
Les RFC (Request For Comments) sont les documents de référence de l'Internet. Produits par l'IETF pour la plupart, ils spécifient des normes, documentent des expériences, exposent des projets...
Leur gratuité et leur libre distribution ont joué un grand rôle dans le succès de l'Internet, notamment par rapport aux protocoles OSI de l'ISO organisation très fermée et dont les normes coûtent cher.
Je ne tente pas ici de traduire les RFC en français (un projet pour cela existe mais je n'y participe pas, considérant que c'est une mauvaise idée), mais simplement, grâce à une courte introduction en français, de donner envie de lire ces excellents documents. (Au passage, si vous les voulez présentés en italien...)
Le public visé n'est pas le gourou mais l'honnête ingénieur ou l'étudiant.
RFC 10008: The HTTP QUERY Method
Date de publication du RFC : Juin 2026
Auteur(s) du RFC : J. Reschke (greenbytes), J.M. Snell
(Cloudflare), M. Bishop (Akamai)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 16 juin 2026
Ce n'est pas tous les jours qu'on normalise une nouvelle méthode HTTP. Bienvenue, donc, à QUERY, qui rejoint des méthodes bien plus anciennes comme GET et POST. QUERY peut être décrit comme « GET mais avec un corps dans la requête ». Comme GET, elle est idempotente et donc sûre à répéter.
L'idée est de pouvoir interroger, par exemple, un service de recherche (vous verrez un exemple plus loin sur mon blog). Sans QUERY, on envoyait quelque chose du genre :
GET /feed?q=foo&limit=10&sort=published HTTP/1.1
On est donc obligés de mettre les paramètres dans l'URL. Cela peut poser problème si les paramètres sont nombreux et de grande taille, cela oblige à les pourcent-encoder et cela peut poser des problèmes de vie privée (l'URL demandé a des chances d'être enregistré dans un journal).
Des gens utilisent donc POST pour une recherche, bien qu'il n'ait pas la bonne sémantique :
POST /feed HTTP/1.1
q=foo&limit=10&sort=published
Mais on ne voit plus que la requête est idempotente. Un navigateur Web n'osera pas la répéter ou bien demandera confirmation à l'utilisateur. Et on ne pourra pas facilement mémoriser le résultat (puisque le client ne sait pas si la requête n'a pas d'effets de bord). QUERY résout le problème :
QUERY /feed HTTP/1.1
q=foo&limit=10&sort=published
La méthode est idempotente, le résultat peut être mémorisé.
La section 2 du RFC décrit avec précision QUERY. À lire si vous écrivez des clients ou des serveurs qui l'utilisent. Par exemple, puisque QUERY, contrairement à GET, inclut un corps dans la requête, le client doit indiquer le type de média utilisé, et sans se tromper, sinon le serveur lui renverra un 400. (Et un 415 si le type est bien là mais que le serveur ne le connait pas.) Autre chose à noter : en cas de redirection, le client ne doit pas changer de méthode (alors qu'on pouvait changer un POST en GET si la redirection était faite avec 301 ou 302). Autrement, QUERY ressemble beaucoup dans son comportement à GET. QUERY est désormais enregistré dans le registre des méthodes HTTP.
Un serveur HTTP qui met en œuvre QUERY n'accepte pas forcément
n'importe quel format en entrée. Pour documenter ce qu'il accepte
comme corps de la requête, notre RFC introduit un nouveau
champ HTTP, Accept-Query: (section 3)
qui est la liste des types de média
acceptés.
Vous avez plein d'exemples de requêtes et de réponses dans l'annexe A.
Il y a une mise en œuvre de QUERY sur ce blog, pour fournir un
moteur de recherche des
articles. L'URL est
https://www.bortzmeyer.org/methodquery et voici
un exemple d'utilisation avec curl :
% curl --request QUERY --data query=framasoft https://www.bortzmeyer.org/methodquery
Query of "framasoft" OK
https://www.bortzmeyer.org/capitole-du-libre-2023.html "Capitole du Libre 2023, et mon exposé sur la censure de l'Internet"
…
Vous pouvez avoir une documentation plus détaillée de ce service
au début de son code source (en Python),
method-query.pytest-http-query.py
En parlant de curl, notez que, lorsqu'il suit
une redirection HTTP (option --location), il ne
transmet pas actuellement le
corps de la requête, ce qui casse ce service. Il faut de toute façon
utiliser
--follow.
La création de cette nouvelle méthode (ce qui est rare, je crois que la précédente avait été PATCH dans le RFC 5789 il y a quinze ans) a pris du temps. Le premier projet avait été rédigé en 2015 et le travail a connu plusieurs interruptions. Une des discussions avait porté sur le nom de la méthode, qui aurait pu s'appeler SEARCH (réutilisant une méthode normalisée dans le RFC 5323). L'annexe B du RFC discute le choix qui a été fait.
Une autre discussion portait sur le code de retour HTTP, un problème classique de tous les services tournant sur HTTP : si la requête est bien transmise et traitée mais qu'on n'a pas de résultat, doit-on quand même renvoyer le 200, qui signifie que tout s'est bien passé ? Avec GET, on utilise souvent 404 dans ce cas, mais c'est parce que le terme de recherche est dans l'URL, ce qui n'est plus le cas ici. On aurait pu aussi avoir un nouveau code commençant par 2. Finalement, le choix a été de renvoyer 200 quand la requête est bien arrivée et que le moteur de recherche a fonctionné, même s'il n'a rien trouvé. (Une discussion analogue avait eu lieu pendant le développement de DoH. Le RFC 8484 avait finalement décidé de répondre 200 même si le nom de domaine demandé n'existait pas.)
Ah, et si vous voulez superviser votre service HTTP utilisant QUERY, le programme check_http des monitoring plugins le permet. Voici un exemple de configuration pour Icinga :
vars.http_vhosts["query"] = {
http_uri = "/methodquery"
http_vhost = "www.bortzmeyer.org"
http_ssl = true
http_sni = true
http_method = "QUERY"
# Notez que le nom de la variable n'est pas très heureux.
http_post = "query=foobar"
http_content_type = "application/x-www-form-urlencoded"
http_string = "foobar\" OK"
http_timeout = 15
}
Sinon, si vous voulez d'autres lectures, il y a un bon article de Tykok.
L'article seul
RFC 9998: Report from the IAB/W3C Workshop on Age-Based Restrictions on Content Access
Date de publication du RFC : Juin 2026
Auteur(s) du RFC : M. Nottingham, M. Thomson
Pour information
Première rédaction de cet article le 3 juillet 2026
En octobre 2025, l'IAB et le W3C ont organisé un atelier à Londres sur la restriction d'accès à des services Internet en fonction de l'âge. Ce RFC est le compte-rendu de l'atelier. En tant que compte-rendu, il n'exprime donc pas une position officielle de l'IAB.
Le sujet est d'actualité, avec de nombreux politiciens qui proposent d'interdire les réseaux sociaux ou la pornographie aux mineurs. Des lois sont déjà votées, comme en Australie. L'UE a un plan en cours et un projet de logiciel. Vous pouvez consulter le site du projet logiciel. En France, où l'une des questions secondaires était la compatibilité d'un éventuel contrôle avec le droit européen, un arrêt du 16 juin 2026 de la Cour de justice de l’Union européenne a estimé que la France pouvait obliger des sociétés basées dans un État membre à mettre en place une vérification d’âge.
L'atelier
devait explorer les différents techniques et choix
d'architecture liés à ce désir de restriction. Comment combiner
cette exigence de restriction aux mineurs tout en préservant les
principes d'universalité et de décentralisation de l'Internet, ainsi
que la vie privée ? Comment le faire sans mettre en place un
système de contrôle qui fera le bonheur de gouvernements
autoritaires voire dictatoriaux ? Et faut-il déléguer la sécurité
des enfants aux opérateurs Internet, plutôt qu'aux adultes qui s'en
occupent (parents, enseignants, etc) ? Les politiciens qui réclament
des restrictions d'âge « pour protéger les enfants » ne se posent
évidemment jamais ces questions (et les avertissements
des experts sont systèmatiquement ignorés). Un exemple
non technique : ces restrictions peuvent servir à un gouvernement
religieux et/ou réactionnaire pour bloquer l'accès à des sites Web
LGBT, au détriment des mineurs en
questionnement qui voudraient s'informer (notez que le RFC ne
mentionne pas ce point). L'atelier n'a pas essayé de traiter les
problèmes politiques, mais uniquement d'analyser les techniques
existantes et de pointer leurs caractéristiques et leurs
conséquences. Comme indiqué au début, cet atelier a été l'occasion
d'exprimer des points de vue variés (sous la règle de
Chatham House), ce RFC ne prétend pas en faire un synthèse, ni
donner La Bonne Réponse. Le RFC inclut notamment une liste des
propriétés attendues d'une « bonne » solution, dans l'annexe D. Ce
point de départ d'un vrai cahier des charges manque dans la plupart
des discours politiciens, où on ne fait que répéter des slogans,
sans dire clairement quels sont les avantages attendus et les
inconvénients acceptables. (L'annexe C est une intéressante liste
des impacts - positifs ou négatifs - possibles du contrôle d'âge.)
L'agenda complet de l'atelier figure dans l'annexe A du RFC, la liste des participants dans l'annexe B. Passons maintenant au contenu.
Les « solutions » techniques peuvent être mises en œuvre dans le
terminal de l'utilisateurice, dans le réseau (par exemple dans le
résolveur DNS) ou bien dans le
service (regardez https://fr.pornhub.com/
depuis la France, pour voir ; n'hésitez pas, c'est
SFW). Dans le terminal ? Cela donne du
pouvoir à Microsoft ou
Google et encourage les systèmes
privateurs sur lesquels l'utilisateurice n'a
aucun contrôle. (Encore que le logiciel libre
peut aussi, par souci de conformité et pour se faire bien voir des
politiciens, mettre en œuvre
ces contrôles.) Dans le réseau ? Cela met en danger le cœur
de l'Internet. Et cela donne du pouvoir aux acteurs de
l'infrastructure. Et ce n'est pas très précis (pensez au cas d'un
foyer où il y a adultes et enfants mais une seule adresse IP). Dans
les services ? Cela met le problème sur le dos de chaque
webmestre.
L'atelier a examiné quelques technologies « miracle » censées permettre de vérifier l'âge tout en préservant la vie privée (comme les ZKP). Même si elles résolvaient parfaitement le problème de vie privée, elles laissent ouverts les autres problèmes. Et ces technologies sont souvent récentes et leur sécurité n'est pas toujours testée en profondeur.
Bref, l'atelier n'a pas débouché sur une « solution » ni même sur un plan de travail pour l'IETF. La question reste très ouverte.
Le RFC pointe en section 3 les aspects les plus importants de ce sujet. D'abord, le fait que l'atelier a été utile car, alors que le sujet a bénéficié de nombreux articles dans la presse généraliste, et de nombreux discours politiciens, les discussions techniques ont été rares, de même que les forums impliquant toutes les parties prenantes. Et quand des techniciens étaient consultés, c'était toujours du point de vue des services, jamais de celui de l'infrastructure.
Ensuite, les discussions sont souvent peu productives car il y a eu peu d'efforts pour identifier les différentes rôles impliqués (cf. la présentation d'Hanson) :
- Le vérificateur qui doit tester si une personne donnée a plus que l'âge requis,
- Le contrôleur qui doit empêcher une personne qui a « raté » le test précédent d'accéder au service,
- Le sélecteur de politique, qui définit la politique à appliquer (elle dépend en général du pays de résidence du client, qui est difficile à déterminer sur l'Internet),
- Et le classificateur qui doit déterminer si un contenu donné ou un certain service doit être restreint d'accès.
Cette question est aussi liée à celle de la terminologie, souvent peu définie. (Tiens, j'apprends dans le RFC qu'il existe une norme ISO sur la vérification d'âge, ISO/IEC 27566-1:2025, évidemment pas accessible aux mineurs - il faut laisser plein de données personnelles pour l'obtenir.)
Autre sujet mis en évidence à l'atelier, l'importance de la préservation de la vie privée. Cette exigence est largement méprisée par les défenseurs du contrôle d'âge, le record de connerie ayant récemment été battu par une parlementaire canadienne qui affirmait que la reconnaissance faciale respectait l'anonymat puisque le logiciel ne connaissait pas le nom de la personne. Une partie des acteurs cités plus haut va connaitre des informations personnelles sur les clients des services, et ces acteurs ne sont pas forcément connus de ces clients. Imaginez que vous alliez sur un site Web de contenu pour adultes puis soudainement vous êtes redirigé vers le site Web du vérificateur qui va vous demander de prouver votre âge. Si vous êtes raisonnablement prudent, vous refusez. Si vous tenez à voir le contenu, vous répondez et voilà : on a habitué les utilisateurs à faire confiance à des sites inconnus et inattendus. Une vraie aide au hameçonnage.
En parlant de confiance, un des points difficiles de toute solution technique au problème du contrôle d'âge est la nécessité de faire confiance à de nouveaux acteurs. Certes, il existe des méthodes mathématiques pour prouver quelque chose sans divulguer d'information mais elles sont récentes, peu testées, et sont loin d'épuiser le problème de la confiance. Le fait que beaucoup de techniques proposées ne soient pas en logiciel libre n'arrange rien. (Le RFC ne mentionne pas ce point, sauf pour enfoncer une porte ouverte en rappelant que le logiciel libre ne résout pas tous les problèmes de confiance.)
Les participants à l'atelier ont aussi noté qu'il y avait peu de chances qu'une seule technique suffise : toutes ont des défauts graves. Les techniques reposant sur des documents étatiques écartent les gens qui n'en ont pas, ou ceux qui ont des documents non reconnus. Les techniques probabilistes d'estimation de l'âge (par exemple par examen du visage) ont beaucoup de faux positifs et de faux négatifs (et, pire, cela dépend de la couleur de peau). Une approche possible serait d'essayer successivement plusieurs techniques, en commençant par les moins invasives (mais cela créerait une discrimination envers les catégories de population qui échouent à ces premières techniques).
L'imperfection de toutes ces techniques a des conséquences sérieuses : exclusion de certaines personnes, contournement par d'autres (certains utilisateurs de contenu « pour adultes » n'ont pas l'âge mais sont motivés, techniquement compétents et ont du temps libre).
La plupart des architectures proposées ajoutent des parties à la relation traditionnelle entre le visiteur d'un site Web et le site en question, notamment le vérificateur et le contrôleur. On complique donc l'architecture du Web en ajoutant de nouvelles dépendances.
Et, bien sûr, la technique n'est pas tout. La sécurité des mineurs ne doit pas dépendre uniquement de techniques dont l'atelier a largement montré la fragilité. Le problème, il est vrai, est très difficile puisqu'il faut à la fois protéger les mineurs contre les dangers bien réels, tout en les préparant à leur future vie de majeur, où il n'y aura pas de restrictions techniques. Les contrôles techniques sont forcément grossiers et binaires, et ne prennent pas en compte toutes les nuances du monde. Il ne faudrait surtout pas déléguer des tâches aussi complexes et délicates que l'éducation à des « solutions » techniques.
Quelques autres ressources :
- La vidéo de présentation de l'atelier.
- Les documents présentés à l'atelier.
- La prise de position de l'Internet Society.
- Un précédent Internet-Draft sur les conséquences d'une restriction d'âge pour l'Internet.
L'article seul
RFC 9991: Domain-Based Message Authentication, Reporting, and Conformance (DMARC) Failure Reporting
Date de publication du RFC : Mai 2026
Auteur(s) du RFC : S. Jones (DMARC.org), A. Vesely (Tana)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dmarc
Première rédaction de cet article le 20 mai 2026
DMARC (RFC 9989)
permet de demander l'envoi, par les destinataires des messages, de
rapports indiquant les éventuels problèmes notés, afin de diminuer
le nombre de faux positifs (messages légitimes incorrectement
considérés comme invalides). Cette demande de rapports se fait en
ajoutant l'option ruf à l'enregistrement
DMARC. Ce RFC
décrit ces rapports.
Il y a au moins deux raisons de demander ces rapports :
- Comprendre pourquoi certains des messages qu'on envoie sont classés comme invalides alors qu'ils ne devraient pas l'être. On va donc analyser des rapports concernant des messages qu'on a réellement envoyés.
- Détecter les tentatives d'usurpation du domaine. On va donc analyser des rapports concernant des messages qu'on ne connaissait pas, et qu'un méchant a envoyés.
Notez qu'il existe aussi des rapports agrégés (RFC 9990, avec un format très différent, fondé sur XML) et qu'on demande parfois des rapports individuels parce qu'on note dans les rapports agrégés qu'il y a beaucoup d'erreurs et qu'on voudrait comprendre leur origine.
Le format normalisé ici dérive du format ARF (Abuse
Reporting Format, RFC 6591), qui
décrivait les rapports pour les problèmes SPF et DKIM. L'option
ruf dans l'enregistrement DMARC (RFC 9989, section 4.7) indique à quelle adresse de
courrier le
rapport doit être envoyé. Voici par exemple l'enregistrement DMARC
de afnic.fr :
dig +short _dmarc.afnic.fr TXT "v=DMARC1; p=quarantine; pct=100; ruf=mailto:dmarc-feedback@afnic.fr; rua=mailto:dmarc-feedback@afnic.fr; fo=1"
Vous voyez le ruf ? Il indique que les rapports
doivent être envoyés à
dmarc-feedback@afnic.fr. Attention, j'ai écrit
« doivent » mais, évidemment, les récepteurs de courrier ne sont
pas obligés d'envoyer ces rapports, qui peuvent
leur coûter des ressources et poser des problèmes de vie privée.
Pour DMARC, notre RFC ajoute au format du RFC 6591 les champs (section 4, ils sont listés dans un registre IANA) :
Identity-Alignment:, qui liste les mécanismes d'authentification où il n'y a pas d'alignement avec l'expéditeur,Delivery-Result:,DKIM-Domain:, et quelques autres au sujet de DKIM,SPF-DNS:.
Il y a un autre piège avec les rapports, c'est la possibilité
d'indiquer dans ruf l'adresse de quelqu'un
d'autre, pour l'embêter avec beaucoup de rapports qui ne le
concernent pas. La section 4 du RFC 9990
explique les précautions que devrait prendre un receveur de courrier
avant d'envoyer un rapport vers une adresse qui n'est pas dans le
domaine concerné, comme de tester le sous-domaine
_report._dmarc. (Dans l'exemple
afnic.fr plus haut, il n'y avait pas de
problème, le destinataire des rapports est dans le domaine
concerné.)
J'ai mentionné un peu plus haut la question de la vie privée. Les rapports détaillés, contrairement à leurs copains agrégés du RFC 9990, peuvent être très indiscrets, notamment parce qu'ils contiennent souvent des données personnelles, par exemple dans les champs indiquant l'expéditeur et le destinataire. Et il ne suffit pas de se dire « Bon, de toute façon, le gestionnaire du système envoyeur avait accès au message quand il est parti de son système » car le message a pu être transmis et re-transmis et le rapport donnera des informations sur des destinataires finaux. Une section 7, très détaillée, couvre donc ce problème. Elle note par exemple que beaucoup de gros receveurs de courrier n'envoient pas du tout de rapport individuel, seulement des rapports agrégés. Et elle recommande que, même si on envoie les rapports, on en supprime les éléments les plus sensibles (voir le RFC 6590).
Enfin, à envoyer un rapport par message, on noiera l'expéditeur supposé sous des rapports qui concerneront des spams envoyés en nombre. Donc, prudence.
Un point amusant, que je vois pour la première fois dans un
RFC : ce RFC 9991 recommande de modifier les URL présents dans les rapports en
remplaçant http par
hxxp. Cette convention est assez courante dans
le monde de la sécurité Internet, pour éviter qu'un humain ne clique
trop vite sur un lien malveillant.
L'annexe A du RFC donne un exemple de rapport, je ne montre ici que la partie MIME qui concerne le rapport proprement dit :
--=_mime_boundary_ Content-Type: message/feedback-report Content-Transfer-Encoding: 7bit Feedback-Type: auth-failure Version: 1 User-Agent: DMARC-Filter/1.2.3 Auth-Failure: dmarc Authentication-Results: gen.example; dmarc=fail header.from=consumer.example Identity-Alignment: dkim DKIM-Domain: consumer.example DKIM-Identity: @consumer.example DKIM-Selector: epsilon Original-Envelope-Id: 65E1A3F0A0 Original-Mail-From: author=gen.example@forwarder.example Source-IP: 192.0.2.2 Source-Port: 12345 Reported-Domain: consumer.example
Le message prétend venir de consumer.example
mais aucune signature DKIM n'est valide, sans doute suite à des
modifications chez forwarder.example ou bien
parce que la clé DKIM n'a pu être récupérée dans le DNS.
Apparemment, OpenDKIM est capable de générer ces rapports, mais je n'ai pas testé.
L'article seul
RFC 9989: Domain-based Message Authentication, Reporting, and Conformance (DMARC)
Date de publication du RFC : Mai 2026
Auteur(s) du RFC : T. Herr (Valimail), J. Levine (Standcore)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dmarc
Première rédaction de cet article le 20 mai 2026
DMARC est une technique
d'authentification du courrier
électronique qui permet à un domaine d'indiquer quelle
est sa politique de sécurité vis-à-vis des messages dont
l'expéditeur (le champ From: de l'en-tête)
indique ce domaine. Il donne au gérant du domaine la possibilité
d'annoncer sa politique de sécurité « tous les messages de ce
domaine sont authentifiés (via SPF ou DKIM) ». Typiquement, DMARC est le couronnement
d'une démarche de sécurité du courrier, ce qu'on annonce quand on a
bien tout authentifié. Par contre, attention, en authentifiant la
donnée visible par les utilisateurs et pas les données techniques,
il casse certains usages du courrier. DMARC était à l'origine
normalisé dans le RFC 7489, que ce nouveau
RFC
remplace. Mais rassurez-vous si vous avez déjà déployé DMARC : les
changements ne sont pas radicaux. Le principal est le nouvel
algorithme pour trouver l'enregistrement DMARC pertinent (celui à
l'apex du domaine enregistré).
Revenons sur les problèmes de sécurité du courrier électronique. Un message typique, tel que normalisé par le RFC 5322, comprend dans son en-tête ce genre d'informations :
Date: Wed, 18 Mar 2026 17:28:36 +0800 From: Jiankang Yao <yaojk@cnnic.cn> To: 125attendees@ietf.org Subject: [125attendees] Wednesday 8:00 pm, Shenzhen light show for IETF 125 X-Mailer: iPhone Mail (21D61) [et bien d'autres]
Une qui nous intéresse particulièrement est l'expéditeur. Cette
notion est plus compliquée qu'il n'y parait (il y a plusieurs
définitions possibles de « expéditeur ») mais pour DMARC, c'est
simple : le champ qui nous intéresse est uniquement le
From: (section 3.6.2 du RFC 5322). C'est en effet celui qui est typiquement affiché
par les MUA, et
c'est celui que DMARC va protéger. On l'appelle souvent RFC5322-From
pour le distinguer de celui qui apparait dans l'enveloppe du
courrier, le RFC5321-From (et qui n'est pas montré dans mon
exemple).
Les techniques d'authentification existantes avant DMARC,
SPF (RFC 7208) et DKIM (RFC 6376),
n'authentifient pas ce champ mais d'autres (le
RFC5321-From pour SPF et le domaine indiqué dans la signature pour
DKIM), qui ne sont pas en général affichés à l'utilisateurice
final·e. DMARC va permettre d'utiliser ces deux techniques, SPF et
DKIM, pour les appliquer à l'expéditeur (RFC5322-From). Un test
DMARC réussi signifie que SPF ou DKIM a réussi
mais aussi que le domaine authentifié par SPF ou DKIM est le même
que celui présent dans le From: ; on parle
d'alignement du nom de domaine. Cela ne va pas
de soi car il y a de nombreux usages légitimes
du courrier où ces domaines ne sont pas alignés, et DMARC casse donc
ces usages.
Dans les exemples de messages reçus après traitement par DMARC,
on va regarder les champs
Authentication-Results. Normalisés dans le RFC 8601, ils sont ajoutés par le récepteur et
indiquent le résultat d'une technique d'authentification. Ici, un
exemple où SPF et DKIM ont marché (tous les exemples ici sont réels,
issus de mes boites aux lettres):
Authentication-Results: mail.bortzmeyer.org; dmarc=pass (p=quarantine dis=none) header.from=afnic.fr
Authentication-Results: mail.bortzmeyer.org;
dkim=pass (2048-bit key; secure) header.d=afnic.fr header.i=@afnic.fr header.a=rsa-sha256 header.s=afnic-20240601
header.b=bdGM6W8o;
dkim-atps=neutral
Authentication-Results: mail.bortzmeyer.org; spf=pass (sender SPF authorized) smtp.mailfrom=afnic.fr
(client-ip=2001:67c:2218:10::51:1; helo=mx1.nic.fr; envelope-from=quelqu.un@afnic.fr; receiver=bortzmeyer.org)
Le domaine afnic.fr a bien été authentifié, à
la fois par SPF et par DKIM, et DMARC passe donc (le champ
From: n'est pas montré ici mais il indiquait
bien une adresse @afnic.fr).
Il est également important de se souvenir que DMARC ne fait
qu'authentifier le
domaine, il ne garantit pas que le message soit sincère, sûr, utile ou quoi
que ce soit d'autre. Si on reçoit un message de
Trump, on peut prouver qu'il vient bien de
whitehouse.gov mais il sera quand même
certainement mensonger. C'est pour cela qu'il est absurde, comme on
le lit dans certains forums, de dire « je ne comprends pas, j'ai
bien mis un enregistrement DMARC et mes messages finissent quand
même dans la boite Spam » : les spammeurs font du DMARC, eux aussi.
L'inverse est vrai aussi, un message légitime et désiré peut parfaitement échouer au test DMARC, d'autant plus, que, comme indiqué plus haut, DMARC casse plusieurs usages légitimes du courrier. Il vaut donc mieux ne pas refuser un message uniquement sur la base d'un échec DMARC mais traiter cet échec comme une indication parmi d'autres. Ce RFC 9989 insiste sur ce point (notamment sa section 7), en mentionnant également le RFC 7960, qui détaille les problèmes venant de l'utilisation de DMARC.
La section 2 du RFC détaille le cahier des charges de DMARC. Comme avec toutes les solutions de sécurité, il faut garder en tête ce cahier des charges lorsqu'on évalue DMARC. Aucune solution de sécurité n'est parfaite : elles collent simplement plus ou moins bien à leur cahier des charges. Celui-ci, en résumé, est :
- Permettre aux gérants de noms de domaine d'annoncer leur politique d'authentification du courrier et leurs souhaits quant au traitement du courrier qui ne passerait pas cette authentification.
- Fonctionner dans le contexte de l'Internet (donc, sans autorité centrale).
- Traiter uniquement les cas où le message malveillant copie
exactement un nom de domaine qu'on gère. En d'autres termes, les
usurpations utilisant des noms qui ressemblent
(
goog1e.comau lieu degoogle.com) sont hors-sujet. - Authentifier uniquement le nom de domaine qui est dans
l'adresse (RFC 5322, section 3.4). En d'autres termes, dans un
From:« Emmanuel Macron<emmanuel5561@gmail.com>, DMARC ne se préoccupe que dugmail.com, pas duemmanuel5561. - Authentifier uniquement l'adresse, pas le nom affiché (« Emmanuel Macron » dans l'exemple ci-dessus). La section 11.4 rappelle ce point très important.
Un bon cahier des charges a une autre section très importante : celle des non-objectifs, des choses qu'on n'essaie pas de faire. (Regardez les documents commerciaux : ils n'ont jamais l'honnêteté de lister ce qu'ils ne font pas.) Pour DMARC :
- Il ne dit évidemment rien sur les domaines qui ont choisi de ne pas avoir d'enregistrement DMARC dans le DNS. Dit autrement, DMARC est opt-in.
- Il n'essaie pas de s'occuper des autres informations
présentes dans l'en-tête (comme
Reply-To:ouDate:). - Il ne s'occupe pas des tricheries sur le nom affiché, comme
dans l'exemple « Emmanuel Macron » plus haut (ou bien, tiré de ma
boite Spam
From: "amendes.gouv.fr" <amendes-gouv-nepasrepondre.C9717A5D-EA39-D865-765A6C98B4A0BB03@therugest.com>). Tant pis pour ceux et celles qui s'obstinent à utiliser un logiciel qui, par défaut, n'affiche que ce nom (Outlook fait encore ça). Relisez la section 11.4 du RFC. - Et naturellement, DMARC ne s'occupe pas du contenu du message, qu'il soit mensonger (« je suis l'ex-ministre des finances du Nigéria ») ou malveillant (logiciel qui va tenter d'exploiter une faille de sécurité pour prendre le contrôle de votre ordinateur).
Par exemple, voici un spam, prétendant venir de l'ANTAI mais qui passe tous les tests (le nom de domaine dans l'adresse n'a rien à voir avec l'ANTAI mais beaucoup d'utilisateurs n'y feront pas attention, et ce nom avait bien un enregistrement DMARC) :
Authentication-Results: mail.bortzmeyer.org; dmarc=pass (p=quarantine dis=none) header.from=rtm.gov.my
Authentication-Results: mail.bortzmeyer.org;
dkim=pass (2048-bit key; secure) header.d=rtm.gov.my header.i=@rtm.gov.my header.a=rsa-sha256 header.s=rtm
header.b=MaKApt+s;
dkim-atps=neutral
DKIM-Signature: v=1; a=rsa-sha256; c=relaxed/relaxed;
d=rtm.gov.my; s=rtm; t=1775231898; x=1775836698; darn=bortzmeyer.org;
h=content-transfer-encoding:mime-version:subject:message-id:to:from
:date:from:to:cc:subject:date:message-id:reply-to;
bh=L6c3f6fDBrQyBjkO1RiiF3vHHNmYjLDd4A1urn+cNJg=;
b=MaKApt+s0vgkVsgh3VoFE0/MgCt8ilWkghyQKUbj2NnhgInADkR8G3aW0UbklkuDDV
…
Authentication-Results: mail.bortzmeyer.org; spf=pass (sender SPF authorized) smtp.mailfrom=rtm.gov.my
(client-ip=2607:f8b0:4864:20::f64; helo=mail-qv1-xf64.google.com; envelope-from=antai.gouv.fr@rtm.gov.my;
receiver=bortzmeyer.org)
Subject: ACTION REQUISE SOUS 24H
From: "Antai.gouv.fr" <Antai.gouv.fr@rtm.gov.my>
La section 3 du RFC décrit les termes utilisés par DMARC, entre autres :
- Domaine de l'auteur : ce qui est après
l'arobase dans l'adresse indiquée par le
champ
From:de l'en-tête (rappel : pas celui de l'enveloppe). - Domaine DKIM : celui indiqué par le paramètre
d=dans la signature DKIM (rappel : le domaine DKIM peut n'avoir aucun rapport avec l'adresse de l'en-tête ou avec celle de l'enveloppe). - Domaine SPF : ce qui est après
l'arobase dans l'adresse indiquée par le
champ
Fromde l'enveloppe (rappel : pas celui de l'en-tête). Dans le contexte de DMARC, ce terme ne s'applique pas au domaine indiqué dans la commande EHLO (ou HELO) de SMTP. - Titulaire du domaine : la personne physique ou morale qui décidé d'enregistrer un nom de domaine et qui le gère ensuite.
- Domaine organisationnel : le domaine au sommet du sous-arbre
qui a la même administration (le RFC 5598
est une bonne lecture ici). Ainsi,
bortzmeyer.orgest le domaine organisationnel demail.bortzmeyer.org. En pratique, c'est souvent le domaine enregistré du RFC 9499, domaine qui a été enregistré auprès d'un registre. - Suffixe public : domaine où le public peut enregistrer un
sous-domaine, par exemple
.froueu.org. Ainsi, dansmail.foobar.eu.org,foobar.eu.orgest le domaine organisationnel eteu.orgle suffixe public, ou domaine d'enregistrement.
Armé de cela (mais il y a d'autres termes, que je présenterai au fur et à mesure), on peut passer à la section 4, qui explique les concepts importants.
DMARC permet à un titulaire de domaine d'annoncer sa politique
d'authentification d'un domaine de l'auteur d'un courrier. On
n'authentifie donc que le domaine, pas toute l'adresse (je l'ai déjà
dit mais c'est important). Et DMARC ne s'intéresse qu'à ce qu'il
appelle le domaine de l'auteur, donc le From:
dans l'en-tête (également appelé « RFC5322.From »). DMARC annonce
juste une politique, l'authentification est faite avec SPF (RFC 7208) ou DKIM (RFC 6376).
Un concept essentiel dans DMARC est celui
d'alignement. Il y a alignement quand le
domaine authentifié par SPF (celui de l'enveloppe, le
« RFC5321.From ») ou par DKIM (celui indiqué dans le
d= de la signature) coïncide avec le domaine de
l'auteur (celui du From: de l'en-tête). Plus
précisément, il peut y avoir un alignement strict (les deux noms de
domaine sont identiques) ou relâché (les deux noms sont dans le même
domaine organisationnel). Le choix se fait dans l'enregistrement
DMARC publié.
Justement, on le publie où ? Via le DNS, dans un enregistrement de type TXT, publié
dans le sous-domaine _dmarc, par exemple :
% dig +short _dmarc.proton.me TXT "v=DMARC1; p=quarantine; fo=1; aspf=s; adkim=s;"
On bénéficie ainsi de toute l'infrastructure,
très fiable et éprouvée, du DNS. Ce sous-domaine
_dmarc figure dans le
registre IANA des noms commençant par un trait bas, créé par le RFC 8552.
Au passage, si vous voulez voir (ou enregistrer), sur un serveur DNS faisant
autorité, uniquement les requêtes DNS pour le sous-domaine
_dmarc, dnscap permet
de le faire facilement :
% dnscap -g -x _dmarc
(Je triche un peu, le -x attrape en effet
davantage que cela mais ça suffit en première approximation.)
Le format exact de l'enregistrement DMARC utilise des doublets clé=valeur, comme celui de DKIM. (Sa description formelle, en ABNF - RFC 5234 - est dans la section 4.8.) Les clés possibles figurent dans un registre IANA. Les plus courantes sont :
v: c'est obligatoirement le premier doublet clé=valeur et il indique la version de DMARC, actuellementDMARC1.p: c'est la clé la plus importante, celle qui indique la politique à appliquer aux messages qui ne passent pas la validation DMARC. Une valeurrejectindique que le titulaire du domaine recommande le rejet des messages invalides (cela ne peut être qu'une recommandation, car le récepteur du courrier reste évidemment libre de sa politique).quarantinerecommande une mise en attente quelque part (un dossier « peut-etre-spam » par exemple). Enfin,noneindique qu'on recommande de ne rien faire. Cela peut être utilisé quand on craint les conséquences de DMARC sur certains usages (cf. RFC 7960) mais qu'on pense que certains récepteurs vont mal traiter les messages des domaines sans DMARC. Ou bien cela peut être utile dans certains audits « de sécurité » qui demandent un enregistrement DMARC, n'importe lequel. Enfin, unp=nonepeut être utilisé lors d'un déploiement progressif de DMARC, quand on veut juste tester, avant de publier une politique plus fasciste. Comme DMARC permet de solliciter l'envoi de rapports d'erreur, unp=nonepeut être accompagné d'une telle sollicitation.sp: commepmais pour les sous-domaines du domaine qui a l'enregistrement DMARC. Les valeurs possibles sont les mêmes que pourp.np: nouveauté, initialement décrite dans le RFC 9091. C'est le traitement à appliquer aux sous-domaines non existants du domaine pour lequel une politique DMARC est publiée. Les valeurs possibles sont les mêmes que pourp.ruf: c'est ainsi qu'on sollicite l'envoi de rapports d'erreur. On indique les URI où envoyer ces rapports (souvent des URI de planmailto:, pour demander des rapports par courrier). Le format des rapports est spécifié dans les RFC 9991, RFC 6651 et RFC 6552.rufdemande un rapport par message invalide,ruapermet de demander des rapports agrégés. Leur format figure dans le RFC 9990.psd: nouveauté de notre RFC, s'il a la valeury, il indique que le domaine est un suffixe public (PSD : Public Suffix Domain), c'est-à-dire un domaine dont les sous-domaines peuvent être délégués à d'autres entités (comme c'est le cas de.reoueu.org).fo: diverses options pour la génération de rapports d'erreur.adkimetadpf: tous les deux peuvent prendre la valeurs(strict) our(relâché, ou laxiste). Ils indiquent si l'alignement duFrom:avec l'identificateur authentifié par DKIM ou SPF doit être strict (les deux identificateurs sont rigoureusement identiques) ou relâché (l'identificateur authentifié peut se contenter d'être dans le même domaine enregistré que celui qui a un enregistrement DMARC). Par défaut, DMARC est laxiste. Notez que cela permet à quelqu'un qui peut utiliser un sous-domaine de se faire authentifier comme étant dans l'apex (section 11.8 du RFC). Demander un alignement strict résout ce problème (mais impose que vous contrôliez bien les sous-domaines).
Les clés inconnues doivent être ignorées, ce qui permet d'en ajouter de nouvelles sans tout casser. La politique pour un éventuel ajout est « Spécification nécessaire » (RFC 8126).
On a parlé du domaine organisationnel, l'apex du domaine testé
par DMARC. C'est en fait une notion administrative, pas technique,
ce qui fait que ce domaine organisationnel n'est pas évident à
identifier dans le DNS. Pour le trouver, l'ancien RFC, le RFC 7489, suggérait de faire appel à une liste de suffixes
publics, comme la PSL (rappel : il n'existe
pas de liste officielle). Notre nouveau RFC suggère une autre
méthode, en remontant l'arbre des noms de domaine. On commence par
le domaine qu'on veut authentifier, et, si on n'y trouve pas de
politique DMARC, on essaie son domaine parent et ainsi de suite,
jusqu'à ce qu'on trouve un enregistrement DMARC. Ainsi, pour
truc.machin.example.com, on essaiera
successivement _dmarc.truc.machin.example.com,
_dmarc.machin.example.com,
_dmarc.example.com et enfin
_dmarc.com. La dernière requête permet donc au
registre de
.com de définir une
politique DMARC qui s'appliquera à tous les domaines sans politique
DMARC. C'est très dangereux, pour les raisons expliquées dans le
RFC 1535 mais cela permet de se passer de
liste de suffixes publics, et c'est plus souple pour le cas des
grosses organisations, qui peuvent avoir des politiques DMARC dans
des sous-domaines qui ne sont pas délégués.
Notez que l'éventuelle présence de la clé
psd va compliquer les choses mais je n'ai pas
vraiment le courage de détailler ici l'algorithme complet.
Maintenant, voyons quels sont les acteurs d'un déploiement de
DMARC. D'abord, le titulaire du domaine qui envoie des messages. Il
doit publier un enregistrement SPF à l'apex du domaine. Il doit
signer les courriers sortants avec DKIM (ce qui implique de publier
les clés publiques DKIM dans le DNS). Notez que DMARC n'a pas besoin
de SPF et de DKIM, un seul des deux suffit
mais, bon, autant tout faire. Il a intérêt à créer une boite dédiée
pour recevoir les rapports sur les messages invalides. Le titulaire
doit enfin publier dans le DNS l'enregistrement DMARC (celui qui
commence par _dmarc). Au début, on utilise
typiquement une politique indulgente
(p=none). Puis on teste.
Comment teste-t-on ? En lisant les rapports indiquant des
messages invalides (RFC 9990 et RFC 9991). Les
rapports agrégés sont du
XML, assez
lisibles par un humain mais, en pratique, on préférera typiquement
utiliser un programme qui les synthétisera dans une forme plus
lisible. (Je n'utilise pas actuellement un tel programme, car je
n'en ai pas trouvé. Il faut qu'il tourne en local - pas question de
confier les rapports à un tiers - et ne nécessite pas d'installer
toute une batterie de cuisine PHP et MariaDB.)
Une fois qu'on a trouvé les problèmes (une application oubliée dans
un coin qui envoie des courriers sans passer par les serveurs
centraux…) et qu'on les a corrigés, on peut durcir la politique
(p=quarantine, par exemple). Il est raisonnable
d'attendre plusieurs semaines, voire mois, pour être sûr d'avoir vu
tous les problèmes.
(Et si vous êtes gérant d'un suffixe public - un domaine sous
lequel d'autres entités peuvent enregistrer des noms, demandez-vous
si vous devez publier du DMARC avec psd=y. Ce
n'est pas obligatoire, cf. section 5.2.)
Et le récepteur du courrier, que doit-il faire ? Il extrait du message le domaine de l'auteur. Il cherche s'il y a un enregistrement DMARC. Il exécute les tests SPF et DKIM. S'il récupère un ou plusieurs domaines authentifiés, il vérifie l'alignement (strict ou relâché). Si au moins un domaine authentifié est aligné avec le domaine de l'auteur, le test DMARC est un succès. Sinon, c'est un échec. Notez bien qu'il n'est pas nécessaire que SPF et DKIM réussissent tous les deux. Si le test DMARC se termine en échec, on applique un traitement, qui dépend de la politique suggérée dans l'enregistrement DMARC, et de la politique propre du receveur. Voici un exemple où DMARC dit que tout s'est bien passé :
From: "Projet Arcadie" <admin@projetarcadie.com>
Authentication-Results: mail.bortzmeyer.org; dmarc=pass (p=none dis=none) header.from=projetarcadie.com
Authentication-Results: mail.bortzmeyer.org;
dkim=pass (2048-bit key; unprotected) header.d=projetarcadie.com header.i=@projetarcadie.com header.a=rsa-sha256 header.s=alternc
header.b=plrnZlsJ;
dkim=pass (2048-bit key) header.d=projetarcadie.com header.i=@projetarcadie.com header.a=rsa-sha256 header.s=alternc
header.b=m84VgM5U;
dkim-atps=neutral
Authentication-Results: mail.bortzmeyer.org; spf=pass (sender SPF authorized) smtp.mailfrom=projetarcadie.com (client-ip=91.194.60.11;
helo=arcadieweb01.octopuce.fr; envelope-from=admin@projetarcadie.com; receiver=bortzmeyer.org)
Ici, il y avait un enregistrement SPF (qui autorise l'émetteur
SMTP
donc cela suffit), deux signatures DKIM, toutes les deux correctes,
il y a alignement strict, et donc DMARC passe, il n'y a aucun doute
que le domaine émetteur était bien
projetarcadie.com. (La politique DMARC était
p=none donc un éventuel échec n'aurait sans
doute pas eu beaucoup de conséquences.)
Ici, DKIM a échoué (pourquoi ? mystère mais c'est peut-être la faute de SpamAssassin qui a modifié le sujet, il faudrait que je vérifie ma configuration) mais SPF réussit (le message vient bien de Gmail) donc DMARC est content (il s'agissait bien d'un spam, tentative d'escroquerie financière) :
Authentication-Results: mail.bortzmeyer.org;
dkim=fail reason="signature verification failed" (2048-bit key; unprotected) header.d=gmail.com header.i=@gmail.com
header.a=rsa-sha256 header.s=20230601 header.b=K6F+sj7y;
dkim-atps=neutral
Authentication-Results: mail.bortzmeyer.org; dmarc=pass (p=none dis=none) header.from=gmail.com
Authentication-Results: mail.bortzmeyer.org; spf=pass (sender SPF authorized) smtp.mailfrom=gmail.com
(client-ip=2a00:1450:4864:20::133; helo=mail-lf1-x133.google.com; envelope-from=mrsbalex@gmail.com;
receiver=sources.org)
From: "Mr. Mike Christopher" <mrsbalex@gmail.com>
Et ici, un échec, SPF est correct, il n'y a pas de signature DKIM
et il n'y a pas d'alignement des domaines, la tentative du spammeur
pour se faire passer pour saison.co.jp échoue :
From: 株式会社クレディセゾン <admin@saison.co.jp>
Authentication-Results: mail.bortzmeyer.org; dmarc=fail (p=none dis=none) header.from=saison.co.jp
Authentication-Results: mail.bortzmeyer.org; spf=pass (sender SPF authorized) smtp.mailfrom=zh-cht-jjb.com (client-ip=34.130.185.194;
helo=zh-cht-jjb.com; envelope-from=admin@zh-cht-jjb.com; receiver=bortzmeyer.org)
Et ici, l'émetteur tente de faire croire qu'il vient de
Gmail mais l'enregistrement SPF de
Gmail se termine par un ~all, son
adresse IP n'y est pas listée et il n'y a pas de signature DKIM dans
le message. Même pas besoin de tester l'alignement puisqu'il n'y a
pas de domaine authentifié du tout :
From: Axel.Bouvier <mailrmicro+Axel.Bouvier@gmail.com>
Authentication-Results: mail.internatif.org; dmarc=fail (p=none dis=none) header.from=gmail.com
Authentication-Results: mail.internatif.org; spf=softfail (domain owner discourages use of this host)
smtp.mailfrom=gmail.com (client-ip=78.246.109.210; helo=gmail225.com;
envelope-from=mailrmicro+axel.bouvier@gmail.com; receiver=internatif.org)
De nombreux autres exemples, avec succès ou échec, figurent dans l'annexe B du RFC.
C'est pas mal si le récepteur de courrier qui fait tourner DMARC
en profite pour générer les rapports (RFC 9991), s'ils sont
demandés (par un ruf ou un
rua dans l'enregistrement DMARC de
l'envoyeur). Néanmoins, le RFC note qu'il peut ne pas le faire, s'il
craint pour la vie privée (cf. section 10) ou tout simplement si ça
lui consomme trop de ressources.
D'ailleurs, le RFC insiste bien sur un point que j'avais déjà mentionné : la décision finale (de livrer le message, ou de le mettre dans le dossier Spam ou de le jeter) revient toujours au destinataire (section 5.4). Celui-ci applique la politique qu'il veut. Il serait ridicule de croire que, parce qu'on a SPF, DKIM et DMARC bien configurés, nos messages seraient systématiquement livrés. Après tout, un spammeur peut en faire autant.
À l'inverse, un récepteur peut parfaitement décider d'acheminer jusqu'à ses utilisateurices un message qui échoue aux testes DMARC, par exemple parce qu'il a lu le RFC 7960 (et la section 7.4 de notre RFC) et qu'il sait que DMARC échoue dans des cas d'usage pourtant légitimes, notamment les listes de diffusion. DMARC fournit de la traçabilité et de la responsabilité, il n'est pas un oracle tout-puissant sur l'authenticité du message.
La section 7 du RFC est surtout intéressante pour les historien·nes et pour les technicien·nes qui veulent comprendre les choix faits par DMARC. C'est un pot-pourri de diverses discussions.
D'abord, SPF. SPF a été conçu pour être utilisable
pendant la session SMTP, parfois avant même que l'en-tête du
message ait été transmis. Une politique SPF « dure » (se terminant
en -all) peut amener au rejet du message avant
que DMARC n'ait été évalué. Ainsi, si un message échoue en SPF mais
réussit en DKIM, normalement, DMARC réussirait. Mais, si le test SPF
mène à un rejet dès la session SMTP, le message n'arrivera
pas. Attention donc en configurant vos enregistrements SPF. (Relisez
les « M3AAWG Best
Practices for Managing SPF Records » et
« M3AAWG
Email Authentication Recommended Best
Practices ».)
Et à propos de rejet précoce (dans le cours de la session SMTP, avant d'avoir accepté le message) : le RFC recommande cette méthode car elle évite la génération d'un avis de non-remise (RFC 3464), avis qui irait sans doute à un innocent si l'adresse était usurpée. Deux façons de mettre en œuvre ce rejet précoce, en renvoyant un code d'erreur (commençant par 5 RFC 5321, section 4.2.5) au client SMTP, qui saura ainsi que son message a été refusé, ou, plus méchamment, en prétendant que le message a bien été reçu (code commençant par 2) mais en le jetant silencieusement. La deuxième solution est évidemment horrible (le serveur SMTP ment, l'émetteur ne sait pas ce qui s'est passé, le déboguage devient très difficile) mais elle est parfois nécessaire pour éviter le backscatter, l'envoi de messages d'erreur à un innocent, une des plaies du spam qui usurpe votre adresse. Et elle évite de donner des informations à quelqu'un qu'on estime être un usurpateur.
Contrairement à ce qu'on voit dans certains
articles pro-DMARC imprudents qui promeuvent DMARC sans
insister sur ses limites et ses faiblesses, notre RFC précise bien
qu'il y a des cas où DMARC pose problème (sections 7.3 et 7.4). Par
exemple, citant le RFC 7960, il rappelle que
DMARC peut casser des cas d'usage légitimes comme les adresses
d'anciens élèves que certaines universités fournissent (en faisant
suivre automatiquement le courrier à l'adresse actuelle), comme des
alias où le courrier vers une même adresse est distribuée à
plusieurs personnes, qui ne sont pas forcément dans le même domaine,
ou comme les listes de
diffusion. Pour les deux premiers cas, des solutions
relativement simples existent (réécrire l'enveloppe pour ne pas
casser SPF, ce qui est de toute façon une bonne pratique car
l'envoyeur du message ne saurait pas quoi faire si la vraie adresse
finale ne marcherait pas) et ne pas du tout toucher au message, pour
éviter de casser DKIM), pour les listes de diffusion, c'est plus
délicat. En pratique, plusieurs gestionnaires de liste adoptent la
solution très intrusive de réécrire le champ
From: comme ici dans ce message envoyé à une
liste de l'OARC (le vrai
From: a été reporté en
Reply-To:) :
Authentication-Results: nic.fr;
spf=pass smtp.mailfrom=dns-operations-bounces@dns-oarc.net;
dmarc=pass header.from=dns-oarc.net
Reply-To: Walter Russo <walter@secureme.it>
From: Walter Russo via dns-operations <dns-operations@dns-oarc.net>
Le problème est évidemment particulièrement sérieux si on a une
politique DMARC restrictive (p=reject) et le
RFC conseille fortement dans ce cas de systématiquement signer avec
DKIM, pour éviter de compter sur le seul SPF (qui sera cassé par les
serveurs qui font suivre un message sans réécrire l'enveloppe). Et
il rappelle aux récepteurs de courrier qu'il est très imprudent de
rejeter un message sur la seule base de DMARC. Ces consignes, qui ne
sont pas toujours respectées par les serveurs actuels, sont
cruciales pour le bon fonctionnement du courrier. Le RFC note bien
ce problème de filtrage excessif et explique que c'est ce qui a mené
plusieurs gestionnaires de liste à tripoter le champ
From:, par exemple en changeant le vrai champ
bob@example.com en un
bob=example.com@user.somelist.example, où on
peut toujours retrouver la vraie adresse. (On ajoute également
parfois un Reply-To: indiquant la vraie adresse
de l'expéditeur, comme dans l'exemple ci-dessus.) Le RFC n'approuve
pas cette modification mais note qu'elle est répandue et qu'il faut
faire avec. Il existe des solutions techniquement plus propres comme
le ARC du RFC 8617 mais que presque personne
n'utilise.
En résumé, pour faire du DMARC complet, l'émetteur du courrier devrait idéalement :
- Produire des messages qui auront un identificateur SPF aligné avec le domaine de l'auteur (une exigence qui me parait très excessive),
- produire des messages avec une signature DKIM valide et alignée,
- configurer une boite aux lettres qui recevra les rapports,
- publier l'enregistrement DMARC (je rajoute : après avoir soigneusement testé les trois points précédents),
- ne pas compter sur le seul SPF.
Et le receveur devrait idéalement :
- Tester s'il y a un enregistrement DMARC pour le domaine de l'auteur,
- tester s'il y a des identificateurs authentifiés par SPF ou DKIM,
- tester si au moins l'un d'entre eux est aligné avec le domaine de l'auteur,
- déterminer ainsi si le résultat final est pass ou fail,
- envoyer des rapports, si demandé,
- ne pas rejeter des messages juste parce
qu'il y a eu un échec DMARC, même si la politique de l'émetteur
est
p=reject.
La section 11 du RFC creuse les questions de sécurité. Que faut-il savoir pour utiliser DMARC de manière sûre ? D'abord, DMARC est évidemment dépendant des mécanismes d'authentification utilisés, SPF et DKIM (le groupe de travail IETF avait même envisagé de supprimer SPF, considéré comme trop permissif). Si vous publiez votre clé privée DKIM, DMARC ne pourra rien pour vous. Et SPF, DKIM et DMARC dépendent tous les trois du DNS donc il est crucial de gérer ses serveurs DNS sérieusement. Malheureusement, les RFC sur ces trois techniques n'imposent pas DNSSEC (RFC 9364) mais ils devraient : sans DNSSEC, l'envoi de fausses informations dans le DNS est plus facile. Compter sur SPF, DKIM et DMARC sans avoir DNSSEC me semble peu sérieux mais, bon, le vrai but de la cybersécurité est de réussir l'audit de conformité, pas d'améliorer la sécurité concrète. D'autre part, l'examen du trafic DNS (qui n'est pas limité aux deux parties qui s'envoient du courrier) donne des informations sur le trafic. Utiliser DoT (RFC 7858) ou DoH (RFC 8484) peut donc être une bonne idée.
Comme toujours en ingénierie, d'autres solutions techniques auraient été possibles. L'annexe A de notre RFC examine certaines de ces alternatives et explique pourquoi elles n'ont pas été retenues. Ainsi, on aurait pu utiliser S/MIME (RFC 8551) pour signer le message, ajoutant cette technique à SPF et DKIM. Mais S/MIME a un cahier des charges différent de celui de DMARC, il vise plutôt à une authentification de bout en bout du message entier. Et puis il faut bien constater qu'en dehors de quelques environnements bureaucratiques fermés, personne n'utilise S/MIME. C'est en partie dû à la nécessité d'une PKI, dont le RFC note qu'elle a été souvent promise mais ne s'est jamais matérialisée. (Curieusement, le RFC ne cite pas OpenPGP - RFC 9580 - qui est pourtant nettement plus utilisé que S/MIME.)
Une autre décision de conception cruciale de DMARC est le fait d'accepter n'importe quelle technique d'authentification ; SPF ou DKIM, c'est pareil pour lui. Il a pourtant été souvent proposé de permettre au titulaire du domaine de spécifier, dans l'enregistrement DMARC, de préciser qu'on ne veut que SPF, ou que DKIM. Mais DMARC est assez compliqué comme cela et la décision a finalement été de permettre l'une ou l'autre des méthodes d'authentification. Débrouillez-vous pour qu'au moins une (et de préférence les deux) fonctionne.
Un point essentiel de DMARC est qu'il authentifie l'expéditeur
(plus exactement son alignement) en
considérant que l'expéditeur est indiqué par le champ
From: de l'en-tête. Cela casse bien des usages
légitimes (comme les listes de diffusion). Ne serait-il pas
préférable d'authentifier un champ plus technique comme
Sender: (RFC 5322,
section 3.6.2) ? Cela avait même été spécifié dans le RFC 4870, puis retiré. Finalement, le choix a été
de se concentrer sur From: puisqu'il est le
seul à être toujours montré à l'utilisateur. (SPF, comme DKIM,
peuvent authentifier un identificateur que l'utilisateur ordinaire
ne voit pas.)
Notre RFC 9989 introduit une nouvelle clé,
np, qui spécifie la politique à appliquer aux
sous-domaines non existants du domaine authentifié. Cela soulève le
problème de la définition de non existant. Le RFC dit que cela
inclut les réponses NXDOMAIN (No Such Domain),
évidemment, mais pas forcément les réponses NOERROR où la section
Réponses est vide, car le nom existe mais ne contient ni
enregistrement MX, ni enregistrement d'adresse (A ou AAAA). Ce test
de la présence de certains types d'enregistrement est déjà
couramment utilisé en pratique (il n'y a aucune raison d'accepter du
courrier d'un domaine qui ne permettrait pas les réponses) mais le
RFC ne l'impose pas. Et, sinon, le RFC rappelle que, si une requête
pour un domaine renvoie NXDOMAIN, tous ses sous-domaines n'existent
pas non plus (RFC 8020).
Évidemment, un débat ancien et récurrent pour DMARC est celui des
frontières organisationnelles. Comment sait-on si
cis.cnrs.fr dépend de la même autorité que
cnrs.fr (ou bien
pick.eu.org et eu.org). Il
n'y a pas de réel moyen de trouver cette information dans le
DNS. (On peut trouver les frontières techniques
en demandant l'enregistrement de type SOA. Mais cela ne donne pas
les frontières
administratives. gouv.fr
n'est pas géré par la même organisation que fr,
même s'ils sont dans la même zone.) Des efforts ont été faits à
l'IETF
pour résoudre ce problème mais sans
résultat. L'ancien RFC DMARC, le RFC 7489 suggérait d'utiliser une liste de suffixes d'enregistrement mais
notre RFC 9989 a finalement préféré une autre méthode,
la « montée à l'arbre » (on grimpe l'arbre des noms de domaine,
cherchant des enregistrements DMARC).
Passons à la pratique, maintenant. OpenDMARC est aujourd'hui très répandu, aussi bien côté envoyeur que côté récepteur, et apparait souvent dans les articles de marketing « comment s'assurer que votre spam pardon votre newsletter sera bien livrée partout ». Sur mon serveur de messagerie personnel, j'annonce une politique DMARC et, pour valider les messages entrants, j'utilise OpenDMARC (notez que son développement semble bien avoir stoppé et qu'il y a donc peu de chances qu'il prenne en compte les nouveautés de ce RFC). Ma configuration est très proche de celle par défaut :
Socket inet:54321 # Les autres ont leur valeur par défaut
Et Postfix le lance ainsi, juste après DKIM :
smtpd_milters = unix:run/opendkim.sock, inet:localhost:54321
Et c'est ainsi que sont produits les champs
Authenticated-Results: que vous avez vus.
Pour apprendre DMARC, je recommande l'excellent et interactif https://www.learndmarc.com/
Le chemin vers ce RFC a été très long (plusieurs années). L'annexe C du RFC résume les changements depuis le précédent RFC, le RFC 7489. Les principaux sont :
- Nouvel algorithme (« montée dans l'arbre » pour trouver le domaine organisationnel, au lieu de l'utilisation d'une liste de suffixes publics). C'est la suite du RFC 9091.
- Introduction de nouveaux concepts comme le PSD (Public Suffix Domain) et le PSO (Public Suffix Operator).
- Le RFC n'est plus seulement « Pour information », il passe sur le chemin des normes.
- Plusieurs nouvelles clés sont possibles dans
l'enregistrement DMARC :
np,psdett. - Mise à l'écart de certaines clés comme
pct(partiellement remplacé part). - Résolution des erreurs du précédent RFC.
Les articles suivants sont de bonnes lectures pour les nouveautés de DMARC :
L'article seul
RFC 9987: SSH Agent Protocol
Date de publication du RFC : Mai 2026
Auteur(s) du RFC : D. Miller (OpenSSH)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF sshm
Première rédaction de cet article le 28 mai 2026
Voici encore un RFC qui normalise quelque chose qui existait depuis longtemps : le protocole Agent de SSH.
SSH est normalisé dans le RFC 4251 et il permet la connexion à distance (RFC 4253) avec authentification (RFC 4252 et RFC 4254) par exemple avec une clé publique. Il est probablement inutile de le présenter davantage aux lecteurices de ce blog. Une des fonctions géniales de SSH est la possibilité d'avoir un agent (rien à voir avec l'IA agentique qui est à la mode en ce moment) qui mémorise les clés privées et peut effectuer les opérations demandées. Ainsi mémorisées, les clés seront utilisables sans nouvelle intervention de l'utilisateur (taper une phrase de passe, etc) tout en restant bien sécurisées. Et l'agent peut intervenir sur des connexions distantes, ce qui évite de copier sa clé privée sur des serveurs à qui on ne fait pas forcément totalement confiance. L'agent ne tourne pas dans le client SSH mais dans un processus dédié, ce qui améliore sa sécurité. Si vous êtes connecté en ce moment, vous avez sans doute un agent SSH qui tourne (ici sur une Debian) :
% ps uxwww | grep ssh bortzme+ 459934 0.0 0.0 10700 4964 ? Ss 09:44 0:00 /usr/bin/ssh-agent /home/bortzmeyer/.xsession
Comme indiqué au début, ce mécanisme d'agent est connu, mis en œuvre
et utilisé depuis très longtemps, ce RFC est une documentation a posteriori (le très ancien document
draft-ietf-secsh-agent
décrivait un protocole différent).
Donc, comment fonctionne ce protocole Agent (section 2 du RFC) ? Il est client-serveur, le serveur étant l'agent et le client de l'agent n'étant pas forcément un client SSH (mais, bon, c'est le cas le plus courant). Le client envoie des requêtes à l'agent et reçoit des réponses (comme dans beaucoup de protocoles réseau…). L'agent est un serveur pur, il ne fait que répondre au client, sans prendre d'initiatives. Les requêtes typiques sont le chargement d'une clé, la suppression d'une clé, la signature en utilisant une des clés. Le serveur reste maitre d'accepter ou pas les requêtes et le client doit donc être prêt à voir une requête refusée, par exemple parce que l'agent n'accepte que les clés d'un certain type.
La section 3 du RFC détaille les messages échangés entre le
client et l'agent (le serveur). Ils sont de type TLV et les types figurent dans
un
registre IANA. La longueur peut être nulle, par exemple il
existe des messages de type SSH_AGENT_FAILURE
(type numérique 5) qui n'ont pas de valeur. Le client demande
l'ajout d'une clé avec des messages de type
SSH_AGENTC_ADD_IDENTITY (type numérique 17). La
valeur est composée du type de la clé, de la clé elle-même et du
commentaire que vous avez indiqué lors de la création de la clé ; si
vous utilisez, par exemple, une clé Ed25519,
cf. RFC 8709, le type est
ssh-ed25519 (la liste est dans un
registre IANA). Avec OpenSSH, vous
trouverez ce commentaire dans
~/.ssh/id_ed25519.pub.
De la même façon,
on peut retirer une clé avec les messages de type
SSH_AGENTC_REMOVE_IDENTITY (type 18) et
SSH_AGENTC_REMOVE_ALL_IDENTITIES (type 19).
Une fois les clés dans l'agent, le client peut lui demander de
signer avec le type de
message SSH_AGENTC_SIGN_REQUEST (type 13),
message qui comprendra les données à signer.
Pour se
connecter à l'agent (section 4 du RFC), le client doit utiliser une
méthode sûre. Èvidemment pas question d'ouvrir l'agent à tout
l'Internet. Sur Unix, la méthode la plus
courante est d'utiliser une prise locale. Souvent, elle est trouvée
par une variable d'environnement définie lors
de la connexion, en général
SSH_AUTH_SOCK. C'est ce que fait
OpenSSH mais ce n'est pas imposé par la
norme, qui laisse le choix aux programmes.
Voici un exemple avec OpenSSH :
# On lance l'agent (on aurait normalement utilisé eval ou un # équivalent, pour définir la variable d'environnement) : % ssh-agent SSH_AUTH_SOCK=/tmp/ssh-xrLh0tnpVwLF/agent.23934; export SSH_AUTH_SOCK; SSH_AGENT_PID=23935; export SSH_AGENT_PID; echo Agent pid 23935; % ls -l /tmp/ssh-ZzouiZGBumyI/agent.23934 srw------- 1 stephane stephane 0 May 4 18:38 /tmp/ssh-ZzouiZGBumyI/agent.23934 % SSH_AUTH_SOCK=/tmp/ssh-xrLh0tnpVwLF/agent.23934; export SSH_AUTH_SOCK % ssh -vvv SERVEUR-DISTANT … debug1: Next authentication method: publickey debug3: ssh_get_authentication_socket_path: path '/tmp/ssh-xrLh0tnpVwLF/agent.23934' debug1: get_agent_identities: bound agent to hostkey debug1: get_agent_identities: ssh_fetch_identitylist: agent contains no identities [Et si on ajoute une clé dans l'agent ?] % ssh-add ~/.ssh/id_ed25519 Enter passphrase for /home/stephane/.ssh/id_ed25519: Identity added: /home/stephane/.ssh/id_ed25519 (stephane@foobar) % ssh -vvv SERVEUR-DISTANT … debug1: Next authentication method: publickey debug3: ssh_get_authentication_socket_path: path '/tmp/ssh-xrLh0tnpVwLF/agent.23934' debug1: get_agent_identities: bound agent to hostkey debug1: get_agent_identities: agent returned 1 keys
Autre possibilité très intéressante de l'agent (section 5), on peut faire suivre les communications sur un canal SSH (un peu comme avec X11). Cela permet, lorsque la machine A se connecte à la machine B puis à la C, d'utiliser les clés de la machine A pour s'authentifier sur la machine C. Cela utilise le mécanisme d'extension à SSH qui avait été normalisé dans le RFC 8308 pour signaler qu'on gère cette possibilité (mais comme le protocole Agent existait avant ce RFC, certains programmes n'annoncent pas cette gestion). La section 9 du RFC rappelle toutefois que cette fonction, si pratique, crée de nouveaux risques puisque elle introduit une relation de confiance transitive. Le RFC exige donc qu'elle ne soit pas activée par défaut.
Le protocole a entrainé la création de cinq nouveaux registres IANA (section 7), dont celui des types de messages (pour en ajouter un, politique « Examen par un expert », cf. RFC 8126.)
Un petit mot sur la sécurité (section 8 du RFC) puisqu'après tout, SSH est là pour améliorer notre sécurité. L'agent est chargé de garder des clés privées, il est donc très sensible et doit être de confiance. Mais le RFC rappelle aussi que l'accès à l'agent est évidemment très critique et doit être sécurisé (regardez les permissions de la prise dans l'exemple Unix plus haut), le protocole ne prévoyant aucune authentification.
Si on a accès à l'agent, et qu'il a chargé des clés, on peut
signer ce qu'on veut et donc s'authentifier auprès de serveurs
distants. Par contre, on ne peut pas récupérer de clés privées via
le protocole, qui n'a pas d'opération pour cela. Mais comme l'agent
garde les clés privées en mémoire, il faut faire attention à ce que
personne ne puisse lire cette mémoire. (La page de manuel de OpenSSH
est très nette à ce sujet et conseille d'utiliser plutôt la fonction
ProxyJump, via le -J.)
Ah, et puisque l'agent, lorsqu'il charge une clé, demande la phrase de passe de la clé, il faut aussi qu'il prenne des précautions pour limiter le risque d'une attaque par force brute (quand un attaquant essaie plein de phrases possibles). Par exemple, il peut introduire un délai après une phrase incorrecte.
Le protocole Agent est très ancien et est donc déjà mis en œuvre dans de nombreux programmes, par exemple OpenSSH (depuis 2000 !), PuTTY, Dropbear, Paramiko, la bibliothèque standard de Go, etc.
Si vous voulez afficher les messages échangés entre le client SSH
et l'agent, je ne connais pas
l'équivalent de tcpdump ou
Wireshark pour cela. Avec
OpenSSH, ssh-agent -d
affiche les connexions mais pas les messages. Sinon, on peut lire les
messages échangés avec socat (ici, un exemple
pour OpenSSH sur
Debian) :
[Dans une fenêtre] % ssh-agent -D [Dans une autre] [Copier-coller la première ligne, celle qui définit SSH_AUTH_SOCK] % mv $SSH_AUTH_SOCK /tmp/real-agent.sock % socat -x UNIX-LISTEN:$SSH_AUTH_SOCK,fork UNIX-CONNECT:/tmp/real-agent.sock [Dans une troisième] [Copier-coller la première ligne, celle qui définit SSH_AUTH_SOCK] % ssh un-serveur
Mais les messages seront bruts, sans formatage. À vous de les décoder.
Par exemple, ici,suite à un ssh-add, on voit :
> 2026/05/11 17:47:13.000145101 length=142 from=1152 to=1293 00 00 00 8a 11 00 00 00 … < 2026/05/11 17:47:13.000146117 length=5 from=10 to=14 00 00 00 01 06
(Pour décoder, référez-vous au RFC, section 3, et au registre
IANA.) Le premier message (après le >) a une longueur de 138 octets (les
quatre premiers octets, 0000008A, nous le disent, socat l'affiche
mais lui ajoute les quatre octets de la longueur). Le type du
message (indiqué par l'octet suivant) est 17,
SSH_AGENTC_ADD_IDENTITY. L'agent répond (après
la <) par un message d'un seul octet, de type 6
(SSH_AGENT_SUCCESS) et de contenu nul. Si je me
connecte en SSH à un serveur, en utilisant la clé qui vient d'être
chargée, j'ai :
> 2026/05/11 17:59:54.000526321 length=5 from=665 to=669
00 00 00 01 0b
< 2026/05/11 17:59:54.000526468 length=535 from=5 to=539
00 00 02 13 0c 00 00 00 …
> 2026/05/11 17:59:54.000609874 length=1017 from=670 to=1686
00 00 03 f5 0d 00 00 01 …
< 2026/05/11 17:59:54.000615719 length=285 from=540 to=824
00 00 01 19 0e 00 00 01 14 …
Le premier message, très court, est de type 11,
SSH_AGENTC_REQUEST_IDENTITIES, il obtient une
réponse 12 (SSH_AGENT_IDENTITIES_ANSWER), puis
le client SSH demande une signature avec la clé privée que stocke
l'agent (type 13,
SSH_AGENTC_SIGN_REQUEST) et a une réponse (type
14, SSH_AGENT_SIGN_RESPONSE).
Enfin, le fichier ./PROTOCOL.agent dans le source
de OpenSSH documente les extensions d'OpenSSH
pour ce protocole agent-client.
L'article seul
RFC 9982: JSContact Version 2.0: A JSON Representation of Contact Data
Date de publication du RFC : Mai 2026
Auteur(s) du RFC : R. Stepanek (Fastmail)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF calext
Première rédaction de cet article le 28 mai 2026
Voici la version 2 du format de représentation d'entités
(personnes ou organisations) JSContact (RFC 9553). En fait, ce numéro de version est trompeur, il n'y
a qu'un seul changement, le membre uid qui
était obligatoire devient facultatif. Mais ce petit changement, qui
casse la compatibilité, oblige à changer de numéro de version.
Dans la section 2.1.9 du RFC 9553,
l'uid (User IDentifier)
était obligatoire. Alors que le vieux format
vCard (RFC 6350) le
disait facultatif, ce qui rendait difficile toute traduction
automatique de vCard vers JSContact. En outre, s'il était cool
d'avoir la garantie d'un identificateur unique pour chaque carte de
visite au format JSContact, cela ne convenait pas dans tous les
cas. Ainsi, RDAP (RFC 9083)
n'utilise pas du tout cette propriété uid.
Donc, seul changement entre les versions 1 et 2, l'attribut
uid devient optionnel. On passe de :
uid: String (mandatory)
à :
*uid: String (optional).*
Mais c'est suffisant pour obliger à changer le numéro de version de JSContact (RFC 9553, section 1.9).
Par exemple, cet object JSContact (qui n'a pas
d'uid) est désormais légal :
{
"@type": "Card",
"version": "2.0",
"name": {"components": [{"kind": "given","value": "Jean"},
{"kind": "surname","value": "Durand"}]},
"emails": {
"email": {
"address": "jean.durand@example.com"
}
}
}
(Avec la version 1, il aurait fallu quelque chose comme
"uid": "a73c940e-b1d3-4f3c-aa50-c9749352c253"
après la version.)
L'article seul
RFC 9980: Post-Quantum Cryptography in OpenPGP
Date de publication du RFC : Juin 2026
Auteur(s) du RFC : S. Kousidis
(BSI), J. Roth, F. Strenzke (MTG
AG), A. Wussler (Proton AG)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF openpgp
Première rédaction de cet article le 1 juillet 2026
Vous le savez, le jour où des CRQC (Cryptographically Relevant Quantum Computer, un calculateur quantique capable de calculs non triviaux, contrairement aux modèles d'aujourd'hui) seront disponibles, la cryptographie sera sérieusement secouée. Il est donc important de travailler dès maintenant sur des algorithmes pour l'après-quantique, et de les intégrer dans les protocoles et les formats utilisés sur l'Internet. Ce RFC documente l'utilisation des algorithmes normalisés par le NIST dans le format OpenPGP.
Le format OpenPGP, utilisé par de nombreux logiciels de cryptographie, est normalisé dans le RFC 9580. La liste des algorithmes de chiffrement n'est pas figée et de nouveaux algorithmes peuvent être disponibles pour ce format. C'est le cas de ceux pour la cryptographie post-quantique, un sujet d'actualité. Les messages chiffrés et/ou signés au format OpenPGP peuvent avoir besoin de résister à la décryption et/ou à l'usurpation pendant de nombreuses années. Aujourd'hui, ces messages utilisent typiquement RSA ou des algorithmes à courbes elliptiques, tous étant vulnérables aux calculateurs quantiques. C'est notamment en raison de cette nécessité de sécurité sur une longue période qu'il ne faut pas attendre que les CRQC soient disponibles pour intégrer les algorithmes post-quantiques à OpenPGP. Il y a peut-être des attaquants qui stockent aujourd'hui des messages OpenPGP, en attendant d'avoir un CRQC pour les lire (ou pour imiter des signatures).
(Rappelons au passage qu'OpenPGP n'est pas utilisé que dans le courrier électronique. Il sert, par exemple, à authentifier le code avec git, ou les paquetages compilés, avec apt et rpm.)
Il ne suffit pas d'ajouter les nouveaux algorithmes aux registres IANA. Il y a des problèmes spécifiques, comme les clés hybrides (une PQ et une classique) et composées (hybrides, mais présentées d'une manière unifiée). En effet, il ne servirait à rien de déployer des algorithmes post-quantiques si ceux-ci étaient cassables par de la cryptanalyse classique. Rien ne dit que ces « nouveaux » algorithmes soient incassables. Et comme ils sont relativement récents, on ne peut pas avoir le même degré de confiance qu'avec RSA ou ECDSA. L'approche la plus courante aujourd'hui, et que ce RFC suit, est d'utiliser une technique hybride : combinaison d'un algorithme traditionnel et d'un algorithme post-quantique. On n'abandonne donc pas RSA ou ECDSA, on les flanque d'un collègue, ce qu'on appelle le PQ/T (post-quantique/traditionnel, cf. section 1.1.1).
Plus précisément, notre RFC utilise des composés, des hybrides PQ/T mais où les deux clés, la post-quantique et la traditionnelle, sont gérées comme une seule. Le RFC 9794 est la bonne lecture, si vous voulez approfondir ces notions d'hybride et de composé et vous avez aussi intérêt à lire le RFC 9958, « Post-Quantum Cryptography for Engineers ».
Quels sont ces nouveaux algorithmes ? La section 1.2 les résume :
- ML-KEM, normalisé dans la norme FIPS-203, pour l'échange de clés préalable au chiffrement,
- ML-DSA, normalisé dans FIPS-204, pour la signature,
- SLH-DSA, normalisé dans FIPS-205, également pour la signature.
Notez que l'algorithme SLH-DSA, lui, est considéré suffisamment sûr pour se passer de l'assistance d'un algorithme traditionnel (il utilise des problèmes mathématiques complètement différents de ceux utilisés par ML-KEM ou ML-DSA). Les deux autres vont être utilisés par OpenPGP avec de la cryptographie traditionnelle, en l'occurrence ECDH avec les courbes X25519 et X448 (RFC 7748) et EdDSA (RFC 8032). Pour la vérification d'une signature, les deux (post-quantique et traditionnelle) signatures doivent être valides (cf. sections 3 et 5.2.3). Pour le chiffrement, les deux clés obtenues doivent être utilisées.
Le format OpenPGP permet d'avoir plusieurs signatures dans un message mais ces signatures parallèles sont différentes des clés composées utilisées pour le PQ/T car le succès d'une seule signature suffit à la validation. (Idem pour le chiffrement, cf. section 3.) Évidemment, le système n'est résistant aux CRQC que si toutes les signatures utilisent un algorithme PQ ou PQ/T. Si ces signatures multiples, incluant au moins une clé T (traditionnelle, sans post-quantique) sont moins sûres, elles ont par contre l'avantage d'assurer la compatibilité avec les vieilles versions des logiciels OpenPGP (section 5.2.5 du RFC 9580).
La section 2 du RFC donne la liste exhaustive des algorithmes qui viennent d'être officiellement ajoutés. À partir des trois cités plus haut, il y a quelques variantes, fondées sur la taille de certains paramètres ou sur la courbe elliptique utilisée dans le composé. Ainsi, SLH-DSA a trois variantes, SLH-DSA-SHAKE-128f (f pour fast car il optimise la vitesse), SLH-DSA-SHAKE-128s (s pour short car il optimise la taille) et SLH-DSA-SHAKE-256s. ML-KEM a deux variantes, ML-KEM-768+X25519 et ML-KEM-1024+X448, avec des courbes différentes.
Notez enfin que les clés PQ/T ne doivent être utilisées qu'avec des données OpenPGP des versions 4 ou 6 (et même uniquement version 6 pour ML-KEM-1024+X448 et ML-DSA). Ici, par exemple, GnuPG montre un paquet OpenPGP de version 3, trop vieux pour gérer le post-quantique :
% gpg --list-packets review.txt.gpg … :pubkey enc packet: version 3, algo 1, keyid XXXXXXXXX data: [4096 bits]
Les sections 4, 5 et 6 du RFC expliquent en détail le format des nouvelles clés et comment les utiliser. La section 7 donne des conseils sur les algorithmes de cryptographie symétrique, par exemple qu'il est nécessaire de mettre en œuvre AES-256 (la version à 128 bits est possiblement cassable grâce à l'algorithme de Grover).
Et la migration depuis les anciens algorithmes ? Tous les logiciels qui mettent en œuvre OpenPGP ne vont pas passer au post-quantique en même temps. On aura des messages qui vont passer d'un logiciel récent à un ancien, qui ne pourra pas les lire. La section 8 ajoute des conseils pour bien réussir sa migration. Déjà, un logiciel récent, qui pense que les récepteurs de ses messages seront pré-quantiques peut chiffrer ses messages avec une clé PQ (ou PQ/T) et une clé traditionnelle (chiffrement en parallèle, où une seule clé est nécessaire, et pas en série, comme c'est le cas ave les solutions hybrides citées plus haut, où les deux clés sont nécessaires). Bien sûr, s'il fait cela, le message sera déchiffrable par un calculateur quantique. Il faut donc choisir entre sécurité et interopérabilité (avec les vieux logiciels). PGP étant conçu pour des communications asynchrones (comme le courrier électronique), il n'est pas possible de savoir à l'avance les capacités du récepteur.
Le même problème se pose pour les signatures. Lors d'une vérification de signature, n'importe laquelle des deux signatures sera acceptée (là encore, on parle de signatures séparées, qui ont toujours existé dans OpenPGP, pas des hybrides du PQ/T). Le RFC permet toutefois à un vérificateur paranoïaque, ou simplement un vérificateur qui sait que l'émetteur a une clé PQ ou PQ/T, d'ignorer les signatures traditionnelles.
Enfin, la section 9 du RFC discute un certain nombre de questions de sécurité. Par exemple, elle explique comment les signatures composites du PQ/T ne sont pas vulnérables aux attaques par suppression d'une des signatures (les métadonnées indiquent l'identificateur de l'algorithme hybride).
Quelles sont les mises en œuvre de ces nouveaux algorithmes ? Malheureusement, il semble que GnuPG ne suive pas les récents RFC sur le format OpenPGP (sur cette affaire, lire le point de vue de Debian ou celui d'Arch Linux), entre autre (mais pas uniquement) sur le post-quantique. On va donc tester avec les autres (il existe une liste).
Si vous voulez écrire votre propre programme OpenPGP (ce que je ne conseillerai pas : la cryptographie, c'est difficile, et les bogues ne se voient pas forcément), l'annexe A du RFC, qui fait la grande majorité du RFC, est composée de vecteurs de test.
Les programmes testés sont conformes au
projet de standard SOP et ont donc à
peu près la même interface utilisateur (actuellement en projet, dans
draft-dkg-openpgp-stateless-cli). Souvent, le post-quantique
n'est pas encore intégré dans les versions officielles et il va
falloir changer de branche et compiler.
Commençons avec rsop, écrit en
Rust. Après le
cargo install pgp :
% rsop list-profiles generate-key default: v4 key using Curve25519 (alias: draft-koch-eddsa-for-openpgp-00) compatibility: v4 key using RSA (alias: rfc4880) performance: v6 key using Ed25519/X25519 (alias: rfc9580) security: v6 key using Ed448/X448 (alias: rfc9580-curve448)
Je vous l'avais bien dit : pas de post-quantique. Mais la FAQ dans le code nous le dit « ### Is rPGP adding support for Post Quantum Cryptography (PQC)? Yes, rPGP implements the IETF draft [Post-Quantum Cryptography in OpenPGP](https://datatracker.ietf.org/doc/draft-ietf-openpgp-pqc/), gated behind the feature `draft-pqc`. ». Ah, c'est planqué dans une feature. Compilons :
% cargo install --features draft-pqc rsop % rsop list-profiles generate-key default: v4 key using Curve25519 (alias: draft-koch-eddsa-for-openpgp-00) compatibility: v4 key using RSA (alias: rfc4880) performance: v6 key using Ed25519/X25519 (alias: rfc9580) security: v6 key using Ed448/X448 (alias: rfc9580-curve448) draft-ietf-openpgp-pqc-14-v4-ed25519-mlkem768x25519: TESTING ONLY draft-ietf-openpgp-pqc-14-v6-ed25519-mlkem768x25519: TESTING ONLY draft-ietf-openpgp-pqc-14-v6-mldsa65ed25519-mlkem768x25519: TESTING ONLY draft-ietf-openpgp-pqc-14-v6-mldsa87ed448-mlkem1024x448: TESTING ONLY draft-ietf-openpgp-pqc-14-v6-slhdsashake128s-mlkem768x25519: TESTING ONLY draft-ietf-openpgp-pqc-14-v6-slhdsashake128f-mlkem768x25519: TESTING ONLY draft-ietf-openpgp-pqc-14-v6-slhdsashake256s-mlkem1024x448: TESTING ONLY
Ça marche, on a du post-quantique, utilisons-le :
% rsop generate-key --profile draft-ietf-openpgp-pqc-14-v6-ed25519-mlkem768x25519 > key.asc
OK, on a une clé hybride (ML-KEM et Ed25519). Créeons la clé publique :
% cat key.asc | rsop extract-cert > cert.asc
Et maintenant, on peut chiffrer un fichier avec la clé publique :
% cat hello.txt | rsop encrypt cert.asc > hello.asc
Et le déchiffrer avec la clé privée :
% cat hello.asc | rsop decrypt key.asc Hello, world
Bon, on a tout fait avec le même programme, mais le but d'OpenPGP est l'interopérabilité. Essayons avec un deuxième programme, Sequoia, pour lequel il y a des instructions détaillées pour le compiler avec gestion du post-quantique :
% sudo apt install libsqlite3-dev % git clone https://gitlab.com/sequoia-pgp/sequoia-sq.git % git checkout pqc % cargo build --release --locked --no-default-features --features crypto-openssl
Et utilisons-le pour regarder les fichiers produits par rsop :
% sq inspect key.asc
key.asc: Transferable Secret Key.
Fingerprint: AC7FD6CBD09E90C928C2ED5796A69001B5F0535CE6BF09C227DFE71063006BD0
Public-key algo: Ed25519
Public-key size: 256 bits
Secret key: Unencrypted
Creation time: 2026-02-09 17:36:25 UTC
Key flags: certification, signing
Subkey: 91BED065B7E654656D3354CA16E901D8F8B192874385EB6C325421055AFB5B9E
Public-key algo: ML-KEM-768+X25519
Secret key: Unencrypted
Creation time: 2026-02-09 17:36:25 UTC
Key flags: transport encryption, data-at-rest encryption
Joli, non ? rsop avait bien fabriqué une clé hybride et sq arrive à la lire.
% cat hello.asc | sq decrypt --recipient-file key.asc Encrypted and protected using AES-256/OCB Hello, world Decrypted by AC7FD6CBD09E90C928C2ED5796A69001B5F0535CE6BF09C227DFE71063006BD0, unknown 0 authenticated signatures.
Et Sequoia peut déchiffrer les messages chiffrés par rsop.
% sq inspect --cert-file cert.asc < hello.asc
OpenPGP Certificate.
Fingerprint: AC7FD6CBD09E90C928C2ED5796A69001B5F0535CE6BF09C227DFE71063006BD0
Public-key algo: Ed25519
Public-key size: 256 bits
Creation time: 2026-02-09 17:36:25 UTC
Key flags: certification, signing
Subkey: 91BED065B7E654656D3354CA16E901D8F8B192874385EB6C325421055AFB5B9E
Public-key algo: ML-KEM-768+X25519
Creation time: 2026-02-09 17:36:25 UTC
Key flags: transport encryption, data-at-rest encryption
Et examiner ses clés. rsop et sq étaient tous les deux écrits en Rust donc testons l'interopérabilité avec un programme en Go :
% git clone https://github.com/ProtonMail/gosop.git % cd gosop % git checkout gosop-gopenpgp-v3-pqc % go build % ./gosop list-profiles generate-key default: Generate v4 keys using Curve25519 compatibility: Generate v4 keys using 3072-bit RSA (alias: rfc4880) performance: Generate v6 keys using Ed25519/X25519 (alias: rfc9580) security: Generate v6 keys using Ed448/X448 draft-ietf-openpgp-pqc-09: ML-KEM-768 and ML-DSA-65 draft-ietf-openpgp-pqc-09-high-security: ML-KEM-1024 and ML-DSA-87 draft-ietf-openpgp-persistent-symmetric-keys-00: AEAD and HMAC % ./gosop/gosop decrypt key.asc < hello.asc Hello, world
Et tout se passe bien.
L'article seul
RFC 9975: Clarifications on CDS/CDNSKEY and CSYNC Consistency
Date de publication du RFC : Mai 2026
Auteur(s) du RFC : P. Thomassen (SSE - Secure Systems
Engineering)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 28 mai 2026
Pour compléter un processus de sécurisation des noms de domaine avec DNSSEC, il faut transmettre au domaine parent votre clé publique. Le faire manuellement via l'interface Web du BE n'est pas pratique donc il existe un moyen d'automatiser cela, les CDS/CDNSKEY, moyen décrit dans le RFC 7344. Mais attention à la sécurité ! Ce moyen n'est sûr que si on suit quelques précautions, décrites dans ce nouveau RFC.
Bon, je sais, j'ai simplifié, on ne transmet pas forcément au domaine parent sa clé publique mais parfois un condensat de celle-ci. (Le domaine parent publiera ensuite un enregistrement DS, contenant un condensat que vous aurez donné ou bien qu'il aura calculé à partir de la clé.) Ça ne change pas grand'chose en pratique. Le RFC 7344 décrit comment automatiser le changement de clé en publiant dans son domaine des enregistrements CDS et/ou CDNSKEY, qui informent le parent. (Et le RFC 9615 permet de le faire pour la configuration initiale, pas juste pour un changement.) Avec une technique proche, les enregistrements CSYNC du RFC 7477, on peut aussi automatiser le changement des serveurs de noms faisant autorité.
À partir de là, le gestionnaire du domaine parent (typiquement un registre de noms de domaine) va récupérer ces enregistrements et agir (modifier les enregistrements DS et NS dans son domaine). La façon la plus simple de récupérer les CDS, CDNSKEY et CSYNC est de faire une bête requête DNS classique, donc via son résolveur par défaut :
% dig turris.cz CDS … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 16850 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 … ;; ANSWER SECTION: turris.cz. 5 IN CDS 53148 13 2 9A0E997A2992D4089CE39C1976DC65C00C9D20A6C36187F897E71D6E 23368E6E ;; Query time: 24 msec ;; SERVER: 192.168.2.254#53(192.168.2.254) (UDP) ;; WHEN: Fri Jan 09 11:15:20 CET 2026 ;; MSG SIZE rcvd: 86 % dig alatienne.fr CDNSKEY … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 53877 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 … ;; ANSWER SECTION: alatienne.fr. 3600 IN CDNSKEY 257 3 13 ( mdsswUyr3DPW132mOi8V9xESWE8jTo0dxCjjnopKl+Gq JxpVXckHAeF+KkxLbxILfDLUT0rAK9iUzy1L53eKGQ== ) ; KSK; alg = ECDSAP256SHA256 ; key id = 2371 ;; Query time: 52 msec ;; SERVER: 127.0.0.1#53(127.0.0.1) (UDP) ;; WHEN: Thu Feb 05 16:35:32 CET 2026 ;; MSG SIZE rcvd: 229
Mais cette méthode n'est pas très sûre et nous allons voir pourquoi, et comment arranger les choses.
Ici, la réponse CDS était signée par DNSSEC (le
flag ad, pour
Authentic Data). Mais ce n'est pas toujours le
cas (avec les CSYNC, ou tout simplement lors de la configuration
initiale de DNSSEC, cf. RFC 8078). Le fond du
problème est que les serveurs faisant
autorité pour le domaine qui publie CDS, CDNSKEY ou CSYNC
peuvent être en désaccord. (Ou bien, mais le RFC ne semble pas le
mentionner, il y a eu empoisonnement de la mémoire du résolveur.) Ce
désaccord peut être dû à un piratage d'un des serveurs (ou à une
malveillance de ses opérateurs) mais il peut être aussi le résultat
d'un cafouillage technique
(un serveur ne se synchronisant plus) ou organisationnel, les
serveurs n'étant pas forcément gérés par la même entité. Sans
compter le risque d'une délégation boiteuse (lame
delegation) où un des serveurs listés dans l'ensemble NS
n'est pas censé être serveur pour ce domaine. D'ailleurs, même
DNSSEC ne protège pas dans tous les cas, s'il y a plusieurs signeurs
(RFC 8901), ils peuvent aussi déconner
séparement. Avec le comportement par défaut du résolveur typique
(accepter la réponse du premier serveur faisant autorité qui
répond), un seul des serveurs faisant autorité peut déclencher un
changement de configuration dans le domaine parent. Le cœur de notre
nouveau RFC est
de dire que le logiciel qui récupère CDS/CDNSKEY/CSYNC doit
s'assurer que les serveurs faisant autorité sont
cohérents, qu'ils renvoient tous la même
réponse.
Cela ne peut pas se faire via un résolveur typique, je n'en connais pas qu'on puisse configurer pour faire cela, il faut donc interroger directement les serveurs faisant autorité. Par exemple, pour la requête dig ci-dessus, un moyen de le faire serait, par exemple en shell :
% for ns in $(dig +short turris.cz NS); do dig @$ns +short turris.cz CDS done 53148 13 2 9A0E997A2992D4089CE39C1976DC65C00C9D20A6C36187F897E71D6E 23368E6E 53148 13 2 9A0E997A2992D4089CE39C1976DC65C00C9D20A6C36187F897E71D6E 23368E6E 53148 13 2 9A0E997A2992D4089CE39C1976DC65C00C9D20A6C36187F897E71D6E 23368E6E
Et il faudrait ensuite s'assurer que toutes les réponses sont identiques. Sinon, le domaine parent s'abstient d'agir. (Comme les lecteurs et lectrices de ce blog sont très fort·es en réseau, ielles ont certainement remarqué que j'avais simplifié : comme un serveur peut avoir plusieurs adresses IP, il faudrait les tester toutes. Des exemples de programmes plus perfectionnés figurent par la suite.)
Ces nouvelles règles amènent à mettre à jour quelques RFC, qui ne les spécifiaient pas : les RFC 7344 et la section 3.1 du RFC 7477, qui conseillait de ne demander qu'à un seul serveur faisant autorité (ce que fait le résolveur typique mais qui n'est pas assez sûr).
La section 3 du RFC liste plus formellement les nouvelles exigences :
- Tester la présence et le contenu des CDS/CDNSKEY/CSYNC via toutes les adresses IP des serveurs faisant autorité.
- Toutes les réponses doivent être identiques.
- On peut arrêter le test dès qu'au moins une des réponses correspond au DS/NS existant. Cela veut dire qu'au moins un des serveurs faisant autorité ne veut pas qu'on change.
Si et seulement si toutes les réponses sont identiques, et différentes de la situation actuelle, le gestionnaire du domaine parent peut envisager de modifier NS et DS.
Notez que, si les serveurs faisant autorité utilisent l'anycast, le test ne sera pas complet, le vérificateur de cohérence ne testera qu'une seule instance d'un nuage anycast. Dans ce cas, il peut être intéressant de tester la cohérence depuis plusieurs points de mesure, pour avoir des chances de contacter plusieurs instances anycast.
La même règle s'applique aux enregistrements CSYNC du RFC 7477. La section 3.2 de notre RFC détaille comment traiter ces enregistrements, qui permettent notamment de synchroniser les enregistrements NS du domaine parent (et la colle) avec ceux du domaine fils. Il y a une petite nuance pour le numéro de série de la zone que contient l'enregistrement CSYNC (il doit être identique à celui du SOA du même serveur, pas forcément à ceux des CSYNC des autres serveurs faisant autorité).
La section 5 de notre RFC discute les conséquences pour la sécurité. Si on ne fait pas les vérifications décrites ici, il y a un risque de copier dans la zone parente des données incorrectes, voire créées par un attaquant, par exemple parce qu'il a réussi à pirater un des serveurs faisant autorité ou bien parce qu'il gérait un de ces serveurs mais agissant sans autorisation du gérant de la zone (cas courant si on sous-traite certains de ses serveurs secondaires). Ce RFC privilégie donc l'intégrité des données, au risque, on peut le remarquer, qu'un changement souhaité prenne davantage de temps, si un des serveurs faisant autorité a des problèmes. Que faire si un de ces serveurs ne veut vraiment pas jouer le jeu et, par exemple, ne se synchronise plus et ne publie pas le nouveau CDS/CDNSKEY/CSYNC ? La section 5 dit qu'il faut donc maintenir un canal traditionnel (via le BE, par exemple), pour pouvoir changer quand même les données publiées par la zone parente. C'est par exemple le rôle d'EPP (RFC 5730).
Cette vérification de la cohérence a déjà été mise en œuvre dans les logiciels de TANGO et CORE, ainsi que déployée par le registre suisse. Zonemaster fait ce test.
Enfin, l'annexe A du RFC décrit plus en détail des scénarios où l'incohérence entre les serveurs faisant autorité pour un domaine a eu des conséquences fâcheuses. Par exemple, si un domaine a une délégation boiteuse, vers un serveur qui n'existe pas, un malveillant peut créer le serveur en question, mettre un CSYNC en indiquant uniquement des serveurs qu'il contrôle et transformer une simple délégation boiteuse en un détournement complet du nom. Si le serveur non existant était dans un nom de domaine non enregistré, l'attaquant n'a qu'à enregistrer ce nom (attaque flamant). Si le serveur non existant était sur une adresse IP libre chez un hébergeur public, l'attaquant n'a qu'à créer des machines chez cet hébergeur jusqu'à tomber sur l'adresse en question (une variante de l'attaque des sous-domaines). Ce genre d'attaques est décrit dans des articles comme « Unresolved Issues: Prevalence, Persistence, and Perils of Lame Delegations » ou « Risky BIZness: risks derived from registrar name management ». Bon, si le domaine est signé avec DNSSEC, il est protégé, non ? Oui, sauf si l'attaquant peut changer la clé avec un CDS… D'où l'importance de la vérification de cohérence de ce RFC.
Autre exemple d'accident possible (et qui n'est pas dû à une attaque délibérée), dans le cas où un domaine a plusieurs signeurs DNSSEC (RFC 8901), si un des serveurs faisant autorité ne publie que ses propres clés dans un CDS. Sans vérification de cohérence, au lieu d'avoir plusieurs DS comme prévu, on n'en aura qu'une partie.
Et si vous cherchez un programme simple qui fait à peu près ce
que demande le RFC, vous avez cds-consistency.py
% ./cds-consistency.py knot-resolver.cz knot-resolver.cz is consistent, data is "None" % ./cds-consistency.py àlacon.fr àlacon.fr is consistent, data is "7177 13 2 fa99827c7aca1681b8905285e7fa33ec5adccb430393b4fa1e9f9aa3d9263709"
L'article seul
RFC 9969: IAB AI-CONTROL Workshop Report
Date de publication du RFC : Mai 2026
Auteur(s) du RFC : M. Nottingham, S. Krishnan
Pour information
Première rédaction de cet article le 20 mai 2026
Ah, l'IA… Vaste sujet, et d'actualité. Une des questions qui reviennent souvent est celle de l'utilisation du contenu qu'on trouve sur le Web pour entrainer les grands modèles, sa légitimité, la charge qu'elle induit pour les serveurs, les moyens de la contrôler, etc. Un colloque avait été organisé par l'IAB en septembre 2024 sur ces questions et ce RFC en est le compte-rendu. Ce colloque avait lancé le projet IETF aipref.
Une petite précision politique d'abord : le RFC précise bien qu'il s'agit d'un compte-rendu et que l'IAB n'approuve pas forcément tout ce qui a été dit à ce colloque (section 1.2 du RFC). Je rajoute que j'ai aussi des opinions sur le sujet, donc je mettrais [entre crochets] ce qui est mon opinion, et ne vient pas du RFC. Le reste n'est donc pas de moi, j'en rends compte, c'est tout, ne me tapez pas.
Ce colloque fait partie de la série de colloques qu'organise régulièrement l'IAB pour explorer des tendances à plus ou moins long terme, sans les obligations de l'IETF de produire normes et documents.
Donc, les LLM (qui ne sont qu'une partie des techniques qu'on regroupe sous le terme marketing d'« IA ») fonctionnent en deux phases : on entraine le modèle en lui faisant ingérer une grande quantité de contenu (textes, images ou autres), puis il va pouvoir inférer du contenu à partir de ce qu'il a digéré pendant la phase d'entrainement, et d'une demande (dite prompt). Le contenu inféré n'est jamais tout à fait identique à celui utilisé pour l'entrainement (autrement, cela serait du plagiat, potentiellement illégal). Les LLM ne marchant bien, à l'heure actuelle, que si le corpus d'entrainement était énorme, ils sont très gourmands en données et une source évidente de contenu en grande quantité est le Web. Des bots ou crawlers parcourent donc le Web, ramassant du contenu. Voici par exemple un extrait du journal du serveur qui héberge ce blog, montrant le bot de Perplexity récoltant du contenu :
18.210.92.235:64884 - - [09/Jan/2026:07:26:15 +0000] "GET /images/TCP_state_diagram.jpg HTTP/1.1" 200 96551 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)" www.bortzmeyer.org TLS 18.97.9.103:64398 - - [09/Jan/2026:08:31:39 +0000] "GET /bitcoin-metamorphoses.html HTTP/1.1" 200 8982 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)" www.bortzmeyer.org TLS 18.97.9.101:57493 - - [09/Jan/2026:08:31:39 +0000] "GET /robots.txt HTTP/1.1" 404 3250 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)" www.bortzmeyer.org TLS 18.97.9.103:48122 - - [09/Jan/2026:08:47:36 +0000] "GET /nist-pq.pdf HTTP/1.1" 200 84543 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)" www.bortzmeyer.org TLS 18.97.9.96:25157 - - [09/Jan/2026:08:51:37 +0000] "GET /files/capitole-libre-2019-quic-pour-impression.pdf HTTP/1.1" 200 212507 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)" www.bortzmeyer.org TLS
Une des questions soulevées par cette récolte de données est qu'elle n'était pas prévue à l'origine. Certains webmestres qui mettent du contenu en ligne estiment donc qu'un nouvel usage (l'entrainement des LLM) justifie de nouvelles règles et de nouvelles possibilités de contrôle par le serveur Web. C'est par exemple ce que prévoit l'AI Act européen.
Le colloque (ou atelier) de l'IAB s'est tenu les 19 et 20 septembre 2024 (oui, le RFC met trop longtemps à sortir) et prévoyait de travailler sur tous les aspects liés à cette récolte de données (cf. l'appel à participation). Le colloque regroupait des personnes de divers horizons, experts techniques, entreprises d'IA, fournisseurs de contenu, décideurs politiques, etc. La liste figure dans l'annexe A.2. La règle suivie était celle de Chatham House (tout ce qui se dit est public mais sans le lier à un·e participant·e particulier·ère). D'ailleurs, le RFC note qu'au moins un participant n'a pas voulu que son identité soit dévoilée, juste qu'il était un représentant officiel d'un gouvernement. Et, comme déjà dit, le RFC rend compte des discussions, cela ne signifie pas que l'IAB approuve tout ce qui a été dit.
La section 2 du RFC résume les discussions (la totalité des
soumissions sont en
ligne). Aujourd'hui, les fournisseurs de contenu, les
webmestres, peuvent exprimer leurs choix quant à la récolte de
données par divers moyens. Il y a par exemple une solution technique
existante, c'est le
robots.txt, qui est
décrit dans le RFC 9309. Notez que, en
l'absence du fichier robots.txt, les
bots peuvent tout récolter. C'est donc une
solution opt-out. Il y a
aussi des solutions non techniques par exemple les
conditions d'utilisation (ainsi, ce blog est sous licence GFDL et les contenus peuvent
donc être réutilisés, à la condition que les destinataires jouissent
des mêmes droits de réutilisation). [Tiens, par contre, il n'existe pas
de licence
CC-BY-NoAI ?] Pour revenir à la technique, les webmestres
peuvent aussi bloquer les crawlers par leur
adresse IP, ou leur User-Agent (RFC 9110, section 10.1.5), ou carrément tout mettre derrière
un paywall.
Comme indiqué plus haut, ces solutions sont en général opt-out, donc par défaut, la récolte est autorisée. (Sur ce blog, et c'est apparemment le cas de la plupart des serveurs HTTP, plus de la moitié des requêtes sont faites par des bots, mais pas forcément liés à l'IA, c'était déjà le cas avant les LLM.) On constate (cf. l'exposé « Consent in Crisis: The Rapid Decline of the AI Data Commons ») une tendance à la fermeture : la récolte devient de plus en plus difficile car de nombreux serveurs bloquent les accès qu'ils pensent dûs à un bot. Le Web tend donc à se fermer.
[Le RFC n'est pas clair sur ce point mais, pour moi, il est important de faire la différence entre les problèmes techniques et opérationnels posés par certains bots qui, qu'ils travaillent pour l'IA ou pas, « matraquent » avec excès les serveurs, et les problèmes politiques et financiers liés à l'utilisation qui est faite des données récoltées. Les problèmes techniques et opérationnels causés par des « bots fous » existaient bien avant les LLM. Par contre, les problèmes politiques (légitimité à réutiliser le contenu) et financiers (perte de revenus pour les ayant droits, comme mentionné dans le RFC) sont plus spécifiques de l'IA. Le RFC ne parle pas vraiment des problèmes opérationnels posés par l'agressivité de certains bots - pas forcément liés à l'IA, d'ailleurs - mais la réunion IETF 123 à Madrid avait vu de très intéressants exposés à ce sujet.]
À l'heure actuelle, il est difficile de savoir ce qui est permis,
au delà des simples consignes du
robots.txt. Les gérants des serveurs n'ont pas
de moyen standard et automatiquement analysable de faire connaitre
leurs conditions d'utilisation, et les bots n'ont
donc pas non plus de moyen de savoir ce qui est permis. [Il va de
soi qu'il y a des bots qui, de toute façon, s'en
foutent. Le travail de normalisation à l'IETF ne pourra concerner que les
bots honnêtes et ne dispensera pas de mesures de
sécurité contre les malhonnêtes.]
Le RFC creuse certain aspects de la question. Par exemple, en
section 2.1, le problème de la différence entre le moment du
ramassage des données et celui de leur utilisation. Les consignes du
serveur (comme le robots.txt) sont lues au
moment du ramassage mais certains responsables de contenu voudraient
exprimer des choix concernant l'utilisation, or celle-ci se fait à
un autre moment, décorrélé du premier. Certaines récoltes, comme
celle faite par Common Crawl, peuvent servir
à de multiples usages et des consignes concernant le ramassage ne
sont donc pas appropriées. Autre exemple que Common Crawl, on peut
avoir une organisation qui gère un moteur de recherche du
Web et développe un LLM, et qui
utilise le même crawler pour les deux
usages. Certains webmestres estiment que la première utilisation ne
pose pas de problème (au bout du compte, cela ramènera du trafic sur
leur site Web) mais s'opposent à la seconde car elle n'apportera pas
de trafic, le LLM donnant des réponses qui suffiront à
l'utilisateur.
Du point de vue technique, il faut aussi noter que le principe d'entrainement d'un LLM fait qu'on utilise toutes les données et, qu'une fois le modèle créé, il n'y a pas d'étiquetage spécifique de la source de telle ou telle réponse du LLM. (C'est pour cela que les LLM ont du mal à indiquer leurs sources.) Un webmestre qui souhaiterait dire « d'accord pour servir à l'entrainement des IA mais pas pour que ces IA aient un usage militaire, ou bien pas un usage commercial » ne le peut pas, en raison de cette limite technique. Et même si ce moyen existait, le gérant du LLM serat obligé de faire N modèles, pour toutes les permutations des différents critères (ou tout simplement d'exclure tous les contenus ayant une licence restrictive, ce qui limiterait la représentativité du corpus d'entrainement du modèle).
Enfin, les préférences changent dans le temps et celles exprimées au moment de la récolte des données peuvent ne pas être à jour lorsque les données seront utilisées pour l'entrainement d'un LLM.
Le problème est déjà compliqué si on suppose que tous les acteurs sont de bonne foi et respectent les règles. Mais, évidemment, la confiance ne règne pas, et pour de bonnes raisons. [Les entreprises capitalistes trichent, que ce soit celles qui entrainent les LLM ou bien celles des ayant droits.] Il n'y a pas de moyen facile de vérifier le respect des préférences exprimées par les gérants du contenu. Et c'est d'autant plus inquiétant que les entreprises de l'IA n'ont pas vraiment de motivation pour respecter les règles : aucun risque de sanction [surtout compte-tenu des déclarations de Trump contre tout projet de régulation de l'IA]. Cette absence de confiance entraine l'utilisation importante de moyens techniques de blocage, comme de bloquer les adresses IP des bots connus. Il y a même un bot qui suggère cette solution :
119.28.89.249:58834 - - [21/Jan/2026:15:32:02 +0000] "GET /5153.xml HTTP/1.1" 200 6891 "-" "Mozilla/5.0 (compatible; Thinkbot/0.5.8; +In_the_test_phase,_if_the_Thinkbot_brings_you_trouble,_please_block_its_IP_address._Thank_you.)" www.bortzmeyer.org TLS
L'atelier de l'IAB a passé du temps sur la question de
l'attachement des préférences au contenu (section 2.3). Le
robots.txt (RFC 9309) est
très bien, très déployé et largement reconnu. Mais il manque de
souplesse pour les gros sites qui souhaitent un système plus
granulaire. Par exemple, si un site de vidéos souhaitait restreindre
l'accès à certaines vidéos, la seule solution est de les placer dans
un espace particulier (par exemple un
répertoire distinct), et donc de devoir
changer l'URL
si la classification change. Et, comme le
robots.txt est à la racine du site Web, il
n'est pas sous le contrôle des créateurs de contenu qui ont accès à
un espace dédié mais pas à la totalité du site. Si le CMS que vous
utilisez permet des créations de contenu et des mises à jour
décentralisées, où certaines personnes peuvent modifier une partie
du site, regardez s'il permet à ces personnes d'influencer le
robots.txt. Je suis preneur d'exemples.
Une autre solution (qui ne serait pas forcément exclusive du
robots.txt mais complémentaire) serait
d'inclure les préférences d'utilisation dans le contenu
lui-même. C'est ce que permet l'élément HTML <meta>
ou le format XMP pour les images. Des formats
comme XML
ou JSON
permettraient certainement d'ajouter ces préférences d'utilisation,
qui ont l'avantage de forcément voyager avec le contenu,
contrairement au robots.txt. Évidemment, cela
ne marchera pas si ces métadonnées sont retirées par le programme
de collecte (pas forcément pour des raisons malveillantes, cela peut
être pour diminuer la taille des données). Et certains formats ne se
prêtent pas à cette inclusion des préférences d'utilisation, comme
le texte brut, ou comme les contenus qui ont
plusieurs auteurs (pensez à un fil de discussion sur les réseaux
sociaux).
Une autre solution serait de placer les préférences d'utilisation dans un registre, extérieur aux œuvres, comme cela se fait souvent pour, par exemple, la musique ou les photographies. C'est plus robuste que l'inclusion de métadonnées mais ça passe mal à l'échelle de l'Internet (les registres existants avaient été conçus pour des écosystèmes plus petits et relativement fermés).
Enfin, parmi les difficultés, il faut noter qu'exprimer
préférences et conditions d'utilisation un peu fines nécessite de
disposer d'un vocabulaire (par exemple pour décrire les différentes
techniques qui sont regroupées sous le terme marketing et flou
d'« IA ») et qu'il n'existe pas de vocabulaire standard. Ce serait
une tâche difficile que d'en établir un (un travail est en cours,
dans draft-ietf-aipref-vocab). Je
me souviens d'une réunion IETF où il y avait eu un long débat sur la
question de savoir si la traduction rentrait
dans la catégorie « IA générative » (après
tout, elle génère des textes…).
La section 3 du RFC, en conclusion, essaie de synthétiser et
d'identifier les points sur lesquels l'IETF pourrait
travailler. L'atelier avait un relatif consensus sur le fait que la
situation actuelle est mauvaise et que le principal outil technique
disponible, robots.txt, ne convient pas. Les
pistes de travail discutées ont été :
- Améliorer
robots.txtou bien développer un meilleur système d'attachement aux sites Web, - Définir des attachements pour les protocoles IETF (par exemple dans l'en-tête HTTP, HTML ou XML dépendant d'un autre organisme),
- Définition d'un vocabulaire commun (le groupe de travail IETF aipref y travaille),
- Description de comment les différentes techniques (attachées au site Web ou bien attachées au contenu) se combinent.
Par contre, le consensus était que les points suivants n'étaient pas du ressort de l'IETF ou ne pouvaient pas, pour l'instant, faire l'objet d'un travail concret :
- Faire respecter les directives données aux récoltants (les licences du logiciel libre ont un problème analogue),
- Développer des mécanismes de transparence de la récolte,
- Créer des registres des contenus,
- Identifier et authentifier les bots (à
noter que Cloudflare a lancé cette
idée, ce qui a donné naissance aux brouillons
draft-meunier-web-bot-auth-architectureetdraft-meunier-web-bot-auth-glossary).
Notez qu'un résumé de l'atelier avait été publié juste après. Et, sinon, vous pouvez regarder l'intéressant site Web « Dealing With Bots » et, sur les projets de contrôle de l'accès aux ressources et leurs risques, l'excellent article « No One Should Control the Internet After AI: Freedom to Build Cleopatra GPT ».
L'article seul
RFC 9959: Convergence of Congestion Control from Retained State
Date de publication du RFC : Mai 2026
Auteur(s) du RFC : N. Kuhn (Thales Alenia
Space), E. Stephan
(Orange), G. Fairhurst, R. Secchi
(University of Aberdeen), C. Huitema (Private
Octopus)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tsvwg
Première rédaction de cet article le 12 mai 2026
Traditionnellement, les protocoles de transport comme QUIC ou TCP partaient de zéro à chaque connexion. On se connecte, on démarre prudemment (ne pas envoyer trop de données pour éviter de congestionner le réseau), puis on augmente le débit petit à petit. Mais c'est dommage de ne pas tenir compte des connexions précédentes, où on avait déjà suivi ce processus. Ne pourrait-on pas se souvenir des mesures précédentes pour aller plus vite la prochaine fois ? C'est justement ce que propose ce RFC.
Évidemment, si l'idée est simple, la réalisation soulève plein de problèmes, d'autant plus qu'on touche ici à une activité dangereuse : si on se trompe, on risque d'aggraver la congestion. Le RFC détaille donc plus précisément comment réutiliser ces mesures passées, pour ne pas faire s'écrouler le réseau. Tout protocole de transport doit utiliser un algorithme de contrôle de la congestion (RFC 2914) ou bien s'auto-modérer (RFC 8085). Mais concevoir un bon algorithme de contrôle de la congestion n'est pas trivial et, par exemple, le RFC 5783 notait que les algorithmes existants marchaient mal pour les liaisons avec un BDP élevé et/ou très variable, comme les liaisons satellite.
Pour comprendre pourquoi, revenons un peu au fonctionnement typique d'un algorithme de contrôle de la congestion. Il a typiquement deux phases. D'abord, au début de la connexion, on envoie moins de données que ce qu'on pourrait, afin de ne pas congestionner le réseau. Puis on augmente le débit, jusqu'au moment où des indicateurs comme la perte de paquets ou le rythme des accusés de réception (RFC 9406) signalent qu'on a atteint la capacité maximale pour ce flux de données. La dépasser (overshoot) congestionnerait le réseau ou, si les autres flux qui se partagent le réseau sont mieux élevés, entrainerait des diminutions de ressources pour ces autres, voire un écroulement du réseau sous la charge. Voilà pourquoi il faut démarrer lentement.
Au passage, le RFC note que, bien sûr, la connexion TCP ou QUIC qui réutiliserait les mesures d'une précédente connexion doit s'assurer qu'on compare ce qui est comparable : mêmes adresses IP source et destination, et peut-être même DSCP (Differentiated Services Code Point, cf. RFC 2474). On verra plus loin que ce n'est pas suffisant (les choses peuvent changer, le passé peut ne pas être un bon indicateur du présent), mais patientez encore un peu.
La méthode de notre RFC se nomme « reprise prudente » (careful resume) ou, en plus joli « partage temporel » (temporal sharing), puisqu'on reprend des mesures passées (mesures de la capacité, du RTT, etc). Ces mesures pouvant ne plus être d'actualité (trop vieilles et/ou le chemin suivi a changé), il faut en effet être prudent (cf. RFC 9000 et RFC 9040).
Dans quels cas cette reprise (prudente) de données d'une connexion précédente peut être utile ? La section 1.4 du RFC liste un certain nombre de cas d'usages. Entre autres, il y a le cas d'une application qui utilise plusieurs connexions, les connexions peuvent alors utiliser les données récupérées par la première d'entre elles. Ou bien lorsqu'une connexion a été violemment interrompue et repart tout de suite après. Et il y a aussi une autre utilisation, lorsque la latence du chemin utilisé est bien plus importante que dans une liaison Internet typique, ce qui est le cas des satellites lorsqu'ils ne sont pas en orbite basse. L'article « Google QUIC performance over a public SATCOM access » note ainsi que sur une liaison via un satellite géostationnaire, avec l'algorithme classique, transférer 5,3 Mo prendra 9 secondes alors que le partage temporel, si on peut réutiliser les mesures d'une connexion précédente, prendra 4 secondes. (Si les 9 secondes vous semblent trop, compte-tenu de la capacité du lien, rappelez-vous que la capacité n'est pas le seul facteur limitant ; TCP, surtout au démarrage, n'utilise pas toute la capacité, et il met longtemps à converger si la latence est élevée.) Une autre présentation, à l'IETF « Feedback from using QUIC's 0- RTT-BDP extension over SATCOM public access », calcule une réduction du temps de transfert de 62 % pour faire voyager 1 Mo. Enfin, le RFC recommande la lecture de la synthèse « Careful Resumption of Internet Congestion Control from Retained Path State ».
Le récepteur des données peut avoir des informations que l'envoyeur n'a pas, et cela peut le pousser à vouloir désactiver la reprise que l'envoyeur croit prudente. Par exemple, le récepteur sait peut-être quelle quantité de données va être envoyée, ou bien il sait que le chemin sur le réseau a changé.
Toujours pour compliquer les choses, il faut aussi se souvenir que d'autres facteurs peuvent limiter la quantité de données qu'on envoie, par exemple le contrôle de flux, donc les fenêtres de TCP (RFC 9293, section 3.8.6) ou le système de crédit de QUIC (RFC 9000, section 4).
Prenant en compte tout cela, la section 1.5 du RFC résume les principes de la « reprise prudente » :
- D'abord, s'assurer que les conditions n'ont pas changé depuis la dernière connexion ; le chemin est-il le même ? (La mesure du RTT donne une première bonne idée.) À l'issue de cette phase de reconnaissance, si les conditions ont changé, on utilise la méthode classique, on ne tient pas compte des mesures qui ont été sauvegardées.
- Ensuite, OK, on va plus vite qu'avec la méthode classique mais pas aussi vite que ne l'indiquent les mesures sauvegardées. Après tout, la reconnaissance ne permet pas toujours d'identifier un changement dans les conditions.
- Enfin, on se prépare à faire marche arrière, et à revenir à la méthode classique, si on s'aperçoit qu'on est en train de créer de la congestion. (Le RFC note qu'il faut la détecter rapidement, avant que les autres flots de données n'aient détecté la congestion et réduit leur débit.)
Un peu de terminologie avant de continuer (section 2) : le partenaire distant (remote endpoint) est l'ensemble des informations qui identifie à qui on envoie des données, typiquement l'identificateur d'une interface réseau locale couplé à l'adresse IP de la machine avec qui on parle et peut-être (c'est une décision locale, et forcément très dépendante du système d'exploitation utilisé) des informations comme DSCP. Si le partenaire distant change, on en déduit que le chemin a changé (l'inverse n'est pas vrai : le chemin peut changer alors que le partenaire distant est le même). Si on a une indication que le chemin a changé, on revient au mécanisme traditionnel, on n'utilise pas les paramètres gardés des précédentes connexions.
Le mécanisme de notre RFC a donc plusieurs phases (section 3, mais regardez aussi le joli tableau de l'annexe A, qui est peut-être plus clair) : celle de reconnaissance, où on cherche si les caractéristiques du chemin correspondent à un chemin connu, puis , selon son résultat, on passe à la phase dite normale, si on a reconnu un chemin déjà vu, ou bien à la phase non validée (chemin inconnu, on démarre prudemment), puis à la phase de validation (y a t-il un indicateur de congestion ou bien tout est-il beau et propre ?), ou bien à celle de retraite (on jette les informations enregistrées, la situation a changé, on retourne en mode traditionnel), avant de passer à la phase normale. (Des exemples détaillés figurent dans l'annexe B.)
La section 4 du RFC fournit des détails sur la mise en œuvre des principes de ce RFC. Par exemple, la détermination pratique d'un changement du chemin. Un bon indicateur est le RTT. Cette section conseille aussi, même en l'absence d'indications que le chemin a changé, de ne pas garder les paramètres sauvegardés trop longtemps : comme la détection d'un éventuel changement n'est pas parfaite, il vaut mieux avoir une durée de vie maximale pour les paramètres enregistrés. Le RFC suggère quelques heures, voire moins si on sait que le chemin est très dynamique.
Enfin, l'annexe B détaille à l'octet près des exemples de fonctionnement de l'algorithme de reprise prudente, pour différents cas.
Vous pouvez aussi avoir une introduction aux principes de ce RFC dans l'exposé d'un des auteurs à la Journée du Conseil Scientifique de l'Afnic en 2021 (avec les supports).
Merci à Nicolas Kuhn pour sa relecture.
L'article seul
RFC 9958: Post-Quantum Cryptography for Engineers
Date de publication du RFC : Juin 2026
Auteur(s) du RFC : A. Banerjee, T. Reddy, D. Schoinianakis
(Nokia), T. Hollebeek
(DigiCert), M. Ounsworth (Entrust)
Pour information
Réalisé dans le cadre du groupe de travail IETF pquip
Première rédaction de cet article le 20 juin 2026
Tout le monde parle des calculateurs quantiques et du risque qu'ils font peser sur la cryptographie traditionnelle. La solution ? Remplacer ces algorithmes par des algorithmes post-quantiques, c'est-à-dire résistant aux calculateurs quantiques. Ces algorithmes existent déjà, plusieurs sont normalisés et beaucoup ont déjà été mis en œuvre dans des programmes. Mais les intégrer dans les protocoles de l'Internet n'est pas trivial. Ce RFC vise à guider les ingénieur·es qui vont appliquer ces algorithmes post-quantiques à des logiciels et des protocoles du monde de l'Internet.
Il ne s'agit pas ici d'expliquer le fonctionnement des algorithmes de cryptographie post-quantiques. Le RFC les considère acquis et se demande comment on va les utiliser. (Note personnelle : de toute façon, je ne comprends rien à la cryptographie, post-quantique ou pas. Mais ce n'est pas forcément grave, ce RFC est conçu pour des ingénieur·es normaux·les, le doctorat en cryptographie n'est pas indispensable.) Notez aussi, question terminologie, que « post-quantique » ne fait pas l'unanimité. On pourrait dire (section 2 du RFC), « après quantique » ou bien « résistant au quantique » ou encore « prêt pour le quantique ». Chaque terme a ses qualités et ses défauts : « résistant au quantique » serait inapproprié si, finalement, on trouvait un algorithme quantique pour casser un algorithme qui se prétendait sûr face aux calculateurs quantiques.
D'abord, résumons le problème : la
quantique est aujourd'hui un domaine très
bien connu et dont les bases théoriques sont solides et établies. Un
calculateur quantique peut effectuer
certains calculs plus vite qu'un ordinateur
classique. Parmi ces calculs, il y a les problèmes mathématiques
sous-jacents aux algorithmes de cryptographie courants, comme
RSA et
ECDSA. Aujourd'hui, certes, les calculateurs
quantiques sont très loin de pouvoir être utilisés en pratique
contre la cryptographie. Il faudrait des millions de
qubits physiques ou des milliers de qubits
logiques (ceux qui ont un système de correction d'erreurs). On n'en
est qu'à quelques centaines de qubits physiques (malgré certaines
annonces sensationnalistes), et la difficulté de fabrication et de
fonctionnement augmente très vite avec le nombre de qubits. Mais, à
force de progrès, on aura peut-être un jour des CRQC
(Cryptographically Relevant Quantum Computer,
prononcez « cric », cf. section 2 du RFC), des calculateurs
quantiques utilisables dans le monde réel. 
Ce jour-là, on pourra, par exemple, trouver une clé privée RSA ou ECDSA à partir de la clé publique, cassant ainsi effectivement ces algorithmes. Et, comme le déploiement des algorithmes post-quantiques va prendre du temps, il ne faut pas attendre que des CRQC soient disponibles pour commencer.
On pourrait croire que le problème, pour les protocoles IETF, est simple : tous ont la propriété d'agilité cryptographique (RFC 7696), qui permet de remplacer un algorithme par un autre sans changer le protocole et le code. Mais ça serait trop simple : les algorithmes post-quantiques ont des propriétés qui font qu'il n'est pas toujours possible de les utiliser tels quels, sans adaptation du protocole. Par exemple, leurs clés et signatures sont souvent bien plus grandes, et ne rentrent pas dans les protocoles existants.
Donc, quelques points à garder en tête (j'ai déjà lu des erreurs sur ces sujets, dans divers articles) :
- Un algorithme post-quantique n'a rien de quantique, et ne nécessite pas de calculateur quantique pour tourner. Nous travaillons sur la défense (la cryptographie post-quantique), pas sur l'attaque (les calculateurs quantiques). Pas besoin donc de s'y connaitre en quantique pour comprendre ces algorithmes.
- Les algorithmes « quantiques » ne sont pas 100 % quantiques. Ils ont tous une partie classique et un calculateur quantique ne sera donc pas utilisé seul, mais comme une partie d'un ordinateur mixte (section 3 du RFC).
- Un calculateur quantique n'est pas un ordinateur : il n'est rapide que pour certains problèmes, et c'est cela qui permet de concevoir des algorithmes dont on pense qu'ils ne seront pas vulnérables aux futurs CRQC. (Le RFC fait une analogie avec les GPU qui ne sont pas plus rapides que les CPU dans l'absolu, seulement plus rapides pour certains problèmes.)
- Un algorithme post-quantique peut, si on trouve une faille dans sa conception ou dans sa mise en œuvre, être cassé par un ordinateur classique. C'est d'autant plus gênant que ces algorithmes sont plus récents que RSA ou ECDSA, et ont été moins testés au feu.
Donc (section 1 du RFC), aujourd'hui, des gens construisent des calculateurs quantiques et ceux-ci sont de plus en plus perfectionnés, capable d'attaquer des problèmes plus gros. Pas mal d'argent et d'efforts sont investis dans ces travaux. Mais on reste loin du CRQC (Cryptographically Relevant Quantum Computer), les calculateurs connus du public ne peuvent casser que des clés RSA ou ECDSA ridiculement courtes. Il est très difficile de prévoir quand on aura un CRQC. (Lorsque j'ai fait mon exposé à Pas Sage En Seine, plusieurs personnes m'ont dit que les CRQC seraient disponibles « bientôt ». C'était en 2018 et on ne les a toujours pas.) Le problème est difficile et il ne suffit pas d'extrapoler les prototypes actuels, le monde quantique est difficile et, plus on rassemble de composants, plus il est difficile de maintenir les propriétés quantiques qui nous intéressent. Des prédictions sensationnalistes sur l'arrivée « prochaine » de calculateurs quantiques ont déjà été faites et se sont montrées fausses. Ceci dit, il faut noter qu'il n'y a pas que la recherche publique : on peut toujours imaginer que, dans la zone 51, la NSA fait tourner un CRQC utilisant des technologies obtenues auprès des extra-terrestres…
Mais le fait que les CRQC n'arrivent pas n'est pas une raison pour attendre : le déploiement effectif des algorithmes post-quantiques va prendre beaucoup de temps (il s'agit d'une migration très complexe) et il ne faut donc pas rester les bras croisés en attendant qu'un CRQC soit réellement disponible (d'autant plus qu'il existe toujours la possibilité de percées soudaines dans la recherche scientifique). Mais, en raison de l'incertitude, la question est délicate (cf. mon exposé à NetGouv 26).
Euclide concevait des algorithmes bien avant qu'on ait des ordinateurs et Lovelace écrivait des programmes alors que l'ordinateur à qui ils étaient destinés n'existait pas (et n'a finalement pas existé). De même, des chercheurs écrivent des algorithmes pour les calculateurs quantiques sans avoir de calculateurs quantiques. C'est notamment le cas de l'algorithme de Shor, qui résout le problème de la décomposition en facteurs premiers qui est à la base de RSA. Et une variante de l'algorithme résout le problème du logarithme discret qui est à la base des algorithmes à courbes elliptiques comme ECDSA (RFC 6090).
Il existe aussi un algorithme, l'algorithme de Grover, qui permet de s'attaquer aux clés utilisées en cryptographie symétrique mais il est loin de l'efficacité spectaculaire de l'algorithme de Shor et notre RFC estime donc (section 3.1 pour les détails) que les éventuels futurs calculateurs quantiques n'auront que peu d'impact sur la cryptographie symétrique, notamment parce que cet algorithme n'est pas facilement parallélisable. Et il y a des raisons de penser que Grover ne sera sans doute pas amélioré. Un algorithme comme AES-128 est donc a priori sûr (et c'est encore plus vrai pour AES-256). Le RFC se concentre donc sur l'asymétrique.
Pour la cryptographie asymétrique, la situation est moins rose (section 3.2). Des algorithmes très courants comme RSA et les algorithmes à courbes elliptiques, mais aussi des algorithmes moins connus comme ElGamal (RFC 6090) ou Schnorr (RFC 8235) seront cassables dès qu'on aura un CRQC. En quelques heures, voire en quelques secondes, celui-ci pourra casser une clé RSA de 2 048 bits, comme étudié dans « Circuit for Shor’s algorithm using 2n+3 qubits », « How to factor 2048 bit RSA integers in 8 hours using 20 million noisy qubits » ou bien « Breaking RSA Encryption - an Update on the State-of-the-Art ». (Rappel : tous ces articles supposent l'existence d'un CRQC, et on n'en a pas encore.) Bon, après, vous pouvez toujours faire des clés RSA d'un téra-octet mais ça ne serait pas pratique.
La section 4 du RFC détaille les services pour lesquels on utilise de la cryptographie asymétrique :
- Transport de clé symétrique. C'était la façon traditionnelle de chiffrer. Pour des raisons de performance, on ne chiffre pas avec les algorithmes de cryptographie asymétrique, qui sont trop lents. Une des parties génère une clé de cryptographie symétrique, qui doit donc être connue des deux parties, et on la chiffre avec l'algorithme de cryptographie asymétrique avant de l'envoyer à l'autre partie. Cette méthode ne fournit pas de confidentialité persistante donc on ne l'utilise plus beaucoup.
- Accord sur une clé. C'est la façon la plus courante aujourd'hui pour que les deux parties aient la même clé de chiffrement symétrique. Un exemple pour réaliser cet accord est la méthode Diffie-Hellman.
- Signature de documents et authentification d'une autre partie.
Les algorithmes courants utilisés en cryptographie asymétrique sont vulnérables aux futurs éventuels CRQC. Ce problème étant connu depuis longtemps, plusieurs algorithmes pour lesquels on ne connait pas d'algorithme quantique susceptible de les casser ont été développés. On peut donc les qualifier de « post-quantiques ». Suite à un concours lancé en 2016, le NIST a normalisé plusieurs de ces algorithmes (et d'autres le seront dans le futur). Mais, en général, ces algorithmes ne peuvent pas tout simplement remplacer les algorithmes traditionnels. Par exemple, RSA et ECDSA peuvent servir de KEM (Key Encapsulation Mechanism, cf. section 9) et faire des signatures alors que les algorithmes post-quantiques existants ne savent faire qu'un des deux. Et puis ils ne s'utilisent pas de la même façon et la transition vers ces algorithmes sera donc plus complexe que l'a été celle depuis RSA vers ECDSA.
Quels sont ces algorithmes normalisés par le NIST (section 5) ? Pour le KEM, ce sont :
- ML-KEM (autrefois nommé Kyber), normalisé dans la norme FIPS-203.
- HQC, approuvé mais pas encore normalisé.
Et pour les signatures :
- ML-DSA (autrefois nommé Dilithium), normalisé dans FIPS-204. (Voir aussi la section 10.2.)
- SLH-DSA (autrefois nommé SPHINCS+), normalisé dans FIPS-205.
- FN-DSA (autrefois nommé Falcon), qui sera apparemment normalisé dans FIPS-206.
D'autres algorithmes sont en cours de normalisation à l'ISO (section 6) :
- FrodoKEM.
- ClassicMcEliece.
- NTRU.
OK, on a plein d'algorithmes résistants aux calculateurs quantiques. Maintenant, de quel délai dispose t-on pour faire la transition, avant que les CRQC ne fichent toute la cryptographie traditionnelle en l'air ? La section 7 de notre RFC explore cette difficile question. Je divulgâche tout de suite : on ne sait pas. Le progrès des calculateurs quantiques ne dépend pas de progrès d'ingénierie relativement prévisibles mais de percées scientifiques encore inconnues. Mais d'un autre côté, attendre n'est pas non plus une bonne solution. Il y a sans doute des attaquants qui enregistrent des messages aujourd'hui, dans l'espoir qu'un CRQC permettra de les décrypter un jour (ce qu'on nomme HNDL pour Harvest Now, Decrypt Later). Si certains secrets sont à courte durée de vie, d'autres peuvent être encore sensibles dans des dizaines d'années (la France ne publie toujours pas complètement les archives étatiques sur la guerre d'Algérie). Pour de tels secrets, il serait peut-être plus prudent de passer au post-quantique tout de suite.
Pour les signatures, le RFC prend l'exemple de l'authentification : les signatures utilisées dans l'établissement d'une connexion TLS ne sont sensibles que pendant le très court temps entre leur génération et leur vérification. Par contre, la signature du microcode d'un objet connecté peut rester critique pendant toute la durée de vie de l'objet.
Pour analyser le délai dont on dispose, on utilise souvent le
modèle de Mosca. Dans ce modèle, X est le temps pendant lequel les secrets
doivent rester secrets (rappelez-vous que, pour certains secrets,
cela peut être de nombreuses années), Y est la durée de la
transition (rappelez-vous qu'en informatique, les transitions complètes
prennent toujours beaucoup
plus de temps que prévu, la publication par le NIST d'une norme ne
suffit pas) et Z est le temps qu'il nous reste avant que les CRQC
soient disponibles (c'est la durée la plus incertaine des trois,
d'autant plus qu'on ne peut pas exclure la possibilité de progrès soudains). Si
Z > X + Y, tout va bien. Sinon, on a un trou pendant lequel
certains usages vont être vulnérables. Notons aussi que Z va être
plus court pour les États (qui ont sans doute quelques années
d'avance sur la recherche publique en matière de calculateurs
quantiques) que pour le pirate de base, qui doit attendre qu'un CRQC
soit en vente sur AliExpress. 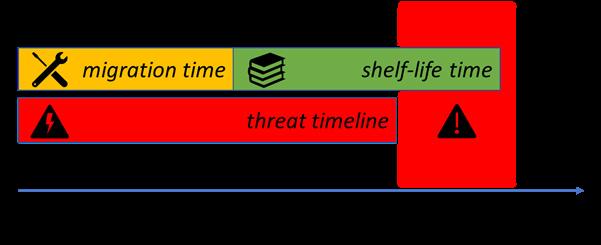
Quant à Y, son estimation varie beaucoup. S'il faut juste faire une mise à jour d'un logiciel, cela peut être rapide. Mais de la cryptographie est aussi présente dans bien des matériels, qu'on ne remplace pas du jour au lendemain, comme les puces accélératrices des opérations de cryptographie ou les HSM. Et certaines clés doivent rester stables pendant longtemps comme la clé DNSSEC de la racine du DNS. Et il y a aussi le temps de programmer, de tester, de faire valider, de déployer, etc. Bref, entre la publication d'une norme comme FIPS-203 et sa généralisation, il faut compter de nombreuses années. C'est une des raisons qui justifie que le travail de transition vers la cryptographie post-quantique n'ait pas attendu la sortie du premier CRQC.
Si vous voulez apprendre un peu de cryptographie, vous pouvez aussi lire la section 8 du RFC, qui expose les principales catégories d'algorithmes post-quantiques :
- Réseaux euclidiens (non, ne me demandez pas d'expliquer) : c'est la technique sous-jacente à ML-KEM, ML-DSA et FrodoKEM, donc la technique « principale » à l'heure actuelle. Clés et surtout signatures sont bien plus grandes qu'avec ECDSA ou même RSA mais quand même plus courtes qu'avec les autres catégories. (La cryptographie post-quantique n'est pas écologique.)
- Condensation : c'est la technique derrière SLH-DSA. Il y a même des algorithmes spécifiés dans un RFC, les RFC 8391 et RFC 8554. Attention : bien des algorithmes de cette catégorie sont à état (il ne faut pas signer deux fois avec le même état) et sont donc difficiles à utiliser de manière sûre (et pas du tout adapté aux protocoles comme DNSSEC, qui sont habitués à un environnement sans état).
- Codes correcteurs : c'est là qu'on trouve HQC et ClassicMcEliece.
La façon la plus courante d'utiliser la cryptographie sur l'Internet est de combiner de la cryptographie symétrique, avec une clé générée pour chaque utilisation, et de la cryptographie asymétrique, qui sert à authentifier et à faire en sorte que la clé de cryptographie symétrique soit partagée par les deux parties (cf. RFC 9180 mais attention au fait que le terme « hybride » peut désigner autre chose en cryptographie post-quantique). La façon la plus simple (mais pas la plus sûre !) de réaliser ce partage est qu'une des deux parties génère la « clé de session », celle utilisée pour la cryptographie symétrique, puis la chiffre en cryptographie asymétrique avec la clé publique de l'autre partie. (On combine cryptographie symétrique et asymétrique, alors qu'on pourrait assurer le même service uniquement avec l'asymétrique, car, si l'asymétrique est souple, la symétrique est beaucoup plus rapide.) Ce transport de la clé d'une partie à l'autre est une des façons de faire en sorte que les deux parties aient la même clé, mais il en existe d'autres (ne me demandez pas un exposé détaillé, et encore moins un avis !). Et ces différentes façons ont typiquement des API différentes, ce qui complique le remplacement d'une façon par une autre. La section 9, consacrée aux KEM, détaille cette question. Après l'avoir lue, vous comprendrez les concepts d'AKE et de NIKE ☺.
La section 10 du RFC, consacrée aux signatures, intéressera entre autres les gens qui font du DNSSEC, comme moi. Un point amusant (section 10.4) et qui illustre bien qu'on ne peut pas toujours remplacer purement et simplement un algorithme traditionnel par un post-quantique : ML-DSA incorpore dans son calcul la condensation de la donnée à signer, ce qui le rend plus résistant à certaines attaques. Les protocoles qui calculent un condensat eux-mêmes avant de signer (comme DNSSEC) ne bénéficient donc pas de cette sécurité accrue et, idéalement, devraient être modifiés.
Un autre exemple du fait qu'on ne peut pas brancher un algorithme post-quantique et espérer que tout soit pareil qu'avant est le problème des performances. Ce n'est pas juste que les algorithmes post-quantiques sont plus lents, c'est qu'ils sont parfois tellement lents et avec des clés tellement grosses qu'il faut changer sa façon de travailler. Les tableaux de la section 12 donnent une idée du problème. Alors que des clés traditionnelles font, par exemple, 65 et 32 octets (pour la clé publique et la clé privée), les plus petites clés ML-KEM font respectivement 800 et 1632 octets (et c'est pire pour ML-DSA). Pour des protocoles comme TLS, qui fonctionne sur des connexions TCP ou QUIC, ce n'est pas très grave, OK, ce n'est pas écologique, mais l'augmentation de données due aux clés n'est probablement qu'une faible partie de ce que transportera la connexion. À part avec des middleboxes boguéees qui auraient une limite stupide à la taille des paquets TLS, ça devrait marcher (mais elles ont d'autres problèmes). Mais pour des protocoles comme IKE ou le DNS, qui tournent sur UDP et ont des limites bien plus strictes, c'est ennuyeux. Et le même problème se pose pour les objets contraints et leurs protocoles spécifiques (cf. section 14, qui leur est dédiée). Il existe bien des solutions (cf. RFC 9242 et RFC 9370 pour IKE) mais qui compliquent et ralentissent le protocole.
Autre problème, la sécurité des algorithmes post-quantiques face
aux ordinateurs traditionnels. C'est bien joli,
de résister aux CRQC mais, si l'algorithme peut être cassé par de la
cryptanalyse traditionnelle, cela ne sert à
rien (cf. sections 15.1 et 15.4 du RFC). Lors de la dernière grande
transition cryptographique sur l'Internet, celle depuis RSA vers
ECDSA, il y avait de très bonnes raisons de penser que le nouvel
algorithme était plus sûr et qu'on pouvait donc simplement remplacer
l'ancien par le nouveau.
Ce n'est pas le cas avec les algorithmes post-quantiques,
dont on ne peut pas être certains de leur résistance (regardez par
exemple l'attaque KyberSide, contre
ML-KEM). C'est d'autant plus vrai que les programmes qui les
mettent en œuvre sont, eux aussi, récents et pas forcément testés
longuement au feu. Et, comme les algorithmes traditionnels sont
vulnérables aux CRQC, que faire ? Que choisir ? L'idée dominante
aujourd'hui est d'avoir les deux, un système
hybride (ou « PQ/T », pour « Post-quantique et
Traditionnel », cf. RFC 9794). Par exemple,
lors d'un échange de clé symétrique, on va créer la clé en
concaténant deux clés qui ont été obtenues, l'une par un algorithme
traditionnel, l'autre par un post-quantique (c'est ce que fait le
futur RFC
draft-ietf-tls-hybrid-design). Ainsi,
la défaillance d'un des deux algorithmes ne permettra pas à
l'attaquant d'obtenir la clé. On peut aussi appliquer la
fonction de dérivation autant de fois qu'on a
de clés dans la structure hybride (RFC 9370). Pour
l'authentification, on peut authentifier avec les deux algorithmes
et exiger que les deux donnent le même résultat (draft-ietf-lamps-pq-composite-sigs).
Pour faciliter la tâche des programmeur·ses, il vaut mieux que
les deux clés (la PQ et la T) soient manipulées ensemble, dans une
seule structure de données (composite). On
évitera ainsi de compliquer le protocole comme cela serait le cas
si, par exemple, on exigeait qu'il y ait deux
certificats. Un travail de normalisation va
être nécessaire pour le format de ces clés composées
(cf. draft-bonnell-lamps-chameleon-certs). Il
faudra aussi définir quelles paires PQ/T ont du sens, question
sécurité, et ne pas juste accepter n'importe quel algorithme
post-quantique avec n'importe quel algorithme traditionnel.
Voilà, maintenant, si vous voulez sérieusement apprendre la cryptographie post-quantique, le RFC recommande le livre « Serious Cryptography » (la deuxième édition), de Jean-Philippe Aumasson (qui a aussi une traduction française). Si vous voulez voir du code post-quantique, il y a le projet OQS (avec une très bonne FAQ pour les débutants et un dépôt Github). Et si vous vous demandez ce que fait l'IETF en matière de normalisation de la cryptographie post-quantique dans ses protocoles, il y a une liste maintenue à jour. Je rajoute « awesome-post-quantum », qui maintient une liste de ressources sur la cryptographie post-quantique, Cloudflare avait fait un article détaillé sur les finalistes du concours NIST, qui expliquait bien les différentes questions techniques, et enfin lisez le texte de position de l'ANSSI.
Bon, mais je vais quand même vous montrer des exemples d'utilisation d'algorithmes post-quantiques dans des protocoles Internet. D'abord, avec SSH :
% ssh -v autre-machine-debian … debug1: kex: algorithm: mlkem768x25519-sha256
Oui, OpenSSH sait faire du ML-KEM pour l'échange de clés, depuis la version 10. Celui-ci ne permet pas de faire de l'authentification donc OpenSSH ne sait apparemment pas générer des clés de machines avec des algorithmes post-quantiques.
Pour TLS, voici un échange de clés hybride (ML-KEM et
traditionnel) vu par Firefox (« Outils de
développement Web » puis « Réseau » puis « Sécurité », tout au
bout) :  .
.
Pour DNSSEC, il existe une zone d'exemple expérimentale signée avec ML-DSA :
% dig +dnssec dilithium2.pdns.pq-dnssec.dedyn.io DNSKEY
;; Truncated, retrying in TCP mode.
…
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 55771
;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1
…
;; ANSWER SECTION:
dilithium2.pdns.pq-dnssec.dedyn.io. 3598 IN DNSKEY 257 3 18 (
XVrPO18btCpMLjXFiZYJNyMbQLXB7oOwk6ZXEmxhm8PP
EKiKP1+t/j7pwBUNYXp3s0U+3AFp3moviOf4cnl4K4MH
…
) ; KSK; alg = 18 ; key id = 47389
dilithium2.pdns.pq-dnssec.dedyn.io. 3598 IN RRSIG DNSKEY 18 5 3600 (
20260129000000 20260108000000 47389 dilithium2.pdns.pq-dnssec.dedyn.io.
aGU3rLJ8vb1AYln+y3bxcOO0RHboWfh03i8H1XhLd9f/
TxhGJNwsTCoRGOnJPjdB2ZDHMB7EnfUfgOitDjvcvcsd
…
;; Query time: 0 msec
;; SERVER: 127.0.0.1#53(127.0.0.1) (TCP)
;; WHEN: Tue Jan 20 15:16:45 CET 2026
;; MSG SIZE rcvd: 3877
Notez la taille de la réponse, et la nécessité de se rabattre sur TCP. D'autre part, l'algorithme de numéro 18, utilisé ici, n'est pas enregistré. Aujourd'hui, le monde du DNS semble plutôt attentiste, il n'y a pas d'algorithme de signature post-quantique qui convienne vraiment au DNS. Une synthèse de l'ICANN est relativement sceptique.
Et merci à Magali Bardet pour sa relecture attentive. (Et, naturellement, les erreurs restantes en crypto sont de moi, pas d'elle.)
L'article seul
RFC 9953: DNS over the Constrained Application Protocol (DoC)
Date de publication du RFC : Mars 2026
Auteur(s) du RFC : M. S. Lenders (TU
Dresden), C. Amsüss, C. Gündoğan
(NeuralAgent GmbH), T. C. Schmidt (HAW
Hamburg), M. Wählisch (TU Dresden & Barkhausen Institut)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF core
Première rédaction de cet article le 1 avril 2026
Le protocole CoAP est un protocole léger, conçu pour les objets connectés. Ce RFC décrit comment faire du DNS au-dessus de CoAP. Si votre brosse à dents a besoin de faire du DNS, c'est ce RFC qu'il faut lire.
CoAP, normalisé dans le RFC 7252, ressemble à HTTP mais en plus simple. Il vise le marché des objets contraints (en mémoire, énergie, en capacité réseau, en puissance de calcul…, voir le RFC 7228). CoAP permet à un client d'envoyer des requêtes à un serveur, et notre tout neuf RFC 9953 explique comment utiliser CoAP pour faire des requêtes DNS et recevoir des réponses DNS. Comme CoAP peut être vu, de manière simplifiée, comme une variante légère de HTTP, ce DNS sur CoAP, alias DoC (DNS over CoAP), est très proche dans ses principes de DoH (RFC 8484). Les contraintes de l'Internet des objets empêchent votre tournevis ou votre ampoule électrique de faire du DoH (qui implique HTTPS), d'où ce DoC. Bien sûr, il y avait toujours la possibilité de faire du DNS sur DTLS, comme le décrit le RFC 8094, mais CoAP a plein de fonctions sympas pour les objets contraints (transferts par blocs - RFC 7959, qui résout les problèmes de MTU, relais CoAP, etc).
L'architecture générale de DoC est très proche de celle de DoH : le client DoC interroge un serveur DoC qui est lui-même un client DNS, parlant typiquement à un résolveur DNS. La communication entre le client DoC et le serveur DoC utilise CoAP, celle entre le serveur DoC et le résolveur utilise le DNS normal, sur UDP, TCP, TLS, etc.
Le serveur DoC sera a priori désigné par le chemin
/. Le but est que
les messages soient plus courts (DoH utilise souvent
le chemin /dns-query). Au fait, comment le
client DoC trouve-t-il le serveur (section 3 du RFC) ? Plusieurs méthodes
sont admises, de la configuration manuelle (« le serveur DoC est en
coaps://doc.foobar.example/ ») aux répertoires
CORE (RFC 9176) en passant par les
classiques DHCP ou
RA ou bien par la découverte de résolveurs du
RFC 9462. Ces différentes solutions sont plus ou
moins sûres, et plus ou moins pratiques pour
l'administrateur/utilisateur (et en général les plus pratiques sont
les moins sûres).
Mais ce n'est pas tout : le serveur DoC peut aussi être trouvé
via le DNS, avec un enregistrement SVCB (RFC 9460 et RFC 9461), si
l'objet contraint a déjà un moyen d'interroger le DNS (la clé SVCB
est docpath, numéro
10).
Une fois qu'on connait le serveur, on peut lui parler. La section
4 décrit les messages CoAP échangés. Ils sont étiquetés avec le type
application/dns-message (valeur numérique 553).
La méthode CoAP utilisée est FETCH
(RFC 8132), qui n'a pas d'équivalent HTTP,
contrairement à la plupart des méthodes CoAP. DoC utilise le
principe REST (RFC 6690). Le RFC recommande de ne pas oublier le champ
Accept: pour indiquer le type de
données accepté. Le type recommandé est
application/dns-message. Dans la requête, le Query
ID DNS devrait être à 0, CoAP se charge de mettre en
correspondance requêtes et réponses donc cet identificateur n'est
pas utile (c'est pareil pour DoH).
Et les réponses ? Là encore, comme pour DoH, les codes de retour
CoAP indiquent si le serveur DoC a pu être joint et a pu faire son
travail, pas si la requête DNS a eu une réponse
satisfaisante. Autrement dit, tant que le serveur DoC fonctionne
bien, il renvoie le code 2.05 (RFC 7252, section 5.9.1.5.) et
c'est dans le message DNS qu'on saura si la résolution DNS a renvoyé
NOERROR, SERVFAIL,
NXDOMAIN, etc.
La mémorisation des réponses joue un rôle plus grand en CoAP
qu'en HTTP (rappelez-vous que CoAP sert à des objets contraints). Le
RFC demande donc que les TTL dans la réponse
DNS soient constants, afin que l'ETag (RFC 7252, section 5.10.6), s'il est calculé via un
condensat, ne change pas. Le serveur DoC doit
par contre mettre un champ Max-Age: dans sa
réponse (section 4.3.2).
Voici, tiré du RFC, un exemple de réponse CoAP, formaté en texte :
2.05 Content
Content-Format: 553 (application/dns-message)
Max-Age: 58719
Payload (human-readable):
;; ->>Header<<- opcode: QUERY, status: NOERROR, id: 0
;; flags: qr rd ad; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;example.org. IN AAAA
;; ANSWER SECTION:
;example.org. 79689 IN AAAA 2001:db8:1:0:1:2:3:4
Et la sécurité ? Le RFC recommande de sécuriser la communication avec le système OSCORE du RFC 8613 (ou, sinon, le DTLS du RFC 9147, ce qui donne du CoAPS). Le RFC note que cela assure la sécurité de la communication entre le client DoC et le serveur DoC mais que, après, on ne sait pas ce que fait le serveur (la section 8 recommande évidemment que le serveur DoC valide avec DNSSEC).
Questions mises en œuvre de DoC, on trouve (mais je ne les ai pas testées, je ne fais pas d'Internet des Objets), par les auteurs du RFC, dans RIOT, un client en C (source sur Github) et un serveur en Python.
Si vous voulez allez plus loin que ce résumé sommaire, une bonne lecture est le papier de 2023 des auteurs, « Securing Name Resolution in the IoT: DNS over CoAP ».
L'article seul
RFC 9945: IETF Community Moderation
Date de publication du RFC : Février 2026
Auteur(s) du RFC : L. Eggert (Mozilla), E. Lear (Cisco
Systems)
Réalisé dans le cadre du groupe de travail IETF modpod
Première rédaction de cet article le 2 mars 2026
Comme toute organisation humaine, l'IETF doit gérer le cas de personnes pénibles, qui font perdre du temps à tout le monde, mettent une mauvaise ambiance ou cherchent activement à perturber le travail commun. Ce RFC (qui remplace les RFC 3683 et RFC 3934) établit la politique de l'IETF vis-à-vis de ces gens : être patient mais pas trop.
Les principes de base de la gestion des abusifs sont les principes de l'IETF (RFC 3935 et RFC 7154). Il ne s'agit pas d'empêcher les désaccords (ils sont attendus et sains). L'IETF est une organisation très ouverte et ses participant·es sont divers·es. On recherche un consensus approximatif (RFC 7282) mais, bien sûr, s'opposer au consensus n'est pas en soi un problème. L'IETF n'est pas une religion. Mais certains vont « sortir des clous ». L'annexe B du RFC donne quelques exemples (messages hors-sujet sur un groupe, ton agressif, remise en cause permanente des décisions et une pratique que je ne connaissais pas, le sealioning). L'IETF devra réagir, en suivant ces lignes directrices :
- Avoir une politique qui soit cohérente et équitable. Elle doit s'appliquer uniquement sur la base du comportement de la personne et pas, par exemple, selon le nombre de RFC qu'elle a écrit, ni selon son ancienneté.
- Permettre des appels contre les décisions prises (le contrôle est une activité délicate et les décisions seront parfois difficiles).
- Essayer de respecter la vie privée tout en maintenant une certaine transparence (exemple de problème : les sanctions doivent-elles être publiques ?).
- Être flexible car il faudra pouvoir s'appliquer à des cas variés. (Notez la tension entre cet objectif et le premier cité…)
Le travail de contrôle reposera essentiellement sur l'équipe de contrôle (moderation team), décrite en section 2. Elle comportera au moins cinq personnes, nommées par l'IESG, qui devra essayer de respecter une certaine diversité. Ces personnes ne doivent pas être membres de l'IESG ou de l'IAB. La diversité souhaitée inclut celle des fuseaux horaires car l'équipe devra parfois réagir vite. L'IETF LLC, la structure administrative décrite dans le RFC 8711, se chargera de leur financer une formation. (La première équipe a été nommée le 3 juillet 2026.)
Leur travail couvrira toutes les discussions publiques en ligne à l'IETF, qu'elles soient sur une liste de diffusion, un dépôt GitHub, etc. Le RFC distingue les administrateurs, qui gèrent un de ces lieux de discussion, de l'équipe de contrôle. Les administrateurs signalent les problèmes et appliquent les décisions de l'équipe de contrôle. Mais, évidemment, pour éviter de surcharger cette équipe, les administrateurs sont aussi censés gérer la plupart des problèmes localement. L'idée derrière l'équipe centrale (moderators) est d'avoir un groupe formé et qui pourra s'assurer d'une politique cohérente au niveau de l'IETF. Vu la taille de l'IETF, les contrôleurs ne pourront pas tout surveiller préventivement et dépendront donc beaucoup des signalements faits, par exemple par les administrateurs.
Vous ne l'avez peut-être pas noté plus haut mais le mot important est « publiques ». L'équipe de contrôle ne va pas gérer les communications privées. Par ailleurs, elle contrôle des comportements, pas le contenu (donc, pas la peine de lui demander de censurer telle ou telle partie d'un Internet-Draft). Quand au spam, il est effectivement un exemple de comportement perturbateur mais il y a déjà une politique à ce sujet.
Ce sera à l'équipe de contrôle de définir ses processus de fonctionnement et ses détails de politique, pour ce qui n'est pas déjà couvert dans ce RFC 9945. Tout cela devra évidemment être discuté au sein de l'IETF et, au bout du compte, approuvé par l'IESG et rendu public (mais pas forcément dans un RFC).
Qu'est-ce que pourra faire en pratique l'équipe de contrôle ? Le RFC donne quelques exemples (section 4) :
- Faire passer les messages d'une personne par un système d'approbation explicite (par défaut, l'IETF n'a pas de contrôle a priori),
- Engueuler quelqu'un, en privé ou en public,
- Supprimer complètement le droit d'écriture à une personne.
Et l'équipe de contrôle devra évidemment garder trace de ces actions, pour en rendre compte. Et des appels sont possibles (RFC 2026, sections 6.5.1 et 6.5.4).
Il y a d'autres fonctions dans l'IETF qui ont un rapport avec cette nécessité de contrôler les débordements de certains participants (section 5). C'est le cas de l'ombudsteam et de l'incarnation administrative de l'IETF, la LLC (notamment si le comportement de certains entraine des risques juridiques pour l'IETF). Il y a aussi plein d'autres RFC à lire, comme le RFC 7776, sur les mesures contre le harcèlement ou le RFC 9245, sur la gestion des listes de diffusion (rappelez-vous que l'équipe de contrôle ne sera pas limitée à ces listes).
Le RFC remarque à juste titre (section 6) que toute politique peut être utilisée de manière abusive, par exemple à des fins de censure. La section 6 revient sur les différentes décisions décrites par le RFC et comment elles contribuent à minimiser ce risque.
Notez que ce RFC s'applique à l'IETF uniquement, et pas aux autres organisations proches comme l'IRTF.
Enfin, l'annexe A explique les motivations derrière ce RFC et le pourquoi des différents choix. Malgré la quantité de RFC et de décisions documentées, il n'était pas toujours évident de reconnaitre ce qui était un comportement perturbateur. Et les processus existants étaient trop lents, en partie parce qu'ils supposaient que tout le monde était de bonne foi. D'où ce nouveau RFC qui explique comment un meilleur mécanisme va être défini.
L'article seul
RFC 9943: An Architecture for Trustworthy and Transparent Digital Supply Chains
Date de publication du RFC : Juin 2026
Auteur(s) du RFC : H. Birkholz (Fraunhofer SIT), A. Delignat-Lavaud, C. Fournet (Microsoft Research), Y. Deshpande (ARM), S. Lasker
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF scitt
Première rédaction de cet article le 1 juillet 2026
Des attaques sur la chaine d'approvisionnement du logiciel, il y en a tout le temps. L'attaquant arrive à glisser du code malveillant dans un logiciel, en amont de son installation par la victime et, quand celle-ci fait tourner le logiciel, le code de l'attaquant est exécuté et paf. Il n'y a pas de solution miracle à ce problème mais on peut au moins essayer de fournir une traçabilité forte des logiciels, qui permet d'être sûr de ce qu'on fait tourner sur ses machines, et, dans le cas d'une enquête postérieure, de mieux comprendre ce qui s'est passé. Ce RFC décrit une architecture, très inspirée du Certificate Transparency du RFC 9162.
Vous voulez des exemples d'attaques contre la chaine d'approvisionnement du logiciel ? Deux cas récents sont la faille Trivy/Aqua Security, annoncée le 1er avril de cette année mais qui n'est pas une blague (tout juste de l'ironie car le logiciel Trivy servait à détecter les problèmes de sécurité…). Cette attaque a notamment permis l'accès aux données de la Commission Européenne. Et il y a aussi, encore plus récente, l'attaque contre le paquetage Python litellm. Mais le cas le plus fameux, quoique un peu moins récent, est celui du détournement de la bibliothèque XZ. (Olivier Poncet en a fait une conférence.)
Les attaquants peuvent frapper à de nombreux endroits différents dans la chaine d'approvisionnement d'un logiciel. Cela peut être en modifiant une bibliothèque utilisée par le logiciel, en modifiant directement le code source, en modifiant l'environnement de compilation (de manière à produire un code exécutable malveillant à partir d'un code source intact), en remplaçant le code exécutable dans un magasin d'applications, etc. La figure 1 dans la section 2.1 du RFC donne une liste complète. Le choix va dépendre des capacités de l'attaquant, de ses choix de discrétion, et des solutions de sécurité déployées.
Je l'ai dit au début, il n'y a pas de solution parfaite au problème, qui est complexe. Dans le cas de XZ, le mainteneur a eu tort de faire confiance à un inconnu mais, si on arrêtait d'accepter des volontaires inconnus, tout le logiciel libre s'effondrerait. Et le logiciel privateur a d'autres failles, comme l'opacité, qui empêche de savoir quels sont les composants logiciels intégrés.
Que propose le groupe de travail SCITT, auteur de ce RFC ? L'approche choisie est celle de la transparence et de la traçabilité. Il faut qu'on puisse vérifier de quels logiciels on dépend. La principale source d'inspiration est le Certificate Transparency du RFC 9162 et l'architecture SCITT peut être vue comme une généralisation de Certificate Transparency au logiciel. Il repose sur une structure de données ordonnée, et qui garantit que seul l'ajout de données est possible, et que tout dans cette structure de données est signé. (Si vous criez « chaine de blocs » ici, vous avez tort : une chaine de blocs fournit en effet ce service mais elle n'est pas nécessaire, d'autres mécanismes existent depuis longtemps, tels que ceux utilisés par le RFC 9162.) D'autre part, il est important de se souvenir que notre RFC ne présente qu'une architecture, pas un protocole complet. Les programmeurs et programmeuses ne peuvent donc pas se mettre au travail tout de suite. L'architecture SCITT est conçue pour les chaines d'approvisionnement de logiciel mais peut a priori être étendue plus tard pour d'autres usages.
Le mécanisme de base consiste en des données en CBOR (RFC 8949), dont la structure est spécifiée en CDLL (RFC 8610), signées avec COSE (RFC 9052) et récupérable via des arbres de Merkle (RFC 9942). Grâce à cela, celui ou celle qui veut vérifier des informations sur un logiciel peut les récupérer facilement et efficacement, puis les vérifier (là encore, comme avec Certificate Transparency). C'est par exemple ce que le NIST appelle DevSecOps.
La section 2.2 du RFC fournit trois cas d'usages de cette technologie. L'un d'eux concerne l'assemblage du logiciel pour un véhicule. (Dans le monde réel, les gens qui assemblent le logiciel pour une voiture ou pour n'importe quel objet connecté ne se soucient guère de sécurité ; comme il y a zéro conséquence négative pour eux en cas de bogue, ou même de faille de sécurité, ils utilisent des versions antédiluviennes de logiciels non testés.) La chaine de dépendance est longue car une voiture est faite de plusieurs composants, chacun apportant du logiciel qui, à son tour, dépend de diverses bibliothèques. SCITT permettrait au moins d'avoir des idées claires sur les composants logiciels utilisés, chacun ayant fait l'objet d'un ajout dans la structure de données de traçabilité.
Bon, maintenant, si on veut être un peu plus précis et comprendre ce qu'est l'architecture SCITT, par quoi on commence ? Par le vocabulaire, peut-être. Découvrons-le dans la section 3 du RFC :
- Déclaration (statement) : une information portant sur un fait (par exemple « la version actuelle est la 3.14 » ou bien « ce logiciel dépend de libfoobar et de grutzbaum-plus »). Les logiciels peuvent être identifiés par un grand nombre d'identificateurs, notre RFC cite entre autres CoSWID (RFC 9393), in-toto, SPDX, SWID, etc.
- Enveloppe (envelope) : les méta-données comme l'identité de l'émetteur.
- Émetteur (issuer) : l'entité qui déclare quelque chose, et qui a une clé privée pour signer cette déclaration.
- Utilisateur (relying party) : l'entité qui va utiliser les déclarations.
- Équivoque (equivocation, quoiqu'il me semble que le terme soit moins fort en français) : déclarations contradictoires (ce qui est clairement mauvais).
- Reçu (receipt) : preuve comme quoi une
déclaration signée a bien été incluse dans la structure de
données. Si on les distribue sur l'Internet, le type de
média à utiliser est
application/scitt-receipt+cose - Déclaration signée (signed statement) :
ce sont elles qui sont encodées en COSE
(RFC 9052). Si on les distribue sur
l'Internet, le type de média à utiliser est
application/scitt-statement+cose. - Structure de données vérifiable (verifiable data structure) : là où on met les déclarations. Cette structure de données doit être à ajout seul (et, je me répète, une chaine de blocs a cette propriété mais les chaines de blocs ne sont nullement indispensables pour cela), doit empêcher l'équivoque (cf. section 5.1.3) et doit permettre l'examen complet (peut-être après autorisation) pour vérifier sa cohérence. Le RFC 9942 donne des détails techniques.
Armé de ces termes, nous pouvons décrire l'architecture SCITT (mais regardez aussi la figure 2 du RFC) :
- Des émetteurs produisent des déclarations signées et les envoient à des services de transparence,
- ces services de transparence authentifient l'émetteur, vérifient les signatures, vérifient la conformité des déclarations à leur politique (cf. section 5.2.1), mettent la déclaration dans la structure de données vérifiable et produisent un reçu (suivant le RFC 9942),
- des utilisateurs vont accéder à ces informations pour vérifier les informations (« est-ce que je dépend ou pas de libfoobar ? », sachant que la dépendance peut être transitive), ou bien pour vérifier la cohérence du service de transparence, par exemple lors d'un audit (c'est une propriété importante d'un service de transparence, on doit pouvoir vérifier son intégrité).
Il peut y avoir plusieurs services de transparence (comme c'est le cas pour Certificate Transparency), personne n'envisage évidemment d'avoir un unique point de dépôt des déclarations.
Le format des déclarations signées et des reçus figure (en CDDL, cf. RFC 8610) en section 6.1.
La section 9 du RFC est vraiment à lire car c'est celle consacrée à l'analyse de sécurité de l'architecture SCITT. D'abord, il faut être bien conscient que SCITT fournit de la transparence et de la traçabilité mais pas de la vérité. Si un émetteur signe que son logiciel tourne avec toutes les versions de libfrobnicate mais qu'en fait il lui faut au moins la version 2, le service de transparence ne va pas regarder les sources du logiciel pour vérifier. C'est vrai pour les erreurs des émetteurs et encore plus pour leurs malhonnêtetés. « Transparency does not prevent dishonest or compromised Issuers, but it holds them accountable ».
Un émetteur grognon ou négligent peut aussi ne pas enregistrer toutes les informations qu'il a. Un utilisateur ne doit donc pas utiliser une déclaration signée sans vérifier le reçu, qui seul prouvera que la déclaration a été enregistrée.
Il existe apparemment au moins trois mises en œuvre de cette technique, chez deux entreprises spécialisées dans la traçabilité des chaines d'approvisionnement, Datatrails et Tradeverifyd, mais aussi chez Microsoft (cf. leur article).
Enfin, une bonne lecture sur ces structures de données vérifiables est « Attested Append-Only Memory: Making Adversaries Stick to their Word ».
L'article seul
RFC 9935: Internet X.509 Public Key Infrastructure - Algorithm Identifiers for the Module-Lattice-Based Key-Encapsulation Mechanism (ML-KEM)
Date de publication du RFC : Mars 2026
Auteur(s) du RFC : S. Turner (sn3rd), P. Kampanakis, J. Massimo (AWS), B. E. Westerbaan (Cloudflare)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF lamps
Première rédaction de cet article le 7 mars 2026
Ce RFC spécifie comment mettre des clés ML-KEM dans un certificat X.509. Vous allez me dire « Mais ML-KEM est un algorithme d'échange de clés, pas de signature, que fait-il dans un certificat ? » Et je vous répondrai que vous avez raison, d'ailleurs le RFC restreint sérieusement ce qu'on peut faire avec cet algorithme.
ML-KEM a l'intéressante propriété d'être résistant aux calculateurs quantiques. Il est normalisé dans FIPS 203. Ce RFC permet de l'utiliser dans les certificats normalisés dans le RFC 5280, et il décrit trois variantes, ML-KEM-512, ML-KEM-768 et ML-KEM-1024.
Comme indiqué plus haut, autant il était normal de permettre ML-DSA dans les certificats (RFC 9881), autant cela peut sembler surprenant pour ML-KEM. La section 1.1 de notre RFC explique les usages (limités) d'un algorithme d'échange de clés dans un certificat. C'est par exemple utile pour un protocole où vous avez besoin d'une clé publique, que vous allez tirer du certificat. Mais vous ne pourrez pas utiliser les certificats de ce RFC pour faire du TLS sur l'Internet public, aucune AC ne vous en produira, même si TLS le permet un jour. Pour la même raison, vous n'en trouverez pas dans les journaux Certificate Transparency.
Les trois algorithmes sont identifiés en suivant le RFC 5912, par un OID via le NIST ; Ce sont
id-alg-ml-kem-512
(2.16.840.1.101.3.4.4.1),
id-alg-ml-kem-768
(2.16.840.1.101.3.4.4.2) et
id-alg-ml-kem-1024
(2.16.840.1.101.3.4.4.3).
La section 5 du RFC précise que les bits indiquant les utilisations possibles de ces certificats (RFC 5280, section 4.2.1.3) doivent indiquer uniquement le chiffrement d'une clé (et pas l'authentification, comme avec les certificats habituels).
Le module ASN.1 figure dans l'annexe A, si
vous voulez implémenter ce RFC (il faut aussi importer les modules
des RFC 5912 et RFC 9629). Le module est identifié
par id-mod-x509-ml-kem-2025 et a l'OID
1.3.6.1.5.5.7.0.121. Le gros du RFC est
constitué d'exemples de clés et de certificats ML-KEM (annexe C),
dans l'encodage en texte du RFC 7468.
Allez, un peu de pratique avec OpenSSL 3.5 :
% openssl genpkey -algorithm ML-KEM-512 -out ml-kem-key.pem -outform PEM % cat ml-kem-key.pem -----BEGIN PRIVATE KEY----- MIIGvgIBADALBglghkgBZQMEBAEEggaqMIIGpgRAOwWCnP71SklfOIuwiLrIddsm Up4AlOMwvwjqCy4PHr8fSq5jRjFoP6XYXnl8IQCR9HhzSRVffI09hBezOUrmxgSC … # Analysons cette clé : % openssl pkey -text -in ml-kem-key.pem # Demandons une signature du certificat : % openssl req -new -key ml-kem-key.pem -provider default -out req.csr … 40E7CEC0027F0000:error:03000096:digital envelope routines:do_sigver_init:operation not supported for this keytype:../crypto/evp/m_sigver.c:305:
Ah, là, c'est raté, et c'est logique. OpenSSL n'accepte pas de fabriquer un CSR pour ces clés « operation not supported for this keytype » puisque ML-KEM ne permet pas de signer. La solution :
# Extraire la clé publique :
% openssl pkey -in ml-kem-key.pem -pubout -out mlkem.pub
# Fabriquer une clé ECDSA pour signer :
% openssl ecparam -out ec_key.pem -name secp256r1 -genkey
# Signer :
% openssl x509 -new \
-subj "/CN=test-mlkem" \
-force_pubkey mlkem.pub \
-signkey ec_key.pem \
-days 365 \
-out mlkem-cert.pem
Warning: Signature key and public key of cert do not match
L'avertissement est normal, puisqu'on a effectivement utilisé une autre clé, d'un autre algorithme, pour signer le certificat contenant notre clé publique ML-KEM. Mais tout s'est bien passé :
% openssl x509 -text -in mlkem-cert.pem
Certificate:
Data:
Version: 3 (0x2)
Serial Number:
69:33:f9:1e:e5:34:64:84:d9:f4:b2:15:3b:50:ec:36:db:0b:71:5c
Signature Algorithm: ecdsa-with-SHA256
Issuer: CN=test-mlkem
Validity
Not Before: Feb 16 15:30:02 2026 GMT
Not After : Feb 16 15:30:02 2027 GMT
Subject: CN=test-mlkem
Subject Public Key Info:
Public Key Algorithm: ML-KEM-512
ML-KEM-512 Public-Key:
ek:
d8:d2:6c:c4:9b:96:48:23:0d:ce:f7:0d:b3:0b:85:
…
X509v3 extensions:
X509v3 Subject Key Identifier:
E7:B2:03:92:37:EC:C6:35:E4:F0:2E:AC:4E:1C:F2:81:67:F7:95:29
X509v3 Authority Key Identifier:
15:E5:2A:5E:B1:C3:50:69:7E:E4:48:EA:0F:DD:3C:5C:90:4B:7C:CC
Signature Algorithm: ecdsa-with-SHA256
L'article seul
RFC 9934: Privacy-Enhanced Mail (PEM) File Format for Encrypted ClientHello (ECH)
Date de publication du RFC : Mars 2026
Auteur(s) du RFC : S. Farrell (Trinity College Dublin)
Chemin des normes
Première rédaction de cet article le 5 mars 2026
La technique ECH (Encrypted Client Hello) permet de boucher une faille de TLS, la transmission en clair du nom du serveur demandé. Elle est normalisée dans le RFC 9849 mais il y manquait la description d'un format standard pour envoyer les données nécessaires à ECH. C'est désormais fait (et vous reconnaitrez le classique format PEM, cf. RFC 7468).
Le principe d'ECH
est de chiffrer le
nom du serveur demandé,
avec la clé
publique du serveur TLS. Pour configurer le serveur, il faut la
clé privée correspondante et différents détails, la
ECHConfig (RFC 9849,
section 4). C'est pour ECHConfig que notre RFC
normalise un format.
Le fichier PEM (RFC 7468) contient une ou plusieurs clés privées et des informations de configuration (pour un ou plusieurs serveurs), le tout en Base64 (section 4 du RFC 4648). Les informations publiques sont typiquement mises dans le DNS (RFC 9848), la clé privée, cela va sans dire (mais le RFC le dit quand même, on ne sait jamais) n'est pas publiée. Un fichier PEM contenant des clés privées doit évidemment être bien protégé.
Voici un exemple, tiré du RFC (la clé privée a donc déjà été publiée 😁) :
-----BEGIN PRIVATE KEY----- MC4CAQAwBQYDK2VuBCIEICjd4yGRdsoP9gU7YT7My8DHx1Tjme8GYDXrOMCi8v1V -----END PRIVATE KEY----- -----BEGIN ECHCONFIG----- AD7+DQA65wAgACA8wVN2BtscOl3vQheUzHeIkVmKIiydUhDCliA4iyQRCwAEAAEA AQALZXhhbXBsZS5jb20AAA== -----END ECHCONFIG-----
Dans le DNS, la publication de la clé publique et de la configuration donnerait quelque chose du genre :
% dig +short HTTPS foo.example.com 1 . ech=AD7+DQA65wAgACA8wVN2BtscOl3vQheUzHeIkVmKIiydUhDCliA4iyQRwAEAAEAAQALZXhhbXBsZS5jb20AAA==
Bien des logiciels reconnaissent cette syntaxe. Je ne les ai pas testés mais, apparemment :
- Dans une
branche d'OpenSSL (les tests sont dans
test/ech_test.c, avec des exemples du format de ce RFC. Apache ou HAProxy peuvent l'utiliser. - Pour BoringSSL, il y a ce script.
L'article seul
RFC 9926: Prefix Registration for IPv6 Neighbor Discovery
Date de publication du RFC : Février 2026
Auteur(s) du RFC : P. Thubert
Chemin des normes
Première rédaction de cet article le 14 février 2026
Une addition sympa au mécanisme de découverte des voisins d'IPv6 (RFC 4861), utile pour les réseaux d'objets contraints, genre Internet des Objets mais aussi les réseaux à connectivité imparfaite, par exemple avec des hauts et des bas : la possibilité pour une machine qui est connectée à un réseau d'un préfixe donné d'enregistrer ce préfixe auprès des routeurs voisins. Ceux-ci sauront alors où envoyer les paquets pour ce préfixe. Cela ne remplace pas les protocoles de routage traditionnels, c'est plutôt une addition pour optimiser les protocoles spécialisés dans les réseaux contraints.
Le cœur de cible de ce RFC, ce sont les LLN (Low power and Lossy Networks, les réseaux « pauvres », avec pas beaucoup d'énergie et des liaisons pourries, cf. RFC 7102 et RFC 7228). La préoccupation principale est d'économiser l'énergie ; éviter de transmettre (la radio coûte cher) et s'endormir le plus souvent possible. Ces LLN utilisent des technologies comme 6LoWPAN (RFC 4919) et le protocole de routage RPL du RFC 6550. Les protocoles conçus pour les LLN n'utilisent donc pas d'émissions périodiques (comme le fait OSPF), qui consomment de l'énergie, et obligent tout le monde à écouter tout le temps, donc à ne pas dormir. L'idée de ce RFC est de compter sur quelques routeurs qui sont moins contraints (par exemple parce qu'ils sont connectés à une prise de courant) et que les autres signalent aux routeurs les préfixes connus, lorsqu'ils sont réveillés.
Autre exemple, les mécanismes IPv6 de
découverte du voisin (RFC 4861 et RFC 4862) ont été conçus en pensant à des machines
alimentées électriquement en permanence, sur des réseaux comme
Ethernet, où diffuser à tout le monde est peu
coûteux. Mais ils ne fonctionnent plus si, par exemple, certaines
machines sont endormies, et ne répondent donc pas aux
sollicitations. D'où des idées comme le RFC 6775, où une machine n'attend pas les sollicitations,
elle profite de ses périodes d'éveil pour enregistrer son adresse
auprès du routeur. Idem avec le projet draft-ietf-6man-ipv6-over-wireless. L'idée
a ensuite été généralisée par le RFC 8505,
sur lequel s'appuie notre nouveau RFC, qui permet d'enregistrer un
préfixe IP entier. Notez bien que cette technique est indépendante
de la manière dont la machine a reçu ce préfixe en allocation, et de
la manière dont le routeur auprès duquel on s'enregistre va ensuite
diffuser son préfixe dans son domaine de routage.
La section 3 du RFC donne une vision générale du nouveau mécanisme, je vous laisse la lire 😃.
Notez (section 11) que la machine qui enregistre un préfixe peut mentir et que cette technique doit donc être déployée en comprenant les caractéristiques spécifiques du réseau (par exemple, fermé ou au contraire ouvert sur l'Internet). Le RFC 8928 est ici une bonne lecture, ainsi que la section 9 de notre RFC.
Et merci à Pascal Thubert pour sa relecture. (Naturellement, je reste responsable des erreurs et approximations.)
L'article seul
RFC 9925: Unsigned X.509 Certificates
Date de publication du RFC : Février 2026
Auteur(s) du RFC : D. Benjamin (Google)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF lamps
Première rédaction de cet article le 27 février 2026
Un certificat est signé par une AC, normalement, ou à la rigueur auto-signé, ce qui ne sert pas à grand'chose mais est obligatoire dans X.509. Mais voici que ce RFC rend la signature facultative.
À ma connaissance, le seul intérêt d'auto-signer son certificat
est de prouver qu'on a bien la clé privée correspondante (car un
plaisantin peut toujours fabriquer un certificat avec la clé
publique de quelqu'un d'autre) et, en prime, de vérifier
l'intégrité. C'est pas crucial. Mais la norme
X.509 (cf. RFC 5280) ne
permet pas d'avoir un certificat sans
signature. Notre RFC 9925 contourne
cette obligation en enregistrant un nouvel algorithme,
id-alg-unsigned,
qui indique qu'il n'y a pas de signature du tout.
C'est parce que, parfois, on n'a pas besoin des signatures. Un exemple typique se trouve dans votre magasin d'AC : vous ne vérifiez pas les signatures (vous ne pouvez pas, puisque les AC sont à la racine de la validation, RFC 5280, section 6), la seule présence du certificat dans le magasin inspire la confiance. Les certificats des AC sont donc auto-signés, ce qui ne sert pas à grand'chose, à part à satisfaire les exigences syntaxiques du format X.509. Ici, le certificat d'une AC du magasin de ma machine Ubuntu ; Issuer est égal à Subject, le certificat est auto-signé :
% openssl x509 -text -in /etc/ssl/certs/Autoridad_de_Certificacion_Firmaprofesional_CIF_A62634068.pem
Certificate:
Issuer: C = ES, CN = Autoridad de Certificacion Firmaprofesional CIF A62634068
Subject: C = ES, CN = Autoridad de Certificacion Firmaprofesional CIF A62634068
…
X509v3 Basic Constraints: critical
CA:TRUE, pathlen:1
X509v3 Key Usage: critical
Certificate Sign, CRL Sign
…
(Une autre solution serait le RFC 5914 mais il ne semble pas très courant.)
Un autre cas où on se moque de la signature du certificat est celui où le certificat est validé d'une autre façon, par exemple un serveur EPP sur TLS qui a une liste de tous les clients possibles, et des certificats que le registre a distribués à ses BE.
Donc, il y a des cas où la signature ne sert guère, voire pas du tout. Mais est-ce gênant ? Ce n'est pas dramatique mais, dans certains cas, c'est sous-optimal, par exemple :
- Les signatures post-quantiques sont souvent de grande taille, donc cela rend les certificats plus gros pour rien.
- La clé publique dans le certificat peut utiliser un
algorithme qui ne permet pas la signature (comme
ML-KEM, cf. le
futur RFC
draft-ietf-lamps-kyber-certificates).
La section 3 du RFC fournit les détails techniques. Dans le
certificat, on met le champ signatureAlgorithm
à id-alg-unsigned et le champ
signatureValue à une chaine vide. Le champ
issuer pourrait être vide puisque personne n'a
signé le certificat, mais comme il était obligatoire, pour éviter de
choquer les applications actuelles, il vaut mieux mettre un
issuer égal au subject
(comme pour un auto-signé). On a le droit de mettre plutôt un nom
/id-rdna-unsigned= (en fait
1.3.6.1.5.5.7.25.1 mais je montre la
représentation textuelle du RFC 4514). RDNA signifie
Relative
Distinguished Name Attribute et un nouveau
registre, « SMI
Security for PKIX Relative Distinguished Name
Attribute », est créé pour accueillir
id-rdna-unsigned et d'autres futurs noms
(politique de Spécification nécessaire, cf. RFC 8126).
Quand une application rencontre un de ces certificats non signés, si elle valide les signatures, elle doit évidemment rejeter le certificat. Si elle est plus laxiste (ou bien a d'autres mécanismes de vérification), elle peut l'accepter (section 4). Les applications et bibliothèques existantes font déjà cela (elles rejettent les signatures d'algorithmes inconnus) donc l'introduction des certificats non signés ne devrait rien casser.
Quelques conseils de sécurité figurent en section 5, par exemple de ne pas réutiliser les clés dans des contextes différents. (X.509, jusqu'à présent, ignorait ce conseil pour les certificats auto-signés puisque la clé publiée servait aussi à signer. Plus de signature, plus de problème.)
Désolé, mais je n'ai pas trouvé comment générer aujourd'hui de tels certificats, que ce soit avec OpenSSL (c'est en cours) ou d'autres logiciels. Si vous trouvez, ça m'intéresse, je pourrais mettre des essais pratiques ici.
L'article seul
RFC 9923: The FNV Non-Cryptographic Hash Algorithm
Date de publication du RFC : Février 2026
Auteur(s) du RFC : G. Fowler (Google), L. Noll (Cisco
Systems), K. Vo (Google), D. Eastlake
(Independent), T. Hansen
(AT&T)
Pour information
Première rédaction de cet article le 28 février 2026
L'algorithme de condensation FNV, présenté dans ce RFC n'est pas neuf (et certains disent même qu'il est dépassé). Mais il est utilisé par de nombreux logiciels alors qu'il n'avait jamais été spécifié « proprement ». Voilà qui est fait.
FNV a comme principal avantage ses performances : il est rapide et le code est court. Comme le précise le titre du RFC, il n'a pas les caractéristiques des algorithmes de condensation utilisés pour des services de sécurité. Mais cela ne l'empêche pas d'être déployé depuis de nombreuses années pour bien d'autres usages.
Le RFC fait 137 pages mais ne vous affolez pas, FNV est simple et l'essentiel de ces pages est composé de code mettant en œuvre FNV de diverses manières. J'emprunte au RFC, section 2 (avec les modifications de l'article de Wikipédia pour que ce soit plus clair) l'essentiel de l'algorithme, en pseudo-code :
algorithm fnv-1 is
hash := FNV_offset_basis
for each byte_of_data to be hashed do
hash := hash × FNV_prime
hash := hash XOR byte_of_data
return hash
C'est court et rapide, non ? Mais, et le RFC le rappelle plusieurs fois (car des critiques sérieuses du projet de RFC avait insisté sur cette question) : cet algorithme ne doit pas être utilisé pour le cas où on veut de la résistance aux attaques comme la pré-image (section 1.1 du RFC). Ainsi, Python utilisait FNV mais a arrêté.
Qu'est-ce qui fait que FNV se retrouve qualifié de « non-cryptographique » et pas utilisable pour la sécurité ? La section 1.3 liste les limites de FNV (voir aussi la section 6) comme le fait que chaque bit du condensat ne dépend pas de tous les bits de la donnée d'entrée ou comme le fait que FNV est trop rapide. Oui, pour la sécurité, cela peut être un problème : si on utilise une fonction pour condenser des mots de passe, on ne veut pas faciliter la tâche de l'attaquant qui va chercher un mot de passe ayant ce condensat, en essayant beaucoup de mots de passe possibles. Une fonction de condensation a donc intérêt à être lente, comme Argon 2 (RFC 9106).
Vous trouverez par contre du FNV un peu partout (la section 1.2 vous donne une liste), dès que ces questions de sécurité ne sont pas pertinentes. FNV est même cité dans des RFC, le RFC 7357 ou le RFC 7873 (les cookies du DNS) ou bien dans la norme IEEE 802.1Qbp.
FNV a une longue histoire (section 7 du RFC), ayant commencé en
1991. On notera que la définition de FNV inclut quelques valeurs
largement arbitraires comme, par exemple, la chaine de caractères
« chongo <Landon Curt Noll> /\../\ », dont le condensat
fournit le paramètre offset_basis (section
2.2). Cette chaine était dans le .signature
d'un des auteurs de FNV mais, c'est amusant, avait été mal
recopiée.
Le gros (en nombre de pages) du RFC étant constitué de code source en C, avec des variantes selon le nombre de bits produits, plutôt que de tenter de l'extraire du RFC, utilisons cette archive tar que j'ai constituée :
% tar xzvf FNV-RFC.tar.gz % cd FNV-RFC % echo -n toto > tmp % make FNVhash % ./FNVhash -t 64 -f tmp FNV-64 test of return values passed. FNV-64 Hash of contents of file 'tmp': ADC7B038EFF1F42F
Et voilà, FNV marche. Il existe d'autres mises en œuvre. Celle de référence est présentée ici et est également sur Github :
% git clone https://github.com/lcn2/fnv % cd fnv % make % ./fnv1a64 -s toto 0x2ff4f1ef38b0c7ad [Oui, les octets ne sont pas affichés dans le même ordre qu'avec le code du RFC.]
Vous avez aussi d'autres mises en œuvre (une des plus rigolotes est en Fortran). Et elle n'est pas listée mais il y a une mise en œuvre de FNV dans le langage Zig (notez son utilisation de comptime).
Et pour finir, si vous vous demandez quelle fonction de condensation utiliser, il y a une comparaison de FNV avec SHA-1 (RFC 3174) et SHA-256 (RFC 6234) dans l'annexe A.
L'article seul
RFC 9920: RFC Editor Model (Version 3)
Date de publication du RFC : Février 2026
Auteur(s) du RFC : P. Hoffman (ICANN), A. Rossi (RFC
Series Consulting Editor)
Pour information
Réalisé dans le cadre de l'activité d'édition des RFC rswg
Première rédaction de cet article le 12 février 2026
Vous avez toujours voulu savoir qui s'occupait de publier les RFC et qu'est-ce que ce mystérieux « RFC Editor » ? Ce nouveau RFC décrit ce rôle et la façon dont il doit accomplir sa tâche. Il s'agit d'une légère mise à jour du RFC 9280, sans changement de version. (Parmi les nouveautés, la définition de la notion d'utilisateurice des RFC, avant, on ne parlait que des auteurices.)
Les RFC sont un ensemble de documents techniques au sujet de l'Internet, qui comprend notamment, mais pas uniquement, les normes TCP/IP. Les RFC sont librement accessibles en ligne et sont publiés depuis 1969 (cf. RFC 8700).
Il y a très longtemps, quand les dinosaures étaient petits, le rôle de RFC Editor s'incarnait bien dans une personne unique, Jon Postel. Aujourd'hui, c'est plus complexe et il n'y a plus, depuis la version 2 du modèle (qui était dans le RFC 8728), de RFC Editor unique. Ce rôle est désormais réparti en deux tâches principales, définir la politique, et la mettre en œuvre. La première tâche est du ressort du RSWG (RFC Series Working Group), pour discuter et proposer (tout le monde, et son chat, peut y participer), puis du RSAB (RFC Series Approval Board), pour décider (ce comité est plus fermé). La deuxième tâche, la mise en œuvre de la politique, est du ressort du RFC Production Center, typiquement une organisation privée sous contrat avec l'IETF LLC, l'organisation administrative derrière l'IETF (RFC 8711). Ce sont donc tous ces groupes ensemble qui composent le « RFC Editor ». Tout ceci, et quelques autres points, étaient déjà dans le RFC 9280, notre nouveau RFC 9920 n'apporte que des changements de détail.
Les RFC sont publiés par cinq voies (streams) différentes, dont une, la voie IETF, sert pour les normes (mais tous les RFC ne sont pas des normes). Chaque voie a une organisation ou une personne responsable du contenu des RFC (pour la voie IETF, le responsable est… l'IETF), la fonction RFC Editor ne gère pas le contenu (ou seulement la forme, mais pas le fond des documents) mais la publication. Le RFC 8729, dans sa section 5.1, décrit les quatre voies classiques (IETF, IRTF, IAB et indépendante). En plus, le RFC 9280 avait introduit la voie éditoriale, dédiée aux évolutions des RFC (les RFC parlant des RFC…). C'est via cette voie que seront publiés les propositions issues du RSWG et approuvées par le RSAB. Un exemple est le récent RFC 9896, dont vous pouvez suivre l'historique.
Dans les deux tâches décrites plus haut (la définition de la politique, et sa mise en œuvre), je n'ai pas mentionné un acteur supplémentaire (comme s'il n'y en avait pas déjà assez !), le RFC Series Consulting Editor, qui est un·e expert·e en édition, membre du RSAB.
Et donc, si vous avez des idées géniales pour améliorer les RFC, il faut faire comment pour qu'elles triomphent ? Lisez la section 3 et notamment la 3.2.2 :
- Les propositions sont écrites (un Internet draft) et diffusées au RSWG (rappelez-vous : il est ouvert, tout le monde peut y participer),
- Après un dernier appel dans le RSWG, puis plus large, s'il y a un consensus approximatif (RFC 2418),
- Les propositions atterrissent au RSAB, qui décidera (avec des votes YES ou CONCERN, le second n'étant pas un NO mais une demande de discussion).
Chaque acteur est décrit ensuite plus en détail. Le RSWG est le groupe le plus ouvert du lot, vous vous abonnez à sa liste de diffusion et c'est parti, vous êtes membre. Et ceci que vous soyez déjà participant à l'IETF ou pas. Les développeur·ses qui mettent en œuvre les RFC, les auteurs de RFC, les auteurs de logiciels qui traitent les RFC, les gens qui citent les RFC dans leurs appels d'offres, tous ceux et toutes celles là sont les bienvenu·es. Les discussions sont publiques. Le RSWG peut aussi utiliser des outils en ligne comme MicrosoftHub (RFC 8874).
Le RSAB, lui, est relativement fermé, aussi bien dans sa composition (les membres avec droit de vote sont un représentant de chaque voie plus le RFC Series Consulting Editor, cf. section 5) que dans son travail (mais les comptes-rendus des réunions sont publics). Par contre, il n'est pas censé court-circuiter le RSWG : toutes les propositions doivent d'abord être discutées au RSWG.
Les boilerplates, ces textes rigides présents au début de chaque RFC et expliquant le statut de celui-ci, décrits dans le RFC 7841, sont décidés par chaque voie puis approuvés par le RSAB, le RFC Production Center et l'IETF Trust.
Le RPC (RFC Production Center) est décrit en section 4. C'est actuellement AMS. C'est ce RPC qui va écrire et maintenir le guide stylistique à respecter (RFC 7322 et documents en ligne), décider des formats acceptés (par exemple du profil restreint de SVG, cf. RFC 9896), et préciser les points que le RFC 7991 laissait libres. C'est aussi le RPC qui doit faire le travail de publication effectif :
- Attribuer les numéros des RFC (qui sera le numéro 10 000 ?),
- Relire et corriger les textes soumis, en respectant le sens technique,
- Garder trace de toutes les modifications faites (des « corrections » peuvent accidentellement changer le fond du texte),
- Assurer la communication avec les auteurs et avec des organisations comme l'IANA, quand le futur RFC leur donne un rôle, par exemple de créer un nouveau registre de paramètres, et archiver tous ces dialogues,
- Demander le cas échéant au RSCE et/ou au RSAB, et leur faire des suggestions, fondées sur son expérience de publication des RFC,
- Participer au RSWG,
- Rendre compte à la communauté des auteurs et lecteurs de RFC, d'une part, et à l'IETF LLC d'autre part,
- Mettre les RFC en ligne, veiller au serveur
www.rfc-editor.orgqui les distribue, archiver les RFC (RFC 8153), annoncer les publications (le RPC est sur le fédivers, voyez par exemple cette annonce, et il y a bien sûr un flux de syndication sur le site Web), - Maintenir le système d'errata (« Submit an issue »),
- Et répondre aux demandes judiciaires car il y a parfois des procès impliquant un RFC.
Le RPC est choisi suite à un appel d'offres de l'IETF LLC, qui est chargée d'écrire le cahier des charges détaillé et de sélectionner le vainqueur. L'argent vient du budget de l'IETF LLC, qui paie le RPC (AMS, actuellement, comme indiqué plus haut).
Et le RSCE (RFC Series Consulting Editor) ? La section 5 le décrit plus en détail. C'est une personne expérimentée dans les questions d'édition. Il ou elle doit guider le RPC sur les questions techniques liées à la publication (la section 4 du RFC 8729 donne une liste complète de ces questions). La RSCE actuelle, depuis 2022, est Alexis Rossi, une des auteures de ce RFC.
Une des nouveautés du RFC 9280 était la voie éditoriale (Editorial Stream), la cinquième voie de création de RFC, consacrée aux RFC qui parlent des RFC. La section 6 de notre RFC la détaille. Cette voie est empruntée par les RFC discutés par le RSWG puis approuvés par le RSAB, comme ce RFC 9920 dont vous êtes en train de lire le résumé. Le statut de ces RFC est forcément « Pour information » (informational, cf. RFC 8729), mais ce sont bien des règles impératives pour les RFC qu'ils spécifient.
Et, pour finir, la section 7 de notre RFC liste les propriétés « historiques » des RFC qui, si elles n'ont pas forcément été mises par écrit, surtout au début, ont toujours été respectées et ne doivent pas être prises à la légère lors des propositions d'évolution :
- Libre disponibilité des documents, que tout le monde peut télécharger, lire, redistribuer. (Ce n'est pas évident, puisque des organisations fermées comme l'AFNOR ou l'ISO ne fournissent toujours pas d'accès libre à leurs documents et, même si vous avez payé pour en avoir un, vous ne pouvez pas le redistribuer.)
- Accessibilité (format texte d'abord, puis XML avec plusieurs formats de sortie), sans dépendance vis-à-vis de logiciels privateurs comme le font les organisations fermées.
- En anglais (notez que la licence permet de faire une traduction sans demander d'autorisation). Opinion personnelle : ce n'est évidemment pas génial mais il n'y pas d'alternative réaliste : traduire des documents normatifs en N autres langues est très coûteux (chaque virgule compte et, par exemple, un texte en français tend facilement à être plus directif que le texte en anglais).
- Diversité : tous les RFC ne sont pas des normes, il y a des informations, des discussions, de l'humour…
- Qualité des documents.
- Stabilité et longévité : le contenu sémantique des RFC n'est jamais modifié, et les formats sont choisis pour garantir qu'ils seront toujours lisibles dans des dizaines d'années (formats standards, acceptés par de nombreux logiciels). À part le cas particulier du RFC 20, le RFC le plus ancien et qui est toujours applicable est le RFC 768, qui a presque un demi-siècle. L'archivage à long terme est un point crucial des RFC, à la fois pour les RFC anciens mais toujours d'actualité, et aussi pour les historien·nes de l'informatique.
La section 1.1 de notre RFC résume les changements depuis le RFC 9280, qui avait spécifié la version 3 du modèle « RFC Editor ». On reste en version 3 et les changements sont peu importants :
- Précisions des responsabilités de développement des outils informatiques nécessaires. C'est au RFC Production Center de s'en occuper. Cela implique des choses comme les choix de formats ou bien les grammaires XML.
- Définition de la notion d'utilisateur des RFC (consumer of RFCs, section 3.3), en se référant au RFC 3935, qui décrit la mission de l'IETF mais qui n'expliquait pas clairement cette notion. Les utilisateurs des RFC sont un ensemble plus large que celui des participants à l'IETF, et un RFC doit être utilisable par des gens qui ne connaissent rien à l'IETF.
- En cohérence avec le RFC 9720, on précise désormais qu'un RFC, une fois publié, peut être modifié (sa forme, mais pas son fond).
La section 9, quant à elle, raconte les changements qu'il y avait eu depuis la version 2 du modèle (la version 1 du modèle était dans le RFC 5620 en 2009 et la version 2 dans le RFC 6635 en 2012) :
- Éclatement de la fonction de RFC Editor en plusieurs acteurs (RSWG, RSAB, etc).
- Fusion des fonctions RFC Production Center et RFC Publisher.
- Suppression du RSOC (RFC Series Oversight Commitee).
- Création de la voie éditoriale pour les RFC parlant des RFC.
L'article seul
RFC des différentes séries : 0 1000 10000 2000 3000 4000 5000 6000 7000 8000 9000
{kind=link}