANA (cf. RFC 7012, sur le modèle de données d'IPFIX), registre auquel ce nouveau RFC 7133 ajoute les éléments de couche 2.
Parmi les éléments qui existaient déjà (section 3.1), on trouvait
dataLinkFrameSize, d'ID 312, qui décrivait la
longueur d'une trame. Mais le gros de notre RFC
est évidemment fait des nouveaux éléments d'information. En voici
quelques-uns.
Il y a dataLinkFrameType (ID 408), qui
indique le type d'une trame (0x01 étant
l'Ethernet original et 0x02 l'IEEE
802.11). Il y a l2OctetTotalCount
(ID 419) qui indique combien d'octets sont passés en tout par le
point de mesure. (Comme on mesure la couche 2, ce nombre d'octets
inclut l'en-tête Ethernet, et est donc distinct du
octetTotalCount du RFC 5102.) On trouve aussi
minimumL2TotalLength (ID 422) qui est la taille
de la plus petite trame observée depuis le début des mesures.
Bien d'autres éléments sont disponibles, par exemple pour
l'observation des VLAN (avec des noms commençant
par dot1q). Bonne lecture du RFC !
L'article seul
RFC 7249: Internet Numbers Registries
Date de publication du RFC : Mai 2014
Auteur(s) du RFC : R. Housley (Vigil Security)
Pour information
Première rédaction de cet article le 20 mai 2014
Le système de registre pour les adresses IP est décrit dans le RFC 7020. Cet ultra-court RFC liste les registres IANA qui font partie de ce système.
Pour distribuer des ressources qui doivent être uniques, comme les adresses IP mais aussi les numéros d'AS, l'IETF fait appel à l'IANA (RFC 2860). Le RFC 7020 décrit en détail ce système. Il faut trois registres IANA pour le mettre en œuvre : celui des numéros d'AS, celui des adresses IPv4 et celui des adresses IPv6.
Le registre des numéros d'AS stocke ensemble les numéros sur 16 bits (l'ancienne norme) et les plus récents numéros sur 32 bits. L'allocation de ces numéros d'AS se fait selon les politiques de chaque RIR. Certains numéros d'AS sont réservés et d'autres le seront peut-être dans le futur, selon la politique IETF review (RFC 5226). Ce registre des AS spéciaux est nouveau, créé par ce RFC 7249, consolidant les numéros réservés par divers RFC (comme 23456 pour le RFC 6793, ou 65536 à 65551 réservés pour la documentation par le RFC 5398.
Même chose pour les adresses IPv4 (passage par les RIR et leurs politiques). Là aussi, il existe un registre des adresses spéciales (même politique IETF review).
Et pour IPv6 ? Pour l'instant, la grande majorité de cet immense espace est réservée (RFC 3513). Le reste est alloué par les RIR selon leurs politiques, comme pour IPv4. Il y a aussi un registre spécial.
L'article seul
RFC 7225: Learning NAT64 PREFIX64s using Port Control Protocol (PCP)
Date de publication du RFC : Mai 2014
Auteur(s) du RFC : M. Boucadair (France Telecom)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF pcp
Première rédaction de cet article le 19 mai 2014
Lorsqu'on est situé derrière un routeur NAT64, parce qu'on n'a pas d'adresse IPv4 et qu'on dépend de ce routeur pour la communication avec les vieux systèmes qui sont encore uniquement en IPv4, on peut, la plupart du temps, ignorer ce que fait ledit routeur et, notamment, le préfixe qu'il utilise pour synthétiser des adresses IPv6 à partir des adresses IPv4 des systèmes archaïques. C'est la cuisine interne du routeur. Mais, parfois, ce n'est pas possible et on aurait besoin de connaître ce préfixe pour faire la synthèse d'adresses IPv6 soi-même. Ce nouveau RFC décrit une option du protocole PCP permettant d'apprendre le préfixe de synthèse.
Un petit rappel sur NAT64, normalisé dans le
RFC 6146. Lorsqu'on a un réseau purement
IPv6, mais qu'on veut pouvoir communiquer avec
les machines purement IPv4, une des techniques possibles est
d'installer un routeur NAT64 qui va faire de la traduction d'adresses
d'IPv6 vers IPv4 et retour. Les machines du réseau étant purement
IPv6, il faut qu'elles trouvent une adresse IPv6 lorsqu'elles
demandent, même si la machine avec qui elles veulent communiquer n'en
a pas. NAT64 est donc inséparable de DNS64 (RFC 6147) qui synthétise ces adresses IPv6 en les préfixant avec
un préfixe spécial, que le routeur NAT64 reconnaîtra (RFC 6052). Le choix de ce
préfixe est une décision locale et les machines du réseau local
purement IPv6 ne connaissent pas ce préfixe. La plupart du temps, cela
ne les gêne pas. Elles croiront parler en IPv6 avec leur
partenaire. Mais, parfois, cela pourrait être utile. Par exemple, dans
certains protocoles (par exemple SIP), il y a des références :
Alice écrit à Bob en IPv6, le routeur NAT64 transmet à Bob en IPv4 et
Bob, voyant une session en IPv4, répond à Alice « envoies les paquets à l'adresse
192.0.34.19 ». Le routeur NAT64 n'analyse pas les
paquets SIP et ne peut donc pas traduire cette référence. C'est donc
Alice qui doit le faire, ce qui implique de connaître le préfixe à
utiliser, pour que le routeur NAT64 sache quoi faire de ces
paquets. Le RFC 7051 faisait le tour des
possibilités existantes pour découvrir ce préfixe et le RFC 7050 proposait une solution. Notre RFC 7225 en
suggère une autre.
PCP (RFC 6887) est un protocole (assez récent et encore
très peu déployé) de communication entre une machine sur un réseau
local et la box qui relie ce
réseau à l'Internet. Son utilité principale est pour l'ouverture de
trous dans le NAT, pour permettre, par exemple,
les connexions entrantes. Il permet la définition d'options qui
ajoutent des possibilités comme celle décrite dans ce RFC,
PREFIX64.
La section 3 de notre RFC décrit le cahier des charges. On veut :
- distinguer les adresses IPv6 natives de celles qui ont été synthétisées par NAT64.
- pouvoir synthétiser des adresses IPv6 pour NAT64, à partir d'adresses IPv4, même quand DNS64 n'est pas disponible ou utilisable.
- permettre l'utilisation de DNSSEC.
- gérer des cas compliqués comme la découverte du préfixe lorsque le préfixe dépend de la destination.
- fonctionner même s'il y a plusieurs routeurs NAT64 sur le réseau local (avec des préfixes différents, sinon, cela ne serait pas drôle).
La section 4 du RFC 7051 contient des études de cas plus détaillées. Par exemple, on peut souhaiter avoir son propre résolveur DNS, sur sa machine, et donc on doit faire la synthèse des adresses IPv6 soi-même. Cela nécessite de connaître le préfixe utilisé sur ce réseau local. Il existe de nombreuses raisons pour avoir un résolveur local sur sa machine mais le RFC en cite surtout une : pouvoir faire du DNSSEC proprement, c'est-à-dire avec validation locale. Autre cas où un mécanisme pour apprendre le préfixe est nécessaire, celui cité plus haut où une application transmet des références, sous forme d'une adresse IP. Cela ne concerne pas que SIP, cité plus haut (RFC 3261 et RFC 4566) mais aussi WebRTC (RFC 8825), BitTorrent (lorsque le tracker indique les adresses des leechers et seeders), etc.
La section 4 du RFC décrit le format de la nouvelle option,
PREFIX64, de numéro 129 (cf. le registre IANA). Le point important est que, pour chaque
préfixe IPv6 listé dans le champ Prefix64, il y a
une liste (pouvant être de taille nulle) de préfixes IPv4 pour
lesquels ce préfixe s'applique.
Que doit faire le serveur PCP avec cette option ? Lorsque le client
le demande (en mettant l'option PREFIX64 dans sa
requête), le serveur lui répond poliment, avec le préfixe que lui,
serveur, utilisera pour les synthèses d'adresses IPv6. Le serveur a le
droit d'envoyer cette option PREFIX64 même si on
ne lui a rien demandé. Il peut y avoir plusieurs occurrences de
l'option si le serveur PCP (le routeur NAT64) utilise plusieurs
préfixes.
Et le client ? Il peut demander explicitement le préfixe, en
utilisant l'option PREFIX64 avec une valeur
spéciale pour le préfixe (::/96). Attention à ne
pas paniquer si la réponse contient plusieurs préfixes IPv6, c'est
normal. Le client ne doit pas garder en vrac les préfixes mais les
laisser associés à un serveur PCP particulier (au cas où il y en ait
plusieurs sur le réseau, ce qui est rare, mais permis).
Des exemples d'usage figurent dans la section 5, avec un exemple
détaillé pour le (compliqué) cas de SIP : le client SIP (le
softphone, qui n'a que IPv6)
va envoyer une requête PCP de type MAP avec les
options PORT_SET et
PREFIX64. Il récupère les ports à utiliser et le préfixe, mettons
2001:db8:122::/48. Avec les informations sur son
adresse IPv4 externe, il va construire une offre
SDP, qui ne contiendra que de l'IPv4. Ensuite,
le logiciel fait une requête SIP INVITE, en IPv6,
en utilisant une adresse de destination formée à partir du préfixe et
de l'adresse IPv4 du serveur SIP. Le routeur NAT64, voyant ce préfixe,
va ensuite faire son travail (conversion en v4, transmission). Pareil
pour le message de routeur (l'acceptation de l'appel). Notez que
l'« intelligence » était presque entièrement dans le client : le
routeur NAT64 n'a pas d'ALG.
À ma connaissance, il n'existe encore aucun client ou serveur PCP avec cette option.
L'article seul
RFC 7196: Making Route Flap Damping Usable
Date de publication du RFC : Mai 2014
Auteur(s) du RFC : C. Pelsser, R. Bush (Internet Initiative Japan), K. Patel (Cisco Systems), P. Mohapatra (Cumulus Systems), O. Maennel (Loughborough University)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF idr
Première rédaction de cet article le 17 mai 2014
L'amortissement des annonces de routes lorsque ces routes sont instables (annoncées et retirées fréquemment) est une vieille technique pour limiter la charge sur les routeurs. Le principe est d'ignorer (pendant un certain temps) une route s'il y a eu trop de changements dans une période récente, de façon à éviter que le routeur BGP ne passe tout son temps à gérer une route qui part et revient en permanence. Le terme officiel est Route Flap Damping (RFD, on dit aussi dampening). L'idée est bonne mais l'expérience a montré que l'amortissement pénalisait excessivement les sites très richement connectés : plus on a de connexions, plus il y a des changements sur ses préfixes et plus on sera amorti. Résultat, ces dernières années, un certain nombre d'opérateurs ont préféré couper l'amortissement. Ce nouveau RFC propose de le rétablir, mais avec des nouveaux paramètres quantitatifs, qui devraient, cette fois, ne pénaliser réellement que les routes qui déconnent et pas les sites qui sont simplement très connectés.
L'amortissement a été formellement décrit dans ripe-178 puis
dans le RFC 2439. Le problème des faux positifs
a été décrit en 2002, dans « Route
Flap Damping Excacerbates Internet Routing
Convergence ». Cela a mené à des révisions des
politiques des opérateurs, allant dans le sens de
déconseiller l'amortissement, comme raconté dans
ripe-378, qui dit que le remède (le RFD, l'amortissement) est
pire que le mal et conclut « the application of flap damping
in ISP networks is NOT recommended ».
Des nouvelles études (comme « Route Flap
Damping Made Usable », par les auteurs du RFC) ont
mené à une approche intermédiaire : garder l'amortissement, mais avec
de nouveaux paramètres, comme déjà recommandé dans ripe-580
(document RIPE très proche de ce RFC), qui
annule le ripe-378. Il existe aussi un Internet-Draft contenant le résultat d'une étude faite auprès des opérateurs sur leurs pratiques, le document draft-shishio-grow-isp-rfd-implement-survey.
En effet, un tout petit nombre de préfixes d'adresses IP est responsable de la majorité du travail (le churn) des routeurs BGP, comme indiqué dans « BGP Extreme Routing Noise » ou bien dans l'article Route Flap Damping Made Usable cité plus haut. Cet article a testé des annonces BGP réelles pendant une semaine et note que 3 % des préfixes font 36 % des messages BGP. Ce sont ces préfixes qu'il faut pénaliser par l'amortissement, en épargnant les 97 % restants.
Quels sont les paramètres d'amortissement sur lesquels on peut jouer ? La section 3 les rappelle dans un tableau. Certains sont modifiables par l'administrateur du routeur, d'autres pas. Et le tableau, qui liste les valeurs par défaut existant chez Cisco et chez Juniper, montre qu'il n'y a pas de consensus sur ces valeurs par défaut. Attention, en lisant le tableau. Il n'existe malheureusement pas de vocabulaire unique pour ces paramètres (malgré la section 4.2 du RFC 2439) et le nom varie d'un document à l'autre. Ainsi, le RFC 2439 nomme cutoff threshold ce que ripe-580 et notre RFC nomment suppress threshold. C'est dommage, c'est le paramètre le plus important : c'est le nombre de retraits (WITHDRAW BGP) de routes après lequel on supprime la route (multiplié par un facteur, la pénalité). Il vaut 2 000 par défaut sur IOS et 3 000 sur JunOS, ce qui est trop bas.
La section 4 de notre RFC cite en effet l'article Route Flap Damping Made Usable mentionné plus haut, qui estime qu'un seuil remonté à 6 000 permettrait de réduire le rythme de changement BGP de 19 %, contre 51 % avec un seuil de 2 000, mais en impactant dix fois moins de préfixes, donc en faisant beaucoup moins de victimes collatérales. Monter le seuil à 12 000 supprimerait presque complètement l'amortissement, très peu de préfixes étant à ce point instables.
Notre RFC recommande donc :
- De ne pas changer les valeurs par défaut dans les systèmes d'exploitation de routeurs, même si elles sont mauvaises, car cela changerait la sémantique de certaines configurations actuelles, qui comptent sur ces valeurs par défaut,
- Remonter le suppress threshold à 6 000 dans les configurations actives,
- Si possible, ajouter un mode de test (dry run) aux routeurs où les calculs d'amortissement seraient faits mais pas appliqués aux routes. Cela permettrait aux opérateurs de tester les paramètres qu'ils envisagent.
Ces recommandations, notamment la valeur du seuil de déclenchement de l'amortissement (suppress threshold) permettraient d'utiliser l'amortissement sans gros inconvénients.
Ah, un petit mot sur la sécurité (section 7) : un attaquent peut générer des faux retraits pour déclencher l'amortissement et mener à des dégâts supérieurs à ce qu'il aurait pu faire directement. Les paramètres plus conservateurs de ce nouveau RFC devraient limiter ce risque.
Pour configurer l'amortissement sur IOS, voir la documentation officielle, pour Quagga, c'est très semblable, et pour JunOS, voir leur documentation. Sur un routeur IOS, une route supprimée par l'amortissement sera affichée ainsi (voyez notamment la dernière ligne) :
R2# sh ip bgp BGP table version is 12, local router ID is 192.168.0.1 Status codes: s suppressed, d damped, h history, * valid, > best, i – internal, r RIB-failure, S Stale Origin codes: i – IGP, e – EGP, ? – incomplete Network Next Hop Metric LocPrf Weight Path d 12.12.12.12/32 192.168.0.2 0 0 2 i *> 13.13.13.13/32 192.168.0.2 0 0 2 i R2# sh ip bgp 12.12.12.12 BGP routing table entry for 12.12.12.12/32, version 12 Paths: (1 available, no best path) Flag: 0x820 Not advertised to any peer 2, (suppressed due to dampening) (history entry) 192.168.0.2 from 192.168.0.2 (13.13.13.13) Origin IGP, metric 0, localpref 100, external Dampinfo: penalty 3018, flapped 4 times in 00:04:11, reuse in 00:03:20
L'article seul
RFC 7228: Terminology for Constrained Node Networks
Date de publication du RFC : Mai 2014
Auteur(s) du RFC : C. Bormann (Universitaet Bremen
TZI), M. Ersue (Nokia Siemens
Networks), A. Keranen (Ericsson)
Pour information
Réalisé dans le cadre du groupe de travail IETF lwig
Première rédaction de cet article le 15 mai 2014
Il existe désormais de nombreux protocoles et donc de nombreux documents (par exemple des RFC) pour les objets limités (en puissance de calcul, en énergie, en capacité réseau...). L'Internet, conçu d'abord pour de gros ordinateurs alimentés en permanence, s'adapte de plus en plus à ces objets limités. D'où l'importance d'une terminologie standard : ce nouveau RFC définit un certain nombre de termes utilisés dans la normalisation de protocoles pour ces petits objets.
Des exemples de tels objets ? Des capteurs mis dans la nature, un actionneur dans une usine, des Arduino au fond d'un placard, et bien d'autres encore. Ils ont en commun de manquer sérieusement d'une ou plusieurs ressources, qui étaient considérées comme virtuellement illimitées : énergie électrique, capacité réseau, capacité de calcul... Tous ensemble, ces objets contribuent à ce qu'on appelle (un terme médiatique sans définition rigoureuse) « l'Internet des Objets ».
Adapter les protocoles Internet à cet Internet des Objets nécessite deux adaptations quantitatives :
- « scaling up », s'adapter à un réseau comptant beaucoup plus de machines, peut-être des dizaines de milliards. Le modèle dominant, aux débuts de l'Internet, était d'un ordinateur par entreprise. Il est passé à un par département (l'« informatique départementale » des années 70 et 80) puis à un par personne avec la micro-informatique. Aujourd'hui, le modèle est plutôt de plusieurs ordinateurs par personne, même si on ne pense pas forcément à ces objets comme étant des ordinateurs.
- « scaling down », s'adapter à des machines ayant des capacités considérées aujourd'hui comme très faibles (tout en étant parfois supérieures à celles des machines des débuts de l'Arpanet).
La section 2 de notre RFC définit la terminologie utilisée. Le RFC est en anglais et les traductions sont de moi, donc n'ont pas de caractère normatif, contrairement au texte anglais. Premier terme défini, celui de « nœud contraint » (constrained node). Ce sont nos objets. Ils sont définis négativement, par le fait qu'il n'ont pas certaines caractéristiques que l'on associe d'habitude automatiquement à un ordinateur moderne. Par exemple, certains objets n'ont pas d'alimentation électrique permanente et doivent donc économiser la batterie. Certains objets n'ont pas de MMU et ne peuvent donc pas gérer de mémoire virtuelle, ce qui implique de faire très attention à la consommation mémoire des programmes. Certains objets n'ont aucune interface utilisateur (pas d'écran, même limité), ce qui rend impossible certaines opérations (« pour sécuriser l'Internet des Objets, on va utiliser des mots de passe, qu'il faudra rentrer dans chaque objet »). Les objets ont aussi des contraintes quantitatives, comme une ROM très limitée, qui impose un code de petite taille. Un nœud contraint est donc très différent d'un PC de bureau (où le programmeur de Gnome ou de Windows ne réfléchit, ni à la consommation électrique, ni à la consommation de mémoire...) mais même également d'un smartphone, engin finalement très perfectionné et qui peut faire tourner un Unix peu modifié. On voit avec cet exemple que la définition de nœud contraint n'est pas complètement rigoureuse (après tout, le smartphone est très contraint en énergie électrique).
La section 3 du RFC tente de quantifier cette notion de nœud contraint, en introduisant des classes de nœuds, selon leurs caractéristiques. (Petit rappel : un kibioctet, noté Kio, c'est 1 024 octets.) La classe 0 (aussi notée C0), la plus contrainte, a une mémoire vive bien en dessous de 10 Kio, et une mémoire morte très inférieure à 100 Kio. La classe 1 a des mémoires aux alentours, respectivement, de 10 et 100 Kio. Et la classe 2, la plus riche, a dans les 50 Kio de RAM et 250 de ROM. Ne comptez pas sur la loi de Moore pour tirer ces chiffres vers le haut dans le futur : dans le domaines des objets, les progrès sont utilisés pour baisser les prix et/ou la consommation électrique, et équiper davantage d'objets, pas pour augmenter les capacités. Pour comparer, un Raspberry Pi typique a 512 Mio (oui, je sais, c'est souvent écrit Mo mais c'est une erreur, il faut dire que la situation est compliquée). Il n'est donc pas considéré comme objet contraint. En revanche, un Arduino typique peut n'avoir que 2 à 8 Kio, ce qui les met dans la classe 0.
Les nœuds de la classe 0 ne peuvent pas espérer avoir de vraie communication TCP/IP. Le terme d'« Internet des Objets » est tout à fait impropre pour eux, ils ne peuvent pas se connecter à l'Internet, et surtout pas de manière sécurisée. Typiquement, leur connexion aux réseaux se fera via une passerelle. La classe 1 a plus de chance : ils n'arriveront certes pas à faire tourner HTTP + TLS + XML + XSLT mais ils peuvent utiliser des protocoles TCP/IP spécialement prévus pour eux, comme CoAP. Les nœuds de la classe 2, eux, peuvent faire tourner plus ou moins les mêmes protocoles qu'un serveur ordinaire ou qu'une machine de bureau. Bien sûr, ils restent contraints et toute optimisation est donc bonne à prendre, par exemple pour économiser la batterie. Il n'y a pas de classe 3 ou au delà : les machines ayant de meilleures capacités que la classe 2 n'ont pas de contraintes comparables et il n'y a donc pas besoin que l'IETF développe des normes ou pratiques particulières pour eux.
Deuxième terme important dans la section 2 de notre RFC, « réseau contraint ». Un réseau contraint (constrained network, cf. RFC 7102) est un réseau auquel manquent certaines caractéristiques qu'on a l'habitude de tenir pour acquises sur l'Internet : le débit maximum est fortement limité, le taux de pertes de paquets très élevé, les liens sont souvent très asymétriques (ça marche dans un sens mais pas dans l'autre)... Ces contraintes peuvent venir du coût (on a serré les budgets), du milieu ambiant (pensez à un réseau sous-marin...), des contraintes légales (limitation de la puissance maximale), ou des contraintes techniques (vieilles technologies dont on ne peut pas se débarasser).
Il ne faut pas confondre le réseau contraint avec le « réseau de nœuds contraints » (constrained node network). Ce dernier est un réseau composé en grande partie de nœuds contraints, ce qui réduit ses possibilités, même si le réseau lui-même est parfait.
Plus grave que le réseau contraint, le « réseau limité » (challenged network). C'est un réseau qui a du mal à fournir des services IP de bout en bout : pas de connectivité complète, interruptions fréquentes (voir RFC 4838 pour des exemples rigolos), délais d'acheminement des paquets qui sont supérieurs au MSL (Maximum Segment Lifetime) de TCP, empêchant ainsi d'établir des connexions TCP, même si ping fonctionne (les réseaux RFC 1149 sont un bon exemple)...
Enfin, la section 2 rappelle deux termes fréquemment utilisés dans les RFC et déjà définis. Un LLN (Low-power Lossy Network), défini dans le RFC 7102, est un réseau contraint et formé de nœuds contraints. Cela oblige à des protocoles spécifiques comme RPL (RFC 6550). Et un LowPAN (Low-Power Wireless Personal Area Network, RFC 4919) était le nom d'un groupe de travail IETF et le terme est souvent utilisé comme synonyme de LLN (le Personal dans LowPAN n'ayant plus guère de signification aujourd'hui). Un dérivé, 6LowPAN, désigne le travail fait pour utiliser IPv6 sur ces réseaux LowPAN.
L'une des contraintes les plus fréquentes et les plus pénibles est évidemment la consommation électrique. La section 4 de notre RFC définit des termes pour ce domaine. Deux termes sont importants pour caractériser la consommation d'un nœud contraint : Ps (pour Power sustainable) indique la consommation instantanée de la machine en train de tourner (en watts) et Et est l'énergie totale qui sera consommée avant que la machine ne s'arrête, sa batterie à plat. « Ps » doit être indiqué pour chaque mode du nœud contraint si, comme c'est souvent le cas, il existe plusieurs modes de fonctionnement, consommant plus ou moins de courant. « Et » est infini pour une machine connectée au courant général, et se mesure en joules.
Cela permet de définir des classes selon des critères liés à l'énergie électrique disponible : E0 est la classe des machines dont la disponibilité en électricité à liée à des évenements extérieurs (recharge par une action mécanique externe, par exemple), E1 celle des machines dont la consommation électrique est limitée durant une certaine période (la durée entre deux recharges, ou bien le cycle quotidien du soleil si la recharge se fait par énergie solaire), E2, celle des machines qui ont une durée de vie limitée (une batterie non remplaçable, par exemple, ce qui fait que bien des machines sont à la fois E1 et E2), et E9 la classe des machines illimitées, qui peuvent puiser du courant à volonté.
Du fait de ces limites d'énergie disponibles, les nœuds contraints doivent s'adapter. Souvent, la radio est le principal poste de consommation : il est bien plus coûteux d'envoyer un paquet que de le fabriquer, même si on a utilisé le chiffrement. Les machines peuvent être classées selon leur stratégie de consommation. P0 est la classe des machines qui sont éteintes la plupart du temps et ne sont allumées que pour une tâche spécifique. Cela veut dire que leur attachement au réseau doit recommencer à chaque allumage, une tâche coûteuse en énergie (émission d'une requête DHCP, attente...) et qu'il est intéressant d'optimiser. P1 est une classe de machines qui sont sous tension en permanence, mais dans un mode à consommation réduite, où les réactions ne sont pas forcément très rapides. Elles restent donc attachées au réseau en permanence. Enfin, P9 regroupe les machines qui sont tout le temps complètement réveillées, connectées au réseau en consommation maximale. Ce serait le cas d'un routeur, par exemple. (Le RFC 7102 ne distinguait que deux niveaux, correspondant à nos classes P0 et P9.)
L'article seul
RFC 7258: Pervasive Monitoring Is an Attack
Date de publication du RFC : Mai 2014
Auteur(s) du RFC : S. Farrell (Trinity College Dublin), H. Tschofenig (ARM)
Première rédaction de cet article le 13 mai 2014
Assez des RFC qui décrivent un protocole réseau, jusque dans les plus infimes détails, au bit près ? Et des RFC bureaucratiques sur le fonctionnement de l'IETF et de tout son zoo de groupes et de comités ? Voici un RFC 100 % politique, et un excellent, en plus. Ce RFC 7258 résume la politique de l'IETF vis-à-vis de l'espionnage de masse que pratique, entre autres, la NSA : cet espionnage de masse est, techniquement, une attaque, et il est justifié de faire tout ce qu'on peut techniquement pour combattre cette attaque.
Cette affirmation n'allait pas de soi. Rappelez-vous qu'un des mécanismes utilisés par la NSA (et révélé par le héros Snowden) pour faciliter l'espionnage est justement d'affaiblir les systèmes de sécurité, au nom du « il faut bien que nous, qui sommes les gentils, puissions écouter les plans des méchants pédonazis ». (C'est notamment le programme BULLRUN.) Après quelques discussions, l'IETF affirme haut et fort que cet argument ne tient pas : si on affaiblit la sécurité du réseau pour faciliter les écoutes légales, on l'affaiblit face à tous les espions, qu'on les trouve légitimes ou pas.
Avant de faire face à une attaque, il faut la définir. Notre RFC considère (section 1) que l'espionnage de masse (PM pour Pervasive Monitoring) est une attaque d'un nouveau genre. Ce n'est plus simplement le lycéen dans son garage qui écoute un réseau Wi-Fi proche et mal protégé. L'espionnage de masse n'est pas une nouveauté technique (les révélations de Snowden ne contiennent aucune surprise technique, aucune technique ultra-avancée, genre X-Files) mais se distingue des attaques précédentes par son caractère indiscriminé (on écoute tout le monde, innocent ou coupable, avant même tout soupçon), et sa simple taille (la STASI, avec les moyens techniques de l'époque, devait choisir qui elle écoutait ; la NSA peut, grâce aux méthodes de traitement du big data, écouter tout le monde).
L'espionnage de masse est défini comme l'écoute à très grande échelle des communications sur le réseau (qu'on se limite aux métadonnées ou pas), en utilisant des mécanismes passifs (l'écoutant traditionnel des analyses de risque), ou actifs (le programme Tailored Access Operations avec son QUANTUM et son FOXACID).
L'IETF a considéré depuis le début que l'espionnage massif était une attaque contre la vie privée. La question a fait l'objet de beaucoup de débats à la réunion IETF de Vancouver en novembre 2013, débats qui ont donné lieu à plein de bonnes résolutions (cf. les documents de la session plénière). Pour les résumer : l'IETF doit modifier ses protocoles réseau et concevoir les futurs protocoles de manière à rendre l'espionnage plus difficile. Le rendre impossible est sans doute irréaliste (et, certains le pensent, non souhaitable, car ils estiment que la surveillance ciblée, par exemple d'un suspect par la police, doit rester possible). L'idée est donc plutôt de rendre la surveillance de masse si difficile, et donc si coûteuse, que les organisations qui écoutent devront se limiter à une écoute ciblée sur les seules personnes sur lesquels pèsent des soupçons sérieux. « Don't give them anything for free. »
Le mot « attaque » est utilisé par l'IETF dans un sens purement technique (cf. RFC 4949 pour de la terminologie) : il s'agit d'une action délibérée par un tiers pour remettre en cause les attentes des deux parties qui communiquent (ici, leur attente que la communication soit privée), et il n'implique rien quant à la légitimité ou la légalité de telles attaques. Une attaque peut donc être légale, elle pose néanmoins exactement les mêmes problèmes techniques, et nécessite les mêmes solutions. Il serait ridicule de croire qu'on pourrait concevoir des systèmes de sécurité qui empêchent les « méchants » d'écouter mais autoriseraient les « gentils ». Quelle que soit l'opinion qu'on a sur ces « gentils », il est important de garder en tête qu'on ne peut pas se protéger contre les « méchants » sans bloquer ou gêner aussi les écoutes des « gentils ». Toute l'approche de l'IETF est techniquement neutre, dans le sens où on ne se préoccupe pas des motivations des espions : ceux-ci peuvent être une puissante agence gouvernementale, une entreprise commerciale qui veut récolter de l'information sur ses clients (ce qui peut être légal dans certains pays), un gang de délinquants dans leur sous-sol, ils peuvent agir pour le fric, l'idéologie, le goût du pouvoir ou n'importe quelle autre raison : c'est le même problème technique et les solutions seront les mêmes.
Après ces préalables, la section 2 du RFC décrit la position de l'IETF : on va travailler pour limiter l'espionnage de masse. On l'a vu, le rendre complètement impossible est sans doute peu réaliste. L'idée, suivant l'exposé de Schneier à la réunion de Vancouver, est d'augmenter les coûts pour l'attaquant, le forçant à mieux cibler ses opérations, et/ou exposant de l'espionnage qui serait resté caché autrement.
Les protocoles IETF avaient déjà souvent des mécanismes permettant de protéger la vie privée, typiquement du chiffrement afin d'empêcher un tiers d'accéder aux données échangées. Ces mécanismes sont recommandés par le RFC 3552. Mais ils ne prennent pas en compte le changement de catégorie que représente l'espionnage de masse. Le chiffrement, en général, ne protège pas les métadonnées, il ne tient pas compte des risques d'analyse de trafic, et il ne protège pas si les extrémités de la communication trahissent (cas du programme PRISM), ce qui nécessiterait une minimisation des données, pas uniquement leur chiffrement. Il est donc nécessaire d'adapter les normes de la famille TCP/IP, suivant la prise de conscience qui a suivi les révélations d'Edward Snowden.
En pratique, notre RFC demande aux auteurs de protocoles de prendre en considération le risque d'espionnage massif. Cela n'implique pas forcément une section « Pervasive Monitoring Considerations » dans leur RFC (comme il existe une « Security Considerations » obligatoire). Mais cela veut dire que les auteurs doivent regarder la question et être prêt à répondre aux questions à ce sujet. (Ce point était l'un des plus contestés lors de la création de ce RFC : certaines versions étaient plus directives, imposant des contraintes moins vagues.) En matière de lutte contre l'espionnage massif, comme souvent en sécurité, il vaut mieux prévoir les protections dès qu'on conçoit l'architecture, les mettre après est souvent très complexe.
À propos de complexité, une des difficultés de la lutte contre l'espionnage massif est qu'on a toujours besoin de gérer ses réseaux et que certaines activités de gestion sont proches de l'espionnage (surveiller les caractéristiques du trafic à partir de NetFlow, par exemple, ou bien utiliser tcpdump pour déboguer une application). Il serait dommage que les mesures techniques de protection de la vie privée bloquent ces pratiques. En fait, il y a même des mesures de sécurité qui reposent sur la publication, comme la Certificate Transparency du RFC 9162 (ou comme, mais le RFC ne le cite pas, Bitcoin). Il y a donc là un difficile compromis à négocier.
Enfin, la section 2 du RFC rappelle que l'IETF a des pouvoirs limités : c'est une SDO, elle écrit des normes, elle ne fait pas les programmes qui mettent en œuvre ces normes, encore moins les pratiques de déploiement et de sécurité. (Sans même mentionner les activités politiques et juridiques, qui sont encore plus loin de l'IETF.) Or, la sécurité (vie privée ou autre) dépend bien plus des programmes et des pratiques que des normes techniques.
La section 3 du RFC résume ce qui a déjà été fait à l'IETF, et le processus suivi : les RFC 1984 et RFC 2804 étaient déjà des déclarations technico-politiques sur la sécurité, et avaient été faits en commun entre l'IAB et l'IESG. L'IETF ayant changé ses règles bureaucratiques internes depuis, ce RFC 7258 est publié par l'IETF, sans l'IAB. C'était également le cas du RFC le plus complet sur la vie privée, l'excellent RFC 6973, dont la lecture est très recommandée.
L'article seul
RFC 7227: Guidelines for Creating New DHCPv6 Options
Date de publication du RFC : Mai 2014
Auteur(s) du RFC : D. Hankins (Google), T. Mrugalski, M. Siodelski (ISC), S. Jiang (Huawei Technologies), S. Krishnan (Ericsson)
Réalisé dans le cadre du groupe de travail IETF dhc
Première rédaction de cet article le 11 mai 2014
Le protocole DHCPv6, normalisé dans le RFC 8415, permet de configurer des clients IPv6 depuis un serveur central, qui maintient un état (adresses IP attribuées, par exemple). Des tas d'options aux requêtes et réponses DHCPv6 permettent de fournir toutes sortes d'informations utiles. La liste de ces options n'est pas figée, on peut en définir de nouvelles (sections 21 et 24 du RFC 8415). Ce nouveau RFC guide les concepteurs d'options (et leurs collègues à l'IETF qui examineront les nouvelles demandes d'options) : que faire lorsqu'on crée une nouvelle option DHCPv6 et surtout que faut-il ne pas faire. Il s'adresse donc surtout à un public de normalisateurs et de programmeurs.
Pour les programmeurs, la question (section 2 du RFC) est « qu'est-ce que la nouvelle option va nécessiter comme travail ? Un ajout trivial aux clients et serveurs DHCP ou au contraire de vrais changements ? » Dans le second cas, les chances de déploiement de la nouvelle option sont minces... (Aussi bien en DHCPv4 pour IPv4 qu'en DHCPv6, des tas d'options ont été normalisées mais jamais réellement déployées dans la nature, ou parfois au bout de plusieurs années seulement.) En effet, la nouvelle option ne nécessite pas que des changements dans le message tel qu'il circule sur le réseau : il faut changer toute la chaîne de traitement, par exemple l'interface de configuration du serveur. Si ce dernier est configuré par un fichier de configuration, il faudra modifier l'analyseur pour reconnaître la définition d'une valeur dans cette option. S'il est configuré par un GUI, il faudra ajouter menus et boîtes de dialogues. Ensuite, il faudra que les administrateurs réseaux utilisent cette option, ce qui plaide en faveur d'options simples, ne nécessitant pas de lire des tonnes de documentation pour être configurée.
Donc, l'option qui a le plus de chances d'être adoptée, est celle qui ne nécessite que peu ou pas de changement dans les fichiers de configuration, celle qui ne nécessite pas trop de changement (voire pas du tout, en utilisant les capacités de traitement d'options inconnues) dans le code source, celle qui est proche d'options existantes, et, évidemment, celle qui est utile dans une grande gamme de cas.
La section 3 du RFC rappelle dans quel cas il est intéressant d'utiliser DHCPv6. Contrairement à IPv4 où il n'y a guère le choix (pas de mécanisme d'auto-configuration général), IPv6 a deux méthodes de configuration automatique, SLAAC (RFC 4862) et DHCPv6 (RFC 8415). Tout (« Any knob, dial, slider, or checkbox on the client system », dit le RFC) peut être configuré par DHCP, de l'adresse IP du client, au nom de domaine qu'il utilisera par défaut, en passant par la température à laquelle il doit automatiquement s'arrêter (ce dernier exemple n'est pas normalisé). Comme DHCP est une configuration centralisée, sous le contrôle de l'administrateur réseaux du réseau local où la machine est actuellement attachée, le client n'a pas forcément envie de tout laisser configurer. DHCP est utile pour les paramètres qui dépendent étroitement du réseau actuel (l'adresse IP étant l'exemple typique) mais pas pour les paramètres où le client veut garder le contrôle.
Enfin, la section 3 rappelle que le client a le dernier mot : il peut toujours ignorer les options reçues en DHCP ou les remplacer par les siennes. Par contre, cela peut l'empêcher, notamment dans les réseaux d'entreprise, d'accéder à certains services. Par exemple, si le client DHCP ignore le résolveur DNS indiqué, il pourra rater certains noms qui n'existent que dans une vue DNS locale.
Bon, assez de préliminaires : la section 4 liste les principes généraux qui président à la définition de nouvelles options. Principe n° 1 : la réutilisation. La nouvelle option doit réutiliser autant que possible ce qui existe déjà. Ainsi, si une option prend comme valeur (prenons un exemple irréaliste) un ISBN, il est peu probable que le code pour analyser des ISBN dans le fichier de configuration existe. En revanche, si elle prend comme valeur une adresse IP, le code existe certainement car des tas d'options ont déjà besoin d'une adresse IP.
Il y a deux sortes d'options : les simples qui se contentent de transporter des données du serveur vers le client et qui peuvent donc être gérées par du code générique. Et les compliquées, qui nécessitent un traitement spécifique par le serveur (comme l'option du RFC 4704), avant d'envoyer les données. Inutile de dire que les premières seront plus... simples à déployer.
La réutilisation est surtout importante dans les formats. Si l'option n'utilise que des éléments déjà connus (comme les adresses IP citées plus haut), elles seront bien plus simples à ajouter aux serveurs et aux clients, le code étant déjà là. Bien qu'il puisse être nécessaire de définir des nouveaux formats, notre RFC recommande fortement de construire plutôt à partir des briques existantes. La section 5 détaille ce point. Car, pour le concepteur d'une nouvelle option, fouiller tous les RFC définissant une option DHCPv6, pour voir ce qui serait réutilisable, serait très long. Notre RFC propose donc une liste d'éléments (de briques) courants. Si on a besoin de structures un peu compliquées, on pourra toujours les construire à partir de ces briques.
Premier élément commun et courant, l'adresse IPv6. Des tas d'options en incluent une (liste de serveurs SIP - RFC 3319, résolveurs DNS - RFC 3646, serveur NTP - RFC 5908, etc). Il suffit donc, lorsqu'on définit une option qui distribue (entre autres) des adresses IPv6 de reprendre la définition (l'encodage est résumé dans la section 5.1)... et le code marchera tout seul.
Si on veut un préfixe IPv6 (adresse + longueur du préfixe), cela existe également déjà (quoique ce soit bien plus rare, cela ne se trouve pour l'instant pas encore dans des RFC).
Plus court qu'une adresse IPv6, le
booléen. Il existe dans au moins une option (le
rapid commit du RFC 8415,
section 22.14). Plutôt que de le représenter sous forme d'un octet (un
bit pour la valeur et sept pour le remplissage), le RFC recommande
plutôt que la seule présence ou absence de l'option indique la
valeur. On définit une valeur par défaut et, si l'option est présente,
sa valeur sera l'opposé de la valeur par défaut. Cela permet d'encoder
uniquement le code et la longueur (forcément zéro mais DHCPv6 impose la
présence de ce champ Longueur), sans aucun contenu. Le nom de l'option
doit refléter l'effet qu'aura sa présence. Par exemple, s'il existe un
booléen FOO et que sa valeur par défaut est Vrai,
l'option devra s'appeler DISABLE_FOO puisque sa
présence mettra FOO à Faux.
Plus grands que les booléens, les entiers, comme le refresh time du RFC 4242. Si on veut transmettre un entier de 32 bits, on peut réutiliser ce format.
Plus grand encore, et plus compliqué, un
URI. Par exemple, le RFC 5970 fournit
une option qui permet d'indiquer les coordonnées du code à charger au
démarrage d'une machine. Ces coordonnées sont un URI, par exemple
ftp://[2001:db8:23a::1]/bootfiles/pi.exe. Sur le
câble, cette option est encodée exactement comme du texte libre
(exemple suivant) mais le fait de la marquer comme contenant un URI
permet au serveur DHCP de tester sa syntaxe avant de charger cette option.
Ah, le texte, justement. Le RFC recommande que toutes les options utilisant du texte libre imposent à celui-ci d'être en Unicode, avec les restrictions du RFC 5198, et encodé en UTF-8. (Rappelez-vous que du texte en pur ASCII remplit ces conditions.) Le RFC 4833, qui définit une option en texte libre pour indiquer le fuseau horaire, sans le dire clairement, se limite au seul ASCII et, donc, si on créait une option prenant du texte libre en Unicode, il faudrait probablement développer du code spécifique, personne ne l'ayant encore fait.
Certaines options prennent comme valeurs des listes et pas de simples scalaires. C'est le cas d'options comme la liste de serveurs SIP déjà vue plus haut.
À part la réutilisation des formats, que conseille notre RFC ? La section 7 recommande d'éviter les alias, ces options qui donnent accès au même paramètre mais via des formats différents. Par exemple, si on veut indiquer un serveur réseau, avoir deux options, une prenant en paramètre une adresse IP et l'autre un nom de domaine, est fortement déconseillé. Cela augmente la quantité de code et laisse dans l'ambiguité la question de savoir quelle option gagne si les deux sont présentes. À la place, il faut une seule option, le type de paramètre dépendant des propriétés que l'on veut (ici, la simplicité pour l'adresse IP, la liaison retardée pour le nom de domaine).
La section 8 brode davantage sur ce thème du choix entre nom de domaine et adresse IP. S'il est fortement conseillé de n'avoir qu'une option, laquelle ? Le RFC évite de faire une recommandation générale, car cela dépend du paramètre. Par exemple, le résolveur DNS doit évidemment être indiqué par une adresse IP. Les paramètres qui sont liés à la topologie du réseau (les paramètres « couche 3 » comme le serveur de mobilité) sont sans doute mieux représentés par des adresses IP. Ceux qui sont plus proches des applications (les paramètres « couche 7 » comme un serveur SIP) ont plutôt intérêt à utiliser des noms de domaines, voire des URI.
Il y a d'autres points à prendre en compte. Par exemple, les applications réagissent en général mieux aux problèmes DNS temporaires qu'aux problèmes réseau. Un nom de domaine sera donc intéressant si on veut éviter qu'une panne plante l'application. Le problème de résolution DNS est attendu et, en pratique, souvent bien géré, ce qui n'est pas le cas si, par exemple, un client DHCP reçoit une adresse IP qui, en pratique, ne marche pas : ce cas n'est pas prévu et le client ne réessaiera pas automatiquement.
L'indirection supplémentaire fournie par le nom de domaine est, la plupart du temps, un avantage. Un exemple où, au contraire, c'est un inconvénient, est celui où on veut fournir un service qui dépend de la localisation. Le DNS est bâti sur le principe qu'une question entrainera la même réponse partout. Il existe des services DNS géo-localisés mais qui, en pratique, ne sont pas très satisfaisants puisqu'ils violent ce principe. Au contraire, le serveur DHCP sait forcément où est connecté le client (sinon, il ne pourrait pas choisir des paramètres comme l'adresse IP) et est donc bien placé pour renvoyer une adresse IP qui dépend de la localisation.
Autre question soulevée par ce choix entre adresse IP et nom de
domaine : le temps qu'il faudra pour qu'un changement dans la
configuration soit pris en compte. Si le serveur DHCP renvoie une
adresse IP, et décide ensuite de la changer, il ne peut pas garantir
que les clients la recevront immédiatement. Certes, il existe une
option reconfigure dans DHCPv6 (RFC 8415, sections 16.11, 18.2.11 et 18.3.11), permettant au serveur
des notifications non sollicitées, mais elle n'est pas
obligatoire et il semble que bien des clients ne la gèrent pas. En
revanche, si le serveur avait renvoyé un nom de domaine, et si
l'application pense à le redemander souvent (un gros Si...), la
nouvelle valeur sera effective au bout de N secondes où N est le
TTL choisi par le serveur DNS. Le choix dépend
donc de pas mal de paramètres (par exemple, est-ce que
l'administrateur du serveur DHCP contrôle aussi le serveur DNS et peut
choisir le TTL à volonté ?) que le concepteur de l'option ne peut
hélas pas connaître à l'avance.
Autre argument de prudence avant d'utiliser des noms de domaine : il crée une dépendance envers le DNS. Il faut donc s'assurer que le serveur envoie bien la liste des résolveurs DNS, et que ceux-ci fonctionnent correctement.
Une caractéristique de DHCPv6 est le fait que les options peuvent être incluses dans d'autres options. Cela permet de faire des options spécifiques à certains cas, du genre une option Y qui n'a de sens que si on a aussi accepté l'option X. On encapsule alors Y dans X. Il y a donc des options top-level et des options encapsulées. Il y a aussi des sous-options, qui n'ont pas de numéro d'option propre mais sont numérotées par rapport au numéro de l'option qui les contient. Les numéros d'options dans DHCPv6 sont codés sur 16 bits (8 bits pour DHCPv4) et il y a donc abondance de numéros disponibles. Le RFC conseille donc de ne pas chercher à les économiser et recommande les options encapsulées plutôt que les sous-options. Plus rigolo, l'encapsulation peut être à plus de deux niveaux : c'est le cas de la délégation de préfixe du RFC 8415, où le préfixe peut contenir une option d'exclusion qui elle-même contient une option préfixe, indiquant le préfixe exclu.
DHCP (v4 ou v6) est un mécanisme à état : le serveur DHCP se souvient de ce qu'il a fait et en tient compte pour les réponses suivantes. L'exemple le plus classique concerne l'allocation d'adresses IP : le serveur doit se souvenir de quelles adresses ont été allouées, pour ne pas allouer deux fois la même. Toutefois, dès qu'il faut maintenir un état supplémentaire, en général pour donner des réponses différentes par client, on augmente la complexité du serveur. Le RFC recommande donc d'éviter de définir de nouvelles options imposant le maintien d'un état. On peut souvent obtenir le même effet en laissant le client générer une valeur unique, à partir de son adresse IP et d'informations générales.
J'ai déjà parlé plus haut du fait que les clients DHCP ne vont pas
magiquement chercher des nouveaux paramètres dès que le serveur DHCP a
été reconfiguré. Le mécanisme reconfigure ne va
pas forcément marcher avec tous les clients et l'administrateur du
serveur DHCP doit donc être prêt à voir des clients continuer à
utiliser des vieux paramètres. Cela peut être important aussi pour le
concepteur d'options, au cas où il espérerait des options dont les
valeurs changent souvent (section 11).
Un autre cas rigolo est celui où il y a plusieurs serveurs DHCP sur le même réseau. Cela n'est pas forcément le résultat d'une erreur ou d'un piratage. Par exemple, si un réseau à la maison est connecté par deux FAI, chacun apportant sa box, deux serveurs DHCP répondront aux requêtes des clients. Le protocole DHCP ne fournit pas de mécanisme pour gérer cela, juste quelques conseils dans le RFC 8415, conseils qui ne semblent pas suivis par les implémentations actuelles. En pratique, bien des clients n'écoutent que le premier serveur qui leur a répondu (section 12 de notre RFC). Ils n'essaient pas de fusionner intelligemment les différentes sources. Par exemple, il serait logique d'utiliser le résolveur DNS du FAI 1 lorsqu'on va utiliser les adresses IP, et la ligne, de ce FAI, et le résolveur du FAI 2 dans l'autre cas. Mais ce n'est pas ce qui se passe et, aujourd'hui, le cas de la machine à plusieurs connexions réseau est toujours assez mal géré. C'est un problème général, qui n'est pas soluble dans le cadre d'une option DHCP particulière (voir les RFC du groupe de travail MIF).
En DHCP, la taille compte. C'est ce qu'explique la section 15, qui note que les paquets DHCPv6 ont une taille maximale de 64 ko. Contrairement à DHCPv4, il n'y a pas de trucs utilisés en couche 2, DHCPv6 est purement une application tournant sur UDP sur IPv6, avec des adresses locales au lien. Bon, c'est la théorie. En pratique, si on bourre un paquet d'options de grande taille, peut-on vraiment aller jusqu'à 64 ko ? Le RFC 8415 est plus prudent et dit « The server must be aware of the recommendations on packet sizes and the use of fragmentation as discussed in Section 5 of RFC 8200. ». Il ne semble pas qu'aucune mise en œuvre de DHCPv6 ait câblé en dur des limites de taille inférieures aux 64 ko légaux. Donc, ça devrait marcher mais, dans la réalité, personne n'a encore testé des réponses DHCP supérieures aux 1 280 octets qui sont le miminum qu'IPv6 doit accepter ou aux 1 500 octets qui sont la MTU d'Ethernet. Notre RFC suggère que, si on veut vraiment envoyer des grandes quantités de données, une option DHCP n'est pas la meilleure solution et qu'il vaut mieux envoyer au client un URL indiquant où chercher ces données.
Pas encore épuisé par tous les points qu'il faut garder en tête en définissant une nouvelle option DHCP ? C'est que le RFC n'est pas terminé. Une option peut-elle apparaître plusieurs fois dans une réponse DHCP (section 16) ? Par défaut, non, mais c'est possible si et seulement si c'est indiqué explicitement dans la spécification de l'option. Attention, l'ordre d'apparition n'est pas significatif (section 17). Un client peut mettre les options dans une structure de données qui ne préserve pas l'ordre (un dictionnaire, par exemple).
Autre piège lorsqu'il y a plusieurs options : il faut spécifier la
sémantique des données ainsi récupérées. Ainsi, l'option
AFTR du RFC 6334 (utilisée
pour DS-Lite) est un singleton, une option à apparition
unique. Il avait été envisagé de permettre plusieurs occurrences de
l'option, permettant d'indiquer plusieurs AFTR (l'extrémité du
tunnel DS-Lite auquel on se connecte, cf. RFC 6333). Mais comment le client devait-il choisir
parmi eux ? Une répartition de charge entre les
AFTR était-elle possible ? Et une bascule automatique d'un AFTR à
l'autre en cas de panne ? Spécifier tout cela aurait été trop
compliqué et l'option est donc restée un
singleton.
Les messages DHCPv6 peuvent être relayés afin d'atteindre des réseaux où il n'y a pas de serveur DHCP. Contrairement à DHCPv4, les options spécifiques aux relais sont des options ordinaires, prises dans le même espace de numérotation que les autres (section 18 de notre RFC).
Au fait, comment un serveur sait-il quelles sont les options
acceptées et gérées par le client ? Il existe une option
ORO (Option Request Option),
normalisé dans le RFC 8415,
pour que le client indique ses capacités, à la fois ce qu'il
acceptera, et ce qu'il utilisera réellement. Elle n'est pas
obligatoire et ne représente donc pas un vrai mécanisme de négociation
des options.
Et les innombrables techniques de transition d'IPv4 vers IPv6 ? Elles nécessitent sûrement des options DHCPv6, non (section 20) ? En fait, non. Notre RFC recommande de les transporter via DHCPv4 puisqu'elles deviendront inutiles lorsque IPv4 disparaitra (ah, l'optimisme...) et elles ne doivent donc pas encombrer l'espace des options DHCPv6.
Arrivés à ce point, les auteurs de nouvelles options DHCPv6 doivent se demander s'ils arriveront un jour à compléter le futur RFC décrivant leur option chérie. La section 21 est là pour les aider en fournissant une liste de points à couvrir, avec un exemple de texte pour chacun. Le RFC recommande trois sous-sections, une pour les clients DHCP, une pour les serveurs et une pour les relais (pour ces derniers, la plupart du temps, il n'y aura rien à faire, un relais doit relayer aveuglément les options qu'il ne connait pas). Par exemple, pour les clients, le RFC suggère de commencer par « Clients MAY request option foo, as defined in [RFC3315], sections 17.1.1, 18.1.1, 18.1.3, 18.1.4, 18.1.5 and 22.7. As a convenience to the reader, we mention here that the client includes requested option codes in Option Request Option. »... Plus qu'à copier/coller en mettant le vrai nom de l'option à la place.
Autre question bureaucratique, le RFC décrivant la nouvelle option doit-il indiquer dans ses métadonnées qu'il met à jour les RFC existants comme le RFC 8415 ? Non, répond la section 22. Il y a aujourd'hui environ 80 options définies et si toutes mettaient à jour le RFC 8415, l'implémenteur de DHCPv6 en aurait, des documents à lire ! Donc, la plupart des RFC définissant des options ne changeront pas les RFC existants. Par contre, s'il est nécessaire de remplacer une partie de la norme existante, alors, oui, on doit indiquer cette mise à jour. C'est le cas du RFC 6644 qui est bien décrit ainsi dans l'index des RFC « 6644 Rebind Capability in DHCPv6 Reconfigure Messages. D. Evans, R. Droms, S. Jiang. July 2012. (Format: TXT=19176 bytes) (Updates RFC3315) (Status: PROPOSED STANDARD) ».
Un peu de sécurité et de vie privée pour terminer. La section 23 rappelle aux auteurs d'options l'importance de la sécurité. DHCP est bien connu pour son absence totale d'authentification, qui fait qu'un serveur « pirate » peut facilement se glisser à la place d'un vrai et servir n'importe quoi. Il existe pourtant en théorie un mécanisme d'authentification (section 21 du RFC 3315) mais soyons francs : presque personne ne l'a programmé et quasiment personne ne l'a déployé. Bref, les concepteurs d'options doivent être conscients que les options seront transmises en clair et, pire, qu'un méchant pourra envoyer des fausses valeurs.
Autre problème de sécurité, la longueur des options. Si elle est de taille fixe, le client qui la lit devra vérifier que la longueur réelle est bien la longueur théorique (autrement, il risque un débordement de tampon). Si elle est de taille variable (un URI, par exemple), le lecteur de l'option doit se méfier, l'option peut être très longue... Des valeurs ayant la taille normale peuvent néanmoins donner de drôles de résultats. Par exemple, une option contenant une adresse IP peut indiquer, si le serveur est malveillant ou bien s'il a été doublé par un serveur pirate, une adresse de diffusion, pour pousser le client à arroser tout le réseau...
À noter que le RFC ne rappelle pas une spécificité de DHCPv6 : il est courant qu'un réseau IPv6 n'ait pas de serveur DHCP légitime du tout, l'administrateur réseaux préférant la configuration SLAAC. Dans ce cas, un serveur pirate aurait la partie très facile, n'ayant pas à faire la course avec le serveur légitime.
Enfin, il reste la question de la vie privée (section 24). Les messages DHCP sont transmis quasiment toujours en clair et il ne faut donc pas compter sur leur confidentialité. En théorie, on pourrait utiliser IPsec pour les chiffrer mais personne ne le fait.
L'article seul
Vente de vulnérabilités logicielles ; vrai ou pas vrai ?
Première rédaction de cet article le 8 mai 2014
Normalement, les gens qui découvrent une faille de sécurité dans un logiciel préviennent les mainteneurs du logiciel et ne publient qu'après avoir laissé du temps à ceux-ci de corriger la faille. C'est ce qu'on nomme le « responsible disclosure » (publication responsable). Évidemment, tout le monde n'est pas un être humain civilisé, il y a aussi des agents secrets qui gardent l'information pour que leur État puisse attaquer les autres, et il y a des pourris qui vendent ce genre d'informations à quiconque paiera. Question intéressante : avant d'acheter, comment on sait que la vulnérabilité est réelle ?
Un cas d'école récent est apparu le 30 avril. Un anonyme olckrrii3@openmailbox.org a envoyé
un message sur Pastebin prétendant qu'il avait
trouvé une faille dans OpenSSH permettant la
lecture de la mémoire du serveur (comme
Heartbleed permettait de lire la mémoire d'un
serveur TLS). Il appuie ses dires par des
transcriptions d'une exploitation de la faille, avec affichage de la
mémoire du serveur. Le message est toujours sur
Pastebin, mais, s'il disparait, j'en ai une copie ici (ce qui ne signifie
pas que je soutienne cette démarche). L'auteur du
message réclame 20 bitcoins pour révéler la
faille (soit dans les 6 300 € au cours actuel, ce qui est plutôt bon
marché pour une faille aussi grave dans un logiciel aussi
répandu).
La question à 20 bitcoins : est-ce que ce message est véridique ? A-t-il vraiment découvert une faille ou bien le succès médiatique de Heartbleed lui a-t-il simplement donné des idées ? La réponse est simple : il n'y a aucun moyen de le savoir. Ce qu'il affiche dans son message a pu être fabriqué de toutes pièces, le monde numérique ne permet pas de produire des preuves en enregistrant une session...
La seule ressource des gens qui veulent vérifier ces affirmations
est de regarder le message et de voir s'il est cohérent. La grande
majorité des tentatives précédentes étaient grossières (comme la
grande majorité des spams sont
ridicules et ne peuvent tromper que les gogos les plus naïfs). Il
était facile d'y relever des incohérences ou des invraisemblances, qui
ruinaient tout l'édifice (par exemple, une bannière
SSH annonçant une Debian
alors que le reste de l'attaque montrait une machine
Fedora). Mais, si je parle du message de
olckrrii3@openmailbox.org, c'est parce qu'il a
été composé avec bien plus de soin que d'habitude. Il prétend avoir un
numéro CVE, il donne les numéros de version
exacts des logiciels testés, il affiche un dump
mémoire convaincant... Tout cela a pu être fabriqué (et l'a
probablement été) mais cela lui a pris plus de cinq minutes,
contrairement à la plupart de ces escroqueries. Résultat, son annonce
a été relayée par pas mal de gens, attirés par le côté sensationnel de
l'annonce (« Major Heartbleed-like vulnerability in OpenSSH! »).
Certaines personnes ont relevé des choses étonnantes dans le message (le programme d'exploitation qui pèse 236 ko, ce qui est énorme pour un client C d'attaque typique, sauf s'il contient du code généré automatiquement, ou un blob binaire) ou des incohérences (la taille du répertoire est inférieure à celle de l'unique fichier qu'il contient) mais cela n'est pas une preuve formelle, juste une indication. Bref, si on veut savoir, il faut être prêt à risquer ses 20 bitcoins... (Personne ne l'a encore fait, comme on peut le voir dans la blockchain Bitcoin, me rappelle Yan.)
Le responsable d'OpenSSH a estimé que ce message était un faux. Si vous voulez acheter des vulnérabilités logicielles à un mercenaire, vous pouvez vous adresser à plusieurs sociétés à faible éthique comme le français Vupen (« leading provider of defensive & offensive cyber security capabilities, advanced vulnerability research & government-grade zero-day exploits », se vante leur profil Twitter).
L'article seul
La sécurité de BIND, et le gonflationnage par le marketing
Première rédaction de cet article le 6 mai 2014
Le 29 avril 2014, l'université Technion a publié un communiqué ridicule prétendant que leurs chercheurs avaient trouvé un moyen de subvertir les requêtes DNS. C'est apparemment sa reprise par The Hacker News le 5 mai qui a lancé le « buzz ». Comme le communiqué du service marketing de l'université, l'article de The Hacker News est fertile en superlatifs et, à le lire, on se dit qu'Heartbleed n'était que de la petite bière. Sauf que tout est tellement gonflé qu'il est très difficile d'apercevoir le vrai problème de sécurité derrière cette accumulation de sensationnalisme.
Revenons aux choses sérieuses. Lorsqu'un client veut utiliser le
DNS pour résoudre un nom de
domaine en données (par exemple l'adresse
IP), il s'adresse à un résolveur
DNS. Les logiciels les plus courants pour cette fonction sont
BIND et Unbound. Le
résolveur n'a pas d'informations propres, il doit les obtenir auprès
des serveurs faisant autorité pour la zone
considérée. Par exemple, linuxfr.org a deux
serveurs faisant autorité :
% dig +short NS linuxfr.org ns1.tuxfamily.net. ns2.tuxfamily.net.
Lequel des deux sera interrogé par un résolveur dont le client veut
visiter http://linuxfr.org ? Cela dépend d'un algorithme
suivi par le résolveur, qui prend en compte le
RTT des réponses lors des requêtes précédentes,
mais aussi une certaine dose de hasard, à la fois pour voir si les
temps de réponse ont changé, et aussi pour compliquer la tâche d'un
attaquant. En effet, lors de certaines attaques, notamment l'attaque
d'empoisonnement Kaminsky, l'attaquant a besoin de savoir quel
serveur faisant autorité sera utilisé. En tirant partiellement au
sort, on complique sa tâche.
Venons-en à l'attaque elle-même, documentée dans un article à Usenix (et je ne sais pas pourquoi l'université de Technion a choisi de buzzer maintenant, sur une publication de l'année dernière). Son titre résume bien le peu d'étendue de l'attaque : « Subverting BIND's SRTT Algorithm Derandomizing NS Selection ». Les auteurs ont trouvé une méthode (astucieuse, je ne dis pas le contraire) pour influencer l'algorithme par lequel un résolveur BIND choisit le serveur d'une zone à qui il va parler pour résoudre les noms dans cette zone. (Notez que ce n'est donc pas une vulnérabilité DNS mais une - faible - vulnérabilité BIND.)
Lorsque cette attaque est en cours, l'attaquant peut donc forcer
l'usage d'un serveur faisant autorité, parmi tous ceux de la
zone. Cela diminue un tout petit peu le nombre de paramètres qu'un
attaquant qui tente un empoisonnement doit deviner. Pourquoi « un tout
petit peu » ? Parce qu'un attaquant doit deviner bien d'autres
paramètres (RFC 5452 pour les détails). Et
celui-ci, le serveur interrogé, est un des moins importants, la grande
majorité des zones (comme linuxfr.org cité plus
haut), n'ont que deux serveurs faisant autorité ! L'attaque, même
quand elle réussit complètement, ne fait donc gagner qu'un seul bit
d'entropie à l'attaquant... J'emprunte donc une conclusion à Dan
Kaminsky « While a neat trick, the recent DNS security
research by the Technion students is in no way a critical
vulnerability in BIND. »
Un résumé de l'attaque et de ses conséquences pour BIND avait été fait par l'ISC (et réitérée après la nouvelle vague de buzz). Par contre, la correction promise n'a pas encore été apportée. Une bonne réfutation avait été écrite l'année dernière par Tony Finch (et la relance marketing de cette année n'en a pas tenu compte.) Un des auteurs de l'article original a publiquement dénoncé le gonflage.
À noter que DNSSEC résout complètement ce problème : quel que soit le serveur interrogé, on peut vérifier la validité des données.
Merci à X_cli pour les tweets stimulants.
L'article seul
RFC 7217: A Method for Generating Semantically Opaque Interface Identifiers with IPv6 Stateless Address Autoconfiguration (SLAAC)
Date de publication du RFC : Avril 2014
Auteur(s) du RFC : F. Gont (SI6 Networks / UTN-FRH)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF 6man
Première rédaction de cet article le 2 mai 2014
Il existe actuellement de nombreuses méthodes (y compris manuelles) de générer les adresses IPv6 mais le mode SLAAC (Stateless Address Autoconfiguration, normalisé dans le RFC 4862) est particulièrement intéressant car il permet aux machines IPv6 de s'auto-configurer, sans qu'il soit nécessaire de mémoriser un état dans un serveur central. SLAAC fonctionne en concaténant à un préfixe, appris en écoutant les annonces des routeurs, un identifiant d'interface spécifique à la machine. Au tout début d'IPv6, il n'existait qu'une seule façon de générer ces identifiants d'interface, via l'adresse MAC de la machine. Puis une deuxième façon a été ajoutée, en tirant au sort l'identifiant d'interface, et en en changeant souvent, pour préserver sa vie privée (RFC 8981). Et une troisième, la plus sûre, où l'identifiant d'interface est dérivé d'une clé cryptographique (RFC 3972, mais ces CGA sont peu utilisés et notre RFC n'en parle guère). Notre nouveau RFC propose une quatrième façon, en condensant un secret, un certain nombre de caractéristiques de la machine et le préfixe, de manière à avoir des identifiants stables (comme ceux de la première façon), mais préservant quand même partiellement la vie privée (comme ceux de la deuxième façon) : l'identifiant d'interface change quand la machine change de réseau, ne permettant plus de la suivre à la trace. Cette méthode permet de choisir l'identifiant d'interface, elle ne modifie pas l'algorithme présenté dans le RFC 4862.
Les identifiants d'interface obtenus par l'adresse MAC simplifient bien des choses, notamment grâce à leur stabilité : on éteint la machine et on la rallume, on est sûr de retrouver la même adresse IPv6. Ainsi, lorsqu'on regarde le journal des connexions, on peut facilement retrouver la machine qu'on a repéré. Et créer des ACL est simple, puisque les adresses ne changent pas. Mais, en échange, ces identifiants ont des inconvénients, notamment pour la vie privée (cf. l'étude de l'IAB). La stabilité permet de suivre à la trace une machine pendant une longue période. Pire, même si la machine change de réseau, l'identifiant d'interface ne change pas, permettant de suivre cette trace même en cas de mobilité. D'autre part, comme l'adresse MAC dépend du constructeur, les adresses IPv6 d'un même parc ont donc souvent pas mal de bits en commun. Cette prévisibilité facilite notamment le balayage des adresses réseau (qui est normalement difficile en IPv6, vu le nombre d'adresses, cf. RFC 7707) et cette utilisation a été mise en œuvre dans des outils de reconnaissance existants (cf. mon article sur les attaques contre IPv6). Enfin, des opérations de maintenance matérielle, comme de changer une carte Ethernet, vont faire changer l'adresse, annulant l'avantage de stabilité.
Le RFC 8981 voulait s'attaquer à ces problèmes avec ses adresses temporaires, où l'identifiant d'interface est choisi aléatoirement et change de temps en temps. L'idée est que la machine aurait une (ou plusieurs) adresses temporaires, une (ou plusieurs) adresses stables et qu'on utiliserait l'adresse temporaire pour les connexions sortantes, et l'autre pour les entrantes. Cela fournit une bonne protection, question vie privée, mais au prix de quelques inconvénients. Comme rien n'est gratuit en ce bas monde, ces adresses compliquent la vie de l'administrateur réseaux : interpréter le trafic qu'on voit passer est moins simple (beaucoup de techniques de protection de la vie privée ont ce défaut). On voit donc des entreprises couper ces adresses temporaires, afin de mieux surveiller leurs employés (cf. le récit de Ron Broersma). Les adresses privées peuvent également poser des problèmes pour les commutateurs réseaux. En outre, pour des engins aux capacités limités (Internet des objets), la mise en œuvre d'une technique supplémentaire de génération des adresses peut être trop coûteuse. Enfin, comme les adresses traditionnelles sont toujours en place, certaines activités, comme le balayage d'adresses en suivant certains motifs, liés aux préfixes des constructeurs, restent possibles. Bref, la situation actuelle n'est pas complètement satisfaisante.
Notre nouveau RFC 7217 ne vise pas à remplacer les adresses temporaires, qui restent la bonne solution pour limiter le suivi d'une machine à la trace. Il veut plutôt remplacer les adresses basées sur l'adresse MAC, en gardant l'importante propriété de stabilité. L'idée est que les machines IPv6, dans le futur, auront uniquement une adresse stable, générée selon ce RFC, ou bien une adresse stable générée selon ce RFC et une adresse temporaire. L'adresse fondée sur l'adresse MAC aurait vocation à disparaître à terme (même si le RFC n'est pas aussi radical, cf. section 4, dernier élément de l'énumération), car elle facilite trop le balayage des réseaux et le suivi d'une machine mobile, sans avoir d'avantages par rapport à la solution de ce RFC.
L'objectif principal est le mécanisme SLAAC d'auto-configuration sans état mais la solution de ce RFC peut aussi s'appliquer à d'autres méthodes comme DHCP (RFC 8415), où le serveur peut utiliser un algorithme identique pour générer les adresses qu'il va distribuer.
La section 4 formalise le cahier des charges de la nouvelle méthode de génération des identifiants d'interface :
- Identifiant stable dans le temps, tant qu'on est connecté au même réseau (ce qui permet la corrélation entre les différentes activités de la machine dans le temps : si on ne veut pas cela, il faut utiliser les adresses temporaires),
- Identifiant dépendant du préfixe, de manière non prévisible par un observateur : si un client IPv6 contacte un serveur, puis change de réseau, puis contacte le même serveur, le serveur ne doit pas pouvoir facilement rapprocher les deux adresses (l'un des plus gros inconvénients de la méthode historique de génération d'adresses était cette possibilité de rapprochement),
- Identifiant non prévisible pour un observateur, même s'il connait des identifiants sur le même réseau,
- Il serait souhaitable, si possible, que l'identifiant soit indépendant de l'adresse MAC, de manière à ce qu'un changement de carte Ethernet ne se traduise pas par un changement d'adresss IP (les identifiants de la méthode historique sont trop stables pour préserver la vie privée mais changent trop lorsqu'on modifie le matériel).
À noter que l'algorithme exact utilisé pour le choix de l'identifiant d'interface (et donc de l'adresse) est une décision purement locale. Chaque machine fait comme elle veut, cela n'affecte pas l'interopérabilité. Sur un même réseau peuvent donc coexister des machines utilisant des algorithmes différents.
Je crois que j'ai un peu abusé de votre patience avec ces longs préliminaires. Peut-être auriez-vous préféré qu'on commence directement avec l'algorithme, la solution avant la description du problème ? En tout cas, arrivé à la section 5, vous avez cet algorithme. Il est trivial : l'identifiant d'interface est le résultat de l'application d'une fonction de condensation à plusieurs paramètres. Cette fonction doit donner un résultat qui, vu de l'extérieur, sera imprévisible, et elle ne doit pas être inversible. Un exemple d'une telle fonction est la fonction de condensation cryptographique SHA-256, dont on conservera les 64 bits de plus faible poids (par contre, MD5 ne doit pas être utilisé, cf. RFC 6151). Rappelez-vous que la génération de l'identifiant d'interface est un processus purement local et que différentes machines peuvent donc utiliser des fonctions de condensation différentes. Les paramètres de la fonction de condensation comportent au moins :
- Le préfixe des adresses IP (donc, changer de réseau fait changer d'identifiant d'interface, ce qui est souhaité), tel qu'on l'a appris, par exemple via les RA (Router Advertisement),
- Le nom de l'interface réseau, par exemple
eth0pour une machine Linux, le but étant que la machine ait des adresses différentes pour chaque réseau, même s'ils utilisent le même préfixe, - Un compteur des conflits (duplication d'adresses), qui part de zéro et est incrémenté chaque fois qu'une collision d'adresses (deux adresses identiques sur le même lien) a lieu,
- Une clé secrète, spécifique à la machine (tous les autres paramètres et, bien sûr, l'algorithme exact utilisé, peuvent être découverts plus ou moins facilement par un observateur : cette clé est donc indispensable si on veut des adresses vraiment imprévisibles),
- Et, facultativement, un identifiant du réseau, par exemple le SSID ou bien une des idées du RFC 6059.
L'annexe A du RFC fournit plusieurs idées pour le nom de l'interface
réseau.On peut se servir de l'index d'interface (RFC 3493), du nom s'il est assez stable (un système
d'exploitation où les interfaces réseau portent des noms
dépendant du pilote utilisé aura des noms moins
stables que Linux, où ce nom est générique,
eth1, wlan0, etc), ou de
tout autre identificateur fourni par le système (certains ont un
UUID par interface réseau).
La clé secrète sera typiquement générée à l'initialisation de la machine, par un processus aléatoire ou pseudo-aléatoire, et stockée de manière à survivre aux redémarrages. Mais le RFC prévoit aussi le cas où elle pourrait être affichée, voire modifiée, par l'administrateur système. Le point important est de se rappeler que toute la sécurité de ce système en dépend donc elle doit être bien choisie.
Cet algorithme est largement inspiré de celui décrit dans le RFC 1948, pour un usage très différent.
Une fois obtenu un identifiant d'interface, il faut vérifier qu'il n'est pas dans les identifiants réservés du RFC 5453. Sinon, tous les bits de l'identifiant d'interface sont opaques (au sens du RFC 7136) et il ne faut donc pas leur chercher de signification particulière. Dernière vérification à faire avant d'utiliser l'adresse construite avec cet identifiant d'interface : tester qu'il n'y a pas de conflits avec une autre machine. En effet, comme chaque machine du réseau tire son identifiant d'interface au hasard, il y a une probabilité non nulle (mais très faible) que deux machines tirent le même identifiant et donc la même adresse IP. Elles doivent donc suivre la procédure de détection de conflits « DAD » du RFC 4862 (section 5.4).
C'est désormais la méthode de ce RFC qui est recommandée lorsqu'on veut des adresses stables (cf. RFC 8064), à la place des anciennes adresses dérivées de l'adresse MAC.
Il existait une mise en œuvre pour Linux, par Hannes Frederic Sowa, mais, apparemment, cela a été intégré dans la distribution officielle peu après la sortie du RFC. (Par contre, à ma connaissance, rien pour Windows ou pour les BSD.)
L'article seul
RFC 7221: Handling of Internet Drafts by IETF Working Groups
Date de publication du RFC : Avril 2014
Auteur(s) du RFC : A. Farrel (Juniper Networks), D. Crocker (Brandenburg InternetWorking)
Pour information
Première rédaction de cet article le 30 avril 2014
Voici un nouveau RFC procédural, consacré à la gestion des Internet Drafts, ces brouillons de futurs RFC. L'IETF est structurée en groupes de travail (WG, pour Working Groups) et ces groupes doivent, comme leur nom l'indique, travailler. Mais pour produire quoi ? Des documents. L'IETF n'écrit pas de logiciels, ne fabrique pas de matériel, cette organisation de normalisation est entièrement vouée à produire des documents, les fameux RFC. Mais avant d'être un RFC, le document passe par le stade Internet Draft. D'où viennent les Internet Drafts des groupes de travail ? Comment sont-ils créés ?
Quand un groupe de travail développe un Internet
Draft, il y a eu plusieurs points de départ possibles. Le
groupe a pu partir d'une feuille blanche, le document ayant été rédigé
dans le cadre du travail du groupe. Parfois, également, le document
existait avant, et a été adopté par le groupe de
travail. Des fois, lors de son adoption, le document était très
avancé, presque prêt et, des fois, il méritait largement son nom de
draft (brouillon). L'IETF se méfie (en théorie) des processus
trop formalisés et les groupes de travail ont donc une grande latitude
dans les choix. Si la charte du groupe de travail met des limites, ces
limites laissent souvent bien des possibilités. (Les chartes des
groupes de travail existants sont disponibles en
ligne ; notez que beaucoup d'entre elles font référence à des
Internet Drafts avec des formules du genre « le
groupe partira du document
draft-smith-foo-bar ».) Ce RFC n'ajoute pas de
nouvelles règles (mon opinion personnelle est qu'il y en a déjà
beaucoup, pour une organisation qui aime bien afficher son mépris des
règles bureaucratiques) mais décrit les pratiques
existantes. « Pragmatics over niceties »
D'abord, un point important (section 1.1), il y a draft et draft. N'importe qui peut publier un draft, et il y a effectivement très peu de formalités pour cela. La plupart des drafts ne sont donc pas des Working Group drafts. Ces drafts des groupes de travail sont des documents sous le contrôle de l'IETF (et pas d'un individu, même pas de leur auteur, ou des présidents du groupe de travail), et leur avancement vers la publication en RFC dépend donc du consensus approximatif (rough consensus) au sein du groupe dans son ensemble. Ce mécanisme de décision est décrit dans le Tao et de manière plus formelle dans la section 3.3 du RFC 2418.
On peut dire que le draft individuel représente la liberté quasi-totale alors que le draft de groupe de travail est une œuvre collective, représentant l'opinion du groupe. Résultat, le processus est parfois laborieux, voire excessivement frustrant, mais c'est nécessaire pour s'assurer que le document représente bien une vue collective et a donc plus de signification qu'un article publié sur un blog personnel. L'auteur du document a un rôle particulier mais, en théorie, pas de pouvoir de décision (bien sûr, être celui qui tient le clavier a quelques avantages lorsqu'il faut traduire en mots le consensus du groupe). Comme le dit le proverbe africain, « si tu veux voyager vite, pars seul, si tu veux voyager loin, pars en groupe ». Les règles précises pour ces drafts sont formalisées dans le RFC 2026 (notamment la section 2.2), la liste des points à vérifier, le RFC 2418 (notamment sa section 7.2) et enfin bien sûr le Tao.
On reconnait un draft de groupe de travail à son
nom. Il est nommé draft-ietf-WGNAME-... où
WGNAME est le nom du groupe. Au contraire, le
draft individuel se nomme
draft-LASTNAME-... où
LASTNAME est le nom de l'auteur. Ainsi, au moment
où j'écris (avril 2014), le draft draft-ietf-precis-framework
est un document du groupe de travail precis (dont le nom
apparait comme deuxième composant du nom du document) alors que
draft-bortzmeyer-dns-qname-minimisation
est, pour l'instant, un document individuel (avec mon nom en deuxième
composant). Certains drafts individuels seront
adoptés par un groupe de travail et deviendront alors des documents de
groupe, en changeant de nom. Par exemple, comme on peut le
voir sur le « DataTracker », le draft
individuel draft-sheffer-uta-tls-attacks a été
adopté par le groupe
de travail UTA et est devenu le draft-ietf-uta-tls-attacks.
Maintenant, les détails. La section 2 couvre l'adoption d'un draft individuel par un groupe de travail. Rappelez-vous, il n'y a pas de règles formelles et générales sur les critères d'adoption, le groupe de travail doit prendre ses responsabilités. En pratique, notre RFC note que les critères importants sont :
- Mention explicite du draft dans la charte du groupe,
- Document qui coïncide avec le sujet du groupe, et ne demande pas de modification de la charte, ou alors très légère,
- Document de qualité, suffisamment clair et réaliste pour que, en l'utilisant comme base de travail, le groupe ait des chances d'aboutir à un RFC (l'IETF se méfie des groupes qui s'agitent pendant des années sans rien produire),
- Risques liés à l'appropriation intellectuelle,
- Et, bien sûr, soutien du groupe.
Rappelez-vous que les groupes fonctionnent par consensus approximatif. L'unanimité n'est pas nécessaire. D'autre part, le draft est un... brouillon. Il n'est pas exigé qu'il soit paré pour la publication, tout juste vérifie-t-on quelques détails pratiques. Et le groupe peut toujours adopter un document qui sera finalement abandonné : l'adoption ne garantit absolument pas la publication. On voit même parfois des drafts d'un groupe de travail redevenir finalement des documents individuels (cf. section 5.2).
Une fois la décision prise, les présidents (ils sont toujours deux) du groupe de travail doivent ensuite :
- Vérifier que le groupe est d'accord pour cette adoption (curieusement, ce point n'est pas mis en premier dans le RFC).
- Bien s'assurer que l'auteur comprend que le contrôle est transféré à l'IETF. Ce n'est plus lui qui décide du contenu du document (il y a eu quelques cas contentieux, par exemple où l'auteur demandait qu'on retire son nom, car il n'était plus d'accord, mais les plus gros problèmes surviennent lorsque le document était issu d'une entreprise privée, et décrivait une technologie que cette entreprise aurait voulu voir l'IETF adopter sans discussion).
- Vérifier si les requins de l'appropriation intellectuelle ont des brevets possibles sur cette technique (cf. RFC 6302).
- Respecter quelques règles procédurales comme l'annonce officielle de l'adoption sur la liste de diffusion du groupe, la notification du changement de nom aux gérants du DataTracker pour que les outils IETF gardent l'historique, etc.
La section 3 décrit le rôle des auteurs et rédacteurs (editors). Certaines personnes à l'IETF font la différence entre ces deux concepts (voir « RFC Editorial Guidelines and Procedures -- Author Overload » et la section 6.3 du RFC 2418), l'auteur étant vu comme mettant réellement du sien dans le document, formant de nouvelles idées, et le rédacteur comme étant un simple exécutant, quasiment passif, des volontés du groupe de travail. Mais notre RFC ne fait pas de différence, estimant qu'elle serait trop subjective. Auteurs et/ou rédacteurs sont choisis par les présidents du groupe de travail (rappelez-vous qu'une fois un document adopté, le contrôle passe à l'IETF) et ne sont pas forcément le ou les auteurs originaux. En pratique, toutefois, il est fréquent que l'auteur original continue après l'adoption.
La section 4 couvre la façon de traiter les documents existants. Un groupe de travail n'est pas forcé de prendre ces documents, de corriger deux ou trois fautes d'orthographe, et de les publier comme RFC. Bien au contraire. L'IETF, contrairement à certaines SDO, ne se contente pas de mettre un coup de tampon approbateur sur des documents qui arrivent tout cuits. Les documents existants peuvent être considérés comme :
- Des idées, dont on peut s'inspirer, mais sans plus,
- Un mécanisme raisonnable dans son principe mais dont de nombreux points vont devoir être traités, révisés, détaillés,
- Une description d'un bon système, qui a juste besoin de quelques aménagements,
- Une technique déjà déployée, et où tout changement doit donc être abordé avec prudence, afin de ne pas remettre en cause la base installée.
Bref, la palette est très large. Tout document extérieur adopté par un groupe de travail ne sera pas traité de la même façon. Certains documents arrivent à l'IETF après des années d'usage de la technologie qu'ils décrivent, d'autres sont des idées purement théoriques, et encore, où l'analyse théorique est souvent sommaire.
Il y a aussi quelques points divers traités dans la section
5. D'abord, entre les drafts purement individuels
et ceux d'un groupe de travail, il y a aussi des
drafts individuels mais qui sont sous le parapluie
d'un groupe de travail (voir le document « Guidance on Area Director Sponsoring of
Documents »). On les reconnait à leur nom
draft-LASTNAME-WGNAME-.... C'est rare, mais cela
arrive. (Notez aussi qu'il n'existe pas de police des
drafts, donc certains auteurs choisissent parfois
des noms qui violent ces conventions.)
Autre cas spécifique, celui de drafts différents sur le même sujet, par exemple deux protocoles jouant le même rôle, chacun d'entre eux soutenu par une partie du groupe de travail. Un groupe n'est pas obligé de trancher. Les différences entre les deux propositions peuvent refléter des choix fondamentaux, chaque draft ayant ses mérites propres. Le groupe de travail peut suggérer une fusion, mais ce n'est pas obligatoire. Dans le domaine technique, la fusion de deux bons systèmes peut parfaitement donner une horreur, ce que le RFC illustre par l'histoire du sous-marin et de l'hélicoptère : les sous-marins sont utiles et bien adaptés à leur tâche. Les hélicoptères aussi. Mais tenter de concevoir un engin qui aurait les caractéristiques des deux produirait probablement une machine inadaptée aux deux rôles. (L'histoire est originellement due à Marshall Rose.)
Le problème des deux drafts concurrents est d'autant plus sensible si un des deux drafts arrive après l'autre : les auteurs du premier peuvent mal prendre cette « intrusion ». En même temps, l'IETF travaille par écrit et encourage fortement l'expression des idées sous forme d'un draft, pour obliger les concepteurs à raffiner leurs idées, à ne pas se contenter d'un résumé dans un message de deux paragraphes. Donc, ce genre de concurrence continuera à se produire.
L'article seul
RFC 7216: Location Information Server (LIS) Discovery using IP address and Reverse DNS
Date de publication du RFC : Avril 2014
Auteur(s) du RFC : M. Thomson (Mozilla), R. Bellis (Nominet UK)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF geopriv
Première rédaction de cet article le 30 avril 2014
Normalement, pour trouver le serveur de localisation (LIS) qui lui permettra d'en connaître plus sur sa position physique, et donc d'accéder à des services fondés sur cette position, une machine utilise les techniques du RFC 5986. Mais celles-ci nécessitent une coopération de la part de la box, coopération qui a l'air difficile à obtenir. Ce nouveau RFC propose donc une autre solution, fondée entièrement sur le DNS.
Un LIS est normalement un service du système d'accès à l'Internet (et on en change donc quand on change de réseau). Il connait la topologie du réseau et pourra donc répondre aux requêtes des machines clients lorsqu'elles voudront connaître leur place dans le monde (en utilisant le protocole du RFC 5985). Cette localisation est utilisée, par exemple, dans les services d'urgence (imaginez un appel VoIP au 112 où l'appelant n'a pas le temps de donner sa position : il faut que son logiciel le fasse pour lui.) Reste à trouver ce LIS. Le RFC 5986 proposait une méthode simple, une option DHCP (comme il en existe pour trouver les serveurs DNS ou NTP). Mais cela suppose que le serveur DHCP soit mis à jour pour suivre le RFC 5986 et, apparemment, peu le sont. Déployer une nouvelle option DHCP sur toutes les boxes du monde prend un temps fou (convaincre les développeurs, modifier le code, mettre à jour les millions de boxes existantes ou bien attendre leur remplacement...)
Donc, il vaut mieux une méthode qui ne dépende pas de la box. C'est ce que propose notre RFC. Le principe est de partir de l'adresse IP de la machine, de la transformer en un nom de domaine et d'utiliser ensuite ce nom pour des requêtes DDDS, comme c'était le cas avec le RFC 5986, qui partait d'un nom de domaine reçu en DHCP puis le soumettait à DDDS.
Bon, mais le lecteur attentif a dû noter un piège : la machine typique du réseau local typique du M. Michu typique a une adresse IPv4 privée. Ce n'est pas très utile pour faire des requêtes dans le DNS public. Il va donc falloir que la machine commence par utiliser un protocole comme STUN pour trouver son adresse IP publique. Donc, le principe de notre RFC 7216 est :
- D'abord, on essaie la requête DHCP du RFC 5986. Si elle réussit, c'est bon, sinon, on continue avec la nouvelle méthode,
- On cherche la ou les adresses IP publiques de la machine,
- On les convertit en noms de
domaine dans les zones comme
in-addr.arpa. Par exemple,192.0.2.143devient143.2.0.192.in-addr.arpa. - On passe alors à la découverte DDDS de la section 4 du RFC 5986. En gros, on fait une requête pour le type
NAPTR, service
LIS:HELD, sur le nom de domaine obtenu à l'étape précedente. - Si ça ne donne rien, on raccourcit le nom de domaine (on retire le composant le plus à gauche) et on réessaie la requête NAPTR.
Pour l'étape « trouver l'adresse IP publique de la machine », on a
vu que la méthode suggérée est STUN (RFC 8489), avec un message de type Binding
Request et une réponse dans le paramètre
XOR-MAPPED-ADDRESS. Mais une machine a aussi le
droit de se servir de PCP (RFC 6887, sections 10.1 et 11.4, la réponse à un MAP request va
contenir l'adresse publique) ou UPnP pour
cela. Notez que, parfois, l'adresse ainsi obtenue peut être à son tour
une adresse privée (RFC 1918) et que cela
n'empêche pas la procédure de découverte du LIS de fonctionner (à
condition que le résolveur DNS utilisé sache rediriger les requêtes
vers un serveur local qui fait autorité pour les
in-addr.arpa correspondants).
Quant au raccourcissement du nom de domaine, il est prévu pour
tenir compte du fait qu'il n'y aura pas forcément un enregistrement
NAPTR pour tous les noms de domaine correspondant à une adresse
publique. Parfois, le LIS servira une population plus large (en
IPv4, un /24, voire même un /16) et on n'aura
de NAPTR que pour le nom raccourci. Ainsi, avec l'adresse IP publique
citée plus haut, si on ne trouve pas de NAPTR pour
143.2.0.192.in-addr.arpa, on essaiera avec
2.0.192.in-addr.arpa puis 0.192.in-addr.arpa.
Pour IPv6,
notre RFC recommande de raccourcir le nom de domaine pour
correspondre successivement à un /64, un /56, un /48 ou un /32.
Comme toujours avec la géolocalisation, il y a des questions de vie privée délicates (section 5, et voir aussi le RFC 6280). Ce RFC décrit un mécanisme pour permettre à une machine de trouver son LIS, et donc finalement sa localisation. Ceci n'est pas un risque pour la vie privée. Par contre, une fois cette information obtenue, il faudra faire attention à qui on l'envoie.
Il y a apparemment plusieurs mises en œuvre de ce mécanisme alternatif de découverte du LIS mais je n'ai pas de liste sous la main.
L'article seul
RFC 7208: Sender Policy Framework (SPF) for Authorizing Use of Domains in Email, Version 1
Date de publication du RFC : Avril 2014
Auteur(s) du RFC : S. Kitterman (Kitterman Technical Services)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF spfbis
Première rédaction de cet article le 27 avril 2014
On le sait, le courrier électronique, tel
qu'il est spécifié dans les RFC 5321 et RFC 5322, ne fournit aucune authentification, même
faible, de l'émetteur. Un expéditeur de courrier peut toujours
prétendre être François Hollande
<president@elysee.fr> et il n'y a aucun moyen de l'en
empêcher. C'est parfois pratique mais c'est aussi un gros obstacle
lorsqu'on tente de gérer le problème des courriers non désirés comme
le spam. SPF
vise à diminuer cette facilité de frauder en permettant à un titulaire
de nom de domaine de déclarer quelle(s)
adresse(s) IP sont autorisées
à envoyer du courrier pour ce domaine. Ce nouveau
RFC représente la première norme SPF (le
premier RFC, le RFC 4408, était officiellement une
expérimentation, sans le statut de norme.)
SPF dépend
donc du DNS. Le principe de base est d'ajouter
à sa zone DNS, par exemple bortzmeyer.org, un
enregistrement de type TXT. Cet enregistrement déclare, dans un langage
ad hoc, quelle(s) adresse(s) IP
peuvent envoyer du courrier pour ce domaine. Par exemple,
bortzmeyer.fr a "v=spf1 mx
-all", ce qui veut dire en français que seuls les
MX (les serveurs
qui reçoivent le courrier) de ce domaine peuvent en émettre, le reste
de l'Internet (all) est exclu.
Pour voir ces enregistrements SPF, on peut par exemple utiliser dig :
% dig +short TXT bortzmeyer.org "v=spf1 mx ?all" % dig +short TXT freebsd.org "v=spf1 ip4:8.8.178.116 ip6:2001:1900:2254:206a::19:2 ~all" dig +short TXT archlinux.org "v=spf1 ip4:66.211.214.128/28 ip4:78.46.78.247 ip6:2a01:4f8:120:34c2::2 a:aur.archlinux.org ~all"
Le langage en question, très simple dans la plupart des cas (comme
ci-dessus) mais permettant des choses très (trop ?) compliquées, est
décrit dans la section 5 du RFC. Le premier enregistrement SPF
contient mx indiquant que les machines dans
l'enregistrement MX du domaine sont
autorisées. Les deux autres enregistrements d'exemple listent
explicitement les adresses IP.
Notez qu'il existe plein d'exemples en annexe A de ce RFC.
Le langage de SPF, on l'a vu, est riche et complexe. D'où l'avertissement en section 11.1 de ce RFC : attention en l'évaluant. Il est prudent de prévoir des limites, par exemple de temps écoulé, du nombre d'inclusions emboîtées, ou de requêtes DNS envoyées, afin de ne pas être victime d'un déni de service (ou de contribuer à en faire un).
Et si on veut annoncer clairement qu'on n'envoie jamais de courrier ?
Par exemple, un organisme de paiement a acheté des tas de noms de
domaines dans plusieurs TLD mais il envoie
toujours du courrier depuis example.com et
l'usage de tout autre nom ne peut être qu'une erreur ou une tentative
de fraude.
On met alors un enregistrement v=spf1 -all. (Notez
qu'il n'existait aucun mécanisme avant SPF pour annoncer qu'on
n'envoyait pas de courrier. On voit parfois des MX bidons pour cela,
par exemple pointant vers 0.0.0.0 mais cela n'est
pas standard.)
On note que SPF, comme la plupart de ses concurrents, n'authentifie que le domaine, pas la personne émettrice (ce point, et plusieurs autres, est discuté en détail dans la section 11, « Sécurité », de notre RFC).
Le récepteur du courrier, s'il utilise SPF, va comparer
l'adresse IP du client
SMTP aux adresses autorisées par
l'enregistrement SPF et le résultat pourra être (section 2.6)
none (sans opinion, typiquement parce qu'il n'y
avait pas d'enregistrement SPF publié), neutral
(il y avait bien un enregistrement SPF mais il se terminait par un
avis neutre, typiquement avec le qualificateur « ? »,
pass (cette adresse IP est autorisée pour ce
domaine) ou fail (cette adresse IP n'est pas
autorisée pour ce domaine). Il y a aussi deux cas d'erreurs,
temperror et pererror.
Une fois que le domaine est authentifié, on en fait quoi ? En soi, être authentifié n'est évidemment pas une garantie de bon comportement (c'est toute la différence entre authentification et autorisation). C'est simplement une première étape du processus de sécurité : une fois une identité solidement établie, on peut utiliser les mécanismes de réputation existants (en prime, un nom de domaine est plus stable qu'une adresse IP).
La décision finale est une décision locale. Les gens à qui on
explique SPF pour la première fois disent souvent « et que fait le
serveur SMTP si l'authentification SPF échoue ? » et la réponse est
toujours « ça dépend », car, en effet, cela dépend de la politique de
ce serveur SMTP. Certains seront violents, rejettant complètement le
message, d'autres se contenteront de noter (peut-être en transmettant
l'information avec le RFC 6652), d'autres enfin tiendront
compte du résultat de SPF mais comme une indication parmi
d'autres. Une fois la décision prise, le message peut
être rejeté dès la session SMTP ou bien peut être accepté mais marqué
d'une manière ou d'une autre (ce qui pourra lui « enlever des points »
pour une évaluation ultérieure). Il existe deux façons de marquer un
message, avec l'en-tête Received-SPF: (défini
dans ce RFC, section 9.1) ou bien avec un en-tête non spécifique à
SPF, Authentication-Results: (RFC 5451). Autre différence entre les deux en-têtes,
Received-SPF: donne des informations détaillées,
utiles pour le débogage, alors que
Authentication-Results: vise surtout à donner un
résultat simple sur la base duquel des logiciels ultérieurs (comme le
MUA) pourront agir. Voici deux exemples, tirés
du RFC :
Authentication-Results: myhost.example.org; spf=pass
smtp.mailfrom=example.net
Received-SPF: pass (myhost.example.org: domain of
myname@example.com designates 192.0.2.1 as permitted sender)
receiver=mybox.example.org; client-ip=192.0.2.1;
envelope-from="myname@example.com"; helo=foo.example.com;
Il y avait eu des discussions à l'IETF autour de la suppression d'un des deux en-têtes mais cela n'a finalement pas été fait.
Authentifier le courrier électronique est plus compliqué qu'il ne semble au premier abord, en partie parce qu'il existe plusieurs identités possibles :
- L'expéditeur de l'enveloppe (
MAIL FROMde la session SMTP), - L'expéditeur indiqué dans les en-têtes, qui lui-même dépend de l'en-tête
qu'on choisit (
From:?Sender:?).
Les partisans de la première approche (celle de SPF) lisent le RFC 5321 et s'appuient sur l'identité MAIL
FROM (dite aussi RFC5321.MailFrom,
cf. section 1.1.3). Chacune a ses avantages et ses
inconvénients. (Notez que SPF utilise également le nom annoncé par la
commande HELO de SMTP, cf. section 2.3.)
Attention, un vérificateur SPF doit bien prendre soin de
n'utiliser que cette identité, autrement, les résultats peuvent être
faux (par exemple, un MLM va changer le
MAIL FROM mais pas l'en-tête From:).
Les changements depuis l'ancien RFC 4408
figurent dans l'annexe B. Le principal est le changement de statut : RFC 4408 était
expérimental, notre nouveau RFC est sur le chemin des
normes. Autrement, des détails, rien de vital, le principal changement
technique étant l'abandon du type d'enregistrement DNS
SPF pour les raisons expliquées dans l'annexe A du RFC 6686.
Parmi les sujets polémiques qu'a rencontré le groupe de travail, et
qui ont engendré l'essentiel du trafic sur la liste de diffusion :
- La décision douloureuse d'abandonner le type d'enregistrement
DNS
SPF. - La revendication récurrente, par certaines personnes, que le RFC impose un traitement particulier (rejeter le message) en cas d'échec SPF. Comme cela n'affecte pas l'interopérabilité, le groupe a logiquement décidé que c'était une décision de politique locale.
- Il y a régulièrement une discussion dans le milieu SPF pour
savoir ce que doit faire un serveur de messagerie lorsqu'il n'y a pas
d'enregistrement SPF pour le serveur qu'il veut authentifier. Certains
prônent un « enregistrement SPF par défaut » par exemple
v=spf1 ~allou encorev=spf1 mx/24/48 a/24/48 ~all. Une telle valeur est complètement arbitraire et n'a jamais été normalisée. - Les discussions sur le forwarding de courrier et sur les listes de diffusion sont également des traditions du monde SPF.
- Pour des raisons de sécurité (nombreux traitements, et nombreuses requêtes DNS), certains avaient proposé d'abandonner la compatibilité avec les premières versions de SPF et de supprimer du langage quelques mécanismes très gourmands. Ce projet n'a pas été retenu.
SPF est aujourd'hui très répandu, de nombreux domaines l'annoncent et bien des logiciels de courrier peuvent traiter du SPF.
L'article seul
RFC 7215: LISP Network Element Deployment Considerations
Date de publication du RFC : Avril 2014
Auteur(s) du RFC : L. Jakab (Cisco
Systems), A. Cabellos-Aparicio, F. Coras, J. Domingo-Pascual
(Technical University of Catalonia), D. Lewis (Cisco
Systems)
Expérimental
Réalisé dans le cadre du groupe de travail IETF lisp
Première rédaction de cet article le 23 avril 2014
Le protocole réseau LISP a été normalisé il y a plus d'un an et plusieurs déploiements de taille significative ont déjà eu lieu. La norme LISP n'impose pas un modèle unique de déploiement et laisse bien des choix à la discrétion de l'administrateur réseaux sur le terrain, notamment pour le placement des différents éléments qui composent un réseau LISP. Ce nouveau RFC fait le point sur les différents modèles de déploiement possibles. Il est donc orienté vers les opérationnels, ceux (et celles) qui vont déployer LISP en production.
Petit rappel, LISP vise à résoudre le problème de la croissance de la table de routage globale de l'Internet (problème décrit dans le RFC 4984), par le moyen d'une séparation entre identificateurs, les EID (Endpoint IDentifiers) et les localisateurs, les RLOC (Routing LOCators). LISP est normalisé dans le RFC 6830. À l'heure actuelle, les RFC sur LISP ont le statut « expérimental » (y compris ce RFC 7215), reflétant le caractère assez disruptif de ce protocole. Il n'y a notamment aucune solution aux différents problèmes de sécurité étudiés dans la section 15 du RFC 6830.
Un principe essentiel de LISP est la distinction faite entre les réseaux de bordure, qui ne travaillent qu'avec des EID, et le cœur de l'Internet qui ne travaille qu'avec des RLOC. Mais où placer la frontière, frontière d'autant plus importante que c'est là où vont devoir se situer les routeurs LISP (les routeurs de bordure et du cœur sont, eux, des routeurs IP non modifiés) ? L'idée initiale était que la frontière était aux limites des AS « feuille », ceux qui n'ont pas de trafic de transit. Mais, en fait, LISP permet plusieurs choix. Un « site LISP » peut être un AS feuille mais peut aussi être un simple réseau local.
LISP tunnelise les paquets d'un site LISP à l'autre, à travers le cœur. Le routeur LISP, connecté à la fois à la bordure et au cœur se nomme un ITR (Ingress Tunnel Router) à l'entrée (encapsulation des paquets) et un ETR (Egress Tunnel Router) à la sortie (décapsulation des paquets). Quand on veut parler des deux types en même temps, on dit juste « un xTR ».
Passons maintenant aux scénarios, section 2.1. Premier scénario possible de déploiement, le « Customer Edge ». Le routeur LISP est dans les locaux du client, contrôlé par lui, et sur la frontière entre réseau du client et réseau de l'opérateur. Ce sera a priori le cas le plus fréquent chez les LISPiens et c'est la solution recommandée par notre RFC. A priori, si on déploie LISP, c'est qu'on a un réseau de grande taille, multi-homé, et qu'on souhaite faire de la gestion de trafic (faire entrer le trafic Internet préferentiellement par un des opérateurs, par exemple). Dans le scénario Customer Edge, le client a le complet contrôle des xTR et peut déployer les politiques qu'il veut sans rien demander à personne. L'information de joignabilité des ETR, si importante en LISP, peut être maintenue correctement, tous les routeurs LISP étant sous le contrôle de la même organisation. Les Locator Status Bits mis par l'ITR sont également toujours conformes à la réalité.
Autre avantage, le réseau interne, son plan d'adressage, son protocole de routage et ses régles de filtrage ne changent pas.
Comme toutes les techniques utilisant des tunnels, LISP est très sensible aux problèmes de MTU (RFC 4459), le tunnel consommant quelques octets qui vont diminuer la MTU du lien. Si la connexion entre le client et son opérateur a une MTU supérieure aux traditionnels 1 500 octets d'Ethernet, il n'y a pas de problème. Sinon, ce scénario peut entraîner des problèmes de MTU.
Second scénario possible, le « Provider Edge ». Cette fois, on met les xTR chez l'opérateur, sous son contrôle. Le client n'a pas à mettre à jour ses routeurs, ou à les configurer. Et, avec un seul xTR, l'opérateur peut servir plusieurs clients LISP.
Par contre, cela fait perdre à LISP une de ses principales qualités, la possibilité de contrôler la répartition du trafic entrant (ingress traffic engineering). En effet, les xTR ne sont plus sous le contrôle du client. Et si le client est multi-homé, c'est encore pire, les xTR étant chez des opérateurs concurrents.
Les xTR qui servent un site LISP n'étant plus coordonnés, ils ne vont pas forcément avoir de l'information correcte et à jour sur la joignabilité, et ne pourront donc pas servir cette information.
Par contre, ce scénario peut limiter les risques d'un problème de MTU, les xTR étant directement dans le réseau de l'opérateur, où la MTU disponible est souvent plus grande.
Mais on peut commettre des perversions bien pires avec LISP. Par exemple, on peut mettre les xTR derrière des routeurs NAT, par exemple si on n'a pas assez d'adresses IPv4. Dans ce troisième scénario, l'ITR encapsule les paquets qui sont ensuite NATés. Attention, les paquets LISP Map Requests n'auront alors pas le même en-tête IP que les Map Reply correspondants, qui seront alors jetés par le routeur NAT. Il faudra une configuration explicite (par exemple diriger tous les paquets UDP de port source 4342 vers l'ITR) pour éviter cela.
Ce RFC ne s'arrête pas à ces trois scénarios possibles. Il décrit aussi comment les fonctions LISP peuvent être réparties dans divers équipements. Par exemple, les fonctions d'ITR et d'ETR ne sont pas forcément présentes dans le même boîtier. On a le droit de les placer dans deux routeurs différents, par exemple pour mettre les ITR très près des machines terminales, afin d'encapsuler le plus tôt possible.
Comme toutes les solutions de séparation de l'identificateur et du localisateur, LISP dépend énormément des mécanismes de correspondance (RFC 6833), permettant de trouver un localisateur (RLOC) lorsqu'on connait l'identificateur (EID). Pour résoudre le problème de bootstrap, les serveurs de correspondance doivent être désignés par des RLOC uniquement. Le système de correspondance a deux composants, les Map Servers et les Map Resolvers. Voyons d'abord les premiers (section 3.1).
Les Map Servers apprennent la correspondance EID->RLOC de leurs ETR (message Map Register) et publient ensuite cette information, par exemple via le protocole ALT (RFC 6836) ou via le protocole DDT (RFC 8111). ALT s'inspire plutôt de BGP, DDT plutôt du DNS. Les gérants des Map Servers se nomment les MSP (Mapping Service Provider). Ils peuvent être opérateurs réseaux ou bien des organisations spécialisées dans le service de correspondance, se faisant payer pour publier un préfixe EID (section 5.2). A priori, les bonnes pratiques existantes pour la gestion de BGP s'appliquent à ALT, et celles pour le DNS à DDT. Mais notre RFC ne va pas plus loin : il est encore trop tôt pour graver dans le marbre de strictes politiques pour les gérants de Map Servers.
DDT (RFC 8111) est arborescent et repose donc sur une racine. Cette racine est actuellement gérée par plusieurs organisations volontaires. Comme pour la racine du DNS, elle est servie par plusieurs serveurs, chacun géré par une organisation différente, et désignés par une lettre de l'alphabet grec. Au moins un de ces serveurs est anycasté. La racine doit normalement vérifier que les organisations qui enregistrent un EID sont autorisés à le faire, via un RIR qui leur a attribué le préfixe en question.
Et les Map Resolvers (section 3.2) ? Leur travail (RFC 6833) est de recevoir des requêtes Map Request, typiquement envoyées par un ITR, de trouver une correspondance EID->RLOC dans la base de données distribuée, et de la renvoyer au demandeur. (Les habitués du DNS peuvent se dire qu'un Map Server est un « serveur faisant autorité » et un Map Resolver un « résolveur » ou « serveur récursif ».) Vu leurs « clients », les Map Resolvers ont tout intérêt à être situés près des ITR qu'ils servent.
Les ITR vont devoir être configurés avec les adresses de leurs Map Resolvers. Un préfixe anycast (RFC 4786) commun faciliterait cette tâche, l'ITR trouvant ainsi automatiquement le résolveur le plus proche et donc en général le plus rapide.
Comme toute technologie nouvelle sur le réseau, LISP doit faire face au problème de la coexistence avec les anciens systèmes. Aujourd'hui, il y a peu de sites LISP. Ceux-ci doivent donc se poser la question de la coexistence avec les sites non-LISP. Plusieurs techniques sont envisagées pour cela, comme les P-ITR, Proxy ITR du RFC 6832. Un site LISP qui veut envoyer des paquets à un site non-LISP peut le faire simplement en n'utilisant pas l'encapsulation LISP. Par contre, pour en recevoir, il doit déployer une technique comme le P-ITR.
Et puisqu'on parle de coexistence avec les sites non-LISP, il faut aussi envisager le processus de migration provisoire depuis l'état actuel vers LISP (section 5 et annexe A). Le RFC est ambitieux, partant de l'état initial (peu de sites LISP) en allant vers un état intermédiaire où il y aurait une majorité de sites LISP, pour terminer par un Internet complètement LISPisé.
Au début, un site LISP n'a pas le choix. Sauf à ne communiquer qu'avec les autres sites LISP, il a intérêt à annoncer ses préfixes dans le Map system LISP mais aussi en BGP, pour que les sites non-LISP sachent où le trouver. On notera donc que, dans cette situation, LISP ne contribue guère à la réduction de la table de routage globale, puisque tous les réseaux doivent toujours être publiés dans BGP. Heureusement, au fur et à mesure que le nombre de sites LISP augmente, il y aura de moins en moins besoin d'utiliser les techniques de traffic engineering pour contrôler les flux de données. Comme ces techniques (par exemple la désagrégation des préfixes) sont largement responsables de la croissance de la table de routage globale, LISP aura donc déjà un intérêt concret à ce stade (encore lointain).
On l'a vu, l'inconvénient de cette méthode (annoncer les préfixes en BGP) est qu'on ne diminue pas la taille de la DFZ. Pire, si on est un nouveau réseau sans infrastructure BGP existante, on augmente cette taille. Pour ces réseaux neufs, notre RFC recommande donc plutôt de ne pas déployer BGP du tout et d'utiliser les P-ITR. C'est alors le titulaire d'un préfixe englobant qui annonce le préfixe et le route vers les ETR du client. Ainsi, il n'y a pas de désagrégation des préfixes. Par contre, l'opérateur qui fournit ce service doit router tout le trafic non-LISP du client, ce qui n'est pas forcément raisonnable si c'est un gros client (comparez cela aux tunnels IPv6 que fournissent gratuitement des opérateurs comme Hurricane Electric : cela n'est réaliste que si le trafic est faible). Le problème disparaitra petit à petit si LISP se développe, lorsqu'il n'y aura plus que des reliquats non-LISP (on en est très loin).
L'annexe A du RFC décrit un plan de migration concret pour les responsables opérationnels, sous forme d'une liste d'étapes, avec des points à vérifier à chaque étape :
- Faire un état des lieux quantitatif du réseau, pour avoir combien de paquets par seconde et de bits par seconde il faudra acheminer.
- Vérifier les capacités LISP des routeurs existants : peuvent-ils être utilisés ou bien va t-il falloir en acheter d'autres ?
- Faire bien attention aux questions de MTU, LISP utilisant des tunnels. Si tous les liens externes peuvent accepter une MTU de 1 556 octets, parfait. Dans tous les cas, testez que cela passe et qu'il n'y a pas un pare-feu trop zélé qui bloque les messages ICMP indispensables à la découverte de la MTU du chemin.
- Vérifiez que vos préfixes IP sont utilisables pour LISP. Si c'est du PI, pas de problème.
- Configurez les routeurs LISP.
- Testez la joignabilité des ETR (par exemple avec ping) et l'enregistrement des préfixes avec lig (RFC 6835).
- etc (la liste est longue...)
L'article seul
RFC 7218: Adding acronyms to simplify DANE conversations
Date de publication du RFC : Avril 2014
Auteur(s) du RFC : O. Gudmundsson (Shinkuro)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dane
Première rédaction de cet article le 23 avril 2014
Le système DANE permet de publier des clés cryptographiques ou des certificats dans le DNS, en les authentifiant avec DNSSEC. Ces clés ou certificats sont mis dans un enregistrement de type TLSA et cet enregistrement comprend plusieurs champs portant des valeurs numériques. Jusqu'à ce RFC, il n'existait pas d'acronymes standards pour désigner les valeurs possibles, ce qui rendait difficile la communication entre humains, et le choix des noms de variables dans les programmes. Ce nouveau RFC ne change pas le système DANE mais décrit simplement ces acronymes standards.
Voici un exemple actuel d'enregistrement TLSA (enregistrement DANE) :
_443._tcp.fedoraproject.org. 300 IN TLSA 0 0 1 ( D4C4C99819F3A5F2C6261C9444C62A8B263B39BC6ACC E35CDCABE272D5037FB2 )
Les champs dont les valeurs sont ici 0, 0 et 1 sont les champs dont on
souhaite pouvoir parler plus facilement. La norme DANE, le RFC 6698, ne définit pas de noms courts pour les
valeurs. Par exemple, le deuxième champ, le Sélecteur,
qui vaut 0 ici, peut prendre deux valeurs, que le RFC 6698 nomme Full certificate et
SubjectPublicKeyInfo, alors que notre nouveau
RFC 7218 propose d'ajouter les acronymes
Cert et SPKI. Dans le futur,
on peut même imaginer que les logiciels puissent charger directement
une zone DNS où les valeurs numériques seraient
remplacées par ces acronymes (et dig pourrait
les afficher au lieu des valeurs numériques actuelles).
Le registre IANA en https://www.iana.org/assignments/dane-parameters/dane-parameters.xhtml
- 0, contrainte sur l'AC, désormais
PKIX-TA, - 1, contrainte sur le certificat, désormais
PKIX-EE(EE pour End Entity), - 2, déclaration de l'AC, désormais
DANE-TA, - 3, déclaration du certificat, désormais
DANE-EE.
Notez le regroupement des acronymes en deux groupes : les acronymes
commençant par PKIX sont les utilisations où on
fait toujours la validation PKIX classique
(RFC 5280) et ceux commençant par
DANE sont ceux où on n'utilise plus le modèle de
validation de X.509, on est purement dans un
monde DANE.
Le champ « Sélecteur » (Selector), lui, peut être :
- 0, le certificat complet, désormais
Cert, - 1, la clé seule, désormais
SPKI.
Et le champ « Méthode de correspondance » (Matching type, et merci à Romain Tartière pour avoir trouvé une erreur dans mon article original) :
La section 3 donne des exemples d'enregistrements affichés avec ces acronymes. Pour celui cité plus haut, ce serait :
_443._tcp.fedoraproject.org. 300 IN TLSA PKIX-TA Cert SHA2-256 ( D4C4C99819F3A5F2C6261C9444C62A8B263B39BC6ACC E35CDCABE272D5037FB2 )
Les humains étant particulièrement sensibles aux noms, les discussions ont été longues quant au choix des acronymes. Tout le monde était d'accord qu'il vallait mieux des acronymes que des nombres, simplement, chacun avait les siens comme favoris.
Pour la petite histoire, une bonne partie de la démarche menant à ce RFC vient de l'introduction de DANE dans Postfix. Viktor Dukhovni, en faisant ce travail, a découvert DANE et signalé à l'IETF nombre de problèmes et de limites, et notamment la difficulté à ne manipuler que des valeurs numériques, par exemple dans les documentations.
L'article seul
RFC 7203: IODEF-extension for structured cybersecurity information
Date de publication du RFC : Avril 2014
Auteur(s) du RFC : T. Takahashi (NICT), K. Landfield (McAfee), T. Millar (USCERT), Y. Kadobayashi (NAIST)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF mile
Première rédaction de cet article le 22 avril 2014
Le format IODEF permet l'échange de données structurées (et donc analysables par un programme) sur des incidents de sécurité. Ce nouvel RFC étend le format IODEF avec des informations utiles pour le monde de la « cybersécurité ».
Le RFC commence par prétendre que le nombre d'incidents de cybersécurité augmente tous les jours (alors qu'on n'en sait rien). Ce qui est sûr, c'est que la quantité d'informations échangées sur ces incidents augmente et qu'il existe une quantité impressionnante de formats structurés et de référentiels (quelques exemples au hasard, pris dans ceux cités par le RFC : CVSS, OVAL, SCAP, XCCDF...). Notre RFC en ajoute donc un, sous forme, non pas d'un format nouveau mais d'une extension de IODEF, un format fondé sur XML et qui avait été normalisé dans le RFC 5070 (remplacé depuis par le RFC 7970). Signe des temps : un des auteurs du RFC travaille au ministère de l'intérieur états-unien...
La section 3 du RFC rappelle ses buts, et l'importance de ne pas
repartir de zéro, d'agréger les formats cités plus haut au lieu
d'essayer de les remplacer. Les extensions IODEF elles-mêmes
figurent en section 4. En gros, il s'agit de permettre d'incorporer
dans IODEF des descriptions issues de normes extérieures déjà
existantes. Un nouveau registre IANA
stocke les spécifications ainsi incorporées. Pour l'instant, le
registre n'en compte qu'une seule,
urn:ietf:params:xml:ns:mile:mmdef:1.2 qui est
fondée sur la
norme IEEE MMDEF, qui permet de décrire des
logiciels malveillants.
Chacune de ces entrées dans le nouveau registre dérivera d'une
classe (notre RFC utilise le vocabulaire de la
programmation objet, et le langage
UML pour la modélisation) parmi les huit : AttackPattern,
Platform, Vulnerability,
Scoring, Weakness,
EventReport, Verification et
Remediation. Ainsi, MMDEF, la première entrée,
hérite de AttackPattern. Chacune de ces classes
est décrite en détail en section 4.5
Et voici, tiré du RFC, un exemple de rapport IODEF incorporant des
éléments MMDEF, décrivant un
malware de nom
eicar_com.zip (un fichier de test connu) :
<?xml version="1.0" encoding="UTF-8"?>
<IODEF-Document version="1.00" lang="en"
xmlns="urn:ietf:params:xml:ns:iodef-1.0"
xmlns:iodef="urn:ietf:params:xml:ns:iodef-1.0"
xmlns:iodef-sci="urn:ietf:params:xml:ns:iodef-sci-1.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<Incident purpose="reporting">
<IncidentID name="iodef-sci.example.com">189493</IncidentID>
<ReportTime>2013-06-18T23:19:24+00:00</ReportTime>
<Description>a candidate security incident</Description>
<Assessment>
<Impact completion="failed" type="admin" />
</Assessment>
<Method>
<Description>A candidate attack event</Description>
<AdditionalData dtype="xml">
<iodef-sci:AttackPattern
SpecID="http://xml/metadataSharing.xsd">
<iodef-sci:RawData dtype="xml">
<malwareMetaData xmlns="http://xml/metadataSharing.xsd"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xml/metadataSharing.xsd
file:metadataSharing.xsd" version="1.200000" id="10000">
<company>N/A</company>
<author>MMDEF Generation Script</author>
<comment>Test MMDEF v1.2 file generated using genMMDEF
</comment>
<timestamp>2013-03-23T15:12:50.726000</timestamp>
<objects>
<file id="6ce6f415d8475545be5ba114f208b0ff">
<md5>6ce6f415d8475545be5ba114f208b0ff</md5>
<sha1>da39a3ee5e6b4b0d3255bfef95601890afd80709</sha1>
<sha256>e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca4
95991b7852b855</sha256>
<sha512>cf83e1357eefb8bdf1542850d66d8007d620e4050b5715dc83
f4a921d36ce9ce47d0d13c5d85f2b0ff8318d2877eec2f63b9
31bd47417a81a538327af927da3e</sha512>
<size>184</size>
<filename>eicar_com.zip</filename>
<MIMEType>application/zip</MIMEType>
</file>
<file id="44d88612fea8a8f36de82e1278abb02f">
<md5>44d88612fea8a8f36de82e1278abb02f</md5>
<sha1>3395856ce81f2b7382dee72602f798b642f14140</sha1>
<sha256>275a021bbfb6489e54d471899f7db9d1663fc695ec2fe2a2c4
538aabf651fd0f</sha256>
<sha512>cc805d5fab1fd71a4ab352a9c533e65fb2d5b885518f4e565e
68847223b8e6b85cb48f3afad842726d99239c9e36505c64b0
dc9a061d9e507d833277ada336ab</sha512>
<size>68</size>
<crc32>1750191932</crc32>
<filename>eicar.com</filename>
<filenameWithinInstaller>eicar.com
</filenameWithinInstaller>
</file>
</objects>
<relationships>
<relationship type="createdBy" id="1">
<source>
<ref>file[@id="6ce6f415d8475545be5ba114f208b0ff"]</ref>
</source>
<target>
<ref>file[@id="44d88612fea8a8f36de82e1278abb02f"]</ref>
</target>
<timestamp>2013-03-23T15:12:50.744000</timestamp>
</relationship>
</relationships>
</malwareMetaData>
</iodef-sci:RawData>
</iodef-sci:AttackPattern>
</AdditionalData>
</Method>
<Contact role="creator" type="organization">
<ContactName>iodef-sci.example.com</ContactName>
<RegistryHandle registry="arin">iodef-sci.example-com
</RegistryHandle>
<Email>contact@csirt.example.com</Email>
</Contact>
<EventData>
<Flow>
<System category="source">
<Node>
<Address category="ipv4-addr">192.0.2.200</Address>
<Counter type="event">57</Counter>
</Node>
</System>
<System category="target">
<Node>
<Address category="ipv4-net">192.0.2.16/28</Address>
</Node>
<Service ip_protocol="4">
<Port>80</Port>
</Service>
</System>
</Flow>
<Expectation action="block-host" />
<Expectation action="other" />
</EventData>
</Incident>
</IODEF-Document>
On notera que bien des discussions préalables au RFC portaient sur cette plaie de l'appropriation intellectuelle, plusieurs des schémas référencés ayant des noms qui sont des marques déposées.
L'article seul
RFC 7157: IPv6 Multihoming without Network Address Translation
Date de publication du RFC : Mars 2014
Auteur(s) du RFC : O. Troan (Cisco), D. Miles (Alcatel-Lucent), S. Matsushima (Softbank Telecom), T. Okimoto (NTT West), D. Wing (Cisco)
Pour information
Réalisé dans le cadre du groupe de travail IETF v6ops
Première rédaction de cet article le 22 avril 2014
Pour la petite entreprise ou association, il est très intéressant d'être multi-homé, c'est-à-dire d'avoir plusieurs connexions à l'Internet, afin d'être sûr que l'accès fonctionne toujours. Financièrement, acheter deux connexions Internet grand public, de fiabilité moyenne, est nettement moins cher qu'une seule connexion supposée de grande fiabilité. Il reste à permettre aux machines du réseau local à utiliser les deux connexions. En IPv4, cela se fait traditionnellement en utilisant le NAT, qui est de toute façon nécessaire en raison de la pénurie d'adresses. Et en IPv6 ?
On pourrait utiliser le NAT, comme le mettent en œuvre un certain nombre de boîtiers existants actuellement. Les machines du réseau local utiliseraient un seul préfixe, un ULA et le routeur traduirait vers les préfixes de l'un ou l'autre FAI (peut-être en tenant compte de la charge, du prix, etc). Mais le NAT a de nombreux inconvénients et l'un des buts d'IPv6 était justement de s'en débarrasser (ceci dit, si vous voulez tenter l'aventure, il existe un RFC sur ce sujet, le RFC 6296, cf. section 7.1). Autre solution, faire du beau multi-homing propre avec des adresses PI et BGP. Mais c'est complètement hors de portée de la petite organisation, notamment par les ressources humaines que cela nécessite. (Voir le RFC 3582 pour un cahier des charges d'une solution idéale pour le multi-homing.)
Je vous le dis tout de suite, il n'existe pas encore de solution propre et déployable pour ce problème. À court terme, le RFC 6296 reste la seule solution. Notre RFC explore ce qui pourrait être utilisé pour après, en supposant un réseau multi-homé avec plusieurs préfixes IP (MHMP pour multihomed with multi-prefix). C'est donc plutôt un cahier des charges qu'un catalogue de solutions.
A priori, IPv6 permet parfaitement d'avoir deux préfixes d'adresses (un par FAI, si on est multi-homé à seulement deux FAI) sur le même réseau. Mais cela laisserait les machines face à bien des problèmes :
- S'il y a deux routeurs (un pour chaque FAI), lequel choisir pour sortir ?
- Quelle adresse IP source choisir pour les connexions sortantes ? Notez que c'est lié au problème précédent : si le FAI met en œuvre le filtrage du RFC 2827, il faut choisir le préfixe correspondant au FAI de sortie.
- Et c'est encore pire si le FAI impose l'usage de ses résolveurs
DNS car il y met des informations spécifiques à
ses clients (comme Orange où
smtp.wanadoo.fretsmtp.orange.frdonnent des résultats différents selon le réseau, interne ou externe).
Bref, simplement connecter le réseau local à deux FAI et distribuer leurs adresses sur ledit réseau ne suffit pas.
La section 3 décrit plusieurs scénarios typiques, pour rendre plus concret le problème. Le premier est celui où le réseau a deux routeurs, chacun connecté à un FAI et ignorant de l'autre routeur. C'est le cas par exemple de l'abonnement à deux FAI ADSL avec chaque FAI fournissant sa box. Le deuxième scénario imagine un seul routeur sur le réseau local, connecté à deux FAI. L'unique routeur du réseau local peut publier sur le réseau local tout ou partie des informations (préfixe IP, résolveurs DNS) reçues. Ce scénario peut se trouver, entre autres, si on a un abonnement Internet plus un tunnel vers un fournisseur de VPN. Enfin, dans le troisième scénario, c'est la machine terminale qui a deux connexions et qui doit les gérer. C'est le cas du téléphone drôlement intelligent qui est connecté en WiFi et en 3G.
Quels vont être les principaux problèmes à résoudre avec ces trois scénarios (section 3.3) ?
- Dans le premier cas, celui à deux routeurs, la sélection, par une machine du réseau local, de son adresse IP source, en cohérence avec le routeur choisi pour la sortie (si elle se trompe, le paquet sera refusé par le FAI s'il met en œuvre le RFC 2827), et la répartition de charge (chaque machine n'enverra du trafic qu'à un seul routeur),
- Dans le deuxième scénario, avec un seul routeur sur le réseau local, le même problème de sélection d'adresse IP source, si le routeur publie les deux préfixes sur le réseau local, et la sélection du FAI de sortie par le routeur,
- Pour le troisième exemple, celui de la machine terminale à plusieurs connexions, le manque d'informations (sur la facturation, par exemple) pour décider quel trafic envoyer à quelle interface (curieusement, notre RFC ne cite pas l'excellent RFC 6419, entièrement consacré à cette question des machines terminales multi-homées).
Et, dans les trois scénarios, le problème du résolveur DNS, si les deux résolveurs ne donnent pas les mêmes résultats.
Maintenant, il faut résoudre ces problèmes, en respectant deux principes (section 4) : maintien du principe de bout en bout (donc pas de NAT), puisque c'est l'un des principaux buts d'IPv6, et passage à l'échelle, la solution devant fonctionner même pour des gros déploiements.
Les sections 5 et 6 explore les angles d'attaque possibles. Pour la
sélection de l'adresse IP source (sections 5.1 et 6.1), la référence actuelle
est le RFC 3484, qui est loin de donner un
résultat optimum, puisqu'il utilise uniquement l'adresse IP de destination (dans la scénario 1 ci-dessus, il ne garantit pas
qu'on sélectionne une adresse qui correspondra au routeur de
sortie). Une approche actuellement étudiée à l'IETF serait de
distribuer (par exemple en DHCP), depuis le routeur, des politiques de sélection d'adresse
(actuellement, elles sont configurées dans chaque machine,
/etc/gai.conf sur la plupart des
Linux, par exemple). Pour que ces politiques
soient complètes, cela nécessitera la coopération du FAI..
Pour la sélection du routeur (sections 5.2 et 6.2), c'est à peu près la même chose : les machines terminales n'ayant actuellement pas assez d'informations pour prendre une décision intelligente, il faudra leur envoyer (via DHCP), les informations permettant de choisir le routeur. Une telle information ne peut pas facilement être transmise avec les RA (Router Advertisement), qui ne permettent pas d'envoyer des informations différentes selon la machine. (On pourrait envisager d'utiliser les protocoles de routage eux-mêmes mais il y a bien longtemps qu'on a cessé de les faire tourner sur les machines terminales, et pour de bonnes raisons.)
Enfin, pour le dernier gros problème, la sélection du résolveur
DNS (sections 5.3 et 6.3), notre RFC rappelle que les
machines ont pu connaître le résolveur via DHCP (RFC 3646) ou RA (RFC 8106). Dans le cas
du multi-homing, la machine aura typiquement
plusieurs résolveurs DNS. Parfois, il faudra utiliser un résolveur
spécifique pour un domaine donné (dans l'exemple
d'Orange, cité plus haut, il faut utiliser les
résolveurs d'Orange pour les noms en wanadoo.fr,
car on obtient des résultats différents avec les serveurs
publics). Cette pratique, connue sous le nom de split
DNS est typiquement très mal vue (entre autres, elle rend le
débogage très compliqué) mais elle existe. Notre RFC décide donc,
sans l'entériner, de « faire avec ».
Là encore, un travail est en cours à l'IETF pour normaliser une politique de sélection du résolveur, en fonction du domaine à résoudre, et distribuée par DHCP (RFC 6731).
Bien sûr, il existe des tas d'autres techniques qui peuvent aider dans ce cas du multi-homing. Le RFC cite SHIM6 (RFC 5533), SCTP (RFC 4960), HIP (RFC 5206), etc. Mais elles sont aujourd'hui trop peu déployées pour qu'on puisse compter dessus.
Enfin, la section 8 nous rappelle que tout ceci va certainement poser des problèmes de sécurité amusants. Par exemple, si on distribue une politique de sélection (d'adresse IP source, de résolveur DNS, etc) sur le réseau, il y aura toujours des machines qui n'obéiront pas. Contrôle et filtrage resteront donc nécessaires. D'autre part, il existe déjà aujourd'hui des serveurs DHCP pirates, qui répondent à la place du vrai, et le problème sera pire encore lorsque des politiques de sélection (de routeur, de réolveur DNS, etc) seront distribuées via DHCP.
L'article seul
RFC 7207: A Uniform Resource Name (URN) Namespace for Eurosystem Messaging
Date de publication du RFC : Avril 2014
Auteur(s) du RFC : M. Ortseifen (Deutsche
Bundesbank), G. Dickfeld (Deutsche Bundesbank)
Pour information
Première rédaction de cet article le 18 avril 2014
Une famille d'URN de plus, pour les messages d'Eurosystem, famille gérée par la Bundesbank pour le compte de l'ESCB. Vous ne connaissez pas le secteur bancaire ? L'ESCB est un regroupement de banques centrales européennes (mais n'ayant pas forcément adopté l'euro) comme la Bundesbank. L'Eurosystem, comme son nom l'indique, est commun aux membres de l'ESCB qui ont adopté l'euro (voir la présentation par l'ESCB).
Et pourquoi ont-ils besoin d'URN ? Parce
qu'ils échangent des messages par le système
TARGET2 (un système à la norme
ISO 20022) et qu'un certain nombre d'éléments
dans ces messages ont besoin d'être identifiés de manière unique et
stable dans le temps (les messages ont toujours besoin d'être lus et
compris des années après). Les identifiants doivent être indépendants
du protocole d'accès, ce qu'offrent les URN, normalisés dans le RFC 8141.
Il est important que
l'Eurosystem puisse être un registre
d'identificateurs, avec son propre NID, son propre espace de noms pour
ses URN (RFC 8141). Cet espace se nomme
eurosystem et est enregistré à l'IANA.
Il n'y a pas de structure à l'intérieur de ces URN
(donc, après le urn:eurosystem:), juste une suite
de caractères. L'exemple donné par le RFC est urn:eurosystem:xsd:reda.012.001.02.
L'article seul
RFC 7165: Use Cases and Requirements for JSON Object Signing and Encryption (JOSE)
Date de publication du RFC : Avril 2014
Auteur(s) du RFC : R. Barnes (BBN Technologies)
Pour information
Réalisé dans le cadre du groupe de travail IETF jose
Première rédaction de cet article le 15 avril 2014
Il est traditionnel de classer les mécanismes de sécurité de l'Internet en deux, ceux fondés sur la sécurité du canal et ceux fondés sur la sécurité de l'objet. Pour les premiers, on garantit certaines propriétés de l'objet pendant son transit dans un canal donné. Pour les seconds, l'objet se déplace en permanence dans une armure cryptographique qui le protège, quelle que soit la sécurité du canal où il voyage. Le groupe de travail JOSE de l'IETF cherche à procurer une sécurité de l'objet aux textes encodés en JSON. Son premier RFC est consacré à décrire les cas d'usage et le cahier des charges de cette sécurité.
JSON (RFC 7159) est un format très répandu, notamment sur le Web. Il peut être transporté dans des protocoles qui assurent la sécurité du canal comme HTTPS. Mais, comme toujours avec la sécurité du canal (IPsec, TLS, etc), elle ne garantit pas de sécurité de bout en bout. Par exemple, si le serveur d'origine est piraté, et les textes en JSON modifiés, HTTPS ne protégera plus. Même chose si on utilise certains relais, chose courante sur le Web : HTTPS ne protège pas contre les intermédiaires. Il existe à l'IETF des mécanismes assurant la sécurité du message (de l'objet) comme CMS (RFC 5652) pour l'ASN.1/DER. Mais pour le JSON ? Il y a là un manque à combler. Car la sécurité du message est nécessaire pour permettre la manipulation du messages par des intermédiaires à qui on ne fait pas forcément confiance. Pour le courrier électronique, la sécurité du canal est fournie par SMTP sur TLS - RFC 3207, et la sécurité du message par PGP - RFC 4880 - ou S/MIME - mais le RFC, curieusement, ne cite pas PGP. Par contre, il n'existe pas encore de solution propre pour JSON transporté sur HTTP. Les gens de XML ont choisi XML Signature et XML Encryption, les gens de JSON travaillent donc activement à leur propre solution.
Ce RFC parle de sécurité et utilise donc largement la terminologie standard du RFC 4949. Il peut être utile aussi de lire le RFC 5652 sur CMS car ce RFC le cite souvent.
Le groupe de travail JOSE (JSON Object Signing and Encryption) est chargé de développer trois formats :
- Un format assurant la confidentialité du texte JSON par chiffrement, JWE (JSON Web Encryption),
- Un format assurant l'intégrité et l'authenticité du texte JSON par signature numérique, JWS (JSON Web Signature),
- Un format pour représenter les clés cryptographiques utilisées, JWK (JSON Web Key).
Rappelez-vous que ce RFC 7165 n'est que le premier RFC du groupe, il ne donne pas encore de solutions, il explore le problème et précise les exigences du travail à effectuer (la liste officielle et numérotée de ces exigences figure en section 6).
Le cahier des charges débute en section 3 avec un résumé des exigences « de base » :
- Le format pour l'objet chiffré doit permettre l'utilisation de la cryptographie symétrique et de la cryptographie asymétrique.
- Le format pour l'objet signé doit permettre une vérification de l'intégrité par MAC pour le cas où les deux parties partagent une clé (cryptographie symétrique), et par signature avec de la cryptographie asymétrique.
- Comme les textes JSON protégés ne seront pas forcément traités dans le contexte d'une communication synchrone avec possibité de négociation ou d'échange, il faut (le RFC prévoit des exceptions très encadrées) que tous les paramètres cryptographiques nécessaires (à part les clés) soient inclus dans l'objet. À noter que la liste des paramètres dépend de l'algorithme cryptographique utilisé (qui doit donc être indiqué clairement).
- Conséquence de l'exigence précédente, les applications qui traitent les textes JSON protégés doivent avoir un moyen simple de déterminer si elles sont en possession de la clé nécessaire, et de produire un message d'erreur clair si ce n'est pas le cas.
La section 4 rappelle que l'application qui utilisera les textes JSON protégés a aussi des responsabilités, par exemple c'est elle qui décidera quels algorithmes sont acceptables, comment seront échangées les clés, etc.
La liste complète des exigences est en section 6 du RFC. Mais, avant cela, la section 5 contient les études de cas. La première est celle des jetons (security tokens), ces petits textes qu'on s'échange pour authentifier ou autoriser un tiers dans une communication (« il a le doit de lire les fichiers, laisse-le y accéder »). C'est par exemple le cas des assertions de SAML, de Persona, et d'OpenID Connect. Certains utilisent XML mais un autre groupe de travail IETF développe un format JSON, JWT (JSON Web token), déjà utilisé dans des systèmes comme Persona. Ce format a besoin des techniques JOSE pour être sécurisé. Le RFC note qu'il faudra aussi que le format final puisse être mis dans un URL, ce qui nécessite qu'il doit très compact. Le fait qu'une permission soit donnée peut être parfois confidentiel et le format de signature peut donc ne pas suffire. Même dans ce cas d'usage, il faudra donc aussi penser à la confidentialité. Autre exemple de jeton, dans OAuth (RFC 6749). Ici, la norme impose un transport par HTTPS donc la confidentialité est normalement assurée, il ne reste que l'authentification.
Ces jetons de sécurité sont également utilisés dans les cas de fédérations d'identité. Ainsi, OpenID Connect, déjà cité, repose sur OAuth et JSON et est un des gros demandeurs des fonctions JOSE.
Autre étude de cas, pour le protocole XMPP (RFC 6120), surtout connu pour la messagerie instantanée. Un instant, vous allez me dire, le X dans XMPP rappelle qu'il a XML comme format. Que vient-il faire dans un RFC parlant de JSON ? C'est parce que la sécurité de XMPP, aujourd'hui, est uniquement une sécurité du canal : les communications entre clients et serveurs, ou bien entre les serveurs, sont protégées par TLS (et de nombreux acteurs du monde XMPP se sont engagés à ce que le chiffrement soit systématisé avant mai 2014). Mais cela ne fournit pas de sécurité de bout en bout, ce qui est d'autant plus gênant que les sessions XMPP sont rarement établies directement entre deux pairs, mais passent par des serveurs qui sont la plupart du temps gérés par une organisation différente. XMPP, tel qu'utilisé aujourd'hui, est donc vulnérable à l'espionnage par le fournisseur. Le problème est identifié depuis longtemps, mais la seule solution standard, décrite dans le RFC 3923, n'a jamais été adoptée (comme la plupart des techniques S/MIME). Actuellement, la solution la plus commune pour résoudre ce problème de sécurité est OTR.
Une autre solution est donc en cours de développement dans la
communauté XMPP, fondée sur JSON et JOSE. C'est certes bizarre de
transporter des textes JSON dans les flux XML de XMPP et cela
complique un peu les choses (il faut être sûr que le texte JSON ne
contienne pas de caractères qui sont spéciaux pour XML, ou alors il
faut tout mettre dans un bloc CDATA ou encore
encoder tout en Base64, au prix d'un
accroissement de taille).
Autre système qui aura besoin de JOSE, ALTO (RFC 6708). Ce système permet à un client de s'informer, auprès d'un serveur, sur le pair le plus « proche » pour les cas où plusieurs pairs peuvent rendre le même service. Dans son mode le plus simple, ALTO est simplement un protocole requête/réponse, où les échanges se font en JSON sur HTTP. HTTPS est suffisant pour sécuriser ce mode. Mais les futures versions d'ALTO pourraient avoir des objets d'information relayés entre plusieurs parties, et JOSE deviendrait alors utile pour les sécuriser.
Continuons la riche liste de cas d'école possibles pour JOSE, avec les systèmes d'alerte. Il y a des travaux en cours à l'IETF sur l'utilisation de l'Internet pour diffuser des alertes, par exemple concernant une catastrophe naturelle proche. Une exigence absolument critique de ces systèmes est l'impossibilité de fabriquer une fausse alerte. Si c'était possible, une grave panique pourrait être déclenchée à volonté. Et, sans même parler des effets de la panique, la confiance dans le système disparaitrait rapidement. Or, les alertes doivent être diffusées très vite, à beaucoup de gens, quel que soit le mécanisme par lequel ils sont actuellement connectés. Elles passent donc par des intermédiaires, cherchant à toucher tout le monde. Une protection du canal ne suffit donc pas, une protection du message (du texte JSON) est nécessaire.
Dernier cas que je vais citer, l'API Web Cryptography. Cette API normalisée permet notamment au code JavaScript s'exécutant dans un navigateur de demander au navigateur de réaliser des opérations cryptographiques. L'un des intérêts (par rapport à une mise en œuvre complètement en JavaScript) est la sécurité : les clés peuvent rester dans le navigateur, JavaScript n'y a pas accès. Ceci dit, dans certains cas, la capacité d'exporter une clé (par exemple pour la copier vers un autre appareil) est utile. L'API prévoit donc cette fonction (avec, on l'espère, de stricts contrôles et vérifications) et cela implique donc un format standard pour ces clés (publiques ou privées). Au moins pour les clés privées, la confidentialité de ce format est cruciale. JOSE (son format JWK) va donc être utilisé.
La section 6 du RFC liste les exigences précises du projet JOSE. Chacune, pour faciliter les références ultérieures, porte un identificateur composé d'une lettre et d'un nombre. La lettre est F pour les exigences fonctionnelles, S pour celles de sécurité et D si c'est une simple demande, pas une exigence. Par exemple, F1 est simplement l'exigence de base d'un format standard permettant authentification, intégrité et confidentialité. F2 et F3 couvrent le format des clés (dans le cas de la cryptographie symétrique comme dans celui de l'asymétrique). F4 rappelle que le format doit être du JSON, et F5 qu'il faut une forme compacte, utilisable dans les URL.
Parmi les simples désirs, D1 rappelle l'importance de se coordonner avec le groupe de travail WebCrypto du W3C, D2 souhaite qu'on n'impose pas (contrairement à beaucoup d'autres normes de cryptographie comme XML Signature) de canonicalisation du contenu, D3 voudrait qu'on se focalise sur le format, pas sur les opérations, de manière que les formats JOSE soient utilisables par des applications très différentes, utilisant des protocoles de cryptographie bien distincts.
À noter que la section 7 revient sur la canonicalisation en reconnaissant que, comme il n'existe pas de moyen automatique simple de déterminer si deux textes JSON représentent la même information, cela peut avoir des conséquences sur la sécurité de JOSE.
Merci à Virginie Galindo pour sa relecture.
L'article seul
Copie d'un disque dur sur Windows
Première rédaction de cet article le 14 avril 2014
Il m'est arrivé une aventure bizarre : j'ai dû intervenir sur une machine Windows. Le problème semblait simple, copier le disque d'une ancienne machine vers une nouvelle. Mais c'est plus difficile que cela n'en a l'air.
L'ancienne machine était sous Windows XP, qui, comme tout le monde le sait, n'est plus maintenu depuis quelques jours. La nouvelle était sous Windows 8 et il fallait évidemment récupérer les fichiers, les préférences, les données diverses. Comme les machines récentes ont forcément un disque plus gros que les anciennes, je me suis dit, dans mon ignorance totale, « le plus simple est de copier l'ancien disque dans un dossier du nouveau, on pourra arrêter tout de suite l'ancienne machine et ensuite déplacer à loisir les données vers le bon emplacement ». Certes, je ne connais rien à Windows. Mais ce n'est pas grave, n'importe quel commercial vous expliquera que Windows, contrairement à Unix, est convivial, est utilisable par M. Michu sans formation, et qu'il n'y aura donc pas de problème.
Je passe sur la configuration du partage de fichiers : Windows 7 avait introduit un nouveau mécanisme d'authentification, le Groupe résidentiel et configurer le serveur sous Windows 8 pour que la machine Windows XP puisse s'y connecter n'a pas été trivial, Windows XP ne pouvant pas rejoindre le groupe résidentiel. Bon, une fois que c'était fait, je me suis dit « c'est bon, je lance le cliquodrome, euh, l'Explorateur de fichiers et je copie tout le disque vers le serveur Windows 8 ». Problème (que les experts Windows ont sans doute senti venir depuis un certain temps) : il n'y a pas moyen de copier une arborescence si un seul fichier a un problème. La copie entière s'arrête. « Copying File c:\pagefile.sys The process cannot access the file because it is being used by another process. » Le problème est bien connu des utilisateurs avertis de Windows mais, curieusement, lorsque la question est posée sur un forum, tous les fanboys Microsoft se succèdent pour expliquer que c'est normal (un exemple où, comme le dit un participant frustré qui voulait juste copier ses fichiers « My GOD, you people are thick! Does MVP = something I don't know about, or could you all be that thick?! Only one poster all the way thru here so far bothered to know what the OP said. The rest of you appear to be quacks! »). Le raisonnement est que le fait qu'on ne puisse pas copier un fichier est une erreur fatale, puisque le dossier résultant ne sera pas complet. OK, que ce soit le comportement par défaut, je peux comprendre, mais qu'il n'y ait aucun moyen, avec l'Explorateur de fichiers officiel, de passer outre et de lui dire « copie-moi ce que tu peux », c'est très agaçant.
Comment on fait, alors ? Eh bien, si on veut le faire uniquement
avec des logiciels standard Windows XP, une seule solution, abandonner le
cliquodrome et passer en
ligne de commande. L'outil xcopy
a une option /C (comme
Continue) qui permet d'ignorer les erreurs. Une
commande comme :
xcopy /C /H /F /S /E c:\ \\nouvellemachine\data\anciennemachine
fait à peu près ce qu'il faut et copie ce qu'elle peut, ignorant les
erreurs (fichiers inutiles comme l'espace de
pagination ou fichiers ouverts par une application). Sauf
qu'au bout d'un moment, xcopy s'arrête avec le message
Insufficient memory. N'ajoutez pas de
RAM, cela ne servirait à rien, le message est
faux. Ce n'est pas de mémoire que manque xcopy, c'est simplement qu'il
a rencontré un fichier dont le nom complet (avec le chemin dans les
dossiers) est trop long. Problème bien connu des experts et largement
documenté en ligne (mais comment on faisait pour régler les
problèmes Windows quand on n'avait pas
Google ?). Supprimer ce fichier (affiché juste
avant, grâce à /F) ne suffirait pas, il peut y en
avoir d'autres plus tard.
On passe donc à un outil plus perfectionné, qui figure par défaut
dans les Windows récents mais qui n'était pas dans Windows XP,
robocopy (il faut le chercher dans Windows
Server 2003 Resource Kit Tools). L'option pour dire d'ignorer
les erreurs est plus tordue qu'avec xcopy (/R:0
/W:0) mais elle marche, et la longueur des noms de fichier
n'est plus un problème :
robocopy c:\ \\nouvellemachine\data\anciennemachine /MIR /R:0 /W:0
Avec robocopy et quelques heures de patience, tout a été copié. 
Alors, quelles leçons à en tirer ? D'abord, je suis bien conscient de mes limites en Windows. Je n'ai aucun doute qu'un vrai expert Windows aurait fait cela en dix fois moins de temps, sans cafouiller et sans utiliser Google. Je ne prétends pas avoir choisi la meilleure méthode (au lieu de robocopy, on aurait pu installer des logiciel tiers comme Supercopier ou xxcopy ou bien utiliser la fonction de « transfert facile » de Windows). Mais pourquoi prétend-on que Windows est utilisable par tous, sans lire la documentation et sans faire d'efforts ? Je suis au courant qu'Unix a aussi ses inconvénients mais, au moins, Unix ne prétend pas être « convivial ». La leçon à en tirer me semble être que, dès qu'on veut faire une opération peu commune, on doit faire appel à un spécialiste. (Je connais un utilisateur qui, achetant un nouvel ordinateur, a payé le vendeur pour faire cette opération de copie des anciens fichiers.)
L'article seul
RFC 7181: The Optimized Link State Routing Protocol version 2
Date de publication du RFC : Avril 2014
Auteur(s) du RFC : T. Clausen (LIX, Ecole Polytechnique), C. Dearlove (BAE Systems ATC), P. Jacquet (Alcatel-Lucent Bell Labs), U. Herberg (Fujitsu Laboratories of America)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF manet
Première rédaction de cet article le 11 avril 2014
Il existe désormais plusieurs protocoles de routage pour le problème difficile des MANETs, ces réseaux ad hoc (c'est-à-dire non organisés et non gérés) de machines diverses connectées de manière intermittente. On est loin des réseaux structurés classiques, avec leurs routeurs bien administrés qui se parlent en OSPF. Dans un MANET, le réseau doit se configurer tout seul, il n'y aura pas d'administrateur pour cela (le RFC 2501 examine les différents aspects du problème des MANETs). Notre nouveau RFC décrit la version 2 d'un de ces protocoles de routage les plus répandus, OLSR, dont la version 1 était dans le RFC 3626.
OLSR v2 est incompatible avec la v1, c'est un nouveau protocole. Il garde toutefois les mêmes principes de base (qui étaient avant ceux d'HiperLAN), notamment l'utilisation de MPR, des nœuds du réseau choisis comme routeurs (dans un MANET, il n'y a pas de routeur désigné, chaque machine peut se voir affecter cette tâche, cf. section 18). Ainsi, toutes les machines n'ont pas à émettre de l'information sur leurs interfaces, seul un sous-ensemble des nœuds, les MPR, le fait (c'est particulièrement rentable si le réseau est très dense ; s'il ne l'est pas, la plupart des nœuds seront des MPR puisqu'il n'y aura pas le choix). D'autre part, OLSR v2 est un protocole proactif, il calcule les routes en permanence et elles sont toujours prêtes (contrairement à d'autres protocoles qui calculent les routes à la demande). Principales nouveautés dans OLSR v2 : d'autres façons d'évaluer le coût d'une route que le simple nombre de sauts, et davantage de souplesse dans la signalisation. Notez enfin qu'OLSR peut fonctionner sur des liens de couche 2 variés. Ces liens ne sont pas forcément fiables (par exemple, les liens radio perdent souvent des paquets).
Pour comprendre, et surtout si vous voulez mettre en œuvre OLSR v2, il va falloir lire plusieurs RFC. En effet, la structure des normes OLSR v2 est modulaire : il y a un protocole de découverte des voisins (NHDP, dans le RFC 6130), un format de messages décrit dans le RFC 5444, des TLV normalisés dans le RFC 5497, et (mais celui-ci est optionnel) les considérations sur la gigue du RFC 5148 (variations aléatoires ajoutées pour éviter que tous les messages n'arrivent en même temps). Et, naturellement, il faut ensuite lire ce nouveau RFC 7181 (113 pages).
La section 4 résume le fonctionnement du protocole. Comme les
MANETs sont loin de mes domaines de compétence, je ne vais pas la
reprendre complètement. Quelques points qui me semblent
importants. D'abord, le routeur OLSR a plusieurs bases de données (cf.
RFC 6130) dans
sa mémoire : il y a sa configuration locale (ses adresses IP), sa
liste d'interfaces réseau, avec les métriques de chacune (le « coût »
d'utilisation), la base des voisins (très dynamique puisque, dans un
MANET, les choses changent souvent, le protocole du RFC 6130
permet de découvrir les voisins, voir aussi la section 15 de ce
RFC). Cette dernière base contient les
volontés d'un voisin (un nœud peut indiquer sa volonté à être routeur, elle va de
WILL_NEVER à
WILL_ALWAYS). Et il y a bien sûr la base de la
topologie, indiquant la vision du réseau de la machine (les routes
qu'elle connait).
Ensuite, OLSR v2, contrairement à son prédécesseur, dispose de plusieurs métriques pour mesurer les coûts d'utilisation d'une route. Un coût est unidirectionnel (il n'a pas forcément la même valeur dans les deux directions).
Le protocole dépend d'un certain nombre de paramètres (section 5). Certains sont spécifiés dans le RFC 5498 comme le numéro de port lorsque OLSR tourne sur UDP (269).
Comme souvent avec les réseaux ad hoc, la sécurité est souvent à peu près nulle. La section 23 de notre RFC fait le point sur les risques associés à OLSR v2 et sur l'approche utilisée si on souhaite sécuriser un MANET. Premier principe, chaque routeur doit valider les paquets (pas seulement leur syntaxe mais aussi leur contenu) puisqu'il ne peut a priori pas faire confiance aux autres. Deuxième principe, la sécurité d'OLSR v2 est réglable. On peut aller de « open bar », on fait confiance à tout le monde, à l'authentification des messages par le biais de signatures attachées aux messages (RFC 7182 et RFC 7183).
Cette sécurité, si on choisit de l'activer, nécessite que les routeurs connaissent les clés cryptographiques servant à l'authentification. OLSR v2 n'a pas de protocoles de gestion de clés. Dans le contexte d'un MANET, il n'y aura souvent pas de moyen de configurer une clé avant d'installer les machines. (Rappelez-vous qu'un MANET est censé être « zéro administration »).
Il existe bien des mises en œuvre de cette version 2 de OLSR, un protocole qui avait commencé sa carrière vers 2005. Citons entre autres (attention, elles ne sont pas forcément libres) :
L'article seul
Superviser ses signatures DNSSEC
Première rédaction de cet article le 7 avril 2014
Dernière mise à jour le 15 mars 2019
Le système DNSSEC permet d'authentifier les données distribuées via le DNS et protège donc ainsi des attaques par empoisonnement. C'est un outil nécessaire dans la boîte à outils de sécurisation du DNS. Mais rien n'est gratuit en ce bas monde : la cryptographie protège mais elle complique les choses et crée des risques. Parmi ceux-ci, le risque d'expiration des signatures. Il est donc nécessaire de superviser ses signatures DNSSEC. Comment ? Et avec quoi ?
Si vous voulez une introduction à DNSSEC en français, vous pouvez lire mon exposé à JRES. Notez-y un point important : les signatures des enregistrements DNSSEC expirent au bout d'un moment et il est donc nécessaire de re-signer de temps en temps. Si ce processus de re-signature ne marche pas, les signatures vont finir par expirer, rendant le domaine inutilisable. Voici un exemple de signature DNSSEC :
% dig +dnssec A www.bortzmeyer.org ... ;; ANSWER SECTION: www.bortzmeyer.org. 68585 IN A 204.62.14.153 www.bortzmeyer.org. 68585 IN RRSIG A 8 3 86400 20140414143956 ( 20140325120748 15774 bortzmeyer.org. dgJ3BOjUz3hdlRWEbcFK14Jqyl+az/tas/dKEcBs/2QK 4vUd2VihXtEmpLQ6D+FVtMh6n7OubrEpLezEGkHtXKOe 3FO6l+EhrjH82BwjGGnd50RMNDHGk8IR0TOsOj/cNGZM V4Gj24mOV5ANbYWxlqWXYPl9BVi81MVhluw9sas= ) ...
On voit dans la réponse l'adresse IPv4 du
serveur et la signature (enregistrement
RRSIG). dig formate la
signature de manière lisible par un humain, avec une date de mise en
service (inception) au 25 mars et une date
d'expiration au 14 avril. Ce jour-là, à 14h39
UTC, la signature expirera (le but est d'éviter
les attaques par rejeu). Il faudra donc,
avant, signer à nouveau. Dans le cas de
bortzmeyer.org, c'est fait avec
OpenDNSSEC. On pourrait aussi lancer un
dnssec-signzone ou bien un
ldns-signzone depuis
cron. Ou laisser BIND
prendre cela en charge avec son mécanisme de signature automatique. Mais toutes ces solutions ont un point
commun, elles sont fragiles. Pendant des mois, elles fonctionnent
puis, un jour, un léger changement fait qu'elles ne marchent plus et
qu'on risque de ne pas s'en apercevoir. Un exemple qui m'était arrivé en
changeant de version de Debian : la
bibliothèque de SoftHSM avait changé
d'emplacement, le fichier de configuration d'OpenDNSSEC pointait donc
au mauvais endroit et le signeur d'OpenDNSSEC ne tournait donc
plus. Quelques temps après, bortzmeyer.fr expirait...
Le problème n'est pas spécifique à DNSSEC. Dans toutes les solutions de sécurité, il y a des dates limites, conçues pour éviter qu'un méchant qui aurait mis la main sur des informations secrètes puisse les utiliser éternellement. C'est par exemple pour cela que les certificats X.509 ont une date d'expiration (attention, avec DNSSEC, les clés n'expirent pas, seules les signatures le font). Comme le savent les utilisateurs de HTTPS, il est très fréquent que le webmestre oublie de renouveler les certificats et paf. À part des bonnes procédures (rappel mis dans l'agenda...), la solution est de superviser. Tout responsable sérieux d'un site Web HTTPS supervise l'expiration. Il faut faire la même chose pour DNSSEC.
La solution que je vais montrer ici fonctionne avec ma configuration Icinga mais elle ne repose que sur des outils compatibles avec l'API Nagios donc elle devrait marcher avec beaucoup d'outils de supervision.
Après plusieurs essais (voir les notes de ces essais plus loin), j'ai choisi comme outil de base le script de test de Duane Wessels. Ses spécifications collent parfaitement à ce que je veux : il se connecte à tous les serveurs DNS d'une zone, demande les signatures, regarde les dates d'expiration et peut signaler un avertissement ou une erreur selon des seuils choisis par l'utilisateur. Un exemple à la main :
% perl check_zone_rrsig_expiration -Z nic.fr ZONE OK: No RRSIGs expiring in the next 3 days; (1.04s) |time=1.042905s;;;0.000000
On peut choisir les seuils, donc mettons qu'on veut un avertissement s'il reste moins d'une semaine :
% perl check_zone_rrsig_expiration -Z nic.fr -W 7 ZONE WARNING: MX RRSIG expires in 3.7 days at ns6.ext.nic.fr; (0.28s) |time=0.281515s;;;0.000000
Pour installer et exécuter ce script, il faut
Perl et certains modules indiqués dans la
documentation. Sur ma machine Arch Linux, ils
n'étaient pas en paquetage standard, il faut donc utiliser AUR, un
dépôt non officiel, accessible avec les commandes
pacaur ou yaourt :
% yaourt -S perl-net-dns perl-net-dns-sec
Attention, si vous n'installez pas tous les paquetages indiqués dans la documentation, vous aurez un message pas clair du tout :
*** WARNING!!! The program has attempted to call the method *** "sigexpiration" for the following RR object:
Une fois le programme correctement installé, je vous recommande
l'option -d si vous voulez déboguer en détail ce
qu'il fait.
On configure ensuite Icinga, par exemple :
object Host NodeName {
import "generic-host"
address = "127.0.0.1"
address6 = "::1"
vars.role = "AuthDNS"
[...]
}
object CheckCommand "CheckDNSSEC" {
import "plugin-check-command"
command = [ PluginDir + "/check_zone_rrsig_expiration" ]
arguments = {
"-Z" = "$zone$"
"-W" = "$warn$"
"-C" = "$crit$"
}
vars.warn = "14"
vars.crit = "7"
}
apply Service "DNSSEC" {
check_command = "CheckDNSSEC"
check_interval = 86400
vars.zone = "example.org"
assign where host.vars.role == "AuthDNS"
}
(Merci à Xavier Humbert à ce sujet.) Cette configuration était pour Icinga 2. Pour Icinga 1 :
define command {
command_name check-zone-rrsig
command_line /usr/local/sbin/check_zone_rrsig_expiration -Z $HOSTADDRESS$ -W $ARG1$ -C $ARG2$
}
...
define service {
use dns-rrsig-service
hostgroup_name My-zones
service_description SIGEXPIRATION
# Five days left: warning. Two days left: panic.
check_command check-zone-rrsig!5!2
}
define host{
name my-zone
use generic-host
check_command check-always-up
check_period 24x7
check_interval 5
retry_interval 1
max_check_attempts 3
contact_groups admins
notification_period 24x7
notification_options u,d,r
register 0
}
define hostgroup{
hostgroup_name My-zones
members bortzmeyer.org,bortzmeyer.fr,etc-etc
}
define host{
use moi-zone
host_name bortzmeyer.fr
}
Une fois que c'est fait, on redémarre Icinga. Ici, voici un test avec
une zone délibérement cassée (elle a été signée manuellement en
indiquant la date d'expiration ldns-signzone -e
20140322100000 -o broken.rd.nic.fr. broken.rd.nic.fr
Kbroken.rd.nic.fr.+008+15802 et sans re-signer
ensuite). Icinga enverra ce genre d'avertissement :
Notification Type: PROBLEM Service: DNSRRSIG Host: broken.rd.nic.fr Address: broken.rd.nic.fr State: WARNING Date/Time: Fri Mar 28 06:50:38 CET 2014 Additional Info: ZONE WARNING: DNSKEY RRSIG expires in 1.2 days at ns2.bortzmeyer.org: (1.12s)
Puis un CRITICAL puis, lorsque la zone aura
vraiment expiré :
Notification Type: PROBLEM Service: DNSRRSIG Host: broken.rd.nic.fr Address: broken.rd.nic.fr State: CRITICAL Date/Time: Mon Mar 31 09:10:38 CEST 2014 Additional Info: ZONE CRITICAL: ns2.bortzmeyer.org has expired RRSIGs: (1.10s)
Si on re-signe à ce moment, le problème disparait :
Notification Type: RECOVERY Service: DNSRRSIG Host: broken.rd.nic.fr Address: broken.rd.nic.fr State: OK Date/Time: Mon Mar 31 09:40:38 CEST 2014 Additional Info: ZONE OK: No RRSIGs expiring in the next 3 days: (1.04s)
Et, dans le journal d'Icinga, cela apparaitra :
[Fri Mar 21 21:40:32 2014] SERVICE ALERT: broken.rd.nic.fr;DNSRRSIG;CRITICAL;SOFT;2;ZONE CRITICAL: DNSKEY RRSIG expires in 0.6 days at ns2.bortzmeyer.org: (1.09s) ... [Fri Mar 21 21:42:32 2014] SERVICE ALERT: broken.rd.nic.fr;DNSRRSIG;OK;SOFT;3;ZONE OK: No RRSIGs expiring in the next 7 days: (0.68s)
Pour les utilisateurs d'OpenDNSSEC, le
paramètre important à régler en même temps que les seuils de la
supervision est le paramètre
<Refresh>. Comme le dit la
documentation :
« The signature will be refreshed when the time until the signature
expiration is closer than the refresh interval. »
Donc, en pratique, c'est la durée qu'il faut indiquer avec l'option
-C (seuil critique). Attention, OpenDNSSEC
ajoute de légères variations (jitter).
J'ai indiqué plus haut qu'il y avait des alternatives à la solution finalement choisie. Il en existe même une liste sur le site d'Icinga. Voici quelques pistes avec mes commentaires.
J'aurais pu développer une solution complète avec Python et dnspython qui a une bonne gestion de DNSSEC. J'ai réalisé un prototype mais, dans la vie, il faut savoir reconnaître un logiciel meilleur que le sien.
Il y a un outil développé par les gens de
.se, dnssec_monitor. Écrit
en Perl, il a les mêmes dépendances que le script choisi. Mais je
n'arrive pas réellement à comprendre comment il s'intègre avec Nagios.
Il existe un outil en Ruby dans OpenDNSSEC (il est même décrit en détail dans la documentation d'Icinga). Il a pas mal de dépendences Ruby donc j'ai renoncé.
L'outil nagval est très bien mais il n'a pas le même cahier des charges et, notamment, il ne permet pas de tester l'expiration qui va survenir.
Il existe un énorme
ensemble de programmes de tests Nagios qui semble intéressant,
et qui compte un check_dnssec_expiration. Il se
compile bien :
% ./configure --without-man % make
mais l'exécution est incohérente, une fois sur deux :
% ./dns/check_dnssec_expiration -v -D nic.fr -w 20 -c 3 CRITICAL - SOA is not signed.
La bogue a été signalée à l'auteur mais pas encore résolue. Il semble
que l'outil soit très sensible au résolveur utilisé et qu'il faille
forcer (via resolv.conf ou via l'option
-H) un résolveur rapide et fiable.
Mat a également un
script à lui en awk (avec une version en shell). Mais il est à mon avis très dépendant d'un environnement
local, pas utilisable tel quel, sans sérieuses modifications, à mon
avis. Je cite l'auteur : « c'est tout à
fait adaptable, il suffit de remplacer /usr/bin/make -VSIGNED par la
liste des fichiers de zones signés et /usr/bin/make -VSIGNED:R:T par
l'ensemble des noms des zones. SIGNED étant défini dans le Makefile
comme
SIGNED!= find -s * -name '*.signed'. ».
Du même auteur, un outil permet de tester des fichiers, pas facilement des zones vivantes :
% cat *.signed | awk -f check-expire.awk
Pour tester une zone vivante, il faut que le transfert de zone soit autorisé :
% dig +noall +answer axfr @$SERVERNAME $ZONE | awk -f check-expire.awk
Je n'ai pas encore testé l'outil check_dnssec_expiry.
Enfin, SURFnet a développé un outil (qui dépend de ldns) mais que je n'ai pas réussi à compiler :
... cc -lcrypto `ldns-config --libs` -o sigvalcheck sigvalcheck.o rrsig_valcheck.o query.o rrsig_valcheck.o: In function `ldns_rrsig_time_until_expire': /home/stephane/tmp/sigvalcheck-0.1/rrsig_valcheck.c:42: undefined reference to `ldns_rr_rrsig_expiration' /home/stephane/tmp/sigvalcheck-0.1/rrsig_valcheck.c:41: undefined reference to `ldns_rdf2native_time_t'
L'article seul
Détournement DNS en Turquie à la réunion FRnog
Première rédaction de cet article le 6 avril 2014
Le 4 avril, à la réunion FRnog 22, j'ai fait un très rapide exposé sur le détournement de serveurs DNS pratiqué par le gouvernement turc.
J'avais déjà analysé ce détournement dans un article en anglais. À FRnog, j'ai présenté une courte synthèse en français dont voici :
Un exposé équivalent a été fait en anglais à la réunion RIPE de Varsovie en mai: voyez le support (également au RIPE), et la vidéo (il faut hélas Flash).
L'article seul
RFC 7143: iSCSI Protocol (Consolidated)
Date de publication du RFC : Avril 2014
Auteur(s) du RFC : Mallikarjun Chadalapaka (Microsoft), Julian Satran (Infinidat), Kalman Meth (IBM), David Black (EMC)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF storm
Première rédaction de cet article le 5 avril 2014
Le protocole iSCSI permet à une machine d'accéder à des disques (ou autres dispositifs de stockage) situés en dehors, loin de l'atteinte des bus internes de la machine. iSCSI consiste à faire passer les traditionnelles requêtes SCSI sur IP, autorisant ainsi l'utilisation de tous les équipements réseaux qui font passer de l'IP, et dispensant ainsi d'acheter des équipements spécialisés dans les SAN, comme le très coûteux Fibre Channel. iSCSI était à l'origine normalisé dans plusieurs RFC, que ce nouveau document rassemble en une seule (très) grosse spécification.
Résultat, le RFC faisant autorité pour iSCSI est un document de 344 pages, un record ! Il remplace les anciennes normes, les RFC 3720, RFC 3980, RFC 4850 et RFC 5048.
Si jamais vous envisagez de lire le RFC entier, je vous souhaite bon courage. Si vous voulez juste apprendre deux ou trois choses sur iSCSI, révisez d'abord un peu SCSI (les section 2.1 et 2.2 du RFC détaillent la terminologie, la 4.1 les concepts) : c'est un protocole client/serveur où le client (typiquement un ordinateur) se nomme l'initiateur et le serveur (typiquement un disque) la cible. L'initiateur envoie des commandes à la cible, qui répond. Le transport des commandes et des réponses peut se faire sur bien des supports, entre autres SAS, Parallel SCSI et FireWire. Ces supports traditionnels de SCSI ont généralement des faibles portées. iSCSI, au contraire, met les commandes et les réponses sur TCP, donc IP, et les cibles peuvent être à n'importe quelle distance de l'initiateur (même si, en pratique, initiateurs et cibles seront souvent dans le même réseau local).
SCSI peut aussi être utilisé pour parler à des lecteurs de bande, à des DVD, mais aussi, autrefois, à des imprimantes ou des scanners. Chaque dispositif d'entrée/sortie SCSI se nomme un LU (Logical Unit). Une même cible peut comporter plusieurs LU, chacun ayant un numéro, le LUN (Logical Unit Number).
Les commandes sont regroupées en tâches. Chaque tâche est séquentielle (une commande après l'autre) mais un initiateur et une cible peuvent avoir plusieurs tâches en cours d'exécution parallèle.
Les données peuvent évidemment voyager dans les deux sens : si un ordinateur écrit sur un disque, l'initiateur (l'ordinateur) envoie des données à la cible (le disque). Si l'ordinateur lit un fichier, ce sera le contraire, les données iront de la cible vers l'initiateur. Le sens de voyage des données est toujours exprimé du point de vue de l'initiateur. Donc, du « trafic entrant » désigne des données allant de la cible vers l'initiateur (une lecture sur le disque, par exemple).
iSCSI consiste à envoyer les messages SCSI, baptisés PDU (pour Protocol data unit), sur TCP (port 3260 ou à la rigueur 860). Contrairement à ce qui se passe pour d'autres protocoles (comme SIP), données et commandes voyagent dans les mêmes connexions TCP. Pour diverses raisons, il peut y avoir plusieurs connexions TCP actives entre l'initiateur et la cible. On les appelle collectivement la session (équivalent du nexus en SCSI classique). Chaque session a son propre identificateur et chaque connexion TCP de la session a un identificateur de connexion. Des connexions TCP peuvent être ajoutées ou retirées en cours de session, augmentant ainsi la résilience.
La réponse à une commande donnée doit être envoyée sur la même connexion TCP que celle où la commande avait été reçue (« allégeance à la connexion »). Ainsi, si un initiateur demande une lecture de données, celles-ci arriveront sur la même connexion.
L'ordre des commandes est parfois essentiel en SCSI. Pour cela, elles sont numérotées (Command Sequence Number, et cette numérotation est valable globalement pour toute la session), afin que la cible les exécute dans l'ordre. Il existe aussi d'autres numéros (Status Sequence Number) qui ne servent que dans une connexion TCP donnée et sont plutôt utiliser en cas d'erreurs, pour associer un message d'erreur à une commande précise. (Le RFC 3783 décrit avec bien plus de détails le concept d'ordre dans iSCSI.)
À noter que les réponses aux commandes, en SCSI (et donc en iSCSI), ne respectent typiquement aucun ordre. Si une cible exécute la commande A puis la commande B, la réponse à B pourra arriver à l'initiateur avant la réponse à A (ce qui est logique, les opérations d'entrée/sortie pouvant avoir des durées très variables ; la commande B était peut-être très rapide à exécuter).
Les données, elles, ont un ordre. Si on lit 10 000 octets, on veut évidemment recevoir le premier octet des données en premier. D'où le Data Sequence Number qui se trouve dans les paquets de données et qui indique où se trouvent ces données dans le flux transmis.
Un autre point important : TCP fournit un service de flot d'octets continu. Il n'y a pas de séparation entre les PDU (les messages) iSCSI. Pour que le destinataire puisse donc savoir où se termine le PDU (et où commence le suivant), ceux-ci sont préfixés par leur longueur (comme dans beaucoup d'autres protocoles utilisant TCP, par exemple dans EPP et dans le DNS).
Les données peuvent être sensibles (confidentielles, par exemple) et iSCSI doit donc prévoir des mécanismes d'authentification. Ainsi, au début d'une session, l'initiateur se présente et prouve son identité. La cible doit aussi prouver qu'elle est bien la cible visée (authentification mutuelle). Il existe plusieurs mécanismes pour cela, décrits en détail en sections 6 et 12. La recommandation de ce RFC est de protéger les sessions avec IPsec (cf. section 9, ainsi que le RFC 3723).
Au fait, comme toujours en réseau, il faut des identificateurs pour désigner cibles et initiateurs. En iSCSI, il sont appelés noms. Contrairement au SCSI classique où les identificateurs n'ont besoin d'être uniques qu'à l'interieur d'un domaine très restreint (souvent un seul boîtier, parfois une salle machines), iSCSI permet de faire parler des machines situées sur l'Internet et les noms doivent donc être mondialement uniques. (Pour une vue générale du nommage en iSCSI, voir le RFC 3721.) En outre, ces noms doivent (section 4.2.7.1) être stables sur le long terme, ne pas être dépendant de la localisation physique des machines, ni même du réseau où elles sont connectées, et le système de nommage doit être un système déjà existant : pas question de réinventer la roue ! À noter que ce sont des principes analogues à ceux des URN du RFC 1737. Les noms doivent en outre pouvoir être écrits en Unicode, canonicalisés par le profil stringprep de iSCSI, spécifié dans le RFC 3722, puis encodés en UTF-8, forme normale C.
iSCSI fournit trois formats pour atteindre ces objectifs. Un nom commence par un type indiquant quel format est utilisé, puis comprend le nom proprement dit. Les trois types sont :
- Nom de domaine, type
iqn. Comme ceux-ci ne sont pas forcément stables sur le long terme (pour des raisons juridico-politiques, pas pour des raisons techniques), le format iSCSI ajoute une date indiquant un moment où le titulaire avait effectivement ce nom. C'est le même principe que les URItag:du RFC 4151. Un nom valide comporte le nom de domaine (écrit à l'envers) et donc, on peut voir, par exemple,iqn.2001-04.com.example:storage:diskarrays-sn-a8675309, attribué par le titulaire deexample.com. - NAA (Network Address Authority), type
naa, un système spécifique au monde Fibre Channel. Un exemple de nom NAA estnaa.52004567BA64678D. - EUI, type
eui. un format de l'IEEE permettant de donner des noms uniques aux machines. Par exemple, un nom iSCSI EUI peut êtreeui.02004567A425678D.
Il existe également des mécanismes de découverte des noms accessibles, décrits dans les RFC 3721 et RFC 4171. Notre RFC note que, malheureusement, certains de ces mécanismes dépendent de SLP (protocole décrit dans le RFC 2608) qui n'a jamais vraiment été implémenté et déployé.
Attention, ce RFC 7143 ne décrit que le transport de SCSI sur IP (en fait, sur TCP). SCSI, lui, reste décrit par ses normes originales (qui ne semblent plus accessibles en ligne). Pour décrire le modèle, elles se servent d'UML, une technique qu'on trouve rarement dans un RFC, d'autant plus qu'elle repose sur de jolis dessins, qu'on ne peut pas facilement reproduire dans un RFC, avec leurs règles de formatage actuelles. Ce RFC comporte donc des diagrammes UML... en art ASCII (section 3).
iSCSI est décrit par une machine à nombre fini d'états et ladite machine figure en section 8.
Évidemment, les disques durs peuvent tomber en panne ou bien le réseau entre l'initiateur et la cible partir en vacances. Il faut donc prévoir des mécanismes de gestion des erreurs, et ils font l'objet de la section 7. C'est ainsi que, par exemple, une tâche qui échoue sur une connexion TCP peut être reprise sur une autre (qui peut passer par un chemin réseau différent). Notez que cette norme n'impose pas aux acteurs iSCSI de tous mettre en œuvre des techniques sophistiquées de récupération d'erreurs, juste de réagir proprement lorsque les erreurs se produisent. La section 7 est très détaillée : après tout, on ne veut pas perdre ses précieuses données juste parce que l'Internet a eu un hoquet pendant une opération d'écriture en iSCSI.
Mais comment détecte-t-on un problème sur une connexion TCP ? Cela
peut être un message ICMP qui coupe la
connexion mais aussi une absence prolongée de réponse à une
commande, ou bien à un test iSCSI (la commande
NOP, équivalente du ping
IP) ou TCP (les keep-alives du RFC 1122,
section 4.2.3.6).
Les pannes, c'est ennuyeux, mais les piratages, c'est pire. On ne veut pas qu'un méchant situé sur le trajet puisse lire nos données secrètes ou modifier ce qu'on écrit sur le disque. En SCSI traditionnel, une grande partie de la sécurité est physique : initiateur et cible sont dans le même boîtier (celui du serveur) ou à la rigueur dans la même armoire avec juste un SAN entre les deux. En iSCSI, on perd cette sécurité physique. Si l'initiateur et la cible sont connectés par le grand Internet, tout peut arriver sur le chemin. La section 9, « Security Considerations », fait donc le tour des menaces et des contre-mesures. (À quoi il faut ajouter le RFC 3723.)
iSCSI peut être utilisé sans sécurité, comme l'ancien SCSI, si on est parfaitement sûr de la sécurité physique. Mais notre RFC déconseille de courir ce risque. iSCSI fournit deux mécanismes de sécurité et le RFC demande qu'on les utilise. Le premier est interne à iSCSI, c'est l'authentification réciproque des deux parties lors de l'établissement de la session. Le deuxième est externe, et c'est IPsec. Ces deux mécanismes doivent être mis en œuvre (même s'ils ne seront pas forcément activés par l'administrateur système, notamment pour IPsec, complexe et pas forcément utile si tout le monde est dans la même salle machines).
À noter qu'une limite d'IPsec est que les systèmes d'exploitation typiques ne permettent pas à une application de savoir si ses connexions sont protégées ou non par IPsec. Ainsi, une application qui voudrait faire une authentification par mot de passe en clair uniquement si la connexion est chiffrée ne peut pas être sûre et doit donc supposer le pire (une connexion non chiffrée). L'authentification interne ne doit donc jamais utiliser de mot de passe en clair. La méthode recommandée est CHAP (RFC 1994, mais avec quelques ajouts). Dans le futur, un mécanisme comme celui du RFC 5433 ou comme SRP - RFC 2945 - sera peut-être utilisé.
Le mécanisme interne n'assure que l'authentification réciproque. Il ne protège pas contre l'écoute, ni même contre la modification des messages en cours de route. Il ne doit donc être utilisé seul que si on est sûr que ces écoutes et ces modifications sont impossibles (par exemple si on a une bonne sécurité physique du réseau). Imaginez les conséquences d'une modification des données avant leur écriture sur le disque !
IPsec dans iSCSI doit suivre le RFC 3723 et le tout récent RFC 7146. Avec IPsec, les sessions iSCSI peuvent garantir la confidentialité et l'intégrité des données. À noter que les numéros de séquence IPsec ne sont par défaut que sur 32 bits. iSCSI verra probablement des débits élevés (par exemple plusieurs Gb/s) et ce numéro sera donc vite arrivé au bout. Le RFC demande donc les numéros de séquence étendus (64 bits) de la section 2.2.1 du RFC 4303.
Les programmeurs tireront profit de la section 10, qui rassemble des conseils utiles pour mettre en œuvre iSCSI sans se planter. Un des enjeux de iSCSI est la performance, vu les grandes quantités de données à traiter... et l'impatience des clients. Le protocole a été soigneusement conçu pour permettre d'éventuelles implémentations directement dans le matériel, et pour permettre le DDP (Direct Data Placement, RFC 5041). Ainsi, on peut mettre iSCSI dans le firmware, permettant le démarrage sur une cible iSCSI.
Parmi les points notés par cette section, la gestion des machines dotées de plusieurs cartes réseau (on peut en utiliser plusieurs pour la même session iSCSI), le délicat choix des délais d'attente maximaux (non normalisés, car dépendant de l'infrastructure, notamment matérielle), et l'ordre des commandes (une commande qui change l'état de la cible, par exemple un vidage - flush - des tampons, ne doit pas être envoyée comme commande immédiate, pour éviter qu'elle ne double d'autres commandes).
La section 11 décrit le format exact des PDU sur le câble. Si vous le désirez, on trouve des traces iSCSI sur pcapr.
Il existe de nombreuses mises en œuvre d'iSCSI et des programmeurs de nombreuses entreprises (Dell, EMC, Microsoft, NetApp, Red Hat, VMware, etc) ont participé à la création de ce RFC. Une liste partielle de mises en œuvre :
- Sur Linux, en cible, et en initiateur. Pour l'administrateur système, consulter le HOWTO.
- Pour NetBSD :
ftp://ftp.netbsd.org/pub/NetBSD/misc/agc/.
À part le gros changement éditorial (consolider plusieurs RFC en un seul), les changements de iSCSI dans ce RFC sont peu nombreux. Par exemple, une stricte prohibition des caractères de ponctuation dans les noms SCSI est devenue une forte mise en garde. La section 2.3 liste toutes les modifications.
Merci à Bertrand Petit pour sa relecture attentive.
L'article seul
RFC 7164: RTP and Leap Seconds
Date de publication du RFC : Mars 2014
Auteur(s) du RFC : K. Gross (AVA Networks), R. van Brandenburg (TNO)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF avtcore
Première rédaction de cet article le 1 avril 2014
Les secondes intercalaires sont une source de complication et de polémique depuis longtemps. Voilà qu'elles affectent même le protocole de distribution de multimédia RTP : si on regarde un film, ou qu'on a une communication téléphonique, au moment où une seconde intercalaire est ajoutée, RTP va mal le vivre. Ce RFC propose donc un léger changement dans la façon dont RTP tient compte du temps, afin de rester heureux même pendant les secondes intercalaires.
RTP est normalisé dans le RFC 3550. Il est conçu pour l'envoi de flux multimédias (audio ou vidéo) entre un émetteur et un récepteur. Les caractéristiques propres des flux multimédias font que TCP n'est pas très adapté, donc RTP utilise UDP. UDP, par défaut, ne prévoit pas de rétroaction (l'émetteur ne sait pas ce que le récepteur a reçu) donc RTP ajoute des fonctions permettant d'informer son pair de ce qui se passe. Certains flux étant temps réel, ces informations (sender reports et receiver reports, section 6.4 du RFC 3550) incluent des estampilles temporelles. Un des champs de ces informations, NTP timestamp, fait référence à une horloge absolue (l'horloge située sur le mur, synchronisée avec l'échelle UTC). Une horloge qui a des soubresauts, les secondes intercalaires. Or, jouer proprement un flux audio ou vidéo nécessite au contraire une horloge sans à-coups.
La section 3 de notre RFC est un rappel sur les secondes intercalaires. Il y a deux échelles de temps standard. L'une est bien adaptée à l'informatique, à l'Internet et aux activités scientifiques en général, c'est TAI, une échelle fondée sur un phénomène physique (les atomes de césium dans une horloge atomique) et où le temps est strictement croissant et prévisible. Une autre échelle est bien adaptée à l'organisation des pique-niques et autres activités au grand air, c'est UTC. La référence d'UTC est la rotation de la Terre. Comme la Terre, au contraire des atomes de césium, est imparfaite, UTC ne garantit pas que le temps progresse régulièrement, et n'est pas prévisible (je ne peux pas dire aujourd'hui quelle sera l'heure UTC dans cinq cents millions de secondes, alors que c'est trivial en TAI). Depuis 1972, UTC est définie comme étant TAI plus la correction des secondes intercalaires, qui ajoutées de temps en temps, permettent de compenser les variations de la rotation de la Terre. Ces secondes intercalaires sont forcément le dernier jour du mois et, en pratique, ont toujours été fin décembre ou fin juin (cf. texte UIT TF.460). Elles sont annoncées moins d'un an à l'avance dans le bulletin C (rappelez-vous que la rotation de la Terre n'est pas prévisible), par l'IERS.
S'il y a une seconde intercalaire, elle est forcément à la fin de la journée. Elle peut être positive (la dernière seconde de la journée est doublée, et s'affiche « 23 h 59 mn 60 s ») ou négative (la dernière seconde de la journée est omise). Jusqu'à présent, toutes les secondes intercalaires étaient positives, puisque la Terre ralentit (le jour devient plus long). À noter qu'il y a depuis des années une discussion sur la suppression des secondes intercalaires (ce qui serait une mauvaise idée), mais qu'elle n'est pas encore close. Voir mon article sur ce sujet et le document de l'UIT.
La référence de temps la plus commune sur l'Internet, NTP (RFC 5905) est en UTC (ce qui est une mauvaise idée, selon moi, les ordinateurs n'ayant pas besoin de savoir s'il fait jour ou pas). Au moment de la seconde intercalaire positive, l'horloge NTP ralentit (ce qui permet au moins de s'assurer que deux mesures successives donneront un temps strictement croissant) ou s'arrête, ce qui fait que la dernière seconde du jour dure deux secondes. Pour tout processus temps-réel, comme RTP, c'est un gros problème.
Les applications obtiennent en général l'heure via une interface normalisée POSIX. L'échelle de temps de POSIX est UTC, mais sans vraie spécification de la gestion des secondes intercalaires. En pratique, les différentes mises en œuvre de POSIX ont des comportements différents. Par exemple, certaines répètent l'heure, pendant la seconde intercalaire et deux lectures successives du temps à une seconde d'intervalle, peuvent donc donner une heure identique. Pire, l'horloge peut même aller en arrière (ce qu'UTC ne fait pas). D'autres ralentissent l'horloge, permettant une adaptation en douceur (et pas de répétition) mais cela n'est pas idéal non plus pour des applications temps-réel ! (Un bon article sur les problèmes d'utiliser une échelle de temps à secondes intercalaires est donné dans un excellent article de Google.)
Conséquences de ces comportements ? La section 4 note que l'envoyeur et le récepteur RTP peuvent donc avoir une seconde entière de décalage, ce qui est beaucoup pour la plupart des applications RTP. Cela peut mener à l'abandon de paquets RTP bien reçus mais considérés comme trop vieux, ou bien au contraire à la conservation de paquets dans les tampons d'entrée/sortie même lorsqu'ils ne sont plus utiles. Cela peut se traduire par une coupure du son ou de l'image. Certains récepteurs reconnaîtront un problème et se resynchroniseront avec l'émetteur. Les autres devront attendre.
La section 5 liste les recommandations pour éviter ce
problème. D'abord, elle note que les récepteurs et émetteurs qui ne
sont pas synchronisés avec l'horloge au mur, mais qui se contentent de
mesurer le temps écoulé depuis leur démarrage n'auront jamais le
problème. Ensuite, la section 5 note aussi que les émetteurs et
récepteurs RTP qui utilisent une échelle de temps sans secondes
intercalaires (évidemment TAI mais aussi
IEEE 1588 ou GPS) n'ont
également pas de problèmes. Mais pourquoi diable RTP n'utilise pas
systématiquement TAI ? Cette échelle de temps a toutes les propriétés
souhaitables pour la communication au sein d'un réseau
informatique. Le RFC ne le dit pas, mais c'est probablement parce que
TAI est, hélas, trop
difficile d'accès sur la majorité des plate-formes. NTP et l'horloge
du système fournissent un temps qui convient à beaucoup d'activités
humaines, mais ne convient pas aux ordinateurs. Et il n'y a souvent
pas de moyen simple d'accéder à TAI ou une autre échelle
prédictible. (C'est le cas des fonctions POSIX
gettimeoday() et
clock_gettime().)
Pour les autres, les mises en œuvre de RTP qui doivent utiliser une échelle de temps qui a des secondes intercalaires, elles sont dans l'obligation de gérer ces secondes intercalaires. Cela implique d'abord un moyen de les connaître à l'avance (par exemple via le champ Leap Indicator de NTP). Ce n'est pas forcément réaliste (bien des machines reçoivent l'heure par des mécanismes qui n'indiquent pas l'approche d'une seconde intercalaire). Une solution un peu crade mais qui marche est alors de prendre les mesures citées plus loin tous les mois, lors de la fin du dernier jour du mois.
Les secondes intercalaires négatives ne posent aucun problème. Mais, on l'a vu, toutes les secondes intercalaires jusqu'à présent ont été positives. Dans ce cas, le RFC recommande que les logiciels RTP n'envoient pas de sender reports pendant les deux secondes où le temps est ambigu, car une seconde intercalaire a été ajoutée. Et les récepteurs doivent ignorer de tels messages. Ce changement aux règles du RFC 3550 est la principale recommandation concrète de ce RFC. Elle ne semble pas encore mise en œuvre dans un seul logiciel RTP. Est-ce que le problème, quoique joli techniquement, est assez grave en pratique pour justifier ce changement ?
L'article seul
Hijacking of public DNS servers in Turkey, through routing
First publication of this article on 29 March 2014
Last update on of 30 March 2014
A new step in the fight between the Turkish government and the Internet occurred recently when the access providers in Turkey started, not only to install lying DNS resolvers, but also to hijack the IP addresses of some popular open DNS resolvers, like Google Public DNS.
The first attempt of censorship by the Turkish government was to
request (around 20 March) the IAP (Internet Access Providers), who typically provide a
recursive DNS service to their users, to configure these recursors to
lie, providing false answers when queried about censored names like
twitter.com. This is a very common censorship
technique, which is used sometimes for business reasons (lying about
non-existing domain names, to direct the user to an advertisement page)
and sometimes for plain censorship (this was done in France, Bulgaria,
Ireland,
etc).
An obvious workaround to this technique is to use other resolvers
than the IAP's ones. Hence the calls on the walls of many Turkish
cities to use a service like Google Public DNS,
with the IP addresses of its resolvers 
Now, the Turkish governement, replying to the reply, went
apparently further. Before discussing what they have done, let's see
the facts. We will use the network of RIPE Atlas probes to query Google
Public DNS from various places, in the world and in Turkey, since the
excellent RIPE Atlas interface allows you to select probes based on
many criteria, including the country. The probe can resolve names
(like twitter.com, the first censored name) with
its local DNS resolver (typically configured by a
DHCP reply when the probe starts) but we won't
use this possibility, we already know the the IAP's DNS resolvers in
Turkey lie. We will instead instruct the Atlas probes to query Google
Public DNS, at its IP address 8.8.4.4 (it is less
known than 8.8.8.8 but Atlas have an automatic rate-limiter
and, since so many people are currently investigating Turkish
censorship, Atlas does not accept queries to
8.8.8.8.)
First, to see the ground truth, let's ask a hundred probes
worldwide to resolve twitter.com. The
measurement ID is #1605067 for those who want to check (most Atlas
measurements are public, anyone can download the results as a big
JSON file and analyze them by
themselves). Since Twitter is implemented by
many machines, the IP addresses vary and it's normal. Here is an
excerpt:
... [199.59.148.10 199.59.149.198 199.59.150.7] : 2 occurrences [199.16.156.38 199.16.156.6 199.16.156.70] : 8 occurrences [199.59.149.230 199.59.150.39 199.59.150.7] : 5 occurrences ...
All IP addresses do belong to Twitter (checked with whois), which makes sense. Now, let's query only Turkish probes. There are ten available Atlas probes in Turkey. This is measurement #1605068. Here is the full result:
10 probes reported, 10 successes [199.16.156.230 199.16.156.6 199.16.156.70] : 1 occurrences [195.175.254.2] : 8 occurrences [199.16.156.198 199.16.156.230 199.16.156.70] : 1 occurrences Test done at 2014-03-29T16:57:38Z
Two probes give normal results, with three IP addresses, all in
Twitter space. The majority of probes, eight, give an IP address at a
Turkish provider (Turk Telekomunikasyon Anonim
Sirketi alias ttnet.com.tr). So, there
is clearly something fishy: even when you request
specifically Google Public DNS, you get a lie.
We can measure with another censored name,
youtube.com and we get similar
results. In Turkey, measurement #1606453 reports:
10 probes reported, 10 successes [173.194.34.160 173.194.34.161 173.194.34.162 173.194.34.163 173.194.34.164 173.194.34.165 173.194.34.166 173.194.34.167 173.194.34.168 173.194.34.169 173.194.34.174] : 1 occurrences [195.175.254.2] : 8 occurrences [195.22.207.20 195.22.207.24 195.22.207.25 195.22.207.29 195.22.207.30 195.22.207.34 195.22.207.35 195.22.207.39 195.22.207.40 195.22.207.44 195.22.207.45 195.22.207.49 195.22.207.50 195.22.207.54 195.22.207.55 195.22.207.59] : 1 occurrences Test done at 2014-03-30T15:16:22Z
The same IP address is obtained, and of course it is not possible that the real Twitter and the real YouTube are hosted at the same place.
[All measurements show that two Atlas probes in Turkey do not see the hijacking. Why are they spared? According to the manager of one of these probes, his entire network was tunneled to a foreign server, to escape filtering, which explains why the probe on the network saw normal DNS replies.]
If you try another well-known DNS resolver, such as OpenDNS, you'll get the same problem: a liar responds instead.
So, someone replies, masquerading as the real Google Public DNS resolver. Is it done by a network equipment on the path, as it is common in China where you get DNS responses even from IP addresses where no name server runs? It seems instead it was a trick with routing: the IAP announced a route to the IP addresses of Google, redirecting the users to an IAP's own impersonation of Google Public DNS, a lying DNS resolver. Many IAP already hijack Google Public DNS in such a way, typically for business reasons (gathering data about the users, spying on them). You can see the routing hijack on erdems' Twitter feed, using Turkish Telecom looking glass: the routes are no normal BGP routes, with a list of AS numbers, they are injected locally, via the IGP (so, you won't see it in remote BGP looking glasses, unless someone in Turkey does the same mistake that Pakistan Telecom did with YouTube in 2008). Test yourself:
u*>? 8.8.4.4/32 100 None 212.156.250.157 None - No As-Path
while a normal route wil look like:
u*>i 74.82.42.0/24 100 1 212.156.100.1 None - 6939 *i 74.82.42.0/24 100 1 212.156.100.1 None - 6939
(6939 being the origin AS of the remote route, here a foreign one,
while 8.8.4.4/32 is local)
Another indication that the hijacking is not done by a man in the middle mangling any DNS reply (as it is done in China) is that, if you try a little-known open DNS resolver, there is no problem, even from Turkey, you get correct results (measurement #1605104).
Also, a traceroute to Google Public DNS shows the user is going to Turkish servers, unrelated to the Californian corporation (see this example). RIPE Atlas probes can do traceroutes, too, but for the probes I used, the traceroute gets lost in the network of TTNET Turk Telekomunikasyon Anonim Sirketi, the lying DNS resolver, unlike the real Google Public DNS, does not reply to UDP traceroutes :
From: 212.58.13.159 8685 DORUKNET Doruk Iletisim ve Otomasyon Sanayi ve Ticaret A.S.,TR Source address: 212.58.13.159 Probe ID: 3506 1 212.58.13.253 8685 DORUKNET Doruk Iletisim ve Otomasyon Sanayi ve Ticaret A.S.,TR [3.98, 3.235, 3.101] 2 82.151.154.193 8685 DORUKNET Doruk Iletisim ve Otomasyon Sanayi ve Ticaret A.S.,TR [3.15, 3.044, 3.11] 3 212.156.133.117 9121 TTNET Turk Telekomunikasyon Anonim Sirketi,TR [4.146, 4.807, 4.157] 4 [u'*', u'*', 'late', u'*'] 5 81.212.204.205 9121 TTNET Turk Telekomunikasyon Anonim Sirketi,TR [11.185, 10.657, 10.67] 6 81.212.204.149 9121 TTNET Turk Telekomunikasyon Anonim Sirketi,TR [10.864, 11.007, 10.685] 7 ['late', u'*', 'late', u'*', u'*'] 8 [u'*', u'*', u'*'] 9 [u'*', u'*', u'*'] 10 [u'*', u'*', u'*'] 11 [u'*', u'*', u'*'] 255 [u'*', u'*', u'*']
But RIPE Atlas probes are able to do traceroute with ICMP and, this time, it works:
From: 212.58.13.159 8685 DORUKNET Doruk Iletisim ve Otomasyon Sanayi ve Ticaret A.S.,TR Source address: 212.58.13.159 Probe ID: 3506 1 212.58.13.253 8685 DORUKNET Doruk Iletisim ve Otomasyon Sanayi ve Ticaret A.S.,TR [3.866, 3.13, 3.132] 2 82.151.154.193 8685 DORUKNET Doruk Iletisim ve Otomasyon Sanayi ve Ticaret A.S.,TR [3.316, 3.012, 3.176] 3 212.156.133.117 9121 TTNET Turk Telekomunikasyon Anonim Sirketi,TR [4.362, 5.976, 4.394] 4 [u'*', u'*', 'late', u'*'] 5 81.212.204.205 9121 TTNET Turk Telekomunikasyon Anonim Sirketi,TR [13.922, 13.574, 13.753] 6 81.212.204.149 9121 TTNET Turk Telekomunikasyon Anonim Sirketi,TR [13.933, 17.873, 13.571] 7 8.8.4.4 15169 GOOGLE - Google Inc.,US [11.689, 11.761, 11.897]
Is the lying resolver a full standalone resolver or does it just
proxy requests to the real servers, after censoring some names? To be
sure, we ask the Atlas probes to query Google Public DNS with the name
whoami.akamai.net, which is delegated to special
Akamai servers in order to reply with the IP
address of their DNS client (thanks to Alexander Neilson for the
idea). Measurement #1606450 shows:
10 probes reported, 10 successes [74.125.18.80] : 2 occurrences [195.175.255.66] : 8 occurrences Test done at 2014-03-30T14:49:39Z
We learn with whois that 74.125.18.80 is Google, 195.175.255.66 Turkish Telecom. So, no, Google
Public DNS is not proxied but replaced by an impostor which is a full
recursor.
There is no other easy way to be sure we talk to the real Google Public DNS or not: Google's servers, unfortunately, do not support the NSID identification system and, anyway, even if they did, it is easy to forge. The only real solution to be sure is the resolver you use, is cryptography. OpenDNS implements DNScrypt but Google DNS has nothing.
Of course, DNSSEC would solve the problem, if and only if validation were done on the user's local machine, something that most users don't do today.
About censoring with DNS, I recommend the comprehensive report of AFNIC Scientific Council. Thanks to Sedat Kapanoğlu for his measurements. Some other articles on this issue:
- My talk at the RIPE meeting in Warsaw in may: the slides (also hosted at RIPE), and the video (Flash unfortunately required),
- At BGPmon,
- At Google,
- At Renesys,
- At RIPE Labs (with a new proof of the hijacking, based on the latency),
- At the Internet Society, with an emphasis on the possible solutions (I disagree with the emphasis they put on BGP security since this hijacking was not done with BGP).
On the political side, see the good statement by Internet Society (the previous one was technical).
L'article seul
Répartition des serveurs de noms d'une zone dans plusieurs AS
Première rédaction de cet article le 27 mars 2014
L'accès aux services sur
l'Internet commence presque toujours par une
requête DNS. Si ce dernier est en panne, il n'y
a quasiment pas d'usage de l'Internet possible (sauf si vous vous
contentez de traceroute -n...) D'où l'importance
de la notion de résilience du DNS. Contrairement
à ce qu'on lit parfois, le DNS n'est pas juste une application parmi
d'autres : c'est une infrastructure de
l'Internet, presque aussi vitale que BGP. La
résilience est un phénomène complexe, pas trivial à mesurer. Dans ce
très court article, je me concentre sur un seul aspect, la variété des
AS parmi les serveurs de noms d'une zone
DNS.
Pourquoi est-ce que cette variété des AS est un critère pertinent pour l'évaluation de la résilience ? Parce que certains pannes affectent un site physique (c'est le cas des incendies, par exemple), certaines affectent telle ou telle marque de serveurs de noms ou de routeurs (pensez à cisco-sa-20140326-ipv6) mais d'autres frappent un AS entier. Ce fut le cas de la panne CloudFlare de février 2013 ou de celle d'OVH en juillet 2013, à cause d'OSPF. C'est pour cette raison que ce critère (diversité des AS) figure parmi les métriques de l'Observatoire sur la résilience de l’Internet français. Vous trouverez tous les détails dans ce rapport, mon but est différent, il s'agit d'explorer des zones individuelles.
Bon, OK, toutes choses égales par ailleurs, c'est mieux de répartir
les serveurs de noms faisant autorité pour une zone vers plusieurs
AS. Mais comment le vérifier ? Si vous avez un flux BGP complet et les
outils pour l'analyser, vous pouvez partir de là (regarder les
annonces BGP et noter l'AS d'origine). Et si ce n'est pas le cas ? Eh
bien, l'excellent service RouteViews exporte, à partir
de flux BGP reçus, cette information sur l'AS d'origine d'une route,
et la publie notamment dans le DNS, via la zone
asn.routeviews.org, qui met en correspondance une
adresse IP (IPv4 seulement, hélas, je suis
preneur d'informations sur une service équivalent pour
IPv6) et le numéro d'AS d'origine :
% dig +short TXT 1.9.0.194.asn.routeviews.org "2484" "194.0.9.0" "24"
La commande ci-dessus a permis de voir que l'adresse IP
194.0.9.1 était annoncée (sous forme du préfixe
194.0.9.0/24) par l'AS 2484.
On peut alors construire un petit script shell qui va prendre un nom de zone DNS et afficher les AS d'origine de tous les serveurs. Bien sûr, cela ne donnera qu'un aspect de la résilience (notion bien plus riche que juste la variété des AS) et les résultats de ce script doivent être interprétés avec raison. Mais écrire un shell script est un remède souverain lorsqu'on est déprimé ou énervé donc je l'ai fait et il est disponible, fin des avertissements.
Voici un exemple sur le domaine de ce blog. L'outil affiche, pour chaque adresse IPv4 d'un serveur de la zone, l'AS d'origine :
% asns.sh bortzmeyer.org 93.19.226.142: "15557" 79.143.243.129: "29608" 204.62.14.153: "46636" 178.20.71.2: "29608" 106.186.29.14: "2516" 217.174.201.33: "16128" 217.70.190.232: "29169" 83.169.77.115: "8784" 95.130.11.7: "196689"
On voit une grande variété d'AS (y compris un sur 32 bits, cf. RFC 6793). De ce strict point de vue, la zone a des chances d'être robuste.
Essayons avec une autre zone :
% asns.sh icann.org 199.43.132.53: "42" 199.43.133.53: "1280" 199.43.134.53: "12041" 199.4.138.53: "26710"
Également une bonne variété, on y trouve aussi le fameux AS 42. Et sur un grand site de e-commerce ?
% asns.sh amazon.com 204.74.114.1: "12008" 208.78.70.31: "33517" 204.74.115.1: "12008" 208.78.71.31: "33517" 204.13.250.31: "33517" 204.13.251.31: "33517" 204.74.108.1: "12008" 204.74.109.1: "12008" 199.7.68.1: "12008" 199.7.69.1: "12008"
Celui-ci n'a que deux hébergeurs DNS en tout, donc deux AS seulement.
Un cas plus délicat est fourni par
.com :
% asns.sh com 192.54.112.30: "36623" 192.55.83.30: "36618" 192.35.51.30: "36620" 192.33.14.30: "26415" 192.43.172.30: "36632" 192.31.80.30: "36617" 192.5.6.30: "36621" 192.48.79.30: "36626" 192.12.94.30: "36627" 192.42.93.30: "36624" 192.26.92.30: "36619" 192.52.178.30: "36622" 192.41.162.30: "36628"
Il y a beaucoup d'AS mais c'est en fait le même fournisseur, Verisign, qui met un AS par serveur, suivant le RFC 6382.
Et des gens qui ont choisi de mettre tous leurs œufs dans le même panier ? On en trouve :
% asns.sh leboncoin.fr 213.186.33.102: "16276" 213.251.128.136: "16276"
% asns.sh laposte.net 195.234.36.4: "35676" 178.213.67.14: "35676" 195.234.36.5: "35676" 178.213.66.14: "35676"
L'article seul
TSIG si on n'utilise pas BIND ?
Première rédaction de cet article le 26 mars 2014
Il existe des zillions (voire des zilliards) de HOWTO et d'articles de blog sur la configuration d'un serveur DNS BIND pour une authentification avec TSIG, par exemple entre serveur maître et serveurs esclaves. Et si on n'utilise pas les outils BIND ? Là, il y a nettement moins de documents. Voici donc un exemple.
Un petit rappel sur TSIG d'abord. Normalisée dans le RFC 8945, cette technique permet à deux serveurs DNS de s'authentifier mutuellement, en utilisant un secret partagé (une sorte de mot de passe, quoi). Comme les secrets partagés ne sont pas pratiques du tout à distribuer et à garder confidentiels, TSIG ne peut pas réalistement s'envisager comme solution générale de sécurisation du DNS. Mais, pour un petit groupe de serveurs qui se connaissent (typiquement les serveurs faisant autorité pour une zone donnée), c'est utile. Cela évite notamment qu'un serveur esclave, croyant parler au maître, parle en fait (par exemple par suite d'un détournement BGP) à un serveur pirate qui lui enverra des fausses données. Bien sûr, si tout le monde faisait du DNSSEC, le problème n'existerait pas, les fausses données seraient détectées par la validation DNSSEC. Mais tant que DNSSEC n'est pas largement répandu, TSIG est un moyen simple et pas cher de sécuriser les communications entre serveurs faisant autorité pour une zone (et qui transfèrent le contenu de la zone avec le mécanisme du RFC 5936).
Supposons maintenant qu'on gère une zone
example.com et qu'on ait comme maître un serveur de noms n'utilisant pas
du tout BIND ou les outils qui viennent
avec. On va alors se servir des outils de la bibliothèque ldns pour générer
les clés (les secrets partagés) et NSD comme
serveur de noms.
D'abord, on va décider d'avoir une clé (un secret) différente par
couple esclave/zone. Mettons que ns1.example.net
soit esclave pour la zone example.com, on va
nommer la clé ns1.example.net@example.com et on va
générer la clé ainsi :
% ldns-keygen -a hmac-sha256 ns1.example.net@example.com Kns1.example.net@example.com.+159+63629
(L'algorithme
HMAC-SHA256 est
considéré comme sûr aujourd'hui, TSIG utilisait traditionnellement
MD5 qui est fortement déconseillé aujourd'hui.)
On obtient alors deux fichiers mais qui ont le même contenu, seul le
format est différent. Prenons
Kns1.example.net@example.com.+159+63629.private :
% cat Kns1.example.net@example.com.+159+63629.private Private-key-format: v1.2 Algorithm: 159 (HMAC_SHA256) Key: E8mRpGdzXXiT5UZaeUvcecKEjLOu95PJJSN6e4aFnD+cnn4BqkyYgbK2HNyA1m/aSpJIIm9jxS8QnCqvQU2685zO71ozLU02Erhoio1RsdJ0NbU6aYmPt2J+WTms0+yhctHe7XbpXVrhf/XSUAcgwiiAe5t58PDbZQR1Y+ZJbSE=
Le secret partagé est le champ Key: (évidemment, ce secret particulier ne doit plus être utilisé, depuis qu'il a été publié sur ce blog...) Mettons-le
dans la configuration du maître NSD :
key:
name: ns1.example.net@example.com
algorithm: hmac-sha256
secret: "E8mRpGdzXXiT5UZaeUvcecKEjLOu95PJJSN6e4aFnD+cnn4BqkyYgbK2HNyA1m/aSpJIIm9jxS8QnCqvQU2685zO71ozLU02Erhoio1RsdJ0NbU6aYmPt2J+WTms0+yhctHe7XbpXVrhf/XSUAcgwiiAe5t58PDbZQR1Y+ZJbSE="
...
zone:
name: "example.com"
...
notify: 2001:db8:1::3:83 ns1.example.net@example.com
provide-xfr: 2001:db8:1::3:83 ns1.example.net@example.com
La ligne notify: indique que les notifications de
mise à jour (RFC 1996) doivent être signées avec
TSIG et notre nouvelle clé. La ligne provide-xfr:
indique qu'on n'accepte de transférer la zone qu'à la machine
authentifiée avec cette clé. Si vous avez dans le
journal :
Mar 23 16:49:05 foobar nsd[23773]: axfr for zone example.com. \
from client 2001:db8:2::3:83 refused, no acl matches
C'est qu'il y a une erreur (ici, adresse IP inconnue) dans la configuration.
Il ne vous reste plus qu'à envoyer le secret au gérant du serveur esclave, qu'il fasse la configuration de son côté. Naturellement, cela doit se faire de manière confidentielle, par exemple par un message chiffré avec PGP.
L'article seul
L'option GnuPG qui permet de ne pas indiquer les ID...
Première rédaction de cet article le 19 mars 2014
La sécurité, ce n'est pas gratuit. Il y a parfois des techniques
qui améliorent la sécurité mais qui sont tellement embêtantes à
l'usage qu'on préfère les abandonner. C'est ainsi que je viens de
supprimer l'option throw-keyids de ma
configuration GnuPG.
Cette option est a priori bonne pour la sécurité : pour citer la
documentation elle permet de « ne pas mettre les identificateurs de clé dans
le message ». Qu'est-ce que cela veut dire ? Par défaut,
GnuPG, lorsqu'il chiffre un message, indique
dans le message l'identificateur de la clé du (ou des
destinataires). C'est décrit dans le RFC 4880, section 5.1. On peut l'afficher avec gpg :
% gpg report.txt.gpg
gpg: encrypted with 2048-bit RSA key, ID 336525BB, created 2009-12-15
"ISC Security Officer <security-officer@isc.org>"
...
Ici, tout le monde peut voir que ce document a été chiffré pour
la clé publique 336525BB, même si, en l'absence de
la clé privée, on ne peut pas le déchiffrer. Ainsi, quelqu'un qui a
accès au fichier a quand même une information utile, que j'écris des
choses pour l'ISC. C'est une
métadonnée qui peut être utile à un
espion.
L'option throw-keyids permet de résoudre cette
indiscrétion :
% gpg report.txt.gpg gpg: anonymous recipient; ...
Et voilà, l'information a disparu. En mettant
throw-keyids dans son
~/.gnupg/gpg.conf, on fabriquera toujours des
messages anonymes. J'avais mis cette option dans ma configuration à
l'occasion d'un durcissement de sécurité qui accompagnait ma nouvelle clé PGP.
Mais, car il y a un mais, le destinataire légitime ne saura donc pas si le message est bien pour lui, il devra essayer toutes ses clés secrètes. Cela prend du temps et, surtout, cela crée des messages ennuyeux :
gpg: anonymous recipient; trying secret key 1B217B95 ... gpg: protection algorithm 1 (IDEA) is not supported gpg: the IDEA cipher plugin is not present gpg: please see http://www.gnupg.org/faq/why-not-idea.html for more information gpg: anonymous recipient; trying secret key 1CE01D31 ... gpg: protection algorithm 1 (IDEA) is not supported gpg: anonymous recipient; trying secret key CCC66677 ... gpg: anonymous recipient; trying secret key 96A4A254 ... ...
Notez que GnuPG a essayé toutes les clés secrètes de mon trousseau (y compris les révoquées : le message est peut-être un très ancien, fait avec une vieille clé). Comme certaines sont vraiment anciennes, elles utilisent même IDEA d'où l'avertissement anti-IDEA. D'expérience avec cette option, la plupart de mes correspondants ne comprennent pas ces messages, les interprètent mal, s'énervent, etc. Bref, j'ai fini par supprimer cette option de mon fichier de configuration.
Notez que, pour l'utilisation de PGP pour le
courrier électronique, ce n'est pas forcément
très grave. Dans le cas « normal » (pas celui du prudent qui change d'adresse de courrier tout le temps), l'espion éventuel a de toute façon tous les en-têtes RFC 5322 à sa disposition pour accéder à la même
information. Pour des fichiers transmis par un autre moyen, il peut
être toujours utile de se servir de throw-keyids,
par exemple ponctuellement sur la ligne de commande :
% gpg --recipient 9EE8C47B --throw-keyids --encrypt report.txt
Attention, il existe d'autres possibilités de fuite de l'information.
Merci à Ollivier Robert et Florian Maury pour des discussions intéressantes.
L'article seul
Compter sérieusement le nombre d'attaques informatiques ?
Première rédaction de cet article le 15 mars 2014
La presse à sensation et les rapports des sociétés qui vendent de la sécurité informatique sont pleins de chiffres sur les « cyber-attaques ». Des titres comme « de 10 à 100 attaques à la seconde » ou « une cyber-attaque toutes les 1,5 secondes en moyenne » sont courants. Que signifient-ils ? Quelle est la méthodologie de mesure ? Est-ce sérieux ?
On trouve sans peine des exemples de tels articles. Par exemple dans un journal peu regardant. D'autres ont un ton plus mesuré mais fournissent également leur lot de chiffres invérifiables. En l'absence de détails sur la définition des termes utilisés, aucune comparaison n'est possible. Un autre article de la presse à sensation voit moins d'une attaque par seconde (cent fois moins que l'article cité en premier, cela donne une idée du sérieux de ces chiffres)... Certains font des jolis dessins plus sérieux mais ne divulguent quasiment aucun détail sur leur méthodologie. D'autres sont tellement ignorants qu'ils se trompent aussi bien sur le vocabulaire du droit que sur celui de l'informatique (en appelant « cybercrime » des délits qui ne sont pas des crimes).
Donc, première observation, les chiffres publiés ne veulent rien
dire car ils ne sont jamais accompagnés d'une méthodologie, d'une
description des indicateurs utilisés. D'où les variations ridicules
d'un article à l'autre, et la surenchère. Par exemple, voici un
extrait du journal de ce blog, où la machine
188.143.234.90 essaie successivement plusieurs
attaques PHP contre le serveur (je n'ai mis qu'une partie des requêtes
HTTP) :
188.143.234.90 - - [13/Mar/2014:03:36:14 +0000] "GET /mysql-admin/index.php HTTP/1.1" 404 281 "-" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; MS-RTC LM 8; .NET4.0C; .NET4.0E; Zune 4.7)" www.bortzmeyer.org 188.143.234.90 - - [13/Mar/2014:03:36:15 +0000] "GET /PMA/index.php HTTP/1.1" 404 281 "-" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; MS-RTC LM 8; .NET4.0C; .NET4.0E; Zune 4.7)" www.bortzmeyer.org 188.143.234.90 - - [13/Mar/2014:03:36:15 +0000] "GET /php-my-admin/index.php HTTP/1.1" 404 281 "-" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; MS-RTC LM 8; .NET4.0C; .NET4.0E; Zune 4.7)" www.bortzmeyer.org 188.143.234.90 - - [13/Mar/2014:03:36:15 +0000] "GET /webdb/index.php HTTP/1.1" 404 281 "-" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; MS-RTC LM 8; .NET4.0C; .NET4.0E; Zune 4.7)" www.bortzmeyer.org 188.143.234.90 - - [13/Mar/2014:03:36:15 +0000] "GET /webadmin/index.php HTTP/1.1" 404 281 "-" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; MS-RTC LM 8; .NET4.0C; .NET4.0E; Zune 4.7)" www.bortzmeyer.org 188.143.234.90 - - [13/Mar/2014:03:36:15 +0000] "POST /cgi-bin/php?%2D%64+%61%6C%6C%6F%77%5F%75%72%6C%5F%69%6E%63%6C%75%64%65%3D%6F%6E+%2D%64+%73%61%66%65%5F%6D%6F%64%65%3D%6F%66%66+%2D%64+%73%75%68%6F%...
Comment dois-je compter ce qui est clairement une attaque ? Il est
probable que 188.143.234.90 n'en voulait pas
spécialement à mon blog et balayait tout simplement tout un tas de
serveurs. Auquel cas, il serait logique de ne compter qu'une
attaque pour tous ces serveurs. Mais, si chaque administrateur système compte le passage du
bot 188.143.234.90 sur son
site comme une attaque, le nombre total d'attaques sera bien plus
élevé. Et, si je veux franchement abuser, je peux aussi compter chaque
requête HTTP comme une attaque (il y en avait
bien plus que ce que je montre ici). Comment font les organisations
qui publient les chiffres que la presse reprend sans jamais enquêter,
sans jamais chercher un point de vue critique ? Eh bien, on ne sait
pas. La publication des chiffres n'est jamais
accompagnée de la méthodologie et ces chiffres n'ont donc aucun intérêt.
Peut-être pensez-vous que j'ai vraiment trop abusé avec l'idée de compter chaque requête HTTP comme une attaque. Mais j'ai déjà vu cela en vrai, par exemple sur des firewalls cliquodromesques avec un bouton permettant de générer des jolis camemberts pour PHBs. Chaque paquet rejeté par le pare-feu était compté comme une attaque, ce qui permettait au PHB de se dire chaque matin qu'il avait bien dépensé son argent. (Pour les gens qui ne sont pas administrateurs système ou réseau, précisons que toute adresse IP reçoit en permanence un trafic non sollicité d'attaque ou de reconnaissance, qu'on appelle l'IBR.)
Autre cause de désaccord, comment compter les tentatives de reconnaissance, qui peuvent être malveillantes mais peuvent aussi être de la curiosité. J'ai connu un site où l'administrateur notait chaque telnet (un paquet TCP vers le port 23) comme une attaque... Et que dire alors d'un examen avec nmap qui va illuminer l'IDS comme un arbre de Noël ? Une attaque, aussi ? On voit que l'absence de définition rigoureuse permet toutes les manipulations, dans un sens ou dans l'autre. Enfin, on voit aussi des webmestres crier à l'attaque dès que leur site ralentit sous la charge. Beaucoup de site Web dynamiques sont programmés de telle façon (avec 10 000 lignes de code Java ou PHP à exécuter à chaque requête HTTP) qu'ils s'écroulent très vite dès qu'ils ont un peu de succès. Il est alors tentant d'enregistrer cela comme une attaque plutôt que de reconnaître qu'on avait mal calculé son coup...
Il faut dire que la mauvaise qualité des données n'est pas uniquement due à la paresse et à l'incompétence. Les intérêts économiques ou politiques jouent également un rôle. Il n'existe en effet pas de « chiffres officiels » sur les attaques informatiques (je ne garantis évidemment pas que des chiffres officiels seraient plus fiables...) Les données publiées dans la presse sont donc uniquement issues de dossiers de presse faits par des entreprises qui vendent de la sécurité informatique, et qui ont donc tout intérêt à produire des chiffres élevés. Comme la grande majorité des journalistes n'a ni le temps, ni les moyens, ni la volonté de creuser un peu le sujet, les grands médias ne font que reformuler légèrement ces dossiers de presse, qui leur fournissent du contenu à bas prix. Il y a donc les intérêts économiques (peindre le problème sous les couleurs les plus noires pour vendre ensuite des solutions techniques miracles) et les buts politiques (justifier des lois répressives). Les deux concourent à exagérer les chiffres, et d'autant plus facilement qu'il n'y a jamais d'enquête indépendante et de fact checking.
On a donc un problème qui n'est pas très éloigné de la classique polémique sur les chiffres de la délinquance, mais avec encore moins d'indicateurs fiables. Comme le note Nicolas Caproni « les gens veulent comparer mais comme on n'aura jamais de référentiel commun, ça semble impossible ou tout du moins très imparfait ».
Bon, assez râlé, vont se dire les plus positifs de mes lecteurs, c'est facile de critiquer mais que proposes-tu ? Je n'ai hélas pas de solution miracle. Mais il n'est pas interdit d'explorer quelques pistes :
- Un représentant des forces de l'ordre m'avait dit une fois que le problème était simple : la définition d'un délit en informatique est claire, il suffit de compter comme attaque toute action illégale. Cette métrique a l'avantage d'être objective mais l'inconvénient de mener à des chiffres colossaux : chaque fois qu'un malware infecte une machine Windows, pouf, article 323-1 du Code Pénal et on a une attaque de plus pour les statistiques.
- Autre métrique à base juridique, compter le nombre de plaintes
déposées. Là, c'est le contraire, on va sous-estimer le nombre
d'attaques puisque la plupart ne font pas l'objet d'une plainte (je
n'ai pas porté plainte pour les tentatives de
188.143.234.90, trop cher et trop compliqué...) - Alors, prenons une métrique moins juridique et plus opérationnelle : compter le nombre de tickets ouverts par le NOC pour incident de sécurité ? Le problème est que cela mesure l'activité du NOC, pas celle des attaquants. Si on augmente les moyens du NOC, mécaniquement, cela augmentera le nombre d'attaques.
- Bon, et le point de vue rationnel et pragmatique ? L'administrateur système, surchargé de travail, ne compte comme attaque que ce qui perturbe effectivement le service. Mais ce critère utilitariste permet quand même des faux positifs (le slashdottage, cité plus haut, compte comme une attaque puisqu'il perturbe effectivement le service) et des faux négatifs (un pirate qui ne fait que de l'espionnage passif du système se gardera bien de perturber le service et ne sera donc pas compté comme une attaque.)
- Et compter comme attaque uniquement ce qui réussit ? Le balayage
par
188.143.234.90cité plus haut est ridicule puisque cette machine n'a aucun script PHP. De même, un balayage du port 22 sur une machine où sshd tourne sur un autre port ne serait pas compté comme une attaque. L'inconvénient de ce critère est qu'il dépend davantage de l'activité et de la compétence du défenseur que de l'activité des attaquants. - Bref, je ne connais pas de solution idéale. Et vous ? Je suis sûr que vous avez une idée. (Merci à Xavier Belanger pour ses suggestions.)
L'article seul
La NSA a t-elle une webcam dans votre salle de bains ?
Première rédaction de cet article le 14 mars 2014
Dernière mise à jour le 15 mars 2014
Hier, 13 mars 2014, à l'ESGI à Paris, j'ai participé au « Security Day » avec un exposé de spéculation sur les capacités effectives de la NSA. Peut-elle tout écouter et déchiffrer même ce qu'on a chiffré avec les meilleures clés RSA ? HTTPS nous protège t-il contre un tel ennemi ?
Les supports de l'exposé :
- En version adaptée à la vue sur écran,
- En version adaptée à l'impression,
- Bien sûr le source,
- Quant à la vidéo, elle est disponible sur les serveurs de NSA Tube. (Errata : Grigori Perelman n'a pas démontré la conjecture de Riemann mais celle de Poincaré.)
Parmi les autres exposés de la journée, je vous recommanderais bien celui de Damien Cauquil sur la sécurité des set-top boxes mais, pour des raisons de sécurité, rien n'est en ligne (résumé : il est trivial de pirater une télé, notamment parce que le chiffrement n'est pas utilisé, et cela fait des jolies copies d'écran).
Merci à Manuel Pégourié-Gonnard pour sa relecture. Et merci aux organisateurs, notamment Dylan Dubief, pour tout le travail. Et merci pour la bière « Cuvée des trolls » en cadeau :-)
L'article seul
RFC 7153: IANA Registries for BGP Extended Communities
Date de publication du RFC : Mars 2014
Auteur(s) du RFC : Eric C. Rosen (Cisco Systems), Yakov Rekhter (Juniper Networks)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF idr
Première rédaction de cet article le 14 mars 2014
Rien de dramatiquement nouveau dans ce RFC sur le protocole de routage BGP. Il s'agit juste d'une réorganisation des registres qui stockent les « communautés étendues », des attributs d'une annonce BGP. Les communautés étendues déjà enregistrées ne sont pas modifiées, les valeurs ne changent pas, le code continue à tourner comme avant, c'est juste la relation entre registres et les règles d'enregistrement qui sont clarifiées.
Ces communautés étendues sont normalisées dans le RFC 4360. Plus grandes que les anciennes communautés du RFC 1997, elles sont structurées en un type, parfois un sous-type et une valeur. (Rappel : il existe en ligne une liste des communautés des principaux opérateurs.) Le type indique entre autres si la communauté est transitive (si elle doit être transmise aux AS voisins) ou pas. S'il n'y a pas de sous-type, on parle de « types normaux » et, s'il y en a un, de « types étendus ». Types et sous-types sont mis dans un registre IANA. Les politiques d'allocation (cf. RFC 5226) varient, une partie de l'espace étant sous une politique restrictive (pour garantir qu'elle ne s'épuisera pas trop vite) et une autre sous une politique plus laxiste (pour faciliter la vie des utilisateurs). Par exemple, une communauté étendue qui commence par 0x0107 indique une propriété spécifique à un préfixe IPv4 (type 0x01), en l'occurence le Route ID / route type (sous-type 0x07) d'OSPF (cf. RFC 4577).
Les anciennes règles étaient spécifiées dans le RFC 4360 mais d'une manière qui s'est avérée trop confuse. D'où la réforme des registres (pas du protocole : les annonces BGP ne changent pas).
Donc, les nouveaux registres, tels que les décrit la section 2 de notre RFC :
- Un registre des types transitifs,
- Un registre des types non transitifs,
- Un registre des sous-types par type étendu (ceux qui ont des sous-types)., par exemple il y en a un pour les sous-types spécifiques à un AS de quatre octets, un autre pour les sous-types spécifiques à une adresse IPv4, etc.
Les registres des types doivent découper l'espace de nommage en trois, chaque partie ayant une politique d'allocation différente. De 0x00 à 0x3F, c'est du premier arrivé, premier servi. De 0x80 à 0x8F, réservé à un usage expérimental (depuis, le RFC 9184 a un peu grignoté cette plage). Et de 0x90 à 0xBF, il faut une norme. Pour les registres des sous-types, ce découpage est fait une fois pour toutes : de 0x00 à 0xBF (les sous-types sont codés sur un octet, cf. RFC 4360, section 3), la politique est « premier arrivé, premier servi » (très laxiste, donc, cf. RFC 5226), de 0xC0 à 0xFF, la politique « Examen par l'IETF » (très stricte, au contraire : il faut un RFC, et pas un RFC soumis individuellement). Rappelez-vous que tous les types n'ont pas de sous-types. Le fait d'avoir des sous-types est une propriété définie à la création du type (et indiquée dans le registre).
Un cas particulier est traité dans la section 3, celui des communautés étendues spécifiques pour les adresses IPv6. Créées par le RFC 5701, sur le modèle de communautés étendues spécifiques pour les adresses IPv4, elles n'ont en fait jamais été alignées, malgré la demande du RFC 5701 : les sous-types ne correspondent pas toujours. Notre RFC 7153 en prend donc acte et supprime cette demande d'alignement entre les sous-types IPv6 et les IPv4. Les deux registres pour IPv6 sont disponibles, un pour les transitifs et un pour les non-transitifs.
OK, et si je veux déclarer un type ou un sous-type et qu'il se retrouve dans ces beaux registres qui viennent d'être réorganisés, je fais quoi ? La section 4 décrit les procédures d'enregistrement. D'abord, le demandeur doit se poser la question « faut-il un nouveau type ou bien un sous-type d'un type existant peut-il suffire ? » Ensuite, s'il faut un type, doit-il être transitif ou pas ? (Certains types ont un sens dans les deux cas et doivent donc être ajoutés dans deux registres.) Et le type aura t-il des sous-types ? (Ce n'est pas obligatoire d'en avoir mais cela doit être mentionné dès le début.) Et, si oui, ces sous-types seront-ils dans un registre à part (c'est le cas de tous les types à sous-types aujourd'hui) ou bien réutiliseront-ils un registre de sous-types existant ?
Enfin, la section 5 du RFC contient la valeur actuelle des registres, qui sont désormais en ligne à l'IANA.
L'article seul
RFC 7166: Supporting Authentication Trailer for OSPFv3
Date de publication du RFC : Mars 2014
Auteur(s) du RFC : M. Bhatia (Alcatel-Lucent), V. Manral (Hewlett Packard), A. Lindem (Ericsson)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF ospf
Première rédaction de cet article le 13 mars 2014
La version 2 du protocole de routage OSPF avait un mécanisme d'authentification (annexe D du RFC 2328). Lors de la conception de la version 3 (qui permettait notamment d'ajouter IPv6), ce mécanisme avait été abandonné, l'idée étant que l'IETF avait déjà un mécanisme d'authentification plus général, IPsec, et qu'il « suffisait » de l'utiliser. Selon cette analyse, il n'y avait plus besoin de doter chaque protocole de son propre mécanisme d'authentification. C'était très bien sur le papier. Mais, en pratique, le déploiement d'IPsec est très limité, à la fois en raison de sa complexité et du caractère imparfait de ses implémentations. Résultat, les utilisateurs d'OPSFv3 n'ont, la plupart du temps, pas déployé de mécanisme de sécurité du tout. En voulant faire trop propre, on a donc diminué la sécurité du routage. Le RFC 6506 corrigeait le tir en dotant enfin OSPFv3 d'un mécanisme d'authentification léger et réaliste. Ce mécanisme a été expliqué par l'un des auteurs du RFC sur son blog. Ce nouveau RFC remplace le RFC 6506 et le met légèrement à jour.
OSPFv3 est normalisé dans le RFC 5340, dont le titre (« OSPF pour IPv6 ») est trompeur car, depuis le RFC 5838, OSPFv3 peut gérer plusieurs familles d'adresses et peut donc, en théorie, remplacer complètement OSPFv2. En pratique, toutefois, ce n'est pas encore le cas, notamment pour le problème de sécurité qui fait l'objet de ce RFC : contrairement aux autres protocoles de routage internes, OSPFv3 ne disposait d'aucun mécanisme d'authentification. N'importe quel méchant sur le réseau local pouvait se proclamer routeur et envoyer de fausses informations de routage. L'argument répété était « pas besoin de mécanisme spécifique à OSPFv3, utilisez les mécanismes IPsec, comme expliqué dans le RFC 4552 ». Mais on constate que cette possibilité a été très peu utilisée. Le RFC se contente de noter que c'est parce que IPsec est mal adapté à certains environnements comme les MANET mais il ne parle pas des autres environnements, où IPsec est simplement rejeté en raison de la difficulté à trouver une implémentation qui marche, et qu'un administrateur système normal arrive à configurer.
IPsec a également des faiblesses plus fondamentales pour des protocoles de routage comme OSPF. Ainsi, les protocoles d'échange de clés comme IKE ne sont pas utilisables tant que le routage ne fonctionne pas. Pour résoudre le problème d'œuf et de poule, et parce que les communications OSPF sont de type un-vers-plusieurs (et pas un-vers-un comme le suppose IKE), le RFC 4552 prône des clés gérées manuellement, ce qui n'est pas toujours pratique.
Enfin, l'absence de protection contre le rejeu affaiblit la sécurité d'IPsec dans ce contexte, comme le note le RFC 6039.
La solution proposée figure en section 2. L'idée est d'ajouter à la fin du packet OSPF un champ qui contienne un condensat cryptographique du paquet et d'une clé secrète, comme pour OSPFv2 (RFC 5709) (D'autres types d'authentification pourront être utilisés dans le futur, un registre IANA des types a été créé.) Les options binaires du paquet, au début de celui-ci (RFC 5340, section A.2), ont un nouveau bit, en position 13, AT (pour Authentication Trailer, désormais dans le registre IANA), qui indique la présence ou l'absence du champ final d'authentification (tous les paquets n'ont pas ce champ Options, donc le routeur devra se souvenir des valeurs de ce champ pour chaque voisin).
Pour chaque couple de routeurs ainsi protégés, il y aura un certain nombre de paramètres, qui forment ce qu'on nomme un accord de sécurité (security association, section 3) :
- Un identifiant sur 16 bits, manuellement défini, le Security Association ID. L'émetteur le choisit et le récepteur le lit dans le paquet. Cette indirection va permettre de modifier des paramètres comme les clés cryptographiques (ou même l'algorithme cryptographique), tout en continuant le routage.
- L'algorithme utilisé, par exemple HMAC-SHA1 ou HMAC-SHA512,
- La clé,
- Des paramètres temporels indiquant, par exemple, à partir de quand la clé sera valide.
Une fois qu'on a toutes ces informations, que met-on dans le paquet OSPF envoyé sur le câble ? La section 4 décrit le mécanisme. Le champ final d'authentification (Authentication Trailer) est composé notamment de l'identifiant d'un accord de sécurité (SA ID, décrit au paragraphe précédent, et qui permet au récepteur de trouver dans sa mémoire les paramètres cryptographiques liés à une conversation particulière), d'un numéro de séquence (qui sert de protection contre le rejeu ; il est augmenté à chaque paquet émis et il comprend 64 bits) et du condensat cryptographique du paquet concaténé avec la clé (la section 4.5 décrit l'algorithme en détail et notamment quels champs du paquet sont inclus dans les données condensées).
Le routeur qui reçoit un paquet utilisant l'authentification (il le sait grâce au bit AT qui était notamment présent dans les paquets OSPF Hello) va accéder au champ d'authentification (le champ Longueur du paquet OSPF lui permet de savoir où commence le champ d'authentification, éventuellement en tenant compte du bloc Link-Local Signaling du RFC 5613, un routeur doit donc gérer au moins en partie ce dernier RFC s'il veut authentifier). Le récepteur refait alors le calcul cryptographique et vérifie si le champ final d'authentification est correct. Le calcul est très proche de celui du RFC 5709 à part l'inclusion de l'adresse IPv6 source.
Supposons que nous soyons administrateur réseaux et que nos routeurs gèrent tous ce RFC. Comment déployer l'authentification sans tout casser ? La section 5 recommande de migrer tous les routeurs connectés au même lien simultanément. Autrement, les routeurs qui n'utilisent pas l'authentification ne pourront pas former d'adjacences OSPF avec ceux qui l'utilisent. Le RFC prévoit un mode de transition, où le routeur envoie le champ final d'authentification mais ne le vérifie pas en entrée mais l'implémentation de ce mode n'est pas obligatoire.
La section 6 contient l'analyse de sécurité de cette extension d'OSPF. Elle rappelle qu'elle ne fournit pas de confidentialité (les informations de routage seront donc accessibles à tout espion). Son seul but est de permettre l'authentification des routeurs, résolvant les problèmes notés par le RFC 6039. À noter que cette extension ne permet pas d'authentifier un routeur particulier mais simplement de s'assurer que l'émetteur est autorisé à participer au routage sur ce lien (tous les routeurs ont la même clé). La clé, rappelle cette section 6, devrait être choisie aléatoirement, pour ne pas être trop facile à deviner (cf. RFC 4552).
Des implémentations de cette option dans le logiciel d'un routeur ? Elle existe dans Cisco (voir leur documentation) et Quagga.
Les changements depuis le RFC 6506 ne sont pas très importants (section 1.2) et sont surtout des clarifications et des corrections de quelques erreurs dans l'ancienne spécification. Ainsi, ce nouveau RFC dit clairement que certaines calculs de somme de contrôle, redondants, doivent être omis (cela avait fait l'objet des errata 3567 et 3568). Et il supprime la possibilité d'utiliser des clés expirées lorsqu'il n'existe plus de clé valide (qui était à la fin de la section 3 de l'ancien RFC ; la nouvelle suggestion est de notifier l'opérateur et d'arrêter d'envoyer les paquets OSPF).
L'article seul
RFC 7151: File Transfer Protocol HOST Command for Virtual Hosts
Date de publication du RFC : Mars 2014
Auteur(s) du RFC : P. Hethmon (Hethmon
Brothers), R. McMurray (Microsoft)
Chemin des normes
Première rédaction de cet article le 12 mars 2014
On ne peut pas dire que le protocole de transfert de fichiers
FTP soit encore très utilisé, largement
concurrencé qu'il est par HTTP ou
BitTorrent. Mais il existe encore de nombreuses
ressources accessibles en FTP et de nombreux serveurs FTP donc
l'IETF continue à améliorer le protocole. Cette
nouvelle extension résout un problème : lorsque plusieurs noms
pointent vers la même adresse IP et donc le même serveur FTP, ce
serveur ne savait pas sous quel nom il avait été désigné à l'origine,
et ne pouvait donc pas ajuster son comportement à ce nom. L'extension
HOST résout ce problème en permettant au client
FTP d'indiquer le nom original.
Cela se fait depuis longtemps pour HTTP (RFC 2616 qui a
créé HTTP 1.1, remplaçant le HTTP 1.0 du RFC 1945) avec
l'en-tête Host: envoyé dans la requête, qui
permet le mécanisme de virtual hosting (plusieurs
serveurs, ayant des comportements différents, sur la même adresse
IP). Mais FTP n'avait pas encore l'équivalent. FTP est normalisé dans
le RFC 959. Si vous ne connaissez pas ce protocole ou son
histoire, je recommande le texte de Jason
Scott. Traditionnellement, on n'accédait à un serveur FTP que
par un seul nom, et les ressources (fichiers) disponibles ensuite
étaient rangés dans des répertoires différents. Si le même serveur
FTP anonyme hébergeait un miroir de
FreeBSD et un autre de
NetBSD, on pouvait créer deux noms, mettons
ftp.freebsd.example et
ftp.netbsd.example pointant vers la même adresse
IP mais, comme la connexion ne se fait qu'avec les adresses IP (après
que le logiciel client ait résolu le nom de domaine en adresse IP,
grâce au DNS), le
logiciel serveur FTP ne pouvait pas savoir le nom utilisé par le
client. Résultat, le serveur devait présenter le même contenu, et
l'utilisateur, qu'il soit fan de FreeBSD ou de NetBSD voyait à la
racine les répertoires de deux systèmes (et probablement de bien d'autres).
Un exemple avec l'excellent client ncftp sur un
site miroir de FreeBSD :
% ncftp ftp.fr.freebsd.org NcFTP 3.2.5 (Feb 02, 2011) by Mike Gleason (http://www.NcFTP.com/contact/). Connecting to 158.255.96.2... Welcome free.org FTP service Logging in... Login successful. Logged in to ftp.fr.freebsd.org. ncftp / > ls debian@ mirrors/ private/ pub/ stats/ ubuntu@ ncftp / > cd mirrors/ Directory successfully changed. ncftp /mirrors > ls archive.ubuntu.com/ ftp.freebsd.org/ releases.ubuntu-fr.org/ cdimage.debian.org/ ftp.ubuntu.com/ releases.ubuntu.com/ ftp.debian.org/ ftp.xubuntu.com/ videolan/
Il aurait quand même été plus pratique d'arriver directement dans
mirrors/ftp.freebsd.org ! Le fait que le serveur
ne connaisse pas le nom original a d'autres conséquences, comme de ne
pas pouvoir utiliser des systèmes
d'authentification différents selon le nom
(accès FTP anonyme sur certains et pas sur d'autres, par exemple).
La section 3 du RFC décrit cette extension
HOST. Elle a la forme d'une commande qui doit
être envoyée au serveur avant l'authentification
(rappelez-vous qu'un des buts de cette commande est d'avoir la
possibilité d'authentifications différentes selon le serveur
virtuel). Le serveur doit répondre par un code 220 si tout s'est bien
passé. Le RFC recommande que le serveur n'envoie le message de
bienvenue qu'après la commande
HOST puisque cela lui permettrait d'adapter le
message de bienvenue au nom utilisé. Voici un exemple, où « C> »
indique un message envoyé par le client FTP et « S> » un message
envoyé par le serveur FTP :
C> HOST ftp.example.com S> 220 Host accepted
Et, en cas d'authentification :
C> HOST ftp.example.com S> 220 Host accepted C> USER foo S> 331 Password required C> PASS bar S> 230 User logged in ftp.example.com
La commande HOST prend comme paramètre le
nom de domaine qui a été utilisé par le client,
après d'éventuelles normalisations comme l'ajout d'un suffixe
(par contre, si c'est un alias dans le DNS, on
utilise l'alias, pas le nom canonique). Si le nom est un
IDN, c'est la forme
Punycode qui doit être utilisée dans la
commande HOST :
% logiciel-client ftp.café-crème.example C> HOST ftp.xn--caf-crme-60ag.example S> 220 Host accepted
Si l'utilisateur humain avait
utilisé directement une adresse IP, c'est elle qu'on passe à la
commande HOST :
C> HOST [2001:db8::c000:201] S> 220 Host accepted
Ou bien :
C> HOST 192.0.2.1 S> 220 Host accepted (but you should use IPv6)
Par contre, le client ne doit pas indiquer le numéro de port, même lorsque c'était un port non-standard. En effet, le serveur le connait déjà, puisqu'il a cette information dans les données de connexion.
Que doit faire le serveur en recevant un
HOST ? Il doit normalement vérifier que ce nom
correspond bien à un des serveurs virtuels déclarés dans sa
configuration. Sinon :
C> HOST ftp.example.net S> 504 Unknown virtual host
(Le serveur peut, à la place, décider d'envoyer le client vers le serveur virtuel par défaut.) En cas de succès, le serveur peut ensuite s'adapter à ce nom : changer de répertoire par défaut, activer un autre méthode d'authentification, etc.
Mais que se passe t-il si l'utilisateur a un vieux client FTP qui
n'envoie pas de HOST ? Là aussi, c'est au serveur de
décider quoi faire dans ce cas (utiliser un serveur virtuel par
défaut, refuser la connexion, etc). Et si c'est le serveur qui est
vieux et qui ne connait pas HOST ? C'est alors le
cas normal d'une commande inconnue (RFC 959,
section 4.2) :
C> HOST ftp.example.com S> 502 Unimplemented
Un peu plus compliqué, le cas où la session est protégée par
TLS. Si le client utilise l'indication TLS du
nom, normalisée dans l'extension server_name
(RFC 6066), le serveur doit vérifier que le nom
donné en paramètre à HOST est le même que celui
de la session TLS.
Des questions de sécurité ? Comme indiqué plus haut, l'utilisation
de la commande HOST peut faire changer de système
d'authentification. Il est donc crucial que le serveur FTP sépare bien
les serveurs virtuels pour éviter, par exemple, qu'on puisse se
connecter sur un serveur virtuel avec les lettres de créance d'un
autre. Idem lorsque le client authentifie le serveur avec les
certificats du RFC 4217. Notre RFC rappelle également l'utilité des extensions
d'authentification du RFC 2228 et l'intérêt de la (re)lecture
du RFC 2577 sur la sécurité des serveurs FTP.
La nouvelle commande HOST est désormais
officiellement enregistrée dans le registre IANA.
L'annexe A discute des autres choix qui auraient pu être faits mais
qui ont finalement été rejetés. Une solution possible était d'étendre
la commande déjà existante CWD (Change
Working Directory) en lui donnant
comme argument le nom du serveur virtuel. Cela permettrait ainsi
d'avoir des sous-répertoires différents par serveur virtuel, comme
c'est déjà souvent le cas (regardez l'exemple de
ftp.fr.freebsd.org et de son répertoire
mirrors/). Mais cela a des limites :
CWD n'est accepté qu'après l'authentification et
ne permet donc pas d'avoir des mécanismes d'authentification
différents selon le serveur virtuel. Et ça manque de souplesse en
forçant une certaines organisation des répertoires du serveur (ou bien
en modifiant le code du serveur pour traiter cette première commande
CWD différemment. Et ce n'est pas terrible du
côté sécurité, un visiteur pouvant facilement voir tous les serveurs
virtuels.
Une autre solution qui avait été suggérée était la commande
ACCT qui permet de choisir un compte particulier,
mais après l'authentification. Elle a donc un défaut en commun avec
CWD, elle ne permet pas une authentification
différente par serveur virtuel. (Ni d'utiliser des certificats
différents, lorsqu'on utilise les extensions
de sécurité des RFC 2228 et RFC 4217).
Et la commande USER ? Pourquoi ne pas
l'étendre en ajoutant le serveur virtuel ?
C> USER foo@example.com S> 331 Password required C> PASS bar S> 230 User logged in
Le problème est que certains environnements ont déjà des comptes
utilisateurs comportant un @domaine, cas qu'on ne
pourrait pas distinguer de celui où on indique un serveur virtuel. Et
les extensions de sécurité de FTP mentionnées plus haut font la
négociation de certificats avant le USER donc, là
encore, on ne pourrait pas avoir des certificats différents selon le
serveur virtuel.
Cette extension à FTP est ancienne (première proposition en 2007, apparemment), même si elle n'avait pas été formellement normalisée. Elle est incluse dans IIS comme documenté par un des auteurs du RFC, dans le serveur ncftpd, dans le serveur proftpd... Mais je n'ai pas testé ce que cela donnait en vrai (il faudrait déjà trouver un client qui le gère).
L'article seul
RFC 7149: Software-Defined Networking: A Perspective From Within A Service Provider
Date de publication du RFC : Mars 2014
Auteur(s) du RFC : M. Boucadair (France Telecom), C. Jacquenet (France Telecom)
Pour information
Première rédaction de cet article le 6 mars 2014
Ah, le SDN (Software-Defined Networking)... Un buzz word fort du moment, il est, chez les techniciens, l'équivalent de cloud chez les commerciaux... Le terme est tellement vague et mal défini qu'il peut désigner tout et n'importe quoi. Dans ce RFC, les deux auteurs explorent le concept, tentent une définition, et nous exposent leur analyse (plutôt critique) du SDN.
SDN désigne en général un ensemble de techniques (dont la plus connue est OpenFlow) permettant de gérer centralement un réseau, lorsque ce réseau est sous une autorité unique (contrairement à ce qu'on lit parfois, le SDN n'a donc pas vocation à être déployé sur l'Internet). L'idée est de ne plus confier aux seuls protocoles de routage la capacité de configurer les éléments du réseau, mais de définir une politique, de la configurer dans une machine centrale, et de l'appliquer ensuite aux éléments du réseau. On voit que, dans la définition la plus générale du SDN, si on remplace les employés qui se loguent sur les routeurs et les commutateurs pour les configurer par un logiciel du type de Ansible ou Puppet, on fait du SDN sans le savoir.
Ah, mais justement, quelle est la bonne définition de « SDN » ? Notre RFC 7149 commence par noter qu'il n'existe pas de définition rigoureuse unique (comme avec tous les buzz words). L'approche des auteurs est de partir des services réseaux (d'où le titre du RFC) puis de tenter une introduction à SDN. La section 1 du RFC se penche sur les problèmes du fournisseur de services, à partir de l'exemple du VPN. Fournir un service de VPN à ses clients nécessite l'activation de plein de capacités différentes : adressage et routage, bien sûr, mais aussi création des tunnels, qualité de service, filtrage pour la sécurité, et bien sûr tout ce qui est nécessaire à la supervision. La méthode traditionnelle, qui consiste à configurer manuellement (via la ligne de commandes ou via une interface graphique) un grand nombre de machines différentes (car ce n'est pas une seule machine qui va avoir toutes les capacités citées plus haut) est lente, coûteuse et l'erreur arrive vite. Il est évident qu'il faut automatiser, si on ne veut pas laisser le client attendre son VPN pendant des jours... pour qu'il découvre finalement qu'une des fonctions attendues ne marche pas suite à une légère erreur humaine. Donc, si vous voulez survivre dans le business du VPN, vous allez utiliser un programme pour configurer tout cela.
Bon, mais, d'abord, c'est quoi le SDN ? La section 2 du RFC se penche sur le problème de la définition. C'est évidemment difficile car le sigle a été usé et abusé par les marketeux. Par exemple, on définit parfois le SDN comme la séparation, dans les routeurs entre le système de contrôle (en général fait en logiciel sur un processeur généraliste) et le système de transmission (souvent fait par des circuits électroniques spécialisés donc considéré à tort comme n'étant pas du logiciel). Cette séparation offre plus de souplesse d'un côté et plus de performances de l'autre. Mais notre RFC pointe tout de suite que cette séparation est faite depuis de nombreuses années : si c'est là toute la nouveauté du SDN, cela ne vaut pas la peine. En fait, quand on dit « SDN », on ajoute souvent un point important à cette séparation : que le système de contrôle, au lieu d'être dans chaque routeur, vaguement coordonnés par un protocole de routage comme OSPF, soit centralisé, et standardisé pour que le contrôleur et le contrôlé puissent être achetés à des fournisseurs différents. Dans cette définition du SDN, les routeurs et autres équipements réseaux sont « bêtes », juste capables de transmettre les paquets, et un contrôleur « intelligent » fait tous les calculs avant de transmettre des ordres simples aux routeurs. (On parle de PDP - Policy Decision Point - pour le contrôleur et de PEP - Policy Enforcement Point - pour les équipements réseau.)
L'argument en général donné par les pro-SDN est celui de la flexibilité. Lorsque de nouvelles exigences apparaissent, par exemple pour offrir un nouveau service aux clients, on change juste le logiciel du contrôleur et tout le reste du réseau suit gentiment. À noter que cela va au delà du routage : il faut aussi pouvoir transmettre aux clients des ordres portant sur la réservation de capacité réseau, par exemple. (Les solutions commerciales qui se disent « SDN » se vantent toutes de leur flexibilité, sans toujours préciser qu'est-ce qui est flexible et qu'est-ce qui est fixé.)
À noter que ces calculs dans le contrôleur supposent que celui-ci dispose d'un bon modèle du réseau. Puisque les équipements réseau vont lui obéir aveuglément, il ne faut pas qu'il transmette des ordres qui mènent à, par exemple, une congestion du réseau. Pour cela, il doit donc connaître les détails du réseau, de façon à être capable de prédire les conséquences de ces actions (ou de façon à pouvoir dire à l'administrateur réseaux « désolé, Dave, ce que tu me demandes est impossible »). Cela peut nécessiter le développement de meilleurs émulateurs de réseau, pour pouvoir tester les conséquences d'un ordre avant de l'envoyer.
Armés de ces précautions, les auteurs du RFC définissent donc le SDN comme « l'ensemble des techniques utilisées pour :
- faciliter l’ingénierie,
- améliorer le temps de production,
- simplifier l’exploitation de services réseau d’une manière déterministe, dynamique et capable d’être déployée à grande échelle.
». On note qu'ils n'insistent pas sur le côté « logiciel » (le S de SDN), les mécanismes réseau étant par essence à base de logiciels.
Ce beau programme nécessite des techniques pour :
- Découvrir la topologie du réseau (on ne peut pas commander un réseau qu'on ne connait pas), les capacités des équipements actifs, et comment les configurer,
- Donner des ordres aux équipements réseau,
- Avoir un retour sur l'exécution des ordres donnés, et sur leurs résultats.
OK, c'est très joli mais est-ce réaliste ? La section 3 se le demande. Un écosystème comme l'Internet est l'un des objets les plus complexes jamais conçus par l'humanité (et il existe des tas de réseaux qui, sans être aussi gros que l'Internet, sont d'une taille et d'une complexité redoutables). Les exigences des utilisateurs sont innombrables et souvent difficiles à concilier (résilience, y compris face aux attaques délibérées, performances, flexibilité, rapidité de déploiement des changements...) Le RFC suggère donc une certaine modestie. D'abord, se souvenir du passé. On l'a vu, les promesses du SDN étaient souvent plus ancrées dans le verbiage commercial que dans la réalité. Quand elles faisaient référence à quelque chose de concret, c'était parfois quelque chose qui existait depuis longtemps mais qui avait été rebaptisé « SDN » (qui se souvient des vieux slogans commerciaux comme « Active Networks » ou « Programmable Networks » ?) C'est ainsi que les NMS ou le PCE (RFC 4655) ont parfois été enrôlés contre leur gré sous la bannière « SDN ». Pour la séparation du système de contrôle et du système de transmission, on peut aussi citer le routage via le DNS (RFC 1383) ou évidemment ForCES (RFC 5810).
Autre suggestion de modestie, être pragmatique. Le SDN doit être utilisé s'il aide, pas juste pour le plaisir de faire des exposés à NANOG. Par exemple, la centralisation du contrôle ne doit pas conduire à diminuer la résilience du réseau en en faisant un SPOF. Si le contrôleur est en panne ou injoignable, il faut que les équipements réseau puissent au moins continuer à assurer leurs tâches de base (bien sûr, les contrôleurs sont redondés mais cela ne suffit pas dans tous les cas). Autre exemple de pragmatisme, il faut mesurer le réseau et s'assurer qu'on a réellement obtenu le résultat voulu.
D'autant plus que rien n'est gratuit dans ce monde cruel. La souplesse et la réactivité que fournissent les possibilités de configuration des équipements ont un coût, par exemple en rendant plus difficile, si on utilise des interfaces standard, d'optimiser les performances, puisqu'on ne pourra pas forcément toucher aux fonctions les plus spécifiques du matériel.
Lorsqu'on dit « SDN », on pense souvent immédiatement à OpenFlow, la plus connue des techniques vendues sous ce nom. Mais le SDN ne se réduit pas à OpenFlow et bien d'autres protocoles peuvent être utilisés pour de la configuration à distance (de PCEP - RFC 5440 - à NETCONF - RFC 6241 en passant par COPS-PR - RFC 3084 - ou RPSL - RFC 2622). OpenFlow n'est donc qu'un composant possible d'une boîte à outils plus large.
Enfin, lorsqu'on fait une analyse technique d'un mécanisme, il est important de voir quels sont les « non-objectifs », les choses qu'on n'essaiera même pas d'atteindre (dans le discours commercial, il n'y a pas de non-objectifs, la solution proposée est miraculeuse, guérit le cancer systématiquement et fait toujours le café) :
- La flexibilité rencontrera toujours des limites, ne serait-ce que les capacités du matériel (aucune quantité de SDN ne permettra à un routeur d'aller plus vite que ce que lui permettent ses interfaces réseaux et ses ASIC),
- La modularité et la programmabilité se heurteront aux limites du logiciel, comme la nécessité de tests (le software est nettement moins soft que ne s'imaginent les décideurs),
- Le contrôle absolu depuis un point central est très tentant pour certains mais il se heurte aux problèmes de passage à l'échelle et à la nécessité que les équipements aient assez d'autonomie pour gérer les déconnexions temporaires.
La section 4 du RFC discute ensuite plus en détail certains problèmes qu'on rencontre sur la route du SDN. Premier problème cité, toute automatisation d'un processus est vulnérable aux bogues dans le logiciel : c'est par exemple le syndrome du « robot fou » qui, ne se rendant pas compte que ses actions mènent à des catastrophes, les continue aveuglément (deux exemples, un avec Ansible et un avec Flowspec). Autre difficulté qui ne disparaitra pas facilement, l'amorçage du SDN : la première fois qu'on le met en place, les équipements et le contrôleur ne se connaissent pas et doivent apprendre leurs capacités. (Et utiliser le réseau pour configurer le réseau soulève plein de problèmes intéressants...)
Gérer un réseau, ce n'est pas seulement le configurer et faire en sorte qu'il démarre. Il faut aussi assurer le débogage, la maintenance, les statistiques, la détection (et la correction) de problèmes, tout ce qui est désigné sous le sigle OAM (Operations And Management, cf. RFC 6291). Le SDN doit prendre cela en compte.
On l'a vu, un des principes du SDN est la concentration de l'« intelligence » en un point central, le PDP (Policy Decision Point, là où on configure les services attendus). Cela pose des problèmes pour la résilience du réseau ou tout simplement pour son passage à l'échelle. Un mécanisme permettant d'avoir plusieurs PDP synchronisés semble donc nécessaire. En parlant de passage à l'échelle, le RFC signale aussi que certaines promesses du SDN vont être difficiles à tenir. Par exemple, avoir des machines virtuelles ayant des politiques de QoS différentes, et migrant librement d'un data center à l'autre est faisable en laboratoire mais ne va pas passer à l'échelle facilement.
Enfin, il ne faut pas oublier les risques, souvent négligés lors de la présentation d'une belle technologie qui brille. Le contrôleur va devenir le point faible du réseau, par exemple. Et la sécurité du SDN n'a pas encore été tellement mise à l'épreuve (section 6 du RFC).
Merci à Mohamed Boucadair et Christian Jacquenet pour leur relecture.
L'article seul
RFC 7159: The JSON Data Interchange Format
Date de publication du RFC : Mars 2014
Auteur(s) du RFC : T. Bray (Google)
Chemin des normes
Première rédaction de cet article le 3 mars 2014
Il existe une pléthore de langages pour décrire des données structurées. JSON, normalisé dans ce RFC (qui succède au RFC 4627), est actuellement le plus à la mode. JSON se veut plus léger que XML. Comme son concurrent XML, c'est un format textuel, et il permet de représenter des structures de données hiérarchiques. Ce RFC est l'ancienne norme JSON, remplacée depuis par le RFC 8259.
À noter que JSON doit son origine, et son nom complet
(JavaScript Object Notation) au langage de
programmation JavaScript, dont il est un
sous-ensemble. La norme officielle de JavaScript est à l'ECMA
actuellement la version 5.1 du document ECMA-262. JSON est dans la section 15.12 de ce document mais est aussi dans ECMA-404, qui lui est réservé. Il était prévu
une publication commune
ECMA/IETF mais elle n'a
finalement pas eu lieu. Contrairement à JavaScript, JSON n'est pas un langage de programmation,
seulement un langage de description de données, et il ne peut donc pas
servir de véhicule pour du code
méchant (sauf si on fait des bêtises comme de soumettre du
texte JSON à eval(), cf. section 12 et erratum #3607 qui donne des détails sur cette vulnérabilité).
Voici un exemple, tiré du RFC, d'un objet exprimé en JSON :
{
"Image": {
"Width": 800,
"Height": 600,
"Title": "View from 15th Floor",
"Thumbnail": {
"Url": "http://www.example.com/image/481989943",
"Height": 125,
"Width": "100"
},
"IDs": [116, 943, 234, 38793]
}
}
Les détails de syntaxe sont dans la section 2 du RFC. Cet objet d'exemple
a un seul champ, Image, qui est un autre objet
(entre { et }) et qui a plusieurs champs. (Les objets sont appelés
dictionnaires ou maps dans
d'autres langages.) L'ordre des éléments de l'objet n'est pas
significatif (certains analyseurs JSON le conservent, d'autres pas). Un
de ces champs, IDs, a pour valeur un
tableau (entre [ et ]). Les éléments d'un
tableau ne sont pas forcément du même type (section 5, qui précise un
point qui n'était pas clair dans le précédent RFC). Autrefois, un texte JSON était forcément un objet ou un
tableau. Ce n'est plus le cas aujourd'hui donc, par exemple :
"Hello world!"
est un texte JSON légal (composé d'une chaîne de caractères en tout et pour tout). Ce point a d'ailleurs suscité de vigoureuses protestations car un lecteur de JSON qui lit au fil de l'eau peut ne pas savoir si le texte est fini ou pas (avant, il suffisait de compter les crochets et accolades).
Et quel encodage utiliser pour les textes
JSON (section 8) ? Le RFC 4627 était presque muet à ce
sujet. Cette question est désormais plus développée. Le jeu de
caractères est toujours Unicode et l'encodage
par défaut est
UTF-8. UTF-16 et
UTF-32 sont permis mais UTF-8 est le seul qui assure
l'interopérabilité, bien des mises en œuvre de JSON ne peuvent en lire
aucun autre. Les textes JSON ne doivent pas utiliser de
BOM et le RFC ne dit pas comment le récepteur
sait quel est l'encodage utilisé, on suppose qu'il doit être indiqué
par ailleurs (par exemple dans l'en-tête
Content-Type: en HTTP).
Notre RFC ne spécifie pas un comportement particulier à adopter lorsqu'une chaîne de caractères n'est pas légale pour l'encodage choisi. Cela peut varier selon l'implémentation.
Autre problème classique d'Unicode, la comparaison de chaînes de
caractères. Ces comparaisons doivent se faire selon les caractères
Unicode et pas selon les octets (il y a plusieurs façons de
représenter la même chaîne de caractères, par exemple
foo*bar et foo\u002Abar sont la
même chaîne).
JSON est donc un format simple, il n'a même pas la possibilité de commentaires dans le fichier... Voir sur ce sujet une intéressante compilation.
Le premier RFC décrivant JSON était le RFC 4627. Quels changements apporte cette première révision (section 1.3 et annexe A) ? Au début du travail, l'IETF était partagée entre des ultras voulant réparer tous les problèmes de la spécification et les conservateurs voulant changer le moins de choses possible. Finalement, rien de crucial n'a été modifié, quelques bogues ont été corrigées et des points flous du premier RFC ont été précisés (quelques uns ont déjà été présentés plus haut). Cela a quand même posé quelques problèmes philosophiques. Ainsi, le RFC 4627 disait dans sa section 2.2 « The names within an object SHOULD be unique ». Et s'ils ne l'étaient pas, que se passait-il ? Si un producteur de JSON, ignorant l'avertissement, envoie :
{
"name": "Jean Dupont",
"city": "Paris",
"city": "London"
}
Que va faire le récepteur ? Planter ? Prendre la première ville ? La
dernière ? Un ensemble de toutes les villes ? Une solution possible aurait été de transformer le
SHOULD en MUST (cf. RFC 2119) et donc de déclarer cet objet JSON
illégal. Mais cela aurait rendu illégaux des tas d'objets JSON
circulant sur l'Internet et qui n'étaient que déconseillés. Le choix a
donc été de décréter (section 4) que l'objet respectant la règle
« noms uniques » serait interopérable (tous les
récepteurs en feront la même interprétation) alors que celui qui viole
cette règle (comme l'exemple avec deux city plus
haut) aurait un comportement imprévisible. Un programme mettant en
œuvre l'analyse de JSON a donc le droit de choisir parmi tous les
comportements mentionnés plus haut.
Autres changements, un avertissement (section 6) sur la précision des nombres (on peut écrire 3.141592653589793238462643383279 mais on n'a aucune garantie que le récepteur pourra conserver une telle précision).
Voici un exemple d'un programme Python pour écrire un objet Python en JSON (on notera que la syntaxe de Python et celle de JavaScript sont très proches) :
import json
objekt = {u'Image': {u'Width': 800,
u'Title': u'View from Smith\'s, 15th Floor, "Nice"',
u'Thumbnail': {u'Url':
u'http://www.example.com/image/481989943',
u'Width': u'100', u'Height': 125},
u'IDs': [116, 943, 234, 38793],
u'Height': 600}} # Example from RFC 4627, lightly modified
print json.dumps(objekt)
Et un programme pour lire du JSON et le charger dans un objet Python :
import json
# One backslash for Python, one for JSON
objekt = json.loads("""
{
"Image": {
"Width": 800,
"Height": 600,
"Title": "View from Smith's, 15th Floor, \\\"Nice\\\"",
"Thumbnail": {
"Url": "http://www.example.com/image/481989943",
"Height": 125,
"Width": "100"
},
"IDs": [116, 943, 234, 38793]
}
}
""") # Example from RFC 4267, lightly modified
print objekt
print ""
print objekt["Image"]["Title"]
Le code ci-dessus est très simple car Python (comme Perl
ou Ruby ou, bien sûr,
JavaScript) a un typage complètement
dynamique. Dans les langages où le typage est plus statique, c'est
moins facile et on devra souvent utiliser des méthodes dont certains programmeurs
se méfient, comme des conversions de types à l'exécution. Si vous voulez le faire en Go, il existe
un bon
article d'introduction au paquetage standard json.
Pour Java, qui a le même « problème » que Go, il existe une quantité impressionnante de bibliothèques différentes pour faire du JSON (on trouve en ligne plusieurs tentatives de comparaison). J'ai utilisé JSON Simple. Lire un texte JSON ressemble à :
import org.json.simple.*;
...
Object obj=JSONValue.parse(args[0]);
if (obj == null) { // May be use JSONParser instead, it raises an exception when there is a problem
System.err.println("Invalid JSON text");
System.exit(1);
} else {
System.out.println(obj);
}
JSONObject obj2=(JSONObject)obj; // java.lang.ClassCastException if not a JSON object
System.out.println(obj2.get("foo")); // Displays member named "foo"
Et le produire :
JSONObject obj3=new JSONObject();
obj3.put("name","foo");
obj3.put("num",new Integer(100));
obj3.put("balance",new Double(1000.21));
obj3.put("is_vip",new Boolean(true));
JSON dispose d'une page Web officielle, où vous trouverez plein d'informations. Pour tester dynamiquement vos textes JSON, il y a ce service. Il y a aussi des gens critiques, voir par exemple, cette analyse détaillée (avec beaucoup de références au RFC).
L'article seul
RFC 7154: IETF Guidelines for Conduct
Date de publication du RFC : Mars 2014
Auteur(s) du RFC : S. Moonesamy
Première rédaction de cet article le 3 mars 2014
L'IETF, comme toute organisation humaine, a parfois des problèmes avec le comportement de certains de ses membres. Et, même quand il n'y a pas encore eu de problèmes (ce qui semble le cas à l'IETF), cela peut être une bonne idée de les traiter avant qu'ils ne surviennent. C'était le but du RFC 3184 en 2001, RFC que ce nouveau RFC remplace. Voici donc les règles de comportement à l'IETF. Résumées en quelques mots « ne vous comportez pas comme une brute ».
Ce n'est pas forcément une règle triviale à appliquer. En effet, l'IETF rassemble des participants d'origines très diverses. Ils et elles sont de pays différents, de cultures différentes, et ont des avis très distincts sur ce qui constitue un comportement poli et digne. L'idée de base est que chaque participant soit traité avec respect et qu'il n'est pas question de tolérer, par exemple (cet exemple n'est pas dans le RFC, qui évite soigneusement tous les exemples qui auraient l'air féministes) le harcèlement systématiques des participantes qui se fait à DEF CON.
Malheureusement, ce RFC se sent obligé d'ajouter qu'il faut se comporter de manière « professionnelle » comme si les amateurs, eux, étaient des brutes avinées et qu'il n'y a que dans le cadre du travail qu'on peut être civilisé.
Donc, les règles concrètes, en section 2 de ce RFC. D'abord, respect et courtoisie vis-à-vis des collègues, « traitez-les comme vous voudriez être traité » (notez que ce conseil ne tient pas compte, justement, de la diversité... Pas facile de normaliser la politesse.) Le RFC insiste sur le rôle de la langue : l'IETF fait tout en anglais et cette langue n'est pas la langue maternelle de tous les participants. Il est donc crucial que les anglophones en tiennent compte, parlent lentement, en évitant l'argot, et surtout en essayant sincèrement de comprendre le non-anglophone, sans le mépriser parce qu'il ne maîtrise pas la langue de Turing.
Ensuite, le RFC insiste sur le fait qu'on discute d'idées, pas de personnes, et qu'on utilise des arguments rationnels. Les tactiques d'intimidation (« il faut vraiment ne rien connaître à TLS pour proposer une telle modification ») ne sont pas admises. (Ce type de réponse est connu sous l'acronyme SQCFCR, Simple Question, Content-Free Condescending Response. À la place, il faut utiliser le SQPA, Simple Question, Polite Answer.)
Autre règle, qui ne concerne pas directement l'interaction entre les participants, l'obligation de chercher, en conscience, les meilleures solutions pour l'Internet, pas seulement celles qui correspondent aux intérêts d'un groupe particulier. Même si le RFC ne cite pas cet exemple, on peut penser à un participant travaillant pour la NSA qui chercherait à faire adopter une cryptographie de qualité inférieure comme norme IETF, pour faciliter l'espionnage.
Et une dernière règle, l'obligation de ne pas faire perdre son temps aux autres en travaillant sérieusement, en lisant les documents, et en n'oubliant pas de regarder l'historique d'une discussion avant de sauter dedans à pieds joints.
Et en cas de violation de ces règles ? Les témoins, signale l'annexe A du RFC, peuvent les signaler à l'IETF chair ou à l'IESG. L'annexe B décrit les conséquences qui peuvent s'ensuivre, par exemple le refus de laisser la parole à certaines personnes en raison de leur comportement (RFC 2418) ou la mise sur une liste noire des gens dont les messages aux listes de diffusion seront rejetés (RFC 3683 et RFC 3934).
Quels changements depuis le RFC 3184 ? Ils sont documentés dans l'annexe C. Pas de changements de fond, une phrase malheureuse demandant aux débutants de se taire et d'écouter a été retirée, le texte sur l'usage de l'anglais a été changé...
Je recommande la lecture de l'excellent exposé de Radia Perlman à l'IETF 53...
L'article seul
RFC 7158: The JSON Data Interchange Format
Date de publication du RFC : Mars 2014
Auteur(s) du RFC : T. Bray (Google)
Chemin des normes
Première rédaction de cet article le 2 mars 2014
Suite à une stupide erreur de date, ce RFC a été annulé le lendemain de sa publication et remplacé par le RFC 7159 (les RFC ne sont jamais modifiés, leur contenu est immuable).
L'article seul
Un exemple d'attaque NTP par réflexion
Première rédaction de cet article le 27 février 2014
J'ai déjà écrit ici à propos des attaques par déni de service utilisant NTP et la réflexion. Une caractéristique peu connue des attaques sur l'Internet est qu'elles sont rarement étudiées en détail et de manière publique. Chacun garde jalousement ses traces, il y a parfois une étude faite par le service informatique local ou par une organisation extérieure mais il est rare que les détails soient publiés, surtout lorsqu'une procédure judiciaire a été lancée. Résultat, la science ne progresse pas, puisqu'on ne peut pas tenir compte de l'expérience des autres, et on trouve sur les forums publics des tas d'affirmations non sourcées et souvent fausses. Voici donc l'examen sommaire d'une vraie attaque NTP.
Relisez mon article précédent pour le
contexte et notamment sur le fait que ces attaques par réflexion sont
un jeu à trois, l'Attaquant, la Victime et le Réflecteur. Dans le cas
de cette attaque, observée hier (et merci au donateur pour le pcap), le Réflecteur était un
routeur Juniper (oui,
c'est un réflecteur
NTP par défaut). Il avait bien les ACL
nécessaires mais, apparemment suite à une bogue de
JunOS, elles n'étaient pas appliquées (mettre à
jour JunOS a guéri le problème). Son adresse IP est
192.0.2.67 (et, comme disent les articles dans
la presse, les adresses IP ont été changées pour protéger les témoins).
L'attaque a été détectée par la quantité de données pompées par la machine. Une fois détectée, l'administrateur du routeur a pu capturer 24 secondes de trafic pour l'analyser. Premier problème, les fichiers pcap n'étaient pas normaux. Par exemple, cette commande tcpdump marchait bien :
reading from file attack-ntp-bis-february-2014.pcap, link-type JUNIPER_ETHER (Juniper Ethernet) 14:22:05.732503 IP 192.0.2.67.22 > 198.51.100.1.3004: Flags [P.], seq 3663360956:3663361164, ack 954084525, win 33304, options [nop,nop,TS val 6360857 ecr 101630013], length 208 14:22:05.746028 IP 198.51.100.1.3004 > 192.0.2.67.22: Flags [.], ack 0, win 1267, options [nop,nop,TS val 101630083 ecr 6360815], length 0 14:22:05.746176 IP 198.51.100.1.3004 > 192.0.2.67.22: Flags [.], ack 208, win 1267, options [nop,nop,TS val 101630083 ecr 6360857], length 0 ...
Mais une commande très proche mais ne voulant garder que les paquets NTP échoue :
% tcpdump -n -r attack-ntp-bis-february-2014.pcap udp and port 123 reading from file attack-ntp-bis-february-2014.pcap, link-type JUNIPER_ETHER (Juniper Ethernet) tcpdump: pcap_loop: bogus savefile header
Bon, fichier bizarre ou corrompu. Certains programmes s'en tiraient
mieux que d'autres (tshark y
arrivait) mais le mieux est d'essayer de réparer, avec l'excellent
pcapfix. Comme le dit sa
documentation, « pcapfix tries to repair your broken pcap files, fixing the global header and
recovering the packets by searching and guessing the packet
headers ». Une fois pcapfix appliqué (pcapfix -v
attack-ntp-february-2014.pcap, qui produit un fichier
fixed_attack-ntp-february-2014.pcap), cela se
passe un peu mieux (sans être parfait, mais je n'avais pas le temps de
me plonger dans les détails du format pcap et
de ses variations). On voit bien l'attaque, un seul paquet de requête
générant quatre paquets de réponse, pour un facteur d'amplification
NTP de 193 (le facteur réel est bien plus bas, car il y a les en-têtes
UDP, IP et Ethernet) :
14:22:16.653701 IP 203.0.113.220.8080 > 192.0.2.67.123: NTPv2, Reserved, length 8 14:22:16.653912 IP 192.0.2.67.123 > 203.0.113.220.8080: NTPv2, Reserved, length 440 14:22:16.653984 IP 192.0.2.67.123 > 203.0.113.220.8080: NTPv2, Reserved, length 440 14:22:16.654069 IP 192.0.2.67.123 > 203.0.113.220.8080: NTPv2, Reserved, length 440 14:22:16.654152 IP 192.0.2.67.123 > 203.0.113.220.8080: NTPv2, Reserved, length 224
L'examen avec Wireshark des paquets montre
qu'il y a bien utilisation de la fameuse commande
monlist (MON_GETLIST_1 dans
le paquet). Ici, 203.0.113.220 est la Victime, qui va se recevoir tout le trafic amplifié dans la figure. Le premier paquet a une adresse IP source usurpée, il est en fait envoyé par l'Attaquant au Réflecteur, prétendant venir de la Victime.
Avec un petit coup de tshark, on peut trouver les victimes, au nombre de quinze pendant cette période :
% tshark -n -r attack-ntp-bis-february-2014.pcap -T fields -e ip.dst udp.srcport eq 123 \
| sort |uniq |wc -l
15
(Pour ceux qui ne connaissent pas bien tshark : -e
ip.dst lui dit de n'afficher que l'adresse IP de
destination et udp.srcport eq 123 lui dit de
n'afficher que les paquets UDP envoyés par le réflecteur à la
victime.)
Rappelons que c'était en seulement 24 secondes. L'attaquant change
donc de cible souvent, ou bien attaque plusieurs victimes en même
temps. L'examen des adresses IP avec whois montre de tout : une banque japonaise,
un gros pétrolier, un FAI, un gros éditeur de
logiciels, etc.
Quels sont les ports utilisés ? Demandons à awk un coup de main :
% tshark -n -r attack-ntp-bis-february-2014.pcap -T fields -e udp.dstport udp.srcport eq 123 \
| awk '{ ports[$1] = ports[$1] + 1 } END {for(p in ports) { print p, "=", ports[p]}}'
...
80 = 19711
8080 = 5380
123 = 1
43594 = 1848
Traditionnellement, NTP utilisait le port 123, aussi bien en source qu'en destination. Cela peut expliquer l'unique paquet ayant ce port de destination (qui était le port source du paquet envoyé au réflecteur, rappelez-vous qu'on analyse ici les paquets sortants du réflecteur). Plus étonnant est la place de 80. La première réaction est évidemment que l'attaquant visait un serveur HTTP et voulait être sûr de l'atteindre. Mais HTTP fonctionne sur TCP, pas sur UDP (sauf des cas non-standards comme les serveurs de Call of Duty). Donc, si l'attaquant craignait qu'un pare-feu ne lui bloque le trajet, se servir du port 80 ne va pas l'aider, le port 80/UDP est souvent fermé. Il y a plusieurs hypothèses : attaquant incompétent, choix d'un port un peu au pifomètre, hypothèse par l'attaquant que les pare-feux seront mal configurés, autorisant 80 aussi bien en UDP qu'en TCP, désir d'être moins visible sur les données NetFlow, etc.
L'article seul
RFC 7141: Byte and Packet Congestion Notification
Date de publication du RFC : Février 2014
Auteur(s) du RFC : B. Briscoe (BT), J. Manner (Aalto University)
Réalisé dans le cadre du groupe de travail IETF tsvwg
Première rédaction de cet article le 27 février 2014
Lorsqu'un routeur de l'Internet doit stocker des paquets en attente d'envoi au routeur suivant, et que la file d'attente est pleine ou menace de l'être, que doit-il faire ? Il y a très longtemps, le routeur attendait le remplissage de la file et jetait les paquets arrivés ensuite (on appelle cette « méthode » le drop-tail). De nos jours, les routeurs ont en général une approche plus « intelligente », souvent nommée AQM (Active Queue Management) qui consiste à utiliser divers algorithmes pour mieux réagir à cette situation, et limiter ainsi les risques de congestion. Il existe de nombreux algorithmes d'AQM comme, par exemple, RED (la section 1.1 en donne une liste : le RFC utilise en général RED comme exemple). Ce nouveau RFC ne décrit pas encore un algorithme de plus mais expose trois bonnes pratiques qui devraient être suivies par tous les algorithmes d'AQM :
- Les protocoles de transport devraient tenir compte de la taille des paquets, lorsqu'ils réagissent à des signaux indiquant l'arrivée de la congestion,
- Par contre, les routeurs ne devraient pas tenir compte de cette taille lorsqu'ils décident d'agir parce que les tuyaux se remplissent,
- Dans le cas spécifique de l'algorithme RED, son mode « octet », qui privilégie les petits paquets en cas de congestion, ne devrait pas être utilisé (contrairement à ce que recommandait le RFC 2309, section 3, RFC depuis remplacé par le RFC 7567).
À noter que les actions prises par les routeurs lorsqu'ils détectent l'approche de la congestion sont variées : autrefois, il n'y en avait qu'une, laisser tomber des paquets mais, aujourd'hui, un routeur peut faire d'autres choix comme de marquer les paquets (ECN - RFC 3168 ou PCN - RFC 5670).
Le problème de la prise en compte (ou pas) de la taille des paquets lorsqu'on détecte ou réagit à la congestion a occupé les chercheurs depuis de nombreuses années. Les mécanisme pré-AQM, genre drop-tail (lorque la file d'attente est pleine, on jette les messages qui arrivent, ceux qui auraient normalement été mis à la fin de la file), traitaient tous les paquets pareils. Or, il y a des gros et des petits paquets et, en prime, les ressources réseau peuvent être pleines en nombre d'octets (bit-congestible, maximum de b/s atteinte, la limite importante pour les réseaux lents, genre radio) ou en nombre de paquets (packet-congestible, maximum de paquets/s atteint, un indicateur beaucoup moins cité que le précédent mais souvent crucial, par exemple pour la fonction de recherche d'une route dans un routeur). À l'époque, on ne se posait pas trop de questions. Aujourd'hui, on se demande :
- Lorsqu'on mesure la congestion, faut-il mesurer la longueur de la file d'attente en octets, en paquets (rappelez-vous qu'il y a des gros et des petits paquets, donc cela ne donnera pas le même résultat que l'indicateur précédent) ou en temps d'attente ? Le consensus actuel est que le mieux est de compter en temps d'attente mais, si cela n'est pas possible, de compter avec l'indicateur pour lequel le réseau est effectivement limité.
- Lorsqu'un routeur a détecté et signale la congestion (en marquant ou en jetant des paquets), doit-il tenir compte de la taille des paquets, et, par exemple, jeter/marquer préférentiellement les gros ? Il y avait nettement moins de consensus sur cette question, que notre RFC tranche en disant que, non, le routeur devrait ignorer la taille des paquets. Avant ce RFC, les discussions qui avaient mené au RFC 2309 (et qui n'ont pas forcément été documentées dans le RFC 2309, voir ce résumé) recommandaient de marquer/jeter en fonction du nombre d'octets et donc de privilégier les petits paquets. Cela épargnait les importants paquets de contrôle (qui sont en général petits). L'une des raisons du changement de stratégie est que ce n'est pas au routeur de se préoccuper du débit de TCP, ce devrait être à TCP de gérer cela (RFC 2914).
- Lorsque les protocoles de transport comme TCP agissent lorsqu'ils voient un signal de congestion, doivent-ils tenir compte de la taille des paquets ? Il y avait nettement moins de consensus sur cette question, que notre RFC tranche en disant que, oui, TCP devrait prendre en compte la taille des paquets (contrairement au routeur).
L'algorithme RED, tel que décrit dans le RFC 2309, a deux modes, nommés packet mode et byte mode et le second a un effet pervers, encourager les protocoles des couches supérieures à utiliser des petits paquets, qui ont moins de chances d'être jetés. (Notre RFC note que ce mode ne semble heureusement plus utilisé aujourd'hui.) La section 1.2 contient un tableau qui indique la différence de comportement pour deux flots de 48 Mb/s, un comportant uniquement des paquets de 60 octets (donc 100 kp/s) et un autre des paquets de 1 500 octets (donc 4 kp/s). En mode paquet (probabilité de perte de paquet constante), RED maintient le débit (certes, il dégomme davantage de petits paquets mais ceux-ci transportent moins). En mode octet (probabilité de perte d'un octet constante), le débit diminue davantage pour le flot ayant les gros paquets.
TCP, aujourd'hui, ne tient typiquement pas compte de la taille des paquets lorsqu'il prend des décisions comme de diminuer la taille de la fenêtre. En pratique, cela n'a jamais été un problème car, dans une connexion TCP donnée, tous les paquets dans une direction donnée ont la même taille. Mais, dans le futur, cela pourra changer et il est donc utile de rappeler aux auteurs de mises en œuvre de TCP qu'il est au contraire recommandé de considérer la congestion comme plus sérieuse lorsque des gros paquets sont perdus.
Est-ce que le système est limité en nombre de paquets/s (packet-congestible) ou en nombre de bits/s (bit-congestible) ? Tout réseau comporte des composants des deux types. Par exemple, si une machine a des tampons d'entrée-sortie de taille variable, ces tampons seront une ressource bit-congestible (trop de bits et toute la mémoire sera utilisée). S'ils sont de taille fixe, on sera plutôt packet-congestible. Si tout est bien conçu, les deux limites devraient être approchées à peu près en même temps. En pratique, les ressources Internet sont en général actuellement limitées en bits/s (cf. RFC 6077, section 3.3). Il y a aussi des cas plus complexes par exemple un pare-feux à état qui serait limité en nombre de flots simultanés gérés et serait donc flow-congestible.
La section 2 du RFC reprend les recommandations concrètes résumées plus tôt. (Elles sont à nouveau résumés dans la section 7 donc, si vous êtes pressés, vous pouvez vous contenter de lire cette section 7, qui est la conclusion du RFC.) D'abord, la mesure de la taille de la file d'attente. On l'a vu, l'idéal est lorsque cette mesure se fait en secondes (le temps que passera le paquet dans la file, qui peut être élevé en raison du bufferbloat). Mais on ne peut mesurer de manière exacte ce temps que lorsque le paquet quitte la file d'attente, ce qui est trop tard. Donc, en pratique, on mesure en général la file en octets ou en paquets. La première méthode est meilleure si la file d'attente mène à une ressource bit-congestible, la seconde est meilleure si la ressource en aval est packet-congestible. Ainsi, une file d'attente menant à un lien réseau typique se mesurera en octets, une file d'attente menant au moteur de filtrage d'un pare-feu se mesurera plutôt en paquets. Traduit en vocabulaire RED, cela veut dire de choisir le mode octet pour les mesures. Et le RFC déconseille de rendre ce choix configurable, car le fait d'être bit-congestible ou packet-congestible est une propriété inhérente à la file d'attente, et ne dépend pas des opinions de l'administrateur système.
Ensuite, la notification de la congestion. Qu'elle se fasse par la méthode traditionnelle d'IP (jeter le paquet) ou bien par les méthodes plus douces comme l'ECN, elle ne devrait pas dépendre de la taille du paquet. Traduit en langage RED, cela veut dire d'utiliser le mode paquet pour la notification de la congestion (alors que le RFC recommandait l'autre mode, le mode octet, pour la mesure de la file d'attente, attention à ne pas mélanger les deux). Le but principal est de ne pas encourager les flots à multiplier les petits paquets. L'étude des implémentations publiée dans l'annexe A indique que tout le monde fait déjà comme cela, donc le RFC ne fait que documenter l'existant.
Et il reste le cas de la réaction à la congestion. Des paquets
manquent, ou bien arrivent avec un bit ECN. Que doivent faire
TCP ou les autres protocoles de transport ? Ils
devraient considérer l'« intensité » de la congestion comme étant
proportionnelle à la taille des paquets. Comme si l'indication de la
congestion portait sur chaque octet du paquet. Notez que le RFC ne dit
pas ce que TCP doit faire mais comment il doit aborder le
diagnostic. Ensuite, les actions éventuelles doivent être prises par
TCP, pas par le réseau. Si, par exemple, on souhaite que deux flots
TCP utilisant des paquets de taille différentes doivent tourner au
même débit (mesuré en b/s), c'est TCP qui doit s'en occuper, et ne pas
compter que le réseau ajustera les pertes de paquets pour cela. Même
chose pour les paquets de contrôle (un paquet SYN
par exemple).
C'est bon ? Vous avez bien compris ce que le RFC recommandait ? Alors, maintenant, pourquoi ? C'est le rôle de la section 3 que de justifier ces recommandations. D'abord, comme indiquer plus haut, ne pas donner des raisons à une implémentation de privilégier les petits paquets. Comme noté dans le RFC 3426 (ou le papier de Gibbens et Kelly), toujours penser aux effets pervers des bonnes intentions. Favoriser les paquets de petite taille peut sembler raisonnable, mais cela encourage les protocoles de transport à réduire la taille des paquets, donc à augmenter la charge des routeurs. Pire, cela ouvre une voie à certaines attaques par déni de service (en envoyant beaucoup de petits paquets, on peut empêcher les gros de passer).
Ensuite, une des motivations pour l'ancienne recommandation de
privilégier les petits paquets venait du fait que les paquets de
contrôle (qu'il faut essayer de favoriser) sont en général
petits (c'est le cas des paquets TCP SYN et
ACK mais aussi des paquets de certaines
applications par exemple les requêtes DNS et même
les GET HTTP). Mais l'inverse n'est pas vrai, un petit paquet pouvant n'avoir
pas de rôle dans le contrôle. Là encore, favoriser aveuglément tous
les petits paquets encouragerait les protocoles des couches
supérieures à tout découper en petits paquets, ce qui n'est pas le but
recherché.
Une autre raison de donner la priorité aux petits paquets était d'égaliser le débit de deux flots TCP qui enverraient les données dans des segments de taille différente (pour deux flots, TCP maintient le même nombre de segments donc on a plus de débit avec des segments plus grands). Mais, même si on estime ce but souhaitable, il ne devrait pas être réalisé dans les routeurs, qui ne connaissent pas forcément le protocole de transport utilisé (même entre deux TCP, les résultats d'un paquet perdu vont dépendre de l'algorithme utilisé, par exemple NewReno - RFC 5681 - vs. Cubic), mais dans les protocoles de transport, qui peuvent toujours ajuster leur politique comme ils veulent.
Il ne faut pas oublier non plus que le déploiement d'AQM est incomplet : certains routeurs font de l'AQM, d'autres pas. Les protocoles de transport doivent donc de toute façon gérer leur propre politique, ils ne peuvent pas être sûrs que le réseau le fera pour eux. C'est une variante de l'argument classique en faveur d'un contrôle de bout en bout (cf. J.H. Saltzer, D.P. Reed et David Clark, « End-To-End Arguments in System Design ») : ne faites pas dans le réseau ce que vous pouvez faire aux extrémités.
Une critique plus détaillée des anciennes recommandations, notamment à propos de RED, figure en section 4. Très intéressante lecture pour les étudiants qui veulent comprendre la congestion et les moyens de la combattre. Le papier originel de RED (Floyd et Van Jacobson, « Random Early Detection (RED) gateways for Congestion Avoidance ») introduisait les deux modes dont j'ai parlé, mode octet et mode paquet. Mais il ne recommandait pas un mode spécifique. Quand RED est devenu la recommandation officielle dans le RFC 2309, cinq ans plus tard, il n'y avait pas encore une recommandation claire (depuis, RED a perdu son statut, cf. RFC 7567). C'est dans les échanges de courrier cités plus haut que s'était forgée petit à petit l'idée qu'il fallait distinguer la mesure de la congestion (en octets ou en paquets) et l'action (même probabilitité d'abandon pour tous les paquets, ou bien une probabilité qui dépend de leur taille).
La mesure de la congestion n'est pas triviale. Par exemple, un routeur peut avoir une file d'attente packet-congestible (par exemple parce que le routeur utilise un tampon de taille fixe par paquet en attente) mais qui donne accès à une ressource bit-congestible. Que choisir dans ce cas ? Notre RFC dit qu'il faut quand même compter en octets : c'est la congestion de la ressource la plus en aval qu'il faut compter. Cette règle simple à l'avantage de marcher aussi si la file d'attente est plus compliquée, se servant de plusieurs jeux de tampons (des petits, des grands...), chaque jeu étant d'une taille donnée (ce que Cisco nomme buffer carving).
Et s'il n'y a pas de file d'attente à proprement parler ? Par exemple, l'alimentation électrique d'un engin qui communique par radio est en général bit-congestible car la consommation électrique dépend du nombre de bits transmis. Mais il n'existe pas de file d'attente des paquets attendant que la batterie se remplisse. En fait, AQM n'impose pas une file d'attente. D'autres moyens que la longueur de cette file permettent de mesurer la congestion, comme expliqué dans « Resource Control for Elastic Traffic in CDMA Networks » dans le cas de l'exemple de l'engin sans fil.
Le problème d'une discrimination envers les grands paquets n'est pas spécifique aux mécanismes « avancés » d'AQM. Le bête et traditionnel tail-drop (jeter les nouveaux paquets entrants quand la file est pleine) tend à rejeter surtout les grands paquets (s'il y a un peu de place, on n'acceptera que les petits paquets : donc, dès que la file d'attente « avance », les petits paquets la rempliront avant qu'elle n'ait eu le temps de se vider assez pour un grand paquet). Même chose lorsqu'on a plusieurs jeux de tampons et qu'on autorise les petits paquets à occuper les grands tampons.
Et du côté des protocoles de transport, qu'est-ce qui a été fait ? Suivant la ligne du RFC 5348, le protocole TFRC-SP, spécifié dans le RFC 4828 vise à favoriser les petits paquets mais au bon endroit, dans le protocole de transport aux extrémités, pas dans les routeurs.
Cela ne résout pas le problème des paquets de contrôle, qui sont en général de petite taille (mais rappelez-vous que l'inverse n'est pas vrai). Une solution possible est de rendre TCP plus solide face à la perte de paquets de contrôle. Cela a été décrit dans les RFC 5562 et RFC 5690. Ces deux RFC disent d'ailleurs qu'il vaudrait peut-être mieux que les routeurs ne laissent pas tomber les petits paquets. Mais notre RFC 7141 dit au contraire qu'il faut résoudre le problème aux extrémités, pas dans les routeurs. D'autres propositions de réforme de TCP ont été proposées, parfois assez rigolotes comme la proposition de Wischik de dupliquer systématiquement les trois premiers paquets de toute connexion TCP, ce qui ajouterait peu de trafic (ces paquets sont petits) mais rendrait TCP bien plus résistant aux pertes des petits paquets, ou encore une proposition similaire qui a été testée sur les serveurs de Google.
La section 5 du RFC est consacrée aux questions non répondues. Notre RFC est clair dans ses recommendations (que le routeur ne tienne pas compte de la taille des paquets mais que le transport le fasse). Mais cela ne répond pas à tout :
- Comment gérer le cas des routeurs à AQM existants, s'ils mettent en œuvre le mode octet désormais déconseillé ?
- Comment déployer les nouvelles recommandations dans les protocoles de transport ?
La première question est relativement facile car l'étude documentée dans l'annexe A montre que le mode octet a été peu déployé. On peut donc ignorer le problème. Pour la deuxième, il existe des modifications expérimentales des protocoles de transport (RFC 4828) mais rien de systématique.
Il n'y a donc pas trop de problèmes si l'Internet reste comme il est, essentiellement composés de ressources bit-congestible. Mais s'il se peuplait petit à petit de ressources packet-congestible ? La question avait déjà été posée dans la section 3 du RFC 6077 mais n'a pas encore de réponse.
Ces recommandations ont-elles des conséquences sur la sécurité de l'Internet ? La section 6 de notre RFC dit que oui, dans un sens positif. En effet, l'ancienne recommandation, de jeter en priorité les gros paquets, facilitait certaines attaques par déni de service. Après tout, une des raisons de déployer AQM était d'éviter le biais en faveur des petits paquets qui était un conséquence du tail drop. Le mode octet d'AQM pouvait donc être vu comme une réintroduction d'une vulnérabilité qu'AQM voulait justement éviter.
L'annexe A rend compte de l'étude de 2007 qui montre qu'aucun des vendeurs d'équipement (routeurs, pare-feux, etc) ayant répondu à l'enquête (16 répondants) ne mettait en œuvre le mode octet pour décider de laisser tomber les paquets (donc, ils n'auront rien à faire, ce RFC 7141 rend juste compte de leur pratique actuelle). À noter que la plupart des vendeurs n'ont pas voulu être identifiés (les deux exceptions sont Alcatel-Lucent et Cisco, plus Linux qui a pu être étudié sans le vendeur, puisqu'en logiciel libre). Autre sujet d'amusement, deux vendeurs n'étaient pas sûrs et devaient vérifier. Les justifications données étaient plutôt égoïstes : prendre en compte la taille des paquets avant de décider de les jeter aurait compliqué le code. Maintenant, qu'est-ce qui est déployé dans le vrai Internet ? Bien qu'il n'y ait pas d'étude à ce sujet, les auteurs du RFC pensent que bien des files d'attente sur l'Internet sont encore tail drop, pré-AQM, notamment dans les équipements de bas de gamme. Les équipements qui font de l'AQM mais avec des tampons de taille fixe, comme ceux en tail drop continuent à favoriser (légèrement) les paquets de petite taille mais il est difficile de mesurer l'exacte ampleur de leur déploiement.
L'article seul
NSD 4, plus dynamique
Première rédaction de cet article le 26 février 2014
J'ai déjà parlé ici du serveur de noms nsd, le logiciel actuellement le plus rapide pour servir des zones DNS. Un reproche souvent fait à NSD est son côté très statique. Pour ajouter ou retirer une zone, voire simplement pour changer l'adresse IP d'un serveur maître, il faut redémarrer complètement le serveur. La version 4 de NSD, sortie il y a peu, règle ce problème.
Avec la version 4, NSD dispose enfin d'un logiciel de contrôle,
nsd-control (équivalent du
unbound-control d'Unbound, du rndc de
BIND ou du knotc de Knot). Cela permet des choses triviales comme :
% sudo nsd-control status version: 4.0.1 verbosity: 1 ratelimit: 200
Mais on peut aussi avoir des informations par zone. Un des serveurs de
nom d'eu.org
utilise ainsi NSD 4 depuis deux mois :
% sudo nsd-control zonestatus eu.org zone: eu.org state: ok served-serial: "2014022601 since 2014-02-26T09:43:38" commit-serial: "2014022601 since 2014-02-26T09:43:38"
On a aussi des statistiques (ici, juste après un démarrage du serveur) :
% sudo nsd-control stats num.queries=27 num.type.A=18 num.type.MX=4 num.type.TXT=1 num.type.AAAA=2 num.type.SRV=1 ... num.rcode.NOERROR=26 num.rcode.NXDOMAIN=1 ... num.edns=19 ... num.udp=24 num.udp6=3 num.tcp=0 num.tcp6=0 ...
Mais tout ceci est en lecture seule. L'important est qu'on peut
aussi modifier la configuration du serveur en vol. Je modifie le
nsd.conf pour diminuer la tolérance du limiteur
de trafic (rrl-ratelimit: 100) puis :
% sudo nsd-control reconfig reconfig start, read /etc/nsd/nsd.conf ok % sudo nsd-control status version: 4.0.1 verbosity: 1 ratelimit: 100
Et j'ai la nouvelle valeur.
Et si je veux ajouter une zone à servir ? On peut simplement
l'ajouter à nsd.conf et faire un
nsd-control reconfig :
% sudo nsd-control reconfig reconfig start, read /etc/nsd/nsd.conf ok % sudo nsd-control zonestatus ... zone: example.com state: refreshing served-serial: none commit-serial: none
Et, très peu de temps après :
% sudo nsd-control zonestatus example.com zone: example.com state: ok served-serial: "2014022601 since 2014-02-26T10:17:27" commit-serial: "2014022601 since 2014-02-26T10:17:27"
Et le serveur va alors répondre avec autorité aux requêtes DNS concernant cette zone.
Mais il existe une autre méthode, plus adaptée aux gens qui gèrent
plein de zones à la configuration identique. Avec cette seconde
méthode, on n'ajoute pas la zone dans nsd.conf.
Il faut qu'il existe dans
le nsd.conf un pattern
indiquant les paramètres de la zone. On pourra ensuite ajouter la zone
dynamiquement en se référant à ce pattern. Voici
un exemple de pattern nommé
personalslave :
pattern:
name: personalslave
allow-notify: 2001:db8:cafe::1:53 NOKEY
request-xfr: AXFR 2001:db8:cafe::1:53 NOKEY
Et la création d'une zone qui ne sera pas dans
nsd.conf :
% sudo nsd-control addzone example.org personalslave ok % sudo nsd-control zonestatus example.org zone: example.org pattern: personalslave state: ok served-serial: "2014022400 since 2014-02-26T10:26:40" commit-serial: "2014022400 since 2014-02-26T10:26:40"
La détruire est aussi simple :
% sudo nsd-control delzone example.org ok
Il y a encore plein de choses à voir mais je vous laisse déjà vous amuser avec cela.
L'article seul
RFC 7142: Reclassification of RFC 1142 to Historic
Date de publication du RFC : Février 2014
Auteur(s) du RFC : M. Shand, L. Ginsberg (Cisco Systems)
Pour information
Réalisé dans le cadre du groupe de travail IETF isis
Première rédaction de cet article le 26 février 2014
Voilà ce qui arrive lorsqu'un protocole est normalisé par deux organisations à la fois... Il existe depuis longtemps un doute sur le RFC 1142, censé décrire le protocole de routage IS-IS. Est-ce bien la norme de référence ? Non, dit notre nouveau RFC 7142. La norme de référence est à l'ISO et le RFC 1142, plus à jour, ne doit pas être utilisé.
IS-IS est en effet normalisé par l'ISO sous le numéro ISO/IEC 10589:2002. L'ISO, vieux dinosaure bureaucratique, n'a pas encore été informée de l'existence de l'Internet et ne distribue donc la plupart de ses normes que sous forme papier (IS-IS, on le verra, est une exception). Le RFC 1142 avait été prévu à l'origine pour être une reprise de la norme ISO 10589, distribuée librement et donc plus accessible. Mais IS-IS a évolué pendant ce temps, et le RFC 1142 n'a pas bougé, devenant de plus en plus décalé par rapport à la norme ISO officielle. (À noter aussi le RFC 1195, qui adapte IS-IS à IP.) Mettre à jour le RFC 1142 semble impossible pour des raisons de propriété intellectuelle à l'ISO.
Notre RFC 7142 prend donc acte de ce décalage et reclassifie le RFC 1142 comme « d'intérêt historique seulement ». Si vous voulez lire la norme officielle sur IS-IS, il faut aller à l'ISO.
À noter qu'il existe un autre protocole de routage interne, OSPF et que lui est normalisé dans des documents librement accessibles (RFC 2328 pour la v2 ou bien RFC 5340 et RFC 5838 pour la v3, moins déployée aujourd'hui).
L'article seul
RFC 7132: Threat Model for BGP Path Security
Date de publication du RFC : Février 2014
Auteur(s) du RFC : S. Kent (BBN), A. Chi (UNC-CH)
Pour information
Réalisé dans le cadre du groupe de travail IETF sidr
Première rédaction de cet article le 22 février 2014
Tout le monde le sait, le système de routage de l'Internet, fondé sur le protocole BGP, n'est pas sûr. Il est trop facile d'y injecter des annonces de routes mensongères. Le premier pas vers une sécurité plus forte était de sécuriser la communication entre routeurs (RFC 5925). Un second pas a été réalisé avec le déploiement de la RPKI. Un troisième pas avec la normalisation de la solution RPKI+ROA. Cette dernière protège uniquement l'origine d'une annonce BGP. Cela suffit à arrêter pas mal d'erreurs mais une attaque délibérée gardera probablement l'origine authentique et trichera sur le chemin d'AS présent dans l'annonce BGP. D'où la nécessité de continuer le travail. C'est le projet PATHSEC (Path Security) pour lequel ce nouveau RFC énumère les motivations. (Le terme de BGPSEC avait été utilisé dans le passé mais PATHSEC semble plus fréquent aujourd'hui.)
Le but de PATHSEC est simple : garantir que le chemin
d'AS dans une annonce BGP est
authentique, et que les NLRI (Network Layer Reachability
Information) soient celles originellement annoncées. (Rappelez-vous que les ROA du RFC 6482 ne protègent que le début du chemin, l'origine.) Le
chemin d'AS est transporté dans l'annonce BGP par l'attribut
AS_PATH (RFC 4271, sections 4.3 et 5.1.2). La
stratégie de PATHSEC est de s'appuyer sur la RPKI (RFC 6487), une infrastructure de distribution de
certificats et d'objets signés. PATHSEC ne
comptera pas sur une instance centrale qui connaitrait toutes les
annonces BGP et pourrait tout vérifier. Au contraire, comme BGP
lui-même, PATHSEC s'appuiera sur une vue locale, celle des routeurs
d'un AS.
Pour concevoir proprement PATHSEC, il faut analyser les menaces, faire une analyse de risque. Que peut faire un méchant, même si tout le monde a déployé la RPKI et émet des ROA ? Il existe déjà des documents d'analyse des faiblesses de la sécurité du routage comme le RFC 4272 ou comme l'article de Kent, Lynn et Seo, « Design and Analysis of the Secure Border Gateway Protocol (S-BGP) » à la conférence IEEE DISCEX en 2000. Ce RFC détaille les faiblesses, notamment en indiquant celles qui resteront même dans un monde futur où tout les acteurs auront déployé PATHSEC. Le cahier des charges formel, lui, a été publié plus tard, dans le RFC 7353.
La section 3 résume les concepts. Une menace est un adversaire motivé et compétent. Il existe plusieurs catégories de menaces. Les opérateurs du réseau en sont une. L'opérateur peut demander à ses routeurs BGP d'émettre des messages visant à perturber le réseau ou à dérouter du trafic, par exemple pour le faire passer par des liens financièrement avantageux pour lui. Le contrôle légitime de routeurs BGP de la DFZ fait de cette catégorie d'attaquants potentiels une menace sérieuse. Si cet opérateur participe à la RPKI, il peut aussi émettre des vrais/faux certificats et ROA. Avec PATHSEC, il pourra donc signer de faux chemins d'AS.
Autre catégorie d'attaquants, les pirates informatiques qui prendraient le contrôle d'un ou plusieurs routeurs. Leurs capacités de nuisance seraient donc à peu près les mêmes que celles d'un opérateur, mais avec des limites (monter une attaque de l'Homme du Milieu serait plus difficile pour eux, le contrôle des routeurs ne donne pas forcément le contrôle de l'AC RPKI, etc). Le pirate est distinct du délinquant, étudié dans le paragraphe suivant, non par ses motivations (elles n'ont pas d'importance pour cette analyse technique du routage et de sa sécurité), mais par le fait que cette catégorie opère en général purement à distance, sans accès physique aux équipements. Le délinquant, lui, a d'autres possibilités. Par menace, chantage ou corruption, il peut même enrôler dans ses activités des employés de l'opérateur réseau. Contrairement au pirate, qui a parfois des motivations politiques, le délinquant est typiquement motivé par l'argent. Par exemple, il peut être payé pour réaliser une attaque par déni de service.
Les RIR sont aussi une menace pour le routage. Attribuant les ressources Internet (notamment les adresses IP), et étant à la racine de la RPKI, ils ont la possibilité de casser le routage. Pour prendre un exemple souvent cité, « l'attaque de la police néerlandaise », une action en justice aux Pays-Bas contre le RIPE-NCC pourrait mener à une perturbation du routage de l'opérateur dont les ressources auraient été reprises par le RIR.
Enfin, les États sont eux-même souvent la principale menace. L'État contrôle, directement ou indirectement, les opérateurs sur son territoire, il a parfois des capacités de surveillance massive, il peut monter des attaques de l'Homme du Milieu (l'Iran l'a fait plusieurs fois et les mollahs ne sont certainement pas les seuls à le faire). Comme expliqué plus haut, l'État peut aussi avoir barre sur le RIR situé sur son territoire. Certaines de ces attaques peuvent se commettre en dehors du territoire de l'État (la NSA ou la DGSE espionnent à l'extérieur).
Après ce tour des (méchants) acteurs, la section 4 de notre RFC
décrit les catégories d'attaques. D'abord, les attaques contre la
session BGP établie entre deux routeurs. Un attaquant peut perturber
une telle session (envoyer des paquets TCP
RST) et ainsi fait du déni de service. Il peut
aussi faire l'Homme du Milieu : le routeur d'Alice croit qu'il parle
au routeur de Bob alors qu'en fait il parle au routeur pirate. Dans
tous les cas, si la session BGP n'est pas protégée, l'attaquant peut
faire des choses comme modifier les annonces BGP. Le problème est
connu depuis longtemps, le RFC 4272 en parle en
détail, et décrit les solutions. En gros, on peut considérer ce
problème particulier comme étant résolu depuis des années.
Mais l'attaquant peut aussi viser directement le routeur. Que ce soit par piratage ou bien parce que l'attaquant est le gérant légitime du routeur, le résultat est le même. Une fois qu'on contrôle un routeur, on peut effectuer plein d'attaques. Attention, BGP permettant un contrôle détaillé de la politique de routage, toute manipulation BGP n'est pas forcément une attaque. Le RFC cite l'exemple d'une fuite où certaines routes sont propagées au-delà de ce que d'autres opérateurs considèrent comme légitime ; cela peut être une mauvaise idée égoïste, sans être forcément une attaque. (Un autre exemple pourrait être les annonces ultra-larges.) Par contre, ces manipulations seront unanimement considérées commes des attaques :
- Insérer d'autres numéros d'AS que les siens dans le chemin,
- Être à l'origine d'une route sans autorisation (les ROA - RFC 6482 - sont justement là pour bloquer cela),
- Voler (par copie) les clés privées utilisées par le routeur, soit pour l'authentification avec les routeurs voisins (s'ils utilisent l'AO du RFC 5925) soit pour signer les annonces de route avec PATHSEC,
- Et plusieurs autres (voir le RFC pour les détails).
Autres attaques possibles, moins directes : viser non pas les routeurs mais les machines de gestion du réseau. Si les routeurs sont gérés par un système central, avec Ansible ou Chef ou un logiciel équivalent, prendre le contrôle du système central permet de contrôler tous les routeurs.
La RPKI a ses propres vulnérabilités. L'attaquant peut viser un dépôt d'objets de la RPKI. S'il détruit les objets du dépôt ou bien rend celui-ci inutilisable, il a réalisé une attaque par déni de service contre la RPKI (voir aussi la section 5, sur ce risque). Notons quand même que la RPKI n'a jamais été prévu pour être synchrone. Les validateurs sont censés garder des copies locales et peuvent donc survivre un certain temps à une panne d'un dépôt en utilisant ces copies locales (et les durées typiques de synchronisation sont bien plus longues qu'avec le DNS, donc la mise en cache isolera de l'attaque pendant plus longtemps). Et, les objets étant signés, l'attaquant qui contrôle un dépôt ne peut pas changer les objets. Les manifestes du RFC 6486 protègent également contre certaines manipulations. Par contre, la RPKI reste vulnérable à certaines attaques par rejeu. Les opérateurs de la RPKI doivent donc choisir des dates de validité de leurs objets assez courtes pour les protéger du rejeu mais assez longues pour ne pas entraîner des problèmes opérationnels si, par exemple, le système de signature a un problème. (On note que c'est un problème très proche de celui de la sélection des durées de vie de signatures DNSSEC.)
Bien plus grave serait l'attaque réussie contre l'autorité de certification, et plus seulement contre le dépôt de publication. Parce que, cette fois, l'attaquant serait en mesure de créer des objets signés à sa guise. Il n'y a même pas besoin que l'attaquant réussisse à copier la clé privée de l'AC : il suffit qu'il prenne le contrôle du dispositif de gestion des données, avant la signature (c'est pour cela que les HSM ne protègent pas autant qu'on le croit, même s'ils ont le gros avantage de faciliter la réparation, une fois le problème détecté).
L'expérience de DNSSEC permet de prédire que les problèmes provoqués par la négligence, les bogues ou l'incompétence seront sans doute au moins aussi fréquents que les attaques. Pour reprendre une citation dans Pogo, rappelée par notre RFC, « We Have Met the Enemy, and He is Us ».
Enfin, la section 5 liste les vulnérabilités résiduelles, celles que même un déploiement massif de PATHSEC ne limiterait pas. Par exemple, une AC peut mal se comporter avec ses propres ressources (émettre un ROA pour un de ses préfixes mais avec le mauvais numéro d'AS, suite à une faute de frappe, par exemple). Même avec PATHSEC, quelques risques resteront. On a déjà parlé des fuites (route réannoncée alors qu'elle ne le devrait pas, mais avec un chemin d'AS correct), qu'on peut d'autant moins empêcher qu'il n'existe pas de définition consensuelle de ce qu'est une fuite. Il y a aussi le fait que PATHSEC ne protège pas tous les attributs d'une annonce BGP, alors même que certains sont utilisés pour prendre des décisions de routage. Et puis PATHSEC permet de vérifier une annonce mais pas de vérifier que l'annonce n'a pas été retirée entre temps. Si un lien est coupé, que des routeurs BGP retirent la route, mais qu'un méchant intercepte et détruit ces retraits de route, les anciennes annonces resteront valables un certain temps.
L'article seul
RFC 7128: RPKI Router Implementation Report
Date de publication du RFC : Février 2014
Auteur(s) du RFC : R. Bush (Internet Initiative Japan), R. Austein (Dragon Research Labs), K. Patel (Cisco Systems), H. Gredler (Juniper Networks), M. Waehlisch (FU Berlin)
Pour information
Réalisé dans le cadre du groupe de travail IETF sidr
Première rédaction de cet article le 22 février 2014
Le protocole RTR (RPKI to Router Protocol), normalisé dans le RFC 6810, est utilisé entre un routeur et un cache/validateur qui vérifie les objets signés de la RPKI. Ce nouveau RFC fait le point sur les mises en œuvre effectives de RTR et leur degré de couverture de la norme.
C'est un RFC un peu particulier : ce n'est pas la normalisation d'un protocole (c'est fait dans le RFC 6810) et ce n'est pas une étude indépendante, juste une collecte de réponses à un questionnaire. Les auteurs du RFC n'ont pas vérifié ces réponses, envoyées par les auteurs des différentes mises en œuvre de RTR.
Petit rappel sur la RPKI : les titulaires de ressources Internet (les préfixes d'adresses IP, notamment) émettent des objets cryptographiquement signés attestant notamment de la légitimité d'un AS à annoncer tel préfixe en BGP. La vérification de ces objets nécessite des calculs cryptographiques pour lesquels le routeur moyen n'est pas forcément bien équipé. L'architecture conseillée est donc d'avoir une machine Unix ordinaire, le cache/validateur, qui va faire ces calculs, et le routeur se contentera de charger les résultats depuis un cache/validateur de confiance. Entre les deux, le protocole RTR, où le serveur est le cache/validateur et le client est le routeur.
La section 2 du RFC liste les mises en œuvre interrogées, aussi bien clients que serveur. (J'ai écrit une bibliothèque très minimum pour faire des clients RTR en Go à des fins notamment de statistiques : GoRTR. Très réduite et peu utilisée, elle ne fait pas partie de la liste étudiée par notre RFC.) On trouve donc dans ce RFC :
- Des clients RTR, aussi bien des routeurs (IOS, XR ou JunOS) que des bibliothèques permettant de bâtir des clients (RTRlib).
- Des serveurs RTR, deux en logiciel libre, rpki.net (rcynic) et le logiciel du RIPE-NCC, puis celui de BBN (rpstir).
Le reste du RFC contient les résultats du questionnaire. D'abord, la gestion des différents types de message (section 3). Tout le monde le fait, évidemment, sauf XR et JunOS qui ne gèrent pas encore les messages Error Report. Ensuite, la gestion des échanges entre client et serveur (section 4) : presque complet sauf le programme du RIPE-NCC qui, aux questions Serial Query, envoie toujours un Cache Reset, forçant le client à tout télécharger.
Une des questions chaudes lors de la mise au point de RTR était le mécanisme de transport entre le client et le serveur, notamment pour assurer la sécurité (si le client, le routeur, parce qu'il a été trompé, parle à un serveur pirate, la sécurité fournie par la RPKI disparait, puisque le routeur ne fait pas les vérifications cryptographiques lui-même). Finalement, pour tenir compte des capacités très différentes des routeurs du marché, le RFC 6810 avait laissé les programmeurs choisir leur transport sécurisé librement. L'étude montre (section 5) que le seul protocole commun à toutes les mises en œuvre de RTR est le TCP pur, non sécurisé... Un autre choix, TCP protégé par le vieil RFC 2385, n'a au contraire rencontré aucun adepte. Même chose, hélas, pour TLS, pour le TCP-AO du RFC 5925 (ce dernier était pourtant recommandé par le RFC 6810), et pour IPsec. SSH, par contre, est une solution possible pour la moitié des implémentations. Bref, la sécurité des sessions RTR reste un sujet de préoccupation.
Et la gestion des différents codes d'erreur possible (section 6) ? À part JunOS, qui ignore les erreurs, tous ont répondu positivement.
Pour éviter de télécharger la liste des préfixes autorisés, avec leurs AS d'origine, à chaque changement, RTR a un système de mise à jour incrémentale. Nos programmes le mettent-ils en œuvre (section 7) ? Oui, sauf le serveur du RIPE-NCC et ceux des routeurs Cisco. Pour le concept de Session ID, qui permet d'indiquer que le cache/validateur a redémarré, c'est mieux, seul le validateur du RIPE-NCC ne le gère pas (section 8).
La section 10 termine ce RFC avec des questions sur les tests d'interopérabilité qui ont été faits. On notera avec amusement que les vendeurs de solutions privatrices, comme Cisco ou Juniper, n'ont pas testé leurs produits entre eux, mais l'ont fait uniquement face aux logiciels libres.
L'article seul
RFC 7129: Authenticated Denial of Existence in the DNS
Date de publication du RFC : Février 2014
Auteur(s) du RFC : R. Gieben (Google), W. Mekking (NLnet Labs)
Pour information
Première rédaction de cet article le 13 février 2014
Voilà une expression un peu effrayante, « la négation d'existence
authentifiée ». C'est en fait un terme utilisé dans le
DNS et notamment dans
DNSSEC, pour indiquer qu'un résolveur DNS a pu
prouver qu'un nom n'existe pas, ou bien qu'il existe mais qu'il n'a
pas de données de tel type. Dans DNSSEC, cela se fait typiquement avec
des enregistrements NSEC et
NSEC3, dont la définition n'est pas toujours
claire pour tout le monde. Ce RFC a donc pour
but d'expliquer « tout ce qu'il faut savoir sur la négation
d'existence authentifiée ». C'est une lecture indispensable pour les
programmeurs qui vont mettre en œuvre DNSSEC, mais aussi pour les
étudiants ou ingénieurs qui veulent comprendre DNSSEC y compris dans
ses tréfonds les plus obscurs.
C'est que NSEC et, surtout,
NSEC3 sont très compliqués, reconnait ce RFC dès
sa première section. C'est même une des parties les plus compliquées
de DNSSEC, qui n'en manque pourtant pas.
DNSSEC fonctionne en signant
cryptographiquement les données retournées. Mais il ne
signe pas les messages. Il y a deux codes de retour pour une réponse DNS lorsque le nom
n'existe pas ou bien qu'il n'y a pas de données du type demandé. Dans
le premier cas, le serveur DNS répond NXDOMAIN
(No Such Domain), dans le second
NOERROR mais avec un champ Answer
Count à zéro, ce qu'on nomme une réponse
NODATA. Dans les deux cas, aucun enregistrement
n'est renvoyé. Comment signer le vide ? C'est pourtant indispensable,
autrement un attaquant pourrait, par exemple, fabriquer une réponse
prétendant qu'un enregistrement DS (délégation
signée) n'existe pas, débrayant ainsi la sécurité qu'offre DNSSEC
(section 6 de notre RFC).
Tous les exemples du RFC sont faits avec une petite zone d'exemple,
example.org dont voici le contenu non signé :
example.org. SOA ( ... )
NS a.example.org.
a.example.org. A 192.0.2.1
TXT "a record"
d.example.org. A 192.0.2.1
TXT "d record"
Chargeons-la dans NSD pour voir et pouvoir
reproduire les tests (le serveur va écouter sur le
port 9053). D'abord (section 2 du RFC), avec une zone non
signée. Premier test, le résolveur demande les enregistrements de type
TXT pour a.example.org (le
fichier de configuration de dig contient
l'option +dnssec et donc impose
EDNS) :
% dig @::1 -p 9053 TXT a.example.org ; <<>> DiG 9.9.3-rpz2+rl.13214.22-P2-Ubuntu-1:9.9.3.dfsg.P2-4ubuntu1.1 <<>> @::1 -p 9053 TXT a.example.org ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 46585 ;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 1, ADDITIONAL: 2 ;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 4096 ;; QUESTION SECTION: ;a.example.org. IN TXT ;; ANSWER SECTION: a.example.org. 3600 IN TXT "a record" ;; AUTHORITY SECTION: example.org. 3600 IN NS a.example.org. ;; ADDITIONAL SECTION: a.example.org. 3600 IN A 192.0.2.1 ;; Query time: 1 msec ;; SERVER: ::1#9053(::1) ;; WHEN: Mon Jan 20 18:46:25 CET 2014 ;; MSG SIZE rcvd: 93
On a bien le code de retour NOERROR et un seul
enregistrement en réponse. On récupère aussi des informations
facultatives dans les sections Authority et
Additional. Si on demande par contre
b.example.org :
% dig @::1 -p 9053 TXT b.example.org ; <<>> DiG 9.9.3-rpz2+rl.13214.22-P2-Ubuntu-1:9.9.3.dfsg.P2-4ubuntu1.1 <<>> @::1 -p 9053 TXT b.example.org ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 10555 ;; flags: qr aa rd; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 1 ;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 4096 ;; QUESTION SECTION: ;b.example.org. IN TXT ;; AUTHORITY SECTION: example.org. 3600 IN SOA a.example.org. root.example.org. ( 2014012000 ; serial 604800 ; refresh (1 week) 86400 ; retry (1 day) 2419200 ; expire (4 weeks) 86400 ; minimum (1 day) ) ;; Query time: 0 msec ;; SERVER: ::1#9053(::1) ;; WHEN: Mon Jan 20 18:48:18 CET 2014 ;; MSG SIZE rcvd: 85
On a bien un NXDOMAIN. La section
Authority nous donne le SOA
de la zone.
Il y a un autre cas où la négation d'existence est nécessaire : lorsque le nom existe mais qu'il n'y a pas de données de ce type. Par exemple, si je demande une adresse IPv6 (qui n'est pas dans la zone) :
% dig @::1 -p 9053 AAAA a.example.org ; <<>> DiG 9.9.3-rpz2+rl.13214.22-P2-Ubuntu-1:9.9.3.dfsg.P2-4ubuntu1.1 <<>> @::1 -p 9053 AAAA a.example.org ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 55053 ;; flags: qr aa rd; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 1 ;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 4096 ;; QUESTION SECTION: ;a.example.org. IN AAAA ;; AUTHORITY SECTION: example.org. 3600 IN SOA a.example.org. root.example.org. ( 2014012000 ; serial 604800 ; refresh (1 week) 86400 ; retry (1 day) 2419200 ; expire (4 weeks) 86400 ; minimum (1 day) ) ;; Query time: 0 msec ;; SERVER: ::1#9053(::1) ;; WHEN: Thu Jan 23 10:07:06 CET 2014 ;; MSG SIZE rcvd: 83
Ici, a.example.org a bien une adresse
IPv4 dans la zone (et donc, le nom existe) mais
pas d'adresse IPv6. Le code de retour est NOERROR
(pas de problème) mais le compteur de réponses
(ANSWER:) indique zéro. C'est ce qu'on appelle
une réponse NODATA même si ce code n'apparait
jamais dans les normes DNS.
Maintenant, passons en DNSSEC (section 3). D'abord, le rappel de quelques principes :
- Les signatures DNSSEC peuvent être calculées à la volée (lors d'une requête) ou bien pré-calculées puis mises dans la zone. Les deux modes sont possibles (DNSSEC a été soigneusement conçu pour que les serveurs de noms ne soient pas obligés de faire de la cryptographie en temps réel) mais la plupart des déploiements actuels utilisent le pré-calcul. Pourquoi ne pas avoir imposé la signature dynamique (elle aurait simplifié certaines choses) ? Parce que le matériel de l'époque de la conception de DNSSEC ne permettait pas de signer à ce rythme et, même aujourd'hui, il faut se rappeler que des serveurs travaillent fréquemment à plus de 10 000 requêtes par seconde, avec des pics plus élevés. D'autre part, la signature à la volée nécessite que la clé privée soit distribuée à tous les serveurs faisant autorité, ce qui peut être difficile et est certainement peu sûr.
- La réponse DNS n'est jamais signée, ce sont les données qui le
sont. Ce qui veut dire que tous les en-têtes de la réponse DNS (comme
le code de retour
NXDOMAIN, ou comme le bit AD - Authentic Data) peuvent être mensongers. - Les alias (
CNAME) et surtout les jokers (cf. RFC 4592) compliquent sérieusement les choses. Sans eux, le RFC 5155, par exemple, serait bien plus court ! (Une bonne leçon lorsqu'on conçoit des protocoles : des fonctions qui semblent cool et utiles peuvent se payer très cher plus tard, par exemple lorsqu'on tente de sécuriser le protocole.)
En raison du premier principe, il faut pouvoir pré-calculer les
réponses négatives alors que la liste des questions menant à une
réponse négative est quasi-infinie. Pas question donc de générer une
réponse signée pour toutes les questions théoriquement possibles (si
on imposait la génération dynamique de réponses à la volée, cela serait
possible). On ne peut pas non plus utiliser
un enregistrement générique (ne dépendant pas du nom demandé) pour
toutes les réponses négatives car il pourrait facilement être utilisé
dans une attaque par rejeu (on demande
foobar.example.org, on a une réponse négative
signée, on l'enregistre et on la sert ensuite à des résolveurs qui
demandent a.example.org pour leur faire croire
que ce nom n'existe pas).
La solution adoptée par DNSSEC a été de
« signer les trous ». Un enregistrement spécial définit un intervalle
entre deux noms, signifiant « il n'y a rien entre ces deux noms ». Et
cet enregistrement est signé et peut donc être vérifié. Au début, cet
enregistrement spécial se nommait le NXT
(NeXT name) et était normalisé dans le RFC 2535, abandonné depuis. Il a été remplacé par le
NSEC (Next SECure) avec le
RFC 3755.
Le NSEC nécessite que la zone soit triée. Pour
qu'un enregistrement affirmant « il n'y a rien entre
jack.example.com et
susie.example.com » soit utilisable, il faut savoir
quels noms tomberaient entre ces deux noms. Le choix a été d'utiliser
l'ordre alphabétique (RFC 4034, section 6.1). Donc, monica.example.com
est entre ces deux noms mais pas
bob.example.com. Dans notre zone d'exemple
example.org, cela veut dire qu'il y aura trois
NSEC : un allant de l'apex (example.org, l'apex
est souvent notée @) à
a.example.org, un allant de
a.example.org à
d.example.org et un bouclant la chaîne, en allant
de d.example.org à l'apex. Signons la zone pour
voir :
[On crée une clé]
% dnssec-keygen -a RSASHA256 -f KSK -b 4096 example.org
Generating key pair..................................................................................................................................................................................................................................++ .............................................++
Kexample.org.+008+37300
[On édite le fichier de zone pour mettre "$INCLUDE
Kexample.org.+008+37300.key"]
[On signe]
% dnssec-signzone -z example.org
dnssec-signzone: warning: example.org:3: no TTL specified; using SOA MINTTL instead
Verifying the zone using the following algorithms: RSASHA256.
Zone fully signed:
Algorithm: RSASHA256: KSKs: 1 active, 0 stand-by, 0 revoked
ZSKs: 0 active, 0 stand-by, 0 revoked
example.org.signed
Examinons le fichier example.org.signed, il a
bien trois NSEC (et ils sont signés) :
% grep NSEC example.org.signed example.org. 86400 IN NSEC a.example.org. NS SOA RRSIG NSEC DNSKEY example.org. 86400 IN RRSIG NSEC 8 2 86400 20140222083601 20140123083601 37300 example.org. J9kDD... a.example.org. 86400 IN NSEC d.example.org. A TXT RRSIG NSEC a.example.org. 86400 IN RRSIG NSEC 8 3 86400 20140222083601 20140123083601 37300 example.org. IVc/rrR... d.example.org. 86400 IN NSEC example.org. A TXT RRSIG NSEC d.example.org. 86400 IN RRSIG NSEC 8 3 86400 20140222083601 20140123083601 37300 example.org. b/DHgE...
(J'ai un peu triché, j'ai mis des noms absolus partout avec named-compilezone -s full.)
Chargeons cette zone signée et interrogeons-la pour un nom inexistant :
% dig @::1 -p 9053 A b.example.org ; <<>> DiG 9.9.3-rpz2+rl.13214.22-P2-Ubuntu-1:9.9.3.dfsg.P2-4ubuntu1.1 <<>> @::1 -p 9053 A b.example.org ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 16186 ;; flags: qr aa rd; QUERY: 1, ANSWER: 0, AUTHORITY: 6, ADDITIONAL: 1 ;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 4096 ;; QUESTION SECTION: ;b.example.org. IN A ;; AUTHORITY SECTION: a.example.org. 86400 IN NSEC d.example.org. A TXT RRSIG NSEC a.example.org. 86400 IN RRSIG NSEC 8 3 86400 ( 20140222083601 20140123083601 37300 example.org. IVc/rr... example.org. 86400 IN NSEC a.example.org. NS SOA RRSIG NSEC DNSKEY example.org. 86400 IN RRSIG NSEC 8 2 86400 ( 20140222083601 20140123083601 37300 example.org. J9kDDpefX... example.org. 86400 IN SOA a.example.org. root.example.org. ( 2014012000 ; serial 604800 ; refresh (1 week) 86400 ; retry (1 day) 2419200 ; expire (4 weeks) 86400 ; minimum (1 day) ) example.org. 86400 IN RRSIG SOA 8 2 86400 ( 20140222083601 20140123083601 37300 example.org. QcFJIEpCs... ;; Query time: 0 msec ;; SERVER: ::1#9053(::1) ;; WHEN: Thu Jan 23 10:45:38 CET 2014 ;; MSG SIZE rcvd: 1821
On obtient logiquement un NXDOMAIN et on a en
plus le NSEC
(signé) affirmant « il n'existe rien entre
a.example.org et
d.example.org ». Le résolveur a donc la preuve
(signée) de la non-existence de b.example.org. Un
attaquant qui enregistre cette réponse ne pourra pas l'utiliser
contre, disons, k.example.org, puisque celui-ci
n'est pas couvert par le NSEC.
Et avec un nom existant mais un type de données qui ne l'est pas :
% dig @::1 -p 9053 AAAA a.example.org ; <<>> DiG 9.9.3-rpz2+rl.13214.22-P2-Ubuntu-1:9.9.3.dfsg.P2-4ubuntu1.1 <<>> @::1 -p 9053 AAAA a.example.org ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 15504 ;; flags: qr aa rd; QUERY: 1, ANSWER: 0, AUTHORITY: 4, ADDITIONAL: 1 ;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 4096 ;; QUESTION SECTION: ;a.example.org. IN AAAA ;; AUTHORITY SECTION: example.org. 86400 IN SOA a.example.org. root.example.org. ( 2014012000 ; serial 604800 ; refresh (1 week) 86400 ; retry (1 day) 2419200 ; expire (4 weeks) 86400 ; minimum (1 day) ) example.org. 86400 IN RRSIG SOA 8 2 86400 ( 20140222083601 20140123083601 37300 example.org. QcFJIE... a.example.org. 86400 IN NSEC d.example.org. A TXT RRSIG NSEC a.example.org. 86400 IN RRSIG NSEC 8 3 86400 ( 20140222083601 20140123083601 37300 example.org. IVc/rrRD5... ;; Query time: 0 msec ;; SERVER: ::1#9053(::1) ;; WHEN: Thu Jan 23 10:56:28 CET 2014 ;; MSG SIZE rcvd: 1228
Ls NSEC contiennent à la fin une liste des types
de données présents pour le nom en partie gauche du
NSEC. On a un NSEC qui dit « oui,
a.example.org existe mais les seules données sont
des types A, TXT et
évidemment RRSIG et
NSEC ». Le résolveur validant peut alors
s'assurer que le AAAA n'existe pas.
Bon, tout cela est très joli mais les NSEC ont
quand même deux inconvénients (section 3.4). Le premier est qu'ils
permettent le zone walking : en testant avec un nom
pris au hasard, on récupére le nom existant suivant. On teste alors ce
nom avec un type inexistant et on a le nom encore suivant. Et, en
itérant, on a toute la zone. À la main (mais cela s'automatise
facilement) :
% dig @::1 -p 9053 A $RANDOM.example.org ... example.org. 86400 IN NSEC a.example.org. [Donc, le nom suivant est a.example.org. On continue avec un type de données rare.] % dig @::1 -p 9053 NAPTR a.example.org ... a.example.org. 86400 IN NSEC d.example.org. ... [On a le nom suivant, d.example.org, plus qu'à continuer]
Ce zone walking permet d'accéder au contenu entier
d'une zone, même si le transfert de
zones est fermé. Cela n'est pas gênant pour certaines zones
(zones très structurées comme celles sous
ip6.arpa ou bien petites zones au contenu
évident, l'apex et www) mais inacceptable pour
d'autres. Il existe des techniques astucieuses pour le
limiter (cf. RFC 4470) mais la solution la plus
répandue est le NSEC3, présenté plus loin.
Le second inconvénient des NSEC ne concerne
que les grandes zones composées essentiellement de délégations,
typiquement les TLD. Chaque enregistrement va
nécessiter un NSEC et sa signature, augmentant
considérablement la taille de la zone, même quand elle ne comporte que
peu de délégations sécurisées. Cela pourrait faire hésiter à adopter
DNSSEC.
La solution à ces deux inconvénients est
NSEC3, normalisé dans le RFC 5155. Mais, avant de voir NSEC3, voyons
les autres solutions qui avaient été envisagées puis abandonnées
(section 4 du RFC). Il y avait le NO, où la
chaîne qui faisait le tour de la zone n'était pas fondée sur les noms,
comme dans NSEC mais sur un
condensat des noms, ne permettant pas de
remonter au nom. (NSEC3 a plus tard repris cette
idée.) Sur le moment, le danger du zone walking
n'était pas considéré comme très grave, et NO
était vite tombé dans l'oubli. Le problème que posait le zone
walking a resurgi par la suite, menant à la conception de
NSEC2, qui utilisait également des condensats des
noms protégés. NSEC2 travaillait main dans la
main avec un nouvel enregistrement, EXIST, qui
servait à prouver l'existence d'un nom sans avoir besoin d'indiquer
des données. C'était utile en cas d'utilisation des jokers (RFC 4592). Prouver que
b.example.org n'existe pas est une chose, mais il
faut aussi prouver qu'il n'y avait pas de joker qui aurait pu
l'engendrer. C'est lors du travail sur NSEC2
qu'on a compris que les jokers étaient très compliqués et très mal compris.
Par contre, NSEC2 n'avait pas de système
d'opt-out qui aurait pu résoudre le second
inconvénient de NSEC, l'augmentation de la taille
de la zone pour un TLD. D'où le développement
de DNSNR, un enregistrement expérimental qui
avait été le premier à prévoir une option pour ne faire aller la
chaîne que d'un nom signé à un autre nom signé (alors que la chaîne
NSEC va d'un nom à un
nom). DNSNR affaiblit un peu la sécurité (on ne
peut plus prouver la non-existence d'un nom qui n'est pas signé) mais
d'une manière cohérente avec la philosophie de DNSSEC (où la signature
n'est pas obligatoire). Et il permettait de diminuer l'augmentation de
taille de la
zone, la rendant proprotionnelle au nombre de noms signés, pas au
nombre de noms. NSEC3 a donc également repris ce
concept.
Il est donc temps de passer à NSEC3 (section 5
de notre RFC). NSEC3 ajoute la
condensation des noms et
l'opt-out, mais au prix d'une certaine complexité,
qui fait qu'encore de nos jours, peu de gens arrivent à déboguer un
problème NSEC3. C'est entre autre pour cela que
NSEC3 ne remplace pas NSEC :
les deux restent définis (par exemple, la racine est signée avec
NSEC, le zone walking n'étant
pas un problème, puisque les données sont publiques ; la taille n'en est pas
un non plus, la majorité des TLD étant signés,
l'opt-out ne ferait pas gagner grand'chose).
Donc, le principe de NSEC3 : lorsqu'on signe, on met un
enregistrement NSEC3 pour le condensat du nom,
pointant vers le condensat suivant. La chaîne qui couvre tous les
trous est donc une chaîne de condensats et pas de noms. Lorsqu'une
question arrive, et que la réponse est négative, le serveur faisant
autorité doit condenser le nom pour savoir quel enregistrement
NSEC3 renvoyer (donc, NSEC3
est le seul cas dans DNSSEC où un serveur faisant autorité doit faire
de la crypto à chaque requête, mais il est vrai que ce n'est qu'une
condensation, opération typiquement très rapide). Pour éviter qu'un
attaquant n'utilise des tables pré-calculées, stockant les condensats
de noms possibles, on ajoute un sel et on peut
faire plus d'une itération si on veut.
Pour tester NSEC3, signons cette fois notre
zone avec NSEC3. Il va falloir ajouter deux
arguments, -3 pour indiquer le sel et
-H pour le nombre d'itérations supplémentaires à faire
(-A permettrait d'activer
l'opt-out, ce que je ne fais pas ici). Les exemples
du RFC utilisent un sel amusant, DEAD. C'est une
mauvaise idée que de choisir un sel comme cela, car ces mots amusants
sont en nombre limité et des méchants ont peut-être déjà généré des
tables de condensats utilisant ces sels. Je prends donc un sel
aléatoire (avec $RANDOM et sha256sum ci-dessous). Par contre, je garde les autres options du RFC, 2 pour le
nombre d'itérations supplémentaires, pas d'opt-out
et SHA-1 comme algorithme :
% dnssec-signzone -3 $(echo $RANDOM$RANDOM | sha256sum | cut -d' ' -f1) -H 2 \
-z example.org
dnssec-signzone: warning: example.org:3: no TTL specified; using SOA MINTTL instead
Verifying the zone using the following algorithms: RSASHA256.
Zone fully signed:
Algorithm: RSASHA256: KSKs: 1 active, 0 stand-by, 0 revoked
ZSKs: 0 active, 0 stand-by, 0 revoked
example.org.signed
Et, lorsque je charge cette zone et que je demande un nom
non-existant, je récupère des NSEC3 au lieu des
NSEC :
% dig @::1 -p 9053 A b.example.org ; <<>> DiG 9.9.3-rpz2+rl.13214.22-P2-Ubuntu-1:9.9.3.dfsg.P2-4ubuntu1.1 <<>> @::1 -p 9053 A b.example.org ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 7591 ;; flags: qr aa rd; QUERY: 1, ANSWER: 0, AUTHORITY: 8, ADDITIONAL: 1 ;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 4096 ;; QUESTION SECTION: ;b.example.org. IN A ;; AUTHORITY SECTION: ui6pc9ajfb1e6ge0grul67qnckig9bck.example.org. 86400 IN NSEC3 1 0 2 DD438FBA32EC3FFA4B1849EF2F41F64A83A17D220D22F57BC9903300A861BFE9 ( ASPD8T7IP6MGQ09OPQQP3KMH9D7VVODA A TXT RRSIG ) ui6pc9ajfb1e6ge0grul67qnckig9bck.example.org. 86400 IN RRSIG NSEC3 8 3 86400 ( 20140223065356 20140124065356 37300 example.org. PIb9Y8T... l6m3op8qm1vr3t47jnm6dbl6s4qm2bl8.example.org. 86400 IN NSEC3 1 0 2 DD438FBA32EC3FFA4B1849EF2F41F64A83A17D220D22F57BC9903300A861BFE9 ( UI6PC9AJFB1E6GE0GRUL67QNCKIG9BCK NS SOA RRSIG DNSKEY NSEC3PARAM ) l6m3op8qm1vr3t47jnm6dbl6s4qm2bl8.example.org. 86400 IN RRSIG NSEC3 8 3 86400 ( 20140223065356 20140124065356 37300 example.org. WKf8OkW... aspd8t7ip6mgq09opqqp3kmh9d7vvoda.example.org. 86400 IN NSEC3 1 0 2 DD438FBA32EC3FFA4B1849EF2F41F64A83A17D220D22F57BC9903300A861BFE9 ( L6M3OP8QM1VR3T47JNM6DBL6S4QM2BL8 A TXT RRSIG ) aspd8t7ip6mgq09opqqp3kmh9d7vvoda.example.org. 86400 IN RRSIG NSEC3 8 3 86400 ( 20140223065356 20140124065356 37300 example.org. YrR7/0vxWT... [SOA omis...] ;; Query time: 0 msec ;; SERVER: ::1#9053(::1) ;; WHEN: Fri Jan 24 08:57:43 CET 2014 ;; MSG SIZE rcvd: 2639
À quel nom correspondent ces condensats ? On va utiliser le programme
nsec3hash livré avec
BIND. On prend les paramètres de condensation
dans l'enregistrement NSEC3PARAM (cet
enregistrement est nécessaire car tous les serveurs faisant autorité
pour une zone, pas seulement le ou les maîtres, doivent calculer ces condensats, ce qui implique de
disposer de ces informations ; si le DNS avait été prévu avec DNSSEC
et NSEC3 dès le début, on les aurait probablement
mises dans le SOA) :
% dig +short @::1 -p 9053 NSEC3PARAM example.org 1 0 2 DD438FBA32EC3FFA4B1849EF2F41F64A83A17D220D22F57BC9903300A861BFE9 ...
On voit donc le nombre d'itérations à faire et la valeur du sel (ce n'est pas le même sel que dans les exemples du RFC, ne vous étonnez donc pas si les valeurs sont différentes ; celles du RFC sont résumées dans l'annexe C). Testons avec l'apex :
% nsec3hash DD438FBA32EC3FFA4B1849EF2F41F64A83A17D220D22F57BC9903300A861BFE9 1 2 example.org L6M3OP8QM1VR3T47JNM6DBL6S4QM2BL8 (salt=DD438FBA32EC3FFA4B1849EF2F41F64A83A17D220D22F57BC9903300A861BFE9, hash=1, iterations=2)
Et pareil pour les autres noms qu'on connait. On peut donc trouver le
NSEC3 correspondant à chacun. Ici, pour l'apex,
c'était :
l6m3op8qm1vr3t47jnm6dbl6s4qm2bl8.example.org. 86400 IN NSEC3 1 0 2 DD438FBA32EC3FFA4B1849EF2F41F64A83A17D220D22F57BC9903300A861BFE9 ( UI6PC9AJFB1E6GE0GRUL67QNCKIG9BCK NS SOA RRSIG DNSKEY NSEC3PARAM )
Avec à la fin la liste des types qui existent pour ce nom. Et avec
dans la valeur le condensat suivant, UI6PC9AJFB1E6GE0GRUL67QNCKIG9BCK.
Ici, on n'a pas utilisé l'opt-out. Il n'aurait
pas de sens pour cette zone car l'opt-out ne
dispense de signatures et de preuves de non-existence que les
délégations ou les non-terminaux vides (les domaines qui n'ont pas
d'enregistrement et qui n'existent que parce qu'ils ont des
sous-domaines). Mais, dans un gros TLD, l'opt-out
peut aider à garder la taille des zones à des valeurs
raisonnables. Regardons la zone
.fr :
% dig A nexistesurementpasmaisquisait.fr ... ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 38993 ;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 8, ADDITIONAL: 1 ... 9GVSHUTCOU5FH6SKL75VBHIJQ6KLB8HR.fr. 5346 IN NSEC3 1 1 1 BE174A99 9GVTDB9F17RKAOJKIK7GIH3EHS89GGJ6 NS SOA TXT NAPTR RRSIG DNSKEY NSEC3PARAM ...
Le deuxième chiffre, qui est à 1 et plus à 0 comme dans
l'exemple précédent, montre que .fr utilise
l'opt-out. Les enregistrements
NSEC3 ne couvrent donc que les délégations
signées (et qui ont donc un enregistrement
DS). Bref, ceux qui ne voulaient pas utiliser
DNSSEC ne sont pas protégés par DNSSEC, ce qui est finalement plus
logique que ce qui arrive avec NSEC.
NSEC3 peut encore peut-être paraître simple comme cela mais la norme est très complexe et on y découvre encore des cas bizarres, pas ou mal prévus comme l'erratum 3441.
Maintenant, le problème difficile, les jokers (section 5.3). Ajoutons dans notre zone d'exemple :
*.example.org. TXT "wildcard record"
Si un client DNS demande le TXT de
z.example.org, il aura une réponse (il aurait eu
un NXDOMAIN avec la zone précédente). Revenons
aux enregistrements NSEC pour un moment :
% dig -p 9053 @::1 TXT z.example.org ; <<>> DiG 9.9.3-rpz2+rl.13214.22-P2-Ubuntu-1:9.9.3.dfsg.P2-4ubuntu1.1 <<>> -p 9053 @::1 TXT z.example.org ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 49955 ;; flags: qr aa rd; QUERY: 1, ANSWER: 2, AUTHORITY: 2, ADDITIONAL: 1 ;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 4096 ;; QUESTION SECTION: ;z.example.org. IN TXT ;; ANSWER SECTION: z.example.org. 86400 IN TXT "wildcard record" z.example.org. 86400 IN RRSIG TXT 8 2 86400 ( 20140227062210 20140128062210 37300 example.org. G8THJnlRf... ;; AUTHORITY SECTION: d.example.org. 86400 IN NSEC example.org. A TXT RRSIG NSEC d.example.org. 86400 IN RRSIG NSEC 8 3 86400 ( 20140227062210 20140128062210 37300 example.org. JoewWY... ;; Query time: 0 msec ;; SERVER: ::1#9053(::1) ;; WHEN: Tue Jan 28 08:23:49 CET 2014 ;; MSG SIZE rcvd: 1215
On reçoit une réponse. Comment savoir qu'elle vient d'un joker ? C'est
grâce à un champ discret de la signature, dont je n'ai pas encore
parlé, le champ Labels (RFC 4034, section 3.1.3), le troisième du
RRSIG. Il vaut 3 pour
d.example.org, ce qui est normal car ce nom
comporte trois composants. Mais il ne vaut que 2 pour
z.example.org qui a aussi trois composants, car
cet enregistrement dans la réponse a été dynamiquement généré grâce au
joker. Ainsi, le résolveur DNS validant a toutes les informations
nécessaires pour vérifier la signature de
z.example.org. Comme on peut le vérifier en
lisant le fichier de zone, cette signature n'a pas été générée
dynamiquement, c'est celle du joker,
*.example.org.
L'enregistrement NSEC dans la réponse
ci-dessus empêche les attaques où le méchant essaierait de faire
croire que, par exemple, a.example.org a aussi l'enregistrement
TXT du joker. a.example.org
ayant son propre TXT, celui du joker n'est pas
utilisé et le NSEC - obligatoire - permettrait de prouver
cela. Ici, le NSEC dit qu'il n'y a pas de
TXT entre d.example.org et
example.org donc rien pour
z.example.org, achevant de prouver que la réponse
vient d'un joker.
Et avec NSEC3 ? Pareil :
% dig -p 9053 @::1 TXT z.example.org ; <<>> DiG 9.9.3-rpz2+rl.13214.22-P2-Ubuntu-1:9.9.3.dfsg.P2-4ubuntu1.1 <<>> -p 9053 @::1 TXT z.example.org ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 10172 ;; flags: qr aa rd; QUERY: 1, ANSWER: 2, AUTHORITY: 2, ADDITIONAL: 1 ;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 4096 ;; QUESTION SECTION: ;z.example.org. IN TXT ;; ANSWER SECTION: z.example.org. 86400 IN TXT "wildcard record" z.example.org. 86400 IN RRSIG TXT 8 2 86400 ( 20140223162550 20140124162550 37300 example.org. i69nAYi... ;; AUTHORITY SECTION: l6m3op8qm1vr3t47jnm6dbl6s4qm2bl8.example.org. 86400 IN NSEC3 1 0 2 DD438FBA32EC3FFA4B1849EF2F41F64A83A17D220D22F57BC9903300A861BFE9 ( UI6PC9AJFB1E6GE0GRUL67QNCKIG9BCK NS SOA RRSIG DNSKEY NSEC3PARAM ) l6m3op8qm1vr3t47jnm6dbl6s4qm2bl8.example.org. 86400 IN RRSIG NSEC3 8 3 86400 ( 20140223162550 20140124162550 37300 example.org. ZbfNK6xD++... ;; Query time: 0 msec ;; SERVER: ::1#9053(::1) ;; WHEN: Tue Jan 28 08:15:15 CET 2014 ;; MSG SIZE rcvd: 1292
L'enregistrement NSEC3 prouve qu'il n'y a pas de
TXT pour z.example.org, dont
le condensat, TIIAIPBQRUI8LQOQVUOTC1RGS4VR3BA5,
tomberait entre L6M3OP8QM1VR3T47JNM6DBL6S4QM2BL8
(l'apex) et UI6PC9AJFB1E6GE0GRUL67QNCKIG9BCK
(a.example.org).
Je vous épargne (et à moi aussi), la section 5.4 sur les
CNAME combinés aux
jokers.
Plus utile (mais pas facile) est la section 5.5, sur la notion de
« boîte la plus proche » (closest encloser). Une
particularité de NSEC3 est qu'on perd
l'information sur la profondeur de la zone : les condensats sont dans
un espace plat, quel que soit le nombre de composants dans le nom
condensé. Il va donc falloir ajouter un enregistrement
NSEC3 pour la boîte la plus proche. Cette boîte
(closest encloser, défini dans le RFC 4592) est le nœud existant dans la zone qui a le plus de
composants correspondant à la requête. Si la requête portait sur
x.2.example.org et qu'il n'existe rien se
terminant en 2.example.org, la boîte la plus
proche est example.org. Autre notion, le « nom
plus proche [de la boîte la plus proche] » est le nom (non existant,
au contraire de la boîte la plus proche) ayant un composant de plus
que la boîte la plus proche. Dans l'exemple précédent, ce serait
2.example.org. Une preuve
NSEC3 doit parfois comprendre un enregistrement
pour prouver la boîte la plus proche, et un pour prouver que le nom
plus proche n'existe pas.
% dig @::1 -p 9053 A x.2.example.org ; <<>> DiG 9.9.3-rpz2+rl.13214.22-P2-Ubuntu-1:9.9.3.dfsg.P2-4ubuntu1.1 <<>> @::1 -p 9053 A x.2.example.org ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 52476 ;; flags: qr aa rd; QUERY: 1, ANSWER: 0, AUTHORITY: 8, ADDITIONAL: 1 ;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 4096 ;; QUESTION SECTION: ;x.2.example.org. IN A ;; AUTHORITY SECTION: ui6pc9ajfb1e6ge0grul67qnckig9bck.example.org. 86400 IN NSEC3 1 0 2 DD438FBA32EC3FFA4B1849EF2F41F64A83A17D220D22F57BC9903300A861BFE9 ( ASPD8T7IP6MGQ09OPQQP3KMH9D7VVODA A TXT RRSIG ) ui6pc9ajfb1e6ge0grul67qnckig9bck.example.org. 86400 IN RRSIG NSEC3 8 3 86400 ( 20140227063446 20140128063446 37300 example.org. eqpl3Vp... ... l6m3op8qm1vr3t47jnm6dbl6s4qm2bl8.example.org. 86400 IN NSEC3 1 0 2 DD438FBA32EC3FFA4B1849EF2F41F64A83A17D220D22F57BC9903300A861BFE9 ( UI6PC9AJFB1E6GE0GRUL67QNCKIG9BCK NS SOA RRSIG DNSKEY NSEC3PARAM ) l6m3op8qm1vr3t47jnm6dbl6s4qm2bl8.example.org. 86400 IN RRSIG NSEC3 8 3 86400 ( 20140227063446 20140128063446 37300 example.org. GaK0HrQ... je5k991emd1g7f9p37a3ajr96jrl0fvi.example.org. 86400 IN NSEC3 1 0 2 DD438FBA32EC3FFA4B1849EF2F41F64A83A17D220D22F57BC9903300A861BFE9 ( L6M3OP8QM1VR3T47JNM6DBL6S4QM2BL8 TXT RRSIG ) je5k991emd1g7f9p37a3ajr96jrl0fvi.example.org. 86400 IN RRSIG NSEC3 8 3 86400 ( 20140227063446 20140128063446 37300 example.org. U5zFverPJT... ;; Query time: 0 msec ;; SERVER: ::1#9053(::1) ;; WHEN: Tue Feb 04 18:10:08 CET 2014 ;; MSG SIZE rcvd: 2641
Si vous voulez suivre les explications qui suivent, vous devez calculer les condensats des noms. Les voici déjà calculés (avec mon sel ; avec le sel du RFC, voir l'annexe C qui résume les valeurs) :
Noms dans la zone : L6M3OP8QM1VR3T47JNM6DBL6S4QM2BL8 : apex UI6PC9AJFB1E6GE0GRUL67QNCKIG9BCK : a.example.org ASPD8T7IP6MGQ09OPQQP3KMH9D7VVODA : d.example.org JE5K991EMD1G7F9P37A3AJR96JRL0FVI : *.example.org Noms dans la requête : C9PVNA4KK7P5CH0L8C5RFDDI377RMJTO : x.2.example.org 4TPLI2PU4PVISAQ3OK4BNE06FL1ESDKJ : 2.example.org TIIAIPBQRUI8LQOQVUOTC1RGS4VR3BA5 : z.example.org
Ici, il a fallu pas moins de trois NSEC3 pour
prouver que le nom n'existait pas. Le premier prouve que
2.example.org n'existe pas (son condensat tombe
entre les deux valeurs de l'enregistrement
NSEC3) et que donc
x.2.example.org n'existe pas non plus, puisqu'il était
sous 2.example.org. Le second
prouve que la boîte la plus proche, example.org
existe (son condensat est la partie gauche du
NSEC3). Et le troisième prouve qu'il y a un joker
sous la boîte la plus proche (son condensat est la partie gauche du
NSEC3) mais seulement pour les
TXT. S'il n'y avait pas de joker dans la zone, le
troisième NSEC3 servirait à prouver cette absence
(section 5.6).
Sinon, si vous aimez lire le code source, le RFC recommande celui d'Unbound, dans validator/val_nsec3.c...
Si votre cerveau n'est pas complètement frit après ce RFC, l'annexe
A présente un mécanisme pour utiliser des NSEC en
rendant plus difficile l'énumération de la zone, la technique de la
« couverture minimale » (RFC 4470). Elle impose par
contre une signature en ligne, en réponse à la question posée. En
pratique, cette technique ne semble pas déployée. Une technique analogue existe pour NSEC3 avec
les « mensonges blancs » rappelés dans l'annexe B. Ils sont mis en
œuvre dans le serveur de noms Phreebird.
L'article seul
RFC 7126: Recommendations on filtering of IPv4 packets containing IPv4 options
Date de publication du RFC : Février 2014
Auteur(s) du RFC : F. Gont (UTN-FRH / SI6 Networks), R. Atkinson (Consultant), C. Pignataro (Cisco)
Réalisé dans le cadre du groupe de travail IETF opsec
Première rédaction de cet article le 12 février 2014
Le protocole IPv4 permet d'ajouter dans l'en-tête d'un paquet un certain nombre d'options qui peuvent influencer le traitement de ce paquet par les routeurs et les machines terminales. Certaines de ces options ayant eu des conséquences négatives pour la sécurité des réseaux, il est courant que les paquets portant des options soient filtrés par les pare-feux. Est-ce une bonne idée ? Est-ce que le choix dépend de l'option ? Quelles options faut-il filtrer ? Ce RFC rappelle brièvement la fonction de chaque option et donne des conseils sur le filtrage qu'il faudrait (ou pas) lui appliquer. C'est donc un document orienté vers le concret, vers les questions opérationnelles.
Aujourd'hui, note le RFC, une politique fréquente semble de bloquer systématiquement tout paquet IPv4 contenant des options, quelles que soient ces options. Une politique aussi violente a des tas de conséquences négatives sur le fonctionnement de l'Internet (section 6 de notre RFC, qui s'oppose à cette politique), la principale étant d'interdire de facto le déploiement de toute nouvelle option, si utile qu'elle puisse être. Une machine terminale peut toujours accepter ou rejeter les paquets IPv4 contenant des options, ce sont les paquets dont elle est destinataire, c'est son affaire (encore que le réglage par défaut du système d'exploitation soit important puisqu'on sait que beaucoup de gens ne le modifieront pas). Mais pour un intermédiaire comme un routeur ou un pare-feu; c'est plus délicat : s'il jette les paquets contenant des options, il brise le modèle de bout en bout et empêche toutes les machines situées plus loin de tirer profit de ces options. La situation est toutefois plus compliquée que cela puisque certaines options sont prévues pour être lues et traitées par les intermédiaires. Ce n'est donc pas une pure affaire de transparence du réseau.
Pour un engin intermédiaire, il y a trois stratégies possibles, en plus de la méthode paresseuse et violente de jeter tous les paquets ayant des options :
- Laisser passer les paquets contenant des options,
- Par défaut, laisser passer les paquets contenant des options mais avoir une liste d'options dangereuses, qu'on ne laissera pas passer,
- Par défaut, jeter les paquets contenant des options mais avoir une liste des options acceptables, et laisser passer les paquets ne contenant que ces options.
Les études sur ce sujet montrent que les paquets contenant des options ont du mal à passer sur l'Internet, bien des intermédiaires les refusant systématiquement (méthode paresseuse et violente). Sur beaucoup de routeurs ou de pare-feux, le choix est binaire : ou on accepte toutes les options, ou on les jette toutes (notre RFC déconseille fortement cette limitation). On trouve les résultats de ces études dans « Measuring Interactions Between Transport Protocols and Middleboxes » de Medina, A., Allman, M., et S. Floyd, à Usenix / ACM Sigcomm en octobre 2004 ou dans « IP Options are not an option » de Fonseca, R., Porter, G., Katz, R., Shenker, S., et I. Stoica en décembre 2005. Sans compter les études montrant, comme « Spoofing prevention method » de Bremier-Barr, A. et H. Levy (IEEE InfoCom 2005), que bien des routeurs bas de gamme ne savent tout simplement pas gérer les options IPv4.
Avant les recommandations concrètes de ce RFC, un petit rappel des options IPv4, telles que normalisées par le RFC 791 (section 3.1). Physiquement, les options peuvent avoir deux formats (le second étant de très loin le plus commun) :
- Un octet indiquant le type de l'option, sans arguments,
- Un triplet {type de l'option, longueur de l'option, arguments de l'option}, les deux premiers champs étant stockés sur un octet.
On voit que ce n'est pas trivial à analyser lorsqu'on traite des
centaines de millions de paquets par seconde. (Exercice : essayez
d'écrire du code le plus rapide possible pour cela.) Mais IPv4 étant
très ancien, le problème est bien connu et semble donc moins
angoissant. Pour cette analyse des options, la machine IPv4 doit
connaître la liste officielle des options (stockée dans un registre IANA). Le programmeur y verra par
exemple les options 0 - fin de la liste d'options - et 1 - neutre. Ces deux
options n'ont pas d'argument et donc tout tient dans un seul
octet. Les options sont organisées en liste, la liste se terminant par
l'option 0.
Voici par exemple le code utilisé dans le noyau
Linux pour lire les options (fichier
net/ipv4/ip_options.c) :
unsigned char *optptr; /* Pointe vers la prochaine option */
...
switch (*optptr) {
/* Deux cas particuliers au début, les deux options formées d'un
seul octet */
case IPOPT_END:
...
goto eol;
case IPOPT_NOOP:
l--;
optptr++;
continue;
}
/* Le cas général, où la longueur de l'option est indiquée par le
deuxième octet (le premier étant le type) */
optlen = optptr[1];
switch (*optptr) {
/* Un "case" pour chaque option possible */
case IPOPT_SSRR:
...
Le champ qui indique le type de l'option est lui-même subdivisé en trois sous-champs : un booléen qui indique si l'option doit être copiée dans tous les fragments au cas où la machine doive fragmenter le paquet, une classe stockée sur deux bits (deux classes seulement sont définies, option de contrôle et option de débogage et de mesure), et le numéro de l'option à proprement parler. Par exemple, 131 (Loose Source and Record Route) a le premier bit à un et doit donc être copiée en cas de fragmentation.
Si vous aimez fabriquer des paquets avec Scapy, il faut savoir (cf. cet article) qu'il faudra formater les options vous-même, Scapy ne fournit pas de mécanisme pour cela. Vous devez donc indiquer la liste d'octets qui compose la liste d'options. Ici, je ne mets qu'une option (inexistante), de type 42 et de longueur des données nulle (mais il faut compter dans le champ longueur l'octet de type et l'octet de longueur) :
p = IP(dst="127.0.0.1",
options=IPOption("\x2A\x02"))/
UDP(sport=RandShort(),dport=53)/
DNS(qr=0, rd=1, id=666, qd=DNSQR(qname="www.example"))
Affiché par tcpdump, cela donnera :
15:36:11.243193 IP (tos 0x0, ttl 64, id 1, offset 0, flags [none], proto UDP (17), length 61, options (unknown 42,EOL))
127.0.0.1.54932 > 127.0.0.1.53: [udp sum ok] 42+ A? www.example. (29)
La section 3 détaille ce travail d'analyse des options. Pendant longtemps, les routeurs IP utilisaient un processeur généraliste pour traiter les paquets et donc les options. Le processeur gère les paquets mais aussi le routage (OSPF, BGP...) et les protocoles de plus haut niveau comme SNMP ou SSH. Un influx important de paquets IPv4 portant des options peut permettre une attaque par déni de service : occupé à analyser toutes ces options et à agir en fonction de leur contenu, le processeur n'aurait plus le temps de faire les autres tâches. Depuis le milieu des années 1990, de tels routeurs sont souvent remplacés par des routeurs disposant de circuits spécialisés pour traiter les paquets (FPGA, ASIC...). Le routeur a deux catégories de tâches : traiter les paquets entrants et les faire suivre (tâche effectuée à très grande vitesse par le circuit spécialisé) et le reste du travail, du routage à la gestion de l'interface utilisateur (tâche qui reste confiée à un processeur généraliste). Un des avantages de cette architecture est que le traitement des paquets ne rentre plus en concurrence avec les tâches de gestion du routeur (cf. RFC 6192). Mais elle peut compliquer les choses pour les options car ces circuits spécialisés sont rigides et il est difficile d'y mettre du code complexe. Certains routeurs simplifient donc en transmettant aveuglément les paquets, sans tenir compte du fait qu'ils contiennent des options ou pas. D'autres peuvent jeter les paquets contenant certaines options. Et d'autres enfin arrivent même à traiter les options qu'ils sont censés traiter (rappelez-vous que les options d'IPv4 peuvent être destinées à la machine de destination, ou bien à tous les routeurs intermédiaires ; contrairement à IPv6, les deux catégories ne sont pas facilement distinguables, le routeur doit connaître la liste complète des options enregistrées, pour savoir si une option est pour lui). Bref, quand on décide une politique de traitement des options, il faut d'abord se pencher sur ses routeurs et regarder si leurs ASIC sont capables de mettre en œuvre cette politique.
Place maintenant aux recommandations concrètes. La longue section 4 de notre RFC va donner un avis pour chaque option IPv4 enregistrée. À chaque option, notre RFC indique :
- À quoi elle sert,
- Les risques de sécurité connus,
- Les conséquences d'un blocage des paquets portant cette option,
- Une recommandation sur le blocage.
Commençons par un cas trivial, l'option de type 1 qui indique qu'il n'y a rien à faire :
- Son utilité principale est d'aligner l'en-tête du paquet sur un multiple de 32 bits,
- Il n'y a pas de risques connus,
- Quelles que soient les options utiles, il y a des bonnes chances que le paquet soit complété par des options de type 1. Donc, jeter les paquets contenant cette option revient à interdire les options,
- Les routeurs, pare-feux et autres intermédiaires ne devraient pas bloquer les paquets ayant l'option de type 1.
C'est évidemment la même chose pour l'option de type 0, qui indique la fin de la liste d'options, et qui est donc souvent présente dans tous les paquets ayant des options (le RFC 791 explique dans quels cas elle peut être omise).
Maintenant, les autres options, plus complexes. Je ne vais pas reprendre dans cet article la liste complète. Si vous voulez tout voir, regardez le RFC. Par exemple, les options de type 131 (LSSR, Loose Source and Record Route) ou 137 (SSSR, Strict Source and Record Route) :
- Elles permettent à l'émetteur de définir une route qui devra être suivie par les paquets (routage par la source), et/ou d'enregistrer la route suivie dans le paquet, à des fins de débogage,
- Les risques de sécurité sont énormes (RFC 6274, sections 3.12.2.3 et 3.12.2.4), ces options permettent de contourner les pare-feux, de joindre des machines normalement inaccessibles, d'apprendre le topologie d'un réseau, de faire du déni de service en créant des paquets qui rebondiront éternellement dans le réseau... En outre, sa mise en œuvre est complexe et mène facilement à des failles de sécurité comme celle qui avait frappé OpenBSD en 1998,
- Si on les bloque, les outils de débogage qui s'en servent
(comme traceroute avec
l'option
-g) ne marcheront plus mais, de toute façon, en pratique, ces options marchent rarement (à cause des fréquents blocages mais aussi à cause de leurs propres limitations, comme la faible taille maximale de l'en-tête IPv4, qui ne permet pas de stocker des longues routes), - La recommandation est, par défaut, de jeter les paquets contenant cette option, et d'avoir un réglage permettant de les accepter.
L'option 7, Record Route, ne spécifie pas de
route mais demande que les routeurs enregistrent dans le paquet par où
on est passé. Voici ce que voit tcpdump en mode
bavard (-vvv) lorsqu'on utilise ping avec l'option
-R (on n'est pas allé loin, on a juste pingué
localhost) :
[Un ping normal, les paquets IP n'ont pas d'option]
08:26:44.040128 IP (tos 0x0, ttl 64, id 17400, offset 0, flags [DF], proto ICMP (1), length 84)
127.0.0.1 > 127.0.0.1: ICMP echo request, id 7811, seq 1, length 64
08:26:44.040178 IP (tos 0x0, ttl 64, id 17401, offset 0, flags [none], proto ICMP (1), length 84)
127.0.0.1 > 127.0.0.1: ICMP echo reply, id 7811, seq 1, length 64
[Le ping avec -R. Notez le NOP dans la requête, pour aligner les
options, et le EOL dans la réponse, pour marquer la fin.]
08:26:47.126729 IP (tos 0x0, ttl 64, id 17405, offset 0, flags [DF], proto ICMP (1), length 124, options (NOP,RR 127.0.0.1, 0.0.0.0 0.0.0.0 0.0.0.0 0.0.0.0 0.0.0.0 0.0.0.0 0.0.0.0 0.0.0.0))
127.0.0.1 > 127.0.0.1: ICMP echo request, id 7812, seq 1, length 64
08:26:47.126784 IP (tos 0x0, ttl 64, id 17406, offset 0, flags [none], proto ICMP (1), length 124, options (RR 127.0.0.1, 127.0.0.1, 127.0.0.1, 0.0.0.0 0.0.0.0 0.0.0.0 0.0.0.0 0.0.0.0 0.0.0.0,EOL))
127.0.0.1 > 127.0.0.1: ICMP echo reply, id 7812, seq 1, length 64
Comme les deux options précédentes, elle marche rarement en pratique
(c'est pour cela que je me suis limité à
localhost), en raison des nombreux équipements
intermédiaires qui bloquent les paquets qui la contiennent. La
recommandation est la même, la jeter par défaut. En attendant, dans un réseau où cette option marche, elle fournit une alternative à traceroute :
% ping -R www.free.fr PING www.free.fr (212.27.48.10) 56(124) bytes of data. 64 bytes from www.free.fr (212.27.48.10): icmp_req=1 ttl=55 time=28.2 ms RR: ... vau75-1-v900.intf.nra.proxad.net (78.254.255.41) rke75-1-v902.intf.nra.proxad.net (78.254.255.45) cev75-1-v906.intf.nra.proxad.net (78.254.255.49) p16-9k-1-be1000.intf.routers.proxad.net (212.27.56.150) bzn-crs16-2-be1000.intf.routers.proxad.net (212.27.59.102) bzn-crs16-1-be1501.intf.routers.proxad.net (212.27.51.69) bzn-6k-sys.routers.proxad.net (212.27.60.254) 64 bytes from www.free.fr (212.27.48.10): icmp_req=2 ttl=55 time=29.4 ms (same route) ...
Il existe aussi bien des options IPv4 qui sont dépassées et officiellement abandonnées (cf. RFC 6814). C'est par exemple le cas de l'option 136, Stream Identifier, déjà marquée comme inutile par les RFC 1122 et RFC 1812 ou des options 11 et 12 (Probe MTU et Reply MTU), décrites dans le RFC 1063 et abandonnées depuis le RFC 1191. Même chose pour celles qui avaient été oubliées dans un grenier, puis officiellement abandonnées par le RFC 6814, comme l'option 82 (Traceroute) ou l'option 142 (VISA). La recommandation, pour toutes ces options abandonnées, est de jeter les paquets qui les contiennent. Notez que les trois options de débogage citées plus haut, ne sont pas abandonnées, juste citées comme dangereuses. Si la recommandation par défaut est la même (jeter les paquets), notre RFC demande également un mécanisme pour pouvoir les accepter, chose qu'il ne demande pas pour les options abandonnées.
Continuons avec l'option 68, Timestamp.
- Elle permet d'enregistrer dans le paquet l'heure à laquelle le paquet a été traité par la machine,
- Cela peut fournir des informations indiscrètes sur la dite machine, par exemple en utilisant son décalage temporel pour l'identifier (cf. « Remote Physical Device Fingerprinting » de Kohno, T., Broido, A., et kc. Claffy, dans les IEEE Transactions on Dependable and Secure Computing en 2005, qui utilise une technique légèrement différente),
- Si on bloque cette option, des commandes comme
ping -Tne marcheront plus mais, de toute façon, elles ne marchent pas toujours aujourd'hui, cette option étant souvent bloquée (mais on trouve encore des réseaux dont les opérateurs, non seulement ne jettent pas ces paquets, mais traitent l'option, et mettent l'estampille dans le paquet), - L'avis de notre RFC est de jeter les paquets avec cette option.
Si on trouve un réseau où cette option passe, notez que ping affiche les délais de manière relative (mais regardez le paquet avec Wireshark, vous verrez les vraies valeurs, qui sont absolues). En cas de non-synchronisation des horloges, comme ici, cela peut donner des temps négatifs (en milli-secondes) :
% ping -c 1 -T tsandaddr www.example.org [J'ai déjà vu des réseaux qui acceptaient cette option avec le paramètre tsonly mais pas avec tsandaddr.] ... TS: fooobar (192.168.2.4) 50202455 absolute 192.168.2.254 -14 vau75-1-v900.intf.nra.proxad.net (78.254.255.41) 19 rke75-1-v902.intf.nra.proxad.net (78.254.255.45) 1 Unrecorded hops: 8
(Notez que huit routeurs ont ignoré cette option, ou tout simplement n'avaient plus de place pour mettre leur estampille, mais ont laissé passer le paquet.)
Et la 148, Router Alert ?
- Normalisée dans le RFC 2113, elle demande aux routeurs intermédiaires d'examiner le contenu de l'option, qui contient des demandes pour eux (la liste des demandes possibles figure dans un registre IANA créé par le RFC 5350),
- Obligeant le routeur à examiner en détail le paquet et à effectuer un traitement spécial, c'est évidemment une voie royale pour les attaques par déni de service, comme expliqué dans le RFC 6398,
- Mais, si on la bloque, on bloque aussi les services qui l'utilisent comme RSVP (RFC 2205),
- Elle ne devrait être utilisée que dans des environnements fermés et contrôlés. Comme le routeur ne sait pas s'il est dans un tel environnement, il devrait par défaut ignorer cette option (sans bloquer le paquet) et avoir un mécanisme pour demander son traitement ou, au contraire, pour jeter les paquets ayant cette option.
Autre option qui a un sens dans des environnements fermés (tous les réseaux IP ne sont pas connectés à l'Internet), l'option 130, DoD Basic Security Option.
- Conçue pour les militaires, dans le RFC 1108, elle permet d'indiquer dans le paquet son niveau de sécurité, ce qui permet des politiques comme « ne pas transmettre les paquets Top Secret sur les lignes non chiffrées ». Elle est mise en œuvre dans plusieurs systèmes comme SELinux, Solaris ou Cisco IOS (voyez la documentation pour la configurer). Elle est effectivement utilisée, mais en général dans des réseaux à part, réservés à l'armée. Ces réseaux utilisent du matériel standard (PC / Linux, routeurs Cisco, etc) mais ne sont pas reliés à l'Internet public. Ironie de la normalisation, cette option avait été retirée du chemin des normes par l'IESG alors que son déploiement a plutôt augmenté depuis. Si vous voulez des détails sur ce mécanisme, vous pouvez consulter le RFC 5570, qui décrit une option similaire pour IPv6,
- Cette option ne crée pas de problème de sécurité,
- Si elle est bloquée, ce système de sécurité ne fonctionne plus,
- Certes, elles n'est utilisée que dans des réseaux fermés. Mais comme un routeur ordinaire du marché n'a aucun moyen de savoir s'il est dans un tel réseau, le RFC déconseille fortement de jeter par défaut les paquets contenant cette option.
C'est un peu pareil pour son équivalent civil, l'option 134 (CIPSO, Commercial IP Security Option, pas normalisée dans un RFC mais dans un document FIPS), avec les mêmes recommandations de non-blocage. Elle aussi est mise en œuvre dans SELinux.
Et les options marquées comme expérimentales ? C'est le cas de la 25 (Quick Start).
- Elle fait partie d'une expérience décrite dans le RFC 4782, d'un mécanisme permettant d'informer la couche transport sur la capacité du tuyau,
- Elle permet plusieurs attaques par déni de service, aggravant la charge du routeur, ou bien encourageant TCP à avaler toute la capacité réseau avec une seule connexion,
- Bloquer les paquets empêcherait Quick Start de fonctionner,
- Notre RFC recommande plutôt d'ignorer cette option par défaut (ne pas bloquer les paquets, les transmettre ou les traiter, mais sans avoir tenu compte de l'option).
Bon, cela faisait une longue liste et encore, je n'ai pas répété toutes les options. Et les options inconnues (comme la numéro 42 que j'ai montré dans l'exemple Scapy), que faut-il faire ? La section 4.23 dit clairement qu'il faut les ignorer, faire comme si elles n'étaient pas là (c'était déjà écrit dans le RFC 1122, section 3.2.1.8, et le RFC 1812, section 4.2.2.6). Autrement, si le comportement par défaut était de jeter les paquets contenant des options inconnues, il serait impossible de déployer une nouvelle option ! Malheureusement, bien des middleboxes ont ce comportement (bloquer ce qu'on ne connait pas), ce qui contribue à l'ossification de l'Internet. Notez d'ailleurs que notre RFC renonce à appliquer les directives des RFC 1122 et RFC 1812 qui disaient qu'il ne fallait pas jeter les paquets portant les options inconnues, en aucun cas. Au contraire, ce nouveau RFC 7126 permet qu'il existe une méthode pour changer la configuration et jeter les paquets portant des options inconnues (chose qui existe déjà largement).
L'article seul
RFC 7136: Significance of IPv6 Interface Identifiers
Date de publication du RFC : Février 2014
Auteur(s) du RFC : B. Carpenter (Univ. of Auckland), S. Jiang (Huawei Technologies)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF 6man
Première rédaction de cet article le 12 février 2014
Les adresses IPv6 sont souvent composées en utilisant un truc nommé « interface identifiers » (identifiant d'interface réseau). Ces identifiants peuvent être formés, par exemple, en utilisant les adresses MAC, en utilisant des bits ayant un sens particulier dans les normes IEEE. Résultat, dans le passé, certains ont attribué à des bits de l'identifiant d'interface une signification qu'ils n'avaient pas. Ce nouveau RFC clarifie la question : les identifiants d'interface doivent être considérés comme opaques et il ne faut pas tirer de conclusion du fait que tel ou tel bit est mis.
Un exemple typique de construction d'adresse
IPv6 est donné dans la section 2.5 du RFC 4291. L'adresse IPv6 de 128 bits est formée en
concaténant un préfixe avec un interface
identifier. Ce dernier est censé être unique sur le lien où
la machine est connectée. Cet objectif peut être atteint en prenant
l'adresse MAC de la machine et en la
transformant en utilisant le format Modified
EUI-64. Dans ce
format, le bit U (pour universal) est inversé, 1
signifiant que l'identifiant EUI-64 est unique mondialement, 0 qu'il
ne l'est pas (ainsi, les adresses fabriquées manuellement comme
2001:db8:33::1 ont un identifiant d'interface où
le bit U est à zéro). Un autre bit est spécial, le G, qui indique s'il
s'agit d'une adresse de groupe ou de machine individuelle. Ces deux
bits perdent leur signification dès qu'ils sont
mis dans une adresse IPv6, c'est le point important de ce RFC.
Un exemple ? Si la machine a l'adresse MAC
b8:27:eb:ba:90:94, son identifiant d'interface va
être ba27:ebff:feba:9094 (suivant le tutoriel
sur le format EUI-48, on ajoute ff:fe au
milieu, l'adresse Ethernet ne faisant que 48 bits, et on inverse le
bit U, transformant le b8 en ba).
Comme indiqué, il y a bien d'autres façons de fabriquer un
identifiant d'interface (notre nouveau RFC 7136 utilise le
sigle « IID » qui n'apparait pas dans le RFC 4291 original). Si celle utilisant une adresse MAC est la
plus souvent présentée dans les tutoriels IPv6, elle n'est pas la
seule et on a des identifiants d'interface formés à partir d'un
processus cryptographique
(RFC 3972 ou RFC 5535), générés aléatoirement et utilisés
temporairement, pour protéger la vie privée (RFC 8981), ou fabriqués à partir des adresses IPv4
(RFC 5214). Sans compter la méthode manuelle de choisir
l'identifiant d'interface à volonté, en en faisant un nombre
significatif (::53 pour un serveur
DNS) ou rigolo
(::dead:beef). Et de nouvelles méthodes apparaissent de temps en
temps. Pour chacune de ces méthodes, la norme stipule la valeur que
doivent prendre les bits U et G. Par exemple, le RFC 3972 les met à zéro tous les deux et le RFC 8981 (section 3.3) met U à zéro et ne dit rien pour G. Les
identifiants formés à partir de ces méthodes ont donc des valeurs
très variables pour ces deux bits. En fait, l'identifiant d'interface
ne fait même pas forcément 64 bits, comme illustré par le RFC 6164, qui le réduit à un seul bit pour les
liaisons point à point entre deux routeurs !
Bref, l'affirmation du RFC 4291 (section 2.5.1) comme quoi le bit U signifie réellement que l'adresse est unique ou pas n'est plus vraie. Et, même si on n'avait gardé qu'une seule méthode de création des identifiants d'interface, celle fondée sur l'adresse MAC, les exemples n'ont pas manqué de constructeurs livrant plusieurs cartes Ethernet avec la même adresse (et c'est encore plus vrai sur les machines virtuelles). Simon Castaing m'a fourni une bonne liste :
On ne peut donc pas espérer que les identifiants d'interface soient mondialement uniques. On ne peut pas compter sur le bit U.
Même des protocoles qui, au début, voulaient pouvoir compter sur l'unicité de l'identifiant d'interface ont fait marche arrière. Par exemple ILNP (RFC 6741) prévoit que les 64 derniers bits de l'adresse soient uniques pour un localisateur donné. Mais il a quand même un système de détection de duplication, car utiliser EUI-64 pour ces 64 derniers bits ne suffit pas, comme on l'a vu.
Ah, et puis on a beaucoup parlé du bit U et nettement moins du bit G. Les adresses IPv6 formées à partir de l'adresse Ethernet ne devraient pas avoir le bit G à 1 (on n'utilise pas les adresses de groupe) mais cela ne veut pas dire que ce bit ait une signification particulière, dans une adresse IPv6. Comme pour le bit U, une fois l'adresse fabriquée, on ne peut plus l'analyser. Si on sait, par un moyen ou un autre, qu'une adresse IPv6 a été formée à partir d'une adresse MAC, on peut recalculer l'adresse MAC, ce qui peut avoir des avantages opérationnels, lors du débogage d'un réseau. Mais, si on ne le sait pas, il vaut mieux s'abstenir : ce n'est pas parce que l'identifiant d'interface a le bit U à 1 et le bit G à 0 qu'il a forcément été engendré à partir d'une adresse MAC.
Parfois, le mécanisme de génération d'identifiants d'interface par une adresse MAC est présenté comme garantissant l'unicité, sans autre effort. Comme on l'a vu, ce n'est pas le cas, même si tout le monde utilisait ce mécanisme. C'est pour cela qu'IPv6 a un système de détection des duplications d'adresses, le DAD (Duplicate Address Detection, RFC 4862). Comme ce système est obligatoire, on n'a pas besoin de trouver des méthodes de génération d'adresse qui assurent l'unicité : il suffit de laisser le DAD trouver les collisions et, dans ce cas, de réessayer. Par exemple, la section 3.4 du RFC 8981 dit qu'en cas de collision, on refait tourner l'algorithme (de génération aléatoire de l'identifiant) et on obtient donc un nouvel identifiant aléatoire.
Les sections 3 et 5 du RFC sont la partie normative de ce document : les bits U et G peuvent être utilisés librement par les méthodes de génération des identifiants d'interface (et donc des adresses IPv6) et, lorsqu'on lit une adresse IPv6 sans connaître le mécanisme de génération, il ne faut pas croire qu'on peut déduire quelque chose de la valeur de ces deux bits. Dans certains cas (identifiants temporaires aléatoires du RFC 8981), c'est même un facteur de sécurité (donner le moins d'information possible, cf. section 6).
Cela nécessite de modifier le RFC 4291 : la régle comme quoi les identifiants d'interface (à part ceux commençant par trois bits mis à zéro) doivent être formés à partir d'une adresse MAC est officiellement retirée, et l'allusion aux bénéfices du bit U pour détecter un identifiant d'interface mondialement unique également. Comme le note notre RFC, cela ne devrait gêner aucune implémentation, cette réforme alignant simplement la norme sur la pratique constatée.
L'article seul
RFC 7113: Implementation Advice for IPv6 Router Advertisement Guard (RA-Guard)
Date de publication du RFC : Février 2014
Auteur(s) du RFC : F. Gont (UK CPNI)
Pour information
Réalisé dans le cadre du groupe de travail IETF v6ops
Première rédaction de cet article le 12 février 2014
La sécurité, ce n'est pas facile et il faut faire attention à beaucoup de choses. Ce RFC est entièrement consacré à un oubli de pas mal de programmeurs lorsqu'ils mettent en œuvre une technique de sécurité pour IPv6, le RA guard : il est en effet courant d'oublier qu'un paquet IPv6 peut avoir plusieurs en-têtes, chaînés, et que chercher un motif dans le paquet, à un nombre d'octets fixes depuis le début du paquet, est une mauvaise stratégie. (Le RFC décrit également un second problème, lié à la fragmentation.)
Le RA guard est une protection contre les RAcailles, ces annonces d'un routeur IPv6 (RA = Router Advertisement) qui ne sont pas émises par un routeur légitime. Les RAcailles sont un phénomène courant, en général provoqué par une erreur de configuration mais elles peuvent aussi être utilisées pour une attaque. Dans ce cas, le méchant s'annonce lui-même comme le routeur du réseau, reçoit donc le trafic et peut alors le jeter, l'espionner, le détourner, ou autres méchancetés. (Le RFC 6104 pose le problème.)
Il n'est pas facile de lutter contre ce phénomène, tout en gardant la simplicité de l'auto-configuration sur le réseau local (si on renonce à la simplicité, il existe une solution, le RFC 3971). Le problème est d'ailleurs le même avec DHCP depuis longtemps (le méchant peut générer de fausses réponses DHCP). Comme le problème est ancien, il y a longtemps que des solutions sont déployées en IPv4. Typiquement, le commutateur examine les paquets (oui, de la DPI), regarde si c'est une réponse DHCP et, si c'est le cas et que le port du commutateur n'est pas censé abriter un serveur DHCP, on jette le paquet. (Il existe plusieurs méthodes pour déterminer si un serveur DHCP légitime est sur ce port, de la confiugration manuelle, jusqu'à l'écoute préalable, pour apprendre automatiquement.)
Cette méthode peut s'étendre facilement aux annonces de routeur d'IPv6, les RA : le RFC 6105 la décrit en détail, sous le nom de RA guard. Mais les premières mises en œuvre ont souvent souffert d'un oubli de la part des programmeurs.
En effet, pour examiner la charge utile du paquet, il faut sauter l'en-tête IP. En IPv4, il est de taille variable et il faut donc lire le champ Longueur, sauter le bon nombre d'octets et on regarde alors la charge utile. En IPv6, l'en-tête étant de taille fixe, cela semble plus facile et c'est ce qui a trompé pas mal d'implémenteurs. Car plusieurs ont fait la même erreur : oublier les en-têtes d'extensions. IPv6 permet en effet d'ajouter plusieurs en-têtes entre l'en-tête principal et la charge utile. Pour contourner le RA Guard, tout ce qu'avait à faire le méchant était d'ajouter un de ces en-têtes, décalant ainsi la charge utile et empêchant sa reconnaissance.
Le problème est bien connu, j'avais même fait un article là-dessus il y a quatre ans mais il y avait de nombreuses autres analyses avant. Mais les programmeurs d'engins réseaux comme les commutateurs ne prennent pas toujours le temps de se renseigner : le marketing dit « nos clients réclament du RA Guard, il faut qu'on puisse l'écrire sur la feuille de spécifications, et ça doit être livré avant-hier », le programmeur programme et cela semble marcher avec des paquets normaux, personne ne fait de tests avec des paquets inhabituels, précisement ceux qu'utilisera l'attaquant.
Ce RFC 7113 rappelle donc qu'un commutateur qui met en œuvre RA Guard doit analyser tous les en-têtes, pas seulement sauter le premier. Sinon, cette protection ne vaut pas grand'chose. À noter que le RFC se focalise sur le cas des RA Guard mais, en fait, des tas de systèmes de sécurité IPv6, des IDS aux limiteurs de trafic ont exactement la même vulnérabilité : en ajoutant un simple en-tête Destination, vous passez outre la plupart des contrôles. (Des logiciels très utiles comme NDPmon, ramond ou rafixd sont apparemment vulnérables.)
Cette première attaque est exposée en section 2.1. On peut noter qu'il n'existe actuellement aucun usage légitime des en-têtes d'extension dans une annonce RA. Mais l'attaque marche car les mises en œuvre de RA guard n'en tiennent pas compte.
Une deuxième attaque, fondée sur la fragmentation, est décrite en section 2.2. L'idée est de fragmenter l'annonce RA en deux paquets IP, les bits qui permettent d'identifier le paquet comme une annonce RA étant dans le deuxième fragment. Si le commutateur ne fait pas de réassemblage des paquets, il ne pourra pas détecter la RAcaille et donc pas le bloquer. Toutes les implémentations testées par l'auteur du RFC sont vulnérables.
Bon, c'est bien joli de décrire les attaques mais comment réparer ? La section 3 décrit les obligations d'un système de RA GUard sérieux :
- Si le paquet a une adresse source qui n'est pas locale au lien
(les adresses locales au lien sont dans le préfixe
fe80::/10), le laisser passer. Un RA doit toujours avoir une adresse source locale au lien (puisqu'il est forcément générer par un routeur connecté au lien) donc inutile d'examiner ce paquet, si c'est une RAcaille, il sera refusé de toute façon (RFC 4861, section 6.1.2). - Si le nombre de sauts maximum (champ Hop Limit) n'est pas à 255, laisser passer le paquet. Les RA utilisent ce champ comme protection contre une injection de RA par une machine extérieure au réseau local. S'il est à moins de 255, ce qui indique qu'il a traversé au moins un routeur, il sera rejeté par les machines terminales donc, comme dans le cas précédent, pas la peine de se fatiguer à l'examiner.
- Si le paquet est un fragment et n'est pas le premier fragment d'une série, le laisser passer (en raison de la règle suivante).
- Le système RA Guard doit analyser tous les en-têtes, pas juste le premier. Cette tâche est complexe mais elle a été rendue plus facile par le RFC 6564. En outre, le RFC 7112 impose que la totalité des en-têtes soient dans le premier fragment, ce qui fait qu'il n'y a pas besoin de réassembler le paquet d'origine pour effectuer cette analyse (on a désormais le droit de jeter les paquets où le premier fragment ne contient pas toute la chaîne d'en-têtes). Par contre, le RFC interdit à RA Guard de se limiter aux N premiers octets : il faut analyser tout le paquet (les en-têtes d'extension peuvent être arbitrairement grands).
- Ensuite, on peut appliquer l'algorithme RA Guard classique : si le paquet est un RA et que ce n'est pas autorisé sur ce port, le jeter. Autrement, le laisser passer.
À noter que les paquets ESP (RFC 4303) seront toujours acceptés (puisque le RA est après l'en-tête ESP, qui est considéré comme l'en-tête final d'IP). C'est logique : c'est IPsec qui, dans ce cas, assure la sécurité des paquets, RA Guard s'efface alors devant IPsec.
Un dernier détail lié à la fragmentation : IPv6 permettait à l'origine des fragments non-disjoints. Ces fragments arriveraient à passer les règles ci-dessus. Mais ils ont été interdits par le RFC 5722 et l'étude « IPv6 NIDS evasion and improvements in IPv6 fragmentation/reassembly » montrait, qu'en 2012, la plupart des mises en œuvre d'IPv6 faisaient respecter cette interdiction. Plus radical, le RFC 6980 interdit complètement la fragmentation pour les RA mais il ne sera pas déployé immédiatement dans toutes les machines terminales, donc RA Guard ne peut pas encore compter dessus.
Un document équivalent pour DHCP sera publié
comme RFC, pour l'instant, c'est
l'Internet-Draft draft-ietf-opsec-dhcpv6-shield,
qui utilise les mêmes techniques que notre RFC 7113.
Si vous voulez tenter les attaques décrites ici, vous avez la boîte à outils de SI6 ou bien l'ensemble logiciel THC.
L'article seul
RFC 7088: Session Initiation Protocol Service Example -- Music on Hold
Date de publication du RFC : Février 2014-02-11
Auteur(s) du RFC : D. Worley (Ariadne)
Pour information
Première rédaction de cet article le 11 février 2014
Une des fonctions les plus demandées d'un service de téléphonie, dans les entreprises, est la musique d'attente, cette insupportable ritournelle qu'il faut supporter en attendant un interlocuteur qui ne viendra peut-être jamais. Comment déployer ce service si on utilise SIP pour la téléphonie ? Il existe plusieurs méthodes et ce nouveau RFC en documente une. Il peut être utilisé comme exemple d'un service mis en œuvre au dessus de SIP, sans nécessiter de modification ou d'extension du protocole.
A priori, ce n'est pas évident. Rappelons brièvement comment fonctionne SIP (RFC 3261), lorsqu'Alice veut contacter Bob. Le client SIP de Bob s'est enregistré auprès d'un fournisseur SIP (SIP permet aussi du pair-à-pair, sans ces fournisseurs, mais c'est plus rare). Alice appelle le serveur SIP de Bob, et lui indique (dans un SDP, cf. RFC 4566) où envoyer le flux audio. Le serveur de Bob prévient son client et, si celui-ci accepte, il indique à son tour où envoyer le son. La communication est établie. Le flux audio ne voyage pas dans le même canal que la signalisation. Les machines SIP doivent indiquer où envoyer ce flux car elles sont souvent coincées derrière un routeur NAT et elles doivent d'abord faire un trou dans le NAT, par exemple avec STUN. Maintenant, si le serveur SIP de Bob ne peut pas établir la communication avec Bob tout de suite et qu'il veut envoyer une musique d'attente, genre « Les quatre saisons » de Vivaldi ? L'architecture de SIP fait que ce n'est pas complètement trivial. Plusieurs méthodes avaient été documentées (par exemple en section 2.3 du RFC 5359) mais avaient des effets parfois gênants, par exemple entraînaient des messages inattendus dans l'interface utilisateur du client SIP, ou bien marchant mal en cas d'authentification des partenaires.
D'où la nouvelle méthode décrite dans ce RFC
(section 2) : comme dans la section 2.3 du RFC 5359, Bob envoie à son tour un message
INVITE à Alice pour la mettre en attente, mais il
ne fournit pas de SDP, pas de description des détails techniques de la
session audio. Alice va alors en envoyer un à elle. Bob utilise
l'option de la section 5.2 du RFC 4235 pour
indiquer qu'il ne jouera pas le flux audio. Bob transmet le SDP
d'Alice au serveur de musique d'attente, via un nouvel
INVITE. Le serveur de musique va alors envoyer la
musique en RTP (RFC 3550)
à Alice. Cette sorte d'indirection (ici, Bob contactant le serveur de
musique mais en lui disant d'envoyer le son à Alice) est très courant
dans le monde SIP (et pose d'ailleurs d'amusants problèmes de
sécurité).
Pour mettre fin à l'attente, le serveur de Bob ré-envoie un
INVITE à Alice, un INVITE
habituel, cette fois, avec un SDP de Bob. Et il coupe la session avec
le serveur de musique d'attente.
Tiré du RFC (qui contient la session complète, avec tous les détails), voici la requête de Bob (ou plutôt du serveur de Bob) à Alice lorsqu'il la met en
attente. Notez l'absence de SDP (de descripteur de session, le corps a
une taille nulle) et le
+sip.rendering="no" du RFC 4235 pour
indiquer que Bob n'écoute pas, pour l'instant :
INVITE sips:a8342043f@atlanta.example.com;gr SIP/2.0
Via: SIP/2.0/TLS biloxi.example.com:5061
;branch=z9hG4bK874bk
To: Alice <sips:alice@atlanta.example.com>;tag=1234567
From: Bob <sips:bob@biloxi.example.com>;tag=23431
Call-ID: 12345600@atlanta.example.com
CSeq: 712 INVITE
Contact: <sips:bob@biloxi.example.com>;+sip.rendering="no"
Allow: INVITE, ACK, CANCEL, OPTIONS, BYE, REFER, NOTIFY
Supported: replaces
Content-Length: 0
Et la sollicitation de Bob auprès du serveur de musique
d'attente. Cette fois, un SDP est inclus, contenant
l'adresse IP où Alice recevra le flux
(192.0.2.69), le port où envoyer ce flux
(49170) et le paramètre recvonly indiquant au
serveur de musique qu'Alice écoutera mais ne parlera pas au dit
serveur :
INVITE sips:music@source.example.com SIP/2.0
Via: SIP/2.0/TLS biloxi.example.com:5061
;branch=z9hG4bKnashds9
Max-Forwards: 70
From: Bob <sips:bob@biloxi.example.com>;tag=02134
To: Music Source <sips:music@source.example.com>
Call-ID: 4802029847@biloxi.example.com
CSeq: 1 INVITE
Contact: <sips:bob@biloxi.example.com>
Allow: INVITE, ACK, CANCEL, OPTIONS, BYE, REFER, NOTIFY
Supported: replaces, gruu
Content-Type: application/sdp
Content-Length: [omitted]
v=0
o=bob 2890844534 2890844534 IN IP4 atlanta.example.com
s=
c=IN IP4 192.0.2.69
t=0 0
m=audio 49170 RTP/AVP 0
a=rtpmap:0 PCMU/8000
a=recvonly
Les avantages de ce mécanisme (section 3) ? Pas de transfert du
dialogue SIP donc les adresses affichées par les logiciels SIP ne
changent pas en cours de session. Pas d'utilisation de la commande
REFER, introduite dans le RFC 3515 mais
peu déployée. Lien direct entre le serveur de musique et l'appelant
mis en attente (Alice), ce qui évite le faire passer le flux audio par
le répondant (Bob).
Et les pièges (section 4) ? Il y a un petit risque qu'Alice n'indique pas, dans le SDP, tous les formats audio que gère son logiciel, mais seulement ceux qu'elle a utilisé avec Bob. C'est une violation des sections 5.1 et 5.3 du RFC 6337 mais cela peut arriver. Et, dans ce cas, il pourra arriver qu'elle ne reçoive rien parce que le serveur de musique d'attente croit, à tort, qu'elle ne gère pas les formats qu'il possède. Si Alice (enfin, son logiciel SIP), gère les formats X et Y, que B gère les formats X et Z, et que le serveur de musique gère les formats Y et Z, si Alice n'annonce dans son SDP que le format X (le seul qu'elle a en commun avec Bob), le serveur de musique croira qu'il ne peut pas la satisfaire, alors que le format Y aurait convenu.
Quelques mots enfin sur la sécurité (section 5). Le serveur de musique est un tiers qui n'est pas forcément sous la même administration que le serveur de Bob. Il va récupérer quelques informations (l'adresse IP d'Alice) et il faut donc que Bob (enfin, son fournisseur SIP), veille à ce que la sécurité du serveur de musique soit assurée. Le RFC suggère que le plus simple est que le fournisseur de Bob évite la sous-traitance et utilise un serveur de musique d'attente installé chez lui.
Quelles mises en œuvre de SIP ont une fonction de musique d'attente
conforme à ce RFC ? Apparemment (mais je n'ai pas vérifié), les
téléphones SIP de Polycom,
le système OnSIP,
les Cisco (ex-Linksys),
etc. Vous pouvez trouver un pcap d'un dialogue
avec musique d'attente en http://wiki.sipfoundry.org/display/sipXecs/Phone+Certification+Process
(cherchez music on hold).
L'article seul
RFC 7123: Security Implications of IPv6 on IPv4 Networks
Date de publication du RFC : Février 2014
Auteur(s) du RFC : F. Gont (SI6 Networks/UTN-FRH), W. Liu (Huawei Technologies)
Pour information
Réalisé dans le cadre du groupe de travail IETF opsec
Première rédaction de cet article le 11 février 2014
La sécurité d'IPv6 a déjà fait couler beaucoup d'encre. Ce RFC se focalise sur un aspect particulier : la sécurité des techniques de transition/coexistence entre IPv4 et IPv6. En effet, l'incroyable retard que mettent beaucoup de FAI à déployer IPv6 fait que, bien, souvent, pour accéder à IPv6, on doit utiliser des techniques plus ou moins propres, qui étaient appelées autrefois, avec optimisme, « techniques de transition » et qu'on nomme souvent aujourd'hui « techniques de coexistence ». Ces techniques, en général conçues pour être un bouche-trou temporaire, n'ont pas forcément une architecture bien propre, et apportent souvent leurs problèmes de sécurité spécifiques.
Normalement, le problème aurait dû disparaitre depuis longtemps. Comme le pose le RFC 6540, de nos jours, IP veut dire IPv6 et tout devrait être en IPv6. Cela dispenserait de ces techniques de transition et de leurs problèmes. Malheureusement, on constate que bien des réseaux sont encore uniquement en IPv4 et que, pour les traverser, on est forcés de contourner le problème en utilisant une des techniques de transition. Ce RFC décrit les problèmes de sécurité qui peuvent en résulter. Il cible les réseaux d'organisations, pas les réseaux domestiques ou ceux des FAI. Quelques exemples de ces problèmes ?
- Le NIDS peut être aveugle s'il n'analyse qu'IPv4 et que des machines parlent entre elles en IPv6,
- Un pare-feu peut filtrer certains types de trafic en IPv4 et en être incapable en IPv6,
- Même si le NIDS ou le pare-feu comprennent IPv6, l'administrateur du réseau peut se tromper et mettre, par accident, des politiques différentes en IPv4 et en IPv6 (peu de pare-feux ont un langage de configuration de haut niveau, permettant d'exprimer des règles communes à IPv4 et IPv6 d'un seul coup),
- Les mécanismes de transition sont prévus pour échapper aux limitations d'un réseau archaïque, qui n'a encore qu'IPv4. Une conséquence peut donc être qu'ils permettent aussi d'échapper aux politiques de sécurité, en donnant à une machine une connexion à tout l'Internet, qu'elle n'était pas censée avoir (c'est notamment le cas de Teredo, et le NAT ne le bloque pas),
- Si tout le trafic est censé passer par un VPN sécurisé, le trafic IPv6 est parfois oublié et passe alors en dehors du VPN.
Logiquement, tout cela ne devrait pas arriver : le trafic IPv6 devrait être soumis aux mêmes règles (bonnes ou mauvaises) que le trafic IPv4. Mais, en pratique, on observe que ce n'est pas toujours le cas.
Certains administrateurs réseau naïfs croient que, parce qu'ils ont décrété que le réseau était purement IPv4, ou tout simplement parce qu'ils ne connaissent pas IPv6, ils n'auront pas de trafic IPv6. Mais c'est faux (section 2 de notre RFC). La plupart des systèmes d'exploitation ayant désormais IPv6, et celui-ci étant activé par défaut, les machines peuvent se parler en IPv6. Même si les routeurs ne le laissent pas passer, les machines pourront souvent se parler avec leurs adresses locales au lien. Une politique de l'autruche (« je ne vois pas IPv6 donc il ne me voit pas ») n'est donc pas tenable.
La communication entre machines locales en IPv6 peut survenir par accident, sans que personne ne l'ait délibérement cherché. Mais il y a pire : un attaquant peut activer IPv6 en se faisant passer pour un routeur IPv6 et en envoyant des RA (Router Advertisement), fournissant ainsi aux machines une adresse IPv6 globale et peut-être une connectivité globale. Ces attaques (décrites dans l'article de Waters) sont mises en œuvre dans des logiciels comme la boîte à outils SI6 (décrite dans le cours de Fernando Gont), le méchant n'a donc rien à programmer lui-même.
Pour éviter certaines de ces attaques, on peut envisager de filtrer
les paquets IPv6 dans les équipements réseau comme les
commutateurs. S'ils permettent cela (il suffit
de reconnaître le type 0x86dd dans l'en-tête Ethernet), on bloque
ainsi le trafic IPv6, même interne. Mais c'est violent puisqu'on
empêche tout trafic IPv6, on ne fait que rendre la future migration
encore plus pénible. On peut aussi supprimer IPv6 de toutes les
machines qui se connectent au réseau, ce qui nécessite d'avoir accès à
toutes les machines, ce qui est difficile en dehors des réseaux à très
haute sécurité. Sinon, pour ne bloquer que les attaques
SLAAC, on peut utiliser le RA
Guard du RFC 6105 (une technique
équivalente, pas encore décrite dans un RFC, existe pour
DHCP, le DHCP Shield).
Une bonne partie des techniques de transition/coexistence reposent sur des tunnels. Ceux-ci posent des problèmes de sécurité spécifiques (section 3 de notre RFC), qui ne sont d'ailleurs pas spécifiques à IPv6 : un tunnel IPv4-dans-IPv4 est tout aussi dangereux (RFC 6169). Le tunnel n'est pas forcément un danger : tout dépend de comment il est géré. Les mécanismes automatiques, sans gestion du tout, comme Teredo ou 6to4 sont les plus risqués. Le tunnel peut être dangereux par accident, mais aussi parce qu'un utilisateur peut délibérement s'en servir pour contourner les politiques de sécurité.
Si on souhaite empêcher les tunnels IPv6-dans-IPv4, le plus simple est en général de bloquer les paquets IPv4 utilisant le protocole (pas le port, attention) 41, qui désigne l'encapsulation d'IPv6 dans IPv4. Mais il existe des tas de variétés de tunnels, dont certainement pas forcément très bien standardisés (un tunnel IPv6-dans-IPv4 sur IPsec, sur TLS...). L'annexe A du RFC résume, dans un tableau synthétique, toutes les règles à mettre dans son pare-feu selon le type de tunnel qu'on veut bloquer.
Le tunnel le plus basique est 6in4. On met simplement le paquet IPv6 dans un paquet IPv4 de protocole 41, pas d'autres métadonnées, pas de protocole de configuration (c'est typiquement une configuration manuelle). Bloquer le protocole 41 suffit à les arrêter. Par exemple, avec Netfilter, sur Linux, on peut faire :
# iptables --append FORWARD --protocol 41 --jump DROP
Et les paquets du protocole 41 ne seront alors plus transmis par le
routeur Linux. (Rappel : c'est bien le protocole
- de transport - 41, pas le port 41. grep 41 /etc/protocols)
C'est la même chose, on l'a vu, pour bien des mécanismes de tunnels, par exemple pour le 6rd du RFC 5969.
Cela s'applique aussi à 6to4, décrit par le RFC 3056. Il pose bien des problèmes de sécurité, documentés dans le RFC 3964 et, souvent, on souhaiterait le bloquer mais en laissant passer les autres systèmes qui utilisent le protocole 41. On peut alors :
- filtrer les paquets IPv4 sortants qui vont vers le préfixe
192.88.99.0/24, - ou filtrer les paquets IPv4 entrants qui viennent de
192.88.99.0/24(RFC 3068), - (nécessite des capacités d'inspection du paquet plus avancées)
filtrer les paquets IPv4 contenant un paquet IPv6 dont l'adresse
source ou destination est dans
2002::/16.
Le RFC cite aussi la possibilité de filtrer spécifiquement les paquets à destination de, ou en provenance des relais 6to4 connus mais ceux-ci sont nombreux et changent tout le temps.
Et Teredo (RFC 4380) ? Il pose encore plus de problèmes de sécurité à l'administrateur, puisqu'il permet à un utilisateur de court-circuiter toutes les sécurités du réseau, parfois sans même le faire exprès. Il marche même derrière le NAT (encore un exemple montrant que le NAT ne fournit guère de sécurité). Teredo est surtout utilisé sur Windows puisqu'il est installé et activé par défaut sur ce système.
Teredo n'utilise pas le protocole 41 mais UDP. Le client Teredo se connecte à un serveur qui écoute sur le port 3544. Filtrer ce port est donc efficace... sauf qu'il existe des serveurs Teredo écoutant sur des ports non-standard. Au moins, cela évite les connexions accidentelles. Si le pare-feu a des capacités d'inspection profonde, il peut :
- filtrer les paquets sortants qui contiennent de l'UDP et un
paquet IPv6 en charge utile UDP, avec une adresse source dans
2001::/32, - filtrer les paquets entrants qui contiennent de l'UDP et un
paquet IPv6 en charge utile UDP, avec une adresse destination dans
2001::/32.
Ces deux règles ont des faux positifs (charge utile UDP qui ressemble
à de l'IPv6...) et les appliquer n'est pas toujours facile (par
exemple, si les paquets sont fragmentés, il
faut les réassembler). Autre solution pour bloquer Teredo : le client
Windows obtient l'adresse du serveur en résolvant
teredo.ipv6.microsoft.com. Bloquer ce nom sur les
résolveurs DNS (par exemple avec RPZ) peut empêcher les connexions
Teredo que ferait Windows par défaut. On peut aussi bloquer les
adresses IP vers lesquelles ce nom résout (mais attention, elles
changent). Cela ne protège que contre les connexions Teredo
faites par défaut, pas contre un utilisateur qui va délibèrement
chercher à contourner les règles, par exemple en utilisant des
serveurs Teredo non connus.
Un protocole souvent utilisé pour la configuration d'un tunnel est TSP (RFC 5572), où le client se connecte à un intermédiaire, nommé tunnel broker, qui lui indique les paramètres du tunnel (qui utilisera ensuite le protocole 41). La connexion se fait en TCP ou en UDP, vers le port 3653, qu'on peut donc bloquer pour neutraliser TSP.
À noter que la seule raison envisagée jusqu'à présent dans ce RFC pour bloquer les tunnels était la sécurité mais la section 4 rappelle qu'il en existe une autre : empêcher les machines d'établir accidentellement une connexion IPv6 pourrie (par exemple parce qu'elle passe par 6to4), que les applications utiliseraient ensuite, obtenant des performances et une qualité de service très inférieures à ce qu'elles auraient eu avec l'IPv4 natif. C'est en effet un des gros problèmes d'IPv6 : beaucoup de machines croient avoir une connectivité IPv6 alors que celle-ci est incomplète ou de très mauvaise qualité. Bloquer les tentatives de former un tunnel peut donc améliorer l'expérience utilisateur (RFC 6555).
Le RFC envisage une autre solution pour éviter ce problème : laisser les tunnels se faire mais bloquer la résolution de noms pour le type DNS AAAA (adresse IPv6). Si le résolveur ment et supprime les réponses AAAA, les applications n'essaieront pas de se connecter en IPv6. Comme toutes les solutions où le résolveur ment, elle est difficilement compatible avec DNSSEC.
L'article seul
Ma nouvelle clé PGP
Première rédaction de cet article le 9 février 2014
Dernière mise à jour le 17 juin 2014
Je viens de créer une nouvelle clé PGP, pour authentifier mes messages et pour qu'on puisse m'écrire de manière relativement confidentielle. En même temps, c'était l'occasion de créer une clé conforme aux bonnes pratiques de 2014, tenant compte de l'évolution de la cryptographie. C'est malheureusement plus dur que je ne le pensais.
Mon ancienne clé, portant le key ID
97D6D246 et l'empreinte
BE25 EAD6 1B1D CFE9 B9C2 0CD1 4136 4797 97D6
D246 avait en effet été créée il y a treize ans ! Elle
utilisait une clé DSA considérée comme trop
courte aujourd'hui, vu les progrès de la
cryptanalyse, ainsi que des algorithmes de
cryptographie trop faibles. Depuis, les craqueurs ont eu tout le temps
de trouver la clé privée... Voyons cette ancienne clé avec
gpg :
% gpg --edit-key 97D6D246
Secret key is available.
pub 1024D/97D6D246 created: 2000-03-31 expires: never usage: SC
trust: ultimate validity: ultimate
sub 2048g/F08F74D7 created: 2000-03-31 expires: never usage: E
[ultimate] (1). Stephane Bortzmeyer (Personal address) <stephane@bortzmeyer.org>
...
gpg> showpref
[ultimate] (1). Stephane Bortzmeyer (Personal address) <stephane@bortzmeyer.org>
Cipher: AES256, AES192, AES, CAST5, 3DES
Digest: SHA1, SHA256, RIPEMD160
Compression: ZLIB, BZIP2, ZIP, Uncompressed
Features: MDC, Keyserver no-modify
Par exemple, 3DES est aujourd'hui déconseillé (mais, on verra plus tard, il ne peut pas être retiré complètement). Il n'existe pas à ma connaissance de moyen simple et en ligne de vérifier la qualité d'une clé PGP, fournissant un service analogue à celui que fournit SSLlabs pour les serveurs TLS (ou, dans un genre différent, ZoneCheck pour les serveurs DNS). Question outils installables localement, il y a les hopenpgp-tools cités tout à la fin de cet article et Parsifal, très riche et très perfectionné mais pas trivial à installer et utiliser. Il faut donc souvent se contenter de l'exploration manuelle, des logiciels non distribués publiquement, et l'aide d'un gourou, si on veut évaluer la qualité d'une clé publique.
Pour générer une nouvelle clé, le point de départ recommandé est en
général « Creating
the perfect gpg keypair » d'Alex Cabal. Mais on verra que cela
ne suffit pas. Personnellement, j'ai fait des choix différents :
l'article d'Alex Cabal, comme la plupart des articles sur la
génération de clés PGP, donne des exemples en ajoutant des options aux
lignes de commande, ou en modifiant les caractéristiques de la clé
a posteriori. Cette méthode nécessite de suivre des procédures
rigoureuses, et où l'erreur est vite arrivée. Je préfère donc mettre
les bonnes pratiques de cryptographie dans le fichier de
configuration, ~/.gnupg/gpg.conf :
# Crypto preferences # For the keys we create cert-digest-algo SHA256 # For the signatures and other things we generate default-preference-list SHA512 SHA384 SHA256 SHA224 AES256 AES192 AES ZLIB BZIP2 ZIP Uncompressed
Je ne dirais pas qu'il y a un accord unanime sur les bonnes pratiques (par exemple tout le monde n'omet pas CAST5) mais les choix ci-dessus sont relativement consensuels. Notez que cette option change l'ordre de la liste mais ne supprime pas forcément les algorithmes non cités. Par exemple, je n'ai pas cité SHA-1 mais il se retrouve quand même dans les algorithmes car la norme impose de pouvoir gérer cet algorithme. Sans lui, certains messages PGP parfaitement légaux ne seraient pas lisibles.
Maintenant, commençons l'opération de création d'une clé. Pour limiter un peu (un tout petit peu) le risque d'un logiciel malveillant sur ma machine, j'ai d'abord débranché le câble Ethernet, redémarré l'engin (ce qui ne protège pas, je sais, contre un logiciel malveillant qui s'est installé dans le BIOS, mais c'est une précaution qui ne coûte pas cher et ne peut pas faire de mal). Ensuite :
% gpg ‐‐gen-key
Please select what kind of key you want:
(1) RSA and RSA (default)
(2) DSA and Elgamal
(3) DSA (sign only)
(4) RSA (sign only)
Your selection? 1
RSA keys may be between 1024 and 4096 bits long.
What keysize do you want? (2048) 4096
Requested keysize is 4096 bits
Please specify how long the key should be valid.
0 = key does not expire
<n> = key expires in n days
<n>w = key expires in n weeks
<n>m = key expires in n months
<n>y = key expires in n years
Key is valid for? (0) 2y
Key expires at Tue Feb 9 12:20:32 2016 CET
Is this correct? (y/N) y
GnuPG needs to construct a user ID to identify your key.
Real name: Stéphane Bortzmeyer
Email address: stephane@bortzmeyer.org
Comment: Main ID
You are using the `utf-8' character set.
You selected this USER-ID:
"Stéphane Bortzmeyer (Main ID) <stephane@bortzmeyer.org>"
Change (N)ame, (C)omment, (E)mail or (O)kay/(Q)uit? o
You need a Passphrase to protect your secret key.
We need to generate a lot of random bytes. It is a good idea to perform
some other action (type on the keyboard, move the mouse, utilize the
disks) during the prime generation; this gives the random number
generator a better chance to gain enough entropy.
We need to generate a lot of random bytes. It is a good idea to perform
some other action (type on the keyboard, move the mouse, utilize the
disks) during the prime generation; this gives the random number
generator a better chance to gain enough entropy.
gpg: key FEB46FA3 marked as ultimately trusted
public and secret key created and signed.
gpg: checking the trustdb
gpg: 3 marginal(s) needed, 1 complete(s) needed, PGP trust model
gpg: depth: 0 valid: 1 signed: 0 trust: 0-, 0q, 0n, 0m, 0f, 1u
gpg: next trustdb check due at 2016-02-09
pub 4096R/FEB46FA3 2014-02-09 [expires: 2016-02-09]
Key fingerprint = 1D29 A41C 889B 2E20 80D9 9DB5 2AC5 52F6 FEB4 6FA3
uid Stéphane Bortzmeyer (Main ID) <stephane@bortzmeyer.org>
sub 4096R/E8791D6E 2014-02-09 [expires: 2016-02-09]
(Si vous regardez attentivement, vous verrez que ce n'est pas la
session qui a généré la nouvelle clé, mais une répétition avec les
mêmes paramètres. Ma vraie clé a un autre key ID.
Cet article ne montre que des commandes réellements
tapées, mais pas forcément celles qui ont créé ma nouvelle clé.)
Notez que la longueur de clé RSA proposée par
défaut est un peu courte (surtout si la clé doit durer longtemps) et
que la clé n'expire pas, par défaut. L'article d'Alex Cabal propose de
changer la longueur de clé RSA mais il ne change pas l'expiration, qui
fait pourtant partie des bonnes pratiques conseillées (sans elle, en
cas de perte de la clé privée, on risque de ne plus pouvoir se
débarasser de la clé). Une fois la commande ci-dessus terminée, j'ai désormais une nouvelle clé, de
key ID CCC66677 (le joli
key ID est un pur coup de chance, je n'ai pas fait
un million d'essais pour avoir un résultat esthétique). L'empreinte
est F42D 259A 35AD BDC8 5D9B FF3E 555F 5B15 CCC6
6677. Vous pouvez la télécharger ici (ce fichier a été produit par gpg --armor --export CCC66677) ou bien, si vous avez les bonnes autorités de certification, en HTTPS ici.
Alex Cabal suggère ensuite de créer des sous-clés (un bon article chez Debian explique leur utilité). C'est aussi simple que (ici, pour une clé dédiée aux signatures) :
% gpg --edit-key 2ED6226D
gpg> addkey
Key is protected.
You need a passphrase to unlock the secret key for
user: "Stéphane Bortzmeyer (Main ID) <stephane@bortzmeyer.org>"
4096-bit RSA key, ID 2ED6226D, created 2014-02-09
Please select what kind of key you want:
(3) DSA (sign only)
(4) RSA (sign only)
(5) Elgamal (encrypt only)
(6) RSA (encrypt only)
Your selection? 4
RSA keys may be between 1024 and 4096 bits long.
What keysize do you want? (2048) 4096
Requested keysize is 4096 bits
Please specify how long the key should be valid.
0 = key does not expire
<n> = key expires in n days
<n>w = key expires in n weeks
<n>m = key expires in n months
<n>y = key expires in n years
Key is valid for? (0) 2y
Key expires at Tue Feb 9 18:40:19 2016 CET
Is this correct? (y/N) y
Really create? (y/N) y
We need to generate a lot of random bytes. It is a good idea to perform
some other action (type on the keyboard, move the mouse, utilize the
disks) during the prime generation; this gives the random number
generator a better chance to gain enough entropy.
...
sub 4096R/7B5BCD86 created: 2014-02-09 expires: 2016-02-09 usage: S
...
Et pour créer d'autres identités :
gpg> adduid
Real name: Stéphane Bortzmeyer
Email address: stephane@abgenomica.com
Comment:
You are using the `utf-8' character set.
You selected this USER-ID:
"Stéphane Bortzmeyer <stephane@abgenomica.com>"
Change (N)ame, (C)omment, (E)mail or (O)kay/(Q)uit? o
You need a passphrase to unlock the secret key for
...
Une fois qu'on est satisfait de sa clé (mais rappelez-vous qu'il n'y a hélas pas de moyen simple de la tester), vous pouvez la signer avec l'ancienne clé (97D6D246), pour certifier la nouvelle clé (CCC66677) :
% gpg --default-key 97D6D246 --sign-key CCC66677
Il reste à l'envoyer aux serveurs de clés :
% gpg --send-keys CCC66677 gpg: sending key CCC66677 to hkp server pool.sks-keyservers.net
Et la clé est désormais disponible pour tout le monde.
Si on n'a pas modifié son ~/.gnupg/gpg.conf à
l'avance, comme je le recommande, il faut durcir les choix d'algorithmes utilisés après, comme
recommandé par Alex Cabal.
% gpg --edit-key CCC66677
Secret key is available.
pub 4096R/CCC66677 created: 2014-02-08 expires: 2016-02-08 usage: SC
trust: ultimate validity: ultimate
sub 4096R/F9054A15 created: 2014-02-08 expires: never usage: E
[ultimate] (1). Stéphane Bortzmeyer (Main key) <stephane@bortzmeyer.org>
gpg> setpref SHA512 SHA384 SHA256 SHA224 AES256 AES192 AES ZLIB BZIP2 ZIP Uncompressed
Set preference list to:
Cipher: AES256, AES192, AES, 3DES
Digest: SHA512, SHA384, SHA256, SHA224, SHA1
Compression: ZLIB, BZIP2, ZIP, Uncompressed
Features: MDC, Keyserver no-modify
Really update the preferences for the selected user IDs? (y/N) y
You need a passphrase to unlock the secret key for
user: "Stéphane Bortzmeyer (Main key) <stephane@bortzmeyer.org>"
4096-bit RSA key, ID CCC66677, created 2014-02-08
...
Important : faites cette opération avant d'ajouter (éventuellement) d'autres identités, sinon ces autres identités garderont la vieille liste. Tout ça est compliqué, avec ces commandes qui dépendent de l'ordre exact d'exécution ? Oui, je trouve aussi et c'est pour cela que je préfère ma méthode, exposée au début de cet article.
Changer les préférences ne marche pas pour la clé elle-même et les
sous-clés, déjà créées à ce stade. Si on n'utilise pas la méthode que
je recommande (modifier ~/.gnupg/gpg.conf)
avant, et qu'on veut remplacer
SHA-1 par le plus sûr
SHA-256, il faudra dans ce cas le faire après,
en détruisant les signatures et en les refaisant :
% gpg --cert-digest-algo SHA256 --edit-key F9054A15
Secret key is available.
pub 4096R/CCC66677 created: 2014-02-08 expires: 2016-02-08 usage: SC
trust: ultimate validity: ultimate
sub 4096R/F9054A15 created: 2014-02-08 expires: never usage: E
sub 4096R/42EE189F created: 2014-02-08 expires: never usage: S
[ultimate] (1). Stéphane Bortzmeyer (Main key) <stephane@bortzmeyer.org>
[ultimate] (2) Stéphane Bortzmeyer <stephane@sources.org>
[ultimate] (3) Stéphane Bortzmeyer (Work address) <bortzmeyer@nic.fr>
gpg> uid 1
pub 4096R/CCC66677 created: 2014-02-08 expires: 2016-02-08 usage: SC
trust: ultimate validity: ultimate
sub 4096R/F9054A15 created: 2014-02-08 expires: never usage: E
sub 4096R/42EE189F created: 2014-02-08 expires: never usage: S
[ultimate] (1)* Stéphane Bortzmeyer (Main key) <stephane@bortzmeyer.org>
[ultimate] (2) Stéphane Bortzmeyer <stephane@sources.org>
[ultimate] (3) Stéphane Bortzmeyer (Work address) <bortzmeyer@nic.fr>
gpg> delsig
uid Stéphane Bortzmeyer (Main key) <stephane@bortzmeyer.org>
sig!3 CCC66677 2014-02-09 [self-signature]
Delete this good signature? (y/N/q)y
Really delete this self-signature? (y/N)y
uid Stéphane Bortzmeyer (Main key) <stephane@bortzmeyer.org>
sig!3 97D6D246 2014-02-08 Stephane Bortzmeyer (Personal address) <stepha
Delete this good signature? (y/N/q)n
Deleted 1 signature.
gpg> sign
pub 4096R/CCC66677 created: 2014-02-08 expires: 2016-02-08 usage: SC
trust: ultimate validity: ultimate
Primary key fingerprint: F42D 259A 35AD BDC8 5D9B FF3E 555F 5B15 CCC6 6677
Stéphane Bortzmeyer (Main key) <stephane@bortzmeyer.org>
Are you sure that you want to sign this key with your
key "Stéphane Bortzmeyer (Main key) <stephane@bortzmeyer.org>" (CCC66677)
This will be a self-signature.
Really sign? (y/N) y
You need a passphrase to unlock the secret key for
user: "Stéphane Bortzmeyer (Main key) <stephane@bortzmeyer.org>"
4096-bit RSA key, ID CCC66677, created 2014-02-08
(Et idem pour toutes les identités.)
Un petit mot sur l'expiration : contrairement à ce qu'on voit dans l'article d'Alex Cabal, j'ai mis une durée de validité et ma clé va donc expirer dans deux ans. Devrais-je en regénerer dans deux ans ? Non, on peut toujours renouveller sa clé et, contrairement aux noms de domaine ou aux certificats X.509, c'est gratuit :
% gpg --edit-key 2ED6226D
...
gpg> expire
Changing expiration time for the primary key.
Please specify how long the key should be valid.
0 = key does not expire
<n> = key expires in n days
<n>w = key expires in n weeks
<n>m = key expires in n months
<n>y = key expires in n years
Key is valid for? (0) 2y
Key expires at Tue Feb 9 20:55:44 2016 CET
Is this correct? (y/N) y
...
gpg> save
% gpg --send-keys 2ED6226D
Et on est reparti pour deux ans. Il « suffit » donc de ne pas oublier ce renouvellement.
Quelques bonnes références à lire : les options de configuration de GnuPG et les options les plus baroques de ce logiciel et le RFC 4880 pour tout connaître des formats utilisés par PGP. Et un autre exemple de génération de clé, bien plus parano. Voir aussi un très bon article sur les bonnes pratiques PGP où j'ai découvert cet utile outil hopenpgp-tools pour tester la qualité de sa clé :
% hkt export-pubkeys 'F42D 259A 35AD BDC8 5D9B FF3E 555F 5B15 CCC6 6677'|hokey lint
...
Key has potential validity: good
...
Checking to see if key is RSA or DSA (>= 2048-bit): RSA 4096
...
Stéphane Bortzmeyer (Main key) <stephane@bortzmeyer.org>:
Self-sig hash algorithms: [SHA256]
Preferred hash algorithms:
[SHA512,SHA384,SHA256,SHA224,SHA1]
Key expiration times:
[1y11m30d14925s = Mon Feb 8 21:40:05 UTC 2016]
...
Merci à Florian Maury pour m'avoir encouragé à changer ma clé et à essayer d'en faire une « parfaite », et merci aussi pour son aide lors d'un travail difficile.
L'article seul
Des bitcoins pour mon blog !
Première rédaction de cet article le 6 février 2014
Dernière mise à jour le 8 janvier 2022
J'ai déjà exposé, dans mon article sur Flattr, pourquoi il me paraissait normal que les auteurs sur le Web puissent gagner des sous, et pourquoi la publicité, ou l'abonnement, me paraissaient, pour des raisons différentes, de mauvaise idées. La solution est clairement du côté des micropaiements (comme prônés déjà par Jakob Nielsen). Après Flattr, je tente une deuxième expérience de micropaiements, avec Bitcoin.
L'idée est simple : vous aimez ce blog, ou un de ses articles ?
Envoyez-quelques milli-bitcoins à
1HtNJ6ZFUc9yu9u2qAwB4tGdGwPQasQGax. Vous pouvez
aussi utiliser le code QR :

Autre risque, pour la vie privée, cette fois. Les transactions Bitcoin sont publiques et j'ai été trop paresseux pour mettre en place un de ces systèmes compliqués qui génèrent une nouvelle adresse à chaque chargement de la page (et, on l'espère, sauvegardent la clé privée correspondante). Donc, il est trivial de voir le nombre de versements faits à cette adresse et, si vos adresses à vous sont identifiables, de savoir que vous m'avez donné de l'argent.
L'article seul
Les attaques par réflexion utilisant NTP
Première rédaction de cet article le 2 février 2014
Dernière mise à jour le 3 février 2014
Sauf si vous n'êtes abonné à aucune liste de diffusion, aucun canal IRC, aucun rézosocio, aucun flux de syndication, aucun salon XMPP, bref, sauf si vous êtes coupé de tous les moyens d'informations modernes, vous savez que, depuis le mois de décembre 2013, les attaques par réflexion utilisant le protocole NTP ont connu une hausse spectaculaire et ont complètement chassé des médias les « vieilles » attaques DNS.
Un bon résumé de ces « nouvelles » attaques se trouve par exemple
dans l'article
de Dan Godin. L'attaque est en fait connue depuis longtemps
comme le documente un très bon
article du Team Cymru. Le principe est le même que toutes les attaques
par réflexion, l'Attaquant écrit à un tiers, le Réflecteur, en
usurpant l'adresse IP de la Victime (ce qui est
trop facile
aujourd'hui). Le Réflecteur va répondre à celui qu'il croit être
l'émetteur mais qui est en fait la Victime. En soi, la réflexion ne
change pas grand'chose sauf qu'elle est souvent accompagnée
d'amplification : la réponse est plus grande que la question. Cela
permet à l'Attaquant de ne pas « payer » toute l'attaque, c'est le
Réflecteur qui travaille et, en prime, engage sa responsabilité, au
moins civile (article 1382 du Code
Civil - celui qui cause un dommage doit le réparer). Voici un exemple de trafic pendant
une attaque NTP (merci à Benjamin Sonntag) : 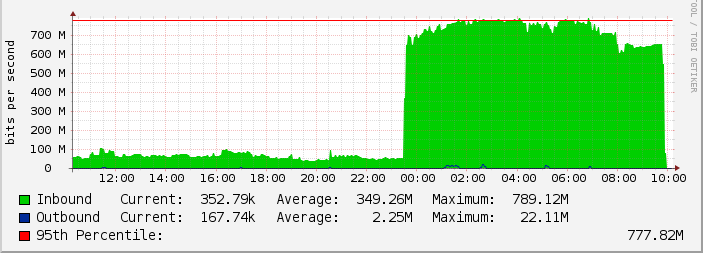
NTP sert à synchroniser les horloges des machines et est normalisé
dans le RFC 5905. Voyons en pratique cette attaque. Le mécanisme le plus simple pour
tester si un serveur NTP est vulnérable est
fourni par la commande ntpdc (qui est livrée avec
la mise en œuvre de référence de
NTP) :
% ntpdc -n -c monlist MACHINEÀTESTER remote address port local address count m ver rstr avgint lstint =============================================================================== 192.168.2.9 46302 192.168.2.4 25 3 4 0 171 41 192.134.4.12 123 192.168.2.4 45 4 4 1d0 101 54 192.168.2.1 123 192.168.2.4 49 3 4 0 85 65 192.168.2.7 37185 192.168.2.4 24 3 4 0 182 117 91.121.92.90 123 192.168.2.4 46 4 4 1d0 99 146 212.27.60.17 123 192.168.2.4 46 4 4 1d0 99 157 212.27.60.18 123 192.168.2.4 46 4 4 1d0 99 185 88.191.184.62 123 192.168.2.4 37 4 4 1d0 123 227 2001:648:2ffc:1225:a80 123 2a01:e35:8bd9:8bb0:ba27:ebff:feba:9094 47 4 4 1d0 96 243
Le serveur a répondu avec la liste de toutes les machines avec qui il a communiqué. C'est embêtant pour la vie privée. Mais c'est surtout embêtant pour la sécurité car la communication se passe sur UDP (qui n'offre aucune protection contre l'usurpation d'adresse IP) et la réponse est bien plus grande que la question :
% tcpdump ... 16:08:00.462739 00:1e:8c:76:29:b6 > b8:27:eb:ba:90:94, ethertype IPv4 (0x0800), length 234: 192.168.2.1.57442 > 192.168.2.4.123: NTPv2, Reserved, length 192 16:08:00.466981 b8:27:eb:ba:90:94 > 00:1e:8c:76:29:b6, ethertype IPv4 (0x0800), length 482: 192.168.2.4.123 > 192.168.2.1.57442: NTPv2, Reserved, length 440 16:08:00.466999 b8:27:eb:ba:90:94 > 00:1e:8c:76:29:b6, ethertype IPv4 (0x0800), length 266: 192.168.2.4.123 > 192.168.2.1.57442: NTPv2, Reserved, length 224
Avec un paquet de 234 octets, on a obtenu deux paquets, faisant en tout 748 octets. Cela fait une amplification d'un facteur 3 mais c'est parce qu'il s'agit d'un tout petit serveur ayant peu de correspondants. Sur un gros serveur public, on peut obtenir des dizaines de milliers d'octets en réponse, donc un facteur d'amplification qui dépasse largement celui du DNS. (Sur votre réseau, pendant une attaque, regardez le port source des paquets : si c'est 123, c'est du NTP, si c'est du 53, c'est du DNS. Et attention, le DNS, contrairement à NTP, peut produire des paquets longs qui seront fragmentés. De toute façon, en pratique, il vaut mieux aussi analyser le contenu des paquets pour savoir si c'est vraiment une attaque par réflexion car les attaquants font des fois des choses compliquées pour se dissimuler.)
Et trouver des serveurs NTP publics permettant cette attaque est facile, il suffit de balayer tout l'espace IPv4. C'est ce que fait, pour le bien général, le projet Open NTP Project. On peut (c'est un exemple réel, j'ai juste modifié les adresses) indiquer son préfixe d'adresses IP et obtenir la liste des réflecteurs potentiels de son réseau :
Responding IP Total bytes 192.0.2.10 44000 192.0.2.66 1104 192.0.2.238 1104
La première machine est un gros serveur NTP public, qui fournissait une énorme amplification (il a été corrigé depuis). À noter que, dans le cas réel, la dernière machine était un routeur Juniper, les routeurs de cette marque fournissant un réflecteur NTP par défaut.
Bon, donc, il faut tester ses serveurs, avec ntpdc -n -c
monlist depuis l'extérieur, et utiliser le Open NTP
Project, pour détecter des machines auxquelles on ne penserait pas
forcément. Attention toutefois en testant avec ntpdc -n -c
monlist, surtout depuis un site distant : si
ntpdc répond Timeout, cela ne
signifie pas forcément que vous êtes sécurisé. La réponse peut prendre
beaucoup de paquets UDP et, si un seul est perdu (UDP ne garantit pas
l'acheminement), ntpdc, n'arrivant pas à tout obtenir, dit
Timeout. Il faut donc utiliser
tcpdump pour voir s'il y a eu des
réponses. Ensuite, si les tests montrent que votre machine est bien un
réflecteur potentiel, comment corriger ?
Pour des machines Unix qui utilisent la mise
en œuvre de référence de NTP, il faut éditer le
/etc/ntp.conf et, par défaut, bloquer les
requêtes comme monlist, en mettant la directive
noquery :
restrict default noquery
Testez avec ntpdc -n -c
monlist, vous devez désormais récupérer un
time out (rappelez-vous que
NTP fonctionne sur UDP, pas TCP).
Cette solution résout le problème de sécurité, votre machine n'est
plus un réflecteur NTP. Mais elle fait perdre un outil de débogage
bien pratique. Par exemple, ntptrace va désormais être
largement inutile, n'obtenant plus de réponses (sauf, ici, au premier pas) :
% ntptrace localhost.localdomain: stratum 4, offset 0.000345, synch distance 0.010345 192.0.2.7: timed out, nothing received ***Request timed out
On peut toutefois autoriser au moins son réseau local (notez que ce logiciel, très ancien, n'accepte pas de notation CIDR) :
# Restriction par défaut restrict default noquery # Pas de restrictions pour les copains restrict 192.0.2.0 mask 255.255.255.0 restrict 127.0.0.1 restrict ::1 restrict 2001:db8:cafe:42:: mask ffff:ffff:ffff:ffff::
Ainsi, le réseau local, au moins, peut poser des questions et ntptrace est un peu plus sympa :
% ntptrace localhost.localdomain: stratum 4, offset 0.000594, synch distance 0.007256 192.0.2.7: stratum 3, offset -0.002068, synch distance 0.014179 193.55.167.2: timed out, nothing received ***Request timed out
Mais attention, authentifier par l'adresse IP n'est pas terrible, une telle configuration permet toujours à un méchant d'attaquer une de vos machines. Il faut encore déployer des bonnes pratiques comme de bloquer sur le pare-feu les paquets entrants qui prétendent venir de chez vous. Ce problème avec ntptrace est un problème courant en sécurité : les mesures de sécurité rendent le débogage plus compliqué. Notez que, si vous utilisez l'excellent programme de test Nagios-compatible check_ntp_time (si vous ne l'utilisez pas, vous devriez), il n'y a pas de problème, il n'utilise pas les commandes de contrôle et marche avec tout serveur NTP :
% /usr/share/nagios/libexec/check_ntp_time -H ntp.nic.fr NTP OK: Offset -0.001630425453 secs|offset=-0.001630s;60.000000;120.000000;
Tous les détails sur la configuration sont en
ligne. J'ai simplement mis noquery car il bloque
l'attaque par réflexion+amplification. Mais il peut y avoir d'autres
et l'excellente documentation
du Team Cymru recommande :
restrict default kod nomodify notrap nopeer noquery
Je n'ai parlé ici que de la mise en œuvre de référence de NTP. Si
vous utilisez le OpenNTPD
d'OpenBSD, il n'y a rien à faire, il ne répond pas aux
requêtes de débogage, de toute façon (et, par défaut, il ne répond
pas du tout aux requêtes du réseau tant que vous n'avez pas mis un
listen on quelquechose). Mais, de toute façon,
n'oubliez pas de tester votre réseau, avec
ntpdc -n -c monlist SERVER et avec le Open NTP Project
(attention, il lui faut quelques jours pour ajuster ses données donc,
si vous changez votre configuration, le résultat ne se verra pas tout
de suite).
Quelques bonnes lectures supplémentaires :
- Un exemple d'analyse du pcap d'une vraie attaque,
- L'avis officiel de vulnérabilité est le CVE-2013-5211.
- Un des premiers articles synthétisant le problème était celui du CERT lituanien.
- Un bon article bien écrit et expliquant tout est celui de CloudFlare.
- En français, notez qu'il y a eu un avis du CERT-FR (ex-CERTA).
- Et l'alerte du CERT RENATER,
- Sur les solutions présentées, voir l'annonce officielle de ntp.org.
- Et, pour le OpenNTPD, l'article de Calomel.
L'article seul
RFC 7127: Characterization of Proposed Standards
Date de publication du RFC : Janvier 2014
Auteur(s) du RFC : O. Kolkman (NLnet Labs), S. Bradner (Harvard University), S. Turner (IECA)
Première rédaction de cet article le 30 janvier 2014
En théorie, il existe à l'IETF une hiérarchie de normes. Un RFC publié sur le chemin des normes peut avoir plusieurs niveaux dans cette hiérarchie. Au nombre de trois à l'origine, ces niveaux ont été ramenés à deux par le RFC 6410. Le premier de ce niveau est « Proposition de Norme » (Proposed Standard), décrit par le RFC 2026. Sauf que la réalité est loin de ce que décrivent les documents officiels.
Le RFC 2026 est toujours le document qui décrit officiellement les normes issues de l'IETF. Sa section 4.1.1 raconte ce qui fait une « Proposition de Norme » mais ce récit est loin de ce qu'on observe en pratique. Ce nouveau RFC 7127 ne change pas le processus de normalisation, il se contente de remplacer la description des Propositions de Norme du RFC 2026 par un texte plus réaliste.
Pour atteindre le niveau Proposition de Norme, le premier niveau du chemin des normes, il faut une décision de l'IESG. Dans la vision originale, les normes allaient ensuite avancer par décisions successives, le long du chemin des normes, jusqu'au statut suprême, celui de « Norme Complète » (Internet Standard). En fait, des tas de protocoles très utilisés et très déployés n'ont jamais suivi cette progression et sont restés Proposition de Norme. Dans la liste des normes, on trouve ainsi, bloqués au niveau Proposition, des tas de protocoles très répandus et indiscutablement réussis, comme les communautés BGP du RFC 1997 ou comme le format OpenPGP du RFC 4880. Il serait donc ridicule et pédant d'écarter une Proposition de Norme en raison de son niveau sur le chemin des normes, alors que beaucoup de normes à ce niveau sont stables, bien testées, mises en œuvre dans beaucoup de programmes...
Donc, la section 3.1 de notre nouveau RFC propose une nouvelle description des Propositions de Norme, description qui remplace la section 4.1.1 du RFC 2026. Une Proposition de Norme est stable, les principaux choix de conception ont été faits et tranchés, elle a fait l'objet d'un examen détaillé par l'IETF, et elle est utile pour les internautes. Si la disponibilité d'une implémentation, et l'expérience opérationnelle de son utilisation, sont très recommandés pour recevoir le statut de Proposition de Norme, cela n'est pas stricto sensu indispensable. Par contre, si le protocole en question touche à une fonction essentielle de l'Internet, l'IESG peut exiger une telle expérience concrète.
Parfois, une norme sera publiée avec le statut de Proposition de Norme alors qu'il reste encore des problèmes non réglés. Dans ce cas, ces problèmes doivent être clairement documentés dans le texte de la norme (section 4 de notre RFC).
La description est plus courte que dans le RFC 2026 et ne contient plus les avertissements et mises en garde de l'ancien RFC.
Notre nouveau RFC ne change pas la description du second niveau, Norme Complète, qui reste présenté par la section 4.1.3 du RFC 2026.
L'article seul
RFC 7112: Implications of Oversized IPv6 Header Chains
Date de publication du RFC : Janvier 2014
Auteur(s) du RFC : F. Gont (SI6 Networks / UTN-FRH), V. Manral (Hewlett-Packard), R. Bonica (Juniper Networks)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF 6man
Première rédaction de cet article le 29 janvier 2014
Résumer ce nouveau RFC en deux mots ? Il dit qu'il ne faut pas, lorsque des paquets IPv6 sont fragmentés, que les en-têtes d'extension se retrouvent dans des fragments différents. Tous ces en-têtes doivent être dans le premier fragment, pour des raisons de sécurité.
Ces en-têtes d'extension, une nouveauté d'IPv6, ont causé bien des casse-têtes aux développeurs, par exemple pour suivre la chaîne qu'ils représentent. Normalisés dans la section 4 du RFC 2460, ils n'ont connu à leur début aucune limite : leur nombre pouvait être quelconque (contrairement à ce qui se passe pour IPv4, où la place réservée aux options a une taille maximale, de 40 octets). Rien ne s'opposait donc à ce que la chaîne de ces en-têtes, avant l'en-tête de transport, soit trop grosse pour tenir dans un seul fragment et soit donc coupée, une partie des en-têtes se retrouvant dans les fragments suivants. Je vous rassure tout de suite, de telles chaînes délirantes n'arrivent jamais en vrai mais, comme les logiciels étaient obligés de les gérer, elles auraient pu être créées et exploitées par des attaquants. Par exemple, un attaquant peut fabriquer délibérement une chaîne d'en-têtes très longue, de façon à ce que les informations de la couche transport soient dans le deuxième paquet, que certains IDS ne verront pas.
La liste des en-têtes d'extension possible est, depuis le RFC 7045, dans un registre IANA. Dans un paquet IPv6, ces en-têtes sont organisés en une chaîne, chaque en-tête ayant un champ Next Header qui indique le type de l'en-tête suivant. La chaîne se termine par un en-tête du protocole de transport (typiquement TCP ou UDP), par un nouvel en-tête IPv6 (dans le cas d'une encapsulation IPv6-dans-IPv6), par un en-tête IPsec, ou bien par un en-tête dont le champ Next Header vaut 59, indiquant que rien ne le suit. Analyser cette chaîne est non trivial, mais c'est nécessaire pour le filtrage ou l'observation. Un pare-feu à qui on dit « tu bloques tout sauf les paquets TCP à destination des ports 22 et 80 » a besoin d'analyser la chaîne des en-têtes, puisqu'il doit arriver à l'en-tête TCP pour y trouver les numéros de ports. Et cet en-tête TCP n'est pas à une position fixe par rapport au début du paquet. Certains équipements de sécurité, par exemple des pare-feux, sont sans état : ils analysent chaque paquet indépendamment des autres, et n'essaient pas, par exemple, de reconstituer les datagrammes fragmentés. Si la chaîne des en-têtes est très longue, l'en-tête TCP peut se retrouver dans le deuxième fragment, ce qui va être très embêtant pour le pare-feu sans état (section 4 de notre RFC). Comme le premier fragment ne contient pas assez d'information pour décider, le pare-feu a deux choix : le bloquer, et il va alors filtrer un datagramme qui était peut-être légitime. Ou bien le laisser passer mais, pour accepter ou non les fragments suivants, le pare-feu a besoin de se souvenir de ce premier fragment, ce qui n'est pas possible sans garder un état.
D'où la nouvelle règle édictée par notre RFC, dans sa section 5 : tous les en-têtes doivent être dans le premier fragment. Si ce n'est pas le cas, les machines terminales devraient jeter le paquet en question (on a le droit de mettre une option de configuration pour les laisser passer quand même). Les machines intermédiaires (routeurs et pare-feux) ont le droit d'en faire autant.
Cette destruction du paquet invalide peut être accompagnée de l'émission d'un paquet ICMP, de type 4 (Parameter problem) et de code 3 (ce nouveau code, First- fragment has incomplete IPv6 Header Chain a été ajouté dans le registre IANA).
On notera que la taille maximale d'une chaîne d'en-têtes dépend donc de la MTU. Si l'émetteur ne fait pas de découverte de la MTU du chemin, il doit se limiter à la taille minimale d'IPv6, 1 280 octets.
Ce RFC fait partie des normes qui sont venues après la mise en œuvre : il existe déjà plusieurs pare-feux IPv6 sans état qui jettent sans merci les paquets lorsque la chaîne complète des en-têtes n'est pas entièrement dans le premier fragment.
L'article seul
RFC 7118: The WebSocket Protocol as a Transport for the Session Initiation Protocol (SIP)
Date de publication du RFC : Janvier 2014
Auteur(s) du RFC : I. Baz Castillo, J. Millan Villegas (Versatica), V. Pascual (Quobis)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF sipcore
Première rédaction de cet article le 29 janvier 2014
Aujourd'hui, de plus en plus de communications sur l'Internet passent sur le port 80, celui de HTTP, parce que c'est souvent le seul que des réseaux d'accès fermés et mal gérés laissent passer. Le protocole WebSocket a été créé juste pour cela, pour fournir un « nouveau TCP » aux applications, notamment celles tournant dans un navigateur Web. Ce nouveau RFC normalise le transport du protocole de communciation SIP sur WebSocket. Une de ses applications sera le développement de softphones sous forme d'applications JavaScript. « Téléphonie IP over Web », en somme.
Le principe de WebSocket, normalisé dans le RFC 6455, est d'ouvrir une connexion HTTP (donc, sur TCP et, éventuellement, sur TLS) puis de la transformer en un canal permanent et bi-directionnel. Sur ce canal passent des messages (et pas un flot d'octets non structuré comme avec TCP). Tous les gros (très gros) navigateurs récents ont déjà un client WebSocket et en permettent l'accès aux applications JavaScript via l'API officielle. Dans le futur, on pourra voir d'autres clients WebSocket, par exemple sous forme d'une bibliothèque pour les programmeurs de smartphones.
Un concept important de WebSocket est celui de
sous-protocole (section 1.9 du RFC 6455), un protocole applicatif au dessus de WebSocket. Indiqué par l'en-tête
Sec-WebSocket-Protocol:, ce sous-protocole permet
d'indiquer l'application qui va utiliser WebSocket, ici SIP.
Voici donc (section 4 de notre RFC) une demande de transformation d'un canal HTTP ordinaire en WebSocket, pour le sous-protocole SIP :
GET / HTTP/1.1 Host: sip-ws.example.com Upgrade: websocket Connection: Upgrade Sec-WebSocket-Key: dGhlIHNhbXBsZSBub25jZQ== Origin: http://www.example.com Sec-WebSocket-Protocol: sip Sec-WebSocket-Version: 13
Si elle est acceptée par le serveur HTTP, cette demande produira un
canal WebSocket de sous-protocole sip. Voici une
réponse positive du serveur :
HTTP/1.1 101 Switching Protocols Upgrade: websocket Connection: Upgrade Sec-WebSocket-Accept: s3pPLMBiTxaQ9kYGzzhZRbK+xOo= Sec-WebSocket-Protocol: sip
Le sous-protocole SIP est désormais dans le registre IANA des sous-protocoles WebSocket.
WebSocket peut avoir des messages textes ou binaires. SIP peut utiliser des données textes ou binaires (pas dans les en-têtes mais dans le corps des messages SIP). Donc, clients et serveurs SIP-sur-WebSocket doivent gérer les deux types de messages.
WebSocket fournit un transport fiable (section 5) donc SIP n'a pas
besoin de prévoir de retransmission. Chaque message SIP se met dans un
et un seul message WebSocket et chaque message WebSocket ne contient
qu'un seul message SIP. Comme WebSocket a son propre mécanisme
d'indication de la longueur, le champ
Content-Length: de SIP (section 20.14 du RFC 3261) est inutile.
Le champ Transport de l'en-tête
Via: de SIP (section 20.42 du RFC 3261) vaut WS (ou
WSS si TLS est utilisé) lorsque les messages SIP
sont transportés sur WebSocket. Le paramètre
received de cet en-tête
Via:, qui indique normalement l'adresse IP du
client, n'a guère de sens pour WebSocket, où le passage par un
relais HTTP sera probablement fréquent. Et il
est inutile puisque la réponse peut uniquement être transmise sur la
connexion WebSocket. Le RFC 3261, section 18.2.1
est donc modifié pour rendre ce received
facultatif. Ah, et, sinon, dans un URI
SIP, ws: ou wss: (S pour
secure) indique l'utilisation de WebSocket. On verra par exemple wss://sip.example.com:8443/ (comme dans la documentation de JSSIP). Pour trouver un serveur SIP WebSocket en utilisant
NAPTR (RFC 3263), on met
la valeur SIP+D2W dans l'enregistrement
NAPTR (valeur désormais notée dans le registre IANA). Mais c'est purement théorique puisque, malheureusement, le code
JavaScript ne peut en général pas faire de requête DNS de type NAPTR
(c'est hélas pareil pour les SRV).
La section 8 fournit des nombreux exemples de dialogues SIP sur
WebSocket. Par exemple, lorsqu'Alice, utilisant
son navigateur Web, charge la page avec le code
SIP-sur-WebSocket, elle va commencer par s'enregistrer auprès de son
serveur SIP, ici codé en dur comme étant
proxy.example.com. Elle commence en HTTP :
GET / HTTP/1.1 Host: proxy.example.com Upgrade: websocket Connection: Upgrade Sec-WebSocket-Key: dGhlIHNhbXBsZSBub25jZQ== Origin: https://www.example.com Sec-WebSocket-Protocol: sip Sec-WebSocket-Version: 13
Et, lorsque la connexion WebSocket est acceptée, elle continue en SIP :
REGISTER sip:proxy.example.com SIP/2.0
Via: SIP/2.0/WSS df7jal23ls0d.invalid;branch=z9hG4bKasudf
From: sip:alice@example.com;tag=65bnmj.34asd
To: sip:alice@example.com
Call-ID: aiuy7k9njasd
CSeq: 1 REGISTER
Max-Forwards: 70
Supported: path, outbound, gruu
Contact: <sip:alice@df7jal23ls0d.invalid;transport=ws>
;reg-id=1
;+sip.instance="<urn:uuid:f81-7dec-14a06cf1>"
Notez le .invalid dans
l'adresse mise en Contact:, parce que le code
JavaScript n'a pas de moyen de déterminer l'adresse IP locale. Notez
aussi que TLS était utilisé, d'où le WSS dans le
Via:.
Ensuite, Alice appelle l'habituel Bob en envoyant le message SIP :
INVITE sip:bob@example.com SIP/2.0
Via: SIP/2.0/WSS df7jal23ls0d.invalid;branch=z9hG4bK56sdasks
From: sip:alice@example.com;tag=asdyka899
To: sip:bob@example.com
Call-ID: asidkj3ss
CSeq: 1 INVITE
Max-Forwards: 70
Supported: path, outbound, gruu
Route: <sip:proxy.example.com:443;transport=ws;lr>
Contact: <sip:alice@example.com
;gr=urn:uuid:f81-7dec-14a06cf1;ob>
Content-Type: application/sdp
...
Le relais proxy.example.com va alors router cet
appel vers Bob (pas forcément avec WebSocket, dans l'exemple de la
section 8 de notre RFC, c'est UDP qui est utilisé) et le relais va dire à
Alice que c'est bon :
SIP/2.0 200 OK
Via: SIP/2.0/WSS df7jal23ls0d.invalid;branch=z9hG4bK56sdasks
Record-Route: <sip:proxy.example.com;transport=udp;lr>,
<sip:h7kjh12s@proxy.example.com:443;transport=ws;lr>
From: sip:alice@example.com;tag=asdyka899
To: sip:bob@example.com;tag=bmqkjhsd
Call-ID: asidkj3ss
CSeq: 1 INVITE
Contact: <sip:bob@203.0.113.22:5060;transport=udp>
Content-Type: application/sdp
Il y a apparemment au moins deux mises en œuvre de ce mécanisme, comme JSSIP, SIP router (c'est documenté) ou encore OverSIP (voir sa documentation WebSocket). L'annexe B du RFC donne des détails pour les programmeurs.
L'article seul
RFC 7102: Terms used in Routing for Low power And Lossy Networks
Date de publication du RFC : Janvier 2014
Auteur(s) du RFC : JP. Vasseur (Cisco Systems)
Pour information
Réalisé dans le cadre du groupe de travail IETF roll
Première rédaction de cet article le 25 janvier 2014
Le terme de ROLL (Routing for Low power And Lossy Networks) désigne à l'IETF un travail en cours pour l'adaptation des algorithmes de routage à ce que le marketing appelle l'Internet des Objets, ces petits engins connectés en TCP/IP, mais dotés de faibles capacités et de liaisons physiques très imparfaites. On parle aussi de LLN pour Low power and Lossy Networks. Le groupe de travail du même nom a déjà produit plusieurs RFC et se voit désormais doté, avec ce nouveau document, d'un texte décrivant la terminologie de ROLL.
Les LLN, ces réseaux d'engins aux capacités limitées, sont utilisés dans de nombreux contextes, de la domotique (voir la fameuse maison qui tweete) au contrôle de processus industriel en passant par la surveillance de l'environnement, avec plein de capteurs semés, littéralement, dans la nature. Les machines connectées à un LLN n'ont pas l'équipement d'un ordinateur de bureau. Pas de MMU, pas de processeur 64 bits, pas de disque dur et surtout pas d'alimentation électrique permanente. Il faut donc faire durer la batterie (low power...) Leurs connexions au réseau se font en général sans fil, en 802.15.4 ou WiFi, donc sur des liens où les pertes de paquet ne sont pas rares (d'où le lossy dans le nom).
Les machines visées dans ce RFC sont en général des engins très spécifiques, conçus pour une tâche donnée, dans le contexte d'une application précise. Le vocabulaire des LLN est donc varié, chaque communauté qui utilise des LLN ayant développé le sien. D'où l'intérêt de ce RFC, qui essaie d'unifier le vocabulaire des RFC du groupe ROLL, comme le RFC 5548 (le cahier des charges général), RFC 5673 (le cahier des charges spécifique aux applications industrielles), RFC 5826 (le cahier des charges pour la domotique), RFC 5867 (le cahier des charges pour la surveillance et gestion d'immeubles), etc. À noter qu'un autre RFC de terminologie pour ce monde des Objets est le RFC 7228.
La terminologie est décrite en section 2. Je ne vais pas reprendre ici tous les termes (vous devrez lire le RFC si vous voulez tout savoir) mais seulement certains qui me semblent particulièrement importants, dans l'ordre du RFC (l'ordre alphabétique en anglais).
- Un actionneur (actuator) est un engin qui peut agir en contrôlant quelque chose d'extérieur. Il peut allumer une chaudière, ou actionner un aiguillage ou ouvrir une vanne.
- AMI (Advanced Metering Infrastructure) désigne l'utilisation de la « Smart grid » pour la mesure.
- Un canal (channel) est une bande de fréquences utilisée pour la communication. Sa largeur dépend de la sensibilité des équipements radio.
- L'outil d'avitaillement (commissioning tool) est un logiciel, ou un matériel dédié avec le logiciel adapté, servant à configurer le réseau. Notez que beaucoup de LLN ne sont pas configurés du tout : on branche et ça doit marcher.
- Le contrôleur (controller) est l'engin qui reçoit les informations des capteurs et qui, sur la base de ces informations, va décider des actions à entreprendre, actions qui seront demandées aux actionneurs.
- Un puits de données (data sink) est tout engin qui reçoit des données. Le terme est discutable car on a l'impression que les données sont juste avalées, comme par un trou noir, alors qu'elles sont gardées et/ou analysées.
- La direction descendante (downstream) est celle qui va du monde extérieur (par exemple l'Internet) vers le LLN. Sur un dessin, il faut donc placer le LLN en bas, pour être cohérent avec cette définition.
- Un engin de terrain (field device) est n'importe quel engin qui, au lieu d'être installé dans le confort d'une salle machines, est placé près du système qu'il doit surveiller et/ou commander. Cela inclut donc les capteurs et les actionneurs. Les engins de terrain sont souvent, vu les contraintes de coût et d'encombrement, des engins limités en capacité CPU, RAM, et en énergie. Par exemple, un capteur typique d'aujourd'hui peut n'avoir que quelques ko de RAM, quelques dizaines de ko de mémoire flash, un microcontrôleur 8 ou 16 bits, et une capacité réseau parfois de seulement quelques kb/s.
- FMS (Facility Management System) est un terme qui désigne globalement toutes les fonctions de gestion d'un immeuble, de la sécurité incendie à l'air conditionné.
- Le standard HART (Highway Addressable Remote Transducer), géré par l'organisation du même nom, couvre la commande et la surveillance de processus industriels.
- Le sigle HVAC (pour Heating, Ventilation and Air Conditioning, chauffage, ventilation et climatisation en français) désigne l'ensemble des systèmes qui contrôlent le chauffage, la ventilation et le conditionnement d'air dans un bâtiment.
- L'ISA (International Society of Automation) est une organisation qui établit des standards dans le champ de l'automatisation, notamment industrielle.
- Un routeur de bord (LBR, c'est-à-dire LLN Border Router) est un routeur qui assure l'interface entre le LLN, le réseau d'objets, et le reste du monde (l'Internet, ou bien un réseau local d'entreprise dont le LLN n'est qu'une partie).
- Le réseau à petits moyens (LLN, Low power and Lossy Network), déjà présenté, est le centre de l'attention de ce RFC. Quelqu'un a un plus joli terme en français ? Réseau pauvre ? Réseau économe ? Laurent Toutain suggère « réseau contraint », Emmanuel Saint-James « réseau léger » ce qui, je le cite, « conserve le L de l'anglais, ça évoque que c'est pas lourd à mettre en œuvre mais qu'en terme de fiabilité c'est ... léger ».
- Une machine qui ne dort jamais (machine insomniaque ? en anglais, c'était non-sleepy node) est un engin qui est toujours sous tension, et ne se met jamais en hibernation ou autre mode d'économie d'énergie. Le LBR est probablement une machine qui ne dort jamais, puisque connecté à des réseaux extérieurs qui sont toujours en activité. C'est sans doute la même chose pour le contrôleur.
- Le contrôle ouvert (open loop control) est un mode de fonctionnement où un opérateur peut prendre des décisions et les faire appliquer par les actionneurs (contrairement à un mode complètement automatique).
- Le terme point-à-point (ou P2P, point to point) a un sens très particulier dans le contexte de ROLL, qui n'a qu'un lointain rapport avec sa signification dans d'autres domaines. P2P signifie ici qu'on parle du trafic échangé entre deux machines, même indirectement connectées.
- Au contraire, le point-à-multipoint (P2MP, point to multipoint) est le trafic entre une machine et un groupe d'autres machines. C'est l'équivalent du multicast (RFC 4461 ou RFC 4875).
- Rappelons que le RFID (Radio Frequency IDentification) est une technique de communication avec des étiquettes fixées à des objets, étiquettes qui sont actives mais n'ont en général pas de source d'énergie propre.
- Le protocole RPL est un protocole de routage conçu spécialement pour les LLN. Il est normalisé dans le RFC 6550. Un domaine RPL (RPL domain) est un ensemble de routeurs RPL situés sous la même administration.
- Un capteur (sensor) est un engin qui fait des mesures (par opposition à l'actionneur, qui agit). Il y a plein de choses à mesurer, la température, les caractéristiques d'un courant électrique, l'humidité, le bruit, le pourcentage d'oxyde de carbone dans l'air, etc.
- Une machine qui dort parfois (sleepy node) est un engin doté d'un mode d'économie d'énergie où il cesse de participer au réseau pendant un moment (mise en sommeil automatique au bout de N secondes d'inactivité, par exemple).
- La direction montante (upstream) est celle qui va du LLN vers le monde extérieur (par exemple l'Internet).
L'article seul
RFC 7120: Early IANA Allocation of Standards Track Code Points
Date de publication du RFC : Janvier 2014
Auteur(s) du RFC : M. Cotton (ICANN)
Première rédaction de cet article le 25 janvier 2014
Bien des protocoles réseaux nécessitent l'allocation de nombres particuliers, un numéro de protocole, une valeur pour une option, etc (ce que ce RFC nomme des « code points »). Cette allocation est typiquement stockée dans un registre IANA. Lorsque l'allocation nécessite un examen formel par l'IETF ou un de ses groupes et comités, un problème d'œuf et de poule surgit : pour avoir l'allocation du nombre, il faut un document, par exemple un RFC mais pour publier ce document, il faut une allocation du nombre. Pour briser ce cercle vicieux, ce RFC, héritier du RFC 4020, expose les règles selon lesquelles l'IANA peut allouer un nombre avant une publication formelle d'une norme.
Les politiques d'allocation de nombres et autres code points à l'IETF sont exposées dans le RFC 5226. Dans certains cas, le problème ne se pose pas. Par exemple, la politique PAPS « Premier Arrivé, Premier Servi » (First come, first served), où toute requête est acceptable et est faite dans l'ordre d'arrivée, ne nécessite pas de document publié et peut donc se faire sans tambours ni trompettes. Même chose pour « Examen par un expert » (Expert review). Par contre, certaines politiques sont plus restrictives, par exemple parce que l'espace de nommage utilisé est très étroit et qu'il faut l'utiliser prudemment. La politique « Examen par l'IETF » (IETF review) impose par exemple un RFC et pas n'importe lequel. La politique « Action de normalisation » (Standards action) impose en outre que ce RFC soit sur le « chemin des normes ». Dans ces deux cas, on a le problème d'œuf et de poule mentionné plus haut. Parfois, les auteurs d'un protocole résolvent le problème « à la rache » en s'attribuant d'autorité un numéro qui leur semble libre et en l'utilisant dans le futur RFC... et dans des mises en œuvre du protocole qui sont testées sur le réseau. Si l'IANA choisit ensuite d'allouer un autre numéro au moment de la normalisation, des ennuis sans nombre vont surgir. Par exemple, les premières mises en œuvre n'interagiront pas avec celles qui ont été faites après la normalisation.
Faut-il taper sur ces auteurs trop pressés ? Non, car ce n'est pas entièrement de leur faute : le processus de normalisation est long, très long, et on ne peut pas décemment leur reprocher d'avoir voulu essayer leur nouveau jouet à l'avance. En outre, c'est dans l'intérêt général que les nouveaux protocoles soient testés pour de bon, avant la publication officielle de la norme. Cela permet d'éliminer les mauvaises idées au feu de la réalité. Cette importance donné aux « programmes qui marchent » (running code) est justement un des points qui a assuré le succès de l'IETF face à des SDO concurrentes. D'ailleurs, les règles de certains groupes à l'IETF imposent ce déploiement avant la normalisation (voir par exemple le RFC 4794 qui a remplacé le RFC 1264, qui était encore plus radical).
Donc, puisque ces allocations précoces (early allocations) sont une bonne chose, quelles règles doivent-elles suivre ? La section 2 de notre RFC impose que toutes ces conditions soient remplies avant qu'une allocation précoce soit acceptée :
- La politique d'allocation pour l'espace de nommage considéré doit être « Norme nécessaire » (si cette norme est un RFC), « RFC obligatoire », « Examen par l'IETF », ou « Action de normalisation ». (La liste de ces politiques était bien plus courte dans le RFC 4020.)
- Un document Internet-Draft doit exister, décrivant le protocole ou le système qui a besoin de cette allocation. Rappelons qu'un Internet-Draft ne nécessite pas d'autorisation et peut être publié sans formalités.
- La spécification dans cet Internet-Draft doit être stable, le protocole ne doit plus changer de manière incompatible (ce qui nécessiterait d'allouer un nouveau numéro après).
- Les présidents du groupe de travail et les directeurs de zone d'activité IETF doivent approuver cette allocation, en prenant en compte l'intérêt de la communauté pour ce nouveau protocole.
C'est contraignant, mais le but est d'éviter les abus qui mèneraient à un épuisement rapide d'un des registres IANA (cf. section 5).
Une fois ces prérequis rassemblés, les auteurs de l'Internet-Draft font une requête à l'IANA. Celle-ci alloue le nouveau numéro ou code point, et le marque comme Temporaire, en indiquant la date. En effet, une allocation précoce n'est valable qu'un an. Au bout d'un an, elle doit avoir été transformée en allocation ferme, ou bien renouvelée en répétant tout le processus. Sinon, elle sera marquée comme expirée (pas de réutilisation possible) puis comme abandonnée (réutilisation possible, s'il n'y a pas de mises en œuvre du protocole qui trainent, et si l'espace de nommage est presque épuisé).
Un exemple d'un enregistrement temporaire ? Aujourd'hui, vous
trouvez par exemple la valeur 5 dans les modes de réponse du test de
connectivité de MPLS : https://www.iana.org/assignments/mpls-lsp-ping-parameters/mpls-lsp-ping-parameters.xml#reply-modes note « 5 - Reply via specified path (TEMPORARY - expires 2012-01-20) [sic] ».
Pas de changements drastiques depuis le RFC 4020, le principal étant l'extension des allocations précoces à d'autres politiques d'allocation. Il y a eu peu de débats sur ce nouveau RFC : après tout, il s'agit de cas spécifiques qui ne concernent pas tous les participants à l'IETF.
L'article seul
Mon premier nom Namecoin enregistré
Première rédaction de cet article le 19 janvier 2014
Dernière mise à jour le 2 mars 2016
Il y a depuis plusieurs années une énorme activité de recherche et
de programmation pour développer des outils de communication sur
l'Internet échappant ou limitant la censure et/ou
l'espionnage. Ces outils reposent en général sur les idées de
communication pair-à-pair et l'absence d'un
élément jouant un rôle particulier (pas de
racine, pas d'AC, pas de
tiers de confiance, etc), puisqu'un tel élément, même s'il est sympa
au début, peut toujours devenir
un facteur de censure et/ou d'espionnage. La grande majorité de ces
projets ne sont pas allés très loin, et beaucoup étaient même
ridicules dès le début. Assurer les fonctions d'un élément
particulier, notamment les fonctions de sécurité, en pair-à-pair pur
est vraiment difficile ! Parmi les rares survivants d'un processus de
sélection très sévère, il y a les techniques fondées sur une chaîne de blocs
publique, vérifiable par tous, chaîne popularisée par
Bitcoin. Par exemple, un motif d'insatisfaction
parfois exprimé vis-à-vis du système de noms de domaines est sa structure
arborescente, qui fait dépendre, même si c'est
très indirectement, d'une racine. Peut-on se passer d'une telle
structure ? C'est hautement non trivial mais on peut essayer et
Namecoin est une technique prometteuse. Je viens
de l'utiliser pour mes premiers noms Namecoin,
bortzmeyer et d/bortzmeyer
(et vous allez devoir lire l'article jusqu'au bout pour savoir à quoi
rime ce d/).
Un bon exemple du problème posé par l'actuel système de noms de domaine est donné dans un article récent de TechDirt. Les lobbies qui veulent artificiellement maintenir un modèle d'affaires menacé par l'Internet sont très prompts à réclamer la suppression (« take down ») des noms de domaines utilisés pour des activités qu'ils n'aiment pas (comme le partage des œuvres culturelles). Le risque de censure est donc élevé car, dans de nombreux cas, ces lobbies ont eu gain de cause. Beaucoup de titulaires de noms de domaines ne se sentent pas protégés contre l'arbitraire de ces suppressions ou détournements de noms.
Comment est-ce que Namecoin prétend résoudre ce problème ? Je ne vais pas ici détailler son fonctionnement technique (l'article du Wikipédia anglophone cité plus haut, ainsi que les différents articles cités dans cet article vous en diront plus), mon but est plutôt de raconter une expérience vécue. Disons que Namecoin repose sur un livre des opérations, une chaîne publique de blocs, comme Bitcoin (c'est d'ailleurs à l'origine le même code, mais la chaîne est différente et on ne peut pas acheter des noms avec des bitcoins). (Et merci à Nathanaelle pour le terme de livre des opérations.) On l'oublie souvent, mais les transactions Bitcoins incluent un programme, écrit dans un langage simple et limité, exécuté pour valider la transaction. Dans Bitcoin, ce langage est très limité, notamment pour des raisons de sécurité. Il est un peu plus riche dans Namecoin, il comporte notamment des méthodes pour enregistrer un nom. L'existence d'un nom se vérifie donc en validant toute la chaîne et en relevant la création d'un nom, pas trop ancienne (les noms sont enregistrés pour une certaine période). On a donc, sinon vaincu, du moins sérieusement endommagé le triangle de Zooko : on a des noms sympas (on choisit le nom qu'on veut), sûrs (tout le monde peut vérifier l'intégrité du livre des opérations) et uniques (de même qu'avec Bitcoin, tout le monde peut vérifier qu'un bitcoin n'a pas été dépensé deux fois, avec Namecoin, tout le monde peut vérifier qu'un nom n'a pas été enregistré deux fois).
Bon, et qu'est-ce qui empêche d'enregistrer plein de noms ? Ah, mais je n'ai pas dit que Namecoin était gratuit. Il faut payer, en namecoins. Cette monnaie s'obtient, comme les bitcoins, en minant, ou bien en l'achetant à quelqu'un d'autre. Cette seconde voie est plus facile, j'ai donc acheté mes namecoins sur Kraken.
Maintenant, place à la pratique. Pour créer un nom Namecoin, il
faut installer un nœud Namecoin. Je n'ai pas l'impression qu'il
existe, comme il y a pour Bitcoin,
un logiciel permettant de faire un client léger, ne minant pas et ne
validant pas. J'ai donc installé un nœud complet (la chaîne est bien
plus courte que celle de Bitcoin et il y a moins de mineurs donc le
travail est bien plus raisonnable). Une fois téléchargé et
compilé, le démon s'utilise comme le classique
nœud Bitcoin. Notez l'option -gen qui lui dit de
participer au minage (et qui fait donc tourner votre
CPU en permanence). Vérifions que le démon
tourne bien :
% namecoin-cli getinfo
{
"version" : 37300,
"balance" : 0.11000000,
"blocks" : 157803,
"timeoffset" : -1,
"connections" : 8,
"proxy" : "",
"generate" : false,
"genproclimit" : -1,
"difficulty" : 1546423251.74634910,
"hashespersec" : 0,
"testnet" : false,
"keypoololdest" : 1389730666,
"keypoolsize" : 101,
"paytxfee" : 0.00000000,
"mininput" : 0.00010000,
"errors" : ""
}
On en est au bloc 157803 (on aurait pu avoir juste le numéro de bloc
avec namecoin-cli getblockcount). On peut vérifier sur un
explorateur public du Livre des Opérations, comme http://explorer.dot-bit.org/, à quel bloc lui en est. La
première fois qu'on lance le nœud, on est évidemment loin
derrière. Personnellement, mon PC ordinaire à la maison a mis trois
heures pour rattraper la chaîne publique, trois heures pendant
lesquelles je faisais des namecoin-cli
getblockcount de temps en temps pour vérifier si ça
avançait.
% date; namecoin-cli getblockcount Thu Jan 16 10:01:01 CET 2014 84566 % date; namecoin-cli getblockcount Thu Jan 16 10:11:11 CET 2014 92468
Mais la vitesse de progression de cette chaîne de blocs n'est pas du tout prévisible, il vaut mieux être patient. Au bout du compte, une fois qu'on est synchrone (ou même avant mais, dans ce cas, on ne verra pas ses propres transactions), on peut commencer à travailler.
D'abord, le fric ! Créons une adresse pour recevoir des namecoins, en indiquant un nom de compte (vous pouvez en avoir plusieurs, cela ne sert que localement, pour gérer vos namecoins) :
% namecoin-cli getnewaddress bortzmeyer Myw9PZkBDjjKpaCjSMnWNGrVd7AnDpQoBY % namecoin-cli getreceivedbyaddress Myw9PZkBDjjKpaCjSMnWNGrVd7AnDpQoBY 0.00000000
(Vous avez vu, j'ai subtilement affiché mon adresse : si vous aimez cet article, vous pouvez y envoyer des namecoins. Mais rappelez-vous que tout est public, cela se verra, par exemple avec l'explorateur.) J'envoie ensuite depuis Kraken des namecoins à cette adresse :
% namecoin-cli getreceivedbyaddress Myw9PZkBDjjKpaCjSMnWNGrVd7AnDpQoBY 0.09500000
Les sous sont arrivés, on va pouvoir créer des noms. (Si on était
sérieux, on commencerait par faire une sauvegarde des fichiers en
~/.namecoin. Comme avec Bitcoin, si on perd sa
clé privée, on perd tout, et sans recours possible.) Commençons avec
un nom au hasard :
% namecoin-cli name_new bortzmeyer
[
"abd0330ed6d82e425...65d77bca37b3",
"3789f...a9d31"
]
Notez bien les deux nombres qui serviront par la suite. À ce stade, n'est enregistré dans le livre des opérations qu'un condensat du nom (pour éviter qu'un malin ne voit passer votre demande et ne l'enregistre aussitôt, avant que plusieurs pairs n'aient pu valider votre transaction). Dès que l'explorateur public a reçu le nouveau bloc (sa page d'accueil affiche le dernier bloc reçu), vous pouvez vérifier que la transaction a eu lieu (utilisez comme critère de recherche le premier nombre affiché ci-dessus, abd033...) mais une recherche par nom échouera puisque seul le condensat est présent. La FAQ dit d'attendre douze blocs. Au rythme d'aujourd'hui, cela peut faire plusieurs heures. Puis « abattez vos cartes » et indiquez le vrai nom :
% namecoin-cli name_firstupdate bortzmeyer 3789fa452d9a9d31 abd0330ed6d82e4250a17d0bc8c709461c3a7218d59958efd2d965d77bca37b3 1 02cd4cc2283bbba6586e988ce141e1b6cfa3ceabc7752617fb0a99c15efafb93
(J'ai bien dit name_firstupdate, et pas
first_update, la FAQ est fausse.) Cette fois, une
fois l'explorateur synchronisé au nouveau bloc, une recherche par nom
va fonctionner (testez http://explorer.dot-bit.org/n/140495). Félicitations, vous
avez un nom Namecoin, qui vous assurera l'admiration de vos ami(e)s, le
désir de vos amant(e)s et une augmentation par votre entreprise.
À noter que, si vous aviez fait un name_new
pour un nom déjà existant, c'est au moment du
name_firstupdate que la collision serait
détectée.
Sinon, le dernier
argument de la commande est la valeur associée au nom. Ici, j'ai juste
mis 1 pour uniquement réserver le nom. Mais, en fait, on peut associer
des valeurs à des attributs, en indiquant des données en
JSON. Ici, je mets mon adresse de courrier (il
y a une liste temporaire
de valeurs possibles) :
% namecoin-cli name_update bortzmeyer '{"email": "stephane+namecoin@bortzmeyer.org"}'
On peut voir que cela a bien été pris en compte. Du fait que le livre des transactions est public, tout le monde peut voir toutes les données :
% namecoin-cli name_filter bortzmeyer
[
{
"name" : "bortzmeyer",
"value" : "{\"email\": \"stephane+namecoin@bortzmeyer.org\"}",
"expires_in" : 35962
},
...
Attention, le JSON envoyé n'est pas testé et des erreurs de syntaxe
idiotes peuvent donc empêcher son interprétation. Il peut être prudent
de vérifier d'abord, par exemple avec http://dot-bit.org/tools/domainCheck.php.
Prêtez attention au membre expires_in (noté en nombre de blocs). Avec
Namecoin, les noms ne sont réservés que pour une période
donnée. Pensez à les renouveler. Et mettez en place une supervision,
par exemple avec Name
Alert. Ainsi, vous serez prévenus lorsqu'un nom approchera de
l'expiration, par un message du genre :
Date: Thu, 22 Jan 2015 09:45:02 -0000 From: alert@namealert.mvps.eu To: stephane+namealert@bortzmeyer.org Subject: Your domain d/bortzmeyer will soon expire One of your Namecoin domains, d/bortzmeyer will expire in 96 blocks. Current rate is 150.027387087 blocks per day, so your domain will expire in approximately 0 days.
(En fait, c'est théorique, Name Alert ne marche apparemment pas bien
et j'ai perdu d/bortzmeyer ainsi. Pas de
renouvellement, pas d'alerte, et, une fois le nom détruit, quelqu'un
d'autre l'a enregistré et Name Alert ne m'a prévenu que plusieurs mois
après. On peut voir cette histoire en https://namecha.in/name/id/bortzmeyer. En raison d'une bogue, http://explorer.namecoin.info/ n'arrive pas à l'afficher.)
Bref, Namecoin reprend un des problèmes les plus énervants du système
des noms de domaine, l'obligation de veiller
à l'expiration et au renouvellement. Pour renouveler, vous
n'avez pas de commande spéciale, vous faites juste un
name_update en indiquant les mêmes valeurs
(malheureusement, il n'y a pas de solution plus simple et moins
risquée) :
% namecoin-cli name_update d/bortzmeyer '{"ip":"204.62.14.153", "ip6":"2605:4500:2:245b::42", "email": "stephane+namecoin@bortzmeyer.org"}'
3393a1f8b428053c2b343deec3f3ff5ec10f360e9a7a82ae91606052c5edab76
Bien, nous avons maintenant une base de données fiable, à
l'intégrité vérifiable, et qui contient nos jolis noms. Nous pouvons
associer à ces noms des informations intéressantes comme l'adresse de
courrier ou comme des adresses
IP. Mais tout le monde n'a pas forcément un résolveur
Namecoin chez lui et dans toutes ses applications. Pour l'instant, le
protocole nettement dominant pour résoudre les noms, c'est le
DNS. Si on ne peut pas utiliser le DNS pour
résoudre les noms Namecoin, personne n'utilisera Namecoin (problème
classique des nouvelles techniques). Mais, heureusement, on peut. Le
principe est d'utiliser un TLD dédié,
.bit (non
officiellement enregistré, attention, des problèmes pourront
survenir). Il faut monter un serveur DNS faisant autorité pour
.bit et/ou configurer ses résolveurs pour
utiliser des serveurs de .bit. Les
différentes méthodes possibles sont documentées en
ligne. Commençons par le plus trivial, configurer le résolveur
Unbound pour interroger les serveurs
existants. On met dans la configuration d'Unbound :
domain-insecure: "bit"
stub-zone:
name: "bit"
stub-addr: 178.32.31.41
stub-addr: 78.47.86.43
stub-addr: 95.211.195.245
stub-addr: 2001:1af8:4020:a037:1::1000
stub-addr: 162.243.56.54
La première ligne est nécessaire puisque la racine du DNS est signée
avec DNSSEC mais que .bit
n'y est pas enregistré. Les dernières lignes donnent les adresses de
serveurs publics faisant autorité pour .bit. On
trouve une liste
en ligne mais la liste est peu à jour, et compte pas mal de
serveurs qui ne marchent pas. Bon, Unbound est assez intelligent pour
n'utiliser que ceux qui répondent et :
% dig ANY explorer.bit ; <<>> DiG 9.8.4-rpz2+rl005.12-P1 <<>> ANY explorer.bit ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 25144 ;; flags: qr rd ra; QUERY: 1, ANSWER: 6, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 4096 ;; QUESTION SECTION: ;explorer.bit. IN ANY ;; ANSWER SECTION: explorer.bit. 86162 IN SOA ns0.web-sweet-web.net. root.srv01.web-sweet-web.net. ( 2014010900 ; serial 21600 ; refresh (6 hours) 3600 ; retry (1 hour) 604800 ; expire (1 week) 86400 ; minimum (1 day) ) explorer.bit. 86162 IN NS ns1.web-sweet-web.net. explorer.bit. 86162 IN NS ns0.web-sweet-web.net. explorer.bit. 86162 IN TXT "v=spf1 a mx ?all" explorer.bit. 86162 IN A 178.32.102.200 explorer.bit. 86162 IN MX 5 srv01.web-sweet-web.net. ;; Query time: 0 msec ;; SERVER: ::1#53(::1) ;; WHEN: Sun Jan 19 18:29:24 2014 ;; MSG SIZE rcvd: 202
C'est parfait, tout marche. Notez que cela laisse deux gros problèmes
de sécurité : ces serveurs publics faisant autorité pour
.bit ne sont pas forcément de confiance (on
trouve de tout parmi eux) et, même s'ils sont de confiance, il n'y a
rien qui protège la liaison réseau entre vous et eux. C'est d'autant
plus embêtant que les outils de débogage manquent. Par exemple, on ne
peut pas se fier au numéro de série dans l'enregistrement
SOA de .bit : chaque serveur le met à
sa guise selon un algorithme différent.
Avant de revenir à ces problèmes de sécurité et de montrer la
solution, un mot sur la publication. Est-ce qu'il suffit d'enregistrer
le nom bortzmeyer pour qu'il soit publié dans
.bit ? Non. Il existe une convention qui
partitionne Namecoin en plusieurs espaces de
nommage. Pour être publié dans .bit, le
nom doit être préfixe par d/. On va donc
enregistrer d/bortzmeyer. Au
name_firstupdate, il va bien être publié dans
.bit (attention, les serveurs publics ne se
mettent pas à jour en temps réel, on peut avoir à patienter des
heures). Voici un exemple, en publiant des adresses IP :
% namecoin-cli name_update d/bortzmeyer '{"ip":"204.62.14.153", "ip6":"2605:4500:2:245b::42"}'
46c5e87df04a491166d9c4a407007ed32b2a149362f52b7c5a65504362b84f70
Si vous avez vous-même un résolveur qui gère les
.bit, vous pouvez vérifier que cela marche :
% dig AAAA bortzmeyer.bit ; <<>> DiG 9.8.4-rpz2+rl005.12-P1 <<>> AAAA bortzmeyer.bit ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 42151 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 4096 ;; QUESTION SECTION: ;bortzmeyer.bit. IN AAAA ;; ANSWER SECTION: bortzmeyer.bit. 86357 IN AAAA 2605:4500:2:245b::42 ;; Query time: 0 msec ;; SERVER: ::1#53(::1) ;; WHEN: Sun Jan 19 18:40:44 2014 ;; MSG SIZE rcvd: 71
Et comme j'ai en prime ajouté une directive
ServerAlias dans Apache,
vous pouvez, si votre résolveur gère .bit,
visiter http://bortzmeyer.bit/.
Comme on a une copie de toute la base des noms, des opérations comme de trouver les données sur un nom sont triviales :
% namecoin name_filter d/bortzmeyer
[
{
"name" : "d/bortzmeyer",
"value" : "{\"ip\":\"204.62.14.153\",\"ip6\":\"2605:4500:2:245b::42\"}",
"expires_in" : 35666
}
]
(Notez le JSON dans le JSON...) On peut faire la même interrogation en
ligne via l'explorateur public : http://explorer.dot-bit.org/n/140687 ou via n'importe quelle
passerelle comme DNSchain. Contrairement au système actuel des
noms de domaines, qui utilise deux protocoles complètement différents
pour distribuer les données, le DNS et
whois, Namecoin n'a qu'un mécanisme pour
tout. (Vous
pouvez aussi utiliser un moteur de recherche public.) Voici un exemple avec un domaine qui, au lieu de mettre
directement des données (comme les adresses IP) dans Namecoin, utilise
un mécanisme de délégation, ici vers deux serveurs DNS :
% namecoin name_filter d/explorer
[
{
"name" : "d/explorer",
"value" : "{\"info\":{\"registrar\":\"http://register.dot-bit.org\"},\"email\": \"register@dot-bit.org\",\"ns\":[\"ns0.web-sweet-web.net\",\"ns1.web-sweet-web.net\"],\"map\":{\"\":{\"ns\":[\"ns0.web-sweet-web.net\",\"ns1.web-sweet-web.net\"]}}}",
"expires_in" : 3859
}
]
Nous avions vu que la solution pour accéder aux domaines
.bit en utilisant des serveurs publics n'était
pas idéale, question de sécurité. La seule solution sûre est d'avoir
un serveur .bit chez soi. Cela peut se faire, par
exemple, avec le programme NamecoinToBind. Lorsqu'on
le fait tourner, il fabrique un fichier de zone à la syntaxe du RFC 1035 (contrairement à ce que son nom pourrait
faire croire, il n'a rien de spécifique à
BIND), en se connectant au nœud Namecoin et en
chargeant toute la liste des noms :
% php namescan.php PHP Warning: PHP Startup: Unable to load dynamic library '/usr/lib/php5/20100525+lfs/suhosin.so' - /usr/lib/php5/20100525+lfs/suhosin.so: cannot open shared object file: No such file or directory in Unknown on line 0 New blocks : 1 New names : 22 Write : /home/stephane/namecoin/NamecoinToBind/cache/getinfo_seri New domains : 1 Write : /home/stephane/namecoin/NamecoinToBind/cache/names_block_seri Write : /home/stephane/namecoin/NamecoinToBind/cache/bind_tree_seri PHP Notice: Undefined variable: templateFile in /home/stephane/namecoin/NamecoinToBind/namescan.php on line 106 Write : /etc/bind/dotbit/db.namecoin.bit PHP Notice: Undefined variable: statDir in /home/stephane/namecoin/NamecoinToBind/namescan.php on line 130
On peut ensuite dire au serveur de noms de charger ce fichier
/etc/bind/dotbit/db.namecoin.bit. ici, pour BIND :
zone "bit" {
type master;
file "/etc/bind/dotbit/db.namecoin.bit";
};
Attention, plusieurs noms dans Namecoin ont une syntaxe incorrecte (pas pour le DNS, qui est tolérant, mais pour les règles plus strictes que BIND suit par défaut) :
Jan 18 17:29:17 ludwigVII named[23967]: /etc/bind/dotbit/db.namecoin.bit:15421: jdt_test.bit: bad owner name (check-names)
Il doit y avoir une option de BIND pour être plus laxiste mais je ne
l'ai pas sous la main, j'ai donc supprimé manuellement. Évidemment, en production, il faudra trouver une solution plus
stable (et faire tourner php namescan.php depuis
cron).
Notez qu'il existe une solution pratique pour accéder aux sites
Web en .bit sans
configurer son résolveur, mais en utilisant un
relais en bit.pe. Essayez,
par exemple http://bortzmeyer.bit.pe.
Parmi les fonctions avancées (et, à ma connaissance, absolument pas
déployées) de Namecoin, on peut noter un équivalent de DANE, documenté en https://github.com/namecoin/wiki/wiki/Domain-Name-Specification-2.0
et discuté en http://blog.mediocregopher.com/namecoind-ssl.html (discussion
bien vieille ?) ou encore http://dot-bit.org/forum/viewtopic.php?f=5&t=1137.
Merci notamment aux participants au canal
IRC #namecoin sans lesquels je n'y serais pas
arrivé. Si vous voulez davantage d'informations, commencez par le site « officiel ».
L'article seul
RFC 7086: Host Identity Protocol-Based Overlay Networking Environment (HIP BONE) Instance Specification for REsource LOcation And Discovery (RELOAD)
Date de publication du RFC : Janvier 2014
Auteur(s) du RFC : A. Keranen, G. Camarillo, J. Maenpaa (Ericsson)
Expérimental
Réalisé dans le cadre du groupe de travail IETF hip
Première rédaction de cet article le 17 janvier 2014
Le protocole pair-à-pair RELOAD, spécifié dans le RFC 6940, définit un certain nombre d'éléments minimum pour créer un réseau pair-à-pair mais pas la totalité. Il doit être complété par des descriptions d'un overlay particulier, un réseau utilisant RELOAD. Ce RFC est la spécification d'un overlay basé sur HIP.
HIP est normalisé dans le RFC 7401 et le cadre pour construire des overlays avec HIP est dans le RFC 6079. Ce RFC 7086 combine donc RELOAD et HIP BONE pour faire des réseaux pair-à-pair. À noter que tout RELOAD n'est pas utilisé : le Forwarding and link management layer de RELOAD (section 6.5 du RFC 6940 est complètement remplacé par HIP (section 3 de notre RFC).
Définir une classe d'instances RELOAD nécessite de spécifier les identificateurs utilisés pour les machines (Node ID dans RELOAD). Dans le cas de HIP, les Node ID peuvent être de deux types (section 4 de notre RFC) :
- Les identificateurs HIP classiques, les ORCHID (RFC 7343), qui ont l'avantage de pouvoir s'utiliser dans les API existantes, puisqu'ils ont la forme d'une adresse IPv6, dans un préfixe dédié,
- Des identificateurs RELOAD complets, qui permettent d'avantage de machines (2^128 au lieu de 2^100) mais qui ne sont plus compatibles avec les applications existantes.
Il faut aussi définir la correspondance entre les messages RELOAD
et les messages HIP (section 5). Les messages RELOAD sont transportés
dans des messages HIP de type DATA (RFC 6078) mais certains services
assurés par des parties du message RELOAD sont déplacés vers
HIP. Ainsi, le forwarding header de RELOAD (qui
sert à contrôler l'envoi vers la destination finale) est
remplacé par des fonctions HIP comme les listes
Via (RFC 6028) qui
permettent de mieux contrôler le routage, et le security
block de RELOAD se déplace vers des extensions HIP comme les certificats du
RFC 6253.
Normalement, les messages RELOAD sont sécurisés par l'utilisation de TLS (RFC 5246). Mais HIP peut déjà tout chiffrer. Plus besoin de TLS, donc, remplacé par le chiffrement HIP du RFC 6261.
Dans tout système pair-à-pair, le recrutement et l'arrivée de nouveaux pairs sont
des points délicats (section 8). Ici, on utilise les mécanismes de RELOAD, avec
quelques détails différents. Par exemple, les certificats échangés contiennent des HIT
(condensat d'un HI, d'un identificateur HIP) et
pas des URI RELOAD. Ces HIT sont placés dans le
champ subjectAltName du certificat (RFC 6253).
Il a aussi fallu étendre un peu la définition du document de
configuration initial (section 11 du RFC 6940 et
section 10 de notre RFC). Récupéré par les pairs, ce document contient
les informations nécessaires pour rejoindre
l'overlay. L'élément XML
<bootstrap-node> contient désormais un HIT.
Ce nouveau type d'overlay est désormais noté dans le registre IANA.
Il existe apparemment au moins une mise en œuvre de ce RFC mais je n'ai pas eu l'occasion de l'essayer.
L'article seul
RFC 7111: URI Fragment Identifiers for the text/csv Media Type
Date de publication du RFC : Janvier 2014
Auteur(s) du RFC : M. Hausenblas (DERI, NUI Galway), E. Wilde (EMC Corporation), J. Tennison (Open Data Institute)
Pour information
Première rédaction de cet article le 17 janvier 2014
Le classique format CSV est normalisé dans
le RFC 4180. Lorsqu'un
URI désigne un fichier CSV, comment indiquer
une partie spécifique du fichier ? Jusqu'à présent, il n'y avait pas
de mécanisme pour cela. Ce nouveau RFC comble ce manque et définit une
syntaxe (fragment identifier) pour désigner une
ligne particulière, une colonne spécifique, voir une seule cellule d'un fichier
CSV. http://www.example.org/data.csv#row=12
fonctionnera désormais, pour indiquer qu'on veut sauter à la douzième
ligne du fichier data.csv.
Les ressources au format CSV sont
identifiées par le type text/csv. Ce type a deux
paramètres, charset qui indique
l'encodage et header qui
indique si l'en-tête facultatif de CSV est présent ou pas (cet en-tête
donne le nom des colonnes). Rappelons que la syntaxe et la sémantique
des identificateurs de fragment dans un URI
dépendent du type de la ressource. Par exemple, « la cellule en 2ème
ligne et 5ème colonne » a un sens en CSV mais pas en texte brut, alors
que « le 292ème caractère » a un sens en texte brut (RFC 5147 pour les identificateurs de fragments du texte
brut).
Attention, les identificateurs de fragments sont interprétés uniquement par le client Web. Leur bon fonctionnement dépend donc du déploiement du logiciel nécessaire chez les clients, ce qui va prendre du temps (je me demande combien de navigateurs Web gèrent le RFC 5147...). Le serveur n'a même pas un moyen de savoir si le client gère ces identificateurs de fragment. Mais ce n'est pas forcément un problème grave : si le client ne comprend pas la syntaxe des identificateurs de fragments pour CSV, il charge quand même le fichier CSV, il ne peut juste pas aller directement à la partie intéressante. Le repli se fait donc en douceur. Pour l'instant, à ma connaissance, il n'existe pas de logiciel qui gère ces fragments CSV.
Bref, voyons maintenant la sémantique des identificateurs de fragments pour CSV (section 2 du RFC). Le RFC contient un exemple avec des données de température mais je vais plutôt prendre les données BGP de la récente panne de l'Internet à Saint-Pierre-et-Miquelon. Les données originales étaient au format MRT (RFC 6396) mais bgpdump peut les traduire en quasi-CSV, il suffit d'un petit coup de sed ensuite :
% bgpdump -m updates.20140104.1930.bz2 | sed 's/|/,/g' > updates.20140104.1930.csv
Le fichier utilisé pour les exemples est panne-spm.csv (oui, il contient une ligne optionnelle
d'en-tête au début, mais ne l'indique pas dans le type MIME, violant
ainsi la section 3 du RFC 4180). Chaque ligne comprend
notamment l'heure (deuxième colonne, vous pouvez traduire 1388864007
avec date -u --date=@1388864007), le type de
message (troisième colonne, avec A = Announce et W
= Withdraw), le pair qui a
envoyé le message (quatrième colonne), le préfixe d'adresse IP
concerné (sixième colonne), etc.
D'abord, on peut sélectionner une ligne particulière, la première
étant numérotée 1 (pas zéro, attention, les informaticiens). La ligne
d'en-tête, facultative, compte pour une ligne normale si elle est
présente. Ainsi, la ligne 5 est BGP4MP,1388864007,W,195.66.224.32,3257,70.36.8.0/22. On peut
aussi indiquer un intervalle des lignes. Ainsi, 5-7 est :
BGP4MP,1388864007,W,195.66.224.32,3257,70.36.8.0/22 BGP4MP,1388864007,A,195.66.225.76,251,70.36.8.0/22,251 3257 11260 3695,IGP,195.66.225.76,0,0,3257:4000 3257:8093 3257:50002 3257:50122 3257:51400 3257:51401 65020:10708,NAG,, BGP4MP,1388864007,W,195.66.236.32,3257,70.36.8.0/22
Le signe * indique « la dernière ligne » donc * désigne :
BGP4MP,1388864142,W,195.66.224.215,31500,70.36.12.0/22
On peut aussi désigner une colonne donnée. Là aussi, on part de 1. La sixième colonne sera :
70.36.8.0/22 70.36.8.0/22 70.36.8.0/22 70.36.8.0/22 70.36.8.0/22 70.36.8.0/22 70.36.8.0/22 70.36.8.0/22 70.36.8.0/22 70.36.8.0/22 ...
(Les Unixiens noteront que c'est l'équivalent de cut : cut -d, -f6 panne-spm.csv.)
Et les colonnes 2-4 :
1388864007,A,195.66.224.32 1388864007,A,195.66.225.111 1388864007,A,195.66.236.32 1388864007,W,195.66.224.32 1388864007,A,195.66.225.76 1388864007,W,195.66.236.32 1388864007,A,195.66.224.32 ...
Le signe * est également utilisable.
Enfin, on peut indiquer une cellule
particulière, identifiée par une ligne et une colonne. 4,2 désignera
donc 195.66.224.32. La syntaxe des intervalles marche
aussi, donc 2-3,4-5 désignera quatre cellules :
1388864007,A 1388864007,W
Les identificateurs de fragments de ressources CSV peuvent aussi être composés de plusieurs sélections disjointes, mais, bon, cela devient un peu compliqué.
La syntaxe précise figure en section 3. Pour indiquer si le numéro
désigne une ligne, une colonne, ou une cellule, on le préfixe avec
row= (« rangée »), col= ou
cell=. Comme montré dans l'exemple
ci-dessus, les valeurs d'un intervalle sont séparées par un
-, les lignes et colonnes d'une cellule par une
,. Si on a plusieurs sélections disjointes,
elles sont séparées par un ;. Et, comme
toujours avec les URI, l'identificateur de fragment est séparé du
reste de l'URI par un #. Ainsi,
l'URL pour récupérer la cellule 3,5 de mon
fichier d'exemple sera http://www.bortzmeyer.org/files/panne-spm.csv#cell=3,5. Et, si
vous avez un navigateur Web qui gère ce RFC, http://www.bortzmeyer.org/files/panne-spm.csv#row=10 devrait
vous pointer directement sur la dixième ligne.
La section 4 donne des détails sur la manière exacte dont un client
devrait gérer ces fragments, notamment en cas d'erreurs. S'il y a une erreur de syntaxe
(par exemple http://www.bortzmeyer.org/files/panne-spm.csv#line=10, avec
line au lieu de row),
l'identificateur doit être ignoré (tout se passera donc comme si on
était simplement allé en http://www.bortzmeyer.org/files/panne-spm.csv).
Même chose si les nombres pointent en dehors du fichier, parce que
trop grands.
L'enregistrement du type text/csv a été mis à jour pour inclure cette possibilité supplémentaire.
L'article seul
RFC 7098: Using the IPv6 Flow Label for Load Balancing in Server Farms
Date de publication du RFC : Janvier 2014
Auteur(s) du RFC : B. Carpenter (Univ. of Auckland), S. Jiang (Huawei Technologies), W. Tarreau (HAProxy)
Pour information
Réalisé dans le cadre du groupe de travail IETF intarea
Première rédaction de cet article le 17 janvier 2014
Le champ « Flow label » dans l'en-tête des paquets IPv6 est un des mystères de l'Internet. Bien qu'il ait désormais un RFC entièrement pour lui, le RFC 6437, et qu'il soit obligatoire, selon le RFC 6434, personne n'a l'air de savoir à quoi il peut vraiment servir en pratique. Lorsqu'on observe des paquets IPv6, ce champ est souvent mis à zéro. Des gens ont déjà réfléchi à des utilisations possibles et ont documenté leurs idées dans le RFC 6294. Notre nouvel RFC, lui propose un usage : faciliter la répartition de charge dans les fermes de serveurs. Comment ? Pas si vite, d'abord un petit rappel sur le flow label.
La section 2 de notre RFC rafraichit la mémoire de ceux qui ont lu les RFC 2460 et RFC 6437 trop vite. Le champ flow label fait 20 bits et doit avoir une valeur fixe pour un flot donné (par exemple pour une connexion TCP donnée). Sa valeur doit être uniformément répartie parmi les valeurs possibles (et, pour des raisons de sécurité, il vaut mieux qu'elle soit imprévisible de l'extérieur, cf. le cours de sécurité de Gont). Si le nœud de départ n'a pas mis une valeur non nulle dans ce champ, un nœud ultérieur (par exemple un routeur) a le droit de le faire. Le flow label est à une position fixe par rapport au début du paquet, ce qui le rend facilement lisible, même à grande vitesse, contrairement à l'en-tête TCP, qui peut se situer à une distance quelconque du début du paquet. Comme IPv6, contrairement à IPv4, n'a pas de champ qui indique la longueur des en-têtes de couche 3 (permettant de les sauter facilement pour arriver à l'en-tête de couche 4), le flow label pourrait être un meilleur moyen d'identifier un flot donné, d'autant plus qu'il est répété dans tous les paquets (alors que, en cas de fragmentation, l'en-tête de couche 4 ne sera que dans un seul paquet). Mais c'est purement théorique : aujourd'hui, il est rare, dans la nature, de rencontrer des paquets IPv6 avec un flow label non nul (1,4 % des paquets HTTP/IPv6 entrant sur mon blog ont un flow label non nul - vu avec tshark). Vingt bits de perdus pour rien.
Avant d'utiliser le flow label pour faire de la répartition de charge, la section 3 de notre RFC résume les techniques qui existent aujourd'hui pour faire cette répartition. (On peut aussi lire à ce sujet une synthèse d'un des auteurs du RFC.) Les exemples sont tous empruntés à HTTP mais la plupart des ces techniques s'appliquent à tous les protocoles. Première méthode, donc, mettre plusieurs adresses IP dans le DNS. Si le serveur faisant autorité, ou le résolveur, renvoient ces adresses dans un ordre aléatoire, cela assurera une répartition égalitaire entre toutes les adresses. (Le RFC ne mentionne pas que l'usage des enregistrement SRV du RFC 2782 résoudrait bien des limites du DNS. Mais cela dépend de clients bien faits et certains gérants de serveurs préfèrent donc contrôler tout le processus de répartition de charge.) Cette méthode était indépendante du protocole applicatif utilisé. Une méthode spécifique à HTTP serait d'avoir un relais inversé (reverse proxy) en face des vrais serveurs, qui redirige vers un des serveurs. Les clients ne verraient alors qu'une seule adresse IP. Bien sûr, le relais inversé sera seul à la tâche (alors que le but était de faire de la répartition de charge) mais relayer une connexion TCP est bien moins de travail que de servir une page Web complexe. Une variante de cette technique est utilisée pour HTTPS où le répartiteur de charge est également la terminaison de la session TLS, relayant ensuite en clair le trafic jusqu'au vrai serveur.
Mais la technique la plus répandue est sans doute d'avoir un répartiteur de charge opérant en couches 3 et 4, indépendamment du protocole de couche 7. Cela peut être un boîtier fermé spécialisé, un PC ordinaire avec, par exemple IPVS, une fonction embarquée sur le routeur, etc. L'adresse IP du répartiteur est publiée dans le DNS et les clients n'ont donc rien à faire. Comme la solution précédente, elle ne dépend donc pas du comportement du client. Certains de ces répartiteurs sont sans état, relayant chaque paquet IP indépendemment, typiquement en utilisant comme clé un condensat d'informations faciles à trouver dans le paquet (comme l'adresse IP source). Et d'autres sont à état, gardant en mémoire les connexions TCP en cours, et envoyant tous les paquets d'une même connexion vers le même serveur.
Au passage, une fois la décision prise de joindre tel ou tel serveur parmi tous ceux présents dans la ferme, comment le répartiteur redirige-t-il les paquets ? Si le répartiteur et les serveurs sont sur le même LAN, changer l'adresse MAC peut être suffisant (« liaison directe »). Les paquets de retour seront alors transmis sans passer par le répartiteur, qui aura moins de travail. Autre solution, mettre chaque serveur derrière un routeur et utiliser de l'anycast (contrairement à ce que croient certains, l'anycast n'est pas spécifique à BGP). Mais le RFC ne détaille pas cette solution (l'anycast ne se marie pas bien avec la nécessité de maintenir les paquets d'une même connexion TCP épinglés au même serveur).
Troisième solution pour la transmission des paquets vers le « vrai » serveur, donner à chaque serveur sa propre adresse IP et faire un tunnel (GRE, par exemple, car c'est le plus simple et le plus facile à déboguer) vers le serveur, encapsulant le paquet destiné à l'adresse IP du service. Là aussi, le paquet de retour n'a pas besoin de passer par le répartiteur. Selon la taille des paquets utilisés pour l'encapsulation, on pourra rencontrer des problèmes de MTU. Enfin, dernier cas, le NAT où le répartiteur fait une traduction d'adresse IP vers celle du serveur. Attention, dans ce cas, il faut bien configurer le serveur pour qu'il renvoie les paquets de retour vers le répartiteur, pour que celui-ci puisse faire la traduction d'adresse dans l'autre sens. Avec cette solution, le répartiteur, et son état, devient un point de défaillance unique.
Sur toutes ces questions de répartition de charge, on peut consulter l'exposé et l'article d'Alexandre Simon aux JRES 2011.
Comme les relais travaillant au niveau 7 doivent de toute façon analyser tous les paquets, l'utilisation du flow label a peu de chances d'améliorer leurs performances. Donc, le reste du RFC se limite aux redirecteurs travaillant aux niveaux 3 et 4.
Qu'est-ce qui est proposé pour ceux-ci (section 4) ? C'est le cœur de ce RFC, la recommandation pour les répartiteurs de charge d'utiliser cette étiquette des flots.
- Si le flow label est à zéro (la grande majorité aujourd'hui), continuer comme maintenant,
- Si le flow label a été mis, comme spécifié par le RFC 6437, utiliser le couple {adresse IP source, flow label} pour la répartition de charge : un répartiteur sans état condense ce couple (RFC 6438), on utilise le condensat comme clé, et on envoie tous les paquets ayant la même clé vers le même serveur. Cela marchera même si les paquets IPv6 sont fragmentés alors qu'un redirecteur classique sans état, qui ne peut donc pas réassembler les paquets, ne pourra pas fonctionnner car il ne trouvera pas le port source dans les fragments (sauf le premier). Un répartiteur avec état dirige le premier paquet du flot vers un serveur et mémorise l'association {adresse IP source, flow label} -> serveur. Si les paquets IPv6 comprennent des en-têtes d'extension, l'utilisation du flow label sera nettement plus rapide que de chercher l'en-tête de transport, et cela malgré le test supplémentaire (« est-ce que le flow label est nul ? »).
- Les redirecteurs qui font du NAT vers le serveur n'ont aucun intérêt à utiliser le flow label puisqu'ils doivent de toute façon atteindre la couche transport afin de trouver les ports.
Certaines configurations pourraient empêcher un bon fonctionnement de cette méthode. Par exemple, s'il y a partage massif d'adresses derrière un CGN, les risques de collision des flow labels augmentent. Comme il n'y a guère de bonnes raisons de faire un tel partage massif en IPv6, on peut espérer que cela ne soit pas un problème. (Un rappel : en IPv6, traduction d'adresses n'implique pas partage d'adresses, cf. RFC 6296.)
Des problèmes de sécurité avec cette approche ? La section 5 note que le flow label n'est pas spécialement sécurisé (à part si on utilise IPsec) mais c'est également le cas de tous les champs utilisés par les répartiteurs de charge. Néanmoins, comme le rappelle le RFC 6437, un répartiteur paranoïaque peut vérifier que, par exemple, les paquets ne sont pas envoyés de manière déséquilibrée vers un seul serveur car un petit malin modifie les flow label en cours de route. En pratique, en raison de l'utilisation de l'adresse IP source dans la clé, d'une fonction de condensation cryptographique comme SHA-1 et, possiblement, d'un secret concaténé au couple {adresse IP source, flow label} avant sa condensation, une telle attaque ne serait pas triviale.
À noter qu'aujourd'hui, il ne semble pas qu'il existe déjà de répartiteur de charge qui mette en œuvre les préconisations de ce document. (Par exemple, apparemment rien dans l'IPVS de Linux en 3.1.7.)
Merci à Alexandre Simon pour sa relecture.
L'article seul
RFC 6940: REsource LOcation And Discovery (RELOAD) Base Protocol
Date de publication du RFC : Janvier 2014
Auteur(s) du RFC : C. Jennings (Cisco), B. Lowekamp (Skype), E. Rescorla (RTFM, Inc.), S. Baset, H. Schulzrinne (Columbia University)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF p2psip
Première rédaction de cet article le 17 janvier 2014
Le groupe de travail IETF p2psip travaille à permettre la communication (par exemple téléphonique) entre utilisateurs de SIP sans passer par un fournisseur SIP, mais en se débrouillant en pair-à-pair. Pour cela, le groupe a choisi une approche modulaire et a d'abord développé un protocole de communication pair-à-pair, qui va servir de socle aux futures utilisations. Ce protocole se nomme RELOAD (pour REsource LOcation And Discovery), et fait l'objet de ce très long RFC, le premier du groupe p2psip.
L'enjeu est d'importance : le système fermé Skype a obtenu beaucoup d'utilisateurs en s'appuyant partiellement sur des techniques pair-à-pair. Le SIP traditionnel, où deux correspondants ne communiquent que via leurs fournisseurs SIP respectifs devait être amélioré en exploitant ces capacités pair-à-pair. Échanger des paquets RTP directement est facile. Se trouver et initier la communication l'est moins. Pour le faire en pair-à-pair, il n'existait pas de protocole ouvert et normalisé. On notera d'ailleurs que RELOAD est le premier protocole pair-à-pair (au sens moderne parce que, objectivement, IP a toujours été pair-à-pair) normalisé par l'IETF.
RELOAD est suffisemment général pour pouvoir être utilisé dans le futur par d'autres systèmes que SIP. Qu'est-ce qu'il fournit comme service que les autres protocoles existants ne fournissaient pas ?
- Une gestion de la sécurité, avec un serveur central d'inscription qui laisse entrer (ou pas) les pairs. Si vous pensez qu'un tel serveur n'est pas pair-à-pair, vous avez raison. Si vous pensez qu'on peut s'en passer, vous avez tort.
- La possibilité d'être utilisé par des applications différentes (par exemple SIP et XMPP),
- Des fonctions de passage à travers les NAT (un point pénible pour SIP et ses équivalents),
- La possibilité d'utiliser plusieurs algorithmes pour la gestion de l'overlay (le réseau virtuel entre les pairs). Le pair-à-pair est en effet un domaine encore relativement récent et il serait imprudent de croire qu'on connait le bon algorithme d'overlay et qu'on peut ignorer tous les autres. RELOAD permet des réseaux structurés (comme les DHT) et des non structurés. À des fins d'interopérabilité, RELOAD impose la possibilité d'utiliser la classique DHT Chord (ainsi, deux mises en œuvre de RELOAD sont sûres d'avoir au moins un algorithme en commun) mais permet aux overlays d'en utiliser d'autres. La section 3.5 détaille cette particularité de RELOAD. Les systèmes possibles sont stockés dans un registre IANA.
- Une distinction entre pairs et clients, qui permet de profiter de RELOAD sans y participer comme pair. Le même protocole est utilisé (section 3.2 pour les détails). L'annexe B du RFC explique plus en détail pourquoi on autorise les « simples » clients, notamment parce que certaines machines n'ont pas assez de ressources pour assurer les tâches (routage et stockage) d'un pair (machines sur batterie, par exemple).
Si vous voulez vous cultiver sur Chord, l'article original est « Chord: A Scalable Peer-to-peer Lookup Protocol for Internet Applications » (IEEE/ACM Transactions on Networking Volume 11, Issue 1, 17-32, Feb 2003, 2001) et Wikipédia en anglais a un bon article.
Une instance RELOAD est donc un overlay (un réseau virtuel utilisant un algorithme donné) où chaque nœud (pair ou simple client) a un identificateur, le Node-ID. Cet overlay forme un graphe où tout nœud n'a pas forcément directement accès à tout autre nœud, et les pairs doivent donc se préparer à router les messages (les simples clients en sont dispensés).
L'instance RELOAD offre deux services, la transmission de messages et le stockage de données (données de petite taille, a priori, celles nécessaires à la communication). Chaque donnée a un identificateur, le Resource-ID, qui utilise le même espace de nommage que les Node-ID. Il y a ensuite une relation entre les Node-ID et les Resource-ID par exemple, qu'un nœud est responsable de toutes les données dont le Resource-ID est compris entre son Node-ID et le Node-ID précédent (si vous connaissez les DHT, ce genre de concept vous est familier. Sinon, cela peut être le moment de s'arrêter pour lire des choses sur les DHT.) La relation exacte dépend de l'algorithme d'overlay utilisée. Celle donnée en exemple est valable pour Chord.
Pour accomplir ses tâches, RELOAD a plusieurs composants. De haut en bas (si cela ressemble au modèle en couches, c'est exprès, sauf que ces couches sont entassées sur l'overlay, pas sur un réseau physique) :
- L'application, par exemple SIP (la liste des applications est dans un registre IANA).
- Un composant de transport des messages, qui assure des fonctions comme la fiabilité de bout en bout. Ce composant permet donc d'envoyer un message de n'importe quel pair de l'overlay à n'importe quel autre.
- Un composant de stockage des données.
- Un greffon de gestion de la topologie. RELOAD utilise le terme de topology plugin, pour mettre en avant le fait qu'il est modifiable : on peut remplacer le greffon par défaut, qui utilise Chord, par un autre.
- Un composant de gestion des liens entre pairs, qui s'occupera notamment du difficile problème de la traversée des NAT, grâce à ICE (RFC 8445 et section 6.5.1.3).
- Et plusieurs composants de transport sur les liens, entre deux pairs. Un exemple est un composant utilisant TLS (RFC 5246) sur TCP. Un autre composant au même niveau pourrait être DTLS (RFC 6347) sur UDP. Contrairement au composant de transport des messages, le premier cité, qui avait une responsabilité de bout en bout, ces composants de transport sur un lien ne sont responsables que d'envoyer des octets d'un pair à un pair voisin (voisin dans l'overlay, pas du point de vue IP...)
La sécurité est traditionnellement le point
faible des DHT (et du pair-à-pair en général). (Voir l'excellent exposé d'Eric Rescorla.) Le principe de base de la sécurité de RELOAD est que chaque
pair aura un certificat délivré par une
instance centrale (qui ne sera responsable que de l'inscription des
pairs : elle ne participera ni au routage, ni à l'envoi des messages,
ni au stockage,). Chaque message, et chaque objet stocké, sera signé avec ce certificat et
toutes les communications de bas niveau chiffrées (par exemple avec
TLS). Une machine qui veut rejoindre
l'overlay doit se connecter en
HTTPS au serveur central, qui lui attribuera un
Node-ID (dans le champ
subjectAltName du certificat RFC 5280). Le serveur central demandera probablement une
authentification (par exemple nom et mot de passe). Ce serveur et les
vérifications qu'il fait sont le cœur de la sécurité de RELOAD. La machine joindra ensuite le réseau virtuel (les détails
sur la façon dont elle le fait dépendent de l'algorithme utilisé pour
le maintien de l'overlay).
Ne vous inquiétez pas forcément de ces obligations de sécurité : elles ne sont valables que pour un overlay installé sur le grand Internet public. Si vous avez un environnement restreint et sécurisé (disons un groupe de machines formant un réseau ad hoc local), vous avez le droit de vous en dispenser et de vous contenter de certificats auto-signés par les pairs, où le Node-ID est simplement un condensat de la clé publique. Une telle façon de fonctionner laisse le réseau très vulnérable aux attaques Sybil mais peut convenir si vous savez que vous êtes « entre vous ». Autre possibilité de simplification de la sécurité : RELOAD a un mode où les pairs s'authentifient, non pas par un certificat, mais par un secret partagé (par exemple RFC 4279).
Voici donc les grands principes de RELOAD. Je ne vais pas ensuite détailler les 186 pages du RFC, juste quelques points que je trouve intéressants. Le mécanisme de routage est présenté en section 3.3. Par défaut, RELOAD utilise du récursif symétrique (section 6.2). La requête enregistre les nœuds par lesquels elle est passée (dans la Via List) et la réponse suivra le même chemin en sens inverse. Si la topologie a changé entre-temps, la réponse sera perdue et ce sera aux couches supérieures de réémettre. (Il existe une alternative à ce stockage du chemin dans le message lui-même : si les pairs intermédiaires peuvent stocker des données, ils peuvent garder la mémoire des routes suivies, au lieu d'utiliser la Via List.)
L'inscription initiale dans l'overlay est un
problème intéressant, car on voudrait que cela soit simple pour
l'utilisateur, par exemple qu'il n'ait pas à rentrer 50 paramètres
dans son client SIP. L'idée est que le nouveau pair n'a à connaître que le
nom de l'overlay (un FQDN)
et peut-être des informations d'authentification. Une requête
SRV dans le DNS à partir
du nom du réseau (précédé de _reload-config._tcp) donne le nom du serveur de configuration, qu'on
contacte en HTTPS en lui demandant la ressource
.well-known/reload-config (RFC 8615 pour .well-known). Ce serveur envoie alors tous les détails de
configuration de l'overlay, en
XML, un exemple figure en section 11 et à la
fin de cet article. (Une machine peut aussi avoir cette
configuration dans un fichier local.) C'est alors que le futur pair
connait le nom du serveur d'inscription et peut le contacter pour
apprendre son Node-ID.
Le stockage pair-à-pair dans RELOAD (section 4.1) permet de stocker différents
types (kind) d'objets. Un type peut être défini
comme stockant un scalaire, un
tableau ou un
dictionnaire (section 7.2 pour les détails). Tous les objets stockés sont
signés par le déposant, qui pourra ainsi vérifier que ses pairs ne se
sont pas moqués de lui. (Voir mon article « Assurer l'authenticité des données
stockée dans une DHT».) À noter qu'un pair ne peut pas stocker des
objets sous des noms arbitraires. Typiquement (cela dépend de l'application), il ne peut stocker que
sous son propre nom (alice@example.com pour du SIP), ce qui fait qu'il ne pourra pas noyer tous les
nœuds de la DHT sous des objets à stocker.
Une des choses les plus nécessaires pour communiquer en pair-à-pair est la découverte. Trouver quelqu'un ou quelque chose dans l'immensitude de l'Internet est difficile (alors que c'est trivial en centralisé, d'où le succès de services comme Facebook). Il existe actuellement plusieurs Internet-Drafts décrivant de futurs services de découverte qui tourneront au dessus de RELOAD.
Le format des messages RELOAD est décrit en section 6.3 : format binaire, avec les premiers en-têtes, qui sont obligatoires, à une position fixe (pour une analyse plus rapide) et les suivants, qui sont optionnels, encodés en TLV (pour la souplesse et l'extensibilité). Chaque message est auto-suffisant, un peu comme un datagramme. Sa première partie, le Forwarding Header, est la seule qui ait besoin d'être examinée par les routeurs intermédiaires. Les deux autres, le Message Content et le Security Block (les signatures), ne concernent que la machine de destination.
Notre RFC utilise une syntaxe analogue à celle du
C pour décrire le format des messages (un peu
comme le fait le RFC 5246). Principal point à
noter pour lire cette syntaxe (la section 6.3.1 fournit tous les détails) : les termes entre
chevrons sont des valeurs de taille
variable. Par exemple data<0..15> désigne
de zéro à quinze octets de données.
Le Forwarding Header contient les Via Lists vues plus haut et les destinations (la plupart du temps, il n'y en a qu'une seule mais RELOAD permet d'indiquer une liste de destinations à parcourir successivement : pour comparer avec le datagramme IP, disons que la liste des destinations est une fusion de l'adresse IP de destination et de l'option Source route). Cela donne :
struct {
...
uint32 overlay; /* Un condensat du nom */
...
uint8 ttl;
...
uint32 length;
...
uint16 via_list_length; /* Pour le routage
symétrique */
uint16 destination_list_length;
...
Destination via_list[via_list_length];
Destination destination_list
[destination_list_length];
...
} ForwardingHeader;
Pour cet en-tête, qui doit être lu très vite par les routeurs
intermédiaires, RELOAD utilise l'encodage {longueur, tableau}. Les
autres termes de longueur variable utiliseront un encodage moins
rapide à analyser mais plus propre. Le type
Destination est, en résumant, un Node
ID ou Resource ID (rappelez-vous que ces
ID ont la même forme - dépendante du type
d'overlay - et sont tirés du même espace).
La deuxième partie du message, Message Content, est largement opaque :
struct {
uint16 message_code;
opaque message_body<0..2^32-1>;
MessageExtension extensions<0..2^32-1>;
} MessageContents;
C'est donc surtout une suite d'octets, 2^32 au maximum. Le code indique la sémantique du message (demande de stockage de données, « ping », annonce d'un nouveau pair, etc) et la liste des codes est dans un registre IANA.
La troisième et dernière partie du message, le Security Block, est une liste de certificats X.509 et une signature :
struct {
GenericCertificate certificates<0..2^16-1>;
Signature signature;
} SecurityBlock;
Tous les messages doivent être signés et les signatures vérifiées à la réception.
Les responsabilités du greffon de gestion de la topologie figurent
dans la section 6.4. Elles sont décrites sous forme de messages
abstraits, à incarner pour chaque algorithme
d'overlay. Un exemple, le message
Join lorsqu'un nouveau pair arrive :
struct {
NodeId joining_peer_id;
opaque overlay_specific_data<0..2^16-1>;
} JoinReq;
Les protocoles de communication entre deux nœuds devront fournir des mécanimes d'authentification du Node ID, d'intégrité et de confidentialité, par exemple en s'appuyant sur TLS (section 6.6.1). Le RFC suggère d'explorer la possibilité d'utiliser HIP (RFC 7401 et section 6.6.1.1) qui a toutes les propriétés voulues. Ils doivent aussi respecter les principes du RFC 8085, i.e. ne pas noyer les destinataires sous les retransmissions.
Le stockage des données fait l'objet de la section 7. On stocke des objets qui ont cette forme :
struct {
uint32 length;
uint64 storage_time;
uint32 lifetime;
StoredDataValue value;
Signature signature;
} StoredData;
On voit qu'ils sont signés, et ont une durée de vie maximale.
On l'a dit, RELOAD utilise par défaut la DHT Chord et toutes les mises en œuvre de RELOAD doivent connaître Chord, pour assurer l'interopérabilité. Le mécanisme utilisé par RELOAD est légèrement différent du Chord original et la section 10 détaille ces différences. Les deux principales :
- Chord ne permettait qu'un seul prédécesseur et un seul successeur par nœud, alors que plusieurs sont possibles avec Chord-RELOAD,
- Le routage dans Chord était itératif (le nœud de départ devait contacter directement celui d'arrivée, les autres pairs ne servaient qu'à indiquer où le trouver), il est devenu récursif (les autres pairs transmettent le message, difficile de faire autrement avec les NAT). L'annexe A du RFC discute en détail les raisons de ce choix.
Les grands principes de Chord sont gardés : nœuds organisés en un anneau (le dernier nœud dans l'ordre des Node ID est donc le précédesseur du premier), utilisation de SHA-1 (tronqué aux 128 premiers bits dans Chord-RELOAD) pour trouver le Resource ID à partir des données, table de routage composée, non seulement des voisins immédiats, mais aussi de pointeurs (les fingers) vers un certain nombre de non-voisins (pour des raisons de performance, car cela évite de parcourir la moitié de l'anneau, mais aussi de résilience, pour survivre à la perte des voisins), etc
Un exemple de fichier de configuration d'un réseau virtual (overlay) figure en section 11 :
<overlay>
<configuration instance-name="overlay.example.org" sequence="22"
expiration="2002-10-10T07:00:00Z" ext:ext-example="stuff" >
<!-- Le greffon de topologie par défaut : -->
<topology-plugin>CHORD-RELOAD</topology-plugin>
<!-- Le certificat qui va signer tout : -->
<root-cert>
MIIDJDCCAo2gAwIBAgIBADANBgkqhkiG9w0BAQUFADBwMQswCQYDVQQGEwJVUzET...
</root-cert>
<!-- Les serveurs à contacter pour avoir Node-ID et
certificat : -->
<enrollment-server>https://example.org</enrollment-server>
<enrollment-server>https://example.net</enrollment-server>
<!-- Les pairs à contacter pour rejoindre l'overlay : -->
<bootstrap-node address="192.0.0.1" port="6084" />
<bootstrap-node address="192.0.2.2" port="6084" />
<bootstrap-node address="2001:db8::1" port="6084" />
<!-- Les paramètres spécifiques à la DHT : -->
<chord:chord-update-interval>
400</chord:chord-update-interval>
<chord:chord-ping-interval>30</chord:chord-ping-interval>
<chord:chord-reactive>true</chord:chord-reactive>
<!-- Et bien d'autres choses encor... -->
</overlay>
6084 est le port par défaut pour RELOAD (section 14.2). La grammaire pour ce fichier de configuration est normalisée (en Relax NG) en section 11.1.1.
Pour contacter les serveurs d'inscription (enrollment
server), le protocole à utiliser est en section 11.3. L'IETF
a choisi de ne pas réutiliser les protocoles existants (RFC 5272 et RFC 5273) car ils sont trop complexes. À la
place, le futur pair fait juste une requête HTTPS
POST dont le contenu comprend
du PKCS#10 (contenant la demande de certificat,
cf. RFC 2311). Cette requête doit aussi contenir les
informations d'authentification du pair (par exemple un nom et un mot
de passe). En échange, le serveur enverra un certificat dont le sujet
(le nom) sera un Node ID, choisi au hasard (RFC 4086 ; c'est important car certaines attaquent
contre les DHT nécessitent que l'attaquant choisisse son Node
ID). En outre, le champ subjectAltName
doit contenir le nom que l'utilisateur sera autorisé à présenter à
l'application (pour SIP, ce sera un nom de type
machin@truc.example). Certaines autorisations
(par exemple d'accès aux données stockées) dépendront de ce nom.
La faiblesse traditionnelle des DHT (ou du pair-à-pair en général) est la sécurité (RFC 5765). Sans chef pour contrôler les échanges, que faire si un méchant s'insère dans le réseau pair-à-pair pour l'espionner, modifier les données, ou bien empêcher le réseau de fonctionner ? La section 13 revient en détail sur les questions de sécurité. Le fond du problème est qu'on dépend des pairs (pour envoyer des messages à d'autres pairs ou bien pour stocker des données) et qu'on n'a pas de relation bien définie avec ces pairs. Sur un réseau public comme l'Internet, les pairs peuvent être n'importe qui, y compris des méchants. Si la majorité des pairs sont dans ce cas, on est fichu, aucun algorithme astucieux ne peut marcher dans ces conditions. Il faut donc agir sur l'inscription (enrollment). C'est ce que fait RELOAD (section 13.3) en imposant le passage par un serveur d'inscription pour obtenir un certificat, puis en imposant de prouver la possession d'un tel certificat (en signant les messages avec la clé).
RELOAD permet des certificats auto-signés mais, dans ce cas, l'overlay peut être vite noyé sous les pairs malveillants (ce qu'on nomme une attaque Sybil). La seule sécurité qui reste est le Node ID (qui est dérivé du certificat et est donc cryptographiquement vérifiable). Bref, une telle sécurité ne convient que dans des environnements fermés, où on est sûr de toutes les machines présentes. Un exemple typique est un réseau ad hoc entre les machines des participants à une réunion (et encore, en Wifi, attention à l'attaquant de l'autre côté du mur...). Dans ce cas, on peut même se passer complètement des certificats en choisissant la solution du secret partagé : on le distribue à tous les participants à la réunion et ça roule (section 13.4).
L'article seul
RFC 7094: Architectural Considerations of IP Anycast
Date de publication du RFC : Janvier 2014
Auteur(s) du RFC : D. McPherson (Verisign), D. Oran (Cisco Systems), D. Thaler (Microsoft), E. Osterweil (Verisign)
Pour information
Première rédaction de cet article le 17 janvier 2014
La technologie de l'anycast est maintenant largement déployée dans l'Internet. C'est l'occasion de faire un point architectural : quelles sont les conséquences de l'anycast ? Telle est la question de ce RFC de l'IAB.
Qu'est-ce que l'anycast ? C'est simplement le fait qu'une adresse IP, celle à laquelle répond un service offert sur l'Internet, soit configurée en plusieurs endroits (cf. RFC 4786). Cette technique est surtout connue par son utilisation massive dans le DNS, notamment pour les serveurs racine. Fin 2007, il y avait déjà dix des treize serveurs racine qui utilisaient l'anycast (cf. les minutes de la réunion 29 du RSSAC). Sans compter la quasi-totalité des gros TLD qui reposent, eux aussi, sur cette technique pour tout ou partie de leurs serveurs. À part le DNS, l'utilisation la plus importante de l'anycast est sans doute pour les serveurs NTP (RFC 5905).
L'adresse IP perd donc sa caractéristique « est unique dans tout l'Internet ». La même adresse IP est configurée en plusieurs endroits, et un paquet IP à destination de cette adresse IP de service arrivera dans un seul de ces endroits, le « plus proche » (en termes de métriques de routage, pas forcément en terme de distance géographique ou de RTT).
À noter que rien ne distingue, syntaxiquement, une adresse anycast d'une adresse habituelle. D'ailleurs, déterminer si un service donné est « anycasté » n'est pas toujours facile. (Quelques traceroutes depuis divers points, ainsi qu'une interrogation directe du serveur, par exemple avec le RFC 5001 pour le DNS, peuvent répondre à cette question, mais on n'a pas toujours une certitude.)
Le RFC 4786 discute en détail différentes façons de faire de l'anycast. Notre nouveau RFC 7094 ajoute une nouvelle distinction : « off-link anycast » et « on-link anycast ». Le premier mode est celui de l'anycast actuel, largement déployé comme on l'a vu. Plusieurs sites annoncent la même route et le « plus proche » est choisi. C'est ce mode qui est discuté dans le RFC 4786.
Le second mode, on-link anycast, n'est pas réellement déployé. Il désigne un système où le protocole de résolution d'adresses sur un réseau local peut gérer, sans protocole de routage, l'envoi à une machine parmi celles qui répondent à une adresse IP donnée. Dans le monde IP, il n'est normalisé que pour IPv6 (RFC 4861, notamment la section 7.2.7).
Lorqu'on utilise le premier mode, le off-link anycast, quel AS d'origine doit-on mettre dans l'annonce BGP ? La plupart des sites anycast utilisent le même AS pour chaque site mais le RFC 6382 documente une méthode où un AS différent est utilisé par site (méthode « multi-origines »).
De quand date l'anycast ? La section 2.1 se penche sur l'histoire de ce concept. La première spécification était le RFC 1546 en 1993, ce qui ne nous rajeunit pas. À l'époque, c'était purement théorique mais le RFC 1546 liste bien toutes les questions. La première utilisation documentée était l'année suivante, pour de la distribution de vidéo, et est notée dans l'IMR 9401. Il s'agissait de trouver le serveur de vidéos « le plus proche ». La rumeur de l'Internet dit que des FAI ont utilisé l'anycast pour leurs résolveurs DNS à partir de cette époque mais il n'y a pas de traces écrites. En 1997, l'IAB s'en mêle pour la première fois, avec quelques phrases dans le RFC 2101.
L'anycast a également été mentionné lors de l'atelier sur le routage organisé par l'IAB l'année suivante et documenté dans le RFC 2902. Cette technique est encore présentée comme « à étudier » (« We need to describe the advantages and disadvantages of anycast »). Donc, en 1999, à la 46ème réunion de l'IETF, une BoF sur l'anycast a eu lieu. Les deux principales conclusions étaient que l'usage de l'anycast pour TCP n'était pas forcément une bonne idée, mais que par contre l'application qui serait la plus suceptible d'utiliser l'anycast avec profit était le DNS.
Par la suite, IPv6 est arrivé et a spécifié des adresses anycast dans le RFC 2526 et dans le RFC 3775. Il était aussi prévu d'avoir des relais anycastés pour la coexistence IPv4-IPv6 (RFC 2893) mais cela a été supprimé par la suite, avant que 6to4 ne réintroduise l'idée dans le RFC 3068. L'expérience de 6to4 a d'ailleurs bien servi à mesurer les conséquences de l'utilisation de l'anycast « en vrai » et cela a été documenté dans le RFC 3964.
Mais c'est le DNS qui a popularisé l'anycast, d'abord avec l'AS 112 (décrit dans le RFC 7534) puis avec la racine. En 2002, le RFC 3258 décrit cette utilisation. Il est amusant de constater que ce RFC n'utilise pas le terme anycast, considéré à l'époque comme devant désigner uniquement les techniques reposant sur une infrastructure spécifique (comme le multicast). Le RFC 3258 note aussi qu'aucun changement des mécanismes de routage n'est nécessaire. Et que l'utilisation d'UDP par le DNS suffisait à résoudre le problème du changement des routes en cours de session : le DNS étant requête/réponse, sur un protocole (UDP) sans état, il n'y avait pas de risque de parler à deux instances différentes pendant une session. Le RFC 3258 recommandait d'arrêter le serveur DNS, plutôt que de couper le routage, en cas de panne, arguant du fait que les clients DNS savent se débrouiller avec un serveur en panne. Couper le routage a en effet l'inconvénient de propager des mises à jour BGP dans toute la DFZ, ce qui peut mener à leur rejet (RFC 2439). Cet argument ne vaut que pour les serveurs faisant autorité (se débrouiller avec un résolveur en panne est bien plus lent). Aujourd'hui, on conseille plutôt le contraire, notamment lorsqu'on a des SLA par serveur DNS (ce qui est absurde, puisque le DNS se débrouille très bien avec un serveur en panne, mais cela se voit dans certains contrats). La section 4.5 de notre RFC revient plus en détail sur ce conseil.
Sur la base notamment du déploiement de l'anycast dans le DNS de 2002 à 2006 a été écrit le RFC 4786, sur les aspects pratiques de l'anycast. Il insiste sur la nécessité que le routage soit « stable », c'est-à-dire dure plus longtemps que la transaction typique (ce qui est facile à réaliser avec les protocoles requête/réponse comme le DNS). Il note aussi que l'anycast peut compliquer la gestion des réseaux, en ajoutant de nouvelles causes de perturbation.
Il y a d'autres cas où le vocabulaire a changé. Par exemple, IPv6 venait dès le début avec quelque chose nommé anycast mais qui était uniquement du on-link anycast, pas le off-link anycast qui est massivement utilisé par le DNS. Cela impliquait des restrictions sur l'usage (interdiction de mettre une adresse anycast en source d'un paquet, cf. section 2.5 du RFC 1884) qui ont été supprimées en 2006 par le RFC 4291. L'on-link anycast d'IPv6 existe toujours (section 7.2.7 du RFC 4861) mais semble très peu employé.
La section 3 de notre RFC pose ensuite les principes d'architecture
à suivre pour l'anycast. Elle est assez restrictive, limitant
l'anycast à quelques protocoles simples comme le DNS. D'abord, le modèle en couches est considéré
comme essentiel par sa modularité. Cela veut dire qu'une application
(couche 7) ne devrait pas avoir à être modifiée
pour s'adapter au système de routage (couche
3). L'application ne devrait pas non plus être concernée
par la stabilité des routes, comme elle n'est pas concernée par le
taux de perte de paquets, qui est en général traité dans une couche
plus basse. Avec les protocoles de transport à états, comme TCP, un changement de routage
qui fait arriver à une autre instance et c'est la fin de tout,
puisque cette instance n'a pas l'état associé : elle enverra purement
et simplement un RST, mettant fin à la
connexion. À noter que c'est un des cas où quelque chose peut très
bien marcher dans le laboratoire et pas dans le vrai Internet (où les
changements de routes sont un événement relativement fréquent).
Donc, si une adresse de destination d'un paquet est anycast, différents paquets à destination de cette adresse pourront être envoyés à des machines distinctes. Ce n'est pas un problème si on respecte les principes posés par ce RFC : une requête qui tient dans un seul paquet, un transport sans état (comme UDP), pas d'état côté serveur entre deux requêtes, et des requêtes idempotentes. Le DNS obéit à tous ces principes.
Et les adresses anycast en source et pas seulement en destination ? Si on fait cela, deux réponses au même paquet pourront arriver à deux machines différentes. Cela marchera quand même s'il n'y a pas de réponses (cas du DNS : le demandeur ne répond pas à la réponse, venant d'un serveur anycast). Ou si elles sont distribuées à la bonne instance par un autre mécanisme, spécifique à l'application. Mais il y a un autre piège avec une adresse anycast en source : si on met en œuvre le filtrage RPF (RFC 4778), le paquet entrant sera peut-être refusé puisque rien ne dit que le paquet d'une instance donnée arrivera par l'interface par lequel une réponse serait sortie. La section 4.4.5 du RFC 4786 donne quelques conseils à ce sujet.
Une solution au problème du changement de routage, amenant à une autre instance, serait de n'utiliser l'anycast que pour la découverte du serveur, pas pour la communication avec ce serveur (section 3.4). Cela ne convient pas au DNS, puisque cela augmente d'un aller-retour le temps total d'interaction mais ce n'est pas grave, le DNS ne craint pas les changements de route. En revanche, pour un protocole utilisant TCP, on pourrait envoyer un paquet UDP à l'adresse anycast de découverte, recevoir en réponse l'adresse unicast du serveur et interagir ensuite en TCP avec cette adresse unicast. Ainsi, on serait à l'abri des changements de route ultérieurs, tout en gardant les avantages de l'anycast, notamment la sélection du serveur le plus proche. Je ne connais pas encore de système qui utilise cette approche, pourtant prometteuse.
Enfin, la section 4 du RFC analyse certains points précis de l'anycast. Par exemple, son passage à l'échelle pour le système de routage. Chaque serveur anycast public sur l'Internet va nécessiter une route dans la DFZ et va donc charger tous les routeurs de la DFZ. Il est donc préférable que l'usage de l'anycast reste limité à quelques services (comme c'est le cas actuellement). Certes, on peut mettre plusieurs serveurs derrière un même préfixe anycast (et donc une seule route) mais cela imposerait qu'à chaque site, on trouve la totalité des serveurs.
On a vu qu'on pouvait avoir le beurre (l'anycast) et l'argent du
beurre (la résistance au changement de routes) en commençant les
connexions TCP par un échange UDP pour trouver l'adresse du serveur le
plus proche. Cela se paie par un aller-retour supplémentaire (celui en
UDP). Il existe une façon astucieuse d'éviter ce coût mais elle
requiert une modification de TCP. L'idée est la suivante : le premier
paquet TCP, le paquet SYN, est envoyé à l'adresse
anycast. La réponse, SYN-ACK est émise depuis
une adresse source unicast. Le reste de la communication (fin de la
triple poignée de mains avec un ACK puis échange
de données) se ferait avec l'adresse unicast du serveur, à l'abri des
fluctuations du routage. Les mises en œuvre actuelles de TCP
rejetteraient le deuxième paquet, le SYN-ACK car l'adresse source ne
correspond pas. Mais, si elles étaient modifiées pour accepter
n'importe quelle adresse source en réponse à un
SYN envoyé à une adresse anycast, cela marcherait
(le paquet entrant serait envoyé au processus qui a une prise réseau
avec les mêmes ports et
un numéro de séquence TCP qui
convient.) Modifier TCP est peut-être trop risqué mais la même idée
pourrait être appliquée à des protocoles de transport plus récents
comme SCTP.
La section 4.4 se penche sur les questions de sécurité. On utilise souvent l'anycast avant tout pour limiter les effets des dDoS, en ayant plusieurs sites pour amortir l'attaque, avec en outre un contingentement géographique (chaque zombie de l'attaquant ne peut taper que sur un seul site). On peut même s'en servir pour faire couler le trafic non désiré au fond de l'évier, dans l'esprit du RFC 3882. Cette méthode a bien marché dans le cas de grosses erreurs de configuration comme la bavure Netgear/NTP documentée dans le RFC 4085.
On a parlé plus haut du conseil de ce RFC de ne pas retirer une route en cas de panne mais de laisser le trafic arriver au serveur en panne. Ce conseil est contesté mais, en cas d'attaque, il n'y a guère de doute qu'il faut laisser la route en place, sinon l'attaque ira simplement vers une autre instance, probablement plus lointaine, en gênant davantage de monde au passage. Une exception est celle où on retire la route pour aider à trouver la vraie source d'une attaque.
Autre question de sécurité, le risque d'un faux serveur. Ce n'est
pas un risque purement théorique, loin de là. Ainsi, à la Journée du Conseil Scientifique de l'AFNIC du 4 juillet 2012, Daniel Karrenberg avait expliqué que le
RIPE-NCC avait identifié plusieurs copies
pirates du serveur DNS racine
K.root-servers.net. Bien sûr, annoncer un préfixe
qui n'est pas à vous et attirer ainsi le trafic légitime vers le
pirate a toujours été possible en BGP. Mais l'anycast rend cette
attaque plus facile : si on voit une annonce d'un préfixe d'un
ministère français par un opérateur biélorusse,
on s'étonnera et on cherchera. Avec l'anycast, il est tout à fait
normal de voir des annonces BGP (ou d'un protocole de routage
interne) du même préfixe jaillir d'un peu
partout, même d'AS différents. Il est donc très recommandé d'avoir un
mécanisme d'authentification, permettant de s'assurer qu'on parle à
une instance anycast légitime, et pas à un pirate. (Dans le cas de
DNS, c'est DNSSEC qui assure ce rôle. Comme
DNSSEC protège les données, et pas juste le canal, si la zone DNS est
signée, peu importe que le résultat soit obtenu via un serveur
légitime ou pas.)
D'autres attaques que l'envoi de réponses mensongères sont possibles en faisant des annonces de routage d'un préfixe utilisé en anycast. Par exemple, on peut empêcher les paquets d'atteindre les serveurs légitimes, leur masquant ainsi le trafic. La section 6.3 du RFC 4786 et l'article de Fan, X., Heidemann, J., et R. Govindan, « Evaluating Anycast in the Domain Name System » fournissent davantage de détails sur ces attaques spécifiques à l'anycast.
L'article seul
Twister, un concurrent libre et pair-à-pair pour Twitter
Première rédaction de cet article le 16 janvier 2014
Dernière mise à jour le 19 janvier 2014
Les « réseaux sociaux » d'aujourd'hui sont dans leur écrasante majorité des gros monstres centralisés, contrôlés chacun par une seule grosse entreprise capitaliste, états-unienne et envoyant ses données à la NSA via PRISM. Il est donc logique que l'Internet, fondé sur des idées de pair-à-pair dès le début, cherche à secouer cette domination des GAFA (les énormes silos centralisés). Par exemple, peut-on remplacer Twitter par un système libre ? C'est ce que tente le projet Twister.
Le problème n'est pas trivial. Il y a des tas de raisons qui font que la plupart des projets « rézosocio libre, acentré, pair-à-pair, de gauche, etc » ont capoté (cf. mon exposé à Pas Sage En Seine). Une des difficultés est le refus, par pas mal de développeurs, d'admettre que le problème est techniquement difficile. Il s'agit entre autres de vaincre le triangle de Zooko. Pour prendre l'exemple de Twitter, si on en fait un service réparti et décentralisé, il y a deux gros problèmes techniques à gérer, la création des comptes (qui va avoir le compte « françoishollande » ?) et la découverte des autres utilisateurs. Beaucoup de « rézosocios alternatifs » avaient choisi d'aborder le problème en le niant. Pas Twister, dont les auteurs ont fait l'effort de documenter le fonctionnement dans un excellent article.
Je ne vais pas reprendre cet article ici, juste résumer en quelques points comment fonctionne Twister :
- La création des comptes, assurant l'unicité des noms (sans dépendre d'un système arborescent comme les noms de domaines) est faite par un système à chaîne de blocs publique, comme Bitcoin (c'est d'ailleurs le même code qui est utilisé). Cela résout largement le triangle de Zooko. Ce n'est pas une idée nouvelle que d'utiliser une telle « blockchain » pour enregistrer des noms uniques, Namecoin le faisait aussi. Mais, contrairement à Namecoin, l'enregistrement dans la chaîne Twister est pour l'instant gratuit.
- Les messages eux-mêmes sont stockés dans une DHT, fondée sur Kademlia.
- Mais les DHT ne sont pas forcément fiables sur le long terme donc un second système permet de stocker les messages (les « twists » ?), système fondé sur BitTorrent. Chaque utilisateur va avoir un essaim de pairs BitTorrent, qui stockeront ses messages. Les gens qui suivent un utilisateur donné rejoignent l'essaim, pour avoir un accès facile aux messages.
OK, ça, c'était la théorie (mais lisez le papier, il est vraiment
très bien fait). Et la pratique ? Le logiciel est libre et on peut le faire
fonctionner sur sa machine. Un avertissement : pour l'instant, c'est
plutôt du brut de fonderie, pas forcément très accessible à tous. On doit d'abord
récupérer le logiciel. Je
recommande ensuite de bien lire le fichier INSTALL qui
décrit les instructions (et, pour Unix, le
fichier doc/build-unix.md). Je suis arrivé à compiler Twister sur une
Debian version stable, en installant les
paquetages autoconf, automake, libtool, libminiupnpc-dev, libboost-all-dev, libssl-dev et
libdb5.1-dev et la méthode de compilation « 2b) Using standard makefile ». Attention, j'ai aussi supprimé
l'option HARDENING+=-fstack-protector-all
-Wstack-protector du Makefile. Avec
cette option, ça compile mais ça plante au premier usage. (Un autre témoignage sur la compilation de Twister sur Debian est en ligne.)
Ah, et n'oubliez pas non plus les pages
HTML (module twister-html), à installer séparément (voir le fichier README.md), sinon l'interface
Web ne va guère marcher.
Une fois que c'est fait, on place dans ~/.twister un fichier twister.conf avec :
rpcuser=user rpcpassword=pwd
(Attention, il ne faut pas changer ces valeurs.) Et on démarre le démon :
% ./src/twisterd
On peut vérifier son bon fonctionnement en style Bitcoin classique. Si vous êtes habitué à gérer un nœud Bitcoin, vous ne serez pas dépaysé :
% src/twisterd getinfo
{
"version" : 90000,
"protocolversion" : 70001,
"walletversion" : 60000,
"blocks" : 20217,
"timeoffset" : -3,
"connections" : 10,
"addrman_total" : 1352,
"addrman_get" : 1352,
"dht_nodes" : 84,
"dht_global_nodes" : 336,
"proxy" : "",
"difficulty" : 0.01538494,
"testnet" : false,
"errors" : "This is a pre-release test build - use at your own risk"
}
Ou avec des commandes spécifiques à Twister (voir des exemples dans le
README.md, ou bien avec twisterd help), par exemple pour
récupérer un profil d'un utilisateur :
% ./src/twisterd dhtget fredix profile s
[
{
"p" : {
"height" : 16835,
"seq" : 6,
"target" : {
"n" : "fredix",
"r" : "profile",
"t" : "s"
},
"time" : 1389010692,
"v" : {
"bio" : "hello",
"fullname" : "Frédéric Logier",
"location" : "France",
"url" : "http://frederic.logier.org"
}
},
"sig_p" : "20ae4859b3dc17c6a03e241c93174fa42903db4b77d822c83ab6b2cf89cb5b5b287f1ba4125844519cf1b2ca214c74382ca211d20434b1c0260478c5b618111f76",
"sig_user" : "fredix"
}
]
Mais, bon, la plupart des interactions se feront sans doute au début
via l'interface Web, qui copie largement celle de Twitter. On se
connecte à http://localhost:28332/network.html et
on vérifie que la connectivité marche (ici, 9 connexions et 84
machines dans la DHT) : 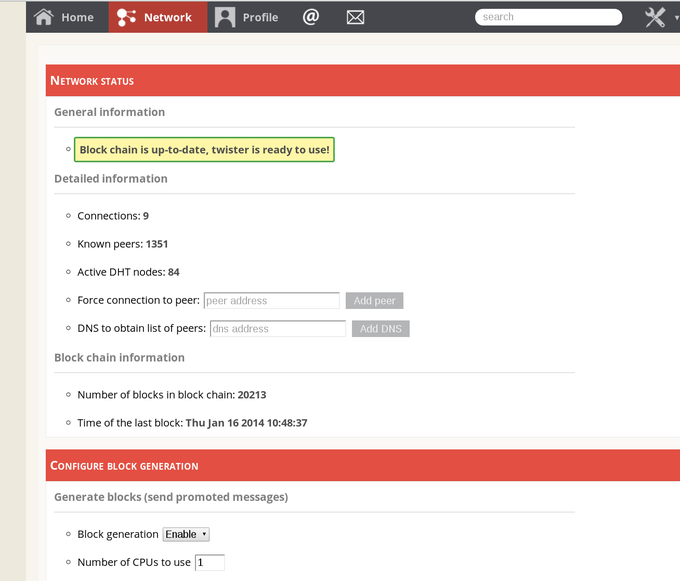 On en
était au bloc 20 213 dans la chaîne publique (
On en
était au bloc 20 213 dans la chaîne publique (twisterd
getblockcount vous aurait donné la même information) mais
je ne crois pas qu'il existe un explorateur de la chaîne publique,
analogue à Blockchain.info pour Bitcoin.
L'interface Web permet de créer un compte mais, dans mon
expérience, c'est parfois frustrant. Au minimum, il faut attendre
quelques minutes (rappelez-vous que c'est comme Bitcoin : les pairs
doivent valider la transaction), et cela plante parfois, il faut
essayer des commandes magiques (twisterd
sendnewusertransaction) ou re-tenter sa chance.
Mais, bon au bout du compte, j'y suis arrivé, j'ai un compte,
bortzmeyer (attention, Twister est à la mode,
tout le monde se précipite pour enregistrer « son » nom en ce
moment et c'est d'ailleurs présenté dans l'article comme un moyen
d'inciter les utilisateurs à l'adopter, en fournissant une prime au
premier arrivé). Ensuite, le fonctionnement est le même qu'avec l'interface
Web de Twitter. Je ne fournis pas de lien ici, Twister n'a pas encore
de passerelle depuis le Web public, il faut faire tourner un noeud
Twister pour voir.
Twister est très récent et, comme on l'a vu, pas évident à utiliser. Sa sécurité est loin d'être parfaite. Par exemple, le relativement faible nombre des noeuds fait qu'un connard disposant d'une grande puissance de calcul peut, sans compétences particulières, faire une « vraie-fausse chaîne » de blocs plus longue que la chaîne légitime, ce qui lui donne la possibilité d'annuler ou de piquer une partie des enregistrements, comme cela s'est produit le 18 janvier.
En conclusion ? Si le logiciel est encore franchement alpha, le concept est brillant : les auteurs de Twister, contrairement à tant d'autres, ont abordé de front les problèmes des réseaux sociaux décentralisés et ont des bonnes solutions. Bien sûr, il n'y a pas de miracle : notamment, il faut accepter les inconvénients de Bitcoin (le CPU qui tourne au maximum en permanence...).
Merci à Hoʍlett pour avoir
attiré mon attention sur Twister et pour deux discussions sur
SeenThis : http://seenthis.net/messages/212810 et http://seenthis.net/messages/216913. En français, il y a aussi
deux discussions sur LinuxFr : http://linuxfr.org/users/fredix/journaux/twister-un-microblog-opensource-p2p puis http://linuxfr.org/news/twister-un-microblog-opensource-p2p. En anglais, on peut lire une bonne documentation pratique sur l'installation de Twister sur un Raspberry Pi dédié.
L'article seul
RFC 7103: Advice for Safe Handling of Malformed Messages
Date de publication du RFC : Janvier 2014
Auteur(s) du RFC : M. Kucherawy, G. Shapiro, N. Freed
Pour information
Réalisé dans le cadre du groupe de travail IETF appsawg
Première rédaction de cet article le 16 janvier 2014
Dans un monde idéal, les messages transmis par le système de courrier électronique de l'Internet seraient tous parfaitement conformes aux normes, comme le RFC 5322. Dans la réalité, l'ancienneté du courrier, et son succès, qui a mené à une explosion du nombre de logiciels, font que beaucoup de messages sont incorrects, « malformed », dit ce nouveau RFC. Que doivent faire les logiciels confrontés à ces messages incorrects ? Voici une série d'avis pour les programmeurs qui veulent essayer de faire le moins mal possible.
Les normes du courrier électronique sont pourtant anciennes, remontant aux années 1970 (le RFC 733 semble avoir été le premier), et on pourrait penser qu'elles sont désormais bien intégrées partout. Mais ce n'est clairement pas le cas en pratique. Une approche « fasciste » de ce problème serait de rejeter ces messages invalides. Mais cela éliminerait une bonne partie de l'intérêt du courrier électronique, la capacité à communiquer avec un grand nombre de gens. La pression du « marché » va donc plutôt vers un certain laxisme. Un logiciel qui rejetterait tous les messages erronés n'auraient pas beaucoup de clients ! Il est en général plutôt conseillé de faire preuve de souplesse et d'accepter ces messages non-standard dans certains cas, dans la logique du principe de robustesse. Cela ne veut pas dire qu'il faut tout tolérer et ce RFC 7103 rassemble des conseils pour les auteurs de logiciels de gestion du courrier. Une interprétation extrémiste du principe de robustesse serait en effet qu'un émetteur peut envoyer n'importe quoi, le récepteur ayant tout à faire tout travail d'interprétation (« mais qu'est-ce qu'il a voulu dire ? »).
Une autre variante du problème de non-conformité aux normes est que certains logiciels, côté réception, ont des bogues qui peuvent pousser les émetteurs à violer la norme... pour ne pas déclencher ces bogues. Bref, ce RFC est confus parce que le problème est confus. Le courrier électronique est un gros b....l.
Le principe de robustesse a plutôt bien marché pour le courrier, estime notre RFC. Faire un message qui sera accepté partout est relativement facile, vu la tolérance des récepteurs face à des erreurs de détail. Mais les temps ont changé : notamment, la montée des préoccupations de sécurité rend difficile de continuer à être tolérant. Par exemple, un méchant peut placer un piège dans un message invalide, piège qui sera détecté par certains logiciels et pas par d'autres. Cette différence d'appréciation, inoffensive pour des messages normaux, peut devenir critique face à des messages portant du logiciel malveillant.
Un autre cas où le problème peut devenir critique est celui du spam. Les logiciels d'envoi de spam sont souvent particulièrement négligents (vite et mal écrits) et pas mal de logiciels antispam mettent des mauvais points aux messages qui ont des erreurs techniques, ce qui peut mener à leur classement comme spam. Le principe de robustesse rencontre donc une autre limite ici.
Il faut se rappeler que le courrier est non-interactif, ce qui rend difficile de faire respecter les règles. Dans une communication interactive, on peut imaginer un récepteur qui rejette les messages invalides, indiquant clairement à l'émetteur qu'il doit recommencer en respectant les règles. Pour le courrier, ce n'est pas possible : le récepteur doit se débrouiller avec ce qu'il a. L'auteur du logiciel de réception préférera donc toujours accepter les messages invalides plutôt que de subir les plaintes de ses utilisateurs, qui ne recevraient pas les messages attendus.
Néanmoins, notre RFC précise (section 1.2) qu'il n'approuve pas ces innombrables erreurs que commettent les émetteurs négligents. Le code en cause devrait être réparé de toute façon, ne serait-ce que pour des raisons de sécurité. Mais les conseils donnés par la suite sont là pour permettre au courrier de fonctionner en attendant cette réparation (fort hypothétique, je dois dire). Cela n'empêche pas de rappeler aux émetteurs de courrier qu'il est dans leur intérêt, et dans celui de tout l'Internet, d'essayer de fabriquer et d'envoyer des messages le plus parfaits possible. Bien relire les RFC 5598, RFC 5322 et RFC 2045 est donc nécessaire si on écrit du logiciel qui traite des messages.
Pour les récepteurs des messages mal formés, notre RFC suggère les principes suivants :
- Lorsqu'il y a une erreur syntaxique mais que l'intention sémantique est claire (exemple : un excès de < autour d'une adresse), accepter le message.
- Autrement, ne pas essayer d'accepter le message, sauf si on a de bonnes raisons de penser qu'un rejet aurait de pires conséquences.
- Et ne pas oublier la sécurité, qui peut imposer des choix qui ne sont pas conformes aux deux principes ci-dessus.
Maintenant, les conseils pratiques. D'abord, en section 4, tout ce qui est lié à la différence entre fond et forme : un message électronique peut avoir plusieurs représentations équivalentes du point de vue du contenu. C'est déjà le cas en transit mais c'est encore plus vrai lorsqu'il est stocké sur un système. Il a pu, par exemple, être mis dans un SGBD. Le principe que pose notre RFC est qu'il faut toujours garder quelque part la forme originale et que c'est elle qui doit être passée aux différents modules qui vont traiter le message. C'est la seule façon de garantir que chaque module ait toute l'information disponible, qu'on ne l'ait pas digérée pour lui. Par exemple, si un module ajoute des en-têtes locaux au message, les modules ultérieurs doivent recevoir le message sans ces en-têtes (si on veut communiquer avec eux, il vaut mieux utiliser des méthodes extérieures au message).
Cet avis est particulièrement important pour les modules voués au traitement de messages abusifs, que l'on souhaite signaler : les modifications faites par les modules précédents, même dans une bonne intention, pourraient empêcher, par exemple, de reconnaître le vrai expéditeur.
Même des changements qui semblent purement syntaxiques (supprimer les espaces non significatifs, par exemple), peuvent affecter d'autres traitements (comme les signatures).
Mais, au fait, quel agent dans l'ensemble de la chaîne de traitement a le plus de responsabilité dans la production de messages corrects ? La section 5 de notre RFC confie ce rôle au MSA : premier jalon en dehors de la machine de l'utilisateur, il est le point recommandé pour le respect des règles. Notamment, il a encore la possibilité de rejeter un message de façon à ce que le vrai émetteur soit prévenu, ce que ne pourront pas toujours faire les MTA situés plus loin sur le trajet (qui peuvent générer un courrier de rejet mais ne sont jamais sûrs qu'il ira à l'émetteur original).
Une cause fréquente de non-conformité des messages est une fin de ligne incorrecte (section 6). La seule fin de ligne standard dans un message est la combinaison CR LF (Carriage Return, 13 en ASCII suivi de Line Feed, 10 en ASCII), sauf si on utilise le RFC 3030. Mais d'autres systèmes ont des conventions différentes, par exemple Unix, où la fin de ligne est le seul LF. En pratique, on voit sur le réseau des messages avec uniquement des LF, et des messages avec un mélange de LF et de CR LF !
Comme il y a très peu de chance qu'un CR ou un LF isolé se retrouvent dans un texte, notre RFC recommande de les traiter comme des CR LF et donc des fins de ligne. (Cet avis ne vaut que pour le texte transporté en SMTP brut, pas pour des parties encodées en MIME.)
Une grosse section du RFC, la 7, est ensuite consacrée à toutes les erreurs qu'on peut trouver dans les en-têtes d'un message. Ce Musée des Horreurs doit son existence en partie à la longévité du courrier électronique, utilisé et maltraité partout depuis de nombreuses années. Ainsi, cet en-tête :
To: <@example.net:fran@example.com>
est marqué comme dépassé par le RFC 5322
(c'était du routage par la source : envoyer d'abord à
example.net, pour qu'il transmette à
fran@example.com). Mais l'intention est claire et
on peut donc l'interpréter sans risques comme :
To: <fran@example.com>
Même chose pour les excès de chevrons déjà cités. Il n'y a pas de mal à traiter :
To: <<<user2@example.org>>>
comme étant en fait :
To: <user2@example.org>
C'est plus gênant quand ces chevrons ne sont pas égaux en ouverture et en fermeture :
To: <another@example.net
peut quand même être lu :
To: <another@example.net>
Et si ce sont les guillemets qui ne sont pas équilibrés ?
To: "Joe <joe@example.com>
Ce cas est plus vicieux car il y a plusieurs interprétatations possibles. Mais le RFC recommande la plus simple :
To: "Joe" <joe@example.com>
Autre bogue qui se voit dans la nature, les lignes dans l'en-tête qui ne sont pas des en-têtes :
From: user@example.com To: userpal@example.net Subject: This is your reminder about the football game tonight Date: Wed, 20 Oct 2010 20:53:35 -0400
Manifestement, le sujet, trop long, a subi un retour chariot anormal :
les en-têtes sur plusieurs lignes sont légaux dans le format des
messages, mais les lignes de continuation doivent commencer par un
espace (section 2.2.3 du RFC 5322).
Les conséquences de cette bogue peuvent être graves : certains
logiciels vont considérer que les en-têtes s'arrêtent à la première
ligne qui n'est pas un en-tête, et donc ne verront pas le champ
Date:, repoussé dans le corps du message,
d'autres vont corriger en reconnaissant la ligne anormale et d'autres
enfin rejetteront complètement le message comme étant invalide (ce
qu'il est). Ce genre de
différences de comportement peut être exploité par un attaquant : s'il
sait que l'antispam a un comportement, et le
MUA un autre, il peut glisser des informations
qui échapperont à l'antispam mais seront vues par le lecteur. Le RFC
suggère donc, mais mezzo voce, de
rejeter le message.
Il y a aussi des cas où les normes n'étaient pas claires, menant à des différences de comportement des logiciels. Ce message était parfaitement légal :
From: user@example.com To: userpal@example.net Subject: This is your reminder about the football game tonight Date: Wed, 20 Oct 2010 20:53:35 -0400
Le champ Subject: a été replié en trois lignes,
chacune commençant bien par un espace. Donc, ce message n'a
normalement qu'une seule interprétation possible (« This is your
reminder about the football game tonight »). Mais certains
logiciels vont d'abord supprimer les espaces inutiles, la seconde
ligne du sujet va alors être vide, devenant un séparateur entre
l'en-tête et le corps... Depuis le RFC 5322, ce
message est toujours légal mais marqué comme utilisant une syntaxe
dépassée. Aujourd'hui, les émetteurs ne devraient plus envoyer de
telles lignes.
On voit aussi des en-têtes ayant diverses erreurs de syntaxe :
MIME-Version : 1.0
Ici, il y a un espace anormal, entre le nom du champ et le :. Comme l'interprétation est évidente, le RFC recommande de supprimer les espaces avant le séparateur « : ».
Autre cas rigolo, le nombre d'en-têtes. Certains en-têtes ont une
cardinalité imposée (voir le tableau au début
de la section 3.6 du RFC 5322). C'est ainsi que
From: et Subject:, s'ils
sont présents, doivent l'être à un seul exemplaire, alors que
Received:, en-tête de trace, peut être
répété. Que doit faire un logiciel lorsqu'il rencontre :
From: reminders@example.com To: jqpublic@example.com Subject: Automatic Meeting Reminder Subject: 4pm Today -- Staff Meeting Date: Wed, 20 Oct 2010 08:00:00 -0700 Reminder of the staff meeting today in the small auditorium. Come early!
Certains logiciels ne vont garder que le premier sujet, d'autres que
le dernier. Là encore, un attaquant peut se dissimuler à certains
logiciels en fabriquant des messages invalides, qui seront interprétés
de manière différente par les différents logiciels. Pour le sujet, le
RFC recommande tout simplement de concaténer les deux valeurs
(« Automatic Meeting Reminder 4pm Today -- Staff
Meeting ») en un seul sujet. Même chose pour l'expéditeur
(on l'oublie souvent mais un champ From: peut
parfaitement contenir plusieurs adresses). Donc,
From: president@example.com From: vice-president@example.com
devient :
From: president@example.com, vice-president@example.com
Et si c'est le contraire ? Si des champs obligatoires dans
l'en-tête comme From:, Message-ID: ou
Date: sont manquants ? Le choix recommandé par
notre RFC est de les ajouter, en synthétisant l'information (pour
Date:, c'est assez facile, pour
From:, une solution est d'extraire l'adresse du
MAIL FROM de SMTP, une autre est de fabriquer à
partir de l'adresse IP du client, par exemple unknown@[192.0.2.2]). Mais
attention : rappelez-vous la régle précédente comme quoi les modules
de traitement doivent recevoir le message original. Par exemple, un
module antispam peut être intéressé par le fait que
Date: manque, cela peut être une signature
révelant un problème de spam.
Et les problèmes liés au jeu de caractères et à l'encodage ? Les erreurs d'étiquetage sont fréquentes, par exemple un message marqué :
Content-Type: text/plain; charset=US-ASCII
peut parfaitement contenir des caractères en dehors d'ASCII. Pour détecter l'encodage, notre RFC suggère des heuristiques simples (« si aucun octet n'a le bit de poids fort à zéro, c'est probablement de l'ASCII, sauf si on trouve les séquences d'échappement d'encodages connus comme ISO-2022-JP ; sinon, si le texte est de l'UTF-8 légal, c'est probablement de l'UTF-8 car cela ne peut pas arriver par accident »). Un logiciel de courrier est donc autorisé à utiliser ces heuristiques pour trouver le vrai jeu de caractères et l'encodage utilisé, afin de traiter ce message selon ce jeu et pas selon celui indiqué dans les en-têtes.
Puisqu'on en vient aux jeux de caractères, il faut noter que l'introduction de MIME a suscité de nouvelles occasions de bogues, au point qu'une section entière de notre RFC, la 8, leur est consacrée. Par exemple, Base64 a fait l'objet de plusieurs spécifications (la « bonne » est aujourd'hui celle du RFC 4648) et toutes n'étaient pas d'accord entre elles sur l'attitude à adopter lors de la rencontre de caractères situés en dehors de l'alphabet limité de Base64. Là encore, comme tout ce qui permet deux interprétations, cela peut être utilisé par un attaquant pour produire un message qui sera ignoré par l'IDS ou l'antispam mais accepté par le lecteur.
Enfin, le dernier problème envisagé dans ce RFC est celui des lignes trop longues : la norme (section 2.1.1 du RFC 5322) les limite à 1 000 caractères mais on trouve parfois davantage. Le RFC ne donne pas de conseil explicite (rejeter ? corriger ?) mais met en garde contre les logiciels qui ignorent les caractères supplémentaires : cela fournit encore un autre moyen de dissimulation de contenu.
À noter qu'une des propositions alternatives, lors de la création de ce RFC, était de faire un registre en ligne, contenant les erreurs dans les messages et les actions conseillées. Cela aurait été plus facile à mettre à jour qu'un RFC. Mais documenter dans un registre des erreurs semblait trop étrange...
L'article seul
RFC 7095: jCard: The JSON format for vCard
Date de publication du RFC : Janvier 2014
Auteur(s) du RFC : P. Kewisch (Mozilla)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF jcardcal
Première rédaction de cet article le 15 janvier 2014
Le format vCard permet de décrire de manière standard, compréhensible par tous les logiciels de gestion de carnet d'adresses, les informations sur un individu ou une organisation. Très connu et largement déployé, il est présent à de nombreux endroits. vCard est à la fois un modèle de données (décrivant ce qu'on stocke) et une syntaxe particulière. Des syntaxes alternatives sont possibles et ce nouveau RFC en propose une, fondée sur JSON. Elle se nomme donc jCard.
Il y avait déjà une autre syntaxe alternative, fondée sur XML, dans le RFC 6351. Celle-ci s'inscrit dans la mode JSON actuelle et promet de rendre le vieux format vCard plus accessible pour les applications Web, notamment celles écrites en JavaScript.
vCard est actuellement en version 4, normalisée dans le RFC 6350. Il a plusieurs points techniques en commun avec le format iCalendar de gestion d'agendas, normalisé dans le RFC 5545. Le travail portait donc également sur une syntaxe JSON pour iCalendar, normalisée dans le RFC 7265. JSON, lui, est normalisé dans le RFC 8259. La section 1 du RFC résume le cahier des charges du projet jCard :
- Possibilité de conversion vCard -> jCard et retour, sans perte sémantique,
- Pas d'impératif de préservation de l'ordre des éléments,
- Maintien du modèle de données de vCard,
- Les futures extensions de vCard devront pouvoir être intégrées naturellement, sans nécessiter un nouveau RFC jCard.
La section 3 est le gros morceau du RFC, indiquant comment convertir les vCard actuelles en jCard. Rappelons qu'une vCard comprend plusieurs propriétés (de cardinalité pouvant être différente de 1), chacune ayant une valeur et, parfois, des paramètres, ces derniers ayant un nom et une valeur. Par exemple, dans :
TEL;TYPE=VOICE,TEXT,WORK;VALUE=uri:tel:+1-666-555-1212
La propriété est TEL, il y a deux paramètres,
TYPE qui a trois valeurs, et
VALUE qui n'en a qu'une. La valeur de la
propriété est un numéro de téléphone, ici +1-666-555-1212.
vCard a quelques particularités syntaxiques. Par exemple, les lignes trop longues peuvent être repliées, et certaines valeurs ont besoin d'échappement. Pour passer à jCard, on déplie toutes les lignes et on retire les échappements. Puis on applique les échappements de JSON.
Une vCard est représentée par un tableau JSON de deux éléments, le
premier étant juste la chaîne de caractères vcard
et le second étant un tableau JSON avec un élément par propriété. Si on veut mettre plusieurs vCard
ensemble, on peut faire un tableau JSON dont chaque élément est une
vCard représentée en JSON comme ci-dessus.
Chaque élément qui représente une propriété se compose d'un tableau d'au moins quatre éléments, les quatre obligatoires étant le nom de la propriété (forcément en minuscule, alors que cela ne comptait pas en vCard), les paramètres, une chaîne identifiant le type de la valeur, et la valeur. Si la propriété avait plusieurs valeurs, ce qui est permis en vCard, on ajoute des éléments au tableau. Un exemple de jCard est donc :
["vcard",
[
["version", {}, "text", "4.0"],
["fn", {}, "text", "John Doe"],
["gender", {}, "text", "M"],
["categories", {}, "text", "computers", "cameras"],
...
]
]
On voit ici une propriété gender
(genre, normalisée dans la section 6.2.7 du
RFC 6350), et ayant une valeur de type texte. La
propriété categories (section 6.7.1 du RFC 6350), elle, a deux valeurs. On notera que, dans
cet exemple, aucune propriété n'a de paramètre, ce qui est représenté
par l'objet JSON vide {}. On notera aussi qu'un seul type est utilisé,
text mais on verra plus loin quelques exemples de
la riche liste de types possibles (le type doit être indiqué
explicitement en jCard pour permettre à jCard de traiter des futures
extensions à vCard, sans avoir besoin de connaître les nouvelles
propriétés ; voir la section 5 pour les détails).
Quelques propriétés sont traitées de manière particulière. Ainsi,
version (4.0 à l'heure actuelle) doit être la
première du tableau. Certaines propriétés, en vCard, sont
structurées : l'exemple le plus classique est l'adresse
ADR, avec des champs séparés par un
point-virgule. En jCard, on les représente par
un tableau. Ainsi, la propriété vCard :
ADR:;;123 Main Street;Any Town;CA;91921-1234;U.S.A.
devient en jCard :
["adr", {}, "text",
[
"", "", "123 Main Street",
"Any Town", "CA", "91921-1234", "U.S.A."
]
]
(Notez les deux champs manquants au début, le numéro de la boîte postale, s'il y en a une, et le numéro de l'appartement.)
Et les paramètres ? C'est un objet JSON (ce qu'on nomme un
dictionnaire dans d'autres langages). Chaque
membre de l'objet a pour clé un nom de paramètre et pour valeur la
valeur du paramètre. Si l'adresse ci-dessus avait eu le paramètre
vCard LANGUAGE avec une valeur indiquant
une adresse rédigée en anglais, la première ligne du jCard
deviendrait :
["adr", {"language": "en"}, "text",
...
On a fait les propriétés, les paramètres, restent les valeurs. Il
existe de nombreux types possibles pour les valeurs, je ne vais pas
les citer tous. Commençons par l'exemple uri. Une
valeur de ce type contient... un URI :
["photo", {}, "uri", "http://www.bortzmeyer.org/images/moi.jpg"]
Les dates n'ont pas tout à fait le même format qu'en vCard. En jCard, elles suivent la norme ISO 8601 2004 donc, par exemple :
["bday", {}, "date", "1412-01-06"]
(au lieu du BDAY:14120106 de vCard.)
Autre exemple de type utile, language-tag,
pour indiquer que la valeur est une étiquette de
langue :
["lang", {}, "language-tag", "de"]
(Petit rappel vCard au passage : language est la
langue dans laquelle est écrite un élément d'information, par exemple
une adresse. lang est la langue qu'on peut
utiliser pour contacter l'entité décrite par une vCard.)
La section 4 explique, elle, les détails de l'opération inverse, convertir du jCard en vCard.
Reste le problème des propriétés ou paramètres inconnus (section
5). Si un nouveau RFC crée des extensions à
vCard, par exemple en ajoutant des propriétés, comme le RFC 6474 ajoutait BIRTHPLACE,
DEATHPLACE et DEATHDATE, que
faire ? La
section 5 étudie leur représentation en jCard. Rappelez-vous qu'un des
éléments du cahier des charges était la possibilité d'étendre vCard
sans avoir besoin de créer un nouveau RFC pour jCard. Lorsqu'un
convertisseur vCard -> jCard rencontre une propriété de type
inconnu, il peut mettre unknown comme
type. Ainsi, FOO:http://www.foo.example/ deviendra :
["foo", {}, "unknown", "http://www.foo.example/"]
alors qu'un convertisseur plus récent, connaissant la propriété
(imaginaire, hein, c'est juste un exemple) FOO
pourra traduire :
["foo", {}, "uri", "http://www.foo.example/"]
Ce nouveau format jCard a désormais son propre type
MIME,
application/vcard+json (et pas
jcard+json, attention).
Parmi les mises en œuvre de jCard, on note :
- ICAL.js en JavaScript (mais surtout prévu pour iCalendar en JSON),
- Py Calendar, en Python, également surtout pour iCalendar,
- ez-vcard,
en Java. Ne compile pas du premier coup
(
mvn install-> Tests in error: HCardPageTest.create_then_parse:259 NullPointer) mais semble bien conçu, généralement.
Voici ma vCard présentée dans mon article sur le RFC 6350, traduite en jCard (un exemple complet se trouve sinon dans l'annexe B.1 du RFC) :
["vcard",
[
["version", {}, "text", "4.0"],
["fn", {}, "text", "Stéphane Bortzmeyer"],
["n", {}, "text", ["Bortzmeyer", "Stéphane", "", ""]],
["uid", {}, "uri", "urn:uuid:a06340f8-9aca-41b8-bf7a-094cbb33d57e"],
["gender", {}, "text", "M"],
["kind", {}, "text", "individual"],
["email", {}, "text", "individual"],
["title", {}, "text", "Indigène de l'Internet"],
["photo", {}, "uri", "http://www.bortzmeyer.org/images/moi.jpg"],
["lang", {"pref": "1"}, "language-tag", "fr"],
["lang", {"pref": "2"}, "language-tag", "en"],
["impp", {"pref": "1"}, "uri", "xmpp:bortzmeyer@dns-oarc.net"],
["impp", {"pref": "2"}, "uri", "xmpp:bortzmeyer@gmail.com"],
["url", {}, "uri", "http://www.bortzmeyer.org/"],
["key", {}, "uri", "http://www.bortzmeyer.org/files/pgp-key.asc"]
]
]
L'article seul
RFC 7108: A Summary of Various Mechanisms Deployed at L-Root for the Identification of Anycast Node
Date de publication du RFC : Janvier 2014
Auteur(s) du RFC : J. Abley (Dyn), T. Manderson (ICANN)
Pour information
Première rédaction de cet article le 15 janvier 2014
L'anycast a des tas
d'avantages pour les serveurs DNS mais il a au
moins un inconvénient : le débogage peut être plus difficile, car
deux points de mesure peuvent
tomber sur une instance différente du service. Si toutes les instances
sont réellement identiques, ce n'est pas un problème. Mais si l'une
d'elles a un comportement, ou des données, légèrement différent, de
laquelle s'agit-il lorsqu'un utilisateur se plaint que « j'interroge
ns2.nic.example et sa réponse n'est pas
correcte ? » Ce RFC documente l'ensemble des
techniques utilisées par l'un des serveurs racine du
DNS, le serveur L géré par
l'ICANN.
Le problème se résume donc à « j'interroge
l.root-servers.net et je voudrais savoir sur
quelle instance je suis tombé, et ceci sans faire appel à des
connaissances internes à l'ICANN ». On peut s'intéresser à cette
information par curiosité, ou bien pour déboguer un problème (comme
dans l'exemple du paragraphe précédent) ou encore pour évaluer la bonne
distribution des sites anycast (comme dans mon article aux RIPE labs).
Est-ce une bonne chose que cette information soit disponible à l'extérieur ? Oui, répond clairement l'ICANN, on gère un service qui est public et destiné au public et cette transparence est nécessaire, notamment du point de vue opérationnel. Et puis la localisation de ces serveurs n'est pas vraiment un secret (contrairement à ce qu'on a parfois lu dans des articles de presse sensationnalistes). Félicitons donc l'ICANN pour cet effort de publication (tous les serveurs racine du DNS ne le font pas, loin de là, cf. section 6 pour des éléments à ce sujet) et passons à la technique.
La gestion de services
anycast est décrite dans le
RFC 4786. Cette technique permet de répartir sur
toute la planète les
serveurs qui répondent à une adresse (pour L, ce sont actuellement
199.7.83.42 en IPv4 et
2001:500:3::42 en IPv6). Beaucoup d'information est disponible
en ligne sur la gestion de la racine, notamment en http://www.root-servers.org/. Une liste des instances de
« L-root » (actuellement 143 sites et 273 machines) est également en ligne.
Comment
sont nommées ces instances de L (section 3 de notre RFC) ? Chaque copie de
L-root a un nom, <IATA
Code><NN>.l.root-servers.org où <IATA
Code> est un code IATA
identifiant l'aéroport le plus proche. Cette
technique de nommage des équipements réseau est très courante chez les
opérateurs Internet. Par exemple, cdg est
l'aéroport de Roissy près de
Paris. Le nombre <NN> sert à distinguer
deux machines proches du même aéroport (par exemple dans le même centre de traitement de données). Si un site est situé à mi-chemin
entre deux aéroports, on en choisit arbitrairement un.
Bien, c'est très joli, ces noms mais comment trouve-t-on celui de l'instance de L-root qui nous a répondu ? La section 4 du RFC décrit les différentes méthodes possibles. Commençons par NSID (Name Server Identifier, normalisé dans le RFC 5001). C'est une option du DNS qui permet de demander au serveur, s'il le veut bien, de renvoyer son nom. Testons là avec dig :
% dig +nsid @l.root-servers.net SOA .
...
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 4096
; NSID: 6b 62 70 30 31 2e 6c 2e 72 6f 6f 74 2d 73 65 72 76 65 72 73 2e 6f 72 67 \
(k) (b) (p) (0) (1) (.) (l) (.) (r) (o) (o) (t) (-) (s) (e) (r) (v) (e) (r) (s) (.) (o) (r) (g)
La question posée (le SOA de la racine) ne nous intéresse pas, on
voulait juste le nom du serveur, ici kbp01.l.root-servers.org (donc à Kiev). C'est
la méthode recommandée et la plus fiable. Si vous voulez signaler à
l'ICANN un problème avec L-root, c'est cette technique qu'il faut
utiliser pour envoyer un rapport de bogue utile. C'est d'ailleurs vrai
pour la majorité des serveurs anycast DNS (par exemple, le serveur
d.nic.fr qui fait autorité pour
.fr accepte également
cette option). Par contre, dans certains cas, cela ne marchera pas car
NSID dépend de EDNS (RFC 6891) et certains équipements réseaux bloquent (bêtement) EDNS.
Une autre technique existe, bien plus ancienne que NSID et qui est
sans doute plus connue des administrateurs réseaux : interroger le
serveur sur les noms hostname.bind ou
id.server, avec le type TXT
et la classe CH. Par exemple :
% dig @l.root-servers.net CH TXT hostname.bind ... ;; ANSWER SECTION: hostname.bind. 0 CH TXT "lys01.l.root-servers.org" ...
(C'est près de Lyon.)
Notez bien que .bind et
.server ne sont pas des vrais
TLD. Ils n'ont de signification que locale, sur
le serveur en question. Chaque machine répondra de manière
différente. Comme son nom l'indique,
hostname.bind a été à l'origine introduit par le
logiciel BIND mais a depuis été adopté par
d'autres (L-root utilise nsd). id.server, qui donne le
même résultat, a été créé pour faire moins spécifique à BIND mais n'a
jamais été très populaire.
hostname.bind et
id.server ne dépendent pas d'EDNS et ne
nécessitent pas un client DNS qui comprend l'option NSID. Mais ils ont
tous les deux un gros défaut : si on reçoit une réponse surprenante et
que, dans la foulée, on fait une requête
hostname.bind pour enquêter, rien ne dit que le routage n'aura
pas changé entre temps, et qu'on n'aura pas désormais affaire à une
autre instance. NSID, où l'option voyage en même temps que la requête,
n'a pas cet inconvénient.
Aussi bien NSID que hostname.bind nécessitent
un client DNS (comme dig ou
drill), ce que tout le monde n'a pas sur sa
machine (notamment sur Windows). Et, même si on
a un client DNS, taper la ligne de commande correctement peut être un
exploit inaccessible à certains utilisateurs. Lorsqu'un problème se
pose avec, semble t-il, une instance spécifique de L-root, il vaudrait
mieux pouvoir donner des instructions simples à l'utilisateur qui
signale le problème. C'est le but de la dernière technique,
identity.l.root-servers.org, présentée en section
4.4. Chaque instance de L-root fait autorité pour ce nom mais donne
une réponse différente, révélant l'identité de l'instance. Ce nom a un
enregistrement TXT mais surtout un enregistrement A (une adresse IPv4)
donc, si on peut interroger ce nom avec un client DNS, comme
ci-dessus :
% dig identity.l.root-servers.org ... ;; ANSWER SECTION: identity.l.root-servers.org. 3600 IN A 77.88.206.134
(en profitant du fait que le type A est la valeur par défaut pour dig donc n'a pas besoin d'être spécifiée), on peut aussi demander à l'utilisateur de juste faire :
% ping identity.l.root-servers.org PING identity.l.root-servers.org (77.88.206.134) 56(84) bytes of data. 64 bytes from hostmaster.kiev.customer.top.net.ua (77.88.206.134): icmp_req=2 ttl=47 time=86.5 ms 64 bytes from hostmaster.kiev.customer.top.net.ua (77.88.206.134): icmp_req=4 ttl=47 time=90.7 ms ...
et d'indiquer la valeur qu'il voit pour l'adresse. Au passage, la traduction d'adresse en nom nous indique qu'on touche bien l'instance de Kiev. ping, lui, est installé partout. C'est le gros intérêt de cette technique, son accessibilité pour des non-techniciens. Elle est spécifique à L-root (alors que les deux précédentes sont « standard » et largement déployées). Notez bien que ping est juste un moyen (simple et toujours disponible) de faire une résolution de nom en adresse IPv4. Rien ne garantit que cette adresse sera routable, c'est juste un identificateur unique permettant de distinguer les différentes instances de L-root.
Si on a un client DNS (ici, drill), on peut aussi demander le TXT, plus riche :
% drill identity.l.root-servers.org TXT ... ;; ANSWER SECTION: identity.l.root-servers.org. 3600 IN TXT "kbp01.l.root-servers.org" "Kiev" "" "Ukraine" "Europe"
On trouve le nom du serveur, suivant le schéma de nommage indiqué plus haut, la ville en clair, le pays et la région (au sens ICANN du terme).
Pour cette dernière technique, celle avec
identity.l.root-servers.org, on n'a pas interrogé directement
l.root-servers.net mais on est passé par le
serveur récursif (le résolveur) utilisé par la machine de
l'utilisateur. Le résolveur peut être sur un réseau différent et donc
parfois utiliser une instance de L-root différente de celle de son
client, lorsque celui-ci fait des requêtes directes. En outre, le
cache du résolveur peut compliquer l'interprétation des résultats. Par
exemple, les réponses à une requête A et à une TXT peuvent être
incohérentes, si elles sont entrées dans le cache à des moments
différents et que les routes avaient changé entre temps.
Si vous voulez voir la liste complète des instances de L-root, elle
est stockée dans le DNS, sous forme d'un (très gros) enregistrement
TXT dans nodes.l.root-servers.org. On l'interroge
en TCP car la réponse sera en général trop
grande pour le serveur DNS s'il utilise UDP :
% dig +tcp nodes.l.root-servers.org TXT ... ;; ANSWER SECTION: nodes.l.root-servers.org. 28681 IN TXT "pom01.l.root-servers.org" "Port Moresby" "" "Papua New Guinea" "AsiaPacific" nodes.l.root-servers.org. 28681 IN TXT "ppt01.l.root-servers.org" "Papeete" "Tahiti" "French Polynesia" "AsiaPacific" nodes.l.root-servers.org. 28681 IN TXT "ppt02.l.root-servers.org" "Papeete" "Tahiti" "French Polynesia" "AsiaPacific" nodes.l.root-servers.org. 28681 IN TXT "prg01.l.root-servers.org" "Prague" "" "Czech Republic" "Europe" ...
Si vous aimez les détails techniques sur le fonctionnement de
identity.l.root-servers.org, voyez la section
5. identity.l.root-servers.org est une sous-zone
de l.root-servers.org, déléguée à un seul serveur
de noms, dont l'adresse IP est dans le même préfixe que
l.root-servers.net :
% dig NS identity.l.root-servers.org ... ;; ANSWER SECTION: identity.l.root-servers.org. 3600 IN NS beacon.l.root-servers.org. ...
Chacun des serveurs sert une zone
identity.l.root-servers.org différente, reflétant
la localisation du serveur. La zone
identity.l.root-servers.org n'est donc pas
cohérente et c'est fait exprès. Cela n'empêcherait pas la signature
avec DNSSEC mais cela la compliquerait
(installer les logiciels et générer des clés sur chaque nœud...) et
donc identity.l.root-servers.org n'est pas signé
(de toute façon, les zones au-dessus ne le sont pas non plus).
L'article seul
RFC 7115: RPKI-Based Origin Validation Operation
Date de publication du RFC : Janvier 2014
Auteur(s) du RFC : R. Bush (Internet Initiative Japan)
Réalisé dans le cadre du groupe de travail IETF sidr
Première rédaction de cet article le 15 janvier 2014
Le mécanisme de sécurisation des annonces de route pour BGP, connu sous le nom de RPKI+ROA, est normalisé depuis un an et il existe désormais un peu d'expérience opérationnelle. Que nous enseigne-t-elle ? Peut-on commencer à définir des « bonnes pratiques » de déploiement et de fonctionnement de la RPKI ?
Outre la publication des normes sur RPKI+ROA, comme le RFC 6480, il existe plusieurs logiciels permettant de mettre en œuvre ces normes. On trouve encore peu de comptes-rendus d'expérience concrète avec la RPKI. En français, je vous recommande fortement l'excellent mémoire de master de Guillaume Lucas. Il faut dire qu'on en est encore aux débuts (ce qui explique la faible taille de ce nouveau RFC). Par exemple, il n'existe toujours pas de point de départ (trust anchor) unique pour la validation, chaque RIR ayant son propre certificat, chacun étant une racine pour la validation. Le RFC estime qu'une racine unique finira par apparaître, ce dont je doute fort, en raison des nombreux conflits de gouvernance à ce sujet.
Notre nouveau RFC, ce RFC 7115, a une vision très optimiste : il affirme même que, déployée intelligemment et prudemment, RPKI+ROA entraînera peu de perturbations du système de routage de l'Internet. L'expérience récente de DNSSEC semble pourtant indiquer le contraire, à savoir qu'il n'est pas trivial de déployer de la sécurité cryptographique et qu'on casse parfois quelque chose en le faisant. À moins que les gens de BGP soient bien plus compétents que ceux du DNS ?
Bon, assez de généralités, place aux recommandations concrètes. N'oubliez pas d'abord de lire les RFC RPKI+ROA. Puis, attaquons la section 3, le cœur de ce nouveau RFC. La RPKI est la base de données répartie (RFC 6481) stockant les autorisations de routage (les ROA, RFC 6482), les certificats (RFC 6484), les révocations, les enregistrements Ghostbuster (RFC 6493), etc. Elle a été conçue pour être distribuée de manière hiérarchique, des dépôts mondiaux nourrissant des dépôts plus locaux qui à leur tout nourriraient des dépôts très locaux. En pratique, cela ne semble pas encore très fréquent : l'architecture la plus courante semble être encore à deux étages, le dépôt du RIR et celui de l'opérateur. Notez qu'on peut parfaitement utiliser des dépôts et des caches validateurs situés dans un autre réseau que le sien, par exemple chez son transitaire : si on lui fait confiance pour router les paquets, on peut bien lui faire confiance pour gérer la RPKI, et s'appuyer sur son travail.
Le cache validateur, dans le réseau de l'opérateur, collecte toutes les données de la RPKI (en utilisant rsync) et les valide en utilisant un logiciel comme rcynic ou le validateur du RIPE-NCC. Les routeurs qui font confiance à ce cache iront alors chercher ces informations sur la validité des routes (typiquement en utilisant le protocole RTR du RFC 6810), sans avoir à faire de crypto eux-mêmes. Cela impose que les routeurs soient configurés uniquement avec des adresses de caches validateurs de confiance. Et que la connexion entre le routeur et le cache soit bien sécurisée, par exemple par SSH, particulièrement si le cache validateur est dans un AS différent. Pour des raisons de résilience, le cache doit être joignable sans avoir besoin de ressources extérieures, comme le DNS ou comme la RPKI elle-même (si le routeur devait valider la route vers le cache, on aurait un beau problème de bootstrap). Il vaut sans doute mieux que les routes entre le routeur et le cache validateur ne dépendent pas du tout de BGP. Et, toujours pour la résilience, un routeur devrait utiliser plusieurs caches (comme une machine a plusieurs résolveurs DNS).
La validation dans la RPKI est arborescente : on part d'un certificat d'une autorité de confiance, le TAL (Trust Anchor Locator, cf. RFC 7730 et, oui, je simplifie parce que le TAL est en fait un pointeur vers le certificat), et on valide récursivement les certificats des titulaires de ressources (adresses IP, par exemple) à partir de ces TAL. Si le gérant d'un cache validateur met n'importe quoi comme TAL (des certificats mal ou pas gérés), toute la confiance s'écroule. Il faut donc bien choisir ses TAL ! Voici un contre-exemple, une installation de rcynic où ont été installées toutes les TAL possibles, test et production mêlées :
% ls etc/trust-anchors afrinic.tal lacnic.tal testbed-apnicrpki.tal apnic.tal ripe-ncc-root.tal testbed-arin.tal bbn-testbed.tal testbed-apnic.tal testbed-ripe.tal % cat etc/trust-anchors/ripe-ncc-root.tal rsync://rpki.ripe.net/ta/ripe-ncc-ta.cer MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEA0URYSGqUz2m yBsOzeW1jQ6NsxNvlLMyhWknvnl8NiBCs/T/S2XuNKQNZ+wBZxIgPPV ...
Le RFC insiste ensuite sur un des points les plus faibles de la RPKI : les délais de mise à jour ne sont spécifiés nulle part (voir aussi la section 6 du RFC, qui revient sur ce problème). Un cache validateur pourrait, par exemple, ne charger les données avec rsync que deux fois par semaine et travailler ainsi avec des données relativement anciennes, sans violer aucune norme technique. (La section 6 du RFC prétend que c'est la même chose avec le DNS, qui n'est que « synchrone à terme ». Mais c'est tout à fait faux : dans le DNS, les délais sont parfaitement connus et standards, le principal étant le TTL.) À l'intérieur de son réseau, un opérateur qui a plusieurs caches peut décider de les synchroniser très fréquemment : ce sont ses machines, il décide. Mais, à l'extérieur, même si ce RFC n'en parle pas, il n'est pas du tout sûr que les serveurs rsync des RIR résistent en cas de synchronisation trop agressive.
Après ces questions d'architecture de la validation, la section 3
de notre RFC continue avec la création des ROA (Route Origin
Authorizations, les objets signés qui authentifient la
prétention d'un AS à être à l'origine de
l'annonce BGP d'un préfixe). D'abord, bien se rappeler
qu'IP est arborescent : un ROA pour
192.0.2.0/24 peut concerner aussi
192.0.2.128/26. Avant d'émettre un ROA couvrant
un gros préfixe, il faut donc être sûr que tous les préfixes
inférieurs qui auront besoin d'être routés ont déjà des ROA
corrects. Sinon, toutes leurs annonces deviendront subitement
invalides.
Les ROA disposent d'un attribut maxLength qui
permet d'être un peu laxiste en cas d'annonce d'un sous-préfixe. Si le
ROA concerne le préfixe 192.0.2.0/24-26 (avec 24
= longueur du préfixe, et 26 = longueur maximale des annonces), une
annonce 192.0.2.128/26 sera acceptée (alors que
192.0.2.128/27 serait refusée). Mais c'est
dangereux car une annonce plus spécifique (préfixe plus long) créera
une entrée prioritaire dans la table de routage (IP donnant la
priorité au préfixe le plus long), facilitant le
détournement que RPKI+ROA avait pour mission d'empêcher. Le RFC
conseille donc, d'abord que les logiciels de gestion de la RPKI
mettent, par défaut, une longueur maximale égale à la longueur du
préfixe (aucun sous-préfixe autorisé) et ensuite que
maxLength soit utilisé avec précaution. Si on a
juste trois sous-préfixes, il vaut sans doute mieux générer trois ROA
pour eux, plutôt que d'affaiblir la sécurité en ayant une longueur
maximale supérieure à la longueur du préfixe. (Ou un seul ROA
contenant trois préfixes s'ils ont tous le même AS d'origine.)
On l'oublie souvent, mais un préfixe peut être « multi-origine », c'est-à-dire être annoncé par plusieurs AS. C'est même recommandé dans certains cas, par le RFC 6382. Dans ce cas, il faut faire autant de ROA qu'il y a d'AS d'origine possibles (un ROA peut contenir plusieurs préfixes mais pas plusieurs AS).
Enfin (il y a aussi plein d'autres recommandations que je n'ai pas reprises ici), le RFC recommande d'utiliser des outils automatiques pour superviser ses objets RPKI et, par exemple, avertir lors de l'expiration proche d'un certificat (comme on devrait le faire pour tous les certificats).
Au fait, à quel endroit du réseau doit-on installer les routeurs qui utiliseront la validation ? La section 4 se penche sur cette question. A priori, seuls les routeurs de bord, ceux situés au contact d'un autre AS, seront dans ce cas. Les autres routeurs font confiance aux routes distribuées en interne. On peut même déployer cette utilisation de la validation de manière incrémentale, un routeur après l'autre. Mais attention à la répartition du trafic : les premiers routeurs qui utiliseront la validation pourront refuser certaines routes, que les autres accepteront, menant à des déplacements de trafic d'un lien vers un autre.
J'ai dit que les routeurs qui utilisent la validation pourraient refuser certaines routes. Justement, que doit faire un routeur qui se connecte à un cache validateur lorsque ledit cache a marqué une route comme invalide (cf. RFC 6811 pour les différents résultats de validation) ? La section 5 du RFC décrit les politiques possibles. Le principe cardinal est « chaque opérateur décide ». Ce n'est pas le RFC qui décide de ce que doit faire le routeur.
L'approche radicale serait évidemment que le routeur rejette les routes invalides. Mais, si on se fie au déploiement d'autres techniques de sécurité comme DNSSEC, au début, il y aura plein d'erreurs par les opérateurs et bien des routes seront marquées à tort comme invalides. Rejeter ces routes dès le début serait sans doute une erreur. Il vaudrait sans doute mieux commencer par une approche moins violente, se contentant d'attribuer une priorité plus basse aux routes invalides.
Le problème est que cela permet des attaques avec des préfixes plus
spécifiques, comme dans l'exemple plus haut. Soit un ROA
192.0.2.0/24-24 (le 24-24 indiquant que la
longueur du préfixe et la longueur maximale admise sont la même, 24
bits). Un méchant annonce
192.0.2.128/26. Cette annonce sera marquée comme
invalide par le système RPKI+ROA. Mais si elle est quand même
acceptée, même avec la priorité la plus basse, elle s'installera dans
les tables de routage et, étant plus spécifique que
192.0.2.0/24, elle gagnera, et les paquets IP seront
envoyés à l'endroit désigné par l'annonce du méchant. Bref, pas de
solution idéale à ce dilemme, le RFC suggère néanmoins de ne pas
accepter les routes invalides sans une bonne raison.
Et si le résultat de la validation est qu'aucun ROA couvrant cette annonce n'a été trouvé (le cas le plus fréquent aujourd'hui, où seule une minorité de préfixes sont signés) ? Le RFC recommande évidemment d'accepter ces routes. Ce n'est pas demain la veille qu'on pourra dire « quasiment tout le monde a des ROA, arrêtons de router les autres ».
Enfin, la section 6 couvre quelques recommandations diverses : avoir des mécanismes spéciaux pour les préfixes « importants », par exemple ceux des serveurs racine du DNS, afin d'être prévenu si la RPKI veut tout à coup les invalider, gérer les AS sur quatre octets du RFC 6793, et avoir des horloges à l'heure, puisque certificats et ROA peuvent expirer.
Le but de RPKI+ROA est d'améliorer la sécurité du routage Internet, notamment face à des détournements comme celui de YouTube par Pakistan Telecom. Cet objectif est-il atteint ? La section 7 de notre RFC appelle à la prudence : les ROA, comme leur nom l'indique, ne protègent que l'origine d'une annonce (l'AS le plus à droite dans un chemin d'AS). Dans quasiment tous les détournements accidentels (comme celui de Pakistan Telecom cité plus tôt), l'origine est changée et RPKI+ROA le détecterait donc. Mais, si le détournement n'est pas un accident mais une attaque délibérée, on peut penser que le méchant va soigner ses annonces BGP. Il mettra probablement la vraie origine et ne bricolera que la suite du chemin. Pour l'instant, la RPKI n'a pas de mécanisme pour faire face à cela. De même, toute manipulation du chemin faite après l'émission par l'AS d'origine ne sera pas détectée, tant que l'origine est respectée.
Ah, et une autre limite de ce système : BGP ne fait que transmettre des annonces de route, que les routeurs ne respectent pas forcément (« les données ne suivent pas forcément le contrôle »). Donc, même si BGP est parfaitement sécurisé, des routeurs défaillants ou piratés peuvent encore faire échouer la sécurité.
Une bonne lecture concrète en français sur le système RPKI+ROA ? « Sécuriser le routage sur Internet » de Guillaume Lucas. Sinon, il existe une liste de diffusion des opérateurs RPKI mais avec très peu de trafic.
Merci à Guillaume Lucas pour sa relecture très attentive, mais cela ne veut pas dire qu'il est d'accord avec tout.
L'article seul
RFC 7078: Distributing Address Selection Policy using DHCPv6
Date de publication du RFC : Janvier 2014
Auteur(s) du RFC : A. Matsumoto, T. Fujisaki (NTT), T. Chown (University of Southampton)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF 6man
Première rédaction de cet article le 9 janvier 2014
Lorqu'une machine IPv6 a plusieurs adresses IP, laquelle choisir pour une connexion sortante ? Le RFC 6724 définit une politique par défaut, consistant en règles du genre « préférer les adresses temporaires du RFC 8981, pour des raisons de préservation de la vie privée ». Comme ce sont seulement des règles par défaut, on peut les changer. Un des mécanismes est que le serveur DHCP indique à ses clients d'autres règles et ce RFC décrit une nouvelle option DHCP permettant en effet de changer de politique de sélection d'adresse IP source. L'administrateur qui gère le serveur DHCP pourra alors fixer d'autres règles.
En effet, il y a peu de chances que la politique par défaut définie dans le RFC 6724 convienne à tout le monde. Le RFC 5221 demandait donc qu'on puisse changer de politique et ne pas être tenu éternellement par celle du RFC 6724. À noter que l'obéissance au serveur DHCP, quoique recommandée, n'est pas obligatoire : au bout du compte, l'administrateur de la machine contrôle la politique de sélection d'adresses IP source.
La syntaxe de la nouvelle option DHCP figure en section 2. L'option
a le numéro 84 (dans le registre DHCP), et comprend deux booléens, A et P, suivis par une
suite d'options de numéro 85 (rappelez-vous que DHCPv6 permet de mettre des options dans d'autres options). Chaque option de cette suite vaut pour
une ligne dans la table des politiques (une ligne dans le fichier
/etc/gai.conf si vous êtes sur
Linux), donc une règle, et comprend :
- Une étiquette (cf. RFC 6724, section 2.1),
- Une précédence,
- La longueur du préfixe,
- Le préfixe des adresses IP.
Des exemples figurent en annexe A, en utilisant les scénarios du RFC 5220.
Le booléen A signifie « Automatic row addition flag » et veut dire, lorsqu'il est mis à 0, que la règle en question peut poser des problèmes et ne devrait pas être ajoutée automatiquement à la politique. Normalement, il est à 1. Le booléen P signifie « Privacy preference flag » et exprime la préférence donnée aux adresses temporaires (RFC 8981) pour préserver la vie privée. Il est normalement à 1, le choix le plus sûr (on sélectionne de préférence les adresses temporaires comme adresses sources).
En recevant ces options, le client DHCP met à jour sa propre table. C'est le comportement par défaut recommandé, avec une option pour débrayer cette mise à jour, et garder sa propre table originale.
Cette politique de sélection de l'adresse IP source est globale à la machine. Même si elle a plusieurs interfaces réseau, la table est commune à toutes. Une des raisons de ce choix est que l'interface de sortie est souvent choisie après l'adresse IP source et en fonction de celle-ci.
Quelques détails utiles pour le programmeur figurent en section 4 : l'étiquette est représentée dans le protocole par un entier non signé mais, en fait, la seule opération sur les étiquettes est la comparaison, et l'ordre n'a aucune signification. Le client peut donc la convertir dans n'importe quel type.
Il n'y a pas de limite de taille dans ce RFC et on pourrait donc en théorie envisager des tables énormes. En pratique, la taille maximale d'un datagramme UDP met une limite aux alentours de 3 000 règles et, de toute façon, la plupart des implémentations auront des problèmes bien avant (par exemple, parce qu'elles n'accepteront pas le datagramme UDP fragmenté).
Enfin, un peu de sécurité (section 5) : DHCP n'offrant aucune protection, un méchant peut facilement se faire passer pour le serveur DHCP officiel et envoyer des tables délirantes, menant à sélectionner une mauvaise adresse. Notez quand même qu'un tel serveur DHCP méchant peut faire bien d'autre chose que de d'envoyer de mauvaises tables. Les protections posisbles sont l'utilisation de techniques cryptographiques comme IPsec (ce que quasiment personne ne fait) ou bien le contrôle des messages DHCP par le commutateur (DHCP snooping).
L'article seul
RFC 7048: Neighbor Unreachability Detection Is Too Impatient
Date de publication du RFC : Janvier 2014
Auteur(s) du RFC : E. Nordmark (Arista Networks), I. Gashinsky (Yahoo!)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF 6man
Première rédaction de cet article le 8 janvier 2014
Le service de découverte des voisins d'IPv6, normalisé dans le RFC 4861, inclut une fonction de détection de l'injoignabilité du voisin (section 7.3 du RFC 4861). En trois secondes, elle permet de détecter la panne d'un voisin et donc, s'il existe un autre voisin pouvant assurer la même fonction, de basculer vers un voisin qui marche. Seulement, s'il n'existe pas de voisin équivalent, il ne sert à rien de détecter la panne (puisqu'on n'a pas d'alternative) et ce service est, dans ce cas, bien trop impatient, menant à une charge inutile du réseau.
Tout mécanisme de détection de la panne d'un composant réseau fait face à la même nécessité de compromis : si on essaie très souvent, on détectera les pannes rapidement mais on chargera le réseau. Autre problème, on risque de croire à tort qu'il y a une panne alors qu'on avait un problème temporaire dans les couches basses (convergence spanning tree prenant plusieurs secondes, par exemple). Si on essaie rarement, on épargnera le réseau, on risquera moins de détecter de fausses pannes, mais on risque de ne pas voir les vraies pannes aussi vite.
Le RFC 4861 optimise plutôt
du côté de la rapidité de la détection. Un cas typique où on peut avoir un voisin équivalent est celui de
deux routeurs sur le même réseau local. Il est
important de détecter la panne d'un routeur très vite, pour pouvoir
passer à l'autre avant que les applications ne s'en aperçoivent. Les
délais spécifiés dans la section 10 du RFC 4861
(MAX_UNICAST_SOLICIT, trois
transmissions séparées par une seconde) sont donc raisonnables. Mais
ce nouveau RFC se focalise sur le cas où il n'y
a pas d'alternative et où une détection agressive et repétée de la
joignabilité est donc inutile. Il faut donc faire un compromis
différent. Le RFC 6583 décrit ce problème,
ainsi que d'autres questions opérationnelles liées à la découverte des voisins.
Notez que le protocole équivalent pour IPv4, ARP (RFC 826), n'a pas ce problème car le RFC ne spécifie pas de délais particuliers, les mises en œuvre d'ARP sont donc libres d'optimiser selon leur goût, par exemple vers moins de nervosité dans la détection des pannes.
La section 3 décrit les changements faits dans le protocole. On a
désormais le droit d'envoyer plus de
MAX_UNICAST_SOLICIT s'il n'existe pas de voisin
alternatif. Dans ce cas, on est censé utiliser un repli
exponentiel entre deux transmissions. Le modèle de la
section 7.3.2 du RFC 4861 est mis à jour pour
ajouter un état : UNREACHABLE. On y entre lorsqu'il
n'y a plus de réponses aux sollicitations. Lorsqu'un voisin est
dans cet état, on continue à lui envoyer des paquets, comme dans
l'état PROBE, mais les tests
de joignabilité
utilisent le multicast, car
le voisin a peut-être changé d'adresse MAC. Et,
évidemment, on ne choisit plus ce voisin comme routeur par défaut.
Au bout d'un moment (le RFC recommande un maximum de soixante secondes), le voisin est considéré comme définitivement mort et retiré de la table des voisins. Au fait, pour voir cette table, sur Linux, c'est (ici avec trois routeurs possibles) :
% ip -6 neighbour show fe80::641 dev eth0 lladdr 00:07:b4:02:b2:01 router DELAY fe80::250:3eff:fe97:7c00 dev eth0 lladdr 00:50:3e:97:7c:00 router STALE fe80::20e:39ff:fe43:6400 dev eth0 lladdr 00:0e:39:43:64:00 router REACHABLE
Sur une autre machine, avec plusieurs voisins, dont un routeur :
% ip -6 neighbour show fe80::21e:8cff:fe7f:48fa dev eth0 lladdr 00:1e:8c:7f:48:fa REACHABLE fe80::a2f3:c1ff:fec4:5b6e dev eth0 lladdr a0:f3:c1:c4:5b:6e REACHABLE fe80::f6ca:e5ff:fe4d:1f41 dev eth0 lladdr f4:ca:e5:4d:1f:41 router REACHABLE fe80::f6ec:38ff:fef0:d6f9 dev eth0 lladdr f4:ec:38:f0:d6:f8 REACHABLE
Sur ce même Linux, les paramètres de la détection d'injoignabilité
sont réglables avec sysctl, variables
net.ipv6.neigh.default.ucast_solicit et net.ipv6.neigh.default.mcast_solicit.
Si vous aimez la programmation, la section 4 de notre RFC contient un algorithme (spécifié en langage naturel) mettant en œuvre les nouvelles possibilités, et donc moins impatient que l'algorithme actuel.
L'article seul
Flattr sur mon blog
Première rédaction de cet article le 7 janvier 2014
Dernière mise à jour le 21 novembre 2019
Si vous regardiez attentivement en bas des pages de ce blog, il y avait un bouton Flattr. Pourquoi ? À quoi servait-il ?
Un des problèmes les plus difficiles du Web est la rémunération des créateurs. Cette rémunération est importante, non pas que je craigne que le Web diminue dramatiquement de taille si on ne payait pas les créateurs (la plupart ne sont pas payés aujourd'hui et le Web est quand même très gros) mais parce que je trouve que c'est une question de justice : créer du contenu intéressant prend du temps, de la compétence et des efforts, et il est normal d'avoir une rémunération pour cela. Aujourd'hui, quelles sont les possibilités de rémunération pour un blogueur ? Il y en a plusieurs, que certains blogueurs combinent. (Je parle du point de vue du blogueur car c'est celui que je connais bien mais la presse en ligne, par exemple, a un problème très proche, regardez ce que propose reflets.info.)
- Il peut faire cela le soir en dehors du temps de travail. Cela limite évidemment la quantité et la qualité de la production : le soir, les prolétaires sont fatigués.
- Il peut avoir un patron compréhensif, voire encourageant, qui le laisse bloguer pendant le travail, ou même le paie pour cela. C'est évidemment fragile car l'employeur peut changer d'avis.
- Il peut trouver un mécène, un riche qui va donner de l'argent à une association ou une personne pour leur permettre de bloguer. Cela ne va pas forcément dans le sens de l'indépendance du blogueur...
- Il peut être un riche oisif, à qui un héritage non mérité permet de bloguer sans travailler. Le principal problème est qu'il faut une vieille tante riche sans enfants.
- Il peut mettre de la publicité sur son blog. Cela ne rapporte pas tant que cela, cela insupporte les visiteurs (la publicité est l'une des plaies de la société) et, au lieu d'être dépendant d'un mécène, on l'est d'une régie publicitaire.
- Il peut faire payer l'accès à son blog, via un abonnement. Je n'ai pas de problème moral contre cela mais un gros problème pratique : cela rend difficile ou impossible le partage de contenu, qui est quand même à la base du Web. Envoyer un simple lien à des amis devient impossible, si on est abonné à ce site et qu'ils ne le sont pas. Et puis, c'est lourd de s'abonner pour un blog qu'on ne visitera que de temps en temps.
- Il peut enfin demander des contributions volontaires, comme les chanteurs dans le métro. Mais on se heurte alors au problème du manque de moyens techniques pour permettre des petits paiements simples, rapides et où on ne laisse pas sa chemise en frais de transaction. C'est cette dernière voie que j'ai choisi d'explorer, d'abord avec Flattr.
Le principe de Flattr est le suivant : on s'inscrit sur leur site, on peut alors recevoir des « flattrs » (des flatteries ?) et, si on a déposé des fonds, en envoyer. Pour déposer des fonds, on a droit aux classiques cartes de crédit, à PayPal et même aux bitcoins. Lorsqu'on se promène sur un site Web et qu'on voit le bouton Flattr, on clique dessus, et le titulaire du bouton est « flattrisé » et verra son compteur augmenter. Au-delà d'une certaine valeur, il pourra même retirer des fonds. Cela marche aussi, sans avoir à ajouter de boutons, pour des services comme GitHub (quand un utilisateur de Flattr « starre » un dépôt, son titulaire est « flattrisé »). Ainsi, en novembre 2013, j'ai gagné pas moins de 0,19 € uniquement avec Twitter (chaque mise en favori « flattre »).
J'ai donc décidé de sauter un pas et de tenter Flattr sur mon blog. (Cela a posé des problèmes techniques avec le format XHTML de mon blog, le code du bouton proposé par Flattr n'étant pas compatible.) Ouvrez des comptes Flattr, déposez-y un peu d'argent et, si un article vous plait, cliquez sur le bouton Flattr en bas, je vous remercie d'avance.
Je n'utilise plus le bouton par défaut de Flattr : il fait systématiquement une requête vers les serveurs de Flattr pour chaque visite. Cela peut poser des problèmes à certains de mes visiteurs, de se voir ainsi suivis par Flattr. Je l'ai donc remplacé par un bouton statique qui ne charge rien si on ne clique pas.
Je ne suis pas du tout juriste, mais, a priori, je suppose que je vais devoir déclarer mon compte Flattr comme compte à l'étranger (pour ne pas faire comme Cahuzac) et qu'il faudra que j'intègre mes gains Flattr (dont je ne pense pas qu'ils seront colossaux...) dans ma déclaration de revenus. Sur la fiscalité des dons en France, Éric D. suggère ses articles « Un don, ça se déclare comment ? » et « Et si… oui mais en fait non. » dont les conclusions sont assez pessimistes (la fiscalité ne permet pas de faire des microdons simplement). La documentation officielle est en ligne et est manifestement conçue uniquement pour un petit nombre de dons importants (et uniquement entre gens qui se connaissent, oubliant les dons par des inconnus), pas par beaucoup de microdons, sans pour autant exclure explicitement les dons en dessous d'un certain montant. Enfin, les dons ne sont pas imposés comme des revenus (taxation progressive, avec un taux qui augmente avec le revenu) mais d'un taux fixe, et colossal (60 %). En pratique, il n'y a pas de problèmes aujourd'hui parce que tout cela se passe « sous le radar » (les gens qui touchent 10 € par mois avec Flattr ne le déclarent pas et le fisc a autre chose à faire que de les poursuivre) mais si ce mécanisme de financement de la création se répandait, il y aurait de vrais problèmes fiscaux. Autre possibilité, les déclarer comme revenus non commerciaux, comme c'est apparemment possible pour les bitcoins. Sinon, les gens de Tipeee (un autre système de rémunération, basé en France) ont fait une page très détaillée sur le sujet.
Et est-ce que Flattr n'a pas des défauts ? Si, certainement, commission trop élevée, système centralisé... Il y a eu une bonne discussion sur SeenThis sur ces sujets.
Autres articles sur Flattr et les microdons :
- « Ce besoin de reconnaissance »
- « Flattr-ies et Kurbettes » qui explique bien le fonctionnement de Flattr et note que les chances de vivre uniquement de « flattries » sont limitées (mais, personnellement, je n'en demande pas tant).
- « La monnaie électronique, 33 questions à Lionel Dricot (alias Ploum) », à propos de Flattr et Bitcoin.
En pratique, Flattr a été un échec, je n'ai presque rien reçu par ce biais et j'ai donc finalement supprimé le bouton.
L'article seul
Panne Internet à Saint-Pierre-et-Miquelon
Première rédaction de cet article le 4 janvier 2014
Dernière mise à jour le 5 janvier 2014
Aujourd'hui, vers 19:30 UTC, une coupure complète de la connexion Internet de Saint-Pierre-et-Miquelon a eu lieu. C'est l'occasion de regarder ce que fait le protocole de routage de l'Internet, BGP, dans ce cas, puisque toutes les données sont publiques.
La panne a été signalée par BGPmon sur
Twitter. Il y a normalement quatre préfixes d'adresses IP, qui
sont émis depuis l'île, 70.36.4.0/22,
70.36.12.0/22, 70.36.8.0/22 et
70.36.0.0/22. Tous pourraient s'agréger en un
70.36.0.0/20 mais ce n'est pas le cas. Il y a
apparemment un seul opérateur à
Saint-Pierre-et-Miquelon, SPM Télécom (qui gère
le portail http://www.cheznoo.net à l'adresse
70.36.0.23). Tous ces services étaient
inaccessibles (cela remarche
désormais). On notera que le domaine
cheznoo.net n'a que deux serveurs
DNS, ce qui est insuffisant, et que les deux
sont dans les préfixes affectés (manque de redondance) rendant donc le
domaine complètement inaccessible. Cela permet, pendant la panne, de
regarder des sites comme un blog parlant de la vie à
Saint-Pierre-et-Miquelon et des problèmes
de réseau.
Pour analyser les données BGP, nous allons utiliser les données de RouteViews. Elles sont en binaire, au format MRT (RFC 6396), il faut les transformer en texte avec bgpdump. On sait d'après BGPmon l'heure approximative de la panne, on va donc récupérer le fichier, le transformer en texte et le fouiller. RouteViews offre deux types de fichier, "RIBS" qui contient l'état courant des tables de routage, et "UPDATES" qui contient les mises à jour. Vérifions d'abord l'état avant la panne, en prenant le fichier de 18:00 :
% wget ftp://archive.routeviews.org/route-views.linx/bgpdata/2014.01/RIBS/rib.20140104.1800.bz2 % bgpdump rib.20140104.1800.bz2 > rib.20140104.1800.txt % fgrep -B3 -A5 70.36.0. rib.20140104.1800.txt ... TIME: 01/04/14 18:00:02 TYPE: TABLE_DUMP_V2/IPV4_UNICAST PREFIX: 70.36.0.0/22 SEQUENCE: 95877 FROM: 195.66.225.111 AS5580 ORIGINATED: 12/29/13 19:25:03 ORIGIN: IGP ASPATH: 5580 1299 3356 11260 3695 ...
Et on voit que le préfixe 70.36.0.0/22 existait
bien à 18:00. L'AS 3695, à l'origine de cette annonce, est SPM Télécom. Et à 20:00 ?
% wget ftp://archive.routeviews.org/route-views.linx/bgpdata/2014.01/RIBS/rib.20140104.2000.bz2 % bgpdump rib.20140104.2000.bz2 > rib.20140104.2000.txt % fgrep -B3 -A5 70.36.0. rib.20140104.2000.txt %
Le préfixe a disparu. Quand exactement et que lui est-il arrivé ? Regardons cette fois les "UPDATES" :
% wget ftp://archive.routeviews.org/route-views.linx/bgpdata/2014.01/UPDATES/updates.20140104.1930.bz2 % bgpdump updates.20140104.1930.bz2 > updates.20140104.1930.txt
Et explorons ce fichier, bien plus petit que les "RIBS", avec un éditeur ordinaire. On voit le premier retrait du préfixe à 19:33:57 :
TIME: 01/04/14 19:33:57 TYPE: BGP4MP/MESSAGE/Update FROM: 195.66.236.32 AS3257 TO: 195.66.237.222 AS6447 WITHDRAW 70.36.12.0/22 70.36.8.0/22 70.36.4.0/22 70.36.0.0/22
Ce retrait est suivi de plusieurs annonces. En effet, tous les routeurs BGP ne sont pas synchrones. Certains croient que la route qu'ils connaissent est toujours valable et l'annoncent à nouveau, avant de la retirer quelques secondes plus tard. Le dernier retrait, définitif, n'aura lieu que deux minutes après, ce qui donne une bonne idée du temps typique de propagation des annonces BGP :
TIME: 01/04/14 19:35:42 TYPE: BGP4MP/MESSAGE/Update FROM: 195.66.224.215 AS31500 TO: 195.66.225.222 AS6447 WITHDRAW 70.36.0.0/22 70.36.4.0/22 70.36.8.0/22 70.36.12.0/22
Et la cause de cette panne ? Apparemment une importante
coupure de courant à Terre-Neuve.
La connectivité a été rétablie le lendemain vers 00:30 UTC. Le fichier
ftp://archive.routeviews.org/route-views.linx/bgpdata/2014.01/UPDATES/updates.20140105.0030.bz2
contient les nouvelles annonces :
TIME: 01/05/14 00:34:35 TYPE: BGP4MP/MESSAGE/Update FROM: 195.66.224.32 AS3257 TO: 195.66.225.222 AS6447 ORIGIN: IGP ASPATH: 3257 11260 3695 NEXT_HOP: 195.66.224.32 MULTI_EXIT_DISC: 751 COMMUNITY: 3257:4000 3257:8138 3257:50002 3257:50120 3257:51100 3257:51105 ANNOUNCE 70.36.8.0/22 70.36.0.0/22 70.36.12.0/22
Notez que Saint-Pierre-et-Miquelon a son propre
TLD,
.pm mais que les serveurs
DNS de celui-ci sont en dehors de l'île et n'ont donc pas été
affectés. De même, des sites Web comme http://www.tourisme-saint-pierre-et-miquelon.com/ sont
manifestement hébergés en France métropolitaine et ont continué à
fonctionner. Des sites Web comme celui de la compagnie
aérienne, hébergés localement, ont par contre été mis hors d'usage.
La connexion actuelle de Saint-Pierre-et-Miquelon ne se fait que par un faisceau hertzien vers Terre-Neuve (cette grande île étant ensuite connectée par un câble sous-marin, sans doute Greenland Connect). Elle utilise l'opérateur canadien Eastlink. Ce n'est pas la première panne de cette liaison (voir le blog du président du conseil territorial). Un projet est en cours pour remplacer l'hertzien par un câble sous-marin. Si vous voulez candidater pour la pose du futur câble, l'appel d'offres est ici.
Merci à Andree Tonk pour BGPmon, et à Marc Albert Cormier pour ses informations.
L'article seul
Le serveur DNS Knot
Première rédaction de cet article le 4 janvier 2014
Curieusement, des tas d'endroits où tourne un serveur DNS faisant autorité, font tourner BIND. Ce qui est curieux, ce n'est pas ce choix (BIND est un excellent logiciel), c'est le fait qu'aucune alternative n'a été considérée. Peut-on vraiment se dire administrateur système si on ne se pose même pas la question « y a-t-il d'autres possibilités ? ». Parmi les alternatives sérieuses, pour cette fonction de serveur DNS faisant autorité, le logiciel Knot.
J'ai déjà présenté ici une autre alternative, le logiciel NSD. NSD est extrêmement rapide et fiable mais sa principale faiblesse (qui a été corrigée en version 4) était que l'ajout ou le retrait d'une zone à sa configuration nécessitait le redémarrage du serveur. NSD est donc très bien pour les gérants de TLD ou d'autres grandes zones mais il ne convient pas forcément au cas d'un hébergeur gérant des milliers de zones, avec ajouts et retraits fréquents. Autre manque, NSD ne gère pas les mises à jour dynamiques du RFC 2136. NSD est conçu pour deux choses, vitesse et fiabilité. Si on veut la richesse fonctionnelle, Knot mérite un coup d'œil.
Les tests ci-dessous ont été faits avec la version 1.4rc2, la 1.4
définitive devrait sortir « bientôt ». Voici la configuration minimale
d'un serveur Knot gérant example.com :
interfaces {
my-iface { address 0.0.0.0;}
}
zones {
storage "/var/knot";
example.com {
file "./example.com"; # Relative to "zones / storage"
}
}
Indiquer au moins une interface est obligatoire, Knot est sourd, autrement. On peut alors démarrer le serveur (ici, à la main, pour des tests mais, en production, cela serait fait par un script de démarrage) :
# knotd -c ultra-simple.conf -v 2014-01-03T14:46:31 Reading configuration '/home/stephane/System/DNS/Knot-tests/ultra-simple.conf' ... 2014-01-03T14:46:31 Knot DNS 1.4.0-rc2 starting. 2014-01-03T14:46:31 Binding to interface 0.0.0.0 port 53. 2014-01-03T14:46:31 Configured 1 interfaces and 1 zones. 2014-01-03T14:46:31 Server started in foreground, PID = 12472 2014-01-03T14:46:31 Server running without PID file. 2014-01-03T14:46:31 Zone 'example.com.' loaded (serial 2013122101) 2014-01-03T14:46:31 Loaded 1 out of 1 zones. 2014-01-03T14:46:31 Starting server... 2014-01-03T14:46:31 Binding remote control interface to /usr/local/var/run/knot/knot.sock
Et on peut tester que le serveur répond bien :
% dig @192.168.2.7 SOA example.com ; <<>> DiG 9.8.4-rpz2+rl005.12-P1 <<>> @verite SOA example.com ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 36598 ;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 2, ADDITIONAL: 1 ;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 4096 ;; QUESTION SECTION: ;example.com. IN SOA ;; ANSWER SECTION: example.com. 600 IN SOA ns1.example.com. root.example.com. ( 2013122101 ; serial 604800 ; refresh (1 week) 86400 ; retry (1 day) 2419200 ; expire (4 weeks) 86400 ; minimum (1 day) ) ... ;; Query time: 1 msec ;; SERVER: 192.168.2.7#53(192.168.2.7) ;; WHEN: Fri Jan 3 15:46:35 2014 ;; MSG SIZE rcvd: 127
Knot dispose, comme BIND et contrairement à NSD (avant la version 4)
d'un canal de contrôle. Par défaut, ce canal passe par une prise
locale, ici /usr/local/var/run/knot/knot.sock. Le
programme knotc permet de parler au serveur
(knotd) :
# knotc status OK # knotc zonestatus example.com. type=master | serial=2013122101 | busy |
Contrairement à NSD (avant la version 4), on peut ajouter des zones « en vol ». Ajoutons dans le fichier de configuration :
example.net {
file "./example.net";
}
Et un simple :
# knotc reload OK
sera suffisant pour charger la nouvelle zone :
2014-01-03T14:54:02 Reloading configuration... 2014-01-03T14:54:02 Zone 'example.com.' is up-to-date (serial 2013122101) 2014-01-03T14:54:02 Zone 'example.net.' loaded (serial 2013122101) 2014-01-03T14:54:02 Loaded 2 out of 2 zones. 2014-01-03T14:54:02 Configuration reloaded.
Le canal de contrôle peut être mis sur autre chose qu'une prise locale :
remotes {
ctl { address 127.0.0.1;}
}
control {
listen-on { address 127.0.0.1@5533;}
allow ctl;
}
Et le serveur répond alors sur cette prise réseau :
% knotc -s localhost -p 5533 status OK % knotc -s localhost -p 5533 zonestatus example.com. type=master | serial=2013122101 | busy |
Autre fonction intéressante, la mise à jour dynamique. Si on
configure une zone avec update-in :
remotes {
updater { address 127.0.0.1;}
}
zones {
storage "/var/knot";
example.com {
file "./example.com";
update-in {
updater;
}
}
}
Et qu'on utilise, par exemple, ce script (qui utilise le
nsupdate livré avec BIND) pour les mises à jour :
#!/bin/sh nsupdate -d <<EOF server 127.0.0.1 zone example.com update delete monportable.example.com update add monportable.example.com 300 A 192.0.2.42 send EOF
La mise à jour est bien faite :
2014-01-03T15:04:58 UPDATE of 'example.com.' from '127.0.0.1@22672' Started. 2014-01-03T15:04:58 UPDATE of 'example.com.' from '127.0.0.1@22672' Finished.
Ce qu'on peut vérifier avec dig :
% dig -p 5353 @127.0.0.1 A monportable.example.com ... ;; ANSWER SECTION: monportable.example.com. 300 IN A 192.0.2.42
Maintenant, si je me mets dans la peau de l'hébergeur qui gère plein de zones, est-ce Knot va tenir le coup ? Testons sur une petite machine, un Raspberry Pi sous Arch Linux avec mille zones (c'est peu, mais c'est vraiment une petite machine). En cinq secondes, les mille zones sont chargées et Knot répond. 50 Mo de RAM sont utilisés dont 20 en résident. Et si on bombarde le serveur de requêtes avec queryperf ? On atteint 3 800 requêtes par seconde, sans aucune perte.
Et si on compare avec BIND ? Un BIND 9.9.4-P1 sur le même Raspberry Pi consomme effectivement deux fois moins de mémoire mais ses performances avec queryperf sont bien moins bonnes, avec 1 000 requêtes par seconde (en débrayant la journalisation des requêtes refusées, qui est faite par défaut et ralentit beaucoup BIND). Rien d'étonnant (BIND a toujours été très lent dans tous les tests de performance, l'accent est mis par ses développeurs sur la richesse fonctionnelle).
Knot gère évidemment les trucs modernes : DNSSEC (si le fichier de zone est signé, il active automatiquement le mode DNSSEC), NSID (RFC 5001) et RRL (limitation du rythme des réponses). Pour NSID, on met :
system {
identity "ns1.example.com"; # For the old CH TXT hostname.bind trick
nsid "ns1.example.com";
}
Et on obtient le résultat attendu :
% dig +nsid -p 5353 @127.0.0.1 SOA example.com ... ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ; NSID: 6e 73 31 2e 65 78 61 6d 70 6c 65 2e 63 6f 6d (n) (s) (1) (.) (e) (x) (a) (m) (p) (l) (e) (.) (c) (o) (m) ...
Knot dispose également évidemment de la fonction RRL (Response-Rate Limiting) qui permet de limiter la contribution du serveur aux attaques par réflexion. Par exemple, on configure avec :
system {
...
rate-limit 20;
}
Et on limite le serveur à 20 réponses par seconde pour la même
question depuis la même adresse IP. Sur le graphique, on voit bien la
différence : le premier pic correspond à une attaque par réflexion
sans RRL (autant de paquets sortants qu'entrants), le second pic au
cas où la RRL est
activée (le nombre de paquets sortants chute). 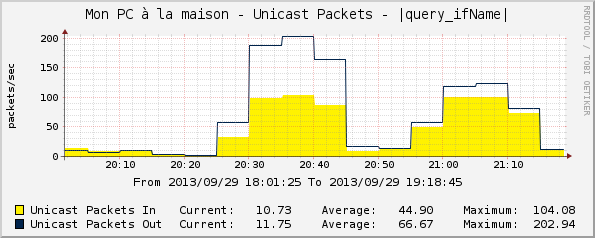
Si vous voulez en apprendre plus sur Knot en français, vous pouvez lire l'article de ses auteurs à JRES.
L'article seul
Articles des différentes années : 2024 2023 2022 2021 2020 2019 2018 Précédentes années
Syndication : Flux Atom avec seulement les résumés et Flux Atom avec tout le contenu.
{kind=link}