
Les RFC (Request For Comments) sont les documents de référence de l'Internet. Produits par l'IETF pour la plupart, ils spécifient des normes, documentent des expériences, exposent des projets...
Leur gratuité et leur libre distribution ont joué un grand rôle dans le succès de l'Internet, notamment par rapport aux protocoles OSI de l'ISO organisation très fermée et dont les normes coûtent cher.
Je ne tente pas ici de traduire les RFC en français (un projet pour cela existe mais je n'y participe pas, considérant que c'est une mauvaise idée), mais simplement, grâce à une courte introduction en français, de donner envie de lire ces excellents documents. (Au passage, si vous les voulez présentés en italien...)
Le public visé n'est pas le gourou mais l'honnête ingénieur ou l'étudiant.
RFC 9998: Report from the IAB/W3C Workshop on Age-Based Restrictions on Content Access
Date de publication du RFC : Juin 2026
Auteur(s) du RFC : M. Nottingham, M. Thomson
Pour information
Première rédaction de cet article le 3 juillet 2026
En octobre 2025, l'IAB et le W3C ont organisé un atelier à Londres sur la restriction d'accès à des services Internet en fonction de l'âge. Ce RFC est le compte-rendu de l'atelier. En tant que compte-rendu, il n'exprime donc pas une position officielle de l'IAB.
Le sujet est d'actualité, avec de nombreux politiciens qui proposent d'interdire les réseaux sociaux ou la pornographie aux mineurs. Des lois sont déjà votées, comme en Australie. L'UE a un plan en cours et un projet de logiciel. Vous pouvez consulter le site du projet logiciel. En France, où l'une des questions secondaires était la compatibilité d'un éventuel contrôle avec le droit européen, un arrêt du 16 juin 2026 de la Cour de justice de l’Union européenne a estimé que la France pouvait obliger des sociétés basées dans un État membre à mettre en place une vérification d’âge.
L'atelier
devait explorer les différents techniques et choix
d'architecture liés à ce désir de restriction. Comment combiner
cette exigence de restriction aux mineurs tout en préservant les
principes d'universalité et de décentralisation de l'Internet, ainsi
que la vie privée ? Comment le faire sans mettre en place un
système de contrôle qui fera le bonheur de gouvernements
autoritaires voire dictatoriaux ? Et faut-il déléguer la sécurité
des enfants aux opérateurs Internet, plutôt qu'aux adultes qui s'en
occupent (parents, enseignants, etc) ? Les politiciens qui réclament
des restrictions d'âge « pour protéger les enfants » ne se posent
évidemment jamais ces questions (et les avertissements
des experts sont systèmatiquement ignorés). Un exemple
non technique : ces restrictions peuvent servir à un gouvernement
religieux et/ou réactionnaire pour bloquer l'accès à des sites Web
LGBT, au détriment des mineurs en
questionnement qui voudraient s'informer (notez que le RFC ne
mentionne pas ce point). L'atelier n'a pas essayé de traiter les
problèmes politiques, mais uniquement d'analyser les techniques
existantes et de pointer leurs caractéristiques et leurs
conséquences. Comme indiqué au début, cet atelier a été l'occasion
d'exprimer des points de vue variés (sous la règle de
Chatham House), ce RFC ne prétend pas en faire un synthèse, ni
donner La Bonne Réponse. Le RFC inclut notamment une liste des
propriétés attendues d'une « bonne » solution, dans l'annexe D. Ce
point de départ d'un vrai cahier des charges manque dans la plupart
des discours politiciens, où on ne fait que répéter des slogans,
sans dire clairement quels sont les avantages attendus et les
inconvénients acceptables. (L'annexe C est une intéressante liste
des impacts - positifs ou négatifs - possibles du contrôle d'âge.)
L'agenda complet de l'atelier figure dans l'annexe A du RFC, la liste des participants dans l'annexe B. Passons maintenant au contenu.
Les « solutions » techniques peuvent être mises en œuvre dans le
terminal de l'utilisateurice, dans le réseau (par exemple dans le
résolveur DNS) ou bien dans le
service (regardez https://fr.pornhub.com/
depuis la France, pour voir ; n'hésitez pas, c'est
SFW). Dans le terminal ? Cela donne du
pouvoir à Microsoft ou
Google et encourage les systèmes
privateurs sur lesquels l'utilisateurice n'a
aucun contrôle. (Encore que le logiciel libre
peut aussi, par souci de conformité et pour se faire bien voir des
politiciens, mettre en œuvre
ces contrôles.) Dans le réseau ? Cela met en danger le cœur
de l'Internet. Et cela donne du pouvoir aux acteurs de
l'infrastructure. Et ce n'est pas très précis (pensez au cas d'un
foyer où il y a adultes et enfants mais une seule adresse IP). Dans
les services ? Cela met le problème sur le dos de chaque
webmestre.
L'atelier a examiné quelques technologies « miracle » censées permettre de vérifier l'âge tout en préservant la vie privée (comme les ZKP). Même si elles résolvaient parfaitement le problème de vie privée, elles laissent ouverts les autres problèmes. Et ces technologies sont souvent récentes et leur sécurité n'est pas toujours testée en profondeur.
Bref, l'atelier n'a pas débouché sur une « solution » ni même sur un plan de travail pour l'IETF. La question reste très ouverte.
Le RFC pointe en section 3 les aspects les plus importants de ce sujet. D'abord, le fait que l'atelier a été utile car, alors que le sujet a bénéficié de nombreux articles dans la presse généraliste, et de nombreux discours politiciens, les discussions techniques ont été rares, de même que les forums impliquant toutes les parties prenantes. Et quand des techniciens étaient consultés, c'était toujours du point de vue des services, jamais de celui de l'infrastructure.
Ensuite, les discussions sont souvent peu productives car il y a eu peu d'efforts pour identifier les différentes rôles impliqués (cf. la présentation d'Hanson) :
- Le vérificateur qui doit tester si une personne donnée a plus que l'âge requis,
- Le contrôleur qui doit empêcher une personne qui a « raté » le test précédent d'accéder au service,
- Le sélecteur de politique, qui définit la politique à appliquer (elle dépend en général du pays de résidence du client, qui est difficile à déterminer sur l'Internet),
- Et le classificateur qui doit déterminer si un contenu donné ou un certain service doit être restreint d'accès.
Cette question est aussi liée à celle de la terminologie, souvent peu définie. (Tiens, j'apprends dans le RFC qu'il existe une norme ISO sur la vérification d'âge, ISO/IEC 27566-1:2025, évidemment pas accessible aux mineurs - il faut laisser plein de données personnelles pour l'obtenir.)
Autre sujet mis en évidence à l'atelier, l'importance de la préservation de la vie privée. Cette exigence est largement méprisée par les défenseurs du contrôle d'âge, le record de connerie ayant récemment été battu par une parlementaire canadienne qui affirmait que la reconnaissance faciale respectait l'anonymat puisque le logiciel ne connaissait pas le nom de la personne. Une partie des acteurs cités plus haut va connaitre des informations personnelles sur les clients des services, et ces acteurs ne sont pas forcément connus de ces clients. Imaginez que vous alliez sur un site Web de contenu pour adultes puis soudainement vous êtes redirigé vers le site Web du vérificateur qui va vous demander de prouver votre âge. Si vous êtes raisonnablement prudent, vous refusez. Si vous tenez à voir le contenu, vous répondez et voilà : on a habitué les utilisateurs à faire confiance à des sites inconnus et inattendus. Une vraie aide au hameçonnage.
En parlant de confiance, un des points difficiles de toute solution technique au problème du contrôle d'âge est la nécessité de faire confiance à de nouveaux acteurs. Certes, il existe des méthodes mathématiques pour prouver quelque chose sans divulguer d'information mais elles sont récentes, peu testées, et sont loin d'épuiser le problème de la confiance. Le fait que beaucoup de techniques proposées ne soient pas en logiciel libre n'arrange rien. (Le RFC ne mentionne pas ce point, sauf pour enfoncer une porte ouverte en rappelant que le logiciel libre ne résout pas tous les problèmes de confiance.)
Les participants à l'atelier ont aussi noté qu'il y avait peu de chances qu'une seule technique suffise : toutes ont des défauts graves. Les techniques reposant sur des documents étatiques écartent les gens qui n'en ont pas, ou ceux qui ont des documents non reconnus. Les techniques probabilistes d'estimation de l'âge (par exemple par examen du visage) ont beaucoup de faux positifs et de faux négatifs (et, pire, cela dépend de la couleur de peau). Une approche possible serait d'essayer successivement plusieurs techniques, en commençant par les moins invasives (mais cela créerait une discrimination envers les catégories de population qui échouent à ces premières techniques).
L'imperfection de toutes ces techniques a des conséquences sérieuses : exclusion de certaines personnes, contournement par d'autres (certains utilisateurs de contenu « pour adultes » n'ont pas l'âge mais sont motivés, techniquement compétents et ont du temps libre).
La plupart des architectures proposées ajoutent des parties à la relation traditionnelle entre le visiteur d'un site Web et le site en question, notamment le vérificateur et le contrôleur. On complique donc l'architecture du Web en ajoutant de nouvelles dépendances.
Et, bien sûr, la technique n'est pas tout. La sécurité des mineurs ne doit pas dépendre uniquement de techniques dont l'atelier a largement montré la fragilité. Le problème, il est vrai, est très difficile puisqu'il faut à la fois protéger les mineurs contre les dangers bien réels, tout en les préparant à leur future vie de majeur, où il n'y aura pas de restrictions techniques. Les contrôles techniques sont forcément grossiers et binaires, et ne prennent pas en compte toutes les nuances du monde. Il ne faudrait surtout pas déléguer des tâches aussi complexes et délicates que l'éducation à des « solutions » techniques.
Quelques autres ressources :
- La vidéo de présentation de l'atelier.
- Les documents présentés à l'atelier.
- La prise de position de l'Internet Society.
- Un précédent Internet-Draft sur les conséquences d'une restriction d'âge pour l'Internet.
L'article seul
RFC 9991: Domain-Based Message Authentication, Reporting, and Conformance (DMARC) Failure Reporting
Date de publication du RFC : Mai 2026
Auteur(s) du RFC : S. Jones (DMARC.org), A. Vesely (Tana)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dmarc
Première rédaction de cet article le 20 mai 2026
DMARC (RFC 9989)
permet de demander l'envoi, par les destinataires des messages, de
rapports indiquant les éventuels problèmes notés, afin de diminuer
le nombre de faux positifs (messages légitimes incorrectement
considérés comme invalides). Cette demande de rapports se fait en
ajoutant l'option ruf à l'enregistrement
DMARC. Ce RFC
décrit ces rapports.
Il y a au moins deux raisons de demander ces rapports :
- Comprendre pourquoi certains des messages qu'on envoie sont classés comme invalides alors qu'ils ne devraient pas l'être. On va donc analyser des rapports concernant des messages qu'on a réellement envoyés.
- Détecter les tentatives d'usurpation du domaine. On va donc analyser des rapports concernant des messages qu'on ne connaissait pas, et qu'un méchant a envoyés.
Notez qu'il existe aussi des rapports agrégés (RFC 9990, avec un format très différent, fondé sur XML) et qu'on demande parfois des rapports individuels parce qu'on note dans les rapports agrégés qu'il y a beaucoup d'erreurs et qu'on voudrait comprendre leur origine.
Le format normalisé ici dérive du format ARF (Abuse
Reporting Format, RFC 6591), qui
décrivait les rapports pour les problèmes SPF et DKIM. L'option
ruf dans l'enregistrement DMARC (RFC 9989, section 4.7) indique à quelle adresse de
courrier le
rapport doit être envoyé. Voici par exemple l'enregistrement DMARC
de afnic.fr :
dig +short _dmarc.afnic.fr TXT "v=DMARC1; p=quarantine; pct=100; ruf=mailto:dmarc-feedback@afnic.fr; rua=mailto:dmarc-feedback@afnic.fr; fo=1"
Vous voyez le ruf ? Il indique que les rapports
doivent être envoyés à
dmarc-feedback@afnic.fr. Attention, j'ai écrit
« doivent » mais, évidemment, les récepteurs de courrier ne sont
pas obligés d'envoyer ces rapports, qui peuvent
leur coûter des ressources et poser des problèmes de vie privée.
Pour DMARC, notre RFC ajoute au format du RFC 6591 les champs (section 4, ils sont listés dans un registre IANA) :
Identity-Alignment:, qui liste les mécanismes d'authentification où il n'y a pas d'alignement avec l'expéditeur,Delivery-Result:,DKIM-Domain:, et quelques autres au sujet de DKIM,SPF-DNS:.
Il y a un autre piège avec les rapports, c'est la possibilité
d'indiquer dans ruf l'adresse de quelqu'un
d'autre, pour l'embêter avec beaucoup de rapports qui ne le
concernent pas. La section 4 du RFC 9990
explique les précautions que devrait prendre un receveur de courrier
avant d'envoyer un rapport vers une adresse qui n'est pas dans le
domaine concerné, comme de tester le sous-domaine
_report._dmarc. (Dans l'exemple
afnic.fr plus haut, il n'y avait pas de
problème, le destinataire des rapports est dans le domaine
concerné.)
J'ai mentionné un peu plus haut la question de la vie privée. Les rapports détaillés, contrairement à leurs copains agrégés du RFC 9990, peuvent être très indiscrets, notamment parce qu'ils contiennent souvent des données personnelles, par exemple dans les champs indiquant l'expéditeur et le destinataire. Et il ne suffit pas de se dire « Bon, de toute façon, le gestionnaire du système envoyeur avait accès au message quand il est parti de son système » car le message a pu être transmis et re-transmis et le rapport donnera des informations sur des destinataires finaux. Une section 7, très détaillée, couvre donc ce problème. Elle note par exemple que beaucoup de gros receveurs de courrier n'envoient pas du tout de rapport individuel, seulement des rapports agrégés. Et elle recommande que, même si on envoie les rapports, on en supprime les éléments les plus sensibles (voir le RFC 6590).
Enfin, à envoyer un rapport par message, on noiera l'expéditeur supposé sous des rapports qui concerneront des spams envoyés en nombre. Donc, prudence.
Un point amusant, que je vois pour la première fois dans un
RFC : ce RFC 9991 recommande de modifier les URL présents dans les rapports en
remplaçant http par
hxxp. Cette convention est assez courante dans
le monde de la sécurité Internet, pour éviter qu'un humain ne clique
trop vite sur un lien malveillant.
L'annexe A du RFC donne un exemple de rapport, je ne montre ici que la partie MIME qui concerne le rapport proprement dit :
--=_mime_boundary_ Content-Type: message/feedback-report Content-Transfer-Encoding: 7bit Feedback-Type: auth-failure Version: 1 User-Agent: DMARC-Filter/1.2.3 Auth-Failure: dmarc Authentication-Results: gen.example; dmarc=fail header.from=consumer.example Identity-Alignment: dkim DKIM-Domain: consumer.example DKIM-Identity: @consumer.example DKIM-Selector: epsilon Original-Envelope-Id: 65E1A3F0A0 Original-Mail-From: author=gen.example@forwarder.example Source-IP: 192.0.2.2 Source-Port: 12345 Reported-Domain: consumer.example
Le message prétend venir de consumer.example
mais aucune signature DKIM n'est valide, sans doute suite à des
modifications chez forwarder.example ou bien
parce que la clé DKIM n'a pu être récupérée dans le DNS.
Apparemment, OpenDKIM est capable de générer ces rapports, mais je n'ai pas testé.
L'article seul
RFC 9989: Domain-based Message Authentication, Reporting, and Conformance (DMARC)
Date de publication du RFC : Mai 2026
Auteur(s) du RFC : T. Herr (Valimail), J. Levine (Standcore)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dmarc
Première rédaction de cet article le 20 mai 2026
DMARC est une technique
d'authentification du courrier
électronique qui permet à un domaine d'indiquer quelle
est sa politique de sécurité vis-à-vis des messages dont
l'expéditeur (le champ From: de l'en-tête)
indique ce domaine. Il donne au gérant du domaine la possibilité
d'annoncer sa politique de sécurité « tous les messages de ce
domaine sont authentifiés (via SPF ou DKIM) ». Typiquement, DMARC est le couronnement
d'une démarche de sécurité du courrier, ce qu'on annonce quand on a
bien tout authentifié. Par contre, attention, en authentifiant la
donnée visible par les utilisateurs et pas les données techniques,
il casse certains usages du courrier. DMARC était à l'origine
normalisé dans le RFC 7489, que ce nouveau
RFC
remplace. Mais rassurez-vous si vous avez déjà déployé DMARC : les
changements ne sont pas radicaux. Le principal est le nouvel
algorithme pour trouver l'enregistrement DMARC pertinent (celui à
l'apex du domaine enregistré).
Revenons sur les problèmes de sécurité du courrier électronique. Un message typique, tel que normalisé par le RFC 5322, comprend dans son en-tête ce genre d'informations :
Date: Wed, 18 Mar 2026 17:28:36 +0800 From: Jiankang Yao <yaojk@cnnic.cn> To: 125attendees@ietf.org Subject: [125attendees] Wednesday 8:00 pm, Shenzhen light show for IETF 125 X-Mailer: iPhone Mail (21D61) [et bien d'autres]
Une qui nous intéresse particulièrement est l'expéditeur. Cette
notion est plus compliquée qu'il n'y parait (il y a plusieurs
définitions possibles de « expéditeur ») mais pour DMARC, c'est
simple : le champ qui nous intéresse est uniquement le
From: (section 3.6.2 du RFC 5322). C'est en effet celui qui est typiquement affiché
par les MUA, et
c'est celui que DMARC va protéger. On l'appelle souvent RFC5322-From
pour le distinguer de celui qui apparait dans l'enveloppe du
courrier, le RFC5321-From (et qui n'est pas montré dans mon
exemple).
Les techniques d'authentification existantes avant DMARC,
SPF (RFC 7208) et DKIM (RFC 6376),
n'authentifient pas ce champ mais d'autres (le
RFC5321-From pour SPF et le domaine indiqué dans la signature pour
DKIM), qui ne sont pas en général affichés à l'utilisateurice
final·e. DMARC va permettre d'utiliser ces deux techniques, SPF et
DKIM, pour les appliquer à l'expéditeur (RFC5322-From). Un test
DMARC réussi signifie que SPF ou DKIM a réussi
mais aussi que le domaine authentifié par SPF ou DKIM est le même
que celui présent dans le From: ; on parle
d'alignement du nom de domaine. Cela ne va pas
de soi car il y a de nombreux usages légitimes
du courrier où ces domaines ne sont pas alignés, et DMARC casse donc
ces usages.
Dans les exemples de messages reçus après traitement par DMARC,
on va regarder les champs
Authentication-Results. Normalisés dans le RFC 8601, ils sont ajoutés par le récepteur et
indiquent le résultat d'une technique d'authentification. Ici, un
exemple où SPF et DKIM ont marché (tous les exemples ici sont réels,
issus de mes boites aux lettres):
Authentication-Results: mail.bortzmeyer.org; dmarc=pass (p=quarantine dis=none) header.from=afnic.fr
Authentication-Results: mail.bortzmeyer.org;
dkim=pass (2048-bit key; secure) header.d=afnic.fr header.i=@afnic.fr header.a=rsa-sha256 header.s=afnic-20240601
header.b=bdGM6W8o;
dkim-atps=neutral
Authentication-Results: mail.bortzmeyer.org; spf=pass (sender SPF authorized) smtp.mailfrom=afnic.fr
(client-ip=2001:67c:2218:10::51:1; helo=mx1.nic.fr; envelope-from=quelqu.un@afnic.fr; receiver=bortzmeyer.org)
Le domaine afnic.fr a bien été authentifié, à
la fois par SPF et par DKIM, et DMARC passe donc (le champ
From: n'est pas montré ici mais il indiquait
bien une adresse @afnic.fr).
Il est également important de se souvenir que DMARC ne fait
qu'authentifier le
domaine, il ne garantit pas que le message soit sincère, sûr, utile ou quoi
que ce soit d'autre. Si on reçoit un message de
Trump, on peut prouver qu'il vient bien de
whitehouse.gov mais il sera quand même
certainement mensonger. C'est pour cela qu'il est absurde, comme on
le lit dans certains forums, de dire « je ne comprends pas, j'ai
bien mis un enregistrement DMARC et mes messages finissent quand
même dans la boite Spam » : les spammeurs font du DMARC, eux aussi.
L'inverse est vrai aussi, un message légitime et désiré peut parfaitement échouer au test DMARC, d'autant plus, que, comme indiqué plus haut, DMARC casse plusieurs usages légitimes du courrier. Il vaut donc mieux ne pas refuser un message uniquement sur la base d'un échec DMARC mais traiter cet échec comme une indication parmi d'autres. Ce RFC 9989 insiste sur ce point (notamment sa section 7), en mentionnant également le RFC 7960, qui détaille les problèmes venant de l'utilisation de DMARC.
La section 2 du RFC détaille le cahier des charges de DMARC. Comme avec toutes les solutions de sécurité, il faut garder en tête ce cahier des charges lorsqu'on évalue DMARC. Aucune solution de sécurité n'est parfaite : elles collent simplement plus ou moins bien à leur cahier des charges. Celui-ci, en résumé, est :
- Permettre aux gérants de noms de domaine d'annoncer leur politique d'authentification du courrier et leurs souhaits quant au traitement du courrier qui ne passerait pas cette authentification.
- Fonctionner dans le contexte de l'Internet (donc, sans autorité centrale).
- Traiter uniquement les cas où le message malveillant copie
exactement un nom de domaine qu'on gère. En d'autres termes, les
usurpations utilisant des noms qui ressemblent
(
goog1e.comau lieu degoogle.com) sont hors-sujet. - Authentifier uniquement le nom de domaine qui est dans
l'adresse (RFC 5322, section 3.4). En d'autres termes, dans un
From:« Emmanuel Macron<emmanuel5561@gmail.com>, DMARC ne se préoccupe que dugmail.com, pas duemmanuel5561. - Authentifier uniquement l'adresse, pas le nom affiché (« Emmanuel Macron » dans l'exemple ci-dessus). La section 11.4 rappelle ce point très important.
Un bon cahier des charges a une autre section très importante : celle des non-objectifs, des choses qu'on n'essaie pas de faire. (Regardez les documents commerciaux : ils n'ont jamais l'honnêteté de lister ce qu'ils ne font pas.) Pour DMARC :
- Il ne dit évidemment rien sur les domaines qui ont choisi de ne pas avoir d'enregistrement DMARC dans le DNS. Dit autrement, DMARC est opt-in.
- Il n'essaie pas de s'occuper des autres informations
présentes dans l'en-tête (comme
Reply-To:ouDate:). - Il ne s'occupe pas des tricheries sur le nom affiché, comme
dans l'exemple « Emmanuel Macron » plus haut (ou bien, tiré de ma
boite Spam
From: "amendes.gouv.fr" <amendes-gouv-nepasrepondre.C9717A5D-EA39-D865-765A6C98B4A0BB03@therugest.com>). Tant pis pour ceux et celles qui s'obstinent à utiliser un logiciel qui, par défaut, n'affiche que ce nom (Outlook fait encore ça). Relisez la section 11.4 du RFC. - Et naturellement, DMARC ne s'occupe pas du contenu du message, qu'il soit mensonger (« je suis l'ex-ministre des finances du Nigéria ») ou malveillant (logiciel qui va tenter d'exploiter une faille de sécurité pour prendre le contrôle de votre ordinateur).
Par exemple, voici un spam, prétendant venir de l'ANTAI mais qui passe tous les tests (le nom de domaine dans l'adresse n'a rien à voir avec l'ANTAI mais beaucoup d'utilisateurs n'y feront pas attention, et ce nom avait bien un enregistrement DMARC) :
Authentication-Results: mail.bortzmeyer.org; dmarc=pass (p=quarantine dis=none) header.from=rtm.gov.my
Authentication-Results: mail.bortzmeyer.org;
dkim=pass (2048-bit key; secure) header.d=rtm.gov.my header.i=@rtm.gov.my header.a=rsa-sha256 header.s=rtm
header.b=MaKApt+s;
dkim-atps=neutral
DKIM-Signature: v=1; a=rsa-sha256; c=relaxed/relaxed;
d=rtm.gov.my; s=rtm; t=1775231898; x=1775836698; darn=bortzmeyer.org;
h=content-transfer-encoding:mime-version:subject:message-id:to:from
:date:from:to:cc:subject:date:message-id:reply-to;
bh=L6c3f6fDBrQyBjkO1RiiF3vHHNmYjLDd4A1urn+cNJg=;
b=MaKApt+s0vgkVsgh3VoFE0/MgCt8ilWkghyQKUbj2NnhgInADkR8G3aW0UbklkuDDV
…
Authentication-Results: mail.bortzmeyer.org; spf=pass (sender SPF authorized) smtp.mailfrom=rtm.gov.my
(client-ip=2607:f8b0:4864:20::f64; helo=mail-qv1-xf64.google.com; envelope-from=antai.gouv.fr@rtm.gov.my;
receiver=bortzmeyer.org)
Subject: ACTION REQUISE SOUS 24H
From: "Antai.gouv.fr" <Antai.gouv.fr@rtm.gov.my>
La section 3 du RFC décrit les termes utilisés par DMARC, entre autres :
- Domaine de l'auteur : ce qui est après
l'arobase dans l'adresse indiquée par le
champ
From:de l'en-tête (rappel : pas celui de l'enveloppe). - Domaine DKIM : celui indiqué par le paramètre
d=dans la signature DKIM (rappel : le domaine DKIM peut n'avoir aucun rapport avec l'adresse de l'en-tête ou avec celle de l'enveloppe). - Domaine SPF : ce qui est après
l'arobase dans l'adresse indiquée par le
champ
Fromde l'enveloppe (rappel : pas celui de l'en-tête). Dans le contexte de DMARC, ce terme ne s'applique pas au domaine indiqué dans la commande EHLO (ou HELO) de SMTP. - Titulaire du domaine : la personne physique ou morale qui décidé d'enregistrer un nom de domaine et qui le gère ensuite.
- Domaine organisationnel : le domaine au sommet du sous-arbre
qui a la même administration (le RFC 5598
est une bonne lecture ici). Ainsi,
bortzmeyer.orgest le domaine organisationnel demail.bortzmeyer.org. En pratique, c'est souvent le domaine enregistré du RFC 9499, domaine qui a été enregistré auprès d'un registre. - Suffixe public : domaine où le public peut enregistrer un
sous-domaine, par exemple
.froueu.org. Ainsi, dansmail.foobar.eu.org,foobar.eu.orgest le domaine organisationnel eteu.orgle suffixe public, ou domaine d'enregistrement.
Armé de cela (mais il y a d'autres termes, que je présenterai au fur et à mesure), on peut passer à la section 4, qui explique les concepts importants.
DMARC permet à un titulaire de domaine d'annoncer sa politique
d'authentification d'un domaine de l'auteur d'un courrier. On
n'authentifie donc que le domaine, pas toute l'adresse (je l'ai déjà
dit mais c'est important). Et DMARC ne s'intéresse qu'à ce qu'il
appelle le domaine de l'auteur, donc le From:
dans l'en-tête (également appelé « RFC5322.From »). DMARC annonce
juste une politique, l'authentification est faite avec SPF (RFC 7208) ou DKIM (RFC 6376).
Un concept essentiel dans DMARC est celui
d'alignement. Il y a alignement quand le
domaine authentifié par SPF (celui de l'enveloppe, le
« RFC5321.From ») ou par DKIM (celui indiqué dans le
d= de la signature) coïncide avec le domaine de
l'auteur (celui du From: de l'en-tête). Plus
précisément, il peut y avoir un alignement strict (les deux noms de
domaine sont identiques) ou relâché (les deux noms sont dans le même
domaine organisationnel). Le choix se fait dans l'enregistrement
DMARC publié.
Justement, on le publie où ? Via le DNS, dans un enregistrement de type TXT, publié
dans le sous-domaine _dmarc, par exemple :
% dig +short _dmarc.proton.me TXT "v=DMARC1; p=quarantine; fo=1; aspf=s; adkim=s;"
On bénéficie ainsi de toute l'infrastructure,
très fiable et éprouvée, du DNS. Ce sous-domaine
_dmarc figure dans le
registre IANA des noms commençant par un trait bas, créé par le RFC 8552.
Au passage, si vous voulez voir (ou enregistrer), sur un serveur DNS faisant
autorité, uniquement les requêtes DNS pour le sous-domaine
_dmarc, dnscap permet
de le faire facilement :
% dnscap -g -x _dmarc
(Je triche un peu, le -x attrape en effet
davantage que cela mais ça suffit en première approximation.)
Le format exact de l'enregistrement DMARC utilise des doublets clé=valeur, comme celui de DKIM. (Sa description formelle, en ABNF - RFC 5234 - est dans la section 4.8.) Les clés possibles figurent dans un registre IANA. Les plus courantes sont :
v: c'est obligatoirement le premier doublet clé=valeur et il indique la version de DMARC, actuellementDMARC1.p: c'est la clé la plus importante, celle qui indique la politique à appliquer aux messages qui ne passent pas la validation DMARC. Une valeurrejectindique que le titulaire du domaine recommande le rejet des messages invalides (cela ne peut être qu'une recommandation, car le récepteur du courrier reste évidemment libre de sa politique).quarantinerecommande une mise en attente quelque part (un dossier « peut-etre-spam » par exemple). Enfin,noneindique qu'on recommande de ne rien faire. Cela peut être utilisé quand on craint les conséquences de DMARC sur certains usages (cf. RFC 7960) mais qu'on pense que certains récepteurs vont mal traiter les messages des domaines sans DMARC. Ou bien cela peut être utile dans certains audits « de sécurité » qui demandent un enregistrement DMARC, n'importe lequel. Enfin, unp=nonepeut être utilisé lors d'un déploiement progressif de DMARC, quand on veut juste tester, avant de publier une politique plus fasciste. Comme DMARC permet de solliciter l'envoi de rapports d'erreur, unp=nonepeut être accompagné d'une telle sollicitation.sp: commepmais pour les sous-domaines du domaine qui a l'enregistrement DMARC. Les valeurs possibles sont les mêmes que pourp.np: nouveauté, initialement décrite dans le RFC 9091. C'est le traitement à appliquer aux sous-domaines non existants du domaine pour lequel une politique DMARC est publiée. Les valeurs possibles sont les mêmes que pourp.ruf: c'est ainsi qu'on sollicite l'envoi de rapports d'erreur. On indique les URI où envoyer ces rapports (souvent des URI de planmailto:, pour demander des rapports par courrier). Le format des rapports est spécifié dans les RFC 9991, RFC 6651 et RFC 6552.rufdemande un rapport par message invalide,ruapermet de demander des rapports agrégés. Leur format figure dans le RFC 9990.psd: nouveauté de notre RFC, s'il a la valeury, il indique que le domaine est un suffixe public (PSD : Public Suffix Domain), c'est-à-dire un domaine dont les sous-domaines peuvent être délégués à d'autres entités (comme c'est le cas de.reoueu.org).fo: diverses options pour la génération de rapports d'erreur.adkimetadpf: tous les deux peuvent prendre la valeurs(strict) our(relâché, ou laxiste). Ils indiquent si l'alignement duFrom:avec l'identificateur authentifié par DKIM ou SPF doit être strict (les deux identificateurs sont rigoureusement identiques) ou relâché (l'identificateur authentifié peut se contenter d'être dans le même domaine enregistré que celui qui a un enregistrement DMARC). Par défaut, DMARC est laxiste. Notez que cela permet à quelqu'un qui peut utiliser un sous-domaine de se faire authentifier comme étant dans l'apex (section 11.8 du RFC). Demander un alignement strict résout ce problème (mais impose que vous contrôliez bien les sous-domaines).
Les clés inconnues doivent être ignorées, ce qui permet d'en ajouter de nouvelles sans tout casser. La politique pour un éventuel ajout est « Spécification nécessaire » (RFC 8126).
On a parlé du domaine organisationnel, l'apex du domaine testé
par DMARC. C'est en fait une notion administrative, pas technique,
ce qui fait que ce domaine organisationnel n'est pas évident à
identifier dans le DNS. Pour le trouver, l'ancien RFC, le RFC 7489, suggérait de faire appel à une liste de suffixes
publics, comme la PSL (rappel : il n'existe
pas de liste officielle). Notre nouveau RFC suggère une autre
méthode, en remontant l'arbre des noms de domaine. On commence par
le domaine qu'on veut authentifier, et, si on n'y trouve pas de
politique DMARC, on essaie son domaine parent et ainsi de suite,
jusqu'à ce qu'on trouve un enregistrement DMARC. Ainsi, pour
truc.machin.example.com, on essaiera
successivement _dmarc.truc.machin.example.com,
_dmarc.machin.example.com,
_dmarc.example.com et enfin
_dmarc.com. La dernière requête permet donc au
registre de
.com de définir une
politique DMARC qui s'appliquera à tous les domaines sans politique
DMARC. C'est très dangereux, pour les raisons expliquées dans le
RFC 1535 mais cela permet de se passer de
liste de suffixes publics, et c'est plus souple pour le cas des
grosses organisations, qui peuvent avoir des politiques DMARC dans
des sous-domaines qui ne sont pas délégués.
Notez que l'éventuelle présence de la clé
psd va compliquer les choses mais je n'ai pas
vraiment le courage de détailler ici l'algorithme complet.
Maintenant, voyons quels sont les acteurs d'un déploiement de
DMARC. D'abord, le titulaire du domaine qui envoie des messages. Il
doit publier un enregistrement SPF à l'apex du domaine. Il doit
signer les courriers sortants avec DKIM (ce qui implique de publier
les clés publiques DKIM dans le DNS). Notez que DMARC n'a pas besoin
de SPF et de DKIM, un seul des deux suffit
mais, bon, autant tout faire. Il a intérêt à créer une boite dédiée
pour recevoir les rapports sur les messages invalides. Le titulaire
doit enfin publier dans le DNS l'enregistrement DMARC (celui qui
commence par _dmarc). Au début, on utilise
typiquement une politique indulgente
(p=none). Puis on teste.
Comment teste-t-on ? En lisant les rapports indiquant des
messages invalides (RFC 9990 et RFC 9991). Les
rapports agrégés sont du
XML, assez
lisibles par un humain mais, en pratique, on préférera typiquement
utiliser un programme qui les synthétisera dans une forme plus
lisible. (Je n'utilise pas actuellement un tel programme, car je
n'en ai pas trouvé. Il faut qu'il tourne en local - pas question de
confier les rapports à un tiers - et ne nécessite pas d'installer
toute une batterie de cuisine PHP et MariaDB.)
Une fois qu'on a trouvé les problèmes (une application oubliée dans
un coin qui envoie des courriers sans passer par les serveurs
centraux…) et qu'on les a corrigés, on peut durcir la politique
(p=quarantine, par exemple). Il est raisonnable
d'attendre plusieurs semaines, voire mois, pour être sûr d'avoir vu
tous les problèmes.
(Et si vous êtes gérant d'un suffixe public - un domaine sous
lequel d'autres entités peuvent enregistrer des noms, demandez-vous
si vous devez publier du DMARC avec psd=y. Ce
n'est pas obligatoire, cf. section 5.2.)
Et le récepteur du courrier, que doit-il faire ? Il extrait du message le domaine de l'auteur. Il cherche s'il y a un enregistrement DMARC. Il exécute les tests SPF et DKIM. S'il récupère un ou plusieurs domaines authentifiés, il vérifie l'alignement (strict ou relâché). Si au moins un domaine authentifié est aligné avec le domaine de l'auteur, le test DMARC est un succès. Sinon, c'est un échec. Notez bien qu'il n'est pas nécessaire que SPF et DKIM réussissent tous les deux. Si le test DMARC se termine en échec, on applique un traitement, qui dépend de la politique suggérée dans l'enregistrement DMARC, et de la politique propre du receveur. Voici un exemple où DMARC dit que tout s'est bien passé :
From: "Projet Arcadie" <admin@projetarcadie.com>
Authentication-Results: mail.bortzmeyer.org; dmarc=pass (p=none dis=none) header.from=projetarcadie.com
Authentication-Results: mail.bortzmeyer.org;
dkim=pass (2048-bit key; unprotected) header.d=projetarcadie.com header.i=@projetarcadie.com header.a=rsa-sha256 header.s=alternc
header.b=plrnZlsJ;
dkim=pass (2048-bit key) header.d=projetarcadie.com header.i=@projetarcadie.com header.a=rsa-sha256 header.s=alternc
header.b=m84VgM5U;
dkim-atps=neutral
Authentication-Results: mail.bortzmeyer.org; spf=pass (sender SPF authorized) smtp.mailfrom=projetarcadie.com (client-ip=91.194.60.11;
helo=arcadieweb01.octopuce.fr; envelope-from=admin@projetarcadie.com; receiver=bortzmeyer.org)
Ici, il y avait un enregistrement SPF (qui autorise l'émetteur
SMTP
donc cela suffit), deux signatures DKIM, toutes les deux correctes,
il y a alignement strict, et donc DMARC passe, il n'y a aucun doute
que le domaine émetteur était bien
projetarcadie.com. (La politique DMARC était
p=none donc un éventuel échec n'aurait sans
doute pas eu beaucoup de conséquences.)
Ici, DKIM a échoué (pourquoi ? mystère mais c'est peut-être la faute de SpamAssassin qui a modifié le sujet, il faudrait que je vérifie ma configuration) mais SPF réussit (le message vient bien de Gmail) donc DMARC est content (il s'agissait bien d'un spam, tentative d'escroquerie financière) :
Authentication-Results: mail.bortzmeyer.org;
dkim=fail reason="signature verification failed" (2048-bit key; unprotected) header.d=gmail.com header.i=@gmail.com
header.a=rsa-sha256 header.s=20230601 header.b=K6F+sj7y;
dkim-atps=neutral
Authentication-Results: mail.bortzmeyer.org; dmarc=pass (p=none dis=none) header.from=gmail.com
Authentication-Results: mail.bortzmeyer.org; spf=pass (sender SPF authorized) smtp.mailfrom=gmail.com
(client-ip=2a00:1450:4864:20::133; helo=mail-lf1-x133.google.com; envelope-from=mrsbalex@gmail.com;
receiver=sources.org)
From: "Mr. Mike Christopher" <mrsbalex@gmail.com>
Et ici, un échec, SPF est correct, il n'y a pas de signature DKIM
et il n'y a pas d'alignement des domaines, la tentative du spammeur
pour se faire passer pour saison.co.jp échoue :
From: 株式会社クレディセゾン <admin@saison.co.jp>
Authentication-Results: mail.bortzmeyer.org; dmarc=fail (p=none dis=none) header.from=saison.co.jp
Authentication-Results: mail.bortzmeyer.org; spf=pass (sender SPF authorized) smtp.mailfrom=zh-cht-jjb.com (client-ip=34.130.185.194;
helo=zh-cht-jjb.com; envelope-from=admin@zh-cht-jjb.com; receiver=bortzmeyer.org)
Et ici, l'émetteur tente de faire croire qu'il vient de
Gmail mais l'enregistrement SPF de
Gmail se termine par un ~all, son
adresse IP n'y est pas listée et il n'y a pas de signature DKIM dans
le message. Même pas besoin de tester l'alignement puisqu'il n'y a
pas de domaine authentifié du tout :
From: Axel.Bouvier <mailrmicro+Axel.Bouvier@gmail.com>
Authentication-Results: mail.internatif.org; dmarc=fail (p=none dis=none) header.from=gmail.com
Authentication-Results: mail.internatif.org; spf=softfail (domain owner discourages use of this host)
smtp.mailfrom=gmail.com (client-ip=78.246.109.210; helo=gmail225.com;
envelope-from=mailrmicro+axel.bouvier@gmail.com; receiver=internatif.org)
De nombreux autres exemples, avec succès ou échec, figurent dans l'annexe B du RFC.
C'est pas mal si le récepteur de courrier qui fait tourner DMARC
en profite pour générer les rapports (RFC 9991), s'ils sont
demandés (par un ruf ou un
rua dans l'enregistrement DMARC de
l'envoyeur). Néanmoins, le RFC note qu'il peut ne pas le faire, s'il
craint pour la vie privée (cf. section 10) ou tout simplement si ça
lui consomme trop de ressources.
D'ailleurs, le RFC insiste bien sur un point que j'avais déjà mentionné : la décision finale (de livrer le message, ou de le mettre dans le dossier Spam ou de le jeter) revient toujours au destinataire (section 5.4). Celui-ci applique la politique qu'il veut. Il serait ridicule de croire que, parce qu'on a SPF, DKIM et DMARC bien configurés, nos messages seraient systématiquement livrés. Après tout, un spammeur peut en faire autant.
À l'inverse, un récepteur peut parfaitement décider d'acheminer jusqu'à ses utilisateurices un message qui échoue aux testes DMARC, par exemple parce qu'il a lu le RFC 7960 (et la section 7.4 de notre RFC) et qu'il sait que DMARC échoue dans des cas d'usage pourtant légitimes, notamment les listes de diffusion. DMARC fournit de la traçabilité et de la responsabilité, il n'est pas un oracle tout-puissant sur l'authenticité du message.
La section 7 du RFC est surtout intéressante pour les historien·nes et pour les technicien·nes qui veulent comprendre les choix faits par DMARC. C'est un pot-pourri de diverses discussions.
D'abord, SPF. SPF a été conçu pour être utilisable
pendant la session SMTP, parfois avant même que l'en-tête du
message ait été transmis. Une politique SPF « dure » (se terminant
en -all) peut amener au rejet du message avant
que DMARC n'ait été évalué. Ainsi, si un message échoue en SPF mais
réussit en DKIM, normalement, DMARC réussirait. Mais, si le test SPF
mène à un rejet dès la session SMTP, le message n'arrivera
pas. Attention donc en configurant vos enregistrements SPF. (Relisez
les « M3AAWG Best
Practices for Managing SPF Records » et
« M3AAWG
Email Authentication Recommended Best
Practices ».)
Et à propos de rejet précoce (dans le cours de la session SMTP, avant d'avoir accepté le message) : le RFC recommande cette méthode car elle évite la génération d'un avis de non-remise (RFC 3464), avis qui irait sans doute à un innocent si l'adresse était usurpée. Deux façons de mettre en œuvre ce rejet précoce, en renvoyant un code d'erreur (commençant par 5 RFC 5321, section 4.2.5) au client SMTP, qui saura ainsi que son message a été refusé, ou, plus méchamment, en prétendant que le message a bien été reçu (code commençant par 2) mais en le jetant silencieusement. La deuxième solution est évidemment horrible (le serveur SMTP ment, l'émetteur ne sait pas ce qui s'est passé, le déboguage devient très difficile) mais elle est parfois nécessaire pour éviter le backscatter, l'envoi de messages d'erreur à un innocent, une des plaies du spam qui usurpe votre adresse. Et elle évite de donner des informations à quelqu'un qu'on estime être un usurpateur.
Contrairement à ce qu'on voit dans certains
articles pro-DMARC imprudents qui promeuvent DMARC sans
insister sur ses limites et ses faiblesses, notre RFC précise bien
qu'il y a des cas où DMARC pose problème (sections 7.3 et 7.4). Par
exemple, citant le RFC 7960, il rappelle que
DMARC peut casser des cas d'usage légitimes comme les adresses
d'anciens élèves que certaines universités fournissent (en faisant
suivre automatiquement le courrier à l'adresse actuelle), comme des
alias où le courrier vers une même adresse est distribuée à
plusieurs personnes, qui ne sont pas forcément dans le même domaine,
ou comme les listes de
diffusion. Pour les deux premiers cas, des solutions
relativement simples existent (réécrire l'enveloppe pour ne pas
casser SPF, ce qui est de toute façon une bonne pratique car
l'envoyeur du message ne saurait pas quoi faire si la vraie adresse
finale ne marcherait pas) et ne pas du tout toucher au message, pour
éviter de casser DKIM), pour les listes de diffusion, c'est plus
délicat. En pratique, plusieurs gestionnaires de liste adoptent la
solution très intrusive de réécrire le champ
From: comme ici dans ce message envoyé à une
liste de l'OARC (le vrai
From: a été reporté en
Reply-To:) :
Authentication-Results: nic.fr;
spf=pass smtp.mailfrom=dns-operations-bounces@dns-oarc.net;
dmarc=pass header.from=dns-oarc.net
Reply-To: Walter Russo <walter@secureme.it>
From: Walter Russo via dns-operations <dns-operations@dns-oarc.net>
Le problème est évidemment particulièrement sérieux si on a une
politique DMARC restrictive (p=reject) et le
RFC conseille fortement dans ce cas de systématiquement signer avec
DKIM, pour éviter de compter sur le seul SPF (qui sera cassé par les
serveurs qui font suivre un message sans réécrire l'enveloppe). Et
il rappelle aux récepteurs de courrier qu'il est très imprudent de
rejeter un message sur la seule base de DMARC. Ces consignes, qui ne
sont pas toujours respectées par les serveurs actuels, sont
cruciales pour le bon fonctionnement du courrier. Le RFC note bien
ce problème de filtrage excessif et explique que c'est ce qui a mené
plusieurs gestionnaires de liste à tripoter le champ
From:, par exemple en changeant le vrai champ
bob@example.com en un
bob=example.com@user.somelist.example, où on
peut toujours retrouver la vraie adresse. (On ajoute également
parfois un Reply-To: indiquant la vraie adresse
de l'expéditeur, comme dans l'exemple ci-dessus.) Le RFC n'approuve
pas cette modification mais note qu'elle est répandue et qu'il faut
faire avec. Il existe des solutions techniquement plus propres comme
le ARC du RFC 8617 mais que presque personne
n'utilise.
En résumé, pour faire du DMARC complet, l'émetteur du courrier devrait idéalement :
- Produire des messages qui auront un identificateur SPF aligné avec le domaine de l'auteur (une exigence qui me parait très excessive),
- produire des messages avec une signature DKIM valide et alignée,
- configurer une boite aux lettres qui recevra les rapports,
- publier l'enregistrement DMARC (je rajoute : après avoir soigneusement testé les trois points précédents),
- ne pas compter sur le seul SPF.
Et le receveur devrait idéalement :
- Tester s'il y a un enregistrement DMARC pour le domaine de l'auteur,
- tester s'il y a des identificateurs authentifiés par SPF ou DKIM,
- tester si au moins l'un d'entre eux est aligné avec le domaine de l'auteur,
- déterminer ainsi si le résultat final est pass ou fail,
- envoyer des rapports, si demandé,
- ne pas rejeter des messages juste parce
qu'il y a eu un échec DMARC, même si la politique de l'émetteur
est
p=reject.
La section 11 du RFC creuse les questions de sécurité. Que faut-il savoir pour utiliser DMARC de manière sûre ? D'abord, DMARC est évidemment dépendant des mécanismes d'authentification utilisés, SPF et DKIM (le groupe de travail IETF avait même envisagé de supprimer SPF, considéré comme trop permissif). Si vous publiez votre clé privée DKIM, DMARC ne pourra rien pour vous. Et SPF, DKIM et DMARC dépendent tous les trois du DNS donc il est crucial de gérer ses serveurs DNS sérieusement. Malheureusement, les RFC sur ces trois techniques n'imposent pas DNSSEC (RFC 9364) mais ils devraient : sans DNSSEC, l'envoi de fausses informations dans le DNS est plus facile. Compter sur SPF, DKIM et DMARC sans avoir DNSSEC me semble peu sérieux mais, bon, le vrai but de la cybersécurité est de réussir l'audit de conformité, pas d'améliorer la sécurité concrète. D'autre part, l'examen du trafic DNS (qui n'est pas limité aux deux parties qui s'envoient du courrier) donne des informations sur le trafic. Utiliser DoT (RFC 7858) ou DoH (RFC 8484) peut donc être une bonne idée.
Comme toujours en ingénierie, d'autres solutions techniques auraient été possibles. L'annexe A de notre RFC examine certaines de ces alternatives et explique pourquoi elles n'ont pas été retenues. Ainsi, on aurait pu utiliser S/MIME (RFC 8551) pour signer le message, ajoutant cette technique à SPF et DKIM. Mais S/MIME a un cahier des charges différent de celui de DMARC, il vise plutôt à une authentification de bout en bout du message entier. Et puis il faut bien constater qu'en dehors de quelques environnements bureaucratiques fermés, personne n'utilise S/MIME. C'est en partie dû à la nécessité d'une PKI, dont le RFC note qu'elle a été souvent promise mais ne s'est jamais matérialisée. (Curieusement, le RFC ne cite pas OpenPGP - RFC 9580 - qui est pourtant nettement plus utilisé que S/MIME.)
Une autre décision de conception cruciale de DMARC est le fait d'accepter n'importe quelle technique d'authentification ; SPF ou DKIM, c'est pareil pour lui. Il a pourtant été souvent proposé de permettre au titulaire du domaine de spécifier, dans l'enregistrement DMARC, de préciser qu'on ne veut que SPF, ou que DKIM. Mais DMARC est assez compliqué comme cela et la décision a finalement été de permettre l'une ou l'autre des méthodes d'authentification. Débrouillez-vous pour qu'au moins une (et de préférence les deux) fonctionne.
Un point essentiel de DMARC est qu'il authentifie l'expéditeur
(plus exactement son alignement) en
considérant que l'expéditeur est indiqué par le champ
From: de l'en-tête. Cela casse bien des usages
légitimes (comme les listes de diffusion). Ne serait-il pas
préférable d'authentifier un champ plus technique comme
Sender: (RFC 5322,
section 3.6.2) ? Cela avait même été spécifié dans le RFC 4870, puis retiré. Finalement, le choix a été
de se concentrer sur From: puisqu'il est le
seul à être toujours montré à l'utilisateur. (SPF, comme DKIM,
peuvent authentifier un identificateur que l'utilisateur ordinaire
ne voit pas.)
Notre RFC 9989 introduit une nouvelle clé,
np, qui spécifie la politique à appliquer aux
sous-domaines non existants du domaine authentifié. Cela soulève le
problème de la définition de non existant. Le RFC dit que cela
inclut les réponses NXDOMAIN (No Such Domain),
évidemment, mais pas forcément les réponses NOERROR où la section
Réponses est vide, car le nom existe mais ne contient ni
enregistrement MX, ni enregistrement d'adresse (A ou AAAA). Ce test
de la présence de certains types d'enregistrement est déjà
couramment utilisé en pratique (il n'y a aucune raison d'accepter du
courrier d'un domaine qui ne permettrait pas les réponses) mais le
RFC ne l'impose pas. Et, sinon, le RFC rappelle que, si une requête
pour un domaine renvoie NXDOMAIN, tous ses sous-domaines n'existent
pas non plus (RFC 8020).
Évidemment, un débat ancien et récurrent pour DMARC est celui des
frontières organisationnelles. Comment sait-on si
cis.cnrs.fr dépend de la même autorité que
cnrs.fr (ou bien
pick.eu.org et eu.org). Il
n'y a pas de réel moyen de trouver cette information dans le
DNS. (On peut trouver les frontières techniques
en demandant l'enregistrement de type SOA. Mais cela ne donne pas
les frontières
administratives. gouv.fr
n'est pas géré par la même organisation que fr,
même s'ils sont dans la même zone.) Des efforts ont été faits à
l'IETF
pour résoudre ce problème mais sans
résultat. L'ancien RFC DMARC, le RFC 7489 suggérait d'utiliser une liste de suffixes d'enregistrement mais
notre RFC 9989 a finalement préféré une autre méthode,
la « montée à l'arbre » (on grimpe l'arbre des noms de domaine,
cherchant des enregistrements DMARC).
Passons à la pratique, maintenant. OpenDMARC est aujourd'hui très répandu, aussi bien côté envoyeur que côté récepteur, et apparait souvent dans les articles de marketing « comment s'assurer que votre spam pardon votre newsletter sera bien livrée partout ». Sur mon serveur de messagerie personnel, j'annonce une politique DMARC et, pour valider les messages entrants, j'utilise OpenDMARC (notez que son développement semble bien avoir stoppé et qu'il y a donc peu de chances qu'il prenne en compte les nouveautés de ce RFC). Ma configuration est très proche de celle par défaut :
Socket inet:54321 # Les autres ont leur valeur par défaut
Et Postfix le lance ainsi, juste après DKIM :
smtpd_milters = unix:run/opendkim.sock, inet:localhost:54321
Et c'est ainsi que sont produits les champs
Authenticated-Results: que vous avez vus.
Pour apprendre DMARC, je recommande l'excellent et interactif https://www.learndmarc.com/
Le chemin vers ce RFC a été très long (plusieurs années). L'annexe C du RFC résume les changements depuis le précédent RFC, le RFC 7489. Les principaux sont :
- Nouvel algorithme (« montée dans l'arbre » pour trouver le domaine organisationnel, au lieu de l'utilisation d'une liste de suffixes publics). C'est la suite du RFC 9091.
- Introduction de nouveaux concepts comme le PSD (Public Suffix Domain) et le PSO (Public Suffix Operator).
- Le RFC n'est plus seulement « Pour information », il passe sur le chemin des normes.
- Plusieurs nouvelles clés sont possibles dans
l'enregistrement DMARC :
np,psdett. - Mise à l'écart de certaines clés comme
pct(partiellement remplacé part). - Résolution des erreurs du précédent RFC.
Les articles suivants sont de bonnes lectures pour les nouveautés de DMARC :
L'article seul
RFC 9987: SSH Agent Protocol
Date de publication du RFC : Mai 2026
Auteur(s) du RFC : D. Miller (OpenSSH)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF sshm
Première rédaction de cet article le 28 mai 2026
Voici encore un RFC qui normalise quelque chose qui existait depuis longtemps : le protocole Agent de SSH.
SSH est normalisé dans le RFC 4251 et il permet la connexion à distance (RFC 4253) avec authentification (RFC 4252 et RFC 4254) par exemple avec une clé publique. Il est probablement inutile de le présenter davantage aux lecteurices de ce blog. Une des fonctions géniales de SSH est la possibilité d'avoir un agent (rien à voir avec l'IA agentique qui est à la mode en ce moment) qui mémorise les clés privées et peut effectuer les opérations demandées. Ainsi mémorisées, les clés seront utilisables sans nouvelle intervention de l'utilisateur (taper une phrase de passe, etc) tout en restant bien sécurisées. Et l'agent peut intervenir sur des connexions distantes, ce qui évite de copier sa clé privée sur des serveurs à qui on ne fait pas forcément totalement confiance. L'agent ne tourne pas dans le client SSH mais dans un processus dédié, ce qui améliore sa sécurité. Si vous êtes connecté en ce moment, vous avez sans doute un agent SSH qui tourne (ici sur une Debian) :
% ps uxwww | grep ssh bortzme+ 459934 0.0 0.0 10700 4964 ? Ss 09:44 0:00 /usr/bin/ssh-agent /home/bortzmeyer/.xsession
Comme indiqué au début, ce mécanisme d'agent est connu, mis en œuvre
et utilisé depuis très longtemps, ce RFC est une documentation a posteriori (le très ancien document
draft-ietf-secsh-agent
décrivait un protocole différent).
Donc, comment fonctionne ce protocole Agent (section 2 du RFC) ? Il est client-serveur, le serveur étant l'agent et le client de l'agent n'étant pas forcément un client SSH (mais, bon, c'est le cas le plus courant). Le client envoie des requêtes à l'agent et reçoit des réponses (comme dans beaucoup de protocoles réseau…). L'agent est un serveur pur, il ne fait que répondre au client, sans prendre d'initiatives. Les requêtes typiques sont le chargement d'une clé, la suppression d'une clé, la signature en utilisant une des clés. Le serveur reste maitre d'accepter ou pas les requêtes et le client doit donc être prêt à voir une requête refusée, par exemple parce que l'agent n'accepte que les clés d'un certain type.
La section 3 du RFC détaille les messages échangés entre le
client et l'agent (le serveur). Ils sont de type TLV et les types figurent dans
un
registre IANA. La longueur peut être nulle, par exemple il
existe des messages de type SSH_AGENT_FAILURE
(type numérique 5) qui n'ont pas de valeur. Le client demande
l'ajout d'une clé avec des messages de type
SSH_AGENTC_ADD_IDENTITY (type numérique 17). La
valeur est composée du type de la clé, de la clé elle-même et du
commentaire que vous avez indiqué lors de la création de la clé ; si
vous utilisez, par exemple, une clé Ed25519,
cf. RFC 8709, le type est
ssh-ed25519 (la liste est dans un
registre IANA). Avec OpenSSH, vous
trouverez ce commentaire dans
~/.ssh/id_ed25519.pub.
De la même façon,
on peut retirer une clé avec les messages de type
SSH_AGENTC_REMOVE_IDENTITY (type 18) et
SSH_AGENTC_REMOVE_ALL_IDENTITIES (type 19).
Une fois les clés dans l'agent, le client peut lui demander de
signer avec le type de
message SSH_AGENTC_SIGN_REQUEST (type 13),
message qui comprendra les données à signer.
Pour se
connecter à l'agent (section 4 du RFC), le client doit utiliser une
méthode sûre. Èvidemment pas question d'ouvrir l'agent à tout
l'Internet. Sur Unix, la méthode la plus
courante est d'utiliser une prise locale. Souvent, elle est trouvée
par une variable d'environnement définie lors
de la connexion, en général
SSH_AUTH_SOCK. C'est ce que fait
OpenSSH mais ce n'est pas imposé par la
norme, qui laisse le choix aux programmes.
Voici un exemple avec OpenSSH :
# On lance l'agent (on aurait normalement utilisé eval ou un # équivalent, pour définir la variable d'environnement) : % ssh-agent SSH_AUTH_SOCK=/tmp/ssh-xrLh0tnpVwLF/agent.23934; export SSH_AUTH_SOCK; SSH_AGENT_PID=23935; export SSH_AGENT_PID; echo Agent pid 23935; % ls -l /tmp/ssh-ZzouiZGBumyI/agent.23934 srw------- 1 stephane stephane 0 May 4 18:38 /tmp/ssh-ZzouiZGBumyI/agent.23934 % SSH_AUTH_SOCK=/tmp/ssh-xrLh0tnpVwLF/agent.23934; export SSH_AUTH_SOCK % ssh -vvv SERVEUR-DISTANT … debug1: Next authentication method: publickey debug3: ssh_get_authentication_socket_path: path '/tmp/ssh-xrLh0tnpVwLF/agent.23934' debug1: get_agent_identities: bound agent to hostkey debug1: get_agent_identities: ssh_fetch_identitylist: agent contains no identities [Et si on ajoute une clé dans l'agent ?] % ssh-add ~/.ssh/id_ed25519 Enter passphrase for /home/stephane/.ssh/id_ed25519: Identity added: /home/stephane/.ssh/id_ed25519 (stephane@foobar) % ssh -vvv SERVEUR-DISTANT … debug1: Next authentication method: publickey debug3: ssh_get_authentication_socket_path: path '/tmp/ssh-xrLh0tnpVwLF/agent.23934' debug1: get_agent_identities: bound agent to hostkey debug1: get_agent_identities: agent returned 1 keys
Autre possibilité très intéressante de l'agent (section 5), on peut faire suivre les communications sur un canal SSH (un peu comme avec X11). Cela permet, lorsque la machine A se connecte à la machine B puis à la C, d'utiliser les clés de la machine A pour s'authentifier sur la machine C. Cela utilise le mécanisme d'extension à SSH qui avait été normalisé dans le RFC 8308 pour signaler qu'on gère cette possibilité (mais comme le protocole Agent existait avant ce RFC, certains programmes n'annoncent pas cette gestion). La section 9 du RFC rappelle toutefois que cette fonction, si pratique, crée de nouveaux risques puisque elle introduit une relation de confiance transitive. Le RFC exige donc qu'elle ne soit pas activée par défaut.
Le protocole a entrainé la création de cinq nouveaux registres IANA (section 7), dont celui des types de messages (pour en ajouter un, politique « Examen par un expert », cf. RFC 8126.)
Un petit mot sur la sécurité (section 8 du RFC) puisqu'après tout, SSH est là pour améliorer notre sécurité. L'agent est chargé de garder des clés privées, il est donc très sensible et doit être de confiance. Mais le RFC rappelle aussi que l'accès à l'agent est évidemment très critique et doit être sécurisé (regardez les permissions de la prise dans l'exemple Unix plus haut), le protocole ne prévoyant aucune authentification.
Si on a accès à l'agent, et qu'il a chargé des clés, on peut
signer ce qu'on veut et donc s'authentifier auprès de serveurs
distants. Par contre, on ne peut pas récupérer de clés privées via
le protocole, qui n'a pas d'opération pour cela. Mais comme l'agent
garde les clés privées en mémoire, il faut faire attention à ce que
personne ne puisse lire cette mémoire. (La page de manuel de OpenSSH
est très nette à ce sujet et conseille d'utiliser plutôt la fonction
ProxyJump, via le -J.)
Ah, et puisque l'agent, lorsqu'il charge une clé, demande la phrase de passe de la clé, il faut aussi qu'il prenne des précautions pour limiter le risque d'une attaque par force brute (quand un attaquant essaie plein de phrases possibles). Par exemple, il peut introduire un délai après une phrase incorrecte.
Le protocole Agent est très ancien et est donc déjà mis en œuvre dans de nombreux programmes, par exemple OpenSSH (depuis 2000 !), PuTTY, Dropbear, Paramiko, la bibliothèque standard de Go, etc.
Si vous voulez afficher les messages échangés entre le client SSH
et l'agent, je ne connais pas
l'équivalent de tcpdump ou
Wireshark pour cela. Avec
OpenSSH, ssh-agent -d
affiche les connexions mais pas les messages. Sinon, on peut lire les
messages échangés avec socat (ici, un exemple
pour OpenSSH sur
Debian) :
[Dans une fenêtre] % ssh-agent -D [Dans une autre] [Copier-coller la première ligne, celle qui définit SSH_AUTH_SOCK] % mv $SSH_AUTH_SOCK /tmp/real-agent.sock % socat -x UNIX-LISTEN:$SSH_AUTH_SOCK,fork UNIX-CONNECT:/tmp/real-agent.sock [Dans une troisième] [Copier-coller la première ligne, celle qui définit SSH_AUTH_SOCK] % ssh un-serveur
Mais les messages seront bruts, sans formatage. À vous de les décoder.
Par exemple, ici,suite à un ssh-add, on voit :
> 2026/05/11 17:47:13.000145101 length=142 from=1152 to=1293 00 00 00 8a 11 00 00 00 … < 2026/05/11 17:47:13.000146117 length=5 from=10 to=14 00 00 00 01 06
(Pour décoder, référez-vous au RFC, section 3, et au registre
IANA.) Le premier message (après le >) a une longueur de 138 octets (les
quatre premiers octets, 0000008A, nous le disent, socat l'affiche
mais lui ajoute les quatre octets de la longueur). Le type du
message (indiqué par l'octet suivant) est 17,
SSH_AGENTC_ADD_IDENTITY. L'agent répond (après
la <) par un message d'un seul octet, de type 6
(SSH_AGENT_SUCCESS) et de contenu nul. Si je me
connecte en SSH à un serveur, en utilisant la clé qui vient d'être
chargée, j'ai :
> 2026/05/11 17:59:54.000526321 length=5 from=665 to=669
00 00 00 01 0b
< 2026/05/11 17:59:54.000526468 length=535 from=5 to=539
00 00 02 13 0c 00 00 00 …
> 2026/05/11 17:59:54.000609874 length=1017 from=670 to=1686
00 00 03 f5 0d 00 00 01 …
< 2026/05/11 17:59:54.000615719 length=285 from=540 to=824
00 00 01 19 0e 00 00 01 14 …
Le premier message, très court, est de type 11,
SSH_AGENTC_REQUEST_IDENTITIES, il obtient une
réponse 12 (SSH_AGENT_IDENTITIES_ANSWER), puis
le client SSH demande une signature avec la clé privée que stocke
l'agent (type 13,
SSH_AGENTC_SIGN_REQUEST) et a une réponse (type
14, SSH_AGENT_SIGN_RESPONSE).
Enfin, le fichier ./PROTOCOL.agent dans le source
de OpenSSH documente les extensions d'OpenSSH
pour ce protocole agent-client.
L'article seul
RFC 9982: JSContact Version 2.0: A JSON Representation of Contact Data
Date de publication du RFC : Mai 2026
Auteur(s) du RFC : R. Stepanek (Fastmail)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF calext
Première rédaction de cet article le 28 mai 2026
Voici la version 2 du format de représentation d'entités
(personnes ou organisations) JSContact (RFC 9553). En fait, ce numéro de version est trompeur, il n'y
a qu'un seul changement, le membre uid qui
était obligatoire devient facultatif. Mais ce petit changement, qui
casse la compatibilité, oblige à changer de numéro de version.
Dans la section 2.1.9 du RFC 9553,
l'uid (User IDentifier)
était obligatoire. Alors que le vieux format
vCard (RFC 6350) le
disait facultatif, ce qui rendait difficile toute traduction
automatique de vCard vers JSContact. En outre, s'il était cool
d'avoir la garantie d'un identificateur unique pour chaque carte de
visite au format JSContact, cela ne convenait pas dans tous les
cas. Ainsi, RDAP (RFC 9083)
n'utilise pas du tout cette propriété uid.
Donc, seul changement entre les versions 1 et 2, l'attribut
uid devient optionnel. On passe de :
uid: String (mandatory)
à :
*uid: String (optional).*
Mais c'est suffisant pour obliger à changer le numéro de version de JSContact (RFC 9553, section 1.9).
Par exemple, cet object JSContact (qui n'a pas
d'uid) est désormais légal :
{
"@type": "Card",
"version": "2.0",
"name": {"components": [{"kind": "given","value": "Jean"},
{"kind": "surname","value": "Durand"}]},
"emails": {
"email": {
"address": "jean.durand@example.com"
}
}
}
(Avec la version 1, il aurait fallu quelque chose comme
"uid": "a73c940e-b1d3-4f3c-aa50-c9749352c253"
après la version.)
L'article seul
RFC 9980: Post-Quantum Cryptography in OpenPGP
Date de publication du RFC : Juin 2026
Auteur(s) du RFC : S. Kousidis
(BSI), J. Roth, F. Strenzke (MTG
AG), A. Wussler (Proton AG)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF openpgp
Première rédaction de cet article le 1 juillet 2026
Vous le savez, le jour où des CRQC (Cryptographically Relevant Quantum Computer, un calculateur quantique capable de calculs non triviaux, contrairement aux modèles d'aujourd'hui) seront disponibles, la cryptographie sera sérieusement secouée. Il est donc important de travailler dès maintenant sur des algorithmes pour l'après-quantique, et de les intégrer dans les protocoles et les formats utilisés sur l'Internet. Ce RFC documente l'utilisation des algorithmes normalisés par le NIST dans le format OpenPGP.
Le format OpenPGP, utilisé par de nombreux logiciels de cryptographie, est normalisé dans le RFC 9580. La liste des algorithmes de chiffrement n'est pas figée et de nouveaux algorithmes peuvent être disponibles pour ce format. C'est le cas de ceux pour la cryptographie post-quantique, un sujet d'actualité. Les messages chiffrés et/ou signés au format OpenPGP peuvent avoir besoin de résister à la décryption et/ou à l'usurpation pendant de nombreuses années. Aujourd'hui, ces messages utilisent typiquement RSA ou des algorithmes à courbes elliptiques, tous étant vulnérables aux calculateurs quantiques. C'est notamment en raison de cette nécessité de sécurité sur une longue période qu'il ne faut pas attendre que les CRQC soient disponibles pour intégrer les algorithmes post-quantiques à OpenPGP. Il y a peut-être des attaquants qui stockent aujourd'hui des messages OpenPGP, en attendant d'avoir un CRQC pour les lire (ou pour imiter des signatures).
(Rappelons au passage qu'OpenPGP n'est pas utilisé que dans le courrier électronique. Il sert, par exemple, à authentifier le code avec git, ou les paquetages compilés, avec apt et rpm.)
Il ne suffit pas d'ajouter les nouveaux algorithmes aux registres IANA. Il y a des problèmes spécifiques, comme les clés hybrides (une PQ et une classique) et composées (hybrides, mais présentées d'une manière unifiée). En effet, il ne servirait à rien de déployer des algorithmes post-quantiques si ceux-ci étaient cassables par de la cryptanalyse classique. Rien ne dit que ces « nouveaux » algorithmes soient incassables. Et comme ils sont relativement récents, on ne peut pas avoir le même degré de confiance qu'avec RSA ou ECDSA. L'approche la plus courante aujourd'hui, et que ce RFC suit, est d'utiliser une technique hybride : combinaison d'un algorithme traditionnel et d'un algorithme post-quantique. On n'abandonne donc pas RSA ou ECDSA, on les flanque d'un collègue, ce qu'on appelle le PQ/T (post-quantique/traditionnel, cf. section 1.1.1).
Plus précisément, notre RFC utilise des composés, des hybrides PQ/T mais où les deux clés, la post-quantique et la traditionnelle, sont gérées comme une seule. Le RFC 9794 est la bonne lecture, si vous voulez approfondir ces notions d'hybride et de composé et vous avez aussi intérêt à lire le RFC 9958, « Post-Quantum Cryptography for Engineers ».
Quels sont ces nouveaux algorithmes ? La section 1.2 les résume :
- ML-KEM, normalisé dans la norme FIPS-203, pour l'échange de clés préalable au chiffrement,
- ML-DSA, normalisé dans FIPS-204, pour la signature,
- SLH-DSA, normalisé dans FIPS-205, également pour la signature.
Notez que l'algorithme SLH-DSA, lui, est considéré suffisamment sûr pour se passer de l'assistance d'un algorithme traditionnel (il utilise des problèmes mathématiques complètement différents de ceux utilisés par ML-KEM ou ML-DSA). Les deux autres vont être utilisés par OpenPGP avec de la cryptographie traditionnelle, en l'occurrence ECDH avec les courbes X25519 et X448 (RFC 7748) et EdDSA (RFC 8032). Pour la vérification d'une signature, les deux (post-quantique et traditionnelle) signatures doivent être valides (cf. sections 3 et 5.2.3). Pour le chiffrement, les deux clés obtenues doivent être utilisées.
Le format OpenPGP permet d'avoir plusieurs signatures dans un message mais ces signatures parallèles sont différentes des clés composées utilisées pour le PQ/T car le succès d'une seule signature suffit à la validation. (Idem pour le chiffrement, cf. section 3.) Évidemment, le système n'est résistant aux CRQC que si toutes les signatures utilisent un algorithme PQ ou PQ/T. Si ces signatures multiples, incluant au moins une clé T (traditionnelle, sans post-quantique) sont moins sûres, elles ont par contre l'avantage d'assurer la compatibilité avec les vieilles versions des logiciels OpenPGP (section 5.2.5 du RFC 9580).
La section 2 du RFC donne la liste exhaustive des algorithmes qui viennent d'être officiellement ajoutés. À partir des trois cités plus haut, il y a quelques variantes, fondées sur la taille de certains paramètres ou sur la courbe elliptique utilisée dans le composé. Ainsi, SLH-DSA a trois variantes, SLH-DSA-SHAKE-128f (f pour fast car il optimise la vitesse), SLH-DSA-SHAKE-128s (s pour short car il optimise la taille) et SLH-DSA-SHAKE-256s. ML-KEM a deux variantes, ML-KEM-768+X25519 et ML-KEM-1024+X448, avec des courbes différentes.
Notez enfin que les clés PQ/T ne doivent être utilisées qu'avec des données OpenPGP des versions 4 ou 6 (et même uniquement version 6 pour ML-KEM-1024+X448 et ML-DSA). Ici, par exemple, GnuPG montre un paquet OpenPGP de version 3, trop vieux pour gérer le post-quantique :
% gpg --list-packets review.txt.gpg … :pubkey enc packet: version 3, algo 1, keyid XXXXXXXXX data: [4096 bits]
Les sections 4, 5 et 6 du RFC expliquent en détail le format des nouvelles clés et comment les utiliser. La section 7 donne des conseils sur les algorithmes de cryptographie symétrique, par exemple qu'il est nécessaire de mettre en œuvre AES-256 (la version à 128 bits est possiblement cassable grâce à l'algorithme de Grover).
Et la migration depuis les anciens algorithmes ? Tous les logiciels qui mettent en œuvre OpenPGP ne vont pas passer au post-quantique en même temps. On aura des messages qui vont passer d'un logiciel récent à un ancien, qui ne pourra pas les lire. La section 8 ajoute des conseils pour bien réussir sa migration. Déjà, un logiciel récent, qui pense que les récepteurs de ses messages seront pré-quantiques peut chiffrer ses messages avec une clé PQ (ou PQ/T) et une clé traditionnelle (chiffrement en parallèle, où une seule clé est nécessaire, et pas en série, comme c'est le cas ave les solutions hybrides citées plus haut, où les deux clés sont nécessaires). Bien sûr, s'il fait cela, le message sera déchiffrable par un calculateur quantique. Il faut donc choisir entre sécurité et interopérabilité (avec les vieux logiciels). PGP étant conçu pour des communications asynchrones (comme le courrier électronique), il n'est pas possible de savoir à l'avance les capacités du récepteur.
Le même problème se pose pour les signatures. Lors d'une vérification de signature, n'importe laquelle des deux signatures sera acceptée (là encore, on parle de signatures séparées, qui ont toujours existé dans OpenPGP, pas des hybrides du PQ/T). Le RFC permet toutefois à un vérificateur paranoïaque, ou simplement un vérificateur qui sait que l'émetteur a une clé PQ ou PQ/T, d'ignorer les signatures traditionnelles.
Enfin, la section 9 du RFC discute un certain nombre de questions de sécurité. Par exemple, elle explique comment les signatures composites du PQ/T ne sont pas vulnérables aux attaques par suppression d'une des signatures (les métadonnées indiquent l'identificateur de l'algorithme hybride).
Quelles sont les mises en œuvre de ces nouveaux algorithmes ? Malheureusement, il semble que GnuPG ne suive pas les récents RFC sur le format OpenPGP (sur cette affaire, lire le point de vue de Debian ou celui d'Arch Linux), entre autre (mais pas uniquement) sur le post-quantique. On va donc tester avec les autres (il existe une liste).
Si vous voulez écrire votre propre programme OpenPGP (ce que je ne conseillerai pas : la cryptographie, c'est difficile, et les bogues ne se voient pas forcément), l'annexe A du RFC, qui fait la grande majorité du RFC, est composée de vecteurs de test.
Les programmes testés sont conformes au
projet de standard SOP et ont donc à
peu près la même interface utilisateur (actuellement en projet, dans
draft-dkg-openpgp-stateless-cli). Souvent, le post-quantique
n'est pas encore intégré dans les versions officielles et il va
falloir changer de branche et compiler.
Commençons avec rsop, écrit en
Rust. Après le
cargo install pgp :
% rsop list-profiles generate-key default: v4 key using Curve25519 (alias: draft-koch-eddsa-for-openpgp-00) compatibility: v4 key using RSA (alias: rfc4880) performance: v6 key using Ed25519/X25519 (alias: rfc9580) security: v6 key using Ed448/X448 (alias: rfc9580-curve448)
Je vous l'avais bien dit : pas de post-quantique. Mais la FAQ dans le code nous le dit « ### Is rPGP adding support for Post Quantum Cryptography (PQC)? Yes, rPGP implements the IETF draft [Post-Quantum Cryptography in OpenPGP](https://datatracker.ietf.org/doc/draft-ietf-openpgp-pqc/), gated behind the feature `draft-pqc`. ». Ah, c'est planqué dans une feature. Compilons :
% cargo install --features draft-pqc rsop % rsop list-profiles generate-key default: v4 key using Curve25519 (alias: draft-koch-eddsa-for-openpgp-00) compatibility: v4 key using RSA (alias: rfc4880) performance: v6 key using Ed25519/X25519 (alias: rfc9580) security: v6 key using Ed448/X448 (alias: rfc9580-curve448) draft-ietf-openpgp-pqc-14-v4-ed25519-mlkem768x25519: TESTING ONLY draft-ietf-openpgp-pqc-14-v6-ed25519-mlkem768x25519: TESTING ONLY draft-ietf-openpgp-pqc-14-v6-mldsa65ed25519-mlkem768x25519: TESTING ONLY draft-ietf-openpgp-pqc-14-v6-mldsa87ed448-mlkem1024x448: TESTING ONLY draft-ietf-openpgp-pqc-14-v6-slhdsashake128s-mlkem768x25519: TESTING ONLY draft-ietf-openpgp-pqc-14-v6-slhdsashake128f-mlkem768x25519: TESTING ONLY draft-ietf-openpgp-pqc-14-v6-slhdsashake256s-mlkem1024x448: TESTING ONLY
Ça marche, on a du post-quantique, utilisons-le :
% rsop generate-key --profile draft-ietf-openpgp-pqc-14-v6-ed25519-mlkem768x25519 > key.asc
OK, on a une clé hybride (ML-KEM et Ed25519). Créeons la clé publique :
% cat key.asc | rsop extract-cert > cert.asc
Et maintenant, on peut chiffrer un fichier avec la clé publique :
% cat hello.txt | rsop encrypt cert.asc > hello.asc
Et le déchiffrer avec la clé privée :
% cat hello.asc | rsop decrypt key.asc Hello, world
Bon, on a tout fait avec le même programme, mais le but d'OpenPGP est l'interopérabilité. Essayons avec un deuxième programme, Sequoia, pour lequel il y a des instructions détaillées pour le compiler avec gestion du post-quantique :
% sudo apt install libsqlite3-dev % git clone https://gitlab.com/sequoia-pgp/sequoia-sq.git % git checkout pqc % cargo build --release --locked --no-default-features --features crypto-openssl
Et utilisons-le pour regarder les fichiers produits par rsop :
% sq inspect key.asc
key.asc: Transferable Secret Key.
Fingerprint: AC7FD6CBD09E90C928C2ED5796A69001B5F0535CE6BF09C227DFE71063006BD0
Public-key algo: Ed25519
Public-key size: 256 bits
Secret key: Unencrypted
Creation time: 2026-02-09 17:36:25 UTC
Key flags: certification, signing
Subkey: 91BED065B7E654656D3354CA16E901D8F8B192874385EB6C325421055AFB5B9E
Public-key algo: ML-KEM-768+X25519
Secret key: Unencrypted
Creation time: 2026-02-09 17:36:25 UTC
Key flags: transport encryption, data-at-rest encryption
Joli, non ? rsop avait bien fabriqué une clé hybride et sq arrive à la lire.
% cat hello.asc | sq decrypt --recipient-file key.asc Encrypted and protected using AES-256/OCB Hello, world Decrypted by AC7FD6CBD09E90C928C2ED5796A69001B5F0535CE6BF09C227DFE71063006BD0, unknown 0 authenticated signatures.
Et Sequoia peut déchiffrer les messages chiffrés par rsop.
% sq inspect --cert-file cert.asc < hello.asc
OpenPGP Certificate.
Fingerprint: AC7FD6CBD09E90C928C2ED5796A69001B5F0535CE6BF09C227DFE71063006BD0
Public-key algo: Ed25519
Public-key size: 256 bits
Creation time: 2026-02-09 17:36:25 UTC
Key flags: certification, signing
Subkey: 91BED065B7E654656D3354CA16E901D8F8B192874385EB6C325421055AFB5B9E
Public-key algo: ML-KEM-768+X25519
Creation time: 2026-02-09 17:36:25 UTC
Key flags: transport encryption, data-at-rest encryption
Et examiner ses clés. rsop et sq étaient tous les deux écrits en Rust donc testons l'interopérabilité avec un programme en Go :
% git clone https://github.com/ProtonMail/gosop.git % cd gosop % git checkout gosop-gopenpgp-v3-pqc % go build % ./gosop list-profiles generate-key default: Generate v4 keys using Curve25519 compatibility: Generate v4 keys using 3072-bit RSA (alias: rfc4880) performance: Generate v6 keys using Ed25519/X25519 (alias: rfc9580) security: Generate v6 keys using Ed448/X448 draft-ietf-openpgp-pqc-09: ML-KEM-768 and ML-DSA-65 draft-ietf-openpgp-pqc-09-high-security: ML-KEM-1024 and ML-DSA-87 draft-ietf-openpgp-persistent-symmetric-keys-00: AEAD and HMAC % ./gosop/gosop decrypt key.asc < hello.asc Hello, world
Et tout se passe bien.
L'article seul
RFC 9975: Clarifications on CDS/CDNSKEY and CSYNC Consistency
Date de publication du RFC : Mai 2026
Auteur(s) du RFC : P. Thomassen (SSE - Secure Systems
Engineering)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 28 mai 2026
Pour compléter un processus de sécurisation des noms de domaine avec DNSSEC, il faut transmettre au domaine parent votre clé publique. Le faire manuellement via l'interface Web du BE n'est pas pratique donc il existe un moyen d'automatiser cela, les CDS/CDNSKEY, moyen décrit dans le RFC 7344. Mais attention à la sécurité ! Ce moyen n'est sûr que si on suit quelques précautions, décrites dans ce nouveau RFC.
Bon, je sais, j'ai simplifié, on ne transmet pas forcément au domaine parent sa clé publique mais parfois un condensat de celle-ci. (Le domaine parent publiera ensuite un enregistrement DS, contenant un condensat que vous aurez donné ou bien qu'il aura calculé à partir de la clé.) Ça ne change pas grand'chose en pratique. Le RFC 7344 décrit comment automatiser le changement de clé en publiant dans son domaine des enregistrements CDS et/ou CDNSKEY, qui informent le parent. (Et le RFC 9615 permet de le faire pour la configuration initiale, pas juste pour un changement.) Avec une technique proche, les enregistrements CSYNC du RFC 7477, on peut aussi automatiser le changement des serveurs de noms faisant autorité.
À partir de là, le gestionnaire du domaine parent (typiquement un registre de noms de domaine) va récupérer ces enregistrements et agir (modifier les enregistrements DS et NS dans son domaine). La façon la plus simple de récupérer les CDS, CDNSKEY et CSYNC est de faire une bête requête DNS classique, donc via son résolveur par défaut :
% dig turris.cz CDS … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 16850 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 … ;; ANSWER SECTION: turris.cz. 5 IN CDS 53148 13 2 9A0E997A2992D4089CE39C1976DC65C00C9D20A6C36187F897E71D6E 23368E6E ;; Query time: 24 msec ;; SERVER: 192.168.2.254#53(192.168.2.254) (UDP) ;; WHEN: Fri Jan 09 11:15:20 CET 2026 ;; MSG SIZE rcvd: 86 % dig alatienne.fr CDNSKEY … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 53877 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 … ;; ANSWER SECTION: alatienne.fr. 3600 IN CDNSKEY 257 3 13 ( mdsswUyr3DPW132mOi8V9xESWE8jTo0dxCjjnopKl+Gq JxpVXckHAeF+KkxLbxILfDLUT0rAK9iUzy1L53eKGQ== ) ; KSK; alg = ECDSAP256SHA256 ; key id = 2371 ;; Query time: 52 msec ;; SERVER: 127.0.0.1#53(127.0.0.1) (UDP) ;; WHEN: Thu Feb 05 16:35:32 CET 2026 ;; MSG SIZE rcvd: 229
Mais cette méthode n'est pas très sûre et nous allons voir pourquoi, et comment arranger les choses.
Ici, la réponse CDS était signée par DNSSEC (le
flag ad, pour
Authentic Data). Mais ce n'est pas toujours le
cas (avec les CSYNC, ou tout simplement lors de la configuration
initiale de DNSSEC, cf. RFC 8078). Le fond du
problème est que les serveurs faisant
autorité pour le domaine qui publie CDS, CDNSKEY ou CSYNC
peuvent être en désaccord. (Ou bien, mais le RFC ne semble pas le
mentionner, il y a eu empoisonnement de la mémoire du résolveur.) Ce
désaccord peut être dû à un piratage d'un des serveurs (ou à une
malveillance de ses opérateurs) mais il peut être aussi le résultat
d'un cafouillage technique
(un serveur ne se synchronisant plus) ou organisationnel, les
serveurs n'étant pas forcément gérés par la même entité. Sans
compter le risque d'une délégation boiteuse (lame
delegation) où un des serveurs listés dans l'ensemble NS
n'est pas censé être serveur pour ce domaine. D'ailleurs, même
DNSSEC ne protège pas dans tous les cas, s'il y a plusieurs signeurs
(RFC 8901), ils peuvent aussi déconner
séparement. Avec le comportement par défaut du résolveur typique
(accepter la réponse du premier serveur faisant autorité qui
répond), un seul des serveurs faisant autorité peut déclencher un
changement de configuration dans le domaine parent. Le cœur de notre
nouveau RFC est
de dire que le logiciel qui récupère CDS/CDNSKEY/CSYNC doit
s'assurer que les serveurs faisant autorité sont
cohérents, qu'ils renvoient tous la même
réponse.
Cela ne peut pas se faire via un résolveur typique, je n'en connais pas qu'on puisse configurer pour faire cela, il faut donc interroger directement les serveurs faisant autorité. Par exemple, pour la requête dig ci-dessus, un moyen de le faire serait, par exemple en shell :
% for ns in $(dig +short turris.cz NS); do dig @$ns +short turris.cz CDS done 53148 13 2 9A0E997A2992D4089CE39C1976DC65C00C9D20A6C36187F897E71D6E 23368E6E 53148 13 2 9A0E997A2992D4089CE39C1976DC65C00C9D20A6C36187F897E71D6E 23368E6E 53148 13 2 9A0E997A2992D4089CE39C1976DC65C00C9D20A6C36187F897E71D6E 23368E6E
Et il faudrait ensuite s'assurer que toutes les réponses sont identiques. Sinon, le domaine parent s'abstient d'agir. (Comme les lecteurs et lectrices de ce blog sont très fort·es en réseau, ielles ont certainement remarqué que j'avais simplifié : comme un serveur peut avoir plusieurs adresses IP, il faudrait les tester toutes. Des exemples de programmes plus perfectionnés figurent par la suite.)
Ces nouvelles règles amènent à mettre à jour quelques RFC, qui ne les spécifiaient pas : les RFC 7344 et la section 3.1 du RFC 7477, qui conseillait de ne demander qu'à un seul serveur faisant autorité (ce que fait le résolveur typique mais qui n'est pas assez sûr).
La section 3 du RFC liste plus formellement les nouvelles exigences :
- Tester la présence et le contenu des CDS/CDNSKEY/CSYNC via toutes les adresses IP des serveurs faisant autorité.
- Toutes les réponses doivent être identiques.
- On peut arrêter le test dès qu'au moins une des réponses correspond au DS/NS existant. Cela veut dire qu'au moins un des serveurs faisant autorité ne veut pas qu'on change.
Si et seulement si toutes les réponses sont identiques, et différentes de la situation actuelle, le gestionnaire du domaine parent peut envisager de modifier NS et DS.
Notez que, si les serveurs faisant autorité utilisent l'anycast, le test ne sera pas complet, le vérificateur de cohérence ne testera qu'une seule instance d'un nuage anycast. Dans ce cas, il peut être intéressant de tester la cohérence depuis plusieurs points de mesure, pour avoir des chances de contacter plusieurs instances anycast.
La même règle s'applique aux enregistrements CSYNC du RFC 7477. La section 3.2 de notre RFC détaille comment traiter ces enregistrements, qui permettent notamment de synchroniser les enregistrements NS du domaine parent (et la colle) avec ceux du domaine fils. Il y a une petite nuance pour le numéro de série de la zone que contient l'enregistrement CSYNC (il doit être identique à celui du SOA du même serveur, pas forcément à ceux des CSYNC des autres serveurs faisant autorité).
La section 5 de notre RFC discute les conséquences pour la sécurité. Si on ne fait pas les vérifications décrites ici, il y a un risque de copier dans la zone parente des données incorrectes, voire créées par un attaquant, par exemple parce qu'il a réussi à pirater un des serveurs faisant autorité ou bien parce qu'il gérait un de ces serveurs mais agissant sans autorisation du gérant de la zone (cas courant si on sous-traite certains de ses serveurs secondaires). Ce RFC privilégie donc l'intégrité des données, au risque, on peut le remarquer, qu'un changement souhaité prenne davantage de temps, si un des serveurs faisant autorité a des problèmes. Que faire si un de ces serveurs ne veut vraiment pas jouer le jeu et, par exemple, ne se synchronise plus et ne publie pas le nouveau CDS/CDNSKEY/CSYNC ? La section 5 dit qu'il faut donc maintenir un canal traditionnel (via le BE, par exemple), pour pouvoir changer quand même les données publiées par la zone parente. C'est par exemple le rôle d'EPP (RFC 5730).
Cette vérification de la cohérence a déjà été mise en œuvre dans les logiciels de TANGO et CORE, ainsi que déployée par le registre suisse. Zonemaster fait ce test.
Enfin, l'annexe A du RFC décrit plus en détail des scénarios où l'incohérence entre les serveurs faisant autorité pour un domaine a eu des conséquences fâcheuses. Par exemple, si un domaine a une délégation boiteuse, vers un serveur qui n'existe pas, un malveillant peut créer le serveur en question, mettre un CSYNC en indiquant uniquement des serveurs qu'il contrôle et transformer une simple délégation boiteuse en un détournement complet du nom. Si le serveur non existant était dans un nom de domaine non enregistré, l'attaquant n'a qu'à enregistrer ce nom (attaque flamant). Si le serveur non existant était sur une adresse IP libre chez un hébergeur public, l'attaquant n'a qu'à créer des machines chez cet hébergeur jusqu'à tomber sur l'adresse en question (une variante de l'attaque des sous-domaines). Ce genre d'attaques est décrit dans des articles comme « Unresolved Issues: Prevalence, Persistence, and Perils of Lame Delegations » ou « Risky BIZness: risks derived from registrar name management ». Bon, si le domaine est signé avec DNSSEC, il est protégé, non ? Oui, sauf si l'attaquant peut changer la clé avec un CDS… D'où l'importance de la vérification de cohérence de ce RFC.
Autre exemple d'accident possible (et qui n'est pas dû à une attaque délibérée), dans le cas où un domaine a plusieurs signeurs DNSSEC (RFC 8901), si un des serveurs faisant autorité ne publie que ses propres clés dans un CDS. Sans vérification de cohérence, au lieu d'avoir plusieurs DS comme prévu, on n'en aura qu'une partie.
Et si vous cherchez un programme simple qui fait à peu près ce
que demande le RFC, vous avez cds-consistency.py
% ./cds-consistency.py knot-resolver.cz knot-resolver.cz is consistent, data is "None" % ./cds-consistency.py àlacon.fr àlacon.fr is consistent, data is "7177 13 2 fa99827c7aca1681b8905285e7fa33ec5adccb430393b4fa1e9f9aa3d9263709"
L'article seul
RFC 9973: TLS 1.3 Extension for Using Certificates with an External Pre-Shared Key
Date de publication du RFC : Juillet 2026
Auteur(s) du RFC : R. Housley (Vigil Security)
Chemin des normes
Première rédaction de cet article le 16 juillet 2026
L'authentification dans TLS se fait typiquement soit à partir d'un certificat, soit par une clé partagée à l'avance. Ce RFC spécifie une extension de TLS qui permet d'utiliser certificat et clé partagée à l'avance. Il remplace le RFC 8773 mais ne change pas grand'chose, la principale modification étant que ce nouveau RFC a le statut de norme (au lieu d'être considéré comme expérimental).
Rappelons d'abord qu'il y a deux sortes de clés partagées à l'avance (PSK, pour Pre-Shared Key) : celles qui ont été négociées dans une session précédente (resumption PSK) et celles qui ont été négociées par un mécanisme extérieur (envoi par pigeon voyageur sécurisé…), les external PSK. Ce RFC ne concerne que les secondes. Les certificats et les clés partagées à l'avance ont des avantages et des inconvénients. Les certificats ne nécessitent pas d'arrangement préalable entre client et serveur, ce qui est pratique. Mais il faut se procurer un certificat auprès d'une AC. Et les certificats, comme ils reposent sur des algorithmes comme RSA ou ECDSA, sont vulnérables aux progrès de la cryptanalyse, par exemple en utilisant un (futur) ordinateur quantique (enfin, un CRQC, un Cryptographically Relevant Quantum Computer). Utiliser une clé partagée à l'avance n'est pas forcément commode (par exemple quand on veut la changer) mais cela peut être plus sûr. Or, la norme TLS (RFC 9846) ne permettait d'utiliser qu'une seule des deux méthodes d'authentification. Si on les combinait ? L'ajout d'une clé externe permettrait de rendre la sécurité plus solide.
Le principe est simple : notre RFC spécifie une extension à TLS,
tls_cert_with_extern_psk (valeur
33). Le client TLS l'envoie dans son
ClientHello. Elle indique la volonté de
combiner certificat et PSK. Elle est accompagnée d'extensions
indiquant quelle est la clé partagée à utiliser. Si le serveur TLS
est d'accord, il met l'extension
tls_cert_with_extern_psk dans son message
ServerHello. (Le serveur ne peut pas décider
seul de l'utilisation de cette extension, il faut que le client ait
demandé d'abord.)
Les clés ont une identité, une série d'octets sur lesquels client
et serveur se sont mis d'accord avant (PSK = Pre-Shared
Key, clé partagée à l'avance). C'est cette identité qui
est envoyée dans l'extension pre_shared_key,
qui accompagne tls_cert_with_extern_psk. La clé
elle-même est bien sûr un secret, connu seulement du client et du
serveur (et bien protégée : ne la mettez pas sur un fichier lisible
par tous). Voyez la section 7 du RFC pour une discussion plus
détaillée de la gestion de la PSK.
Une fois que client et serveur sont d'accord pour utiliser l'extension, et ont bien une clé en commun, l'authentification se fait via le certificat (sections 4.4.2 et 4.4.3 du RFC 9846) et on utilise ensuite, non pas seulement la clé générée (typiquement par Diffie-Hellman), mais la combinaison de la clé générée et de la PSK. L'entropie de la PSK s'ajoute donc à celle de la clé générée de manière traditionnelle.
Du point de vue de la sécurité, on note donc que cette technique de la PSK est un strict ajout à la sécurité actuelle, donc on peut garantir que son utilisation ne diminuera pas la sécurité.
L'annexe A du RFC liste les changements depuis l'ancien RFC 8773 :
- Le principal est le changement de statut, d'Expérimental à Norme. La technique spécifiée dans ce RFC est désormais considérée comme stable et validée.
- La menace des calculateurs quantiques est un peu relativisée. (Elle ne semble pas se rapprocher.)
- Autre relativisation, le RFC insiste désormais sur le fait que la PSK ne va pas servir à l'authentification (mon article sur le RFC 8773 était confus sur ce point).
- Une erreur a été corrigée (mélange entre client et serveur).
- Le terme de master secret a été remplacé par le plus gentillet main secret.
L'article seul
RFC 9969: IAB AI-CONTROL Workshop Report
Date de publication du RFC : Mai 2026
Auteur(s) du RFC : M. Nottingham, S. Krishnan
Pour information
Première rédaction de cet article le 20 mai 2026
Ah, l'IA… Vaste sujet, et d'actualité. Une des questions qui reviennent souvent est celle de l'utilisation du contenu qu'on trouve sur le Web pour entrainer les grands modèles, sa légitimité, la charge qu'elle induit pour les serveurs, les moyens de la contrôler, etc. Un colloque avait été organisé par l'IAB en septembre 2024 sur ces questions et ce RFC en est le compte-rendu. Ce colloque avait lancé le projet IETF aipref.
Une petite précision politique d'abord : le RFC précise bien qu'il s'agit d'un compte-rendu et que l'IAB n'approuve pas forcément tout ce qui a été dit à ce colloque (section 1.2 du RFC). Je rajoute que j'ai aussi des opinions sur le sujet, donc je mettrais [entre crochets] ce qui est mon opinion, et ne vient pas du RFC. Le reste n'est donc pas de moi, j'en rends compte, c'est tout, ne me tapez pas.
Ce colloque fait partie de la série de colloques qu'organise régulièrement l'IAB pour explorer des tendances à plus ou moins long terme, sans les obligations de l'IETF de produire normes et documents.
Donc, les LLM (qui ne sont qu'une partie des techniques qu'on regroupe sous le terme marketing d'« IA ») fonctionnent en deux phases : on entraine le modèle en lui faisant ingérer une grande quantité de contenu (textes, images ou autres), puis il va pouvoir inférer du contenu à partir de ce qu'il a digéré pendant la phase d'entrainement, et d'une demande (dite prompt). Le contenu inféré n'est jamais tout à fait identique à celui utilisé pour l'entrainement (autrement, cela serait du plagiat, potentiellement illégal). Les LLM ne marchant bien, à l'heure actuelle, que si le corpus d'entrainement était énorme, ils sont très gourmands en données et une source évidente de contenu en grande quantité est le Web. Des bots ou crawlers parcourent donc le Web, ramassant du contenu. Voici par exemple un extrait du journal du serveur qui héberge ce blog, montrant le bot de Perplexity récoltant du contenu :
18.210.92.235:64884 - - [09/Jan/2026:07:26:15 +0000] "GET /images/TCP_state_diagram.jpg HTTP/1.1" 200 96551 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)" www.bortzmeyer.org TLS 18.97.9.103:64398 - - [09/Jan/2026:08:31:39 +0000] "GET /bitcoin-metamorphoses.html HTTP/1.1" 200 8982 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)" www.bortzmeyer.org TLS 18.97.9.101:57493 - - [09/Jan/2026:08:31:39 +0000] "GET /robots.txt HTTP/1.1" 404 3250 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)" www.bortzmeyer.org TLS 18.97.9.103:48122 - - [09/Jan/2026:08:47:36 +0000] "GET /nist-pq.pdf HTTP/1.1" 200 84543 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)" www.bortzmeyer.org TLS 18.97.9.96:25157 - - [09/Jan/2026:08:51:37 +0000] "GET /files/capitole-libre-2019-quic-pour-impression.pdf HTTP/1.1" 200 212507 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)" www.bortzmeyer.org TLS
Une des questions soulevées par cette récolte de données est qu'elle n'était pas prévue à l'origine. Certains webmestres qui mettent du contenu en ligne estiment donc qu'un nouvel usage (l'entrainement des LLM) justifie de nouvelles règles et de nouvelles possibilités de contrôle par le serveur Web. C'est par exemple ce que prévoit l'AI Act européen.
Le colloque (ou atelier) de l'IAB s'est tenu les 19 et 20 septembre 2024 (oui, le RFC met trop longtemps à sortir) et prévoyait de travailler sur tous les aspects liés à cette récolte de données (cf. l'appel à participation). Le colloque regroupait des personnes de divers horizons, experts techniques, entreprises d'IA, fournisseurs de contenu, décideurs politiques, etc. La liste figure dans l'annexe A.2. La règle suivie était celle de Chatham House (tout ce qui se dit est public mais sans le lier à un·e participant·e particulier·ère). D'ailleurs, le RFC note qu'au moins un participant n'a pas voulu que son identité soit dévoilée, juste qu'il était un représentant officiel d'un gouvernement. Et, comme déjà dit, le RFC rend compte des discussions, cela ne signifie pas que l'IAB approuve tout ce qui a été dit.
La section 2 du RFC résume les discussions (la totalité des
soumissions sont en
ligne). Aujourd'hui, les fournisseurs de contenu, les
webmestres, peuvent exprimer leurs choix quant à la récolte de
données par divers moyens. Il y a par exemple une solution technique
existante, c'est le
robots.txt, qui est
décrit dans le RFC 9309. Notez que, en
l'absence du fichier robots.txt, les
bots peuvent tout récolter. C'est donc une
solution opt-out. Il y a
aussi des solutions non techniques par exemple les
conditions d'utilisation (ainsi, ce blog est sous licence GFDL et les contenus peuvent
donc être réutilisés, à la condition que les destinataires jouissent
des mêmes droits de réutilisation). [Tiens, par contre, il n'existe pas
de licence
CC-BY-NoAI ?] Pour revenir à la technique, les webmestres
peuvent aussi bloquer les crawlers par leur
adresse IP, ou leur User-Agent (RFC 9110, section 10.1.5), ou carrément tout mettre derrière
un paywall.
Comme indiqué plus haut, ces solutions sont en général opt-out, donc par défaut, la récolte est autorisée. (Sur ce blog, et c'est apparemment le cas de la plupart des serveurs HTTP, plus de la moitié des requêtes sont faites par des bots, mais pas forcément liés à l'IA, c'était déjà le cas avant les LLM.) On constate (cf. l'exposé « Consent in Crisis: The Rapid Decline of the AI Data Commons ») une tendance à la fermeture : la récolte devient de plus en plus difficile car de nombreux serveurs bloquent les accès qu'ils pensent dûs à un bot. Le Web tend donc à se fermer.
[Le RFC n'est pas clair sur ce point mais, pour moi, il est important de faire la différence entre les problèmes techniques et opérationnels posés par certains bots qui, qu'ils travaillent pour l'IA ou pas, « matraquent » avec excès les serveurs, et les problèmes politiques et financiers liés à l'utilisation qui est faite des données récoltées. Les problèmes techniques et opérationnels causés par des « bots fous » existaient bien avant les LLM. Par contre, les problèmes politiques (légitimité à réutiliser le contenu) et financiers (perte de revenus pour les ayant droits, comme mentionné dans le RFC) sont plus spécifiques de l'IA. Le RFC ne parle pas vraiment des problèmes opérationnels posés par l'agressivité de certains bots - pas forcément liés à l'IA, d'ailleurs - mais la réunion IETF 123 à Madrid avait vu de très intéressants exposés à ce sujet.]
À l'heure actuelle, il est difficile de savoir ce qui est permis,
au delà des simples consignes du
robots.txt. Les gérants des serveurs n'ont pas
de moyen standard et automatiquement analysable de faire connaitre
leurs conditions d'utilisation, et les bots n'ont
donc pas non plus de moyen de savoir ce qui est permis. [Il va de
soi qu'il y a des bots qui, de toute façon, s'en
foutent. Le travail de normalisation à l'IETF ne pourra concerner que les
bots honnêtes et ne dispensera pas de mesures de
sécurité contre les malhonnêtes.]
Le RFC creuse certain aspects de la question. Par exemple, en
section 2.1, le problème de la différence entre le moment du
ramassage des données et celui de leur utilisation. Les consignes du
serveur (comme le robots.txt) sont lues au
moment du ramassage mais certains responsables de contenu voudraient
exprimer des choix concernant l'utilisation, or celle-ci se fait à
un autre moment, décorrélé du premier. Certaines récoltes, comme
celle faite par Common Crawl, peuvent servir
à de multiples usages et des consignes concernant le ramassage ne
sont donc pas appropriées. Autre exemple que Common Crawl, on peut
avoir une organisation qui gère un moteur de recherche du
Web et développe un LLM, et qui
utilise le même crawler pour les deux
usages. Certains webmestres estiment que la première utilisation ne
pose pas de problème (au bout du compte, cela ramènera du trafic sur
leur site Web) mais s'opposent à la seconde car elle n'apportera pas
de trafic, le LLM donnant des réponses qui suffiront à
l'utilisateur.
Du point de vue technique, il faut aussi noter que le principe d'entrainement d'un LLM fait qu'on utilise toutes les données et, qu'une fois le modèle créé, il n'y a pas d'étiquetage spécifique de la source de telle ou telle réponse du LLM. (C'est pour cela que les LLM ont du mal à indiquer leurs sources.) Un webmestre qui souhaiterait dire « d'accord pour servir à l'entrainement des IA mais pas pour que ces IA aient un usage militaire, ou bien pas un usage commercial » ne le peut pas, en raison de cette limite technique. Et même si ce moyen existait, le gérant du LLM serat obligé de faire N modèles, pour toutes les permutations des différents critères (ou tout simplement d'exclure tous les contenus ayant une licence restrictive, ce qui limiterait la représentativité du corpus d'entrainement du modèle).
Enfin, les préférences changent dans le temps et celles exprimées au moment de la récolte des données peuvent ne pas être à jour lorsque les données seront utilisées pour l'entrainement d'un LLM.
Le problème est déjà compliqué si on suppose que tous les acteurs sont de bonne foi et respectent les règles. Mais, évidemment, la confiance ne règne pas, et pour de bonnes raisons. [Les entreprises capitalistes trichent, que ce soit celles qui entrainent les LLM ou bien celles des ayant droits.] Il n'y a pas de moyen facile de vérifier le respect des préférences exprimées par les gérants du contenu. Et c'est d'autant plus inquiétant que les entreprises de l'IA n'ont pas vraiment de motivation pour respecter les règles : aucun risque de sanction [surtout compte-tenu des déclarations de Trump contre tout projet de régulation de l'IA]. Cette absence de confiance entraine l'utilisation importante de moyens techniques de blocage, comme de bloquer les adresses IP des bots connus. Il y a même un bot qui suggère cette solution :
119.28.89.249:58834 - - [21/Jan/2026:15:32:02 +0000] "GET /5153.xml HTTP/1.1" 200 6891 "-" "Mozilla/5.0 (compatible; Thinkbot/0.5.8; +In_the_test_phase,_if_the_Thinkbot_brings_you_trouble,_please_block_its_IP_address._Thank_you.)" www.bortzmeyer.org TLS
L'atelier de l'IAB a passé du temps sur la question de
l'attachement des préférences au contenu (section 2.3). Le
robots.txt (RFC 9309) est
très bien, très déployé et largement reconnu. Mais il manque de
souplesse pour les gros sites qui souhaitent un système plus
granulaire. Par exemple, si un site de vidéos souhaitait restreindre
l'accès à certaines vidéos, la seule solution est de les placer dans
un espace particulier (par exemple un
répertoire distinct), et donc de devoir
changer l'URL
si la classification change. Et, comme le
robots.txt est à la racine du site Web, il
n'est pas sous le contrôle des créateurs de contenu qui ont accès à
un espace dédié mais pas à la totalité du site. Si le CMS que vous
utilisez permet des créations de contenu et des mises à jour
décentralisées, où certaines personnes peuvent modifier une partie
du site, regardez s'il permet à ces personnes d'influencer le
robots.txt. Je suis preneur d'exemples.
Une autre solution (qui ne serait pas forcément exclusive du
robots.txt mais complémentaire) serait
d'inclure les préférences d'utilisation dans le contenu
lui-même. C'est ce que permet l'élément HTML <meta>
ou le format XMP pour les images. Des formats
comme XML
ou JSON
permettraient certainement d'ajouter ces préférences d'utilisation,
qui ont l'avantage de forcément voyager avec le contenu,
contrairement au robots.txt. Évidemment, cela
ne marchera pas si ces métadonnées sont retirées par le programme
de collecte (pas forcément pour des raisons malveillantes, cela peut
être pour diminuer la taille des données). Et certains formats ne se
prêtent pas à cette inclusion des préférences d'utilisation, comme
le texte brut, ou comme les contenus qui ont
plusieurs auteurs (pensez à un fil de discussion sur les réseaux
sociaux).
Une autre solution serait de placer les préférences d'utilisation dans un registre, extérieur aux œuvres, comme cela se fait souvent pour, par exemple, la musique ou les photographies. C'est plus robuste que l'inclusion de métadonnées mais ça passe mal à l'échelle de l'Internet (les registres existants avaient été conçus pour des écosystèmes plus petits et relativement fermés).
Enfin, parmi les difficultés, il faut noter qu'exprimer
préférences et conditions d'utilisation un peu fines nécessite de
disposer d'un vocabulaire (par exemple pour décrire les différentes
techniques qui sont regroupées sous le terme marketing et flou
d'« IA ») et qu'il n'existe pas de vocabulaire standard. Ce serait
une tâche difficile que d'en établir un (un travail est en cours,
dans draft-ietf-aipref-vocab). Je
me souviens d'une réunion IETF où il y avait eu un long débat sur la
question de savoir si la traduction rentrait
dans la catégorie « IA générative » (après
tout, elle génère des textes…).
La section 3 du RFC, en conclusion, essaie de synthétiser et
d'identifier les points sur lesquels l'IETF pourrait
travailler. L'atelier avait un relatif consensus sur le fait que la
situation actuelle est mauvaise et que le principal outil technique
disponible, robots.txt, ne convient pas. Les
pistes de travail discutées ont été :
- Améliorer
robots.txtou bien développer un meilleur système d'attachement aux sites Web, - Définir des attachements pour les protocoles IETF (par exemple dans l'en-tête HTTP, HTML ou XML dépendant d'un autre organisme),
- Définition d'un vocabulaire commun (le groupe de travail IETF aipref y travaille),
- Description de comment les différentes techniques (attachées au site Web ou bien attachées au contenu) se combinent.
Par contre, le consensus était que les points suivants n'étaient pas du ressort de l'IETF ou ne pouvaient pas, pour l'instant, faire l'objet d'un travail concret :
- Faire respecter les directives données aux récoltants (les licences du logiciel libre ont un problème analogue),
- Développer des mécanismes de transparence de la récolte,
- Créer des registres des contenus,
- Identifier et authentifier les bots (à
noter que Cloudflare a lancé cette
idée, ce qui a donné naissance aux brouillons
draft-meunier-web-bot-auth-architectureetdraft-meunier-web-bot-auth-glossary).
Notez qu'un résumé de l'atelier avait été publié juste après. Et, sinon, vous pouvez regarder l'intéressant site Web « Dealing With Bots » et, sur les projets de contrôle de l'accès aux ressources et leurs risques, l'excellent article « No One Should Control the Internet After AI: Freedom to Build Cleopatra GPT ».
L'article seul
RFC 9959: Convergence of Congestion Control from Retained State
Date de publication du RFC : Mai 2026
Auteur(s) du RFC : N. Kuhn (Thales Alenia
Space), E. Stephan
(Orange), G. Fairhurst, R. Secchi
(University of Aberdeen), C. Huitema (Private
Octopus)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tsvwg
Première rédaction de cet article le 12 mai 2026
Traditionnellement, les protocoles de transport comme QUIC ou TCP partaient de zéro à chaque connexion. On se connecte, on démarre prudemment (ne pas envoyer trop de données pour éviter de congestionner le réseau), puis on augmente le débit petit à petit. Mais c'est dommage de ne pas tenir compte des connexions précédentes, où on avait déjà suivi ce processus. Ne pourrait-on pas se souvenir des mesures précédentes pour aller plus vite la prochaine fois ? C'est justement ce que propose ce RFC.
Évidemment, si l'idée est simple, la réalisation soulève plein de problèmes, d'autant plus qu'on touche ici à une activité dangereuse : si on se trompe, on risque d'aggraver la congestion. Le RFC détaille donc plus précisément comment réutiliser ces mesures passées, pour ne pas faire s'écrouler le réseau. Tout protocole de transport doit utiliser un algorithme de contrôle de la congestion (RFC 2914) ou bien s'auto-modérer (RFC 8085). Mais concevoir un bon algorithme de contrôle de la congestion n'est pas trivial et, par exemple, le RFC 5783 notait que les algorithmes existants marchaient mal pour les liaisons avec un BDP élevé et/ou très variable, comme les liaisons satellite.
Pour comprendre pourquoi, revenons un peu au fonctionnement typique d'un algorithme de contrôle de la congestion. Il a typiquement deux phases. D'abord, au début de la connexion, on envoie moins de données que ce qu'on pourrait, afin de ne pas congestionner le réseau. Puis on augmente le débit, jusqu'au moment où des indicateurs comme la perte de paquets ou le rythme des accusés de réception (RFC 9406) signalent qu'on a atteint la capacité maximale pour ce flux de données. La dépasser (overshoot) congestionnerait le réseau ou, si les autres flux qui se partagent le réseau sont mieux élevés, entrainerait des diminutions de ressources pour ces autres, voire un écroulement du réseau sous la charge. Voilà pourquoi il faut démarrer lentement.
Au passage, le RFC note que, bien sûr, la connexion TCP ou QUIC qui réutiliserait les mesures d'une précédente connexion doit s'assurer qu'on compare ce qui est comparable : mêmes adresses IP source et destination, et peut-être même DSCP (Differentiated Services Code Point, cf. RFC 2474). On verra plus loin que ce n'est pas suffisant (les choses peuvent changer, le passé peut ne pas être un bon indicateur du présent), mais patientez encore un peu.
La méthode de notre RFC se nomme « reprise prudente » (careful resume) ou, en plus joli « partage temporel » (temporal sharing), puisqu'on reprend des mesures passées (mesures de la capacité, du RTT, etc). Ces mesures pouvant ne plus être d'actualité (trop vieilles et/ou le chemin suivi a changé), il faut en effet être prudent (cf. RFC 9000 et RFC 9040).
Dans quels cas cette reprise (prudente) de données d'une connexion précédente peut être utile ? La section 1.4 du RFC liste un certain nombre de cas d'usages. Entre autres, il y a le cas d'une application qui utilise plusieurs connexions, les connexions peuvent alors utiliser les données récupérées par la première d'entre elles. Ou bien lorsqu'une connexion a été violemment interrompue et repart tout de suite après. Et il y a aussi une autre utilisation, lorsque la latence du chemin utilisé est bien plus importante que dans une liaison Internet typique, ce qui est le cas des satellites lorsqu'ils ne sont pas en orbite basse. L'article « Google QUIC performance over a public SATCOM access » note ainsi que sur une liaison via un satellite géostationnaire, avec l'algorithme classique, transférer 5,3 Mo prendra 9 secondes alors que le partage temporel, si on peut réutiliser les mesures d'une connexion précédente, prendra 4 secondes. (Si les 9 secondes vous semblent trop, compte-tenu de la capacité du lien, rappelez-vous que la capacité n'est pas le seul facteur limitant ; TCP, surtout au démarrage, n'utilise pas toute la capacité, et il met longtemps à converger si la latence est élevée.) Une autre présentation, à l'IETF « Feedback from using QUIC's 0- RTT-BDP extension over SATCOM public access », calcule une réduction du temps de transfert de 62 % pour faire voyager 1 Mo. Enfin, le RFC recommande la lecture de la synthèse « Careful Resumption of Internet Congestion Control from Retained Path State ».
Le récepteur des données peut avoir des informations que l'envoyeur n'a pas, et cela peut le pousser à vouloir désactiver la reprise que l'envoyeur croit prudente. Par exemple, le récepteur sait peut-être quelle quantité de données va être envoyée, ou bien il sait que le chemin sur le réseau a changé.
Toujours pour compliquer les choses, il faut aussi se souvenir que d'autres facteurs peuvent limiter la quantité de données qu'on envoie, par exemple le contrôle de flux, donc les fenêtres de TCP (RFC 9293, section 3.8.6) ou le système de crédit de QUIC (RFC 9000, section 4).
Prenant en compte tout cela, la section 1.5 du RFC résume les principes de la « reprise prudente » :
- D'abord, s'assurer que les conditions n'ont pas changé depuis la dernière connexion ; le chemin est-il le même ? (La mesure du RTT donne une première bonne idée.) À l'issue de cette phase de reconnaissance, si les conditions ont changé, on utilise la méthode classique, on ne tient pas compte des mesures qui ont été sauvegardées.
- Ensuite, OK, on va plus vite qu'avec la méthode classique mais pas aussi vite que ne l'indiquent les mesures sauvegardées. Après tout, la reconnaissance ne permet pas toujours d'identifier un changement dans les conditions.
- Enfin, on se prépare à faire marche arrière, et à revenir à la méthode classique, si on s'aperçoit qu'on est en train de créer de la congestion. (Le RFC note qu'il faut la détecter rapidement, avant que les autres flots de données n'aient détecté la congestion et réduit leur débit.)
Un peu de terminologie avant de continuer (section 2) : le partenaire distant (remote endpoint) est l'ensemble des informations qui identifie à qui on envoie des données, typiquement l'identificateur d'une interface réseau locale couplé à l'adresse IP de la machine avec qui on parle et peut-être (c'est une décision locale, et forcément très dépendante du système d'exploitation utilisé) des informations comme DSCP. Si le partenaire distant change, on en déduit que le chemin a changé (l'inverse n'est pas vrai : le chemin peut changer alors que le partenaire distant est le même). Si on a une indication que le chemin a changé, on revient au mécanisme traditionnel, on n'utilise pas les paramètres gardés des précédentes connexions.
Le mécanisme de notre RFC a donc plusieurs phases (section 3, mais regardez aussi le joli tableau de l'annexe A, qui est peut-être plus clair) : celle de reconnaissance, où on cherche si les caractéristiques du chemin correspondent à un chemin connu, puis , selon son résultat, on passe à la phase dite normale, si on a reconnu un chemin déjà vu, ou bien à la phase non validée (chemin inconnu, on démarre prudemment), puis à la phase de validation (y a t-il un indicateur de congestion ou bien tout est-il beau et propre ?), ou bien à celle de retraite (on jette les informations enregistrées, la situation a changé, on retourne en mode traditionnel), avant de passer à la phase normale. (Des exemples détaillés figurent dans l'annexe B.)
La section 4 du RFC fournit des détails sur la mise en œuvre des principes de ce RFC. Par exemple, la détermination pratique d'un changement du chemin. Un bon indicateur est le RTT. Cette section conseille aussi, même en l'absence d'indications que le chemin a changé, de ne pas garder les paramètres sauvegardés trop longtemps : comme la détection d'un éventuel changement n'est pas parfaite, il vaut mieux avoir une durée de vie maximale pour les paramètres enregistrés. Le RFC suggère quelques heures, voire moins si on sait que le chemin est très dynamique.
Enfin, l'annexe B détaille à l'octet près des exemples de fonctionnement de l'algorithme de reprise prudente, pour différents cas.
Vous pouvez aussi avoir une introduction aux principes de ce RFC dans l'exposé d'un des auteurs à la Journée du Conseil Scientifique de l'Afnic en 2021 (avec les supports).
Merci à Nicolas Kuhn pour sa relecture.
L'article seul
RFC 9958: Post-Quantum Cryptography for Engineers
Date de publication du RFC : Juin 2026
Auteur(s) du RFC : A. Banerjee, T. Reddy, D. Schoinianakis
(Nokia), T. Hollebeek
(DigiCert), M. Ounsworth (Entrust)
Pour information
Réalisé dans le cadre du groupe de travail IETF pquip
Première rédaction de cet article le 20 juin 2026
Tout le monde parle des calculateurs quantiques et du risque qu'ils font peser sur la cryptographie traditionnelle. La solution ? Remplacer ces algorithmes par des algorithmes post-quantiques, c'est-à-dire résistant aux calculateurs quantiques. Ces algorithmes existent déjà, plusieurs sont normalisés et beaucoup ont déjà été mis en œuvre dans des programmes. Mais les intégrer dans les protocoles de l'Internet n'est pas trivial. Ce RFC vise à guider les ingénieur·es qui vont appliquer ces algorithmes post-quantiques à des logiciels et des protocoles du monde de l'Internet.
Il ne s'agit pas ici d'expliquer le fonctionnement des algorithmes de cryptographie post-quantiques. Le RFC les considère acquis et se demande comment on va les utiliser. (Note personnelle : de toute façon, je ne comprends rien à la cryptographie, post-quantique ou pas. Mais ce n'est pas forcément grave, ce RFC est conçu pour des ingénieur·es normaux·les, le doctorat en cryptographie n'est pas indispensable.) Notez aussi, question terminologie, que « post-quantique » ne fait pas l'unanimité. On pourrait dire (section 2 du RFC), « après quantique » ou bien « résistant au quantique » ou encore « prêt pour le quantique ». Chaque terme a ses qualités et ses défauts : « résistant au quantique » serait inapproprié si, finalement, on trouvait un algorithme quantique pour casser un algorithme qui se prétendait sûr face aux calculateurs quantiques.
D'abord, résumons le problème : la
quantique est aujourd'hui un domaine très
bien connu et dont les bases théoriques sont solides et établies. Un
calculateur quantique peut effectuer
certains calculs plus vite qu'un ordinateur
classique. Parmi ces calculs, il y a les problèmes mathématiques
sous-jacents aux algorithmes de cryptographie courants, comme
RSA et
ECDSA. Aujourd'hui, certes, les calculateurs
quantiques sont très loin de pouvoir être utilisés en pratique
contre la cryptographie. Il faudrait des millions de
qubits physiques ou des milliers de qubits
logiques (ceux qui ont un système de correction d'erreurs). On n'en
est qu'à quelques centaines de qubits physiques (malgré certaines
annonces sensationnalistes), et la difficulté de fabrication et de
fonctionnement augmente très vite avec le nombre de qubits. Mais, à
force de progrès, on aura peut-être un jour des CRQC
(Cryptographically Relevant Quantum Computer,
prononcez « cric », cf. section 2 du RFC), des calculateurs
quantiques utilisables dans le monde réel. 
Ce jour-là, on pourra, par exemple, trouver une clé privée RSA ou ECDSA à partir de la clé publique, cassant ainsi effectivement ces algorithmes. Et, comme le déploiement des algorithmes post-quantiques va prendre du temps, il ne faut pas attendre que des CRQC soient disponibles pour commencer.
On pourrait croire que le problème, pour les protocoles IETF, est simple : tous ont la propriété d'agilité cryptographique (RFC 7696), qui permet de remplacer un algorithme par un autre sans changer le protocole et le code. Mais ça serait trop simple : les algorithmes post-quantiques ont des propriétés qui font qu'il n'est pas toujours possible de les utiliser tels quels, sans adaptation du protocole. Par exemple, leurs clés et signatures sont souvent bien plus grandes, et ne rentrent pas dans les protocoles existants.
Donc, quelques points à garder en tête (j'ai déjà lu des erreurs sur ces sujets, dans divers articles) :
- Un algorithme post-quantique n'a rien de quantique, et ne nécessite pas de calculateur quantique pour tourner. Nous travaillons sur la défense (la cryptographie post-quantique), pas sur l'attaque (les calculateurs quantiques). Pas besoin donc de s'y connaitre en quantique pour comprendre ces algorithmes.
- Les algorithmes « quantiques » ne sont pas 100 % quantiques. Ils ont tous une partie classique et un calculateur quantique ne sera donc pas utilisé seul, mais comme une partie d'un ordinateur mixte (section 3 du RFC).
- Un calculateur quantique n'est pas un ordinateur : il n'est rapide que pour certains problèmes, et c'est cela qui permet de concevoir des algorithmes dont on pense qu'ils ne seront pas vulnérables aux futurs CRQC. (Le RFC fait une analogie avec les GPU qui ne sont pas plus rapides que les CPU dans l'absolu, seulement plus rapides pour certains problèmes.)
- Un algorithme post-quantique peut, si on trouve une faille dans sa conception ou dans sa mise en œuvre, être cassé par un ordinateur classique. C'est d'autant plus gênant que ces algorithmes sont plus récents que RSA ou ECDSA, et ont été moins testés au feu.
Donc (section 1 du RFC), aujourd'hui, des gens construisent des calculateurs quantiques et ceux-ci sont de plus en plus perfectionnés, capable d'attaquer des problèmes plus gros. Pas mal d'argent et d'efforts sont investis dans ces travaux. Mais on reste loin du CRQC (Cryptographically Relevant Quantum Computer), les calculateurs connus du public ne peuvent casser que des clés RSA ou ECDSA ridiculement courtes. Il est très difficile de prévoir quand on aura un CRQC. (Lorsque j'ai fait mon exposé à Pas Sage En Seine, plusieurs personnes m'ont dit que les CRQC seraient disponibles « bientôt ». C'était en 2018 et on ne les a toujours pas.) Le problème est difficile et il ne suffit pas d'extrapoler les prototypes actuels, le monde quantique est difficile et, plus on rassemble de composants, plus il est difficile de maintenir les propriétés quantiques qui nous intéressent. Des prédictions sensationnalistes sur l'arrivée « prochaine » de calculateurs quantiques ont déjà été faites et se sont montrées fausses. Ceci dit, il faut noter qu'il n'y a pas que la recherche publique : on peut toujours imaginer que, dans la zone 51, la NSA fait tourner un CRQC utilisant des technologies obtenues auprès des extra-terrestres…
Mais le fait que les CRQC n'arrivent pas n'est pas une raison pour attendre : le déploiement effectif des algorithmes post-quantiques va prendre beaucoup de temps (il s'agit d'une migration très complexe) et il ne faut donc pas rester les bras croisés en attendant qu'un CRQC soit réellement disponible (d'autant plus qu'il existe toujours la possibilité de percées soudaines dans la recherche scientifique). Mais, en raison de l'incertitude, la question est délicate (cf. mon exposé à NetGouv 26).
Euclide concevait des algorithmes bien avant qu'on ait des ordinateurs et Lovelace écrivait des programmes alors que l'ordinateur à qui ils étaient destinés n'existait pas (et n'a finalement pas existé). De même, des chercheurs écrivent des algorithmes pour les calculateurs quantiques sans avoir de calculateurs quantiques. C'est notamment le cas de l'algorithme de Shor, qui résout le problème de la décomposition en facteurs premiers qui est à la base de RSA. Et une variante de l'algorithme résout le problème du logarithme discret qui est à la base des algorithmes à courbes elliptiques comme ECDSA (RFC 6090).
Il existe aussi un algorithme, l'algorithme de Grover, qui permet de s'attaquer aux clés utilisées en cryptographie symétrique mais il est loin de l'efficacité spectaculaire de l'algorithme de Shor et notre RFC estime donc (section 3.1 pour les détails) que les éventuels futurs calculateurs quantiques n'auront que peu d'impact sur la cryptographie symétrique, notamment parce que cet algorithme n'est pas facilement parallélisable. Et il y a des raisons de penser que Grover ne sera sans doute pas amélioré. Un algorithme comme AES-128 est donc a priori sûr (et c'est encore plus vrai pour AES-256). Le RFC se concentre donc sur l'asymétrique.
Pour la cryptographie asymétrique, la situation est moins rose (section 3.2). Des algorithmes très courants comme RSA et les algorithmes à courbes elliptiques, mais aussi des algorithmes moins connus comme ElGamal (RFC 6090) ou Schnorr (RFC 8235) seront cassables dès qu'on aura un CRQC. En quelques heures, voire en quelques secondes, celui-ci pourra casser une clé RSA de 2 048 bits, comme étudié dans « Circuit for Shor’s algorithm using 2n+3 qubits », « How to factor 2048 bit RSA integers in 8 hours using 20 million noisy qubits » ou bien « Breaking RSA Encryption - an Update on the State-of-the-Art ». (Rappel : tous ces articles supposent l'existence d'un CRQC, et on n'en a pas encore.) Bon, après, vous pouvez toujours faire des clés RSA d'un téra-octet mais ça ne serait pas pratique.
La section 4 du RFC détaille les services pour lesquels on utilise de la cryptographie asymétrique :
- Transport de clé symétrique. C'était la façon traditionnelle de chiffrer. Pour des raisons de performance, on ne chiffre pas avec les algorithmes de cryptographie asymétrique, qui sont trop lents. Une des parties génère une clé de cryptographie symétrique, qui doit donc être connue des deux parties, et on la chiffre avec l'algorithme de cryptographie asymétrique avant de l'envoyer à l'autre partie. Cette méthode ne fournit pas de confidentialité persistante donc on ne l'utilise plus beaucoup.
- Accord sur une clé. C'est la façon la plus courante aujourd'hui pour que les deux parties aient la même clé de chiffrement symétrique. Un exemple pour réaliser cet accord est la méthode Diffie-Hellman.
- Signature de documents et authentification d'une autre partie.
Les algorithmes courants utilisés en cryptographie asymétrique sont vulnérables aux futurs éventuels CRQC. Ce problème étant connu depuis longtemps, plusieurs algorithmes pour lesquels on ne connait pas d'algorithme quantique susceptible de les casser ont été développés. On peut donc les qualifier de « post-quantiques ». Suite à un concours lancé en 2016, le NIST a normalisé plusieurs de ces algorithmes (et d'autres le seront dans le futur). Mais, en général, ces algorithmes ne peuvent pas tout simplement remplacer les algorithmes traditionnels. Par exemple, RSA et ECDSA peuvent servir de KEM (Key Encapsulation Mechanism, cf. section 9) et faire des signatures alors que les algorithmes post-quantiques existants ne savent faire qu'un des deux. Et puis ils ne s'utilisent pas de la même façon et la transition vers ces algorithmes sera donc plus complexe que l'a été celle depuis RSA vers ECDSA.
Quels sont ces algorithmes normalisés par le NIST (section 5) ? Pour le KEM, ce sont :
- ML-KEM (autrefois nommé Kyber), normalisé dans la norme FIPS-203.
- HQC, approuvé mais pas encore normalisé.
Et pour les signatures :
- ML-DSA (autrefois nommé Dilithium), normalisé dans FIPS-204. (Voir aussi la section 10.2.)
- SLH-DSA (autrefois nommé SPHINCS+), normalisé dans FIPS-205.
- FN-DSA (autrefois nommé Falcon), qui sera apparemment normalisé dans FIPS-206.
D'autres algorithmes sont en cours de normalisation à l'ISO (section 6) :
- FrodoKEM.
- ClassicMcEliece.
- NTRU.
OK, on a plein d'algorithmes résistants aux calculateurs quantiques. Maintenant, de quel délai dispose t-on pour faire la transition, avant que les CRQC ne fichent toute la cryptographie traditionnelle en l'air ? La section 7 de notre RFC explore cette difficile question. Je divulgâche tout de suite : on ne sait pas. Le progrès des calculateurs quantiques ne dépend pas de progrès d'ingénierie relativement prévisibles mais de percées scientifiques encore inconnues. Mais d'un autre côté, attendre n'est pas non plus une bonne solution. Il y a sans doute des attaquants qui enregistrent des messages aujourd'hui, dans l'espoir qu'un CRQC permettra de les décrypter un jour (ce qu'on nomme HNDL pour Harvest Now, Decrypt Later). Si certains secrets sont à courte durée de vie, d'autres peuvent être encore sensibles dans des dizaines d'années (la France ne publie toujours pas complètement les archives étatiques sur la guerre d'Algérie). Pour de tels secrets, il serait peut-être plus prudent de passer au post-quantique tout de suite.
Pour les signatures, le RFC prend l'exemple de l'authentification : les signatures utilisées dans l'établissement d'une connexion TLS ne sont sensibles que pendant le très court temps entre leur génération et leur vérification. Par contre, la signature du microcode d'un objet connecté peut rester critique pendant toute la durée de vie de l'objet.
Pour analyser le délai dont on dispose, on utilise souvent le
modèle de Mosca. Dans ce modèle, X est le temps pendant lequel les secrets
doivent rester secrets (rappelez-vous que, pour certains secrets,
cela peut être de nombreuses années), Y est la durée de la
transition (rappelez-vous qu'en informatique, les transitions complètes
prennent toujours beaucoup
plus de temps que prévu, la publication par le NIST d'une norme ne
suffit pas) et Z est le temps qu'il nous reste avant que les CRQC
soient disponibles (c'est la durée la plus incertaine des trois,
d'autant plus qu'on ne peut pas exclure la possibilité de progrès soudains). Si
Z > X + Y, tout va bien. Sinon, on a un trou pendant lequel
certains usages vont être vulnérables. Notons aussi que Z va être
plus court pour les États (qui ont sans doute quelques années
d'avance sur la recherche publique en matière de calculateurs
quantiques) que pour le pirate de base, qui doit attendre qu'un CRQC
soit en vente sur AliExpress. 
Quant à Y, son estimation varie beaucoup. S'il faut juste faire une mise à jour d'un logiciel, cela peut être rapide. Mais de la cryptographie est aussi présente dans bien des matériels, qu'on ne remplace pas du jour au lendemain, comme les puces accélératrices des opérations de cryptographie ou les HSM. Et certaines clés doivent rester stables pendant longtemps comme la clé DNSSEC de la racine du DNS. Et il y a aussi le temps de programmer, de tester, de faire valider, de déployer, etc. Bref, entre la publication d'une norme comme FIPS-203 et sa généralisation, il faut compter de nombreuses années. C'est une des raisons qui justifie que le travail de transition vers la cryptographie post-quantique n'ait pas attendu la sortie du premier CRQC.
Si vous voulez apprendre un peu de cryptographie, vous pouvez aussi lire la section 8 du RFC, qui expose les principales catégories d'algorithmes post-quantiques :
- Réseaux euclidiens (non, ne me demandez pas d'expliquer) : c'est la technique sous-jacente à ML-KEM, ML-DSA et FrodoKEM, donc la technique « principale » à l'heure actuelle. Clés et surtout signatures sont bien plus grandes qu'avec ECDSA ou même RSA mais quand même plus courtes qu'avec les autres catégories. (La cryptographie post-quantique n'est pas écologique.)
- Condensation : c'est la technique derrière SLH-DSA. Il y a même des algorithmes spécifiés dans un RFC, les RFC 8391 et RFC 8554. Attention : bien des algorithmes de cette catégorie sont à état (il ne faut pas signer deux fois avec le même état) et sont donc difficiles à utiliser de manière sûre (et pas du tout adapté aux protocoles comme DNSSEC, qui sont habitués à un environnement sans état).
- Codes correcteurs : c'est là qu'on trouve HQC et ClassicMcEliece.
La façon la plus courante d'utiliser la cryptographie sur l'Internet est de combiner de la cryptographie symétrique, avec une clé générée pour chaque utilisation, et de la cryptographie asymétrique, qui sert à authentifier et à faire en sorte que la clé de cryptographie symétrique soit partagée par les deux parties (cf. RFC 9180 mais attention au fait que le terme « hybride » peut désigner autre chose en cryptographie post-quantique). La façon la plus simple (mais pas la plus sûre !) de réaliser ce partage est qu'une des deux parties génère la « clé de session », celle utilisée pour la cryptographie symétrique, puis la chiffre en cryptographie asymétrique avec la clé publique de l'autre partie. (On combine cryptographie symétrique et asymétrique, alors qu'on pourrait assurer le même service uniquement avec l'asymétrique, car, si l'asymétrique est souple, la symétrique est beaucoup plus rapide.) Ce transport de la clé d'une partie à l'autre est une des façons de faire en sorte que les deux parties aient la même clé, mais il en existe d'autres (ne me demandez pas un exposé détaillé, et encore moins un avis !). Et ces différentes façons ont typiquement des API différentes, ce qui complique le remplacement d'une façon par une autre. La section 9, consacrée aux KEM, détaille cette question. Après l'avoir lue, vous comprendrez les concepts d'AKE et de NIKE ☺.
La section 10 du RFC, consacrée aux signatures, intéressera entre autres les gens qui font du DNSSEC, comme moi. Un point amusant (section 10.4) et qui illustre bien qu'on ne peut pas toujours remplacer purement et simplement un algorithme traditionnel par un post-quantique : ML-DSA incorpore dans son calcul la condensation de la donnée à signer, ce qui le rend plus résistant à certaines attaques. Les protocoles qui calculent un condensat eux-mêmes avant de signer (comme DNSSEC) ne bénéficient donc pas de cette sécurité accrue et, idéalement, devraient être modifiés.
Un autre exemple du fait qu'on ne peut pas brancher un algorithme post-quantique et espérer que tout soit pareil qu'avant est le problème des performances. Ce n'est pas juste que les algorithmes post-quantiques sont plus lents, c'est qu'ils sont parfois tellement lents et avec des clés tellement grosses qu'il faut changer sa façon de travailler. Les tableaux de la section 12 donnent une idée du problème. Alors que des clés traditionnelles font, par exemple, 65 et 32 octets (pour la clé publique et la clé privée), les plus petites clés ML-KEM font respectivement 800 et 1632 octets (et c'est pire pour ML-DSA). Pour des protocoles comme TLS, qui fonctionne sur des connexions TCP ou QUIC, ce n'est pas très grave, OK, ce n'est pas écologique, mais l'augmentation de données due aux clés n'est probablement qu'une faible partie de ce que transportera la connexion. À part avec des middleboxes boguéees qui auraient une limite stupide à la taille des paquets TLS, ça devrait marcher (mais elles ont d'autres problèmes). Mais pour des protocoles comme IKE ou le DNS, qui tournent sur UDP et ont des limites bien plus strictes, c'est ennuyeux. Et le même problème se pose pour les objets contraints et leurs protocoles spécifiques (cf. section 14, qui leur est dédiée). Il existe bien des solutions (cf. RFC 9242 et RFC 9370 pour IKE) mais qui compliquent et ralentissent le protocole.
Autre problème, la sécurité des algorithmes post-quantiques face
aux ordinateurs traditionnels. C'est bien joli,
de résister aux CRQC mais, si l'algorithme peut être cassé par de la
cryptanalyse traditionnelle, cela ne sert à
rien (cf. sections 15.1 et 15.4 du RFC). Lors de la dernière grande
transition cryptographique sur l'Internet, celle depuis RSA vers
ECDSA, il y avait de très bonnes raisons de penser que le nouvel
algorithme était plus sûr et qu'on pouvait donc simplement remplacer
l'ancien par le nouveau.
Ce n'est pas le cas avec les algorithmes post-quantiques,
dont on ne peut pas être certains de leur résistance (regardez par
exemple l'attaque KyberSide, contre
ML-KEM). C'est d'autant plus vrai que les programmes qui les
mettent en œuvre sont, eux aussi, récents et pas forcément testés
longuement au feu. Et, comme les algorithmes traditionnels sont
vulnérables aux CRQC, que faire ? Que choisir ? L'idée dominante
aujourd'hui est d'avoir les deux, un système
hybride (ou « PQ/T », pour « Post-quantique et
Traditionnel », cf. RFC 9794). Par exemple,
lors d'un échange de clé symétrique, on va créer la clé en
concaténant deux clés qui ont été obtenues, l'une par un algorithme
traditionnel, l'autre par un post-quantique (c'est ce que fait le
RFC 9954). Ainsi,
la défaillance d'un des deux algorithmes ne permettra pas à
l'attaquant d'obtenir la clé. On peut aussi appliquer la
fonction de dérivation autant de fois qu'on a
de clés dans la structure hybride (RFC 9370). Pour
l'authentification, on peut authentifier avec les deux algorithmes
et exiger que les deux donnent le même résultat (draft-ietf-lamps-pq-composite-sigs).
Pour faciliter la tâche des programmeur·ses, il vaut mieux que
les deux clés (la PQ et la T) soient manipulées ensemble, dans une
seule structure de données (composite). On
évitera ainsi de compliquer le protocole comme cela serait le cas
si, par exemple, on exigeait qu'il y ait deux
certificats. Un travail de normalisation va
être nécessaire pour le format de ces clés composées
(cf. draft-bonnell-lamps-chameleon-certs). Il
faudra aussi définir quelles paires PQ/T ont du sens, question
sécurité, et ne pas juste accepter n'importe quel algorithme
post-quantique avec n'importe quel algorithme traditionnel.
Voilà, maintenant, si vous voulez sérieusement apprendre la cryptographie post-quantique, le RFC recommande le livre « Serious Cryptography » (la deuxième édition), de Jean-Philippe Aumasson (qui a aussi une traduction française). Si vous voulez voir du code post-quantique, il y a le projet OQS (avec une très bonne FAQ pour les débutants et un dépôt Github). Et si vous vous demandez ce que fait l'IETF en matière de normalisation de la cryptographie post-quantique dans ses protocoles, il y a une liste maintenue à jour. Je rajoute « awesome-post-quantum », qui maintient une liste de ressources sur la cryptographie post-quantique, Cloudflare avait fait un article détaillé sur les finalistes du concours NIST, qui expliquait bien les différentes questions techniques, et enfin lisez le texte de position de l'ANSSI.
Bon, mais je vais quand même vous montrer des exemples d'utilisation d'algorithmes post-quantiques dans des protocoles Internet. D'abord, avec SSH :
% ssh -v autre-machine-debian … debug1: kex: algorithm: mlkem768x25519-sha256
Oui, OpenSSH sait faire du ML-KEM pour l'échange de clés, depuis la version 10. Celui-ci ne permet pas de faire de l'authentification donc OpenSSH ne sait apparemment pas générer des clés de machines avec des algorithmes post-quantiques.
Pour TLS, voici un échange de clés hybride (ML-KEM et
traditionnel) vu par Firefox (« Outils de
développement Web » puis « Réseau » puis « Sécurité », tout au
bout) : 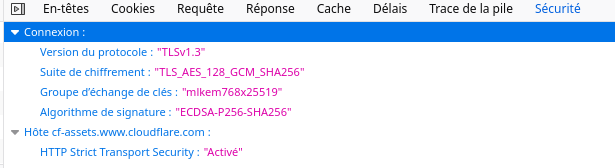 .
.
Pour DNSSEC, il existe une zone d'exemple expérimentale signée avec ML-DSA :
% dig +dnssec dilithium2.pdns.pq-dnssec.dedyn.io DNSKEY
;; Truncated, retrying in TCP mode.
…
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 55771
;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1
…
;; ANSWER SECTION:
dilithium2.pdns.pq-dnssec.dedyn.io. 3598 IN DNSKEY 257 3 18 (
XVrPO18btCpMLjXFiZYJNyMbQLXB7oOwk6ZXEmxhm8PP
EKiKP1+t/j7pwBUNYXp3s0U+3AFp3moviOf4cnl4K4MH
…
) ; KSK; alg = 18 ; key id = 47389
dilithium2.pdns.pq-dnssec.dedyn.io. 3598 IN RRSIG DNSKEY 18 5 3600 (
20260129000000 20260108000000 47389 dilithium2.pdns.pq-dnssec.dedyn.io.
aGU3rLJ8vb1AYln+y3bxcOO0RHboWfh03i8H1XhLd9f/
TxhGJNwsTCoRGOnJPjdB2ZDHMB7EnfUfgOitDjvcvcsd
…
;; Query time: 0 msec
;; SERVER: 127.0.0.1#53(127.0.0.1) (TCP)
;; WHEN: Tue Jan 20 15:16:45 CET 2026
;; MSG SIZE rcvd: 3877
Notez la taille de la réponse, et la nécessité de se rabattre sur TCP. D'autre part, l'algorithme de numéro 18, utilisé ici, n'est pas enregistré. Aujourd'hui, le monde du DNS semble plutôt attentiste, il n'y a pas d'algorithme de signature post-quantique qui convienne vraiment au DNS. Une synthèse de l'ICANN est relativement sceptique.
Et merci à Magali Bardet pour sa relecture attentive. (Et, naturellement, les erreurs restantes en crypto sont de moi, pas d'elle.)
L'article seul
RFC 9954: Hybrid key exchange in TLS 1.3
Date de publication du RFC : Juillet 2026
Auteur(s) du RFC : D. Stebila (University of
Waterloo), S. Fluhrer (Cisco
Systems), S. Gueron (U. Haifa &
Meta)
Pour information
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 16 juillet 2026
Dans le monde merveilleux de la cryptographie post-quantique (RFC 9958), un problème se pose : si en voulant éviter le Charybde des calculateurs quantiques, on tombe dans le Scylla d'un algorithme, certes post-quantique, mais pour lequel une attaque cryptanalytique est trouvée ? N'aurait-on pas lâché la proie pour l'ombre ? La solution, que ce RFC décrit pour le cas de l'échange de clés dans TLS, est la cryptographie hybride : on utilise à la fois un algorithme traditionnel et un post-quantique (RFC 9794). Un éventuel attaquant devrait alors casser les deux pour réussir.
Si vous n'êtes pas à l'aise avec la terminologie de la cryptographie post-quantique, la section 1.2 de notre RFC la rappelle. Notamment, un algorithme traditionnel est un de ceux qu'on utilisait avant la menace des calculateurs quantiques, comme par exemple RSA ou ECDH. Un algorithme post-quantique est un algorithme dont on a de bonnes raisons de penser qu'il résistera aux futurs CRQC (Cryptographically-Relevant Quantum Computer, les calculateurs quantiques capables de traiter des problèmes de cryptographie réels). Un algorithme de nouvelle génération est un de ceux récemment créés et dont on n'est pas complètement sûrs de la sécurité. Cela inclut certains algorithmes post-quantiques, par exemple ML-KEM. Un algorithme hybride combine un traditionnel et un post-quantique. On parle de clé composée quand elle est faite de deux clés, une traditionnelle et une post-quantique, gérées ensemble comme un seul algorithme. Mais les termes ne sont pas universellement adoptés : comme « hybride » a un autre sens en cryptographie (un protocole qui utilise à la fois la cryptographie symétrique et l'asymétrique, comme TLS ou OpenPGP), certains préfèrent dire « composé » pour tout système PQ/T (post-quantique et traditionnel).
« Nouvelle génération » pour parler (entre autres) des algorithmes post-quantiques est inhabituel mais le but est de montrer que la technique décrite dans ce RFC ne se limite pas au post-quantique : elle s'applique dès qu'on n'a aucun algorithme parfait et qu'on en compose deux, que ces algorithmes soient post-quantiques ou pas.
Et puisqu'on pinaille sur le terminologie, le RFC note que TLS utilise le terme de « groupe » pour parler des algorithmes d'échange de clé alors que tous ces algorithmes ne font pas référence à un groupe. Mais l'habitude s'est prise.
Pourquoi créer des systèmes hybrides, PQ/T, plutôt que, par exemple, attendre tranquillement que les algorithmes post-quantiques soient mieux testés, et qu'on leur fasse autant confiance qu'à, par exemple, RSA ? Avoir un seul algorithme serait plus simple. Mais le but des hybrides est de permettre aux adopteurs précoces de se lancer tout de suite dans le post-quantique, en étant sûrs de ne pas diminuer leur sécurité actuelle. (D'autant plus que l'utilisation des algorithmes traditionnels peut être une obligation réglementaire, par exemple pour respecter FIPS.) Ces adopteurs précoces peuvent être motivés, entre autres, par la crainte d'un décryptage rétroactif, lorsqu'un attaquant qui n'a pas de CRQC aujourd'hui enregistre quand même les communications, pour les décrypter dès qu'il pourra acheter un CRQC sur AliExpress. Si vous gérez des secrets qui ont une longue durée de vie (secrets d'État…), vous ne devez pas attendre qu'un CRQC existe réellement, même s'il n'arrive que dans 20 ans, certains secrets durent plus longtemps que ça.
Bon, maintenant, au boulot ; ce RFC sur les échanges de clé hybrides dans TLS 1.3 (RFC 9846) ne va pas vous dire quel algorithme post-quantique utiliser, et il ne va pas parler d'authentification (vu la façon dont fonctionne TLS, le risque d'attaque rétroactive n'existe pas, donc on a le temps de voir venir). Par contre, il va dire comment faire que les deux parties aient la clé (clé pour la cryptographie symétrique, celle qui va chiffrer la communication une fois la session TLS établie) avec une configuration hybride, PQ/T. Parmi ses objectifs, il y a évidemment la compatibilité avec le TLS existant (un client récent doit interopérer avec un serveur ancien et réciproquement, sans compter les exaspérantes middleboxes entre les deux), et de préférence sans exiger des aller-retours supplémentaires, car il ne faut pas dégrader la latence. Il faut aussi être rapide (ne pas imposer des calculs démesurés, voir « Benchmarking Post-Quantum Cryptography in TLS » et « Post-quantum confidentiality for TLS »). Et il ne faut pas trop augmenter la taille des paquets : bien sûr, TLS fonctionne sur TCP et n'a pas les problèmes que la fragmentation des paquets pose à UDP mais quand même. Or, les algorithmes post-quantiques ont souvent des clés et des signatures bien plus grosses que les algorithmes traditionnels.
Plus spécifiquement qu'un général échange de clés, ce RFC parle de KEM (Key Encapsulation Mechanism). Si vous ne vous souvenez pas bien de ce qu'est un KEM, la section 2 du RFC vous le résume. Un KEM est utilisé lorsque la clé est générée par une seule des deux parties, et communiquée à l'autre. Le but d'un KEM est que les deux parties qui communiquent utilisent la même clé secrète pour le chiffrement en cryptographie symétrique. Un KEM permet de communiquer de manière sécurisée même face à un attaquant actif qui peut modifier les paquets à sa guise (au pire, il fera un déni de service mais ne pourra jamais lire les messages).
Maintenant, les détails pratiques, en section 3. Le nom du
mécanisme hybride va être annoncé au début de la session TLS (dans
l'extension supported_groups et rappelez-vous
que ce ne sont pas forcément des groupes). Le nom, même si on y
retrouve les noms des deux algorithmes (le traditionnel et le
post-quantique) désigne le mécanisme hybride, quand on fera du
post-quantique pur, il y aura un autre nom. Un exemple de nom (RFC pas encore publié) est X25519MLKEM768 (le
traditionnel X25519 et le post-quantique
ML-KEM). Ensuite, on fait simple : on fait un
double échange de clefs (un traditionnel et un post-quantique) et on
dérive ensuite les clefs de session à partir des deux. Plus
précisément, on concatène les messages traités avec chacun des deux
algorithmes du mécanisme hybride. Même chose pour le secret généré
par chacun des deux algorithmes. La concaténation de ces secrets
sera le point d'entrée du calcul de la clé.
La sécurité du système (section 6) vient du fait qu'un attaquant devrait réussir à casser les deux algorithmes : il lui faudrait un CRQC et une attaque (aujourd'hui inconnue) contre l'algorithme quantique. C'est l'avantage de ces systèmes hybrides. Mais si vous voulez creuser la cryptographie qui est derrière ces mécanismes hybrides, le RFC recommande « KEM Combiners » et « Hybrid Key Encapsulation Mechanisms and Authenticated Key Exchange ». Et si vous voulez en apprendre plus sur le calcul quantique, l'annexe A du RFC cite quelques bonnes lectures.
La section 4 discute quelques problèmes avec cette approche (ou, parfois, avec la cryptographie post-quantique en général). Par exemple, les clés sont grandes. Bon, qu'on fasse de l'hybride ou du post-quantique pur, ça ne change pas grand'chose, c'est la clé post-quantique qui est responsable de la grande majorité des octets : Classic McEliece a des clés d'au moins 200 kilo-octets ! Une telle taille se heurterait à des limites de TLS (65 536 octets pour la clé publique) mais heureusement les algorithmes post-quantiques normalisés par le NIST ont des clés plus petites, et qui tiennent dans les messages TLS (mais pas forcément dans un seul paquet IP). L'encodage de notre RFC aggrave les choses si on annonce deux hybrides, chacun utilisant la même clé post-quantique, qui sera alors envoyée deux fois.
Les noms des mécanismes hybrides seront mis dans le
registre IANA (X25519MLKEM768 et
quelques autres y sont déjà) au fur et à mesure de leur spécification.
Côte mises en œuvre, les expérimentations sont anciennes : CECPQ2 ou OQS, par exemple, et des tests de performance ont été faits. Aujourd'hui, le mécanisme hybride est possible avec Chrome, Firefox, OpenSSL, wolfSSL, Cloudflare, Google, BoringSSL, Rustls…(Je n'ai pas testé Firefox.)
L'article seul
RFC 9953: DNS over the Constrained Application Protocol (DoC)
Date de publication du RFC : Mars 2026
Auteur(s) du RFC : M. S. Lenders (TU
Dresden), C. Amsüss, C. Gündoğan
(NeuralAgent GmbH), T. C. Schmidt (HAW
Hamburg), M. Wählisch (TU Dresden & Barkhausen Institut)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF core
Première rédaction de cet article le 1 avril 2026
Le protocole CoAP est un protocole léger, conçu pour les objets connectés. Ce RFC décrit comment faire du DNS au-dessus de CoAP. Si votre brosse à dents a besoin de faire du DNS, c'est ce RFC qu'il faut lire.
CoAP, normalisé dans le RFC 7252, ressemble à HTTP mais en plus simple. Il vise le marché des objets contraints (en mémoire, énergie, en capacité réseau, en puissance de calcul…, voir le RFC 7228). CoAP permet à un client d'envoyer des requêtes à un serveur, et notre tout neuf RFC 9953 explique comment utiliser CoAP pour faire des requêtes DNS et recevoir des réponses DNS. Comme CoAP peut être vu, de manière simplifiée, comme une variante légère de HTTP, ce DNS sur CoAP, alias DoC (DNS over CoAP), est très proche dans ses principes de DoH (RFC 8484). Les contraintes de l'Internet des objets empêchent votre tournevis ou votre ampoule électrique de faire du DoH (qui implique HTTPS), d'où ce DoC. Bien sûr, il y avait toujours la possibilité de faire du DNS sur DTLS, comme le décrit le RFC 8094, mais CoAP a plein de fonctions sympas pour les objets contraints (transferts par blocs - RFC 7959, qui résout les problèmes de MTU, relais CoAP, etc).
L'architecture générale de DoC est très proche de celle de DoH : le client DoC interroge un serveur DoC qui est lui-même un client DNS, parlant typiquement à un résolveur DNS. La communication entre le client DoC et le serveur DoC utilise CoAP, celle entre le serveur DoC et le résolveur utilise le DNS normal, sur UDP, TCP, TLS, etc.
Le serveur DoC sera a priori désigné par le chemin
/. Le but est que
les messages soient plus courts (DoH utilise souvent
le chemin /dns-query). Au fait, comment le
client DoC trouve-t-il le serveur (section 3 du RFC) ? Plusieurs méthodes
sont admises, de la configuration manuelle (« le serveur DoC est en
coaps://doc.foobar.example/ ») aux répertoires
CORE (RFC 9176) en passant par les
classiques DHCP ou
RA ou bien par la découverte de résolveurs du
RFC 9462. Ces différentes solutions sont plus ou
moins sûres, et plus ou moins pratiques pour
l'administrateur/utilisateur (et en général les plus pratiques sont
les moins sûres).
Mais ce n'est pas tout : le serveur DoC peut aussi être trouvé
via le DNS, avec un enregistrement SVCB (RFC 9460 et RFC 9461), si
l'objet contraint a déjà un moyen d'interroger le DNS (la clé SVCB
est docpath, numéro
10).
Une fois qu'on connait le serveur, on peut lui parler. La section
4 décrit les messages CoAP échangés. Ils sont étiquetés avec le type
application/dns-message (valeur numérique 553).
La méthode CoAP utilisée est FETCH
(RFC 8132), qui n'a pas d'équivalent HTTP,
contrairement à la plupart des méthodes CoAP. DoC utilise le
principe REST (RFC 6690). Le RFC recommande de ne pas oublier le champ
Accept: pour indiquer le type de
données accepté. Le type recommandé est
application/dns-message. Dans la requête, le Query
ID DNS devrait être à 0, CoAP se charge de mettre en
correspondance requêtes et réponses donc cet identificateur n'est
pas utile (c'est pareil pour DoH).
Et les réponses ? Là encore, comme pour DoH, les codes de retour
CoAP indiquent si le serveur DoC a pu être joint et a pu faire son
travail, pas si la requête DNS a eu une réponse
satisfaisante. Autrement dit, tant que le serveur DoC fonctionne
bien, il renvoie le code 2.05 (RFC 7252, section 5.9.1.5.) et
c'est dans le message DNS qu'on saura si la résolution DNS a renvoyé
NOERROR, SERVFAIL,
NXDOMAIN, etc.
La mémorisation des réponses joue un rôle plus grand en CoAP
qu'en HTTP (rappelez-vous que CoAP sert à des objets contraints). Le
RFC demande donc que les TTL dans la réponse
DNS soient constants, afin que l'ETag (RFC 7252, section 5.10.6), s'il est calculé via un
condensat, ne change pas. Le serveur DoC doit
par contre mettre un champ Max-Age: dans sa
réponse (section 4.3.2).
Voici, tiré du RFC, un exemple de réponse CoAP, formaté en texte :
2.05 Content
Content-Format: 553 (application/dns-message)
Max-Age: 58719
Payload (human-readable):
;; ->>Header<<- opcode: QUERY, status: NOERROR, id: 0
;; flags: qr rd ad; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;example.org. IN AAAA
;; ANSWER SECTION:
;example.org. 79689 IN AAAA 2001:db8:1:0:1:2:3:4
Et la sécurité ? Le RFC recommande de sécuriser la communication avec le système OSCORE du RFC 8613 (ou, sinon, le DTLS du RFC 9147, ce qui donne du CoAPS). Le RFC note que cela assure la sécurité de la communication entre le client DoC et le serveur DoC mais que, après, on ne sait pas ce que fait le serveur (la section 8 recommande évidemment que le serveur DoC valide avec DNSSEC).
Questions mises en œuvre de DoC, on trouve (mais je ne les ai pas testées, je ne fais pas d'Internet des Objets), par les auteurs du RFC, dans RIOT, un client en C (source sur Github) et un serveur en Python.
Si vous voulez allez plus loin que ce résumé sommaire, une bonne lecture est le papier de 2023 des auteurs, « Securing Name Resolution in the IoT: DNS over CoAP ».
L'article seul
RFC 9945: IETF Community Moderation
Date de publication du RFC : Février 2026
Auteur(s) du RFC : L. Eggert (Mozilla), E. Lear (Cisco
Systems)
Réalisé dans le cadre du groupe de travail IETF modpod
Première rédaction de cet article le 2 mars 2026
Comme toute organisation humaine, l'IETF doit gérer le cas de personnes pénibles, qui font perdre du temps à tout le monde, mettent une mauvaise ambiance ou cherchent activement à perturber le travail commun. Ce RFC (qui remplace les RFC 3683 et RFC 3934) établit la politique de l'IETF vis-à-vis de ces gens : être patient mais pas trop.
Les principes de base de la gestion des abusifs sont les principes de l'IETF (RFC 3935 et RFC 7154). Il ne s'agit pas d'empêcher les désaccords (ils sont attendus et sains). L'IETF est une organisation très ouverte et ses participant·es sont divers·es. On recherche un consensus approximatif (RFC 7282) mais, bien sûr, s'opposer au consensus n'est pas en soi un problème. L'IETF n'est pas une religion. Mais certains vont « sortir des clous ». L'annexe B du RFC donne quelques exemples (messages hors-sujet sur un groupe, ton agressif, remise en cause permanente des décisions et une pratique que je ne connaissais pas, le sealioning). L'IETF devra réagir, en suivant ces lignes directrices :
- Avoir une politique qui soit cohérente et équitable. Elle doit s'appliquer uniquement sur la base du comportement de la personne et pas, par exemple, selon le nombre de RFC qu'elle a écrit, ni selon son ancienneté.
- Permettre des appels contre les décisions prises (le contrôle est une activité délicate et les décisions seront parfois difficiles).
- Essayer de respecter la vie privée tout en maintenant une certaine transparence (exemple de problème : les sanctions doivent-elles être publiques ?).
- Être flexible car il faudra pouvoir s'appliquer à des cas variés. (Notez la tension entre cet objectif et le premier cité…)
Le travail de contrôle reposera essentiellement sur l'équipe de contrôle (moderation team), décrite en section 2. Elle comportera au moins cinq personnes, nommées par l'IESG, qui devra essayer de respecter une certaine diversité. Ces personnes ne doivent pas être membres de l'IESG ou de l'IAB. La diversité souhaitée inclut celle des fuseaux horaires car l'équipe devra parfois réagir vite. L'IETF LLC, la structure administrative décrite dans le RFC 8711, se chargera de leur financer une formation. (La première équipe a été nommée le 3 juillet 2026.)
Leur travail couvrira toutes les discussions publiques en ligne à l'IETF, qu'elles soient sur une liste de diffusion, un dépôt GitHub, etc. Le RFC distingue les administrateurs, qui gèrent un de ces lieux de discussion, de l'équipe de contrôle. Les administrateurs signalent les problèmes et appliquent les décisions de l'équipe de contrôle. Mais, évidemment, pour éviter de surcharger cette équipe, les administrateurs sont aussi censés gérer la plupart des problèmes localement. L'idée derrière l'équipe centrale (moderators) est d'avoir un groupe formé et qui pourra s'assurer d'une politique cohérente au niveau de l'IETF. Vu la taille de l'IETF, les contrôleurs ne pourront pas tout surveiller préventivement et dépendront donc beaucoup des signalements faits, par exemple par les administrateurs.
Vous ne l'avez peut-être pas noté plus haut mais le mot important est « publiques ». L'équipe de contrôle ne va pas gérer les communications privées. Par ailleurs, elle contrôle des comportements, pas le contenu (donc, pas la peine de lui demander de censurer telle ou telle partie d'un Internet-Draft). Quand au spam, il est effectivement un exemple de comportement perturbateur mais il y a déjà une politique à ce sujet.
Ce sera à l'équipe de contrôle de définir ses processus de fonctionnement et ses détails de politique, pour ce qui n'est pas déjà couvert dans ce RFC 9945. Tout cela devra évidemment être discuté au sein de l'IETF et, au bout du compte, approuvé par l'IESG et rendu public (mais pas forcément dans un RFC).
Qu'est-ce que pourra faire en pratique l'équipe de contrôle ? Le RFC donne quelques exemples (section 4) :
- Faire passer les messages d'une personne par un système d'approbation explicite (par défaut, l'IETF n'a pas de contrôle a priori),
- Engueuler quelqu'un, en privé ou en public,
- Supprimer complètement le droit d'écriture à une personne.
Et l'équipe de contrôle devra évidemment garder trace de ces actions, pour en rendre compte. Et des appels sont possibles (RFC 2026, sections 6.5.1 et 6.5.4).
Il y a d'autres fonctions dans l'IETF qui ont un rapport avec cette nécessité de contrôler les débordements de certains participants (section 5). C'est le cas de l'ombudsteam et de l'incarnation administrative de l'IETF, la LLC (notamment si le comportement de certains entraine des risques juridiques pour l'IETF). Il y a aussi plein d'autres RFC à lire, comme le RFC 7776, sur les mesures contre le harcèlement ou le RFC 9245, sur la gestion des listes de diffusion (rappelez-vous que l'équipe de contrôle ne sera pas limitée à ces listes).
Le RFC remarque à juste titre (section 6) que toute politique peut être utilisée de manière abusive, par exemple à des fins de censure. La section 6 revient sur les différentes décisions décrites par le RFC et comment elles contribuent à minimiser ce risque.
Notez que ce RFC s'applique à l'IETF uniquement, et pas aux autres organisations proches comme l'IRTF.
Enfin, l'annexe A explique les motivations derrière ce RFC et le pourquoi des différents choix. Malgré la quantité de RFC et de décisions documentées, il n'était pas toujours évident de reconnaitre ce qui était un comportement perturbateur. Et les processus existants étaient trop lents, en partie parce qu'ils supposaient que tout le monde était de bonne foi. D'où ce nouveau RFC qui explique comment un meilleur mécanisme va être défini.
L'article seul
RFC 9943: An Architecture for Trustworthy and Transparent Digital Supply Chains
Date de publication du RFC : Juin 2026
Auteur(s) du RFC : H. Birkholz (Fraunhofer SIT), A. Delignat-Lavaud, C. Fournet (Microsoft Research), Y. Deshpande (ARM), S. Lasker
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF scitt
Première rédaction de cet article le 1 juillet 2026
Des attaques sur la chaine d'approvisionnement du logiciel, il y en a tout le temps. L'attaquant arrive à glisser du code malveillant dans un logiciel, en amont de son installation par la victime et, quand celle-ci fait tourner le logiciel, le code de l'attaquant est exécuté et paf. Il n'y a pas de solution miracle à ce problème mais on peut au moins essayer de fournir une traçabilité forte des logiciels, qui permet d'être sûr de ce qu'on fait tourner sur ses machines, et, dans le cas d'une enquête postérieure, de mieux comprendre ce qui s'est passé. Ce RFC décrit une architecture, très inspirée du Certificate Transparency du RFC 9162.
Vous voulez des exemples d'attaques contre la chaine d'approvisionnement du logiciel ? Deux cas récents sont la faille Trivy/Aqua Security, annoncée le 1er avril de cette année mais qui n'est pas une blague (tout juste de l'ironie car le logiciel Trivy servait à détecter les problèmes de sécurité…). Cette attaque a notamment permis l'accès aux données de la Commission Européenne. Et il y a aussi, encore plus récente, l'attaque contre le paquetage Python litellm. Mais le cas le plus fameux, quoique un peu moins récent, est celui du détournement de la bibliothèque XZ. (Olivier Poncet en a fait une conférence.)
Les attaquants peuvent frapper à de nombreux endroits différents dans la chaine d'approvisionnement d'un logiciel. Cela peut être en modifiant une bibliothèque utilisée par le logiciel, en modifiant directement le code source, en modifiant l'environnement de compilation (de manière à produire un code exécutable malveillant à partir d'un code source intact), en remplaçant le code exécutable dans un magasin d'applications, etc. La figure 1 dans la section 2.1 du RFC donne une liste complète. Le choix va dépendre des capacités de l'attaquant, de ses choix de discrétion, et des solutions de sécurité déployées.
Je l'ai dit au début, il n'y a pas de solution parfaite au problème, qui est complexe. Dans le cas de XZ, le mainteneur a eu tort de faire confiance à un inconnu mais, si on arrêtait d'accepter des volontaires inconnus, tout le logiciel libre s'effondrerait. Et le logiciel privateur a d'autres failles, comme l'opacité, qui empêche de savoir quels sont les composants logiciels intégrés.
Que propose le groupe de travail SCITT, auteur de ce RFC ? L'approche choisie est celle de la transparence et de la traçabilité. Il faut qu'on puisse vérifier de quels logiciels on dépend. La principale source d'inspiration est le Certificate Transparency du RFC 9162 et l'architecture SCITT peut être vue comme une généralisation de Certificate Transparency au logiciel. Il repose sur une structure de données ordonnée, et qui garantit que seul l'ajout de données est possible, et que tout dans cette structure de données est signé. (Si vous criez « chaine de blocs » ici, vous avez tort : une chaine de blocs fournit en effet ce service mais elle n'est pas nécessaire, d'autres mécanismes existent depuis longtemps, tels que ceux utilisés par le RFC 9162.) D'autre part, il est important de se souvenir que notre RFC ne présente qu'une architecture, pas un protocole complet. Les programmeurs et programmeuses ne peuvent donc pas se mettre au travail tout de suite. L'architecture SCITT est conçue pour les chaines d'approvisionnement de logiciel mais peut a priori être étendue plus tard pour d'autres usages.
Le mécanisme de base consiste en des données en CBOR (RFC 8949), dont la structure est spécifiée en CDLL (RFC 8610), signées avec COSE (RFC 9052) et récupérable via des arbres de Merkle (RFC 9942). Grâce à cela, celui ou celle qui veut vérifier des informations sur un logiciel peut les récupérer facilement et efficacement, puis les vérifier (là encore, comme avec Certificate Transparency). C'est par exemple ce que le NIST appelle DevSecOps.
La section 2.2 du RFC fournit trois cas d'usages de cette technologie. L'un d'eux concerne l'assemblage du logiciel pour un véhicule. (Dans le monde réel, les gens qui assemblent le logiciel pour une voiture ou pour n'importe quel objet connecté ne se soucient guère de sécurité ; comme il y a zéro conséquence négative pour eux en cas de bogue, ou même de faille de sécurité, ils utilisent des versions antédiluviennes de logiciels non testés.) La chaine de dépendance est longue car une voiture est faite de plusieurs composants, chacun apportant du logiciel qui, à son tour, dépend de diverses bibliothèques. SCITT permettrait au moins d'avoir des idées claires sur les composants logiciels utilisés, chacun ayant fait l'objet d'un ajout dans la structure de données de traçabilité.
Bon, maintenant, si on veut être un peu plus précis et comprendre ce qu'est l'architecture SCITT, par quoi on commence ? Par le vocabulaire, peut-être. Découvrons-le dans la section 3 du RFC :
- Déclaration (statement) : une information portant sur un fait (par exemple « la version actuelle est la 3.14 » ou bien « ce logiciel dépend de libfoobar et de grutzbaum-plus »). Les logiciels peuvent être identifiés par un grand nombre d'identificateurs, notre RFC cite entre autres CoSWID (RFC 9393), in-toto, SPDX, SWID, etc.
- Enveloppe (envelope) : les méta-données comme l'identité de l'émetteur.
- Émetteur (issuer) : l'entité qui déclare quelque chose, et qui a une clé privée pour signer cette déclaration.
- Utilisateur (relying party) : l'entité qui va utiliser les déclarations.
- Équivoque (equivocation, quoiqu'il me semble que le terme soit moins fort en français) : déclarations contradictoires (ce qui est clairement mauvais).
- Reçu (receipt) : preuve comme quoi une
déclaration signée a bien été incluse dans la structure de
données. Si on les distribue sur l'Internet, le type de
média à utiliser est
application/scitt-receipt+cose - Déclaration signée (signed statement) :
ce sont elles qui sont encodées en COSE
(RFC 9052). Si on les distribue sur
l'Internet, le type de média à utiliser est
application/scitt-statement+cose. - Structure de données vérifiable (verifiable data structure) : là où on met les déclarations. Cette structure de données doit être à ajout seul (et, je me répète, une chaine de blocs a cette propriété mais les chaines de blocs ne sont nullement indispensables pour cela), doit empêcher l'équivoque (cf. section 5.1.3) et doit permettre l'examen complet (peut-être après autorisation) pour vérifier sa cohérence. Le RFC 9942 donne des détails techniques.
Armé de ces termes, nous pouvons décrire l'architecture SCITT (mais regardez aussi la figure 2 du RFC) :
- Des émetteurs produisent des déclarations signées et les envoient à des services de transparence,
- ces services de transparence authentifient l'émetteur, vérifient les signatures, vérifient la conformité des déclarations à leur politique (cf. section 5.2.1), mettent la déclaration dans la structure de données vérifiable et produisent un reçu (suivant le RFC 9942),
- des utilisateurs vont accéder à ces informations pour vérifier les informations (« est-ce que je dépend ou pas de libfoobar ? », sachant que la dépendance peut être transitive), ou bien pour vérifier la cohérence du service de transparence, par exemple lors d'un audit (c'est une propriété importante d'un service de transparence, on doit pouvoir vérifier son intégrité).
Il peut y avoir plusieurs services de transparence (comme c'est le cas pour Certificate Transparency), personne n'envisage évidemment d'avoir un unique point de dépôt des déclarations.
Le format des déclarations signées et des reçus figure (en CDDL, cf. RFC 8610) en section 6.1.
La section 9 du RFC est vraiment à lire car c'est celle consacrée à l'analyse de sécurité de l'architecture SCITT. D'abord, il faut être bien conscient que SCITT fournit de la transparence et de la traçabilité mais pas de la vérité. Si un émetteur signe que son logiciel tourne avec toutes les versions de libfrobnicate mais qu'en fait il lui faut au moins la version 2, le service de transparence ne va pas regarder les sources du logiciel pour vérifier. C'est vrai pour les erreurs des émetteurs et encore plus pour leurs malhonnêtetés. « Transparency does not prevent dishonest or compromised Issuers, but it holds them accountable ».
Un émetteur grognon ou négligent peut aussi ne pas enregistrer toutes les informations qu'il a. Un utilisateur ne doit donc pas utiliser une déclaration signée sans vérifier le reçu, qui seul prouvera que la déclaration a été enregistrée.
Il existe apparemment au moins trois mises en œuvre de cette technique, chez deux entreprises spécialisées dans la traçabilité des chaines d'approvisionnement, Datatrails et Tradeverifyd, mais aussi chez Microsoft (cf. leur article).
Enfin, une bonne lecture sur ces structures de données vérifiables est « Attested Append-Only Memory: Making Adversaries Stick to their Word ».
L'article seul
RFC 9935: Internet X.509 Public Key Infrastructure - Algorithm Identifiers for the Module-Lattice-Based Key-Encapsulation Mechanism (ML-KEM)
Date de publication du RFC : Mars 2026
Auteur(s) du RFC : S. Turner (sn3rd), P. Kampanakis, J. Massimo (AWS), B. E. Westerbaan (Cloudflare)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF lamps
Première rédaction de cet article le 7 mars 2026
Ce RFC spécifie comment mettre des clés ML-KEM dans un certificat X.509. Vous allez me dire « Mais ML-KEM est un algorithme d'échange de clés, pas de signature, que fait-il dans un certificat ? » Et je vous répondrai que vous avez raison, d'ailleurs le RFC restreint sérieusement ce qu'on peut faire avec cet algorithme.
ML-KEM a l'intéressante propriété d'être résistant aux calculateurs quantiques. Il est normalisé dans FIPS 203. Ce RFC permet de l'utiliser dans les certificats normalisés dans le RFC 5280, et il décrit trois variantes, ML-KEM-512, ML-KEM-768 et ML-KEM-1024.
Comme indiqué plus haut, autant il était normal de permettre ML-DSA dans les certificats (RFC 9881), autant cela peut sembler surprenant pour ML-KEM. La section 1.1 de notre RFC explique les usages (limités) d'un algorithme d'échange de clés dans un certificat. C'est par exemple utile pour un protocole où vous avez besoin d'une clé publique, que vous allez tirer du certificat. Mais vous ne pourrez pas utiliser les certificats de ce RFC pour faire du TLS sur l'Internet public, aucune AC ne vous en produira, même si TLS le permet un jour. Pour la même raison, vous n'en trouverez pas dans les journaux Certificate Transparency.
Les trois algorithmes sont identifiés en suivant le RFC 5912, par un OID via le NIST ; Ce sont
id-alg-ml-kem-512
(2.16.840.1.101.3.4.4.1),
id-alg-ml-kem-768
(2.16.840.1.101.3.4.4.2) et
id-alg-ml-kem-1024
(2.16.840.1.101.3.4.4.3).
La section 5 du RFC précise que les bits indiquant les utilisations possibles de ces certificats (RFC 5280, section 4.2.1.3) doivent indiquer uniquement le chiffrement d'une clé (et pas l'authentification, comme avec les certificats habituels).
Le module ASN.1 figure dans l'annexe A, si
vous voulez implémenter ce RFC (il faut aussi importer les modules
des RFC 5912 et RFC 9629). Le module est identifié
par id-mod-x509-ml-kem-2025 et a l'OID
1.3.6.1.5.5.7.0.121. Le gros du RFC est
constitué d'exemples de clés et de certificats ML-KEM (annexe C),
dans l'encodage en texte du RFC 7468.
Allez, un peu de pratique avec OpenSSL 3.5 :
% openssl genpkey -algorithm ML-KEM-512 -out ml-kem-key.pem -outform PEM % cat ml-kem-key.pem -----BEGIN PRIVATE KEY----- MIIGvgIBADALBglghkgBZQMEBAEEggaqMIIGpgRAOwWCnP71SklfOIuwiLrIddsm Up4AlOMwvwjqCy4PHr8fSq5jRjFoP6XYXnl8IQCR9HhzSRVffI09hBezOUrmxgSC … # Analysons cette clé : % openssl pkey -text -in ml-kem-key.pem # Demandons une signature du certificat : % openssl req -new -key ml-kem-key.pem -provider default -out req.csr … 40E7CEC0027F0000:error:03000096:digital envelope routines:do_sigver_init:operation not supported for this keytype:../crypto/evp/m_sigver.c:305:
Ah, là, c'est raté, et c'est logique. OpenSSL n'accepte pas de fabriquer un CSR pour ces clés « operation not supported for this keytype » puisque ML-KEM ne permet pas de signer. La solution :
# Extraire la clé publique :
% openssl pkey -in ml-kem-key.pem -pubout -out mlkem.pub
# Fabriquer une clé ECDSA pour signer :
% openssl ecparam -out ec_key.pem -name secp256r1 -genkey
# Signer :
% openssl x509 -new \
-subj "/CN=test-mlkem" \
-force_pubkey mlkem.pub \
-signkey ec_key.pem \
-days 365 \
-out mlkem-cert.pem
Warning: Signature key and public key of cert do not match
L'avertissement est normal, puisqu'on a effectivement utilisé une autre clé, d'un autre algorithme, pour signer le certificat contenant notre clé publique ML-KEM. Mais tout s'est bien passé :
% openssl x509 -text -in mlkem-cert.pem
Certificate:
Data:
Version: 3 (0x2)
Serial Number:
69:33:f9:1e:e5:34:64:84:d9:f4:b2:15:3b:50:ec:36:db:0b:71:5c
Signature Algorithm: ecdsa-with-SHA256
Issuer: CN=test-mlkem
Validity
Not Before: Feb 16 15:30:02 2026 GMT
Not After : Feb 16 15:30:02 2027 GMT
Subject: CN=test-mlkem
Subject Public Key Info:
Public Key Algorithm: ML-KEM-512
ML-KEM-512 Public-Key:
ek:
d8:d2:6c:c4:9b:96:48:23:0d:ce:f7:0d:b3:0b:85:
…
X509v3 extensions:
X509v3 Subject Key Identifier:
E7:B2:03:92:37:EC:C6:35:E4:F0:2E:AC:4E:1C:F2:81:67:F7:95:29
X509v3 Authority Key Identifier:
15:E5:2A:5E:B1:C3:50:69:7E:E4:48:EA:0F:DD:3C:5C:90:4B:7C:CC
Signature Algorithm: ecdsa-with-SHA256
L'article seul
RFC 9934: Privacy-Enhanced Mail (PEM) File Format for Encrypted ClientHello (ECH)
Date de publication du RFC : Mars 2026
Auteur(s) du RFC : S. Farrell (Trinity College Dublin)
Chemin des normes
Première rédaction de cet article le 5 mars 2026
La technique ECH (Encrypted Client Hello) permet de boucher une faille de TLS, la transmission en clair du nom du serveur demandé. Elle est normalisée dans le RFC 9849 mais il y manquait la description d'un format standard pour envoyer les données nécessaires à ECH. C'est désormais fait (et vous reconnaitrez le classique format PEM, cf. RFC 7468).
Le principe d'ECH
est de chiffrer le
nom du serveur demandé,
avec la clé
publique du serveur TLS. Pour configurer le serveur, il faut la
clé privée correspondante et différents détails, la
ECHConfig (RFC 9849,
section 4). C'est pour ECHConfig que notre RFC
normalise un format.
Le fichier PEM (RFC 7468) contient une ou plusieurs clés privées et des informations de configuration (pour un ou plusieurs serveurs), le tout en Base64 (section 4 du RFC 4648). Les informations publiques sont typiquement mises dans le DNS (RFC 9848), la clé privée, cela va sans dire (mais le RFC le dit quand même, on ne sait jamais) n'est pas publiée. Un fichier PEM contenant des clés privées doit évidemment être bien protégé.
Voici un exemple, tiré du RFC (la clé privée a donc déjà été publiée 😁) :
-----BEGIN PRIVATE KEY----- MC4CAQAwBQYDK2VuBCIEICjd4yGRdsoP9gU7YT7My8DHx1Tjme8GYDXrOMCi8v1V -----END PRIVATE KEY----- -----BEGIN ECHCONFIG----- AD7+DQA65wAgACA8wVN2BtscOl3vQheUzHeIkVmKIiydUhDCliA4iyQRCwAEAAEA AQALZXhhbXBsZS5jb20AAA== -----END ECHCONFIG-----
Dans le DNS, la publication de la clé publique et de la configuration donnerait quelque chose du genre :
% dig +short HTTPS foo.example.com 1 . ech=AD7+DQA65wAgACA8wVN2BtscOl3vQheUzHeIkVmKIiydUhDCliA4iyQRwAEAAEAAQALZXhhbXBsZS5jb20AAA==
Bien des logiciels reconnaissent cette syntaxe. Je ne les ai pas testés mais, apparemment :
- Dans une
branche d'OpenSSL (les tests sont dans
test/ech_test.c, avec des exemples du format de ce RFC. Apache ou HAProxy peuvent l'utiliser. - Pour BoringSSL, il y a ce script.
L'article seul
RFC 9926: Prefix Registration for IPv6 Neighbor Discovery
Date de publication du RFC : Février 2026
Auteur(s) du RFC : P. Thubert
Chemin des normes
Première rédaction de cet article le 14 février 2026
Une addition sympa au mécanisme de découverte des voisins d'IPv6 (RFC 4861), utile pour les réseaux d'objets contraints, genre Internet des Objets mais aussi les réseaux à connectivité imparfaite, par exemple avec des hauts et des bas : la possibilité pour une machine qui est connectée à un réseau d'un préfixe donné d'enregistrer ce préfixe auprès des routeurs voisins. Ceux-ci sauront alors où envoyer les paquets pour ce préfixe. Cela ne remplace pas les protocoles de routage traditionnels, c'est plutôt une addition pour optimiser les protocoles spécialisés dans les réseaux contraints.
Le cœur de cible de ce RFC, ce sont les LLN (Low power and Lossy Networks, les réseaux « pauvres », avec pas beaucoup d'énergie et des liaisons pourries, cf. RFC 7102 et RFC 7228). La préoccupation principale est d'économiser l'énergie ; éviter de transmettre (la radio coûte cher) et s'endormir le plus souvent possible. Ces LLN utilisent des technologies comme 6LoWPAN (RFC 4919) et le protocole de routage RPL du RFC 6550. Les protocoles conçus pour les LLN n'utilisent donc pas d'émissions périodiques (comme le fait OSPF), qui consomment de l'énergie, et obligent tout le monde à écouter tout le temps, donc à ne pas dormir. L'idée de ce RFC est de compter sur quelques routeurs qui sont moins contraints (par exemple parce qu'ils sont connectés à une prise de courant) et que les autres signalent aux routeurs les préfixes connus, lorsqu'ils sont réveillés.
Autre exemple, les mécanismes IPv6 de
découverte du voisin (RFC 4861 et RFC 4862) ont été conçus en pensant à des machines
alimentées électriquement en permanence, sur des réseaux comme
Ethernet, où diffuser à tout le monde est peu
coûteux. Mais ils ne fonctionnent plus si, par exemple, certaines
machines sont endormies, et ne répondent donc pas aux
sollicitations. D'où des idées comme le RFC 6775, où une machine n'attend pas les sollicitations,
elle profite de ses périodes d'éveil pour enregistrer son adresse
auprès du routeur. Idem avec le projet draft-ietf-6man-ipv6-over-wireless. L'idée
a ensuite été généralisée par le RFC 8505,
sur lequel s'appuie notre nouveau RFC, qui permet d'enregistrer un
préfixe IP entier. Notez bien que cette technique est indépendante
de la manière dont la machine a reçu ce préfixe en allocation, et de
la manière dont le routeur auprès duquel on s'enregistre va ensuite
diffuser son préfixe dans son domaine de routage.
La section 3 du RFC donne une vision générale du nouveau mécanisme, je vous laisse la lire 😃.
Notez (section 11) que la machine qui enregistre un préfixe peut mentir et que cette technique doit donc être déployée en comprenant les caractéristiques spécifiques du réseau (par exemple, fermé ou au contraire ouvert sur l'Internet). Le RFC 8928 est ici une bonne lecture, ainsi que la section 9 de notre RFC.
Et merci à Pascal Thubert pour sa relecture. (Naturellement, je reste responsable des erreurs et approximations.)
L'article seul
RFC 9925: Unsigned X.509 Certificates
Date de publication du RFC : Février 2026
Auteur(s) du RFC : D. Benjamin (Google)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF lamps
Première rédaction de cet article le 27 février 2026
Un certificat est signé par une AC, normalement, ou à la rigueur auto-signé, ce qui ne sert pas à grand'chose mais est obligatoire dans X.509. Mais voici que ce RFC rend la signature facultative.
À ma connaissance, le seul intérêt d'auto-signer son certificat
est de prouver qu'on a bien la clé privée correspondante (car un
plaisantin peut toujours fabriquer un certificat avec la clé
publique de quelqu'un d'autre) et, en prime, de vérifier
l'intégrité. C'est pas crucial. Mais la norme
X.509 (cf. RFC 5280) ne
permet pas d'avoir un certificat sans
signature. Notre RFC 9925 contourne
cette obligation en enregistrant un nouvel algorithme,
id-alg-unsigned,
qui indique qu'il n'y a pas de signature du tout.
C'est parce que, parfois, on n'a pas besoin des signatures. Un exemple typique se trouve dans votre magasin d'AC : vous ne vérifiez pas les signatures (vous ne pouvez pas, puisque les AC sont à la racine de la validation, RFC 5280, section 6), la seule présence du certificat dans le magasin inspire la confiance. Les certificats des AC sont donc auto-signés, ce qui ne sert pas à grand'chose, à part à satisfaire les exigences syntaxiques du format X.509. Ici, le certificat d'une AC du magasin de ma machine Ubuntu ; Issuer est égal à Subject, le certificat est auto-signé :
% openssl x509 -text -in /etc/ssl/certs/Autoridad_de_Certificacion_Firmaprofesional_CIF_A62634068.pem
Certificate:
Issuer: C = ES, CN = Autoridad de Certificacion Firmaprofesional CIF A62634068
Subject: C = ES, CN = Autoridad de Certificacion Firmaprofesional CIF A62634068
…
X509v3 Basic Constraints: critical
CA:TRUE, pathlen:1
X509v3 Key Usage: critical
Certificate Sign, CRL Sign
…
(Une autre solution serait le RFC 5914 mais il ne semble pas très courant.)
Un autre cas où on se moque de la signature du certificat est celui où le certificat est validé d'une autre façon, par exemple un serveur EPP sur TLS qui a une liste de tous les clients possibles, et des certificats que le registre a distribués à ses BE.
Donc, il y a des cas où la signature ne sert guère, voire pas du tout. Mais est-ce gênant ? Ce n'est pas dramatique mais, dans certains cas, c'est sous-optimal, par exemple :
- Les signatures post-quantiques sont souvent de grande taille, donc cela rend les certificats plus gros pour rien.
- La clé publique dans le certificat peut utiliser un
algorithme qui ne permet pas la signature (comme
ML-KEM, cf. le
futur RFC
draft-ietf-lamps-kyber-certificates).
La section 3 du RFC fournit les détails techniques. Dans le
certificat, on met le champ signatureAlgorithm
à id-alg-unsigned et le champ
signatureValue à une chaine vide. Le champ
issuer pourrait être vide puisque personne n'a
signé le certificat, mais comme il était obligatoire, pour éviter de
choquer les applications actuelles, il vaut mieux mettre un
issuer égal au subject
(comme pour un auto-signé). On a le droit de mettre plutôt un nom
/id-rdna-unsigned= (en fait
1.3.6.1.5.5.7.25.1 mais je montre la
représentation textuelle du RFC 4514). RDNA signifie
Relative
Distinguished Name Attribute et un nouveau
registre, « SMI
Security for PKIX Relative Distinguished Name
Attribute », est créé pour accueillir
id-rdna-unsigned et d'autres futurs noms
(politique de Spécification nécessaire, cf. RFC 8126).
Quand une application rencontre un de ces certificats non signés, si elle valide les signatures, elle doit évidemment rejeter le certificat. Si elle est plus laxiste (ou bien a d'autres mécanismes de vérification), elle peut l'accepter (section 4). Les applications et bibliothèques existantes font déjà cela (elles rejettent les signatures d'algorithmes inconnus) donc l'introduction des certificats non signés ne devrait rien casser.
Quelques conseils de sécurité figurent en section 5, par exemple de ne pas réutiliser les clés dans des contextes différents. (X.509, jusqu'à présent, ignorait ce conseil pour les certificats auto-signés puisque la clé publiée servait aussi à signer. Plus de signature, plus de problème.)
Désolé, mais je n'ai pas trouvé comment générer aujourd'hui de tels certificats, que ce soit avec OpenSSL (c'est en cours) ou d'autres logiciels. Si vous trouvez, ça m'intéresse, je pourrais mettre des essais pratiques ici.
L'article seul
RFC 9923: The FNV Non-Cryptographic Hash Algorithm
Date de publication du RFC : Février 2026
Auteur(s) du RFC : G. Fowler (Google), L. Noll (Cisco
Systems), K. Vo (Google), D. Eastlake
(Independent), T. Hansen
(AT&T)
Pour information
Première rédaction de cet article le 28 février 2026
L'algorithme de condensation FNV, présenté dans ce RFC n'est pas neuf (et certains disent même qu'il est dépassé). Mais il est utilisé par de nombreux logiciels alors qu'il n'avait jamais été spécifié « proprement ». Voilà qui est fait.
FNV a comme principal avantage ses performances : il est rapide et le code est court. Comme le précise le titre du RFC, il n'a pas les caractéristiques des algorithmes de condensation utilisés pour des services de sécurité. Mais cela ne l'empêche pas d'être déployé depuis de nombreuses années pour bien d'autres usages.
Le RFC fait 137 pages mais ne vous affolez pas, FNV est simple et l'essentiel de ces pages est composé de code mettant en œuvre FNV de diverses manières. J'emprunte au RFC, section 2 (avec les modifications de l'article de Wikipédia pour que ce soit plus clair) l'essentiel de l'algorithme, en pseudo-code :
algorithm fnv-1 is
hash := FNV_offset_basis
for each byte_of_data to be hashed do
hash := hash × FNV_prime
hash := hash XOR byte_of_data
return hash
C'est court et rapide, non ? Mais, et le RFC le rappelle plusieurs fois (car des critiques sérieuses du projet de RFC avait insisté sur cette question) : cet algorithme ne doit pas être utilisé pour le cas où on veut de la résistance aux attaques comme la pré-image (section 1.1 du RFC). Ainsi, Python utilisait FNV mais a arrêté.
Qu'est-ce qui fait que FNV se retrouve qualifié de « non-cryptographique » et pas utilisable pour la sécurité ? La section 1.3 liste les limites de FNV (voir aussi la section 6) comme le fait que chaque bit du condensat ne dépend pas de tous les bits de la donnée d'entrée ou comme le fait que FNV est trop rapide. Oui, pour la sécurité, cela peut être un problème : si on utilise une fonction pour condenser des mots de passe, on ne veut pas faciliter la tâche de l'attaquant qui va chercher un mot de passe ayant ce condensat, en essayant beaucoup de mots de passe possibles. Une fonction de condensation a donc intérêt à être lente, comme Argon 2 (RFC 9106).
Vous trouverez par contre du FNV un peu partout (la section 1.2 vous donne une liste), dès que ces questions de sécurité ne sont pas pertinentes. FNV est même cité dans des RFC, le RFC 7357 ou le RFC 7873 (les cookies du DNS) ou bien dans la norme IEEE 802.1Qbp.
FNV a une longue histoire (section 7 du RFC), ayant commencé en
1991. On notera que la définition de FNV inclut quelques valeurs
largement arbitraires comme, par exemple, la chaine de caractères
« chongo <Landon Curt Noll> /\../\ », dont le condensat
fournit le paramètre offset_basis (section
2.2). Cette chaine était dans le .signature
d'un des auteurs de FNV mais, c'est amusant, avait été mal
recopiée.
Le gros (en nombre de pages) du RFC étant constitué de code source en C, avec des variantes selon le nombre de bits produits, plutôt que de tenter de l'extraire du RFC, utilisons cette archive tar que j'ai constituée :
% tar xzvf FNV-RFC.tar.gz % cd FNV-RFC % echo -n toto > tmp % make FNVhash % ./FNVhash -t 64 -f tmp FNV-64 test of return values passed. FNV-64 Hash of contents of file 'tmp': ADC7B038EFF1F42F
Et voilà, FNV marche. Il existe d'autres mises en œuvre. Celle de référence est présentée ici et est également sur Github :
% git clone https://github.com/lcn2/fnv % cd fnv % make % ./fnv1a64 -s toto 0x2ff4f1ef38b0c7ad [Oui, les octets ne sont pas affichés dans le même ordre qu'avec le code du RFC.]
Vous avez aussi d'autres mises en œuvre (une des plus rigolotes est en Fortran). Et elle n'est pas listée mais il y a une mise en œuvre de FNV dans le langage Zig (notez son utilisation de comptime).
Et pour finir, si vous vous demandez quelle fonction de condensation utiliser, il y a une comparaison de FNV avec SHA-1 (RFC 3174) et SHA-256 (RFC 6234) dans l'annexe A.
L'article seul
RFC 9920: RFC Editor Model (Version 3)
Date de publication du RFC : Février 2026
Auteur(s) du RFC : P. Hoffman (ICANN), A. Rossi (RFC
Series Consulting Editor)
Pour information
Réalisé dans le cadre de l'activité d'édition des RFC rswg
Première rédaction de cet article le 12 février 2026
Vous avez toujours voulu savoir qui s'occupait de publier les RFC et qu'est-ce que ce mystérieux « RFC Editor » ? Ce nouveau RFC décrit ce rôle et la façon dont il doit accomplir sa tâche. Il s'agit d'une légère mise à jour du RFC 9280, sans changement de version. (Parmi les nouveautés, la définition de la notion d'utilisateurice des RFC, avant, on ne parlait que des auteurices.)
Les RFC sont un ensemble de documents techniques au sujet de l'Internet, qui comprend notamment, mais pas uniquement, les normes TCP/IP. Les RFC sont librement accessibles en ligne et sont publiés depuis 1969 (cf. RFC 8700).
Il y a très longtemps, quand les dinosaures étaient petits, le rôle de RFC Editor s'incarnait bien dans une personne unique, Jon Postel. Aujourd'hui, c'est plus complexe et il n'y a plus, depuis la version 2 du modèle (qui était dans le RFC 8728), de RFC Editor unique. Ce rôle est désormais réparti en deux tâches principales, définir la politique, et la mettre en œuvre. La première tâche est du ressort du RSWG (RFC Series Working Group), pour discuter et proposer (tout le monde, et son chat, peut y participer), puis du RSAB (RFC Series Approval Board), pour décider (ce comité est plus fermé). La deuxième tâche, la mise en œuvre de la politique, est du ressort du RFC Production Center, typiquement une organisation privée sous contrat avec l'IETF LLC, l'organisation administrative derrière l'IETF (RFC 8711). Ce sont donc tous ces groupes ensemble qui composent le « RFC Editor ». Tout ceci, et quelques autres points, étaient déjà dans le RFC 9280, notre nouveau RFC 9920 n'apporte que des changements de détail.
Les RFC sont publiés par cinq voies (streams) différentes, dont une, la voie IETF, sert pour les normes (mais tous les RFC ne sont pas des normes). Chaque voie a une organisation ou une personne responsable du contenu des RFC (pour la voie IETF, le responsable est… l'IETF), la fonction RFC Editor ne gère pas le contenu (ou seulement la forme, mais pas le fond des documents) mais la publication. Le RFC 8729, dans sa section 5.1, décrit les quatre voies classiques (IETF, IRTF, IAB et indépendante). En plus, le RFC 9280 avait introduit la voie éditoriale, dédiée aux évolutions des RFC (les RFC parlant des RFC…). C'est via cette voie que seront publiés les propositions issues du RSWG et approuvées par le RSAB. Un exemple est le récent RFC 9896, dont vous pouvez suivre l'historique.
Dans les deux tâches décrites plus haut (la définition de la politique, et sa mise en œuvre), je n'ai pas mentionné un acteur supplémentaire (comme s'il n'y en avait pas déjà assez !), le RFC Series Consulting Editor, qui est un·e expert·e en édition, membre du RSAB.
Et donc, si vous avez des idées géniales pour améliorer les RFC, il faut faire comment pour qu'elles triomphent ? Lisez la section 3 et notamment la 3.2.2 :
- Les propositions sont écrites (un Internet draft) et diffusées au RSWG (rappelez-vous : il est ouvert, tout le monde peut y participer),
- Après un dernier appel dans le RSWG, puis plus large, s'il y a un consensus approximatif (RFC 2418),
- Les propositions atterrissent au RSAB, qui décidera (avec des votes YES ou CONCERN, le second n'étant pas un NO mais une demande de discussion).
Chaque acteur est décrit ensuite plus en détail. Le RSWG est le groupe le plus ouvert du lot, vous vous abonnez à sa liste de diffusion et c'est parti, vous êtes membre. Et ceci que vous soyez déjà participant à l'IETF ou pas. Les développeur·ses qui mettent en œuvre les RFC, les auteurs de RFC, les auteurs de logiciels qui traitent les RFC, les gens qui citent les RFC dans leurs appels d'offres, tous ceux et toutes celles là sont les bienvenu·es. Les discussions sont publiques. Le RSWG peut aussi utiliser des outils en ligne comme MicrosoftHub (RFC 8874).
Le RSAB, lui, est relativement fermé, aussi bien dans sa composition (les membres avec droit de vote sont un représentant de chaque voie plus le RFC Series Consulting Editor, cf. section 5) que dans son travail (mais les comptes-rendus des réunions sont publics). Par contre, il n'est pas censé court-circuiter le RSWG : toutes les propositions doivent d'abord être discutées au RSWG.
Les boilerplates, ces textes rigides présents au début de chaque RFC et expliquant le statut de celui-ci, décrits dans le RFC 7841, sont décidés par chaque voie puis approuvés par le RSAB, le RFC Production Center et l'IETF Trust.
Le RPC (RFC Production Center) est décrit en section 4. C'est actuellement AMS. C'est ce RPC qui va écrire et maintenir le guide stylistique à respecter (RFC 7322 et documents en ligne), décider des formats acceptés (par exemple du profil restreint de SVG, cf. RFC 9896), et préciser les points que le RFC 7991 laissait libres. C'est aussi le RPC qui doit faire le travail de publication effectif :
- Attribuer les numéros des RFC (qui sera le numéro 10 000 ?),
- Relire et corriger les textes soumis, en respectant le sens technique,
- Garder trace de toutes les modifications faites (des « corrections » peuvent accidentellement changer le fond du texte),
- Assurer la communication avec les auteurs et avec des organisations comme l'IANA, quand le futur RFC leur donne un rôle, par exemple de créer un nouveau registre de paramètres, et archiver tous ces dialogues,
- Demander le cas échéant au RSCE et/ou au RSAB, et leur faire des suggestions, fondées sur son expérience de publication des RFC,
- Participer au RSWG,
- Rendre compte à la communauté des auteurs et lecteurs de RFC, d'une part, et à l'IETF LLC d'autre part,
- Mettre les RFC en ligne, veiller au serveur
www.rfc-editor.orgqui les distribue, archiver les RFC (RFC 8153), annoncer les publications (le RPC est sur le fédivers, voyez par exemple cette annonce, et il y a bien sûr un flux de syndication sur le site Web), - Maintenir le système d'errata (« Submit an issue »),
- Et répondre aux demandes judiciaires car il y a parfois des procès impliquant un RFC.
Le RPC est choisi suite à un appel d'offres de l'IETF LLC, qui est chargée d'écrire le cahier des charges détaillé et de sélectionner le vainqueur. L'argent vient du budget de l'IETF LLC, qui paie le RPC (AMS, actuellement, comme indiqué plus haut).
Et le RSCE (RFC Series Consulting Editor) ? La section 5 le décrit plus en détail. C'est une personne expérimentée dans les questions d'édition. Il ou elle doit guider le RPC sur les questions techniques liées à la publication (la section 4 du RFC 8729 donne une liste complète de ces questions). La RSCE actuelle, depuis 2022, est Alexis Rossi, une des auteures de ce RFC.
Une des nouveautés du RFC 9280 était la voie éditoriale (Editorial Stream), la cinquième voie de création de RFC, consacrée aux RFC qui parlent des RFC. La section 6 de notre RFC la détaille. Cette voie est empruntée par les RFC discutés par le RSWG puis approuvés par le RSAB, comme ce RFC 9920 dont vous êtes en train de lire le résumé. Le statut de ces RFC est forcément « Pour information » (informational, cf. RFC 8729), mais ce sont bien des règles impératives pour les RFC qu'ils spécifient.
Et, pour finir, la section 7 de notre RFC liste les propriétés « historiques » des RFC qui, si elles n'ont pas forcément été mises par écrit, surtout au début, ont toujours été respectées et ne doivent pas être prises à la légère lors des propositions d'évolution :
- Libre disponibilité des documents, que tout le monde peut télécharger, lire, redistribuer. (Ce n'est pas évident, puisque des organisations fermées comme l'AFNOR ou l'ISO ne fournissent toujours pas d'accès libre à leurs documents et, même si vous avez payé pour en avoir un, vous ne pouvez pas le redistribuer.)
- Accessibilité (format texte d'abord, puis XML avec plusieurs formats de sortie), sans dépendance vis-à-vis de logiciels privateurs comme le font les organisations fermées.
- En anglais (notez que la licence permet de faire une traduction sans demander d'autorisation). Opinion personnelle : ce n'est évidemment pas génial mais il n'y pas d'alternative réaliste : traduire des documents normatifs en N autres langues est très coûteux (chaque virgule compte et, par exemple, un texte en français tend facilement à être plus directif que le texte en anglais).
- Diversité : tous les RFC ne sont pas des normes, il y a des informations, des discussions, de l'humour…
- Qualité des documents.
- Stabilité et longévité : le contenu sémantique des RFC n'est jamais modifié, et les formats sont choisis pour garantir qu'ils seront toujours lisibles dans des dizaines d'années (formats standards, acceptés par de nombreux logiciels). À part le cas particulier du RFC 20, le RFC le plus ancien et qui est toujours applicable est le RFC 768, qui a presque un demi-siècle. L'archivage à long terme est un point crucial des RFC, à la fois pour les RFC anciens mais toujours d'actualité, et aussi pour les historien·nes de l'informatique.
La section 1.1 de notre RFC résume les changements depuis le RFC 9280, qui avait spécifié la version 3 du modèle « RFC Editor ». On reste en version 3 et les changements sont peu importants :
- Précisions des responsabilités de développement des outils informatiques nécessaires. C'est au RFC Production Center de s'en occuper. Cela implique des choses comme les choix de formats ou bien les grammaires XML.
- Définition de la notion d'utilisateur des RFC (consumer of RFCs, section 3.3), en se référant au RFC 3935, qui décrit la mission de l'IETF mais qui n'expliquait pas clairement cette notion. Les utilisateurs des RFC sont un ensemble plus large que celui des participants à l'IETF, et un RFC doit être utilisable par des gens qui ne connaissent rien à l'IETF.
- En cohérence avec le RFC 9720, on précise désormais qu'un RFC, une fois publié, peut être modifié (sa forme, mais pas son fond).
La section 9, quant à elle, raconte les changements qu'il y avait eu depuis la version 2 du modèle (la version 1 du modèle était dans le RFC 5620 en 2009 et la version 2 dans le RFC 6635 en 2012) :
- Éclatement de la fonction de RFC Editor en plusieurs acteurs (RSWG, RSAB, etc).
- Fusion des fonctions RFC Production Center et RFC Publisher.
- Suppression du RSOC (RFC Series Oversight Commitee).
- Création de la voie éditoriale pour les RFC parlant des RFC.
L'article seul
RFC 9915: Dynamic Host Configuration Protocol for IPv6 (DHCPv6)
Date de publication du RFC : Janvier 2026
Auteur(s) du RFC : T. Mrugalski (ISC), B. Volz
(Individual Contributor), M. Richardson
(SSW), S. Jiang (BUPT), T. Winters (QA
Cafe)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dhc
Première rédaction de cet article le 11 février 2026
IPv6 dispose de trois mécanismes principaux pour l'allocation d'une adresse IP à une machine. L'allocation statique, « à la main », le système d'« autoconfiguration » SLAAC du RFC 4862 et DHCP. DHCP pour IPv6 était normalisé dans le RFC 8415, que notre RFC met à jour. Le protocole n'a guère changé, le principal changement est la suppression de certaines fonctions peu utilisées.
DHCP permet à une machine (qui n'est pas forcément un ordinateur, ou plus exactement qui n'est pas perçue comme telle) d'obtenir une adresse IP (ainsi que plusieurs autres informations de configuration) à partir d'un serveur DHCP du réseau local. C'est donc une configuration « avec état », du moins dans son mode d'utilisation le plus connu. (Notre RFC documente également un mode sans état.) DHCP nécessite un serveur, par opposition à l'autoconfiguration du RFC 4862 qui ne dépend pas d'un serveur (cette autoconfiguration sans état peut être utilisée à la place de ou bien en plus de DHCP). Deux utilisations typiques de DHCP sont le SoHo où le routeur est également serveur DHCP pour les trois PC connectés et le réseau local d'entreprise où deux ou trois machines Unix distribuent adresses IP et informations de configuration à des centaines de machines.
Le principe de base de DHCP (IPv4 ou IPv6) est simple : la nouvelle machine annonce à la cantonade qu'elle cherche une adresse IP, le serveur lui répond, l'adresse est allouée pour une certaine durée, le bail, la machine cliente devra renouveler le bail de temps en temps.
L'administrateur d'un réseau IPv6 se pose souvent la question « DHCP ou SLAAC » ? Notez que les deux peuvent coexister, ne serait-ce que parce que certaines possibilités n'existent que pour un seul des deux protocoles. Ainsi, DHCP seul ne peut indiquer l'adresse du routeur par défaut. Pour le reste, c'est une question de goût.
Le DHCP spécifié par notre RFC ne fonctionne que pour IPv6, les RFC 2131 et RFC 2132 traitant d'IPv4. Les deux protocoles restent donc complètement séparés, le RFC 4477 donnant quelques idées sur leur coexistence. Il a parfois été question de produire une description unique de DHCPv4 et DHCPv6, ajoutant ensuite les spécificités de chacun, mais le projet n'a pas eu de suite (section 1.2 de ce RFC), les deux protocoles étant trop différents.
DHCP fonctionne par diffusion
restreinte. Un client DHCP,
c'est-à-dire une machine qui veut obtenir une adresse, diffuse (DHCP
fonctionne au-dessus d'UDP, RFC 768, le
port source est 546,
le port de destination, où le serveur écoute, est 547) sa demande à
l'adresse multicast locale au lien
ff02::1:2. Le serveur se reconnait et lui
répond. S'il n'y a pas de réponse, c'est, comme dans le DNS, c'est au client de
réémettre (section 15). L'adresse IP source du client est également
une adresse locale au lien.
(Notez qu'une autre adresse de diffusion restreinte est réservée,
ff05::1:3 ; elle inclut également tous les
serveurs DHCP mais, contrairement à la précédente, elle exclut les
relais, qui transmettent les requêtes DHCP d'un réseau local à un
autre.)
Le serveur choisit sur quels critères il alloue les adresses IP. Il peut les distribuer de manière statique (une même machine a toujours la même adresse IP) ou bien les prendre dans un pool d'adresses et chaque client aura donc une adresse « dynamique ». Le fichier de configuration du serveur DHCP Kea ci-dessous montre un mélange des deux approches.
Il faut bien noter (et notre RFC le fait dans sa section 22) que DHCP n'offre aucune sécurité. Comme il est conçu pour servir des machines non configurées, sur lesquelles on ne souhaite pas intervenir, authentifier la communication est difficile. Un serveur DHCP pirate, ou, tout simplement, un serveur DHCP accidentellement activé, peuvent donc être très gênants.
Outre l'adresse IP, DHCP peut indiquer des options comme les adresses des serveurs DNS à utiliser (RFC 3646).
Notre version IPv6 de DHCP est assez différente de la version IPv4 (et le RFC est plus de trois fois plus long). Par exemple, l'échange « normal » entre client et serveur prend quatre paquets IP (section 5) et non pas deux. (Mais il y a aussi un échange simplifié à deux paquets, cf. section 5.1.) L'encodage des messages est très différent, et il y a des différences internes comme l'IA (Identity Association) de la section 12. Il y a aussi des différences visibles à l'utilisateur comme le concept de DUID (DHCP Unique IDentifier), section 11, qui remplace les anciens client identifier et server identifier de DHCP v4. Les différences sont telles que le RFC précise que leur intégration avec DHCP pour IPv4 n'est pas envisagée.
À l'heure actuelle, il existe plusieurs mises en œuvre de DHCPv6, comme Kea (serveur seulement) et dhcpcd (client seulement). (Notez qu'une liste complète figurait dans le brouillon du RFC.) Pour celles et ceux qui utilisent une Freebox comme serveur DHCP, il semble qu'elle ait DHCPv6 depuis 2018 (je n'ai pas testé). Il parait que la Livebox le fait également. Je n'ai pas non plus essayé pour la Turris Omnia mais cela devrait marcher puisqu'elle utilise le serveur odhcpd, qui sait faire du DHCPv6 (ceci dit, je ne vois pas comment l'activer depuis les menus de Luci). Et il y a bien sûr des implémentations non-libres dans des équipements comme les Cisco. Notez que ces mises en œuvre de DHCPv6 n'ont pas forcément déjà intégré les modifications de notre RFC 9915.
Il existe aussi des programmes qui ne sont plus maintenus comme Dibbler (client et serveur), l'ancien programme de l'ISC (le nouveau est Kea), etc.
Voici un exemple d'utilisation de Dibbler, face à Kea, qui nous
affiche les quatre messages (Solicit - Advertise - Request
- Reply) :
% sudo dibbler-client run ... 2026.02.11 08:28:04 Client Notice DUID creation: Generating 14-bytes long link-local+time (duid-llt) DUID. 2026.02.11 08:28:04 Client Notice DUID creation: generated using wlan0/4 interface. 2026.02.11 08:28:04 Client Info My DUID is 00:01:00:01:31:1e:fa:14:f6:fc:69:10:65:09. ... 2026.02.11 08:28:04 Client Info Creating SOLICIT message with 1 IA(s), no TA and 0 PD(s) on eth1/3 interface. 2026.02.11 08:28:04 Client Debug Sending SOLICIT(opts:1 3 39 8 6 ) on eth1/3 to multicast. 2026.02.11 08:28:04 Client Info Received ADVERTISE on eth1/3,trans-id=0x5ded1b, 5 opts: 1 2 3 23 39 2026.02.11 08:28:05 Client Info Processing msg (SOLICIT,transID=0x5ded1b,opts: 1 3 39 8 6) 2026.02.11 08:28:05 Client Info Creating REQUEST. Backup server list contains 1 server(s). 2026.02.11 08:28:05 Client Debug Advertise from Server ID=00:01:00:01:31:19:db:68:38:f7:cd:ce:22:c6, preference=0.[using this] 2026.02.11 08:28:05 Client Debug Sending REQUEST(opts:1 3 39 6 2 8 ) on eth1/3 to multicast. 2026.02.11 08:28:05 Client Info Received REPLY on eth1/3,trans-id=0x6eb008, 5 opts: 1 2 3 23 39 2026.02.11 08:28:05 Client Notice Address fc00:cafe:1234:4321:5678::2/128 added to eth1/3 interface. 2026.02.11 08:28:05 Client Debug RENEW(IA_NA) will be sent (T1) after 1000, REBIND (T2) after 2000 seconds. 2026.02.11 08:28:08 Client Notice FQDN: About to perform DNS Update: DNS server=2001:db8:2::dead:beef, IP=fc00:cafe:1234:4321:5678::2 and FQDN=grace ...
Le serveur en face était un Kea ainsi configuré :
"subnet6": [
{
"interface": "eth0", // Ce n'est pas bien documenté mais
// cette option est cruciale, autrement le client reçoit
// des « Server could not select subnet for this client ».
"subnet": "fc00:cafe:1234:4321::/64",
"pools": [ { "pool": "fc00:cafe:1234:4321:5678::/80" } ],
...
Si vous voulez, le pcap de l'échange est disponible (capture faite avec
tcpdump -w /tmp/dhcpv6-bis.pcap udp and \(port 546 or port
547\)). tcpdump voit le trafic
ainsi :
09:28:04.624687 IP6 fe80::606d:ad11:58ca:6cab.546 > ff02::1:2.547: dhcp6 solicit 09:28:04.639479 IP6 fe80::6ee4:5672:da95:1018.547 > fe80::606d:ad11:58ca:6cab.546: dhcp6 advertise 09:28:05.652900 IP6 fe80::606d:ad11:58ca:6cab.546 > ff02::1:2.547: dhcp6 request 09:28:05.667843 IP6 fe80::6ee4:5672:da95:1018.547 > fe80::606d:ad11:58ca:6cab.546: dhcp6 reply
La requête est émise depuis une adresse
lien-local (ici
fe80::606d:ad11:58ca:6cab) pas depuis une
adresse « tout zéro » comme en IPv4 (section 17 du RFC). On voit
bien les quatre messages (Solicit - Advertise - Request -
Reply), décrits section 5.2 (et la liste des types
possibles est en section 7.3). Le serveur n'a pas répondu
directement avec un Reply, parce que le client
n'a pas inclut l'option Rapid Commit (section
21.14). Dans l'échange à quatre messages, le client demande à tous
(Solicit), un(s) serveur(s) DHCP répond(ent)
(Advertise), le client envoie alors sa requête
au serveur choisi (Request), le serveur donne
(ou pas) son accord (Reply). Avec l'option
-vvv, tcpdump est plus bavard et montre qu'il
analyse bien DHCPv6 :
09:28:04.624687 IP6 (flowlabel 0x51d28, hlim 1, next-header UDP (17) payload length: 99) fe80::606d:ad11:58ca:6cab.546 > ff02::1:2.547: [udp sum ok] dhcp6 solicit (xid=5ded1b (client-ID hwaddr/time type 1 time 824113684 f6fc69106509) (IA_NA IAID:1 T1:4294967295 T2:4294967295 (IA_ADDR :: pltime:4294967295 vltime:4294967295)) (Client-FQDN) (elapsed-time 0) (option-request DNS-server Client-FQDN)) 09:28:04.639479 IP6 (flowlabel 0xf6846, hlim 64, next-header UDP (17) payload length: 140) fe80::6ee4:5672:da95:1018.547 > fe80::606d:ad11:58ca:6cab.546: [udp sum ok] dhcp6 advertise (xid=5ded1b (client-ID hwaddr/time type 1 time 824113684 f6fc69106509) (server-ID hwaddr/time type 1 time 823778152 38f7cdce22c6) (IA_NA IAID:1 T1:1000 T2:2000 (IA_ADDR fc00:cafe:1234:4321:5678::2 pltime:3000 vltime:4000)) (DNS-server 2001:db8:2::dead:beef 2001:db8:2::cafe:babe) (Client-FQDN)) 09:28:05.652900 IP6 (flowlabel 0x51d28, hlim 1, next-header UDP (17) payload length: 117) fe80::606d:ad11:58ca:6cab.546 > ff02::1:2.547: [udp sum ok] dhcp6 request (xid=6eb008 (client-ID hwaddr/time type 1 time 824113684 f6fc69106509) (IA_NA IAID:1 T1:4294967295 T2:4294967295 (IA_ADDR fc00:cafe:1234:4321:5678::2 pltime:3000 vltime:4000)) (Client-FQDN) (option-request DNS-server Client-FQDN) (server-ID hwaddr/time type 1 time 823778152 38f7cdce22c6) (elapsed-time 0)) 09:28:05.667843 IP6 (flowlabel 0xf6846, hlim 64, next-header UDP (17) payload length: 140) fe80::6ee4:5672:da95:1018.547 > fe80::606d:ad11:58ca:6cab.546: [udp sum ok] dhcp6 reply (xid=6eb008 (client-ID hwaddr/time type 1 time 824113684 f6fc69106509) (server-ID hwaddr/time type 1 time 823778152 38f7cdce22c6) (IA_NA IAID:1 T1:1000 T2:2000 (IA_ADDR fc00:cafe:1234:4321:5678::2 pltime:3000 vltime:4000)) (DNS-server 2001:db8:2::dead:beef 2001:db8:2::cafe:babe) (Client-FQDN))
Mais si vous préférez tshark, l'analyse de cet échange est également disponible.
Notez que certains clients DHCP dépendent de la présence d'un routeur qui envoie des RA (RFC 4861) avec le bit M - Managed - à 1 (RFC 4861, section 4.2). En l'absence de ces annonces, le client se contente de demander des informations diverses au serveur DHCP, mais pas d'adresse IP.
Et si vous voulez compiler dhcpcd vous-même, c'est simple :
wget https://github.com/NetworkConfiguration/dhcpcd/releases/download/v10.3.0/dhcpcd-10.3.0.tar.xz dhcpcd-10.3.0.tar.xz tar xvf dhcpcd-10.3.0.tar dhcpcd-10.3.0 ./configure make sudo make install
L'échange à deux messages (Solicit - Reply)
est, lui, spécifié dans la section 5.1. Il s'utilise si le client
n'a pas besoin d'une adresse IP, juste d'autres informations de
configuration comme l'adresse du serveur NTP, comme décrit dans le RFC 4075. Même si le client demande une adresse IP, il est
possible d'utiliser l'échange à deux messages, via la procédure
rapide avec l'option Rapid Commit.
Tout client ou serveur DHCP v6 a un DUID (DHCP Unique
Identifier, décrit en section 11). Le DUID est opaque et
ne devrait pas être analysé par la machine qui le reçoit. La seule
opération admise est de tester si deux DUID sont égaux (indiquant
qu'en face, c'est la même machine). Il existe plusieurs façons de
générer un DUID (dans l'exemple plus haut, Dibbler avait choisi la
méthode duid-llt, adresse locale et heure) et
de nouvelles pourront apparaitre dans le futur. Par exemple, un DUID
peut être fabriqué à partir d'un UUID (RFC 6355).
Mais l'utilisation exclusive du DUID, au détriment de l'adresse MAC, n'est pas une obligation du RFC (le RFC, section 11, dit juste « DHCP servers use DUIDs to identify clients for the selection of configuration parameters », ce qui n'interdit pas d'autres méthodes). On peut utiliser l'adresse Ethernet. En combinaison avec des commutateurs qui filtrent sur l'adresse MAC, cela peut améliorer la sécurité.
Puisqu'on peut aussi attribuer des adresses statiquement à une machine, en la reconnaissant, par exemple, à son adresse MAC ou à son DUID, voici comment on peut configurer Kea pour donner une adresse IP fixe au client d'un certain DUID :
"reservations": [
{
"duid": "00:01:00:01:31:1e:fa:14:f6:fc:69:10:65:09",
"ip-addresses": [ "fc00:cafe:1234:4321:b0f:1111::1" ]
}
La section 6 de notre RFC décrit les différentes façons d'utiliser DHCPv6. On peut se servir de DHCPv6 en mode sans état (section 6.1), lorsqu'on veut juste des informations de configuration, ou avec état (section 6.2, qui décrit la façon historique d'utiliser DHCP), lorsqu'on veut réserver une ressource (typiquement l'adresse IP) et qu'il faut alors que le serveur enregistre (et pas juste dans sa mémoire, car il peut redémarrer) ce qui a été réservé. On peut aussi faire quelque chose qui n'a pas d'équivalent en IPv4, se faire déléguer un préfixe d'adresses IP entier (section 6.3). Un client DHCP qui reçoit un préfixe, mettons, /60, peut ensuite redéléguer des bouts, par exemple ici des /64. (Le RFC 7084 est une utile lecture au sujet des routeurs installés chez M. Toutlemonde.)
Le format détaillé des messages est dans la section 8. Le début des messages est toujours le même, un type d'un octet (la liste des types est en section 7.3) suivi d'un identificateur de transaction de trois octets. Le reste est variable, dépendant du type de message.
On a déjà parlé du concept de DUID plus haut, donc sautons la section 11 du RFC, qui parle du DUID, et allons directement à la section 12, qui parle d'IA (Identity Association). Une IA est composée d'un identifiant numérique, l'IAID (IA IDentifier) et d'un ensemble d'adresses et de préfixes. Le but du concept d'IA est de permettre de gérer collectivement un groupe de ressources (adresses et préfixes). Pour beaucoup de clients, le concept n'est pas nécessaire, on n'a qu'une IA, d'identificateur égal à zéro. Pour les clients plus compliqués, on a plusieurs IA, et les messages DHCP (par exemple d'abandon d'un bail) indiquent l'IA concernée.
Comme pour DHCPv4, une bonne partie des informations est transportée dans des options, décrites dans la section 21. Certaines options sont dans ce RFC, d'autres pourront apparaitre dans des RFC ultérieurs. Toutes les options commencent par deux champs communs, le code identifiant l'option (deux octets), et la longueur de l'option. Ces champs sont suivis par des données, spécifiques à l'option. Ainsi, l'option Client Identifier a le code 1, et les données sont un DUID (cf. section 11). Autre exemple, l'option Vendor Class (code 16) permet d'indiquer le fournisseur du logiciel client (notez qu'elle pose des problèmes de sécurité, cf. RFC 7824, et section 23 de notre RFC). Notez qu'il peut y avoir des options dans les options, ainsi, l'adresse IP (code 5) est toujours dans les données d'une option IA (les IA sont décrites en section 12).
Puisqu'on a parlé de sécurité, la section 22 du RFC détaille les questions de sécurité liées à DHCP. Le fond du problème est qu'il y a une profonde incompatibilité entre le désir d'une autoconfiguration simple des clients (le but principal de DHCP) et la sécurité. DHCP n'a pas de chiffrement et tout le monde peut donc écouter les échanges de messages, voire les modifier. Et, de toute façon, le serveur n'est pas authentifié, donc le client ne sait jamais s'il parle au serveur légitime. Il est trivial pour un méchant de configurer un serveur DHCP « pirate » et de répondre à la place du vrai, indiquant par exemple un serveur DNS que le pirate contrôle. Les RFC 7610 et RFC 7513 décrivent des solutions possibles à ce problème.
Des attaques par déni de service sont également possibles, par exemple via un client méchant qui demande des ressources (comme des adresses IP) en quantité. Un serveur prudent peut donc limiter la quantité de ressources accessible à un client.
Maintenant, les questions de vie privée. La section 23 rappelle que DHCP est très indiscret. Le RFC 7824 décrit les risques que DHCP fait courir à la vie privée du client (et le RFC 7844 des solutions possibles).
Les registres IANA ne changent pas par rapport à l'ancien RFC. Les différents paramètres sont en ligne.
L'annexe A de notre RFC décrit les changements depuis l'ancien RFC 8415. Rien d'essentiel n'a été changé. On notera :
- Suppression de certains mécanismes optionnels (comme ils étaient de toute façon optionnels, cela n'affecte pas l'interopérabilité) qui étaient complexes et peu mis en œuvre : les adresses temporaires (IA_TA), il faut désormais relâcher explicitement celles qu'on veut temporaires, la possibilité de faire de l'unicast, et donc, logiquement, l'option qui forçait le multicast.
- Correction de plusieurs erreurs signalées (certaines n'ont pas été corrigées puisqu'elles s'appliquaient à des options supprimées).
- Texte plus précis sur les ports UDP utilisés.
- Progression du RFC au statut de norme Internet complète (alors que le RFC 8415 était officiellement une proposition de norme).
L'article seul
RFC 9910: Registration Data Access Protocol (RDAP) Regional Internet Registry (RIR) Search
Date de publication du RFC : Janvier 2026
Auteur(s) du RFC : T. Harrison (APNIC), J. Singh (ARIN)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 8 janvier 2026
Le protocole RDAP, successeur de whois, n'est pas utilisé que par les registres de noms de domaine. Il sert aussi chez les RIR, pour obtenir des informations sur les entités qui sont derrière une adresse IP (ou un AS). RDAP dispose dès le début de fonctions de recherche (regardez le RFC 9082) mais ce nouveau RFC ajoute des choses en plus.
Traditionnellement, les serveurs whois des RIR disposaient de fonction de recherche « avancées » comme la possibilité de chercher par valeur (« quels sont tous les préfixes IP de tel titulaire ? »). L'idée de ce RFC est de permettre la même chose en RDAP. RDAP de base permet les recherches des informations associées à une adresse IP :
% curl -s https://rdap.db.ripe.net/ip/2001:41d0:302:2200::180 | jq .
{
"handle": "2001:41d0::/32",
"name": "FR-OVH-20041115",
"country": "FR",
"parentHandle": "2001:4000::/23",
…
"status": [
"active"
],
"entities": [
{
"handle": "OK217-RIPE",
…
"text",
"Octave Klaba"
…
En plus de ip, ce RFC ajoute
ips (section 2.1) qui permet une recherche sur
tous les préfixes dont le nom correspond à un certain motif (ici,
tous ceux d'OVH) :
% curl -s https://rdap.db.ripe.net/ips\?name="FR-OVH-*" | jq '.ipSearchResults.[].handle' "109.190.0.0 - 109.190.255.255" "135.125.0.0 - 135.125.255.255" "137.74.0.0 - 137.74.255.255" "141.94.0.0 - 141.95.255.255" "145.239.0.0 - 145.239.255.255" "147.135.128.0 - 147.135.255.255" "149.202.0.0 - 149.202.255.255" "152.228.128.0 - 152.228.255.255" "159.173.0.0 - 159.173.255.255" "162.19.0.0 - 162.19.255.255" …
J'ai utilisé ici curl et jq mais, évidemment, l'avantage de RDAP est que vous pouvez utiliser un client dédié ou bien n'importe quel logiciel qui sait faire du HTTP et du JSON (voyez plus loin un exemple en Python).
Et chez un autre RIR :
% curl -s https://rdap.arin.net/registry/ips\?name='CLOUDFLARE*' | \
jq '.ipSearchResults.[].handle'
"NET-104-16-0-0-1"
"NET-108-162-192-0-1"
"NET-156-146-101-152-1"
"NET-162-158-0-0-1"
"NET-172-64-0-0-1"
"NET-173-245-48-0-1"
"NET-198-41-128-0-1"
"NET-199-27-128-0-1"
"NET6-2606-4700-1"
De la même façon, vous pouvez chercher par numéro d'AS :
% curl -s https://rdap.db.ripe.net/autnums\?name="*NIC-FR*" | \
jq '.autnumSearchResults.[].handle'
"AS2483"
"AS2484"
"AS2485"
"AS2486"
La section 3 décrit ensuite des moyens de trouver les objets parents et enfants (puisque l'allocation des adresses IP est hiérarchique, toute adresse est dans un préfixe plus général et contient des préfixes plus spécifiques, cf. la section 3.2.1 du RFC) :
% curl -s https://rdap.db.ripe.net/ips/rirSearch1/rdap-up/2001:41d0:302:2200::180 | \
jq '.handle'
"2001:41d0::/32"
% curl -s https://rdap.db.ripe.net/ips/rirSearch1/rdap-down/2001:4000::/23 | \
jq '.ipSearchResults.[].handle'
"2001:4000::/32"
"2001:4010::/32"
"2001:4018::/29"
"2001:4020::/32"
…
Notez la relation (rdap-up et
rdap-down). Notez aussi que
rdap-up renvoie au maximum un objet alors que
rdap-down peut en renvoyer plusieurs
(cf. section 4.2), et c'est pour cela qu'il a fallu itérer en jq (le
.[] parcourt le tableau). Quant au
rirSearch1, le 1 indique la version de cette
extension de recherche chez les RIR (désormais enregistrée
à l'IANA).
Et en Python, ça donnerait :
#!/usr/bin/python
# Example of using search extensions to RDAP (RFC 9910)
# https://requests.readthedocs.io
import requests
# Standard library
import json
import sys
# Yes, we should use the registry documented in RFC 7484…
BASE_URL = "https://rdap.db.ripe.net/ips/rirSearch1/rdap-down"
if len(sys.argv) != 2:
raise Exception("Usage: %s ip-prefix-at-ripe" % sys.argv[0])
arg = sys.argv[1]
response = requests.get("%s/%s" % (BASE_URL, arg))
if response.status_code != 200:
raise Exception("Wrong HTTP return code from %s: %s" % (BASE_URL, response.status_code))
data = json.loads(response.text)
for prefix in data["ipSearchResults"]:
print(prefix["handle"])
Et les recherches inverses, telles que décrites dans le RFC 9536 ? La section 5 du RFC les présente et voici un exemple qui marche (trouver tous les préfixes de Webflow) :
% curl -s 'https://rdap.arin.net/registry/ips/reverse_search/entity?handle=WEBFL' | \
jq '.ipSearchResults.[].handle'
"NET-198-202-211-0-1"
"NET6-2620-CB-2000-1"
Un serveur RDAP qui gère les extensions de ce RFC doit le signaler dans ses réponses (section 6) :
…
"rdapConformance" : [ "geofeed1", "rirSearch1", "ips", "cidr0",
"rdap_level_0", "nro_rdap_profile_0", "redacted" ],
…
Mais aussi dans les liens donnés dans les réponses (ici, en réponse
à une requête traditionnelle ip) :
"links": [
{
"value": "https://rdap.db.ripe.net/ip/2001:41d0:302:2200::180",
"rel": "rdap-up",
"href": "https://rdap.db.ripe.net/ips/rirSearch1/rdap-up/2001:41d0::/32",
"type": "application/rdap+json"
},
Et bien sûr dans les réponses d'aide :
% curl -s https://rdap.arin.net/registry/help
{
"rdapConformance" : [ "nro_rdap_profile_0", "rdap_level_0", "cidr0", "nro_rdap_profile_asn_flat_0", "arin_originas0", "rirSearch1", "ips", "ipSearchResults", "autnums", "autnumSearchResults", "reverse_search" ],
"notices" : [ {
"title" : "Terms of Service",
"description" : [ "By using the ARIN RDAP/Whois service, you are agreeing to the RDAP/Whois Terms of Use" ],
"links" : [ {
"value" : "https://rdap.arin.net/registry/help",
"rel" : "terms-of-service",
"type" : "text/html",
"href" : "https://www.arin.net/resources/registry/whois/tou/"
} ]
…
Les fonctions de recherche, c'est très bien mais c'est, par construction, indiscret. La section 8 de notre RFC détaille les risques de ces extensions de recherche pour la vie privée (relire le RFC 7481 est une bonne idée).
Les extensions de ce RFC, rirSearch1,
ips, autnums,
ipSearchResults et
autnumSearchResults ont été enregistrées
à l'IANA (section 10 du RFC). Les relations
rdap-up, rdap-down,
rdap-top et rdap-bottom
sont dans le registre
des liens (RFC 8288). Et le registre
des recherches inverses inclut désormais
fn, handle,
email et role, avec leur
correspondance en JSONPath.
Et question mise en œuvre et déploiement, on a quoi ? ARIN et RIPE ont annoncé avoir programmé les extensions de ce RFC mais elles ne sont pas forcément accessibles via le serveur RDAP public, entre autre pour les raisons de vie privée discutées dans la section 8. Aujourd'hui, comme vous le voyez dans les exemples ci-dessus, au moins ARIN et RIPE rendent une partie de ces extensions utilisables.
L'article seul
RFC 9896: SVG in RFCs
Date de publication du RFC : Janvier 2026
Auteur(s) du RFC : A. Rossi (RFC Series Consulting
Editor), N. Brownlee, J. Mahoney (RFC
Production Center), M. Thomson
Pour information
Réalisé dans le cadre de l'activité d'édition des RFC rswg
Première rédaction de cet article le 5 février 2026
Le RFC 7996 avait introduit la possibilité de mettre des images dans les RFC. Ce nouveau document le remplace, il décrit les règles pour inclure du SVG. Il est très court, se limitant aux principes, il n'a plus de mention d'un profil SVG particulier.
On peut donc mettre des images vectorielles car, a priori, dans un RFC, il y aura beaucoup plus de schémas que de photos. Donc, pas de bitmap.
Au fait, c'est quoi, SVG ? Il s'agit d'une norme d'un format d'images vectoriel, gérée par le W3C, et fondée sur XML. Voici un exemple d'un simple dessin en SVG :
<svg xmlns="http://www.w3.org/2000/svg" version="1.2"> <rect x="25" y="25" width="200" height="200" fill="white" stroke-width="4" stroke="black" /> <circle cx="125" cy="125" r="75" fill="black" /> <polyline points="50,150 50,200 200,200 200,100" stroke="black" stroke-width="4" fill="none" /> <line x1="50" y1="50" x2="200" y2="200" stroke="white" stroke-width="4" /> </svg>
Et voici son rendu :
Ce RFC décrit des objectifs, une politique. Contrairement à son prédécesseur, le RFC 7996, il ne décrit pas de profil de SVG, il fixe des buts, pas les moyens de les atteindre. Ces buts sont :
- Le schéma en SVG ne doit jamais être la seule représentation. Le RFC doit être compréhensible sans les schémas.
- Le SVG ne doit pas inclure d'animations et ne doit pas être trop réactif (pas question de changer quand on tourne le téléphone).
- Le but étant d'être vu et compris par le public le plus large possible, il ne faut pas utiliser les fonctions de SVG qui ne sont pas largement mises en œuvre. Pas de pointeurs vers des ressources externes, pas de script exécutable (pas de JavaScript actif dans un RFC…), attention portée à l'accessibilité, en suivant WAI. Pour la même raison, il ne faut pas de dépendance vis-à-vis des couleurs (RFC 6949, section 3.2) et pas de choix arbitraire de police.
Il est crucial que les RFC soient accessibles à tou·te·s, non seulement quel que soit le matériel utilisé, mais également quels que soient les handicaps dont souffre leur propriétaire. C'est bien joli de vouloir ajouter des tas de choses dans les RFC mais encore faut-il ne pas creuser ainsi davantage le fossé entre les utilisateurs. Ainsi, accepter de la couleur (le RFC 6949 limite les futurs RFC au noir et blanc) fait courir le risque que les daltoniens ne puissent pas comprendre un RFC. De même, les graphiques, qui ont l'air comme ça d'être une bonne idée, peuvent aggraver la situation des malvoyants. Le texte seul peut toujours être lu à voix haute par un synthétiseur de parole mais pas le graphique.
La traduction de ces principes en conseils techniques concrets, et l'application de ces règles seront du ressort du RFC Production Center. Il suivra peut-être les nombreux détails pratiques décrits dans le RFC 7996 mais il n'y est pas obligé.
Comment on écrit du SVG ? S'il est évidemment possible de le faire entièrement à la main avec un éditeur ordinaire, gageons que peu de gens le tenteront. Le RFC 7996 citait des éditeurs graphiques, produisant du SVG, comme les logiciels libres Inkscape et Dia. (Et, si on aime programmer en Python, il y a svgwrite, que je présente plus en détail à la fin.) Attention, Inkscape et Dia produisent du SVG généraliste, qui peut inclure des fonctions de SVG qui ne suivent pas les principes de notre RFC.
Autre solution, utiliser la bibliothèque Fletcher de Typst :
% typst compile --format svg essai-fletcher.typ
Le texte « Tips for Creating Accessible SVG » donne des bons conseils pour faire du SVG accessible. Et il y a bien sûr la norme ARIA, dont il existe une introduction et de bons exemples. (Désolé, je n'ai pas suivi ces excellents principes dans les exemples ci-dessous, mais j'accepte les patches.)
Avec Inkscape, il faut veiller à sauver le
fichier en Plain SVG (autrement, on a des ennuis
avec les éléments spécifiques d'Inkscape, ex-Sodipodi). Mais il
reste malgré cela deux ou trois trucs à corriger manuellement, avant
que le document produit par Inkscape soit accepté. Pour Dia, il faut utiliser l'action
Export (par défaut, Dia n'enregistre pas en SVG),
mais Dia produit alors un document avec une DTD. Si on la retire
(manuellement, ou bien avec xmllint --dropdtd),
tout se passe bien.
Si vous voulez voir des exemples concrets de RFC utilisant SVG, vous avez entre beaucoup d'autres, le RFC 8899, le RFC 9869 ou encore le RFC 9750. Ainsi, le RFC 8899 inclut un schéma qui a deux formes alternatives, en art ASCII :
<artwork type="ascii-art" name="" alt="" align="left" pn="section-4.4-2.1.2">
Any additional
headers .--- MPS -----.
| | |
v v v
+------------------------------+
| IP | ** | PL | protocol data |
+------------------------------+
<----- PLPMTU ----->
<---------- PMTU -------------->
</artwork>
Et en SVG, que vous pouvez admirer dans le rendu HTML du RFC et son rendu en PDF.
Une alternative, pour tester les SVG est svgcheck. Ici avec le vrai source du RFC 9750 :
% svgcheck rfc9750.xml INFO: File conforms to SVG requirements.
Et si je tente de mettre des couleurs vives en modifiant le XML :
% svgcheck rfc9750.xml rfc9750.xml:438: The attribute 'stroke' does not allow the value 'red', replaced with 'black' ERROR: File does not conform to SVG requirements
Autre solution que j'aime bien pour faire du SVG, dès qu'on a des éléments répétitifs et qu'on veut donc automatiser (en Python), svgwrite. Ce schéma en art ASCII :
+--------------+ +----------------+ | Alice |------------------------------------| Bob | | 2001:db8::1 | | 2001:db8::2 | +--------------+ +----------------+
aurait pu être créé avec svgwrite avec network-schema-svgwrite.py, qui donne
Bien sûr, pour un schéma aussi simple, le gain n'est pas évident, mais il le devient pour les schémas comportant beaucoup d'éléments récurrents. Mais notez que svgwrite, par défaut, peut donc produire des SVG non conformes aux règles du RFC (par exemple avec de la couleur). Le programmeur doit donc faire attention.
L'article seul
RFC 9881: Internet X.509 Public Key Infrastructure -- Algorithm Identifiers for the Module-Lattice-Based Digital Signature Algorithm (ML-DSA)
Date de publication du RFC : Octobre 2025
Auteur(s) du RFC : J. Massimo, P. Kampanakis (AWS), S. Turner (sn3rd), B. E. Westerbaan (Cloudflare)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF lamps
Première rédaction de cet article le 18 février 2026
Vous reprendrez bien un peu de post-quantique ? Ce RFC normalise l'utilisation de signatures ML-DSA dans les certificats X.509.
ML-DSA est un des premiers gagnants du concours du NIST (il se nommait Dilithium à l'époque). Il est normalisé dans FIPS-204. Il utilise les réseaux euclidiens. C'est un algorithme de signature et il a donc toute sa place dans les certificats X.509, aux côtés des plus classiques RSA et ECDSA. Petit rappel de cryptographie post-quantique au passage : contrairement à RSA, ML-DSA ne sait faire que les signatures, pas l'échange de clés. Vous pouvez donc mettre des clés publiques ML-DSA dans un certificat, le signer avec ML-DSA mais, pour un protocole comme TLS, il faudra utiliser autre chose pour l'échange de clés (par exemple ML-KEM, autre vainqueur du concours NIST).
Mettre du post-quantique dans les certificats était moins urgent que dans l'échange de clés : ici, pas de risque qu'un attaquant prévoyant stocke des communications chiffrées, en attendant d'avoir un calculateur quantique pour les décrypter. Avec TLS, le risque est nul car la signature est au moment de la connexion, les calculateurs quantiques ne pourront usurper que les communications futures. Mais, bon, les certificats sont utilisés pour autre chose que TLS, et, comme il faut se préparer à un lent déploiement, il vaut mieux s'y prendre tout de suite.
Notez aussi qu'il n'y a pas que les certificats qui sont signés, les CRL le sont aussi, et ce RFC s'applique aussi à ces listes.
Des deux variantes normalisées dans FIPS-204, « pure » et « HashML-DSA », seule la première est utilisée dans notre RFC, pour les raisons qu'explique la section 8.3.
Le RFC utilise trois niveaux de sécurité différents, et les
identificateurs pour les trois niveaux sont
id-ml-dsa-44 (OID
2.16.840.1.101.3.4.3.17),
id-ml-dsa-65 (OID
2.16.840.1.101.3.4.3.18) et
id-ml-dsa-87 (OID
2.16.840.1.101.3.4.3.19). (Ces OID sont enregistrés
par le NIST.) D'autre part, l'IANA a
enregistré l'identificateur
id-mod-x509-ml-dsa-2025 (OID
1.3.6.1.5.5.7.0.119) pour le module ML-DSA
(annexe A).
Un certificat X.509 contient des indications sur les utilisations
permises (section 4.2.1.3 du RFC 5280). Comme
ML-DSA sait faire des signatures mais pas des échanges de clés, un
certificat avec ML-DSA aura les utilisations de signature, comme
keyCertSign mais pas celles d'échange de clés
comme keyEncipherment.
Le format de la clé privée (section 6) a été un des sujets de discussions chauds à l'IETF (et chez les implémenteurs). Dans la norme FIPS-204, on peut définir une clé privée de deux façons, une optimisée (section 4 de la norme) où on ne stocke que la graine (notée ξ) ou bien une forme longue avec la graine, les éléments de la clé secrète, etc. On peut déduire la clé de la graine (section 6.1 de la norme), mais pas l'inverse donc si vous ne gardez pas la graine, vous pourrez toujours signer mais pas retrouver la graine. Le RFC permet de stocker la clé privée de trois façons, la graine seule (la méthode recommandée, cf. section 8.1), la clé seule (déconseillé) ou les deux (voir un exemple plus loin).
Je n'ai pas trouvé de certificat utilisant ML-DSA dans la nature.
crt.sh ne permet pas de
chercher par algorithme, même dans ses fonctions avancées. Il
faudrait écrire son propre client d'examen des journaux
Certificate Transparency (RFC 9162) et j'avais la flemme. Donc, on va utiliser
OpenSSL 3.5 pour fabriquer des certificats (je
n'ai pas testé pour voir s'ils étaient parfaitement conformes au RFC…).
% openssl req -new -newkey mldsa44 -keyout mldsa.key -out mldsa.csr -nodes -subj "/CN=test" % openssl x509 -in mldsa.csr -out mldsa.crt -req -signkey mldsa.key -days 2001 Certificate request self-signature ok subject=CN=test
Et hop, nous voilà avec un beau certificat :
% openssl x509 -text -in mldsa.crt
Certificate:
Data:
Version: 3 (0x2)
Serial Number:
54:5b:c0:5d:0e:85:83:43:90:77:93:4f:53:83:e1:38:a2:12:9f:61
Signature Algorithm: ML-DSA-44
Issuer: CN=test
Validity
Not Before: Feb 17 15:01:53 2026 GMT
Not After : Aug 11 15:01:53 2031 GMT
Subject: CN=test
Subject Public Key Info:
Public Key Algorithm: ML-DSA-44
ML-DSA-44 Public-Key:
pub:
15:10:02:cc:d6:ec:53:12:bb:6d:34:23:82:65:ec:
…
X509v3 extensions:
X509v3 Subject Key Identifier:
6E:F9:AD:56:9C:AA:60:EF:ED:B7:A1:7B:70:F6:71:55:74:B8:68:B9
Signature Algorithm: ML-DSA-44
…
Autre solution, de plus bas niveau, en découpant les étapes :
# Créer la clé privée
openssl genpkey -algorithm ML-DSA-44 -out private.pem
# Extraire la clé publique (mais on ne s'en servira pas ici)
openssl pkey -in private.pem -pubout -out public.pem
# Créer la demande de signature du certificat
openssl req -new -subj /CN=Test -key private.pem -out cert.csr
# (Auto-)Signer
openssl x509 -req -in cert.csr -signkey private.pem -out cert.pem
Certificate request self-signature ok
subject=CN=Test
# Vérifier
openssl x509 -text -in cert.pem
Certificate:
Data:
Version: 3 (0x2)
Serial Number:
7c:65:cb:17:5b:ed:ee:08:c9:1a:6b:a5:97:da:ac:b8:0e:6e:df:cd
Signature Algorithm: ML-DSA-44
Issuer: CN=Test
Validity
Not Before: Feb 18 13:24:05 2026 GMT
Not After : Mar 20 13:24:05 2026 GMT
Subject: CN=Test
Subject Public Key Info:
Public Key Algorithm: ML-DSA-44
ML-DSA-44 Public-Key:
…
Signature Algorithm: ML-DSA-44
…
Et si vous voulez utiliser des extensions comme la restriction d'utilisation du certificat (ici, on se limite à la signature), remplacez la demande de signature et la signature par :
openssl req -new -subj /CN=Test -key private.pem -out cert.csr -addext "keyUsage=digitalSignature" openssl x509 -req -in cert.csr -signkey private.pem -out cert.pem -copy_extensions copy
Si vous voulez regarder ce qu'il y a dans la clé privée :
% openssl pkey -text -in private.pem
…
ML-DSA-44 Private-Key:
seed:
48:c8:e4:e3:63:16:c0:e4:57:da:22:31:94:36:98:
..
priv:
d9:0b:5b:8d:18:4f:61:8d:c0:8f:85:6c:97:28:46:
…
Vous voyez que sont stockées graine et clé (et la clé publique, plus loin).
Pour wolfSSL, vous pouvez regarder ici.
Pour des « vrais » certificats, notez que Digicert en fait apparemment, ainsi que l'AC pour usage privé d'AWS. Vous connaissez d'autres AC qui permettraient ML-DSA ? Je note que, comme d'habitude, les boitiers intermédiaires conçus avec les pieds (donc la plupart d'enre eux) rendent compliqué le déploiement de nouveaux algorithmes .
Sinon, l'annexe C du RFC comprend de nombreux exemples de clés et de signatures.
L'article seul
RFC 9874: Best Practices for Deletion of Domain and Host Objects in the Extensible Provisioning Protocol (EPP)
Date de publication du RFC : Septembre 2025
Auteur(s) du RFC : S. Hollenbeck (Verisign Labs), W. Carroll (Verisign), G. Akiwate (Stanford University)
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 5 octobre 2025
Dans un registre de noms de domaine, il existe une classe d'objets pour les domaines et parfois une pour les serveurs de noms (hosts). C'est en se basant sur les objets de ces classes que des informations sont ensuite publiées dans le DNS. Que se passe-t-il si on retire un objet de ces classes, alors que d'autres objets en dépendaient ? Va-t-on scier une branche sur laquelle quelqu'un est assis ? Ce RFC fait le point sur les solutions existantes, notant que certaines sont moins bonnes que d'autres, notamment pour la sécurité.
Prenons un exemple simple : le domaine
monbeaudomaine.example est enregistré auprès du
registre
du TLD .example. Ses
serveurs de noms sont ns1.domaine-d-un-copain.example et
ns1.hébergeur.example et on va supposer que le
registre de .example traite les serveurs de
noms comme une classe distincte dans sa base de données. Maintenant,
supposons que le domaine
domaine-d-un-copain.example soit supprimé parce
que son titulaire n'en voit plus l'utilité. Que va devenir le
serveur de noms
ns1.domaine-d-un-copain.example ? Il existe de
nombreuses façons de traiter ce problème, et c'est le rôle de ce RFC
de les analyser toutes.
Ainsi, la section 3.2.2 du RFC 5731 dit que
ce n'est pas bien de détruire un domaine si des objets de type
serveur de noms sont sous ce domaine. Dans l'exemple précédent, le
registre de .example aurait refusé la
suppression de
domaine-d-un-copain.example. Mais cela laisse
le problème entier : si le titulaire ne veut plus payer et donc veut
supprimer le domaine, que faire ?
Un cas similaire se produit si on veut supprimer un serveur de
noms. Si le client EPP demande au serveur EPP
du registre de .example la suppression de
l'objet ns1.domaine-d-un-copain.example, que
doit faire le registre, sachant que ce serveur de noms est utilisé
par monbeaudomaine.example ? La section 3.2.2
du RFC 5732 dit que le registre devrait
refuser la suppression. C'est d'autant plus gênant que, dans le
modèle RRR (Registrant-Registrar-Registry), domaine et serveur(s) peuvent
être gérés par des BE différents, n'ayant
pas le droit de toucher aux objets des autres BE.
Vous pouvez trouver des bonnes explications et des exemples réels dans les supports d'une présentation qui avait été faite à l'IETF.
Quelles sont donc les recommandations concrètes de ce RFC ? La section 6 les résume. Au choix :
- Renommer les serveurs de noms vers le nom d'un serveur maintenu par le client EPP (le BE), comme décrit dans la section 5.1.3.4.
- Demander au client EPP de supprimer les serveurs de noms mais avec possibilité de rétablissement (RFC 3915) comme décrit en section 5.2.2.3.
- Renommer les serveurs de noms dans un nom de domaine
spécial, dont il est garanti qu'il ne sera jamais utilisé, comme décrit en
section 5.1.4.3. Pour éviter d'avoir à créer une nouvelle entrée
dans le registre des noms de domaine
spéciaux, le nom
sacrificial.invalid, utilisant un TLD existant, est recommandé.
Le protocole EPP permet de changer le nom
d'un serveur de noms (section 3.2.5 du RFC 5732). Une pratique déjà observée est donc de renommer les
serveurs de noms. Dans l'exemple ci-dessus, recevant la demande de
suppression de domaine-d-un-copain.example, le
registre (ou le BE s'il le peut) renommerait
ns1.domaine-d-un-copain.example en, mettons,
ns1.domaine-d-un-copain.renamed.invalid. Ici,
.invalid, TLD réservé
par le RFC 6761, ne poserait pas vraiment de
problème mais renommer dans un domaine ouvert à l'enregistrement
pourrait créer un risque de sécurité, si le domaine de destination
n'existe pas, un méchant pouvant alors l'enregistrer et être ainsi en
mesure de répondre aux requêtes DNS.
La section 3 du RFC explique brièvement pourquoi les RFC 5731 et RFC 5732 déconseillent fortement de permettre la suppression d'un domaine tant que des serveurs de noms dans ce domaine existent. Il y a deux risques de sécurité si on détruisait le domaine en laissant les serveurs de noms tels quels dans la base de données du registre : un de déni de service (le nom ne se résout plus et le serveur va donc être inutile) et un de détournement (si un méchant peut ré-enregistrer le nom de domaine supprimé). Il y a aussi le problème de la colle orpheline, décrit dans le rapport du SSAC, « Comment on Orphan Glue Records in the Draft Applicant Guidebook ».
Si la clé qui identifie un serveur de noms est un numéro quelconque et pas son nom, on peut renommer le serveur sans changer les délégations, ce qui est particulièrement utile si le client EPP n'a pas le droit de changer des délégations qui appartiennent à un autre client du registre. Le nouveau nom ne va en général pas être associé à un serveur opérationnel : on sacrifie un serveur pour pouvoir supprimer le domaine parent. Mais cela entraine quelques risques (section 4 du RFC et l'article d' Akiwate, G., Savage, S., Voelker, G., et K. Claffy, « Risky BIZness: Risks Derived from Registrar Name Management »). Si on renomme vers un nom actuellement inexistant, le domaine peut être détourné si un malveillant enregistre ensuite ce domaine.
Compte tenu de tout cela, la section 5 du RFC étudie les différentes pratiques possibles, leurs avantages et leurs inconvénients. Pour les illustrer, je vais utiliser une base de données simple, décrite en SQL (les essais ont été faits avec PostgreSQL). Voici par exemple une création d'une telle base :
CREATE TABLE Domains (name TEXT UNIQUE);
-- Ici, la table Nameservers n'offre aucune valeur ajoutée par rapport
-- au fait de tout mettre dans Domains. Mais ce ne sera pas le cas par
-- la suite.
CREATE TABLE Nameservers (name TEXT UNIQUE);
CREATE TABLE Delegation (domain TEXT REFERENCES Domains(name),
server TEXT REFERENCES Nameservers(name));
INSERT INTO Domains VALUES ('monbeaudomaine.example');
INSERT INTO Domains VALUES ('domaine-d-un-copain.example');
INSERT INTO Nameservers VALUES ('ns1.domaine-d-un-copain.example');
INSERT INTO Nameservers VALUES ('ns1.hébergeur.example');
INSERT INTO Delegation VALUES ('monbeaudomaine.example', 'ns1.domaine-d-un-copain.example');
INSERT INTO Delegation VALUES ('monbeaudomaine.example', 'ns1.hébergeur.example');
Dans ce premier cas très simple, la suppression du domaine
domaine-d-un-copain.example est triviale :
registry=> DELETE FROM Domains WHERE name='domaine-d-un-copain.example'; DELETE 1
Mais elle laisse la possibilité de colle
orpheline et surtout d'un détournement de monbeaudomaine.example si
quelqu'un ré-enregistre
domaine-d-un-copain.example. Ce premier essai
n'est pas conforme aux exigences des RFC 5731
et RFC 5732. On va essayer de
faire mieux.
Si on interdit (à juste titre) la suppression d'un domaine lorsque des serveurs de noms sont nommés dans ce domaine, on peut arriver à supprimer un domaine en supprimant d'abord les serveurs de noms qui sont nommés dans ce domaine (section 5.2) :
CREATE TABLE Domains (name TEXT UNIQUE);
-- Ajout d'une dépendance au domaine parent, pour éviter les suppressions.
CREATE TABLE Nameservers (name TEXT UNIQUE, parent TEXT REFERENCES Domains(name));
CREATE TABLE Delegation (domain TEXT REFERENCES Domains(name),
server TEXT REFERENCES Nameservers(name));
INSERT INTO Domains VALUES ('monbeaudomaine.example');
INSERT INTO Domains VALUES ('domaine-d-un-copain.example');
INSERT INTO Domains VALUES ('hébergeur.example');
-- Pour une vraie base, on écrirait du code SQL qui extrait le parent
-- automatiquement.
INSERT INTO Nameservers VALUES ('ns1.domaine-d-un-copain.example', 'domaine-d-un-copain.example');
INSERT INTO Nameservers VALUES ('ns1.hébergeur.example', 'hébergeur.example');
INSERT INTO Delegation VALUES ('monbeaudomaine.example', 'ns1.domaine-d-un-copain.example');
INSERT INTO Delegation VALUES ('monbeaudomaine.example', 'ns1.hébergeur.example');
registry=> DELETE FROM Domains WHERE name='domaine-d-un-copain.example';
ERROR: update or delete on table "domains" violates foreign key constraint "nameservers_parent_fkey" on table "nameservers"
DETAIL: Key (name)=(domaine-d-un-copain.example) is still referenced from table "nameservers".
-- Ce comportement est ce que recommandent les RFC 5731 et 5732.
-- Cela oblige le client à supprimer les serveurs de noms d'abord, ce qui à
-- son tour nécessite potentiellement de changer les délégations :
registry=> DELETE FROM Delegation WHERE server = 'ns1.domaine-d-un-copain.example';
DELETE 1
registry=> DELETE FROM Nameservers WHERE name='ns1.domaine-d-un-copain.example';
DELETE 1
registry=> DELETE FROM Domains WHERE name='domaine-d-un-copain.example';
DELETE 1
Ici, il y a eu suppression explicite des serveurs de noms par le
client (section 5.2.2.1). Cela peut poser des problèmes de permission, dans le cadre du
système RRR, si tous les objets ne sont pas
chez le même BE. Mais la suppression explicite est
une des trois solutions recommandées, notamment si on ajoute la
possibilité de rétablir l'état précédent (commande EPP
<restore>, RFC 3915).
On peut aussi envisager une suppression implicite (section 5.2.1.1), le registre se
chargeant du nettoyage (c'est le rôle
de la directive SQL ON DELETE
CASCADE) :
CREATE TABLE Domains (name TEXT UNIQUE);
CREATE TABLE Nameservers (name TEXT UNIQUE,
parent TEXT REFERENCES Domains(name) ON DELETE CASCADE);
CREATE TABLE Delegation (domain TEXT REFERENCES Domains(name) ON DELETE CASCADE,
server TEXT REFERENCES Nameservers(name) ON DELETE CASCADE);
INSERT INTO Domains VALUES ('monbeaudomaine.example');
INSERT INTO Domains VALUES ('domaine-d-un-copain.example');
INSERT INTO Domains VALUES ('hébergeur.example');
-- Pour une vraie base, on écrirait du code SQL qui extrait le parent
-- automatiquement.
INSERT INTO Nameservers VALUES ('ns1.domaine-d-un-copain.example', 'domaine-d-un-copain.example');
INSERT INTO Nameservers VALUES ('ns1.hébergeur.example', 'hébergeur.example');
INSERT INTO Delegation VALUES ('monbeaudomaine.example', 'ns1.domaine-d-un-copain.example');
INSERT INTO Delegation VALUES ('monbeaudomaine.example', 'ns1.hébergeur.example');
registry=> SELECT Domains.name,Nameservers.name FROM Domains,Delegation,Nameservers WHERE Delegation.domain=Domains.name AND Delegation.server=Nameservers.name;
name | name
------------------------+---------------------------------
monbeaudomaine.example | ns1.domaine-d-un-copain.example
monbeaudomaine.example | ns1.hébergeur.example
(2 rows)
registry=> DELETE FROM Domains WHERE name='domaine-d-un-copain.example';
DELETE 1
-- Serveur de noms et délégation ont été détruits en cascade. Ce n'est
-- pas déraisonnable mais c'est quand même un peu effrayant.
registry=> SELECT Domains.name,Nameservers.name FROM Domains,Delegation,Nameservers WHERE Delegation.domain=Domains.name AND Delegation.server=Nameservers.name;
name | name
------------------------+-----------------------
monbeaudomaine.example | ns1.hébergeur.example
(1 row)
Cette solution est simple et efficace mais détruire implicitement des objets de la base de données peut inquiéter les responsables de cette base. Et cela peut laisser un domaine avec trop peu de serveurs de noms pour assurer sa continuité de service voire, dans le pire des cas, sans serveurs du tout. Et il serait bon de prévenir le client de cette suppression implicite, par exemple par le mécanisme de poll d'EPP (RFC 8590).
Si on interdit (à juste titre, le RFC le recommande) la suppression d'un
domaine lorsque des serveurs de noms sont nommés dans ce domaine, une
solution possible est de
renommer les serveurs avant de supprimer le domaine (section 5.1). Le nouveau nom
permet d'indiquer clairement la raison du renommage. Mais ce
renommage laisse dans la base des « déchets » qu'il faudra nettoyer
un jour. Cette catégorie
contient de nombreuses variantes. Par exemple, on peut renommer dans
un TLD spécial (RFC 6761), ici, .invalid :
CREATE TABLE Domains (name TEXT UNIQUE);
-- On introduit un identificateur du serveur de noms qui n'est *pas*
-- son nom, pour permettre le renommage.
CREATE TABLE Nameservers (id SERIAL UNIQUE, name TEXT UNIQUE,
parent TEXT REFERENCES Domains(name));
CREATE TABLE Delegation (domain TEXT REFERENCES Domains(name),
server INTEGER REFERENCES Nameservers(id));
INSERT INTO Domains VALUES ('monbeaudomaine.example');
INSERT INTO Domains VALUES ('domaine-d-un-copain.example');
INSERT INTO Domains VALUES ('hébergeur.example');
-- Pour le renommage, un nom qui indique clairement le but :
INSERT INTO Domains VALUES ('renamed.invalid');
-- Pour une vraie base, on écrirait du code SQL qui extrait le parent
-- automatiquement.
INSERT INTO Nameservers (name, parent) VALUES ('ns1.domaine-d-un-copain.example', 'domaine-d-un-copain.example');
INSERT INTO Nameservers (name, parent) VALUES ('ns1.hébergeur.example', 'hébergeur.example');
INSERT INTO Delegation VALUES ('monbeaudomaine.example',
(SELECT id FROM Nameservers WHERE name='ns1.domaine-d-un-copain.example'));
INSERT INTO Delegation VALUES ('monbeaudomaine.example',
(SELECT id FROM Nameservers WHERE name='ns1.hébergeur.example'));
registry=> SELECT Domains.name,Nameservers.name FROM Domains,Delegation,Nameservers WHERE Delegation.domain=Domains.name AND Delegation.server=Nameservers.id;
name | name
------------------------+---------------------------------
monbeaudomaine.example | ns1.domaine-d-un-copain.example
monbeaudomaine.example | ns1.hébergeur.example
(2 rows)
registry=> UPDATE Nameservers SET name='ns1.domaine-d-un-copain.example.renamed.invalid', parent='renamed.invalid' WHERE id=1;
UPDATE 1
registry=> DELETE FROM Domains WHERE name='domaine-d-un-copain.example';
DELETE 1
registry=> SELECT Domains.name,Nameservers.name FROM Domains,Delegation,Nameservers WHERE Delegation.domain=Domains.name AND Delegation.server=Nameservers.id;
name | name
------------------------+-------------------------------------------------
monbeaudomaine.example | ns1.domaine-d-un-copain.example.renamed.invalid
monbeaudomaine.example | ns1.hébergeur.example
(2 rows)
Par contre, il ne faut pas utiliser .alt, qui
est explicitement réservé aux protocoles non-DNS (RFC 9476). Notez que certains serveurs EPP peuvent tester le
nom des serveurs de noms et refuser des TLD « inconnus ».
Dans la nature, on a pu observer d'autres pratiques, comme de
renommer dans un sous-domaine de as112.arpa, nom
garanti ne pas exister (RFC 7535), mais qui
n'est pas censé servir à cela (RFC 6305). On a
vu aussi des renommages vers des résolveurs DNS publics, ce qui est
également une horreur, la délégation doit être faite vers des serveurs faisant
autorité, pas des résolveurs.
Certains clients EPP maintiennent des serveurs de noms actifs qui
servent pour le renommage. Cela fait davantage de travail mais cela
protège contre le détournement. Le DNS va continuer à fonctionner
normalement. On pourrait aussi imaginer des serveurs de noms actifs, répondant
NXDOMAIN (« ce domaine n'existe pas »), qui soient
gérés collectivement (section 5.1.4.4) ; un tel service serait
certainement utile. On pourrait même créer un nom de domaine pour ce
service (sacrificial.arpa ?) mais personne ne
l'a encore fait. Pour l'instant, la solution des serveurs maintenus
par le client EPP (section 5.1.3.4) fait partie des trois solutions
recommandées. Le client prudent doit bien verrouiller le domaine dans
lequel ces serveurs sont nommés (enregistrement multi-années,
verrouillage par le registre, etc).
On peut aussi renommer les serveurs de noms vers un nom
non-existant dans un TLD existant. Ça s'est déjà vu mais il ne faut
surtout pas faire cela : un attaquant pourrait enregistrer le nom et
capter ainsi le trafic (.invalid n'a pas ce
problème). Idem si le nom n'est pas sous votre contrôle. Un exemple
est donné par le domaine lenvol.re : ses
serveurs de noms étaient ns.hostin.io,
ns.hostin.mu et
ns.hostin.re. Lors de la suppression de
hostin.re en octobre 2024, le dernier serveur
de noms a été renommé
host1.renamedbyregistry.com (et, en dépit du
nom, pas par le registre). Ce domaine
renamedbyregistry.com étant enregistré, et par
un autre BE, on voit le risque.
% whois lenvol.re domain: lenvol.re status: ACTIVE … nserver: host1.renamedbyregistry.com nserver: ns.hostin.io nserver: ns.hostin.mu
D'autres noms qui utilisaient ce même serveur ont également le problème :
% dig @d.nic.fr savanna.re. NS … ;; AUTHORITY SECTION: savanna.re. 3600 IN NS host1.renamedbyregistry.com. savanna.re. 3600 IN NS ns.hostin.mu. savanna.re. 3600 IN NS ns.hostin.io. ;; Query time: 8 msec ;; SERVER: 2001:678:c::1#53(d.nic.fr) (UDP) ;; WHEN: Tue Jun 24 14:33:32 CEST 2025
En lecture supplémentaire, notre RFC recommande le rapport « SSAC 125 "Report on Registrar Nameserver Management" », ainsi que l'article « Risky BIZness: Risks Derived from Registrar Name Management ».
L'article seul
RFC 9868: Transport Options for UDP
Date de publication du RFC : Octobre 2025
Auteur(s) du RFC : J. Touch, C. Heard
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tsvwg
Première rédaction de cet article le 5 décembre 2025
Des protocoles de transport, comme TCP, ont le concept d'options, ajoutées à l'en-tête et permettant de régler divers paramètres. Ce RFC ajoute ce concept à UDP et standardise quelques options. Désormais, il y a des moyens standards de faire du « ping » en UDP.
Mais comment ajouter des options à un vénérable protocole (UDP a été normalisé en 1980, dans le RFC 768), qui n'a pas de place pour cela dans son en-tête très minimal ? L'astuce est que UDP indique une taille de paquet qui peut être différente de celle indiquée par IP. Si elle est supérieure, les octets ainsi disponibles peuvent stocker des options, à la fin du paquet. Ce sera donc un pied (trailer) et pas un en-tête.
Voici un paquet UDP simplifié (j'ai aussi mis une partie de l'en-tête IP) analysé par tshark :
Internet Protocol Version 6, Src: 2a04:cec0:10fc:5bd8:efd1:79bb:7356:4583, Dst: 2001:db8::1
0110 .... = Version: 6
…
Payload Length: 56
Next Header: UDP (17)
Hop Limit: 64
Source Address: 2a04:cec0:10fc:5bd8:efd1:79bb:7356:4583
Destination Address: 2001:db8::1
User Datagram Protocol, Src Port: 57560 (57560), Dst Port: domain (53)
Source Port: 57560 (57560)
Destination Port: domain (53)
Length: 56
…
UDP payload (48 bytes)
Vous avez vu ? Il y a deux champs qui indiquent la longueur du paquet UDP, un dans l'en-tête IP (Payload length) et un dans l'en-tête UDP (Length). Ici, les deux sont identiques, ce qui est le cas « normal ». Mais s'ils sont différents ? C'est le point de départ de ce RFC. Les options se nicheront dans la différence entre la longueur du paquet UDP et celle du paquet IP qui l'encapsule, dans une zone connue sous le nom de surplus (surplus area). Normalement, elles seront ainsi ignorées de tous les vieux programmes (mais il y a parfois eu des bogues).
Comme TCP (RFC 9293), les protocoles de transport SCTP (RFC 9260) et DCCP (RFC 4340) ont dans leur en-tête un espace réservé pour d'éventuelles options. Pas UDP. C'est ce manque que comble notre RFC. Comme UDP est un protocole sans connexion, ces options ne serviront que pour un seul paquet (alors que TCP peut les garder pour toute la connexion). Des options, dans les autres protocoles de transport, il y en a plein. Pour TCP, le RFC cite par exemple, la dilatation de fenêtres (RFC 7323), l'authentification (RFC 5925) et d'autres. On en trouve pour des protocoles avec état (comme TCP, où elles vont s'appliquer à toute la connexion) ou sans état (comme IP, où elles ne s'appliquent qu'au paquet qui les porte). Comme vu plus haut, seul UDP (RFC 768) n'avait pas le moyen d'ajouter des options.
À quoi vont servir ces options (section 5 du RFC) ? À court
terme, à permettre des mécanismes de
fragmentation, de test (« ping UDP »), etc. À
plus long terme (mais ce n'est pas encore normalisé), elles rendront
possible d'ajouter de l'authentification ou
du chiffrement à UDP (DTLS, RFC 9147 chiffre mais ne protège pas l'en-tête de
la couche Transport). On pourra aussi faire de la découverte de la
MTU du
chemin, comme spécifié dans le RFC 9869. Et enfin, cela
pourra permettre d'augmenter la taille des paquets DNS comme proposé dans
draft-heard-dnsop-udp-opt-large-dns-responses.
La section 6 du RFC spécifie le cahier des charges de ces options UDP :
- UDP est sans état (sans connexion) et doit le rester.
- UDP est unidirectionnel et doit le rester. Les protocoles requête/réponse (comme le DNS) sont bâtis sur UDP mais doivent s'occuper de faire correspondre requêtes et réponses sans l'aide d'UDP.
- Les options UDP n'ont pas de taille maximale (à part celle du paquet UDP lui-même, 65 536 octets).
- Les options UDP ne visent pas à remplacer des protocoles existants. Le « ping UDP » ne cherche pas à être équivalent au ping utilisant ICMP. Après tout, UDP est fait pour être minimal, et il doit le rester.
- Les options UDP ne constituent pas un protocole à elles seules : un protocole situé au-dessus d'UDP va devoir spécifier bien des détails (par exemple le RFC 9869 qui décrit le protocole PLPMTUD).
- Tout le mécanisme est conçu pour qu'un logiciel ancien, qui ne connaisse pas ces options, fonctionne comme aujourd'hui.
Un peu de terminologie avant d'attaquer les détails, notamment (section 3) :
- Option sûre (SAFE option) : option qui pourra être ignorée par un receveur qui ne la comprend pas. Elle ne modifie pas la compréhension du paquet.
- Option non sûre (UNSAFE option) : option qui ne doit pas être ignorée, car elle modifie la compréhension du paquet (par exemple car elle indique qu'il est chiffré).
La description technique de l'emplacement des options figure en section 7 du RFC. Le champ Longueur de l'en-tête UDP, qui a toujours été redondant avec celui d'IP, peut désormais prendre une valeur inférieure à celle du champ dans IP (mais supérieure à huit, la taille de l'en-tête UDP). La différence entre les deux longueurs est la taille du surplus, la zone à la fin du paquet où se logent les options (qui ne sont donc pas dans l'en-être mais dans le pied). Notez qu'il n'y a pas d'obligation que le surplus soit aligné sur des multiples (2 ou 4) d'octets. Si les longueurs IP et UDP sont identiques, c'est qu'il n'y a pas d'options.
La structuration du surplus en options est dans la section 8. Le surplus commence avec un champ de deux octets qui est une somme de contrôle. Cet OCS (Option CheckSum) est une somme de contrôle Internet traditionnelle (RFC 791, section 3.1, et RFC 1071). Pourquoi cette somme de contrôle alors qu'UDP en a déjà une ? Pour détecter les cas où un autre mécanisme jouerait avec la différence des champs Longueur d'IP et d'UDP et aurait son propre pied, distinct de celui normalisé dans notre RFC. Simple somme de contrôle, l'OCS ne joue pas un rôle en sécurité, il ne sert qu'à vérifier que le surplus est bien utilisé conformément à la norme sur les options UDP. (Les options sont ignorées si l'OCS n'est pas correcte, voir la section 14.) La section 18 insiste sur ce point : comme cette distinction entre deux champs Longueur est ancienne, il est possible que certains s'en servaient et il faut donc faire face à la possibilité que des paquets UDP aient des champs Longueur différents sans pour autant avoir des options telles que normalisées ici. L'OCS est donc aussi une sorte de nombre magique mais en plus fort, puisqu'il n'est pas statique.
Comme toujours, il faut prévoir le cas de middleboxes boguées qui calculeraient la somme de contrôle UDP sur tout le paquet IP, au lieu de s'arrêter à la longueur indiquée dans l'en-tête UDP. L'OCS est conçu pour annuler l'effet d'une telle bogue (merveille des sommes de contrôle, qui n'ont pas de dispersion des résultats). La somme de contrôle UDP étant optionnelle (mais c'est évidemment très déconseillé), l'OCS l'est aussi (et peut donc valoir zéro). Rappelez-vous que ce qui marchait avant en UDP doit encore marcher avec les options donc, par défaut, même si l'OCS est incorrect, le paquet doit être transmis aux applications réceptrices.
À propos de middleboxes, le RFC précise aussi (section 16) que les options sont de bout en bout et ne doivent pas être modifiées par les équipements intermédiaires (mais cela risque de rester un vœu pieux). Des tests effectués ont montré que des systèmes d'exploitation courants (Linux, macOS, Windows) n'avaient pas de problème en recevant des paquets UDP contenant des options (section 18). Ils n'envoient à l'application que la partie du paquet indiquée par le champ Longueur d'UDP, et ignorent donc les options, qu'on peut donc envoyer sans craindre de perturber les systèmes pré-existants. Toutefois, au moins un objet connecté (non nommé par le RFC) passe tout le datagramme (y compris, donc, le surplus contenant les options) à l'application. Et au moins un IDS, l'Alcatel-Lucent Brick considère les paquets UDP ayant des options comme des attaques (les IDS sont un des facteurs importants de l'ossification de l'Internet car ils interprètent tout ce qui ne colle pas à leur vision étroite comme une attaque).
Les options suivent la somme de contrôle et la plupart sont encodées selon un classique schéma TLV, comme pour la plupart des options TCP (RFC 9293, section 3.1). Les deux exceptions à cet encodage TLV sont les options NOP (un seul octet, qui vaut un, cette option, comme son nom l'indique, ne sert à rien, à part éventuellement à aligner les données) et EOL (End Of Options, un seul octet, qui vaut zéro, elle indique la fin de la liste d'options). Autrement, les options sont en TLV, le premier octet indiquant le type, la longueur faisant un octet (un mécanisme existe pour des options faisant plus de 255 octets). Les options sûres ont un type de 0 à 191, les autres sont non sûres. Parmi les options sûres enregistrées par notre RFC, outre EOL et NOP, on trouve entre autres (section 11) :
- APC (Additional Payload Checksum), type 2, qui ajoute une somme de contrôle plus forte (CRC32c, la même que celle utilisée dans iSCSI, RFC 3385 et SCTP).
- FRAG (Fragmentation), type 3, qui permet une fragmentation au niveau UDP. Peut se combiner avec MDS (Maximum Datagram Size, type 4), qui indique la taille maximale qu'un récepteur peut accepter sans que le datagramme soit fragmenté.
- REQ (Echo Request, type 6) et RES (Echo Response, type 7) permettent de faire un « ping UDP ». (Plus propre que les trucs abusivement baptisés « ping UDP » comme cet exemple ou celui-ci.)
- TIME, type 8, permet d'envoyer et de recevoir l'heure, sous forme d'une estampille temporelle de quatre octets. C'est l'analogue de l'option TCP Timestamp (RFC 7323, section 3). UDP ne garantit pas que ces estampilles correspondent à l'heure officielle, juste qu'elles seront monotones (toujours croissantes).
- AUTH (Authentication), n'est pas
réellement spécifiée. Son type, 9, est réservé mais les autres
points sont repoussés à un futur RFC, peut-être à partir de
l'Internet-Draft
draft-touch-tsvwg-udp-auth-opt.
Les options EOL, NOP et quelques autres doivent normalement être reconnues par toutes les mises en œuvres des options UDP (cf. section 14).
Et les options non sûres ? Rappelons que ce sont celles qui modifient l'interprétation du contenu du paquet. On y trouve (section 12 du RFC) entre autres :
- UCMP (Unsafe Compression), type 192, pour des contenus comprimés.
- UENC (Unsafe Encryption), type 193, pour des contenus chiffrés.
Ces deux options ne sont pas autrement spécifiées, seul un type est réservé. Le reste devra être précisé dans un RFC ultérieur.
De nouvelles options seront peut-être rajoutées dans le futur au registre des options (section 13 du RFC). La politique IANA (section 26) est « action de normalisation » ou « approbation par l'IESG », donc des procédures assez lourdes (RFC 8126) : il ne sera pas facile d'ajouter des options.
Question mise en œuvre, ce n'est pas forcément trivial à faire soi-même. Pour pouvoir lire et à plus forte raison écrire des options UDP, il faut actuellement court-circuiter UDP et écrire directement au-dessus d'IP (raw sockets) ou pire, dans certains cas, directement sur le réseau. Notre RFC propose des extensions à l'API socket pour lire et écrire les options (avec aussi des variables sysctl) mais je ne connais pas encore de système d'exploitation qui les intègre. Notez que ces API ne permettent pas d'influencer l'ordre des options, et c'est exprès.
Une difficulté supplémentaire vient du fait qu'UDP est sans état, sans connexion. D'une part, les options ne peuvent pas être négociées lors de l'établissement de la connexion (puisqu'il n'y a pas de connexion), d'autre part, elles doivent être répétées dans chaque paquet (puisqu'il n'y a pas d'état). Le RFC précise donc (section 19) qu'il faut ignorer les options qu'on ne connait pas (du moins celles marquées comme sûres). D'autre part il impose qu'on passe les données à l'application même si on ne comprend pas les options. Ah, et aussi, les options UDP sont conçues pour l'unicast essentiellement.
Et leurs conséquences pour la sécurité (section 25 du RFC) ? Fondamentalement, les options UDP ne posent pas plus (ou pas moins…) de problèmes de sécurité que les options TCP, qui sont normalisées depuis longtemps. Comme pour TCP, elles ne sont pas sécurisées par TLS (ici, DTLS, RFC 9147), TLS qui protège uniquement les données applicatives. Si vous voulez les protéger, il faudra attendre la spécification des futures options AUTH (qui fournira à peu près le même service que le AO de TCP, normalisé dans le RFC 5925) et UENC. Ou alors, protégez toute la couche transport avec IPsec (RFC 4301).
Mais il y a un autre danger, dans la façon dont vont être traitées les options UDP par le récepteur. Si celui-ci boucle imprudemment, en attendant juste l'option EOL, le risque de débordement est élevé. Ou si le récepteur alloue de la mémoire en utilisant le champ Longueur d'UDP puis y copie tout le paquet, les options faisant alors déborder son tampon.
Voilà, je n'ai pas tout détaillé, la section 25 est longue, lisez-la.
Un petit point d'histoire (section 4) : pourquoi diable UDP a-t-il ce champ Longueur, alors que celui d'IP suffisait, d'autant plus que l'en-tête UDP est de taille fixe ? Aucun autre protocole de transport ne fait cela (à part peut-être Teredo, RFC 6081). Le RFC note que des historiens de l'Internet ont été consultés mais sans résultat. Les raisons de ce choix (qu'on apprécie aujourd'hui mais qui est resté sans utilité pratique pendant 45 ans) restent mystérieuses. Permettre de placer plusieurs paquets UDP dans un seul datagramme IP ? Pour remplir les paquets de manière à ce qu'ils soient alignés sur des multiples d'octets ? Aucune explication ne semble satisfaisante et les archives sont muettes.
Notez aussi que d'autres propositions avaient été faites pour
ajouter des options à UDP, comme celle décrite dans
l'Internet Draft
draft-hildebrand-spud-prototype.
Autre question que vous vous posez peut-être : et UDP-Lite (RFC 3828) ? Lui aussi jouait avec la différence des champs Longueur d'IP et d'UDP, pour indiquer la partie du paquet couverte par la somme de contrôle. De ce fait, le mécanisme d'options ne peut pas être utilisé pour UDP-Lite (section 17).
Et les mises en œuvre concrètes ? Il n'existe pas, à ma connaissance, de serveurs de test publics sur l'Internet. Mais vous avez une liste des programmes existants (je n'en ai pas vu en Python utilisant Scapy, ce qui serait pourtant une expérience intéressante).
D'autres lectures sur ces options UDP ? Vous avez l'article de Raffaele Zullo et les supports d'un de ses exposés, qui expliquent bien la question. Et, sinon ChatGPT, consulté s'en ne s'en est pas trop mal tiré, inventant un mécanisme qui ressemble à celui de TCP.
L'article seul
RFC 9861: KangarooTwelve and TurboSHAKE
Date de publication du RFC : Octobre 2025
Auteur(s) du RFC : B. Viguier (ABN AMRO Bank), D. Wong
(zkSecurity), G. Van Assche
(STMicroelectronics), Q. Dang
(NIST), J. Daemen (Radboud
University)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF cfrg
Première rédaction de cet article le 13 octobre 2025
Vous trouvez qu'il n'y a pas assez d'algorithmes en cryptographie ? En voici quatre de plus, ici pour condenser cryptographiquement des données, plus rapidement que les algorithmes existants.
Il s'agit de quatre fonctions, TurboSHAKE128 et TurboSHAKE256 (variantes de TurboSHAKE) ainsi que de KT128 et KT256 (variantes de Kangaroo Twelve qui est décrit dans cet article). Toutes sont des XOF (eXtendable Output Function), des fonctions dont le résultat peut être infiniment long (comme ce que produit un générateur pseudo-aléatoire), mais qu'on tronque à la valeur souhaitée (cf. section 2.1). Kangaroo Twelve (section 3) est bâti sur TurboSHAKE et apporte le parallélisme : il permet de répartir le travail sur plusieurs processeurs alors que SHA-3 et TurboSHAKE sont strictement séquentiels. TurboSHAKE (section 2), lui, est bâti sur Keccak (qui est aussi la base de SHA-3, la cryptographie, c'est compliqué). D'ailleurs, le logiciel qui met en œuvre les algorithmes de ce RFC est développé par l'équipe de Keccak.
Ne comptez pas sur moi pour des explications cryptographiques détaillées, je n'y connais rien, lisez les sections 2 et 3 du RFC. Mais Sakura, le système utilisé par Kangaroo Twelve pour répartir le travail semble intéressant (cf. l'article original).
En section 4 du RFC, vous trouverez comment utiliser Kangaroo Twelve pour faire un MAC (on condense le message puis on condense la concaténation de la clé et du résultat de la première condensation).
Et si vous voulez mettre en œuvre Kangaroo Twelve vous-même, la
section 5 vous offre de nombreux vecteurs de
test. Mais, avant, regardez l'annexe A qui vous offre du
pseudo-code et rappelle qu'il y a une
implémentation en C, XKCP (par l'équipe Keccak)
et une en Python,
décrite dans l'article « KangarooTwelve: fast
hashing based on Keccak-p » (les vecteurs de test
du RFC viennent de là, normal, ce sont les mêmes auteurs). Enfin,
une
troisième est en Zig.
Commençons en Python (j'ai fait une copie du code de l'article dans
kangarootwelve.pytest-kangarootwelve.py
KT128(M=ptn(17 bytes), C=`00`^0, 32):
`6B F7 5F A2 23 91 98 DB 47 72 E3 64 78 F8 E1 9B
0F 37 12 05 F6 A9 A9 3A 27 3F 51 DF 37 12 28 88`
Le programme affiche :
% python test-kangarootwelve.py 6b f7 5f a2 23 91 98 db 47 72 e3 64 78 f8 e1 9b 0f 37 12 05 f6 a9 a9 3a 27 3f 51 df 37 12 28 88
Ce qui est bien la bonne valeur.
Et avec XKCP, compilons la bibliothèque et le programme de test test-kangarootwelve.c
git submodule update --init make generic64/libXKCP.so gcc -I ./bin/generic64/libXKCP.so.headers -L ./bin/generic64 test-kangarootwelve.c -lXKCP # ou # gcc -I ./bin/generic64/libXKCP.so.headers test-kangarootwelve.c ./bin/generic64/libXKCP.so LD_LIBRARY_PATH=./bin/generic64 ./a.out
Et le programme affiche bien le vecteur de test indiqué dans le RFC.
Kangaroo Twelve a été ajouté au registre IANA, et les quatre algorithmes sont dans le registre de COSE (RFC 8152).
L'article seul
RFC 9859: Generalized DNS Notifications
Date de publication du RFC : Septembre 2025
Auteur(s) du RFC : J. Stenstam (The Swedish Internet
Foundation), P. Thomassen (deSEC, Secure Systems
Engineering), J. Levine (Standcore
LLC)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 5 octobre 2025
Vous le savez, le protocole DNS permet plusieurs sortes de messages, identifiés par un code d'opération. Si le classique QUERY, pour demander à résoudre un nom en informations pratiques, est le plus connu, il y a aussi le UPDATE (modifier les données), le DSO (DNS Stateful Operations) et quelques autres. Et puis il y a le NOTIFY, qui sert à indiquer à un serveur DNS qu'il y a quelque chose de nouveau et d'intéressant. NOTIFY est surtout connu pour son utilisation afin de… notifier un serveur secondaire que le primaire a une nouvelle version de la zone (c'est dans le RFC 1996). Ce nouveau RFC généralise le concept et permet d'utiliser NOTIFY pour d'autres choses comme un changement dans la liste des serveurs faisant autorité ou un changement de clé DNSSEC.
Si vous avez oublié à quoi servait initialement NOTIFY, relisez le RFC 1996. Il permettait de donner une indication (uniquement une indication, le NOTIFY ne fait pas autorité) comme quoi il faudrait envisager un nouveau transfert de zone (RFC 5936) pour mettre à jour un serveur. Cela permettait des mises à jour plus rapides qu'avec le système traditionnel où chaque serveur esclave devait de temps en temps demander à son maître s'il y avait du nouveau. Mais il y a d'autres cas où un serveur DNS voudrait dire à un autre qu'il y a quelque chose à regarder, par exemple si une nouvelle clé doit être utilisée. D'où l'extension d'utilisation que permet notre RFC 9859. Elle ne change pas le protocole, elle se contente d'utiliser plus largement une fonction existante.
Bon, mais c'est bien joli de dire qu'on peut notifier pour bien
des choses mais on notifie qui ? Dans le cas traditionnel d'une
nouvelle version de la zone, le primaire savait qu'il devait
notifier ses secondaires, qu'il connait (après tout, il doit leur
autoriser le transfert de zone et, dans le pire des cas, il peut
toujours regarder l'ensemble d'enregistrements NS de sa zone). Mais
si on généralise le NOTIFY, on peut ne pas savoir qui notifier (les
autres mécanismes de notification, comme une API ou comme la mise à
jour dynamique du RFC 2136, ont d'ailleurs le
même problème). La section 3 du RFC couvre ce problème. La méthode
recommandée est de publier un enregistrement de type DSYNC, normalisé
dans notre RFC, section 2. Il se place sous le nom
_dsync de la zone :
sousdomaine._dsync IN DSYNC CDS NOTIFY 5359 cds-scanner.example.net.
Notez qu'un joker est possible, par exemple :
*._dsync IN DSYNC CDS NOTIFY 5359 cds-scanner.example.net. *._dsync IN DSYNC CSYNC NOTIFY 5359 cds-scanner.example.net.
Ce nom _dsync a été ajouté dans le registre
des noms précédés d'un trait bas (RFC 8552).
Voici un autre exemple
d'enregistrement DSYNC :
_dsync.example.net. IN DSYNC CDS NOTIFY 5359 cds-scanner.example.net.
Que dit-il ? Qu'example.net, a priori un
hébergeur DNS, voudrait que ses clients, lorsqu'ils ont un nouvel
enregistrement CDS (indiquant l'activation d'une nouvelle clé
DNSSEC, cf. RFC 8078),
notifient cds-scanner.example.net sur le
port 5359. Ce nouveau type DSYNC a été ajouté
au registre des types, avec la valeur 66.
La section 4.1 détaille comment on trouve le serveur à qui
envoyer la notification en utilisant
_dsync. Imaginons qu'on gère
extra.sub.exodus-privacy.eu.org et qu'on
veuille notifier la zone parente. On insère le composant
_dsync après le premier composant (cela donne
extra._dsync.sub.exodus-privacy.eu.org) et on
fait une requête pour ce nom et le type DSYNC. Si ça marche, c'est
bon, sinon, on utilise le SOA dans la réponse pour trouver la zone
parente, et on met le _dsync devant. Si ça ne
donne toujours rien, on retire les composants avant la zone parente
et on recommence. Donc, on interrogera successivement (jusqu'au
premier succès),
extra._dsync.sub.exodus-privacy.eu.org,
extra.sub._dsync.exodus-privacy.eu.org et
_dsync.exodus-privacy.eu.org.
Et le NOTIFY dans l'enregistrement DSYNC d'exemple plus haut ? C'est le plan (scheme, à ne pas confondre avec le code d'opération - opcode - NOTIFY) car DSYNC, dans le futur, pourra servir à autre chose que les notifications. Pour l'instant, dans le nouveau registre des plans, il n'y a que NOTIFY mais dans le futur, d'autres pourront être ajoutés (suivant la politique « Examen par un expert » du RFC 8126).
Comment utiliser ce mécanisme de notification généralisé pour
traiter les enregistrements CDS et CDNSKEY des RFC 7344, RFC 8078 et RFC 9615 ? Ces enregistrements servent à signaler à la zone
parente la disponibilité de nouvelles clés DNSSEC. La section 4 de
notre RFC détaille comment le mécanisme de notification permet
d'indiquer qu'un CDS ou un CDNSKEY a changé. Cela évite au
gestionnaire de la zone parente de balayer toute la zone ce qui,
pour un TLD
de plusieurs millions de noms comme
.fr serait long et
pénible. La solution de ce RFC 9859 est donc de
chercher les DSYNC puis d'envoyer les NOTIFY, au moins deux, un pour
le type CDS et un pour le type CDNSKEY (on ne sait pas forcément à
l'avance lesquels utilisent la zone parente). La zone parente doit
effectuer les mêmes vérifications que lorsqu'elle a détecté un
nouveau CDS (ou CDNSKEY) : RFC 9615 si on
active une zone signée pour la première fois et RFC 7344 et RFC 8078 autrement.
Les messages utilisant le code d'opération NOTIFY sont censés produire une réponse (RFC 1996, section 4.7). Si aucune réponse n'arrive avant l'expiration du délai de garde, on réessaie. Si on a trop réessayé, on peut signaler le problème avec la technique du RFC 9567.
Il est important de se souvenir qu'une notification n'est pas sérieusement authentifiée, et que le récepteur doit donc, s'il choisit d'agir sur une notification, être prudent. Dans le RFC 1996, rien de grave ne pouvait arriver, le récepteur du NOTIFY demandait juste le SOA de la zone puis, si nécessaire, un transfert de zone. Mais avec les CDS et CDNSKEY, des attaques plus sérieuses sont possibles et le destinataire de la notification doit donc effectuer davantage de vérifications (par exemple, si la zone est déjà signée, faire une requête pour le CDS ou le CDNSKEY et vérifier que la réponse est valide et sécurisée, si elle ne l'est pas, faire tous les contrôles du RFC 9615). La notification elle-même n'est pas un problème de sécurité (elle dit juste « tu devrais regarder cela »), c'est l'action qui en résulte qui doit être bien réfléchie. Voilà pourquoi les notifications, même généralisées, ne sont pas plus sécurisées que cela. (Voir aussi la section 5 du RFC, qui insiste sur ce point ; la notification peut accélérer les choses mais ne doit pas à elle-même changer quelque chose.) Il est quand même préférable de limiter le nombre de notifications qu'on traite, au cas où un client malveillant vous bombarde de notifications.
Ces notifications généralisées pourront aussi s'utiliser pour les CSYNC du RFC 7477.
Qui met en œuvre ce RFC à l'heure actuelle ? Des opérateurs comme
deSEC ont annoncé que c'était
en cours, côté client. Côté serveur, les registres de
.ch et
.se ont annoncé que
c'était en cours, ou bien prévu.
Voici un exemple d'un client en Python (utilisant dnspython) qui notifie pour un nouveau CDS :
import dns.message
import dns.query
import dns.opcode
notify = dns.message.make_query("bortzmeyer.fr", "CDS")
notify.set_opcode(dns.opcode.NOTIFY)
response = dns.query.udp(notify, "192.0.2.211")
print(response)
Et en C ? Vous pouvez
utiliser le programme d'exemple generalized-notify.c
% gcc -o generalized-notify -Wall generalized-notify.c -lldns % ./generalized-notify bortzmeyer.fr 192.0.2.211 Reply code: NOERROR
Je note à ce sujet que certains serveurs faisant autorité, lorsqu'ils ne font pas autorité pour le domaine signalé, répondent REFUSED, ce qui est logique, mais on voit aussi des FORMERR ou NXDIOMAIN (!), sans doute parce que le type CDS ne leur plait pas.
L'annexe A du RFC prend de la hauteur et décrit plus en détail le
problème du balayage DNS. Comment savoir qu'il y a du nouveau, sans
tout examiner (dans le cas du SOA, au rythme indiqué par le champ
Refresh ; mais il n'y a pas de telle solution pour les CDS et
CDNSKEY). Le DNS traditionnel ne marchait que sur un modèle
pull (et c'est pour cela qu'il est faux de parler
de propagation DNS) mais les
NOTIFY du RFC 1996 introduisaient un peu de
push. Heureusement car balayer
.com à la recherche de
nouveaux enregistrements serait lent (et attirerait probablement
l'attention des IDS). Pour les CDS et CDNSKEY, cela serait
d'autant plus agaçant qu'ils seront a priori peu nombreux et que la
plupart des requêtes ne donneront donc rien.
L'article seul
RFC 9852: New Protocols Using TLS Must Require TLS 1.3
Date de publication du RFC : Juillet 2026
Auteur(s) du RFC : R. Salz (Akamai
Technologies), N. Aviram
Réalisé dans le cadre du groupe de travail IETF uta
Première rédaction de cet article le 17 juillet 2026
Si vous concevez des protocoles réseau utilisant la cryptographie, vous utiliserez souvent TLS. Dans ce cas, pour un nouveau protocole, n'ayant pas à gérer l'existant, l'IETF vous conseille fortement, dans ce RFC, d'exiger dans la définition du protocole qu'il faut au moins la version 1.3 de TLS.
TLS 1.3 (RFC 9846) est largement déployé (vous trouverez difficilement un serveur Internet qui n'ait que la version précédente, la 1.2, normalisée dans le RFC 5246), a de meilleures preuves de sécurité, et protège mieux. Il est donc raisonnable de le définir comme version minimum. Attention, ce RFC est destiné aux gens qui conçoivent des protocoles réseau, par exemple à l'IETF, pas à l'administrateur réseaux de terrain. Celui-ci ou celle-ci peut continuer à utiliser TLS 1.2.
La section 6 de notre RFC détaille les faiblesses de TLS 1.2, en remarquant qu'on peut configurer TLS 1.2 de manière sûre (couper la renégociation, désactiver les algorithmes de cryptographie faibles, etc) mais que ce n'est pas toujours fait en pratique. Et bien des failles de sécurité ont frappé 1.2, alors que 1.3 n'y était pas vulnérable (on parle bien d'une faille du protocole, pas d'un programme particulier mettant en œuvre ce protocole). C'était par exemple le cas de Beast.
Certains protocoles ont déjà pris cette décision d'exiger TLS 1.3, par exemple QUIC (RFC 9001), qui impose de couper tout de suite la connexion si l'autre partie ne fait pas de 1.3. D'autres n'ont pas encore sauté le pas, ainsi, DoT (RFC 8310) permet encore TLS 1.2. Notez que le RFC 9325, que notre RFC met à jour, ne donnait TLS 1.3 que comme « recommandé » (section 5).
La plupart des bibliothèques TLS permettent au programmeur d'imposer une version minimale de TLS donc respecter cette exigence « au moins 1.3 » ne devrait pas poser de problème (section 4).
Le RFC note (section 3) qu'à l'heure actuelle, le monde de la cryptographie est occupé à préparer une transition vers des algorithmes post-quantiques (RFC 9958). Comme TLS 1.2 est gelé (cf. RFC 9851), les solutions post-quantiques n'y seront pas intégrées et, si un CRQC (Cryptographically Relevant Quantum Computer) finit par apparaitre un jour, TLS 1.2 ne sera plus sûr.
Notez enfin que cette exigence d'avoir la version 1.3 s'applique à TLS, mais pas à DTLS.
L'article seul
RFC 9851: TLS 1.2 is in Feature Freeze
Date de publication du RFC : Juillet 2026
Auteur(s) du RFC : R. Salz (Akamai
Technologies), N. Aviram
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 16 juillet 2026
Vous pouvez toujours utiliser la version 1.2 de TLS mais ne demandez pas des ajouts, des extensions, etc. Elle est désormais gelée, aucune nouvelle fonction ne sera ajoutée, tout le travail se fait désormais sur la meilleure version, la 1.3, normalisée dans le RFC 9846.
TLS 1.3 (RFC 9846) a en effet plusieurs avantages : il chiffre une plus grande proportion de la négociation au début de la session et, surtout, il a fait l'objet d'une analyse de sécurité formelle, donc il est considéré comme plus sûr. Dans ces conditions, continuer à travailler sur la version 1.2 (RFC 5246) n'a plus guère de sens. TLS 1.2 n'est pas abandonné (ne paniquez pas si vous l'utilisez encore), mais il n'évoluera plus.
Il y aura quand même quelques nouveautés permises : les identificateurs ALPN, les exporter labels, et, bien sûr, des éventuels changements nécessaires en urgence si une faille de sécurité était découverte dans la version 1.2.
Sinon, vous avez certainement entendu parler de cryptographie post-quantique, qui remplacera les bons vieux RSA et ECDSA si un calculateur quantique futur le nécessite. Les algorithmes sont déjà normalisés mais il reste à les intégrer dans TLS. Celui-ci va permettre d'utiliser ces nouveaux algorithmes mais cela ne concernera que la version 1.3 (section 2 du RFC), la 1.2 étant gelée. La 1.2 ne survivra donc pas aux CRQC (Cryptographically Relevant Quantum Computers). (Le RFC rappelle que la première discussion sérieuse à l'IETF sur ce sujet était en 2016. La normalisation prend du temps.)
L'article seul
RFC 9850: The SSLKEYLOGFILE Format for TLS
Date de publication du RFC : Juillet 2026
Auteur(s) du RFC : M. Thomson (Mozilla), Y. Rosomakho
(Zscaler), H. Tschofenig (H-BRS)
Pour information
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 16 juillet 2026
Déboguer une application réseau qui utilise le chiffrement est difficile. Le but du chiffrement est justement d'empêcher un tiers (par exemple l'analyseur de paquets) de regarder ce qui se passe. Une approche possible est de demander gentiment à l'application d'exporter ses clés de chiffrement dans un fichier que l'analyseur pourra importer pour ensuite déchiffrer la communication. Ce RFC décrit le format le plus répandu pour exporter ses clés, connu sous le nom de SSLKEYLOGFILE et très commun aujourd'hui.
Le nom est trompeur car SSL est abandonné depuis
longtemps (RFC 7568), ce format est en fait
pour TLS mais
l'ancien nom est resté. Il vient d'une convention courante, définir
une variable
d'environnement nommée
SSLKEYLOGFILE, qui va indiquer à l'application
qu'on demande à recevoir les clés dans un fichier dont le nom est la
valeur de la variable SSLKEYLOGFILE. Mais ce
RFC n'indique pas
comment activer cette fonction d'exportation de clés, il documente
juste le format résultant.
Un petit rappel de cryptographie telle
qu'elle est faite dans TLS (RFC 8446) :
l'authentification est faite avec de la
cryptographie
asymétrique puis un échange de clés a lieu, permettant aux deux parties
de se mettre d'accord sur des clés utilisés en cryptographie
symétrique. Ce sont ces clés, qui sont évidemment
secrètes (seules les deux parties qui communiquent les connaissent)
qui nous intéressent ici. Sans elles, l'analyseur de paquets ne peut
que baisser les bras et dire « ici, il y a des données chiffrées
mais je ne peux pas te les montrer ». Ici, par exemple,
Wireshark peut juste dire que c'est du TLS et
que c'est chiffré : 
Donc, le format du fichier des clés est simple (section 2 du RFC) : un fichier texte en UTF-8 (la partie signifiante est forcément en ASCII mais il peut y avoir des commentaires qui n'ont pas cette restriction). La fin de ligne n'est pas normalisée (on aurait pu exiger le respect du RFC 5198 mais, bon, ces fichiers ne sont typiquement pas échangés entre machines différentes). Les commentaires commencent par le croisillon. Chaque secret enregistré tient sur une ligne, le nom du secret, la valeur d'un champ TLS aléatoire qui permet d'identifier la connexion (il peut y avoir des secrets de plusieurs connexions distinctes dans le fichier) et enfin la valeur du secret, en hexadécimal. Ces trois champs sont séparés par des espaces. Par contre, aucune indication sur les paramètres cryptographiques de la connexion, comme l'algorithme de cryptographie utilisé donc, si on n'a pas le début de la session TLS, le fichier peut être inutilisable. Le RFC suggère d'être indulgent dans l'analyse du fichier et d'ignorer les lignes incorrectes, ce qui permet d'extraire des secrets d'un fichier abimé.
Le RFC liste ensuite les noms possibles pour les secrets. Ils dépendent de la version de TLS. Essayons avec curl et une connexion TLS 1.3 :
% export SSLKEYLOGFILE=./keys.sslkeylogfile % curl https://www.example.com % cat keys.sslkeylogfile SERVER_HANDSHAKE_TRAFFIC_SECRET 09d… 2d7d2e4090c6… EXPORTER_SECRET 09d… 21cbb457ee72aa… SERVER_TRAFFIC_SECRET_0 09d… 7e0027e87… CLIENT_HANDSHAKE_TRAFFIC_SECRET 09d… 7ef813bf0… CLIENT_TRAFFIC_SECRET_0 09d… f4a7ab14e…
Lisez le RFC et la norme TLS pour avoir des explications sur chaque secret. Un registre IANA des valeurs possibles a été créé et de nouveaux noms pourront y être ajoutés en suivant la procédure « Spécification nécessaire » du RFC 8126.
De toute façon, ce n'est pas vous qui allez le lire mais un
logiciel comme Wireshark. En parlant de
Wireshark, si on le configure pour lire ce fichier de secrets (dans
le fichier ~/.config/wireshark/preferences,
mettre tls.keylog_file:
/some/where/tmp/keys.sslkeylogfile), Wireshark saura
déchiffrer la session TLS vue plus haut (même
pcap). Vous voyez les requêtes HTTP complètes, qui
étaient masquées par le chiffrement : 
L'ordre des secrets dans le fichier n'est pas pertinent. Ah et, sinon, les noms de secret se terminant par un tiret bas et un chiffre sont là pour le cas où TLS génère plusieurs clés pendant une session (RFC 8446, section 7.2). « nomDuSecret_0 » est la première.
Évidemment, l'usage de cette possibilité d'écrire les clés secrètes annule tout l'intérêt de TLS. La section 3 du RFC insiste sur ce point. Cette possibilité est très pratique pour le débogage mais ne doit surtout pas être utilisée avec des vraies sessions TLS sensibles. La lecture du fichier permet de tout déchiffrer et même la confidentialité persistante est compromise si on a ce fichier. Il faut faire attention à ce que les fichiers SSLKEYLOGFILE ne circulent pas et ne soient pas accessibles par tout le monde (bien des programmes les créent avec les autorisations d'accès par défaut, qui peuvent être assez laxistes). Et, de manière tout aussi évidente, un programme ne doit pas écrire ces secrets s'il n'est pas certain que la demande vient du vrai utilisateur. (L'utilisation d'une variable d'environnement dans l'exemple avec curl satisfait cette condition.) Le RFC suggère aussi une option de compilation permettant de compiler l'application sans gestion de SSLKEYLOGFILE.
Une note amusante : si la session TLS est de longue durée, un attaquant qui mettrait la main sur le fichier SSLKEYLOGFILE pourrait non seulement lire les données chiffrées mais également interférer avec la session tant qu'elle est en cours.
Le format ainsi normalisé peut marcher avec diverses versions de TLS, y compris dépassées (RFC 8996). Il fonctionne avec d'autres protocoles, s'ils utilisent le mécanisme de génération de clés de TLS, ce qui est le cas de DTLS (RFC 9147) ou de QUIC (RFC 9000).
Le type de média
application/sslkeylogfile
a été ajouté au registre
IANA.
Ce format SSLKEYLOGFILE est largement adopté par de nombreuses applications depuis des années, par exemple tous les navigateurs Web. (J'ai bien dit des applications ; contrairement à ce qu'on lit parfois, ce ne sont pas les bibliothèques TLS comme OpenSSL qui le mettent en œuvre. Certains programmes utilisant OpenSSL ont cette fonction d'exportation de clés et d'autres pas.) Un exemple avec mon client Gemini Agunua :
% export SSLKEYLOGFILE=./keys.sslkeylogfile % agunua gemini.bortzmeyer.org % cat keys.sslkeylogfile SERVER_HANDSHAKE_TRAFFIC_SECRET 724f8f07224… 8bcf43772bc21b45ad… …
Agunua est écrit en Python et activer cette fonction est simple, on s'appuie sur le fait qu'OpenSSL fournit une fonction pour demander à recevoir notification de la génération des clés :
def write_keys(conn, keys):
keylogfile.write(keys.decode() + "\n")
if "SSLKEYLOGFILE" in os.environ:
keylogfile = open(os.environ["SSLKEYLOGFILE"], "a")
context.set_keylog_callback(write_keys)
(Pour curl, cité plus haut, regarde le fichier
lib/vtls/keylog.c.)
La question plus générale du débogage des applications dans un monde où tout est chiffré avait fait l'objet de mon exposé à Capitole du Libre 2022 dont voici mes supports.
L'article seul
RFC 9849: TLS Encrypted Client Hello
Date de publication du RFC : Mars 2026
Auteur(s) du RFC : E. Rescorla (Knight-Georgetown Institute), K. Oku (Fastly), N. Sullivan
(Cryptography Consulting), C. A. Wood (Cloudflare)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 4 mars 2026
La cryptographie est indispensable à la sécurité dans l'Internet d'aujourd'hui. Mais sa mise en œuvre peut être délicate, par exemple lorsqu'il y a un problème d'œuf et de poule : quand un client TLS se connecte, il envoie en clair au serveur le nom de domaine utilisé, le serveur ayant besoin de cette information pour choisir le bon certificat qui servira pour choisir les paramètres de chiffrement qui protégeront le reste de la session. Cet envoi en clair pose un problème de vie privée, et est parfois utilisé pour la censure, par exemple en Russie. Il faut donc chiffrer ce nom annoncé, ce SNI. Mais avec quelle clé, puisqu'on a besoin du nom pour avoir une clé ? Ce RFC fournit un mécanisme pour cela, ECH (Encrypted Client Hello), qu'on pourrait traduire par « salutation chiffrée ».
Pour voir une communication TLS classique, avant ECH, vous pouvez
regarder un pcap, sni.pcap
Extension: server_name (len=20) name=www.langtag.net
Le nom demandé est donc en clair. Pas bien. C'est ainsi qu'en Russie, le système TSPU (ТСПУ, технические средства противодействия угрозам, mesures techniques de protection) détecte les noms censurés dans le SNI et envoie un faux paquet TCP RST (ReSeT). C'est mis en œuvre, par exemple, dans les boitiers SORM.
Un petit avertissement tout de suite : on lit assez souvent que la version 1.3 de TLS (normalisée dans le RFC 8446) chiffre ce SNI. C'est faux et, si vous lisez cela dans un article, vous saurez que l'auteur ne vérifie pas ce qu'il raconte. TLS 1.3 chiffre davantage de choses que les versions précédentes, mais pas le SNI.
C'est que chiffrer le SNI, ou, encore mieux, tout le Client Hello, est compliqué puisque le client doit obtenir une clé publique du serveur, avant d'avoir pu lui indiquer le nom de domaine souhaité. Il faut donc au client une autre clé publique que celle du certificat. Notez qu'il n'y a pas que le SNI qui est sensible, l'ALPN (RFC 7301) l'est aussi, et c'est pour cela que le choix de notre RFC est de chiffrer tout le message Client Hello. Toujours côté analyse de la menace, notez qu'ECH n'est utile que si le même serveur TLS gère plusieurs domaines. S'il n'en a qu'un, un observateur saura lequel, juste par l'adresse IP du serveur. ECH vise à empêcher cet observateur de savoir quel domaine était choisi, au sein d'un anonymity set, l'ensemble des domaines hébergés sur ce serveur.
Le RFC est long mais le principe d'ECH est simple. (Au fait, le cahier des charges d'ECH est dans le RFC 8744.) La section 3 le résume. ECH a deux modes, shared et split mais qui fonctionnent de manière très proche. Pour les configurations simples (le serveur est composé d'une seule machine), shared suffit. Pour les cas où le « serveur » est en fait composé de deux machines, une frontale (qui relaie le TLS sans l'interpréter) et une dorsale, le split est utilisé. Oubliez cela tout de suite, si c'est important pour vous, voyez la section 10 du RFC pour les détails (et rappelez-vous d'un point de terminologie TLS : « terminer » une session TLS, ce n'est pas y mettre fin, c'est juste être l'extrémité de la session).
On l'a dit, toute la difficulté d'ECH est que le serveur doit
publier une clé qui permettra le chiffrement du
ClientHello. Notre RFC n'impose pas une manière
unique de la publier. Elle peut être manuellement et statiquement
configurée chez le client, par exemple. Mais la méthode qui sera
sans doute la plus courante est une publication dans le DNS, via les enregistrements
SVCB (RFC 9848). (En fait, le serveur va publier une clé et des
métadonnées associées.) Une fois muni de cette clé, le client
chiffre son Client Hello et met le message
chiffré (ClientHelloInner, dit le RFC) dans une
extension du Client Hello normal (appelé
ClientHelloOuter dans le RFC), extension nommée
encrypted_client_hello (enregistrée avec
le numéro 65037). Le serveur va déchiffrer l'extension,
récupérant le bon nom de domaine, et continuera ensuite comme
d'habitude.
Notez que le client doit bien mettre un nom de domaine dans le
SNI du ClientHelloOuter (envoyé en clair). La
section 6.1 du RFC détaille ce qu'il faut placer dans cette
« salutation chiffrée ».
Et voici le pcap produit : ech.pcapcover.defo.ie dans le SNI mais le vrai nom
(defo.ie) est dans l'extension ECH (et vous ne
le voyez pas, bien sûr, il est chiffré) :
Extension: encrypted_client_hello (len=473)
Type: encrypted_client_hello (65037)
Length: 473
Client Hello type: Outer Client Hello (0)
Cipher Suite: HKDF-SHA256/AES-128-GCM
Config Id: 185
Enc length: 32
Enc: 6acfeceeea540b510bad0b28f5a9913af4e52cbdc1496750d91658d1e2200a3e
Payload length: 431
Payload [truncated]: b8f50aa3492607d8c05c1150b4f12496cf3910468ed82e775c0c0d64…
Et un exemple de requête DNS pour récupérer la clé ECH :
% dig tls-ech.dev HTTPS ; <<>> DiG 9.18.18-0ubuntu0.22.04.2-Ubuntu <<>> tls-ech.dev HTTPS ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 33050 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 1472 ;; QUESTION SECTION: ;tls-ech.dev. IN HTTPS ;; ANSWER SECTION: tls-ech.dev. 60 IN HTTPS 1 . ech=AEn+DQBFKwAgACABWIHUGj4u+PIggYXcR5JF0gYk3dCRioBW8uJq9H4mKAAIAAEAAQABAANAEnB1YmxpYy50bHMtZWNoLmRldgAA ;; Query time: 132 msec ;; SERVER: 192.168.0.254#53(192.168.0.254) (UDP) ;; WHEN: Mon Apr 15 18:46:04 CEST 2024 ;; MSG SIZE rcvd: 134
(Pour Cloudflare, regardez cloudflare-ech.com,
le nom choisi par cette entreprise pour ECH.)
À ce stade, vous savez l'essentiel. Lisez le RFC si vous voulez les détails de syntaxe (sections 5 à 7). Voyons plutôt le problème de déploiement pratique dans l'Internet (section 8 du RFC). ECH nécessite de changer clients et serveurs et nous pouvons être sûrs qu'il y aura une longue période de coexistence de logiciels ECH et non-ECH. On verra sans doute aussi des cafouillages comme un serveur qui publie une clé pour ECH mais ne gère pas ECH (le RFC prévoit un mécanisme de détection de ce problème et de ré-essai - section 6.1.6 - dans ce cas, si bien que le serveur qui ferait cette erreur imposera un délai de connexion plus long à ses clients).
Pour éviter que l'utilisation de ECH se remarque trop, le RFC spécifie également (section 2) comment graisser (RFC 9170) les communications TLS afin de rendre plus difficile la détection des vrais usages.
Ah, et le RFC précise, avec un humour discret, qu'ECH va casser « certains usages », euphémisme pour désigner la surveillance mais aussi la censure, que le SNI en clair permettait (pour la censure, on fait du DPI et, si on trouve un nom censuré dans un SNI, on envoie un message TCP RST - ReSeT - mensonger au client). Cela a déjà fait l'objet de critiques, regrettant qu'on ne puisse plus espionner autant.
Cette technique de censure (DPI puis envoi d'un RST TCP si on trouve un nom censuré) est rare en Europe mais très répandue en Russie, notamment depuis le début de la guerre. ECH permet de l'empêcher.
Le but d'ECH est d'améliorer la sécurité de TLS, il n'est donc pas étonnant que la section d'analyse de sécurité, la section 10, soit très détaillée. Elle commence par expliquer le modèle de menace (un attaquant situé sur le trajet, qui peut être actif, capable d'injecter des paquets). ECH empêchera cet attaquant de savoir quel service était demandé, parmi tous ceux hébergés à cette adresse IP (et cela a été formellement prouvé dans « A Symbolic Analysis of Privacy for TLS 1.3 with Encrypted Client Hello »). Mais il reste des pièges.
ECH peut récupérer la clé du serveur dans le DNS (c'est en tout cas la méthode par défaut) mais n'impose pas DNSSEC donc un attaquant qui peut injecter de faux enregistrements DNS peut casser ECH. La solution est évidemment d'utiliser DNSSEC. (Le RFC note aussi que, si l'attaquant est sur le réseau local de la victime, utiliser DoT ou DoH pour la résolution de noms va aider.)
Certaines extensions de TLS peuvent défaire ECH, par exemple la
cached_info du RFC 7924. Elles ne
doivent pas être utilisées dans le
ClientHelloOuter. ALPN peut aussi être
révélateur si un client envoie des ALPN différents à différents
serveurs. Là encore, ne pas le mettre dans le
ClientHelloOuter.
La vérification du certificat contient également des risques, si on utilise OCSP, dont la requête peut trahir le nom du serveur contacté.
Le RFC note à juste titre qu'un observateur indélicat a d'autres moyens à sa disposition pour découvrir le domaine demandé. Le plus évident est le DNS (cf. RFC 7626), et il faut donc utiliser les mécanismes de protection de la vie privée (RFC 7858, RFC 8484, mais aussi RFC 9156, que le RFC sur ECH a malencontreusement oublié).
Et il y a bien d'autres faiblesses possibles si on utilise mal ECH, lisez la section 10 si vous voulez en savoir plus, vous apprendrez plein de choses.
ECH a été défini il y a déjà plusieurs années. (Le projet ECH à
l'IETF
a duré bien plus longtemps que prévu. Ce RFC a commencé
sa vie en 2018.) Il existe de nombreuses mises en œuvre. On
le trouve par exemple dans Firefox (cf. leur documentation « Comprendre
le client chiffré Hello (ECH) » ou bien le
wiki pour des détails pointus). Les bibliothèques TLS en
logiciel libre, comme BoringSSL ou
OpenSSL ont souvent ECH (mais pas forcément
dans une version officielle et publiée). Si vous voulez tester si votre client TLS
gère ECH, il existe plusieurs sites Web pour cela : https://defo.ie/ech-check.phphttps://tls-ech.dev/https://www.cloudflare.com/ssl/encrypted-sni/SSLECHKeyDir). Et
nginx a eu ECH en
février 2026.
Pour tester vos serveurs, vous pouvez utiliser curl si vous avez un curl récent, compilé
avec les bonnes options. Car, sinon (sur un
Arch à jour) :
% curl --ech true tls-ech.dev curl: option --ech: the installed libcurl version does not support this
Pour davantage de tests, il y a echspec :
% echspec www.bortzmeyer.org TLS Encrypted Client Hello Server … HTTPS resource record for www.bortzmeyer.org does NOT have ech SvcParams. 1 failure
(Pas d'ECH encore sur ce blog mais ça n'aurait guère d'intérêt puisque peu de sites sont sur ce serveur.)
% echspec tls-ech.dev TLS Encrypted Client Hello Server … Failures: 1) MUST abort with an "illegal_parameter" alert, if ECHClientHello.type is not a valid ECHClientHelloType in ClientHelloOuter. [7-5] https://datatracker.ietf.org/doc/html/draft-ietf-tls-esni-22#section-7-5 did not send expected alert: illegal_parameter 1 failure
À part un point de détail subtil, tout va bien.
Par
contre, https://ssllabs.com
Quelques lectures intéressantes :
- « Say (an encrypted) hello to a more private internet », une courte explication par Mozilla.
- L'annonce de Cloudflare.
- D'un intérêt historique seulement, la première annonce de Cloudflare, quand ECH s'appelait encore ESNI (car il ne chiffrait que le SNI, pas tout le ClientHello, laissant par exemple l'ALPN sans protection).
L'article seul
RFC 9848: Bootstrapping TLS Encrypted ClientHello with DNS Service Bindings
Date de publication du RFC : Mars 2026
Auteur(s) du RFC : B. Schwartz (Meta Platforms), M. Bishop, E. Nygren (Akamai Technologies)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 4 mars 2026
Le protocole ECH (Encrypted Client Hello, normalisé dans le RFC 9849) permet de chiffrer la salutation TLS (le ClientHello), notamment le nom du serveur auquel on se connecte. Mais pour cela, il faut la clé publique du serveur. Un des moyens de la récupérer est dans le DNS, comme normalisé dans notre RFC 9848.
C'est qu'ECH pose un problème de cercle vicieux : le serveur TLS (RFC 9846) a besoin du nom demandé par le client pour choisir le bon certificat, donc la bonne clé or, si on veut chiffrer ce nom, il nous faut bien une clé. ECH (RFC 9849) résout le problème en disant que le client TLS va récupérer une clé publique distincte de celle contenue dans le certificat, quelque part. Où ça ? Le RFC 9849 ne le dit pas, mais plusieurs solutions existent, dont notre nouveau RFC qui propose de récupérer cette clé dans le DNS.
Il s'appuie sur les enregistrements SVCB du RFC 9460. Ces enregistrements permettent d'indiquer un grand nombre de paramètres, sous une forme nom=valeur (les « SvcParams »). Les enregistrements HTTPS sont une des formes des SVCB et c'est en général eux qui seront utilisés pour ECH :
% dig defo.ie HTTPS
…
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 44251
;; flags: qr rd ra ad; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
…
;; ANSWER SECTION:
defo.ie. 1750 IN HTTPS 1 . ipv4hint=213.108.108.101 ech=AMD+DQA8ngAgACCBNprc0M4mwJt8Z+q6DtisBc3nQQUwLcEvepAUv27sLQAEAAEAAQANY292ZXIuZGVmby5pZQAA/g0APJsAIAAg4dzhbvv/9BNikgK3mrvQwKGdWhTiXwd9jpkNhgJ2rgkABAABAAEADWNvdmVyLmRlZm8uaWUAAP4NADzTACAAIEwBExilsbqu9AdG7lutdyZQrIm6Lo4fErwINXCylJNDAAQAAQABAA1jb3Zlci5kZWZvLmllAAA= ipv6hint=2a00:c6c0:0:116:5::10
…
Que voit-on ? Que defo.ie a bien un
enregistrement de type HTTPS (dont je rappelle qu'il est une
spécialisation du SVCB), qui contient un paramètre ECH (la clé
publique et quelques autres informations, mais je ne connais pas de
moyen simple d'afficher ces informations).
La section 3 est l'essentiel du RFC. Elle définit le paramètre
(« SvcParam ») ech, dont la valeur est la clé
publique ECH du serveur TLS. Plus précisément, sa valeur est une
« ECHConfigList », concept créé par le RFC 9849 (cf. sa section 4), et qui décrit tous les paramètres
utiles pour faire de l'ECH. Ce paramètre a été ajouté au registre
IANA des SvcParams (section 9 de notre RFC).
Si vous voulez fabriquer vous-même un tel enregistrement, la documentation d'Apache donne des explications (mais il faudra des versions très récentes des logiciels et probablement compilées par vous-même avec les bonnes options).
La section 4 du RFC décrit les conditions d'un déploiement
efficace, côté serveur. Si on publie un enregistrement SVCB incluant
du ech, il faut évidemment s'assurer que le
serveur TLS gère ECH. (Un exemple d'outil qui fait ce genre de
vérification est echspec.) La
section 5 du RFC fait la même chose, mais côté client ; elle
discute notamment des questions de latence puisqu'un client TLS ne
peut pas paralléliser la récupération de l'enregistrement DNS avec
l'établissement de la session TLS, celle-ci dépendant de ce qu'on
trouvera dans l'enregistrement SVCB.
Il existe un autre moyen d'influencer la session TLS, c'est le
champ HTTP Alt-Svc: du RFC 7838. Comme le note la section 6,
Alt-Svc: ne peut pas actuellement indiquer de
paramètres ECH donc pas de risque de contradiction entre les deux
moyens d'obtenir des paramètres TLS sur ce point. En revanche, le
serveur doit veiller à ce qu'il publie des enregistrements SVCB avec
ECH pour tous les noms qui seraient mentionnés dans le
Alt-Svc:.
Et puis, bien sûr (section 8), rappelez-vous que ECH servant à dissimuler le nom du serveur demandé, il ne servirait plus à grand'chose si la requête DNS pour ce nom (et le type HTTPS ou SVCB) était en clair et/ou envoyée à des serveurs qui ne sont pas dignes de confiance. Le RFC recommande donc des connexions DNS chiffrées et authentifiées, avec un résolveur de confiance.
L'article seul
RFC 9846: The Transport Layer Security (TLS) Protocol Version 1.3
Date de publication du RFC : Juillet 2026
Auteur(s) du RFC : E. Rescorla (Independent)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 12 juillet 2026
Ce RFC met à jour la norme de la version 1.3 du protocole de cryptographie TLS. Il n'y a pas de grand changement par rapport à son prédécesseur, le RFC 8446.
Regardons un peu en détail le protocole TLS 1.3. Revenons d'abord sur les fondamentaux : TLS est un mécanisme permettant aux applications client/serveur de communiquer au travers d'un réseau non sûr (par exemple l'Internet) tout en empêchant l'écoute et la modification des messages. TLS suppose un mécanisme sous-jacent pour acheminer les bits dans l'ordre, et sans perte. En général, ce mécanisme est TCP (mais une partie de TLS est aussi utilisée pour QUIC). Avec ce mécanisme de transport, et les techniques cryptographiques mises en œuvre par dessus, TLS garantit :
- L'authentification du serveur (celle du client est facultative), authentification qui permet d'empêcher l'attaque de l'intermédiaire, et qui se fait en général via la cryptographie asymétrique,
- La confidentialité des données (mais attention, TLS ne masque pas la taille des données, permettant certaines analyses de trafic),
- L'intégrité des données (qui est inséparable de l'authentification : il ne servirait pas à grand'chose d'être sûr de l'identité de son correspondant, si les données pouvaient être modifiées en route).
Ces propriétés sont vraies même si l'attaquant contrôle complètement le réseau entre le client et le serveur (le modèle de menace est détaillé dans la section 3 - surtout la 3.3 - du RFC 3552, et dans l'annexe F de notre RFC).
TLS est un protocole gros et compliqué (ce qui n'est pas forcément optimum pour la sécurité). Le RFC fait 161 pages. Pour dompter cette complexité, TLS est séparé en deux composants :
- Le protocole de salutation (handshake protocol), chargé d'organiser les échanges du début, qui permettent de choisir les paramètres de la session (c'est un des points délicats de TLS, et plusieurs failles de sécurité ont déjà été trouvées dans ce protocole pour les anciennes versions de TLS),
- Et le protocole des enregistrements (record protocol), au plus bas niveau, chargé d'acheminer les données chiffrées.
Pour comprendre le rôle de ces deux protocoles, imaginons un protocole fictif simple, qui n'aurait qu'un seul algorithme de cryptographie symétrique, et qu'une seule clé, connue des deux parties (par exemple dans leur fichier de configuration). Avec un tel protocole, on pourrait se passer du protocole de salutation, et n'avoir qu'un protocole des enregistrements, indiquant comment encoder les données chiffrées. Le client et le serveur pourraient se mettre à communiquer immédiatement, sans salutation, poignée de mains et négociation, réduisant ainsi la latence. Un tel protocole serait très simple, donc sa sécurité serait bien plus facile à analyser, ce qui est une bonne chose. Mais il n'est pas du tout réaliste : changer la clé utilisée serait complexe (il faudrait synchroniser exactement les deux parties), remplacer l'algorithme si la cryptanalyse en venait à bout (comme c'est arrivé à RC4, cf. RFC 7465) créerait un nouveau protocole incompatible avec l'ancien, communiquer avec un serveur qu'on n'a jamais vu serait impossible (puisque on ne partagerait pas de clé commune), etc. D'où la nécessité du protocole de salutation, où les partenaires :
- S'authentifient avec leur clé publique (ou, si on veut faire comme dans le protocole fictif simple, avec une clé secrète partagée),
- Sélectionnent l'algorithme de cryptographie symétrique qui va chiffrer la session, ainsi que ses paramètres divers,
- Choisissent la clé de la session TLS (et c'est là que se sont produites les plus grandes bagarres lors de la conception de TLS 1.3).
Notez que TLS n'est en général pas utilisé tel quel mais via un protocole de haut niveau, comme HTTPS pour sécuriser HTTP. TLS ne suppose pas un usage particulier : on peut s'en servir pour HTTP, pour SMTP (RFC 7672), pour le DNS (RFC 7858), etc. Cette intégration dans un protocole de plus haut niveau pose parfois elle-même des surprises en matière de sécurité, par exemple si l'application utilisatrice ne fait pas attention à la sécurité (Voir mon exposé à Devoxx, et ses transparents.)
TLS 1.3 est plutôt un nouveau protocole qu'une nouvelle version, et il n'est pas directement compatible avec son prédécesseur, TLS 1.2 (une application qui ne connait que 1.3 ne peut pas parler avec une application qui ne connait que 1.2). En pratique, les bibliothèques qui mettent en œuvre TLS incluent en général les différentes versions, et un mécanisme de négociation de la version utilisée permet normalement de découvrir la version maximum que les deux parties acceptent (historiquement, plusieurs failles sont venues de ce point, avec des pare-feux stupidement configurés qui interféraient avec la négociation).
La section 1.3 de notre RFC liste les différences importantes entre TLS 1.2 (qui était normalisé dans le RFC 5246) et 1.3 :
- La liste des algorithmes de cryptographie symétrique acceptés a été violemment réduite. Beaucoup trop longue en TLS 1.2, offrant trop de choix, comprenant plusieurs algorithmes faibles, elle ouvrait la voie à des attaques par repli. Les « survivants » de ce nettoyage sont tous des algorithmes à chiffrement intègre.
- Un nouveau service apparait, 0-RTT (zero round-trip time, la possibilité d'établir une session TLS avec un seul paquet, en envoyant les données tout de suite), qui réduit la latence du début de l'échange. Attention, rien n'est gratuit en ce monde, et 0-RTT présente des nouveaux dangers, et ce nouveau service a été un des plus controversés lors de la mise au point de TLS 1.3, entrainant de nombreux débats à l'IETF.
- Désormais, la sécurité future est systématique, la compromission d'une clé secrète ne permet plus de déchiffrer les anciennes communications. Plus de clés publiques statiques, tout se fera par clés éphémères. C'était le point qui a suscité le plus de débats à l'IETF, car cela complique sérieusement la surveillance (ce qui est bien le but) et le débogage. L'ETSI, représentante du patronat, a même normalisé son propre TLS délibérément affaibli,eTLS (depuis disparu de leur site Web, ils ont dû avoir honte).
- Plusieurs messages de négociation qui étaient auparavant en clair sont désormais chiffrés. Par contre, l'indication du nom du serveur (SNI, section 3 du RFC 6066) reste en clair, sauf si on utilise le tout nouveau ECH (Encrypted Client Hello), normalisé en même temps que ce RFC, dans le RFC 9849 (cf. son cahier des charges dans le RFC 8744.)
- Les fonctions de dérivation de clé ont été refaites.
- La machine à états utilisée pour l'établissement de la connexion également (elle est détaillée dans l'annexe A du RFC).
- Les algorithmes asymétriques à courbes elliptiques font maintenant partie de la définition de base de TLS (cf. RFC 7748), et on voit arriver des nouveaux comme ed25519 (cf. RFC 8422).
- Par contre, DSA a été retiré.
- Le mécanisme de négociation du numéro de version (permettant à deux machines n'ayant pas le même jeu de versions TLS de se parler) a changé. L'ancien était très bien mais, mal implémenté, il a suscité beaucoup de problèmes d'interopérabilité. Le nouveau est censé mieux gérer les innombrables systèmes bogués qu'on trouve sur l'Internet (la bogue ne provenant pas tant de la bibliothèque TLS utilisée que des pare-feux mal programmés et mal configurés qui sont souvent mis devant). J'en profite pour vous recommander l'article « HTTPS : de SSL à TLS 1.3 », sur ce sujet de la négociation de version.
- La reprise d'une session TLS précédente fait l'objet désormais d'un seul mécanisme, qui est le même que celui pour l'usage de clés pré-partagées. La négociation TLS peut en effet être longue, en terme de latence, et ce mécanisme permet d'éviter de tout recommencer à chaque connexion. Deux machines qui se parlent régulièrement peuvent ainsi gagner du temps.
Un bon résumé de ce protocole est dans l'article de Mark Nottingham.
Ce RFC concerne TLS 1.3 mais il contient aussi quelques changements pour la version 1.2 (section 1.4 du RFC), comme un mécanisme pour limiter les attaques par repli portant sur le numéro de version, et des mécanismes de la 1.3 « portés » vers la 1.2 sous forme d'extensions TLS.
Et les changements depuis le RFC 8446, le
premier qui avait normalisé TLS 1.3 ? Ils sont peu importants, le
plus spectaculaire étant le remplacement de toutes les occurrences de
master par main dans les noms
de variable. Ainsi, resumption_master_secret
est devenu resumption_secret et le
extended_master_secret du RFC 7627 est
devenu extended_main_secret. Il s'agissait de
répondre à une obsession étatsunienne mais je ne sais pas si ce
changement sera propagé dans les programmes qui mettent en œuvre
TLS (noms des variables et texte affiché, regardez l'exemple
Wireshark plus bas). Tous ces changements depuis le RFC 8446
sont résumés dans la section 1.2 mais il s'agit surtout de détails
et de précisions : la version 1.3 du protocole ne change pas.
La section 2 du RFC est un survol général de TLS 1.3 (le RFC fait 161 pages, et peu de gens le liront intégralement). Au début d'une session TLS, les deux parties, avec le protocole de salutation, négocient les paramètres (version de TLS, algorithmes cryptographiques) et définissent les clés qui seront utilisées pour le chiffrement de la session. En simplifiant, il y a trois phases dans l'établissement d'une session TLS :
- Définition des clés de session, et des paramètres
cryptographiques, le client envoie un
ClientHello, le serveur répond avec unServerHello, - Définition des autres paramètres (par exemple
l'application utilisée au-dessus de TLS, ou bien la demande
CertificateRequestd'un certificat client), cette partie est chiffrée, contrairement à la précédente, - Authentification du serveur, avec le message
Certificate(qui ne contient pas forcément un certificat, cela peut être une clé brute - RFC 7250 ou une clé d'une session précédente - RFC 7924).
Un message Finished termine cette ouverture
de session.
(Si vous êtes fana de futurisme, notez que seule la première étape
pourrait être remplacée par la distribution quantique
de clés, les autres resteraient
indispensables. Contrairement à ce que promettent ses promoteurs,
la QKD ne dispense pas d'utiliser les protocoles existants.)
Comment les deux parties se mettent-elles d'accord sur les clés ? Trois méthodes :
- Diffie-Hellman sur courbes elliptiques qui sera sans doute la plus fréquente,
- Clé pré-partagée,
- Clé pré-partagée avec Diffie-Hellman,
- Et la méthode RSA, elle, disparait de la norme (mais RSA peut toujours être utilisé pour l'authentification, autrement, cela ferait beaucoup de certificats à jeter…)
Si vous connaissez la cryptographie, vous savez que les PSK, les clés partagées, sont difficiles à gérer, puisque devant être transmises de manière sûre avant l'établissement de la connexion. Mais, dans TLS, une autre possibilité existe : si une session a été ouverte sans PSK, en n'utilisant que de la cryptographie asymétrique, elle peut être enregistrée, et resservir, afin d'ouvrir les futures discussions plus rapidement. TLS 1.3 utilise le même mécanisme pour des « vraies » PSK, et pour celles issues de cette reprise de sessions précédentes (contrairement aux précédentes versions de TLS, qui utilisaient un mécanisme séparé, celui du RFC 5077, désormais abandonné).
Si on a une PSK (gérée manuellement, ou bien via la reprise de session), on peut même avoir un dialogue TLS dit « 0-RTT ». Le premier paquet du client peut contenir des données, qui seront acceptées et traitées par le serveur. Cela permet une importante diminution de la latence, dont il faut rappeler qu'elle est souvent le facteur limitant des performances. Par contre, comme rien n'est idéal dans cette vallée de larmes, cela se fait au détriment de la sécurité :
- Plus de confidentialité persistante, si la PSK est compromise plus tard, la session pourra être déchiffrée,
- Le rejeu devient possible, et l'application doit donc savoir gérer ce problème.
La section 8 du RFC et l'annexe F.5 détaillent ces limites, et les mesures qui peuvent être prises.
Le protocole TLS est décrit avec un langage spécifique, décrit de manière relativement informelle dans la section 3 du RFC. Ce langage manipule des types de données classiques :
- Scalaires
(
uint8,uint16), - Tableaux, de taille fixe -
Datum[3]ou variable, avec indication de la longueur au début -uint16 longer<0..800>, - Énumérations (
enum { red(3), blue(5), white(7) } Color;), - Enregistrements structurés, y compris avec variantes (la présence de certains champs dépendant de la valeur d'un champ).
Par exemple, tirés de la section 4 (l'annexe B fournit la liste complète), voici, dans ce langage, la liste des types de messages pendant les salutations, une énumération :
enum {
client_hello(1),
server_hello(2),
new_session_ticket(4),
end_of_early_data(5),
encrypted_extensions(8),
certificate(11),
certificate_request(13),
certificate_verify(15),
finished(20),
key_update(24),
message_hash(254),
(255)
} HandshakeType;
Et le format de base d'un message du protocole de salutation :
struct {
HandshakeType msg_type; /* handshake type */
uint24 length; /* bytes in message */
select (Handshake.msg_type) {
case client_hello: ClientHello;
case server_hello: ServerHello;
case end_of_early_data: EndOfEarlyData;
case encrypted_extensions: EncryptedExtensions;
case certificate_request: CertificateRequest;
case certificate: Certificate;
case certificate_verify: CertificateVerify;
case finished: Finished;
case new_session_ticket: NewSessionTicket;
case key_update: KeyUpdate;
};
} Handshake;
La section 4 fournit tous les détails sur le protocole de
salutation, notamment sur la délicate négociation des paramètres
cryptographiques. Notez que la renégociation en cours de session a
disparu, donc un ClientHello ne peut
désormais plus être envoyé qu'au début.
Un problème auquel a toujours dû faire face TLS est celui de la
négociation de version, en présence de mises en œuvre boguées, et,
surtout, en présence de boitiers intermédiaires encore plus
bogués (pare-feux ignorants, par exemple, que
des DSI ignorantes placent un peu
partout). Le modèle original de TLS pour un client était d'annoncer
dans le ClientHello le plus grand numéro de
version qu'on gère, et de voir dans ServerHello
le maximum imposé par le serveur. Ainsi, un client TLS 1.2 parlant à
un serveur qui ne gère que 1.1 envoyait
ClientHello(client_version=1.2) et, en recevant
ServerHello(server_version=1.1), se repliait
sur TLS 1.1, la version la plus élevée que les deux parties
gèraient. En pratique, cela ne marche pas aussi bien. On voyait par
exemple des serveurs (ou, plus vraisemblablement, des pare-feux
bogués) qui raccrochaient brutalement en présence d'un numéro de
version plus élevé, au lieu de suggérer un repli. Le client n'avait
alors que le choix de renoncer, ou bien de se lancer dans une série
d'essais/erreurs (qui peut être longue, si le serveur ou le pare-feu
bogué ne répond pas).
TLS 1.3 change donc complètement le
mécanisme de négociation. Le client annonce toujours la version 1.2
(en fait 0x303, pour des raisons historiques), et la vraie version
est mise dans une extension, supported_versions
(section 4.2.1), dont on espère qu'elle sera ignorée par les
serveurs mal gérés. (L'annexe D du RFC détaille ce problème de la
négociation de version.) Dans la réponse
ServerHello, un serveur 1.3 doit inclure cette
extension, autrement, il faut se rabattre sur TLS 1.2.
En
parlant d'extensions, concept qui avait été introduit originellement
dans le RFC 4366, notre RFC reprend des
extensions déjà normalisées, comme le SNI (Server Name
Indication) du RFC 6066, le
battement de cœur du RFC 6520, le remplissage
du ClientHello du RFC 7685, et en ajoute dix, dont
supported_versions. Certaines de ces extensions
doivent être présentes dans les messages Hello,
car la sélection des paramètres cryptographiques en dépend, d'autres
peuvent être uniquement dans les messages
EncryptedExtensions, une nouveauté de TLS 1.3,
pour les extensions qu'on n'enverra qu'une fois le chiffrement
commencé. Le RFC en profite pour rappeler que les messages
Hello ne sont pas protégés cryptographiquement,
et peuvent donc être modifiés (le message
Finished résume les décisions prises et peut
donc protéger contre ce genre d'attaques).
Autrement, parmi les autres nouvelles extensions :
- Le petit gâteau (cookie), pour tester la joignabilité,
- Les données précoces (early data), extension qui permet d'envoyer des données dès le premier message (« 0-RTT »), réduisant ainsi la latence, un peu comme le fait le TCP Fast Open du RFC 7413,
- Liste des AC (certificate authorities), qui, en indiquant la liste des AC connues du client, peut aider le serveur à choisir un certificat qui sera validé (par exemple en n'envoyant le certificat CAcert que si le client connait cette AC).
La section 5 décrit le protocole des enregistrements (record protocol). C'est ce sous-protocole qui va prendre un flux d'octets, le découper en enregistrements, les protéger par le chiffrement puis, à l'autre bout, déchiffrer et reconstituer le flux… Notez que « protégé » signifie à la fois confidentialité et intégrité puisque TLS 1.3, contrairement à ses prédécesseurs, impose AEAD (RFC 5116).
Les enregistrements sont typés et marqués handshake (la salutation, vue dans la section précédente), change cipher spec, alert (pour signaler un problème) et application data (les données elle-mêmes) :
enum {
invalid(0),
change_cipher_spec(20),
alert(21),
handshake(22),
application_data(23),
(255)
} ContentType;
Le contenu des données est évidemment incompréhensible, en raison du chiffrement (voici un enregistrement de type 23, données, vu par tshark) :
TLSv1.3 Record Layer: Application Data Protocol: http-over-tls
Opaque Type: Application Data (23)
Version: TLS 1.2 (0x0303)
Length: 6316
Encrypted Application Data: eb0e21f124f82eee0b7a37a1d6d866b075d0476e6f00cae7...
Et décrite par la norme dans son langage formel :
struct {
ContentType opaque_type = application_data; /* 23 */
ProtocolVersion legacy_record_version = 0x0303; /* TLS v1.2 */
uint16 length;
opaque encrypted_record[TLSCiphertext.length];
} TLSCiphertext;
(Oui, le numéro de version reste à TLS 1.2 pour éviter d'énerver les stupides middleboxes.) Notez que des extensions à TLS peuvent introduire d'autres types d'enregistrements.
Une faiblesse classique de TLS est que la taille des données chiffrées n'est pas dissimulée. Si on veut savoir à quelle page d'un site Web un client HTTP a accédé, on peut parfois le déduire de l'observation de cette taille. D'où la possibilité de faire du remplissage pour dissimuler cette taille (section 5.4 du RFC). Notez que le RFC ne suggère pas de politique de remplissage spécifique (ajouter un nombre aléatoire ? Tout remplir jusqu'à la taille maximale ?), c'est un choix compliqué. Il note aussi que certaines applications font leur propre remplissage, et qu'il n'est alors pas nécessaire que TLS le fasse.
La section 6 du RFC est dédiée au cas des alertes. C'est un des types d'enregistrements possibles, et, comme les autres, il est chiffré, et les alertes sont donc confidentielles. Une alerte a un niveau et une description :
struct {
AlertLevel level;
AlertDescription description;
} Alert;
Le niveau indiquait si l'alerte est fatale mais n'est plus utilisé en TLS 1.2, où il faut se fier uniquement à la description, une énumération des problèmes possibles (message de type inconnu, mauvais certificat, enregistrement non décodable - rappelez-vous que TLS 1.3 n'utilise que du chiffrement intègre -, problème interne au client ou au serveur, extension non acceptée, etc). La section 6.2 donne une liste des erreurs fatales, qui doivent mener à terminer immédiatement la session TLS.
La section 8 du RFC est entièrement consacrée à une nouveauté délicate, le « 0-RTT ». Ce terme désigne la possibilité d'envoyer des données dès le premier paquet, sans les nombreux échanges de paquets qui sont normalement nécessaires pour établir une session TLS. C'est très bien du point de vue des performances, mais pas forcément du point de vue de la sécurité puisque, sans échanges, on ne peut plus vérifier à qui on parle. Un attaquant peut réaliser une attaque par rejeu en envoyant à nouveau un paquet qu'il a intercepté. Un serveur doit donc se défendre en se souvenant des données déjà envoyées et en ne les acceptant pas deux fois. (Ce qui peut être plus facile à dire qu'à faire ; le RFC contient une bonne discussion très détaillée des techniques possibles, et de leurs limites. Il y en a des subtiles, comme d'utiliser des systèmes de mémorisation ayant des faux positifs, comme les filtres de Bloom, parce qu'ils ne produiraient pas d'erreurs, ils rejetteraient juste certains essais 0-RTT légitimes, cela ne serait donc qu'une légère perte de performance.)
La section 9 de notre RFC se penche sur un problème difficile, la
conformité des mises en œuvres de TLS. D'abord, les algorithmes
obligatoires. Afin de permettre l'interopérabilité,
toute mise en œuvre de TLS doit avoir la suite
de chiffrement TLS_AES_128_GCM_SHA256
(AES en
mode GCM avec
SHA-256). D'autres suites sont recommandées
(cf. annexe B.4). Pour l'authentification, RSA avec SHA-256
et ECDSA sont obligatoires. Ainsi, deux
programmes différents sont sûrs de pouvoir trouver des algorithmes
communs. La possibilité
d'authentification par certificats PGP du RFC 6091 a été
retirée.
De plus, certaines extensions à TLS sont obligatoires, un pair TLS 1.3 ne peut pas les refuser :
supported_versions, nécessaire pour annoncer TLS 1.3,cookie,signature_algorithms,signature_algorithms_cert,supported_groupsetkey_share,server_name, c'est à dire SNI (Server Name Indication), souvent nécessaire pour pouvoir choisir le bon certificat (cf. section 3 du RFC 6066).
La section 9 précise aussi le comportement attendu des équipements intermédiaires. Ces dispositifs (pare-feux, par exemple, mais pas uniquement) ont toujours été une plaie pour TLS. Alors que TLS vise à fournir une communication sûre, à l'abri des équipements intermédiaires, ceux-ci passent leur temps à essayer de s'insérer dans la communication, et souvent la cassent. Normalement, TLS 1.3 est conçu pour que ces interférences ne puissent pas mener à un repli (le repli est l'utilisation de paramètres moins sûrs que ce que les deux machines auraient choisi en l'absence d'interférence).
Il y a deux grandes catégories d'intermédiaires, ceux qui tripotent la session TLS sans être le client ou le serveur, et ceux qui terminent la session TLS de leur côté. Attention, dans ce contexte, « terminer » ne veut pas dire « y mettre fin », mais « la sécurité TLS se termine ici, de manière à ce que l'intermédiaire puisse accéder au contenu de la communication ». Typiquement, une middlebox qui « termine » une session TLS va être serveur TLS pour le client et client TLS pour le serveur, s'insérant complètement dans la conversation. Normalement, l'authentification vise à empêcher ce genre de pratiques, et l'intermédiaire ne sera donc accepté que s'il a un certificat valable. C'est pour cela qu'en entreprise, les machines officielles sont souvent installées avec une AC contrôlée par le vendeur du boitier intermédiaire, de manière à permettre l'interception.
Le RFC ne se penche pas sur la légitimité de ces pratiques, uniquement sur leurs caractéristiques techniques. (Les boitiers intermédiaires sont souvent programmés avec les pieds, et ouvrent de nombreuses failles.) Le RFC rappelle notamment que l'intermédiaire qui termine une session doit suivre le RFC à la lettre (ce qui devrait aller sans dire…)
Depuis le RFC 4346, il existe plusieurs registres IANA pour TLS, décrits en section 11, avec leurs nouveautés. En effet, plusieurs choix pour TLS ne sont pas « câblés en dur » dans le RFC mais peuvent évoluer indépendamment. Par exemple, le registre de suites cryptographiques a une politique d'enregistrement « spécification nécessaire » (cf. RFC 8126, sur les politiques d'enregistrement). La cryptographie fait régulièrement des progrès, et il faut donc pouvoir modifier la liste des suites acceptées (par exemple lorsqu'il faudra y ajouter les algorithmes post-quantiques) sans avoir à toucher au RFC (l'annexe B.4 donne la liste actuelle). Le registre des types de contenu, lui, a une politique d'enregistrement bien plus stricte, « action de normalisation ». On crée moins souvent des types que des suites cryptographiques. Même chose pour le registre des alertes ou pour celui des salutations.
L'annexe C du RFC plaira aux programmeurs, elle donne plusieurs conseils pour une mise en œuvre correcte de TLS 1.3 (ce n'est pas tout d'avoir un protocole correct, il faut encore qu'il soit programmé correctement). Pour aider les développeurs à déterminer s'ils ont correctement fait le travail, le RFC 8448 fournit des vecteurs de test.
Un des conseils les plus importants est évidemment de faire
attention au générateur de nombres aléatoires, source de
tant de failles de sécurité en cryptographie. TLS utilise des
nombres qui doivent être imprévisibles à un attaquant pour générer
des clés de session. Si ces nombres sont prévisibles, toute la
cryptographie s'effondre. Le RFC conseille fortement d'utiliser un
générateur existant (comme /dev/urandom sur les
systèmes Unix) plutôt que d'écrire le sien,
ce qui est bien plus difficile qu'il ne semble. (Si on tient quand
même à le faire, le RFC 4086 est une lecture
indispensable.)
Le RFC conseille également de vérifier le certificat du partenaire par défaut (quitte à fournir un moyen de débrayer cette vérification). Si ce n'est pas le cas, beaucoup d'utilisateurs du programme ou de la bibliothèque oublieront de le faire. Il suggère aussi de ne pas accepter certains certificats trop faibles (clé RSA de seulement 1 024 bits, par exemple).
Il existe plusieurs moyens avec TLS de ne pas avoir d'authentification du serveur : les clés brutes du RFC 7250 (à la place des certificats), ou bien les certificats auto-signés. Dans ces conditions, une attaque de l'homme du milieu est parfaitement possible, et il faut donc prendre des précautions supplémentaires (par exemple DANE, normalisé dans le RFC 6698, que le RFC oublie malheureusement de citer).
Autre bon conseil de cryptographie, se méfier des attaques fondées sur la mesure du temps de calcul, et prendre des mesures appropriées (par exemple en vérifiant que le temps de calcul est le même pour des données correctes et incorrectes).
Il n'y a aucune bonne raison d'utiliser certains algorithmes faibles (comme RC4, abandonné depuis le RFC 7465), et le RFC demande que le code pour ces algorithmes ne soit pas présent, afin d'éviter une attaque par repli (annexes C.3 et D.5 du RFC). De la même façon, il demande de ne jamais accepter SSL v3 (RFC 7568).
L'expérience a prouvé que beaucoup de mises en œuvre de TLS ne réagissaient pas correctement à des options inattendues, et le RFC rappelle donc qu'il faut ignorer les suites cryptographiques inconnues (autrement, on ne pourrait jamais introduire une nouvelle suite, puisqu'elle casserait les programmes), et ignorer les extensions inconnues (pour la même raison).
L'annexe D, elle, est consacrée au problème de la communication
avec un vieux partenaire, qui ne connait pas TLS 1.3. Le mécanisme
de négociation de la version du protocole à utiliser a complètement
changé en 1.3. Dans la 1.3, le champ version du
ClientHello contient 1.2, la vraie version
étant dans l'extension supported_versions. Si
un client 1.3 parle avec un serveur <= 1.2, le serveur ne
connaitra pas cette extension et répondra sans l'extension,
avertissant ainsi le client qu'il faudra parler en 1.2 (ou plus
vieux). Ça, c'est si le serveur est correct. S'il ne l'est pas ou,
plus vraisemblablement, s'il est derrière une middlebox
boguée, on verra des problèmes comme par exemple le refus de
répondre aux clients utilisant des extensions inconnues (ce qui sera
le cas pour supported_versions), soit en
rejettant ouvertement la demande soit, encore pire, en
l'ignorant. Arriver à gérer des
serveurs/middleboxes incorrects est un problème
complexe. Le client peut être tenté de re-essayer avec d'autres
options (par exemple tenter du 1.2, sans l'extension
supported_versions). Cette méthode n'est pas
conseillée. Non seulement elle peut prendre du temps (attendre
l'expiration du délai de garde, re-essayer…) mais surtout, elle
ouvre la voie à des attaques par repli : l'attaquant bloque les
ClientHello 1.3 et le client, croyant bien
faire, se replie sur une version plus ancienne et sans doute moins
sûre de TLS.
En parlant de compatibilité, le « 0-RTT » n'est évidemment pas
compatible avec les vieilles versions. Le client qui envoie du
« 0-RTT » (des données dans le ClientHello)
doit donc savoir que, si la réponse est d'un serveur <= 1.2,
la session ne pourra pas être établie, et il faudra donc réessayer
sans 0-RTT.
Naturellement, les plus gros problèmes ne surviennent pas avec
les clients et les serveurs mais avec les
middleboxes. Plusieurs études ont montré leur
caractère néfaste (cf. présentation
à l'IETF 100, mesures
avec Chrome (qui indique également que certains serveurs TLS
sont gravement en tort, comme celui installé dans les imprimantes
Canon), mesures
avec Firefox, et encore
d'autres mesures). Le RFC suggère qu'on limite les risques en
essayant d'imiter le plus possible une salutation de TLS 1.2, par
exemple en envoyant des messages
change_cipher_spec, qui ne sont plus utilisés
en TLS 1.3, mais qui peuvent rassurer la
middlebox (annexe D.4).
Enfin, le RFC se termine par l'annexe E, qui énumère les propriétés de sécurité de TLS 1.3 : même face à un attaquant actif (RFC 3552), le protocole de salutation de TLS garantit des clés de session communes et secrètes, une authentification du serveur (et du client si on veut), et une sécurité persistante, même en cas de compromission ultérieure des clés (sauf en cas de 0-RTT, un autre des inconvénients sérieux de ce service, avec le risque de rejeu). De nombreuses analyses détaillées de la sécurité de TLS sont listées dans l'annexe E.1.6. À lire si vous voulez travailler ce sujet.
Quant au protocole des enregistrements, celui de TLS 1.3 garantit confidentialité et intégrité (RFC 5116).
TLS 1.3 a fait l'objet de nombreuses analyses de sécurité par des chercheurs, avant même sa normalisation, ce qui est une bonne chose (et qui explique en partie les retards). Notre annexe E pointe également les limites restantes de TLS :
- Il est vulnérable à l'analyse de trafic. TLS n'essaie pas de cacher la taille des paquets, ni l'intervalle de temps entre eux. Ainsi, si un client accède en HTTPS à un site Web servant quelques dizaines de pages aux tailles bien différentes, il est facile de savoir quelle page a été demandée, juste en observant les tailles. (Voir « I Know Why You Went to the Clinic: Risks and Realization of HTTPS Traffic Analysis », de Miller, B., Huang, L., Joseph, A., et J. Tygar et « HTTPS traffic analysis and client identification using passive SSL/TLS fingerprinting », de Husak, M., Čermak, M., Jirsik, T., et P. Čeleda). TLS fournit un mécanisme de remplissage avec des données bidon, permettant aux applications de brouiller les pistes. Certaines applications utilisant TLS ont également leur propre remplissage (par exemple, pour le DNS, c'est le RFC 7830). De même, une mise en œuvre de TLS peut retarder les paquets pour rendre l'analyse des intervalles plus difficile. On voit que dans les deux cas, taille des paquets et intervalle entre eux, résoudre le problème fait perdre en performance (c'est pour cela que ce n'est pas intégré par défaut).
- TLS peut être également vulnérable à des attaques par canal auxiliaire. Par exemple, la durée des opérations cryptographiques peut être observée, ce qui peut donner des informations sur les clés. TLS fournit quand même quelques défenses : l'AEAD facilite la mise en œuvre de calculs en temps constant, et format uniforme pour toutes les erreurs, empêchant un attaquant de trouver quelle erreur a été déclenchée.
Le 0-RTT introduit un nouveau risque, celui de rejeu. (Et 0-RTT a sérieusement contribué aux délais qu'a connu le projet TLS 1.3, plusieurs participants à l'IETF protestant contre cette introduction risquée.) Si l'application est idempotente, ce n'est pas très grave. Si, par contre, les effets d'une requête précédentes peuvent être rejoués, c'est plus embêtant (imaginez un transfert d'argent répété…) TLS ne promet rien en ce domaine, c'est à chaque serveur de se défendre contre le rejeu (la section 8 donne des idées à ce sujet). Voilà pourquoi le RFC demande que les requêtes 0-RTT ne soient pas activées par défaut, mais uniquement quand l'application au-dessus de TLS le demande. (Cloudflare, par exemple, n'active pas le 0-RTT par défaut.)
Voilà, vous avez maintenant fait un tour complet du RFC, mais vous savez que la cryptographie est une chose difficile, et pas seulement dans les algorithmes cryptographiques (TLS n'en invente aucun, il réutilise des algorithmes existants comme AES ou ECDSA), mais aussi dans les protocoles cryptographiques, un art complexe. N'hésitez donc pas à lire le RFC en détail, et à vous méfier des résumés forcément toujours sommaires, comme cet article.
À part le 0-RTT, le plus gros débat lors de la création de TLS
1.3 avait été autour du concept que ses partisans nomment
« visibilité » et ses adversaires « surveillance ». C'est l'idée
qu'il serait bien pratique si on (on : le patron, la police, le
FAI…)
pouvait accéder au contenu des communications TLS. « Le chiffrement,
c'est bien, à condition que je puisse lire les données quand même »
est l'avis des partisans de la visibilité. Cela avait été proposé
dans les Internet-Drafts draft-green-tls-static-dh-in-tls13
et draft-rhrd-tls-tls13-visibility. Je
ne vais pas ici pouvoir capturer la totalité du débat, juste noter
quelques points qui sont parfois oubliés dans la discussion. Côté
partisans de la visibilité :
- Dans une entreprise capitaliste, il n'y pas de citoyens, juste un patron et des employés. Les ordinateurs appartiennent au patron, et les employés n'ont pas leur mot à dire. Le patron peut donc décider d'accéder au contenu des communications chiffrées.
- Il existe des règles (par exemple PCI-DSS dans le secteur financier ou HIPAA dans celui de la santé) qui requièrent de certaines entreprises qu'elles sachent en détail tout ce qui circule sur le réseau. Le moyen le plus simple de le faire est de surveiller le contenu des communications, même chiffrées. (Je ne dis pas que ces règles sont intelligentes, juste qu'elles existent. Notons par exemple que les mêmes règles imposent d'utiliser du chiffrement fort, sans faille connue, ce qui est contradictoire.)
- Enregistrer le trafic depuis les terminaux est compliqué en pratique : applications qui n'ont pas de mécanisme de journalisation du trafic, systèmes d'exploitation fermés, boîtes noires…
- TLS 1.3 risque de ne pas être déployé dans les entreprises qui tiennent à surveiller le trafic, et pourrait même être interdit dans certains pays, où la surveillance passe avant les droits humains.
Et du côté des adversaires de la surveillance :
- La cryptographie, c'est compliqué et risqué. TLS 1.3 est déjà assez compliqué comme cela. Lui ajouter des fonctions (surtout des fonctions délibérement conçues pour affaiblir ses propriétés de sécurité) risque fort d'ajouter des failles de sécurité. D'autant plus que TLS 1.3 a fait l'objet de nombreuses analyses de sécurité avant son déploiement, et qu'il faudrait tout recommencer.
- Contrairement à ce que semblent croire les partisans de la « visibilité », il n'y a pas que HTTPS qui utilise TLS. Ils ne décrivent jamais comment leur proposition marcherait avec des protocoles autres que HTTPS.
- Pour HTTPS, et pour certains autres protocoles, une solution simple, si on tient absolument à intercepter tout le trafic, est d'avoir un relais explicite, configuré dans les applications, et combiné avec un blocage dans le pare-feu des connexions TLS directes. Les partisans de la visibilité ne sont en général pas enthousiastes pour cette solution car ils voudraient faire de la surveillance furtive, sans qu'elle se voit dans les applications utilisées par les employés ou les citoyens.
- Les partisans de la « visibilité » disent en général que l'interception TLS serait uniquement à l'intérieur de l'entreprise, pas pour l'Internet public. Mais, dans ce cas, tous les terminaux sont propriété de l'entreprise et contrôlés par elle, donc elle peut les configurer pour copier tous les messages échangés. Et, si certains de ces terminaux sont des boîtes noires, non configurables et dont on ne sait pas bien ce qu'ils font, eh bien, dans ce cas, on se demande pourquoi des gens qui insistent sur leurs obligations de surveillance mettent sur leur réseau des machines aussi incontrôlables.
- Dans ce dernier cas (surveillance uniquement au sein d'une entreprise), le problème est interne à l'entreprise, et ce n'est donc pas à l'IETF, organisme qui fait des normes pour l'Internet, de le résoudre. Après tout, rien n'empêche ces entreprises de garder TLS 1.2.
Revenons maintenant aux choses sérieuses, avec les mises en œuvre de TLS 1.3. Il y en existe au moins une dizaine à l'heure actuelle et la version 1.3 est désormais largement déployée.
Par exemple, avec un GnuTLS récent, on peut utiliser le
programme en ligne de commande gnutls-cli avec
un serveur qui accepte TLS 1.3 :
% gnutls-cli -V gmail.com ... - Description: (TLS1.3-X.509)-(ECDHE-SECP256R1)-(ECDSA-SECP256R1-SHA256)-(AES-256-GCM) - Ephemeral EC Diffie-Hellman parameters - Using curve: SECP256R1 - Curve size: 256 bits - Version: TLS1.3 - Server Signature: ECDSA-SECP256R1-SHA256 - Cipher: AES-256-GCM - MAC: AEAD ...
Et ça marche, on fait du TLS 1.3. Si vous préférez écrire le
programme vous-même, regardez ce petit
programme. Si GnuTLS est en /local, il
se compilera avec cc -I/local/include -Wall -Wextra -o
test-tls13 test-tls13.c -L/local/lib -lgnutls et
s'utilisera avec :
% ./test-tls13 www.ietf.org TLS connection using "TLS1.3 AES-256-GCM" % ./test-tls13 gmail.com TLS connection using "TLS1.3 AES-256-GCM" % ./test-tls13 blog.cloudflare.com TLS connection using "TLS1.3 AES-256-GCM" % ./test-tls13 cr.yp.to TLS connection using "TLS1.2 CHACHA20-POLY1305"
Cela vous donne une petite idée des serveurs qui acceptent TLS 1.3 (le dernier testé ne l'accepte pas).
Un pcap d'une session TLS 1.3 est
disponible en tls13-2.pcap. Regardez le numéro de
version de TLS dans l'extension (0x304), qui identifie TLS 1.3. Voici la
session vue par tshark :
1 0.000000 2001:41d0:302:2200::180 → 2606:4700::6810:7b60 TCP 94 56462 → 443 [SYN] Seq=0 Win=64800 Len=0 MSS=1440 SACK_PERM TSval=2022119812 TSecr=0 WS=1024
2 0.005516 2606:4700::6810:7b60 → 2001:41d0:302:2200::180 TCP 94 443 → 56462 [SYN, ACK] Seq=0 Ack=1 Win=65535 Len=0 MSS=1360 SACK_PERM TSval=4271324975 TSecr=2022119812 WS=8192
3 0.005539 2001:41d0:302:2200::180 → 2606:4700::6810:7b60 TCP 86 56462 → 443 [ACK] Seq=1 Ack=1 Win=65536 Len=0 TSval=2022119818 TSecr=4271324975
4 0.005837 2001:41d0:302:2200::180 → 2606:4700::6810:7b60 TLSv1 492 Client Hello (SNI=www.cloudflare.com)
5 0.011387 2606:4700::6810:7b60 → 2001:41d0:302:2200::180 TCP 86 443 → 56462 [ACK] Seq=1 Ack=407 Win=131072 Len=0 TSval=4271324981 TSecr=2022119818
6 0.013523 2606:4700::6810:7b60 → 2001:41d0:302:2200::180 TLSv1.3 1434 Server Hello, Change Cipher Spec
7 0.013523 2606:4700::6810:7b60 → 2001:41d0:302:2200::180 TCP 520 [TCP Previous segment not captured] 443 → 56462 [PSH, ACK] Seq=2697 Ack=407 Win=131072 Len=434 TSval=4271324983 TSecr=2022119818 [TCP segment of a reassembled PDU]
8 0.013523 2606:4700::6810:7b60 → 2001:41d0:302:2200::180 TCP 1434 [TCP Out-Of-Order] 443 → 56462 [ACK] Seq=1349 Ack=407 Win=131072 Len=1348 TSval=4271324983 TSecr=2022119818
9 0.013543 2001:41d0:302:2200::180 → 2606:4700::6810:7b60 TCP 86 56462 → 443 [ACK] Seq=407 Ack=1349 Win=68608 Len=0 TSval=2022119826 TSecr=4271324983
10 0.013555 2001:41d0:302:2200::180 → 2606:4700::6810:7b60 TCP 98 [TCP Dup ACK 9#1] 56462 → 443 [ACK] Seq=407 Ack=1349 Win=68608 Len=0 TSval=2022119826 TSecr=4271324983 SLE=2697 SRE=3131
11 0.013560 2001:41d0:302:2200::180 → 2606:4700::6810:7b60 TCP 86 56462 → 443 [ACK] Seq=407 Ack=3131 Win=68608 Len=0 TSval=2022119826 TSecr=4271324983
12 0.013799 2001:41d0:302:2200::180 → 2606:4700::6810:7b60 TLSv1.3 92 Change Cipher Spec
13 0.028771 2001:41d0:302:2200::180 → 2606:4700::6810:7b60 TLSv1.3 160 Application Data
14 0.034250 2606:4700::6810:7b60 → 2001:41d0:302:2200::180 TCP 86 443 → 56462 [ACK] Seq=3131 Ack=488 Win=131072 Len=0 TSval=4271325004 TSecr=2022119826
15 0.035800 2606:4700::6810:7b60 → 2001:41d0:302:2200::180 TCP 86 443 → 56462 [FIN, ACK] Seq=3131 Ack=488 Win=131072 Len=0 TSval=4271325005 TSecr=2022119826
16 0.035821 2001:41d0:302:2200::180 → 2606:4700::6810:7b60 TCP 86 56462 → 443 [ACK] Seq=488 Ack=3132 Win=69632 Len=0 TSval=2022119848 TSecr=4271325005
Et, complètement décodée par tshark :
Transport Layer Security
TLSv1 Record Layer: Handshake Protocol: Client Hello
Content Type: Handshake (22)
Version: TLS 1.0 (0x0301)
Length: 401
Handshake Protocol: Client Hello
Handshake Type: Client Hello (1)
Length: 397
Version: TLS 1.2 (0x0303)
Cipher Suites Length: 58
Cipher Suites (29 suites)
Cipher Suite: TLS_AES_256_GCM_SHA384 (0x1302)
Cipher Suite: TLS_CHACHA20_POLY1305_SHA256 (0x1303)
…
Compression Methods Length: 1
Compression Methods (1 method)
Compression Method: null (0)
Extensions Length: 266
Extension: ec_point_formats (len=2)
Type: ec_point_formats (11)
Length: 2
EC point formats Length: 1
Elliptic curves point formats (1)
EC point format: uncompressed (0)
Extension: key_share (len=107) secp256r1, x25519
Type: key_share (51)
Length: 107
Key Share extension
Client Key Share Length: 105
Key Share Entry: Group: secp256r1, Key Exchange length: 65
Group: secp256r1 (23)
Key Exchange Length: 65
Key Exchange: 04baaae9e5261e75a052917c5266e92491905e012c8403dacdb3ae5cd4edc025d87d6d1131fb01e1c71d031cd5c1e4eaa49a8db64dceea2238a2f459206f5e592a
Key Share Entry: Group: x25519, Key Exchange length: 32
Group: x25519 (29)
Key Exchange Length: 32
Key Exchange: 81f6e52c0e771d320529cdff1729c1c290842a68044f86223a80cf608926be5d
Extension: server_name (len=23) name=www.cloudflare.com
Type: server_name (0)
Length: 23
Server Name Indication extension
Server Name list length: 21
Server Name Type: host_name (0)
Server Name length: 18
Server Name: www.cloudflare.com
Extension: status_request (len=5)
Type: status_request (5)
Length: 5
Certificate Status Type: OCSP (1)
Responder ID list Length: 0
Request Extensions Length: 0
Extension: session_ticket (len=0)
Type: session_ticket (35)
Length: 0
Session Ticket: <MISSING>
Extension: supported_groups (len=22)
Type: supported_groups (10)
Length: 22
Supported Groups List Length: 20
Supported Groups (10 groups)
Supported Group: secp256r1 (0x0017)
Supported Group: secp384r1 (0x0018)
Supported Group: secp521r1 (0x0019)
Supported Group: x25519 (0x001d)
Supported Group: x448 (0x001e)
Supported Group: ffdhe2048 (0x0100)
Supported Group: ffdhe3072 (0x0101)
Supported Group: ffdhe4096 (0x0102)
Supported Group: ffdhe6144 (0x0103)
Supported Group: ffdhe8192 (0x0104)
Extension: record_size_limit (len=2)
Type: record_size_limit (28)
Length: 2
Record Size Limit: 16385
Extension: encrypt_then_mac (len=0)
Type: encrypt_then_mac (22)
Length: 0
Extension: supported_versions (len=9) TLS 1.3, TLS 1.2, TLS 1.1, TLS 1.0
Type: supported_versions (43)
Length: 9
Supported Versions length: 8
Supported Version: TLS 1.3 (0x0304)
Supported Version: TLS 1.2 (0x0303)
Supported Version: TLS 1.1 (0x0302)
Supported Version: TLS 1.0 (0x0301)
Extension: psk_key_exchange_modes (len=3)
Type: psk_key_exchange_modes (45)
Length: 3
PSK Key Exchange Modes Length: 2
PSK Key Exchange Mode: PSK with (EC)DHE key establishment (psk_dhe_ke) (1)
PSK Key Exchange Mode: PSK-only key establishment (psk_ke) (0)
Extension: extended_master_secret (len=0)
Type: extended_master_secret (23)
Length: 0
Extension: signature_algorithms (len=40)
Type: signature_algorithms (13)
Length: 40
Signature Hash Algorithms Length: 38
Signature Hash Algorithms (19 algorithms)
Signature Algorithm: Unknown SM2 (0x0904)
Signature Hash Algorithm Hash: Unknown (9)
Signature Hash Algorithm Signature: SM2 (4)
Signature Algorithm: Unknown Unknown (0x0905)
Signature Hash Algorithm Hash: Unknown (9)
Signature Hash Algorithm Signature: Unknown (5)
…
Extension: renegotiation_info (len=1)
Type: renegotiation_info (65281)
Length: 1
Renegotiation Info extension
Renegotiation info extension length: 0
Le texte complet est en tls13-2.txt. Notez bien que la négociation est
en clair. D'autres exemples de traces TLS 1.3 figurent dans le RFC 8448.
Quelques autres articles à lire :
- L'annonce officielle de l'IETF,
- Le bon résumé de Cloudflare sur la version 1.3,
- Liste complète des réponses aux partisans de la visbilité,
- Bon article historique très détaillé sur l'histoire de TLS, jusqu'à la version 1.3,
- Un exemple d'un des ateliers où a été étudié la sécurité de TLS 1.3 à San Diego en 2016,
- Bon article sur la question des middleboxes, expliquant notamment les extensions « inutiles », mais permettant de tromper ces middleboxes pour ressembler à TLS 1.2.
L'article seul
RFC 9844: Entering IPv6 Zone Identifiers in User Interface
Date de publication du RFC : Août 2025
Auteur(s) du RFC : B. Carpenter (Univ. of
Auckland), R. Hinden (Check Point Software)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF 6man
Première rédaction de cet article le 17 février 2026
Ce très court RFC normalise la façon d'indiquer la zone quand il faut écrire une adresse IPv6 locale. Il remplace le RFC 6874, et est très différent, notamment parce qu'il ne s'applique plus aux URI.
Les zones sont définies et expliquées dans le RFC 4007. En gros, une adresse IPv6
n'est pas forcément globale, elle peut avoir une signification
limitée à une seule zone, une zone étant un ensemble de sous-réseaux
contigus, souvent composé d'un seul lien Ethernet. Les adresses
locales au lien, par exemple, celles qui sont dans le préfixe
fe80::/10, sont dans ce cas, le lien qui les
relie forme une zone. Une zone n'a de signification que locale, elle
n'a pas de sens sur l'Internet public. Comment préciser la zone dans
une interface qui accepte les adresses IPv6 ? La syntaxe de
celles-ci est normalisée dans le RFC 4291 et
le RFC 5952 mais ne prévoit rien pour la
zone. C'est surtout ennuyeux pour les réseaux purement IPv6 (RFC 8925) ou essentiellement IPv6 (draft-ietf-v6ops-6mops). Notre
RFC impose donc (section 5) que toute interface qui permet
d'indiquer des adresses IP permette également d'indiquer la
zone.
Indiquer la zone est utile pour les applications de déboguage (cf. l'exemple avec ping plus loin) ou pour configurer une machine (« ton serveur pour le service XXX est à l'adresse YYY »).
Pour indiquer cette zone, ce RFC normalise l'utilisation d'un %, puis l'identificateur de la zone, après l'adresse. La convention du % est décrite en section 11 du RFC 4007. Si l'interface utilisée pour entrer des adresses IP a un problème spécifique avec le %, le RFC autorise à utiliser le tiret à la place. Et si même cela est impossible, le RFC recommande deux champs, un pour l'adresse seule et un pour la zone. Ici, sur une machine Linux, avec le % :
% ping -c 3 fe80::f437:ded0:7b2:1241%enp1s0 PING fe80::f437:ded0:7b2:1241%enp1s0 (fe80::f437:ded0:7b2:1241%enp1s0) 56 data bytes 64 bytes from fe80::f437:ded0:7b2:1241%enp1s0: icmp_seq=1 ttl=64 time=68.0 ms 64 bytes from fe80::f437:ded0:7b2:1241%enp1s0: icmp_seq=2 ttl=64 time=13.2 ms 64 bytes from fe80::f437:ded0:7b2:1241%enp1s0: icmp_seq=3 ttl=64 time=15.6 ms --- fe80::f437:ded0:7b2:1241%enp1s0 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2003ms rtt min/avg/max/mdev = 13.175/32.268/68.015/25.296 ms
On teste la machine fe80::f437:ded0:7b2:1241
reliée au réseau identifié par enp1s0 (dans le
cas de Linux, c'est le nom d'une interface réseau mais d'autres
systèmes d'exploitation peuvent utiliser une syntaxe différente, par
exemple identifier les zones par un simple numéro comme le fait
Microsoft Windows).
Notez que ce n'est pas ping qui a reconnu et traité l'indication
de la zone mais le sous-programme
getaddrinfo (RFC 3493). Autrement, on aurait pu utiliser un
bricolage pour se connecter à une adresse lien local via une
bibliothèque LD_PRELOAD, où
l'application n'a pas besoin de connaitre cette syntaxe. Notez que
la fonction inet_pton ne va pas
accepter les adresses avec indication de zone, il faut utiliser
getaddrinfo ou bien, séparement,
inet_pton et
if_nametoindex.
Autre exemple d'utilisation, comme indiqué plus haut, la
configuration d'un équipement, par exemple pour lui indiquer « ton
résolveur DNS est
fe80::f437:ded0:7b2:1241%enp1s0 ». Ou bien les
filtres utilisés pour ne capturer que le trafic d'une machine. Mais
tcpdump (ou Wireshark)
ne reconnaissent pas actuellement cette syntaxe :
% tcpdump -n host fe80::f437:ded0:7b2:1241%enp1s0 tcpdump: can't parse filter expression: syntax error
(Pour tcpdump, il faudrait faire tcpdump -n -i enp1s0 host
fe80::f437:ded0:7b2:1241.)
Plus pittoresque, le système OneNet Marine IPv6 Ethernet Networking Standard de la NMEA utilise uniquement des adresses locales au lien et doit donc absolument utiliser un mécanisme permettant d'indiquer la zone.
Le RFC ne liste pas les différences avec son prédécesseur RFC 6874 car elles sont trop nombreuses. Le
principal changement est certainement l'abandon d'une
standardisation des zones dans les URI, qui n'avait jamais vraiment marché
(cf. draft-schinazi-httpbis-link-local-uri-bcp).
L'article seul
RFC 9824: Compact Denial of Existence in DNSSEC
Date de publication du RFC : Septembre 2025
Auteur(s) du RFC : S. Huque (Salesforce), C. Elmerot
(Cloudflare), O. Gudmundsson
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 12 décembre 2025
Plus fort que le chat de Schrödinger qui était à la fois mort et vivant, ce RFC permet à un nom de domaine d'être à la fois existant et non-existant. Plus précisément, il permet de fournir une preuve cryptographique avec DNSSEC, prouvant que le nom existe (alors qu'il n'existe pas) mais n'a pas les données demandées. Cette technique (autrefois connue sous le nom de « black lies », et largement déployée) est particulièrement adaptée au cas des signatures générées dynamiquement, mais a l'inconvénient de « mentir » sur l'existence du nom.
Pour comprendre, il faut revenir à un problème agaçant pour
DNSSEC : le déni d'existence. Ce terme
désigne le fait de prouver qu'un nom, ou qu'un certain type de
données pour un nom, n'existe pas. Car DNSSEC fonctionne en
signant les données. Mais en
cas de non-existence, il n'y a rien à signer. DNSSEC a donc ajouté
un type d'enregistrement nommé NSEC qui encadre le nom manquant. Et
ces enregistrements, eux, sont signés. Un enregistrement NSEC affirme
« ce nom n'existe pas » en donnant le nom précédent et le nom
suivant (ici, la réponse d'un serveur racine
à qui on a demandé www.trump alors que le
TLD
.trump n'existe pas) :
;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 65362 ;; flags: qr aa rd; QUERY: 1, ANSWER: 0, AUTHORITY: 6, ADDITIONAL: 1 … travelersinsurance. 86400 IN NSEC trust. NS DS RRSIG NSEC
On obtient un NXDOMAIN (ce nom n'existe pas), zéro réponse (la
section Answer est vide) et l'enregistrement NSEC nous dit qu'il n'y
a rien entre travelersinsurance et
trust. Comme il est signé (je n'ai pas montré
les signatures), nous avons une preuve de non-existence.
Et si le nom existe, mais n'a pas de données du type
demandé ? J'interroge mon résolveur sur la localisation
associée au nom www.iis.se :
% dig +dnssec www.iis.se LOC … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 39872 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 0, AUTHORITY: 4, ADDITIONAL: 1 … www.iis.se. 480 IN NSEC xmpp01.iis.se. A AAAA RRSIG NSEC …
Le NOERROR est normal (le nom existe) mais la section Answer est
vide (puisqu'il n'y a pas d'enregistrement de type LOC) et le NSEC
nous dit que le nom existe bien (le nom suivant étant
xmpp01.iis.se.) mais n'a comme type
d'enregistrement que A, AAAA, RRSIG et NSEC. On a donc prouvé que le
LOC n'existe pas.
Bon, tout ça, c'est du DNSSEC classique, tel que normalisé dans les RFC 4034 et RFC 4035. Ça marche, mais cela a des inconvénients, notamment pour les signatures générées dynamiquement. Cela nécessite plusieurs NSEC (il faut aussi montrer qu'il n'y a pas de joker), avec leurs signatures.
CDE (Compact Denial of Existence, alias
black lies) fonctionne (section 3 du RFC) en
calculant un intervalle minimal entre les noms, comme le faisaient
les white lies du RFC 4470. Mais, contrairement à eux, CDE fait partir cet
intervalle du nom demandé. Par exemple, si on demande
foobar.example et que ce nom n'existe pas, les
white lies fabriqueront un NSEC allant de
~.foobaq~.example à
foobar!.example alors que les black
lies de notre RFC feront un NSEC allant de
foobar.example à
\000.foobar.example. Cet intervalle démarrant
au nom de domaine demandé, il ne faut plus jamais renvoyer de
NXDOMAIN, uniquement des NODATA (NOERROR mais avec une section
Answer vide).
Voici un exemple de black lie chez Cloudflare (qui a déployé CDE il y a longtemps) :
% dig +dnssec doesnotexistcertainly.cloudflare.com … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 43853 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 0, AUTHORITY: 4, ADDITIONAL: 1 … ;; AUTHORITY SECTION: doesnotexistcertainly.cloudflare.com. 300 IN NSEC \000.doesnotexistcertainly.cloudflare.com. RRSIG NSEC TYPE128 … ;; Query time: 14 msec ;; SERVER: 192.168.2.254#53(192.168.2.254) (UDP) ;; WHEN: Fri Dec 12 14:10:39 CET 2025 ;; MSG SIZE rcvd: 400
Mais puisqu'on ne renvoie jamais de NXDOMAIN, comment distinguer
un nom qui n'existe pas d'un nom qui n'a simplement pas le type
demandé ? La section 2 du RFC présente le type NXNAME (enregistré avec le numéro 128, d'où le TYPE128
ci-dessus). Sa présence dans le NSEC indique que le nom n'existe
pas. Comparez la réponse ci-dessus avec celle-ci, où le nom existe,
mais pas le type (hex.pm
est chez
Cloudflare et n'a pas d'adresse
IPv6 associée à son nom) :
% dig +dnssec hex.pm AAAA … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 5431 ;; flags: qr aa rd; QUERY: 1, ANSWER: 0, AUTHORITY: 4, ADDITIONAL: 1 … hex.pm. 1800 IN NSEC \000.hex.pm. A NS SOA HINFO MX TXT LOC SRV NAPTR CERT SSHFP RRSIG NSEC DNSKEY TLSA SMIMEA HIP CDS CDNSKEY OPENPGPKEY SVCB HTTPS URI CAA
La longue liste de types dans le NSEC (mais sans le NXNAME/TYPE128) est due au fait que le serveur, qui génère des NSEC (et des signatures) dynamiquement ne connait pas la vraie liste donc il met tout ce qu'il connait.
Un résolveur qui connait les NXNAME peut donc refabriquer un code de retour NXDOMAIN et l'envoyer à ses clients (section 5 du RFC). Un nouveau booléen dans la question envoyée aux serveurs faisant autorité, le CO (Compact Answers OK) peut être utilisé pour dire au serveur faisant autorité qu'il peut répondre avec un NXDOMAIN, le client DNS qui met le CO indique qu'il saura lire et interpréter le NXNAME. (Le CO a été enregistré à l'IANA, le premier booléen d'une requête EDNS à être enregistré depuis DO il y a vingt-quatre ans.) Cette possibilité de rétablissement du NXDOMAIN ne semble pas très souvent mise en œuvre actuellement.
Notez (section 4) qu'on peut utiliser CDE avec NSEC3 mais que cela n'a aucun intérêt, vu que la compacité de l'intervalle des noms empêche déjà l'énumération des noms.
Enfin, si vous aimez les détails, l'annexe A du RFC discute des raisons des choix faits, et des alternatives étudiées (et même testées dans la nature), mais non retenues.
CDE est largement déployé aujourd'hui, notamment chez Cloudflare,
déjà cité, mais aussi chez d'autres hébergeurs utilisant la
signature dynamique, comme NS1. En logiciel libre, Knot permet le CDE. Il y a
aussi une implémentation (mais qui n'a pas été maintenue
synchrone avec le RFC) dans mon serveur Drink. Elle fut
développée lors d'un hackathon
IETF. Elle n'est pas activée par défaut, il faut changer un
paramètre dans le source (lib/drink/dnssec.ex).
L'article seul
RFC 9816: Usage and Applicability of BGP Link-State Shortest Path Routing (BGP-SPF) in Data Centers
Date de publication du RFC : Juillet 2025
Auteur(s) du RFC : K. Patel (Arrcus), A. Lindem (LabN Consulting), S. Zandi, G. Dawra (Linkedin), J. Dong (Huawei Technologies)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF lsvr
Première rédaction de cet article le 27 janvier 2026
Le RFC 9815 normalise l'utilisation de l'algorithme de routage SPF avec BGP. Dans quels cas est-ce que ça peut s'appliquer à l'intérieur d'un centre de données ? Ce RFC 9816 donne des éléments de réponse.
Il s'agit donc d'un court complément au RFC 9815 pour un cas courant, le centre de données qui suit la topologie décrite par Charles Clos dans son article de 1952, « A study of non-blocking switching networks ». (On trouve aussi cet article sur Sci-Hub ou à divers endroits sur le Web.) Pour que le trafic circule de n'importe quel nœud d'entrée vers n'importe quel nœud de sortie, on peut connecter tous les nœuds d'entrée à tous les nœuds de sortie mais cela fait beaucoup de connexions, qui coûtent cher. Ou bien on peut connecter tous les nœuds d'entrée à un dispositif de commutation qui ira vers tous les nœuds de sortie. Mais le trafic risque d'être bloqué si ce dispositif est surchargé. Dans un réseau Clos, on met des nœuds intermédiaires, avec une connectivité suffisante pour qu'on ne soit pas bloqué dans la plupart des cas. Il y a donc plusieurs chemins possibles d'un bout à l'autre du tissu ainsi formé (ce qui fait qu'un algorithme de routage comme le spanning tree n'est pas optimal puisqu'il ne trouve qu'un seul chemin). Dans un centre de données moderne, il y a en général une épine dorsale formée des commutateurs rapides et, dans chaque baie, un commutateur ToR (Top of Rack, rien à voir avec Tor). Tous les commutateurs ToR sont connectés à l'épine dorsale (liaison dite Nord-Sud, l'épine dorsale étant représentée en haut, le Nord) alors qu'il n'y a pas forcément de liaison entre les commutateurs ToR (liaison dite Est-Ouest).
Dans un centre de données non public (où toutes les machines appartiennent à la même entité), quel protocole de routage utiliser ? A priori, un IGP, non, puisqu'il s'agit de routage interne ? Mais pour diverses raisons, entre autres pour se simplifier la vie avec un seul protocole pour tout, certains utilisent BGP (RFC 7938) et même EBGP (External BGP), où les routeurs sont dans des AS différents (regardez la section 5 du RFC 7938 pour comprendre ce choix). Mais avec EBGP, les sessions BGP correspondent au chemin des données, ce qui empêche d'utiliser des réflecteurs de route. Et puis l'algorithme de routage classique de BGP ne converge pas assez vite en cas de changement, ce qui n'est pas grave sur l'Internet public mais est plus gênant à l'intérieur du centre de données. C'est là que le BGP-SPF du RFC 9815 devient intéressant, en remplaçant l'algorithme de routage traditionnel par SPF.
Utiliser BGP permet aussi de simplifier l'authentification, en se reposant sur les mécanismes existants comme celui du RFC 5925.
Autre avantage, les équipements réseau de ce centre de données aiment bien avoir de l'information détaillée sur la topologie et c'est justement ce que fournit l'extension BGP Link State, normalisée dans le RFC 9552, et dont BGP-SPF dépend. Il n'y a plus qu'à écouter le trafic BGP pour tout apprendre du réseau et bâtir ainsi divers services.
Plusieurs topologies d'appairage sont possibles entre les routeurs, collant à la topologie physique ou bien s'en écartant. Les routeurs peuvent utiliser BFD (RFC 5880) pour vérifier en permanence qu'ils arrivent bien à se joindre.
Même si le vieux protocole IPv4 est présent, on peut ne s'appairer qu'en IPv6 (cf. le RFC 8950) voire qu'avec des adresses locales (RFC 7404).
Et si un routeur veut jouer à BGP avec les autres routeurs mais sans être utilisé pour transmettre des paquets ? (Par exemple parce qu'il héberge des services applicatifs qui doivent être joignables.) Le TLV SPF status (RFC 9815, section 5.2.1.1) sert à cela : s'il est présent, avec une valeur de 2, le nœud ne sera pas utilisé pour le transit des paquets.
L'article seul
RFC 9815: BGP Link-State Shortest Path First (SPF) Routing
Date de publication du RFC : Juillet 2025
Auteur(s) du RFC : K. Patel (Arrcus), A. Lindem (LabN Consulting), S. Zandi (LinkedIn), W. Henderickx (Nokia)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF lsvr
Première rédaction de cet article le 27 janvier 2026
Vous le savez (peut-être), le protocole de routage BGP est du type « vecteur de chemin ». Mais il peut aussi transporter des états des liens, si on souhaite faire des choses plus proches des protocoles à état des liens. Ce RFC décrit comment, avec ces informations sur l'état des liens, décider du routage par l'algorithme SPF (Shortest Path First) plutôt que par la méthode traditionnelle de BGP.
Pour simplifier, un protocole à état des liens (comme OSPF ou IS-IS) permet à chaque routeur d'avoir l'état complet du réseau, et donc de faire tourner des algorithmes comme SPF, qui nécessite justement cette connaissance totale. Par contre, un protocole à vecteur de distance comme RIP ou à vecteur de chemin comme BGP n'a pas besoin de cette information et consomme donc moins de mémoire (pour BGP, stocker l'état de tous les liens de l'Internet serait évidemment impossible). Mais le protocole doit développer des mécanismes pour éviter, par exemple, les boucles de routage, qui pourraient arriver puisque chaque routeur décide sur la base d'une information incomplète.
Les deux types de protocole ont des avantages et des inconvénients et il est donc tentant de les combiner. Le RFC 9552 normalise justement un moyen de transporter l'état des liens avec BGP. Cela permet des prises de décision plus « intelligentes », comme dans le cas du RFC 9107 pour un réflecteur ou du RFC 7971 pour le mécanisme de décision ALTO. Pour transporter cet état, le RFC 9552 normalise un AFI (Address Family Identifier, RFC 4760, section 3) et un SAFI (Sub-address Family Identifier, même référence). Ce sont l'AFI 16388 et le SAFI 71. Ce BGP-LS (Border Gateway Protocol - Link State) sert de base à ce nouveau RFC, qui décrit une des manières d'utiliser cette information sur l'état des liens. (Cette technique a plusieurs années mais le développement du RFC a été long.)
Beaucoup de gros centres de données utilisent en interne BGP (RFC 4271) pour distribuer l'information de routage, car la densité des équipements créerait trop de trafic, avec les protocoles plus bavards comme OSPF (c'est documenté dans le RFC 7938 et RFC 9816). (Ces gros centres sont parfois appelés MSDC pour Massively Scaled Data Centers.) En outre, BGP repose sur TCP, ce qui élimine les problèmes de gestion des paquets perdus qu'ont les IGP traditionnels. Et puis cela permet de n'utiliser qu'un seul protocole comme IGP et EGP. Il ne restait qu'à étendre BGP pour pouvoir utiliser l'algorithme SPF de certains IGP, ce que fait notre RFC. Le principal avantage (section 1.2 du RFC) de cet ajout est que tous les routeurs auront désormais une vue complète de tout le réseau, sans qu'il y ait besoin de multiplier les sessions BGP. C'est utile pour des services comme ECMP, le calcul à l'avance de routes de secours (RFC 5286), etc.
Un peu de terminologie s'impose pour suivre ce RFC (section 1.1) :
- Domaine de routage BGP SPF : un ensemble de routeurs sous la même administration (cf. section 10.1) qui échangent de l'information sur l'état des liens via BGP, et calculent la table de routage avec SPF.
- NLRI (Network Layer Reachability Information) BGP-LS-SPF (LS = Link State, état des liens) : les NLRI (RFC 4271, section 3.1) sont les données envoyées dans les messages BGP. Ce type particulier de NLRI sert à transmettre les informations sur l'état des liens. Il a le numéro 80 et est encodé exactement comme le NLRI BGP-LS (tout court) du RFC 9552.
- Algorithme de Dijkstra : un autre nom de SPF (Shortest Path First), la grande nouveauté de notre RFC.
Bon, maintenant, le protocole lui-même. C'est bien sûr le bon vieux BGP du RFC 4271, avec l'extension LS du RFC 9552 et « juste » en plus l'utilisation de SPF pour le mécanisme de décision (« quelle route choisir ? »). Autrement, le RFC insiste, c'est du BGP normal, avec son automate, son format de paquets, ses signalements d'erreurs (RFC 7606), etc. Du fait du nouveau mécanisme de décision, les attributs optionnels des chemins annoncés n'ont pas à être transmis (les attributs obligatoires, comme leur nom l'indique, sont toujours transmis, même si SPF ne les utilise pas). Comme le calcul des routes se fait sur la base de l'information sur l'état des liens, un routeur BGP-LS-SPF n'attend pas d'avoir fait son calcul local avant de transmettre une annonce, il envoie tout (section 2). Le traditionnel mécanisme de décision de BGP (celui de la section 9.1 du RFC 4271) disparait et est remplacé par celui décrit en section 6. Cela implique, entre autres, que le chemin d'AS n'est plus utilisé pour empêcher les boucles.
On l'a dit, BGP-LS-SPF s'appuie sur le BGP-LS du RFC 9552 mais, avec un nouveau SAFI (Subsequent Address Family Identifier), le 80, puisque le SAFI du RFC 9552 supposait le processus de décision traditionnel de BGP (SPF ne doit être utilisé qu'avec les informations obtenues via les NLRI BGP-LS-SPF, cf. section 5.1). Par contre, les autres paramètres de BGP-LS sont utilisés tels quels (section 5.1.1). Il y a aussi des ajouts, par exemple pour indiquer qu'un lien ou un préfixe doit être considéré comme inutilisable par BGP-LS-SPF.
Les messages peuvent être gros, vu qu'on doit transporter l'information au sujet de tout le domaine de routage. Il est donc recommandé de mettre en œuvre le RFC 8654, qui permet d'avoir des messages BGP de plus de 4 096 octets.
La section 4 du RFC explique comment s'appairer pour échanger des informations sur les états des liens. En gros, rien de spécial, appairage direct ou passage par un réflecteur (RFC 4456) sont possibles comme avant.
L'article seul
RFC 9803: Extensible Provisioning Protocol (EPP) mapping for DNS Time-To-Live (TTL) values
Date de publication du RFC : Juin 2025
Auteur(s) du RFC : G. Brown (ICANN)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 14 juin 2025
Traditionnellement, les registres de noms de domaine publiaient toutes les informations des sous-domaines avec la même durée de vie maximale (TTL : Time To Live). Certain·es client·es demandent à pouvoir choisir un TTL plus court (ou, parfois, plus long) et ce RFC décrit comment faire cela avec le protocole EPP.
Cet EPP, normalisé dans les RFC 5730 et suivants, est aujourd'hui le plus utilisé par les
gros registres pour recevoir les commandes de
leurs BE. (Cf. cet
article de l'Afnic.) Tel que normalisé dans le RFC 5731, EPP ne permet pas, lors de la création
d'un nom de domaine, de spécifier le
TTL des
enregistrements NS
(NameServer) qui seront publiés. Prenons
l'exemple de l'enregistrement d'un
.fr. Le ou la titulaire
va sur l'interface Web de son BE, réserve le nom
cyberstructure.fr, le BE transmet la demande de
création en utilisant EPP et le registre publie ensuite dans le
DNS les
informations de délégation, ici récupérées avec dig :
% dig @d.nic.fr cyberstructure.fr NS … ;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 9, ADDITIONAL: 1 … ;; AUTHORITY SECTION: cyberstructure.fr. 3600 IN NS puck.nether.net. cyberstructure.fr. 3600 IN NS fns2.42.pl. cyberstructure.fr. 3600 IN NS ns2.bortzmeyer.org. cyberstructure.fr. 3600 IN NS ns4.bortzmeyer.org. cyberstructure.fr. 3600 IN NS ns2.afraid.org. cyberstructure.fr. 3600 IN NS fns1.42.pl. cyberstructure.fr. 3600 IN NS ns1.bortzmeyer.org. …
À aucun moment, la·e titulaire ou le BE n'a spécifié de TTL (les 3 600 secondes), il a été choisi par le registre seul. Certain·es titulaires peuvent pourtant avoir des préférences différentes. (Je rappelle que la notion de TTL est définie rigoureusement dans le RFC de terminologie DNS, le RFC 9499, voir sa section 5.)
Si vous voulez creuser ce concept de délégation, l'article de l'Afnic sur DELEG l'explique dans sa première partie.
L'exemple ci-dessus montrait les enregistrements NS (NameServer) mais ce problème concerne aussi les DS (RFC 9364), la colle et les éventuels DNAME (par exemple pour mettre en œuvre le RFC 6927).
Ce RFC normalise une extension à EPP pour permettre au client (le BE) d'indiquer le TTL souhaité pour la délégation. (Ce qui ne signifie pas que le registre satisfera ce souhait, lisez plus loin.) Plus précisément, il étend les classes (mappings) EPP pour les noms de domaine (RFC 5731) et pour les serveurs de noms (RFC 5732), les seules classes dont les données se retrouveront dans le DNS (rappelez-vous qu'EPP n'est pas limité aux noms de domaine, c'est un protocole d'avitaillement générique).
La section 1.2 du RFC contient les informations
essentielles. D'abord, l'espace de noms
urn:ietf:params:xml:ns:epp:ttl-1.0 (enregistré
à
l'IANA), qui identifie cette extension (le RFC utilise
l'alias ttl mais rappelez-vous qu'en XML, c'est l'espace de
noms qui compte, l'alias est choisi par l'auteur du document
XML). Ensuite, l'élément <ttl:ttl> (donc,
en complet,
{urn:ietf:params:xml:ns:epp:ttl-1.0}ttl), qui
peut être ajouté aux demandes EPP ou aux réponses. Parmi ses
attributs :
for(le seul qui soit obligatoire) indique le type de données DNS auxquelles l'élément s'applique (uniquement des types qui jouent un rôle dans la délégation, NS, DS, DNAME, A et AAAA, ainsi que la valeur spécialecustom, qu'il faut compléter avec un attributcustomqui suit l'expression rationnelle de la section 3.1 du RFC 6895, et évidemment utilise un type enregistré),min(uniquement dans les réponses) qui indique la valeur minimale que le serveur (donc le registre) accepte (le registre est toujours libre de sa politique et peut refuser une valeur trop basse ou trop haute, répondant avec le code d'erreur EPP 2004, Parameter value range error),max, la contrepartie demin, avec les mêmes propriétés,default, qu'on ne trouve également que dans les réponses, et qui permet de connaitre la valeur qu'utiliserait le serveur si le client ne demande rien de spécifique.
L'élément <ttl:ttl> a pour contenu une
valeur en secondes. Si cette valeur est vide, le serveur prendra la
valeur par défaut (mais autant ne pas mettre d'élément
<ttl:ttl> dans ce cas).
L'extension de ce RFC décrit des possibilités mais le registre,
qui gère le serveur EPP, reste libre de ne pas tout accepter. Par
exemple, il peut refuser l'utilisation de l'attribut
custom, ou bien la restreindre à certains types
(et, si le client demande quand même, répondre avec le code d'erreur
EPP 2306 Parameter value policy error). Les types
qui ont une syntaxe privilégiée (pas besoin de l'attribut XML
custom) sont ceux qu'on peut actuellement
trouver au-dessus de la coupure de zone (section 7 du RFC 9499).
Vous avez noté que, dans les types qui ont une syntaxe privilégiée dans ce RFC, il y a les types pour les adresses IP. Ils sont utilisés pour la colle DNS (section 7 du RFC 9499), si le serveur EPP met en œuvre la classe EPP pour les serveurs de noms (RFC 5732).
Un deuxième élément XML est spécifié par ce RFC,
<ttl:info>, qui sert à demander ou à
indiquer des informations sur la politique du serveur (voir des
exemples plus loin).
La section 2 décrit dans quelles commandes EPP on peut ajouter
les nouveaux éléments. Je ne vais pas toutes les détailler, juste
montrer quelques exemples du XML envoyé et des réponses. Ainsi, ici, le
client va utiliser la commande <epp:info>
pour se renseigner sur la politique du serveur :
… C: <info> C: <domain:info C: xmlns:domain="urn:ietf:params:xml:ns:domain-1.0"> C: <domain:name>example.com</domain:name> C: </domain:info> C: </info> C: <extension> C: <ttl:info C: xmlns:ttl="urn:ietf:params:xml:ns:epp:ttl-1.0" C: policy="false"/> C: </extension> …
Et la réponse du serveur :
… S: <response> S: <result code="1000"> S: <msg>Command completed successfully</msg> S: </result> S: <resData> … S: <domain:name>example.com</domain:name> S: <domain:status s="ok"/> … S: </resData> S: <extension> S: <ttl:infData S: xmlns:ttl="urn:ietf:params:xml:ns:epp:ttl-1.0"> S: <ttl:ttl for="NS">172800</ttl:ttl> S: <ttl:ttl for="DS">300</ttl:ttl> S: </ttl:infData> … S: </response> …
Le serveur indique que le TTL des enregistrements NS sera
de deux jours. Sinon, vous avez repéré le
policy="false" ? S'il avait été à
true, le serveur aurait renvoyé l'information
sur sa politique pour tous les types d'enregistrements DNS
(section 2.1.1.2).
Créons maintenant un nom de domaine en spécifiant un TTL :
C: <command>
C: <create>
C: <domain:create
C: xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
C: <domain:name>example.com</domain:name>
C: <domain:ns>
C: <domain:hostObj>ns1.example.com</domain:hostObj>
C: <domain:hostObj>ns1.example.net</domain:hostObj>
C: </domain:ns>
C: </domain:create>
C: </create>
C: <extension>
C: <ttl:create
C: xmlns:ttl="urn:ietf:params:xml:ns:epp:ttl-1.0">
C: <ttl:ttl for="NS">172800</ttl:ttl>
C: <ttl:ttl for="DS">300</ttl:ttl>
C: </ttl:create>
C: </extension>
C: </command>
C: </epp>
Cela marcherait aussi dans un
<domain:update>, pour changer les TTL.
Je l'ai déjà dit plusieurs fois, la demande du client ne va pas
forcément être honorée par le serveur. La section 3 de notre RFC
détaille l'interaction entre cette demande et la politique du
serveur (donc du registre). Ainsi, le serveur peut limiter les types d'enregistrement DNS auxquels
ces commandes s'appliquent, par exemple en n'acceptant de changer
le TTL que pour les DS (d'où l'intérêt des demandes avec
policy=…, pour savoir à l'avance).
D'autre part, le TTL des enregistrements publiés peut changer en dehors d'EPP, par une action du registre. Auquel cas, le registre (section 4) peut gentiment prévenir ses clients par le système de messagerie du RFC 8590.
La possibilité pour le client d'indiquer un TTL souhaité a aussi des conséquences opérationnelle (section 5). Ainsi, des TTL courts vont accroitre la charge sur les serveurs faisant autorité puisque les résolveurs auront besoin de demander plus souvent, les expirations se rapprochant. Souvent, les utilisateurs veulent des TTL courts, pour la réactivité, et n'ont pas conscience des conséquences, notamment en terme d'accroissement du trafic, d'autant plus que l'utilisation des serveurs DNS faisant autorité est gratuite pour eux. C'est pour cela que le registre peut fixer des valeurs minimales (et maximales, pour traiter d'autres problèmes) aux TTL souhaités par le client.
Une erreur parfois commise est de penser qu'un changement du TTL
(via une commande EPP <epp:update>) va se
voir instantanément. Mais, en fait, les informations, avec l'ancien
TTL, sont encore dans la mémoire de plusieurs résolveurs. Il est
donc recommandé de planifier les changements à
l'avance, en tenant compte de cette mémorisation (section 5.2 du
RFC). D'ailleurs, la politique du registre aussi peut changer, et
les TTL par défaut, ainsi que les valeurs maximales et minimales,
sont susceptibles d'être modifiées (un registre sérieux va informer
ses utilisateurices de ces changements mais parfois, c'est
oublié).
Un gros morceau de notre RFC est consacré à la sécurité (section 6) car les TTL ont une influence sur ce sujet. Premièrement, le fast flux (changement rapide des données de délégation DNS, cf. RFC 9499, section 7). Des malveillants utilisent cette technique pour rendre l'investigation numérique plus difficile et pour échapper à certaines règles de filtrage (voir le rapport SAC-025 du SAAC). Un TTL court peut faciliter ce changement rapide. Le rapport du SAAC suggère un TTL minimum de 30 minutes et/ou de limiter le nombre de changements qu'on peut faire par jour.
Si un malveillant réussit à obtenir les secrets qui lui permettent de soumettre des demandes de modification (au passage, pensez à activer l'authentification à plusieurs facteurs), il mettra sans doute des TTL très élevés pour que son détournement dure plus longtemps. D'où l'intérêt d'une valeur maximale pour les TTL.
Notre extension à EPP pour les TTL figure désormais dans le registre IANA des extensions et sa syntaxe complète, si vous êtes curieux·se, figure dans la section 8 (au format des schémas XML). Question mises en œuvre, vous en trouverez au moins deux, dans le SDK de Verisign et dans le logiciel Pepper (plus exactement dans la bibliothèque qu'il utilise, Net::EPP).
L'article seul
RFC 9799: Automated Certificate Management Environment (ACME) Extensions for ".onion" Special-Use Domain Names
Date de publication du RFC : Juin 2025
Auteur(s) du RFC : Q. Misell (AS207960)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF acme
Première rédaction de cet article le 27 juin 2025
Le protocole ACME,
normalisé dans le RFC 8555, permet
d'automatiser le processus de création et de renouvellement de
certificats utilisables, par exemple, pour
TLS. L'extension normalisée dans ce nouveau
RFC permet
d'obtenir et de renouveler des certificats pour un service utilisant
le .onion de
Tor. Si vous voulez passer à la télévision en
disant « j'ai obtenu un certificat pour le Dark Web », ce RFC est la
bonne lecture.
Ces services en
.onion sont décrits dans
la spécification de
Tor. Le nom .onion a été enregistré
comme « nom spécial » (RFC 6761) par le RFC 7686. Ces noms en .onion
ne sont pas résolvables via le DNS et on ne peut donc pas utiliser les défis
ACME (RFC 8555, section 8) classiques avec une
AC habituelle.
La norme ACME, le
RFC 8555, définit dans sa section 9.7.7 des
types d'identificateurs. Pour les
.onion, ce sera le type
dns, même si Tor
n'utilise pas le DNS. J'aurais préféré que ce type se nomme
domainname, ça aurait été plus cohérent (voir
l'annexe A du RFC, qui discute ce choix, qui prend place dans un
cadre très embrouillé, avec beaucoup de gens qui confondent noms de
domaine et DNS). L'identificateur est le nom dans
.onion, éventuellement avec des
sous-domaines. Par exemple, le JSON envoyé par ACME, pour la version en .onion de ce blog,
serait :
{
"type": "dns",
"value": "sjnrk23rmcl4ie5atmz664v7o7k5nkk4jh7mm6lor2n4hxz2tos3eyid.onion"
}
Reste à permettre au serveur ACME (l'AC)
de le valider. Le forum AC/Navigateur permet les
.onion (annexe B.2 de ses « Baseline
Requirements for the Issuance and Management of Publicly-Trusted
Certificates »). ACME utilise le concept de
défi pour ces validations. Le client ACME
demande un certificat pour un certain identificateur, le serveur lui
renvoie un défi, une tâche à accomplir, du genre « prouve-moi que tu
peux mettre ces données que je t'envoie dans un endroit accessible
en HTTP
via le nom pour lequel tu veux un certificat ». Il existe plusieurs
défis utilisables avec les .onion :
http-01(section 8.3 du RFC 8555), notre RFC dit qu'il faut suivre les redirections HTTP, même si elles mènent à un serveur HTTP qui n'est pas en.onion; c'est ce défi que j'ai utilisé pour mon blog.tls-alpn-01(RFC 8737).onion-csr-01, qui, contrairement aux deux précédents, est spécifique aux.onionet normalisé dans ce RFC 9799. C'est aussi le seul des trois défis utilisables qui permettre des jokers dans l'identificateur (*.bbcweb3hytmzhn5d532owbu6oqadra5z3ar726vq5kgwwn6aucdccrad.onion). Je le décris en détail plus loin. Cette méthode de validation figure désormais dans le registre des types de défis.dns-01(section 8.4 du RFC 8555), par contre, ne peut pas être utilisé pour les.onion, ceux-ci ne se servant pas du DNS.
Le défi onion-csr-01 consiste à demander au
client de générer une CSR (RFC 2986) signée avec la clé privée du
nom en .onion (je rappelle qu'un nom en
.onion est une clé publique, plus exactement
est dérivé d'une clé publique). Pour cela, le serveur ACME envoie un
numnique et sa clé publique
Ed25519, qu'il utilise pour Tor. Le client
doit répondre avec le CSR, signé avec sa clé privée, CSR contenant
parmi ses attributs le numnique choisi par le serveur, et un autre
choisi par le client. Le serveur vérifie alors ce CSR (le nom en
.onion, et bien sûr la signature).
Notez qu'on peut imaginer une AC qui ne soit elle-même accessible
que via un nom en .onion, ce qui serait
cohérent (section 5 du RFC). Par contre, en sortie, une AC doit
utiliser Tor pour se connecter aux .onion (je
veux dire l'utiliser directement, pas en passant par une passerelle,
cf. section 8.8) mais une AC ne doit
pas utiliser Tor pour se connecter à des
domaines non-onion (section 8.4) car il y a des
nœuds
de sortie méchants.
Et les enregistrements de type CAA, normalisés dans le RFC 8659, et qui augmentent la sécurité du système
en indiquant à quelles AC le client ACME a recours ? On ne peut pas
utiliser le CAA traditionnel puisqu'il dépend du DNS. La solution,
décrite dans la section 6 du RFC, est de mettre cette information
dans le descripteur de service Tor (celui que le serveur en
.onion envoie aux serveurs d'annuaire Tor).
Passons à la pratique. Il existe une AC
expérimentale (et qui ne prétend pas offrir les
garanties de sécurité d'une « vraie »), par l'auteure du RFC,
documentée sur le site Web du
projet. Je m'en suis servi pour obtenir un certificat pour
mon blog. Vous pouvez donc
désormais vous connecter en HTTPS, à https://sjnrk23rmcl4ie5atmz664v7o7k5nkk4jh7mm6lor2n4hxz2tos3eyid.onion/
Quelle est la marche à suivre pour obtenir un tel certificat ? D'abord, configurer Tor pour accepter le port de HTTPS :
HiddenServiceDir /var/lib/tor/blogv2/ HiddenServicePort 80 127.0.0.1:80 HiddenServicePort 443 127.0.0.1:443
Ensuite, configurer son serveur HTTP, Apache dans mon cas :
# Pour le client ACME (qui écoutera sur le port 8080) : ProxyPass /.well-known/acme-challenge http://localhost:8080/.well-known/acme-challenge ProxyPassReverse /.well-known/acme-challenge http://localhost:8080/.well-known/acme-challenge ProxyPreserveHost on # Ne pas oublier d'activer mod_proxy *et* mod_proxy_http. # HTTPS : <VirtualHost _default_:443> ServerName sjnrk23rmcl4ie5atmz664v7o7k5nkk4jh7mm6lor2n4hxz2tos3eyid.onion # Liens symboliques vers les certificats obtenus par ACME, dans mon # cas /etc/letsencrypt/live/sjnrk23rmcl4ie5atmz664v7o7k5nkk4jh7mm6lor2n4hxz2tos3eyid.onion/… SSLCertificateFile /etc/apache2/server.pem SSLCertificateKeyFile /etc/apache2/server.key
On lance ensuite le client ACME. J'ai utilisé certbot :
% sudo certbot certonly -v --server https://acme.api.acmeforonions.org/directory \
--standalone --http-01-port 8080 --http-01-address 127.0.0.1 \
-d sjnrk23rmcl4ie5atmz664v7o7k5nkk4jh7mm6lor2n4hxz2tos3eyid.onion
…
Performing the following challenges:
http-01 challenge for sjnrk23rmcl4ie5atmz664v7o7k5nkk4jh7mm6lor2n4hxz2tos3eyid.onion
Waiting for verification...
Cleaning up challenges
Successfully received certificate.
Certificate is saved at: /etc/letsencrypt/live/sjnrk23rmcl4ie5atmz664v7o7k5nkk4jh7mm6lor2n4hxz2tos3eyid.onion/fullchain.pem
Key is saved at: /etc/letsencrypt/live/sjnrk23rmcl4ie5atmz664v7o7k5nkk4jh7mm6lor2n4hxz2tos3eyid.onion/privkey.pem
This certificate expires on 2025-05-28.
…
(Et pensez à configurer le renouvellement automatique du certificat, normalement, certbot l'a fait tout seul, mais vérifiez.)
Un tcpdump montre le trafic échangé entre Apache (qui a reçu le défi de l'AC, via Tor) et certbot (qui avait envoyé la demande et stocké le défi du serveur ACME), sur ma machine :
127.0.0.1.60978 > 127.0.0.1.8080: Flags [P.] … HTTP, length: 376
GET /.well-known/acme-challenge/G4JwaWsRDG42H_FAESGCQrY7ZYk3D3mY9Ob_j458z6M HTTP/1.1
Host: sjnrk23rmcl4ie5atmz664v7o7k5nkk4jh7mm6lor2n4hxz2tos3eyid.onion
X-Forwarded-For: 127.0.0.1
X-Forwarded-Host: sjnrk23rmcl4ie5atmz664v7o7k5nkk4jh7mm6lor2n4hxz2tos3eyid.onion
X-Forwarded-Server: sjnrk23rmcl4ie5atmz664v7o7k5nkk4jh7mm6lor2n4hxz2tos3eyid.onion
127.0.0.1.8080 > 127.0.0.1.60978: Flags [P.] … HTTP, length: 92
HTTP/1.0 200 OK
Server: BaseHTTP/0.6 Python/3.11.2
Date: Thu, 27 Feb 2025 17:04:53 GMT
Si vous voulez ajouter cette AC (mais rappelez-vous qu'elle est
expérimentale et sans garanties de sécurité) au Tor
Browser, vous devrez sans doute, dans
about:config, configurer,
avant d'importer l'AC :
security.nocertdb false browser.privatebrowsing.autostart false security.ssl.enable_ocsp_stapling false
Mais je répète mon avertissement : cela peut affecter votre vie privée. Ne le faites pas si vous ne comprenez pas en détail les conséquences.
J'ai utilisé le défi http-01, avec un
certbot ordinaire. Le défi onion-01 nécessite
un certbot modifié (du code est disponible).
Petite anecdote : l'auteure du RFC travaille pour l'AS 207960, dont l'objet RIPE annonce :
aut-num: AS207960 as-name: AS-TRANSRIGHTS descr: Trans Rights! Hell Yeah!
Et le site Web montre d'ailleurs le drapeau correspondant. Il est assez rare de voir des prises de position politiques dans la base des RIR.
L'article seul
RFC 9794: Terminology for Post-Quantum Traditional Hybrid Schemes
Date de publication du RFC : Juin 2025
Auteur(s) du RFC : F. Driscoll, M. Parsons (UK National
Cyber Security Centre), B. Hale (Naval Postgraduate School)
Pour information
Réalisé dans le cadre du groupe de travail IETF pquip
Première rédaction de cet article le 14 juin 2025
La cryptographie post-quantique vise à développer des algorithmes de cryptographie qui résistent à des ordinateurs quantiques. Mais ces algorithmes sont relativement récents et peuvent avoir des faiblesses, voire des failles, que la cryptanalyse classique pourra exploiter. La tendance actuelle est donc aux protocoles et formats hybrides, combinant algorithmes classiques et post-quantiques. Ce RFC spécifie la terminologie de ces protocoles hybrides.
On peut aussi dire AQ, pour après-quantique car le sigle anglophone PQ de post-quantum peut faire drôle en France. D'ailleurs, les termes à utiliser (post-quantique ? résistant au quantique ?) ont fait l'objet de chaudes discussions dans le groupe de travail IETF.
Le point de départ de tout le tintouin autour de l'après-quantique, c'est l'algorithme de Shor. Conçu pour les calculateurs quantiques, et donc inutilisable encore aujourd'hui, il permet de résoudre des problèmes mathématiques qu'on croyait difficiles, comme la décomposition en facteurs premiers (qui est derrière RSA) ou le logarithme discret (qui est derrière ECDSA). Le jour, qui n'est pas encore arrivé, où on aura des CRQC (Cryptographically-Relevant Quantum Computer, un calculateur quantique qui puisse s'attaquer à des problèmes de taille réelle, et pas juste faire des démonstrations), ce jour-là, la cryptographie classique, ou traditionnelle, aura un problème.
Les CRQC sont loin dans le futur, un lointain dont il est très difficile d'estimer la distance. Comme on ne sait pas quand les CRQC seront disponibles, et que certains secrets qu'on chiffre maintenant devront rester secrets pendant de nombreuses années, il est prudent de travailler dès maintenant aux algorithmes AQ, après-quantique, ceux pour lesquels on ne connait pas d'algorithme (quantique ou classique) pour les casser. Ce travail a effectivement commencé depuis des années et on a déjà des algorithmes AQ normalisés comme ML-KEM (ex-Kyber). Notez toutefois qu'aucune norme IETF n'a encore été publiée en intégrant ces algorithmes, mais le travail est en cours, entre autres au sein du groupe de travail pquip.
Mais remplacer complètement les algorithmes traditionnels par les
algorithmes AQ n'est pas forcément satisfaisant. Au contraire de
RSA et
ECDSA, testés au feu depuis longtemps et qui
ont toujours résisté, les algorithmes AQ peuvent sembler un peu
jeunes. Que se passerait-il si un·e
cryptanalyste cassait un de ces algorithmes ?
Pour limiter les dégâts, on envisage d'utiliser des mécanismes
hybrides, combinant cryptographie classique
(pré-quantique) et après-quantique. Ainsi, un chiffrement hybride
verrait le texte en clair chiffré par un mécanisme classique puis
par un mécanisme après-quantique. Une signature hybride se ferait en
mettant deux signatures et en vérifiant ensuite que les deux sont
valides. Cette méthode « ceinture et bretelles » est utilisée par
exemple dans les RFC 9370 et RFC 9954 ou dans les Internet-Drafts
draft-ietf-lamps-pq-composite-kem
ou draft-ietf-lamps-cert-binding-for-multi-auth. On
peut aussi consulter la FAQ
du NIST (« A hybrid key-establishment mode is
defined here to be a key establishment scheme that is a combination
of two or more components that are themselves cryptographic
key-establishment schemes. ») ou bien le document
ETSI TS 103 744 nommé « Quantum-safe Hybrid Key
Exchanges ». Attention toutefois avec
cette terminologie car l'adjectif « hybride » est également souvent
utilisé en cryptographie pour désigner la combinaison d'un
algorithme de cryptographie asymétrique avec
un algorithme de cryptographie symétrique
(quand on crée une clé de session échangée via de la cryptographie
asymétrique puis qu'on chiffre les données avec cette clé et de la
cryptographie symétrique ; c'est ce que font TLS et
OpenPGP, par exemple). C'est le sens
qu'utilisent les RFC 4949 et RFC 9180, par exemple. Notre RFC 9794 note que
ces deux usages du terme « hybride » vont certainement prêter à
confusion mais qu'il n'y avait pas trop le choix : chaque usage
était déjà solidement installé dans un milieu particulier. Essayer
de promouvoir un autre terme pour la cryptographie après-quantique,
comme « double algorithme » ou « multi algorithme » était sans doute
voué à l'échec.
Passons maintenant aux définitions. Je ne vais pas les reprendre toutes mais donner quelques exemples. La section 2 du RFC commence par les mécanismes de base et d'abord, mécanisme hybride traditionnel / post-quantique (post-quantum traditional hybrid scheme, ou PQ/T), un mécanisme qui combine la cryptographie existante et celle du futur. On peut aussi simplifier en disant juste mécanisme hybride. Il y a aussi :
- Multi-algorithme, qui est plus large qu'hybride puisqu'il inclut les mécanismes ayant deux algorithmes traditionnels ou deux algorithmes après-quantique.
- Composé (composite), qui désigne les mécanismes hybrides où le mécanisme est exposé aux couches supérieures sous forme d'une interface unique (ce qui est évidemment plus simple et plus sûr pour le ou la programmeur·se).
Ensuite, on grimpe d'un niveau (section 3 du RFC), avec les éléments, qui sont les données en entrée ou en sortie d'un processus cryptographique. Quand on dit « l'algorithme X prend en entrée un texte en clair et une clé secrète et produit un texte chiffré », le texte en clair, la clé et le texte chiffré sont des éléments. Dans le mécanisme hybride décrit dans le RFC 9954, il y a deux clés publiques, qui sont deux éléments. Un élément peut à son tour être composé de plusieurs éléments.
On peut maintenant utiliser tout cela pour faire des protocoles (section 4). Un protocole hybride PQ/T est, comme vous vous en doutez, un protocole qui utilise au moins deux algorithmes, un classique et un après-quantique. C'est ce qui est proposé dans le RFC 9954. Ce dernier est même composé (dans le mécanisme de désignation de la clé, le KEM). Alors que le mécanisme du RFC 9370 est hybride mais pas composé (on fait un échange de clés classique et un KEM après-quantique).
Les noms des services de sécurité qu'on souhaite utiliser vont de soi (section 5) : confidentialité hybride PQ/T (confidentialité assurée par un mécanisme hybride traditionnel/après-quantique) et authentification hybride PQ/T.
Idem pour les certificats (section 6). Un
« certificat hybride PQ/T » contient au moins deux clés publiques,
une pour un algorithme traditionnel et une pour un algorithme
après-quantique (alors que le certificat traditionnel et le
certificat après-quantique ne contiennent qu'un seul type de clé
publique, comme c'est le cas du certificat décrit dans
draft-ietf-lamps-dilithium-certificates).
Et merci à Magali Bardet pour sa relecture mais, bien sûr, les erreurs sont de moi et moi seul.
L'article seul
RFC 9774: Deprecation of AS_SET and AS_CONFED_SET in BGP
Date de publication du RFC : Mai 2025
Auteur(s) du RFC : W. Kumari
(Google), K. Sriram, L. Hannachi (USA
NIST), J. Haas (Juniper Networks)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF idr
Première rédaction de cet article le 22 mai 2025
Dans le protocole de routage BGP, les annonces de
routes sont marquées avec l'AS d'origine et avec les AS qui ont relayé
l'annonce. Dans ce chemin des AS, on pouvait indiquer un
ensemble d'AS, l'AS_SET
(ainsi que l'AS_CONFED_SET). C'était
déconseillé depuis le RFC 6472 et ce nouveau RFC 9774 l'interdit désormais. Le but est de simplifier BGP et
notamment ses mécanismes de sécurité. Il faut maintenant forcément
indiquer une suite
ordonnée d'AS, une AS_SEQUENCE.
Ces AS_SET (et les
AS_CONFED_SET du RFC 5065 mais je vais
passer rapidement sur les confédérations) sont spécifiés par le RFC 4271, sections 4.3 et 5.1.2. Attention à ne pas
confondre avec les objets de type as-set des
bases des RIR comme, par exemple, celui
de l'Afnic.
Un des inconvénients de ces AS_SET est que,
puisqu'un ensemble n'est pas ordonné, il
n'est pas évident de déterminer l'AS d'origine, le premier AS, ce
qui est pourtant nécessaire pour la sécurité (ROV ou Route
Origin Validation, cf. RFC 6811).
Pourquoi mettait-on des AS_SET alors ? Parce
que c'est utile lorsqu'on effectue de l'agrégation de
routes. L'agrégation, spécifiée dans les sections 9.1.2.2 et 9.1.4
du RFC 4271 est le mécanisme par lequel un
routeur rassemble plusieurs routes en une route plus générale. Si
les routes originales venaient de plusieurs AS, on pouvait les
rassembler en un AS_SET. Mais, évidemment, cela
brouille l'information sur la vraie origine d'une route. C'est pour
cela que les techniques de sécurisation de BGP, comme le BGPsec du
RFC 8205 ne s'entendent pas bien avec les
AS_SET.
La section 3 est la partie normative du RFC : désormais, une
machine qui parle BGP ne doit plus utiliser
d'AS_SET ou
d'AS_CONFED_SET dans les chemins d'AS de ses
messages de mise à jour de routes. Une machine qui reçoit ce genre
de messages doit les traiter comme une erreur et retirer les routes
(cf. RFC 7606). Les techniques de sécurisation
comme ROV (RFC 6811) ou BGPsec (RFC 8205) considèrent toute annonce incluant des
AS_SET comme invalide.
Sur l'agrégation, voyez par exemple cette réponse sur StackExchange. La procédure désormais suggérée pour en faire (section 5) est d'indiquer comme AS d'origine du préfixe agrégé l'AS qui a fait l'agrégation (en s'assurant bien qu'il y a un ROA - RFC 6482). Les annexes A et B donnent des exemples détaillés.
Il est frappant de constater que la majorité des documentations
BGP des routeurs continue à mettre AS_SET et
AS_SEQUENCE sur un pied d'égalité, alors que le
RFC 6472 date de déjà 14 ans.
Le RFC note que les
AS_SET sont peu utilisés, et parfois mal (un
AS_SET ne comportant qu'un seul AS, ou bien
ayant des numéros
d'AS spéciaux…). Cherchons un peu. Je prends une RIB
(Routing Information Base) complète sur RouteViews. Elle est au format
MRT (Multi-Threaded Routing Toolkit, RFC 6396). Passons là à travers bgpdump, produisant
un fichier texte. Comment trouver les AS_SET ?
J'ai simplement lu le code source de bgpdump :
if (space)
{
if (segment->type == AS_SET
|| segment->type == AS_CONFED_SET)
as->str[pos++] = ',';
else
as->str[pos++] = ' ';
}
OK, il y a des virgules entre les AS (et une autre partie du code
montre que les AS_SET sont placés entre
accolades). On peut alors chercher le fichier texte et
trouver, par exemple, cette annonce :
TIME: 04/16/25 12:00:02
TYPE: TABLE_DUMP_V2/IPV4_UNICAST
PREFIX: 45.158.28.0/23
FROM: 12.0.1.63 AS7018
ORIGINATED: 04/15/25 06:11:28
ASPATH: 7018 3356 3223 {8262,34224} 201200
NEXT_HOP: 12.0.1.63
COMMUNITY: 7018:5000 7018:37232
L'annonce du préfixe 45.158.28.0/23, dont l'origine est
l'AS 201200, est passée par l'AS 8262 ou bien le 34224, ou bien il y
a eu agrégation de deux routes, chacune passée par un de ces deux AS
(mais cela n'a pas été marqué).
Sur un
looking glass, on voit le
passage par le 8262 uniquement :
Mon Apr 21 10:30:34.855 CEST
BGP routing table entry for 45.158.28.0/23
Paths: (3 available, best #2, not advertised to any peer)
Path #1: Received by speaker 0
174 3356 3223 8262 201200, (received-only)
149.6.34.5 from 149.6.34.5 (38.28.1.70)
Origin IGP, metric 17060, localpref 100, valid, external
Community: 174:21100 174:22009
Origin-AS validity: not-found
…
Soit ce looking glass a reçu une autre annonce,
soit son code n'affiche que l'un des AS de
l'AS_SET.
Autre exemple, où l'AS_SET est à l'origine :
TIME: 04/16/25 12:00:04
TYPE: TABLE_DUMP_V2/IPV4_UNICAST
PREFIX: 67.204.16.0/22
FROM: 89.149.178.10 AS3257
ORIGINATED: 04/10/25 00:44:05
ASPATH: 3257 13876 {15255,396519,396895}
NEXT_HOP: 89.149.178.10
MULTI_EXIT_DISC: 10
AGGREGATOR: AS13876 67.204.31.4
COMMUNITY: 3257:4000 3257:8118 3257:50002 3257:50120 3257:51100 3257:51110
Là, il y a eu agrégation, par l'AS 13876, qui a placé un
AS_SET. Vu par le looking
glass :
Mon Apr 21 10:39:46.348 CEST
BGP routing table entry for 67.204.16.0/22
Paths: (3 available, best #2, not advertised to any peer)
Path #1: Received by speaker 0
174 3356 13876 {15255,396519,396895}, (aggregated by 13876 67.204.31.4), (received-only)
149.6.34.5 from 149.6.34.5 (38.28.1.70)
Origin IGP, metric 17060, localpref 100, valid, external
Community: 174:21100 174:22009
Origin-AS validity: not-found
Je ne suis pas sûr que tous les looking
glass affichent correctement les
AS_SET. Mais étant donné que notre nouveau RFC
met les AS_SET à la poubelle, il ne servirait à
rien de demander au développeur d'ajouter ce service. Ah, et mon
bot fédivers qui lit la table
BGP gère ça
bien.
L'article seul
RFC 9773: ACME Renewal Information (ARI) Extension
Date de publication du RFC : Juin 2025
Auteur(s) du RFC : A. Gable (Internet Security Research
Group)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF acme
Première rédaction de cet article le 18 juin 2025
Si vous utilisez Let's Encrypt (et tout le monde l'utilise, de nos jours), vous avez sans doute reçu les messages « Let's Encrypt Expiration Emails Update » qui vous préviennent que cette AC n'enverra plus de rappels que vos certificats vont bientôt expirer. C'est parce qu'un meilleur système est maintenant disponible, ARI (ACME Renewal Information). ARI permet à une AC utilisant le protocole ACME d'indiquer à ses clients des suggestions sur le renouvellement des certificats. Il est décrit dans ce RFC.
ACME est normalisé dans le RFC 8555 et est surtout connu via le succès de Let's Encrypt. Les certificats sont de courte durée (aujourd'hui trois mois mais ça va diminuer) et il faut donc les renouveler souvent. On peut le faire automatiquement via cron, ou bien analyser le certificat et renouveler quand sa date d'expiration approche. L'un des problèmes est que cela peut mener à ce que plusieurs demandes de renouvellement arrivent en même temps sur l'AC. Le pic d'activité qui en résulterait pourrait charger l'AC inutilement. L'idée est donc que ce soit le serveur ACME, l'AC, qui planifie les renouvellements, et pas le client ACME. Cela permettrait aussi des changements de planning, comme une réduction des durées de validité, ou bien une révocation.
Donc, ARI ajoute un nouvel URL à la description d'une AC,
renewalInfo. Voici celui de Let's Encrypt (qui
met
en œuvre ARI depuis deux ans) :
% curl https://acme-v02.api.letsencrypt.org/directory
{
"keyChange": "https://acme-v02.api.letsencrypt.org/acme/key-change",
"meta": {
"caaIdentities": [
"letsencrypt.org"
],
"profiles": {
…
},
"termsOfService": "https://letsencrypt.org/documents/LE-SA-v1.5-February-24-2025.pdf",
…
},
"newAccount": "https://acme-v02.api.letsencrypt.org/acme/new-acct",
"newNonce": "https://acme-v02.api.letsencrypt.org/acme/new-nonce",
"newOrder": "https://acme-v02.api.letsencrypt.org/acme/new-order",
"renewalInfo": "https://acme-v02.api.letsencrypt.org/draft-ietf-acme-ari-03/renewalInfo",
"revokeCert": "https://acme-v02.api.letsencrypt.org/acme/revoke-cert"
Ce nouveau membre a été ajouté au registre IANA.
Et comment on obtient quelque chose à cet URL
https://acme-v02.api.letsencrypt.org/draft-ietf-acme-ari-03/renewalInfo ?
On doit passer un identificateur du certificat. Il est formé par la
concaténation de l'identifiant de l'AC et du numéro de série du
certificat (pour garantir qu'il soit unique). Je passe sur les
détails de construction (lisez la section 4 du RFC pour cela) mais
ce petit script Python ari-make-path.py
% openssl x509 -text -in cert.pem
[Notez les valeurs]
% python ari-make-path.py 93:27:46:98:03:A9:51:68:8E:98:D6:C4:42:48:DB:23:BF:58:94:D2 00:06:7d:03:91:c6:49:b8:83:ba:e5:c6:da:8a:dc:be:4d:33:78
kydGmAOpUWiOmNbEQkjbI79YlNI.AAZ9A5HGSbiDuuXG2orcvk0zeA
% curl -i https://acme-v02.api.letsencrypt.org/draft-ietf-acme-ari-03/renewalInfo/kydGmAOpUWiOmNbEQkjbI79YlNI.AAZ9A5HGSbiDuuXG2orcvk0zeA
…
retry-after: 21600
…
{
"suggestedWindow": {
"start": "2025-06-23T03:50:00Z",
"end": "2025-06-24T23:00:50Z"
}
}
Voilà, on a fait un URL en concaténant la valeur de
renewalInfo avec celle obtenue à partir du
certificat et on sait désormais quand est-ce que Let's Encrypt
suggère de renouveler ce certificat. Le format de sortie est clair
mais vous avez les détails dans la section 4.2. Les dates sont
évidemment au format du RFC 3339. Au passage,
la date d'expiration est le 24 juillet 2025 donc Let's Encrypt
n'attend pas le dernier moment. (Comme le dit un commentaire dans le
code source du serveur, « calculate a point 2/3rds of the
way through the validity period (or halfway through, for short-lived
certs) ».)
Le RFC précise qu'un membre explanationURL
peut être ajouté mais Let's Encrypt ne le fait pas. Les membres
possibles figurent dans un
nouveau registre IANA, auquel on pourra ajouter de nouveaux
membres, en fournissant une spécification (« Spécification
nécessaire » du RFC 8126).
Et on utilise cet intervalle entre deux dates comment ? Le RFC
recommande de choisir une date au hasard dans l'intervalle. Le
client ACME ne doit pas dormir jusqu'à la date sélectionnée, il doit
réessayer de temps en temps car l'AC a pu changer la date (c'est
tout le principe d'ARI). Mais attention à respecter le
Retry-After: (six heures, ici), cf. RFC 9110, section 10.2.3.
Notre RFC ajoute également un membre à la description d'une
commande de certificat : replaces indique quel
certificat on est censé remplacer. (En utilisant le même
identificateur de certificat qu'indiqué plus haut.) Il a été ajouté
au
registre IANA.
ARI est mis en œuvre dans le serveur ACME de Let's Encrypt, Boulder. Regardez
core/objects.go et notamment la fonction
RenewalInfoSimple. Côté client, Lego, acmez et le CertMagic
de Caddy ont ARI mais
certbot ou dehydrated
ne gèrent pas ARI. Si vous voulez vous y mettre, Let's Encrypt a
écrit un guide
d'intégration d'ARI.
L'article seul
RFC 9771: Properties of AEAD Algorithms
Date de publication du RFC : Mai 2025
Auteur(s) du RFC : A. Bozhko (CryptoPro)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF cfrg
Première rédaction de cet article le 8 mai 2025
Aujourd'hui, sur l'Internet, on n'utilise plus (ou, en tout cas, cela devrait être le cas) que des algorithmes de chiffrement AEAD (Authenticated Encryption with Associated Data). Ils assurent confidentialité et intégrité des données. Mais on peut être gourmand et vouloir en plus d'autres propriétés. Ce nouveau RFC classe ces propriétés et définit la terminologie.
Les algorithmes de chiffrement anciens, non-AEAD, assuraient la confidentialité, mais pas l'intégrité. Un méchant (ou un accident) pouvait modifier les données sans que ce soit détectable et le déchiffrement produisait ensuite un texte qui n'était pas le texte original. Bien sûr, s'il s'agissait d'un texte en langue naturelle, ou bien d'un texte dans un format structuré, l'utilisateurice pouvait parfois voir qu'il y avait eu un problème, puisque, avec certains modes de chiffrement, ielle ne récupérait que du n'importe quoi. Mais il serait souhaitable de détecter l'attaque (ou le problème) le plus tôt possible. Et il y a aussi des raisons de sécurité pour assurer confidentialité et intégrité en même temps. Sinon, certaines attaques (comme Poodle) sont possibles. Et il faut aussi compter avec le fait que les programmeurs peuvent se tromper s'ils doivent appliquer confidentialité et intégrité séparément (cf. RFC 7366).
Vérifier l'intégrité peut se faire avec une somme de contrôle avec clé (MAC), ou une technique équivalente mais l'AEAD fait mieux, en intégrant chiffrement et vérification de l'intégrité. Cela a plusieurs avantages, dont les performances (plus besoin de chiffrer et de calculer un MAC successivement) et, comme indiqué plus haut, la sécurité.
Dans la famille des normes de l'Internet, l'AEAD est décrit plus en détail dans le RFC 5116. À partir de la version 1.3 (normalisée dans le RFC 9846), TLS impose l'utilisation d'algorithmes AEAD. Même chose pour QUIC (RFC 9000). Parmi les algorithmes AEAD courants, on trouve AES-GCM et ChaCha20-Poly1305 (RFC 8439) mais aussi Aegis ou OCB (RFC 7253).
Au passage, je trouve que le terme en anglais, authenticated encryption et sa traduction en français, chiffrement authentifié, sont trompeurs. Le service qu'ils assurent n'est pas l'authentification telle qu'on peut la faire avec RSA ou ECDSA. Je préférerais qu'on parle de chiffrement intègre.
Tout cela est bien connu depuis des années. Mais l'appétit vient en mangeant et certaines utilisations bénéficieraient de services supplémentaires. Les algorithmes existants sont sûrs par rapport aux modèles de menace « traditionnels » mais il en existe d'autres, auxquels tous les algorithmes AEAD ne répondent pas forcément. Ces services supplémentaires, pour répondre à ces modèles de menace, existaient parfois, et parfois ont déjà été développés, mais des équipes différentes leur donnent des noms différents. D'où le projet d'unification de la terminologie de ce RFC 9771. Il présente les propriétés supplémentaires (en plus de la confidentialité et de l'intégrité, que tout algorithme AEAD fournit), des noms d'algorithmes qui les fournissent et des cas d'usage. Le but est que les futurs RFC normalisant des protocoles qui dépendent de ces propriétés utilisent le vocabulaire de notre RFC.
Les propriétés supplémentaires, au-delà de la confidentialité et de l'intégrité basiques, sont listées dans la section 4. Il y a deux catégories :
- Propriétés de sécurité, lorsque la propriété permet de parer certaines attaques,
- propriétés de mise en œuvre, lorsqu'elles permettent de meilleures implémentations,
- et, pour, voir si vous savez compter jusqu'à deux, il y a aussi une catégorie un peu fourre-tout, pour les propriétés qui ajoutent de nouvelles fonctions, mais je n'en parlerai pas plus ici (consultez l'annexe A du RFC).
Avant d'exposer les propriétés additionnelles, le RFC présente les traditionnelles, en suivant le même schéma (définition, exemples, éventuels synonymes, cas d'usage, lectures pour approfondir) : confidentialité et intégrité sont ainsi exposées. Passons ensuite aux choses sérieuses, avec les propriétés de sécurité supplémentaires.
D'abord, la sécurité face aux changements (blockwise security) : c'est le fait d'être sûr même quand un adversaire particulièrement puissant peut modifier le texte en clair en fonction de ce qui a déjà été chiffré. Tous les adversaires n'ont heureusement pas ce pouvoir mais cela peut arriver, par exemple lors du streaming. Ainsi, la famille Deoxys résiste à ce type d'attaque.
Ensuite, l'engagement complet (full commitment). C'est l'extrême difficulté à trouver deux jeux {clé, numnique, données en clair} qui donneront le même texte chiffré. Cela sert dans le message franking mais ne me demandez pas ce que c'est, lisez cet article. Ascon a cette propriété. Et, au passage, le AD de AEAD veut dire « données associées » (associated data, des méta-données ajoutées au message) et les « données en clair » incluent donc ces données associées.
La résistance aux fuites (leakage resistance) est une propriété des algorithmes cryptographiques (pas seulement AEAD) dont la sécurité ne diminue pas même si l'attaquant obtient des informations via un canal secondaire. Un exemple d'un tel canal secondaire est le temps de calcul (si l'attaquant peut le chronométrer et si l'algorithme n'est pas résistant aux fuites, l'attaquant pourra obtenir des informations sur la clé) ou bien la consommation électrique. Bien sûr, cela dépend de l'implémentation (essayer de faire tous les calculs en un temps constant, quelle que soit la clé) mais un algorithme résistant aux fuites est un algorithme qui ne dépend pas trop (mild requirement, dit le RFC) de son implémentation concrète pour être sûr. Cette propriété est particulièrement importante pour les machines que l'attaquant peut contrôler physiquement (cartes à puce, objets connectés) alors que mesurer le temps de calcul, et a fortiori la consommation électrique, d'un serveur Internet distant est une autre affaire. (Mais ça reste possible dans certains cas, notamment si l'attaquant est proche, par exemple chez le même hébergeur : voir l'article « Remote Timing Attacks Are Practical » ou bien la faille Hertzbleed.)
La sécurité multi-utilisateurs (multi-user
security) est atteinte quand la sécurité décroit moins vite que linéairement avec le nombre
d'utilisateurs (les algorithmes ont des limites quantitatives, cf. draft-irtf-cfrg-aead-limits). C'est indispensable pour des protocoles comme
TLS, où
plusieurs « utilisateurs » peuvent se retrouver sur la même session
TLS. Des algorithmes comme AES-GCM
ou
ChaCha20-Poly1305 ont cette sécurité (si
on ne dépasse pas les limites). Vous pouvez lire « The Multi-user Security of Authenticated Encryption: AES-GCM in TLS 1.3 »
pour les détails.
Bien sûr, il fallait mentionner la propriété de résistance aux calculateurs quantiques (Quantum security). AEAD ou pas, un algorithme est résistant au quantique si on ne connait pas d'algorithme pour calculateur quantique capable de casser cet algorithme. Les algorithmes comme AES-GCM ou ChaCha20-Poly1305 sont ainsi résistants (au prix parfois d'une augmentation raisonnable de la taille de la clé). Cette résistance permet de faire face au cas où un indiscret stocke aujourd'hui des messages qu'il ne sait pas déchiffrer, en attendant qu'il dispose d'un calculateur quantique. Notez que si on fait face à un adversaire mieux armé, qui n'a pas seulement un calculateur quantique mais peut en plus accéder à l'état quantique de votre système de chiffrement, ça devient plus compliqué. Dans ce cas très futuriste, il faut passer à des algorithmes comme QCB (cf. « QCB: Efficient Quantum-Secure Authenticated Encryption »).
Tout cela, c'étaient les propriétés de sécurité des algorithmes, liés à la définition de ces algorithmes. Mais, en pratique, on n'utilise pas un algorithme mais une mise en œuvre de l'algorithme, réalisée dans un programme. La section 4.4 du RFC liste des propriétés souhaitables des mises en œuvre (en plus de la propriété évidente que le programme soit rapide), propriétés qui n'affectent pas la sécurité (que ce soit en bien ou en mal). Par exemple, on souhaite que le programme soit léger, au sens où il tourne sur des machines contraintes (en mémoire, en processeur, en énergie, etc). Le rapport du NIST « NISTIR 8114 - Report on Lightweight Cryptography » est une lecture intéressante à ce sujet.
On souhaite ensuite un programme qui puisse exploiter le parallélisme de la machine qui l'exécute. Si celle-ci a plusieurs processeurs et/ou plusieurs cœurs, il serait bon que le travail puisse être réparti entre ces cœurs. Des algorithmes comme le mode CBC ne permettent pas le parallélisme lors du chiffrement.
Autres propriétés souhaitables citées par le RFC : ne pas nécessiter un travail supplémentaire ou de nouvelles ressources quand on introduit une nouvelle clé, fonctionner en une passe unique sur les données, permettre de chiffrer un flux de données continu, sans attendre sa fin…
Merci beaucoup à Manuel Pégourié-Gonnard et Florian Maury pour une relecture détaillée avec plein de bonnes remarques. Comme toujours, les erreurs et approximations sont de moi, pas des relecteurs.
L'article seul
RFC 9755: IMAP Support for UTF-8
Date de publication du RFC : Mars 2025
Auteur(s) du RFC : P. Resnick (Episteme Technology
Consulting), J. Yao
(CNNIC), A. Gulbrandsen (ICANN)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF extra
Première rédaction de cet article le 18 mars 2025
Successeur du RFC 6855, voici la normalisation de la gestion d'Unicode par le protocole IMAP (dans sa version 4rev1) d'accès aux boîtes aux lettres.
Normalisé dans le RFC 3501, IMAP version 4rev1 permet d'accéder à des boîtes aux lettres situées sur un serveur distant. Ces boîtes peuvent avoir des noms en Unicode, les utilisateurs peuvent utiliser Unicode pour se nommer et les adresses gérées peuvent être en Unicode. L'encodage utilisé est UTF-8 (RFC 3629). C'est donc une des composantes d'un courrier électronique complètement international (RFC 6530). (Il existe un RFC équivalent pour POP le RFC 6856. Pour IMAP 4rev2, normalisé dans le RFC 9051, UTF-8 est prévu dès le début.)
Tout commence par la possibilité d'indiquer le support
d'UTF-8. Un serveur IMAP, à l'ouverture de la connexion, indique les
extensions d'IMAP qu'il gère et notre RFC normalise
UTF8=ACCEPT (section 3). En l'utilisant, le
serveur proclame qu'il sait faire de l'UTF-8. Par le biais de
l'extension ENABLE (RFC 5161), le
client peut à son tour indiquer qu'il va utiliser UTF-8. Une fois
que cela sera fait, client et serveur pourront faire de l'IMAP
UTF-8. Cette section 3 détaille la représentation des chaînes de
caractères UTF-8 sur le réseau.
Les nouvelles capacités sont toutes décrites dans la section 10 et enregistrées dans le registre IANA.
On peut donc avoir des boîtes aux lettres qui ne peuvent être manipulées qu'en UTF-8. Les noms de ces boîtes doivent se limiter au profil « Net-Unicode » décrit dans le RFC 5198, avec une restriction supplémentaire : pas de caractères de contrôle.
Il n'y a bien sûr pas que les boîtes, il y a aussi les noms
d'utilisateurs qui peuvent être en Unicode, et la section 5 spécifie
ce point. Elle note que le serveur IMAP s'appuie souvent sur un
système d'authentification externe (comme
/etc/passwd sur Unix) et
que, de toute façon, ce système n'est pas forcément UTF-8. Prudence,
donc.
Aujourd'hui, encore rares sont les serveurs IMAP qui gèrent
l'UTF-8. Mais, dans le futur, on peut espérer que
l'internationalisation devienne la norme et la limitation à US-ASCII
l'exception. Pour cet avenir radieux, la section 7 du RFC prévoit
une capacité UTF8=ONLY. Si le serveur
l'annonce, cela indique qu'il ne gère plus l'ASCII seul, que tout
est forcément en UTF-8.
Outre les noms des boîtes et ceux des utilisateurs, cette norme IMAP UTF-8 permet à un serveur de stocker et de distribuer des messages dont les en-têtes sont en UTF-8, comme le prévoit le RFC 6532.
La section 8 expose le problème général des clients IMAP
très anciens. Un serveur peut savoir si le client accepte UTF-8 ou
pas (par le biais de l'extension ENABLE) mais,
si le client ne l'accepte pas, que peut faire le serveur ? Le
courrier électronique étant asynchrone, l'expéditeur ne savait pas,
au moment de l'envoi si tous les composants, côté réception, étaient
bien UTF-8. Le RFC n'impose pas une solution unique. Le serveur peut
dissimuler le message problématique au client archaïque. Il peut
générer un message d'erreur. Ou il peut créer un substitut, un
ersatz du message originel, en utilisant les
algorithmes du RFC 6857 ou du RFC 6858. Ce ne sera pas parfait, loin de là. Par exemple, de
tels messages « de repli » auront certainement des
signatures invalides. Et, s'ils sont lus par
des logiciels différents (ce qui est un des avantages d'IMAP),
certains gérant l'Unicode et d'autres pas, l'utilisateur sera
probablement très surpris de ne pas voir le même message, par
exemple entre son client traditionnel et depuis son
webmail. C'est affreux, mais inévitable :
bien des solutions ont été proposées, discutées et même décrites
dans des RFC (RFC 5504) mais aucune d'idéale
n'a été trouvée.
Je n'ai pas testé les implémentations en logiciel libre mais, apparemment, la bibliothèque standard de Python est déjà conforme à ce RFC (cherchez "UTF" dans la documentation), ainsi que celle de Java. Si vous connaissez des utilisateurices du courrier électronique en Unicode, demandez leur quel serveur IMAP ielles utilisent.
Le résumé des différences (peu importantes) avec son
prédécesseur, le RFC 6855 est dans l'annexe
B. UTF8=APPEND disparait, et FETCH
BODYSTRUCTURE voit sa sémantique modifiée.
L'article seul
RFC 9750: The Messaging Layer Security (MLS) Architecture
Date de publication du RFC : Avril 2025
Auteur(s) du RFC : B. Beurdouche (Inria & Mozilla), E. Rescorla (Windy Hill Systems), E. Omara, S. Inguva, A. Duric (Wire)
Pour information
Réalisé dans le cadre du groupe de travail IETF mls
Première rédaction de cet article le 23 avril 2025
On le sait, un des problèmes stratégiques de l'Internet est l'absence d'un protocole de messagerie instantanée standard et largement répandu. Autant le courrier électronique fonctionne relativement bien entre logiciels différents, autant la messagerie instantanée est un monde de jardins clos, incompatibles entre eux, et qui nécessite d'installer vingt applications différentes sur son ordiphone. L'interopérabilité reste un objectif lointain. Il n'y a pas de solution simple à ce problème mais le système MLS (Messaging Layer Security) vise à au moins fournir un mécanisme de sécurité pour les groupes, mécanisme qui peut ensuite être utilisé par un protocole complet, comme XMPP (RFC 6120). MLS est normalisé dans le RFC 9420 et cet autre RFC, le RFC 9750, décrit l'architecture générale.
Les services de sécurité que doit offrir MLS sont les classiques (confidentialité, notamment) et, bien sûr, doivent être assurés de bout en bout (l'opérateur du service ne doit pas pouvoir casser la sécurité et, par exemple, ne doit pas pouvoir lire les messages). Quand il n'y a que deux participants, c'est relativement facile mais MLS est prévu pour des groupes, allant de deux à potentiellement des centaines de milliers de participant·es.
Le protocole, on l'a vu, est spécifié dans le RFC 9420. Il repose sur l'envoi de messages de maintenance du
groupe, comme le message Proposal, qui demande
un changement dans la composition du groupe, ou
Commit, qui va créer une nouvelle
epoch, c'est-à-dire un nouvel état du groupe (la
ressemblance avec le commit d'un VCS comme
git est volontaire). Les clés effectivement
utilisées pour le chiffrement sont liées à cet état, et changent
avec lui.
Le protocole MLS repose sur deux services, qui doivent être fournis pour qu'il puisse fonctionner (voir aussi la section 7) :
- Un service d'authentification des utilisateurices, l'AS (Authentication Service, section 4 du RFC), qui permettre d'obtenir les clés publiques, avec la garantie qu'elles sont bien liées à l'identificateur utilisé par l'utilisateurice,
- Un service de livraison, le DS (Delivery Service, section 5), qui va se charger de porter les messages.
Il n'y a pas besoin de faire confiance au DS, tous les messages étant chiffrés. La seule possibilité d'action d'un DS malveillant serait de ne pas transmettre les messages. (Par contre, un AS malveillant pourrait casser toute la sécurité, en envoyant des clés publiques mensongères, permettant par exemple l'espionnage.)
MLS n'impose pas une forme particulière à l'AS et au DS. Par exemple, il pourrait utiliser une PKI (RFC 5280) traditionnelle comme AS. On l'a dit, MLS n'est pas une solution complète de messagerie instantanée, une telle solution nécessite aussi l'AS, le DS et plein d'autres choses. Parmi les systèmes existants, on peut noter que PGP repose sur les serveurs de clés et le Web of Trust comme AS et sur le courrier comme DS. Signal repose sur un système centralisé comme DS et sur une vérification des clés par les utilisateurices comme AS (voir aussi la section 8.4.3.1 de notre RFC, sur l'authentfication des utilisateurices).
Le RFC rappelle que MLS ne met pas de contrainte à ces messages de changement du groupe. Si on veut le faire (par exemple créer des groupes fermés au public), cela doit être fait dans le protocole complet, qui inclut MLS pour la partie « chiffrement au groupe ». Par contre, MLS impose que tous les membres du groupe connaissent tous les autres membres. Il n'y a pas de possibilité d'avoir des membres cachés (cela serait difficilement compatible avec le chiffrement de bout en bout). Et le DS peut, selon les cas, être capable de trouver ou de déduire la composition d'un groupe (voir section 8.4.3.2).
Mais alors, que fait MLS ? Il gère la composition des groupes et ses changements dans le temps, et le matériel cryptographique associé. Via le DS, tous les membres du groupe génèrent les clés secrètes nécessaires et les messages peuvent être chiffrés pour tout le monde. MLS ne comprend pas le format des messages, il chiffre des octets, sans avoir besoin de connaitre l'application au-dessus.
Ah, et un peu de sécurité (section 8 du RFC). Il est très recommandé de faire tourner MLS sur un transport chiffré, comme QUIC (RFC 9000) ou TCP+TLS (RFC 9846) car, même si certains messages sont chiffrés, des métadonnées ne le sont pas. MLS fonctionne sur l'hypothèse que tout ce qui n'est pas une extrêmité du réseau (une des machines qui communiquent) est un ennemi (RFC 3552).
Autre question de sécurité, les push tokens, qui ont fait parler d'eux lors de discussions sur la sécurité de certaines messageries instantanées. Ils sont utilisés pour la distribution de contenu, par exemple pour prévenir les utilisateurices qu'un nouveau message est arrivé. Sans système de push, les machines clients devraient périodiquement interroger les serveurs, ce dont leurs batteries se plaindraient certainement. Mais les push tokens ont l'inconvénient de pouvoir être liés à des informations permettant d'identifier un·e utilisateurice. Cela ne compromet pas le contenu des messages (qui est chiffré) mais donne accès à des métadonnées bien révélatrices. Et les États utilisent cette possibilité. Le problème est compliqué car il n'y a pas de solution de remplacement, à part l'attente active. C'est ainsi que Proton a noté : « That said, we will continue to use Apple and Google push notifications when the services are available on the device because unfortunately they are favored heavily by the operating system in terms of performance and battery life. » Mais Tuta a fait un autre choix. Notre RFC suggère quelques pistes comme l'introduction de délais aléatoires.
La section 8 donne beaucoup d'autres conseils de sécurité et sa lecture est recommandée. Notez par exemple que le protocole MLS du RFC 9420 a fait l'objet de plusieurs analyses de sécurité (la liste figure dans la section 8.6).
Il existe un site Web du projet MLS mais il a très peu de contenu. Question mises en œuvre de MLS, une liste est disponible, citant, par exemple, la bibliothèque BouncyCastle ou bien OpenMLS (avec une documentation très complète).
L'article seul
RFC 9745: The Deprecation HTTP Header Field
Date de publication du RFC : Mars 2025
Auteur(s) du RFC : S. Dalal, E. Wilde
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpapi
Première rédaction de cet article le 17 mars 2025
Ce nouveau champ de l'en-tête HTTP sert à indiquer que la ressource demande va être (ou a été) abandonné et qu'il faut penser à migrer. Il sert surtout pour les API HTTP.
(Et si vous ne savez pas ce qu'est une ressource, dans le monde HTTP, voyez la section 3.1 du RFC 9110.)
L'idée de ce champ est de permettre aux clients HTTP d'être
informés, de préférence à l'avance, du fait qu'une ressource est
considérée comme abandonnée et qu'ils devraient donc aller voir
ailleurs. Par exemple, si on a une API avec une fonction d'URL
https://api.example.com/v1/dosomething et que
cette fonction est finalement jugée inutile, on pourra faire en
sorte que tout appel à cet URL renvoie un champ
Deprecation: dans l'en-tête, que les clients
HTTP comprendront. (Ce champ a été ajouté dans le registre
des champs de l'en-tête HTTP.)
Deprecation: est juste une information, la
ressource continue à fonctionner.
Un exemple est disponible sur ce blog (je n'en ai pas trouvé de « vraies »), qui a quelques API :
% curl -i https://www.bortzmeyer.org/apps/limit HTTP/1.1 200 OK Date: Sat, 22 Feb 2025 15:50:23 GMT Server: Apache/2.4.62 (Debian) Deprecation: @2147483648 Link: <https://www.bortzmeyer.org/9745.html>; rel="deprecation"; type="text/html" Content-Type: text/plain Will be deprecated on 2038-01-19T03:14:08Z.
Que veut dire « @2147483648 » ? Le champ
Deprecation: indique le nombre de secondes
depuis l'epoch
Unix. La commande GNU
date vous permet de voir facilement cet instant :
% date --date=@2147483648 mar. 19 janv. 2038 03:14:08 UTC
C'est, dans cet exemple, au moment de la bogue de
2038 que cette ressource ne sera plus maintenue. La
syntaxe utilisée est celle des objets de type Date des champs HTTP
structurés (RFC 9651, section
3.3.7). D'ailleurs, cette question de syntaxe avait fait l'objet
d'une intéressante
discussion à l'IETF, d'autres champs HTTP, comme
Sunset:, mentionné plus loin, utilisent une
autre syntaxe pour les dates. Et vous trouverez, par exemple sur
Stack Overflow, d'innombrables articles qui
utilisent pour le champ Deprecation:, la
syntaxe qui avait été initialement proposée (et qui était la même
que celle de Sunset:).
Cette indication d'un futur abandon ne s'applique qu'à la
ressource demandée. Si vous retirez un ensemble de ressources (par
exemple votre API avait plusieurs ressources commençant par
https://api.example.com/v1/ et désormais vous
êtes passé à une nouvelle version, avec le préfixe
https://api.example.com/v2/), vous devrez le
spécifier dans la documentation associée (continuez la lecture, on va
parler de cette documentation).
Vous avez sans doute remarqué dans l'exemple plus haut le champ
Link:. Il sert à donner des détails, sous forme
d'un URL où vous trouverez davantage d'informations. Au passage, le
moment indiqué dans le champ Deprecation: peut
être dans le passé indiquant que, quoi que la ressource fonctionne
encore, elle est déjà considérée comme abandonnée (et donc sans doute
plus maintenue). Les liens sont normalisés dans le RFC 8288 et le type de lien deprecation
est désormais dans le registre
des types de liens.
Arrivés à ce stade, si vous connaissez bien HTTP, vous vous
demandez sans doute « Et Sunset: (RFC 8594), alors, il
sert à quoi ? » Je dois dire qu'il n'est pas évident d'expliquer
pourquoi les deux existent, mais notez quand même que
Deprecation: est toujours
plus tôt que Sunset:, qui représente donc la
fin effective (Deprecation: pouvant être
simplement une reclassification de la ressource, sans qu'elle cesse
de fonctionner). Un exemple donné par le
RFC :
Deprecation: @1688169599 Sunset: Sun, 30 Jun 2024 23:59:59 UTC
Dans cet exemple, la ressource cesse d'être officiellement disponible le 1 juillet 2023 mais n'est réellement retirée que le 30 juin 2024. Après cette deuxième date, on peut supposer qu'à cet URL, on récupèrera un code de retour 404 ou, mieux, 410 (RFC 9110, section 15.5.11).
Quelques articles qui peuvent être utiles lors d'une stratégie de retrait d'une ressource :
- Je vous recommande la lecture de « API Lifecycle, Versioning, and Deprecation ». Notez que la solution qu'il propose pour indiquer le futur retrait d'une API n'utilisait pas encore la syntaxe de ce RFC, qui est venu après, mais les concepts sont les mêmes.
- « How to deprecate an entire API in OpenAPI? » sur Stack Overflow,
- « The right way to turn off your old APIs » (attention, il utilise l'ancienne syntaxe pour exprimer la date d'abandon).
Et le champ Expires: (RFC 9111, section 5.3) ? Rien à voir,
Expires: concerne le contenu, mais l'URL reste
stable et fonctionnel.
Un petit mot sur la sécurité (section 7 du RFC). Le champ
Deprecation: n'est qu'une indication et il ne
faut sans doute pas agir automatiquement sur la base de ce
champ. Toujours vérifier la documentation !
Pour traiter ce champ, ainsi que le Sunset: du
RFC 8594, regardez ce script Python. Quelques exemples
d'utilisation dans le monde :
- L'entreprise de mode Zalando a un guide de la conception d'API qui recommande ce champ.
- La mise en œuvre dans la bibliothèque Requests a été discutée mais le consensus a plutôt été que c'était à l'application utilisatrice de gérer cela.
- Mon client pour l'API RIPE Atlas, Blaeu, a ce code pour tester si l'API utilisée ne va pas être abandonnée, tiré de l'exemple Python cité plus haut.
- Et bien plus encore qui ont le concept mais avec une autre syntaxe, choisie avant ce RFC.
L'article seul
RFC 9743: Specifying New Congestion Control Algorithms
Date de publication du RFC : Mars 2025
Auteur(s) du RFC : M. Duke (Google), G. Fairhurst (University of Aberdeen)
Réalisé dans le cadre du groupe de travail IETF ccwg
Première rédaction de cet article le 14 mars 2025
La lutte contre la congestion du réseau est une tâche permanente des algorithmes utilisés dans l'Internet. Si les émetteurs de données envoyaient des octets aussi vite qu'ils le pouvaient, sans jamais réfléchir, l'Internet s'écroulerait vite. Des protocoles comme TCP ou QUIC contiennent donc des algorithmes de contrôle de la congestion. Il y en a plusieurs, certains peuvent être néfastes, et ce RFC, qui remplace le RFC 5033, explique comment de nouveaux algorithmes doivent être évalués avant d'être déployés en vrai. Bref, la prudence est nécessaire.
Le RFC 2914 expose les principes généraux du contrôle de congestion du réseau. Notre RFC 9743 a un autre but : créer un cadre d'évaluation des algorithmes de contrôle de la congestion. Car c'est très difficile de concevoir et de spécifier un tel algorithme. Songez qu'il doit fonctionner sur des types de liens très différents, des réseaux à énorme capacité sur les courtes distance d'un centre de données (RFC 8257) à des liaisons radio à grande distance et avec un fort taux de perte de paquets. Il doit fonctionner en Wifi, sur la fibre, sur des liens surchargés, bien exploiter des liens à forte capacité, supporter des liens à forte latence, etc. Et l'efficacité de ces algorithmes dépend aussi de l'application qui va les utiliser, la vidéoconférence ne produisant pas les mêmes effets que le transfert de fichiers, le visionnage de vidéos haute définition, les connexions interactives type SSH, l'accès à des sites Web, etc).
La plupart des protocoles de transport normalisés par l'IETF ont du contrôle de congestion. Quand le RFC 5033 a été publié, cela concernait surtout TCP (RFC 9293), avec des outsiders comme DCCP (RFC 4340) ou SCTP (RFC 9260). Mais il y a aussi désormais QUIC (RFC 9000) et RMCAT (RFC 8836).
Parmi les algorithmes de contrôle de la congestion développés
pour l'Internet, on peut citer CUBIC RFC 9438,
Reno RFC 5681, BBR (pas encore de RFC mais il y a un
brouillon, draft-ietf-ccwg-bbr),
et autres.
Le RFC 5033 ne dit pas clairement si on a « le droit » de déployer un nouvel algorithme de contrôle de la congestion sans l'avoir normalisé dans un RFC. En tout cas, en pratique, comme le montre le déploiement de CUBIC et BBR, on n'attend pas le RFC (l'Internet est sans permission), on publie le code, sous une licence libre dans le cas ci-dessus (CUBIC a été surtout porté par sa mise en œuvre dans Linux) et on y va. Pourtant, avoir une spécification écrite et disponible, revue par l'IETF, serait certainement bénéficiaire pour tout le monde, permettant un examen large du nouvel algorithme et de certaines de ses conséquences imprévues.
(Le RFC cite un très bizarre argument comme quoi, dans certaines entreprises, les développeurs ont le droit de lire les RFC mais pas le code source publié sous une licence libre. Je ne suis pas juriste mais cela ressemble à un disjonctage sérieux de la part du juriste qui a prétendu cela.)
Notre RFC 9743 est donc un guide pour les gens qui vont faire cette très souhaitable évaluation des algorithmes de lutte contre la congestion, dans le prolongement du RFC 2914.
Donc, place au guide, en section 3, le centre de ce RFC. Premier objectif, qu'il existe plusieurs mises en œuvre de l'algorithme, et sous une licence libre. Ce n'est pas une obligation (surtout si le RFC décrivant l'algorithme a le statut « Expérimental ») mais c'est souhaité.
En parlant d'algorithmes expérimentaux, le RFC rappelle que la spécification d'un tel algorithme doit indiquer quels résultats on attend de l'expérience, et ce qu'il faudrait pour progresser. La section 12 du RFC 6928 et la section 4 du RFC 4614 sont de bons exemples en ce sens.
Un algorithme expérimental ne doit pas être activé par défaut et doit être désactivable s'il a des comportements désagréables. Mais il faut quand même le tester sinon il ne progressera jamais et ce test peut, au début, être fait dans un simulateur (RFC 8869) mais il doit, à un moment, être fait en vrai grandeur, dans l'Internet réel. Le RFC ajoute donc que tout déploiement ne doit être fait qu'accompagné de mesures qui permettront d'obtenir des informations.
Comme résultat de l'évaluation, tout RFC décrivant un algorithme de contrôle de congestion doit indiquer explicitement, dès le début, s'il est sûr et peut être déployé massivement sans précautions particulières. (Un exemple d'expérimentation figure dans le RFC 3649.)
Une exception est faite par notre RFC sur les « environnements contrôlés » (section 4). Il s'agit de réseaux qui sont sous le contrôle d'une seule organisation, qui maitrise tout ce qui s'y passe, sans conséquences pour des tiers (RFC 8799), et peuvent donc utiliser des algorithmes de contrôle de la congestion qu'on ne voudrait pas voir déployés dans l'Internet public. Un exemple typique d'un tel « environnement contrôlé » est un centre de données privé, avec souvent des commutateurs qui signalent aux machines terminales l'état du réseau, leur permettant d'ajuster leur débit (sur les centres de données, voir aussi la section 7.11).
Une fois passé ce cas particulier, allons voir la section 5, qui est le cœur de ce RFC ; elle liste les critères d'évaluation d'un algorithme de contrôle de la congestion. D'abord, dans le cas relativement simple où plusieurs flux de données sont en compétition sur un même lien mais que tous utilisent l'algorithme évalué. Est-ce que chaque flux a bien sa juste part (qui est une part égale aux autres, lorsque les flux veulent transmettre le plus possible) ? En outre, est-ce que l'algorithme évite l'écroulement qui se produit lorsque, en raison de pertes de paquets, les émetteurs ré-émettent massivement, aggravant le problème ? Pour cela, il faut regarder si l'algorithme ralentit en cas de perte de paquets, voire arrête d'émettre lorsque le taux de pertes devient trop important (cf. RFC 3714). Lire aussi les RFC 2914 et RFC 8961, qui posent les principes de cette réaction à la perte de paquets. Ce critère d'évaluation n'impose pas que le mécanisme d'évitement de la congestion soit identique à celui de TCP.
Une façon d'éviter de perdre les paquets est de les mettre dans une file d'attente, en attendant qu'ils puissent être transmis. Avec l'augmentation de la taille des mémoires, on pourrait penser que cette solution est de plus en plus bénéfique. Mais elle mène à de longues files d'attente, où les paquets séjourneront de plus en plus longtemps, au détriment de la latence, un phénomène connu sous le nom de bufferbloat. Le RFC demande donc qu'on évalue les mécanismes de contrôle de la congestion en regardant comment ils évitent ces longues files d'attente (RFC 8961 et RFC 8085, notez que Reno et CUBIC ne font rien pour éviter le bufferbloat).
Il est bien sûr crucial d'éviter les pertes de paquets ; même si
les protocoles comme TCP savent les rattraper (en demandant une
réémission des paquets manquants), les performances en souffrent, et
c'est du gaspillage que d'envoyer des paquets qui seront perdus en
route. Un algorithme comme la première version de BBR (dans
draft-cardwell-iccrg-bbr-congestion-control-00)
avait ce
défaut de mener à des pertes de paquets. Mais cette exigence
laisse quand même pas mal de marge de manœuvre aux protocoles de
contrôle de la congestion.
Autre exigence importante, l'équité (ou la justice). On la décrit souvent en disant que tous les flux doivent avoir le même débit. Mais c'est une vision trop simple : certains flux n'ont pas grand'chose à envoyer et il est alors normal que leur débit soit plus faible. L'équité se mesure entre des flux qui sont similaires.
En parlant de flux, il faut noter que, comme les algorithmes de contrôle de congestion n'atteignent leur état stable qu'au bout d'un certain temps, les flux courts, qui peuvent représenter une bonne partie du trafic (songez à une connexion TCP créée pour une seule requête HTTP d'une page de petite taille) n'auront jamais leur débit théorique. Les auteurs d'un protocole de contrôle de la congestion doivent donc étudier ce qui se passe lors de flux courts, qui n'atteignent pas le débit asymptotique.
La question de l'équité ne concerne pas que les flux utilisant tous le même algorithme de contrôle de la congestion. Il faut aussi penser au cas où plusieurs flux se partagent la capacité du réseau, tout en utilisant des algorithmes différents (section 5.2). Le principe, lorsqu'on envisage un nouveau protocole, est que les flux qui l'utilisent ne doivent pas obtenir une part de la capacité plus grande que les flux utilisant les autres protocoles (RFC 5681, RFC 9002 et RFC 9438). Les algorithmes du nouveau protocole doivent être étudiés en s'assurant qu'ils ne vont pas dégrader la situation, et ne pas supposer que le protocole sera le seul, il devra au contraire coexister avec les autres protocoles. (Dans un réseau décentralisé comme l'Internet, on ne peut pas espérer que tout le monde utilise le même protocole de contrôle de la congestion.)
Pour compliquer la chose, il y a aussi des algorithmes qui visent à satisfaire les besoins spécifiques des applications « temps réel ». Leur débit attendu est faible mais ils sont par contre très exigeants sur la latence maximale (cf. RFC 8836). La question est étudiée dans les RFC 8868 et RFC 8867 ainsi que, pour le cas spécifique de RTP, dans le RFC 9392. Si on prétend déployer un nouveau protocole de contrôle de la congestion, il doit coexister harmonieusement avec ces protocoles temps réel. La tâche est d'autant plus difficile, note notre RFC, que ces protocoles sont souvent peu ou mal documentés.
Bon, quelques autres trucs à garder en tête. D'abord, il faut évidemment que tout nouveau protocole soit déployable de manière incrémentale. Pas question d'un flag day où tout l'Internet changerait de mécanisme de contrôle de la congestion du jour au lendemain (section 5.3.2). Si le protocole est conçu pour des environnements très spécifiques (comme l'intérieur d'un centre de données privé), il peut se permettre d'être plus radical dans ses choix mais le RFC insiste sur l'importance, dans ce cas, de décrire les mesures par lesquelles on va s'assurer que le protocole n'est réellement utilisé que dans ces environnements. Un exemple de discussion sur le déploiement incrémental figure dans les sections 10.3 et 10.4 du RFC 4782.
La section 6 de notre RFC rappelle que le protocole doit être
évalué dans des environnements différents qu'on peut rencontrer sur
l'Internet public. Ainsi, les liaisons filaires se caractérisent par
une très faible quantité de perte de paquets, sauf dans les routeurs,
lorsque leur file d'attente est pleine. Et leurs caractéristiques sont
stables dans le temps. En revanche, les liens sans fil ont des
caractéristiques variables (par exemple en fonction d'évènements
météorologiques) et des pertes de paquets en route, pas seulement
dans les routeurs. Le RFC 3819 et le
brouillon draft-irtf-tmrg-tools
(dans sa section 16) discutent ce problème, que l'algorithme de
contrôle de congestion doit prendre en compte.
Tout cela est bien compliqué, vous allez me dire ? Mais ce n'est pas fini, il reste les « cas spéciaux » de la section 7. D'abord, si le routeur fait de l'AQM, c'est-à-dire jette des paquets avant que la file d'attente ne soit pleine. Des exemples de tels algorithmes sont Flow Queue CoDel (RFC 8290), PIE (Proportional Integral Controller Enhanced, RFC 8033) ou L4S (Low Latency, Low Loss, and Scalable Throughput, RFC 9332). L'évaluation doit donc tenir compte de ces algorithmes.
Certains réseaux disposent de disjoncteurs (breakers, RFC 8084), qui surveillent le trafic et coupent ou réduisent lorsque la congestion apparait. Là encore, tout nouvel algorithme de contrôle de la congestion qu'on utilise doit gérer le cas où de tels disjoncteurs sont présents.
Autre cas qui complique les choses, les réseaux à latence variable. Avec un réseau simple, la latence dans les câbles est fixe et la latence vue par les flux ne varie qu'avec l'occupation des files d'attentes du routeur. Mais un chemin à travers l'Internet n'est pas simple, et la latence peut varier dans le temps, par exemple parce que les routes changent et qu'on passe par d'autres réseaux. (Voir par exemple les conséquences d'une coupure de câble.) Bref, le protocole de contrôle de la congestion ne doit pas supposer une latence constante. En parlant de latence, il y a aussi des liens qui ont une latence bien plus élevée que ce que qu'attendent certains protocoles simples. C'est par exemple le cas des liens satellite (RFC 2488 et RFC 3649). Et en parlant de variations, l'Internet voit souvent des brusques changements, par exemple un brusque afflux de paquets, et notre protocole devra gérer cela (section 9.2 du RFC 4782). J'avais dit que l'Internet était compliqué !
Et pour ajouter à cette complication, il y a des réseaux qui changent l'ordre des paquets. Oui, vous savez cela. Tout le monde sait qu'IP ne garantit pas l'ordre d'arrivée des paquets. Tout le monde le sait mais notre RFC juge utile de le rappeler car c'est un des défis que devra relever un protocole de contrôle de la congestion : bien fonctionner même en cas de sérieux réordonnancement des paquets, comme discuté dans le RFC 4653.
L'algorithme utilisé pour gérer la congestion ne doit pas non plus être trop subtil, car il faudra qu'il puisse être exécuté par des machines limitées (en processeur, en mémoire, etc, cf. RFC 7228).
Le cas où un flux emprunte plusieurs chemins (Multipath TCP, RFC 8684, mais lisez aussi le RFC 6356) est délicat. Par exemple, on peut avoir un seul des chemins qui est congestionné (le protocole de gestion des chemins peut alors décider d'abandonner ce chemin) mais aussi plusieurs chemins qui partagent le même goulet d'étranglement.
Et, bien sûr, l'Internet est une jungle. On ne peut pas compter que toutes les machines seront gérées par des gentilles licornes arc-en-ciel bienveillantes. Tout protocole de contrôle de la congestion déployé dans l'Internet public doit donc tenir compte des méchants. (Il y a aussi, bien plus nombreux, les programmes bogués et les administrateurs système incompétents. Mais, si un protocole tient le coup en présence d'attaques, a fortiori, il résistera aux programmes non conformes.) Une lecture intéressante est le RFC 4782, dans ses sections 9.4 à 9.6.
L'annexe A résume les changements depuis le RFC 5033. Il y a notamment :
- L'ajout de QUIC,
- un texte plus précis sur le bufferbloat,
- le cas des machines contraintes (pour l'IoT),
- des discussions sur l'AQM, les flux courts, le temps réel…
L'article seul
RFC 9741: Concise Data Definition Language (CDDL): Additional Control Operators for the Conversion and Processing of Text
Date de publication du RFC : Mars 2025
Auteur(s) du RFC : C. Bormann (Universität Bremen TZI)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF cbor
Première rédaction de cet article le 5 mars 2025
Le langage CDDL, qui permet de créer un schéma formel pour des formats comme CBOR, peut s'étendre via l'ajout d'« opérateurs de contrôle ». Ce RFC en spécifie quelques uns, notamment pour agir sur du texte ou convertir d'une forme dans une autre.
CDDL est normalisé dans le RFC 8610. Sa principale utilisation est pour fournir des schémas afin de valider des données encodées en CBOR (RFC 8949). Du fait de l'extensibilité de CDDL (voir notamment RFC 8610, section 3.8), le RFC 9165 a pu ajouter l'addition, la concaténation, etc. Notre nouveau RFC 9741 ajoute encore d'autres opérateurs, surtout de conversion d'une représentation dans une autre.
Je ne vais pas tous les citer ici (lisez le RFC), juste donner
quelques exemples. D'abord, .b64u, qui va
convertir une chaine d'octets en sa représentation en
Base64 (RFC 4648 et,
rassurez-vous, il y a aussi des opérateurs pour
Base32 et les autres).
Voici un exemple. Mais d'abord, on installe l'outil cddl. Écrit en Ruby, il s'installe avec :
% gem install cddl
Ensuite, on écrit un schéma CDDL utilisant l'opérateur
.b45 (Base45 est
normalisé dans le RFC 9285) :
% cat base.cddl encoded = text .b45 "Café ou thé ?"
En utilisant les fonctions de génération de l'outil cddl, on trouve :
% cddl base.cddl generate "EN8R:C6HL34ES44:AD6HLI1"
C'est bien l'encodage en Base45 de la chaine de caractères utilisée (évidemment, dans un vrai schéma, on utiliserait une variable, pas une chaine fixe).
Ensuite, .printf va formater du texte, en
utilisant les descriptions de format du printf de
C.
% cat printf.cddl my_alg_19 = hexlabel<19> hexlabel<K> = text .printf (["0x%04x", K]) % cddl printf.cddl generate "0x0013"
Bien sûr, ce n'est pas la méthode la plus simple pour convertir le 19 décimal en 13 hexadécimal. Mais le but est simplement d'illustrer le fonctionnement des nouveaux opérateurs.
Enfin, .join va transformer un tableau en
chaine d'octets.
Voici l'exemple du RFC, avec des adresses
IPv4 :
% cat address.cddl
legacy-ip-address = text .join legacy-ip-address-elements
legacy-ip-address-elements = [bytetext, ".", bytetext, ".",
bytetext, ".", bytetext]
bytetext = text .base10 byte
byte = 0..255
% cddl address.cddl generate
"108.58.234.211"
% cddl address.cddl generate
"42.65.53.156"
% cddl address.cddl generate
"77.233.49.115"
Les nouveaux opérateurs ont été placés dans le registre
IANA. Ils sont mis en œuvre dans l'outil de référence de CDDL
(le cddl utilisé ici). Écrit en
Ruby, on peut l'installer avec la méthode
Ruby classique :
% gem install cddl
Il existe une autre mise en œuvre de CDDL (qui porte malheureusement le même nom). Elle est en Rust et peut donc s'installer avec :
% cargo install cddl
Elle n'inclut pas encore les opérateurs de ce RFC :
% ~/.cargo/bin/cddl validate --cddl schema.cddl --json person.json Error: "error: lexer error\n ┌─ input:7:26\n │\n7 │ legacy-ip-address = text .join legacy-ip-address-elements\n │ ^^^^^ invalid control operator\n\n"
L'article seul
RFC 9727: api-catalog: A Well-Known URI and Link Relation to Help Discovery of APIs
Date de publication du RFC : Juin 2025
Auteur(s) du RFC : K. Smith (Vodafone)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpapi
Première rédaction de cet article le 14 juin 2025
Les API réseau, c'est très bien. Tout le monde en fait aujourd'hui, typiquement bâties au-dessus de HTTP. Mais il est parfois difficile de s'y retrouver parmi toutes les API. « Je suis sûr que l'INSEE avait une API pour faire ça mais où est-elle exactement et où est sa documentation ? La solution pour cela ? Les catalogues d'API, rassemblant nom, description, URL, etc, des API. Il ne reste plus qu'à trouver le catalogue… Ce RFC fournit pour cela un URL standard et un mécanisme de lien. Il fournit également un format standard pour écrire ce catalogue, bâti sur Linkset (RFC 9264, section 4.2).
Comme disait M. de la Palice, et comme le rappelle la section 1 du RFC, pour utiliser une API, il faut d'abord la découvrir. Cela veut dire apprendre son existence, quel va être l'URL à appeler (le endpoint), les paramètres à passer, quelles sont les conditions d'utilisation (gratuite ? nombre maximal de requêtes par jour ?), etc. Il existe des formats pour cela (le plus connu étant celui d'OpenAPI) mais il reste à trouver les fichiers de ce format. Pour faciliter cette tâche du développeur ou de la développeuse qui utilisera l'API, l'éditeur (publisher dans le RFC) qui publie l'API va fabriquer un joli catalogue, et le rendre lui-même découvrable. Un catalogue est une liste organisée des API offertes par une organisation donnée.
Première solution décrite par notre RFC (section 2) : un URL bien
connu, et donc prévisible,
https://www.example.net/.well-known/api-catalog
(si l'éditeur est en www.example.net). Ces URL
bien connus sont normalisés dans le RFC 8615. Évidemment, une redirection HTTP est
possible. api-catalog a été ajouté au registre
des URL bien connus.
Deuxième solution, un lien (section 3)
api-catalog. Les liens, vous connaissez, et ils
sont normalisés dans le RFC 8288. Ils peuvent
se représenter de plusieurs façons, en HTML :
<!DOCTYPE HTML>
<html>
<head>
<title>Welcome to Example Publisher</title>
</head>
<body>
<p>
<a href="my_api_catalog.json" rel="api-catalog">
Example Publisher's APIs
</a>
</p>
<p>(remainder of content)</p>
</body>
</html>
Ou bien en HTTP, dans la réponse :
HTTP/1.1 200 OK Content-Type: text/html; charset=UTF-8 Location: /index.html Link: </my_api_catalog.json>; rel=api-catalog Content-Length: 356
Désormais, api-catalog figure dans le registre
des types de liens.
Cette norme concerne la découverte du catalogue, mais aussi la syntaxe de son contenu. La section 4 du RFC donne des indications sur le contenu du catalogue, sa sémantique (inclure la politique d'utilisation, lien vers une spécification formelle, etc) et sa syntaxe, le format Linkset du RFC 9264. Des exemples figurent dans l'annexe A du RFC mais vous pouvez aussi regarder le catalogue des mes API (en construction). Voici le premier exemple de catalogue donné dans le RFC, utilisant les relations du RFC 8631 :
{
"linkset": [
{
"anchor": "https://developer.example.com/apis/foo_api",
"service-desc": [
{
"href": "https://developer.example.com/apis/foo_api/spec",
"type": "application/yaml"
}
],
"service-doc": [
{
"href": "https://developer.example.com/apis/foo_api/doc",
"type": "text/html"
}
],
"service-meta": [
{
"href": "https://developer.example.com/apis/foo_api/policies",
"type": "text/xml"
}
]
},
{
"anchor": "https://developer.example.com/apis/bar_api",
"service-desc": [
{
"href": "https://developer.example.com/apis/bar_api/spec",
"type": "application/yaml"
}
],
"service-doc": [
{
"href": "https://developer.example.com/apis/bar_api/doc",
"type": "text/plain"
}
]
}
]
}
D'autres formats que Linkset sont possibles (mais Linkset doit être présent), par exemple via la négociation de contenu. Quelques formats possibles cités par le RFC :
Ce catalogue peut, et ce serait souhaitable, être écrit automatiquement par le cadriciel qu'on utilise pour développer ses API.
Et, sinon, où est-ce qu'on publie cette API ? La méthode
recommandée (section 5) est de la publier à plusieurs endroits. Si
on gère www.example.net et que les URL des API
sont en api.example.com, le RFC recommande de
les publier aux deux endroits. Rappelez-vous que les redirections
HTTP sont permises, donc vous pouvez n'avoir qu'un seul exemplaire
du catalogue, ce qui simplifie sa maintenance. Car, puisqu'on parle
de maintenance, un gros défi sera clairement de garder ce catalogue
à jour au fur et à mesure de l'évolution des API… (La section 8, sur
la sécurité, revient sur ce problème.)
Je n'ai pas trouvé d'exemple réel dans le Web, même chez
Vodafone, où travaille l'auteur. Mais j'ai fait un catalogue pour mes propres
API. En l'absence d'outils de test et de validation pour les
catalogues, il a peut-être quelques erreurs. (Si vous lisez la
section 2 du RFC, vous verrez que mon serveur HTTP ne répond pas aux
requêtes HEAD avec un lien dans
l'en-tête, un Link:. Il devrait.)
L'article seul
RFC 9726: Operational Considerations for Use of DNS in Internet of Things (IoT) Devices
Date de publication du RFC : Mars 2025
Auteur(s) du RFC : M. Richardson (Sandelman Software Works), W. Pan (Huawei Technologies)
Réalisé dans le cadre du groupe de travail IETF opsawg
Première rédaction de cet article le 1 avril 2025
Les objets connectés, vous le savez, sont une source d'ennuis et de risques de sécurité sans fin. Non seulement ils ne sont pas forcément utiles (faut-il vraiment connecter une brosse à dents au réseau ?) mais en outre, comme ils incluent un ordinateur complet, ils peuvent faire des choses auxquelles l'acheteur ne s'attend pas. Pour limiter un peu les risques, le RFC 8520 normalisait MUD (Manufacturer Usage Description), un mécanisme pour que le fournisseur du machin connecté documente sous un format analysable les accès au réseau dont l'objet avait besoin ce qui permet, par exemple, de configurer automatiquement un pare-feu, qui va s'assurer que la brosse à dents ne se connecte pas à Pornhub. Dans un fichier MUD, les services avec lesquels l'objet communique sont typiquement indiqués par un nom de domaine. Mais le DNS a quelques subtilités qui font que l'utilisation de ces noms nécessite quelques précautions, décrites dans ce nouveau RFC.
En fait, le RFC 8520 permet d'utiliser des noms ou bien des adresses IP, qui seront ensuite ajoutées dans les ACL du pare-feu. Évidemment, les noms de domaine, c'est mieux. Pas pour la raison qu'on trouve dans tous les articles des médias « les noms de domaine sont plus simples à retenir pour les humains » puisque les fichiers MUD ne sont pas prévus pour être traités par des humains. Mais parce qu'ils sont stables (contrairement aux adresses IP, qui changent quand on change d'hébergeur), qu'ils gèrent à la fois IPv4 et IPv6 et parce qu'ils permettent la répartition de charge, par exemple via un CDN.
Mais le pare-feu (sauf s'il espionne la résolution DNS préalable) ne voit pas les noms de domaine, il voit des paquets IP, avec des adresses IP source et destination. (Ainsi que les ports, si le paquet n'est pas chiffré.) Il va donc falloir résoudre les noms en adresses si on veut configurer le pare-feu à partir du fichier MUD, et c'est là que les ennuis commencent. Les exigences de sécurité sont contradictoires (section 9 du RFC) : on veut bloquer les accès au réseau mais « en même temps » les permettre. Cette permission est nécessaire pour que l'objet connecté puisse mettre à jour son logiciel, par exemple lorsqu'une faille de sécurité est découverte. Et c'est également nécessaire pour que le vendeur de l'objet puisse recevoir des quantités de données personnelles, qu'il revendra (ou se fera voler suite à un piratage).
Le plus simple (section 3 du RFC) pour traduire les noms de domaine du fichier MUD en adresses IP est évidemment que le contrôleur MUD, la machine qui lit les fichiers MUD et les traduit en instructions pour le pare-feu (RFC 8520, sections 1.3 et 1.6) fasse une résolution DNS normale et utilise le résultat. C'est simple et direct. Mais notre section 3 décrit aussi pourquoi ça risque de ne pas donner le résultat attendu. Par exemple, le résolveur DNS peut renvoyer les résultats (les différentes adresses IP) dans un ordre variable, voire aléatoire, comme décrit dans le RFC 1794. C'est souvent utilisé pour faire une forme grossière de répartition de charge. Si le résolveur renvoie toutes les adresses IP possibles, OK, le contrôleur MUD les autorise toutes dans le pare-feu. Mais s'il n'en renvoie qu'une partie, on est mal, celle(s) autorisée(s) ne sera pas forcément celle(s) utilisée(s) par l'objet connecté. Et la résolution peut dépendre du client (le RFC parle de « non-déterminisme » ; en fait, c'est parfaitement déterministe mais ça dépend du client, par exemple de sa géolocalisation). Si le serveur faisant autorité renvoie une seule adresse qui dépend de la localisation physique supposée de son client, et que le machin connecté et le contrôleur MUD n'utilisent pas le même résolveur DNS, des ennuis sont à prévoir : l'adresse autorisée sur le pare-feu ne sera pas celle réellement utilisée.
Si contrôleur et truc connecté utilisent le même résolveur, le risque d'incohérence est plus faible. Les réponses seront les mêmes pour les deux (contrôleur et chose connectée). Cela peut être le cas dans un environnement résidentiel où tout le monde passe par le CPE (la box) qui fait à la fois résolveur DNS, routeur NAT et pare-feu. Mais que faire si, par exemple, la brosse à dents ou l'aspirateur connecté utilisent un résolveur DNS public, quelque part dans le mythique nuage ?
La section 4 du RFC liste tout ce qu'il ne faudrait pas faire en matière d'utilisation du DNS par les objets connectés. Typiquement, l'objet connecté utilise HTTPS pour se connecter à son maitre (le vendeur de l'objet ; le gogo qui a acheté l'objet connecté croit en être propriétaire mais il dépend du vendeur, qui peut arrêter le service à tout moment). Pour le cas d'une mise à jour logicielle, le maitre informe alors si une mise à jour du logiciel est nécessaire, en indiquant l'URL où l'objet va pouvoir récupérer cette mise à jour. Évidemment, il est préférable pour la sécurité que cette mise à jour soit signée (RFC 9019). Notez que ce qui est bon pour la sécurité face au risque de piratage par un tiers n'est pas forcément bon pour le consommateur : la vérification de la signature va empêcher les utilisateurs de mettre leur propre logiciel par exemple parce que le vendeur ne fournit plus de mise à jour.
Questions bonnes pratiques, d'abord, il faut utiliser le DNS, donc un nom de domaine dans l'URL, pas des adresses IP littérales. Cette approche aurait certes l'avantage de fonctionner même quand la résolution DNS est défaillante, mais elle souffre des problèmes suivants :
- Il faut choisir entre une adresse IPv4 et IPv6, alors que le maitre ne sait pas forcément de quelle connectivité dispose l'objet. Si l'objet se connecte en IPv4 au maitre, celui-ci pourrait croire qu'une adresse IPv4 littérale est acceptable ce qui n'est pas vrai si l'objet est connecté via NAT64 (RFC 6146). Dans cet exemple, le DNS marcherait (RFC 6147) mais pas l'adresse littérale.
- Ensuite, l'adresse IP peut changer fréquemment, par exemple si le vendeur change d'hébergeur. C'est justement le principal avantage du DNS que de permettre une stabilité des identificateurs sur le long terme et non pas, comme on le lit souvent parce que « les noms sont plus lisibles et plus mémorisables que les adresses », argument qui ne s'applique pas aux objets connectés.
- Enfin, si la mise à jour est récupérée via HTTPS, ce qui est évidemment recommandé, le serveur doit obtenir un certificat et peu d'AC acceptent d'émettre des certificats pour des adresses IP (à l'heure de la publication de ce RFC, Let's Encrypt a annoncé qu'ils allaient le permettre mais cela ne semble pas encore fait).
Autre problème, des noms de domaine qui, en raison des systèmes utilisés sur le service HTTP, par exemple un CDN, changent souvent et de manière qui semble non déterministe. Modifier les fichiers MUD ne sera alors pas possible. Le RFC recommande, s'il faut absolument changer les noms souvent, de mettre un alias dans le fichier MUD, modifié à chaque fois que le nom change.
Toujours du côté des CDN, même s'ils ne sont pas les seuls à poser ce genre de problème, les noms trop génériques. Si tous les clients du service d'hébergement sont derrière le même nom de domaine, celui-ci sera difficile à modifier, et les effets d'une compromission pourront être plus étendus que souhaitable. Il vaut mieux des noms spécifiques à chaque client.
Les requêtes faites par le contrôleur MUD peuvent poser des problèmes de confidentialité (section 5 du RFC). Si le résolveur local n'est pas jugé digne de confiance, et que le contrôleur MUD utilise un résolveur distant, par exemple un résolveur public comme ceux de Cloudflare ou Quad9 (de préférence avec chiffrement, via DoH RFC 8484, DoT RFC 7858 ou DoQ RFC 9250), il faut s'assurer que l'objet va utiliser ce même résolveur (il n'y a pas aujourd'hui de mécanisme dans MUD pour faire cela automatiquement).
Les recommandations positives, maintenant (section 6). Le fichier MUD peut être obtenu de diverses façons (par exemple via un code QR comme documenté dans le RFC 9238), c'est son contenu qui compte. Les conseils de la section 6 sont en général du simple bon sens, qui correspondent aux bonnes pratiques habituelles d'utilisation des URL, mais qui ne sont pas toujours appliquées par les objets connectés. Notre RFC recommande :
- D'utiliser le DNS (et pas des adresses IP littérales comme le font trop de vendeurs),
- d'utiliser des noms contrôlés par le vendeur de l'objet (et pas par son hébergeur Web), éventuellement en utilisant des alias (RFC 9499, section 2),
- d'utiliser des CDN dont les serveurs faisant autorité retournent plusieurs réponses, quitte à les réordonnancer pour la répartition de charge, pour augmenter la probabilité que le contrôleur MUD et l'objet aient des adresses en commun,
- de ne pas utiliser des réponses adaptées au client DNS ; un mécanisme comme ECS (RFC 7871) permet de donner des réponses différentes selon l'adresse IP du client final (et pas celle du client que voit le serveur faisant autorité), ce qui va créer des problèmes si le contrôleur MUD et l'objet passent par des connexions Internet différentes,
- d'utiliser le résolveur local (celui indiqué via DHCP ou RA - RFC 8106), en s'appuyant sur les techniques décrites dans les RFC 9462 et RFC 9463 ; l'utilisation de résolveurs DNS publics est découragée, à mon avis pour de mauvaises raisons.
Notez que l'objet peut aussi utiliser des noms mais ne pas se servir du DNS pour les traduire en adresses IP. C'est le cas par exemple s'il utilise mDNS (RFC 6762 et RFC 8882) qui, en dépit de son nom, n'est pas du DNS, ce qui peut également poser des problèmes d'incohérence (l'objet n'obtenant pas la même adresse IP que le contrôleur MUD).
La section 8 revient sur les questions de vie privée (RFC 7626). Elle dit (ce qui est peut-être contestable) que les requêtes DNS d'un four à micro-ondes ne sont pas forcément un enjeu d'intimité mais que celles d'un sextoy le sont davantage. L'utilisation de DoT ou DoH va supprimer le risque d'une écoute par un tiers mais le résolveur, dans tous les cas, voit la requête et il faut donc choisir un résolveur de confiance, sauf à utiliser des techniques qui sont pour l'instant très rares, comme celle du RFC 9230. Ah, et le RFC discute aussi des risques posés par la divulgation de la version de logiciel actuellement utilisée par l'objet (qui va lui servir à savoir s'il faut une mise à jour) mais le RFC 9019 a déjà traité cela.
L'article seul
RFC 9724: Randomized and Changing MAC Address State of Affairs
Date de publication du RFC : Mars 2025
Auteur(s) du RFC : JC. Zúñiga (CISCO), CJ. Bernardos (UC3M), A. Andersdotter (Safespring AB)
Pour information
Réalisé dans le cadre du groupe de travail IETF madinas
Première rédaction de cet article le 20 mars 2025
Dans le contexte de la surveillance massive qui s'exerce contre les utilisateurices de l'Internet, tout identifiant un peu stable peut être utilisé pour pister quelqu'un. On en laisse, des traces ! C'est par exemple le cas avec l'adresse MAC. Ce nouveau RFC décrit les mécanismes existants pour diminuer le risque de pistage par l'adresse MAC. Il ne spécifie pas un protocole, il liste les solutions.
Ne croyez donc pas les médias et les politiciens qui vous diraient que le problème de l'Internet, c'est l'anonymat. C'est tout le contraire : il est extrêmement difficile d'utiliser l'Internet sans laisser de traces partout, traces qui peuvent être corrélées si on réutilise un identifiant, comme l'adresse MAC (dite également adresse Ethernet ou bien adresse physique).
(Au passage, le RFC contient une remarque très désagréable comme quoi l'une des causes des problèmes de vie privée serait « le manque d'éducation [des utilisateurices ?] ». S'il est vrai que la littératie numérique en matière de sécurité est très perfectible, il ne faudrait pas pour autant tout rapporter à l'ignorance. Les utilisateurices ne sont pas responsables de la surveillance massive, dont l'ubiquité et la sophistication font qu'il est difficile de se défendre, même pour un·e expert·e. Et les innombrables entreprises et États qui pistent les utilisateurices ne le font pas par ignorance mais cherchent en toute conscience à récolter le maximum de données.)
Le problème du pistage se place à tous les niveaux du modèle en couches ; les adresses MAC en couche 2, les adresses IP en couche 3, les cookies pour le Web en couche 7, etc. Pour la couche 2, sujet de notre RFC, voyez par exemple l'analyse « Wi-Fi internet connectivity and privacy: Hiding your tracks on the wireless Internet » (comme l'IEEE fait partie de ces organisations de normalisation réactionnaires qui ne permettent pas l'accès libre à leurs documents, prenez une copie), ou bien cet article décrivant comment les poubelles vous pistent.
Le problème est d'autant plus sérieux qu'aujourd'hui, plein d'équipements électroniques ont la WiFi (en termes plus techniques, IEEE 802.11) et donc une adresse MAC unique, qui peut servir au pistage. On ne pense pas forcément à ces équipements comme étant des ordinateurs, susceptibles d'émettre et donc de révéler leur présence. Quiconque écoute le réseau va voir ces adresses, il n'y a pas besoin d'être actif, une écoute passive suffit. Même sans association avec la base, la machine se signale par les Probe Request qu'elle envoie. Dans le cas typique, l'adresse 802.11 est composée de deux parties, l'OUI (Organizationally Unique Identifier), qui identifie le fournisseur, et le Network Interface Controller Specific, qui identifie une des machines (en toute rigueur, plutôt une des interfaces réseau) dudit fournisseur. La combinaison des deux fait une adresse unique (au moins en théorie), traditionnellement attribuée à la fabrication et pas changée ensuite. Cette adresse unique est donc, malheureusement pour la vie privée, un bon identificateur stable. Mais une adresse MAC peut aussi être localement gérée (elle n'est alors plus forcément unique), et, contrairement à ce que croient certaines personnes, l'adresse globale par défaut n'est pas obligatoire. (Un bit dans l'adresse indique si elle est globale ou locale. Le RFC 8948 définit même un plan d'adressage pour ces adresses locales.) On peut donc échapper au pistage en changeant d'adresse de temps en temps (cf. l'article de Gruteser et D. Grunwald, « Enhancing location privacy in wireless LAN through disposable interface identifiers: a quantitative analysis »). Ces questions de vie privée liées à l'adresse MAC sont décrites plus en détail dans l'article « Privacy at the Link Layer », de Piers O'Hanlon, Joss Wright et Ian Brown, présenté à l'atelier STRINT, dont le compte-rendu a été le RFC 7687. Notre RFC rappelle aussi que, bien sûr, la protection de la vie privée ne dépend pas uniquement de cette histoire d'adresse MAC et que les surveillants ont d'autres moyens de pistage, qu'il faut combattre également, cf. section 9.
Un peu d'histoire : l'IEEE, qui normalise 802.11 et donc les adresses MAC, avait pour la première fois traité le problème lors d'un tutoriel en 2014, qui avait suivi l'atelier STRINT (celui dont le compte-rendu est dans le RFC 7687). Suite à ce tutoriel, l'IEEE avait créé l'IEEE 802 EC Privacy Recommendation Study Group, ce qui avait finalement donné naissance à des documents IEEE comme IEEE 802E-2020 - IEEE Recommended Practice for Privacy Considerations for IEEE 802 Technologies et 802c-2017 - IEEE Standard for Local and Metropolitan Area Networks:Overview and Architecture--Amendment 2: Local Medium Access Control (MAC) Address Usage. Les idées documentées avaient été testées lors de réunions plénières de l'IEEE et de l'IETF. Ces tests ont montré que les collisions (deux adresses MAC identiques) étaient extrêmement rares. Elles ont aussi permis de constater que certains identificateurs visibles (comme celui envoyé en DHCP, cf. RFC 7819) restent stables et qu'il ne suffit donc pas de changer l'adresse MAC. Je recommande la lecture du rapport « IEEE 802E Privacy Recommendations & Wi-Fi Privacy Experiment @ IEEE 802 & IETF Networks> », présenté à l'IETF 96 à Berlin en 2016.
Depuis, l'aléatoirisation des adresses MAC a été largement déployée, sur iOS, sur Android, sur Microsoft Windows, sur Fedora, etc. Il n'y a évidemment pas de solution parfaite et des chercheurs ont déjà trouvé comment contourner l'aléatoirisation. Cela a mené à une nouvelle norme IEEE, 802.11aq.
Ce changement de l'adresse MAC a ensuite posé problème à certains opérateurs de réseaux mobiles. (Voir aussi « IEEE 802.11 Randomized And Changing MAC Addresses Topic Interest Group Report » et « RCM A PAR Proposal ».)
La question de la vie privée s'est beaucoup posée à l'IETF dans le contexte de l'auto-affectation des adresses IPv6 (SLAAC : Stateless Address Autoconfiguration). Le RFC 1971 et ses successeurs (le dernier en date est le RFC 4862) prévoyaient que la partie spécifique à la machine de l'adresse IPv6 soit fondée sur l'adresse MAC, ce qui permettait le pistage. Cette méthode, qui a fait couler beaucoup d'encre, est désormais déconseillée (RFC 8064). La méthode recommandée maintenant est celle du RFC 8981, avec ses adresses aléatoires et temporaires. (Elles ont d'autres avantages, comme de limiter la durée pendant laquelle on peut se connecter à une machine depuis l'extérieur.) Évidemment, ces adresses temporaires ne conviennent pas aux serveurs (qui doivent être joignables) ni aux cas où l'administrateur réseau veut pouvoir garder trace des adresses IP des machines (dans ce dernier cas, le RFC 7217, avec ses adresses stables tant qu'on reste dans le même réseau, est la solution recommandée).
On l'a dit, l'adresse MAC n'est pas le seul moyen qu'on a de suivre une machine à la trace. Les identifiants qui figurent dans la requête DHCP en sont un autre. Le RFC 7844 rassemble les recommandations faites aux auteur·es de logiciels DHCP pour limiter ce pistage.
On a donc vu qu'on pouvait changer son adresse MAC et que c'était une bonne chose pour la protection de sa vie privée. Mais la changer pour quoi ? La section 6 de notre RFC résume toutes les politiques possibles :
- Adresse MAC fixe déterminée par le fournisseur (c'est la politique ancienne et traditionnelle) et enregistrée en dur dans l'interface réseau.
- Adresse permanente mais générée localement, sur la machine, typiquement au premier démarrage. On parle de PDGM (Per-Device Generated MAC).
- Adresse temporaire générée localement, au démarrage de la machine. On parle de PBGM (Per-Boot Generated MAC). Plus besoin de mémoire stable.
- Adresse fixe générée localement, pour chaque réseau. L'adresse est stockée dans une mémoire stable, indexée par un identificateur du réseau (le SSID pour le Wifi, et diverses heuristiques utilisant par exemple STP pour les réseaux fixes). Cette politique empêche le pistage trans-réseau mais permet une stabilité utile pour l'administrateur du réseau. On parle de PNGM (Per-Network Generated MAC).
- Adresse temporaire renouvelée régulièrement, par exemple toutes les douze heures. On parle de PPGM (Per-Period Generated MAC).
- Adresse temporaire par « session ». La session étant par exemple une connexion via le portail captif. On parle de PSGM (Per-Session Generated MAC).
Que font les systèmes d'exploitation
d'aujourd'hui ? La section 7 détaille les pratiques actuelles. Un
point important est que, depuis longtemps, tous ces systèmes mettent
en œuvre une forme ou l'autre d'aléatoirisation, pour les questions
de vie privée citées ici. Comme la situation évolue, plutôt que de
lire cette section du RFC, vous avez peut-être intérêt à suivre
en ligne. Au moment de la rédaction de cet article, les
versions actuelles d'Android et
d'iOS étaient en PNGM (adresse choisie
aléatoirement mais liée au SSID). Idem pour
Debian et
Windows. Mais lisez les détails, qui peuvent
dépendre de points subtils. 
L'article seul
RFC 9720: RFC Formats and Versions
Date de publication du RFC : Janvier 2025
Auteur(s) du RFC : P. Hoffman (ICANN), H. Flanagan
(Spherical Cow Consulting)
Pour information
Première rédaction de cet article le 18 janvier 2025
Vous le savez, les RFC ne sont plus en texte brut depuis des années, leur format officiel est du XML. Le système était décrit dans le RFC 7990, que ce nouveau RFC remplace. Il y a beaucoup de changements sur la forme et aussi sur le fond, notamment la possibilité de modifier un fichier déjà publié (sans changer sa sémantique, bien sûr).
La section 2 de notre RFC décrit ce qu'est la « version définitive » d'un RFC. Écrite dans le format RFCXML spécifié dans le RFC 7991, elle peut donc comporter des images en SVG (voir le RFC 7996) et des caractères non-ASCII (cf. RFC 7997). Cette version définitive contient tout ce qui est nécessaire pour produire le RFC publié. (Les versions de développement, avant la publication, peuvent utiliser des références externes, qui devront être résolues dans la version définitive, qui sera auto-suffisante.)
Mais le changement le plus spectaculaire de notre RFC 9720 est que cette version « définitive » peut désormais changer. Si on découvre un problème dans le fichier XML, il pourra être modifié, si cela ne change pas le sens, bien sûr. La section 2.1 décrit précisément les règles de changement. En cas de modification, les versions antérieures devront être gardées, avec leurs métadonnées (comme la date) et accessibles publiquement, comme les RFC l'ont toujours été (section 4), ce qui a beaucoup contribué au succès de l'Internet.
De nouvelles versions de publication, produites à partir de la version définitive, seront produites, soit parce que la version définitive a changé, soit parce que les outils ont évolué et permettent un meilleur rendu (section 3). (La re-publication pour corriger des erreurs de rendu existait déjà et la liste des cas est en ligne.)
Notez que ce RFC ne s'applique qu'au produit final. L'élaboration des RFC, via les Internet drafts, n'est pas concernée, même si elle va sans doute s'aligner. (Si vous en écrivez et que vous voulez utiliser le format XML, ce que je recommande, une page Web dédiée est là pour vous aider.)
La section 1.1 résume les changements depuis le RFC 7990. On garde le format XML normalisé dans le RFC 7991 mais on change le concept de « format canonique », qui mélangeait plusieurs choses. Il y a désormais :
- le format final, forcément en XML, donc, c'est le format de référence, qui s'appelait « xml2rfc version 3 » et se nomme désormais RFCXML,
- la version finale qui, en dépit de son nom, peut désormais changer,
- le format de publication (texte brut, HTML ou PDF),
- la version de publication, c'est-à-dire un document dans un format de publication, fait à partir de la version finale.
Notre RFC spécifie dans quelles conditions on peut désormais changer la version finale. En gros, il faut que la sémantique reste inchangée. Cela permet d'effectuer les changements suite à des erreurs de format XML ou bien lorsqu'une évolution des logiciels ne permet plus de traiter l'ancien fichier. Mais cela pose peut-être des problèmes de sécurité et la section 6 appelle à la vigilance face au risque d'utiliser une version non-officielle.
Et, sinon, le RFC Editor » devient le « RFC Production Center » (mais je parie que l'ancien terme, chargé d'histoire, va rester encore longtemps).
On sait que le premier RFC publié sous le nouveau système (format de référence en XML) était le RFC 8651. Depuis, tous les autres RFC ont suivi ce système.
L'article seul
RFC 9718: DNSSEC Trust Anchor Publication for the Root Zone
Date de publication du RFC : Janvier 2025
Auteur(s) du RFC : J. Abley (Cloudflare), J. Schlyter
(Kirei AB), G. Bailey
(Independent), P. Hoffman (ICANN)
Pour information
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 25 janvier 2025
Le mécanisme d'authentification des informations DNS nommé DNSSEC repose sur la même structure arborescente que le DNS : une zone publie un lien sécurisé vers les clés de ses sous-zones. Un résolveur DNS validant n'a donc besoin, dans la plupart des cas, que d'une seule clé publique, celle de la racine. Elle lui servira à vérifier les clés des TLD, qui serviront à valider les clés des domaines de deuxième niveau et ainsi de suite. Reste donc à configurer la clé de la racine dans le résolveur : c'est évidemment crucial, puisque toute la sécurité du système en dépend. Si un résolveur est configuré avec une clé fausse pour la racine, toute la validation DNSSEC est menacée. Comment est-ce que l'ICANN, qui gère la clé principale de la racine, publie cette clé cruciale ? C'est documenté dans ce RFC qui remplace le RFC 7958, avec plusieurs changements, comme l'abandon des signatures PGP.
Notez que ce nouveau RFC documente l'existant, déjà mis en œuvre, et ne prétend pas décrire la meilleure méthode. Notez aussi que ce format et cette méthode de distribution pourraient encore changer à l'avenir, comme ils l'ont fait depuis la sortie du RFC 7958.
Si vous voulez réviser DNSSEC d'abord, outre les RFC de base sur ce système (RFC 4033, RFC 4034, RFC 4035...), notez surtout le RFC 6781, qui décrit les questions opérationnelles liées au bon fonctionnement de DNSSEC.
Les clés publiques configurées dans les résolveurs qui valident avec DNSSEC, sont appelées « points de départ de la confiance » (trust anchors). Un point de départ de la confiance est une clé dont l'authenticité est admise, et non pas dérivée d'une autre clé, via une chaîne de signatures. Il en faut au moins un, celui de la racine, bien que certains résolveurs en ajoutent parfois deux ou trois pour des zones qu'ils veulent vérifier indépendamment. Lorsque le résolveur recevra une réponse de la racine, signée, il l'authentifiera avec la clé publique de la racine (le point de départ de la confiance). S'il veut vérifier une réponse d'un TLD, il l'authentifiera avec la clé publique du TLD, elle-même signée (et donc authentifiée) par la clé de la racine. Et ainsi de suite même pour les zones les plus profondes.
(Notez qu'il existe deux clés pour la plupart des zones, la KSK - Key Signing Key, et la ZSK - Zone Signing Key, mais on ne s'intéresse ici qu'aux KSK, c'est elles qui sont signées par la zone parente, et configurées comme points de départ de la confiance.)
La gestion de la clé de la racine par l'ICANN (via sa filiale PTI) est décrite dans leur DPS (DNSSEC Practice Statement).
Le RFC rappelle aussi qu'il y a d'autres possibilités d'installation d'un point de départ de la confiance. Par exemple, si un tel point a été configuré une fois, ses remplacements éventuels peuvent être faits via le RFC 5011.
La section 2 du RFC décrit le format des clés publiées par l'IANA. Il s'agit d'un fichier XML contenant les condensats des clés, utilisant le format de présentation du RFC 4034. Leur syntaxe formelle est exprimée en Relax NG, le schéma est en section 2.1 du RFC (copie locale). Une vérification du fichier avec rnv fonctionne :
% rnv dnssec-root-trust-anchors.rnc root-anchors.xml
root-anchors.xml
Voici un exemple du fichier XML (à ne pas prendre comme s'il faisait autorité, évidemment) :
<TrustAnchor id="0C05FDD6-422C-4910-8ED6-430ED15E11C2"
source="http://data.iana.org/root-anchors/root-anchors.xml">
<Zone>.</Zone>
<KeyDigest id="Klajeyz" validFrom="2017-02-02T00:00:00+00:00">
<KeyTag>20326</KeyTag>
<Algorithm>8</Algorithm>
<DigestType>2</DigestType>
<Digest>E06D44B80B8F1D39A95C0B0D7C65D08458E880409BBC683457104237C7F8EC8D</Digest>
<PublicKey>AwEAAaz/…</PublicKey>
<Flags>257</Flags>
</KeyDigest>
</TrustAnchor>
L'élément <KeyTag> indique
l'identifiant de la clé, actuellement 20326, comme on peut le
voir avec dig :
% dig +multi +nodnssec . DNSKEY
...
;; flags: qr rd ra ad; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1
...
;; ANSWER SECTION:
. 86254 IN DNSKEY 257 3 8 (
AwEAAaz/tAm8yTn4Mfeh5eyI96WSVexTBAvkMgJzkKTO
…
) ; KSK; alg = RSASHA256 ; key id = 20326
...
L'attribut id de l'élément
<TrustAnchor> est un UUID. L'attribut
id de l'élément
<KeyDigest> sert à identifier un
condensat particulier. Le fichier peut également comporter des
commentaires XML (mais ce n'est pas le cas actuellement). Le fichier
indique aujourd'hui le condensat de la clé et la clé mais cette
dernière est optionnelle (on ne s'en sert pas par la suite).
Pour produire un enregistrement DS à partir de
ce fichier XML, il suffit de mettre
<KeyTag>,
<Algorithm>,
<DigestType> et
<Digest> bout à bout. Par exemple, avec
le fichier XML ci-dessus, cela donnerait :
. IN DS 20326 8 2 E06D44B80B8F1D39A95C0B0D7C65D08458E880409BBC683457104237C7F8EC8D
(Des résolveurs comme Unbound acceptent ce format, pour le point de confiance de départ.)
Ici, je n'ai montré qu'une clé mais il peut y en avoir plusieurs,
donc plusieurs <KeyDigest>. En novembre
2024, le fichier comportait trois clés, l'ancienne 19036, abandonnée
il y a des années, l'actuelle 20326 et la future 38696 (qui n'était pas encore
publiée dans le DNS mais qui l'a été en janvier 2025).
Comment récupérer le fichier XML de
manière à être sûr de son authenticité ? C'est ce que spécifie la
section 3 du RFC : on utilise HTTPS (ou HTTP tout court mais ce n'est pas
forcément une bonne idée et, de toute façon, aujourd'hui, une
politique HSTS le rend difficile). L'URL est
https://data.iana.org/root-anchors/root-anchors.xml. Si
on fait confiance à l'AC utilisée par
l'ICANN, on peut être sûr de l'authenticité du fichier. (Mais notez,
comme le fait remarquer gregR, que
data.iana.org et iana.org
n'ont pas d'enregistrement CAA, RFC 8659.)
Une
autre solution est de le récupérer en HTTP et de le vérifier avec la
signature fournie, en CMS (RFC 5652) - son URL est
https://data.iana.org/root-anchors/root-anchors.p7s. (Non,
je ne sais pas comment la vérifier.)
Bien sûr, un résolveur
validant n'est pas obligé d'utiliser ces points de départ de la
confiance. Cela reste une décision locale. La très grande majorité
des résolveurs utiliseront sans doute plutôt un
paquetage fourni par leur système
d'exploitation, comme dns-root-data
sur Debian.
Pour les amateurs d'histoire, l'annexe B rappelle que la clé 19036 (également appelée KSK-2010) avait été générée au cours d'une cérémonie à Culpeper, le 16 juin 2010. Elle avait été publiée dans le DNS pour la première fois le 15 juillet 2010. La clé actuelle, la 20326 (également nommée KSK-2017), a été également générée à Culpeper le 27 octobre 2016 et publiée le 11 novembre 2018. La liste des cérémonies de création de clés est en ligne.
L'annexe A de notre RFC contient les changements depuis le RFC 7958. Notamment :
- Correction d'une sérieuse erreur technique,
- Suppression des certificats qui étaient distribués avec les versions précédentes,
- Suppression de la signature OpenPGP,
- Et divers points de détail.
L'article seul
RFC 9717: A Routing Architecture for Satellite Networks
Date de publication du RFC : Janvier 2025
Auteur(s) du RFC : T. Li (Juniper Networks)
Pour information
Première rédaction de cet article le 29 janvier 2025
Tout le monde connait aujourd'hui l'utilisation de constellations de satellites en orbite basse pour les télécommunications et, par exemple, pour l'accès à l'Internet. Contrairement à l'ancienne technique de communication via des satellites en orbite géostationnaire, la communication directe entre satellites y joue un rôle important. Les satellites se déplacent les uns par rapport aux autres, changeant en permanence la topologie de ce réseau. Alors, comment se fait le routage ? Ce RFC décrit une méthode possible, reposant largement sur le protocole IS-IS.
Ce n'est pas forcément la technique réellement utilisée. Les constellations existantes, dont la plus connue est Starlink, sont des entreprises privées, très secrètes, et qui ne décrivent pas leur configuration interne. Ce RFC est donc un travail de réflexion, mené à partir des rares informations publiques. Il ne peut pas spécifier une solution complète. Si vous envisagez de créer une constellation, il vous restera du travail pour avoir une solution de routage.
D'abord, il faut voir les particularités de ce réseau de satellites. Il est bien moins fiable qu'un réseau terrestre (l'espace est agité, un satellite en panne n'est pas facile à réparer) et il est tout le temps en mouvement. Ce rythme important de changement est un défi pour les protocoles de routage. Sauf si les satellites sont exactement sur la même orbite, leur mouvement relatif fait qu'on a une possibilité de communiquer à certains moments seulement, voire quasiment jamais. Si deux satellites se déplacent en direction opposée, leur vitesse relative, de l'ordre de dizaines de milliers de km/h, ne permettra guère de communication entre eux.
Par contre, un point qui va faciliter les choses est que ces mouvements, et donc l'établissement et la coupure du lien, sont prévisibles. On peut compter sur Kepler et Newton !
La section 1.2 du RFC rappelle le vocabulaire important. Notons le sigle ISL, pour Inter-Satellite Link, la liaison directe entre satellites, typiquement via un faisceau laser. (Le RFC cite ce très vieil article de Bell, « On the Production and Reproduction of Sound by Light ».) Si vous ne le connaissez pas, il faut aussi apprendre le sigle LEO, pour Low Earth Orbit, désignant les satellites qui orbitent à moins de 2 000 km de la surface de la Terre. On utilisera aussi SR (Segment Routing), la technique du routage par segments, décrite dans le RFC 8402 et SID (Segment IDentifier), qui vient de cette technique. Et IS-IS (Intermediate System to Intermediate System ) ? Ce protocole de routage est normalisé par l'ISO (et donc la spécification n'est normalement pas librement disponible) mais il est aussi décrit dans le RFC 1142 et le RFC 1195 explique comment s'en servir pour IP. Attention : c'est un vieux RFC, datant d'une époque où on pensait encore que les protocoles OSI avaient peut-être un avenir (aujourd'hui, ils n'ont même pas de page Wikipédia). Le RFC 1195 se concentre donc sur la possibilité d'utiliser IS-IS pour router à la fois OSI et TCP/IP. Aujourd'hui, il ne sert plus qu'aux protocoles Internet.
La section 2 de notre RFC rappelle les points essentiels des satellites LEO, qui vont impacter les choix techniques. Quand deux satellites se parlent via un ISL (Inter-Satellite Link), la liaison ne peut avoir qu'une durée limitée, les deux satellites ne restant pas visibles l'un par l'autre éternellement, s'ils sont sur des orbites différentes. Par contre, les périodes de visibilité et de non-visibilité peuvent être calculées à l'avance, on peut compter sur les lois de la physique.
Les constellations peuvent être de grande taille. En 2021, déjà, celle du milliardaire d'extrême-droite représentait un tiers du total des satellites en orbite. Aujourd'hui, des constellations de dizaines de milliers de satellites sont prévues (occupant l'espace public et bloquant la visibilité sans vergogne). Les protocoles de routage traditionnels peuvent gérer des réseaux de grande taille mais à condition qu'ils soient relativement statiques, avec juste une panne ou une addition d'un lien de temps en temps, ce qui n'est pas le cas pour des réseaux de satellites en mouvement. L'IETF a sous la main deux protocoles de routage normalisés pour les réseaux mono-organisation, OSPF (RFC 2328 et RFC 5340) et IS-IS (RFC 1195). (Il existe d'autres protocoles pour ces réseaux mais convenant plutôt à des réseaux plus petits.) Tous les deux sont à état des liaisons et, pour passer à l'échelle, tous les deux permettent de partitionner le réseau en zones (areas) à l'intérieur desquelles l'information de routage est complète, alors qu'entre zones, on ne passe qu'une partie de l'information. Dans OSPF, il y a forcément une zone spéciale, l'épine dorsale (backbone, la zone de numéro 0). Rien que pour cela, le RFC estime qu'OSPF ne serait pas un bon choix : contrairement aux réseaux terrestres, les constellations n'ont rien qui pourrait servir d'épine dorsale. IS-IS repose sur un système différent, où des zones dites « L1 » (de niveau 1) regroupent des parties du réseau qui ne servent pas au transit entre zones, qui est assuré par des zones « L2 ». La machine individuelle peut aussi bien être dans L1 que dans L2 ou même dans les deux. Si on adoptait le système simple de mettre chaque satellite dans une zone L2 (puisque tout satellite peut servir au transit), on perdrait tous les avantages du partitionnement. L'utilisation de IS-IS va donc nécessiter des ajustements.
La section 3 du RFC expose le mécanisme de transmission des paquets choisi. Elle propose d'utiliser MPLS (RFC 3031), en raison de sa souplesse (puisque la topologie change tout le temps), avec le SR (Segment Routing) du RFC 8402 (et RFC 8660 pour son adaptation à MPLS). Dans cette vision, il n'y a pas de transmission au niveau IP et donc un traceroute ne montrerait pas le trajet entre les satellites.
Reste le choix de l'IGP. La section 4 décrit la préférence de l'auteur pour IS-IS. Dans cette hypothèse, tous les satellites seraient des nœuds L1L2 (appartement aux deux types de zones). Le passage à l'échelle serait assuré grâce au système des relais, normalisé dans le RFC 9666. Un réseau de 1 000 zones L1, chacune comportant 1 000 satellites, n'aurait besoin que de mille entrées (et pas un million) dans ses tables de routage, aussi bien L1 que L2. Idem pour la table des étiquettes MPLS.
La section 5 introduit le concept de bande (stripe). La bande est un ensemble de satellites dont les orbites sont suffisamment proches pour que la connectivité entre eux change peu.
On l'a dit,
une particularité importante des réseaux de satellites est la
prévisibilité des coupures. Un calcul de mécanique
céleste permet de dire quand deux satellites
ne pourront plus communiquer. On peut bien sûr router comme s'il
s'agissait de pannes imprévues, mais on améliorera certainement la
qualité du routage (et on diminuera le nombre de pertes de paquets
lorsque la topologie change) si on prévient les satellites à
l'avance. Par exemple, une fois informés d'un changement proche, les
routeurs peuvent annoncer une métrique très élevée pour les ISL qui
vont bientôt être coupés, comme on le fait sur les réseaux
terrestres quand une maintenance est prévue. Il y a une proposition
concrète d'un mécanisme d'information dans le brouillon
draft-ietf-tvr-schedule-yang.
Quelques lectures recommandées par notre RFC :
- une étude de 2023 de la documentation disponible, « LEO Satellite Networking Relaunched: Survey and Current Research Challenges »,
- une précédente analyse de l'utilisation de protocoles de routage à état des liens pour les satellites, « Dynamic Routings in Satellite Networks: An Overview »,
- et une autre, « ASER: Scalable Distributed Routing Protocol for LEO Satellite Networks ».
L'article seul
RFC 9715: IP Fragmentation Avoidance in DNS over UDP
Date de publication du RFC : Janvier 2025
Auteur(s) du RFC : K. Fujiwara (JPRS), P. Vixie (AWS
Security)
Pour information
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 28 janvier 2025
Les requêtes et réponses DNS peuvent voyager sur divers transports, mais le plus fréquent est UDP. Une réponse de grande taille sur UDP peut dépasser la MTU et donc devoir être fragmentée. La fragmentation crée divers problèmes et ce RFC décrit les problèmes, et comment éviter la fragmentation.
Un peu de rappel : avec UDP (RFC 768), il n'y a pas de négociation de la taille des paquets et un émetteur UDP peut donc, en théorie, envoyer ce qu'il veut, jusqu'à la limite maximum de 65 536 octets. Bon, en pratique, on voit rarement un paquet aussi grand. Déjà, la norme originelle du DNS mettait une limite à 512 octets. Cette limite a disparu depuis longtemps, grâce à EDNS (RFC 6891) et, désormais, le logiciel DNS peut indiquer la taille maximale qu'il est prêt à recevoir. Pendant longtemps, on voyait souvent une taille de 4 096 octets, ce qui excède la MTU de la plupart des liens Internet. Un paquet aussi grand devait donc être fragmenté (que cela soit en IPv4 ou en IPv6). Voici un exemple de réponse plus grande que la MTU typique :
% dig oracle.com TXT … ;; MSG SIZE rcvd: 3242
Si cette réponse était transmise dans un seul datagramme UDP, elle serait fragmentée, ce qui ne marcherait pas toujours, comme l'explique le RFC 8900 et créerait des risques de sécurité.
TCP (RFC 9293) évite le problème grâce à la négociation de la MSS (Maximum Segment Size, section 3.7.1 du RFC 9293) et au découpage en paquets plus petits que la MTU. La requête DNS ci-dessus ne poserait aucun problèmes avec TCP :
% dig +tcp oracle.com TXT … ;; SERVER: 192.168.2.254#53(192.168.2.254) (TCP) ;; MSG SIZE rcvd: 3242
Mais UDP, plus rigide, n'a pas un tel mécanisme. On pourrait tout faire en TCP (le RFC 7766 rappelle opportunément qu'il n'est pas en option : tout serveur DNS doit l'accepter) mais cela a d'autres inconvénients donc restons avec UDP pour l'instant.
Donc, il est recommandé d'éviter la fragmentation. La section 3
traduit cela en recommandations concrètes : ne pas fragmenter au
départ (IPv6) et mettre le bit DF (Don't fragment,
pour IPv4, cf. RFC 791) car, sinon, un paquet
IPv4 pourra être fragmenté en route (cf. section 7.1). Malheureusement, tous
les systèmes
d'exploitation ne donnent pas un accès facile à ce
bit. Sur Linux, par
exemple, il faut passer (ce qui n'est pas très intuitif) par
l'option IP_MTU_DISCOVER, ce qui mène à
d'autres problèmes (cf. annexe C du RFC).
Le logiciel qui répond à une requête DNS doit la maintenir sous une taille qui est le miminum de ces quatre tailles :
- la taille indiquée par le demandeur, via EDNS,
- la MTU de l'interface réseau par laquelle partira la réponse,
- la MTU du chemin (si on la connait),
- 1 400 octets (la valeur sûre : aller au-delà serait risqué).
Si on ne peut pas fabriquer une réponse de taille inférieure à ce minimum, il faut mettre le bit TC (TrunCated) dans la réponse DNS.
Ça, c'était pour les répondeurs (les serveurs DNS). Et pour les
demandeurs (les clients) ? Ils ne devraient pas indiquer en EDNS une
taille supérieure au minimum des trois dernières valeurs citées plus
haut. Ici, vue par tshark,
la requête faite par dig avec l'option
+dnssec mais sans autre mention, notamment de
taille. dig indique une taille maximale de 1 232 octets, conforme
aux recommandations du RFC :
Domain Name System (query)
Flags: 0x0120 Standard query
0... .... .... .... = Response: Message is a query
…
Queries
re: type NS, class IN
Name: re
[Name Length: 2]
[Label Count: 1]
Type: NS (2) (authoritative Name Server)
Class: IN (0x0001)
Additional records
<Root>: type OPT
Name: <Root>
Type: OPT (41)
UDP payload size: 1232
Higher bits in extended RCODE: 0x00
EDNS0 version: 0
Z: 0x8000
1... .... .... .... = DO bit: Accepts DNSSEC security RRs
.000 0000 0000 0000 = Reserved: 0x0000
Data length: 12
Option: COOKIE
Option Code: COOKIE (10)
Option Length: 8
Option Data: 83d7d3e78b76b45d
Client Cookie: 83d7d3e78b76b45d
Server Cookie: <MISSING>
Le RFC demande également aux clients DNS de refuser les réponses fragmentées, compte tenu de certains risques de sécurité (risque de ne pas pouvoir valider les réponses), et de ne pas hésiter à essayer avec d'autres protocoles de transport, comme TCP.
La section 4, elle, rassemble les recommandations pour les hébergeurs DNS. Comme ils contrôlent les zones publiées, ils peuvent faire en sorte que les réponses ne soient pas trop longues, rendant la fragmentation inutile. Par exemple, ils devraient faire attention à ne pas lister « trop » de serveurs de noms, ne pas mettre « trop » d'enregistrements d'adresses à ces serveurs, etc. Un conseil DNSSEC : certains algorithmes cryptographiques ont des clés et des signatures plus courtes que d'autres. Utilisez-les. (Et, donc, ECDSA ou EdDSA, plutôt que RSA.)
Le RFC note aussi que certains logiciels ne sont pas conformes à la norme. Par exemple, la taille maximale indiquée dans la requête est ignorée et une réponse plus grande que cette taille renvoyée. Et, bien sûr, on trouve encore des serveurs qui n'acceptent pas TCP.
Mais quel était le problème de sécurité avec la fragmentation, au juste ? Comme détaillé en section 7.3, qui cite le papier « Fragmentation Considered Poisonous », de Amir Herzberg et Haya Shulman, l'empoisonnement de la mémoire d'un résolveur est plus facile lorsqu'il y a fragmentation, puisque certains des éléments dans le paquet qui peuvent être utilisés pour juger de la légitimité d'une réponse peuvent se retrouver dans un autre fragment. (Voir aussi cet exposé au RIPE.) Ces attaques permettent ensuite plein d'autres attaques, par exemple contre les autorités de certification.
DNSSEC résout évidemment ces problèmes mais attention, les délégations ne sont pas signées donc DNSSEC ne protège que si les victimes ont signé leur zone et, en prime, DNSSEC permet de détecter la tentative d'empoisonnement et de la refuser, mais pas d'obtenir la bonne réponse.
L'annexe A du RFC détaille les observations quantitatives sur la taille des réponses et les raisons qui peuvent guider le choix des tailles maximum. La section 5 du RFC 8200 garantit que 1 280 octets passeront partout en IPv6, c'est la MTU minimale (mais elle est bien plus basse dans l'ancienne version d'IP). Le RFC 4035 (section 3) impose 1 220 octets minimums pour DNSSEC. Le DNS flag day 2020 proposait 1 232 octets comme taille maximale acceptée (MTU de 1 280 octets, moins 48 octets d'en-têtes). La MTU typique dans l'Internet est de 1 500 octets et, au moins dans le cœur, il n'y a pratiquement pas de liens avec une MTU plus basse. Une taille de 1 452 octets (la MTU moins les en-têtes) est donc réaliste mais, pour tenir compte de certaines techniques qui abaissent la MTU effective, comme les tunnels, notre RFC arrive finalement aux 1 400 octets cités plus haut (section 3).
L'annexe B, elle, décrit le concept de « réponses minimisées ». Certaines mises en œuvre du DNS ont une option qui permet de dire « essaie de réduire la taille de la réponse, en n'incluant pas certaines informations non indispensables ». Attention, des informations comme la colle (les adresses IP des serveurs nommés dans la zone qu'ils servent) sont indispensables (RFC 9471).
Par exemple, pour un serveur faisant autorité qui fait tourner BIND, qui envoie des réponses minimales par défaut, si on lui demande de ne pas être si économe :
options {
minimal-responses no;
};
Il va alors renvoyer des informations qu'on n'avait pas demandé et dont l'utilité se discute (ici, les deux enregistrements NS) :
% dig @::1 -p 8053 under.michu.example … ;; ANSWER SECTION: under.michu.example. 600 IN A 192.0.2.56 ;; AUTHORITY SECTION: michu.example. 600 IN NS ns2.nic.fr. michu.example. 600 IN NS ns1.nic.fr. …
Par défaut, BIND, conformément aux recommandations de notre RFC, n'enverra pas ces deux NS. Ici, il s'agissait d'un serveur faisant autorité mais cette option s'applique aussi aux résolveurs. (Notez que, pour d'autres logiciels, le fait d'envoyer des réponses minimales est par défaut, et pas modifiable.)
En parlant de logiciels, l'annexe C liste un certain nombre de serveurs DNS libres (BIND, Knot, Knot resolver, Unbound, PowerDNS, PowerDNS recursor et dnsdist) en regardant quelles recommandations de ce RFC sont appliquées.
L'article seul
RFC 9712: IETF Meeting Venue Requirements Review
Date de publication du RFC : Janvier 2025
Auteur(s) du RFC : J. Daley, S. Turner (IETF
Administration LLC)
Première rédaction de cet article le 27 janvier 2025
L'IETF utilise, pour le cœur de son travail de normalisation, l'Internet : listes de diffusion, forge de documents, outils divers de travail en groupe. Mais il y a quand même des réunions physiques, trois par an, rien ne remplaçant à 100 % le contact direct. Les discussions sur les lieux de ces réunions sont un des sujets favoris à l'IETF et ce RFC résume les règles actuelles de sélection d'un lieu. Pour savoir pourquoi il n'y a jamais eu de réunion en Inde, une seule en Chine et une seule en Amérique du Sud, lisez-le.
La politique officielle est documentée dans les RFC 8718 et RFC 8719. Ce nouveau RFC 9712 vise à détailler ces RFC et à expliquer certains points, d'autant plus que des choses ont pu changer depuis ces RFC (écrits avant la pandémie de Covid-19…). Pas de changements radicaux de la politique, surtout des clarifications (la section 2 de notre RFC les résume).
Ainsi, le RFC explique que ce sera toujours l'IASA (IETF Administration Support, RFC 8711), qui décidera, pas l'IETF dans son ensemble. Il y a déjà eu des cas d'enthousiasme de l'IETF pour un lieu de réunion… qui ne se traduisaient pas par un grand nombre de participants, bien au contraire (je me souviens que ce fut le cas de la réunion de Buenos Aires).
Le RFC 8718 énonçait que les hôtels devaient être « proches » du lieu de la réunion. Certains avaient interprété cela comme imposant un seul lieu (la one-roof policy). Notre nouveau RFC clarifie donc que « proche » veut dire « moins de dix minutes à pied », pas forcément sous le même toit.
L'IASA réservait traditionnellement un grand nombre de chambres dans les hôtels proches mais cela a toujours fait courir un risque financier en cas d'annulation, comme cela s'est produit pendant la pandémie de Covid-19. Depuis cette pandémie, les hôtels sont d'ailleurs bien plus prudents, demandant des paiements en avance. Bref, notre RFC n'impose plus de chiffre minimal de réservation, contrairement à ce que disait la section 3.2.4 du RFC 8718.
Une ancienne tradition disparait avec ce RFC : dans les réunions professionnelles d'informaticiens·nes, il y avait toujours une terminal room, ainsi appelée car elle était autrefois équipée de terminaux pour se connecter à ses ordinateurs distants. L'évolution de l'informatique fait que cette salle n'a plus de terminaux, mais juste tables, chaises et prises de courant. Désormais, elle n'est même plus obligatoire dans les réunions IETF (où on voyait de toute façon souvent des gens ouvrir leur ordinateur portable assis par terre dans le couloir, ou au bistrot d'à côté).
L'article seul
RFC 9707: IAB Barriers to Internet Access of Services (BIAS) Workshop Report
Date de publication du RFC : Février 2025
Auteur(s) du RFC : M. Kühlewind, D. Dhody, M. Knodel
Pour information
Première rédaction de cet article le 26 février 2025
L'Internet est aujourd'hui un service indispensable à toutes les activités humaines. Un accès correct à ce réseau est donc crucial. Mais plusieurs problèmes limitent l'accès à l'Internet ou à plusieurs de ses services. L'IAB avait organisé en janvier 2024 un atelier sur cette question, atelier dont ce RFC est le compte-rendu.
Trois thèmes principaux étaient à l'agenda de cet atelier, qui s'est tenu entièrement en ligne : l'état de la fracture numérique, le rôle des réseaux communautaires et la question de la censure. Oui, il y aurait eu plein d'autres thèmes possibles (comme les difficultés d'accès aux services en ligne, par exemple parce que leur utilisation est anormalement difficile) mais en trois jours d'atelier, ce n'est déjà pas mal.
Comme tous les ateliers de l'IAB, celui-ci a fonctionné en demandant aux participants des position papers expliquant leur point de vue. Ne participent à l'atelier que des gens ayant écrit un de ces articles, ce qui garantit que tout le monde a dû travailler le sujet. Ces articles sont disponibles en ligne.
Le RFC commence en rappelant que, dans une société où tout se fait via l'Internet, ne pas avoir accès à l'Internet, ou bien n'avoir un accès que dans de mauvaises conditions, est une discrimination inacceptable. Le RFC insiste sur ce deuxième point : aujourd'hui, le problème n'est plus uniquement l'absence totale d'accès Internet, c'est souvent l'accès de mauvaise qualité (liaison trop lente, intermittente, ordinateur trop lent pour les sites Web modernes surchargés de gadgets, censure, etc). L'atelier de l'IAB visait à :
- récolter des informations sur les diverses inégalités d'accès,
- mieux comprendre les différentes façons dont les gens accèdent à l'Internet (et pas uniquement dans les pays riches),
- et ce que veut dire « être connecté à l'Internet » pour les utilisateurs, quels sont leurs usages et leurs exigences.
Le premier jour, l'atelier a surtout travaillé sur les réseaux dits « communautaires » (terminologie très étatsunienne, je m'excuse mais c'est celle du RFC). Ces réseaux bâtis localement par leurs utilisateurices, sans but lucratif, sont décrits plus en détail dans le RFC 7962 et un groupe de recherche IRTF existe, GAIA. Le plus connu et le plus souvent cité est Guifi. Ces réseaux communautaires souffrent de divers problèmes, dont bien sûr le coût élevé du transit, qui est nécessaire pour joindre le reste de l'Internet. Une des pistes évoquées était l'installation des CDN dans ces réseaux communautaires, pour limiter l'utilisation du transit. Cette piste était par exemple citée dans cette intervention, dont on notera qu'un des auteurs travaille pour un CDN, qui a par ailleurs un projet caritatif pour les réseaux communautaires. Opinion personnelle : c'est très discutable, les CDN ne servent qu'à la consommation passive de contenu et, pire, renforcent le contenu déjà très populaire.
L'accès au transit peut se faire par liaison terrestre fixe mais aussi par satellite, les satellites en orbite basse (LEO) étant actuellement en plein développement. Notez que cela ne résout pas les problèmes de contrôle, comme l'a montré la coupure de l'Ukraine par Starlink.
Le RFC note aussi un problème social : les opérateurs des réseaux communautaires sont peu présents à l'IETF et donc leurs questions et problèmes ne sont pas forcément bien pris en compte dans la normalisation technique.
Autre sujet, le deuxième jour, la fameuse fracture numérique. Comme dit plus haut, elle ne se réduit pas au fait de ne pas avoir d'accès du tout, problème qu'on pourrait régler en posant de la fibre optique. Il y a aussi une fracture entre celleux qui accèdent à l'Internet dans de bonnes conditions et celleux qui sont du mauvais côté de la fracture. Des bonnes conditions, cela concerne à la fois la technique (liaison rapide et fiable) mais aussi la maitrise de son activité en ligne (ne pas être dépendant des GAFA, par exemple, ce que le RFC ne mentionne guère).
À l'atelier, Holz a par exemple étudié les serveurs DNS faisant autorité pour divers domaines australiens et montré que les organisations indigènes étaient nettement moins bien servies.
Les différentes personnes vivant sur Terre parlant de nombreuses langues différentes, la question de la possibilité de chacun·e d'utiliser sa langue a toute sa place dans toute discussion sur les inégalités d'accès. D'où l'exposé de Hussain sur le projet Universal Acceptance de l'ICANN, qui vise à faire en sorte que, par exemple, les noms de domaine en Unicode soient acceptés partout. Actuellement, si le travail de normalisation est largement fini, le déploiement effectif est loin d'être complet. (Opinion personnelle : cette question de l'acceptation universelle des TLD ICANN en Unicode n'est qu'une toute petite partie de la question des langues sur l'Internet.)
Il y a aussi le problème des performances : bien des sites Web modernes sont développées par une personne riche et bien connectée, munie d'un ordinateur rapide. Ils sont souvent pénibles à utiliser lorsque la liaison est lente et/ou la machine de l'utilisateur un peu ancienne. (Et, dans mon expérience, les remarques aux développeurs Web sur ce point sont souvent accueillies par des remarques méprisantes.) L'étude de Habib et al. analyse très bien ce problème, notamment pour les pays « du Sud » (et propose une solution technique mais, quoi qu'on pense de cette solution, l'étude reste très pertinente). Sinon, le RFC n'en parle pas, mais ce problème est une des motivations du projet Gemini.
Gros morceau pour la troisième session, la censure. C'est évidemment un des principaux obstacles sur la route des utilisateurices. Ainsi, le projet iMAP (rien à voir avec IMAP) a documenté la censure dans plusieurs pays asiatiques, notamment en utilisant les sondes OONI. De nombreuses techniques différentes sont utilisées, par exemple des résolveurs DNS menteurs, ou bien, plus sophistiqué, une interférence avec les connexions HTTPS, utilisant le SNI pour repérer le site visité. Parfois, l'utilisateurice est redirigé·e vers une page expliquant le blocage (comme je l'avais vu il y a déjà seize ans à Dubaï, la censure n'est pas une invention récente). Parfois, la censure est plus hypocrite et ne s'avoue pas comme telle.
Une autre étude détaillée est celle de Grover, portant notamment sur l'Inde et le Pakistan. Il insiste notamment sur le caractère inégal de la mise en œuvre de la censure, bien des ressources n'étant bloquées que par certains FAI.
Évidemment, en Russie, la guerre avec l'Ukraine est le prétexte pour un durcissement considérable de la censure. Basso l'a étudié avec OONI. Notez que son étude montre des domaines bloqués sans être pour autant sur la liste officielle de blocage.
Comme la censure, comme dans ce cas russe, est souvent hypocrite, voire dissimulée, il y a beaucoup de travail à faire du point de vue technique pour l'analyser. C'est ainsi que Wang et al ont présenté les solutions utilisables pour cela. (Et le problème est complexe !)
Tous les intervenants sur la question de la censure ont insisté sur l'importance de l'information des utilisateurices, souvent laissé·es délibèrement dans le noir sur les raisons d'un blocage ou même sur sa simple existence. Les solutions normalisées existantes pour cela incluent le code de retour 451 de HTTP (normalisé dans le RFC 7725) ou les codes EDE, notamment le code 16, pour le DNS (normalisés dans le RFC 8914). Voici deux exemples, respectivement par Google et par Cloudflare, vus en juillet 2024, à propos de la censure en France de sites qui diffusent des spectacles sportifs en violation des intérêts financiers des entreprises comme Canal+ :
% dig @8.8.8.8 tarjetarojatvlive.net … ;; ->>HEADER<<- opcode: QUERY, status: REFUSED, id: 7912 ;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 512 ; EDE: 16 (Censored): (The requested domain is on a court ordered copyright piracy blocklist for FR (ISO country code). To learn more about this specific removal, please visit https://lumendatabase.org/notices/41939614.) … ;; SERVER: 8.8.8.8#53(8.8.8.8) (UDP) ;; WHEN: Wed Jul 03 10:34:44 CEST 2024
% curl -v jokersportshd.net … * Connected to jokersportshd.net (2606:4700:3034::6815:5b9) port 80 (#0) > GET / HTTP/1.1 > Host: jokersportshd.net > User-Agent: curl/7.81.0 > Accept: */* … < HTTP/1.1 451 < Date: Wed, 03 Jul 2024 08:36:59 GMT < Content-Type: text/html … <!DOCTYPE html><html class="no-js" lang="en-US"> <head> <title>Unavailable For Legal Reasons</title> … <p>This website is unavailable for legal reasons.</p><p>Please see <a rel="noopener noreferrer" href="https://lumendatabase.org/notices/42038946" target="_blank">https://lumendatabase.org/notices/42038946</a> for more details.</p> ..
(Il y aurait aussi le RFC 6108, mais il est aujourd'hui techniquement dépassé.) Les mécanismes standardisés pour signaler une censure sont peu utilisés aujourd'hui, et les explications sont rares.
Notons que rediriger les utilisateurs vers une page Web d'information leur annonçant qu'ils ont été bloqués (comme le fait en France la Main Rouge) est dangereux : cela permet au gestionnaire de la page en question de voir l'adresse IP (et d'autres informations envoyées par le navigateur) du visiteur ou de la visiteuse. En France, le ministère de l'Intérieur avait ainsi supprimé les données récoltées… après avoir juré qu'il n'en récoltait pas !
Qui dit censure dit évidemment contournement, car les utilisateurices ne vont pas rester les bras ballants face aux mesures de blocage. Ont été discutés à l'atelier les VPN, par exemple, y compris leurs problèmes actuels (cf. l'excellente étude de Ramesh sur les VPN et leurs limites, à lire la prochaine fois qu'un youtubeur vous fera la pub de NordVPN).
Voilà, maintenant, il y a du travail pour des groupes IRTF comme GAIA, HRPC, PEARG, et MAPRG (section 2.4 du RFC, sur le travail à faire).
L'article seul
RFC 9695: The 'haptics' Top-level Media Type
Date de publication du RFC : Mars 2025
Auteur(s) du RFC : Y. K. Muthusamy, C. Ullrich
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF mediaman
Première rédaction de cet article le 19 mars 2025
L'enregistrement d'un nouveau type de
média de premier niveau est plutôt rare (le dernier
avait été font/ en 2017). Notre
RFC introduit le type
haptics/, pour les formats de fichier des
interfaces haptiques, celles qu'on touche et
qui vous touchent (une manette de jeu vidéo à retour
d'effort, par exemple).
De telles interfaces se trouvent dans de nombreux secteurs, le jeu vidéo, bien sûr, mais aussi la simulation (simulateurs de vol, par exemple), la robotique, des trucs pour adultes, etc. Contrairement à l'audio et à la vidéo, qui s'affichent directement, l'haptique est une réaction à votre toucher. (Enfin, c'est ce que dit le RFC mais les fauteuils de cinéma haut de gamme qui vous secouent pendant les scènes d'action sont aussi de l'haptique.) Les interfaces haptiques peuvent être mises en œuvre de diverses façons, par exemple des petits moteurs ou des matériaux piézoélectriques.
Il existe divers formats pour représenter des actions haptiques
et il est donc nécessaire de les étiqueter proprement pour quand les
fichiers voyagent sur l'Internet. Le mécanisme des types
de médias est décrit dans le RFC 6838. Il est complété par le RFC 9694 pour la création de nouveaux types de premier niveau,
comme haptics/, créé
par notre RFC.
On trouve des dispositifs haptiques dans un certain nombre de machines (PlayStation, Switch, etc) et le W3C a une norme pour les vibrations (et même deux).
À noter que les données haptiques peuvent être combinées avec des
données audio et vidéo, par exemple pour une simulation plus
réussie. La norme ISOBMFF (ISO 14496) est
un exemple mais on trouve aussi des instructions haptiques
transportées, par exemple, dans RTP. Je n'ai pas 216 francs suisses pour
vérifier mais le RFC dit que la première mention d'un type de médias
haptics/ vient de cette norme ISO. On pourra
donc avoir, par exemple, dans le futur,
haptics/mp4.
haptics/ ne concerne pas que le toucher au
sens strict. Outre les effects tactiles, il y a aussi la
kinésthésique (des forces plus importantes),
la friction, l'utilisation de sons qu'on n'entend pas (par exemple
ultrasons) mais qui ont quand même un effet
sur le corps et même la température. Vous voyez que cela ne pouvait
pas rentrer dans audio/ ou
video/.
Il existe déjà plusieurs formats pour les données haptiques :
- IVS que l'on trouve chez certains fournisseurs d'ordiphones,
- hjif (norme ISO 23090),
- hmpg (norme ISO 23090),
- AHAP, d'origine Apple,
- Une extension d'origine Google à Ogg,
- HAPT, qui semble surtout utilisé au Japon,
- IEEE 1918 (126 dollars étatsuniens, l'IEEE est moins chère que l'ISO) ,
- Et j'en oublie…
Les trois premiers ont déjà été mis dans le
registre : haptics/ivs,
haptics/hjif
et haptics/hmpg.
Le type application/ aurait pu convenir mais
haptics/ est plus spécifique et, surtout, ce
sont des données, pas du code. En parlant de cela, la section 3 du
RFC détaille quelques points de sécurité. Outre les problèmes
classiques d'analyser des données venues de l'extérieur (les formats
complexes mènent souvent à des failles de sécurité dans
l'analyseur), les actuateurs peuvent être
dangereux (un actuateur thermique qui brûle, un actuateur à retour
de force qui brutalise) et il ne faut donc pas exécuter aveuglément
toutes les instructions que contient un fichier de type
haptics/.
L'article seul
RFC 9694: Guidelines for the Definition of New Top-Level Media Types
Date de publication du RFC : Mars 2025
Auteur(s) du RFC : M.J. Dürst (Aoyama Gakuin University)
Réalisé dans le cadre du groupe de travail IETF mediaman
Première rédaction de cet article le 19 mars 2025
Vous savez que les types de médias
comportent un type de premier niveau et un sous-type. Dans
image/gif, image est le
type de premier niveau et gif le sous-type. On
crée des sous-types tout le temps mais les types, l'identificateur
qui est au premier niveau, c'est bien plus rare. La création du type
haptics
(données haptiques), qui a été faite dans le RFC 9695, a été l'occasion de formaliser un
peu plus le processus de création de types de médias.
Vous voulez créer un nouveau type de
médias (également appelé type MIME) ? Les
types existants comme text,
image et application ne
vous suffisent pas ? Alors, il vaut mieux lire ce RFC 9694, qui explique les principes. Le RFC 6838, qui spécifie les types de médias est assez vague sur
la création de nouveaux types de premier niveau (cf. sa section
4.2.7), sans doute parce qu'on ne comptait pas en voir arriver
beaucoup. Notre RFC 9694 comble ce manque, devenu
évident avec la création du type haptics
dans le RFC 9695.
Attention, ne pas confondre les types de médias de premier niveau
avec les arbres qui permettent d'étiqueter les sous-types, comme
vnd (abréviation de vendor),
pour les sous-types spécifiques à un fournisseur, comme
application/vnd.adobe.flash.movie pour
un format qu'on ne regrettera
pas.
Donc, contrairement aux sous-types, qui apparaissent tout le
temps et ne font pas forcément l'objet d'un RFC, la création de types est plus
rare. Le dernier créé, avant haptics/, était
font/, par le RFC 8081. L'une des raisons de la séparation type/sous-type
est que, dans certains cas, le type peut indiquer, au logiciel qui
lit un fichier, une application générique (si on tombe sur un
image/sous-type-inconnu, lancer un logiciel de
visualisation d'imges qui gère beaucoup de formats est une solution
raisonnable ; si on tombe sur un
text/sous-type-inconnu, on sait qu'un humain
pourra à peu près le lire avec un éditeur générique). Le RFC note
qu'autrefois il était même prévu que cet aiguillage puisse se faire
vers différents matériels (envoyer
image/nimporte-quoi à l'imprimante,
video/nimporte-quoi à la télé) mais
qu'aujourd'hui, où les machines sont bien plus généralistes, cela
n'a plus trop de sens.
Donc, si vous voulez enregistrer un nouveau type de médias de premier niveau, la section 2 de notre RFC liste les critères obligatoires d'évaluation :
- Le type doit être décrit dans un RFC qui est sur le chemin des normes (Standards Track, cf. la politique « Action de normalisation », RFC 8126, section 4.9) donc approuvé par l'IETF.
- La spécification doit citer, dans sa section IANA considerations l'ajout au registre des types de premier niveau,
- Elle doit bien indiquer les critères d'évaluation pour les sous-types (qu'est-ce qui est acceptable et qu'est-ce qui ne l'est pas).
- Il faut qu'au moins un sous-type soit décrit, pour bien
montrer qu'il y a un usage réel, pas juste
théorique. (
haptics/a commencé avec trois sous-types.)
Moins cruciaux sont d'autres critères, comme :
- Si le type est déjà utilisé informellement, c'est un bon signe de son utilité.
- Mais en même temps, le RFC déconseille d'utiliser des types non enregistrés, ce qui est contradictoire avec le critère précédent.
- Il n'est pas nécessaire de créer un groupe de travail
IETF
dédié mais ça arrive parfois.
model/a été créé par le RFC 2077 sans groupe de travail,font/(RFC 8081) a été l'œuvre d'un groupe de travail dédié,haptics/(RFC 9695) a été fait par un groupe de travail qui avait également d'autres sujets.
Il y a aussi des anti-critères.
- Un type de premier niveau ne doit pas être juste un pointeur
vers un autre registre (le RFC cite le cas fictif d'un type
oid/qui pointerait vers des object identifiers). - Les types de médias sont prévus pour aider les applications qui lisent des ressources Internet à les faire traiter par le logiciel approprié. Ce ne sont pas un mécanisme de typage générique, on ne va pas faire une ontologie avec.
- Un éventuel nouveau type ne doit pas marcher sur les
plate-bandes d'un type existant. On ne pourrait sans doute pas
créer un
code/pour le code source puisqu'il existe déjàtext/(même si peu de langages de programmation ont eu un sous-type enregistré, le RFC 9239 est plutôt une exception). - Et pas question de commencer un nom de type par
x-, le RFC 6648 explique pourquoi.
La section 3 du RFC est pour les féru·es d'histoire. Elle
documente l'évolution de ces types de médias. Leur apparition date du
RFC 1341 en 1992, qui
créait les « classiques » text/,
image/, audio/… Le premier
type de premier niveau créé par la suite a été
matter-transport/ (pour indiquer que le message
contient de la matière, pas juste de l'information) en
1993 dans le RFC 1437
(mais regardez la date du RFC avant de critiquer). Le premier
« sérieux » type de premier niveau en dehors des « classiques »,
model/, n'a été créé qu'en
1997 par le RFC 2077. example/ date de
2006 (RFC 4735) et
font/ de 2017 (RFC 8081). Enfin, le dernier,
haptics/, date de cette
année, avec le RFC 9695.
Il existe aussi des types utilisés mais pas enregistrés. Wikipédia parle d'un type chemical/, décrit dans un article mais jamais passé par le mécanisme d'enregistrement que décrit notre RFC, et donc absent du registre.
La section 4 de notre RFC synthétise les règles et procédures pour l'enregistrement d'un nouveau type (rappel : politique « Action de normalisation », RFC 8126) et crée formellement le registre des types de premier niveau.
Si vous voulez créer un nouveau type de médias de premier niveau,
je signale que scent/
(pour distribuer des odeurs sur l'Internet) n'a pas été
enregistré. Il faut dire qu'à ma connaissance, il n'existe pas de
format pour les odeurs, qui permettrait d'avoir le premier
sous-type. Et ce manque de format vient probablement du fait qu'on
n'a pas de synthétiseur d'odeurs qui serait capable de rendre le
contenu du fichier de manière perceptible par notre odorat. (Trois
autres sens sont couverts par image/,
audio/
et haptics/
mais on n'a rien non plus pour le
goût.)
_L%27Odorat_(La_Dame_%C3%A0_la_licorne)_-_Mus%C3%A9e_de_Cluny_Paris.jpg){kind=link}
_Le_Vue_(La_Dame_%C3%A0_la_licorne)_-_La_Dame_-_Mus%C3%A9e_de_Cluny_Paris.jpg){kind=link}
_L%27Ou%C3%AFe_(La_Dame_%C3%A0_la_licorne)_-_Mus%C3%A9e_de_Cluny_Paris.jpg){kind=link}
_Le_toucher_(La_Dame_%C3%A0_la_licorne)_-_Mus%C3%A9e_de_Cluny_Paris_-_Le_toucher.jpg){kind=link}
_Le_Go%C3%BBt_(La_Dame_%C3%A0_la_licorne)_-_Mus%C3%A9e_de_Cluny_Paris.jpg){kind=link}
L'article seul
RFC 9687: Border Gateway Protocol 4 (BGP-4) Send Hold Timer
Date de publication du RFC : Novembre 2024
Auteur(s) du RFC : J. Snijders
(Fastly), B. Cartwright-Cox (Port
179), Y. Qu (Futurewei)
Chemin des normes
Première rédaction de cet article le 8 novembre 2024
Que doit faire un routeur BGP lorsque le pair en face ne traite manifestement plus ses messages ? Ce n'était pas précisé avant mais la réponse est évidente : raccrocher (mettre fin à la communication).
Un problème classique lors d'une connexion réseau, par exemple sur TCP, est de détecter si la machine en face est toujours là. Par défaut, TCP ne fournit pas ce service : s'il n'y a aucun trafic, vous ne pouvez pas savoir si votre partenaire est mort ou simplement s'il n'a rien à dire. Une coupure de réseau, par exemple, ne sera pas détectée tant que vous n'avez pas de trafic à transmettre (avec attente d'une réponse). Et BGP ne transmet que les changements donc l'absence de trafic ne signale pas forcément un problème. Il existe des solutions, comme d'envoyer périodiquement des messages même quand on n'a rien à dire (RFC 4271, section 4.4), mais aucune n'est parfaite : un programme qui utilise TCP ne sait typiquement pas immédiatement si ses messages sont vraiment partis (et l'alarme actuelle ne couvre que la réception des messages, pas leur envoi). Et BGP n'a pas de fonction « ping », qui exigerait une réponse.
Quand la coupure est franche et détectée, aucun problème, la session BGP (RFC 4271) s'arrête et les routes correspondantes sont retirées de la table de routage. Mais ce RFC traite le cas de où le routeur BGP d'en face a un problème mais qu'on ne détecte pas. Un exemple : si ce routeur en face a complètement fermé sa fenêtre TCP de réception (RFC 9293, notamment la section 3.8.6), on ne pourra pas lui envoyer de messages, mais la session BGP ne sera pas coupée et les paquets continueront à être transmis selon des annonces de routage dépassées, alors qu'ils finiront peut-être dans un trou noir (le problème des « zombies BGP »).
La solution (section 3 de notre RFC) est de modifier
l'automate de BGP (RFC 4271, section 8), en ajoutant une alarme (RFC 4271, section 10),
SendHoldTimer. Quand elle expire, on coupe la
connexion TCP et on retire les routes qu'avait annoncé le pair dont
on n'a plus de nouvelles. Le RFC recommande une configuration par
défaut de huit minutes de patience avant de déclencher l'alarme.
L'erreur « Send Hold Timer Expired » est désormais dans le registre IANA des erreurs BGP et tcpdump sait l'afficher. Il existe plusieurs mises en œuvre de ce RFC :
- Celle d'OpenBGPD (son source),
- Celle de FRRouting (son source),
- Celle de BIRD (son source).
Si les processus IETF vous passionnent, il y a une documentation des discussions autour de ce RFC.
L'article seul
RFC 9682: Updates to the CDDL grammar of RFC 8610
Date de publication du RFC : Novembre 2024
Auteur(s) du RFC : C. Bormann (Universität Bremen
TZI)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF cbor
Première rédaction de cet article le 19 novembre 2024
Voici une légère mise à jour de la grammaire du langage de description de schéma CDDL (Concise Data Definition Language), originellement normalisé dans le RFC 8610. Pas de gros changement.
Il y avait juste quelques errata à traiter, et des ambiguités concernant notamment les chaines de caractères. Il était devenu nécessaire de modifier l'ABNF. CDDL a été décrit dans le RFC 8610, puis étendu par le RFC 9165. Il vise à décrire un schéma pour des fichiers CBOR ou JSON. Depuis quatre ans qu'il est normalisé, plusieurs erreurs ont été relevées dans la norme. (Dont une, c'est amusant, causée par le traitement du source du RFC, traitement qui avait fait disparaitre accidentellement des barres obliques inversées.)
Donc, notre RFC 9682 modifie l'ABNF qui décrit les littéraux pour les chaines de caractères, ABNF qui était trop laxiste (section 2 du RFC). Il change également la grammaire générale (section 3) pour autoriser (au niveau syntaxique) des schémas vides (ils restent interdits au niveau sémantique). Ainsi, l'ancienne règle :
cddl = S 1*(rule S)
devient :
cddl = S *(rule S)
L'article seul
RFC 9680: Antitrust Guidelines for IETF Participants
Date de publication du RFC : Octobre 2024
Auteur(s) du RFC : J. M. Halpern (Ericsson), J. Daley
(IETF Administration LLC)
Pour information
Première rédaction de cet article le 31 octobre 2024
Les normes publiées par l'IETF ne sont pas que des documents techniques à seule destination des techniciens. L'Internet et, de manière plus générale, les protocoles TCP/IP sont aussi une grosse industrie qui brasse beaucoup d'argent. Il y a donc un risque que des acteurs de cette industrie essaient d'influencer les normes à leur profit, par exemple en formant des alliances qui, dans certains pays, seraient illégales au regard des lois antitrust. Ce court RFC administratif explique aux participant·es IETF ce que sont ces lois et comment éviter de les violer.
En effet, les organisations, notamment les entreprises à but lucratif, qui participent à l'IETF peuvent être concurrentes sur leurs marchés. Or, le développement de normes nécessite de la collaboration entre ces concurrents. Pour maintenir une concurrence et pour éviter les ententes, plusieurs pays ont des lois, dites « antitrust », lois que des participant·es à l'IETF ne connaissent pas forcément bien. La justification idéologique de ces lois est rappelée par le RFC, dans le cas étatsunien mais d'autres pays capitalistes ont des principes similaires : « Competition in a free market benefits consumers through lower prices, better quality and greater choice. Competition provides businesses the opportunity to compete on price and quality, in an open market and on a level playing field, unhampered by anticompetitive restraints. » Que ce soit vrai ou pas, peu importe, les lois antitrust doivent être respectées. Ce RFC n'édicte pas de règles pour l'IETF (« respectez la loi » est de toute façon déjà obligatoire), mais il explique des subtilités juridiques aux participant·es à l'IETF.
Il y a en effet deux risques pour l'IETF, qu'un·e représentant officiel de l'IETF soit accusé de comportement anti-concurrentiel, engageant la responsabilité de l'organisation, ou que des participant·es soient accusés de comportement anti-concurrentiel, ce qui n'engagerait pas la responsabilité de l'IETF mais pourrait affecter sa réputation.
Les participant·es à l'IETF sont censés suivre des règles dont certaines limitent déjà le risque de comportement anti-concurrentiel, entre autres :
- Suivre les procédures officielles (RFC 2026, RFC 2418 et plusieurs autres),
- Agir en tant qu'individu (RFC 7154) et non pas en tant que représentant de son employeur (ce qui est assez théorique, il faut bien le dire…), voir aussi cet article de l'administration de l'IETF,
- Respecter les règles concernant la propriété intellectuelle (RFC 5378 et RFC 8179),
- Et les règles sur le conflit d'intérêt (il y a celle de l'IESG, celle de l'IAB et enfin celle de l'organisation administrative de l'IETF ; mais les trois politiques sont très semblables).
Maintenant, s'y ajoutent les questions spécifiques au respect des lois sur la concurrence. La section 4, le cœur de ce RFC, attire l'attention sur :
- La nécessité d'éviter de parler de certains sujets comme les prix des produits, les marges bénéficiaires, les accords avec des tiers, les analyses marketing, bref tout ce qui concerne le business, auquel le RFC ajoute les salaires et avantages divers (allez au bistrot le plus proche si vous voulez en parler librement). Des discussions sur ces sujets ne violent pas forcément les lois antitrust mais, dans le doute, mieux vaut être prudent.
- L'importance de consulter un·e expert·e juridique en cas de doute. (L'IETF ne fournit pas de conseils juridiques.)
- Le fait que les problèmes peuvent être signalés à l'équipe
juridique de l'IETF (
legal@ietf.org) ou via le service spécifique pour les lanceurs d'alerte.
L'article seul
RFC 9676: A Uniform Resource Name (URN) Namespace for Sources of Law (LEX)
Date de publication du RFC : Mai 2025
Auteur(s) du RFC : P. Spinosa, E. Francesconi (National Research Council of Italy (CNR)), C. Lupo
Pour information
Première rédaction de cet article le 21 mai 2025
Les textes de loi (et assimilés : décrets, par exemple) ne sont
pas évidents à trouver et donc à citer. Ce RFC crée un espace URN (RFC 8141), lex, pour pouvoir identifier
les textes juridiques. S'il est largement adopté par les juristes
(ce n'est pas gagné…), il facilitera les références aux textes
légaux. Ainsi,urn:lex:fr:etat:loi:2011-03-22;2011-302
pourrait identifier la loi
n° 2011-302 portant diverses dispositions d'adaptation de la
législation au droit de l'Union européenne en matière de santé, de
travail et de communications électroniques, par exemple (elle
change entre autres le régime applicable aux noms de domaine).
Comme toujours avec les URN (RFC 8141) et avec les URI en général, le but est d'attribuer des identificateurs uniques désignant une source de loi. Cette source peut être une loi, un décret, un texte d'une autorité de régulation, un jugement, etc. En revanche, les opinions et commentaires des juristes ne sont pas prévus. Comme avec tous les URN, l'identificateur ne dépend pas de la localisation en ligne d'un document (c'est un URN, pas un URL), ou même d'ailleurs de si le document est en ligne ou pas. Le but est que l'identificateur soit unique, et stable sur le long terme.
Le projet est né en Italie, sur la base du projet NormeInRete, datant de 2001. Des projets similaires existent dans d'autres pays. (Voir le livre « Technologies for European Integration; Standards-based Interoperability of Legal Information Systems ». Au niveau européen, voir « Law via the Internet; Free Access, Quality of Information, Effectiveness of Rights ».) Au niveau mondial, on peut noter que le document « Access to Foreign Law in Civil and Commercial Matters » pronait « State Parties are encouraged to adopt neutral methods of citation of their legal materials, including methods that are medium-neutral, provider-neutral and internationally consistent. ». Un tel système d'identificateurs est évidemment d'autant plus indispensable que l'inflation législative fait qu'on dépend tout le temps de textes de lois, et qu'on a besoin de les référencer dans de nombreux contextes. Toute ambiguïté dans cette référence serait bien sûr très gênante.
En pratique, le problème n'est pas trivial. Le mécanisme pour créer ces identificateurs doit être assez rigide pour assurer l'interopérabilité mais en même temps assez souple pour s'adapter aux évolutions futures. Et il doit être décentralisé car il n'y a pas d'institution mondiale supervisant les lois de tous les pays et chaque pays (voire davantage, notamment dans les États fédéraux) a déjà un mécanisme d'identification des lois.
L'approche choisie est donc un système hiérarchique, indiquant
successivement le pays (via son TLD, ou via un nom de second niveau comme
un.org pour l'ONU qui,
curieusement, n'utilise pas son
.int), la juridiction
émettrice et enfin le document. On ne change donc pas les systèmes
existants et on n'oblige pas les juridictions locales à adopter un
système radicalement différent. La référence locale du document suit
donc un schéma qui dépend de la juridiction, schéma qu'il n'est pas
prévu d'uniformiser. Ainsi,
urn:lex:eu:commission:directive:2010-03-09;2010-19-EU
sera un texte européen (le eu), émis par la Commission, plus
précisément ce sera une directive, la 2010-19-EU
(la directive « modifiant la directive 91/226/CEE du Conseil et la
directive 2007/46/CE du Parlement européen et du Conseil afin de les
adapter aux progrès techniques dans le domaine des systèmes
antiprojections de certaines catégories de véhicules à moteur et de
leurs remorques »). Et
urn:lex:be:conseil.etat:decision:2024-08-29;260.536
sera une décision du Conseil d'État belge (demande
l’annulation de « la décision de non-classement et de non-retenue de
la candidature notifiée par la partie adverse le 14 mars 2022 à la
partie requérante »). Pour un pays
fédéral, on aura une indication de l'entité
qui émet le texte, par exemple
urn:lex:br;sao.paulo:governo:decreto précédera
l'identificateur d'un décret de l'État de São
Paulo. (Notez le point-virgule,
certains caractères sont réservés pour séparer des sous-champs dans
l'URN, cf. section 3.2.)
Il devrait y avoir dans le futur un registre (pas un registre IANA) des codes identifiants les juridictions (section 2.2) du RFC mais, en septembre 2024, il n'était pas encore créé. Sa politique d'enregistrement sera « Examen par un expert » (« Expert review » du RFC 8126). Même en cas de changement géopolitique (fusion de deux pays, par exemple), les codes ne sont jamais réattribués, puisque les URN doivent être stables sur le long terme.
Les URN n'ont
pas de mécanisme de résolution standard. Si on veut, à partir d'un
URN, accéder à une ressource en ligne, il faut une méthode
spécifique à chaque espace sous les URN. Pour
lex, il est envisagé d'utiliser le DNS, en transformant l'URN en
un URL,
contenant un nom de
domaine (section 10 du RFC, commentée plus loin). C'est
d'ailleurs pour faciliter la correspondance avec les noms de domaine
que le RFC (à tort, à mon avis), déconseille (section 3.4)
d'utiliser des caractères non-ASCII dans les URN
lex et donc d'utiliser un système de
correspondance, depuis la langue de la juridiction concernée
(urn:lex:de:stadt.muenchen:rundschreiben:... au
lieu de
urn:lex:de:stadt.münchen:rundschreiben:...). Si
c'est assez évident pour l'italien ou le français (ministère →
ministere), cela va nécessiter des correspondances plus élaborées
dans d'autres cas. Si c'est vraiment trop difficile, le RFC
recommande d'utiliser Unicode et, si on
utilise le DNS et qu'on fait une correspondance en nom de domaine,
de se servir de Punycode.
Quant au nom des juridictions, le RFC recommande de ne pas
utiliser d'abréviations (même si elles sont courantes dans les
textes juridiques), car elles ne sont pas toujours cohérentes. Donc,
ministere et pas
min.. Toujours pour des raisons d'uniformité,
les dates doivent être en ISO 8601. [Encore
une mauvaise idée : contrairement à ce qu'on lit souvent, cette
norme ne garantit pas un format unique, loin de là. Utiliser le RFC 3339 aurait été une meilleure idée. Mais, en
fait, le RFC suggère un profil réduit de ISO 8601 donc, en pratique,
cela devrait marcher.]
Parmi les pièges amusants, il y a le fait que certains textes
sont issus de plusieurs juridictions. C'est le cas des traités
internationaux, par exemple. Si l'Espagne et le Portugal signent un
accord, doit-il être sous urn:lex:es ou bien
urn:lex:pt ? La solution du RFC (section 5.5)
est simple : le texte a plusieurs URN (deux dans l'exemple ibérique
ci-dessus). D'autres cas peuvent d'ailleurs se produire où un texte
légal a plusieurs URN donc il n'y a pas d'URL « canonique » pour un
texte. La fonction URN → texte est sans ambiguïté mais il n'y a pas
de fonction texte → URN.
Maintenant, un peu de bureaucratie (section 9). Si je veux
enregistrer un ou plusieurs URN lex, quelle est
la marche à suivre ? D'abord, trouver le code de juridiction (en
général le TLD du pays) puis l'organisation
(registrar dans le RFC) chargée de gérer ce
code. (Rappelez-vous que cette infrastructure n'existe pas encore.)
Ces organisations doivent être stables sur le long terme, si on veut
assurer la stabilité des identificateurs. Ensuite, comme chacune de
ces organisations a sa propre politique, il faut suivre la politique
en question.
Bon, c'est bien joli d'avoir des identificateurs stables. Mais,
de nos jours, la plupart des utilisateurices voudraient
davantage. Ils voudraient de l'opérationnel : je mets (je tape, je
copie/colle…) un identificateur dans un navigateur et pouf, j'ai une
jolie page avec le texte de loi ainsi identifié. Pour que ce beau
projet fonctionne, il faut un système de
résolution (section 10), qui va prendre en
entrée un URN dans l'espace lex et nous donner
un identificateur de plus bas niveau, un URL, par exemple, utilisable par le
logiciel pour récupérer un contenu. La conception d'un tel système
n'est pas triviale, entre autres parce que certains des URN
lex seront invalides, par exemple lorsqu'ils
auront été fabriqués automatiquement ou semi-automatiquement à partir
de références informelles.
La méthode proposée dans cette section 10 (mais rappelez-vous
que, pour l'instant, tout cela n'existe que sur le papier) est de
s'appuyer sur le DNS et plus précisément sur les enregistrements
de type NAPTR (normalisés dans le RFC 3404). Cela passera par le nom (déjà créé,
cf. section 12 du RFC) lex.urn.arpa :
% dig lex.urn.arpa NAPTR … ;; ANSWER SECTION: lex.urn.arpa. 86400 IN NAPTR 100 10 "" "" "" lex-nameserver.nic.it.
Du point de vue gouvernance, il est prévu que le
CNR maintienne la racine du système,
notamment le serveur lex-nameserver.nic.it
mentionné plus haut (ne cherchez pas à l'interroger, il semble ne
pas avoir de données encore). Quand tout cela fonctionnera, un URN
lex sera traduit en un
URL (RFC 3405), par
exemple quand le Brésil aura mis en place son
système, et envoyé au CNR les informations nécessaires,
urn:lex:br:senado:… sera traduit via les NAPTR en
https://lex.senado.gov.br/… qui sera ensuite
utilisé, par exemple par un navigateur.
L'espace lex a été enregistré (section 12)
dans le registre
des espaces de noms pour les URN via cette
demande.
L'article seul
RFC 9673: IPv6 Hop-by-Hop Options Processing Procedures
Date de publication du RFC : Octobre 2024
Auteur(s) du RFC : R. Hinden (Check Point
Software), G. Fairhurst (University of
Aberdeen)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF 6man
Première rédaction de cet article le 31 octobre 2024
Parmi les différentes options qui peuvent être placées dans un en-tête d'un paquet IPv6, certaines sont à traiter par chaque routeur situé sur le trajet. On les appelle les options « par saut » (hop-by-hop). Elles sont très peu utilisées en pratique, entre autres parce que leur traitement, tel que spécifié dans le RFC 8200, est trop contraignant pour les routeurs. Ce nouveau RFC change donc les règles, dans le sens d'un plus grand pragmatisme.
À part l'en-tête « Hop-by-hop Options » (RFC 8200, section 4.3), tous les en-têtes IPv6 ne concernent que les machines terminales. « Hop-by-hop Options », lui, concerne les routeurs et, avant le RFC 8200, tous les routeurs sur le trajet avaient l'obligation de le lire et d'agir en fonction des options qu'il contenait (la liste complète des options possibles est dans un registre IANA). Bien trop coûteuse pour les routeurs, cette obligation a été supprimée par le RFC 8200. Ce nouveau RFC 9673 modifie le traitement des options de cet en-tête (et donc le RFC 8200) dans l'espoir qu'il voit enfin un vrai déploiement dans l'Internet (actuellement, cet en-tête par saut - hop-by-hop - est quasiment inutilisé). Si vous concevez des routeurs, et êtes pressé·e, sautez directement à la section 5 du RFC, qui décrit les nouvelles règles, mais ce serait dommage.
Petite révision sur l'architecture des routeurs (section 3 du RFC). Les routeurs de haut de gamme ont une voie rapide (fast path) pour le traitement des paquets, lorsque ceux-ci n'ont pas de demande particulière. Mise en œuvre en dehors du processeur principal du routeur, cette voie rapide est traitée par des circuits spécialisés, typiquement des ASIC. Si le paquet nécessite des opérations plus complexes, on passe par une voie plus lente, utilisant des méthodes et du matériel plus proches de ceux d'un ordinateur classique. (Les RFC 6398 et RFC 6192 sont des lectures recommandées ici.) D'autre part, on distingue souvent, dans le routeur, la transmission (forwarding plane) et le contrôle (control plane). La transmission est le travail de base du routeur (transmettre les paquets reçus sur une interface via une autre interface, et le plus vite possible), le contrôle regroupe notamment les opérations de manipulation de la table de routage, par exemple lors de mises à jour reçues via des protocoles comme OSPF ou BGP. Contrairement à la transmission, le contrôle n'est pas en « temps réel ».
Aujourd'hui, un paquet IPv6 utilisant des options par saut risque fort de ne même pas arriver à destination, sacrifié par des routeurs qui ne veulent pas le traiter. (Voir le RFC 7872, l'exposé « Internet Measurements: IPv6 Extension Header Edition » ou l'article « Is it possible to extend IPv6? ».)
Que disent donc les nouvelles procédures (section 5) ?
- Un routeur ne devrait pas jeter un paquet uniquement parce que celui-ci contient l'en-tête par saut (voir aussi RFC 9288). Même si le routeur ne traite pas les options de cet en-tête, il devrait transmettre le paquet.
- Il est très recommandé que les routeurs disposent d'une option de configuration permettant d'indiquer s'il faut ou non traiter les options par saut. Et d'une autre pour indiquer quelles options dans l'en-tête doivent être gérées, que cela ne soit pas du tout ou rien.
- IPv6 dispose de deux bits dans chaque option par saut pour indiquer le traitement souhaité du paquet si le routeur ne connait pas l'option. La nouvelle procédure permet d'être plus indulgent et, par exemple, de ne pas jeter un paquet même si l'émetteur le demandait, si le routeur ne veut pas traiter cette option (cf. le premier item de cette liste de règles).
- Les émetteurs qui mettent l'en-tête par saut dans les paquets doivent être bien conscients que tous les routeurs ne le traiteront pas (c'est le cas depuis longtemps, le RFC ne fait que décrire cet état de fait).
- Les machines terminales devraient examiner cet en-tête et le traiter, il ne concerne pas que les routeurs.
Pour faciliter la tâche des routeurs, et toujours dans l'espoir que les options par saut deviennent enfin une possibilité réaliste, la section 6 du RFC encadre la définition de nouveaux en-têtes (le RFC 8200 recommandait carrément de ne plus en définir, tant qu'on n'avait pas mieux défini leur utilisation). Les éventuelles futures options doivent être simples à traiter et conçues en pensant au travail qu'elles imposeront au routeur. Le protocole qui les utilise doit intégrer le fait que le routeur est autorisé à ignorer cette option, voire qu'il puisse jeter le paquet.
Ah, et un mot sur la sécurité (section 8). Plusieurs RFC ont déjà documenté les problèmes de sécurité que peuvent poser les options par saut, notamment le risque qu'elles facilitent une attaque par déni de service sur le routeur : RFC 6398, RFC 6192, RFC 7045 et RFC 9098.
Est-ce que le déploiement de ce RFC va améliorer les choses pour l'en-tête par saut, qui est jusqu'à présent un exemple d'échec ? Je suis assez pessimiste, étant donné la difficulté à changer des comportements bien établis.
Un peu d'histoire pour terminer (section 4 du RFC) : les
premières normes IPv6 (RFC 1883, puis RFC 2460) imposaient à tous les routeurs d'examiner
et de traiter les options par saut. Le RFC 7045 avait été le premier à constater que cette règle
n'était pas respectée et ne pouvait pas l'être vu l'architecture des
routeurs modernes. Le problème de performance dans le traitement des
options était d'autant plus grave que les options n'avaient pas
toutes le même format (cela a été résolu par le RFC 6564, qui imposait un format unique). Le résultat, comme
vu plus haut, était que les routeurs ignoraient les options par saut
ou, pire, jetaient le paquet qui les contenait. (Le RFC 9288 et l'article « Threats
and Surprises behind IPv6 Extension Headers »
expliquent pourquoi c'est une mauvaise
idée. L'Internet Draft
draft-ietf-v6ops-hbh discute également cette
question.)
L'article seul
RFC 9669: BPF Instruction Set Architecture (ISA)
Date de publication du RFC : Octobre 2024
Auteur(s) du RFC : D. Thaler
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF bpf
Première rédaction de cet article le 1 novembre 2024
On a souvent envie de faire tourner des programmes à soi dans le noyau du système d'exploitation, par exemple à des fins de débogage ou d'observation du système. Cela soulève plein de problèmes (programmer dans le noyau est délicat) et la technique eBPF permet, depuis de nombreuses années, de le faire avec moins de risques. Ce RFC spécifie le jeu d'instructions eBPF. Programmeureuses en langage d'assemblage, ce RFC est pour vous.
eBPF désigne ici un jeu d'instructions (comme ARM ou RISC-V). Programmer en eBPF, c'est donc programmer en langage d'assemblage et, en général, on ne le fait pas soi-même, on écrit dans un langage de plus haut niveau (non spécifié ici mais c'est souvent un sous-ensemble de C) et on confie à un compilateur le soin de générer les instructions. Ce jeu d'instructions a plusieurs particularités. Notamment, il est délibérément limité, puisque toute bogue dans le noyau est particulièrement sérieuse, pouvant planter la machine ou pire, permettre son piratage. Vous ne pouvez pas faire de boucles générales, par exemple. eBPF est surtout répandu dans le monde Linux (et c'est là où vous trouverez beaucoup de ressources) où il est une alternative aux modules chargés dans le noyau. Pas mal du code réseau d'Android est ainsi en eBPF. Normalisé ici, eBPF peut être mis en œuvre sur d'autres noyaux (il tourne sur Windows, par exemple). Le monde eBPF est très riche, il y a plein de logiciels (pas toujours faciles à utiliser), plein de tutoriels (pas toujours à jour et qui ne correspondent pas toujours à votre système d'exploitation) mais cet article se focalise sur le sujet du RFC : le jeu d'instructions.
On trouve de nombreux exemples d'utilisation en production par exemple le répartiteur de charge Katran chez Facebook, via lequel vous êtes certainement passé, si vous utilisez Facebook. En plus expérimental, j'ai trouvé amusant qu'on puisse modifier les réponses DNS en eBPF.
Passons tout de suite à la description de ce jeu
d'instructions (ISA = Instruction Set
Architecture). D'abord, les types (section 2.1) :
u32 est un entier non
signé sur 32 bits, s16, un signé
sur 16 bits, etc. eBPF fournit des fonctions de conversions utiles
(section 2.2) comme be16 qui convertit en
gros boutien (le RFC cite IEN137…). Au
passage, une mise en œuvre d'eBPF n'est pas obligée de tout fournir
(section 2.4). La norme décrit des groupes de conformité et une
implémentation d'eBPF doit lister quels groupes elle met en
œuvre. Le groupe base32 (qui n'a rien à voir
avec le Base32 du RFC 4648) est le minimum requis dans tous les cas. Par
exemple, divmul32 ajoute multiplication et
division. Tous ces groupes figurent dans un registre IANA.
Les instructions eBPF sont encodées en 64 ou 128 bits (section
3). On y trouve les instructions classiques de tout jeu, les
opérations arithmétiques (comme ADD), logiques
(comme AND), les sauts
(JA, JEQ et autrs), qui se
font toujours vers l'avant, pour, je suppose, ne pas permettre de boucles
(souvenez-vous du problème de l'arrêt, qui n'a
pas de solution avec un jeu
d'instructions plus étendu), l'appel de fonction, etc.
En parlant de fonctions, eBPF ne peut pas
appeler n'importe quelle fonction. Il y a deux sortes de fonctions
utilisables, les fonctions d'aide (section 4.3.1), pré-définies par
la plateforme utilisée, et non normalisées (pour celles de Linux,
voir la
documentation, qui est sous
Documentation/bpf si vous avez les sources du
noyau). Il y a aussi les fonctions locales (section 4.3.2), définies
par le programme eBPF.
Il y a enfin des instructions pour lire et écrire dans la mémoire
(LD, ST, etc). Pour
mémoriser plus facilement, eBPF utilise
des dictionnaires (maps,
cf. section 5.4.1).
La section 6 concerne la sécurité, un point évidemment crucial puisque les programmes eBPF tournent dans le noyau, où les erreurs ne pardonnent pas. Un programme eBPF malveillant peut provoquer de nombreux dégâts. C'est pour cela que, sur Linux, seul root peut charger un tel programme dans le noyau. Le RFC recommande de faire tourner ces programmes dans un environnement limité (bac à sable), de limiter les ressources dont ils disposent et de faire tourner des vérifications sur le programme avant son exécution (par exemple, sur Linux, regardez cette documentation ou bien l'article « Simple and Precise Static Analysis of Untrusted Linux Kernel Extensions »).
Enfin, section 7, les registres (pas les registres du processeur, ceux où on enregistre les codes utilisés). Deux registres IANA sont créés, celui des groupes de conformité et celui du jeu d'instructions. L'annexe A du RFC donne les valeurs actuelles. Les registres sont extensibles et la politique d'enregistrement est « Spécification nécessaire » et « Examen par un expert », cf. RFC 8126. (J'avoue ne pas savoir pourquoi, si les opcodes sont enregistrés, les mnémoniques ne le sont pas, cela rend les registres difficiles à lire.)
Un peu d'histoire, au passage. eBPF est dérivé de BPF, ce qui voulait dire Berkeley Packet Filter, et était spécifique au filtrage des paquets réseau. Cet usage a été notamment popularisé par tcpdump. D'ailleurs, ce programme a une option pour afficher le code BPF produit :
% sudo tcpdump -d port 53 (000) ldh [12] (001) jeq #0x86dd jt 2 jf 10 (002) ldb [20] (003) jeq #0x84 jt 6 jf 4 (004) jeq #0x6 jt 6 jf 5 (005) jeq #0x11 jt 6 jf 23 (006) ldh [54] … (021) jeq #0x35 jt 22 jf 23 (022) ret #262144 (023) ret #0
Si vous voulez vous mettre à eBPF (attention, la courbe
d'apprentissage va être raide), man 4 bpf est
utile. Typiquement, vous écrirez vos programmes dans un
sous-ensemble de C et vous
compilerez en eBPF, par exemple avec clang,
après avoir installé tous les outils et bibliothèques nécessaires
(il faut souvent des versions assez récentes) :
% cat count.c
…
int count_packets(struct __sk_buff *skb) {
__u32 key = 0;
__u64 *counter;
counter = bpf_map_lookup_elem(&pkt_counter, &key);
if (counter) {
(*counter)++;
}
return 0;
}
…
% clang -target bpf -c count.c
% file count.o
count.o: ELF 64-bit LSB relocatable, eBPF, version 1 (SYSV), not stripped
% objdump -d count.o
…
0000000000000000 <count_packets>:
0: 7b 1a f8 ff 00 00 00 00 stxdw [%r10-8],%r1
8: b7 01 00 00 00 00 00 00 mov %r1,0
10: 63 1a f4 ff 00 00 00 00 stxw [%r10-12],%r1
18: 18 01 00 00 00 00 00 00 lddw %r1,0
20: 00 00 00 00 00 00 00 00
28: bf a2 00 00 00 00 00 00 mov %r2,%r10
30: 07 02 00 00 f4 ff ff ff add %r2,-12
(Notez l'utilisation du désassembleur objdump.) Vous pouvez alors charger le code eBPF dans votre noyau, par exemple avec bpftool (et souvent admirer de beaux messages d'erreur comme « libbpf: elf: legacy map definitions in 'maps' section are not supported by libbpf v1.0+ »). Si tout fonctionne, votre code eBPF sera appelé par le noyau lors d'événements particuliers que vous avez indiqués (par exemple la création d'un processus, ou bien l'arrivée d'un paquet par le réseau) et fera alors ce que vous avez programmé. Comme me le fait remarquer Pierre Lebeaupin, il y a une bogue dans le source ci-dessus : l'incrémentation du compteur n'est pas atomique et donc, si on a plusieurs CPU, on risque de perdre certaines incrémentations. La solution de ce problème est laissé à la lectrice.
Un exemple d'utilisation d'eBPF pour observer ce que fait le noyau (ici avec un outil qui fait partie de bcc), on regarde les exec :
% sudo /usr/sbin/execsnoop-bpfcc PCOMM PID PPID RET ARGS check_disk 389622 1628 0 /usr/lib/nagios/plugins/check_disk -c 10% -w 20% -X none -X tmpfs -X sysfs -X proc -X configfs -X devtmpfs -X devfs -X check_disk 389623 1628 0 /usr/lib/nagios/plugins/check_disk -c 10% -w 20% -X none -X tmpfs -X sysfs -X proc -X configfs -X devtmpfs -X devfs -X check_swap 389624 1628 0 /usr/lib/nagios/plugins/check_swap -c 25% -w 50% check_procs 389625 1628 0 /usr/lib/nagios/plugins/check_procs -c 400 -w 250 ps 389627 389625 0 /bin/ps axwwo stat uid pid ppid vsz rss pcpu etime comm args sh 389632 389631 0 /bin/sh -c [ -x /usr/lib/php/sessionclean ] && if [ ! -d /run/systemd/system ]; then /usr/lib/php/sessionclean; fi sessionclean 389633 1 0 /usr/lib/php/sessionclean sort 389635 389633 0 /usr/bin/sort -rn -t: -k2,2 phpquery 389638 389634 0 /usr/sbin/phpquery -V expr 389639 389638 0 /usr/bin/expr 2 - 1 sort 389642 389638 0 /usr/bin/sort -rn
Le code eBPF est interprété par une machine virtuelle ou bien traduit à la volée en code natif.
Même ChatGPT peut écrire de l'eBPF (les tours de Hanoi et un serveur DNS).
De nombreux exemples se trouvent dans le répertoire
samples/bpf des sources du noyau Linux. (Le
fichier README.rst explique comment compiler
mais seulement dans le cadre de la compilation d'un noyau. En gros,
c'est make menuconfig , cd
samples/bpf puis make -i.) Un bon
exemple, relativement simple, pour commencer avec le réseau est
tcp_clamp_kern.c.
Si vous préférez travailler en Go (là aussi, avec un Go récent…), il existe un bon projet. Si vous suivez bien la documentation, vous pourrez compiler des programmes et les charger :
% go mod init ebpf-test % go mod tidy % go get github.com/cilium/ebpf/cmd/bpf2go % go generate % go build % sudo ./ebpf-test 2024/08/20 15:21:43 Counting incoming packets on veth0.. … 2024/08/20 15:22:03 Received 25 packets 2024/08/20 15:22:04 Received 26 packets 2024/08/20 15:22:05 Received 27 packets 2024/08/20 15:22:06 Received 502 packets <- ping -f 2024/08/20 15:22:07 Received 57683 packets 2024/08/20 15:22:08 Received 75237 packets ^C2024/08/20 15:22:09 Received signal, exiting..
Vous trouverez beaucoup de ressources eBPF sur https://ebpf.io/
Ce RFC avait fait l'objet de pas mal de débats à l'IETF car, normalement, l'IETF ne normalise pas de langages de programmation ou de jeux d'instructions. (La première réunion était à l'IETF 116 en mars 2023 donc c'est quand même allé assez vite.)
L'article seul
RFC 9660: The DNS Zone Version (ZONEVERSION) Option
Date de publication du RFC : Octobre 2024
Auteur(s) du RFC : H. Salgado (NIC Chile), M. Vergara (DigitalOcean), D. Wessels (Verisign)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 13 octobre 2024
Cette nouvelle option du DNS permet au client d'obtenir du serveur le numéro de version de la zone servie. (Et, non, le numéro de série dans l'enregistrement SOA ne suffit pas, lisez pour en savoir plus.)
Cela permettra de détecter les problèmes de mise à jour des serveurs faisant autorité si, par exemple, un des secondaires ne se met plus à jour. C'est surtout important pour l'anycast, qui complique le déboguage. En combinaison avec le NSID du RFC 5001, vous trouverez facilement le serveur qui a un problème. Cette nouvelle option ressemble d'ailleurs à NSID et s'utilise de la même façon.
Vous le savez, le DNS ne garantit pas que tous les serveurs faisant
autorité d'une zone servent la même version de la zone au
même moment. Si je regarde la zone
.com à cet instant (14
juillet 2024, 09:48 UTC) avec check-soa, je
vois :
% check-soa com a.gtld-servers.net. 2001:503:a83e::2:30: OK: 1720950475 192.5.6.30: OK: 1720950475 b.gtld-servers.net. 192.33.14.30: OK: 1720950475 2001:503:231d::2:30: OK: 1720950475 c.gtld-servers.net. 2001:503:83eb::30: OK: 1720950475 192.26.92.30: OK: 1720950475 d.gtld-servers.net. 2001:500:856e::30: OK: 1720950475 192.31.80.30: OK: 1720950475 e.gtld-servers.net. 2001:502:1ca1::30: OK: 1720950475 192.12.94.30: OK: 1720950475 f.gtld-servers.net. 2001:503:d414::30: OK: 1720950475 192.35.51.30: OK: 1720950475 g.gtld-servers.net. 192.42.93.30: OK: 1720950475 2001:503:eea3::30: OK: 1720950475 h.gtld-servers.net. 192.54.112.30: OK: 1720950475 2001:502:8cc::30: OK: 1720950475 i.gtld-servers.net. 2001:503:39c1::30: OK: 1720950460 192.43.172.30: OK: 1720950475 j.gtld-servers.net. 2001:502:7094::30: OK: 1720950475 192.48.79.30: OK: 1720950475 k.gtld-servers.net. 192.52.178.30: OK: 1720950460 2001:503:d2d::30: OK: 1720950475 l.gtld-servers.net. 192.41.162.30: OK: 1720950475 2001:500:d937::30: OK: 1720950475 m.gtld-servers.net. 2001:501:b1f9::30: OK: 1720950475 192.55.83.30: OK: 1720950475
On observe que, bien que le numéro de série dans l'enregistrement SOA soit 1720950475, certains serveurs sont restés à 1720950460. Le DNS est « modérement cohérent » (RFC 3254, sur ce concept).
Dans l'exemple ci-dessus, check-soa a simplement fait une requête pour le type de données SOA (section 4.3.5 du RFC 1034). Une limite de cette méthode est que, si on observe des données d'autres types qui ne semblent pas à jour et que, pour vérifier, on fait une requête de type SOA, on n'a pas de garantie de tomber sur le même serveur, notamment en cas d'utilisation d'anycast (RFC 4786) ou bien s'il y a un répartiteur de charge avec plusieurs serveurs derrière. (D'ailleurs, dans l'exemple ci-dessus, vous avez remarqué que vous n'avez pas la même réponse en IPv4 et IPv6, probablement parce que vous arriviez sur deux instances différentes du nuage anycast.) Il faut donc un mécanisme à l'intérieur même de la requête qu'on utilise, comme pour le NSID. C'est le cas du ZONEVERSION de ce RFC, qui permet d'exprimer la version sous forme d'un numéro de série (comme avec le SOA) ou par d'autres moyens dans le futur, puisque toutes les zones n'utilisent pas le mécanisme de synchronisation habituel du DNS. On peut par exemple avoir des zones entièrement dynamiques et tirées d'une base de données, ou bien d'un calcul.
Notez aussi que certaines zones, comme
.com, changent très
vite, et que donc, même si on tombe sur le même serveur, le numéro
de série aura pu changer entre une requête ordinaire et celle pour
le SOA. C'est une raison supplémentaire pour avoir le mécanisme
ZONEVERSION.
Bref, le nouveau mécanisme (section 2 du RFC), utilise EDNS (section 6.1.2 du RFC 6891). La nouvelle option EDNS porte le numéro 19. Encodée en TLV comme toutes les options EDNS, elle comprend une longueur et une chaine d'octets qui est la version de la zone. La longueur vaut zéro dans une requête (le client indique juste qu'il souhaite connaitre la version de la zone) et, dans la réponse, une valeur non nulle. La version est elle-même composée de trois champs :
- Le nombre de composants dans le nom de domaine pour la zone
concernée. Si la requête DNS portait sur le nom de domaine
foo.bar.example.orget que le serveur renvoie la version de la zoneexample.org, ce champ vaudra deux. - Le type de la version. Différents serveurs faisant autorité utiliseront différentes méthodes pour se synchroniser et auront donc des types différents. Pour l'instant, un seul est normalisé, le 0 (alias SOA-SERIAL), qui est le numéro de série, celui qu'on trouverait dans le SOA, cf. section 3.3.13 du RFC 1035. La longueur sera donc de 6, les 4 octets de ce numéro, le type et le nombre de composants, un octet chacun. Un nouveau registre IANA accueillera peut-être d'autres types dans le futur, suivant la procédure « spécification nécessaire » du RFC 8126. (Cette procédure nécessite un examen par un expert, et la section 7.2.1 guide l'expert pour ce travail.)
- La valeur à proprement parler.
Si vous voulez voir dans un pcap, regardez
zoneversion.pcap
L'option ZONEVERSION n'est renvoyée au client qui si celui-ci l'avait demandé, ce qu'il fait en mettant une option ZONEVERSION vide dans sa requête (section 3 du RFC). Si le serveur fait autorité pour la zone concernée (ou une zone ancêtre), et qu'il gère cette nouvelle option, il répond avec une valeur. Même si le nom demandé n'existe pas (réponse NXDOMAIN), l'option est renvoyée dans la réponse.
Comme les autres options EDNS, elle n'est pas signée par DNSSEC (section 8). Il n'y a donc pas de moyen de vérifier son authenticité et elle ne doit donc être utilisée qu'à titre informatif, par exemple pour le déboguage. (En outre, elle peut être modifiée en route, sauf si on utilise un mécanisme comme DoT - RFC 7858.)
Question mises en œuvre de cette option, c'est surtout du code expérimental pour l'instant, voir cette liste (pas très à jour ?). Personnellement, j'ai ajouté ZONEVERSION à Drink, et écrit un article sur l'implémentation d'options EDNS (mais notez que l'option a changé de nom et de format depuis). Notez que, contrairement à presque toutes les options EDNS, ZONEVERSION est par zone, pas par serveur, ce qui est une contrainte pour le ou la programmeureuse, qui ne peut pas choisir la valeur avant de connaitre le nom demandé. Du côté des autres logiciels, NSD a vu un patch (mais apparemment abandonné). Voici ce que voit dig actuellement (en attendant une intégration officielle de l'option) :
% dig +ednsopt=19 @ns1-dyn.bortzmeyer.fr dyn.bortzmeyer.fr SOA
…
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 64655
;; flags: qr aa rd; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1
…
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 1440
; OPT=19: 03 00 78 a5 08 cc ("..x...")
…
;; ANSWER SECTION:
dyn.bortzmeyer.fr. 0 IN SOA ns1-dyn.bortzmeyer.fr. stephane.bortzmeyer.org. (
2024081612 ; serial
…
Vous noterez que "03" indique trois composants
(dyn.bortzmeyer.fr), "00" le SOA-SERIAL, et "78
a5 08 cc" égal 2024081612. Vous pouvez aussi tester ZONEVERSION avec
le serveur de test 200.1.122.30 (un NSD
modifié), avec le domaine example.com.
L'article seul
RFC 9651: Structured Field Values for HTTP
Date de publication du RFC : Septembre 2024
Auteur(s) du RFC : M. Nottingham
(Cloudflare), P-H. Kamp (The Varnish Cache
Project)
Chemin des normes
Première rédaction de cet article le 6 octobre 2024
Plusieurs en-têtes HTTP sont structurés,
c'est-à-dire que le contenu n'est pas juste une suite de caractères
mais est composé d'éléments qu'un logiciel peut analyser. C'est par
exemple le cas de Accept-Language: ou de
Content-Disposition:. Mais chaque en-tête ainsi
structuré a sa propre syntaxe, sans rien en commun avec les autres
en-têtes structurés, ce qui en rend l'analyse pénible. Ce nouveau
RFC (qui
remplace le RFC 8941) propose donc
des types de données et des algorithmes que les futurs en-têtes qui
seront définis pourront utiliser pour standardiser un peu l'analyse
d'en-têtes HTTP. Les en-têtes structurés anciens ne sont pas
changés, pour préserver la compatibilité. De nombreux RFC utilisent
déjà cette syntaxe (RFC 9209, RFC 9211, etc).
Imaginez : vous êtes un concepteur ou une conceptrice d'une extension au protocole HTTP qui va nécessiter la définition d'un nouvel en-tête. La norme HTTP, le RFC 9110, section 16.3.2, vous guide en expliquant ce à quoi il faut penser quand on conçoit un en-tête HTTP. Mais même avec ce guide, les pièges sont nombreux. Et, une fois votre en-tête spécifié, il vous faudra attendre que tous les logiciels, serveurs, clients, et autres (comme Varnish, pour lequel travaille un des auteurs du RFC) soient mis à jour, ce qui sera d'autant plus long que le nouvel en-tête aura sa syntaxe spécifique, avec ses amusantes particularités. Amusantes pour tout le monde, sauf pour le programmeur ou la programmeuse qui devra écrire l'analyse.
La solution est donc que les futurs en-têtes structurés réutilisent les éléments fournis par notre RFC, ainsi que son modèle abstrait, et la sérialisation proposée pour envoyer le résultat sur le réseau. Le RFC recommande d'appliquer strictement ces règles, le but étant de favoriser l'interopérabilité, au contraire du classique principe de robustesse, qui mène trop souvent à du code compliqué (et donc dangereux) car voulant traiter tous les cas et toutes les déviations. L'idée est que s'il y a la moindre erreur dans un en-tête structuré, celui-ci doit être ignoré complètement.
La syntaxe est malheureusement spécifiée sous forme d'algorithmes d'analyse. L'annexe C fournit toutefois aussi une grammaire en ABNF (RFC 5234).
Voici un exemple fictif d'en-tête structuré très simple
(tellement simple que, si tous étaient comme lui, on n'aurait sans
doute pas eu besoin de ce RFC) :
Foo-Example: est défini comme ne prenant qu'un
élément comme valeur, un entier compris entre 0 et 10. Voici à quoi
il ressemblera en HTTP :
Foo-Example: 3
Il accepte des paramètres après un
point-virgule, un seul paramètre est défini,
foourl dont la valeur est un URI. Cela pourrait
donner :
Foo-Example: 2; foourl="https://foo.example.com/"
Donc, ces solutions pour les en-têtes structurés ne serviront que pour les futurs en-têtes, pas encore définis, et qui seront ajoutés au registre IANA. Imaginons donc que vous soyez en train de mettre au point une norme qui inclut, entre autres, un en-tête HTTP structuré. Que devez-vous mettre dans le texte de votre norme ? La section 2 de notre RFC vous le dit :
- Inclure une référence à ce RFC 9651.
- J'ai parlé jusqu'à présent d'en-tête structuré mais en fait ce RFC 9651 s'applique aussi aux pieds (trailers) (RFC 9110, section 6.5 ; en dépit de leur nom, les pieds sont des en-têtes eux aussi). La norme devra préciser si elle s'applique seulement aux en-têtes classiques ou bien aussi aux pieds.
- Spécifier si la valeur sera une liste, un dictionnaire ou
juste un élément (ces termes sont définis en section 3). Dans
l'exemple ci-dessus
Foo-Example:, la valeur était un élément, de type entier. - Penser à définir la sémantique.
- Et ajouter les règles supplémentaires sur la valeur du
champ, s'il y en a. Ainsi, l'exemple avec
Foo-Example:imposait une valeur entière entre 0 et 10.
Une spécification d'un en-tête structuré ne peut que rajouter des contraintes à ce que prévoit ce RFC 9651. S'il en retirait, on ne pourrait plus utiliser du code générique pour analyser tous les en-têtes structurés.
Rappelez-vous que notre RFC est strict : si une erreur est présente
dans l'en-tête, il est ignoré. Ainsi, s'il était spécifié que la
valeur est un élément de type entier et qu'on trouve une chaîne de
caractères, on ignore l'en-tête. Idem dans l'exemple ci-dessus si on
reçoit Foo-Example: 42, la valeur excessive
mène au rejet de l'en-tête.
Les valeurs peuvent inclure des paramètres (comme le
foourl donné en exemple plus haut), et le RFC
recommande d'ignorer les paramètres inconnus, afin de permettre
d'étendre leur nombre sans tout casser.
On a vu qu'une des plaies du Web était le laxisme trop grand dans l'analyse des données reçues (c'est particulièrement net pour HTML). Mais on rencontre aussi des cas contraires, des systèmes (par exemple les pare-feux applicatifs) qui, trop fragiles, chouinent lorsqu'ils rencontrent des cas imprévus, parce que leurs auteurs avaient mal lu le RFC. Cela peut mener à l'ossification, l'impossibilité de faire évoluer l'Internet parce que des nouveautés, pourtant prévues dès l'origine, sont refusées. Une solution récente est le graissage, la variation délibérée des messages pour utiliser toutes les possibilités du protocole. (Un exemple pour TLS est décrit dans le RFC 8701.) Cette technique est recommandée par notre RFC.
La section 3 du RFC décrit ensuite les types qui sont les briques de base avec lesquelles on va pouvoir définir les en-têtes structurés. La valeur d'un en-tête peut être une liste, un dictionnaire ou un élément. Les listes et les dictionnaires peuvent à leur tour contenir des listes. Une liste est une suite de termes qui, dans le cas de HTTP, sont séparés par des virgules :
ListOfStrings-Example: "foo", "bar", "It was the best of times."
Et si les éléments d'une liste sont eux-mêmes des listes, on met ces listes internes entre parenthèses (et notez la liste vide à la fin, et l'espace comme séparateur) :
ListOfListsOfStrings-Example: ("foo" "bar"), ("baz"), ("bat" "one"), ()
Un en-tête structuré dont la valeur est une liste a toujours une valeur, la liste vide, même si l'en-tête est absent.
Un dictionnaire est une suite de termes nom=valeur. En HTTP, cela donnera :
Dictionary-Example: en="Applepie", fr="Tarte aux pommes"
Et nous avons déjà vu les éléments simples dans le premier
exemple. Les éléments peuvent être de type
entier,
chaîne de
caractères, booléen,
identificateur, valeur binaire, date, et un dernier type plus exotique
(lisez le RFC pour en savoir plus). L'exemple avec
Foo-Example: utilisait un entier. Les exemples
avec listes et dictionnaires se servaient de chaînes de
caractères. Ces chaînes sont encadrées de
guillemets (pas
d'apostrophes).
Compte-tenu des analyseurs HTTP
existants, les chaînes de caractères ordinaires
doivent être en ASCII (RFC 20). Si on veut envoyer de l'Unicode, il faut utiliser
un autre type, Display String. Quant aux booléens, notez qu'il faut
écrire 1 et 0 (pas true et
false), et préfixé d'un point
d'interrogation.
Toutes ces valeurs peuvent prendre des paramètres, qui sont eux-mêmes une suite de couples clé=valeur, après un point-virgule qui les sépare de la valeur principale (ici, on a deux paramètres) :
ListOfParameters: abc;a=1;b=2
J'ai dit au début que ce RFC définit un modèle abstrait, et une sérialisation concrète pour HTTP. La section 4 du RFC spécifie cette sérialisation, et son inverse, l'analyse des en-têtes (pour les programmeur·ses seulement).
Ah, et si vous êtes fana de formats structurés, ne manquez pas l'annexe A du RFC, qui répond à la question que vous vous posez certainement depuis plusieurs paragraphes : pourquoi ne pas avoir tout simplement décidé que les en-têtes structurés auraient des valeurs en JSON (RFC 8259), ce qui évitait d'écrire un nouveau RFC, et permettait de profiter du code JSON existant ? Le RFC estime que le fait que les chaînes de caractères JSON soient de l'Unicode est trop risqué, par exemple pour l'interopérabilité. Autre problème de JSON, les structures de données peuvent être emboîtées indéfiniment, ce qui nécessiterait des analyseurs dont la consommation mémoire ne peut pas être connue et limitée. (Notre RFC permet des listes dans les listes mais cela s'arrête là : on ne peut pas poursuivre l'emboîtement.)
Une partie des problèmes avec JSON pourrait se résoudre en se limitant à un profil restreint de JSON, par exemple en utilisant le RFC 7493 comme point de départ. Mais, dans ce cas, l'argument « on a déjà un format normalisé, et mis en œuvre partout » tomberait.
Enfin, l'annexe A note également qu'il y avait des considérations d'ordre plutôt esthétiques contre JSON dans les en-têtes HTTP.
Toujours pour les programmeur·ses, l'annexe B du RFC donne quelques conseils pour les auteur·es de bibliothèques mettant en œuvre l'analyse d'en-têtes structurés. Pour les aider à suivre ces conseils, une suite de tests est disponible. Quant à une liste de mises en œuvre du RFC, vous pouvez regarder celle-ci.
Actuellement, il y a dans le registre
des en-têtes plusieurs en-têtes structurés, comme le
Accept-CH: du RFC 8942 (sa valeur est une liste d'identificateurs), le
Cache-Status: du RFC 9211
ou le Client-Cert: du RFC 9440.
Si vous voulez un exposé synthétique sur ces en-têtes structurés, je vous recommande cet article par un des auteurs du RFC.
Voyons maintenant un peu de pratique avec une des mises en œuvre citées plus haut, http_sfv, une bibliothèque Python. Une fois installée :
% python3 >>> import http_sfv >>> my_item=http_sfv.Item() >>> my_item.parse(b"2") >>> print(my_item) 2
On a analysé la valeur « 2 » en déclarant que cette valeur devait être un élément et, pas de surprise, ça marche. Avec une valeur syntaxiquement incorrecte :
>>> my_item.parse(b"2, 3")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/stephane/.local/lib/python3.12/site-packages/http_sfv/util.py", line 61, in parse
raise ValueError("Trailing text after parsed value")
ValueError: Trailing text after parsed value
Et avec un paramètre (il sera accessible après l'analyse, via le
dictionnaire Python params) :
>>> my_item.parse(b"2; foourl=\"https://foo.example.com/\"")
>>> print(my_item.params['foourl'])
https://foo.example.com/
Avec une liste :
>>> my_list=http_sfv.List()
>>> my_list.parse(b"\"foo\", \"bar\", \"It was the best of times.\"")
>>> print(my_list)
"foo", "bar", "It was the best of times."
Et avec un dictionnaire :
>>> my_dict=http_sfv.Dictionary()
>>> my_dict.parse(b"en=\"Applepie\", fr=\"Tarte aux pommes\"")
>>> print(my_dict)
en="Applepie", fr="Tarte aux pommes"
>>> print(my_dict["fr"])
"Tarte aux pommes"
L'annexe D résume les principaux changements depuis le RFC 8941. Rien de trop crucial, à part le fait que l'ABNF est reléguée à une annexe. Sinon, il y a deux nouveaux types de base, pour les dates et les chaines de caractères en Unicode (Display Strings).
L'article seul
RFC 9649: WebP Image Format
Date de publication du RFC : Novembre 2024
Auteur(s) du RFC : J. Zern, P. Massimino, J. Alakuijala
(Google)
Pour information
Première rédaction de cet article le 19 novembre 2024
Un RFC sur un
format d'image : il décrit le format WebP et
enregistre officiellement le type image/webp.
Bon, des images au format WebP, vous en avez forcément vu un peu partout sur le Web. Mais le format n'était pas encore documenté par un organisme de normalisation. C'est désormais fait. WebP s'appuie sur le format RIFF. Plus précisément, RIFF est un cadre générique qui peut se décliner en divers formats. C'est pour cela que les fichiers WebP commencent par les quatre codes ASCII correspondant à "RIFF".
WebP permet de la compression avec perte ou sans perte, et, d'une manière générale, tout ce qu'on attend d'un format graphique. C'est donc un concurrent de JPEG, PNG (RFC 2083), GIF… L'encodage lors de la compression avec perte est celui de VP8 (RFC 6386), produisant des images plus petites que ses prédécesseurs, ce qui est bon pour le réseau. La compression sans perte est faite en LZ77 et Huffman. WebP permet également le stockage de métadonnées codées en EXIF ou en XMP. Ah, et WebP permet des animations.
Cette image, sur un sujet politique qui est toujours d'actualité,
est au format WebP :
La section 2 du RFC décrit le format en détail. Les trois premiers champs sont la chaine "RIFF", la taille du fichier en binaire et la chaine "WEBP", chacun sur quatre octets. Affichons ces trois champs :
% dd if=how-do-you-like-it-wrapped.webp bs=4 count=3 RIFFXWEBP 3+0 records in 3+0 records out 12 bytes copied…
La section 3 décrit ensuite le stockage des pixels sans perte.
Comme avec tout format, les logiciels qui lisent les fichiers WebP (qu'on télécharge souvent depuis l'Internet, via des sources pas forcément de confiance) doivent être prudents dans l'analyse des fichiers. Les fichiers peuvent être invalides, par accident ou délibérément, et mener le logiciel négligent à lire en dehors d'un tableau ou déréférencer un pointeur invalide. La paranoïa est recommandée quand on lit ces fichiers. Plusieurs failles ont touché la libwebp, l'implémentation de référence, dont la grave CVE-2023-4863 en 2023 qui avait fait, à juste titre, beaucoup de bruit.
Toujours question sécurité, WebP n'a pas de contenu exécutable (contrairement à, par exemple, TrueType). Mais les métadonnées EXIF ou en XMP peuvent poser des problèmes de sécurité et doivent donc être interprétées avec prudence.
Le type
image/webp est désormais dans
le registre des types de médias (cf. le
formulaire rempli).
Si on regarde des fichiers WebP, on a ce genre d'informations :
% file resolution-dns.webp resolution-dns.webp: RIFF (little-endian) data, Web/P image % file --mime-type resolution-dns.webp resolution-dns.webp: image/webp
Pour finir, produisons un peu d'images WebP pour voir. Si on utilise Asymptote, c'est facile :
% asy -f webp -o resolution-dns.webp resolution-dns.asy
On peut aussi convertir depuis les formats existants, ici avec ImageMagick :
% convert -verbose resolution-dns.png resolution-dns.webp resolution-dns.png PNG 823x508 823x508+0+0 8-bit sRGB 31713B 0.020u 0:00.011 resolution-dns.png=>resolution-dns.webp PNG 823x508 823x508+0+0 8-bit sRGB 16580B 0.040u 0:00.047
Si on fait des graphiques depuis ses programmes en Python avec Matplotlib, il suffit, depuis la version 3.6, de :
plot.savefig(fname="test.webp") # No need to indicate the format, it
# is taken from the file extension.
(Voir aussi ce beau résultat sur Wikimedia Commons.)
{kind=link}
L'article seul
RFC 9639: Free Lossless Audio Codec
Date de publication du RFC : Décembre 2024
Auteur(s) du RFC : M.Q.C. van
Beurden, A. Weaver
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF cellar
Première rédaction de cet article le 19 décembre 2024
Le format FLAC, normalisé dans ce RFC, permet de stocker et de transmettre du son sans perte (contrairement à des mécanismes de compression comme MP3). Il est donc utile, par exemple pour l'archivage à long terme (mais aussi pour la haute fidélité).
Le multimédia, c'est compliqué. Le RFC fait près de 100 pages, pour un format audio qui se veut pourtant simple. FLAC fait de la compression pour limiter l'espace de stockage nécessaire mais en prenant soin de permettre une décompression qui redonne exactement le fichier originel (d'où le « sans perte » dans son nom, qu'il partage avec d'autres formats, comme le FFV1 du RFC 9043). Je ne connais pas assez le domaine de l'audio pour faire un résumé intelligent du RFC donc je vous invite à le lire si vous voulez comprendre comment FLAC fonctionne (les sections 4 à 6 vous font une description de haut niveau).
Si on prend un fichier FLAC, un programme comme file peut le comprendre :
% file Thélème.flac Thélème.flac: FLAC audio bitstream data, 24 bit, stereo, 44.1 kHz, length unknown
Le fait que l'échantillonage soit à 44,1 kHz est encodé dans les métadonnées (cf. section 9.1.2 du RFC), que file a pu lire (section 9.1.3 pour le fait que le fichier soit en stéréo).
Il y a quelques fichiers FLAC sur Wikimedia Commons. Mais un bon exemple de l'utilisation de FLAC est donné par l'enregistrement des Variations Goldberg par Kimiko Ishizaka, que vous pouvez télécharger en FLAC et sous une licence libre (CC0).
La mise en œuvre de référence de FLAC est en logiciel libre et se nomme libFLAC. Mais il existe beaucoup d'autres programmes qui savent gérer FLAC (j'ai écouté plusieurs fichiers FLAC avec vlc pour cet article), le lire, l'écrire, l'analyser, etc. Une liste est disponible sur le site du groupe de travail IETF. Il faut dire que FLAC, bien qu'il vienne seulement d'être normalisé, est un format ancien, dont le développement a commencé en 2000, et il n'est donc pas étonnant que les programmeur·ses aient eu le temps de travailler.
Si vous voulez ajouter du code à cette liste, lisez bien la section 11 du RFC, sur la sécurité. Un programme qui lit du FLAC doit être paranoïaque (comme avec n'importe quel autre format, bien sûr) et se méfier des cas pathologiques. Ainsi, le RFC note qu'on peut facilement créer un fichier FLAC de 49 octets qui, décomprimé, ferait 2 mégaoctets, ce qui pourrait dépasser la mémoire qui avait été réservée. Ce genre de surprises peut arriver à plusieurs endroits. L'annexe D du RFC contient plusieurs fichiers FLAC intéressants (et vous pouvez les retrouver en ligne) et il existe également une collection de fichiers FLAC, dont certains sont délibérément anormaux, pour que vous puissiez tester la robustesse de votre programme. Autre piège (mais lisez toute la section 11, il y en a beaucoup), FLAC permet de mettre des URL dans les fichiers, URL qu'il ne faut évidemment pas déréférencer bêtement.
Ce RFC est également la documentation pour l'enregistrement
du type MIME audio/flac
(section 12.1).
Pour une analyse technique de la prétention « sans perte » de FLAC, voir cet article de Guillaume Seznec.
L'article seul
RFC 9637: Expanding the IPv6 Documentation Space
Date de publication du RFC : Août 2024
Auteur(s) du RFC : G. Huston (APNIC), N. Buraglio (Energy Sciences Network)
Pour information
Réalisé dans le cadre du groupe de travail IETF v6ops
Première rédaction de cet article le 28 août 2024
Le préfixe IPv6 normalisé pour les
documentations, 2001:db8::/32 était trop petit
pour vous ? Vous aviez du mal à exprimer des architectures réseau
complexes, avec beaucoup de préfixes ? Ne pleurez plus, un nouveau
préfixe a été alloué, c'est désormais un /20, le 3fff::/20.
Ce RFC modifie
légèrement le RFC 3849, qui normalisait ce
préfixe de documentation. Le but d'un préfixe IP de documentation est
d'éviter que les auteur·es de ces documentations ne prennent des
adresses IP qui existent
par ailleurs, au risque que des administrateurices
réseaux maladroit·es ne copient ces adresses IP (songez
au nombre d'articles qui parlent d'IPv4 en
utilisant des exemples comme les adresses
1.1.1.1 ou 1.2.3.4, qui
existent réellement). On doit donc utiliser les noms de domaine du RFC 2606, les adresses IPv4 du RFC 5737, et les numéros d'AS du RFC 5398. Pour IPv6, l'espace de
documentation est désormais 3fff::/20 (l'ancien
préfixe 2001:db8::/32
reste réservé et valable donc pas besoin de modifier les
documentations existantes).
Cette nouvelle taille permet de documenter des réseaux réalistes,
par exemple où deux /32 se parlent.
Si ce préfixe est désormais dans le registre des adresses spéciales, il ne semble pas (encore ?) décrit dans la base d'un RIR, contrairement à son prédécesseur.
L'article seul
RFC 9636: The Time Zone Information Format (TZif)
Date de publication du RFC : Octobre 2024
Auteur(s) du RFC : A.D. Olson, P. Eggert
(UCLA), K. Murchison (Fastmail)
Chemin des normes
Première rédaction de cet article le 31 octobre 2024
Ce nouveau RFC
documente un format déjà ancien et largement déployé, TZif, un
format de description des fuseaux
horaires. Il définit également des types MIME pour ce format,
application/tzif et
application/tzif-leap. Il remplace le premier
RFC de normalisation de ce format, le RFC 8536, mais il y a très peu de changements. Bienvenue donc
à la version 4 du format, spécifiée dans ce RFC.
Ce format existe depuis quarante ans (et a pas mal évolué pendant ce temps) mais n'avait apparemment jamais fait l'objet d'une normalisation formelle avant le RFC 8536 en 2019. La connaissance des fuseaux horaires est indispensable à toute application qui va manipuler des dates, par exemple un agenda. Un fuseau horaire se définit par un décalage par rapport à UTC, les informations sur l'heure d'été, des abréviations pour désigner ce fuseau (comme CET pour l'heure de l'Europe dite « centrale ») et peut-être également des informations sur les secondes intercalaires. Le format iCalendar du RFC 5545 est un exemple de format décrivant les fuseaux horaires. TZif, qui fait l'objet de ce RFC, en est un autre. Contrairement à iCalendar, c'est un format binaire.
TZif vient à l'origine du monde Unix et est apparu dans les années 1980, quand le développement de l'Internet, qui connecte des machines situées dans des fuseaux horaires différents, a nécessité que les machines aient une meilleure compréhension de la date et de l'heure. Un exemple de source faisant autorité sur les fuseaux horaires est la base de l'IANA décrite dans le RFC 6557 et dont l'usage est documenté à l'IANA. Pour la récupérer, voir par exemple le RFC 7808.
La section 2 de notre RFC décrit la terminologie du domaine :
- Temps Universel Coordonné (UTC est le sigle officiel) : la base du temps légal. Par exemple, en hiver, la France métropolitaine est en UTC + 1. (GMT n'est utilisé que par les nostalgiques de l'Empire britannique.)
- Heure d'été (le terme français est incorrect, l'anglais DST - Daylight Saving Time est plus exact) : le décalage ajouté ou retiré à certaines périodes, pour que les activités humaines, et donc la consommation d'énergie, se fassent à des moments plus appropriés (cette idée est responsable d'une grande partie de la complexité des fuseaux horaires).
- Temps Atomique International (TAI) : contrairement à UTC, qui suit à peu près le soleil, TAI est déconnecté des phénomènes astronomiques. Cela lui donne des propriétés intéressantes, comme la prédictibilité (alors qu'on ne peut pas savoir à l'avance quelle sera l'heure UTC dans un milliard de secondes) et la monotonie (jamais de sauts, jamais de retour en arrière, ce qui peut arriver à UTC). Cela en fait un bon mécanisme pour les ordinateurs, mais moins bon pour les humains qui veulent organiser un pique-nique. Actuellement, il y a 37 secondes de décalage entre TAI et UTC.
- Secondes intercalaires : secondes ajoutées de temps en temps à UTC pour compenser les variations de la rotation de la Terre.
- Correction des secondes intercalaires : TAI - UTC - 10 (lisez le RFC pour savoir pourquoi 10). Actuellement 27 secondes.
- Heure locale : l'heure légale en un endroit donné. La différence avec UTC peut varier selon la période de l'année, en raison de l'heure d'été. En anglais, on dit aussi souvent « le temps au mur » (wall time) par référence à une horloge accrochée au mur. Quand on demande l'heure à M. Toutlemonde, il donne cette heure locale, jamais UTC ou TAI ou le temps Unix.
- Epoch : le point à partir duquel on compte le temps. Pour Posix, c'est le 1 janvier 1970 à 00h00 UTC.
- Temps standard : la date et heure « de base » d'un fuseau horaire, sans tenir compte de l'heure d'été. En France métropolitaine, c'est UTC+1.
- Base de données sur les fuseaux horaires : l'ensemble des informations sur les fuseaux horaires (cf. par exemple RFC 7808). Le format décrit dans ce RFC est un des formats possibles pour une telle base de données.
- Temps universel : depuis 1960, c'est équivalent à UTC, mais le RFC préfère utiliser UT.
- Temps Unix : c'est ce qui est renvoyé
par la fonction
time(), à savoir le nombre de secondes depuis l'epoch, donc depuis le 1 janvier 1970. Il ne tient pas compte des secondes intercalaires, donc il existe aussi un « temps Unix avec secondes intercalaires » (avertissement : tout ce qui touche au temps et aux calendriers est compliqué). C'est ce dernier qui est utilisé dans le format TZif, pour indiquer les dates et heures des moments où se fait une transition entre heure d'hiver et heure d'été.
La section 3 de notre RFC décrit le format lui-même. Un fichier TZif est composé d'un en-tête (taille fixe de 44 octets) indiquant entre autres le numéro de version de TZif. La version actuelle est 4. Ensuite, on trouve les données. Dans la version 1 de TZif, le bloc de données indiquait les dates de début et de fin des passages à l'heure d'été sur 32 bits, ce qui les limitait aux dates situées entre 1901 et 2038. Les versions ultérieures de TZif sont passées à 64 bits, ce qui permet de tenir environ 292 milliards d'années mais le bloc de données de la version 1 reste présent, au cas où il traine encore des logiciels ne comprenant que la version 1. Notez que ces 64 bits permettent de représenter des dates antérieures au Big Bang, mais certains logiciels ont du mal avec des valeurs situées trop loin dans le passé.
Les versions 2, 3 et 4 ont un second en-tête de 44 octets, et un bloc de données à elles. Les vieux logiciels arrêtent la lecture après le premier bloc de données et ne sont donc normalement pas gênés par cet en-tête et ce bloc supplémentaires. Les logiciels récents peuvent sauter le bloc de données de la version 1, qui ne les intéresse a priori pas (voir section 4 et annexe A). C'est au créateur du fichier de vérifier que les blocs de données destinés aux différentes versions sont raisonnablement synchrones, en tout cas pour les dates antérieures à 2038.
Nouveauté apparue avec la version 2, il y a aussi un pied de page à
la fin. Les entiers sont stockés en gros boutien, et en complément à deux. L'en-tête
commence par la chaîne magique « TZif » (U+0054 U+005A U+0069
U+0066), et comprend la longueur du bloc de données (qui dépend du
nombre de transitions, de secondes intercalaires et d'autres
informations à indiquer). Le bloc de données contient la liste des
transitions, le décalage avec UT, le nom du fuseau horaire, la liste des
secondes intercalaires, etc. Vu par le mode hexadécimal
d'Emacs, voici le début d'un fichier Tzif
version 2 (pris sur une Ubuntu, dans
/usr/share/zoneinfo/Europe/Paris). On voit bien
la chaîne magique, puis le numéro de version, et le début du bloc de
données :
00000000: 545a 6966 3200 0000 0000 0000 0000 0000 TZif2...........
00000010: 0000 0000 0000 000d 0000 000d 0000 0000 ................
00000020: 0000 00b8 0000 000d 0000 001f 8000 0000 ................
00000030: 9160 508b 9b47 78f0 9bd7 2c70 9cbc 9170 .`P..Gx...,p...p
00000040: 9dc0 48f0 9e89 fe70 9fa0 2af0 a060 a5f0 ..H....p..*..`..
...
Avec od, ça donnerait :
% od -x -a /usr/share/zoneinfo/Europe/Paris
0000000 5a54 6669 0032 0000 0000 0000 0000 0000
T Z i f 2 nul nul nul nul nul nul nul nul nul nul nul
0000020 0000 0000 0000 0d00 0000 0d00 0000 0000
nul nul nul nul nul nul nul cr nul nul nul cr nul nul nul nul
0000040 0000 b800 0000 0d00 0000 1f00 0080 0000
nul nul nul 8 nul nul nul cr nul nul nul us nul nul nul nul
0000060 6091 8b50 479b f078 d79b 702c bc9c 7091
dc1 ` P vt esc G x p esc W , p fs < dc1 p
...
Des exemples détaillés et commentés de fichiers TZif figurent en annexe B. À lire si vous voulez vraiment comprendre les détails du format.
Le pied de page indique notamment les extensions à la variable d'environnement TZ. Toujours avec le mode hexadécimal d'Emacs, ça donne :
00000b80: 4345 542d 3143 4553 542c 4d33 2e35 2e30 CET-1CEST,M3.5.0
00000b90: 2c4d 3130 2e35 2e30 2f33 0a ,M10.5.0/3.
On a vu que le format TZif avait une histoire longue et compliquée. La section 4 du RFC est entièrement consacrée aux problèmes d'interopérabilité, liés à la coexistence de plusieurs versions du format, et de beaucoup de logiciels différents. Le RFC conseille (sections 4 et 5) :
- De ne plus générer de fichiers suivant la version 1, qui ne marchera de toute façon plus après 2038.
- Les logiciels qui en sont restés à la version 1 doivent faire attention à arrêter leur lecture après le premier bloc (dont la longueur figure dans l'en-tête).
- La version 4 n'apporte pas beaucoup par rapport à la 2 et à la 3 et donc, sauf si on utilise les nouveautés spécifiques de la 4, il est recommandé de produire plutôt des fichiers conformes à la version 2 ou 3.
- Un fichier TZif transmis via l'Internet devrait être
étiqueté
application/tzif-leapouapplication/tzif(s'il n'indique pas les secondes intercalaires). Ces types MIME sont désormais dans le registre officiel (cf. section 9 du RFC).
L'annexe A du RFC en rajoute, tenant compte de l'expérience accumulée ; par exemple, certains lecteurs de TZif n'acceptent pas les noms de fuseaux horaires contenant des caractères non-ASCII et il peut donc être prudent de ne pas utiliser ces caractères. Plus gênant, il existe des lecteurs assez bêtes pour planter lorsque des temps sont négatifs. Or, les entiers utilisant dans TZif sont signés, afin de pouvoir représenter les moments antérieurs à l'epoch. Donc, attention si vous avez besoin de données avant le premier janvier 1970, cela perturbera certains logiciels bogués.
En parlant des noms de fuseaux horaires, le RFC rappelle (section 5) que le sigle utilisé dans le fichier Tzif (comme « CET ») est en anglais et que, si on veut le traduire, cela doit être fait dans l'application, pas dans le fichier. Le RFC donne comme exemple CST, qui peut être présenté comme « HNC », pour « Heure Normale du Centre ».
Autre piège avec ces sigles utilisés pour nommer les fuseaux horaires : ils sont ambigus. PST peut être la côte Ouest des USA mais aussi l'heure du Pakistan ou des Philippines.
La section 7 du RFC donne quelques conseils de sécurité :
- L'en-tête indique la taille des données mais le programme qui lit le fichier doit vérifier que ces indications sont correctes, et n'envoient pas au-delà de la fin du fichier.
- TZif, en lui-même, n'a pas de mécanisme de protection de l'intégrité, encore moins de mécanisme de signature. Il faut fournir ces services extérieurement (par exemple avec curl, en récupérant via HTTPS).
Enfin, l'annexe C du RFC liste les changements depuis le RFC 8536, changements qui mènent à cette nouvelle version, la 4. Rien de crucial mais :
- Formalisation de l'ancienne convention comme quoi un décalage de « - 0 » avec UTC indique qu'on ne connait pas le vrai décalage.
- Correction de plusieurs erreurs.
Une bonne liste de logiciels traitant ce format figure à l'IANA.
L'article seul
RFC 9622: An Abstract Application Layer Interface to Transport Services
Date de publication du RFC : Janvier 2025
Auteur(s) du RFC : B. Trammell (Google Switzerland), M. Welzl (University of Oslo), R. Enghardt (Netflix), G. Fairhurst (University of Aberdeen), M. Kuehlewind (Ericsson), C. Perkins (University of Glasgow), P. Tiesel (SAP SE), T. Pauly (Apple)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF taps
Première rédaction de cet article le 23 janvier 2025
Voici un des RFC du projet TAPS, qui vise à proposer une vision cohérente des protocoles de transport aux applications. Ce RFC décrit (mais de manière assez abstraite) l'API de TAPS.
Avant de le lire, il est très fortement recommandé de réviser le RFC 9621, qui décrit les buts du projet TAPS, et les principes de l'API Transport Services (autrefois surnommée « post-sockets »). Mais le RFC 9621 restait assez abstrait, et notre RFC 9622 se fait un peu plus concret (sans aller jusqu'à une vraie API puisqu'il reste partiellement indépendant du langage de programmation utilisé).
Rappelons quelques principes de TSAPI (Transport Services API, l'API qui est le but final du projet TAPS). D'abord, l'API est asynchrone (ce qui n'est pas idéal pour les langages avec parallélisme comme Go ou Elixir). On crée des Connexions (la majuscule au début est là pour se distinguer du concept flou de connexion, et pour désigner un type d'objets particulier), voire des Préconnexions si on veut les configurer avant, on leur définit des propriétés (en indiquant si elles sont impératives ou facultatives), on peut ensuite activer les Connexions (ou écouter passivement que l'autre machine les active), puis on envoie et on reçoit des Messages. La section 3 du RFC résume l'API, et, si vous êtes pressé·e, vous pouvez vous contenter de cette section. Elle contient quelques exemples pratiques, en pseudo-code.
À propos de pseudo-code, le RFC note que les conventions de nommage de l'API ne pourront pas forcément être suivies religieusement par toutes les mises en œuvre puisque certains langages de programmation ont des règles différentes. Mais c'est un détail.
Parmi les points dignes d'intérêt dans le RFC, on note que les applications peuvent indiquer le domaine d'avitaillement (PvD, ProVisioning Domain, défini dans le RFC 7556) qu'elles veulent utiliser. Elles peuvent par exemple l'identifier par son nom de domaine (RFC 8801).
Autre point intéressant, les cadreurs (framers). Décrits dans la section 9.1.2, ce sont des couches logicielles qui vont mettre en œuvre les exigences du protocole sous-jacent. Lors d'une opération d'envoi ou de réception d'un Message, les cadreurs vont tenir compte du protocole pour transformer un Message en flux d'octets et réciproquement. (Le RFC suggère de regarder le RFC 9329, pour un exemple.)
Pour mettre en œuvre cette API assez abstraite dans un langage de programmation spécifique, l'annexe A du RFC donne quelques conseils. Il y a des mises en œuvre de TAPS (plusieurs sont listées dans le RFC 9623, annexe C). On peut citer :
- En Python, PyTaps, mais qui n'est plus maintenu depuis longtemps (le projet TAPS existe depuis des années et ne semble pas susciter d'enthousiasme délirant),
- En C, NEAT, qui semble également abandonné.
Notez un point positif dans le RFC : l'annexe C du RFC 9623, qui décrit les mises en œuvre existantes donne non
seulement les URL « normaux » du projet, et ceux sur
GitHub mais aussi un lien
Software Heritage, pour la pérennité. C'est
une très bonne chose, car certains RFC ont une longue durée de
vie). Par exemple, NEAT est https://github.com/NEAT-project/neathttps://archive.softwareheritage.org/swh:1:dir:737820840f83c4ec9493a8c0cc89b3159e2e1a57;origin=https://github.com/NEAT-project/neat;visit=swh:1:snp:bbb611b04e355439d47e426e8ad5d07cdbf647e0;anchor=swh:1:rev:652ee991043ce3560a6e5715fa2a5c211139d15c
L'article seul
RFC 9621: Architecture and Requirements for Transport Services
Date de publication du RFC : Janvier 2025
Auteur(s) du RFC : T. Pauly (Apple), B. Trammell (Google Switzerland), A. Brunstrom (Karlstad University), G. Fairhurst (University of Aberdeen), C. Perkins (University of Glasgow)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF taps
Première rédaction de cet article le 23 janvier 2025
Ce RFC s'inscrit dans un projet IETF datant de quelques années : formaliser davantage les services que rend la couche Transport aux applications. Le but est de permettre de développer des applications en indiquant ce qu'on veut de la couche Transport, en rentrant le moins possible dans les détails. Ce RFC décrit l'architecture générale, le RFC 9622 spécifiant quant à lui une API plus concrète.
Des API pour les applications parlant à la couche Transport, il y en a beaucoup. La plus connue est bien sûr l'interface « socket », qui a pour principal avantage d'être ancienne et très documentée, dans des livres (comme le génial Stevens) et dans d'innombrables logiciels libres à étudier (mais, par contre, la norme POSIX qui la spécifie officiellement, n'est toujours pas disponible publiquement). C'est d'ailleurs cette multiplicité d'API, donc beaucoup sont solidement installées dans le paysage, qui fait que je doute du succès du projet et de sa TSAPI (Transport Services API) : la base installée à déplacer est énorme.
Pourtant, ces API traditionnelles ont de nombreux défauts. Le RFC
cite par exemple l'incohérence : pour envoyer des données sur une
prise qui utilise du TCP en clair, on
utilise send() mais quand
la communication est chiffrée avec TLS, c'est une autre
fonction (non normalisée). Pourtant, pour l'application, c'est la
même chose.
Toujours question cohérence, la terminologie n'est pas fixée et des termes comme flow, stream, connection et message ont des sens très différents selon les cas.
Le but de la nouvelle architecture est donc de permettre le développement d'une API (normalisée dans le RFC 9622) qui unifiera tout cela. (Notez que l'IETF, habituellement, normalise des protocoles et pas des API. Mais il y a déjà eu des exceptions à cette règle.) Un autre objectif est de permettre de mettre dans les bibliothèques du code qui autrefois était souvent dupliqué d'une application à l'autre, comme la mise en œuvre de l'algorithme des « globes oculaires heureux » (RFC 8305).
J'avais déjà présenté le projet TAPS, qui était alors nettement moins avancé, dans un exposé à la conférence MiXiT (dont voici le support).
L'architecture présentée ici est dérivée de l'analyse des protocoles de transport du RFC 8095 et de leur synthèse dans le RFC 8923. Pour les questions de sécurité, il est également conseillé de lire le RFC 8922.
L'interface pour les applications (TSAPI : Transport Services Application Programming Interface) sera fondée sur l'asynchronicité, en mode programmation par évènements. (Opinion personnelle : c'est une mauvaise idée, excessivement favorable aux langages sans vrai parallélisme, comme C. J'aurais préféré un modèle synchrone, fondé sur des fils d'exécution parallèle, plus simple pour la·e programmeur·se.)
Une des idées de base du projet est de développer une API qui soit indépendante du langage de programmation. C'est à mon avis fichu dès le départ. Outre cette question du parallélisme, la gestion des erreurs est très variable d'un langage à l'autre : codes de retour (en C), exceptions, valeurs mixtes comme en Haskell ou en Zig… L'API du RFC 9622 ne plaira donc pas à tout le monde.
La section 2 du RFC expose le modèle utilisé par l'API. D'abord, un résumé de la traditionnelle API « socket » :
- TCP et UDP sont mis en œuvre dans le noyau,
- les applications utilisent l'API socket pour parler au
noyau, choisissant TCP ou UDP (même si l'API socket se prétend
plus abstraite que cela, avec des termes comme
SOCK_STREAMmais, en pratique, son utilisation nécessite de connaitre le protocole de transport utilisé), - la résolution de noms en adresses se fait par un mécanisme distinct (typiquement, en appelant le résolveur DNS, directement ou indirectement).
La nouvelle API généralisera ce modèle : l'application utilise l'API Transport Services (TSAPI), en indiquant les propriétés souhaitées pour la connexion, et la mise en œuvre de l'API parlera à tous les protocoles de transport (et de chiffrement) possibles, qu'ils soient placés dans le noyau ou pas. La résolution de noms est intégrée dans ce cadre, entre autres parce que certains services sous-jacents, notamment TLS, nécessitent de connaitre le nom du service auquel on accède (ce qui n'est pas le cas avec l'API socket, qui ne manipule que des adresses IP).
Pendant qu'on en parle, cette idée d'intégrer la résolution de
noms est également dans des projets comme Connect by
Name, qui vise à permettre aux applications de juste
demander connect(domain-name, port, tls=true)
et que tout soit fait proprement par l'API, notamment les fonctions
de sécurité (vérifier le nom dans le
certificat, par exemple, ce qui n'est pas
trivial à faire proprement).
On l'a dit plus haut, TSAPI est asynchrone. Le RFC estime que ce mode d'interaction avec le réseau, fondé sur des évènements, est plus fréquent et même « plus naturel ». C'est un des reproches que je ferais au projet. Je préfère le modèle d'interactions synchrone, notamment pour des langages de programmation ayant la notion de fils d'exécution séparés (les goroutines en Go, les processus en Erlang ou Elixir, les tâches d'Ada…), dans l'esprit des Communicating sequential processes (et j'en profite pour recommander le génial livre de Hoare, bien qu'il soit assez abstrait et d'un abord austère). Rien n'est naturel en programmation (ou ailleurs : « la seule interface utilisateur naturelle est le téton ; tout le reste est appris ») et le RFC se débarrasse un peu vite du choix effectué et ne cherche pas vraiment à le justifier.
Donc, l'application qui veut, par exemple, recevoir des données, va appeler l'API pour demander une lecture et l'API préviendra l'application quand des données seront prêtes. Au contraire, dans un modèle synchrone, le fil qui veut lire sera bloqué tant qu'il n'y aura rien à lire, les autres fils continuant leur travail.
Dans l'API socket, on peut avoir des messages séparés lorsqu'on utilise UDP mais, avec TCP, c'est forcément une suite d'octets, sans séparation des éventuels messages. Chaque protocole applicatif doit donc, s'il en a besoin, inventer sa méthode de découpage en messages : DNS et EPP indiquent la longueur du message avant d'envoyer le message, HTTP/1 l'indique dans l'en-tête mais a un mécanisme de découpage fondé sur des délimiteurs (cf. RFC 9112, sections 6.1 et 7), HTTP/2 et HTTP/3 ont leurs ruisseaux (une requête par ruisseau), TLS utilise également une indication de longueur. Au contraire, avec TSAPI, il y a toujours un découpage en messages, qui seront encodés en utilisant les capacités du protocole de transport sous-jacent (par un mécanisme nommé cadreur - framer).
TSAPI permet des choses qui n'étaient pas possibles avec les API classiques, comme d'avoir plusieurs paires d'adresses IP entre les machines qui communiquent, avec changement de la paire utilisée pendant une connexion.
Un des intérêts de cette nouvelle API est de permettre aux applications de fonctionner de manière plus déclarative et moins impérative. Au lieu de sélectionner tel ou tel protocole précis, l'application déclare ses exigences, et TSAPI se débrouillera pour les lui fournir (section 3.1).
Bon, c'est bien joli, de vouloir que les applications ne connaissent pas les protocoles (ce qui permet de les faire évoluer plus facilement) mais, quand même, parfois, il existe des fonctions très spécifiques d'un protocole particulier qu'il serait bien sympa d'utiliser. La section 3.2 de notre RFC couvre donc cette question. Par exemple, l'option User Timeout de TCP (RFC 5482) est bien pratique, même si elle est spécifique à TCP. Donner accès à ces spécificités soulève toutefois un problème : parfois, l'application souhaite une certaine fonction, et peut donc s'en passer, et parfois elle l'exige et la connexion doit échouer si elle n'est pas disponible pour un certain protocole. L'API devra donc distinguer les deux cas.
Une fois que l'application a indiqué ses préférences et ses exigences, l'API devra sélectionner un protocole de transport. Parfois, plusieurs protocoles conviendront. Si l'application demande juste un transport fiable d'une suite d'octets, TCP, SCTP et QUIC conviendront tous les trois (alors qu'UDP serait exclu).
Comme rien n'est gratuit en ce bas monde, le progrès de l'abstraction, et une relative indépendance de l'application par rapport aux particularités des protocoles de transport, ont un inconvénient : le système devient plus complexe. Les développeureuses d'application lorsqu'il faut déboguer, et les administrateurices système qui vont installer (et essuyer les plâtres !) les applications vont avoir des difficultés nouvelles. Des fonctions de déboguage devront donc être intégrées. (Personnellement, je pense aussi à la nécessité que la bibliothèque qui mette en œuvre TSAPI coopère au déboguage pour les protocoles chiffrés, qui ne permettront pas tellement d'utiliser Wireshark. Voir mon exposé à Capitole du Libre.)
Et enfin, après ces généralités, passons aux concepts qui devront être visibles par l'application, rapprochons-nous de la future API (section 4 du RFC). D'abord, la Connexion. Non, ce n'est pas une erreur d'avoir capitalisé le mot. Le RFC utilise la même méthode pour montrer qu'il s'agit d'un concept abstrait, qui ne correspond pas forcément parfaitement aux connexions du protocole de transport (pour ceux qui ont ce concept). La Connexion est donc au cœur de l'API Transport Services. Elle se fait entre deux points, le local et le distant, chacun identifié par un Endpoint Identifier. Elle a un certain nombre de propriétés, qui peuvent s'appliquer avant (et influenceront la sélection du protocole de transport, et/ou des machines auxquelles ont se connecte), juste avant ou pendant la Connexion, par exemple l'utilisation du 0-RTT (RFC 9622, section 6.2.5) ou l'exigence du chiffrement (cf. RFC 8922), mais il y a aussi des propriétés pour chaque message individuel. Ensuite, on va :
- Pré-établir : ce sont les opérations qu'on fait avant de se connecter, comme de définir des paramètres de la Pré-Connexion, la future Connexion.
- Établir : là, ça y est, on se connecte.
- Transférer des données (lire et écrire).
- Gérer des évènements qui surviennent comme « la Connexion est prête » ou « le chemin a changé ». Rappelez-vous que TSAPI est asynchrone, pilotée par des évènements.
- Et, comme les meilleures choses ont une fin, on peut
terminer la Connexion (proprement avec
Closeou salement avecAbort).
Un écoutant va créer une Pré-Connexion et attendre les demandes, ce
n'est pas lui qui va établir les connexions. L'entité active, elle,
va se connecter (fonctions Listen et
Initiate). Et le
pair-à-pair ? Il sera également possible via
la fonction Rendezvous. Ce sera à l'API de
gérer les services comme STUN (RFC 8489),
souvent indispensables en pair-à-pair.
Le transfert de données a les classiques fonctions
Send et Receive (qui n'est
pas synchrone, rappelons-le, donc qui ne bloque pas). Mais il y a
aussi un nouveau concept, le cadreur (traduction peu imaginative de
framer). C'est la couche logicielle qui va ajouter et/ou modifier les
données du message pour mettre en œuvre des exigences du protocole,
par exemple indiquer les frontières entre messages dans un protocole
de transport qui n'a pas ce concept (comme TCP). Ainsi, les
protocoles EPP (RFC 5734) et
DNS (RFC 7766) nécessitent que chaque message soit
préfixé d'un seizet indiquant sa longueur. Un
cadreur peut faire cela automatiquement pour chaque message,
simplifiant la tâche de l'application (par exemple la bibliothèque
standard d'Erlang a cette
option - cf. packet).
Enfin, un peu de sécurité et de vie privée (section 6). D'abord, les implémentations devront faire attention aux risques pour la vie privée si on réutilise l'état des connexions passées. C'est le cas des sessions TLS (RFC 9846, section 2.2) ou des gâteaux HTTP (RFC 6265), qui peuvent permettre de relier deux connexions entre elles, lien qu'on ne souhaite peut-être pas.
Et puis, en sécurité, le RFC rappelle qu'on ne doit pas se replier sur des solutions non sécurisées si la technique sécurisée échoue. Ainsi, si une application demande du chiffrement, mais que la connexion chiffrée échoue, il ne faut pas se rabattre sur une connexion en clair.
Notez que l'ensemble du projet TAPS a bénéficié de divers financements publics, par exemple de l'UE.
Une opinion personnelle sur ce projet ? Outre des critiques sur tel ou tel choix, comme l'asynchronisme, je suis malheureusement sceptique quant aux chances de réussite. Les API actuelles, avec tous leurs défauts, sont solidement installées, et dans le meilleur des cas, il faudra de nombreuses années pour que les formations s'adaptent et enseignent une API comme TSAPI.
L'article seul
RFC 9620: Guidelines for Human Rights Protocol and Architecture Considerations
Date de publication du RFC : Septembre 2024
Auteur(s) du RFC : G. Grover, N. ten Oever (University of Amsterdam)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF hrpc
Première rédaction de cet article le 17 septembre 2024
Voici un RFC explicitement politique, puisqu'il documente la façon dont les concepteur·rices de protocoles à l'IETF devraient examiner les conséquences de leurs protocoles sur l'exercice des droits humains. Si vous concevez un protocole réseau (IETF ou pas), c'est une lecture recommandée.
Les protocoles ne sont pas neutres puisqu'ils ont des conséquences concrètes sur les utilisateurices, conséquences positives ou négatives. S'ils n'en avaient pas, on ne passerait pas du temps à les développer, et on ne dépenserait pas d'argent à les déployer. Ces conséquences ne sont pas forcément faciles à déterminer, surtout avant tout déploiement effectif, mais ce RFC peut guider la réflexion et permettre d'identifier les points qui peuvent avoir des conséquences néfastes. Il comprend de nombreux exemples tirés de précédents RFC. Il met à jour partiellement le RFC 8280, dont il reprend la section 6, et s'inspire de la méthode du RFC 6973, qui documentait les conséquences des protocoles sur la vie privée.
La question est évidemment complexe. Les protocoles n'ont pas forcément un pouvoir direct sur ce que les utilisateurices peuvent faire ou pas (c'est l'argument central de ceux qui estiment que les techniques sont neutres : HTTP transférera aussi bien un article de la NASA qu'un texte complotiste sur les extra-terrestres). Leur rôle est plutôt indirect, en ce qu'ils encouragent ou découragent certaines choses, plutôt que d'autoriser ou interdire. Et puis, comme le note le RFC, cela dépend du déploiement. Par exemple, pour le courrier électronique, des faits politiques importants ne s'expliquent pas par le protocole. Ce ne sont pas les particularités de SMTP (RFC 5321) qui expliquent la domination de Gmail par exemple. Il ne faut en effet pas tomber dans le déterminisme technologique (comme le font par exemple les gens qui critiquent DoH) : l'effet dans le monde réel d'un protocole dépend de bien d'autres choses que le protocole.
Ah, et autre point dans l'introduction, la définition des droits humains. Notre RFC s'appuie sur la déclaration universelle des droits humains et sur d'autres documents comme le International Covenant on Economic, Social and Cultural Rights.
Parmi les droits humains cités dans cette déclaration universelle, nombreux sont ceux qui peuvent être remis en cause sur l'Internet : liberté d'expression, liberté d'association, droit à la vie privée, non-discrimination, etc. L'absence d'accès à l'Internet mène également à une remise en cause des droits humains, par exemple parce que cela empêche les lanceurs d'alerte de donner l'alerte. Les atteintes aux droits humains peuvent être directes (censure) ou indirectes (la surveillance des actions peut pousser à l'auto-censure, et c'est souvent le but poursuivi par les acteurs de la surveillance ; cf. « Chilling Effects: Online Surveillance and Wikipedia Use »). Et les dangers pour les individus ne sont pas seulement « virtuels », ce qui se passe en ligne a des conséquences physiques quand, par exemple, une campagne de haine contre des gens accusés d'attaques contre une religion mène à leur assassinat, ou quand un État emprisonne ou tue sur la base d'informations récoltées en ligne.
C'est pour cela que, par exemple, le conseil des droits humains de l'ONU mentionne que les droits qu'on a dans le monde physique doivent aussi exister en ligne. [La propagande des médias et des politiciens en France dit souvent que « l'Internet est une zone de non-droit » et que « ce qui est interdit dans le monde physique doit aussi l'être en ligne », afin de justifier des lois répressives. Mais c'est une inversion complète de la réalité. En raison des particularités du numérique, notamment la facilité de la surveillance de masse, et de l'organisation actuelle du Web, avec un petit nombre d'acteurs médiant le trafic entre particuliers, les droits humains sont bien davantage menacés en ligne.] Sur la question de l'application des droits humains à l'Internet, on peut aussi lire les « 10 Internet Rights & Principles> » et le « Catalog of Human Rights Related to ICT Activities ».
Comme les droits humains sont précieux, et sont menacés sur l'Internet, l'IETF doit donc veiller à ce que son travail, les protocoles développés, n'aggravent pas la situation. D'où la nécessité, qui fait le cœur de ce RFC, d'examiner les protocoles en cours de développement. Ces examens (reviews, section 3 du RFC) devraient être systématiques et, évidemment, faits en amont, pas une fois le protocole déployé. [En pratique, ces examens ont assez vite été arrêtés, et ce RFC ne reflète donc pas la situation actuelle.]
Vu la façon dont fonctionne l'IETF, il n'y a pas besoin d'une autorité particulière pour effectuer ces examens. Tout·e participant·e à l'IETF peut le faire. Ce RFC 9620 vise à guider les examinateurs (reviewers). L'examen peut porter sur le contenu d'un Internet Draft mais aussi être complété, par exemple, avec des interviews d'experts de la question (les conséquences de tel ou tel paragraphe dans un Internet Draft ne sont pas forcément évidentes à la première lecture, ou même à la seconde) mais aussi des gens qui seront affectés par le protocole en question. Si un futur RFC parle d'internationalisation, par exemple, il ne faut pas interviewer que des anglophones, et pas que des participants à l'IETF, puisque l'internationalisation concerne tout le monde.
Une grosse difficulté, bien sûr, est que le protocole n'est pas tout. Les conditions effectives de son déploiement, et son évolution dans le temps, sont cruciales. Ce n'est pas en lisant le RFC 5733 (ou le RFC 9083) qu'on va tout comprendre sur les enjeux de la protection des données personnelles des titulaires de noms de domaine ! Le RFC 8980 discute d'ailleurs de cette importante différence entre le protocole et son déploiement.
La plus importante section de notre RFC est sans doute la section 4, qui est une sorte de check-list pour les auteur·es de protocoles et les examinateurices. Idéalement, lors de la phase de conception d'un protocole, il faudrait passer toutes ces questions en revue. Bien évidemment, les réponses sont souvent complexes : la politique n'est pas un domaine simple.
Premier exemple (je ne vais pas tous les détailler, rassurez-vous), les intermédiaires. Est-ce que le protocole permet, voire impose, des intermédiaires dans la communication ? C'est une question importante car ces intermédiaires, s'ils ne sont pas sous le contrôle des deux parties qui communiquent, peuvent potentiellement surveiller la communication (risque pour la confidentialité) ou la perturber (risque pour la liberté de communication). Un exemple est l'interception HTTPS (cf. « The Security Impact of HTTPS Interception »). Le principe de bout en bout (RFC 1958 ou bien « End-to-End Arguments in System Design ») promeut plutôt une communication sans intermédiaires, mais on trouve de nombreuses exceptions dans les protocoles IETF (DNS, SMTP…) ou en dehors de l'IETF (ActivityPub), car les intermédiaires peuvent aussi rendre des services utiles. En outre, ces intermédiaires tendent à ossifier le protocole, en rendant plus difficile le déploiement de tout changement (cf. RFC 9846 pour les problèmes rencontrés par TLS 1.3).
Le RFC fait aussi une différence entre intermédiaires et services. Si vous êtes utilisateurice de Gmail, Gmail n'est pas un intermédiaire, mais un service car vous êtes conscient·e de sa présence et vous l'avez choisi. [L'argument me semble avoir des faiblesses : ce genre de services pose exactement les mêmes problèmes que les intermédiaires et n'est pas forcément davantage maitrisé.]
Un bon moyen de faire respecter le principe de bout en bout est de chiffrer au maximum. C'est pour cela que QUIC (RFC 9000) chiffre davantage de données que TLS. C'est aussi pour cela que l'IETF travaille au chiffrement du SNI (RFC 9849).
Autre exemple, la connectivité (section 4.2). Car, si on n'a pas accès à l'Internet du tout, ou bien si on y a accès dans des conditions très mauvaises, tout discussion sur les droits humains sur l'Internet devient oiseuse. L'accès à l'Internet est donc un droit nécessaire (cf. la décision du Conseil Constitutionnel sur Hadopi, qui posait le principe de ce droit d'accès à l'Internet). Pour le protocole, cela oblige à se pencher sur son comportement sur des liens de mauvaise qualité : est-ce que ce protocole peut fonctionner lorsque la liaison est mauvaise ?
Un sujet délicat (section 4.4) est celui des informations que le protocole laisse fuiter (l'« image vue du réseau » du RFC 8546). Il s'agit des données qui ne sont pas chiffrées, même avec un protocole qui fait de la cryptographie, et qui peuvent donc être utilisées par le réseau, par exemple pour du traitement différencié (de la discrimination, pour dire les choses franchement). Comme recommandé par le RFC 8558, tout protocole doit essayer de limiter cette fuite d'informations. C'est pour cela que TCP a tort d'exposer les numéros de port, par exemple, que QUIC va au contraire dissimuler.
L'Internet est mondial, on le sait. Il est utilisé par des gens qui ne parlent pas anglais et/ou qui n'utilisent pas l'alphabet latin. Il est donc crucial que le protocole fonctionne pour tout le monde (section 4.5). Si le protocole utilise des textes en anglais, cela doit être de manière purement interne (le GET de HTTP, le Received: de l'IMF, etc), sans être obligatoirement montré à l'utilisateurice. Ce principe, formulé dans le RFC 2277, dit que tout ce qui est montré à l'utilisateur doit pouvoir être traduit. (En pratique, il y a des cas limites, comme les noms de domaine, qui sont à la fois éléments du protocole, et montrés aux utilisateurs.)
Si le protocole sert à transporter du texte, il doit évidemment utiliser Unicode, de préférence encodé en UTF-8. S'il accepte d'autres encodages et/ou d'autres jeux de caractère (ce qui peut être dangereux pour l'interopérabilité), il doit permettre d'étiqueter ces textes, afin qu'il n'y ait pas d'ambiguité sur leurs caractéristiques. Pensez d'ailleurs à lire le RFC 6365.
Un contre-exemple est le vieux protocole whois (RFC 3912), qui ne prévoyait que l'ASCII et, si on peut l'utiliser avec d'autres jeux de caractères, comme il ne fournit pas d'étiquetage, le client doit essayer de deviner de quoi il s'agit. (Normalement, whois n'est plus utilisé, on a le Web et RDAP, mais les vieilles habitudes ont la vie dure.)
Toujours question étiquetage, notre RFC rappelle l'importance de pouvoir, dans le protocole, indiquer explicitement la langue des textes (RFC 5646). C'est indispensable afin de permettre aux divers logiciels de savoir quoi en faire, par exemple en cas de synthèse vocale.
Le RFC parle aussi de l'élaboration des normes techniques (section 4.7). Par exemple, sont-elles dépendantes de brevets (RFC 8179 et RFC 6701) ? [Personnellement, je pense que c'est une question complexe : les brevets ne sont valables que dans certains pays et, en outre, la plupart des brevets logiciels sont futiles, brevetant des technologies banales et déjà connues. Imposer, comme le proposent certains, de ne normaliser que des techniques sans brevet revient à donner un doit de veto à n'importe quelle entreprise qui brevète n'importe quoi. Par exemple, le RFC 9156 n'aurait jamais été publié si on s'était laissé arrêter par le brevet.]
Mais un autre problème avec les normes techniques concerne leur disponibilité. Si l'IETF, le W3C et même l'UIT publient leurs normes, ce n'est pas le cas de dinosaures comme l'AFNOR ou l'ISO, qui interdisent même la redistribution de normes qu'on a légalement acquises. Si les normes IETF sont de distribution libre, elles dépendent parfois d'autres normes qui, elles, ne le sont pas.
Un peu de sécurité informatique, pour continuer. La section 4.11 traite de l'authentification des données (ce que fait DNSSEC pour le DNS, par exemple). Cette possibilité d'authentification est évidemment cruciale pour la sécurité mais le RFC note qu'elle peut aussi être utilisée négativement, par exemple avec les menottes numériques.
Et il y a bien sûr la confidentialité (section 4.12 mais aussi RFC 6973), impérative depuis toujours mais qui était parfois sous-estimée, notamment avant les révélations Snowden. Les auteur·es de protocoles doivent veiller à ce que les données soient et restent confidentielles et ne puissent pas être interceptées par un tiers. Il y a longtemps que tout RFC doit contenir une section sur la sécurité (RFC 3552), exposant les menaces spécifiques à ce RFC et les contre-mesures prises, entre autre pour assurer la confidentialité. L'IETF refuse, à juste titre, toute limitation de la cryptographie, souvent demandée par les autorités (RFC 1984). Les exigences d'accès par ces autorités (en invoquant des arguments comme la lutte contre le terrorisme ou la protection de l'enfance) ne peuvent mener qu'à affaiblir la sécurité générale puisque ces accès seront aussi utilisés par les attaquants, ou par un État qui abuse de son pouvoir.
Le modèle de menace de l'Internet, depuis longtemps, est que tout ce qui est entre les deux machines situées aux extrémités de la communication doit être considéré comme un ennemi. Pas parce que les intermédiaires sont forcément méchants, loin de là, mais parce qu'ils ont des possibiliés techniques que certains exploiteront et il faut donc protéger la communication car on ne sait jamais ce que tel ou tel intermédiaire fera (RFC 7258 et RFC 7624). Bref, tout protocole doit chiffrer le contenu qu'il transporte (RFC 3365). Aujourd'hui, les principales exceptions à ce principe sont le très vieil whois (RFC 3912) et surtout le DNS qui a, certes, des solutions techniques pour le chiffrement (RFC 7858 et RFC 8484) mais qui sont loin d'être universellement déployées.
Ce chiffrement doit évidemment être fait de bout en bout, c'est-à-dire directement entre les deux machines qui communiquent, afin d'éviter qu'un intermédiaire n'ait accès à la version en clair. Cela pose un problème pour les services store-and-forward comme le courrier électronique (RFC 5321). De même, chiffrer lorsqu'on communique en HTTPS avec Gmail ne protège pas la communication contre Google, seulement contre les intermédiaires réseau ! Relire le RFC 7624 est recommandé.
Question vie privée, le RFC recommande également de faire attention aux métadonnées et à l'analyse de trafic. Les conseils du RFC 6973, section 7, sont ici utiles.
Un sujet encore plus délicat est celui de l'anonymat et du pseudonymat. On sait qu'il n'y a pas réellement d'anonymat sur l'Internet (quoiqu'en disent les politiciens malhonnêtes et les journalistes avides de sensationnalisme), le numérique permettant au contraire de récolter et de traiter beaucoup de traces de la communication. Néanmoins, le protocole doit permettre, autant que possible, de s'approcher de l'anonymat. Par exemple, les identificateurs persistents sont évidemment directement opposés à cet objectif puisqu'ils rendent l'anonymat impossible (rappel important : anonymat ≠ pseudonymat). Au minimum, il faudrait permettre à l'utilisateur de changer facilement et souvent ces identificateurs. Et, bien sûr, ne pas imposer qu'ils soient liés à l'identité étatique. Des exemples d'identificateurs qui sont parfois utilisés sur le long terme sont les adresses IP, les Connection ID de QUIC (un bon exemple d'un protocole qui permet leur changement facilement), les biscuits de HTTP, et les adresses du courrier électronique, certainement très difficiles à changer. Comme le montre l'exemple de ces adresses, les identificateurs stables sont utiles et on ne peut pas forcément les remplacer par des identificateurs temporaires. Ici, le souci de vie privée rentre en contradiction avec l'utilité des identificateurs, une tension courante en sécurité. Le fait qu'on ne puisse en général pas se passer d'identificateurs, à relativement longue durée de vie, est justement une des raisons pour lesquelles il n'y a pas de vrai anonymat sur l'Internet.
Notons que les politiciens de mauvaise foi et les journalistes incompétents parlent parfois d'anonymat dès qu'un identificateur stable n'est pas l'identité étatique (par exemple quand je crée un compte Gmail « anonymous652231 » au lieu d'utiliser le nom qui est sur ma carte d'identité). Mais tout identificateur stable peut finir par se retrouver lié à une autre identité, peut-être aussi à l'identité étatique, par exemple si deux identificateurs sont utilisés dans le même message. Et certains identificateurs sont particulièrement communs, avec plusieurs usages, ce qui les rend encore plus dangereux pour la vie privée. Le numéro de téléphone, que certaines messageries instantanées imposent, est particulièrement sensible et est donc déconseillé.
Donc, s'il faut utiliser des identificateurs stables, ils doivent au moins pouvoir être des pseudonymes.
D'autres façons de désanonymiser existent, par exemple quand les gens ont bêtement cru que condenser un identificateur n'était pas réversible (cf. l'article « Four cents to deanonymize: Companies reverse hashed email addresses »).
Notre RFC rappelle ainsi les discussions animées qu'avait connu l'IETF en raison d'un mécanisme d'allocation des adresses IPv6, qui les faisaient dériver d'un identificateur stable, l'adresse MAC, qui permettait de suivre à la trace un utilisateur mobile. Depuis, le RFC 8981 (et le RFC 7217 pour les cas où on veut une stabilité limitée dans l'espace) ont résolu ce problème (le RFC 7721 résume le débat). À noter que l'adresse MAC peut aussi devenir variable (RFC 9724).
Autre exemple où un protocole IETF avait une utilisation imprudente des identificateurs, DHCP, avec ses identificateurs stables qui, certes, n'étaient pas obligatoires mais, en pratique, étaient largement utilisés (RFC 7844).
Une autre question très sensible est celle de la censure. Le protocole en cours de développement a-t-il des caractéristiques qui rendent la censure plus facile ou au contraire plus difficile (section 4.16) ? Par exemple, si le protocole fait passer par des points bien identifiés les communications, ces points vont certainement tenter les censeurs (pensez aux résolveurs DNS et à leur rôle dans la censure…). Les RFC 7754 et RFC 9505 décrivent les techniques de censure. Elles sont très variées. Par exemple, pour le Web, le censeur peut agir sur les résolveurs DNS mais aussi bloquer l'adresse IP ou bien, en faisant du DPI, bloquer les connexions TLS en regardant le SNI. Certains systèmes d'accès au contenu, comme Tor, ou de distribution du contenu, comme BitTorrent, résistent mieux à la censure que le Web mais ont d'autres défauts, par exemple en termes de performance. L'exemple du SNI montre en tout cas très bien une faiblesse de certains protocoles : exposer des identificateurs aux tierces parties (qui ne sont aucune des deux parties qui communiquent) facilite la censure. C'est pour cela que l'IETF développe ECH (cf. RFC 9849).
Le protocole, tel que normalisé dans un RFC, c'est bien joli, mais il faut aussi tenir compte du déploiement effectif. Comme noté au début, ce n'est pas dans le RFC 5321 qu'on trouvera les causes de la domination de Gmail ! Les effets du protocole dans la nature sont en effet très difficiles à prévoir. La section 4.17 se penche sur cette question et demande qu'on considère, non seulement le protocole mais aussi les effets qu'il aura une fois déployé. [Ce qui, à mon avis, relève largement de la boule de cristal, surtout si on veut tenir compte d'effets économiques. Et les exemples du RFC ne sont pas géniaux, comme de reprocher au courrier sa gratuité, qui encourage le spam. L'exemple de l'absence de mécanisme de paiement sur le Web, qui pousse à développer des mécanismes néfastes comme la publicité, est meilleur.] La section 4.21 traite également ce sujet des conséquences, parfois inattendues, du déploiement d'un protocole.
Le RFC a aussi un mot (section 4.18) sur les questions d'accessibilité, notamment aux handicapés. Cette question, très présente dans les discussions autour des couches hautes du Web (cf. les réunions Paris Web) semble plus éloignée de ce que fait l'IETF mais le RFC cite quand même l'exemple du RFC 9071, sur l'utilisation de RTP dans des réunions en ligne, avec une alternative en texte pour les personnes malentendantes.
L'Internet est aujourd'hui très, trop, centralisé, notamment pour ce qui concerne les services (la connectivité, quoique imparfaitement répartie, est moins dépendante d'un petit nombre d'acteurs). Il est donc utile, lors de la conception d'un protocole, de réfléchir aux caractéristiques du protocole qui risquent d'encourager la centralisation (par exemple par la création d'un, ou d'un petit nombre de points de contrôle). Le RFC 3935 donne explicitement à l'IETF un objectif de promotion de la décentralisation.
En conclusion, même si l'activité organisée d'examen des futurs RFC n'a pas pris, ce RFC reste utile pour réfléchir à l'impact de nos protocoles sur les droits des humains.
L'article seul
RFC 9619: In the DNS, QDCOUNT is (usually) One
Date de publication du RFC : Juillet 2024
Auteur(s) du RFC : R. Bellis (ISC), J. Abley
(Cloudflare)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 25 juillet 2024
Dans un message DNS, il y a quatre sections qui peuvent prendre un nombre variable d'enregistrements (resource records). Chaque section est précédée d'un chiffre qui indique ce nombre d'enregistrements. L'une de ces sections indique la question posée. Est-ce que cela a un sens de mettre plusieurs questions dans un message ? Non, répond, ce très court RFC, qui clarifie le RFC 1035 sur ce point.
Regardons une requête DNS avec tshark :
% tshark -V -r dns.pcap
…
Domain Name System (query)
Transaction ID: 0x0dfd
Flags: 0x0120 Standard query
0... .... .... .... = Response: Message is a query
.000 0... .... .... = Opcode: Standard query (0)
…
Questions: 1
Answer RRs: 0
Authority RRs: 0
Additional RRs: 1
Queries
wylag.de: type A, class IN
Name: wylag.de
[Name Length: 8]
[Label Count: 2]
Type: A (Host Address) (1)
Class: IN (0x0001)
Additional records
<Root>: type OPT
Name: <Root>
Type: OPT (41)
UDP payload size: 4096
Higher bits in extended RCODE: 0x00
EDNS0 version: 0
Z: 0x8000
1... .... .... .... = DO bit: Accepts DNSSEC security RRs
.000 0000 0000 0000 = Reserved: 0x0000
Data length: 12
Option: COOKIE
Option Code: COOKIE (10)
Option Length: 8
Option Data: 93c545f2aaf3f12c
Client Cookie: 93c545f2aaf3f12c
Server Cookie: <MISSING>
Il s'agit d'une requête, pas d'une réponse, donc il est normal que
les sections Answer et Authority soient vides (taille à zéro). La
section Additional n'est pas vide car elle contient l'enregistrement
EDNS. Et la section Question contient un seul
enregistrement, la question (« quelle est l'adresse IPv4 de
wylag.de ? »).
Tout le problème traitée par ce RFC est : que se passe t-il si la section Question d'une requête contient plus d'un enregistrement ? Je divulgâche tout de suite : c'est interdit, il ne faut pas. (Pour le cas des requêtes/réponses ordinaires, avec l'opcode 0 ; d'autres messages DNS peuvent avoir des règles différentes.) La principale raison pour cette interdiction est que, dans la réponse, certains champs sont globaux à toute la réponse (comme le code de réponse, le rcode) et on ne peut donc pas se permettre d'accepter des questions qui risqueraient de nécessiter des réponses différentes. Désormais, un serveur DNS qui voit passer une requête avec un nombre de questions supérieur à 1 doit répondre avec le code de retour FORMERR (format error).
Le RFC 1035, la norme originelle, traitait ce point mais restait flou.
Il y avait une autre façon de régler le problème, en imposant que, s'il y a plusieurs questions, toutes portent sur le même nom de domaine. Cela aurait réglé le doute sur le code de retour et aurait pu être pratique pour des cas comme la demande simultanée de l'adresse IPv4 et IPv6. Mais cette solution a été écartée au profit de la solution plus simple qui était d'interdire les questions multiples. (Et, de toute façon, on ne peut pas garantir que le code de retour sera le même pour tous les types, même si le nom est le même. Pensez aux serveurs DNS générant dynamiquement les données.)
L'article seul
RFC 9616: Delay-based Metric Extension for the Babel Routing Protocol
Date de publication du RFC : Septembre 2024
Auteur(s) du RFC : B. Jonglez (ENS Lyon), J. Chroboczek (IRIF, Université Paris Cité)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF babel
Première rédaction de cet article le 14 septembre 2024
Voici un RFC sur le protocole de routage Babel. Il normalise une extension au protocole pour tenir compte du RTT, le temps d'aller-retour sur un segment du réseau. C'est l'occasion de revenir sur ce critère de routage, souvent cité mais rarement utilisé (et pour de bonnes raisons).
On lit parfois des affirmations rapides comme « les routeurs Internet choisissent la route la plus rapide ». Outre que « rapide » n'a pas de définition précise (parle-t-on de la latence ? De la capacité ?), la phrase est fausse : le routage se fait sur des critères nettement moins dynamiques. Dans le cas de BGP, ce sont en bonne partie des critères de business. Das le cas d'un IGP, des critères de performance sont pris en compte, mais en se limitant à des critères assez statiques. En effet, si on prend en compte naïvement une variable très dynamique, qui change souvent, comme l'est le RTT, on risque d'avoir un routage très instable : un lien est peu utilisé, ses performances sont bonnes, les routeurs vont y envoyer tout le trafic, ses performances vont chuter, les routeurs vont tout envoyer ailleurs, les performances vont remonter, les routeurs vont encore changer d'avis, etc. Tenir compte des performances immédiates du lien est donc une fausse bonne idée ou, plus précisément, ne doit pas être fait naïvement.
C'est justement ce que fait ce RFC qui explique comment utiliser intelligemment un critère très mouvant, le RTT (la latence, mais mesurée en aller-retour), pour le choix des routes dans Babel. Babel est un protocole de routage de type IGP, normalisé dans le RFC 8966, surtout prévu pour des réseaux sans administration centrale.
Si par exemple (section 1 du RFC), une machine A à Paris a deux moyens de joindre une machine D également à Paris, une des routes passant par un routeur B à Paris et une autre par un routeur C à Tokyo, il est assez évident qu'il vaut mieux rester à Paris. Mais ce n'est pas forcément ce que feront les mises en œuvre de Babel, qui se disent simplement que les deux routes ont le même nombre de segments (deux). Bien sûr, attribuer manuellement des préférences aux segments résoudrait le problème (un lien vers le Japon est plus « cher ») mais l'un des buts de Babel est de ne pas requérir de configuration manuelle par un administrateur réseaux.
Utiliser le RTT, qui est relativement facile à évaluer (mais continuez la lecture : il y a des pièges) semble une solution évidente. Mais, comme dit plus haut, cela peut mener à de violentes instabilités du routage. Il faut donc évaluer le RTT, puis le traiter avant de l'utiliser, pour éviter des oscillations du routage. Et attention, la latence n'est pas toujours le meilleur critère de choix, d'autres, comme le coût monétaire, peuvent être pris en compte, par exemple pour privilégier un lien WiFi sur un lien 5G. Babel n'impose pas de critère unique de choix des routes.
Cette extension ne nécessite pas que les différents routeurs aient une horloge synchronisée (ce qui serait difficile à faire dans un réseau sans administration), juste que les horloges ne dérivent pas trop vite l'une par rapport à l'autre. D'autre part, comme l'algorithme essaie de limiter les oscillations de routes, il ne s'ajustera pas instantanément aux changements, et ne sera donc pas optimal dans tous les cas.
Commençons par l'évaluation du RTT. Il ne suffit pas de soustraire le temps de départ d'une question au temps d'arrivée d'une réponse, entre autre parce que la génération de la réponse peut prendre du temps (et puis un routeur Babel n'est pas obligé de répondre à tous les messages Hello). Et rappelez-vous que cette extension n'impose pas une synchronisation des horloges. L'algorithme est donc un peu plus compliqué, c'est celui créé par Mills et utilisé entre autres pour NTP. Un routeur nommé Alice qui envoie un message Hello (RFC 8966, section 3.4.1) ajoute à ces messages le temps de départ, appelé t1. Le routeur nommé Bob le reçoit à un temps t1'. Comme les horloges ne sont pas forcément synchronisées, on ne peut pas comparer directement t1 et t1'. Au lieu de cela, Bob, quand il enverra un message Babel IHU (I Heard yoU) indiquera à la fois t1 et t1' dans ce message, ainsi que le temps t2' d'émission. Alice, recevant ce message, n'aura qu'à calculer (t2 - t1) - (t2' - t1') et aura ainsi le RTT, même si les horloges sont différentes (tant qu'elles ne dérivent pas trop dans l'intervalle entre t1 et t2). Bon, j'ai simplifié, mais vous avez tous les détails dans le RFC, section 3.2.
Notez que cet algorithme impose aux deux routeurs de garder des informations supplémentaires sur leurs voisins, dans la table documentée dans la section 3.2.4 du RFC 8966. Celle-ci devra stocker les estampilles temporelles reçues.
Ces estampilles étant stockées sur 32 bits et ayant une
résolution en microsecondes, elles reviendront à zéro toutes les 71
minutes. Le routeur doit donc prendre garde à ignorer les
estampilles situées dans son futur (par exemple s'il a redémarré et
perdu la notion du temps) ou trop éloignées. Sur un système
POSIX, le routeur peut donc utiliser
clock_gettime(CLOCK_MONOTONIC).
Bon, désormais, nous avons le RTT. Qu'en faire ? Comme indiqué plus haut, il ne faut pas l'utiliser tel quel comme critère de sélection des routes, sous peine d'osccilations importantes des tables de routage. Il y a plusieurs opérations à faire (section 4). D'abord, il faut lisser le RTT, éliminant ainsi les cas extrêmes. Ainsi, on va utiliser la formule RTT ← α RTT + (1 - α) RTTn, où RTTn désigne la mesure qu'on vient juste de faire, et où la constante α a une valeur recommandée de 0,836. (Les détails figurent dans l'article « A delay-based routing metric ».)
Ensuite, pour nourrir l'algorithme de choix des routes, il faut convertir ce RTT en un coût. La fonction est simple : de 0 à une valeur rtt-min, le coût est constant, il augmente ensuite linéairement vers une valeur maximale, atteinte pour un RTT égal à rtt-max, et constante ensuite. Les valeurs par défaut recommandées sont de 10 ms pour rtt-min et 150 ms pour rtt-max. En d'autres termes, sur l'Internet, tout RTT inférieur à 10 ms est bon, tout RTT supérieur à 150 ms est à éviter autant que possible.
Enfin, car il reste encore des variations, la section 4 sur les traitements du RTT se termine en demandant l'application d'un mécanisme d'hystérésis, comme celui du RFC 8966, annexe A.3.
Le format des paquets, maintenant. Rappelons que Babel encode les données en TLV et permet des sous-TLV (la valeur d'un TLV est elle-même un TLV). Un routeur doit ignorer les sous-TLV qu'il ne comprend pas, ce qui permet d'ajouter des nouvelles informations sans risque (section 5).
Donc, notre RFC normalise le sous-TLV Timestamp (type 3), qui permet de stocker les estampilles temporelles, et peut apparaitre sous les sous-TLV Hello et IHU. Dans le premier cas, il stockera juste une valeur (t1 ou t2' dans l'exemple plus haut), dans le second, deux valeurs (t1 et t1' dans l'exemple plus haut).
La mise en œuvre « officielle » de Babel a, dans sa version de
développement, la capacité de déterminer ces RTT (option
enable-timestamps dans la configuration).
L'article seul
RFC 9609: Initializing a DNS Resolver with Priming Queries
Date de publication du RFC : Février 2025
Auteur(s) du RFC : P. Koch (DENIC
eG), M. Larson, P. Hoffman
(ICANN)
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 12 février 2025
Un résolveur DNS ne connait au début, rien du contenu du DNS. Rien ? Pas tout à fait, il connait une liste des serveurs de noms faisant autorité pour la racine, car c'est par eux qu'il va commencer le processus de résolution de noms. Cette liste est typiquement en dur dans le code du serveur, ou bien dans un de ses fichiers de configuration. Mais peu d'administrateurs système la maintiennent à jour. Il est donc prudent, au démarrage du résolveur, de chercher une liste vraiment à jour, et c'est le priming (amorçage, comme lorsqu'on amorce une pompe pour qu'elle fonctionne seule ensuite), opération que décrit ce RFC, qui remplace l'ancienne version, le RFC 8109 (les changements sont nombreux mais sont surtout des points de détail).
Le problème de départ d'un résolveur est un problème d'œuf et de
poule. Le résolveur doit interroger le DNS pour avoir
des informations mais comment trouve-t-il les serveurs DNS à
interroger ? La solution est de traiter la racine du DNS de manière
spéciale : la liste de ses serveurs est connue du résolveur au
démarrage. Elle peut être dans le code du serveur lui-même, ici un
Unbound qui contient les adresses IP des
serveurs de la racine (je ne montre que les trois premiers,
A.root-servers.net,
B.root-servers.net et
C.root-servers.net) :
% strings /usr/sbin/unbound | grep -i 2001: 2001:503:ba3e::2:30 2001:500:84::b 2001:500:2::c ...
Ou bien elle est dans un fichier de configuration (ici, sur un Unbound) :
server: directory: "/etc/unbound" root-hints: "root-hints"
Ce fichier peut être téléchargé via
l'IANA, il peut être spécifique au logiciel résolveur, ou bien fourni
par le système d'exploitation (cas du
paquetage dns-root-data chez
Debian). Il contient la liste des serveurs
de la racine et leurs adresses :
. 3600000 NS A.ROOT-SERVERS.NET. . 3600000 NS B.ROOT-SERVERS.NET. ... A.ROOT-SERVERS.NET. 3600000 A 198.41.0.4 A.ROOT-SERVERS.NET. 3600000 AAAA 2001:503:ba3e::2:30 B.ROOT-SERVERS.NET. 3600000 A 192.228.79.201 B.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:84::b ...
Tous les résolveurs actuels mettent en œuvre le priming. En effet, les configurations locales tendent à ne plus être à jour au bout d'un moment. (Sauf dans le cas où elles sont dans un paquetage du système d'exploitation, mis à jour avec ce dernier, comme dans le bon exemple Debian ci-dessus.)
Les changements des serveurs racines sont rares. Si on regarde sur le site des opérateurs des serveurs racine, on voit :
- 2017-08-10 B-Root's IPv4 address to be renumbered on 2017-10-24
- 2016-12-02 Announcement of IPv6 addresses
- 2015-11-05 L-Root IPv6 Renumbering
- 2015-08-31 H-Root to be renumbered
- 2014-03-26 IPv6 service address for c.root-servers.net (2001:500:2::C)
- 2012-12-14 D-Root IPv4 Address to be Renumbered
Bref, peu de changements. Ils sont en général annoncés sur les listes de diffusion opérationnelles (comme ici). Mais les fichiers de configuration ayant une fâcheuse tendance à ne pas être mis à jour et à prendre de l'âge, les anciennes adresses des serveurs racine continuent à recevoir du trafic des années après (comme le montre cette étude de J-root). Notez que la stabilité de la liste des serveurs racine n'est pas due qu'au désir de ne pas perturber les administrateurs système : il y a aussi des raisons politiques (aucun mécanisme en place pour choisir de nouveaux serveurs, ou pour retirer les « maillons faibles »). C'est pour cela que la liste des serveurs (mais pas leurs adresses) n'a pas changé depuis 1997 ! (Une histoire - biaisée - des serveurs racine a été publiée par l'ICANN.)
Notons aussi que l'administrateur système d'un résolveur peut changer la liste des serveurs de noms de la racine pour une autre liste, par exemple s'ielle veut utiliser une racine alternative.
Le priming, maintenant. Le principe du priming est, au démarrage, de faire une requête à un des serveurs listés dans la configuration et de garder sa réponse (certainement plus à jour que la configuration) :
% dig +bufsize=4096 +norecurse +nodnssec @i.root-servers.net . NS ; <<>> DiG 9.18.28-0ubuntu0.24.04.1-Ubuntu <<>> +bufsize +norecurse +nodnssec @i.root-servers.net . NS ; (2 servers found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 54419 ;; flags: qr aa; QUERY: 1, ANSWER: 13, AUTHORITY: 0, ADDITIONAL: 27 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 1232 ; COOKIE: c0a47c1200bf6bfc0100000067377b40981cc05cdb33b736 (good) ;; QUESTION SECTION: ;. IN NS ;; ANSWER SECTION: . 518400 IN NS k.root-servers.net. . 518400 IN NS h.root-servers.net. . 518400 IN NS m.root-servers.net. . 518400 IN NS l.root-servers.net. . 518400 IN NS b.root-servers.net. . 518400 IN NS e.root-servers.net. . 518400 IN NS d.root-servers.net. . 518400 IN NS f.root-servers.net. . 518400 IN NS g.root-servers.net. . 518400 IN NS i.root-servers.net. . 518400 IN NS a.root-servers.net. . 518400 IN NS j.root-servers.net. . 518400 IN NS c.root-servers.net. ;; ADDITIONAL SECTION: m.root-servers.net. 518400 IN A 202.12.27.33 l.root-servers.net. 518400 IN A 199.7.83.42 k.root-servers.net. 518400 IN A 193.0.14.129 j.root-servers.net. 518400 IN A 192.58.128.30 i.root-servers.net. 518400 IN A 192.36.148.17 h.root-servers.net. 518400 IN A 198.97.190.53 g.root-servers.net. 518400 IN A 192.112.36.4 f.root-servers.net. 518400 IN A 192.5.5.241 e.root-servers.net. 518400 IN A 192.203.230.10 d.root-servers.net. 518400 IN A 199.7.91.13 c.root-servers.net. 518400 IN A 192.33.4.12 b.root-servers.net. 518400 IN A 170.247.170.2 a.root-servers.net. 518400 IN A 198.41.0.4 m.root-servers.net. 518400 IN AAAA 2001:dc3::35 l.root-servers.net. 518400 IN AAAA 2001:500:9f::42 k.root-servers.net. 518400 IN AAAA 2001:7fd::1 j.root-servers.net. 518400 IN AAAA 2001:503:c27::2:30 i.root-servers.net. 518400 IN AAAA 2001:7fe::53 h.root-servers.net. 518400 IN AAAA 2001:500:1::53 g.root-servers.net. 518400 IN AAAA 2001:500:12::d0d f.root-servers.net. 518400 IN AAAA 2001:500:2f::f e.root-servers.net. 518400 IN AAAA 2001:500:a8::e d.root-servers.net. 518400 IN AAAA 2001:500:2d::d c.root-servers.net. 518400 IN AAAA 2001:500:2::c b.root-servers.net. 518400 IN AAAA 2801:1b8:10::b a.root-servers.net. 518400 IN AAAA 2001:503:ba3e::2:30 ;; Query time: 6 msec ;; SERVER: 192.36.148.17#53(i.root-servers.net) (UDP) ;; WHEN: Fri Nov 15 17:48:00 CET 2024 ;; MSG SIZE rcvd: 851
(Les raisons du choix des trois options données à dig sont indiquées plus loin.)
La section 3 de notre RFC décrit en détail à quoi ressemblent les
requêtes de priming. Le type de données demandé
(QTYPE) est NS (Name Servers,
type 2) et le nom demandé (QNAME) est « . » (oui,
juste la racine). D'où le dig . NS
ci-dessus. Le bit RD (Recursion Desired) est
typiquement mis à zéro (d'où le +norecurse dans
l'exemple avec dig). La taille de la réponse dépassant les 512
octets (limite très ancienne du DNS), il faut utiliser
EDNS (cause du
+bufsize=4096 dans l'exemple). On peut utiliser
le bit DO (DNSSEC OK) qui indique qu'on demande
les signatures DNSSEC mais ce n'est pas habituel (d'où le
+nodnssec dans l'exemple). En effet, si la
racine est signée, permettant d'authentifier l'ensemble
d'enregistrements NS, la zone root-servers.net,
où se trouvent actuellement tous les serveurs de la racine, ne l'est
pas, et les enregistrements A et AAAA ne peuvent donc pas être
validés avec DNSSEC.
Cette requête de priming est envoyée lorsque le résolveur démarre, et aussi lorsque la réponse précédente a expiré (regardez le TTL dans l'exemple : six jours). Si le premier serveur testé ne répond pas, on essaie avec un autre. Ainsi, même si le fichier de configuration n'est pas parfaitement à jour (des vieilles adresses y trainent), le résolveur finira par avoir la liste correcte.
Et comment choisit-on le premier serveur qu'on interroge ? Notre RFC recommande (section 3.2) un tirage au sort, pour éviter que toutes les requêtes de priming ne se concentrent sur un seul serveur (par exemple le premier de la liste). Une fois que le résolveur a démarré, il peut aussi se souvenir du serveur le plus rapide, et n'interroger que celui-ci, ce qui est fait par la plupart des résolveurs, pour les requêtes ordinaires (mais n'est pas conseillé pour le priming).
Et les réponses au priming ? Il faut bien
noter que, pour le serveur racine, les requêtes
priming sont des requêtes comme les autres, et ne
font pas l'objet d'un traitement particulier. Normalement, la
réponse doit avoir le code de retour NOERROR
(c'est bien le cas dans mon exemple). Parmi les
flags, il doit y avoir AA (Authoritative
Answer). La section de réponse doit évidemment contenir
les NS de la racine, et la section additionnelle les adresses IP. Le
résolveur garde alors cette réponse dans son cache, comme il le
ferait pour n'importe quelle autre réponse. Notez que là aussi, il
ne faut pas de traitement particulier. Par exemple, le résolveur ne
doit pas compter sur le fait qu'il y aura exactement 13 serveurs,
même si c'est le cas depuis longtemps (ça peut changer).
Normalement, le serveur racine envoie la totalité des adresses IP
(deux par serveur, une en IPv4 et une en
IPv6). S'il ne le fait pas (par exemple par
manque de place parce qu'on a bêtement oublié
EDNS), le résolveur va devoir envoyer des
requêtes A et AAAA explicites pour obtenir les adresses IP (ici, on
interroge k.root-servers.net) :
% dig @2001:7fd::1 g.root-servers.net AAAA ; <<>> DiG 9.18.33-1~deb12u2-Debian <<>> @2001:7fd::1 g.root-servers.net AAAA ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 10640 ;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 1232 ;; QUESTION SECTION: ;g.root-servers.net. IN AAAA ;; ANSWER SECTION: g.root-servers.net. 3600000 IN AAAA 2001:500:12::d0d ;; Query time: 3 msec ;; SERVER: 2001:7fd::1#53(2001:7fd::1) (UDP) ;; WHEN: Thu Feb 13 17:26:51 CET 2025 ;; MSG SIZE rcvd: 75
Vous pouvez voir ici les requêtes et réponses de priming d'un Unbound. D'abord, décodées par tcpdump :
17:57:14.439382 IP (tos 0x0, ttl 64, id 26437, offset 0, flags [none], proto UDP (17), length 56)
10.10.156.82.51893 > 198.41.0.4.53: [bad udp cksum 0x6cbf -> 0x49dc!] 63049% [1au] NS? . ar: . OPT UDPsize=1232 DO (28)
17:57:14.451715 IP (tos 0x40, ttl 52, id 45305, offset 0, flags [none], proto UDP (17), length 1125)
198.41.0.4.53 > 10.10.156.82.51893: [udp sum ok] 63049*- q: NS? . 14/0/27 . [6d] NS l.root-servers.net., . [6d] NS j.root-servers.net., . [6d] NS f.root-servers.net., . [6d] NS h.root-servers.net., . [6d] NS d.root-servers.net., . [6d] NS b.root-servers.net., . [6d] NS k.root-servers.net., . [6d] NS i.root-servers.net., . [6d] NS m.root-servers.net., . [6d] NS e.root-servers.net., . [6d] NS g.root-servers.net., . [6d] NS c.root-servers.net., . [6d] NS a.root-servers.net., . [6d] RRSIG ar: l.root-servers.net. [6d] A 199.7.83.42, l.root-servers.net. [6d] AAAA 2001:500:9f::42, j.root-servers.net. [6d] A 192.58.128.30, j.root-servers.net. [6d] AAAA 2001:503:c27::2:30, f.root-servers.net. [6d] A 192.5.5.241, f.root-servers.net. [6d] AAAA 2001:500:2f::f, h.root-servers.net. [6d] A 198.97.190.53, h.root-servers.net. [6d] AAAA 2001:500:1::53, d.root-servers.net. [6d] A 199.7.91.13, d.root-servers.net. [6d] AAAA 2001:500:2d::d, b.root-servers.net. [6d] A 170.247.170.2, b.root-servers.net. [6d] AAAA 2801:1b8:10::b, k.root-servers.net. [6d] A 193.0.14.129, k.root-servers.net. [6d] AAAA 2001:7fd::1, i.root-servers.net. [6d] A 192.36.148.17, i.root-servers.net. [6d] AAAA 2001:7fe::53, m.root-servers.net. [6d] A 202.12.27.33, m.root-servers.net. [6d] AAAA 2001:dc3::35, e.root-servers.net. [6d] A 192.203.230.10, e.root-servers.net. [6d] AAAA 2001:500:a8::e, g.root-servers.net. [6d] A 192.112.36.4, g.root-servers.net. [6d] AAAA 2001:500:12::d0d, c.root-servers.net. [6d] A 192.33.4.12, c.root-servers.net. [6d] AAAA 2001:500:2::c, a.root-servers.net. [6d] A 198.41.0.4, a.root-servers.net. [6d] AAAA 2001:503:ba3e::2:30, . OPT UDPsize=4096 DO (1097)
Et ici par tshark :
1 0.000000 10.10.156.82 → 198.41.0.4 DNS 70 Standard query 0xf649 NS <Root> OPT 2 0.012333 198.41.0.4 → 10.10.156.82 DNS 1139 Standard query response 0xf649 NS <Root> NS l.root-servers.net NS j.root-servers.net NS f.root-servers.net NS h.root-servers.net NS d.root-servers.net NS b.root-servers.net NS k.root-servers.net NS i.root-servers.net NS m.root-servers.net NS e.root-servers.net NS g.root-servers.net NS c.root-servers.net NS a.root-servers.net RRSIG A 199.7.83.42 AAAA 2001:500:9f::42 A 192.58.128.30 AAAA 2001:503:c27::2:30 A 192.5.5.241 AAAA 2001:500:2f::f A 198.97.190.53 AAAA 2001:500:1::53 A 199.7.91.13 AAAA 2001:500:2d::d A 170.247.170.2 AAAA 2801:1b8:10::b A 193.0.14.129 AAAA 2001:7fd::1 A 192.36.148.17 AAAA 2001:7fe::53 A 202.12.27.33 AAAA 2001:dc3::35 A 192.203.230.10 AAAA 2001:500:a8::e A 192.112.36.4 AAAA 2001:500:12::d0d A 192.33.4.12 AAAA 2001:500:2::c A 198.41.0.4 AAAA 2001:503:ba3e::2:30 OPT
Et un décodage plus détaillé de tshark dans ce fichier.
Enfin, la section 6 de notre RFC traite des problèmes de sécurité du priming. Évidemment, si un attaquant injecte une fausse réponse aux requêtes de priming, il pourra détourner toutes les requêtes ultérieures vers des machines de son choix. À part le RFC 5452, et l'utilisation de cookies (RFC 7873, mais seuls les serveurs racine C, F, G et I les gèrent aujourd'hui), la seule protection est DNSSEC : si le résolveur valide (et a donc la clé publique de la racine), il pourra détecter que les réponses sont mensongères (voir aussi la section 3.3). Cela a l'avantage de protéger également contre d'autres attaques, ne touchant pas au priming, comme les attaques sur le routage.
Notez que DNSSEC est recommandé pour valider les réponses
ultérieures mais, comme on l'a vu, n'est pas important pour valider
la réponse de priming elle-même, puisque
root-servers.net n'est pas signé. Si un
attaquant détournait, d'une manière ou d'une autre, vers un faux
serveur racine, servant de fausses données, ce ne serait qu'une
attaque par déni de
service, puisque le résolveur validant pourrait détecter
que les réponses sont fausses.
L'annexe A du RFC liste les changements depuis le RFC 8109. Rien de vraiment crucial, juste une longue liste de clarifications et de précisions.
L'article seul
RFC 9606: DNS Resolver Information
Date de publication du RFC : Juin 2024
Auteur(s) du RFC : T. Reddy.K (Nokia), M. Boucadair
(Orange)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF add
Première rédaction de cet article le 18 août 2024
Traditionnellement, tous les résolveurs DNS fournissaient un service équivalent. Le client avait un résolveur configuré, soit statiquement, soit via DHCP, et ne se souciait pas vraiment du résolveur ainsi désigné, tous étaient pareils. Aujourd'hui, ce n'est plus vraiment le cas : les résolveurs fournissent des services très différents, par exemple en matière de chiffrement, ou de blocage de certains noms. Il est donc utile que le client puisse se renseigner sur son résolveur, ce que permet cette nouvelle technique, le type de données RESINFO, que le client va récupérer dans le DNS.
Voici une liste (non-limitative !) des caractéristiques d'un résolveur et qui peuvent être présentes ou pas :
- Chiffrement des requêtes, avec DoT, DoH ou DoQ.
- Blocage de certains noms, par exemple la publicité, ou le porno, ou bien les noms qui gênent le gouvernement, ou encore les noms des services qui osent enfreindre la propriété intellectuelle sacrée.
- Protection de la vie privée via la minimisation des requêtes (RFC 9156) et/ou l'absence de stockage de l'historique des requêtes.
Avant la solution de ce RFC, la seule manière pour le client DNS de savoir ce que son résolveur proposait était manuelle, en lisant des documentations (cf. par exemple celle de mon résolveur). Ce n'est pas pratique quand la configuration du résolveur est automatique ou semi-automatique, via DHCP, ou avec les solutions des RFC 9462 et RFC 9463.
Ce nouveau RFC propose donc un mécanisme qui permet au client de découvrir les caractéristiques d'un résolveur et de les analyser, avant de décider quel résolveur choisir. (Un point important est que ce RFC se veut neutre : il ne dit pas quelles sont les bonnes caractéristiques d'un résolveur, le client reçoit une information, il est libre de l'utiliser comme il veut.)
Place à la technique (section 3 du RFC) : un nouveau type de
données DNS est défini, RESINFO (code
261). Son contenu est l'information recherchée, sous forme de
couples clé=valeur. Le nom de domaine auquel il est rattaché est le
nom du résolveur, récupéré par les méthodes des RFC 9462 et RFC 9463, ou manuellement
configuré. Ce nom est désigné par le sigle ADN, pour
Authentication Domain Name (RFC 9463, section 3.1.1). Si on a utilisé le nom spécial
resolver.arpa (RFC 9462,
section 4), on peut lui demander son RESINFO.
Le format du RESINFO (section 4 du RFC) est copié sur celui des enregistrements TXT. Chaque chaine de caractères suit le modèle clé=valeur du RFC 6763, section 6.3. Les clés inconnues doivent être ignorées, ce qui permettra dans le futur d'ajouter de nouvelles clés au registre des clés. Un exemple d'enregistrement RESINFO :
resolver IN RESINFO "qnamemin" "exterr=15,17" "infourl=https://resolver.example.com/guide"
Il indique (section 5, sur la signification des clés) que ce résolveur fait de la minimisation des requêtes (RFC 9156), et notez que cette clé n'a pas de valeur, c'est juste un booléen dont la présence indique la QNAME minimisation. L'enregistrement continue en donnant les codes EDE (Extended DNS Errors, RFC 8914) que peut renvoyer le résolveur. C'est surtout utile pour indiquer ce qu'il bloque (15 = bloqué par décision de l'administrateurice du résolveur, 17 = bloqué par demande de l'utilisateurice). Et enfin il donne un URL où on peut aller chercher davantage d'information en langue naturelle.
La section 7 du RFC donne quelques conseils de sécurité : avoir
un lien sécurisé avec le résolveur qu'on interroge (par exemple avec
DoT), pour éviter qu'un méchant ne modifie le
RESINFO, et valider la réponse avec DNSSEC (sauf pour
resolver.arpa, qui est un cas spécial).
La section 8 précise le registre
des clés disponibles. Pour ajouter des clés (on note qu'à
l'heure actuelle, il n'y en a pas pour indiquer la disponibilité de
DoT ou DoH, ou pour la politique de conservation des
requêtes), la procédure est « spécification nécessaire » (RFC 8126). Si on veut des clés non normalisées, on
doit les préfixer par temp-.
RESINFO est récent et donc pas forcément mis en œuvre dans tous les logiciels DNS que vous utilisez. Un dig récent fonctionne :
% dig dot.bortzmeyer.fr RESINFO … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 34836 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1 … ;; ANSWER SECTION: dot.bortzmeyer.fr. 86369 IN CNAME radia.bortzmeyer.org. radia.bortzmeyer.org. 86369 IN RESINFO "qnamemin" "infourl=https://doh.bortzmeyer.fr/policy" ;; Query time: 0 msec ;; SERVER: 192.168.2.254#53(192.168.2.254) (UDP) ;; WHEN: Sun Aug 18 08:15:55 UTC 2024 ;; MSG SIZE rcvd: 142
Si vous avez un dig plus ancien, il faudra demander TYPE261 et pas RESINFO. Notez que, physiquement, un RESINFO est juste un TXT, ce qui facilite sa mise en œuvre (dans le futur dnspython, la classe RESINFO hérite simplement de TXT).
Trouve-t-on beaucoup de RESINFO dans la nature ? La plupart des grands résolveurs DNS publics ne semblent pas en avoir. Une exception est DNS4ALL :
% dig +short dot.dns4all.eu RESINFO "qnamemin exterr=0-1,3,5-12,18,20 infourl=https://dns4all.eu"
Et, comme vous le voyez plus haut, j'en ai mis un dans mon résolveur. Le logiciel du serveur primaire ne connaissant pas encore ce type, j'ai utilisé la technique des types inconnus du RFC 3597 :
; Pour le résolveur public : ; Type RESINFO (RFC 9606), enregistré à l'IANA mais pas encore connu des logiciels radia IN TYPE261 \# 50 08716e616d656d696e 28696e666f75726c3d68747470733a2f2f646f682e626f72747a6d657965722e66722f706f6c696379
Cette série de chiffres hexadécimaux ayant été produite à partir de
la version texte et du programme text-to-unknown-txt-type.py
L'article seul
RFC 9583: Application Scenarios for the Quantum Internet
Date de publication du RFC : Juin 2024
Auteur(s) du RFC : C. Wang (InterDigital Communications), A. Rahman (Ericsson), R. Li (Kanazawa University), M. Aelmans (Juniper Networks), K. Chakraborty (The University of Edinburgh)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF qirg
Première rédaction de cet article le 27 février 2025
Peut-être, dans le futur, nous aurons un Internet quantique, où les communications utiliseront à fond les surprenantes propriétés de la physique quantique. Ce RFC se penche sur les applications que cela pourrait avoir, et les utilisations possibles.
Un Internet quantique, décrit dans le RFC 9340, ce serait un Internet où les machines terminales et les routeurs utiliseraient des propriétés purement quantiques, comme l'intrication. Ces divers engins seraient reliés par des liens, par exemple des photons circulant en dehors de tout câble, une configuration bien adaptée à l'utilisation de la quantique. Si vous voulez apprendre plus en détail ce que pourrait être un Internet quantique, voyez l'article de Wehner, S., Elkouss, D. et R. Hanson, « Quantum internet: A vision for the road ahead », publié dans Science. Rappelons qu'il n'y a pas de perspective réaliste de grand remplacement de l'Internet classique : l'Internet quantique va venir en plus, pas à la place.
À quoi va pouvoir servir un Internet quantique ? On peut imaginer, par exemple, des calculs quantiques répartis, ou de la synchronisation d'horloges atomiques.
Un peu de terminologie, ensuite. La section 2 du RFC définit les termes importants. Ce sont ceux du RFC 9340 plus, notamment :
- Qubit : unité d'information en calcul quantique. Sa valeur, quand on le mesure, est 0 ou 1, comme un bit classique mais, tant qu'il n'a pas été mesuré, ce n'est qu'une probabilité. Diverses particules élémentaires peuvent être utilisées pour faire un qubit, par exemple les photons et, pour chaque particule, tout degré de liberté (comme le spin) peut servir à encoder le qubit.
- Paires de Bell : deux qubits intriqués, par exemple (en utilisant la notation de Dirac) (|00>+|11>)/Sqrt(2).
- NISQ (Noisy Intermediate-Scale Quantum) : l'état actuel des calculateurs quantiques, petits et faisant plein d'erreurs.
- « Préparer et mesurer » : se dit des protocoles quantiques les plus simples, où on prépare des qubits et où on les mesure ensuite. Le protocole de distribution quantique de clés BB84 est un exemple.
- Téléportation : déplacer quantiquement un qubit d'un point à un autre (c'est moins évident que pour déplacer un bit). Notez qu'il existe une différence subtile entre téléporter un qubit et le transmettre mais l'explication de cette différence est au-dessus de mes forces.
Revenons maintenant aux applications, le but de ce RFC. Il y a plusieurs catégories :
- Cryptographie quantique (terme sans doute excessif - il s'agit plutôt d'aider des opérations cryptographiques par la quantique - mais largement utilisé),
- Capteurs quantiques,
- Calcul quantique.
Voyons-les dans l'ordre. D'abord, utilisations de la quantique pour aider la cryptographie. (Au passage, la cryptographie post-quantique est tout le contraire : elle utilise des calculateurs classiques pour faire de la cryptographie qui résiste aux calculateurs quantiques.) Cela inclut :
- Distribution quantique de clés (dont j'ai déjà dit du mal).
- Négociation byzantine rapide : une solution quantique au problème des généraux byzantins.
- Argent quantique : la quantique peut tout, même gérer de l'argent. Plus fort que les cryptomonnaies ! Après tout, une propriété essentielle des états quantiques est le fait qu'on ne puisse pas les copier. C'est certainement utile pour l'argent mais ce n'est pas facile à faire (cf. les attaques décrites dans « Cryptanalysis of Three Quantum Money Schemes »).
Il y a aussi des capteurs quantiques ; intriqués, ils permettent des mesures particulièrement sensibles (voir « Multiparameter Estimation in Networked Quantum Sensors » ou, par exemple, pour la synchronisation d'horloges, « A quantum network of clocks »).
On connait également les possibilités de la physique quantique pour le calcul, notamment via la possibilité de casser des algorithmes de cryptographie. On peut envisager des calculateurs quantiques répartis, où plusieurs calculateurs séparés travailleraient ensemble, donnant l'impression d'un calculateur unique. Il pourrait également exister du calcul quantique en aveugle, où le calcul serait fait sur des données, sans avoir les données en question, ce qui serait utile pour la confidentialité. (Oui, cela semble magique, mais c'est souvent comme cela dans le monde quantique, et ce calcul en aveugle est détaillé dans la section 4.2. Voir « Private quantum computation: an introduction to blind quantum computing and related protocols ».)
La section 4 présente ensuite des scénarios d'usage plus détaillés, par exemple sur la distribution quantique de clés (voir l'article sceptique de l'ANSSI), le calcul en aveugle et le calcul quantique réparti.
Tout cela est bien joli mais, pour passer de ces applications futuristes à un vrai Internet quantique, il faut des machines, et les connecter. La section 5 du RFC détaille ce qui sera nécessaire pour ce déploiement. Actuellement, on a quelques centaines de qubits physiques dans les plus gros calculateurs (et ce sont des NISQ, avec beaucoup d'erreurs), ce qui est très insuffisant. Suivant la classification de Wehner, le RFC cite six étapes possibles vers un Internet quantique :
- Première étape, des répéteurs de confiance (et donc pas de sécurité de bout en bout, c'est la situation actuelle de pas mal de réalisations quantiques lourdement vantées dans les médias ignorants, dans les articles technobéats sur la QKD),
- Deuxième étape, quand l'utilisateur final peut lui-même préparer et mesurer des qubits,
- Ensuite, chemin quantique de bout en bout, donc de la vraie distribution quantique de clés, par exemple,
- À la quatrième étape, les répéteurs peuvent agir sur les qubits (section 5.1 pour les détails), ce qui permettra plein d'autres applications comme le calcul en aveugle,
- Puis ils deviennent capables de correction d'erreurs, ce qui évite de consommer plein de qubits physiques pour faire un qubit logique,
- Et enfin, sixième et dernière étape, quand le nombre de qubits sera suffisant pour faire toutes les applications dont on rêve.
Cette image vient de l'article « Quantum
internet: A vision for the road ahead : 
Comme toujours dans un RFC, il y a une section sur la sécurité, qui douche toujours un peu les espoirs. Ce n'est pas tout de communiquer, il faut aussi le faire de manière sûre. Si la distribution quantique de clés résiste à toute tentative d'espionnage (elle est protégée par la physique, et pas par la mathématique mais attention quand même), une autre technologie quantique fait courir des risques à la cryptographie, les calculateurs quantiques peuvent casser des algorithmes très utilisés comme RSA et ECDSA. Dans un monde (très futuriste…) où on aurait des calculateurs quantiques significatifs (CRQC = Cryptographically Relevant Quantum Computers) reliés par un réseau quantique pour qu'ils se partagent les calculs, toutes les clés RSA du monde seraient cassées rapidement. Il est donc important de travailler dès maintenant sur la cryptographie post-quantique.
À ce stade, la constatation est que malheureusement nous n'avons pas encore d'Internet quantique pour faire des ping et des traceroute…
L'article seul
RFC 9581: Concise Binary Object Representation (CBOR) Tags for Time, Duration, and Period
Date de publication du RFC : Août 2024
Auteur(s) du RFC : C. Bormann (Universität Bremen TZI), B. Gamari (Well-Typed), H. Birkholz (Fraunhofer SIT)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF cbor
Première rédaction de cet article le 17 août 2024
Ce RFC ajoute au format de données binaire CBOR la possibilité de stocker des données temporelles plus détaillées, incluant par exemple l'échelle utilisée (UTC ou TAI), ou bien ayant une précision supérieure.
Petit rappel : CBOR est normalisé dans le RFC 8949, il incluait deux étiquettes pour les données temporelles, permettant d'indiquer date et heure en format lisible par un humain, et sous forme d'un nombre de secondes depuis l'epoch, avec une résolution d'une seconde. Le RFC 8943 y ajoute les dates (sans indication de l'heure). Au passage, le concept d'étiquette en CBOR est normalisé dans la section 3.4 du RFC 8949.
Notre nouveau RFC 9581 ajoute :
- Une étiquette, 1001, pour un temps étendu, sous forme d'un dictionnaire CBOR. La clé 1 doit être présente, pour indiquer le temps de base, des clés négatives servent pour indiquer des fractions de seconde, la clé -1 sert pour l'échelle (UTC ou TAI, notamment).
- Une étiquette, 1002, pour indiquer une durée. C'est également un dictionnaire CBOR.
- Une étiquette, 1003, pour indiquer une période, représentée par une date de début et une date de fin.
Ces nouvelles étiquettes ont été ajoutées au registre des étiquettes CBOR. Les clés possibles pour les dictionnaires indiquant les temps étendus sont dans un nouveau registre à l'IANA. Ajouter une entrée à ce registre nécessite un RFC et un examen par un expert.
Un service sur ce blog, https://www.bortzmeyer.org/apps/date-in-cbor
% curl -s https://www.bortzmeyer.org/apps/date-in-cbor | cbor2diag.rb
["Current date in CBOR, done with Python 3.11.2 (main, Mar 13 2023, 12:18:29) [GCC 12.2.0] and the flunn library <https://github.com/funny-falcon/flunn>",
0("2024-04-17T14:21:07Z"),
1(1713363667),
100(19830),
1004("2024-04-17"),
1001({1: 1713363667, -1: 0, -9: 193986759}),
1001({1: 1713363704, -1: 1}),
"Duration since boot: ",
1002({1: 1742903})]
On voit alors successivement :
- Les deux valeurs étiquetées 0 et 1 du RFC 8949 et les deux valeurs étiquetées 100 et 1004 du RFC 8943.
- Puis les nouveautés de notre RFC.
- D'abord, un temps étendu étiqueté 1001. Le dictionnaire a trois éléments, celui de clé 1 est la date et heure, celui de clé -1 indique qu'il s'agit d'un temps UTC, celui de clé -9 indique qu'il s'agit de nanosecondes (-3 : millisecondes, -6 : microsecondes, etc). On a ainsi une meilleure résolution.
- Un autre temps étendu est en TAI (la clé -1 a la valeur 1) et vous voyez qu'il est situé 37 secondes dans le futur (l'actuel décalage entre UTC et TAI).
- Une durée, qui est le temps écoulé (en secondes) depuis le démarrage de la machine.
- On n'indique pas des informations comme la qualité de l'horloge car, franchement, je n'ai pas vraiment compris comment elle était représentée.
Question programmation, le service a été écrit en
Python. Ce langage a une fonction
time_ns,
qui permet d'obtenir les nanosecondes. Pour le TAI, cela a été un
peu plus difficile, la machine doit être configurée spécialement.
L'article seul
RFC 9580: OpenPGP
Date de publication du RFC : Juillet 2024
Auteur(s) du RFC : P. Wouters (Aiven), D. Huigens
(Proton AG), J. Winter
(Sequoia-PGP), Y. Niibe (FSIJ)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF openpgp
Première rédaction de cet article le 1 août 2024
Dernière mise à jour le 4 janvier 2025
Le logiciel PGP est synonyme de cryptographie pour beaucoup de gens. Un des plus anciens et des plus utilisés pour les fonctions de confidentialité mais aussi d'authentification. Le format de PGP, OpenPGP, est normalisé dans ce RFC, qui remplace le RFC 4880 (il n'y a pas de changement crucial, juste une mise à jour longtemps attendue).
PGP a vu son
format de données normalisé pour la première fois en août 1996, dans
le RFC 1991. Cette norme a été révisée par la suite, dans
le RFC 2440, puis le RFC 4880, puis par des RFC ponctuels (comme les RFC 5581 et RFC 6637, désormais inclus)
et notre RFC est la dernière version, qui synthétise tout. Sa
gestation a été longue et douloureuse et a suscité des controverses,
menant à un projet concurrent, LibrePGP (qui prévoit son propre
RFC, actuellement draft-koch-librepgp,
que j'avoue n'avoir pas lu).
Cette normalisation permet à diverses mises en œuvre de PGP d'interopérer. La plus connue aujourd'hui est le logiciel libre, GNU Privacy Guard (qui n'existait pas encore au moment de la publication du premier RFC) mais il y en a d'autres comme Sequoia (qui a annoncé qu'il suivrait notre récent RFC). Il ne faut donc pas confondre le logiciel PGP, écrit à l'origine par Phil Zimmermann, et qui est non-libre, avec le format OpenPGP que décrit notre RFC (cf. section 1.1) et que des logiciels autres que PGP peuvent lire et écrire.
Le principe du chiffrement avec PGP est simple. Une clé de session (le terme est impropre puisqu'il n'y a pas de session au sens de TLS mais c'est celui utilisé par le RFC) est créée pour chaque destinataire, elle sert à chiffrer le message et cette clé est chiffrée avec la clé publique du destinataire (section 2.1 du RFC).
Pour l'authentification, c'est aussi simple conceptuellement. Le message est condensé et le condensé est chiffré avec la clé privée de l'émetteur (section 2.2 du RFC).
Le format OpenPGP permet également la compression (qui améliore la sécurité en supprimant les redondances) et l'encodage en Base64 (RFC 4648), baptisé ASCII armor, pour passer à travers des logiciels qui n'aiment pas le binaire (la section 6 détaille cet encodage).
La section 3 explique les éléments de base utilisés par le format PGP. L'un des plus importants est le concept d'entier de grande précision (MPI pour Multi-Precision Integers), qui permet de représenter des entiers de très grande taille, indispensables à la cryptographie, sous forme d'un doublet longueur + valeur.
Enfin les sections 4 et 5 expliquent le format lui-même. Un message PGP est constitué de paquets (rien à voir avec les paquets réseau). Chaque paquet a un type, une longueur et un contenu. Par exemple, un paquet de type 1 est une clé de session chiffrée, un paquet de type 2 une signature, un paquet de type 9 du contenu chiffré, etc.
La section 7 du RFC décrit un type de message un peu particulier, qui n'obéit pas à la syntaxe ci-dessus, les messages en clair mais signés. Ces messages ont l'avantage de pouvoir être lus sans avoir de logiciel PGP. Ils nécessitent donc des règles spéciales.
On notera que gpg
permet d'afficher les paquets présents dans un message PGP, ce qui
est pratique pour l'apprentissage ou le débogage. Voyons un exemple
avec un fichier test.txt de 17 octets, signé
mais non chiffré (j'ai un peu simplifié la sortie du logiciel) :
% gpg --list-packets test.gpg :compressed packet: algo=2 :onepass_sig packet: keyid 3FA836C996A4A254 version 3, sigclass 0x00, digest 10, pubkey 1, last=1 :literal data packet: mode b (62), created 1721800388, name="test.txt", raw data: 17 bytes :signature packet: algo 1, keyid 3FA836C996A4A254 version 4, created 1721800388, md5len 0, sigclass 0x00 digest algo 10, begin of digest 2b d9 hashed subpkt 33 len 21 (issuer fpr v4 C760CAFC6387B0E8886C823B3FA836C996A4A254) hashed subpkt 2 len 4 (sig created 2024-07-24) subpkt 16 len 8 (issuer key ID 3FA836C996A4A254) data: [4096 bits]
Malheureusement, gpg n'affiche pas les valeurs numériques des types, telles que listées par le RFC. Mais les noms qu'il utilise sont les mêmes que dans le RFC, on peut donc facilement trouver la section qui explique ce qu'est un "onepass_sig packet" (section 5.4).
Avec un message chiffré, on obtient :
% gpg --list-packets test.txt.gpg
gpg: encrypted with 4096-bit RSA key, ID 9045E02757F02AA1, created 2014-02-09
"Stéphane Bortzmeyer (Main key) <stephane@bortzmeyer.org>"
gpg: encrypted with 2048-bit RSA key, ID 516CB37B336525BB, created 2009-12-15
"ISC Security Officer <security-officer@isc.org>"
gpg: decryption failed: No secret key
:pubkey enc packet: version 3, algo 1, keyid 516CB37B336525BB
data: [2046 bits]
:pubkey enc packet: version 3, algo 1, keyid 9045E02757F02AA1
data: [4096 bits]
:encrypted data packet:
length: 78
mdc_method: 2
Conformément au principe d'agilité cryptographique (RFC 7696), le format OpenPGP n'est pas lié à un algorithme cryptographique particulier, et permet d'en ajouter de nouveaux. La section 15 détaille comment demander à l'IANA d'ajouter de nouveaux paramètres dans les registres PGP.
L'annexe B, quant à elle, énumère les principaux changements depuis le RFC 4880. Ce dernier RFC a été publié il y a plus de seize ans mais son remplacement par notre nouveau RFC 9580 a été une opération longue et difficile, et les changements se sont accumulés (Daniel Huigens en a fait un bon résumé). Ceci dit, le format OpenPGP ne change pas radicalement, et l'interopérabilité avec les anciens programmes est maintenue. Parmi les principales modifications :
- des nouveaux algorithmes cryptographiques de signature comme Ed25519, ou bien ECDSA avec les courbes Brainpool (RFC 5639),
- des nouveaux algorithmes cryptographiques de chiffrement, comme X25519 ; comme pour ceux de signature, ils étaient parfois mentionnés dans le RFC 4880 sans que leur utilisation dans OpenPGP soit complètement spécifiée, et parfois avaient été intégrés via un RFC spécifique, comme le RFC 6637, sur certains algorithmes à courbe elliptique,
- des nouveaux modes pour le chiffrement intègre, comme GCM (nouveaux pour OpenPGP, mais anciens en cryptographie),
- des nouvelles fonctions de dérivation de clé comme Argon2 (RFC 9106) ou de condensation comme SHA-3,
- au contraire, certains algorithmes sont désormais marqués comme dépassés et ne devant plus être utilisés pour de nouveaux messages ; c'est le cas de DSA, ElGamal, MD5, SHA-1… (rappelez-vous que PGP peut avoir à lire des messages anciens et qu'on ne peut donc pas retirer purement et simplement ces algorithmes, d'autant plus qu'autrefois ils étaient parfois les seuls obligatoires pour une mise en œuvre standard d'OpenPGP),
- nouvelle version (version 6) pour plusieurs types de paquets,
- réduction de l'en-tête de la protection ASCII des messages (OpenPGP est du binaire mais peut être transcrit en ASCII armor, par exemple pour le courrier électronique) ; vous ne verrez plus le « Version: » dans cet en-tête,
- redressement de la terminologie, qui était parfois trop floue.
Enfin, un grand nombre d'errata ont été traités (la liste complète est dans l'annexe D).
L'article seul
RFC 9567: DNS Error Reporting
Date de publication du RFC : Avril 2024
Auteur(s) du RFC : R. Arends (ICANN), M. Larson
(ICANN)
Chemin des normes
Première rédaction de cet article le 27 avril 2024
Lorsqu'un résolveur DNS détecte un problème avec une zone, l'empêchant de résoudre les noms dans cette zone, il n'avait pas de moyen simple et automatique de prévenir les gérants des serveurs faisant autorité pour cette zone. Leur envoyer un message en utilisant l'information dans l'enregistrement SOA ou les adresses classiques du RFC 2142 ? Mais, justement, si la zone ne marche pas, le courrier ne partira pas forcément. Ce nouveau RFC propose un nouveau système. Les serveurs faisant autorité annoncent un domaine (qui marche, espérons-le), qui acceptera des requêtes DNS spéciales signalant le problème.
Cela dépend évidemment du problème pratique qui se pose. Si la zone n'a aucun serveur faisant autorité qui marche, il n'y a évidemment rien à faire. Mais s'ils marchent, tout en servant des données problématiques (par exemple des signatures DNSSEC expirées), alors, le résolveur pourra agir. Les serveurs faisant autorité mettent dans leurs réponses une option EDNS qui indique le domaine qui recevra les rapports (cela doit être un autre domaine, qui n'a pas de problème), le résolveur fera alors une requête DNS se terminant par le nom du domaine de signalement, et encodant le problème. L'agent, le domaine de signalement, pourra alors récolter ces requêtes et savoir qu'il y a un problème. Cela ne traite pas tous les cas (il faudra toujours utiliser RDAP ou whois pour récolter des informations sur les contacts du domaine erroné, puis leur écrire depuis un autre réseau) mais c'est simple, léger et automatisable. Les gérants de domaine sérieux, qui prennent au sérieux les signalements de problèmes techniques (soit 0,00001 % des domaines) pourront alors agir. (Note si vous gérez un résolveur et que vous constatez un problème avec un domaine et que les contacts ne répondent pas : un message méchant sur Twitter est souvent plus efficace.)
Donc, les détails techniques : le domaine qui veut recevoir les éventuels signalements va devoir configurer ses serveurs faisant autorité pour renvoyer une option EDNS, de numéro 18 (section 5 du RFC), indiquant l'agent, c'est-à-dire le domaine qui va recevoir les signalements (il faut évidemment veiller à ce qu'il n'ait pas de point de défaillance commun avec le domaine surveillé). Notez que cette option est systématiquement envoyée, le client (le résolveur) n'a pas à dire quoi que ce soit (la question avait fait l'objet d'un sérieux débat à l'IETF).
En cas de problème, notamment DNSSEC, le résolveur qui a noté le problème va alors construire un nom de domaine formé, successivement (section 6.1.1) par :
- Le composant
_er, - Le type de données qui posait problème (adresse IP, enregistrement de service, etc),
- Le nom de domaine qui était initialement demandé par le résolveur,
- L'erreur étendue (EDE, RFC 8914),
- Le composant
_er(oui, encore), - Le nom de domaine de l'agent.
Par exemple, si le domaine dyn.bortzmeyer.fr
annonce comme agent report.dyn.sources.org, et
qu'un résolveur découvre des signatures DNSSEC expirées (EDE 7) en
cherchant à résoudre hello.dyn.bortzmeyer.fr /
TXT (TXT a la valeur 16), la
requête de signalement du résolveur sera
_er.16.hello.dyn.bortzmeyer.fr.7._er.report.dyn.sources.org
(ouf). Le type demandé est TXT. Lorsque cette requête
arrivera au serveur faisant autorité pour
report.dyn.sources.org, il pourra enregistrer
qu'il y a eu un problème, et mettre cette information à la
disposition de son administrateur système.
Ce serveur faisant autorité est censé répondre au signalement avec une réponse de type TXT comme ici :
% dig _er.16.hello.dyn.bortzmeyer.fr.7._er.report.dyn.sources.org TXT … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 12032 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1 … ;; ANSWER SECTION: _er.16.hello.dyn.bortzmeyer.fr.7._er.report.dyn.sources.org. 30 IN TXT "Thanks for the report of error 7 on hello.dyn.bortzmeyer.fr" …
L'agent peut ensuite être interrogé, par des méthodes propres à la mise en œuvre utilisée :
% echo report | socat - UNIX-CONNECT:/home/drink/drink.sock REPORT state: hello.dyn.bortzmeyer.fr, 7 ip.dyn.bortzmeyer.fr, 7
Ici, on voit que deux domaines ont été signalés comme ayant des signatures expirées (rassurez-vous, c'était juste des tests). Le nombre de signalements n'est pas indiqué, ni la source des signalements (travail futur).
Quelques petits points de sécurité à garder en tête (section 9 du RFC) :
- Le fait de signaler va, par définition, donner au serveur faisant autorité des informations sur le résolveur (par exemple, un résolveur menteur qui signalerait les blocages informerait sur sa politique, ce que les censeurs ne font en général pas).
- Il en donnera aussi aux serveurs des zones parentes du domaine agent, et il est donc très recommandé de minimiser le nom (RFC 9156).
- Il n'y a pas spécialement d'authentification donc tous ces rapports doivent être traités avec prudence. Un méchant peut facilement fabriquer de faux rapports, de toute façon. Ils doivent donc toujours être vérifiés.
Cette technique a été mise en œuvre dans Drink lors d'un hackathon IETF. Drink peut à la fois signaler un domaine agent, et être serveur pour un domaine agent.
Un exemple de signalisation EDNS de cette option, vu la version
de développement de Wireshark (merci à Alexis La Goutte) : 
L'article seul
RFC 9562: Universally Unique IDentifiers (UUIDs)
Date de publication du RFC : Mai 2024
Auteur(s) du RFC : K. Davis (Cisco Systems), B. Peabody (Uncloud), P. Leach (University of Washington)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF uuidrev
Première rédaction de cet article le 12 mai 2024
Ce RFC normalise les UUID, une famille d'identificateurs uniques, obtenus sans registre central. Il remplace l'ancienne norme, le RFC 4122, avec pas mal de nouveautés et un RFC complètement refait.
Les UUID, également connus autrefois sous le nom de GUID (Globally Unique IDentifiers), sont issus à l'origine du système des Apollo, adopté ensuite dans la plate-forme DCE. Les UUID ont une taille fixe, 128 bits, et sont obtenus localement, par exemple à partir d'un autre identificateur unique comme un nom de domaine, ou bien en tirant au hasard, la grande taille de leur espace de nommage faisant que les collisions sont très improbables (section 6.7 du RFC). Ce RFC reprend la spécification (bien oubliée aujourd'hui) de DCE de l'Open Group (ex-OSF) et ajoute la définition d'un espace de noms pour des URN (sections 4 et 7). (Il existe aussi une norme ITU sur les UUID et un registre des UUID, pour ceux qui y tiennent.)
Les UUID peuvent donc convenir pour identifier une entité sur le réseau, par exemple une machine mais aussi, vu leur nombre, comme identificateur unique pour des transactions (ce qui était un de leurs usages dans DCE). En revanche, ils ne sont pas résolvables, contrairement aux noms de domaine. Mais ils sont présents dans beaucoup de logiciels (Windows, par exemple, les utilise intensivement). On les utilise comme clé primaire dans les bases de données, comme identificateur de transaction, comme nom de machine, etc.
Les UUID peuvent se représenter sous forme d'un nombre binaire de
128 bits (la section 5 du RFC décrit les différents champs qui
peuvent apparaitre) ou bien sous forme texte. Sur
Unix, on peut fabriquer un UUID avec la
commande uuidgen, qui affiche la représentation
texte standard que normalise notre RFC (section 4) :
% uuidgen 317e8ed3-1428-4ef1-9dce-505ffbcba11a % uuidgen ec8638fd-c93d-4c6f-9826-f3c71436443a
Sur Linux, vous pouvez aussi simplement
faire cat /proc/sys/kernel/random/uuid. Sur une machine FreeBSD, un UUID de la
machine est automatiquement généré (par le script
/etc/rc.d/hostid) et stocké dans le fichier
/etc/hostid.
Pour l'affichage sous forme d'URN (RFC 8141), on ajoute
juste l'espace uuid par exemple
urn:uuid:ec8638fd-c93d-4c6f-9826-f3c71436443a. Il
a été ajouté au registre
IANA des espaces de noms des URN.
La section 4 du RFC détaille le format de l'UUID. En dépit des apparences, l'UUID n'est pas plat, il a une structure, mais il est très déconseillé aux applications de l'interpréter (section 6.12). Un des champs les plus importants est le champ Version (qui devrait plutôt s'appeler Type) car il existe plusieurs types d'UUID :
- UUID version 1, fondé sur le temps (notez tout de suite que les versions 6 et 7 sont recommandées à sa place).
- UUID version 2, réservé, non utilisé.
- UUID version 3, fondé sur un espace de noms (par exemple le DNS) et un nom qui est condensé en MD5 (la version 5 est préférable).
- UUID version 4, aléatoire.
- UUID version 5, fondé sur un espace de noms et un nom qui est condensé en SHA-1.
- UUID version 6, fondé sur le temps, avec les mêmes champs que la version 1, mais avec un format différent.
- UUID version 7, fondé sur le temps, avec une autre définition, et des champs différents.
- UUID version 8, pour les usages expérimentaux, si vous voulez jouer localement avec un nouveau mécanisme de génération.
Ces différents types / versions figurent dans un registre IANA. Ce registre ne peut être modifié que par une action de normalisation (cf. RFC 8126).
uuidgen, vu plus haut, peut générer des UUID de
version 1 option -t, de version 3
(-m), de version 4 (c'est son comportement par
défaut, mais on peut utiliser l'option -r si on
veut être explicite) ou de version 5 (-s). Ici,
on voit les UUID fondés sur une estampille temporelle (version 1)
augmenter petit à petit :
% uuidgen -t 42ff1626-0fc7-11ef-8162-49e9505fb2f3 % uuidgen -t 4361fae8-0fc7-11ef-8162-49e9505fb2f3 % uuidgen -t 45381d02-0fc7-11ef-8162-49e9505fb2f3
Ici, dans le cas d'un UUID fondé sur un nom (version 3), l'UUID est stable (essayez chez vous, vous devriez obtenir le même résultat que moi), une propriété importante des UUID de version 3 et 5 :
% uuidgen -m -n @dns -N foobar.example 8796bf1a-793c-3c44-9ec5-a572635cd3d4 % uuidgen -m -n @dns -N foobar.example 8796bf1a-793c-3c44-9ec5-a572635cd3d4
Les espaces de noms sont enregistrés dans un
registre IANA, d'autres peuvent être ajoutés si on écrit une spécification
(cf. RFC 8126). Notez que chaque espace a son
UUID (6ba7b810-9dad-11d1-80b4-00c04fd430c8 pour
l'espace DNS).
Les UUID de version 6 et 7, nouveautés de ce RFC 9562, ne sont pas mis en œuvre par uuidgen, ni d'ailleurs par beaucoup d'autres programmes.
Les sections 6.1 et 6.2, elles, décrivent le processus de génération d'un UUID à base temporelle. Idéalement, il faut utiliser une graine enregistrée sur le disque (pour éviter de générer des UUID identiques) ainsi que l'instant de la génération. Mais lire sur le disque prend du temps (alors qu'on peut vouloir générer des UUID rapidement, par exemple pour identifier des transactions) et l'horloge de la machine n'a pas toujours une résolution suffisante pour éviter de lire deux fois de suite le même instant. Ces sections contiennent donc également des avis sur la génération fiable d'UUID, par exemple en gardant en mémoire le nombre d'UUID générés, pour les ajouter à l'heure.
La section 8, consacrée à la sécurité, rappelle qu'un UUID ne doit pas être utilisé comme capacité (car il est trop facile à deviner) et qu'il ne faut pas demander à un humain de comparer deux UUID (ils se ressemblent trop pour un œil humain).
Il est évidemment recommandé d'utiliser les UUID de version 5 plutôt que de version 3 (RFC 6151) mais SHA-1 a aussi ses problèmes (RFC 6194) et, de toute façon, pour la plupart des utilisations des UUID, les faiblesses cryptographiques de MD5 et de SHA-1 ne sont pas gênantes.
La section 2.1 du RFC détaille les motivations pour la mise à jour du RFC 4122 et quels sont les changements effectués. Certaines utilisations des UUID ont remis en cause des suppositions originales. Ainsi, les UUID sont souvent utilisés dans un contexte réparti, où leur capacité à être uniques sans registre central est très utile. Mais quelques points manquaient au RFC 4122 :
- UUID version 4 (aléatoire) avait une mauvaise localité : deux UUID créés l'un après l'autre en un temps très court n'ont aucun rapport, ce qui est gênant pour certains usages (par exemple comme étiquette dans un B-tree).
- UUID version 1 (fondé entre autre sur le temps écoulé depuis l'epoch) utilise un incrément peu pratique (cent nanosecondes).
- Certaines méthodes fabrication des UUID posaient des gros problèmes de vie privée, par exemple l'utilisation des adresses MAC dans UUID version 1, désormais déconseillée.
- Le RFC 4122 descendait trop dans les détails de mise en œuvre.
- Le RFC 4122 ne séparait pas les exigences pour la génération d'UUID et celles pour leur stockage.
Seize mises en œuvre des UUID ont été étudiées pour préparer le nouveau RFC (vous avez la liste dans la section 2.1), menant aux constations suivantes :
- Beaucoup d'errata dans le RFC 4122.
- Spécification du format qui mélangeait trop les diverses versions d'UUID.
- Absence de vecteurs de test (ils figurent désormais dans l'annexe A).
En Python, il existe un module UUID qui offre des fonctions de génération d'UUID de différentes versions (mais pas les plus récentes) :
import uuid
myuuid = uuid.uuid1() # Version 1, Time-based UUID
heruuid = uuid.uuid3(uuid.NAMESPACE_DNS, "foo.bar.example") # Version
# 3, Name-based ("hash-based") UUID, a name hashed by MD5
otheruuid = uuid.uuid4() # Version 4, Random-based UUID
yetanotheruuid = uuid.uuid5(uuid.NAMESPACE_DNS,
"www.example.org")
# Version 5, a name hashed by SHA1
if (myuuid == otheruuid or \
myuuid == heruuid or \
myuuid == yetanotheruuid or \
otheruuid == yetanotheruuid):
raise Exception("They are equal, PANIC!")
print(myuuid)
print(heruuid) # Will always be the same
print(otheruuid)
print(yetanotheruuid) # Will always be the same
Et comme le dit la documentation, Note that uuid1() may compromise privacy since it creates a UUID containing the computer’s network address. (méthode de génération des UUID version 1 qui est désormais déconseillée).
Le SGBD PostgreSQL inclut un type UUID. Cela évite de stocker les UUID sous leur forme texte, ce qui est techniquement absurde et consomme 288 bits au lieu de 128 (section 6.13 du RFC).
essais=> CREATE TABLE Transactions (id uuid, value INT);
CREATE TABLE
essais=> INSERT INTO Transactions VALUES
('74738ff5-5367-5958-9aee-98fffdcd1876', 42);
INSERT 0 1
essais=> INSERT INTO Transactions VALUES
('88e6441b-5f5c-436b-8066-80dca8222abf', 6);
INSERT 0 1
essais=> INSERT INTO Transactions VALUES ('Pas correct', 3);
ERROR: invalid input syntax for type uuid: "Pas correct"
LINE 1: INSERT INTO Transactions VALUES ('Pas correct', 3);
^
-- PostgreSQL peut seulement générer la version 4, les aléatoires
essais=> INSERT INTO Transactions VALUES (gen_random_uuid () , 0);
INSERT 0 1
essais=> SELECT * FROM Transactions;
id | value
--------------------------------------+-------
74738ff5-5367-5958-9aee-98fffdcd1876 | 42
88e6441b-5f5c-436b-8066-80dca8222abf | 6
41648aef-b123-496e-8a4c-52e573d17b6a | 0
(3 rows)
Attention, le RFC (section 6.13) déconseille l'utilisation des UUID fondés sur un nom pour servir de clé primaire dans la base de données, sauf si on est absolument certain (mais c'est rare) que les noms ne changeront pas.
Il existe plusieurs exemples d'utilisation des UUID. Par exemple,
Linux s'en sert pour identifier les disques
attachés à la machine, de préférence à l'ancien système où l'ajout
d'un nouveau disque pouvait changer l'ordre des numéros sur le bus et
empêcher le système de trouver un disque. Un
/etc/fstab typique sur Linux contient donc
des :
UUID=da8285a0-3a70-413d-baed-a1f48d7bf7b2 /home ext3 defaults ...
plutôt que les anciens :
/dev/sda3 /home ext3 defaults
car sda3 n'est pas un identificateur
stable. L'UUID, lui, est dans le système de fichiers et ne changera
pas avec les changements sur le bus. On peut
l'afficher avec dumpe2fs :
# dumpe2fs -h /dev/sda3 ... Filesystem UUID: da8285a0-3a70-413d-baed-a1f48d7bf7b2 ...
Un exemple d'utilisation de la nouvelle version 7 est décrit dans l'excellent article « Goodbye integers. Hello UUIDv7! ». Une mise en œuvre de cette version 7 apparait dans « UUIDv7 in 20 languages ».
La section 6 décrit les bonnes pratiques de génération d'un UUID. Ainsi :
- Pour tous les UUID fondés sur le temps, si vous avez besoin d'unicité des UUID, attention aux cas où l'horloge peut changer, en raison d'une modification manuelle, d'une seconde intercalaire ou d'un ajustement fait par NTP.
- Si vous générez des UUID de manière répartie, sur plusieurs machines, ce qui est un des points forts des UUID, mais que vous voulez quand même de l'unicité, vous pouvez préfixer vos UUID avec un identificateur de la machine, ou bien compter sur un registre central (mais, en général, c'est justement ce qu'on veut éviter avec des UUID).
- UUID rend les collisions (génération de deux UUID identiques) peu probables mais pas impossibles. Lorsque vous concevez une application, demandez-vous si une collision est juste un petit inconvénient ou bien si elle est inacceptable (le RFC cite l'exemple fictif d'un système de contrôle aérien où chaque avion serait identifié par un UUID ; l'attribution du même UUID à deux avions différents serait clairement catastrophique). Dans ce cas, vous devez trouver un moyen de ne pas avoir de collision.
- Si vous voulez des UUID qui ne soient pas prévisibles par un observateur extérieur, utilisez la version 4 et assurez vous que votre générateur de nombres aléatoires suit bien les prescriptions des RFC 4086 et RFC 8937, ainsi que « Random Number Generator Recommendations for Applications ».
- Les versions 6 et 7 (nouveautés de ce RFC 9562) sont prévues pour que les UUID soient triables chronologiquement, sans avoir besoin d'analyse, uniquement en triant la version binaire. Un des avantages est que des UUID générés à des moments proches ont des valeurs proches, ce qui peut être utile dans certaines applications.
L'article seul
RFC 9559: Matroska Media Container Format Specification
Date de publication du RFC : Octobre 2024
Auteur(s) du RFC : S. Lhomme, M. Bunkus, D. Rice
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF cellar
Première rédaction de cet article le 15 octobre 2024
Matroska est un format de conteneur pour du contenu multimédia (son, image, sous-titres, etc). Ce n'est pas un format de données (format utilisé par un codec), mais un moyen de regrouper de manière structurée des données différentes.
Je vous préviens tout de suite, le RFC fait 167 pages, et, en prime, le multimédia n'est pas ma spécialité. Donc, je vais faire court. Matroska est fondé sur un langage qui utilise le modèle de données XML, EBML (normalisé dans le RFC 8794). Notre nouveau RFC 9559 est donc surtout une très longue liste des éléments XML qu'on peut y trouver (Matroska est riche !), encodés en binaire. Matroska n'est pas nouveau (il en est à la version 4), mais c'est sa première normalisation. Notez que vous trouverez de l'information sur la page Web du projet.
Le caractère hiérarchique d'un fichier Matroska (des éléments dans d'autres éléments) est bien rendu par cet outil (qui fait partie de MKVToolNix, cité plus loin) :
% mkvinfo ./format/matroska/testdata/sweep-with-DC.mkvmerge13.mka
+ EBML head
|+ EBML version: 1
|+ EBML read version: 1
|+ Maximum EBML ID length: 4
|+ Maximum EBML size length: 8
|+ Document type: matroska
|+ Document type version: 4
|+ Document type read version: 2
+ Segment: size 18507
|+ Seek head (subentries will be skipped)
|+ EBML void: size 4031
|+ Segment information
| + Timestamp scale: 22674
| + Multiplexing application: libebml v1.4.2 + libmatroska v1.6.2
| + Writing application: mkvmerge v52.0.0 ('Secret For The Mad') 64-bit
| + Duration: 00:00:02.607714066
| + Date: 2022-08-28 18:32:21 UTC
| + Segment UID: 0x3b 0x9f 0x28 0xc7 0xc4 0x90 0x8a 0xe0 0xcd 0x66 0x8f 0x11 0x8f 0x7c 0x2f 0x54
|+ Tracks
| + Track
| + Track number: 1 (track ID for mkvmerge & mkvextract: 0)
| + Track UID: 3794791294650729286
| + Track type: audio
| + Codec ID: A_FLAC
| + Codec's private data: size 133
| + Default duration: 00:00:00.040634920 (24.609 frames/fields per second for a video track)
| + Language: und
| + Language (IETF BCP 47): und
| + Audio track
| + Sampling frequency: 44100
| + Bit depth: 16
|+ EBML void: size 1063
|+ Cluster
On voit un document de la version 4 (celle du RFC), commençant
(forcément, cf. section 4.5 du RFC) par un en-tête EBML, et
comportant une seule piste (l'élément
Tracks est décrit en section 5.1.4), un son au
format FLAC
(RFC 9639). L'extension
.mka est souvent utilisée pour des conteneurs
n'ayant que de l'audio (et .mkv s'il y a de la
vidéo). La piste audio est dans une langue indéterminée,
und. Plusieurs éléments existent pour noter la
langue car Matroska n'utilisait autrefois que la norme
ISO 639 mais la version 4 recommande les bien
plus riches étiquettes de langue IETF (RFC 5646, alias « IETF BCP 47 »).
Un autre document a deux pistes, le son et l'image :
% mkvinfo ~/Videos/2022-01-22\ 13-17-28.mkv … |+ Tracks | + Track | + Track number: 1 (track ID for mkvmerge & mkvextract: 0) | + Track UID: 1 | + "Lacing" flag: 0 | + Language: und | + Codec ID: V_MPEG4/ISO/AVC | + Track type: video | + Default duration: 00:00:00.033333333 (30.000 frames/fields per second for a video track) | + Video track | + Pixel width: 852 | + Pixel height: 480 | + Display unit: 4 | + Codec's private data: size 41 (H.264 profile: High @L3.1) | + Track | + Track number: 2 (track ID for mkvmerge & mkvextract: 1) | + Track UID: 2 | + "Lacing" flag: 0 | + Name: simple_aac_recording | + Language: und | + Codec ID: A_AAC | + Track type: audio | + Audio track | + Channels: 2 | + Sampling frequency: 44100 | + Bit depth: 16 | + Codec's private data: size 5
L'arborescence des fichiers Matroska peut être très profonde et ça se reflète dans la numérotation des sections du RFC (il y a une section 5.1.4.1.28.18 !).
Les types MIME à utiliser sont audio/matroska
et video/matroska
(section 27.3 du RFC).
Il existe plusieurs mises en œuvre de Matroska en logiciel libre comme MKVToolNix, qui sait faire beaucoup de choses (comme afficher les éléments Matroska comme vu plus haut) et qui existe en ligne de commande ou GUI. Et VLC sait évidemment jouer les fichiers Matroska. OBS, quant à lui, permet d'en produire. Par exemple, cette vidéo sans intérêt a été faite avec OBS.
L'article seul
RFC 9558: Use of GOST 2012 Signature Algorithms in DNSKEY and RRSIG Resource Records for DNSSEC
Date de publication du RFC : Avril 2024
Auteur(s) du RFC : B. Makarenko (The Technical center of Internet, LLC), V. Dolmatov (JSC "NPK Kryptonite")
Pour information
Première rédaction de cet article le 21 octobre 2024
Ce RFC marque l'arrivée d'un nouvel algorithme de signature dans les enregistrements DNSSEC, algorithme portant le numéro 23. Bienvenue au GOST R 34.10-2012 (alias ECC-GOST12), algorithme russe, spécifié en anglais dans le RFC 7091, une légère mise à jour de GOST R 34.10-2001.
La liste des algorithmes DNSSEC est un registre à l'IANA, https://www.iana.org/assignments/dns-sec-alg-numbers/dns-sec-alg-numbers.xml#dns-sec-alg-numbers-1. Elle
comprend désormais GOST R 34.10-2012 (qui succède au R 34.10-2001 du
RFC 5933). Notez que GOST désigne en fait une
organisation de
normalisation, le terme correct serait donc de ne jamais
dire « GOST » tout court, mais plutôt « GOST R 34.10-2012 » pour
l'algorithme de signature et « GOST R 34.11-2012 » pour celui de
condensation,
décrit dans le RFC 6986 (voir la section 1 de notre RFC 9558).
La section 2 décrit le format des enregistrements
DNSKEY avec GOST, dans lequel
on publie les clés GOST R 34.10-2012. Le champ Algorithme vaut 23,
le format de la clé sur le réseau suit le RFC 7091. GOST
est un algorithme à courbes elliptiques, courbes décrites par Q
= (x,y). Les 32 premiers octets de la clé sont x et les 32 suivants
y (en petit-boutien,
attention, contrairement à la majorité des protocoles Internet).
Parmi les bibliothèques cryptographiques existantes, au moins OpenSSL met en œuvre GOST R 34.10-2012 (testé avec la version 3.3.2). Voir RFC 9215 pour de l'aide à ce sujet. Sinon, on trouve parfois seulement l'ancienne version dans certains logiciels et certaines bibliothèques.
La section 2.2 donne un exemple de clé GOST publiée dans le DNS,
je n'ai pas trouvé d'exemple réel dans la nature, même en
.ru.
La section 3 décrit le format des enregistrements RRSIG, les signatures (avec un
exemple). On suit les RFC 5958 et RFC 7091.
Attention, une particularité de GOST fait que deux signatures des
mêmes données peuvent donner des résultats différents, car un
élément aléatoire est présent dans la signature.
La section 4
décrit le format des enregistrements DS pour GOST. La clé publique de
la zone fille est condensée par GOST R 34.11-2012, algorithme de
numéro
5.
Les sections 5 et 6 couvrent des questions pratiques liées au développement et au déploiement de systèmes GOST, par exemple un rappel sur la taille de la clé (512 bits) et sur celle du condensat cryptographique (256 bits).
GOST peut se valider avec Unbound si la bibliothèque de cryptographie utilisée gère GOST. Et, comme indiqué plus haut, ce ne sera sans doute que l'ancienne version, celle du RFC 5933. Pour les programmeurs Java, DNSjava a le dernier GOST depuis la version 3.6.2. Pour le statut (recommandé ou non) de l'algorithme GOST pour DNSSEC, voir le RFC 8624. En Python, dnspython en version 2.7.0 n'a que l'ancien algorithme.
L'article seul
RFC 9557: Date and Time on the Internet: Timestamps with Additional Information
Date de publication du RFC : Avril 2024
Auteur(s) du RFC : U. Sharma (Igalia, S.L.), C. Bormann (Universität Bremen TZI)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF sedate
Première rédaction de cet article le 29 avril 2024
Ce RFC modifie légèrement le format des estampilles temporelles du RFC 3339, changeant à la marge une définition et, surtout, permettant d'y attacher des informations supplémentaires.
Le RFC 3339 décrit un des formats d'estampilles temporelles possibles sur l'Internet (car, malheureusement, toutes les normes Internet ne l'utilisent pas). Un exemple, sur Unix :
% date --rfc-3339=seconds 2024-04-29 06:22:33+00:00
Le format du RFC 3339 est du type « YYYY-MM-DD HH:MM:SS » avec, à la fin, ajout d'une information sur le décalage avec le temps de référence (on verra que notre nouveau RFC 9557 change un peu cette dernière information). Un format gros boutien, donc, qui permet notamment de trier les dates-et-heures uniquement en suivant l'ordre lexicographique des caractères.
Mais certaines applications voudraient en savoir plus, et ajouter
à ce format des détails. D'ailleurs, c'est déjà fait dans des
solutions non normalisées, comme le
format de Java, très populaire, qui permet des estampilles
comme 2011-12-03T10:15:30+01:00[Europe/Paris]
(fuseau horaire, ajouté après la date au
format du RFC 3339 ; lisez le RFC 6557 pour en savoir davantage sur les fuseaux
horaires).
Ce nouveau RFC prévoit donc une extension optionnelle (les dates-et-heures qui suivaient le format de l'ancien RFC restent parfaitement valdies), compatible avec celle de Java, et généraliste (on pourra indiquer autre chose que le fuseau horaire). Ce format étendu est baptisé IXDTF pour Internet Extended Date/Time Format. En revanche, le nouveau format ne gère pas des cas compliqués (la gestion du temps en informatique est toujours compliquée) comme les dates futures lorque la définition du fuseau horaire changera, par exemple en supprimant l'heure d'été, ou des échelles de temps différentes, comme TAI (le format IXDTF ne marche que pour l'échelle d'UTC).
Donc, concrètement, notre RFC commence par changer un peu la définition du décalage à la fin des estampilles. Dans le RFC 3339, il y avait trois cas subtilement différents pour une estampille indiquant l'absence de décalage :
- Une lettre Z indiquait qu'on utilisait UTC comme référence,
- Un
+00:00indiquait qu'on utilisait UTC comme référence (identique au cas précédent), - Un
-00:00indiquait qu'on n'avait aucune idée sur la référence (typiquement parce qu'on voudrait connaitre l'heure locale mais qu'on ne la connait pas).
(Au passage, si vous ne connaissiez pas ces trois cas et leurs
différences, ne vous inquiétez pas, vous n'étiez pas seul·e.) Notre
RFC change cela (section 2) en décidant que Z est désormais synonyme
de -00:00 plutôt que de
+00:00, un changement qui aura sans doute peu
d'importance en pratique.
L'autre nouveauté de ce RFC 9557 est plus marquante, c'est le format étendu IXDTF (section 3). Il consiste à ajouter à la fin de l'estampille une série (facultative) de couples {clé, valeur}, entre crochets. Si la clé est absente, c'est que la valeur est un fuseau horaire, suivant la syntaxe de la base TZ. Voici un exemple :
2022-07-08T12:14:37+02:00[Europe/Paris][u-ca=hebrew]
Cet exemple indique que le fuseau horaire était celui de
Paris (cf. le format de
ces noms de fuseaux) et que le calendrier préféré (clé
u-ca), pour afficher cette date, serait le
calendrier hébreu (ce qui indiquera 9 Tammouz
5782, sauf erreur).
Un point d'exclamation avant la clé indiquerait que la clé doit être comprise par le lecteur, sinon, il faut qu'il ignore l'estampille temporelle (la plupart du temps, l'application peut ignorer les clés et leurs valeurs). Un trait bas indique une clé expérimentale, non officiellement enregistrée.
Car notre RFC crée aussi un registre
des clés. Pour l'instant, il ne compte qu'une seule clé,
u-ca, pour indiquer le calendrier préféré. Pour
enregistrer une nouvelle clé, il faut une spécification écrite
(cf. RFC 8126), mais il y a aussi des
enregistrements temporaires, plus légers.
Et on termine par un petit mot sur la sécurité (section 7). Le RFC rappelle que plus on donne d'informations, plus on risque d'en donner trop. Ainsi, l'indication du calendrier préféré peut indiquer une origine ethnique ou religieuse, qui peut être considérée comme privée, surtout s'il y a des risques d'attaques racistes.
L'article seul
RFC 9549: Internationalization Updates to RFC 5280
Date de publication du RFC : Mars 2024
Auteur(s) du RFC : R. Housley (Vigil Security)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF lamps
Première rédaction de cet article le 22 novembre 2024
Ce court RFC ajoute aux certificats PKIX du RFC 5280 la possibilité de contenir des adresses de courrier électronique dont la partie locale est en Unicode. Et il modifie légèrement les règles pour les noms de domaine en Unicode dans les certificats. Il remplace le RFC 8399, avec peu de changements.
Les certificats sur
l'Internet sont normalisés dans le RFC 5280, qui décrit un profil de
X.509 nommé PKIX
(définir un profil était nécessaire car la norme X.509 est bien trop
riche et complexe). Ce RFC 5280 permettait des
noms de domaine en
Unicode (sections 4.2.1.10 et 7 du RFC 5280) mais il suivait l'ancienne norme IDN, celle des
RFC 3490 et suivants. Depuis, les IDN sont
normalisés dans le RFC 5890 et suivants, et
notre nouveau RFC 9549 modifie très légèrement le RFC 5280 pour s'adapter à cette nouvelle norme de
noms de domaines en Unicode. Les noms de domaine dans un certificat
peuvent être présents dans les champs Sujet (titulaire du
certificat) et Émetteur (AC ayant signé le certificat) mais aussi
dans les contraintes sur le nom (une autorité de certification peut être
limitée à des noms se terminant en example.com,
par exemple).
Notez que, comme avant, ces noms sont exprimés dans le certificat
en Punycode (RFC 3492,
xn--caf-dma.fr au lieu de
café.fr), appelé A-label
dans notre RFC. C'est un bon exemple du fait que les
limites qui rendaient difficiles d'utiliser des noms de domaine en
Unicode n'avaient rien à voir avec le DNS (qui n'a jamais été limité à
ASCII, contrairement à ce qu'affirme une légende
courante). En fait, le problème venait des applications (comme
PKIX), qui ne s'attendaient pas à des noms en
Unicode. Un logiciel qui traite des certificats aurait été bien
étonné de voir des noms de domaines non-ASCII, et
aurait peut-être planté. D'où ce choix du
Punycode (A-label) par opposition à la forme plus
lisible du U-label.
Nouveauté plus importante du RFC 8399, mis à jour par notre RFC 9549, les adresses de courrier électronique en Unicode (EAI pour Email Address Internationalization). Elles étaient déjà permises par la section 7.5 du RFC 5280, mais seulement pour la partie domaine (à droite du @). Désormais, elles sont également possibles dans la partie locale (à gauche du @). Le RFC 8398 donne tous les détails sur ce sujet.
Reste à savoir quelles AC acceptent
Unicode. En 2018, j'avais testé avec
Let's Encrypt (avec le
client Dehydrated, en
mettant le Punycode dans domains.txt) et ça
marchait, regardez le certificat de https://www.potamochère.fr/
% gnutls-cli www.potamochère.fr
...
- subject `CN=www.xn--potamochre-66a.fr', issuer `CN=R10,O=Let's Encrypt,C=US', serial 0x03a34cfc017b4311da0b21797cd250ebd3c0, RSA key 4096 bits, signed using RSA-SHA256, activated `2024-11-01 05:26:59 UTC', expires `2025-01-30 05:26:58 UTC', pin-sha256="6y…
D'autres AC acceptent ces noms en Unicode : Gandi le fait aussi, par exemple. On
notera que le célèbre service de test de la qualité des
configurations TLS, SSLlabs, gère bien les IDN :
Enfin, le registre du
.ru a participé au développement de
logiciels pour traiter l'Unicode dans les certificats.
La section 1.2 résume les changements depuis le RFC 8399. Notamment :
- Le RFC 8399 ne les mentionnait pas
mais les emojis ne sont pas
autorisés dans les noms de domaine (ils appartiennent à la
catégorie Unicode So, « Autres symboles », que le RFC 5890 n'inclut pas). Comme le rappelle notre RFC 9549, un nom comme
♚.examplene serait pas légal. Ce point est désormais explicite. - Si le RFC 8399 prescrivait certains
traitements à faire sur la forme Unicode
(U-label) des noms, désormais, tout se fait sur
la forme en Punycode (A-label, donc
xn--potamochre-66a.fret paspotamochère.fr). Cela permet d'éviter de déclencher certaines failles de sécurité.
L'article seul
RFC 9547: Report from the IAB Workshop on Environmental Impact of Internet Applications and Systems, 2022
Date de publication du RFC : Février 2024
Auteur(s) du RFC : J. Arkko, C. S. Perkins, S. Krishnan
Pour information
Première rédaction de cet article le 24 avril 2024
La question de l'empreinte environnementale du numérique suscite beaucoup de débats. L'IAB avait organisé en décembre 2022 un atelier sur le cas de l'empreinte environnementale de l'Internet dont ce RFC est le compte-rendu (tardif, oui, je sais, mais mon propre article de résumé du RFC est aussi en retard).
Le sujet est très complexe, relativement nouveau, et surtout noyé sous beaucoup d'approximations, voire de franches bêtises (l'ADEME s'en est fait une spécialité, avec des chiffres tirés du chapeau et à la méthodologie inconnue). Il y a donc du travail sur la planche. L'IAB commence par estimer que l'Internet a certes une empreinte environnementale mais peut aussi servir à diminuer l'empreinte environnementale globale, ce qui n'est franchement pas étayé (le RFC cite l'exemple de réunions physiques remplacées par des réunions en ligne, sans citer de calcul détaillé qui permettrait de voir s'il y a vraiment un gain, et en oubliant que de toute façon une réunion en ligne ne rend pas les mêmes services). Mais l'IAB note aussi que l'Internet a des effets indirects, et pas forcément positifs : il cite l'exemple de l'augmentation de la consommation de biens matériels que produit le commerce en ligne.
Clairement, l'Internet n'est pas virtuel, contrairement à ce que prétend le marketing qui abuse de termes comme cloud pour faire croire que le numérique est immatériel. A contrario, l'Internet dépend de machines, de l'électricité (et des humains qui font fonctionner ces machines). Que peut-on faire pour diminuer l'empreinte environnementale de l'Internet ? (Sans pour autant suivre les conseils débiles de l'ADEME, comme de supprimer ses messages.)
Comme tous les ateliers de l'IAB, celui-ci a fonctionné en demandant aux participants des position papers expliquant leur point de vue. Ne participent à l'atelier que des gens ayant écrit un de ces articles, ce qui garantit que tout le monde a dû travailler le sujet. Ces articles sont disponibles en ligne, plus exactement à cet endroit. (Tous les documents liés à cet atelier sont également disponibles.) Parmi les papiers acceptés :
- « Extending IPv6 to support Carbon Aware Networking », où comment rendre les équipements réseau plus conscients des conséquences environnementales,
- « Frugal Computing », sur la sobriété numérique,
- « Internet Infrastructure and Climate Justice », qui se focalise davantage sur l'aspect politique (il y a d'autres prises de position de l'auteure, et une collection de liens utiles),
- Et de nombreux autres, souvent très intéressants.
La section 2 du RFC détaille les sujets qui étaient dans le programme de l'atelier :
- Les impacts environnementaux directs de l'Internet (consommation électrique des machines, des routeurs aux serveurs en passant par les machines terminales, refroidissement, fabrication des machines, et leur traitement final, souvent oublié dans les études),
- Les impacts indirects de l'Internet, provenant des effets qu'il a sur la société,
- Les métriques (souvent très maltraitées dans les artcles parlant de l'empreinte environnementale du numérique, par exemple en confondant énergie et puissance), un sujet crucial puisqu'on ne peut pas améliorer ce qu'on ne peut pas mesurer,
- Les questions non techniques, comme les enjeux financiers ou comme la régulation,
- Les questions techniques où l'IETF pourrait travailler pour améliorer les choses (par exemple, mais non cité par le RFC, annoncer dans les réponses HTTP le coût environnemental de la requête),
- Mais aussi les questions liées aux usages et aux utilisateurices, qui sont souvent sollicités, mais en général de manière culpabilisatrice (« regardez les vidéos en basse définition et pas de porno »).
Ah et, si vous vous le demandez, l'atelier a été entièrement en ligne (section 2.1 du RFC).
La première des quatre sessions de l'atelier essayait d'aborder le problème de manière générale. Le problème du réchauffement climatique est évidemment bien plus vaste que l'Internet seul et n'a pas de solution simple et unique. Et les solutions ne sont pas toutes techniques, donc il y a des limites à ce que l'IETF peut faire (ce qui ne veut pas dire qu'il ne faut rien faire !). Même la publicité est mentionnée dans cette section du RFC, avec un très prudent « davantage d'études sont nécessaires » (opinion personnelle : son attitude au sujet de la publicité est un bon moyen de savoir si votre interlocuteur veut sérieusement lutter contre le réchauffement climatique, ou bien s'il veut juste faire des discours).
Ensuite, deuxième session sur les mesures et la récolte des faits. Par exemple, où sont les gros postes de consommation électrique dans le numérique ? Les serveurs ? Les routeurs ? Les terminaux ? C'est d'autant plus important que le RFC note la quantité de fausses informations qui circulent (citant par exemple un article qui confondait MB/s et Mb/s, soit un facteur 8 de différence). De même, contrairement à ce qui est encore souvent dit, la session a mis en évidence le fait que la consommation électrique n'est pas du tout proportionnelle au trafic. Des phrases comme « envoyer un courrier dégage autant de dioxyde de carbone qu'un vol Paris-Quelquepart » n'ont donc aucun sens. (Un des papiers acceptés, « Towards a power-proportional Internet » expliquait pourquoi il fallait changer cela et comment le faire.) Par contre, les usages impactent la consommation car ils peuvent nécessiter des mises à jour du réseau.
La troisième session regardait du côté des pistes d'amélioration,
plus précisement de celles sur lesquelles l'IETF pouvait agir. Le
premier point est celui des mesures (insuffisantes et parfois
contradictoires). Le deuxième point concernait l'influence de
phénomènes comme la gigue (RFC 4689) ou l'élongation du
trajet (RFC 7980) sur la consommation énergétique (si on
réduit ces phénomènes grâce à de meilleurs protocoles, est-ce qu'on
diminue la consommation ?). Parmi les autres optimisations
possibles, le choix de meilleurs formats, plus optimisés
(CBOR - RFC 8949 - est
cité). Notez qu'un des articles acceptés pour l'atelier faisait le
point sur toutes les activités de l'IETF liées à l'énergie,
draft-eckert-ietf-and-energy-overview.
Et la quatrième et dernière session portait sur les étapes suivantes du travail ; en résumé, il y a du travail et, même si l'IETF ne peut pas tout, elle doit en prendre sa part. Il faut toujours garder en tête que le but n'est pas de réduire l'empreinte environnementale de l'Internet mais de réduire celle de l'ensemble de la société. Éteindre l'Internet diminuerait certainement son empreinte environnementale mais pourrait avoir des effets négatifs sur d'autres secteurs, comme les transports. Pour améliorer l'Internet sans le supprimer, plusieurs axes ont été mis en avant :
- Mesurer, toujours mesurer, on manque d'informations,
- Pouvoir diminuer la consommation quand il n'y a pas de travail en cours, voire hiberner, serait utile (comme dans beaucoup de cas, le problème est complexe : un routeur ne peut pas hiberner car il ne sait pas quand arrivera le prochain paquet, et il ne peut pas se réveiller instantanément),
- Adopter de meilleurs formats de données. Comme le disait un des articles présentés, « CBOR est plus vert ».
Et les actions concrètes (section 2.4.3) ?
- Faut-il imposer dans chaque RFC une section Environmental considerations comme il y a déjà une Security considerations obligatoire ? (La question s'était déjà posée pour une éventuelle Human rights considerations.) Pour l'instant, ce n'est pas prévu notamment parce que, dans l'état actuel des choses, la plupart des auteurs de RFC n'ont pas de connaissances suffisamment approfondies ur le sujet pour écrire une section utile.
- Plusieurs groupes à l'IETF sont déjà au travail sur ce sujet environnemental : NMRG travaille sur les métriques (et a, par exemple, un Internet-Draft « Challenges and Opportunities in Management for Green Networking »), même chose à OPSAWG et le nouveau groupe TVR (Time-Variant Routing), comme il travaille sur le routage intermittent, a également un rôle, par exemple lorsqu'on coupe des liens pour économiser de l'énergie. Là, on est pile dans le rôle de l'IETF.
- Curieusement, le RFC parle aussi d'éviter les NFT, qui ne sont pourtant plus guère à la mode (et n'ont jamais suscité beaucoup d'intérêt à l'IETF, de toute façon). En outre, la plupart d'entre eux tournent sur Ethereum, qui n'utilise plus la preuve de travail et n'est donc pas crucial du point de vue environnemental.
Si vous voulez participer au nouveau programme de l'IAB E-IMPACT, tout est là.
Puisqu'on parlait de la section sur la sécurité qui est obligatoire dans les RFC, notre RFC en a une, qui rappelle que :
- Tout mécanisme par lequel on donne des pénalités (financières ou bien en terme de diminution des ressources allouées) en fonction de métriques d'empreinte environnementale doit se préparer à ce qu'il y ait des tricheurs (cf. P. McDaniel, « Sustainability is a Security Problem », à la conférence SIGSAC en 2022), qui faussent les mesures pour échapper à ces pénalités.
- De même, tout mécanisme qui va agir sur le réseau, par exemple pour diminuer l'empreinte environnementale, peut être détourné pour une attaque par déni de service, et doit donc prévoir le problème.
L'article seul
RFC 9537: Redacted Fields in the Registration Data Access Protocol (RDAP) Response
Date de publication du RFC : Mars 2024
Auteur(s) du RFC : J. Gould, D. Smith (VeriSign), J. Kolker, R. Carney (GoDaddy)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 14 juillet 2024
RDAP est le protocole recommandé pour accéder aux données sociales sur un nom de domaine, comme le nom du titulaire ou son adresse postale. Pour d'évidentes raisons de vie privée, certains registres ne renvoient pas la totalité de l'information dont ils disposent. Que doit-on mettre dans RDAP dans ce cas ? La question n'était pas tranchée et chaque registre faisait différemment. Désormais, il existe une solution normalisée.
Au passage, oui, d'accord, il n'y a pas que
RDAP pour obtenir les données sociales (cet
article vous en indiquera d'autres). Mais c'est le service le
plus moderne et le plus adapté
aux programmeur·ses. Contacté en HTTPS, le serveur RDAP va
renvoyer du JSON que le client n'aura plus qu'à filtrer et
formatter. Voici par exemple une partie de la réponse RDAP obtenue
en se renseignant sur
nouveaufrontpopulaire.fr :
% curl -s https://rdap.nic.fr/domain/nouveaufrontpopulaire.fr | jq
…
[
"fn",
{},
"text",
"Parti Socialiste"
],
[
"org",
{},
"text",
"Parti Socialiste"
],
[
"adr",
{},
"text",
[
"",
"",
"99 Rue Moliere",
"Ivry-sur-Seine",
"",
"94200",
"FR"
]
],
…
Ici, il s'agit d'une personne morale donc les données sont toutes envoyées. Et s'il s'agissait d'une personne physique, pour laquelle la loi Informatique & et Libertés s'applique, depuis 1978 ? La solution évidente est de ne pas envoyer les données qu'on ne veut pas diffuser mais attention, il y a un piège, il ne faut pas casser la syntaxe JSON. Par exemple, RDAP utilise (c'est en cours de changement, cf. RFC 9553) jCard pour formater les adresses (RFC 7095) et les champs dans jCard ne sont pas étiquetés, c'est leur position dans le tableau qui indique leur rôle (c'est un des nombreux inconvénients de jCard). On ne peut donc pas supprimer, par exemple, la rue, en indiquant :
[
"adr",
{},
"text",
[
"",
"",
"Ivry-sur-Seine",
"",
"94200",
"FR"
]
],
[
"email",
{},
"text",
"e5d92838d5f0268143ac47d86880b5f7-48916400@contact.gandi.net"
],
Car, alors, on ne saurait plus si "Ivry-sur-Seine" est la rue ou bien la ville.
Le principe de notre RFC est donc : si on peut, retirer le membre
JSON. Si on ne peut pas (cas du tableau de taille fixe), mettre une
valeur vide ou null.
Petit point de terminologie : comment traduire le redacted du titre ? « Censuré » est inadapté (l'intervention ne vient pas d'un tiers mais d'une des deux parties). Je vais dire « élidé », mais « caviardé », « biffé » et « expurgé » sont également de bonnes solutions. Le nom correspondant est « élision ». Évidemment, il ne faut surtout pas dire « anonymisé », il n'y a rien d'anonyme ici, puisque le registre connait toute l'information, il refuse simplement de la diffuser.
La section 1 du RFC expose les grands principes de
l'élision. Elle explique notamment qu'en cas d'élision, il faut
ajouter un membre (nommé redacted) à la réponse
JSON, expliquant les raisons et utilisant le langage
JSONPath (RFC 9535)
pour désigner de manière formelle la partie élidée.
Compte-tenu des contraintes sur la syntaxe de la réponse JSON (RFC 9083), le RFC normalise quatre façons d'élider (section 3) :
- Suppression d'un champ, si possible (c'est la méthode préférée). Cela marche dans la plupart des cas. Par exemple, si on ne veut pas publier le titulaire d'un domaine, on ne l'inclut pas dans la réponse, point.
- Mettre une valeur vide. Quand les contraintes de syntaxe empêchent de supprimer complètement un champ, on lui met une valeur vide. C'est notamment nécessaire pour les tableaux que jCard utilise abondamment : le retrait d'un champ casserait le tableau, qui est censé avoir un nombre d'élements fixe.
- Une valeur trop détaillée peut être remplacée par une
valeur partielle. L'adresse
"label":"123 Maple Ave\nSuite 901\nVancouver BC\nCanada"(un exemple du RFC 7095) peut être remplacée par une valeur moins précise comme"label":"Vancouver\nBC\nCanada\n". - Enfin, la dernière méthode est de remplacer une valeur par
une autre, par exemple une adresse de courrier par une adresse qui masque la
vraie, comme
e5d92838d5f0268143ac47d86880b5f7-48916400@contact.gandi.netdans l'exemple plus haut.
Et le RFC insiste qu'il ne faut pas utiliser de texte bidon (« XXX », « lorem ipsum dolor » ou « Ano Nymous ») car ce texte ne correspond pas forcément aux règles de syntaxe du champ (et, j'ajoute, peut être difficile à identifier pour le lecteur, qui peut ne pas avoir la référence).
Pour la première méthode, la suppression d'un champ, si on
supprime le titulaire, on aura un membre nommé
redacted (élidé) ajouté ainsi :
"redacted": [
{
"name": {
"description": "Remove registrant"
},
"prePath": "$.entities[?(@.roles[0]=='registrant')]",
"method": "removal"
}
]
Notez le (difficile à lire) code JSONPath
$.entities[?(@.roles[0]=='registrant')].
Le deuxième cas, celui d'une valeur vide, donnerait, pour le cas où on supprime juste le nom du titulaire (qui est en position 1 dans le jCard, et son nom en position 3 - sachant qu'on part de 0) :
[
"fn",
{},
"text",
""
]
…
"redacted": [
{
"name": {
"description": "Registrant Name"
},
"postPath": "$.entities[?(@.roles[0]=='registrant')].
vcardArray[1][?(@[0]=='fn')][3]",
"pathLang": "jsonpath",
"method": "emptyValue",
"reason": {
"description": "Server policy"
}
}
]
Troisième technique d'élision, réduire une valeur. Le
redacted devient :
"redacted": [
{
"name": {
"description": "Home Address Label"
},
"postPath": "$.vcardArray[1][?(@[0]=='adr')][1].label",
"pathLang": "jsonpath",
"method": "partialValue",
"reason": {
"description": "Server policy"
}
}
]
Et pour finir, la quatrième et dernière méthode, le remplacement :
"redacted": [
{
"name": {
"description": "Registrant Email"
},
"postPath": "$.entities[?(@.roles[0]=='registrant')].
vcardArray[1][?(@[0]=='email')][3]",
"pathLang": "jsonpath",
"method": "replacementValue",
}
]
Ce membre appelé redacted est spécifié en
détail dans la section 4 du RFC. (Et il est enregistré à l'IANA parmi les extensions RDAP.) Pour signaler qu'il peut
apparaitre, le membre rdapConformance de la
réponse JSON va l'indiquer :
{
"rdapConformance": [
"itNic",
"redacted",
"rdap_level_0"
],
…
Dès qu'il y a élision, redacted doit être
ajouté. Il contient un tableau JSON d'objets, dont les membres
peuvent être (seul le premier est obligatoire) :
name: un terme qui décrit le champ élidé,prePathetpostPath: des expressions JSONPath (RFC 9535) qui dénotent le membre retiré ou modifié,method: la technique d'élision utilisée (suppression, nettoyage, remplacement, etc),reason: texte libre décrivant la raison de l'élision.
L'article seul
RFC 9536: Registration Data Access Protocol (RDAP) Reverse Search
Date de publication du RFC : Avril 2024
Auteur(s) du RFC : M. Loffredo, M. Martinelli (IIT-CNR/Registro.it)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 28 octobre 2024
Ce RFC normalise une extension au protocole d'accès à l'information RDAP pour permettre des recherches inversées, des recherches par le contenu (« quels sont tous les noms de domaine de cette personne ? »).
Alors, tout d'abord, un avertissement. L'extension normalisée dans ce RFC est dangereuse pour la vie privée. Je détaille ce point plus loin mais ne réclamez pas tout de suite le déploiement de cette extension : lisez tout d'abord. C'est dès sa section 1 que le RFC met en garde contre un déploiement hâtif !
RDAP (normalisé dans les RFC 9082 et RFC 9083), comme son prédécesseur whois, permet d'obtenir des informations dites sociales (nom, adresse, numéro de téléphone, etc) sur les personnes (morales ou physiques) associées à une ressource Internet réservée, comme un nom de domaine ou un adresse IP. Une limite importante de ces deux protocoles est qu'il faut connaitre l'identifiant (nom de domaine, adresse IP) de la ressource. Or, certaines personnes seraient intéressés à faire l'inverse, découvrir les ressources à partir d'informations sociales. C'est le cas par exemple de juristes cherchant le portefeuille de noms de domaine de quelqu'un qu'ils soupçonnent de menacer leur propriété intellectuelle. Ou de chercheurs en sécurité informatique étudiant toutes les adresses IP utilisées par le C&C d'un botnet et voulant en découvrir d'autres. Ce RFC normalise justement un moyen de faire des recherches inverses. whois n'avait jamais eu une telle normalisation, à cause des risques pour la vie privée, risques qui sont peut-être moins importants avec RDAP.
(Notez quand même que le RFC 9082, section 3.2.1, prévoyait déjà certaines recherches inverses, d'un domaine à partir du nom ou de l'adresse d'un de ses serveurs de noms.)
Passons aux détails techniques (section 2). L'URL
d'une requête inverse va inclure dans son chemin
/reverse_search et, bien sûr, des critères de
recherche. Par exemple,
/domains/reverse_search/entity?fn=Jean%20Durand&role=registrant
donnera tous les domaines dont le titulaire
(registrant) se nomme Jean Durand
(fn est défini dans la section 6.2.1 du RFC 6350). Le terme après
/reverse_search indique le type des données
auxquelles s'appliquent les critères de recherche (actuellement,
c'est forcément entity, une personne morale ou
physique).
La plupart des recherches inverses porteront sans doute sur quelques champs comme l'adresse de courrier électronique ou le handle (l'identifiant d'une entité). La section 8 décrit les possibilités typiques mais un serveur RDAP choisit de toute façon ce qu'il permet ou ne permet pas.
La sémantique exacte d'une recherche inverse est décrite en
JSONPath (RFC 9535). Vous trouvez le JSONPath dans la réponse (section
5 du RFC), dans le membre
reverse_search_properties_mapping. Par exemple :
"reverse_search_properties_mapping": [
{
"property": "fn",
"propertyPath": "$.entities[*].vcardArray[1][?(@[0]=='fn')][3]"
}
]
L'expression JSONPath
$.entities[*].vcardArray[1][?(@[0]=='fn')][3]
indique que le serveur va faire une recherche sur le membre
fn du tableau vCard
(RFC 7095). Oui, elle est compliquée, mais
c'est parce que le format vCard est compliqué. Heureusement, on
n'est pas obligé de connaitre JSONPath pour utiliser les recherches
inverses, uniquement pour leur normalisation (section 3).
Pour savoir si le serveur RDAP que vous interrogez gère cette
extension et quelles requêtes il permet, regardez sa réponse à la
question help (RFC 9082,
section 3.1.6, et RFC 9083, section 7) ; s'il
accepte les requêtes inverses, vous y trouverez la valeur
reverse_search dans le membre
rdapConformance (section 9), par exemple :
"rdapConformance": [
"rdap_level_0",
"reverse_search"
]
Pour les recherches acceptées, regardez le membre
reverse_search_properties. Par exemple :
"reverse_search_properties": [
{
"searchableResourceType": "domains",
"relatedResourceType": "entity",
"property": "fn"
}
]
Ici, le serveur indique qu'il accepte les requêtes inverses pour trouver des noms de domaine en fonction d'un nom d'entité (ce que nous avons fait dans l'exemple plus haut). Voir la section 4 pour les détails. Si vous tentez une requête inverse sur un serveur, et que le serveur n'accepte pas les requêtes inverses, ou tout simplement n'accepte pas ce type particulier de recherche inverse que vous avez demandé, il répondra avec le code de retour HTTP 501 (section 7). Vous aurez peut-être aussi un 400 si votre requête déplait au serveur pour une raison ou l'autre.
L'extension est désormais placée dans le registre des extensions RDAP. En outre, deux nouveaux registres sont créés, RDAP Reverse Search, pour les recherches possibles et RDAP Reverse Search Mapping pour les règles JSONPath. Pour y ajouter des valeurs, la politique (RFC 8126) est « spécification nécessaire ».
Revenons maintenant aux questions de vie privée (RFC 6973), que je vous avais promises. La section 12 du RFC détaille le problème. La puissance des recherches inverses les rend dangereuses. Une entreprise concurrente pourrait regarder vos noms de domaine et ainsi se tenir au courant, par exemple, d'un nouveau projet ou d'un nouveau produit. Un malveillant pourrait regarder les noms de domaine d'une personne et identifier ainsi des engagements associatifs que la personne ne souhaitait pas forcément rendre très visibles. Les données stockées par les registres sont souvent des données personnelles et donc protégées par des lois comme le RGPD. Le gestionnaire d'un serveur RDAP doit donc, avant d'activer la recherche inverse, bien étudier la sécurité du serveur (section 13) mais aussi (et ce point n'est hélas pas dans le RFC) se demander si cette activation est vraiment une bonne idée.
En théorie, RDAP pose moins de problème de sécurité que whois pour ce genre de recherches, car il repose sur HTTPS (le chiffrement empêche un tiers de voir questions et réponses) et, surtout, il permet l'authentification ce qui rend possible, par exemple, de réserver les recherches inverses à certains privilégiés, avec un grand choix de contrôle d'accès (cf. annexe A). Évidemment, cela laisse ouvertes d'autres questions comme « qui seront ces privilégiés ? » et « comment s'assurer qu'ils n'abusent pas ? » (là, les journaux sont indispensables pour la traçabilité, cf. l'affaire Haurus).
Notons qu'outre les problèmes de vie privée, la recherche inverse pose également des problèmes de performance (section 10). Attention avant de la déployer, des requêtes apparemment innocentes pourraient faire ramer sérieusement le serveur RDAP. Si vous programmez un serveur RDAP ayant des recherches inverses, lisez bien les recommandations d'optimisation de la section 10, par exemple en ajoutant des index dans votre SGBD. Et le serveur ne doit pas hésiter, en cas de surcharge, à répondre seulement de manière partielle (RFC 8982 ou RFC 8977).
Je n'ai pas trouvé de code public mettant en œuvre ces recherches inverses. De même, je ne connais pas encore de serveur RDAP déployé qui offre cette possibilité.
L'article seul
RFC 9535: JSONPath: Query Expressions for JSON
Date de publication du RFC : Février 2024
Auteur(s) du RFC : S. Gössner (Fachhochschule Dortmund), G. Normington, C. Bormann (Universität Bremen TZI)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF jsonpath
Première rédaction de cet article le 14 février 2025
Le langage JSONPath sert à désigner une partie d'un document JSON. Il est donc utile pour, par exemple, extraire des valeurs qui nous intéressent.
Il existe de nombreux langages pour cela (une liste partielle figure à la fin de l'article), pas forcément normalisés mais mis en œuvre dans tel ou tel logiciel (dont, évidemment, jq). Ce RFC est, je crois, la première normalisation formelle d'un tel langage. Voici tout de suite un exemple, utilisant le logiciel jpq, sur la la base des arbres parisiens :
% jpq '$[*].libellefrancais' arbres.json [ "Marronnier", "Aubépine", "Cerisier à fleurs", …
Cela se lit « affiche les noms d'espèce
[libellefrancais, dans le fichier] de tous
[vous avez vu l'astérisque] les
arbres ». (Avec jq, on aurait écrit jq
'.[].libellefrancais' arbres.json.) Voyons maintenant les
détails.
JSONPath travaille sur des
documents JSON, JSON étant normalisé dans le RFC 8259. Il n'est sans doute pas utile de
présenter JSON, qui est utilisé partout aujourd'hui. Notons
simplement que l'argument d'une requête JSONPath, écrit en JSON, est
ensuite modélisé comme un arbre, composé de
nœuds. Le JSON {"foo": 3, "bar": 0} a ainsi une
racine de l'arbre sous laquelle se trouvent deux nœuds, avec comme
valeur 3 et 0 (les noms des membres JSON, foo
et bar, ne sont pas sélectionnables par
JSONPath et donc pas considérés comme nœuds).
Vous êtes impatient·e de vous lancer ? On va utiliser le logiciel jpq cité plus haut. Pensez à installer un Rust très récent puis :
cargo install jpq
Ou bien, si vous voulez travailler à partir des sources :
git clone https://codeberg.org/KMK/jpq.git cd jpq cargo install --path .
Puis pensez à modifier votre chemin de recherche d'exécutables si ce n'est pas déjà fait (notez que l'excellente Julia Evans vient justement de faire un très bon article sur ce sujet). Testez :
% echo '["bof"]' | jpq '$[0]' [ "bof" ]
Les choses utiles à savoir pour écrire des expressins JSONPath :
- Le dollar indique la racine de l'arbre JSON.
- L'expression JSONPath est faite de
segments, chaque segment permettant de
filtrer une partie du document JSON (dans l'exemple immédiatement
au-dessus,
[0]est un segment sélectionnant le premier élément d'un tableau, ici, le seul). - Des sélecteurs sont utilisés dans les segments pour sélectionner via le nom d'un membre JSON ou via un indice (0 dans l'exemple plus haut).
La grammaire complète (en ABNF, RFC 5234) figure dans l'annexe A du RFC.
Allez, passons aux exemples, avec les arbres parisiens comme document JSON. Le quatrième arbre du document (on part de zéro) :
% jpq '$[3]' arbres.json
[
{
"idbase": 143057,
"typeemplacement": "Arbre",
"domanialite": "CIMETIERE",
"arrondissement": "PARIS 20E ARRDT",
"complementadresse": null,
"numero": null,
"adresse": "CIMETIERE DU PERE LACHAISE / DIV 41",
"idemplacement": "D00000041050",
"libellefrancais": "Erable",
…
Tous les genres (dans la classification de Linné) :
% jpq '$[*].genre' arbres.json [ "Aesculus", "Crataegus", "Prunus", …
Les sélecteurs par nom peuvent s'écrire avec un point, comme ci-dessus, ou bien entre crochets avec des apostrophes (notez comme c'est moins pratique pour le shell Unix) :
% jpq "\$[*]['genre']" arbres.json [ "Aesculus", "Crataegus", "Prunus", …
La forme avec les crochets est la forme canonique pour une expression JSONPath. La notation avec un point n'est acceptée que pour les noms, pas pour les indices :
% echo '[1, 2, 3]' | jpq '$[1]' [ 2 ] % echo '[1, 2, 3]' | jpq '$.1' Error: × Invalid JSONPath: at position 2, in dot member name, must start with lowercase alpha or '_' ╭──── 1 │ $.1 · ▲ · ╰── in dot member name, must start with lowercase alpha or '_' ╰────
La taille de tous les arbres qui font plus de 50 mètres de haut :
% jpq '$[?@.hauteurenm > 50].hauteurenm' < arbres.json [ 120, 69, 100, 67, 58, 74, 911 ]
L'arobase indique le nœud en cours d'évaluation. Et, oui, l'arbre de 911 mètres de haut est une erreur, chose courante dans les données ouvertes.
Comme vous avez vu, la requête JSONPath renvoie toujours une liste de nœuds, affichée par jpq dans la syntaxe des tableaux JSON.
Vous avez vu, dans l'exemple où on cherchait les plus grands arbres, que JSONPath permet de faire des comparaisons. Vous avez droit à tous les opérateurs booléens classiques. Ici, l'identificateur de tous les arbres situés dans un cimetière :
% jpq '$[?@.domanialite == "CIMETIERE"].idbase' < arbres.json [ 143057, 165296, 166709, …
JSONPath permet d'ajouter des fonctions, qui ne sont utilisables
que pour les comparaisons (je ne crois pas qu'on puisse mettre leur
résultat dans la valeur retournée par JSONPath). Plusieurs d'entre
elles sont définies par ce RFC, comme length(),
mais pas forcément mises en œuvre dans tous les programmes. Et pour
compliquer les choses, des implémentations de JSONPath ajoutent
leurs propres fonctions non enregistrées et qui rendent l'expression
non portable.
Deux de ces fonctions,
search() et match(),
prennent en paramètre une expression
rationnelle, à la syntaxe du RFC 9485.
Les expressions JSONPath, quand on les envoie via l'Internet,
peuvent être marquées avec le type application/jsonpath,
désormais enregistré
(section 3 du RFC). En plus, un
nouveau registre IANA est créé, pour stocker les fonctions
mentionnées au paragraphe précédent. Pour ajouter des fonctions à ce
registre, il faut passer par la procédure « Examen par un expert »
du RFC 8126.
La section 4, sur la sécurité, est très détaillée. JSONPath était souvent mis en œuvre en passant directement l'expression ou une partie d'entre elle au langage sous-jacent (typiquement JavaScript). Inutile de détailler les énormes problèmes de sécurité que cela pose si l'expression évaluée est, en tout ou en partie, fournie par un client externe (par exemple via un formulaire Web), permettant ainsi l'injection de code. Une validation de ces expressions avant de les passer étant irréaliste, le RFC insiste sur le fait qu'une mise en œuvre de JSONPath doit avoir son propre code et ne pas compter sur une évaluation par le langage de programmation sous-jacent.
Même ainsi, une expression JSONPath peut permettre une attaque par déni de service, si une expression mène à une consommation de ressources excessive. (Cf. la section 10 du RFC 8949 et la section 8 du RFC 9485.)
La section 1.2 de notre RFC décrit l'histoire un peu
compliquée de JSONPath. (Une des raisons pour lesquelles il
existe plusieurs langages de requête dans JSON est que JSONPath a
mis du temps à être terminé.) L'origine de JSONPath date de
2007, dans cet article de
Gössner (un des auteurs du RFC). L'interprétation de ce premier
JSONPath était souvent déléguée au langage sous-jacent (le
eval() de JavaScript…)
avec les problèmes de sécurité qu'on imagine. Le JSONPath actuel se
veut portable, au sens où il ne dépend pas d'un langage
d'implémentation particulier, ni d'un moteur
d'expressions rationnelles
particulier. L'inconvénient est qu'il n'est pas forcément compatible
avec l'ancien JSONPath.
JSONPath a aussi été inspiré par le XPath de XML (cf. annexe B de notre RFC, qui détaille cette inspiration, et compare les deux langages). On peut aussi comparer JSONPath à JSON Pointer (RFC 6901), ce qui est fait dans l'annexe C.
Il existe bien sûr d'autres mises en œuvre de JSONPath que jpq. Mais attention : certaines sont très anciennes (comme Python JSONPath RW) et ne correspondent pas à ce qui est normalisé dans le RFC. Essayons Python JSONPath Next-Generation :
% python
Python 3.13.2 (main, Feb 5 2025, 01:23:35) [GCC 14.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from jsonpath_ng.ext import filter, parse
>>> import json
>>> data = json.load(open("arbres.json"))
>>> expr = parse("$[?@.hauteurenm > 50].hauteurenm")
>>> result = expr.find(data)
>>> for r in result:
... print(r.value)
...
120
69
100
67
58
74
911
D'autres langages de requête dans le JSON existent, chacun avec sa syntaxe :
L'article seul
RFC 9499: DNS Terminology
Date de publication du RFC : Mars 2024
Auteur(s) du RFC : P. Hoffman (ICANN), K. Fujiwara
(JPRS)
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 3 mai 2024
Comme beaucoup de protocoles très utilisés sur l'Internet, le DNS est ancien. Très ancien (la première norme, le RFC 882, date de 1983). Les normes techniques vieillissent, avec l'expérience, on comprend mieux, on change les points de vue et donc, pour la plupart des protocoles, on se lance de temps en temps dans une révision de la norme. Mais le DNS est une exception : la norme actuelle reste fondée sur des textes de 1987, les RFC 1034 et RFC 1035. Ces documents ne sont plus à jour, modifiés qu'ils ont été par des dizaines d'autres RFC. Bref, aujourd'hui, pour comprendre le DNS, il faut s'apprêter à lire de nombreux documents. En attendant qu'un courageux et charismatique participant à l'IETF se lance dans la tâche herculéenne de faire un jeu de documents propre et à jour, ce RFC 9499, successeur du RFC 8499 (il y a peu de modifications), se limite à une ambition plus modeste : fixer la terminologie du DNS. Ce n'est pas un tutoriel : vous n'y apprendrez pas le DNS. C'est plutôt une encyclopédie.
En effet, chacun peut constater que les discussions portant sur le DNS sont difficiles : on manque de terminologie standard, et celle des RFC officielles ne suffit pas, loin de là. Souvent, le DNS a tellement changé que le RFC officiel est même trompeur : les mots ne veulent plus dire la même chose. D'autres protocoles ont connu des mises à jour de la norme. Cela a été le cas de SMTP, passé successivement du RFC 772 à l'actuel RFC 5321, en passant par plusieurs révisions successives. Ou de XMPP, qui a vu sa norme originale mise à jour dans le RFC 6120. Et bien sûr de HTTP, qui a connu plusieurs toilettages complets (cf. RFC 9110). Mais personne n'a encore osé faire pareil pour le DNS. Au moins, ce RFC 9499, comme son prédécesseur RFC 8499, traite l'un des problèmes les plus criants, celui du vocabulaire. Le RFC est évidemment en anglais, les traductions proposées dans cet article, et qui n'ont pas de valeur « officielle » sont de moi seul.
Notre RFC 9499 rassemble donc des définitions pour des termes qui étaient parfois précisément définis dans d'autres RFC (et il fournit alors un lien vers ce RFC original), mais aussi qui n'étaient définis qu'approximativement ou parfois qui n'étaient pas définis du tout (et ce RFC fournit alors cette définition). Du fait du flou de certains RFC anciens, et des changements qui ont eu lieu depuis, certaines définitions sont différentes de l'original. Le document a fait l'objet d'un consensus relatif auprès des experts DNS mais quelques termes restent délicats. Notez aussi que d'autres organisations définissent des termes liés au DNS par exemple le WHATWG a sa définition de ce qu'est un domaine, et le RSSAC a développé une terminologie.
Ironiquement, un des termes les plus difficiles à définir est
« DNS » lui-même (section 1 de notre RFC). D'accord, c'est le sigle
de Domain Name System mais ça veut dire quoi ?
« DNS » peut désigner le schéma de nommage (les noms de domaine comme
signal.eu.org, leur syntaxe, leurs
contraintes), la base de données répartie (et faiblement cohérente)
qui associe à ces noms des informations (comme des certificats, des
adresses IP, etc), ou le
protocole
requête/réponse (utilisant le port 53) qui permet d'interroger cette
base. Parfois, « DNS » désigne uniquement le protocole, parfois,
c'est une combinaison des trois éléments indiqués plus haut
(personnellement, quand j'utilise « DNS », cela désigne uniquement
le protocole, un protocole relativement simple, fondé sur l'idée
« une requête => une réponse »).
Bon, et ces définitions rigoureuses et qui vont mettre fin aux discussions, ça vient ? Chaque section du RFC correspond à une catégorie particulière. D'abord, en section 2, les noms eux-même, ces fameux noms de domaine. Un système de nommage (naming system) a plusieurs aspects, la syntaxe des noms, la gestion des noms, le type de données qu'on peut associer à un nom, etc. D'autres systèmes de nommage que celui présenté dans ce RFC existent, et sont distincts du DNS sur certains aspects. Pour notre système de nommage, le RFC définit :
- Nom de domaine (domain
name) : la définition est différente de celle du RFC 7719, qui avait simplement repris celle du
RFC 1034, section 3.1. Elle est désormais
plus abstraite, ce qui permet de l'utiliser pour d'autres systèmes
de nommage. Un nom de domaine est désormais simplement une liste
(ordonnée) de composants (labels). Aucune
restriction n'est imposée dans ces composants, simplement formés
d'octets (tant pis pour la
légende comme quoi le DNS serait limité à ASCII). Comme on peut représenter les
noms de domaine sous forme d'un arbre (la racine de l'arbre étant à la fin
de la liste des composants) ou bien sous forme texte
(
www.madmoizelle.com), le vocabulaire s'en ressent. Par exemple, on va dire quecomest « au-dessus demadmoizelle.com» (vision arborescente) ou bien « à la fin dewww.madmoizelle.com» (vision texte). Notez aussi que la représentation des noms de domaine dans les paquets IP n'a rien à voir avec leur représentation texte (par exemple, les points n'apparaissent pas). Enfin, il faut rappeler que le vocabulaire « standard » n'est pas utilisé partout, même à l'IETF, et qu'on voit parfois « nom de domaine » utilisé dans un sens plus restrictif (par exemple uniquement pour parler des noms pouvant être résolus avec le DNS, pour lesquels il avait été proposé de parler de DNS names). - FQDN (Fully Qualified Domain
Name, nom de domaine complet) : apparu dans le RFC 819, ce terme désigne un nom de domaine où tous les
composants sont cités (par exemple,
ldap.potamochère.fr.est un FQDN alors queldaptout court ne l'est pas). En toute rigueur, un FQDN devrait toujours s'écrire avec un point à la fin (pour représenter la racine) mais ce n'est pas toujours le cas. (Notre RFC parle de « format de présentation » et de « format courant d'affichage » pour distinguer le cas où on met systématiquement le point à la fin et le cas où on l'oublie.) - Composant
(label) : un nœud de l'arbre des noms de
domaine, dans la chaîne qui compose un FQDN. Dans
www.laquadrature.net, il y a trois composants,www,laquadratureetnet. - Nom de machine (host
name) : ce n'est pas la
même chose qu'un nom de domaine. Utilisé dans de nombreux
RFC (par exemple RFC 952) mais jamais défini, un nom de
machine est un nom de domaine avec une syntaxe plus
restrictive, définie dans la section 3.5 du RFC 1035 et amendée par la section 2.1 du RFC 1123 : uniquement des lettres, chiffres, points et le
tiret. Ainsi,
brienne.tarth.got.examplepeut être un nom de machine maiswww.&#$%?.examplene peut pas l'être. Le terme de « nom de machine » est parfois aussi utilisé pour parler du premier composant d'un nom de domaine (briennedansbrienne.tarth.got.example). - TLD (Top Level
Domain, domaine de premier niveau ou domaine de
tête) : le dernier composant d'un nom de domaine, celui juste
avant (ou juste en dessous) de la racine. Ainsi,
frounamesont des TLD. N'utilisez surtout pas le terme erroné d'« extension ». Et ne dites pas que le TLD est le composant le plus à droite, ce n'est pas vrai dans l'alphabet arabe. La distinction courante entre gTLD, gérés par l'ICANN, et ccTLD, indépendants de l'ICANN, est purement politique et ne se reflète pas dans le DNS. - DNS mondial (Global DNS), nouveauté du RFC 8499, désigne l'ensemble des noms qui obéissent aux règles plus restrictives des RFC 1034 et RFC 1035 (limitation à 255 octets, par exemple). En outre, les noms dans ce « DNS mondial » sont rattachés à la racine officiellement gérée par l'ICANN, via le service Public Technical Identifiers (PTI). Une racine alternative, si elle sert un contenu différent de celui de PTI, n'est donc pas le « DNS mondial » mais ce que le RFC nomme « DNS privé » (private DNS). Évidemment, un système de nommage qui n'utilise pas le DNS du tout mais qui repose, par exemple, sur le pair-à-pair, ne doit pas être appelé DNS (« DNS pair-à-pair » est un oxymore, une contradiction dans les termes.)
- IDN (Internationalized Domain Name, nom de domaine internationalisé) : un nom de domaine en Unicode, normalisé dans le RFC 5890, qui définit des termes comme U-label (le nom Unicode) et A-label (sa représentation en Punycode). Sur l'internationalisation des noms, vous pouvez aussi consulter le RFC de terminologie RFC 6365.
- Sous-domaine
(subdomain) : domaine situé sous un autre,
dans l'arbre des noms de domaines. Sous forme texte, un domaine
est sous-domaine d'un autre si cet autre est un suffixe. Ainsi,
www.cl.cam.ac.ukest un sous-domaine decl.cam.ac.uk, qui est un sous-domaine decam.ac.uket ainsi de suite, jusqu'à la racine, le seul domaine à n'être sous-domaine de personne. Quand le RFC parle de suffixe, il s'agit d'un suffixe de composants, pas de caractères :foo.example.netn'est pas un sous-domaine deoo.example.net. - Alias (alias) :
attention, il y a un piège. Le DNS permet à un nom d'être un
alias d'un autre, avec le type d'enregistrement CNAME (voir la
définition suivante). L'alias est le terme de gauche de
l'enregistrement CNAME. Ainsi, si on met dans un fichier de zone
vader IN CNAME anakin, l'alias estvader(et c'est une erreur de dire que c'est « le CNAME »). - CNAME (Canonical
Name, nom canonique, le « vrai » nom) : le membre
droit dans l'enregistrement CNAME. Dans l'exemple de la
définition précédente,
anakinest le CNAME, le « nom canonique ».
Fini avec les noms, passons à l'en-tête des messages DNS et aux codes qu'il peut contenir. Cet en-tête est défini dans le RFC 1035, section 4.1. Il donne des noms aux champs mais pas forcément aux codes. Ainsi, le code de réponse 3 indiquant qu'un domaine demandé n'existe pas est juste décrit comme name error et n'a reçu son mnémonique de NXDOMAIN (No Such Domain) que plus tard. Notre RFC définit également, dans sa section 3 :
- NODATA : un mnémonique pour une réponse où le nom de domaine demandé existe bien mais ne contient aucun enregistrement du type souhaité. Le code de retour est 0, NOERROR, et le nombre de réponses (ANCOUNT pour Answer Count) est nul.
- Réponse négative (negative answer) : le terme recouvre deux choses, une réponse disant que le nom de domaine demandé n'existe pas (code de retour NXDOMAIN), ou bien une réponse indiquant que le serveur ne peut pas répondre (code de retour SERVFAIL ou REFUSED). Voir le RFC 2308.
- Renvoi (referral) : le DNS étant décentralisé, il arrive qu'on pose une question à un serveur qui ne fait pas autorité pour le domaine demandé, mais qui sait vous renvoyer à un serveur plus proche. Ces renvois sont indiqués dans la section Authority d'une réponse.
Voici un renvoi depuis la racine vers .fr :
% dig @l.root-servers.net A blog.imirhil.fr
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 16572
;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 5, ADDITIONAL: 11
...
;; AUTHORITY SECTION:
fr. 172800 IN NS d.ext.nic.fr.
fr. 172800 IN NS d.nic.fr.
fr. 172800 IN NS e.ext.nic.fr.
fr. 172800 IN NS f.ext.nic.fr.
fr. 172800 IN NS g.ext.nic.fr.
La section 4 s'intéresse aux transactions DNS. Un des termes définis est celui de QNAME (Query NAME), nouveauté du RFC 8499. Il y a trois sens possibles (le premier étant de très loin le plus commun) :
- Le sens original, le QNAME est la question posée (le nom de domaine demandé),
- Le sens du RFC 2308, la question finale (qui n'est pas la question posée s'il y a des CNAME sur le trajet),
- Un sens qui n'apparait pas dans les RFC mais est parfois présent dans les discussions, une question intermédiaire (dans une chaîne de CNAME).
Le RFC 2308 est clairement en tort ici. Il aurait dû utiliser un terme nouveau, pour le sens nouveau qu'il utilisait.
Passons maintenant aux enregistrements DNS, stockés dans cette base de données répartie (section 5 du RFC) :
- RR (Resource Record) : un enregistrement DNS.
- Enregistrements d'adresses (Address records) : enregistrements DNS A (adresses IPv4) et AAAA (adresses IPv6). Beaucoup de gens croient d'ailleurs que ce sont les seuls types d'enregistrements possibles (« le DNS sert à traduire les noms en adresses IP » est une des synthèses erronées du DNS les plus fréquentes).
- Ensemble d'enregistrements (RRset pour Resource Record set) : un ensemble d'enregistrements ayant le même nom (la même clé d'accès à la base), la même classe, le même type et le même TTL. Cette notion avait été introduite par le RFC 2181. Notez que la définition originale parle malheureusement de label dans un sens incorrect. La terminologie du DNS est vraiment compliquée !
- Fichier maître (master file) : un fichier texte contenant des ensembles d'enregistrement. Également appelé fichier de zone, car son utilisation la plus courante est pour décrire les enregistrements que chargera le serveur maître au démarrage. (Ce format peut aussi servir à un résolveur quand il écrit le contenu de sa mémoire sur disque.)
- EDNS (Extension for DNS, également appelé EDNS0) : normalisé dans le RFC 6891, EDNS permet d'étendre l'en-tête du DNS, en spécifiant de nouvelles options, en faisant sauter l'antique limitation de taille de réponses à 512 octets, etc.
- OPT (pour Option) : une astuce d'EDNS pour encoder les informations de l'en-tête étendu. C'est un enregistrement DNS un peu spécial, défini dans le RFC 6891, section 6.1.1.
- Propriétaire (owner ou owner name) : le nom de domaine d'un enregistrement. Ce terme est très rarement utilisé, même par les experts.
- Champs du SOA (SOA field names) : ces noms des enregistrements SOA (comme MNAME ou RNAME) sont peu connus et malheureusement peu utilisés (RFC 1035, section 3.3.13). Notez que la sémantique du champ MINIMUM a complètement changé avec le RFC 2308.
- TTL (Time To Live) : la durée de vie maximale d'un enregistrement dans les caches des résolveurs. C'est un entier non signé (même si le RFC 1035 dit le contraire), en secondes.
Voici un ensemble d'enregistrements (RRset), comptant ici deux enregistrements :
rue89.com. 600 IN MX 50 mx2.typhon.net.
rue89.com. 600 IN MX 10 mx1.typhon.net.
(Depuis, ça a changé.)
Et voici un pseudo-enregistrement OPT, tel qu'affiché par dig, avec une indication de la taille maximale et l'option client subnet (RFC 7871) :
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 512
; CLIENT-SUBNET: 13.176.144.0/24/0
Ensuite, un sujet chaud où le vocabulaire est particulièrement peu défini, et très mal utilisé (voir les forums grand public sur le DNS où les discussions prennent un temps fou car les gens utilisent mal les mots) : les différents types de serveurs et clients DNS (section 6). Pour commencer, il est crucial de se méfier quand un texte parle de « serveur DNS » tout court. Si le contexte ne permet pas de savoir de quel genre de serveur DNS on parle, cela indique un manque de compréhension du DNS par l'auteur du texte. Serveurs faisant autorité et serveurs résolveurs, quoique utilisant le même protocole, sont en effet très différents.
- Résolveur (resolver) : un client DNS qui va produire une réponse finale (pas juste un renvoi, pas juste une information ponctuelle comme le fait dig). Il existe plusieurs types de résolveurs (voir ci-dessous) et, en pratique, quand on dit « résolveur » tout court, c'est en général un « résolveur complet ».
- Résolveur minimum (stub
resolver) : un résolveur qui ne sait pas suivre les
renvois et qui dépend donc d'un ou de plusieurs résolveurs
complets pour faire son travail. Ce type est défini dans la
section 6.1.3.1 du RFC 1123. C'est ce
résolveur minimum qu'appellent les applications lorsqu'elles font
un
getaddrinfo()ougetnameinfo(). Sur Unix, le résolveur minimum fait en général partie de la libc et trouve l'adresse du ou des résolveurs complets dans/etc/resolv.conf. - Résolveur complet (full resolver) : un résolveur qui sait suivre les renvois et donc fournir un service de résolution complet. Des logiciels comme Unbound ou PowerDNS Resolver assurent cette fonction. Le résolveur complet est en général situé chez le FAI ou dans le réseau local de l'organisation où on travaille, mais il peut aussi être sur la machine locale. On le nomme aussi « résolveur récursif ». Notez que « résolveur complet » fait partie de ces nombreux termes qui étaient utilisés sans jamais avoir été définis rigoureusement.
- Resolveur complet avec mémoire (full-service resolver) : un résolveur complet, qui dispose en plus d'une mémoire (cache) des enregistrements DNS récoltés.
- Serveur faisant autorité
(authoritative server et traduire ce terme
par « serveur autoritaire » montre une grande ignorance de
l'anglais ; un adjudant est autoritaire,
un serveur DNS fait autorité) : un serveur DNS qui connait une
partie des données du DNS (il « fait autorité » pour une ou
plusieurs zones) et peut donc y répondre (RFC 2182,
section 2). Ainsi, au moment de l'écriture de cet article,
f.root-servers.netfait autorité pour la racine,d.nic.frfait autorité pourpm, etc. Des logiciels comme NSD ou Knot assurent cette fonction. Les serveurs faisant autorité sont gérés par divers acteurs, les registres, les hébergeurs DNS (qui sont souvent en même temps bureaux d'enregistrement), mais aussi parfois par M. Michu. La commandedig NS $ZONEvous donnera la liste des serveurs faisant autorité pour la zone$ZONE. Ou bien vous pouvez utiliser un service sur le Web en visitanthttps://dns.bortzmeyer.org/DOMAIN/NSoù DOMAIN est le nom de domaine qui vous intéresse. - Serveur mixte : ce terme n'est pas dans ce RFC. Autrefois, il était courant que des serveurs DNS fassent à la fois résolveur et serveur faisant autorité. Cette pratique est fortement déconseillée depuis de nombreuses années (entre autres parce qu'elle complique sérieusement le débogage, mais aussi pour des raisons de sécurité parce qu'elle mène à du code plus complexe) et n'est donc pas dans ce RFC.
- Initialisation
(priming) : le processus par lequel un
résolveur complet vérifie l'information sur les serveurs de la
racine. Ce concept est décrit en détail dans le RFC 9609. Au démarrage, le résolveur ne sait rien. Pour
pouvoir commencer la résolution de noms, il doit demander aux
serveurs de la racine. Il a donc dans sa configuration leur
liste. Mais ces configurations ne sont pas forcément mises à
jour souvent. La liste peut donc être trop vieille. La première
chose que fait un résolveur est donc d'envoyer une requête
«
NS .» à un des serveurs de sa liste. Ainsi, tant qu'au moins un des serveurs de la vieille liste répond, le résolveur est sûr d'apprendre la liste actuelle. - Indications de la racine (root hints) : la liste des noms et adresses des serveurs racine, utilisée pour l'initialisation. L'administrateur d'un résolveur utilisant une racine alternative changera cette liste.
- Mémorisation des négations (negative caching, ou « cache négatif ») : mémoriser le fait qu'il n'y a pas eu de réponse, ou bien une réponse disant qu'un nom de domaine n'existe pas.
- Serveur primaire (primary
server mais on dit aussi serveur maître, master
server) : un serveur faisant autorité qui a accès à la
source des données (fichier de zone, base de données,
etc). Attention, il peut y avoir plusieurs serveurs
primaires (autrefois, ce n'était pas clair et beaucoup de gens
croient qu'il y a un serveur primaire, et qu'il est indiqué dans
l'enregistrement SOA). Attention bis, le terme ne s'applique qu'à des
serveurs faisant autorité, l'utiliser pour les résolveurs (« on
met en premier dans
/etc/resolv.confle serveur primaire ») n'a pas de sens. - Serveur secondaire (secondary server mais on dit aussi « serveur esclave », slave server) : un serveur faisant autorité qui n'est pas la source des données, qui les a prises d'un serveur primaire (dit aussi serveur maître), via un transfert de zone (RFC 5936).
- Serveur furtif (stealth server) : un serveur faisant autorité mais qui n'apparait pas dans l'ensemble des enregistrements NS. (Définition du RFC 1996, section 2.1.)
- Maître caché (hidden master) : un serveur primaire qui n'est pas annoncé publiquement (et n'est donc accessible qu'aux secondaires). C'est notamment utile avec DNSSEC : s'il signe, et donc a une copie de la clé privée, il vaut mieux qu'il ne soit pas accessible de tout l'Internet (RFC 6781, section 3.4.3).
- Transmission (forwarding) : le fait, pour un résolveur, de faire suivre les requêtes à un autre résolveur (probablement mieux connecté et ayant un cache partagé plus grand). On distingue parfois (mais ce n'est pas forcément clair, même dans le RFC 5625) la transmission, où on émet une nouvelle requête, du simple relayage de requêtes sans modification.
- Transmetteur
(forwarder) : le terme est parfois utilisé
confusément. Il désigne tantôt la machine qui transmet une
requête et tantôt celle vers laquelle on transmet (c'est dans
ce sens qu'il est utilisé dans la configuration de
BIND, avec la directive
forwarders). La définition de notre RFC est le premier sens. - Résolveur politique (policy-implementing resolver) : un résolveur qui modifie les réponses reçues, selon sa politique. On dit aussi, moins diplomatiquement, un « résolveur menteur ». C'est ce que permet, par exemple, le système RPZ. Sur l'utilisation de ces « résolveurs politiques » pour mettre en œuvre la censure, voir entre autres mon article aux RIPE Labs. Notez que le résolveur politique a pu être choisi librement par l'utilisateur (par exemple comme élément d'une solution de blocage des publicités) ou bien qu'il lui a été imposé.
- Résolveur ouvert (open resolver) : un résolveur qui accepte des requêtes DNS depuis tout l'Internet. C'est une mauvaise pratique (cf. RFC 5358) et la plupart de ces résolveurs ouverts sont des erreurs de configuration. Quand ils sont délibérement ouverts, comme Google Public DNS ou Quad9, on parle plutôt de résolveurs publics.
- Collecte DNS passive (passive DNS) : désigne les systèmes qui écoutent le trafic DNS, et stockent tout ou partie des informations échangées. Le cas le plus courant est celui où le système de collecte ne garde que les réponses (ignorant donc les adresses IP des clients et serveurs), afin de constituer une base historique du contenu du DNS (c'est ce que font DNSDB ou le système de PassiveDNS.cn).
- Serveur protégeant la vie privée (privacy-enabled server) : ce terme désigne un serveur, typiquement un résolveur, qui permet les requêtes DNS chiffrées, avec DNS-sur-TLS (RFC 7858) ou avec DoH (RFC 8484).
- Anycast : le fait d'avoir un service en plusieurs sites physiques, chacun annonçant la même adresse IP de service (RFC 4786). Cela résiste mieux à la charge, et permet davantage de robustesse en cas d'attaque par déni de service. Les serveurs de la racine, ceux des « grands » TLD, et ceux des importants hébergeurs DNS sont ainsi « anycastés ». Chaque machine répondant à l'adresse IP de service est appelée une instance.
- DNS divisé (split
DNS) : le fait de donner des réponses différentes
selon que le client est interne à une organisation ou
externe. Le but est, par exemple, de faire en sorte que
www.organisation.exampleaille sur le site public quand on vient de l'Internet mais sur un site interne de la boîte quand on est sur le réseau local des employés.
Voici, vu par tcpdump, un exemple d'initialisation d'un résolveur BIND utilisant la racineYeti (RFC 8483) :
15:07:36.736031 IP6 2a01:e35:8bd9:8bb0:21e:8cff:fe76:29b6.35721 > 2001:6d0:6d06::53.53: \
21476% [1au] NS? . (28)
15:07:36.801982 IP6 2001:6d0:6d06::53.53 > 2a01:e35:8bd9:8bb0:21e:8cff:fe76:29b6.35721: \
21476*- 16/0/1 NS yeti-ns.tisf.net., NS yeti-ns.lab.nic.cl., NS yeti-ns.wide.ad.jp., NS yeti.ipv6.ernet.in., NS yeti-ns.as59715.net., NS ns-yeti.bondis.org., NS yeti-dns01.dnsworkshop.org., NS dahu2.yeti.eu.org., NS dahu1.yeti.eu.org., NS yeti-ns.switch.ch., NS bii.dns-lab.net., NS yeti.bofh.priv.at., NS yeti-ns.conit.co., NS yeti.aquaray.com., NS yeti-ns.ix.ru., RRSIG (619)
La question était « NS . » (quels sont les
serveurs de la racine) et la réponse contenait les noms des seize
serveurs racine qu'avait Yeti à l'époque.
Voici aussi des exemples de résultats avec un résolveur ou bien avec un serveur faisant autorité. Si je demande à un serveur faisant autorité (ici, un serveur racine), avec mon client DNS qui, par défaut, demande un service récursif (flag RD, Recursion Desired) :
% dig @2001:620:0:ff::29 AAAA www.iab.org
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 54197
;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 9, ADDITIONAL: 13
;; WARNING: recursion requested but not available
...
;; AUTHORITY SECTION:
org. 172800 IN NS b0.org.afilias-nst.org.
...
C'est pour cela que dig affiche WARNING: recursion requested but not available. Notez aussi que le serveur, ne faisant autorité que pour la racine, n'a pas donné la réponse mais juste un renvoi aux serveurs d'Afilias. Maintenant, interrogeons un serveur récursif (le service de résolveur public Yandex DNS) :
% dig @2a02:6b8::feed:0ff AAAA www.iab.org
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 63304
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
...
;; ANSWER SECTION:
www.iab.org. 1800 IN AAAA 2001:1900:3001:11::2c
Cette fois, j'ai obtenu une réponse, et avec le
flag RA, Recursion
Available. Si je pose une question sans le
flag RD (Recursion Desired,
avec l'option +norecurse de dig) :
% dig +norecurse @2a02:6b8::feed:0ff AAAA www.gq.com
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 59438
;; flags: qr ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
...
;; ANSWER SECTION:
www.gq.com. 293 IN CNAME condenast.map.fastly.net.
J'ai obtenu ici une réponse car l'information était déjà dans le cache (la mémoire) de Yandex DNS (on le voit au TTL, qui n'est pas un chiffre rond, il a été décrémenté du temps passé dans le cache). Si l'information n'est pas dans le cache :
% dig +norecurse @2a02:6b8::feed:0ff AAAA blog.keltia.net
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 19893
;; flags: qr ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 0
...
Je n'obtiens alors pas de réponse (ANSWER: 0, donc NODATA). Si je demande au serveur faisant autorité pour cette zone :
% dig +norecurse @2a01:e0d:1:3:58bf:fa61:0:1 AAAA blog.keltia.net
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 62908
;; flags: qr aa; QUERY: 1, ANSWER: 2, AUTHORITY: 6, ADDITIONAL: 15
...
;; ANSWER SECTION:
blog.keltia.net. 86400 IN AAAA 2a01:240:fe5c:1::2
...
J'ai évidemment une réponse et, comme il s'agit d'un serveur faisant autorité, elle porte le flag AA (Authoritative Answer, qu'un résolveur ne mettrait pas). Notez aussi le TTL qui est un chiffre rond (et qui ne change pas si on rejoue la commande).
Passons maintenant à un concept relativement peu connu, celui de zones, et le vocabulaire associé (section 7) :
- Zone : un groupe de domaines contigus
dans l'arbre des noms, et gérés ensemble, par le même ensemble
de serveurs de noms (ma définition, celle du RFC étant très
abstraite). Beaucoup de gens croient que tout domaine est une
zone, mais c'est faux. Ainsi, au moment de la publication de ce
RFC,
gouv.frn'est pas une zone séparée, il est dans la même zone quefr(cela se teste facilement :gouv.frn'a pas d'enregistrement NS ou de SOA). - Parent : le domaine « du
dessus ». Ainsi, le parent de
wikipedia.orgestorg, le parent de.orgest la racine. - Apex : le sommet d'une zone, là où on trouve les enregistrements NS et SOA. Si la zone ne comprend qu'un domaine, l'apex est ce domaine. Si la zone est plus complexe, l'apex est le domaine le plus court. (On voit parfois des gens utiliser le terme erroné de racine pour parler de l'apex.)
- Coupure de zone (zone cut) : l'endroit où on passe d'une zone à l'autre. Au-dessus de la coupure, la zone parente, en dessous, la zone fille.
- Délégation (delegation) : un concept évidemment central dans le DNS, qui est un système décentralisé. En ajoutant un ensemble d'enregistrements NS pointant vers les serveurs de la zone fille, une zone parente délègue une partie de l'arbre des noms de domaine à une autre entité. L'endroit où se fait la délégation est donc une coupure de zone.
- Colle (glue
records) : lorsqu'une zone est déléguée à des serveurs
dont le nom est dans la zone fille, la résolution DNS se heurte
à un problème d'œuf et de poule. Pour trouver l'adresse de
ns1.mazone.example, le résolveur doit passer par les serveurs demazone.example, qui est déléguée àns1.mazone.exampleet ainsi de suite... On rompt ce cercle vicieux en ajoutant, dans la zone parente, des données qui ne font pas autorité sur les adresses de ces serveurs (RFC 1034, section 4.2.1). Il faut donc bien veiller à les garder synchrones avec la zone fille. (Tanguy Ortolo me suggère d'utiliser « enregistrement de raccord » plutôt que « colle ». Cela décrit bien leur rôle, en effet.) - Délégation boiteuse (lame delegation) : un ou plusieurs des serveurs à qui la zone est déléguée ne sont pas configurés pour servir cette zone. La délégation peut avoir été boiteuse depuis le début (parce que le titulaire a indiqué des noms un peu au hasard) ou bien l'être devenue par la suite. C'est certainement une des erreurs techniques les plus courantes. Mais le RFC note que l'usage du terme a dérivé et qu'aujourd'hui, il est devenu plus flou, désignant hélas des erreurs très variées.
- Dans le bailliage (in bailiwick) : terme absent des textes DNS originaux et qui peut désigner plusieurs choses. (La définition du RFC 8499, embrouillée, a été heureusement remplacée.) « Dans le bailliage » est (très rarement, selon mon expérience) parfois utilisé pour parler d'un serveur de noms dont le nom est dans la zone servie (et qui nécessite donc de la colle, voir la définition plus haut), mais le sens le plus courant désigne des données pour lesquelles le serveur qui a répondu fait autorité, soit pour la zone, soit pour un ancêtre de cette zone. L'idée est qu'il est normal dans la réponse d'un serveur de trouver des données situées dans le bailliage et, par contre, que les données hors-bailliage sont suspectes (elles peuvent être là suite à une tentative d'empoisonnement DNS). Un résolveur DNS prudent ignorera donc les données hors-bailliage.
- ENT (Empty
Non-Terminal pour nœud non-feuille mais vide) : un
domaine qui n'a pas d'enregistrements mais a des
sous-domaines. C'est fréquent, par exemple, sous
ip6.arpaou sous les domaines très longs de certains CDN. Cela se trouve aussi avec les enregistrements de service : dans_sip._tcp.example.com,_tcp.example.comest probablement un ENT. La réponse correcte à une requête DNS pour un ENT est NODATA (code de réponse NOERROR, liste des répoonses vide) mais certains serveurs bogués, par exemple, à une époque, ceux d'Akamai, répondaient NXDOMAIN. - Zone de délégation (delegation-centric zone) : zone composée essentiellement de délégations vers d'autres zones. C'est typiquement le cas des TLD et autres suffixes publics. Il est amusant de noter que les RFC 4956 et RFC 5155 utilisaient ce terme sans le définir.
- Changement rapide (fast flux) : une technique notamment utilisée par les botnets pour mettre leur centre de commande à l'abri des filtrages ou destructions. Elle consiste à avoir des enregistrements d'adresses IP avec des TTL très courts et à en changer fréquemment.
- DNS inverse (reverse DNS) : terme qui désigne en général les requêtes pour des enregistrements de type PTR, permettant de trouver le nom d'une machine à partir de son adresse IP. À ne pas confondre avec les vraies requêtes inverses, qui avaient été normalisées dans le RFC 1035, avec le code IQUERY, mais qui, jamais vraiment utilisées, ont été abandonnées dans le RFC 3425.
Voyons ici la colle retournée par un serveur faisant autorité (en
l'occurrence un serveur de .net) :
% dig @a.gtld-servers.net AAAA labs.ripe.net
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 18272
;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 8, ADDITIONAL: 9
...
;; AUTHORITY SECTION:
ripe.net. 172800 IN NS ns3.nic.fr.
ripe.net. 172800 IN NS sec1.apnic.net.
ripe.net. 172800 IN NS sec3.apnic.net.
ripe.net. 172800 IN NS tinnie.arin.net.
ripe.net. 172800 IN NS sns-pb.isc.org.
ripe.net. 172800 IN NS pri.authdns.ripe.net.
...
;; ADDITIONAL SECTION:
sec1.apnic.net. 172800 IN AAAA 2001:dc0:2001:a:4608::59
sec1.apnic.net. 172800 IN A 202.12.29.59
sec3.apnic.net. 172800 IN AAAA 2001:dc0:1:0:4777::140
sec3.apnic.net. 172800 IN A 202.12.28.140
tinnie.arin.net. 172800 IN A 199.212.0.53
tinnie.arin.net. 172800 IN AAAA 2001:500:13::c7d4:35
pri.authdns.ripe.net. 172800 IN A 193.0.9.5
pri.authdns.ripe.net. 172800 IN AAAA 2001:67c:e0::5
On notera :
- La section ANSWER est vide, c'est un renvoi.
- Le serveur indique la colle pour
pri.authdns.ripe.net: ce serveur étant dans la zone qu'il sert, sans son adresse IP, on ne pourrait jamais le joindre. - Le serveur envoie également les adresses IP d'autres
machines comme
sec1.apnic.net. Ce n'est pas strictement indispensable (on pourrait l'obtenir par une nouvelle requête), juste une optimisation. - Les adresses de
ns3.nic.fretsns-pb.isc.orgne sont pas renvoyées. Le serveur ne les connait probablement pas et, de toute façon, elles seraient hors-bailliage, donc ignorées par un résolveur prudent.
Voyons maintenant, un ENT,
gouv.fr (notez que, depuis, ce domaine n'est
plus un ENT) :
% dig @d.nic.fr ANY gouv.fr
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 42219
;; flags: qr aa rd; QUERY: 1, ANSWER: 0, AUTHORITY: 2, ADDITIONAL: 1
Le serveur fait bien autorité pour ce domaine (flag AA dans la réponse), le domaine existe (autrement, le status aurait été NXDOMAIN, pas NOERROR) mais il n'y a aucun enregistrement (ANSWER: 0).
Et, ici, une délégation boiteuse, pour
.ni :
% check-soa ni
dns.nic.cr.
2001:13c7:7004:1::d100: ERROR: SERVFAIL
200.107.82.100: ERROR: SERVFAIL
ns.ideay.net.ni.
186.1.31.8: OK: 2013093010
ns.ni.
165.98.1.2: ERROR: read udp 10.10.86.133:59569->165.98.1.2:53: i/o timeout
ns.uu.net.
137.39.1.3: OK: 2013093010
ns2.ni.
200.9.187.2: ERROR: read udp 10.10.86.133:52393->200.9.187.2:53: i/o timeout
Le serveur dns.nic.cr est déclaré comme
faisant autorité pour .ni mais il ne le sait
pas, et répond donc SERVFAIL.
Les jokers ont une section à eux, la section 8 du RFC. S'appuyant sur le RFC 4592, elle définit, entre autres :
- Joker
(wildcard) : une source de confusion
considérable depuis les débuts du DNS. Si on pouvait refaire le
DNS en partant de zéro, ces jokers seraient la première chose à
supprimer. Pour les résumer, le nom
*dans une zone déclenche la synthèse automatique de réponses pour les noms qui n'existent pas dans la zone. Si la zonefoo.examplecontientbar.foo.exampleet*.foo.example, une requête pourthing.foo.examplerenverra le contenu de l'enregistrement avec le joker, une requête pourbar.foo.exampledonnera les données debar.foo.example. Attention, l'astérisque n'a son rôle particulier que s'il est le composant le plus spécifique (le premier). Dansfoo.*.bar.example, il n'y a pas de joker. - Ancêtre le plus proche
(closest encloser) : c'est le plus long
ancêtre existant d'un nom. Si
foo.bar.baz.examplen'existe pas, quebar.baz.examplen'existe pas non plus, mais quebaz.exampleexiste, alorsbaz.exampleest l'ancêtre le plus proche defoo.bar.baz.example. Ce concept est nécessaire pour le RFC 5155.
Allez courage, ne faiblissons pas, il reste encore la question de l'enregistrement des noms de domaine (section 9) :
- Registre
(registry) : l'organisation ou la personne
qui gère les délégations d'une zone. Le terme est parfois
employé uniquement pour les gérants de grandes zones de
délégation, mais ce n'est pas obligatoire. Je suis à moi tout
seul le registre de
bortzmeyer.org😁. C'est le registre qui décide de la politique d'enregistrement, qui peut être très variable selon les zones (sauf dans celles contrôlées par l'ICANN, où une certaine uniformité est imposée). Mes lecteurs français noteront que, comme le terme « registre » est court et largement utilisé, le gouvernement a inventé un nouveau mot, plus long et jamais vu auparavant, « office d'enregistrement ». - Titulaire (registrant, parfois holder) : la personne ou l'organisation qui a enregistré un nom de domaine.
- Bureau d'enregistrement (registrar) : dans le modèle RRR (Registry-Registrar-Registrant, mais ce modèle n'est pas obligatoire et pas universel), c'est un intermédiaire entre le titulaire et le registre.
- Hébergeur DNS (DNS operator) : la personne ou l'organisation qui gère les serveurs DNS. Cela peut être le titulaire, son bureau d'enregistrement, ou encore un acteur spécialisé dans cette gestion.
- Suffixe public (public
suffix) : ce terme pas très officiel est parfois
utilisé pour désigner un suffixe de noms de domaine qui est
contrôlé par un registre public (au sens où il accepte des
enregistrements du public). Mais le terme est trompeur car, par
exemple,
.aquarellese trouve dans la Public Suffix List alors qu'il s'agit d'un «.marque», un de ces TLD où une seule entreprise peut enregistrer des noms. Le terme est ancien mais est apparu pour la première fois dans un RFC avec le RFC 6265, section 5.3.com,co.uketeu.orgsont des suffixes publics. Rien dans la syntaxe du nom n'indique qu'un nom de domaine est un suffixe public, puisque ce statut ne dépend que d'une politique d'enregistrement (qui peut changer). Il est parfaitement possible qu'un domaine, et un de ses enfants, soient tous les deux un suffixe public (c'est le cas de.orgeteu.org). - EPP (Extensible Provisioning Protocol) : normalisé dans le RFC 5730, c'est le protocole standard entre bureau d'enregistrement et registre. Ce protocole n'a pas de lien avec le DNS, et tous les registres ne l'utilisent pas.
- Whois (nommé d'après la question Who Is?) : un protocole réseau, sans lien avec le DNS, normalisé dans le RFC 3912. Il permet d'interroger les bases de données du registre pour trouver les informations dites « sociales », informations qui ne sont pas dans le DNS (comme le nom du titulaire, et des moyens de le contacter). Les termes de « base Whois » ou de « données Whois » sont parfois utilisés mais ils sont erronés puisque les mêmes bases peuvent être interrogées par d'autres protocoles que Whois, comme RDAP (voir définition suivante).
- RDAP (Registration Data Access Protocol) : un protocole concurrent de Whois, mais plus moderne. RDAP est décrit notamment dans les RFC 9082 et RFC 9083.
Prenons par exemple le domaine eff.org. Au
moment de la publication du RFC :
Enfin, pour terminer, les sections 10 et 11 de notre RFC couvrent DNSSEC. Pas grand'chose de nouveau ici, DNSSEC étant plus récent et donc mieux défini.
L'annexe A de notre RFC indique quelles définitions existaient dans de précédents RFC mais ont été mises à jour par le nôtre. (C'est rare, puisque le but de ce RFC de terminologie est de rassembler les définitions, pas de les changer.) Par exemple, la définition de QNAME du RFC 2308 est corrigée ici.
L'annexe B liste les termes dont la première définition formelle se trouve dans ce RFC (ou dans un de ses prédécesseurs, les RFC 7719 et "RFC 8499). Cette liste est bien plus longue que celle de l'annexe A, vu le nombre de termes courants qui n'avaient jamais eu l'honneur d'une définition stricte.
Notre RFC ne contient pas une liste exhaustive des changements depuis son prédécesseur, le RFC 8499, mais ils sont peu importants. Parmi les changements sérieux :
- DoT (RFC 7858), DoH (RFC 8484) et DoQ (RFC 9250) ont maintenant une définition complète.
- Par contraste, le DNS traditionnel (Classic DNS), celui qui tourne directement sur UDP ou TCP, et en clair, a sa définition.
- L'importance de TLS se traduit aussi par l'arrivée des définitions de DoT vers le résolveur (RDoT, pour Recursive DNS over TLS), de DoT vers le serveur faisant autorité (ADoT pour Authoritative DNS over TLS) et XoT (zone transfer over TLS, normalisé dans le RFC 9103).
- Le RFC prend également acte du fait que le terme désignant les délégations invalides, lame delegation, a beaucoup dérivé.
L'article seul
RFC 9490: Report from the IAB Workshop on Management Techniques in Encrypted Networks (M-TEN)
Date de publication du RFC : Janvier 2024
Auteur(s) du RFC : M. Knodel, W. Hardaker, T. Pauly
Pour information
Première rédaction de cet article le 9 mai 2024
Aujourd'hui, l'essentiel du trafic sur l'Internet est chiffré, et pour d'excellentes raisons. Pas question de revenir là-dessus, mais, ceci dit, il va falloir adapter certaines pratiques de gestion des réseaux. L'IAB a organisé en 2022 un atelier sur ce sujet, dont ce RFC est le compte-rendu.
Comme les autres ateliers de l'IAB, il s'agit de faire s'exprimer diverses personnes, pas forcément d'arriver à une position commune (surtout sur un sujet… sensible). Tenu entièrement en ligne, cet atelier commençait par la soumission d'articles, qui devaient être lus d'abord, et discutés lors de l'atelier. La liste des articles figure dans l'annexe A du RFC, et les articles sont disponibles en ligne.
D'abord, notre RFC réaffirme que la cryptographie est absolument nécessaire à la protection de la vie privée. Les difficultés réelles qu'elle peut poser ne doivent jamais être un prétexte pour réduire ou affaiblir le chiffrement. Qu'il y ait une tension entre l'impératif du chiffrement et certaines méthodes de gestion du réseau, OK, mais la priorité reste la lutte contre la surveillance (RFC 7258).
Ensuite (section 1), le RFC pose le paysage : le trafic étant largement chiffré, des méthodes traditionnelles de gestion du réseau ne fonctionnent plus. tcpdump ne montre plus les données, on ne peut donc pas distinguer différentes méthodes HTTP, par exemple. Avec QUIC (RFC 9000), c'est même une partie de la couche transport qui est chiffrée donc un observateur extérieur ne peut plus, par exemple, évaluer le RTT d'une session qu'il observe (ce qui était possible avec TCP). Il va donc falloir s'adapter notamment en coopérant davantage avec les applications qui, elles, ont accès à tout. Pour l'instant, on a vu surtout passer des récriminations d'acteurs habitués à surveiller le trafic et qui se plaignent que le chiffrement les en empêchent (le RFC 8404 est un bon exemple de ces récriminations). Au contraire, il faut chercher à résoudre une contradiction : permettre aux réseaux d'appliquer leur politique sans céder d'un millimètre sur le principe du chiffrement.
Outre le cas des opérateurs réseau qui veulent examiner le trafic, à des fins louables (améliorer le réseau) ou critiquables (défavoriser certains usages), on peut aussi citer, parmi les intermédiaires qui voudraient observer et/ou interférer avec le trafic réseau, les réseaux d'entreprise qui veulent, par exemple, empêcher les employés d'accéder à certains services, ou bien les mécanismes de contrôle des enfants (appelés à tort « contrôle parental », alors que leur but est justement de remplacer les parents).
Trois thèmes importants étaient discutés à l'atelier : la situation actuelle, les futures techniques et la façon dont on pourrait arriver à déployer ces futures techniques.
Pour la situation actuelle, on sait que, depuis longtemps, les administrateurices réseau comptent sur de l'observation passive, par exemple pour classer le trafic (tant de HTTP, tant de SSH, etc). C'est à la base de techniques comme IPFIX (RFC 7011), qui permet de produire de beaux camemberts. Outre la production de rapports, cette observation passive peut (mais n'est pas forcément) être utilisée pour prévoir les évolutions futures, prioriser certains types de trafic, détecter des comportements malveillants, etc. Les protocoles Internet étaient en effet traditionnellement trop bavards, faisant fuiter des informations vers des observateurs passifs (cf. le concept de « vue depuis le réseau », RFC 8546).
La lutte
de l'épée et de la cuirasse étant éternelle, il y a évidemment eu
des travaux sur des mécanismes pour empêcher ce genre d'analyses
comme l'article soumis pour l'atelier « WAN
Traffic Obfuscation at Line Rate ». (Au passage,
sur cette idée d'obfuscation, je recommande le
livre de Brunton et Nissenbaum.)
Le RFC mentionne aussi une discussion sur l'idée d'exiger une
permission explicite des utilisateurs pour les analyses du trafic
(je ne vous dis pas les difficultés pratiques…). Voir
l'Internet-Draft
draft-irtf-pearg-safe-internet-measurement.
Dans un monde idéal, le réseau et les applications coopéreraient (et, dans un monde idéal, licornes et bisounours s'embrasseraient tous les jours) mais on voit plutôt une lutte, le réseau essayant d'en savoir plus, les applications de préserver leur intimité. Pourtant, le RFC note qu'une coopération pourrait être dans leur intérêt réciproque. Bien sûr, des applications comme Tor refuseraient certainement toute coopération puisque leur but est de laisser fuiter le moins d'information possible, mais d'autres applications pourraient être tentées, par exemple en échange d'informations du réseau sur la capacité disponible. Après tout, certaines techniques sont justement conçues pour cela, comme ECN (RFC 3168).
OK, maintenant, quelles sont les techniques et méthodes pour résoudre le problème de la gestion des réseaux chiffrés (section 2.2) ? Le RFC exprime bien le fait que le but du chiffrement est d'empêcher tout tiers d'accéder aux informations. Donc, sauf faille de sécurité, par exemple suite à une faiblesse du chiffrement, tout accès à l'information impose la coopération d'une des deux parties qui communiquent. Cette question du consentement est cruciale. Si on n'a pas le consentement d'une des deux extrémités de la communication, on n'a pas le droit d'accéder aux données, point. Cf. la contribution « What’s In It For Me? Revisiting the reasons people collaborate ». Comme le répète souvent Eric Rescorla « Sur l'Internet, tout ce qui n'est pas une des extrémités est un ennemi. » (Cela inclut donc tous les équipements réseaux et les organisations qui les contrôlent.) Bref, les utilisateurs doivent pouvoir donner un consentement éclairé, et juger si les bénéfices de la visibilité l'emportent sur les risques. Évidemment, ce principe correct va poser de sérieuses difficultés d'application, car il n'est pas évident d'analyser proprement les bénéfices, et les risques (songez aux bandeaux cookies ou aux permissions des application sur votre ordiphone). Développer des nouveaux mécanismes de communication avec l'utilisateurice sont nécessaires, sinon, comme le note le RFC, « les ingénieurs devront choisir pour les utilisateurs ». Le RFC estime que les utilisateurs donneront toujours la priorité à leur vie privée (notamment parce qu'ils ne comprennent pas l'administration de réseaux et ses exigences), mais cela ne me semble pas si évident que cela. Personnellement, il me semble que le choix par défaut est crucial, car peu d'utilisateurices le modifieront.
Une des techniques qui permettent d'avoir accès à de l'information sans avoir toute l'information est celle des relais (cf. « Relying on Relays: The future of secure communication ». Le principe est de séparer les fonctions : l'utilisateur parle à un relais qui parle au serveur final. Le relais ne connait pas le contenu de la demande, le serveur ne connait pas le demandeur. C'est utilisé dans des techniques comme Oblivious HTTP (RFC 9458) ou Oblivious DNS (RFC 9230). La préservation de la vie privée est donc bien meilleure qu'avec, par exemple, un VPN, où l'opérateur du VPN voit tout, le demandeur et la demande (contrairement à ce que prétendent les publicités pour NordVPN que de nombreux youtubeurs transmettent avec leurs vidéos). Le relais permet donc un accès à une information limitée, ce qui permet d'assurer certaines fonctions (comme le filtrage de contenu malveillant) sans avoir un accès complet.
Un exemple souvent cité par les opérateurs de l'intérêt d'accéder à la communication et de la modifier est celui de l'optimisation des flux TCP. Des PEP (Performance Enhancing Proxies) violant le modèle en couches (car, normalement, TCP est de bout en bout) sont souvent déployés, notamment sur les liaisons satellites, dont les performances sont plus mauvaises, et les caractéristiques techniques très spéciales. (Cf. l'exposé de Nicolas Kuhn, « QUIC for satellite communications » à la Journée du Conseil Scientifique de l'Afnic en 2021.) Le PEP va modifier les en-têtes TCP, voire parfois boucler la connexion TCP et en faire une autre lui-même. Cette technique ne marche évidemment plus avec QUIC, qui chiffre même la couche transport. Et elle mène à l'ossification de l'Internet puisqu'elle rend plus difficile de faire évoluer TCP, car toute évolution risque de perturber les PEP. QUIC avait en partie été explicitement développé pour empêcher ces intermédiaires de bricoler la session. Une autre approche est celle proposée dans « The Sidecar: "Opting in" to PEP Functions ».
Bon, maintenant, comment arriver à déployer de meilleures méthodes ? Dans un environnement fermé ou semi-fermé, cela doit être possible de faire en sorte que, par exemple, toutes les machines mettent en œuvre telle fonction (cf. RFC 8520 pour un exemple). Mais cela ne marche clairement pas pour l'Internet.
Parmi les moyens proposés de résolution de la contradiction entre visibilité par le réseau et protection de la vie privée, le RFC mentionne les Zero-Knowledge Middleboxes. Décrites dans l'article du même nom, cette méthode utilise les preuves à divulgation nulle de connaissance pour prouver à l'intermédiaire qui fait le filtrage qu'on a bien respecté sa politique de filtrage, sans lui dire ce qu'on a fait. L'article détaille par exemple comment cela peut s'appliquer au DNS, qui est le principal outil de censure de l'Internet dans l'Union européenne. Ces preuves à divulgation nulle de connaissance ayant toujours été mystérieuses pour moi, je ne vous expliquerai pas comment elles marchent, mais notez que les auteurs ont fait un article pédagogique.
Enfin, le RFC mentionne la proposition Red Rover, qui propose encore un arrangement bisounours où les utilisateurs et les opérateurs collaboreraient pour un filtrage géré en commun. Les auteurs disent que ça marcherait car les utilisateurs « ne veulent probablement pas violer les CGU » (ben si : ils veulent utiliser Sci-Hub même si c'est censuré).
En conclusion, le RFC note en effet qu'on peut être sceptique quant aux chances d'une solution négociée. Mais il met aussi en avant le fait qu'il va être très difficile de trouver une solution qui marche pour toute la variété des réseaux. Et que l'expérience prouve largement que toute nouvelle technique va avoir des effets inattendus et que, par exemple, une solution qui visait à donner aux opérateurs des informations utiles pour la gestion de réseaux, va parfois être détournée pour d'autres buts.
Sinon, sur la question du déboguage des applications dans un monde où tout est chiffré, j'avais fait un exposé à Capitole du Libre.
L'article seul
RFC 9476: The .alt Special-Use Top-Level Domain
Date de publication du RFC : Septembre 2023
Auteur(s) du RFC : W. Kumari (Google), P. Hoffman (ICANN)
Chemin des normes
Première rédaction de cet article le 30 septembre 2023
Le TLD
.alt a été réservé pour les utilisations
non-DNS. Si demain
je crée une chaine de blocs nommée Catena et
que j'enregistre des noms dessus, il est recommandé qu'ils se
terminent par catena.alt (mais comme toujours
sur l'Internet, il n'y a pas de police mondiale chargée de faire
respecter les RFC).
Ce nouveau RFC
est l'occasion de rappeler que noms
de domaine et DNS, ce
n'est pas pareil. Les noms de domaine existaient avant le DNS
et, même aujourd'hui, peuvent être résolus par d'autres techniques
que le DNS (par exemple votre fichier local
/etc/hosts ou équivalent).
Mais le DNS est un tel succès que cette « marque » est utilisée
partout. On voit ainsi des systèmes de résolution de noms n'ayant
rien à voir avec le DNS se prétendre « DNS pair-à-pair » ou « DNS
sur la blockchain », ce
qui n'a aucun sens. Ce nouveau RFC, lui, vise clairement uniquement
les systèmes non-DNS. Ainsi, des racines alternatives ou des
domaines privés comme le
.local du RFC 6762 ne
rentrent pas dans son champ d'application. De plus, il ne s'applique
qu'aux noms de domaine ou en tout cas aux identificateurs qui leur
ressemblent suffisamment. Si vous créez un système complètement
disruptif où les identificateurs ne ressemblent pas à des noms de
domaine, ce RFC ne vous concerne pas non plus. Mais si, pour des
raisons techniques (être compatible avec les applications
existantes) ou marketing (les noms de domaine, c'est bien, tout le
monde les reconnait), vous choisissez des noms de domaine comme
identificateurs, lisez ce RFC.
En effet, il existe plusieurs de ces systèmes. Ils permettent, en
indiquant un nom de domaine (c'est-à-dire une
série de composants séparés par des points comme
truc.machin.chose.example) d'obtenir des
informations techniques, permettant, par exemple, de trouver un
serveur ou de s'y connecter. Un exemple d'un tel système est le
mécanisme de résolution utilisé par Tor. Les
identificateurs sont construits à partir d'une clé
cryptographique et suffixés d'un
.onion (réservé par le RFC 7686). Ainsi, ce blog est en
http://sjnrk23rmcl4ie5atmz664v7o7k5nkk4jh7mm6lor2n4hxz2tos3eyid.onion/. N'essayez
pas ce nom dans le DNS : vous ne le trouverez pas, il se résout via
Tor.
Pendant longtemps, cette pratique de prendre, un peu au hasard,
un nom et de l'utiliser comme TLD a été la façon la plus courante de créer des
noms de domaine dans son espace à soi. C'est ainsi que
Namecoin a utilisé le
.bit, ENS (Ethereum Name Service) le
.eth et GNUnet le
.gnu. Chacun prenait son nom comme il voulait,
sans concertation (il n'existe pas de forum ou d'organisation pour
discuter de ces allocations). Cela entraine deux risques, celui de
collision (deux systèmes de nommage utilisent le même TLD, ou bien
un système de nommage utilise un TLD qui est finalement alloué dans
le DNS, ce qui est d'autant plus probable qu'il n'existe pas de
liste de ces TLD non-DNS). Il y a plusieurs solutions à ce problème,
et l'IETF en a longuement discuté (cf. par exemple
l'atelier
EName de 2017, ou bien le très contestable RFC 8244). Ce RFC a donc mis des années à sortir. L'ICANN, par exemple, a essayé de diaboliser ces
noms, attirant surtout l'attention sur leurs dangers. Autre méthode,
il a été suggéré de créer un mécanisme de concertation pour éviter
les collisions, création qui n'a jamais eu lieu, et pas pour des
raisons techniques. Ce RFC 9476 propose simplement de
mettre les noms non-DNS sous un TLD unique, le
.alt. Ce TLD est réservé dans le registre
des noms spéciaux (créé par le RFC 6761). Ainsi, si le système de résolution de Tor était
créé aujourd'hui, on lui proposerait d'être en
.onion.alt. Est-ce que les concepteurs de
futurs systèmes de résolution non-DNS se plieront à cette demande ?
Je suis assez pessimiste à ce sujet. Et il serait encore plus
utopique de penser que les TLD non-DNS existants migrent vers
.alt.
Comme .alt, par construction, regroupe des
noms qui ne sont pas résolvables dans le DNS, un résolveur purement
DNS ne peut que répondre tout de suite NXDOMAIN (ce nom n'existe
pas) alors qu'un résolveur qui parle plusieurs protocoles peut
utiliser le suffixe du nom comme une indication qu'il faut utiliser
tel ou tel protocole. Si jamais des noms sous
.alt sont réellement utilisés, ils ne devraient
jamais apparaitre dans le DNS (par exemple dans les requêtes aux
serveurs racine) mais, compte-tenu de
l'expérience, il n'y a aucun doute qu'on les verra fuiter dans le
DNS. Espérons que des techniques comme celles du RFC 8020, du RFC 8198 ou du RFC 9156 réduiront la
charge sur les serveurs de la racine; et préserveront un peu la vie
privée (section 4 du RFC).
Le nom .alt est évidemment une référence à
alternative mais il rappelera des souvenirs aux utilisateurs
d'Usenet. D'autres noms avaient été
sérieusement discutés comme de préfixer
tous les TLD non-DNS par un tiret
bas. Mon catena.alt aurait été
_catena :-) Tout ce qui touche à la
terminologie est évidemment très sensible, et le RFC prend soin de
souligner que le terme de « pseudo-TLD », qu'il utilise pour
désigner les TLD non-DNS n'est pas péjoratif…
On note que le risque de collision existe toujours, mais sous
.alt. Notre RFC ne prévoit pas de registre des
noms sous .alt (en partie parce que
l'IETF
ne veut pas s'en mêler, son protocole, c'est le DNS, et en partie
parce que ce milieu des mécanismes de résolution différents est très
individualiste et pas du tout organisé).
L'article seul
RFC 9460: Service Binding and Parameter Specification via the DNS (SVCB and HTTPS Resource Records)
Date de publication du RFC : Novembre 2023
Auteur(s) du RFC : B. Schwartz (Meta Platforms), M. Bishop, E. Nygren (Akamai Technologies)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 8 avril 2024
Dernière mise à jour le 31 mars 2025
Ces deux nouveaux types d'enregistrement DNS, SVCB et sa variante HTTPS, permettent de donner des informations supplémentaires à un client réseau avant qu'il ne tente de se connecter à un serveur. On peut envoyer ainsi des indications sur les versions des protocoles gérées, des clés cryptographiques ou des noms de serveurs supplémentaires.
Un client d'un service réseau a en effet plein de questions à se poser avant de tenter une connexion. Quelle adresse IP utiliser ? Quel port ? Chiffrement ou pas ? Les anciens mécanismes traitent la question de l'adresse IP (on la trouve par une requête DNS) et celle du port, si on se limite aux ports bien connus (comme 43 pour whois). Mais cela ne dit pas, par exemple, si le serveur HTTP distant accepte ou non HTTP/3 (RFC 9114). Par contre, cet enregistrement HTTPS de Cloudflare va bien nous dire que ce serveur accepte HTTP/2 et 3 :
% dig cloudflare.com HTTPS … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 28399 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1 … ;; ANSWER SECTION: cloudflare.com. 300 IN HTTPS 1 . alpn="h3,h2" ipv4hint=104.16.132.229,104.16.133.229 ipv6hint=2606:4700::6810:84e5,2606:4700::6810:85e5 … ;; WHEN: Mon Apr 08 09:27:01 CEST 2024 ;; MSG SIZE rcvd: 226
Bon, en quoi consiste cet enregistrement SVCB ? Il a deux modes de fonctionnement, alias et service. Le premier mode sert à faire d'un nom une version canonique d'un autre, un peu comme le CNAME mais en étant utilisable à l'apex d'une zone. Le second mode sert à indiquer les paramètres techniques de la connexion. Un enregistrement SVCB (ou HTTPS) a trois champs dans ses données :
SvcPriority: quand il vaut zéro, il indique le mode alias. Autrement (par exemple dans le cas ci-dessus), il indique la priorité de ces paramètres.TargetName: en mode alias, il indique le nom canonique, ou autrement un nom alternatif (pour un service accessible via plusieurs noms). Dans l'exemple Cloudflare ci-desssus, il valait la racine (un point) ce qui indique l'absence de nom alternatif (section 2.5).SvcParams: une liste de couples {clé,valeur} pour les paramètres de connexion (uniquement en mode service). Dans le cas avec Cloudflare, c'étaitalpn="h3,h2" ipv4hint=104.16.132.229,104.16.133.229 ipv6hint=2606:4700::6810:84e5,2606:4700::6810:85e5. (Si vous vous intéressez aux débats à l'IETF, la question de la syntaxe de ces paramètres avait suscité une longue discussion.)
Les enregistrements SVCB ont le type 64 (enregistré à l'IANA) et les HTTPS, qui ont la même syntaxe et le même contenu, mais sont spécifiques à HTTP, ont le 65 (SVCB est générique). Les enregistrements HTTPS (et de futurs enregistrements pour d'autres protocoles) sont dits « compatibles avec SVCB » car ils ont la même syntaxe et la même sémantique.
Notre RFC définit (section 7) une liste de paramètres possibles mais d'autres peuvent être ajoutés dans un registre IANA, via la procédure « Examen par un expert » (RFC 8126). Pour l'instant, il y a, entre autres :
L'enregistrement peut (cela dépend des protocoles qui
l'utilisent, HTTP ne le fait pas) être placé sur un sous-domaine
indiquant le service, par exemple
_8765._baz.api.example.com (section
10.4.5).
Idéalement, un serveur faisant autorité devrait renvoyer les SVCB et les HTTPS, s'ils sont présents, dans la section additionnelle de la réponse, lorsque le type demandé était une adresse IP. Mais ceux de Cloudflare ne semblent pas le faire actuellement. (PowerDNS le fait.)
Si vous vous intéressez aux questions opérationnelles, et que vous voulez mettre des enregistrements SVCB/HTTPS dans votre zone, la section 10 du RFC est faite pour vous. J'ai des enregistrements HTTPS pour ce blog :
# Un alias à l'apex (la priorité 0 indique le mode alias) % dig +short +nodnssec bortzmeyer.org HTTPS 0 www.bortzmeyer.org. # J'ai HTTP/2 (mais pas encore HTTP/3) % dig +short +nodnssec www.bortzmeyer.org HTTPS 1 . alpn="h2"
Pour cela, j'ai mis dans le fichier de zone :
; Enregistrements SVCB (HTTPS). ; HTTP/2 (mais pas encore - au 2024-04-08 - de HTTP/3) www IN HTTPS 1 . alpn="h2" ; alias @ IN HTTPS 0 www.bortzmeyer.org.
Les clients HTTP récents, qui gèrent SVCB/HTTPS vont alors se
connecter directement en HTTP/2 à
https://www.bortzmeyer.org/ même si
l'utilisateur demandait originellement
http://bortzmeyer.org/ (le type
d'enregistrement HTTPS, comme son nom l'indique, sert aussi à
annoncer qu'on accepte HTTPS, ce qui permettra d'abandonner HSTS). Les clients
HTTP plus anciens, évidemment, ne connaissent pas le système
SVCB/HTTPS et il faut donc garder une configuration pour eux (par
exemple des adresses IP à l'apex). Il y a aussi les autres méthodes,
comme le Alt-Svc: du RFC 7838. La section 9.3 du RFC décrit le comportement attendu
lorsque les différentes méthodes coexistent.
Faites attention toutefois, lorsque vous mettez ce type d'enregistrements dans votre zone, je ne connais pas encore d'outils de test permettant de vérifier la syntaxe des enregistrements, encore moins leur correspondance avec la réalité (par exemple, SSLLabs ne semble pas le faire). C'est un problème général de la signalisation sur l'Internet, quand on signale (notamment via le DNS) les capacités d'un serveur : le logiciel client doit de toute façon être prêt à tout, car il ne peut jamais être sûr que le signal est conforme aux faits.
En parlant d'anciens logiciels (clients et serveurs), vous pouvez trouver une liste de mises en œuvre de SVCB/HTTPS. Attention, elle est incomplète et pas à jour. Notez qu'il y a parfois des contraintes particulières, ainsi, il semble que Firefox ne demande des enregistrements HTTPS que s'il utilise DoH. iOS envoie des requêtes HTTPS depuis iOS 14, publié en septembre 2020, ce qui avait étonné, à l'époque.
En parlant de Firefox, s'il est assez
récent, et s'il est configuré
pour faire du DoH, vous pouvez tester le SVCB/HTTPS en allant dans
about:networking#dnslookuptool. En entrant un
nom de domaine, le champ « RR HTTP » doit renvoyer l'enregistrement
HTTPS.
curl utilise désormais le type HTTPS mais il faut le compiler avec une certaine option.
Avec un tcpdump récent, voici le trafic
DNS utilisant le nouvel enregistrement DNS, qu'on peut observer sur
un serveur faisant autorité pour
bortzmeyer.org :
09:49:23.354974 IP6 2a04….31362 > 2001:4b98:dc0:41:216:3eff:fe27:3d3f.53: 13024% [1au] HTTPS? www.bortzmeyer.org. (47) 09:52:06.094314 IP6 2a00….56551 > 2001:4b98:dc0:41:216:3eff:fe27:3d3f.53: 40948% [1au] HTTPS? wWw.bOrTZmEyER.ORg. (62) 10:06:21.501437 IP6 2400….11624 > 2001:4b98:dc0:41:216:3eff:fe27:3d3f.53: 59956 [1au] HTTPS? doh.bortzmeyer.fr. (46) 10:06:21.999608 IP6 2400….36887 > 2001:4b98:dc0:41:216:3eff:fe27:3d3f.53: 17231 [1au] HTTPS? radia.bortzmeyer.org. (49) 10:25:53.947096 IP6 2001….54476 > 2001:4b98:dc0:41:216:3eff:fe27:3d3f.53: 26123% [1au] HTTPS? www.bortzmeyer.org. (47)
Si votre tcpdump est plus ancien, vous verrez Type65 au lieu de HTTPS.
Sinon, si vous aimez les bricolages (et celui-ci sera de moins en moins utile avec le temps, au fur et à mesure que les serveurs géreront ce type), pour fabriquer les enregistrements, vous pouvez utiliser cet outil, qui va fabriquer la forme binaire, directement chargeable par les serveurs faisant autorité :
% perl type65_https.pl 'example.net HTTPS 1 . alpn="h3,h2" ipv4hint="192.0.2.42" ipv6hint="2001:db8::42"' example.net. TYPE65 ( \# 41 00010000010006026833026832000400 04c000022a0006001020010db8000000 000000000000000042 )
(Il faut un Net::DNS
récent sinon « unknown type "HTTPS" at /usr/share/perl5/Net/DNS/RR.pm line 671.
in new Net::DNS::RR( www.bortzmeyer.org HTTPS 1 . alpn="h2" )
at type65_https.pl line 30. ».)
Quelques articles pas mal :
- Simple HTTPS Records par Kal Feher.
- Use of HTTPS Resource Records avec le résultat de mesures sur le déploiement effectif.
- Autres mesures dans le monde, l'article Deciphering the Digital Veil: Exploring the Ecosystem of DNS HTTPS Resource Records.
L'article seul
RFC 9432: DNS Catalog Zones
Date de publication du RFC : Juillet 2023
Auteur(s) du RFC : P. van Dijk (PowerDNS), L. Peltan
(CZ.NI), O. Sury (Internet Systems
Consortium), W. Toorop (NLnet
Labs), C.R. Monshouwer, P. Thomassen
(deSEC, SSE - Secure Systems
Engineering), A. Sargsyan (Internet Systems
Consortium)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 29 mars 2024
L'idée de base de ces « zones catalogue » est d'automatiser la configuration d'une nouvelle zone DNS sur les serveurs secondaires, en publiant dans le DNS les caractéristiques des zones qu'ils devront servir. Cela concerne donc surtout les gros hébergeurs qui ont beaucoup de zones.
Petit rappel : une zone, dans le DNS, est une partie contigüe de l'arbre des
noms de domaine, gérée
comme un tout (mêmes serveurs faisant
autorité). Ainsi, si vous venez de louer le nom
machin.example, un hébergeur DNS va configurer
ses serveurs pour faire autorité pour ce nom. Par exemple, avec le
logiciel NSD, sur
le primaire (serveur maitre) :
zone:
name: "machin.example"
zonefile: "primary/machin.example"
# Les serveurs secondaires :
notify: 2001:db8:1::53
provide-xfr: 2001:db8:1::53
…
Et, sur un serveur secondaire (serveur esclave), qui transférera la zone depuis le primaire (RFC 5936) :
zone: name: "machin.example" # Le primaire : allow-notify: 2001:db8:cafe::1 NOKEY request-xfr: AXFR 2001:db8:cafe::1 NOKEY
Si on gère beaucoup de zones, avec des ajouts et des retraits tout le temps, l'avitaillement manuel est long et risqué (et si on oublie un serveur ?). Éditer ces fichiers sur tous les serveurs secondaires devient vite pénible. Et si les logiciels sur les secondaires sont différents les uns des autres (ce qui est recommandé, pour la robustesse), il faut se souvenir des différentes syntaxes. Pourquoi faire manuellement ce qu'on peut automatiser ? C'est le principe des zones catalogue.
Le principe est simple : une zone catalogue est une zone comme
une autre, produite par les mêmes mécanismes (par exemple
emacs) et qui sera servie par un serveur
primaire à tous les secondaires, qui changeront alors
automatiquement leur configuration en fonction du contenu de la zone
catalogue. Chaque zone à configurer est un enregistrement de type
PTR, dont la partie gauche est une étiquette interne et la partie
droite indique le nom de la zone. Ici, on configure la zone
rutaba.ga, l'étiquette (qui doit être unique)
label1 est à usage interne (section 4.1 du RFC) :
label1.zones.catalog.example. IN PTR rutaba.ga.
Le reste est listé sous forme de propriétés (section 4.2). Une
propriété évidente est l'adresse IP du primaire. Pour l'instant,
elle doit être indiquée via le composant ext
qui désigne les propriétés pas encore normalisées :
primaries.ext.catalog.example. IN AAAA 2001:db8:bad:dcaf::42
La liste des propriétés figure dans un registre IANA.
À l'heure actuelle, de nombreux logiciels gèrent ces zones catalogues. Le site Web du projet (pas mis à jour depuis très longtemps) en liste plusieurs.
Voici un exemple complet de zone catalogue :
; -*- zone -*-
catalog.example. IN SOA ns4.bortzmeyer.org. stephane.bortzmeyer.org. 2023120902 900 600 86400 1
catalog.example. IN NS invalid. ; Le NS est inutile mais
; obligatoire et "invalid" est la valeur
; recommandée (section 4).
version.catalog.example. IN TXT "2" ; Obligatoire, section 4.2.1
label1.zones.catalog.example. IN PTR rutaba.ga.
primaries.ext.catalog.example. IN AAAA 2001:db8:bad:dcaf::42
La configuration de BIND pour l'utiliser :
# La zone catalogue se charge comme n'importe quelle zone. Ceci dit,
# vu le caractère critique de la zone catalogue, la section 7 du RFC
# insiste sur l'importance de sécuriser ce transfert, par exemple avec
# TSIG (RFC 8945) :
zone "catalog.example" {
type slave;
file "catalog.example";
masters {
2001:db8:666::;
};
};
# Et, ici, on la désigne comme spéciale :
options {
...
catalog-zones {
zone "catalog.example"
in-memory no;
};
};
Naturellement, comme toujours lorsque on automatise, on risque le syndrome de l'apprenti sorcier. Attention donc en générant la zone catalogue. Comme le note le RFC (section 6) : « Great power comes with great responsibility. Catalog zones simplify zone provisioning by orchestrating zones on secondary name servers from a single data source: the catalog. Hence, the catalog producer has great power and changes must be treated carefully. For example, if the catalog is generated by some script and this script generates an empty catalog, millions of member zones may get deleted from their secondaries within seconds, and all the affected domains may be offline in a blink of an eye. »
L'article seul
RFC 9421: HTTP Message Signatures
Date de publication du RFC : Février 2024
Auteur(s) du RFC : A. Backman (Amazon), J. Richer (Bespoke Engineering), M. Sporny (Digital Bazaar)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 17 janvier 2025
Ce RFC spécifie comment on peut signer cryptographiquement et vérifier des messages HTTP, afin de s'assurer de leur authenticité. Des signatures HTTP conceptuellement proches, mais syntaxiquement différentes sont notamment utilisées par le fédivers. (Notez que le RFC, délibérément, ne spécifie pas un protocole complet mais une des briques, qui devra impérativement être complétée avec d'autres règles.)
Alors, attention, vous allez me dire « mais tout le monde utilise HTTPS, de toute façon » mais ce n'est pas tout à fait la même chose. Comme l'explique la section 1 de notre RFC, TLS protège une connexion mais ne fonctionne pas de bout en bout, s'il y a sur le trajet des relais qui terminent une session TLS et ouvrent une autre connexion (la section 7.1.2 détaille les limites de TLS pour les scénarios envisagés). Et TLS ne permet pas d'authentifier le client, sauf à utiliser des certificats client, que beaucoup trouvent peu pratique, et qui dépendent d'un système centralisé, les AC. En prime, dans un contexte d'utilisation serveur-serveur, comme dans le fédivers, on n'a pas envie de confier sa clé privée à son serveur. Donc, il y a un besoin pour une signature des messages (TLS n'est pas inutile pour autant, il fournit notamment la confidentialité, cf. section 8.2 de notre RFC). Voilà pourquoi Mastodon, par exemple, a commencé à utiliser des signatures HTTP pour la sécurité. Le format ActivityPub ne prévoyait en effet aucune sécurité, d'où la nécessité de développer des techniques ad hoc. Mais notez que la technique de Mastodon, non normalisée et même pas spécifiée quelque part, sauf dans le code source, n'est pas compatible avec celle du RFC. Un travail est en cours pour documenter cela.
Notons qu'il existe aussi des solutions pour signer le corps d'un message HTTP, comme JWS (RFC 7515) si le corps est en JSON (RFC 8259). Mais les signatures HTTP de notre RFC 9421 protègent non seulement le corps (quel que soit son format) mais aussi une partie des champs de l'en-tête. Il n'y a pas de solution générale de protection des contenus en HTTP, juste une protection du canal de communication, avec HTTPS.
Donc, le principe est simple : le signeur canonicalise certains champs de l'en-tête (et, indirectement, le corps, via la condensation du RFC 9530), les signe et met la signature dans l'en-tête. Par exemple, avec ce message HTTP (une simple demande de lecture, qui n'a donc probablement pas besoin d'être authentifiée mais c'est juste un exemple) :
GET /9421.html HTTP/1.1 Host: www.bortzmeyer.org Date: Fri, 17 Jan 2025 10:53:17 +0100 Content-Type: text/plain Content-Digest: sha-256=:591b6607e9e257e26808e2ccf3984c23a5742b78defad9ec7b2966ddcef29909=: Hello, HTTP
La signature ajoutera ces deux champs :
Signature-Input: sig=("date" "host";sf "content-type";sf "content-digest" "@method" "@target-uri" "@authority" "@scheme" "@request-target" "@path" "@query");alg="ecdsa-p256-sha256"
Signature: sig=:0dnCVeCDOJ9fQiLqUXLE8hwBDNpAVlO3TJZgqm/FBJ1x2h5/g5qU20UM87BkJt0iK9vpRRgPF9fmWobf6Y5iYQ==:
(« sig » est un identificateur arbitraire, qui sert à faire la correspondance entre une signature et ses paramètres, dans le cas où il y a plusieurs signatures.) Le vérificateur devra récupérer la clé publique (notez que le RFC ne précise pas comment : chaque application utilisant les signatures HTTP devra décrire sa méthode de récupération des clés), canonicaliser et refaire les calculs cryptographiques, validant (ou non) la signature.
Voilà, vous connaissez l'essentiel du RFC, maintenant, place aux
détails. D'abord, un peu de terminologie : en dépit de leur nom, les
signatures HTTP peuvent être aussi bien de « vraies » signatures, faites avec de la
cryptographie asymétrique que des
MAC incluant une clé secrète (avec de la
cryptographie symétrique, donc). Ensuite,
relisez bien le RFC 9651 : les champs
structurés dans l'en-tête sont un cas particulier, en raison de la
canonicalisation qu'ils vont subir. (Vous
avez remarqué le sf dans le champ
Signature-Input: plus haut ? Il veut dire
Structured Field et indique un traitement
particulier.)
Ensuite, la question évidemment compliquée de la
canonicalisation. HTTP permet et même parfois impose des
transformations du message faites par des intermédiaires (la section
1.3 donne une liste partielle des transformations possibles). Il est
très difficile, voire impossible, de définir quels champs de
l'en-tête vont être respectés et lesquels vont être modifiés. Il n'y
a donc pas de liste officielle des champs à signer, chaque
application va indiquer les siens. Dans l'exemple ci-dessus, on
signe les quatre champs présents, et on l'indique dans le
Signature-Input:. Si un intermédiaire ajoute un
champ quelconque (par exemple le Forwarded: du
RFC 7239), la signature restera valide. Le
récepteur ne devra donc pas considérer ce champ comme
authentifié. Même chose pour le corps si on ne signe pas son
condensat (RFC 9530). La section 7.2.8 du RFC
rappelle l'importance de signer le corps, pour la plupart des
cas. Notez également que le Signature-Input:
plus haut incluait aussi des composants qui ne sont pas des champs
de l'en-tête mais qu'on veut signer, comme la méthode (GET) ou
les composants de l'URL. Leur nom est précédé d'un arobase.
Autre problème du monde réel : les programmes n'ont pas un contrôle complet du message HTTP produit. Par exemple, le programme va utiliser une bibliothèque qui va formater les champs à sa manière, en ajouter, etc. C'est pour cela qu'il est important de laisser ouverte la question de la liste des champs à signer. Chaque application choisira.
Les signatures HTTP ne sont pas une solution complète prête à l'emploi : bien des points sont délibérément laissés vides dans le RFC. Une solution complète de sécurité doit donc spécifier :
- quels sont les champs qui doivent être signés, la section
7.2.3 fournissant des indications sur ce choix (par exemple,
Mastodon impose que
Date:soit présent et signé, pour détecter les messages trop anciens que quelqu'un essaierait de rejouer, cf. la section 7.2.2), - comment récupérer la clé publique d'un correspondant (sur le fédivers, c'est fait en utilisant WebFinger, système normalisé dans le RFC 7033),
- et les autres exigences diverses spécifiques à cette application (la section 3.2.1 donne une bonne idée de ce qu'elles peuvent être).
Un exemple d'une telle solution complète est dans
l'Internet draft
draft-meunier-web-bot-auth-architecture. La
récupération des clés est documentée dans l'Internet
draft draft-meunier-http-message-signatures-directory.
Les noms des composants signés (champs de l'en-tête et autres)
sont décrits dans la section 2 de notre RFC. Pour un champ, c'est
simplement son nom en minuscules (comme "date"
dans le Signature-Input: plus haut). Autrement,
les noms commencent par un arobase par exemple
@method indique la méthode HTTP
utilisée. Les méthodes de canonicalisation (complexes, surtout pour
les champs structurés !) sont dans la même section.
Les différents paramètres de la signature, comme un
identificateur pour la clé utilisée, ou comme la date de signature,
peuvent également être inclus dans le
Signature-Input:.
Tous ces paramètres forment ce qu'on appelle la base (section 2.5). Celle du message donné comme exemple plus haut est :
"date": Fri, 17 Jan 2025 10:53:17 +0100
"host";sf: www.bortzmeyer.org
"content-type";sf: text/plain
"content-digest": sha-256=:591b6607e9e257e26808e2ccf3984c23a5742b78defad9ec7b2966ddcef29909=:
"@method": GET
"@target-uri": https://www.bortzmeyer.org/9421.html
"@authority": www.bortzmeyer.org
"@scheme": https
"@request-target": /9421.html
"@path": /9421.html
"@query": ?
"@signature-params": ("date" "host";sf "content-type";sf "content-digest" "@method" "@target-uri" "@authority" "@scheme" "@request-target" "@path" "@query");alg="ecdsa-p256-sha256"
Ici, elle est relativement courte, la plupart des métadonnées n'étant pas mentionnée.
Une fois la signature générée, le signeur ajoute deux champs à l'en-tête (section 4 du RFC) :
Signature-Input:qui indique les paramètres de la signature (liste des champs signés, et optionnellement métadonnées sur la signature),- Et
Signature:, qui contient la signature elle-même.
Les deux champs sont structurés selon la syntaxe du RFC 9651. (Notez que ces deux champs sont une des différences
avec l'ancienne version des signatures HTTP, utilisée dans le
fédivers. Cette ancienne version n'avait qu'un champ,
Signature:. Un vérificateur qui veut gérer les
deux versions peut donc utiliser la présence du champ
Signature-Input: comme indication que la
version utilisée est celle du RFC. L'annexe A expose cette
heuristique, qui figure également dans le
projet d'intégration avec ActivityPub.)
Voici un exemple de signature avec des métadonnées (date de signature et identifiant de la clé :
Signature-Input: reqres=("@status" "content-digest" "content-type" \
"@authority";req "@method";req "@path";req "content-digest";req)\
;created=1618884479;keyid="test-key-ecc-p256"
Signature: reqres=:dMT/A/76ehrdBTD/2Xx8QuKV6FoyzEP/I9hdzKN8LQJLNgzU\
4W767HK05rx1i8meNQQgQPgQp8wq2ive3tV5Ag==:
Notez que notre RFC décrit aussi une méthode pour demander qu'un
correspondant signe ses messages : inclure un champ
Accept-Signature: (section 5 du RFC).
Les signatures HTTP nécessitent la modification ou la création de plusieurs registres IANA :
- Les champs
Accept-Signature:,Signature:etSignature-Input:ont été ajoutés au registre des champs d'en-tête HTTP. - Un registre
des algorithmes de signature a été créé. On va y trouver
par exemple
ecdsa-p256-sha256, que j'ai utilisé dans mon exemple (algorithme ECDSA). On peut y ajouter des algorithmes via la politique « Spécification nécessaire » du RFC 8126. - Un registre
des métadonnées des signatures a été créé. On y trouve par
exemple
created(la date de signature) oukeyid(l'identificateur de la clé, selon un schéma de nommage spécifique à l'application). On peut y ajouter des valeurs via la politique « Examen par un expert » du RFC 8126. - Un registre
des noms de composants a été créé, pour mettre ces noms
commençant par « @ », comme
@method. On peut y ajouter des noms via la politique « Examen par un expert » du RFC 8126. - Un registre
des noms des paramètres des composants a été créé. Vous
avez déjà rencontré
sf, par exemple, qui indique qu'un champ de l'en-tête est un champ structuré et doit donc être traité de manière spéciale. On peut y ajouter des noms via la politique « Examen par un expert » du RFC 8126.
Si vous voulez un article d'introduction :
Questions mises en œuvre, on dispose désormais de bibliothèques pour de nombreux langages de programmation (je ne les ai pas testées) :
- Pour Go, il y a
https://github.com/superseriousbusiness/httpsighttps://github.com/cloudflareresearch/web-bot-auth/ - Pour PHP,
https://imrannazar.com/articles/http-signatures-in-php - Pour Rust, regardez
https://docs.rs/crate/http-signatures/latest - Pour Python,
https://pypi.org/project/http-message-signatures/
Une discussion est en
cours pour ajouter ces signatures à
curl (c'est fait depuis
la 8.22). Lisez aussi l'article de Cloudflare
sur l'authentification des bots, qui propose (entre autres)
l'utilisation des signatures HTTP pour authentifier un
crawler
Web. Apparemment, en mai 2025,
OpenAI le fait déjà.
Si vous programmez, pour tester votre code, je recommande fortement le service en ligne
https://httpsig.org/
openssl ecparam -out server.pem -name prime256v1 -genkey openssl req -new -key server.pem -nodes -days 1000 -out server.csr openssl x509 -in server.csr -out server.crt -req -signkey server.pem -days 2001
La clé privée sera dans server.pem et la
publique dans server.crt. Sinon, il y a aussi
https://http-message-signatures-example.research.cloudflare.com/
Concernant l'ancienne version des signatures HTTP, vous pouvez consulter :
- Eugen Rochko a fait deux bons
articles d'introduction :
https://blog.joinmastodon.org/2018/06/how-to-implement-a-basic-activitypub-server/https://blog.joinmastodon.org/2018/07/how-to-make-friends-and-verify-requests/ - Dans Mobilizon, le code de signature
est
Mobilizon.Federation.HTTPSignatures.Signatureet il vient à l'origine de Pleroma. - Dans PeerTube (le code vient, je crois, de Misskey, à moins que ce ne soit le contraire) : c'est ici (et pour Misskey, ici).
- J'ai écrit (avec Chloé Baut) une mise en œuvre des protocoles du fédivers, en Python, purement expérimentale mais qui peut être intéressante à lire pour comprendre comment tout cela marche.
Cette technique des signatures HTTP a eu une histoire longue et
compliquée. Née chez Amazon, elle avait d'abord été
décrite dans un Internet draft, draft-cavage-http-signatures
en 2013, et déployée, notamment dans le secteur financier. En 2017,
Mastodon avait utilisé la technique telle que décrite dans ce
document (forçant le reste du fédivers à s'aligner sur « ce que fait
Mastodon »). C'est après l'adoption par le groupe de travail
httpbis que le projet avait pris sa forme finale. (Regardez
les
supports de présentation à l'IETF en 2019 et la vidéo de la
réunion.) L'auteur du projet initial avait écrit un
bon résumé en 2020, décrivant de l'intérieur comment se passe
la normalisation dans l'Internet. Les différences principales avec ce que fait le fédivers :
- Deux champs au lieu d'un,
Signature-Input:etSignature:, - Les champs utilisent la syntaxe des champs structurés du RFC 9651,
- Les métadonnées sont également signées.
Et pour terminer, voilà comment ça se fait dans le fédivers (qui, je le rappelle, n'utilise pas la syntaxe de ce RFC mais des concepts proches) :
- le client annonce son identité (pour moi,
bortzmeyer@mastodon.gougere.fr), - le serveur fait alors une requête WebFinger vers l'instance indiquée
(comme un
wget https://mastodon.gougere.fr/.well-known/webfinger/\?resource=acct:bortzmeyer@mastodon.gougere.fr), - puis il va suivre suivre l'URL
indiquée dans le membre
self(comme uncurl -o bortzmeyer.json -H 'Accept: application/activity+json' "https://mastodon.gougere.fr/users/bortzmeyer"), et la clé publique est dans le membrepublicKey, - et le serveur peut
alors vérifier les signatures et voir que c'était bien
bortzmeyer@mastodon.gougere.frqui écrivait (en toute rigueur, on vérifie juste que c'est bienmastodon.gougere.frqui écrit et on lui fait confiance pour avoir authentifié ses propres utilisateurs).
L'article seul
RFC 9340: Architectural Principles for a Quantum Internet
Date de publication du RFC : Mars 2023
Auteur(s) du RFC : W. Kozlowski, S. Wehner
(QuTech), R. Van Meter (Keio
University), B. Rijsman, A. S. Cacciapuoti, M. Caleffi
(University of Naples Federico II), S. Nagayama
(Mercari)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF qirg
Première rédaction de cet article le 3 avril 2024
Voici un RFC assez futuriste qui explore à quoi pourrait ressembler un futur « Internet » quantique. Je divulgâche tout de suite : ce ne sera pas de si tôt.
Quelques avertissements s'imposent d'abord. Avant tout, rappelez-vous que la quantique produit des résultats qui sont parfaitement cohérents théoriquement et très bien vérifiés expérimentalement mais qui sont hautement non-intuitifs. Avant d'aborder le monde merveilleux de la quantique, n'oubliez pas d'oublier tout ce que vous croyez savoir sur le monde physique. Et ne comptez pas trop sur moi comme guide, on sort nettement ici de mon domaine de compétence. Ensuite, « quantique » est un terme à très forte charge marketing (moins que « IA » mais davantage que « métavers » ou même « blockchain », qui semblent bien passés de mode). Il faut donc être prudent chaque fois qu'un commercial ou un éditorialiste va dire que « c'est quantique » ou que « la quantique va bouleverser tel ou tel domaine ». Enfin, il y a loin de la coupe aux lèvres : de même qu'on n'a pas encore d'ordinateur quantique utile, on n'a pas encore de réseau quantique. Le RFC est à juste titre prudent, pointant les différents obstacles qui restent sur le chemin de l'Internet quantique.
Bon, ces précautions étant posées, qu'est-ce qu'un réseau quantique et pourquoi y consacrer un RFC ? La section 1 du RFC le résume : un réseau quantique est un réseau qui ferait communiquer des dispositifs quantiques pour faire des choses inimaginables avec un réseau classique. Il s'appuierait sur des propriétés spécifiques au monde quantique, notamment l'intrication, propriétés qui n'ont pas d'équivalent dans le monde classique. Attention, et le RFC insiste bien là-dessus, personne n'envisage de remplacer l'Internet classique par un Internet quantique (de la même façon que les futurs ordinateurs quantiques, étant loin d'être généralistes, ne remplaceront pas les ordinateurs classiques). Au contraire, le scénario envisagé est celui d'un réseau hybride, partiellement quantique. (Une lecture recommandée par le RFC est « The quantum internet ».)
Un exemple typique qui ne serait pas possible avec un réseau classique est celui de la distribution quantique de clés (parfois appelée du terme erroné de « cryptographie quantique »), dont l'utilité pratique est douteuse mais qui est assez spectaculaire et, contrairement à d'autres applications, est assez avancée techniquement. D'autres applications sont envisageables à plus long terme. C'est le cas par exemple du blind quantum computation, qui n'a pas encore d'article Wikipédia mais est expliqué dans cet article.
En laboratoire, beaucoup de résultats ont été obtenus. Les chercheurs et chercheuses ont déjà mis au point bien des dispositifs physiques étonnants. Mais à l'échelle du réseau, il n'y a pas encore eu beaucoup de travaux. Le RFC compare cette situation à celle d'un réseau classique où on aurait des fibres optiques et des lasers pour les illuminer mais aucun protocole de transport, aucun mécanisme de routage, encore moins de moyens de gérer le réseau. Développer une application pour un réseau quantique revient à toucher directement au matériel, comme, pour un réseau classique, s'il fallait que chaque application parle aux interfaces physiques, sans avoir d'interface de plus haut niveau comme les prises.
La section 2 du RFC est un rappel sur la quantique. Comme dit plus haut, c'est un domaine riche et complexe, où l'intuition ordinaire ne sert pas à grand'chose. Donc, lire ce rappel est une bonne idée mais n'espérez pas tout comprendre si vous n'êtes pas spécialiste de la question. Cette section est conçue pour des gens qui ne connaissent rien à la physique quantique, elle recommande, pour aller plus loin, le livre de Sutor Dancing with Qubits ou bien celui de Nielsen et Chuang, Quantum Computation and Quantum Information.
Le rappel commence avec la notion d'état quantique. Vous avez sans doute déjà entendu dire qu'un bit classique peut prendre deux valeurs, 0 ou 1, alors que son équivalent quantique, le qubit, a un état qui est une superposition de valeurs possibles, avec des probabilités. Lorsqu'on le mesure, on trouve un 0 ou un 1. (Oui, comme le célèbre chat qui est à la fois vivant et mort.) Attention, ces non-certitudes ne sont pas la conséquence d'un manque d'information mais sont une propriété fondamentale du monde quantique (Alain Aspect a eu un prix Nobel pour avoir prouvé cela). Notez que les versions HTML ou PDF du RFC sont recommandées ici, car il y a quelques équations. Comme un qubit est dans un état qui superpose les deux valeurs possibles, les opérations quantiques agissent sur tout l'état, par exemple l'équivalent quantique d'une porte NOT va inverser les probabilités du 0 et du 1 mais pas transformer un 0 en 1.
Le terme « qubit » (et cette distinction revient souvent dans le RFC) peut désigner aussi bien le concept abstrait que le truc physique qui va le mettre en œuvre (il existe plusieurs techniques pour fabriquer un engin qui gérera des qubits).
On peut ensuite assembler des qubits et, très vite, le nombre de possibilités croît. Mais l'intérêt de mettre des qubits ensemble est qu'on peut les intriquer et ce concept est au cœur de beaucoup de solutions quantiques, notamment du réseau quantique. Une fois intriqués, les deux qubits verront leur sort lié. Une mesure sur l'un affectera l'autre. (Rappel : la quantique n'est pas intuitive et l'intrication n'a pas d'équivalent dans le monde non-quantique, celui sur lequel a été bâtie notre intuition.) La mesure, comme toujours en quantique, est « destructive » au sens où elle ramène à un système classique (le qubit vaut 0 ou 1 quand on le mesure, pas un mélange des deux, et le chat est vivant ou mort quand on ouvre la boite).
Cette intrication est au cœur des réseaux quantiques (section 3 du RFC). Tous les projets de réseaux quantiques utilisent cette propriété (qui, rappelons-le, n'a pas d'équivalent non-quantique). L'intrication permet de corréler deux nœuds du réseau. Par exemple, pour se mettre d'accord sur une valeur, deux machines n'ont pas besoin de faire tourner des algorithmes de consensus, elles peuvent utiliser deux qubits intriqués, chacune en gardant un. Quand une machine lira la valeur de son qubit, elle sera certaine de la valeur lue par l'autre. Et l'intrication ne peut pas être partagée : un tiers ne peut pas s'intriquer avec une intrication existante, ce qui peut avoir des applications en sécurité.
Un réseau quantique est donc défini par notre RFC comme un ensemble de nœuds qui peuvent échanger des qubits intriqués.
Bon, tout ça, c'est très joli, mais comment on le réalise, ce réseau quantique ? La section 4 se penche sur les défis :
- Comme toute mesure détruit le caractère quantique du qubit et le transforme en un bit ordinaire, des opérations banales dans le monde classique, comme la copie d'un bit, deviennent non triviales.
- Et copier un qubit sans le mesurer ? On ne peut pas (c'est le théorème d'impossibilité du clonage).
- Tout cela rend très difficile la correction d'erreurs. Un réseau réel, reposant sur des objets physiques, va forcément voir des erreurs (un rayon cosmique passe et paf, un 0 est transformé en 1) et de nombreuses techniques existent pour gérer ce problème dans le monde classique. Mais elles ne peuvent en général pas s'appliquer dans le monde quantique, qui va donc avoir un problème de fidélité : la fidélité est la conformité à ce qu'on souhaitait (elle va de 0 à 1), et les applications doivent en tenir compte.
Distribuer sur le réseau des qubits quelconques n'est pas forcément facile, donc le RFC suggère de plutôt distribuer des paires de Bell. On peut alors plus facilement (tout est relatif) faire de la téléportation, c'est-à-dire « transporter » un qubit d'un point à un autre. Ce n'est pas une violation du théorème d'impossibilité du clonage puisque le qubit n'est pas copié (il disparait de son point de départ). Notez que le terme de « téléportation » est surtout marketing : vous ne pourrez pas déplacer votre chat ou vous-même de cette façon.
Dernier problème, amplifier le signal (sans le copier !) pour tenir compte de sa dégradation avec la distance. Il existe une astuce, l'échange d'intrication, que je ne vais pas essayer d'expliquer, mais qui permet des réseaux quantiques sur des distances importantes.
Revenons à la correction d'erreurs. Les réseaux quantiques ne sont pas complètement démunis, et ont des solutions possibles, comme les codes quantiques.
OK, on a vu que le monde quantique était très spécial. Donc, le réseau quantique va être bizarre aussi, aux yeux de quelqu'un qui a l'habitude des réseaux classiques (section 5 du RFC). Par exemple, il fera face à ces problèmes :
- C'est bien joli, les paires de Bell, mais ce n'est pas l'équivalent d'un paquet portant une charge utile. Il n'y a pas l'équivalent de l'en-tête du paquet, et le réseau quantique va donc devoir utiliser un réseau classique pour l'information de contrôle. On ne fera pas un réseau purement quantique.
- Toute action sur des qubits intriqués doit être coordonnée entre les nœuds puisque l'action sur un qubit va déterminer le résultat d'une action sur les autres (il faut donc que chaque nœud sache contacter les autres).
Répétons-le, chaque nœud du réseau quantique devra également être relié à un réseau classique. Le réseau sera donc complexe et son administration pas évidente.
Une fois qu'on a accepté cela, le réseau classique pourra s'occuper d'opérations comme la construction des tables de routage, pour laquelle les algorithmes et méthodes classiques semblent suffire. On n'aura donc peut-être qu'un seul plan de contrôle (le classique) mais deux plans de données, le classique et le quantique.
Que faut-il construire comme machines pour le plan de données quantique ? D'abord, des répéteurs quantiques qui vont pouvoir créer les intrications, les échanger et contrôler la fidélité. Ensuite :
- Des routeurs quantiques, qui, en plus des fonctions ci-dessus, participeront au routage.
- Les nœuds ordinaires, des répéteurs qui ne participent pas au routage.
- Les nœuds terminaux, qui pourront émettre et recevoir des qubits mais pas faire d'échange d'intrication. C'est là que tourneront les applications.
Facile, me direz-vous ? Non, construire ces machines va nécessiter de s'attaquer à quelques problèmes physiques :
- Stocker un qubit est un défi ! Le monde classique n'aime pas les objets quantiques et essaie régulièrement de les rappeler à ses lois. Les bruits divers de l'environnement font rapidement perdre aux qubits leurs propriétés quantiques. (C'est d'ailleurs pour cela que vous ne rencontrez pas de chats de Schrödinger dans la vraie vie.) Cela se nomme la décohérence et c'est l'un des principaux obstacles sur la route des réseaux quantiques (ou des calculateurs quantiques). Les durées de vie qu'on atteint étaient, lors de la rédaction du RFC, de l'ordre de la seconde (ou de la minute si on n'est pas connecté au réseau, source de perturbations).
- La capacité des liens quantiques est un autre problème. Générer des qubits intriqués prend du temps. Quand on en fabrique dix par seconde, on est contents. Bien sûr, la technique progresse sans cesse (pas mal des références du RFC sont un peu datées, car il a mis du temps à sortir) mais pas assez.
- On l'a dit, on peut réaliser des qubits intriqués par différentes méthodes physiques, avec des performances différentes selon la métrique utilisée. Mais ces méthodes ne communiquent pas entre elles, ce qui veut dire que tous les nœuds du réseau doivent utiliser la même.
Si vous n'êtes pas découragé·e (mais il ne faut pas l'être : même si les difficultés sont colossales, le chemin est rigolo), il faut maintenant, en supposant qu'on aura les composants de base d'un réseau, les assembler. (À moins que le choix décrit dans le RFC des paires de Bell et de l'échange d'intrication ne soit remis en cause par les futurs progrès…) La section 6 se penche sur la question. Elle démarre par un bel excès d'optimisme, en expliquant que, contrairement à ce qui s'est passé avec l'Internet classique, on a de l'expérience sur la construction de réseau, et qu'on pourra donc ne pas faire d'erreur comme la taille trop réduite des adresses IPv4.
Des services essentiels pour un réseau réel seront difficiles à assurer sur un réseau quantique. Par exemple, l'impossibilité du clonage interdira d'utiliser un logiciel équivalent à tcpdump (remarquez, pour la sécurité, c'est un plus). Le RFC liste les principes de base d'un réseau quantique :
- Le service de base sera l'intrication.
- La fidélité est aussi un service (contrairement au réseau classique où on peut espérer une fidélité parfaite).
- Le temps va être un facteur crucial, compte tenu de la décohérence. Pas question de faire patienter des qubits trop longtemps dans une file d'attente, par exemple.
- Il faudra être flexible, notamment parce que le matériel va continuer à évoluer.
Et le RFC se termine par une exploration d'une architecture de réseau quantique possible, inspirée de MPLS. Dans ce réseau (pour l'instant) imaginaire, tout fonctionne en mode connecté (comme MPLS) : on doit d'abord créer un circuit virtuel (car créer les paires de Bell et les utiliser va nécessiter de la coordination, donc il vaut mieux établir d'abord une connexion). Ce QVC (Quantum Virtual Circuit) a des caractéristiques comme une qualité de service choisie, qui se décline en, par exemple, une capacité mesurée en nombre de paires de Bell par seconde et bien sûr une fidélité (toutes les applications des réseaux quantiques n'ont pas les mêmes exigences en terme de fidélité). La signalisation peut être décentralisée (comme avec RSVP) ou centralisée (comme avec OpenFlow). Comme vous le verrez en lisant cette conclusion du RFC, les détails sont encore approximatifs.
Ce RFC a mis longtemps à être écrit, vous pouvez trouver une description ancienne du projet sur le blog de l'IETF. Notez que l'écriture de ce RFC a été en partie financée par la Quantum Internet Alliance européenne.
N'hésitez pas à vous plonger dans la bibliographie très détaillée de ce RFC, vous y trouverez beaucoup de lectures passionnantes. Il y a même déjà des livres entiers sur les réseaux quantiques comme celui de Van Meter.
L'article seul
RFC 9311: Running an IETF Hackathon
Date de publication du RFC : Septembre 2022
Auteur(s) du RFC : C. Eckel (Cisco Systems)
Pour information
Réalisé dans le cadre du groupe de travail IETF shmoo
Première rédaction de cet article le 31 octobre 2024
L'IETF, l'organisation qui normalise les protocoles de l'Internet a toujours prôné le pragmatisme et le réalisme : ce n'est pas tout d'écrire des normes, il faut encore qu'elles fonctionnent en vrai. Un des outils pour cela est le hackathon qui se déroule traditionnellement le week-end avant les réunions physiques de l'IETF. Ce RFC, écrit par le responsable de ces hackathons, décrit l'organisation de ces événements.
La salle (en cours d'installation) du hackathon à
Yokohama en 2023 :

Paradoxalement, alors que cette ambition de réalisme (« we believe in rough consensus and running code ») est ancienne à l'IETF, les hackathons sont relativement récents. Le premier était en 2015 à Dallas. Mais les hackathons font désormais partie de la culture IETF et on n'imagine plus de réunion sans eux. Ils accueillent désormais systématiquement plusieurs centaines de participant·es (cf. section 6 du RFC). (Mon premier était à Chicago.) Au passage, si vous êtes programmeur·se et que vous allez à une réunion IETF, ne ratez pas le hackathon, il en vaut la peine. Le prochain commence ce samedi, le 2 novembre 2024, à Dublin.
Donc, le but du hackathon à l'IETF (section 1 du RFC) est de tester les normes en cours d'élaboration, de voir si la future spécification est claire et réaliste, et de faire en sorte que les gens qui écrivent les normes (qui ne sont pas forcément des développeur·ses) interagissent avec ceux et celles qui mettent en œuvre les normes. (Cela peut paraitre étonnant, mais beaucoup de SDO ne fonctionnent pas comme cela ; la norme est écrite par des gens qui sont très loin du terrain et qui se moquent du caractère réaliste et effectif de leurs textes.) Le code qui tourne est souvent plus significatif qu'une opinion exprimée pendant la réunion. Et le hackathon est aussi l'occasion de travailler en commun (surtout si on est présent·e physiquement), ce qui fait avancer les projets.
Ah, et puisqu'on parle de collaboration, contrairement à certains hackathons, ceux de l'IETF n'ont plus aucune forme de compétition : pas de classement, pas de prix. (Voir la section 7.6 sur le rôle qu'avaient les juges de la compétition et pourquoi cela a été vite supprimé.) En outre, la plupart du code écrit pendant les hackathons est sous une licence libre (la principale exception concerne les gens qui ont modifié un logiciel privateur, par exemple le code de certains routeurs). Du point de vue « juridique », notez que le hackathon est un événement de l'IETF et donc soumis aux règles IETF (voir aussi la section 5.3).
Les hackathons de l'IETF sont gratuits (et il n'est pas forcément nécessaire de payer son voyage, on peut le faire à distance, voir plus loin) et ouverts à tous (cf. section 5.3). On s'inscrit en ligne puis on y va. Si vous êtes débutant·e, ne vous inquiétez pas, on a tous été débutant·es et les hackathons sont justement l'occasion de mêler étudiant·es, expert·es, etc. Une large participation est encouragée.
Comment organise t-on un tel événement ? Charles Eckel, l'auteur du RFC, est pour l'instant le pilier de ces hackathons. Le RFC a été écrit, entre autres, pour transmettre son expérience et permette à d'autres de le seconder ou de lui succéder. La section 2 du RFC détaille les choix effectués. Le hackathon se tient le week-end pour faciliter la participation des gens qui travaillent, notamment de ceux et celles qui ne viennent pas à la réunion IETF la semaine suivante. Et puis ça renforce le côté informel.
Questions horaires, le hackathon de l'IETF n'essaie pas de faire travailler les gens 24 heures sur 24 tout le week-end. La majorité des participant·es au hackathon viennent à l'IETF ensuite et doivent donc rester frai·ches. Le hackathon dure typiquement le samedi de 09:00 à 22:00 et le dimanche de 09:00 à 16:00 (il y a déjà des réunions IETF le dimanche en fin d'après-midi). Si des gens veulent travailler toute la nuit, ielles doivent le faire dans leur chambre.
La nourriture est fournie sur place pour éviter qu'on doive sortir (mais on a évidemment le droit de sortir, les participant·es ne sont pas attaché·es et peuvent estimer plus important d'aller discuter avec d'autres participant·es en dehors du hackathon). Et, comme le note le RFC, c'est une motivation supplémentaire pour faire venir les gens (on mange bien).
Et pour les gens qui sont à distance ? Le problème avait commencé à se poser pour la réunion IETF 107 prévue à Vancouver et annulée au dernier moment pour cause de Covid. Il y avait eu un effort pour maintenir un hackathon en distanciel mais cela n'avait pas intéressé grand'monde. (Un des plus gros problèmes du distanciel est le décalage horaire. Les gens qui n'étaient pas en PST n'avaient montré aucun enthousiasme pour le hackathon.) Cela s'est mieux passé par la suite, avec des réunions entièrement en ligne pendant la pandémie. Aujourd'hui, les réunions ont repris en présentiel mais une partie des participant·es, aussi bien à l'IETF qu'au hackathon, sont à distance. (Mon opinion personnelle est que c'est peu utile ; l'intérêt du hackathon est la collaboration intense avec les gens qui sont juste là. En travaillant à distance, on perd cette collaboration. Autant travailler tout seul dans son coin.) Une approche intermédiaire, très utilisée à Maurice, est d'avoir une réunion en présentiel locale, où les gens travaillent à distance sur le hackathon. Cela permet de garder un côté collectif sympa.
Tout cela (à commencer par les repas, et bien sûr la salle, mais elle est parfois incluse dans le contrat global de l'IETF pour sa réunion) coûte de l'argent. La section 3 décrit les sources de financement, qui permettent de garder le hackathon gratuit pour les participant·es. Il y a, comme souvent dans les conférences techniques, des sponsors. (Pour le prochain hackathon, ce seront Ericsson, Meta et l'ICANN.) Mais il y a aussi un financement par l'IETF elle-même (car on ne trouve pas toujours des sponsors). Le RFC précise même quels repas seront sacrifiés s'il n'y a pas assez d'argent (le diner du samedi est considéré comme moins important que les déjeuners, car les participant·es pourront toujours diner en rentrant).
Ah, et les T-shirts ? Pas de hackathon sans T-shirt. Le RFC donne des statistiques intéressantes, comme la répartition par taille aux précédents hackathons.
La participation à distance dispense du coût des repas mais il faut ajouter celle des systèmes de communication utilisés, notamment Meetecho et Gather. (Avant de proposer un autre système, rappelez-vous qu'il y a des centaines de participant·es actif·ves au hackathon et qu'il faut une solution qui tienne la charge.)
À la fin du hackathon, les participant·es présentent leur travail, les résultats obtenus et les conclusions qu'on peut en tirer pour les normes en cours de développement (section 4). Au début, il y avait également une session de présentation des projets au début du hackathon mais elle a dû être abandonnée au fur et à mesure que le hackathon grossissait. La présentation initiale se fait désormais sur le Wiki (voir par exemple la prochaine et la page où on peut aller si on cherche une équipe ou bien des volontaires). C'est sur ce Wiki que les champions (les gens qui ont une idée et organisent une activité particulière au hackathon, cf section 7.4) essaient de recruter. Quant aux présentations finales, elles sont publiées sur Github. C'est aussi là qu'on trouvera le code produit lorsqu'il n'est pas sur un dépôt extérieur (section 5.6).
La liste des projets affichés dans la salle du hackathon de
Yokohama en 2023 :

On a parlé des outils utilisés, lors de la section sur le financement. La section 5 dresse une liste plus complète des outils logiciels qui servent pour le hackathon. Il y a évidemment, comme pour tout travail IETF, le Datatracker (qui a une section sur le hackathon). Tout aussi évidemment, puisque l'IETF travaille largement avec des listes de diffusion, il y a une liste des participant·es au hackathon.
Pour profiter de tous ces outils, il faut un réseau à forte capacité, fiable, et évidemment sans aucun filtrage. Lors de la réunion de Beijing, les négociations avec les autorités avaient été serrées et l'accord final imposait un contrôle d'accès aux salles de l'IETF, pour éviter que des citoyens chinois n'en profitent. (Normalement, il n'y a aucun contrôle à l'entrée de l'IETF, personne ne vérifie les badges.) Le groupe qui s'occupe de monter et de démonter le réseau de l'IETF a donc en plus la charge du réseau du hackathon. Celui-ci peut en outre nécessiter des services spéciaux, afin de tester en présence de tels services (NAT64, prefix delegation, etc). Il y a même un accès VPN, pour celles et ceux qui travaillent à distance.
L'article seul
RFC 9309: Robots Exclusion Protocol
Date de publication du RFC : Septembre 2022
Auteur(s) du RFC : M. Koster, G. Illyes, H. Zeller, L. Sassman
(Google)
Chemin des normes
Première rédaction de cet article le 14 septembre 2022
Quand vous gérez un serveur Internet (pas forcément un serveur
Web) prévu pour des humains, une bonne partie du trafic, voire la
majorité, vient de robots. Ils ne sont pas
forcément malvenus mais ils peuvent être agaçants, par exemple s'ils
épuisent le serveur à tout ramasser. C'est pour cela qu'il existe
depuis longtemps une convention, le fichier
robots.txt, pour dire aux robots gentils ce
qu'ils peuvent faire et ne pas faire. La spécification originale
était très limitée et, en pratique, la plupart des robots comprenait
un langage plus riche que celui du début. Ce nouveau RFC documente plus ou moins
le format actuel.
L'ancienne spécification, qui date de
1996, est toujours en ligne
sur le site de
référence (qui ne semble plus maintenu, certaines
informations ont des années de retard). La réalité des fichiers
robots.txt d'aujourd'hui est différente, et
plus riche. Mais, comme souvent sur
l'Internet, c'est assez le désordre, avec
différents robots qui ne comprennent pas la totalité du langage
d'écriture des robots.txt. Peut-être que la
publication de ce RFC aidera à uniformiser les choses.
Donc, l'idée de base est la suivante : le
robot qui veut ramasser des ressources sur un
serveur va d'abord télécharger un fichier situé sur le chemin
/robots.txt. (Au passage, si cette norme était
faite aujourd'hui, on utiliserait le
/.well-known du RFC 8615.) Ce fichier va contenir des instructions pour le
robot, lui disant ce qu'il peut récupérer ou pas. Ces instructions
concernent le chemin dans l'URI (et robots.txt n'a
donc de sens que pour les serveurs utilisant ces URI du RFC 3986, par exemple les serveurs Web). Un exemple très simple
serait ce robots.txt :
User-Agent: * Disallow: /private
Il dit que, pour tous les robots, tout est autorisé sauf les chemins
d'URI commençant par /private. Un robot qui
suit des liens (RFC 8288) doit donc ignorer
ceux qui mènent sous /private.
Voyons maintenant les détails pratiques (section 2 du RFC). Un
robots.txt est composé de
groupes, chacun s'appliquant à un robot ou un
groupe de robots particulier. Les groupes sont composés de
règles, chaque règle disant que telle partie de
l'URI est interdite ou autorisée. Par défaut, tout est autorisé
(même chose s'il n'y a pas de robots.txt du
tout, ce qui est le cas de ce blog). Un groupe commence par une
ligne User-Agent qui va identifier le robot (ou
un astérisque pour désigner tous les
robots) :
User-Agent: GoogleBot
Le robot va donc chercher le ou les groupes qui le concernent. En
HTTP,
normalement, l'identificateur que le robot cherche dans le
robots.txt est une sous-chaine de
l'identificateur envoyé dans le champ de l'en-tête HTTP
User-Agent (RFC 9110,
section 10.1.5).
Le robot doit combiner tous les groupes qui s'appliquent à lui,
donc on voit parfois plusieurs groupes avec le même
User-Agent.
Le groupe est composé de plusieurs règles, chacune commençant par
Allow ou Disallow (notez
que la version originale de la spécification n'avait pas
Allow). Si plusieurs règles correspondent, le
robot doit utiliser la plus spécifique, c'est-à-dire celle dont le
plus d'octets correspond. Par exemple, avec :
Disallow: /private Allow: /private/notcompletely
Une requête pour /private/notcompletely/foobar
sera autorisée. L'ordre des règles ne compte pas (mais certains
robots sont bogués sur ce point). C'est du fait de cette notion de
correspondance la plus spécifique qu'on ne peut pas compiler un
robots.txt en une simple expression
rationnelle, ce qui était possible avec la
spécification originelle. Si une règle Allow
et une Disallow correspondent, avec le même
nombre d'octets, l'accès est autorisé.
Le robot a le droit d'utiliser des instructions supplémentaires, par exemple pour les sitemaps.
En HTTP, le robot peut rencontrer une redirection
lorsqu'il essaie de récupérer le robots.txt
(code HTTP 301, 302, 307 ou 308). Il devrait dans ce cas la suivre
(mais pas infinement : le RFC recommande cinq essais au
maximum). S'il n'y a pas de robots.txt (en
HTTP, code de retour 404), tout est autorisé (c'est le cas de mon
blog). Si par contre il y a une erreur (par exemple 500 en HTTP), le
robot doit attendre et ne pas se croire tout permis. Autre point
HTTP : le robot peut suivre les instructions de mémorisation du
robots.txt données, par exemple, dans le champ
Cache-control de l'en-tête.
Avant de passer à la pratique, un peu de sécurité. D'abord, il
faut bien se rappeler que le respect du
robots.txt dépend de la bonne volonté du
robot. Un robot malveillant, par exemple, ne tiendra certainement
pas compte du robots.txt. Mais il peut y avoir
d'autres raisons pour ignorer ces règles. Par exemple, l'obligation
du dépôt légal fait que la
BNF
annonce explicitement qu'elle ignore ce
fichier. (Et un programme comme wget a
une option, -e robots=off, pour débrayer la vérification
du robots.txt.) Bref, un robots.txt ne remplace pas
les mesures de sécurité, par exemple des règles d'accès aux
chemins définies dans la configuration de votre serveur HTTP. Le
robots.txt peut même diminuer la sécurité, en
indiquant les fichiers « intéressants » à un éventuel attaquant.
Passons maintenant à la pratique. On trouve plein de mises en
œuvre de robots.txt un peu partout mais en
trouver une parfaitement conforme au RFC est bien plus
dur. Disons-le clairement, c'est le bordel, et l'auteur d'un
robots.txt ne peut jamais savoir comment il va
être interprété. Il ne faut donc pas être trop subtil dans son
robots.txt et en rester à des règles
simples. Du côté des robots, on a un problème analogue : bien des
robots.txt qu'on rencontre sont bogués. La
longue période sans spécification officielle est largement
responsable de cette situation. Et tout n'est pas clarifié par le
RFC. Par exemple, la grammaire en section 2.2 autorise un
Disallow ou un Allow à
être vide, mais sans préciser clairement la sémantique associée.
Pour Python, il y a un module standard, mais qui est loin de suivre le RFC. Voici un exemple d'utilisation :
import urllib.robotparser
import sys
if len(sys.argv) != 4:
raise Exception("Usage: %s robotstxt-file user-agent path" % sys.argv[0])
input = sys.argv[1]
ua = sys.argv[2]
path = sys.argv[3]
parser = urllib.robotparser.RobotFileParser()
parser.parse(open(input).readlines())
if parser.can_fetch(ua, path):
print("%s can be fetched" % path)
else:
print("%s is denied" % path)
Et, ici, on se sert de ce code :
% cat ultra-simple.txt User-Agent: * Disallow: /private % python test-robot.py ultra-simple.txt foobot /public/test.html /public/test.html can be fetched % python test-robot.py ultra-simple.txt foobot /private/test.html /private/test.html is denied
Mais ce module ne respecte pas la précédence des règles :
% cat precedence.txt User-Agent: * Disallow: / Allow: /bar.html % python3 test-robot.py precedence.txt foobot /bar.html /bar.html is denied
En application de la règle la plus spécifique,
/bar.html aurait dû être autorisé. Si on
inverse Allow et Disallow,
on obtient le résultat attendu. Mais ce n'est pas normal, l'ordre
des règles n'étant normalement pas significatif.
Autre problème du module Python, il ne semble pas gérer les
jokers, comme l'exemple *.gif$ du
RFC. Il existe des modules Python alternatifs pour traiter les
robots.txt mais aucun ne semble vraiment mettre
en œuvre le RFC.
La situation n'est pas forcément meilleure dans les autres langages de programmation. Essayons avec Elixir. Il existe un module pour cela. Écrivons à peu près le même programme qu'en Python :
usage = "Usage: test robotstxtname useragent path"
filename =
case Enum.at(System.argv(), 0) do
nil -> raise RuntimeError, usage
other -> other
end
content =
case File.read(filename) do
{:ok, data} -> data
{:error, reason} -> raise RuntimeError, "#{filename}: #{reason}"
end
ua =
case Enum.at(System.argv(), 1) do
nil -> raise RuntimeError, usage
other -> other
end
statuscode = 200
{:ok, rules} = :robots.parse(content, statuscode)
path =
case Enum.at(System.argv(), 2) do
nil -> raise RuntimeError, usage
other -> other
end
IO.puts(
case :robots.is_allowed(ua, path, rules) do
true -> "#{path} can be fetched"
false -> "#{path} can NOT be fetched"
end)
Et testons-le :
% mix run test-robot.exs ultra-simple.txt foobot /public/test.html /public/test.html can be fetched % mix run test-robot.exs ultra-simple.txt foobot /private/test.html /private/test.html can NOT be fetched
Il semble avoir moins de bogues que le module Python mais n'est quand même pas parfait.
Comme dit plus haut, le robots.txt n'est pas
réservé au Web. Il est utilisé par exemple pour
Gemini. Ainsi, le robot de
collecte Lupa lit les robots.txt et ne
va pas ensuite récupérer les URI interdits. En septembre 2022, 11 %
des capsules Gemini avaient un robots.txt.
L'article seul
RFC 9301: Locator/ID Separation Protocol (LISP) Control-Plane
Date de publication du RFC : Octobre 2022
Auteur(s) du RFC : D. Farinacci (lispers.net), F. Maino (Cisco Systems), V. Fuller (vaf.net Internet Consulting), A. Cabellos (UPC/BarcelonaTech)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF lisp
Première rédaction de cet article le 23 août 2024
Comme pour tous les protocoles de séparation de l'identificateur et du localisateur, le protocole LISP, normalisé dans le RFC 9300, doit faire face au problème de la correspondance (mapping) entre les deux informations. Comment trouver un localisateur, en ne connaissant que l'identificateur ? LISP n'a pas de solution unique et plusieurs protocoles de correspondance peuvent être utilisés. La stabilité du logiciel des routeurs imposait une interface stable avec le système de résolution des identificateurs en localisateurs. C'est ce que fournit notre RFC 9301, qui spécifie l'interface, vue du routeur, et qui ne devrait pas changer, même si de nouveaux systèmes de correspondance/résolution apparaissent. Ce RFC remplace le RFC 6833. L'interface change assez peu mais le texte est sérieusement réorganisé, et la spécification a désormais le statut de norme et plus simplement d'expérimentation.
LISP prévoit deux sortes de machines impliquées dans la résolution d'identificateurs (les EID, Endpoint ID) en localisateurs (les RLOC, Routing Locator). Ces deux machines sont les Map-Resolver et les Map-Server. Pour ceux qui connaissent le DNS, on peut dire que le Map-Server est à peu près l'équivalent du serveur faisant autorité et le Map-Resolver joue quasiment le même rôle que celui du résolveur. Toutefois, il ne faut pas pousser la comparaison trop loin, LISP a ses propres règles. Pour résumer en deux phrases, un routeur LISP d'entrée de tunnel (un ITR, Ingress Tunnel Router), ayant reçu un paquet à destination d'une machine dont il connait l'identificateur (l'EID), va interroger un Map-Resolver pour connaître le localisateur (le RLOC, auquel l'ITR enverra le paquet). Pour accomplir sa tâche, le Map-Resolver fera suivre les requêtes au Map-Server, qui la transmettra finalement au routeur de sortie du tunnel (l'ETR, Egress Tunnel Router), qui est la vraie source faisant autorité.
C'est entre le Map-Resolver et le Map-Server que se trouvent les détails du système de correspondance. Ils peuvent être connectés par ALT (RFC 6836), par CONS (RFC jamais publié), par NERD (RFC 6837), par DDT (RFC 8111) ou bien par tout autre système de résolution, existant ou encore à créer (ils ne peuvent pas être connectés avec simplement LISP, puisqu'on aurait alors un problème d'œuf et de poule, LISP ayant besoin de ALT qui aurait besoin de LISP… cf. section 8.1). Rappelez-vous que notre RFC 9301 ne décrit qu'une interface, celle des ITR et ETR avec les Map-Resolver et Map-Server. Il est donc relativement court.
Comme avec toute technique nouvelle, il est prudent d'apprendre
le vocabulaire (section 3, puis section 4 pour un survol général du
système). Il y a deux types d'acteurs, les
Map-Server et les Map-Resolver
que nous avons déjà vu, et trois types
importants de messages, Map-Register (un
ETR l'envoie au Map-Server pour indiquer les RLOC
des EID dont il est responsable), Map-Request
(un ITR l'envoie à un Map-Resolver pour obtenir
les RLOC ; le Map-Resolver fait suivre jusqu'au
Map-Server, puis à l'ETR) et enfin
Map-Reply, la réponse au précédent. Notons que
ces types de messages ont leur description complète (avec leur
format) dans le RFC 9300. Notez aussi
que Map-Resolver et Map-Server
sont des fonctions, et que les deux peuvent être assurés par la même
machine, qui serait à la fois Map-Resolver et
Map-Server (dans le DNS, un tel mélange est
déconseillé).
Schéma général du système de correspondance LISP :
La section 8 de notre RFC plonge dans les
détails. Accrochez-vous. Voyons d'abord le premier routeur LISP que
rencontrera le paquet. On le nomme ITR pour Ingress Tunnel
Router. Les routeurs précédents traitaient l'adresse de
destination du paquet comme une adresse IP
ordinaire. L'ITR, lui, va la traiter comme un identificateur (EID
pour Endpoint IDentification). L'EID n'est pas
routable sur l'Internet. Il faut donc encapsuler le paquet en LISP
pour l'envoyer dans le tunnel. La nouvelle adresse IP de destination
est le localisateur (RLOC pour Routing
LOCator). Pour trouver le localisateur, l'ITR va demander
à un ou plusieurs Map-Resolver. Il a été
configuré (typiquement, à la main) avec leurs adresses IP (qui
doivent être des localisateurs, pour éviter un amusant problème
d'œuf et de poule; notez que plusieurs
Map-Resolver peuvent avoir la même adresse, grâce
à l'anycast). L'ITR ne
connait que le protocole de résolution, envoi d'une
Map-Request et récupération d'une
Map-Reply (en termes DNS, l'ITR est un
stub resolver). L'ITR ne connait donc
pas les protocoles utilisés en interne par le
système de correspondance, il ne connait pas ALT (ou ses
concurrents). Cette communication avec le
Map-Resolver peut être testée et déboguée avec
l'outil lig (RFC 6835).
La réponse du Map-Resolver ne sera pas
forcément positive. L'ITR recevra peut-être une
negative Map-Reply, envoyée
en réponse si un Map-Resolver ne trouve pas de
localisateur pour l'identificateur qu'on lui a passé. Cela veut dire
que le site final n'utilise pas LISP, et qu'il faut alors router le
paquet avec les méthodes habituelles d'IP. (Il n'est évidemment pas prévu que tout
l'Internet passe à LISP du jour au lendemain, le routeur LISP doit
donc aussi pouvoir joindre les sites non-LISP.)
Si la réponse est positive, l'ITR peut alors encapsuler le paquet et le transmettre. Comment le Map-Resolver a-t-il trouvé la réponse qu'il a envoyé ? Contrairement aux routeurs LISP comme l'ITR, le Map-Resolver et le Map-Server connaissent le système de correspondance utilisé (si c'est ALT, ils sont tous les deux routeurs ALT) et c'est celui-ci (non traité dans ce RFC) qu'ils utilisent pour savoir s'il y a une réponse et laquelle.
Et, à l'autre bout du tunnel, que s'était-il passé ? Le routeur
de fin de tunnel (l'ETR, pour Egress Tunnel
Router), avait été configuré par un administrateur réseaux
avec une liste d'EID dont il est responsable. Pour que le reste du
monde connaisse ces EID, il les publie auprès d'un
Map-Server en envoyant à ce dernier des messages
Map-Register. Pour d'évidentes raisons de
sécurité, ces messages doivent être authentifiés (champ
Authentication Data du message
Map-Register, avec clés gérées à la main pour
l'instant, avec SHA-256 au minimum), alors
que les Map-Request ne l'étaient pas (la base
de données consultée par les routeurs LISP est publique, pas besoin
d'authentification pour la lire, seulement pour y écrire). Ces
Map-Request sont renvoyés périodiquement (le
RFC suggère toutes les minutes) pour que le
Map-Server sache si l'information est toujours à
jour. Ainsi, si un ETR est éteint, l'information obsolète dans les
Map-Server disparaîtra en trois minutes maximum
(des messages peuvent être perdus, le RFC demande donc de patienter
un peu en cas de non-réception). Cela veut aussi dire que LISP ne
convient pas forcément tel quel pour les situations où on exige une
mobilité très rapide.
Notez que je ne décris pas tous les détails (comme la possibilité pour un ETR de demander un accusé de réception au Map-Server, chose que ce dernier ne fait pas par défaut), voyez le RFC si vous êtes curieux.
Arrivés là, nous avons un Map-Server qui
connait les EID que gère l'ETR. Désormais, si ce
Map-Server reçoit une demande
Map-Request, il peut la faire suivre à l'ETR
(si vous connaissez le DNS, vous avez vu que le
Map-Register n'est pas tout à fait l'équivalent
des mises à jour dynamiques du RFC 2136 : avec
ces dernières, le serveur de noms qui a reçu la mise à jour répondra
ensuite lui-même aux requêtes). Le Map-Server ne
sert donc que de relais, il ne modifie pas la requête
Map-Request, il la transmet telle quelle à
l'ETR. Le rôle des Map-Resolver et des
Map-Server est donc simplement de trouver l'ETR
responsable et de lui faire suivre (sans utiliser l'encapsulation
LISP) les requêtes, pas de répondre à sa place. Cela se fera
peut-être dans le futur lorsque des mécanismes de
cache seront ajoutés. Pour le moment, les
Map-Resolver n'ont pas de cache, de mémoire
(section 4), une
grosse différence avec le DNS (section 1).
La section 9 fait le tour des questions de sécurité liées au service de résolution. Comme les requêtes sont faites avec le format de paquets de LISP, elles héritent des services de sécurité de LISP comme le nonce qui permet de limiter les risques d'usurpation ou comme la sécurité LISP du RFC 9303. Par contre, comme pour les protocoles utilisés dans l'Internet actuel, il n'y a pas de vraie protection contre les annonces faites à tort (un Map-Server qui annoncerait un EID qui n'est pas à lui). C'est un problème très proche de celui de la sécurité de BGP et qui utilisera peut-être le même genre de solutions.
Notez qu'en théorie, l'interface spécifiée dans ce RFC pourrait servir à d'autres protocoles que celui du RFC 9300, comme par exemple GRE (RFC 2890) ou VXLAN (RFC 7348). Mais, pour l'instant, ce n'est pas le cas.
Il y a apparemment trois mises en œuvre. Outre l'outil de débogage lig (RFC 6835), il y a celle de Cisco pour ses routeurs, mais je ne connais pas les autres, sans doute dans des Unix.
Et les changements depuis le précédent RFC ? Ils sont résumés dans la section 11 :
- Ajout du type de message
Map-Notify-Ack, un accusé de réception, - Plein de bits supplémentaires dans les en-têtes des messages,
- Dans les actions qu'un routeur peut prendre lorsqu'un paquet arrive, ajout de possibilités de rejet du paquet (section 5.4).
L'article seul
RFC 9300: The Locator/ID Separation Protocol (LISP)
Date de publication du RFC : Octobre 2022
Auteur(s) du RFC : D. Farinacci (lispers.net), V. Fuller (vaf.net Internet Consulting), D. Meyer (1-4-5.net), D. Lewis (Cisco Systems), A. Cabellos (UPC/BarcelonaTech)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF lisp
Première rédaction de cet article le 14 décembre 2024
Le protocole LISP (qui n'a rien à voir avec le langage de programmation du même nom), vise à résoudre un problème documenté dans le RFC 4984 : les difficultés que rencontre le système de routage de l'Internet devant les pressions imposées par la croissance du réseau et par le désir des utilisateurs de ne pas être lié à un unique fournisseur d'accès. Actuellement, tout changement de routage sur n'importe quel site se propage à tous les autres routeurs de la DFZ. Un tel système ne passe pas réellement à l'échelle (il ne peut pas croitre indéfiniment). LISP propose une solution, dans un ensemble de RFC dont ce RFC 9300 (qui succède au RFC 6830) est le principal. LISP n'est désormais plus considéré comme expérimental et ce nouveau RFC est sur le chemin des normes (Standards Track) mais, en pratique, le projet LISP semble plutôt en panne.
Avant de plonger dans ce RFC, voyons les motivations pour LISP et ses principes essentiels (si vous préférez les lire dans le RFC et pas dans mon article, c'est en section 4 mais la lecture recommandée est le RFC 9299). Aujourd'hui, les adresses IP ont deux rôles, localisation (où suis-je connecté au réseau) et identité (qui suis-je). Une adresse IP est un localisateur car changer de point d'attachement (par exemple parce qu'on change de FAI) vous fait changer d'adresse IP, et c'est un identificateur car c'est ce qui est utilisé par les protocoles de transport comme TCP pour identifier une session en cours : changer d'adresse IP casse les connexions existantes.
Le principal problème de cette approche concerne le routage. Un routage efficace nécessiterait une cohérence entre les adresses et la topologie du réseau, par exemple que deux sites proches sur le réseau aient des adresses proches. Mais on n'a pas cette cohérence actuellement. On notera qu'IPv6 ne résolvait pas ce problème, et délibérément (le cahier des charges d'IPv6 ne prévoyait pas de changer le modèle de routage).
Résultat, les routeurs doivent gérer bien plus de routes que nécessaire, augmentant leur prix (en attendant le jour où, même en payant, on n'arrivera pas à manipuler autant de routes, avec leurs changements fréquents). Le RFC 4984 insistait sur ce problème en affirmant que « The workshop participants believe that routing scalability is the most important problem facing the Internet today and must be solved, although the time frame in which these problems need solutions was not directly specified. »
Cette croissance de la table de routage peut être suivie sur le célèbre site de Geoff Huston. Notez que la taille n'est pas le seul aspect, le rythme de changement (le nombre d'updates BGP par seconde) est au moins aussi important.
LISP vise donc à résoudre ce problème par une technique connue sous le nom de séparation du localisateur et de l'identificateur (son nom, « Locator/ID Separation Protocol », en dérive d'ailleurs, bien qu'il soit loin d'être le seul protocole dans cette catégorie). Au lieu que tous les préfixes IP aillent dans la DFZ, seuls les localisateurs, les RLOC (Routing LOCators) y iront. Les identificateurs, les EID (Endpoint IDentifiers) sont dans un nouveau système, le système de correspondance (mapping, RFC 9301), qui permettra de trouver un RLOC à partir d'un EID. LISP est donc l'application d'un vieux principe de l'informatique : « Tout problème peut être résolu en ajoutant un niveau d'indirection. »
À quoi ressemblent RLOC et EID ? Physiquement, ce sont juste des adresses IP (v4 ou v6), avec une nouvelle sémantique. Le RFC 8060 décrit plus en détail comment représenter les EID.
Par rapport aux autres solutions de séparation de l'identificateur et du localisateur (la plus achevée étant HIP), LISP s'identifie par les points suivants :
- Solution dans le réseau, pas dans les machines terminales. Seuls des routeurs (mais pas tous les routeurs de l'Internet) seront modifiés pour gérer LISP.
- Déployable de manière incrémentale (il n'est pas nécessaire que tout le monde passe à LISP).
- Pas de cryptographie (et donc pas plus de sécurité que l'IP d'aujourd'hui).
- Indépendant de la famille IP utilisée (v4 ou v6).
- Outre une solution au problème du passage à l'échelle du système de routage, LISP se veut aussi utilisable pour la mobilité et la virtualisation de réseaux (imaginez une machine virtuelle migrant d'un centre d'hébergement à un autre sans changer d'identificateur...).
Comment se passe l'envoi d'un paquet avec LISP ? Supposons qu'une machine
veuille écrire à www.example.com. Elle utilise
le DNS comme
aujourd'hui, pour trouver que l'adresse est
2001:db8:110:2::e9 (c'est un EID, un
identificateur, mais la machine n'a pas besoin de le savoir, les
machines terminales ne connaissent pas LISP et ne savent même pas
qu'elles l'utilisent). Elle envoie le paquet à son routeur
habituel. À un moment dans le réseau, le paquet va arriver dans un
routeur LISP (qui, lui, a été modifié pour gérer LISP). Il va alors
chercher le RLOC (le localisateur). Il demande au système de
correspondance (l'équivalent LISP du DNS) qui va lui dire « le RLOC de
2001:db8:110:2::e9 est
198.51.100.178 » (notez au passage que RLOC et
EID peuvent être des adresses v4 ou v6). (L'information est stockée
dans un cache du
routeur, pour le prochain paquet.) Le paquet est alors encapsulé dans un paquet
LISP qui est transmis en UDP (port 4341) à
198.51.100.178. (En raison de ces deux étapes,
correspondance puis encapsulation, LISP fait partie des protocoles
nommés Map and Encap.)
198.51.100.178 décapsule et le paquet suit
ensuite un chemin normal vers la machine
2001:db8:110:2::e9. Pendant le trajet dans le
tunnel,
le paquet aura donc deux en-têtes, l'interne
(celui placé par la machine d'origine et qui utilise des EID dans
les champs « Adresse IP source » et « Adresse IP destination ») et
l'externe (celui placé par le routeur d'entrée du tunnel, et qui
utilise des RLOC).
Si le système de correspondance avait répondu négativement « Ce
n'est pas un EID, je n'ai pas de RLOC pour
2001:db8:110:2::e9 » (Negative map
reply) ? Cela aurait voulu dire que le site cible
n'utilise pas LISP et, dans ce cas, on lui transmet le paquet par
les mécanismes habituels d'IP.
Ainsi, pour prendre le scénario d'usage principal de LISP, un site qui veut être multi-homé n'aura pas besoin de BGP et d'annoncer ses routes dans la DFZ. Il aura ses identificateurs, ses EID, et les paquets entrant ou sortant de son réseau seront encapsulés en LISP (le système de correspondance peut renvoyer plusieurs RLOC pour un EID, avec des préférences différentes, pour faire de l'ingénierie de trafic). Pour les routeurs de la DFZ, ce seront juste des paquets IP ordinaires. Seules les deux extrémités du tunnel sauront que LISP est utilisé.
Le système de correspondance de LISP n'est pas unique : plusieurs choix sont possibles comme ALT (RFC 6836). Comme le DNS, il fonctionne en tirant les informations nécessaires (pas en les poussant vers tout le monde, comme le fait BGP), ce qui devrait lui donner une bonne capacité de croissance. De toute façon, LISP spécifie une interface vers le système de correspondance (RFC 9301) et les différents systèmes ont juste à mettre en œuvre cette interface pour qu'on puisse en changer facilement. Ainsi, ALT pourra être remplacé par un de ses concurrents, CONS, EMACS ou NERD (leurs noms sont des références au langage de programmation). NERD est documenté dans le RFC 6837.
Ce RFC est un gros morceau (d'autant plus que d'autres parties de LISP sont dans d'autres RFC). Je ne vais pas le couvrir en entier. Mais quelques points méritent d'être gardés en tête :
- Un paquet dont l'adresse de destination est un EID ne peut être acheminé que via LISP. L'EID n'est pas routé sur l'Internet habituel. (Les EID peuvent être des adresses RFC 1918, par exemple.)
- Pour éviter que la base des EID ne pose les mêmes problèmes de croissance que la DFZ d'aujourd'hui, les EID seront agrégés, mais cela sera fait de manière indépendante de la topologie : si on change de FAI, cette agrégation ne changera pas.
Pour les fanas de format de paquets, la section 5 décrit l'encapsulation. LISP est indépendant de la famille d'adresses, donc on peut avoir un paquet IP où les EID sont IPv4 qui soit tunnelé avec des RLOC IPv6 ou bien le contraire. Devant le paquet normal, LISP va ajouter un en-tête IP standard pour les RLOC, où la source sera l'ITR (routeur d'entrée du tunnel) et la destination l'ETR (routeur de sortie du tunnel), puis un en-tête UDP (l'UDP a davantage de chances de passer les middleboxes que de l'IP mis directement dans l'IP, des protocoles comme QUIC ont le même problème), avec le port de destination à 4341, puis un en-tête spécifique à LISP et enfin le paquet original. Donc, pour résumer :
- En-tête du paquet original (inner header en terminologie LISP) : les adresses IP source et destination sont des identificateurs, des EID,
- En-tête vu par les routeurs situés entre l'ITR et l'ETR (outer header) : les adresses IP source et destination sont des localisateurs, des RLOC.
L'en-tête spécifique à LISP contient notamment (section 5 si vous voulez tout connaître) :
- Cinq bits de contrôle, nommés N, L, E, V et I
- Si le bit N est à 1, un champ Nonce (section 10.1). Il s'agit d'un nombre tiré au hasard : si le destinataire d'un paquet peut le renvoyer, cela prouve qu'il avait reçu le message original (et qu'on parle donc bien au bon destinataire : ce numnique sert à éviter les attaques en aveugle).
- Si le bit L est à 1, un champ Locator Status Bits, qui indique l'état (joignable ou pas) des machines situées sur le site de départ du paquet. (À ne pas utiliser sur l'Internet public, cf. section 4.1.)
Comme toutes les solutions à base de tunnel, LISP va souffrir de la mauvaise gestion de la PMTUD dans l'Internet d'aujourd'hui (cf. RFC 4459), l'en-tête LISP supplémentaire réduisant la MTU (cf. section 7 pour des solutions possibles).
La section 5 décrivait les paquets de données, ceux encapsulant les données envoyées par le site original. La section 6 couvre les paquets de contrôle, utilisés par LISP pour ses propres besoins, notamment le système de correspondance (cf. RFC 9301 pour les détails). On y retrouve l'utilisation d'UDP :
- Map Requests, où le port de destination est 4342,
- Map Replies,
- et quelques autres qui partagent des formats proches.
Il est évidemment essentiel qu'on sache si son correspondant est joignable ou pas. Comment cette « joignabilité » est-elle vérifiée ? La section 6.3 énumère les mécanismes disponibles. Entre autres :
- Les Locator Status Bits où un ITR (le routeur LISP à l'entrée du tunnel) indique si les sites qu'il contrôle sont joignables. Si on souhaite répondre à un message transmis en LISP, c'est une information cruciale. (Ils ne doivent pas être utilisés sur l'Internet public, voir la section 4.1 pour les détails.)
- Les classiques messages ICMP comme Host Unreachable. Comme ils ne sont pas authentifiés, les croire aveuglément est dangereux. Mais les ignorer totalement serait dommage.
- La réception récente d'un message Map Reply est une bonne indication que le site à l'autre bout fonctionne.
Mais on peut aussi tester explicitement, par le mécanisme Echo Nonce de la section 10.1. Le testeur émet un message LISP avec les bits N (numnique présent) et E (écho demandé), met le numnique à une valeur aléatoire (RFC 4086), et envoie le paquet. (La section 4.1 précise toutefois que cela ne doit pas être utilisé sur l'Internet public.) L'ETR à l'autre bout doit normalement renvoyer ce numnique dans son prochain paquet. Notons que cela teste la bidirectionnalité de la connexion. Si on n'obtient pas de réponse, cela peut signifier que la connexion est complètement coupée ou tout simplement qu'elle ne marche que dans un seul sens. Mais, surtout, l'absence de réponse peut indiquer le cas où l'ETR qui reçoit le trafic pour un site n'est pas le même routeur que l'ITR qui génère le trafic sortant. Dans ce cas, l'absence de réponse n'est pas un problème. Enfin, le routeur en face peut tout simplement être configuré pour ignorer les demandes d'écho.
Une autre solution pour tester est donc d'utiliser les messages du système de correspondance EID->RLOC, les Map Request et Map Reply. Ces messages ont un bit P (pour probe) qui indique que le demandeur est intéressé par la joignabilité du site demandé.
LISP impose donc des traitements supplémentaires, par rapport à ceux de l'IP classique. Est-ce que cela ne ralentit pas trop les routeurs ? La section 15 explore le problème et explique pourquoi LISP ne nécessite pas de changement du matériel de forwarding (les ASIC du routeur). La plupart des routeurs ont déjà du code prévu pour gérer des tunnels (encapsuler et décapsuler) rapidement.
Comment sera déployé LISP ? Le RFC 7215 décrit plusieurs scénarios possibles et les détails. Principal problème : combien d'ITR et d'ETR pour un opérateur ? Grâce aux tunnels, on peut n'avoir qu'un seul ITR et un seul ETR pour tout le trafic. Cela poserait évidemment des problèmes de redondance et de performance. Mais avoir beaucoup de xTR peut poser des problèmes d'administration. Si les ITR sont largement automatiques (leur cache des correspondance EID->RLOC est bâti dynamiquement), avoir beaucoup d'ETR risque d'être compliqué à maintenir (car l'ETR doit avoir dans sa configuration une liste des EID qu'il va gérer).
Un des gros problèmes que pose la séparation de l'identificateur et du localisateur est la sécurité : nouvelles attaques (par exemple contre le système de correspondance), nouveaux pièges (une machine qui utiliserait le vrai RLOC mais mentirait sur l'EID, par exemple). La section 16 du RFC examine les risques théoriquement présents dans LISP, mais lisez aussi les RFC 7835 et RFC 9303.
Comme avec toutes les techniques de tunnel, un émetteur peut facilement tricher sur l'adresse source interne (celle qui sera utilisée après décapsulation par l'ETR). Pour se protéger, un ITR devrait n'encapsuler un paquet que si l'adresse source est un EID qu'il contrôle. Et un ETR ne devrait transmettre un paquet que si la destination est un EID sous sa responsabilité.
Le test de la réversibilité (via les numniques, cf. section 3) est essentiel contre ces risques. Sans ce test, un ETR pirate pourrait par exemple envoyer un Map Reply en réponse aveugle à un Map Request, et le voir accepté, avec des données mensongères (naturellement, l'ITR n'accepte que des Map Replies qui sont en réponse à un Map Request de sa part). Avec ce système de numnique que le récepteur doit mettre dans sa réponse, un attaquant aveugle (qui n'est pas situé sur le chemin des paquets et ne peut donc pas les observer) aura donc peu de chances de réussir à faire accepter ses paquets.
En revanche, un attaquant situé sur le chemin, et qui peut observer les paquets qui passent, a la possibilité de commettre bien plus de dégâts. Mais c'est déjà le cas avec les protocoles actuels (par exemple, les numéros de séquence difficiles à deviner du RFC 6528 ne protègent pas TCP contre des attaquants situés sur le chemin).
Les attaques par déni de service sont évidemment possibles avec LISP : une des précautions recommandées est de limiter le trafic des Map Requests et Map Replies. Autre attaque par déni de service, un ITR peut être victime d'une machine qui essaie de remplir la table des correspondances EID->RLOC du routeur. Il est donc important d'envisager ce cas, par exemple en permettant de garder dans le cache les entrées les plus fréquemment accédées (pour éviter qu'elles ne soient retirées automatiquement pour faire de la place). Mais il n'existe pas de solution miracle contre ce problème d'envahissement de cache.
Le fonctionnement de LISP est schématisé sur ce dessin : Alice a l'identificateur (EID)
2001:db8:1::1 et veut écrire à Bob qui a le
2001:db8:2::42 (dans la plupart des cas, Alice
aura trouvé l'adresse de Bob dans le DNS, comme aujourd'hui). Ni Alice, ni Bob n'ont
à connaître LISP, chacun croit utiliser de l'IP normal. Alice envoie
donc un paquet standard, à destination de
2001:db8:2::42. Mais, sur le trajet, il y a un
ITR, un routeur LISP. Celui-ci va chercher (dans le système de
correspondance, non montré ici) le RLOC (le localisateur) de Bob
(ou, plus exactement, de son site). Une fois qu'il a trouvé
2001:db8:ff::666, il encapsule le paquet
derrière un en-tête LISP et envoie ce paquet à l'ETR, l'autre
routeur LISP en face, 2001:db8:ff::666. Les
routeurs de l'Internet, entre l'ITR et l'ETR, ne connaissent pas
LISP non plus et routent ce qui leur semble un paquet IP
normal. Arrivé à l'ETR, le paquet est décapsulé et poursuit son
chemin par du routage IP classique. Sur tout le schéma, seuls l'ITR
et l'ETR sont des nouveautés LISP.
Modifions légèrement le schéma pour y mettre le système de
correspondance : On y voit l'ITR
demander à son résolveur « Quel est le localisateur de
2001:db8:2::42 ? » et son résolveur lui
répondre. Le résolveur avait demandé au serveur qui avait reçu de
l'ETR un enregistrement disans « Le localisateur de
2001:db8:2::42 est
2001:db8:ff::666 ». Entre le résolveur et le
serveur se trouve le cœur du système de correspondance. LISP
en a plusieurs possibles, comme le ALT du RFC 6836.
Où trouve-t-on du code LISP aujourd'hui ?
- Bien sûr dans IOS puisque LISP est l'enfant de Cisco.
- FreeBSD avait OpenLISP, qui semble abandonné (ou intégré dans le système ? Quelqu'un sait ?).
- Pour Linux, je ne connais que LispMob, qui traite un besoin spécifique (la mobilité).
- Il parait qu'un code Cisco mettant en œuvre LISP tourne sur Android.
Comme pour tous les protocoles fondés sur le principe de la séparation de l'identificateur et du localisateur, il est toujours utile, si on veut en comprendre les principes, de (re)lire l'article fondateur de Chiappa, « Endpoints and Endpoint names: A Proposed Enhancement to the Internet Architecture ». Autres articles à lire :
- Le RFC 9299, une introduction à LISP et ses concepts,
- Un bon résumé de LISP.
- Le premier article pratique sur le protocole. Avec instructions, commandes, et résultat (sur des routeurs Cisco). Parfait pour les ingénieurs qui ont du mal à se taper les RFC LISP mais veulent quand même comprendre comment ça marche. Très détaillé. Le même auteur a d'autres articles sur LISP comme celui expliquant comment tunneler IPv6 sur IPv4.
- Le compte-rendu de la connexion de Facebook à LISP (Facebook a été le premier gros site à sauter le pas mais je ne sais pas si cela fonctionne toujours aujourd'hui).
La section 18 de notre RFC décrit les changements depuis le RFC 6830. Le principal est bien sûr que LISP n'est plus considéré comme expérimental, on peut le déployer sur l'Internet public, modulo les précautions de la section 4.1. Sinon :
- Les trois bits qui étaient réservés dans l'en-tête ont été alloués par le RFC 8061,
- La récolte automatique d'informations de correspondance entre EID et RLOC (gleaning) est désormais optionnelle,
- Sur la forme, notons que bien des points, notamment le mécanisme de contrôle (et pas seulement d'acheminement de données) ont été déplacés vers le RFC 9301.
La section 4.1 décrit ce qu'il faut faire et ne pas faire lorsqu'on déploie LSIP « en vrai » sur l'Internet public. Quand on n'est plus expérimental, il faut faire attention. Bien des techniques de LISP (comme la mise à jour automatique des données des routeurs juste en regardant un paquet qui passe, le gleaning, clairement dangereux) ne sont sûres que dans un environnement fermé.
L'article seul
RFC 9299: An Architectural Introduction to the Locator/ID Separation Protocol (LISP)
Date de publication du RFC : Octobre 2022
Auteur(s) du RFC : A. Cabellos
(UPC-BarcelonaTech), D. Saucez
(INRIA)
Pour information
Réalisé dans le cadre du groupe de travail IETF lisp
Première rédaction de cet article le 3 novembre 2022
Le protocole réseau LISP (Locator/ID Separation Protocol, rien à voir avec le langage de programmation du même nom) est normalisé dans le RFC 6830 et plusieurs autres qui l'ont suivi. Ce RFC 6830 est un peu long à lire et ce nouveau RFC propose donc une vision de plus haut niveau, se focalisant sur l'architecture de LISP. Cela peut donc être un bon point de départ vers les RFC LISP.
L'idée de base de LISP est de séparer l'identificateur du localisateur, comme recommandé par le RFC 4984. Un identificateur désigne une machine, un localisateur sa position dans l'Internet. Aujourd'hui, les adresses IP servent pour les deux, ne satisfaisant parfaitement aucun des deux buts : les identificateurs devraient être stables (une machine qui change de réseau ne devrait pas en changer), les localisateurs devraient être efficaces et donc être liés à la topologie, et agrégeables.
LISP a donc deux classes : les identificateurs, ou EID (End-host IDentifier) et les localisateurs, ou RLOC (Routing LOCators). Les deux ont la syntaxe des adresses IP (mais pas leur sémantique). Un système de correspondance permet de passer de l'un à l'autre (par exemple, je connais l'EID de mon correspondant, je cherche le RLOC pour lui envoyer un paquet). LISP est plutôt prévu pour être mis en œuvre dans les routeurs, séparant un cœur de l'Internet qui n'utilise que les RLOC, d'une périphérie qui utiliserait les EID (avec, entre les deux, les routeurs LISP qui feraient la liaison).
En résumé (accrochez-vous, c'est un peu compliqué) :
- LISP peut être vu comme un réseau virtuel (overlay) au-dessus de l'Internet existant (underlay),
- Les RLOC n'ont de sens que dans le réseau sous-jacent, l'underlay,
- Les EID n'ont de sens que dans le réseau virtuel overlay,
- Entre les deux, le système de correspondance,
- Dans le réseau sous-jacent, les RLOC servent de localisateur et d'identificateur,
- Dans un site à la périphérie, les EID servent d'identificateur et de localisateur pour les autres machines du site.
C'est ce côté « solution dans les routeurs » et donc le fait que les machines terminales ne savent même pas qu'elles font du LISP, qui distingue LISP des autres solutions fondées sur la séparation de l'identificateur et du localisateur, comme ILNP (RFC 6740).
Au passage, pourquoi avoir développé LISP ? Quel était le problème à résoudre ? Outre la beauté conceptuelle de la chose (il n'est pas esthétique de mêler les fonctions d'identificateur et de localisateur), le principal problème à traiter était celui du passage à l'échelle du système de routage de l'Internet, décrit dans le RFC 4984. En gros, le nombre de routes distinctes augmente trop vite et menace la stabilité des routeurs de la DFZ. Le but était donc, par une nouvelle architecture, de rendre inutile certains choix qui augmentent la taille de la table de routage (comme la désagrégation des préfixes IP, afin de faire de l'ingénierie de trafic). Le RFC 7215 décrit comment LISP aide dans ce cas.
La section 7 du RFC décrit les différents scénarios d'usage de LISP :
- Ingénierie de trafic : aujourd'hui, dans l'Internet classique BGP, quand on veut orienter le trafic entrant, le faire passer par un chemin donné, on utilise souvent la désagrégation des préfixes. Comme indiqué plus haut, cela aggrave la pression sur la table de routage globale. L'indirection que permet LISP dispense de cette solution : on peut publier dans le système de correspondance les RLOC qu'on veut.
- Transition vers IPv6 : les EID et les RLOC ont la forme syntaxique d'une adresse IP, v4 ou v6, et il n'y a pas d'obligation qu'EID et RLOC aient la même version. On peut avoir des EID IPv6 et des RLOC IPv4, et cela fournit un mécanisme de tunnel permettant de connecter deux sites LISP IPv6 au-dessus de réseaux qui seraient purement IPv4. L'avantage par rapport aux techniques de transition actuelles est l'intégration dans une solution plus générale et plus « propre ».
- LISP permet également de faire des VPN, ou de gérer la mobilité de réseaux entiers (un réseau qui se déplace, et donc change de RLOC, c'est juste la correspondance dans le sous-système de contrôle qu'il faut changer, et tout les partenaires routeront vers les nouveaux RLOC).
La section 3 du RFC décrit en détail l'architecture de LISP (après, vous serez mûr·e·s pour lire les RFC LISP eux-mêmes, en commençant par le RFC 6830). Elle repose sur quatre principes :
- La séparation entre l'identificateur (le EID) et le localisateur (le RLOC),
- Deux sous-systèmes différents, le contrôle et les données, utilisant des protocoles différents, et pouvant évoluer séparement (enfin, dans une certaine mesure),
- Une architecture overlay : LISP est déployé sur un réseau virtuel au-dessus de l'Internet existant, ce qui évite les approches « table rase », qui ont une probabilité de déploiement à peu près nulle,
- Un protocole déployable de manière incrémentale, pas besoin d'attendre que tout le monde s'y mette, il y a des avantages à déployer LISP même pour les premiers à l'adopter (ce problème de déploiement est une des plaies de l'Internet actuel, comme on le voit avec IPv6).
La séparation entre identificateur et localisateur n'est pas faite au niveau de la machine individuelle, comme avec ILNP, mais à la frontière entre la périphérie de l'Internet (the edge) et son cœur (the core, en gros, la DFZ et quelques routeurs en plus). La périphérie travaille avec des EID (elle ne sait même pas que LISP est utilisé), le cœur avec des RLOC. Contrairement à ILNP, il n'y a donc pas une stricte séparation entre identificateurs et localisateurs : ils ont la même syntaxe (qui est celle d'une adresse IP, v4 ou v6) et, à part les routeurs d'entrée et de sortie des tunnels LISP, personne ne sait s'il utilise un EID ou un RLOC : les machines terminales manipulent des EID, les routeurs du cœur des RLOC, tout en croyant que ce sont des adresses IP ordinaires. Seuls les routeurs à la frontière entre les deux mondes connaissent LISP (et auront donc besoin d'un logiciel adapté).
Un Internet LISP est donc une série de « sites LISP » (des
réseaux de périphérie accessibles par LISP) connectés par des
tunnels entre eux, au-dessus du cœur
actuel. Le routeur d'entrée du tunnel se nomme ITR (pour
Ingress Tunnel Router) et celui de sortie ETR
(pour Egress Tunnel Router). Le terme de xTR
(pour « ITR ou bien ETR ») est parfois utilisé pour désigner un
routeur LISP, qu'il soit d'entrée ou de sortie
Le sous-système des données (data plane) se charge d'encapsuler et de décapsuler les paquets, puis de les transmettre au bon endroit. (Sa principale qualité est donc la rapidité : il ne faut pas faire attendre les paquets.) Les ITR encapsulent un paquet IP qui vient d'un site LISP (dans un paquet UDP à destination du port 4341), puis l'envoient vers l'ETR. À l'autre bout du tunnel, les ETR décapsulent le paquet. Dans le tunnel, les paquets ont donc un en-tête intérieur (un en-tête IP normal, contenant les EID source et destination), qui a été placé par la machine d'origine, et un en-tête extérieur (contenant le RLOC source, celui de l'ITR, et le RLOC de destination, celui de l'ETR puis, après l'en-tête UDP, l'en-tête spécifique de LISP). Rappelez-vous que les routeurs du cœur ne connaissent pas LISP, ils font suivre ce qui leur semble un paquet IP ordinaire. Les routeurs LISP utilisent des tables de correspondance entre EID et RLOC pour savoir à quel ETR envoyer un paquet.
Ces tables ont été apprises du sous-système de contrôle (control plane, qui contient la fonction de correspondance - mapping), le routeur ayant un cache des correspondances les plus récentes. Cette fonction de correspondance, un des points les plus délicats de LISP (comme de tout système de séparation de l'identificateur et du localisateur) est décrite dans le RFC 6833. Son rôle peut être comparé à celui du DNS et de BGP dans l'Internet classique.
Une correspondance est une relation entre un préfixe d'identificateurs (rappelez-vous que les EID sont, syntaxiquement, des adresses IP ; on peut donc utiliser des préfixes CIDR) et un ensemble de localisateurs, les RLOC des différents routeurs possibles pour joindre le préfixe convoité.
Le RFC 6833 normalise une interface avec ce système de correspondance. Il y a deux sortes d'entités, le Map Server, qui connait les correspondances pour certains préfixes (car les ETR lui ont raconté les préfixes qu'ils servent), et le Map Resolver, qui fait les requêtes (il est typiquement dans l'ITR, ou proche). Quatre messages sont possibles (les messages de contrôle LISP sont encpasulés en UDP, et vers le port 4342) :
Map-Register: un ETR informe son Map Server des préfixes EID qu'il sait joindre,Map-Notify: la réponse de l'ETR au message précédent,Map-Request: un ITR (ou bien un outil de débogage comme lig, cf. RFC 6835) cherche les RLOC correspondant à un EID,Map-Reply: un Map Server ou un ETR lui répond.
Un point important de LISP est qu'il peut y avoir plusieurs mécanismes de correspondance EID->RLOC, du moment qu'ils suivent les messages standard du RFC 6833. On pourra donc, dans le cadre de l'expérience LISP, changer de mécanisme pour voir, pour tester des compromis différents. Notre RFC rappele l'existence du système ALT (RFC 6836, fondé, comme BGP sur un graphe. Mais aussi celle d'un mécanisme utilisant une base « plate » (NERD, RFC 6837), un mécanisme arborescent nommé DDT (RFC 8111), des DHT, etc. On pourrait même, dans des déploiements privés et locaux, avoir une base centralisée avec un seul serveur.
ALT, normalisé dans le RFC 6836, est le système de correspondance « historique » de LISP, et il est souvent présenté comme le seul dans les vieux documents. Il repose sur BGP, protocole bien maitrisé par les administrateurs de routeurs, ceux qui auront à déployer LISP. L'idée de base est de connecter les serveurs ALT par BGP sur un réseau virtuel au-dessus de l'Internet.
DDT, dans le RFC 8111, lui, ressemble beaucoup plus au DNS, par sa structuration arborescente des données, et sa racine.
Évidemment, tout l'Internet ne va pas migrer vers LISP instantanément. C'est pour cela que notre RFC mentionne les problèmes de communication avec le reste du monde. Les EID ne sont typiquement pas annoncés dans la table de routage globale de l'Internet. Alors, comment un site pourra-t-il communiquer avec un site LISP ? Le mécanisme décrit dans le RFC 6832 utilise deux nouvelles sortes de routeurs : les PITR (Proxy Ingress Tunnel Router) et les PETR (Proxy Egress Tunnel Router). Le PITR annonce les EID en BGP vers l'Internet, en les agrégeant le plus possible (l'un des buts de LISP étant justement d'éviter de charger la table de routage globale). Il recevra donc les paquets envoyés par les sites Internet classiques et les fera suivre par les procédures LISP normales. A priori, c'est tout : le site LISP peut toujours envoyer des paquets vers l'Internet classiques en ayant mis un EID en adresse IP source. Mais cela peut échouer pour diverse raisons (uRPF, par exemple) donc on ajoute le PETR : il recevra le paquet du site LISP et le transmettra.
Voici pour les principes de LISP. Mais, si vous travaillez au quotidien comme administrateur d'un réseau, vous avez sans doute à ce stade plein de questions concrètes et opérationnelles. C'est le moment de lire la section 4 de ce RFC. Par exemple, la gestion des caches : un routeur LISP ne peut pas faire appel au système de correspondance pour chaque paquet qu'il a à transmettre. Le sous-système des données tuerait complètement le sous-système de contrôle, si un routeur s'avisait de procéder ainsi. Il faut donc un cache, qui va stocker les réponses aux questions récentes. Qui dit cache dit problèmes de cohérence des données, puisque l'information a pu changer entre la requête, et l'utilisation d'une réponse mise en cache. Pour gérer cette cohérence, LISP dispose de divers mécanismes, notamment un TTL (Time To Live) : l'ETR le définit, indiquant combien de temps les données peuvent être utilisées (c'est typiquement 24 h, aujourd'hui).
Autre problème pratique cruciale, la joignabilité des
RLOC. C'est bien joli de savoir que telle machine a tel RLOC mais
est-ce vrai ? Peut-on réellement lui parler ou bien tous les
paquets vont-ils finir dans un trou noir ? Un premier mécanisme
pour transporter l'information de joignabilité est les LSB
(Locator Status Bits). Transportés dans les
paquets LISP, ces bits indiquent si un RLOC donné est joignable
par l'ETR qui a envoyé le paquet. Évidemment, eux aussi peuvent
être faux, donc, s'il existe une communication bi-directionnelle,
il est préférable d'utiliser le mécanisme des numniques. Quand un ITR écrit à un ETR, il
met un numnique dans le paquet, que l'ETR renverra dans son
prochain paquet. Cette fois, plus de doute, l'ETR est bien
joignable. Si l'ITR est impatient et veut une réponse tout de
suite, il peut tester activement la joignabilité, en envoyant des Map-Request.
LISP est souvent présenté avec un modèle simplifié où chaque site est servi par un seul ETR, qui connait les EID du site et les annonce au Map Server. Mais, dans la réalité, les sites sérieux ont plusieurs ETR, pour des raisons de résilience et de répartition de charge. Cela soulève le problème de leur synchronisation : ces ETR doivent avoir des configurations compatibles, pour annoncer les mêmes RLOC pour leurs EID. Pour l'instant, il n'existe pas de protocole pour cela, on compte sur une synchronisation manuelle par l'administrateur réseaux.
Enfin, comme LISP repose sur des tunnels, il fait face à la malédiction habituelle des tunnels, les problèmes de MTU. Du moment qu'on encapsule, on diminue la MTU (les octets de l'en-tête prennent de la place) et on peut donc avoir du mal à parler avec les sites qui ont une MTU plus grande, compte-tenu de la prévalence d'erreurs grossières de configuration, comme le filtrage d'ICMP. La section 4.4 de notre RFC décrit le traitement normal de la MTU dans LISP et ajoute que des mécanismes comme celui du RFC 4821 seront peut-être nécessaires.
Dans l'Internet d'aujourd'hui, une préoccupation essentielle est bien sûr la sécurité : d'innombrables menaces pèsent sur les réseaux (section 8 du RFC). Quelles sont les problèmes spécifiques de LISP en ce domaine ? Par exemple, certains systèmes de correspondance, comme DDT, sont de type pull : on n'a pas l'information à l'avance, on va la chercher quand on en a besoin. Cela veut dire qu'un paquet de données (sous-système des données) peut indirectement déclencher un événement dans le sous-système de contrôle (par la recherche d'une correspondance EID->RLOC afin de savoir où envoyer le paquet). Cela peut affecter la sécurité.
D'autant plus que le sous-système de contrôle sera typiquement
mis en œuvre dans le processeur généraliste des routeurs, beaucoup
moins rapide que les circuits électroniques spécialisés qui
servent à la transmission des données. Un attaquant qui enverrait
des tas de paquets vers des EID différents pourrait, à un coût
très faible pour lui, déclencher plein de demandes à DDT,
ralentissant ainsi sérieusement les routeurs LISP. Une mise en œuvre naïve de LISP où toute requête pour
un EID absent du cache déclencherait systématiquement une
MAP-Request serait très vulnérable. Une
limitation du trafic est donc
nécessaire.
En parlant du système de correspondance, il représente évidemment un talon d'Achille de LISP. Si son intégrité est compromise, si des fausses informations s'y retrouvent, les routeurs seront trahis et enverront les paquets au mauvais endroit. Et si le système de correspondance est lent ou en panne, par exemple suite à une attaque par déni de service, le routage ne se fera plus du tout (à part pour les EID encore dans les caches des routeurs). On peut donc comparer ce système de correspondance au DNS dans l'Internet classique, par son côté crucial pour la sécurité.
Il faut donc des « bons » Map Server, qui suivent bien le RFC 6833 (notamment sa section 6) et, peut-être dans le futur, des Map Servers qui gèrent l'extension de sécurité LISP-Sec (si son RFC est publié un jour).
Dernier point de sécurité, le fait que LISP puisse faire du routage asymétrique (le chemin d'Alice à Bob n'est pas le même que celui de Bob à Alice). Rien d'extraordinaire à cela, c'est pareil pour lee routage Internet classique, mais il faut toujours se rappeler que cela a des conséquences de sécurité : par exemple, un pare-feu ne verra, dans certains cas, qu'une partie du trafic.
On trouvera plus de détails sur les attaques qui peuvent frapper LISP dans le RFC 7835.
Pour ceux qui sont curieux d'histoire des technologies, l'annexe A du RFC contient un résumé de LISP. Tout avait commencé à Amsterdam en octobre 2006, à l'atelier qui avait donné naissance au RFC 4984. Un groupe de participants s'était alors formé, avait échangé, et le premier Internet-Draft sur LISP avait été publié en janvier 2007. En même temps, et dans l'esprit traditionnel de l'Internet (running code), la programmation avait commencé et les premiers routeurs ont commencé à gérer des paquets LISP en juin 2007.
Le groupe de travail IETF officiel a été ensuite créé, en mars 2009. Les premiers RFC sont enfin sortis en 2013.
LISP n'a pas toujours été comme aujourd'hui ; le protocole initial était plutôt une famille de protocoles, désignés par des numéros, chacun avec des variantes sur le concept de base. Cela permettait de satisfaire tous les goûts mais cela compliquait beaucoup le protocole. On avait LISP 1, où les EID étaient routables dans l'Internet normal (ce qui n'est plus le cas), LISP 1.5 où ce routage se faisait dans un réseau séparé, LISP 2 où les EID n'étaient plus routables, et où la correspondance EID->RLOC se faisait avec le DNS, et enfin LISP 3 où le système de correspondance était nouveau (il était prévu d'utiliser une DHT...). Le LISP final est proche de LISP 3.
L'article seul
RFC 9297: HTTP Datagrams and the Capsule Protocol
Date de publication du RFC : Août 2022
Auteur(s) du RFC : D. Schinazi (Google), L. Pardue (Cloudflare)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF masque
Première rédaction de cet article le 8 septembre 2022
Ce RFC est le premier du groupe de travail MASQUE qui développe des techniques pour relayer du trafic IP. Dans ce RFC, il s'agit de faire passer des datagrammes sur HTTP.
Pourquoi, sur HTTP ? Parce que c'est le seul protocole dont on est raisonnablement sûr qu'il passera partout. En bâtissant un service de datagrammes sur HTTP (et non pas directement sur IP), on arrivera à le faire fonctionner à tous les endroits où HTTP fonctionne.
En fait, ce RFC décrit deux mécanismes assez différents, mais qui visent le même but, la transmission de datagrammes sur HTTP. Le premier mécanisme est le plus simple, utiliser HTTP juste pour lancer une session qui utilisera les datagrammes de QUIC, normalisés dans le RFC 9221. (QUIC seul ne passe pas partout, d'où la nécessité d'insérer une couche HTTP.) Ce premier mécanisme dépend de QUIC donc ne marche qu'avec HTTP/3 (RFC 9114). Un second mécanisme est normalisé, dans notre RFC ; nommé Capsule, il permet de faire passer des datagrammes (ou à peu près) sur HTTP/2 (RFC 9113) et HTTP/1 (RFC 9112). Capsule est plus général, mais moins efficace.
Ces mécanismes ne sont pas vraiment prévus pour des utilisations par des applications, mais plutôt pour des extensions à HTTP (RFC 9110, section 16). Par exemple, le service CONNECT (RFC 9110, section 9.3.6) pourrait être doublé par un service équivalent, mais utilisant des datagrammes, au lieu du transfert fiable que fait CONNECT (cf. RFC 9298). Même chose pour les Web sockets du RFC 6455.
La section 2 de notre RFC explique de quels datagrammes on parle. Il s'agit de
paquets de données dont l'ordre
d'arrivée et l'acheminement ne sont pas garantis, et qui vont sans
doute consommer moins de ressources. Sur HTTP/3 (qui utilise QUIC),
ils vont utiliser les trames QUIC de type
DATAGRAM (RFC 9221). Ce
sont les « meilleurs » datagrammes HTTP, ceux qui collent le plus à
la sémantique des datagrammes. Sur HTTP/2, tout acheminement de
données est garanti. Si on veut faire des datagrammes, il va falloir
utiliser le protocole Capsule, décrit dans la
section 3. (Notez que HTTP/2 ne garantit pas l'ordre d'arrivée si
les datagrammes sont transportés dans des ruisseaux différents.) Et
pour HTTP/1 ? Le protocole ne convient guère puisqu'il garantit
l'ordre d'arrivée et l'acheminement, justement les propriétés
auxquelles on était prêt à renoncer. Là aussi, on se servira de
Capsule.
HTTP utilise différentes méthodes pour faire ses requêtes (les deux plus connues sont GET et POST). Les datagrammes ne sont utilisables qu'avec des méthodes qui les acceptent explicitement. Donc, pas de GET ni de POST, plutôt du CONNECT.
Sur HTTP/3, le champ de données du datagramme QUIC aura le format :
HTTP/3 Datagram {
Quarter Stream ID (i),
HTTP Datagram Payload (..),
}
Le quarter stream ID est l'identificateur du ruisseau QUIC du client où a été envoyée la requête HTTP, divisé par 4 (ce qu'on peut toujours faire, vu la façon dont sont générés ces identificateurs, RFC 9000, section 2.1).
Ah, et comme les datagrammes ne sont pas acceptés par défaut en
HTTP/3, il faudra envoyer au début de la session un paramètre
SETTINGS_H3_DATAGRAM (enregistré à
l'IANA).
Les capsules, maintenant. Inutiles en HTTP/3, elles sont la seule
façon de faire du datagramme en HTTP/1 et HTTP/2. Le protocole
Capsule permet d'envoyer des données encodées en
TLV sur une connexion HTTP. On indique qu'on
va l'utiliser, en HTTP/1 avec le champ Upgrade:
(RFC 9110, section 7.8) et en HTTP/2 avec un
CONNECT étendu (cf. RFC 8441). Les
upgrade tokens (les identificateurs de protocoles
utilisés, enregistrés à
l'IANA) sont décrits dans la section 16.7 du RFC 9110.
Le format des capsules est décrit en section 3.2 :
Capsule {
Capsule Type (i),
Capsule Length (i),
Capsule Value (..),
}
Les différents types possibles de capsules figurent dans un registre IANA. Une fois le protocole Capsule sélectionné via un upgrade token, on passe du HTTP classique au protocole Capsule. Un premier type de capsule est DATAGRAM (type 0) dont le nom indique bien la sémantique. D'autres types pourront être ajoutés en suivant la procédure « spécification nécessaire » du RFC 8126, sauf les valeurs basses du type (de 0 à 63) qui exigent une action de normalisation, ou bien une approbation par l'IESG.
Si on utilise Capsule, la requête HTTP est accompagnée du champ
Capsule-Protocol (un champ structuré, cf. RFC 9651), champ désormais enregistré
à l'IANA.
Il existe plusieurs mises en œuvre de ces datagramms HTTP. En logiciel libre, on a :
Notez que le protocole Capsule n'est a priori pas accessible au code JavaScript chargé dans le navigateur Web (il faut pouvoir accéder aux upgrade tokens). Mais rappelez-vous que tout ce mécanisme de datagrammes sur HTTP est conçu pour des extensions de HTTP, pas pour l'application finale.
L'article seul
RFC 9293: Transmission Control Protocol (TCP)
Date de publication du RFC : Août 2022
Auteur(s) du RFC : W. Eddy (MTI Systems)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tcpm
Première rédaction de cet article le 20 août 2022
Le protocole de transport TCP est l'un des piliers de l'Internet. La suite des protocoles Internet est d'ailleurs souvent appelée TCP/IP, du nom de ses deux principaux protocoles. Ce nouveau RFC est la norme technique de TCP, remplaçant l'antique RFC 793, qui était vieux de plus de quarante ans, plus vieux que la plupart des lecteurices de ce blog. Il était temps de réviser et de rassembler en un seul endroit tous les détails sur TCP.
TCP est donc un protocole de transport. Rappelons brièvement ce qu'est un protocole de transport et à quoi il sert. L'Internet achemine des paquets IP de machine en machine. IP ne garantit pas leur arrivée : les paquets peuvent être perdus (par exemple parce qu'un routeur n'avait plus de place dans ses files d'attente), peuvent être dupliqués, un paquet peut passer devant un autre, pourtant envoyé avant, etc. Pour la grande majorité des applications, ce n'est pas acceptable. La couche de transport est donc chargée de remédier à cela. Première (en partant du bas) couche à être de bout en bout (les routeurs et autres équipements intermédiaires n'y participent pas, ou plus exactement ne devraient pas y participer), elle se charge de suivre les paquets, de les remettre dans l'ordre, et de demander aux émetteurs de ré-émettre si un paquet s'est perdu. C'est donc un rôle crucial, puisqu'elle évite aux applications de devoir gérer ces opérations très complexes. (Certaines applications, par exemple de vidéo, n'ont pas forcément besoin que chaque paquet arrive, et n'utilisent pas TCP.) Le RFC 8095 contient une comparaison détaillée des protocoles de transport de l'IETF.
Avant de décrire TCP, tel que spécifié dans ce RFC 9293, un petit mot sur les normes techniques de l'Internet. TCP avait originellement été normalisé dans le RFC 761 en 1980 (les couches 3 - IP et 4 étaient autrefois mêlées en une seule). Comme souvent sur l'Internet, le protocole existait déjà avant sa normalisation et était utilisé. La norme avait été rapidement révisée dans le RFC 793 en 1981. Depuis, il n'y avait pas eu de révision générale, et les RFC s'étaient accumulés. Comprendre TCP nécessitait donc de lire le RFC 793 puis d'enchainer sur plusieurs autres. Un RFC, le RFC 7414, avait même été écrit dans le seul but de fournir un guide de tous ces RFC à lire. Et il fallait également tenir compte de l'accumulation d'errata. Désormais, la situation est bien plus simple, tout TCP a été consolidé dans un RFC central, notre RFC 9293. (Notez que ce travail de consolidation a été aussi fait pour HTTP et SMTP, qui ne sont plus décrits par les RFC d'origine mais par des versions à jour, mais pas pour le DNS, qui reste le principal ancien protocole qui aurait bien besoin d'une remise à jour complète des documents qui le spécifient.) Ne vous faites toutefois pas d'illusion : malgré ses 114 pages, ce RFC 9293 ne couvre pas tout, et la lecture d'autres RFC reste nécessaire. Notamment, TCP offre parfois des choix multiples (par exemple pour les algorithmes de contrôle de la congestion, une partie cruciale de TCP), qui ne sont pas décrits intégralement dans la norme de base. Voyez par exemple le RFC 7323, qui n'a pas été intégré dans le RFC de base, et reste une extension optionnelle.
Attaquons-nous maintenant à TCP. (Bien sûr, ce sera une présentation très sommaire, TCP est forcément plus compliqué que cela.) Son rôle est de fournir aux applications un flux d'octets fiable et ordonné : les octets que j'envoie à une autre machine arriveront dans l'ordre et arriveront tous (ou bien TCP signalera que la communication est impossible, par exemple en cas de coupure du câble). TCP découpe les données en segments, chacun voyageant dans un datagramme IP. Chaque octet est numéroté (attention : ce sont bien les octets et pas les segments qui sont numérotés) et cela permet de remettre dans l'ordre les paquets, et de détecter les pertes. En cas de perte, on retransmet. Le flux d'octets est bidirectionnel, la même connexion TCP permet de transmettre dans les deux sens. TCP nécessite l'établissement d'une connexion, donc la mémorisation d'un état, par les deux pairs qui communiquent. Outre les tâches de fiabilisation des données (remettre les octets dans l'ordre, détecter et récupérer les pertes), TCP fournit du démultiplexage, grâce aux numéros de port. Ils permettent d'avoir plusieurs connexions TCP entre deux machines, qui sont distinguées par ces numéros de port (un pour la source et un pour la destination) dans l'en-tête TCP. Le bon fonctionnement de TCP nécessite d'édicter un certain nombre de règles et le RFC les indique avec MUST-n où N est un entier. Par exemple, MUST-2 et MUST-3 indiqueront que la somme de contrôle est obligatoire, aussi bien en envoi qu'en vérification à la réception.
Après ces concepts généraux, la section 3 de notre RFC rentre dans les détails concrets, que je résume ici. D'abord, le format de cet en-tête que TCP ajoute derrière l'en-tête IP et devant les données du segment. Il inclut les numéros de port, le numéro de séquence (le rang du premier octet dans les données), celui de l'accusé de réception (le rang du prochain octet attendu), un certain nombre de booléens (flags, ou bits de contrôle, qui indiquent, par exemple, s'il s'agit d'une connexion déjà établie, ou pas encore, ou la fin d'une connexion), la taille de la fenêtre (combien d'octets peuvent être envoyés sans accusé de réception, ce qui permet d'éviter de surcharger le récepteur), une somme de contrôle, et des options, de taille variable (l'en-tête contient un champ indiquant à partir de quand commencent les données). Une option de base est MSS (Maximum Segment Size) qui indique quelle taille de segment on peut gérer. Il existe d'autres options comme les accusés de réception sélectifs du RFC 2018 ou comme le facteur multiplicatif de la taille de fenêtre du RFC 7323.
Avant d'expliquer la dynamique de TCP, le RFC définit quelques
variables indispensables, qui font partie de l'état de la connexion
TCP. Pour l'envoi de données, ce sont par exemple
SND.UNA (ces noms sont là pour comprendre le
RFC, mais un programme qui met en œuvre TCP peut évidemment nommer
ces variables comme il veut), qui désigne le numéro de séquence du
début des données envoyées, mais qui n'ont pas encore fait l'objet
d'un accusé de réception, ou SND.NXT, le numéro
de séquence du début des données pas encore envoyées ou encore
SND.WND, la taille de la fenêtre
d'envoi. Ainsi, on ne peut pas envoyer d'octets dont le rang serait
supérieur à SND.UNA +
SND.WND, il faut attendre des accusés de
réception (qui vont incrémenter SND.UNA) ou une
augmentation de la taille de la fenêtre. Pour la réception, on a
RCV.NXT, le numéro de séquence des prochains
paquets si tout est normal, et RCV.WND, la
taille de la fenêtre de réception.
TCP est un protocole à état et il a donc une machine à
états, décrite en section 3.3.2. Parmi les états,
LISTEN, qui indique un TCP en train d'attendre
un éventuel pair, ESTAB
(ou ESTABLISHED), où TCP envoie et reçoit des
données, et plusieurs états qui apparaissent lors de l'ouverture ou
de la fermeture d'une connexion.
Et les numéros de séquence ? Un point important de TCP est qu'on ne numérote pas les segments mais les octets. Chaque octet a son numéro et les accusés de réception référencent ces numéros. On n'accuse évidemment pas réception de chaque octet individuel. Les accusés de réception sont cumulatifs ; ils désignent un octet et, implicitement, tous les octets précédents. Quand un récepteur prévient qu'il a bien reçu l'octet N, cela veut dire que tous ceux avant N ont aussi été reçus.
Les numéros ne partent pas de 1 (ni de zéro), ils sont relatifs à un ISN (Initial Sequence Number, rappelez-vous qu'il y a un glossaire, en section 4 du RFC) qui est choisi aléatoirement (pour des raisons de sécurité, cf. RFC 6528) au démarrage de la session. Des logiciels comme Wireshark savent cela et peuvent calculer puis afficher des numéros de séquence qui partent de 1, pour faciliter la lecture.
Les numéros de séquence sont stockés sur 32 bits et il n'y a donc que quatre milliards (et quelques) valeurs possibles. C'était énorme quand TCP a été créé mais cela devient de plus en plus petit, relativement aux capacités des réseaux modernes. Comme TCP repart de zéro quand il atteint le numéro de séquence maximum, il y a un risque qu'un « vieux » paquet soit considéré comme récent. À 1 Gb/s, cela ne pouvait se produire qu'au bout de 34 secondes. Mais à 100 Gb/s, il suffit d'un tiers de seconde ! Les extensions du RFC 7323 deviennent alors indispensables.
Tout le monde sait bien que TCP est un protocole orienté connexion. Cela veut dire qu'il faut pouvoir créer, puis supprimer, les connexions. La section 3.5 de notre RFC décrit cet établissement de connexion, via la fameuse « triple poignée de mains ». En gros, un des TCP (TCP n'est pas client-serveur, et la triple poignée de mains marche également quand les deux machines démarrent la connexion presque en même temps) envoie un paquet ayant l'option SYN (pour synchronization), le second répond avec un paquet ayant les options ACK (accusé de réception du SYN) et SYN, le premier TCP accuse réception. Avec trois paquets, les deux machines sont désormais d'accord qu'elles sont connectées. En d'autres termes (ici, machine A commence) :
- Machine A ⇒ Machine B : je veux te parler,
- B ⇒ A : j'ai noté que tu voulais me parler et je veux te parler aussi,
- A ⇒ B : j'ai noté que tu voulais me parler.
Pour mettre fin à la connexion, un des deux TCP envoie un paquet ayant l'option FIN (pour finish), auquel l'autre répond de même.
Conceptuellement, TCP gère un flux d'octets sans séparation. TCP
n'a pas la notion de message. Si une application envoie (en appelant
print, write ou autre
fonction du langage de programmation utilisé) les octets "AB" puis
"CD", TCP transmettra puis livrera à l'application distante les
quatre octets "ABCD" dans l'ordre, sans indiquer qu'il y avait eu
deux opérations d'écriture sur le réseau. Mais, pour envoyer les
données, TCP doit les segmenter en paquets IP distincts. La
fragmentation IP n'étant pas bonne pour les
performances, et étant peu fiable de toute façon, l'idéal est que
ces paquets IP aient une taille juste inférieure à la MTU du chemin. Cela
nécessite de découvrir cette MTU (section 3.7.2), ou bien d'adopter
la solution paresseuse de faire des paquets de 1 280 octets (la MTU
minimum, en IPv6). Comme la solution paresseuse ne serait pas
optimale en performances, les mises en œuvre de TCP essaient toutes
de découvrir la MTU du chemin. Cela peut se faire avec la méthode
PMTUD, décrite dans les RFC 1191 et RFC 8201, mais qui a l'inconvénient de nécessiter
qu'ICMP ne soit pas bloqué. Or, beaucoup de
middleboxes programmées
avec les pieds, ou configurées par des incompétents, bloquent ICMP,
empêchant le fonctionnement de PMTUD. Une alternative est PLPMTUD,
normalisée dans le RFC 4821, qui ne dépend
plus d'ICMP.
Une fois la connexion établie, on peut envoyer des données. TCP va les couper en segments, chaque segment voyageant dans un paquet IP.
Une mise en œuvre de TCP
n'envoie pas forcément immédiatement les octets qu'on lui a
confiés. Envoyer des petits paquets n'est pas efficace : s'il y a
peu de données, les en-têtes du paquet forment la majorité du trafic
et, de toute façon, le goulet d'étranglement dans le réseau n'est
pas forcément lié au nombre d'octets, il peut l'être au nombre de
paquets. Un des moyens de diminuer le nombre de paquets contenant
peu d'octets est l'algorithme de Nagle. Le
principe est simple : quand TCP reçoit un petit nombre d'octets à
envoyer, il ne les transmet pas tout de suite mais attend un peu
pour voir si l'application ne va pas lui confier des octets
supplémentaires. Décrit dans le RFC 896, et
recommandé dans le RFC 1122, cet algorithme
est aujourd'hui présent dans la plupart des mises en œuvres de
TCP. Notre RFC 9293 le recommande, mais en ajoutant que les
applications doivent pouvoir le débrayer. C'est notamment
indispensable pour les applications interactives, qui n'aiment pas
les délais, même courts. (Sur Unix, cela se
fait avec l'option TCP_NODELAY passée à
setsockopt.)
Un des rôles les plus importants de TCP est de lutter contre la congestion. Il ne faut pas envoyer le plus d'octets possible, ou alors on risque d'écrouler le réseau (RFC 2914). Plusieurs mécanismes doivent être déployés : démarrer doucement (au début de la connexion, TCP ne connait pas le débit que peut supporter le réseau et doit donc être prudent), se calmer rapidement si on constate que des paquets sont perdus (cela peut être un signe de congestion en aval), etc. Ces mesures pour éviter la congestion sont absolument obligatoires (comme tous les biens communs, l'Internet est vulnérables aux parasites, un TCP égoïste qui ne déploierait pas ces mesures anti-congestion serait un mauvais citoyen du réseau). Elles sont décrites plus précisément dans les RFC 1122, RFC 2581, RFC 5681 et RFC 6298. Notez qu'ils énoncent des principes, mais pas forcément les algorithmes exacts à utiliser, ceux-ci pouvant évoluer (et ils l'ont fait depuis la sortie du RFC 793, voir les RFC 9743 et RFC 8961).
Un point qui surprend souvent les programmeur·ses qui écrivent
des applications utilisant TCP est que rien n'indique qu'une
connexion TCP est coupée, par exemple si un câble est
sectionné. C'est seulement lorsqu'on essaie d'écrire qu'on
l'apprendra (ce comportement est une conséquence de la nature sans
connexion d'IP ; pourquoi prévenir d'une coupure alors qu'IP va
peut-être trouver un autre chemin ?). Si on veut être mis au courant
tout de suite, on peut utiliser des keep-alives,
des segments vides qui seront envoyés de temps en temps juste pour
voir s'ils arrivent. Cette pratique est contestée (entre autre parce
qu'elle peut mener à abandonner une connexion qui n'est que
temporairement coupée, et aussi parce que, même si les
keep-alives passent, cela ne garantit pas que la
prochaine écriture de données passera). Notre RFC demande donc que
les keep-alives soient désactivés par défaut, et
que l'application puisse contrôler leur activation (sur Unix, c'est
l'option SO_KEEPALIVE à utiliser avec
setsockopt).
Pendant les quarante ans écoulés depuis la sortie du RFC 793, bien des choses ont changé. Des options ont été ajoutées mais on a vu aussi certaines options qui semblaient être des bonnes idées être finalement abandonnées. C'est le cas du mécanisme de données urgentes, qui n'a jamais vraiment marché comme espéré. Une mise en œuvre actuelle de TCP doit toujours le gérer, pour pouvoir parler avec les anciennes, mais on ne peut pas compter dessus (RFC 6093).
On a parlé plusieurs fois de l'utilisation de TCP par les applications. Pour cela, il faut que TCP offre une API à ces applications. Notre RFC ne décrit pas d'API concrète (cela dépend de toute façon du langage de programmation, et sans doute du système d'exploitation). Il se contente d'une description fonctionnelle de l'interface : les services qu'elle doit offrir à l'application. On y trouve :
- L'ouverture de la connexion, en indiquant l'adresse et le port distant, mais aussi l'adresse locale (MUST-43), pour pouvoir choisir l'adresse si la machine en a plusieurs.
- L'envoi de données, dont TCP garantit qu'elles arriveront toutes et dans l'ordre.
- La lecture de données. Rappelez-vous que TCP fournit un
flot continu d'octets, deux envois de données feront peut-être une
seule lecture ou bien un envoi deux lectures. C'est une des
erreurs les plus courante des programmeurs débutants que de penser
que s'ils font un write d'un côté, un
read de l'autre lira tout ce que le
writea écrit et seulement cela. - La fermeture propre (avec envoi, et réémission si nécessaire, des données écrites) de la connexion.
- Et quelques autres services auxiliaires que je ne détaille pas ici (voir la section 3.9.1).
Rappelez-vous que l'API « socket » n'est qu'un des moyens pour l'application de parler à TCP. Et, à propos de cette API, notez que le RFC utilise le terme de socket avec un sens très différent (cf. le glossaire en section 4).
Et l'autre interface, « sous » TCP, l'interface avec la couche réseau (section 3.9.2) ? TCP peut fonctionner avec des couches réseau variées mais, en pratique, c'est toujours IP, dans une de ses deux versions, v4 ou v6. Un des points délicats est le traitement des messages ICMP que TCP peut recevoir. Au minimum, ils doivent être assignés à une connexion existante. Mais cela ne veut pas dire qu'il faut systématiquement agir lors de la réception d'un de ces messages (RFC 5461). Par exemple, il faut ignorer les messages ICMP de répression de la source (RFC 6633). Et il ne faut pas fermer la connexion juste parce qu'on a reçu une erreur ICMP (MUST-56), car elles peuvent être temporaires.
TCP étant un protocole orienté connexion, la connexion va avoir
un état, représenté par un automate
fini. Ainsi, l'ouverture d'une connexion par le premier
TCP va le faire passer
par les états CLOSED, SYN-SENT puis enfin ESTABLISHED. Récupérée
sur
Wikimedia Commons, voici une représentation de cet automate :
{kind=link}
La section 5 de notre RFC décrit les changements depuis le RFC 793. TCP reste le même et des TCP d'« avant » peuvent interopérer avec ceux qui suivent notre RFC récent. Les principaux changements sont :
- La résolution d'un grand nombre d'errata accumulés depuis quarante ans.
- La « démobilisation » du mécanisme de données urgentes (cf. RFC 6093).
- L'incorporation d'une bonne partie des RFC comme le RFC 1011 ou le RFC 1122.
Le RFC 793 avait été écrit par Jon Postel (comme tant de RFC de cette époque), et notre nouveau RFC 9293 lui rend hommage, en estimant que la longue durée de vie du RFC 793 montre sa qualité.
En application des changements de ce nouveau RFC sur TCP, un registre IANA, celui des bits de l'en-tête comme URG (dont on a vu qu'il était désormais démobilisé), a été mis à jour.
La section 7 de notre nouveau RFC 9293 n'avait pas d'équivalent dans l'ancien RFC 793. Elle concerne la sécurité de TCP. TCP, par lui-même, fournit peu de sécurité (il protège quand même un peu contre l'usurpation d'adresse IP et l'injection de trafic, surtout contre un attaquant qui n'est pas sur le chemin, cf. RFC 5961). Par exemple, il ne fournit pas de services cryptographiques, donc pas de confidentialité ou de vraie garantie d'intégrité. (Son concurrent QUIC, lui, intègre systématiquement la cryptographie.) Si on veut davantage de sécurité pour TCP, il faut mettre IPsec en dessous de TCP ou bien TLS au-dessus. TCP a aussi des mécanismes de sécurité qui lui sont propres, comme AO, normalisé dans le RFC 5925 (mais très peu déployé en pratique). Autre expérience qui n'a pas été un succès, tcpcrypt (RFC 8548).
Il reste des attaques contre lesquelles la cryptographie ne fournit pas vraiment de solution. C'est le cas du SYN flooding, ou d'autres attaques par déni de service.
Mëme si on chiffre les données applicatives avec TLS, TCP expose quand même au réseau tout son fonctionnement. Cette vue depuis le réseau (RFC 8546) soulève plusieurs problèmes (elle peut par exemple faciliter des actions contraires à la neutralité du réseau) et c'est pour cela que le plus récent QUIC masque une grande partie de son fonctionnement (ce qui n'a pas été sans entrainer des polémiques). Toujours côté vie privée, le comportement des mises en œuvre de TCP est suffisamment différent pour qu'il soit possible dans certains cas d'identifier le système d'exploitation d'une machine à distance (ce n'est pas forcément grave, mais il faut le savoir).
Pour les programmeurs et programmeuses, l'annexe A du RFC contient différentes observations utiles pour la mise en œuvre concrète de TCP. Par exemple, cette annexe explique que la validation des numéros de séquence des segments TCP entrants, validation qui est nécessaire pour empêcher un grand nombre d'attaques, peut rejeter des segments légitimes. Ce problème n'a pas de solution idéale.
Un autre point intéressant concerne l'algorithme de
Nagle. Cet algorithme représente un compromis entre la
réactivité de l'application (qui nécessite d'envoyer les données le
plus vite possibles) et l'optimisation de l'occupation du réseau
(qui justifie d'attendre un peu pour voir si on ne va pas recevoir
de nouvelles données à envoyer). Une modification de l'algorithme de
Nagle, décrite dans le document
draft-minshall-nagle peut rendre le choix moins
douloureux.
Enfin, l'annexe B résume sous forme d'un tableau quelles sont les parties de la norme TCP qui doivent être mises en œuvre et quelles sont celles qu'on peut remettre à plus tard.
Si vous voulez sérieusement apprendre TCP, vous pouvez bien sûr lire le RFC en entier, mais il est sans doute plus sage de commencer par un bon livre comme le CNP3.
Un pcap d'une connexion TCP typique est
utilisé ici pour illustrer le fonctionnement de TCP (fichier tcp-typique.pcap). Vu par tshark, cela donne :
8.445772 2a01:4f8:c010:7eb7::106 → 2605:4500:2:245b::42 TCP 94 33672 → 443 [SYN] Seq=0 Win=64800 Len=0 MSS=1440 SACK_PERM=1 TSval=285818465 TSecr=0 WS=128 8.445856 2605:4500:2:245b::42 → 2a01:4f8:c010:7eb7::106 TCP 94 443 → 33672 [SYN, ACK] Seq=0 Ack=1 Win=64260 Len=0 MSS=1440 SACK_PERM=1 TSval=3778761402 TSecr=285818465 WS=128 8.534636 2a01:4f8:c010:7eb7::106 → 2605:4500:2:245b::42 TCP 86 33672 → 443 [ACK] Seq=1 Ack=1 Win=64896 Len=0 TSval=285818554 TSecr=3778761402 8.534897 2a01:4f8:c010:7eb7::106 → 2605:4500:2:245b::42 SSLv3 236 Client Hello 8.534989 2605:4500:2:245b::42 → 2a01:4f8:c010:7eb7::106 TCP 86 443 → 33672 [ACK] Seq=1 Ack=151 Win=64128 Len=0 TSval=3778761491 TSecr=285818554 8.548101 2605:4500:2:245b::42 → 2a01:4f8:c010:7eb7::106 TLSv1.2 1514 Server Hello 8.548111 2605:4500:2:245b::42 → 2a01:4f8:c010:7eb7::106 TCP 1514 443 → 33672 [PSH, ACK] Seq=1429 Ack=151 Win=64128 Len=1428 TSval=3778761504 TSecr=285818554 [TCP segment of a reassembled PDU] 8.548265 2605:4500:2:245b::42 → 2a01:4f8:c010:7eb7::106 TLSv1.2 887 Certificate, Server Key Exchange, Server Hello Done 8.636922 2a01:4f8:c010:7eb7::106 → 2605:4500:2:245b::42 TCP 86 33672 → 443 [ACK] Seq=151 Ack=2857 Win=63616 Len=0 TSval=285818656 TSecr=3778761504 8.636922 2a01:4f8:c010:7eb7::106 → 2605:4500:2:245b::42 TCP 86 33672 → 443 [ACK] Seq=151 Ack=3658 Win=62848 Len=0 TSval=285818656 TSecr=3778761504 8.649899 2a01:4f8:c010:7eb7::106 → 2605:4500:2:245b::42 TCP 86 33672 → 443 [FIN, ACK] Seq=151 Ack=3658 Win=64128 Len=0 TSval=285818669 TSecr=3778761504 8.650160 2605:4500:2:245b::42 → 2a01:4f8:c010:7eb7::106 TCP 86 443 → 33672 [FIN, ACK] Seq=3658 Ack=152 Win=64128 Len=0 TSval=3778761606 TSecr=285818669 8.739117 2a01:4f8:c010:7eb7::106 → 2605:4500:2:245b::42 TCP 86 33672 → 443 [ACK] Seq=152 Ack=3659 Win=64128 Len=0 TSval=285818758 TSecr=3778761606
Ici, 2a01:4f8:c010:7eb7::106 (une sonde RIPE Atlas) veut faire du
HTTPS (donc, port 443)
avec le serveur 2605:4500:2:245b::42. Tout
commence par la triple poignée de mains (les trois premiers paquets,
SYN, SYN+ACK, ACK). Une fois la connexion établie, tshark reconnait
que les machines font du TLS mais, pour TCP, ce ne sont que des données
applicatives (contrairement à QUIC, TCP sépare connexion et
chiffrement). On note qu'il n'y a pas eu
d'optimisation des accusés de réception. Par exemple, l'accusé de
réception du ClientHello TLS voyage dans un paquet séparé, alors
qu'il aurait pu être inclus dans la réponse applicative (le
ServerHello), probablement parce que celle-ci a mis un peu trop de
temps à être envoyée. À la fin de la connexion, chaque machine
demande à terminer (FIN). Une analyse automatique plus complète, avec
tshark -V figure dans tcp-typique.txt.
Ah, au fait, si vous avez pu lire cet article, c'est certainement grâce à TCP… (Ce blog ne fait pas encore de HTTP sur QUIC…).
L'article seul
RFC 9292: Binary Representation of HTTP Messages
Date de publication du RFC : Août 2022
Auteur(s) du RFC : M. Thomson (Mozilla), C. A. Wood (Cloudflare)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 5 mai 2025
Un message HTTP est traditionnellement représenté comme du texte mais ce RFC spécifie une alternative, une représentation binaire d'un message.
À quoi ça sert ? L'un des buts est de faciliter la transmission
de messages HTTP (requêtes ou réponses, cf. RFC 9110) par d'autres protocoles que HTTP. C'est ainsi que
l'oblivious
HTTP du RFC 9458
utilise ce format binaire. D'autre part, un format binaire a des
chances d'être plus compact. (Le RFC dit aussi que cela permet
l'application du chiffrement intègre, mais ce
serait le cas aussi avec du texte, je trouve.) Et l'analyse d'un tel
format est plus simple, avec moins de pièges que celle du format
texte, qui mènent parfois à des failles de sécurité (voir par
exemple la section 11 du RFC 9112). Comme vous
le savez, les versions 2 et 3 de HTTP encodent déjà l'en-tête en
binaire et leurs spécifications (RFC 9113 et
RFC 9114) ont servi de base à ce nouveau
RFC. Le nouveau
format a le type
message/bhttp (le format traditionnel étant
message/http).
On peut encoder le message HTTP en binaire suivant deux modes. Le premier préfixe tous les éléments par leur longueur, ce qui est plus efficace. Le deuxième ne le fait pas, ce qui permet de commencer à encoder sans connaitre la longueur finale.
Notez bien que c'est la sémantique du message qui est encodée, pas sa représentation texte. Concrètement, cela veut dire qu'un message HTTP représenté en texte, traduit en binaire, puis re-traduit en texte ne sera pas identique au bit près.
Bon, mais c'est quoi un message HTTP ? La section 6 du RFC 9110 nous l'apprend. S'il peut être encodé de
plusieurs manières, la vision abstraite du message est toujours la
même : le message est une requête ou une réponse, s'il est une
requête, il y a une méthode (GET, PUT, etc) et la ressource demandée, s'il
est une réponse, un code de retour (comme le fameux 404), puis dans
les deux cas, un en-tête (avec les champs comme
Host: ou Content-Type:),
un corps (qui, comme l'en-tête, peut être vide), un pied (en général
absent), et parfois du remplissage. Dans
notre encodage en binaire, le fait que le message soit une requête
ou une réponse sera indiqué par le framing
indicator, qui vaut 0 dans le premier cas et 1 dans le
second, pour le mode à longueur connue, et 2 ou 3 pour le mode à
longueur pas connue à l'avance (section 3.3).
Le reste de ce que vous devez savoir sur ce format est dans les sections 3.4 (pour les requêtes) et 3.5 (pour les messages). Mais on va voir cela avec des exemples (la section 5 du RFC en contient plusieurs) et du code qui tourne.
Puisque ce format binaire est, à l'heure actuelle, surtout utilisé par oblivious HTTP, on va se tourner vers les mises en œuvre de cette technique. Prenons ohttp. Il est écrit en Rust. Les instructions de compilation marchent bien, je les résume ici (c'était pour une machine Arch) :
export workspace=$HOME/tmp sudo apk add mercurial gyp ca-certificates coreutils curl git make mercurial clang llvm lld ninja-build cd $workspace git clone https://github.com/martinthomson/ohttp.git git clone https://github.com/nss-dev/nss ./nss hg clone https://hg.mozilla.org/projects/nspr ./nspr export NSS_DIR=$workspace/nss export LD_LIBRARY_PATH=$workspace/dist/Debug/lib cd ohttp cargo build cargo test
Et commençons par encoder une simple requête (je vous rappelle que
la section 5 du RFC, et le répertoire examples/ de
ohttp contiennent d'autres exemples, y compris plus complexes) :
% cat request-1.txt GET /hello.txt HTTP/1.1 User-Agent: curl/7.16.3 libcurl/7.16.3 OpenSSL/0.9.7l zlib/1.2.3 Host: www.framasoft.fr % ./ohttp/target/debug/bhttp-convert < ./request-1.txt > request-1.bin
(Attention, le fichier texte doit avoir des fins de ligne CR-LF,
comme le prescrit la norme HTTP et il doit y avoir une ligne vide à
la fin. Si vous éditez avec emacs sur une
machine Unix, C-x RET f puis
dos). Regardons le fichier binaire produit (on
aurait aussi pu utiliser od, ou bien
emacs avec l'excellent mode hexl-mode) :
% xxd request-1.bin 00000000: 0003 4745 5405 6874 7470 7300 0a2f 6865 ..GET.https../he 00000010: 6c6c 6f2e 7478 7440 560a 7573 6572 2d61 llo.txt@V.user-a 00000020: 6765 6e74 3463 7572 6c2f 372e 3136 2e33 gent4curl/7.16.3 00000030: 206c 6962 6375 726c 2f37 2e31 362e 3320 libcurl/7.16.3 00000040: 4f70 656e 5353 4c2f 302e 392e 376c 207a OpenSSL/0.9.7l z 00000050: 6c69 622f 312e 322e 3304 686f 7374 1077 lib/1.2.3.host.w 00000060: 7777 2e66 7261 6d61 736f 6674 2e66 7200 ww.framasoft.fr. 00000070: 00 .
Le premier octet est le framing indicator, encodé
selon la section 16 du RFC 9000 (dans le
source de ohttp, regardez bhttp/src/rw.rs). Il
vaut zéro, indiquant une requête de longueur connue. Le deuxième
octet, de valeur trois, indique la longueur de la méthode HTTP, puis
suivent les octets de cette méthode (G E T).
Encodons ensuite une réponse :
% cat response-1.txt HTTP/1.1 200 OK Date: Mon, 27 Jul 2009 12:28:53 GMT Server: Apache Last-Modified: Wed, 22 Jul 2009 19:15:56 GMT ETag: "34aa387-d-1568eb00" Content-Length: 51 Content-Type: text/plain Hello World! My content includes a trailing CRLF. % ./ohttp/target/debug/bhttp-convert < ./response-1.txt > response-1.bin % xxd response-1.bin 00000000: 0140 c840 a104 6461 7465 1d4d 6f6e 2c20 .@.@..date.Mon, 00000010: 3237 204a 756c 2032 3030 3920 3132 3a32 27 Jul 2009 12:2 00000020: 383a 3533 2047 4d54 0673 6572 7665 7206 8:53 GMT.server. 00000030: 4170 6163 6865 0d6c 6173 742d 6d6f 6469 Apache.last-modi 00000040: 6669 6564 1d57 6564 2c20 3232 204a 756c fied.Wed, 22 Jul 00000050: 2032 3030 3920 3139 3a31 353a 3536 2047 2009 19:15:56 G 00000060: 4d54 0465 7461 6714 2233 3461 6133 3837 MT.etag."34aa387 00000070: 2d64 2d31 3536 3865 6230 3022 0e63 6f6e -d-1568eb00".con 00000080: 7465 6e74 2d6c 656e 6774 6802 3531 0c63 tent-length.51.c 00000090: 6f6e 7465 6e74 2d74 7970 650a 7465 7874 ontent-type.text 000000a0: 2f70 6c61 696e 3348 656c 6c6f 2057 6f72 /plain3Hello Wor 000000b0: 6c64 2120 4d79 2063 6f6e 7465 6e74 2069 ld! My content i 000000c0: 6e63 6c75 6465 7320 6120 7472 6169 6c69 ncludes a traili 000000d0: 6e67 2043 524c 462e 0d0a 00 ng CRLF....
Ici, le framing indicator vaut un, indiquant une réponse de longueur connue. Vous avez vu le C8 en troisième position ? C'est le code de retour 200.
Le format binaire de HTTP a été enregistré
sous le nom message/bhttp.
L'article seul
RFC 9287: Greasing the QUIC bit
Date de publication du RFC : Août 2022
Auteur(s) du RFC : M. Thomson (Mozilla)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF quic
Première rédaction de cet article le 30 août 2022
Dans un monde idéal, nos flux de données sur l'Internet passeraient sans problème et sans être maltraitées par les éléments intermédiaires du réseau. Mais dans le monde réel, de nombreuses middleboxes examinent le trafic et interfèrent avec lui. Les machines émettrices de trafic doivent donc se protéger et une des techniques les plus courantes est le chiffrement : si la middlebox ne peut pas comprendre ce qui est envoyé, elle ne pourra pas interférer. Le protocole de transport QUIC chiffre donc le plus possible. Mais une partie du trafic reste non chiffrée. Une des techniques pour empêcher que les middleboxes ne le lisent et ne prennent des décisions déplorables fondées sur ces informations transmises en clair est le graissage : on fait varier les données le plus possible. Ce RFC normalise une possibilité de graisser un bit de l'en-tête QUIC qui était fixe auparavant.
L'un des principes de conception de QUIC est de diminuer le plus possible la vue depuis le réseau (RFC 8546) ; les éléments intermédiaires, comme les routeurs ne doivent avoir accès qu'à ce qui leur est strictement nécessaire, le reste étant chiffré, pour leur éviter toute tentation. QUIC définit (dans le RFC 8999) des invariants, des informations qui seront toujours vraies même pour les futures versions de QUIC (le RFC 9000 définit QUIC version 1, pour l'instant la seule version). En dehors de ces invariants, tout peut… varier et les équipements intermédiaires du réseau ne doivent pas en tenir compte. Si tous suivaient ce principe, on préserverait la neutralité du réseau, et on éviterait l'ossification (cf. RFC 9170). Mais, en pratique, on sait que ce n'est pas le cas et que toute information visible depuis le réseau sera utilisée par les middleboxes, ce qui peut rendre difficile les évolutions futures (TLS a par exemple beaucoup souffert de ce problème, d'où le RFC 8701, le premier à avoir formalisé ce concept de graissage).
Or, QUIC a un bit qui n'est pas cité dans les invariants du RFC 8999 mais qui est fixe et peur servir à différencier QUIC d'autres protocoles. On l'appele d'ailleurs souvent le « bit QUIC » (même si ça n'est pas son nom officiel, qui est fixed bit, cf. RFC 9000, sections 17.2 et 17.3). Si les middleboxes s'en servent pour appliquer un traitement particulier à QUIC, les futures versions de QUIC ne pourront pas utiliser ce bit pour autre chose (rappelez-vous qu'il ne fait pas partie des invariants).
Notre RFC
ajoute donc à QUIC une option pour graisser ce bit, c'est-à-dire
pour le faire varier au hasard, décourageant ainsi les
middleboxes d'en tenir compte. Un nouveau
paramètre de transport QUIC (ces paramètres sont définis dans le
RFC 9000, section 7.4) est créé,
grease_quic_bit (et ajouté au registre
IANA). Lorsqu'il est annoncé à l'ouverture de la connexion
QUIC, il indique que ce bit est ignoré et que le pair à tout intérêt
à le faire varier.
Les paquets initiaux de la connexion
(Initial et Handshake)
doivent garder le bit QUIC à 1 (puisqu'on n'a pas encore les
paramètres de la connexion), sauf si on reprend une ancienne
connexion (en envoyant un jeton, cf. RFC 9000,
section 19.7).
Tout le but de ce graissage est de permettre aux futures versions
de QUIC (v2, 3, etc) d'utiliser ce bit qui était originellement
fixe. Ces futures versions, ou tout simplement des extensions à QUIC
négociées au démarrage de la connexion, pourront donc utiliser ce
bit (lui donner une sémantique). Le RFC leur recommande d'annoncer
quand même le paramètre grease_quic_bit, ce qui
permettra de graisser même si la future extension n'est pas gérée
par le partenaire.
Le RFC note enfin que ce graissage rend plus difficile d'identifier les flux de données QUIC au milieu de tout le trafic. C'est bien sûr le but, mais cela peut compliquer certains activités d'administration réseau. Un futur RFC explique plus en détail cette situation.
Apparemment, plusieurs mises en œuvre de QUIC gèrent déjà ce graissage.
L'article seul
RFC 9285: The Base45 Data Encoding
Date de publication du RFC : Août 2022
Auteur(s) du RFC : P. Faltstrom (Netnod), F. Ljunggren (Kirei), D. van Gulik (Webweaving)
Pour information
Première rédaction de cet article le 10 août 2022
Ce RFC décrit un encodage en texte de données binaires, l'encodage Base45. Proche conceptuellement d'encodages comme Base64, il est, par exemple, beaucoup utilisé pour le code QR.
Ces codes QR ne permettent pas de stocker directement des données binaires quelconques car le contenu sera toujours interprété comme du texte. Il est donc nécessaire d'encoder et c'est le rôle de Base45. Il existe bien sûr d'innombrables autres mécanismes d'encodage en texte, comme Base16, Base32 et Base64, spécifiés dans le RFC 4648 mais Base45 est plus efficace pour les codes QR, qui réencodent ensuite.
Base45 utilise un sous-ensemble d'ASCII, de 45 caractères (d'où son nom). Deux octets du contenu binaire sont encodés en trois caractères de ce sous-ensemble. Par exemple, deux octets nuls donneront la chaine de caractères "000". Regardons tout de suite avec le module Python base45 :
% pip3 install base45 % python3 >>> import base45 >>> base45.b45encode(b'Bonjour, tout le monde') b'.H86/D34ENJES4434ESUETVDL44-3E6VC' >>>
Et décodons avec le module Elixir base45 :
% iex -S mix
iex(1)> Base45.decode(".H86/D34ENJES4434ESUETVDL44-3E6VC")
"Bonjour, tout le monde"
C'est parfait, tout le monde est d'accord. Ici, évidemment, la chaine originale n'avait pas vraiment besoin d'être encodée donc on va essayer avec du binaire, les trois octets 42, 1 et 6, encodage en Elixir, décodage en Python :
iex(1)> Base45.encode(<<42, 1, 6>>)
"/D560"
>>> base45.b45decode("/D560")
b'*\x01\x06'
Encore une fois, tout va bien, Elixir a encodé les trois octets du binaire en quatre caractères, que Python a su décoder (l'astérisque est affiché car son code ASCII est 42).
Je vous laisse découvrir l'algorithme complet (il est assez simple) dans la section 3 du RFC. Si vous le programmez vous-même (ce qui n'est sans doute pas une bonne idée, il existe déjà de nombreuses mises en œuvre), attention aux cas limites comme un binaire d'un seul octet, ou comme une chaine à décoder qui compte des caractères invalides. Ici, un essai avec un caractère invalide, le signe égal :
% python3
>>> import base45
>>> base45.b45decode("AAAA=")
Traceback (most recent call last):
File "/home/stephane/.local/lib/python3.8/site-packages/base45/__init__.py", line 30, in b45decode
buf = [BASE45_DICT[c] for c in s.rstrip("\n")]
File "/home/stephane/.local/lib/python3.8/site-packages/base45/__init__.py", line 30, in <listcomp>
buf = [BASE45_DICT[c] for c in s.rstrip("\n")]
KeyError: '='
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/stephane/.local/lib/python3.8/site-packages/base45/__init__.py", line 54, in b45decode
raise ValueError("Invalid base45 string")
ValueError: Invalid base45 string
Pensez à tester votre code avec de nombreux cas variés. Le RFC cite
l'exemple des chaines "FGW" (qui se décode en une paire d'octets
valant chacun 255) et "GGW" qui, quoique proche de la précédente et
ne comportant que des caractères de l'encodage Base45 est néanmoins
invalide (testez-la avec votre décodeur). Le code de test dans le module Elixir
donne des idées de tests utiles (certains viennent de bogues
détectées pendant le développement). Regardez
test/base45_test.exs.
Et, comme toujours, lorsque vous recevez des données venues de l'extérieur, soyez paranoïaques dans le décodage ! Un code QR peut être malveillant et chercher à activer une bogue dans le décodeur (section 6 du RFC).
Enfin, le RFC rappelle qu'une chaine encodée n'est pas forcément directement utilisable comme URL, elle peut comporter des caractères qui ne sont pas sûrs, il faut donc encore une étape d'encodage si on veut en faire un URL.
Compte tenu de l'importance des codes QR, on trouve des mises en œuvre de Base45 un peu partout. J'ai par exemple cité celle en Python. Si vous programmez en Elixir, il y a une bibliothèque sur Hex (écrite en Erlang) mais aussi ma bibliothèque (aux performances très basses).
Sinon, si vous cherchez un bon article d'explication sur Base45, je recommande celui-ci.
L'article seul
RFC 9276: Guidance for NSEC3 Parameter Settings
Date de publication du RFC : Août 2022
Auteur(s) du RFC : W. Hardaker (USC/ISI), V. Dukhovni
(Bloomberg)
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 26 août 2024
Si vous êtes responsable d'une zone DNS, et que vous la testez régulièrement avec des outils comme Zonemaster ou DNSviz (ce que font tous les responsables sérieux), vous avez peut-être eu des avertissements comme quoi vos « paramètres NSEC3 » n'étaient pas ceux conseillés. C'est parce que les recommandations en ce sens ont changé avec ce RFC. Lisez-le donc si vous voulez comprendre les recommandations actuelles.
D'abord, un peu de contexte. Ce RFC concerne les zones qui sont
signées avec DNSSEC
et qui utilisent les enregistrements NSEC3 du
RFC 5155. Aujourd'hui, par exemple, c'est le
cas de .fr,
.com mais aussi de
bortzmeyer.org grâce à qui vous êtes arrivés
sur cet article. Mais ce n'est pas le cas de la racine des
noms de domaine, qui
utilise NSEC (RFC 4035). Pour comprendre la
dfifférence entre les deux, je vous renvoie à mon article sur le
RFC 5155.
Un exemple où Zonemaster proteste, sur
icann.org :

Ce RFC 5155 donnait des conseils de sécurité cryptographiques qui, avec le recul et l'expérience se sont avérés sous-optimaux. Ce nouveau RFC 9276 les modifie donc et suggère fortement de ne plus utiliser de sel, ni d'itérations successives, dans le calcul des condensats pour NSEC3.
Lorsqu'une zone est signée avec utilisation de NSEC3, elle comprend un enregistrement de type NSEC3PARAM qui indique quatre choses :
- L'algorithme de condensation utilisé (presque toujours SHA-1, aujourd'hui, c'est le seul normalisé). Il n'est pas discuté ici (voir le RFC 8624 sur le choix des algorithmes).
- Les options, notamment celle nommée
opt-out et qui est un avantage souvent oublié
de NSEC3 par rapport à NSEC : la possibilité de ne pas avoir un
enregistrement NSEC3 par nom mais seulement par nom signé. C'est
un peu moins sûr (les noms non signés, typiquement les délégations
DNS, ne sont pas protégés) mais ça fait une grosse économie de
mémoire pour les zones qui comprennent beaucoup de délégations non
signées (et cela évite de passer trop de temps à modifier les
chaines NSEC3 dans des zones qui changent souvent). C'est
typiquement la cas des gros TLD et cela explique pourquoi
.frou.comutilisent NSEC3, même s'il n'y a pas de problème avec l'énumération des noms (.frdistribue la liste). (Notez que si l'option est à 0 dans le NSEC3PARAM, cela ne signifie pas qu'il n'y a pas d'opt-out, celui-ci est typiquement indiqué uniquement dans les enregistrements NSEC3.) - Le nombre d'itérations supplémentaires (RFC 5155, sections 3.1.3 et 4.1.3) faites lorsqu'on condense un nom.
- Le sel utilisé.
Voici par exemple l'enregistrement de icann.org
en août 2024 :
% dig +short icann.org NSEC3PARAM 1 0 5 A4196F45E2097176
Utilisation de SHA-1 (le 1 est le code de SHA-1), pas
d'opt-out (mais prudence, son utilisation n'est
pas obligatoirement signalée dans les options, voir plus haut), cinq
itérations supplémentaires (donc six au total) et un sel apparemment
aléatoire, A4196F45E2097176.
La première recommandation du RFC concerne le nombre
d'itérations. Comme le sel, le but est de rendre plus difficile
l'utilisation de tables calculées à l'avance par un attaquant. Sans
sel et avec une seule itération, un attaquant qui a à l'avance
calculé tout un dictionnaire et sait donc que le condensat de
foobar est
8843d7f92416211de9ebb963ff4ce28125932878 pourra
donc facilement inverser le condensat dans un enregistrement
NSEC3. C'est pour cela que le RFC 5155
recommandait un nombre variable d'itérations, indiqué par
l'enregistrement NSEC3PARAM. Mais, en pratique, la protection contre
l'énumération n'est pas si solide que ça. Bien des noms peuvent être
devinés (www étant le plus évident mais il y a
aussi les mots d'un dictionnaire de la langue), d'autant plus qu'on
choisit en général un nom de domaine pour être simple
et facilement mémorisable. Et que ces noms se retrouvent à
plein d'endroits comme les journaux Certificate
Transparency (RFC 9162). L'opinion
d'aujourd'hui est que le jeu (la protection contre l'énumération)
n'en vaut pas la chandelle (le coût de signature
et de validation). Notez aussi une externalité négative : les résolveurs aussi devront effectuer ces
itérations et sont donc concernés. Bon, en prime, les techniques
modernes rendent la protection peu efficace de toute façon
(cf. « GPU-Based NSEC3 Hash
Breaking »). La recommandation du RFC
est donc de ne pas avoir d'itérations supplémentaires, donc de
mettre ce nombre à zéro.
Et la deuxième recommandation concerne le sel. Il y a dans NSEC3 un sel implicite, c'est le nom de domaine (RFC 5155, section 5). D'ailleurs, mon exemple de condensat de foobar était faux, puisque j'avais omis cette étape. Si on l'inclut, le sel supplémentaire indiqué dans l'enregistrement NSEC3PARAM perd de son intérêt. En outre, en pratique, on change rarement le sel (cela nécessite de modifier toute la chaine NSEC3) ce qui diminue la protection qu'il offre. La recommandation actuelle est donc de ne pas utiliser de sel (ce qui se note avec un tiret, pas avec une chaine vide).
Si on suit les recommandations du RFC, le NSEC3PARAM aura cette allure :
% dig +short fr NSEC3PARAM 1 0 0 -
Et un des NSEC3 sera du genre :
% dig nexistesurementpas.fr
qu7kmgn3e….fr. 594 IN NSEC3 1 1 0 - (
QU7MMK1…
NS DS RRSIG )
Notez aussi que le RFC recommande (section 3), avant de réfléchir
aux paramètres de NSEC3, de réfléchir à NSEC3 lui-même. Sur une
grosse zone de délégation, changeant souvent, comme
.fr, NSEC3 est tout à fait justifié en raison
des avantages de l'opt-out. Mais sur la zone DNS
typique d'une petite organisation, qui ne compte souvent que des
noms prévisibles (l'apex, www et
mail), NSEC3 peut avantageusement être remplacé
par NSEC, qui consomme moins de ressources. (NSEC3, ou d'ailleurs
les couvertures minimales du RFC 4470, peut, dans le
pire des cas, faciliter certaines attaques par déni de
service.)
Les recommandations précédentes s'appliquaient aux signeurs de zone (côté serveurs faisant autorité, donc). Mais la section 3 a aussi des recommandations pour les résolveurs : compte-tenu du coût que représente pour eux les itérations NSEC3, ils ont le droit d'imposer un maximum, et de le diminuer petit à petit. Ces résolveurs peuvent refuser de répondre (réponse SERVFAIL) ou bien traiter la zone come n'étant pas signée (cf. section 6). Un nouveau code d'erreur étendu (RFC 8914), le numéro 27, Unsupported NSEC3 iterations value, a été réservé pour qu'ils puissent informer leurs clients.
Revenons aux serveurs faisant autorité : le RFC précise aussi qu'un hébergeur DNS devrait informer clairement ses utilisateurs des paramètres NSEC3 qu'il accepte. Il ne faudrait pas qu'on choisisse N itérations et qu'on s'aperçoive au déploiement qu'un des secondaires n'accepte pas d'en faire autant.
Aujourd'hui, la grande majorité des zones utilisant NSEC3 est
passée aux recommandations de ce RFC (comme par
exemple .fr en 2022). Notons que .org a
un sel mais pas d'itérations supplémentaires.
% dig +short org NSEC3PARAM 1 0 0 332539EE7F95C32A
Si vous utilisez OpenDNSSEC pour automatiser les opérations DNSSEC sur vos zones, voici la configuration conforme au RFC que j'utilise :
<Denial>
<NSEC3>
<!-- <OptOut/> -->
<Resalt>P100D</Resalt>
<Hash>
<Algorithm>1</Algorithm>
<Iterations>0</Iterations>
<Salt length="0"/>
</Hash>
</NSEC3>
</Denial>
L'article seul
RFC 9267: Common Implementation Anti-Patterns Related to Domain Name System (DNS) Resource Record (RR) Processing
Date de publication du RFC : Juillet 2022
Auteur(s) du RFC : S. Dashevskyi, D. dos Santos, J. Wetzels, A. Amri (Forescout Technologies)
Pour information
Première rédaction de cet article le 14 septembre 2022
Comme chacun·e sait, l'Internet est une jungle (les politiciens ajouteraient « une jungle Far-West de non-droit qu'il faut civiliser »). Par exemple, les logiciels qui parlent avec les vôtres ne sont pas toujours correctement écrits, voire ils sont franchement malveillants. Le code de votre côté doit donc être robuste, voire paranoïaque, et penser à tout. Ce RFC décrit quelques problèmes qui ont été observés dans des logiciels mettant en œuvre le DNS et explique comment ne pas refaire la même erreur.
Le RFC ne parle pas de failles DNS mais de failles dans les programmes DNS, ce qui est très différent (mais la différence est souvent oubliée dans les médias). Le protocole lui-même n'était pas en cause dans ces cas, ce sont juste les logiciels qui avaient des bogues. Les cas sont nombreux, par exemple SIGRed (CVE-2020-1350) ou DNSpooq (CVE-2020-25681 à CVE-2020-25687). Ces problèmes frappent notamment souvent dnsmasq (personnellement, je n'ai jamais compris pourquoi ce logiciel était si utilisé, mais c'est une autre histoire).
Plusieurs vulnérabilités ont concerné l'analyse des
enregistrements DNS (RR = Resource Record). Les
risques lors de cette analyse devraient être bien connus, la
première faille documentée l'ayant été en 2000 (CVE-2000-0333) !
Tout logiciel qui analyse des enregistrements DNS (client, serveurs,
mais aussi pare-feux, IDS, etc) peut
tomber dans ces pièges, d'où l'importance de les documenter. C'était
déjà fait dans
l'Internet-Draft
draft-ietf-dnsind-local-compression
et dans le RFC 5625 mais c'était perdu au
milieu d'autres choses donc notre RFC choisit d'enfoncer le
clou.
Il commence par le grand classique des bogues de logiciels DNS : le traitement des pointeurs de compression. Pour gagner quelques octets, à l'époque où ça comptait, le DNS prévoit (RFC 1035, section 4.1.4) qu'on peut, dans un enregistrement DNS, remplacer tout ou partie d'un nom de domaine par un pointeur vers un autre endroit du paquet. Ainsi, si on a tous ses serveurs qui se terminent par les mêmes composants (comme c'est le cas, par exemple, de la racine), on peut ne mettre ces composants qu'une fois, et pointer vers eux partout ailleurs. Évidemment, si vous êtes programmeuse ou programmeur, vous avez déjà vu le piège : les pointeurs, c'est dangereux. Ils peuvent pointer en dehors du paquet, ou pointer vers eux-même, par exemple. Si on suit aveuglément un pointeur, un déni de service est possible, si on tape en dehors de la mémoire allouée ou bien si on se lance dans une boucle sans fin.
Rentrons dans les détails. Le RFC 1035 nous dit que l'octet qui indique la longueur d'un composant doit valoir moins de 64 (la taille maximale d'un composant), donc avoir les deux bits de plus fort poids à zéro. S'ils sont tous les deux à un, cela indique qu'on a un pointeur. Cet octet et le suivant (privés des deux bits de plus fort poids) sont alors un pointeur, le nombre d'octets depuis le début du message. On voit qu'on peut atteindre 16 383 octets (2 ** 14 - 1), largement assez pour sortir de la mémoire allouée pour le paquet, avec les conséquences qu'on imagine. Cela s'est produit en vrai (CVE-2020-25767, CVE-2020-24339 et CVE-2020-24335).
Autre exemple amusant cité par le RFC, le cas d'un pointeur pointant sur lui-même. Soit un message DNS minimal. Le premier composant est à 12 octets du début du message. Si on y met les octets 0xC0 et 0x0C, on aura un pointeur (0xC0 = 11000000, les deux bits de plus fort poids à un) qui vaut 12 (0xC0 0x0C moins les deux bits les plus significatifs = 0000000000001100 = 12). Le pointeur pointera alors sur lui-même, entrainant le logiciel DNS imprudent dans une boucle sans fin. Ça aussi, ça s'est déjà produit (CVE-2017-9345).
Dernier exemple amusant avec des pointeurs, le pointeur qui va
mener à un nombre infini de composants. L'attaquant (ou le
programmeur maladroit) met dans le message un composant suivi d'un
pointeur qui revient au début de ce composant. Si le composant était
test, un analyseur DNS imprudent va créer le
nom de domaine test.test.test.test… avant de
tomber à court de mémoire, ou bien, dans un langage de programmation
comme C, d'écrire dans une
autre zone de la mémoire, ce qui peut mener à un
RCE. Notez que les pointeurs ne devraient pas
pointer vers un pointeur : ça n'a aucun intérêt pratique et c'est
dangereux, mais le RFC 1035 ne l'interdit pas
explicitement. Une alternative est de tester le nombre de fois qu'on
a suivi un pointeur ou, encore mieux, de vérifier que le pointeur ne
pointe qu'en avant de lui-même.
Notez que le problème de la répétition infinie d'un composant pourrait également être évité en s'assurant que le nom de domaine reste en dessous de sa taille maximale, 255 octets (section 3 du RFC).
Mais il n'y a pas que les pointeurs. Un nom de domaine doit être
terminé par un octet nul, indiquant la racine. Ainsi, le nom
afnic.fr est encodé 0x05 0x61 0x66 0x6E 0x69
0x63 ("afnic") 0x02 0x66 0x72 ("fr") 0x00 (la racine). Que se
passe-t-il si l'octet nul final manque ? Certains programmes en
C ont été assez imprudents
pour tenter de traiter le nom de domaine avec des routines comme
strlen, qui comptent sur un octet nul pour
terminer les données (section 4 de notre RFC). Le développeur qui ne
veut pas refaire des failles comme CVE-2020-25107, CVE-2020-17440,
CVE-2020-24383 ou CVE-2020-27736 devrait utiliser
strnlen ou une autre méthode sûre.
On n'a pas terminé. Lorsqu'on traite une réponse DNS, les
enregistrements incluent des données. Leur longueur est donné par un
champ RDLENGTH de deux octets, qui précède les données (section
5). Si un analyseur DNS ne fait pas attention, la longueur indiquée
peut être supérieure à la taille du paquet. Un programme qui,
bêtement, lirait RDLENGTH puis ferait un read()
de la longueur indiquée aurait de fortes chances de taper en dehors
de la mémoire accessible (CVE-2020-25108, CVE-2020-24336 et
CVE-2020-27009).
Ah, et le RFC n'en parle pas, mais l'analyse des options EDNS (RFC 6891) offre également ce genre de pièges. Une option est encodée en TLV et une longueur invalide peut mener à lire les valeurs en dehors du paquet.
Un problème du même genre est décrit dans la section 6 du RFC. Un message DNS comprend plusieurs sections (Question, Réponse, Autorité, Additionnelle) et le nombre d'enregistrements par section est indiqué au début du message DNS. Ces nombres (count) peuvent également être faux et ne doivent pas être utilisés aveuglément, sinon, on aura des malheurs du genre CVE-2020-25109, CVE-2020-24340, CVE-2020-24334 ou CVE-2020-27737.
C'est en raison de tous ces risques qu'il faut tester que ses
programmes résistent bien à des messages DNS mal formés. Par
exemple, le serveur faisant autorité
Drink, écrit en Elixir, a dans ses jeux de tests de tels
messages. Regardez par exemple drink_parsing_test.exs. Un
exemple d'un tel test, pour le problème de boucle sans fin sur des
pointeurs, décrit en section 2 du RFC, est :
test "pointerloop1" do # RFC 9267, section 2
result = Drink.Parsing.parse_request(<<@id::unsigned-integer-size(16),
@request::unsigned-integer-size(16),
1::unsigned-integer-size(16), # QDcount
0::unsigned-integer-size(16), # ANcount
0::unsigned-integer-size(16), # NScount
0::unsigned-integer-size(16), # ARcount
0xc0::unsigned-integer-size(8), # First label of the question
# section starts with a
# compression pointer to itself.
0x0c::unsigned-integer-size(8),
@mx::unsigned-integer-size(16),
@in_class::unsigned-integer-size(16)
>>,
false)
assert result == {:error, :badDNS}
end
On fabrique un paquet DNS avec le pointeur invalide, et on
l'analyse. Le sous-programme parse_request ne
doit pas tourner sans fin, et doit renvoyer une erreur.
Un test du même genre en Python, où on envoie un message DNS avec un pointeur pointant sur lui-même (et on espère que ça n'aura pas tué le serveur qui le reçoit) :
id = 12345
misc = 0 # opcode 0, all flags zero
data = struct.pack(">HHHHHHBB", id, misc, 1, 0, 0, 0, 0xc0, 0x0c)
s.sendto(data, sockaddr)
L'article seul
RFC 9260: Stream Control Transmission Protocol
Date de publication du RFC : Juin 2022
Auteur(s) du RFC : R. Stewart (Netflix), M. Tüxen
(Münster Univ. of Appl. Sciences), K. Nielsen (Kamstrup A/S)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF twvwg
Première rédaction de cet article le 6 juin 2022
Une des particularités du protocole IP est que vous avez plusieurs protocoles de transport disponibles. TCP et UDP sont les plus connus mais SCTP, normalisé dans notre RFC, est également intéressant. C'est un protocole déjà ancien (il date de 2000) et ce RFC remplace son prédécesseur, le RFC 4960. Beaucoup de changements de détails, mais rien de crucial.
SCTP ressemble plutôt à TCP, notamment par le fait qu'il fournit un transport fiable. Mais il a plusieurs différences :
- il ne gère pas un flot d'octets continu mais une série de messages, bien séparés,
- il gère plusieurs flux de données séparés, qui partagent le même contrôle de congestion mais gèrent à part les pertes et retransmissions (un peu comme QUIC),
- il gère le cas où la machine a plusieurs adresses IP, ce qui lui fournit normalement plus de redondance, si on est connecté à plusieurs réseaux.
Cette dernière possibilité le rapproche des protocoles qui séparent l'identificateur et le localisateur et lui permet de gérer proprement le multihoming. Cela se fait en indiquant, au début du contact, toutes les adresses IP (autrefois, il y avait même les noms de domaines, cf. la section 3.3.2.1.4) de la machine.
SCTP tient également compte de l'expérience acquise avec TCP. par exemple, l'établissement d'une connexion (que SCTP nomme association) se fait avec un échange de quatre paquets (et non pas trois comme avec TCP), pour offrir une meilleure protection contre les dénis de service. Les SYN cookies, un ajout plus ou moins bancal en TCP, sont ici partie intégrante du protocole.
SCTP est surtout issu des demandes du monde de la téléphonie sur IP, qui avait besoin d'un tel protocole pour la signalisation mais il peut être aussi utilisé dans d'autres domaines.
Un excellent article du Linux Journal explique bien SCTP.
SCTP est depuis longtemps mis en œuvre dans Linux et dans FreeBSD. De même, des programmes de débogage comme Wireshark sont capables de décoder et d'afficher le SCTP. Voici par exemple un pcap entre deux machines dont l'une a envoyé (trame 3) la chaîne de caractères « toto ». (Vous avez également la version texte de ce dialogue.) Des exemples de programmes de tests SCTP se trouvent dans mon article sur le RFC 3286.
Comme tout « nouveau » protocole de transport, SCTP est handicapé par des coupe-feux mal programmés et/ou mal configurés. L'Internet s'ossifiant de plus en plus, il devient très difficile de déployer un nouveau protocole de transport. D'où le RFC 6951, pour faire tourner SCTP sur UDP (comme ce que fait QUIC).
Les changements qu'introduit ce nouveau RFC ne modifient pas en profondeur le protocole mais corrigent les nombreux problèmes survenus pendant ses premières années d'utilisation. Le RFC 8540 donne la liste complète des problèmes corrigés.
L'article seul
RFC 9255: The 'I' in RPKI Does Not Stand for Identity
Date de publication du RFC : Juin 2022
Auteur(s) du RFC : R. Bush (Arrcus & IIJ Research), R. Housley (Vigil Security)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF sidrops
Première rédaction de cet article le 15 juin 2022
Un très court RFC pour un simple rappel, qui ne devrait même pas être nécessaire : les identités utilisées dans la RPKI, la base des identités qui sert aux techniques de sécurisation de BGP, n'ont pas de lien avec les identités attribuées par l'État et ne doivent pas être utilisées pour, par exemple, signer des documents « officiels » ou des contrats commerciaux.
Le RFC 6480 décrit cette RPKI : il s'agit d'un ensemble de certificats et de signatures qui servent de base pour des techniques de sécurité du routage comme les ROA du RFC 6482 ou comme le BGPsec du RFC 8205. Les objets de la RPKI servent à établir l'autorité sur des ressources Internet (INR, Internet Number Resources, comme les adresses IP et les numéros d'AS). Le RFC 6480, section 2.1, dit clairement que cela ne va pas au-delà et que la RPKI ne prétend pas être la source d'identité de l'Internet, ni même une source « officielle ».
Prenons un exemple concret, un certificat
choisi au hasard dans les données du RIPE-NCC (qu'on peut récupérer avec
rsync en
rsync://rpki.ripe.net/repository). Il est au
format DER donc ouvrons-le :
% openssl x509 -inform DER -text -in ./DEFAULT/ztLYANxsM7afpHKR4vFbM16jYA8.cer
Certificate:
Data:
...
Serial Number: 724816122963 (0xa8c2685453)
Validity
Not Before: Jan 1 14:04:04 2022 GMT
Not After : Jul 1 00:00:00 2023 GMT
Subject: CN = ced2d800dc6c33b69fa47291e2f15b335ea3600f
...
X509v3 extensions:
...
sbgp-ipAddrBlock: critical
IPv4:
51.33.0.0/16
...
sbgp-autonomousSysNum: critical
Autonomous System Numbers:
206918
...
Je n'ai pas tout montré, mais seulement les choses importantes :
- Il n'y a pas de vraie identité dedans, le sujet a manifestement été généré automatiquement,
- Il couvre un certain nombre de ressources (INR,
Internet Number Resources), comme le préfixe IP
51.33.0.0/16, utilisant les extensions du RFC 3779.
Ce certificat dit simplement que l'entité qui a la clé privée (RFC 5280) correspondante (une administration britannique, dans ce cas) a autorité sur des ressources comme l'AS 206918. Rien d'autre.
Mais, apparemment, certaines personnes n'avaient pas bien lu le RFC 6480 et croyaient que cet attirail PKIesque leur permettait également de signer des documents sans lien avec les buts de la RPKI, voire n'ayant rien à voir avec le routage. Et d'autant plus que des gens croient que le I dans RPKI veut dire Identity (il veut en fait dire Infrastructure). Il a ainsi été suggéré que les clés de la RPKI pouvaient être utilisées pour signer des LOA demandant l'installation d'un serveur dans une baie.
Pourquoi est-ce que cela serait une mauvaise idée ? Il y a
plusieurs raisons mais la principale est qu'utiliser la RPKI pour
des usages en dehors du monde restreint du routage Internet est que
cela exposerait les AC de cette RPKI à des
risques juridiques qu'elles n'ont aucune envie d'assumer. Et cela
compliquerait les choses, obligeant sans doute ces AC à déployer des
processus bureaucratiques bien plus rigides. Si on veut connaitre
l'identité officielle (que le RFC nomme à tort « identité dans le
monde réel ») d'un titulaire de ressources Internet, on a les bases
des RIR,
qu'on interroge via RDAP ou autres
protocoles. (C'est ainsi que j'ai trouvé le titulaire de
51.33.0.0/16.) Bien sûr, il y a les
enregistrements Ghostbusters du RFC 6493 mais ils sont uniquement là pour aider à trouver un
contact opérationnel, pas pour indiquer l'identité étatique du
titulaire. Même les numéros d'AS ne sont pas l'« identité » d'un acteur de
l'Internet (certains en ont plusieurs).
Notons qu'il y a d'autres problèmes avec l'idée de se servir de la RPKI pour signer des documents à valeur légale. Par exemple, dans beaucoup de grandes organisations, ce ne sont pas les mêmes personnes qui gèrent le routage et qui gèrent les commandes aux fournisseurs. Et, au RIPE-NCC, les clés privées sont souvent hébergées par le RIPE-NCC, pas par les titulaires, et le RIPE-NCC n'a évidemment pas le droit de s'en servir pour autre chose que le routage.
Bref, n'utilisez pas la RPKI pour autre chose que ce pour quoi elle a été conçue.
L'article seul
RFC 9250: DNS over Dedicated QUIC Connections
Date de publication du RFC : Mai 2022
Auteur(s) du RFC : C. Huitema (Private Octopus), S. Dickinson (Sinodun IT), A. Mankin (Salesforce)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dprive
Première rédaction de cet article le 22 mai 2022
Ce nouveau RFC complète la série des mécanismes de protection cryptographique du DNS. Après DoT (RFC 7858) et DoH (RFC 8484), voici DoQ, DNS sur QUIC. On notera que bien que QUIC ait été conçu essentiellement pour les besoins de HTTP, c'est le DNS qui a été la première application normalisée de QUIC.
Fonctionnellement, DoQ est très proche de ses prédécesseurs, et offre les mêmes services de sécurité, confidentialité, grâce au chiffrement, et authentification du serveur, via le certificat de celui-ci. L'utilisation du transport QUIC permet quelques améliorations, notamment dans le « vrai » parallélisme. Contrairement à DoT (RFC 7858) et DoH (RFC 8484), DoQ peut être utilisé pour parler à un serveur faisant autorité aussi bien qu'à un résolveur.
Notez que le terme de DoQ (DNS over QUIC) n'apparait pas dans le RFC de terminologie DNS, le RFC 8499. Il sera normalement dans son successeur.
Logiquement, DoQ devrait faire face aux mêmes problèmes politiques que ceux vécus par DoH (voir aussi mon article dans Terminal) mais cela n'a pas été encore le cas. Il faut dire qu'il y a peu de déploiements (ne comptez pas installer DoQ comme serveur ou client tout de suite, le code est loin d'être disponible partout).
Le cahier des charges de DoQ est (sections 1 et 3 du RFC) :
- Protection contre les attaques décrites dans le RFC 9076.
- Même niveau de protection que DoT (RFC 7858, avec notamment les capacités d'authentification variées du RFC 8310). Rappelez-vous que QUIC est toujours chiffré (actuellement avec TLS, cf. RFC 9001).
- Meilleure validation de l'adresse IP source qu'avec le classique DNS sur UDP, grâce à QUIC.
- Pas de limite de taille des réponses, quelle que soit la MTU du chemin.
- Diminution de la latence, toujours grâce à QUIC et notamment ses possibilités de connexion 0-RTT (RFC 9000, section 5), ses procédures de récupération en cas de perte de paquets (RFC 9002) et la réduction du head-of-line blocking, chaque couple requête/réponse étant dans son propre ruisseau.
En revanche, DoQ n'esssaie pas de :
- Contourner le blocage de QUIC que font certaines middleboxes (DoH est meilleur, de ce point de vue). La section 3.3 du RFC détaille cette limitation de DoQ : il peut être filtré trop facilement, son trafic se distinguant nettement d'autres trafics.
- Ou de permettre des messages du serveur non sollicités (pour cela, il faut utiliser le RFC 8490).
DoQ utilise QUIC. QUIC est un protocole de transport généraliste, un concurrent de TCP. Plusieurs protocoles applicatifs peuvent utiliser QUIC et, pour chacun de ces protocoles, cela implique de définir comment sont utilisés les ruisseaux (streams) de QUIC. Pour HTTP/3, cela a été fait dans le RFC 9113, publié plus tard. Ironiquement, le DNS est donc le premier protocole à être normalisé pour une utilisation sur QUIC. Notez qu'une autre façon de faire du DNS sur QUIC est de passer par DoH et HTTP/3 (c'est parfois appelé DoH3, terme trompeur) mais cette façon n'est pas couverte dans notre RFC, qui se concentre sur DoQ, du DNS directement sur QUIC, sans HTTP.
La spécification de DoQ se trouve en section 4. Elle est plutôt
simple, DoQ étant une application assez directe de QUIC. Comme DoQ
utilise QUIC, il y a forcément un ALPN, en l'occurrence via
l'identificateur doq.
Le port, quant à lui, est par défaut 853,
également nommé domain-s. C'est donc le même
que DoT, et aussi le même que le DNS sur DTLS (RFC 8094, protocole expérimental, jamais vraiment mis en œuvre
et encore moins déployé, et qui est de toute façon distinguable du
trafic QUIC, cf. section 17.2 du RFC 9000). Bien sûr, un client et un serveur DNS majeurs et
vaccinés peuvent toujours se mettre d'accord sur un autre port (mais
pas 53, réservé au DNS classique). Cette utilisation d'un port
spécifique à DoQ est un des points qui le rend vulnérable au
filtrage, comme vu plus haut. Utiliser 443 peut aider. (Le point a
été chaudement discuté à l'IETF, entre
défenseurs de la vie privée et gestionnaires de réseau qui voulaient
pouvoir filtrer facilement les protocoles de leur choix. Si on
utilise le port 443, il faut se rappeler que l'ALPN est pour
l'instant en clair (ça a été corrigé dans le RFC 9849), la lutte de l'épée et de la cuirasse va donc continuer.)
Plus important, la question de la correspondance entre les messages DNS et les ruisseaux QUIC. La règle est simple : pour chaque requête DNS, un ruisseau est créé. La première requête sur une connexion donnée sera donc sur le ruisseau 0 (RFC 9000, section 2.1), la deuxième sur le ruisseau 4, etc. Si les connexions QUIC sont potentiellement de longue durée, en revanche, les ruisseaux ne servent qu'une fois. Le démultiplexage des réponses est assuré par QUIC, pas par le DNS (et l'identificateur de requête DNS est donc obligatoirement à zéro, puisqu'inutile). Le parallélisme est également fourni par QUIC, client et serveur n'ont rien de particulier à faire. Il est donc recommandé de ne pas attendre une réponse pour envoyer les autres questions. Les messages DNS sont précédés de deux octets indiquant leur longueur, comme avec TCP.
Comme avec TCP, client et serveur ont le droit de garder un œil sur les ruisseaux et les connexions inactifs, et de les fermer d'autorité. La section 5.5 donne des détails sur cette gestion de connexion, mais le RFC 7766 est également une bonne lecture (voir aussi le RFC 9103 pour le cas des transferts de zones).
DoQ introduit quelques codes
d'erreur à lui (RFC 9000, section
20.2), comme DOQ_INTERNAL_ERROR (quelque chose
s'est mal passé), DOQ_PROTOCOL_ERROR (quelqu'un
n'a pas lu le RFC, par exemple l'identificateur de requête était
différent de zéro) ou DOQ_EXCESSIVE_LOAD (trop
de travail tue le travail).
Un des gros avantages de QUIC est le 0-RTT, où des données sont envoyées dès le premier paquet, ce qui réduit nettement la latence. Cela implique que le client ait déjà contacté le serveur avant, mémorisant les informations qui seront données au serveur pour qu'il retrouve la session à reprendre. C'est cool, mais cela pose d'évidents problèmes de vie privée (ces informations mémorisées sont une sorte de cookie, et permettent le suivi à la trace d'un client). D'ailleurs, en parlant de vie privée, le RFC signale aussi (section 5.5.4) que la possibilité de migrer une connexion QUIC d'une adresse IP à l'autre a également des conséquences pour la traçabilité.
Autre piège avec le 0-RTT, il ne protège pas contre le rejeu et
il ne faut donc l'utiliser que pour des requêtes DNS
idempotentes comme QUERY
(le cas le plus courant) ou NOTIFY (qui change
l'état du serveur, mais est idempotent). Bon, de toute façon, un
serveur peut toujours être configuré pour ne pas accepter de 0-RTT,
et répondre alors REFUSED (avec un code
d'erreur étendu - RFC 8914 - Too
Early).
La section 5 du RFC liste les exigences auxquelles doivent se soumettre les mises en œuvre de DoQ. Le client doit authentifier le serveur (cf. RFC 7858 et RFC 8310, mais aussi RFC 8932, sur les bonnes pratiques). Comme tous les serveurs ne géreront pas DoQ, en tout cas dans un avenir prévisible, les clients doivent être préparés à ce que ça échoue et à réessayer, par exemple en DoT.
QUIC ne dissimule pas forcément la taille des messages échangés, et celle-ci peut être révélatrice. Malgré le chiffrement, la taille d'une requête ou surtout d'une réponse peut donner une idée sur le nom demandé. Le RFC impose donc l'utilisation du remplissage, soit par la méthode QUIC générique de la section 19.1 du RFC 9000, soit par la méthode spécifique au DNS du RFC 7830. La première méthode est en théorie meilleure car elle dissimule d'autres métadonnées, et qu'elle tient compte de davantage d'éléments, mais les bibliothèques QUIC n'exposent pas forcément dans leur API de moyen de contrôler ce remplissage. Le RFC recommande donc aux clients et serveurs DoQ de se préparer à faire le remplissage eux-mêmes (en relisant bien le RFC 8467 avant).
Un petit retour sur la protection de la vie privée en section 7. Cette section rappele l'importance de lire et suivre le RFC 8932 si vous gérez un service de résolution DNS sécurisé (DoQ ou pas DoQ). Et elle insiste sur le fait que des fonctions de QUIC très pratiques pour diminuer la latence à l'établissement de la connexion, notamment le 0-RTT, ont des conséquences pour la vie privée, en permettant de suivre un même utilisateur (plus exactement une même machine). Et cela marche même si la machine a changé d'adresse IP entretemps. On peut aussi dire que le problème de QUIC est de permettre des sessions de très longue durée (que ce soit une vraie session unique, ou bien une « session virtuelle », formée en reprenant une session existante avec le 0-RTT) et que de telles sessions longues, excellentes pour les performances, le sont forcément moins pour l'intimité.
Les mises en œuvre de DoQ, maintenant. La société AdGuard a produit du code, dont un serveur et un client en Go, dnslookup. (Regardez l'exposé du directeur technique de cette société à l'OARC.) Voici un exemple de compilation, puis d'utilisation de dnslookup :
% git clone https://github.com/ameshkov/dnslookup.git % cd dnslookup % make % ./dnslookup www.bortzmeyer.org quic://dns.adguard.com
On utilisait le serveur DoQ public d'AdGuard. Officiellement, NextDNS en a également un mais je n'arrive pas à l'utiliser :
% ./dnslookup www.bortzmeyer.org quic://3e4935.dns.nextdns.io ... 2022/05/22 08:16:33 Cannot make the DNS request: opening quic session to quic://3e4935.dns.nextdns.io:853: timeout: no recent network activity
Notez que si vous voulez utiliser dnslookup avec un serveur dont le
certificat n'est pas valide, il faut mettre la variable
d'environnement VERIFY à 0 (cela ne semble pas documenté).
Il existe une autre mise en œuvre de DoQ, quicdoq, écrite en C. Elle dépend de la bibliothèque QUIC picoquic qui, à son tour, dépend de picotls, dont la compilation n'est pas toujours évidente. D'une manière générale, les bibliothèques QUIC sont souvent récentes, parfois expérimentales, et ne marchent pas toujours du premier coup. Mais si vous arrivez à compiler les dépendances de quicdoq, vous pouvez lancer le serveur ainsi :
% ./quicdoq_app -p 8053 -d 9.9.9.9
Puis le client :
% ./quicdoq_app ::1 8053 foobar:SOA bv:NS www.bortzmeyer.org:AAAA
Le logiciel de test de performances Flamethrower, écrit en C++ a une branche DoQ en cours de développement.
Le logiciel en Python aioquic ne semble pouvoir interagir qu'avec lui-même. Vu les messages d'erreur (quelque chose à propos de not enough bytes), je soupçonne qu'il utilise l'encodage des débuts de DoQ, quand il n'y avait pas encore le champ de deux octets au début des messages. Même avec lui-même, il a des exigences pénibles en matière de certificat (pas de certificats auto-signés, obligation que le nom du serveur soit dans le SAN - Subject Alternative Name, pas seulement dans le sujet).
Pour PowerDNS, il n'y a pour l'instant qu'un ticket. Et pour Unbound, c'est en cours, ainsi que pour Knot.
Dans les bibliothèques DNS, un travail est en cours pour go-dns.
Pour finir, vous pouvez regarder la présentation de DoQ par une des auteures du RFC au RIPE 84. Et un des premiers articles de recherche sur DoQ est « One to Rule them All? A First Look at DNS over QUIC ».
L'article seul
RFC 9239: Updates to ECMAScript Media Types
Date de publication du RFC : Mai 2022
Auteur(s) du RFC : M. Miller, M. Borins (GitHub), M. Bynens (Google), B. Farias
Pour information
Réalisé dans le cadre du groupe de travail IETF dispatch
Première rédaction de cet article le 11 mai 2022
Ce RFC
documente les types de médias pour le langage
de programmation JavaScript (dont le nom
officiel est ECMAScript, qu'on retrouve dans le titre de ce RFC). Il
remplace le RFC 4329 et le principal
changement est que le type recommandé est désormais
text/javascript et non plus
application/javascript.
Si vous voulez vous renseigner en détail sur
JavaScript, notre RFC recommande de lire la norme
ECMA, en https://262.ecma-international.org/12.0/text/javascript. D'autres types existent,
application/ecmascript,
application/javascript, etc, mais ils sont
maintenant considérés comme dépassés.
Il existe plusieurs versions de la norme JavaScript et d'autres
apparaitront peut-être dans le futur. Mais le type officiel
n'indique pas de version (il a existé des propositions comme
text/javascript1.4) et compte que toutes ces
versions sont suffisamment compatibles pour qu'on ne gère pas la
complexité d'avoir plusieurs types. Normalement,
ECMA s'engage à ne pas bouleverser le
langage.
Le choix de text/ est contestable car la
définition originale de text/ dans le RFC 2045 prévoyait plutôt
application/ pour les programmes. Le RFC 4329 enregistrait les types
text/javascript et
application/javascript, et recommandait le
application/javascript (en accord avec ce que
dit le RFC 6838). Aujourd'hui, c'est le
contraire, text/javascript est le
préféré. D'une manière générale, application/
n'a guère été utilisé (pas seulement dans le cas de
JavaScript). (Personnellement, cela me convient très bien : pour
moi, si ça peut s'afficher avec cat et
s'éditer avec vi, c'est du texte.)
JavaScript est donc officiellement du texte, et la section 4 de
notre RFC précise : du texte en UTF-8. Le
paramètre charset est donc facultatif (même si
le RFC 6838 dit le contraire). Si vous aimez
les détails d'encodage, la section 4 vous ravira (c'est l'un des
points qui a suscité le plus de discussion à l'IETF).
Le type text/javascript est enregistré
à l'IANA ; les types comme
application/javascript sont marqués
comme dépassés. Même chose pour
text/ecmascript. Le nom officiel de JavaScript
est ECMAscript, puisque normalisé à l'ECMA
mais personne n'utilise ce terme. (Il faut quand même noter que
JavaScript est un terme publicitaire mensonger puisqu'il avait été
choisi par le marketing pour profiter de la popularité - à
l'époque - de Java, un
langage avec lequel il n'a rien à voir.) Enfin, les types comme
text/x-javascript qu'on voit parfois trainer
datent d'avant le RFC 6648, qui abandonnait
les identificateurs semi-privés commençant par
x-.
La section 5 couvre les questions de sécurité. Elle est très longue car l'envoi de JavaScript à un programme qui l'exécutera (ce qui est très courant sur le Web) pose plein de problèmes de sécurité. Le RFC rappelle que l'exécution automatique d'un programme fourni par un tiers est évidemment intrinsèquement dangereuse, et doit se faire dans un bac à sable. Parmi les dangers (mais il y en a beaucoup d'autres !) le déni de service puisque JavaScript est un langage de Turing et permet donc, par exemple, des boucles infinies.
L'annexe B du RFC résume les changements depuis le RFC 4329 : le principal est bien sûr l'abandon de
application/javascript au profit de
text/javascript. Il y a aussi l'ajout de
quelques détails comme une faille de sécurité nouvelle, et le cas
des modules JavaScript.
Ah, un point de détail cité au détour d'un paragraphe du RFC : il
n'y a pas de norme pour les identificateurs de fragments dans un
URI
pointant vers une ressource de type
text/javascript. Si
https://code.example/js/foreach.js#l23 pointe
vers du JavaScript, la signification du #l23
(l'identificateur de fragment) n'est pas spécifiée.
L'article seul
RFC 9234: Route Leak Prevention and Detection Using Roles in UPDATE and OPEN Messages
Date de publication du RFC : Mai 2022
Auteur(s) du RFC : A. Azimov (Qrator Labs & Yandex), E. Bogomazov (Qrator Labs), R. Bush (IIJ & Arrcus), K. Patel (Arrcus), K. Sriram (USA NIST)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF idr
Première rédaction de cet article le 25 mai 2022
Vous savez sans doute que l'Internet repose sur le protocole de routage BGP et que ce protocole a été cité dans des accidents (voire des attaques) spectaculaires, par exemple lorsqu'un routeur BGP annonçait ou réannonçait des routes qu'il n'aurait pas dû annoncer (ce qu'on nomme une fuite de routes). Si BGP lui-même est pair-à-pair, en revanche, les relations entre les pairs ne sont pas forcément symétriques et des règles sont largement admises ; par exemple, on n'est pas censé annoncer à un transitaire des routes apprises d'un autre transitaire. Ce RFC étend BGP pour indiquer à l'ouverture de la session le type de relations qu'on a avec son pair BGP, ce qui permet de détecter plus facilement certaines fuites de routes.
La solution proposée s'appuie sur un modèle des relations entre opérateurs, le modèle « sans vallée » (valley-free, même si ce terme n'est pas utilisé dans le RFC). On le nomme aussi modèle Gao-Rexford. Ce modèle structure ces relations de telle façon à ce que le trafic aille forcément vers un opérateur aussi ou plus important (la « montagne »), avant de « redescendre » vers la destination ; le trafic ne descend pas dans une « vallée », sauf si elle est la destination finale. Le but est de permettre un routage optimum et d'éviter boucles et goulets d'étranglement, mais ce modèle a aussi une conséquence politico-économique, maintenir la domination des gros acteurs (typiquement les Tier-1). Les relations entre participants à une session BGP sont de type Client-Fournisseur ou Pair-Pair, et le trafic va toujours dans le sens du client vers le fournisseur, sauf pour les destinations finales (on n'utilise donc pas un pair pour du transit, c'est-à-dire pour joindre d'autres réseaux que ceux du pair).
En raison de ce modèle, un routeur BGP n'est pas censé annoncer à un transitaire des routes apprises d'un autre transitaire, ou annoncer à un pair des routes apprises d'un transitaire, ou bien apprises d'un autre pair (RFC 7908). Une fuite de routes est une annonce qui viole cette politique (qu'elle soit explicite ou implicite).
Traditionnellement, on empêche ces fuites par des règles dans la configuration du routeur. Par exemple, le client d'un transitaire va bloquer l'exportation par défaut, puis lister explicitement les routes qu'il veut annoncer. Et le transitaire va bloquer l'importation par défaut, et lister ensuite les routes qu'il acceptera de son client. Ce nouveau RFC ajoute un autre mécanisme, où la relation entre les deux partenaires BGP est explicitement marquée comme Client-Fournisseur ou Pair-Pair, facilitant la détection des fuites. Un concept qui était auparavant purement business, le type de relation entre acteurs BGP, passe ainsi dans le protocole.
Le RFC utilise donc ces termes, pour désigner la place d'un acteur BGP dans le processus de routage :
- Fournisseur (Provider) : peut envoyer n'importe quelle route (un transitaire est un Fournisseur).
- Client (Customer) : ne peut envoyer que ses propres routes, ou bien celles apprises d'un de ses clients (l'opérateur qui est Client pour une relation BGP peut être Fournisseur pour une autre).
- Serveur de routes (Route Server) : peut envoyer toutes les routes qu'il connait à ses clients.
- Client d'un serveur de routes (Route Server Client) : ne peut envoyer au serveur de routes que ses propres routes, ou bien celles apprises d'un de ses clients.
- Pair (Peer) : ne peut envoyer à un de ses pairs que ses propres routes, ou bien celles apprises d'un de ses clients.
Une violation de ces règles est une fuite de routes (RFC 7908). Le RFC précise qu'il s'agit de relations « techniques », qu'elles n'impliquent pas forcément une relation business mais, en pratique, l'échange entre pairs est souvent gratuit et la relation Client-Fournisseur payante. Le RFC précise aussi qu'il peut exister des cas plus complexes, comme une relation Client-Fournisseur pour certains préfixes IP et Pair-Pair pour d'autres.
Bon, assez de politique et de business, place à la technique et au protocole. Le RFC définit une nouvelle capacité (RFC 5492) BGP, Role, code 9 et dont la valeur, stockée sur un octet, indique un des rôles listés ci-dessus (0 pour Fournisseur, 3 pour Client, 4 pour Pair, etc). D'autres rôles pourront être ajoutés dans le futur (politique « Examen par l'IETF », cf. RFC 8126). Ce rôle indique la place de l'AS et est configuré avec la session BGP (rappelez-vous qu'un AS peut être Client d'un côté et Fournisseur de l'autre). À l'ouverture de la connexion, les routeurs vérifient la compatibilité des rôles (si tous les deux annoncent qu'ils sont Fournisseur, c'est un problème, d'où un nouveau code d'erreur BGP, Role mismatch).
Une fois que les deux routeurs sont d'accord sur les rôles respectifs de leurs AS, les routes annoncées peuvent être marquées avec un nouvel attribut, OTC (Only To Customer, code 35), dont la valeur est un numéro d'AS. Une route ainsi marquée ne sera acceptée que si elle vient d'un Fournisseur, ou d'un pair dont le numéro d'AS coïncide. Autrement, elle sera considérée comme résultant d'une fuite.
Ah, et pour les cas compliqués dont on a parlé plus haut, comme les rôles différents pour chaque préfixe ? Dans ce cas-là, le mécanisme des rôles de ce RFC n'est pas adapté et ne doit pas être utilisé.
Ce système des rôles est apparemment mis en œuvre dans des patches (non encore intégrés ?) pour FRRouting et BIRD. Par exemple, pour FRRouting, on configurerait :
neighbor 2001:db8:999::1 local-role customer
Pour BIRD, cela serait :
configuration
...
protocol bgp {
...
local_role customer;
}
Et la gestion des rôles devrait être bientôt
dans BGPkit. Et une version antérieure à la sortie du RFC
tourne sur les routeurs MikroTik (voir leur
documentation, local.role ebgp-customer…).
Par contre, je ne sais pas pour Cisco ou
Juniper. Si quelqu'un a des informations…
L'article seul
RFC 9233: IDNA2008 and Unicode 12.0.0
Date de publication du RFC : Mars 2022
Auteur(s) du RFC : P. Faltstrom (Netnod)
Chemin des normes
Première rédaction de cet article le 24 avril 2022
La norme pour les noms de domaine en Unicode, dite « IDNA 2008 », prévoit une révision à chaque nouvelle version d'Unicode pour éventuellement s'adapter à des changements dus à ces nouvelles versions. Ce processus de révision a pas mal cafouillé (euphémisme), et ce RFC doit donc traiter d'un coup les versions 6 à 12 d'Unicode.
Le fond du problème est que l'ancienne norme sur les IDN (RFC 3490) était strictement liée à une version donnée d'Unicode et qu'il fallait donc une nouvelle norme pour chacune des versions annuelles d'Unicode. Vu le processus de publication d'une norme à l'IETF, ce n'était pas réaliste. La seconde norme IDN, « IDN 2 » ou « IDN 2008 » (bien qu'elle soit sortie en 2010) remplaçait les anciennes tables fixes de caractères autorisés ou interdits par un algorithme, à faire tourner à chaque sortie d'une version d'Unicode pour produire les tables listant les caractères qu'on peut accepter dans un nom de domaine internationalisé (le mécanisme exact, utilisant les propriétés des caractères listées dans la norme Unicode, figure dans le RFC 5892). En théorie, c'était très bien. En pratique, malgré les règles de stabilité d'Unicode, il se produisait parfois des problèmes. Comme le documente le RFC 8753, un caractère peut ainsi passer d'interdit à autorisé, ce qui n'est pas grave mais aussi dans certains cas d'autorisé à interdit ce qui est bien plus embêtant : que faire des noms déjà réservés qui utilisent ce caractère ? En général, il faut ajouter une exception manuelle, ce qui justifie un mécanisme de révision de la norme IDN, mis en place par ce RFC 8753. Ce nouveau RFC 9233 est le premier RFC de révision. Heureusement, cette fois, aucune exception manuelle n'a été nécessaire.
La précédente crise était due à Unicode version 6 qui avait créé trois incompatibilités (RFC 6452). Une seule était vraiment gênante, le caractère ᧚, qui, autorisé auparavant, était devenu interdit suite au changement de ses propriétés dans la norme Unicode. Le RFC 6452 avait documenté la décision de ne rien faire pour ce cas, ce caractère n'ayant apparemment jamais été utilisé. Unicode 7 a ajouté un autre problème, le ࢡ, qui était un cas différent (la possibilité de l'écrire de plusieurs façons), et la décision a été prise de faire désormais un examen formel de chaque nouvelle version d'Unicode. Mais cet examen a été souvent retardé et voilà pourquoi, alors qu'Unicode 13 est sorti (ainsi qu'Unicode 14 depuis), ce nouveau RFC ne traite que jusqu'à la version 12.
Passons maintenant à l'examen des changements apportés par les versions 7 à 12 d'Unicode, fait en section 3 du RFC :
- À part le cas du ࢡ cité plus haut, Unicode 7 n'a pas apporté de changements gênants pour IDN (par exemple, U+17B4 (caractère non visible) a changé de propriétés mais il était interdit pour IDN et le reste),
- Unicode 8, Unicode 9 et Unicode 10 n'ont appporté aucun changement gênant,
- Unicode 11 a changé les propriétés de certains caractères existants mais le résultat pour IDN ne change pas (par exemple, 𑨇, qui était autorisé, le reste),
- Et Unicode 12 ? Rien de problématique.
En Unicode 11, 𑇉 qui passe d'interdit à autorisé, était un cas peu gênant. Le RFC prend donc la décision de ne pas ajouter d'exception pour ce caractère peu commun.
Voilà, arrivé ici, vous pensez peut-être que cela fait beaucoup de bruit pour rien puisque finalement les différentes versions d'Unicode n'ont pas créé de problème. Mais c'est justement pour s'assurer de cela que cet examen était nécessaire.
Pour compliquer davantage les choses, on notera qu'il existe encore sans doute (section 2.3 du RFC) des déploiements d'IDN qui en sont restés à la première version (celle du RFC 3490) voire qui sont un mélange des deux versions d'IDN, en ce qui concerne l'acceptation ou le refus des caractères.
En avril 2022, le travail pour Unicode 13 ou Unicode 14 n'a apparemment pas encore commencé…
L'article seul
RFC 9231: Additional XML Security Uniform Resource Identifiers (URIs)
Date de publication du RFC : Juillet 2022
Auteur(s) du RFC : D. Eastlake 3rd (Futurewei Technologies)
Chemin des normes
Première rédaction de cet article le 14 janvier 2025
Il existe tout un ensemble de normes pour assurer la sécurité de documents XML, par exemple les protéger contre la lecture non autorisée, ou bien permettre leur authentification. Ces normes dépendent d'algorithmes cryptographiques identifiés par un URI. Ce RFC met à jour la liste précédente de ces URI (qui était dans le RFC 6931) avec les nouveaux algorithmes et corrige quelques erreurs du précédent RFC.
Ces normes de sécurité de XML étaient à l'origine un travail conjoint de l'IETF et du W3C. C'était par exemple le cas des signatures XML du RFC 3275, du XML canonique des RFC 3076 ou RFC 3741. Elles sont désormais maintenues par le W3C qui a produit des versions plus récentes (par exemple pour les signatures XML, le XML canonique ou le chiffrement XML).
Dans un monde dynamique comme celui de la
cryptographie, où les progrès de la
cryptanalyse nécessitent des changements
d'algorithmes, les normes ne sont pas liées à un algorithme
particulier. Elles permettent l'agilité cryptographique (le
changement d'algorithme) et il faut donc pouvoir indiquer quel
algorithme est utilisé pour signer ou chiffrer un document
donné. Pour une norme W3C, on ne s'étonnera pas que l'indication
se fait par le biais d'un URI (RFC 3986). Les
nouveaux algorithmes commencent désormais par le préfixe
http://www.w3.org/2021/04/xmldsig-more# (les
anciens algorithmes pouvant avoir d'autres préfixes). Ces nouveaux
algorithmes (avec 2021/04 dans leur
identificateur) sont relativement rares dans ce RFC : on n'invente
quand même pas un bon algorithme de cryptographie tous les jours et
la plupart des exemples dans cet article utilisent donc le vieux
préfixe. Un exemple récent ? EdDSA (RFC 8032) a l'URI
http://www.w3.org/2021/04/xmldsig-more#eddsa-ed25519. Rappelez-vous
qu'il s'agit d'URI, pas forcément d'URL et que vous
n'obtiendrez donc pas forcément un résultat en pointant votre
navigateur Web vers
http://www.w3.org/2001/04/xmlenc#sha256
(cf. section 5.1).
Notons que notre RFC 9231 ne prend pas position sur la qualité cryptographique des algorithmes : il fournit un moyen de les désigner sans ambiguïté, c'est tout. Si on veut étudier cette qualité cryptographique, il faut lire d'autres documents (comme le RFC 6194 pour SHA-1).
Un exemple d'un ancien algorithme est
SHA-1 pour calculer les condensats
cryptographiques. Son URI est
http://www.w3.org/2000/09/xmldsig#sha1. Sa
sécurité est aujourd'hui sérieusement battue en brèche (cf. RFC 6194). Autre exemple d'un algorithme qui était
déjà dans le RFC 6931, SHA-512,
identifié par http://www.w3.org/2001/04/xmlenc#sha512
.
Il existe aussi des identificateurs pour les MAC combinés
avec une condensation, par exemple
http://www.w3.org/2001/04/xmldsig-more#hmac-sha512
(RFC 6234).
Et pour les signatures avec un système à clé publique ?
L'identificateur indique l'algorithme de cryptographie asymétrique
et celui de condensation, par exemple
http://www.w3.org/2001/04/xmldsig-more#rsa-sha256
(voir aussi le RFC 3447). Si on trouve RSA ennuyeux, il existe
aussi des identificateurs pour un algorithme à courbes
elliptiques (RFC 6090 mais notez
ses
errata), ECDSA, par exemple
http://www.w3.org/2001/04/xmldsig-more#ecdsa-sha512.
Enfin, il y a les algorithmes de chiffrement symétrique. Par exemple,
Camellia (RFC 3713) sera identifié par
http://www.w3.org/2001/04/xmldsig-more#camellia256-cbc. Le
plus récent SEED (RFC 4269) sera
http://www.w3.org/2007/05/xmldsig-more#seed128-cbc.
Un exemple d'utilisation donné par notre RFC, pour de la cryptographie symétrique :
<EncryptionMethod
Algorithm="http://www.w3.org/2021/04/xmldsig-more#chacha20">
<Nonce>0123456789abcdef01234567</Nonce>
<Counter>fedcba09</Counter>
</EncryptionMethod>
Voici pour la cryptographie. Mais les normes de sécurité XML
prévoient aussi une étape de canonicalisation avant chiffrement ou
signature, et là aussi, il y a plusieurs algorithmes, identifiés par
des URI comme
http://www.w3.org/2000/09/xmldsig#minimal ou
http://www.w3.org/2006/12/xmlc14n11#WithComments.
Quelle est la politique d'allocation dans le registre ? La
section 5 décrit celle du W3C (le préfixe
http://www.w3.org/2007/05/xmldsig-more# est
figé, a priori, on n'y mettra pas de nouveaux algorithmes) et celle
de l'IETF : comme il est facile d'obtenir un URI (n'importe qui peut
en créer un), la seule question est celle de leur enregistrement. Il
se fera après un examen par un expert (voir le RFC 8126 pour les politiques d'allocation IETF) après
publication d'un texte décrivant le nouvel algorithme.
Quels changements depuis la version précédente de ce RFC, le RFC 6931 ? L'annexe A les liste. Les principaux, à mon avis, sont :
L'article seul
RFC 9230: Oblivious DNS over HTTPS
Date de publication du RFC : Juin 2022
Auteur(s) du RFC : E. Kinnear (Apple), P. McManus (Fastly), T. Pauly (Apple), T. Verma, C.A. Wood (Cloudflare)
Expérimental
Première rédaction de cet article le 9 juin 2022
Des protocoles de DNS sécurisés comme DoH protègent la liaison entre un client et un résolveur DNS. Mais le résolveur, lui, voit tout, aussi bien le nom de domaine demandé que l'adresse IP du client. Ce nouveau RFC décrit un mécanisme expérimental de relais entre le client et le serveur DoH, permettant de cacher l'adresse IP du client au serveur, et la requête au relais. Une sorte de Tor minimum.
Normalement, DoH (normalisé dans le RFC 8484) résout le problème de la surveillance des requêtes DNS. Sauf qu'évidemment le serveur DoH lui-même, le résolveur, voit le nom demandé, et la réponse faite. (Les utilisateurices de l'Internet oublient souvent que la cryptographie, par exemple avec TLS, protège certes contre le tiers qui écoute le réseau mais pas du tout contre le serveur avec qui on parle.) C'est certes nécessaire à son fonctionnement mais, comme il voit également l'adresse IP du client, il peut apprendre pas mal de choses sur le client. Une solution possible est d'utiliser DoH (ou DoT) sur Tor (exemple plus loin). Mais Tor est souvent lent, complexe et pas toujours disponible (cf. annexe A du RFC). D'où les recherches d'une solution plus légère, Oblivious DoH, décrit dans ce nouveau RFC. L'idée de base est de séparer le routage des messages (qui nécessite qu'on connaisse l'adresse IP du client) et la résolution DNS (qui nécessite qu'on connaisse la requête). Si ces deux fonctions sont assurées par deux machines indépendantes, on aura amélioré la protection de la vie privée.
Les deux machines vont donc être :
- L'Oblivious Proxy, le relais qui connait l'adresse IP du client mais ne voit passer qu'une requête DNS chiffrée ; ce n'est pas un relais HTTP complet, il est spécialisé dans DoH.
- Et l'Oblivious Target, le serveur DoH (le résolveur, donc) ; il a une clé publique avec laquelle le client chiffrera les requêtes à envoyer.
Un schéma simplifié :
Il est important de répéter que, si le relais et le serveur sont complices, Oblivious DoH perd tout intérêt. Ils doivent donc être gérés par des organisations différentes.
La découverte du relais, et de la clé publique du serveur, n'est pas traité dans ce RFC. Au moins au début, elle se fera « manuellement ».
Le gros morceau du RFC est sa section 4. Elle explique les
détails du protocole. Le client qui a une requête DNS à faire doit
la chiffrer avec la clé publique du serveur. Ce client a été
configuré avec un gabarit d'URI (RFC 6570) et avec
l'URL du
serveur DoH, serveur qui doit connaitre le mécanisme
Oblivious DoH. Le gabarit doit contenir deux
variables, targethost (qui sera incarné avec le
nom du serveur DoH) et targetpath (qui sera
incarné avec le chemin dans l'URL du serveur DoH). Par exemple, un
gabarit peut être
https://dnsproxy.example/{targethost}/{targetpath}. Le
client va ensuite faire une requête (méthode HTTP
POST) vers le relais. La requête aura le
type application/oblivious-dns-message
(la réponse également, donc le client a intérêt à indiquer
Accept: application/oblivious-dns-message).
En supposant un serveur DoH d'URL
https://dnstarget.example/dns, la requête sera
donc (en utilisant la syntaxe de description de HTTP/2 et 3) :
:method = POST :scheme = https :authority = dnsproxy.example :path = /dnstarget.example/dns accept = application/oblivious-dns-message content-type = application/oblivious-dns-message content-length = 106 [La requête, chiffrée]
Le relais enverra alors au serveur :
:method = POST :scheme = https :authority = dnstarget.example :path = /dns accept = application/oblivious-dns-message content-type = application/oblivious-dns-message content-length = 106 [La requête, chiffrée]
Le relais ne doit pas ajouter quelque chose qui permettrait
d'identifier le client, ce qui annulerait tout l'intérêt
d'Oblivious DoH. Ainsi, le champ
forwarded (RFC 7239) est
interdit. Et bien sûr, on n'envoie pas de
cookies, non plus.
La réponse utilise le même type de médias :
:status = 200 content-type = application/oblivious-dns-message content-length = 154 [La réponse, chiffrée]
Le relais, en la transmettant, ajoutera un champ
proxy-status (RFC 9209).
Les messages de type
application/oblivious-dns-message sont encodés
ainsi (en utilisant le langage de description de TLS, cf. RFC 9846, section 3) :
struct {
opaque dns_message<1..2^16-1>;
opaque padding<0..2^16-1>;
} ObliviousDoHMessagePlaintext;
Bref, un message DNS binaire, et du remplissage. Le remplissage est nécessaire car TLS, par défaut, n'empêche pas l'analyse de trafic. (Lisez le RFC 8467.) Le tout est ensuite chiffré puis mis dans :
struct {
uint8 message_type;
opaque key_id<0..2^16-1>;
opaque encrypted_message<1..2^16-1>;
} ObliviousDoHMessage;
Le key_id servant à identifier ensuite le
matériel cryptographique utilisé.
J'ai parlé à plusieurs reprises de chiffrement. Le client doit connaitre la clé publique du serveur DoH pour pouvoir chiffrer. (Le RFC ne prévoit pas de mécanisme pour cela.) Comme avec la plupart des systèmes de chiffrement, le chiffrement sera en fait réalisé avec un algorithme symétrique. La transmission ou la génération de la clé de cet algorithme utlisera le mécanisme HPKE (Hybrid Public Key Encryption, spécifié dans le RFC 9180).
Outre l'analyse de trafic, citée plus haut, une potentielle faille d'Oblivious DoH serait le cas d'un serveur indiscret qui essaierait de déduire des informations de l'établissement des connexions DoH vers lui. Le RFC recommande que les relais établissent des connexions de longue durée et les réutilisent pour plusieurs clients, rendant cette éventuelle analyse plus complexe.
Notez aussi que le relais est évidemment libre de sa politique. Les relais peuvent par exemple ne relayer que vers certains serveurs DoH connus.
Le serveur DoH ne connait pas l'adresse IP du client (c'est le but) et ne peut donc pas transmettre aux serveurs faisant autorité les informations qui peuvent leur permettre d'envoyer une réponse adaptée au client final. Si c'est un problème, le client final peut toujours utiliser ECS (EDNS Client Subnet, RFC 7871), en indiquant un préfixe IP assez générique pour ne pas trop en révéler. Mais cela fait évidemment perdre une partie de l'intérêt d'Oblivious DoH.
Bon, et questions mises en œuvre de ce RFC ? Il y en a une dans DNScrypt (et ils publient une liste de serveurs et de relais).
Oblivious DoH est en travaux depuis un certain temps (voyez par exemple cet article de Cloudflare). Notez que la technique de ce RFC est spécifique à DoH. Il y a aussi des travaux en cours à l'IETF pour un mécanisme plus général, comme par exemple un Oblivious HTTP, qui serait un concurrent « low cost » de Tor.
À propos de Tor, j'avais dit plus haut qu'on pouvait évidemment, si on ne veut pas révéler son adresse IP au résolveur DoH, faire du DoH sur Tor. Voici un exemple de requête DoH faite avec le client kdig et le programme torsocks pour faire passer les requêtes TCP par Tor :
% torsocks kdig +https=/ @doh.bortzmeyer.fr ukraine.ua ;; TLS session (TLS1.3)-(ECDHE-SECP256R1)-(RSA-PSS-RSAE-SHA256)-(AES-256-GCM) ;; HTTP session (HTTP/2-POST)-(doh.bortzmeyer.fr/)-(status: 200) ... ;; ANSWER SECTION: ukraine.ua. 260 IN A 104.18.7.16 ukraine.ua. 260 IN A 104.18.6.16 ... ;; Received 468 B ;; Time 2022-06-02 18:45:15 UTC ;; From 193.70.85.11@443(TCP) in 313.9 ms
Et ce résolveur DoH ayant un service
.onion, on peut même :
% torsocks kdig +https=/ @lani4a4fr33kqqjeiy3qubhfx2jewfd3aeaepuwzxrx6zywp2mo4cjad.onion ukraine.ua ;; TLS session (TLS1.3)-(ECDHE-SECP256R1)-(RSA-PSS-RSAE-SHA256)-(AES-256-GCM) ;; HTTP session (HTTP/2-POST)-(lani4a4fr33kqqjeiy3qubhfx2jewfd3aeaepuwzxrx6zywp2mo4cjad.onion/)-(status: 200) ... ;; ANSWER SECTION: ukraine.ua. 212 IN A 104.18.6.16 ukraine.ua. 212 IN A 104.18.7.16 ... ;; Received 468 B ;; Time 2022-06-02 18:46:00 UTC ;; From 127.42.42.0@443(TCP) in 1253.8 ms
Pour comparer les performances (on a dit que la latence de Tor était franchement élevée), voici une requête non-Tor vers le même résolveur :
% kdig +https=/ @doh.bortzmeyer.fr ukraine.ua ;; TLS session (TLS1.3)-(ECDHE-SECP256R1)-(RSA-PSS-RSAE-SHA256)-(AES-256-GCM) ;; HTTP session (HTTP/2-POST)-([2001:41d0:302:2200::180]/)-(status: 200) ... ;; ANSWER SECTION: ukraine.ua. 300 IN A 104.18.6.16 ukraine.ua. 300 IN A 104.18.7.16 ... ;; Received 468 B ;; Time 2022-06-02 18:49:44 UTC ;; From 2001:41d0:302:2200::180@443(TCP) in 26.0 ms
L'article seul
RFC 9229: IPv4 Routes with an IPv6 Next Hop in the Babel Routing Protocol
Date de publication du RFC : Mai 2022
Auteur(s) du RFC : J. Chroboczek (IRIF, University of Paris)
Expérimental
Réalisé dans le cadre du groupe de travail IETF babel
Première rédaction de cet article le 11 mai 2022
Voici une extension sympathique qui réjouira tous les amateurs de routage IP. Elle permet à un routeur qui parle le protocole de routage Babel d'annoncer un préfixe IPv4 où le routeur suivant pour ce préfixe n'a pas d'adresse IPv4 sur cette interface.
Un petit rappel de routage : les annonces
d'un routeur qui parle un protocole de
routage dynamique comme Babel (RFC 8966) comprennent un préfixe IP (comme
2001:db8:543::/48) et l'adresse IP du routeur suivant
(next hop dans la langue de Radia
Perlman). Traditionnellement, le préfixe et l'adresse du
routeur suivant étaient de la même version (famille) : tous les deux
en IPv4 ou tous les deux en
IPv6. Mais, si on veut router IPv6
et IPv4, cela consomme une adresse IP par
interface sur chaque routeur, or les adresses IPv4 sont désormais
une denrée très rare. D'où la proposition de ce RFC : permettre des annonces
d'un préfixe IPv4 avec une adresse de routeur suivant en
IPv6. (Notez que cela ne concerne pas que Babel, cela pourrait être
utilisé pour d'autres protocoles de routage dynamique.)
La section 1 du RFC résume ce que fait un protocole de routage. Son but est de construire des tables de routage, où chaque entrée de la table est indexée par un préfixe d'adresses IP et a une valeur, l'adresse du routeur suivant. Par exemple :
destination next hop 2001:db8:0:1::/64 fe80::1234:5678%eth0 203.0.113.0/24 192.0.2.1
Lorsqu'un routeur doit transmettre un paquet, il regarde dans cette table et trouve l'adresse du routeur suivant. Il va alors utiliser un protocole de résolution d'adresses (ARP - RFC 826 - pour IPv4, ND - RFC 4861 - pour IPv6) pour trouver l'adresse MAC du routeur suivant. Rien dans cette procédure n'impose que le préfixe de destination et l'adresse du routeur suivant soient de la même version d'IP. Un routeur qui veut transmettre un paquet IPv4 vers un routeur dont il ne connait que l'adresse IPv6 procède à la résolution en adresse MAC, puis met simplement le paquet IPv4 dans une trame portant l'adresse MAC en question (l'adresse IPv6 du routeur suivant n'apparait pas dans le paquet).
En permettant des annonces de préfixes IPv4 avec un routeur suivant en IPv6, on économise des adresses IPv4. Un réseau peut fournir de la connectivité IPv4 sans avoir d'adresses IPv4, à part au bord. Et comme les adresses IPv6 des routeurs sont des adresses locales au lien allouées automatiquement (cf. RFC 7404), on peut avoir un réseau dont le cœur n'a aucune adresse statique, ce qui peut faciliter sa gestion.
Notre RFC documente donc une extension au protocole Babel (qui
est normalisé dans le RFC 8966), nommée
v4-via-v6. (Comme dit plus haut, le principe
n'est pas spécifique à Babel, voir le RFC 5549 pour son équivalent pour BGP.)
Bon, le concret, maintenant. Les préfixes annoncés en Babel sont précédés de l'AE (Address Encoding), un entier qui indique la version (famille) du préfixe. Ce RFC crée un nouvel AE, portant le numéro 4, qui a le même format que l'AE 1 qui servait à IPv4. Une annonce d'un préfixe ayant l'AE 4 devra donc contenir un préfixe IPv4 et un routeur suivant en IPv6. Un routeur qui sait router IPv4 mais n'a pas d'adresse IPv4 sur une de ses interfaces peut donc quand même y annoncer les préfixes connus, en les marquant avec l'AE 4 et en mettant comme adresse l'adresse IPv6 pour cette interface. (Cet AE est uniquement pour les préfixes, pas pour l'indication du routeur suivant.)
Les routeurs qui ne gèrent pas l'extension
v4-via-v6 ignoreront cette annonce, comme ils
doivent ignorer toutes les annonces portant un AE inconnu (RFC 8966). Pour
cette raison, si un routeur a une adresse IPv4 sur une interface, il
faut qu'il utilise des annonces traditionnelles, avec l'AE 1, pour
maximiser les chances que son annonce soit acceptée.
Arrivé ici, mes lectrices et mes lecteurs, qui sont très malins, se demandent depuis longtemps « mais un routeur doit parfois émettre des erreurs ICMP (RFC 792), par exemple s'il n'a pas d'entrée dans sa table pour cette destination ». Comment peut-il faire s'il n'a pas d'adresse sur l'interface où il a reçu le paquet coupable ? Ne rien émettre n'est pas acceptable, certains protocoles en dépendent. C'est par exemple le cas de la découverte de la MTU du chemin, documentée dans le RFC 1191, qui a besoin des messages ICMP Packet too big. Certes, il existe un algorithme de découverte de cette MTU du chemin qui est entièrement de bout en bout, et ne dépend donc pas des routeurs et de leurs messages (RFC 4821). Mais ICMP sert à d'autres choses, on ne peut pas y renoncer.
Si le routeur Babel a une adresse IPv4 quelque part, sur une de
ses interfaces, il peut l'utiliser comme adresse IP source pour ses
messages ICMP. S'il n'en a pas, il peut toujours utiliser
192.0.0.8 comme suggéré par la section 4.8 du
RFC 7600. Bien sûr, si tout le monde le fait, des outils
d'administration du réseau très pratiques comme
traceroute seront moins utiles.
La nouvelle extension peut soulever des questions de sécurité (section 6 du RFC). Par exemple, si l'administrateur réseaux croyait que, parce que les routeurs n'avaient pas d'adresse IPv4 sur une interface, les paquets IPv4 ne seraient pas traités sur cette interface, cette supposition n'est plus vraie. Ainsi, une île de machines IPv4 qui se croyaient séparées de l'Internet IPv4 par un ensemble de routeurs qui n'avaient pas d'adresse IPv4 de leur côté peut se retrouver subitement connectée. Si ce n'est pas ce qu'on veut, il faut penser à ne pas se contenter du protocole de routage pour filtrer, mais aussi à filtrer explicitement IPv4.
Question mise en œuvre, cette extension figure dans babeld (voir ici un compte-rendu d'expérience) à partir de la version 1.12, ainsi que dans BIRD.
L'article seul
RFC 9228: Delivered-To Email Header Field
Date de publication du RFC : Avril 2022
Auteur(s) du RFC : D. Crocker (Brandenburg InternetWorking)
Expérimental
Première rédaction de cet article le 14 avril 2022
Le courrier électronique est souvent plus
compliqué et plus varié que ne le croient certains utilisateurs. Par
exemple, rien ne garantit que l'adresse à laquelle un message est
livré soit listée dans les champs de l'en-tête (RFC 5322) comme To: ou
Cc:. Cette adresse de destination est en effet
séparément gérée, dans le protocole SMTP (RFC 5321)
et ses comandes RCPT TO. Et puis un message
peut être relayé, il peut y avoir plusieurs livraisons
successives. Bref, quand on a un message dans sa boite aux lettres,
on ne sait pas forcément quelle adresse avait servi. D'où ce
RFC expérimental
qui propose d'élargir le rôle du champ
Delivered-To: pour en faire un bon outil
d'information.
Ce champ existe déjà et on le voit parfois apparaitre dans les en-têtes, par exemple dans un message que je viens de recevoir :
Delivered-To: monpseudo@sources.org
Mais il n'est pas vraiment normalisé, son contenu exact peut varier et, en pratique, lorsqu'il y a eu plusieurs délivrances successives suivies de transmissions à une autre adresse, il ne reste parfois qu'une occurrence de ce champ, la plus récente. Difficile donc de compter dessus.
Mais c'est quoi, la livraison d'un message ? Comme définie par le RFC 5598, dans sa section 4.3.3, c'est un transfert de responsabilité d'un MTA vers un MDA comme procmail. Il peut y avoir plusieurs délivrances successives par exemple si le MDA, au lieu de simplement écrire dans la boite aux lettres de l'utilisateur, fait suivre le message à une autre adresse. Un exemple typique est celui d'une liste de diffusion, où le message va être délivré à la liste puis, après transmission par le logiciel de gestion de listes, à chaque utilisateur (dont les MDA renverront peut-être le message, créant de nouvelles livraisons).
Pourquoi est-il utile d'avoir de l'information sur ces livraisons successives ? Outre la curiosité, une motivation importante est le débogage. S'il y a des problèmes de livraison, la traçabilité est essentielle à l'analyse. Une autre motivation est la détection automatique de boucles, un problème souvent compliqué.
On l'a dit, Delivered-To: existe déjà, même
s'il n'était normalisé dans aucun RFC, bien qu'il soit cité dans des exemples,
comme dans le RFC 5193. Ce RFC 9228 enregistre le champ (selon la
procédure du RFC 3864), et prévoit d'étendre son
application. (Une tentative de normalisation est en cours dans
draft-duklev-deliveredto.) Du fait de cette
absence de normalisation, il existe de nombreuses variations dans
l'utilisation de Delivered-To:. Par exemple, si
la plupart des logiciels mettent comme valeur une adresse de
courrier et rien d'autre, certains ajoutent des commentaires. Notons
que le champ Received: est souvent utilisé de
la même façon, via sa clause for. On peut ainsi
trouver (regardez le for) :
Received: from bendel.debian.org (bendel.debian.org [82.195.75.100])
(using TLSv1.3 with cipher TLS_AES_256_GCM_SHA384 (256/256 bits)
key-exchange X25519 server-signature RSA-PSS (2048 bits) server-digest SHA256)
(No client certificate requested)
by ayla.bortzmeyer.org (Postfix) with ESMTPS id 6D245A00D9
for <monpseudo@sources.org>; Wed, 16 Feb 2022 13:22:03 +0100 (CET)
Là encore, il n'y a pas de normalisation et il semble qu'on ne
puisse pas compter sur cette clause for. Par
exemple, elle n'indique pas forcément une livraison mais peut être
utilisée pour une simple transmission d'un serveur à un autre.
Venons-en à la définition de l'utilisation de
Delivered-To: proposée par notre RFC dans sa
section 4 :
- Le champ
Delivered-To:est ajouté uniquement lors d'une livraison, - sa valeur est l'adresse de courrier utilisée pour cette livraison (une adresse unique, jamais de liste),
- si une réécriture de l'adresse est faite, on rajoute un
Delivered-To:avec l'adresse réécrite, - comme il peut y avoir plusieurs
Delivered-To:(en cas de livraisons multiples), le logiciel qui en ajoute un doit le mettre en haut (comme pour les autres champs de trace de l'en-tête, par exempleReceived:, cf. RFC 5321, section, 4.1.1.4), l'ordre chronologique desDelivered-To:sera donc de bas en haut, - et donc les logiciels ne doivent pas réordonner les
Delivered-To:ou en supprimer, sous peine de casser cette chronologie.
En conséquence, si un logiciel qui va ajouter un
Delivered-To: avec une certaine adresse voit un
Delivered-To: avec la même adresse, il peut
être sûr qu'il y a une boucle. Voici un exemple de deux
Delivered-To: différents, en raison du passage
par une liste de diffusion (le message comportait évidemment bien
d'autres champs dans son en-tête). La liste a été la première à
traiter le message, la livraison finale ayant eu lieu après (donc
plus haut dans le message, cf. section 5 du RFC) :
Delivered-To: monpseudo@sources.org Delivered-To: lists-debian-user-french@bendel.debian.org
Le RFC donne un exemple imaginaire mais plus détaillé (j'ai
raccourci les exemples du RFC, référez-vous à lui pour avoir les
Received: et autres détails). D'abord, le
message est émis par Ann :
From: Ann Author <aauthor@com.example> Date: Mon, 25 Jan 2021 18:29:00 -0500 To: list@org.example Subject: Sending through a list and alias Sender: Ann Author <aauthor@com.example>
Ce message a été envoyé à une liste de diffusion. Il est donc désormais :
Delivered-To: list@org.example From: Ann Author <aauthor@com.example> Date: Mon, 25 Jan 2021 18:29:06 -0500 To: list@org.example Subject: Sending through a list and alias
Un des abonnés à la liste est
alumn@edu.example. Chez lui, le
message sera :
Delivered-To: alumn@edu.example Delivered-To: list@org.example From: Ann Author <aauthor@com.example> Date: Mon, 25 Jan 2021 18:29:06 -0500 To: list@org.example Subject: Sending through a list and alias
Et cet abonné fait suivre automatiquement son courrier à
theRecipient@example.net. Le message, dans son
état final, sera :
Delivered-To: theRecipient@example.net Delivered-To: alumn@edu.example Delivered-To: list@org.example From: Ann Author <aauthor@com.example> Date: Mon, 25 Jan 2021 18:29:06 -0500 To: list@org.example Subject: Sending through a list and alias
Voilà, vous savez tout désormais sur l'extension proposée de
l'utilisation de Delivered-To:. La section 6
attire toutefois notre attention sur quelques
risques. Delivered-To: a comme valeur une
donnée personnelle. Donc, attention, cela
peut poser des questions de vie
privée. Par exemple, la liste des adresses par
lesquelles est passé un message peut en révéler plus que ce que le
destinataire connaissait. Le problème risque surtout de se poser si
quelqu'un fait suivre manuellement un message en incluant tous les
en-têtes.
Autre problème potentiel, certains systèmes stockent les messages
identiques en un seul exemplaire. Si on écrit à
alice@example.com et
bob@example.com, le serveur
d'example.com pourrait décider de ne stocker
qu'un seul exemplaire du message, avec des liens depuis les boites
aux lettres d'Alice et Bob. Ce serait évidemment incompatible avec
Delivered-To: (et pas question de mettre deux
Delivered-To:, on ne veut pas révéler à Alice
que Bob a reçu le message et réciproquement).
L'article seul
RFC 9224: Finding the Authoritative Registration Data Access Protocol (RDAP) Service
Date de publication du RFC : Mars 2022
Auteur(s) du RFC : M. Blanchet (Viagenie)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 25 avril 2022
Le protocole RDAP d'accès à l'information
sur les objets (noms de
domaines, adresses
IP, etc) stockés dans un registre fonctionne en
interrogeant le serveur en HTTP. Encore faut-il trouver le serveur à
interroger. Comment le client RDAP qui veut des informations sur
2001:67c:288::2 sait-il à quel serveur
demander ? Ce RFC
décrit le mécanisme choisi. En gros, l'IANA gère des
« méta-services » qui donnent la liste de serveurs RDAP, mais il
peut aussi y avoir redirection d'un serveur RDAP vers un autre. Ce
RFC remplace le premier RFC sur le sujet, le RFC 7484, avec très peu de changements.
Le protocole RDAP est décrit entre autres dans le RFC 7480 qui précise comment utiliser HTTP pour transporter les requêtes et réponses RDAP. Comme indiqué plus haut, il ne précise pas comment trouver le serveur RDAP responsable d'un objet donné. Le prédécesseur de RDAP, whois, avait exactement le même problème, résolu par exemple en mettant en dur dans le logiciel client tous les serveurs whois connus. En pratique, beaucoup de gens font simplement une requête Google et accordent une confiance aveugle auu premier résultat venu, quel que soit sa source. Au contraire, ce RFC vise à fournir un mécanisme pour trouver la source faisant autorité.
Avant d'exposer la solution utilisée, la section 1 de notre RFC rappelle comment ces objets (noms de domaine, adresses IP, numéros d'AS, etc) sont alloués et délégués. L'IANA délégue les TLD aux registres de noms de domaines, des grands préfixes IP et les blocs de numéros d'AS aux RIR. Il est donc logique que RDAP suive le même chemin : pour trouver le serveur responsable, on commence par demander à l'IANA, qui a déjà les processus pour cela, et maintient les registres correspondants (adresses IPv4, adresses IPv6, numéros d'AS et domaines).
Pour permettre à RDAP de fonctionner, ce RFC demande donc à l'IANA quelques fichiers supplémentaires, au format JSON (RFC 8259), dont le contenu dérive des registres cités plus haut. Et l'IANA doit aussi prévoir des serveurs adaptés à servir ces fichiers, nommés RDAP Bootstrap Service, à de nombreux clients RDAP.
Le format de ces fichiers JSON est décrit dans la section 3 de
notre RFC. Chaque bootstrap service contient des
métadonnées comme un numéro de version et une date de publication,
et il contient un membre nommé services qui
indique les URL où aller chercher l'information (la syntaxe
formelle figure en section 10). Voici un extrait d'un des fichiers
actuels :
% curl https://data.iana.org/rdap/ipv4.json
"description": "RDAP bootstrap file for IPv4 address allocations",
"publication": "2019-06-07T19:00:02Z",
"services": [
[
[
"41.0.0.0/8",
"102.0.0.0/8",
"105.0.0.0/8",
"154.0.0.0/8",
"196.0.0.0/8",
"197.0.0.0/8"
],
[
"https://rdap.afrinic.net/rdap/",
"http://rdap.afrinic.net/rdap/"
]
],
...
On voit que le contenu est un tableau donnant, pour des objets
donnés, les URL des serveurs RDAP à contacter pour ces objets
indiqués, par exemple pour l'adresse IP
154.3.2.1, on ira demander au serveur RDAP
d'AfriNIC en
https://rdap.afrinic.net/rdap/.
Le membre publication indique la date de
parution au format du RFC 3339. Les URL
indiqués se terminent par une barre oblique,
le client RDAP a juste à leur ajouter une requête formulée selon la
syntaxe du RFC 9082. Ainsi, cherchant des
informations sur 192.0.2.24, on ajoutera
ip/192.0.2.24 à l'URL de base.
Pour les adresses IP (section 5), les entrées sont des préfixes, comme dans le premier exemple montré plus haut et la correspondance se fait avec le préfixe le plus spécifique (comme pour le routage IP). Les préfixes IPv4 suivent la syntaxe du RFC 4632 et les IPv6 celle du RFC 5952. Voici un exemple IPv6 (légèrement modifié d'un cas réel) :
[
[
"2001:200::/23",
"2001:4400::/23",
"2001:8000::/19",
"2001:a000::/20",
"2001:b000::/20",
"2001:c00::/23",
"2001:e00::/23",
"2400::/12"
],
[
"https://rdap.apnic.net/"
]
],
[
[
"2001:200:1000::/36"
],
[
"https://example.net/rdaprir2/"
]
Si on cherche de l'information sur le préfixe
2001:200:1000::/48, il correspond à deux
entrées dans le tableau des services
(2001:200::/23 et
2001:200:1000::/36) mais la règle du préfixe le
plus long (le plus spécifique) fait qu'on va utiliser
2001:200:1000::/36, et la requête finale sera
donc
https://example.net/rdaprir2/ip/2001:200:1000::/48.
Pour les domaines (section 4), les entrées des services sont des noms de domaine :
...
"services": [
[
["net", "com", "org"],
[
"https://registry.example.com/myrdap/"
]
],
[
["foobar.org", "mytld"],
[
"https://example.org/"
]
],
...
L'entrée sélectionnée est la plus longue (en nombre de composants du
nom, pas en nombre de caractères) qui correspond. Dans l'exemple
ci-dessus, si on cherche des informations sur
foobar.org, on ira voir le serveur RDAP en
https://example.org/, si on en cherche sur
toto.org, on ira en
https://registry.example.com/myrdap/. (En
pratique, aujourd'hui, le tableau des serveurs RDAP ne contient que
des TLD.)
Pour les numéros d'AS (section 5.3), on se sert d'intervalles de numéros et de la syntaxe du RFC 5396 :
"services": [
[
["2045-2045"],
[
"https://rir3.example.com/myrdap/"
]
],
[
["10000-12000", "300000-400000"],
[
"http://example.org/"
]
],
...
Les entités (section 6 de notre RFC) posent un problème particulier, elles ne se situent pas dans un espace arborescent, contrairement aux autres objets utilisable avec RDAP. (Rappel : les entités sont les contacts, les titulaires, les BE…) Il n'existe donc pas de bootstrap service pour les entités (ni, d'ailleurs, pour les serveurs de noms, cf. section 9). En pratique, si une requête RDAP renvoie une réponse incluant un handle pour une entité, il n'est pas idiot d'envoyer les requêtes d'information sur cette entité au même serveur RDAP mais il n'est pas garanti que cela marche.
Notez (section 7) que le tableau services ne
sera pas forcément complet et que certains objets peuvent ne pas s'y
trouver. Par exemple, dans un tableau pour les TLD, les registres n'ayant pas
encore de serveur RDAP ne seront logiquement pas cités. On peut
toujours tenter un autre serveur, en espérant qu'il utilisera les
redirections HTTP. Par exemple, ici, on demande au serveur RDAP de
l'APNIC pour une adresse RIPE. On est bien redirigé
avec un code 301 (RFC 7231, section 6.4.2) :
% curl -v http://rdap.apnic.net/ip/2001:67c:288::2 ... > GET /ip/2001:67c:288::2 HTTP/1.1 > User-Agent: curl/7.38.0 > Host: rdap.apnic.net > Accept: */* > < HTTP/1.1 301 Moved Permanently < Date: Wed, 01 Apr 2015 13:07:00 GMT < Location: http://rdap.db.ripe.net/ip/2001:67c:288::2 < Content-Type: application/rdap+json ...
La section 8 couvre quelques détails liés au déploiement de ce
service. C'est que le Bootstrap Service est
différent des autres registres IANA. Ces autres registres ne sont
consultés que rarement (par exemple, lors de l'écriture d'un
logiciel) et jamais en temps réel. Si le serveur HTTP de l'IANA
plante, ce n'est donc pas trop grave. Au contraire, le
Bootstrap Service doit marcher en permanence, car
un client RDAP en a besoin. Pour limiter la pression sur les
serveurs de l'IANA, notre RFC recommande que les clients RDAP ne
consultent pas ce service à chaque requête RDAP, mais qu'au
contraire ils mémorisent le JSON récupéré, en utilisant le champ
Expires: de HTTP (RFC 7234, section 5.3) pour déterminer combien de temps doit
durer cette mémorisation. Néanmoins, l'IANA a dû ajuster ses
serveurs HTTP et louer les services d'un CDN pour assurer ce rôle relativement
nouveau.
Le client RDAP doit d'autre part être conscient que le registre n'est pas mis à jour instantanément. Par exemple, si un nouveau TLD est ajouté par le gouvernement états-unien, via Verisign, TLD dont le registre a un serveur RDAP, cette information ne sera pas disponible immédiatement pour tous les clients RDAP.
Comme son ancêtre whois, RDAP soulève plein de questions de sécurité intéressantes, détaillées plus précisement dans le RFC 7481.
La section 12 de notre RFC détaille les processus IANA à l'œuvre. En effet, et c'est une autre différence avec les registres IANA habituels, il n'y a pas de mise à jour explicite des registres du bootstrap service, ils sont mis à jour implicitement comme effet de bord des allocations et modifications d'allocation dans les registres d'adresses IPv4, adresses IPv6, numéros d'AS et domaines. Il a juste fallu modifier les procédures de gestion de ces registres existants, pour permettre d'indiquer le serveur RDAP. Ainsi, le formulaire de gestion d'un TLD par son responsable a été modifié pour ajouter un champ "serveur RDAP" comme il y avait un champ "serveur Whois".
Aujourd'hui, les fichiers de ce service sont :
https://data.iana.org/rdap/dns.jsonhttps://data.iana.org/rdap/ipv4.jsonhttps://data.iana.org/rdap/ipv6.jsonhttps://data.iana.org/rdap/asn.json
Voici, par exemple, celui d'IPv6 (notez le champ
Expires: dans la réponse) :
% curl -v https://data.iana.org/rdap/ipv6.json
...
* Connected to data.iana.org (2606:2800:11f:bb5:f27:227f:1bbf:a0e) port 80 (#0)
> GET /rdap/ipv6.json HTTP/1.1
> Host: data.iana.org
> User-Agent: curl/7.68.0
> Accept: */*
>
< HTTP/1.1 200 OK
< Expires: Tue, 26 Apr 2022 12:30:52 GMT
< Last-Modified: Wed, 06 Nov 2019 19:00:04 GMT
...
{
"description": "RDAP bootstrap file for IPv6 address allocations",
"publication": "2019-11-06T19:00:04Z",
"services": [
[
[
"2001:4200::/23",
"2c00::/12"
],
[
"https://rdap.afrinic.net/rdap/",
"http://rdap.afrinic.net/rdap/"
...
Et celui des TLD :
% curl -v http://data.iana.org/rdap/dns.json
...
"description": "RDAP bootstrap file for Domain Name System registrations",
"publication": "2022-04-22T16:00:01Z",
"services": [
[
[
"nowruz",
"pars",
"shia",
"tci",
"xn--mgbt3dhd"
],
[
"https://api.rdap.agitsys.net/"
]
],
Testons si cela marche vraiment :
% curl -v https://api.rdap.agitsys.net/domain/www.nowruz
...
"nameservers": [
{
"objectClassName": "nameserver",
"ldhName": "ns1.aftermarket.pl.",
"unicodeName": "ns1.aftermarket.pl."
},
{
"objectClassName": "nameserver",
"ldhName": "ns2.aftermarket.pl.",
"unicodeName": "ns2.aftermarket.pl."
}
]
Parfait, tout marche.
Il y a très peu de changements depuis le RFC précédent, le RFC 7484, quelques nettoyages seulement, et un changement de statut sur le chemin des normes.
Si vous aimez lire des programmes, j'ai fait deux mises en œuvre
de ce RFC, la première en Python est incluse dans le code utilisé pour
mon article « Récupérer la date
d'expiration d'un domaine en RDAP ». Le code principal est
ianardap.pyExpires:. La deuxième, en
Elixir, est plus correcte et est disponible
dans find-rdap-elixir.tar@verbose est vraie, le programme affiche les
étapes. S'il n'a pas mémorisé de données :
% mix run find_rdap.exs quimper.bzh
Starting
No expiration known
Retrieving from https://data.iana.org/rdap/dns.json
Updating the cache
RDAP bootstrap file for Domain Name System registrations published on 2022-04-22T16:00:01Z
RDAP server for quimper.bzh is https://rdap.nic.bzh/
Retrieving RDAP info at https://rdap.nic.bzh/domain/quimper.bzh
{"rdapConformance":["rdap_level_0","...
S'il en a mémorisé :
% mix run find_rdap.exs quimper.bzh
Starting
Expiration is 2022-04-26 12:44:48Z
Using the cache ./iana-rdap-bootstrap.json
RDAP bootstrap file for Domain Name System registrations published on 2022-04-22T16:00:01Z
RDAP server for quimper.bzh is https://rdap.nic.bzh/
Retrieving RDAP info at https://rdap.nic.bzh/domain/quimper.bzh
{"rdapConformance":["rdap_level_0", ...
Mais il existe évidemment une mise en œuvre de ce RFC dans tous les clients RDAP comme :
- L'application de Viagenie,
- Celle de l'ICANN (application Web),
- L'ARIN a un service de redirection,
https://rdap-bootstrap.arin.net/bootstrap, qui lit la base IANA et envoie les redirections appropriées, quand un client RDAP l'interroge.
L'article seul
RFC 9221: An Unreliable Datagram Extension to QUIC
Date de publication du RFC : Mars 2022
Auteur(s) du RFC : T. Pauly, E. Kinnear (Apple), D. Schinazi (Google)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF quic
Première rédaction de cet article le 1 avril 2022
Le protocole QUIC fournit, comme son
concurrent TCP, un canal fiable d'envoi de données. Mais
certaines applications n'ont pas impérativement besoin de cette
fiabilité et se contenteraient très bien d'un service de type
datagramme. Ce nouveau RFC ajoute donc un nouveau
type de trame QUIC, DATAGRAM, pour fournir un
tel service.
Dit comme cela, évidemment, ça semble drôle, de bâtir un service non fiable au-dessus du service fiable que rend QUIC. Mais cela permet plusieurs choses très intéressantes, notamment si deux machines qui communiquent ont besoin des deux types de service : elles pourront utiliser une seule session QUIC pour les deux.
Un petit rappel (mais relisez le RFC 9000
pour les détails) : dans une connexion QUIC sont envoyés des paquets
et chaque paquet QUIC contient une ou plusieurs trames. Chaque trame
a un type et ce type indique si la trame sera retransmise ou non en
cas de perte. Le service habituel (utilisé par exemple par
HTTP/3) se sert de trames de type
STREAM, qui fournissent un service fiable (les
données perdues sont retransmises par QUIC). Mais toutes les
applications ne veulent pas d'une telle fiabilité ou, plus
précisement, ne sont pas prêtes à en payer le coût en termes de
performance. Ces applications sont celles qui préféraient utiliser
UDP (RFC 768) plutôt que TCP. Pour rajouter de la sécurité,
elles utilisaient DTLS (RFC 6347). Si
QUIC remplace TCP, comment remplacer
UDP+DTLS ?
D'ailleurs, faut-il le remplacer ? La section 2 du RFC donne les raisons suivantes :
- Les applications qui ont besoin à la fois d'un canal fiable et d'un canal qui ne l'est pas (par exemple une application de communication qui veut un canal fiable pour la signalisation et un pas forcément fiable pour les données multimédia) peuvent avec QUIC n'avoir qu'une seule session (et donc ne « payer » l'établissement de la session qu'une fois, ce qui diminuera la latence),
- QUIC a un meilleur mécanisme de récupération des pertes que DTLS, lors de l'établissement de la connexion,
- contrairement à UDP+DTLS, QUIC a un mécanisme de contrôle de la congestion, ce qui simplifie la tâche de l'application (cf. RFC 8085).
Ces raisons sont particulièrement importantes pour le streaming audio/vidéo, pour les jeux en ligne, etc. Les datagrammes dans QUIC peuvent aussi être utiles pour un service de VPN. Là aussi, le VPN a besoin à la fois d'un canal fiable pour la configuration de la communication, mais peut se satisfaire d'un service de type datagramme ensuite (puisque les machines connectées via le VPN auront leur propre mécanisme de récupération des données perdues). Permettre la création de VPN au-dessus de QUIC est le projet du groupe de travail MASQUE.
Bien, normalement, maintenant, vous êtes convaincu·es de
l'intérêt des datagrammes au-dessus de QUIC. Pour en envoyer, il
faut toutefois que les deux parties qui communiquent soient
d'accord. C'est le rôle du paramètre de transport QUIC
max_datagram_frame_size, à utiliser lors de
l'établissement de la session. (Ce paramètre est enregistré
à l'IANA.) S'il est absent, on ne peut pas envoyer de
datagrammes (et le partenaire coupe la connexion si on le fait quand
même). S'il est présent, il indique la taille maximale acceptée,
typiquement 65 535 octets. Sa valeur peut être stockée dans la
mémoire d'une machine, de façon à permettre son utilisation lors du
0-RTT (commencer une session QUIC directement sans perdre du temps
en négociations). Un paquet QUIC 0-RTT peut donc inclure des trames
de type DATAGRAM.
Ah, justement, ce type DATAGRAM. Désormais
enregistré
à l'IANA parmi les types de trames QUIC, il sert à indiquer
des trames qui seront traitées comme des datagrammes, et qui ont la
forme suivant :
DATAGRAM Frame {
Type (i) = 0x30..0x31,
[Length (i)],
Datagram Data (..),
}
Le champ de longueur est optionnel, sa présence est indiquée par le dernier bit du type (0x30, pas de champ Longueur, 0x31, il y en a un). S'il est absent, la trame va jusqu'au bout du paquet QUIC (rappelons qu'un paquet QUIC peut contenir plusieurs trames).
Maintenant qu'on a des datagrammes comme QUIC, comment les
utilise-t-on (section 5 du RFC) ? Rien d'extraordinaire,
l'application envoie une trame DATAGRAM et
l'application à l'autre bout la recevra. Si la trame n'est pas
arrivée, l'émetteur ne le saura pas. La trame peut se retrouver avec
d'autres trames (du même type ou pas) dans un même paquet QUIC (et
plusieurs paquets QUIC peuvent se retrouver dans un même datagramme
IP). La notion de
ruisseau (stream) n'existe pas pour les
trames-datagrammes, si on veut pouvoir les démultiplexer, c'est à
l'application de se débrouiller. (Une version préliminaire de cette
extension à QUIC prévoyait un mécanisme de démultiplexage,
finalement abandonné.) Comme toutes les trames QUIC, les trames
DATAGRAM sont protégées par la
cryptographie. Le service est donc équivalent à celui d'UDP+DTLS,
pas UDP seul.
Un service de datagrammes est non fiable, des données peuvent se
perdre. Mais si les trames de type DATAGRAM ne
sont pas réémises (pas par QUIC, en tout cas), elles entrainent
néanmoins l'émission d'accusés de réception (RFC 9002, sections 2 et 3). Une bibliothèque QUIC peut ainsi
(mais ce n'est pas obligatoire) notifier l'application des
pertes. De la même façon, elle a la possibilité de dire à
l'application quelles données ont été reçues par le QUIC à l'autre
bout (ce qui ne garantit pas que l'application à l'autre bout les
aient bien reçues, si on a besoin d'informations sûres, il faut le
faire au niveau applicatif).
Comme l'émetteur n'estime pas
crucial que toutes les données arrivent, une optimisation possible
pour QUIC est que l'accusé de réception d'un paquet ne contenant que
des trames DATAGRAM ne soit pas émis tout de
suite, il peut attendre le paquet suivant.
Cette extension existe déjà dans plusieurs mises en œuvre de QUIC, mais je ne l'ai pas testée.
L'article seul
RFC 9211: The Cache-Status HTTP Response Header Field
Date de publication du RFC : Juin 2022
Auteur(s) du RFC : M. Nottingham (Fastly)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 9 juin 2022
Ce RFC normalise enfin un en-tête HTTP pour permettre aux relais HTTP qui mémorisent les réponses reçues, les caches, d'indiquer au client comment ils ont traité une requête et si, par exemple, la réponse vient de la mémoire du relais ou bien s'il a fallu aller la récupérer sur le serveur HTTP d'origine.
Il existait déjà des en-têtes de débogage analogues mais
non-standards, variant aussi bien dans leur syntaxe que dans leur
sémantique. Le nouvel en-tête standard,
Cache-Status: va, espérons-le, mettre de
l'ordre à ce sujet. Sa syntaxe suit les principes des en-têtes
structurés du RFC 9651. Sa valeur est donc une
liste de relais qui ont traité la requête, séparés par des
virgules, dans l'ordre des traitements. Le
premier relais indiqué dans un Cache-Status:
est donc le plus proche du serveur d'origine et le dernier relais
étant le plus proche de l'utilisateur. Voici un exemple avec un seul
relais, nommé cache.example.net :
Cache-Status: cache.example.net; hit
et un exemple avec deux relais, OriginCache
puis CDN Company Here :
Cache-Status: OriginCache; hit; ttl=1100, "CDN Company Here"; hit; ttl=545
La description complète de la syntaxe figure dans la section 2 de notre RFC. D'abord, il faut noter qu'un relais n'est pas obligé d'ajouter cet en-tête. Il le fait selon des critères qui lui sont propres. Le RFC déconseille fortement d'ajouter cet en-tête si la réponse a été générée localement par le relais (par exemple un 400 qui indique que le relais a détecté une requête invalide). En tout cas, le relais qui s'ajoute à la liste ne doit pas modifier les éventuels relais précédents. Chaque relais indique son nom, par exemple par un nom de domaine mais ce n'est pas obligatoire. Ce nom peut ensuite être suivi de paramètres, séparés par des point-virgules.
Dans le
premier exemple ci-dessus, hit était un
paramètre du relais cache.example.net. Sa
présence indique qu'une réponse était déjà mémorisée par le relais
et qu'elle a été utilisée (hit : succès, on a
trouvé), le serveur d'origine n'ayant pas été contacté. S'il y
avait une réponse stockée, mais qu'elle était rassise (RFC 9111, section 4.2) et qu'il a fallu la
revalider auprès du serveur d'origine, hit ne
doit pas être utilisé.
Le deuxième paramètre possible est fwd (pour
Forward) et il indique qu'il a fallu contacter le
serveur HTTP d'origine. Plusieurs raisons sont possibles pour cela,
entre autres :
bypass, quand le relais a été configuré pour que cette requête soit systématiquement relayée,methodparce que la méthode HTTP utilisée doit être relayée (c'est typiquement le cas d'unPUT, cf. RFC 9110, section 9.3.4),miss, un manque, la ressource n'était pas dans la mémoire du relais (notez qu'il existe aussi deux paramètres plus spécifiques,uri-missetvary-miss),stale, car la ressource était bien dans la mémoire du relais mais, trop ancienne et rassise, a dû être revalidée (RFC 9111, section 4.3) auprès du serveur d'origine.
Ainsi, cet en-tête :
Cache-Status: ExampleCache; fwd=miss; stored
indique que l'information n'était pas dans la mémoire de
ExampleCache et qu'il a donc dû faire suivre au
serveur d'origine (puis qu'il a stocké cette information dans sa
mémoire, le paramètre stored).
Autre paramètre utile, ttl, qui indique
pendant combien de temps l'information peut être gardée (cf. RFC 9111, section 4.2.1), selon les
calculs du relais. Quant à detail,
il permet de donner des informations supplémentaires, de manière non
normalisée (la valeur de ce paramètre ne peut être interprétée que
si on connait le programme qui l'a produite).
Les paramètres sont enregistrés à l'IANA, dans un nouveau registre, et de nouveaux paramètres peuvent y être ajoutés, suivant la politique « Examen par un expert » du RFC 8126. La recommandation est de n'enregistrer que des paramètres d'usage général, non spécifiques à un programme particulier, sauf à nommer le paramètre d'une manière qui identifie clairement sa spécificité.
Questions mises en œuvre, Squid sait
renvoyer cet en-tête (cf. le code qui commence à SBuf
cacheStatus(uniqueHostname()); dans le fichier
src/client_side_reply.cc). Ce code n'est pas
encore présent dans la version 5.2 de Squid, qui n'utilise encore que
d'anciens en-têtes non-standards, il faut attendre de nouvelles versions :
< X-Cache: MISS from myserver < X-Cache-Lookup: NONE from myserver:3128 < Via: 1.1 myserver (squid/5.2)
Je n'ai pas regardé les autres logiciels.
L'article seul
RFC 9210: DNS Transport over TCP - Operational Requirements
Date de publication du RFC : Mars 2022
Auteur(s) du RFC : J. Kristoff (Dataplane.org), D. Wessels (Verisign)
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 15 avril 2022
Ce nouveau RFC décrit les exigences opérationnelles pour le DNS, plus précisement pour son protocole de transport TCP. Le RFC 7766 décrivait la norme technique, et s'imposait donc aux programmeur·ses, ce RFC 9210 est plus opérationnel et concerne donc ceux et celles qui installent et configurent les serveurs DNS et les réseaux qui y mènent.
Les messages DNS sont historiquement surtout transportés sur UDP. Mais le DNS a toujours permis TCP et, de nos jours, il est fréquemment utilisé notamment en conjonction avec TLS (cf. RFC 7858). Il est d'autant plus important que TCP marche bien qu'il est parfois nécessaire pour certains usages, par exemple pour des enregistrements de grande taille (ce qui arrive souvent avec DNSSEC). Une mise en œuvre du DNS doit donc inclure TCP, comme clarifié par le RFC 7766 (les RFC précédents n'étaient pas sans ambiguité). Mais cela ne signifiait pas forcément que les serveurs DNS avaient activé TCP ou que celui-ci marchait bien (par exemple, une stupide middlebox pouvait avoir bloqué TCP). Ce nouveau RFC 9210 ajoute donc que l'obligation d'avoir TCP s'applique aussi aux serveurs effectifs, pas juste au logiciel.
DNS sur TCP a une histoire compliquée (section 2 du RFC). Franchement, le fait que le DNS marche sur TCP aussi bien que sur UDP n'a pas toujours été clairement formulé, même dans les RFC. Et, en dehors de l'IETF, beaucoup de gens ont raconté n'importe quoi dans des articles et des documentations, par exemple que TCP n'était utile qu'aux transferts de zone, ceux normalisés dans le RFC 5936. Cette légende a été propagée par certains auteurs (comme Cheswick et Bellovin dans leur livre Firewalls and Internet Security: Repelling the Wily Hacker) ou par des gens qui ne mesuraient pas les limites de leurs compétences DNS comme Dan Bernstein. Pourtant, TCP a toujours été nécessaire, par exemple pour transporter des données des grande taille (que DNSSEC a rendu bien plus fréquentes). Le RFC 1123, en 1989, insistait déjà sur ce rôle. Certes, EDNS (RFC 6891) permettait déjà des données de taille supérieure aux 512 octets de la norme originelle. Mais il ne dispense pas de TCP. Par exemple, des données de taille supérieure à 1 460 octets (le maximum qui peut tenir avec le MTU typique) seront fragmentées et les fragments, hélas, ne passent pas partout sur l'Internet. (Cf. le « DNS Flag Day » de 2020 et lire « DNS XL » et « Dealing with IPv6 fragmentation in the DNS ».) Et la fragmentation pose également des problèmes de sécurité, voir par exemple « Fragmentation Considered Poisonous ».
Bon, en pratique, la part de TCP reste faible mais elle augmente. Mais, trop souvent, le serveur ne répond pas en TCP (ou bien ce protocole est bloqué par le réseau), ce qui entraine des tas de problèmes, voir par exemple le récit dans « DNS Anomalies and Their Impacts on DNS Cache Servers ».
Notons enfin que TCP a toujours permis que plusieurs requêtes se succèdent sur une seule connexion TCP, même si les premières normes n'étaient pas aussi claires qu'il aurait fallu. L'ordre des réponses n'est pas forcément préservé (cf. RFC 5966), ce qui évite aux requêtes rapides d'attendre le résultat des lentes. Et un client peut envoyer plusieurs requêtes sans attendre les réponses (RFC 7766). Par contre, la perte d'un paquet va entrainer un ralentissement de toute la connexion, et donc des autres requêtes (QUIC résout ce problème et il y a un projet de DNS sur QUIC).
Vous pouvez tester qu'un serveur DNS accepte de faire passer
plusieurs requêtes sur une même connexion TCP avec
dig et son option
+keepopen (qui n'est pas activée par
défaut). Ici, on demande à ns4.bortzmeyer.org
les adresses IP de www.bortzmeyer.org et
mail.bortzmeyer.org :
% dig +keepopen +tcp @ns4.bortzmeyer.org www.bortzmeyer.org AAAA mail.bortzmeyer.org AAAA
Vous pouvez vérifier avec tcpdump qu'il n'y
a bien eu qu'une seule connexion TCP, ce qui ne serait pas le cas
sans +keepopen.
Les exigences opérationnelles pour le DNS sur TCP figurent dans la section 3 du RFC. Il est désormais obligatoire non seulement d'avoir la possibilité de TCP dans le code mais en outre que cela soit activé partout. (En termes du RFC 2119, on est passé de SHOULD à MUST.)
La section 4 discute de certaines considérations opérationnelles que cela pourrait poser. D'abord, certains serveurs ne sont pas joignables en TCP. C'était déjà mal avant notre RFC mais c'est encore pire maintenant. Mais cela arrive (ce n'est pas forcément la faute du serveur, cela peut être dû à une middlebox boguée sur le trajet). Les clients doivent donc être préparés à ce que TCP échoue (de toute façon, sur l'Internet, tout peut toujours échouer). D'autre part, diverses attaques par déni de service sont possibles, aussi bien contre le serveur (SYN flooding, contre lequel la meilleure protection est l'utilisation de cookies, cf. RFC 4987), que contre des machines tierces, le serveur étant utilisé comme réflecteur.
Aussi bien le client DNS que le serveur n'ont pas des ressources illimitées et doivent donc gérer les connexions TCP. Dit plus brutalement, il faut être prêt à couper les connexions qui semblent inutilisées. Bien sûr, il faut aussi laisser les connexions ouvertes suffisamment longtemps pour amortir leur création sur le plus grand nombre de requêtes possibles, mais il y a des limites à tout. (Le RFC suggère une durée maximale dans les dizaines de secondes, pouvant être abaissée à quelques secondes pour les serveurs très chargés.)
TCP est particulièrement intéressant pour le DNS quand TLS est inséré (RFC 7858). Mais il va alors consommer davantage de temps de CPU et, dans certains cas, l'établissement de connexion sera plus lent.
Le RFC donne quelques conseils quantitatifs (à ne pas appliquer aveuglément, bien sûr). Un maximum de 150 connexions TCP simultanées semble raisonnable pour un serveur ordinaire, avec un maximum de 25 par adresse IP source. Un délai de garde après inactivité de 10 secondes est suggéré. Par contre, le RFC ne propose pas de valeur maximale au nombre de requêtes par connexion TCP, ni de durée maximale à une connexion.
Les fanas des questions de sécurité noteront que les systèmes de journalisation et de surveillance peuvent ne pas être adaptés à TCP. Par exemple, un méchant pourrait mettre la requête DNS dans plusieurs segments TCP et donc plusieurs paquets IP. Un système de surveillance qui considérerait qu'une requête = un paquet serait alors aveugle. Notez qu'un logiciel comme dnscap a pensé à cela, et réassemble les paquets. Mais il est sans doute préférable, de nos jours, de se brancher sur le serveur, par exemple avec dnstap, notamment pour éviter de faire le réassemblage deux fois. (Ceux qui lisent mes articles depuis longtemps savent que je donnais autrefois le conseil inverse. Mais le déploiement de plus en plus important de TCP et surtout de TLS impose de changer de tactique.)
L'article seul
RFC 9209: The Proxy-Status HTTP Response Header Field
Date de publication du RFC : Juin 2022
Auteur(s) du RFC : M. Nottingham (Fastly), P. Sikora (Google)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 14 juin 2022
Le protocole HTTP, qui est à la base du Web, n'est pas forcément de bout
en bout, entre client et serveur. Il y a souvent passage par un
relais et ce relais a
parfois des choses à signaler au client HTTP, notamment en cas
d'erreur. Ce RFC
spécifie le champ d'en-tête Proxy-Status pour
cela.
La norme HTTP, le RFC 9110 décrit ces relais, ces intermédiaires, dans sa section 3.7. On en trouve fréquemment sur le Web. Il y a depuis longtemps des codes d'erreur pour eux, comme 502 si le serveur d'origine répond mal et 504 pour les cas où il ne répond pas du tout. Mais ce n'est pas forcément assez précis, d'où le nouveau champ dans l'en-tête (ou dans le pied). Il utilise la syntaxe des champs structurés du RFC 9651. Voici un exemple :
Proxy-Status: proxy.example.net; error="http_protocol_error"; details="Malformed response header: space before colon", "Example CDN"
Cet exemple se lit ainsi : le premier (en partant du serveur
d'origine) s'identifie comme proxy.example.net
et il signale que le serveur d'origine n'avait pas bien lu le RFC 9112. Puis la réponse est passée par un autre
intermédiaire, qui s'identifie comme "Example
CDN" (l'identificateur n'est pas forcément un
nom de domaine), et n'a rien de particulier à
raconter. Le champ Proxy-Status est désormais
dans
le registres des champs d'en-tête (ou de pied).
Vous avez vu dans l'exemple ci-dessus le paramètre
error. Il peut s'utiliser, par exemple, avec le
code de retour 504 :
HTTP/1.1 504 Gateway Timeout Proxy-Status: foobar.example.net; error=connection_timeout
Ici, le relais foobar.example.net n'a eu aucune
réponse du serveur d'origine (ou, plus rigoureusement, du serveur
qu'il essayait de contacter, qui peut être un autre
intermédiaire).
Mais il existe d'autres paramètres possibles, comme :
next-hop: nom ou adresse du serveur contacté, par exempleProxy-Status: cdn.example.org; next-hop=backend.example.org:8001.next-protocol: protocole (ALPN, RFC 7301) utilisé avec le serveur, par exempleProxy-Status: "proxy.example.org"; next-protocol=h2pour du HTTP/2 (RFC 9113).received-status: le code de retour du serveur, comme dansProxy-Status: ExampleCDN; received-status=200, pour un cas où tout s'est bien passé.
Et on peut définir de nouveaux paramètres par la procédure d'examen par un expert (RFC 8126).
Le paramètre error prend comme valeur un
type d'erreur. Il en existe
plusieurs, chacun avec un code de retour recommandé dont (je
ne les indique pas tous, ils sont très nombreux !) :
dns_timeout(pour le code de retour 504) etdns_error(code 502) : c'est la faute du DNS. Le second type permet en outre d'indiquer le paramètrercode(code de retour DNS, commeNXDOMAIN) et le paramètreinfo-code, le code étendu du RFC 8914.connection_timeoutouconnection_refused.destination_ip_prohibited: le pare-feu ne veut pas.tls_protocol_error: là, c'est TLS qui ne veut pas.tls_certificate_error: certificat du serveur problématique, par exemple expiré.http_protocol_error: la réponse du serveur n'était pas du bon HTTP.proxy_internal_error: le relais a un problème interne.
Là aussi, on peut enregistrer de nouveaux types avec la procédure d'examen par un expert du RFC 8126.
La section 4 du RFC détaille les questions de sécurité. Comme
toute information, Proxy-Status peut aider un
attaquant, par exemple en lui donnant des idées sur comment joindre
directement un intermédiaire. Pour cette raison, les logiciels
doivent fournir un moyen de contrôler l'ajout (ou pas) de
Proxy-Status, qu'on peut aussi n'inclure que
dans certains cas. Notez aussi qu'un intermédiaire peut mentir (ou
se tromper) et que le Proxy-Status ne vaut donc
que ce que vaut l'intermédiaire.
Je n'ai pas de liste des logiciels qui mettent en œuvre ce champ Proxy-Status.
L'article seul
RFC 9205: Building Protocols with HTTP
Date de publication du RFC : Juin 2022
Auteur(s) du RFC : M. Nottingham
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 10 juin 2022
Aujourd'hui, la grande majorité des API accessibles via le réseau fonctionnent au-dessus de HTTP. Ce nouveau RFC, qui remplace le RFC 3205, décrit les bonnes pratiques pour la conception de telles API, notamment pour les protocoles IETF bâtis sur HTTP, comme DoH ou RDAP.
Il y a plein d'applications qui fonctionnent au-dessus de HTTP. Ce nouveau RFC se concentre sur celles qui sont d'usage général et qui ont plusieurs mises en œuvre et déploiements. (Si vous faites un service centralisé qui n'a qu'un seul déploiement de son API spécifique, ce RFC ne va pas forcément être pertinent pour vous.) Si vous avez déjà lu le RFC 3205, il faudra tout recommencer, les changements sont nombreux. Ces applications utilisant HTTP sont parfois qualifiées de REST mais, en toute rigueur, toutes ne suivent pas rigoureusement les principes de REST. Notez aussi un sous-ensemble, CRUD, pour les applications dont l'essentiel du travail est de créer/supprimer/gérer des objets distants.
Normalement, HTTP avait été conçu pour le Web et ses usages. Mais on voit aujourd'hui de très nombreuses API réseau être fondées sur HTTP pour diverses raisons :
- Parce que le développeur ou la développeuse ne connait que ça,
- parce qu'il existe un très grand nombre de bibliothèques pour faire les clients (comme l'excellente Requests pour le langage Python, qui sera utilisée ici dans plusieurs exemples), et de cadriciels pour les serveurs,
- parce que dans certains cas, il sera même possible d'utiliser un navigateur Web pour y accéder, et que tout le monde a un navigateur Web et est familier avec ce logiciel,
- parce que certains services comme l'authentification sont déjà disponibles dans les logiciels existants,
- parce que HTTP est le seul protocole dont on peut être sûr qu'il passera même dans les réseaux les plus coincés comme les hotspots des hôtels et des aéroports.
Mais tout n'est pas forcément rose et HTTP peut ne pas être bien adapté à ce qu'envisage le développeur de l'API. Et cette développeuse peut faire des erreurs lors de la conception de l'API, erreurs que ce RFC vise à éviter.
En effet, quand on développe une API sur HTTP, il y a plusieurs décisions à prendre :
La section 2 précise l'applicabilité de ce RFC. Il concerne les
protocoles qui utilisent HTTP (ports 80 ou
443, plans d'URI http: ou
https:). Ceux qui utiliseraient une version
modifiée de HTTP ne comptent pas, et cette pratique est d'ailleurs
déconseillée, puisque ces versions modifiées feraient probablement
perdre les avantages d'utiliser HTTP, notamment la réutilisation des
logiciels et infrastructures existants.
Section 3, maintenant. Quelles sont les caractéristiques
importantes de HTTP, qui gouvernent ce que peuvent faire les
applications qui l'utilisent ? D'abord, sa sémantique très
générale : on peut tout faire avec HTTP. Notammment, HTTP est
indépendant du type de ressources sur lesquelles il agit. Ainsi, des
composants HTTP génériques (bibliothèques, serveurs, relais) peuvent
être développés et déployés pour des applications très différentes,
même des applcations qui n'existent pas encore. (Voilà d'alleurs
pourquoi la section précédente insistait sur le fait q'il ne faut
pas modifier HTTP.) Plus subtile serait l'erreur qui consisterait à
spécifier un certain profil de HTTP, en restreignant ce que HTTP
peut faire ou pas (« la réponse à un POST doit
être 201 »). Une telle restriction, là encore, empêcherait
d'utiliser cerrtains composants génériques, en faisant perdre à HTTP
de sa généralité.
Une autre erreur courante est de s'attribuer tout ou partie de
l'espace de nommage fourni par les liens
hypertextes. C'est par exemple le cas lorsqu'une
application estime qu'elle peut contrôler tout le chemin dans l'URI
et décider que /truc/machin est forcément à
elle (RFC 8820). Cela complique le
déploiement, par exemple si on veut installer cette application sous
/chose et excusivement sous ce chemin
(cf. section 4.4). L'application devrait au contraire permettre de
la souplesse et utiliser les possibilités qu'offre le système de
liens (RFC 8288).
Enfin, HTTP dispose de nombreuses possibilités comme le multiplexage que permettent HTTP/2 (RFC 9113) et HTTP/3 (RFC 9114), l'intégration avec TLS, la possibilité de relayage, la négociation de contenu, la disponibilité de nombreux clients, et l'application qui utilise HTTP doit donc veiller à ne pas casser cet écosystème, et en tout cas à ne pas réinventer la roue, alors que HTTP offre déjà de nombreuses solutions éprouvées.
Bref, compte-tenu de tout cela, comment faire pour bien utiliser HTTP dans sa nouvelle application ? La section 4 est là pour répondre à cette question.
D'abord, bien définir la dépendance de l'application à HTTP, en donnant comme référence RFC 9110 (et surtout pas une version spécifique de HTTP, toujours afin de profiter au maximum de l'écosystème existant). On notera quand même que DoH (RFC 8484) impose (section 5.2 de son RFC) au moins HTTP/2, pour être sûr d'avoir du multiplexage. Notre RFC permet explicitement ce genre d'exceptions.
Le RFC recommande également, quand on montre un dialogue HTTP
titre d'exemple, d'utiliser plutôt les conventions de HTTP/1 (RFC 9112), plus lisibles. Donc, par exemple,
GET /truc HTTP/1.1 plutôt que le
:method = GET :path = /resource de
HTTP/2. C'est ce que fait curl :
% curl -v http://www.example > GET / HTTP/2 > Host: www.example > user-Agent: curl/7.68.0 > accept: */* > < HTTP/2 200 < content-Type: text/plain < content-Length: 13
On l'a dit, il ne faut pas modifier le comportement de base de HTTP. Ce qu'on peut faire, par contre :
- Spécifier le type des données (RFC 6838), par exemple JSON (qu'utilise RDAP),
- spécifier des champs dans l'en-tête,
- spécifier comment on trouve les ressources via des liens (RFC 8288).
Et le client ? L'application qui utilise HTTP ne devrait pas exiger de comportement trop spécifique du client ; idéalement, un navigateur Web normal devrait pouvoir interagir avec l'application. On peut par exemple s'appuyer sur les principes FETCH. Il est également préférable que l'application qui va utiliser HTTP soit claire sur le traitement attendu pour les redirections HTTP, ou pour les cookies (RFC 6265), et rappeler que la vérification des certificats doit se faire selon les principes de la section 4.3.4 du RFC 9110.
Le client doit, idéalement, pouvoir se configurer avec uniquement
un URL. (Par exemple, un serveur DoH est annoncé ainsi, comme
https://doh.bortzmeyer.fr/, la seule
information dont vous avez besoin pour l'utiliser.) Et si on ne
connait qu'un nom de domaine ? La solution du chemin d'URL fixe
qu'on s'alloue
(« obligatoirement /app ») étant interdite (RFC 8820), il y a le choix :
Et le plan d'URI (le premier composant de l'URI) ?
http: et surtout https:
sont évidemment recommandés mais on peut aussi choisir un plan
spécifique. Cela va évidemment rendre l'application inutilisable
par un navigateur Web ordinaire. Certains navigateurs permettent
d'enregistrer un mécanisme de gestion de ces plans non standards
(comme le registerProtocolHandler() du WHATWG) mais cela ne
marche pas partout. Et on aura le même problème avec tout
l'écosystème logiciel de HTTP. Bref, utiliser un plan autre que
http: ou https: fera
perdre une bonne partie des avantages qu'il y avait à utiliser le
protocole HTTP. D'autres problèmes se poseront comme l'impossibilité
d'utiliser le concept d'origine (RFC 6454) par
exemple dans la Same Origin
Policy, ou comme d'autres fonctions utiles
de HTTP (cookies, authentification, mémorisation
- RFC 9111, HSTS - RFC 6797, etc). Si vous tenez encore, après tout ça, à créer
un plan à vous, consultez le RFC 7595.
Et les ports ? HTTP utilise par défaut les
ports 80 pour le trafic en clair et 443 pour le traffic
chiffré. Utiliser un autre port est possible
(https://machin.example:666) mais rend le
trafic de l'application distinguable, ce qui peut être gênant pour
la vie privée. (C'est un des choix de conception de DoH que d'utiliser HTTPS sur le
port 443, pour ne pas être distinguable, et donc être plus difficile
à filtrer.) Le RFC 7605 donne des détails sur
ce choix des ports.
Maintenant, quelles méthodes HTTP utiliser ? Le RFC exige que les
applications utilisant HTTP se servent uniquement des méthodes enregistrées,
comme GET ou PUT. Certes,
une procédure existe pour enregistrer de nouvelles méthodes mais
l'IETF
insiste que ces nouvelles méthodes doivent être génériques, et non
pas limitées aux besoins d'une seule application. (Le RFC 4791 avait créé des méthodes spécifiques, mais c'était
avant. C'est maintenant interdit.)
Donc, pas de méthodes nouvelles. Mais quelle(s) méthode(s)
utiliser ? GET est le choix le plus
évident. Cette méthode est idempotente (et
permet donc, entre autres, la mémorisation), et a une sémantique
simple et compréhensible. Elle a quelques limites (comme le fait que
tous les éventuels paramètres doivent être dans l'URL, ce qui peut
nécessiter un encodage spécial, et peut empêcher des paramètres de
grande taille) mais rien de bien grave. Si c'est trop gênant pour
une application donnée, il ne reste plus qu'à utiliser
POST.
Et pour récupérer des métadonnées sur le
service ? Le RFC note que la méthode OPTIONS
n'est pas très pratique, par exemple parce qu'elle ne permet pas de
donner comme documentation un simple URL (la méthode par défaut
étant GET). Il recommande plutôt un URL dans
/.well-known (RFC 8615),
en créant un nouveau nom, ou
bien avec les URL host-meta (RFC 6415). Pour des métadonnées sur une ressource particulière,
il est recommandé d'utiliser les liens (RFC 8288). Le RFC
note que, dans ce dernier cas, l'en-tête Link:
marche même avec la méthode HEAD donc pas
besoin de récupérer la ressource pour avoir des informations sur ses
métadonnées.
Et les codes de retour HTTP comme 403 ou 404, comment les utiliser ? D'abord, une application qui utilise HTTP n'a pas forcément un complet contrôle sur ces codes de retour, qui peuvent être générés par des composants logiciels différents. Donc, le client HTTP doit se méfier, le code reçu n'est pas forcément significatif de l'application. Ensuite, une application peut avoir davantage de messages différents qu'il n'existe de codes de retour HTTP, ce qui peut pousser à de mauvaises pratiques, comme l'utilisation de codes de retour non standard, ou commme l'utilisation de codes certes standard mais utilisés d'une manière très éloignée de ce qui était prévu. Bref, le RFC conseille de découpler les erreurs applicatives des erreurs HTTP, de ne pas chercher à tout prix un code de retour HTTP pour chaque erreur applicative, et de ne pas hésiter à utiliser les codes de retour génériques (comme 500, pour « quelque chose ne va pas dans le serveur »). Pour envoyer des informations plus détaillées sur l'erreur, il est préférable d'utiliser les techniques du RFC 7807. Autre avertissement du RFC, les raisons envoyées par le serveur après un code de retour (404 File not found) ne sont pas significatives. Dans certains cas (message HTTP dans un message HTTP), elles ne sont pas transmises du tout, contrairement au code de retour, la seule information sur laquelle on peut compter. L'application ne doit donc pas espérer que le client recevra ces raisons.
Autre difficulté pour le concepteur ou la conceptrice
d'applications utilisant HTTP, les redirections. Il y a quatre
redirections différentes en HTTP, chacune pouvant être temporaire ou
définitive, et permettant de changer de méthode ou pas (une requête
POST indiquant une redirection suivie d'une
requête GET par le client). On a donc :
- 301, définitive et permettant de changer de méthode,
- 302, temporaire et permettant de changer de méthode,
- 307, temporaire et ne permettant pas de changer de méthode,
- 308, définitive et ne permettant pas de changer de méthode.
Et il faut donc réfléchir un peu avant de choisir un code de redirection (le RFC privilégie 301 et 302, plus souples).
Et les champs dans l'en-tête ? Une application a souvent envie d'en ajouter, que ce soit dans la requête ou dans la réponse. Mais le RFC n'est pas très chaud, demandant qu'on mette les informations plutôt dans l'URL ou dans le corps du message HTTP. Si on crée de nouveaux en-têtes, en théorie (c'est très théorique…), il faut les enregistrer à l'IANA (RFC 9110, section 16.3). Si ces en-têtes ont une structure, il est très recommandé qu'elles suivent les règles du RFC 9651.
Et le corps du message, justement ? L'application doit spécifier quel format est attendu. C'est souvent JSON (RFC 8259) mais cela peut être aussi XML, CBOR (RFC 8949), etc.
Une des grandes forces d'HTTP est la possibilité de mémorisation,
décrite en détail dans le RFC 9111. La
mémorisation améliore les performances, rend le service moins
sensible aux perturbations, et permet le passage à
l'échelle. Les applications qui utilisent HTTP ont donc
tout intérêt à permettre et à utiliser cette mémorisation. Il est
donc recommandé d'indiquer dans la réponse une durée de vie, de
préférence avec Cache-Control: max-age=… ou
bien, si c'est nécessaire, d'indiquer explicitement que la réponse
ne doit pas être mémorisée (Cache-Control:
no-store).
Un autre avantage pour une application d'utiliser HTTP est l'existence d'un cadre général pour l'authentification (RFC 9110, section 11). Attention, certains mécanismes ne doivent être utilisés qu'au-dessus d'HTTPS, comme la basic authentication du RFC 7617. HTTPS permet également d'utiliser les certificats client pour l'authentification. (Attention, avec TLS ≤ 1.2, ces certificats, qui contiennent des données personnelles, sont transmis en clair.)
Conséquence de l'utilisation de HTTP, l'application est
utilisable via un navigateur Web. Cela peut
être vu comme un avantage (tout le monde a un navigateur Web sous la
main) ou comme un inconvénient (si la sémantique de l'application ne
permet pas réellement un usage pratique depuis un navigateur). Mais
quoi qu'on en pense, l'application sera accessible aux navigateurs,
et il est donc important de s'assurer que cela ne provoquera pas de
problème. Par exemple, si on peut changer un état avec une requête
POST, l'application pourrait être attaquée
assez facilement par CSRF. Si l'application
tire une partie des données qu'elle renvoie en réponse d'une source
que l'attaquant peut contrôler, on risque le XSS. Il est donc recommandé,
même si l'application n'est pas prévue pour être utilisée par un
navigateur, de suivre les mêmes règles de développement sécurisé que
si elle devait être accédée depuis un navigateur, notamment :
- utiliser des champs dans l'en-tête comme
X-Content-Type-Options: nosniff, - utiliser CSP,
- utiliser
Referrer-Policy:, - utiliser l'option
HttpOnlysur les cookies (RFC 6265, section 5.2.6).
Voici un exemple d'une réponse suivant ces principes :
HTTP/1.1 200 OK Content-Type: application/example+json X-Content-Type-Options: nosniff Content-Security-Policy: default-src 'none' Cache-Control: max-age=3600 Referrer-Policy: no-referrer
Il reste à régler la question des frontières de l'application. Le plus simple pour l'application est d'avoir son propre nom de domaine et donc une origine (RFC 6454) unique. Cela simplifie par exemple des problèmes comme les cookies. Mais cela complique le déploiement, empêchant de mettre plusieurs applications derrière le même nom. Le RFC conseille donc plutôt de concevoir des applications pouvant coexister avec d'autres applications sous le même nom (RFC 8820).
Un mot sur la sécurité pour finir (section 6
du RFC). D'abord, une application qui utilise HTTP va évidemment
hériter des questions de sécurité générale de HTTP, comme détaillées
dans la section 17 du RFC 9110. Vu le
caractère sensible des données traitées par beaucoup d'applications,
le RFC recommande l'utilisation de HTTPS. Mais il développe aussi
la question de la vie
privée. HTTP est très bavard et le serveur en apprend
beaucoup, souvent beaucoup trop, sur son client. Ainsi, les
cookies, l'adresse
IP source, les ETags, les tickets
de session TLS sont très utiles au serveur qui voudrait
suivre un client. Et le RFC rappelle que HTTP donne assez
d'informations « auxiliaires » pour pouvoir reconnaitre un client
(ce qu'on nomme le fingerprinting). Bref, le
maintien de son intimité va être aussi difficile que sur le Web.
Ce RFC remplace l'ancien RFC 3205. Comme le note l'annexe A de notre RFC, il y a trop de changements pour les lister ; ce document est très différent de son prédécesseur (qui date de 2002 !).
Voyons maintenant quelques exemples d'application utilisant
HTTP. Dans le monde IETF, il y a évidemment
RDAP (RFC 7480, RFC 9082 et RFC 9083). RDAP
suit bien les principes de ce RFC. Par exemple, les chemins d'URL
comme /domain ou /ip ne
sont pas forcément à la « racine » du serveur HTTP. Autre exemple,
DoH (RFC 8484), également fidéle (heureusement !) aux
recommandations de l'IETF. Notez que ces recommandations laissent
des choix. Ainsi, lorsque le nom de domaine cherché n'est pas
trouvé, RDAP renvoie le code 404 (RFC 7480,
section 5.3) alors que DoH préfère renvoyer un 200 (le serveur HTTP
a bien été joignable et a bien répondu), gardant le signal de
non-existence uniquement dans la réponse DNS (RFC 8484,
section 4.2.1) transportée sur HTTP (l'argument est que DoH ne fait
que transporter les requêtes d'un autre protocole, contrairement à
RDAP).
J'ai parlé plus haut de la possibilité d'utilisation d'un
navigateur Web ordinaire pour accéder aux applications utilisant
HTTP. Mais comme ces applications envoient souvent des données
structurées en JSON, il faut un navigateur qui gère bien le
JSON. Et c'est justement ce que fait Firefox, qui sait l'afficher de manière
pratique : 
Terminons avec quelques exemples d'API « finales » (donc pas le sujet
principal du RFC,
qui parle de protocoles IETF).
Commençons modestement par l'API du DNS
looking glass. A priori, elle suit tous les
principes de ce RFC. En tout cas, elle essaie. Mais si vous
constatez des différences avec le RFC, n'hésitez pas à faire un
rapport.
Autre API intéressante, celle des sondes RIPE Atlas. Elle utilise
toutes les possibilités de HTTP, notamment les multiples méthodes
(DELETE pour supprimer une mesure en cours, par
exemple). J'aurais juste trouvé plus logique d'utiliser
PUT au lieu de POST pour
créer une mesure. L'API de Mastodon
(cf. sa
documentation) est
encore plus incohérente, utilisant POST pour
créer un pouète, mais PUT pour le mettre à jour.
L'article seul
RFC 9204: QPACK: Header Compression for HTTP/3
Date de publication du RFC : Juin 2022
Auteur(s) du RFC : C. Krasic (Netflix), M. Bishop (Akamai Technologies), A. Frindell (Facebook)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF quic
Première rédaction de cet article le 7 juin 2022
QPACK, normalisé dans ce RFC est un mécanime de compression des en-têtes HTTP, prévu spécifiquement pour HTTP/3. Il est proche du HPACK de HTTP/2, mais adapté aux particularités de QUIC.
Car le HPACK du RFC 7541 a un défaut qui n'était pas un problème en HTTP/2 mais le devient avec HTTP/3 : il supposait que les trames arrivent dans l'ordre d'émission, même si elles circulent sur des ruisseaux différents. Ce n'est plus vrai en HTTP/3 qui, grâce à son transport sous-jacent, QUIC, a davantage de parallélisme, et où une trame peut en doubler une autre (si elles n'étaient pas dans le même ruisseau). QPACK ressemble à HPACK, mais en ayant corrigé ce problème. (Au fait, ne cherchez pas ce que veut dire QPACK, ce n'est pas un acronyme.)
Donc, le principe de QPACK. Comme HPACK, on travaille avec deux
tables, qui vont associer aux en-têtes HTTP un nombre (appelé
index). L'une des tables est statique, définie dans ce RFC (annexe
A) et donc identique pour tout le monde. L'autre est dynamique et
construite par un échange de messages transmis dans des ruisseaux
QUIC. Le fonctionnement avec la table statique est simple :
l'encodeur regarde si ce qu'il veut écrire est dans la table, si
oui, il le remplace par l'index. Le décodeur, recevant un index, le
remplace par le contenu de la table. Par exemple, l'en-tête HTTP
if-none-match (RFC 7232,
section 3.2) est dans la table, index 9. L'encodeur remplacera donc
un if-none-match par 9 (12 octets de gagnés si
tout était sous forme de caractères de 8 bits, mais peut-être un peu
plus ou un peu moins, avec l'encodage de QPACK), et le décodeur fera
l'inverse.
J'ai un peu simplifié en supposant que la table ne contenait que
les noms des en-têtes. Elle peut aussi contenir leur valeur si
celle-ci est très courante. Ainsi, accept:
application/dns-message est dans la table, index 30, vu
son utilisation intensive par DoH (RFC 8484). Même chose
pour content-type: text/html;charset=utf-8 à
l'index 52.
La table dynamique est évidemment bien plus complexe. Encodeur (celui qui comprime) et décodeur doivent cette fois partager un état. En outre, le parallélisme inhérent à QUIC fait qu'un message d'ajout d'une entrée dans la table pourrait arriver après le message utilisant cette entrée. QPACK fonctionne de la façon suivante :
- L'encodeur peut envoyer (sur un ruisseau QUIC dédié) des instructions de construction de la table dynamique, notamment pour insérer une nouvelle entrée (mais pas en supprimer).
- Le décodeur accuse réception de ces instructions.
- L'encodeur envoie l'index le plus élevé de sa table, ce qui permet au décodeur, en regardant sa propre table, de savoir s'il est synchronisé ou pas. S'il ne l'est pas, le décodeur se bloque en attendant les instructions d'insertion qui vont faire grandir sa table.
QUIC a un système de contrôle de flux, et des inconvénients peuvent en résulter, par exemple un blocage des messages de contrôle de la table. Pour éviter tout blocage, un encodeur peut n'utiliser que des entrées de la table qui ont déjà fait l'objet d'un accusé de réception. Il comprimera moins mais ne risquera pas d'être bloqué.
Le RFC détaille les précautions à prendre pour éviter l'interblocage. Ainsi, les messages modifiant la table risquent d'être bloqués par ce système alors que le récepteur n'autorise pas de nouvelles trames tant qu'il n'a pas traité des trames qui ont besoin de ces nouvelles entrées dans la table dynamique. L'encodeur a donc pour consigne de ne pas tenter de modifier la table s'il ne lui reste plus beaucoup de « crédits » d'envoi de données. (D'une manière générale, quand il y a des choses compliquées à faire, QPACK demande à l'encodeur de les faire, le décodeur restant plus simple.)
L'encodage des messages QPACK est spécifié dans la section 4. QPACK utilise deux ruisseaux QUIC unidirectionnels, un dans chaque direction. Ils sont enregistrés à l'IANA.
Notez aussi qu'il y a deux instructions d'ajout d'une entrée dans
la table dynamique, une qui ajoute une valeur litérale (comme « ajoute
accept-language: fr ») et une qui ajoute une
valeur exprimée sous forme d'une référence à une entrée d'une table
(qui peut être la statique ou la dynamique). Par exemple, comme
accept-language est dans la table statique, à
l'index 72, on
peut dire simplement « ajoute 72: fr ». Encore quelques octets
gagnés.
Dans la trame SETTINGS de HTTP/3, deux
paramètres concernent spécialement QPACK, pour indiquer la taille
maximale de la table dynamique, et le nombre maximal de ruisseaux
bloqués. Ils sont placés dans un registre IANA.
Quelques mots sur la sécurité : dans certaines conditions, un observateur peut obtenir des informations sur l'état des tables (cf. l'attaque CRIME) même s'il ne peut déchiffrer les données protégées par TLS, celui-ci ne masquant pas la taille. Bien sûr, on pourrait remplir avec des données bidons mais cela annulerait l'avantage de la compression. La section 7 du RFC donne quelques idées sur des mécanismes de limitation du risque.
L'annexe A du RFC spécifie la table statique et ses 98
entrées. Elle a été composée à partir de l'analyse de trafic HTTP en
2018. L'ordre des entrées n'est pas arbitraire : vu comment sont
représentés les entiers, donc les index, dans QPACK, les entrées les
plus fréquentes sont en premier, car QPACK utilise moins de bits pour
les nombres les plus petits. Notez aussi que cette table comprend
les en-têtes HTTP « classiques », comme
content-length ou
set-cookie mais aussi ce que
HTTP/2 appelle les « pseudo-en-têtes », qui
commencent par deux-points. C'est par exemple
le cas de la méthode HTTP (GET,
PUT, etc), notée :method
ou, dans les réponses, du code de retour, noté
:status (tiens, la table statique a une entrée
pour le code 403 mais pas pour le 404).
Si vous envisagez de programmer QPACK, l'annexe B contient des exemples de dialogue entre encodeur et décodeur, et l'annexe C du pseudo-code pour l'encodeur.
L'article seul
RFC 9199: Considerations for Large Authoritative DNS Servers Operators
Date de publication du RFC : Mars 2022
Auteur(s) du RFC : G.C.M. Moura (SIDN Labs/TU Delft), W. Hardaker, J. Heidemann (USC/Information Sciences Institute), M. Davids (SIDN Labs)
Pour information
Première rédaction de cet article le 22 mars 2022
On sait que le DNS est un des services d'infrastructure les plus essentiels de l'Internet. Il est, par exemple, crucial que les serveurs DNS faisant autorité soient correctement gérés, et robustes face aux problèmes qui peuvent survenir. Ce RFC donne un certain nombre de conseils (juste des conseils, il ne s'agit pas d'une norme) aux opérateurs de ces serveurs.
Il n'est pas obligatoire de suivre ces conseils mais il faut noter qu'ils sont tous fondés sur des articles publiés dans des revues techniques avec examen par les pairs. Donc, c'est quand même sérieux, même si ce RFC n'a pas le statut de norme. Le RFC vise surtout les « gros » serveurs faisant autorité, par exemple les serveurs de TLD importants. Ces serveurs sont typiquement anycastés (RFC 1546 et RFC 4786). Si le vôtre est unicast et ne sert qu'à trois visiteurs de temps en temps, vous n'êtes pas forcément concerné·e.
Au passage, cette distinction entre serveurs faisant autorité et résolveurs est cruciale dès qu'on parle du DNS. La section 2 du RFC commence d'ailleurs par un rappel de cette distinction. D'autre part, cette même section insiste sur l'importance du DNS pour le vécu de l'utilisatrice. Par exemple la latence perçue par celle-ci dépend en bonne partie du DNS. Voici un exemple :
% curl-timing https://www.nic.af/ DNS: 0,920891 s TCP connect: 1,124164 s TLS connect: 1,455578 s Start transfer: 1,598288 s Total: 1,735741 s
On voit que la résolution DNS a pris plus de la moitié du temps
total. (La commande curl-timing est définie par
alias curl-timing='curl --silent --output /dev/null
--write-out "DNS: %{time_namelookup} s\nTCP connect: %{time_connect}
s\nTLS connect: %{time_appconnect} s\nStart transfer:
%{time_starttransfer} s\nTotal: %{time_total} s\n"'.) Sur
ce sujet de la latence, voir aussi l'article « The
Internet at the Speed of Light ». La latence dépend
en grande partie de la distance géographique, et la réduire impose
donc une présence mondiale.
Et ces performances, et cette robustesse sont menacées, entre autres, par les nombreuses attaques par déni de service qui visent le DNS, comme celle décrite dans l'article « Anycast vs. DDoS: Evaluating the November 2015 Root DNS Event ».
La section 3 est le cœur du RFC, contenant les recommandations, numérotées de C1 à C6. Commençons par C1, le conseil de n'avoir que des serveurs anycast. L'anycast est indispensable pour répartir très largement les serveurs, assurant la performance et la robustesse de la résolution DNS. Bien sûr, on peut se contenter d'avoir plusieurs enregistrements NS mais cela ne suffit pas : diverses raisons font qu'on ne peut pas avoir des centaines d'enregistrements dans un ensemble NS, alors que certains nuages anycast atteignent cette taille. Donc, avoir plusieurs enregistrements NS est nécessaire mais cela ne dispense pas de l'anycast.
C'est d'autant plus vrai que, parmi les enregistrements NS, la
sélection de celui utilisé est faite par le résolveur. Les
résolveurs corrects mesurent la latence et choisissent le serveur
faisant autorité le plus rapide. Mais il y a d'autres résolveurs qui
n'utilisent pas de bons algorithmes de sélection
(cf. « Recursives
in the Wild: Engineering Authoritative DNS
Servers »). Avec l'anycast, la
sélection de l'instance utilisée est faite par le réseau, via
BGP, et peut
donc être meilleure. Du fait de ces résolveurs sous-performants, un
opérateur a donc intérêt à ce que tous les serveurs faisant autorité
soient anycastés. S'il y a un « maillon faible »,
unicast et mal connecté, il sera quand même
consulté par certains résolveurs, et dégradera donc la latence dans
certains cas. Par exemple, le TLD
.nl est passé en tout
anycast en 2018.
Maintenant, C2, le conseil de travailler son
routage. Une fois qu'on a décidé de mettre de
l'anycast partout, il reste à
optimiser. BGP
ne garantit pas du tout, contrairement à ce qu'on lit parfois, que
la route la plus rapide sera choisie. BGP fait ce que les
administrateurs réseau lui demandent de faire. On voit régulièrement
des traceroute qui montrent qu'on ne va pas à
l'instance anycast la plus proche. Certains
opérateurs DNS compensent en ajoutant davantage d'instances mais
l'article « Anycast
Latency: How Many Sites Are Enough? » montre, en
testant des serveurs de la racine depuis des
sondes RIPE Atlas, que le
nombre d'instances compte moins que le soin apporté au routage. (On
ne parle ici que de performances ; pour la résistance aux attaques
par déni de service, le nombre d'instances reste essentiel.) Ici, le
temps de réponse des serveurs faisant autorité pour
.fr, depuis une machine
en France (il y a une instance proche pour chaque serveur) :
% check-soa -i fr d.nic.fr. 2001:678:c::1: OK: 2230506452 (4 ms) 194.0.9.1: OK: 2230506452 (0 ms) e.ext.nic.fr. 193.176.144.22: OK: 2230506434 (15 ms) 2a00:d78:0:102:193:176:144:22: OK: 2230506434 (15 ms) f.ext.nic.fr. 194.146.106.46: OK: 2230506434 (6 ms) 2001:67c:1010:11::53: OK: 2230506452 (11 ms) g.ext.nic.fr. 2001:678:4c::1: OK: 2230506434 (2 ms) 194.0.36.1: OK: 2230506434 (2 ms)
Le conseil C3 porte sur un concept très important lorsqu'on fait de l'anycast, celui de bassin d'attraction. Ce terme désigne l'ensemble des réseaux qui vont envoyer leurs paquets vers une instance donnée. Si toutes les instances ont à peu près les mêmes capacités de traitement des requêtes, on souhaite en général placer les instances et configurer BGP de manière à ce que toutes les instances reçoivent à peu près la même quantité de requêtes. Mais en pratique c'est rarement le cas : le réseau est une chose compliquée. Il existe des méthodes pour améliorer les choses (cf. l'article « Broad and Load-Aware Anycast Mapping with Verfploeter », qui décrit l'outil Verfploeter) mais ce n'est jamais parfait. Au moins, un outil comme Verfploeter permet de procéder plus scientifiquement qu'au pifomètre, et d'avoir une idée de ce que produiront des changements de configuration BGP pour faire du traffic engineering (par exemple, allonger le chemin d'AS dans les annonces, pour diminuer le trafic d'une instance).
Le conseil C4, quant à lui, porte sur les attaques par déni de service (comme celle décrite dans « Anycast vs. DDoS: Evaluating the November 2015 Root DNS Event ») et sur le comportement des serveurs soumis à un stress intense. Que peut faire l'opérateur lorsque Mirai ou un de ses semblables attaque ?
- Essayer de diminuer le trafic entrant, soit en faisant du traffic engineering BGP pour envoyer le trafic vers une autre instance, si certaines ont davantage de capacité, ou bien ne sont pas attaquées, voire, si on n'a pas de réserves, en arrêtant complètement d'annoncer les routes (ce qui arrête le service - ce qui était le but de l'attaquant - mais cela peut être nécessaire s'il y a d'autres services au même endroit et qu'on veut les épargner),
- Ou bien encaisser en silence, sachant qu'on perdra des requêtes et qu'on ne pourra pas répondre à tout. Si l'attaque ne frappait que certaines instances, cela peut permettre d'épargner les instances non attaquées.
Le conseil C4 est donc d'avoir des plans prêts à l'avance, permettant de prendre une décision en cas de crise, et de l'appliquer.
Et les TTL ? Ils ne sont pas oubliés. La mémorisation des réponses, pendant une durée maximale égale au TTL, est un point essentiel du DNS, et un facteur de performance crucial. Même si un serveur faisant autorité répond souvent en moins de 50 ms, la réponse de la mémoire d'un résolveur, qui peut arriver en 1 ms, sera encore préférable. Ce rôle a été largement étudié (voir par exemple « Modeling TTL- based Internet Caches » ou, plus récemment, « When the Dike Breaks: Dissecting DNS Defenses During DDoS »). Une étude des conséquences du choix du TTL sur les performances est la base du conseil C5, l'étude « Cache Me If You Can: Effects of DNS Time-to- Live ». Elle montre que :
- Des TTL plus longs diminuent le temps de réponse (puisque
les données sont conservées plus longtemps dans la mémoire des
résolveurs), cf. par exemple l'expérience faite sur
.uycitée dans l'article ci-dessus, - Ces TTL plus longs diminuent le trafic DNS, pour la même raison, (logiquement, les gens qui s'inquiètent de l'empreinte environnementale du numérique devraient mettre des TTL longs sur leurs domaines),
- Et ils améliorent la robustesse face aux attaques par déni de service (même si tous les serveurs faisant autorité ont du mal à répondre, les résolveurs pourront continuer à servir les données),
- D'un autre côté, et comme il n'existe pas de solution parfaite, juste des choix et des compromis, des TTL plus longs empêchent de changer rapidement sa configuration ; si le changement était planifié, ce n'est pas grave (on abaisse le TTL avant le changement et on le remonte après), mais si on veut le faire en urgence, c'est plus gênant,
- C'est d'autant plus gênant que certains services d'atténuation des attaques par déni de service fonctionnent en utilisant le DNS pour envoyer le trafic vers l'atténuateur ; des TTL longs limitent cette possibilité (et la planification ne change rien dans ce cas, puisque les attaquants ne se signalent pas forcément à l'avance),
- Même problème avec la répartition de charge utilisant le DNS.
Bref, on ne peut pas faire une recommandation quantitative appliquable à tous les cas. Le conseil C5 est donc plus complexe :
- Pour un domaine ordinaire, des TTL d'au moins une heure, et de préférence d'au moins huit heures sont recommandés,
- Pour les gros registres (par exemple registres de TLD), la plupart des résolveurs utiliseront de toute façon les TTL indiqués dans la zone fille ; pour le bien des autres résolveurs, le RFC recommande un TTL d'au moins une heure,
- Pour les zones « terminales » qui utilisent des répartiteurs de charge ou des services d'atténuation d'attaques qui reposent sur le DNS, on peut se contenter de TTL de 5 minutes, mais le RFC recommande quand même au moins 15 minutes.
Et si les TTL entre la zone parente et la zone fille diffèrent ?
La question se pose typiquement pour les enregistrements
NS. Par exemple, les enregistrements NS dans la zone
racine ont un TTL de 48 heures, alors que dans les zones des TLD,
l'ensemble NS a presque toujours un TTL plus faible (une heure pour
.cl, par exemple). Selon
que le résolveur est parent-centric (une
minorité) ou child-centric (la grande majorité),
il utilisera le TTL de la zone parente ou bien celui de la zone
fille. Le conseil C6 : on ne peut pas compter que le TTL qu'on a mis
soit respecté partout, si l'enregistrement existe aussi dans la zone
parente avec des TTL différents. Attention donc lorsqu'on veut
changer quelque chose, à intégrer le TTL de la zone parente.
Un bon résumé en anglais de ce RFC a été écrit par un des auteurs. Il inclut un récit de la création du RFC et du processus suivi.
L'article seul
RFC 9184: BGP Extended Community Registries Update
Date de publication du RFC : Janvier 2022
Auteur(s) du RFC : C. Loibl (next layer Telekom)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF idr
Première rédaction de cet article le 21 janvier 2022
Les « communautés étendues » de BGP, des attributs d'une annonce de route avec BGP, sont enregistrées dans des registres IANA, décrits par le RFC 7153. Notre nouveau RFC 9184 met légèrement à jour les procédures d'enregistrement dans ces registres.
Le principal changement est simple : les types 0x80, 0x81 et 0x82 du registre des communautés étendues transitives sont désormais utilisables selon une politique d'enregistrement « premier arrivé, premier servi » (cf. RFC 8126 sur ces politiques d'enregistrement à l'IANA). Ils sont en effet utilisés par le RFC 8955 alors qu'ils étaient dans une plage prévue pour les expérimentations. L'erreur est donc désormais rectifiée.
L'article seul
RFC 9172: Bundle Protocol Security (BPSec)
Date de publication du RFC : Janvier 2022
Auteur(s) du RFC : E. Birrane, K. McKeever (JHU/APL)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dtn
Première rédaction de cet article le 1 février 2022
Le protocole Bundle, normalisé dans le RFC 9171, permet la communication entre des machines dont la connectivité est faible et/ou intermittente, par exemple dans le domaine spatial. L'absence de synchronicité interdit beaucoup de solutions de sécurité couramment utilisées sur l'Internet. Ce nouveau RFC présente donc un mécanisme spécifique pour assurer la sécurité (confidentialité et intégrité) des communications faites avec Bundle : ce mécanisme se nomme BPsec (Bundle Protocol security). Notez que le mécanisme est très général, et laisse de côté de nombreux détails.
BPsec peut assurer une sécurité de bout en bout. Ce n'est pas évident dans le contexte d'utilisation de Bundle (RFC 4838), les DTN (Delay Tolerant Networks). Bundle est un protocole qui fonctionne en « enregistre et fais suivre » (store and forward), sans liaisons directes entre émetteur et récepteur, et avec des réseaux lents, imprévisibles, à fort taux de perte de paquets. On ne peut donc pas garantir, par exemple, qu'émetteur et récepteur pourront communiquer à la demande avec un tiers de confiance, genre autorité de certification. On ne peut même pas supposer que toutes les liaisons seront bidirectionnelles, ce qui veut dire, entre autres, qu'un échange de clés Diffie-Hellman ne sera pas possible. Le protocole suppose évidemment que ledit réseau n'est pas de confiance : des méchants peuvent regarder et modifier les bits qui circulent. Cette supposition est classique en sécurité.
BPsec ne va pas essayer de garantir une authentification de chaque étape intermédiaire. D'abord, on ne sait pas si le nœud suivant est réellement adjacent dans l'espace physique (il peut y avoir des intermédiaires « invisibles ») et puis les différents nœuds par lequel le message va passer peuvent avoir des choix de sécurité incompatibles, les réseaux DTN pouvant, comme l'Internet, être composés de nœuds gérés par des organisations différentes.
Si les logiciels sont tous bien programmés, et que les clés privées utilisées n'ont pas été compromises, BPsec va garantir l'intégrité et la confidentialité des messages. BPsec est la continuation du cadre défini dans le RFC 6257, en le simplifiant et en le rendant plus réaliste.
Un peu de terminologie pour suivre ce RFC : d'abord, un rappel qu'un bundle est composé de blocs (RFC 9171, section 4.3). Ensuite :
- Bloc de sécurité (security block) : un bloc d'extension dans un bundle, une unité de données.
- Security acceptor : un nœud qui traite un bloc de sécurité, et le supprime ensuite. Ce n'est pas forcément le destinataire final (sauf évidemment pour les services de sécurité de bout en bout).
- Service de sécurité (security service) : un service particulier, par exemple la confidentialité.
- Source de sécurité (security source) : un nœud qui ajoute un bloc de sécurité. Ce n'est pas forcément l'émetteur initial.
- Vérificateur de sécurité (security verifier) : un nœud qui lit et vérifie un bloc de sécurité mais qui ne le supprime pas.
La section 2 du RFC résume les points importants de la conception de BPsec :
- Sécurité au niveau du bloc, pas du bundle entier.
- Plusieurs sources ont pu mettre des blocs de sécurité dans le bundle.
- Les différents nœuds ont des politiques de sécurité différentes.
- BPsec a une notion de contexte de sécurité (qui définit les techniques admissibles, par exemple les algorithmes de cryptographie), notion détaillée dans la section 9.
- Traitement déterministe des différents blocs de sécurité, notamment de l'ordre de traitement.
Il existe deux sortes de blocs de sécurité (les types de bloc figurent dans un registre IANA, défini dans le RFC 6255), les BIB (Block Integrity Block) et les BCB (Block Confidentiality Block). Les sources de sécurité ajoutent ces blocs et les acceptors les traitent. Dans le cas d'un chiffrement de bout en bout, par exemple, l'émetteur met un BCB que le destinataire déchiffrera. Dans un autre cas, on peut voir un nœud de départ ne mettre aucun bloc de sécurité (peut-être parce que ce nœud est un objet contraint, avec trop peu de ressources de calcul) mais un nœud intermédiaire ajouter un BIB pour protéger le contenu avant un voyage sur un lien qu'on sait dangereux. Ces blocs sont encodés comme spécifié dans le RFC 9171. L'ajout d'un BIB ne modifie pas le contenu du bundle mais celui d'un BCB va le faire, puisque les données seront chiffrées.
Le bloc contient notamment l'identificateur du nœud qui l'a ajouté.
Le bloc doit être mis sous forme canonique de CBOR (RFC 8949, section 4.2). Comme toujours en cryptographie, pour que les signatures soient vérififiables, il faut que les données soient sous une forme canonique.
La section 5 du RFC décrit le traitement des blocs de sécurité. Le nœud peut les passer tels quels, sans les interpréter, s'il n'est qu'un intermédiaire. Ou bien, s'il veut les valider, il va alors vérifier leurs signatures, déchiffrer, etc. En cas d'erreur, notre RFC ajoute cinq codes supplémentaires pour les signaler.
Pas de cryptographie sans clés et la gestion des clés est souvent le point difficile. La section 6 rappelle le problème. Comme les réseaux de type DTN seront très variés, avec des caractéristiques bien différentes, notre RFC ne décrit pas une méthode unique de gestion de clés. Disons que cette gestion est repoussée aux mises en œuvre ultérieures.
Enfin, la section 7 du RFC décrit les différentes politiques possibles, et la section 8 analyse en détail les caractéristiques de sécurité de ce système, face aux différentes menaces. Parmi les points amusants, le RFC note qu'avec les DTN, on peut s'attendre à ce que des bundles restent dans le réseau très longtemps, peut-être même des années (!) et que la cryptographie (choix des algorithmes, par exemple) doit donc être pensée pour durer.
Ce mécanisme de sécurité est mis en œuvre dans le logiciel libre ION.
L'article seul
RFC 9171: Bundle Protocol Version 7
Date de publication du RFC : Janvier 2022
Auteur(s) du RFC : S. Burleigh (JPL, Calif. Inst. Of Technology), K. Fall (Roland Computing Services), E. Birrane (APL, Johns Hopkins University)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dtn
Première rédaction de cet article le 1 février 2022
Après plusieurs itérations, le protocole Bundle, qui sert à transmettre des messages dans des situations où la connectivité est intermittente et la latence importante (par exemple dans l'espace), a atteint sa version 7, la première qui soit officiellement norme de l'Internet. Ce nouveau RFC décrit cette version 7, assez modifiée par rapport à la version 6 qui faisait l'objet du RFC 5050. Les deux versions n'interopèrent pas.
« Dans l'espace, personne ne vous entend crier », disait l'annonce du film Alien. Peut-être, mais on veut quand même communiquer, échanger des messages et des fichiers. Les particularités de cet environnement (et de quelques autres analogues comme par exemple des étendues peu connectées sur Terre ou bien des situations post-catastrophe) ont suscité la création du groupe DTN (Delay-Tolerant Networking), qui travaille à normaliser des techniques pour envoyer une photo de chat à un autre vaisseau spatial. La version 6 du protocole Bundle, spécifié dans le RFC 5050, avait été programmée dans de nombreux langages, et l'expérience acquise avec Bundle v6 a mené cette version 7. Dans les environnements concernés, avec leur latence élevée (et parfois très variable), leur taux de pertes de paquets souvent important, et leur connectivité intermittente, les protocoles de transport comme TCP et les protocoles applicatifs qui les accompagnent ne conviennent pas. Il n'est pas possible de faire du synchrone (on ne peut pas rester à attendre l'autre pendant on ne sait pas combien de temps). D'où la nécessité de protocoles spécifiques, architecturés autour de l'idée de « enregistre et fais suivre » (store and forward), où chaque machine intermédiaire va stocker les messages en attendant une occasion de les livrer. (Oui, ça ressemble à UUCP et c'est logique, les cahiers des charges étant analogues.) Notre RFC résume ce qu'on attend d'un tel protocole :
- Capacité à utiliser des déplacements physiques des données (en gros, la clé USB dans un camion, mécanisme dont on sait qu'il a une latence désastreuse mais une énorme capacité ; cf. l'anecdote amusante de l'Allemand et son cheval, ou bien l'offre SnowMobile d'Amazon).
- Capacité d'un envoyeur à oublier, une fois qu'il a transmis le message au nœud suivant (alors que TCP doit garder les données, en attendant l'accusé de réception de la destination finale).
- Capacité à gérer les connectivités intermittentes, voire les cas où émetteur et récepteur ne sont jamais joignables en même temps.
- Capacité à utiliser les cas où la connectivité arrive à un moment prédit à l'avance, aussi bien que ceux où il faut être opportuniste, utilisant la connectivité quand elle arrive.
Des détails sur ce cahier des charges sont dans les RFC 4838 et dans l'article de K. Fall à SIGCOMM « A delay-tolerant network architecture for challenged internets ».
La section 3 du RFC rappelle les termes utilisés, notamment :
- Bundle (j'ai été trop paresseux pour traduire ce terme mais Bertand Petit suggère « ballot ») : une unité de données transmises. Un message (tel que compris par l'utilisateur humain) va être découpé en bundles qui seront transmis sur le réseau.
- BPA (Bundle Protocol Agent) : le logiciel qui, sur un nœud, met en œuvre le protocole décrit dans ce RFC.
- CLA (Convergence Layer Adapter) : la partie du protocole qui parle aux couches basses, pour effectuer l'envoi et la réception. Cela peut, par exemple, être TCP (RFC 9174).
- Nœud (node) : une machine qui peut
envoyer et recevoir des bundles mais aussi
relayer les bundles des autres. Chaque nœud a
un identificateur, le node ID, qui est un
URI
(RFC 3986), en général de plan
dtn(commedtn://example.com/foobar) ou, de plus bas niveau et de signification seulement locale,ipn, qui avait été créé par le RFC 6260 (commeipn:9.37). Les plans utilisés ont été mis dans le registre IANA. - Transmission (Forwarding) : faire suivre le message au nœud suivant (tout ce protocole est « saut par saut », avec des nœuds qui se refilent les bundles).
- Terminal (endpoint) : un ou plusieurs nœuds qui mettent en œuvre un service. Une sorte de nœud virtuel, quoi. Comme les nœuds, ils ont un identificateur qui est un URI.
La section 4 du RFC décrit le format des bundles. Ce sera du CBOR (RFC 8949). Un bundle comprend un certain nombre de booléens qui indiquent si le récepteur doit accuser réception de l'arrivée du bundle, de la transmission au nœud suivant, etc. (Leur liste figure dans un registre IANA.) Il indique également la destination (sous le forme d'un endpoint ID) et la source (facultative).
Un bundle est en fait composé de blocs, chaque bloc étant un tableau CBOR. Le premier bloc porte les métadonnées indispensables pour les nœuds qui relaieront le bundle (comme l'identificateur de destination) ou comme la durée de vie du bundle (analogue au TTL d'IP). Chaque bloc contient un type et des données. La charge utile du bundle est dans un bloc de type 1, les autres types servant à divers détails (qui, dans IP, seraient mis dans les options du paquet en IPv4 et dans un en-tête d'extension en IPv6). Par exemple, un bloc de type 7 sert à transporter l'âge du bundle, alors qu'un bloc de type 10 à indiquer le nombre de sauts maximum et le nombre déjà effectués. Les différents types figurent dans un registre IANA.
La section 5 du RFC précise comment on traite les bundles. Lors de la réception d'un bundle, le nœud qui n'est pas destination (dont l'identificateur n'apparait pas dans le champ de destination) doit décider s'il transmet le bundle ou pas. S'il décide de le transmettre, il doit ensuite regarder s'il « connait » le nœud de destination (s'il sait le joindre directement) ou bien s'il doit le transmettre à un nœud mieux placé. Comment trouve-t-on ces nœuds mieux placés ? De même que le RFC sur IP ne décrit pas les protocoles de routage, le Bundle Protocol ne précise pas. Cela est fait par des protocoles externes comme SABR.
Une fois prise la décision d'envoyer le bundle à un autre nœud, on sélectionne un CLA adapté à cet autre nœud et on lui transmet. (Puis on le supprime du stockage local.) Bref, tout cela ressemble beaucoup au traitement d'un paquet IP par un routeur IP classique, avec le CLA jouant le rôle de la couche 2. La plus grosse différence est sans doute que le nœud peut garder le paquet pendant un temps assez long, s'il ne peut pas le transmettre tout de suite. La gestion des files d'attentes et des retransmissions sera donc assez différente de celle d'un routeur IP.
En cas d'échec, le nœud peut décider de renvoyer le bundle à l'expéditeur ou de le jeter. Si le bundle a expiré (durée de vie dépassée), il est jeté.
À la réception d'un bundle, le nœud regarde aussi si ce bundle nécessitait un accusé de réception et, si nécessaire, il en envoie. Si le bundle a une destination locale, il est livré à la machine. (Le bundle a pu être fragmenté et, dans ce cas, il faudra attendre que tous les fragments soient là, pour le réassemblage, cf. section 5.8).
La section 6 du RFC couvre le cas des enregistrements administratifs, des messages (envoyés évidemment sous forme de bundles) qui servent à gérer le bon fonctionnement du protocole (un peu comme ICMP pour IP). Ces enregistrements sont un tableau CBOR de deux entrées, un type (un nombre) et les données, un seul type d'enregistrement administratif existe actuellement, de type 1, le rapport d'état, qui va servir à indiquer ce que le message est devenu. Son format et son contenu sont détaillés dans la section 6.1.1. Il dispose d'une liste de codes, comme 1 pour « durée de vie dépassée » ou 5 pour « je n'arrive pas à joindre la destination ».
On a vu que BP, le Bundle Protocol, dépend d'un CLA (Convergence Layer Adapter) pour parler aux couches basses. La section 7 précise ce qu'on attend de ce convergence layer :
- Il doit évidemment permettre d'envoyer un bundle d'un nœud à l'autre,
- il doit rendre des comptes au BP, lui disant s'il a pu transmettre le bundle ou pas,
- il doit pouvoir recevoir des bundles et les livrer localement.
- Certaines extensions peuvent ajouter des exigences au CLA.
Le CLA doit faire tout cela tout en respectant le réseau sous-jacent, par exemple en évitant la congestion. Notez que dans la plupart des cas d'usage de BP, la latence est telle qu'on ne peut pas compter sur les réactions du récepteur, et il faut donc se débrouiller autrement. Un exemple d'un CLA est celui avec TCP du RFC 9174 (mais dans la plupart des scénarios envisagés pour le Bundle Protocol, TCP ne sera pas utilisable).
Il y a actuellement pas moins de sept mises en œuvres différentes de ce BP (Bundle Protocol) :
- µPCN. Écrit en C, pour le système d'exploitation FreeRTOS. Libre. Il semble que ce soit la première mise en œuvre de BP qui intègre la version de notre RFC, la 7.
- µD3TN. Écrit en Python. Licence libre.
- PyDTN (développé par X-works). Écrit en Python. Il ne semble pas publiquement disponible.
- LibDTN/Terra, bibliothèque et applications. En Java.
- dtn7-go est écrit en Go. Licence libre. Met en œuvre la version 7 de BP.
- dtn7-rs est en Rust, également sous une licence libre, et gère également la version 7. Il vise les machines contraintes.
- Bien sûr, vu le plus spectaculaire cas d'usage du DTN, l'espace, la NASA a également développé du logiciel. À propos de la NASA, notez qu'ils produisent beaucoup de documentation sur le DTN.
Notez que deux mises en œuvre de BP ne peuvent interopérer que si elles utilisent le même CLA.
Par défaut, BP n'offre aucune sécurité (cf. section 8). Un attaquant peut suivre le trafic, le modifier, etc. Certes, notre RFC recommande un CLA « sûr » mais cela ne suffit pas. La sécurité doit être fournie par des extensions, comme celle du RFC 9172. Notons aussi que le protocole utilise à plusieurs endroits des estampilles temporelles, donc sa sécurité dépend de celle de son horloge.
L'annexe A détaille les changements depuis le RFC 5050, qui normalisait la version 6 du protocole. Outre le changemente de statut (BP est désormais une norme et plus une « expérience »), les changements techniques sont importants à tel point qu'il n'y a pas d'interopérabilité entre les deux versions. Entre autres, les concepts de node ID et endpoint ID sont désormais séparés, le premier bloc d'un bundle est désormais immuable, de nouveaux types de blocs ont été créés, l'encodage abandonne l'ancien SDNV (RFC 6256) pour CBOR, etc. (Notez qu'il existe un registre IANA des versions de BP.)
Un des avantages de CBOR est l'existence du langage de
description CDDL (RFC 8610), ce qui permet de
donner une description formelle des bundles dans
l'annexe B. Par exemple, voici la description du premier bloc de
chaque bundle, en CDDL (eid
étant l'Endpoint ID) :
primary-block = [
version: 7,
bundle-control-flags,
crc-type,
destination: eid,
source-node: eid,
report-to: eid,
creation-timestamp,
lifetime: uint,
...
? crc-value,
]
Avec un cahier des charges présentant beaucoup de ressemblances avec celui du BP, notez l'existence du système NNCP, qui est également de type « enregistre et fais suivre ». Ça semble très intéressant mais je ne l'ai jamais testé.
L'article seul
RFC 9170: Long-term Viability of Protocol Extension Mechanisms
Date de publication du RFC : Décembre 2021
Auteur(s) du RFC : M. Thomson (Mozilla), T. Pauly (Apple)
Pour information
Première rédaction de cet article le 1 janvier 2022
Après des années de déploiement d'un protocole sur l'Internet, lorsqu'on essaie d'utiliser des fonctions du protocole parfaitement standards et légales, mais qui avaient été inutilisées jusqu'à présent, on découvre souvent que cela ne passe pas : des programmes bogués, notamment dans les middleboxes, plantent de manière malpropre lorsqu'ils rencontrent ces (toutes relatives) nouveautés. C'est ce qu'on nomme l'ossification de l'Internet. Ce RFC de l'IAB fait le point sur le problème et sur les solutions proposées, par exemple le graissage, l'utilisation délibérée et précoce de variations, pour ne pas laisser d'options inutilisées.
Lorsqu'un protocole a du succès (cf. RFC 5218, sur cette notion de succès), on va vouloir le modifier pour traiter des cas nouveaux. Cela n'est pas toujours facile, comme le note le RFC 8170. Tout protocole a des degrés de liberté (extension points) où on pourra l'étendre. Par exemple, le DNS permet de définir de nouveaux types de données (contrairement à ce qu'on lit souvent, le DNS ne sert pas qu'à « trouver des adresses IP à partir de noms ») et IPv6 permet de définir de nouvelles options pour la destination du paquet, voire de nouveaux en-têtes d'extension. En théorie, cela permet d'étendre le protocole. Mais en pratique, utiliser ces degrés de liberté peut amener des résultats imprévus, par exemple, pour le cas du DNS, un pare-feu programmé avec les pieds qui bloque les paquets utilisant un type de données que le pare-feu ne connait pas. Ce RFC se focalise sur des couches relativement hautes, où tout fonctionne de bout en bout (et où, en théorie, les intermédiaires doivent laisser passer ce qu'ils ne comprennent pas). Les couches basses impliquent davantage de participants et sont donc plus problématiques. Ainsi, pour IPv6, l'en-tête « options pour la destination » doit normalement être ignoré et relayé aveuglément par les routeurs alors que l'en-tête « options pour chaque saut » doit (enfin, devait, avant le RFC 8200) être compris et analysé par tous les routeurs du chemin, ce qui complique sérieusement son utilisation.
Notre RFC a été développé par l'IAB dans le cadre du programme « Evolvability, Deployability, & Maintainability (EDM) ».
Déployer une nouvelle version d'un protocole, ou simplement utiliser des options qui n'avaient pas été pratiquées avant, peut donc être très frustrant. Prenons le cas imaginaire mais très proche de cas réels d'un protocole qui a un champ de huit bits inutilisé et donc le RFC d'origine dit que l'émetteur du paquet doit mettre tous ces bits à zéro, et le récepteur du paquet, en application du principe de robustesse, doit ignorer ces bits. Un jour, un nouveau RFC sort, avec une description du protocole où ces bits ont désormais une utilité. Les premiers logiciels qui vont mettre en œuvre cette nouvelle version, et mettre certains bits à un, vont fonctionner lors de tests puis, une fois le déploiement sur l'Internet fait, vont avoir des problèmes dans certains cas. Un pare-feu programmé par des incompétents va jeter ces paquets. Dans son code, il y a un test que le champ vaut zéro partout, car le programmeur n'a jamais lu le RFC et il a juste observé que ce champ était toujours nul. Cette observation a été mise dans le code et bonne chance pour la corriger. (Les DSI qui déploient ce pare-feu n'ont pas regardé s'il était programmé correctement, ils ont juste lu la brochure commerciale.) À partir de là, les programmeurs qui mettent en œuvre le protocole en question ont le choix de foncer et d'ignorer les mines, acceptant que leur programme ne marche pas si les paquets ont le malheur de passer par un des pare-feux bogués (et seront donc perdus), ou bien de revenir à l'ancienne version, ce second choix étant l'ossification : on n'ose plus rien changer de peur que ça casse quelque chose quelque part. Comme les utilisateurs ignorants attribueraient sans doute les problèmes de timeout à l'application, et pas au pare-feu mal écrit, le choix des programmeurs est vite fait : on ne déploie pas la nouvelle version. C'est d'autant plus vrai si le protocole est particulièrement critique pour le bon fonctionnement de l'Internet (BGP, DNS…) ou bien s'il y a de nombreux acteurs non coordonnés (cf. section 2.3). Bien sûr, le blocage de certains paquets peut être volontaire mais, bien souvent, il résulte de la négligence et de l'incompétence des auteurs de middleboxes (cf. section 5).
Les exemples de tels problèmes sont innombrables (l'annexe A du
RFC en fournit plusieurs). Ainsi, TLS a eu bien des ennuis avec des nouvelles
valeurs de l'extension
signature_algorithms.
Si le protocole en question était conçu de nos jours, il est probable que ses concepteurs prendraient la précaution de réserver quelques valeurs non nulles pour le champ en question, et de demander aux programmes d'utiliser de temps en temps ces valeurs, pour être sûr qu'elles sont effectivement ignorées. C'est ce qu'on nomme le graissage et c'est une technique puissante (mais pas parfaite) pour éviter la rouille, l'ossification. (Notez que les valeurs utilisées pour le graissage ne doivent pas être consécutives, pour limiter les risques qu'un programmeur de middlebox paresseux ne les teste facilement. Et qu'il faut les réserver pour que, plus tard, l'utilisation de vraies valeurs pour ce champ ne soit pas empêchée par les valeurs de graissage.) Le graissage ne résout pas tous les problèmes puisqu'il y a toujours le risque que les valeurs utilisées pour graisser finissent par bénéficier d'un traitement de faveur, et soient acceptées, alors que les valeurs réelles poseront des problèmes.
On pourrait penser qu'une meilleure conception des protocoles éviterait l'ossification. (C'est le discours des inventeurs géniaux et méconnus qui prétendent que leur solution magique n'a aucun inconvénient et devrait remplacer tout l'Internet demain.) Après tout, le RFC 6709 contient beaucoup d'excellents conseils sur la meilleure façon de concevoir des protocoles pour qu'ils puissent évoluer. Par exemple, il insiste sur le fait que le mécanisme de négociation qui permet aux deux parties de se mettre d'accord sur une option ou une version doit être simple, pour qu'il y ait davantage de chances qu'il soit mis en œuvre correctement dans tous les programmes. En effet, en l'absence de graissage, ce mécanisme ne sera testé en vrai que lorsqu'on introduira une nouvelle version ou une nouvelle option et, alors, il sera trop tard pour modifier les programmes qui n'arrivent pas à négocier ces nouveaux cas, car leur code de négociation est bogué. Le RFC 6709 reconnait ce problème (tant qu'on n'a pas utilisé un mécanisme, on ne sait pas vraiment s'il marche) et reconnait que le conseil d'un mécanisme simple n'est pas suffisant.
Notre RFC 9170 contient d'ailleurs une petite pique contre QUIC en regrettant qu'on repousse parfois à plus tard le mécanisme de négociation de version, pour arriver à publier la norme décrivant le protocole (exactement ce qui est arrivé à QUIC, qui n'a pas de mécanisme de négociation des futures versions). Le problème est que, une fois la norme publiée et le protocole déployé, il sera trop tard…
Bref, l'analyse du RFC (section 3) est qu'il faut utiliser tôt et souvent les mécanismes d'extension. Une option ou un moyen de négocier de nouvelles options qui n'a jamais été utilisé depuis des années est probablement ossifié et ne peut plus être utilisé. C'est très joli de dire dans le premier RFC d'un protocole « cet octet est toujours à zéro dans cette version mais les récepteurs doivent ignorer son contenu car il pourra servir dans une future version » mais l'expérience prouve largement qu'une telle phrase est souvent ignorée et que bien des logiciels planteront, parfois de façon brutale, le jour où on commencer à utiliser des valeurs non nulles. Il faut donc utiliser les mécanismes ou bien ils rouillent. Par exemple, si vous concevez un mécanisme d'extension dans votre protocole, il est bon que, dès le premier jour, au moins une fonction soit mise en œuvre via ce mécanisme, pour forcer les programmeurs à en tenir compte, au lieu de simplement sauter cette section du RFC. Les protocoles qui ajoutent fréquemment des options ou des extensions ont moins de problèmes que ceux qui attendent des années avant d'exploiter leurs mécanismes d'extension. Et plus on attend, plus c'est pire. C'est pour cela que, par exemple, il faut féliciter le RIPE NCC d'avoir tenté l'annonce de l'attribut BGP 99, même si cela a cassé des choses, car si on ne l'avait pas fait (comme l'avaient demandé certaines personnes qui ne comprenaient pas les enjeux), le déploiement de nouveaux attributs dans BGP serait resté quasi-impossible.
Tester tôt est d'autant plus important qu'il peut être crucial, pour la sécurité, qu'on puisse étendre un protocole (par exemple pour l'agilité cryptographique, cf. RFC 7696). L'article de S. Bellovin et E. Rescorla, « Deploying a New Hash Algorithm » montre clairement que les choses ne se passent pas aussi bien qu'elles le devraient.
Comme dit plus haut, la meilleure façon de s'assurer qu'un
mécanisme est utilisable est de l'utiliser effectivement. Et pour
cela que ce mécanisme soit indispensable au fonctionnement normal du
protocole, qu'on ne puisse pas l'ignorer. Le RFC cite l'exemple de
SMTP :
le principal mécanisme d'extension de SMTP est d'ajouter de nouveaux
en-têtes (comme le Archived-At: dans le RFC 5064) or, SMTP dépend d'un traitement de ces
en-têtes pour des fonctions mêmes élémentaires. Un MTA ne peut pas se permettre
d'ignorer les en-têtes. Ainsi, on est sûr que toute mise en œuvre de
SMTP sait analyser les en-têtes. Et, comme des en-têtes nouveaux
sont assez fréquemment ajoutés, on sait que des en-têtes inconnus
des vieux logiciels ne perturbent pas SMTP. Ce cas est idéal : au
lieu d'un mécanisme d'extension qui serait certes spécifié dans le
RFC mais pas encore utilisé, on a un mécanisme d'extension dont
dépendent des fonctions de base du protocole.
Le RFC cite également le cas de SIP, qui est moins favorable : les relais ne transmettent en général pas les en-têtes inconnus, ce qui ne casse pas la communication, mais empêche de déployer de nouveaux services tant que tous les relais n'ont pas été mis à jour.
Bien sûr, aucune solution n'est parfaite. Si SMTP n'avait pas ajouté de nombreux en-têtes depuis sa création, on aurait peut-être des programmes qui certes savent analyser les en-têtes mais plantent lorsque ces en-têtes ne sont pas dans une liste limitée. D'où l'importance de changer souvent (ici, en ajoutant des en-têtes).
Souvent, les protocoles prévoient un mécanisme de négociation de la version utilisée. On parle de version différente lorsque le protocole a suffisamment changé pour qu'on ne puisse pas interagir avec un vieux logiciel. Un client SMTP récent peut toujours parler à un vieux serveur (au pire, le serveur ignorera les en-têtes trop récents) mais une machine TLS 1.2 ne peut pas parler à une machine TLS 1.3. Dans le cas le plus fréquent, la machine récente doit pouvoir parler les deux versions, et la négociation de version sert justement à savoir quelle version utiliser. Le problème de cette approche est que, quand la version 1 est publiée en RFC, avec son beau mécanisme de négociation de version, il n'y a pas encore de version 2 pour tester que cette négociation se passera bien. Celle-ci ne sortira parfois que des années plus tard et on s'apercevra peut-être à ce moment que certains programmes ont mal mis en œuvre la négociation de version, voire ont tout simplement négligé cette section du RFC…
Première solution à ce problème, utiliser un mécanisme de négociation de version située dans une couche plus basse. Ainsi, IP a un mécanisme de négociation de version dans l'en-tête IP lui-même (les quatre premiers bits indiquent le numéro de version, cf. RFC 8200, section 3) mais ce mécanisme n'a jamais marché en pratique. Ce qui marche, et qui est utilisé, c'est de se servir du mécanisme de la couche 2. Par exemple, pour Ethernet (RFC 2464), c'est l'utilisation du type de protocole (EtherType), 0x800 pour IPv4 et 0x86DD pour IPv6. Un autre exemple est l'utilisation d'ALPN (RFC 7301) pour les protocoles au-dessus de TLS. (Le RFC cite aussi la négociation de contenu de HTTP.)
Une solution récente au problème de l'ossification est le graissage, présenté en section 3.3. Décrit à l'origine pour TLS, dans le RFC 8701, il est désormais utilisé dans d'autres protocoles comme QUIC. Son principe est de réserver un certain nombre de valeurs utilisant des extensions du protocole et de s'en servir, de façon à forcer les différents logiciels, intermédiaires ou terminaux, à lire tout le RFC et à gérer tous les cas. Dans l'exemple cité plus haut d'un protocole qui aurait un champ de huit bits « cet octet est toujours à zéro dans cette version mais les récepteurs doivent ignorer son contenu car il pourra servir dans une future version », on peut réserver les valeurs 3, 21, 90 et 174 comme valeurs de graissage et l'émetteur les mettra de temps en temps dans le champ en question. Dans le cas de TLS, où le client propose des options et le serveur accepte celles qu'il choisit dans ce lot (oui, je sais, TLS est plus compliqué que cela, par exemple lorsque le serveur demande une authentification), le client annonce au hasard des valeurs de graissage. Ainsi, une middlebox qui couperait les connexions TLS serait vite détectée et, on peut l'espérer, rejetée par le marché. Le principe du graissage est donc « les extensions à un protocole s'usent quand on ne s'en sert pas ». Cela évoque les tests de fuzzing qu'on fait en sécurité, où on va essayer plein de valeurs inhabituelles prises au hasard, pour s'assurer que le logiciel ne se laisse pas surprendre. On voit aussi un risque du graissage : si les programmes bogués sont nombreux, le premier qui déploie un mécanisme de graissage va essuyer les plâtres et se faire parfois rejeter. Il est donc préférable que le graissage soit utilisé dès le début, par exemple dans un nouveau protocole.
Évidemment, la solution n'est pas parfaite. On peut imaginer un logiciel mal fait qui reconnait les valeurs utilisées pour le graissage (et les ignore) mais rejette quand même les autres valeurs pourtant légitimes. (La plupart du temps, les valeurs réservées pour le graissage ne sont pas continues, comme dans les valeurs 3, 21, 90 et 174 citées plus haut, pour rendre plus difficile un traitement spécifique au graissage.)
Bien sûr, même sans valeurs réservées au graissage, un programme pourrait toujours faire à peu près l'équivalent, en utilisant les valeurs réservées pour des expérimentations ou bien des usages privés. Mais le risque est alors qu'elles soient acceptées par l'autre partie, ce qui n'est pas le but.
Tous les protocoles n'ont pas le même style d'interaction que TLS, et le graissage n'est donc pas systématiquement possible. Et puis il ne teste qu'une partie des capacités du protocole, donc il ne couvre pas tous les cas possibles. Le graissage est donc utile mais ne résout pas complètement le problème.
Parfois, des protocoles qui ne permettaient pas facilement l'extensibilité ont été assez sérieusement modifiés pour la rendre possible. Ce fut le cas du DNS avec EDNS (RFC 6891). Son déploiement n'a pas été un long fleuve tranquille et, pendant longtemps, les réactions erronées de certains serveurs aux requêtes utilisant EDNS nécessitaient un mécanisme de repli (re-essayer sans EDNS). Il a ensuite fallu supprimer ce mécanisme de repli pour être sûr que les derniers systèmes erronés soient retirés du service, le tout s'étalant sur de nombreuses années. Un gros effort collectif a été nécessaire pour parvenir à ce résultat, facilité, dans le cas du DNS, par le relativement petit nombre d'acteurs et leur étroite collaboration.
La section 4 du RFC cite d'autres techniques qui peuvent être utilisées pour lutter contre l'ossification. D'abord, ne pas avoir trop de possibilités d'étendre le protocole car, dans ce cas, certaines possibilités seront fatalement moins testées que d'autres et donc plus fragiles si on veut s'en servir un jour.
Le RFC suggère aussi l'utilisation d'invariants. Un invariant est une promesse des auteurs du protocole, assurant que cette partie du protocole ne bougera pas (et, au contraire, que tout le reste peut bouger et qu'il ne faut pas compter dessus). Si les auteurs de logiciels lisent les RFC (une supposition audacieuse, notamment pour les auteurs de middleboxes), cela devrait éviter les problèmes avec les évolutions futures. (Il est donc toujours utile de graisser les parties du protocole qui ne sont pas des invariants.) Le RFC 5704, dans sa section 2.2, définit plus rigoureusement ce que sont les invariants. Deux exemples d'utilisation de ce concept sont le RFC 8999 (décrivant les invariants de QUIC) et la section 9.3 du RFC 9846 sur TLS. Notre RFC conseille aussi de préciser explicitement ce qui n'est pas invariant (comme le fait l'annexe A du RFC 8999), ce que je trouve contestable (il y a un risque que cette liste d'exemples de non-invariants soit interprétée comme limitative, alors que ce ne sont que des exemples).
Une autre bonne technique, que recommande notre RFC, est de prendre des mesures techniques pour empêcher les intermédiaires de tripoter la communication. Moins il y a d'entités qui analysent et interprètent les paquets, moins il y aura de programmes à vérifier et éventuellement à modifier en cas d'extension du protocole. Un bon exemple de ces mesures techniques est évidemment la cryptographie. Ainsi, chiffrer le fonctionnement du protocole, comme le fait QUIC, ne sert pas qu'à préserver la vie privée de l'utilisateur, cela sert aussi à tenir à l'écart les intermédiaires, ce qui limite l'ossification. Le RFC 8558 est une bonne lecture à ce sujet.
Bien sûr, si bien conçu que soit le protocole, il y aura des
problèmes. Le RFC suggère donc aussi qu'on crée des mécanismes de
retour, permettant d'être informés des problèmes. Prenons par
exemple un serveur TLS qui refuserait des clients corrects, mais qui
utilisent des extensions que le serveur ne gère pas correctement. Si
le serveur ne journalise pas ces problèmes, ou
bien que l'administrateur système ne lit pas
ces journaux, le problème pourra trainer très longtemps. Idéalement,
ces retours seront récoltés et traités automatiquement, et envoyés à
celles et ceux qui sont en mesure d'agir. C'est plus facile à dire
qu'à faire, et cela dépend évidemment du protocole utilisé. Des
exemples de protocoles ayant un tel mécanisme sont
DMARC (RFC 9989, avec
son étiquette rua, section 7), et SMTP (avec le
TLSRPT du RFC 8460).
Enfin, pour terminer, l'annexe A du RFC présente quelques
exemples de protocoles et comment ils ont géré ce problème. Elle
commence par le DNS
(RFC 1034 et RFC 1035). Le DNS a une mauvaise expérience avec le
déploiement de nouveaux types d'enregistrement qui, par exemple,
provoquaient des rejets violents des requêtes DNS par certains
équipements. C'est l'une des raisons pour lesquelles SPF (RFC 7208) a finalement renoncé à utiliser son propre type
d'enregistrement, SPF (cf. RFC 6686) et pour lesquelles tout le monde se sert de
TXT. Le problème s'est heureusement amélioré
depuis la parution du RFC 3597, qui normalise
le traitement des types inconnus. (Mais il reste d'autres obstacles
au déploiement de nouveaux types, comme la mise à jour des
interfaces « conviviales » d'avitaillement d'une zone DNS,
interfaces qui mettent de nombreuses années à intégrer les nouveaux
types.)
HTTP, lui, a plutôt bien marché, question extensibilité mais il a certains mécanismes d'extension que personne n'ose utiliser et qui ne marcheraient probablement pas, comme les extensions des chunks (RFC 7230, section 4.1.1) ou bien comme l'utilisation d'autres unités que les octets dans les requêtes avec intervalles (RFC 7233, section 2.2).
Et IP lui-même ?
Par exemple, IP avait un mécanisme pour permettre aux équipements
réseau de reconnaitre la version utilisée, permettant donc de faire
coexister plusieurs versions d'IP, le champ Version (les quatre
premiers bits du paquet). Mais il n'a jamais réellement fonctionné,
les équipements utilisant à la place les indications données par la
couche inférieure (l'« ethertype », dans le cas
d'Ethernet, cf. RFC 2464). D'autres problèmes sont arrivés avec IP, par
exemple l'ancienne « classe E ». Le préfixe
224.0.0.0/3 avait été réservé par le RFC 791, section 3.2, mais sans précisions
(« The extended addressing mode is undefined. Both of
these features are reserved for future use. »). Le RFC 988 avait ensuite pris
224.0.0.0/4 pour le
multicast (qui n'a jamais
été réellement déployé sur l'Internet), créant la « classe D », le
reste devenant la « classe E », 240.0.0.0/4 dont on
ne sait plus quoi faire aujourd'hui, même si certains voudraient la
récupérer pour prolonger l'agonie d'IPv4. Son
traitement spécial par de nombreux logiciels empêche de l'affecter
réellement. Une solution souvent utilisée pour changer la
signification de tel ou tel champ dans l'en-tête est la négociation
entre les deux parties qui communiquent, mais cela ne marche pas
pour les adresses (la communication peut être
unidirectionnelle).
SNMP n'a pas eu trop de problèmes avec le déploiement de ses versions 2 et 3. La norme de la version 1 précisait clairement (RFC 1157) que les paquets des versions supérieures à ce qu'on savait gérer devaient être ignorés silencieusement, et cela était vraiment fait en pratique. Il a donc été possible de commencer à envoyer des paquets des versions 2, puis 3, sans casser les vieux logiciels qui écoutaient sur le même port.
TCP, par contre, a eu bien des problèmes avec son mécanisme d'extension. (Lire l'article de Honda, M., Nishida, Y., Raiciu, C., Greenhalgh, A., Handley, M., et H. Tokuda, « Is it still possible to extend TCP? ».) En effet, de nombreuses middleboxes se permettaient de regarder l'en-tête TCP sans avoir lu et compris le RFC, jetant des paquets qui leur semblaient anormaux, alors qu'ils avaient juste des options nouvelles. Ainsi, le multipath TCP (RFC 6824) a été difficile à déployer (cf. l'article de Raiciu, C., Paasch, C., Barre, S., Ford, A., Honda, M., Duchêne, F., Bonaventure, O., et M. Handley, « How Hard Can It Be? Designing and Implementing a Deployable Multipath TCP »). TCP Fast Open (RFC 7413) a eu moins de problèmes sur le chemin, mais davantage avec les machines terminales, qui ne comprenaient pas ce qu'on leur demandait. Comme le but de TCP Fast Open était d'ouvrir une connexion rapidement, ce problème était fatal : on ne peut pas entamer une négociation lorsqu'on veut aller vite.
Et enfin, dernier protocole étudié dans cette annexe A, TLS. Là, la conclusion du RFC est que le mécanisme de négociation et donc d'extension de TLS était correct, mais que la quantité de programmes mal écrits et qui réagissaient mal à ce mécanisme l'a, en pratique, rendu inutilisable. Pour choisir une version de TLS commune aux deux parties qui veulent communiquer de manière sécurisée, la solution était de chercher la plus haute valeur de version commune (HMSV pour highest mutually supported version, cf. RFC 6709, section 4.1). Mais les innombrables bogues dans les terminaux, et dans les middleboxes (qui peuvent accéder à la négociation TLS puisqu'elle est en clair, avant tout chiffrement) ont fait qu'il était difficile d'annoncer une version supérieure sans que les paquets soient rejetés. (Voir l'expérience racontée dans ce message.)
TLS 1.3 (RFC 9846) a donc dû abandonner
complètement le mécanisme HMSV et se présenter comme étant du 1.2,
pour calmer les middleboxes intolérantes,
dissimulant ensuite dans le ClientHello des
informations qui permettent aux serveurs 1.3 de reconnaitre un
client qui veut faire du 1.3 (ici, vu avec tshark) :
TLSv1 Record Layer: Handshake Protocol: Client Hello
Content Type: Handshake (22)
Version: TLS 1.0 (0x0301)
Length: 665
Handshake Protocol: Client Hello
Handshake Type: Client Hello (1)
Length: 661
Version: TLS 1.2 (0x0303)
[Ce champ Version n'est là que pour satisfaire les middleboxes.]
Extension: supported_versions (len=9)
Type: supported_versions (43)
Length: 9
Supported Versions length: 8
Supported Version: TLS 1.3 (0x0304)
Supported Version: TLS 1.2 (0x0303)
Supported Version: TLS 1.1 (0x0302)
Supported Version: TLS 1.0 (0x0301)
[La vraie liste des versions acceptées était dans cette extension.]
Toujours à propos de TLS, SNI (Server Name
Indication, cf. RFC 6066, section 3)
est un autre exemple où la conception était bonne mais le manque
d'utilisation de certains options a mené à l'ossification et ces
options ne sont plus, en pratique, utilisables. Ainsi, SNI
permettait de désigner le serveur par son nom de domaine (host_name
dans SNI) mais aussi en utilisant d'autres types d'identificateurs
(champ name_type) sauf que, en pratique, ces
autres types n'ont jamais été utilisés et ne marcheraient
probablement pas. (Voir l'article de A. Langley, « Accepting
that other SNI name types will never work ».)
L'article seul
RFC 9167: Registry Maintenance Notification for the Extensible Provisioning Protocol (EPP)
Date de publication du RFC : Décembre 2021
Auteur(s) du RFC : T. Sattler, R. Carney, J. Kolker (GoDaddy)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 26 décembre 2021
Un registre, par exemple un registre de noms de domaine, utilise parfois le protocole EPP pour la communication avec ses clients. Ce RFC décrit comment utiliser ce protocole pour informer les clients des périodes d'indisponibilité du registre, par exemple lors d'une opération de maintenance.
Aujourd'hui, un registre prévient de ses periodes
d'indisponibilité prévues par divers moyens : courriers aux BE, messages sur des
réseaux sociaux, page Web dédiée comme : 
Chaque registre le fait de façon différente, il n'existe pas de règles communes, et le côté non-structuré de ces annonces fait qu'il faut une interventon humaine pour les analyser et les mettre dans un agenda. Et un BE peut devoir interagir avec de nombreux registres ! Notre RFC propose d'utiliser EPP (RFC 5730) pour ces annonces.
Donc, premier principe, puisqu'on va souvent manipuler des dates,
les dates et heures seront toutes représentées en UTC et dans le format
du RFC 3339. Ensuite, les annonces seront dans
un élément XML <item>, de
l'espace de noms
urn:ietf:params:xml:ns:epp:maintenance-1.0
(enregistré
à l'IANA). Parmi les sous-éléments de cet élément :
id, un identificateur de l'évènement,systems, qui permettra de désigner les systèmes affectés,environment, pour dire si l'évènement concerne la production ou bien un banc de test,startetend, qui indiquent le début et la fin (prévue…) de l'évènement,- et plusieurs autres éléments.
Un exemple d'évènement, une intervention sur le serveur EPP
epp.registry.example de production, peut être :
<maint:item>
<maint:id>2e6df9b0-4092-4491-bcc8-9fb2166dcee6</maint:id>
<maint:systems>
<maint:system>
<maint:name>EPP</maint:name>
<maint:host>epp.registry.example</maint:host>
<maint:impact>full</maint:impact>
</maint:system>
</maint:systems>
<maint:environment type="production"/>
<maint:start>2021-12-30T06:00:00Z</maint:start>
<maint:end>2021-12-30T07:00:00Z</maint:end>
<maint:reason>planned</maint:reason>
<maint:detail>
https://www.registry.example/notice?123
</maint:detail>
<maint:tlds>
<maint:tld>example</maint:tld>
<maint:tld>test</maint:tld>
</maint:tlds>
</maint:item>
On voit que le serveur EPP sera arrêté pendant une heure
(<impact>full</impact> indiquant
une indisponibilité totale) et que cela affectera les TLD
.example et .test. Une
telle information, étant sous une forme structurée, peut être
analysée par un programme et automatiquement insérée dans un agenda,
ou un système de supervision.
Les commandes EPP exactes, maintenant (section 4 du RFC). La
commande <info> peut renvoyer maintenant
un élément <maint:info> qui contient
l'information de maintenance. Voici l'exemple du RFC. D'abord, la
question du client, qui veut de l'information sur l'évènement
2e6df9b0-4092-4491-bcc8-9fb2166dcee6 :
<info>
<maint:info
xmlns:maint="urn:ietf:params:xml:ns:epp:maintenance-1.0">
<maint:id>2e6df9b0-4092-4491-bcc8-9fb2166dcee6</maint:id>
</maint:info>
</info>
Puis la réponse du serveur :
<response>
<result code="1000">
<msg>Command completed successfully</msg>
</result>
<resData>
<maint:infData
xmlns:maint="urn:ietf:params:xml:ns:epp:maintenance-1.0">
<maint:item>
<maint:id>2e6df9b0-4092-4491-bcc8-9fb2166dcee6
</maint:id>
<maint:type lang="en">Routine Maintenance</maint:type>
<maint:systems>
<maint:system>
<maint:name>EPP</maint:name>
<maint:host>epp.registry.example
</maint:host>
<maint:impact>full</maint:impact>
</maint:system>
</maint:systems>
<maint:environment type="production"/>
<maint:start>2021-12-30T06:00:00Z</maint:start>
<maint:end>2021-12-30T07:00:00Z</maint:end>
<maint:reason>planned</maint:reason>
<maint:detail>
https://www.registry.example/notice?123
</maint:detail>
<maint:description lang="en">free-text
</maint:description>
<maint:description lang="de">Freitext
</maint:description>
<maint:tlds>
<maint:tld>example</maint:tld>
<maint:tld>test</maint:tld>
</maint:tlds>
<maint:intervention>
<maint:connection>false</maint:connection>
<maint:implementation>false</maint:implementation>
</maint:intervention>
<maint:crDate>2021-11-08T22:10:00Z</maint:crDate>
</maint:item>
</maint:infData>
</resData>
...
Ici, le client connaissait l'identificateur d'une opération de maintenance particulière. S'il ne le connait pas et veut récupérer une liste d'événements :
<info>
<maint:info
xmlns:maint="urn:ietf:params:xml:ns:epp:maintenance-1.0">
<maint:list/>
</maint:info>
</info>
Il récupérera alors une <maint:list>, une
liste d'opérations de maintenance.
Le client EPP peut
également être prévenu des maintenances par la commande
<poll>, qui dote EPP d'un système de
messagerie (RFC 5730, section 2.9.2.3). Ainsi,
un message dans la boite aux lettres du client pourra être :
<response>
<result code="1301">
<msg>Command completed successfully; ack to dequeue</msg>
</result>
<msgQ count="1" id="12345">
<qDate>2021-11-08T22:10:00Z</qDate>
<msg lang="en">Registry Maintenance Notification</msg>
</msgQ>
<resData>
<maint:infData
xmlns:maint="urn:ietf:params:xml:ns:epp:maintenance-1.0">
<maint:item>
<maint:id>2e6df9b0-4092-4491-bcc8-9fb2166dcee6</maint:id>
<maint:pollType>create</maint:pollType>
<maint:systems>
<maint:system>
<maint:name>EPP</maint:name>
<maint:host>epp.registry.example
</maint:host>
<maint:impact>full</maint:impact>
...
La section 5 du RFC décrit la syntaxe formelle de cette extension (en XML Schema). Elle est dans le registre IANA des extensions à EPP.
Et question mises en œuvre ? Apparemment, les registres gérés par GoDaddy et Tango envoient déjà ces informations de maintenance.
L'article seul
RFC 9165: Additional Control Operators for Concise Data Definition Language (CDDL)
Date de publication du RFC : Décembre 2021
Auteur(s) du RFC : C. Bormann (Universität Bremen TZI)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF cbor
Première rédaction de cet article le 25 décembre 2021
Le langage CDDL (Concise Data Definition Language) est un langage de description de schémas de données, notamment pour le format CBOR. Ce nouveau RFC étend CDDL avec de nouveaux opérateurs, permettant entre autres l'addition d'entiers et la concaténation de chaines de caractères.
CDDL est normalisé dans le RFC 8610 (et le format CBOR dans le RFC 8949). Il permet l'ajout de nouveaux opérateurs pour étendre le langage, possibilité utilisée par notre nouveau RFC. Notez que, comme les modèles de données de JSON et CBOR sont très proches, les schémas CDDL peuvent également être utilisés pour JSON, ce que je fais ici pour les exemples car le JSON est plus facile à lire et à écrire.
D'abord, l'opérateur .plus. Il permet par
exemple, dans la spécification d'un schéma, de faire dépendre
certains nombres d'autres nombres. L'exemple ci-dessous
définit un type « intervalle » où la borne supérieure doit être
supérieure de 5 à la borne inférieure :
top = interval<3>
interval<BASE> = BASE .. (BASE .plus 5)
Avec un tel schéma, la valeur 4 sera acceptée mais 9 sera refusée :
% cddl tmp.cddl validate tmp.json CDDL validation failure (nil for 9): [9, [:range, 3..8, Integer], ""]
Deuxième opérateur, la
concaténation, avec le nouvel opérateur
.cat :
s = "foo" .cat "bar"
Dans cet exemple, évidemment, .cat n'est pas
très utile, on aurait pu écrire la chaine complète directement. Mais
.cat est plus pertinent quand on veut manipuler
des chaines contenants des sauts de ligne :
s = "foo" .cat ' bar baz '
Ce schéma acceptera la chaine de caractère "foo\n bar\n
baz\n".
Dans l'exemple ci-dessus, bar et
baz seront précédés des espaces qui
apparaissaient dans le code source. Souvent, on souhaite mettre ces
espaces en début de ligne dans le code source, pour
l'indenter joliment, mais les supprimer dans
le résultat final. Cela peut se faire avec l'opérateur pour lequel
notre RFC invente le joli mot de détentation
(dedending), .det, qui
fonctionne comme .cat mais « dédente » les
lignes :
s = "foo" .det ' bar baz '
Cette fois, le schéma n'acceptera que la chaine
"foo\nbar\nbaz\n".
Le RFC note que, comme .det est l'abréviation
de dedending cat, on aurait pu l'appeler
.dedcat mais cela aurait chagriné les amis des
chats.
CDDL est souvent utilisé dans les normes techniques de l'Internet
et celles-ci contiennent souvent des
grammaires en ABNF (RFC 5234). Pour permettre de réutiliser les règles ABNF dans
CDDL, et donc se dispenser d'une ennuyeuse traduction, un nouvel
opérateur fait son apparition, .abnf. Le RFC
donne l'exemple de la grammaire du RFC 3339,
qui normalise les formats de date : abnf-rfc3339.cddl. Avec ce fichier, on peut accepter des
chaines comme "2021-12-15" ou
"2021-12-15T15:52:00Z". Notons qu'il reste
quelques difficultés car les règles d'ABNF ne sont pas parfaitement
compatibles avec celles de CDDL. Si .abnf va
traiter l'ABNF comme de l'Unicode encodé en
UTF-8, un autre opérateur,
.abnfb, va le traiter comme une bête suite
d'octets. D'autre part, comme ABNF exige souvent des sauts de ligne,
les opérateurs .cat et
.det vont être très utiles.
Quatrième et dernier opérateur introduit par ce RFC,
.feature. À quoi sert-il ? Comme le langage
CDDL peut ếtre étendu au-delà de ce qui existait dans le RFC 8610, on court toujours le risque de traiter
un schéma CDDL avec une mise en œuvre de CDDL qui ne connait pas
toutes les fonctions utilisées dans le schéma. Cela produit en
général un message d'erreur peu clair et, surtout, cela mènerait à
considérer des données comme invalides alors qu'elles sont
parfaitement acceptables pour le reste du
schéma. .feature sert donc à marquer les
extensions qu'on utilise. Le programme qui met en œuvre CDDL pourra
ainsi afficher de l'information claire. Par exemple, si on définit
une personne :
person = {
? name: text
? organization: text
}
puis qu'on veut rajouter son groupe sanguin :
{"name": "Jean", "bloodgroup": "O+"}
Cet objet sera rejeté, en raison du champ
bloodgroup. On va faire un schéma plus ouvert, avec
.feature :
person = {
? name: text
? organization: text
* (text .feature "further-person-extension") => any
}
Et, cette fois, l'objet est accepté avec un message d'avertissement clair :
% cddl person-new-feature.cddl validate tmp.json ** Features potentially used (tmp.json): further-person-extension: ["bloodgroup"]
Comme le schéma est assez ouvert, la fonction de génération de fichiers d'exemple de l'outil donne des résultats amusants :
% cddl person-new-feature.cddl generate
{"name": "plain", "dependency's": "Kathryn's", "marvelous": "cleavers"}
Les nouveaux opérateurs ont été placés dans le registre
IANA. Ils sont mis en œuvre dans l'outil de référence de CDDL
(le cddl utilisé ici). Écrit en
Ruby, on peut l'installer avec la méthode Ruby
classique :
% gem install cddl
Il existe une autre mise en œuvre de CDDL (qui porte malheureusement le même nom). Elle est en Rust et peut donc s'installer avec :
% cargo install cddl
Elle n'inclut pas encore les opérateurs de ce RFC :
% /home/stephane/.cargo/bin/cddl validate --cddl plus.cddl plus.json Validation of "plus.json" failed error parsing CDDL: error: lexer error ┌─ input:8:12 │ 8 │ (BASE .plus 1) => int ; upper bound │ ^^^^^ invalid control operator
L'article seul
RFC 9164: Concise Binary Object Representation (CBOR) Tags for IPv4 and IPv6 Addresses
Date de publication du RFC : Décembre 2021
Auteur(s) du RFC : M. Richardson (Sandelman Software Works), C. Bormann (Universität Bremen TZI)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF cbor
Première rédaction de cet article le 14 décembre 2021
Ce nouveau RFC normalise deux étiquettes CBOR pour représenter des adresses IP et des préfixes d'adresses.
Le format de données CBOR, normalisé dans le RFC 8949, a une liste de types prédéfinis mais on peut en créer d'autres, en étiquetant la donnée avec un entier qui permettre de savoir comment interpréter la donnée en question. Notre RFC introduit les étiquettes 52 (pour les adresses IPv4) et 54 (pour les adresses IPv6). Ah, pourquoi 52 et 54 ? Je vous laisse chercher, la solution est à la fin de l'article
La section 3 de notre RFC décrit le format. Pour chaque famille (IPv4 ou IPv6), il y a trois formats (tous avec la même étiquette) :
- Les adresses à proprement parler, représentées sous forme d'une byte string CBOR (suite d'octets, cf. RFC 8949, section 3.1, type majeur 2) et donc pas sous la forme textuelle (celle avec les points pour IPv4 et les deux-points pour IPv6),
- Les préfixes, représentés par un tableau de deux éléments, un entier pour la longueur du préfixe et une suite d'octets pour le préfixe lui-même (les octets nuls à la fin doivent être omis),
- L'interface, sous forme d'un tableau de deux ou trois
éléments, qui comporte une adresse IP, la longueur du préfixe sur
cette interface et éventuellement un identificateur d'interface
(genre
eth0sur Linux, voir la section 6 du RFC 4007 pour IPv6, et les RFC 4001 et RFC 6991 pour IPv4, mais cela peut aussi être un entier), identificateur qui est local à la machine.
La section 5 du RFC contient une description en CDDL (RFC 8610) de ces données.
J'ai écrit une mise en œuvre en Python de ce RFC, qui renvoie à un client
HTTP son
adresse IP, et le préfixe annoncé dans la DFZ en BGP (en utilisant pour cela les
données du RIS,
via le programme WhichASN). Le
service est accessible à l'adresse
https://www.bortzmeyer.org/apps/addresses-in-cbor,
par exemple :
% curl -s https://www.bortzmeyer.org/apps/addresses-in-cbor > tmp.cbor
Le CBOR est du binaire, on peut regarde avec le programme read-cbor :
% read-cbor tmp.cbor Array of 3 items String of length 165: Your IP address in CBOR [...] Tag 54 Byte string of length 16 Tag 54 Array of 2 items Unsigned integer 32 Byte string of length 4
On voit que le service renvoie un tableau CBOR de trois entrées :
- Une chaine de caractères de documentation,
- l'adresse IP (ici, de l'IPv6, d'où l'étiquette 54 et les 16 octets),
- le préfixe routé, sous la forme d'une longueur (ici, 32 bits) et des octets non nuls dudit préfixe (ici, au nombre de 4).
Vu avec le programme cbor2diag, le même fichier :
% cbor2diag.rb tmp.cbor
["Your IP address in CBOR, done with Python 3.9.2 [...]",
54(h'200141D0030222000000000000000180'),
54([32, h'200141D0'])]
(Le préfixe du client HTTP était en effet bien
2001:41d0::/32.) Le code source de service est
dans les sources du moteur de ce
blog, plus précisement en
wsgis/dispatcher.py.
Sinon, la raison du choix des étiquettes est que, en ASCII, 52 est le chiffre 4 et 54 est 6. Les deux étiquettes sont désormais dans le registre IANA. À noter que la représentation des adresses IP en CBOR avait été faite initialement avec les étiquettes 260 et 261, en utilisant un encodage complètement différent. 260 désignait les adresses (v4 et v6), 261, les préfixes. (Ces deux étiquettes sont marquées comme abandonnées, dans le registre IANA.) Au contraire, dans notre nouveau RFC, l'étiquette identifie la version d'IP, la distinction entre adresse et préfixe se faisant par un éventuel entier initial pour indiquer la longueur.
L'article seul
RFC 9162: Certificate Transparency Version 2.0
Date de publication du RFC : Décembre 2021
Auteur(s) du RFC : B. Laurie, A. Langley, E. Kasper, E. Messeri (Google), R. Stradling (Sectigo)
Expérimental
Réalisé dans le cadre du groupe de travail IETF trans
Première rédaction de cet article le 10 décembre 2021
Le système de gestion de certificats PKIX (dérivé des certificats X.509) a une énorme faiblesse. N'importe quelle AC peut émettre un certificat pour n'importe quel nom de domaine. Il ne suffit donc pas de bien choisir son AC, votre sécurité dépend de toutes les AC. Ce RFC propose une approche pour combler cette faille de sécurité : encourager/obliger les AC à publier « au grand jour » les certificats qu'elles émettent. Un titulaire d'un certificat qui craint qu'une AC n'émette un certificat à son nom sans son autorisation n'a alors qu'à surveiller ces publications. (Il peut aussi découvrir à cette occasion que sa propre AC s'est fait pirater ou bien est devenue méchante et émet des certificats qu'on ne lui a pas demandés. L'idée est aussi d'empêcher l'émission « discrète » de vrais/faux certificats qui seraient ensuite utilisés uniquement à certains endroits.) Ce système, dit « Certificate Transparency » (CT) avait initialement été normalisé dans le RFC 6962, que notre RFC remplace, le protocole passant à une nouvelle version, la v2 (toujours considérée comme expérimentale).
Le principe est donc de créer des journaux des certificats émis. Le journal doit être public, pour que n'importe qui puisse l'auditer (section 4 du RFC). Il doit être en mode « ajout seulement » pour éviter qu'on puisse réécrire l'histoire. Les certificats sont déjà signés mais le journal a ses propres signatures, pour prouver son intégrité. Conceptuellement, ce journal est une liste de certificats dans l'ordre de leur création. Toute AC peut y ajouter des certificats (la liste ne peut pas être ouverte en écriture à tous, de crainte qu'elle ne soit remplie rapidement de certificats bidons). En pratique, le RFC estime que la liste des AC autorisées à écrire dans le journal sera l'union des listes des AC acceptées dans les principaux navigateurs Web (voir aussi les sections 4.2 et 5.7, chaque journal est responsable de ce qu'il accepte ou pas comme soumissions).
À chaque insertion, le journal renvoie à l'AC une estampille
temporelle signéee (SCT, pour Signed Certificate
Timestamp), permettant à l'AC de prouver qu'elle a bien
enregistré le certificat. Si on a cette signature mais que le
certificat est absent du journal, l'observateur aura la preuve que
le journal ne marche pas correctement. Le format exact de cette
estampille temporelle est décrit en section 4.8. Idéalement, elle
devra être envoyée au client par les serveurs TLS, dans l'extension
TLS transparency_info (désormais enregistrée
à l'IANA), comme preuve de la bonne foi de l'AC (cf. section
6 et notamment 6.5, car c'est plus compliqué que cela). Bien sûr,
cette validation de l'insertion dans un journal ne dispense pas de
la validation normale du certificat (un certificat peut être
journalisé et mensonger à la fois). Notez aussi que, si le serveur
TLS n'envoie pas toutes les données au client, celui-ci peut les
demander au journal (opérations /get-proof-by-hash et
get-all-by-hash) mais, ce faisant, il informe
le journal des certificats qui l'intéressent et donc, par exemple,
des sites Web qu'il visite.
De même, une extension à OCSP (RFC 6960) peut être utilisée pour appuyer les réponses OCSP. On peut même inclure les preuves d'inclusion dans le journal dans le certificat lui-même, ce qui permet d'utiliser des serveurs TLS non modifiés.
Les titulaires de certificats importants, comme Google, mais aussi des chercheurs, des agences de sécurité, etc, pourront alors suivre l'activité de ces journaux publics (section 8.2 du RFC). Ce qu'ils feront en cas de détection d'un certificat anormal (portant sur leur nom de domaine, mais qu'ils n'ont pas demandé) n'est pas spécifié dans le RFC : cela dépend de la politique de l'organisation concernée. Ce RFC fournit un mécanisme, son usage n'est pas de son ressort. Ce journal n'empêchera donc pas l'émission de vrais/faux certificats, ni leur usage, mais il les rendra visibles plus facilement et sans doute plus vite.
Notons que les certificats client, eux, ne sont typiquement pas journalisés (rappelez-vous que les journaux sont publics et que les certificats client peuvent contenir des données personnelles). Le serveur TLS ne peut donc pas utiliser Certificate Transparency pour vérifier le certificat du client. (Le RFC estime que le principal risque, de toute façon, est celui d'usurpation du serveur, pas du client.)
Pour que cela fonctionne, il faudra que les clients TLS vérifient que le certificat présenté est bien dans le journal (autrement, le méchant n'aurait qu'à ne pas enregistrer son vrai/faux certificat, cf. section 8.3 du RFC).
En pratique, la réalisation de ce journal utilise un arbre de Merkle, une structure de données qui permet de mettre en œuvre un système où l'ajout de certificats est possible, mais pas leur retrait, puisque chaque nœud est un condensat de ses enfants (voir aussi le RFC 8391). La section 2 du RFC détaille l'utilisation de ces arbres et la cryptographie utilisée. (Et les exemples en section 2.1.5 aident bien à comprendre comment ces arbres de Merkle sont utilisés.)
Le protocole utilisé entre les AC et le journal, comme celui
utilisé entre les clients TLS et le journal, est HTTP et le format des
données du JSON (section 5, qui décrit l'API). Ainsi, pour
ajouter un certificat nouvellement émis au journal géré sur
sunlight-log.example.net, l'AC fera :
POST https://sunlight-log.example.net/ct/v2/submit-entry
et le corps de la requête HTTP sera un tableau JSON de certificats encodés en Base64. La réponse contiendra notamment l'estampille temporelle (SCT pour Signed Certificate Timestamp). S'il y a un problème, le client recevra une des erreurs enregistrées. Pour récupérer des certificats, le programme de surveillance fera par exemple :
GET https://sunlight-log.example.net/ct/v2/get-entries
D'autres URL permettront de récupérer les condensats cryptographiques contenus dans l'arbre de Merkle, pour s'assurer qu'il est cohérent.
Comme il n'existe (en octobre 2021) aucune mise en œuvre de la
version 2 du protocole, voici quelques exemples, utilisant des
journaux réels, et la version 1 du protocole (notez le
v1 dans l'URL). Pour trouver les coordonnées
des journaux, j'ai utilisé la liste
« officielle » du projet. Notez que tous les journaux qui y figurent ne fonctionnent pas
correctement. Notez aussi que, comme pour les AC ou les serveurs de clés PGP, il n'y a
pas de « journal de référence », c'est à chacun de choisir les
journaux où il va écrire, et qu'il va lire. Le script test-ct-logs-v1.py teste la liste, et trouve :
50 logs are OK, 54 are currently broken
Si vous vous demandez pourquoi un même opérateur a plusieurs
journaux, c'est en partie parce qu'il n'est pas possible de faire
évoluer les algorithmes cryptographiques au sein d'un même journal
(cf. section 9 du RFC) et qu'il faut donc de temps en temps créer un
nouveau journal. Un journal est identifié par son URL, sa clé publique et
(en v2) par son OID. Par exemple, le journal
« Nimbus 2021 » de Cloudflare est en
https://ct.cloudflare.com/logs/nimbus2021/ et a
la clé
MFkwEwYHKoZIzj0CAQYIKoZIzj0DAQcDQgAExpon7ipsqehIeU1bmpog9TFo4Pk8+9oN8OYHl1Q2JGVXnkVFnuuvPgSo2Ep+6vLffNLcmEbxOucz03sFiematg==
(je ne donne pas l'OID, il n'existe pas encore de journaux qui
utilisent la version 2 du protocole). Voici un exemple d'utilisation
(le STH est le Signed Tree Head, la valeur de la
racine de l'arbre de Merkle, cf. section 4.2.10) :
% curl -s https://ct.cloudflare.com/logs/nimbus2021/ct/v1/get-sth | jq .
{
"tree_size": 408013312,
"timestamp": 1634739692384,
"sha256_root_hash": "7GnGjI7L6O5fn8kQKTdJG2riShNTTbcjRP2WbLoZrvQ=",
"tree_head_signature": "BAMARjBEAiAQ0gb6udc9e28ykUGUzl0HV8U5NlJhPVSTUF4JtXGSeQIgcSbZ9kRgttGzpFETFem4eCv7GgUYPUUnl7lTGGFZSHM="
}
Plus de quatre cents millions de certificats, fichtre. Si on veut récupérer les deux premiers certificats journalisés :
% curl -s https://ct.cloudflare.com/logs/nimbus2021/ct/v1/get-entries\?start=0\&end=1 | jq .
{
"entries": [
{
"leaf_input":
[L'exemple est fait avec un journal v1, l'objet JSON renvoyé est
différent en v2.]
Mais vous pouvez aussi utiliser Certificate
Transparency (CT) sans aller regarder du JSON. Un service en
ligne comme https://crt.sh
On a vu que plusieurs acteurs intervenaient, le gérant du
journal, les AC, les gens qui regardent le journal, par exemple pour
l'auditer, etc. Une utilisation courante de CT est pour surveiller
l'émission de certificats au nom de son entreprise ou de son
organisation, pour repérer les AC qui créent des certificats
incorrects. Pour éviter de programmer tout cela de zéro en partant
du RFC, on peut utiliser le service Certstream, qui sert
d'intermédiaire avec plusieurs journaux, et sa bibliothèque
Python. Ainsi, le petit script test-certstream.py permet de détecter tous les certificats
émis pour les noms de domaine en
.fr :
% pip3 install certstream % ./test-certstream.py ... [2021-10-23T13:21:46] pimpmydrone.fr (SAN: www.pimpmydrone.fr) [2021-10-23T13:21:51] pascal-goldbach.fr (SAN: www.pascal-goldbach.fr) [2021-10-23T13:21:52] leginkobiloba.fr (SAN: www.leginkobiloba.fr) [2021-10-23T13:21:52] promabat-distribution.fr (SAN: www.promabat-distribution.fr) [2021-10-23T13:21:53] maevakaliciak.fr (SAN: mail.maevakaliciak.fr, www.maevakaliciak.fr) [2021-10-23T13:21:55] pascal-goldbach.fr (SAN: www.pascal-goldbach.fr) [2021-10-23T13:21:56] maevakaliciak.fr (SAN: mail.maevakaliciak.fr, www.maevakaliciak.fr) [2021-10-23T13:21:57] blog.nicolas-buffart.itval.fr (SAN: euromillions-generator.itval.fr, itval.fr, loto-generator.itval.fr, password-generator.itval.fr, www.blog.nicolas-buffart.itval.fr, www.euromillions-generator.itval.fr, www.itval.fr, www.loto-generator.itval.fr, www.password-generator.itval.fr) ...
Bien sûr, cela fait beaucoup (regardez les intervalles entre deux messages). En pratique, on modifierait sans doute ce script pour ne regarder que les noms de son organisation. Ainsi, vous pouvez détecter les certificats et chercher ensuite s'ils sont légitimes (ce qui, dans certaines organisations très cloisonnées n'ira pas de soi…).
À part Certstream, Samuel Bizien Filippi me suggère CertSpotter mais qui me semble uniquement payant. Il a une API. Elle peut être utilisée par le programme check_ct_logs, qui peut être utilisé comme script de test pour les programmes de supervision comme Icinga.
Le projet « Certificate Transparency » (largement impulsé par Google) a un site officiel (lecture recommandée) et, une liste de diffusion (sans compter le groupe de travail IETF TRANS, mais qui se limitait à la normalisation, il ne parle pas des aspects opérationnels, et il a de toute façon été clos en août 2021). Questions logiciels, si vous voulez créer votre propre journal, il y a le programme de Google.
Aujourd'hui, on peut dire que « Certificate Transparency » est un grand succès. La plupart (voire toutes ?) des AC y participent, il existe de nombreux journaux publics, et ils sont fréquemment utilisés pour l'investigation numérique (voire pour le renseignement, puisqu'on peut savoir, via les journaux, les noms de domaine pas encore annoncés, ce qui a parfois été cité comme une objection contre CT). Un bon exemple est celui de l'attaque « moyen-orientale » de 2018 (mais il y a aussi l'affaire du certificat révoqué de la Poste). Par contre, un client TLS ne peut pas encore être certain que tous les certificats seront dans ces journaux, et ne peut donc pas encore refuser les serveurs qui ne signalent pas la journalisation du certificat. Et le navigateur Firefox ne teste pas encore la présence des certificats dans le sjournaux.
Un point amusant : le concept de « Certificate Transparency » montre qu'il est parfaitement possible d'avoir un livre des opérations publiquement vérifiable sans chaine de blocs. La chaine de blocs reste nécessaire quand on veut autoriser l'écriture (et pas juste la lecture) au public.
La section 1.3 du RFC résume les principaux changements entre les versions 1 (RFC 6962) et 2 du protocole :
- Les algorithmes cryptographiques utilisés sont désormais dans des registres IANA,
- certains échanges utilisent désormais le format CMS (RFC 5652),
- les journaux qui étaient auparavant idenfiés par un condensat de leur clé publique le sont désormais par un OID, enregistrés à l'IANA (aucun n'est encore attribué),
- nouvelle fonction
get-all-by-hashdans l'API, - remplacement de l'ancienne extension TLS
signed_certificate_timestamp(valeur 18) partransparency_info(valeur 52, et voir aussi le nouvel en-tête HTTPExpect-CT:du RFC 9163, - et d'autres changements, dans les structures de données utilisées.
CT ne change pas de statut avec la version 2 : il est toujours classé par l'IETF comme « Expérimental » (bien que largement déployé). La sortie de cette v2 n'est pas allée sans mal (le premier document étant sorti en février 2014), avec par exemple aucune activité du groupe pendant la deuxième moitié de 2020.
Une des plus chaudes discussions pour cette v2 avait été la
proposition de changer l'API pour que les requêtes, au lieu d'aller
à <BASE-URL>/ct/v2/ partent du chemin
/.well-known/ du RFC 8615. Cette idée a finalement été rejetée, malgré le RFC 8820, qui s'oppose à cette idée de chemins
d'URL en dur.
L'article seul
RFC 9157: Revised IANA Considerations for DNSSEC
Date de publication du RFC : Novembre 2021
Auteur(s) du RFC : P. Hoffman (ICANN)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 1 décembre 2021
Rien de très grave dans ce nouveau RFC, qui règle un problème surtout bureaucratique, le fait que les politiques d'inclusion dans les registres IANA pour certains algorithmes utilisés par DNSSEC n'étaient pas parfaitement alignées.
En effet, le RFC 6014 avait modifié la politique d'enregistrement des algorithmes cryptographiques de « Action de normalisation » à la plus laxiste « RFC nécessaire » (rappelez-vous que tous les RFC ne sont pas des normes, voir le RFC 8126 qui décrit ces politiques possibles). Mais cette « libéralisation » laissait de côté certains algorithmes, ceux utilisés pour les enregistrements DS (RFC 4034), et ceux utilisés pour NSEC3 (RFC 5155), qui restaient en « Action de normalisation ». Notre nouveau RFC aligne les politiques d'enregistrement des algorithmes utilisés pour les DS et pour NSEC3 pour qu'ils soient eux aussi « RFC nécessaire ».
Il modifie également le RFC 8624 pour préciser que les algorithmes normalisés dans des RFC qui ne sont pas sur le chemin des normes sont également couverts par les règles du RFC 8624 ; en gros, ils sont facultatifs (MAY dans le langage du RFC 2119).
Les registres concernés sur celui sur NSEC3 et celui sur DS. Ils portent désormais la mention RFC Required.
Comme l'enregistrement d'algorithmes va, du fait de ce RFC, être plus léger, cela facilitera l'enregistrement de bons algorithmes, mais aussi de mauvais. Le programmeur qui met en œuvre DNSSEC, ou l'administratrice système qui le déploie, ne doit donc pas considérer que la présence dans un registre IANA vaut forcément approbation de la solidité cryptographique de l'algorithme. Il faut consulter la littérature technique avant d'utiliser ces algorithmes.
L'article seul
RFC 9156: DNS Query Name Minimisation to Improve Privacy
Date de publication du RFC : Novembre 2021
Auteur(s) du RFC : S. Bortzmeyer (AFNIC), R. Dolmans (NLnet Labs), P. Hoffman (ICANN)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 19 novembre 2021
Protéger la vie privée sur l'Internet nécessite au moins deux techniques : chiffrer les données en transit pour éviter leur lecture par des tiers et minimiser les données qu'on envoie, pour éviter les abus par les récepteurs des données. Ce deuxième point, pourtant bien mis en avant dans la loi Informatique & Libertés ou dans le RGPD est souvent oublié. Ce RFC applique ce principe au DNS : il ne faut pas envoyer aux serveurs faisant autorité le nom de domaine complet mais seulement la partie du nom de domaine qui lui est strictement nécessaire pour répondre, le minimum. Cette norme succède au RFC 7816, qui était purement expérimental alors que cette minimisation de la requête (QNAME minimisation) est désormais une norme. Le principal changement est la recommandation d'utiliser le type de données A (adresse IPv4) et plus NS (serveurs de noms).
Ce principe de minimisation, qui devrait être central dans toute
approche de la protection de la vie privée
est également exposé dans le RFC 6973, section
6.1. Le DNS violait
ce principe puisque, traditionnellement, un résolveur DNS qui recevait une demande
d'information sur www.foobar.example
transmettait aux serveurs
faisant autorité la question complète, alors que, par
exemple, les serveurs faisant autorité pour la
racine ne connaissent que les TLD et que leur demander simplement
des informations sur le TLD .example aurait
suffi. (Voir le RFC 7626 pour une analyse
complète des relations entre le DNS et la vie privée.) Cette
tradition (qui ne s'appuyait sur aucune norme technique) est remise
en cause par la QNAME minimisation qui demande au
contraire qu'on n'envoie aux serveurs faisant autorité que le nom
minimal (example à la racine,
foobar.example aux serveurs du TLD
.example, etc).
Cette minimisation est unilatérale, elle ne nécessite qu'un changement des résolveurs, sans toucher aux serveurs faisant autorité puisqu'elle ne change pas le protocole DNS. Depuis la sortie du RFC 7816, en 2016, elle a été largement déployée (si le résolveur que vous utilisez ne le fait pas, réclamez-le à votre service informatique !).
Le précédent RFC sur cette technique, le RFC 7816 avait le statut d'expérimentation alors que notre RFC 9156 est désormais une norme. En effet, une expérience considérable a été accumulée depuis le RFC 7816, qui a été mis en œuvre dans pratiquement tous les résolveurs, et souvent activé. Le FUD souvent entendu comme quoi la QNAME minimisation allait tuer Internet et des chatons a été largement réfuté. Les leçons tirées sont documentées dans « DNSThought QNAME minimisation results. Using Atlas probes », « Maximizing Qname Minimization: A New Chapter in DNS Protocol Evolution », « Measuring Query Name Minimization » et « A First Look at QNAME Minimization in the Domain Name System ».
Maintenant, la pratique, comment fait-on de la QNAME
minimisation ? La question envoyée par le résolveur au
serveur faisant autorité comprend un QNAME (Query
Name, le nom demandé) et un QTYPE (Query
Type, le type de données, par exemple serveur de courrier,
adresse IP, texte libre, etc). Avec la QNAME
minimisation, le nom doit être le nom le plus court
possible. Quand le résolveur interroge un serveur
racine, il n'envoie comme QNAME que le TLD, par
exemple. Trouver « le plus court possible » n'est pas forcément
trivial en raison des coupures de zone. Dans un nom comme
miaou.foo.bar.example,
foo.bar.example et
bar.example font peut-être partie de la même
zone (et ont donc les mêmes serveurs faisant autorité) et peut-être
pas. Rien dans la syntaxe du nom ne l'indique. Contrairement à une
idée fausse et répandue, il n'y a pas forcément une coupure de zone
pour chaque point dans le nom. Trouver les
coupures de zone est expliqué dans le RFC 2181, section 6. Un résolveur qui valide avec DNSSEC
doit savoir trouver ces coupures, pour savoir à qui demander les
enregistrements de type DS. Les autres (mais quelle idée, en 2021,
d'avoir un résolveur qui ne valide pas) doivent s'y mettre. Si, par
exemple, foo.bar.example et
bar.example sont dans la même zone, le
résolveur qui veut trouver des données associées à
miaou.foo.bar.example va envoyer le QNAME
example à la racine, puis
bar.example au serveur du TLD, puis
miaou.foo.bar.example au serveur de
bar.example. (Avant la QNAME
minimisation, il aurait envoyé le QNAME
miaou.foo.bar.example à tout le monde.)
Cela, c'était pour le QNAME. Et le QTYPE ? On peut choisir celui qu'on veut (à l'exception de ceux qui ne sont pas dans la zone, comme le DS), puisque les délégations de zones ne dépendent pas du type. Mais, et c'est un sérieux changement depuis le RFC 7816, notre RFC recommande le type A (ou AAAA), celui des adresses IP, et plus le type NS (les serveurs de noms), que recommandait le RFC 7816. Deux raisons à ce changement :
- Certaines middleboxes boguées jettent les questions DNS portant sur des types qu'elles ne connaissent pas. Le type A passe à coup sûr.
- Le but de la QNAME minimisation étant la protection de la vie privée, il vaut mieux ne pas se distinguer et, notamment, ne pas dire franchement qu'on fait de la QNAME minimisation (les requêtes explicites pour le type NS étaient rares). Un serveur faisant autorité, ou un surveillant qui espionne le trafic, ne peut donc pas déterminer facilement si un client fait de la QNAME minimisation.
Vous voyez ici le schéma de la résolution DNS sans la
QNAME minimisation puis avec :
Dans certains cas, la QNAME minimisation peut
augmenter le nombre de requêtes DNS envoyées par le résolveur. Si un
nom comporte dix composants (ce qui arrive dans des domaines
ip6.arpa), il faudra dans certains cas dix
requêtes au lieu de deux ou trois. Les RFC 8020 et RFC 8198
peuvent aider à diminuer ce nombre, en permettant la synthèse de
réponses par le résolveur. Une autre solution est de ne pas ajouter
un composant après l'autre en cherchant le serveur faisant autorité
mais d'en mettre plusieurs d'un coup, surtout après les quatre
premiers composants.
Un algorithme complet pour gérer la QNAME
minimisation figure dans la section 3 du RFC.
Notez que, si vous voulez voir si votre résolveur fait de la QNAME minimisation, vous pouvez utiliser tcpdump pour voir les questions qu'il pose mais il y a une solution plus simple, la page Web de l'OARC (dans les DNS features).
Un test avec les sondes RIPE Atlas semble indiquer que la QNAME minimisation est aujourd'hui largement répandue (les deux tiers des résolveurs utilisés par ces sondes) :
% blaeu-resolve --requested 1000 --type TXT qnamemintest.internet.nl
["hooray - qname minimisation is enabled on your resolver :)!"] : 651 occurrences
["no - qname minimisation is not enabled on your resolver :("] : 343 occurrences
Test #33178767 done at 2021-11-05T14:41:02Z
Il existe aussi une étude récente sur la QNAME minimization en République Tchèque.
Comme son prédécesseur, ce RFC utilise (prétend Verisign) un brevet. Comme la plupart des brevets logiciels, il n'est pas fondé sur une réelle invention (la QNAME minimisation était connue bien avant le brevet).
Ah, et vous noterez que le développement de ce RFC, par trois auteurs, a été fait sur FramaGit.
L'article seul
RFC 9155: Deprecating MD5 and SHA-1 signature hashes in (D)TLS 1.2
Date de publication du RFC : Décembre 2021
Auteur(s) du RFC : L.V. Velvindron (cyberstorm.mu), K.M. Moriarty (CIS), A.G. Ghedini (Cloudflare)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 20 décembre 2021
Vous le savez certainement déjà, car toutes les lectrices et tous les lecteurs de ce blog sont très attentif·ves et informé·es, mais les algorithmes de condensation MD5 et SHA-1 ont des failles connues et ne doivent pas être utilisés dans le cadre de signatures. Vous le savez, mais tout le monde ne le sait pas, ou bien certain·es ont besoin d'un document « officiel » pour agir donc, le voici : notre RFC dit qu'on ne doit plus utiliser MD5 et SHA-1 dans TLS.
Si vous voulez savoir pourquoi ces algorithmes sont mauvais, le RFC 6151 vous renseignera (et la section 1 de notre RFC 9155 vous donnera une bibliographie récente).
La section 2 à 5 sont le cœur du RFC et elle est sont très simples : pas de MD5, ni de SHA-1 pour les signatures. Dans le registre IANA, ces algorithmes sont désormais marqués comme déconseillés.
Les fanas de cryptographie noteront qu'on peut toujours utiliser SHA-1 pour HMAC (où ses faiblesses connues n'ont pas de conséquences).
L'article seul
RFC 9154: Extensible Provisioning Protocol (EPP) Secure Authorization Information for Transfer
Date de publication du RFC : Décembre 2021
Auteur(s) du RFC : J. Gould, R. Wilhelm (VeriSign)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 31 décembre 2021
Le protocole EPP d'avitaillement des noms de domaine permet, entre autres opérations, de transférer un domaine d'un client (typiquement un BE) à un autre. Cette opération ouvre de sérieux problèmes de sécurité, le transfert pouvant être utilisé pour détourner un nom de domaine. En général, la sécurisation de ce transfert est faite par un mot de passe stocké en clair. Notre RFC décrit une méthode pour gérer ces mots de passe qui évite ce stockage, et qui gêne sérieusement les transferts malveillants.
EPP est normalisé dans le RFC 5730 et c'est ce document qui décrit le cadre général
d'autorisation d'un transfert de domaines. La forme exacte que prend
l'autorisation dépend du type d'objets qu'on gère avec EPP. Pour les
domaines (RFC 5731), c'est un élément
<authInfo>, qui peut contenir divers
types de sous-élements mais le plus fréquent est un simple
mot de passe (parfois appelé « code de
transfert » ou « code d'autorisation », ou simplement « authinfo »),
comme dans cet exemple, une réponse à une commande EPP
<info>, où le mot de passe est
« 2fooBAR » :
<domain:infData>
<domain:name>example.com</domain:name>
...
<domain:crDate>1999-04-03T22:00:00.0Z</domain:crDate>
...
<domain:authInfo>
<domain:pw>2fooBAR</domain:pw>
</domain:authInfo>
</domain:infData>
L'utilisation typique de ce mot de passe est que le client (en
général un BE)
le crée, le stocke en clair, l'envoie au serveur, qui le
stocke. Lors d'un transfert légitime, le BE gagnant recevra ce mot
de passe (typiquement via le titulaire de l'objet, ici un nom de
domaine) et le transmettra au registre (RFC 5731, section 3.2.4). Ici, le BE gagnant demande à son
client le code d'autorisation qu'il a normalement obtenu via le BE
perdant (si le client est vraiment le titulaire légitime) :  Et ici le BE perdant indique à
son client le code d'autorisation :
Et ici le BE perdant indique à
son client le code d'autorisation :  (registar = BE)
(registar = BE)
Notez que la façon d'autoriser les transferts, et d'accéder aux informations d'autorisation, dépend de la politique du registre. Les RFC sur EPP normalisent la technique mais pas la politique. Par exemple, lorsqu'un BE demande un transfert sans fournir d'information d'autorisation, certains registres refusent immédiatement le transfert, tandis que d'autres le mettent en attente d'une acceptation ou d'un refus explicite. De même, certains registres permettent de récupérer l'information d'autorisation, comme dans l'exemple ci-dessus, alors que d'autres (comme CentralNic) refusent.
Même chose pour d'autres types d'objets comme les contacts (RFC 5733) même si en pratique la pratique du transfert est plus rare pour ces types. Le mot de passe étant typiquement stocké en clair chez le client, pour pouvoir être donné en cas de transfert, on voit les risques que cela pose en cas d'accès à la base du BE. Aujourd'hui, stocker un mot de passe en clair est nettement considéré comme une mauvaise pratique de sécurité.
À la place, notre RFC décrit, non pas une modification du protocole EPP, mais une nouvelle procédure, une façon créative de se servir du protocole existant pour gérer ces informations d'autorisation de manière plus sérieuse : l'objet (par exemple le nom de domaine) est créé sans information d'autorisation, le serveur EPP (par exemple le registre de noms de domaine) doit refuser le transfert si cette information est manquante. Lors d'un transfert légitime, le client (par exemple un BE) perdant va générer un mot de passe, le transmettre au registre et à son client (typiquement le titulaire du nom de domaine) et ne pas le stocker. Le registre stockera le mot de passe uniquement sous forme condensée et, lorsqu'il recevra la demande de transfert accompagnée d'un mot de passe, il pourra condenser ce mot et vérifier qu'il correspond bien à celui stocké. Le mot ne servira qu'une fois et l'information d'autorisation est détruite après le succès du transfert. Tout ceci ne nécessite pas de modification du protocole, mais, dans certains cas, une modification des pratiques des différents acteurs (par exemple, le serveur EPP doit accepter qu'un objet soit créé sans information d'autorisation, et doit considérer que cela vaut refus de tout transfert).
Le RFC note que la norme EPP ne décrit, logiquement, que le protocole, c'est-à-dire l'interaction entre les deux machines, mais pas ce que fait chaque machine de son côté. Ainsi, la nécessité de stocker les mots de passe de manière sécurisée n'est pas imposée par EPP (mais est néanmoins une bonne pratique).
D'autre part, EPP ne prévoit pas explicitement de durée de vie pour les mots de passe (mais n'interdit pas non plus de les supprimer au bout d'un temps donné, ce qui va être justement la technique de notre RFC).
Petite révision sur les acteurs de l'avitaillement de noms de domaine en section 2 du RFC. La norme EPP parle de client et de serveur, notions techniques, mais du point de vue business, il y a trois acteurs (cf. la terminologie dans le RFC 8499), le registre (qui gère le serveur EPP), le bureau d'enregistrement (BE, qui gère le client EPP) et le titulaire (qui se connecte à son BE via une interface Web ou une API). Dans beaucoup de domaines d'enregistrement, il n'y a aucun lien direct entre le titulaire et le registre, tout devant passer par le BE.
Maintenant, place à la description de la nouvelle manière de faire
des transferts. Bien qu'elle ne change pas le protocole, qu'elle ne
soit qu'une nouvelle façon d'utiliser ce qui existe déjà dans EPP,
elle doit se signaler lors de la connexion EPP, avec
l'espace de noms
urn:ietf:params:xml:ns:epp:secure-authinfo-transfer-1.0
(enregistré
à l'IANA). En effet, la nouvelle manière a besoin que le
serveur accepte des choses qui sont autorisées par EPP mais pas
obligatoires, notamment :
- une information d'autorisation vide (représentée par exemple
par le
NULLdans une base SQL), - la possibilité de supprimer l'information d'autorisation
avec la commande EPP
<update>, - la possibilité de valider l'information d'autorisation
avec la commande EPP
<info>, - le refus de tout transfert si l'information d'autorisation est vide,
- la remise à zéro de l'information d'autorisation lorsque le transfert a été réalisé (mot de passe à usage unique).
Le serveur, lui, en recevant
urn:ietf:params:xml:ns:epp:secure-authinfo-transfer-1.0,
peut compter que le client EPP saura :
- générer une information d'autorisation forte (aléatoire, par exemple),
- ne le faire que lorsqu'un transfert est demandé.
L'autorisation d'information dans l'élement XML
<domain:pw> (RFC 5731, section 3.2.4) est un mot de passe qui doit être
difficile à deviner par un attaquant. Idéalement, il doit être
aléatoire ou équivalent (RFC 4086). Le RFC
calcule que pour avoir 128 bits d'entropie, avec uniquement les
caractères ASCII imprimables, il faut environ 20
caractères.
Pour compenser l'absence de la notion de durée de vie de l'information d'autorisation dans EPP, le client ne doit définir une information d'autorisation que lorsqu'un transfert est demandé, et supprimer cette information ensuite. La plupart du temps, le domaine n'aura pas d'information d'autorisation, et les transferts seront donc refusés.
L'information d'autorisation, comme tout mot de passe, ne doit plus être stockée en clair, mais sous forme d'un condensat. Le BE perdant ne doit pas la stocker (il la génère, la passe au titulaire et l'oublie ensuite). Le BE gagnant ne doit la stocker que le temps de finaliser le transfert. Évidemment, toute la communication EPP doit être chiffrée (RFC 5734). Lors d'une demande de transfert, le registre va vérifier qu'un condensat de l'information d'autorisation transmise par le BE gagnant correspond à ce que le BE perdant avait envoyé. L'information vide est un cas particulier, le registre ne doit pas tester l'égalité mais rejeter le transfert.
La section 4 explique en détail le processus de transfert avec cette nouvelle méthode :
- Quand le domaine est créé, l'information d'autorisation est vide (pas de « authinfo »),
- quand le titulaire veut transférer le nom à un nouveau BE, il demande au BE perdant l'information d'autorisation,
- le BE perdant génère un mot de passe, qu'il transmet au titulaire et au registre (qui peut répondre avec le code d'erreur EPP 2202 si ce mot de passe ne lui semble pas assez fort), puis qu'il oublie aussitôt,
- le titulaire donne le mot de passe au BE gagnant,
- le BE gagnant demande le transfert au registre, en fournissant le mot de passe, ce qui permet au transfert d'être accepté immédiatement,
- le registre (ou bien le BE perdant), efface le mot de passe.
Voici en EPP quelques messages pour réaliser ces différentes opérations. D'abord, la création d'un nom (notez le mot de passe vide) :
<create>
<domain:create
xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
<domain:name>example.test</domain:name>
<domain:authInfo>
<domain:pw/>
</domain:authInfo>
</domain:create>
</create>
Ici, la mise à jour de l'information d'autorisation par le BE
perdant, lorsque le titulaire lui a annoncé le départ du domaine ;
le mot de passe est
LuQ7Bu@w9?%+_HK3cayg$55$LSft3MPP (le RFC
rappelle fortement l'importance de générer un mot de passe fort, par
exemple en utilisant des sources bien aléatoires, comme documenté
dans le RFC 4086) :
<update>
<domain:update
xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
<domain:name>example.test</domain:name>
<domain:chg>
<domain:authInfo>
<domain:pw>LuQ7Bu@w9?%+_HK3cayg$55$LSft3MPP</domain:pw>
</domain:authInfo>
</domain:chg>
</domain:update>
</update>
Le BE perdant devra peut-être également supprimer l'état
clientTransferProhibited, si le domaine était
protégé contre les transferts.
Le BE gagnant peut également vérifier l'information
d'autorisation sans déclencher un transfert, avec une requête
<info>, qui lui renverra l'information
d'autorisation. Pour plusieurs exemples par la suite, j'ai utilisé le
logiciel Cocca. Cocca,
par défaut, ne stocke pas l'autorisation d'information en clair et
ne peut donc pas la renvoyer.
Ou bien le client EPP peut envoyer une commande
<info> en indiquant l'information
d'autorisation. S'il obtient une erreur EPP 2202 (RFC 5730, section 3), c'est que cette
information n'était pas correcte. Ici, la
réponse EPP de Cocca lorsqu'on lui envoie un
<info> avec information d'autorisation correcte :
Client : <info xmlns="urn:ietf:params:xml:ns:epp-1.0"><info xmlns="urn:ietf:params:xml:ns:domain-1.0"><name>foobar.test</name><authInfo xmlns="urn:ietf:params:xml:ns:domain-1.0"><pw xmlns="urn:ietf:params:xml:ns:domain-1.0">tropfort1298</pw></authInfo></info></info> Serveur : ... <ns1:authInfo><ns1:pw>Authinfo Correct</ns1:pw></ns1:authInfo> ...
Et si cette information est incorrecte :
Serveur : ... <ns1:authInfo><ns1:pw>Authinfo Incorrect</ns1:pw></ns1:authInfo>
(Mais Cocca répond quand même avec un code EPP 1000, ce qui n'est pas correct.)
Et enfin, bien sûr, voici la demande de transfert elle-même :
<transfer op="request">
<domain:transfer
xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
<domain:name>example1.com</domain:name>
<domain:authInfo>
<domain:pw>LuQ7Bu@w9?%+_HK3cayg$55$LSft3MPP</domain:pw>
</domain:authInfo>
</domain:transfer>
</transfer>
Et si c'est bon :
<ns0:response xmlns:ns0="urn:ietf:params:xml:ns:epp-1.0" xmlns:ns1="urn:ietf:params:xml:ns:domain-1.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"><ns0:result code="1000"><ns0:msg>Command completed successfully</ns0:msg></ns0:result><ns0:msgQ count="2" id="3" />
<ns1:trStatus>serverApproved</ns1:trStatus> ...
Et avec une mauvaise information d'autorisation :
<ns0:response xmlns:ns0="urn:ietf:params:xml:ns:epp-1.0"><ns0:result code="2202"><ns0:msg>Invalid authorization information; (T07) Auth Info Password incorrect</ns0:msg></ns0:result>...
La section 6 du RFC décrit le problème de la transition depuis
l'ancien modèle d'autorisation vers le nouveau. Notez que certains
registres peuvent avoir une partie du nouveau système déjà en
place. Le registre qui désire transitionner doit d'abord s'assurer
que l'information d'autorisation absente ou vide équivaut à un
rejet. Il doit ensuite permettre aux BE de mettre une information
d'autorisation vide, permettre que la commande
<info> puisse tester une information
d'autorisation, s'assurer que l'acceptation d'un transfert supprime
l'information d'autorisation, etc.
L'extension à EPP décrite dans ce RFC a été enregistrée dans le registre des extensions EPP. Quelles sont les mises en œuvre de ce RFC ? Cocca, déjà cité, le fait partiellement (par exemple en ne stockant pas les mots de passe en clair). Je n'ai pas testé avec ce logiciel ce qui se passait avec une information d'autorisation vide. Sinon, CentralNic a déjà ce mécanisme en production. Et Verisign l'a mis dans son SDK.
L'article seul
RFC 9153: Requirements and Terminology for the Drone Remote Identification Protocol (DRIP)
Date de publication du RFC : Février 2022
Auteur(s) du RFC : S. Card, A. Wiethuechter (AX Enterprize), R. Moskowitz (HTT Consulting), A. Gurtov (Linköping University)
Pour information
Réalisé dans le cadre du groupe de travail IETF drip
Première rédaction de cet article le 11 février 2022
Il y a aujourd'hui beaucoup plus de drones que d'avions pilotés. Ces drones, qui se déplacent dans un espace partagé, soulèvent un certain nombre de questions de sécurité, ce qui justifie des mécanismes obligatoires d'immatriculation et d'identification. Dans tous les pays, des règles imposent aux drones ou au moins à certains d'entre eux de diffuser leur identité. Mais, ensuite, une fois que l'observateur du drone a cette identité, qu'en fait-on ? Le but du projet DRIP à l'IETF est de mettre au point des mécanismes pour utiliser cette identité. Ce RFC est le premier du projet, dédié à établir les exigences pour les futurs protocoles. Ce n'est pas gagné, vu qu'il y a beaucoup de grosses organisations sur le chemin qui vont privilégier des solutions fermées.
Pour aider à comprendre le problème, imaginons le scénario suivant. Un gardien fait sa ronde autour d'une centrale nucléaire. Un drone approche. Sa présence ici est-elle normale ? Est-il encore sous contrôle ou bien a-t-il échappé à son propriétaire ? Peut-on contacter son propriétaire pour vérifier ? S'il s'agissait d'un avion piloté traditionnel, les règles de circulation aérienne imposeraient tout un tas de contraintes au pilote (par exemple d'enregistrement de son vol à l'avance), qui permettraient d'éviter des incertitudes. On ne peut pas imposer des procédures aussi lourdes à un simple drone de loisirs. Mais on ne peut pas laisser non plus l'espace partagé qu'est l'air sans règles minimales. Prenons un autre scénario : un drone se promène au-dessus de votre jardin. Il a sans doute une caméra, comme la plupart des drones. Comment faire en sorte qu'il déguerpisse au lieu de vous filmer tranquillement en train de bronzer ? Peut-on lui tirer dessus, comme ça se fait aux États-Unis (« get off my lawn »), s'il ne répond pas ? Faut-il faire des sommations, et comment ? Comme l'analyse correctement la Quadrature du Net, le danger des drones ne vient pas que d'individus malveillants, une utilisation de ces engins par l'État crée également de nombreux risques.
Depuis quelques années, de nombreuses règles ont été édictées dans divers pays. Ainsi, en France, l'arrêté du 29 décembre 2019 impose la signalisation électronique des appareils pour tous les drones de plus de 800 grammes (cet article du Monde résume les obligations). Le drone doit être enregistré sur le site officiel AlphaTango (uniquement le drone, pas chaque vol, contrairement aux obligations des avions). Aux États-Unis, il existe des règles similaires . La plupart du temps, l'obligation minimale est que le drone diffuse son identité, de la même façon qu'une voiture a une plaque d'immatriculation. Mais cette règle est très insuffisante pour répondre à tous les scénarios. Le drone peut facilement mentir sur son identité. Et puis à quoi sert cette identité si elle ne fournit pas de moyen de retrouver le propriétaire ? Et ne serait-ce pas souhaitable d'avoir un moyen de contacter celui-ci en temps réel ? Ces questions ne sont pas évidentes et, comme toutes les questions liées à la sécurité, soulèvent d'innombrables problèmes politiques, juridiques et techniques. L'IETF se concentre sur une partie limitée de ces problèmes : ne pouvons-nous pas utiliser notre expérience en matière de protocoles réseau pour développer des mécanismes permettant de retrouver des données sur le drone à partir de son identité et, pourquoi pas, permettant de communiquer avec lui ? Voyons d'abord en détail le problème, les exigences de notre RFC pour les futurs protocoles ne seront présentées qu'à la fin de cet article.
Ah, si vous voyez ce drone, c'est le mien : 
La section 1 de notre RFC détaille pourquoi les drones posent des problèmes. Il existe plusieurs types de drones (à aile fixe, à aile tournante, capables de décollage vertical ou non, avec un ou plusieurs moteurs…). Le type le plus répandu et le plus connu, notamment grâce aux petits drones de loisir, est le multi-moteur à ailes tournantes (multicoptère). Disposant de systèmes de stabilisation automatiques, ils peuvent être pilotés par des amateurs, contrairement aux avions et hélicoptères. Mais il existe aussi des drones dont la taille et le prix rappelle davantage un avion. Être pilotés à distance par un humain tenant un joystick n'est pas la seule possibilité : doté d'un récepteur GPS, certains drones sont partiellement autonomes et, dans le futur, seront totalement autonomes.
Un petit drone, comme celui que vous achetez pour quelques dizaines d'euros en magasin, a des propriétés importantes pour la sécurité de l'espace aérien :
- ils sont nombreux,
- il est difficilement détectable par les radars,
- s'il est bruyant, voire insupportable, à courte distance, il est en général indétectable au bout de quelques centaines de mètres, alors qu'il peut couvrir cette distance rapidement ; un drone grand public peut faire 500 mètres en 13 secondes,
- il vole à très basse altitude,
- il est souvent piloté par un amateur sans vraie formation,
- très manœuvrant, il peut passer sous les arbres, rentrer dans un immeuble, etc.
Un drone peut donc être très utile pour l'espionnage, voire l'attaque. Il peut porter une caméra pour surveiller, et des explosifs pour attaquer (cf. l'attentat contre le premier ministre irakien en novembre 2021). Même sans explosifs, le drone peut jouer un rôle de projectile, involontaire ou volontaire. Un article de Kaspersky donne une bonne idée des dangers possibles (mais notez qu'il est publié par une entreprise qui vend des solutions et peut donc être soupçonnée de dramatiser).
Il n'y a évidemment pas de solution magique à ces risques mais la plupart des approches nécessitent a priori qu'on découvre un identificateur du drone, qu'on ait une solution RID (Remote IDentification and tracking). Dans le scénario typique de RID, un ou plusieurs drones volent dans un espace restreint, et des observateurs, certains ayant un rôle particulier (policiers, par exemple) et d'autres étant du grand public, veulent obtenir un identificateur, qui va être le point de départ de leurs actions (s'informer sur ce drone, peut-être le contacter). Il est donc prévu un ou plusieurs registres d'identificateurs, et des informations associées. Il existe déjà des normes pour cela, comme la F3411-19, développée par le comité F38 de l'ASTM. Elle coûte 91 dollars étatsuniens. Comme beaucoup de normes développées par des organismes privés, elle n'est pas librement et gratuitement disponible, mais on peut apparemment trouver des brouillons en ligne. F3411-19 est la référence dans ce domaine, normalisant les messages que le drone doit envoyer pour annoncer son identifiateur mais, pour l'instant, c'est à peu près tout, on ne peut pas forcément faire grand'chose de cet identificateur. Elle ne précise pas comment l'observateur se renseigne sur les personnes ou organisations derrière un identificateur. Elle ne traite pas la communication entre drones ou avec l'observateur. Elle n'a pas de mécanisme d'authentification de l'identificateur. Le RFC, étant surtout développé par des Étatsuniens, est très inspiré par le travail de l'ASTM, qui ne s'applique pas forcément partout dans le monde. En Europe, ASD-STAN, associée à CEN, publie une norme DIN EN 4709-002:2021-02 (également chère et pas libre). Un résumé est disponible en ligne. Cette norme décrit un système de DRI (Drone Remote Identification) où le drone diffuse par radio :
- le numéro d'identification de l'opérateur du drone (qui doit donc s'enregistrer),
- celui du drone (en suivant CTA2063A - aussi désignée ANSI/CTA/2063-A, enfin une norme gratuitement disponible mais attention, il faut laisser plein de données personnelles pour l'obtenir).
- l'heure qu'il est, la position du drone (en trois dimensions),
- la vitesse et le cap du drone,
- la position du pilote ou, à défaut, la position d'où le drone a décollé.
Un exemple d'identificateur de drone (celui donné par la norme) est
MFR1C123456789ABC. (Le C en cinquième position
est l'encodage de la longueur du numéro de série, ici 123456789ABC).
Même avec ces normes, de nombreux problème subsistent. Si trois drones sont proches, chacun diffusant son identité, et qu'un seul des trois a un comportement inquiétant, comment distinguer les trois identités ? Et puis les informations envoyées peuvent être erronnées (les drones bon marché n'incluent pas du matériel de mesure perfectionné) voire mensongères, notamment si le drone est malveillant.
Notez aussi que les groupes techniques comme DRIP ne peuvent qu'établir des normes techniques. Définir des règles politiques est une autre affaire. Et les faire respecter sera largement l'affaire des CAA.
Autre problème, comme le drone diffuse des informations en clair, tout le monde peut les capter et certaines informations (comme l'identificateur de l'opérateur) sont des données personnelles, ce qui soulève des questions de vie privée. On a là un beau débat politique en perspective, entre intimité et transparence.
Le RFC note qu'un déploiement massif d'un système de RID (Remote IDentification and Tracking) est à la fois urgent et important. Le déploiement doit être massif car, comme le dit le RFC, « quel serait l'intérêt des plaques minéralogiques si seulement 90 % des voitures en avaient ? ».
Un autre défi des systèmes d'identification réside dans le caractère capricieux des ondes radio. Elles peuvent être bloquées par des bâtiments ou du feuillage. Si le drone émet avec davantage de puissance, il va épuiser rapidement sa batterie. Et il aggravera la congestion dans cet espace partagé (d'autant plus que le drone émet dans des fréquences où une licence n'est pas nécessaire). Bref, d'une manière générale, la liaison radio sera lente et non fiable.
En parlant de batterie, il faut noter que le drone est typiquement un objet contraint (au sens du RFC 8352). Son « budget » en énergie, puissance de calcul et poids (ce qu'on désigne en général par le sigle CSWaP, Cost, Size, Weight, and Power, parfois écrit $SWaP) est très limité. Cela impose des protocoles de communication simples et frugaux, ce qui va rendre difficile l'utilisation de la cryptographie. Actuellement, il y a zéro authentification : un drone mensonger peut annoncer l'identificateur qu'il veut, sans qu'on puisse vérifier. (Dans des réunions, j'ai entendu des affirmations ridicules, comme de confondre la somme de contrôle avec un mécanisme d'authentification. Comme souvent en cybersécurité, on entend beaucoup de n'importe quoi dans les réunions.)
Et il n'y a pas que le drone, il y a aussi la machine de l'observateur. Dans des zones reculées, on ne peut pas compter sur une connectivité Internet permanente, et c'est une des raisons du choix du Broadcast RID (le drone diffuse son identificateur, également appelé Direct ID) plutôt que du Network ID (l'observateur obtient l'identificateur via un réseau public, typiquement l'Internet). Mais si vous voulez en savoir plus sur ce débat Network ID vs. Broadcast ID, voyez l'article « Why Did the FAA Go with Broadcast Remote ID for Drones Over Network? ».
Bref, les mécanismes actuellement normalisés et déployés sont très insuffisants. Le projet DRIP de l'IETF vise, non pas à remplacer les normes existantes, mais à les compléter pour traiter les manques. Ce RFC est le cahier des charges du projet.
Le monde des drones utilise une grande quantité d'acronymes. La section 2 du RFC en donne une liste complète, mais il faut au moins connaitre :
- CAA (Civil Aviation Authority), l'autorité de régulation de l'aviation comme la DGAC en France ou la FAA aux États-Unis. Le milieu aérien, partagé et complexe, est très régulé dans tous les pays.
- DRI (Direct Remote Identification), la possibilité d'obtenir l'identificateur d'un drone (le cœur du système).
- LOS (Line Of Sight), la ligne qui va mener au drone pour le contrôler. Ce n'est pas forcément un lien visuel (voir « VLOS »), le pilote peut obtenir l'information sur le drone par d'autres moyens. Lorsque le drone n'est pas sur la LOS, il est incontrôlable (sauf s'il peut agir de manière autonome).
- RID Remote IDentification ou UAS RID, le système qui permet aux observateurs d'obtenir l'identificateur du drone et, par extension, l'identificateur du drone.
- UA (Unmanned Aircraft), un drone.
- UAS (Unmanned Aircraft System), le drone, et tout ce qui lui permet de voler et d'être piloté (la télécommande, par exemple).
- UAS ID (Unmanned Aircraft System IDentifier), l'identificateur de l'UAS (en fait, en pratique, c'est plutôt celui de l'UA).
- VLOS (Visual Line Of Sight), lorsque le pilote voit son drone. Dans certains pays, la reglémentation peut imposer que le vol du drone se fasse en permanence à vue, et que le pilote ait donc une VLOS avec son engin, ce qui interdit par exemple de le faire voler derrière un bâtiment.
Pour les RID, les identificateurs des drones, il existe plusieurs textes normatifs. Le plus répandu est F3411-19, déjà mentionné, qui décrit les notions de Network RID et Broadcast RID. Pour le premier, l'observateur va récolter l'information via le réseau (le drone s'étant au préalable enregistré, on est dans le publish-subscribe), alors que dans le cas du second, il va écouter directement ce que diffuse le drone par ondes radio. Comme l'observateur, le pilote du drone et surtout le drone lui-même n'ont pas forcément d'accès à l'Internet, c'est le Broadcast RID qui est privilégié. Il fonctionne donc indépendamment de l'Internet.
Le Broadcast RID soulève de nombreux problèmes techniques, notamment en raison des caractéristiques physiques des ondes radio. Si on utilise Bluetooth, on a de sérieuses contraintes de taille des données, au cas où on veuille transmettre, en sus de l'identificateur, des informations de position, de vitesse et de route. En outre, les normes existantes ne standardisent pas les couches basses (Bluetooth 4, 5, Wifi NAN, Wifi Beacon…), donc il sera difficile de capter tous les drones, et surtout pas avec n'importe quel ordiphone, le drone émettant peut-être avec une technologie que l'ordiphone ne connait pas. En outre, sur beaucoup d'ordiphones, on n'a pas accès direct à Bluetooth (cf. les problèmes de l'application TousAntiCovid) et/ou pas accès aux paquets bruts, ce qui va compliquer la vie des développeurs. (Le projet AltBeacon vise à traiter ce problème.)
Comment est attribué le RID ? F3411-19 propose plusieurs méthodes :
- Un identificateur statique attribué par le fabricant du drone, comme prévu par la norme ANSI/CTA-2063-A,
- Un identificateur statique attribué par une CAA, comme cela se fait aujourd'hui pour les avions,
- Un UUID (RFC 9562), statique ou dynamique, attribué par un système spécifique aux drones (une nouvelle autorité ?),
- Un identificateur dynamique spécifique au vol.
Actuellement, l'Union Européenne impose le premier type, les États-Unis le premier ou le troisième. La situation est compliquée, et le choix fait a des implications évidentes en terme de vie privée (un identificateur statique permet de suivre à la trace un drone). C'est d'autant plus important que cette information, étant diffusée unilatéralement, ne peut pas être chiffrée, les protocoles de type défi-réponse étant inutilisables. Pour prendre un exemple, Amazon ne serait sans doute pas ravi qu'un concurrent puisse suivre précisement leurs drones de livraison.
La simple diffusion du RID est donc déjà un problème compliqué. Mais d'autres organismes que l'IETF s'en occupent. Par contre, cette diffusion laisse entier un autre problème : une fois qu'on a récupéré le RID, qu'en fait-on ? Comment, par exemple, communiquer avec le pilote du drone ? Si le message contenait, en sus de l'identificateur, la position du pilote, on peut toujours s'y rendre. Cela peut être lent, voire infaisable si le pilote est, par exemple, de l'autre côté d'une voie ferrée. Dans l'hypothèse où il existe un registre des identificateurs, associé à des informations de contact (comme on fait pour les noms de domaine), on pourrait imaginer que l'observateur regarde dans le registre (avec des protocoles comme RDAP ou whois) et appelle au téléphone le pilote. Reste à savoir si c'est une bonne idée que le pilote réponde alors que son attention devrait être concentrée sur le pilotage…
L'IETF, via son groupe DRIP, va donc tenter de développer des solutions pour :
- authentifier l'identificateur de drone,
- permettre l'interrogation d'un registre de ces identificateurs,
- faciliter la coordination entre observateurs pour qu'ils puissent vérifier collectivement ce que fait un drone,
- contacter le pilote.
Le but est évidemment que ces solutions reposent sur des normes ouvertes et accessibles. (Un certain nombre d'organisations font déjà du lobbying pour pousser au déploiement et à l'obligation légale de solutions privées et fermées, leur assurant le contrôle, et les revenus associés.)
Les normes existantes comme F3411-19 ne permettent pas cela, d'où ce cahier des charges du projet DRIP, dont les exigences forment la section 4 de notre RFC. Chacune est identifiée par trois lettres indiquant sa catégorie, puis un numéro. Ainsi, la première exigence est dans la catégorie des généralités et se nomme GEN-1 : « DRIP doit permettre d'authentifier les affirmations du drone » (puisque, actuellement, un drone peut raconter ce qu'il veut). Je ne vais pas vous lister toutes les exigences, seulement de quoi vous donner une idée du projet. Ainsi, GEN-2 suit GEN-1 en demandant qu'en outre, tous les messages du drone puissent être reliés à ceux qui prouvent l'identité du drone (et pas uniquement parce que les messages sont émis depuis la même adresse MAC). GEN-3 impose qu'il existe un moyen de vérifier l'enregistrement du drone dans un registre, même en l'absence de connexion Internet (par exemple le drone pourrait diffuser un certificat signé par le registre). GEN-6 concerne la prise de contact, il faut qu'il existe un moyen de contacter le pilote. (Attention, comme tout ce cahier des charges, il s'agit d'une exigence technique, pas politique. L'IETF n'a pas l'autorité pour édicter des règles disant, par exemple, que le pilote doit accepter les communications entrantes. Elle dit juste qu'un moyen technique doit exister, mais son utlisation pourra, par exemple, être restreinte à des appelants identifiés et autorisés.) Un protocole envisagé pour cette communication est HIP.
GEN-8 demande que tout cela fonctionne même si le drone (évidemment), son pilote et l'observateur sont en déplacement, GEN-9 veut un mode multicast, et GEN-10 un moyen de superviser le bon fonctionnement du système (notamment pour le Network RID).
La catégorie suivante concerne plus spécifiquement les identificateurs. ID-1 met une taille maximale à 19 octets (c'est une limite de F3411-19, sauf erreur). ID-2 dit que sur ces 19 octets au maximum, il faut placer un identificateur du registre. ID-4 exige que l'identificateur soit unique (ce qui est du simple bon sens) et ID-5, reprenant GEN-1, demande que le drone ne puisse pas mentir sur son identificateur. ID-6 veut qu'on puisse empêcher de suivre un drone ou son propriétaire à la trace (et il faut donc permettre des identificateurs qui ne soient pas statiques sur le long teme). Là encore, rappelez-vous l'avertissement de la catégorie précédente : DRIP ne définit pas une politique, l'activation ou non de la technique demandée par ID-6 n'est pas une question purement technique.
En parlant de gêner la surveillance, la troisième catégorie concerne la vie privée (voir aussi la section 7). PRIV-1 rappelle l'importance de protéger les données privées (par exemple en ne distribuant pas le nom et l'adresse du pilote publiquement) et PRIV-4 demande pour cela que le système d'enregistrement sépare ce qui est public et ce qui ne l'est pas (données personnelles, par exemple).
Et les registres ? Sur l'Internet, il existe de nombreux types de registres, comme les registres de noms de domaine ou les RIR. Certains problèmes, comme l'arbitrage entre les exigences opérationnelles (où on voudrait obtenir facilement beaucoup d'informations sur les titulaires des noms de domaine) et celles de vie privée, sont bien connues depuis longtemps (le « problème whois » de l'ICANN, par exemple). J'ai pris plusieurs exemples tirés des registres de noms de domaines car c'est là où je travaille. La quatrième et dernière catégorie d'exigences DRIP concerne précisément les futurs registres de drones. En raison des limites de taille très strictes sur ce que le drone peut diffuser, il est essentiel de disposer de registres permettant l'accès à davantage d'informations. REG-1 commence par demander qu'il existe un moyen d'interroger le registre (la solution évidente étant RDAP, RFC 9082). Ce moyen doit (exigence REG-2), contrairement à whois (RFC 3912), permettre l'accès différencié (davantage d'informations pour certains clients). REG-3 réclame qu'on puisse ajouter, retirer et modifier de l'information dans le registre (là, la solution évidente est EPP, RFC 5730). Notez qu'une présentation sur l'utilisation de registres avait été faite lors d'une réunion professionnelle des acteurs du monde des registres : les supports.
Enfin, la section 6 du RFC concerne l'analyse de sécurité du futur système. Quelles que soient les solutions adoptées, il faudra faire attention aux attaques Sybil, aux attaques par déni de service utilisant, par exemple, de nombreux messages incorrectement signés, aux attaques de l'Homme du Milieu, etc. On pourra voir aussi des attaques plus subtiles comme, suggère le RFC, un drone de petite taille, a priori pas très effrayant, et qui s'authentifiera proprement, mais derrière lequel surgira le vrai attaquant.
Pour les curieuses et les curieux, je recommande également l'annexe A du RFC, qui discute les choix effectués dans ce RFC et leurs raisons. Par exemple, l'analogie avec les plaques d'immatriculation des voitures, souvent utilisée dans les débats sur l'identification des drones a ses limites. Dans certains pays, par exemple des États des USA, n'importe qui peut accéder, parfois même gratuitement, aux données du registre, et donc aux informations personnelles sur les propriétaires de véhicules. Faut-il faire pareil pour les drones ? Même en Europe, si le registre n'est pas accessible, en revanche, les voitures ont un identificateur statique stable, qui peut faciliter certaines formes de surveillance. Veut-on cela pour les drones ?
Les avions (civils) pilotés et les bateaux ont l'habitude depuis longtemps de diffuser leur identité à qui veut écouter (le transpondeur pour les avions). D'excellentes et utiles applications comme OpenSky et Flightradar24 exploitent cette information. Souhaite-t-on un même fonctionnement pour les drones ? Outre les questions politiques, cela peut poser des problèmes techniques, par exemple parce que le nombre de codes utilisables est limité et qu'il y a beaucoup plus de drones que d'avions. Avec les 24 bits typiquement utilisés, on ne pourrait traiter que seize millions de drones, ce qui est loin des nombres envisagés.
Les drones qui diffusent leur identité le font en Wi-Fi ou en Bluetooth. Ces techniques ont l'avantage d'être très répandues, aussi bien du côté des drones que des observateurs (tous ont un ordiphone), peu chères, libres d'usage, et elles permettent la diffusion. Par contre, leur portée est faible. Il pourrait être intéressant de travailler sur des technologies conçues pour les grandes distances (comme WiMAX), ou pour les réseaux de capteurs (comme LoRA).
Voilà, le groupe DRIP est évidemment au travail pour mettre au point des protocoles correspondant à ces exigences. Le problème posé par les drones ne peut que devenir de plus en plus sérieux, notamment parce que leur discrétion augmentera. Dans les romans de la série Harry Potter (par J. K. Rowling), une journaliste-sorcière sans scrupule peut se transformer en insecte pour aller espionner les gens chez eux. Un drone suffisamment petit pour être quasiment indétectable serait un cauchemar pour la vie privée…
Pour en savoir plus, quelques ressources utiles :
- Pour développer des solutions ouvertes, le projet OpenDroneID.
- Autre projet analogue, Paparazzi UAV.
- La vidéo de l'atelier drones de CEN et CENELEC du 9 février 2021.. Les organisateurs sont deux organisations de normalisation traditionnelles.
- Un résumé de la situation européenne, par ASD-STAN (une organisation de normalisation spécialisée dans l'aéronautique).
- Un intéressant projet d'étudiants de l'université de Linköping sur DRIP et sur l'utilisation de HIP pour contacter le drone.
- La chaire de recherche sur les drones à l'ENAC. Et la volière de l'ENAC (une volière étant un endroit fermé où on peut faire des expérimentations avec les drones).
- Et enfin, divers dispositifs de réalité augmentée pour aider à piloter les drones.
L'article seul
RFC 9151: Commercial National Security Algorithm (CNSA) Suite Profile for TLS and DTLS 1.2 and 1.3
Date de publication du RFC : Avril 2022
Auteur(s) du RFC : D. Cooley (NSA)
Pour information
Première rédaction de cet article le 26 avril 2022
Le choix est vaste parmi les algorithmes de cryptographie. Des protocoles comme TLS offrent de l'agilité cryptographique, c'est-à-dire la possibilité d'avoir différents algorithmes pour un même protocole. Pour l'administrateur système qui n'est pas un ou une expert en cryptographie, lesquels choisir ? Pour l'aider, les agences de sécurité nationales font souvent des documents synthétisant leur analyse des bons algorithmes du moment. C'est le cas du RGS en France, par exemple. Ce RFC définit le profil TLS de CNSA (Commercial National Security Algorithm), les bons algorithmes recommandés par la NSA.
C'est d'ailleurs le deuxième RFC écrit par un employé de cette agence étatsunienne, après le RFC 5903 mais il est évidemment possible que certains auteurs aient été discrets sur leur affiliation.
Ce profil CNSA (Commercial National Security Algorithm) est destiné à être utilisé dans le cadre de TLS, plus exactement ses versions 1.2 (RFC 5246) et 1.3 (RFC 9846). Le cadre réglementaire étatsunien est SP 80059. Un rappel : il s'agit d'un profil, une restriction des algorithmes possibles, il ne définit pas de nouvel algorithme, il liste juste ceux à utiliser, par exemple ceux des RFC 5288 et RFC 5289. C'est en effet une de missions de la NSA que de conseiller l'État et les entreprises en matière de cryptographie. (La NSA a également une mission offensive, qui va en sens inverse, les encourageant par exemple à garder secrètes des vulnérabilités, pour qu'elle puisse les exploiter.) Cette suite CNSA n'a rien de très novateur, elle est dans la continuation des précédentes, le prochain grand changement, estime la NSA, sera le passage aux algorithmes post-quantiques. (Notez que l'analyse de la NSA sur les mesures à prendre en attendant les calculateurs quantiques est très discutée.)
Après ces préliminaires, la suite CNSA elle-même (section 4). Elle inclut les grands classiques, Diffie-Hellman avec les corps finis, les courbes elliptiques du NIST et encore RSA, les signatures avec les courbes elliptiques (ECDSA seulement) et RSA, et l'algorithme de chiffrement symétrique AES en intègre avec GCM (ChaCha - RFC 8439, sans doute pas assez officiel, n'est pas cité). CNSA impose des tailles minimales de clés, par exemple 3 072 bits pour une signature avec RSA. Pour la condensation, c'est SHA-384 seulement (j'ignore pourquoi SHA-256 et les autres ne sont pas cités).
Pour la version de TLS, la section 5 de notre RFC impose au minimum 1.2 (c'est un des points où le blog que vous êtes en train de lire n'est pas conforme aux recommandations de la NSA…). Si on utilise une courbe elliptique (cf. RFC 8422), cela doit être la P-384 du NIST. (Saviez-vous d'ailleurs qu'il existe une courbe elliptique française, « FRP256 », publiée au Journal officiel ?) Et au passage, les certificats doivent suivre le profil du RFC 8603.
Pour TLS 1.3 (RFC 9846), CNSA impose de
tirer profit de certaines nouveautés de cette version, comme
l'extension signature_algorithms. Par contre,
il faut refuser early_data (les raisons sont
dans la section 2.3 du RFC 9846).
L'article seul
RFC 9150: TLS 1.3 Authentication and Integrity-Only Cipher Suites
Date de publication du RFC : Avril 2022
Auteur(s) du RFC : N. Cam-Winget (Cisco Systems), J. Visoky (ODVA)
Pour information
Première rédaction de cet article le 22 avril 2022
Ce nouveau RFC normalise des algorithmes pour le protocole de sécurité TLS, qui ne fournissent pas de chiffrement (seulement authentification et intégrité). C'est évidemment une option très contestée et l'IETF ne suggère pas d'utiliser ces algorithmes mais, bon, certaines personnes y voient une utilité.
La section 1 du RFC décrit des scénarios d'usage (souvent tirés du monde de l'IoT) où cela peut avoir un sens de ne pas chiffrer. Le premier exemple est celui d'un bras robotique commandé via un protocole TCP/IP. L'authentification est importante mais la confidentialité ne l'est peut-être pas, ce qui rendrait acceptable l'absence de chiffrement. Autre exemple, des rapports météo, ou bien l'envoi de signaux d'horloges, qu'il faut évidemment authentifier mais qui ne sont pas secrets. Le RFC cite aussi des exemples de communication avec des trains ou des avions, où l'intégrité des données est cruciale, mais pas leur confidentialité. Mais attention avant de jeter le chiffrement à la poubelle, le RFC dit bien qu'il faut faire une analyse soignée de la menace. Pour reprendre l'exemple du bras robotique, l'écoute des messages pourrait permettre la rétro-ingénierie, ce qu'on ne souhaite pas forcément.
Mais pourquoi se passer de chiffrement, d'ailleurs, alors qu'il est plus simple de l'utiliser systématiquement ? Parce que dans certains cas, il coûte cher, notamment en latence. En outre, certains équipements, notamment du genre objets connectés, ont des capacités de calcul très limitées. Bref, si le chiffrement systématique et par défaut reste la politique de l'IETF, ce RFC présente quelques façons de s'en passer, si on sait ce qu'on fait (si vous ne savez pas, continuez à chiffrer !).
Les algorithmes sans chiffrement sont présentés dans la section
4. Ils se nomment TLS_SHA256_SHA256 et
TLS_SHA384_SHA384, et sont évidemment dans
le
registre IANA. Ils utilisent une fonction de
condensation comme SHA-256 pour
faire du HMAC, protégeant ainsi l'intégrité des
communications.
Rappelez-vous bien : aucun chiffrement n'est fourni. Les certificats client, par exemple, qui sont normalement chiffrés depuis TLS 1.3, seront envoyés en clair.
Publier un tel RFC n'a pas été facile, la crainte de beaucoup étant que des gens qui ne comprennent pas bien les conséquences utilise ces algorithmes sans mesurer les risques. Le RFC demande (section 9) donc qu'ils ne soient pas utilisés par défaut et qu'ils requièrent une configuration explicite. Et rappelez-vous que ce RFC n'est que « pour information » et ne fait pas l'objet d'un consensus à l'IETF.
L'article seul
RFC 9147: The Datagram Transport Layer Security (DTLS) Protocol Version 1.3
Date de publication du RFC : Avril 2022
Auteur(s) du RFC : E. Rescorla (RTFM), H. Tschofenig (Arm Limited), N. Modadugu (Google)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 22 avril 2022
Pour sécuriser vos applications TCP sur l'Internet, vous utilisez TLS, pas vrai ? Et si vos applications préfèrent UDP, par exemple pour faire de la voix sur IP ? La solution est alors DTLS, dont la nouvelle version, la 1.3, est normalisée dans ce RFC 9147. Elle a vocation à remplacer l'ancienne version 1.2, qui était dans le RFC 6347.
DTLS fournit normalement les mêmes services de sécurité que TLS, notamment la confidentialité (via un chiffrement du trafic) et l'authentification (via une signature). Les seuls services TLS que DTLS ne peut pas rendre sont la protection de l'ordre des messages (ce qui est logique pour UDP) et, selon les options choisies, la protection contre le rejeu. DTLS a été conçu pour être aussi proche que possible de TLS, pour pouvoir réutiliser le code et s'appuyer sur des propriétés de sécurité déjà établies. DTLS 1.0 et 1.2 (il n'y a jamais eu de 1.1) avaient été normalisés sous forme de différences avec la version de TLS correspondante. De même, DTLS 1.3, objet de notre RFC, est défini en décrivant les différences avec TLS 1.3. Il faut donc lire le RFC 9846 avant. À propos de lectures, il faut aussi lire le RFC 9146, pour le concept d'identificateur de connexion (Connection ID).
La section 3 du RFC pose le problème : on veut un truc comme TLS mais qui marche sur un service de datagrammes, en général UDP (RFC 768). Un service de datagrammes ne garantit pas l'ordre d'arrivée, ni même que les datagrammes arrivent. DTLS ajoute de la sécurité au service de datagrammes mais ne change pas ses propriétés fondamentales : une application qui utilise DTLS ne doit pas s'étonner que les messages n'arrivent pas tous, ou bien arrivent dans le désordre. C'est un comportement connu des applications de diffusion vidéo ou de jeu en ligne, qui préfèrent sauter les parties manquantes plutôt que de les attendre.
Pourquoi un protocole distinct, DTLS, plutôt que de reprendre TLS ? C'est parce que TLS ne marche que si le service de transport sous-jacent garantit certaines propriétés qu'UDP ne fournit pas. TLS a besoin de :
- Une numérotation croissante des données. Ces numéros ne sont pas explicites dans TLS, ils sont déduits de l'ordre d'arrivée. DTLS les rend explicites.
- L'établissement d'une association TLS nécessite un échange fiable, où les messages arrivent dans l'ordre d'émission. Là aussi, DTLS doit ajouter des numéros de séquence explicites pour pouvoir remettre dans l'ordre les messages d'établissement d'association (cf. section 4.2).
- Certains messages TLS n'ont pas d'accusé de réception explicite, TLS compte sur les messages suivants pour savoir si son message a été reçu. Avec DTLS, ces messages doivent avoir un accusé de réception puisque la couche transport ne nous dit plus si le message a été perdu.
- Certains messages TLS peuvent être de grande taille (chaines de certificats, par exemple), supérieure à celle du datagramme (qui est typiquement de 1 500 octets) et DTLS doit donc être capable de les fragmenter et de les réassembler (la fragmentation IP étant hélas souvent bloquée par des équipements réseau mal programmés et/ou mal configurés).
- Tout protocole utilisant les datagrammes doit se méfier des attaques par réflexion, où l'attaquant ment sur son adresse IP. TCP protège contre cela, mais DTLS, ne pouvant compter sur TCP, doit avoir son propre mécanisme de test de réversibilité.
La section 4 présente la couche Enregistrements de DTLS, c'est-à-dire le format des paquets sur le réseau. Les messages sont transportés dans des enregistrements (record) TLS, et il peut y avoir plusieurs messages dans un seul datagramme UDP. Le format des messages est différent de celui de TLS (ajout d'un numéro de séquence) et de celui de DTLS 1.2 :
struct {
ContentType type;
ProtocolVersion legacy_record_version;
uint16 epoch = 0
uint48 sequence_number;
uint16 length;
opaque fragment[DTLSPlaintext.length];
} DTLSPlaintext;
struct {
opaque unified_hdr[variable];
opaque encrypted_record[length];
} DTLSCiphertext;
La première structure est en clair, la seconde
contient des données chiffrées. Un message dans un datagramme est,
soit un DTLSPlaintext (ils sont notamment
utilisés pour l'ouverture de connexion, quand on ne connait pas
encore le matériel cryptographique à utiliser) ou bien un
DTLSCiphertext.
La partie chiffrée du
DTLSCiphertext est composée d'un :
struct {
opaque content[DTLSPlaintext.length];
ContentType type;
uint8 zeros[length_of_padding];
} DTLSInnerPlaintext;
Comme pour TLS 1.3, le champ
legacy_record_version est ignoré (il n'est là
que pour tromper les middleboxes). Le
unified_hdr contient notamment l'identificateur
de connexion (Connection ID), concept expliqué
dans le RFC 9146 (comme avec QUIC, ils peuvent augmenter la
traçabilité). Les détails de la structure des messages
figurent dans l'annexe A du RFC.
À l'arrivée d'un datagramme, c'est un peu compliqué, vu la
variété de formats. La section 4.1 suggère un mécanisme de
démultiplexage, permettant de déterminer rapidement si le message
était du DTLSPlaintext, du
DTLSCipherext, ou une erreur. Un datagramme
invalide doit être silencieusement ignoré (c'est peut-être une
tentative d'un méchant pour essayer d'injecter des données ; couper
la connexion au premier datagramme invalide ouvrirait une facile
voie d'attaque par déni de service).
Qui dit datagramme dit problèmes de MTU, une des plaies de l'Internet. Normalement, c'est l'application qui doit les gérer, après tout le principe d'un service de datagrammes, c'est que l'application fait tout. Mais DTLS ne lui facilite pas la tâche, car le chiffrement augmente la taille des données, « dans le dos » de l'application. Et, avant même que l'application envoie ses premières données, la poignée de main DTLS peut avoir des datagrammes dépassant la MTU, par exemple en raison de la taille des certificats. Et puis dans certains cas, le système d'exploitation ne transmet pas à l'application les signaux indispensables, comme les messages ICMP Packet Too Big. Bref, pour aider, DTLS devrait transmettre à l'application, s'il la connait, la PMTU (la MTU du chemin complet, que la couche Transport a peut-être indiqué à DTLS). Et DTLS doit gérer la découverte de la PMTU tout seul pour la phase initiale de connexion.
La section 5 du RFC décrit le protocole d'établissement de l'association entre client et serveur (on peut aussi dire connexion, si on veut, mais pas session, ce dernier terme devrait être réservé au cas où on reprend une même session sur une connexion différente). Il est proche de celui de TLS 1.3 mais il a fallu ajouter tout ce qu'UDP ne fournit pas, la détection de la MTU (Path MTU, la MTU du chemin complet), des accusés de réception explicites et la gestion des cas de pertes de paquets. Voici l'allure d'un message DTLS d'établissement de connexion :
enum {
client_hello(1),
server_hello(2),
new_session_ticket(4),
end_of_early_data(5),
encrypted_extensions(8),
certificate(11),
certificate_request(13),
certificate_verify(15),
finished(20),
key_update(24),
message_hash(254),
(255)
} HandshakeType;
struct {
HandshakeType msg_type; /* handshake type */
uint24 length; /* bytes in message */
uint16 message_seq; /* DTLS-required field */
uint24 fragment_offset; /* DTLS-required field */
uint24 fragment_length; /* DTLS-required field */
select (msg_type) {
case client_hello: ClientHello;
case server_hello: ServerHello;
case end_of_early_data: EndOfEarlyData;
case encrypted_extensions: EncryptedExtensions;
case certificate_request: CertificateRequest;
case certificate: Certificate;
case certificate_verify: CertificateVerify;
case finished: Finished;
case new_session_ticket: NewSessionTicket;
case key_update: KeyUpdate;
} body;
} Handshake;
Le message ClientHello, comme en TLS 1.3, a un
champ legacy_version qui sert à faire croire
aux middleboxes (et aux
serveurs bogués qui ne gèrent pas correctement la négociation de
version) qu'il
s'agit d'un TLS ancien.
Un établissement de connexion DTLS typique est :
- Le client envoie un
ClientHello, - le serveur répond avec un
HelloRetryRequestqui contient le cookie, - le client renvoie le
ClientHello, cette fois avec le cookie (le serveur est désormais certain que le client ne ment pas sur son adresse IP), - le serveur peut alors transmettre son
ServerHello, - le client peut alors envoyer un message
Finishedet transmettre des données.
Il existe également, comme en TLS 1.3, un mode rapide, quand le client a déjà contacté ce serveur et obtenu du matériel cryptographique qu'il peut ré-utiliser. (C'est ce qu'on appelle aussi le « 0-RTT » ou la « reprise de session », et ça existe aussi dans des protocoles comme QUIC.) Tous les paquets pouvant se perdre, DTLS doit avoir un mécanisme de réémission.
Les risques d'attaques par déni de service sont très élevés dans le cas où on utilise des datagrammes. Un méchant peut envoyer des demandes de connexion répétées, pour forcer le serveur à faire des calculs cryptographiques et surtout à allouer de la mémoire pour les connexions en attente. Pire, il peut utiliser un serveur DTLS pour des attaques par réflexion où le méchant ment sur son adresse IP pour que le serveur dirige ses réponses vers une victime innocente. Les attaques par réflexion sont encore pires lorsqu'elles sont combinées à une amplification, quand la réponse est plus grosse que la question.
Pour éviter ces attaques, DTLS reprend, comme vu plus haut, le principe des cookies sans état de Photuris (RFC 2522) et IKE (RFC 7296).
L'extension connection_id (cf. RFC 9146) peut être mise
dans le ClientHello. Notez qu'une nouveauté par
rapport au RFC 9146 est la possibilité de
changer les identifiants de connexion pendant une association.
En section 7, une nouveauté de DTLS 1.3, et qui n'a pas
d'équivalent dans TLS, les accusés de réception
(ACK), nécessaires puisqu'on fonctionne
au-dessus d'un service de datagrammes, qui ne garantit pas l'arrivée
de tous les paquets. Un ACK permet d'indiquer
les numéros de séquence qu'on a vu. Typiquement, on envoie des
ACK quand on a l'impression que le partenaire
est trop silencieux (ce qui peut vouloir dire que ses messages se
sont perdus). Ces accusés de réception sont facultatifs, on peut
décider que la réception des messages (par exemple un
ServerHello quand on a envoyé un
ClientHello) vaut accusé de réception. Ils
servent surtout à exprimer son impatience « allô ? tu ne dis
rien ? »
Dans sa section 11, notre RFC résume les points importants, question sécurité (en plus de celles communes à TLS et DTLS, qui sont traitées dans le RFC 9846). Le principal risque, qui n'a pas vraiment d'équivalent dans TLS, est celui de déni de service via une consommation de ressources déclenchée par un partenaire malveillant. Les cookies à la connexion ne sont pas obligatoires mais fortement recommandés. Pour être vraiment sûrs, ces cookies doivent dépendre de l'adresse IP du partenaire, et d'une information secrète pour empêcher un tiers de les générer.
À noter d'autre part que, si DTLS garantit plusieurs propriétés de sécurité identiques à celle de TLS (confidentialité et authentification du serveur), il ne garantit pas l'ordre d'arrivée des messages (normal, on fait du datagramme…) et ne protège pas parfaitement contre le rejeu (sections 3.4 et 4.5.1 du RFC si vous voulez le faire).
Les sections 12 et 13 résument les principaux changements depuis DTLS 1.2 (seulement les principaux car DTLS 1.3 est très différent de 1.2) :
- n'accepte désormais que du chiffrement intègre,
- le mécanisme de reprise de session est différent, et la terminologie a changé (on parle désormais de PSK, Pre-Shared Key pour désigner les données stockées chez le client),
- la négociation de version a changé, pour tenir compte des nombreuses middleboxes boguées,
- les numéros de séquence sont chiffrées (sans cela, corréler deux échanges utilisant des adresses IP différentes serait trivial). En fait, c'est plus compliqué que cela, il y a le numéro de séquence complet dans la partie chiffrée, et un numéro réduit à ses derniers bits en clair.
Si jamais vous vous lancez dans la programmation d'une bibliothèque DTLS, lisez l'annexe C, qui vous avertit sur quelques pièges typiques de DTLS.
En octobre 2021, il n'y avait pas encore de DTLS 1.3 dans GnuTLS (ticket en cours), BoringSSL ou dans OpenSSL (ticket en cours).
Merci à Manuel Pégourié-Gonnard pour sa relecture attentive.
L'article seul
RFC 9146: Connection Identifiers for DTLS 1.2
Date de publication du RFC : Mars 2022
Auteur(s) du RFC : E. Rescorla (RTFM), H. Tschofenig, T. Fossati (Arm Limited), A. Kraus (Bosch.IO)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 20 mars 2022
Ce RFC ajoute au protocole de sécurité DTLS 1.2 la possibilité d'identificateurs de connexion (connection ID), permettant de relier entre eux des paquets d'une même session DTLS, même si l'adresse IP source change. C'est une solution simple et minimale, DTLS 1.3 (RFC 9147) l'utilise (avec quelques ajouts).
Dans le DTLS habituel, version de TLS qui tourne sur UDP et qui est normalisée dans le RFC 6347, lorsqu'un paquet arrive à une machine, celle-ci trouve l'association de sécurité appropriée (ce qui permet de trouver le matériel crptographique qui permettra de déchiffrer et de vérifier les signatures) en regardant le tuple {protocole, adresse IP source, adresse IP destination, port source, port destination}. Mais si la machine avec qui on correspond a changé d'adresse IP, par exemple parce qu'il s'agit d'un malinphone qui est passé de WiFi à 4G ? Ou bien si elle a changé de port car un routeur NAT a trouvé intelligent de considérer la session terminée, effaçant une entrée dans sa table de correspondance ? Dans ce cas, le paquet entrant va être considéré comme une nouvelle session, il faudra reprendre la négociation TLS, et c'est du temps perdu (la poignée de main cryptographique est coûteuse, et on souhaite amortir ce coût sur la plus longue durée possible).
Le RFC note que le problème est particulièrement sérieux pour les déploiements type Internet des Objets, où les objets peuvent se mettre souvent en sommeil pour économiser leur batterie, amenant le routeur NAT à oublier la session en cours.
Notez aussi qu'outre l'identificateur de connexion, notre RFC apporte quelques changements supplémentaires, notamment pour permettre le remplissage.
La section 3 du RFC spécifie l'extension DTLS
connection_id (numéro 54 dans le
registre IANA) qui permet de spécifier des identifiants des
connexions DTLS, et donc ainsi de construire une connexion qui
résistera aux changements d'adresses IP et de ports. Dans son
ClientHello, le client DTLS indiquera
l'identifiant qu'il utilisera (idem pour le serveur DTLS dans son
ServerHello). Par contre, on ne peut pas
changer d'identifiant de connexion en cours de connexion
(contrairement à ce que permettent, par exemple, QUIC ou, tout simplement, DTLS 1.3). Une fois
l'utilisation de connection IDs négociée, les
données sont envoyées dans une nouvelle structure, de type
tls12_cid (numéro 25 dans le
registre IANA). (Pour DTLS 1.3, il faudra regarder le RFC qui
lui sera consacré.) On peut
ajouter des zéros avant le chiffrement, à des
fins de remplissage. Voici la structure de
données avant le chiffrement :
struct {
opaque content[length];
ContentType real_type;
uint8 zeros[length_of_padding];
} DTLSInnerPlaintext;
Et une fois chiffrée, on envoie ça sur le réseau :
struct {
ContentType outer_type = tls12_cid;
ProtocolVersion version;
uint16 epoch;
uint48 sequence_number;
opaque cid[cid_length]; // L'identifiant de
// connexion est là.
uint16 length;
opaque enc_content[DTLSCiphertext.length];
} DTLSCiphertext;
Que se passe-t-il quand on reçoit un message pour un identifiant
de connexion connu mais une nouvelle adresse IP ? Il ne faut pas lui
faire une confiance aveugle (des méchants ont pu usurper l'adresse
IP) et envoyer immédiatement des réponses à
la nouvelle adresse IP. Il faut d'abord vérifier que le message est
correctement signé, qu'il a une epoch plus
récente que le précédent message (dans certains cas, comme l'ordre
des messages n'est pas garanti, cela peut mener à ignorer un message
valide), et l'application doit tester que le pair est toujours
d'accord (la méthode dépend de l'application).
Les identifiants de connexion posent évidemment des questions de vie privée (section 8 du RFC). Ils doivent être en clair (puisqu'ils servent au récepteur à découvrir le matériel cryptographique de la connexion, qui servira au déchiffrement) et sont donc observables par quiconque est situé sur le trajet, ce qui améliore la traçabilité (ce qui est mauvais pour la vie privée). Et, contrairement à QUIC, on n'a qu'un identifiant, on ne peut pas en changer (c'est mieux en DTLS 1.3).
L'article seul
RFC 9141: Updating References to the IETF FTP Service
Date de publication du RFC : Novembre 2021
Auteur(s) du RFC : R. Danyliw (Software Engineering Institute)
Chemin des normes
Première rédaction de cet article le 19 novembre 2021
L'IETF distribuait un certain nombre de documents
en FTP anonyme. Ce service,
ftp.ietf.org, va être interrompu. Mais un
certain nombre de RFC continuent à le citer comme source. Comme
on ne peut pas modifier un RFC après publication, notre RFC 9141 fait la liste des mises à jour à lire pour corriger ces
RFC et indiquer la nouvelle source des documents.
FTP, qui avait été le premier protocole de transfert de fichiers de l'Internet, avant même l'adoption de TCP/IP, a été pendant longtemps le principal moyen de copier des fichiers à travers le réseau. Une de ces fonctions, le FTP anonyme (qui n'était en fait pas anonyme du tout) permettait d'accéder aux fichiers, lorsque le serveur le voulait bien, sans avoir de compte sur le serveur. D'immenses archives de logiciels, de documents, d'images, ont été ainsi distribuées pendant des années. Aujourd'hui, FTP n'est guère plus utilisé (entre autres parce qu'il fonctionne en clair, cf. la section 4 sur la sécurité) et maintenir un service FTP anonyme n'a plus guère de sens. D'où la décision de l'IETF en 2020 de fermer le sien (cf. l'annonce). Le plan élaboré à cette occasion (une lecture recommandée sur les détails de cette décision, par exemple les statistiques d'utilisation) notait qu'il y avait trente RFC qui référençaient ce service, le dernier, le RFC 7241, datant de 2014. Tous ces RFC sont donc formellement mis à jour par notre RFC 9141. (Comme le note GuB, « C'est pire que légifrance cette histoire ».)
Par exemple, le RFC 2077 dit « Copies of RFCs are available on:
ftp://ftp.isi.edu/in-notes/ » alors qu'il
faudra désormais lire « Copies of RFCs are available
on: https://www.rfc-editor.org/rfc/ ».
Voici par exemple, pour la nostalgie, le fonctionnement du serveur
en novembre 2021, avant sa fermeture. On cherche les archives
indiquées par le RFC 5098, et qui sont désormais en https://www.ietf.org/ietf-ftp/ietf-mail-archive/ipcdn/
% ncftp ftp.ietf.org NcFTP 3.2.5 (Feb 02, 2011) by Mike Gleason (http://www.NcFTP.com/contact/). Copyright (c) 1992-2011 by Mike Gleason. All rights reserved. Connecting to 4.31.198.44... FTP server ready Logging in... Anonymous access granted, restrictions apply Logged in to ftp.ietf.org. ncftp / > ls charter/ ietf/ internet-drafts/ slides/ concluded-wg-ietf-mail-archive/ ietf-mail-archive/ review/ status-changes/ conflict-reviews/ ietf-online-proceedings/ rfc/ yang/ ncftp / > ncftp / > cd ietf-mail-archive/ipcdn ncftp /ietf-mail-archive/ipcdn > ls ... 1996-12 1999-07.mail 2001-09.mail 2003-11.mail 2006-01.mail 2008-03.mail 1997-01 1999-08.mail 2001-10.mail 2003-12.mail 2006-02.mail 2008-04.mail 1997-02 1999-09.mail 2001-11.mail 2004-01.mail 2006-03.mail 2008-05.mail 1997-03 1999-10.mail 2001-12.mail 2004-02.mail 2006-04.mail 2008-06.mail ...
L'article seul
RFC 9138: Design Considerations for Name Resolution Service in Information-Centric Networking (ICN)
Date de publication du RFC : Novembre 2021
Auteur(s) du RFC : J. Hong, T. You (ETRI, L. Dong, C. Westphal (Futurewei Technologies), B. Ohlman (Ericsson)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF icnrg
Première rédaction de cet article le 1 décembre 2021
L'ICN est l'idée (très contestable) qu'un réseau informatique sert à accéder à du « contenu » et que le réseau doit donc être architecturé autour de cette idée de contenu. Les noms identifient ainsi un contenu donné. Mais il faut bien ensuite trouver le contenu donc résoudre ces noms en quelque chose de plus concret. Ce RFC est le cahier des charges d'un tel système de résolution de noms pour les projets ICN. Comme beaucoup de cahier des charges, il est très « liste au Père Noël », accumulant des desiderata sans se demander s'ils sont réalistes (et compatibles entre eux !).
Comme avec beaucoup de documents qui promeuvent l'ICN, ce RFC donne une description erronée du nommage et de l'adressage dans l'Internet d'aujourd'hui. Passons, et voyons ce que l'ICN propose. L'idée est que le contenu est stocké dans des NDO (Named Data Objects) et que toute activité dans le réseau coniste à récupérer des NDO. Les NDO sont identifiés par un nom. Il ne s'agit pas seulement d'un identificateur mis au-dessus d'un réseau architecturé sur d'autres concepts (comme le sont les URI) mais du concept de base du réseau ; les routeurs ne routent plus selon des adresses mais selon les noms des NDO. Le problème est évidemment qu'il faudra bien, à la fin, trouver l'objet désiré. Cela nécessite (cf. RFC 7927) :
- Un mécanisme de résolution des noms en de l'information plus concrète (une localisation, un autre nom, etc),
- un mécanisme de routage vers l'endroit où se trouve le NDO,
- un mécanisme de récupération du NDO.
Ce RFC se focalise sur le premier point, le NRS (Name Resolution Service), et en est le cahier des charges. Le RFC 9236 a depuis décrit l'architecture envisagée. Si vous voulez apprendre des choses sur les ICN en général et la résolution de noms en particulier, voir par exemple « A Survey of Information-Centric Networking » ou « A Survey of Information-Centric Networking Research ».
Si on compare avec l'Internet actuel, le NRS aura un rôle analogue à celui de BGP (plutôt que du DNS, car le NRS sera au cœur du réseau, et complètement inséparable). Bon, ceci dit, c'est plus compliqué que cela car, derrière l'étiquette « ICN », il y a des tas de propositions différentes. Par exemple, certaines ressemblent plutôt à l'Internet actuel, avec une résolution de noms en localisateurs qui servent ensuite pour le routage (comme dans IDnet, cf. « IDNet: Beyond All-IP Network), alors que d'autres versions du concept d'ICN utilisent les noms pour le routage (comme le NDN ou le CCNx du RFC 8569). La section 2.4 du RFC compare ces approches.
La section 3 du RFC est ensuite le cahier des charges proprement dit. Malheureusement, elle plane au-dessus des réalités quand elle affirme par exemple qu'il faut un NRS qui fonctionnera de la même façon que l'espace de nommage soit plat ou hiérarchique. C'est très irréaliste, il n'y a pas de nette séparation entre la structure de l'espace de nommage et le mécanisme de résolution. Ainsi, ce mécanisme, dans le cas du DNS, est très lié à la structure des noms. Si on la change, tout le DNS serait à refaire (et sans doute en moins efficace). Parmi les systèmes d'ICN qui utilisent un nommage hiérarchique (et réintroduisent donc une forme de « localisation » dans les noms), on trouve NDN et CCNx.
Certains des mécanismes de résolution discutés ont déjà un RFC, par exemple le NI du RFC 6920, utilisé dans NetInf (cf. « Network of Information (NetInf) - An information-centric networking architecture »).
Bref, les principes du NRS :
- Fonctionner avec des structures d'espaces de noms différentes (cf. ma critique ci-dessus),
- accepter la mobilité des contenus,
- passer à l'échelle (ce qui est trivial avec des noms hiérarchiques, beaucoup moins avec des noms plats),
- permettre la mémorisation (caching),
- accepter que les objets soient identifiés par un nom choisi ou par un condensat du contenu (ce que le RFC nomme les « objets sans nom », ce qui me semble accroitre encore la confusion),
- permettre enfin de récupérer des métadonnées et pas seulement le localisateur.
Et le cahier des charges à proprement parler est en section 4. Je ne cite pas tout mais la liste au Père Noël comprend :
- Des réponses rapides (« en un temps raisonnable »),
- des réponses correctes (on voit bien le ridicule de l'approche par cahier des charges, quand il faut préciser explicitement des points aussi évidents), et à jour (là encore, « raisonnablement »),
- des réponses justes, respectant un principe de neutralité (pas de censure ? L'ARCOM n'aimerait pas),
- un fonctionnement satisfaisant sur des réseaux de grande taille (le RFC mentionne au moins 10^21 objets),
- un système gérable (pouvant s'adapter avec par exemple l'ajout et le retrait de nœuds),
- la capacité à être réellement déployé (là encore, on a envie de dire « encore heureux »),
- la résistance aux pannes (la panne d'une machine ne doit pas arrêter le NRS), et aux attaques par déni de service,
- la confidentialité des requêtes (un problème pour le DNS, cf. RFC 7626), mais aussi des données (le RFC mentionne des ACL sur les noms, chose qui n'existe pas vraiment dans le DNS)
- l'authentification des serveurs, des producteurs de noms (par exemple pour que seule l'entité qui a enregistré un nom puisse modifier les données associées), et des données elle-mêmes (ce que DNSSEC fournit au DNS),
Une conclusion ? Les projets regroupés sous le nom d'ICN sont assez anciens, n'ont rien fait de vraiment nouveau récemment, et il y a peu de chances que ce RFC soit suivi de réalisations concrètes.
L'article seul
RFC 9137: Considerations for Cancellation of IETF Meetings
Date de publication du RFC : Octobre 2021
Auteur(s) du RFC : M. Duke (F5 Networks)
Réalisé dans le cadre du groupe de travail IETF shmoo
Première rédaction de cet article le 12 octobre 2021
Pour son travail de normalisation technique, l'IETF tient normalement trois réunions physiques par an. La pandémie de Covid-19 a évidemment changé tout cela. Les premières décisions d'annulation ont été prises selon un procédure ad hoc, mais ce nouveau RFC fournit des critères plus rigoureux pour les prochaines décisions d'annulation.
La dernière réunion physique de l'IETF a eu lieu à Singapour en novembre 2019. Depuis, les conditions sanitaires ont forcé à annuler toutes les réunions. Mais notre nouveau RFC ne se limite pas au cas de la Covid-19. Une réunion, après tout, peut devoir être annulée pour d'autres raisons, un problème de dernière minute dans le bâtiment où elle devait se tenir, une catastrophe naturelle dans le pays d'accueil, un brusque changement dans la politique de visa de ce pays, etc. (Le RFC cite même le cas d'une guerre civile, mais ce n'est encore jamais arrivé à une réunion IETF.) Dans ces cas, l'IETF LLC (la direction administrative de l'IETF) et l'IESG vont devoir décider si on maintient la réunion ou pas.
La section 3 du RFC expose les critères de décision. L'IETF LLC (cf. RFC 8711) détermine si la réunion peut se tenir, l'IESG si cela vaut la peine de la tenir. L'IETF LLC doit évidemment travailler en toute transparence, informant l'IETF de la situation, des décisions possibles et d'un éventuel « plan B ». Il n'est pas toujours possible de procéder proprement et démocratiquement si la situation est urgente (tremblement de terre trois jours avant la réunion…). Dans ce cas, l'IETF LLC doit déterminer seule si la réunion peut se tenir (ce qui implique certaines garanties de sécurité pour les participants, de la restauration mais également un accès Internet qui marche ; les participants à l'IETF n'ont pas juste besoin de dormir et de manger, il leur faut aussi du réseau). L'IETF LLC doit aussi intégrer des paramètres internes comme la disponibilité de ses employés et des bénévoles, et bien sûr les conséquences financières du maintien ou de l'annulation (si le lieu de la réunion considère qu'il n'y avait pas force majeure et ne veut pas rembourser…). La section 3 du RFC 8718 contient des indications utiles à cette évaluation.
L'IESG, lui, doit déterminer s'il y aura suffisamment de monde à la réunion pour que ça vaille la peine. Il ne serait pas malin de maintenir une réunion pour que personne ne vienne.
La section 4 du RFC couvre les alternatives. Si on annule, que peut-on proposer à la place ? Il faut évaluer ces alternatives en tenant compte de leur efficacité (une réunion en ligne est moins efficace) et de leur coût (changer les billets d'avion au dernier moment coûte cher). Ces alternatives peuvent être, dans l'ordre décroissant de préférence :
- Changer le lieu de la réunion. C'est ce qui dérange le moins le travail, surtout si le nouveau lieu est proche de l'ancien. Naturellement, le nouveau lieu doit correspondre aux critères des RFC 8718 et RFC 8719.
- Passer en ligne, à une réunion « virtuelle », ce qui a été fait pour toutes les réunions annulées en raison de la Covid-19.
- Repousser la réunion à plus tard. Ce n'est en général pas facilement faisable, puisque cela perturbe les agendas de tout le monde.
- Annuler complètement, sans alternative. Le RFC note que cela aura des conséquences, non seulement sur le travail de normalisation, mais également sur des processus politiques comme la détermination de qui peut siéger dans des comités comme le NomCom (comité de nomination, cf. RFC 8788 et RFC 8989).
La section 5 de notre RFC couvre les questions financières. En gros, l'IETF ne remboursera pas les dépenses engagées par les participants (avion, hôtel, etc), seulement les frais d'inscription à la réunion, en totalité s'il y a annulation complète et partiellement dans les autres cas.
L'article seul
RFC 9132: Distributed Denial-of-Service Open Threat Signaling (DOTS) Signal Channel Specification
Date de publication du RFC : Septembre 2021
Auteur(s) du RFC : M. Boucadair (Orange), J. Shallow, T. Reddy.K (Akamai)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dots
Première rédaction de cet article le 10 octobre 2021
Le protocole DOTS (Distributed Denial-of-Service Open Threat Signaling) vise à permettre au client d'un service anti-dDoS de demander au service de mettre en route des mesures contre une attaque. Ce RFC décrit le canal de signalisation de DOTS, celui par lequel passera la demande d'atténuation de l'attaque. Il remplace le RFC 8782, mais les changements sont mineurs.
Si vous voulez mieux comprendre DOTS, il est recommandé de lire le RFC 8612, qui décrit le cahier des charges de ce protocole, et le RFC 8811, qui décrit l'architecture générale. Ici, je vais résumer à l'extrême : un client DOTS, détectant qu'une attaque par déni de service est en cours contre lui, signale, par le canal normalisé dans ce RFC, à un serveur DOTS qu'il faudrait faire quelque chose. Le serveur DOTS est un service anti-dDoS qui va, par exemple, examiner le trafic, jeter ce qui appartient à l'attaque, et transmettre le reste à son client.
Ces attaques par déni de service sont une des plaies de l'Internet, et sont bien trop fréquentes aujourd'hui (cf. RFC 4987 ou RFC 4732 pour des exemples). Bien des réseaux n'ont pas les moyens de se défendre seuls et font donc appel à un service de protection (payant, en général, mais il existe aussi des services comme Deflect). Ce service fera la guerre à leur place, recevant le trafic (via des manips DNS ou BGP), l'analysant, le filtrant et envoyant ce qui reste au client. Typiquement, le client DOTS sera chez le réseau attaqué, par exemple en tant que composant d'un IDS ou d'un pare-feu, et le serveur DOTS sera chez le service de protection. Notez donc que client et serveur DOTS sont chez deux organisations différentes, communiquant via le canal de signalisation (signal channel), qui fait l'objet de ce RFC.
La section 3 de notre RFC expose les grands principes du
protocole utilisé sur ce canal de signalisation. Il repose sur
CoAP, un équivalent léger de HTTP, ayant beaucoup
de choses communes avec HTTP. Le choix d'un protocole différent de
HTTP s'explique par les spécificités de DOTS : on l'utilise quand ça
va mal, quand le réseau est attaqué, et il faut donc pouvoir
continuer à fonctionner même quand de nombreux paquets sont
perdus. CoAP a les caractéristiques utiles pour DOTS, il est conçu
pour des réseaux où il y aura des pertes, il tourne sur UDP, il permet des
messages avec ou sans accusé de réception, il utilise peu de
ressources, il peut être sécurisé par DTLS… TCP est également
utilisable mais UDP est préféré, pour éviter le head-of-line
blocking. CoAP est normalisé dans le RFC 7252. Parmi les choses à retenir, n'oubliez pas
que l'encodage du chemin dans l'URI est un peu spécial, avec une option
Uri-Path: par segment du chemin (RFC 7252, section 5.10.1). Par abus de langage,
j'écrirai « le client CoAP demande
/foo/bar/truc.cbor » alors qu'il y aura en fait
trois options Uri-Path: :
Uri-Path: "foo" Uri-Path: "bar" Uri-Path: "truc.cbor"
Par défaut, DOTS va utiliser le port 4646 (et non pas le port par
défaut de CoAP, 5684, pour éviter toute confusion avec d'autres
services tournant sur CoAP). Ce port a été choisi pour une bonne
raison, je vous laisse la chercher, la solution est à la fin de cet
article. Le plan d'URI sera coaps ou
coaps+tcp (RFC 7252,
section 6, et RFC 8323, section 8.2).
Le fonctionnement de base est simple : le client DOTS se connecte au serveur, divers paramètres sont négociés. Des battements de cœur peuvent être utilisés (par le client ou par le serveur) pour garder la session ouverte et vérifier son bon fonctionnement. En cas d'attaque, le client va demander une action d'atténuation. Pendant que celle-ci est active, le serveur envoie de temps en temps des messages donnant des nouvelles. L'action se terminera, soit à l'expiration d'un délai défini au début, soit sur demande explicite du client. Le serveur est connu du client par configuration manuelle, ou bien par des techniques de découverte comme celles du RFC 8973.
Les messages sont encodés en CBOR (RFC 8949). Rappelez-vous que le modèle de données de CBOR est
très proche de celui de JSON, et notre RFC spécifie donc les messages
avec une syntaxe JSON, même si ce n'est pas l'encodage utilisé sur
le câble. Pour une syntaxe formelle des messages, le RFC utilise
YANG (cf. RFC 7951). Le type
MIME des messages est application/dots+cbor.
La section 4 du RFC décrit les différents messages possibles plus
en détail. Je ne vais pas tout reprendre ici, juste donner quelques
exemples. Les URI commencent toujours par
/.well-known/dots
(.well-known est normalisé dans le RFC 8615, et dots est
désormais enregistré
à l'IANA). Les différentes actions ajouteront au chemin dans
l'URI /mitigate pour les demandes d'actions
d'atténuation, visant à protéger de l'attaque,
/hb pour les battements de cœur, etc.
Voici par exemple une demande de protection, effectuée avec la méthode CoAP PUT :
Header: PUT (Code=0.03)
Uri-Path: ".well-known"
Uri-Path: "dots"
Uri-Path: "mitigate"
Uri-Path: "cuid=dz6pHjaADkaFTbjr0JGBpw"
Uri-Path: "mid=123"
Content-Format: "application/dots+cbor"
{
... Données en CBOR (représentées en JSON dans le RFC et dans
cet article, pour la lisibilité).
}
L'URI, en notation traditionnelle, sera donc
/.well-known/dots/mitigate/cuid=dz6pHjaADkaFTbjr0JGBpw/mid=123. CUID
veut dire Client Unique IDentifier et sert à
identifier le client DOTS, MID est Mitigation
IDentifier et identifie une demande d'atténuation
particulière. Si ce client DOTS fait une autre demande de
palliation, le MID changera mais le CUID sera le même.
Que met-on dans le corps du message ? On a de nombreux champs définis pour indiquer ce qu'on veut protéger, et pour combien de temps. Par exemple, on pourrait avoir (je rappelle que c'est du CBOR, format binaire, en vrai) :
{
"ietf-dots-signal-channel:mitigation-scope": {
"scope": [
{
"target-prefix": [
"2001:db8:6401::1/128",
"2001:db8:6401::2/128"
],
"target-port-range": [
{
"lower-port": 80
},
{
"lower-port": 443
}
],
"target-protocol": [
6
],
"lifetime": 3600
}
]
}
}
Ici, le client demande qu'on protège
2001:db8:6401::1 et
2001:db8:6401::2 (target
veut dire qu'ils sont la cible d'une attaque, pas qu'on veut les
prendre pour cible), sur
les ports 80 et 443,
en TCP, pendant une heure. (lower-port seul,
sans upper-port indique un port unique, pas un
intervalle.)
Le serveur va alors répondre avec le code 2.01 (indiquant que la requête est acceptée et traitée) et des données :
{
"ietf-dots-signal-channel:mitigation-scope": {
"scope": [
{
"mid": 123,
"lifetime": 3600
}
]
}
}
La durée de l'action peut être plus petite que ce que le client a demandé, par exemple si le serveur n'accepte pas d'actions trop longues. Évidemment, si la requête n'est pas correcte, le serveur répondra 4.00 (format invalide), si le client n'a pas payé, 4.03, s'il y a un conflit avec une autre requête, 4.09, etc. Le serveur peut donner des détails, et la liste des réponses possibles figure dans des registres IANA, comme celui de l'état d'une atténuation, ou celui des conflits entre ce qui est demandé et d'autres actions en cours.
Le client DOTS peut ensuite récupérer des informations sur une action de palliation en cours, avec la méthode CoAP GET :
Header: GET (Code=0.01) Uri-Path: ".well-known" Uri-Path: "dots" Uri-Path: "mitigate" Uri-Path: "cuid=dz6pHjaADkaFTbjr0JGBpw" Uri-Path: "mid=123"
Ce GET
/.well-known/dots/mitigate/cuid=dz6pHjaADkaFTbjr0JGBpw/mid=123
va renvoyer de l'information sur l'action d'identificateur (MID)
123 :
{
"ietf-dots-signal-channel:mitigation-scope": {
"scope": [
{
"mid": 123,
"mitigation-start": "1507818393",
"target-prefix": [
"2001:db8:6401::1/128",
"2001:db8:6401::2/128"
],
"target-protocol": [
6
],
"lifetime": 1755,
"status": "attack-stopped",
"bytes-dropped": "0",
"bps-dropped": "0",
"pkts-dropped": "0",
"pps-dropped": "0"
}
]
}
}
Les différents champs de la réponse sont assez évidents. Par
exemple, pkts-dropped indique le nombre de
paquets qui ont été jetés par le protecteur.
Pour mettre fin aux actions du système de protection, le client utilise évidemment la méthode CoAP DELETE :
Header: DELETE (Code=0.04) Uri-Path: ".well-known" Uri-Path: "dots" Uri-Path: "mitigate" Uri-Path: "cuid=dz6pHjaADkaFTbjr0JGBpw" Uri-Path: "mid=123"
Le client DOTS peut se renseigner sur les capacités du serveur avec
un GET de /.well-known/dots/config.
Ce RFC décrit le canal de signalisation de DOTS. Le RFC 8783, lui, décrit le canal de données. Le canal de signalisation est prévu pour faire passer des messages de petite taille, dans un environnement hostile (attaque en cours). Le canal de données est prévu pour des données de plus grande taille, dans un environnement où les mécanismes de transport normaux, comme HTTPS, sont utilisables. Typiquement, le client DOTS utilise le canal de données avant l'attaque, pour tout configurer, et le canal de signalisation pendant l'attaque, pour déclencher et arrêter l'atténuation.
Les messages possibles sont modélisés en YANG. YANG est normalisé dans le RFC 7950. Notez que YANG avait été initialement créé pour décrire les commandes envoyées par NETCONF (RFC 6241) ou RESTCONF (RFC 8040) mais ce n'est pas le cas ici : DOTS n'utilise ni NETCONF, ni RESTCONF mais son propre protocole basé sur CoAP. La section 5 du RFC contient tous les modules YANG utilisés.
La mise en correspondance des modules YANG avec l'encodage
CBOR figure dans la section
6. (YANG permet une description abstraite d'un message mais ne dit
pas, à lui tout seul, comment le représenter en bits sur le réseau.)
Les clés CBOR sont toutes des entiers ; CBOR permet d'utiliser des
chaînes de caractères comme clés mais DOTS cherche à gagner de la
place. Ainsi, les tables de la section 6 nous apprennent que le
champ cuid (Client Unique
IDentifier) a la clé 4, suivie d'une chaîne de caractères
en CBOR. (Cette correspondance est désormais un
registre IANA.) D'autre part, DOTS introduit une étiquette
CBOR, 271 (enregistrée
à l'IANA, cf. RFC 8949, section 3.4)
pour marquer un document CBOR comme lié au protocole DOTS.
Évidemment, DOTS est critique en matière de sécurité. S'il ne fonctionne pas, on ne pourra pas réclamer une action de la part du service de protection. Et s'il est mal authentifié, on risque de voir le méchant envoyer de faux messages DOTS, par exemple en demandant l'arrêt de l'atténuation. La section 8 du RFC rappelle donc l'importance de sécuriser DOTS par TLS ou plutôt, la plupart du temps, par son équivalent pour UDP, DTLS (RFC 9147). Le RFC insiste sur l'authentification mutuelle du serveur et du client, chacun doit s'assurer de l'identité de l'autre, par les méthodes TLS habituelles (typiquement via un certificat). Le profil de DTLS recommandé (TLS est riche en options et il faut spécifier lesquelles sont nécessaires et lesquelles sont déconseillées) est en section 7. Par exemple, le chiffrement intègre est nécessaire.
La section 11 revient sur les questions de sécurité en ajoutant
d'autres avertissements. Par exemple, TLS ne protège pas contre
certaines attaques par déni de service, comme un paquet TCP RST
(ReSeT). On peut sécuriser la communication avec
TCP-AO (RFC 5925) mais c'est un vœu pieux, il
est très peu déployé à l'heure actuelle. Ah, et puis si les
ressources à protéger sont identifiées par un nom de domaine, et pas une adresse ou un
préfixe IP (target-fqdn au lieu de
target-prefix), le RFC dit qu'évidemment la
résolution doit être faite avec DNSSEC.
Question mises en œuvre, DOTS dispose d'au moins quatre implémentations, dont l'interopérabilité a été testée plusieurs fois lors de hackathons IETF (la première fois ayant été à Singapour, lors de l'IETF 100) :
Notez qu'il existe des serveurs de test DOTS
publics comme
coaps://dotsserver.ddos-secure.net:4646.
Ah, et la raison du choix du port 4646 ? C'est parce que 46 est le code ASCII pour le point (dot en anglais) donc deux 46 font deux points donc dots.
L'annexe A de notre RFC résume les principaux changements depuis le RFC 8782. Le principal changement touche les modules YANG, mis à jour pour réparer une erreur et pour tenir compte du RFC 8791. Il y a aussi une nouvelle section (la 9), qui détaille les codes d'erreur à renvoyer, et l'espace des valeurs des attributs a été réorganisé… Rien de bien crucial, donc.
L'article seul
RFC 9124: A Manifest Information Model for Firmware Updates in Internet of Things (IoT) Devices
Date de publication du RFC : Janvier 2022
Auteur(s) du RFC : B. Moran, H. Tschofenig (Arm Limited), H. Birkholz (Fraunhofer SIT)
Pour information
Réalisé dans le cadre du groupe de travail IETF suit
Première rédaction de cet article le 15 janvier 2022
On le sait, la sécurité des gadgets nommés « objets connectés » est abyssalement basse. Une de raisons (mais pas la seule, loin de là !) est l'absence d'un mécanisme de mise à jour du logiciel, mécanisme qui pourrait permettre de corriger les inévitables failles de sécurité. Le problème de la mise à jour de ces machins, souvent contraints en ressources, est très vaste et complexe. Le groupe de travail SUIT de l'IETF se focalise sur un point bien particulier : un format de manifeste permettant de décrire une mise à jour. Ce RFC décrit le modèle de données des informations qui seront placées dans ce manifeste.
Donc, que faut-il indiquer pour permettre une mise à jour du logiciel (et des réglages) d'un objet connecté ? Le groupe de travail est parti des expériences concrètes, de scénarios et de menaces, pour arriver à la liste que contient ce RFC. Certes, cette liste n'est pas exhaustive (cela serait impossible) mais donne quand même un bon point de départ. Attention, ce RFC décrit le modèle d'information (cf. RFC 3444), pas le format du manifeste (qui sera en CBOR, et fera l'objet d'un futur RFC).
Pour suivre le contenu de ce RFC, il vaut mieux avoir déjà lu le premier RFC du groupe de travail, le RFC 9019, qui explique l'architecture générale du système, ainsi que le RFC 8240, qui était le compte-rendu d'un atelier de réflexion sur cette histoire de mise à jour des objets connectés..
La (longue) section 3 du RFC est consacrée à énumérer tous les éléments à mettre dans le manifeste. Je ne vais pas reproduire toute la liste, juste quelques éléments intéressants. Notez que pour chaque élément, le RFC précise s'il doit être présent dans le manifeste ou bien s'il est facultatif. Le premier élément listé est l'obligatoire identificateur de version de la structure du manifeste, qui permettra de savoir à quel modèle ce manifeste se réfère.
Autre élément obligatoire, un numéro de séquence, croissant de façon monotone, et qui permettra d'éviter les reculs accidentels (« mise à jour » avec une version plus ancienne que celle installée). On peut utiliser pour cela une estampille temporelle (si on a une horloge sûre).
Ensuite, le RFC recommande (mais, contrairement aux deux précédents éléments, ce n'est pas obligatoire) de placer dans le manifeste un identificateur du fournisseur de la mise à jour. Il n'est pas prévu pour d'autres comparaisons que la simple égalité. Le format recommandé pour cet identificateur est un UUID (RFC 9562) de « version 5 », c'est-à-dire formé à partir d'un nom de domaine, qui est forcément unique. L'avantage des UUID (surtout par rapport au texte libre) est leur taille fixe, qui simplifie analyse et comparaison. Si on veut un identificateur de fournisseur qui soit lisible par des humains, il faut le placer dans un autre élément.
L'identificateur de la classe (class ID), indique un type de machines, les machines d'une même classe acceptant le même logiciel (cette acceptation dépend du matériel mais aussi d'autres facteurs comme la version du microcode). Il doit être unique par identificateur de fournisseur (et, en cas de vente en marque blanche, il doit être fourni par le vrai fournisseur, pas par le vendeur). Là aussi, un UUID de « version 5 » est recommandé. Il ne doit pas dépendre juste du nom commercial, un même nom commercial pouvant recouvrir des produits qui n'acceptent pas les mêmes mises à jour. Si un objet peut recevoir des mises à jour indépendantes, pour différents composants de l'objet, il faut des identificateurs de classe différents (surtout si certains objets du fournisseur utilisent une partie des mêmes composants, mais pas tous ; l'identificateur doit identifier le composant, pas l'objet).
Le manifeste contient aussi (mais ce n'est pas obligatoire), une date d'expiration, indiquant à partir de quand il cesse d'être valable.
Le manifeste peut (mais ce n'est pas obligatoire) contenir directement l'image utilisée pour la mise à jour du logiciel de l'objet. Cela peut être utile pour les images de petite taille ; plus besoin d'une étape supplémentaire de téléchargement.
Par contre, l'indication du format de l'image, qu'elle soit directement incluse ou non, est obligatoire, ainsi que celle de la taille de la dite image.
Question sécurité, le RFC impose également la présence d'une signature du manifeste. Le manifeste peut aussi contenir des éléments qui vont servir à établir si on a une délégation sûre depuis une autorité reconnue : des Web Tokens en CBOR (RFC 8392), avec peut-être des preuves du RFC 8747.
La sécurité est au cœur des problèmes que traite ce RFC. Après cette liste d'élements facultatifs ou obligatoires dans un manifeste, la section 4 de notre RFC expose le modèle des menaces auxquelles il s'agit de faire face. Le RFC rappelle que la mise à jour elle-même peut être une menace : après tout, mettre à jour du logiciel, c'est exécuter du code distant. Juste répéter « il faut mettre à jour le logiciel de sa brosse à dents connectée » ne suffit pas, si le mécanisme de mise à jour permet d'insérer du code malveillant. (Et encore, le RFC est gentil, tendance bisounours, il ne rappelle pas que l'attaquant peut être le fournisseur, envoyant du code nouveau pour désactiver certaines fonctions ou pour espionner l'utilisateur, voir les exemples de Hewlett-Packard et de Sony. Sans même parler de la possibilité d'une attaque contre la chaine de développement comme celle contre SolarWinds.)
L'analyse part du modèle STRIDE. Je ne vais pas citer toutes les menaces possibles (il y en a beaucoup !), lisez le RFC pour avoir une vue complète. Notez que les attaques physiques contre les objets (ouvrir la boite et bricoler à l'intérieur) ne sont pas incluses.
Évidemment, la première menace est celle d'une mise à jour qui serait modifiée par un attaquant. Le code correspondant serait exécuté, avec les conséquences qu'on imagine. La signature prévient cette attaque.
Ensuite, le cas d'une vieille mise à jour, qui était honnête et signée, mais n'est plus d'actualité. Si elle a une faiblesse connue, un attaquant pourrait essayer de faire réaliser une « mise à jour » vers cette vieille version. Le numéro de séquence dans le manifeste, qui est strictement croissant, est là pour protéger de cette attaque.
Autre risque, celui d'une mise à jour signée mais qui concerne en fait un autre type d'appareil. Appliquer cette mise à jour pourrait mener à un déni de service. La protection contre ce risque est assurée par l'identificateur du type d'objet.
Le RFC liste la menace d'une rétro-ingénierie de l'image. Outre que cela ne s'applique qu'au logiciel privateur, du point de vue de la sécurité, cela n'est pas crucial, puisqu'on ne compte pas sur la STO. Si on y tient quand même, le chiffrement de l'image (qui n'est pas obligatoire) pare ce risque.
Sinon la section 4.4 contient des scénarios typiques d'utilisation, où une histoire décrit les acteurs, les menaces, les solutions possibles, rendant ainsi plus vivants et plus concrets les problèmes de sécurité étudiés dans ce RFC.
L'article seul
RFC 9120: Nameservers for the Address and Routing Parameter Area ("arpa") Domain
Date de publication du RFC : Octobre 2021
Auteur(s) du RFC : K. Davies (IANA), J. Arkko (Ericsson)
Pour information
Première rédaction de cet article le 30 octobre 2021
Dernière mise à jour le 4 mai 2022
Le TLD
.arpa sert pour
différentes fonctions techniques et est géré directement par
l'IAB. Ce
RFC décrit un
changement dans ses serveurs de noms.
Ce TLD
est décrit dans le RFC 3172. Le nom de
.arpa fait référence à
l'ancien nom de la DARPA, l'agence qui avait
financé le développement de l'Internet. Mais,
aujourd'hui, il veut dire « Address and Routing Parameter
Area » et le TLD sert à diverses fonctions techniques comme
la résolution d'adresses IP
en noms de domaine via
des sous-domaines comme ip6.arpa. Par exemple,
l'adresse IP du serveur Web de l'IAB a pour nom correspondant :
% dig -x 2001:1900:3001:11::2c ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 53150 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ... ;; ANSWER SECTION: c.2.0.0.0.0.0.0.0.0.0.0.0.0.0.0.1.1.0.0.1.0.0.3.0.0.9.1.1.0.0.2.ip6.arpa. 3600 IN PTR mail.ietf.org.
Comme vous le voyez, dig a inversé l'adresse IP et ajouté
ip6.arpa à la
fin. .arpa sert
également à d'autres fonctions comme le
home.arpa du RFC 8375.
Traditionnellement, le domaine .arpa était
hébergé sur une partie des serveurs de noms de la
racine. Le 22 octobre 2021, voici quels étaient les
serveurs faisant
autorité pour .arpa :
% dig +nodnssec NS arpa ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 43670 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 12, AUTHORITY: 0, ADDITIONAL: 1 ... ;; ANSWER SECTION: arpa. 15910 IN NS b.root-servers.net. arpa. 15910 IN NS f.root-servers.net. arpa. 15910 IN NS d.root-servers.net. arpa. 15910 IN NS l.root-servers.net. arpa. 15910 IN NS e.root-servers.net. arpa. 15910 IN NS a.root-servers.net. arpa. 15910 IN NS c.root-servers.net. arpa. 15910 IN NS i.root-servers.net. arpa. 15910 IN NS h.root-servers.net. arpa. 15910 IN NS g.root-servers.net. arpa. 15910 IN NS k.root-servers.net. arpa. 15910 IN NS m.root-servers.net. ;; Query time: 0 msec ;; SERVER: ::1#53(::1) ;; WHEN: Fri Oct 22 20:35:36 CEST 2021 ;; MSG SIZE rcvd: 241
Comme vous pouvez le voir, c'était presque tous les serveurs de la
racine (si vous aimez les jeux : quel serveur de la racine n'hébergeait
pas .arpa ?). La raison pour cela est que
.arpa est critique et doit donc bénéficier d'un
hébergement solide. Profiter des serveurs de la racine était donc
intéressant. Mais le problème est que ça lie
.arpa à la racine. On pourrait avoir envie de
faire des changements dans les serveurs faisant autorité pour
.arpa sans toucher aux serveurs de la racine,
celle-ci étant encore plus critique (cf. RFC 7720). Le principe de base de notre nouveau RFC est donc : découpler les
serveurs DNS de .arpa de ceux de la racine (ce
qui avait été fait pour ip6.arpa il y a dix ans,
voir le RFC 5855).
Le changement ne concerne que l'hébergement DNS, pas la gestion
de .arpa (section 2 de notre RFC), qui reste un
TLD
critique, et soumis au RFC 3172. Le choix des sous-domaines
et de leur administration est inchangé (par exemple, pour
ip6.arpa, c'est décrit dans le RFC 5855).
La section 3 du RFC décrit le nouveau système. Le principe est de commencer par utiliser des
noms différents pour les serveurs, mais qui pointeront vers les
mêmes machines, au moins au début. Les nouveaux noms sont dans le
sous-domaine ns.arpa, on a donc
a.ns.arpa, b.ns.arpa,
etc. Aucune modification dans les serveurs ne sera nécessaire pour
cette première étape, qui n'affectera que la zone racine et la zone
.arpa. Comme tous les noms seront dans la zone qu'ils
servent, il faudra ajouter de la colle aux réponses DNS (ne pas
juste dire « le serveur est c.ns.arpa » mais
également indiquer son adresse
IP). Il n'y a désormais
plus de nom de serveur commun à la racine et à
.arpa, et il sera possible dans le futur de
migrer vers d'autres serveurs. (Toujours en respectant le RFC 3172.) Voici l'état actuel :
% dig +nodnssec NS arpa ; <<>> DiG 9.16.1-Ubuntu <<>> +nodnssec NS arpa ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 15962 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 12, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 1232 ;; QUESTION SECTION: ;arpa. IN NS ;; ANSWER SECTION: arpa. 517877 IN NS h.ns.arpa. arpa. 517877 IN NS i.ns.arpa. arpa. 517877 IN NS k.ns.arpa. arpa. 517877 IN NS l.ns.arpa. arpa. 517877 IN NS m.ns.arpa. arpa. 517877 IN NS a.ns.arpa. arpa. 517877 IN NS b.ns.arpa. arpa. 517877 IN NS c.ns.arpa. arpa. 517877 IN NS d.ns.arpa. arpa. 517877 IN NS e.ns.arpa. arpa. 517877 IN NS f.ns.arpa. arpa. 517877 IN NS g.ns.arpa. ;; Query time: 3 msec ;; SERVER: 192.168.2.254#53(192.168.2.254) ;; WHEN: Wed May 04 08:57:47 CEST 2022 ;; MSG SIZE rcvd: 228
Vous pouvez également voir cet état actuel de .arpa à l'IANA
ou bien
dans le DNS.
Notez enfin que certains des serveurs de
.arpa autorisent le transfert de zones. Voici une copie faite le 24 octobre 2021.
L'article seul
RFC 9117: Revised Validation Procedure for BGP Flow Specifications
Date de publication du RFC : Août 2021
Auteur(s) du RFC : J. Uttaro (AT&T), J. Alcaide, C. Filsfils, D. Smith (Cisco), P. Mohapatra (Sproute Networks)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF idr
Première rédaction de cet article le 28 septembre 2021
Le RFC 8955 spécifie comment utiliser BGP pour diffuser des règles de filtrage (dites « FlowSpec ») aux routeurs. On voit facilement qu'une annonce de règles de filtrage maladroite ou malveillante pourrait faire bien des dégâts et c'est pour cela que le RFC 8955 insiste sur l'importance de valider ces annonces. Mais les règles de validation étaient trop strictes et ce nouveau RFC les adoucit légèrement.
Le changement ? Le RFC 8955 imposait que la machine qui annonce une règle de filtrage pour un préfixe de destination donné soit également le routeur suivant (next hop) pour le préfixe en question. Cela limitait l'annonce aux routeurs situés sur le trajet des données. En iBGP (BGP interne à un AS, où les routeurs qui annoncent ne sont pas toujours ceux qui transmettent les paquets), cette règle était trop restrictive. (Pensez par exemple à un réflecteur de routes interne, par exemple géré par le SOC, réflecteur qui n'est même pas forcément un routeur.)
La règle nouvelle, plus libérale, ne concerne que du iBGP, interne à un AS ou à une confédération d'AS (RFC 5065). Entre des AS gérés par des organisations différentes (par exemple un AS terminal informant son opérateur Internet de ses désirs de filtrage), la règle de validation reste inchangée.
Plus formellement, la section 6 du RFC 8955, sur la validation des annonces de filtrage, est modifiée, l'étape « l'annonceur doit être également l'annonceur de la meilleure route » devient « l'annonceur doit être l'annonceur de la meilleure route ou bien le chemin d'AS doit être vide (ou n'inclure que des AS de la confédération, s'il y en a une) ». Le RFC précise également que cette validation relâchée doit pouvoir être désactivée par l'administrateur réseaux (s'ielle sait qu'il n'y aura pas d'annonces de filtrage par un routeur qui n'est pas sur le chemin des paquets). Vous noterez plus bas que, pour l'instant, seul Huawei le permet.
Il y a également un léger changement des règles de validation du chemlin d'AS, pour les cas des serveurs de route (a priori, ils ne relaient pas ce genre d'annonces et peuvent donc les rejeter). Le RFC note que, même avec une validation stricte, certaines faiblesses de BGP permettent quand même dans certains cas à tort l'envoi de règles de filtrage. C'est un problème fondamental du RFC 8955, qui n'est donc pas nouveau.
Les nouvelles règles de ce RFC sont déjà largement mises en œuvre chez les routeurs.
L'article seul
RFC 9116: A File Format to Aid in Security Vulnerability Disclosure
Date de publication du RFC : Avril 2022
Auteur(s) du RFC : E. Foudil, Y. Shafranovich (Nightwatch Cybersecurity)
Pour information
Première rédaction de cet article le 28 avril 2022
Lorsqu'on repère un problème de sécurité sur un site Web ou, plus
généralement, dans l'informatique d'une organisation, de deux choses
l'une : soit on est un méchant et on exploite l'information à son
profit, soit on fait partie des bons et on va essayer de faire en
sorte que le problème soit résolu. Une solution évidente est de
signaler le problème à l'organisation qui gère le site Web. Mais
comment ? Entre le formulaire de contact cassé qui refuse votre
adresse de courrier en prétendant qu'elle est illégale, et le
message envoyé à un humain sous-payé et sous-qualifié qui cliquera
tout de suite sur « Problème résolu » pour faire grimper ses
chiffres de résolution, prévenir quelqu'un de compétent et de
responsable est souvent un parcours du combattant ! D'où le choix de
ce RFC de
proposer encore une nouvelle méthode : un fichier à un endroit bien
connu sur le site Web, au format structuré, et contenant les
informations essentielles, le security.txt.
Comme beaucoup de techniques utilisées sur l'Internet, ce format a été déployé bien avant d'être officiellement décrit dans un RFC. On trouve aujourd'hui de tels fichiers sur plusieurs sites, y compris sur ce blog (regardez-le tout de suite si vous voulez avoir une idée de ce qu'on y met).
La section 1 du RFC décrit plus en détail le problème. Toute personne qui a déjà essayé de signaler un problème de sécurité à une organisation reconnaitra ses propres mésaventures. Le RFC commence par rappeler que trouver un contact, quoique très difficile, n'est pas tout : il faut aussi s'informer sur la politique de traitement des signalements de cette organisation, car plus d'un citoyen ayant voulu signaler une vulnérabilité s'est retrouvé accusé d'être un vilain pirate, et a parfois réellement été poursuivi en justice. Et enfin il faut s'informer sur les moyens de communications sécurisés puisque, par définition, on va transmettre des informations délicates. Est-ce qu'on peut utiliser PGP (RFC 9580), par exemple ? Pour ce qui est des contacts, il existe en théorie plusieurs solutions :
- Le RFC 2142 exige un certain nombre
d'adresses de courrier pour chaque domaine, comme
security@LE-DOMAINEpour les signalements de sécurité. Il y a peu d'organisations où cette adresse fonctionne techniquement et, même quand c'est le cas, elle n'est pas forcément lue. - Les RFC 3013 (section 2), RFC 2350 (section 3.2) et RFC 2196 (section 5.2) prévoient des adresses de contact pour différents types d'acteurs. (Même remarque que sur le point précédent.)
- Les bases des registres (de noms de domaine et d'adresses IP) contiennent également des adresses de contacts, en général accessibles via whois (cf. RFC 7485) ou RDAP. (Même remarque que sur le point précédent, en ajoutant que ces bases sont purement déclaratives, que leur exactitude est faible et baisse avec le temps.)
- Aucune de ces solutions ne donne facilement accès à la politique de divulgation de l'organisation. Et, surtout, même si le RFC garde un silence poli sur la question, toute personne qui a essayé de contacter une organisation sait bien que ces adresses de contact sont souvent erronées, dépassées, ou bien arrivent chez des gens qui s'en f...ent.
Le dernier point est à la fois une motivation important pour créer
une nouvelle solution et une des principales critiques qui avaient
été formulées à l'encontre du projet
security.txt lors de la discussion à
l'IETF : pourquoi est-ce que ça serait mieux avec
un nouveau format ? Si une organisation est assez négligente pour ne
pas tenir à jour les informations présentes chez le registre de son
nom de domaine, comment
espérer qu'elle tienne à jour son
security.txt ? Il n'y a évidemment pas de
certitude à ce sujet, juste l'espoir qu'un autre format, et surtout
un autre mécanisme de mise à jour augmentera les chances que
l'information soit correcte.
Le
security.txt est un fichier analysable par un
programme (mais quand même lisible par un humain), et qui permet
d'indiquer tout ce qui est nécessaire, par exemple au chercheur de
vulnérabilités qui a trouvé quelque chose. Il vise à signaler les
vulnérabilités (pas encore exploitées), pas les
incidents (car un attaquant qui a réussi a
peut-être modifié le fichier security.txt).
La spécification, maintenant (section 2 du
RFC). Le security.txt est un simple fichier
texte qui doit être déposé à un endroit précis du site Web,
/.well-known (RFC 8615,
et security.txt a été enregistré dans le registre
des URL bien connus). Son type doit être text/plain et
il doit être accessible en HTTPS, pour d'évidentes raisons de
sécurité. Il doit être en Unicode, utilisant
le profil du RFC 5198. Analysable par un
programme, il doit se conformer à la
grammaire spécifiée dans le RFC. Il comporte
plusieurs champs, chacun sur une ligne, et ayant un nom et une
valeur. La plupart des champs sont optionnels. Le champ le plus
connu est Contact, qui est obligatoire, et
voici un exemple :
Contact: mailto:stephane%2Bsecurity@bortzmeyer.org
(Vous avez reconnu l'encodage de l'URI spécifié dans la section 2.1 du RFC 3986. %2B est le signe
plus.) Les
lignes commençant par un croisillon sont des
commentaires.
Le RFC recommande que les security.txt
soient signés avec
OpenPGP (RFC 9580). Naturellement, comme avec n'importe quelle
signature, sa valeur dépend de si le vérificateur connait de manière
certaine la clé publique qui a été utilisée.
Un certain nombre de champs sont définis aujourd'hui, la plupart optionnels. Parmi eux :
Acknowledgments: un lien vers une page des remerciements, pour que la personne ayant l'intention de signaler un problème sache qu'elle pourra être remerciée publiquement. Question carotte pour les chercheurs de vulnérabilités, il y a aussi un champHiring☺.Canonical: l'URL officiel de cesecurity.txt. Cela peut permettre de détecter certaines erreurs de configuration (security.txtcopié sur le mauvais site).Contact: sans doute le champ le plus important, et un des rares qui soit obligatoire. Il contient un URI indiquant comment contacter quelqu'un de responsable, à qui confier le problème de sécurité. L'intérêt de définir la valeur de ce champ comme un URI est que cela permet de ne pas se limiter à une méthode de contact particulière. Puisque c'est un URI, les adresses de courrier électronique doivent être mises sous forme d'URImailto:(RFC 6068). Pareil pour les numéros de téléphone (RFC 3966). Le champContactpeut être répété, afin d'avoir plusieurs mécanismes de signalement (dans ce cas, l'ordre est important, la méthode recommandée est la première).Encryption: indique la clé de chiffrement à utiliser pour contacter. C'est encore un URI (qui peut être un URI de plandns:, pour les clés stockées dans le DNS du RFC 7929).Expires: ce champ est obligatoire et indique (au format du RFC 3339) la date limite d'utilisation de cesecurity.txt(pour éviter que de vieux fichiers pas maintenus restent utilisés).Policy: un lien vers la page décrivant la politique de l'organisation en matière de signalement de vulnérabilités. Rappelez-vous qu'un problème de beaucoup de personnes qui ont détecté une vulnérabilité est le risque que le signalement de celle-ci leur vaille des ennuis juridiques, en raison de la politique de beaucoup d'organisations qui est de nier les problèmes et de poursuivre devant les tribunaux ceux qui les signalent.Preferred-Languages: des étiquettes de langue (RFC 5646) indiquant dans quelles langues on préfère recevoir les rapports (et là, je pense à cet informaticien étatsunien qui s'était étonné publiquement qu'un webmestre chinois ne répondait pas à ses signalements de vulnérabilité faits en anglais…).
Les champs figurent dans un
registre IANA. D'autres champs pourront être rajoutés à ce
registre dans le futur, en suivant la politique « Examen par un
expert » (RFC 8126). Pour faciliter ces futurs
ajouts, il faut ignorer les champs qu'on ne connait pas. Un exemple
réel de security.txt ? Regardez celui de ce blog.
Le security.txt est publié via le site Web
mais ne s'applique pas forcément qu'au Web, il peut aussi servir
pour l'organisation en général. Par contre, il ne s'applique pas aux
sous-domaines : un security.txt sur
eu.org n'est pas valable pour
exodus-privacy.eu.org.
Vu le but de ce security.txt, il n'est pas
étonnant que la section 5 du RFC, consacrée à la
sécurité, soit si détaillée, d'autant plus qu'elle a fait l'objet de
vigoureuses discussions à l'IETF. Je n'en cite ici qu'une partie,
n'hésitez pas à lire toute cette section 5. D'abord,
l'objection la plus évidente : si le site Web a été piraté, le
security.txt ne peut plus être considéré comme
digne de confiance. Les signalements risquent d'être perdus ou même
envoyés à l'attaquant qui aura mis son adresse dans le
security.txt. C'est vrai, mais c'est le cas de
toutes les informations de contact. Par exemple, si le compte de
l'organisation auprès du BE a été piraté (comme dans l'attaque moyen-orientale
de 2018), les informations attachées au nom de domaine, et
récupérées par whois ou RDAP, sont également suspectes. Le RFC
recommande que les organisations qui ont un
security.txt le supervisent automatiquement et
vérifient notamment le champ Canonical. Et,
bien sûr, que le security.txt soit signé. Les
personnes qui signalent une vulnérabilité ont tout intérêt à
vérifier le security.txt. Et puis surtout,
security.txt est conçu pour la
réponse à vulnérabilité, pas la
réponse à incident. L'utiliser pour signaler
« vous avez une faille » est raisonnable, s'en servir pour signaler
« vous êtes piraté » l'est moins.
Comme toutes les informations mises en ligne (cf. l'exemple des
informations sociales sur un nom de domaine…), le
security.txt peut être faux, soit dès le début,
soit parce qu'il n'a pas été maintenu correctement. En tapant cet
article, je regardais le security.txt d'une
entreprise française de sécurité informatique et le champ
Encryption contenait un URL qui pointait… vers
un 404. Dans une très grosse entreprise française travaillant sur de
la haute technologie, notamment en sécurité, un URL dans le
security.txt donne… 403 ! Au même endroit, la
signature du security.txt est incorrecte… Le champ Expires permet de détecter les
security.txt trop vieux et pas maintenus mais
le problème est vaste et on peut s'attendre à se casser souvent le
nez sur des informations incorrectes. Comme pour toutes les
informations en ligne, les organisations qui publient un
security.txt devraient s'assurer, dans leurs
procédures, qu'il est maintenu à jour.
Certains croient qu'ils ont le droit de se livrer à des
tests d'attaques sur tout
site Web trouvé sur l'Internet. C'est évidemment faux, de même qu'on
n'a pas le droit dans le rue de tenter de crocheter toutes les
serrures pour voir lesquelles sont vulnérables. Même l'existence
d'un security.txt ne vaut pas autorisation de
tester le site. Le champ Policy peut indiquer
si des tests d'attaque sont autorisés et dans quelles
conditions. Sinon, on doit se limiter aux failles découvertes dans
le cours de l'utilisation normale du site (ceci n'est pas un conseil
juridique : la loi est compliquée et dépend du pays).
Naturellement, comme toujours lorsqu'on publie une adresse de
courrier, elle va recevoir du spam. Plus
gênant, le fait que le security.txt soit
analysable par un programme pourrait amener certains
bots qui font des soi-disant tests de
sécurité à envoyer des messages automatiques de faible
valeur. (Par exemple, j'ai vu un bot qui regardait la version
d'Apache et
envoyait automatiquement un courrier si la version lui semblait trop
vieille. Ce genre d'avertissements mécaniques n'a aucune valeur,
notamment parce que certains systèmes d'exploitation bouchent les
failles de sécurité sans changer la version et, surtout, parce qu'il
y a peu de chance qu'un logiciel puisse faire avec succès quelque
chose d'aussi délicat qu'une analyse de sécurité ; les logiciels
sont utiles pour une première reconnaissance, mais il ne faut pas
envoyer de message d'avertissement avant qu'un humain compétent
n'ait vérifié.)
Voilà, nous avons fait le tour du RFC. Si vous êtes responsable
de la sécurité d'une organisation, à vous de vous mettre au travail
pour concevoir et documenter une politique de signalement des
failles de sécurité (c'est le gros du travail), de rédiger un
security.txt (c'est trivial) et de faire en
sorte qu'il soit maintenu (ce n'est pas évident). Si vous avez
trouvé une faille de sécurité dans un site Web ou ailleurs chez une
organisation, pensez à regarder si elle a un
security.txt mais ne l'utilisez pas
aveuglément, comparez avec d'autres sources d'information. Pour vous
instruire, vous pouvez regarder le site Web du projet. Il
comprend notamment un bon formulaire pour aider à fabriquer son
security.txt (mais rappelez-vous que ce qui est
difficile, c'est l'élaboration de la politique). Ce site contient
également une liste de
logiciels qui peuvent aider. Le moteur de recherche
Shodan lit les
security.txt et les affiche proprement mais,
avec le virtual hosting,
comme Shodan travaille par adresse IP, ça ne marche pas
souvent. Sinon, YesWeHack fournit une extension
aux navigateurs Web pour afficher le
security.txt (pas très utile, je trouve, elle
se contente d'afficher le fichier tel quel, sans vraie valeur
ajoutée).
Le security.txt est-il obligatoire ? Cela
dépend de votre environnement. Le DHS
étatsunien le
recommande pour les organismes qui dépendent de lui. En
France, l'arrêté
du 18 septembre 2018 portant approbation du cahier des clauses
simplifiées de cybersécurité, dans son article 6.4, dit que
« Afin que ces signalements soient effectifs et efficaces, les
conventions d'usage en cybersécurité sont respectées (security.txt,
abuse@). Dans tous les cas, il faut moins d'une minute pour trouver
le point d'entrée approprié du signalement. ».
Terminons par un tour des security.txt
existants (mes commentaires concernent l'état de ce fichier en août 2021 ;
il a pu changer depuis). Commençons par un exemple très simple, mais correct,
celui de la société
Cyberzen :
% curl https://www.cyberzen.com/.well-known/security.txt Contact: contact@cyberzen.com Expires: Sun, 31 Dec 2023 23:59 +0200 Preferred-Languages: fr, en
Ensuite le registre de
.be a un très bon
security.txt, très complet, avec commentaires :
% curl https://www.dnsbelgium.be/.well-known/security.txt # Our security address Contact: mailto:csirt@dnsbelgium.be?subject=rdp_dnsbelgium.be # Our OpenPGP key Encryption: https://www.dnsbelgium.be/.well-known/pgp-key.txt # Canonical URL Canonical: https://www.dnsbelgium.be/.well-known/security.txt # Our security policy Policy: https://www.dnsbelgium.be/responsible-disclosure-policy Preferred-Languages: en, nl, fr Expires: Mon, 1 Nov 2021 00:00:00 +0100
Autre exemple, Google a un
security.txt :
Contact: https://g.co/vulnz Contact: mailto:security@google.com Encryption: https://services.google.com/corporate/publickey.txt Acknowledgements: https://bughunter.withgoogle.com/ Policy: https://g.co/vrp Hiring: https://g.co/SecurityPrivacyEngJobs
Le champ Expires, pourtant obligatoire, manque
encore (il a été ajouté dans les dernières révisions du projet de
spécification).
En France, la Sécu en a un et, contrairement à celui de Google, il est signé avec OpenPGP :
% curl https://www.ameli.fr/.well-known/security.txt -----BEGIN PGP SIGNED MESSAGE----- Hash: SHA512 Contact: mailto:abuse@assurance-maladie.fr Encryption: https://raw.githubusercontent.com/AssuranceMaladieSec/abuse/master/abuse-gpg-public-key.txt Policy: https://assurancemaladiesec.github.io/abuse/reporting/ Acknowledgments: https://assurancemaladiesec.github.io/abuse/thanks/ Preferred-Languages: fr,en -----BEGIN PGP SIGNATURE----- iQIzBAEBCgAdFiEEDSx9bqnSlmkiIRXbSDqGYCymPFIFAl4V9/cACgkQSDqGYCym PFIB7Q/9EI7fNOfyoCqnEH4chiTIW8fx32ldnlaE6WTgdMeQJmkyJrhd2osPAV/j ...
Ah, profitons-en pour vérifier la signature (la clé publique, curieusement, est hébergé chez un tiers, GitHub) :
% wget https://www.ameli.fr/.well-known/security.txt ... 2020-04-08 18:41:10 (6.87 MB/s) - ‘security.txt’ saved [1189] % wget https://raw.githubusercontent.com/AssuranceMaladieSec/abuse/master/abuse-gpg-public-key.txt ... 2021-08-12 09:03:52 (11,1 MB/s) - ‘abuse-gpg-public-key.txt’ saved [3159/3159] % gpg --import abuse-gpg-public-key.txt gpg: key 483A86602CA63C52: public key "Abuse Assurance Maladie <abuse@assurance-maladie.fr>" imported gpg: Total number processed: 1 gpg: imported: 1 % gpg --verify security.txt gpg: Signature made Wed Jan 8 16:40:39 2020 CET gpg: using RSA key 0D2C7D6EA9D29669222115DB483A86602CA63C52 gpg: Good signature from "Abuse Assurance Maladie <abuse@assurance-maladie.fr>" [unknown] gpg: WARNING: This key is not certified with a trusted signature! gpg: There is no indication that the signature belongs to the owner. Primary key fingerprint: 0D2C 7D6E A9D2 9669 2221 15DB 483A 8660 2CA6 3C52
C'est parfait, tout fonctionne (et c'est documenté).
Autre exemple en France, le service Flus, dont le
security.txt est décrit dans un bon article. Voici le fichier :
% curl https://flus.fr/.well-known/security.txt Contact: https://flus.fr/contact Contact: security@flus.io Expires: Fri, 01 Apr 2022 00:00 +0000 Policy: https://flus.fr/securite Acknowledgments: https://flus.fr/securite Canonical: https://flus.fr/.well-known/security.txt Preferred-Languages: fr, en
OpenSSL
a bien sûr un security.txt. À une époque, la
signature PGP était incorrecte…
% gpg --verify security.txt.asc security.txt gpg: Signature made Thu Jan 4 04:22:26 2018 CET gpg: using RSA key EFC0A467D613CB83C7ED6D30D894E2CE8B3D79F5 gpg: BAD signature from "OpenSSL OMC <openssl-omc@openssl.org>" [unknown]
Cela illustre un problème commun à tous les mécanismes de publication d'information de contact : l'information n'est pas facile à maintenir et tend à se dégrader avec le temps.
Quelques lectures supplémentaires qui peuvent être intéressantes :
- Si vous êtes prêt à payer, la norme ISO ISO.29147.2018 parle de « Security techniques - Vulnerability disclosure ».
- CMU a un « CERT Guide to Coordinated Vulnerability Disclosure ».
- Le projet
https://disclose.io/ - Autres articles en français sur le
security.txt: celui de Bruno Kerouanton et celui de y0no. - Et un article de l'ANSSI sur le signalement de vulnérabilités.
L'article seul
RFC 9115: An Automatic Certificate Management Environment (ACME) Profile for Generating Delegated Certificates
Date de publication du RFC : Septembre 2021
Auteur(s) du RFC : Y. Sheffer (Intuit), D. López, A. Pastor Perales (Telefonica I+D), T. Fossati (ARM)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF acme
Première rédaction de cet article le 21 septembre 2021
Ce nouveau RFC décrit un profil du protocole ACME d'obtention de certificat, profil qui permet de déléguer la demande à un tiers. C'est surtout utile pour le cas où vous sous-traitez l'hébergement de votre site Web (par exemple sur un CDN) : le sous-traitant peut alors demander un certificat, avec sa clé privée à lui, pour un nom de domaine que vous contrôlez et prouver qu'il héberge bien le serveur pour ce nom. Serveurs et clients TLS n'ont pas besoin d'être modifiés (seuls les serveurs et clients ACME le seront), et, bien entendu, le titulaire du nom de domaine garde un complet contrôle et peut, par exemple, révoquer les certificats obtenus par ses sous-traitants.
Ce profil utilise lui-même le profil STAR (Short-Term,
Automatically Renewed) décrit dans le RFC 8739 donc faites bien attention à avoir lu le RFC 8739 avant. Le cas typique d'utilisation de ce
mécanisme de délégation est le CDN. Un webmestre (l'IdO pour
Identifier Owner car il est titulaire du
nom de domaine, mettons
foobar.example) a un site Web et sous-traite
tout ou partie du service à un CDN, appelé ici NDC pour
Name Delegation Consumer (et la ressemblance
entre les sigles CDN et NDC est volontaire). Le CDN devra pouvoir
répondre aux requêtes HTTPS pour
www.foobar.example et donc présenter un
certificat au nom www.foobar.example. Avec
ACME, l'IdO peut
obtenir un tel certifiat mais il ne souhaite probablement pas
transmettre la clé
privée correspondante au NDC. La solution de notre RFC
est d'utiliser une extension à ACME, permettant la délégation du
nom. Le NDC pourra alors obtenir un certificat STAR (de courte durée
de vie, donc) pour www.foobar.example. Pas
besoin de partager une clé privée, ni de transmettre des secrets de
longue durée de vie (les délégations sont révocables, et les
certificats STAR ne durent pas longtemps, le NDC devra renouveller
souvent et ça cessera en cas de révocation). C'est l'utilisation
typique de la délégation mais d'autres sont possibles (par exemple
avec des certificats ordinaires, non-STAR). Le RFC note que la
solution de délégation ne modifie qu'ACME, et pas TLS, et qu'elle
marche donc avec les clients et serveurs TLS actuels (contrairement
à d'autres propositions qui sont étudiées).
Pour que la délégation fonctionne, l'IdO doit avoir un serveur ACME, auquel le NDC devra se connecter, et s'être mis d'accord avec le NDC sur les paramètres à utiliser. C'est donc une étape relativement nouvelle, l'utilisateur d'ACME typique n'ayant qu'un client ACME, seule l'AC a un serveur. Mais c'est quand même plus simple que de monter une AC. Le serveur ACME chez l'IdO ne signera pas de certificats, il relaiera simplement la requête. Quand le NDC aura besoin d'un certificat, il enverra une demande à l'IdO, qui la vérifiera et, devenant client ACME, l'IdO enverra une demande à l'AC. Si ça marche, l'IdO prévient le NDC, et celui-ci récupérera le certificat chez l'AC (par unauthenticated GET, RFC 8739, section 3.4).
Le protocole ACME gagne un nouveau type d'objet, les délégations, qui indiquent ce qu'on permet au NDC. Comme les autres objets ACME, elles sont représentées en JSON et voici un exemple :
{
"csr-template": {
"keyTypes": [
{
"PublicKeyType": "id-ecPublicKey",
"namedCurve": "secp256r1",
"SignatureType": "ecdsa-with-SHA256"
}
],
"subject": {
"country": "FR",
"stateOrProvince": "**",
"locality": "**"
},
"extensions": {
"subjectAltName": {
"DNS": [
"www.foobar.example"
]
},
"keyUsage": [
"digitalSignature"
],
"extendedKeyUsage": [
"serverAuth"
]
}
}
}
(Les champs des extensions comme keyUsage sont
dans un
nouveau registre IANA ; on peut ajouter des champs, selon la
politique « spécification nécessaire ».)
Ici, le NDC est autorisé à demander des certificats ECDSA
pour le nom www.foobar.example. Quand le NDC
enverra sa requête de certificat à l'IdO, il devra inclure cet objet
« délégation », que l'IdO pourra comparer avec ce qu'il a configuré
pour ce NDC. Voici un exemple partiel, envoyé lors d'un POST HTTPS
au serveur ACME de l'IdO :
{
"protected": base64url({
"alg": "ES256",
"kid": "https://acme.ido.example/acme/acct/evOfKhNU60wg",
"nonce": "Alc00Ap6Rt7GMkEl3L1JX5",
"url": "https://acme.ido.example/acme/new-order"
}),
"payload": base64url({
"identifiers": [
{
"type": "dns",
"value": "www.foobar.example"
}
],
"delegation":
"https://acme.ido.example/acme/delegation/gm0wfLYHBen"
}),
"signature": ...
(Le nouveau champ delegation a été placé dans
le
registre IANA.) Le NDC enverra ensuite le CSR, et l'IdO
relaiera la requête vers le serveur ACME de l'AC (moins l'indication
de délégation, qui ne regarde pas l'AC).
Quand on utilise un CDN, il est fréquent qu'on doive configurer un alias dans le DNS pour pointer vers un nom indiqué par l'opérateur du CDN. Voici par exemple celui de l'Élysée :
% dig CNAME www.elysee.fr ... ;; ANSWER SECTION: www.elysee.fr. 3600 IN CNAME 3cifmt6.x.incapdns.net. ...
L'extension au protocole ACME spécifiée dans notre RFC permet au NDC d'indiquer cet alias dans sa requête, l'IdO peut alors l'inclure dans sa zone DNS.
Tous les serveurs ACME ne seront pas forcément capables de gérer
des délégations, il faudra donc l'indiquer dans les capacités du
serveur, avec le champ delegation-enabled (mis
dans le
registre IANA).
Comme indiqué plus haut, l'IdO peut arrêter la délégation quand il veut, par exemple parce qu'il change de CDN. Cet arrêt se fait par une interruption explicite de la demande STAR (RFC 8739, section 3.1.2). Si les certificats ne sont pas des STAR, le mécanisme à utiliser est la révocation normale des certificats.
Après cet examen du protocole, la section 3 de notre RFC décrit le comportement de l'AC. Il n'y a pas grand'chose à faire pour l'AC (le protocole est entre le NDC et l'IdO) à part à être capable d'accepter des récupérations non authentifiées de certificats (car le NDC n'a pas de compte à l'AC).
On a parlé plus haut du CSR. Il doit se conformer à un certain gabarit, décidé par l'IdO. Ce gabarit est évidemment au format JSON, comme le reste d'ACME. La syntaxe exacte est décrite avec le langage CDDL (RFC 8610) et figure dans l'annexe A ou bien, si vous préférez, avec le langage JSON Schema, utilisé dans l'annexe B. Voici l'exemple de gabarit du RFC :
{
"keyTypes": [
{
"PublicKeyType": "rsaEncryption",
"PublicKeyLength": 2048,
"SignatureType": "sha256WithRSAEncryption"
},
{
"PublicKeyType": "id-ecPublicKey",
"namedCurve": "secp256r1",
"SignatureType": "ecdsa-with-SHA256"
}
],
"subject": {
"country": "CA",
"stateOrProvince": "**",
"locality": "**"
},
"extensions": {
"subjectAltName": {
"DNS": [
"abc.ido.example"
]
},
"keyUsage": [
"digitalSignature"
],
"extendedKeyUsage": [
"serverAuth",
"clientAuth"
]
}
}
Dans cet exemple, l'IdO impose au NDC un certificat RSA ou ECDSA et rend impérative (c'est le sens des deux astérisques) l'indication de la province et de la ville. L'IdO doit évidemment vérifier que le CSRT reçu se conforme bien à ce gabarit.
Le RFC présente (en section 5) quelques autres cas d'utilisation de cette délégation. Par exemple, un IdO peut déléguer à plusieurs CDN, afin d'éviter que la panne d'un CDN n'arrête tout. Avec la délégation, ça se fait tout seul, chacun des CDN est authentifié, et demande séparément son certificat.
Autre cas rigolo, celui où le CDN délègue une partie du service à un CDN plus petit. Le modèle de délégation ACME peut s'y adapter (le petit CDN demande un certificat au gros, qui relaie à l'IdO…), si les différentes parties sont d'accord.
Enfin, la section 7 du RFC revient sur les propriétés de sécurité de ces délégations. En gros, il faut avoir confiance en celui à qui on délègue car, pendant la durée de la délégation, il pourra faire ce qu'il veut avec le nom qu'on lui a délégué, y compris demander d'autres certificats en utilisant sa délégation du nom de domaine. Il existe quelques mesures techniques que l'IdO peut déployer pour empêcher le NDC de faire trop de bêtises. C'est le cas par exemple des enregistrements DNS CAA (RFC 8659) qui peuvent limiter le nombre d'AC autorisées (voir aussi le RFC 8657).
Je ne connais pas encore d'opérateur de CDN qui mette en œuvre cette solution.
L'article seul
RFC 9114: Hypertext Transfer Protocol Version 3 (HTTP/3)
Date de publication du RFC : Juin 2022
Auteur(s) du RFC : M. Bishop (Akamai)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF quic
Première rédaction de cet article le 7 juin 2022
Le protocole de transport QUIC, bien que permettant plusieurs protocoles applicatifs au-dessus de lui, a été surtout conçu pour HTTP. Il est donc logique que le premier protocole applicatif tournant sur QUIC et normalisé soit HTTP. Voici donc HTTP/3, la nouvelle version d'HTTP, et la première qui tourne sur QUIC, les précédentes tournant sur TCP (et, souvent, sur TLS sur TCP). À part l'utilisation de QUIC, HTTP/3 est très proche de HTTP/2.
Un petit point d'histoire sur HTTP : la version 1.1 (dont la norme précédente datait de 2014) utilise du texte, ce qui est pratique pour les humains (on peut se servir de netcat ou telnet comme client HTTP), mais moins pour les programmes. En outre, il n'a aucun multiplexage, encourageant les auteurs de navigateurs à ouvrir plusieurs connexions TCP simultanées avec le serveur, connexions qui ne partagent pas d'information entre elles et sont donc inefficaces. La version 2 de HTTP (RFC 9113) est binaire et donc plus efficace, et elle inclut du multiplexage. Par contre, les limites de TCP (une perte de paquet va affecter toutes les ressources en cours de transfert, une ressource lente peut bloquer une rapide, etc) s'appliquent toujours. D'où le passage à QUIC pour HTTP/3. QUIC améliore la latence, notamment grâce à la fusion avec TLS, et fournit du « vrai » multiplexage. Autrement, HTTP/3 est très proche de HTTP/2, mais il est plus simple, puisque le multiplexage est délégué à la couche transport.
QUIC offre en effet plusieurs fonctions très pratiques pour HTTP/3, notamment le multiplexage (complet : plus de head-of-line blocking), le contrôle de débit par ruisseau et pas par connexion entière, et l'établissement de connexion à faible latence. QUIC a été conçu en pensant à HTTP et aux problèmes spécifiques du Web.
Nous avons maintenant toute une panoplie de versions de HTTP, du HTTP/1.1 du RFC 9112 et suivants, au HTTP/2 du RFC 9113, puis désormais à notre HTTP/3. De même que HTTP/2 n'a pas supprimé HTTP/1, HTTP/3 ne supprimera pas HTTP/2, ne serait-ce que parce qu'il existe encore beaucoup de réseaux mal gérés et/ou restrictifs, où QUIC ne passe pas. Toutes ces versions de HTTP ont en commun les mêmes sémantiques, décrites dans le RFC 9110.
La section 2 du RFC fait un panorama général de HTTP/3. Quand le
client HTTP sait (on verra plus tard comment il peut savoir) que le
serveur fait du HTTP/3, il ouvre une connexion QUIC avec ce
serveur. QUIC fera le gros du travail. À l'intérieur de chaque
ruisseau QUIC, il y aura un seul couple requête/réponse HTTP. La
requête et la réponse seront placées dans des trames
QUIC de type STREAM (les trames de
contenu dans QUIC). À l'intérieur des trames QUIC, il y aura des
trames
HTTP, dont deux types sont particulièrement importants,
HEADERS et DATA. QUIC
étant ce qu'il est, chaque couple requête/réponse est séparé et, par
exemple, la lenteur à envoyer une réponse n'affectera pas les autres
requêtes, mêmes envoyées après celle qui a du mal à avoir une
réponse. (Il y a aussi la possibilité pour le serveur d'envoyer des
données spontanément, avec les trames HTTP de type
PUSH_PROMISE et quelques autres.) Les requêtes
et les réponses ont un encodage binaire comme en HTTP/2, et sont
comprimées avec QPACK (RFC 9114), alors que HTTP/2 utilisait HPACK (qui nécessitait
une transmission ordonnées des octets, qui n'existe plus dans une
connexion QUIC).
Après cette rapide présentation, voyons les détails, en
commençant par le commencement, l'établissement des connexions entre
client et serveur. D'abord, comment savoir si le serveur veut bien
faire du HTTP/3 ? Le client HTTP a reçu consigne de l'utilisateur
d'aller en
https://serveur-pris-au-hasard.example/,
comment va t-il choisir entre HTTP/3 et des versions plus classiques
de HTTP ? Il n'y a rien dans l'URL qui indique que QUIC est possible mais il y
a plusieurs méthodes de découverte, permettant au client une grande
souplesse. D'abord, le client peut simplement tenter sa chance : on
ouvre une connexion QUIC vers le port 443 et
on voit bien si ça marche ou si on reçoit un message ICMP nous
disant que c'est raté. Ici, un exemple vu avec
tcpdump :
11:07:20.368833 IP6 (hlim 64, next-header UDP (17) payload length: 56) 2a01:e34:ec43:e1d0:554:492d:1a13:93e4.57926 > 2001:41d0:302:2200::180.443: [udp sum ok] UDP, length 48 11:07:20.377878 IP6 (hlim 52, next-header ICMPv6 (58) payload length: 104) 2001:41d0:302:2200::180 > 2a01:e34:ec43:e1d0:554:492d:1a13:93e4: [icmp6 sum ok] ICMP6, destination unreachable, unreachable port, 2001:41d0:302:2200::180 udp port 443
Si ça rate, on se rabat en une version de HTTP sur TCP (les premiers tests menés par Google indiquaient qu'entre 90 et 95 % des utilisateurs avaient une connectivité UDP correcte et pouvaient donc utiliser QUIC). Mais le cas ci-dessus était le cas idéal où on avait reçu le message ICMP et où on avait pu l'authentifier. Comme il est possible qu'un pare-feu fasciste et méchant se trouve sur le trajet, et jette silencieusement les paquets UDP, sans qu'on reçoive de réponse, même négative, il faut que le client soit plus intelligent que cela, et essaie très vite une autre version de HTTP, suivant le principe des globes oculaires heureux (RFC 8305). L'Internet est en effet farci de middleboxes qui bloquent tout ce qu'elles ne connaissent pas, et le client HTTP ne peut donc jamais être sûr qu'UDP passera. C'est même parfois un conseil explicite de certains vendeurs.
Sinon, le serveur
peut indiquer explicitement qu'il gère HTTP/3 lors d'une connexion
avec une vieille version de HTTP, via l'en-tête
Alt-Svc: (RFC 7838). Le
client essaie d'abord avec une vieille version de HTTP, puis est
redirigé, et se souviendra ensuite de la redirection. Par exemple,
si la réponse HTTP contient :
Alt-Svc: h3=":443"
Alors le client sait qu'il peut essayer HTTP/3 sur le port
443. Il peut y avoir plusieurs services alternatifs dans un
Alt-Svc: (par exemple les versions
expérimentales de HTTP/3).
Dernière possibilité, celle décrite dans le RFC 8164. (Par contre, l'ancien mécanisme
Upgrade: et sa réponse 101 n'est plus utilisé
par HTTP/3.)
À propos de port, j'ai cité jusqu'à
présent le 443 car c'est le port par défaut, mais on peut évidemment
en utiliser un autre, en l'indiquant dans
l'URL, ou via
Alt-Svc:. Quant aux URL de plan
http: (tout court, sans le S), ils ne sont pas
utilisables directement (puisque QUIC n'a pas de mode en clair, TLS
est obligatoire) mais peuvent quand même rediriger vers du HTTP/3,
via Alt-Svc:.
Le client a donc découvert le serveur, et il se connecte. Il doit
utiliser l'ALPN TLS (RFC 7301,
qui est quasi-obligatoire avec QUIC, et indiquer comme application
h3 (cf. le registre
IANA des applications). Les réglages divers qui
s'appliqueront à toute la connexion (la liste des réglages possibles
est dans un
registre IANA) sont envoyés dans une trame HTTP de type
SETTINGS. La connexion QUIC peut évidemment
rester ouverte une fois les premières requêtes envoyées et les
premières réponses reçues, afin d'amortir le coût de connexion sur
le plus grand nombre de requêtes possible. Évidemment, le serveur
est autorisé à couper les connexions qui lui semblent inactives (ce
qui se fait normalement en envoyant une trame HTTP de type
GOAWAY), le client doit donc être prêt à les
réouvrir.
Voilà pour la gestion de connexions. Et, une fois qu'on est
connecté, comment se font les requêtes (section 4 du RFC) ? Pour
chaque requête, on envoie une trame HTTP de type
HEADERS contenant les en-têtes HTTP (encodés,
je le rappelle, en binaire) et la méthode utilisée
(GET, POST, etc), puis une
trame de type DATA si la requête contient des
données. Puis on lit la réponse envoyée par le serveur. Le ruisseau
est fermé ensuite, chaque ruisseau ne sert qu'à un seul couple
requête/réponse. (Rappelez-vous que, dans QUIC, envoyer une trame
QUIC de type STREAM suffit à créer le ruisseau
correspondant. Tout ce qui nécessite un état a été fait lors de la
création de la connexion QUIC.)
Comme expliqué plus haut, les couples requête/réponse se font sur un ruisseau, qui ne sert qu'une fois. Ce ruisseau est bidirectionnel (section 6), ce qui permet de corréler facilement la requête et la réponse : elles empruntent le même ruisseau. C'est celui de numéro zéro dans l'exemple plus loin, qui n'a qu'un seul couple requête/réponse. La première requête se fera toujours sur le ruisseau 0, les autres seront que les ruisseaux 4, 8, etc, selon les règles de génération des numéros de ruisseau de QUIC.
Voici,
un exemple, affiché par tshark d'un échange HTTP/3. Pour
pouvoir le déchiffrer, on a utilisé la méthode classique, en
définissant la variable
d'environnement SSLKEYLOGFILE avant
de lancer le client HTTP (ici, curl), puis en disant à Wireshark d'utiliser
ce fichier contenant la clé (tls.keylog_file:
/tmp/quic.key dans
~/.config/wireshark/preferences). Cela donne :
% tshark -n -r /tmp/quic.pcap 1 0.000000 10.30.1.1 → 45.77.96.66 QUIC 1294 Initial, DCID=94b8a6888cb47e3128b13d875980b557d9e415f0, SCID=57e2ce80152d30c1f66a9fcb3c3b49c81c98f329, PKN: 0, CRYPTO, PADDING 2 0.088508 45.77.96.66 → 10.30.1.1 QUIC 1242 Handshake, DCID=57e2ce80152d30c1f66a9fcb3c3b49c81c98f329, SCID=3bd5658cf06b1a5020d44410ab9682bcf277610f, PKN: 0, CRYPTO[Malformed Packet] 3 0.088738 10.30.1.1 → 45.77.96.66 QUIC 185 Handshake, DCID=3bd5658cf06b1a5020d44410ab9682bcf277610f, SCID=57e2ce80152d30c1f66a9fcb3c3b49c81c98f329, PKN: 0, ACK 4 0.089655 45.77.96.66 → 10.30.1.1 QUIC 1239 Handshake, DCID=57e2ce80152d30c1f66a9fcb3c3b49c81c98f329, SCID=3bd5658cf06b1a5020d44410ab9682bcf277610f, PKN: 1, CRYPTO 5 0.089672 10.30.1.1 → 45.77.96.66 QUIC 114 Handshake, DCID=3bd5658cf06b1a5020d44410ab9682bcf277610f, SCID=57e2ce80152d30c1f66a9fcb3c3b49c81c98f329, PKN: 1, ACK, PING 6 0.090740 45.77.96.66 → 10.30.1.1 QUIC 931 Handshake, DCID=57e2ce80152d30c1f66a9fcb3c3b49c81c98f329, SCID=3bd5658cf06b1a5020d44410ab9682bcf277610f, PKN: 2, CRYPTO 7 0.091100 10.30.1.1 → 45.77.96.66 HTTP3 257 Protected Payload (KP0), DCID=3bd5658cf06b1a5020d44410ab9682bcf277610f, PKN: 0, NCI, STREAM(2), SETTINGS, STREAM(10), STREAM(6) 8 0.091163 10.30.1.1 → 45.77.96.66 HTTP3 115 Protected Payload (KP0), DCID=3bd5658cf06b1a5020d44410ab9682bcf277610f, PKN: 1, STREAM(0), HEADERS 9 0.189511 45.77.96.66 → 10.30.1.1 HTTP3 631 Protected Payload (KP0), DCID=57e2ce80152d30c1f66a9fcb3c3b49c81c98f329, PKN: 0, ACK, DONE, CRYPTO, STREAM(3), SETTINGS 10 0.190684 45.77.96.66 → 10.30.1.1 HTTP3 86 Protected Payload (KP0), DCID=57e2ce80152d30c1f66a9fcb3c3b49c81c98f329, PKN: 1, STREAM(7) 11 0.190792 10.30.1.1 → 45.77.96.66 QUIC 85 Protected Payload (KP0), DCID=3bd5658cf06b1a5020d44410ab9682bcf277610f, PKN: 2, ACK 12 0.192047 45.77.96.66 → 10.30.1.1 HTTP3 86 Protected Payload (KP0), DCID=57e2ce80152d30c1f66a9fcb3c3b49c81c98f329, PKN: 2, STREAM(11) 13 0.193299 45.77.96.66 → 10.30.1.1 HTTP3 604 Protected Payload (KP0), DCID=57e2ce80152d30c1f66a9fcb3c3b49c81c98f329, PKN: 3, STREAM(0), HEADERS, DATA 14 0.193421 10.30.1.1 → 45.77.96.66 QUIC 85 Protected Payload (KP0), DCID=3bd5658cf06b1a5020d44410ab9682bcf277610f, PKN: 3, ACK
On y voit au début l'ouverture de la connexion QUIC. Puis, à partir
du datagramme 7 commence HTTP/3, avec la création des ruisseaux
nécessaires et l'envoi de la trame SETTINGS
(ruisseau 3) et de HEADERS (ruisseau 0). Pas de
trame DATA, c'était une simple requête HTTP
GET, sans corps. Le serveur répond par son
propre SETTINGS, une trame
HEADERS et une DATA (la
réponse est de petite taille et tient dans un seul datagramme). Vous
avez l'analyse complète et détaillée de cette session QUIC dans le fichier
http3-get-request.txt.
La section 7 décrit les différents types de trames définis pour
HTTP/3 (rappelez-vous que ce ne sont pas les mêmes que les trames
QUIC : toutes voyagent dans des trames QUIC de type
STREAM), comme :
HEADERS(type 1), qui transporte les en-têtes HTTP, ainsi que les « pseudo en-têtes » comme la méthode HTTP. Ils sont comprimés avec QPACK (RFC 9114).DATA(type 0) qui contient le corps des messages. Une requêteGETne sera sans doute pas accompagnée de ce type de trames mais la réponse aura, dans la plupart des cas, un corps et donc une ou plusieurs trames de typeDATA.SETTINGS(type 4), qui définit des réglages communs à toute la connexion. Les réglages possibles figurent dans un registre IANA.GOAWAY(type 7) sert à dire qu'on s'en va.
Les différents types de trames QUIC sont dans un registre IANA. Ce registre est géré selon les politiques (cf. RFC 8126) « action de normalisation » pour une partie, et « spécification nécessaire » pour une autre partie de l'espace des types, plus ouverte. Notez que les types de trame HTTP/3 ne sont pas les mêmes que ceux de HTTP/2, même s'ils sont très proches. Des plages de types sont réservées (section 7.2.8) pour le graissage, l'utilisation délibérée de types non existants pour s'assurer que le partenaire respecte bien la norme, qui commande d'ignorer les types de trame inconnus. (Le graissage et ses motivations sont expliqués dans le RFC 8701.)
Wireshark peut aussi analyser graphiquement les données et vous
pouvez voir ici une trame QUIC de type STREAM
(ruisseau 0) contenant une trame HTTP/3 de type
HEADERS. Notez que cette version de Wireshark
ne décode pas encore la requête HTTP (ici, un simple
GET) : 
Et une fois qu'on a terminé ? On ferme la connexion (section 5), ce qui peut arriver pour plusieurs raisons, par exemple :
- La connexion n'a pas été utilisée depuis longtemps (« longtemps » étant défini par les paramètres de la connexion) et une des deux parties décide de la fermer,
- une des deux parties décide de fermer une connexion car son
travail est terminé, et envoie donc une trame de type
GOAWAY, - une erreur a pu se produire, empêchant de continuer la connexion, par exemple parce que le réseau est coupé.
Bien sûr, des tas de choses peuvent aller mal pendant une connexion HTTP/3. La section 8 du RFC définit donc un certain nombre de codes d'erreurs pour signaler les problèmes. Ils sont stockés dans un registre IANA.
L'un des buts essentiels de QUIC était d'améliorer la
sécurité. La section 10 du RFC discute de ce qui a été fait. En
gros, la sécurité de HTTP/3 est celle de HTTP/2 quand il est combiné
avec TLS, mais il y a quelques points à garder en tête. Par exemple,
HTTP/3 a des fonctions, comme la compression d'en-têtes (RFC 9114) ou comme le
contrôle de flux de chaque ruisseau qui, utilisées sans précaution,
peuvent mener à une importante allocation de ressources. Les
réglages définis dans la trame SETTINGS servent
entre autres à mettre des limites strictes à la consommation de
ressources.
Autre question de sécurité, liée cette fois à la protection de la
vie privée, la taille des
données. Par défaut, TLS ne cherche pas à dissimuler la taille des
paquets. Si on ne sait pas quelle page a chargé un client HTTPS,
l'observation de la taille des données reçues, comparée à ce qu'on
obtient en se connectant soi-même au serveur, permet de trouver avec
une bonne probabilité les ressources demandées (c'est ce qu'on nomme
l'analyse de trafic). Pour contrer cela, on peut utiliser le
remplissage. HTTP/3 peut utiliser celui de
QUIC (avec les trames QUIC de type PADDING) ou
bien faire son propre remplissage avec des trames HTTP utilisant des
types non alloués, mais dont l'identificateur est réservé (les
trames HTTP de type inconnu doivent être ignorées par le
récepteur).
Toujours question sécurité, l'effort de QUIC et de HTTP/3 pour diminuer la latence, avec notamment la possibilité d'envoyer des données dès le premier paquet (early data), a pour conséquences de faciliter les attaques par rejeu. Il faut donc suivre les préconisations du RFC 8470.
La possibilité qu'offre QUIC de faire migrer une session d'une
adresse IP vers une autre (par exemple quand un ordiphone passe de
4G en WiFi ou réciproquement) soulève également des questions de
sécurité. Ainsi, journaliser l'adresse IP du
client (le access_log d'Apache…) n'aura plus forcément le même
sens, cette adresse pouvant changer en cours de route. Idem pour les
ACL.
Ah, et question vie privée, le fait que HTTP/3 et QUIC encouragent à utiliser une seule session pour un certain nombre de requêtes peut permettre de corréler entre elles des requêtes. Sans cookie, on a donc une traçabilité des utilisateurs.
HTTP/3 a beaucoup de ressemblances avec HTTP/2. L'annexe A de
notre RFC détaille les différences entre ces deux versions et
explique comment passer de l'une à l'autre. Ainsi, la gestion des
ruisseaux qui, en HTTP/2, était faite par HTTP, est désormais faite
par QUIC. Une des conséquences est que l'espace des identificateurs
de ruisseau est bien plus grand, limitant le risque qu'on tombe à
cours. HTTP/3 a moins de types de trames que HTTP/2 car une partie
des fonctions assurées par HTTP/2 le sont par QUIC et échappent donc
désormais à HTTP (comme PING ou WINDOW_UPDATE).
HTTP/3 est en plein déploiement actuellement et vos logiciels
favoris peuvent ne pas encore l'avoir, ou bien n'avoir qu'une
version expérimentale de HTTP/3 et encore pas par défaut. Par
exemple, pour Google
Chrome, il faut le lancer google-chrome
--enable-quic --quic-version=h3-24
(h3-24 étant une version de développement de
HTTP/3). Pour Firefox, vous pouvez suivre
cet article ou celui-ci. Quand vous lirez ces lignes, tout sera
peut-être plus simple, avec le HTTP/3 officiel dans beaucoup de
clients HTTP.
J'ai montré plus haut quelques essais avec curl. Pour avoir HTTP/3 avec curl, il faut actuellement quelques bricolages, HTTP/3 n'étant pas forcément compilé dans le curl que vous utilisez. Déjà, il faut utiliser un OpenSSL spécial, disponible ici. Sinon, vous aurez des erreurs à la compilation du genre :
openssl.c:309:7: warning: implicit declaration of function ‘SSL_provide_quic_data’ [-Wimplicit-function-declaration]
309 | if (SSL_provide_quic_data(ssl, from_ngtcp2_level(crypto_level), data,
| ^~~~~~~~~~~~~~~~~~~~~
ngtcp2 peut se compiler avec GnuTLS et pas le
OpenSSL spécial, mais curl ne l'accepte pas (configure:
error: --with-ngtcp2 was specified but could not find
ngtcp2_crypto_openssl pkg-config file.). Ensuite, il
faut les bibliothèques ngtcp2 et nghttp3. Une fois
celles-ci prêtes, vous configurez curl :
% ./configure --with-ngtcp2 --with-nghttp3 ... HTTP2: enabled (nghttp2) HTTP3: enabled (ngtcp2 + nghttp3) ...
Vérifiez bien que vous avez la ligne HTTP3
indiquant que HTTP3 est activé. De même, un curl
--version doit vous afficher HTTP3
dans les protocoles gérés. Vous pourrez enfin faire du HTTP/3 :
% curl -v --http3 https://quic.tech:8443 * Trying 45.77.96.66:8443... * Connect socket 5 over QUIC to 45.77.96.66:8443 * Connected to quic.tech () port 8443 (#0) * Using HTTP/3 Stream ID: 0 (easy handle 0x55879ffd4c40) > GET / HTTP/3 > Host: quic.tech:8443 > user-agent: curl/7.76.1 > accept: */* > * ngh3_stream_recv returns 0 bytes and EAGAIN * ngh3_stream_recv returns 0 bytes and EAGAIN * ngh3_stream_recv returns 0 bytes and EAGAIN < HTTP/3 200 < server: quiche < content-length: 462 < <!DOCTYPE html> <html> ...
Pour davantage de lecture sur HTTP/3 :
- La référence est bien sûr le livre libre et gratuit de Daniel Stenberg (l'auteur de curl), HTTP/3 explained. Il a une traduction en français. Le source du livre est en ligne.
- Rob Graham a fait un bon résumé de HTTP/3.
- Et on en trouve un autre sur le blog de Cloudflare.
- Et il y a une étude détaillée de Robin Marx.
- C'est en 2018 que HTTP/3 a reçu son nom, suite à cette annonce
Si vous utilisez Tor, notez que QUIC et HTTP/2 (j'ai bien dit HTTP/2, puisque Tor ne gère pas UDP et donc pas QUIC) peuvent mettre en cause la protection qu'assure Tor. Une analyse sommaire est disponible En gros, si QUIC, grâce à son chiffrement systématique, donne moins d'infos au réseau, il en fournit peut-être davantage au serveur.
Ah, sinon j'ai présenté HTTP/3
à ParisWeb et
les supports sont disponibles en parisweb2021-http3-bortzmeyer.pdf. Et Le blog de curl est désormais accessible
en HTTP/3. Voici d'autres parts quelques articles
intéressants annonçant la publication de HTTP/3 :
- Celui de Cloudflare, avec d'intéressantes statistiques sur l'utilisation des différentes versions de HTTP,
- Celui d'Akamai,
- Celui de Mark Nottingham.
L'article seul
RFC 9113: HTTP/2
Date de publication du RFC : Juin 2022
Auteur(s) du RFC : M. Thomson (Mozilla), C. Benfield (Apple)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 7 juin 2022
Le protocole HTTP, à la base des échanges sur le Web, a plusieurs versions, 1, 2 et 3. Toutes ont en commun la même sémantique, décrite dans le RFC 9110. Mais l'encodage sur le câble est différent. HTTP/2 a un encodage binaire et un transport spécifique (binaire, multiplexé, avec possibilité de push). Fini de déboguer des serveurs HTTP avec telnet. En échange, cette version promet d'être plus rapide, notamment en diminuant la latence lors des échanges. Ce RFC remplace l'ancienne norme HTTP/2 (RFC 7540), mais le protocole ne change pas, il s'agit surtout d'une réécriture pour suivre le nouveau cadre de normalisation, où un RFC générique, le RFC 9110 spécifie la sémantique de HTTP et où il y a un RFC spécifique par version.
La section 1 de notre RFC résume les motivations derrère cette version 2, et notamment les limites de HTTP/1.1, normalisé dans le RFC 9112 :
- Une seule requête au plus en attente sur une connexion TCP donnée. Cela veut dire que, si on a deux requêtes à envoyer au même serveur, et que l'une est lente et l'autre rapide, il faudra faire deux connexions TCP (la solution la plus courante), ou bien se résigner au risque que la lente bloque la rapide. (La section 9.3.2 du RFC 9112 permet d'envoyer la seconde requête tout de suite mais les réponses doivent être dans l'ordre des requêtes, donc pas moyen pour une requête rapide de doubler une lente.)
- Un encodage des en-têtes inefficace, trop bavard et trop redondant.
Au contraire, HTTP/2 n'utilise toujours qu'une seule connexion TCP, de longue durée (ce qui sera plus sympa pour le réseau). L'encodage étant entièrement binaire, le traitement par le récepteur est normalement plus rapide. Le RFC note toutefois que HTTP/2, qui dépend de TCP et n'utilise qu'une seule connexion TCP, ne résout pas le problème du head-of-line blocking. (Pour cela, il faudrait HTTP/3, normalisé dans le RFC 9114.)
La section 2 de notre RFC résume l'essentiel de ce qu'il faut
savoir sur HTTP/2. Il garde la sémantique générale de HTTP (donc,
par exemple, un GET de
/cetteressourcenexistepas fait un 404). La
norme HTTP/2 ne normalise que le transport des messages, pas les
messages ou leurs réponses (qui sont décrits par le RFC 9110). Notez que HTTP/2 s'appelait il y a très longtemps
SPDY (initialement lancé par
Google).
Avec HTTP/2, l'unité de base de la communication est la
trame (frame, et, dans
HTTP/2, vous pouvez oublier la définition traditionnelle qui en fait
l'équivalent du paquet, mais pour la couche 2). Chaque trame a un type et, par exemple,
les échanges HTTP traditionnels se feront avec simplement une trame
HEADERS en requête et une
DATA en réponse. Certains types sont
spécifiques aux nouvelles fonctions de HTTP/2, comme
SETTINGS ou
PUSH_PROMISE.
Les trames voyagent ensuite dans des ruisseaux
(streams), chaque ruisseau hébergeant un et un
seul échange requête/réponse. On crée donc un ruisseau à chaque fois
qu'on a un nouveau GET ou
POST à faire. Les petits ruisseaux sont ensuite
multiplexés dans une grande rivière, l'unique connexion TCP entre un
client HTTP et un serveur. Les ruisseaux ont des mécanismes de
contrôle du trafic (ils avaient aussi un mécanisme de prioritisation
entre eux, que notre RFC abandonne).
Les en-têtes sont comprimés, en favorisant le cas le plus courant, de manière à s'assurer, par exemple, que la plupart des requêtes HTTP tiennent dans un seul paquet de la taille des paquets Ethernet.
Bon, maintenant, les détails pratiques (le RFC fait 90
pages). D'abord, l'établissement de la connexion. HTTP/2 tourne
au-dessus de TCP. Comment on fait pour savoir si le serveur
accepte HTTP/2 ? C'est marqué dans l'URL ? Non, les URL sont les mêmes,
avec les plans http: et
https:. On utilise un nouveau port, succédant au 80 de HTTP ?
Non. Les ports sont les mêmes, 80 et 443. On regarde dans le
DNS ou ailleurs si
le serveur sait faire du HTTP/2 ? Pas encore, bien que le futur
type de données DNS HTTPS permettra cela. Aujourd'hui, les
méthodes pour savoir si le client doit tenter HTTP/2 sont :
- Une configuration explicite (comme l'option
--http2de curl dans les exemples plus loin), - L'en-tête
Alt-Svc:du RFC 7838, qui nécessite de tenter en HTTP/1 d'abord, - Si on fait du HTTPS et donc du TLS, on peut utiliser ALPN (RFC 7301), en indiquant l'identificateur
h2(HTTP/2 sur TLS). Le serveur, recevant l'extension ALPN avech2, saura ainsi qu'on fait du HTTP/2 et on pourra tout de suite commencer l'échange de trames HTTP/2. (h2est dans le registre IANA. Dans le RFC 7540, il y avait aussi unh2cdont l'usage est maintenant abandonné.) - L'en-tête
HTTP
Upgrade:qui était dans la section 6.7 du RFC 7230 est désormais abandonné.
Une fois qu'un client aura réussi à établir une connexion avec un serveur en HTTP/2, il sait que le serveur gère ce protocole. Il peut s'en souvenir, pour les futures connexions (mais attention, ce n'est pas une indication parfaite : un serveur peut abandonner HTTP/2, par exemple).
Maintenant, c'est parti, on s'envoie des trames (il y a d'abord
une préface, un nombre magique qui permet de
s'assurer que tout le monde comprend bien HTTP/2, mais je n'en
parlerai pas davantage). À quoi
ressemblent ces trames (section 4) ? Elles commencent par un en-tête
indiquant leur longueur, leur type (comme
SETTINGS, HEADERS,
DATA… cf. section 6), des options (comme
ACK qui sert aux trames de type
PING à distinguer requête et réponse) et
l'identificateur du ruisseau auquel la trame appartient (un nombre
sur 31 bits). Le format complet est en section 4.1.
Les en-têtes HTTP sont comprimés selon la méthode normalisée dans le RFC 7541.
Les ruisseaux (streams), maintenant. Ce sont donc des suites ordonnées de trames, bi-directionnelles, à l'intérieur d'une connexion HTTP/2. Une connexion peut comporter plusieurs ruisseaux, chacun identifié par un stream ID (un entier de quatre octets, pair si le ruisseau a été créé par le serveur et impair autrement). Les ruisseaux sont ouverts et fermés dynamiquement et leur durée de vie n'est donc pas celle de la connexion HTTP/2. Contrairement à TCP, il n'y a pas de « triple poignée de mains » : l'ouverture d'un ruisseau est unilatérale et peut donc se faire très vite (rappelez-vous que chaque échange HTTP requête/réponse nécessite un ruisseau qui lui est propre ; pour vraiment diminuer la latence, il faut que leur création soit rapide). Les identificateurs ne sont jamais réutilisés (si on tombe à cours, la seule solution est de fermer la connexion TCP et d'en ouvrir une autre).
Un mécanisme de contrôle du flot s'assure que les ruisseaux se
partagent pacifiquement la connexion. C'est donc une sorte de TCP
dans le TCP, réinventé pour les besoins de HTTP/2 (section 5.2 et
relire aussi le RFC 1323). Le récepteur
indique (dans une trame WINDOWS_UPDATE) combien
d'octets il est prêt à recevoir (64 Kio par défaut) et l'émetteur
s'arrête dès qu'il a rempli cette fenêtre d'envoi. (Plus exactement,
s'arrête d'envoyer des trames DATA : les
autres, les trames de contrôle, ne sont pas soumises au contrôle du
flot).
Comme si ce système des connexions dans les connexions n'était pas assez compliqué comme cela, il y a aussi des dépendances entre ruisseaux. Un ruisseau peut indiquer qu'il dépend d'un autre et, dans ce cas, les ressources seront allouées d'abord au ruisseau dont on dépend. Par exemple, le code JavaScript ne peut en général commencer à s'exécuter que quand toute la page est chargée, et on peut donc le demander dans un ruisseau dépendant de celle qui sert à charger la page. On peut dépendre d'un ruisseau dépendant, formant ainsi un arbre de dépendances.
Il peut bien sûr y avoir des erreurs dans la
communication. Certaines affectent toute la connexion, qui devra
être abandonnée, mais d'autres ne concernent qu'un seul
ruisseau. Dans le premier cas, celui qui détecte l'erreur envoie une
trame GOAWAY (dont on ne peut pas garantir
qu'elle sera reçue, puisqu'il y a une erreur) puis coupe la
connexion TCP. Dans le second cas, si le problème ne concerne qu'un
seul ruisseau, on envoie la trame RST_STREAM
qui arrête le traitement du ruisseau.
HTTP/2 avait (RFC 7540, section 5.3) un mécanisme de priorité entre trames, qui permettait d'éviter, par exemple, que la récupération d'une grosse image ne ralentisse le chargement d'une feuille de style. Mais il était trop complexe, et a été peu mis en œuvre, la plupart des serveurs ignoraient les demandes de priorité des clients. Un nouveau mécanisme est décrit dans le RFC 9218.
Notre section 5 se termine avec des règles qui indiquent comment gérer des choses inconnues dans le dialogue. Ces règles permettent d'étendre HTTP/2, en s'assurant que les vieilles mises en œuvre ne pousseront pas des hurlements devant les nouveaux éléments qui circulent. Par exemple, les trames d'un type inconnu doivent être ignorées et mises à la poubelle directement, sans protestation.
On a déjà parlé plusieurs fois des trames, la section 6 du RFC détaille leur définition. Ce sont aux ruisseaux ce que les paquets sont à IP et les segments à TCP. Les trames ont un type (un entier d'un octet). Les types possibles sont enregistrés à l'IANA. Les principaux types actuels sont :
DATA(type 0), les trames les plus nombreuses, celles qui portent les données, comme les pages HTML (elles peuvent aussi contenir du remplissage, pour éviter qu'un observateur ne déduise de la taille des réponses la page qu'on regardait, cf. section 10.7),HEADERS(type 1), qui portent les en-têtes HTTP, dûment comprimés selon le RFC 7541,PRIORITY(type 2) indiquait la priorité que l'émetteur donne au ruisseau qui porte cette trame, mais ce type de trame n'est désormais plus utilisé,RST_STREAM(type 3), dont j'ai parlé plus haut à propos des erreurs, permet de terminer un ruisseau (filant la métaphore, on pourrait dire que cela assèche le ruisseau ?),SETTINGS(type 4), permet d'envoyer des paramètres, commeSETTINGS_HEADER_TABLE_SIZE, la taille de la table utilisée pour la compression des en-têtes,SETTINGS_MAX_CONCURRENT_STREAMSpour indiquer combien de ruisseaux est-on prêt à gérer, etc (la liste des paramètres est dans un registre IANA),PUSH_PROMISE(type 5) qui indique qu'on va transmettre des données non sollicitées (push), du moins si le paramètreSETTINGS_ENABLE_PUSHest à 1,PING(type 6) qui permet de tester le ruisseau (le partenaire va répondre avec une autre tramePING, ayant l'optionACKà 1),GOAWAY(type 7) que nous avons déjà vu plus haut, sert à mettre fin proprement (le pair est informé de ce qui va se passer) à une connexion,WINDOW_UPDATE(type 8) sert à faire varier la taille de la fenêtre (le nombre d'octets qu'on peut encore accepter, cf. section 6.9.1),CONTINUATION(type 9), indique la suite d'une trame précédente. Cela n'a de sens que pour certains types commeHEADERS(ils peuvent ne pas tenir dans une seule trame) ouCONTINUATIONlui-même. Mais une trameCONTINUATIONne peut pas être précédée deDATAou dePING, par exemple.
Dans le cas vu plus haut d'erreur entrainant la fin d'un ruisseau
ou d'une connexion entière, il est nécessaire d'indiquer à son
partenaire en quoi consistait l'erreur en question. C'est le rôle
des codes d'erreur de la section 7. Stockés sur quatre octets (et
enregistrés dans un
registre IANA), ils sont transportés par les trames
RST_STREAM ou GOAWAY qui
terminent, respectivement, ruisseaux et connexions. Parmi ces
codes :
NO_ERROR(code 0), pour les cas de terminaison normale,PROTOCOL_ERROR(code 1) pour ceux où le pair a violé une des règles de HTTP/2, par exemple en envoyant une trameCONTINUATIONqui n'était pas précédée deHEADERS,PUSH_PROMISEouCONTINUATION,INTERNAL_ERROR(code 2), un malheur est arrivé,ENHANCE_YOUR_CALM(code 11), qui ravira les amateurs de spam et de Viagra, demande au partenaire en face de se calmer un peu, et d'envoyer moins de requêtes.
Toute cette histoire de ruisseaux, de trames, d'en-têtes
comprimés et autres choses qui n'existaient pas en HTTP/1 est bien
jolie mais HTTP/2 n'a pas été conçu comme un remplacement de TCP,
mais comme un moyen de faire passer des dialogues HTTP. Comment met-on
les traditionnelles requêtes/réponses HTTP sur une connexion
HTTP/2 ? La section 8 répond à cette question. D'abord, il faut se
rappeler que HTTP/2 est du HTTP. La sémantique est donc celle du
RFC 9110. Il y a quelques différences comme le
fait que certains en-têtes disparaissent, par exemple
Connection: (section 8.2.2) qui n'est plus
utile en HTTP/2 ou Upgrade: (section 8.6).
HTTP est requête/réponse. Pour envoyer une requête, on utilise un
nouveau ruisseau (envoi d'une trame avec un numéro de ruisseau non
utilisé), sur laquelle on lira la réponse (les ruisseaux ne sont pas
persistents). Dans le cas le plus fréquent, la requête sera composée
d'une trame HEADERS contenant les en-têtes
(comme User-Agent: ou
Host:, cf. RFC 9110,
section 10.1) et les « pseudo-en-têtes » comme la méthode
(GET, POST, etc), avec
parfois des trames DATA (cas d'un
POST). La réponse comprendra une trame
HEADERS avec les en-têtes (comme
Content-Length:) et les pseudo-en-têtes comme
le code de retour HTTP (200, 403, 500, etc) suivie de plusieurs
trames DATA contenant les données (HTML, CSS, images,
etc). Des variantes sont possibles (par exemple, les trames
HEADERS peuvent être suivies de trames
CONTINUATION). Les en-têtes ne sont pas
transportés sous forme texte (ce qui était le cas en HTTP/1, où on
pouvait utiliser telnet comme client HTTP)
mais encodés en binaire, et comprimés selon
le RFC 7541. À noter que cet encodage implique
une mise du nom de l'en-tête en minuscules.
J'ai parlé plus haut des pseudo-en-têtes : c'est le mécanisme
HTTP/2 pour traiter des informations qui ne sont pas des en-têtes
en HTTP (section 8.3). Ces informations sont mises dans les
HEADERS HTTP/2, précédés d'un
deux-points. C'est le cas de la méthode (RFC 9110, section 9.3), donc GET
sera encodé :method GET. L'URL sera éclaté dans
les pseudo-en-têtes :scheme,
:path, etc. Idem pour la réponse HTTP, le
fameux code à trois lettres est désormais un pseudo-en-tête,
:status.
Le RFC met en garde les programmeur·ses : certains caractères peuvent être dangereux car profitant des faiblesses de certains analyseurs ou bien utilisant le fait que HTTP n'est pas toujours de bout en bout et qu'un message peut être traduit de HTTP/1 en HTTP/2 (ou réciproquement). Un deux-points dans le nom d'un champ, par exemple, pourrait produire un message dont l'interprétation ne serait pas celle attendue (ce qu'on nomme le request smuggling).
Voici des exemples de requêtes HTTP (mais vous ne le verrez pas ainsi si vous espionnez le réseau, en raison de la compression du RFC 7541) :
### HTTP/1, pas de corps dans la requête ### GET /resource HTTP/1.1 Host: example.org Accept: image/jpeg ### HTTP/2 (une trame HEADERS) :method = GET :scheme = https :path = /resource host = example.org accept = image/jpeg
Puis une réponse qui n'a pas de corps :
### HTTP/1 ### HTTP/1.1 304 Not Modified ETag: "xyzzy" Expires: Thu, 23 Jan ... ### HTTP/2, une trame HEADERS ### :status = 304 etag = "xyzzy" expires = Thu, 23 Jan ...
Une réponse plus traditionnelle, qui inclut un corps :
### HTTP/1 ###
HTTP/1.1 200 OK
Content-Type: image/jpeg
Content-Length: 123
{binary data}
### HTTP/2 ###
# trame HEADERS
:status = 200
content-type = image/jpeg
content-length = 123
# trame DATA
{binary data}
Plus compliqué, un cas où les en-têtes de la requête ont été mis dans deux trames, et où il y avait un corps dans la requête :
### HTTP/1 ###
POST /resource HTTP/1.1
Host: example.org
Content-Type: image/jpeg
Content-Length: 123
{binary data}
### HTTP/2 ###
# trame HEADERS
:method = POST
:path = /resource
:scheme = https
# trame CONTINUATION
content-type = image/jpeg
host = example.org
content-length = 123
# trame DATA
{binary data}
Nouveauté introduite par HTTP/2, la possibilité pour le serveur
de pousser (push, section 8.4 de notre RFC) du
contenu non sollicité vers le client (sauf si cette possibilité a
été coupée par le paramètre
SETTINGS_ENABLE_PUSH). Pour cela, le serveur
(et lui seul) envoie une trame de type
PUSH_PROMISE au client, en utilisant le
ruisseau où le client avait fait une demande originale (donc, la
sémantique de PUSH_PROMISE est « je te promets
que lorsque le moment sera venu, je répondrai plus longuement à ta
question »). Cette trame contient une requête HTTP. Plus tard,
lorsque le temps sera venu, le serveur tiendra sa promesse en
envoyant la « réponse » de cette « requête » sur le ruisseau qu'il
avait indiqué dans le PUSH_PROMISE.
Et enfin, à propos des méthodes HTTP/1 et de leur équivalent en
HTTP/2, est-ce que CONNECT (RFC 9110, section 9.3.6) fonctionne toujours ? Oui, on peut
l'utiliser pour un tunnel sur un
ruisseau. (Un tunnel sur un ruisseau... Beau défi pour le
génie civil.)
La section 9 de notre RFC rassemble quelques points divers. Elle rappelle que, contrairement à HTTP/1, toutes les connexions sont persistentes et que le client n'est pas censé les fermer avant d'être certain qu'il n'en a plus besoin. Tout doit passer à travers une connexion vers le serveur et les clients ne doivent plus utiliser le truc d'ouvrir plusieurs connexions HTTP avec le serveur. De même, le serveur laisse les connexions ouvertes le plus longtemps possible, mais a le droit de les fermer s'il doit économiser des ressources.
À noter qu'on peut utiliser une connexion prévue pour un autre
nom, du moment que cela arrive au même serveur (même adresse IP). Le
pseudo-en-tête :authority sert à départager les
requêtes allant à chacun des serveurs. Mais attention si la session
utilise TLS !
L'utilisation d'une connexion avec un autre
:authority (host + port)
n'est possible que si le certificat serveur qui a été utilisé est
valable pour tous (par le biais des
subjectAltName, ou bien d'un joker).
À propos de TLS, la section
9.2 prévoit quelques règles qui n'existaient pas en HTTP/1 (et dont
la violation peut entrainer la coupure de la connexion avec l'erreur
INADEQUATE_SECURITY) :
- TLS 1.2 (RFC 5246), minimum,
- Gestion de SNI (RFC 6066) obligatoire,
- Compression coupée (RFC 3749), comme indiqué dans le RFC 7525 (permettre la compression de données qui mêlent informations d'authentification comme les cookies, et données contrôlées par l'attaquant, permet certaines attaques comme BREACH) ce qui n'est pas grave puisque HTTP a de meilleures capacités de compression (voir aussi la section 10.6),
- Renégociation coupée, ce qui empêche de faire une renégociation en réponse à une certaine requête (pas de solution dans ce cas) et peut conduire à couper une connexion si le mécanisme de chiffrement sous-jacent ne permet pas d'encoder plus de N octets sans commencer à faire fuiter de l'information.
- Très sérieuse limitation du nombre d'algorithmes de chiffrement acceptés (voir l'annexe A pour une liste complète), en éliminant les algorithmes trop faibles cryptographiquement (comme les algorithmes « d'exportation » utilisés dans la faille FREAK). Peu d'algorithmes restent utilisables après avoir retiré cette liste !
Puisqu'on parle de sécurité, la section 10 traite un certain nombre de problèmes de sécurité de HTTP/2. Elle rappelle que TLS est fortement recommandé (mais il n'est devenu obligatoire qu'avec HTTP/3, HTTP/2 permettant toutefois une utilisation « opportuniste », cf. RFC 8164). Parmi les problèmes qui sont spécifiques à HTTP/2, on note que ce protocole demande plus de ressources que HTTP/1, ne serait-ce que parce qu'il faut maintenir un état pour la compression. Il y a donc potentiellement un risque d'attaque par déni de service. Une mise en œuvre prudente veillera donc à limiter les ressources allouées à chaque connexion.
Enfin, il y a la question de la vie privée, un sujet chaud dans le monde HTTP depuis longtemps. Les options spécifiques à HTTP/2 (changement de paramètres, gestion du contrôle de flot, traitement des innombrables variantes du protocole) peuvent permettre d'identifier une machine donnée par son comportement. HTTP/2 facilite donc le fingerprinting.
En outre, comme une seule connexion TCP est utilisée pour toute une visite sur un site donné, cela peut rendre explicite une information comme « le temps passé sur un site », information qui était implicite en HTTP/1, et qui devait être reconstruite.
Comme on le voit, HTTP/2 est bien plus complexe que HTTP/1. On ne peut pas espérer programmer un client ou un serveur en quelques heures, comme on le fait avec HTTP/1. C'est en partie pour cela que personne ne prévoit un abandon de HTTP/1, qui continuera à coexister avec HTTP/2 (et HTTP/3 !) pendant très longtemps encore.
Question mises en œuvre, HTTP/2 est désormais présent dans la quasi-totalité des clients, serveurs et bibliothèques HTTP. Ici, avec curl, en forçant l'utilisation de HTTP/2 dès le début :
% curl -v --http2 https://www.bortzmeyer.org/7540.html * Trying 2001:4b98:dc0:41:216:3eff:fe27:3d3f:443... * Connected to www.bortzmeyer.org (2001:4b98:dc0:41:216:3eff:fe27:3d3f) port 443 (#0) * ALPN, offering h2 * ALPN, offering http/1.1 ... * ALPN, server accepted to use h2 * Server certificate: * subject: CN=www.bortzmeyer.org ... * Using HTTP2, server supports multiplexing * Copying HTTP/2 data in stream buffer to connection buffer after upgrade: len=0 * h2h3 [:method: GET] * h2h3 [:path: /7540.html] * h2h3 [:scheme: https] * h2h3 [:authority: www.bortzmeyer.org] * h2h3 [user-agent: curl/7.82.0] * h2h3 [accept: */*] * Using Stream ID: 1 (easy handle 0x5639a5d10cf0) > GET /7540.html HTTP/2 > Host: www.bortzmeyer.org > user-agent: curl/7.82.0 > accept: */* ... < HTTP/2 200 ... < etag: "b4b0-5de09d5830d11" < content-type: text/html; charset=UTF-8 < date: Thu, 05 May 2022 13:07:08 GMT < server: Apache/2.4.53 (Debian) < <?xml version="1.0" ?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xml:lang="fr" lang="fr" xmlns="http://www.w3.org/1999/xhtml"> <head> ...
Vous voulez voir un joli pcap de HTTP/2 ? La plupart des sites accessibles en HTTP/2 (et parfois des clients) imposent TLS. Il faut donc, si on veut voir « à l'intérieur » des paquets, utiliser la technique classique d'exportation de la clé :
% export SSLKEYLOGFILE=/tmp/http2.key % curl --http2 https://www.bortzmeyer.org/7540.html
Puis vérifiez que dans les préférences de
Wireshark, on a cette clé (par exemple dans
~/.config/wireshark/preferences, une ligne
tls.keylog_file: /tmp/http2.key). On peut alors
regarder le pcap en détail. Voici un tel
pcap et la clé
correspondante. Cela permet de regarder le contenu des
messages avec Wireshark :
Cela permet aussi, avec une commande comme
tshark -V -r http2.pcap > http2.txt, de
produire un joli fichier
d'analyse. Notez les identificateurs de ruisseaux
(Stream ID) : il n'y en a que deux, 0 et 1, car
on n'a chargé qu'une ressource (il y a un ruisseau dans chaque direction). Je
vous laisse faire vous-même l'opération pour le cas de deux
ressources, avec une commande comme curl -v --http2
https://www.bortzmeyer.org/7540.html
https://www.bortzmeyer.org/9116.html. Vous verrez alors
le parallélisme de HTTP/2 et les multiples ruisseaux.
Et, sinon, si vous voulez activer HTTP/2 sur un serveur
Apache, c'est aussi
simple que de charger le module http2 et de
configurer :
Protocols h2 http/1.1
Sur Debian, la commande a2enmod
http2 fait tout cela automatiquement. Pour vérifier que
cela a bien été fait, vous pouvez utiliser curl
-v comme vu plus haut, ou bien un site de test (comme
KeyCDN) ou
encore la fonction Inspect element (clic droit
sur la page, puis onglet Network puis
sélectionner une des ressources chargées) de Firefox :
L'annexe B liste les principaux changements depuis le RFC 7540, notamment :
- L'abandon du mécanisme de priorité entre ruisseaux, trop complexe, remplacé par celui du RFC 9218.
- L'abandon de l'utilisation de
Upgrade:pour passer de HTTP/1 en HTTP/2, - Obligation plus strictes de valider la syntaxe des en-têtes,
- Meilleure description des en-têtes spécifiques à la gestion de la connexion, et qui ne doivent plus être utilisés,
- Et bien sûr un certain nombre de changements pour s'aligner avec le nouveau cadre générique du RFC 9110 et notamment sa terminologie.
Et, sinon, si vous voulez vous instruire sur HTTP/2 sans lire tout le RFC, il y a évidemment le livre de Daniel Stenberg.
L'article seul
RFC 9112: HTTP/1.1
Date de publication du RFC : Juin 2022
Auteur(s) du RFC : R. Fielding (Adobe), M. Nottingham (Fastly), J. Reschke (greenbytes)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 7 juin 2022
Ce nouveau RFC normalise HTTP/1.1, la plus ancienne version de HTTP encore en service. Il décrit les détails de comment les messages sont représentés sur le réseau, la sémantique de haut niveau étant désormais dans un document séparé, le RFC 9110. Ensemble, ces deux RFC remplacent le RFC 7230.
HTTP est certainement le protocole Internet le plus connu. Il en existe plusieurs versions, ayant toutes en commun la sémantique normalisée dans le RFC 9110. Les versions les plus récentes, HTTP/2 et HTTP/3 sont loin d'avoir remplacé la version 1, plus précisément 1.1, objet de notre RFC et toujours largement répandue. Un serveur HTTP actuel doit donc gérer au moins cette version. (Par exemple, en octobre 2021, les ramasseurs de Google et Baidu utilisaient toujours exclusivement HTTP/1.1.)
Un des avantages de HTTP/1, et qui explique sa longévité, est que c'est un protocole simple, fondé sur du texte et qu'il est donc relativement facile d'écrire clients et serveurs. D'ailleurs, pour illustrer cet article, je vais prendre exemple sur un simple serveur HTTP/1 que j'ai écrit (le code source complet est disponible ici). Le serveur ne gère que HTTP/1 (les autres versions sont plus complexes) et ne vise pas l'utilisation en production : c'est une simple démonstration. Il est écrit en Elixir. Bien sûr, Elixir, comme tous les langages de programmation sérieux, dispose de bibliothèques pour créer des serveurs HTTP (notamment Cowboy). Le programme que j'ai écrit ne vise pas à les concurrencer : si on veut un serveur HTTP pour Elixir, Cowboy est un bien meilleur choix ! C'est en référence à Cowboy que mon modeste serveur se nomme Indian.
Commençons par le commencement, la section 1 de notre RFC rappelle les bases de HTTP (décrites plus en détail dans le RFC 9110).
La section 2 attaque ce qui est spécifique à la version 1 de
HTTP. Avec les URL de plan http:, on
commence par établir une connexion TCP avec le serveur. Ensuite, un
message en HTTP/1 commence par une ligne de démarrage, suivie d'un
CRLF (fin de ligne sous la forme des deux octets Carriage
Return et Line Feed), d'une série
d'en-têtes ressemblant à celui de l'IMF du
RFC 5322 (par exemple Accept:
text/*), d'une ligne vide et peut-être d'un corps du
message. Les requêtes du client au serveur et les réponses du
serveur au client sont toutes les deux des messages, la seule
différence étant que, pour la requête, la ligne de démarrage est une
ligne de requête et, pour la réponse, c'est une ligne d'état. (Le
RFC note qu'on pourrait réaliser un logiciel HTTP qui soit à la fois
serveur et client, distinguant requêtes et réponses d'après les
formats distincts de ces deux lignes. En pratique, personne ne
semble l'avoir fait.)
Pour une première démonstration de HTTP, on va utiliser le module http.server du langage Python, qui permet d'avoir un serveur HTTP opérationnel facilement :
% python3 -m http.server Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ...
Hop, nous avons un serveur HTTP qui tourne sur le
port 8000. On va utiliser
curl et son option -v,
qui permet de voir le dialogue (le > indique ce qu'envoie curl,
le < ce qu'il reçoit du serveur en Python) :
% curl -v http://localhost:8000/
> GET / HTTP/1.1
> Host: localhost:8000
> User-Agent: curl/7.68.0
> Accept: */*
>
< HTTP/1.0 200 OK
< Server: SimpleHTTP/0.6 Python/3.8.10
< Date: Thu, 06 Jan 2022 17:24:13 GMT
< Content-type: text/html; charset=utf-8
< Content-Length: 660
<
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
<html>
<head>
...
La ligne qui commence par GET est la ligne de
démarrage, ici une requête, curl a envoyé trois lignes d'en-tête. La
ligne qui commence par HTTP/1.0 est la ligne de
démarrage de la réponse, et elle est suivie par quatre lignes
d'en-tête. La requête n'avait pas de corps, mais la réponse en a un
(il commence par <!DOCTYPE HTML PUBLIC), ici
au format HTML. En dépit du H de son nom, HTTP n'a pas
grand'chose de spécifiquement lié à
l'hypertexte, et peut être utilisé pour tout
type de données (le serveur Indian ne renvoie que du texte
brut).
Pour le corps des messages, HTTP utilise certains concepts de MIME (RFC 2045). Mais HTTP n'est pas MIME : l'annexe B détaille les différences.
Le client est censé lire la réponse, commençant par la ligne
d'état, puis tout l'en-tête jusqu'à une ligne vide, puis le corps,
dont la taille est indiquée par le champ
Content-Length:, ici 660 octets. (Sans ce
champ, le client va lire jusqu'à la fin de la connexion TCP sous-jacente.)
Notez qu'Indian ne fait pas cela bien : il fait une seule opération
de lecture et analyse ensuite le résultat (alors qu'il faudra
peut-être plusieurs opérations, et que, si on utilise les connexions
persistentes, on ne peut découvrir la fin du corps que si on tient
compte de Content-Length:, ou des délimiteurs
de Transfer-Encxoding: chunked). Ce choix a été
fait pour simplifier l'analyse syntaxique
(qui devrait normalement être incrémentale,
contrairement à ce que fait Indian, mais la bibliothèque
utilisée ne le permet pas, contrairement à, par exemple tree-sitter). Rappelez-vous que
ce n'est qu'un programme de démonstration.
Quand la réponse est du texte, le client ne doit pas supposer un encodage particulier, il doit lire des octets, quitte à les convertir dans des concepts de plus haut niveau (comme les caractères) plus tard.
Notez tout de suite qu'on trouve de tout dans le monde HTTP, et que beaucoup de clients et de serveurs ne suivent pas forcément rigoureusement la norme dans ses moindres détails. En général, Indian est plutôt strict et colle à la norme, sauf dans les cas où il était absolument nécessaire d'être plus tolérant pour pouvoir être testé avec les clients que j'ai utilisé. Comme souvent sur l'Internet, ces déviations par rapport à la norme permettent des attaques rigolotes comme le request smuggling (section 11.2 du RFC) ou le response splitting (section 11.1).
La réponse du serveur indique un numéro de version, sous la forme de deux chiffres séparés par un point. Ce RFC spécifie la version 1.1 de HTTP (Indian peut aussi gérer la version 1.0).
Commençons par la requête (section 3 du RFC). Elle commence par
une ligne qui comprend la méthode, le chemin et la version de
HTTP. Elles sont séparées par un espace. Pour analyser les requêtes,
Indian utilise la combinaison
d'analyseurs syntaxiques avec NimbleParsec, l'analyseur de la
requête est donc : method |> ignore(string(" ")) |>
concat(path) |> ignore(string(" ")) |>
concat(version). (La norme ne prévoit qu'un seul espace,
autrement, on aurait pu prévoir une répétition de string("
"). Le RFC suggère que cette version plus laxiste est
acceptable mais peut être dangereuse.) La méthode indique ce
que le client veut faire à la ressource désignée. La plus connue des
méthodes est
GET (récupérer la ressource) mais il en existe
d'autres, et la
liste peut changer. Indian ne met donc pas un choix limitatif
mais accepte tout nom de méthode (method =
ascii_string([not: ?\ ], min: 1)), quitte à vérifier plus
tard. La ressource sur laquelle le client veut agir est indiquée par
un chemin (ou, dans certains cas par l'URL complet). Ainsi, un client qui
veut récupérer
http://www.example.org/truc?machin va envoyer
au serveur au moins :
GET /truc?machin HTTP/1.1 Host: www.example.org
Il existe d'autres formes pour la requête mais je ne les présente pas ici (lisez le RFC).
La première ligne de la requête est suivie de l'en-tête, composée
de plusieurs champs (cf. section 5). Voici la requête que génère
wget pour récupérer
https://cis.cnrs.fr/a-travers-les-infrastructures-c-est-la-souverainete-numerique-des-etats-qui-se-joue/ :
% wget -d https://cis.cnrs.fr/a-travers-les-infrastructures-c-est-la-souverainete-numerique-des-etats-qui-se-joue/ ... GET /a-travers-les-infrastructures-c-est-la-souverainete-numerique-des-etats-qui-se-joue/ HTTP/1.1 User-Agent: Wget/1.20.3 (linux-gnu) Accept: */* Accept-Encoding: identity Host: cis.cnrs.fr Connection: Keep-Alive
Une particularité souvent oubliée de HTTP est qu'il n'y a pas de limite de taille à la plupart des éléments du protocole. Les programmeurs se demandent souvent « quelle place dois-je réserver pour tel élément ? » et la réponse est souvent qu'il n'y a pas de limite, juste des indications. Par exemple, notre RFC dit juste qu'il faut accepter des lignes de requête de 8 000 octets au moins.
Le serveur répond avec une ligne d'état et un autre en-tête (section 4). La ligne d'état comprend la version de HTTP, un code de retour formé de trois chiffres, et un message facultatif (là encore, avec un espace comme séparateur). Voici par exemple la réponse d'Indian :
HTTP/1.1 200 Content-Type: text/plain Content-Length: 18 Server: myBeautifulServerWrittenInElixir
Le message est d'autant plus facultatif (Indian n'en met pas) qu'il n'est pas forcément dans la langue du destinataire et qu'il n'est pas structuré, donc pas analysable. Le RFC recommande de l'ignorer.
Beaucoup plus important est le code de retour. Ces trois chiffres indiquent si tout s'est bien passé ou pas. Ils sont décrits en détail dans le RFC 9110, section 15. Bien qu'il s'agisse normalement d'éléments de protocole, certains sont bien connus des utilisatrices et utilisateurs, comme le célèbre 404. Et ils ont une représentation en chats et on a proposé de les remplacer par des émojis.
L'en-tête, maintenant (section 5 du RFC). Il se compose de
plusieurs lignes, chacune comportant le nom du champ, un
deux-points (pas d'espace avant ce
deux-points, insiste le RFC), puis la valeur du champ. Cela
s'analyse dans Indian avec header_line = header_name |>
ignore(string(":")) |> ignore(repeat(string(" "))) |>
concat(header_value) |> ignore(eol). Les noms de champs
possibles sont dans un
registre IANA (on peut noter qu'avant ce RFC, ils étaient
mêlés aux champs du courrier électronique dans un même registre).
Après les en-têtes, le corps. Il est en général absent des
requêtes faites avec la méthode GET mais il est
souvent présent pour les autres méthodes, et il est en général dans
les réponses. Ici, une réponse d'un serveur avec le corps en
JSON :
% curl -v https://atlas.ripe.net/api/v2/measurements/34762605/results/
...
< HTTP/1.1 200 OK
< Server: nginx
< Date: Tue, 11 Jan 2022 20:19:31 GMT
< Content-Type: application/json
< Transfer-Encoding: chunked
...
[{"fw":5020,"mver":"2.2.0","lts":4,"resultset":[{"time":1641657433,"lts":4,"subid":1,"submax":1,"dst_addr":"127.0.0.1","dst_port":"53","af":4,"src_addr":"127.0.0.1","proto":"UDP","result":{"rt":487.455,"size":127,"abuf":"9+SBgAABA ...
Le champ Content-Length: est normalement
obligatoire dans la réponse, sauf s'il y a un champ
Transfer-Encoding:, comme ici. Il permet au
client de gérer sa mémoire, et de savoir s'il a bien tout
récupéré. (Avec TLS, si on reçoit un signal de fin de
l'application, on sait qu'on a toute les données mais, sans TLS, on
ne pourrait pas être sûr, s'il n'y avait ce
Content-Length:.)
HTTP/1.1 est un protocole simple (quoiqu'il y ait un certain nombre de pièges pour une mise en œuvre réelle) et on peut donc se contenter de telnet comme client HTTP :
% telnet evil.com 80 Trying 66.96.146.129... Connected to evil.com. Escape character is '^]'. GET / HTTP/1.1 Host: evil.com HTTP/1.1 200 OK Date: Sun, 16 Jan 2022 11:31:05 GMT Content-Type: text/html Content-Length: 4166 Connection: keep-alive Server: Apache/2 Last-Modified: Sat, 15 Jan 2022 23:21:33 GMT Accept-Ranges: bytes Cache-Control: max-age=3600 Etag: "1046-5d5a72e24309e" Expires: Sun, 16 Jan 2022 12:14:45 GMT Age: 980 <HTML> <HEAD> <meta content="Microsoft FrontPage 6.0" name="GENERATOR"> <meta content="FrontPage.Editor.Document" name="ProgId">
Les lignes GET / HTTP/1.1 et Host:
evil.com ont été tapées à la main, une fois telnet
connecté. HTTP/1.1 (contrairement aux versions 2 et 3) fait partie
de ces protocoles en texte, qu'on peut déboguer à la main avec
telnet.
En plus perfectionné que telnet, il y a netcat :
% echo -n "GET /hello HTTP/1.1\r\nConnection: close\r\n\r\n" | nc ip6-localhost 8080 HTTP/1.1 200 Content-Type: text/plain Content-Length: 12 Server: myBeautifulServerWrittenInElixir Hello, ::1!
On a dit plus haut que HTTP/1.1 fonctionnait au-dessus d'une connexion TCP. La section 9 de notre RFC décrit la gestion de cette connexion. (En HTTP 0.9, c'était simple, une transaction = une connexion, mais ça a changé avec HTTP 1.) HTTP n'a pas forcément besoin de TCP (d'ailleurs, HTTP/3 fonctionne sur QUIC), il lui faut juste une liaison fiable faisant passer les octets dans l'ordre et sans perte. Dans HTTP/1.1, c'est TCP qui fournit ce service. (Avec TLS si on fait du HTTPS.) L'établissement d'une connexion TCP prend du temps, et la latence est un des plus gros ennemis de HTTP. Il est donc recommandé de ne pas établir une connexion TCP par transaction HTTP, mais de réutiliser les connexions. Le problème est délicat car le serveur peut avoir envie de supprimer des connexions pour récupérer des ressources. Clients et serveurs doivent donc s'attendre à des comportements variés de la part de leur partenaire.
HTTP/1 n'a pas d'identificateur de requête (comme
a, par exemple, le DNS). Les transactions doivent donc se faire
dans l'ordre : si on envoie une requête A puis une requête B sur la
même connexion TCP, on recevra forcément la réponse A puis la
B. (HTTP/2 et encore plus HTTP/3 ont par contre une certaine dose de
parallélisme.) Les connexions sont persistentes par défaut dans
HTTP/1.1 (ce n'était pas le cas en HTTP/1.0) et des champs de
l'en-tête servent à contrôler cette persistence
(Connection: close indique qu'on ne gardera pas
la connexion ouverte, et un client poli qui ne fait qu'une requête
doit envoyer ce champ). Dans le code source d'Indian, les accès à
context["persistent-connection"] vous
montreront la gestion de connexion.
Si le client et le serveur gère les connexions persistentes, le client peut aussi envoyer plusieurs requêtes à la suite, sans attendre les réponses (ce qu'on nomme le pipelining). Les réponses doivent parvenir dans le même ordre (puisqu'il n'y a pas d'identificateur de requête, qui permettrait de les associer à une requête), donc HTTP/1.1 ne permet pas un vrai parallélisme.
Pour économiser les ressources du serveur, un client ne devrait pas ouvrir « trop » de connexions vers un même serveur. (Le RFC 2616, section 8.1.4, mettait une limite de 2 connexions mais cette règle a disparu par la suite.)
Jusqu'à présent, on a parlé de HTTP tournant directement sur
TCP. Mais cela fait passer toutes les données en clair, ce qui est
inacceptable du point de vue sécurité, dans un monde de surveillance
massive. Aujourd'hui, la grande majorité des connexions HTTP passent
sur TLS, un
mécanisme cryptographique qui assure
notamment la confidentialité et
l'authentification du serveur. HTTPS (HTTP
sur TLS) était autrefois normalisé dans le RFC 2818 mais qui a désormais été abandonné au profit du RFC 9110 et de notre RFC 9112. Le principe
pour HTTP/1.1 est simple : une fois la connexion TCP établie, le
client HTTP démarre une session TLS (RFC 9846)
par dessus et voilà. (L'ALPN à utiliser est
http/1.1.) Lors de la fermeture de la connexion, TLS envoie normalement
un message qui permet de différencier les coupures volontaires et
les pannes (close_notify, RFC 9846, section 6.1). (Indian ne gère pas TLS, si on veut
le sécuriser - mais ce n'est qu'un programme de démonstration, il
faut le faire tourner derrière stunnel ou
équivalent.)
Pour tester HTTPS à la main, on peut utiliser un programme
distribué avec GnuTLS, ici pour récupérer https://fr.wikipedia.org/wiki/Hunga_Tonga :
% gnutls-cli fr.wikipedia.org
...
Connecting to '2620:0:862:ed1a::1:443'...
- subject `CN=*.wikipedia.org,O=Wikimedia Foundation\, Inc.,L=San Francisco,ST=California,C=US', issuer `CN=DigiCert ...
...
- Simple Client Mode:
GET /wiki/Hunga_Tonga HTTP/1.1
Host: fr.wikipedia.org
Connection: close
HTTP/1.1 200 OK
Date: Sun, 16 Jan 2022 20:41:56 GMT
Content-Type: text/html; charset=UTF-8
Content-Length: 79568
...
<!DOCTYPE html>
<html class="client-nojs" lang="fr" dir="ltr">
<head>
<meta charset="UTF-8"/>
<title>Hunga Tonga — Wikipédia</title>
...
Les trois lignes commençant par GET ont été
tapées à la main par l'utilisateur.
La section 10 de notre RFC traite d'une fonction plus rare :
l'inclusion d'un message HTTP comme donnée d'un protocole (qui peut
être HTTP ou un autre). Un tel message est étiqueté avec le
type MIME application/http.
Quelques mots sur la sécurité pour finir (section 11) : en raison de la complexité du protocole (qui est moins simple qu'il n'en a l'air !) et des mauvaises mises en œuvre qu'il faut quand même gérer car elles sont largement présentes sur le Web, deux programmes peuvent interpréter la même session HTTP différemment. Cela permet par exemple l'attaque de response splitting (cf. l'article de Klein « Divide and Conquer - HTTP Response Splitting, Web Cache Poisoning Attacks, and Related Topics »). Autre attaque possible, le request smuggling (cf. l'article de Linhart, Klein, Heled et Orrin, « HTTP Request Smuggling »).
Notre section 11 rappelle aussi que HTTP tout seul ne fournit pas de mécanisme pour assurer l'intégrité et la confidentialité des communications. Il dépend pour cela d'un protocole sous-jacent, en pratique TLS (HTTP+TLS étant appelé HTTPS).
L'annexe C décrit les changements de HTTP jusqu'à cette version
1.1. Ainsi, HTTP/1.0 a introduit la notion d'en-têtes, qui a permis,
entre autres, le virtual
hosting, grâce au champ
Host:. HTTP/1.1 a notamment changé la
persistence par défaut des connexions (de non-persistente à
désormais persistente). Et notre RFC, par rapport à la précédente
norme de HTTP/1.1, le RFC 7230 ? Le plus gros
changement est éditorial, toutes les parties indépendantes du numéro
de version de HTTP ont été déplacées vers le RFC 9110, notre RFC ne gardant que ce qui est spécifique à
HTTP/1.1. S'il y a beaucoup de changements de détail, le protocole
n'est pas modifié, un client ou un serveur HTTP/1.1 reste
compatible.
Vous noterez que j'ai fait un cours HTTP au CNAM, dont les supports et la vidéo sont disponibles. HTTP/1 est un protocole simple, très simple, et trivial à programmer. Cela en fait un favori des enseignants en informatique car on peut écrire un client (ou même un serveur) HTTP très facilement, et il peut être utilisé contre des serveurs (ou des clients) réels, ce qui est motivant pour les étudiant·es.
L'article seul
RFC 9111: HTTP Caching
Date de publication du RFC : Juin 2022
Auteur(s) du RFC : R. Fielding (Adobe), M. Nottingham (Fastly), J. Reschke (greenbytes)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 7 juin 2022
Le protocole HTTP transporte énormément de données tous les
jours et consomme donc à lui seul une bonne partie des ressources de
l'Internet. D'où l'importance de
l'optimiser. Une des méthodes les plus efficaces pour cela est le
cache (terme anglais qui
fait très bizarre en français : pour mieux accéder à une ressource,
on la cache...). Ce RFC spécifie le modèle de cachage (de
mémorisation ?) de HTTP et comment les clients et les serveurs
peuvent l'utiliser. Il remplace le RFC 7234
avec peu de modifications importantes (la plus spectaculaire étant
l'abandon du champ Warning: dans
l'en-tête).
Un cache Web est un espace de stockage local où on peut conserver la représentation d'une ressource qu'on a récupérée. Si la même ressource est à nouveau désirée, on pourra la récupérer depuis cette mémoire, le cache, plus proche et donc plus rapide que le serveur d'origine. Outre le temps d'accès, le cachage a l'avantage de diminuer la consommation de capacité réseau. Un cache peut être partagé entre plusieurs utilisateurs, augmentant ainsi les chances qu'une ressource désirée soit présente, ce qui améliore l'efficacité. (S'il n'a qu'un seul utilisateur, on parle de cache privé.) Comme tous les caches, les caches Web doivent gérer le stockage, l'accès et la place disponible, avec un mécanisme pour gérer le cas du cache plein. Comme tous les caches, les caches Web doivent aussi veiller à ne servir que de l'information fraîche. Cette fraîcheur peut être vérifiée de différentes façons, y compris par la validation (vérification auprès du serveur d'origine). Donc, même si l'information stockée dans le cache n'est pas garantie fraîche, on pourra quand même l'utiliser, si le serveur d'origine confirme qu'elle est toujours utilisable (dans ce cas, on aura quand même un accès réseau distant à faire, mais on évitera de transférer une ressource qui peut être de grande taille).
Le cache est optionnel pour HTTP, mais recommandé, et utiliser un cache devrait être le comportement par défaut, afin d'épargner le réseau, pour lequel HTTP représente une bonne part du trafic.
On peut garder en cache plusieurs sortes de réponses HTTP. Bien
sûr, le résultat d'une récupération après un
GET (code 200, cf. RFC 9110) est cachable et représente l'utilisation la plus
courante. Mais on peut aussi conserver dans le cache le résultat de
certaines redirections, ou bien des résultats négatifs (un code 410,
indiquant que la ressource est définitivement partie), ou même le
résultat de méthodes autres que GET (bien que
cela soit plus rare en pratique).
Ici, un exemple où une page a été stockée par un cache
Squid, et récupérée ensuite. L'argument de
GET est l'URI complet, pas juste le chemin :
% curl -v http://www.w3.org/WAI/
...
> GET http://www.w3.org/WAI/ HTTP/1.1
> User-Agent: curl/7.26.0
> Host: www.w3.org
...
< HTTP/1.0 200 OK
< Last-Modified: Thu, 12 Jun 2014 16:39:11 GMT
< ETag: "496a-4fba6335209c0"
< Cache-Control: max-age=21600
< Expires: Sun, 15 Jun 2014 15:39:30 GMT
< Content-Type: text/html; charset=utf-8
< Age: 118
< X-Cache: HIT from cache.example.org
< X-Cache-Lookup: HIT from cache.example.org:3128
< Via: 1.1 cache.example.org:3128 (squid/2.7.STABLE9)
...
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
Le client HTTP curl suit la
variable d'environnement
http_proxy et contacte donc le relais/cache
Squid en cache.example.org en HTTP. À son tour,
celui-ci se connectera au serveur d'origine si nécessaire (ce ne
l'était pas ici, l'information a été trouvée dans le cache, comme
l'indique la mention HIT.)
Les données stockées dans le cache sont identifiées par une
clé (section 2 de notre RFC). Pour un cache
simple, qui ne gère que GET, la clé principale
est l'URI
de la ressource convoitée. On verra plus loin que la clé peut en
fait être plus complexe que cela, en raison de certaines fonctions
du protocole HTTP, comme la négociation de contenu, qui
impose d'utiliser comme clé certains en-têtes de la requête. A
priori, un cache ne mémorise que les réponses positives (codes de
retour 200) mais certains mémorisent des réponses négatives comme le
404 (ressource non trouvée).
La section 3 du RFC normalise les cas où le cache a le droit de stocker une réponse, pour réutilisation ultérieure. Le RFC définit ces cas négativement : le cache ne doit pas stocker une réponse sauf si toutes ces conditions sont vraies :
- La méthode est cachable (c'est notamment le cas de
GET), - Le code de retour est compris du cache (200 est le cas évident),
- Il n'y a pas de directive dans la réponse qui interdise le
cachage (en-tête
Cache-Control:, voir plus loin), - L'accès à la ressource n'était pas soumis à autorisation (cf. RFC 9110, section 11), dans le cas d'un cache partagé entre plusieurs utilisateurs,
- La réponse contient des indications permettant de calculer la
durée de vie pendant laquelle elle restera fraîche (comme l'en-tête
Expires:).
Un cache peut stocker des réponses partielles, résultat de requêtes avec intervalles (cf. RFC 9110, section 14), si lui-même comprend ces requêtes. Il peut concaténer des réponses partielles pour ensuite envoyer une ressource complète.
Une fois la ressource stockée, le cache ne doit pas la renvoyer sauf si (là encore, la norme - section 4 - est formulée de manière négative, ce qui est déroutant) toutes ces conditions sont vraies :
- Les URI correspondent,
- Les en-têtes désignés par l'en-tête
Vary:correspondent (cela concerne surtout le cas où il y a négociation du contenu), - La requête ne contient pas de directive interdisant de la servir avec des données stockées dans le cache,
- La ressource stockée est encore fraîche, ou bien a été re-validée avec succès.
L'exigence sur la clé secondaire (les en-têtes sur lesquels se fait
la négociation de contenu) est là pour s'assurer qu'on ne donnera
pas à un client une ressource variable et correspondant aux goûts
d'un autre client. Si le client dont la requête a déclenché la mise
en cache avait utilisé l'en-tête Accept-Language:
fr indiquant qu'il voulait du français, et que le second
client du cache demande la même ressource, mais avec
Accept-Language: en, il ne faut évidemment pas
donner la copie du premier client au second. Si la réponse avait
l'en-tête Vary: accept-language indiquant
qu'elle dépend effectivement de la langue, le cache ne doit la
donner qu'aux clients ayant le même
Accept-Language:.
Et la fraîcheur, elle se définit comment (section 4.2, une des
plus importantes du RFC) ? Le cas le plus simple est celui où le
serveur d'origine envoie un en-tête Expires (ou
une directive max-age), par exemple
Expires: Mon, 15 Jun 2015 09:33:06 GMT. Dans ce
cas, la ressource gardée en cache est fraîche jusqu'à la date
indiquée. Attention : les formats de date de HTTP sont compliqués
et il faut être prudent en les analysant. Si le
Expires: indique une date syntaxiquement
incorrecte, le cache doit supposer le pire et considérer que la
ressource a déjà expiré. En pratique, bien des serveurs HTTP ne
fournissent pas cet en-tête Expires: et le
cache doit donc compter sur des heuristiques. La plus courante est
d'utiliser le champ Last-Modified: et de
considérer que, plus le document est ancien, plus il restera frais
longtemps (section 4.2.2). (La FAQ
de Squid explique bien l'heuristique de ce
logiciel de cache.) Le RFC ne normalise pas une heuristique
particulière mais met des bornes à l'imagination des programmeurs :
ces heuristiques ne doivent être employées que s'il n'y a pas de
date d'expiration explicite, et la durée de fraîcheur doit être
inférieure à l'âge du document (et le RFC suggère qu'elle ne soit
que 10 % de cet âge).
Dans sa réponse, le cache inclut un en-tête
Age:, qui peut donner au client une idée de la
durée depuis la dernière validation (auprès du serveur
d'origine). Par exemple, Age: 118, dans le
premier exemple, indiquait que la page était dans le cache depuis
presque deux minutes.
Une réponse qui n'est pas fraîche peut quand même être renvoyée
au client dans certains cas, notamment lorsque le cache est
déconnecté du réseau et ne peut pas donc valider que sa copie est
toujours bonne. Le client peut empêcher l'envoi de ces réponses
rassises avec Cache-Control: must-revalidate ou
no-cache.
Comment se fait cette validation dont on a déjà parlé plusieurs
fois ? Lorsque le serveur a une copie d'une ressource, mais que sa
date maximum de fraîcheur est dépassée, il peut demander au serveur
d'origine. Cela se fait typiquement par une requête conditionnelle
(cf. RFC 9110, section 13.1) : si le serveur a une copie
plus récente, il l'enverra, autrement, il répondra par un 304,
indiquant que la copie du cache est bonne. La requête conditionnelle
peut se faire avec un If-Modified-Since: (RFC 9110, section 8.8.2) en
utilisant comme date celle qui avait été donnée dans le
Last-Modified:. Ou bien elle peut se faire avec
l'entity tag (RFC 9110,
section 8.8.3) et un
If-None-Match: :
% telnet cache 3128 ... GET http://www.w3.org/WAI/ HTTP/1.1 Host: www.w3.org If-None-Match: "496a-4fba6335209c0" HTTP/1.0 304 Not Modified Date: Sun, 15 Jun 2014 09:39:30 GMT Content-Type: text/html; charset=utf-8 Expires: Sun, 15 Jun 2014 15:39:30 GMT Last-Modified: Thu, 12 Jun 2014 16:39:11 GMT ETag: "496a-4fba6335209c0" Age: 418 X-Cache: HIT from cache.example.org X-Cache-Lookup: HIT from cache.example.org:3128 Via: 1.0 cache.example.org:3128 (squid/2.7.STABLE9) Connection: close
Le cache peut aussi utiliser la méthode HEAD
pour tester sa copie locale auprès du serveur d'origine, par exemple
pour invalider la copie locale, sans pour autant transférer la
ressource. Et s'il voit passer un URL connu avec des méthodes qui ont
de fortes chances de changer la ressource, comme
PUT ou POST, le cache doit
invalider la ressource stockée.
La section 5 liste tous les en-têtes des requêtes et des réponses
qui sont utilisés pour le bon fonctionnement des caches, comme
Age: (en secondes), Expires:, etc. Ils
sont enregistrés à
l'IANA, dans le registre des en-têtes (désormais séparé du registre
utilisé pour les en-têtes du courrier électronique).
Parmi ces en-têtes, Cache-Control: permet de
spécifier des directives concernant le cache. Un client d'un cache
peut spécifier l'âge maximum qu'il est prêt à accepter (directive
max-age), une fraîcheur minimum (directive
min-fresh), que la ressource ne doit pas être
stockée dans le cache (directive no-store, qui
est là pour des raisons de vie privée mais,
bien sûr, est loin de suffire pour une véritable confidentialité),
ou bien qu'elle peut être stockée mais ne doit pas être servie à un
client sans revalidation (directive no-cache),
etc. Il y a aussi l'opposé de no-cache,
only-if-cached, qui indique que le client ne
veut la ressource que si elle est stockée dans le cache. (Attention,
dans un cache partagé, cela peut permettre à un client de voir ce que
les autres clients ont demandé, ce qu'on nomme le cache
snooping.) L'ensemble des directives possibles sont
stockées dans un
registre IANA. Ainsi, le RFC 8246 avait
ajouté une valeur possible à Cache-Control:, pour
indiquer l'immuabilité d'une ressource.
L'en-tête
Cache-Control: peut aussi être utilisé dans des
réponses. Un serveur peut lui aussi indiquer
no-cache, typiquement parce que ce qu'il envoie
change fréquemment et doit donc être revalidé à chaque fois,
private s'il veut insister sur le fait que la
réponse n'était destinée qu'à un seul utilisateur et ne doit donc
pas être transmise à d'autres (le RFC insiste que c'est une
protection vraiment minimale de la vie privée), etc.
À noter qu'un cache HTTP n'est pas forcément un serveur spécialisé. Tous les navigateurs Web ont des fonctions d'historique (comme le bouton Back). Est-ce que celles-ci nécessitent des précautions analogues à celles des caches, pour éviter que le navigateur ne serve des données dépassées ? Pas forcément, dit le RFC, qui autorise un navigateur à afficher une page peut-être plus à jour lorsqu'on utilise le retour en arrière dans l'historique (mais lisez la section 6 du RFC : cette autorisation vient avec des limites).
La section 7 détaille les problèmes de sécurité qui peuvent affecter les caches. Un cache, par exemple, peut permettre d'accéder à une information qui n'est plus présente dans le serveur d'origine, et donc de rendre plus difficile la suppression d'une ressource. Un cache doit donc être géré en pensant à ces risques. Plus grave, l'empoisonnement de cache : si un malveillant parvient à stocker une fausse représentation d'une ressource dans un cache (avec une longue durée de fraîcheur), tous les utilisateurs du cache recevront cette information au lieu de la bonne.
Un cache peut aussi avoir des conséquences pour la vie privée : en demandant une ressource à un cache partagé, un utilisateur peut savoir, à partir du temps de chargement et d'autres informations envoyées par le cache, si un autre utilisateur avait déjà consulté cette page. Et si un cache est privé (restreint à un·e seule·e utilisateurice), les données qu'il a stocké permettent d'avoir un panorama complet des activités Web de l'utilisateur.
L'annexe B liste les différences depuis le texte précédent, celui du RFC 7234 :
- Clarification de certaines parties de la norme,
- Quelques légers changements dans les obligations et interdictions que le logiciel de mémorisation doit respecter,
- Nouvelle directive
must-understand, qui permet au serveur d'indiquer que la ressource ne doit être mémorisée que si le cache connait et comprend le code de retour indiqué, - Et le plus spectaculaire, le
Warningdans les réponses est abandonné, car il était peu utilisé et souvent redondant avec l'information déjà présente dans la réponse.
Question mise en œuvre, notez qu'il existe un projet de tests des caches pour vérifier leur conformité.
L'article seul
RFC 9110: HTTP Semantics
Date de publication du RFC : Juin 2022
Auteur(s) du RFC : R. Fielding (Adobe), M. Nottingham (Fastly), J. Reschke (greenbytes)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 7 juin 2022
Que voilà une épaisse lecture (252 pages). Mais c'est parce qu'il s'agit de réécrire complètement la totalité des normes de HTTP. Pas le protocole lui-même, je vous rassure, HTTP ne change pas. Mais la rédaction de ses normes est profondément réorganisée, avec un RFC (notre RFC 9110) qui décrit une vision de haut niveau de HTTP, puis un autre RFC par version majeure de HTTP, décrivant les détails de syntaxe de chaque version.
Par exemple, HTTP/1 (RFC 9112) a un
encodage en texte alors que HTTP/2 (RFC 9113)
a un encodage binaire. Pourtant, tous les deux suivent les mêmes
principes, décrits dans ce RFC 9110 (méthodes comme
GET, en-têtes de la requête et de la réponse,
codes de retour à trois chiffres…) mais avec des encodages
différents, chacun dans son propre RFC. Notre RFC 9110 est donc la vision de haut niveau de HTTP, commune à
toutes les versions, et d'autres RFC vous donneront les
détails. Inutile de dire que cette réorganisation a été un gros
travail, commencé en 2018.
Les trois versions de HTTP actuellement en large usage (1.1, 2 et 3) reposent toutes sur des concepts communs. Par exemple, les codes d'erreur (comme le fameux 404) sont les mêmes. Il n'est pas prévu, même à moyen terme, que les versions les plus anciennes soient abandonnées (HTTP/1.1 reste d'un usage très courant, et souvent pour de bonnes raisons). D'où cette réorganisations des normes HTTP, avec notre RFC 9110 qui décrit ce qui est commun aux trois versions, d'autres RFC communs aux trois versions, et un RFC par version :
Vous connaissez certainement déjà HTTP, mais notre RFC ne présuppose pas de connaissances préalables et explique tout en partant du début, ce que je fais donc également ici. Donc, HTTP est un protocole applicatif, client/serveur, sans état, qui permet l'accès et la modification de ressources distantes (une ressource pouvant être du texte, une image, et étant générée dynamiquement ou pas, le protocole est indépendant du format de la ressource ou de son mode de création, le RFC insiste bien sur ce point). Le client se connecte, envoie une requête, le serveur répond. HTTP ne fonctionne pas forcément de bout en bout, il peut y avoir des relais sur le trajet, et leur présence contribue beaucoup à certaines complexités de la norme.
S'il fallait résumer HTTP rapidement, on pourrait dire qu'il décrit un moyen d'interagir avec une ressource distante (la ressource peut être un fichier, un programme…). Il repose sur l'échange de messages, avec une requête du client vers le serveur et une réponse en sens inverse. Outre la méthode qui indique ce que le client veut faire avec la ressource, HTTP permet de transporter des métadonnées.
La section 3 du RFC décrit les concepts centraux de ce protocole,
comme celui de ressource présenté plus haut. (Qui est parfois appelé
« page » ou « fichier » mais ces termes ne sont pas assez
génériques. Une ressource n'est pas forcément une page HTML !) HTTP identifie
les ressources par des URI. Une représentation
est la forme concrète d'une ressource, les bits qu'on reçoit ou
envoie. (Du fait de la négociation de contenu et d'autres facteurs,
récupérer une ressource en utilisant le même URI ne donnera pas
forcément les mêmes bits, même s'ils sont censés être sémantiquement
équivalents.) La ressource n'est pas non plus forcément un fichier, pensez à une ressource qui indique l'heure qu'il est,
ou le temps qu'il fait, par exemple. Ou à l'URI
https://www.bortzmeyer.org/apps/random qui vous
renvoie une page choisie aléatoirement de ce blog. HTTP agit
sur une ressource (dont le type n'est pas forcément connu) via une
méthode qui va peut-être retourner une représentation de cette
ressource. C'est ce qu'on nomme le principe REST et de
nombreuses API se réclament de ce principe.
HTTP est un protocole client/serveur. Le serveur attend le client. (Le client est parfois appelé user agent.) Entre les deux, HTTP utilisera un protocole de transport fiable, comme TCP (HTTP/1 et 2) ou QUIC (HTTP/3). Par défaut, HTTP est sans état : une fois une requête servie, le serveur oublie tout. Les clients sont très variés : il y a bien sûr les navigateurs Web, mais aussi les robots, des outils en ligne de commande comme wget, des objets connectés, des programmes vite faits en utilisant une des zillions de bibliothèques qui permettent de développer rapidement un client HTTP, des applications sur un ordiphone, etc. Notamment, il n'y a pas forcément un utilisateur humain derrière le client HTTP. (Pensez à cela si vous mettez des éléments d'interfaces qui demandent qu'un humain y réponde ; le client ne peut pas forcément faire de l'interactivité.)
Les messages envoyés par le client au serveur sont des requêtes et ceux envoyés par le serveur des réponses.
La section 2 du RFC explique ce qu'on attend d'un client ou d'un serveur HTTP conforme. Un point important et souvent ignoré est que HTTP ne donne pas de limites quantitatives à beaucoup de ses éléments. Par exemple, la longueur maximale de la première ligne de la requête (celle qui contient le chemin de la ressource) n'est pas spécifiée, car il serait trop difficile de définir une limite qui convienne à tous les cas, HTTP étant utilisé dans des contextes très différents. Comme les programmes ont forcément des limites, cela veut dire qu'on ne peut pas toujours compter sur une limite bien connue.
Une mise en œuvre conforme pour HTTP doit notamment bien gérer la notion de version de HTTP. Cette version s'exprime par deux chiffres séparés par un point, le premier chiffre étant la version majeure (1, 2 ou 3) et le second la mineure (il est optionnel, valant 0 par défaut, donc HTTP/2 veut dire la même chose que HTTP/2.0). Normalement, au sein d'une même version majeure, on doit pouvoir interopérer sans trop de problème alors qu'entre deux versions majeures, il peut y avoir incompatibilité totale. La sémantique est forcément la même (c'est du HTTP, après tout) mais la syntaxe peut être radicalement différente (pensez à l'encodage texte de HTTP/1 vs. le binaire de HTTP/2 et 3). Donc, être conforme à HTTP/1.1 veut dire lire ce RFC 9110 mais aussi le RFC 9112, qui décrit la syntaxe spécifique de HTTP/1.1.
Comme, dans la nature, des programmes ne sont pas corrects, le
RFC autorise du bout des lèvres à utiliser le contenu des champs
User-Agent: ou Server: de
l'en-tête pour s'ajuster à des bogues connues (mais, normalement, ce
doit être uniquement pour contourner des bogues, pas pour servir un
contenu différent).
De même qu'un client HTTP n'est pas forcément un navigateur Web, un serveur HTTP n'est pas forcément une grosse machine dans un centre de données chez un GAFA. Le serveur HTTP peut parfaitement être une imprimante, un petit objet connecté, une caméra de vidéosurveillance, un Raspberry Pi dans son coin… Le RFC parle de « serveur d'origine » pour le serveur qui va faire autorité pour les données servies. Pourquoi ce concept ? Parce que HTTP permet également l'insertion d'un certain nombre d'intermédiaires, les relais (proxy ou gateway en anglais), entre le client et le serveur d'origine. Leurs buts sont très variés. Par exemple, un relais (proxy, pour le RFC) dans le réseau local où se trouve le client HTTP peut servir à mémoriser les ressources Web les plus souvent demandées, pour améliorer les performances. Un relais (gateway ou reverse proxy, pour le RFC) qui est au contraire proche du serveur d'origine peut servir à répartir la charge entre diverses instances. Revenons à la mémorisation des ressources (caching en anglais). La mémoire (cache en anglais) est un stockage de ressources Web déjà visitées, prêtes à être envoyées aux clients locaux pour diminuer la latence. La mémorisation est un sujet suffisamment fréquent et important pour avoir son propre RFC, le RFC 9111.
On a vu que HTTP servait à agir sur des ressources distantes. Des
ressources, il y en a beaucoup. Comment les identifier ? Le Web va
utiliser des URI comme
identificateurs. Ces URI sont normalisés dans
le RFC 3986, mais qui ne spécifie qu'une
syntaxe générique. Chaque plan d'URI (la chaine
de caractères avant le deux-points, souvent
appelée à tort protocole) doit spécifier un certain nombre de
détails spécifique à ce plan. Pour les plans
http et https, cette
spécification est la section 4 de notre RFC. (Tous les plans sont
dans un
registre IANA.) Un URI de plan http ou
https indique forcément une autorité (un
identificateur du serveur d'origine, en pratique un nom de machine)
et un chemin (identificateur de la ressource à l'intérieur d'un
autorité. Ainsi, dans
https://www.afnic.fr/observatoire-ressources/consultations-publiques/,
le plan est https, l'autorité
www.afnic.fr et le chemin
/observatoire-ressources/consultations-publiques/. Le
port par défaut est 80 pour
http et 443 pour
https (tous les deux sont enregistrés
à l'IANA). La différence entre les deux plans est que
https implique l'utilisation du protocole de
sécurité TLS
(RFC 9846), pour assurer notamment la
confidentialité des requêtes.
En théorie, un URI de plan http et un autre
identique, sauf pour l'utilisation de https,
sont complètement distincts. Ils ne représentent pas la même origine
(l'origine est un triplet {plan, machine, port}) et les deux
ressources peuvent être complètement différentes. Mais notre RFC
note que certaines normes violent ce principe, notamment celle sur
les cookies (RFC 6265),
avec parfois des conséquences fâcheuses pour la sécurité.
En HTTPS, puisque ce protocole s'appuie sur TLS, le serveur présente un certificat, que le client doit vérifier (section 4.3.4), en suivant les règles du RFC 6125.
Pour expliquer plusieurs des propriétés de HTTP, je vais beaucoup
utiliser le logiciel curl, un
client HTTP en ligne de commande, dont
l'option -v permet d'afficher tout le dialogue
HTTP. Si vous voulez faire des essais vous aussi, interrompez
momentanément votre lecture pour installer curl. […] C'est fait ? On
peut reprendre ?
% curl -v http://www.hambers.mairie53.fr/ ... > GET / HTTP/1.1 > Host: www.hambers.mairie53.fr > User-Agent: curl/7.68.0 > Accept: */* > < HTTP/1.1 200 OK < Date: Wed, 02 Mar 2022 16:25:02 GMT < Server: Apache ... < Content-Length: 61516 < Content-Type: text/html; charset=UTF-8 < <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> ...
Nous avons vu que la requête et la réponse HTTP contenaient des métadonnées dans un en-tête composé de champs. (Il peut aussi y avoir un pied, une sorte de post-scriptum, mais c'est peu utilisé.) Chaque champ a un nom et une valeur. La section 5 du RFC détaille cet important concept. Les noms de champs sont insensibles à la casse. Ils sont enregistrés dans un registre IANA spécifique à HTTP (ils étaient avant dans le même registre que les champs du courrier électronique). Un client, un serveur ou un relais HTTP doivent ignorer les champs qu'ils ne connaissent pas, ce qui permet d'introduire de nouveaux champs sans tout casser. Le même champ peut apparaitre plusieurs fois. Comme pour d'autres éléments du protocole HTTP, la norme ne fixe pas de limite de taille. La valeur d'un champ peut donc être très grande.
La valeur d'un champ obéit à des règles qui dépendent du champ. Les caractères doivent être de l'ASCII, une limite très pénible de HTTP. Si on veut utiliser Unicode (ou un autre jeu de caractères), il faut l'encoder comme indiqué dans le RFC 8187. Le RFC rappelle qu'autrefois Latin-1 était autorisé (avec l'encodage du RFC 2047 pour les autres jeux) mais cela ne devrait normalement plus être le cas (mais ça se rencontre parfois encore). Si une valeur comprend plusieurs termes, ils doivent normalement être séparés par des virgules (et on met entre guillemets les valeurs qui comprennent des virgules). Les valeurs peuvent inclure des paramètres, écrits sous la forme nom=valeur. Certaines valeurs ont leur propre structure (RFC 9651). Ainsi, plusieurs champs peuvent inclure une estampille temporelle. La syntaxe pour celles-ci n'est hélas pas celle du RFC 3339 mais celle de l'IMF (RFC 5322), plus complexe et plus ambigüe. (Sans compter, vu l'âge de HTTP, qu'on rencontre parfois de vieux formats comme celui du RFC 850.) Voici des exemples de champs vus avec curl :
% curl -v http://confiance-numerique.clermont-universite.fr/
...
> GET / HTTP/1.1
> Host: confiance-numerique.clermont-universite.fr
> User-Agent: curl/7.68.0
> Accept: */*
< HTTP/1.1 200 OK
< Date: Fri, 28 Jan 2022 17:21:38 GMT
< Server: Apache/2.4.6 (CentOS)
< Last-Modified: Tue, 01 Sep 2020 13:29:41 GMT
< ETag: "1fbc1-5ae4082ec730d"
< Accept-Ranges: bytes
< Content-Length: 129985
< Content-Type: text/html; charset=UTF-8
<
<!DOCTYPE HTML SYSTEM>
<html>
<head>
<title>Séminaire Confiance Numérique</title>
Le client HTTP (curl) a envoyé trois champs,
Host: (le serveur qu'on veut contacter),
User-Agent: (une chaine de caractères décrivant
le client) et Accept: (les formats acceptés,
ici tous). Le serveur a répondu avec divers champs comme
Server: (l'équivalent du
User-Agent:) et
Content-Type: (le format utilisé, ici
HTML). Et voici ce qu'envoie le navigateur Firefox :
Host: localhost:8080 User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:96.0) Gecko/20100101 Firefox/96.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8 Accept-Language: en-US,en;q=0.5 Accept-Encoding: gzip, deflate Connection: keep-alive Upgrade-Insecure-Requests: 1 Sec-Fetch-Dest: document Sec-Fetch-Mode: navigate Sec-Fetch-Site: none Sec-Fetch-User: ?1
On notera surtout un Accept: plus complexe
(curl accepte tout car il ne s'occupe pas de l'affichage).
Maintenant, les messages (requêtes et réponses). La façon exacte dont ils sont transmis dépend de la version de HTTP. Par exemple, la version 1 les encode en texte alors que les versions 2 et 3 préfèrent le binaire. Autre exemple, la version 3 ne prévoit pas de mécanisme de début et de fin d'un message car chaque ruisseau QUIC ne porte qu'un seul message, un peu comme les versions 0 de HTTP, avec le ruisseau QUIC au lieu de la connexion TCP (notez qu'avec TCP sans TLS, le client peut ne pas savoir s'il a bien reçu toutes les données). La section 6 de notre RFC ne donne donc qu'une description abstraite. Un message comprend donc une information de contrôle (la première ligne, dans le cas de HTTP/1, un « pseudo en-tête » avec des noms de champs commençant par un deux-points pour les autres versions), un en-tête, un corps (optionnel) et un pied (également optionnel). L'information de contrôle donne plusieurs informations nécessaires pour la suite, comme la version de HTTP utilisée. Le contenu (le corps) est juste une suite d'octets, que HTTP transporte sans l'interpréter (ce n'est pas forcément de l'HTML). Dans la réponse, l'information de contrôle comprend notamment un code numérique de trois chiffres, qui indique comment la requête a été traitée (ou pas).
Beaucoup moins connu que l'en-tête, un message peut aussi comporter un pied, également composé de champs « nom: valeur ». Il est nécessaire de les utiliser dans les cas où l'information est générée dynamiquement et que certaines choses ne peuvent être déterminées qu'après coup (une signature numérique, par exemple).
Dans le cas le plus simple, le client HTTP parle directement au
serveur d'origine et il n'y a pas de complications de routage du
message. Le serveur traite le message reçu, point. Mais HTTP permet
d'autres cas, par exemple avec un relais qui
reçoit le message avant de le transmettre au « vrai » serveur
(section 7 du RFC). Ainsi, dans une requête, l'information de
contrôle n'est pas forcément un simple chemin
(/publications/cahiers-soutenabilites) mais
peut être un URL complet
(https://www.strategie.gouv.fr/publications/cahiers-soutenabilites). C'est
ce que fait le client HTTP s'il est configuré pour utiliser un
relais, par exemple pour mémoriser les réponses des requêtes (RFC 9111), ou bien parce que l'accès direct aux
ports 80 et 443 est
bloqué et qu'on est obligé d'utiliser un relais. Dans le cas où la
ressource demandées est identifiée par un URL complet, le relais
doit alors se transformer en client HTTP et faire une requête vers
le serveur d'origine (ou bien vers un autre relais…).
La section 8 de notre RFC s'attaque à une notion cruciale en
HTTP, celle de représentation. La
représentation d'une ressource est la suite d'octets qu'on obtient
en réponse à une requête HTTP (« représentation » est donc plus
concret que « ressource »). Une même ressource peut avoir plusieurs
représentations, par exemple selon les métadonnées que le client a
indiqué dans sa requête. Le type de la représentation est indiqué par le champ
Content-Type: de l'en-tête (et aussi par
Content-Encoding:). Sa valeur est un
type MIME (RFC 2046). Voici par exemple le type de la page que vous êtes
en train de lire :
Content-Type: text/html; charset=UTF-8
(Notez que le paramètre charset est mal nommé,
c'est en fait un encodage, pas un
jeu de caractères. L'erreur vient du fait que
dans les vieilles normes comme ISO-8859-1, les
deux concepts étaient confondus.)
Normalement, du fait de ce Content-Type:, le
client HTTP n'a pas à deviner le type de la représentation, il se
fie à ce que le serveur raconte. Ceci dit, certains clients ont la
mauvaise idée de chercher à deviner le
type. Cette divination est toujours incertaine (plusieurs
types de données peuvent se ressembler) et ouvre même la possibilité
de failles de sécurité.
Un autre champ, Content-Language:, indique
la langue de la représentation récupérée. Sa
valeur est une étiquette de langue, au sens
du RFC 5646. Si le texte est multilingue, ce
champ peut prendre plusieurs valeurs. Le RFC illustre cela avec le
traité de Waitangi, qui est en
maori et en anglais :
Content-Language: mi, en
Attention, la seule présence de différentes langues ne signifie pas qu'il faut mettre plusieurs étiquettes de langue. Un cours d'introduction à l'arabe écrit en français, pour un public francophone, sera :
Content-Language: fr
Les étiquettes de langue peuvent être plus complexes que l'indication de la seule langue, mais il me semble que c'est rarement utilisé sur le Web.
La taille de la représentation, elle, est exprimée avec
Content-Length:, un champ très pratique pour le
client HTTP qui sait ainsi combien d'octets il va devoir lire (avant
HTTP/1, c'était facile, on lisait jusqu'à la fin de la connexion
TCP ;
mais ça ne marche plus depuis qu'il y a des connexions persistentes
et, de toute façon, en l'absence de TLS, cela ne permettait pas de
détecter des coupures prématurées). Évidemment, le client doit
rester paranoïaque et supposer que l'information puisse être
fausse. curl (avec -v) avertit ainsi, si la
taille indiquée est trop faible :
* Excess found in a read: excess = 1, size = 12, maxdownload = 12, bytecount = 0
Si la taille indiquée est trop grande, curl attend pour essayer de lire davantage sur le connexion qui reste ouverte. Autre raison d'être paranoïaque, la taille indiquée peut être énorme, menant par exemple un client imprudent, qui allouerait la mémoire demandée à épuiser celle-ci. Sans compter l'éventualité d'un débordement d'entier si la taille ne peut pas être représentée dans les entiers utilisés par le client HTTP.
Ensuite vient un autre point pas forcément très connu : les
validateurs. HTTP permet d'indiquer des pré-conditions à la
récupération d'une ressource, pour épargner le réseau. Un client
HTTP peut ainsi demander « donne-moi cette ressource, si elle n'a
pas changé ». Pour cela, HTTP repose sur ces validateurs, qui sont
des métadonnées qui accompagnent la requête (avec des champs qui
expriment la requête conditionnelle, comme
If-Modified-Since:, et qui sont détaillés en
section 13) et que le serveur vérifiera. Il existe deux sortes de
validateurs, les forts et les faibles. Les faibles sont faciles à
générer mais ne garantissent pas une comparaison réussie, les forts
sont plus difficiles à faire mais sont plus fiables. Par exemple, un
condensat du contenu est fort. Il changera
forcément (sauf malchance inouïe) dès qu'on changera un seul bit du
contenu. Si le contenu est géré par un VCS, celui-ci fournit également des
validateurs forts : l'identificateur de
commit. Au contraire, une
estampille temporelle est un validateur faible. Si sa résolution est
d'une seconde, deux modifications dans la même seconde ne seront pas
détectées et le serveur croira à tort que le contenu n'a pas
changé.
Pour connaitre la valeur actuelle d'un futur validateur, le
client HTTP dispose de champs comme
Last-Modified: (une estampille temporelle) ou
ETag: (Entity Tag,
l'étiquette de la ressource, une valeur opaque, qui peut s'utiliser
avec des requêtes conditionnelles comme
If-None-Match:). Voici un exemple :
Last-Modified: Mon, 07 Feb 2022 12:20:20 GMT ETag: "5278-5d76c9fc1c9f4"
(Le serveur utilisé était un Apache. Par
défaut, Apache génère des étiquettes qui sont un
condensat de divers attributs du fichier
comme l'inœud, la taille et la date de
modification. Apache permet de configurer
cet algorithme. Rappelez-vous que l'étiquette est opaque, le
serveur peut donc la générer comme il veut, il doit juste s'assurer
qu'elle change à chaque modification de la ressource. Le serveur peut par
exemple utiliser un SHA-1 du contenu de la ressource.)
A priori, l'étiquette de la ressource est un validateur fort,
autrement, le serveur doit la préfixer par W/
(W pour Weak).
Passons maintenant aux méthodes (section 9
du RFC). Il y a très longtemps, HTTP n'avait qu'une seule méthode
pour agir sur les ressources, la méthode
GET. Désormais, il y a nettement plus de
méthodes, chacune agissant sur la ressource indiquée d'une manière
différente et ayant donc une sémantique différente. Par exemple,
GET va récupérer une représentation de la
ressource, alors que PUT va au contraire écrire
le contenu envoyé, remplaçant celui de la ressource et que
DELETE va… détruire la ressource. La liste
complète des méthodes figure dans un
registre IANA.
Certaines des méthodes sont dites sûres car elles ne modifient
pas la ressource et ne casseront donc rien. Bien sûr, une méthode
sûre peut avoir des effets de bord (comme d'écrire une ligne dans le
journal du serveur, mais ce n'est pas la
faute du client). GET, HEAD
et les moins connues OPTIONS et
TRACE sont sûres. Du fait de cette garantie de
sûreté, un programme qui ne fait que des requêtes sûres a moins
d'inquiétudes à avoir, notamment s'il agit sur la base
d'informations qu'il ne contrôle pas. Ainsi, le
ramasseur d'un moteur de
recherche ne fait a priori que des requêtes sûres, pour
éviter qu'une page Web malveillante ne l'entraine à effectuer des
opérations qui peuvent changer le contenu des sites Web visités.
Une autre propriété importante d'une méthode est d'être
idempotente ou pas. Une méthode idempotente a
le même effet qu'on l'exécute une ou N fois. Les méthodes sûres sont
toutes idempotentes mais l'inverse n'est pas vrai :
PUT et DELETE sont
idempotentes (qu'on détruise une ressource une ou N fois donnera le
même résultat : la ressource est supprimée) mais pas
sûres. L'intérêt de cette propriété d'idempotence est qu'elles
peuvent être répétées sans risque, par exemple si le réseau a eu un
problème et qu'on n'est pas certain que la requête ait été
exécutée. Les méthodes non-idempotentes ne doivent pas, par contre,
être répétées aveuglément.
La méthode la plus connue et sans doute la plus utilisée,
GET, permet de récupérer une représentation
d'une ressource. La syntaxe avec laquelle s'exprime le chemin de
cette ressource fait penser à l'arborescence d'un système
de fichiers et c'est en effet souvent ainsi que c'est
mis en œuvre dans les serveurs (par exemple dans Apache, où le chemin, mettons
/foo/bar, est ajouté à la fin de la variable de
configuration DocumentRoot, avant d'être
récupéré sur le système de fichiers : si
DocumentRoot vaut
/var/www, le fichier demandé sera
/var/www/foo/bar). Mais ce n'est pas une
obligation de HTTP, qui ne normalise que le protocole entre le client
et le serveur, pas la façon dont le serveur obtient les
ressources.
La méthode HEAD fait la même chose que
GET mais sans renvoyer la représentation de la
ressource.
POST est plus compliquée. Contrairement à
GET, la requête contient des données qui vont
être envoyés au serveur. Celui-ci va les
traiter. POST est souvent utilisé pour
soumettre le contenu d'un formulaire Web, par
exemple pour envoyer un texte qui sera le contenu d'un commentaire
lors d'une discussion sur un forum Web. Avec
GET, POST est probablement
la méthode la plus souvent vue sur le Web.
PUT, lui, est également accompagné de
données qui vont être écrites à la place de la ressource
désignée. On peut donc mettre en œuvre un serveur de fichiers
distant avec des PUT et des
GET. On peut y ajouter
DELETE pour supprimer les ressources devenues
inutiles.
La méthode CONNECT est plus complexe. Elle
n'agit pas sur une ressource mais permet d'établir une connexion
avec un service distant. Sa principale utilité est de permettre
d'établir un tunnel au-dessus de
HTTP. Ainsi :
CONNECT server.example.com:80 HTTP/1.1 Host: server.example.com
va établir une connexion avec
server.example.com et les octets envoyés par la
suite sur cette connexion HTTP seront relayés aveuglément vers
server.example.com.
Quant à la méthode OPTIONS, elle permet
d'obtenir des informations sur les options gérées par le
serveur. curl permet d'indiquer une méthode avec son option
--request (ou -X) :
% curl -v --request OPTIONS https://www.bortzmeyer.org/ ... > OPTIONS / HTTP/2 > Host: www.bortzmeyer.org > user-agent: curl/7.68.0 > accept: */* > ... < HTTP/2 200 < permissions-policy: interest-cohort=() < allow: POST,OPTIONS,HEAD,GET ...
La section 10 du RFC est ensuite une longue section qui décrit le contexte des messages HTTP, c'est-à-dire les métadonnées qui accompagnent requêtes et réponses. Je ne vais évidemment pas en reprendre toute la liste ici. Juste quelques exemples de champs intéressants :
From:permet d'indiquer l'adresse de courrier du responsable du logiciel. Il est surtout utilisé par les bots (par exemple ceux qui ramassent les pages pour le compte d'un moteur de recherche) pour indiquer qui contacter si le bot se comporte mal, par exemple en faisant trop de requêtes. Comme le rappelle le RFC, un navigateur ordinaire ne doit évidemment pas transmettre une telle donnée personnelle à tous les sites Web visités !Referer:(oui, avec une faute d'orthographe) sert à indiquer l'URL d'où vient le client HTTP. Le Web étant fondé sur l'idée d'hypertexte, l'utilisateur est peut-être venu ici en suivant un lien, et il peut ainsi indiquer où il a trouvé ce lien, ce qui peut permettre au webmestre de voir d'où viennent ses visiteurs. Lui aussi pose des problèmes de vie privée, et j'ai toujours été surpris que le Tor Browser l'envoie.User-Agent:indique le type du client HTTP. À part s'amuser en regardant le genre de visiteurs qu'on a, il n'a pas de vraie utilité, le Web reposant sur des normes, et précisant une structure et pas une présentation, il ne devrait pas y avoir besoin de changer une ressource en fonction du logiciel du visiteur. Mais c'est quand même ce que font certains serveurs HTTP, poussant les clients à mentir pour obtenir un certain résultat, ce qui donne des champsUser-Agent:ridicules comme (vu sur ce blog)Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36(probablement le navigateur Safari indiquant autant de logiciels que possible ; le RFC dit qu'il ne faut pas le faire mais c'est courant, pour tenir compte de serveurs qui interprètent ce champ). Là encore, on a une métadonnée qui contribue puissamment à la fuite d'information si commune sur le Web (votre client HTTP est certainement trop bavard). LeUser-Agent:est très utile pour le fingerprinting, l'identification d'un visiteur particulier, comme le démontre le Panopticlick.Server:est l'équivalent deUser-Agent:mais pour le serveur.
Jusqu'à présent, on a supposé que les ressources servies étaient
accessibles à tous et toutes. Mais en pratique, on souhaite parfois
servir du contenu à accès restreint et on veut donc n'autoriser que certains visiteurs. Il
faut donc disposer de mécanismes
d'authentification, exposés dans la section
11 du RFC. HTTP n'a pas un mécanisme unique
d'authentification. Chaque mécanisme est identifié par un nom (et
les possibilités sont dans un
registre IANA). Le serveur indique le mécanisme à utiliser
dans un champ WWW-Authenticate: de sa première
réponse. Par exemple, basic, normalisé dans le
RFC 7617, est un mécanisme simple de
mot de passe, alors que
digest (normalisé dans le RFC 7616) permet de s'authentifier via un
défi/réponse. Le mécanisme est spécifique à
un royaume, une information donnée par le serveur pour le cas où le
même serveur gérerait des types d'authentification différents selon
la ressource.
Voici un exemple d'authentification (avec le service
d'administration d'un serveur
dnsdist, celui utilisé pour mon résolveur
public) où l'identificateur est admin et
le mot de passe 2e12 :
% curl -v --user admin:2e12 https://doh.bortzmeyer.fr:8080/ > GET / HTTP/1.1 > Host: doh.bortzmeyer.fr:8080 > Authorization: Basic YWRtbW...OTcyM= > User-Agent: curl/7.68.0 > Accept: */* > ... < HTTP/1.1 200 OK ...
La représentation renvoyée peut dépendre du client, c'est ce
qu'on nomme la négociation de contenu (section 12 du RFC). La
méthode officielle est que le client annonce avec le champ
Accept: les types
de données qu'il accepte, et le serveur lui envoie de
préférence ce qu'il a demandé. (C'est utilisé sur ce blog pour les
images. En pratique, ça ne se passe pas toujours bien.)
La demande du client n'est pas strictement binaire « je veux du
format WebP ». Elle peut s'exprimer de
manière plus nuancée, via le système de qualité. Ainsi :
Accept: text/plain; q=0.5, text/html
signifie que le client comprend le texte brut et l'HTML mais préfère ce dernier (le poids par défaut est 1, supérieur, donc, au 0,5 du texte brut).
La négociation de contenu ne s'applique pas qu'au format des
représentations, elle peut aussi s'appliquer à la
langue, avec le champ
Accept-Language:. Ainsi, en disant :
Accept-Language: da, en;q=0.8
veut dire « je préfère le danois (poids de 1 par défaut), mais j'accepte l'anglais ». En pratique, ce n'est pas très utile sur le Web car cela ne permet pas d'indiquer la qualité de la traduction. Si on indique qu'on préfère le français, mais qu'on peut lire l'anglais, en visitant des sites Web d'organisations internationales, on se retrouve avec un texte français mal traduit, alors qu'on aurait préféré la version originale. En outre, comme beaucoup de champs de l'en-tête de la requête, il contribue à identifier le client (fingerprinting). C'est d'autant plus gênant que l'indication des langues préférées peut vous signaler à l'attention de gens peu sympathiques, si ces langues sont celles d'une minorité opprimée.
Comme la représentation envoyée peut dépendre de ces demandes du
client, le serveur doit indiquer dans sa réponse s'il a effectivement
tenu compte de la négociation de contenu. C'est notamment important
pour les relais Web qui mémorisent le contenu des réponses (RFC 9111). Le champ Vary:
permet d'indiquer de quoi a réellement dépendu la réponse. Ainsi :
Vary: accept-language
indique que la réponse ne dépendait que de la langue. Si un client d'un relais Web demande la même ressource mais avec une autre langue, il ne faut pas lui donner le contenu mémorisé.
HTTP permet d'exprimer des requêtes conditionnelles. Un client HTTP peut par exemple demander une ressource « sauf si elle n'a pas été modifiée depuis 08:00 ». Cela permet d'économiser des ressources, notamment dans les relais qui mémorisent RFC 9111. C'est également utile aux clients de syndication, qui récupèrent régulièrement (polling) le flux Atom pour voir s'il a changé. Les requêtes conditionnelles permettent, la plupart du temps, d'éviter tout téléchargement de ce flux.
Un autre scénario d'utilisation des requêtes conditionnelles est
le cas de la mise à jour perdue (lost
update). Prenons un client qui met à jour une ressource,
en récupérant d'abord son état actuel (avec un
GET), en la modifiant, puis en téléversant la
version modifiée (avec par exemple un PUT). Si
deux clients font l'opération à peu près en même temps, il y a un
risque d'une séquence :
- Client 1 fait un
GET, - Client 2 fait pareil,
- Client 1 fait un
PUTavec sa version modifiée, - Client 2 en fait autant,
- La mise à jour de Client 1 est perdue
Les mises à jour conditionnelles résoudraient ce problème : si
Client 2 fait sa mise à jour en ajoutant « seulement si la ressource
n'a pas changé », son PUT sera refusé, il devra
refaire un GET et il récupérera alors les
changeements de Client 1 avant d'appliquer les siens.
En pratique, les requêtes conditionnelles se font avec des champs
comme If-Modified-Since: dont la valeur est une
date. Par exemple, le client de syndication qui a récupéré une page
le 24 février à 18:11, va envoyer un If-Modified-Since:
Thu, 24 Feb 2022 18:11:00 GMT et le serveur ne lui
enverra la ressource Atom ou
RSS que si elle est plus récente (il recevra
un code de retour 304 dans le cas contraire). Autre exemple de
champ d'en-tête pour les requêtes conditionnelles,
If-Match:. Ce champ demande que la requête ne
soit exécutée que si la ressource correspond à la valeur du
If-Match:. La valeur est un validateur, comme
expliqué plus haut. If-Match: permet ainsi de
résoudre le problème de la mise à jour perdue.
Les ressources chargées en HTTP peuvent être de grande
taille. Parfois, le réseau a un hoquet et le transfert s'arrête. Il
serait agréable de pouvoir ensuite reprendre là où on s'était
arrêté, au lieu de tout reprendre à zéro. HTTP le permet via les
requêtes d'un intervalle (section 14). Le client indique par le
champ Range: quel intervalle de la ressource il
souhaite. Cet intervalle peut se formuler en plusieurs unités, le
champ Accept-Ranges: permettant au serveur
d'indiquer qu'il gère ces demandes, et dans quelles unités. En
pratique, seuls les octets
marchent réellement. Par exemple, ici, j'utilise curl pour récupérer
50 octets d'un article :
% curl -v --range 3100-3150 https://www.bortzmeyer.org/1.html ... > GET /1.html HTTP/2 > Host: www.bortzmeyer.org > range: bytes=3100-3150 ... ocuments, qui forme l'ossature de la <b><a class="
Passons maintenant aux codes de retour HTTP (section 15). Il y en a au moins un qui est célèbre, 404, qui indique que la ressource demandée n'a pas été trouvée sur ce serveur et qui est souvent directement visible par l'utilisateur humain (pensez aux « pages 404 » d'erreur). Ces codes sont composés de trois chiffres, le premier indiquant la classe :
- 1 indique que l'opération n'est pas terminée,
- 2 indique que l'opération a été finie et avec succès,
- 3 indique que l'opération n'a pas été faite mais il ne s'agit pas pour autant d'une erreur (contrairement à ce que dit le RFC, ce n'est pas forcément une redirection, plutôt « la vérité est ailleurs », ainsi 304 signifie, en réponse à une requête conditionnelle, que la ressource n'a pas été modifiée),
- 4 indique une erreur due au client, et qu'il n'est donc pas utile que celui-ci réessaie à l'identique,
- 5 indique une erreur due au serveur et le client peut donc avoir intérêt à réessayer plus tard.
Les deux autres chiffres fournissent des détails mais un client HTTP simple peut se contenter de comprendre la classe et d'ignorer les deux autres chiffres. Par exemple, 100 signifie que le serveur a compris la requête mais qu'il faut encore attendre pour la vraie réponse, 200 veut dire qu'il n'y a rien à dire, que tout s'est bien passé comme demandé, 308 indique qu'il faut aller voir à un autre URL, 404, comme signalé plus haut, indique que le serveur n'a pas trouvé la ressource, 500 est une erreur générique du serveur, en général renvoyée quand le serveur a eu un problème imprévu. Peut-être connaissez-vous également :
- 201 qui indique que la ressource a été créée (en réponse à
un
PUT), - 304, pour répondre à une requête conditionnelle, qui veut dire que le contenu n'ayant pas été modifié, le serveur n'envoie pas de réponse (si votre serveur a un flux de syndication, vous trouverez souvent cette réponse dans vos journaux),
- 400 qui signifie que la requête était syntaxiquement incorrecte,
- 401, pour demander que le client s'authentifie avant d'accéder à cette ressource, et 403 qui lui refuse purement et simplement l'accès,
- 410 qui veut dire la même chose que 404 mais en ajoutant que la ressource a bien existé dans le passé mais a été retirée (utilisé par exemple dans un article de ce blog),
- 409 indique un conflit entre l'état de la ressource et une modification demandée par le client (lorsqu'on se sert de HTTP pour éditer des ressources),
- 414 pour un URL trop long pour ce serveur (la norme HTTP ne met pas de limite quantitative à la taille des URL mais chaque serveur, lui, a une telle limite),
- 418 n'est pas réellement dans le registre IANA mais il avait été utilisé dans un RFC du premier avril et il apparait souvent dans les blagues,
- 503 que le serveur utilise quand il est temporairement à bout de moyens (surcharge, par exemple),
De nouveaux codes sont créés de temps en temps, et mis dans le registre IANA.
curl -v vous affichera entre autres ce code
de retour. Si vous ne voulez que le code, et pas tous les messages
que l'utilisation de -v entrainera, l'option
--write-out est bien pratique :
% curl --silent --write-out "%{http_code}\n" --output /dev/null https://www.bortzmeyer.org/1.html
200
% curl --silent --write-out "%{http_code}\n" --output /dev/null https://www.bortzmeyer.org/2.html
404
Sinon, pour rire avec les codes de statut HTTP, il existe des photos de chats et une proposition d'illustrer ces codes par des émojis.
Beaucoup de choses dans HTTP peuvent être étendues (section 16). On peut créer de nouvelles méthodes, de nouveaux codes de retour, etc. Un logiciel client ou serveur ne doit donc pas s'étonner de voir apparaitre des questions ou des réponses qui n'existaient pas quand il a été programmé.
Ainsi, des nouvelles méthodes, en sus des traditionnelles
GET, POST,
PUT, etc , peuvent être créées, comme l'avait
été PATCH par le RFC 5789. La liste à jour des méthodes est dans un
registre IANA. Si vous programmez côté serveur, et que vous utilisez l'interface
CGI, la méthode est indiquée dans la variable
REQUEST_METHOD et vous pouvez la tester, par
exemple ici en Python :
if environ["REQUEST_METHOD"] == "FOOBAR": ... Do something useful else: return unsupported(start_response, environ["REQUEST_METHOD"])
Des codes de retour peuvent également être ajoutés, comme le 451 (censure) du RFC 7725. Là aussi, la liste faisant autorité est le registre IANA.
Bien sûr, le registre le plus dynamique, celui qui voit le plus
d'ajouts, est celui des champs de
l'en-tête. Mais attention : du fait qu'il bouge beaucoup, les
nouveaux champs ne seront pas compris et utilisés par une bonne
partie des logiciels. (Au passage, notre RFC rappelle que l'ancienne
convention de préfixer les noms de champs non officiels par un
X- a été abandonnée, par le RFC 6648.)
Et enfin, on peut étendre les listes de mécanismes d'authentification, et plusieurs autres.
Très utilisé, HTTP a évidemment connu sa part de problèmes de sécurité. La section 17 du RFC analyse les principaux risques. (Certains risques spécifiques sont traités dans d'autres RFC. Ainsi, les problèmes posés par l'analyse de l'encodage textuel de HTTP/1 sont étudiés dans le RFC 9112. Ceux liés aux URL sont dans le RFC 3986.) D'autre part, beaucoup de problème de sécurité du Web viennent :
- du code qui tourne sur le serveur ; notre RFC ne va pas parler de la sécurité de WordPress,
- des failles du client (par exemple si en exécutant du code JavaScript, il permet un accès excessif à la machine cliente),
- de l'Internet lui-même (comme la divulgation de l'adresse IP source).
Cette section 17 se concentre sur les problèmes de sécurité de HTTP, ce qui est déjà pas mal. Le RFC recommande la lecture des documents OWASP pour le reste.
Bon, premier problème, la notion d'autorité. Une réponse fait
autorité si elle vient de l'origine, telle
qu'indiquée dans l'URL. Le client HTTP va donc dépendre du mécanisme
de résolution de nom. Si, par exemple, la machine du client utilise
un résolveur DNS menteur, tout est
fichu. On croit aller sur http://pornhub.com/
et on se retrouve sur une page Web de
l'ARCOM. Il est donc crucial que cette
résolution de noms soit sécurisée, par exemple en utilisant un
résolveur DNS de confiance, et qui valide les réponses avec
DNSSEC. HTTPS protège partiellement. Une des
raisons pour lesquelles sa protection n'est pas parfaite est qu'il
est compliqué de valider proprement (cf. RFC 7525). Et puis les problèmes sont souvent non techniques,
par exemple la plupart des tentatives
d'hameçonnage ne vont pas viser l'autorité
mais la perception que l'utilisateur en a. Une page Web copiée sur
celle d'une banque peut être prise pour celle de la banque même si,
techniquement, il n'y a eu aucune subversion des techniques de
sécurité. Le RFC recommande qu'au minimum, les navigateurs Web
permettent d'examiner facilement l'URL vers lequel va un lien, et de
l'analyser (beaucoup d'utilisateurs vont croire, en voyant
https://nimportequoi.example/banque-de-confiance.com
que le nom de domaine est
banque-de-confiance.com…).
On a vu qu'HTTP n'est pas forcément de bout en bout et qu'il est même fréquent que des intermédiaires se trouvent sur le trajet. Évidemment, un tel intermédaire est idéalement placé pour certaines attaques. Bref, il ne faut utiliser que des intermédiaires de confiance et bien gérés. (De nombreuses organisations placent sur le trajet de leurs requêtes HTTP des boites noires au logiciel privateur qui espionnent le trafic et font Dieu sait quoi avec les données récoltées.)
HTTP est juste un protocole entre le client et le serveur. Le
client demande une ressource, le serveur lui envoie. D'où le serveur
a-t-il tiré cette ressource ? Ce n'est pas l'affaire de HTTP. En
pratique, il est fréquent que le serveur ait simplement lu un
fichier pré-existant sur ses disques et, en outre, que le chemin
menant à ce fichier vienne d'une simple transformation de l'URL. Par
exemple, Apache,
avec la directive DocumentRoot valant
/var/doc/mon-beau-site et une requête HTTP
GET /toto/tata.html va chercher un fichier
/var/www/mon-beau-site/toto/tata.html. Dans ce
cas, attention, certaines manipulations sur le chemin donné en
paramètre à GET peuvent donner au client
davantage d'accès que ce qui était voulu. Ainsi, sans précautions
particulières, une requête GET
/../toto/tata.html serait traduite en
/var/www/mon-beau-site/../toto/tata.html, ce
qui, sur Unix, équivaudra à
/var/www/toto/tata.html, où il n'était
peut-être pas prévu que le client puisse se promener. Les auteurs de
serveurs doivent donc être vigilants : ce qui vient du client n'est
pas digne de confiance.
Autre risque lorsqu'on fait une confiance aveugle aux données envoyées par le client, l'injection. Ces données, par exemple le chemin dans l'URL, sont traitées par des langages qui ont des règles spéciales pour certains caractères. Si un de ces caractères se retrouve dans l'URL, et qe le programme, côté serveur, n'est pas prudent avec les données extérieures, le ou les caractères spéciaux seront interprétés, avec parfois d'intéressantes failles de sécurité à la clé. (Mais, attention, tester la présence de « caractères dangereux » n'est en général pas une bonne idée.)
La liste des questions de sécurité liées à HTTP ne s'arrête pas là. On a vu que HTTP ne mettait pas de limite de taille à des éléments comme l'URL. Un analyseur imprudent, côté serveur, peut se faire attaquer par un client qui enverrait un chemin d'URL très long, déclenchant par exemple un débordement de tableau.
HTTP est un protocole très bavard, et un client HTTP possède
beaucoup d'informations sur l'utilisateur humain qui est
derrière. Le client doit donc faire très attention à ne pas envoyer
ces données. Le RFC ne donne pas d'exemple précis mais on peut par
exemple penser au champ Referer qui indique
l'URL d'où on vient. Si le client l'envoie systématiquement, et que
l'utilisateur visitait un site Web interne de l'organisation avant de
cliquer vers un lien externe, son navigateur enverra des détails sur
le site Web interne. Autre cas important,
un champ comme Accept-Language, qu'on peut
estimer utile dans certains cas, est dangereux pour la vie privée,
transmettant une information qui peut être sensible, par exemple si
on a indiqué une langue minoritaire et mal vue dans son pays. Et
User-Agent facilite le ciblage d'éventuelles
attaques du serveur contre le client.
Du fait de ce caractère bavard, et aussi parce que, sur l'Internet, il y a des choses qu'on ne peut pas dissimuler facilement (comme l'adresse IP source), ce que le serveur stocke dans ses journaux est donc sensible du point de vue de la vie privée. Des lois comme la loi Informatique & Libertés encadrent la gestion de telles bases de données personnelles. Le contenu de ces journaux doit donc être protégé contre les accès illégitimes.
Comme HTTP est bavard et que le client envoie beaucoup de choses
(comme les Accept-Language et
User-Agent cités plus haut), le serveur peut
relativement facilement faire du
fingerprinting,
c'est-à-dire reconnaitre un client HTTP parmi des dizaines ou des
centaines de milliers d'aures. (Vous ne me croyez pas ? Regardez le
Panopticlick.) Un serveur peut ainsi suivre un client
à la trace, même sans
cookies (voir
« A
Survey on Web Tracking: Mechanisms, Implications, and
Defenses »).
Voilà, et encore je n'ai présenté ici qu'une partie des questions de sécurité liées à l'utilisation de HTTP. Lisez le RFC pour en savoir plus. Passons maintenant aux différents registres IANA qui servent à stocker les différents éléments du protocole HTTP. Je les ai présenté (au moins une partie d'entre eux !) plus haut mais je n'ai pas parlé de la politique d'enregistrement de nouvaux éléments. En suivant la terminologie du RFC 8126, il y a entre autres le registre des méthodes (pour ajouter une nouvelle méthode, il faut suivre la politique « Examen par l'IETF », une des plus lourdes), le registre des codes de retour (même politique), le registre des champs (désormais séparé de celui des champs du courrier, politique « Spécification nécessaire »), etc.
Ah, et si vous voulez la syntaxe complète de HTTP sous forme d'une grammaire formelle, lisez l'ABNF en annexe A.
Et avec un langage de programmation ? Vu le succès de HTTP et sa présence partout, il n'est pas étonnant que tous les langages de programmation permettent facilement de faire des requêtes HTTP. HTTP, en tout cas HTTP/1, est suffisamment simple pour qu'on puisse le programmer soi-même en appelant les fonctions réseau de bas niveau, mais pourquoi s'embêter ? Utilisons les bibliothèques prévues à cet effet et commençons par le langage Python. D'abord avec la bibliothèque standard http.client :
conn = http.client.HTTPConnection(HOST)
conn.request("GET", PATH)
result = conn.getresponse()
body = result.read().decode()
Et hop, la variable body contient une
représentation de la ressource demandée (le programme complet est en
sample-http-client.py). En pratique, la plupart des
programmeurs Python utiliseront sans doute une autre
bibliothèque standard, qui n'est pas spécifique à HTTP et
permet de traiter des URL quelconques (cela
donne le programme sample-http-urllib.py). D'encore
plus haut niveau (mais pas incluse dans la bibliothèque standard, ce
qui ajoute une dépendance à votre programme) est la bibliothèque
Requests, souvent utilisée (voir par exemple sample-http-requests.py).
Ensuite, avec le langage Go. Là aussi, il dispose de HTTP dans sa bibliothèque standard :
response, err := http.Get(Url) defer response.Body.Close() body, err := ioutil.ReadAll(response.Body)
Le programme complet est sample-http.go.
Et ici un client en Elixir, utilisant la bibliothèque HTTPoison :
HTTPoison.start()
{:ok, result} = HTTPoison.get(@url)
La version longue est en sample-http.ex
L'annexe B de notre RFC fait la liste des principaux changements depuis les précédents RFC. Je l'ai dit, le protocole ne change pas réellement mais il y a quand même quelques modifications, notamment des clarifications de textes trop ambigus (par exemple la définition des intervalles). Et bien sûr le gros changement est qu'il y a désormais une définition abstraite de ce qu'est un message HTTP, séparée des définitions concrètes pour les trois versions de HTTP en service. En outre, il y a désormais des recommandations explicites de taille minimale à accepter pour certains élements (par exemple 8 000 octets pour les URI).
HTTP est, comme vous le savez, un immense succès, dû à la place prise par le Web, dont il est le protocole de référence. Le RFC résume l'histoire de HTTP :
- Publié pour la première fois en
1990, au début un protocole ultra-simple,
réduit à la méthode
GET, et qui n'a été documenté qu'après, - HTTP/1.0 (RFC 1945 en 1996 mais le protocole existait bien avant le RFC) en a fait un protocole bien plus riche (en-tête, plusieurs méthodes), avec indication du type des ressources, et virtual hosting,
- HTTP/1.1 en 1995 (normalisé dans le RFC 2068 à l'origine, et aujourd'hui RFC 9112), au moment de l'explosion de l'usage du Web, a apporté beaucoup d'améliorations, comme le fait que les connexions sont persistentes par défaut,
- HTTP/2 a marqué plusieurs ruptures en 2015 (RFC 7540), avec son parallélisme (les réponses n'arrivent plus forcément dans l'ordre des requêtes) et son encodage binaire, rompant avec la tradition textuelle de beaucoup de protocoles IETF,
- Et enfin HTTP/3 (RFC 9114, en 2022) a abandonné TCP pour QUIC,
L'article seul
RFC 9109: Network Time Protocol Version 4: Port Randomization
Date de publication du RFC : Août 2021
Auteur(s) du RFC : F. Gont, G. Gont (SI6 Networks), M. Lichvar (Red Hat)
Chemin des normes
Première rédaction de cet article le 13 septembre 2021
Le protocole NTP utilisait traditionnellement un port bien connu, 123, comme source et comme destination. Cela facilite certaines attaques en aveugle, lorsque l'attaquant ne peut pas regarder le trafic, mais sait au moins quels ports seront utilisés. Pour compliquer ces attaques, ce RFC demande que NTP utilise des numéros de ports aléatoires autant que possible.
NTP est un très vieux protocole (sa norme actuelle est le RFC 5905 mais sa première version date de 1985, dans le RFC 958). Dans son histoire, il a eu sa dose des failles de sécurité. Certaines des attaques ne nécessitaient pas d'être sur le chemin entre deux machines qui communiquent car elles pouvaient se faire en aveugle. Pour une telle attaque, il faut deviner un certain nombre de choses sur la communication, afin que les paquets de l'attaquant soient acceptés. Typiquement, il faut connaitre les adresses IP source et destination, ainsi que les ports source et destination et le key ID de NTP (RFC 5905, section 9.1). NTP a plusieurs modes de fonctionnement (RFC 5905, sections 2 et 3). Certains nécessitent d'accepter des paquets non sollicités et, dans ce cas, il faut bien écouter sur un port bien connu, en l'occurrence 123. Mais ce n'est pas nécessaire dans tous les cas et notre RFC demande donc qu'on n'utilise le port bien connu que si c'est nécessaire, au lieu de le faire systématiquement comme c'était le cas au début de NTP et comme cela se fait encore trop souvent (« Usage Analysis of the NIST Internet Time Service »). C'est une application à NTP d'un principe général sur l'Internet, documenté dans le RFC 6056 : n'utilisez pas de numéros de port statiques ou prévisibles. Si on suit ce conseil, un attaquant en aveugle aura une information de plus à deviner, ce qui gênera sa tâche. Le fait d'utiliser un port source fixe a valu à NTP un CVE, CVE-2019-11331.
La section 3 du RFC résume les considérations à prendre en compte. L'idée de choisir aléatoirement le port source pour faire face aux attaques en aveugle est présente dans bien d'autres RFC comme le RFC 5927 ou le RFC 4953. Elle est recommandée par le RFC 6056. Un inconvénient possible (mais mineur) est que la sélection du chemin en cas d'ECMP peut dépendre du port source (calcul d'un condensat sur le tuple à cinq éléments {protocole, adresse IP source, adresse IP destination, port source, port destination}, avant d'utiliser ce condensat pour choisir le chemin) et donc cela peut affecter les temps de réponse, troublant ainsi NTP, qui compte sur une certaine stabilité du RTT. D'autre part, le port source aléatoire peut gêner certaines stratégies de filtrage par les pare-feux : on ne peut plus reconnaitre un client NTP à son port source. Par contre, un avantage du port source aléatoire est que certains routeurs NAT sont suffisamment bogués pour ne pas traduire le port source s'il fait partie des ports « système » (inférieurs à 1 024), empêchant ainsi les clients NTP situés derrière ces routeurs de fonctionner. Le port source aléatoire résout le problème.
Assez de considérations, passons à la norme. Le RFC 5905, section 9.1, est modifié pour remplacer la supposition qui était faite d'un port source fixe par la recommandation d'un port source aléatoire.
Cela ne pose pas de problème particulier de mise en œuvre. Par
exemple, sur un système POSIX, ne
pas faire de bind() sur la
prise suffira à ce que les paquets associés
soient émis avec un port source aléatoirement sélectionné par le
système d'exploitation.
À propos de mise en œuvre, où en sont les logiciels actuels ? OpenNTPD n'a jamais utilisé le port source 123 et est donc déjà compatible avec la nouvelle règle. Même chose pour Chrony. Par contre, à ma connaissance, ntpd ne suit pas encore la nouvelle règle.
L'article seul
RFC 9108: YANG Types for DNS Classes and Resource Record Types
Date de publication du RFC : Septembre 2021
Auteur(s) du RFC : L. Lhotka (CZ.NIC), P. Spacek (ISC)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 9 septembre 2021
YANG est le langage standard à
l'IETF
pour décrire des modèles de données, afin de, par exemple, gérer
automatiquement des ressources. Ce RFC décrit le module YANG
iana-dns-class-rr-type, qui rassemble les
définitions des types d'enregistrements DNS.
YANG est normalisé dans le RFC 7950, et d'innombrables RFC décrivent des modules YANG pour de nombreux protocoles. YANG est utilisé par des protocoles de gestion à distance de ressources, comme RESTCONF (RFC 8040) ou NETCONF (RFC 6241). Mais ce RFC est le premier qui va utiliser YANG pour le DNS. L'un des objectifs (à long terme pour l'instant) est d'utiliser RESTCONF ou un équivalent pour gérer des serveurs DNS, résolveurs ou serveurs faisant autorité. (C'est un très vieux projet que cette gestion automatisée et normalisée des serveurs DNS.) Un mécanisme standard de gestion des serveurs nécessite un modèle de données commun, et c'est là que YANG est utile. Notre RFC est encore loin d'un modèle complet, il ne définit que le socle, le type des données que le DNS manipule. C'est la version YANG de deux registres IANA, celui des types d'enregistrements DNS et celui des classes (même si ce dernier concept est bien abandonné aujourd'hui).
Le registre IANA pour le DNS contient treize sous-registres. Le RFC n'en passe que deux en YANG, les classes et les types d'enregistrement. Les autres devront attendre un autre RFC. Les types d'enregistrement sont modélisés ainsi :
typedef rr-type-name {
type enumeration {
enum A {
value 1;
description
"a host address";
reference
"RFC 1035";
}
enum NS {
value 2;
description
"an authoritative name server";
...
Et les classes (mais, rappelez-vous, seule la classe
IN compte aujourd'hui) :
typedef dns-class-name {
type enumeration {
enum IN {
value 1;
description
"Internet (IN)";
reference
"RFC 1035";
}
enum CH {
value 3;
description
"Chaos (CH)";
reference
"D. Moon, 'Chaosnet', A.I. Memo 628, Massachusetts Institute of
Technology Artificial Intelligence Laboratory, June 1981.";
}
...
Le module YANG complet se retrouve dans le registre IANA (créé par le RFC 6020).
Le module YANG devra suivre l'actuel registre IANA, qui utilise un autre format. Pour faciliter la synchronisation, le RFC contient une feuille de style XSLT pour convertir l'actuel format, qui est la référence, vers le format YANG. La feuille de style est dans l'annexe A du RFC mais vous avez une copie ici. Voici comment produire et vérifier le module YANG :
% wget https://www.iana.org/assignments/dns-parameters/dns-parameters.xml % xsltproc iana-dns-class-rr-type.xsl dns-parameters.xml > iana-dns-class-rr-type.yang % pyang iana-dns-class-rr-type.yang
Le moteur XSLT xsltproc fait partie de la
libxslt. Le vérificateur YANG Pyang
est distribué via
GitHub mais on peut aussi l'installer avec pip (pip
install pyang).
L'article seul
RFC 9107: BGP Optimal Route Reflection (BGP ORR)
Date de publication du RFC : Août 2021
Auteur(s) du RFC : R. Raszuk (NTT Network Innovations), B. Decraene (Orange), C. Cassar, E. Aman, K. Wang (Juniper Networks)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF idr
Première rédaction de cet article le 13 septembre 2021
Les grands AS ont tellement de routeurs BGP qu'ils ne peuvent pas connecter chaque routeur à tous les autres. On utilise alors souvent des réflecteurs de route, un petit nombre de machines parlant BGP auxquelles tout le monde se connecte, et qui redistribuent les routes externes apprises. Mais une machine BGP ne redistribue que les routes qu'elle utiliserait elle-même. Or, le réflecteur risque de faire un choix en fonction de sa position dans le réseau, qui n'est pas la même que celle du routeur « client ». Les routeurs risquent donc d'apprendre du réflecteur des routes sous-optimales (la route optimale étant typiquement celle qui amène à la sortie le plus vite possible, en application de la méthode de la patate chaude). Ce RFC définit une extension de BGP qui va permettre de sélectionner des routes spécifiques à un client, ou à un groupe de clients.
Un petit rappel : un réflecteur de routes (route reflector) fonctionne sur iBGP (Internal BGP), à l'intérieur d'un AS, alors que les serveurs de routes (route server) font de l'eBGP (External BGP), par exemple sur un point d'échange. Ces réflecteurs sont décrits dans le RFC 4456. Ils ne sont pas la seule méthode pour distribuer l'information sur les routes externes à l'intérieur d'un grand AS, mais c'est quand même la solution la plus fréquente.
Le RFC 4456 notait déjà que, vu les coûts attribués aux liens internes à l'AS, le réflecteur ne choisirait pas forcément les mêmes routes que si on avait utilisé un maillage complet. Le routage « de la patate chaude » (qui consiste à essayer de faire sortir le paquet de son réseau le plus vite possible, pour que ce soit un autre qui l'achemine) risque donc de ne pas aussi bien marcher : le point de sortie lorsqu'on utilise le réflecteur sera peut-être plus éloigné que si on avait le maillage complet, surtout si le réflecteur est situé en dehors du chemin habituel des paquets et n'a donc pas la même vision que les routeurs « normaux ». Or, c'est un cas fréquent. Le réflecteur choisira alors des routes qui sont optimales pour lui, mais qui ne le sont pas pour ces routeurs « normaux ».
La solution ? Permettre à l'administrateur réseaux de définir une localisation virtuelle pour le réflecteur, à partir de laquelle il fera ses calculs et choisira ses routes, au lieu d'utiliser sa localisation physique. Cette localisation virtuelle sera une adresse IP. Le réflecteur peut avoir plusieurs de ces localisations virtuelles, adaptées à des publics différents. Bref, le texte du RFC 4271 qui concerne la sélection de la meilleure route (section 9.1.2.2 du RFC 4271) est modifié pour remplacer « en fonction du saut suivant » par « en fonction de l'adresse IP configurée dans le réflecteur ».
Pour que cela marche, il faut que le réflecteur ait une vue complète du réseau, pour pouvoir calculer des coûts à partir de n'importe quel point du réseau. C'est possible avec les IGP à état des liens comme OSPF, ou bien avec BGP-LS (RFC 9552).
Et si le réflecteur a plusieurs clients ayant des desiderata différents, par exemple parce qu'ils sont situés à des endroits différents ? Dans ce cas, il doit faire tourner plusieurs processus de décision, chacun configuré avec une localisation vituelle différente.
Les principales marques de routeurs mettent déjà en œuvre ce RFC, comme on peut le voir sur la liste des implémentations. Du côté des logiciels qui ne sont pas forcément installés sur des routeurs, il semble que BIRD ne sache pas encore faire comme décrit dans ce RFC.
L'article seul
RFC 9106: Argon2 Memory-Hard Function for Password Hashing and Proof-of-Work Applications
Date de publication du RFC : Septembre 2021
Auteur(s) du RFC : A. Biryukov, D. Dinu (University of Luxembourg), D. Khovratovich (ABDK Consulting), S. Josefsson (SJD AB)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF cfrg
Première rédaction de cet article le 8 septembre 2021
En général, en informatique, on essaie de diminuer la consommation de mémoire et de processeur des programmes, afin de les rendre plus efficaces. Mais il y a aussi des cas où on va tenter de réduire délibérement l'efficacité d'un programme. C'est le cas des fonctions de condensation qui sont utilisées en sécurité : on ne veut pas faciliter la tâche de l'attaquant. Ainsi, Argon2, spécifié dans ce RFC est volontairement très consommatrice de mémoire et d'accès à cette mémoire. Elle peut être utilisée pour condenser des mots de passe, ou pour des sytèmes à preuve de travail.
L'article original décrivant Argon2 est « Argon2: the memory-hard function for password hashing and other applications » et vous pouvez également lire « Argon2: New Generation of Memory-Hard Functions for Password Hashing and Other Applications ». Notre RFC reprend la description officielle, mais en s'orientant davantage vers les programmeurs et programmeuses qui devront mettre en œuvre cette fonction. Argon2 est conçu pour être memory-hard, c'est-à-dire faire souvent appel à la mémoire de la machine. Cela permet notamment aux ordinateurs classiques de tenir tête aux systèmes à base d'ASIC. (Par exemple, nombreuses sont les chaînes de blocs utilisant des preuves de travail. La fonction utilisée par Bitcoin, SHA-256, conçue pour être simple et rapide, n'est pas memory-hard et le résultat est qu'il y a belle lurette qu'un ordinateur, même rapide, n'a plus aucune chance dans le minage de Bitcoin. Seules les machines spécialisées peuvent rester en course, ce qui contribue à centraliser le minage dans peu de fermes de minage.) Argon2 est donc dur pour la mémoire, comme décrit dans l'article « High Parallel Complexity Graphs and Memory-Hard Functions ». À noter qu'Argon2 est très spécifique à l'architecture x86.
Argon2 se décline en trois variantes, Argon2id (celle qui est recommandée par le RFC), Argon2d et Argon2i. Argon2d a des accès mémoire qui dépendent des données, ce qui fait qu'il ne doit pas être employé si un attaquant peut examiner ces accès mémoire (attaque par canal auxiliaire). Il convient donc pour du minage de cryptomonnaie mais pas pour une carte à puce, que l'attaquant potentiel peut observer en fonctionnement. Argon2i n'a pas ce défaut mais est plus lent, ce qui ne gêne pas pour la condensation de mots de passe mais serait un problème pour le minage. Argon2id, la variante recommandée, combine les deux et est donc à la fois rapide et résistante aux attaques par canal auxiliaire. (Cf. « Tradeoff Cryptanalysis of Memory-Hard Functions », pour les compromis à faire en concevant ces fonctions dures pour la mémoire.) Si vous hésitez, prenez donc Argon2id. La section 4 du RFC décrit plus en détail les paramètres des variantes, et les choix recommandés.
Argon repose sur une fonction de condensation existante (qui n'est pas forcément dure pour la mémoire) et le RFC suggère Blake (RFC 7693).
La section 3 du RFC décrit l'algorithme mais je n'essaierai pas de vous le résumer, voyez le RFC.
La section 5 contient des vecteurs de test si vous voulez programmer Argon2 et vérifier les résultats de votre programme.
La section 7 du RFC revient en détail sur certaines questions de sécurité, notamment l'analyse de la résistance d'Argon2, par exemple aux attaques par force brute.
L'article seul
RFC 9103: DNS Zone Transfer over TLS
Date de publication du RFC : Août 2021
Auteur(s) du RFC : W. Toorop (NLnet Labs), S. Dickinson (Sinodun IT), S. Sahib (Brave Software), P. Aras, A. Mankin (Salesforce)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dprive
Première rédaction de cet article le 12 septembre 2021
Traditionnellement, le transfert d'une zone DNS depuis le serveur maitre vers ses esclaves se fait en clair. Si l'authentification et l'intégrité sont protégées, par exemple par TSIG, le transfert en clair ne fournit pas de confidentialité. Or on n'a pas forcément envie qu'un tiers puisse lire l'entièreté de la zone. Ce RFC normalise un transfert de zones sur TLS, XoT (zone transfer over TLS). Il en profite pour faire quelques ajustement dans l'utilisation de TCP pour les transferts de zone.
Le RFC fait quarante-deux pages mais le principe est très simple. Au lieu de faire le transfert de zones (aussi nommé AXFR, RFC 5936) directement sur TCP, on le fait sur du TLS, comme le fait DoT (RFC 7858). Le reste du RFC est consacré à des détails pratiques, mais le concept tient en une seule phrase.
Le DNS sur TLS est normalisé depuis cinq
ans, mais il ne couvre officiellement que la communication entre la
machine terminale et le résolveur. Bien que des essais aient
été faits pour communiquer en TLS avec des serveurs faisant
autorité, rien n'est encore normalisé. Mais, au fait, est-ce
que les transferts de zone ont vraiment besoin de confidentialité ?
Le RFC 9076 ne traite pas le problème, le
renvoyant aux RFC 5936 (la norme du transfert
de zones, qui parle de la possibilité de restreindre ce transfert à
des machines autorisées) et au RFC 5155 (qui
parle des risques d'énumération de tous les noms d'une
zone). Certes, le DNS étant public, tout le monde peut interroger
les serveurs faisant autorité, et connaitre ainsi les données
associées à un nom de
domaine, mais il faut pour cela connaitre les noms. Si
les petites zones n'ont rien de secret (elles ne contiennent que
l'apex et www), si certaines zones sont
publiques (la racine, par exemple), pour les autres zones, leur
responsable ne souhaite pas forcément qu'on ait accès à tous les
noms. Certains peuvent être le nom d'une personne
(le-pc-de-henri.zone.example), et donc être des
données personnelles, à protéger (le RFC note bien sûr que c'est une
mauvaise pratique, mais elle existe), certains noms peuvent
renseigner sur les activités et les projets d'une entreprise. Bref,
il peut être tout à fait raisonnable de ne pas vouloir transmettre
la zone en clair.
À noter qu'une surveillance du réseau pendant un transfert de zones fait en clair n'est pas la seule façon de trouver tous les noms. Une autre technique est l'énumération, utilisant par exemple les enregistrement NSEC de DNSSEC. Les enregistrement NSEC3 du RFC 5155 ont été conçus pour limiter ce risque (mais pas le supprimer ; le projet NSEC5 va essayer de résoudre le problème mais c'est loin d'être garanti).
Comment sécurise-t-on les transferts de zone aujourd'hui ? Les TSIG du RFC 8945 protègent l'intégrité mais pas la confidentialité. Vous pouvez trouver des détails pratiques sur la sécurisation des transferts de zone, combinant TSIG et ACL, dans un document du NIST en anglais et un document de l'ANSSI en français. On peut aussi en théorie utiliser IPsec entre maitre et esclaves mais cela semble irréaliste. D'où l'idée de base de ce nouveau RFC : mettre le transfert de zones sur TLS. Après tout, on utilise déjà TLS pour sécuriser la communication entre le client final et le résolveur : le protocole DoT, normalisé dans le RFC 7858.
Notre RFC introduit quelques nouveaux acronymes rigolos :
- XFR : couvre à la fois AXFR (RFC 5936) et IXFR (transferts incrémentaux, RFC 1995). Donc, XFR-over-TLS, c'est un transfert de zones, complet ou incrémental, sur TLS.
- XoT : acronyme pour XFR-over-TLS.
- AXoT : AXFR sur TLS.
- IXoT : IXFR sur TLS.
Pour la terminologie liée à la vie privée, voir le RFC 6973.
La section 3 du RFC spécifie le modèle de menace : on veut protéger le transfert de zones contre l'espionnage par un tiers, mais on n'essaie pas de cacher l'existence de la zone, ou le fait que telle machine soit serveur faisant autorité pour la zone. En effet, ces informations peuvent être obtenues facilement en interrogeant le DNS ou, dans le cas d'un maitre caché, en regardant le trafic réseau, sans même en décrypter le contenu.
Les principes de conception de XoT ? Fournir de la confidentialité et de l'authentification grâce à TLS, mais aussi en profiter pour améliorer les performances. Un certain nombre de programmes DNS ne peuvent pas, par exemple, utiliser la même connexion TCP pour plusieurs transferts de zone (même si le RFC 5936 le recommande). Il est difficile de résoudre ce problème sans casser les programmes existants et pas encore mis à jour. Par contre, XoT étant nouveau, il peut spécifier dès le début certains comportements qui améliorent les performances, comme l'utilisation d'une seule connexion pour plusieurs transferts.
Petit rappel de comment fonctionne le transfert de zones (RFC 5936, si vous voulez tous les détails). D'abord, le fonctionnement le plus courant : le serveur maitre (ou primaire) envoie un NOTIFY (RFC 1996) à ses esclaves (ou secondaires). Ceux-ci envoient une requête de type SOA au maitre puis, si le numéro de série récupéré est supérieur au leur, ils lancent l'AXFR sur TCP. Il y a des variations possibles : si le maitre n'envoie pas de NOTIFY ou bien s'ils sont perdus, les esclaves testent quand même de temps en temps le SOA (paramètre Refresh du SOA). Autre variante possible : les esclaves peuvent utiliser IXFR (RFC 1995) au lieu de AXFR pour ne transférer que la partie de la zone qui a changé. Et ils peuvent avoir à se rabattre en AXFR si le maitre ne gérait pas IXFR. Et les messages IXFR peuvent être sur UDP ou sur TCP (en pratique, BIND, NSD et bien d'autres font toujours l'IXFR sur TCP). Bref, il y a plusieurs cas. Les messages NOTIFY et SOA ne sont pas considérés comme sensibles du point de vue de la confidentialité et XoT ne les protège pas.
Maintenant, avec XoT, comment ça se passera (section 6 du RFC) ?
Une fois le transfert de zones décidé (via SOA, souvent précédé du
NOTIFY), le client (qui est donc le serveur secondaire) doit établir
une connexion TLS (1.3 minimum), en utilisant ALPN, avec
le nom dot (on notera que c'est donc le même
ALPN pour XoT et pour DoT, l'annexe A du RFC explique ce choix). Le
port est par défaut le classique 853 de
DoT. Le client authentifie le serveur via les techniques du RFC 8310. Le serveur vérifie le client, soit avec
des mécanismes TLS (plus sûrs mais plus compliqués à mettre en
œuvre), soit avec les classiques ACL. Le client TLS (le serveur DNS esclave) fait
ensuite de l'IXFR ou du AXFR classique sur ce canal TLS. Le serveur
doit être capable d'utiliser les codes d'erreur étendus du RFC 8914.
Voilà, c'est tout. Maintenant, quelques détails
pratiques. D'abord, rappelez-vous qu'il n'existe pas à l'heure
actuelle de norme pour du DoT entre résolveur et serveur faisant
autorité. Mais il y a des expériences en cours. Ici, par exemple, je
fais du DoT avec un serveur faisant autorité pour facebook.com :
% kdig +tls @a.ns.facebook.com. SOA facebook.com ;; TLS session (TLS1.3)-(ECDHE-X25519)-(RSA-PSS-RSAE-SHA256)-(AES-256-GCM) ... ;; ANSWER SECTION: facebook.com. 3600 IN SOA a.ns.facebook.com. dns.facebook.com. 1631273358 14400 1800 604800 300 ;; Received 86 B ;; Time 2021-09-10 13:35:44 CEST ;; From 2a03:2880:f0fc:c:face:b00c:0:35@853(TCP) in 199.0 ms
Mais on pourrait imaginer des serveurs faisant autorité qui ne fournissent pas ce service, pas encore normalisé, mais qui veulent faire du XoT. Est-ce possible de réserver TLS aux transferts de zone, mais sans l'utiliser pour les requêtes « normales » ? Oui, et dans ce cas le serveur doit répondre REFUSED à ces requêtes normales, avec le code d'erreur étendu 21 (Not supported). Ceci dit, il est difficile de dire comment réagiront les clients ; ils risquent d'ignorer le code d'erreur étendu et de recommencer bêtement (ou au contraire d'arrêter complètement d'utiliser le serveur).
Le but de XoT est de protéger le contenu de la zone contre les regards indiscrets. Mais comme vous le savez, TLS ne dissimule pas la taille des données qui passent entre ses mains et l'observation de cette taille peut donner des informations à un observateur, par exemple la taille des mises à jour en IXFR indique l'activité d'une zone. Le RFC suggère donc de remplir les données. Cela peut nécessiter d'envoyer des réponses vides, ce qui était interdit par les précédents RFC mais est maintenant autorisé.
Et les différentes formes de parallélisme des requêtes que permet le DNS sur TCP (et donc DoT) ? Elles sont décrites dans le RFC 7766. Si elles sont nécessaires pour exploiter le DNS de manière satisfaisante, elles ne sont pas forcément utiles pour XoT et notre RFC explique qu'on n'est pas forcé, par exemple, de permettre le pipelining (envoi d'une nouvelle requête quand la réponse à la précédente n'est pas encore arrivée) quand on fait du XoT. Par contre, comme avec tous les cas où on utilise du DNS sur TCP, il est recommandé de garder les connexions ouvertes un certain temps, par exemple en suivant le RFC 7828.
J'ai parlé plus haut de l'authentification dans une session XoT. La section 9 du RFC revient en détail sur cette question. Quels sont les mécanismes existants pour authentifier un transfert de zones ? Ils diffèrent par les services qu'ils rendent :
- Authentification de la source des données DNS.
- Authentification du correspondant (qui n'est pas forcément la source des données).
- Confidentialité.
Les mécanismes possibles sont :
- TSIG (RFC 8945) ; utiisant des clés partagées (ce qui n'est pas pratique), il permet d'authentifier la source des données.
- SIG(0) (RFC 2931) ; utilisant de la cryptographie asymétrique, il permet d'authentifier la source des données. Ceci dit, il n'est quasiment jamais mis en œuvre dans les programmes DNS.
- TLS en mode « opportuniste » (sans authentification) ; il ne garantit rien, sauf peut-être contre un observateur passif.
- TLS en mode strict (obligation d'authentification du serveur par le client, RFC 8310) ; cela permet l'authentification du correspondant, et la confidentialité (mais ne garantit pas que le correspondant est la vraie source des données).
- TLS mutuel ; le client s'authentifie également.
- ACL fondées sur l'adresse IP ; très répandu, ce mécanisme permet au serveur d'« authentifier » le client. Une faiblesse pour le cas de XoT : le serveur doit accepter l'établissement de la session TLS avant de savoir s'il s'agit de XoT ou de DNS ordinaire sur TLS.
- ZONEMD (RFC 8976) ; ce n'est pas vraiment une technique d'authentification mais elle peut être utile, en combinaison avec XoT.
Quelles sont les mises en œuvres actuelles de XoT ? Une liste existe. Actuellement, il n'y a guère que NSD qui permet le XoT mais le travail est en cours pour d'autres. Voyons comment faire du XoT avec NSD. On télécharge la dernière version (XoT est apparu en 4.3.7), on la compile (pas besoin d'options particulières) et on la configure, par exemple ainsi :
server:
port: 7053
...
tls-service-key: "server.key"
tls-service-pem: "server.pem"
# No TLS service if the port is not explicit in an interface definition
ip-address: 127.0.0.1@7153
tls-port: 7153
zone:
name: "fx"
zonefile: "fx"
# NSD 4.3.7 (september 2021) : not yet a way to restrict XoT
provide-xfr: 127.0.0.1 NOKEY
Ainsi configuré, NSD va écouter sur le port 7153 en TLS. Notons qu'il n'y a pas de moyen de configurer finement : il accepte forcément XoT et les requêtes « normales ». De même, on ne peut pas obliger un client DNS à n'utiliser que XoT. Testons avec kdig, un client DNS qui accepte TLS, d'abord une requête normale :
% kdig +tls @localhost -p 7153 SOA fx
;; TLS session (TLS1.3)-(ECDHE-SECP256R1)-(RSA-PSS-RSAE-SHA256)-(AES-256-GCM)
;; ->>HEADER<<- opcode: QUERY; status: NOERROR; id: 11413
...
;; ANSWER SECTION:
fx. 600 IN SOA ns1.fx. root.fx. 2021091201 604800 86400 2419200 86400
...
;; Time 2021-09-12 11:06:39 CEST
;; From 127.0.0.1@7153(TCP) in 0.2 ms
Parfait, tout marche. Et le transfert de zones ?
% kdig +tls @localhost -p 7153 AXFR fx ;; AXFR for fx. fx. 600 IN SOA ns1.fx. root.fx. 2021091201 604800 86400 2419200 86400 ... ;; Received 262 B (1 messages, 9 records) ;; Time 2021-09-12 11:07:25 CEST ;; From 127.0.0.1@7153(TCP) in 2.3 ms
Excellent, nous faisons du XoT. Wireshark nous le confirme :
% tshark -d tcp.port==7153,tls -i lo port 7153 ... 4 0.001200185 127.0.0.1 → 127.0.0.1 TLSv1 439 Client Hello ... 6 0.006305031 127.0.0.1 → 127.0.0.1 TLSv1.3 1372 Server Hello, Change Cipher Spec, Application Data, Application Data, Application Data, Application Data ... 10 0.007385823 127.0.0.1 → 127.0.0.1 TLSv1.3 140 Application Data
Dans ce cas, on utilisait NSD comme serveur primaire, recevant les clients XoT. Il peut aussi fonctionner comme serveur secondaire et il est alors client XoT. Je n'ai pas testé mais John Shaft l'a fait et en gros la configuration ressemble à :
tls-auth: name: un-nom-pour-identifier-ce-bloc auth-domain-name: nom-du-serveur-principal zone: ... request-xfr: AXFR 2001:db8::1 NOKEY un-nom-pour-identifier-ce-bloc
L'article seul
RFC 9102: TLS DNSSEC Chain Extension
Date de publication du RFC : Août 2021
Auteur(s) du RFC : V. Dukhovni (Two Sigma), S. Huque (Salesforce), W. Toorop (NLnet Labs), P. Wouters (Aiven), M. Shore (Fastly)
Expérimental
Première rédaction de cet article le 12 août 2021
Lorsqu'on authentifie un serveur TLS (par exemple un serveur
DoT) avec DANE, le client TLS
doit utiliser un résolveur DNS
validant et tenir compte de son résultat
(données validées ou pas), ce qui n'est pas toujours facile, ni même
possible dans certains environnements. Ce RFC propose une solution pour cela : une
extension à TLS, dnssec_chain, qui permet au
serveur TLS d'envoyer l'ensemble des enregistrements DNS pertinents
au client, le dispensant ainsi de solliciter un résolveur
validant. Toute la cuisine de vérification peut ainsi se faire sans
autre canal que TLS.
TLS
(normalisé dans les RFC 5246 et RFC 9846) fournit un canal de communication
sécurisé, si on a authentifié le serveur situé en face. La plupart
du temps, on authentifie via un certificat
PKIX (RFC 5280). Dans certains
cas, ce n'est pas facile d'utiliser PKIX. Par exemple, pour
DoT (RFC 7858), le
résolveur DoT n'est typiquement connu que par une adresse IP, alors que le
certificat ne contient en général qu'un nom
(oui, le RFC 8738 existe, mais n'est pas
toujours activé par les autorités de
certification). Les serveurs DoT sont souvent
authentifiables par DANE (RFC 6698 et
RFC 7671). Par exemple, mon résolveur DoT
public, dot.bortzmeyer.fr, est authentifiable
avec DANE (regardez les données TLSA de
_853._tcp.dot.bortzmeyer.fr). Mais DANE dépend
de la disponibilité d'un résolveur DNS
validant. Diverses raisons font que le
client TLS peut avoir du mal à utiliser un résolveur validant, et à
récupérer l'état de la validation (toutes les API de résolution de
noms ne donnent pas accès à cet état). L'article « Discovery
method for a DNSSEC validating stub resolver »
donne des informations sur ces difficultés. Bref, devoir récupérer
ces enregistrements DANE de manière sécurisée peut être un
problème. Et puis utiliser le DNS pour récupérer des données
permettant d'authentifier un résolveur DNS pose un
problème d'œuf et de poule.
D'où l'idée centrale de ce RFC : le client TLS demande au serveur de lui envoyer ces enregistrements. Le client n'a plus « que » à les valider à partir d'une clé de confiance DNSSEC (typiquement celle de la racine, commune à tout le monde). Le serveur peut aussi, s'il n'utilise pas DANE, renvoyer la preuve de non-existence de ces enregistrements, le client saura alors, de manière certaine, qu'il peut se rabattre sur un autre mécanisme d'authentification. L'extension TLS de notre RFC peut servir à authentifier un certificat complet, ou bien une clé brute (RFC 7250). Dans ce dernier cas, cette extension protège en outre contre les attaques dites « Unknown Key-Share ».
Notez le statut de ce RFC : cette spécification est pour l'instant expérimentale, elle n'a pas vraiment réuni de consensus à l'IETF, mais elle fait partie des solutions proposées pour sécuriser DoT, dans le RFC 8310 (section 8.2.2).
Bon, maintenant, l'extension elle-même (section 2). C'est une
extension TLS (ces extensions sont spécifiées dans la section 4.3 du
RFC 9846), elle est nommée
dnssec_chain et enregistrée
dans le registre IANA, avec le code 59. Son champ de données
(extension_data) vaut, dans le
ClientHello, le port de
connexion et, dans le ServerHello, un ensemble
d'enregistrements DNS au format binaire du DNS (pour TLS 1.2 ; en
1.3, cet ensemble est attaché au certificat du serveur). Dans le
langage de description des données TLS, cela donne, du client vers
le serveur :
struct {
uint16 PortNumber;
} DnssecChainExtension;
Et du serveur vers le client :
struct {
uint16 ExtSupportLifetime;
opaque AuthenticationChain<1..2^16-1>
} DnssecChainExtension;
(Le ExtSupportLifetime indique que le serveur
s'engage à continuer à gérer cette extension pendant au moins ce
temps - en heures. Si ce n'est plus le cas avant l'expiration du
délai, cela peut indiquer une usurpation par un faux serveur.)
Cette extension est donc une forme, assez spéciale, de « DNS sur
TLS ». Le client ne doit pas oublier d'envoyer un SNI (RFC 6066), pour que le serveur sache quel nom va
être authentifié et donc quels enregistrements DNS renvoyer. Quant
au serveur, s'il ne gère pas cette extension, il répond au client
avec un ServerHello n'ayant pas l'extension
dnssec_chain. Même chose si le serveur accepte
l'extension mais, pour une raison ou pour une autre, n'a pas pu
rassembler tous les enregistrements DNS.
Et pourquoi le client doit-il indiquer le port auquel il voulait se connecter ? Le serveur le connait, non ? Mais ce n'est pas forcément le cas, soit parce qu'il y a eu traduction de port quelque part sur le chemin, soit parce que le client a été redirigé, par exemple via le type d'enregistrement SVCB (RFC 9460). Le port indiqué par le client doit être le port original, avant toute traduction ou redirection.
Revenons à la « chaine », l'ensemble d'enregistrements DNS qui va
permettre la validation DANE. Le format est le format binaire
habituel du DNS, décrit dans le RFC 1035,
section 3.2.1. L'utilisation de ce format, quoiqu'il soit inhabituel
dans le monde TLS, permet, entre autres avantages, l'utilisation des
bibliothèques logicielles DNS existantes. Le RFC recommande
d'inclure dans l'ensemble d'enregistrements une chaine complète, y
compris la racine et incluant donc les clés DNSSEC de celle-ci
(enregistrements DNSKEY), même si le client les connait probablement
déjà. Cela donne par exemple la chaine suivante, pour le serveur
www.example.com écoutant sur le port 443. Notez
qu'on inclut les signatures (RRSIG) :
_443._tcp.www.example.comTLSA- RRSIG(
_443._tcp.www.example.comTLSA) example.com. DNSKEY- RRSIG(
example.comDNSKEY) example.comDS- RRSIG(
example.comDS) comDNSKEY- RRSIG(
comDNSKEY) comDS- RRSIG(
comDS) .DNSKEY- RRSIG(
.DNSKEY)
(L'exemple suppose que
_443._tcp.www.example.com et
example.com sont dans la même zone.) Voilà,
avec tous ces enregistrements, le client peut, sans faire appel à un
résolveur DNS validant, vérifier (s'il a confiance dans la clé de la
racine) l'authenticité de l'enregistrement DANE (type TLSA) et donc
le certificat du serveur. De la même façon, si on n'a pas
d'enregistrement TLSA, le serveur peut envoyer les preuves de
non-existence (enregistrements NSEC ou NSEC3). Bon, évidemment, dans
ce cas, c'est moins utile, autant ne pas gérer l'extension
dnssec_chain… Face à ce déni, le client TLS
n'aurait plus qu'à se rabattre sur une autre méthode
d'authentification.
Le serveur TLS construit la chaine des enregistrements comme il veut, mais pour l'aider, la section 3 du RFC fournit une procédure possible, à partir d'interrogations du résolveur de ce serveur. Une autre possibilité, plus simple pour le serveur, serait d'utiliser les requêtes chainées du RFC 7901 (mais qui n'ont pas l'air très souvent déployées aujourd'hui).
Comme tous les enregistrements DNS, ceux inclus dans l'extension
TLS dnssec_chain ont une durée de vie. Et les signatures DNSSEC ont
une période de validité (en général plus longue que la durée de
vie). Le serveur TLS qui construit l'ensemble d'enregistrements qu'il
va renvoyer peut donc mémoriser cet ensemble, dans la limite du
TTL et de l'expiration
des signatures DNSSEC. Le client TLS peut lui aussi mémoriser ces
informations, dans les mêmes conditions.
On a vu plus haut que les données de l'extension TLS incluaient
un ExtSupportLifetime qui indiquait combien de
temps le client pouvait s'attendre à ce que le serveur TLS continue
à gérer cette extension. Car le client peut épingler
(pinning) cette information. Cela permet de
détecter certaines attaques (« ce serveur gérait l'extension
dnssec_chain et ce n'est maintenant plus le
cas ; je soupçonne un détournement vers un serveur pirate »). Cet
engagement du serveur est analogue au HSTS de HTTPS (RFC 6797) ; dans les deux cas, le serveur s'engage à rester
« sécurisé » pendant un temps minimum (mais pas infini, car on doit
toujours pouvoir changer de politique). À noter que « gérer
l'extension dnssec_chain » n'est pas la même
chose que « avoir un enregistrement TLSA », on peut accepter
l'extension mais ne pas avoir de données à envoyer (il faudra alors
envoyer la preuve de non-existence mentionnée plus haut). Bien sûr,
le client TLS est libre de sa politique. Il peut aussi décider
d'exiger systématiquement l'acceptation de l'extension TLS
dnssec_chain (ce qui, aujourd'hui, n'est
réaliste que si on ne parle qu'à un petit nombre de serveurs).
Si un serveur gérait l'extension
dnssec_chain mais souhaite arrêter, il doit
bien calculer son coup : d'abord réduire
ExtSupportLifetime à zéro puis attendre que
la durée annoncée dans le précédent
ExtSupportLifetime soit écoulée, afin que tous
les clients aient arrêté de l'épingler comme serveur à
dnssec_chain. Il peut alors proprement stopper
l'extension (cf. section 10 du RFC).
Un petit problème se pose si on fait héberger le serveur TLS chez
un tiers. Par exemple, imaginons que le titulaire du domaine
boulanger.example ait un serveur chez la
société JVL (Je Vous Loge) et que
server.boulanger.example soit un alias
(enregistrement de type CNAME) vers
clients.jvl.example. Le client TLS va envoyer
server.boulanger.example comme SNI. Il ne sera
pas pratique du tout pour JVL de coordonner la chaine
d'enregistrements DNS et le certificat. Il est donc conseillé que
l'enregistrement TLSA du client soit lui aussi un alias vers un
enregistrement TLSA de l'hébergeur. Cela pourrait donner (sans les
signatures, pour simplifier la liste) :
server.boulanger.exampleCNAME (versclients.jvl.example)_443._tcp.server.boulanger.exampleCNAME (vers_dane443.node1.jvl.example)clients.jvl.exampleAAAA_dane443.node1.jvl.exampleTLSA
Les deux premiers enregistrements sont gérés par l'hébergé, les deux
derniers par l'hébergeur. (La section 9 du RFC explique pourquoi
l'enregistrement TLSA de l'hébergeur n'est pas en
_443._tcp…)
Comme dit plus haut, le client TLS est maitre de sa politique : il peut exiger l'extension TLS, il peut l'accepter si elle existe, il peut l'ignorer. Si l'authentification par DANE échoue mais que celle par PKIX réussit, ou le contraire, c'est au client TLS de décider, en fonction de sa politique, ce qu'il fait.
Est-ce que le serveur TLS qui gère cette extension doit envoyer la chaine complète de certificats ? S'il veut pouvoir également être identifié avec PKIX, oui. Si non, s'il se contente de DANE et plus précisément de DANE-EE ou DANE-TA (ces deux termes sont définis dans le RFC 7218), il peut envoyer uniquement le certificat du serveur (pour DANE-EE).
Question mise en œuvre, l'excellente bibliothèque ldns a (je n'ai pas testé…) tout ce qu'il faut pour générer et tester ces chaines d'enregistrements DNS. Si vous voulez développer du code pour gérer cette extension, l'annexe A du RFC contient des vecteurs de test qui vous seront probablement bien utiles.
L'article seul
RFC 9099: Operational Security Considerations for IPv6 Networks
Date de publication du RFC : Août 2021
Auteur(s) du RFC : E. Vyncke (Cisco), K. Chittimaneni (Square), M. Kaeo (Double Shot Security), E. Rey (ERNW)
Pour information
Réalisé dans le cadre du groupe de travail IETF opsec
Première rédaction de cet article le 7 septembre 2021
Tous les gens qui gèrent des réseaux IPv4 savent comment les sécuriser (normalement…). Et pour IPv6 ? Si ce n'est pas un protocole radicalement différent, il a quand même quelques particularités de sécurité. Ce RFC donne des conseils pratiques et concrets sur la sécurisation de réseaux IPv6. (Je le répète, mais c'est juste une nouvelle version d'IP : l'essentiel du travail de sécurisation est le même en v4 et en v6.)
Les différences entre IPv4 et IPv6 sont subtiles (mais, en sécurité, la subtilité compte, des petits détails peuvent avoir de grandes conséquences). Ceci dit, le RFC a tendance à les exagérer. Par exemple, il explique que la résolution d'adresses de couche 3 en adresses de couche 2 ne se fait plus avec ARP (RFC 826) mais avec NDP (RFC 4861). C'est vrai, mais les deux protocoles fonctionnent de manière très proche et ont à peu près les mêmes propriétés de sécurité (en l'occurrence, aucune sécurité). Plus sérieusement, le remplacement d'un champ d'options de taille variable dans IPv4 par les en-têtes d'extension d'IPv6 a certainement des conséquences pour la sécurité. Le RFC cite aussi le cas du NAPT (Network Address and Port Translation, RFC 2663). Souvent appelée à tort NAT (car elle ne traduit pas que l'adresse mais également le port), cette technique est très utilisée en IPv4. En IPv6, on ne fait pas de traduction ou bien on fait du vrai NAT, plus précisement du NPT (Network Prefix Translation, RFC 6296) puisqu'on change le préfixe de l'adresse. La phrase souvent entendue « en IPv6, il n'y a pas de NAT » est doublement fausse : c'est en IPv4 qu'on n'utilise pas le NAT, mais le NAPT, et on peut faire de la traduction d'adresses en IPv6 si on veut. NAT, NAPT ou NPT ne sont évidemment pas des techniques de sécurité mais elles peuvent avoir des conséquences pour la sécurité. Par exemple, toute traduction d'adresse va complexifier le réseau, ce qui introduit des risques. Autre facteur nouveau lié à IPv6 : la plupart des réseaux vont devoir faire de l'IPv4 et de l'IPv6 et les différentes techniques de coexistence de ces deux versions peuvent avoir leur propre impact sur la sécurité (RFC 4942).
La section 2 du RFC est le gros morceau du RFC ; c'est une longue liste de points à garder en tête quand on s'occupe de la sécurité d'un réseau IPv6. Je ne vais pas tous les citer, mais en mentionner quelques-uns qui donnent une bonne idée du travail du ou de la responsable de la sécurité.
D'abord, l'adressage. Aux débuts d'IPv6, l'idée était que les spécificités d'IPv6 comme le SLAAC allaient rendre la renumérotation des réseaux tellement triviale qu'on pourrait changer les adresses souvent. En pratique, ce n'est pas tellement le cas (RFC 7010) et il faut donc prêter attention à la conception de son adressage : on aura du mal à en changer. Heureusement, c'est beaucoup plus facile qu'en IPv4 : l'abondance d'adresses dispense des astuces utilisées en IPv4 pour essayer d'économiser chaque adresse. Par exemple, on peut donner à tous ses sous-réseaux la même longueur de préfixe, quelle que soit leur taille, ce qui simplifie bien les choses (le RFC 6177 est une lecture instructive). Comme en IPv4, les adresses peuvent être liées au fournisseur d'accès (PA, Provider Allocated) ou bien obtenues indépendamment de ce fournisseur (PI, Provider Independent). Le RFC 7381 discute ce cas. Cela peut avoir des conséquences de sécurité. Par exemple, les adresses PA sont en dernier ressort gérées par l'opérateur à qui il faudra peut-être demander certaines actions. Et ces adresses PA peuvent pousser à utiliser la traduction d'adresses, qui augmente la complexité. (D'un autre côté, les adresses PI sont plus difficiles à obtenir, surtout pour une petite organisation.) Ah, et puis, pour les machines terminales, le RFC 7934 rappelle à juste titre qu'il faut autoriser ces machines à avoir plusieurs adresses (il n'y a pas de pénurie en IPv6). Une des raisons pour lesquelles une machine peut avoir besoin de plusieurs adresses est la protection de la vie privée (RFC 8981).
Les gens habitués à IPv4 demandent souvent quel est l'équivalent du RFC 1918 en IPv6. D'abord, de telles adresses privées ne sont pas nécessaires en IPv6, où on ne manque pas d'adresses. Mais si on veut, on peut utiliser les ULA (Unique Local Addresses) du RFC 4193. Par rapport aux adresses privées du RFC 1918, elles ont le gros avantage d'être uniques, et donc d'éviter toute collision, par exemple quand deux organisations fusionnent leurs réseaux locaux. Le RFC 4864 décrit comment ces ULA peuvent être utilisés pour la sécurité.
Au moment de concevoir l'adressage, un choix important est celui de donner ou non des adresses IP stables aux machines. (Ces adresses stables peuvent leur être transmises par une configuration statique, ou bien en DHCP.) Les adresses stables facilitent la gestion du réseau mais peuvent faciliter le balayage effectué par un attaquant pendant une reconnaissance préalable. Contrairement à ce qu'on lit parfois encore, ce balayage est tout à fait possible en IPv6, malgré la taille de l'espace d'adressage, même s'il est plus difficile qu'en IPv4. Le RFC 7707 explique les techniques de balayage IPv6 possibles. Même chose dans l'article « Mapping the Great Void ». Bref, on ne peut pas compter sur la STO et donc, adresses stables ou pas, les machines connectées à l'Internet peuvent être détectées, et doivent donc être défendues.
Cela n'empêche pas de protéger la vie privée des utilisateurs en utilisant des adresses temporaires pour contacter l'extérieur. L'ancien système de configuration des adresses par SLAAC était mauvais pour la vie privée puisqu'il utilisait comme partie locale de l'adresse (l'IID, Interface IDentifier) l'adresse MAC, ce qui permettait d'identifier une machine même après qu'elle ait changé de réseau. Ce système est abandonné depuis longtemps (RFC 8064) au profit d'adresses aléatoires (RFC 8981). Ceci dit, ces adresses aléatoires posent un autre problème : comme elles changent fréquemment, elles ne permettent pas à l'administrateur réseau de suivre les activités d'une machine (c'est bien leur but), et on ne peut plus utiliser de mécanismes comme les ACL. Une solution possible est d'utiliser des adresses qui sont stables pour un réseau donné mais qui ne permettent pas de suivre une machine quand elle change de réseau, les adresses du RFC 7217. C'est dans beaucoup de cas le meilleur compromis. (Le RFC 7721 contient des détails sur les questions de sécurité liées aux adresses IP.)
On peut aussi couper SLAAC (cela peut se faire à distance avec des annonces RA portant le bit M) et n'utiliser que DHCP mais toutes les machines terminales n'ont pas un client DHCP.
En parlant de DHCP, lui aussi pose des problèmes de vie privée (décrits dans le RFC 7824) et si on veut être discret, il est recommandé d'utiliser le profil restreint défini dans le RFC 7844.
Après les adresses, la question des en-têtes d'extension, un concept nouveau d'IPv6. En IPv4, les options sont placées dans l'en-tête, qui a une longueur variable, ce qui complique et ralentit son analyse. En IPv6, l'en-tête a une longueur fixe (40 octets) mais il peut être suivi d'un nombre quelconque d'en-têtes d'extension (RFC 8200, section 4). Si on veut accéder à l'information de couche 4, par exemple pour trouver le port TCP, il faut suivre toute la chaîne d'en-têtes. Ce système était conçu pour être plus facile et plus rapide à analyser que celui d'IPv4, mais à l'usage, ce n'est pas le cas (le RFC estime même que le système d'IPv6 est pire). En partie pour cette raison, certains nœuds intermédiaires jettent tous les paquets IPv6 contenant des en-têtes d'extension (RFC 7872, RFC 9288). D'autres croient que la couche Transport suit immédiatement l'en-tête, sans tenir compte de la possibilité qu'il y ait un en-tête d'extension, ce qui fausse leur analyse. L'en-tête d'extension Hop-by-hop options était particulièrement problématique, car devant être traité par tous les routeurs (le RFC 8200 a adouci cette règle).
Pour faciliter la tâche des pare-feux, plusieurs règles ont été ajoutées aux en-têtes d'extension depuis les débuts d'IPv6 : par exemple le premier fragment d'un datagramme doit contenir la totalité des en-têtes d'extension.
À l'interface
d'IPv6 et de la couche 2, on
trouve quelques problèmes supplémentaires. D'abord, concernant la
résolution d'adresses IP en adresses
MAC, pour laquelle IPv6 utilise le protocole NDP
(Neighbor Discovery Protocol, RFC 4861). NDP partage avec ARP un problème fondamental :
n'importe quelle machine du réseau local peut répondre ce qu'elle
veut. Par exemple, si une machine demande « qui est
2001:db8:1::23:42:61 ? », toutes les machines
locales peuvent techniquement répondre « c'est moi » et donner leur
adresse MAC. Ce problème et quelques autres analogues sont
documentés dans les RFC 3756 et RFC 6583. DHCP pose le même genre de problèmes,
toute machine peut se prétendre serveur DHCP et répondre aux
requêtes DHCP à la place du serveur légitime. Pour se prémunir
contre les attaques faites par des machines envoyant de faux
RA, on peut aussi isoler les machines, par
exemple en donnant un /64 à chacune, ou bien en configurant
commutateurs ou points d'accès Wifi pour bloquer les communications
de machine terminale à machine terminale (celles qui qui ne sont pas
destinées au routeur). Le RFC recommande le RA
guard du RFC 6105.
Et sur les mobiles ? Un lien 3GPP est un lien point-à-point, l'ordiphone qui est à un bout ne peut donc pas parler aux autres ordiphones, même utilisant la même base. On ne peut parler qu'au routeur (GGSN - GPRS Gateway Support Node, ou bien PGW - Packet GateWay). Pour la même raison, il n'y a pas de résolution des adresses IP et donc pas de risque liés à cette résolution. Ce mécanisme empêche un grand nombre des attaques liées à NDP. Si vous voulez en apprendre plus à ce sujet, il faut lire le RFC 6459.
Le
multicast peut être
dangereux sur un réseau local, puisqu'il permet d'écrire à des
machines qui n'ont rien demandé. Certains réseaux WiFi bloquent le
multicast. En IPv6, cela empêche des actions
néfastes comme de pinguer
ff01::1 (l'adresse multicast
qui désigne toutes les machines du réseau local), mais cela bloque
aussi des protocoles légitimes comme mDNS
(RFC 6762).
Compte-tenu de la vulnérabilité du réseau local, et des risques associés, il a souvent été proposé de sécuriser l'accès à celui-ci et IPv6 dispose d'un protocole pour cela, SEND, normalisé dans le RFC 3971, combiné avec les CGA du RFC 3972. Très difficile à configurer, SEND n'a connu aucun succès, à part dans quelques environnements ultra-sécurisés. On ne peut clairement pas compter dessus.
Voyons maintenant la sécurité du plan de contrôle : les routeurs et le routage (RFC 6192). Les problèmes de sécurité sont quasiment les mêmes en IPv4 et en IPv6, la principale différence étant le mécanisme d'authentification pour OSPF. Un routeur moderne typique sépare nettement le plan de contrôle (là où on fait tourner les protocoles comme OSPF, mais aussi les protocoles de gestion comme SSH qui sert à configurer le routeur) et le plan de transmission, là où se fait la transmission effective des paquets. Le second doit être très rapide, car il fonctionne en temps réel. Il utilise en général du matériel spécialisé, alors que le plan de contrôle est la plupart du temps mis en œuvre avec un processeur généraliste, et un système d'exploitation plus classique. Pas toujours très rapide, il peut être submergé par un envoi massif de paquets. Le plan de contrôle ne gère que les paquets, relativement peu nombreux, qui viennent du routeur ou bien qui y arrivent, le plan de transmission gérant les innombrables paquets que le routeur transmet, sans les garder pour lui. Chaque paquet entrant est reçu sur l'interface d'entrée, le routeur consulte une table qui lui dit quel est le routeur suivant pour ce préfixe IP, puis il envoie ce paquet sur l'interface de sortie. Et le tout très vite.
Notre RFC conseille donc de protéger le plan de contrôle en bloquant le plus tôt possible les paquets anormaux, comme des paquets OSPF qui ne viendraient pas d'une adresse locale au lien, ou les paquets BGP qui ne viennent pas d'un voisin connu. (Mais, bien sûr, il faut laisser passer l'ICMP, essentiel au débogage et à bien d'autres fonctions.) Pour les protocoles de gestion, il est prudent de jeter les paquets qui ne viennent pas du réseau d'administration. (Tout ceci est commun à IPv4 et IPv6.)
Protéger le plan de contrôle, c'est bien, mais il faut aussi protéger le protocole de routage. Pour BGP, c'est pareil qu'en IPv4 (lisez le RFC 7454). Mais OSPF est une autre histoire. La norme OSPFv3 (RFC 4552) comptait à l'origine exclusivement sur IPsec, dont on espérait qu'il serait largement mis en œuvre et déployé. Cela n'a pas été le cas (le RFC 8504 a d'ailleurs supprimé cette obligation d'IPsec dans IPv6, obligation qui était purement théorique). Le RFC 7166 a pris acte de l'échec d'IPsec en créant un mécanisme d'authentification pour OSPFv3. Notre RFC recommande évidemment de l'utiliser.
Sinon, les pratiques classiques de sécurité du routage tiennent toujours. Ne pas accepter les routes « bogons » (conseil qui n'est plus valable en IPv4, où tout l'espace d'adressage a été alloué), celles pour des adresses réservées (RFC 8190), etc.
Pas de sécurité sans surveillance (c'est beau comme du Ciotti, ça) et journalisation. En IPv6 comme en IPv4, des techniques comme IPFIX (RFC 7011), SNMP (RFC 4293), etc sont indispensables. Comme en IPv4, on demande à son pare-feu, son serveur RADIUS (RFC 2866) et à d'autres équipements de journaliser les évènements intéressants. À juste titre, et même si ça va chagriner les partisans de la surveillance massive, le RFC rappelle que, bien que tout cela soit très utile pour la sécurité, c'est dangereux pour la vie privée, et que c'est souvent, et heureusement, encadré par des lois comme le RGPD. Administrateur réseaux, ne journalise pas tout, pense à tes responsabilités morales et légales !
Bon, mais cela, c'est commun à IPv4 et IPv6. Qu'est-ce qui est spécifique à IPv6 ? Il y a le format textuel canonique des adresses, normalisé dans le RFC 5952, qui permet de chercher une adresse sans ambiguité. Et la mémoire des correspondances adresses IP adresses MAC dans les routeurs ? Elle est très utile à enregistrer, elle existe aussi en IPv4, mais en IPv6 elle est plus dynamique, surtout si on utilise les adresses favorables à la vie privée du RFC 8981. Le RFC recommande de la récupérer sur le routeur au moins une fois toutes les 30 secondes. Et le journal du serveur DHCP ? Attention, en IPv6, du fait de l'existence de trois mécanismes d'allocation d'adresses (DHCP, SLAAC et statique) au lieu de deux en IPv4, le journal du serveur DHCP ne suffit pas. Et puis il ne contiendra pas l'adresse MAC mais un identificateur choisi par le client, qui peut ne rien vous dire. (Ceci dit, avec les machines qui changent leur adresse MAC, DHCPv4 a un problème du même genre.) En résumé, associer une adresse IP à une machine risque d'être plus difficile qu'en IPv4.
Une autre spécificité d'IPv6 est l'existence de nombreuses technologies de transition entre les deux protocoles, technologies qui apportent leurs propres problèmes de sécurité (RFC 4942). Normalement, elles n'auraient dû être que temporaires, le temps que tout le monde soit passé à IPv6 mais, comme vous le savez, la lenteur du déploiement fait qu'on va devoir les supporter longtemps, les réseaux purement IPv6 et qui ne communiquent qu'avec d'autres réseaux IPv6 étant une petite minorité. La technique de coexistence la plus fréquente est la double pile, où chaque machine a à la fois IPv4 et IPv6. C'est la plus simple et la plus propre, le trafic de chaque version du protocole IP étant natif (pas de tunnel). Avec la double pile, l'arrivée d'IPv6 n'affecte pas du tout IPv4. D'un autre côté, il faut donc gérer deux versions du protocole. (Anecdote personnelle : quand j'ai commencé dans le métier, IP était très loin de la domination mondiale, et il était normal, sur un réseau local, de devoir gérer cinq ou six protocoles très différents. Prétendre que ce serait une tâche insurmontable de gérer deux versions du même protocole, c'est considérer les administrateurs réseaux comme très paresseux ou très incompétents.) L'important est que les politiques soient cohérentes, afin d'éviter, par exemple, que le port 443 soit autorisé en IPv4 mais bloqué en IPv6, ou le contraire. (C'est parfois assez difficile à réaliser sans une stricte discipline : beaucoup de pare-feux n'ont pas de mécanisme simple pour indiquer une politique indépendante de la version du protocole IP.)
Notez que certains réseaux peuvent être « double-pile » sans que l'administrateur réseaux l'ait choisi, ou en soit conscient, si certaines machines ont IPv6 activé par défaut (ce qui est fréquent et justifié). Des attaques peuvent donc être menées via l'adresse locale au lien même si aucun routeur du réseau ne route IPv6.
Mais les plus gros problèmes de sécurité liés aux techniques de coexistence/transition viennent des tunnels. Le RFC 6169 détaille les conséquences des tunnels pour la sécurité. Sauf s'ils sont protégés par IPsec ou une technique équivalente, les tunnels permettent bien des choses qui facilitent le contournement des mesures de sécurité. Pendant longtemps, l'interconnexion entre réseaux IPv6 isolés se faisait via des tunnels, et cela a contribué aux légendes comme quoi IPv6 posait des problèmes de sécurité. Aujourd'hui, ces tunnels sont moins nécessaires (sauf si un réseau IPv6 n'est connecté que par des opérateurs archaïques qui n'ont qu'IPv4).
Les tunnels les plus dangereux (mais aussi les plus pratiques) sont les tunnels automatiques, montés sans configuration explicite. Le RFC suggère donc de les filtrer sur le pare-feu du réseau, en bloquant le protocole IP 41 (ISATAP - RFC 5214, 6to4 - RFC 3056, mais aussi 6rd - RFC 5969 - qui, lui, ne rentre pas vraiment dans la catégorie « automatique »), le protocole IP 47 (ce qui bloque GRE, qui n'est pas non plus un protocole « automatique ») et le port UDP 3544, pour neutraliser Teredo - RFC 4380. D'ailleurs, le RFC rappelle plus loin que les tunnels statiques (RFC 2529), utilisant par exemple GRE (RFC 2784), sont plus sûrs (mais IPsec ou équivalent reste recommandé). 6to4 et Teredo sont de toute façon très déconseillés aujourd'hui (RFC 7526 et RFC 3964).
Et les mécanismes de traduction d'adresses ? On peut en effet traduire des adresses IPv4 en IPv4 (le traditionnel NAT, qui est plutôt du NAPT en pratique, puisqu'il traduit aussi le port), ce qui est parfois présenté à tort comme une fonction de sécurité, mais on peut aussi traduire de l'IPv4 en IPv6 ou bien de l'IPv6 en IPv6. Le partage d'adresses que permettent certains usages de la traduction (par exemple le CGNAT) ouvre des problèmes de sécurité bien connus. Les techniques de traduction d'IPv4 en IPv6 comme NAT64 - RFC 6146 ou 464XLAT - RFC 6877 apportent également quelques problèmes, décrits dans leurs RFC.
J'ai parlé plus haut du fait que les systèmes d'exploitation modernes ont IPv6 et l'activent par défaut. Cela implique de sécuriser les machines contre les accès non voulus faits avec IPv6. Du classique, rien de spécifique à IPv6 à part le fait que certains administrateurs système risqueraient de sécuriser les accès via IPv4 (avec un pare-feu intégré au système d'exploitation, par exemple) en oubliant de le faire également en IPv6.
Tous les conseils donnés jusqu'à présent dans cette section 2 du RFC étaient communs à tous les réseaux IPv6. Les sections suivantes s'attaquent à des types de réseau spécifiques à certaines catégories d'utilisateurs. D'abord (section 3), les « entreprises » (en fait, toutes les organisations - RFC 7381, pas uniquement les entreprises capitalistes privées, comme le terme étatsunien enterprise pourrait le faire penser). Le RFC contient quelques conseils de sécurité, proches de ce qui se fait en IPv4, du genre « bloquer les services qu'on n'utilise pas ». (Et il y a aussi le conseil plus évident : bloquer les paquets entrants qui ont une adresses IP source interne et les paquets sortants qui ont une adresse IP source externe.)
Et pour les divers opérateurs (section 4 du RFC) ? C'est plus délicat car ils ne peuvent pas, contrairement aux organisations, bloquer ce qu'ils ne veulent pas (sauf à violer la neutralité, ce qui est mal). Le RFC donne des conseils de sécurisation BGP (identiques à ceux d'IPv4) et RTBH (RFC 5635). Il contient également une section sur l'« interception légale » (le terme politiquement correct pour les écoutes et la surveillance). Légalement, les exigences (et les problèmes qu'elles posent) sont les mêmes en IPv4 et en IPv6. En IPv4, le partage d'adresses, pratique très répandue, complique sérieusement la tâche des opérateurs quand ils reçoivent un ordre d'identifier le titulaire de telle ou telle adresse IP (RFC 6269). En IPv6, en théorie, la situation est meilleure pour la surveillance, une adresse IP n'étant pas partagée. Par contre, l'utilisateur peut souvent faire varier son adresse au sein d'un préfixe /64.
Quand au réseau de l'utilisateur final, il fait l'objet de la section 5. Il n'y a pas actuellement de RFC définitif sur la délicate question de la sécurité de la maison de M. Michu. Notamment, les RFC 6092 et RFC 7084 ne prennent pas position sur la question très sensible de savoir si les routeurs/pare-feux d'entrée de ce réseau devraient bloquer par défaut les connexions entrantes. La sécurité plaiderait en ce sens mais ça casserait le principe de bout en bout.
Voilà, nous avons terminé cette revue du long RFC. Je résumerai mon opinion personnelle en disant : pour la plupart des questions de sécurité, les ressemblances entre IPv4 et IPv6 l'emportent sur les différences. La sécurité n'est donc pas une bonne raison de retarder la migration si nécessaire vers IPv6. J'ai développé cette idée dans divers exposés et articles.
L'article seul
RFC 9098: Operational Implications of IPv6 Packets with Extension Headers
Date de publication du RFC : Septembre 2021
Auteur(s) du RFC : F. Gont (SI6 Networks), N. Hilliard (INEX), G. Doering (SpaceNet AG), W. Kumari (Google), G. Huston (APNIC), W. Liu (Huawei Technologies)
Pour information
Réalisé dans le cadre du groupe de travail IETF v6ops
Première rédaction de cet article le 20 septembre 2021
IPv6 souffre de réseaux mal gérés qui se permettent de jeter les paquets ayant des caractéristiques normales, mais qui déplaisent à certains équipements réseau. C'est par exemple le cas des paquets utilisant les en-têtes d'extension. Pourquoi les paquets utilisant ces en-têtes sont-ils souvent jetés ?
Ces en-têtes d'extension (qui n'ont pas d'équivalent en IPv4) sont normalisés dans le RFC 8200, section 4. Ils servent à la fois à des fonctions de base d'IPv6 (comme la fragmentation) et à étendre le protocole si nécessaire. Mais, en pratique, on observe trop souvent que les paquets IPv6 utilisant ces en-têtes d'extension ne passent pas sur certains réseaux. Ce RFC vise à étudier pourquoi, et à expliquer les conséquences. Comme toujours quand on explique un phénomène (la délinquance, par exemple), des gens vont comprendre de travers et croire qu'on justifie le phénomène en question (« expliquer, c’est déjà vouloir un peu excuser », avait stupidement dit un ancien premier ministre français, à propos du terrorisme djihadiste). Le cas est d'autant plus fréquent qu'en français, « comprendre » est ambigu, car il peut désigner l'explication (qui est utile aussi bien aux partisans qu'aux adversaires d'un phénomène) que la justification. Bref, ce RFC explique pourquoi des paquets innocents sont détruits, il ne dit pas qu'il faut continuer à le faire !
La section 4 du RFC explique la différence entre l'en-tête d'un paquet IPv6 et celui d'un paquet de l'ancienne version. Dans les deux versions, le problème est de placer des options dans les en-têtes. Le gros changement est l'utilisation par IPv6 d'un en-tête de taille fixe (40 octets), suivi d'une liste chainée d'en-têtes d'extension permettant d'encoder ces options. Au contraire, IPv4 avait un en-tête de taille variable (entre 20 et 60 octets), avec un champ indiquant sa longueur, champ qu'il fallait lire avant d'accéder à l'en-tête. Le mécanisme d'IPv4 n'était ni pratique, ni rapide, mais celui d'IPv6 n'est pas plus satisfaisant : il faut lire toute la liste chainée (dont la longueur est quelconque et non limitée) si on veut accéder aux informations au-dessus de la couche 3. Ce n'est pas un problème pour les routeurs, à qui la couche 3 suffit (à part le cas de l'en-tête Hop-by-hop options), mais c'est ennuyeux pour les autres boitiers situés sur le chemin, comme les pare-feux. Les évolutions récentes d'IPv6 ont aidé, comme l'obligation que tous les en-têtes d'extension soient dans le premier fragment, si le datagramme est fragmenté (RFC 7112), ou comme l'imposition d'un format commun aux futurs en-têtes d'extension (dans le RFC 6564), mais l'analyse de la liste des en-têtes d'extension reste un travail pénible pour les machines.
Le problème est identifié depuis longtemps. Il est analysé dans
l'Internet-Draft
draft-taylor-v6ops-fragdrop,
dans draft-wkumari-long-headers,
dans draft-kampanakis-6man-ipv6-eh-parsing
mais aussi dans des RFC, le RFC 7113, le
RFC 8900 et le RFC 9288. Cela a mené à plusieurs changements
dans la norme, je vous renvoie aux RFC 5722,
RFC 7045, RFC 8021,
etc. Plusieurs changements ont été intégrés dans la dernière
révision du RFC principal de la norme, le RFC 8200. Ainsi, celui-ci dispense désormais les routeurs de
chercher un éventuel en-tête d'extension Hop-by-hop
options.
Parallèlement à ces analyses du protocole, diverses études ont porté sur le phénomène des paquets jetés s'ils contenaient des en-têtes d'extension. Cela a été documenté dans « Discovering Path MTU black holes on the Internet using RIPE Atlas », dans « IPv6 Extension Headers in the Real World v2.0 », également dans « Dealing with IPv6 fragmentation in the DNS » et « Measurement of IPv6 Extension Header Support » ainsi que dans le RFC 7872.
Comment est-ce que les équipements intermédiaires du réseau fonctionnent, et pourquoi est-ce que les en-têtes d'extension IPv6 peuvent parfois les défriser ? La section 6 du RFC rappelle l'architecture de ces machines. Un routeur de cœur de réseau est très différent de l'ordinateur de base, avec son processeur généraliste et sa mémoire de grande taille, ce qui le rend lent, mais souple. Au contraire, la transmission des paquets par le routeur est en général faite par du matériel spécialisé, ASIC ou NPU. (Vous pouvez consulter des explications dans l'exposé fait à l'IETF « Modern Router Architecture for Protocol Designers » et dans l'article « Modern router architecture and IPv6 ».) Avant de transmettre un paquet reçu sur l'interface de sortie, le routeur doit trouver quelle interface utiliser. Une méthode courante est de prendre les N premiers octets du paquet et de les traiter dans une TCAM ou une RLDRAM, où se fera la détermination du saut suivant (et donc de l'interface de sortie). Le choix du nombre N est crucial : plus il est petit, plus le routeur pourra traiter de paquets, mais moins il aura d'information sur le paquet. (En pratique, on observe des N allant de 192 à 384 octets.) Du fait qu'un routeur se limite normalement à la couche Réseau, et que l'en-tête IPv6 a une taille fixe, envoyer simplement les 40 octets de cet en-tête devrait suffire. Mais lisez plus loin : certains routeurs ou autres équipements intermédiaires sont configurés pour regarder au-delà, et voudraient des informations de la couche Transport, plus dure à atteindre.
Une solution, pour les routeurs qui ne lisent qu'un nombre limité d'octets avant de prendre une décision, est de lire les en-têtes d'extension un par un, et de réinjecter le reste du paquet dans le dispositif de traitement. Ça se nomme la recirculation, c'est plus lent, mais ça marche quelle que soit la longueur de la chaîne des en-têtes d'extension.
Comme le routeur comprend toujours un processeur généraliste (ne serait-ce que pour faire tourner les fonctions de contrôle comme SSH et les protocoles de routage), une autre solution serait d'envoyer à ce processeur les paquets « compliqués » (mais lire le RFC 6192 d'abord). L'énorme différence de performance entre le processeur généraliste et les circuits spécialisés fait que ce ne serait pas une solution réaliste sauf pour un trafic très modéré. (Le RFC note que certains routeurs ont trois dispositifs de traitement des paquets, et pas seulement deux comme présenté plus haut : outre le processeur généraliste, qui ne leur sert qu'aux fonctions de contrôle, et des circuits matériels spécialisés, ils ont un dispositif logiciel de transmission des paquets. Plus souple que les circuits spécialisés, il n'est pas forcément plus rapide que le processeur généraliste mais, au moins, il n'interfère pas avec les fonctions de contrôle.)
Bon, on l'a déjà dit, mais cela vaut la peine de le répéter : à part le cas (agaçant) de l'en-tête Hop-by-hop options, un routeur, équipement de couche 3 n'a normalement aucun besoin d'aller regarder tous les en-têtes d'extension (qui sont presque tous pour la machine terminale de destination uniquement). Encore moins de faire du DPI et d'aller chercher des informations dans les couches 4 à 7. Mais la section 7 du RFC explique pourquoi certains routeurs le font quand même (il s'agit d'une description de leurs pratiques, pas une approbation ; beaucoup des raisons données sont mauvaises).
D'abord, la répartition de charge et l'ECMP. Si un routeur peut faire passer un paquet via deux interfaces différentes, laquelle choisir ? Alterner (un coup à gauche, un coup à droite) augmenterait la probabilité d'une arrivée des paquets dans le désordre. On préfère la prédictabilité : tous les paquets d'un même flot doivent suivre le même chemin. Comment déterminer le « flot », notion parfois un peu floue ? En restant dans les couches basses, on peut utiliser uniquement les adresses IP de source et de destination mais elles ne sont pas assez discriminantes. En IPv6, on peut en théorie utiliser l'étiquette de flot (normalisé dans le RFC 6437, ainsi que les RFC 6438 et RFC 7098 pour son utilisation) mais elle n'est pas toujours présente, en partie (encore !) par la faute de middleboxes qui, ignorant ce concept d'étiquette de flot, jetaient les paquets qui en avaient une. (Voir les articles de I. Cunha, « IPv4 vs IPv6 load balancing in Internet routes » et J. Jaeggli, « IPv6 flow label: misuse in hashing ».) En pratique, les systèmes qui ont besoin d'identifier les flots utilisent plutôt une heuristique : le tuple à cinq élements {protocole de transport, adresse IP source, adresse IP destination, port source, port destination}. Ce n'est pas parfait mais, en pratique, cela marche à peu près. On voit que cela nécessite d'accéder à de l'information de la couche Transport, les ports. (Cette heuristique a d'autres limites : par exemple elle ne marche pas si une partie de la couche Transport est chiffrée, comme c'est le cas avec QUIC.)
Autre cas où un boitier intermédiaire ressent le besoin d'accéder aux informations des couches supérieures, les ACL. La plupart des pare-feux permettent d'utiliser comme critère de filtrage les numéros de ports, ce qui va nécessiter d'analyser la chaine des en-têtes d'extension IPv6 pour parvenir à la couche Transport. Entre les pare-feux mal faits qui cherchent les informations de la couche Transport immédiatement après l'en-tête fixe (car le programmeur a tout simplement sauté la partie du RFC qui parlait des en-têtes d'extension) et les difficultés posées par le fait, qu'avant le RFC 6564, les en-têtes d'extension inconnus étaient impossibles à analyser, on voit qu'arriver à la couche Transport n'est pas si facile que ça (le RFC dit qu'il est plus compliqué d'analyser IPv6 qu'IPv4, ce qui est très contestable ; mais ce n'est en effet pas plus facile). Cela peut avoir des conséquences en terme de sécurité, par exemple si un méchant ajoute des en-têtes d'extension dans l'espoir que ses paquets ne soient pas correctement identifiés (cf. RFC 7113).
Autre exemple, le réassemblage des paquets fragmentés nécessite un état (mémoriser les fragments en cours de réassemblage), ce qui peut être fatal à la mémoire du pare-feu, notamment en cas d'attaque. Pour les coûts de ce filtrage, voir l'article d'E. Zack « Firewall Security Assessment and Benchmarking IPv6 Firewall Load Tests ». Cette difficulté peut encourager les pare-feux à jeter les paquets ayant des en-têtes d'extension, surtout si un administrateur réseaux ignorant dit bien fort « ces en-têtes d'extension ne servent à rien de toute façon » (RFC 7872).
Un problème proche est celui de la protection contre les attaques par déni de service. Filtrer avec les adresses IP peut être fait rès efficacement (cf. RFC 5635) mais ne marche pas, par exemple si l'adresse IP source est usurpée. Une des méthodes utilisées alors est de repérer un motif récurrent dans les paquets envoyés par l'attaquant, et de filtrer sur ce motif (vous pouvez lire ici un exemple avec le DNS). Là encore, des informations au-delà de la couche Réseau sont nécessaires. Toujours en sécurité, les NIDS ont aussi besoin de plus d'informations que ce que fournit la couche Réseau.
Et, bien sûr, comme toute complexité, les en-têtes d'extension augmentent les risques de sécurité, d'autant plus qu'il y a un cercle vicieux : comme ils sont peu utilisés, le code qui les traite est peu testé, donc il y a des bogues, donc ils sont peu utilisés, etc.
Donc, un certain nombre de machines intermédiaires, qui assurent des fonctions allant au-delà de ce que fait un « simple » routeur, ont des problèmes avec les en-têtes d'extension IPv6 et choisissent souvent la solution de facilité, qui est de les jeter systématiquement.
L'article seul
RFC 9097: Metrics and Methods for One-Way IP Capacity
Date de publication du RFC : Novembre 2021
Auteur(s) du RFC : A. Morton (AT&T Labs), R. Geib (Deutsche Telekom), L. Ciavattone (AT&T Labs)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF ippm
Première rédaction de cet article le 10 novembre 2021
Ce RFC
revisite la notion de capacité du RFC 5136 et spécifie une nouvelle métrique,
Type-P-One-way-Max-IP-Capacity.
Il y a déjà plusieurs RFC qui spécifient rigoureusement des métriques pour déterminer la capacité réseau. (Attention, les publicités des FAI et les articles dans les médias parlent souvent à tort de débit pour désigner ce qui est en fait la capacité, c'est-à-dire le débit maximum.) Une définition rigoureuse est en effet nécessaire car il peut y avoir, pour une même connexion et un même chemin, des capacités différentes selon ce qu'on mesure. Par exemple, est-ce qu'on compte les bits/s à la couche 3 ou à la couche 7 ? Compte-tenu de l'encapsulation et des retransmissions, la seconde est forcément plus basse. Les définitions actuelles sont surtout dans le RFC 5136 et le RFC 3148 mais le travail n'est jamais terminé et ce nouveau RFC vient donc compléter le RFC 5136. Vu l'importance de cette notion de capacité dans les publicités (« Nouveau : accès Premium Gold Plus à 10 Gb/s ! »), il est crucial que des associations de consommateurs ou des régulateurs puissent mesurer et vérifier les annonces.
Une des raisons pour lesquelles le travail sur la définition des métriques ne cesse jamais est que l'Internet évolue. Ainsi, note le RFC, depuis quelques années :
Première métrique défnie dans notre RFC (section 5), et venant
s'ajouter à celles du RFC 5136,
Type-P-One-way-IP-Capacity. C'est le nombre de
bits par seconde, mesurés en couche 3 et au-dessus (donc incluant
l'en-tête IP, par exemple). Le Type-P est là
pour rappeler que cette métrique n'a de sens que pour un certain
type de trafic, car des équipements réseau « intelligents » peuvent
faire que, par exemple, les paquets vers le port 22 passent plus vite que ceux pour un
autre port. Type-P est donc la description
complète des paquets utilisés. À noter que le RFC recommande
d'indiquer la valeur de cette métrique en mégabits par seconde (et
pas en mébibits, on
utilise plutôt les préfixes des télécoms que ceux de
l'informatique).
Deuxième métrique (section 6),
Type-P-One-way-Max-IP-Capacity, qui indique la
capacité maximum (la différence avec la métrique précédente vient du
fait que certains réseaux peuvent avoir une capacité variable, par
exemple les réseaux radio, oui, je sais, c'est compliqué).
Troisième métrique (section 7),
Type-P-IP-Sender-Bit-Rate. Elle désigne la
capacité de l'émetteur à envoyer des bits. En effet, lors d'une
mesure, le goulet d'étranglement peut être l'expéditeur et on croit
alors que le réseau a une capacité inférieure à ce qu'elle est
réellement.
La section 8 se penche sur la mesure effective de ces valeurs. Il faut une mesure active (envoi de bits sur le réseau uniquement pour faire la mesure), et elle possiblement très perturbatrice puisqu'on va chercher à remplir les tuyaux le plus possible. Le RFC inclut un algorithme d'ajustement du trafic mais qui n'est pas un vrai algorithme de contrôle de congestion. Le pseudo-code de cet algorithme est dans l'annexe A.
La mesure est bidirectionnelle (envoyeur et récepteur doivent
coopérer) même si la métrique est unidirectionnelle (le
One-Way dans le nom). Le RFC recommande de la
faire sur UDP
(attention au RFC 8085, UDP n'ayant pas de
contrôle de congestion propre, c'est à l'application de mesure de
faire attention à ne pas écrouler le réseau).
Jouons maintenant un peu avec une mise en œuvre de ce RFC, le
programme udpst, sur
deux machines Arch Linux (un
Raspberry Pi 1, donc avec un réseau très
lent) et Debian, sur le même
commutateur. On l'installe :
% git clone https://github.com/BroadbandForum/obudpst.git % cd obudpst % cmake . % make
On peut alors lancer le serveur :
% ./udpst UDP Speed Test Software Ver: 7.2.1, Protocol Ver: 8, Built: Sep 28 2021 15:46:40 Mode: Server, Jumbo Datagrams: Enabled, Authentication: Available, sendmmsg syscall: Available
Et le client, le Raspberry Pi :
% ./udpst -u 2001:db8:fafa:35::1
UDP Speed Test
Software Ver: 7.2.1, Protocol Ver: 8, Built: Sep 28 2021 18:25:23
Mode: Client, Jumbo Datagrams: Enabled, Authentication: Available, sendmmsg syscall: Available
Upstream Test Interval(sec): 10, DelayVar Thresholds(ms): 30-90 [RTT], Trial Interval(ms): 50, Ignore OoO/Dup: Disabled,
SendingRate Index: <Auto>, Congestion Threshold: 3, High-Speed Delta: 10, SeqError Threshold: 10, IPv6 TClass: 0
...
Sub-Interval[10](sec): 10, Delivered(%): 100.00, Loss/OoO/Dup: 0/0/0, OWDVar(ms): 2/8/18, RTTVar(ms): 2-16, Mbps(L3/IP): 65.73
Upstream Summary Delivered(%): 100.00, Loss/OoO/Dup: 0/0/0, OWDVar(ms): 0/3/23, RTTVar(ms): 0-16, Mbps(L3/IP): 49.87
Upstream Minimum One-Way Delay(ms): 2 [w/clock difference], Round-Trip Time(ms): 1
Upstream Maximum Mbps(L3/IP): 67.29, Mbps(L2/Eth): 67.45, Mbps(L1/Eth): 67.63, Mbps(L1/Eth+VLAN): 67.67
En sens inverse, avec l'option -d, où le
Raspberry Pi va envoyer des données :
Downstream Summary Delivered(%): 84.90, Loss/OoO/Dup: 8576/0/0, OWDVar(ms): 0/641/956, RTTVar(ms): 0-39, Mbps(L3/IP): 38.86 Downstream Minimum One-Way Delay(ms): -927 [w/clock difference], Round-Trip Time(ms): 1 Downstream Maximum Mbps(L3/IP): 46.98, Mbps(L2/Eth): 47.68, Mbps(L1/Eth): 48.46, Mbps(L1/Eth+VLAN): 48.62
(Notez le taux de pertes élevé, la pauvre machine n'arrive pas à suivre.)
L'article seul
RFC 9096: Requirements for Customer Edge Routers to Mitigate IPv6 Renumbering Events
Date de publication du RFC : Août 2021
Auteur(s) du RFC : F. Gont (SI6 Networks), J. Zorz (6connect), R. Patterson (Sky UK), B. Volz (Cisco)
Réalisé dans le cadre du groupe de travail IETF v6ops
Première rédaction de cet article le 7 septembre 2021
Quand un FAI modifie la configuration de son réseau IPv6, les routeurs chez les clients finaux, les CPE, ne retransmettent pas toujours rapidement ce changement, ce qui mène parfois à des problèmes de connectivité. Ce RFC décrit ce que doivent faire ces CPE pour minimiser les conséquence négatives d'une rénumérotation d'un réseau.
Le problème est documenté dans le RFC 8978 : par exemple, lorsqu'un routeur chez M. Toutlemonde (une « box ») redémarre et « oublie » sa configuration réseau précédente, si elle a changé chez le FAI entretemps, les machines du réseau local de M. Toutlemonde risquent de continuer à utiliser pendant un certain une ancienne configuration, désormais invalide. Comment éviter cela ?
Notre RFC se penche surtout sur le cas où le routeur de M. Toutlemonde a appris son préfixe IPv6 depuis le FAI via la délégation de préfixe DHCP du RFC 9915, et qu'il retransmet l'information sur ce préfixe dans le réseau local avec le SLAAC du RFC 4862 (via les RA, Router Advertisements, RFC 4861) ou bien DHCP. Les machines terminales sur le réseau local peuvent aussi agir (ce sera dans un futur RFC) mais l'actuel RFC ne concerne que les routeurs. Il consiste en une série d'exigences auxquelles doivent se prêter les routeurs, exigences qui s'ajoutent à celles déjà présentes dans le RFC 7084 ou bien qui modifient des exigences de ce RFC 7084.
Beaucoup de ces exigences nécessitent un mécanisme de stockage d'informations sur le routeur, stockage qui doit survivre aux redémarrages, ce qui ne sera pas évident pour tous les routeurs. Ainsi, le RFC demande que, du côté WAN, le routeur utilise toujours le même identificateur (IAID, Identity Association IDentifier, RFC 9915, section 4.2) en DHCP (pour essayer de garder le même préfixe). Certains routeurs choisissent apparemment l'IAID au hasard à chaque démarrage, ce qui leur obtient un nouveau préfixe. Il vaut mieux le garder, mais cela nécessite qu'il puisse être stocké et mémorisé même en cas de redémarrage. Comme tous les routeurs n'ont pas de mécanisme de stockage stable, les exigences du RFC sont exprimées (dans le langage du RFC 2119) par un SHOULD et pas un MUST.
Autre exigence, qui relève du bon sens, le routeur ne doit pas, lorsqu'il utilise un préfixe du côté LAN (le réseau local), utiliser une durée de vie plus longue (options Preferred Lifetime et Valid Lifetime du message d'information sur le préfixe envoyé par le routeur, RFC 4861, section 4.6.2) que celle qu'il a lui-même appris en DHCP côté WAN. On ne doit pas promettre ce qu'on ne peut pas tenir, la durée du bail DHCP s'impose au routeur et aux annonces qu'il fait sur le réseau local.
Enfin, le routeur ne doit pas, au redémarrage, envoyer
systématiquement un abandon du préfixe appris en DHCP (message DHCP
RELEASE). Certains routeurs font apparemment
cela, ce qui risque de déclencher une renumérotation brutale (RFC 8978).
Lorsque le préfixe change, le routeur devrait aussi signaler cela sur le réseau local. Là encore, cela impose une mémoire, un stockage stable. Il doit se souvenir de ce qu'il a reçu, et annoncé, précédemment, pour pouvoir annoncer sur le réseau local que ces anciens préfixes ne doivent plus être utilisés (cela se fait en annonçant ces préfixes, mais avec une durée de vie nulle). Dans un monde idéal, le routeur sera prévenu des changements de préfixe parce que le FAI réduira la durée de vie de ses baux DHCP, permettant un remplacement ordonné d'un préfixe par un autre. Dans la réalité, on a parfois des renumérotations brutales, sans préavis (RFC 8978). Le routeur doit donc également gérer ces cas.
L'article seul
RFC 9095: Extensible Provisioning Protocol (EPP) Domain Name Mapping Extension for Strict Bundling Registration
Date de publication du RFC : Juillet 2021
Auteur(s) du RFC : J. Yao, L. Zhou, H. Li (CNNIC), N. Kong (Consultant), W. Tan (Cloud Registry), J. Xie
Pour information
Première rédaction de cet article le 30 juillet 2021
Le bundling est le rassemblement de plusieurs noms de domaine dans un seul lot (bundle) qui va être traité comme un nom unique pour des opérations comme l'enregistrement du nom ou son transfert à un autre titulaire. Il est surtout pratiqué par les registres qui ont beaucoup de noms en écriture chinoise. Ce RFC décrit une extension au protocole d'avitaillement EPP pour pouvoir traiter ces lots.
Le problème n'existe pas qu'en chinois mais ce sont surtout les
sinophones qui se sont manifestés à ce sujet, en raison de la
possibilité d'écrire le même mot en écriture
traditionnelle ou en écriture
simplifiée (on parle de variantes :
l'ensemble des variantes forme le lot). Pour prendre un exemple
non-chinois, PIR avait décidé qu'un nom dans
.ngo et dans .ong devaient
être dans le même lot. Un registre qui décide que ces deux termes
sont équivalents et doivent être gérés ensemble (par exemple,
appartenir au même titulaire) les regroupent dans un lot
(bundle, ou parfois
package). C'est la politique suggérée dans les
RFC 3743 et RFC 4290, et
le RFC 6927 décrit les pratiques
existantes. Par exemple, certains registres peuvent n'autoriser
qu'une variante par lot, et bloquer les autres (empêcher leur
enregistrement), tandis que d'autres enregistreront tous les noms
ensemble. Sans compter bien sûr les registres qui n'ont pas de
système de lot du tout. Notre nouveau RFC 9095 ne prend pas
position sur ce sujet délicat, il décrit juste un moyen technique de
manipuler ces lots avec EPP (RFC 5731).
Les variantes dans un même lot n'ont pas forcément tout en commun. Un registre peut par exemple décider que l'enregistrement des variantes doit être fait par le même titulaire mais qu'un nom du lot peut ensuite être transféré à un autre titulaire. Notre RFC se limite au cas strict où les membres du lot ont presque tous leurs attributs (titulaires, contacts, date d'expiration, peut-être serveurs de noms et, pourquoi pas, clés DNSSEC) en commun.
La
lecture du RFC nécessite un peu de terminologie spécifique, décrite
dans sa section 2. Par exemple, le RDN (Registered Domain
Name) est celui qui a été demandé par le titulaire lors de
l'enregistrement, et le BDN (Bundled Domain Name)
est un nom qui a été inclus dans le lot, en fonction des règles du
registre. Par exemple, si un registre décidait que tout nom avec des
traits d'union était équivalent au même nom
sans traits d'union, et qu'un titulaire enregistre
tarte-poireaux.example (le RDN), alors
tartepoireaux.example et
tarte-poi-reaux.example seraient des BDN,
membres du même lot que le RDN. Dans le modèle de notre RFC, les
métadonnées comme la date d'expiration ou comme l'état du domaine
sont attachées au RDN, les BDN du lot partageant ces
métadonnées.
Notons aussi que le RFC n'envisage que le cas de lots assez
petits (par exemple le nom en écriture chinoise traditionnelle et
celui en écriture chinoise simplifiée). L'exemple que je donnais
avec le trait d'union ne rentre pas tellement dans le cadre de ce
RFC car le nombre de BDN est alors beaucoup plus élevé et serait
difficile à gérer. (Amusez-vous à calculer combien de variantes de
tartepoireaux.example existeraient si un
décidait que le trait d'union n'est pas significatif.)
Dans l'extension EPP décrite dans ce RFC, le RDN
est représenté (section 5 du RFC) en Unicode
(le « U-label ») ou bien en ASCII (le « A-label »,
la forme « punycodée »). L'élement XML est
<b-dn:rdn> (où b-dn
est un préfixe possible pour l'espace de noms
XML de notre RFC, urn:ietf:params:xml:ns:epp:b-dn). Si le RDN est représenté en ASCII, un attribut XML
uLabel permet d'indiquer la version Unicode du
nom. Cela donnerait, par exemple, <b-dn:rdn
uLabel="实例.example">xn--fsq270a.example</b-dn:rdn>.
Enfin, la section 6 décrit les commandes et réponses EPP pour
notre extension. La commande <check>
n'est pas modifiée dans sa syntaxe mais le RFC impose que, si un nom
qui fait partie d'un lot est envoyé dans la question, la réponse
doit contenir le RDN et le BDN. Pour un RDN en
sinogrammes, on aurait ainsi la version en
écriture traditionnelle et en écriture simplifiée (ici, le nom est
disponible à l'enregistrement) :
<response>
<result code="1000">
<msg>Command completed successfully</msg>
</result>
<resData>
<domain:chkData
xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
<domain:cd>
<domain:name avail="1">
xn--fsq270a.example</domain:name>
</domain:cd>
<domain:cd>
<domain:name avail="1">
xn--fsqz41a.example
</domain:name>
<domain:reason>This associated domain name is
a produced name based on bundle name policy.
</domain:reason>
</domain:cd>
</domain:chkData>
...
La commande <info> n'est pas non plus
modifiée mais sa réponse l'est, par l'ajout d'un élément
<bundle> qui décrit le lot :
<response>
<result code="1000">
<msg>Command completed successfully</msg>
</result>
<resData>
<domain:infData
xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
<domain:name>xn--fsq270a.example</domain:name>
<domain:roid>58812678-domain</domain:roid>
<domain:status s="ok"/>
...
</domain:infData>
</resData>
<extension>
<b-dn:infData
xmlns:b-dn="urn:ietf:params:xml:ns:epp:b-dn">
<b-dn:bundle>
<b-dn:rdn uLabel="实例.example">
xn--fsq270a.example
</b-dn:rdn>
<b-dn:bdn uLabel="實例.example">
xn--fsqz41a.example
</b-dn:bdn>
</b-dn:bundle>
</b-dn:infData>
</extension>
Quand on crée un domaine qui fait partie d'un lot, la commande
<create> doit inclure une extension
indiquant que le client EPP connait la gestion de lots, et la
réponse à <create> lui donnera le
BDN. D'une manière analogue, la commande
<delete> détruira tout le lot et
l'indiquera dans la réponse. La commande
<update> fonctionne sur le même
principe : elle modifie le RDN et indique dans sa réponse le BDN
affecté. La syntaxe complète de cette extension EPP figure dans la
section 7 du RFC, sous forme d'un schéma
W3C. Par ailleurs, cette extension est enregistrée dans
le
registre des extensions EPP (celui créé par le RFC 7451).
Un petit mot sur la sécurité, car de nombreux adversaires de l'internationalisation, notamment anglophones, ont critiqué les noms de domaine en Unicode, les accusant de tous les maux : les auteurs du RFC notent que des noms en chinois sont enregistrés depuis plus de quinze ans, et qu'aucun problème particulier n'a été signalé.
Questions mises en œuvre de ce RFC, les registres chinois (comme
.cn ou
.tw) suivent les
principes de ce RFC (l'enregistrement d'un lot) depuis
longtemps. CNNIC déploie cette extension
EPP. En dehors de la sinophonie, PIR utilise
les lots pour .ngo et
.ong. Et cette extension EPP est mise en œuvre
dans Net::DRI.
Et, comme souvent, il y a un brevet de Verisign sur la technique décrite dans ce RFC. Je ne l'ai pas lu mais il y a des chances qu'il soit sans mérite, comme beaucoup de brevets logiciels.
L'article seul
RFC 9083: JSON Responses for the Registration Data Access Protocol (RDAP)
Date de publication du RFC : Juin 2021
Auteur(s) du RFC : S. Hollenbeck (Verisign Labs), A. Newton (AWS)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 16 juin 2021
Dans l'ensemble des normes sur le protocole RDAP, ce RFC est destiné à décrire le format de sortie, celui des réponses envoyées par le serveur d'information RDAP. Ce format est basé sur JSON et, pour utiliser RDAP en remplacement de whois, il faudra donc se munir de quelques outils pour traiter le JSON. Ce RFC remplace le RFC 7483 mais il y a très peu de changements.
JSON est normalisé dans le RFC 8259 et représente aujourd'hui le format de choix pour les données structurées c'est-à-dire analysables par un programme. (L'annexe E de notre RFC explique en détail le pourquoi du choix de JSON.) Une des caractéristiques importantes de whois est en effet que son format de sortie n'a aucune structure, c'est du texte libre, ce qui est pénible pour les programmeurs qui essaient de le traiter (mais, d'un autre côté, cela ralentit certains usages déplorables, comme la récolte d'adresses de courrier à des fins de spam, jouant ainsi un rôle de semantic firewall). L'utilisation typique de RDAP est en HTTP (RFC 7480) avec les requêtes exprimées dans la syntaxe des URL du RFC 9082. Voici tout de suite un exemple réel, avec la réponse JSON :
% curl https://rdap.afilias.net/rdap/info/domain/kornog-computing.info
...
{
"entities": [
...
"objectClassName": "entity",
"roles": [
"technical",
"billing",
"administrative"
],
"vcardArray": [
"vcard",
[
[
"version",
{},
"text",
"4.0"
],
[
"fn",
{},
"text",
"KORNOG computing"
],
[
"adr",
{
"cc": "FR"
},
"text",
{}
]
...
"events": [
{
"eventAction": "registration",
"eventDate": "2007-08-14T17:02:33Z"
},
{
"eventAction": "last changed",
"eventDate": "2014-08-14T01:54:07Z"
},
{
"eventAction": "expiration",
"eventDate": "2015-08-14T17:02:33Z"
}
],
"handle": "D19378523-LRMS",
"lang": "en",
"ldhName": "kornog-computing.info",
...
"nameservers": [
{
"ldhName": "ns1.kornog-computing.net",
"objectClassName": "nameserver",
"remarks": [
{
"description": [
"Summary data only. For complete data, send a specific query for the object."
],
"title": "Incomplete Data",
"type": "object truncated due to unexplainable reasons"
}
]
},
{
"ldhName": "ns2.kornog-computing.net",
"objectClassName": "nameserver",
"remarks": [
{
"description": [
"Summary data only. For complete data, send a specific query for the object."
],
"title": "Incomplete Data",
"type": "object truncated due to unexplainable reasons"
}
]
}
],
"notices": [
{
"description": [
"Access to AFILIAS WHOIS information is provided to assist persons in determining the contents of a domain name registration record in the Afilias registry database. The data in this record is provided by Afilias Limited for informational purposes only, and Afilias does not guarantee its accuracy. [...]"
],
"title": "TERMS OF USE"
}
],
"objectClassName": "domain",
...
"rdapConformance": [
"rdap_level_0"
],
"secureDNS": {
"zoneSigned": false
},
"status": [
"clientDeleteProhibited -- http://www.icann.org/epp#clientDeleteProhibited",
"clientTransferProhibited -- http://www.icann.org/epp#clientTransferProhibited"
]
}
La section 1.2 présente le modèle de données de RDAP. Dans les réponses, on trouve des types simples (comme des chaînes de caractères), des tableaux JSON, et des objets JSON qui décrivent les trucs sur lesquels on veut de l'information (noms de domaine, adresses IP, etc). Ces objets peuvent comporter des tableaux ou d'autres objets et, lorsqu'une réponse renvoie plusieurs objets (cas des recherches ouvertes, cf. RFC 9082, section 3.2), peuvent eux-même être regroupés en tableaux. Il existe plusieurs classes de ces objets. D'abord, les classes communes aux registres de noms de domaine et aux RIR (registres d'adresses IP) :
- Domaines (oui, même pour les RIR, pensez à
in-addr.arpaetip6.arpa), - Serveurs de noms,
- Entités diverses, comme les handles, les
identificateurs des contacts, genre
GR283-FRNIC.
Deux classes sont spécifiques aux RIR :
- Réseaux IP, identifiés par leur préfixe,
- Systèmes autonomes.
On verra peut-être apparaître d'autres classes avec le temps, si l'usage de RDAP se répand.
La section 2 de notre RFC décrit comment JSON est utilisé. Le
type MIME renvoyé est
application/rdap+json. La section 2 commence
par un rappel que le client RDAP doit ignorer
les membres inconnus dans les objets JSON, afin de préserver la
future extensibilité. (Cette règle ne s'applique pas au jCard
- cf. RFC 7095 - embarqué.) Si un serveur veut
ajouter des membres qui lui sont spécifiques, il est recommandé
qu'il préfixe leur nom avec un identificateur court suivi d'un
tiret bas. Ainsi, cet objet
RDAP standard :
{
"handle" : "ABC123",
"remarks" :
[
{
"description" :
[
"She sells sea shells down by the sea shore.",
"Originally written by Terry Sullivan."
]
}
]
}
S'il est servi par le « registre de la Lune » (registre imaginaire
qui fournit les exemples de ce RFC), celui-ci, lorsqu'il voudra
ajouter des membres, les précédera de
lunarNIC_ :
{
"handle" : "ABC123",
"lunarNic_beforeOneSmallStep" : "TRUE THAT!",
"remarks" :
[
{
"description" :
[
"She sells sea shells down by the sea shore.",
"Originally written by Terry Sullivan."
]
}
],
"lunarNic_harshMistressNotes" :
[
"In space,",
"nobody can hear you scream."
]
}
(Je vous laisse décoder les références geeks dans l'exemple.)
La section 3 s'occupe des types de données de base. On utilise du
JSON normal, tel que spécifié dans le RFC 8259, avec ses chaînes de caractères, ses booléens, son
null... Un handle
(l'identifiant unique - par registre - d'un contact, parfois nommé
NIC handle ou registry ID) est
une chaîne. Les adresses IP se représentent également par une chaîne
de caractères (ne pas oublier le RFC 5952 pour
IPv6). Les pays sont identifiés par le code à
deux lettres de ISO 3166. Les noms de
domaines peuvent être sous une forme ASCII ou bien en
Unicode. Les dates et heures suivent le RFC 3339, et les URI le RFC 3986.
Les informations plus complexes (comme les détails sur un contact) utilisent jCard, normalisé dans le RFC 7095.
Que trouve-t-on dans les objets JSON renvoyés par un serveur RDAP ? Une indication de la version de la norme :
"rdapConformance" :
[
"rdap_level_0"
]
(Éventuellement avec d'autres identificateurs pour les extensions locales.) Et des liens vers des ressources situées ailleurs, suivant le cadre du RFC 8288 :
"links": [
{
"href": "http://rdg.afilias.info/rdap/entity/ovh53ec16bekre5",
"rel": "self",
"type": "application/rdap+json",
"value": "http://rdg.afilias.info/rdap/entity/ovh53ec16bekre5"
}
On peut aussi avoir du texte libre, comme dans l'exemple plus haut
avec le membre remarks. Ce membre sert aux
textes décrivant la classe, alors que notices
est utilisé pour le service RDAP. Un exemple :
"notices": [
{
"description": [
"Access to AFILIAS WHOIS information is provided to assist persons in determining the contents of a domain name registration record in the Afilias registry database. The data in this record is provided by Afilias Limited for informational purposes only, and Afilias does not guarantee its accuracy. [...]"
],
"title": "TERMS OF USE"
}
],
Contrairement à whois, RDAP permet l'internationalisation sous tous ses aspects. Par exemple, on peut indiquer la langue des textes avec une étiquette de langue (RFC 5646) :
"lang": "en",
Enfin, la classe (le type) de l'objet renvoyé par RDAP est
indiquée par un membre objectClassName :
"objectClassName": "domain",
Ces classes, justement. La section 5 les décrit. Il y a d'abord
la classe Entity qui correspond aux requêtes
/entity du RFC 9082. Elle
sert à décrire les personnes et les organisations. Parmi les membres
importants pour les objets de cette classe,
handle qui est un identificateur de l'instance
de la classe, et roles qui indique la relation
de cette instance avec l'objet qui la contient (par exemple
"roles": ["technical"] indiquera que cette
Entity est le contact technique de
l'objet). L'information de contact sur une
Entity se fait avec le format
vCard du RFC 7095, dans
un membre vcardArray. Voici un exemple avec le
titulaire du domaine uba.ar :
% curl https://rdap.nic.ar/entity/30546666561
...
"objectClassName": "entity",
"vcardArray": [
"vcard",
[
[
"version",
{},
"text",
"4.0"
],
[
"fn",
{},
"text",
"UNIVERSIDAD DE BUENOS AIRES"
]
]
],
...
(jCard permet de mentionner plein d'autres choses qui ne sont a priori pas utiles pour RDAP, comme la date de naissance ou le genre.)
La classe Nameserver correspond aux requêtes
/nameserver du RFC 9082. Notez qu'un registre peut gérer les serveurs de noms
de deux façons : ils peuvent être vus comme des objets autonomes,
enregistrés tels quel dans le registre (par exemple via le RFC 5732), ayant des attributs par exemple des
contacts, et interrogeables directement par whois ou RDAP (c'est le
modèle de .com, on dit
alors que les serveurs de noms sont des « objets de première
classe »). Ou bien ils peuvent être simplement des attributs des
domaines, accessibles via le domaine. Le principal attribut d'un
objet Nameserver est son adresse IP, pour
pouvoir générer des colles dans le DNS (enregistrement DNS d'une
adresse IP, pour le cas où le serveur de noms est lui-même dans la
zone qu'il sert). Voici un exemple avec un des serveurs de noms de
la zone afilias-nst.info :
% curl https://rdap.afilias.net/rdap/info/nameserver/b0.dig.afilias-nst.info
...
"ipAddresses": {
"v4": [
"65.22.7.1"
],
"v6": [
"2a01:8840:7::1"
]
},
...
Notez que l'adresse IP est un tableau, un serveur pouvant avoir plusieurs adresses.
La classe Domain correspond aux requêtes
/domain du RFC 9082. Un
objet de cette classe a des membres indiquant les serveurs de noms,
si la zone est signée avec DNSSEC ou pas, l'enregistrement DS si elle est signée, le
statut (actif ou non, bloqué ou non), les contacts, etc. Voici un
exemple :
% curl http://rdg.afilias.info/rdap/domain/afilias-nst.info
...
"nameservers": [
{
"ldhName": "a0.dig.afilias-nst.info",
...
"secureDNS": {
"delegationSigned": false
},
...
"status": [
"client transfer prohibited",
"server delete prohibited",
"server transfer prohibited",
"server update prohibited"
],
...
La classe IP network rassemble les objets
qu'on trouve dans les réponses aux requêtes /ip
du RFC 9082. Un objet de cette classe ne
désigne en général pas une seule adresse IP mais un préfixe, dont on
indique la première (startAddress) et la
dernière adresse (endAddress). Personnellement,
je trouve cela très laid et j'aurai préféré qu'on utilise une
notation préfixe/longueur. Voici un exemple :
% curl https://rdap.db.ripe.net/ip/131.111.150.25
...
{
"handle" : "131.111.0.0 - 131.111.255.255",
"startAddress" : "131.111.0.0/32",
"endAddress" : "131.111.255.255/32",
"ipVersion" : "v4",
"name" : "CAM-AC-UK",
"type" : "LEGACY",
"country" : "GB",
...
La dernière classe normalisée à ce stade est
autnum (les AS), en réponse aux requêtes
/autnum du RFC 9082. Elle
indique notamment les contacts de l'AS. Pour l'instant, il n'y a pas
de format pour indiquer la politique de routage (RFC 4012). Un exemple d'un objet de cette classe :
% curl https://rdap.db.ripe.net/autnum/20766
{
"handle" : "AS20766",
"name" : "GITOYEN-MAIN-AS",
"type" : "DIRECT ALLOCATION",
...
"handle" : "GI1036-RIPE",
"vcardArray" : [ "vcard", [ [ "version", { }, "text", "4.0" ], [ "fn", { }, "text", "NOC Gitoyen" ], [ "kind", { }, "text", "group" ], [ "adr", {
"label" : "Gitoyen\n21 ter rue Voltaire\n75011 Paris\nFrance"
}, "text", null ], [ "email", { }, "text", "noc@gitoyen.net" ] ] ],
...
Comme, dans la vie, il y a parfois des problèmes, une section de
notre RFC, la section 6, est dédiée aux formats des erreurs que
peuvent indiquer les serveurs RDAP. Le code de retour HTTP fournit
déjà des indications (404 = cet objet n'existe pas ici, 403 = vous
n'avez pas le droit de le savoir, etc) mais on peut aussi ajouter un
objet JSON pour en indiquer davantage, objet ayant un membre
errorCode (qui reprend le code HTTP), un membre
title et un membre
description. Voici un exemple sur le serveur
RDAP de l'ARIN :
% curl -v http://rdap.arin.net/registry/autnum/99999
< HTTP/1.0 404 Not Found
< Mon, 10 May 2021 09:07:52 GMT
< Server: Apache/2.4.6 (CentOS) OpenSSL/1.0.2k-fips
...
{
...
"errorCode" : 404,
"title" : "AUTNUM NOT FOUND",
"description" : [ "The autnum you are seeking as '99999' is/are not here." ]
Plus positive, la possibilité de demander de l'aide à un serveur
RDAP, en se renseignant sur ses capacités, avec la requête
/help. Son résultat est décrit dans la section
7 mais tous les serveurs RDAP actuels n'utilisent pas
cette possibilité. En voici un où ça marche, à
l'ARIN :
% curl -s https://rdap.arin.net/registry/help
{
"rdapConformance" : [ "rdap_level_0" ],
"notices" : [ {
"title" : "Terms of Service",
"description" : [ "By using the ARIN RDAP/Whois service, you are agreeing to the RDAP/Whois Terms of Use" ],
"links" : [ {
"value" : "https://rdap.arin.net/registry/help",
"rel" : "about",
"type" : "text/html",
"href" : "https://www.arin.net/resources/registry/whois/tou/"
} ]
}, {
"title" : "Whois Inaccuracy Reporting",
"description" : [ "If you see inaccuracies in the results, please visit: " ],
"links" : [ {
"value" : "https://rdap.arin.net/registry/help",
"rel" : "about",
"type" : "text/html",
"href" : "https://www.arin.net/resources/registry/whois/inaccuracy_reporting/"
} ]
}, {
"title" : "Copyright Notice",
"description" : [ "Copyright 1997-2021, American Registry for Internet Numbers, Ltd." ]
} ]
}
Et les résultats des recherches ouvertes (section 3.2 du RFC 9082), qui peuvent renvoyer plusieurs objets ?
Ce sont des tableaux JSON, dans des membres dont le nom se termine
par Results. Par exemple, en cherchant les noms
de domaines commençant par ra (ce test a été
fait sur un serveur expérimental qui ne marche plus depuis) :
% curl http://rdg.afilias.info/rdap/domains\?name=ra\*|more
"domainSearchResults": [
{
"ldhName": "RAINSTRAGE.INFO",
...
"objectClassName": "domain",
"remarks": [
{
"description": [
"Summary data only. For complete data, send a specific query for the object."
],
"title": "Incomplete Data",
"type": "object truncated due to unexplainable reasons"
}
...
"ldhName": "RADONREMOVAL.INFO",
...
"ldhName": "RANCONDI.INFO",
...
Les vrais serveurs RDAP en production ne répondent pas forcément à ces requêtes trop coûteuses et qui peuvent trop facilement être utilisées pour le renseignement économique :
% curl https://rdap.afilias.net/rdap/info/domains\?name=ra\*
...
"errorCode": 422,
"title": "Error in processing the request",
"description": [
"WildCard search is not supported on sub-zone or tld"
]
Vous avez peut-être noté dans le tout premier exemple le membre
events (section 4.5 du RFC). Ces événements
comme created ou
last-changed donnent accès à l'histoire d'un
objet enregistré. Ici, nous apprenons que le domaine
kornog-computing.info a été enregistré en
2007.
Certaines valeurs qui apparaissent dans les résultats sont des
chaînes de caractères fixes, stockées dans un nouveau registre
IANA. Elles sont conçues pour être utilisées dans les
notices, remarks,
status, roles et quelques
autres. Parmi les remarques, on trouvera le cas où une réponse a été
tronquée (section 9 du RFC), comme dans l'exemple ci-dessus avec la
mention Incomplete Data. Parmi les statuts, on
trouvera, par exemple validated (pour un objet
vérifié, par exemple un nom de domaine dont on a vérifié les
coordonnées du titulaire), locked (pour un
objet verrouillé), obscured (qui n'est pas un
statut dans le base du données du registre mais simplement la
mention du fait que le serveur RDAP a délibérement modifié certaines
informations qu'il affiche, par exemple pour protéger la vie
privée), etc. Pour les rôles, on trouvera
registrant (titulaire),
technical (contact technique), etc.
Pour ceux qu'intéressent les questions d'internationalisation, la section 12 contient d'utiles mentions. L'encodage des données JSON doit être de l'UTF-8. Et, comme indiqué plus haut, les IDN peuvent être sous la forme Punycode ou bien directement en UTF-8.
Et la vie privée, un problème permanent
avec whois, où il faut toujours choisir entre la distribution de
données utiles pour contacter quelqu'un et les risques pour sa vie
privée ? La section 13 revient sur
cette question. Un point important : RDAP est un protocole, pas une
politique. Il ne définit pas quelles règles suivre (c'est de la
responsabilité des divers registres) mais il fournit les outils pour
mettre en œuvre ces règles. Notamment, RDAP permet de marquer des
parties de la réponse comme étant connues du registre, mais n'ayant
délibérement pas été envoyées (avec les codes
private et removed) ou
bien comme ayant été volontairement rendues peu ou pas lisibles
(code obscured).
Vous avez vu dans les exemples précédents que les réponses d'un serveur RDAP sont souvent longues et, a priori, moins lisibles que celles d'un serveur whois. Il faudra souvent les traiter avec un logiciel qui comprend le JSON. Un exemple très simple et que j'apprécie est jq. Il peut servir à présenter le résultat de manière plus jolie :
% curl -s https://rdap.centralnic.com/pw/domain/centralnic.pw | jq .
...
{
"objectClassName": "domain",
"handle": "D956082-CNIC",
"ldhName": "centralnic.pw",
"nameservers": [
{
"objectClassName": "nameserver",
"ldhName": "ns0.centralnic-dns.com",
...
(Essayez ce même serveur RDAP sans jq !)
Mais on peut aussi se servir de jq pour extraire un champ particulier, ici le pays :
% curl -s https://rdap.db.ripe.net/ip/131.111.150.25 | jq ".country" "GB" % curl -s https://rdap.db.ripe.net/ip/192.134.1.1 | jq ".country" "FR"
Il y a évidemment d'autres logiciels que jq sur ce créneau, comme
JSONpath,
jpath
ou, pour les programmeurs Python, python -m
json.tool.
Un dernier mot, sur le choix de JSON pour le format de sortie, alors que le protocole standard d'avitaillement des objets dans les bases Internet, EPP (RFC 5730) est en XML. L'annexe E de notre RFC, qui discute ce choix, donne comme principaux arguments que JSON est désormais plus répandu que XML (cf. l'article « The Stealthy Ascendancy of JSON ») et que c'est surtout vrai chez les utilisateurs (EPP étant utilisé par une population de professionnels bien plus réduite).
Quels changements depuis le RFC 7483 ? La
plupart sont mineurs et sont de l'ordre de la
clarification. D'autres sont des corrections
d'erreurs, par exemple une coquille
qui avait mis registrant là où il aurait fallu
dire registrar (la proximité des mots en anglais
entraine souvent des erreurs, même chez les professionnels). Il y a
une certaine tendance au durcissement des règles, des éléments qui
étaient optionnels dans le RFC 7483 sont
devenus obligatoires comme, par exemple,
rdapConformance (dont le statut optionnel avait
causé des
problèmes).
Et question logiciels qui mettent en œuvre RDAP ? Beaucoup de logiciels de gestion de registre le font aujourd'hui, notamment ceux sous contrat avec l'ICANN, puisqu'ils n'ont pas le choix. Mais les logiciels ne sont pas forcément publiquement disponibles. Parmi ceux qui le sont, il y a RedDog, Fred, celui de l'APNIC…
L'article seul
RFC 9082: Registration Data Access Protocol (RDAP) Query Format
Date de publication du RFC : Juin 2021
Auteur(s) du RFC : S. Hollenbeck (Verisign Labs), A. Newton (AWS)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 16 juin 2021
Le protocole d'information RDAP, qui vise à remplacer whois, est décrit dans un ensemble de RFC. Celui présenté ici normalise la façon de former les requêtes RDAP. Celles-ci ont la forme d'une URL, puisque RDAP repose sur l'architecture REST. Ce RFC remplace l'ancienne norme sur les requêtes RDAP, qui était dans le RFC 7482, mais il n'y a pas de changement significatif.
RDAP peut être utilisé pour beaucoup de sortes d'entités différentes mais ce RFC ne couvre que ce qui correspond aux usages actuels de whois, les préfixes d'adresses IP, les AS, les noms de domaine, etc. Bien sûr, un serveur RDAP donné ne gère pas forcément tous ces types d'entités, et il doit renvoyer le code HTTP 501 (Not implemented) s'il ne sait pas gérer une demande donnée. Ce RFC ne spécifie que l'URL de la requête, le format de la réponse est variable (JSON, XML...) et le seul actuellement normalisé, au-dessus de JSON, est décrit dans le RFC 9083. Quant au protocole de transport, le seul actuellement normalisé pour RDAP (dans le RFC 7480) est HTTP. D'autre part, ces RFC RDAP ne décrivent que le protocole entre le client RDAP et le serveur, pas « l'arrière-cuisine », c'est-à-dire l'avitaillement (création, modification et suppression) des entités enregistrées. RDAP est en lecture seule et ne modifie pas le contenu des bases de données qu'il interroge.
Passons aux choses concrètes. Une requête RDAP est un
URL (RFC 3986). Celui-ci est obtenu en ajoutant un chemin
spécifique à une base. La base (par exemple
https://rdap.example.net/) va être obtenue par
des mécanismes divers, comme celui du RFC 7484, qui spécifie un registre que vous pouvez
trouver en ligne. On met ensuite un chemin qui dépend du type
d'entité sur laquelle on veut se renseigner, et qui indique
l'identificateur de l'entité. Par exemple, avec la base ci-dessus,
et une recherche du nom de domaine
internautique.fr, on construirait un URL
complet
https://rdap.example.net/domain/internautique.fr. Il
y a cinq types d'entités possibles :
ip: les préfixes IP (notez qu'on peut chercher un préfixe en donnant juste une des adresses IP couvertes par ce préfixe),autnum: les numéros de systèmes autonomes,domain: un nom de domaine (notez que cela peut être un domaine dansin-addr.arpaouipv6.arpa),nameserver: un serveur de noms,entity: une entité quelconque, comme un bureau d'enregistrement, ou un contact identifié par un handle.
La requête est effectuée avec la méthode HTTP
GET (les méthodes permettant de modifier le
contenu du registre n'ont pas de sens ici, les modifications dans le
registre sont plutôt faites avec EPP). Pour juste savoir si un
objet existe, on peut aussi utiliser la méthode
HEAD. Si on n'obtient pas de code 404, c'est
que l'objet existe.
Pour ip, le chemin dans l'URL est
/ip/XXX où XXX peut être
une adresse IPv4 ou
IPv6 sous forme texte. Il peut aussi y avoir
une longueur de préfixe à la fin donc
/ip/2001:db8:1:a::/64 est un chemin
valable. Ainsi, sur le service RDAP du RIPE-NCC,
https://rdap.db.ripe.net/ip/2001:4b98:dc0:41::
est un URL possible. Testons-le avec curl (le format de sortie, en JSON, est décrit dans
le RFC 9083, vous aurez peut-être
besoin de passer le résultat à travers jq
pour l'afficher joliment) :
% curl https://rdap.db.ripe.net/ip/2001:4b98:dc0:41::
{
"handle" : "2001:4b98:dc0::/48",
"startAddress" : "2001:4b98:dc0::/128",
"endAddress" : "2001:4b98:dc0:ffff:ffff:ffff:ffff:ffff/128",
"ipVersion" : "v6",
"name" : "GANDI-HOSTING-DC0",
"type" : "ASSIGNED",
"country" : "FR",
"rdapConformance" : [ "rdap_level_0" ],
"entities" : [ {
"handle" : "GAD42-RIPE",
"vcardArray" : [ "vcard", [ [ "version", { }, "text", "4.0" ], [ "fn", { }, "text", "Gandi Abuse Department" ], [ "kind", { }, "text", "group" ], [ "adr", {
"label" : "63-65 Boulevard Massena\n75013 Paris\nFrance"
...
J'ai utilisé curl mais, notamment pour formater plus joliment la
sortie de RDAP, les vrais utilisateurs se serviront plutôt d'un
client RDAP dédié comme RDAPBrowser sur
Android, ou nicinfo. Voici
une vue de RDAPbrowser: 
Pour autnum, on met le numéro de
l'AS après
/autnum/ (au format
« asplain » du RFC 5396). Toujours dans l'exemple RIPE-NCC,
https://rdap.db.ripe.net/autnum/208069 permet de
chercher de l'information sur l'AS
208069 :
% curl https://rdap.db.ripe.net/autnum/208069
{
"handle" : "AS208069",
"name" : "ATAXYA",
"type" : "DIRECT ALLOCATION",
"entities" : [ {
"handle" : "mc40833-RIPE",
"roles" : [ "administrative", "technical" ],
"objectClassName" : "entity"
}, {
...
Pour les noms de domaines, on met le nom après
/domain/. Ainsi, sur le serveur RDAP d'Afilias,
https://rdap.afilias.net/rdap/info/domain/rmll.info
nous donnera de l'information sur le domaine
rmll.info. On peut mettre un nom en
Unicode donc
https://rdap.example.net/domain/potamochère.fr
est valable, mais il devra être encodé comme l'explique la section
6.1, plus loin (en gros, UTF-8 en
NFC). Si on ne veut pas lire cette
information sur l'encodage, on peut aussi utiliser la forme
Punycode, donc chercher avec
https://rdap.example.net/domain/xn--potamochre-66a.fr. Un
exemple réel, en Russie :
% curl https://api.rdap.nic.рус/domain/валфекс.рус
...
{
"eventAction": "registration",
"eventDate": "2018-12-26T07:53:41.776927Z"
},
...
"adr",
{
"type": "Registrar Contact"
},
"text",
[
"",
"",
"125476, g. Moskva, ul. Vasilya Petushkova, dom 3, str. 1",
"",
"",
"",
"RU"
]
]
...
(Attention, le certificat ne sera accepté par curl que si curl a été compilé avec l'option « IDN ».)
On peut aussi se servir de RDAP pour les noms de domaines qui servent à traduire une adresse IP en nom :
% curl https://rdap.db.ripe.net/domain/1.8.a.4.1.0.0.0.0.d.1.4.1.0.0.2.ip6.arpa
{
"handle" : "0.d.1.4.1.0.0.2.ip6.arpa",
"ldhName" : "0.d.1.4.1.0.0.2.ip6.arpa",
"nameServers" : [ {
"ldhName" : "dns15.ovh.net"
}, {
"ldhName" : "ns15.ovh.net"
} ],
"rdapConformance" : [ "rdap_level_0" ],
"entities" : [ {
"handle" : "OK217-RIPE",
"roles" : [ "administrative" ]
}, {
"handle" : "OTC2-RIPE",
"roles" : [ "zone", "technical" ]
}, {
"handle" : "OVH-MNT",
"roles" : [ "registrant" ]
} ],
"remarks" : [ {
"description" : [ "OVH IPv6 reverse delegation" ]
} ],
...
Pour un serveur de noms, on met son nom après
/nameserver donc, chez Afilias :
% curl https://rdap.afilias.net/rdap/info/nameserver/rmll1.rmll.info
{
...
"ipAddresses": {
"v4": [
"80.67.169.65"
]
},
"lang": "en",
"ldhName": "rmll1.rmll.info",
...
Pour entity, on indique juste un
identificateur. Voici un exemple :
% curl http://rdg.afilias.info/rdap/entity/81
{
"handle": "81",
"lang": "en",
...
"roles": [
"registrar"
],
"vcardArray": [
"vcard",
[
[
"version",
{},
"text",
"4.0"
],
[
"fn",
{},
"text",
"Gandi SAS"
],
[
"adr",
{},
"text",
[
"",
"",
"63-65 boulevard Massena",
"Paris",
"",
"F-75013",
"FR"
]
...
Certains registres, qui stockent d'autres types d'objets,
pourront ajouter leurs propres requêtes, en prenant soin
d'enregistrer les préfixes de ces requêtes dans le
registre IANA. Par exemple, le logiciel de gestion de
registres FRED permet
d'interroger le registre sur les clés DNSSEC avec les requêtes
/fred_keyset
(la syntaxe des requêtes locales est identificateur du préfixe +
tiret bas + type cherché).
Dernière possibilité, un chemin spécial indique qu'on veut
récupérer de l'aide sur ce serveur RDAP particulier. En envoyant
help (par exemple
https://rdap.example.net/help), on obtient un
document décrivant les capacités de ce serveur, ses conditions
d'utilisation, sa politique vis-à-vis de la vie
privée, ses possibilités d'authentification (via les
mécanismes de HTTP), l'adresse
où contacter les responsables, etc. C'est l'équivalent de la
fonction d'aide qu'offrent certains serveurs whois, ici celui de
l'AFNIC :
% whois -h whois.nic.fr -- -h ... %% Option Function %% ------- ------------------------------------- %% -r turn off recursive lookups %% -n AFNIC output format %% -o old fashioned output format (Default) %% -7 force 7bits ASCII output format %% -v verbose mode for templates and help options %% (may be use for reverse query) %% -T type return only objects of specified type %% -P don't return individual objects in case of contact search %% -h informations about server features %% -l lang choice of a language for informations (you can specify US|EN|UK for %% english or FR for french) %% ...
Pour RDAP, voyez par exemple https://rdap.nic.bzh/helphttp://rdap.apnic.net/helphttps://rdap.nic.cz/help
Toutes les recherches jusque-là ont été des recherches exactes
(pas complètement pour les adresses IP, où on pouvait chercher un
réseau par une seule des adresses contenues dans le réseau). Mais on
peut aussi faire des recherches plus ouvertes, sur une partie de
l'identificateur. Cela se fait en ajoutant une requête (la partie
après le point
d'interrogation) dans l'URL et en ajoutant un
astérisque (cf. section 4.1). Ainsi,
https://rdap.example.net/domains?name=foo*
cherchera tous les domaines dont le nom commence par la chaîne de
caractères foo. (Vous avez noté que c'est
/domains, au pluriel, et non plus
/domain ?) Voici un exemple d'utilisation :
% curl https://rdap.afilias.net/rdap/info/domains\?name=rm\*
...
"errorCode": 422,
"title": "Error in processing the request",
"description": [
"WildCard search is not supported on sub-zone or tld"
]
...
Eh oui, les requêtes ouvertes comme celle-ci posent à la fois des problèmes techniques (la charge du serveur) et politico-juridiques (la capacité à extraire de grandes quantités de la base de données). Elles sont donc typiquement utilisables seulement après une authentification.
On peut aussi chercher un domaine d'après ses serveurs de noms,
par exemple
https://rdap.example.net/domains?nsLdhName=ns1.example.com
chercherait tous les domaines délégués au serveur DNS
ns1.example.com. Une telle fonction peut être
jugée très indiscrète et le serveur RDAP est toujours libre de
répondre ou pas mais, ici, cela marche, on trouve bien le domaine
qui a ce serveur de noms :
% curl https://rdap.afilias.net/rdap/info/domains\?nsLdhName=ns0.abul.org
...
"domainSearchResults": [
{
"objectClassName": "domain",
"handle": "D10775367-LRMS",
"ldhName": "rmll.info",
...
Deux autres types permettent ces recherches ouvertes,
/nameservers (comme dans
https://rdap.example.net/nameservers?ip=2001:db8:42::1:53,
mais notez qu'on peut aussi chercher un serveur par son nom) et
/entities (comme dans
https://rdap.example.net/entities?fn=Jean%20Dupon*) :
% curl http://rdg.afilias.info/rdap/entities\?fn=go\*
{
"entitySearchResults": [
{
"fn": "Go China Domains, Inc.",
...
"fn": "Gotnames.ca Inc.",
...
Notez que ce type de recherche peut représenter un sérieux danger pour la vie privée (comme noté dans le RFC, par exemple en section 4.2) puisqu'elle permet, par exemple de trouver tous les titulaires prénommés Jean. Elle est donc parfois uniquement accessible à des clients authentifiés, et de confiance.
La section 4 détaille le traitement des requêtes. N'oubliez pas qu'on travaille ici sur HTTP et que, par défaut, les codes de retour RDAP suivent la sémantique HTTP (404 pour un objet non trouvé, par exemple). Il y a aussi quelques cas où le code à retourner est moins évident. Ainsi, si un serveur ne veut pas faire une recherche ouverte, il va répondre 422 (Unprocessable Entity).
Vous avez noté plus haut, mais la section 6 le rappelle aux
distraits, que le nom de domaine peut être exprimé en
Unicode ou en ASCII. Donc,
https://rdap.example.net/domain/potamochère.fr
et
https://rdap.example.net/domain/xn--potamochre-66a.fr
sont deux requêtes acceptables.
Enfin, la section 8 rappelle quelques règles de sécurité comme :
- Les requêtes ouvertes peuvent mener à une forte consommation de ressources sur le serveur. Le serveur qui ne vaut pas se faire DoSer doit donc faire attention avant de les accepter.
- Les requêtes RDAP, et surtout les requêtes ouvertes, peuvent soulever des questions liées à la vie privée. Les serveurs RDAP doivent donc réfléchir avant de renvoyer de l'information. Rappelez-vous que RDAP, contrairement à whois, peut avoir un mécanisme d'authentification, donc peut envoyer des réponses différentes selon le client.
- Et, corollaire du précédent point, les gérants de serveurs RDAP doivent définir une politique d'autorisation : qu'est-ce que je renvoie, et à qui ?
Les changements depuis le RFC 7482 sont peu nombreux et sont surtout de clarification.
L'article seul
RFC 9079: Source-Specific Routing in Babel
Date de publication du RFC : Août 2021
Auteur(s) du RFC : M. Boutier, J. Chroboczek (IRIF, University of Paris)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF babel
Première rédaction de cet article le 29 août 2021
Traditionnellement, le routage dans l'Internet se fait sur la base de l'adresse IP de destination. Mais on peut aussi envisager un routage où l'adresse IP source est prise en compte. Ce nouveau RFC étend le protocole de routage Babel en lui ajoutant cette possibilité.
Babel, normalisé dans le RFC 8966 est un protocole de routage à vecteur de
distance. Il est prévu par défaut pour du routage
IP traditionnel, où
le protocole de routage construit une table de transmission qui
associe aux préfixes IP de destination le routeur suivant
(next hop). Un paquet
arrive dans un routeur ? Le routeur regarde
dans sa table le préfixe le plus spécifique qui correspond à
l'adresse IP de destination (utilisant pour cela une structure de
données comme, par exemple, le Patricia trie)
et, lorsqu'il le trouve, la table contient les coordonnées du
routeur suivant. Par exemple, si une entrée de la table dit que
2001:db8:1:fada::/64 a pour routeur suivant
fe80::f816:3eff:fef2:47db%eth0, un paquet
destiné à 2001:db8:1:fada::bad:1234 sera
transmis à ce fe80::f816:3eff:fef2:47db, sur
l'interface réseau eth0. Cette transmission
classique a de nombreux avantages : elle est simple et rapide, et
marche dans la plupart des cas.
Mais ce mécanisme a des limites. On peut vouloir prendre en compte d'autres critères que l'adresse de destination pour la transmission d'un paquet. Un exemple où un tel critère serait utile est le multihoming. Soit un réseau IP qui est connecté à plusieurs opérateurs, afin d'assurer son indépendance et pour faire face à un éventuel problème (technique ou commercial) chez l'un des opérateurs. La méthode officielle pour cela est d'acquérir des adresses indépendantes du fournisseur et de faire router ces adresses par les opérateurs auxquels on est connectés (par exemple en leur parlant en BGP). Mais avoir de ces adresses PI (Provider-Independent) est souvent difficile. Quand on est passionnée, on y arrive mais ce n'est pas vraiment accessible à tout le monde. On se retrouve donc en général avec des adresses dépendant du fournisseur. C'est par exemple le cas de loin le plus courant pour le particulier, la petite association ou la PME. Dans ce cas, le multihoming est compliqué. Mettons que les deux fournisseurs d'accès se nomment A et B et que chacun nous fournisse un préfixe d'adresses IP. Si une machine interne a deux adresses IP, chacune tirée d'un des préfixes, et qu'elle envoie vers l'extérieur un paquet ayant comme adresse source une adresse de B, que se passe-t-il ? Si le paquet est envoyé via le fournisseur B, tout va bien. Mais s'il est envoyé via le fournisseur A, il sera probablement jeté par le premier routeur de A, puisque son adresse IP source ne sera pas une adresse du fournisseur (RFC 3704 et RFC 8704). Pour éviter cela, il faudrait pouvoir router selon l'adresse IP source, envoyant les paquets d'adresse source A vers le fournisseur A et ceux ayant une adresse source B vers B. En gros, soit l'information de routage influe sur le choix de l'adresse source, soit c'est le choix de l'adresse source qui influe sur le routage. On ne peut pas faire les deux, ou alors on risque une boucle de rétroaction. Ce RFC choisit la deuxième solution.
La première solution serait que la machine émettrice choisisse l'adresse IP source selon que les adresses de destination soient routées vers A ou vers B. Le RFC 3484 explique comment le faire en séquentiel et le RFC 8305 le fait en parallèle (algorithme dit des « globes oculaires heureux »). Mais les systèmes actuels ne savent typiquement pas le faire et, de toute façon, cela ne réglerait pas le cas où le routage change pendant la vie d'une connexion TCP. TCP, contrairement à QUIC ou SCTP, ne supporte pas qu'une adresse IP change en cours de route, sauf à utiliser les extensions du RFC 8684. Une dernière solution serait de laisser les applications gérer cela (cf. RFC 8445) mais on ne peut pas compter que toutes les applications le fassent. Bref, le routage tenant compte de la source reste souvent la meilleure solution.
À part le cas du multihoming, d'autres usages peuvent tirer profit d'un routage selon la source. Ce routage peut simplifier la configuration des tunnels. Il peut aussi être utile dans le cas de l'anycast. Lorsqu'on utilise du routage classique, fondé uniquement sur la destination, il est difficile de prédire quels clients du groupe anycast seront servis par quelle instance du groupe. Cela rend la répartition de charge compliquée (il faut jouer avec les paramètres des annonces BGP, par exemple) et cela pose des problèmes aux protocoles avec état, comme TCP, où un même client doit rester sur la même instance du groupe anycast. (Des utilisations de l'anycast pour des services sans état, comme le DNS sur UDP, n'ont pas ce problème.) Au contraire, avec du routage fait selon la source, chaque instance anycast peut annoncer sa route avec le ou les préfixes IP qu'on veut que cette instance serve.
D'ailleurs, si vous voulez en savoir plus sur le routage selon la source (ou SADR Source-Address Dependent Routing, également appelé SSR pour Source-Specific Routing), vous pouvez lire l'article détaillé des auteurs du RFC, « Source-Specific Routing ». On peut aussi noter que ce routage dépendant de la source n'est pas la même chose qu'un routage décidé par la source (source routing), qui indiquerait une liste de routeurs par où passer. Ici, chaque routeur reste maitre du saut suivant (sur le routage décidé par la source, voir RFC 8354, et un exemple dans le RFC 6554).
Bon, le routage tenant compte de la source est intéressant,
OK. Mais, avant de s'y lancer, il faut faire attention à un petit
problème, la spécificité des routes. Lorsqu'on route uniquement
selon la destination, et que plusieurs routes sont possibles, la
règle classique d'IP est celle de la spécificité. La route avec le
préfixe le plus spécifique (le plus long) gagne. Mais que se passe
t-il si on ajoute l'adresse source comme critère ? Imaginons qu'on
ait deux routes, une pour la destination
2001:db8:0:1::/64 et s'appliquant à toutes les
sources et une autre route pour toutes les destinations (route par
défaut), ne s'appliquant qu'à la source
2001:db8:0:2::/64. On va noter ces deux routes
sous forme d'un tuple (destination, source) donc, ici,
(2001:db8:0:1::/64, ::/0)
et (::/0,
2001:db8:0:2::/64). Pour un paquet venant de
2001:db8:0:2::1 et allant en
2001:db8:0:1::1, quelle est la route la plus
spécifique ? Si on considère la spécificité de la destination
d'abord, la route choisie sera la
(2001:db8:0:1::/64,
::/0). Mais si on regarde la spécificité de la
source en premier, ce sera l'autre route, la (::/0,
2001:db8:0:2::/64) qui sera adoptée. Doit-on
laisser chaque machine libre de faire du destination d'abord ou du
source d'abord ? Non, car tous les routeurs du domaine doivent
suivre la même règle, autrement des boucles pourraient se former, un
paquet faisant du ping-pong éternel entre un routeur « destination
d'abord » et un routeur « source d'abord ». Babel impose donc une
règle : pour déterminer la spécificité d'une route, on regarde la
destination d'abord. Le choix n'est pas arbitraire, il correspond à
des topologies réseau typique, avec des réseaux locaux pour
lesquelles on a une route spécifique, et une route par défaut pour
tout le reste.
Un autre point important est celui du système de transmission des paquets. Il faut en effet rappeler que le terme « routage » est souvent utilisé pour désigner deux choses très différentes. La première est le routage à proprement parler (routing en anglais), c'est-à-dire la construction des tables de transmission, soit statiquement, soit avec des protocoles de routage comme Babel. La seconde est la transmission effective des paquets qui passent par le routeur (forwarding en anglais). Si on prend un routeur qui tourne sur Unix avec le logiciel babeld, ce dernier assure bien le routage au sens strict (construire les tables de routage grâce aux messages échangés avec les autres routeurs) mais c'est le noyau Unix qui s'occupe de la transmission. Donc, si on veut ajouter des fonctions de routage tenant compte de la source, il ne suffit pas de le faire dans le programme qui fait du Babel, il faut aussi s'assurer que le système de transmission en est capable, et avec la bonne sémantique (notamment l'utilisation de la destination d'abord pour trouver la route la plus spécifique). Si Babel, avec les extensions de ce RFC, tourne sur un système qui ne permet pas cela, il faut se résigner à ignorer les annonces spécifiques à une source. (Pour des systèmes comme Linux, qui permet le routage selon la source mais avec une mauvaise sémantique, puisqu'il utilise la source d'abord pour trouver la route la plus spécifique, la section V-B de l'article des auteurs cité plus haut fournit un algorithme permettant de créer des tables de transmission correctes.)
Le passage du routage classique au routage tenant compte de la
source nécessite de modifier les structures de données du protocole
de routage, ici Babel (section 3 du RFC). Les différentes structures
de données utilisées par une mise en œuvre de Babel doivent être
modifiées pour ajouter le préfixe de la source, et plusieurs des
TLV dans les messages que s'échangent les
routeurs Babel doivent être étendus avec un sous-TLV (RFC 8966, section 4.4) qui contient un préfixe
source. La section 5 du RFC détaille les modifications nécessaires
du protocole Babel. Les trois types de TLV
qui indiquent un préfixe de destination, Updates,
Route Requests et Seqno,
doivent désormais transporter en plus un sous-TLV indiquant le
préfixe source, marqué comme obligatoire (RFC 8966, section 4.4), de façon à ce qu'une version de Babel
ne connaissant pas le routage selon la source n'accepte pas des
annonces incomplètes. Si une annonce ne dépend pas de l'adresse IP
source, il ne faut pas envoyer un sous-TLV avec le préfixe
::/0 mais au contraire ne pas mettre de
sous-TLV (les autres versions de Babel accepteront alors
l'annonce).
Ainsi, des versions de Babel gérant les extensions de notre RFC 9079 et d'autres qui ne les gèrent pas (fidèles au RFC 8966) pourront coexister sur le même réseau, sans que des boucles de routage ne se forment. En revanche, comme la notion de sous-TLV obligatoire n'est apparue qu'avec le RFC 8966, les vieilles versions de Babel, qui suivent l'ancien RFC 6126, ne doivent pas être sur le même réseau que les routeurs à routage dépendant de la source.
Le nouveau sous-TLV Source Prefix a le type 128 et sa valeur comporte un préfixe d'adresses IP, encodé en {longueur, préfixe}.
Notez que si les routeurs qui font du routage selon la source n'annoncent que des routes ayant le sous-TLV indiquant un préfixe source, les routeurs qui ne gèrent pas ce routage selon la source, et qui ignorent donc cette annonce, souffriront de famine : il n'y aura pas de routes vers certaines destinations, conduisant le routeur à jeter les paquets. Il peut donc être prudent, par exemple, d'avoir une route par défaut sans condition liée à la source, pour ces routeurs qui ignorent cette extension.
Question sécurité, il faut signaler (section 9 du RFC), que cette extension au routage apporte davantage de souplesse, et que cela peut nécessiter une révision des règles de sécurité, si celles-ci supposaient que tous les paquets vers une destination donnée suivaient le même chemin. Ainsi, le filtrage des routes (RFC 8966, annexe C) pourra être inutile si des routes spécifiques à une source sont présentes. Autre supposition qui peut être désormais fausse : une route spécifique à une machine de destination (host route, c'est-à-dire un préfixe /128) n'est plus forcément obligatoire, une autre route pour certaines sources peut prendre le dessus.
Au moins deux mises en œuvre de cette extension existent, dans babeld depuis la version 1.6 (en IPv6 seulement), et dans BIRD depuis la 2.0.2.
Merci à Juliusz Chroboczek pour sa relecture, et pour ses bonnes remarques sur le choix entre le routage selon la source et les autres solutions.
L'article seul
RFC 9078: Reaction: Indicating Summary Reaction to a Message
Date de publication du RFC : Août 2021
Auteur(s) du RFC : D. Crocker (Brandenburg InternetWorking), R. Signes (Fastmail), N. Freed (Oracle)
Expérimental
Première rédaction de cet article le 5 août 2021
Vous trouvez que le courrier électronique, c'est vieux et ringard, et que les réseaux sociaux avec leurs possibilités de réaction (« J'aime ! », « Je partage ! », « Je rigole ! »), c'est mieux ? Et bien, vous n'êtes pas le seul ou la seule. Ce nouveau RFC normalise un mécanisme pour mettre des réactions courtes et impulsives dans le courrier électronique.
L'idée de base est que, si ce RFC plait et est mis en œuvre par les auteurs de MUA, on verra près du message qu'on lit un menu avec des émojis, et on cliquera dessus, et l'émetteur du message verra sur son propre MUA le message qu'il a envoyé accompagné de ces réactions. (Le RFC ne normalise pas une apparence particulière à ces réactions, cf. section 5.2 pour des idées qui ne sont que des suggestions.)
Bien sûr, on peut déjà répondre à un message avec des émojis dans le corps de la réponse. Mais l'idée est de structurer cette réaction pour permettre une utilisation plus proche de celle des réseaux sociaux, au lieu que la réaction soit affichée comme un message comme les autres. Liée au message originel, cette structuration permettra, par exemple, au MUA de l'émetteur originel de voir le nombre de Likes de son message… (Quant à savoir si c'est utile, c'est une autre histoire…)
Techniquement, cela fonctionnera avec la combinaison des en-têtes
Content-Disposition: et
In-Reply-To:. Voici un exemple montrant le
format d'une réaction (négative…) à un message (le
12345@example.com) :
To: author@example.com
From: recipient@example.org
Date: Today, 29 February 2021 00:00:10 -800
Message-id: 56789@example.org
In-Reply-To: 12345@example.com
Subject: Re: Meeting
Mime-Version: 1.0
Content-Type: text/plain; charset=utf-8
Content-Disposition: Reaction
👎
(Si vous n'avez pas les bons émojis sur votre système, le caractère
en question était le pouce vers le
bas.) Recevant cette réponse, le MUA de l'auteur
(author@example.com) peut rechercher le message
12345@example.com et afficher que
recipient@example.org n'est pas enthousiaste.
Le paramètre Reaction pour l'en-tête
Content-Disposition: (RFC 2183) a été ajouté
au registre IANA.
Le texte dans la partie MIME qui a l'en-tête
Content-Disposition: Reaction est une ligne
d'émojis. On
peut utiliser les séquences
d'émojis. Tous les émojis sont utilisables mais le RFC en
liste cinq qui sont particulièrement importants car considérés comme
la base, le minimum que devrait reconnaitre tout MUA :
Notez que le concept de séquence d'émojis n'est pas simple. Ce concept permet d'éviter de normaliser des quantités astronomiques d'émojis, en autorisation la combinaison d'émojis. Il est utilisé entre autres pour les drapeaux nationaux, ainsi le drapeau libanais sera 🇱🇧 (U+1F1F1 qui indique le L du code pays ISO 3166 et U+1F1E7 qui indique le B). Le RFC rappelle qu'écrire du code dans son application pour gérer ces séquences n'est pas raisonnable et qu'il vaut mieux utiliser une bibliothèque Unicode existante.
Les sections 4 et 5 du RFC donnent quelques idées aux auteurs de MUA sur la gestion de ces réactions. Normalement, l'IETF normalise des protocoles, pas des interfaces utilisateur. Mais cela n'interdit pas de parler un peu d'UX dans le RFC, comme indiqué plus haut. En outre, l'interface utilisateur vers le courrier est typiquement assez différente de celle des réseaux sociaux où ce concept de réaction existe. Ainsi, le RFC ne tranche pas sur la question de savoir s'il faut envoyer la réaction uniquement à l'auteur original du message, ou bien à tous les destinataires. Ou bien s'il faut envoyer un message contenant juste la partie Réaction ou si on peut la combiner avec un autre contenu. Et que faire si, depuis la même adresse, on reçoit plusieurs réactions, éventuellement contradictoires ? Ne garder que la dernière (attention, le courrier électronique ne conserve pas l'ordre d'envoi) ? Les additionner ?
Toujours en UX, le RFC note que la réception d'une image dépend beaucoup du récepteur. (Et, contrairement à ce que laisse entendre le RFC, ce n'est pas juste une question de « culture », des personnes de la même « culture » peuvent comprendre différemment la même image.) Il faut donc faire attention aux réactions, qui peuvent être mal comprises. (Ceci dit, c'est exactement pareil avec le texte seul.) Et, comme toujours sur l'Internet, cette possibilité pourra ouvrir de nouveaux problèmes de sécurité (utilisation pour l'hameçonnage ?).
L'article seul
RFC 9077: NSEC and NSEC3: TTLs and Aggressive Use
Date de publication du RFC : Juillet 2021
Auteur(s) du RFC : P. van Dijk (PowerDNS)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 25 juillet 2021
Ce nouveau RFC corrige une légère bavure. Lorsqu'on utilise la mémorisation énergique du RFC 8198 pour synthétiser des réponses DNS en utilisant les informations DNSSEC, les normes existantes permettaient une mémorisation pendant une durée bien trop longue. Cette erreur (peu grave en pratique) est désormais corrigée.
Rappelons que le principe du RFC 8198 est
d'autoriser un résolveur DNS à synthétiser
des informations qu'il n'a normalement pas dans sa mémoire,
notamment à partir des enregistrements NSEC de
DNSSEC (RFC 4034,
section 4). Si un résolveur interroge la racine du DNS :
% dig @a.root-servers.net A foobar
...
;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 37332
...
foo. 86400 IN NSEC food. NS DS RRSIG NSEC
La réponse est négative (NXDOMAIN)
et un enregistrement NSEC annonce au client DNS
qu'il n'y a pas de nom dans la racine entre
.foo et .food. Si le
résolveur mémorise cette information et qu'on lui demande par la
suite un nom en .foocat, il n'aura pas besoin
de contacter la racine, il sait, en raison de l'enregistrement NSEC
que ce nom ne peut pas exister.
Bon, mais combien de temps le résolveur peut-il mémoriser cette
non-existence ? Le RFC 2308 disait qu'une
réponse négative (NXDOMAIN) pouvait être
mémorisée pendant une durée indiquée par le
minimum du champ Minimum
de l'enregistrement SOA et du TTL de ce même enregistrement
SOA. Mais le RFC 4034, normalisant DNSSEC,
disait que l'enregistrement NSEC devait avoir un TTL égal au champ
Minimum du SOA. Dans l'exemple de la racine du
DNS, à l'heure actuelle, cela ne change rien, ces durées sont toutes
égales. Mais elles pourraient être différentes. Si un enregistrement
SOA a un Minimum à une journée mais un TTL
d'une heure, le RFC 2308 impose une heure de
mémorisation au maximum, le RFC 4034
permettait une journée… Ça pourrait même être exploité pour une
attaque en faisant des requêtes qui retournent des enregistrements
NSEC, afin de nier l'existence d'un nom pendant plus longtemps que
prévu. [Bon, dans le monde réel, je trouve que
c'est un problème assez marginal mais ce n'est pas une raison pour ne
pas le corriger.]
Le RFC 8198 avait déjà tenté de corriger le
problème mais sans y réussir. Notre nouveau RFC impose désormais
clairement que, contrairement à ce que dit le RFC 4034 (et deux ou trois autres RFC sur DNSSEC), la durée
maximale de mémorisation est bien le minimum du
champ Minimum de l'enregistrement
SOA et du TTL
de ce même enregistrement SOA.
Si les logiciels que vous utilisez pour signer les zones ne
peuvent pas être corrigées immédiatement, le RFC demande que vous
changiez le contenu de la zone pour mettre la même valeur au champ
Minimum de l'enregistrement
SOA et au TTL
de ce même enregistrement SOA.
En pratique, les signeurs suivants ont déjà été corrigés :
- PowerDNS (par l'auteur du RFC) dans la version 4.3.0 (voir cette note dans la documentation).
- BIND dans la version 9.16 (voyez la correction, qui est très courte).
- Knot DNS dans la 3.1 (apparemment pas encore publiée, mais la correction a déjà été incluse).
- ldns dans une correction pas encore intégrée ?
- Pour les autres logiciels, une liste est en ligne.
L'article seul
RFC 9076: DNS Privacy Considerations
Date de publication du RFC : Juillet 2021
Auteur(s) du RFC : T. Wicinski
Pour information
Réalisé dans le cadre du groupe de travail IETF dprive
Première rédaction de cet article le 24 juillet 2021
La surveillance généralisée sur l'Internet est un gros problème pour la vie privée. L'IETF s'active donc à améliorer la protection de la vie privée contre cette surveillance (RFC 7258). Un protocole qui avait souvent été négligé dans ce travail est le DNS. Ce RFC décrit les problèmes de vie privée liés au DNS. Il remplace le RFC 7626, avec deux changements important, l'intégration des techniques de protection développées et déployées depuis l'ancien RFC et, malheureusement, beaucoup de propagande anti-chiffrement imposée par les acteurs traditionnels des résolveurs DNS qui ne veulent pas se priver de leurs possibilités de contrôle et de surveillance.
Ce RFC est en fait à la croisée de deux activités. L'une d'elles consiste à documenter les problèmes de vie privée, souvent ignorés jusqu'à présent dans les RFC. Cette activité est symbolisée par le RFC 6973, dont la section 8 contient une excellente analyse de ces problèmes, pour un service particulier (la présence en ligne). L'idée est que, même si on ne peut pas résoudre complètement le problème, on peut au moins le documenter, pour que les utilisateurs soient conscients des risques. Et la seconde activité qui a donné naissance à ce RFC est le projet d'améliorer effectivement la protection de la vie privée des utilisateurs du DNS, en marchant sur deux jambes : minimiser les données envoyées et les rendre plus résistantes à l'écoute, via le chiffrement. L'objectif de diminution des données a débouché sur la QNAME minimization spécifiée dans le RFC 9156 et le chiffrement a donné DoT (RFC 7858) et DoH (RFC 8484).
Donc, pourquoi un RFC sur les questions de vie privée dans le
DNS ? Ce dernier est un très ancien protocole, dont l'une des
particularités est d'être mal spécifié : aux deux RFC originaux, les
RFC 1034 et RFC 1035, il
faut ajouter dix ou vingt autres RFC dont la lecture est nécessaire
pour tout comprendre du DNS. Et aucun travail de consolidation n'a
jamais été fait, contrairement à ce qui a eu lieu pour XMPP,
HTTP ou
SMTP. Or, le DNS est crucial, car quasiment
toutes les transactions Internet mettent en jeu au moins une requête
DNS (ne me dites pas des bêtises du genre « moi, je télécharge avec
BitTorrent, je
n'utilise pas le DNS » : comment allez-vous sur
thepiratebay.am ?) Mais, alors que les
questions de vie privée liées à HTTP ont fait l'objet d'innombrables articles
et études, celles liées au DNS ont été largement ignorées pendant
longtemps (voir la bibliographie du RFC pour un état de
l'art). Pourtant, on peut découvrir bien des choses sur votre
activité Internet uniquement en regardant le trafic DNS.
Une des raisons du manque d'intérêt pour le thème « DNS et vie privée » est le peu de compétences concernant le DNS : le protocole est souvent ignoré ou mal compris. C'est pourquoi le RFC doit commencer par un rappel (section 1) du fonctionnement du DNS.
Je ne vais pas reprendre tout le RFC ici. Juste quelques rappels
des points essentiels du DNS : il existe deux sortes de serveurs
DNS, qui n'ont pratiquement aucun rapport. Il y a les
serveurs
faisant autorité et les résolveurs. Les premiers
sont ceux qui connaissent de première main l'information pour une
zone DNS donnée (comme fr ou
wikipedia.org). Ils sont gérés par le titulaire
de la zone ou bien sous-traités à un hébergeur DNS. Les seconds, les
résolveurs, ne connaissent rien (à part l'adresse IP des serveurs de la racine). Ils
interrogent donc les serveurs faisant autorité, en partant de la
racine. Les résolveurs sont gérés par le FAI ou le service
informatique qui s'occupe du réseau local de l'organisation. Ils
peuvent aussi être individuels, ou bien au
contraire être de gros serveurs publics comme Google Public DNS, gros fournisseur de la
NSA. Pour
prendre un exemple concret (et en simplifiant un peu), si M. Michu
veut visiter le site Web
http://thepiratebay.am/, son navigateur va
utiliser les services du système d'exploitation sous-jacent pour
demander l'adresse IP de
thepiratebay.am. Le système d'exploitation va
envoyer une requête DNS au résolveur (sur
Unix, les adresses IP des résolveurs sont
dans /etc/resolv.conf). Celui-ci va demander
aux serveurs de la racine s'ils connaissent
thepiratebay.am, il se fera rediriger vers les
serveurs faisant autorité pour am, puis vers ceux faisant
autorité pour thepiratebay.am. Le résolveur
aura alors une réponse qu'il pourra transmettre au navigateur de
M. Michu.
Principal point où j'ai simplifié : le DNS s'appuie beaucoup sur
la mise en cache des données, c'est-à-dire sur
leur mémorisation pour gagner du temps la fois suivante. Ainsi, si
le même M. Michu, cinq minutes après, veut aller en
http://armenpress.am/, son résolveur ne
demandera rien aux serveurs de la racine : il sait déjà quels sont
les serveurs faisant autorité pour am.
Le trafic DNS est un trafic IP ordinaire, typiquement porté par UDP. Mais il peut aussi fonctionner sur TCP et bientôt sur QUIC. Il peut être écouté, et comme il n'est pas toujours chiffré, un indiscret peut tout suivre. Voici un exemple pris avec tcpdump sur un serveur racine (pas la racine officielle, mais, techniquement, cela ne change rien) :
15:29:24.409283 IP6 2001:67c:1348:8002::7:107.10127 > \
2001:4b98:dc2:45:216:3eff:fe4b:8c5b.53: 32715+ [1au] \
AAAA? www.armenpress.am. (46)
On y voit que le client
2001:67c:1348:8002::7:107 a demandé l'adresse
IPv6 de
www.armenpress.am.
Pour compléter le tableau, on peut aussi noter que les logiciels
génèrent un grand nombre de requêtes DNS, bien supérieur à ce que
voit l'utilisateur. Ainsi, lors de la visite d'une page Web, le
résolveur va envoyer la requête primaire (le
nom du site visité, comme thepiratebay.am), des
requêtes secondaires dues aux objets contenus
dans la page Web (JavaScript, CSS, divers
traqueurs et autres outils de cyberflicage ou de cyberpub) et même
des requêtes tertiaires, lorsque le
fonctionnement du DNS lui-même nécessitera des requêtes. Par
exemple, si abc.xyz est hébergé sur des
serveurs dans google.com, une visite de
http://abc.xyz/ nécessitera de résoudre les
noms comme ns1.google.com, donc de faire des
requêtes DNS vers les serveurs de
google.com.
Bien sûr, pour un espion qui veut analyser tout cela, le trafic DNS représente beaucoup de données, souvent incomplètes en raison de la mise en cache, et dont l'interprétation peut être difficile (comme dans l'exemple ci-dessus). Mais les organisations qui pratiquent l'espionnage massif, comme la NSA, s'y connaissent en matière de big data et savent trouver les aiguilles dans les bottes de foin.
Les sections 3 à 7 du RFC détaille les risques pour la vie privée
dans les différents composants du DNS. Notez que la confidentialité
du contenu du DNS n'est pas prise en compte (elle l'est dans les
RFC 5936 et RFC 5155). Il est important de noter qu'il y a une énorme
différence entre la confidentialité du contenu
et la confidentialité des requêtes. L'adresse
IP de www.charliehebdo.fr
n'est pas un secret : les données DNS sont publiques, dès qu'on
connait le nom de domaine, et tout le monde peut faire une requête
DNS pour la connaitre. Mais le fait que vous fassiez une requête
pour ce nom ne devrait pas être public. Vous n'avez pas forcément
envie que tout le monde le sache. (On peut quand même nuancer un peu
le côté « public » des données DNS : on peut avoir des noms de
domaine purement internes à une organisation. Mais ces noms
« fuitent » souvent, par la marche sur la zone décrite dans le RFC 4470, ou via des systèmes de « passive DNS).
Pour comprendre les risques, il faut aussi revenir un peu au protocole DNS. Les deux informations les plus sensibles dans une requête DNS sont l'adresse IP source et le nom de domaine demandé (qname, pour Query Name, cf. RFC 1034, section 3.7.1). L'adresse IP source est celle de votre machine, lorsque vous parlez au résolveur, et celle du résolveur lorsqu'il parle aux serveurs faisant autorité. Elle peut indiquer d'où vient la demande. Lorsque on utilise un gros résolveur, celui-ci vous masque vis-à-vis des serveurs faisant autorité (par contre, ce gros résolveur va avoir davantage d'informations). Ceci dit, l'utilisation d'ECS (RFC 7871) peut trahir votre adresse IP, ou au moins votre préfixe. (Cf. cette analyse d'ECS. D'autre part, certains opérateurs se permettent d'insérer des informations comme l'adresse MAC dans des options EDNS de la requête.)
Quant au qname, il peut être très révélateur :
il indique les sites Web que vous visitez, voire, dans certains cas,
les logiciels utilisés. Au moins un client
BitTorrent fait des requêtes DNS pour
_bittorrent-tracker._tcp.domain.example,
indiquant ainsi à beaucoup de monde que vous utilisez un protocole
qui ne plait pas aux ayant-droits. Et si vous utilisez le RFC 4255, pas mal de serveurs verront à quelles
machines vous vous connectez en SSH...
Donc où un méchant qui veut écouter votre trafic DNS peut-il se placer ? D'abord, évidemment, il suffit qu'il écoute le trafic réseau. On l'a dit, le trafic DNS aujourd'hui est souvent en clair donc tout sniffer peut le décoder. Même si vous utilisez HTTPS pour vous connecter à un site Web, le trafic DNS, lui, ne sera pas chiffré. (Les experts pointus de TLS noteront qu'il existe d'autres faiblesses de confidentialité, comme le SNI du RFC 6066, qui n'est pas encore protégé, cf. RFC 8744.) À noter une particularité du DNS : le trafic DNS peut passer par un autre endroit que le trafic applicatif. Alice peut naïvement croire que, lorsqu'elle se connecte au serveur de Bob, seul un attaquant situé physiquement entre sa machine et celle de Bob représente une menace. Alors que son trafic DNS peut être propagé très loin, et accessible à d'autres acteurs. Si vous utilisez, par exemple, le résolveur DNS public de FDN, toute la portion de l'Internet entre vous et FDN peut facilement lire votre trafic DNS.
Donc, l'éventuel espion peut être près du câble, à écouter. Mais il peut être aussi dans les serveurs. Bercé par la musique du cloud, on oublie souvent cet aspect de la sécurité : les serveurs DNS voient passer le trafic et peuvent le copier. Pour reprendre les termes du RFC 6973, ces serveurs sont des assistants : ils ne sont pas directement entre Alice et Bob mais ils peuvent néanmoins apprendre des choses à propos de leur conversation. Et l'observation est très instructive. Elle est utilisée à de justes fins dans des systèmes comme DNSDB (section 6 du RFC) mais il n'est pas difficile d'imaginer des usages moins sympathiques comme dans le cas du programme NSA MORECOWBELL.
Les résolveurs voient tout le trafic puisqu'il y a peu de mise en cache en amont de ces serveurs. Il faut donc réfléchir à deux fois avant de choisir d'utiliser tel ou tel résolveur ! Il est déplorable qu'à chaque problème DNS (ou supposé tel), des ignorants bondissent sur les réseaux sociaux pour dire « zyva, mets 8.8.8.8 [Google Public DNS] comme serveur DNS et ça ira plus vite » sans penser à toutes les données qu'ils envoient à la NSA ainsi.
Les serveurs faisant autorité voient passer moins de trafic (à cause des caches des résolveurs) mais, contrairement aux résolveurs, ils n'ont pas été choisis délibérement par l'utilisateur. Celui-ci peut ne pas être conscient que ses requêtes DNS seront envoyées à plusieurs acteurs du monde du DNS, à commencer par la racine. Le problème est d'autant plus sérieux que, comme le montre une étude, la concentration dans l'hébergement DNS est élevée : dix gros hébergeurs hébergent le tiers des domaines des 100 000 sites Web les plus fréquentés (listés par Alexa).
Au passage, le lecteur attentif aura noté qu'un résolveur personnel (sur sa machine ou dans son réseau local) a l'avantage de ne pas envoyer vos requêtes à un résolveur peut-être indiscret mais l'inconvénient de vous démasquer vis-à-vis des serveurs faisant autorité, puisque ceux-ci voient alors votre adresse IP. Une bonne solution (qui serait également la plus économe des ressources de l'Internet) serait d'avoir son résolveur local et de faire suivre les requêtes non résolues au résolveur du FAI. Du point de vue de la vie privée, ce serait sans doute la meilleure solution mais cela ne résout hélas pas un autre problème, celui des DNS menteurs, contre lesquels la seule protection est d'utiliser uniquement un résolveur de confiance. On peut résoudre ce problème en ayant son propre résolveur mais qui fait suivre à un résolveur public de confiance. Notez que la taille compte : plus un résolveur est petit, moins il protège puisque ses requêtes sortantes ne seront dues qu'à un petit nombre d'utilisateurs.
Enfin, il y a aussi les serveurs DNS « pirates » (installés, par
exemple, via un serveur DHCP lui-même pirate) qui détournent le trafic
DNS, par exemple à des fins de surveillance. Voir par exemple
l'exposé de Karrenberg à JCSA
2012 disponible
en ligne (transparents 27 et 28, Unknown
et Other qui montrent l'existence de clones
pirates du serveur racine
K.root-servers.net).
Pour mes lecteurs en France férus de droit, une question intéressante : le trafic DNS est-il une « donnée personnelle » au sens de la loi Informatique & Libertés ? Je vous laisse plancher sur la question, qui a été peu étudiée.
Les changements depuis le RFC 7626 sont résumés dans l'annexe A. Outre des retours d'expérience basés sur le déploiement de solutions minimisant et/ou chiffrant les données, ils consistent essentiellement en remarques négatives sur le chiffrement, défendant le mécanisme traditionnel de résolution DNS. Il n'y avait d'ailleurs pas forcément d'urgence à sortir un nouveau RFC. Comme le demandait Alissa Cooper, l'auteure du RFC 6973, « Why not wait to see how QUIC, DOH, ADD, ODNS, etc. shake out in the next few years and take this up then? ». C'est en raison de ces changements négatifs que je ne suis pas cité comme auteur du RFC (contraitement à son prédécesseur). Sara Dickinson, qui avait géré l'essentiel du travail pour les débuts de ce nouveau RFC, s'est également retirée, en raison de la dureté des polémiques qui ont déchiré l'IETF sur ce document.
Depuis la sortie du RFC 7626, il y a eu un certain nombre de déploiement de techniques améliorant la protection de la vie privée dans le cas du DNS, notamment la minimisation des données (RFC 9156) et le chiffrement (DoT, RFC 7858, DoH, RFC 8484, et le futur DoQ). Cela permet des retours d'expérience. Par exemple, sur l'ampleur du déploiement de la minimisation, ou sur les performances du chiffrement (voir « An End-to-End, Large-Scale Measurement of DNS-over-Encryption »). Il y a eu également des discussions politiques à propos de ces techniques et de leur déploiement, souvent malhonnêtes ou confuses (et ce RFC en contient plusieurs) comme l'accusation de « centralisation », qui sert surtout à protéger l'état actuel, où l'opérateur de votre réseau d'accès à l'Internet peut à la fois vous surveiller et contrôler ce que vous voyez, via sa gestion de la résolution DNS. Mais il est vrai que rien n'est simple en matière de sécurité et que DoH (mais pas DoT) est trop bavard, puisqu'il hérite des défauts de HTTP, en envoyant trop d'informations au serveur.
Le RFC essaie de décourager les utilisateurs d'utiliser le chiffrement (dans l'esprit du RFC 8404) en notant que ce n'est pas une technologie parfaite (par exemple, l'observation des métadonnées peut donner des indications ou, autre exemple, une mauvaise authentification du résolveur peut vous faire envoyer vos requêtes à un méchant). C'est vrai mais c'est le cas de toutes les solutions de sécurité et on ne trouve pas de tels avertissements dans d'autres RFC qui parlent de chiffrement. L'insistance des opérateurs pour placer ces messages anti-chiffrement dans ce RFC montre bien, justement, l'importance de se protéger contre la curiosité des opérateurs.
Le RFC remarque également qu'il n'existe pas actuellement de moyen de découvrir automatiquement le résolveur DoT ou DoH. Mais c'est normal : un résolveur DoT ou DoH annoncé par le réseau d'accès, par exemple via DHCP, n'aurait guère d'intérêt, il aurait les mêmes défauts (et les mêmes qualités) que le résolveur traditionnel. DoT et DoH n'ont de sens qu'avec un résolveur configuré statiquement. Le RFC cite des déploiements de résolveurs DNS avec chiffrement faits par plusieurs FAI (aucun en France, notons-le). Cela montre une grosse incompréhension du problème : on ne chiffre pas pour le plaisir de chiffrer, mais parce que cela permet d'aller de manière sécurisée vers un autre résolveur. Chiffrer la communication avec le résolveur habituel ne fait pas de mal mais on ne gagne pas grand'chose puisque ce résolveur a les mêmes capacités de surveillance et de modification des réponses qu'avant. Notons que le RFC, inspiré par la propagande des telcos, raconte que le risque de surveillance est minimisé par le chiffrement du lien radio dans les réseaux 4G et après. Cela oublie le fait que la surveillance peut justement venir de l'opérateur.
Plus compliqué est le problème de l'endroit où se fait cette configuration. Traditionnellement, la configuration du résolveur à utiliser était faite globalement par le système d'exploitation. Ce n'est pas du tout une règle du protocole DNS (les RFC normalisant le DNS ne contrôlent que ce qui circule sur le câble, pas les choix locaux de chaque machine) et il serait donc absurde d'invoquer un soi-disant principe comme quoi le DNS serait forcément géré au niveau du système. Certains déploiements de DoH (celui de Firefox, par exemple), mettent le réglage dans l'application (en l'occurrence le navigateur Web). La question est discutable et discutée mais, de toute façon, elle ne relève pas de l'IETF (qui normalise ce qui passe sur le réseau) et il est anormal que le RFC en parle.
Le temps passé depuis le RFC 7626 a également permis la mise en service d'un plus grand nombre de résolveurs publics, comme Quad9 ou comme celui de Cloudflare. Mais il n'y a pas que les grosses boîtes états-uniennes qui gèrent des résolveurs DNS publics. Ainsi, je gère moi-même un modeste résolveur public. Le très intéressant RFC 8932 explique le rôle des politiques de vie privée dans ces résolveurs publics et comment en écrire une bonne. Bien sûr, comme toujours en sécurité, la lutte de l'épée contre la cuirasse est éternelle et des nouvelles actions contre la vie privée et la liberté de choix apparaissent, par exemple des réseaux qui bloquent l'accès à DoT (en bloquant son port 853) ou aux résolveurs DoH connus (DoH a été développé en partie pour être justement plus difficile à bloquer).
L'article seul
RFC 9075: Report from the IAB COVID-19 Network Impacts Workshop 2020
Date de publication du RFC : Juillet 2021
Auteur(s) du RFC : J. Arkko (Ericsson), S. Farrell (Trinity College Dublin), M. Kühlewind (Ericsson), C. Perkins (University of Glasgow)
Pour information
Première rédaction de cet article le 23 juillet 2021
La pandémie de Covid-19 en 2020 a affecté de nombreux aspects de notre vie. Concernant plus spécifiquement l'Internet, elle a accru l'utilisation d'outils de communication informatiques. Quels ont été les effets de ces changements sur l'Internet ? Un atelier de l'IAB fait le point sur ces effets et en tire des leçons. Je vous le dis tout de suite : contrairement à certains discours sensationnalistes, l'Internet n'a pas subi de conséquences sérieuses.
De janvier à mars 2020, de nombreux pays ont imposé un confinement plus ou moins strict. Des activités comme le travail ou l'éducation devaient se faire à distance, en utilisant les outils numériques. Certains politiciens ont tenu des discours dramatisants, prétendant que, si on ne renonçait pas à regarder ses vidéos favorites, l'Internet allait s'écrouler. Même si aucun professionnel des réseaux n'a repris ce discours, cela ne veut pas dire qu'il ne s'est rien passé. L'IAB a donc organisé en novembre 2020 un atelier (évidemment tenu en ligne car il n'y avait pas le choix) pour étudier les effets de ces confinements sur l'Internet, comprendre ce qui est arrivé et peut-être formuler des recommandations.
Donc, pendant le confinement et l'augmentation du télétravail qui en a résulté, le trafic Internet a changé. Il n'a pas toujours augmenté (les travailleurs utilisaient également Internet quand ils étaient au bureau, et les gens regardaient déjà Netflix avant la pandémie) mais il s'est déplacé : trafic de type différent, à des heures différentes, etc. Et, dans la plupart des pays, c'est arrivé assez soudainement, laissant peu de temps pour l'adaptation. La sécurité a été également très affectée, les mesures de sécurité conçues sur la base d'un lieu physique n'ayant plus de sens. Tout à coup, il a fallu autoriser beaucoup d'accès distants, avec tous les risques que cela impliquait. L'atelier lui-même a été différent des précédents ateliers de l'IAB, qui étaient fondés sur une participation physique pendant deux jours continus. Cette fois, l'atelier s'est fait en trois sessions à distance, avec respiration et réflexion entre les sessions.
Qu'ont observé les acteurs de l'Internet ? À l'atelier, certains
FAI ou
gérants de points d'échange Internet ont
signalé des accroissements de 20 % du trafic. C'est à la fois
beaucoup et peu. C'est beaucoup car c'est survenu soudainement, sans
être étalé sur une période permettant le déploiement de nouvelles
ressources, et c'est peu, car la croissance de l'utilisation des
réseaux est un phénomène permanent : il faut toujours augmenter la
capacité (20 % représente une
augmentation annuelle typique, mais qui fut concentrée en quelques
semaines). On voit ici le trafic sur le point d'échange
Internet de Francfort (la source
est ici). S'il y a bien une brusque montée début 2020 avec le
démarrage du confinement, il faut noter qu'elle s'inscrit dans une
augmentation du trafic Internet sur le long terme :
Cette montée du trafic lors du confinement est également
relativisée sur les statistiques de trafic au point
d'échange parisien (la source est ici) :
De même, l'article « Measurement of congestion on ISP interconnection links » mesure des moments de congestion limités aux États-Unis en mars. Cette croissance était très inégalement répartie selon les services. Vous ne serez pas surpris d'apprendre que certains opérateurs de services de vidéo-conférence ont vu leur activité tripler, voire décupler. Une intéressante conclusion est que, contrairement à ce que certains discours sensationnalistes comme ceux de Thierry Breton prétendaient, l'Internet n'a pas connu de problème généralisé. Comme toujours dans ce réseau mondial, les problèmes sont restés localisés, ralentissements à certains endroits, baisse automatique de la qualité des vidéos à d'autres, mais pas de problème systémique. Ce bon résultat n'a pas été obtenu uniquement par la capacité du réseau existant à encaisser la montée en charge. Il y a eu également de nombreuses actions prises par les différents acteurs du réseau, qui ne sont pas restés les bras croisés face au risque. Bref, vu du point de vue scientifique, c'était une expérience intéressante, qui montre que l'Internet peut résister à des crises, ce qui permet de penser que les problèmes futurs ne seront pas forcément fatals.
[L'atelier portait bien sur l'Internet, sur l'infrastructure, pas sur les services hébergés. Il est important de faire la distinction car certains services (comme ceux de l'Éducation Nationale en France) ont été incapables de résister à la charge et se sont vite écroulés. Mais ce n'était pas une défaillance de l'Internet, et renoncer à regarder des vidéos n'aurait pas protégé le CNED contre ces problèmes. Notons qu'il n'y avait pas de fatalité à ces problèmes des services : Wikipédia et Pornhub, deux services très différents dans leur utilisation et leur gestion, ont continué à fonctionner correctement.]
Voyons maintenant les détails, dans la section 3 du RFC. On commence avec la sous-section 3.1, les mesures. Que s'est-il passé ? Comme on pouvait s'y attendre, le trafic résidentiel a augmenté (en raison du travail à la maison), tandis que celui des réseaux mobiles chutait (on se déplaçait moins). Le trafic vers les opérateurs de services de vidéo-conférence (comme Zoom) a augmenté, ainsi que celui des services de distraction (VoD) pendant la journée. Mais il y a eu surtout un gros déplacement des pics d'activité. En semaine, l'activité Internet était très liée au rythme de la journée, avec des trafics très différents dans la journée et le soir. Pendant les confinements, on a vu au contraire une activité plus étalée dans le temps chez les FAI résidentiels, et une activité de la semaine qui ressemble à celle des week-ends. Là encore, pas de conséquences graves, bien que certains FAI aient signalé des ralentissements notamment en mars 2020. Bref, l'Internet sait bien résister aux sautes de trafic qui, il est vrai, font partie de son quotidien depuis sa création.
Parmi les articles soumis pour l'atelier, je vous recommande, sur
la question des mesures, le très détaillé « A
view of Internet Traffic Shifts at ISP and IXPs during the COVID-19
Pandemic ». Les auteurs ont observé le trafic chez
plusieurs opérateurs et points d'échange (le
seul nommé est le réseau académique de
Madrid). Par exemple, en utilisant diverses
heuristiques (le port seul ne suffit plus,
tout le monde étant sur 443),
les auteurs ont des chiffres concernant diverses applications
(vidéo-conférence, vidéo à la demande, jeux en ligne, etc). Moins
détaillé, il y a le « IAB
COVID-19 Workshop: Interconnection Changes in the United
States » (à l'origine publié dans un
Internet-Draft,
draft-feamster-livingood-iab-covid19-workshop).
Un exemple de changement du trafic est donné par le Politecnico de Turin qui a vu son trafic sortant multiplié par 2,5, en raison de la diffusion de ses 600 cours en ligne par jour, alors que le trafic entrant était divisé par 10. Dans les universités, le trafic entrant est typiquement bien plus gros que le sortant (les étudiants et enseignants sont sur le campus et accèdent à des ressources distantes) mais cela a changé pendant le confinement, les ressources externes étant accédées depuis la maison. (Une entreprise aurait pu voir des effets différents, si les employés accèdent à ces ressources externes via le VPN de l'entreprise.) Le REN REDIMadrid a vu également de gros changements dans son trafic. Effet imprévu, les communications avec les AS d'Amérique latine a augmenté, probablement parce que les étudiants hispanophones américains profitaient des possibilités de cours à distance pour suivre les activités des universités de l'ex-métropole.
Comme dit plus haut, les réseaux mobiles, 4G et autres, ont vu leur activité baisser. L'article « A Characterization of the COVID-19 Pandemic Impact on a Mobile Network Operator Traffic » note une mobilité divisée par deux en Grande-Bretagne et un trafic diminué d'un quart. (Certaines personnes ne sont plus mobiles mais utilisent la 4G à la maison, et il y a bien d'autres phénomènes qui rendent compliquée l'analyse.) L'observation des signaux envoyés par les téléphones (le réseau mobile sait où vous êtes…) a également permis de mesurer l'ampleur de la fuite hors des grandes villes (10 % des Londoniens).
Et dans la connexion des FAI avec les services sur le cloud ? Les liens d'interconnexion entre FAI et fournisseurs de services ont-ils tenu ? Pas de congestion persistante mais des moments de tension, par exemple aux États-Unis vers les petits FAI, qui n'avaient pas toujours une interconnexion suffisante pour encaisser tout le trafic accru. Comme toujours sur l'Internet, malgré le caractère mondial de la pandémie, il y a peu d'observations valables partout et tout le temps, vu la variété des capacités des liaisons. Malgré l'observation générale « globalement, ça a tenu », il y a toujours des endroits où ça rame à certains moments.
En effet, le bon fonctionnement de l'Internet mondial ne signifiait pas que tous les MM. Toutlemonde de la Terre avaient une bonne qualité de connexion. L'article « The Impact of COVID-19 on Last-mile Latency » (plus de détails sur le blog de l'auteur) rend compte de mesures faites avec les sondes RIPE Atlas, qui trouvent une congestion plus fréquente sur le « premier kilomètre » (le lien entre la maison de M. Toutlemonde et le premier POP de son FAI) pendant le confinement. Cela dépend évidemment beaucoup du FAI et du pays, le Japon ayant été particulièrement touché. La situation s'est toutefois améliorée au fur et à mesure, notamment en raison des déploiements de capacité supplémentaire par les opérateurs (et, au Japon, des investissements qui étaient prévus pour les Jeux Olympiques). L'Internet se retrouve donc plus robuste qu'avant. Le RFC cite même Nietzsche « Ce qui ne me tue pas me rend plus fort ».
On l'a dit, le trafic n'a pas seulement changé quantitativement mais aussi qualitativement. La vidéo-conférence a, fort logiquement, crû. Le trafic très asymétrique de certains FAI grand public (beaucoup plus de trafic entrant vers les consommateurs que de trafic sortant) s'est un peu égalisé, en raison des flux vidéos sortants. NCTA et Comcast signalent plus de 30 % de hausse de ce trafic sortant, Vodafone 100 %. Un rapport d'Ericsson sur les utilisateurs signale :
- Une augmentation de l'utilisation de l'Internet par 9 utilisateurs sur 10 (le dixième était peut-être déjà connecté tout le temps ?) et des usages nouveaux par 1 utilisateur sur 5 (des gens comme moi qui se mettent à la vidéo-conférence alors qu'ils détestaient cela avant).
- Peu de plaintes concernant les performances.
- Évidemment un changement dans les applications utilisées, les applications de vidéo-conférence voient leur usage s'accroitre, celles liées à la location d'hôtels ou de restaurants (ou, note le RFC, celles permettant la recherche d'une place de parking) le voient diminuer.
Ces changements sont-ils permanents ? Resteront-ils dans le « monde d'après » ? Le RFC estime que le télétravail s'est désormais installé et restera ; on peut donc prévoir que l'utilisation intensive d'outils de réunion à distance persistera (cf. le rapport « Work-At-Home After Covid-19—Our Forecast »).
Après ces observations, la section 3 du RFC continue avec des considérations sur les problèmes opérationnels constatés. D'abord, un point de fracture numérique. Aux États-Unis, et probablement dans bien d'autres pays, le débit entrant chez les utilisateurs est corrélé au niveau de vie. Mais on a constaté pendant la pandémie une réduction de l'écart entre riches et pauvres (l'étude ne portait pas sur des foyers individuels mais sur des zones géographiques identifiées par leur code postal, un bon indicateur de niveau de vie, au moins aux USA). Cette réduction de l'écart n'était pas forcément liée à un changement de comportement des utilisateurs mais l'était peut-être au fait que certains FAI comme Comcast ont étendu la capacité liée à des abonnements bon marché, par souci de RSE pendant la crise. L'écart entre riches et pauvres était donc peut-être dû à une différence dans les abonnements souscrits, pas à une différence d'utilisation de l'Internet.
Les applications vedettes des confinements ont évidemment été les outils de réunion en ligne, gros services privateurs et capteurs de données personnelles comme Microsoft Teams ou Zoom, ou bien services reposant sur des logiciels libres comme BigBlueButton (dont le RFC, qui reflète un point de vue surtout étatsunien, ne parle pas). D'autres outils de distribution de vidéo, comme YouTube ont vu également leur trafic augmenter soudainement. Certains acteurs, comme justement YouTube, ont délibérement réduit la qualité des vidéos pour diminuer la charge sur le réseau, mais il n'est pas évident que cela ait eu un effet majeur. Autre catégorie d'applications qui a vu son utilisation augmenter, les jeux en ligne. Souvent très consommateurs de ressources, ils ont la particularité de demander à la fois une forte capacité (en raisons des contenus multimédias riches à télécharger) et une faible latence (quand on tire sur le zombie, il doit tomber tout de suite). La mise à jour d'un jeu très populaire a un effet très net sur le réseau des FAI ! Mais il faut noter que ce n'est pas un phénomène spécifique au confinement. Les opérateurs ont déjà dû faire face à des évènements soudains, comme une nouvelle version d'un logiciel très utilisé ou comme une nouvelle mode, par exemple une application qui connait un succès rapide, ce qui est assez fréquent sur l'Internet. Outre ces « effets Slashdot », il y a aussi les attaques par déni de service, qui nécessitent de suravitailler (mettre davantage de capacité que strictement nécessaire). Les opérateurs ont donc déjà de l'expérience dans ce domaine mais, note le RFC, cette expérience n'est pas toujours partagée.
Une discussion lors de l'atelier a porté sur la possibilité de gérer ce genre de problèmes par des mesures discriminatoires, de type qualité de service (un terme propagandiste, il faut le noter : si on discrimine, certains auront une meilleure qualité et d'autres une moins bonne). Marquer le trafic « pas essentiel » (qui décidera de ce qui n'est pas essentiel ?) avec DSCP pour le faire passer par les chemins les plus lents aurait-il aidé ? Compte-tenu du caractère très brûlant de ce débat, il n'est pas étonnant qu'aucun consensus n'est émergé de l'atelier. Le RFC se réjouit qu'au moins les engueulades ont été moins graves que d'habitude.
Une bonne partie de cet atelier était consacré à l'étude de faits : qu'ont vu les opérateurs ? Or, ils n'ont pas vu la même chose. Cela reflète les différences de situation mais aussi les différences dans les outils d'observation. La métrologie n'est pas une chose facile ! Par exemple, les applications de vidéo-conférence ou de distribution de vidéo à la demande ont des mécanismes de correction d'erreur et de gestion de la pénurie très élaborés. L'application s'adapte en permanence aux caractéristiques du réseau, par exemple en ajustant son taux de compression. C'est très bien pour l'utilisateur, cela permet de lui dissimuler une grande partie des problèmes, mais cela complique l'observation. Et quand il y a un problème, il est difficile à analyser. L'autre jour, sans que cela ait de rapport avec un confinement, je regardais une vidéo sur Netflix et la qualité de l'image était vraiment médiocre, gâchant le plaisir. Mais où était le problème ? Mon PC était trop lent ? Le Wifi était pourri ? Le réseau de Free surchargé ? L'interconnexion entre Free et Netflix était-elle encombrée ? Les serveurs de Netflix ramaient-ils ? C'est très difficile à dire, et cela dépend de beaucoup de choses (par exemple, deux utilisateurs de Netflix ne tombent pas forcément sur le même serveur chez Netflix et peuvent donc avoir des vécus différents). Et puis, globalement, on manque de capacités d'observation sur l'Internet. Le client ne voit pas ce qui se passe sur le serveur, le serveur ne sait pas grand'chose sur le client, et peut-être qu'aucun des deux n'a pas visibilité sur l'interconnexion. Chacun connait bien son réseau, mais personne ne connait l'Internet dans son ensemble. Le RFC note que, paradoxalement, la Covid-19 a amélioré les choses, en augmentant le niveau de coopération entre les acteurs de l'Internet.
Et la sécurité ? Elle a aussi été discutée à l'atelier car le passage brusque de tant de gens au télétravail a changé le paysage de la sécurité. On ne pouvait plus compter sur le pare-feu corporate et sur les machines du bureau soigneusement verrouillées par la DSI. Au lieu de cela, tout le monde utilisait des VPN pas toujours bien maitrisés (cf. l'article « IAB COVID-19 Network Impacts »). Et la pandémie a été l'occasion de nombreuses escroqueries (décrites dans le même article). À propos de sécurité, le RFC en profite pour vanter les résolveurs DNS menteurs et critiquer DoH (qui n'est pour rien dans ces escroqueries).
En conclusion, le RFC note que le bon fonctionnement de l'Internet pendant la pandémie n'était pas dû uniquement à ses qualités intrinsèques, mais aussi à l'action de nombreux acteurs. Comme d'autres professions, les techniciens et techniciennes de l'Internet étaient une des lignes de défense face à l'épidémie et cette ligne était très motivée, et a tenu. Ces techniciennes et techniciens méritent donc de chaudes félicitations. Mais on peut quand même améliorer les choses :
- En continuant à étudier le fonctionnement de l'Internet. Le caractère critique de l'Internet pour tant d'activités humaines justifie qu'on continue à analyser ses caractéristiques et ses faiblesses.
- Le partage d'informations et la communication sont essentiels et doivent être accrus.
- La lutte contre la fracture numérique doit se poursuivre, puisqu'en période de confinement, être coupé du réseau, ou y accéder dans de mauvaises conditions (accès lent, matériel inadapté, manque de littératie numérique), aggrave encore l'isolement.
Et le RFC se conclut par un bilan de cet atelier qui, contrairement aux ateliers précédents de l'IAB, a été fait entièrement en ligne. Les participants ont été plutôt contents, notamment du fait que le travail à distance a permis de changer le format : au lieu de deux jours complets de discussions, l'atelier a pu se tenir en alternant des moments de discussion et du travail chez soi, pour approfondir et critiquer les discussions. Toutefois, le RFC note que cela a bien marché car la quasi-totalité des présents se connaissaient bien, étant des participants de longue date à l'IETF. Il n'est pas du tout évident que cela aurait aussi bien marché avec des gens nouveaux, le présentiel étant crucial pour créer des liens informels.
L'ensemble des articles écrits par les participants à l'atelier (pour participer, il fallait avoir écrit un texte) est disponible en ligne (en bas de la page).
L'article seul
RFC 9065: Considerations around Transport Header Confidentiality, Network Operations, and the Evolution of Internet Transport Protocols
Date de publication du RFC : Juillet 2021
Auteur(s) du RFC : G. Fairhurst (University of Aberdeen), C. Perkins (University of Glasgow)
Pour information
Réalisé dans le cadre du groupe de travail IETF tsvwg
Première rédaction de cet article le 20 juillet 2021
La couche Transport n'est pas celle qui suscite le plus de passions dans l'Internet. Mais la récente normalisation du protocole QUIC a mis cette couche en avant et l'usage du chiffrement par QUIC a relancé le débat : quelles sont les conséquences d'un chiffrement de plus en plus poussé de la couche Transport ?
Traditionnellement, la couche Transport ne faisait pas de chiffrement (cf. RFC 8095 et RFC 8922). On chiffrait en-dessous (IPsec) ou au-dessus (TLS, SSH). IPsec ayant été peu déployé, l'essentiel du chiffrement aujourd'hui sur l'Internet est fait par TLS. Toute la mécanique TCP est donc visible aux routeurs sur le réseau. Ils peuvent ainsi mesurer le RTT, découvrir début et fin d'une connexion, et interférer avec celle-ci, par exemple en envoyant des paquets RST (ReSeT) pour mettre fin à la session. Cela permet de violer la vie privée (RFC 6973), par exemple en identifiant une personne à partir de son activité en ligne. Et cette visibilité de la couche Transport pousse à l'ossification : de nombreux intermédiaires examinent TCP et, si des options inhabituelles sont utilisées, bloquent les paquets. Pour éviter cela, QUIC chiffre une grande partie de la couche 4, pour éviter les interférences par les intermédiaires et pour défendre le principe de bout en bout et la neutralité du réseau. Comme souvent en sécurité, cette bonne mesure de protection a aussi des inconvénients, que ce RFC examine. Notons tout de suite que ce qui est un inconvénient pour les uns ne l'est pas forcément pour les autres : pour un FAI, ne pas pouvoir couper les connexions TCP de BitTorrent avec RST est un inconvénient mais, pour l'utilisateur, c'est un avantage, cela le protège contre certaines attaques par déni de service.
On ne peut pas sérieusement aujourd'hui utiliser des communications non-chiffrées (RFC 7258). Personne n'ose dire publiquement le contraire. Par contre, on entend souvent un discours « je suis pour le chiffrement, mais » et, comme toujours avec ce genre de phrase, c'est ce qui est après le « mais » qui compte. Ce RFC essaie de documenter les avantages et les inconvénients du chiffrement de la couche Transport, mais, en pratique, est plus détaillé sur les inconvénients, ce qui était déjà le cas du RFC 8404.
La section 2 du RFC explique quel usage peut être fait des informations de la couche Transport par les équipements intermédiaires. En théorie, dans un modèle en couches idéal, il n'y en aurait aucun : la couche Transport est de bout en bout, les routeurs et autres équipements intermédiaires ne regardent rien au-dessus de la couche Réseau. Mais en pratique, ce n'est pas le cas, comme l'explique cette section. (Question pour mes lecteurices au passage : vous semble-t-il légitime de parler de DPI quand un routeur regarde le contenu de la couche Transport, dont il n'a en théorie pas besoin, ou bien doit-on réserver ce terme aux cas où il regarde dans la couche Application ?)
Première utilisation de la couche Transport par des intermédiaires : identifier des flots de données (une suite d'octets qui « vont ensemble »). Pourquoi en a-t-on besoin ? Il y a plusieurs raisons possibles, par exemple pour la répartition de charge, où on veut envoyer tous les paquets d'un flot donné au même serveur. Cela se fait souvent en prenant un tuple d'informations dans le paquet (tuple qui peut inclure une partie de la couche Transport, comme les ports source et destination) et en le condensant pour avoir un identificateur du flot. Si la couche Transport est partiellement ou totalement chiffrée, on ne pourra pas distinguer deux flots différents entre deux machines. En IPv6, l'étiquette de flot (RFC 6437) est une solution possible (RFC 6438, RFC 7098), mais je n'ai pas l'impression qu'elle soit très utilisée.
Maintenant, passons à la question de l'identification d'un flot. Était-ce un transfert de fichiers, de la vidéo, une session interactive ? Il faut déduire cette identification à partir des informations de la couche Transport (voir le RFC 8558). Mais pourquoi identifier ces flots alors que l'opérateur doit tous les traiter pareil, en application du principe de neutralité ? Cela peut être dans l'intérêt de l'utilisateur (mais le RFC ne donne pas d'exemple…) ou bien contre lui, par exemple à des fins de surveillance, ou bien pour discriminer certains usages (comme le réclament régulièrement certains politiciens et certains opérateurs), voire pour les bloquer complètement. Autrefois, on pouvait souvent identifier un service uniquement avec le numéro de port (43 pour whois, 25 pour le courrier, etc, cf. RFC 7605) mais cela n'a jamais marché parfaitement, plusieurs services pouvant utiliser le même port et un même service pouvant utiliser divers ports. De toute façon, cette identification par le numéro de port est maintenant finie, en partie justement en raison de cette discrimination selon les usages, qui pousse tout le monde à tout faire passer sur le port 443. Certains services ont un moyen simple d'être identifié, par exemple par un nombre magique, volontairement placé dans les données pour permettre l'identification, ou bien simple conséquence d'une donnée fixe à un endroit connu (RFC 3261, RFC 8837, RFC 7983…). Lors de la normalisation de QUIC, un débat avait eu lieu sur la pertinence d'un nombre magique permettant d'identifier du QUIC, idée finalement abandonnée.
Si les équipements intermédiaires indiscrets n'arrivent pas à déterminer le service utilisé, le flot va être considéré comme inconnu et le RFC reconnait que certains opérateurs, en violation de la neutralité de l'Internet, ralentissent ces flots inconnus.
L'étape suivante pour ceux qui veulent identifier à quoi servent les données qu'ils voient passer est d'utiliser des heuristiques. Ainsi, une visio-conférence à deux fera sans doute passer à peu près autant d'octets dans chaque sens, alors que regarder de la vidéo à la demande créera un trafic très asymétrique. Des petits paquets UDP régulièrement espacés permettent de soupçonner du trafic audio, même si on n'a pas pu lire l'information SDP (RFC 4566). Des heuristiques plus subtiles peuvent permettre d'en savoir plus. Donc, il faut se rappeler que le chiffrement ne dissimule pas tout, il reste une vue qui peut être plus ou moins précise (le RFC 8546 décrit en détail cette notion de vue depuis le réseau).
Autre motivation pour analyser la couche Transport, l'amélioration des performances. Inutile de dire que le FAI typique ne va pas se pencher sur les problèmes de performance d'un abonné individuel (si ça rame avec Netflix, appeler le support de son FAI ne déclenche pas de recherches sérieuses). Mais cela peut être fait pour des analyse globales. Là encore, les conséquences peuvent être dans l'intérêt de l'utilisateur, ou bien contre lui. Le RFC note que les mesures de performance peuvent amener à une discrimination de certains services (« QoS », qualité de service, c'est-à-dire dégradation de certains services). Que peut-on mesurer ainsi, qui a un impact sur les performances ? Il y a la perte de paquets, qu'on peut déduire, en TCP, des retransmissions. Dans l'Internet, il y a de nombreuses causes de pertes de paquets, du parasite sur un lien radio à l'abandon délibéré par un routeur surchargé (RFC 7567) en passant par des choix politiques de défavoriser certains paquets (RFC 2475). L'étude de ces pertes peut permettre dans certains cas de remonter aux causes.
On peut aussi mesurer le débit. Bon, c'est facile, sans la couche Transport, uniquement en regardant le nombre d'octets qui passent par les interfaces réseaux. Mais l'accès aux données de la couche Transport permet de séparer le débit total du débit utile (goodput, en anglais, pour le différencier du débit brut, le throughput, cf. section 2.5 du RFC 7928, et le RFC 5166). Pour connaitre ce débit utile, il faut pouvoir reconnaitre les retransmissions (si un paquet est émis trois fois avant enfin d'atteindre le destinataire, il ne contribue qu'une fois au débit utile). Une retransmission peut se voir en observant les numéros de séquence en TCP (ou dans d'autres protocoles comme RTP).
La couche Transport peut aussi nous dire quelle est la latence. Cette information est cruciale pour évaluer la qualité des sessions interactives, par exemple. Et elle influe beaucoup sur les calculs du protocole de couche 4. (Voir l'article « Internet Latency: A Survey of Techniques and their Merits ».) Comment mesure-t-on la latence ? Le plus simple est de regarder les accusés de réception TCP et d'en déduire le RTT. Cela impose d'avoir accès aux numéros de séquence. Dans TCP, ils sont en clair, mais QUIC les chiffre (d'où l'ajout du spin bit).
D'autres métriques sont accessibles à un observateur qui regarde la couche Transport. C'est le cas de la gigue, qui se déduit des observations de la latence, ou du réordonnancement des paquets (un paquet qui part après un autre, mais arrive avant). L'interprétation de toutes ces mesures dépend évidemment du type de lien. Un lien radio (RFC 8462) a un comportement différent d'un lien filaire (par exemple, une perte de paquets n'est pas forcément due à la congestion, elle peut venir de parasites).
Le RFC note que la couche Réseau, que les équipements intermédiaires ont tout à fait le droit de lire, c'est son rôle, porte parfois des informations qui peuvent être utiles. En IPv4, ce sont les options dans l'en-tête (malheureusement souvent jetées par des pare-feux trop fascistes, cf. RFC 7126), en IPv6, les options sont après l'en-tête de réseau, et une option, Hop-by-hop option est explicitement prévue pour être examinée par tous les routeurs intermédiaires.
Outre les statistiques, l'analyse des données de la couche Transport peut aussi servir pour les opérations (voir aussi le RFC 8517), pour localiser un problème, pour planifier l'avitaillement de nouvelles ressources réseau, pour vérifier qu'il n'y a pas de tricheurs qui essaient de grapiller une part plus importante de la capacité, au risque d'aggraver la congestion (RFC 2914). En effet, le bon fonctionnement de l'Internet dépend de chaque machine terminale. En cas de perte de paquets, signal probable de congestion, les machines terminales sont censées réémettre les paquets avec prudence, puisque les ressources réseau sont partagées. Mais une machine égoïste pourrait avoir plus que sa part de la capacité. Il peut donc être utile de surveiller ce qui se passe, afin d'attraper d'éventuels tricheurs, par exemple une mise en œuvre de TCP qui ne suivrait pas les règles habituelles. (Si on utilise UDP, l'application doit faire cela elle-même, cf. RFC 8085. Ainsi, pour RTP, comme pour TCP, un observateur extérieur peut savoir si les machines se comportent normalement ou bien essaient de tricher.)
Autre utilisation de l'observation de la couche Transport pour l'opérationnel, la sécurité, par exemple la lutte contre les attaques par déni de service, l'IDS et autres fonctions. Le RFC note que cela peut se faire en coopération avec les machines terminales, si c'est fait dans l'intérêt de l'utilisateur. Puisqu'on parle de machines terminales, puisque le chiffrement d'une partie de la couche Transport est susceptible d'affecter toutes les activités citées plus haut, le RFC rappelle la solution évidente : demander la coopération des machines terminales. Il y a en effet deux cas : soit les activités d'observation de la couche Transport sont dans l'intérêt des utilisateurs, et faites avec leur consentement, et dans ce cas la machine de l'utilisateur peut certainement coopérer, soit ces activités se font contre l'utilisateur (discrimination contre une application qu'il utilise, par exemple), et dans ce cas le chiffrement est une réponse logique à cette attaque. Bien sûr, c'est la théorie ; en pratique, certaines applications ne fournissent guère d'informations et de moyens de débogage. Les protocoles de transport qui chiffrent une bonne partie de leur fonctionnement peuvent aussi aider, en exposant délibérement des informations. C'est par exemple ce que fait QUIC avec son spin bit déjà cité, ou avec ses invariants documentés dans le RFC 8999.
Autre cas où le chiffrement de la couche Transport peut interférer avec certains usages, les réseaux d'objets contraints, disposant de peu de ressources (faible processeur, batterie qu'il ne faut pas vider trop vite, etc). Il arrive dans ce cas d'utiliser des relais qui interceptent la communication, bricolent dans la couche Transport puis retransmettent les données. Un exemple d'un tel bricolage est la compression des en-têtes, courante sur les liens à très faible capacité (cf. RFC 2507, RFC 2508, le ROHC du RFC 5795, RFC 6846, le SCHC du RFC 8724, etc). Le chiffrement rend évidemment cela difficile, les relais n'ayant plus accès à l'information. C'est par exemple pour cela que le RTP sécurisé du RFC 3711 authentifie l'en-tête mais ne le chiffre pas. (Je suis un peu sceptique sur cet argument : d'une part, les objets contraints ne vont pas forcément utiliser des protocoles de transport chiffrés, qui peuvent être coûteux, d'autre part un sous-produit du chiffrement est souvent la compression, ce qui rend inutile le travail des relais.)
Un dernier cas cité par le RFC où l'observation du fonctionnement de la couche Transport par les machines intermédiaires est utile est celui de la vérification de SLA. Si un contrat ou un texte légal prévoit certaines caractéristiques pour le réseau, l'observation de la couche 4 (retransmission, RTT…) est un moyen d'observer sans avoir besoin d'impliquer les machines terminales. (Personnellement, je pense justement que ces vérifications devraient plutôt se faire depuis les machines terminales, par exemple avec les sondes RIPE Atlas, les SamKnows, etc.)
La section 3 du RFC décrit un autre secteur qui est intéressé par l'accès aux données de transport, la recherche. Par exemple, concevoir de nouveaux protocoles doit s'appuyer sur des mesures faites sur les protocoles existants, pour comprendre leurs forces et leurs faiblesses. C'est possible avec un protocole comme TCP, où l'observation passive permet, via notamment les numéros de séquence, de découvrir le RTT et le taux de perte de paquets. (Passive : sans injecter de paquets dans le réseau. Voir le RFC 7799.) Mais ces mêmes informations peuvent aussi servir contre l'utilisateur. Même s'il n'y a pas d'intention néfaste (par exemple de discrimination contre certains usages), toute information qui est exposée peut conduire à l'ossification, l'impossibilité de changer le protocole dans le futur. Une des motivations des protocoles chiffrés comme QUIC est en effet d'éviter l'ossification : une middlebox ne pourra pas prendre de décisions sur la base d'informations qu'elle n'a pas. QUIC affiche des données au réseau seulement s'il le veut (c'est le cas du spin bit). D'où également le choix délibéré de graisser, c'est-à-dire de faire varier certaines informations pour éviter que des programmeurs de middleboxes incompétents et/ou paresseux n'en déduisent que cette information ne change jamais (le graissage est décrit dans le RFC 8701).
La bonne solution pour récolter des données sans sacrifier la vie
privée est, comme dit plus haut, de faire participer les extrémités,
les machines terminales, ce qu'on nomme en anglais le
endpoint-based logging. Actuellement,
malheureusement, les mécanismes de débogage ou de récolte
d'information sur ces machines terminales sont trop réduits, mais
des efforts sont en cours. Par exemple, pour QUIC, c'est la
normalisation du format « qlog » d'enregistrement des informations
vues par la couche Transport
(Internet-Draft
draft-ietf-quic-qlog-main-schem)
ou bien le format Quic-Trace. Mais
le RFC note que la participation des machines terminales ne suffit
pas toujours, notamment si on veut déterminer
où, dans le réseau, se produit un problème.
Après qu'on ait vu les utilisations qui sont faites de l'analyse de la couche Trnsport par les équipements intermédiaires, la section 4 du RFC revient ensuite sur les motivations du chiffrement de cette couche. Pourquoi ne pas se contenter de ce que font TLS et SSH, qui chiffrent uniquement la couche Application ? L'une des premières raisons est d'empêcher l'ossification, ce phénomène qui fait qu'on ne peut plus faire évoluer la couche Transport car de stupides équipements intermédiaires, programmés avec les pieds par des ignorants qui ne lisent pas les RFC, rejettent les paquets légaux mais qui ne correspondent pas à ce que ces équipements attendaient. Ainsi, si un protocole de transport permet l'utilisation d'un octet dans l'en-tête, mais que cet octet est à zéro la plupart du temps, on risque de voir des middleboxes qui jettent les paquets où certains bits de ce champ sont à un car « ce n'est pas normal ». Tout ce qui est observable risque de devenir ossifié, ne pouvant plus être modifié par la suite. Chiffrer permet de garantir que les équipements intermédiaires ne vont pas regarder ce qui ne les regarde pas. Le RFC donne plusieurs exemples édifiants des incroyables comportements de ces logiciels écrits par des gens qui ne comprenaient qu'une partie d'un protocole :
- Pendant le développement de TLS 1.3 (qui mènera au RFC 8446), il a fallu concevoir 1.3 de manière à ce qu'il ressemble à 1.2, car certaines middleboxes rejettaient du TLS légal, mais différent de ce qu'elles attendaient.
- MPTCP (RFC 8684) a également dû être modifié pour tenir compte de boitiers intermédiaires qui observaient le fonctionnement de la fenêtre TCP et se permettaient de couper les connexions qui leur semblaient anormales.
- D'une manière générale, tout protocole qui permet des options est confronté à des middleboxes qui interfèrent dès qu'on utilise des options nouvelles. C'est le cas par exemple de TCP Fast Open (RFC 7413).
- Encore pire, si c'est possible, on a vu des équipements intermédiaires qui changeaient les numéros de séquence TCP, ce qui cassait les accusés de réception SACK (RFC 2018).
Il n'est donc pas étonnant que les concepteurs de protocole cherchent désormais à chiffrer au maximum, pour éviter ces interférences. Le RFC 8546 rappelle ainsi que c'est la vue depuis le réseau (wire image), c'est-à-dire ce que les équipements intermédiaires peuvent observer, pas la spécification écrite du protocole, qui détermine, dans le monde réel, ce qu'un intermédiaire peut observer et modifier. Il faut donc réduire cette vue au strict minimum ; tout ce qui n'est pas chiffré risque fortement d'être ossifié, figé. Et le RFC 8558 affirme lui qu'on ne doit montrer au réseau que ce qui doit être utilisé par le réseau, le reste, qui ne le regarde pas, doit être dissimulé.
Une autre motivation du chiffrement de la couche Transport est évidemment de mieux protéger la vie privée (RFC 6973). L'ampleur de la surveillance massive (RFC 7624) est telle qu'il est crucial de gêner cette surveillance le plus possible. Le RFC note qu'il n'y a pas que la surveillance passive, il y a aussi l'ajout de données dans le trafic, pour faciliter la surveillance. Du fait de cet « enrichissement », il peut être utile, quand un champ doit être observable (l'adresse IP de destination est un bon exemple), d'utiliser quand même la cryptographie pour empêcher ses modifications, via un mécanisme d'authentification. C'est ce que fait TCP-AO (RFC 5925, mais qui semble peu déployé), et bien sûr le service AH d'IPsec (RFC 4302).
Comme on le voit, il y a une tension, voire une lutte, entre les opérateurs réseau et les utilisateurs. On pourrait se dire que c'est dommage, qu'il vaudrait mieux que tout le monde travaille ensemble. Cela a été discuté à l'IETF, avec des expressions comme « un traité de paix entre machines terminales et boitiers intermédiaires ». Pour l'instant, cela n'a pas débouché sur des résultats concrets, en partie parce qu'il n'existe pas d'organisations représentatives qui pourraient négocier, signer et faire respecter un tel traité de paix. On en reste donc aux mesures unilatérales. Les machines terminales doivent chiffrer de plus en plus pour maintenir le principe de bout en bout. Comme dans tout conflit, il y a des dégâts collatéraux (le RFC 8922 en décrit certains). Le problème n'étant pas technique mais politique, il est probable qu'il va encore durer. La tendance va donc rester à chiffrer de plus en plus de choses.
À noter qu'une autre méthode que le chiffrement existe pour taper sur les doigts des boitiers intermédiaires pénibles, qui se mêlent de ce qui ne les regarde pas, et s'en mêlent mal : c'est le graissage. Son principe est d'utiliser délibérément toutes les options possibles du protocole, pour habituer les middleboxes à voir ces variations. Le RFC 8701 en donne un exemple, pour le cas de TLS.
Déterminer ce qu'il faut chiffrer, ce qu'il faut authentifier, et ce qu'il vaut mieux laisser sans protection, autorisant l'observation et les modifications, n'est pas une tâche facile. Autrefois, tout était exposé parce qu'on avait moins de problèmes avec les boitiers intermédiaires et que les solutions, comme le chiffrement, semblaient trop lourdes. Aujourd'hui qu'on a des solutions réalistes, on doit donc choisir ce qu'on montre ou pas. Le choix est donc désormais explicite (cf. RFC 8558).
Au passage, une façon possible d'exposer des informations qui peuvent être utiles aux engins intermédiaires est via un en-tête d'extension. Par exemple en IPv6, l'en-tête Hop-by-hop (RFC 8200, section 4.3) est justement fait pour cela (voir un exemple dans le RFC 8250, quoiqu'avec un autre type d'en-tête). Toutefois, cet en-tête Hop-by-hop est clairement un échec : beaucoup de routeurs jettent les paquets qui le portent (RFC 7872), ou bien les traitent plus lentement que les paquets sans cette information. C'est encore pire si cet en-tête porte des nouvelles options, inconnues de certaines middleboxes, et c'est pour cela que le RFC 8200 déconseille (dans sa section 4.8) la création de nouvelles options Hop-by-hop.
Mais, bon, le plus important est de décider quoi montrer, pas juste comment. Le RFC rappelle qu'il serait sympa d'exposer explicitement des informations comme le RTT ou le taux de pertes vu par les machines terminales, plutôt que de laisser les machines intermédiaires le calculer (ce qu'elles ne peuvent de toute façon plus faire en cas de chiffrement). Cela permettrait de découpler l'information de haut niveau des détails du format d'un protocole de transport. Pourquoi une machine terminale ferait-elle cela, au risque d'exposer des informations qu'on peut considérer comme privées ? Le RFC cite la possibilité d'obtenir un meilleur service, sans trop préciser s'il s'agit de laisser les opérateurs offrir un traitement préférentiel aux paquets portant cette information, ou bien si c'est dans l'espoir que l'information exposée serve à l'opérateur pour améliorer son réseau. (Comme le note le RFC 8558, il y a aussi le risque que la machine terminale mente au réseau. Au moins, avec le chiffrement, les choses sont claires : « je refuse de donner cette information » est honnête.)
Dernière note, cet ajout d'informations utiles pour l'OAM peut être faite par la machine terminale mais aussi (section 6 du RFC) par certains équipements intermédiaires.
En conclusion ? La section 7 du RFC reprend et résume les points importants :
- Le chiffrement et l'authentification dans la couche de Transport sont une bonne chose. Personne n'ose dire ouvertement qu'il faudrait rester à des protocoles de transport non sécurisés. C'est un point sur lequel le document a beaucoup évolué. Dans les versions antérieures, comme le notait Christian Huitema, « Much of the draft reads like a lamentation of the horrible consequences of encrypting transport headers », reflétant unilatéralement le point de vue des opérateurs réseau, et des vendeurs de middleboxes. Une relecture par Christopher Wood au début du projet avait déjà pointé ce problème, notant que le document était très anti-chiffrement. Cette question a, fort logiquement, été le principal point de discussion à l'IETF.
- Le RFC, officiellement, ne tranche pas sur la pertinence et l'éthique des pratiques qu'il décrit, il explique juste ce qui se fait. (Le même argument, que je trouve un peu hypocrite, avait été utilisé pour le très contestable RFC 8404.)
- Comme souvent en sécurité, il n'y a pas de solution idéale, il faudra trouver un compromis, par exemple entre la vie privée et l'OAM. Le RFC cite le spin bit de QUIC, qui avait été très chaudement discuté, comme un exemple de compromis, en tout cas par le sérieux de l'analyse de ses coûts et de ses bénéfices.
- Le RFC reconnait que tout ce qui est exposé au réseau s'ossifiera et deviendra une spécification de fait, qu'on ne pourra plus changer. Qu'un protocole choisisse d'exposer beaucoup ou au contraire très peu, il doit de toute façon faire ce choix explicitement.
- Même le chiffrement de la couche Transport ne cache pas tout, et les couches inférieures exposent toujours des métadonnées. Un surveillant déterminé n'est donc pas désarmé. (Même si des organisations comme Interpol prétendent que le chiffrement rend la police « aveugle ».)
- Les opérationnels se sont habitués depuis longtemps à disposer de certaines informations, que le chiffrement de la couche Transport peut rendre inutilisables. Il faudra donc changer certaines pratiques et certains outils, par exemple avec davantage de coopération des machines terminales (sinon, les opérations seront affectées).
- Le RFC rappelle aussi qu'il existe différents types de réseaux, et qui n'ont pas forcément les mêmes contraintes et les mêmes buts. Entre le réseau d'une entreprise qui veut contrôler tout ce que font les employés et le réseau d'un FAI qui doit respecter (en théorie…) le principe de neutralité, il n'est pas du tout sûr qu'on puisse trouver des solutions qui plaisent à tout le monde. (A priori, l'IETF travaille et normalise pour l'Internet ouvert, pas forcément pour chaque réseau connecté à l'Internet avec ses règles spécifiques.)
- L'Internet est un réseau partagé et son bon fonctionnement dépend donc du respect de certaines règles par tous. Par exemple, un protocole de transport doit penser aux autres, en ne noyant pas le réseau sous les paquets de retransmission. Si un fournisseur de logiciels était tenté de développer un protocole de transport égoïste, qui tente d'obtenir plus que sa part de la capacité du réseau, la tricherie pourrait se détecter en observant le fonctionnement de ce protocole. Le chiffrement de la couche Transport rend évidemment la vérification plus complexe.
- Le bon fonctionnement de l'Internet sur le long terme dépend également d'une activité de recherche et développement, qui s'appuie sur des mesures, que le chiffrement de la couche Transport peut gêner. (C'est bien, de se préoccuper des chercheurs.)
L'article seul
RFC 9063: Host Identity Protocol Architecture
Date de publication du RFC : Juillet 2021
Auteur(s) du RFC : R. Moskowitz (HTT Consulting), M. Komu (Ericsson)
Pour information
Réalisé dans le cadre du groupe de travail IETF hip
Première rédaction de cet article le 15 juillet 2021
Ce RFC propose d'aborder l'architecture de l'Internet en utilisant un nouveau type d'identificateur, le Host Identifier (HI), pour beaucoup d'usages qui sont actuellement ceux des adresses IP. Il remplace le RFC 4423, qui était la description originale du protocole HIP, mais il n'y a pas de changements fondamentaux. HIP était un projet très ambitieux mais, malgré ses qualités, la disponibilité de plusieurs mises en œuvre, et des années d'expérimentation, il n'a pas percé.
Une adresse IP sert actuellement à deux choses : désigner une machine (l'adresse IP sert par exemple à distinguer plusieurs connexions en cours) et indiquer comment la joindre (routabilité). Dans le premier rôle, il est souhaitable que l'adresse soit relativement permanente, y compris en cas de changement de FAI ou de mobilité (actuellement, si une machine se déplace et change d'adresse IP, les connexions TCP en cours sont cassées). Dans le second cas, on souhaite au contraire une adresse qui soit le plus « physique » possible, le plus dépendante de la topologie. Ces deux demandes sont contradictoires.
HIP résout le problème en séparant les deux fonctions. Avec HIP, l'adresse IP ne serait plus qu'un identifiant « technique », ne servant qu'à joindre la machine, largement invisible à l'utilisateur et aux applications (un peu comme une adresse MAC aujourd'hui). Chaque machine aurait un HI (Host Identifier) unique. Contrairement aux adresses IP, il n'y a qu'un HI par machine multi-homée mais on peut avoir plusieurs HI pour une machine si cela correspond à des usages différents, par exemple une identité publique, et une « anonyme ».
Pour pouvoir être vérifié, le nouvel identificateur, le HI sera (dans la plupart des cas) une clé publique cryptographique, qui sera peut-être allouée hiérarchiquement par PKI ou plutôt de manière répartie par tirage au sort (comme le sont les clés SSH ou PGP aujourd'hui, ce qui serait préférable, question vie privée). Ces identificateurs fondés sur la cryptographie permettent l'authentification réciproque des machines (contrairement à IP, où il est trivial de mentir sur son adresse), et d'utiliser ensuite IPsec (RFC 7402) pour chiffrer la communication (HIP n'impose pas IPsec, plusieurs encapsulations des données sont possibles, et négociées dynamiquement, mais, en pratique, la plupart des usages prévus reposent sur IPsec).
L'authentification permet d'être sûr du HI de la machine avec qui on parle et, si le HI était connu préalablement à partir d'une source de confiance, d'être sûr qu'on parle bien à l'interlocuteur souhaité. (Si on ne connait pas le HI à l'avance, on dit que HIP est en mode « opportuniste ».)
Cette séparation de l'identificateur et du localisateur est un sujet de recherche commun et d'autres propositions que HIP existent, comme LISP (RFC 9300) ou ILNP (RFC 6740). Dans tous les cas, les couches supérieures (comme TCP) ne verront que l'identificateur, permettant au localisateur de changer sans casser les sessions de transport en cours. (Un mécanisme ressemblant est le Back to My Mac du RFC 6281.) L'annexe A.1 de notre RFC rappelle les avantages de cette approche. Et l'annexe A.2, lecture très recommandée, note également ses défauts, l'indirection supplémentaire ajoutée n'est pas gratuite, et entraine des nouveaux problèmes. Notamment, il faut créer un système de correspondance - mapping - entre les deux, système qui complexifie le projet. Il y a aussi la latence supplémentaire due au protocole d'échange initial, qui est plus riche. Comparez cette honnêteté avec les propositions plus ou moins pipeau de « refaire l'Internet en partant de zéro », qui ne listent jamais les limites et les problèmes de leurs solutions miracle.
Ce HI (Host Identifier) pourra être stocké dans des annuaires publics, comme le DNS (RFC 8005), ou une DHT (RFC 6537), pour permettre le rendez-vous (RFC 8004) entre les machines.
Notez que ce n'est pas directement le Host Identifier, qui peut être très long, qui sera utilisé dans les paquets IP, mais un condensat, le HIT (Host Identity Tag).
HIP intègre les leçons de l'expérience avec IP, notamment de l'importance d'authentifier la machine avec qui on parle. C'est ce qui est fait dans l'échange initial qui permet à un initiateur et un répondeur de se mettre à communiquer. Notamment, il y a obligation de résoudre un puzzle cryptographique, pour rendre plus difficile certaines attaques par déni de service. Voir à ce sujet « DOS-Resistant Authentication with Client Puzzles » de Tuomas Aura, Pekka Nikander et Jussipekka Leiwo, « Deamplification of DoS Attacks via Puzzles » de Jacob Beal et Tim Shepard ou encore « Examining the DOS Resistance of HIP » de Tritilanunt, Suratose, Boyd, Colin A., Foo, Ernest, et Nieto, Juan Gonzalez.
La sécurité est un aspect important de HIP. Les points à garder en tête sont :
- Protection contre certaines attaques par déni de service via le puzzle cryptographique à résoudre.
- Protection contre les attaques de l'homme du milieu si le HI a été obtenu par un mécanisme sûr. Cela ne marche évidemment pas en mode opportuniste, où l'initiateur ne connait pas le HI de son correspondant, et le découvre une fois la connexion faite.
- Le mode opportuniste peut être renforcé, question sécurité, par le TOFU (RFC 7435).
- Tout mécanisme de séparation de l'identificateur et du localisateur ouvre de nouveaux problèmes : que se passe-t-il si le correspondant ment sur son localisateur ? Est-ce que cela permet des attaques par réflexion ? C'est pour éviter cela que les systèmes à séparation de l'identificateur et du localisateur prévoient, comme HIP, un test de l'existence d'une voie de retour (Cf. RFC 4225).
- Enfin, on peut évidemment mettre des ACL sur des HI mais leur structure « plate » fait qu'il n'y a pas d'agrégation possible de ces ACL (il faut une ACL par machine avec qui on correspond).
Au sujet du TOFU, le RFC cite « Leap-of-faith security is enough for IP mobility » de Miika Kari Tapio Komu et Janne Lindqvist, « Security Analysis of Leap-of-Faith Protocols » de Viet Pham et Tuomas Aura et « Enterprise Network Packet Filtering for Mobile Cryptographic Identities » de Janne Lindqvist, Essi Vehmersalo, Miika Komu et Jukka Manner.
Notre RFC ne décrit qu'une architecture générale, il est complété par les RFC 7401, qui décrit le protocole, RFC 7402, RFC 8003, RFC 8004, RFC 8005, RFC 8046 et RFC 5207. Si des implémentations expérimentales existent déjà et que des serveurs publics utilisent HIP, aucun déploiement significatif n'a eu lieu (cf. l'article « Adoption barriers of network layer protocols: The case of host identity protocol de T. Leva, M. Komu, A. Keranen et S. Luukkainen). Comme le disait un des relecteurs du RFC, « There's a lot of valuable protocol design and deployment experience packed into this architecture and the associated protocol RFCs. At the same time, actual adoption and deployment of HIP so far appears to have been scarce. I don't find this surprising. The existing Internet network/transport/application protocol stack has already become sufficiently complicated that considerable expertise is required to manage it in all but the simplest of cases. Teams of skilled engineers routinely spend hours or days troubleshooting operational problems that crop up within or between the existing layers, and the collection of extensions, workarounds, identifiers, knobs, and failure cases continues to grow. Adding a major new layer--and a fairly complicated one at that--right in the middle of the existing stack seems likely to explode the already heavily-strained operational complexity budget of production deployments. ». L'annexe A.3 décrit les questions pratiques liées au déploiement. Elle rappelle le compte-rendu d'expérience chez Boeing de Richard Paine dans son livre « Beyond HIP: The End to Hacking As We Know It ». Elle tord le cou à certaines légendes répandues (que HIP ne fonctionne pas à travers les routeurs NAT, ou bien qu'il faut le mettre en œuvre uniquement dans le noyau.)
Ah, question implémentations (RFC 6538), on a au moins HIP for Linux et OpenHIP qui ont été adaptés aux dernières versions de HIP, et des protocoles associés.
Les changements depuis le RFC 4423 sont résumés en section 14. Il n'y en a pas beaucoup, à part l'intégration de l'expérience, acquise dans les treize dernières années (et résumée dans le RFC 6538) et des améliorations du texte. La nouvelle annexe A rassemble plein d'informations concrètes, notamment que les questions pratiques de déploiement de HIP, et sa lecture est très recommandée à tous ceux et toutes celles qui s'intéressent à la conception de protocoles. La question de l'agilité cryptographique (RFC 7696) a également été détaillée.
L'article seul
RFC 9057: Email Author Header Field
Date de publication du RFC : Juin 2021
Auteur(s) du RFC : D. Crocker (Brandenburg InternetWorking)
Expérimental
Première rédaction de cet article le 23 juin 2021
Qui est l'auteur d'un message reçu par courrier
électronique ? La réponse semblait autrefois simple,
c'est forcément la personne ou l'organisation indiquée dans le champ
From:. Sauf que des changements récents (et pas
forcément bien inspirés) dans le traitement des messages ont amené à
ce que le From: soit parfois modifié, par
exemple par certaines listes de diffusion. Il
ne reflète donc plus le vrai auteur. D'où ce RFC qui crée un nouvel
en-tête, Author:, qui identifie le vrai
émetteur.
La norme pertinente est le RFC 5322, qui
définit des en-têtes comme From: (auteur d'un
message) ou Sender: (personne ou entité qui n'a
pas écrit le message mais réalise l'envoi, par exemple parce que
l'auteur n'avait pas le temps, ou bien parce que le message a été
relayé par un intermédiaire). Les amateurs d'archéologie noteront
que le courrier électronique est très ancien,
plus ancien que l'Internet, cette ancienneté étant la preuve de son
efficacité et de sa robustesse. Le premier RFC avec la notion formelle d'auteur d'un
message était le RFC 733.
Une particularité du courrier électronique est que le message ne
va pas toujours directement de la machine de l'auteure à celle du
lecteur (cf. le RFC 5598, sur l'architecture
du courrier). Il y a souvent des intermédiaires
(mediators) comme les gestionnaires de
listes de diffusion, qui prennent un message
et le redistribuent aux abonnées. En raison du problème du
spam, plusieurs mécanismes de protection ont
été développés, qui peuvent poser des problèmes pour ces
intermédiaires. SPF (RFC 7208),
contrairement à une légende tenace, n'affecte pas les listes de
diffusion. (C'est en raison de la distinction entre enveloppe et
en-tête d'un message. Si vous entendez quelqu'un pontifier sur SPF
et la messagerie, et qu'il ne connait pas la différence entre
l'émetteur indiqué dans l'enveloppe et celui marqué dans l'en-tête,
vous pouvez être sûre que cette personne est ignorante.) En
revanche, DKIM (RFC 6376), surtout
combiné avec DMARC (RFC 9989), peut poser des problèmes dans certains cas (le
RFC 6377 les détaille). Pour gérer ces
problèmes, certaines listes de diffusion choisissent de carrément
changer le From: du message et d'y mettre, par
exemple (ici tiré de l'utile liste
outages, informant des pannes Internet) :
From: Erik Sundberg via Outages <outages@outages.org>
Alors que le message avait en fait été écrit par « Erik Sundberg
<ESundberg@nitelusa.com> ». C'est une
mauvaise idée, mais elle est commune. Dans ce cas, la liste s'est
« approprié » le message et on a perdu le vrai auteur, privant ainsi
la lectrice d'une information utile (dans le cas de la liste
Outages, il a toutefois été préservé dans le
champ Reply-To:). [Personnellement, il me semble
que l'idéal serait de ne pas modifier le message, préservant ainsi
les signatures DKIM, et donc les vérifications DMARC. Dans les cas
où le message est modifié, DMARC s'obstine à vérifier le
From: et pas le Sender:,
ce qui serait pourtant bien plus logique.]
Maintenant, la solution (section 3 du RFC) : un nouvel en-tête,
Author:, dont la syntaxe est la même que celle
de From:. Par exemple :
Author: Dave Crocker <dcrocker@bbiw.net>
Cet en-tête peut être mis au départ, par le MUA, ou bien ajouté par un intermédiaire
qui massacre le champ From: mais veut garder
une trace de sa valeur originale en la recopiant dans le champ
Author:. Cela n'est possible que s'il n'y a pas
déjà un champ Author:. S'il existe, il est
strictement interdit de le modifier ou de le supprimer.
À la lecture, par le MUA de réception, le RFC conseille
d'utiliser le champ Author:, s'il est présent,
plutôt que le From:, pour afficher ou trier sur
le nom de l'expéditrice.
Comme dans le cas du champ From:, un
malhonnête peut évidemment mettre n'importe quoi dans le champ
Author: et il faut donc faire attention à ne
pas lui accorder une confiance aveugle.
Author: a été ajouté au registre
des en-têtes.
On notera qu'une tentative précédente de préservation de
l'en-tête From: original avait été faite dans
le RFC 5703, qui créait un
Original-From: mais uniquement pour les
intermédiaires, pas pour les MUA.
L'article seul
RFC 9051: Internet Message Access Protocol (IMAP) - Version 4rev2
Date de publication du RFC : Août 2021
Auteur(s) du RFC : A. Melnikov (Isode), B. Leiba (Futurewei Technologies)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF extra
Première rédaction de cet article le 3 septembre 2021
IMAP, protocole d'accès distant à des boites aux lettres n'est pas juste un protocole, c'est tout un écosystème, décrit dans de nombreux RFC. Celui-ci est le socle de la version actuelle d'IMAP, la « 4rev2 ». Elle remplace la précédente version, « 4rev1 » (normalisée dans le RFC 3501). Le principal changement est sans doute une internationalisation plus poussée pour les noms de boites aux lettres et les en-têtes des messages.
Les protocoles traditionnels du courrier électronique, notamment SMTP ne permettaient que d'acheminer le courrier jusqu'à destination. Pour le lire, la solution la plus courante aujourd'hui est en mode client/serveur, avec IMAP, qui fait l'objet de notre RFC. IMAP ne permet pas d'envoyer du courrier, pour cela, il faut utiliser le RFC 6409. IMAP fonctionne sur un modèle où les messages ont plutôt vocation à rester sur le serveur, et où les clients peuvent, non seulement les récupérer mais aussi les classer, les détruire, les marquer comme lus, etc. IMAP permet de tout faire à distance.
Pour apprendre IMAP, il vaut mieux ne pas commencer par le RFC,
qui est très riche. (La lecture du RFC 2683 est recommandée
aux implémenteurs.) Pourtant, le principe de base est simple. IMAP
est client/serveur. Le
client se connecte en TCP au serveur, sur le
port 143, et envoie des commandes sous forme
de texte, comme avec SMTP. Il s'authentifie avec la commande
LOGIN, choisit une boite aux lettres avec la
commande SELECT, récupère un message avec la
commande FETCH. IMAP peut aussi utiliser du
TLS
implicite, sur le port 993. Voici un exemple de session. Notons tout
de suite, c'est un point très important du protocole IMAP, que
chaque commande est précédée d'une étiquette
(tag, voir les sections 2.2.1 et 5.5 du RFC)
arbitraire qui change à chaque commande et qui permet d'associer une
réponse à une commande, IMAP permettant d'envoyer plusieurs
commandes sans attendre de réponse. Les réponses portent
l'étiquette correspondante, ou bien un
astérisque s'il s'agit d'un message du
serveur non sollicité. Ici, le serveur utilise le logiciel Archiveopteryx :
% telnet imap.example.org imap Trying 192.0.2.23... Connected to imap.example.org. Escape character is '^]'. * OK [CAPABILITY IMAP4rev1 AUTH=CRAM-MD5 AUTH=DIGEST-MD5 AUTH=PLAIN COMPRESS=DEFLATE ID LITERAL+ STARTTLS] imap.example.org Archiveopteryx IMAP Server com1 LOGIN stephane vraimentsecret com1 OK [CAPABILITY IMAP4rev1 ACL ANNOTATE BINARY CATENATE CHILDREN COMPRESS=DEFLATE CONDSTORE ESEARCH ID IDLE LITERAL+ NAMESPACE RIGHTS=ekntx STARTTLS UIDPLUS UNSELECT URLAUTH] done com2 SELECT INBOX * 189 EXISTS * 12 RECENT * OK [UIDNEXT 1594] next uid * OK [UIDVALIDITY 1] uid validity * FLAGS (\Deleted \Answered \Flagged \Draft \Seen) * OK [PERMANENTFLAGS (\Deleted \Answered \Flagged \Draft \Seen \*)] permanent flags com2 OK [READ-WRITE] done
Le serveur préfixe ses réponses par OK si tout va bien, NO s'il ne pas réussi à faire ce qu'on lui demande et BAD si la demande était erronnée (commande inconnue, par exemple). Ici, avec l'étiquette A2 et un Dovecot :
A2 CAVAPAS A2 BAD Error in IMAP command CAVAPAS: Unknown command (0.001 + 0.000 secs).
Si le serveur n'est accessible qu'en TLS implicite (TLS démarrant
automatiquement au début, sans STARTTLS), on
peut utiliser un client TLS en ligne de commande, comme celui de
GnuTLS :
% gnutls-cli -p 993 imap.maison.example
- Certificate[0] info:
- subject `CN=imap.maison.example', issuer `CN=CAcert Class 3 Root,OU=http://www.CAcert.org,O=CAcert Inc.', serial 0x02e9bf, RSA key 2048 bits, signed using RSA-SHA512, activated `2020-12-14 14:47:42 UTC', expires `2022-12-14 14:47:42 UTC', pin-sha256="X21ApSVQ/Qcb5Q8kgL/YqlH2XuEco/Rs2X2EgkvDEdI="
...
- Status: The certificate is trusted.
- Description: (TLS1.3)-(ECDHE-SECP256R1)-(RSA-PSS-RSAE-SHA256)-(AES-256-GCM)
[À partir d'ici, on fait de l'IMAP]
* OK [CAPABILITY IMAP4rev1 SASL-IR LOGIN-REFERRALS ID ENABLE IDLE LITERAL+ AUTH=PLAIN] Dovecot (Debian) ready.
A1 LOGIN stephane vraimenttropsecret
A1 OK [CAPABILITY IMAP4rev1 SASL-IR LOGIN-REFERRALS ID ENABLE IDLE SORT SORT=DISPLAY THREAD=REFERENCES THREAD=REFS THREAD=ORDEREDSUBJECT MULTIAPPEND URL-PARTIAL CATENATE UNSELECT CHILDREN NAMESPACE UIDPLUS LIST-EXTENDED I18NLEVEL=1 CONDSTORE QRESYNC ESEARCH ESORT SEARCHRES WITHIN CONTEXT=SEARCH LIST-STATUS BINARY MOVE SNIPPET=FUZZY PREVIEW=FUZZY STATUS=SIZE SAVEDATE LITERAL+ NOTIFY SPECIAL-USE] Logged in
A2 SELECT INBOX
...
* 0 EXISTS
* 0 RECENT
A2 OK [READ-WRITE] Select completed (0.002 + 0.000 + 0.001 secs).
...
A14 FETCH 1 (BODY.PEEK[HEADER.FIELDS (SUBJECT)])
* 1 FETCH (BODY[HEADER.FIELDS (SUBJECT)] {17}
Subject: Test
)
A14 OK Fetch completed (0.007 + 0.000 + 0.006 secs).
Les commandes IMAP, comme FETCH dans l'exemple
ci-dessus, sont décrites dans la section 6 du RFC.
Pour tester son serveur IMAP, on peut aussi utiliser fetchmail et
lui demander d'afficher toute la session avec -v
-v :
% fetchmail -v -v -u MYLOGIN imap.1and1.fr Enter password for MYLOGIN@imap.1and1.fr: fetchmail: 6.3.6 querying imap.1and1.fr (protocol auto) at Tue Apr 15 12:00:27 2008: poll started fetchmail: 6.3.6 querying imap.1and1.fr (protocol IMAP) at Tue Apr 15 12:00:27 2008: poll started Trying to connect to 212.227.15.141/143...connected. fetchmail: IMAP< * OK IMAP server ready H mimap3 65564 fetchmail: IMAP> A0001 CAPABILITY fetchmail: IMAP< * CAPABILITY IMAP4rev1 LITERAL+ ID STARTTLS CHILDREN QUOTA IDLE NAMESPACE UIDPLUS UNSELECT SORT AUTH=LOGIN AUTH=PLAIN fetchmail: IMAP< A0001 OK CAPABILITY finished. fetchmail: Protocol identified as IMAP4 rev 1 fetchmail: IMAP> A0002 STARTTLS fetchmail: IMAP< A0002 OK Begin TLS negotiation. fetchmail: Issuer Organization: Thawte Consulting cc fetchmail: Issuer CommonName: Thawte Premium Server CA fetchmail: Server CommonName: imap.1and1.fr fetchmail: imap.1and1.fr key fingerprint: 93:13:99:6A:3F:23:73:C3:00:37:4A:39:EE:22:93:AB fetchmail: IMAP> A0003 CAPABILITY fetchmail: IMAP< * CAPABILITY IMAP4rev1 LITERAL+ ID CHILDREN QUOTA IDLE NAMESPACE UIDPLUS UNSELECT SORT AUTH=LOGIN AUTH=PLAIN fetchmail: IMAP< A0003 OK CAPABILITY finished. fetchmail: Protocol identified as IMAP4 rev 1 fetchmail: imap.1and1.fr: upgrade to TLS succeeded. fetchmail: IMAP> A0004 LOGIN "m39041005-1" * fetchmail: IMAP< A0004 OK LOGIN finished. fetchmail: selecting or re-polling default folder fetchmail: IMAP> A0005 SELECT "INBOX"
En IMAP, un message peut être identifié par un UID
(Unique Identifier) ou par un numéro. Le numéro
n'est pas global, il n'a de sens que pour une boite donnée, et il
peut changer, par exemple si on détruit des messages. L'UID, lui,
est stable, au moins pour une session (et de préférence pour
toutes). Les messages ont également des attributs
(flags). Ceux qui commencent par une
barre oblique inverse comme
\Seen (indique que le message a été lu),
\Answered (on y a répondu), etc, sont
obligatoires, et il existe également des attributs optionnels
commençant par un dollar comme
$Junk (spam). Les
fonctions de recherche d'IMAP pourront utiliser ces attributs comme
critères de recherche. Les attributs optionnels
(keywords) sont listés dans un
registre IANA, et on peut en ajouter (le RFC 5788
explique comment).
IMAP a des fonctions plus riches, notamment la possibilité de chercher dans les messages (section 6.4.4 du RFC), ici, on extrait les messages de mai 2007, puis on récupère le sujet du premier message, par son numéro :
com10 SEARCH since 1-May-2007 before 31-May-2007
* SEARCH 12
com10 OK done
com11 FETCH 1 (BODY.PEEK[HEADER.FIELDS (SUBJECT)])
* 1 FETCH (BODY[HEADER.FIELDS (Subject)] {17}
Subject: Rapport sur les fonctions de vue dans Archiveopteryx
)
com11 OK done
IMAP 4rev2 est complètement internationalisé et, par exemple, peut gérer des en-têtes en UTF-8, comme décrits dans le RFC 6532, ce qui est une des améliorations par rapport à 4rev1.
Vous noterez dans les réponses CAPABILITY
montrées plus haut, que le serveur indique la ou les versions d'IMAP
qu'il sait gérer. Il peut donc annoncer 4rev1 et 4rev2, s'il est
prêt à gérer les deux. Le client devra utiliser la commande
ENABLE pour choisir. S'il choisit 4rev2, le
serveur pourra utiliser les nouveautés de 4rev2, notamment dans le
domaine de l'internationalisation (noms de boites en UTF-8, alors
que 4rev1 savait tout juste utiliser un bricolage basé sur
UTF-7).
IMAP 4rev2 est compatible avec 4rev1 (un logiciel de la précédente norme peut interagir avec un logiciel de la nouvelle). Il peut même interagir avec l'IMAP 2 du RFC 1776 (IMAP 3 n'a jamais été publié), cf. RFC 2061.
L'annexe E résume les principaux changements depuis le RFC 3501, qui normalisait IMAP 4rev1 :
- Messages plus grands (taille stockée sur 63 bits et plus seulement 32). Un serveur qui accepte les messages de plus de quatre gigoctets devra donc les masquer aux clients 4rev1 (ou bien trouver une autre stratégie).
- UTF-8 pour les noms de boites et les sujets des messages.
- Incorporation de nombreuses extensions précédemment
séparées, trop nombreuses pour que je les cite toutes. Il y a par
exemple le
BINARYdu RFC 3516 ou leLIST-EXTENDEDdu RFC 5258. - Beaucoup de clarifications du texte.
- Abandon de certaines choses, aussi, comme le code de réponse
UNSEENde la commandeSELECT. - Application des progrès de la cryptanalyse, donc remplacement de MD5 par SHA-256.
- Suppression de la convention du préfixe « X- », en application du RFC 6648.
La réalisation d'un client ou d'un serveur IMAP soulève plein de problèmes pratiques, que la section 5 de notre RFC traite. Par exemple, les noms des boites aux lettres peuvent être en Unicode, plus précisément le sous-ensemble d'Unicode du RFC 5198 (cela n'était pas possible en 4rev1). Un logiciel doit donc s'attendre à rencontrer de tels noms.
IMAP est mis en œuvre dans de nombreux serveurs comme Dovecot, Courier, ou Archiveopteryx, déjà cité (mais qui semble abandonné). Mais, comme vous l'avez vu dans les exemples de session IMAP cités plus haut, la version de notre RFC, « 4rev2 » n'a pas encore forcément atteint tous les logiciels.
Côté client, on trouve du IMAP dans beaucoup de logiciels, des webmails, des MUA classiques comme mutt, des MUA en ligne de commande comme fetchmail, très pratique pour récupérer son courrier. (Si vous écrivez un logiciel IMAP à partir de zéro, ce RFC recommande la lecture préalable du RFC 2683.)
Il existe également des bibliothèques toutes faites pour programmer son client IMAP à son goût comme imaplib pour Python. Voici un exemple d'un court programme Python qui se connecte à un serveur IMAP, sélectionne tous les messages et les récupère. On note que la bibliothèque a choisi de rester très proche du vocabulaire du RFC :
import imaplib
# Unlike what the documentation says, "host" has no proper default.
connection = imaplib.IMAP4_SSL(host='localhost')
connection.login("stephane", "thisissecret")
connection.select() # Select the default mailbox
typee, data = connection.search(None, "ALL")
for num in data[0].split():
# Fetches the whole message
# "RFC822" est le terme traditionnel mais le format des messages
# est désormais dans le RFC 5322.
typ, data = connection.fetch(num, '(RFC822)')
print('Message %s\n%s\n' % (num, data[0][1]))
connection.close()
connection.logout()
L'article seul
RFC 9043: FFV1 Video Coding Format Version 0, 1, and 3
Date de publication du RFC : Août 2021
Auteur(s) du RFC : M. Niedermayer, D. Rice, J. Martinez
Pour information
Réalisé dans le cadre du groupe de travail IETF cellar
Première rédaction de cet article le 24 août 2021
Ce RFC décrit FFV1, un encodage de flux vidéo sans pertes, et sans piège connu, par exemple de brevet.
Certains encodages vidéo font perdre de l'information, c'est-à-dire que, après décompression, on ne retrouve pas tout le flux original. Ces encodages avec pertes tirent profit des limites de l'œil humain (on n'encode pas ce qui ne se voit pas) mais peut poser des problèmes dans certains cas. Par exemple, si on veut stocker une vidéo sur le long terme, il est certainement préférable qu'elle soit aussi « authentique » que possible, et donc encodée sans pertes. Les organisations qui font de l'archivage sur le long terme (comme l'INA) ont tout intérêt à privilégier un format sans pertes et libre, qui sera encore utilisable dans 50 ans, plutôt que de choisir les derniers gadgets à la mode. Si on souhaite faire analyser cette vidéo par autre chose qu'un œil humain, par exemple un programme qui souhaite avoir la totalité des informations, là encore, le « sans perte » est nécessaire. FFV1 est sans perte, pour le plus grand bénéfice de l'archivage et de la science. C'est le premier codec sans perte documenté par l'IETF.
FFV1 ne date pas d'aujourd'hui, et le RFC traite d'un coup trois versions de FFV1 (section 4.2.1) :
- La version 0, qui date de 2006,
- la version 1, de 2009,
- la version 2 qui n'était qu'expérimentale et n'a pas été officiellement utilisée,
- la version 3, la dernière, en 2013.
Le nom FFV1 veut dire « FF Video 1 » et FF est une référence à FFmpeg, le programme de référence (qui a largement précédé la spécification officielle) dont le nom venait de Fast Forward (avance rapide).
Je ne vais pas vous décrire les algorithmes de FFV1, ça dépasse largement mes compétences. Comme le note le RFC, il faut d'abord connaitre le codage par intervalle, et le modèle YCbCr. Je vous renvoie donc à l'article en français d'un des auteurs et bien sûr au RFC lui-même. FFV1 utilise souvent des techniques un peu anciennes, pour éviter les problèmes de brevet.
Le RFC utilise du pseudo-code pour décrire l'encodage FFV1. Ce pseudo-code particulier est assez proche de C. Vous verrez donc du pseudo-code du genre :
for (i = 0; i < quant_table_set_count; i++) {
states_coded
if (states_coded) {
for (j = 0; j < context_count[ i ]; j++) {
for (k = 0; k < CONTEXT_SIZE; k++) {
initial_state_delta[ i ][ j ][ k ]
}
}
}
}
Le type de média video/FFV1
a été enregistré
à l'IANA pour les flux encodés en FFV1.
FFV1 décrit un encodage d'un flux vidéo, pas un format de conteneur. Le flux en question doit donc être inclus dans un conteneur, par exemple aux formats AVI, NUT ou Matroska (section 4.3.3 pour les détails de l'inclusion dans chaque format).
Comme pour tout codec utilisé sur le grand méchant Internet, un programme qui lit du FFV1 doit être paranoïaque et ne doit pas supposer que le flux vidéo est forcément correct. Même si le contenu du fichier est délibérement malveillant, le décodeur ne doit pas allouer de la mémoire à l'infini ou boucler sans fin (ou, pire encore, exécuter du code arbitraire par exemple parce qu'il y aura eu un débordement de pile ; FFV1 lui-même ne contient pas de code exécutable). Le RFC (section 6) donne l'exemple d'un calcul de taille d'une image où on multiplie la largeur par la hauteur, sans plus de précautions. Si cela provoque un dépassement d'entier, des tas de choses vilaines peuvent arriver. Un exemple de précaution : FFmpeg a été soumis à des flux FFV1 corrects et à des données aléatoires, tout en étant examiné par Valgrind et le vérificateur de Clang et aucun accès mémoire anormal n'a été détecté.
Question mises en œuvre, FFV1 est suffisamment ancien pour que de nombreux programmes sachent le décoder. L'implémentation de référence est FFmpeg (qui sait aussi encoder en FFV1). Il y a également un décodeur en Go, développé en même temps que la spécification et il y a aussi MediaConch dont le développement a permis de détecter des incohérences entre le projet de spécification et certains programmes. La spécification elle-même a été développée sur GitHub si vous voulez suivre son histoire, et son futur (une version 4 est prévue).
Comme exemple d'une vidéo encodée en FFV1, j'ai pris les 20
premières secondes de mon
exposé au FOSDEM 2021. Le fichier (pour 20 secondes de
vidéo !) fait 60 mégaoctets : la
compression sans perte est évidemment moins efficace que si on
accepte les pertes. Le fichier a été produit par FFmpeg
(ffmpeg -i retro_gemini.webm -vcodec ffv1 -level 3 -to
00:00:20 retro_gemini.mkv, notez que, si FFV1 lui-même
est sans perte, si vous encodez en FFV1 à partir d'un fichier déjà
comprimé avec perte, vous ne recupérez évidemment pas ce qui a été
perdu). mediainfo vous montre son contenu :
% mediainfo retro_gemini.mkv General ... Format : Matroska Movie name : Gemini, a modern protocol that looks retro ... DATE : 2021-02-07 EVENT : FOSDEM 2021 SPEAKERS : Stéphane Bortzmeyer Video ID : 1 Format : FFV1 Format version : Version 3.4 Codec ID : V_MS/VFW/FOURCC / FFV1 Duration : 20 s 0 ms Bit rate mode : Variable Bit rate : 25.7 Mb/s Width : 1 280 pixels Height : 720 pixels Frame rate mode : Constant Frame rate : 25.000 FPS Color space : YUV Compression mode : Lossless ...
Ou bien avec ffprobe :
% fprobe -show_format -show_streams retro_gemini.mkv
...
Input #0, matroska,webm, from 'retro_gemini.mkv':
Metadata:
title : Gemini, a modern protocol that looks retro
DATE : 2021-02-07
...
[STREAM]
index=0
codec_name=ffv1
codec_long_name=FFmpeg video codec #1
codec_type=video
codec_time_base=1/25
codec_tag_string=FFV1
width=1280
height=720
...
Merci à Jérôme Martinez pour sa relecture attentive.
L'article seul
RFC 9039: Uniform Resource Names for Device Identifiers
Date de publication du RFC : Juin 2021
Auteur(s) du RFC : J. Arkko (Ericsson), C. Jennings (Cisco), Z. Shelby (ARM)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF core
Première rédaction de cet article le 1 juillet 2021
Voici un nouvel espace de noms pour des URN, dev, afin de
stocker des identificateurs pour des équipements matériels, par
exemple pour les inventaires.
Les URN, un
sous-ensemble des URI, et des cousins des URL, sont normalisés
dans le RFC 8141. On peut placer des URN
partout où on peut mettre des URI, par exemple comme noms dans
SenML (RFC 8428). Pour
des objets contraints, les URN risquent d'être un peu longs par
rapport à, par exemple, une adresse IPv4,
mais ils sont plus souples. Un URN commence par le plan
urn:, suivie d'un espace de noms. Ces espaces
sont stockés
dans un registre IANA. Ce nouveau RFC crée un nouvel espace de noms,
dev. On pourra donc désormais avec des URN
comme urn:dev:os:32473-123456 (qui identifie la
machine 123456 de l'organisation 32473). Ces identificateurs de
machines pourront être utilisés toutes les fois où on a besoin de
désigner une machine, dans les données du RFC 8428, dans
des inventaires, etc.
Passons au concret maintenant, avec la section 3 du RFC, qui
donne la définition formelle de l'espace de noms
dev. Ces URN sont évidemment conformes à la
norme des URN, le RFC 8141. Comme tous les
URN, ceux sous urn:dev: ne sont pas prévus pour
être résolus automatiquement. Contrairement aux URL, ils ne
fournissent pas de moyen d'accès à une ressource. Bien sûr, si on
les met dans une base de données, d'inventaire de ses machines, par
exemple, on pourra retrouver l'information, mais ce RFC ne spécifie
aucun mécanisme de résolution standard (section 3.6 du RFC).
Après le urn:dev:, ces URN prennent
un composant supplémentaire, qui identifie le type d'identificateur
dont dérive l'URN. Cela peut être :
mac, où l'identificateur est une adresse MAC, enregistrée selon les procédures IEEE, au format EUI-64. C'est par exempleurn:dev:mac:acde48234567019f(pour l'adresse MACac:de:48:23:45:67:01:9f). Si vous faites varier l'adresse MAC, par exemple pour protéger votre vie privée, l'URN n'est plus un identifiant stable.ow, qui s'appuie sur 1-Wire, un système privateur.org, avec des identificateurs spécifiques à une organisation, identifiée par son PEN (les PEN sont normalisés dans le RFC 2578). Les PEN sont enregistrés à l'IANA. Prenons comme exemple celui d'une entreprise dont j'étais un co-fondateur, 9319. Si cette entreprise utilise des noms pour ses machines, la machinemarxaurait comme URNurn:dev:org:9319-marx.os, comme lesorgmais plutôt prévus pour des numéros de série. Si cette entreprise numérote toutes ses machines en partant de 1, un URN seraiturn:dev:os:9319-1. (Notez que des versions précédentes des URNdevutilisaientospour les identificateurs LwM2M.) Ainsi, le RIPE-NCC qui a le PEN 15854 pourrait nommer ses sondes Atlas d'après leur numéro unique et donc la sonde 6593 pourrait être désignée parurn:dev:os:15854-6593. Notez qu'on pourrait avoir ici une intéressante discussion sur l'intérêt respectif des URN (urn:dev:os:15854-6593) et des URL (https://atlas.ripe.net/probes/6593/).ops, qui ressemble à l'os, mais avec un identificateur de produit entre le PEN et le numéro de série, par exempleurn:dev:ops:9319-coffeemachine-2pour la deuxième machine à café de l'organisation. (Commeos, il avait été utilisé pour l'Open Mobile Alliance.)- Un autre type, qui sera défini dans le futur (cf. section 7
du RFC). En attendant, on peut utiliser
examplepour des exemples, commeurn:dev:example:1234.
Enfin, une machine identifiée par un de ces URN peut avoir une
partie particulière de la machine désignée par une chaine de
caractères après un tiret bas. Ainsi,
urn:dev:os:9319-1_alimentation serait
l'alimentation de la machine
urn:dev:os:9319-1.
Notez que l'équivalence de deux URN est sensible à la casse donc attention, par exemple, à la façon dont vous écrivez les adresses MAC. Le RFC recommande de tout mettre en minuscules.
Idéalement, on veut bien sûr qu'un URN dev
identifie une machine et une seule. Mais, en pratique, cela peut
dépendre du type d'identificateurs utilisé. Ainsi, les adresses MAC
ne sont pas forcément uniques, entre autres parce que certains
fabricants ont déjà réutilisé des adresses.
Petit avertissement sur la vie privée : les identificateurs décrits dans ce RFC sont prévus pour être très stables sur le long terme (évidemment, puisque leur but est de garder trace d'une machine) et leur utilisation imprudente (par exemple si on envoie un de ces URN avec les données d'un utilisateur anonyme) peut permettre une surveillance accrue (sections 3.4 et 6.1 du RFC). Le RFC 7721 détaille les risques de ces identificateurs à longue durée de vie.
Le RFC note (section 1) qu'il existe d'autres catégories
d'identificateurs qui, selon le cas, pourraient concurrencer nos URN
de l'espace de noms dev. C'est le cas par
exemple des condensats du RFC 6920, des
IMEI du RFC 7254, des
MEID du RFC 8464 et
bien sûr des UUID du RFC 9562. Tous peuvent se
représenter sous forme d'URI, et parfois d'URN. Ils ont leurs
avantages et leurs inconvénients, le choix est vaste.
Pour les gens qui utiisent le SGBD
PostgreSQL, notez qu'il n'a pas de type de
données « URI » donc, si on veut stocker les URN de
notre RFC dans PostgreSQL, il faut utiliser le type
TEXT, ou bien installer une extension comme
pguri. Selon ce
qu'on veut faire de ces URN, on peut aussi prendre une solution plus
simple qui ne nécessite pas d'installer d'extension, ici pour une
organisation qui met toutes ces machines en
urn:dev:os:9319-… :
CREATE DOMAIN urndev AS text CHECK (VALUE ~ '^urn:dev:os:9319-[0-9]+(_[a-z0-9]+)?$');
COMMENT ON DOMAIN urndev IS 'URN DEV (RFC 9039) for our devices';
CREATE TABLE Devices (id SERIAL, urn urndev UNIQUE NOT NULL, comments TEXT);
INSERT INTO Devices (urn, comments) VALUES ('urn:dev:os:9319-2', 'No comment');
INSERT INTO Devices (urn) VALUES ('urn:dev:os:9319-1_alimentation');
INSERT INTO Devices (urn, comments) VALUES ('urn:dev:os:9319-666', 'Beast');
L'article seul
RFC 9038: Extensible Provisioning Protocol (EPP) Unhandled Namespaces
Date de publication du RFC : Mai 2021
Auteur(s) du RFC : J. Gould (VeriSign), M. Casanova (SWITCH)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 30 mai 2021
Le protocole EPP, qui sert notamment lors de la communication entre un registre (par exemple de noms de domaine) et son client, est extensible : on peut rajouter de nouveaux types d'objets et de nouvelles informations. Normalement, le serveur EPP n'envoie au client ces nouveautés que si le client a annoncé, lors de la connexion, qu'il savait les gérer. Et s'il ne l'a pas fait, que faire de ces données, ces unhandled namespaces ? Ce nouveau RFC propose de les envoyer quand même, mais dans un élément XML prévu pour des informations supplémentaires, et qui ne devrait donc rien casser chez le client.
Le but est de rester compatible avec l'EPP standard,
tel que normalisé dans le RFC 5730. Prenons
l'exemple de l'extension pour DNSSEC du RFC 5910. Comme toutes les extensions EPP, elle utilise les
espaces de noms XML. Cette extension
particulière est identifiée par l'espace de noms
urn:ietf:params:xml:ns:secDNS-1.1. À
l'établissement de la connexion, le serveur annonce les extensions
connues :
<greeting
<svcMenu>
...
<svcExtension>
<extURI>urn:ietf:params:xml:ns:secDNS-1.1</ns0:extURI>
Et le client annonce ce qu'il sait gérer :
<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
<command>
<login>
...
<svcs>
<svcExtension><extURI>urn:ietf:params:xml:ns:secDNS-1.1</extURI></svcExtension>
...
(<svcExtension> est décrit dans le RFC 5730, sections 2.4 et 2.9.1.1). Ici, le serveur
a annoncé l'extension DNSSEC et le client l'a acceptée. Tout le
monde va donc pouvoir envoyer et recevoir des messages spécifiques à
cette extension, comme l'ajout d'une clé :
<extension>
<update xmlns="urn:ietf:params:xml:ns:secDNS-1.1">
<add xmlns="urn:ietf:params:xml:ns:secDNS-1.1">
<dsData xmlns="urn:ietf:params:xml:ns:secDNS-1.1">
...
<digest xmlns="urn:ietf:params:xml:ns:secDNS-1.1">076CF6DA3692EFE72434EA1322177A7F07023400E4D1A1F617B1885CF328C8AA</digest>
...
Mais, si le client ne gère pas une extension (et ne l'a donc pas
indiquée dans son <login>), que peut
faire le serveur s'il a quand même besoin d'envoyer des messages
spécifiques à cette extension inconnue du client, ce
unhandled namespace ? C'est particulièrement
important pour la messagerie EPP (commande
<poll>) puisque le serveur peut, par
exemple, mettre un message dans la boite sans connaitre les
capacités du client, mais cela peut affecter également d'autres
activités.
La solution de notre RFC est d'utiliser un élément EPP déjà
normalisé (RFC 5730, secton 2.6),
<extValue>, qui permet d'ajouter des
informations que le client ne pourra pas analyser automatiquement,
comme par exemple un message d'erreur lorsque le serveur n'a pas pu
exécuter l'opération demandée. Notre RFC étend cet
<extValue> au cas des espaces de noms non
gérés. Le sous-élément <value> contiendra
l'élément XML appartenant à l'espace de noms que le client ne sait
pas gérer, et le sous-élément <reason>
aura comme contenu un message d'information dont la forme
recommandée est NAMESPACE-URI not in login
services où NAMESPACE-URI est le
unhandled namespace. Par exemple, le RFC cite un
cas où le registre ne gère pas l'extension DNSSEC du RFC 5910 et répond :
<response>
...
<extValue>
<value>
<secDNS:infData
xmlns:secDNS="urn:ietf:params:xml:ns:secDNS-1.1">
<secDNS:dsData>
...
<secDNS:digest>49FD46E6C4B45C55D4AC</secDNS:digest>
</secDNS:dsData>
</secDNS:infData>
</value>
<reason>
urn:ietf:params:xml:ns:secDNS-1.1 not in login services
</reason>
</extValue>
(Le RFC a aussi un autre exemple, avec l'extension de rédemption du RFC 3915.)
Ce RFC ne change pas le protocole EPP : il ne fait que décrire
une pratique, compatible avec les clients actuels, pour leur donner
le plus d'informations possible. Toutefois, pour informer tout le
monde, cette pratique fait l'objet elle-même d'une extension,
urn:ietf:params:xml:ns:epp:unhandled-namespaces-1.0,
que le serveur va inclure dans son
<greeting> et que le client mettra dans
sa liste d'extensions acceptées. (Cet espace de nom a été mis
dans le registre IANA créé par le RFC 3688. L'extension a été ajoutée au registre
des extensions EPP introduit par le RFC 7451.) De toute façon, le client a tout intérêt à inclure
dans sa liste toutes les extensions qu'il gère
et à regarder s'il y a des
<extValue> dans les réponses qu'il reçoit
(même si la commande EPP a été un succès) ; cela peut donner des
idées aux développeurs sur des extensions supplémentaires qu'il
serait bon de gérer. Quant au serveur, il est bon que son
administrateur regarde s'il y a eu des réponses pour des
unhandled namespaces et prenne ensuite contact
avec l'administrateur du client pour lui signaler ce manque.
Notez que ce RFC s'applique aux extensions portant sur les objets manipulés en EPP (par exemple les noms de domaine) et à celles portant sur les séquences de commandes et de réponses EPP, mais pas aux extensions portant sur le protocole lui-même (cf. RFC 3735).
Question mises en œuvre de ce RFC, le SDK de Verisign
inclut
le code nécessaire (dans le fichier
gen/java/com/verisign/epp/codec/gen/EPPFullExtValuePollMessageFilter.java). D'autre
part, le registre du .ch
utilise ce concept d'espaces de noms inconnus pour indiquer au
BE les
changements d'un domaine provoqués par l'utilisation du CDS du RFC 7344, puisque ces changements ne sont pas
passés par EPP.
L'article seul
RFC 9022: Domain Name Registration Data (DNRD) Objects Mapping
Date de publication du RFC : Mai 2021
Auteur(s) du RFC : G. Lozano (ICANN), J. Gould, C. Thippeswamy (VeriSign)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 30 mai 2021
Le RFC 8909 normalisait un format générique pour les séquestres d'objets enregistrés dans un registre. Ce nouveau RFC 9022 précise ce format pour le cas spécifique des registres de noms de domaine (dont les objets enregistrés sont les noms de domaine, les contacts, les serveurs de noms, etc).
Rappelons que le but d'un séquestre est de permettre à un tiers de reprendre les opérations d'un registre (par exemple un registre de noms de domaine) en cas de défaillance complète de celui-ci. Pas juste une panne matérielle qui fait perdre des données, non, une défaillance grave, par exemple une faillite, qui fait que plus rien ne marche. Le registre doit donc envoyer régulièrement des données à l'opérateur de séquestre qui, au cas où la catastrophe survient, enverra ces données au nouveau registre, qui sera en mesure (en théorie…) de charger les données dans une nouvelle base et de reprendre les opérations. Sous quel format sont envoyées ces données ? Car il faut évidemment un format ouvert et documenté, pour que le nouveau registre ait pu développer un programme d'importation des données. C'est le but du RFC 8909 et de notre nouveau RFC 9022. Ils spécifient un format à base de XML (avec possibilité de CSV).
Par rapport au format générique du RFC 8909, notre RFC ajoute les objets spécifiques de l'industrie des noms de domaine (il est recommandé de réviser la terminologie du RFC 8499) :
- Les noms de domaine, tels que manipulés en EPP selon le RFC 5731.
- Les serveurs de noms (pour les registres où ils sont enregistrés comme objets séparés, ce qui n'est pas obligatoire), tels que gérés via EPP selon le RFC 5732.
- Les contacts (le titulaire du nom de domaine, le contact technique avec qui on verra les problèmes DNS, etc), selon le modèle utilisé en EPP par le RFC 5733.
- Les BE (Bureaux d'Enregistrement). Le cas est un peu différent car ils ne sont typiquement pas gérés via EPP puisque les sessions EPP sont justement établies par un BE, qui a donc dû être créé par un autre moyen.
- Les noms spéciaux, qui sont des noms de domaine qui ne sont pas des noms de domaines habituels mais, par exemple, des gros mots dont l'enregistrement est interdit. En anglais, le sigle officiel est NNDN, qui veut récursivement dire NNDN's Not a Domain Name.
- Les tables liées à IDN, pour les registres qui maintiennent des informations restreignant l'usage de ces noms de domaine en Unicode (cf. RFC 6927).
- Certains paramètres de configuration des serveurs EPP du registre.
- Des compteurs du nombre d'objets enregistrés.
- Des objets qui sont importants pour le registre mais pas assez répandus pour avoir fait l'objet d'une normalisation.
Le format concret du séquestre se décline en deux « modèles », un en XML et un en CSV (RFC 4180), mais j'ai l'impression que le XML est nettement plus utilisé. Dans tous les cas :
- Les dates sont au format du RFC 3339.
- Les noms des pays sont les identificateurs à deux lettres de ISO 3166.
- Les numéros de téléphone sont au format E.164.
- Les adresses IP doivent suivre le format du RFC 5952. Pour IPv4, le RFC est vague, car il n'y a pas de format standard (vous ne verrez pas une seule adresse IP dans le RFC 791, que cite notre RFC…).
Pour CSV, chaque fichier CSV représente une table (les noms de
domaine, les contacts, les serveurs de noms…) et chaque ligne du
fichier un objet. Le modèle de données est décrit plus précisément
en section 4.6. Voici un exemple d'une ligne extraite du fichier des
noms de domaine, décrivant le domaine
domain1.example, créé le 3 avril 2009, et dont
le titulaire a pour identificateur (handle)
registrantid :
domain1.example,Ddomain2-TEST,,,registrantid,registrarX,registrarX,clientY,2009-04-03T22:00:00.0Z,registrarX,clientY,2009-12-03T09:05:00.0Z,2025-04-03T22:00:00.0Z
Les contacts seraient mis dans un autre fichier CSV, avec un fichier de jointure pour faire le lien entre domaines et contacts.
Et pour XML ? Il s'inspire beaucoup des éléments XML échangés
avec EPP, par exemple pour la liste des états
possibles pour un domaine. Voici un exemple (RDE = Registry
Data Escrow, et l'espace de noms
correspondant rdeDom est
urn:ietf:params:xml:ns:rdeDomain-1.0) :
<rdeDom:domain>
<rdeDom:name>jdoe.example</rdeDom:name>
<rdeDom:roid>DOM03-EXAMPLE</rdeDom:roid>
<rdeDom:status s="ok"/>
<rdeDom:registrant>IZT01</rdeDom:registrant>
<rdeDom:contact type="tech">IZT01</rdeDom:contact>
<rdeDom:contact type="billing">IZT01</rdeDom:contact>
<rdeDom:contact type="admin">IZT01</rdeDom:contact>
<rdeDom:ns>
<domain:hostObj>ns.jdoe.example</domain:hostObj>
</rdeDom:ns>
<rdeDom:clID>RAR03</rdeDom:clID>
<rdeDom:crRr>RAR03</rdeDom:crRr>
<rdeDom:crDate>2019-12-26T14:18:40.65647Z</rdeDom:crDate>
<rdeDom:exDate>2020-12-26T14:18:40.509742Z</rdeDom:exDate>
</rdeDom:domain>
On voit que cela ressemble en effet beaucoup à ce qui avait été envoyé en EPP pour créer le domaine (cf. RFC 5731). Si vous voulez un exemple complet et réaliste, regardez les sections 14 et 15 du RFC.
Et voici un exemple de contact (RFC 5733) :
<rdeContact:contact>
<rdeContact:id>IZT01</rdeContact:id>
<rdeContact:status s="ok"/>
<rdeContact:postalInfo type="loc">
<contact:name>John Doe</contact:name>
<contact:addr>
<contact:street>12 Rue de la Paix</contact:street>
<contact:city>Paris</contact:city>
<contact:pc>75002</contact:pc>
<contact:cc>FR</contact:cc>
</contact:addr>
</rdeContact:postalInfo>
<rdeContact:voice>+33.0353011234</rdeContact:voice>
<rdeContact:email>john.doe@foobar.example</rdeContact:email>
<rdeContact:clID>RAR03</rdeContact:clID>
<rdeContact:crRr>RAR03</rdeContact:crRr>
<rdeContact:crDate>2019-12-26T13:47:05.580392Z</rdeContact:crDate>
<rdeContact:disclose flag="0">
<contact:name type="loc"/>
<contact:addr type="loc"/>
<contact:voice/>
<contact:fax/>
<contact:email/>
</rdeContact:disclose>
</rdeContact:contact>
On notera l'élement <disclose> qui
indique qu'on ne doit pas diffuser le nom, l'adresse ou d'autres
éléments sur le contact (normal, il s'agit d'une personne physique,
et la loi Informatique & Libertés
s'applique, cf. section 14 du RFC). La jointure avec les domaines
dont il est contact (comme le jdoe.example plus
haut), se fait sur l'identificateur (élément
<id>, dit aussi
handle). L'information sur l'adresse a le type
loc, ce qui veut dire qu'elle peut utiliser
tout le jeu de caractères Unicode. Avec le
type int, elle serait restreinte à l'ASCII (une très ancienne erreur fait que
EPP appelle loc - local, ce
qui est internationalisé et int -
international ce qui est restreint aux lettres
utilisées en anglais).
Et enfin, un objet représentant un serveur de noms (RFC 5732) :
<rdeHost:host>
<rdeHost:name>ns1.foobar.example</rdeHost:name>
<rdeHost:status s="ok"/>
<rdeHost:addr ip="v6">2001:db8:cafe:fada::53</rdeHost:addr>
<rdeHost:clID>RAR02</rdeHost:clID>
<rdeHost:crRr>RAR02</rdeHost:crRr>
<rdeHost:crDate>2020-05-13T12:37:41.788684Z</rdeHost:crDate>
</rdeHost:host>
Ce format de séquestre permet aussi de représenter des objets qui n'ont pas d'équivalent en EPP, comme les bureaux d'enregistrement, qui ne peuvent pas être créés en EPP puisque la session EPP est liée au client du registre, donc au bureau d'enregistrement. Un exemple de BE (Bureau d'Enregistrement) :
<rdeRegistrar:registrar>
<rdeRegistrar:id>RAR21</rdeRegistrar:id>
<rdeRegistrar:name>Name Business</rdeRegistrar:name>
<rdeRegistrar:status>ok</rdeRegistrar:status>
<rdeRegistrar:postalInfo type="loc">
<rdeRegistrar:addr>
<rdeRegistrar:street>1 rue du Test</rdeRegistrar:street>
<rdeRegistrar:city>Champignac</rdeRegistrar:city>
<rdeRegistrar:cc>FR</rdeRegistrar:cc>
</rdeRegistrar:addr>
</rdeRegistrar:postalInfo>
<rdeRegistrar:voice>+33.0639981234</rdeRegistrar:voice>
<rdeRegistrar:fax>+33.0199001234</rdeRegistrar:fax>
<rdeRegistrar:email>master-of-domains@namebusiness.example</rdeRegistrar:email>
</rdeRegistrar:registrar>
On peut aussi mettre dans le séquestre des références vers ses tables IDN (que l'ICANN exige mais qui n'ont aucun intérêt). Plus intéressant, la possibilité de stocker dans le séquestre les listes de termes traités spécialement, par exemple interdits ou bien soumis à un examen manuel. Cela se nomme NNDN pour « NNDN's not domain name », oui, c'est récursif. Voici un exemple :
<rdeNNDN:NNDN>
<rdeNNDN:uName>gros-mot.example</rdeNNDN:uName>
<rdeNNDN:nameState>blocked</rdeNNDN:nameState>
<rdeNNDN:crDate>2005-04-23T11:49:00.0Z</rdeNNDN:crDate>
</rdeNNDN:NNDN>
Tous les registres n'ont pas les mêmes règles et le RFC décrit également les mécanismes qui permettent de spécifier dans le séquestre les contraintes d'intégrité spécifiques d'un registre. L'opérateur de séquestre, qui reçoit le fichier XML ou les fichiers CSV, est censé vérifier tout cela (autrement, il ne joue pas son rôle, s'il se contente de stocker aveuglément un fichier). La section 8 de notre RFC décrit plus en profondeur les vérifications recommandées, comme de vérifier que les contacts indiqués pour chaque domaine sont bien présents. Pour vérifier un séquestre, il faut importer beaucoup de schémas. Voici, la liste, sous forme d'une commande shell :
for schema in contact-1.0.xsd host-1.0.xsd rdeDomain-1.0.xsd rdeIDN-1.0.xsd rgp-1.0.xsd domain-1.0.xsd rde-1.0.xsd rdeEppParams-1.0.xsd rdeNNDN-1.0.xsd secDNS-1.1.xsd epp-1.0.xsd rdeContact-1.0.xsd rdeHeader-1.0.xsd rdePolicy-1.0.xsd eppcom-1.0.xsd rdeDnrdCommon-1.0.xsd rdeHost-1.0.xsd rdeRegistrar-1.0.xsd); do
wget https://www.iana.org/assignments/xml-registry/schema/${schema}
done
Ensuite, on importe (fichier escrow-wrapper.xsd) et
on utilise xmllint sur l'exemple de séquestre de la section 14 du
RFC (fichier escrow-example.xml) :
% xmllint --noout --schema wrapper.xsd escrow-example.xml escrow-example.xml validates
Ouf, tout va bien, le registre nous a envoyé un séquestre correct.
Enfin, la syntaxe formelle de ce format figure dans la section 9 du RFC, dans le langage XML Schema.
Ce format est mis en œuvre par tous les TLD qui sont liés par un contrat avec l'ICANN. 1 200 TLD envoient ainsi un séquestre une fois par semaine à l'ICANN.
Le concept de séquestre pose de sérieux problèmes de sécurité car le ou les fichiers transmis sont typiquement à la fois confidentiels, et cruciaux pour assurer la continuité de service. Lors du transfert du fichier, le registre et l'opérateur de séquestre doivent donc vérifier tous les deux l'authenticité du partenaire, et la confidentialité de la transmission. D'autant plus qu'une bonne partie du fichier est composée de données personnelles.
L'article seul
RFC 9019: A Firmware Update Architecture for Internet of Things
Date de publication du RFC : Avril 2021
Auteur(s) du RFC : B. Moran, H. Tschofenig (Arm Limited), D. Brown (Linaro), M. Meriac (Consultant)
Pour information
Réalisé dans le cadre du groupe de travail IETF suit
Première rédaction de cet article le 1 mai 2021
On le sait, le « S » dans « IoT » veut dire « sécurité ». Cette plaisanterie traditionnelle rappelle une vérité importante sur les brosses à dents connectées, les télés connectées, les voitures connectées et les sextoys connectés : leur sécurité est catastrophique. Les vendeurs de ces objets ont vingt ou trente ans de retard en matière de sécurité et c'est tous les jours qu'un nouveau piratage spectaculaire d'un objet connecté est annoncé. Une partie des vulnérabilités pourrait être bouchée en mettant à jour plus fréquemment les objets connectés. Mais cela ne va pas sans mal. Ce RFC fait partie d'un projet qui vise à construire certaines briques qui seront utiles pour permettre cette mise à jour fréquente. Il définit l'architecture générale.
Une bonne analyse du problème est décrite dans le RFC 8240, qui faisait le compte-rendu d'un atelier de réflexion sur la question. L'atelier avait bien montré l'ampleur et la complexité du problème ! Notre nouveau RFC est issu du groupe de travail SUIT de l'IETF, créé suite à cet atelier. La mise à jour du logiciel des objets connectés compte beaucoup d'aspects, et l'IETF se focalise sur un format de manifeste (en CBOR) qui permettra de décrire les mises à jour. (Le modèle d'information a été publié dans le RFC 9124, le format effectif sera dans un futur RFC.)
Le problème est compliqué : idéalement, on voudrait que les mises à jour logicielles de ces objets connectés se passent automatiquement, et sans casse. Ces objets sont nombreux, et beaucoup d'objets connectés sont installés dans des endroits peu accessibles ou, en tout cas, ne sont pas forcément bien suivis. Et ils n'ont souvent pas d'interface utilisateur du tout. Une solution réaliste doit donc être automatique (on sait que les injonctions aux humains « mettez à jour vos brosses à dents connectées » ne seront pas suivies). D'un autre côté, cette exigence d'automaticité va mal avec celle de consentement de l'utilisateur, d'autant plus que des mises à jour peuvent éliminer certaines fonctions de l'objet, ou en ajouter des peu souhaitables (cf. RFC 8240). En moins grave, elles peuvent aussi annuler des réglages ou modifications faits par les utilisateurs.
Le format de manifeste sur lequel travaille le groupe SUIT vise à authentifier l'image (le code), par exemple en la signant. Un autre point du cahier des charges, mais qui n'est qu'optionnel [et que je trouve peu réaliste dans la plupart des environnements] est d'assurer la confidentialité de l'image, afin d'empêcher la rétro-ingénierie du code. Ce format de manifeste vise avant tout les objets de classe 1 (selon la terminologie du RFC 7228). Il est prévu pour du logiciel mais peut être utilisé pour décrire d'autres ressources, comme des clés cryptographiques.
On l'a dit, le travail du groupe SUIT se concentre sur le format du manifeste. Mais une solution complète de mise à jour nécessite évidemment bien plus que cela, le protocole de transfert de fichiers pour récupérer l'image, un protocole pour découvrir qu'il existe des mises à jour (cf. le status tracker en section 2.3), un pour trouver le serveur pertinent (par exemple avec DNS-SD, RFC 6763). Le protocole LwM2M (Lightweight M2M) peut par exemple être utilisé.
Et puis ce n'est pas tout de trouver la mise à jour, la récupérer, la vérifier cryptographiquement. Une solution complète doit aussi fournir :
- La garantie que la mise à jour ne va pas tout casser (si beaucoup d'utilisateurs débrayent les mises à jour automatiques, ce n'est pas par pure paranoïa), ce qui implique des mises à jour bien testées, et une stratégie de repli si la mise à jour échoue,
- des mises à jour rapides, puisque les failles de sécurité sont exploitées dès le premier jour, alors que les mises à jour nécessitent souvent un long processus d'approbation, parfois pour de bonnes raisons (les tests dont je parlais au paragraphe précédent), parfois pour des mauvaises (processus bureaucratiques), et qu'elles doivent souvent passer en cascade par plusieurs acteurs (bibliothèque intégrée dans un système d'exploitation intégré dans un composant matériel intégré dans un objet, tous les quatre par des acteurs différents),
- des mises à jour économes en énergie, l'objet pouvant être contraint dans ce domaine,
- des mises à jour qui fonctionnent même après que les actionnaires de l'entreprise aient décidé de mettre leur argent ailleurs et aient abandonné les objets vendus (on peut toujours rêver).
Bon, maintenant, après cette liste au Père Noël, au travail. Un peu de vocabulaire pour commencer :
- Image (ou firmware) : le code qui sera téléchargé sur l'objet et installé (je n'ai jamais compris pourquoi ça s'appelait « ROM » dans le monde Android). L'image peut être juste le système d'exploitation (ou une partie de celui-ci) ou bien un système de fichiers complet.
- Manifeste : les métadonnées sur l'image, par exemple date, numéro de version, signature, etc.
- Point de départ de la validation (trust anchor, RFC 5914 et RFC 6024) : la clé publique à partir de laquelle se feront les validations cryptographiques.
- REE (Rich Execution Environment) : un environnement logiciel général, pas forcément très sécurisé. Par exemple, Alpine Linux est un REE.
- TEE (Trusted Execution Environment) : un environnement logiciel sécurisé, typiquement plus petit que le REE et doté de moins de fonctions.
Le monde de ces objets connectés se traduit par une grande dispersion des parties prenantes. On y trouve par exemple :
- Les auteurs de logiciel, qui sont souvent très loin du déploiement et de la maintenance des objets,
- les fabricants de l'objet,
- les opérateurs des objets qui ne sont pas les propriétaires de l'objet : la plupart du temps, pour piloter votre objet, celui que vous avez acheté, vous devez passer par cet opérateur, en général le fabricant, s'il n'a pas fait faillite ou abandonné ces objets,
- les gestionnaires des clés (souvent le fabricant),
- et le pauvre utilisateur tout en bas.
[Résultat, on a des chaînes d'approvisionnement longues, compliquées, opaques et vulnérables. Une grande partie des problèmes de sécurité des objets connectés vient de là, et pas de la technique. Par exemple, il est fréquent que les auteurs des logiciels utilisés se moquent de la sécurité et ne fournissent pas de mise à jour pour combler les failles dans les programmes.]
La section 3 du RFC présente l'architecture générale de la solution. Elle doit évidemment reposer sur IP (ce RFC étant écrit par l'IETF, un choix contraire aurait été étonnant), et, comme les images sont souvent de taille significative (des dizaines, des centaines de kilo-octets, au minimum), il faut utiliser en prime un protocole qui assurera la fiabilité du transfert et qui ne déclenchera pas de congestion, par exemple TCP, soit directement, soit par l'intermédiaire d'un protocole applicatif comme MQTT ou CoAP. En dessous d'IP, on pourra utiliser tout ce qu'on veut, USB, BLE, etc. Outre IP et TCP (pas évident pour un objet contraint, cf. RFC 9006), l'objet devra avoir le moyen de consulter le status tracker pour savoir s'il y a du nouveau, la capacité de stocker la nouvelle image avant de l'installer (si la mise à jour échoue, il faut pouvoir revenir en arrière, donc stocker l'ancienne image et la nouvelle), la capacité de déballer, voire de déchiffrer l'image et bien sûr, puisque c'est le cœur du projet SUIT, la capacité de lire et de comprendre le manifeste. Comme le manifeste comprend de la cryptographie (typiquement une signature), il faudra que l'objet ait du logiciel pour des opérations cryptographiques typiques, et un magasin de clés cryptographiques. Notez que la sécurité étant assurée via le manifeste, et non pas via le mécanisme de transport (sécurité des données et pas du canal), le moyen de récupération de l'image utilisé n'a pas de conséquences pour la sécurité. Ce sera notamment pratique pour le multicast.
Le manifeste peut être inclus dans l'image ou bien séparé. Dans le second cas, l'objet peut décider de charger l'image ou pas, en fonction du manifeste.
La mise à jour du code d'un objet contraint pose des défis particuliers. Ainsi, ces objets ne peuvent souvent pas utiliser de code indépendant de sa position. La nouvelle image ne peut donc pas être mise n'importe où. Cela veut dire que, lorsque le code est exécuté directement à partir du moyen de stockage (et donc pas chargé en mémoire), il faut échanger l'ancienne et la nouvelle image, ce qui complique un éventuel retour en arrière, en cas de problème.
Avec tout ça, je n'ai pas encore tellement parlé du manifeste lui-même. C'est parce que notre RFC ne décrit que l'architecture, donc les généralités. Le format du manifeste sera dans deux RFC, un pour décrire le format exact (fondé sur CBOR, cf. RFC 8949) et un autre, le RFC 9124 pour le modèle d'information (en gros, la liste des éléments qui peuvent être mis dans le manifeste).
La section 7 de notre RFC fait la synthèse des questions de sécurité liées à la mise à jour. Si une mise à jour fréquente du logiciel est cruciale pour la sécurité, en permettant de fermer rapidement des failles découvertes dans le logiciel de l'objet, la mise à jour peut elle-même présenter des risques. Après tout, mettre à jour son logiciel, c'est exécuter du code récupéré via l'Internet… L'architecture présentée dans ce RFC fournit une sécurité de bout en bout, par exemple en permettant de vérifier l'authenticité de l'image récupérée (et, bien sûr, son intégrité). Pas question d'exécuter un code non authentifié, ce qui est pourtant couramment le cas aujourd'hui avec les mises à jour de beaucoup d'équipements informatiques.
Cette même section en profite pour noter que la cryptographie nécessite de pouvoir changer les algorithmes utilisés. Le RFC cite même l'importance de la cryptographie post-quantique. (C'est un des tous premiers RFC publiés à en parler, après le RFC 8773.) D'un côté, ce genre de préoccupations est assez décalée : la réalité de l'insécurité des objets connectés est tellement abyssale qu'on aura bien des problèmes avant que les calculateurs quantiques ne deviennent une menace réelle. De l'autre, certains objets connectés peuvent rester en service pendant longtemps. Qui sait quelles seront les menaces dans dix ans ? (Un article comme « Quantum Annealing for Prime Factorization » estimait que, dans le pire des cas, les algorithmes pré-quantiques commenceraient à être cassés vers 2030, mais il est très difficile d'estimer la fiabilité de ces prédictions, cf. mon exposé à Pas Sage En Seine.)
J'insiste, mais je vous recommande de lire le RFC 8240 pour bien comprendre tous les aspects du problème. D'autre part, vous serez peut-être intéressés par l'évaluation faite du projet SUIT sous l'angle des droits humains. Cette évaluation suggérait (ce qui n'a pas été retenu) que le chiffrement des images soit obligatoire.
L'article seul
RFC 9018: Interoperable Domain Name System (DNS) Server Cookies
Date de publication du RFC : Avril 2021
Auteur(s) du RFC : O. Sury (Internet Systems Consortium), W. Toorop (NLnet Labs), D. Eastlake 3rd (Futurewei Technologies), M. Andrews (Internet Systems Consortium)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 6 avril 2021
Le RFC 7873 normalisait un mécanisme, les cookies, pour qu'un serveur DNS authentifie raisonnablement l'adresse IP du client (ce qui, normalement, n'est pas le cas en UDP). Comme seul le serveur avait besoin de reconnaitre ses cookies, le RFC 7873 n'imposait pas un algorithme particulier pour les générer. Cela posait problème dans certains cas et notre nouveau RFC propose donc un mécanisme standard pour fabriquer ces cookies.
L'un des scénarios d'utilisation de ces « cookies standards » est le cas d'un serveur anycast dont on voudrait que toutes les instances génèrent des cookies standardisés, pour qu'une instance puisse reconnaitre les cookies d'une autre. Le RFC 7873, section 6, disait bien que toutes les instances avaient intérêt à partir du même secret mais ce n'était pas plus détaillé que cela. La situation actuelle, où chaque serveur peut faire différemment, est décrite dans le RFC par un mot en anglais que je ne connaissais pas, gallimaufry. D'où l'idée de spécifier cet algorithme, pour simplifier la vie des programmeuses et programmeurs avec un algorithme de génération de cookie bien étudié et documenté ; plus besoin d'en inventer un. Et cela permet de créer un service anycast avec des logiciels d'auteurs différents. S'ils utilisent cet algorithme, ils seront compatibles. Il ne s'agit que d'une possibilité : les serveurs peuvent utiliser cet algorithme mais ne sont pas obligés, le RFC 7873 reste d'actualité.
Comment, donc, construire un cookie ?
Commençons par celui du client (section 3). Rappel : le but est
d'authentifier un minimum donc, par exemple, le client doit choisir
un cookie différent par serveur (sinon, un
serveur pourrait se faire passer pour un autre, d'autant plus que le
cookie circule en clair), et, donc, il faut
utiliser quelque chose de spécifique au serveur dans l'algorithme,
par exemple son adresse IP. Par contre, pas besoin de le changer
souvent, il peut parfaitement durer des mois, sauf évidemment si un
élément entrant dans sa construction change, ou est
compromis. Autrefois, il était suggéré d'utiliser l'adresse IP du
client dans la construction du cookie client,
mais cette suggestion a été retirée car le logiciel ne connait
parfois son adresse IP que trop tard (ça dépend de l'API réseau utilisée
et, par exemple, avec l'API sockets de si on
a déjà fait un bind() et, de toute façon, si on
est derrière un routeur NAT, connaitre
l'adresse IP locale ne sert pas à grand'chose). Néanmoins, pour
éviter qu'un cookie ne permette à un observateur
de relier deux requêtes d'une même machine, le
cookie doit changer quand l'adresse IP change,
comme rappelé par la section 8.1. (C'est particulièrement important
si on utilise des techniques de protection de la vie privée comme
celle du RFC 8981.)
Voilà, c'est tout parce que ce qui est important dans notre RFC, c'est le cookie serveur (section 4), puisque c'est là qu'on voudrait un cookie identique pour toutes les instances du service. Les éléments utilisés pour le générer sont le cookie du client, l'adresse IP du serveur, quelques métadonnées et un secret (qu'il faudra donc partager au sein du service anycast). Le secret changera, par exemple une fois par mois. Une fois qu'on a tous ces éléments, on va ensuite condenser le tout, ici avec SipHash (cf. J. Aumasson, et D. J. Bernstein, « SipHash: A Fast Short- Input PRF »). (Parmi les critères de choix d'une fonction de condensation, il y a les performances, un serveur DNS actif pouvant avoir à faire ce calcul souvent, pour vérifier les cookies.) Le cookie comprendra un numéro de version, un champ réservé, une estampille temporelle et le condensat. L'algorithme de génération du condensat inclus dans le cookie est donc : Condensat = SipHash-2-4 ( Cookie client | Version | Réservé | Estampille | Client-IP, Secret ), avec :
- Le signe | indique la concaténation.
- Le champ Version vaut actuellement 1 (les futures versions seront dans un registre IANA).
- Le champ Réservé ne comporte pour l'instant que des zéros.
- L'estampille temporelle sert à éviter les attaques par rejeu et permet de donner une durée de validité aux cookies (le RFC recommande une heure, avec cinq minutes de battement pour tenir compte des horloges mal synchronisées).
On a vu qu'il fallait changer le secret connu du serveur de temps en temps (voire plus rapidement s'il est compromis). Pour que ça ne casse pas tout (un serveur ne reconnaissant pas les cookies qu'il avait lui-même émis avec l'ancien secret…), il faut une période de recouvrement où le serveur connait déjà le nouveau secret (et accepte les cookies ainsi générés, par exemple par les autres instances du service anycast), puis une période où le serveur génère les cookies avec le nouveau secret, mais continue à accepter les cookies anciens (par exemple gardés par des clients). La section 5 rappelle, comme on le fait pour les remplacements de clés DNSSEC, de tenir compte des TTL pour calculer les délais nécessaires.
Si vous voulez mettre en œuvre vous-même cet algorithme, notez que l'annexe A du RFC contient des vecteurs de test, permettant de vérifier si vous ne vous êtes pas trompé.
La section 2 de notre RFC décrit les changements depuis le RFC 7873. Les algorithmes données comme simples suggestions dans les annexes A.1 et B.1 sont trop faibles et ne doivent pas être utilisés. Celui de l'annexe B.2 ne pose pas de problèmes de sécurité mais celui de notre nouveau RFC est préféré.
Plusieurs mises en œuvre de ce nouvel algorithme ont été faites, et leur interopérabilité testée (notamment au cours du hackathon de la réunion IETF 104 à Prague). Au moins BIND, Knot et getdns ont déjà cet algorithme dans leurs versions publiées.
L'article seul
RFC 9011: Static Context Header Compression and Fragmentation (SCHC) over LoRaWAN
Date de publication du RFC : Avril 2021
Auteur(s) du RFC : O. Gimenez (Semtech), I. Petrov (Acklio)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF lpwan
Première rédaction de cet article le 23 avril 2021
Le RFC 8724 décrivait un mécanisme général de compression pour les réseaux LPWAN (réseaux contraints pour objets contraints). Ce nouveau RFC 9011 précise ce mécanisme pour le cas spécifique de LoRaWAN.
Ces « réseaux contraints pour objets contraints » sont décrits dans le RFC 8376. Ils ont des concepts communs mais aussi des différences, ce qui justifie la séparation de SCHC en un cadre générique (celui du RFC 8724) et des spécifications précises par réseau, comme ce que fait notre RFC pour LoRaWAN, la technique qui est utilisée dans divers réseaux déployés. Donc, rappelez-vous, LoRaWAN = la technologie, LoRa = un réseau déployé utilisant cette technologie (mais d'autres réseaux concurrents peuvent utiliser LoRaWAN). LoRaWAN est normalisé par l'alliance LoRa (cf. le texte de la norme) et les auteurs du RFC sont actifs dans cette alliance. Si vous voulez un exemple d'utilisation de LoRaWAN, je recommande cet article en français sur une Gateway LoRaWAN réalisée sur un Raspberry Pi.
La section 3 du RFC fait un rappel de SCHC : si vous n'avez pas le courage de lire le RFC 8724, apprenez que SCHC a deux parties, une de compression des en-têtes, et une de fragmentation, les liens des réseaux contraints ayant souvent une faible MTU. La section 4, elle, explique LoRaWAN (vous avez aussi le RFC 8376, notamment sa section 2.1). La terminologie de SCHC et celle de LoRaWAN ne coïncident pas parfaitement donc il faut se souvenir que Gateway dans LoRaWAN s'appelle plutôt RGW (Radio GateWay) dans SCHC, que le Network Server de LoRaWAN est le NGW (Network GateWay) de SCHC et que les utilisateurs de LoRaWAN doivent se souvenir que leur Application Server est nommé C/D (Compression/Décompression) ou F/R (Fragmentation/Réassemblage) chez SCHC. Les objets connectés par LoRaWAN sont très souvent contraints et LoRaWAN définit trois classes d'objets, de la classe A, la plus contrainte, à la C. Notamment, les objets de la classe A émettent sur le réseau mais n'ont pas de moment d'écoute dédié, ceux de la classe B écoutent parfois, et ceux de la classe C écoutent en permanence, ce qui consomme pas mal d'énergie. Autant dire que les objets de classe C sont en général alimentés en électricité en permanence.
La section 5 est le cœur du RFC, expliquant en détail comment on met en correspondance les concepts abstraits de SCHC avec les détails du protocole LoRaWAN. Ainsi, le RuleID de SCHC est mis sur huit bits, dans le port (Fport) LoRaWAN (norme LoRaWAN, version 1.04, section 4.3.2), juste avant la charge utile. L'annexe A du RFC donne des exemples d'encodage des paquets.
Merci à Laurent Toutain pour sa relecture.
L'article seul
RFC 9007: Handling Message Disposition Notification with the JSON Meta Application Protocol (JMAP)
Date de publication du RFC : Mars 2021
Auteur(s) du RFC : R. Ouazana (Linagora)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF jmap
Première rédaction de cet article le 23 mars 2021
Les avis de remise d'un message (MDN, Message Disposition Notification) sont normalisés dans le RFC 8098. Ce nouveau RFC normalise la façon de les gérer depuis le protocole d'accès au courrier JMAP (qui est, lui, dans les RFC 8620 et RFC 8621).
Un petit rappel sur JMAP : c'est un protocole générique pour accéder à des données distantes, qu'elles concernent la gestion d'un agenda ou celle du courrier. Il est normalisé dans le RFC 8620. Une extension spécifique, JMAP for Mail, décrit comment l'utiliser pour le cas du courrier (rôle pour lequel JMAP concurrence IMAP).
Quant à MDN (Message Disposition
Notifications), c'est un format qui décrit des accusés de
réception du courrier. Il a été spécifié dans le RFC 8098. Un MDN est un message structuré (en MIME, avec
une partie de type
message/disposition-notification) qui indique
ce qui est arrivé au message. On peut donc envoyer un MDN en
réponse à un message (c'est un accusé de réception, ou avis de
remise), on peut demander l'envoi d'un tel MDN lorsqu'on envoie un
message, on peut recevoir des MDN et vouloir les analyser, par
exemple pour les mettre en rapport avec un message qu'on a
envoyé.
Avant de manier les MDN, il faut les modéliser (section 2). Comme tout en JMAP, un MDN est un objet JSON comprenant entre autres les membres :
forEmailId: l'identifiant JMAP du message auquel se réfère ce MDN,originalMessageId, le Message ID du message auquel se réfère ce MDN, à ne pas confondre avec l'identifiant JMAP,includeOriginalMessage, qui indique qu'un envoyeur souhaite recevoir le message original dans les éventuels MDN,disposition: voir le RFC 8098, section 3.2.6, pour cette notion. Elle indique ce qui est arrivé au message, et les conditions dans lesquelles l'action d'émission du MDN a été prise, par exemple automatiquement, ou bien par une action explicite de l'utilisateur.
L'objet JSON MDN sert à modéliser les MDN reçus mais aussi les options envoyées, comme la demande de génération de MDN par le receveur.
Pour envoyer un MDN, notre RFC introduit une nouvelle
méthode JMAP, MDN/send. Pour analyser un MDN
entrant, la méthode se nomme MDN/parse. Voici
un exemple de MDN JMAP :
[[ "MDN/send", {
...
"send": {
...
"forEmailId": "Md45b47b4877521042cec0938",
"subject": "Read receipt for: World domination",
"textBody": "This receipt shows that the email has been
displayed on your recipient's computer. There is no
guaranty it has been read or understood.",
"reportingUA": "joes-pc.cs.example.com; Foomail 97.1",
"disposition": {
"actionMode": "manual-action",
"sendingMode": "mdn-sent-manually",
"type": "displayed"
},
...
On y voit l'identifiant du message concerné, et l'action qui a été entreprise : le destinataire a activé manuellement l'envoi du message, après avoir vu ledit message.
Et pour demander l'envoi d'un MDN lorsqu'on crée un message ?
C'est la méthode Email/set du RFC 8621 qui permet de créer le message. On doit juste ajouter
l'en-tête Disposition-Notification-To: du RFC 8098 :
[[ "Email/set", {
"accountId": "ue150411c",
"create": {
...
"header:Disposition-Notification-To:asText": "joe@example.com",
"subject": "World domination",
...
Comme un serveur JMAP annonce ses capacités lors de la connexion
(RFC 8620, section 2), notre RFC ajoute une
nouvelle capacité, urn:ietf:params:jmap:mdn, ce
qui permet à un serveur de dire qu'il sait gérer les MDN. Elle est
enregistrée
à l'IANA.
Question mise en œuvre de JMAP qui gère les MDN, il y a le serveur Cyrus, voir ce code, et aussi Apache James.
Merci à Raphaël Ouazana pour sa relecture.
L'article seul
RFC 9006: TCP Usage Guidance in the Internet of Things (IoT)
Date de publication du RFC : Mars 2021
Auteur(s) du RFC : C. Gomez (UPC), J. Crowcroft (University of Cambridge), M. Scharf (Hochschule Esslingen)
Pour information
Réalisé dans le cadre du groupe de travail IETF lwig
Première rédaction de cet article le 28 mars 2021
À côté de machines disposant de ressources matérielles suffisantes (électricité, processeur, etc), qui peuvent faire tourner des protocoles comme TCP sans ajustements particuliers, il existe des machines dites contraintes, et des réseaux de machines contraintes, notamment dans le cadre de l'Internet des Objets. Ces machines, pauvres en énergie ou en capacités de calcul, doivent, si elles veulent participer à des communications sur l'Internet, adapter leur usage de TCP. Ce RFC documente les façons de faire du TCP « léger ».
Ces CNN (Constrained-Node Networks, réseaux contenant beaucoup d'objets contraints) sont décrits dans le RFC 7228. On parle bien d'objets contraints, soit en processeur, soit en énergie. Un Raspberry Pi ou une télévision connectée ne sont pas des objets contraints, ils peuvent utiliser les systèmes habituels, avec un TCP normal, au contraire des objets contraints, qui nécessitent des technologies adaptées. Le RFC 8352 explique ainsi les problèmes liés à la consommation électrique de certains protocoles. Des protocoles spéciaux ont été développés pour ces objets contraints, comme 6LoWPAN (RFC 4944, RFC 6282 et RFC 6775) ou comme le RPL du RFC 6550 ou, au niveau applicatif, le CoAP du RFC 7252.
Côté transport, on sait que les principaux protocoles de transport actuels sur l'Internet sont UDP et TCP. TCP a été parfois critiqué comme inadapté à l'Internet des Objets. Ces critiques n'étaient pas forcément justifiées mais il est sûr que le fait que TCP ait des en-têtes plutôt longs, pas de multicast et qu'il impose d'accuser réception de toutes les données peut ne pas être optimal pour ces réseaux d'objets contraints. D'autres reproches pouvaient être traités, comme expliqué dans l'article « TCP in the Internet of Things: from ostracism to prominence ». Notez que CoAP, à l'origine, tournait uniquement sur UDP mais que depuis il existe aussi sur TCP (RFC 8323). Les CNN (Constrained-Node Networks) utilisent parfois d'autres protocoles applicatifs tournant sur TCP comme HTTP/2 (RFC 9113) ou MQTT.
TCP est certes complexe si on veut utiliser toutes les optimisations qui ont été développées au fil du temps. Mais elles ne sont pas nécessaires pour l'interopérabilité. Un TCP minimum peut parfaitement communiquer avec des TCP optimisés, et notre RFC explique comment réduire l'empreinte de TCP, tout en restant évidemment parfaitement compatible avec les TCP existants. (Notez qu'il y avait déjà eu des travaux sur l'adaptation de TCP à certains environnements, voir par exemple le RFC 3481.)
Bon, maintenant, au travail. Quelles sont les propriétés des CNN (RFC 7228) qui posent problème avec TCP (section 2 du RFC) ? Ils manquent d'énergie et il ne peuvent donc pas émettre et recevoir en permanence (RFC 8352), ils manquent de processeur, ce qui limite la complexité des protocoles, et ils utilisent souvent des réseaux physiques qui ont beaucoup de pertes (voire qui corrompent souvent les paquets), pas vraiment les réseaux avec lesquels TCP est le plus à l'aise (RFC 3819).
La communication d'un objet contraint se fait parfois à l'intérieur du CNN, avec un autre objet contraint et parfois avec une machine « normale » sur l'Internet. Les types d'interaction peuvent aller de l'unidirectionnel (un capteur transmet une mesure qu'il a faite), à la requête/réponse en passant par des transferts de fichiers (mise à jour du logiciel de l'objet contraint, par exemple). Voyons maintenant comment TCP peut s'adapter (section 3 du RFC).
D'abord, la MTU. En IPv6, faire des paquets de plus de 1 280 octets, c'est prendre le risque de la fragmentation, qui n'est pas une bonne chose pour des objets contraints en mémoire (RFC 8900), qui n'ont en plus pas très envie de faire de la Path MTU discovery (RFC 8201). Donc, notre RFC conseille d'utiliser la MSS (Maximum Segment Size) de TCP pour limiter la taille des paquets. Attention, les CNN tournent parfois sur des réseaux physiques assez spéciaux, où la MTU est bien inférieure aux 1 280 octets dont IPv6 a besoin (RFC 8200, section 5). Par exemple, IEEE 802.15.4 a une MTU de 127 octets seulement. Dans ce cas, il faut prévoir une couche d'adaptation entre IPv6 et le réseau physique (ce que fait le RFC 4944 pour IEE 802.15.4, le RFC 7668 pour Bluetooth LE, le RFC 8105 pour DECT LE, etc). Heureusement, d'autres technologies de réseau physique utilisées dans le monde des CNN n'ont pas ces limites de MTU, c'est le cas par exemple de Master-Slave/Token-Passing (cf. RFC 8163), IEEE 802.11ah, etc.
Deuxième endroit où on peut optimiser, ECN (RFC 3168). ECN permet aux routeurs intermédiaires de marquer dans un paquet que la congestion est proche ; le destinataire peut alors prévenir l'émetteur de ralentir. Le RFC 8087 décrit les avantages de l'ECN. Permettant de détecter l'approche de la congestion avant qu'on ait perdu un seul paquet (et donc sans qu'on ait à dépenser des watts pour retransmettre), l'ECN est particulièrement intéressant pour les CNN. Le RFC 7567 donne des conseils pratiques pour son déploiement.
Un problème classique de TCP sur les liens radio est que TCP interprète une perte de paquet comme signal de congestion, le poussant à ralentir, alors que cette perte peut en fait être due à la corruption d'un paquet (suite à une perturbation radio-électrique, par exemple). Il serait donc intéressant de pouvoir signaler explicitement ce genre de perte (la question était déjà discutée dans le RFC 2757 mais aussi dans l'article « Explicit Transport Error Notification (ETEN) for Error-Prone Wireless and Satellite Networks »). Pour l'instant, il n'existe aucun mécanisme standard pour cela, ce qui est bien dommage.
Pour faire tourner TCP sur une machine contrainte, une technique parfois utilisée est de n'envoyer qu'un segment à la fois (et donc d'annoncer une fenêtre dont la taille est d'un MSS - Maximum Segment Size). Dans ce cas, pas besoin de mémoriser plus qu'un segment de données envoyé mais dont l'accusé de réception n'a pas encore été reçu. C'est très économique, mais ça se paie cher en performances puisqu'il faut attendre l'accusé de réception de chaque segment avant d'en envoyer un autre. La capacité effective du lien va chuter, d'autant plus que certaines optimisations de TCP comme le fast recovery dépendent d'une fenêtre plus grande qu'un seul segment. Au niveau applicatif, on voit la même technique avec CoAP, qui est par défaut purement requête/réponse.
Si on veut faire du TCP « un seul segment », le code peut être
simplifié, ce qui permet de gagner encore en octets, mais notre RFC
rappelle quand même que des options comme MSS (évidemment),
NoOp et EndOfOptions
restent nécessaires. En revanche, on peut réduire le code en ne
gérant pas les autres options comme
WindowScaling (RFC 7323),
Timestamps (RFC 7323) ou
SACK (RFC 2018). TCP a le droit d'ignorer ces options, qui,
en « un seul segment » sont parfois inutiles
(WindowScaling, SACK) et parfois moins
importantes (Timestamps). En tout cas, si la
machine a assez de mémoire, il est sûr que transmettre plusieurs
segments avant d'avoir eu l'accusé de réception du premier, et
utiliser des algorithmes comme le fast recovery
améliore certainement les performances. Même chose pour les accusés
de réception sélectifs, les SACK du RFC 2018.
La détermination du RTO (Retransmission TimeOut) est un des points cruciaux de TCP (RFC 6298). S'il est trop long, on attendra longtemps la retransmission, quand un paquet est perdu, s'il est trop court, on ré-émettra parfois pour rien, gâchant des ressources alors que le paquet était juste en retard. Bref, une mise en œuvre de TCP pour les CNN doit soigner ses algorithmes de choix du RTO (cf. RFC 8961).
Continuons avec des conseils sur TCP dans les réseaux d'objets contraints. Notre RFC rappelle que les accusés de réception retardés, utiles pour accuser réception d'une plus grande quantité de données et ainsi diminuer le nombre de ces accusés, peuvent améliorer les performances… ou pas. Cela dépend du type de trafic. Si, par exemple, le trafic est surtout dans une direction, avec des messages courts (ce sera typiquement le cas avec CoAP), retarder les accusés de réception n'est sans doute pas une bonne idée.
Les paramètres par défaut de TCP sont parfois inadaptés aux CNN. Ainsi, le RFC 5681 recommande une taille de fenêtre initiale d'environ quatre kilo-octets. Le RFC 6298 fait des recommandations qui peuvent aboutir à des tailles de fenêtre initiale encore plus grandes. C'est très bien pour un PC connecté via la fibre mais pas pour la plupart des objets contraints, qui demandent des paramètres adaptés. Bref, il ne faut pas lire le RFC 6298 trop littéralement, car il faut en général une taille de fenêtre initiale plus petite.
Il n'y a pas que TCP lui-même, il y a aussi les applications qui l'utilisent. C'est l'objet de la section 4 du RFC. En général, si un objet contraint communique avec un non-contraint, c'est le premier qui initie la connexion (cela lui permet de dormir, et donc d'économiser l'énergie, s'il n'a rien à dire). L'objet contraint a tout intérêt à minimiser le nombre de connexions TCP, pour économiser la mémoire. Certes, cela crée des problèmes de head-of-line blocking (une opération un peu lente bloque les opérations ultérieures qui passent sur la même connexion TCP) mais cela vaut souvent la peine.
Et combien de temps garder la connexion TCP ouverte ? Tant qu'on a des choses à dire, c'est évident, on continue. Mais lorsqu'on n'a plus rien à dire, l'application doit-elle fermer les connexions, qui consomment de la mémoire, sachant que rouvrir la connexion prendra du temps et des ressources (la triple poignée de mains…). C'est un peu le problème de l'automobiliste arrêté qui se demande s'il doit couper son moteur. S'il faut redémarrer tout de suite, il consommera davantage de carburant. D'un autre côté, s'il laisse son moteur tourner, ce sera également un gaspillage. Le problème est soluble si l'application sait exactement quand elle aura à nouveau besoin d'émettre, ou si l'automobiliste sait exactement combien de temps durera l'arrêt mais, en pratique, on ne le sait pas toujours. (Ceci dit, pour l'automobile, le système d'arrêt-démarrage automatique dispense désormais le conducteur du choix.)
Une autre raison pour laquelle il faut être prudent avec les connexions TCP inactives est le NAT. Si un routeur NAT estime que la connexion est finie, il va retirer de ses tables la correspondance entre l'adresse IP interne et l'externe et, lorsqu'on voudra recommencer à transmettre des paquets, ils seront perdus. Le RFC 5382 donne des durées minimales avant ce retrait (deux heures…) mais elles ne sont pas forcément respectées par les routeurs NAT. Ainsi, l'étude « An Experimental Study of Home Gateway Characteristics » trouve que la moitié des boitiers testés ne respectent pas la recommandation du RFC 5382, avec des délais parfois aussi courts que quelques minutes ! Une des façons d'empêcher ces coupures est d'utiliser le mécanisme keep-alive de TCP (RFC 1122, section 4.2.3.6), qui envoie régulièrement des paquets dont le seul but est d'empêcher le routeur NAT d'oublier la connexion. Une autre est d'avoir des « battements de cœur » réguliers dans les applications, comme le permet CoAP (RFC 8323). Et, si on coupe rapidement les connexions TCP inutilisées, avant qu'une stupide middlebox ne le fasse, comment reprendre rapidement ensuite, si le trafic repart ? TCP Fast open (RFC 7413) est une solution possible.
Enfin, la sécurité pose des problèmes particuliers dans les CNN, où les ressources de certaines machines peuvent être insuffisantes pour certaines solutions de sécurité. Ainsi, pour TCP, la solution d'authentification AO (RFC 5925) augmente la taille des paquets et nécessite des calculs supplémentaires.
Il existe un certain nombre de mises en œuvre de TCP qui visent les objets contraints mentionnés dans ce RFC. Une machine 32 bits alimentée en courant en permanence, comme un vieux Raspberry Pi, n'est pas concernée, elle fait tourner le TCP habituel de Linux. On parle ici de TCP pour objets vraiment contraints. C'est par exemple (annexe A du RFC) le cas de :
- uIP, qui vise les microcontrôleurs à 8 et 16 bits. Elle est utilisée dans Contiki et sur la carte d'extension Ethernet (shield) pour Arduino. En 5 ko, elle réussit à faire IP (dont IPv6 dans les dernières versions) et TCP. Elle fait partie de celles qui utilisent le « un segment à la fois », ce qui évite les calculs de fenêtres (qui nécessitent des calculs sur 32 bits, qui seraient lents sur ces processeurs). Et c'est à l'application de se souvenir de ce qu'elle a envoyé, TCP ne le fait pas pour elle. L'utiliser est donc difficile pour le programmeur.
- lwIP, qui vise le même genre de processeurs, mais dont l'empreinte mémoire est supérieure (entre 14 et 22 ko). Il faut dire qu'elle n'est pas limitée à envoyer un segment à la fois et que TCP mémorise les données envoyées, déchargeant l'application de ce travail. Et elle dispose de nombreuses optimisations comme SACK.
- RIOT a sa propre mise en œuvre de TCP, nommée GNRC TCP. Elle vise aussi les engins de classe 1 (cf. RFC 7228 pour cette terminologie). Elle est de type « un segment à la fois » mais c'est TCP, et pas l'application, qui se charge de mémoriser les données envoyées (et qu'il faudra peut-être retransmettre). Par défaut, une application ne peut avoir qu'une seule connexion et il faut recompiler si on veut changer cela. Par contre, RIOT dispose d'une interface sockets, familière à beaucoup de programmeurs.
- freeRTOS a aussi un TCP, pouvant envoyer plusieurs segments (mais une option à un seul segment est possible, pour économiser la mémoire). Il a même les accusés de réception retardés.
- uC/OS peut également faire du TCP avec plusieurs segments en vol.
Un tableau comparatif en annexe A.7 résume les principales propriétés de ces différentes mises en œuvre de TCP sur objets contraints.
L'article seul
RFC 9003: Extended BGP Administrative Shutdown Communication
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : J. Snijders (NTT), J. Heitz (Cisco), J. Scudder (Juniper), A. Azimov (Yandex)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF idr
Première rédaction de cet article le 9 janvier 2021
Ce nouveau RFC normalise un mécanisme pour transmettre un texte en langue naturelle à un pair BGP afin de l'informer sur les raisons pour lesquelles on coupe la session. Il remplace le RFC 8203, notamment en augmentant la longueur maximale du message, afin de faciliter les messages en Unicode.
Le protocole de routage BGP offre un mécanisme
de coupure propre de la session, le message
NOTIFICATION avec le code
Cease (RFC 4271,
section 6.7). En prime, le RFC 4486
ajoutait à ce code des sous-codes permettant de préciser les
raisons de la coupure. Une coupure volontaire et manuelle aura
typiquement les sous-codes 2 (Administrative
Shutdown), 3 (Peer De-configured) ou
4 (Administrative Reset). (Ces sous-codes sont
enregistrés
à l'IANA.) Et enfin le RFC 8203,
déjà cité, ajoutait à ces sous-codes du texte libre, où on pouvait
exprimer ce qu'on voulait, par exemple « [#56554] Coupure de toutes les
sessions BGP au DE-CIX pour mise à jour
logicielle, retour dans trente minutes ». Notre RFC ne modifie que
légèrement cette possibilité introduite par le RFC 8203,
en augmentant la taille maximale du texte envoyé.
Bien sûr, la raison de la coupure peut être connue par d'autres moyens. Cela a pu être, par exemple, pour une session au travers d'un point d'échange, un message envoyé sur la liste du point d'échange, annonçant la date (en UTC, j'espère !) et la raison de la coupure. De tels message se voient régulièrement sur les listes, ici au France-IX :
Date: Wed, 16 Dec 2020 11:54:21 +0000
From: Jean Bon <jbon@operator.example>
To: <paris@members.franceix.net>
Subject: [FranceIX members] [Paris] AS64530 [REF056255] Temporary shut FranceIX sessions
Hi France-IX members,
This mail is to inform you that we are going to shut down all our
sessions on France-IX' Paris POP on 2021-01-05 08:00:00 UTC for 30
minutes, in order to upgrade the router.
Please use the ticket number [REF056255] for every correspondance about
this action.
Mais quand la coupure effective se produit, on a parfois oublié le message d'avertissement, ou bien on a du mal à le retrouver. D'où l'importance de pouvoir rappeler les informations importantes dans le message de coupure, qui, espérons-le, sera affiché quelque part chez le pair, ou bien journalisé par syslog.
La section 2 décrit le format exact de ce mécanisme. La chaîne
de caractères envoyée dans le message BGP
NOTIFICATION doit être en
UTF-8. Sa taille maximale est de 255
octets (ce qui ne fait pas 255 caractères, attention). À part ces
exigences techniques, son contenu est laissé à l'appréciation de
l'envoyeur.
La section 3 de notre RFC ajoute quelques conseils opérationnels. Par exemple, si vous utilisez un système de tickets pour suivre vos tâches, mettez le numéro du ticket correspondant à l'intervention de maintenance dans le message. Vos pairs pourront ainsi plus facilement vous signaler à quoi ils font référence.
Attention à ne pas agir aveuglément sur la seule base d'un message envoyé par BGP, notamment parce que, si la session BGP n'était pas sécurisée par, par exemple, IPsec, le message a pu être modifié en route.
L'annexe B du RFC résume les principaux changements depuis le RFC 8203. Le plus important est que la longueur maximale du message passe de 128 à 255 octets, notamment pour ne pas défavoriser les messages qui ne sont pas en ASCII. Comme l'avait fait remarquer lors de la discussion un opérateur du MSK-IX, si la phrase « Planned work to add switch to stack. Completion time - 30 minutes » fait 65 octets, sa traduction en russe aurait fait 119 octets.
L'article seul
RFC 9002: QUIC Loss Detection and Congestion Control
Date de publication du RFC : Mai 2021
Auteur(s) du RFC : J. Iyengar (Fastly), I. Swett (Google)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF quic
Première rédaction de cet article le 28 mai 2021
Pour tout protocole de transport, détecter les pertes de paquets, et être capable d'émettre et de réémettre des paquets sans provoquer de congestion sont deux tâches essentielles. Ce RFC explique comment le protocole QUIC assure cette tâche.
Pour l'instant, TCP reste le principal protocole de transport sur l'Internet. Mais QUIC pourrait le dépasser. QUIC est normalisé dans une série de RFC et notre RFC 9002 se charge d'une tâche délicate et cruciale : expliquer comment détecter les pertes de paquets, et comment ne pas contribuer à la congestion. Voyons d'abord la conception générale (section 3 du RFC). Les messages QUIC sont mis dans des trames, une ou plusieurs trames sont regroupées dans un paquet (qui n'est pas un paquet IP) et un ou plusieurs paquets sont dans un datagramme UDP qu'on envoie à son correspondant. Les paquets ont un numéro (RFC 9000, section 12.3). Ces numéros ne sont pas des numéros des octets dans les données envoyées, notamment, un numéro de paquet ne se répète jamais dans une connexion. Alors qu'on peut envoyer les mêmes données plusieurs fois, s'il y a perte et réémission ; en cas de retransmission, les données sont renvoyées dans un nouveau paquet, avec un nouveau numéro, contrairement à TCP. Cela permet de savoir facilement si c'est une retransmission. (TCP, lui, essaie de déduire l'ordre de distribution du numéro de séquence, et ce n'est pas trivial.)
La plupart des paquets QUIC feront l'objet d'un accusé de réception mais attention. Il y a des trames dont le type exige un accusé de réception et d'autres non. Si un paquet ne contient que des trames n'exigeant pas d'accusé de réception, ce paquet ne sera confirmé par le récepteur qu'indirectement, lors de la réception d'un paquet ultérieur contenant au moins une trame exigeant un accusé de réception.
QUIC n'est pas TCP, cela vaut la peine de le rappeler. La très intéressante section 4 du RFC enfonce le clou en énumérant les différences entre les algorithmes de TCP et ceux de QUIC, pour assurer les mêmes fonctions. Ainsi, dans TCP, tous les octets sont numérotés selon un seul espace de numérotation (les numéros de séquence) alors que QUIC a plusieurs espaces, les paquets servant à établir la connexion ne partagent pas leurs numéros avec ceux des données. QUIC fonctionne ainsi car les premiers sont moins protégés par la cryptographie.
Pour TCP, le numéro de séquence indique à la fois l'ordre
d'émission et l'ordre de l'octet dans le flux de données. Le
problème de cette approche est que, en cas de retransmission, le
numéro de séquence n'indique plus l'ordre d'émission, rendant
difficile de distinguer une émission initiale et une retransmission
(ce qui serait pourtant bien utile pour estimer le RTT). Au contraire, dans
QUIC, le numéro de paquet n'identifie que l'ordre d'émission. La
retransmission a donc forcément un numéro supérieur à l'émission
initiale. Pour déterminer la place des octets dans le flux de
données, afin de s'assurer que l'application reçoive les données
dans l'ordre, QUIC utilise le champ Offset des
trames de type STREAM, celles qui transmettent
les données (RFC 9000, section
19.8). QUIC a ainsi moins d'ambiguités, par exemple quand il
faut mesurer le taux de pertes.
QUIC, comme TCP, doit estimer le temps optimum pour décider qu'un paquet est perdu (RTO, pour Retransmission TimeOut). QUIC est plus proche de l'algorithme du RFC 8985 que du TCP classique. La section 5 du RFC détaille l'estimation du RTT.
La section 6 porte sur le problème délicat de la détection des pertes de paquets. La plupart des paquets QUIC doivent faire l'objet d'un accusé de réception. S'il n'est pas arrivé avant un temps limite, le paquet est décrété perdu, et il faudra demander une réémission (RFC 9000, section 13.3). Plus précisement, le paquet est considéré comme perdu s'il avait été envoyé avant un paquet qui a fait l'objet d'un accusé de réception et s'il s'est écoulé N paquets depuis ou bien un temps suffisamment long. (TCP fait face à exactement le même défi, et la lecture des RFC 5681, RFC 5827, RFC 6675 et RFC 8985 est recommandée.) La valeur recommandée pour N est 3, pour être proche de TCP. Mais attention si le réseau fait que les paquets arrivent souvent dans le désordre, cela pourrait mener à des paquets considérés à tort comme perdus. Le problème existait déjà pour TCP mais il est pire avec QUIC puisque des équipements intermédiaires sur le réseau qui remettaient les paquets dans l'ordre ne peuvent plus fonctionner avec QUIC, qui chiffre le plus de choses possibles pour éviter ces interventions souvent maladroites. Et le délai avant lequel on déclare qu'un paquet est perdu ? Il doit tenir compte du RTT qu'on doit donc mesurer.
Une fois la ou les pertes détectées, on réémet les paquets. Simple, non ? Sauf qu'il faut éviter que cette réémission n'aggrave les problèmes et ne mène à la congestion (le réseau, trop chargé, perd des paquets, les émetteurs réémettent, chargeant le réseau, donc on perd davantage de paquets, donc les émetteurs réémettent encore plus…). L'algorithme actuellement spécifié pour QUIC (section 7 du RFC) est proche du NewReno de TCP (normalisé dans le RFC 6582). Mais le choix d'un algorithme de contrôle de l'émetteur est unilatéral, et une mise en œuvre de QUIC peut toujours en choisir un autre, comme Cubic (RFC 8312). Évidemment, pas question d'être le gros porc qui s'attribue toute la capacité réseau pour lui seul, et cet algorithme doit de toute façon respecter les principes du RFC 8085 (en résumé : ne soyez pas égoïste, et pensez aux autres, laissez-leur de la capacité).
Pour aider à cette lutte contre la congestion, QUIC, comme TCP, peut utiliser ECN (RFC 3168 et RFC 8311).
Comme TCP, QUIC doit démarrer une nouvelle session doucement (RFC 6928) et non partir bille en tête avec une fenêtre de grande taille.
La réaction aux pertes de paquets peut avoir des conséquences sur
la sécurité (section 8 du RFC). Par exemple, les « signaux »
utilisés par QUIC pour décider qu'il y a eu une perte (l'absence
d'un paquet, le RTT, ECN) ne sont pas protégés par la cryptographie,
contrairement aux données transportées et à certaines
métadonnées. Un attaquant actif peut fausser ces signaux et mener
QUIC à réduire son débit. Il n'y a pas vraiment de protection contre
cela. Autre risque de sécurité, alors que QUIC est normalement conçu
pour priver un observateur de beaucoup d'informations qui, avec TCP
étaient en clair, il n'atteint pas 100 % de succès dans ce
domaine. Par exemple les paquets ne contenant que des accusés de
réception (trames de type ACK) peuvent être
identifiés par leur taille (ils sont tout petits), et l'observateur
peut alors en déduire des informations sur les performances du
chemin. Si on veut éviter cela, il faut utiliser le
remplissage des accusés de réception.
Vous aimez lire des programmes ? L'annexe A du RFC contient du pseudo-code mettant en œuvre les mécanismes de récupération décrits dans le RFC.
L'article seul
RFC 9001: Using TLS to Secure QUIC
Date de publication du RFC : Mai 2021
Auteur(s) du RFC : M. Thomson (Mozilla), S. Turner (sn3rd)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF quic
Première rédaction de cet article le 28 mai 2021
Le protocole de transport QUIC est toujours sécurisé par la cryptographie. Il n'y a pas de communication en clair avec QUIC. Cette sécurisation se fait actuellement par TLS mais QUIC utilise TLS d'une manière un peu spéciale, documentée dans ce RFC.
Fini d'hésiter entre une version avec TLS ou une version sans. Avec QUIC, c'est forcément chiffré et, pour l'instant, avec TLS (dans le futur, QUIC pourra utiliser d'autres protocoles, mais ce n'est pas encore défini). QUIC impose en prime au minimum TLS 1.3 (RFC 9846), qui permet notamment de diminuer la latence, la communication pouvant s'établir dans certains cas dès le premier paquet. Petit rappel de TLS, pour commencer : TLS permet d'établir un canal sûr, fournissant authentification du serveur et confidentialité de la communication, au-dessus d'un media non-sûr (l'Internet). TLS est normalement constitué de deux couches, la couche des enregistrements (record layer) et celle de contenu (content layer), qui inclut notamment le mécanisme de salutation initial. On établit une session avec le protocole de salutation (handshake protocol), puis la couche des enregistrements chiffre les données (application data) avec les clés issues de cette salutation. Les clés ont pu être créées par un échange Diffie-Helman, ou bien être pré-partagées (PSK, pour Pre-Shared Key), ce dernier cas permettant de démarrer la session immédiatement (« 0-RTT »).
QUIC utilise TLS d'une façon un peu spéciale. Certains messages
TLS n'existent pas comme ChangeCipherSpec ou
KeyUpdate (QUIC ayant ses propres mécanismes
pour changer la cryptographie en route, cf. section 6), et, surtout,
la couche des enregistrements disparait, QUIC faisant le chiffrement
selon son format, mais avec les clés négociées par TLS.
La poignée de mains qui établit la session TLS peut donc se faire de deux façons :
- « 1-RTT » où le client et le serveur peuvent envoyer des données après un aller-retour (RTT). Rappelez-vous que c'est ce temps d'aller-retour qui détermine la latence, donc la « vitesse » perçue par l'utilisateur, au moins pour les transferts de faible taille (comme le sont beaucoup de ressources HTML).
- « 0-RTT », où le client peut envoyer des données dès le
premier datagramme transmis. Cette façon de
faire nécessite que client et serveur se soient parlés avant, et
que le client ait stocké un jeton généré par le serveur (sept
jours maximum, dit le RFC 9846), qui
permettra au serveur de trouver tout de suite le matériel
cryptographique nécessaire. Attention, le 0-RTT ne protège pas
contre le rejeu, mais ce n'est pas grave
pour des applications comme HTTP avec la méthode
GET, qui est idempotente. Et le 0-RTT pose également problème avec la PFS (la confidentialité même en cas de compromission ultérieure des clés).
La section 3 du RFC fait un tour d'horizon général du protocole
TLS tel qu'utilisé par QUIC. Comme vu plus haut, la couche des
enregistrements (record layer) telle qu'utilisée
avec TCP n'est plus présente, les messages TLS comme
Handshake et Alert sont
directement transportés sur QUIC (qui, contrairement à TCP, permet
d'assurer confidentialité et intégrité). Avec TCP, la mise en
couches était stricte, TLS
étant entièrement au-dessus de TCP, avec QUIC, l'intégration est
plus poussée, QUIC et TLS coopèrent, le premier chiffrant avec les
clés fournies par le second, et QUIC transportant les messages de
TLS. De même, quand on fait tourner un protocole applicatif sur QUIC, par exemple
HTTP/3 (RFC 9113), celui-ci
est directement placé sur QUIC, TLS s'effaçant complètement. Les
applications vont donc confier leurs données à QUIC, pas à TLS. En
simplifiant (beaucoup…), on pourrait dire que TLS ne sert qu'au
début de la connexion. Pour citer Radia
Perlman, « It is misleading to regard this as a
specification of running QUIC over TLS. It is related to TLS in the
same way that DTLS is related to TLS: it imports much of the syntax,
but there are many differences and its security must be evaluated
largely independently. My initial reaction to this spec was to
wonder why it did not simply run QUIC over DTLS . I believe the
answer is that careful integration improves the performance and is
necessary for some of the address agility/transition
design. ».
La section 4 explique plus en détail comment les messages TLS
sont échangés via QUIC. Les messages cryptographiques sont
transportés dans des trames de type CRYPTO. Par
exemple, le ClientHello TLS sera dans une trame
CRYPTO elle-même située dans un paquet QUIC de
type Initial. Les Alert
sont dans des trames CONNECTION_CLOSE dont le
code d'erreur est l'alerte TLS. Ce sont les seuls messages que QUIC
passera à TLS, il fait tout le reste lui-même.
On a vu que le principal travail de TLS est de fournir du matériel cryptographique à QUIC. Plus précisément, TLS fournit, après sa négociation avec son pair :
- Un secret, d'où la clé sera dérivée,
- une fonction de chiffrement intègre,
par exemple
AEAD_AES_128_GCM(AES avec GCM) ouAEAD_CHACHA20_POLY1305(ChaCha20, RFC 8439), - une fonction de dérivation des clés.
QUIC se servira de tout cela pour chiffrer.
QUIC impose une version minimale de TLS : la 1.3, normalisée dans le RFC 9846. Les versions ultérieures sont acceptées mais elles n'existent pas encore.
Ah et, comme toujours avec TLS, le client doit authentifier le
serveur, typiquement via son certificat. Le
serveur ne doit pas utiliser les possibilités TLS de
ré-authentification ultérieure (message
CertificateRequest) car le multiplexage utilisé
par QUIC empêcherait de corréler cette demande d'authentification
avec une requête précise du client.
Outre le « 0-RTT » de QUIC, qui permet au client d'envoyer des
données applicatives dès le premier paquet, QUIC+TLS fournit un
autre mécanisme pour gagner du temps à l'établissement de la
connexion, la reprise de session (session
resumption, RFC 9846, section
2.2). Si le client a enregistré les informations nécessaires depuis
une précédente session avec ce serveur, il peut attaquer directement
avec un NewSessionTicket dans une trame
CRYPTO et abréger ainsi l'établissement de
session TLS.
Les erreurs TLS, comme bad_certificate,
unexpected_message ou
unsupported_extension, sont définies dans le
RFC 9846, section 6. Dans QUIC, elles sont
transportées dans des trames de type
CONNECTION_CLOSE, et mises dans le champ
d'erreur (Error Code, RFC 9000, section 19.19). Notez que ces trames
mènent forcément à la coupure de toute la session QUIC, et il n'y a
donc pas moyen de transporter un simple avertissement TLS.
Bien, maintenant qu'on a vu le rôle de TLS, comment QUIC
va-t-il utiliser les clés pour protéger les paquets ? La section 5
répond à cette question. QUIC va utiliser les clés fournies par TLS
(je simplifie, car QUIC effectue quelques dérivations avant) comme
clés de chiffrement intègre (RFC 5116). Il utilisera l'algorithme de chiffrement
symétrique indiqué par TLS. Tous les paquets ne sont pas
protégés (par exemple ceux de négociation de version, inutiles pour
l'instant puisque QUIC n'a qu'une version, ne bénéficient pas de
protection puisqu'il faudrait connaitre la version pour choisir les
clés de protection). Le cas des paquets Initial
est un peu plus subtil puisqu'ils sont chiffrés, mais avec une clé
dérivée du connection ID, qui circule en
clair. Donc, en pratique, seule leur
intégrité est protégée, par leur
confidentialité (cf. section 7 pour les
conséquences).
J'ai dit que QUIC n'utilisait pas directement les clés fournies par TLS. Il applique en effet une fonction de dérivation, définie dans la section 7.1 du RFC 9846, elle-même définie à partir des fonctions du RFC 5869.
Il existe plein de pièges et de détails à prendre en compte quand
on met en œuvre QUIC+TLS. Par exemple, en raison du réordonnancement
des datagrammes dans le réseau, et des pertes de datagrammes, un
paquet chiffré peut arriver avant le matériel cryptographique qui
permettrait de le déchiffrer, ou bien avant que les affirmations du
pair aient été validées. La section 5.7 du RFC explique comment
gérer ce cas (en gros, jeter les paquets qui sont « en avance », ou
bien les garder pour déchiffrement ultérieur mais ne surtout pas
tenter de les traiter). Autre piège, QUIC ignore les paquets dont la
vérification d'intégrité a échoué, alors que TLS ferme la
connexion. Cela a pour conséquences qu'avec QUIC un attaquant peut
essayer plusieurs fois. Il faut donc compter les échecs et couper la
connexion quand un nombre maximal a été atteint (section 6.6). Bien
sûr, pour éviter de faciliter une attaque par déni de service (où
l'attaquant enverrait plein de mauvais paquets dans l'espoir de
fermer la connexion), ces limites doivent être assez hautes (2^23
paquets pour AEAD_AES_128_GCM), voir
« Limits on
Authenticated Encryption Use in TLS » ou
« Robust
Channels: Handling Unreliable Networks in the Record Layers of QUIC
and DTLS 1.3 », ainsi que l'annexe B du RFC.
Encore question détails subtils, la poignée de mains de TLS n'est
pas tout à fait la même quand elle est utilisée par QUIC (section
8). Ainsi, ALPN doit être utilisé et avec succès,
autrement on raccroche avec l'erreur
no_application_protocol.
Le but de TLS est de fournir de la sécurité, notamment confidentialité et authentification, donc il est recommandé de bien lire la section 9, qui traite de la sécurité de l'ensemble du RFC. Ainsi, si on utilise les tickets de session de TLS (RFC 9846, section 4.7.1), comme ils sont transmis en clair, ils peuvent permettre à un observateur de relier deux sessions, même si les adresses IP sont différentes.
Le « 0-RTT » est formidable pour diminuer la latence, mais il
diminue aussi la sécurité : il n'y a pas de protection contre le
rejeu. Si QUIC lui-même n'est pas vulnérable
au rejeu, l'application qui travaille au-dessus de QUIC peut
l'être. Prenez un protocole applicatif qui aurait des services
comme, en HTTP, « envoyez-moi une pizza » (sans doute
avec la méthode POST), on voit bien que le
rejeu serait problématique. Bref, les applications qui,
contrairement au protocole QUIC, ne sont pas
idempotentes, ont tout intérêt à désactiver
le 0-RTT.
QUIC tournant sur UDP, qui ne protège pas contre l'usurpation d'adresse IP, il
existe en théorie un risque d'attaque par réflexion, avec
amplification. Par exemple, la réponse à un
ClientHello peut être bien plus grande que le
ClientHello lui-même. Pour limiter les risques,
QUIC impose que le premier paquet du client ait une taille minimale
(pour réduire le facteur d'amplification), en utilisant le
remplissage, et que le serveur ne réponde pas
avec plus de trois fois la quantité de données envoyée par le
client, tant que l'adresse IP de celui-ci n'a pas été validée.
Plus sophistiquées sont les attaques par canal auxiliaire. Par exemple, si une mise en œuvre de QUIC jette trop vite les paquets invalides, un attaquant qui mesure les temps de réaction pourra en déduire des informations sur ce qui n'allait pas exactement dans son paquet. Il faut donc que toutes les opérations prennent un temps constant.
Et puis, bien sûr, comme tout protocole utilisant la cryptographie, QUIC+TLS a besoin d'un générateur de nombres aléatoires correct (cf. RFC 4086).
Question mise en œuvre, notez qu'on ne peut pas forcément utiliser une bibliothèque TLS quelconque. Il faut qu'elle permette de séparer signalisation et chiffrement et qu'elle permette d'utiliser QUIC comme transport. (Et il n'y a pas d'API standard pour cela.) C'est par exemple le cas de la bibliothèque picotls. Pour OpenSSL, il faut attendre (un patch existe) et cela bloque parfois l'intégration de certains logiciels.
Et question tests, à ma connaissance, on ne peut pas actuellement
utiliser openssl s_client ou
gnutls-cli avec un serveur QUIC. Même problème avec le fameux site de
test TLS https://ssllabs.com/
Pour terminer, voici l'analyse d'une communication QUIC+TLS,
analyse faite avec Wireshark. D'abord, le
premier paquet, de type QUIC Initial, qui
contient le ClientHello dans une trame de type
CRYPTO :
QUIC IETF
1... .... = Header Form: Long Header (1)
.1.. .... = Fixed Bit: True
..00 .... = Packet Type: Initial (0)
.... 00.. = Reserved: 0
.... ..11 = Packet Number Length: 4 bytes (3)
Version: 1 (0x00000001)
Destination Connection ID Length: 8
Destination Connection ID: 345d144296b90cff
...
Length: 1226
Packet Number: 0
TLSv1.3 Record Layer: Handshake Protocol: Client Hello
Frame Type: CRYPTO (0x0000000000000006)
Offset: 0
Length: 384
Crypto Data
Handshake Protocol: Client Hello
Handshake Type: Client Hello (1)
Length: 380
...
Extension: quic_transport_parameters (len=85)
Type: quic_transport_parameters (57)
Length: 85
Parameter: initial_max_stream_data_bidi_local (len=4) 2097152
Type: initial_max_stream_data_bidi_local (0x05)
Length: 4
Value: 80200000
initial_max_stream_data_bidi_local: 2097152
...
Dans les extensions TLS, notez l'extension spécifique à QUIC,
quic_transport_parameters. QUIC « abuse » de
TLS en s'en servant pour emballer ses propres paramètres. (La liste
de ces paramètres de transport figure dans un
registre IANA.)
La réponse à ce paquet Initial contiendra le
ServerHello TLS. La poignée de mains se
terminera avec les paquets QUIC de type
Handshake. TLS ne servira plus par la suite,
QUIC chiffrera tout seul.
L'article seul
RFC 9000: QUIC: A UDP-Based Multiplexed and Secure Transport
Date de publication du RFC : Mai 2021
Auteur(s) du RFC : J. Iyengar (Fastly), M. Thomson (Mozilla)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF quic
Première rédaction de cet article le 28 mai 2021
Le protocole de transport QUIC vient d'être normalisé, dans une série de quatre RFC. J'ai écrit un résumé synthétique de QUIC, cet article porte sur le principal RFC du groupe, celui qui normalise le cœur de QUIC, le mécanisme de transport des données. QUIC, comme TCP, fournit aux protocoles applicatifs un service de transport des données fiable, et en prime avec authentification et confidentialité.
L'un des buts principaux de QUIC est de réduire la latence. La capacité des réseaux informatiques augmente sans cesse, et va continuer de la faire, alors que la latence sera bien plus difficile à réduire. Or, elle est déterminante dans la perception de « vitesse » de l'utilisateur. Quels sont les problèmes que pose actuellement l'utilisation de TCP, le principal protocole de transport de l'Internet ?
- Head-of-line blocking, quand une ressource rapide est bloquée par une lente située avant elle dans la file, ou quand la perte d'un seul paquet TCP bloque toute la connexion en attendant que les données manquantes soient réémises. Si on multiplexe au-dessus de TCP, comme le fait HTTP/2 (RFC 9113), tous les ruisseaux d'une même connexion doivent attendre.
- Latence due à l'ouverture de la session TLS, d'autant plus que TCP et TLS étant découplés, TLS doit attendre que TCP ait fini pour commencer sa négociation.
Le cahier des charges de QUIC était à peu près :
- Déployable aujourd'hui, sans changement important de l'Internet. Compte-tenu du nombre de boitiers intermédiaires intrusifs (cf. RFC 7663), cela exclut le développement d'un nouveau protocole de transport reposant directement sur IP : il faut passer sur TCP ou UDP. Les solutions « révolutionnaires » ont donc été abandonnées immédiatement.
- Faible latence, notamment pour le démarrage de la session.
- Meilleure gestion de la mobilité (ne pas casser les sessions si on change de connectivité).
- Assurer la protection de la vie privée au moins aussi bien qu'avec TCP+TLS (donc, tout chiffrer). Le chiffrement ne sert d'ailleurs pas qu'à gêner la surveillance : il a aussi pour but d'empêcher les modifications que se permettent bien des FAI.
- Services aux applications à peu près semblables à ceux de TCP (distribution fiable et ordonnée des données).
- Coexistence heureuse avec TCP, aucun des deux ne doit prendre toute la capacité au détriment de l'autre (cf. RFC 5348). QUIC, comme TCP, contrôle la quantité de données envoyées, pour ne pas écrouler le réseau.
Certains de ces objectifs auraient pu être atteints en modifiant TCP. Mais TCP étant typiquement mis en œuvre dans le noyau du système d'exploitation, tout changement de TCP met un temps trop long à se diffuser. En outre, si les changements à TCP sont importants, ils peuvent être bloqués par les boitiers intermédiaires, comme si c'était un nouveau protocole.
QUIC peut donc, plutôt qu'à TCP, être comparé à SCTP tournant sur DTLS (RFC 8261), et on peut donc se demander pourquoi ne pas avoir utilisé ce système. C'est parce que :
- La latence pour établir une session est très élevée. SCTP et DTLS étant deux protocoles séparés, il faut d'abord se « connecter » avec DTLS, puis avec SCTP (RFC 8261, section 6.1).
- Cette séparation de SCTP et DTLS fait d'ailleurs que d'autres tâches sont accomplies deux fois (alors que dans QUIC, chiffrement et transport sont intégrés, cf. RFC 9001).
Pour une comparaison plus détaillée de SCTP et QUIC, voir
l'Internet-Draft draft-joseph-quic-comparison-quic-sctp.
(SCTP peut aussi tourner sur UDP - RFC 6951
mais j'ai plutôt utilisé SCTP sur DTLS comme point de comparaison,
pour avoir le chiffrement.) Notez que ces
middleboxes intrusives sont particulièrement
répandues dans les réseaux pour mobiles, type
4G (où elles sont parfois appelée
TCP proxies), puisque c'est un monde où on viole
bien plus facilement la neutralité du
réseau.
Faire mieux que TCP n'est pas évident. Ce seul RFC fait 207 pages, et il y a d'autres RFC à lire. Déjà, commençons par un peu de terminologie :
- Client et serveur ont le sens habituel, le client est l'initiateur de la connexion QUIC, le serveur est le répondeur,
- Un paquet QUIC n'est pas forcément un datagramme IP ; plusieurs paquets peuvent se trouver dans un même datagramme envoyé sur UDP,
- Certains paquets déclenchent l'émission d'un accusé de réception (ACK-eliciting packets) mais pas tous,
- Dans un paquet, il y a plusieurs unités de données, les
trames. Il existe plusieurs types de trames, par exemple
PINGsert uniquement à déclencher l'accusé de réception, alors queSTREAMcontient des données de l'application. - Une adresse est la combinaison d'une adresse IP, et d'un port. Elle sert à identifier une extrémité du chemin entre client et serveur mais pas à identifier une connexion.
- L'identifiant de connexion (CID, connection ID) joue ce rôle. Il permet à QUIC de gérer les cas où un routeur NAT change le port source, ou bien celui où on change de type de connexion.
- Un ruisseau (stream) est un canal de données à l'intérieur d'une connexion QUIC. QUIC multiplexe des ruisseaux. Par exemple, pour HTTP/3 (RFC 9113), chaque ressource (image, feuille de style, etc) voyagera dans un ruisseau différent.
Maintenant, plongeons dans le RFC. Rappelez-vous qu'il est long ! Commençons par les ruisseaux (section 2 du RFC). Ils ressemblent aux ruisseaux de HTTP/2 (RFC 9113), ce qui est logique, QUIC ayant été conçu surtout en pensant à HTTP. Chaque ruisseau est un flux ordonné d'octets. Dans une même connexion QUIC, il y a plusieurs ruisseaux. Les octets d'un ruisseau sont reçus dans l'ordre où ils ont été envoyés (plus exactement, QUIC doit fournir ce service mais peut aussi fournir un service dans le désordre), ce qui n'est pas forcément le cas pour les octets d'une même connexion. (Dans le cas de HTTP, cela sert à éviter qu'une ressource lente à se charger ne bloque tout le monde.) Comme avec TCP, les données sont un flot continu, même si elles sont réparties dans plusieurs trames. La création d'un ruisseau est très rapide, il suffit d'envoyer une trame avec l'identifiant d'un ruisseau et hop, il est créé. Les ruisseaux peuvent durer très longtemps, ou au contraire tenir dans une seule trame.
J'ai parlé de l'identifiant d'un ruisseau. Ce numéro, ce stream ID est pair pour les ruisseaux créés par le client, impair s'ils sont créés par le serveur. Cela permet à client et serveur de créer des ruisseaux sans se marcher sur les pieds. Un autre bit dans l'identifiant indique si le ruisseau est bidirectionnel ou unidirectionnel.
Une application typique va donc créer un ou plusieurs ruisseaux,
y envoyer des données, en recevoir, et fermer les ruisseaux,
gentiment (trame STREAM avec le bit
FIN) ou brutalement (trame
RESET_STREAM). La machine à états complète des
ruisseaux figure dans la section 3 du RFC.
Comme avec TCP, il ne s'agit pas d'envoyer des données au débit
maximum, sans se soucier des conséquences. Il faut se contrôler, à
la fois dans l'intérêt du réseau (éviter la
congestion) et dans celui du récepteur, qui a
peut-être du mal à traiter tout ce qu'on lui envoie. D'où, par
exemple, la trame STOP_SENDING qui dit à
l'émetteur de se calmer.
Plus fondamentalement, le système de contrôle de QUIC est décrit
dans la section 4. Il fonctionne aussi bien par ruisseau qu'au
niveau de toute la connexion. C'est le récepteur qui contrôle ce que
l'émetteur peut envoyer, en disant « j'accepte au total N
octets ». Il le fait à l'établissement de la connexion puis,
lorsqu'il peut à nouveau traiter des données, via les trames
MAX_DATA (pour l'ensemble de la connexion) et
MAX_STREAM_DATA (valables, elles, pour un seul
ruisseau). Normalement, les quantités d'octets que l'émetteur peut
envoyer sont toujours croissantes. Par exemple, à l'établissement de
la connexion, le récepteur annonce qu'il peut traiter 1 024
octets. Puis, une fois qu'il a des ressources disponibles, il
signalera qu'il peut traiter 2 048 octets. Si l'émetteur ne lui
avait transmis que 1 024, cette augmentation lui indiquera qu'il
peut reprendre l'émission. Si l'émetteur envoie plus de données
qu'autorisé, le récepteur ferme brutalement la connexion. À noter
que les trames de type CRYPTO ne sont pas
concernées car elles peuvent être nécessaires pour changer les
paramètres cryptographiques (RFC 9001, section 4.1.3).
J'ai parlé des connexions QUIC mais pas encore dit comment elles
étaient établies. La section 5 le détaille. Comme QUIC tourne sur
UDP, un certain
nombre de gens n'ont pas compris le rôle d'UDP et croient que QUIC
est sans connexion. Mais c'est faux, QUIC impose l'établissement
d'une connexion, c'est-à-dire d'un état partagé entre l'initiateur
(celui qui sollicite une connexion) et le répondeur. La négociation
initiale permettra entre autres de se mettre d'accord sur les
paramètres cryptographiques, mais aussi sur le protocole applicatif utilisé (par exemple
HTTP). QUIC permet d'envoyer des données dès le premier paquet (ce
qu'on nomme le « 0-RTT ») mais rappelez-vous que, dans ce cas, vous
n'êtes plus protégé contre les attaques par
rejeu. Ce n'est pas grave pour un
GET HTTP mais cela peut être gênant dans
d'autres cas.
Une fonction essentielle aux connexions QUIC est le
connection ID. Il s'agit d'un identificateur de
la connexion, qui lui permettra notamment de survivre aux
changements de connectivité (passage de 4G dehors en WiFi chez soi,
par exemple) ou aux fantaisies des routeurs NAT qui peuvent
subitement changer les ports utilisés. Quand
un paquet QUIC arrive sur une machine, c'est ce connection
ID qui sert à démultiplexer les paquets entrants, et à
trouver les paramètres cryptographiques à utiliser pour le
déchiffrer. Il n'y a pas qu'un connection ID
mais tout un jeu, car, comme il circule en clair, il pourrait être
utilisé pour suivre à la trace un utilisateur. Ainsi, quand une
machine change d'adresse IP, la bonne pratique est de se mettre à
utiliser un connection ID qui faisait partie du
jeu de départ, mais n'a pas encore été utilisé, afin d'éviter qu'un
surveillant ne fasse le rapprochement entre les deux adresses
IP. Notez que le jeu de connection ID négocié au
début peut ensuite être agrandi avec des trames
NEW_CONNECTION_ID.
Dans quel cas un port peut-il changer ? QUIC utilise UDP, pour maximiser les chances de passer à travers les pare-feux et les routeurs NAT. Cela pose des problèmes si le boitier intermédiaire fait des choses bizarres. Par exemple, si un routeur NAT décide de mettre fin à une connexion TCP qui n'a rien envoyé depuis longtemps, il peut génerer un message RST (ReSeT) pour couper la connexion. Rien de tel en UDP, où le routeur NAT va donc simplement supprimer de sa table de correspondance (entre adresses publiques et privées) une entrée. Après cela, les paquets envoyés par la machine externe seront jetés sans notification, ceux envoyés par la machine interne créeront une nouvelle correspondance, avec un port source différent et peut-être même une adresse IP source différente. La machine externe risque donc de ne pas les reconnaitre comme des paquets appartenant à la même connexion QUIC. En raison des systèmes de traduction d'adresses, l'adresse IP source et le port source vus par le pair peuvent changer pendant une même « session ». Pour permettre de reconnaitre une session en cours, QUIC utilise donc le connection ID, un nombre de longueur variable généré au début de la connexion (un dans chaque direction) et présent dans les paquets. (Le connection ID source n'est pas présent dans tous les paquets.)
Vous avez vu qu'une connexion QUIC peut parfaitement changer
d'adresse IP en cours de route. Cela aura certainement des
conséquences pour tous les systèmes qui enregistrent les adresses
IP comme identificateur d'un dialogue, du
journal d'un serveur HTTP (qu'est-ce que
Apache va mettre dans son
access_log ?) aux surveillances de la
HADOPI.
Pour limiter les risques qu'une correspondance dans un routeur
faisant de la traduction d'adresses n'expire, QUIC dispose de
plusieurs moyens de
keepalive comme les trames
de type PING.
Comment l'application qui utilise QUIC va-t-elle créer des connexions et les utiliser ? La norme QUIC, dans notre RFC, ne spécifie pas d'API. Elle expose juste les services que doit rendre QUIC aux applications, notamment :
- Ouvrir une connexion (si on est initiateur),
- Attendre des demandes de connexions (si on est répondeur),
- Activer les données early data, c'est-à-dire envoyées dès le premier paquet (rappelez-vous que le rejeu est possible donc l'application doit s'assurer que cette première requête est idempotente),
- Configurer certaines valeurs comme le nombre maximal de ruisseaux ou comme la quantité de données qu'on est prêt à recevoir,
- Envoyer des trames
PING, par exemple pour s'assurer que la connexion reste ouverte, - Fermer la connexion.
Le RFC ne le spécifie pas, mais il faudra évidemment que QUIC permette à l'application d'envoyer et de recevoir des données.
Il n'y a actuellement qu'une seule version de QUIC, la 1, normalisée dans notre RFC 9000 (cf. section 15). Dans le futur, d'autres versions apparaitront peut-être, et la section 6 du RFC explique comment se fera la future négociation de version (ce qui sera un point délicat car il faudra éviter les attaques par repli). Notez que toute version future devra se conformer aux invariants du RFC 8999, une garantie de ce qu'on trouvera toujours dans QUIC.
Un point important de QUIC est qu'il n'y a pas de mode « en
clair ». QUIC est forcément protégé par la
cryptographie. L'établissement de la
connexion impose donc la négociation de paramètres cryptographiques
(section 7). Ces paramètres sont mis dans une trame
CRYPTO qui fait partie du premier paquet
envoyé. QUIC version 1 utilise TLS (RFC 9001). Le serveur est toujours authentifié, le client peut
l'être. C'est aussi dans cette négociation cryptographique qu'est
choisie l'application, via ALPN (RFC 7301).
Dans le cas courant, quatre paquets sont échangés,
Initial par chacun des participants, puis
Handshake. Mais, si le 0-RTT est accepté, des
données peuvent être envoyées par l'initiateur dès le premier
paquet.
Puisqu'UDP,
comme IP, ne protège
pas contre l'usurpation
d'adresse IP, QUIC doit valider les adresses IP utilisées,
pour éviter, par exemple, les attaques par réflexion (section
8). Si un initiateur contacte un répondeur en disant « mon adresse
IP est 2001:db8:dada::1 », il ne faut pas le
croire sur parole, et lui envoyer plein de données sans
vérification. QUIC doit valider
l'adresse IP de son correspondant, et le revalider lorsqu'il
change d'adresse IP. À l'établissement de la connexion, c'est la
réception du paquet Handshake, proprement
chiffré, qui montre que le correspondant a bien reçu notre paquet
Initial et a donc bien l'adresse IP qu'il
prétend avoir. En cas de changement d'adresse IP, la validation
vient du fait que le correspondant utilise un des
connection ID qui avait été échangés précédemment
ou d'un test explicite de joignabilité avec les trames
PATH_CHALLENGE et
PATH_RESPONSE. Sur ces migrations, voir aussi
la section 9.
Pour les futures connexions, on utilisera un jeton qui avait été
transmis dans une trame NEW_TOKEN et qu'on a
stocké localement. (C'est ce qui permet le 0-RTT.) Le RFC ne
spécifie pas le format de ce jeton, seule la machine qui l'a créé et
qui l'envoie à sa partenaire a besoin de le comprendre (comme pour un
cookie). Le RFC conseille également de n'accepter
les jetons qu'une fois (et donc de mémoriser leur usage) pour
limiter le risques de rejeu.
Tant que la validation n'a pas été faite, une machine
QUIC ne doit pas envoyer plus de trois fois la quantité de données
reçue (pour éviter les attaques avec
amplification). C'est pour cela que le paquet
Initial est rempli de manière à atteindre une
taille (1 200 octets, exige le RFC) qui garantit que l'autre machine
pourra répondre, même si elle a beaucoup à dire.
Une fois qu'on est connectés, on peut s'échanger des données, qui
feront l'objet d'accusés de réception de la part du voisin (trames
de type ACK). Contrairement au TCP classique,
les accusés de réception ne sont pas forcément contigus, comme dans
l'extension SACK du RFC 2018. Si l'accusé de
réception n'est pas reçu, l'émetteur réémet, comme avec TCP.
Bon, une fois qu'on a ouvert la connexion, et échangé des
données, quand on n'a plus rien à dire, que fait-on ? On
raccroche. La section 10 du RFC explique comment se terminent les
connexions QUIC. Cela peut se produire suite à une inactivité
prolongée, suite à une fermeture explicite normale, ou bien avec le
cas particulier de la fermeture sans état. Chacun des partenaires
peut évidemment estimer que, s'il ne s'est rien passé depuis
longtemps, il peut partir. (Cette durée maximale d'attente peut être
spécifiée dans les paramètres à l'établissement de la connexion.)
Mais on peut aussi raccrocher explicitement à tout moment (par
exemple parce que le partenaire n'a pas respecté le protocole QUIC),
en envoyant une trame de type
CONNECTION_CLOSE. Cela fermera la connexion et,
bien sûr, tous ses ruisseaux.
Pour que la trame CONNECTION_CLOSE soit
acceptée par l'autre machine, il faut que son émetteur connaisse les
paramètres cryptographiques qui permettront de la chiffrer
proprement. Mais il y a un cas ennuyeux, celui où une des deux
machines a redémarré, tout oublié, et reçoit des paquets d'une
ancienne connexion. Comment dire à l'autre machine d'arrêter d'en
envoyer ? Avec TCP, on envoie un paquet RST
(ReSeT) et c'est bon. Mais cette simplicité est
dangereuse car elle permet également à un tiers de faire des
attaques par déni de service en envoyant des
« faux » paquets RST. Des censeurs ou des FAI voulant
bloquer du trafic pair-à-pair ont déjà
pratiqué ce genre d'attaque. La solution QUIC à ce double problème
est la fermeture sans état (stateless
reset). Cela repose sur l'envoi préalable d'un jeton (cela
peut se faire via un paramètre lors de l'établissement de la
connexion, ou via une trame
NEW_CONNECTION_ID). Pour pouvoir utiliser ces
jetons, il faudra donc les stocker, mais il ne sera pas nécessaire
d'avoir les paramètres cryptographiques : on ne chiffre pas le
paquet de fermeture sans état, il est juste authentifié (par le
jeton). Si la perte de mémoire est totale (jeton stocké en mémoire
non stable, et perdu), il ne reste plus que les délais de garde pour
mettre fin à la connexion. Évidemment, le jeton ne peut être utilisé
qu'une fois, puisqu'un surveillant a pu le copier. Notez que les
détails de ce paquet de fermeture sans état sont soigneusement
conçus pour que ce paquet soit indistinguable d'un paquet QUIC
« normal ».
Dans un monde idéal, tout fonctionnera comme écrit dans le
RFC. Mais, dans la réalité, des machines ne vont pas suivre le
protocole et vont faire des choses anormales. La section 11 du RFC
couvre la gestion d'erreurs dans QUIC. Le problème peut être dans la
couche de transport, ou dans l'application (et, dans ce cas, il peut
être limité à un seul ruisseau). Lorsque l'erreur est dans la couche
transport et qu'elle semble irrattrapable, on ferme la connexion
avec une trame CONNECTION_CLOSE. Si le problème
ne touche qu'un seul ruisseau, on peut se contenter d'une trame
RESET_STREAM, qui met fin juste à ce ruisseau.
On a parlé de paquets et de trames. La section 12 précise ces termes :
- Les deux machines s'envoient des datagrammes UDP,
- chaque datagramme contient un ou plusieurs paquets QUIC,
- chaque paquet QUIC peut contenir une ou plusieurs trames. Chacune d'elle a un type, la liste étant dans un registre IANA.
Parmi les paquets, il y a les paquets longs et les paquets
courts. Les paquets longs, qui contiennent tous les détails, sont
Initial, Handshake,
0-RTT et Retry. Ce sont
surtout ceux qui servent à établir la connexion. Les paquets courts
sont le 1-RTT, qui ne peut être utilisé
qu'après l'établissement complet de la connexion, y compris les
paramètres cryptographiques. Bref, les paquets longs (plus
exactement, à en-tête long) sont plus complets, les paquets courts
(à en-tête court) plus efficaces.
Les paquets sont protégés par la cryptographie. (QUIC n'a pas de
mode en clair.) Mais attention, elle ne protège pas la totalité du
paquet. Ainsi, le connection ID est en clair
puisque c'est lui qui sera utilisé à la destination pour trouver la
bonne connexion et donc les bons paramètres cryptographiques pour
déchiffrer. (Mais il est protégé en intégrité
donc ne peut pas être modifié par un attaquant sans que ce soit
détecté.) De même, les paquets Initial n'ont de
protection que contre la modification, pas contre l'espionnage. En
revanche, les paquets qui transportent les données
(0-RTT et 1-RTT) sont
complètement protégés. Les détails de ce qui est protégé et ce qui
ne l'est pas figurent dans le RFC 9001.
La coalescence de plusieurs paquets au sein d'un seul datagramme UDP vise à augmenter les performances en diminuant le nombre de datagrammes à traiter. (J'en profite pour rappeler que la métrique importante pour un chemin sur le réseau n'est pas toujours le nombre d'octets par seconde qui peuvent passer par ce chemin. Parfois, c'est le nombre de datagrammes par seconde qui compte.) Par contre, si un datagramme qui comprend plusieurs paquets, qui eux-mêmes contiennent des trames de données de ruisseaux différents, est perdu, cela va évidemment affecter tous ces ruisseaux.
Les paquets ont un numéro, calculé différemment dans chaque direction, et partant de zéro. Ce numéro est chiffré. Les réémissions d'un paquet perdu utilisent un autre numéro que celui du paquet original, ce qui permet, contrairement à TCP, de distinguer émission et réémission.
Avec QUIC, les datagrammes ne sont jamais fragmentés (en IPv4), on met le bit DF à 1 pour éviter cela. QUIC peut utiliser la PLPMTUD (RFC 8899) pour trouver la MTU du chemin.
Le format exact des paquets est spécifié en section 17. Un paquet
long (plus exactement, à en-tête long) se reconnait par son premier
bit mis à 1. Il comprend un type (la liste est dans le RFC, elle
n'est pas extensible, il n'y a pas de registre IANA), les
deux connection ID et les données, dont la
signification dépend du type. Les paquets de type
Initial comportent entre autres dans ces
données un jeton, qui pourra servir, par exemple pour les futurs
connexions 0-RTT. Les paquets de type Handshake
contiennent des trames de type CRYPTO, qui
indiquent les paramètres cryptographiques. Quant aux paquets courts,
leur premier bit est à 0, et ils contiennent moins d'information,
par exemple, seul le connection ID de destination
est présent, pas celui de la source.
Dans sa partie non chiffrée, le paquet a un bit qui a suscité bien des débats, le spin bit. Comme c'est un peu long à expliquer, ce bit a son propre article.
QUIC chiffre beaucoup plus de choses que TCP. Ainsi, pour les paquets à en-tête court, en dehors du connection ID et de quelques bits dont le spin bit, rien n'est exposé. Par exemple, les accusés de réception sont chiffrés et on ne peut donc pas les observer. Le but est bien de diminuer la vue offerte au réseau (RFC 8546), alors que TCP expose tout (les accusés de réception, les estampilles temporelles, etc). QUIC chiffre tellement qu'il n'existe aucun moyen fiable, en observant le trafic, de voir ce qui est du QUIC et ce qui n'en est pas. (Certaines personnes avaient réclamé, au nom de la nécessité de surveillance, que QUIC se signale explicitement .)
Les différents types de trames sont tous listés en section 19. Il y a notamment :
PADDINGqui permet de remplir les paquets pour rendre plus difficile la surveillance,PINGqui permet de garder une connexion ouverte, ou de vérifier que la machine distante répond (il n'y a pas dePONG, c'est l'accusé de réception de la trame qui en tiendra lieu),ACK, les accusés de réception, qui indiquent les intervalles de numéros de paquets reçus,CRYPTO, les paramètres cryptographiques de la connexion,STREAM, qui contiennent les données, et créent les ruisseaux ; envoyer une trame de typeSTREAMsuffit, s'il n'est pas déjà créé, à créer le ruisseau correspondant (ils sont identifiés par un numéro contenu dans cette trame),CONNECTION_CLOSE, pour mettre fin à la connexion.
Les types de trame figurent dans un registre IANA. On notera que l'encodage des trames n'est pas auto-descriptif : on ne peut comprendre une trame que si on connait son type. C'est plus rapide, mais moins souple et cela veut dire que, si on introduit de nouveaux types de trame, il faudra utiliser des paramètres au moment de l'ouverture de la connexion pour être sûr que l'autre machine comprenne ce type.
Bon, les codes d'erreur, désormais (section 20 du RFC). La liste
complète est dans un
registre IANA, je ne vais pas la reprendre ici. Notons quand
même le code d'erreur NO_ERROR qui signifie
qu'il n'y a pas eu de problème. Il est utilisé lorsqu'on ferme une
connexion sans que pour autant quelque chose de mal se soit
produit.
Si vous voulez une vision plus concrète de QUIC, vous pouvez regarder mon article d'analyse d'une connexion QUIC.
L'une des principales motivations de QUIC est la sécurité, et il est donc logique qu'il y ait une longue section 21 consacrée à l'analyse détaillée de la sécurité de QUIC. D'abord, quel est le modèle de menace ? C'est celui du RFC 3552. En deux mots : on ne fait pas confiance au réseau, tout intermédiaire entre deux machines qui communiquent peut être malveillant. Il y a trois sortes d'attaquants : les attaquants passifs (qui ne peuvent qu'écouter), les attaquants actifs situés sur le chemin (et qui peuvent donc écouter et écrire) et les attaquants actifs non situés sur le chemin, qui peuvent écrire mais en aveugle. Voyons maintenant les attaques possibles.
La poignée de mains initiale est protégée par TLS. La sécurité de QUIC dépend donc de celle de TLS.
Les attaques par réflexion, surtout dangereuses quand elles se combinent avec une amplification sont gênées, sinon complètement empêchées, par la validation des adresses IP. QUIC ne transmet pas plus de trois fois le volume de données à une adresse IP non validée. Ce point n'a pas forcément été compris par tous, et certains ont paniqué à la simple mention de l'utilisation d'UDP. C'est par exemple le cas de cet article, qui est surtout du FUD d'un vendeur.
Du fait du chiffrement, même un attaquant actif qui serait sur le chemin et pourrait donc observer les paquets, ne peut pas injecter de faux paquets ou, plus exactement, ne peut pas espérer qu'ils seront acceptés (puisque l'attaquant ne connait pas la clé de chiffrement). L'attaquant actif qui n'est pas sur le chemin, et doit donc opérer en aveugle, est évidemment encore plus impuissant. (Avec TCP, l'attaquant actif situé sur le chemin peut insérer des paquets qui seront acceptés. Des précautions décrites dans le RFC 5961 permettent à TCP de ne pas être trop vulnérable à l'attaquant aveugle.)
La possibilité de migration des connexions QUIC (changement de port et/ou d'adresse IP) apporte évidemment de nouveaux risques. La validation du chemin doit être refaite lors de ces changements, autrement, un méchant partenaire QUIC pourrait vous rediriger vers une machine innocente.
Bien sûr, les attaques par déni de service restent
possibles. Ainsi, un attaquant actif sur le chemin qui a la
possibilité de modifier les paquets peut tout simplement les
corrompre de façon à ce qu'ils soient rejetés. Mais il y a aussi des
attaques par déni de service plus subtiles. L'attaque dite
Slowloris vise ainsi à épuiser une autre
machine en ouvrant beaucoup de connexions qui ne seront pas
utilisées. Un serveur utilisant QUIC doit donc se méfier et, par
exemple, limiter le nombre de connexions par client. Le méchant
client peut aussi ouvrir, non pas un grand nombre de connexions mais
un grand nombre de ruisseaux. C'est d'autant plus facile que
d'ouvrir le ruisseau de numéro N (ce qui ne nécessite qu'une seule
trame de type STREAM) ouvre tous les ruisseaux
jusqu'à N, dans la limite indiquée dans les paramètres de
transport.
On a vu que dans certains cas, une machine QUIC n'a plus les paramètres qui lui permettent de fermer proprement une connexion (par exemple parce qu'elle a redémarré) et doit donc utiliser la fermeture sans état (stateless reset). Dans certains cas, un attaquant peut mettre la main sur un jeton qu'il utilisera ensuite pour fermer une connexion.
Le chiffrement, comme toute technique de sécurité, a ses
limites. Ainsi, il n'empêche pas l'analyse de
trafic (reconnaitre le fichier récupéré à sa taille, par
exemple). D'où les trames de type PADDING pour
gêner cette attaque.
QUIC a plusieurs registres à l'IANA. Si vous voulez ajouter des valeurs à ces registres, leur politique (cf. RFC 8126) est :
- Pour les ajouts provisoires, ce sera « Examen par un expert », et le RFC donne l'instruction d'être assez libéral,
- Pour les ajouts permanents, il faudra écrire une spécification (« Spécification nécessaire »). Là aussi, le RFC demande d'être assez libéral, les registres ne manquent pas de place. Par exemple, les paramètres de transport jouissent de 62 bits.
- Pour les types de trame, si la majorité de l'espace prévu suit cette politique « Spécification nécessaire », une petite partie est reservée pour enregistrement via une politique plus stricte, « Action de normalisation ».
L'annexe A de notre RFC contient du pseudo-code pour quelques algorithmes utiles à la mise en œuvre de QUIC. Par exemple, QUIC, contrairement à la plupart des protocoles IETF, a plusieurs champs de taille variable. Les encoder et décoder efficacement nécessite des algorithmes astucieux, suggérés dans cette annexe.
Il existe d'ores et déjà de nombreuses mises en œuvre de QUIC, l'écriture de ce RFC ayant été faite en parallèle avec d'innombrables hackathons et tests d'interopérabilité. Je vous renvoie à la page du groupe de travail, qui indique également des serveurs QUIC publics. Elles sont dans des langages de programmation très différents, par exemple celle de Cloudflare, Quiche, est en Rust. À ma connaissance, toutes tournent en espace utilisateur mais ce n'est pas obligatoire, QUIC pourrait parfaitement être intégré dans le noyau du système d'exploitation. Une autre bonne source pour la liste des mises en œuvre de QUIC est le Wikipédia anglophone. Notez que le navigateur Web libre Firefox a désormais QUIC.
Quelques lectures pour aller plus loin :
- Une très bonne explication de QUIC, avec des dessins très parlants à l'Université catholique de Louvain (en anglais).
- Autre très bon article d'introduction à QUIC et à ses choix principaux, celui de Cloudflare.
- Beaucoup d'articles sur QUIC ne mentionnent que ses avantages. Cet article très détaillé expose honnêtement les limites de QUIC et les problèmes qu'il pourrait rencontrer.
- QUIC soulève des problèmes politiques intéressants comme,
par exemple, « vu sa complexité, peut-on encore innover s'il faut
les moyens de Google ? » En effet, qui d'autre aurait pu
développer et surtout pousser QUIC et faire qu'il soit déployé ?
Ces problèmes stratégiques se posent à beaucoup d'endroits dans le
Web, vu son importance dans nos vies. Ils sont discutés (avec
d'autres) dans l'Internet-Draft
draft-martini-hrpc-quichr(dont je remercie d'ailleurs les auteurs, qui m'ont bien aidé à comprendre QUIC). - Sur l'histoire du développement de QUIC à l'IETF et notamment sur les différents choix effectués, les décisions prises, et leurs raisons, je recommande l'article de Fastly (par un des auteurs de ce RFC).
- Sur les performances, je recommande « Taking a long look at QUIC: an approach for rigorous evaluation of rapidly evolving transport protocols » de Arash Molavi Kakhki, Samuel Jero et David Choffnes , qui analysait la version Google de QUIC, avec plein de mesures concrètes (leur code est en ligne).
- Toujours question performance, Uber a ajouté QUIC dans son application et détaille les résultats obtenus.
- Sur la question de l'exposition de données aux machines intermédiaires situées sur le chemin (la « vue depuis le réseau » du RFC 8546), l'article « "A Path Layer for the Internet: Enabling Network Operations on Encrypted Protocols » explore le problème et propose des solutions, notamment dans le contexte de QUIC.
L'article seul
RFC des différentes séries : 0 1000 10000 2000 3000 4000 5000 6000 7000 8000 9000
{kind=link}