
Ce blog n'a d'autre prétention que de me permettre de mettre à la disposition de tous des petits textes que j'écris. On y parle surtout d'informatique mais d'autres sujets apparaissent parfois.
Géolocation d'une adresse IP via le DNS
Première rédaction de cet article le 24 décembre 2017
Pour Noël, un truc complètement inutile mais amusant : trouver la longitude et la latitude d'une adresse IP via le DNS.
Ce service est fourni par Bert Hubert,
l'auteur de PowerDNS, via le domaine
geo.lua.powerdns.org. (Il ne marche
apparemment que pour IPv4.) On inverse
l'adresse IP (comme pour
in-addr.arpa) et on
fait une requête pour le type
TXT. Exemple avec l'adresse du serveur Web de
l'AFNIC, 192.134.5.24 :
% dig TXT 24.5.134.192.geo.lua.powerdns.org
...;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 40951
;; flags: qr rd ra ad; QUERY: 1, ANSWER: 2, AUTHORITY: 2, ADDITIONAL: 1
...
;; ANSWER SECTION:
24.5.134.192.geo.lua.powerdns.org. 3600 IN TXT "48.858200 2.338700"
On peut automatiser l'opération avec awk (merci à Oli Schacher) :
% reverse() { echo $1 | awk -F. '{print $4"."$3"." $2"."$1}' }
% reverse 192.134.5.24
24.5.134.192
Une fois que c'est fait, on peut lancer un navigateur Web directement vers la carte, ici avec OpenStreetMap :
% show-ip() { x-www-browser https://www.openstreetmap.org/\?$(dig $(echo $1 | awk -F. '{print $4"."$3"." $2"."$1}').geo.lua.powerdns.org TXT +short | head -1 | awk '{gsub(/"/, ""); print "mlat="$1"&mlon="$2"&zoom=12"}')}
% show-ip 192.134.5.24
Et si vous préférez Evil Corp. :
% show-ip() { x-www-browser https://maps.google.com/maps\?q=$(dig $(echo $1 | awk -F. '{print $4"."$3"." $2"."$1}').geo.lua.powerdns.org TXT +short | awk '{gsub(/"/, ""); print $1","$2}')}
La base de géolocalisation utilisée est celle de MaxMind qui, comme toutes les bases de géolocalisation vaut ce qu'elle vaut (le serveur Web de l'AFNIC n'est pas au centre de Paris…)
L'article seul
RFC 8305: Happy Eyeballs Version 2: Better Connectivity Using Concurrency
Date de publication du RFC : Décembre 2017
Auteur(s) du RFC : D. Schinazi, T. Pauly (Apple)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF v6ops
Première rédaction de cet article le 21 décembre 2017
Une machine connectée à l'Internet et répondant aux requêtes venues du réseau a souvent plusieurs adresses IP pour son nom. C'est parfois une adresse IPv4 et une IPv6 mais cela peut aussi être plusieurs adresses IPv6, ou bien un mélange en proportions quelconques. Les développeurs d'application et les administrateurs système qui déploieront ces applications ensuite, ont un choix difficile si certaines de ces adresses marchent et d'autres pas (ou mal). Si les différentes adresses IP de cette machine passent par des chemins différents, certains marchant et d'autres pas, l'application arrivera-t-elle à se rabattre sur une autre adresse très vite ou bien imposera-t-elle à l'utilisateur un long délai avant de détecter enfin le problème ? Cette question est connue comme « le bonheur des globes oculaires » (les dits globes étant les yeux de l'utilisateur qui attend avec impatience la page d'accueil de PornHub) et ce RFC spécifie les exigences pour l'algorithme de connexion du client. En les suivant, les globes oculaires seront heureux. Il s'agit de la version 2 de l'algorithme, bien plus élaborée que la version 1 qui figurait dans le RFC 6555.
La section 1 rappelle les données du problème : on veut évidemment que cela marche aussi bien en IPv6 (RFC 8200) qu'en IPv4 (pas question d'accepter des performances inférieures) or, dans l'état actuel du déploiement d'IPv6, bien des sites ont une connexion IPv6 totalement ou partiellement cassée. Si un serveur a IPv4 et IPv6 et que son client n'a qu'IPv4, pas de problème. Mais si le client a IPv6, tente de l'utiliser, mais que sa connexion est plus ou moins en panne, ou simplement sous-optimale, ses globes oculaires vont souffrir d'impatience. On peut aussi noter que le problème n'est pas spécifique à IPv6 : du moment que la machine visée a plusieurs adresses, qu'elles soient IPv4 ou IPv6, le risque que certaines des adresses ne marchent pas (ou moins bien) existe, et l'algorithme des globes oculaires heureux doit être utilisé. (C'est un des gros changements avec le précédent RFC, le RFC 6555, qui n'envisageait que le cas IPv6.)
La bonne solution est donc que l'application elle-même gère le problème (ou, sinon l'application elle-même, la bibliothèque logicielle qu'elle utilise et où se trouve la fonction de connexion). Il existe plusieurs algorithmes pour cela, déjà largement déployés depuis des années. On peut donc se baser sur l'expérience pour spécifier ces algorithmes. Ce RFC normalise les caractéristiques que doivent avoir ces algorithmes. Si on suit ce RFC, le trafic (IP et DNS) va légèrement augmenter (surtout si la connectivité IPv6 marche mal ou pas du tout) mais la qualité du vécu de l'utilisateur va être maintenue, même en présence de problèmes, ce qui compense largement. Autrement, il existerait un risque élevé que certains utilisateurs coupent complètement IPv6, plutôt que de supporter ces problèmes de délai de connexion.
La cible principale de notre RFC est composée des protocoles de transport avec connexion (TCP, SCTP), les protocoles sans connexion comme UDP soulevant d'autres questions (s'ils ont une sémantique requête/réponse, comme dans ICE, les algorithmes de ce RFC peuvent être utilisés).
Donc, on a un nom de machine qu'on veut contacter, mettons
www.example.com, avec plusieurs adresses
associées, peut-être de familles (v4 et v6) différentes. Prenons
une machine ayant une seule adresse IPv4 et une seule adresse
IPv6, avec une connexion IPv6 qui marche mal. Avec l'algorithme
naïf qu'utilisent encore certains logiciels voici la séquence
d'évenements traditionnelle :
- L'initiateur de la connexion utilise le DNS pour demander les enregistrements A (adresse IPv4) et AAAA (IPv6).
- Il récupère
192.0.2.1et2001:db8::1. - Il tente IPv6 (sur Linux, l'ordre des
essais est réglable dans
/etc/gai.conf). L'initiateur envoie un paquet TCPSYNà2001:db8::1. - Pas de réponse (connexion IPv6 incorrecte). L'initiateur réessaie, deux fois, trois fois, faisant ainsi perdre de nombreuses secondes.
- L'initiateur renonce, il passe à IPv4 et envoie un paquet TCP
SYNà192.0.2.1. - Le répondeur envoie un
SYN+ACKen échange, l'initiateur réplique par unACKet la connexion TCP est établie.
Le problème de cet algorithme naïf est donc la longue attente lors des essais IPv6. On veut au contraire un algorithme qui bascule rapidement en IPv4 lorsqu'IPv6 ne marche pas, sans pour autant gaspiller les ressources réseau en essayant par exemple toutes les adresses en même temps.
L'algorithme recommandé (sections 3 à 5, cœur de ce RFC) aura donc l'allure suivante :
- L'initiateur de la connexion utilise le DNS pour demander les enregistrements A (adresse IPv4) et AAAA (IPv6).
- Il récupère
192.0.2.1et2001:db8::1. Il sait donc qu'il a plusieurs adresses, de famille différente. - Il tente IPv6 (l'algorithme du RFC est de toute
façon facilement adaptable à des cas où IPv4 est prioritaire). L'initiateur envoie un paquet
TCP
SYNà2001:db8::1, avec un très court délai de garde. - Pas de réponse quasi-immédiate ? L'initiateur
passe à IPv4 rapidement. Il envoie un paquet TCP
SYNà192.0.2.1. - Le répondeur envoie un
SYN+ACKen échange, l'initiateur réplique par unACKet la connexion TCP est établie.
Si le répondeur réagit à une vitesse normale en IPv6, la connexion sera établie en IPv6. Sinon, on passera vite en IPv4, et l'utilisateur humain ne s'apercevra de rien. Naturellement, si le DNS n'avait rapporté qu'une seule adresse (v4 ou v6), on reste à l'algorithme traditionnel (« essayer, patienter, ré-essayer »).
Maintenant, les détails. D'abord, le DNS (section 3 de notre RFC). Pour récupérer les adresses appartenant aux deux familles (IPv4 et IPv6), il faut envoyer deux requêtes, de type A et AAAA. Pas de délai entre les deux, et le AAAA en premier, recommande le RFC. Notez qu'il n'existe pas de type de requête DNS pour avoir les deux enregistrements d'un coup, il faut donc deux requêtes.
Il ne faut pas attendre d'avoir la réponse aux deux avant de commencer à tenter d'établir une connexion. En effet, certains pare-feux configurés avec les pieds bloquent les requêtes AAAA, qui vont finir par timeouter. Du point de vue du programmeur, cela signifie qu'il faut faire les deux requêtes DNS dans des fils différents (ou des goroutines différentes en Go), ou bien, utiliser une API asynchrone, comme getdns. Ensuite, si on reçoit la réponse AAAA mais pas encore de A, on essaye tout de suite de se connecter, si on a la réponse A, on attend quelques millisecondes la réponse AAAA puis, si elle ne vient pas, tant pis, on essaie en IPv4. (La durée exacte de cette attente est un des paramètres réglables de l'algorithme. Il se nomme Resolution Delay et sa valeur par défaut recommandée est de 50 ms.)
À propos de DNS, notez que le RFC recommande également de privilégier IPv6 pour le transport des requêtes DNS vers les résolveurs (on parle bien du transport des paquets DNS, pas du type des données demandées). Ceci dit, ce n'est pas forcément sous le contrôle de l'application.
Une fois récupérées les adresses, on va devoir les trier selon l'ordre de préférence. La section 4 décrit comment cela se passe. Rappelons qu'il peut y avoir plusieurs adresses de chaque famille, pas uniquement une v4 et une v6, et qu'il est donc important de gérer une liste de toutes les adresses reçues (imaginons qu'on ne récupère que deux adresses v4 et aucune v6 : l'algorithme des globes oculaires heureux est quand même crucial car il est parfaitement possible qu'une des adresses v4 ne marche pas).
Pour trier, le RFC recommande de suivre les règles du RFC 6724, section 6. Si le client a un état (une mémoire des connexions précédentes, ce qui est souvent le cas chez les clients qui restent longtemps à tourner, un navigateur Web, par exemple), il peut ajouter dans les critères de tri le souvenir des succès (ou échecs) précédents, ainsi que celui des RTT passés. Bien sûr, un changement de connectivité (détecté par le DNA des RFC 4436 ou RFC 6059) doit entraîner un vidage complet de l'état (on doit oublier ce qu'on a appris, qui n'est plus pertinent).
Dernier détail sur le tri : il faut mêler les adresses des deux familles. Imaginons un client qui récupère trois adresses v6 et trois v4, client qui donne la priorité à IPv4, mais dont la connexion IPv4 est défaillante. Si sa liste d'adresses à tester comprend les trois adresses v4 en premier, il devra attendre trois essais avant que cela ne marche. Il faut donc plutôt créer une liste {une adressse v4, une adresse v6, une adresse v4…}. Le nombre d'adresses d'une famille à inclure avant de commencer l'autre famille est le paramètre First Address Family Count, et il vaut un par défaut.
Enfin, on essaie de se connecter en envoyant des paquets
TCP SYN (section 5). Il est important de ne pas tester IPv4 tout de suite. Les
premiers algorithmes « bonheur des globes oculaires » envoyaient
les deux paquets SYN en même temps, gaspillant des ressources réseau et
serveur. Ce double essai faisait que les équipements IPv4 du réseau
avaient autant de travail qu'avant, alors qu'on aurait souhaité les
retirer du service petit à petit. En outre, ce test simultané fait
que, dans la moitié des cas, la connexion sera établie en IPv4,
empêchant de tirer profit des avantages d'IPv6 (cf. RFC 6269). Donc, on doit tester en IPv6
d'abord, sauf si on se souvient des tentatives précédentes (voir
plus loin la variante « avec état ») ou bien si l'administrateur
système a délibérement configuré la machine pour préférer IPv4.
Après chaque essai, on attend pendant une durée paramétrable, Connection Attempt Delay, 250 ms par défaut (bornée par les paramètres Minimum Connection Attempt Delay, 100 ms par défaut, qu'on ne devrait jamais descendre en dessous de 10 ms, et Maximum Connection Attempt Delay, 2 s par défaut).
L'avantage de cet algorithme « IPv6 d'abord puis rapidement basculer en IPv4 » est qu'il est sans état : l'initiateur n'a pas à garder en mémoire les caractéristiques de tous ses correspondants. Mais son inconvénient est qu'on recommence le test à chaque connexion. Il existe donc un algorithme avec état (cf. plus haut), où l'initiateur peut garder en mémoire le fait qu'une machine (ou bien un préfixe entier) a une adresse IPv6 mais ne répond pas aux demandes de connexion de cette famille. Le RFC recommande toutefois de re-essayer IPv6 au moins toutes les dix minutes, pour voir si la situation a changé.
Une conséquence de l'algorithme recommandé est que, dans
certains cas, les deux connexions TCP (v4 et
v6) seront établies (si le SYN IPv6 voyage
lentement et que la réponse arrive après que l'initiateur de la
connexion se soit impatienté et soit passé à IPv4). Cela peut être
intéressant dans certains cas rares, mais le RFC recommande plutôt
d'abandonner la connexion perdante (la deuxième). Autrement, cela
pourrait entraîner des problèmes avec, par exemple, les sites Web
qui lient un cookie à l'adresse IP du
client, et seraient surpris de voir deux connexions avec des
adresses différentes.
La section 9 du RFC rassemble quelques derniers problèmes
pratiques. Par exemple, notre algorithme des globes oculaires
heureux ne prend en compte que l'établissement de la connexion. Si
une adresse ne marche pas du tout, il choisira rapidement la
bonne. Mais si une adresse a des problèmes de
MTU et pas l'autre, l'établissement de la
connexion, qui ne fait appel qu'aux petits paquets TCP
SYN, se passera bien alors que le reste de
l'échange sera bloqué. Une solution possible est d'utiliser
l'algorithme du RFC 4821.
D'autre part, l'algorithme ne tient compte que de la possibilité d'établir une connexion TCP, ce qui se fait typiquement uniquement dans le noyau du système d'exploitation du serveur. L'algorithme ne garantit pas qu'une application écoute, et fonctionne.
Parmi les problèmes résiduels, notez que l'algorithme des globes oculaires heureux est astucieux, mais tend à masquer les problèmes (section 9.3). Si un site Web publie les deux adresses mais que sa connectivité IPv6 est défaillante, aucun utilisateur ne lui signalera puisque, pour eux, tout va bien. Il est donc recommandé que l'opérateur fasse des tests de son côté pour repérer les problèmes (le RFC 6555 recommandait que le logiciel permette de débrayer cet algorithme, afin de tester la connectivité avec seulement v4 ou seulement v6, ou bien que le logiciel indique quelque part ce qu'il a choisi, pour mieux identifier d'éventuels problèmes v6.)
Pour le délai entre le premier SYN IPv6 et le
premier SYN IPv4, la section 5 donne des
idées quantitatives en suggérant 250 ms entre deux essais. C'est
conçu pour être quasiment imperceptible à un
utilisateur humain devant son navigateur Web, tout en évitant de
surcharger le réseau inutilement. Les algorithmes avec état ont le
droit d'être plus impatients, puisqu'ils peuvent se souvenir des
durées d'établissement de connexion précédents.
Notez que les différents paramètres réglables indiqués ont des valeurs par défaut, décrites en section 8, et qui ont été déterminées empiriquement.
Si vous voulez une meilleure explication de la version 2 des globes oculaires heureux, il y a cet exposé au RIPE.
Enfin, les implémentations. Notez que les vieilles mises en œuvre du RFC 6555 (et présentées à la fin de mon précédent article) sont toujours conformes à ce nouvel algorithme, elles n'en utilisent simplement pas les raffinements. Les versions récentes de macOS (Sierra) et iOS (10) mettent en œuvre notre RFC, ce qui est logique, puisqu'il a été écrit par des gens d'Apple (l'annonce est ici, portant même sur des versions antérieures). Apple en a d'ailleurs profité pour breveter cette technologie. À l'inverse, un exemple récent de logiciel incapable de gérer proprement le cas d'un pair ayant plusieurs adresses IP est Mastodon (cf. bogue #3762.)
Dans l'annexe A, vous trouverez la liste complète des importants changements depuis le RFC 6555. Le précédent RFC n'envisageait qu'un seul cas, deux adresses IP, une en v4, l'autre en v6. Notre nouveau RFC 8305 est plus riche, augmente le parallélisme, et ajoute :
- La façon de faire les requêtes DNS (pour tenir compte des serveurs bogués qui ne répondent pas aux requêtes AAAA, cf. RFC 4074),
- La gestion du cas où il y a plusieurs adresses IP de la même famille (v4 ou v6),
- La bonne façon d'utiliser les souvenirs des connexions précédentes,
- Et la méthode (dont je n'ai pas parlé ici) pour le cas des réseaux purement IPv6, mais utilisant le NAT64 du RFC 8305.
L'article seul
RFC 8297: An HTTP Status Code for Indicating Hints
Date de publication du RFC : Décembre 2017
Auteur(s) du RFC : K. Oku (Fastly)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 20 décembre 2017
Lorsqu'un serveur HTTP répond, la réponse contient souvent des liens vers d'autres ressources. Un exemple typique est celui de la page Web dont le chargement va déclencher le chargement de feuilles de style, de JavaScript, etc. Pour minimiser la latence, il serait intéressant de prévenir le client le plus tôt possible. C'est le but de ce RFC, qui décrit le code de retour intérimaire 103, qui prévient le client qu'il peut tout de suite commencer à charger ces ressources supplémentaires.
Il existe un type de lien pour cela,
preload, décrit par ses auteurs et
enregistré dans le registre des types de
liens (cf. RFC 8288). Il peut être
utilisé dans la réponse « normale » :
HTTP/1.1 200 OK
Date: Fri, 26 May 2017 10:02:11 GMT
Content-Length: 1234
Content-Type: text/html; charset=utf-8
Link: </main.css>; rel="preload"; as="style"
Link: </script.js>; rel="preload"; as="script"
Mais cela ne fait pas gagner grand'chose : une toute petite fraction de seconde après, le client HTTP verra arriver le source HTML et pourra y découvrir les liens. On voudrait renvoyer tout de suite la liste des ressources à charger, sans attendre que le serveur ait fini de calculer la réponse (ce qui peut prendre du temps, s'il faut dérouler mille lignes de Java et plein de requêtes SQL…)
Le nouveau code de retour, 103, lui, peut être envoyé immédiatement, avec la liste des ressources. Le client peut alors les charger, tout en attendant le code de retour 200 qui indiquera que la ressource principale est prête. (Les codes de retour commençant par 1, comme 103, sont des réponses temporaires, « pour information », en attendant le succès, annoncé par un code commençant par 2. Cf. RFC 7231, sections 6.2 et 6.3.) La réponse HTTP utilisant le nouveau code ressemblera à :
HTTP/1.1 103 Early Hints Link: </main.css>; rel="preload"; as="style" Link: </script.js>; rel="preload"; as="script" HTTP/1.1 200 OK Date: Fri, 26 May 2017 10:02:11 GMT Content-Length: 1234 Content-Type: text/html; charset=utf-8 Link: </main.css>; rel="preload"; as="style" Link: </script.js>; rel="preload"; as="script"
Les détails, maintenant (section 2 du RFC). 103 indique au client qu'il y aura une série de liens vers des ressources supplémentaires qu'il peut être intéressant, par exemple, de charger tout de suite. Les liens finaux seront peut-être différents (dans l'exemple ci-dessus, ils sont identiques). 103 est juste une optimisation, pas une obligation. (Hint = suggestion.) Les liens qu'il indique ne font pas autorité. Le serveur peut indiquer des liens supplémentaires, ne pas indiquer des liens qui étaient dans la réponse 103, indiquer des liens différents, etc.
Il peut même y avoir plusieurs 103 à la suite, notamment si un relais sur le trajet ajoute le sien, par exemple en se basant sur une réponse qu'il avait gardée en mémoire. 103 n'est en effet pas toujours envoyé par le serveur d'origine de la ressource, il peut l'être par un intermédiaire. Voici un exemple qui donne une idée des variantes possibles :
HTTP/1.1 103 Early Hints Link: </main.css>; rel="preload"; as="style" HTTP/1.1 103 Early Hints Link: </style.css>; rel="preload"; as="style" Link: </script.js>; rel="preload"; as="script" HTTP/1.1 200 OK Date: Fri, 26 May 2017 10:02:11 GMT Content-Length: 1234 Content-Type: text/html; charset=utf-8 Link: </main.css>; rel="preload"; as="style" Link: </newstyle.css>; rel="preload"; as="style" Link: </script.js>; rel="preload"; as="script"
On voit que la réponse finale n'est ni la première suggestion, ni la deuxième (ni une union des deux).
Note pour les programmeurs Python/WSGI. Je ne suis pas arrivé à utiliser ce code « intérimaire » avec WSGI, cela ne semble pas possible en WSGI. Mais on trouvera sans doute d'autres implémentations…
Le code 103 est désormais dans le registre IANA des codes de retour.
L'article seul
RFC 8259: The JavaScript Object Notation (JSON) Data Interchange Format
Date de publication du RFC : Décembre 2017
Auteur(s) du RFC : T. Bray (Textuality)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF jsonbis
Première rédaction de cet article le 14 décembre 2017
Il existe une pléthore de langages pour décrire des données structurées. JSON, normalisé dans ce RFC (qui succède au RFC 7159, avec peu de changements), est actuellement le plus à la mode. Comme son concurrent XML, c'est un format textuel, et il permet de représenter des structures de données hiérarchiques.
À noter que JSON doit son origine, et son nom complet (JavaScript Object Notation) au langage de programmation JavaScript, dont il est un sous-ensemble (enfin, approximativement). La norme officielle de JavaScript est à l'ECMA, dans ECMA-262. JSON est dans la section 24.5 de ce document mais est aussi dans ECMA-404, qui lui est réservé. Les deux normes, ce RFC et la norme ECMA, sont écrites de manière différente mais, en théorie, doivent aboutir au même résultat. ECMA et l'IETF sont censés travailler ensemble pour résoudre les incohérences (aucune des deux organisations n'a, officiellement, le dernier mot).
Contrairement à JavaScript, JSON n'est
pas un langage de programmation, seulement un langage de
description de données, et il ne peut donc pas servir de véhicule
pour du code
méchant (sauf si on fait des bêtises comme de
soumettre du texte JSON à eval(), cf. section
12 et erratum
#3607 qui donne des détails sur cette vulnérabilité).
Voici un exemple, tiré du RFC, d'un objet exprimé en JSON :
{
"Image": {
"Width": 800,
"Height": 600,
"Title": "View from 15th Floor",
"Thumbnail": {
"Url": "http://www.example.com/image/481989943",
"Height": 125,
"Width": "100"
},
"IDs": [116, 943, 234, 38793]
}
}
Les détails de syntaxe sont dans la section 2 du RFC. Cet objet
d'exemple a un seul champ, Image, qui est un
autre objet (entre { et }) et qui a plusieurs champs. (Les objets
sont appelés dictionnaires ou maps
dans d'autres langages.) L'ordre des éléments de l'objet n'est pas
significatif (certains analyseurs JSON le conservent, d'autres
pas). Un de ces champs, IDs, a pour valeur un
tableau (entre [ et ]). Les éléments d'un
tableau ne sont pas forcément du même type (section 5).
Un texte JSON n'est pas forcément un objet ou un tableau, par exemple :
"Hello world!"
est un texte JSON légal (composé d'une chaîne de caractères en tout
et pour tout). Une des conséquences est qu'un lecteur de JSON qui lit au fil de l'eau peut
ne pas savoir si le texte est fini ou pas (il ne suffit pas de
compter les crochets et accolades). À part les objets, les tableaux
et les chaînes de caractères, un texte JSON peut être un nombre, ou
bien un littéral, false,
true ou null.
Et quel encodage utiliser pour les textes JSON (section 8) ? Le RFC 4627 était presque muet à ce sujet. Cette question est désormais plus développée. Le jeu de caractères est toujours Unicode et l'encodage est obligatoirement UTF-8 dès qu'on envoie du JSON par le réseau (bien des mises en œuvre de JSON ne peuvent en lire aucun autre). Les textes JSON transmis par le réseau ne doivent pas utiliser de BOM.
Lorsqu'on envoie du JSON par le réseau, le type MIME à utiliser est application/json.
Autre problème classique d'Unicode, la comparaison de chaînes de
caractères. Ces comparaisons doivent se faire selon les caractères
Unicode et pas selon les octets (il y a plusieurs façons de
représenter la même chaîne de caractères, par exemple
foo*bar et foo\u002Abar
sont la même chaîne).
JSON est donc un format simple, il n'a même pas la possibilité de commentaires dans le fichier... Voir sur ce sujet une intéressante compilation.
Le premier RFC décrivant JSON était le RFC 4627, remplacé ensuite par le RFC 7159. Quels changements apporte cette troisième révision (annexe A) ? Elle corrige quelques erreurs, résout quelques incohérences avec le texte ECMA, et donne des avis pratiques aux programmeurs. Les principaux changements :
- Passage d'ECMA-262 seul à ECMA-404 (262 était pour tout JavaScript, 404 pour JSON seul).
- Correction des erreurs, dont une technique, une affirmation trop optimiste sur la compatibilité de JSON avec JavaScript.
- UTF-8 est désormais obligatoire.
- Progression sur le chemin des normes, de « Proposition de norme » à Norme tout court.
Voici un exemple d'un programme Python pour écrire un objet Python en JSON (on notera que la syntaxe de Python et celle de JavaScript sont très proches) :
import json
objekt = {u'Image': {u'Width': 800,
u'Title': u'View from Smith\'s, 15th Floor, "Nice"',
u'Thumbnail': {u'Url':
u'http://www.example.com/image/481989943',
u'Width': u'100', u'Height': 125},
u'IDs': [116, 943, 234, 38793],
u'Height': 600}} # Example from RFC 4627, lightly modified
print(json.dumps(objekt))
Et un programme pour lire du JSON et le charger dans un objet Python :
import json
# One backslash for Python, one for JSON
objekt = json.loads("""
{
"Image": {
"Width": 800,
"Height": 600,
"Title": "View from Smith's, 15th Floor, \\\"Nice\\\"",
"Thumbnail": {
"Url": "http://www.example.com/image/481989943",
"Height": 125,
"Width": "100"
},
"IDs": [116, 943, 234, 38793]
}
}
""") # Example from RFC 4267, lightly modified
print(objekt)
print("")
print(objekt["Image"]["Title"])
Le code ci-dessus est très simple car Python (comme Perl ou
Ruby ou, bien sûr,
JavaScript) a un typage complètement
dynamique. Dans les langages où le typage est plus statique, c'est
moins facile et on devra souvent utiliser des méthodes dont
certains programmeurs se méfient, comme des conversions de types à
l'exécution. Si vous voulez le faire en Go, il existe un bon
article d'introduction au paquetage standard
json. Un exemple en Go figure plus loin, pour
analyser la liste des stations de la RATP.
Pour Java, qui a le même « problème » que Go, il existe une quantité impressionnante de bibliothèques différentes pour faire du JSON (on trouve en ligne plusieurs tentatives de comparaison). J'ai utilisé JSON Simple. Lire un texte JSON ressemble à :
import org.json.simple.*;
...
Object obj=JSONValue.parse(args[0]);
if (obj == null) { // May be use JSONParser instead, it raises an exception when there is a problem
System.err.println("Invalid JSON text");
System.exit(1);
} else {
System.out.println(obj);
}
JSONObject obj2=(JSONObject)obj; // java.lang.ClassCastException if not a JSON object
System.out.println(obj2.get("foo")); // Displays member named "foo"
Et le produire :
JSONObject obj3=new JSONObject();
obj3.put("name","foo");
obj3.put("num",new Integer(100));
obj3.put("balance",new Double(1000.21));
obj3.put("is_vip",new Boolean(true));
Voyons maintenant des exemples réels avec divers outils de traitement de JSON. D'abord, les données issues du service de vélos en libre-service Vélo'v. C'est un gros JSON qui contient toutes les données du système. Nous allons programmer en Haskell un programme qui affiche le nombre de vélos libres et le nombre de places disponibles. Il existe plusieurs bibliothèques pour faire du JSON en Haskell mais Aeson semble la plus utilisée. Haskell est un langage statiquement typé, ce qui est loin d'être idéal pour JSON. Il faut déclarer des types correspondant aux structures JSON :
data Velov =
Velov {values :: [Station]} deriving Show
instance FromJSON Velov where
parseJSON (Object v) =
Velov <$> (v .: "values")
data Station =
Station {stands :: Integer,
bikes :: Integer,
available :: Integer} deriving Show
data Values = Values [Station]
Mais ça ne marche pas : les nombres dans le fichier JSON ont été
représentés comme des chaînes de caractères ! (Cela illustre un
problème fréquent dans le monde de JSON et de
l'open data : les données
sont de qualité technique très variable.) On doit donc les
déclarer en String :
data Station =
Station {stands :: String,
bikes :: String,
available :: String} deriving Show
Autre problème, les données contiennent parfois la chaîne de
caractères None. Il faudra donc filtrer avec
la fonction Haskell filter. La fonction
importante filtre les données, les convertit en entier, et en fait
la somme grâce à foldl :
sumArray a = show (foldl (+) 0 (map Main.toInteger (filter (\i -> i /= "None") a)))
Le programme
complet est velov.hs. Une fois compilé, testons-le :
% curl -s https://download.data.grandlyon.com/ws/rdata/jcd_jcdecaux.jcdvelov/all.json | ./velov "Stands: 6773" "Bikes: 2838" "Available: 3653"
Je n'ai pas utilisé les dates contenues dans ce fichier mais on peut noter que, si elles sont exprimées en ISO 8601 (ce n'est hélas pas souvent le cas), c'est sans indication du fuseau horaire (celui en vigueur à Lyon, peut-on supposer).
Un autre exemple de mauvais fichier JSON est donné par
Le Monde avec la base
des députés français. Le fichier
est du JavaScript, pas du JSON (il commence par une déclaration
JavaScript var datadep = {…) et il contient
plusieurs erreurs de syntaxe (des apostrophes qui n'auraient pas dû
être échappées).
Voyons maintenant un traitement avec le programme spécialisé
dans JSON, jq. On va servir du service de
tests TLS https://tls.imirhil.fr/https://tls.imirhil.fr/https/www.bortzmeyer.org.json
donne accès aux résultats des tests pour la version HTTPS de ce blog :
% curl -s https://tls.imirhil.fr/https/www.bortzmeyer.org.json| jq '.date' "2017-07-23T14:10:25.760Z"
Notons qu'au moins une clé d'un objet JSON n'est pas nommée
uniquement avec des lettres et chiffres, la clé
$oid. jq n'aime pas cela :
% curl -s https://tls.imirhil.fr/https/www.bortzmeyer.org.json| jq '._id.$oid'
jq: error: syntax error, unexpected '$', expecting FORMAT or QQSTRING_START (Unix shell quoting issues?) at <top-level>, line 1:
._id.$oid
jq: 1 compile error
Il faut mettre cette clé entre guillemets :
% curl -s https://tls.imirhil.fr/https/bortzmeyer.org.json| jq '."_id"."$oid"' "596cb76c2525939a3b34120f"
Toujours avec jq, les données de la Deutsche
Bahn, en http://data.deutschebahn.com/dataset/data-streckennetz
% jq '.features | map(select(.properties.geographicalName == "Regensburg Hbf"))' railwayStationNodes.geojson
[
{
"type": "Feature",
"geometry": {
"type": "Point",
"coordinates": [
12.09966625451,
49.011754555481
]
},
"properties": {
"id": "SNode-1492185",
"formOfNode": "railwayStop",
"railwayStationCode": "NRH",
"geographicalName": "Regensburg Hbf",
...
Toujours avec jq, on peut s'intéresser aux données officielles
états-uniennes en
https://catalog.data.gov/dataset?res_format=JSON. Prenons
les données
sur la délinquance à Los
Angeles (j'ai bien dit délinquance et pas criminalité,
celui qui traduit crime par crime ne connait pas
l'anglais, ni le
droit). https://data.lacity.org/api/views/y8tr-7khq/rows.json?accessType=DOWNLOAD
est un très gros fichier (805 Mo) et jq
n'y arrive pas :
% jq .data la-crime.json error: cannot allocate memory
Beaucoup de programmes qui traitent le JSON ont ce problème (un
script Python produit un MemoryError) : ils
chargent tout en mémoire et ne peuvent donc pas traiter des données
de grande taille. Il faut donc éviter de produire de trop gros
fichiers JSON.
Si vous voulez voir un vrai exemple en Python, il y a mon article sur le traitement de la base des codes postaux. Cette base peut évidemment aussi être examinée avec jq. Et c'est l'occasion de voir du GeoJSON :
% jq '.features | map(select(.properties.nom_de_la_commune == "LE TRAIT"))' laposte_hexasmal.geojson
[
{
"type": "Feature",
"geometry": {
"type": "Point",
"coordinates": [
0.820017087099,
49.4836816397
]
},
"properties": {
"nom_de_la_commune": "LE TRAIT",
"libell_d_acheminement": "LE TRAIT",
"code_postal": "76580",
"coordonnees_gps": [
49.4836816397,
0.820017087099
],
"code_commune_insee": "76709"
}
}
]
J'avais promis plus haut un exemple écrit en
Go. On va utiliser la liste des positions
géographiques des stations RATP, en
https://data.ratp.fr/explore/dataset/positions-geographiques-des-stations-du-reseau-ratp/table/?disjunctive.stop_name&disjunctive.code_postal&disjunctive.departement.
Le programme Go read-ratp.go va afficher le nombre
de stations et la liste :
% ./read-ratp < positions-geographiques-des-stations-du-reseau-ratp.json 26560 stations Achères-Ville Alésia Concorde ...
Comme déjà indiqué, c'est plus délicat en Go que dans un langage très dynamique comme Python. Il faut construire à l'avance des structures de données :
type StationFields struct {
Fields Station
}
type Station struct {
Stop_Id int
Stop_Name string
}
Et toute violation du « schéma » des données par le fichier JSON (quelque chose qui arrive souvent dans la nature) plantera le programme.
Si on veut beaucoup de fichiers JSON, le service de données
ouvertes officielles data.gouv.fr permet de
sélectionner des données par format. Ainsi, https://www.data.gouv.fr/fr/datasets/?format=JSONhttps://www.data.gouv.fr/fr/datasets/points-de-frayere-des-especes-de-linventaire-frayeres-des-regions-centre-et-poitou-charentes/.
Il est encodé en ISO-8859-1, ce qui est
explicitement interdit par le RFC. Bref, il faut encore rappeler
qu'on trouve de tout dans le monde JSON et que l'analyse de
fichiers réalisés par d'autres amène parfois des surprises.
On peut aussi traiter du JSON dans
PostgreSQL. Bien sûr, il est toujours
possible (et sans doute parfois plus avantageux) d'analyser le JSON
avec une des bibliothèques présentées plus haut, et de mettre les
données dans
une base PostgreSQL. Mais on peut aussi mettre le JSON directement
dans PostgreSQL et ce SGBD fournit un
type de données JSON et quelques
fonctions permettant de l'analyser. Pour les données, on va
utiliser les centres de santé en Bolivie,
en
http://geo.gob.bo/geoserver/web/?wicket:bookmarkablePage=:org.geoserver.web.demo.MapPreviewPage. On
crée la table :
CREATE TABLE centers (
ID serial NOT NULL PRIMARY KEY,
info json NOT NULL
);
Si
on importe le fichier JSON bêtement dans PostgreSQL (psql -c "copy centers(info) from stdin" mydb < centro-salud.json), on récupère
un seul enregistrement. Il faut donc éclater le fichier JSON en
plusieurs lignes. On peut utiliser les extensions à SQL de
PostgreSQL pour cela, mais j'ai préféré me servir de jq :
% jq --compact-output '.features | .[]' centro-salud.json | psql -c "copy centers(info) from stdin" mydb
COPY 50
On peut alors faire des requêtes dans le JSON, avec l'opérateur
->. Ici, le nom des centres (en jq, on
aurait écrit .properties.nombre) :
mydb=> SELECT info->'properties'->'nombre' AS Nom FROM centers;
nom
------------------------------------------
"P.S. ARABATE"
"INSTITUTO PSICOPEDAGOGICO"
"HOSPITAL GINECO OBSTETRICO"
"HOSPITAL GASTROENTEROLOGICO"
"C.S. VILLA ROSARIO EL TEJAR"
"C.S. BARRIO JAPON"
"C.S. SAN ANTONIO ALTO (CHQ)"
"C.S. SAN JOSE (CHQ)"
"C.S. SAN ROQUE"
...
Bon, sinon, JSON dispose d'une page Web officielle, où vous trouverez plein d'informations. Pour tester dynamiquement vos textes JSON, il y a ce service.
L'article seul
Fiche de lecture : Les dix millénaires oubliés qui ont fait l'histoire
Auteur(s) du livre : Jean-Paul Demoule
Éditeur : Fayard
978-2-213-67757-6
Publié en 2017
Première rédaction de cet article le 10 décembre 2017
Quand on parle de la préhistoire, tout le monde voit ce que c'est : des types vêtus de peaux de bêtes partant chercher du feu ou chassant le mammouth, ou encore inventant plein de choses. Idem pour l'histoire, on a plein de livres et de films sur tous les aspects de l'histoire, depuis qu'on a inventé l'écriture, jusqu'à Stéphane Bern et Franck Ferrand. Mais entre les deux ? Entre les deux, dit l'auteur, il y a « dix millénaires zappés ». La période qui va en gros de 13 000 à 3 000 AEC : qu'en savons-nous ?
Le livre fait le tour des innovations qui ont marqué cette période un peu oubliée : l'agriculture, bien sûr, les villages, les outils en métal, mais aussi la religion organisée. Il y avait bien sûr des croyances depuis longtemps mais, pendant ces dix millénaires, on commence à en voir des manifestations partout, y compris au prix d'efforts colossaux, inimaginables quand on était chasseur-cueilleur. Et cela ne s'arrête pas là. C'est aussi pendant cette période, dix mille ans avant Macron, qu'on invente les inégalités. Avant, il y avait sans doute des chefs. Mais l'examen des tombes ne permettait pas de voir des vraies inégalités. Pendant les dix millénaires, on voit au contraire apparaitre la distinction entre ceux qu'on enterre simplement, et ceux dont le tombeau recèle des richesses qui feront la joie des archéologues. L'auteur examine comment des gens qui vivaient à peu près libres ont pu accepter cet asservissement, et note que cela n'a pas été un processus linéaire, mais qu'il y a eu de nombreux retours à des enterrements égalitaires (suite à des révoltes contre les chefs ?)
Mais la civilisation ne s'est pas arrêtée à la religion et aux chefs. On a aussi inventé la guerre. Oui, bien sûr, il y avait de la violence avant. Mais des armées entières s'affrontant, alors que la plupart des soldats n'avaient aucune raison personnelle de se battre, ça date aussi de cette époque. (L'Europe en dehors de la Grèce était en retard sur la voie de la civilisation, et n'a donc connu sa première grande bataille que vers 1 200 AEC.) Effet amusant de la guerre, c'est aussi pendant cette période que le cannibalisme est devenu tabou…
Et la domination masculine ? A-t-elle toujours existé ? Et, si non, a-t-elle été inventée pendant cette période ? Contrairement aux batailles, cela ne laisse pas forcément beaucoup de traces analysables. Là, on est forcément davantage dans la spéculation, comme les théories de Bachofen, qui cherchait à tout prix à prouver que la domination masculine n'est pas universelle (alors qu'apparemment, elle l'est).
Et je vous laisse découvrir dans ce livre les autres étonnantes innovations de l'époque.
L'article seul
RFC 8270: Increase the Secure Shell Minimum Recommended Diffie-Hellman Modulus Size to 2048 Bits
Date de publication du RFC : Décembre 2017
Auteur(s) du RFC : L. Velvindron (Hackers.mu), M. Baushke (Juniper Networks)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF curdle
Première rédaction de cet article le 6 décembre 2017
Un RFC de moins de quatre pages, boilerplate administratif inclus, pour passer la taille minimum des modules des groupes Diffie-Hellman utilisés par SSH, de 1 024 bits à 2 048.
L'échange Diffie-Hellman dans SSH est décrit dans le RFC 4419, que notre nouveau RFC met à jour. C'est dans le RFC 4419 (sa section 3) que se trouvait la recommandation d'accepter au moins 1 024 bits pour le module du groupe. Or, cette taille est bien faible face aux attaques modernes comme Logjam.
Voilà, c'est tout, on remplace « minimum 1 024 bits » par
« minimum 2 048 » et on peut continuer à utiliser SSH. Si vous
êtes utilisateur d'OpenSSH, la commande de
génération de clés, ssh-keygen, peut
également générer ces modules (cf. la section Moduli
generation dans le manuel.) Les versions un peu
anciennes ne vous empêchent pas de faire des modules bien trop
petits. Ainsi, sur une version 7.2 :
% ssh-keygen -G moduli-512.candidates -b 512
Fri Oct 20 20:13:49 2017 Sieve next 4177920 plus 511-bit
Fri Oct 20 20:14:51 2017 Sieved with 203277289 small primes in 62 seconds
Fri Oct 20 20:14:51 2017 Found 3472 candidates
% ssh-keygen -G moduli-256.candidates -b 256
Too few bits: 256 < 512
modulus candidate generation failed
Le RGS recommande quant à lui 3 072 bits minimum (la règle exacte est « RègleLogp-1. La taille minimale de modules premiers est de 2048 bits pour une utilisation ne devant pas dépasser l’année 2030. RègleLogp-2. Pour une utilisation au delà de 2030, la taille minimale de modules premiers est de 3072 bits. »)
Enfin, la modification d'OpenSSH pour se conformer à ce RFC est juste un changement de la définition de DH_GRP_MIN.
L'article seul
RFC 8273: Unique IPv6 Prefix Per Host
Date de publication du RFC : Décembre 2017
Auteur(s) du RFC : J. Brzozowski (Comcast
Cable), G. Van De Velde (Nokia)
Pour information
Réalisé dans le cadre du groupe de travail IETF v6ops
Première rédaction de cet article le 5 décembre 2017
Ce court RFC explique comment (et pourquoi) attribuer un préfixe IPv6 unique à chaque machine, même quand le média réseau où elle est connectée est partagé avec d'autres machines.
Ce RFC s'adresse aux gens qui gèrent un grand réseau de couche 2, partagé par de nombreux abonnés. Un exemple est celui d'un serveur dédié connecté à un Ethernet partagé avec les serveurs d'autres clients. Un autre exemple est celui d'une connexion WiFi dans un congrès ou un café. Dans les deux cas, la pratique sans doute la plus courante aujourd'hui est de donner une seule adresse IPv6 à la machine (ou, ce qui revient au même, un préfixe de 128 bits). C'est cette pratique que veut changer ce RFC. Le but est de mieux isoler les clients les uns des autres, et de bien pouvoir gérer les abonnements et leur utilisation. (Justement le problème de Comcast, dont un des auteurs du RFC est un employé, cf. section 1.) Les clients ne se connaissent en effet pas les autres et il est important que les actions d'un client ne puissent pas trop affecter les autres (et qu'on puisse attribuer les actions à un client précis, pour le cas où ces actions soient illégales). En outre, certaines options d'abonnement sont « par client » (section 3, qui cite par exemple le contrôle parental, ou la qualité de service, qui peut être plus faible pour ceux qui ne paient pas le tarif « gold ».)
Si chaque client a un préfixe IPv6 à lui (au lieu d'une seule adresse IP), toute communication entre clients passera forcément par le routeur géré par l'opérateur, qui pourra ainsi mieux savoir ce qui se passe, et le contrôler. (Les lecteurs férus de routage ont noté que le client, s'il est administrateur de sa machine, peut toujours changer les tables de routage, mais cela n'affectera que le trafic aller, le retour passera toujours par le routeur. De toute façon, je soupçonne que la technique décrite dans ce RFC ne marche que si le réseau donne un coup de main, pour isoler les participants.)
Le RFC affirme que cela protègera contre des attaques comme l'épuisement de cache Neighbor Discovery, les redirections malveillantes faites avec ICMP ou les RAcailles (RFC 6104). Cela éviterait de devoir déployer des contre-mesures comme le RA Guard (RFC 6105). Là aussi, il me semble personnellement que ça n'est complètement vrai que si l'attaquant n'est pas administrateur sur sa machine. Ou alors, il faut que le réseau ne soit pas complètement partagé, qu'il y ait un mécanisme de compartimentage.
Les mécanismes décrits ici supposent que la machine du client utilise SLAAC (RFC 4862) pour obtenir une adresse IP. Cette obtention peut aussi passer par DHCP (RFC 8415) mais c'est plus rare, relativement peu de clients étant capable de demander une adresse en DHCP (RFC 7934).
La section 4 du RFC décrit comment le client obtient ce
préfixe. Il va envoyer un message RS (Router
Solicitation, voir le RFC 4861,
section 3) et écouter les réponses, qui lui diront son adresse IP
mais aussi d'autres informations comme les résolveurs
DNS à utiliser (voir RFC 8106). Pas de changement côté client, donc (ce qui
aurait rendu ce mécanisme difficile à déployer). Par contre, côté
« serveur », il y a de légers changements. Le routeur qui reçoit les RS
et génère des RA (Router Advertisement), qu'ils
aient été sollicités ou pas, va devoir les envoyer uniquement à
une machine (puisque chaque client a un préfixe différent : il ne
faut donc pas diffuser bêtement). Comme le RFC 4861 (sections 6.2.4 et 6.2.6) impose que
l'adresse IP de destination soit
ff02::1 (« tous les nœuds IPv6 »), l'astuce
est d'utiliser comme adresse MAC, non pas
l'adresse multicast habituelle, mais une
adresse unicast (RFC 6085). Ainsi, chaque client ne recevra que
son préfixe.
Ce RA contient le préfixe que l'opérateur alloue à ce client particulier. Les options du RA (RFC 4861, section 4.2) sont :
- Bit M à zéro (ce qui veut dire « pas d'adresse via DHCP »),
- Bit O à un (ce qui veut dire « d'autres informations sont disponibles par DHCP, par exemple le serveur NTP à utiliser »),
- Bit A du préfixe (RFC 4861, section 4.6.2) mis à un (ce qui veut dire « tu es autorisé à te configurer une adresse dans ce préfixe »),
- Bit L du préfixe (RFC 4861, section 4.6.2) mis à zéro (ce qui veut dire « ce préfixe n'est pas forcément sur le lien où tu te trouves, ne suppose rien, sois gentil, passe par le routeur »).
Le bit A étant mis à un, la machine qui a obtenu le préfixe peut s'attribuer une adresse IP à l'intérieur de ce préfixe, , avec SLAAC, comme indiqué dans le RFC 4862. Elle doit suivre la procédure DAD (Duplicate Address Detection, RFC 4862, section 5.4) pour vérifier que l'adresse IP en question n'est pas déjà utilisée.
Voilà, l'essentiel de ce RFC était là. La section 5 concerne quelques détails pratiques, par exemple ce que peut faire la machine client si elle héberge plusieurs machines virtuelles ou containers (en gros, elle alloue leurs adresses en utilisant le préfixe reçu).
Ce mécanisme de préfixe IP spécifique à chaque client de l'opérateur n'est pas sans poser des questions liées à la vie privée, comme l'explique la section 7 du RFC. (Rappelez-vous la section 1, qui disait qu'un des buts de cette technique était de satisfaire aux « obligations légales », autrement dit de pouvoir suivre à la trace ses utilisateurs.) Bien sûr, la machine cliente peut utiliser le système du RFC 8981, mais, ici, il aurait peu d'impact. Même avec un identificateur d'interface temporaire et imprévisible, le préfixe resterait, et identifierait parfaitement le client. Le RFC mentionne (mais sans l'exiger) qu'on peut limiter les dégâts en changeant le préfixe de temps en temps.
L'article seul
Conserver sa clé avec Let's Encrypt, certbot et dehydrated
Première rédaction de cet article le 2 décembre 2017
Beaucoup de gens utilisent désormais l'AC Let's Encrypt. Ce n'est pas la première autorité de certification qui permet d'avoir un certificat en faisant tout en ligne, ni la première gratuite, mais elle est néanmoins très utilisée (au point de devenir un nouveau SPOF de l'Internet). Par défaut, les outils Let's Encrypt comme certbot créent une nouvelle clé quand le certificat est renouvelé. Dans quels cas est-ce gênant et comment éviter cela ?
Un petit rappel sur les certificats : un certificat, c'est tout bêtement une clé publique, avec quelques métadonnées dont les plus importantes sont la signature de l'AC et la date d'expiration (qui, avec Let's Encrypt, est très rapprochée). Renouveler un certificat, c'est demander une nouvelle signature à l'AC. Si la clé n'est pas trop ancienne, ou n'a apparemment pas été compromise, il n'est pas nécessaire de la changer.
Mais les outils existants le font quand même systématiquement (c'est un choix des outils, comme certbot ou dehydrated, ce n'est pas une obligation du protocole ACME, ni de l'AC Let's Encrypt). Cette décision a probablement été prise pour garantir que la clé soit renouvelée de temps en temps (après tout, il est raisonnable de supposer que, tôt ou tard, elle sera compromise, et ce ne sera pas forcément détecté par le propriétaire).
Et pourquoi est-ce gênant de changer de clé à chaque renouvellement (donc tous les trois mois avec Let's Encrypt) ? Cela ne pose pas de problème pour l'utilisation habituelle d'un serveur HTTPS. Mais c'est ennuyeux si on utilise des techniques de sécurité fondées sur un épinglage de la clé, c'est-à-dire une authentification de la clé publique utilisée. Ces techniques permettent de résoudre une grosse faille de X.509, le fait que n'importe quelle AC, même si vous n'en êtes pas client, puisse émettre un certificat pour n'importe quel domaine. Parmi ces techniques de sécurité :
- DANE, normalisé dans le RFC 6698. Si on met les utilisations 1 (« PKIX-EE ») ou 3 (« DANE-EE »), DANE déclare la clé, un changement de celle-ci invalide donc l'enregistrement DANE.
- HPKP (RFC 7649).
- Et les autres solutions d'épinglage comme celle spécifiée dans la section 4.2 du RFC 7858 pour les serveurs DNS-sur-TLS. La supervision des serveurs publics utilisant ce protocole les authentifie ainsi (« Strict mode - SPKI only »).
Si on utilise l'outil certbot, qui est celui officiellement recommandé par Let's Encrypt, la méthode normale d'utilisation est, la première fois :
% sudo certbot certonly --webroot --webroot-path /var/lib/letsencrypt -d www.example.com Saving debug log to /var/log/letsencrypt/letsencrypt.log Obtaining a new certificate Performing the following challenges: http-01 challenge for www.example.com Using the webroot path /var/lib/letsencrypt for all unmatched domains. Waiting for verification... Cleaning up challenges Generating key (2048 bits): /etc/letsencrypt/keys/0000_key-certbot.pem Creating CSR: /etc/letsencrypt/csr/0000_csr-certbot.pem ...
Let's Encrypt a testé la présence du défi sur le serveur, on le voit dans le journal du serveur HTTP :
2600:3000:2710:200::1d - - [13/Sep/2017:16:08:46 +0000] "GET /.well-known/acme-challenge/2IlM1PbP9QZlAA22xvE4Bz5ivJi5nsB5MHz52uY8xT8 HTTP/1.1" 200 532 "-" "Mozilla/5.0 (compatible; Let's Encrypt validation server; +https://www.letsencrypt.org)"
On va alors créer l'enregistrement TLSA (DANE) :
% tlsa --create --selector 1 www.example.com Got a certificate with Subject: /CN=www.example.com _443._tcp.www.example.com. IN TLSA 3 1 1 f582936844ec355cfdfe8d9d1a42e9565940602c71c7abd2c36c732daa64b9db Got a certificate with Subject: /CN=www.example.com _443._tcp.www.example.com. IN TLSA 3 1 1 f582936844ec355cfdfe8d9d1a42e9565940602c71c7abd2c36c732daa64b9db
(L'option --selector 1 est pour faire
apparaitre dans l'enregistrement TLSA la clé publique seulement et
non pas tout le certificat, ce que ferait le sélecteur par défaut,
0. C'est expliqué plus en détail plus loin.)
À ce stade, on a un certificat Let's Encrypt, un enregistrement
DANE qui correspond et tout le monde est heureux :
% tlsa --verify --resolvconf="" www.example.com SUCCESS (Usage 3 [DANE-EE]): Certificate offered by the server matches the TLSA record (x.y.z.t)
Maintenant, si on renouvelle le certificat quelques mois plus tard :
% certbot --quiet --webroot --webroot-path /usr/share/nginx/local-html renew
Cela change la clé. Regardez avec OpenSSL :
# Avant % openssl x509 -pubkey -in /etc/letsencrypt/live/www.example.com/fullchain.pem -----BEGIN PUBLIC KEY----- MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAsUd3mG5QK6EdTtYh0oLJ nkIovYkWXV8QLQMvAthzURbyeIlQ8CXeTNCT6odh/VVyMn49IwkRJl6B7YNhYiRz pbmIxxzceAhKNAg6TF/QylHa1HWvHPniZF02NJAXCxMO5Y8EZ7n0s0cGz4XD5PGA XctV6ovA3fR8b2bk9t5N+UHklWvIOT7x0nVXWmWmrXzG0LX/P4+utZJjRR6Kf5/H 9GDXprklFCbdCTBkhyPBgdiJDnqzdb6hB1aBEsAMd/Cplj9+JKtu2/8Pq6MOtQeu 364N+RKcNt4seEr6uMOlRXzWAfOHI51XktJT64in1OHyoeRMV9dOWOLWIC2KAlI2 jwIDAQAB -----END PUBLIC KEY----- # Après % openssl x509 -pubkey -in /etc/letsencrypt/live/www.example.com/fullchain.pem -----BEGIN PUBLIC KEY----- MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEA6MF8Dw3JQ58n8B/GvWYI Vd+CG7PNFA+Ke7B+f9WkzEIUPzAHq7qk1v7dOitD3WsRKndJDPxZAq7JrgOiF/0y 4726HhYR1bXOTziAbk0HzR+HwECo1vz26fqPnNpZ3M46PQFQU9uq2pgHtBwCVMQ+ Hi1pYKnB2+ITl11DBLacSHP7WZZGHXbEqW5Cc710m6aTt18L+OgqxuQSgV+khh+W qWqd2bLq32actLEVmfR4uWX7fh/g6I7/p3ohY7Ax4WC30RfWZk3vLyNc/8R0/67c bVIYWmkDhgXy6UlrV2ZgIO2K8oKiJBMHjnaueHIfu1ktubqM1/u1yLKwXW16UAxm 5QIDAQAB -----END PUBLIC KEY-----
À partir de là, l'enregistrement DANE ne correspond plus, la clé copiée à l'extérieur n'est plus la clé utilisée.
Avec certbot, la solution est de ne pas laisser le client ACME choisir le certificat, mais de fabriquer un CSR et de lui indiquer de l'utiliser systématiquement (cf. la documentation officielle) :
% certbot certonly --webroot -w /usr/share/nginx/local-html -d dns-resolver.yeti.eu.org --csr /etc/letsencrypt-local/yeti-resolver.csr --cert-path /etc/letsencrypt-local/tmp.pem No handlers could be found for logger "certbot.crypto_util" Saving debug log to /var/log/letsencrypt/letsencrypt.log Performing the following challenges: http-01 challenge for dns-resolver.yeti.eu.org Using the webroot path /var/lib/letsencrypt for all unmatched domains. Waiting for verification... Cleaning up challenges Server issued certificate; certificate written to /etc/letsencrypt-local/dns-resolver.yeti.eu.org.pem
Comment on avait fabriqué un CSR ? OpenSSL le permet. Faisons-en un joli, utilisant la cryptographie à courbes elliptiques :
% openssl ecparam -out yeti-resolver.pem -name prime256v1 -genkey % openssl req -new -key yeti-resolver.pem -nodes -days 1000 -out yeti-resolver.csr You are about to be asked to enter information that will be incorporated into your certificate request. ... Organization Name (eg, company) [Internet Widgits Pty Ltd]:Dahu Organizational Unit Name (eg, section) []: Common Name (e.g. server FQDN or YOUR name) []:dns-resolver.yeti.eu.org Email Address []:yeti@eu.org
Avec ce CSR, et en appelant certbot depuis
cron avec les options indiquées plus haut,
indiquant le même CSR (certbot certonly --webroot -w /usr/share/nginx/local-html -d dns-resolver.yeti.eu.org --csr /etc/letsencrypt-local/yeti-resolver.csr --cert-path /etc/letsencrypt-local/tmp.pem), la
clé reste constante, et DANE et HPKP fonctionnent. Petit
inconvénient : avec ces options, certbot renouvelle le certificat à
chaque fois, même quand ça n'est pas nécessaire. (Depuis l'écriture
initiale de cet article, certbot a ajouté l'option
--reuse-key, qui résout proprement le problème,
et est donc une meilleure solution que d'utiliser son CSR.)
Et si on utilise dehydrated au lieu de
certbot, comme client ACME ? Là, c'est plus simple, on met dans le fichier de
configuration /etc/dehydrated/config
l'option :
PRIVATE_KEY_RENEW="no"
Et cela suffit. Ceci dit, dehydrated a un gros inconvénient, il est bavard. Quand on le lance depuis cron, il affiche systématiquement plusieurs lignes, même s'il n'a rien à dire.
Pour revenir à la question du choix du sélecteur DANE (RFC 6698 et RFC 7218), il faut
noter que tout renouvellement change le certificat (puisqu'il modifie
au moins la date d'expiration). Il ne faut donc pas utiliser le
sélecteur 0 « Cert » (qui publie le
condensat du certificat entier dans
l'enregistrement TLSA) mais le sélecteur 1
« SPKI » (qui ne met que le condensat de la clé).
Le problème existe avec toutes les AC mais est plus aigu
pour Let's Encrypt où on renouvelle souvent. L'annexe A.1.2 du RFC 6698 l'explique bien.
Enfin, un avertissement de sécurité : avec les méthodes indiquées ici, le client ACME ne change plus de clé du tout. C'est donc désormais à vous de penser à créer une nouvelle clé de temps en temps, pour suivre les progrès de la cryptanalyse.
Si vous voulez des exemples concrets,
dns-resolver.yeti.eu.org (uniquement en
IPv6) utilise certbot, alors que
dns.bortzmeyer.org et
mercredifiction.bortzmeyer.org utilisent
dehydrated. Prenons dns.bortzmeyer.org. Son
enregistrement TLSA :
% dig TLSA _443._tcp.dns.bortzmeyer.org ... ;; ANSWER SECTION: _443._tcp.dns.bortzmeyer.org. 80968 IN TLSA 1 1 1 ( C05BF52EFAB00EF36AC6C8E1F96A25CC2A79CC714F77 055DC3E8755208AAD0E4 ) ... ;; Query time: 0 msec ;; SERVER: 127.0.0.1#53(127.0.0.1) ;; WHEN: Sat Dec 02 17:03:18 CET 2017 ;; MSG SIZE rcvd: 2311
Il déclare une contrainte sur le certificat du serveur (champ Certificate usage à 1, PKIX-EE), ne testant que la clé (champ Selector à 1), l'enregistrement est un condensat SHA-256 (champ Matching type à 1). On peut vérifier que l'enregistrement DANE est correct avec hash-slinger :
% tlsa --verify --resolvconf="" dns.bortzmeyer.org SUCCESS (Usage 1 [PKIX-EE]): Certificate offered by the server matches the one mentioned in the TLSA record and chains to a valid CA certificate (204.62.14.153) SUCCESS (Usage 1 [PKIX-EE]): Certificate offered by the server matches the one mentioned in the TLSA record and chains to a valid CA certificate (2605:4500:2:245b::42)
ou bien avec https://check.sidnlabs.nl/dane/
L'article seul
Choisir son résolveur DNS, pas si facile
Première rédaction de cet article le 28 novembre 2017
Le 26 novembre 2017, à la Cité des Sciences à Paris, j'ai fait un exposé lors de l'Ubuntu Party sur la question des critères de choix d'un bon résolveur DNS..
Les Ubuntu Party sont organisées par les bénévoles utilisateurs d'Ubuntu et comprennent une install party (des dizaines de personnes sont passées) et des exposés plus traditionnels. J'ai beaucoup aimé les deux exposés d'Elzen, le premier sur la piraterie et le piratage, et le second une « conférence dont vous êtes le héros », ainsi que l'exposé de Pamputt sur le remarquable Wiktionnaire, projet moins connu que Wikipédia mais tout aussi intéressant !
La question du choix d'un résolveur DNS fait toujours couler beaucoup d'encre sur les réseaux sociaux et a déjà fait l'objet de plusieurs articles sur ce blog, au sujet de Quad9, au sujet de Google Public DNS, à propos des résolveurs publics en général, de l'intérêt d'avoir son propre résolveur, de la protection de la vie privée (RFC 7626), de la censure, etc. Voici les transparents de l'exposé à l'Ubuntu Party :
- Version adaptée à l'écran,
- Version adaptée à l'impression,
- Source en LaTeX/Beamer.
L'exposé a été filmé, la vidéo est sur PeerTube.
L'article seul
Fiche de lecture : Artemis
Auteur(s) du livre : Andy Weir
Éditeur : Del Rey
9780091956943
Publié en 2017
Première rédaction de cet article le 21 novembre 2017
Le nouveau roman de l'auteur du Martien (oui, c'est nul de présenter un auteur par son bouquin précédent qui a eu du succès mais je n'avais pas d'autre idée). Il garde le côté « hard-tech », mais tend cette fois vers le polar.
Dans « Le Martien », le héros devait se débrouiller tout seul sur la planète Mars et l'un des principaux intérêts du roman était la description détaillée et correcte scientifiquement des différents problèmes qu'il affrontait, et de comment il les résolvait. Cette fois, ça se passe sur la Lune, et il s'agit de problèmes plus policiers, avec des méchants (très méchants), des complots et des sabotages (qui ont tout de suite un caractère plus dramatique quand il n'y a pas d'atmosphère dehors et qu'on ne peut donc pas sortir pour échapper au danger).
Comme le précédent, ce roman plaira aux geeks scientifiques. Ils y trouveront de la physique et de la chimie en quantité. Si vous le lisez en anglais, pensez à réviser la terminologie, notamment du monde de la soudure, qui joue un rôle essentiel dans le livre. « I wasn't sure what grade of steel [they] were made of, but most grades melt at or below 1450° C. So, just to be safe, my plate and stock rods were Grade 416 with a melting point of 1530° C. »
Mais les autres seront également ravis des personnages (surprenants), de la morale (curieuse), de l'intrigue (à rebondissements) et de l'(abondante) action. Mon fils, regardant par-dessus mon épaule, m'avait dit « c'est encore un livre où le héros affronte des épreuves, les surmonte puis pécho la jolie fille à la fin ? » Eh bien, non, ce n'est pas ça du tout, vous verrez en lisant.
L'article seul
RFC 8274: Incident Object Description Exchange Format Usage Guidance
Date de publication du RFC : Novembre 2017
Auteur(s) du RFC : P. Kampanakis (Cisco Systems), M. Suzuki (NICT)
Pour information
Réalisé dans le cadre du groupe de travail IETF mile
Première rédaction de cet article le 20 novembre 2017
Le format IODEF, dont la dernière version est décrite dans le RFC 7970, est un format structuré permettant l'échange de données sur des incidents de sécurité. Cela permet, par exemple, aux CSIRT de se transmettre des données automatiquement exploitables. Ces données peuvent être produites automatiquement (par exemple par un IDS, ou bien issues du remplissage manuel d'un formulaire). IODEF est riche, très riche, peut-être trop riche (certaines classes qu'il définit ne sont que rarement utilisées). Il peut donc être difficile de programmer des outils IODEF, et de les utiliser. (En pratique, il me semble qu'IODEF est peu utilisé.) Ce RFC, officiellement, est donc chargé d'aider ces professionnels, en expliquant les cas les plus courants et les plus importants, et en guidant programmeurs et utilisateurs.
Personnellement, je ne suis pas convaincu du résultat, ce RFC me semble plutôt un pot-pourri de diverses choses qui n'avaient pas été mises dans la norme.
La section 3 du RFC discute de l'utilisation de base d'IODEF. Reprenant la section 7.1 du RFC 7970, elle présente le document IODEF minimum, celui avec uniquement l'information obligatoire :
<?xml version="1.0" encoding="UTF-8"?>
<IODEF-Document version="2.00" xml:lang="en"
xmlns="urn:ietf:params:xml:ns:iodef-2.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.iana.org/assignments/xml-registry/schema/iodef-2.0.xsd">
<Incident purpose="reporting" restriction="private">
<IncidentID name="csirt.example.com">492382</IncidentID>
<GenerationTime>2015-07-18T09:00:00-05:00</GenerationTime>
<Contact type="organization" role="creator">
<Email>
<EmailTo>contact@csirt.example.com</EmailTo> <!-- Pas
réellement obligatoire, mais le document serait vraiment
sans intérêt sans lui. -->
</Email>
</Contact>
</Incident>
</IODEF-Document>
Un tel document, comportant
une instance de la classe Incident, qui comprend elle-même une
instance de la classe Contact, serait syntaxiquement correct mais
n'aurait guère d'intérêt pratique. Des documents un peu plus
réalistes figurent dans l'annexe B.
Le programmeur qui génère ou traite des fichiers IODEF n'a pas
forcément à mettre en œuvre la totalité des classes. Il peut se
contenter de ce qui est important pour son ou ses scénarios
d'utilisation. Par exemple, si on travaille sur les
dDoS, la classe Flow est la plus
importante, puisqu'elle décrit le trafic de l'attaque. (L'annexe
B.2 du RFC contient un fichier IODEF décrivant une attaque faite
avec LOIC. Je l'ai copié ici dans ddos-iodef.xml.) De même, si
on travaille sur le C&C d'un
logiciel malveillant, les classes
Flow et ServiceName
sont cruciales. Bref, il faut analyser ce dont on a besoin.
La section 4 du RFC mentionne les extensions à IODEF. Si riche que soit ce format, on peut toujours avoir besoin d'autres informations et c'est pour cela qu'IODEF est extensible. Par exemple, le RFC 5901 décrit une extension à IODEF pour signaler des cas de hameçonnage. Évidemment, on ne doit définir une extension que s'il n'existe pas de moyen existant de stocker l'information dans de l'IODEF standard.
La section 4 rappelle aussi aux développeurs que, certes, IODEF
bénéfice d'un mécanisme d'indication de la
confidentialité (l'attribut
restriction, qui se trouve dans les deux
exemples que j'ai cité), mais qu'IODEF ne fournit aucun
moyen technique de le faire respecter. Les documents IODEF étant
souvent sensibles, puisqu'ils parlent de problèmes de sécurité, le programmeur qui réalise un système de
traitement de fichiers IODEF doit donc mettre en œuvre des mesures
pratiques de protection de la confidentialité
(chiffrement des fichiers stockés, par
exemple).
Questions mise en œuvre d'IODEF, le RFC 8134 détaille des programmes existants, indique où les récupérer quand ils sont accessibles en ligne, et analyse leurs caractéristiques. C'est le cas par exemple d'iodeflib.
L'article seul
Quad9, un résolveur DNS public, et avec sécurité
Première rédaction de cet article le 16 novembre 2017
Aujourd'hui a été annoncé la disponibilité du résolveur DNS Quad9 (prononcer « quoi de neuf » en français). C'est un résolveur DNS public, mais dont l'originalité est d'être accessible de manière sécurisée, avec TLS (RFC 7858). (There is also an english version of this article.)
Des résolveurs DNS publics, il y en a plein. Le plus connu est Google Public DNS mais il en existe beaucoup d'autres, avec des politiques et des caractéristiques techniques diverses. Le fait que tant d'utilisateurs se servent aveuglément de Google Public DNS, malgré l'énorme quantité de données que Google connait déjà sur nous est inquiétant. Mais il y aussi un problème technique, commun à la plupart des résolveurs publics : le lien avec eux n'est pas sécurisé. Cela permet les détournements, comme vu en Turquie, ainsi que la surveillance par un tiers.
Au contraire, le nouveau service Quad9, géré par l'organisme sans but lucratif bien connu PCH, qui gère une bonne partie de l'infrastructure du DNS, Quad9, donc, permet un accès par DNS sur TLS (RFC 7858). Cela permet d'éviter l'écoute par un tiers, et cela permet d'authentifier le résolveur (je n'ai pas encore testé ce point, Quad9 ne semble pas distribuer de manière authentifiée ses clés publiques).
Question politique, notons encore que Quad9 s'engage à ne pas stocker votre adresse IP. Et que leur résolveur est un résolveur menteur : il ne répond pas (délibérement) pour les noms de domaines considérés comme lié à des activités néfastes comme la distribution de logiciel malveillant. On peut avoir un résolveur non-menteur en utilisant d'autres adresses mais on perd DNSSEC et surtout Quad9 se met à utiliser alors l'indication du réseau du client (RFC 7871), une mauvaise pratique pour la vie privée. Espérons qu'on aura bientôt une adresse pour les réponses non-menteuses, avec DNSSEC et sans l'indication du réseau du client.
Bon, passons maintenant à la pratique, sur une machine Unix. L'adresse IPv4 de Quad9,
comme son nom l'indique, est 9.9.9.9. Son
adresse IPv6 est 2620:fe::fe (cf. la FAQ). D'abord, un accès
classique en UDP en clair :
% dig +nodnssec @9.9.9.9 AAAA irtf.org
; <<>> DiG 9.10.3-P4-Ubuntu <<>> +nodnssec @9.9.9.9 AAAA irtf.org
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 11544
;; flags: qr rd ra ad; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;irtf.org. IN AAAA
;; ANSWER SECTION:
irtf.org. 1325 IN AAAA 2001:1900:3001:11::2c
;; Query time: 4 msec
;; SERVER: 9.9.9.9#53(9.9.9.9)
;; WHEN: Thu Nov 16 09:49:41 +08 2017
;; MSG SIZE rcvd: 65
On y voit que Quad9 valide avec DNSSEC (la réponse a bien le bit AD - Authentic Data).
Si le domaine est sur la liste noire de Quad9 (merci à Xavier Claude pour avoir trouvé un nom), le résolveur répond NXDOMAIN (No Such Domain, ce domaine n'existe pas) :
% dig @9.9.9.9 www.hjaoopoa.top
; <<>> DiG 9.10.3-P4-Debian <<>> @9.9.9.9 www.hjaoopoa.top
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 1143
;; flags: qr rd ad; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 4096
;; QUESTION SECTION:
;www.hjaoopoa.top. IN A
;; Query time: 17 msec
;; SERVER: 9.9.9.9#53(9.9.9.9)
;; WHEN: Sat Nov 18 20:30:41 CET 2017
;; MSG SIZE rcvd: 45
(Avec un résolveur non-menteur, on aurait eu le code de retour
NOERROR et l'adresse IP 54.213.138.248.)
Maintenant, testons la nouveauté importante de ce service, DNS sur TLS (RFC 7858). C'est du TLS donc on peut y aller avec openssl :
% openssl s_client -connect \[2620:fe::fe\]:853 -showcerts
depth=2 O = Digital Signature Trust Co., CN = DST Root CA X3
verify return:1
depth=1 C = US, O = Let's Encrypt, CN = Let's Encrypt Authority X3
verify return:1
depth=0 CN = dns.quad9.net
verify return:1
---
Certificate chain
0 s:/CN=dns.quad9.net
i:/C=US/O=Let's Encrypt/CN=Let's Encrypt Authority X3
-----BEGIN CERTIFICATE-----
...
1 s:/C=US/O=Let's Encrypt/CN=Let's Encrypt Authority X3
i:/O=Digital Signature Trust Co./CN=DST Root CA X3
...
Server certificate
subject=/CN=dns.quad9.net
issuer=/C=US/O=Let's Encrypt/CN=Let's Encrypt Authority X3
---
Peer signing digest: SHA512
Server Temp Key: ECDH, P-256, 256 bits
...
New, TLSv1.2, Cipher is ECDHE-RSA-AES256-GCM-SHA384
Server public key is 2048 bit
Secure Renegotiation IS supported
...
SSL-Session:
Protocol : TLSv1.2
Cipher : ECDHE-RSA-AES256-GCM-SHA384
...
On voit que Quad9 répond bien en TLS, et a un certificat Let's Encrypt.
Testons ensuite avec un client DNS, le
programme getdns_query distribué avec getdns :
% getdns_query @9.9.9.9 -s -l L www.afnic.fr AAAA
{
"answer_type": GETDNS_NAMETYPE_DNS,
"canonical_name": <bindata for lb01-1.nic.fr.>,
"just_address_answers":
[
{
"address_data": <bindata for 2001:67c:2218:30::24>,
"address_type": <bindata of "IPv6">
}
...
(Oui, getdns_query est très bavard.) L'option
-l L lui dit d'utiliser DNS sur TLS.
On va d'ailleurs utiliser tshark pour vérifier qu'on est bien en TLS :
% tshark -n -i wlp2s0 -d tcp.port==853,ssl host 9.9.9.9 Capturing on 'wlp2s0' 1 0.000000000 31.133.136.116 → 9.9.9.9 TCP 74 37874 → 853 [SYN] Seq=0 Win=29200 Len=0 MSS=1460 SACK_PERM=1 TSval=233018174 TSecr=0 WS=128 2 0.002518390 9.9.9.9 → 31.133.136.116 TCP 74 853 → 37874 [SYN, ACK] Seq=0 Ack=1 Win=28960 Len=0 MSS=1460 SACK_PERM=1 TSval=873811762 TSecr=233018174 WS=256 3 0.002551638 31.133.136.116 → 9.9.9.9 TCP 66 37874 → 853 [ACK] Seq=1 Ack=1 Win=29312 Len=0 TSval=233018175 TSecr=873811762 4 0.002642065 31.133.136.116 → 9.9.9.9 SSL 371 Client Hello 5 0.022008585 9.9.9.9 → 31.133.136.116 TLSv1.2 1514 Server Hello 6 0.022042645 31.133.136.116 → 9.9.9.9 TCP 66 37874 → 853 [ACK] Seq=306 Ack=1449 Win=32128 Len=0 TSval=233018180 TSecr=873811781 7 0.022050371 9.9.9.9 → 31.133.136.116 TLSv1.2 108 [TCP Previous segment not captured] , Ignored Unknown Record 8 0.022054712 31.133.136.116 → 9.9.9.9 TCP 78 [TCP Window Update] 37874 → 853 [ACK] Seq=306 Ack=1449 Win=35072 Len=0 TSval=233018180 TSecr=873811781 SLE=2897 SRE=2939 9 0.022667110 9.9.9.9 → 31.133.136.116 TCP 1514 [TCP Out-Of-Order] 853 → 37874 [ACK] Seq=1449 Ack=306 Win=30208 Len=1448 TSval=873811781 TSecr=233018175 10 0.022679278 31.133.136.116 → 9.9.9.9 TCP 66 37874 → 853 [ACK] Seq=306 Ack=2939 Win=37888 Len=0 TSval=233018180 TSecr=873811781 11 0.023537602 31.133.136.116 → 9.9.9.9 TLSv1.2 192 Client Key Exchange, Change Cipher Spec, Encrypted Handshake Message 12 0.037713598 9.9.9.9 → 31.133.136.116 TLSv1.2 117 Change Cipher Spec, Encrypted Handshake Message 13 0.037888417 31.133.136.116 → 9.9.9.9 TLSv1.2 225 Application Data 14 0.093441153 9.9.9.9 → 31.133.136.116 TCP 66 853 → 37874 [ACK] Seq=2990 Ack=591 Win=31232 Len=0 TSval=873811853 TSecr=233018184 15 0.742375719 9.9.9.9 → 31.133.136.116 TLSv1.2 178 Application Data ...
Le -d tcp.port==853,ssl était là pour dire à
tshark d'interpréter ce qui passe sur le
port 853 (celui de DNS-sur-TLS) comme étant
du TLS. On voit bien le dialogue TLS mais
évidemment pas les questions et réponses DNS puisque tout est
chiffré.
Bien, maintenant que les tests se passent bien, comment utiliser Quad9 pour la vraie résolution de noms ? On va utiliser stubby pour parler à Quad9. Le fichier de configuration Stubby sera du genre:
listen_addresses:
- 0::1@8053
# https://github.com/getdnsapi/getdns/issues/358
dns_transport_list:
- GETDNS_TRANSPORT_TLS
upstream_recursive_servers:
# Quad9
- address_data: 9.9.9.9
tls_auth_name: "dns.quad9.net"
- address_data: 2620:fe::fe
tls_auth_name: "dns.quad9.net"
On indique à stubby d'écouter sur l'adresse locale
::1, port 8053, et de faire suivre les
requêtes en DNS sur TLS à 9.9.9.9 ou
2620:fe::fe. On lance stubby :
% stubby [12:28:10.942595] STUBBY: Read config from file /usr/local/etc/stubby/stubby.yml [12:28:10.942842] STUBBY: Starting DAEMON....
Et on peut le tester, en utilisant dig pour interroger à l'adresse et au port indiqué :
% dig @::1 -p 8053 A www.catstuff.com ; <<>> DiG 9.10.3-P4-Ubuntu <<>> @::1 -p 8053 A www.catstuff.com ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 20910 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 65535 ;; QUESTION SECTION: ;www.catstuff.com. IN A ;; ANSWER SECTION: www.catstuff.com. 600 IN A 216.157.88.24 ;; Query time: 974 msec ;; SERVER: ::1#8053(::1) ;; WHEN: Thu Nov 16 20:29:26 +08 2017 ;; MSG SIZE rcvd: 77
Et on peut vérifier avec tshark ou tcpdump que Stubby parle bien avec Quad9, et en utilisant TLS.
Si, à ce stade, vous obtenez une réponse DNS
FORMERR (FORmat ERRor) au
lieu du NOERROR qu'on voit ci-dessus, c'est à
cause de cette
bogue et il faut mettre à jour la bibliothèque getdns
utilisée par Stubby.
Stubby a l'avantage de bien gérer TCP, notamment en réutilisant les connexions (il serait très coûteux d'établir une connexion TCP pour chaque requête DNS, surtout avec TLS par dessus). Mais il n'a pas de cache des réponses, ce qui peut être ennuyeux si on est loin de Quad9. Pour cela, le plus simple est d'ajouter un vrai résolveur, ici Unbound. On le configure ainsi :
server:
interface: 127.0.0.1
do-not-query-localhost: no
forward-zone:
name: "."
forward-addr: ::1@8053
Avec cette configuration, Unbound va écouter sur l'adresse
127.0.0.1 (sur le port par défaut, 53, le
port du DNS) et relayer les requêtes pour lesquelles il n'a pas
déjà une réponse dans son cache vers Stubby
(::1, port 8053). Interrogeons Unbound :
% dig @127.0.0.1 A mastodon.gougere.fr
; <<>> DiG 9.10.3-P4-Ubuntu <<>> @127.0.0.1 A mastodon.gougere.fr
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 40668
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 4096
;; QUESTION SECTION:
;mastodon.gougere.fr. IN A
;; ANSWER SECTION:
mastodon.gougere.fr. 600 IN A 185.167.17.10
;; Query time: 2662 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: Thu Nov 16 20:36:09 +08 2017
;; MSG SIZE rcvd: 64
Unbound a une mémoire (le cache) donc si on recommance la requête aussitôt, la réponse arrivera bien plus vite et on verra le TTL (600 secondes ici) diminué.
Si vous trouvez que tout cela est bien compliqué à installer/configurer, vous pouvez vous servir d'une image Docker, faite par Juzam (voir aussi sur Github).
On note qu'il n'est pas évident de trouver une adresse IPv4
facilement mémorisable comme 9.9.9.9. L'examen
de DNSDB montre que cette adresse a
beaucoup servi avant d'arriver chez PCH, et pour des activités… que
certains peuvent trouver contestables. Cette adresse, sérieusement
marquée, est donc noirlistée à plusieurs endroits. Si cela ne
marche pas de chez vous, essayez d'ailleurs, ou alors en IPv6. On
voit bien cette imparfaite connectivité en testant avec les sondes RIPE Atlas et le programme atlas-reach, comparant Quad9 et Google
Public DNS :
% atlas-resolve -r 200 -e 9.9.9.9 --nsid -t AAAA irtf.org Nameserver 9.9.9.9 [ERROR: SERVFAIL] : 1 occurrences [TIMEOUT] : 9 occurrences [2001:1900:3001:11::2c] : 177 occurrences Test #10205081 done at 2017-11-16T01:41:40Z % atlas-resolve -r 200 -e 8.8.8.8 -g 10205081 --nsid -t AAAA irtf.org Nameserver 8.8.8.8 [TIMEOUT] : 1 occurrences [2001:1900:3001:11::2c] : 186 occurrences Test #10205089 done at 2017-11-16T01:46:38Z
Et merci à Sara Dickinson pour son aide technique.
Si vous vous intéressez aux questions plus politiques, vous pouvez consulter l'article critique de sha_5_1_2 ainsi que la la réponse très détaillée du directeur de Quad9.
L'article seul
RFC 8261: Datagram Transport Layer Security (DTLS) Encapsulation of SCTP Packets
Date de publication du RFC : Novembre 2017
Auteur(s) du RFC : M. Tuexen (Muenster Univ. of Appl. Sciences), R. Stewart (Netflix), R. Jesup (WorldGate Communications), S. Loreto (Ericsson)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tsvwg
Première rédaction de cet article le 16 novembre 2017
Le protocole de transport SCTP est normalement prévu pour tourner directement sur IP. Pour diverses raisons, il peut être utile de le faire tourner sur un autre protocole de transport comme UDP (ce que fait le RFC 6951) ou même sur un protocole qui offre des services de sécurité comme DTLS (ce que fait notre nouveau RFC).
SCTP est défini dans le RFC 4960. C'est un concurrent de TCP, offrant un certain nombre de services que TCP ne fait pas. DTLS, normalisé dans le RFC 6347, est un protocole permettant d'utiliser les services de sécurité de TLS au-dessus d'UDP. Il est notamment très utilisé par WebRTC (RFC 8827), lui donnant ainsi une sécurité de bout en bout.
En théorie, SCTP peut fonctionner directement sur IP. Hélas, dans l'Internet actuel, très ossifié, plein d'obstacles s'y opposent. Par exemple, les routeurs NAT tel que la box de M. Michu à la maison, n'acceptent en général que TCP et UDP. Et bien des pare-feux bloquent stupidement les protocoles que leurs auteurs sont trop ignorants pour connaître. En pratique, donc, SCTP ne passe pas partout. L'encapsuler dans un autre protocole de transport, comme UDP (directement, ou bien via DTLS), est souvent la seule solution pour avoir une connectivité. L'intérêt de DTLS est qu'on a toute la sécurité de TLS, notamment la confidentialité via le chiffrement.
Cette encapsulation est simple (section 3) : on met le paquet SCTP, avec ses en-têtes et sa charge utile, dans les données du paquet DTLS.
Il y a toutefois quelques détails à prendre en compte (section 4 de notre RFC). Par exemple, comme toute encapsulation prend quelques octets, la MTU diminue. Il faut donc un système de PMTUD. Comme l'encapsulation rend difficile l'accès à ICMP (voir la section 6) et que les middleboxes pénibles dont je parlais plus haut bloquent souvent, à tort, ICMP, cette découverte de la MTU du chemin doit pouvoir se faire sans ICMP (la méthode des RFC 4821 et RFC 8899 est recommandée).
Cette histoire de MTU concerne tout protocole encapsulé. Mais il y a aussi d'autres problèmes, ceux liés aux spécificités de SCTP (section 6) :
- Il faut évidemment établir une session DTLS avant de tenter l'association SCTP (« association » est en gros l'équivalent de la connexion TCP),
- On peut mettre plusieurs associations SCTP sur la même session DTLS, elles sont alors identifiées par les numéros de port utilisés,
- Comme DTLS ne permet pas de jouer avec les adresses IP (en ajouter, en enlever, etc), on perd certaines des possibilités de SCTP, notamment le multi-homing, pourtant un des gros avantages théoriques de SCTP par rapport à TCP,
- Pour la même raison, SCTP sur DTLS ne doit pas essayer d'indiquer aux couches inférieures des adresses IP à utiliser,
- SCTP sur DTLS ne peut pas compter sur ICMP, qui sera traité plus bas, et doit donc se débrouiller sans lui.
Cette norme est surtout issue des besoins de WebRTC, dont les implémenteurs réclamaient un moyen facile de fournir sécurité et passage à travers le NAT. Elle est mise en œuvre depuis longtemps, dans des clients WebRTC comme Chrome, Firefox ou Opera.
L'article seul
RFC 8272: TinyIPFIX for Smart Meters in Constrained Networks
Date de publication du RFC : Novembre 2017
Auteur(s) du RFC : C. Schmitt, B. Stiller (University of Zurich), B. Trammell (ETH Zurich)
Pour information
Première rédaction de cet article le 15 novembre 2017
Le format IPFIX, normalisé dans le RFC 7011, permet à un équipement réseau d'envoyer des données résumées à un collecteur, à des fins d'études ou de supervision. À l'origine, l'idée était que l'équipement réseau soit un routeur, une machine relativement grosse, munie de suffisamment de ressources pour pouvoir s'accomoder d'un protocole un peu compliqué, et qui nécessite l'envoi de pas mal d'octets. L'IPFIX original était donc peu adapté aux engins contraints, par exemple aux capteurs connectés. D'où cette variante d'IPFIX, TinyIPFIX, qui vise à être utilisable par des objets connectés comme ceux utilisant le 6LoWPAN du RFC 4944 (un compteur Linky ?)
Mais prenons plutôt comme exemple un capteur non connecté au réseau électrique (donc dépendant d'une batterie, qu'on ne peut pas recharger tout le temps, par exemple parce que le capteur est dans un lieu difficile d'accès) et n'ayant comme connexion au réseau que le WiFi. L'émission radio coûte cher en terme d'énergie et notre capteur va donc souvent éteindre sa liaison WiFi, sauf quand il a explicitement quelque chose à transmettre. Un protocole de type pull ne peut donc pas convenir, il faut du push, que le capteur envoie ses données quand il le décide. Ces contraintes sont détaillées dans « Applications for Wireless Sensor Networks », par l'auteure du RFC (pas trouvé en ligne, c'est publié dans le livre « Handbook of Research on P2P and Grid Systems for Service-Oriented Computing: Models, Methodologies and Applications », édité par Antonopoulos N.; Exarchakos G.; Li M.; Liotta A. chez Information Science Publishing).
Le RFC donne (section 3) l'exemple de l'IRIS de Crossbow : sa taille n'est que de 58 x 32 x 7 mm, et il a 128 ko de flash pour les programmes (512 ko pour les données mesurées), 8 ko de RAM et 4 d'EEPROM pour sa configuration. On ne peut pas demander des miracles à un objet aussi contraint. (Si c'est vraiment trop peu, le RFC cite aussi l'engin d'Advantic avec ses 48 ko de flash « programme », 1024 ko de flash « données », 10 ko de RAM et 16 d'EEPROM.) Question énergie, ce n'est pas mieux, deux piles AA de 2 800 mAh chacune peuvent donner en tout 30 240 J.
Autre contrainte vécue par ces pauvres objets connectés, les limites du protocole réseau (section 3.3 de notre RFC). 6LoWPAN (RFC 4944) utilise IEEE 802.15.4. Ce protocole ne porte que 102 octets par trame. Ce n'est pas assez pour IPv6, qui veut une MTU minimum de 1 280 octets. Il faut donc utiliser la fragmentation, un mécanisme problématique, notamment parce que, si un seul fragment est perdu (et ces pertes sont des réalités, sur les liaisons radio), il faut retransmettre tout le paquet. Il est donc prudent de s'en tenir à des paquets assez petits pour tenir dans une trame. C'est un des apports de TinyIPFIX par rapport au IPFIX classique : des messages plus petits.
Enfin, dernière contrainte, le protocole de transport. IPFIX impose (RFC 7011, section 10.1) que SCTP soit disponible, même s'il permet aussi UDP et TCP. Mais SCTP (et TCP) ne permettent pas d'utiliser les mécanismes de compression des en-têtes de 6LoWPAN. Et SCTP n'est pas toujours présent dans les systèmes d'exploitation des objets, par exemple TinyOS. TinyIPFIX utilise donc UDP. À noter que, comme le demande la section 6.2 du du RFC 5153, TinyIPFIX sur UDP n'est pas prévu pour l'Internet ouvert, mais uniquement pour des réseaux fermés.
TinyIPFIX est dérivé de IPFIX (RFC 7011) et en hérite donc de la plupart des concepts, comme la séparation des données (Data Sets) et de la description des données (dans des gabarits, transmis en Template Sets).
La section 4 du RFC décrit des scénarios d'usage. Comme TinyIPFIX (comme IPFIX) est undirectionnel (de l'exporteur vers le collecteur), et qu'il tourne sur UDP (où les messages peuvent se perdre), le développeur doit être conscient des limites de ce service. Si on perd un paquet de données, on perd des données. Pire, si on perd un paquet de gabarit (RFC 7011, sections 3.4.1 et 8), on ne pourra plus décoder les paquets de données suivants. On ne doit donc pas utiliser TinyIPFIX pour des systèmes où la perte de données serait critique. Un système d'accusés de réception et de retransmission (refaire une partie de TCP, quoi…) serait trop lourd pour ces engins contraints (il faudrait stocker les messages en attendant l'accusé de réception).
Le RFC recommande de renvoyer les paquets de gabarit de temps en temps. C'est normalement inutile (on n'imagine pas un capteur contraint en ressources changer de gabarit), mais cela permet de compenser le risque de perte. Le collecteur qui, lui, n'a pas de contraintes, a tout intérêt à enregistrer tous les messages, même quand il n'y a pas de gabarit, de manière à pouvoir les décoder quand le gabarit arrivera. (Normalement, on ne fait pas ça avec IPFIX, le gabarit ne peut s'appliquer qu'aux messages reçus après, mais, avec TinyIPFIX, il y a peu de chances que les gabarits changent.)
Le RFC donne un exemple animalier qui conviendrait au déploiement de TinyIPFIX, afin de surveiller des oiseaux (Szewczyk, R., Mainwaring, A., Polastre, J., et D. Culler, « An analysis of a large scale habitat monitoring application ».) Les capteurs notent ce que font ces charmants animaux et le transmettent.
Cet exemple sert à illustrer un cas où TinyIPFIX serait bien adapté : collecte de type push, efficacité en terme de nombre de paquets, perte de paquets non critique, pas de nécessité d'un estampillage temporel des messages (qui existe dans IPFIX mais que TinyIPFIX supprime pour alléger le travail).
La section 5 décrit l'architecture de TinyIPFIX, très similaire à celle d'IPFIX (RFC 5470).
Enfin, la section 6 décrit les aspects concrets de TinyIPFIX, notamment le format des messages. Il ressemble beaucoup à celui d'IPFIX, avec quelques optimisations pour réduire la taille des messages. Ainsi, l'en-tête de message IPFIX fait toujours 16 octets, alors que dans TinyIPFIX, il est de taille variable, avec seulement 3 octets dans le meilleur des cas. C'est ainsi que des champs comme le numéro de version (qui valait 11 pour IPFIX) ont été retirés. De même, l'estampille temporelle (« Export Time » dans IPFIX) est partie (de toute façon, les objets contraints ont rarement une horloge correcte).
Les objets contraints déployés sur le terrain n'ont souvent pas à un accès direct à Internet, à la fois pour des raisons de sécurité, et parce qu'un TCP/IP complet serait trop lourd pour eux. Il est donc fréquent qu'ils doivent passer par des relais qui ont, eux, un vrai TCP/IP, voire un accès Internet. (Cette particularité des déploiements d'objets connectés est une des raisons pour lesquelles le terme d'« Internet des Objets » n'a pas de valeur autre que marketing.)
TinyIPFIX va donc fonctionner dans ce type d'environnement et la section 7 de notre RFC décrit donc le mécanisme d'« intermédiation ». L'intermédiaire peut, par exemple, transformer du TinyIPFIX/UDP en TinyIPFIX/SCTP ou, carrément, du TinyIPFIX en IPFIX. Dans ce dernier cas, il devra ajouter les informations manquantes, comme l'estampille temporelle ou bien le numéro de version.
Côté mise en œuvre, Tiny IPFIX a été mis dans
TinyOS et
Contiki. Voir http://www.net.in.tum.de/pub/cs/TinyIPFIX_GUI_Licenced.zip
et http://www.net.in.tum.de/pub/cs/TinyIPFIX_and_Extentions_Licenced.zip.
L'article seul
Fiche de lecture : Une toile large comme le monde
Auteur(s) du livre : Aude Seigne
Éditeur : Zoe
978-2-88927-458-1
Publié en 2017
Première rédaction de cet article le 5 novembre 2017
La cybercatastrophe (plus d'Internet, tout cassé, plus de vidéos de chat) est un thème fréquent dans les médias mais un peu moins dans les romans. Aude Seigne s'y est attelée dans son dernier roman, « Une toile large comme le monde ».
Le roman suit plusieurs personnages plutôt bien intégrés dans la société, plutôt mondialisés, n'ayant pas des boulots idiots (il n'y a jamais de caissière de supermarché, encore moins de vendeur des rues, dans les romans). Mais, pour des raisons diverses, ils décident d'arrêter Internet. Je ne vous en dis pas plus sur l'intrigue.
Disons-le tout de suite, je n'ai pas aimé le roman : l'auteure saute allègrement des pans entiers de son histoire, on ne comprend pas vraiment les motivations des personnages (qui passent pourtant tou·te·s beaucoup de temps à se regarder le nombril en en parlant), et les détails de la constitution et de la coordination de leur groupe sont à peine esquissés. Ça ne peut pourtant pas être aussi simple de monter un complot mondial !
Mais la partie de description de l'infrastructure d'Internet est bien faite, détaillant des aspects de son fonctionnement qui sont peu traités, que ce soit dans les cours d'informatique ou dans les romans. Elle a raison de pointer du doigt que tout le monde aujourd'hui dépend d'Internet, sans avoir la moindre idée de son fonctionnement (et je ne parle pas de la technique, juste des acteurs impliqués). J'ai bien aimé la citation « Ce n’est pas parce qu’on est YouTuber, joueur, programmeur, hacker ou community manager qu’on connaît l’existence des câbles », qui est quasiment celle par laquelle je commence mon cours au CELSA. Je vais réclamer des droits d'auteur 😃 Mais je préfère encore plus une autre phrase de l'auteure, « Internet n'est pas un esprit, il a besoin d'un corps » (et ce corps n'est pas uniquement composé de câbles et de machines).
Outre les câbles, largement décrits dans le roman (ainsi que les centres de données, à l'occasion d'une visite plus pédagogique que littéraire), l'auteure parle aussi des gens qui sont derrière le réseau, ce qui est utile, même si elle verse parfois dans le sensationnalisme (« Ils [les ingénieurs réseaux] sont seulement quelques centaines, à l'échelle mondiale, et ils se réunissent deux à trois fois par an [probablement une allusion aux réunions NANOG]. »).
Techniquement, n'attendez pas de détails sur les techniques utilisées pour arrêter l'Internet. Le livre est globalement bien documenté mais comprend plusieurs exagérations. C'est le cas, par exemple, de l'apparition dans une liste de pannes partielles de l'Internet, de « 2014 ― Panne importante à l'échelle mondiale, suscitée par le dépassement de la limite des 512 000 routes, que d'anciens modèles de routeurs ne peuvent prendre en charge » (alors qu'il ne s'était en fait pas passé grand'chose). Si vous voulez approfondir cette question de la résilience d'Internet, vous pouvez aussi lire mon article au SSTIC.
Il y a eu un article d'Usbek & Rica sur ce livre. Comme souvent dans les médias, l'article ne tient pas les promesses du titre. Le titre parle de couper Internet, et ensuite c'est juste « en 2016, une cyberattaque [celle contre Dyn] prive des millions d’Américains d’accès aux plus grands sites pendant une dizaine d’heures… ». C'est une erreur courante des analyses de la robustesse de l'Internet que de confondre les pannes locales et limitées dans le temps (relativement fréquentes et difficiles à empêcher) avec une vraie cybercastrophe stoppant presque tout l'Internet pendant des semaines.
On trouve aussi dans cet article des grosses bêtises du genre « avoir une boîte mail remplie à ras-bord et pleine de spams est désormais aussi condamnable que de ne pas trier ses déchets ».
Voici la page officielle du livre. Mais, comme vous vous en doutez, je préfère recommander, pour le lecteur intéressé par le « corps d'Internet », le livre Tubes d'Andrew Blum.
L'article seul
RFC 8280: Research into Human Rights Protocol Considerations
Date de publication du RFC : Octobre 2017
Auteur(s) du RFC : N. ten Oever (Article 19), C. Cath (Oxford Internet Institute)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF hrpc
Première rédaction de cet article le 2 novembre 2017
Ce RFC très politique est le premier du groupe de recherche IRTF HRPC, dont le nom veut dire « Human Rights and Protocol Considerations ». À première vue, il n'y a pas de rapport entre les droits humains et les protocoles réseau. Les premiers relèvent de la politique, les seconds de la pure technique, non ? Mais, justement, le groupe HRPC a été créé sur la base de l'idée qu'il y a de la politique dans le travail de l'IETF, que les protocoles ne sont pas complètement neutres, et qu'il était nécessaire de creuser cette relation complexe entre protocoles et droits humains. Le premier RFC analyse le problème de base : « TCP/IP est-il politique ? »
Si vous êtes un concepteur de protocoles, plutôt porté sur le concret, et que les discussions politiques vous gonflent, vous pouvez passer directement à la section 6 du RFC, qui est la check-list Droits Humains pour votre prochain protocole ou format. En la suivant, vous pourrez plus facilement vérifier que votre création n'a pas trop d'effets néfastes, question droits humains. (Depuis, il vaut mieux consulter le RFC 9620, qui la remplace.)
Ce RFC n'est pas le premier RFC « politique », et il ne faudrait pas croire que les ingénieur·e·s qui participent à l'IETF sont tou·ṫe·s des nerds asociaux avec la conscience politique d'un poisson rouge. Parmi les RFC politiques, on peut citer le RFC 1984 (refus d'affaiblir la cryptographie), le RFC 7258 (post-Snowden, RFC affirmant que la surveillance de masse est une attaque contre l'Internet, et qu'il faut déployer des mesures techniques la rendant plus difficile), et bien sûr l'excellent RFC 6973, sur la vie privée, qui sert largement de modèle à notre RFC 8280.
Le groupe de recherche IRTF HRPC va donc travailler sur deux axes (section 3 de notre RFC) :
- Est-ce que les protocoles Internet ont des conséquences en matière de droits humains et, si oui, comment ?
- Si la réponse à la première question est positive, est-il possible d'améliorer ces protocoles, afin de faire en sorte que les droits humains soient mieux protégés ?
Ce RFC particulier a eu une gestation de plus de deux ans. Deux des étapes importantes avaient été la réunion IETF 92 à Dallas, et la réunion IETF 95 à Buenos Aires. À la seconde, vu les opinions politiques de beaucoup des participant·e·s, l'après-réunion s'est tenu dans un restaurant végétarien. En Argentine…
La section 1 du RFC rappelle les nombreux débats qui ont agité le monde de l'Internet sur le rôle politique de ce réseau. Deux belles citations ouvrent cette section, une de Tim Berners-Lee qui dit « There's a freedom about the Internet: As long as we accept the rules of sending packets around, we can send packets containing anything to anywhere. » et un extrait du RFC 3935 « The Internet isn't value-neutral, and neither is the IETF. ». Et le RFC 3935 continue : « We want the Internet to be useful for communities that share our commitment to openness and fairness. We embrace technical concepts such as decentralized control, edge-user empowerment and sharing of resources, because those concepts resonate with the core values of the IETF community. These concepts have little to do with the technology that's possible, and much to do with the technology that we choose to create. ». Le succès immense de l'Internet, contre tous les prophètes de malheur qui prétendaient que ce réseau, qui n'avait pas été conçu par des Messieurs Sérieux, ne pourrait jamais marcher, fait que l'impact social et politique des techniques de la famille TCP/IP est énorme. On trouve donc logiquement de nombreux textes qui affirment que « ce grand pouvoir donne à l'Internet de grandes responsabilités », par exemple cette résolution des Nations Unies, ou bien la déclaration de NETmundial. Une position plus radicale est qu'il faut défendre et renforcer l'Internet, car il serait intrinsèquement un outil aux services des droits humains.
En effet, la connectivité de bout en bout, tout le monde peut parler à tous ceux qui veulent bien, Alice et Bob peuvent échanger sans autorisation, est à la fois un principe fondamental de l'Internet (cf. RFC 1958) et un puissant soutien aux droits humains. Pour citer Benjamin Bayart, « L’imprimerie a permis au peuple de lire, Internet va lui permettre d’écrire. » L'architecture de l'Internet est ouverte (je me souviens de techniciens d'un opérateur de télécommunications historique qui avaient poussé des cris d'horreur quand je leur avais montré traceroute, au début des années 1990. Ils avaient tout de suite demandé comment empêcher le client de regarder l'intérieur du réseau de l'opérateur.) Les normes techniques de l'Internet sont développées selon un processus ouvert, et sont librement distribuées (ce que ne font toujours pas les dinosaures de la normalisation comme l'AFNOR ou l'ISO). En prime, une bonne partie de l'infrastructure de l'Internet repose sur du logiciel libre.
L'Internet a prouvé qu'il pouvait continuer à fonctionner en environnement hostile (RFC 1984 et RFC 3365). Les RFC politiques cités plus haut défendent tous des valeurs qui vont dans le sens des droits humains (par exemple la vie privée, dans les RFC 6973 et RFC 7258). Cela ne va pas de soi : une organisation comme l'UIT n'en a jamais fait autant et développe au contraire des technologies hostiles aux droits humains comme les techniques de surveillance dans le NGN.
On pourrait peut-être même dire que non seulement l'Internet défend les droits humains, mais que ceux-ci sont à la base de l'architecture de l'Internet. (Cf. Cath, C. and L. Floridi, « The Design of the Internet's Architecture by the Internet Engineering Task Force (IETF) and Human Rights », 2017.) On peut citer ici Bless, R. et C. Orwat, « Values and Networks » : « to a certain extent, the Internet and its protocols have already facilitated the realization of human rights, e.g., the freedom of assembly and expression. In contrast, measures of censorship and pervasive surveillance violate fundamental human rights. » ou bien Denardis, L., « The Internet Design Tension between Surveillance and Security » « Since the first hints of Internet commercialization and internationalization, the IETF has supported strong security in protocol design and has sometimes served as a force resisting protocol-enabled surveillance features. ».
Mais la question reste chaudement débattue à l'IETF. Nombreux sont les techniciens qui grommelent « tout ça, c'est de la politique, cela ne nous concerne pas », voire reprennent l'argument classique de la neutralité de la technique « un outil est neutre, c'est l'usage qu'on en fait qui compte, le fabricant du couteau n'est pas responsable d'un meurtre qu'on commet avec ce couteau, donc on ne doit pas se poser la question des droits humains ». Avant Snowden, c'était sans doute l'opinion dominante à l'IETF, mais cela a changé depuis.
Mais, au fait, ce sont quoi, les Droits Humains avec leur majuscule ? Ce sont des droits universels, indivisibles et inaliénables, formalisés dans des textes comme la Déclaration Universelle des Droits de l'Homme ou comme le pacte international relatif aux droits civils et politiques ou le Pacte international relatif aux droits économiques, sociaux et culturels. La section 2 du RFC, sur la terminologie, discute en détail cette définition. Si vous voulez un document unique sur les droits humains, la DUDH citée plus haut est une lecture recommandée. Le fait qu'ils soient universels est important : on entend régulièrement des dirigeants ou des lécheurs de bottes des dirigeants prétendre que les droits humains ne sont pas bons pour le peuple qu'ils oppriment, qu'ils seraient uniquement pour certaines catégories de l'humanité. Si c'était le cas, il serait en effet inutile de discuter des droits humains sur l'Internet, puisque celui-ci connecte tout le monde. Mais, bien sûr, cette soi-disant relativité des droits humains est de la pure rhétorique malhonnête au service de dictateurs locaux.
On notera que, à l'époque de la rédaction de la DUDH, le seul risque de violation envisagée était l'œuvre des États, mais que l'idée s'est imposée depuis que des acteurs non-étatiques pouvaient également être concernés.
Cela ne veut pas dire que les textes comme la DUDH citée plus haut sont parfaits. Ce ne sont pas des textes sacrés, mais le résultat d'un processus politique. Comme toute œuvre humaine, ils peuvent être améliorés, mais il faut juste garder en tête que ceux qui les critiquent ne cherchent pas en général à les améliorer, mais à les affaiblir, voire à les détruire.
Par contre, les droits humains ne sont pas absolus. Un exemple de ce caractère non-absolu des droits humains est qu'ils peuvent être en conflit entre eux. Par exemple, le droit à la liberté d'expression peut rentrer en contradiction avec le droit de ne pas être insulté ou harcelé. Ou avec le droit à la vie privée. Les droits humains ne pourront donc pas être mis en algorithmes.
La section 2 de notre RFC est consacrée à la terminologie. Sujet très difficile car elle est souvent floue dans les domaines liés à la sécurité. Je ne vais pas la reproduire en entier ici (la section est longue, en partie en raison du caractère transversal de notre RFC, cf. section 5.2.1.3), juste noter quelques définitions qui ont fait des histoires (listées dans l'ordre alphabétique de l'original en anglais). Notez que notre RFC 8280 ne fait souvent que reprendre des définitions de RFC précédents. Ainsi, la définition de « connectivité Internet complète » vient du RFC 4084 (et est nécessaire car bien des malhonnêtes vendent comme « accès Internet » des offres plus ou moins bridées). De même le RFC 4949, sur le vocabulaire de la sécurité, et le RFC 6973, sur la vie privée, sont très mis à contribution.
En parlant de vie privée, la définition d'« anonymat » est un des premiers problèmes de terminologie. Le terme est utilisé à tort et à travers dans les médias (« Bitcoin est une monnaie anonyme ») et souvent confondu avec pseudonymat. À leur décharge, il faut dire que les définitions du RFC 4949 et du RFC 6973 sont très abstraites.
Parmi les autres définitions plutôt vagues, notons celle de « neutralité par rapport au contenu » (content agnosticism). C'est bien sûr un concept très important, d'autant plus que cette neutralité est menacée, mais la définition ne va pas très loin. Ce n'est pas mieux pour un autre concept important mais flou, et difficile à saisir, celui de décentralisation, un peu utilisé à toutes les sauces aujourd'hui (cf. mon article pour JRES).
Passons maintenant au principe de bout en bout. C'est un des concepts clés de l'Internet (RFC 2775) : l'« intelligence » (les traitements compliqués) doit être aux extrémités, pas dans le réseau. Plusieurs raisons militent en faveur de ce principe mais, pour en rester aux droits humains, notons surtout que ce principe se traduit par « touche pas à mes données ».
Autre sujet difficile à définir, les « normes ouvertes » (open standards). Il y a plein de SDO, dont le degré d'ouverture varie considérablement. Par exemple, l'ISO ou l'IEEE ne publient pas leurs normes en ligne et, même si on les acquiert, on n'a pas le droit de les redistribuer. L'UIT ne permet de participer que si vous êtes gouvernement ou grande entreprise. L'IETF, sans doute la SDO la plus ouverte, n'a pas de définition claire de ce qu'est une norme ouverte (cf. RFC 2026), à part dans le RFC 6852, qui est surtout un document politicien (et hypocrite).
Un concept important de l'Internet est celui d'« innovation sans autorisation ». Pour le comprendre, regardons l'invention du World-Wide Web. Tim Berners-Lee, Robert Cailliau et les autres ont pu inventer le Web et le déployer, sans rien demander à personne. Aucun comité Machin, aucun gouvernement, n'a été sollicité pour donner son avis ou son autorisation. Au contraire, dans les réseaux de télécommunication pré-Internet, il fallait l'accord préalable de l'opérateur pour tout déploiement d'une application. Sans l'« innovation sans autorisation », nous n'aurions pas le Web.
Et la « vie privée », on la définit comment ? Le RFC 4949 la définit comme le droit à contrôler ce qu'on expose à l'extérieur. C'est actuellement un des droits humains les plus menacés sur l'Internet, en raison des possibilités de surveillance massive que permet le numérique, possibilités largement utilisées par les États. Or, ce droit est lui-même à la base de nombreux autres droits. Ainsi, la liberté d'expression est sérieusement en danger si on n'a pas de droit à la vie privée, par exemple parce que des gens hésiteront à lire certains textes s'ils savent que leurs habitudes de lecture sont surveillées.
La section 4 du RFC est consacrée à un examen du débat (très ancien) sur la neutralité de la technique, et sur les relations entre technique et politique. La littérature scientifique et philosophique dans ce domaine est riche ! (À une réunion de HRPC, la discussion avait tourné à la pure philosophie, et on y avait abondemment cité Foucault, Heidegger, Wittgenstein, Derrida et Kant, ce qui est plutôt rare à l'IETF.)
Les deux opinions extrêmes à ce sujet sont :
- L'IETF fait un travail purement technique. Un protocole de communication est un outil, il est neutre, comme, mettons, une voiture, qui peut servir à des gens sympas à se déplacer, ou à des méchants pour commettre un crime.
- « Tout est politique », toute décision prise par des humains, humains insérés dans un environnement social réel, toute décision va forcément affecter la vie des autres (ou alors c'est que ces décisions n'ont servi à rien) et est donc politique. Pour citer J. Abbate, « protocol is politics by other means ».
Il n'est pas compliqué de trouver plein d'exemples de luttes politiques autour des protocoles Internet, dans les RFC cités plus haut comme le RFC 7258, ou bien dans des articles comme celui de Denardis « The Internet Design Tension between Surveillance and Security ». Les participants à l'IETF ne vivent pas dans une bulle, ils vivent dans un contexte politique, social, historique, culturel, et cela affecte certainement leurs décisions.
Notre RFC cite un grand nombre de publications sur ces sujets, de Francesca Musiani « Giants, Dwarfs and Decentralized Alternatives to Internet-based Services » à Lawrence Lessig, Jonathan Zittrain (« The future of the Internet ») et Milton Mueller. Si vous avez quelques mois de libres devant vous, je vous encourage à lire tous ces livres et articles.
Il y a aussi des études plus spécifiques au rôle des SDO, parmi lesquelles « Engineering 'Privacy by Design' in the Internet Protocols - Understanding Online Privacy both as a Technical and a Human Rights Issue in the Face of Pervasive Monitoring » ou le célèbre article de Clark et ses collègues, « Tussle in Cyberspace ».
Le RFC dégage cinq opinions différentes sur les relations entre le travail des ingénieurs et les droits humains, et sur la question de savoir si les droits humains doivent être intégrés dans les protocoles Internet. La première est celle citée dans l'article de Clark et al., qu'on peut résumer par « ce serait dangereux d'essayer de faire respecter les droits humains par les protocoles » :
- Les droits humains ne sont pas absolus, et un système technique ne peut pas comprendre cela.
- Il y a d'autres outils que les protocoles (l'action politique classique par exemple). C'était un peu l'opinion défendue avec fougue par Milton Mueller à la réunion HRPC lors de l'IETF 99 à Prague.
- Il est mauvais de faire des promesses qu'on ne peut pas tenir. Par exemple, on ne peut pas espérer développer de systèmes cryptographiques invulnérables, et donc on ne doit pas compter uniquement sur eux.
L'article résume en disant que les ingénieurs doivent concevoir le terrain, pas le résultat du match.
Une deuxième position est que certaines valeurs universelles, dont les droits humains tels que formalisés dans la DUDH, devraient être incluses dans l'architecture même du réseau. (Cf. l'article « Should Specific Values Be Embedded In The Internet Architecture? », et attention, c'est un article collectif, avec plusieurs points de vue. Celui résumé ici est celui de Brown.) L'idéal serait que le réseau lui-même protège ces droits. En effet, les techniciens, de part le pouvoir qu'ils ont, ont une obligation « morale » de faire tout ce qui est possible pour faire respecter les droits humains.
Une troisième position, qui part sur un plan différent, est d'estimer qu'on ne peut pas inclure le respect des droits humains dans les protocoles, mais que c'est bien dommage et, qu'à défaut, il faudrait déclarer clairement que le réseau est un bien commun, et que toute tentative de l'utiliser pour le mal est en soi une violation des droits humains. Si on suit ces auteurs (« The public core of the Internet. An international agenda for Internet governance »), l'Internet lui-même, et les protocoles tels que normalisés dans les RFC, seraient un bien commun qu'on ne peut pas tripoter, comme un parc naturel, par exemple. Si le DNS était inclus comme « bien commun », des manipulations comme les résolveurs menteurs deviendraient illégales ou en tout cas immorales.
Les auteurs de « Values and Networks » sont plus prudents. Ils estiment que les protocoles Internet ont effectivement des conséquences sur les droits humains, mais qu'on n'est pas sûrs de quelles conséquences exactement, et qu'il est important de poursuivre les recherches. Cette quatrième position va donc tout à fait dans le sens de la constitution de HRPC comme groupe de recherche de l'IRTF.
Enfin, cinquième possibilité (et vous avez vu qu'elles ne sont pas forcément incompatibles), Berners-Lee et Halpin disent que l'Internet crée également de nouveaux droits. Ainsi, dans une société connectée où ne pas avoir l'Internet est un handicap social, le droit à un accès Internet devient un droit humain.
Quel bilan tirer de cette littérature scientifique et philosophique existante ? D'abord, d'un point de vue pratique, on ne sait pas si créer un réseau qui, par construction, assurerait le respect des droits humains est faisable (avant même de savoir si c'est souhaitable). Mais, au moins, on peut arrêter de croire que la technique est complètement neutre, étudier les conséquences des protocoles sur les droits humains (ce que fait la section 5 de notre RFC) et essayer d'améliorer ces protocoles à la lumière de cette analyse (la section 6 du RFC).
Voyons donc une série d'étude de cas de protocoles Internet existants, et en quoi ils affectent les droits humains (section 5). Une anecdote personnelle au passage : les premières versions de ces études de cas comportaient d'énormes erreurs techniques. Il est en effet difficile de trouver des gens qui sont à la fois sensibilisés aux droits humains et compétents techniquement. Comme le note le RFC, un travail interdisciplinaire est nécessaire. Le travail collectif à l'IRTF fait que cette section 5 est maintenant correcte.
Avant les études de cas techniques, le point de départ est une analyse des discours (selon la méthodologie présentée dans l'article de Cath). Elle s'est faite à la fois informellement (discussion avec des auteurs de RFC, interviews de participants à l'IETF) et formellement, par le biais d'un outil d'analyse automatique. Ce dernier, écrit en Python avec Big Bang, a permis de déterminer les « éléments de langage » importants dans les normes Internet. Et cela donne de jolis graphes.
La partie informelle s'est surtout faite pendant la réunion IETF 92 à Dallas, et a donné le film « Net of Rights ». Mais il y a eu aussi l'observation des groupes de travail IETF en action.
Les protocoles Internet sont bâtis en utilisant des concepts techniques (connectivité, confidentialité, accessibilité, etc) et la section 5.2.2 met en correspondance ces concepts avec les droits humains tels que définis dans la DUDH. Par exemple, le droit de s'assembler s'appuie sur la connectivité, mais aussi sur la résistance à la censure, et sur la sécurité en général.
Maintenant, place à la première partie technique de notre RFC, la section 5.2.3. Elle étudie en détail les conséquences de divers protocoles pour les droits humains. Attention, la conception d'un protocole est une activité complexe, avec des cahiers de charges épais où le respect des droits humains (quand il est présent…) n'est qu'une partie. Et le travail d'ingéniérie nécessite toujours des compromis. Le RFC prévient donc que ce travail est forcément étroit : on n'examine les protocoles que sous l'angle des droits humains, alors qu'une évaluation complète de ces protocoles nécessiterait la prise en compte de bien d'autres aspects. Comme exemple de compromis auquel il faut parfois se résoudre, avoir un serveur distinct de la machine de l'utilisat·eur·rice, possiblement géré par un tiers (c'est le cas de SMTP et XMPP), est certainement mauvais pour la résistance à la censure, car il va fournir un point de contrôle évident, sur lequel des autorités peuvent taper. D'un autre côté, sans un tel serveur, comment communiquerait-on avec des utilisat·eur·rice·s qui ne sont pas connecté·e·s en permanence ou qui sont coincé·e·s derrière un réseau qui interdit les connexions entrantes ? Bref, les protocoles qui sont souvent vertement critiqués par la suite ne sont pas forcément mauvais, encore moins délibérement mauvais. L'idée de cette section est de bien illustrer, sur des cas concrets, que les décisions techniques ont des conséquences politiques. (Ce point avait fait l'objet de vives discussions à l'IETF, des gens estimant que le RFC était trop négatif, et qu'il aurait également fallu indiquer les aspects positifs de l'Internet.)
Donc, pour commencer la série, évidemment, IP lui-même, plus précisement IPv4 (RFC 791). Malgré la normalisation d'IPv6, IPv4 est toujours le principal protocole du réseau. C'est un succès fou, connectant des centaines de millions de machines (et bien plus via les systèmes de traduction d'adresses). Il est conçu pour en faire le moins possible : l'intelligence doit être dans les machines terminales, pas dans le réseau, pas dans la couche 3. (Cf. RFC 3724.) En pratique, toutefois, on voit des intermédiaires agir au niveau IP et, par exemple, ralentir certains types de trafic, ou bien bloquer certaines machines. IP expose en effet certaines informations qui peuvent faciliter ce genre de violations de la neutralité du réseau.
Par exemple, les adresses IP source et destination sont visibles en clair (même si tout le reste du paquet est chiffré) et à un endroit fixe du paquet, ce qui facilite la tâche des routeurs mais aussi des dispositifs de blocage. Avant que vous ne me dites « ben, évidemment, sinon le réseau ne pourrait pas marcher », faites attention. L'adresse IP de destination est effectivement nécessaire aux routeurs pour prendre des décisions de transmission, mais ce n'est pas le cas de l'adresse source. En outre, IP expose le protocole de transport utilisé, encore une information dont les routeurs n'ont pas besoin, mais qui peut aider des intermédiaires à traiter certains types de trafic différemment.
Aujourd'hui, beaucoup de décisions de blocage sont prises sur la base des adresses IP ainsi exposées, ce qui illustre les conséquences d'une décision apparemment purement technique. (Pour les amateurs d'histoire alternative, X.25 n'exposait pas obligatoirement les adresses source et destination dans chaque paquet. Même le serveur final ne les voyait pas forcément. X.25 avait plein de défauts, mais cette anecdote montre que d'autres choix étaient possibles. Il faut juste se rappeler qu'ils avaient leurs propres inconvénients.) Si vous êtes enseignant·e en réseaux informatiques, voici un exercice intéressant faire faire à vos étudiant·e·s : « concevoir un réseau qui n'expose pas à tous des identificateurs uniques mondiaux ». Des alternatives au mécanisme d'IP ont été conçues (comme Hornet ou APIP) mais aucune n'a connu de déploiement significatif. Le routage par la source (combiné avec de la triche sur les adresses IP) aurait également permis de limiter l'exposition des adresses IP sur le trajet mais il pose bien d'autres problèmes. La principale solution employée aujourd'hui, lorsqu'on veut dissimuler les adresses IP des machines qui communiquent, est Tor.
Une autre particularité d'IPv4, qui n'était pas présente à ses débuts, est l'utilisation massive de la traduction d'adresses (RFC 3022). Elle est très répandue. Mais elle casse le modèle de bout en bout, et met le routeur qui fait la traduction dans une position privilégiée (par exemple, beaucoup refusent de faire passer d'autres protocoles de transport que TCP ou UDP). C'est donc une sérieuse limite à la connectivité et donc aux droits humains qui en dépendent.
Et le DNS ? Voilà un protocole dont la relation aux droits humains a été largement discutée. Comme toute opération sur l'Internet commence par une requête DNS, il est un point de contrôle évident. On peut notamment l'utiliser pour la censure. Autre question politique liée au DNS et qui a fait s'agiter beaucoup d'électrons, le pouvoir des organismes qui gèrent les TLD et, bien sûr, la racine du DNS. On peut dire sans exagérer que l'essentiel des débats sur la « gouvernance de l'Internet » ont tourné sur la gestion de la racine du DNS, qui ne représente pourtant pas, et de loin, le seul enjeu politique.
Pourquoi est-ce un enjeu pour les droits humains ? Le DNS a une
structure arborescente, avec
l'ICANN à la racine. Le contrôle de l'ICANN
fait donc saliver bien du monde. Ensuite, les
TLD, qu'ils soient contrôlés par l'ICANN
(les gTLD) ou pas, ont un rôle
politique important, via leur politique d'enregistrement. Celle-ci
varie selon les TLD. Les gTLD historiques
comme .com ont une politique déterminée par
des organisations états-uniennes, l'ICANN et leur registre
(Verisign dans le cas de
.com). Les nouveaux
gTLD ont des registres de nationalité différentes mais dépendent
tous des règles ICANN (cf. l'excellente étude de
l'EFF comparant ces politiques dans l'optique des droits
humains). Les ccTLD, eux, dépendent
de lois nationales très variables. Elles sont par exemple plus ou
moins protectrices de la liberté d'expression. (Voir le fameux
cas
lybien.)
Est-ce que les centaines de nouveaux
gTLD créés depuis quelques années ont amélioré les choses
ou pas, pour cette liberté d'expression ? Certains disent que non
car beaucoup de ces nouveaux TLD ont une politique
d'enregistrement restrictive (cf. le rapport de l'EFF cité plus
haut), d'autres disent que oui car ces nouveaux TLD ont élargi le
choix. Et que la liberté d'association peut ne pas bien s'entendre
avec la liberté d'expression (la première peut justifier des
règles restrictives, pour que des minorités discriminées puissent
se rassembler sans être harcelées). Une chose est sûre, les débats
ont été chauds, par exemple autour d'une éventuelle création du
.gay (un rapport
du Conseil de l'Europe détaille cette question « TLD et
droits humains »).
Le DNS soulève plein d'autres questions liées aux droits humains. Par exemple, il est indiscret (RFC 7626), et des solutions partielles comme le RFC 9156 semblent très peu déployées.
Et, comme trop peu de zones DNS sont protégées par DNSSEC (et, de toute façon, DNSSEC ne protège pas contre toutes les manipulations), il est trop facile de modifier les réponses envoyées. C'est aujourd'hui une des techniques de censure les plus déployées, notamment en Europe (voir à ce sujet le très bon rapport du Conseil Scientifique de l'AFNIC). Parmi les moyens possibles pour censurer via les noms de domaine :
- Faire supprimer le nom auprès du registre ou du BE, comme dans les saisies faites par l'ICE, ou comme dans le cas de Wikileaks. Le protocole ne permet pas de faire la différence entre une saisie au registre, et une réelle suppression. Des systèmes comme Namecoin fournissent une meilleure protection (mais ont leurs propres défauts).
- Si on ne peut pas peser sur le registre ou sur le BE, on peut agir lors de la résolution du nom, avec des résolveurs menteurs ou bien carrément des modifications faites dans le réseau, méthode surtout connue en Chine, mais également en Grèce. La première technique, le résolveur menteur, peut être défaite par un changement de résolveur (ce qui peut créer d'autres problèmes), la seconde attaque nécessite des solutions comme le RFC 7858.
Le RFC étudie ensuite le cas de HTTP, le protocole vedette de l'Internet (RFC 7230 et suivants). Sa simplicité et son efficacité ont largement contribué à son immense succès, qui a à son tour entrainé celui de l'Internet tout entier. On voit même aujourd'hui des tas de services non-Web utiliser HTTP comme substrat. Du fait de cette utilisation massive, les conséquences des caractéristiques de HTTP pour les droits humains ont été beaucoup plus étudiées que le cas du DNS.
Premier problème, HTTP est par défaut peu sûr, avec des communications en clair, écoutables et modifiables. Si la solution HTTPS est très ancienne (le RFC 2828 a dix-sept ans…, et SSL avait été décrit et mis en œuvre avant), elle n'a été massivement déployée que depuis peu, essentiellement grâce au courage d'Edward Snowden.
En attendant ce déploiement massif de HTTPS, d'innombrables équipements réseau de censure et de détournement de HTTP ont été fabriqués et vendus (par exemple par Blue Coat mais ils sont loin d'être les seuls). Celui qui veut aujourd'hui empêcher ou perturber les communications par HTTP n'a pas besoin de compétences techniques, les solutions toutes prêtes existent sur le marché.
Un autre RFC qui touchait directement aux droits humains et qui avait fait pas mal de bruit à l'IETF est le RFC 7725, qui normalise le code d'erreur 451, renvoyé au client lorsque le contenu est censuré. Il permet une « franchise de la censure », où celle-ci est explicitement assumée.
Les discussions à l'IETF avaient été chaudes en partie parce que l'impact politique de ce RFC est évident, et en partie parce qu'il y avait des doutes sur son utilité pratique. Beaucoup de censeurs ne l'utiliseront pas, c'est clair, soit parce qu'ils sont hypocrites, soit parce que les techniques de censure utilisées ne reposent pas sur HTTP mais, par exemple, sur un filtrage IP. Et, lorsque certains l'utilisent, quelle utilité pour les programmes ? Notre RFC explique que le principal intérêt est l'étude du déploiement de la « censure honnête » (ou « censure franche »). C'est le cas de projets comme Lumen. Du code est d'ailleurs en cours de développement pour les analyses automatiques des 451 (on travaillera là-dessus au hackathon de la prochaine réunion IETF).
Outre la censure, l'envoi du trafic en clair permet la surveillance massive, par exemple par les programmes Tempora ou XKeyscore. Cette vulnérabilité était connue depuis longtemps mais, avant les révélations de Snowden, la possibilité d'une telle surveillance de masse par des pays supposés démocratiques était balayée d'un revers de main comme « paranoïa complotiste ». Pour la France, souvenons-nous qu'une société française vend des produits d'espionnage de leur population à des dictatures, comme celle du défunt Khadafi.
D'autre part, l'attaque active, la modification des données en transit, ne sert pas qu'à la censure. Du trafic HTTP changé en route peut être utilisé pour distribuer un contenu malveillant (possibilité utilisée dans QUANTUMINSERT/FOXACID) ou pour modifier du code envoyé lors d'une phase de mise à jour du logiciel d'une machine. Cela semble une attaque compliquée à réaliser ? Ne vous inquiétez pas, jeune dictateur, des sociétés vous vendent ce genre de produits clés en main.
HTTPS n'est évidemment pas une solution magique, qui assurerait la protection des droits humains à elle seule. Pour ne citer que ses limites techniques, sa technologie sous-jacente, TLS (RFC 5246) a été victime de plusieurs failles de sécurité (sans compter les afaiblissements délibérés comme les célèbres « algorithmes pour l'exportation »). Ensuite, dans certains cas, un·e utilisat·eur·rice peut être incité·e à utiliser la version en clair (attaque par repli, contre laquelle des techniques comme celles du RFC 6797 ont été mises au point).
HTTPS n'étant pas obligatoire, la possibilité d'une attaque par repli existe toujours. Pour HTTP/2, il avait été envisagé d'imposer HTTPS, pour qu'il n'y ait plus de version non sûre, mais le RFC 7540 n'a finalement pas entériné cette idée (que le RFC 8164 a partiellement ressorti depuis.)
Autre protocole étudié, XMPP (RFC 6120). Un de ses principes est que le logiciel client (par exemple pidgin) ne parle pas directement au logiciel du correspondant, mais passe forcément par un (ou deux) serveur(s). Cette architecture présente des avantages pratiques (si le correspondant est absent, son serveur peut indiquer cette absence à l'appelant) mais aussi en matière de protection (on ne voit pas l'adresse IP de l'appelant). Ces serveurs sont fédérés entre eux, XMPP, contrairement à des protocoles inférieurs comme Slack ne peut donc pas être arrêté par décision supérieure.
Mais XMPP a aussi des inconvénients. Les utilisat·eurs·rices sont
identifiés par un JID comme
bortzmeyer@example.com/home qui comprend une
« ressource » (le terme après la barre oblique) qui, en pratique,
identifie souvent une machine particulière ou un lieu
particulier. En général, ce JID est présenté tel quel aux
correspondants, ce qui n'est pas idéal pour la vie privée. D'autre
part, les communications sont en clair par défaut, mais peuvent
être chiffrées, avec TLS. Sauf que l'utilisat·eur·rice ne sait pas si
son serveur chiffre avec le serveur suivant, ou bien le serveur
final avec son correspondant. Sans possibilité d'évaluation de la
sécurité, il faut donc faire une confiance
aveugle à tous les serveurs pour prendre des précautions. Et
espérer qu'ils suivront tous le « XMPP
manifesto ».
Si XMPP lui-même est fédéré et donc relativement résistant à la censure, les salles collectives de discussion sont centralisées. Chaque salle est sur un serveur particulier, une sorte de « propriétaire », qui peut donc contrôler l'activité collective, même si aucun des participants n'a de compte sur ce serveur. (En prime, ces salles sont une extension du protocole, spécifiée dans le XEP-0045, pas mise en œuvre de manière identique partout, ce qui est un problème non-politique fréquent avec XMPP.)
Et le pair-à-pair, lui, quelles sont ses implications pour les droits humains ? D'abord, il faut évidemment noter que ce terme ne désigne pas un protocole particulier, qu'on pourrait analyser en détail, mais une famille de protocoles très divers (RFC 5694). L'application la plus connue du pair-à-pair est évidemment l'échange de fichiers culturels, mais le pair-à-pair est une architecture très générale, qui peut servir à plein de choses (Bitcoin, par exemple).
À l'époque des GAFA, monstres centralisés qui contrôlent toutes les interactions entre utilisat·eur·rice·s, le pair-à-pair est souvent présenté comme la solution idéale à tous les problèmes, notamment à la censure. Mais la situation est plus compliquée que cela.
D'abord, les réseaux en pair-à-pair, n'ayant pas d'autorité centrale de certification des contenus, sont vulnérables aux diverses formes d'empoisonnement des données. On se souvient des faux MP3 sur eDonkey, avec un nom prometteur et un contenu décevant. Un attaquant peut aussi relativement facilement corrompre, sinon les données, en tout cas le routage qui y mène.
Comme les protocoles pair-à-pair représentent une bonne part du trafic Internet, et qu'ils sont souvent identifiables sur le réseau, le FAI peut être tenté de limiter leur trafic.
Plus gênant, question droits humains, bien des protocoles pair-à-pair ne dissimulent pas l'adresse IP des utilisat·eur·rice·s. En BitTorrent, si vous trouvez un pair qui a le fichier qui vous intéresse, et que vous le contactez, ce pair apprendra votre adresse IP. Cela peut servir de base pour des lettres de menace ou pour des poursuites judiciaires (comme avec la HADOPI en France). Il existe des réseaux pair-à-pair qui déploient des techniques de protection contre cette fuite d'informations personnelles. Le plus ancien est Freenet mais il y a aussi Bitmessage. Ils restent peu utilisés.
Autre danger spécifique aux réseaux pair-à-pair, les attaques Sybil. En l'absence d'une vérification que l'identité est liée à quelque chose de coûteux et/ou difficile à obtenir, rien n'empêche un attaquant de se créer des millions d'identités et de subvertir ainsi des systèmes de vote. L'attaque Sybil permet de « bourrer les urnes » virtuelles. (Ne ratez pas l'article de Wikipédia sur l'astroturfing.)
C'est pour lutter contre cette attaque que Bitcoin utilise la preuve de travail et que CAcert utilise des certifications faites pendant des rencontres physiques, avec vérification de l'identité étatique. Le RFC note qu'on n'a pas actuellement de solution générale au problèmes des attaques Sybil, si on exige de cette solution qu'elle soit écologiquement durable (ce que n'est pas la preuve de travail) et entièrement pair-à-pair (ce que ne sont pas les systèmes d'enrôlement typiques, où un acteur privilégié vérifie les participants à l'entrée). Quant aux solutions à base de « réseaux de connaissances » (utilisées dans le Web of Trust de PGP), elles sont mauvaises pour la vie privée, puisqu'elles exposent le graphe social des participants.
Bref, le pair-à-pair n'est pas actuellement la solution idéale à tous les problèmes de droits humains, et les recherches doivent se poursuivre.
Un autre outil est souvent présenté comme solution pour bien des problèmes de respect des droits humains, notamment pour la sécurité de ceux qui vivent et travaillent dans des pays dictatoriaux, le VPN. On entend parfois des discussions entre militants des droits humains, ou bien entre journalistes, sur les avantages comparés de Tor et du VPN pour regarder le Web en toute sécurité. En fait, les deux ne fournissent pas réellement le même service et, pire, les propriétés du VPN sont souvent mal comprises. Le VPN fonctionne en établissant une liaison sécurisée (authentifiée, chiffrée) avec un fournisseur, qui va ensuite vous connecter à l'Internet. Il existe plusieurs systèmes techniques ouverts pour cela (IPsec, OpenVPN) mais la question centrale et difficile est le choix du fournisseur. Les VPN sont très populaires, et il existe donc une offre commerciale abondante. Mais, en général, il est impossible d'évaluer sa qualité, aussi bien technique (même si le protocole est standard, le fournisseur impose souvent un logiciel client à lui, binaire non auditable, et des failles ont déjà été découvertes dans certains VPN) que politique (ce fournisseur de VPN qui dit ne pas garder de journaux dit-il la vérité ?) On est très loin de l'attention qui a été portée à la sécurité de Tor, et des innombrables évaluations et analyses dont Tor a fait l'objet !
Il existe aussi des attaques plus sophistiquées (et pas à la portée de la première police venue) comme la corrélation de trafic (entre ce qui entre dans le VPN et ce qui en sort) si l'attaquant peut observer plusieurs points du réseau (la NSA le fait).
Donc, un rappel à tou·te·s les utilisat·eur·rices·s de VPN : la question la plus importante est celle de votre fournisseur. Le VPN peut vous promettre l'anonymat, vous ne serez pas pour autant anonyme vis-à-vis de votre fournisseur. Celui-ci peut vous trahir ou, tout simplement, comme il est situé dans un pays physique, être forcé par les autorités de ce pays de vous dénoncer.
Une question bien plus délicate avait fait l'objet de nombreux débats à l'IETF, celle d'une possibilité de considérer certaines attaques dDoS comme « légitimes ». C'est par exemple un point de vue qui a été défendu par Richard Stallman. La position classique de l'IETF est qu'au contraire toutes les attaques dDoS sont négatives, impactant l'infrastructure (y compris des tas d'innocents) et sont au bout du compte une attaque contre la liberté d'expression. En simplifiant, il existe trois types d'attaques dDoS, les volumétriques (on envoie le plus de paquets ou d'octets possibles, espérant épuiser les ressources du réseau), les attaques sur les protocoles intermédiaires (comme les SYN flood ou comme le très mal nommé ping of death), attaques qui permettent à l'assaillant de n'envoyer que peu de paquets/octets, et enfin les attaques applicatives, visant les failles d'une application. Une attaque faite par LOIC tient de l'attaque volumétrique (on envoie le plus de requêtes HTTP possibles) et de l'attaque applicative, puisqu'elle ne fonctionne que parce que l'application n'arrive pas à suivre (sur la plupart des sites Web, où il faut exécuter des milliers de lignes de code PHP ou Java pour afficher la moindre page, l'application craque avant le réseau).
Dans les trois cas, cette possibilité d'attaque est avant tout une menace contre les médias indépendants, contre les petites associations ou les individus qui ne peuvent pas ou ne veulent pas payer la « protection » (le mot a un double sens en anglais…) des sociétés spécialisées. Et les attaques dDoS peuvent faciliter la tâche des censeurs hypocrites : il suffit de déguiser une censure en une attaque par déni de service. Une des principales raisons pour lesquelles on ne peut pas comparer l'attaque dDoS à une manifestation est que, dans une attaque dDoS, la plupart des participants ne sont pas volontaires, ce sont des zombies. Lorsque des gens manifestent dans la rue, ils donnent de leur temps, et parfois prennent des risques personnels. Lorsqu'une organisation puissante loue les services d'un botnet pour faire taire par dDoS un gêneur, elle ne dépense qu'un peu d'argent.
Il y a bien sûr quelques exceptions (l'opération Abibil ou bien le Green Movement) mais elles sont rares. Il est donc parfaitement justifié que l'IETF fasse tout son possible pour rendre les attaques dDoS plus difficiles (RFC 3552, section 4.6). Dans la discussion menant à ce nouveau RFC 8280, certaines voix se sont élevées pour demander qu'on puisse lutter seulement contre les « mauvaises » dDoS. Mais c'est aussi absurde que l'idée récurrente des ministres de faire de la cryptographie « légale » qui ne pourrait protéger que les gens honnêtes !
Nous en arrivons maintenant à la partie la plus utilitaire de ce RFC, la section 6, qui est la méthodologie qui devrait être suivie lors du développement d'un nouveau protocole, pour comprendre son impact sur les droits humains, et pour essayer de minimiser les conséquences négatives, et maximiser les positives. Cette section 6 (depuis largement remplacée par le RFC 9620) concerne donc surtout les développeurs de protocole, par exemple les auteurs des RFC techniques. (C'est pour cela que le début de la section 6 répète beaucoup de choses dites avant : on pense que pas mal de techniciens ne liront que cette section.) Évidemment, les conséquences (bonnes ou mauvaises) d'un protocole, ne sont pas uniquement dans la norme technique qui le définit. La façon dont le protocole est mis en œuvre et déployé joue un rôle crucial. (Par exemple, la domination excessive de Gmail n'est pas inscrite dans le RFC 5321.)
Un bon exemple d'une telle démarche est donnée par le RFC 6973, sur la protection de la vie privée. La première responsabilité du développeur de protocole est d'examiner les menaces sur les droits humains que ce protocole peut créer ou aggraver. De même qu'il est recommandé de réfléchir aux conséquences d'un nouveau protocole pour la sécurité de l'Internet (RFC 3552), et sur les conditions dans lesquelles ce protocole est utile, de même il faut désormais réfléchir aux conséquences de son protocole sur les droits humains. Notons que notre RFC ne dit pas « voici ce qu'il faut faire pour respecter les droits humains ». Cela serait clairement irréaliste, vu la variété des menaces et la diversité des protocoles. Notre RFC demande qu'on se pose des questions, il ne fournit pas les réponses. Et il n'impose pas d'avoir dans chaque RFC une section « Human Rights Considerations » comme il existe une « Security Considerations » obligatoire.
Bon, maintenant, la liste des choses à vérifier quand vous concevez un nouveau protocole (section 6.2). À chaque fois, il y a une ou plusieurs questions, une explication, un exemple et une liste d'impacts. Par exemple, pour la question de la connectivité, les questions sont « Est-ce que votre protocole nécessite des machines intermédiaires ? Est-ce que ça ne pourrait pas être fait de bout en bout, plutôt ? Est-ce que votre protocole marchera également sur des liens à faible capacité et forte latence ? Est-ce que votre protocole est à état (alors que les protocoles sans état sont souvent plus robustes) ? » L'explication consiste surtout à répéter l'intérêt des systèmes de bout en bout (RFC 1958). L'exemple est évidemment celui des conséquences négatives des middleboxes. Et les impacts sont les conséquences sur la liberté d'expression et la liberté d'association. Bien sûr, tous les protocoles IETF se préoccupent peu ou prou de connectivité, mais ce n'était pas considéré jusqu'à présent comme pouvant impacter les droits humains.
Sur le deuxième point à vérifier, la vie privée, notre RFC renvoie au RFC 6973, qui demandait déjà aux auteurs de protocoles de faire attention à ce point.
Le troisième point est celui de la neutralité vis-à-vis du contenu. Il reste un peu vague, il n'y a pas actuellement d'exemple de protocole IETF qui soit activement discriminant vis-à-vis du contenu.
Quatrième point qui nécessite l'attention du développeur de protocole, la sécurité. Il est déjà largement traité dans de nombreux autres RFC (notamment le RFC 3552), il faut juste rappeler que ce point a des conséquences en matières de droits humains. Si un protocole a une faille de sécurité, cela peut signifier l'emprisonnement, la torture ou la mort pour un dissident.
En prime, le RFC rappelle que, contrairement à une utilisation réthorique fréquente, il n'y a pas une sécurité mais plusieurs services de sécurité. (Et certaines de ses propriétés peuvent avoir des frictions, par exemple la disponibilité et la confidentialité ne s'entendent pas toujours bien.)
Cinquième point que le développeur de protocoles doit vérifier, l'internationalisation (voir aussi le douzième point, sur la localisation). Eh oui, restreindre l'utilisation de l'Internet à ceux qui sont parfaitement à l'aise en anglais n'irait pas vraiment dans le sens des droits humains, notamment des droits à participer à la vie politique et sociale. D'où les questions « Est-ce que votre protocole gère des chaînes de caractères qui seront affichées aux humains ? Si oui, sont-elles en Unicode ? Au passage, avez-vous regardé le RFC 6365 ? » Dans le contexte IETF (qui s'occupe de protocoles et pas d'interfaces utilisateur), l'essentiel du travail d'internationalisation consiste à permettre de l'Unicode partout. Partout ? Non, c'est un peu plus compliqué que cela car l'IETF distingue les textes prévus pour les utilisat·eur·rice·s de ceux prévus pour les programmes (RFC 2277). Seuls les premiers doivent absolument permettre Unicode. (Cette distinction ne marche pas très bien pour les identificateurs, qui sont prévus à la fois pour les utilisat·eur·rice·s et pour les programmes, c'est le cas par exemple des noms de domaine.)
En prime, petite difficulté technique, il ne suffit pas
d'accepter Unicode, il faut encore, si on accepte d'autres
jeux de
caractères et/ou encodages,
l'indiquer (par exemple le charset= de
MIME), sinon on risque le mojibake. Ou alors, si on n'accepte qu'un
seul jeu de caractères / encodage, ce doit être UTF-8.
Sixième point sur la liste, une question dont les conséquences pour les droits humaines sont évidentes, la résistance à la censure. « Est-ce que votre protocole utilise des identificateurs qui peuvent être associés à des personnes ou à un contenu spécifique ? Est-ce que la censure peut être explicite ? Est-ce que la censure est facile avec votre protocole ? Si oui, ne pourrait-on pas le durcir pour la rendre plus difficile ? »
Un exemple est bien sûr la longue discussion du passé au sujet d'une méthode de fabrication des adresses IPv6. Le mécanisme recommandé à l'origine mettait l'adresse MAC dans l'adresse IP. Outre l'atteinte à la vie privée, cela facilitait la censure, permettant de bloquer un contenu pour seulement certaines personnes. (Ce mécanisme a été abandonné il y a longtemps, cf. RFC 4941.) Quand au cas de rendre la censure explicite, c'est une référence au code 451 (RFC 7725).
Septième point, les « normes ouvertes ». Intuitivement, il est évident qu'il vaut mieux des normes ouvertes que fermées. Mais attention, il n'existe pas de définition claire et largement adoptée, même pas à l'intérieur de l'IETF (qui est certainement une organisation très ouverte). Les questions posées dans ce RFC 8280 donnent une idée des critères qui peuvent permettre de décider si une norme est ouverte ou pas : « Le protocole est-il documenté publiquement ? Sa mise en œuvre peut-elle être faite sans code privateur ? Le protocole dépend t-il d'une technologie contrôlée par une entreprise particulière ? Y a-t-il des brevets (RFC 3979 et RFC 6701) ? »
Ce sont les normes ouvertes de la famille TCP/IP qui ont permis le développement et le déploiement massif de l'Internet. Les appropriations intellectuelles comme le secret industriel ou comme les brevets auraient tué l'Internet dans l'œuf. Il est donc logique que l'IETF soit une organisation particulièrement ouverte : les RFC sont publics et librement redistribuables, bien sûr (ce qui n'est pas le cas des normes d'autres SDO comme l'AFNOR, l'ISO ou l'IEEE), mais l'IETF publie également ses documents temporaires, ses listes de diffusion et ses réunions (ce que ne fait pas, par exemple, l'UIT).
(On note que le RFC 6852 traite également cette question mais c'est un document purement tactique, qui fait du « open washing » en faisant comme si l'IEEE était ouverte.)
Je saute le point huit, sur l'acceptation de l'hétérogénéité du réseau, et j'en arrive à l'important point neuf, sur l'anonymat. Le terme est très galvaudé (« Bitcoin est une monnaie anonyme » et autres erreurs). Il est souvent utilisé par les non-spécialistes comme synonyme de « une autre identité que celle de l'état civil » (ce qui est en fait la définition du pseudonyme, traité au point suivant). Normalement, même si la définition du RFC 4949 est très peu claire, l'anonymat implique la non-traçabilité : si un système est réellement anonyme, il ne doit pas être possible d'attribuer deux actions à la même entité.
Autre erreur courante quand on parle d'anonymat, la considérer comme une propriété binaire. C'est ce qui est fait quand un responsable ignorant affirme « les données sont anonymisées » (cela doit en général déclencher un signal d'alarme). En effet, il existe de nombreuses techniques, et en progrès rapide, pour « désanonymiser », c'est-à-dire pour relier des actions qui ne l'étaient a priori pas.
Cette confusion est d'autant plus dommage que l'anonymat est une propriété essentielle pour la sécurité du citoyen dans un monde numérique. Autrefois, la plupart des actions qu'on faisait dans la journée étaient anonymes, au sens où un observateur extérieur ne pouvait pas facilement les relier entre elles. Aujourd'hui, si vous mettez une photo sur Instagram, achetez un livre sur Amazon, et écrivez un document sur Google Docs, toutes ces actions sont facilement reliables entre elles, même si vos comptes se nomment respectivement « titi75 », « jean.durand » et « le_type_du_coin ». Par défaut, dans le monde numérique, tout est traçable, et il faut déployer des technologies compliquées pour retrouver un peu d'obscurité. En tout cas, rappelez-vous que l'anonymat n'est jamais parfait : c'est un but souhaitable, mais pas forcément atteignable.
Par exemple, la présence de votre adresse IP dans chaque paquet est un moyen simple de relier toutes vos activités (il en existe d'autres). Il est donc tout à fait légitime que l'adresse IP soit regardée comme une donnée personnelle.
Le pseudonymat, dixième point, est une propriété moins forte. C'est simplement le fait d'utiliser une identité persistante qui n'est pas l'identité officielle. On va utiliser un pseudonyme quand on veut masquer son orientation sexuelle, ou sa transidentité, ou l'entreprise où on travaille, mais tout en gardant une identité constante, par exemple pour avoir une réputation en ligne. C'est souvent une protection nécessaire contre le harcèlement, dont les femmes sont particulièrement fréquemment victimes en ligne. Outre les pseudonymes qu'on choisit, la nature du monde numérique fait que plein d'identificateurs attribués automatiquement sont des pseudonymes. Ainsi, une adresse IP est un pseudonyme (elle cesse de l'être dès que votre FAI communique le nom et l'adresse de l'abonné aux autorités). Une adresse Bitcoin est un pseudonyme (Bitcoin est très traçable, c'est nécessaire pour son fonctionnement).
L'auteur·e de protocoles doit donc se méfier des informations qu'ielle expose. Si elles permettent de retrouver la personne à l'origine de la communication, ce sont des données personnelles. Par exemple, si vous exportez des données contenant des adresses IP (exemples en RFC 7011 ou bien pour les journaux d'un serveur), une des façons de brouiller la traçabilité (et donc de passer du pseudonymat à un relatif anonymat) est de ne garder qu'un préfixe assez général. Condenser les adresses IP n'est pas très efficace, un attaquant, un « désanonymiseur » peut condenser toutes les adresses possibles et ainsi retrouver l'information. D'une manière générale, soyez modeste : réellement anonymiser est très difficile.
Le onzième point concerne un sujet dont les conséquences en
matière de droits humains sont claires pour quiconque a suivi les
conférences Paris Web :
l'accessibilité à tou·te·s, y compris en cas
de handicap. L'accessibilité est une propriété nécessaire pour
faire respecter le droit à ne pas être victime de
discrimination. Cela ne concerne a priori pas l'IETF, qui ne fait
pas d'interface utilisateur, mais c'est utile pour d'autres
SDO. Ainsi, le RFC donne l'exemple de
HTML, où l'obligation de mettre un attribut
alt pour les images, oblige à réfléchir à
l'accessibilité de la page Web aux malvoyants.
Le treizième point porte sur un concept très flou et d'autant plus répété qu'il n'a pas de définition claire : la « décentralisation ». Mon article à JRES sur ce sujet donne une idée de la complexité de la question. Le RFC traite la question par plusieurs questions : « Est-ce que le protocole a un point de contrôle unique ? Est-ce que le protocole ne pourrait pas être fédéré plutôt ? » Ça reste à mon avis trop vague mais, au moins, ça pousse les concepteurs de protocoles à réfléchir. La plupart des protocoles de base de l'Internet sont décentralisés ou fédérés comme vous voulez (et c'est explicitement souhaité par le RFC 3935), mais les services à la mode sont en général centralisés. (XMPP est fédéré mais dans les startups, on est obligés d'utiliser Slack qui est centralisé.)
Passons sur le point 14, la fiabilité (c'est sûr qu'un réseau qui marche, c'est mieux) et voyons le point 15, la confidentialité. Son impact sur les droits humains est clair : si des gens peuvent lire ma correspondance privée, mes droits sont clairement violés. La solution technique la plus évidente est le chiffrement et, aujourd'hui, le RFC 8280 estime à juste titre qu'un protocole sans possibilité de chiffrement (par exemple RFC 3912) est à éviter (RFC 3365). Et, même si le RFC ne le dit pas explicitement, il doit évidemment choisir d'un chiffrement sérieux, donc sans portes dérobées, sans affaiblissement délibéré.
Rédigé il y a trop longtemps, cette section dit que le DNS ne dispose pas de cette possibilité de chiffrement, mais c'est faux, depuis le RFC 7858.
Le RFC note à juste titre que le chiffrement ne protège pas contre les intermédiaires légitimes, comme dans l'exemple de XMPP cité plus haut : le chiffrement entre le client et le premier serveur XMPP ne protège pas contre ce serveur, qui voit tout passer en clair. Mais le RFC oublie de dire qu'il y a également le problème des extrémités : faire du HTTPS avec Gmail ne vous protège pas contre PRISM. Il faut donc également prévoir de la minimisation (envoyer le moins de données possible) pas seulement du chiffrement.
Je saute les points 16 (intégrité), 17 (authentification) et 18 (adaptabilité), je vous laisse les lire dans le RFC. Le dernier point, le dix-neuvième, porte sur la transparence : les utilisat·eur·rice·s peuvent-il·elle·s voir comment fonctionne le protocole et notamment quels sont les acteurs impliqués ? Par exemple, un service qui semble « gratuit » peut l'être parce qu'il y a derrière une grosse activité économique, avec de la publicité ciblée en exploitant vos données personnelles. Bref, si c'est gratuit, c'est peut-être que vous êtes le produit. Et vous ne le voyez peut-être pas clairement.
Voilà, si vous voulez en savoir plus, le RFC a une colossale bibliographie. Bonne lecture. Si vous préférez les vidéos, il y a mon intervention à Radio-France sur ce sujet.
L'article seul
AXA et le redirecteur
Première rédaction de cet article le 29 octobre 2017
La société AXA (assurance et autres
services financiers) utilise souvent pour sa communication des
URL où le nom de domaine est
go.axa.fr. On le trouve dans les messages envoyés aux
clients, par exemple. Quel est le problème de sécurité et
d'éducation que cela pose ?
Si vous voulez voir de tels URL,
demandez simplement à un moteur de recherche un truc du genre
inurl:go.axa.fr et vous en trouverez
plein, apparemment utilisés dans des campagnes de promotion
(« téléchargez une application permettant de mieux gérer votre
compte AXA Banque » ou bien voir la
page Facebook officielle d'AXA Banque). Prenons par exemple
http://go.axa.fr/promium/, « le programme
d'AXA France destiné aux Professionnels ». Normalement, le client,
même méfiant,
n'hésitera pas à suivre ce lien : il est bien situé sous le
domaine d'AXA,
axa.fr. Si
on suit les conseils
habituels « En passant la souris au-dessus du lien proposé,
vous pouvez repérer s’il pointe bien vers l’adresse du site
annoncée dans le message. Si l’adresse est différente, soyez
méfiant, et évitez de cliquer sur le lien. De manière générale, il
est préférable de saisir manuellement l’adresse dans le
navigateur. », on ne devrait pas se faire avoir. (Oui, je sais
que, dans le monde réel,
personne ne suit ces conseils.)
Sauf que… Le nom go.axa.fr pointe vers
l'adresse IP
74.217.253.90. Hébergée aux États-Unis chez
Internap, elle ne semble pas a priori avoir
de relation avec AXA. Pourtant, s'y connecter en
HTTP redirige bien vers la bonne page :
% curl -v http://go.axa.fr/promium/
* Trying 74.217.253.90...
* TCP_NODELAY set
* Connected to go.axa.fr (74.217.253.90) port 80 (#0)
> GET /promium/ HTTP/1.1
...
< HTTP/1.1 301 Moved Permanently
< Server: post/2.0
< Location: https://mediazone.axa/communique-de-presse/axa-programme-promium#
On est bien renvoyé vers une page d'AXA, dans le
TLD .axa. Mais,
minute, il y a une chose bizarre dans la réponse, le champ
Server:. Il indique post
qui identifie le serveur de redirection utilisé par le service
po.st, un moteur de redirection comme
bit.ly. D'ailleurs, si on visite
http://go.axa.fr/ (sans rien après la
dernière barre oblique), on arrive bien chez
po.st :
% curl -v http://go.axa.fr/
* Trying 74.217.253.90...
* TCP_NODELAY set
* Connected to go.axa.fr (74.217.253.90) port 80 (#0)
> GET / HTTP/1.1
...
< HTTP/1.1 302 Found
< Server: post/2.0
< Location: https://www.po.st
Si vous voulez un autre signe, vous pouvez essayer en
HTTPS,
https://go.axa.fr/promium/. Le
certificat ne sera pas accepté car il ne
couvre que po.st, pas go.axa.fr.
Bon, donc, en fait, AXA utilise
po.st. Est-ce grave ? En tout cas, c'est
ennuyeux, car ces redirecteurs/raccourcisseurs d'URL ont deux problèmes :
- Ils peuvent changer à leur guise la redirection et donc emmener les clients d'AXA où ils veulent,
- Ils peuvent enregistrer les informations sur le client (son adresse IP et surtout l'empreinte du navigateur, grâce aux nombreuses données que celui-ci envoie).
Paranoïa complète de ma part ? po.st est
propriété de RadiumOne (source : https://www.po.st/about/post), société états-unienne, et ces derniers ne cachent pas leurs
activités : « a company that generates first-party data
about actual customers -- from their behaviors, actions and
interests demonstrated across the web and mobile. We access tens
of billions of real-time impressions each day across the Web,
video, social and mobile to reach consumers in real-time no matter
where they are. Our intelligent software and methodologies
increase the relevance and personalization of ads through
sophisticated algorithms that find valuable characteristics, gauge
consumer behaviors, and target ads with laser focus to the right
audiences ». Bref, rediriger à travers
po.st, c'est donner plein d'informations à
une enterprise états-unienne, non tenue par le
RGPD. Le but de surveillance à des fins
marketing est encore plus clair sur l'image en
https://www.po.st/assets/img/sharing/sharing-brands-1.png
ou sur la page
https://www.po.st/sharing/brands.
(Concernant le RGPD, des juristes m'ont fait
remarquer que po.st est bien tenu de
respecter le RGPD, du moment que les données concernées sont
celles de citoyens européens, ce qui est le cas ici (principe
d'extra-territorialité du RGPD). Ils ont bien sûr raison, mais la
question est plutôt « en pratique, que se passera-t-il ? » Je
doute fort qu'AXA soit inquiété pour ces traitements.)
Je ne cherche pas spécialement à taper sur AXA. Des tas
d'entreprises font cela. En général, le service communication
ignore complètement tous les conseils de sécurité. Ainsi, on
s'inscrit à la
newsletter d'une société
dont le domaine est mabanque.example et on
reçoit ensuite des messages envoyés depuis un tout autre
domaine. Impossible dans ces conditions de mettre en pratique les
conseils de l'ANSSI indiqués plus haut !
Mais, ici, le cas est un peu plus original dans le mesure où le
nom affiché au client (go.axa.fr) est conçu
pour inspirer confiance, dissimulant à l'usager qu'il verra ses
données être enregistrées par po.st. Ce genre
de pratiques met donc en péril toutes les tentatives d'éducation à
la sécurité qui ont été faites depuis des années, et qui
encourageaient à faire attention au nom de domaine dans les URL.
(Notons qu'utiliser un nom de domaine à soi pour rediriger via
po.st nécessite l'accord de
po.st. Si, dans
http://go.axa.fr/promium/, vous remplacez
go.axa.fr par po.st,
cela ne marchera pas.)
Et puis c'est dommage que cette utilisation d'un redirecteur étranger et peu soucieux de protection des données personnelles soit le fait d'une société qui s'était permis de promouvoir un « permis Internet » qui avait été, à juste titre, fortement critiqué.
Mes remerciements à Philippe Meyer pour avoir attiré mon attention sur cet intéressant cas.
L'article seul
Fiche de lecture : 1177 b.c. the year the civilization collapsed
Auteur(s) du livre : Eric H. Cline
Éditeur : Princeton University Press
978-0-691-16838-8
Publié en 2014
Première rédaction de cet article le 29 octobre 2017
Vous savez pourquoi tant de civilisations de la Méditerranée orientale ont disparu assez rapidement, autour de 1 177 AEC ? Moi non, mais Eric Cline s'est penché sur le problème, sur lequel je ne connaissais rien. Les grandes catastrophes sont toujours fascinantes. Que savons-nous sur celle-ci ?
Posons donc le décor. Vers 1 200 AEC, dans l'âge du bronze tardif, la Méditerranée orientale abrite une concentration de civilisations avancées. On connait l'Égypte des pharaons, bien sûr, mais il y a aussi les Hittites, les Mycéniens, les Minoens et plein d'autres, ainsi que beaucoup de cités-États riches du commerce, comme Ougarit ou Troie. Tout cela se passait longtemps avant la Grèce antique et a fortiori longtemps avant Rome. Tout ce monde échangeait, s'écrivait (bénédiction pour les archéologues du futur), se visitait et se faisait la guerre.
Mais, quelques dizaines d'années après, tout a disparu. Si l'Égypte a continué, ce ne sera que sous forme d'un royaume très diminué (privé de ses possessions asiatiques). Les malheurs de Troie seront écrits sous forme d'un poème épique, bien plus tard. D'autres disparaitront en laissant peu de traces, comme le royaume hittite, pourtant la deuxième superpuissance de l'époque, après l'Égypte.
Est-ce qu'on connait la cause ? Pas vraiment (oui, désolé, j'anticipe sur la fin du livre). Des tas d'explications ont été proposées, des tremblements de terre, des sécheresses, des invasions par les peu connus peuples de la mer… Aucune ne semble pouvoir tout expliquer, il y a peut-être eu simplement combinaison de facteurs au mauvais moment. On ne sait même pas si les « peuples de la mer » étaient vraiment une armée d'invasion, ou simplement des réfugiés fuyant d'autres lieux touchés par la crise.
C'est que les traces archéologiques sont incomplètes et difficiles à interpréter. Quand on trouve une cité en ruines, était-ce le résultat d'un tremblement de terre ou d'une invasion, ou simplement du temps qui s'est écoulé depuis son abandon ? Eric Cline explique très bien comment l'archéologue d'aujourd'hui doit travailler, déchiffrant des tablettes d'argile, et regardant si on trouve des pointes de flèche (bon indice d'une attaque militaire). Tout est indice de nos jours, et l'auteur déplore le comportement des archéologues d'autrefois, comme Schliemann, qui y allait à la brutale, sans même noter ce qu'ils détruisaient au passage.
Cline fait revivre tout ce monde peu connu des profanes. On a tous entendu parler des pharaons égyptiens et de leurs pyramides, mais beaucoup moins des autres peuples de l'époque. J'ai beaucoup aimé la description du navire d'Uluburun, chargé d'innombrables richesses provenant de toute la région, et qui symbolise l'importance des échanges commerciaux pendant cette « première mondialisation ». Comme le note l'auteur, un pharaon égyptien de l'époque était sans doute autant préoccupé de l'approvisionnement de son pays en étain (indispensable pour le bronze, donc pour les armes), qu'un président états-unien aujourd'hui avec le remplissage des 4x4 en essence.
Bon, et après cette description d'une époque dynamique et d'une civilisation avancée, pourquoi cette disparition relativement rapide ? Bien sûr, le titre du livre est un peu exagéré. L'effondrement des civilisations méditerranéennes n'a pas duré qu'une seule année, le processus a pris plus de temps. Et tout n'a pas été perdu : si les échanges commerciaux se sont effondrés, si les grands royaumes ont disparu, si de nombreuses riches cités sont devenues des ruines, les gens n'ont pas oublié l'écriture, ni l'art, ni leurs techniques et, quelques siècles plus tard, c'est reparti comme avant.
Néanmoins, il y a bien eu une redistribution des cartes spectaculaires, dont les causes ne sont pas bien connues. Cline passe en revue toutes les hypothèses (comme il le note dans la postface, il ne manque que l'épidémie…) mais on reste à la merci de nouvelles découvertes archéologiques, qui changeront notre opinion sur cette crise. Cline note que, contrairement aux cas étudiés par Diamond dans son livre « Effondrement », qui ne couvre que des civilisations isolées, ici, c'est peut-être la forte interconnexion des civilisations méditerranéennes qui a causé leur chute en dominos.
En attendant, si vous voulez aider les scientifiques, je vous rappelle que le linéaire A est toujours à déchiffrer… (Il a cessé d'être utilisé avant l'effondrement, mais il pourrait permettre de mieux comprendre la civiisation minoenne.)
L'article seul
Supervision d'enregistrements DANE
Première rédaction de cet article le 28 octobre 2017
Le système DANE, normalisé dans le RFC 6698, permet de vérifier l'authenticité du certificat d'un serveur TLS, grâce à des enregistrements signés dans le DNS. Comme ces enregistrements doivent toujours être synchrones avec le certificat, il est prudent de les superviser.
DANE fonctionne en publiant dans le DNS un enregistrement qui résume le certificat utilisé par le serveur TLS. Les certificats changents (renouvellement, révocation) et l'enregistrement dans le DNS doit donc suivre ces changements. En outre, dans la plupart des organisations de taille moyenne ou grosse, ce n'est pas la même équipe qui gère le DNS et les serveurs TLS. Il y a donc un gros potentiel de mécommunication, et c'est pour cela que la supervision est cruciale.
J'utilise le logiciel Icinga pour cette
supervision, mais l'essentiel des techniques présentées ici
marcherait avec tous les logiciels compatibles avec
l'API des Monitoring
Plugins. Première étape, il nous faut un programme qui
teste l'état des enregistrements
DANE. Nous allons nous appuyer sur le
programme tlsa, qui fait partie de hash-slinger. Cet ensemble de programme est dans un paquetage
Debian, donc l'installer est aussi simple que :
% aptitude install hash-slinger
Une fois qu'il est installé, testons-le avec un site Web qui a des enregistrements DANE :
% tlsa --verify dns.bortzmeyer.org
SUCCESS (Usage 1 [PKIX-EE]): Certificate offered by the server matches the one mentioned in the TLSA record and chains to a valid CA certificate (204.62.14.153)
SUCCESS (Usage 1 [PKIX-EE]): Certificate offered by the server matches the one mentioned in the TLSA record and chains to a valid CA certificate (2605:4500:2:245b::42)
(Il y a deux lignes car le nom dns.bortzmeyer.org a deux adresses IP et,
potentiellement, il pourrait s'agir de serveurs
HTTP, voire de deux machines différentes.)
En prime, tlsa définit évidemment le code de
retour :
% tlsa --verify dns.bortzmeyer.org ; echo $?
...
0
Si l'enregistrement TLSA a un problème, le code de retour est différent de zéro :
% tlsa --verify dougbarton.us ; echo $?
FAIL: Certificate offered by the server does not match the TLSA record (208.79.90.218)
FAIL: Certificate offered by the server does not match the TLSA record (2607:f2f8:ab14::2)
2
Rien de magique dans la commande tlsa, on
aurait pu faire la vérification manuellement, par exemple pour
mercredifiction.bortzmeyer.org :
% dig TLSA _443._tcp.mercredifiction.bortzmeyer.org
...
;; ANSWER SECTION:
_443._tcp.mercredifiction.bortzmeyer.org. 86400 IN TLSA 1 1 1 (
928DDE55DF4CD94CDCF998C55085FBB5228B561CC237
A122D950260029C5B8C9 )
_443._tcp.mercredifiction.bortzmeyer.org. 86400 IN RRSIG TLSA 8 5 86400 (
20171113165155 20171025071419 50229 bortzmeyer.org.
eRNZfL8ERWhs0SIGYHOIMh1l+tzFFfvDmV7XlPxd8BYa
...
Puis comparer avec ce que donne openssl. Les commandes
exactes à utiliser dépendent évidemment de l'usage et du
sélecteur indiqués dans l'enregistrement TLSA, cf. RFC 6698. Par exemple, avec le sélecteur 0 (on
prend tout le certificat, pas juste la clé), on pourrait utiliser
openssl x509 -fingerprint. Ici, avec le
sélecteur 1 (seulement la clé) :
% openssl s_client -servername mercredifiction.bortzmeyer.org -showcerts -connect mercredifiction.bortzmeyer.org:443 | \
openssl x509 -noout -pubkey | openssl pkey -outform der -pubin | openssl dgst -sha256
...
(stdin)= 928dde55df4cd94cdcf998c55085fbb5228b561cc237a122d950260029c5b8c9
On voit qu'on a le même condensat,
928dde55df4cd94cdcf998c55085fbb5228b561cc237a122d950260029c5b8c9,
donc tout va bien.
(Ne pas oublier le SNI - RFC 6066, l'option
-servername, sans laquelle vous risquez de
récupérer un mauvais certificat.)
Bien, on a désormais un moyen de tester qu'un serveur TLS a bien un certificat qui correspond à l'enregistrement DANE. Maintenant, il faut emballer tout ça dans un script qui est conforme à l'API des monitoring plugins. Le script (trivial), écrit en shell, est disponible ici. Testons-le :
% /usr/local/lib/nagios/plugins/check_dane_http -H www.afnic.fr ; echo $?
OK - SUCCESS (Usage 3 [DANE-EE]): Certificate offered by the server matches the TLSA record (192.134.5.24)
SUCCESS (Usage 3 [DANE-EE]): Certificate offered by the server matches the TLSA record (2001:67c:2218:30::24)
0
% /usr/local/lib/nagios/plugins/check_dane_http -H dougbarton.us ; echo $?
DANE server 'dougbarton.us' has a problem: FAIL: Certificate offered by the server does not match the TLSA record (208.79.90.218)
FAIL: Certificate offered by the server does not match the TLSA record (2607:f2f8:ab14::2)
2
% /usr/local/lib/nagios/plugins/check_dane_http -H ssi.gouv.fr ; echo $?
DANE server 'ssi.gouv.fr' has a problem: Unable to resolve ssi.gouv.fr.: Unsuccessful DNS lookup or no data returned for rrtype TLSA (52).
2
Le premier domaine a un enregistrement TLSA et marche bien. Le second, comme vu plus haut, a un enregistrement TLSA mais incorrect. Le troisième n'a pas d'enregistrement TLSA.
On peut désormais configurer Icinga pour utiliser ce script :
object CheckCommand "dane_http" {
command = [ PluginContribDir + "/check_dane_http" ]
arguments = {
"-H" = "$dane_domain$"
}
}
...
apply Service for (dane_domain => config in host.vars.dane_domains) {
import "generic-service"
check_command = "dane_http"
vars.dane_domain = dane_domain
}
...
vars.dane_domains["dns.bortzmeyer.org"] = true
(Bon, ça serait mieux si on pouvait spécifier indépendemment le nom à tester, l'adresse IP du serveur, et le nom qui va apparaitre dans l'interface Web d'Icinga. Mais j'étais paresseux et j'ai fait simple.)
Voilà, désormais Icinga surveille périodiquement l'enregistrement
DANE et le certificat TLS et tout va bien : 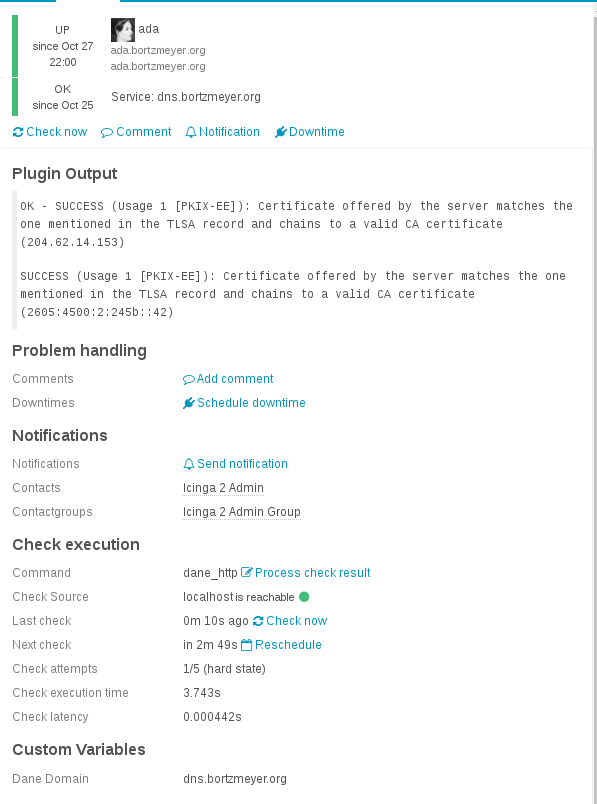
S'il y a un problème, on sera averti et on verra le problème dans l'interface Web d'Icinga. Ici, par exemple, l'enregistrement TLSA était pour le certificat entier (sélecteur 0) et un renouvellement a changé le certificat (mais pas la clé). Le message d'Icinga indiquait :
CRITICAL since 00:59 Service: mercredifiction.bortzmeyer.org Plugin Output DANE server 'mercredifiction.bortzmeyer.org' has a problem: FAIL: Certificate offered by the server does not match the TLSA record (217.70.190.232) FAIL: Certificate offered by the server does not match the TLSA record (2001:4b98:dc0:41:216:3eff:fece:1902)
Cet incident a permis de tester que la supervision de DANE marchait
bien 😁. Mais il mérite davantage de discussion. Dans ce cas
précis, l'enregistrement TLSA commençait par « 1 0 1 ». Cela veut
dire « Usage 1, Sélecteur 0, Correspondance 0 » (voir les
explications dans le RFC 6698) ou bien, en
utilisant les mnémoniques du RFC 7218 (que
tlsa affiche), « Usage PKIX-EE, Sélecteur Cert,
Correspondance SHA-256 ». Et en français ? L'usage PKIX-EE veut dire que
l'enregistrement TLSA doit désigner un certificat qui est à la fois
valide selon les règles PKIX (RFC 5280) traditionnelles et selon DANE,
avec le certificat du serveur, pas celui de
l'AC. Ensuite, le sélecteur Cert indique que
l'enregistrement TLSA doit être un condensat
du certificat entier. Or, le renouvellement d'un certificat change
les métadonnées (comme, évidemment, la date
d'expiration) et donc le condensat. Dans ces conditions, il vaut
mieux utiliser le sélecteur 1 (SPKI), où l'enregistrement TLSA va
désormais indiquer uniquement la clé, pas tout le certificat. C'est
également l'avis
de Let's Encrypt..
Voilà, maintenant que ça marche, prochaine étape : faire la même chose pour
SMTP (RFC 7672),
tlsa sachant gérer le TLS lancé après la
connexion. Exemple :
% tlsa --verify --port 25 --starttls smtp mail.bortzmeyer.org SUCCESS (Usage 2 [DANE-TA]): A certificate in the certificate chain offered by the server (including the end-entity certificate) matches the TLSA record (217.70.190.232) SUCCESS (Usage 2 [DANE-TA]): A certificate in the certificate chain offered by the server (including the end-entity certificate) matches the TLSA record (2001:4b98:dc0:41:216:3eff:fece:1902)
Autres solutions possibles pour tester DANE :
- Notez que tous les tests DANE peuvent être faits avec
opensslseul, avec ses options-dane_tlsa_domainet-dane_tlsa_rrdata: ainsi,openssl s_client -dane_tlsa_domain mercredifiction.bortzmeyer.org -dane_tlsa_rrdata "$(dig +short +nodnssec TLSA _443._tcp.mercredifiction.bortzmeyer.org)" -connect mercredifiction.bortzmeyer.org:443vous affichera un succès (DANE TLSA 1 1 1 ...c237a122d950260029c5b8c9 matched EE certificate at depth 0) et le test sur un domaine à problème (openssl s_client -dane_tlsa_domain dougbarton.us -dane_tlsa_rrdata "$(dig +short +nodnssec TLSA _443._tcp.dougbarton.us)" -connect dougbarton.us:443) donneraVerification error: No matching DANE TLSA records. - Dans la bibliothèque getdns, il y a ce programme, que je n'ai pas testé.
- À noter aussi (non testés) checkdanemx (écrit en Go), check_dane (disponible également sur Icinga Exchange), danecheck (écrit en Haskell), et pydane (écrit en Python).
L'article seul
RFC 8288: Web Linking
Date de publication du RFC : Octobre 2017
Auteur(s) du RFC : M. Nottingham
Chemin des normes
Première rédaction de cet article le 25 octobre 2017
Le lien est à la base du Web. Mais c'est seulement récemment, avec le RFC 5988 que notre RFC remplace, que certains manques ont été comblés :
- Un registre des types de lien,
- Un mécanisme standard pour indiquer un lien dans une réponse HTTP.
Bien sûr, des formats normalisés qui permettent des liens, il y en a
plusieurs, et avant tout HTML, avec le fameux
élément <A> (pour
anchor). Il y a aussi le plus récent
Atom (RFC 4287, notamment
la section 4.2.7). Comme HTML, Atom avait l'idée de registre
des types de liens, mais ces types étaient spécifiques à Atom. L'une
des idées phares du RFC 5988 et de celui-ci, son successeur RFC 8288, est de
généraliser le concept de type de lien et de le rendre accessible à
tous les formats et protocoles qui en ont besoin. Ce RFC
décrit un cadre général pour les types de liens, en partant de celui
d'Atom.
Second apport de cette norme, une (re-)définition de
l'en-tête HTTP Link:,
utilisant évidemment le nouveau cadre général. Cet en-tête permettant
d'indiquer un lien dans la réponse HTTP, indépendamment du document
servi, avait été normalisé dans le RFC 2068, section 19.6.2.4,
puis, peu utilisé, avait été supprimé par le RFC 2616, avant de faire sa
réapparition ici, sous une forme quasi-identique à l'original. On peut
voir cet en-tête comme une représentation concrète du cadre de notre
RFC. D'autres apparaîtront sans doute.
Pour un exemple réel, regardez les en-têtes
Link: de mon blog, il y en a un de type
licence, suivant le RFC 4946. Avec Apache, cela se configure
simplement avec le module headers et la
directive Header set Link "<http://www.gnu.org/copyleft/fdl.html>; rel=\"license\"; title=\"GFDL\"".
Donc, qu'est-ce qu'un lien ? La section 2, la principale du RFC, le définit comme une connexion typée entre deux ressources (une ressource étant typiquement une page Web), nommées respectivement contexte et cible. Les deux ressources sont représentées par leur IRI (cf. RFC 3987, en notant que, dans la plupart des cas, les IRI des liens seront des URI). Le lien comprend :
- Un IRI qui indique le contexte, c'est-à-dire la ressource de départ,
- Le type de la connexion (détaillé en section 2.1),
- L'IRI cible,
- D'éventuels attributs de la cible (comme par exemple le hreflang de HTML). Ce sont des couples clé/valeur.
Par exemple, dans le flux de syndication
Atom de mon blog, on trouvera un lien
<atom:link rel="alternate"
href="http://www.bortzmeyer.org/expose-go.html"/> qui se décompose
en un contexte (l'entrée Atom dont l'IRI est
tag:bortzmeyer.org,2006-02:Blog/expose-go), un
type (alternate, qui indique une version
alternative de la ressource, ici une page HTML au lieu d'une entrée
Atom), et une cible (ici http://www.bortzmeyer.org/expose-go.html). Il n'y a pas dans
cet exemple
d'attributs de la cible mais Atom en permet (par exemple
hfrelang pour indiquer la langue de la cible ou bien
length pour indiquer sa longueur - afin de
prévenir d'un long téléchargement, par exemple).
Cette définition du lien ne place aucune limite sur la cardinalité. Il peut y avoir zéro, un ou plusieurs liens partant d'une ressource et c'est la même chose pour les lients entrants.
La section 2 s'arrête là. Puisque ce RFC propose un cadre général, il ne formalise pas une syntaxe unique pour représenter les liens. Chaque format, chaque protocole, aura la sienne, la sérialisation.
Un des points les plus importants de cette définition des liens,
et qui est souvent ignorée des gens qui écrivent des pages Web, est
la notion de type d'un lien (section 2.1). Par
exemple, on a un type copyright
qui associe, via un lien, un document à l'auteur de
celui-ci. Point à retenir : ce type du lien ne doit pas être
confondu avec le type de médium du RFC 6838
comme text/html ou
audio/ogg.
Il y a deux sortes de type de lien : enregistrés ou bien
extensions. Les premiers font l'objet de la section 2.1.1. Ils ont
fait l'objet d'un processus formel d'enregistrement et leur liste est publiée sous forme d'un
registre
IANA. On y trouve par exemple via (RFC 4287) ou hub (https://github.com/pubsubhubbub). La politique
d'enregistrement est délibérement ouverte, l'idée étant que si un
type est utilisé sur le Web, il faut vraiment qu'il soit indiqué
dans le registre, sauf s'il est gravement dangereux pour la santé
du Web.
Les extensions sont spécifiées dans la section 2.1.2. L'idée est
que, si on n'a pas envie de se fatiguer à enregistrer un type de
lien, et qu'on veut quand même créer un type
unique, n'ayant pas de risque de collision
avec le travail des autres, on peut simplement se servir d'un URI
(forcément unique) pour indiquer le type. Cette URI peut (mais ce
n'est pas obligé) mener à une page Web qui décrira le type en
question. Ainsi, on pourrait imaginer de réécrire le lien plus haut
en <atom:link
rel="http://www.bortzmeyer.org/reg/my-link-type"
href="http://www.bortzmeyer.org/expose-go.html"/> (en
pratique, le format Atom ne permet pas actuellement de telles
valeurs pour l'attribut rel.)
Après le cadre général de description des liens, notre RFC
introduit une syntaxe concrète pour le cas de l'en-tête
Link: des requêtes HTTP. Les autres formats et
protocoles devront s'ajuster à ce cadre chacun de son côté. Pour
HTTP, la section 3 décrit l'en-tête Link:. La
cible doit être un URI (et un éventuel IRI doit donc être
transformé en URI), le contexte (l'origine) est la ressource qui
avait été demandée en HTTP et le type est indiqué dans le paramètre
rel. (Le paramètre rev
qui avait été utilisé dans des vieilles versions est officiellement
abandonné.) Plusieurs attributs sont possibles comme
hreflang, type (qui est
le type MIME, pas le type du lien) ou
title (qui peut être noté
title* s'il utilise les en-têtes étendus du
RFC 8187). Pour la plupart de ces attributs,
leur valeur est juste une indication, la vraie valeur sera obtenue
en accédant à la ressource cible. Ainsi,
hreflang dans le lien ne remplace pas
Content-Language: dans la réponse et
type ne gagnera pas si un
Content-Type: différent est indiqué dans la
réponse.
Voici des exemples d'en-têtes, tirés de la section 3.5 du RFC :
Link: <http://www.example.com/MyBook/chapter2> rel="previous";
title="Previous chapter"
Ici, cet en-tête, dans une réponse HTTP, indique que
http://www.example.com/MyBook/chapter2 est une
ressource liée à la ressource qu'on vient de récupérer et que ce lien
est de type previous, donc précède la ressource
actuelle dans l'ordre de lecture. L'attribut
title indique un titre relatif, alors que la
vraie ressource
http://www.example.com/MyBook/chapter2 aura
probablement un titre du genre « Chapitre 2 ». En application des
règles de la section 3.4, c'est ce dernier titre qui gagnera au
final.
Un seul en-tête Link: peut indiquer plusieurs
liens, comme dans l'exemple suivant :
Link: </TheBook/chapter2>;
rel="previous"; title*=UTF-8'de'letztes%20Kapitel,
</TheBook/chapter4>;
rel="next"; title*=UTF-8'de'n%c3%a4chstes%20Kapitel
Ce dernier montre également les en-têtes complètement
internationalisés du RFC 8187, ici en
allemand (étiquette de langue de).
Cet en-tête a été enregistré à l'IANA, en application du RFC 3864 dans le registre des en-têtes (section 4.1).
D'autre part, un registre des types de liens existe. La section 4.2 décrit en détail ce registre. Voici, à titre d'exemple, quelques-uns des valeurs qu'on peut y trouver :
blocked-byindique l'entité qui a exigé le blocage d'une page Web (avec le fameux code 451, voir RFC 7725),copyrightqui indique le copyright du document (issu de la norme HTML),editqui indique l'URI à utiliser pour une modification de ce document, comme le permet le protocole APP (RFC 5023),first, qui pointe vers le premier document de la série (défini par ce RFC 8288, même s'il était déjà enregistré),hubqui indique l'endroit où s'abonner pour des notifications ultérieures, suivant le protocole PubSubHubbub),latest-versionqui indique où trouver la dernière version d'un document versionné (RFC 5829),licence, qui associe un document à sa licence d'utilisation (RFC 4946),nofollow, qui indique qu'on ne recommande pas la ressource vers laquelle on pointe, et qu'il ne faut donc pas considérer ce lien comme une approbation,related, qui indique un document qui a un rapport avec celui-ci (créé pour Atom, dans le RFC 4287),replies, qui indique les réponses faites à ce document (pour mettre en œuvre le threading, RFC 4685),- Et bien d'autres encore...
Ce registre est peuplé par le mécanisme dit Spécification
Nécessaire (cf. RFC 8126), avec exigence
d'un examen par un expert (l'actuel expert est Mark Nottingham, auteur de
plusieurs RFC, dont celui-ci). Pour chaque type, il faudra indiquer le type (aussi nommé
relation, comme par exemple previous plus haut), une
description et une référence à la norme qui le formalise. Les demandes
d'enregistrement sont reçues par link-relations@ietf.org.
Attention, ce n'est pas parce qu'il y a un lien qu'il faut le suivre automatiquement. La section 5, sur la sécurité, met en garde contre la confiance accordée à un lien.
L'annexe A.1 contient une discussion de l'utilisation des liens avec
HTML 4, d'où le cadre actuel de définition des liens est issu. Le type
y est indiqué par l'attribut rel. Un exemple
indiquant la licence en XHTML est donc :
<link rel="license" type="text/html" title="GFDL in HTML format"
href="http://www.gnu.org/copyleft/fdl.html"/>
L'annexe A.2
discute, elle, de l'utilisation du cadre de définition des liens en
Atom, qui utilise l'élément
<atom:link> avec les attributs
href pour indiquer la cible et
rel pour le type. Par exemple,
<atom:link rel="license" type="text/html"
title="GFDL in HTML format"
href="http://www.gnu.org/copyleft/fdl.html"/> indiquera
la licence du flux Atom qui contient cet élément (et, oui, Atom et
XHTML ont quasiment la même syntaxe).
L'annexe C de notre RFC indique les changements depuis son prédécesseur, le RFC 5988. Rien de très crucial :
- Les enregistrements faits par le RFC 5988 sont faits, donc on ne les répète pas dans ce RFC,
- Un registre des données spécifiques aux applications, qui n'a apparemment pas été un grand succès (il me semble qu'il n'a jamais été créé), n'est plus mentionné,
- Quatre errata ont été pris en compte, dont un était technique et portait sur la grammaire,
- La nouvelle annexe B donne un algorithme pour l'analyse des en-têtes,
- Et enfin ce nouveau RFC apporte pas mal de clarifications et de détails.
Ce nouveau RFC a fait l'objet de peu de discussions à l'IETF, mais il y en a eu beaucoup plus sur GitHub.
Notez qu'à Paris Web
2017, le t-shirt officiel
portait une allusion à ce RFC, avec le texte <link
rel="human" ... >, encourageant les relations entre humains.
L'article seul
Un peu de statistiques sur les TLD ICANN
Première rédaction de cet article le 23 octobre 2017
L'ICANN a pris la bonne initiative de publier sous un format structuré (JSON) la liste des TLD qui dépendent d'elles. Cela permet de faire facilement des statistiques sur ces TLD.
Attention, il n'y a pas tous les TLD, seulement ceux qui dépendent de l'ICANN (qu'on nomme souvent gTLD mais qui ne sont pas tous « génériques »).
Le fichier est en JSON, ce qui permet des analyses faciles avec jq. (Une version précédente, moins complète, était en CSV.) Commençons par télécharger :
% wget https://www.icann.org/resources/registries/gtlds/v2/gtlds.json
Combien y a-t-il de ces gTLD ?
% jq '.gTLDs | length' gtlds.json
1260
Elle est loin, l'époque où on parlait de .cno (
.com,
.net,
.org) car il n'y avait
guère que ces trois-là ! Mais attention, 21 gTLD ont
renoncé :
% jq '.gTLDs | map(select(.contractTerminated)) | map(.gTLD)' gtlds.json
[
"africamagic",
"chloe",
"doosan",
"dstv",
"dwg",
"emerson",
"flsmidth",
"gotv",
"iinet",
"kyknet",
"mnet",
"mtpc",
"multichoice",
"mutuelle",
"mzansimagic",
"naspers",
"orientexpress",
"payu",
"supersport",
"theguardian",
"xn--4gq48lf9j"
]
Certains ont même renoncé après avoir été délégués dans la racine :
% jq '.gTLDs | map(select(.delegationDate!=null and .contractTerminated)) | map(.gTLD)' gtlds.json
[
"chloe",
"doosan",
"flsmidth",
"iinet",
"mtpc",
"mutuelle",
"orientexpress"
]
Et certains ont déjà été retirés de la racine mais n'apparaissent pas encore comme « contrat terminé » :
% jq '.gTLDs | map(select((.contractTerminated | not) and .removalDate!=null)) | map(.gTLD)' gtlds.json
[
"mcd",
"mcdonalds",
"montblanc",
"pamperedchef"
]
Il n'y a donc que 1 234 TLD délégués actuellement (jq
'.gTLDs | map(select(.delegationDate!=null and
(.contractTerminated | not) and (.removalDate==null))) | length' gtlds.json).
Le fichier indique également le nom du registre. Par exemple, on peut avoir tous ceux de Google (46 en tout) :
% jq '.gTLDs | map(select(.registryOperator == "Charleston Road Registry Inc.")) | map(.gTLD)' gtlds.json
[
"ads",
"android",
"app",
"boo",
"cal",
"channel",
"chrome",
"dad",
"day",
"dclk",
"dev",
...
À propos de Google, combien des gTLD sont des
« .corp » (ou « .brand »), des TLD non ouverts au public,
prévus pour une seule entreprise ?
% jq '.gTLDs | map(select(.specification13)) | length' gtlds.json
470
Un gros tiers, donc. Au fait, si vous vous demandez ce qu'est
cette mystérieure « spécification 13 », voyez cette
documentation et le
texte complet.
Notez qu'il n'y a pas (encore ?) de mécanisme pour identifier les
« .geo », les TLD identifiant une zone
géographique, ni d'ailleurs les « .community ». (Les .corp ont des règles
particulières, d'où leur marquage.)
Et les IDN ? Il n'y en a que 96 dont 94 délégués actuellement. Ce sont (attention, préparez vos polices) :
% jq '.gTLDs | map(select(.delegationDate!=null and (.contractTerminated | not) and (.removalDate==null)
and (.uLabel!=null))) |
map(.uLabel + " (" + .gTLD + ")") ' gtlds.json
[
"कॉम (xn--11b4c3d)",
"セール (xn--1ck2e1b)",
"佛山 (xn--1qqw23a)",
"慈善 (xn--30rr7y)",
"集团 (xn--3bst00m)",
"在线 (xn--3ds443g)",
"大众汽车 (xn--3oq18vl8pn36a)",
"点看 (xn--3pxu8k)",
"คอม (xn--42c2d9a)",
"八卦 (xn--45q11c)",
"موقع (xn--4gbrim)",
"公益 (xn--55qw42g)",
"公司 (xn--55qx5d)",
"香格里拉 (xn--5su34j936bgsg)",
"网站 (xn--5tzm5g)",
"移动 (xn--6frz82g)",
"我爱你 (xn--6qq986b3xl)",
"москва (xn--80adxhks)",
"католик (xn--80aqecdr1a)",
"онлайн (xn--80asehdb)",
"сайт (xn--80aswg)",
"联通 (xn--8y0a063a)",
"קום (xn--9dbq2a)",
"时尚 (xn--9et52u)",
"微博 (xn--9krt00a)",
"淡马锡 (xn--b4w605ferd)",
"ファッション (xn--bck1b9a5dre4c)",
"орг (xn--c1avg)",
"नेट (xn--c2br7g)",
"ストア (xn--cck2b3b)",
"삼성 (xn--cg4bki)",
"商标 (xn--czr694b)",
"商店 (xn--czrs0t)",
"商城 (xn--czru2d)",
"дети (xn--d1acj3b)",
"ポイント (xn--eckvdtc9d)",
"新闻 (xn--efvy88h)",
"工行 (xn--estv75g)",
"家電 (xn--fct429k)",
"كوم (xn--fhbei)",
"中文网 (xn--fiq228c5hs)",
"中信 (xn--fiq64b)",
"娱乐 (xn--fjq720a)",
"谷歌 (xn--flw351e)",
"電訊盈科 (xn--fzys8d69uvgm)",
"购物 (xn--g2xx48c)",
"クラウド (xn--gckr3f0f)",
"通販 (xn--gk3at1e)",
"网店 (xn--hxt814e)",
"संगठन (xn--i1b6b1a6a2e)",
"餐厅 (xn--imr513n)",
"网络 (xn--io0a7i)",
"ком (xn--j1aef)",
"诺基亚 (xn--jlq61u9w7b)",
"食品 (xn--jvr189m)",
"飞利浦 (xn--kcrx77d1x4a)",
"手表 (xn--kpu716f)",
"手机 (xn--kput3i)",
"ارامكو (xn--mgba3a3ejt)",
"العليان (xn--mgba7c0bbn0a)",
"اتصالات (xn--mgbaakc7dvf)",
"بازار (xn--mgbab2bd)",
"موبايلي (xn--mgbb9fbpob)",
"ابوظبي (xn--mgbca7dzdo)",
"كاثوليك (xn--mgbi4ecexp)",
"همراه (xn--mgbt3dhd)",
"닷컴 (xn--mk1bu44c)",
"政府 (xn--mxtq1m)",
"شبكة (xn--ngbc5azd)",
"بيتك (xn--ngbe9e0a)",
"عرب (xn--ngbrx)",
"机构 (xn--nqv7f)",
"组织机构 (xn--nqv7fs00ema)",
"健康 (xn--nyqy26a)",
"рус (xn--p1acf)",
"珠宝 (xn--pbt977c)",
"大拿 (xn--pssy2u)",
"みんな (xn--q9jyb4c)",
"グーグル (xn--qcka1pmc)",
"世界 (xn--rhqv96g)",
"書籍 (xn--rovu88b)",
"网址 (xn--ses554g)",
"닷넷 (xn--t60b56a)",
"コム (xn--tckwe)",
"天主教 (xn--tiq49xqyj)",
"游戏 (xn--unup4y)",
"vermögensberater (xn--vermgensberater-ctb)",
"vermögensberatung (xn--vermgensberatung-pwb)",
"企业 (xn--vhquv)",
"信息 (xn--vuq861b)",
"嘉里大酒店 (xn--w4r85el8fhu5dnra)",
"嘉里 (xn--w4rs40l)",
"广东 (xn--xhq521b)",
"政务 (xn--zfr164b)"
]
(Si vous ne savez pas ce qu'est un « U-label », voyez le RFC 5890.)
L'article seul
RFC 8251: Updates to the Opus Audio Codec
Date de publication du RFC : Octobre 2017
Auteur(s) du RFC : JM. Valin (Mozilla
Corporation), K. Vos (vocTone)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF codec
Première rédaction de cet article le 22 octobre 2017
Le codec Opus, normalisé dans le RFC 6716 a une particularité rare à l'IETF : il est spécifié par un programme, pas par une description écrite en langue naturelle. Les programmes ont des bogues et ce nouveau RFC corrige quelques petites bogues pas graves trouvées dans le RFC 6716.
C'est un vieux débat dans le monde de la normalisation : faut-il décrire un protocole ou un format par une description en langue naturelle (vecteur souvent ambigu) ou par une mise en œuvre dans un langage de programmation (qui fournira directement un programme utilisable), dans laquelle il sera difficile de distinguer ce qui est réellement obligatoire et ce qui n'est qu'un détail de cette mise en œuvre particulière ? Presque tout le temps, à l'IETF, c'est la voie de la description en anglais qui est choisie. Mais le RFC 6716, qui normalisait Opus, avait choisi une autre voie, celle du code source, écrit en C. C'est ce code qui est la loi.
Dans les deux cas, en anglais ou en C, les humains qui rédigent les normes font des erreurs. D'où ce RFC de correction, qui répare le RFC 6716 sur des points mineurs (la compatibilité est maintenue, il ne s'agit pas d'une nouvelle version d'Opus).
Chaque section du RFC est ensuite consacrée à une des erreurs. La section 3, par exemple, corrige un simple oubli dans le code de réinitialiser l'état du décodeur lors d'un changement. Le patch ne fait que deux lignes. Notez qu'il change le résultat produit par le décodeur, mais suffisamment peu pour que les vecteurs de test de l'annexe A.4 du RFC 6716 soient inchangés.
L'erreur en section 9 est également une erreur de logique dans la programmation. Sa correction, par contre, nécessite de changer les vecteurs de tests (cf. section 11).
Le reste des bogues, en revanche, consiste en erreurs de programmation
C banales. Ainsi, en section 4, il y a un
débordement d'entier si les données font
plus de 2^31-1 octets, pouvant mener à lire en dehors de la mémoire. En
théorie, cela peut planter le décodeur (mais, en pratique, le
code existant n'a pas planté.) Notez que cela ne peut pas arriver
si on utilise Opus dans RTP, dont les
limites seraient rencontrées avant qu'Opus ne reçoive ces données
anormales. Cette bogue peut quand même avoir des conséquences de
sécurité et c'est pour cela qu'elle a reçu un
CVE, CVE-2013-0899. Le
patch est très court. (Petit
rappel de C : la norme de ce
langage ne spécifie pas ce qu'il faut faire lorsqu'on
incrémente un entier qui a la taille maximale. Le résultat dépend
donc de l'implémentation. Pour un entier
signé, comme le type
int, le comportement le plus courant est de
passer à des valeurs négatives.)
Notez qu'une autre bogue, celle de la section 7, a eu un CVE, CVE-2017-0381.
En section 5, c'est un problème de typage : un entier de 32 bits utilisé au lieu d'un de 16 bits, ce qui pouvait mener une copie de données à écraser partiellement les données originales.
Dans la section 6 du RFC, la bogue était encore une valeur trop grande pour un entier. Cette bogue a été découverte par fuzzing, une technique très efficace pour un programme traitant des données externes venues de sources qu'on ne contrôle pas !
Bref, pas de surprise : programmer en C est difficile, car de trop bas niveau, et de nombreux pièges guettent le programmeur.
La section 11 du RFC décrit les nouveaux vecteurs de test rendus nécessaires par les corrections à ces bogues. Ils sont téléchargeables.
Une version à jour du décodeur normatif figure désormais sur le site officiel. Le patch traitant les problèmes décrits dans ce RFC est en ligne. Ce patch global est de petite taille (244 lignes, moins de dix kilo-octets, ce qui ne veut pas dire que les bogues n'étaient pas sérieuses).
L'article seul
RFC 8254: Uniform Resource Name (URN) Namespace Registration Transition
Date de publication du RFC : Octobre 2017
Auteur(s) du RFC : J. Klensin, J. Hakala (The National Library of Finland)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF urnbis
Première rédaction de cet article le 21 octobre 2017
Pour avoir un espace de noms d'URN, autrefois, il fallait un examen par l'IETF, ce qui était un peu contraignant (et risquait de mener au « squat », avec des gens utilisant un espace de noms qu'ils ne se sont pas donné la peine d'enregistrer). Le RFC 8141 ayant changé cette politique d'enregistrement pour celle, plus facile, d'examen par un expert, il a fallu clarifier quelques processus, ce que fait ce RFC. Dans la foulée, ce RFC change le statut de quelques RFC précédents, qui avaient servi de base à l'enregistrement de certains espaces de noms. Bref, que de la procédure et de la bureaucratie (mais pas inutile).
Un des buts des URN (désormais normalisés dans le RFC 8141) était d'intégrer des systèmes d'identificateurs existants. C'est ainsi que le RFC 2288 avait décrit un espace de noms pour les ISBN, mais sans l'enregistrer formellement à l'IANA, en partie parce que le mécanisme d'enregistrement n'était pas clair à l'époque. Par la suite, le RFC 3187 a remplacé le RFC 2288 et comblé ce manque (dans sa section 5). Idem pour les ISSN dans le RFC 3044. Ces deux RFC 3187 et RFC 3044 sont reclassés comme étant désormais d'intérêt historique uniquement (section 2 de notre RFC), les enregistrements de ces espaces de noms ayant été refaits selon les nouvelles règles (section 5). Voyez le nouvel enregistrement d'isbn et celui d'issn.
Pour ISBN, le principal changement est que l'espace de noms URN fait désormais référence à la nouvelle version de la norme, ISO 2108:2017 (cf. la page officielle et, comme toutes les normes du dinosaure ISO, elle n'est pas disponible en ligne.) Elle permet les ISBN de treize caractères (les ISBN avaient dix caractères au début). Pour ISSN, la norme du nouvel enregistrement est ISO 3297:2007, qui permet notamment à un ISSN de référencer tous les médias dans lesquels a été fait une publication (il fallait un ISSN par média, avant).
Et les NBN (National
Bibliography Number, section 3) ? C'est un cas rigolo,
car NBN ne désigne pas une norme spécifique, ni même une famille
d'identificateurs, mais regroupe tous les mécanismes
d'identificateurs utilisés par les bibliothèques nationales
partout dans le monde. En effet, les bibibliothèques peuvent
recevoir des documents qui n'ont pas d'autre identificateur. Si la
bibliothèque nationale de Finlande reçoit
un tel document, son identificateur national pourrait être,
mettons, fe19981001, et, grâce à l'espace de
noms URN nbn, il aura un URN,
urn:nbn:fi-fe19981001.
Les NBN sont spécifiés dans le RFC 3188, pour lequel il n'y a pas encore de mise à jour prévue, contrairement aux ISBN et ISSN.
Outre les NBN, il y a bien d'autres schémas d'URN qui mériteraient une mise à jour, compte-tenu des changements du RFC 8141 (section 4). Mais il n'y a pas le feu, même si leur enregistrement actuel à l'IANA n'est pas tout à fait conforme au RFC 8141. On peut continuer à les utiliser.
L'article seul
RFC 8244: Special-Use Domain Names Problem Statement
Date de publication du RFC : Octobre 2017
Auteur(s) du RFC : T. Lemon
(Nominum), R. Droms, W. Kumari
(Google)
Pour information
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 20 octobre 2017
Le RFC 6761 créait un
registre de « noms de
domaines d'usage spécial », où l'IETF
enregistrait des noms qui pouvaient nécessiter un traitement
spécial par une des entités de la chaîne d'avitaillement et de
résolution des noms de domaines. Un exemple est celui des noms de
domaine qui n'utilisaient pas le DNS, comme le
.onion du RFC 7686. Certaines personnes ont émis des
réserves sur ce registre, par exemple parce qu'il marchait sur une
pelouse que l'ICANN considère comme sienne. Ce
nouveau RFC,
très controversé, fait la liste de tous les reproches qui ont été
faits au RFC 6761 et à son registre des noms
spéciaux.
La résolution de noms - partir d'un nom de domaine et obtenir des informations
comme l'adresse IP - est une des fonctions
cruciales de l'Internet. Il est donc normal
de la prendre très au sérieux. Et les noms ont une valeur pour les
utilisateurs (la vente record semble être celle de
business.com). Souvent, mais pas
toujours, cette résolution se fait avec le
DNS. Mais, je l'ai dit, pas toujours : il
ne faut pas confondre les noms de domaines (une organisation
arborescente, une syntaxe, les composants séparés par des
points, par exemple
_443._tcp.www.bortzmeyer.org.,
réussir-en.fr. ou
sjnrk23rmcl4ie5atmz664v7o7k5nkk4jh7mm6lor2n4hxz2tos3eyid.onion.) et le DNS, un
protocole réseau particulier (section 2 du RFC, pour la
terminologie). La section 2 de ce RFC, suivant la définition du
RFC 8499, ne considère pas qu'un nom de
domaine utilise forcément le DNS. (Le problème n° 20, en section 3 revient sur
cette question.)
Le registre
des noms de domaines spéciaux a été créé en 2013 par le
RFC 6761. Contrairement à ce que croient
beaucoup de gens, il ne contient pas que des TLD (par exemple, il
a aussi a.e.f.ip6.arpa ou bien
example.org). Depuis sa création, plusieurs
noms ont été ajoutés, le plus spectaculaire ayant été le
.onion en 2015, via le
RFC 7686. Beaucoup d'autres noms ont été
proposés, sans être explicitement rejetés mais sans être acceptés
non plus (voir les
Internet-Drafts
draft-grothoff-iesg-special-use-p2p-gns
et draft-chapin-additional-reserved-tlds). Ces
enregistrements ne se sont pas très bien passés, avec beaucoup
d'engueulades, notamment pour les TLD.
En effet, la bagarre a toujours fait rage pour la gestion des noms dans la racine du DNS. Il y a cinq sortes de TLD :
- Ceux qui sont mis dans la racine publique du DNS, comme
.bo,.net,.guru, etc. Contrairement à ce que dit le RFC, ils ne sont pas forcément délégués par l'ICANN (.dea été créé bien avant l'ICANN, et.surésiste depuis longtemps à toutes les tentatives de l'ICANN de le supprimer). - Ceux gérés par l'IETF « pour des
raisons techniques », et qui sont parfois délégués dans la
racine publique, le plus connu étant
.arpa. Les domaines du registre des noms spéciaux en font partie. Les fanas de gouvernance noteront qu'ils ne passent jamais par l'ICANN. - Ceux que l'ICANN bloque, pour des raisons variées (cf. leurs règles, notamment sections 2.2.1.2.1 ou 2.2.1.4.1).
- Ceux qui sont utilisés en dehors de la racine publique du
DNS, comme
.ethpour Ethereum ou.bitpour Namecoin. Cela inclut aussi des noms très utilisés localement comme.homeou.corp. - Et ceux qui sont libres, que personne n'utilise
encore. Demain, peut-être que
.macronsera utilisé par les fans du Président ?
Cette classification est imparfaite, comme toutes les classifications. Par exemple, un nom peut être sur la liste noire de l'ICANN et être quand même utilisé par des organisations locales, ou via un logiciel particulier.
Ce RFC veut présenter une liste exhaustive des problèmes posés lors de l'enregistrement de ces noms spéciaux. Comme elle est exhaustive (« an unfiltered compilation of issues »), elle n'est pas consensuelle, loin de là ! Plusieurs des problèmes ne sont pas considérés comme tels par tout le monde, ce que le RFC note bien dans les sections 1 et 3.
Le gros du RFC est donc cette liste de problèmes, en section 3. Je ne vais pas tous les citer. Notez tout de suite que ce RFC décrit des problèmes, ou perçus comme tels par certains, pas des solutions. Il ne propose pas de réforme du RFC 6761. Notez aussi que les problèmes ne sont pas classés (leur ordre d'exposition, et le numéro qu'ils reçoivent, n'est pas un ordre d'importance.)
Premier problème cité, la coordination avec
l'ICANN. Les cinq catégories de noms de
TLD cités
plus haut coexistent dans le même espace de noms. S'il y a deux
.macron, il y aura un problème (voir par
exemple le
rapport SAC 090, mais en se rappelant que c'est l'ICANN qui
s'auto-défend). L'IETF et
l'ICANN ont un mécanisme d'information
réciproque mais pas de processus bureaucratique formel de
coordination. Si l'IETF veut réserver .home
(RFC 7788), il n'y a officiellement pas de
mécanisme pour communiquer cette décision à l'ICANN et obtenir
d'elle la confirmation que ce nom n'est pas par ailleurs en cours
de réservation. (Cf. 4.1.4 qui revient sur ce mécanisme
- « liaison » en anglais.)
(Personnellement, cet argument me fait plutôt rire : beaucoup de gens sont actifs à la fois à l'IETF et à l'ICANN, les deux organisations opèrent de manière assez publique, surtout l'IETF, et la possibilité qu'elles réservent chacune un nom sans savoir ce qu'a fait l'autre est purement théorique.)
Le problème 2 est celui de la définition de « pour des raisons techniques », introduit dans le RFC 2860, et qui fonde le droit de l'IETF à réserver des TLD sans passer par la caisse de l'ICANN (« assignments of domain names for technical uses [...] are not considered to be policy issues, and shall remain subject to the provisions of this Section 4 »). Le problème est que ces raisons techniques ne sont définies nulle part et que personne ne sait trop ce que cela veut dire.
Les problèmes 3 et 4 sont qu'il n'y a pas de Directeur Chef de
l'Internet. Ni l'ICANN, ni l'IETF (ni évidemment
l'UIT) ne sont reconnus, ni en droit, ni en
fait, comme ayant une autorité quelconque (le raccourci
journalistique de présenter l'ICANN comme « le régulateur mondial
de l'Internet » est ridiculement faux). Imaginons qu'une
développeuse crée un nouveau logiciel qui utilise le TLD
.zigzag pour son nommage, et diffuse le
logiciel en question : personne ne peut l'en empêcher, même si
l'ICANN souffre de la perte de revenus potentiels, même si des
grognons à l'IETF murmurent bruyamment que c'est du
squatting (voir aussi le début de la section 4). Et heureusement que c'est ainsi :
c'est le côté « innover sans autorisation »
(« permissionless innovation » qui a été si
essentiel pour le succès de l'Internet). Un autre exemple est bien sûr le
projet .42, aujourd'hui abandonné mais qui
illustrait ce côté décentralisé de l'Internet.
La définition du problème 5 note que les organisations (ou les individus) utilisent des TLD (ou des domaines quelconques, mais c'est surtout sur les TLD que se focalise la discussion) sans suivre les procédures. Elles ont plusieurs raisons pour agir ainsi :
- Elles ne savent pas qu'il existe des procédures (c'est sans doute le cas le plus fréquent).
- Elles savent vaguement qu'il existe des procédures mais
elles se disent que, pour une utilisation purement locale, ce
n'est pas important. Le trafic sur les serveurs de noms de la racine montre
au contraire que les fuites sont importantes : les noms locaux
ne le restent pas. Sans compter le risque de
« collisions » entre un nom supposé purement
local et une allocation par l'ICANN :
.corpet.homesont des TLD locaux très populaires et il y a des candidatures (actuellement gelées de facto) pour ces TLD à l'ICANN - Les procédures existent, l'organisation les connait, mais ce n'est pas ouvert. C'est par exemple le cas des TLD ICANN, pour lesquels il n'y a actuellement pas de cycle de candidature, et on n'espère pas le prochain avant 2019 ou 2020.
- Les procédures existent à l'ICANN, l'organisation les connait, c'est ouvert, mais le prix fait reculer (185 000 $ US au précédent cycle ICANN, et uniquement pour déposer le dossier).
- Les procédures existent à l'IETF, l'organisation les connait, c'est ouvert, mais l'organisation refuse délibérement de participer (cas analogue à CARP).
- Les procédures existent, l'organisation les connait, c'est ouvert, mais l'organisation estime, à tort ou à raison, que sa candidature sera refusée (c'est actuellement le cas à l'IETF).
Ensuite, le problème 6 : il y a plusieurs protocoles de résolution de
nom, le DNS n'étant que le principal. En l'absence de
métadonnées indiquant le protocole à
utiliser (par exemple dans les URL),
se servir du TLD comme « aiguillage » est une solution
tentante (if tld == "onion" then use Tor elsif tld ==
"gnu" then use GnuNet else use DNS…)
Le registre des noms de domaines spéciaux est essentiellement
en texte libre, sans grammaire formelle. Cela veut dire que le
code spécifique qui peut être nécessaire pour traiter tous ces
domaines spéciaux (un résolveur doit, par exemple, savoir que
.onion n'utilise pas
le DNS et qu'il ne sert donc à rien de l'envoyer à la racine) doit
être fait à la main, il ne peut pas être automatiquement dérivé du
registre (problème 7). Résultat, quand un nouveau domaine est
ajouté à ce registre, il sera traité « normalement » par les
logiciels pas mis à jour, et pendant un temps assez long. Par
exemple, les requêtes seront envoyées à la racine, ce qui pose des
problèmes de vie privée (cf. RFC 7626).
Comme noté plus haut, certains candidats à un nom de domaine
spécial sont inquiets du temps que prendra l'examen de leur
candidature, et du risque de rejet (problème 8). Ils n'ont pas
tort. L'enregistrement du
.local (RFC 6762) a pris dix ans, et les efforts de Christian Grothoff
pour enregistrer .gnu se sont enlisés dans
d'épaisses couches de bureaucratie. Ce n'est peut-être pas un
hasard si Apple a fini par avoir son
.local (non sans mal) alors que des projets
de logiciel libre
comme GNUnet se sont vu fermer la porte au
nez.
C'est que l'IETF n'est pas toujours facile et qu'un certain nombre de participants à cette organisation ont souvent une attitude de blocage face à tout intervenant extérieur (problème 9). Ils n'ont pas tort non plus de se méfier des systèmes non-DNS, leurs raisons sont variées :
- Absence d'indication du mécanisme de résolution donc
difficulté supplémentaire pour les logiciels (« c'est quoi,
.zkey? »). De plus, un certain nombre de participants à l'IETF estiment qu'il ne faut de toute façon qu'un seul protocole de résolution, afin de limiter la complexité. - Le problème de la complexité est d'autant plus sérieux que les autres protocoles de résolution de noms n'ont pas forcément la même sémantique que le DNS : ils sont peut-être sensibles à la casse, par exemple.
- Conviction que l'espace de nommage est « propriété » de l'IETF et/ou de l'ICANN, et que ceux qui réservent des TLD sans passer par les procédures officielles sont de vulgaires squatteurs.
- Sans compter le risque, s'il existe un moyen simple et gratuit de déposer un TLD via l'IETF, que plus personne n'alimente les caisses de l'ICANN.
- Et enfin le risque juridique : si Ser
Davos fait un procès à l'IETF contre
l'enregistrement de
.onion, cela peut durer longtemps et coûter cher. L'ICANN court le même risque mais, elle, elle a des avocats en quantité, et de l'argent pour les payer.
Le problème 11 est davantage lié au RFC 6761 lui-même. Ce RFC a parfois été compris de travers,
comme pour l'enregistrement de ipv4only.arpa
(RFC 7050, corrigé ensuite dans le RFC 8880) et surtout celui de
.home (RFC 7788, qui
citait le RFC 6761 mais n'avait tenu aucune
de ses obligations). Voir aussi le problème 16.
Les problèmes 12 et 13 concernent les TLD existants (au sens où ils sont utilisés) mais pas enregistrés officiellement (voir par exemple le rapport de l'ICANN sur les « collisions »). Cela serait bien de documenter quelque part cette utilisation, de façon à, par exemple, être sûrs qu'ils ne soient pas délégués par l'ICANN. Mais cela n'a pas marché jusqu'à présent.
Le problème 14 concerne le fait que des noms de domaine spéciaux sont parfois désignés comme spéciaux par leur écriture dans le registre, mais parfois simplement par leur délégation dans le DNS.
Le problème 15 est celui de la différence entre enregistrer un
usage et l'approuver. Avec la règle « géré par l'IETF pour un
usage technique » du RFC 2860, il n'y a pas
moyen d'enregistrer un nom sans une forme d'« approbation ». (Pas
mal d'articles sur l'enregistrement de .onion
avaient ainsi dit, à tort, que « l'IETF approuvait officiellement
Tor ».)
Le problème 17 est un bon exemple du fait que la liste
de Prévert qu'est ce RFC est en effet « non filtrée » et que
toute remarque soulevée y a été mise, quels que soient ses
mérites. Il consiste à dire que l'utilisation du registre des noms
spéciaux est incohérente, car les enregistrements donnent des
règles différentes selon le nom. Cela n'a rien d'incohérent,
c'était prévu dès le départ par le RFC 6761 (section 5) :
il n'y a pas de raison de traiter de la même façon
.onion (qui n'utilise pas le DNS du tout) et
.bit (passerelle entre le DNS et
Namecoin).
Le problème 19 découle du fait que les noms de domaine ne sont
pas de purs identificateurs techniques comme le sont, par exemple,
les adresses MAC. Ils
ont un sens pour les utilisateurs. Bien que, techniquement
parlant, les développeurs de Tor auraient
pu choisir le nom .04aab3642f5 ou onion.torproject.org
comme suffixe pour les services en oignon,
ils ont préféré un nom d'un seul composant, et compréhensible,
.onion. Ce désir
est bien compréhensible (une
proposition à l'IETF est de reléguer tous les noms spéciaux sous
un futur TLD .alt, qui ne connaitra
probablement aucun succès même s'il est créé un jour). Mais il
entraine une pression accrue sur la racine des noms de domaine :
si deux projets réservent .zigzag, lequel des
deux usages faut-il enregistrer ?
Enfin, le dernier problème, le 21, est davantage technique : il
concerne DNSSEC. Si un TLD est enregistré
comme domaine spécial, faut-il l'ajouter dans la racine du DNS et,
si oui, faut-il que cette délégation soit signée ou pas ? S'il n'y
a pas de délégation, le TLD sera considéré comme invalide par les
résolveurs validants. Par exemple, si je fais une requête pour
quelquechose.zigzag, la racine du DNS va
répondre :
% dig @k.root-servers.net A quelquechose.zigzag
; <<>> DiG 9.10.3-P4-Debian <<>> @k.root-servers.net A quelquechose.zigzag
; (2 servers found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 7785
;; flags: qr aa rd; QUERY: 1, ANSWER: 0, AUTHORITY: 6, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 4096
;; QUESTION SECTION:
;quelquechose.zigzag. IN A
;; AUTHORITY SECTION:
zero. 86400 IN NSEC zip. NS DS RRSIG NSEC
zero. 86400 IN RRSIG NSEC 8 1 86400 (
20171017050000 20171004040000 46809 .
wyKfrNEygGCbDscCu6uV/DFofs5DKYiV+jJd2s4xkkAT
...
. 86400 IN NSEC aaa. NS SOA RRSIG NSEC DNSKEY
. 86400 IN RRSIG NSEC 8 0 86400 (
20171017050000 20171004040000 46809 .
kgvHoclQNwmDKfgy4b96IgoOkdkyRWyXYwohW+mpfG+R
...
. 86400 IN SOA a.root-servers.net. nstld.verisign-grs.com. (
2017100400 ; serial
1800 ; refresh (30 minutes)
900 ; retry (15 minutes)
604800 ; expire (1 week)
86400 ; minimum (1 day)
)
. 86400 IN RRSIG SOA 8 0 86400 (
20171017050000 20171004040000 46809 .
GnTMS7cx+XB+EmbMFWt+yEAg29w17HJfUaOqvPsTn0eJ
...
;; Query time: 44 msec
;; SERVER: 2001:7fd::1#53(2001:7fd::1)
;; WHEN: Wed Oct 04 12:58:12 CEST 2017
;; MSG SIZE rcvd: 1036
Et l'enregistrement NSEC prouvera qu'il n'y a
rien entre .zero et
.zip, amenant le résolveur validant à
considérer que .zigzag ne peut pas
exister. Si le nom devait être traité par le DNS (et, par exemple,
résolu localement comme ceux du RFC 6303,
c'est une réponse correcte : la requête n'aurait pas dû aller à la
racine). Dans d'autres cas, cela peut être gênant. De toute façon,
le débat est assez théorique : l'IETF n'a aucun pouvoir sur la
racine du DNS, et aucun moyen d'y ajouter un nom.
Après cet examen des possibles et potentiels problèmes, la section 4 du RFC examine les pratiques existantes. Plusieurs documents plus ou moins officiels examinent déjà ces questions. Mais je vous préviens tout de suite : aucun ne répond complètement au·x problème·s.
Commençons par le RFC 2826 sur la
nécessité d'une racine unique. C'est un document
IAB et qui n'engage donc pas l'IETF, même
s'il est souvent cité comme texte sacré. Sa thèse principale est
qu'il faut une racine unique, et que .zigzag,
.pm ou
.example
doivent donc avoir la même signification partout, sous peine de
confusion importante chez l'utilisateur. Cela n'interdit pas des
noms à usage local à condition que cela reste bien local. Comme
les utilisateurs ne vont pas faire la différence, ces noms locaux
vont forcément fuiter tôt ou tard. (Par exemple, un utilisateur
qui regarde http://something.corp/ ne va pas
réaliser que ce nom ne marche qu'en utilisant les résolveurs de
l'entreprise, et va essayer d'y accéder depuis chez lui. Un autre
exemple serait celui d'un utilisateur qui essaierait de taper
ping sjnrk23rmcl4ie5atmz664v7o7k5nkk4jh7mm6lor2n4hxz2tos3eyid.onion depuis la ligne
de commande, sans se rendre compte que ping
ne connait pas Tor.)
Bref, le RFC 2826 dit clairement qu'une racine unique est nécessaire, et que les noms locaux sont casse-gueule.
Le second RFC à lire est évidemment le RFC 6761, qui a créé le registre des noms de domaine spéciaux. Lui, c'est un document IETF sur le Chemin des Normes. Quelques points qui sont souvent oubliés par les lecteurs du RFC 6761 méritent d'être répétés :
- Certains noms spéciaux ne le sont en fait pas tellement,
et sont résolus par le DNS de la manière habituelle (c'est le
cas de
in-addr.arpa, par exemple, et rappelez-vous bien à son sujet que les noms de domaine spéciaux ne sont pas forcément des TLD). - Parfois, les noms spéciaux sont résolus par le DNS mais de
manière inhabituelle, comme
10.in-addr.arpa(pour les adresses IP du RFC 1918), qui doit être traité par le résolveur, sans jamais interroger la racine (cf. RFC 6303). - D'autres noms spéciaux sont gravement spéciaux et ne
doivent pas utiliser le DNS du tout. Ils servent de
« commutateurs » pour indiquer à la bibliothèque de résolution
de noms (la GNU libc
sur Ubuntu ou Mint par exemple) qu'il faut changer de
protocole. C'est le cas de
.onion(qui doit utiliser Tor) ou de.local(qui doit utiliser mDNS, RFC 6762). - Et tous ces cas sont valides et normaux (même si certains traditionnalistes à l'IETF rechignent devant le dernier).
Notez qu'à l'heure actuelle, tous les noms enregistrés comme noms de domaine spéciaux sont des TLD ou bien sont résolus avec le DNS.
Troisième RFC à lire absolument avant de dire des bêtises sur les noms de domaine spéciaux, le RFC 2860, qui fixe le cadre des relations compliquées entre l'IETF et l'ICANN. En gros, la règle par défaut est que l'ajout (ou le retrait) de TLD dans la racine est une prérogative de l'ICANN sauf les « noms de domaine à usage technique » (notion non définie…) où l'IETF décide. Notez que ce document concerne uniquement les relations entre l'IETF et l'ICANN. Si le W3C, ou la développeuse du logiciel ZigZag, veut créer un TLD, que se passe-t-il ? Ce point n'est pas traité dans le RFC 2860. Certains exégètes estiment que cela veut dire que ces tiers sont implicitement exclus.
Il y a aussi d'autres documents mais moins cruciaux. Le RFC 6762 qui normalise mDNS est celui qui a
réservé .local et c'est donc un
exemple d'un enregistrement réussi (mais qui fut laborieux, plus
de douze années de développement furent nécessaires, cf. l'annexe
H du RFC 6762).
Autre exemple réussi, le RFC 7686 sur le
.onion. .onion était
utilisé depuis longtemps quand le RFC 6761 a
créé le registre des noms de domaine spéciaux. L'enregistrement
a
posteriori a réussi, malgré de
vigoureuses oppositions mais il faut noter que le consensus
approximatif de l'IETF a été facilité par une décision du
CA/B Forum de ne plus allouer
de certificats pour des TLD internes.
Encore un autre RFC à lire, le RFC 6303,
qui décrit les noms qui devraient idéalement être résolus
localement, c'est-à-dire par le résolveur de l'utilisateur, sans
demander aux serveurs faisant autorité. C'est par exemple le cas
des in-addr.arpa
correspondant aux adresses IPv4 privées du RFC 1918. Il ne sert à rien de demander à la racine
l'enregistrement PTR de
3.2.1.10.in-addr.arpa : ces adresses IP étant
purement locales, il ne peut pas y avoir de réponse intelligente
de la racine. Les noms en 10.in-addr.arpa
doivent donc être résolus localement, et sont donc, eux aussi, des
« noms de domaine spéciaux ». Par contre, contrairement à
.local ou à .onion, ils
sont résolus par le DNS.
Pas fatigué·e·s ? Encore envie de lire ? Il y aussi l'étude
d'Interisle sur les « collisions ». Derrière ce nom
sensationnaliste conçu pour faire peur, il y a un vrai problème,
le risque qu'un TLD récent masque, ou soit masqué par, un TLD
alloué localement sans réfléchir (comme .dev). L'étude
montrait par exemple que .home était celui
posant le plus de risques.
Sur un sujet proche, il y a aussi une étude du SSAC, un comité ICANN.
On a dit plus haut que les noms de domaine « spéciaux »
n'étaient pas forcément des TLD. C'est par exemple le cas d'un nom
utilisé pour certaines manipulations IPv6,
ipv4only.arpa, créé par le RFC 7050, mais qui, par suite d'un cafouillage dans le
processus, n'avait pas été ajouté immédiatement au registre des noms de domaine
spéciaux. Dommage : ce nom, n'étant pas un TLD et n'ayant pas de
valeur particulière, n'avait pas posé de problème et avait été
accepté rapidement.
Enfin, un dernier échec qu'il peut être utile de regarder, est
la tentative d'enregistrer comme noms de domaine spéciaux des TLD
très souvent alloués localement, et qu'il serait prudent de ne pas
déléguer dans la racine, comme le .home cité
plus haut. Un projet
avait été rédigé en ce sens, mais n'avait jamais abouti,
enlisé dans les sables procéduraux.
Si vous n'avez pas mal à la tête à ce stade, vous pouvez encore
lire la section 5, qui rappelle l'histoire tourmentée de ce
concept de noms de domaine spéciaux. Lorsque le DNS a été produit
(RFC 882 et RFC 883)
pour remplacer l'ancien système HOSTS.TXT
(RFC 608), la transition ne s'est pas faite sans
douleur, car plusieurs systèmes de résolution coexistaient (le
plus sérieux étant sans doute les Yellow
Pages sur Unix, mais il y avait aussi
NetBIOS name
service/WINS, qui ne tournait pas que sur
Windows). Encore aujourd'hui, des anciens
systèmes de résolution fonctionnent toujours. Le
HOSTS.TXT survit sous la forme du
/etc/hosts d'Unix (et de son équivalent
Windows). Les systèmes d'exploitation ont en général
un « commutateur » qui permet d'indiquer quel mécanisme de
résolution utiliser pour quel nom. Voici un exemple d'un
/etc/nsswitch.conf sur une machine
Debian qui, pour résoudre un nom de
domaine, va utiliser successivement
/etc/hosts, LDAP, puis
le DNS :
hosts: files ldap dns
Le concept de TLD privé, connu uniquement en local, a été (bien à tort) recommandé par certaines entreprises comme Sun ou Microsoft. Il a survécu à la disparition des technologies qui l'utilisaient, comme Yellow Pages. Aujourd'hui, c'est une source d'ennuis sans fin, et bien des administrateurs réseau ont maudit leur prédécesseur pour avoir configuré ainsi tout le réseau local, allumant ainsi une bombe qui allait exploser quand le TLD « privé » s'est retrouvé délégué.
La discussion à l'IETF, notamment dans son groupe de travail
DNSOP a été très chaude. Un premier document avait été
élaboré, draft-adpkja-dnsop-special-names-problem,
puis l'ancêtre de ce RFC avait été écrit, le premier document
étant abandonné (il était très proche du point de vue de
l'ICANN comme quoi seule l'ICANN devrait
pouvoir créer des TLD, les autres acteurs n'étant que de vilains
squatteurs).
L'article seul
RFC 8257: Data Center TCP (DCTCP): TCP Congestion Control for Data Centers
Date de publication du RFC : Octobre 2017
Auteur(s) du RFC : S. Bensley, D. Thaler, P. Balasubramanian (Microsoft), L. Eggert (NetApp), G. Judd (Morgan Stanley)
Pour information
Réalisé dans le cadre du groupe de travail IETF tcpm
Première rédaction de cet article le 19 octobre 2017
DCTCP (Datacenter TCP), décrit dans ce RFC (qui n'est pas une norme, attention), est une variante de TCP avec un contrôle de congestion moins prudent. Elle est conçue pour le cas particulier des centres de données et ne doit pas être utilisée sur l'Internet public.
DCTCP repose sur la technique ECN du RFC 3168. Normalement, cette technique permet de signaler la congestion plus tôt qu'avec la méthode traditionnelle d'attendre les pertes de paquets. L'ECN est binaire : il y a eu de la congestion ou il n'y en a pas eu. DCTCP va plus loin et utilise ECN pour estimer le nombre d'octets qui ont rencontré de la congestion. DCTCP va ensuite refermer sa fenêtre (le nombre d'octets qu'on peut envoyer avant d'avoir reçu des accusés de réception) plus lentement que le TCP classique (et c'est pour cela que la concurrence entre eux est inégale, et que DCTCP ne doit pas être activé dans l'Internet, mais seulement dans des environnements fermés).
Quelles sont les particularités du réseau dans un centre de données ? Il faut beaucoup de commutateurs pour relier ces machines. Il est tentant d'utiliser pour cela des commutateurs bon marché. Mais ceux-ci ont des tampons de taille limitée, et le risque de congestion est donc plus élevé. Dans un centre de données, les flots sont de deux types : des courts et des longs. Les courts veulent en général une faible latence et les longs sont souvent davantage intéressés par une forte capacité. Enfin, le trafic est souvent très synchronisé. Si on fait du MapReduce, tous les serveurs vont voir de l'activité réseau en même temps (quand le travail est réparti, et quand il se termine).
Le cahier des charges des commutateurs est donc plein de contradictions :
- Tampon de petite taille, pour ne pas augmenter la latence (attention au bufferbloat),
- Tampon de grande taille pour être sûr de pouvoir toujours utiliser les liens de sortie au maximum,
- Tampon de grande taille pour pouvoir encaisser les brusques variations de trafic, lorsqu'un flot bavard commence (par exemple une distribution d'un nouveau travail MapReduce).
Avec le TCP traditionnel (pré-ECN), l'indicateur de congestion est la perte de paquets, détectée par l'absence d'accusé de réception. (Voir le RFC 5681 pour une bonne synthèse sur le contrôle de congestion dans TCP.) Attendre la perte de paquets pour ralentir n'est pas très efficace : pour un flot court qui rencontre de la congestion au début, la majorité des paquets aura été jetée avant que TCP ne puisse ralentir. D'où l'invention d'ECN (RFC 3168). ECN permet de réagir avant qu'on perde des paquets. Mais, comme expliqué plus haut, il est binaire : il détecte la congestion, pas son importance. Il va donc souvent mener TCP à refermer trop énergiquement la fenêtre d'envoi.
La section 3 du RFC présente les algorithmes à utiliser. Les
commutateurs/routeurs
détectent la congestion et la signalent via
ECN (RFC 3168). Les
récepteurs des données renvoient l'ECN à l'émetteur et celui-ci
réduit sa fenêtre de congestion (cwnd pour
Congestion WiNDow, cf. RFC 5681, section 2). Tout ceci est
le fonctionnement classique d'ECN. C'est surtout dans la dernière étape,
le calcul de la réduction de la fenêtre, que DCTCP apporte des
nouveautés. Mais, avant, quelques détails sur les deux premières
étapes.
D'abord, la décision des commutateurs et·ou routeurs de considérer qu'il y a congestion. Fondamentalement, c'est une décision locale, qui n'est pas standardisée. En général, on décide qu'il y a congestion dès que le temps de séjour des paquets dans les tampons du commutateur/routeur augmente « trop ». On n'attend donc pas que les files d'attente soient pleines (si elles sont grandes - bufferbloat - la latence va augmenter sérieusement bien avant qu'elles ne soient pleines). Une fois que l'engin décide qu'il y a congestion, il marque les paquets avec ECN (bit CE - Congestion Experienced, cf. RFC 3168).
Le récepteur du paquet va alors se dire « ouh là, ce paquet a rencontré de la congestion sur son trajet, il faut que je prévienne l'émetteur de se calmer » et il va mettre le bit ECE dans ses accusés de réception. Ça, c'est l'ECN normal. Mais pour DCTCP, il faut davantage de détails, puisqu'on veut savoir précisément quels octets ont rencontré de la congestion. Une possibilité serait d'envoyer un accusé de réception à chaque segment (paquet TCP), avec le bit ECE si ce segment a rencontré de la congestion. Mais cela empêcherait d'utiliser des optimisations très utiles de TCP, comme les accusés de réception retardés (on attend un peu de voir si un autre segment arrive, pour pouvoir accuser réception des deux avec un seul paquet). À la place, DCTCP utilise une nouvelle variable booléenne locale chez le récepteur qui stocke l'état CE du précédent segment. On envoie un accusé de réception dès que cette variable change d'état. Ainsi, l'accusé de réception des octets M à N indique, selon qu'il a le bit ECE ou pas, que tous ces octets ont eu ou n'ont pas eu de congestion.
Et chez l'émetteur qui reçoit ces nouvelles notifications de
congestion plus subtiles ? Il va s'en servir pour déterminer quel
pourcentage des octets qu'il a envoyé ont rencontré de la
congestion. Les détails du calcul (dont une partie est laissé à
l'implémenteur, cf. section 4.2) figurent en section 3.3. Le résultat est stocké
dans une nouvelle variable locale,
DCTCP.Alpha.
Une fois ces calculs faits et cette variable disponible,
lorsque la congestion apparait, au lieu de diviser brusquement sa
fenêtre de congestion, l'émetteur la fermera plus doucement, par
la formule cwnd = cwnd * (1 - DCTCP.Alpha /
2) (où cwnd est la taille de la
fenêtre de congestion ; avec l'ancien algorithme, tout se passait
comme si tous les octets avaient subi la congestion, donc
DCTCP.Alpha = 1).
La formule ci-dessus était pour la cas où la congestion était signalée par ECN. Si elle était signalée par une perte de paquets, DCTCP se conduit comme le TCP traditionnel, divisant sa fenêtre par deux. De même, une fois la congestion passée, Datacenter TCP agrandit sa fenêtre exactement comme un TCP normal.
Voilà, l'algorithme est là, il n'y a plus qu'à le mettre en œuvre. Cela mène à quelques points subtils, que traite la section 4. Par exemple, on a dit que DCTCP, plus agressif qu'un TCP habituel, ne doit pas rentrer en concurrence avec lui (car il gagnerait toujours). Une implémentation de DCTCP doit donc savoir quand activer le nouvel algorithme et quand garder le comportement conservateur traditionnel. (Cela ne peut pas être automatique, puisque TCP ne fournit pas de moyen de négocier l'algorithme de gestion de la congestion avec son pair.) On pense à une variable globale (configurée avec sysctl sur Unix) mais cela ne suffit pas : la même machine dans le centre de données peut avoir besoin de communiquer avec d'autres machines du centre, en utilisant DCTCP, et avec l'extérieur, où il ne faut pas l'utiliser. Il faut donc utiliser des configurations du genre « DCTCP activé pour les machines dans le même /48 que moi ».
Une solution plus rigolote mais un peu risquée, serait d'activer DCTCP dès que la mesure du RTT indique une valeur inférieure à N millisecondes, où N est assez bas pour qu'on soit sûr que seules les machines de la même tribu soient concernées.
Après le programmeur en section 4, l'administrateur réseaux en section 5. Comment déployer proprement DCTCP ? Comme on a vu que les flots TCP traditionnels et DCTCP coexistaient mal, la section 5 recommande de les séparer. Par exemple, l'article « Attaining the Promise and Avoiding the Pitfalls of TCP in the Datacenter » décrit un déploiement où le DSCP (RFC 2474) d'IPv4 est utilisé pour distinguer les deux TCP, ce qui permet d'appliquer de l'AQM (RFC 7567) à DCTCP et des méthodes plus traditionnelles (laisser tomber le dernier paquet en cas de congestion) au TCP habituel. (Il faut aussi penser au trafic non-TCP, ICMP, par exemple, quand on configure ses commutateurs/routeurs.)
Aujourd'hui, DCTCP est déjà largement déployé et ce RFC ne fait que prendre acte de ce déploiement On trouve DCTCP dans Linux (cf. ce commit de 2014, notez les mesures de performance qui accompagnent sa description), dans FreeBSD (ce commit, et cette description de l'implémentation), et sur Windows (cette fois, on ne peut pas voir le source mais il y a une documentation). Sur Linux, on peut voir la liste des algorithmes de gestion de la congestion qui ont été compilés dans ce noyau :
% sysctl net.ipv4.tcp_available_congestion_control
net.ipv4.tcp_available_congestion_control = cubic reno
Si DCTCP manque, c'est peut-être parce qu'il faut charger le module :
% modprobe tcp_dctcp
% sysctl net.ipv4.tcp_available_congestion_control
net.ipv4.tcp_available_congestion_control = cubic reno dctcp
Si DCTCP se trouve dans la liste, on peut l'activer (c'est une activation globale, par défaut) :
% sysctl -w net.ipv4.tcp_congestion_control=dctcp
Pour le faire uniquement vers certaines destinations (par exemple à l'intérieur du centre de données) :
% ip route add 192.168.0.0/16 congctl dctcp
Le choix des algorithmes de gestion de la congestion peut
également être fait par chaque application (setsockopt(ns, IPPROTO_TCP, TCP_CONGESTION, …).
Enfin, la section 6 du RFC rassemble quelques problèmes non résolus avec DCTCP :
- Si les estimations de congestion sont fausses, les calculs de DCTCP seront faux. C'est particulièrement un problème en cas de perte de paquets, problème peu étudié pour l'instant.
- Comme indiqué plus haut, DCTCP n'a aucun mécanisme pour négocier dynamiquement son utilisation. Il ne peut donc pas coexister avec le TCP traditionnel mais, pire, il ne peut pas non plus partager gentiment le réseau avec un futur mécanisme qui, lui aussi, « enrichirait » ECN. (Cf. la thèse de Midori Kato.)
Enfin, la section 7 du RFC, portant sur la sécurité, note que DCTCP hérite des faiblesses de sécurité d'ECN (les bits ECN dans les en-têtes IP et TCP peuvent être modifiés par un attaquant actif) mais que c'est moins grave pour DCTCP, qui ne tourne que dans des environnements fermés.
Si vous aimez lire, l'article original décrivant DCTCP en 2010 est celui de Alizadeh, M., Greenberg, A., Maltz, D., Padhye, J., Patel, P., Prabhakar, B., Sengupta, S., et M. Sridharan, « Data Center TCP (DCTCP) ». Le dinosaure ACM ne le rendant pas disponible librement, il faut le récupérer sur Sci-Hub (encore merci aux créateurs de ce service).
Merci à djanos pour ses nombreuses corrections sur la gestion de DCTCP dans Linux.
L'article seul
RFC 8221: Cryptographic Algorithm Implementation Requirements and Usage Guidance for Encapsulating Security Payload (ESP) and Authentication Header (AH)
Date de publication du RFC : Octobre 2017
Auteur(s) du RFC : P. Wouters (Red
Hat), D. Migault, J. Mattsson
(Ericsson), Y. Nir (Check
Point), T. Kivinen
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF ipsecme
Première rédaction de cet article le 18 octobre 2017
Le protocole de cryptographie IPsec vient avec une liste d'obligations concernant les algorithmes cryptographiques qu'il faut inclure. Cette liste figure dans ce RFC 8221 (qui remplace l'ancien RFC 7321, avec beaucoup de changements). Ainsi, les différentes mises en œuvre d'IPsec sont sûres d'avoir un jeu d'algorithmes corrects en commun, assurant ainsi l'interopérabilité. Cette nouvelle version marque notamment l'officialisation de l'algorithme ChaCha20.
Ce nouveau RFC concerne les deux services d'IPsec, ESP (Encapsulating Security Payload, RFC 4303) et AH (Authentication Header, RFC 4302). Les RFC normatifs sur IPsec se veulent stables, alors que la cryptographie évolue. D'où le choix de mettre les algorithmes dans un RFC à part. Par exemple, la section 3.2 du RFC 4303 note « The mandatory-to-implement algorithms for use with ESP are described in a separate RFC, to facilitate updating the algorithm requirements independently from the protocol per se » (c'était à l'époque le RFC 4305, remplacé depuis par le RFC 4835, puis par le RFC 7321, puis par notre RFC 8221, trois ans après son prédécesseur).
Ce RFC « extérieur » à IPsec spécifie les algorithmes obligatoires, ceux sur lesquels on peut toujours compter que le pair IPsec les comprenne, ceux qui ne sont pas encore obligatoires mais qu'il vaut mieux mettre en œuvre car ils vont sans doute le devenir dans le futur, et ceux qui sont au contraire déconseillés, en général suite aux progrès de la cryptanalyse, qui nécessitent de réviser régulièrement ce RFC (voir section 1.1). Cette subtilité (différence entre « obligatoire aujourd'hui » et « sans doute obligatoire demain ») mène à une légère adaptation des termes officiels du RFC 2119 : MUST- (avec le signe moins à la fin) est utilisé pour un algorithme obligatoire aujourd'hui mais qui ne le sera sans doute plus demain, en raison des avancées cryptanalytiques, et SHOULD+ est pour un algorithme qui n'est pas obligatoire maintenant mais le deviendra sans doute.
Les section 5 et 6 donnent la liste des algorithmes. Je ne les répète pas intégralement ici, d'autant plus que tous les algorithmes ne sont pas cités, seulement ceux qu'il faut mettre en œuvre, car ils sont fiables, et ceux qu'il ne faut pas mettre en œuvre, car trop cassés, et qui doivent donc être documentés pour mettre les programmeurs en garde. Parmi les points à noter :
- ESP a un mode de chiffrement intègre (authenticated encryption qu'on peut aussi traduire par chiffrement vérifié ou chiffrement authentifié, que je n'aime pas trop parce qu'on peut confondre avec l'authentification, cf. RFC 5116). Ce mode est préféré à celui où chiffrement et intégrité sont séparés. Ce mode a un algorithme obligatoire, AES-GCM, décrit dans le RFC 4106 (il était SHOULD+ dans le RFC 7321). Il y aussi un algorithme recommandé (SHOULD, pas SHOULD+ car trop récent et pas encore assez souvent présent dans les mises en œuvres d'IPsec), ChaCha20-Poly1305 (normalisé dans le RFC 7539), qui fait son entrée dans la famille IPsec (cf. RFC 7634). Il semble bien parti pour remplacer AES-GCM un jour. Dans le RFC 7321, chiffrement intègre et chiffrement tout court étaient décrits séparément mais ils sont depuis dans le même tableau.
- Le mode le plus connu d'ESP, celui de chiffrement tout
court (le chiffrement intègre est désormais préféré), a deux
algorithmes obligatoires (sans compter AES-GCM, cité
plus haut, qui permet le chiffrement intègre), ces deux
algorithmes sont AES-CBC
(RFC 3602) et le surprenant
NULL, c'est-à-dire l'absence de chiffrement (RFC 2410 ; on peut utiliser ESP pour l'authentification seule, d'où cet algorithme). Il y a aussi plusieurs algorithmes notés MUST NOT, comme DES-CBC (RFC 2405). Ils ne doivent pas être programmés, afin d'être sûr qu'on ne s'en serve pas. - Le mode d'authentification (enfin, intégrité serait peut-être un meilleur mot mais c'est subtil) d'ESP a un MUST, HMAC-SHA-256 (RFC 4868). L'étoile de SHA-1 (RFC 2404) baissant sérieusement, HMAC-SHA1 n'est plus que MUST-. AES-GMAC, GMAC étant une variante de GCM, qui était en SHOULD+ dans le vieux RFC, redescend en MAY.
- Et AH, lui, a les mêmes algorithmes que ce mode d'authentification d'ESP.
La section 4 donne des conseils sur l'utilisation d'ESP et
AH. AH ne fournit que l'authentification, alors qu'ESP peut fournir
également le chiffrement. Bien sûr, le chiffrement sans
l'authentification ne sert pas à grand'chose, puisqu'on risque
alors de parler à l'homme du milieu sans le savoir (voir l'article
de Bellovin, S. « Problem areas for the IP security
protocols » dans les Proceedings of the Sixth
Usenix Unix Security Symposium en 1996). Certaines
combinaisons d'algorithmes ne sont pas sûres, par exemple,
évidemment, ESP avec les algorithmes de chiffrement et
d'authentification tous les deux à NULL (voir
par exemple l'article de Paterson, K. et J. Degabriele,
« On the (in)security of IPsec in MAC-then-encrypt
configurations » à l'ACM Conference on Computer
and Communications Security en 2010). Si on veut de
l'authentification/intégrité sans chiffrement, le RFC recommande
d'utiliser ESP avec le chiffrement NULL,
plutôt que AH. En fait, AH est rarement utile, puisque ESP en est
presque un sur-ensemble, et il y a même eu des propositions de
le supprimer. AH avait été prévu pour une époque où le
chiffrement était interdit d'utilisation ou d'exportation dans
certains pays et un logiciel n'ayant que AH posait donc moins de
problèmes légaux. Aujourd'hui, la seule raison d'utiliser encore AH
est si on veut protéger certains champs de l'en-tête IP, qu'ESP ne défend pas.
Le chiffrement intègre/authentifié d'un algorithme comme AES-GCM (RFC 5116 et RFC 4106) est la solution recommandée dans la plupart des cas. L'intégration du chiffrement et de la vérification d'intégrité est probablement la meilleure façon d'obtenir une forte sécurité.
Triple DES et DES, eux, ont des défauts connus et ne doivent plus être utilisés. Triple DES a une taille de bloc trop faible et, au-delà d'un gigaoctet de données chiffrées avec la même clé, il laisse fuiter des informations à un écoutant, qui peuvent l'aider dans son travail de décryptage. Comme, en prime, il est plus lent qu'AES, il n'y a vraiment aucune raison de l'utiliser. (DES est encore pire, avec sa clé bien trop courte. Il a été cassé avec du matériel dont les plans sont publics.)
Triple DES étant sorti, la « solution de remplacement », si un gros problème est découvert dans AES, sera ChaCha20. Il n'y a aucune indication qu'une telle vulnérabilité existe mais il faut toujours garder un algorithme d'avance.
Pour l'authentification/intégrité, MD5, ayant des vulnérabilités connues (RFC 6151), question résistance aux collisions, est relégué en MUST NOT. (Notez que des vulnérabilités à des collisions ne gênent pas forcément l'utilisation dans HMAC.) SHA-1 a des vulnérabilités analogues mais qui ne concernent pas non plus son utilisation dans HMAC-SHA1, qui est donc toujours en MUST- (le moins indiquant son futur retrait). Les membres de la famille SHA-2 n'ont pas ces défauts, et sont désormais MUST pour SHA-256 et SHOULD pour SHA-512.
Voilà, c'est fini, la section 10 sur la sécurité rappelle juste quelques règles bien connues, notamment que la sécurité d'un système cryptographique dépend certes des algorithmes utilisés mais aussi de la qualité des clés, et de tout l'environnement (logiciels, humains).
Ce RFC se conclut en rappelant que, de même qu'il a remplacé ses prédécesseurs comme le RFC 7321, il sera probablement à son tour remplacé par d'autres RFC, au fur et à mesure des progrès de la recherche en cryptographie.
Si vous voulez comparer avec un autre document sur les algorithmes cryptographiques à choisir, vous pouvez par exemple regarder l'annexe B1 du RGS, disponible en ligne.
Merci à Florian Maury pour sa relecture acharnée. Naturellement, comme c'est moi qui tiens le clavier, les erreurs et horreurs restantes viennent de ma seule décision. De toute façon, vous n'alliez pas vous lancer dans la programmation IPsec sur la base de ce seul article, non ?
La section 8 du RFC résume les changements depuis le RFC 7321. Le RFC a été sérieusement réorganisé, avec une seule section regroupant les algorithmes avec AEAD et sans (j'ai gardé ici la présentation séparée de mon précédent article). Les sections d'analyse et de discussion ont donc été très modifiées. Par exemple, le RFC 7321 s'inquiétait de l'absence d'alternative à AES, problème qui a été résolu par ChaCha20. Parmi les principaux changements d'algorithmes :
- AES-GCM prend du galon en passant de SHOULD+ à MUST comme prévu,
- ChaCha20 et Poly1305 (RFC 7539 et RFC 7634) font leur apparition (ils n'étaient pas mentionnés dans le RFC 7321),
- SHA-1, lui, recule, au profit de SHA-2,
- Triple DES est désormais très déconseillé (SHOULD NOT),
- Un nouveau concept apparait, celui des algorithmes cryptographiques « pour l'IoT », un domaine qui pose des problèmes particuliers, en raisons des fortes contraintes pesant sur ces objets (peu de mémoire, peu de puissance électrique disponible, des processeurs lents). C'est ainsi qu'AES-CCM (RFC 4309) passe à SHOULD mais uniquement pour l'Internet des Objets, et qu'AES-XCBC (RFC 3566), qui semblait voué à disparaitre, refait surface spécifiquement pour les objets connectés (peut remplacer HMAC pour l'authentification, afin de ne pas avoir à implémenter SHA-2). Notez que XCBC est peu connu et n'a même pas de page dans le Wikipédia anglophone ☺
En pratique, ce RFC est déjà largement mis en œuvre, la plupart des algorithmes cités sont présents (quand ils sont MUST ou SHOULD) ou absents (quand ils sont MUST NOT) dans les implémentations d'IPsec. Une exception est peut-être ChaCha20, qui est loin d'être présent partout. Malgré cela, ce RFC n'a pas suscité de controverses particulières, l'IETF avait un consensus sur ces nouveaux choix.
L'article seul
RFC 8255: Multiple Language Content Type
Date de publication du RFC : Octobre 2017
Auteur(s) du RFC : N. Tomkinson, N. Borenstein (Mimecast)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF slim
Première rédaction de cet article le 10 octobre 2017
Dernière mise à jour le 20 mars 2018
La norme MIME permet d'étiqueter un
message en
indiquant la langue, avec l'en-tête
Content-Language: (RFC 4021). Mais
comment faire si on veut envoyer le même message en plusieurs
langues, pour s'adapter à une audience variée, ou bien si on n'est
pas sûr des langues parlées par le destinataire ? C'est ce que
permet le nouveau type de
message multipart/multilingual
qui permet d'étiqueter les messages multilingues.
C'est le premier RFC du groupe de travail SLIM, chargé de créer des normes pour indiquer la langue utilisée dans le courrier et pour les communications synchrones (téléphonie sur IP, par exemple, couverte depuis par le RFC 8373), dans le cas où plusieurs langues sont en présence.
Le type de premier niveau multipart/ (RFC 2046, section 5.1, enregistré à
l'IANA) permet d'indiquer un message (ou une partie de
message, en cas de récursivité) composé de plusieurs
parties. Ainsi, multipart/mixed (RFC 2046, section 5.1.3) indique un message dont
les dfférentes parties sont indépendantes (un texte et une image,
par exemple). Alors que multipart/alternative
(RFC 2046, section 5.1.4) est utilisé pour
le cas où les différentes parties veulent dire la même chose, mais
avec des formats différentes (une version texte
seul et une version HTML, par
exemple, ou bien une image en JPEG et la
même en PNG). Normalement, le lecteur de courrier ne va afficher qu'une
seule des parties d'une
multipart/alternative, celle qui convient le
mieux, selon les capacités du logiciel de lecture et les
préférences de l'utilisateur. Ce sera la même chose avec ce
nouveau multipart/multilingual : l'émetteur
enverra le message en plusieurs langues, le logiciel de lecture
n'affichera que celle qui colle le mieux aux choix de
l'utilisateur. Ce type est désormais enregistré
à l'IANA (section 9 du RFC).
Rappelez-vous que MIME est
récursif : un
multipart/ peut contenir un autre
multipart/. Voici, par exemple, vu par le
MUA mutt, un
multipart/mixed, dont la première partie est
un multipart/alternative et la seconde un
fichier PDF :
I 1 <no description> [multipart/alternative, 7bit, 45K]
I 2 ├─><no description> [text/plain, 8bit, utf-8, 1,8K]
I 3 └─><no description> [text/html, 8bit, utf-8, 43K]
A 4 35378031645-672029836-registration.pdf [application/pdf, base64, 84K]
Cette première partie du corps du message, de type
multipart/alternative, a à son tour deux
parties, une en texte brut et l'autre en HTML. Comme ma
configuration mutt inclut la directive alternative_order
text/plain, seule la version texte sera affichée, le
HTML étant ignoré.
Revenons aux messages multilingues. Avant ce RFC 8255, la solution la plus fréquente, quand on envoyait un message à quelqu'un dont on n'était pas sûr des préférences linguistiques, était de mettre toutes les versions dans un même message. Du genre :
(English translation at the end)
Bonjour, ceci est un message.
Hello, this is a message.
(La première ligne ayant pour but d'éviter que le lecteur anglophone se décourage en ne voyant au début que du français.) Cette solution n'est pas satisfaisante : elle passe mal à l'échelle dès qu'il y a plus de deux langues. Et elle ne permet pas la sélection automatique de la langue par le logiciel du destinataire.
Le type MIME d'un message est mis dans un en-tête
Content-Type:. Par exemple, un message de
plusieurs parties représentant le même contenu serait :
Content-Type: multipart/alternative; boundary="------------E6043EF6F3B557567F3B18F4"
Où boundary indique le texte qui sera le
séparateur entre les parties (RFC 2046,
section 5.1). La section 2 du RFC décrit ce qu'on peut désormais
mettre dans le Content-Type:, avec le nouveau
type multipart/multilingual.
Il ressemble beaucoup au
multipart/alternative et, comme tous les
multipart/quelquechose (RFC 2046, section 5.1.1), a une chaîne de
caractères qui indique le passage d'une partie à une autre :
Content-Type: multipart/multilingual; boundary=01189998819991197253
Chacune des parties d'un message en plusieurs langues doit
indiquer la langue de la partie, avec l'en-tête
Content-Language:. Mais attention, comme il
faut tenir compte des vieux clients de messagerie qui ne
connaissent pas ce RFC, la première partie ne doit
pas avoir de
Content-Language:, elle sert de solution de
repli, car c'est elle qui sera affichée en premier par les logiciels qui ne
connaissent pas multipart/multilingual. Comme
elle sert de secours, il est recommandé qu'elle soit dans le
format le plus simple, donc text/plain, en
UTF-8 (car il faut pouvoir représenter
diverses langues). Cette partie se nomme la préface. En la
lisant, l'utilisateur pourra donc comprendre qu'il doit mettre à
jour vers un logiciel plus récent.
Les parties suivantes, après la préface, vont être écrites dans des langues différentes. Le RFC recommande de les mettre dans l'ordre, avec celles qui ont le plus de chance d'être pertinentes en premier. (Ainsi, une société française ayant une activité européenne, avec une majorité de clients français, et envoyant un message en anglais, allemand et français, mettra sans doute le français en premier, suivi de l'anglais.)
Chacune de ces parties aura un en-tête
Content-Language:, pour indiquer la langue,
et Content-Type: pour indiquer le type
MIME. (Rappelez-vous toujours que MIME est récursif.) Il est
recommandé que chaque partie soit un message complet (avec
notamment le champ Subject:, qui a besoin
d'être traduit, lui aussi, et le champ From:,
dont une partie peut être utilement traduite). Le type conseillé est donc
message/rfc822 (RFC 2046, section 5.2.1), mais on peut aussi utiliser le
plus récent message/global (RFC 6532).
Notez bien que ce RFC ne spécifie évidemment pas comment se fera la traduction : il ne s'occupe que d'étiqueter proprement le résultat.
Le message peut se terminer par une section « indépendante de
la langue » (par exemple une image ne comportant pas de
texte, si le message peut être porté par une image). Dans ce cas, son Content-Language:
doit indiquer zxx, ce qui veut dire
« information non pertinente » (RFC 5646,
section 4.1). C'est elle qui sera sélectionnée si aucune partie ne
correspond aux préférences de l'utilisateur.
Maintenant, que va faire le client de
messagerie qui reçoit un tel message multilingue ? La
section 4 de notre RFC décrit les différents cas. D'abord, avec
les logiciels actuels, le client va afficher les différentes
parties de multipart/multilingual dans
l'ordre où elles apparaissent (donc, en commençant par la
préface).
Mais le cas le plus intéressant est évidemment celui d'un client plus récent, qui connait les messages multilingues. Il va dans ce cas sauter la préface (qui n'a pas de langue indiquée, rappelez-vous) et sélectionner une des parties, celle qui convient le mieux à l'utilisateur.
Un moment. Arrêtons-nous un peu. C'est quoi, la « meilleure » version ? Imaginons un lecteur francophone, mais qui parle anglais couramment. Il reçoit un message multilingue, en français et en anglais. S'il choisissait manuellement, il prendrait forcément le français, non ? Eh bien non, car cela dépend de la qualité du texte. Comme peut le voir n'importe quel utilisateur du Web, les différentes versions linguistiques d'un site Web ne sont pas de qualité égale. Il y a le texte original, les traductions faites par un professionnel compétent, les traductions faites par le stagiaire, et celles faites par un programme (en général, les plus drôles). Sélectionner la meilleure version uniquement sur la langue n'est pas une bonne idée, comme le montre la mauvaise expérience de HTTP. Ici, pour reprendre notre exemple, si la version en anglais est la version originale, et que le français est le résultat d'une mauvaise traduction par un amateur, notre francophone qui comprend bien l'anglais va sans doute préférer la version en anglais.
Il est donc crucial d'indiquer le type de traduction effectuée,
ce que permet le Content-Translation-Type:
exposé plus loin, en section 6. (Les premières versions du projet
qui a mené à ce RFC, naïvement, ignoraient complètement ce
problème de la qualité de la traduction, et de la version
originale.)
Donc, le mécanisme de sélection par le MUA de la « meilleure » partie dans un message multilingue n'est pas complètement spécifié. Mais il va dépendre des préférences de l'utilisateur, et sans doute des règles du RFC 4647.
Si aucune partie ne correspond aux choix de l'utilisateur, le RFC recommande que le MUA affiche la partie indépendante de la langue, ou, si elle n'existe pas, la partie après la préface. Le MUA peut également proposer le choix à l'utilisateur (« Vous n'avez indiqué qu'une langue, le français. Ce message est disponible en anglais et en chinois. Vous préférez lequel ? »)
La section 5 du RFC présente en détail l'utilisation de l'en-tête
Content-Language:. Il doit suivre la norme
existante de cet en-tête, le RFC 3282, et sa valeur doit
donc être une étiquette de langue du RFC 5646. Des exemples (en pratique, il ne faut
évidemment en mettre qu'un) :
Content-Language: fr
Content-Language: sr-Cyrl
Content-Language: ay
Content-Language: aaq
Le premier exemple concerne le français, le second le serbe écrit en alphabet cyrillique, le troisième l'aymara et le quatrième l'abénaqui oriental.
La section décrit le nouvel en-tête
Content-Translation-Type: qui indique le type
de traduction réalisé. Il peut prendre trois valeurs,
original (la version originale),
human (traduit par un humain) et
automated (traduit par un programme). Notez
que les humains (les programmes aussi, d'ailleurs) varient
considérablement dans leurs compétences de traducteur. J'aurais
personnellement préféré qu'on distingue un traducteur
professionnel d'un amateur, mais la traduction fait partie des
métiers mal compris, où beaucoup de gens croient que si on parle
italien et allemand, on peut traduire de l'italien en allemand
correctement. C'est loin d'être le cas. (D'un autre côté, comme
pour tous les étiquetages, si on augmente le nombre de choix, on
rend l'étiquetage plus difficile et il risque d'être incorrect.)
Voici un exemple complet, tel qu'il apparait entre deux logiciels de messagerie. Il est fortement inspiré du premier exemple de la section 8 du RFC, qui comprend également des exemples plus complexes. Dans ce message, l'original est en anglais, mais une traduction française a été faite par un humain.
From: jeanne@example.com
To: jack@example.com
Subject: Example of a message in French and English
Date: Thu, 7 Apr 2017 21:28:00 +0100
MIME-Version: 1.0
Content-Type: multipart/multilingual;
boundary="01189998819991197253"
--01189998819991197253
Content-Type: text/plain; charset="UTF-8"
Content-Disposition: inline
Content-Transfer-Encoding: 8bit
This is a message in multiple languages. It says the
same thing in each language. If you can read it in one language,
you can ignore the other translations. The other translations may be
presented as attachments or grouped together.
Ce message est disponible en plusieurs langues, disant la même chose
dans toutes les langues. Si vous le lisez dans une des langues, vous
pouvez donc ignorer les autres. Dans votre logiciel de messagerie, ces
autres traductions peuvent se présenter comme des pièces jointes, ou
bien collées ensemble.
--01189998819991197253
Content-Type: message/rfc822
Content-Language: en
Content-Translation-Type: original
Content-Disposition: inline
From: Manager <jeanne@example.com>
Subject: Example of a message in French and English
Content-Type: text/plain; charset="US-ASCII"
Content-Transfer-Encoding: 7bit
MIME-Version: 1.0
Hello, this message content is provided in your language.
--01189998819991197253
Content-Type: message/rfc822
Content-Language: fr
Content-Translation-Type: human
Content-Disposition: inline
From: Directrice <jeanne@example.com>
Subject: =?utf-8?q?Message_d=27exemple=2C_en_fran=C3=A7ais_et_en_anglais?=
Content-Type: text/plain; charset="UTF-8"
Content-Transfer-Encoding: 8bit
MIME-Version: 1.0
Bonjour, ce message est disponible dans votre langue.
--01189998819991197253--
On note qu'il y a une préface (la première partie, celle qui
commence par « This is a message in multiple languages »), que
chacun des deux parties étiquetées a un
From: (pour pouvoir adapter le titre de
l'expéditrice) et un sujet (celui en français étant encodé selon
le RFC 2047). Les deux dernières parties
ont un Content-Translation-Type:.
Actuellement, il ne semble pas qu'il existe de
MUA qui gère cette nouvelle norme. Si vous
voulez envoyer des messages à ce format, vous pouvez copier/coller
l'exemple ci-dessus, ou bien utiliser le programme Python send-multilingual.py.
Voici le message d'exemple cité plus haut affiché par
mutt (version NeoMutt 20170113 (1.7.2)) :
Thunderbird affiche à peu près la même chose.
Gmail a stupidement décidé de mettre ce
message dans le dossier Spam. Une fois le
message sorti de ce purgatoire, voici ce que ça donnait : 
Notez l'existence d'une FAQ sur ce format.
Une mise en œuvre dans
mutt a été faite au hackathon
de la réunion IETF 101 par Alexandre Simon. Elle a été soumise en tant que pull
request à mutt. Outre ce travail sur un
MUA, le même auteur a écrit un réflecteur de
courrier permettant de tester ce RFC. Vous envoyez un
message ordinaire en français à
reflector+sl_fr+tl_zh@rfc8255.as-home.fr (sl
= Source Language, tl = Target
Language, ici, on dit que le message est en français, et
on veut une réponse en chinois), et il répond avec
un message conforme au RFC 8255, traduit par Google Translate. Voici par exemple une demande :
To: reflector+sl_fr+tl_zh@rfc8255.as-home.fr MIME-Version: 1.0 Content-Type: text/plain; charset=utf-8 Content-Disposition: inline Content-Transfer-Encoding: 8bit User-Agent: NeoMutt/20170113 (1.7.2) Subject: Test je parle la France From: Stephane Bortzmeyer <stephane@bortzmeyer.org> Alors, ça donne quoi ? Surtout s'il y a plusieurs lignes.
Et sa réponse :
Content-Type: multipart/multilingual;
boundary="----------=_1521485603-32194-0"
Content-Transfer-Encoding: binary
MIME-Version: 1.0
To: Stephane Bortzmeyer <stephane@bortzmeyer.org>
Sender: <reflector@idummy.as-home.fr>
Subject: Test je parle la France
From: Stephane Bortzmeyer <stephane@bortzmeyer.org>
This is a multi-part message in MIME format...
------------=_1521485603-32194-0
Content-Type: text/plain; charset=utf-8
Content-Disposition: inline
Content-Transfer-Encoding: binary
Alors, ça donne quoi ?
Surtout s'il y a plusieurs lignes.
------------=_1521485603-32194-0
Content-Type: message/rfc822
Content-Disposition: inline
Content-Transfer-Encoding: binary
Content-Language: fr
Content-Translation-Type: original
Content-Type: text/plain; charset=utf-8
From: Stephane Bortzmeyer <stephane@bortzmeyer.org>
Subject: Test je parle la France
Alors, ça donne quoi ?
Surtout s'il y a plusieurs lignes.
------------=_1521485603-32194-0
Content-Type: message/rfc822
Content-Disposition: inline
Content-Transfer-Encoding: binary
Content-Language: zh
Content-Translation-Type: automated
Content-Type: text/plain; charset=utf-8
From: Stephane Bortzmeyer <stephane@bortzmeyer.org>
Subject: =?UTF-8?B?5rWL6K+V5oiR6K6y5rOV5Zu9?=
那么,这给了什么?
特别是如果有几条线。
------------=_1521485603-32194-0
Content-Type: message/rfc822
Content-Disposition: inline
Content-Transfer-Encoding: binary
Content-Language: zxx
Content-Translation-Type: human
Content-Type: text/plain; charset=utf-8
/////|
///// |
///// |
|~~~| M |
|===| U |
| | L |
| R | T |
| F | I |
| C | L |
| 8 | I |
| 2 | N |
| 5 | G |
| 5 | U |
| | A |
| | L |
| | |
| | /
| | /
|===|/
'---'
------------=_1521485603-32194-0--
On notera la dernière partie, qui utilise la langue
zxx, code qui veut dire « non spécifiée », et
qui sert à mettre du texte qui sera affiché dans tous les
cas. Notez aussi que le message originel est inclus.
Ce message est ainsi affiché par un mutt actuel :
Et par le mutt patché pendant le hackathon :
L'article seul
RFC 8265: Preparation, Enforcement, and Comparison of Internationalized Strings Representing Usernames and Passwords
Date de publication du RFC : Octobre 2017
Auteur(s) du RFC : P. Saint-Andre (Jabber.org), A. Melnikov (Isode)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF precis
Première rédaction de cet article le 6 octobre 2017
Ah, les plaisirs de l'internationalisation du logiciel... Quand l'informatique ne concernait que les États-Unis, tout était simple. Un utilisateur ne pouvait avoir un nom (un login) que s'il était composé uniquement des lettres de l'alphabet latin (et même chose pour son mot de passe). Mais de nos jours, il n'est pas acceptable de se limiter au RFC 20. Il faut que Пу́тин ou 艾未未 puissent écrire leur nom dans leur écriture et l'informatique doit suivre. Notre RFC décrit comment le faire (il remplace le RFC 7613, mais il y a peu de changements, rassurez-vous).
Mais pourquoi faut-il standardiser quelque chose ? Pourquoi ne
pas dire simplement « les noms d'utilisateur sont en
Unicode » et basta ? Parce que les
logiciels qui gèrent noms d'utilisateurs et mots de passe ont
besoin de les manipuler, notamment de les
comparer. Si ПУ́ТИН
essaie de se loguer, et
que la base de données contient un utilisateur пу́тин, il faut bien déterminer si c'est
le même utilisateur (ici, oui, à part la casse). C'est en général assez simple dans l'alphabet
latin (ou dans le cyrillique utilisé pour
les exemples) mais il y a d'autres cas plus vicieux qui
nécessitent quelques règles supplémentaires.
Le cadre général de l'internationalisation des identificateurs est normalisé dans le RFC 8264. Notre nouveau RFC 8265 est l'adaptation de ce RFC 8264 au cas spécifique des noms d'utilisateur et des mots de passe.
Ces noms et ces mots de passe (aujourd'hui, il faudrait plutôt
dire phrases de passe) sont largement
utilisés pour l'authentification, soit
directement (SASL
PLAIN du RFC 4616, authentification
de base de HTTP du RFC 7617), ou
bien comme entrée d'une fonction de condensation
cryptographique (SASL SCRAM du
RFC 5802 ou bien authentification HTTP
digest du RFC 7616). L'idée est que
les opérations de base sur ces noms (et sur les mots de passe) ne
surprennent pas excessivement l'utilisateur, quel que soit son
pays, sa langue, sa culture. Un Français ou un Belge ne sera probablement pas trop
étonné que Dupont soit accepté comme synonyme
de dupont mais il le serait davantage si
dupond l'était. Évidemment, la tâche est
impossible (les utilisateurs sont tous différents) mais l'idée est
de ne pas faire un système parfait mais un système qui marche la
plupart du temps.
C'est là qu'intervient le cadre PRECIS (PReparation,
Enforcement, and Comparison of Internationalized
Strings) du RFC 8264. Il évite que
chaque développeur d'un système d'authentification doive lire et
comprendre toutes les conséquences d'Unicode, et lui permet de
s'appuyer sur une analyse déjà faite. Un exemple de piège
d'Unicode (et qui montre pourquoi « on va juste dire que les noms
d'utilisateur peuvent être n'importe quel caractère Unicode » est
sans doute une mauvaise politique) est le chiffre 1 en exposant,
U+00B9 (comme ça : « ¹ » Si vous ne voyez rien, c'est parce
que votre logiciel ne sait pas afficher ce caractère. Vous pouvez
toujours regarder le source HTML pour comprendre l'exemple.). Doit-on
l'autoriser ? Le mettre en correspondance avec le 1 traditionnel
de façon à ce que user¹ et
user1 soient le même nom ? Imaginez un client
XMPP qui vous dise
« user¹@example.com veut être votre
copain. Je l'autorise ? » et que vous acceptiez en croyant que
c'était user1@example.com. Bien sûr, on ne
peut pas réellement parler d'« attaque » dans ce cas, une telle
erreur permettrait juste de faire quelques farces mais, pour le
logiciel qui vérifie une identité, des confusions seraient plus
gênantes. Si les « attaques » exploitant la similitude de
caractères Unicode sont surtout un fantasme d'informaticien
anglophone n'ayant jamais réellement accepté
l'internationalisation (plutôt qu'une réalité du terrain), il est
quand même plus prudent de supprimer quelques causes de
cafouillage le plus tôt possible.
(Ce RFC suggère également de séparer le nom d'utilisateur, identificateur formel et n'utilisant qu'un jeu de caractères restreint, et la description (cf. RFC 8266) qui pourrait utiliser davantage de caractères. Twitter ou Mastodon fonctionnent ainsi.)
Notre RFC compte deux sections importantes, décrivant le profil
PRECIS pour les noms d'utilisateur (section 3) et les mots de
passe (section 4). Commençons par les noms d'utilisateur. Un nom
est une chaîne de caractères Unicode
composée de parties séparées par des espaces. Chaque partie doit
être une instance de IdentifierClass et est
normalisée en NFC. Pourquoi cette notion de « parties
séparées par des espaces » ? Parce que la classe
IdentifierClass du RFC 8264 ne permet pas les espaces, ce qui est gênant pour
certains identificateurs (« Prénom Nom » par exemple, cf. section
3.5). D'où la grammaire de la section 3.1 :
username = userpart *(1*SP userpart)
qui dit « un nom d'utilisateur est composé d'au moins une partie,
les parties étant séparées par un nombre quelconque
d'espaces ». Une des conséquences de cette grammaire étant que le
nombre d'espaces n'est pas significatif : Jean
Dupont et Jean Dupont sont
le même identificateur.
Chaque partie étant une instance de
l'IdentifierClass du RFC 8264, les caractères interdits par cette classe sont
donc interdits pour les noms d'utilisateurs. Une application
donnée peut restreindre (mais pas étendre) ce profil. Ces noms
d'utilisateurs sont-ils sensibles à la casse ? Certains protocoles ont
fait un choix et d'autres le choix opposé. Eh bien, il y a
deux sous-profils, un sensible et
un insensible (ce dernier étant recommandé). Les
protocoles et applications utilisant ce RFC 8265
devront annoncer clairement lequel ils utilisent. Et les
bibliothèques logicielles manipulant ces utilisateurs auront
probablement une option pour indiquer le sous-profil à
utiliser.
Le sous-profil UsernameCaseMapped rajoute
donc une règle de préparation des chaînes de caractères : tout
passer en minuscules (avant les comparaisons, les condensations
cryptographiques, etc), en utilisant l'algorithme
toLowerCase d'Unicode (section 3.13 de la norme
Unicode ; et, oui, changer la casse est
bien plus compliqué en Unicode qu'en ASCII). Une
fois la préparation faite, on peut comparer octet par octet, si
l'application a bien pris soin de définir l'encodage.
L'autre sous-profil, UsernameCasePreserved
ne change pas la casse, comme son nom
l'indique. ПУ́ТИН et
пу́тин y sont donc deux identificateurs
différents. C'est la seule différence entre les deux
sous-profils. Notre RFC recommande le profil insensible à la
casse, UsernameCaseMapped, pour éviter des
surprises comme celles décrites dans le RFC 6943 (cf. section 8.2 de notre RFC).
Bon, tout ça est bien nébuleux et vous préféreriez des exemples ? Le RFC nous en fournit. D'abord, des identificateurs peut-être surprenants mais légaux (légaux par rapport à PRECIS : certains protocoles peuvent mettre des restrictions supplémentaires). Attention, pour bien les voir, il vous faut un navigateur Unicode, avec toutes les polices nécessaires :
juliet@example.com: le @ est autorisé donc un JID (identificateur XMPP) est légal.fussball: un nom d'utilisateur traditionnel, purement ASCII, qui passera partout, même sur les systèmes les plus antédiluviens.fußball: presque le même mais avec un peu d'Unicode. Bien qu'en allemand, on traite en général ces deux identificateurs comme identiques, pour PRECIS, ils sont différents. Si on veut éviter de la confusion aux germanophones, on peut interdire la création d'un des deux identificateurs si l'autre existe déjà : PRECIS ne donne que des règles miminales, on a toujours droit à sa propre politique derrière.π: entièrement en Unicode, une lettre.Σ: une lettre majuscule.σ: la même en minuscule. Cet identificateur et le précédent seront identiques si on utilise le profilUsernameCaseMappedet différents si on utilise le profilUsernameCasePreserved.ς: la même, lorsqu'elle est en fin de mot. Le cas de ce sigma final est compliqué, PRECIS ne tente pas de le résoudre. Comme pour le eszett plus haut, vous pouvez toujours ajouter des règles locales.
Par contre, ces noms d'utilisateurs ne sont pas valides :
- Une chaîne de caractères vide.
HenriⅣ: le chiffre romain 4 à la fin est illégal (car il a ce qu'Unicode appelle « un équivalent en compatibilité », la chaîne « IV »).♚: seules les lettres sont acceptées, pas les symboles (même règle que pour les noms de domaine).
Continuons avec les mots de passe (section 4). Comme les noms,
le mot de passe est une chaîne de caractères
Unicode. Il doit
être une instance de FreeformClass. Cette
classe autorise bien plus de caractères que pour les noms
d'utilisateur, ce qui est logique : un mot de passe doit avoir
beaucoup d'entropie. Peu de caractères sont donc interdits (parmi
eux, les caractères de
contrôle, voir l'exemple plus bas). Les
mots de passe sont sensibles à la casse.
Des exemples ? Légaux, d'abord :
correct horse battery staple: vous avez reconnu un fameux dessin de XKCD.Correct Horse Battery Staple: les mots de passe sont sensibles à la casse, donc c'est un mot de passe différent du précédent.πßå: un mot de passe en Unicode ne pose pas de problème.Jack of ♦s: et les symboles sont acceptés, contrairement à ce qui se passe pour les noms d'utilisateur.foo bar: le truc qui ressemble à un trait est l'espace de l'Ogham, qui doit normalement être normalisé en un espace ordinaire, donc ce mot de passe est équivalent àfoo bar.
Par contre, ce mot de passe n'est pas valide :
my cat is a by: les caractères de contrôle, ici une tabulation, ne sont pas autorisés.
Rappelez-vous que ces profils PRECIS ne spécifient que des règles minimales. Un protocole utilisant ce RFC peut ajouter d'autres restrictions (section 5). Par exemple, il peut imposer une longueur minimale à un mot de passe (la grammaire de la section 4.1 n'autorise pas les mots de passe vides mais elle autorise ceux d'un seul caractère, ce qui serait évidemment insuffisant pour la sécurité), une longueur maximale à un nom d'utilisateur, interdire certains caractères qui sont spéciaux pour ce protocole, etc.
Certains profils de PRECIS suggèrent d'être laxiste en acceptant certains caractères ou certaines variantes dans la façon d'écrire un mot (accepter strasse pour straße ? C'est ce qu'on nomme le principe de robustesse.) Mais notre RFC dit que c'est une mauvaise idée pour des mots utilisés dans la sécurité, comme ici (voir RFC 6943).
Les profils PRECIS ont été ajoutés au registre IANA (section 7 de notre RFC).
Un petit mot sur la sécurité et on a fini. La section 8 de notre RFC revient sur quelques points difficiles. Notamment, est-ce une bonne idée d'utiliser Unicode pour les mots de passe ? Ça se discute. D'un côté, cela augmente les possibilités (en simplifiant les hypothèses, avec un mot de passe de 8 caractères, on passe de 10^15 à 10^39 possibilités en permettant Unicode et plus seulement ASCII), donc l'entropie. D'un autre, cela rend plus compliquée la saisie du mot de passe, surtout sur un clavier avec lequel l'utilisateur n'est pas familier, surtout en tenant compte du fait que lors de la saisie d'un mot de passe, ce qu'on tape ne s'affiche pas. Le monde est imparfait et il faut choisir le moindre mal...
L'annexe A du RFC décrit les changements (peu nombreux) depuis
l'ancien RFC 7613. Le principal est le
passage de la conversion de casse de la fonction Unicode
CaseFold() à
toLowerCase(). Et
UTF-8 n'est plus obligatoire, c'est
désormais à l'application de décider (en pratique, cela ne
changera rien, UTF-8 est déjà l'encodage recommandé dans
l'écrasante majorité des applications). Sinon, il y a une petite
correction dans l'ordre des opérations du profil
UsernameCaseMapped, et quelques nettoyages et
mises à jour.
L'article seul
RFC 8264: PRECIS Framework: Preparation, Enforcement, and Comparison of Internationalized Strings in Application Protocols
Date de publication du RFC : Octobre 2017
Auteur(s) du RFC : P. Saint-Andre (Jabber.org), M. Blanchet (Viagenie)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF precis
Première rédaction de cet article le 6 octobre 2017
Dans la longue marche vers une plus grande internationalisation de l'Internet, la question des identificateurs (comme par exemple les noms de domaine) a toujours été délicate. Ce sont en effet à la fois des éléments techniques, traités automatiquement par les programmes, et des marqueurs d'identité, vus par les humains (par exemple sur des cartes de visite) et manipulés par eux. Plutôt que de laisser chaque protocole internationaliser ses identificateurs (plus ou moins bien), l'approche de ce RFC est unificatrice, en élaborant des règles qui peuvent servir à de larges classes d'identificateurs, pour de nombreux protocoles différents. Il remplace le premier RFC qui avait suivi cette voie, le RFC 7564, désormais dépassé (mais les changements sont peu importants, c'est juste de la maintenance).
Cette opposition entre « éléments techniques » et « textes
prévus pour l'utilisateur » est au cœur du RFC 2277 qui pose comme principe politique qu'on
internationalise les seconds, mais pas les premiers. Cet excellent
principe achoppe souvent sur la question des identificateurs, qui
sont les deux à la fois. D'un côté, les programmes doivent les
traiter (les identificateurs doivent donc être clairement définis,
sans ambiguïté), de l'autre les humains les voient, les
communiquent, les échangent (les identificateurs doivent donc
permettre, sinon toutes les constructions du langage humain, en
tout cas un sous-ensemble d'Unicode qui
parait raisonnable aux humains ordinaires : pas question d'imposer
stephane comme nom de login
à un utilisateur nommé Stéphane, avec un accent sur le E). C'est
cette double nature des identificateurs (ainsi, il est vrai, que
l'énorme couche de bureaucratie qui gère les noms de domaine) qui explique la durée et
la vivacité des discussions sur les IDN.
Maintenant que ces IDN existent (depuis plus de quatorze ans, RFC 3490), que faire avec les autres identificateurs ? Une possibilité aurait été que chaque protocole se débrouille avec ses propres identificateurs, comme l'a fait le DNS avec les noms de domaine. Mais cela menait à une duplication du travail (et tous les auteurs de protocole ne sont pas des experts Unicode) et surtout à un risque de choix très différents : certains protocoles autoriseraient tel caractère Unicode et d'autres pas, sans que l'utilisateur ordinaire puisse comprendre clairement les raisons de cette différence. L'idée de base du groupe PRECIS était donc d'essayer de faire des règles qui s'appliqueraient à beaucoup de protocoles, épargnant aux concepteurs de ces protocoles de les concevoir eux-mêmes, et offrant à l'utilisateur une certaine homogénéité. Ce RFC 8264 est le cadre de définition des identificateurs internationalisés. Ce cadre permet la manipulation d'identificateurs internationalisés (par exemple leur comparaison, comme lorsqu'un utilisateur tape son nom et son mot de passe, et qu'il faut les vérifier, cf. RFC 6943.)
Certaines personnes, surtout en Anglosaxonnie, pourraient estimer que c'est bien compliqué tout cela, et qu'il vaudrait mieux limiter les identificateurs à ASCII. Certes, Unicode est compliqué, mais sa complexité ne fait que refléter celle des langues humaines (section 6.1 de notre RFC). On ne peut pas simplifier Unicode, sauf à éliminer une partie de la diversité humaine.
Le nom du groupe de travail PRECIS reflète les trois fonctions essentielles que font les programmes qui manipulent les identificateurs internationalisés :
- PR pour la préparation des identificateurs, les opérations préliminaires comme la conversion depuis un jeu de caractères local non-Unicode,
- E pour l'application (enforcement) des règles, afin de s'assurer qu'une chaîne de caractères Unicode est légale ou pas pour un usage donné,
- C pour la comparaison entre les identificateurs, afin de déterminer leur égalité (« cette ressource n'est accessible qu'à l'utilisateur Thérèse or elle est connectée avec le nom therese »),
- Le IS final étant pour Internationalized Strings.
A priori, les serveurs Internet seront responsables de l'application, les clients n'ayant à faire qu'une préparation. Ayant souvent moins de ressources, les clients pourraient en effet avoir du mal à faire certaines opérations Unicode complexes (section 3).
Les principes du travail de PRECIS sont :
- Définir un petit nombre (deux, actuellement) de classes spécifiant un jeu de caractères autorisés, classes applicables à un grand nombre d'usages.
- Définir le contenu de ces classes en fonction d'un algorithme, reposant sur les propriétés Unicode (contrairement à stringprep où le contenu des classes était énuméré dans le RFC). Ainsi, lorsqu'une nouvelle version d'Unicode sort (la version actuelle est la 10.0), il suffit de refaire tourner l'algorithme et on obtient le contenu à jour de la classe.
- Spécifier les classes par une inclusion : tout caractère non explicitement listé comme membre de la classe est automatiquement exclu.
- Permettre aux protocoles applicatifs de définir un profil d'une classe, à savoir une restriction de ses membres, ou bien d'autres précisions sur des sujets comme la normalisation Unicode. Il y a ainsi un profil pour les noms d'utilisateurs, un profil pour les mots de passe, etc (cf. RFC 8265). Notez qu'il est prévu que le nombre de profils reste limité, pour ne pas réintroduire l'excessive variété que voulait justement éviter PRECIS.
Si tout va bien, ces principes permettront l'indépendance vis-à-vis des versions d'Unicode (ou, plus exactement, la possibilité de passer à une nouvelle version d'Unicode sans faire une nouvelle norme incompatible), le partage des tables et du logiciel entre applications (par exemple par le biais de bibliothèques communes, utilisables si toutes les applications reposent sur PRECIS), et moins de surprises pour les utilisateurs, qui auraient été bien embêtés si chaque protocole Internet avait eu une manière complètement différente de prévoir l'internationalisation.
Bien, quelles sont donc les classes prévues par PRECIS (section 4) ? L'idée est de faire un compromis entre expressivité et sécurité. Qu'est-ce que la sécurité vient faire là dedans ? Personne ne le sait trop (le RFC utilise plusieurs fois safe et safety sans expliquer face à quels risques) mais Unicode fait souvent peur aux informaticiens anglo-saxons et il est donc courant d'estimer qu'il existe des caractères dangereux.
Il y a donc deux classes en tout et pour tout dans PRECIS :
IdentifierClass et
FreeformClass. La première classe servira à
identifier utilisateurs, machines, pièces de discussions en
messagerie instantanée, fichiers, etc, et ne
permettra que les lettres, les nombres et quelques symboles (comme
le ! ou le +, car ils étaient dans ASCII). C'est contraignant mais l'idée est qu'on veut des
désignations simples et sans ambiguïté, pas écrire des romans. La
seconde classe servira à tout le reste (mots de passe, textes
affichés comme la description d'une pièce XMPP, nom complet d'une
machine, etc). Par exemple, une imprimante sera
imprimante-jean-et-thérèse pour les protocoles
qui demandent un nom de la classe
IdentifierClass et Imprimante de
Jean & Thérèse lorsqu'on pourra utiliser un nom
FreeformClass.
Les classes sont définies par les caractères inclus et exclus. Plus précisément, un caractère peut être, pour une classe donnée (voir aussi la section 8) :
- Valide (ou PVALID pour Protocol Valid),
- Interdit,
- Autorisé dans certains contextes seulement, c'est-à-dire que l'autorisation dépendra des caractères voisins (pas facile de trouver un exemple dans l'alphabet latin, cela sert surtout à d'autres écritures),
- Pas encore affecté dans Unicode.
La classe IdentifierClass se définit donc par :
- Caractères valides : les lettres et chiffres (rappelons qu'on définit des identificateurs internationalisés : on ne se limite donc pas aux lettres et chiffres latins), et les symboles traditionnels, ceux d'ASCII (comme le tiret ou le tilde).
- Caractères valides dans certains contextes : ceux de la
rare catégorie
JoinControldu RFC 5892, section 2.8. - Caractères interdits : tout le reste (espaces, ponctuation, la plupart des symboles...).
- Les caractères non encore affectés sont également interdits.
La classe Freeform Class se définit, elle,
par :
- Caractères valides : les lettres et chiffres (rappelons qu'on définit des identificateurs internationalisés : on ne se limite donc pas aux lettres et chiffres latins), les espaces, la ponctuation, les symboles (oui, oui, y compris les emojis comme 🥞 cf. sections 4.3.1 et 9.15).
- Caractères valides dans certains contextes : ceux de la
catégorie
JoinControlplus quelques exceptions. - Caractères interdits : tout le reste, ce qui fait surtout les caractères de contrôle comme U+0007 (celui qui fait sonner votre ordinateur).
- Les caractères non encore affectés sont également interdits.
Ces listes de caractères autorisés ou interdits ne sont pas suffisantes. Il y a d'autres points à régler (section 5), ce qui se fait typiquement dans les profils. Ainsi, un profil doit définir :
- Normalisation Unicode à utiliser. NFC est recommandée.
- La correspondance entre les caractères et leur version large
(width mapping). Est-ce que FULLWIDTH
DIGIT ZERO (U+FF10) doit être considéré comme équivalent au
zéro traditionnel, de largeur « normale », U+0030 ? Notez que
certaines normalisations (mais qui ne sont pas celle recommandée),
comme NFKC, règlent le problème. Autrement, la
recommandation du RFC est « oui, il faut rendre ces caractères
équivalents » car l'utilisateur serait certainement surpris que
target0ettarget0soient considérés différents (le fameux POLA, principe de la moindre surprise). - D'autres correspondances peuvent être spécifiées par le profil (comme de transformer tous les espaces Unicode en l'espace traditionnel ASCII U+0020).
- Changement de la casse des caractères, par exemple pour tout
mettre en minuscules. Si c'est décidé pour un profil, le RFC
recommande que cela soit fait avec la méthode Unicode standard,
toLowerCase()(section 3.13 de la norme Unicode). Attention, cette méthode Unicode ne gère pas des cas qui dépendent de la langue, dont le plus fameux est le i sans point du turc (U+0131 c'est-à-dire ı). Le changement de casse est évidemment déconseillé pour les mots de passe (puisqu'il diminue l'entropie). Notez aussi que ce cas illustre le fait que les transformations PRECIS ne sont pas sans perte : si on met tout en minuscules,Poussinne se distingue plus depoussin. - Interdiction de certains mélanges de caractères de directionnalité différentes. Il y a des écritures qui vont de gauche à droite et d'autres de droite à gauche, et leur combinaison peut entrainer des surprises à l'affichage. Dans certains cas, un profil peut vouloir limiter ce mélange de directionnalités.
Un profil peut également interdire certains caractères normalement autorisés (mais pas l'inverse).
Au passage, pour la comparaison, le RFC (section 7) impose un ordre à ces opérations. Par exemple, la mise en correspondance de la version large sur la version normale doit se faire avant l'éventuel changement de casse. C'est important car ces opérations ne sont pas commutatives entre elles.
Les profils sont enregistrés à l'IANA. Le RFC met bien en garde contre leur multiplication : toute l'idée de PRECIS est d'éviter que chaque protocole ne gère l'internationalisation des identificateurs de manière différente, ce qui empêcherait la réutilisation de code, et perturberait les utilisateurs. Si on avait un cadre commun mais des dizaines de profils différents, on ne pourrait pas dire qu'on a atteint cet objectif. Par exemple, en matière d'interface utilisateur, PRECIS essaie de s'en tenir au POLA (Principle of Least Astonishment) et ce principe serait certainement violé si chaque application trouvait rigolo d'interdire un caractère ou l'autre, sans raison apparente. Le RFC estime d'ailleurs (section 5.1) qu'il ne devrait y avoir idéalement que deux ou trois profils. Mais ce n'est pas possible puisque les protocoles existent déjà, avec leurs propres règles, et qu'on ne peut pas faire table rase de l'existant (tous les protocoles qui ont déjà définis des caractères interdits, comme IRC, NFS, SMTP, XMPP, iSCSI, etc).
Un petit point en passant, avant de continuer avec les
applications : vous avez noté que la classe
IdentifierClass interdit les espaces (tous les
espaces Unicode, pas seulement le U+0020 d'ASCII), alors que
certaines applications acceptent les espaces dans les
identificateurs (par exemple, Unix les
accepte sans problèmes dans les noms de fichier,
Apple permet depuis longtemps de les
utiliser pour nommer iTrucs et imprimantes, etc). La section
5.3 explique cette interdiction :
- Il est très difficile de distinguer tous ces espaces entre eux,
- Certains interfaces utilisateurs risquent de ne pas les
afficher, menant à confondre
françoise durandavecfrançoisedurand.
C'est embêtant (toute contrainte est embêtante) mais le compromis a semblé raisonnable au groupe PRECIS. Tant pis pour les espaces.
Passons maintenant aux questions des développeurs d'applications (section 6 du RFC). Que doivent-ils savoir pour utiliser PRECIS correctement ? Idéalement, il suffirait de lier son code aux bonnes bibliothèques bien internationalisées et tout se ferait automatiquement. En pratique, cela ne se passera pas comme ça. Sans être obligé de lire et de comprendre tout le RFC, le développeur d'applications devra quand même réflechir un peu à l'internationalisation de son programme :
- Il est très déconseillé de créer son propre profil. Non seulement c'est plus compliqué que ça n'en a l'air, mais ça risque de dérouter les utilisateurs, si votre application a des règles légèrement différentes des règles des autres applications analogues.
- Précisez bien quel partie de l'application va être responsable pour la préparation, l'application et la comparaison. Par exemple, le travail d'application sera-t-il fait par le client ou par le serveur ? Demandez-vous aussi à quel stade les applications devront avoir fait ce travail (par exemple, en cas de login, avant de donner un accès).
- Définissez bien, pour chaque utilisation d'un identificateur
(chaque slot, dit le RFC), quel profil doit être
utilisé. Par exemple, « le nom du compte doit être conforme au
profil
UsernameCaseMappedde la classeIdentifierClass» (cf. RFC 8265). - Dressez la liste des caractères interdits (en plus de ceux déjà interdits par le profil) en fonction des spécificités de votre application. Par exemple, un @ est interdit dans la partie gauche d'une adresse de courrier électronique.
Sur ce dernier point, il faut noter que la frontière est mince entre « interdire plusieurs caractères normalement autorisés par le profil » et « définir un nouveau profil ». La possibilité d'interdire des caractères supplémentaires est surtout là pour s'accomoder des protocoles existants (comme dans l'exemple du courrier ci-dessus), et pour éviter d'avoir un profil par application existante.
Votre application pourra avoir besoin de constructions au-dessus
des classes existantes. Par exemple, si un nom d'utilisateur, dans
votre programme, peut s'écrire « Prénom Nom », il ne peut pas être
une instance de la classe IdentifierClass, qui
n'accepte pas les espaces pour la raison indiquée plus haut. Il
faudra alors définir un concept « nom d'utilisateur », par exemple
en le spécifiant comme composé d'une ou plusieurs instances de
IdentifierClass, séparées par des espaces. En
ABNF :
username = userpart *(1*SP userpart) userpart = ... ; Instance d'IdentifierClass
La même technique peut être utilisée pour spécifier des identificateurs
qui ne seraient normalement pas autorisés par
IdentifierClass comme
stéphane@maçonnerie-générale.fr ou /politique/séries/Game-of-Thrones/saison05épisode08.mkv.
On a vu plus haut qu'un des principes de PRECIS était de définir les caractères autorisés de manière algorithmique, à partir de leur propriétés Unicode, et non pas sous la forme d'une liste figée (qu'il faudrait réviser à chaque nouvelle version d'Unicode). Les catégories de caractères utilisées par cet algorithme sont décrites en section 9. Par exemple, on y trouve :
LettersDigitsqui rassemble les chiffres et les lettres. (Rappelez-vous qu'on utilise Unicode : ce ne sont pas uniquement les lettres et les chiffres d'ASCII.)ASCII7, les caractères d'ASCII, à l'exception des caractères de contrôle,Spaces, tous les espaces possibles (comme le U+200A, HAIR SPACE, ainsi appelé en raison de sa minceur),Symbols, les symboles, comme U+20A3 (FRENCH FRANC SIGN, ₣) ou U+02DB (OGONEK, ˛),- Etc.
Plusieurs registres IANA sont nécessaires pour stocker toutes les données nécessaires à PRECIS. La section 11 les recense tous. Le plus important est le PRECIS Derived Property Value, qui est recalculé à chaque version d'Unicode. Il indique pour chaque caractère s'il est autorisé ou interdit dans un identificateur PRECIS. Voici sa version pour Unicode 6.3 (on attend avec impatience une mise à jour…).
Les deux autres registres stockent les classes et les profils (pour l'instant, ils sont quatre). Les règles d'enregistrement (section 11) dans le premier sont strictes (un RFC est nécessaire) et celles dans le second plus ouvertes (un examen par un expert est nécessaire). La section 10 explique aux experts en question ce qu'ils devront bien regarder. Elle note que l'informaticien ordinaire est en général très ignorant des subtilités d'Unicode et des exigences de l'internationalisation, et que l'expert doit donc se montrer plus intrusif que d'habitude, en n'hésitant pas à mettre en cause les propositions qu'il reçoit. Dans beaucoup de RFC, les directives aux experts sont d'accepter, par défaut, les propositions, sauf s'il existe une bonne raison de les rejeter. Ici, c'est le contraire : le RFC recommande notamment de rejeter les profils proposés, sauf s'il y a une bonne raison de les accepter.
La section 12 est consacrée aux problèmes de sécurité qui, comme
toujours lorsqu'il s'agit
d'Unicode, sont plus imaginaires que réels. Un des problèmes
envisagés est celui du risque de confusion entre deux caractères
qui sont visuellement proches. Le problème existe déjà avec le seul
alphabet latin (vous voyez du premier coup
la différence entre google.com et
goog1e.com ?) mais est souvent utilisé comme
prétexte pour retarder le déploiement d'Unicode. PRECIS se voulant
fidèle au principe POLA, le risque de confusion est
considéré comme important. Notez que le risque réel dépend de la
police
utilisée. Unicode normalisant des caractères et non pas des
glyphes, il n'y a pas de
solution générale à ce problème dans Unicode (les écritures
humaines sont compliquées : c'est ainsi). Si le texte
ᏚᎢᎵᎬᎢᎬᏒ ressemble
à STPETER, c'est que vous utilisez une police qui ne distingue pas
tellement l'alphabet
cherokee de l'alphabet latin. Est-ce que ça a des
conséquences pratiques ? Le RFC cite le risque accru de
hameçonnage, sans citer les nombreuses
études qui montrent le contraire (cf. le Unicode Technical Report
36, section 2, « the use of visually
confusable characters in spoofing is often overstated »,
et la FAQ de
sécurité d'Unicode).
Quelques conseils aux développeurs concluent cette partie : limiter le nombre de caractères ou d'écritures qu'on accepte, interdire le mélange des écritures (conseil inapplicable : dans la plupart des alphabets non-latins, on utilise des mots entiers en alphabet latin)... Le RFC conseille aussi de marquer visuellement les identificateurs qui utilisent plusieurs écritures (par exemple en utilisant des couleurs différentes), pour avertir l'utilisateur.
C'est au nom de ce principe POLA que la classe
IdentifierClass est restreinte à un ensemble
« sûr » de caractères (notez que ce terme « sûr » n'est jamais
expliqué ou défini dans ce RFC). Comme son nom l'indique,
FreeformClass est bien plus large et peut donc
susciter davantage de surprises.
PRECIS gère aussi le cas des mots de passe en Unicode. Un bon
mot de passe doit être difficile à deviner ou à trouver par force
brute (il doit avoir beaucoup d'entropie). Et
il faut minimiser les risques de faux positifs (un mot de passe
accepté alors qu'il ne devrait pas : par exemple, des mots de passe
insensibles à la
casse seraient agréables pour les utilisateurs mais
augmenteraient le risque de faux positifs). L'argument de
l'entropie fait que le RFC déconseille de créer des profils
restreints de FreeformClass, par exemple en
excluant des catégories comme la ponctuation. Unicode permet des
mots de passe vraiment résistants à la force brute, comme
« 𝃍🐬ꢞĚΥਟዶᚦ⬧ »... D'un
autre côté, comme le montre l'exemple hypothétique de mots de passe
insensibles à la casse, il y a toujours une tension entre la
sécurité et l'utilisabilité. Laisser les utilisateurs choisir des
mots de passe comportant des caractères « exotiques » peut poser
bien des problèmes par la suite lorsqu'utilisateur tentera de les
taper sur un clavier peu familier. Il faut noter aussi que les mots
de passe passent parfois par des protocoles intermédiaires (comme
SASL, RFC 4422, ou comme RADIUS, RFC 2865) et
qu'il vaut donc mieux que tout le monde utilise les mêmes règles
pour éviter des surprises (comme un mot de passe refusé par un
protocole intermédiaire).
Enfin, la section 13 de notre RFC se penche sur l'interopérabilité. Elle rappele qu'UTF-8 est l'encodage recommandé (mais PRECIS est un cadre, pas un protocole complet, et un protocole conforme à PRECIS peut utiliser un autre encodage). Elle rappelle aussi qu'il faut être prudent si on doit faire circuler ses identificateurs vers d'autres protocoles : tous ne savent pas gérer Unicode, hélas.
Il existe une mise en œuvre de PRECIS en Go : https://godoc.org/golang.org/x/text/secure/precis et une en
JavaScript, precis-js.
Les changements depuis le précédent RFC, le RFC 7564, sont résumés dans l'annexe A. Rien de crucial, le
principal étant le remplacement de
toCaseFold() par
toLower() pour les opérations insensibles à la
casse. Ces deux fonctions sont définies dans la norme
Unicode (section 4.1). La principale différence est que
toCaseFold() ne convertit pas forcément en
minuscules (l'alphabet
cherokee est converti en majuscules). Grâce à Python, dont la version 3
fournit casefold en plus de
lower() et upper(),
voici d'abord la différence sur l'eszett :
>>> "ß".upper()
'SS'
>>> "ß".lower()
'ß'
>>> "ß".casefold()
'ss'
Et sur l'alphabet cherokee (pour le cas, très improbable, où vous ayiez la police pour les minuscules, ajoutées récemment) :
>>> "ᏚᎢᎵᎬᎢᎬᏒ".upper()
'ᏚᎢᎵᎬᎢᎬᏒ'
>>> "ᏚᎢᎵᎬᎢᎬᏒ".lower()
'ꮪꭲꮅꭼꭲꭼꮢ'
>>> "ᏚᎢᎵᎬᎢᎬᏒ".casefold()
'ᏚᎢᎵᎬᎢᎬᏒ'
L'article seul
RFC 8266: Preparation, Enforcement, and Comparison of Internationalized Strings Representing Nicknames
Date de publication du RFC : Octobre 2017
Auteur(s) du RFC : P. Saint-Andre (Jabber.org)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF precis
Première rédaction de cet article le 6 octobre 2017
Bien des protocoles Internet manipulent des noms qui doivent être parlants pour les utilisateurs et donc, de nos jours, doivent pouvoir être en Unicode. Les noms purement ASCII appartiennent à un passé révolu. Le groupe de travail PRECIS de l'IETF établit des règles pour ces noms, de manière à éviter que chaque protocole, chaque application, ne soit obligé de définir ses propres règles. Ce RFC contient les règles pour un sous-ensemble de ces noms : les noms qui visent plutôt à communiquer avec un utilisateur humain (par opposition aux noms qui sont indispensables aux protocoles réseaux, traités dans le RFC 8265). Il remplace le RFC 7700 (mais il y a peu de changements).
Ces noms « humains » sont typiquement ceux qui sont présentés aux utilisateurs. Ils doivent donc avant tout être « parlants » et il faut donc qu'ils puissent utiliser la plus grande part du jeu de caractères Unicode, sans restrictions arbitraires (contrairement aux identificateurs formels du RFC 8265, pour lesquels on accepte des limites du genre « pas d'espaces » ou « pas d'emojis »).
Le terme utilisé par le RFC pour ces noms « humains » est nicknames, terme qui vient du monde de la messagerie instantanée. Il n'y a pas de terme standard pour les désigner, certains protocoles (comme le courrier) parlent de display names (par opposition au login name ou account name), d'autres utilisent encore d'autres termes (l'article « An Introduction to Petname Systems » peut vous intéresser). Par exemple, dans un message électronique, on pourrait voir :
From: Valérie Pécresse <vp@les-républicains.fr>
Et, dans cet exemple, vp serait le nom formel
(mailbox name dans le courrier, login
name pour se connecter), alors que Valérie
Pécresse est le nickname, le nom
montrable aux humains. (Le concept de display
name dans le courrier est normalisé dans la section 3.4.1
du RFC 5322, son exact équivalent XMPP,
le nickname, est dans XEP-0172.)
Autre exemple, le réseau social Mastodon
où mon nom formel est bortzmeyer@mastodon.gougere.fr alors que la description, le
terme affiché est « S. Bortzmeyer 🗸 » (avec un symbole à la fin, le U+1F5F8).
Comme l'illustre l'exemple ci-dessus, on veut évidemment que le nom puisse être en Unicode, sauf pour la petite minorité des habitants de la planète qui utilisent une langue qui peut s'écrire uniquement en ASCII.
Ces noms « parlants », ces nicknames, ne servent pas qu'à désigner des humains, ils peuvent aussi être utilisés pour des machines, des sites Web (dans les signets), etc.
On pourrait penser qu'il n'y a rien à spécifier pour permettre leur internationalisation. On remplace juste ASCII par Unicode comme jeu de caractères autorisé et vas-y, poupoule. Mais Unicode recèle quelques surprises et, pour que les nicknames fonctionnent d'une manière qui paraitra raisonnable à la plupart des utilisateurs, il faut limiter légèrement leur syntaxe.
Ces limites sont exposées dans la section 2 de notre RFC, qui
définit un profil de PRECIS. PRECIS,
Preparation, Enforcement, and Comparison of
Internationalized Strings est le sigle qui désigne le
projet « Unicode dans tous les identificateurs » et le groupe de
travail IETF qui réalise ce projet. PRECIS définit (RFC 8264) plusieurs classes d'identificateurs et
les nicknames sont un cas particulier de la
classe FreeformClass (RFC 8264, section 4.3), la moins restrictive
(celle qui permet le plus de caractères).
Outre les restrictions de FreeformClass
(qui n'est pas complètement laxiste : par exemple, cette classe ne
permet pas les caractères de contrôle), le profil
Nickname :
- Convertit tous les caractères Unicode de type « espace » (la catégorie Unicode Zs) en l'espace ASCII (U+0020),
- Supprime les espaces en début et en fin du
nickname, ce qui fait que "
Thérèse" et "Thérèse" sont le même nom, - Fusionne toutes les suites d'espaces en un seul espace,
- Met tout en minuscules (donc les nicknames sont insensibles à la casse),
- Normalise en NFKC, plus violent que NFC, et réduisant donc les possibilités que deux nicknames identiques visuellement soient considérés comme distincts (cf. section 6, qui prétend à tort que ce serait un problème de sécurité ; comme souvent à l'IETF, le groupe de travail a passé beaucoup de temps sur un faux problème de « confusabilité », cf. UTS#39).
À noter qu'un nickname doit avoir une taille non nulle, après l'application des ces règles (autrement, un nickname de trois espaces serait réduit à... zéro).
Une fois ce filtrage et cette canonicalisation faite, les nicknames peuvent être comparés par une simple égalité bit à bit (s'ils utilisent le même encodage, a priori UTF-8). Un test d'égalité est utile si, par exemple, un système veut empêcher que deux utilisateurs aient le même nickname.
La section 3 de notre RFC fournit quelques exemples amusants et instructifs de nicknames :
- "
Foo" et "foo" sont acceptables, mais sont le même nom (en application de la régle d'insensibilité à la casse), - "
Foo Bar" est permis (les espaces sont autorisés, avec les quelques restrictions indiquées plus haut), - "
Échec au roi ♚" est permis, rien n'interdit les symboles comme cette pièce du jeu d'échecs, le caractère Unicode U+265A, - "
Henri Ⅳ" est permis (ouvrez l'œil : c'est le chiffre romain à la fin, U+2163) mais la normalisation NFKC (précédée du passage en minuscules) va faire que ce nom est équivalent à "henri iv" (avec, cette fois, deux caractères à la fin).
Notez que ces règles ne sont pas idempotentes et le RFC demande qu'elles soient appliquées répétitivement jusqu'à la stabilité (ou, au maximum, jusqu'à ce que trois applications aient été faites).
Comme le rappelle la section 4 de notre RFC, les applications doivent maintenant définir l'utilisation de ces noms parlants, où peut-on les utiliser, etc. L'application peut donc avoir des règles supplémentaires, comme une longueur maximale pour ces nicknames, ou des caractères interdits car ils sont spéciaux pour l'application.
L'application ou le protocole applicatif a également toute
latitude pour gérer des cas comme les duplicatas : j'ai écrit plus
haut que "Foo Bar" et "foo
bar" étaient considérés comme le même
nickname mais cela ne veut pas dire que leur
coexistence soit interdite : certaines applications permettent à
deux utilisateurs distincts d'avoir le même
nickname. Même chose avec d'autres règles
« métier » comme la possibilité d'interdire certains noms (par
exemple parce qu'ils sont grossiers).
Le profil Nickname est désormais ajouté au
registre IANA (section 5 du RFC).
L'annexe A décrit les changements depuis le RFC 7700. Le principal est le remplacement de l'opération
Unicode CaseFold() par
toLower() pour assurer l'insensibilité à la
casse. La différence est subtile, et ne change rien pour la
plupart des écritures. Sinon, l'erreur notée #4570
a été corrigée. Le reste n'est que de la maintenance.
L'article seul
Supervision de serveurs Web .onion (« darquenette »)
Première rédaction de cet article le 4 octobre 2017
Un certain nombre de webmestres
configurent leur serveur Web pour être
accessible via un nom en .onion. Le but
principal est de résister aux tentatives de censure. Un tel
service, si on est soucieux de qualité, doit être
supervisé comme n'importe quel autre
service. J'explique ici comment j'ai configuré cette supervision,
avec le logiciel Icinga, et quelques leçons
apprises à l'occasion.
Tout site Web peut être accédé via le réseau Tor si le visiteur veut garder son
légitime anonymat, ou bien s'il veut
échapper à certaines censures (comme un blocage de l'adresse IP du serveur). Il lui
suffit d'installer le Tor
Browser et hop. Mais cette technique ne protège que le
client, elle ne protège pas le serveur. Des attaques côté serveur
(saisie du nom de
domaine, ou bien saisie du serveur physique) peuvent
couper l'accès. D'où les noms de domaines en
.onion (ce qu'on
appelle parfois, bien à tort, « service caché », alors que ces
services sont complètement publics et que même le
Googlebot y passe). Avec une telle
configuration (utilisée, par exemple, par mon blog), le risque de censure
est bien plus faible (mais pas nul, attention, vous courrez quand
même des risques). Les journalistes ont inventé le terme
sensationnaliste de
darknet (qui désignait à
l'origine tout à
fait autre chose) pour ces services, et les
politiciens français l'ont traduit par « Internet
clandestin », une traduction d'état
d'urgence… (Et vraiment grotesque puisque tout le
monde, vous, moi, la NSA, Google, peut
visiter ces sites.)
De tels services sont de plus en plus nécessaires, et pas
seulement si on est dissident en Iran, en Chine ou en
Arabie saoudite. Les pays censés être
démocratiques utilisent également la censure de l'Internet comme
récemment en Espagne (contre le
référendum catalan et donc
en partie contre le .cat) ou en
France avec la pérennisation de l'état d'urgence.
Donc, il est tout à fait justifié de configurer des services en
.onion. Mais si on veut vérifier que ces
services marchent bien ? Pour les services plus traditionnels
(mettons un site Web classique), on utilise un logiciel de supervision. Mettons qu'on utilise, comme moi,
Icinga (mais la technique expliquée ici
devrait marcher avec n'importe quel logiciel de supervision
compatible avec l'API de
Nagios). Le script de test des serveurs
HTTP est check_http,
qui peut se tester depuis la ligne de commande :
% /usr/lib/nagios/plugins/check_http -H www.elysee.fr
HTTP OK: HTTP/1.1 200 OK - 684876 bytes in 0.791 second response time |time=0.791354s;;;0.000000;10.000000 size=684876B;;;0
Il est appelé régulièrement par Icinga pour tester le serveur, et
déclencher une alarme si quelque chose va mal. Ce script utilise
les bibliothèques « normales » du système, et ne connait pas le
TLD « spécial »
.onion :
% /usr/lib/nagios/plugins/check_http -H sjnrk23rmcl4ie5atmz664v7o7k5nkk4jh7mm6lor2n4hxz2tos3eyid.onion
Name or service not known
HTTP CRITICAL - Unable to open TCP socket
Si on fait tourner le client Tor sur sa machine, il exporte par
défaut une interface SOCKS (paramètres
SOCKSPort et SOCKSPolicy
dans le fichier de configuration de Tor). Cela permet à certains
programmes (ici, curl) d'accéder aux
services en .onion :
% curl -v sjnrk23rmcl4ie5atmz664v7o7k5nkk4jh7mm6lor2n4hxz2tos3eyid.onion ... curl: (6) Could not resolve host: sjnrk23rmcl4ie5atmz664v7o7k5nkk4jh7mm6lor2n4hxz2tos3eyid.onion
Et avec la bonne option (Tor écoute par défaut sur le port 9050) :
% curl -v --socks5-hostname localhost:9050 sjnrk23rmcl4ie5atmz664v7o7k5nkk4jh7mm6lor2n4hxz2tos3eyid.onion
...
* SOCKS5 communication to sjnrk23rmcl4ie5atmz664v7o7k5nkk4jh7mm6lor2n4hxz2tos3eyid.onion:80
* SOCKS5 request granted.
* Connected to localhost (127.0.0.1) port 9050 (#0)
> GET / HTTP/1.1
> Host: sjnrk23rmcl4ie5atmz664v7o7k5nkk4jh7mm6lor2n4hxz2tos3eyid.onion
> User-Agent: curl/7.55.1
> Accept: */*
>
< HTTP/1.1 200 OK
< Date: Fri, 22 Sep 2017 09:31:32 GMT
< Server: Apache
< Content-Type: text/html
<
{ [3245 bytes data]
0 425k 0 3245 0 0 3245 0 0:02:14 0:00:01 0:02:13 2414<?xml version="1.0" ?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xml:lang="fr" lang="fr" xmlns="http://www.w3.org/1999/xhtml">
<head>
...
(Si vous avez un message d'erreur du genre « * connect to 127.0.0.1 port 9050 failed: Connection refused », c'est que le client Tor ne tourne pas sur votre machine - il ne s'agit pas du Tor Browser, mais d'un démon - ou bien qu'il écoute sur un autre port, vérifiez la configuration.)
Petit problème, le script check_http ne
semble pas disposer d'une option SOCKS. Il faut donc utiliser une
autre méthode, le programme torsocks
qui redirige divers appels système pour que l'application parle à
SOCKS en croyant parler directement au serveur HTTP. Pour curl, on
aurait pu faire :
% torsocks curl -v sjnrk23rmcl4ie5atmz664v7o7k5nkk4jh7mm6lor2n4hxz2tos3eyid.onion
On peut donc lancer le script de test des Monitoring Plugins :
% torsocks /usr/lib/nagios/plugins/check_http -H sjnrk23rmcl4ie5atmz664v7o7k5nkk4jh7mm6lor2n4hxz2tos3eyid.onion HTTP OK: HTTP/1.1 200 OK - 436330 bytes in 3.649 second response time |time=3.648528s;;;0.000000;10.000000 size=436330B;;;0
Maintenant que le test marche en ligne de commande, il n'y a plus qu'à configurer Icinga pour l'utiliser. On écrit un petit script shell :
% cat /usr/local/lib/nagios/plugins/check_http_onion #!/bin/sh /usr/bin/torsocks /usr/lib/nagios/plugins/check_http $*
Et on dit à Icinga de l'utiliser. Dans
commands.conf :
object CheckCommand "http-onion" {
command = [ PluginContribDir + "/check_http_onion" ]
arguments = {
"-H" = {
value = "$http_vhost$"
description = "Host name argument for servers using host headers (virtual host)"
}
[On reprend verbatim les options de check_http, qui sont, sur une
Debian, dans /usr/share/icinga2/include/command-plugins.conf]
vars.http_address = "$check_address$"
vars.http_ssl = false
vars.http_sni = false
vars.http_linespan = false
vars.http_invertregex = false
vars.check_ipv4 = "$http_ipv4$"
vars.check_ipv6 = "$http_ipv6$"
vars.http_link = false
vars.http_verbose = false
}
Et dans services.conf :
apply Service for (http_vhost => config in host.vars.http_onion_vhosts) {
import "generic-service"
check_command = "http-onion"
vars += config
}
Avec ces définitions, je peux décider de superviser un service en
mettant une entrée dans le
vars.http_onion_hosts de la machine :
object Host "serveur-secret" {
import "generic-host"
... [Autres tests]
vars.http_onion_vhosts["onion"] = {
http_uri = "/"
http_vhost = "sjnrk23rmcl4ie5atmz664v7o7k5nkk4jh7mm6lor2n4hxz2tos3eyid.onion"
http_ssl = false
http_timeout = 15
}
}
Ou bien en créant un host spécial :
object Host "internet-libre" {
import "generic-host"
check_command = "always_true" /* No ping in Tor */
vars.http_onion_vhosts["aeris"] = {
http_uri = "/"
http_vhost = "aerisryzdvrx7teq.onion"
http_ssl = false
http_timeout = 15
}
vars.http_onion_vhosts["amaelle"] = {
http_uri = "/"
http_vhost = "ozawuyxtechnopol.onion"
http_ssl = false
http_timeout = 15
}
}
Ainsi configuré, Icinga va régulièrement tester ces services via
Tor, et prévenir de la manière habituelle :
Alors, à l'usage, est-ce que ça marche ? Oui, au sens où je suis bien prévenu lorsqu'il y a un problème et Icinga teste bien et enregistre l'historique des pannes. Moins bien au sens où cette supervision révèle que Tor n'est pas parfaitement fiable, en tout cas vu de mon ADSL : les pannes temporaires sont relativement fréquentes (ce qui est logique, la requête étant acheminée par plusieurs nœuds Tor parfois lointains, et pas toujours stables). Cela peut donc valoir la peine de configurer le logiciel de supervision pour être moins prompt à lever une alarme pour ces services. Disons en gros une ou deux pannes d'environ dix minutes par jour, ce qui ne serait pas acceptable pour un serveur Web « normal ».
Ce qui est amusant est que, parfois, pendant une panne, le Tor Browser depuis le même réseau, arrive à se connecter au service. C'est probablement parce que le Tor Browser et le démon Tor utilisé par Icinga ont établi des circuits Tor différents (passant par des nœuds différents), et qu'un seul des circuits déconne.
Mille mercis à Lunar pour m'avoir tout
expliqué patiemment (et, en plus, ça marche). Et merci aussi à
Amaelle et Aeris pour m'avoir permis d'utiliser leurs serveurs pour
les tests. Voici les trois serveurs en .onion
qui ont été utilisé (les liens ne marcheront que si vous regardez
cet article via Tor) :
L'article seul
Deuxième lien Internet pour la Corée du Nord, ça se voit où ?
Première rédaction de cet article le 3 octobre 2017
Dernière mise à jour le 4 octobre 2017
Le premier octobre 2017, le site d'information spécialisé dans la Corée du Nord, 38 North, a publié un excellent article sur la deuxième connexion Internet de la Corée du Nord. Où peut-on vérifier ce genre d'informations ?
L'article est un bon exemple d'OSINT (ou de ROSO ?), ne s'appuyant que sur des sources publiques, et sur l'analyse des experts de Dyn research (l'ancien Renesys, qui a publié son propre article, une lecture très recommandée). Mais, sur le sujet de la Corée du Nord, la propagande tourne à plein régime et énormément d'informations fausses sont diffusées, d'autant plus que la dictature délirante de Kim Jong-un ne permet pas de vérifications sur place. Si les fake news ne sont pas une nouveauté (le mensonge est aussi ancien que le langage), le caractère assez technique de l'information (« la Corée du Nord a désormais un deuxième lien Internet, via la Russie ») rend les vérifications plus difficiles, pour les gens non spécialisés.
Donc, l'article de 38 North dit qu'un opérateur Internet russe connecte désormais la RDPC, qui n'était auparavant connectée que par la Chine. Vu le caractère… spécial de la Corée du Nord, cette connexion n'est pas une pure affaire de business et a sans doute nécessité une approbation par Moscou. Comment la vérifier ?
Car c'est tout l'intérêt de l'OSINT : le but n'est pas uniquement de faire gagner du temps aux espions (au prix d'une certaine perte de glamour : lire le Wikipédia russophone est moins spectaculaire que de pénétrer dans une chambre forte au Kremlin, après avoir séduit une belle espionne russe). L'intérêt politique de l'OSINT est de permettre des vérifications indépendantes : si on n'est pas sûr de l'information, on peut refaire une partie du travail pour la recouper.
Donc, première chose, récolter quelques informations
techniques. Quelles sont les adresses IP de l'(unique) opérateur Internet
nord-coréen ? On peut le savoir en partant des serveurs de noms de leur
TLD, .kp :
% dig NS kp
; <<>> DiG 9.10.3-P4-Debian <<>> NS kp
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 44497
;; flags: qr rd ra; QUERY: 1, ANSWER: 3, AUTHORITY: 0, ADDITIONAL: 3
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 4096
;; QUESTION SECTION:
;kp. IN NS
;; ANSWER SECTION:
kp. 429731 IN NS ns3.kptc.kp.
kp. 429731 IN NS ns1.kptc.kp.
kp. 429731 IN NS ns2.kptc.kp.
;; ADDITIONAL SECTION:
ns1.kptc.kp. 429731 IN A 175.45.176.15
ns2.kptc.kp. 429731 IN A 175.45.176.16
;; Query time: 0 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: Tue Oct 03 11:53:28 CEST 2017
;; MSG SIZE rcvd: 122
Un petit coup de whois pour vérifier :
% whois 175.45.176.15 % [whois.apnic.net] % Whois data copyright terms http://www.apnic.net/db/dbcopyright.html % Information related to '175.45.176.0 - 175.45.179.255' % Abuse contact for '175.45.176.0 - 175.45.179.255' is 'postmaster@star-co.net.kp' inetnum: 175.45.176.0 - 175.45.179.255 netname: STAR-KP descr: Ryugyong-dong descr: Potong-gang District country: KP org: ORG-SJVC1-AP admin-c: SJVC1-AP tech-c: SJVC1-AP status: ALLOCATED PORTABLE mnt-by: APNIC-HM mnt-lower: MAINT-STAR-KP mnt-routes: MAINT-STAR-KP ... organisation: ORG-SJVC1-AP org-name: Star Joint Venture Co. Ltd. country: KP address: Ryugyong-dong address: Potong-gang District phone: +850-2-3812321 fax-no: +850-2-3812100 e-mail: postmaster@star-co.net.kp ...
OK, on a bien trouvé Star JV, l'opérateur coréen. Quel est son numéro d'AS ? Il existe plein de moyens de le trouver, à partir de la base APNIC mais, ayant l'habitude du DNS, j'utilise le service DNS de RouteViews :
% dig +short TXT 0.176.45.175.aspath.routeviews.org "54728 6939 701 4837 131279" "175.45.176.0" "24"
Il nous apprend que le préfixe 175.45.176.0/24
est annoncé par l'AS 131279 (rappelez-vous
que les chemins d'AS se lisent de droite à gauche). Le second AS (rappelez-vous
que les chemins d'AS se lisent de droite à gauche), 4837, est celui
du fournisseur chinois habituel, China Unicom.
L'article de 38 North dit que cela a changé le dimanche 1
octobre. En effet, l'excellent service RIPE stat, quand on
l'interroge sur le routage de
175.45.176.0/24, confirme une activité
importante : 
(Vous pouvez aussi regarder sur le site original.) Cette activité indique qu'un changement a eu lieu, puis s'est propagé par BGP à tout l'Internet, déclenchant en cascade d'autres changements. (Les tables BGP sont publiques, l'Internet est très ouvert. Exercice : cherchez les autres préfixes annoncés par Star JV.)
Bon, en quoi consistait cette nouveauté BGP du dimanche matin ? On va se tourner vers le service de RouteViews qui archive les annonces BGP et les met ensuite à la disposition du public. Les fichiers sont au format MRT (RFC 6396), qui s'analyse avec le programme bgpdump. Et on connait l'heure approximative de l'annonce (dans l'article de 38 North et grâce à RIPE stat) donc on peut télécharger le bon fichier (il change tous les quarts d'heure, regardez le nom de fichier, au format YYYYMMDD) :
% wget http://archive.routeviews.org/bgpdata/2017.10/UPDATES/updates.20171001.0900.bz2
% bunzip2 updates.20171001.0900.bz2
% bgpdump updates.20171001.0900 > updates.20171001.0900.txt
2017-10-03 11:22:24 [info] logging to syslog
%
On charge le updates.20171001.0900.txt dans
un éditeur, on cherche "131279" (l'AS de Star JV) et on trouve
l'annonce cherchée :
TIME: 10/01/17 09:07:51
TYPE: BGP4MP/MESSAGE/Update
FROM: 202.73.40.45 AS18106
TO: 128.223.51.102 AS6447
ORIGIN: INCOMPLETE
ASPATH: 18106 20485 131279
NEXT_HOP: 202.73.40.45
COMMUNITY: 4635:2000
ANNOUNCE
175.45.176.0/24
175.45.178.0/24
175.45.179.0/24
Ici, l'annonce BGP émise par 131279 est transmise à l'AS 20485, le nouveau transitaire de Star JV. Qui est-il ?
% whois AS20485
% This is the RIPE Database query service.
...
aut-num: AS20485
as-name: TRANSTELECOM
org: ORG-CJSC19-RIPE
descr: Moscow, Russia
...
organisation: ORG-CJSC19-RIPE
org-name: Closed Joint Stock Company TransTeleCom
org-type: LIR
address: Testovskayia str., 8 , enterance 3
address: 123317
address: Moscow
address: RUSSIAN FEDERATION
phone: +74957846670
fax-no: +74957846671
...
Il s'agit donc bien d'un russe, TransTelecom.
Maintenant, est-ce que cet opérateur russe est vraiment
utilisé ? Certes, il reçoit les annonces BGP des Nord-Coréens et
les relaie (c'est ainsi qu'elles sont reçues par
RouteViews). Mais, comme disent les opérateurs réseaux,
« The data plane does not always follow the control
plane », ce qui veut dire que les paquets
ne passent pas forcément par le chemin des AS qui ont relayé
l'annonce. Testons depuis TransTelecom, grâce aux sondes RIPE Atlas, en
utilisant le
programme atlas-traceroute. On demande à trois sondes dans
l'AS de TransTelecom d'aller visiter 175.45.176.15 :
% atlas-traceroute --format --as 20485 --requested 3 175.45.176.15 Measurement #9412526 Traceroute 175.45.176.15 from AS #20485 uses 3 probes 3 probes reported Test #9412526 done at 2017-10-03T10:08:23Z From: 79.140.108.66 20485 TRANSTELECOM Moscow, Russia, RU Source address: 79.140.108.66 Probe ID: 1257 1 79.140.108.65 20485 TRANSTELECOM Moscow, Russia, RU [8.027, 1.63, 1.634] 2 217.150.57.50 20485 TRANSTELECOM Moscow, Russia, RU [5.27, 5.079, 5.072] 3 212.73.250.154 3356 LEVEL3 - Level 3 Communications, Inc., US [30.465, 30.464, 31.473] 4 ['*', '*', '*'] 5 ['*', '*', '*'] 6 204.255.173.53 701 UUNET - MCI Communications Services, Inc. d/b/a Verizon Business, US [132.757, 132.524, 132.329] 7 ['*', '*', '*'] 8 152.63.114.26 701 UUNET - MCI Communications Services, Inc. d/b/a Verizon Business, US [205.82, 205.77, 206.587] 9 ['*', '*', '*'] 10 219.158.101.197 4837 CHINA169-BACKBONE CHINA UNICOM China169 Backbone, CN [380.779, 380.674, 380.586] 11 219.158.3.130 4837 CHINA169-BACKBONE CHINA UNICOM China169 Backbone, CN [385.401, 385.712, 385.569] 12 ['*', '*', '*'] 13 219.158.39.42 4837 CHINA169-BACKBONE CHINA UNICOM China169 Backbone, CN [268.096, '*', '*'] ...
(Vous pouvez aussi regarder une représentation
graphique de cette mesure.)
Et on voit bien que, même depuis TransTelecom, fournisseur de
connectivité de Star JV, le trafic n'est pas envoyé via le
pont de l'Amitié, mais à un opérateur
états-unien, Level 3, qui transmettra
ensuite à China Unicom. (Exercice : faites pareil depuis d'autres
AS, comme 18106, pour voir qu'ils envoient bien à TransTelecom - ils
ont bien reçu l'annonce BGP - mais que celui-ci ne transmet pas
ensuite directement aux Coréens.) Le
lien tout neuf n'est donc pas utilisé pour l'instant. Ceci dit, la
situation change régulièrement. Le 4 octobre, il n'y avait plus
qu'un seul préfixe annoncé via TransTelecom, le
175.45.178.0/24 et lui est bien routé
directement vers Star JV :
% atlas-traceroute --format --as 20485 --requested 3 --proto icmp 175.45.178.1 Measurement #9675151 Traceroute 175.45.178.1 from AS #20485 uses 3 probes 3 probes reported Test #9675151 done at 2017-10-04T12:21:50Z From: 79.140.108.66 15774 TTK-RTL Retail, RU Source address: 79.140.108.66 Probe ID: 1257 1 79.140.108.65 15774 TTK-RTL Retail, RU [8.441, 1.936, 1.936] 2 217.150.57.50 20485 TRANSTELECOM Moscow, Russia, RU [5.432, 5.497, 5.441] 3 ['*', '*', '*'] 4 188.43.225.153 20485 TRANSTELECOM Moscow, Russia, RU [131.737, 132.065, 131.744] 5 ['*', '*', '*'] 6 175.45.178.1 131279 STAR-KP Ryugyong-dong, KP [130.062, 130.123, 129.827] ...
[Version graphique disponible
en ligne. Notez l'utilisation du protocole ICMP,
UDP étant bloqué quelque part.] Si votre
FAI reçoit l'annonce via TransTelecom, vous
pouvez aussi faire un traceroute depuis chez
vous (ici depuis Free)
(188.43.225.153 est TransTelecom) :
% traceroute -I 175.45.178.1 traceroute to 175.45.178.1 (175.45.178.1), 30 hops max, 60 byte packets ... 4 rke75-1-v900.intf.nra.proxad.net (78.254.255.42) 40.085 ms 40.079 ms 40.078 ms 5 cev75-1-v902.intf.nra.proxad.net (78.254.255.46) 40.070 ms 40.083 ms 40.084 ms 6 p16-6k-1-po12.intf.nra.proxad.net (78.254.255.50) 40.043 ms 25.274 ms 25.259 ms 7 bzn-crs16-1-be1024.intf.routers.proxad.net (212.27.56.149) 29.072 ms 23.159 ms 16.617 ms 8 194.149.165.206 (194.149.165.206) 31.358 ms 31.041 ms 31.054 ms 9 * * * 10 tenge10-1.br01.frf06.pccwbtn.net (63.218.232.41) 30.996 ms 30.990 ms 32.615 ms 11 63-218-233-6.static.pccwglobal.net (63.218.233.6) 32.616 ms 34.156 ms 34.162 ms 12 * * * 13 188.43.225.153 (188.43.225.153) 191.185 ms 191.210 ms 180.775 ms 14 * * * 15 175.45.178.1 (175.45.178.1) 185.670 ms 185.680 ms 186.084 ms
Peut-être le lien vers TransTelecom est-il un lien de secours, prévu pour faire face à d'éventuelles sanctions chinoises ? Ou peut-être tout simplement le nouveau lien est en cours de configuration et que la situation n'est pas tout à fait stable ?
Notez que, si les tables et les annonces BGP sont publiques (ainsi que l'utilisation des sondes RIPE Atlas), la capacité est bien plus difficile à connaitre et des affirmations comme quoi le nouveau lien représenterait « 60 % de la capacité Internet nord-coréenne » (dans cet article) sont probablement de la pure spéculation.
Merci à Dyn pour des explications supplémentaires.
L'article seul
RFC 8207: BGPsec Operational Considerations
Date de publication du RFC : Septembre 2017
Auteur(s) du RFC : R. Bush (Internet Initiative
Japan)
Réalisé dans le cadre du groupe de travail IETF sidr
Première rédaction de cet article le 28 septembre 2017
Le mécanisme de sécurisation de BGP nommé BGPsec, normalisé dans le RFC 8205 n'a pas encore de déploiement important. Mais le bon sens, l'expérience d'autres mécanismes de sécurité, et les expérimentations déjà faites avec BGPsec permettent de dégager quelques bonnes pratiques opérationnelles, que ce RFC décrit. Le RFC est court : on manque encore de pratique pour être sûr de toutes les bonnes pratiques.
Bien sûr, ces pratiques évolueront. À l'heure de la publication de ce RFC, il y a encore très peu d'expérience concrète avec BGPsec. Au fait, c'est quoi, BGPsec ? Le protocole BGP, la norme pour les annonces de routes sur l'Internet, souffre d'une faiblesse de sécurité : par défaut, n'importe qui peut annoncer n'importe quelle route, même vers un préfixe IP qu'il ne contrôle pas. Il existe plusieurs systèmes pour limiter les dégâts : les IRR, les systèmes d'alarme, et, plus récemment, les ROA (Route Origin Authorizations, cf. RFC 6482). BGPsec est la technique la plus efficace, mais aussi la plus difficile à déployer. Comme les ROA, il repose sur la RPKI. Contrairement aux ROA, il ne valide pas que l'AS d'origine mais tout le chemin d'AS, par une signature de chaque AS. Il introduit donc la cryptographie dans le routage, ce qui causera sans doute quelques perturbations.
Donc, avant de lire ce RFC 8207, c'est sans doute une bonne idée de lire au moins les RFC 4271 sur BGP et RFC 6480 sur la RPKI. Comme BGPsec dépend de la RPKI, il est également bon de lire le RFC 7115, qui parle des questions opérationnelles des ROA (qui reposent également sur la RPKI). Et enfin il faut lire le RFC sur le protocole BGPsec, le RFC 8205.
Avec BGPsec, chaque routeur de bordure de l'AS va avoir une paire {clé privée, clé publique}. On peut avoir une seule paire pour tous ses routeurs (et donc publier un seul certificat dans la RPKI) ou bien une paire par routeur (section 4 du RFC). La première solution est plus simple mais, si un routeur est piraté, il faudra changer la configuration de tous les autres routeurs. Le RFC suggère aussi de pré-publier des clés de secours dans la RPKI, pour qu'elles soient bien distribuées partout le jour où on en aura besoin.
Tous vos routeurs ne sont pas censés parler BGPsec, seulement ceux au bord de l'AS, face au grand monde inconnu du méchant Internet (section 5). Si vous n'avez pas le temps ou l'envie d'activer BGPsec sur tous vos routeurs, commencez par ceux qui font face aux « maillons faibles », les pairs ou les transitaires que vous suspectez d'être le plus capable d'envoyer ou de relayer des annonces erronées ou mensongères. Évidemment, ce sont aussi ceux qui ont le moins de chance de déployer BGPsec…
Si vous ne vous contentez pas de vérifier les signatures BGPsec, mais que vous agissez sur la base de cette vérification (en ignorant les annonces invalides), attendez-vous, comme avec toute technique de sécurité BGP, à ce que le trafic se déplace, par exemple vers d'autres pairs. Un pré-requis au déploiement de BGPsec est donc sans doute un bon système de métrologie.
Attention aux limites de BGPsec : la signature couvre le chemin d'AS, pas les communautés (RFC 1997). Ne vous fiez donc pas à elles.
Si BGPsec vous semble bien compliqué à déployer, et que vous hésitez devant le travail que cela représente, la section 6 vous rassurera : la majorité des AS sont des stubs, ils ne fournissent de connectivité à personne et n'ont donc pas forcément besoin de valider les annonces. Par contre, vous pouvez demander à vos transitaires s'ils utilisent BGPsec (début 2017, la réponse était forcément non).
Les lect·eur·rice·s subtil·e·s ont peut-être noté une
différence avec les ROA. Alors que l'état de la validation ROA
(RFC 6811)
donne un résultat ternaire (pas de ROA, un ROA et valide, un ROA
et invalide), BGPsec est binaire (annonce valide, ou
invalide). C'est parce que les chemins d'AS sécurisés BGPsec_path ne
sont propagés qu'entre routeurs BGPsec, qui signent et, a priori,
valident. Si on reçoit une annonce BGPsec, c'est forcément que
tout le chemin d'AS gérait BGPsec. L'équivalent du « pas de ROA »
est donc une annonce BGP traditionnelle, avec
AS_PATH mais sans
BGPsec_path.
Quant à la décision qu'on prend lorsqu'une annonce est
invalide, c'est une décision locale. Ni
l'IETF, ni l'ICANN,
ni le CSA ne peuvent prendre cette décision
à votre place. Notre RFC recommande (mais c'est juste une
recommandation) de jeter les annonces BGPsec invalides. Certains
opérateurs peuvent se dire « je vais accepter les annonces
invalides, juste leur mettre une préférence plus basse » mais cela
peut ne pas suffire à empêcher leur usage même lorsqu'il existe
des alternatives. Imaginons un routeur qui reçoive une annonce
valide pour 10.0.0.0/16 et une invalide pour
10.0.666.0/24 (oui, je sais que ce n'est pas
une adresse IPv4 correcte, mais c'est le RFC qui a commencé, ce
n'est pas moi). Le routeur installe les deux routes, avec une
préférence basse pour 10.0.666.0/24. Mais les
préférences ne jouent que s'il s'agit de préfixes identiques. Ici,
lorsqu'il faudra transmettre un paquet, c'est la route la plus
spécifique qui gagnera, donc la mauvaise (666 = chiffre
de la Bête). Notez que l'article « Are We There Yet?
On RPKI’s Deployment and Security » contient plusieurs autres exemples où le rejet d'une annonce
invalide a des conséquences surprenantes.
La même section 7 couvre aussi le cas des serveurs de routes, qui est un peu particulier car ces routeurs n'insèrent pas leur propre AS dans le chemin, ils sont censés être transparents.
Enfin, la section 8 traite de quelques points divers, comme le rappel que la RPKI (comme d'ailleurs le DNS) n'est pas cohérente en permanence, car pas transmise de manière synchrone partout. Par exemple, si vous venez d'obtenir un certificat pour un AS, ne l'utilisez pas tout de suite : les annonces BGP se propagent plus vite que les changements dans la RPKI et vos annonces signées risquent donc d'être considérées comme invalides par certains routeurs.
L'article seul
RFC 8210: The Resource Public Key Infrastructure (RPKI) to Router Protocol, Version 1
Date de publication du RFC : Septembre 2017
Auteur(s) du RFC : R. Bush (Internet Initiative
Japan), R. Austein (Dragon Research
Labs)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF sidr
Première rédaction de cet article le 28 septembre 2017
Le protocole décrit dans ce RFC fait partie de la grande famille des RFC sur la RPKI, un ensemble de mécanismes permettant de sécuriser le routage sur l'Internet. Il traite un problème bien particulier : comme la validation des annonces de route, potentiellement complexe en cryptographie, se fait typiquement sur une machine spécialisée, le cache validateur, comment communiquer le résultat de ces validations au routeur, qui va devoir accepter ou rejeter des routes ? C'est le rôle du protocole RTR (RPKI/Router Protocol), un protocole très simple. Ce RFC décrit une nouvelle version de RTR, la version 1, la première (version 0) était dans le RFC 6810.
L'opérateur Internet a donc deux acteurs qui font du RTR entre eux, le cache validateur qui récupère les ROA (Route Origin Authorization, cf. RFC 6482) par rsync, les valide cryptographiquement et garde en mémoire le résultat de cette validation (pour des exemples d'utilisation de deux programmes mettant en œuvre cette fonction, voir mon article sur les logiciels de la RPKI), et le routeur (Cisco, Juniper, Unix avec Quagga, etc). Ce dernier joue un rôle critique et on ne souhaite pas trop charger la barque en lui imposant les opérations assez lourdes du validateur. Dans la plupart des déploiements de la RPKI, le routeur ne fait donc que récupérer des résultats simples (« ce préfixe IP peut être annoncé par cet AS »). Le jeu de données que connait le cache validateur a un numéro de série, qui est incrémenté dès qu'il y a une modification (RFC 1982). Le cache peut donc facilement savoir si un de ses clients routeur est à jour en comparant son numéro de série avec celui du routeur. Le numéro de série est spécifique à un cache donné, il n'a pas de signification globale. Le routeur ne validant pas, le cache qu'il utilise doit donc être une machine de confiance.
Un autre acteur, externe à l'opérateur, est la RPKI, l'ensemble des informations de routage publiées (RFC 6481), et qui sont transportées en général en rsync et validées par les signatures cryptographiques qu'elles portent.
Le routeur va ouvrir une connexion avec un ou plusieurs caches et transmettre le numéro de série de ses données. Le cache va lui envoyer les données plus récentes que ce numéro (ou bien rien, si le routeur est à jour). Le cache dispose aussi d'un mécanisme de notification pour dire à tous les routeurs connectés « j'ai du nouveau ». La section 10 décrit plus en détail le processus avec plusieurs caches.
La section 5 décrit le format des paquets : chacun, outre le classique champ version (1 dans ce RFC, c'était 0 dans le RFC précédent), a un type, indiqué par un entier de 8 bits (requête, réponse, etc), le numéro de série de l'envoyeur et un identifiant de session, qui identifie le serveur du cache (pour détecter une remise à zéro d'un cache, par exemple), la longueur du préfixe annoncé et bien sûr le préfixe lui-même.
Les types de paquets les plus utiles (la liste complète est dans un registre IANA) :
- Serial Notify (type 0) qui sert au cache à envoyer une notification non sollicitée par les routeurs « J'ai du nouveau ».
- Serial Query (type 1) où le routeur demande au cache validateur quelles informations il possède, depuis le numéro de série indiqué par le routeur.
- Cache Response (type 3), la réponse à la requête précédente, composée de :
- IPv4 Prefix (type 4) et IPv6 Prefix (type 6) qui indiquent un préfixe IP avec les numéros de systèmes autonomes autorisés à l'annoncer.
- End of Data (type 7) : comme son nom l'indique.
- Error (type 10), envoyé lorsque le précédent message avait déclenché un problème.
Le dialogue typique entre un routeur et un cache validateur est décrit en section 8 (le RFC détaille aussi le dialogue de démarrage, ici, je ne montre que celui de fonctionnement régulier) :
- Le routeur demande des données avec un Serial Query ou Reset Query),
- Le validateur envoie successivement un Cache Response, plusieurs IPvX Prefix, puis un End of Data.
À noter que puisqu'il y a désormais deux versions de RTR dans la nature, il a fallu mettre en place un système de négociation, décrit dans la section 7. Lorsqu'un cache/validateur connait la version 1 (celle de notre nouveau RFC), et reçoit une requête de version 0 du routeur, il doit se rabattre sur la version 0 (s'il la connait, et veut bien la parler), ou bien envoyer un message d'erreur (code 4 « Unsupported Protocol Version »).
Si c'est l'inverse (routeur récent parlant à un vieux cache/validateur), deux cas, qui dépendent de la politique du validateur. S'il répond avec une erreur, cela peut être intéressant de réessayer avec le protocole 0, si le routeur le connait. Si, par contre, le validateur répond avec des messages de version 0, le routeur peut décider de continuer en version 0.
Les codes d'erreur possibles sont décrits dans la section 12 et font l'objet d'un registre IANA. On y trouve par exemple 0 (données corrompues), 1 (erreur interne dans le client ou le serveur), 2 (pas de nouvelles données ; ce n'est pas à proprement parler une erreur).
La question du transport des données entre le cache et le routeur est traitée dans la section 9. Le principal problème est le suivant : comme le but de l'opération RPKI+ROA est d'augmenter la sécurité du routage, il faut que chaque maillon de la chaîne soit sécurisé. Il ne servirait pas à grand'chose de déployer une telle usine à gaz de validation si la liaison entre le routeur et le cache permettait à un intermédiaire de changer les données en cours de route. Il était donc tentant de normaliser une technique de sécurité particulière pour le transport, comme par exemple TLS. Malheureusement, il n'existe pas à l'heure actuelle de technique accessible sur tous les routeurs. L'IETF ayant toujours soin de normaliser des protocoles réalistes, qui puissent être mis en œuvre et déployés, le choix a été fait de ne pas imposer une technique de sécurisation particulière. L'interopérabilité en souffre (un cache et un routeur peuvent ne pas avoir de protocole de sécurité en commun) mais c'était la seule option réaliste. (J'ajoute que, si le but de la séparation du routeur et du validateur était de dispenser ce dernier des calculs cryptographiques, il ne serait pas logique de lui imposer ensuite une session protégée cryptographiquement avec le validateur.)
Le RFC se contente donc de donner une préférence à AO (TCP Authentication Option, cf. RFC 5925) en signalant qu'elle sera la technique préférée, dès lors qu'elle sera disponible sur tous les routeurs (ce qui est très loin d'être le cas en 2017, les progrès sont faibles depuis le précédent RFC sur RTR). Les algorithmes du RFC 5926 doivent être acceptés.
En attendant AO, et pour s'assurer qu'il y aura au moins un protocole commun, le RFC spécifie que routeurs et caches doivent pouvoir se parler en utilisant du TCP nu, sans sécurité, vers le port 323. Dans ce cas, le RFC spécifie que routeur et cache validateur doivent être sur le même réseau (idéalement, sur le même segment, cf. section 13) et que des mécanismes, par exemple de contrôle d'accès physiques, empêchent les méchants de jouer avec ce réseau.
Au cas où AO ne soit pas disponible (la quasi-totalité des routeurs
aujourd'hui) et où le transport non sécurisé soit jugé nettement trop
faible, le RFC présente plusieurs transports sécurisés possibles. Par
exemple, SSH (RFC 4252), avec une sécurisation des clés
obtenue par un moyen externe (entrée manuelle des clés, par
exemple). Le sous-système SSH à utiliser est nommé
rpki-rtr. Notez que, si SSH n'a pas été rendu
obligatoire, alors que quasiment tous les routeurs ont un programme
SSH, c'est parce que ce programme n'est pas toujours disponible sous
forme d'une bibliothèque, accessible aux
applications comme RTR.
Autre alternative de sécurisation évidente,
TLS. Le RFC impose une authentification par un
certificat client, comportant l'extension
subjectAltName du RFC 5280,
avec une adresse IP (celle du routeur qui se connecte, et que
le serveur RTR, la cache validateur, doit vérifier). Le client RTR,
lui (le routeur), utilisera le nom de
domaine du serveur RTR (le cache) comme entrée pour l'authentification (cf. RFC 6125). N'importe quelle
AC peut être utilisée mais notre RFC estime
qu'en pratique, les opérateurs créeront leur propre AC, et mettront
son certificat dans tous leurs routeurs.
Notez que ce problème de sécurité ne concerne que le transport entre le routeur et le cache validateur. Entre les caches, ou bien entre les caches et les serveurs publics de la RPKI, il n'y a pas besoin d'une forte sécurité, l'intégrité des données est assurée par la validation cryptographique des signatures sur les objets.
Ce RFC spécifie un protocole, pas une politique. Il pourra y avoir plusieurs façons de déployer RTR. La section 11 donne un exemple partiel de la variété des scénarios de déploiement, notamment :
- Le petit site (« petit » est relatif, il fait quand même du BGP) qui sous-traite la validation à un de ses opérateurs. Ses routeurs se connectent aux caches validateurs de l'opérateur.
- Le grand site, qui aura sans doute plusieurs caches en interne, avec peut-être un repli vers les caches de l'opérateur en cas de panne.
- L'opérateur qui aura sans doute plusieurs caches dans chaque POP (pour la redondance).
Pour limiter la charge sur les serveurs rsync de la RPKI (voir RFC 6480), il est recommandé d'organiser les caches de manière hiérarchique, avec peu de caches tapant sur les dépôts rsync publics, et les autres caches se nourrissant (et pas tous en même temps) à partir de ces caches ayant un accès public.
Bien que ce protocole RTR ait été conçu dans le cadre de la RPKI, il peut parfaitement être utilisé avec d'autres mécanismes de sécurisation du routage, puisque RTR se contente de distribuer des autorisations, indépendemment de la manière dont elles ont été obtenues.
Et puis un petit point opérationnel : sur le validateur/cache, n'oubliez pas de bien synchroniser l'horloge, puisqu'il faudra vérifier des certificats, qui ont une date d'expiration…
Quels sont les changements par rapport au RFC original, le RFC 6810, qui normalisait la version 0 de RTR ? Ces changements sont peu nombreux, mais, du fait du changement de version, les versions 0 et 1 sont incompatibles. La section 1.2 résume ce qui a été modifié entre les deux RFC :
- Un nouveau type de paquet, Router Key (type 9),
- Des paramètres temporels explicites (durée de vie des informations, etc),
- Spécification de la négociation de la version du protocole, puisque les versions 0 et 1 vont coexister pendant un certain temps.
Aujourd'hui, qui met en œuvre RTR ? Il existe en logiciel libre une bibliothèque en C, RTRlib. Elle a fait l'objet d'un bon article de présentation (avec schéma pour expliquer RTR). Elle peut tourner sur TCP nu mais aussi sur SSH. RTRlib permet d'écrire, très simplement, des clients RTR en C, pour déboguer un cache/validateur, ou bien pour extraire des statistiques. Un client simple en ligne de commande est fourni avec, rtrclient. Il peut servir d'exemple (son code est court et très compréhensible) mais aussi d'outil de test simple. rtrclient se connecte et affiche simplement les préfixes reçus. Voici (avec une version légèrement modifiée pour afficher la date) son comportement (en face, le RPKI Validator du RIPE-NCC, dont il faut noter qu'il ne marche pas avec Java 9, il faut reculer vers une version plus vieille, et qu'il ne gère pas encore la version 1 de RTR) :
% rtrclient tcp localhost 8282 ... 2012-05-14T19:27:42Z + 195.159.0.0 16-16 5381 2012-05-14T19:27:42Z + 193.247.205.0 24-24 15623 2012-05-14T19:27:42Z + 37.130.128.0 20-24 51906 2012-05-14T19:27:42Z + 2001:1388:: 32-32 6147 2012-05-14T19:27:42Z + 2001:67c:2544:: 48-48 44574 2012-05-14T19:27:42Z + 178.252.36.0 22-22 6714 2012-05-14T19:27:42Z + 217.67.224.0 19-24 16131 2012-05-14T19:27:42Z + 77.233.224.0 19-19 31027 2012-05-14T19:27:42Z + 46.226.56.0 21-21 5524 2012-05-14T19:27:42Z + 193.135.240.0 21-24 559 2012-05-14T19:27:42Z + 193.247.95.0 24-24 31592 ...
Autre bibliothèque pour développer des clients RTR, cette fois en Go, ma GoRTR. Le programmeur doit fournir une fonction de traitement des données, qui sera appelée chaque fois qu'il y aura du nouveau. GoRTR est fournie avec deux programmes d'exemple, un qui affiche simplement les préfixes (comme rtrclient plus haut), l'autre qui les stocke dans une base de données, pour étude ultérieure. Par exemple, on voit ici dans cette base de données que la majorité des préfixes annoncés autorisent une longueur de préfixe égale à la leur (pas de tolérance) :
essais=> SELECT count(id) FROM Prefixes WHERE serialno=(SELECT max(serialno) FROM Prefixes) AND maxlength=masklen(prefix); count ------- 2586 (1 row) essais=> SELECT count(id) FROM Prefixes WHERE serialno=(SELECT max(serialno) FROM Prefixes) AND maxlength>masklen(prefix); count ------- 1110 (1 row)
Et voici une partie de évenements d'une session RTR, stockée dans cette base:
tests=> select * from events; id | time | server | event | serialno ----+----------------------------+---------------------------------+---------------------------------+---------- ... 12 | 2017-06-24 13:31:01.445709 | rpki-validator.realmv6.org:8282 | (Temporary) End of Data | 33099 13 | 2017-06-24 13:31:01.447959 | rpki-validator.realmv6.org:8282 | Cache Response, session is 4911 | 33099 14 | 2017-06-24 13:31:25.932909 | rpki-validator.realmv6.org:8282 | (Temporary) End of Data | 33099 15 | 2017-06-24 13:31:38.64284 | rpki-validator.realmv6.org:8282 | Serial Notify #33099 -> #33100 | 33099 16 | 2017-06-24 13:31:38.741937 | rpki-validator.realmv6.org:8282 | Cache reset | 33099 17 | 2017-06-24 13:31:38.899752 | rpki-validator.realmv6.org:8282 | Cache Response, session is 4911 | 33099 18 | 2017-06-24 13:32:03.072801 | rpki-validator.realmv6.org:8282 | (Temporary) End of Data | 33100 ...
Notez que GoRTR gère désormais les deux versions du protocole mais ne connait pas la négociation de version de la section 7 du RFC : il faut indiquer explicitement quelle version on utilise.
Autrement, Cisco et Juniper ont tous les deux annoncé que leurs routeurs avaient un client RTR, et qu'il a passé des tests d'interopérabilité avec trois mises en œuvre du serveur (celles de BBN, du RIPE et de l'ISC). Ces tests d'interopérabilité ont été documentés dans le RFC 7128. Quant aux serveurs, un exemple est fourni par le logiciel RPKI du RIPE-NCC qui fournit un serveur RTR sur le port 8282 par défaut.
En 2013, un client RTR récupèrait 3696 préfixes (ce qui est plus que le nombre de ROA puisqu'un ROA peut comporter plusieurs préfixes). C'est encore très loin de la taille de la table de routage globale et il reste donc à voir si l'infrastructure suivra. (Sur ma station de travail, le validateur, écrit en Java, rame sérieusement.)
Pour les curieux, pourquoi est-ce que l'IETF n'a pas utilisé Netconf (RFC 6241) plutôt que de créer un nouveau protocole ? Les explications sont dans une discussion en décembre 2011. Le fond de la discussion était « les informations de la RPKI sont des données ou de la configuration » ? La validation est relativement statique mais reste quand même plus proche (fréquence de mise à jour, notamment) des données que de la configuration.
Si vous voulez tester un client RTR, il existe un serveur public
rpki-validator.realmv6.org:8282. Voici le genre de choses
qu'affiche rtrclient (test fait avec un vieux serveur, qui n'est plus disponible) :
% rtrclient tcp rtr-test.bbn.com 12712 ... 2012-05-14T19:36:27Z + 236.198.160.184 18-24 4292108787 2012-05-14T19:36:27Z + 9144:8d7d:89b6:e3b8:dff1:dc2b:d864:d49d 105-124 4292268291 2012-05-14T19:36:27Z + 204.108.12.160 8-29 4292339151 2012-05-14T19:36:27Z + 165.13.118.106 27-28 4293698907 2012-05-14T19:36:27Z + 646:938e:20d7:4db3:dafb:6844:f58c:82d5 8-82 4294213839 2012-05-14T19:36:27Z + fd47:efa8:e209:6c35:5e96:50f7:4359:35ba 20-31 4294900047 ...
Question mise en œuvre, il y a apparemment plusieurs logiciels de validateurs/cache qui mettent en œuvre cette version 1, mais je n'ai pas trouvé lesquels. (Le RPKI Validator du RIPE-NCC ne le fait pas, par exemple, ni le serveur public indiqué plus haut, tous les deux ne connaissent que la version 0.)
Wireshark ne semble pas décoder ce
protocole. Si vous voulez vous y mettre, un
pcap est disponible en rtr.pcap.
L'article seul
RFC 8205: BGPsec Protocol Specification
Date de publication du RFC : Septembre 2017
Auteur(s) du RFC : M. Lepinski (NCF), K. Sriram
(NIST)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF sidr
Première rédaction de cet article le 28 septembre 2017
Ce RFC s'inscrit dans la longue liste des efforts de normalisation d'une solution de sécurité pour BGP. Actuellement, il est trop facile de détourner le routage Internet via BGP (cf. mon article « La longue marche de la sécurité du routage Internet »). Le RFC 6482 introduisait une solution partielle, les ROA (Route Origin Authorizations). S'appuyant sur une infrastructure de clés publiques et de certificats prouvant que vous êtes détenteur légitime d'une ressource Internet (comme un numéro d'AS ou bien un préfixe IP), infrastructure nommée la RPKI (Resource Public Key Infrastructure), ces ROA permettent de valider l'origine d'une annonce BGP, c'est-à-dire le premier AS du chemin. C'est insuffisant pour régler tous les cas. Ainsi, lors de la fuite de Telekom Malaysia en juin 2015, les annonces avaient une origine normale. Avec les ROA, on ne détectait donc pas le problème. D'où cette nouvelle étape, BGPsec. Il s'agit cette fois de valider le chemin d'AS complet de l'annonce BGP, chaque routeur intermédiaire signant cryptographiquement l'annonce avant de la transmettre. BGPsec permet donc de détecter bien plus d'attaques, mais il est aussi bien plus lourd à déployer.
Donc, pour résumer BGPsec en une phrase : un nouvel attribut BGP
est créé, BGPsec_Path, il est transporté dans les
annonces de route BGP, il offre la possibilité de vérifier, via les
signatures, que chaque AS listé dans ce
chemin a bien autorisé l'annonce. BGPsec ne remplace pas les ROA, il
les complète (et, comme elles, il s'appuie sur la
RPKI). Deux bonnes lectures : le modèle de
menace de BGPsec, dans le RFC 7132, et le
cahier des charges de BGPsec, dans le RFC 7353.
Le reste, ce n'est que du détail technique. Contrairement aux ROA, qui sont transportés en dehors de BGP, BGPsec est une modification du protocole BGP. Deux routeurs qui font du BGPsec doivent donc le négocier lors de l'établissement de la session (section 2 de notre RFC). Cela se fait par le mécanisme des capacités du RFC 5492. La capacité annonçant qu'on sait faire du BGPsec est BGPsec Capability, code n° 7. Notez que cette capacité dépend de celle de gérer des AS de quatre octets (normalisée dans le RFC 6793).
Le nouvel attribut est décrit en section 3. (Le concept
d'attributs BGP est dans la section 5 du RFC 4271.) Les annonces BGP avaient
traditionnellement un attribut nommé AS_PATH, qui
indiquait le chemin d'AS suivi par l'annonce. (Deux choses
importantes à se rappeler : lorsqu'on écrit un chemin d'AS, il se lit
de droite à gauche, et vous n'avez aucune garantie que les
paquets IP suivront effectivement ce chemin « the data plane does not always follow
the control plane ».)
Le nouvel attribut remplace
AS_PATH. Il se nomme
BGPsec_path (code 33) et est optionnel et non-transitif,
ce qui veut dire qu'il ne sera pas passé tel quel aux pairs. Au
contraire, le routeur est supposé créer un nouvel attribut
BGPsec_path , ajoutant son AS
(signé) et celui de l'AS à qui il transmet l'annonce. On
n'envoie une annonce portant cet attribut à un pair que si celui-ci a
signalé sa capacité à gérer BGPsec. (Sinon, on lui envoie un
AS_PATH ordinaire, non sécurisé, formé en
extrayant les AS du BGPsec_path, cf. section 4.4.)
La signature contient entre autres un identifiant de l'algorithme utilisé. La liste des algorithmes possibles est dans un registre IANA (RFC 8208).
Pour pouvoir mettre sa signature dans le
BGPsec_path, le routeur doit évidemment disposer
d'une clé
privée. La clé publique correspondante doit être dans un
certificat de la RPKI, certificat valable pour
l'AS qui signe.
Un routeur qui transmet une annonce à un pair BGPsec ne garantit pas forcément qu'il a validé le chemin sécurisé. (Même s'il le garantissait, pourquoi lui faire confiance ?) C'est à chaque routeur de vérifier l'intégrité et l'authenticité du chemin d'AS (section 5 du RFC).
C'est dans cette section 5 qu'est le cœur du RFC, les détails de la validation d'un chemin d'AS. Cette validation peut être faite par le routeur, ou bien par une machine spécialisée dans la validation, avec laquelle le routeur communique via le protocole RTR (RPKI To Router protocol, cf. RFC 8210). Bien sûr, si on valide, c'est sans doute pour que la validation ait des conséquences sur la sélection de routes, mais notre RFC n'impose pas de politique particulière : ce que l'on fait avec les annonces BGPsec mal signées est une décision locale, par chaque routeur (et peut-être, sur un routeur donné, différente pour chaque pair BGP).
L'algorithme de validation est simple :
- Contrôles syntaxiques de l'annonce,
- Vérification que l'AS le plus récemment ajouté est bien celui du pair qui nous l'a envoyé (à part le cas particulier des serveurs de route, traités en section 4.2),
- Test de la présence d'une signature pour chaque AS listé dans
BGPsec_path.
À ce stade, on peut déjà rejeter les annonces qui ont échoué à l'un de ces tests, et les traiter comme signifiant un retrait de la route citée (RFC 7606). Ensuite, on passe aux vérifications cryptographiques :
- Vérification que toutes les signatures sont faites avec un algorithme cryptographique qu'on accepte (voir la section 6 et aussi le RFC 8208),
- Pour chaque AS listé dans le chemin, recherche d'un certificat correspondant à cet AS, et ayant la clé publique avec laquelle l'AS dans le chemin a été signé,
- Test de la signature.
Notez qu'on ne négocie pas les algorithmes cryptographiques au moment de l'établissement de la session BGP, comme cela se fait, par exemple, en TLS. En effet, il ne suffit pas de connaitre l'algorithme de ses pairs, il faut valider tout le chemin, y compris des AS lointains. C'est pour cela que le RFC 8208 liste des algorithmes obligatoires, que tout le monde est censé connaître (actuellement ECDSA avec la courbe P-256 et SHA-256).
On note que l'attribut BGPsec_path avec ses
signatures n'est « transmis » qu'aux routeurs qui comprennent
BGPsec (pour les autres, on envoie un AS_PATH classique). Au début du déploiement, ces attributs ne survivront donc pas
longtemps, et les îlots BGPsec seront donc rares (section 7 du
RFC).
Notez que ce protocole est en développement depuis plus de six ans, et qu'il s'est parfois nommé PathSec dans le passé.
BGPsec est apparemment mis en œuvre au moins dans BIRD et dans Quagga (mais pas dans les versions officielles).
Quelques bonnes lectures sur BGPsec :
- Les transparents de mon exposé à FRnog 29.
- Le RFC 8374 explique et justifie les différents choix effectués lors de la conception de BGPsec.
- La série qui commence ici et les suivants. Très critique de BGPsec mais attention, certains reproches ne sont plus d'actualité (les timers sur les mises à jour, qui devaient limiter le risque d'attaque par rejeu ont été retirés depuis).
Et merci à Guillaume Lucas pour m'avoir rappelé que BGPsec est compliqué et que je suis loin de le maitriser.
L'article seul
Version 10 d'Unicode
Première rédaction de cet article le 26 septembre 2017
Le 20 juin (oui, je suis en retard), la nouvelle version d'Unicode est sortie, la 10.0. Une description officielle des principaux changements est disponible mais voici ceux qui m'ont intéressé particulièrement. (Il n'y a pas de changement radical.)
Pour explorer plus facilement la grande base Unicode, j'utilise un programme qui la convertit en SQL et permet ensuite de faire des analyses variées. Faisons quelques requêtes SQL :
ucd=> SELECT count(*) AS Total FROM Characters; total -------- 136755
Combien caractères sont arrivés avec la version 10 ?
ucd=> SELECT version,count(version) FROM Characters GROUP BY version ORDER BY version::float; ... 8.0 | 7716 9.0 | 7500 10.0 | 8518
8 518 nouveaux. Lesquels ?
ucd=> SELECT To_U(codepoint) AS Codepoint, name FROM Characters WHERE version='10.0'; codepoint | name -----------+---------------------------------------------------------------------------- ... U+20BF | BITCOIN SIGN ... U+11A00 | ZANABAZAR SQUARE LETTER A ... U+11D01 | MASARAM GONDI LETTER AA ... U+1F6F8 | FLYING SAUCER ... U+1F96A | SANDWICH
Le premier cité va évidemment faire plaisir aux possesseurs de bitcoins. Mais on trouve aussi quatre écritures entièrement nouvelles comme le zanabazar ou le masaram gondi cités en exemple plus haut. Et il y a bien sûr l'habituel lot d'emojis pour faire rire les réseaux sociaux. Tiens, d'ailleurs, combien de caractères sont des symboles (il n'y a pas que les emojis parmi eux, mais Unicode n'a pas de catégorie « emoji ») :
ucd=> SELECT count(*) FROM Characters WHERE category IN ('Sm', 'Sc', 'Sk', 'So');
count
-------
6978
Ou, en plus détaillé, et avec les noms longs des catégories :
ucd=> SELECT description,count(category) FROM Characters,Categories WHERE Categories.name = Characters.category AND category IN ('Sm', 'Sc', 'Sk', 'So') GROUP BY category, description;
description | count
-----------------+-------
Currency_Symbol | 54
Other_Symbol | 5855
Modifier_Symbol | 121
Math_Symbol | 948
(4 rows)
L'article seul
RFC 8248: Security Automation and Continuous Monitoring (SACM) Requirements
Date de publication du RFC : Septembre 2017
Auteur(s) du RFC : N. Cam-Winget (Cisco), L. Lorenzin (Pulse Secure)
Pour information
Réalisé dans le cadre du groupe de travail IETF sacm
Première rédaction de cet article le 25 septembre 2017
Le groupe de travail SACM de l'IETF bosse sur une architecture, un modèle de données, et des protocoles pour suivre l'état de la sécurité de ses machines. Ceci est son deuxième RFC, qui vise à définir le cahier des charges de la future solution.
Le cœur de cette idée est l'évaluation de la sécurité sur chaque machine du réseau. Il faut la déterminer, et acheminer le résultat jusqu'aux responsables de la sécurité. Cela nécessite donc un modèle de données (comment on décrit « la sécurité d'une machine » ?) puis un protocole permettant de gérer un très grand nombre de machines. Parmi les informations à récolter sur chaque machine, on trouvera évidemment la liste des logiciels installés, les logiciels serveurs en activité qui écoutent sur le réseau, l'état de la mise à jour (« pas pu joindre le dépôt officiel de logiciels depuis N jours »), etc. Le cahier des charges décrit dans ce RFC part des scénarios d'usage du RFC 7632. Ce sont souvent de grandes généralités. On est loin de mécanismes concrets.
La section 2 forme l'essentiel de ce RFC, avec la liste des exigences du cahier des charges. Je ne vais en citer que quelques unes. La première, nommée G-001 (« G » préfixe les exigences générales sur l'ensemble du système SACM), demande que toute la solution SACM soit extensible, pour les futurs besoins. G-003 est la possibilité de passage à l'échelle. Par exemple, les messages échangés peuvent aller de quelques lignes à, peut-être plusieurs gigaoctets si on fait une analyse détaillée d'une machine. Et il peut y avoir beaucoup de machine avec des échanges fréquents (le RFC n'est pas plus précis sur les chiffres).
Les données traitées sont évidemment sensibles, et G-006 demande que la solution permette évidemment de préserver la confidentialité des données.
Les exigences sur l'architecture de la future solution sont préfixées de « ARCH ». Ainsi, ARCH-009 insiste sur l'importance d'une bonne synchronisation temporelle de toutes les machines. Un journal des connexions/déconnexions des utilisateurs, par exemple, n'aurait guère d'intérêt si l'horloge qui sert à l'estampiller n'est pas exacte.
D'autres sections décrivent les exigences pour le modèle de données et pour les protocoles, je vous laisse les découvrir.
L'article seul
RFC 7632: Endpoint Security Posture Assessment: Enterprise Use Cases
Date de publication du RFC : Septembre 2015
Auteur(s) du RFC : D. Waltermire, D. Harrington
Pour information
Première rédaction de cet article le 25 septembre 2017
La sécurité est évidemment une préoccupation courante quand on gère un réseau (« enterprise network » dit ce document, mais cela s'applique à n'importe quel réseau, capitaliste ou pas). Parmi les problèmes, déterminer l'état de la sécurité de chaque machine du réseau (son logiciel est à jour ? Pas de RAT installé ?) est un des plus importants. Ce RFC décrit des scénarios où on cherche à analyser cet état de la sécurité.
Disons-le tout de suite, une grande partie du RFC est du jargon « process » (quand on remplace l'intelligence par la paperasserie). Si vous n'êtes pas manager chargé d'obtenir une certification ISO 27001, cela ne vous intéressera guère. La seule partie utile est, dans section 2.2 du RFC, quelques scénarios intéressants.
J'ai bien aimé le scénario de la section 2.2.5, où un groupe de chercheurs (ah, justement, ce n'est plus du « enterprise network ») travaille dans la station polaire Zebra (oui, c'est une référence au film) et doit maintenir à jour ses ordinateurs, malgré une liaison Internet intermittente, chère (et la recherche publique n'a jamais d'argent) à faible capacité et énorme latence. Non seulement les conditions sont très dures, mais ils doivent en outre se plier à la « conformité » (compliance), le buzz word à la mode. Une partie du temps de recherche sera donc consommé à suivre les process.
L'article seul
On peut tout mettre dans le DNS, même les codes postaux
Première rédaction de cet article le 24 septembre 2017
Dernière mise à jour le 9 octobre 2020
Petit service juste pour s'amuser : mettre l'ensemble des codes postaux français dans le DNS avec pour chaque code, la ou les communes concernées, leur longitude et leur latitude.
À quoi ça sert ? Pas à grand'chose, je voulais juste
illustrer l'utilisation de deux types d'enregistrements DNS
peu connus, LOC (RFC 1876) et URI (RFC 7553). (Au passage, si vous lisez que le DNS sert à
traduire des noms en adresses IP, allez lire autre chose :
c'est faux, ou, en tout cas, très réducteur.) Et traiter un peu de
JSON en prévision de la prochaine
sortie du nouveau RFC sur JSON, le RFC 8259.. Voyons
d'abord le résultat avec le traditionnel client DNS
dig :
% dig +short +nodnssec TXT 34000.cp.bortzmeyer.fr "MONTPELLIER"
L'enregistrement TXT permet d'indiquer
le nom de la ville concernée. Parfois, il y en a plusieurs :
% dig +short +nodnssec TXT 52100.cp.bortzmeyer.fr "HALLIGNICOURT" "VALCOURT" "CHANCENAY" "SAPIGNICOURT" "ST DIZIER" "PERTHES" "ST EULIEN" "BETTANCOURT LA FERREE" "LANEUVILLE AU PONT" "VILLIERS EN LIEU" "MOESLAINS"
Le même domaine cp.bortzmeyer.fr contient
également la position de la ville (ou plus probablement celle du
bureau de poste principal), avec le type LOC,
normalisé dans le RFC 1876) :
% dig +short +nodnssec LOC 34000.cp.bortzmeyer.fr
43 36 47.108 N 3 52 9.113 E 0.00m 1m 10000m 10m
Nous voyons ici que Montpellier est à 43°
36' 47'' de latitude Nord et 3° 52' 9'' de
longitude Est.
Si vous voulez voir tout de suite où ça se trouve, vous avez
également un URI (type d'enregistrement DNS
normalisé dans le RFC 7553) qui pointe vers
OpenStreetMap (merci à OpenStreetMap de
permettre de fabriquer des URL simples) :
% dig +short +nodnssec URI 52100.cp.bortzmeyer.fr 10 1 "http://www.openstreetmap.org/?mlat=48.646559&mlon=4.912187&zoom=12"
(L'enregistrement URI étant relativement récent, il ne faut pas utiliser un dig trop vieux. Par exemple, avec la version 9.8.3, on n'a pas de résultat avec cette commande.) Enfin, vous pouvez aussi retrouver les codes postaux à partir du nom de la ville :
% dig +short +nodnssec TXT ROUEN.cp.bortzmeyer.fr "76100" "76000"
Mais il y a quelques pièges : la base utilisée n'a que des caractères ASCII donc il faudra écrire « epernay » et pas le nom correct. Et pour Paris, il faudra ajouter un tiret et l'arrondissement, par exemple « paris-16 ».
Ce n'est pas très joli avec dig ? Pas convivial ? Vous pouvez aussi essayer un DNS Looking Glass. Par exemple, toutes les données pour 73370, la localisation de 73700, les les noms associés à 97434 ou bien le(s) code(s) postal(aux) de Beaugency.
Comment est-ce que ce service a été réalisé ? Je suis parti d'un fichier JSON contenant les informations nécessaires, un petit programme Python le transforme en fichier de zone DNS (section 5 du RFC 1035). Que du très simple. Le plus dur était certainement de trouver les données. En France, il y a une tradition régalienne de ne pas donner les informations au citoyen. L'État préfère les garder pour lui, ce qui obligeait à des contorsions compliquées. Le mouvement « données ouvertes » a heureusement changé les choses, même si c'est encore loin d'être parfait.
La source que j'ai utilisée est la « Base officielle des codes postaux » (trouvée via data.gouv.fr). Je ne dis pas que cette base est meilleure que les autres, mais son côté « officiel » me permet de répondre « c'est pas ma faute » si quelqu'un y trouve une erreur ou une approximation. J'ai utilisé la version GeoJSON du fichier. Elle n'est pas parfaite. Ainsi il y a un certain nombre de fautes d'orthographe comme Marolles-sous-Lignières écrit MAROLLES SOUS LIGNIERES, sans l'accent (les tirets et les apostrophes manquent également). D'autre part, certaines communes, notamment en Polynésie française, n'ont pas d'information de localisation. Ici, à Fakarava :
% dig +short +nodnssec LOC 98764.cp.bortzmeyer.fr %
Dernier problème, la liste n'est pas à jour. La commune de Meaulne-Vitray (code postal 03360), créée le 1er janvier 2017, n'apparait pas encore dans la liste, téléchargée le 24 septembre 2017. (Et elle n'est pas la seule.)
D'autres sources possibles de données avaient été considérées (et merci à Sabine Blanc, Olivier Macchioni, Pascal Corpet, Laurent Penou, Adrien Clerc, Ainiton et tous les autre qui m'ont fait d'excellentes suggestions) :
- On trouve à certains endroits des fichiers structurés
contenant cette information, mais ils ne sont pas forcément à jour
(les codes postaux changent rarement mais ils changent). Ainsi,
http://www.aito.fr/maps_ville.sqlest une excellente base MySQL, où les noms sont bien orthographiés, mais qui est vieille de nombreuses années. D'autre part, elle semble incomplète (Lille n'y a qu'un seul code postal alors qu'il en existe plusieurs en pratique). - Geofla a remplacé l'ancien RGC de l'IGN mais il ne semble pas accessible dans un format ouvert. (Et, de toute façon, il a les longitude et latitude mais pas les codes postaux, il aurait donc fallu faire une jointure sur les noms des communes.) À l'IGN, il y a aussi Admin Express, dans un format que je ne connais pas.
- Souvent, les meilleures bases sont celles gérées par des initiatives citoyennes, comme NosDonnées. Le fichier des communes semble une piste intéressante , et où les noms sont correctement orthographiés (mais je préfère JSON à CSV).
- À une époque, la Poste, pourtant service public, vendait la base des codes postaux. Il semble qu'il existe toujours un service commercial à ce sujet.
- Les données nécessaires se trouvent dans Wikipédia (regardez par exemple la fiche de Saint-Dizier, code postal 52100, postition 48° 38′ 21″ nord, 4° 57′ 09″ est). On pourrait l'extraire à partir de liste des communes. Mais peut-être que Wikidata offre désormais une solution plus simple (un exemple de requête SPARQL).
- La base d'adresses nationale est téléchargeable sous forme d'un gros fichier JSON, apparemment à jour, où on trouve les longitudes et latitudes de chaque rue (et associées au code postal). Donc, cela pourrait être une meilleure alternative, et elle est sous une licence libre.
- Le site
http://www.galichon.com/codesgeo/ - La base de données de Geonames semble prometteuse.
Si vous voulez proposer d'autres bases, n'oubliez pas de regarder ces points :
- Format ouvert,
- Base légalement téléchargeable et utilisable,
- Base complète (les COM…),
- Disponibilité de la longitude et de la latitude,
- Téléchargeable en bloc (pas limité à une API),
- Base à jour (les communes changent, et les codes postaux aussi, d'ailleurs, si quelqu'un connait une liste des récents changements, afin de pouvoir tester la fraîcheur des bases… Je trouve des informations non officielles ou anciennes, Christian Quest me signale que la bonne est apparemment à la Poste),
- Orthographe correcte (respect des accents, pas d'abréviation genre ST pour Saint).
Ce service utilise les codes postaux, mais il existe aussi les COG, dits « codes INSEE », qui sont également disponibles. Ce sera pour un autre service.
Un peu de technique pour finir. Le script lancé par cron tous les mois fait :
wget -O laposte_hexasmal.geojson 'https://datanova.legroupe.laposte.fr/explore/dataset/laposte_hexasmal/download/?format=geojson' ./laposte2dns.py laposte_hexasmal.geojson > cp.zone ods-signer sign bortzmeyer.fr
La première commande télécharge le fichier au format JSON. La
seconde (le script laposte2dns.py) convertit le JSON
en fichier de zone DNS qui ressemble donc à :
10130.cp IN TXT "MAROLLES SOUS LIGNIERES" IN LOC 48 3 7.201 N 3 55 56.876 E 0 IN URI 10 1 "http://www.openstreetmap.org/?mlat=48.052000&mlon=3.932466&zoom=12" 10170.cp IN TXT "LES GRANDES CHAPELLES" IN LOC 48 29 29.856 N 3 56 0.604 E 0 IN URI 10 1 "http://www.openstreetmap.org/?mlat=48.491627&mlon=3.933501&zoom=12" 10110.cp IN TXT "MERREY SUR ARCE" IN LOC 48 6 57.679 N 4 25 51.357 E 0 IN URI 10 1 "http://www.openstreetmap.org/?mlat=48.116022&mlon=4.430933&zoom=12" ...
Le fichier ainsi produit (dans les onze mégaoctets) est chargé depuis le fichier de zone
principal de bortzmeyer.fr, via une directive
d'inclusion :
; Codes Postaux $INCLUDE /etc/nsd/primary/cp.incl
Enfin, la troisième commande utilise OpenDNSSEC pour signer la zone, et recharger le serveur de noms.
Un tel service dans le DNS existe déjà pour le
Royaume-Uni, via le domaine
find.me.uk :
% dig +short DY76JP.find.me.uk LOC 52 26 46.924 N 2 13 5.686 W 0.00m 0.00m 0.00m 0.00m
(Ou bien, avec le
Looking Glass.) Un travail similaire a été fait pour la
Suisse avec
zipdns.ch. Par exemple :
% dig +short LOC 1204.zipdns.ch 46 12 14.214 N 6 8 47.064 E 1.00m 1m 10000m 10m
Ce qui est plus joli avec le Looking
Glass. Pour l'Allemagne, c'est en
cours (il n'y a pas encore la position physique)) sur zipde.jpmens.net. Essayons avec
Ratisbonne :
% dig +short TXT 93047.zipde.jpmens.net "Regensburg"
Il y a un œuf de Pâques dans
ce service, faisant référence à une célèbre blague allemande.
Et il y a enfin un service similaire pour les codes IATA à trois lettres des
aéroports (souvent utilisés pour nommer les routeurs dans l'Internet, ce qui aide à
interpréter les traceroutes)
en air.jpmens.net :
% dig +short ORY.air.jpmens.net LOC 48 43 24.000 N 2 22 46.000 E 89.00m 1m 10000m 10m
Une requête TXT vous en dira plus :
% dig +short ORY.air.jpmens.net TXT "u:https://en.wikipedia.org/wiki/Orly_Airport_(Paris)" "cc:FR; m:Paris; t:large, n:Paris-Orly Airport"
Là aussi, vous pouvez préferer le
Looking Glass. Ce service est documenté
dans un intéressant article. (Un service analogue utilisant
les UN/LOCODE existe en
locode.sha256.net mais semble expérimental.)
Et pour rire, une quetsion difficile à la fin : faut-il indiquer la latitude ou la longitude en premier ? (ISO 6709 dit qu'on met la latitude avant).
L'article seul
RFC 8222: Selecting Labels for Use with Conventional DNS and Other Resolution Systems in DNS-Based Service Discovery
Date de publication du RFC : Septembre 2017
Auteur(s) du RFC : A. Sullivan (Dyn)
Pour information
Réalisé dans le cadre du groupe de travail IETF dnssd
Première rédaction de cet article le 22 septembre 2017
DNS-SD (DNS-based Service Discovery, normalisé dans le RFC 6763) permet de découvrir des services dans le réseau, via le DNS, mais aussi via d'autres systèmes de résolution de noms, comme mDNS (RFC 6762). Ces différents systèmes de résolution ayant des propriétés différentes, il peut se poser des problèmes d'interopérabilité. Ce RFC documente ces problèmes et est donc une lecture recommandée pour les développeurs DNS-SD.
Rappelons un peu de contexte (section 1 du RFC) : les applications qui utilisent le DNS imposaient fréquemment une syntaxe réduite aux noms manipulés, la syntaxe « LDH » ([ASCII] Letters, Digits and Hyphen), décrite dans le RFC 952. (Contrairement à ce qu'on lit souvent, le DNS n'impose pas une telle limite, elle est purement dans les applications.) Du fait de ces règles des applications, il a fallu, pour utiliser des lettres Unicode, un système spécial, IDN (RFC 5890). IDN ajoute ses propres contraintes, comme le fait que les « non-lettres » (par exemple les emojis) ne sont pas acceptés.
Le DNS accepte tout à fait du binaire quelconque dans les noms (donc, par exemple, des caractères non-ASCII avec des encodages comme Latin-1). mDNS (RFC 6762) autorise également les caractères non-ASCII, mais impose l'encodage UTF-8. mDNS autorise des caractères qui ne sont pas permis en IDN, du banal espace aux symboles les plus rigolos. DNS-SD recommande même leur usage (RFC 6763, section 4.1.3). La seule contrainte est de se limiter au format Unicode du réseau, décrit dans le RFC 5198.
Bien des développeurs d'application ne sont pas au courant de ces subtilités. Ils manipulent des noms de services comme des chaînes de caractères, et ne se soucient pas du système de résolution sous-jacent et de ses particularités. Or, potentiellement, un même nom peut être accepté par certains de ces systèmes de résolution et refusés par d'autres.
Si le développeur est au courant, et s'il prend soin de faire en sorte que les noms « avancés » ne soient pas envoyés aux systèmes de résolution les plus anciens, ça peut marcher. Mais il ne faut pas se faire d'illusion, les fuites se produisent et tout nom utilisé sur une machine connectée à l'Internet finira tôt ou tard par arriver au DNS, comme le montre le trafic que reçoivent les serveurs de noms de la racine.
Notez enfin que les utilisateurs de DNS-SD, encore plus que ceux des noms classiques, ne tapent que très rarement les noms : presque toujours, ils les choisissent dans une liste.
Maintenant, pourquoi y a-t-il un problème ? (Section 2 du RFC.) Comme je l'ai indiqué plus haut, le DNS accepte n'importe quoi dans un nom. Pourquoi ne pas juste dire « envoyons le nom "Joe's printer, first floor" directement dans le DNS, et ça marchera » ? Il y a deux problèmes avec cette approche. D'abord, l'application qui ne ferait pas attention et enverrait un nom non-ASCII en disant « le DNS s'en tirera de toute façon », cette application oublie qu'il peut y avoir sur le trajet de sa requête une couche logicielle qui fait de l'IDN et va donc encoder en Punycode (transformation du U-label en A-label). Le « vrai » système de résolution ne verra donc pas le nom original. Un problème du même genre arrive avec certains logiciels qui se mêlent de politique, par exemple les navigateurs Web comme Firefox qui se permettent d'afficher certains noms en Unicode et d'autres en ASCII, selon la politique du TLD. Bref, le trajet d'un nom dans les différents logiciels est parsemé d'embûches si on est en Unicode.
En outre, l'approche « j'envoie de l'UTF-8 sans me poser de questions » (suggérée par la section 4.1.3 du RFC 6763) se heurte au fait que la racine du DNS et la plupart des TLD ne permettent de toute façon par d'enregistrer directement de l'UTF-8. (Au passage, le RFC oublie un autre problème de l'UTF-8 envoyé directement : les serveurs DNS ne font pas de normalisation Unicode, et l'insensibilité à la casse du DNS n'est pas évidente à traduire en Unicode.)
La section 3 de notre RFC propose donc de travailler à un profil permettant une meilleure interopérabilité. Un profil est une restriction de ce qui est normalement permis (un dénominateur commun), afin de passer à peu près partout. Un exemple de restriction serait l'interdiction des majuscules. En effet, le DNS est insensible à la casse mais IDN interdit les majuscules (RFC 5894, sections 3.1.3 et 4.2) pour éviter le problème de conversion majuscules<->minuscules, qui est bien plus difficile en Unicode qu'en ASCII.
Notez que notre RFC ne décrit pas un tel profil, il propose sa création, et donne quelques idées. Il y a donc encore du travail.
Pour rendre le problème plus amusant, les noms utilisés par DNS-SD sont composés de trois parties, avec des règles différentes (section 4 de notre RFC, et RFC 6763, section 4.1) :
- « Instance » qui est la partie présentée à l'utilisateur (« Imprimante de Céline »), et où donc tous les caractères sont acceptés,
- « Service », qui indique le protocole de transport, et qui se limite à un court identificateur technique en ASCII, jamais montré à l'utilisateur et qui, commençant par un tiret bas, n'est pas un nom de machine légal et est donc exclu de tout traitement IDN,
- « Domaine », qui est le domaine où se trouve l'instance. Il est conçu pour être tôt ou tard envoyé au DNS, et il suit donc les règles IDN.
L'instance risque d'être « interceptée » par le traitement IDN et, à tort, transformée en Punycode. Limiter le nom de l'instance aux caractères acceptés par IDN serait horriblement restrictif. La seule solution est probablement de mettre en place du code spécifique qui reconnait les noms utilisés par DNS-SD, pour ne jamais les passer au DNS. Quant à la partie « Domaine », l'idée de la traiter comme un nom de domaine normal, et donc sujet aux règles des RFC 5890 et suivants, est restrictive :
- Cela revient à abandonner la stratégie de « on essaie UTF-8, puis Punycode » du RFC 6763, section 4.1.3 (mais cette stratégie a l'inconvénient de multiplier les requêtes, donc le trafic et les délais),
- Elle ne tient pas compte du fait que certains administrateurs de zones DNS peuvent avoir envie de mettre de l'UTF-8 directement dans la zone (ce qui est techniquement possible, mais va nécessiter de synchroniser dans la zone la représentation UTF-8 et la représentation Unicode du même nom, ou qu'il utilise les DNAME du RFC 6672).
L'article seul
Non, BGP ne préfère pas les annonces les plus spécifiques
Première rédaction de cet article le 18 septembre 2017
On lit souvent dans les articles sur la sécurité du routage Internet, ou dans les articles qui décrivent un détournement BGP, volontaire ou non, une phrase du genre « la route pour le préfixe de l'attaquant, un /24, a été acceptée car elle est plus spécifique que le préfixe normal /22, et BGP préfère les routes plus spécifiques ». Ce n'est pas vraiment exact.
La question est importante, car ces détournements BGP arrivent (cf. le rapport de l'ANSSI à ce sujet), le cas le plus célèbre étant Pakistan Telecom contre YouTube, et le plus récent la détournement accidentel par Google, notamment au Japon. Si une organisation annonce un /22, et que l'attaquant publie un /24 mensonger, est-ce que cela aura davantage d'effet que s'il l'attaquant avait publié un /22 ? Et, pour le titulaire légitime du préfixe, est-ce que annoncer des /24 en plus est une bonne défense ? On lit souvent des Oui aux deux questions, avec comme justification que BGP préférerait le préfixe le plus spécifique, et qu'il ne faut donc pas le laisser à l'attaquant. La technique est bonne, mais cette justification n'est pas complètement correcte. (Bien qu'on la trouve même dans des articles sérieux.)
BGP (RFC 4271, notamment la section 9.1), en effet, n'a pas d'opinion sur la longueur des routes. S'il voit un /22 et un /24 plus spécifique, il les considère comme deux préfixes différents, et les garde en mémoire et les passe à ses voisins. (Les experts BGP noteront que j'ai un peu simplifié, BGP ayant plusieurs listes de routes, les RIB - Routing Information Base. La Loc-RIB ne garde que le préfixe spécifique mais l'Adj-RIBs-Out, ce qui est transmis aux voisins, a bien les deux routes.)
C'est IP, pas BGP, qui a une règle « longest prefix » (préfixe le plus spécifique) et qui, lui, choisira le /24. Comme le dit la maxime des opérateurs, « The data plane [IP] does not always follow the control plane [BGP]. »
Vous pouvez facilement voir cela sur un
looking glass. Prenons
par exemple celui de Level 3, en
http://lg.level3.net/2405:fd80::/32 a un plus-spécifique,
2405:fd80:100::/40 (il en a même plusieurs,
mais je simplifie). Les deux sont transportés par BGP. Le
looking glass affiche (j'ai fait deux requêtes
séparées, car l'option Longer prefixes de ce
looking glass ne marche pas pour moi) :
BGP Routing table entry for 2405:fd80::/32
3491 135391
...
BGP Routing table entry for 2405:fd80:100::/40
2914 135391
Le routeur connait donc bien les deux préfixes, le générique et le spécifique. (Il s'agit du comportement par défaut de BGP ; il existe des configurations de routeurs qui ne font pas cela, par exemple parce qu'elles agrègent les préfixes les plus spécifiques en un préfixe moins spécifique. Voir par exemple celle de Juniper.)
Mais, si je tape une adresse IP (pas un préfixe) dans un looking glass ou un routeur, je n'obtiens bien que le préfixe plus spécifique ? Oui, mais ce n'est pas un choix de BGP, c'est le choix du routeur sous-jacent de chercher le préfixe immédiatement englobant cette adresse. Tapez un préfixe au lieu d'une adresse IP et vous aurez bien le préfixe demandé.
[Le reste est plus technique, avec du code qui tourne.]
Si vous voulez vous-même analyser la table de routage mondiale, sans recourir à un service cloud comme RIPE Stat, voici deux façons de faire, l'une avec PostgreSQL, et l'autre avec un programme en C. Les deux utilisent la même source de données, RouteViews. RouteViews distribue des mises à jour et des tables complètes (RIB = Routing Information Base). On télécharge la RIB et on la décomprime :
% wget http://archive.routeviews.org/bgpdata/2017.09/RIBS/rib.20170905.1200.bz2
% bunzip2 rib.20170905.1200.bz2
Elle est au format MRT (RFC 6396). On utilise bgpdump pour la traduire en texte :
% bgpdump rib.20170905.1200>rib.20170905.1200.txt
De manière grossière et sauvage, on ne garde que les lignes indiquant un préfixe, et on les dédoublonne (attention, ça va manger de la RAM) :
% grep PREFIX: rib.20170905.1200.txt | sort | uniq > rib.20170905.1200.sorted
À partir de là, on va utiliser soit PostgreSQL, soit le programme en C.
D'abord, avec PostgreSQL, qui a depuis longtemps d'excellents types de données pour les adresses IP, avec plein d'opérations possibles. On crée la table avec :
bgp=> CREATE TABLE Prefixes (id SERIAL, pfx cidr);
CREATE TABLE
Pour importer le fichier texte dans PostgreSQL, on utilise un tout petit script Python :
% ./dump2psql.py rib.20170905.1200.sorted
Et tout est maintenant dans la base de données, qu'on peut
explorer. Par exemple, trouver tous les préfixes plus générique que 192.134.0.0/24 :
% psql bgp bgp=> SELECT * FROM Prefixes WHERE pfx >> '192.134.0.0/24'; id | pfx ---------+---------------- 1135437 | 192.134.0.0/16 1135438 | 192.134.0.0/22 (2 rows)
Et si on veut la liste de toutes les annonces plus spécifiques qu'une annonce existante, ici en IPv6 :
bgp=> SELECT gen.pfx AS Generic, spec.pfx AS Specific FROM Prefixes gen, Prefixes spec
WHERE family(spec.pfx) = 6 AND masklen(spec.pfx) < 48 AND spec.pfx << gen.pfx;
generic | specific
---------------------+---------------------
2001:1280::/32 | 2001:1280:8000::/36
2001:128c::/32 | 2001:128c:6000::/36
2001:128c::/32 | 2001:128c:7000::/40
2001:12f0::/36 | 2001:12f0:100::/42
...
Et si on n'aime pas les SGBD et qu'on veut le faire en C ? On va se servir de la bibliothèque libcidr. Installons :
% wget http://www.over-yonder.net/~fullermd/projects/libcidr/libcidr-1.2.3.tar.xz % unxz libcidr-1.2.3.tar.xz % tar xvf libcidr-1.2.3.tar % cd libcidr-1.2.3 % ./configure % make % sudo make install
Puis écrivons un petit programme C qui va lire le fichier texte avec
la liste des préfixes et afficher les préfixes plus spécifiques (ou égaux) qu'un préfixe
donné (option -s) ou les plus génériques (option
-g) :
% ./read-mrt rib.20170905.1200.sorted -s 72.249.184.0/21 72.249.184.0/21 (line 700376) 72.249.184.0/24 (line 700377) % ./read-mrt rib.20170905.1200.sorted -g 72.249.184.0/21 72.249.128.0/18 (line 700369) 72.249.184.0/21 (line 700376)
Merci à Bruno Spiquel pour ses conseils.
L'article seul
RFC 8215: Local-Use IPv4/IPv6 Translation Prefix
Date de publication du RFC : Août 2017
Auteur(s) du RFC : T. Anderson (Redpill Linpro)
Chemin des normes
Première rédaction de cet article le 18 septembre 2017
Ce très court RFC documente la
réservation du préfixe IPv6
64:ff9b:1::/48, pour les divers mécanismes de
traduction entre IPv6 et IPv4.
L'adressage de ces mécanismes de traduction est décrit dans le
RFC 6052. Il réservait le préfixe
64:ff9b::/96, qui s'est avéré insuffisant et
est désormais complété par notre RFC 8215.
Ouvrez bien l'œil : ces deux préfixes sont différents, même si leurs quatre premiers octets sont identiques (c'est un problème fréquent en IPv6 : il peut être difficile de distinguer deux adresses du premier coup.)
La section 3 de notre RFC expose le problème : depuis la
publication du RFC 6052, plusieurs
mécanismes de traduction IPv4<->IPv6 ont été proposés (par
exemple dans les RFC 6146 et RFC 7915). Ils ne sont pas inconciliables (ils couvrent
parfois des scénarios différents ) et un opérateur peut donc
vouloir en déployer plusieurs à la fois. Le seul préfixe
64:ff9b::/96 ne va alors plus suffire. Il
faut donc un préfixe plus grand, et dont l'usage n'est pas
restreint à une seule technologie de traduction.
Pourquoi 64:ff9b:1::/48, d'ailleurs ? La
section 4 répond à la question. La longueur de 48 bits a été
choisie pour permettre plusieurs mécanismes de traduction, chacun
utilisant un préfixe plus spécifique. Par exemple, si chaque
mécanisme utilise un /64, le préfixe réservé pour les englober
tous devait être un /48, ou plus général (on se limite aux
multiples de 16 bits, car ils permettent que les préfixes se
terminent sur un deux-points, facilitant la
vie de l'administrateur réseaux qui devra les manipuler).
Ensuite, pourquoi cette valeur
64:ff9b:1:: ? Parce qu'elle est proche
(presque adjacente) du
64:ff9b::/96, minimisant la consommation
d'adresses IPv6. (64:ff9a:ffff::/48 est
complètement adjacent, de l'autre côté, mais l'agrégation avec
64:ff9b::/96 en un seul préfixe est beaucoup
moins efficace. Et puis 64:ff9b:1:: est plus
court.)
À part son usage, 64:ff9b:1::/48 est un
préfixe IPv6 normal et les routeurs, ou autres machines qui
manipulent des adresses IPv6, ne doivent pas le traiter
différemment des autres.
Le nouveau préfixe est désormais enregistré dans le registre des adresses IPv6 spéciales (section 7 de notre RFC).
L'article seul
RFC 8246: HTTP Immutable Responses
Date de publication du RFC : Septembre 2017
Auteur(s) du RFC : P. McManus (Mozilla)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 16 septembre 2017
Lorsqu'un serveur HTTP renvoie une
réponse à un client, il peut indiquer une durée de vie maximale de
la ressource transmise, avec l'en-tête
Cache-Control: (RFC 9111). Mais cela ne donne qu'une durée
maximale. La ressource peut quand même être
modifiée avant la fin de cette période. Un client HTTP prudent va
donc revalider la fraîcheur de cette
ressource de temps en temps. L'extension décrite dans ce
RFC permet de se dispenser de cette
revalidation, en indiquant une durée
minimale, pendant laquelle on est sûrs et
certains que la ressource ne sera pas modifiée.
Le RFC prend l'exemple (section 1) d'un journal dont la page d'accueil indique une durée de vie maximale d'une heure :
Cache-Control: max-age=3600
Le client HTTP qui reçoit cet en-tête dans la réponse sait qu'il doit recontacter le serveur au bout d'une heure. Mais la page sera peut-être modifiée (par exemple en raison d'un évènement soudain et imprévu) avant qu'une heure soit écoulée. Le client est donc partagé entre la revalidation (qui risque de consommer des ressources pour rien, même si elle est moins coûteuse qu'un téléchargement complet, grâce aux trucs du RFC 7232) et le risque de servir à son utilisateur une ressource qui n'est désormais plus à jour. Le problème est d'autant plus ennuyeux que la revalidation d'une bête page Web qui comprend des photos peut générer beaucoup de requêtes, dont la plupart produiront sans doute un 304 (ressource non modifiée, la revalidation était inutile).
Notez que dans certains cas, le contenu pointé par un URL peut changer, mais dans d'autres cas, il est réellement immuable. Par exemple, si on publie chaque version de sa feuille de style sous un URL différent, la CSS n'a pas besoin d'être revalidée. (La mention d'immuabilité est donc intéressante pour les URL faits à partir du RFC 6920.)
Bref, il y avait un besoin de pouvoir indiquer l'immuabilité
d'une ressource. C'est désormais fait (section 2 de ce RFC) avec
une extension à Cache-Control: :
Cache-Control: max-age=3600, immutable
Avec le mot-clé immutable, le serveur indique
que la ressource ne sera pas modifiée pendant la durée de vie
indiquée, le client peut donc se dispenser de
vérifier. (« Client » ici désignant aussi bien le client final,
par exemple le navigateur Web, qu'un
intermédiaire.)
Par exemple, comme les RFC sont immuables (on ne les change
jamais même d'une virgule, même en cas d'erreur), la ressource qui désigne ce RFC,
https://www.rfc-editor.org/rfc/rfc8246.txt,
pourrait parfaitement renvoyer cet en-tête (elle ne le fait
pas). Cela pourrait être :
Last-Modified: Thu, 14 Sep 2017 23:11:35 GMT
Cache-Control: max-age=315576000, immutable
(Oui, dix ans…)
Voilà, c'est tout, la directive a été ajoutée au registre
IANA. Mais la section 3 du RFC se penche encore
sur quelques questions de sécurité. Indiquer qu'une ressource est
immuable revient à la fixer pour un temps potentiellement très
long, et cela peut donc servir à pérenniser une attaque. Si un
méchant pirate un site Web, et sert son contenu piraté avec un
en-tête d'immuabilité, il restera bien plus longtemps dans les
caches. Pire, sans
HTTPS, l'en-tête avec
immutable pourrait être ajouté par un
intermédiaire (le RFC déconseille donc de tenir compte de cette
option si on n'a pas utilisé HTTPS).
Les navigateurs Web ont souvent deux options pour recharger une
page, « douce » et « dure » (F5 et Contrôle-F5 dans
Firefox sur Unix). Le RFC conseille que, dans le second cas
(rechargement forcé), le immutable soit ignoré (afin de
pouvoir recharger une page invalide).
Enfin, toujours question sécurité, le RFC recommande aux
clients HTTP de ne tenir compte de l'en-tête d'immuabilité que
s'ils sont sûrs que la ressource a été transmise proprement
(taille correspondant à Content-Length: par
exemple).
Si vous voulez comparer deux ressources avec et sans
immutable, regardez http://www.bortzmeyer.org/files/maybemodified.txtimmutable) et http://www.bortzmeyer.org/files/forever.txt
[2001:db8:abcd:1234:acd8:9bd0:27c9:3a7f]:45452 - - [16/Sep/2017:17:53:29 +0200] "GET /files/forever.txt HTTP/1.1" 304 - "-" "Mozilla/5.0 (X11; Linux i686; rv:52.0) Gecko/20100101 Firefox/52.0" www.bortzmeyer.org
Apparemment, Firefox gère cette extension mais, ici, le Firefox était sans doute trop vieux (normalement, cela aurait dû arriver avec la version 49, puisque Mozilla était premier intéressé). Les auteurs de Squid ont annoncé qu'ils géreraient cette extension. Côté serveur, notons que Facebook envoie déjà cette extension pour, par exemple, le code JavaScript (qui est versionné et donc jamais changé) :
% curl -v https://www.facebook.com/rsrc.php/v3iCKe4/y2/l/fr_FR/KzpL-Ycd5sN.js
* Connected to www.facebook.com (2a03:2880:f112:83:face:b00c:0:25de) port 443 (#0)
...
< HTTP/2 200
< content-type: application/x-javascript; charset=utf-8
< cache-control: public,max-age=31536000,immutable
...
Idem pour une mise en œuvre d'IPFS.
L'article seul
RFC 8187: Indicating Character Encoding and Language for HTTP Header Field Parameters
Date de publication du RFC : Septembre 2017
Auteur(s) du RFC : J. Reschke (greenbytes)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 14 septembre 2017
Dernière mise à jour le 16 septembre 2017
Les requêtes et réponses du protocole HTTP incluent des
en-têtes (comme
User-Agent: ou
Content-Disposition:) avec des
valeurs, qui, il y a longtemps, ne pouvaient se représenter
directement qu'avec les caractères du jeu ISO
8859-1, voire seulement avec
ASCII (c'était compliqué). Comme MIME, dans le RFC 2231,
prévoyait un mécanisme très riche pour encoder les en-têtes du
courrier électronique, ce RFC 8187
réutilise ce mécanisme pour HTTP (il remplace le RFC 5987, qui avait été le premier à le faire). Pour le corps du
message (voir par exemple le RFC 7578), rien
ne change.
Cette ancienne restriction à Latin-1 (qui n'est plus d'actualité) vient de la norme HTTP, le RFC 2616, dans sa section 2.2, qui imposait l'usage du RFC 2047 pour les caractères en dehors de ISO 8859-1. Le RFC 7230 a changé cette règle depuis (sa section 3.2) mais pas dans le sens d'une plus grande internationalisation (ISO 8859-1 ne convient qu'aux langues européennes), plutôt en supprimant le privilège d'ISO 8859 et en restreignant à ASCII. Et il ne précise pas vraiment comment faire avec d'autres jeux de caractère comme Unicode. Il ne reste donc que la solution du RFC 2231.
Notre nouveau RFC peut être résumé en disant qu'il spécifie un profil du RFC 2231. Ce profil est décrit en section 3, qui liste les points précisés par rapport au RFC 2231. Tout ce RFC n'est pas utilisé, ainsi le mécanisme en section 3 du RFC 2231, qui permettait des en-têtes de plus grande taille, n'est pas importé (section 3.1 de notre RFC).
En revanche, la section 4 du RFC 2231, qui spécifiait
comment indiquer la langue dans laquelle était
écrite la valeur d'un en-tête est repris pour les paramètres dans les
en-têtes. Ainsi, (section 3.2), voici un en-tête (imaginaire :
Information: n'a pas été enregistré), avec un paramètre
title traditionnel en pur ASCII :
Information: news; title=Economy
et en voici un avec les possibilités de notre RFC pour permettre les caractères £ et € (« Sterling and euro rates ») :
Information: news; title*=UTF-8''%c2%a3%20and%20%e2%82%ac%20rates
Par rapport au RFC 2231 (qui était silencieux sur ce point), un encodage de caractères est décrété obligatoire (c'est bien sûr UTF-8), et il doit donc être géré par tous les logiciels. La mention de l'encodage utilisé est également désormais obligatoire (section 3.2 de notre RFC). La langue elle-même est indiquée par une étiquette, selon la syntaxe du RFC 5646. Du fait de ces possibilités plus riches que celles prévues autrefois pour HTTP, les paramètres qui s'en servent doivent se distinguer, ce qui est fait avec un astérisque avant le signe égal (voir l'exemple ci-dessus). Notez que l'usage de l'astérisque n'est qu'une convention : si on trouve un paramètre inconnu dont le nom se termine par un astérisque, on ne peut pas forcément en déduire qu'il est internationalisé.
La valeur du paramètre inclut donc le jeu de caractères et l'encodage (obligatoire), la langue (facultative, elle n'est pas indiquée dans l'exemple ci-dessus) et la valeur proprement dite.
Voici un exemple incluant la langue, ici
l'allemand (code de, la
phrase est « Mit der Dummheit kämpfen Götter
selbst vergebens », ou « contre la bêtise, les dieux
eux-mêmes luttent en vain », tirée de la pièce « La pucelle
d'Orléans ») :
Quote: theater;
sentence*=UTF-8'de'Mit%20der%20Dummheit%20k%C3%A4mpfen%20G%C3%B6tter%20selbst%20vergebens.
La section 4 couvre ensuite les détails pratiques pour les normes qui décrivent un en-tête qui veut utiliser cette possibilité. Par exemple, la section 4.2 traite des erreurs qu'on peut rencontrer en décodant et suggère que, si deux paramètres identiques sont présents, celui dans le nouveau format prenne le dessus. Par exemple, si on a :
Information: something; title="EURO exchange rates";
title*=utf-8''%e2%82%ac%20exchange%20rates
le titre est à la fois en ASCII pur et en UTF-8, et c'est cette
dernière version qu'il faut utiliser, même si normalement il n'y a
qu'un seul paramètre title.
Ces paramètres étendus sont mis en œuvre dans Firefox et Opera ainsi que, dans une certaine mesure, dans Internet Explorer.
Plusieurs en-têtes HTTP se réfèrent formellement à cette façon d'encoder les caractères non-ASCII :
Authentication-Control:, dans le RFC 8053 (« For example, a parameter "username" with the value "Renee of France" SHOULD be sent as username="Renee of France". If the value is "Renée of France", it SHOULD be sent as username*=UTF-8''Ren%C3%89e%20of%20France instead »),Authorization:(pour l'authentification HTTP, RFC 7616, avec également un paramètreusernamepour l'ASCII etusername*pour l'encodage défini dans ce RFC),Content-Disposition:, RFC 6266, qui indique sous quel nom enregistrer un fichier et dont le paramètrefilename*permet tous les caractères Unicode,Link:, normalisé dans le RFC 5988, où le paramètretitle*permet des caractères non-ASCII (titleétant pour l'ASCII pur).
Les changements depuis le RFC 5987, sont expliqués dans l'annexe A. Le plus spectaculaire est le retrait d'ISO 8859-1 (Latin-1) de la liste des encodages qui doivent être gérés obligatoirement par le logiciel. Cela fera plaisir aux utilisateurs d'Internet Explorer 9, qui avait déjà abandonné Latin-1. Autrement, rien de crucial dans ces changements. Le texte d'introduction a été refait pour mieux expliquer la situation très complexe concernant la légalité (ou pas) des caractères non-ASCII dans les valeurs d'en-tête.
Si vous voulez voir un exemple, essayez de télécharger le fichier
http://www.bortzmeyer.org/files/foobar.txt. Si
votre client HTTP gère l'en-tête
Content-Disposition: et le paramètre
internationalisé filename*, le fichier devrait
être enregistré sous le nom föbàr.txt.La
configuration d'Apache pour envoyer le
Content-Disposition: est :
<Files "foobar.txt">
Header set Content-Disposition "attachment; filename=foobar.txt; filename*=utf-8''f%%C3%%B6b%%C3%%A0r.txt"
</Files>
Par exemple, Safari ou Firefox enregistrent bien ce fichier sous son nom international.
Ah, et puisque ce RFC parle d'internationalisation, on notera que c'est le premier RFC (à part quelques essais ratés au début) à ne pas comporter que des caractères ASCII. En effet, suivant les principes du RFC 7997, il comporte cinq caractères Unicode : dans les exemples (« Extended notation, using the Unicode character U+00A3 ("£", POUND SIGN) » et « Extended notation, using the Unicode characters U+00A3 ("£", POUND SIGN) and U+20AC ("€", EURO SIGN) »), dans l'adresse (« Münster, NW 48155 ») et dans les noms des contributeurs (« Thanks to Martin Dürst and Frank Ellermann »).
L'article seul
RFC 8240: Report from the Internet of Things (IoT) Software Update (IoTSU) Workshop 2016
Date de publication du RFC : Septembre 2017
Auteur(s) du RFC : H. Tschofenig (ARM Limited), S. Farrell (Trinity College Dublin)
Pour information
Première rédaction de cet article le 12 septembre 2017
La mode des objets connectés a mené à l'existence de nombreux « objets », qui sont en fait des ordinateurs (avec leurs problèmes, comme le fait que leur logiciel ait des failles de sécurité), mais qui ne sont pas considérés comme des ordinateurs par leurs propriétaires, et ne sont donc pas gérés (pas d'administrateur système, pas de mises à jour des logiciels). L'attaque contre Dyn du 21 octobre 2016, apparemment menée par ces objets, a bien illustré le risque que cette profusion irresponsable crée. Ce nouveau RFC est le compte-rendu d'un atelier sur la mise à jour des objets connectés, atelier de réflexion qui s'est tenu à Dublin les 13 et 14 juin 2016. Il fait le point sur la (difficile) question.
La question de base était « que peut-on faire pour que ces foutus objets soient mis à jour, au moins pour patcher leurs failles de sécurité ? » L'atelier réuni à Trinity College n'a évidemment pas fourni une réponse parfaite, mais a au moins permis de clarifier le problème. Il me semble toutefois, d'après le compte-rendu, qu'il y avait un gros manque : les droits du propriétaire de l'objet. La plupart des solutions discutées tournaient autour de l'idée de mises à jour systématiques et automatiques du logiciel via les serveurs du vendeur, et les éventuelles conséquences néfastes pour le propriétaire (comme l'arrivée de nouvelles fonctions de surveillance, par exemple) ne sont guère mentionnées.
Aujourd'hui, un grand nombre des machines ayant accès, même indirect, à l'Internet, est composé de trucs qualifiés d'objets, qui ont en commun qu'on ne les appelle pas « ordinateurs » (alors que c'est bien cela qu'ils sont). Ces objets sont très divers, allant d'engins qui ont les capacités matérielles d'un ordinateur (une télévision connectée, par exemple) à des petits machins très contraints (CPU et mémoire limités, batterie à la capacité finie, etc). Le risque que font peser ces objets « irresponsables » (pas gérés, pas supervisés) sur l'Internet est connu depuis longtemps. Le RFC cite l'article de Schneier, « The Internet of Things Is Wildly Insecure And Often Unpatchable », qui tirait la sonnette d'alarme en 2014. Il notait que le logiciel de ces objets n'était déjà plus à jour quand l'objet était sorti de sa boite la première fois (les fabricants d'objets connectés aiment bien utiliser des versions antédiluviennes des bibliothèques). Or, des objets peuvent rester branchés et actifs pendant des années, avec leur logiciel dépassé et jamais mis à jour, plein de failles de sécurité que les craqueurs ne vont pas manquer d'exploiter (cf. le logiciel Mirai).
Vers la même époque, un rapport de la FTC, « FTC Report on Internet of Things Urges Companies to Adopt Best Practices to Address Consumer Privacy and Security Risks », et un autre du groupe Article 29, « Opinion 8/2014 on the on Recent Developments on the Internet of Things » faisaient les mêmes remarques.
Donc, le problème est connu depuis des années. Mais il n'est pas facile à résoudre :
- Le mécanisme de mise à jour peut lui-même être une faille de sécurité. Par exemple, un certain nombre d'objets font la mise à jour de leur logiciel en HTTP, sans signature sur le code récupéré, rendant ainsi une attaque de l'homme du milieu triviale.
- Le RFC n'en parle guère, mais, même si on vérifie le code récupéré, celui-ci peut être malveillant. De nombreuses compagnies (par exemple Sony) ont déjà délibérement distribué du malware à leurs clients, et sans conséquences pénales. Une mise à jour automatique pourrait par exemple installer une porte dérobée, ou bien mettre du code DRM nouveau.
- Les problèmes opérationnels ne manquent pas. Par exemple, si les objets vérifient le code récupéré via une signature, et qu'ils comparent à une clé publique qu'ils détiennent, que faire si la clé privée correspondante est perdue ou copiée ? (Cf. « Winks Outage Shows Us How Frustrating Smart Homes Could Be. »)
- Si les objets se connectent automatiquement au serveur pour chercher des mises à jour, cela pose un sérieux problème de vie privée. (Le RFC ne rappelle pas qu'en outre, la plupart de ces objets sont de terribles espions qu'on installe chez soi.)
- Pour une société à but lucratif, gérer l'infrastructure de mise à jour (les serveurs, la plate-forme de développement, les mises à jour du code, la gestion des éventuels problèmes) a un coût non nul. Il n'y a aucune motivation financière pour le faire, la sécurité ne rapportant rien. (Le RFC s'arrête à cette constatation, ne mentionnant pas la solution évidente : des règles contraignantes obligeant les entreprises à le faire. Le Dieu Marché ne sera certainement pas une solution.)
- Si l'entreprise originale défaille, qui va pouvoir et devoir assurer ses mises à jour ? (Repensons à l'ex-chouchou des médias, le lapin Nabaztag, et à son abandon par la société qui l'avait vendu.) Si le RFC ne le mentionne pas, il va de soi que le logiciel libre est la solution au problème du « pouvoir » mais pas à celui du « devoir » (dit autrement, le logiciel libre est nécessaire mais pas suffisant).
Le risque n'est donc pas seulement de l'absence de système de mise à jour. Il peut être aussi d'un système de mise à jour bogué, vulnérable, ou non documenté, donc non maintenable.
Le problème de la mise à jour automatique des logiciels est évidemment ancien, et plusieurs systèmes d'exploitation ont des solutions opérationnelles depuis un certain temps (comme pacman ou aptitude). Le RFC se focalise donc sur les objets les plus contraints, ceux limités dans leurs capacités matérielles, et donc dans les logiciels qu'ils peuvent faire tourner.
Après cette introduction, le RFC fait un peu de terminologie, car le choix des mots a suscité une discussion à l'atelier. D'abord, la notion de classe. Les « objets connectés » vont de systèmes qui ont les capacités matérielles et l'alimentation électrique d'un ordinateur de bureau (une télévision connectée, par exemple) et qui peuvent donc utiliser les mêmes techniques, jusqu'à des objets bien plus contraints dans leurs capacités. Pour prendre un exemple chez les systèmes populaires auprès des geeks, un Raspberry Pi fait tourner un système d'exploitation « normal » et se met à jour comme un ordinateur de bureau, un Arduino ne le peut typiquement pas. Il faudra donc sans doute développer des solutions différentes selon la classe. Ou, si on veut classer selon le type de processeur, on peut séparer les objets ayant plus ou moins l'équivalent d'un Cortex-A (comme le Pi) de ceux ayant plutôt les ressources du Cortex-M (comme l'Arduino, mais notez que cette catégorie est elle-même très variée).
Le RFC définit également dans cette section 2 la différence entre mise à jour du logiciel et mise à jour du firmware. La distinction importante est que les engins les plus contraints en ressources n'ont typiquement qu'une mise à jour du firmware, qui change tout, système et applications, alors que les engins de classe « supérieure » ont des mises à jour modulaires (on peut ne mettre à jour qu'une seule application).
Dernier terme à retenir, hitless (« sans impact »). C'est une propriété des mises à jour qui ne gênent pas le fonctionnement normal. Par exemple, s'il faut arrêter l'engin pour une mise à jour, elle ne sera pas hitless. Évidemment, la mise à jour du logiciel d'une voiture ne sera probablement pas hitless et nécessitera donc des précautions particulières.
Maintenant, le gros morceau du RFC, la section 3, qui regroupe notamment les exigences issues de l'atelier. C'est assez dans le désordre, et il y a davantage de questions que de réponses. Pour commencer, que devraient faire les fabricants d'objets connectés (en admettant qu'ils lisent les RFC et aient le sens des responsabilités, deux paris hasardeux) ? Par exemple, le RFC note que les mises à jour globales (on remplace tout) sont dangereuses et recommande que des mises à jour partielles soient possibles, notamment pour limiter le débit utilisé sur le réseau (comme avec bsdiff ou courgette). Idéalement, on devrait pouvoir mettre à jour une seule bibliothèque, mais cela nécessiterait du liage dynamique et de code indépendant de la position, ce qui peut être trop demander pour les plus petits objets. Mais au moins un système d'exploitation plutôt conçu pour les « classe M », les objets les plus contraints (équivalents au Cortex-M), le système Contiki, a bien un lieur dynamique.
Certains dispositifs industriels ont plusieurs processeurs, dont un seul gère la connexion avec le reste du monde. Il peut être préférable d'avoir une architecture où ce processeur s'occupe de la mise à jour du logiciel de ses collègues qui ne sont pas directement connectés.
Un problème plus gênant, car non exclusivement technique, est celui des engins qui ont plusieurs responsables potentiels. Si une machine sert à plusieurs fonctions, on risque d'avoir des cas où il n'est pas évident de savoir quel département de l'entreprise a « le dernier mot » en matière de mise à jour. Pour les ordinateurs, cette question sociale a été réglée depuis longtemps dans la plupart des organisations (par exemple en laissant le service informatique seul maître) mais les objets connectés redistribuent les cartes. Si le service Communication a une caméra connectée, qui peut décider de la mettre à jour (ou pas) ?
Un cas proche est celui où un appareil industriel inclut un ordinateur acheté à un tiers (avec le système d'exploitation). Qui doit faire la mise à jour ? Qui est responsable ? Pensons par exemple au problème d'Android où les mises à jour doivent circuler depuis Google vers le constructeur du téléphone, puis (souvent) vers l'opérateur qui l'a vendu. En pratique, on constate qu'Android est mal mis à jour. Et ce sera pire pour un réfrigérateur connecté puisque sa partie informatique sera fabriquée indépendamment, et avant le frigo complet. Lorsque celui-ci démarrera pour la première fois, son logiciel aura sans doute déjà plusieurs mois de retard.
Et la sécurité ? Imaginons un objet connecté dont le fabricant soit assez incompétent et assez irresponsable pour que les mises à jour se fassent en récupérant du code en HTTP, sans aucune authentification d'aucune sorte. Un tel objet serait très vulnérable à des attaques visant à remplacer le code authentique par un code malveillant. D'où l'exigence de DAO (Data Origin Authentication). Sans DAO, tout serait fichu. Deux solutions évidentes utilisent la cryptographie, authentifier le serveur qui distribue les mises à jour (par exemple avec HTTPS) ou bien authentifier le code téléchargé, via une signature numérique (notez que l'IETF a un format CMS pour cela, décrit dans le RFC 4108, mais qui semble peu utilisé.) Mais signer et vérifier est plus facile à dire qu'à faire ! D'abord, si la cryptographie n'est pas un problème pour les engins « classe A », comme une télévision connectée ou bien une voiture connectée, elle peut être bien coûteuse pour des objets plus limités. La cryptographie symétrique est typiquement moins coûteuse, mais bien moins pratique. Le problème de fond est que la cryptographie symétrique n'authentifie pas un envoyeur mais une classe d'envoyeurs (tous ceux qui ont la clé). Il faudrait donc une clé différente par objet, ce qui semble ingérable. Faut-il lister comme exigence de base d'utiliser la cryptographie asymétrique ?
Son coût en opérations de calcul n'est pas le seul problème. Par exemple, la clé privée qui signe les mises à jour peut être volée, ou bien tout simplement devenir trop faible avec les progrès de la cryptanalyse (certains objets peuvent rester en production pendans dix ans ou plus). Il faut donc un moyen de mettre la clé publique à jour. Comment le faire sans introduire de nouvelles vulnérabilités (imaginez un attaquant qui trouverait le moyen de subvertir ce mécanisme de remplacement de clé, et changerait la clé de signature pour la sienne). Bref, les méthodes « il n'y a qu'à… » du genre « il n'y a qu'à utiliser des signatures cryptographiques » ne sont pas des solutions magiques.
Et si l'objet utilise du code venant de plusieurs sources ? Faut-il plusieurs clés, et des règles compliquées du genre « l'organisation A est autorisée à mettre à jour les composants 1, 3 et 4 du système, l'organisation B peut mettre à jour 2 et 3 » ? (Les systèmes fermés sont certainement mauvais pour l'utilisateur, mais présentent des avantages en matière de sécurité : une seule source. Pensez à tous les débats autour de l'utilisation du magasin libre F-Droid, par exemple l'opinion de Whisper.)
Un problème plus fondamental est celui de la confiance : à qui un objet connecté doit-il faire confiance, et donc quelle clé publique utiliser pour vérifier les mises à jour ? Faire confiance à son propriétaire ? À son fabricant ? Au sous-traitant du fabricant ?
On n'en a pas fini avec les problèmes, loin de là. Les objets sont conçus pour être fabriqués et distribués en grande quantité. Cela va donc être un difficile problème de s'assurer que tous les objets dont on est responsable soient à jour. Imaginez une usine qui a des centaines, voire des milliers d'objets identiques, et qui veut savoir s'ils sont tous à la même version du logiciel.
On a parlé plus haut de confiance. On peut décider de faire confiance au fabricant d'un objet, parce qu'on juge l'organisation en question honnête et compétente. Mais cette évaluation ne s'étend pas forcément à la totalité de ses employés. Comment s'assurer qu'un employé méchant ne va pas compromettre le processus de mise à jour du logiciel, par exemple en se gardant une copie de la clé privée, ou bien en ajoutant aux objets produits une clé publique supplémentaire (il aurait alors une porte dérobée dans chaque objet, ce qui illustre bien le fait que la mise à jour est elle-même source de vulnérabilités).
On a parlé des risques pour la sécurité de l'objet connecté. Les précautions prises sont actuellement proches de zéro. Espérons que cela va s'améliorer. Mais, même en prenant beaucoup de précautions, des piratages se produiront parfois. Ce qui ouvre la question de la récupération : comment récupérer un objet piraté ? Si on a dix grille-pains compromis, va t-il falloir les reflasher tous les dix, manuellement ? (Avant cela, il y a aussi l'intéressante question de savoir comment détecter qu'il y a eu piratage, sachant que la quasi-totalité des organisations ne lisent pas les messages leur signalant des comportements suspects de leurs machines.)
La cryptographie apporte clairement des solutions intéressantes à bien des problèmes de sécurité. Mais elle nécessite en général une horloge bien à l'heure (par exemple pour vérifier la date d'expiration d'un certificat). Avoir une horloge maintenue par une batterie pendant l'arrêt de la machine et pendant les coupures de courant n'est pas trivial :
- Cela coûte cher (la batterie et l'horloge peuvent coûter bien plus cher que le reste de l'objet),
- C'est encombrant (certains objets sont vraiment petits),
- Les batteries sont des équipements dangereux, en raison du risque d'incendie ou d'explosion, et leur présence impose donc de fortes contraintes au processus de fabrication, d'autant plus que les batteries vieillissent vite (pas question d'utiliser de vieux stocks),
- Les batteries conçues pour la maison peuvent ne pas être adaptées, car, dans un environnement industriel, les conditions sont rudes (la température peut facilement excéder les limites d'une batterie ordinaire),
- Cela ne dure pas longtemps : la présence d'une batterie peut sérieusement raccourcir la durée de vie d'un objet connecté.
Il n'est donc pas évident qu'il y ait une bonne solution à ce problème. (Le RFC cite Roughtime comme une approche prometteuse.)
Et si on a une bonne solution pour distribuer les mises à jour à des milliers ou des millions d'objets connectés, comment ceux-ci vont-ils être informés de l'existence d'une mise à jour. Push ou pull ? Envoyer les mises à jour depuis le serveur est la solution la plus rapide mais elle peut être délicate si l'objet est derrière un pare-feu qui interdit les connexions entrantes (il faudrait que l'objet contacte le serveur de mise à jour, et reste connecté). Et le cas d'objets qui ne sont pas joignables en permanence complique les choses. De l'autre côté, le cas où l'objet contacte le serveur de temps en temps pour savoir s'il y a une mise à jour pose d'autres problèmes. Par exemple, cela consomme de l'électricité « pour rien ».
Vous trouvez qu'il y a assez de problèmes ? Mais ce n'est pas fini. Imaginez le cas d'une mise à jour qui contienne une bogue, ce qui arrivera inévitablement. Comment revenir en arrière ? Refaire une mise à jour (la bogue risque d'empêcher ce processus) ? L'idéal serait que l'objet stocke deux ou trois versions antérieures de son logiciel localement, pour pouvoir basculer vers ces vieilles versions en cas de problème. Mais cela consomme de l'espace de stockage, qui est très limité pour la plupart des objets connectés.
Le consensus de l'atelier a été que les signatures des logiciels (avec vérification par l'objet), et la possibilité de mises à jour partielles, étaient importants. De même, les participants estimaient essentiels la disponibilité d'une infrastructure de mise à jour, qui puisse fonctionner pour des objets qui n'ont pas un accès complet à l'Internet. Par exemple, il faut qu'une organisation puisse avoir une copie locale du serveur de mise à jour, à la fois pour des raisons de performances, de protection de la vie privée, et pour éviter de donner un accès Internet à ses objets.
En parlant de vie privée (RFC 6973), il faut noter que des objets se connectant à un serveur de mise à jour exposent un certain nombre de choses au serveur, ce qui peut ne pas être souhaitable. Et certains objets sont étroitement associés à un utilisateur (tous les gadgets à la maison), aggravant le problème. Le RFC note qu'au minimum, il ne faut pas envoyer un identificateur unique trop facilement, surtout au dessus d'un lien non chiffré. Mais le RFC note à juste titre qu'il y a un conflit entre la vie privée et le désir des vendeurs de se faire de l'argent avec les données des utilisateurs.
On a surtout parlé jusqu'à présent des risques pour l'objet si le serveur des mises à jour est méchant ou piraté. Certains acteurs du domaine vont ajouter des risques pour le serveur : par exemple, si le logiciel est non-libre, certains peuvent souhaiter authentifier l'objet, pour ne pas distribuer leur précieux logiciel privateur à « n'importe qui ».
On en a déjà parlé mais cela vaut la peine d'y revenir : un gros problème de fond est celui de l'autorisation (section 4 du RFC). Qui peut accepter ou refuser une mise à jour ? Oui, il y a de bonnes raisons de refuser : des mises à jour obligatoires sont une forme de porte dérobée, elles permettent d'ajouter des fonctions qui n'étaient pas là avant et qui peuvent être malveillantes. Le cas avait été cité lors de l'affaire de l'iPhone de San Bernardino (des gens proposaient une mise à jour que le téléphone appliquerait, introduisant une porte dérobée). Et le RFC rappelle le cas d'une mise à jour forcée d'imprimantes HP qui avait supprimé des fonctions utiles mais que HP ne voulait plus (la possibilité d'accepter des cartouches d'encre fournies par les concurrents). Un cas analogue révélé la veille de la publication du RFC est celui de Tesla activant une nouvelle fonction à distance (ici, pour améliorer la voiture, mais il est facile de voir que cela pourrait être en sens inverse). Et il y a bien sûr le cas fameux d'Amazon détruisant des livres à distance.
Prenez un téléphone Android programmé par Google, fabriqué par LG, vendu par Orange à la société Michu qui le confie à son employé M. Dupuis-Morizeau. Qui va décider des mises à jour ?
On peut séparer les mises à jour qui corrigent une faille de sécurité et les autres : seules les premières seraient systématiquement appliquées. (Tous les fournisseurs de logiciel ne font pas cette séparation, qui les oblige à gérer deux lignes de mises à jour.) Ceci dit, en pratique, la distinction n'est pas toujours facile, et la correction d'une faille peut en entrainer d'autres.
D'autre part, certains objets connectés sont utilisés dans un environnement très régulé, où tout, matériel et logiciel, doit subir un processus de validation formel avant d'être déployé (c'est le cas des objets utilisés dans les hôpitaux, par exemple). Il y aura forcément une tension entre « faire la mise à jour en urgence car elle corrige une vulnérabilité » et « ne pas faire la mise à jour avant d'avoir tout revalidé, car cet objet est utilisé pour des fonctions vitales ».
Autre problème rigolo, et qui a de quoi inquiéter, le risque élevé d'une cessation du service de mise à jour logicielle (section 5 du RFC). Les vendeurs de logiciel ne sont pas un service public : ils peuvent décider d'arrêter de fournir un service pour des produits qui ne les intéressent plus (ou qui fait concurrence à un produit plus récent, qui offre une meilleure marge). Ou bien ils peuvent tout simplement faire faillite. Que faire face à cet échec du capitalisme à gérer les produits qu'il met sur le marché ? Le problème est d'autant plus fréquent que des objets connectés peuvent rester en service des années, une éternité pour les directions commerciales. Outre le cas du Nabaztag cité plus haut, le RFC mentionne l'exemple d'Eyefi. Un objet un peu complexe peut incorporer des parties faites par des organisations très différentes, dont certaines seront plus stables que d'autres.
Faut-il envisager un service de reprise de la maintenance, par des organisations spécialisées dans ce ramassage des orphelins ? Si ces organisations sont des entreprises à but lucratif, quel sera leur modèle d'affaires ? (Le RFC ne mentionne pas la possibilité qu'il puisse s'agir d'un service public.) Et est-ce que l'entreprise qui abandonne un produit va accepter ce transfert de responsabilité (aucune loi ne la force à gérer ses déchets logiciels) ?
Pour le logiciel, une grosse différence apparait selon qu'il s'agisse de logiciel libre ou pas. Un projet de logiciel libre peut se casser la figure (par exemple parce que l'unique développeur en a eu marre), mais il peut, techniquement et juridiquement, être repris par quelqu'un d'autre. Ce n'est qu'une possibilité, pas une certitude, et des tas de projets utiles ont été abandonnés car personne ne les a repris.
Néanmoins, si le logiciel libre n'est pas une condition suffisante pour assurer une maintenance sur le long terme, c'est à mon avis une condition nécessaire. Parfois, un logiciel est libéré lorsqu'une société abandonne un produit (ce fut le cas avec Little Printer, qui fut un succès, la maintenance étant repris par des développeurs individuels), parfois la société ne fait rien, et le logiciel est perdu. Bref, un système de séquestre du code, pour pouvoir être transmis en cas de défaillance de l'entreprise originale, serait une bonne chose.
Comme souvent en sécurité, domaine qui ne supporte pas le « ya ka fo kon », certaines exigences sont contradictoires. Par exemple, on veut sécuriser les mises à jour (pour éviter qu'un pirate ne glisse de fausses mises à jour dans le processus), ce qui impose des contrôles, par exemple par des signatures numériques. Mais on veut aussi assurer la maintenance après la fin de la société originelle. Si un prestataire reprend la maintenance du code, mais qu'il n'a pas la clé privée permettant de signer les mises à jour, les objets refuseront celles-ci… Le séquestre obligatoire de ces clés peut être une solution, mais elle introduit d'autres risques (vol des clés chez le notaire).
Une solution possible serait que les appareils connectés soient programmés pour cesser tout service s'ils n'arrivent pas à faire de mise à jour pendant N mois, ou bien si le serveur des mises à jour leur dit que le contrat de support est terminé. De telles bombes temporelles seraient bonnes pour la sécurité, et pour le business des fabricants. Mais elles changeraient le modèle d'achat d'équipement : on ne serait plus propriétaire de sa voiture ou de son grille-pain, mais locataire temporaire. De la vraie obsolescence programmée ! De telles bombes dormantes peuvent aussi interférer avec d'autres fonctions de sécurité. Par exemple, un téléphone doit pouvoir passer des appels d'urgence, même si l'abonnement a expiré. Il serait logique qu'il soit en mesure d'appeler le 112, même si son logiciel n'a pas pu être mis à jour depuis longtemps (cf. RFC 7406 pour une discussion sur un compromis similaire.)
Dans une logique libertarienne, ce RFC parle peu de la possibilité d'obligations légales (comme il y a un contrôle technique pour les voitures, il pourrait y avoir obligation de mesures de sécurité quand on vend des objets connectés). Comme il n'y a aucune chance que des entreprises capitalistes fassent spontanément des efforts pour améliorer la sécurité de tous, si on n'utilise pas de contraintes légales, il reste la possibilité d'incitations, discutée dans la section 6. Certaines sont utopiques (« il est dans l'intérêt de tous d'améliorer la sécurité, donc il faut expliquer aux gentils capitalistes l'intérêt de la sécurité, et ils le feront gratuitement »). Une possibilité est celle d'un abonnement : ayant acheté un objet connecté, on devrait payer régulièrement pour le maintenir à jour. Du point de vue de la sécurité, c'est absurde : il est dans l'intérêt de tous que toutes les machines soient à jour, question sécurité. Avec un abonnement, certains propriétaires choisiront de ne pas payer, et leurs engins seront un danger pour tous. (Comparons avec la santé publiqué : il est dans l'intérêt des riches que les pauvres se soignent, sinon, les maladies contagieuses se répandront et frapperont tout le monde. Les vaccinations gratuites ne sont donc pas de la pure générosité.)
Un des problèmes du soi-disant « Internet des objets » est qu'on ne sait pas grand'chose de ce qui s'y passe. Combien de constructeurs d'objets connectés peuvent dire combien ils ont d'objets encore actifs dans la nature, et quel pourcentage est à jour, question logiciel ? La section 7 du RFC se penche sur les questions de mesures. Un des articles présentés à l'atelier notait que, treize ans après la fin de la distribution d'un objet connecté, on en détectait encore des exemplaires actifs.
Garder trace de ces machines n'est pas trivial, puisque certaines ne seront allumées que de manière très intermittente, et que d'autres seront déployées dans des réseaux fermés. Mais ce serait pourtant utile, par exemple pour savoir combien de temps encore il faut gérer des mises à jour pour tel modèle, savoir quels problèmes ont été rencontrés sur le terrain, savoir quelles machines ont été compromises, etc.
La solution simple serait que l'objet ait un identifiant unique et contacte son fabricant de temps en temps, en donnant des informations sur lui-même. Évidemment, cela soulève de gros problèmes de préservation de la vie privée, si le fabricant de brosses à dents connait vos habitudes d'hygiène (« sa brosse à dents n'a pas été allumée depuis six mois, envoyons-lui des pubs pour un dentiste »). Il existe des techniques statistiques qui permettent de récolter des données sans tout révéler, comme le système RAPPOR ou EPID.
Quelle que soit l'efficacité des mises à jour, il ne fait pas de doute que, parfois, des machines seront piratées. Comment les gérer, à partir de là (section 9) ? Car ce ne sera pas seulement un ou deux objets qu'il faudra reformater avec une copie neuve du système d'exploitation. En cas de faille exploitée, ce seront au moins des centaines ou des milliers d'objets qui auront été piratés par un logiciel comme Mirai. (Notez qu'un travail - qui a échoué - avait été fait à l'IETF sur la gestion des machines terminales et leur sécurité, NEA.)
Rien que signaler à l'utilisateur, sans ouvrir une nouvelle voie d'attaque pour le hameçonnage, n'est pas évident (le RFC 6561 propose une solution, mais peu déployée). Bref, pour l'instant, pas de solution à ce problème. Quand on sait que les organisations à but lucratif ne réagissent jamais quand on leur signale un bot dans leur réseau, on imagine ce que ce sera quand on préviendra M. Michu que son grille-pain est piraté et participe à des DoS (comme celles avec SNMP ou bien celle contre Brian Krebs).
Avant d'arriver à une conclusion très partielle, notre RFC, dans sa section 10, traite quelques points divers :
- Pas mal de gadgets connectés seront rapidement abandonnés, ne délivrant plus de service utile et n'intéressant plus leur propriétaire, mais dont certains seront toujours connectés et piratables. Qui s'occupera de ces orphelins dangereux ?
- Que devra faire la machine qui voit qu'elle n'arrive pas à faire ses mises à jour ? Couiner très fort comme le détecteur de fumée dont la batterie s'épuise ? Vous imaginez votre cuisine quand dix appareils hurleront en même temps « Software update failed. Act now! » ? Ou bien les appareils doivent-ils s'éteindre automatiquement et silencieusement ? (Les fabricants adoreront cette solution : pour éliminer les vieilles machines et forcer les clients à acheter les nouvelles, il suffira de stopper le serveur des mises à jour.)
- La cryptographie post-quantique est pour l'instant inutile (et les mécanismes actuels font des signatures énormes, inadaptées aux objets contraints) mais il est impossible de dire quand elle deviendra indispensable. Cinq ans ? Dix ans ? Jamais ? Le problème est que, les objets connectés restant longtemps sur le terrain, il y a un risque qu'un objet soit livré avec de la cryptographie pré-quantique qui soit cassée par les ordinateurs quantiques pendant sa vie. On sera alors bien embêtés.
- Enfin, pour ceux qui utilisent des certificats pour vérifier les signatures, il faut noter que peu testent les révocations (RFC 6961 et ses copains). Il sera donc difficile, voire impossible, de rattraper le coup si une clé privée de signature est volée.
La section 11 rassemble les conclusions de l'atelier. On notera qu'il y a peu de consensus.
- Comme c'est l'IETF, il n'est pas étonnant que les participants soient tombés d'accord sur l'utilité d'une solution normalisée pour la distribution et la signature de logiciels, afin de permettre des mises à jour fiables.
- Il n'est par contre pas clair de savoir si cette solution doit tout inclure, ou seulement certaines parties du système (la signature, par exemple).
- Des mécanismes de « transmission du pouvoir » sont nécessaires, par exemple pour traiter le cas où une société fait faillite, et passe la maintenance des objets qu'elle a vendu à une association ou un service public. Passer le mot de passe de root est un exemple (très primitif).
L'annexe B du RFC liste tous les papiers présentés à l'atelier qui sont, évidemment en ligne. Sinon, vous pouvez regarder le site officiel de l'atelier, et un bon résumé de présentation. Je recommande aussi cet article de l'IETF Journal, et un très bon article critique sur les objets connectés.
L'article seul
Annonces BGP plus spécifiques : bien ou mal ?
Première rédaction de cet article le 4 septembre 2017
L'article de Geoff Huston « BGP More Specifics: Routing Vandalism or Useful? » aborde une question qui a toujours déclenché de chaudes discussions dans les forums d'opérateurs réseaux : est-ce que les opérateurs qui, au lieu d'annoncer un et un seul préfixe IP très général, annoncent plusieurs sous-préfixes, sont des salauds ou pas ? Est-ce l'équivalent de polluer et de taguer ? Après une étude soignée et pas mal de graphiques, il apporte une réponse originale.
Comme d'habitude, je vais commencer par un petit rappel. Le
protocole BGP, normalisé dans le RFC 4271, est le protocole standard de
distribution des routes dans
l'Internet. Une route est annoncée sous forme
d'un préfixe IP, par exemple 2001:db8::/32,
et les routeurs avec qui on communique relaieront cette annnonce,
jusqu'à ce que tout l'Internet soit au courant. Le préfixe annoncé
inclut une longueur (32 bits dans l'exemple ci-dessus). Comme des
expressions comme « grand préfixe » sont ambiguës (parle-t-on de
la longueur du préfixe, ou bien du nombre d'adresses IP qu'il contient ?), on
parle de préfixes plus spécifiques (longueur plus
grande, moins d'adresses IP) ou moins
spécifiques (longueur plus réduite, davantage
d'adresses IP). Ainsi, 2001:db8:42:abcd::/64 est
plus spécifique que 2001:db8:42::/48.
Si un opérateur a le préfixe
2001:db8::/32, et qu'il annonce en
BGP non seulement ce préfixe mais également
2001:db8:42::/48 et
2001:db8:cafe::/48, on dit qu'il annonce des
préfixes plus spécifiques. Comme toute route va devoir être
stockée dans tous les routeurs de la
DFZ, cet opérateur qui annonce
trois routes au lieu d'une seule est vu par
certains comme un gougnafier qui abuse du système (et, là, on
cite en général la fameuse « Tragedy of the
Commons »). Cet opérateur force tous
les routeurs de la DFZ à consacrer des ressources
(CPU, mémoire) à ses
trois préfixes, et cela gratuitement, alors qu'il pourrait se
contenter d'un seul préfixe, qui englobe les trois en
question.
Le problème est d'autant plus complexe que l'Internet est un réseau décentralisé, sans chef et sans police, et que personne ne peut faire respecter des règles mondiales. Donc, même si on pense que les plus spécifiques sont une mauvaise chose, comment les interdire en pratique ?
En général, les opérateurs estiment que les annonces plus
spécifiques sont une mauvaise chose. Néanmoins, pas mal de gens en
font. Huston regarde de plus près pourquoi, et quelles sont les
conséquences. Les plus spécifiques peuvent être utiles pour leur
émetteur, car la transmission de paquets
IP est fondée sur le principe du
« préfixe le plus spécifique » : si un
routeur IP a deux routes pour la destination
2001:db8:cafe::1:443, la première pour le préfixe
2001:db8::/32, et la seconde pour le
préfixe
2001:db8:cafe::/48, il utilisera toujours la
seconde, la plus spécifique. (Si, par contre, il doit envoyer un
paquet à 2001:db8:1337::bad:dcaf, il
utilisera la première route, puisque la seconde ne couvre pas
cette destination.) L'utilisation de préfixes plus spécifiques peut
donc être un moyen de déterminer plus finement le trajet
qu'emprunteront les paquets qui viennent vers vous.
Quel est le pourcentage de ces « plus spécifiques », d'ailleurs ? Huston mesure environ 50 % des routes IPv4 et 40 % en IPv6. C'est donc une proportion non négligeable. La question est « peut-on / doit-on en réduire le nombre ? Est-ce possible ? Quels sont les coûts et les bénéfices ? »
Pour répondre à cette question, Huston développe une taxonomie
des annonces plus spécifiques, avec des exemples réels. (Les exemples ci-dessous ont été
vérifiés mais attention, le looking
glass typique n'indique que le préfixe le
plus spécifique ; si on n'a pas soi-même une copie de la DFZ et les
outils pour l'analyser, il faut utiliser un service qui affiche
également les préfixes englobants - je me sers de RIPE
Stat et un looking
glass - j'utilise celui
de Hurricane Electric.) Huston distingue trois cas. Le premier
est celui de « percement d'un trou » : l'annonce plus générale
n'envoie pas au bon AS et on fait donc une
annonce plus spécifique avec un AS d'origine différent. On voit
ainsi, pour 72.249.184.0/24, sur RIPE Stat :
Originated by: AS394094 (valid route objects in LEVEL3 and RADB)
Covering less-specific prefixes:
72.249.128.0/18 (announced by AS30496)
72.249.184.0/21 (announced by AS36024)
Showing results for 72.249.184.0/24 as of 2017-09-03 08:00:00 UTC
Le /21 est annoncé par l'AS 36024 alors qu'il y a une annonce plus spécifique pour le /24, avec un autre AS, 394094. Huston note que cela pourrait être fait en annonçant un préfixe par /24 mais cela créerait davantage d'entrées dans la table de routage que ce percement de trou avec un plus spécifique.
Le second cas d'annonce plus spécifique est l'ingénierie de trafic. L'AS d'origine est le même, mais l'annonce est différente sur un autre point, par exemple par le prepending (la répétition du même AS dans l'annonce, pour rendre le chemin plus long et donc décourager l'usage de cette route), ou bien en envoyant les deux préfixes, le plus spécifique et le moins spécifique, à des opérateurs différents :
Originated by: AS4775 (valid route objects in RADB and NTTCOM) Covering less-specific prefix: 1.37.0.0/16 (announced by AS4775) Showing results for 1.37.27.0/24 as of 2017-09-03 08:00:00 UTC
Cette fois, l'AS d'origine est le même. Mais on note sur le looking glass que les annonces sont différentes :
Prefix: 1.37.0.0/16
AS_PATH: 4766 4775
Prefix: 1.37.27.0/24
AS_PATH: 4775
Le préfixe plus spécifique n'est pas annoncé aux mêmes opérateurs.
Enfin, le troisième et dernier cas est celui du recouvrement complet : l'annonce plus spécifique est apparemment inutile puisque il existe une annonce moins spécifique qui a exactement les mêmes caractéristiques. Pourquoi ferait-on cela ? Il peut s'agir de négligence ou d'incompétence mais il existe aussi une raison rationnelle : limiter les conséquences d'un détournement BGP.
Dans un tel détournement, l'attaquant annonce un préfixe qui n'est pas le sien, pour perturber l'accès à la victime, ou pour détourner son trafic vers l'attaquant (les cas les plus connus sont accidentels, comme le fameux détournement de YouTube par le Pakistan, mais cela peut aussi se faire délibérement). Si l'annonce normale est un /22, et que l'attaquant annonce aussi un /22, une partie de l'Internet verra toujours l'annonce légitime (les routeurs BGP ne propagent, pour un préfixe donné, que la meilleure route) et ne sera donc pas affectée. Pour qu'une attaque réussisse bien, dans ces conditions, il faut que l'attaquant soit très bien connecté, avec de nombreux partenaires BGP. Par contre, avec cette annonce légitime en /22, un attaquant qui enverrait une annonce pour un /24 verrait son annonce propagée partout (puisqu'il s'agirait d'un préfixe différent). Et, au moment de la transmission des paquets, les routeurs utiliseront la route la plus spécifique, donc le /24. Ainsi, un attaquant mal connecté pourra toujours voir son annonce acceptée et utilisée dans tout l'Internet.
Le fait d'annoncer un recouvrement complet (quatre /24 en plus du /22) protège donc partiellement contre cette technique. Huston rejette cet argument en disant qu'il ne s'agit que d'une protection partielle, mais je ne suis pas d'accord : une protection partielle vaut mieux que pas de protection du tout et, en sécurité, il est courant que les solutions soient partielles.
Un exemple est 1.0.4.0/22. On voit les quatre préfixes plus spécifiques, avec exactement le meme contenu :
Prefix: 1.0.4.0/22
AS_PATH: 4826 38803 56203
Prefix: 1.0.4.0/24
AS_PATH: 4826 38803 56203
Prefix: 1.0.5.0/24
AS_PATH: 4826 38803 56203
Prefix: 1.0.6.0/24
AS_PATH: 4826 38803 56203
Prefix: 1.0.7.0/24
AS_PATH: 4826 38803 56203
Les annonces plus spécifiques forment donc la moitié (en IPv4) des annonces dans la DFZ. Mais ce pourcentage augmente-t-il ou diminue-t-il ? Est-ce que la situation s'aggrave ? Huston utilise les données BGP accumulées depuis dix ans (si vous voulez faire pareil, les annonces BGP sont archivées et disponibles, entre autres à RouteViews). Eh bien, il n'y a pas de changement en IPv4 : le pourcentage de 50 % des annonces étant des annonces plus spécifiques qu'une annonce existante n'a pas changé depuis dix ans (mais la proportion des trois cas a changé : lisez l'article). En revanche, il est passé de 20 à 40 % en IPv6 dans le même temps, mais je ne suis pas sûr qu'on puisse en tirer des conclusions solides : il y a dix ans, IPv6 était peu présent dans la DFZ.
Ça, c'était le pourcentage des préfixes. Le nombre de préfixes à gérer a un effet négatif sur le routeur, car davantage de préfixes veut dire davantage de mémoire consommée par le routeur. La DFZ a actuellement plus de 700 000 préfixes (IPv4 et IPv6 mêlés). Une table de seulement 700 000 entrées ? Cela peut sembler peu à l'ère de la vidéo de chats en haute définition et du big data. Certes, un routeur du cœur de l'Internet n'a pas la même architecture qu'un PC de bureau, et la mémoire n'y est pas disponible dans les mêmes quantités mais, quand même, est-ce si grave ?
En fait, le plus gênant pour le routeur typique n'est pas la quantité de préfixes mais le rythme de changement (le churn). Davantage de préfixes veut surtout dire davantage de changements à traiter. Huston regarde donc dans la suite de son article l'effet des changements. Il constate que les préfixes plus spécifiques sont un peu plus « bruyants » (davantage de changements), au moins en IPv4. Les préfixes plus spécifiques du deuxième cas (ingénierie de trafic) sont les plus bruyants, ce qui est assez logique. Attention avec ces statistiques, toutefois : Huston rappelle que le rythme de changement varie énormément selon les préfixes. Certains changent tout le temps, d'autres sont très stables.
Maintenant, venons-en aux actions possibles. Est-ce que ces préfixes plus spécifiques, émis par des opérateurs égoïstes et payés par tous, doivent être activement combattus, pour en réduire le nombre ? C'est l'idée qui est derrière des actions comme le CIDR report. En analysant automatiquement les préfixes de la DFZ, et en publiant la liste des opérateurs qui abusent le plus, on espère leur faire honte (cette technique du name and shame est très courante sur Internet, puisqu'il n'existe pas d'État central qui puisse faire respecter des règles et que les opérateurs n'ont, heureusement, pas de police ou d'armée privée), et diminuer avec le temps le pourcentage de préfixes « inutiles ». Par exemple, Huston calcule que la suppression de tous les plus spécifiques du cas 3 (recouvrement complet) diminuerait la table de routage globale de 20 % et le rythme des changements de 10 à 15 %.
En conclusion, Huston estime qu'on ne peut pas parler de tous les préfixes moins spécifiques de la même façon, certains sont réellement utiles. Certes, d'autres ne le sont pas, mais les supprimer serait une tâche longue et difficile, pour un bénéfice limité. Huston résume en disant que les préfixes plus spécifiques sont un problème agaçant, mais pas grave.
L'article seul
Observations about the attack on WikiLeaks
First publication of this article on 1 September 2017
On 30 August, this year, a technical attack was performed against WikiLeaks, leading some visitors of WikiLeaks' Web site to see instead a claim by "OurMine" that they seized control of WikiLeaks' servers. A lot of stupid things, by ignorant people (both WikiLeaks fans and enemies), have been said on the networks, about this attack. Most of the time, they did not bother to check any facts, and they did not demonstrate any knowledge of the technical infrastructure. Here, I want to describe the bare facts, as seen from technical observations. Spoiler: I have no sensational revelations to make.
First, the basic fact: some people saw something which was obviously not WikiLeaks' Web site: screenshots of the page are here or here. Some people deduced from that that WikiLeaks' Web server was cracked and the crackers modified its content (you can find this in The Verge for instance). That was a bold deduction: the complete process from the user's browser to the display of the Web page is quite complicated, with a lot of actors, and many things can go wrong.
In the case of WikiLeaks, it appeared rapidly that the Web
server was not cracked but that the attack targeted successfully
the wikileaks.org domain name. Observations
(more on that later) show that the name
wikileaks.org was not resolved into the usual
IP address but in another one, located in a
different hoster. How is it possible? What are the
consequences?
You should remember that investigation of digital incidents on the Internet is difficult. The external analyst does not have all the data. Sometimes, when the analysis starts, it is too late, the data already changed. And the internal analyst almost never publishes everything, and sometimes even lies. There are some organisations that are more open in their communication (see this Cloudflare report or this Gandi report) but they are the exceptions rather than the rule. Here, WikiLeaks reacted like the typical corporation, denying the problem, then trying to downplay it, and not publishing anything of value for the users. So, most of the claims that you can read about network incidents are not backed by facts, specially not publicly-verifiable facts. The problem is obviously worse in that case, because WikiLeaks is at the center of many hot controversies. For instance, some WikiLeaks fans claimed from the beginning "WikiLeaks' servers have not been compromised" while they had zero actual information, and, anyway, not enough time to analyze it.
So, the issue was with the domain name
wikileaks.org. To explain what happened, we
need to go back to the DNS, both a critical
infrastructure of the Internet, and a widely unknown (or underknown) technology. The DNS is a database indexed by
domain names (like
wikileaks.org or
ssi.gouv.fr). When you query the DNS for a
given domain name, you get various technical informations such as
IP addresses of servers, cryptographic keys, name of
servers, etc. When the typical Web browser goes to
http://www.okstate.com/, the
software on the user's machine performs a DNS query for the name
www.okstate.com, and gets back the IP address
of the HTTP server. It then connects to the
server.
From this very short description, you can see that s·he who controls the DNS controls where the user will eventually go and what s·he will see. And the entire DNS resolution process (from a name to the data) is itself quite complicated, offering many opportunities for an attacker. Summary so far: DNS is critical, and most organisations underestimate it (or, worse, claim it is not their responsability).
And where do the data in the DNS come from? That's the biggest
source of vulnerabilities: unlike what many people said, most
so-called "DNS attacks" are not DNS attacks at all, meaning they
don't exploit a weakness in the DNS protocol. Most of the time,
they are attacks against the provisioning
infrastructure, the set of actors and servers that domain name
holders (such as WikiLeaks for wikileaks.org)
use to provision the data. Let's say you are Pat Smith,
responsible for the online activity of an organisation named the
Foobar Society. You have the domain name
foobar.example. The Web site is hosted at
Wonderful Hosting, Inc. After you've choosen a
TLD (and I recommend you read the excellent EFF survey before you do so), you'll
typically need to choose a registrar which
will act as a proxy between you and the actual
registry of the TLD (here, the fictitious
.example). Most of the time, you, Pat Smith,
will connect to the Web site of the registrar, create an account,
and configure the data which will ultimately appear in the
DNS. For instance, when the Web site is created at Wonderful Hosting, Pat will enter
its IP address in the control panel provided by the registrar. You
can see immediately that this required Pat to log in the said
control panel. If Pat used a weak password,
or wrote it down under h·is·er desk or if Pat is gullible and
believes a phone call asking h·im·er to give the password, the account may be
compromised, and the attacker may log in instead of Pat and put
the IP address of h·er·is choosing. This kind of attacks is very
common, and illustrate the fact that not all attacks are
technically complicated.
So, what happened in the WikiLeaks case? (Warning, it will now become more technical.) We'll first use a "passive DNS" base, DNSDB. This sort of databases observes the DNS traffic (which is most of the time in clear, see RFC 7626) and record it, allowing its users to time-travel. DNSDB is not public, I'm sorry, so for this one, you'll have to trust me. (That's why real-time reaction is important: when you arrive too late, the only tools to observe an attack are specialized tools like this one.) What's in DNSDB?
;; bailiwick: org.
;; count: 9
;; first seen: 2017-08-30 04:28:40 -0000
;; last seen: 2017-08-30 04:30:28 -0000
wikileaks.org. IN NS ns1.rivalhost.com.
wikileaks.org. IN NS ns2.rivalhost.com.
wikileaks.org. IN NS ns3.rivalhost.com.
;; bailiwick: org.
;; count: 474
;; first seen: 2017-08-30 04:20:15 -0000
;; last seen: 2017-08-30 04:28:41 -0000
wikileaks.org. IN NS ns1.rival-dns.com.
wikileaks.org. IN NS ns2.rival-dns.com.
wikileaks.org. IN NS ns3.rival-dns.com.
What does it mean? That during the attack (around 04:30
UTC), the
.org registry was
replying with the illegitimate set of servers. The usual servers
are (we use the dig tool, the best tool to
debug DNS issues):
% dig @a0.org.afilias-nst.info. NS wikileaks.org
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 21194
;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 6, ADDITIONAL: 3
...
;; AUTHORITY SECTION:
wikileaks.org. 86400 IN NS ns1.wikileaks.org.
wikileaks.org. 86400 IN NS ns2.wikileaks.org.
;; ADDITIONAL SECTION:
ns1.wikileaks.org. 86400 IN A 46.28.206.81
ns2.wikileaks.org. 86400 IN A 46.28.206.82
...
;; SERVER: 2001:500:e::1#53(2001:500:e::1)
;; WHEN: Fri Sep 01 09:18:14 CEST 2017
...
(And, yes, there is a discrepancy between what is served by the
registry and what's inside nsX.wikileaks.org
name servers: whoever manages WikiLeaks DNS does a sloppy
job. That's why it is often useful to query the parent's name
servers, like I did here.)
So, the name servers were changed, for rogue ones. Note there was also a discrepancy during the attack. These rogue servers gave a different set of NS (Name Servers), according to DNSDB:
;; bailiwick: wikileaks.org. ;; count: 1 ;; first seen: 2017-08-31 02:02:38 -0000 ;; last seen: 2017-08-31 02:02:38 -0000 wikileaks.org. IN NS ns1.rivalhost-global-dns.com. wikileaks.org. IN NS ns2.rivalhost-global-dns.com.
Note that it does not mean that the DNS hoster of the attacker, Rival, is an accomplice. They may simply have a rogue customer. Any big service provider will have some rotten apples among its clients.
You can see the date of the last change in whois output, when everything was put back in place:
% whois wikileaks.org
...
Updated Date: 2017-08-31T15:01:04Z
Surely enough, the rogue name servers were serving IP addresses pointing to the "false" Web site. Again, in DNSDB:
;; bailiwick: wikileaks.org. ;; count: 44 ;; first seen: 2017-08-30 04:29:07 -0000 ;; last seen: 2017-08-31 07:22:05 -0000 wikileaks.org. IN A 181.215.237.148
The normal IP addresses of WikiLeaks are in the prefixes
95.211.113.XXX,
141.105.XXX and
195.35.109.XXX (dig A
wikileaks.org if you want to see
them, or use a
DNS Looking Glass). 181.215.237.148 is the address of the
rogue Web site, hosted by Rival again, as can be seen with the
whois tool:
% whois 181.215.237.148 inetnum: 181.215.236/23 status: reallocated owner: Digital Energy Technologies Chile SpA ownerid: US-DETC5-LACNIC responsible: RivalHost, LLC. address: Waterwood Parkway, 1015, Suite G, C-1 address: 73034 - Edmond - OK country: US owner-c: VIG28 tech-c: VIG28 abuse-c: VIG28 ... nic-hdl: VIG28 person: AS61440 Network Operating Center e-mail: noc@AS61440.NET address: Moneda, 970, Piso 5 address: 8320313 - Santiago - RM country: CL
(It also shows that this prefix was allocated in Chile, the world is a complicated place, and the Internet even more so.)
So, this was the modus operandi of the
cracker. S·he managed to change the set of name servers serving
wikileaks.org, and that gave h·im·er the
ability to send visitors to a server s·he controlled. (Note that
this HTTP server, 181.215.237.148, no longer serves
the cracker's page: it was probably removed by the provider.)
Many people on the social networks claimed that the attack was done by "DNS poisoning". First, a word of warning by a DNS professional: when someone types "DNS poisoning", you can be pretty sure s·he knows next to nothing about DNS. DNS poisoning is a very specific attack, for which we have solutions (DNSSEC, mentioned later), but it does not seem to be very common (read again my warning at the beginning: most attacks are never properly analyzed and documented, so it is hard to be more precise). What is very common are attacks against the domain name provisioning system. This is, for instance, what happened to the New York Times in 2013, from an attack by the infamous SEA (see NYT paper and a technical analysis). More recently, there was the attack against St. Louis Federal Reserve and many others. These attacks don't use the DNS protocol and it is quite a stretch to label them as "DNS attacks" or, even worse, "DNS poisoning".
What are the consequences of such an attack? As explained earlier, once you control the DNS, you control everything. You can redirect users to a Web site (not only the external visitors, but also the employees of the targeted organisation, when they connect to internal services, potentially stealing passwords and other informations), hijack the emails, etc. So, claiming that "the servers were not compromised" (technically true) is almost useless. With an attack on domain names, the cracker does not need to compromise the servers.
Who was cracked in the WikiLeaks case? From the outside, we can
say with confidence that the name servers were changed. The
weakness could have been at the holder (WikiLeaks), at the
registrar (Dynadot, an
information you also get with whois), or
at the registry (.org, administratively
managed by PIR and technically by
Afilias). From the information available,
one cannot say where the problem was (so, people who publicly
shouted that "WikiLeaks is not responsible" were showing their
blind faith, not their analytic abilities). Of course, most of the
times, the weakest link is the user (weak password to the registrar
portal, and not activating 2FA), but some registrars or
registries displayed in the past serious security weaknesses. The
only thing we can say is that no other domain name appeared to have
been hijacked. (When someone takes control of a registrar or
registry, s·he can change many domain names.)
I said before that, when you control a domain name, you can send both external and internal visitors to the server you want. That was not entirely true, since good security relies on defence in depth and some measures can be taken to limit the risk, even if your domain name is compromised. One of them is of course having HTTPS (it is the case of WikiLeaks), with redirection from the plain HTTP site, and HSTS (standardized in RFC 6797), to avoid that regular visitors go through the insecure HTTP. Again, WikiLeaks use it:
% wget --server-response --output-document /dev/null https://wikileaks.org/ ... Strict-Transport-Security: max-age=25920000; includeSubDomains; preload
These techniques will at least raise an alarm, telling the visitor that something is fishy. (There is also HPKP - RFC 7649 - but it does not seem deployed by Wikileaks; it should be noticed it is more risky.)
In the same way, using Tor to go to a
.onion
URL would also help. But I have not been
able to find a .onion for WikiLeaks (the
http://suw74isz7wqzpmgu.onion/ indicated on
the
wiki does not work, the
http://wlupld3ptjvsgwqw.onion seems to be just
for uploading).
One can also limit the risk coming from an account compromise by
enabling registry lock, a technique offered by most TLD (including
.org) to prevent
unauthorized changes. When activated, it requires extra steps and
checking for any change. I cannot say, from the outside, if
WikiLeaks enabled it but sensitive domain names
must do it.
Funny enough, with so many people claiming it was "DNS
poisoning", the best protection against this specific attack,
DNSSEC, is not enabled
by WikiLeaks (there is a DNSSEC key in
wikileaks.org but no signatures and no
DS record in the parent). If
wikileaks.org was signed, and if you
use a validating DNS resolver (everybody should), you cannot fall
for a DNS poisoning attack against WikiLeaks. Of course, if the
attack is, instead, a compromise of holder account, registrar or
registry, DNSSEC would not help a lot.
A bit of technical fun at the end. WikiLeaks uses
glue records for its name servers. They are
nameserver names which are under the domain they serve, thus
creating a chicken-and-egg problem. To
allow the DNS client to query them, the parent has to know the IP
address of this name server. This is what is called a glue
record. DNSDB shows us that the glue for
ns1.wikileaks.org was apparently modified
(note that it was several hours after the main attack):
;; bailiwick: org.
;; count: 546
;; first seen: 2017-08-31 00:23:13 -0000
;; last seen: 2017-08-31 06:22:42 -0000
ns1.wikileaks.org. IN A 191.101.26.67
This machine is still up and serves a funny value for
wikileaks.org (again, you can use a
DNS Looking Glass):
% dig @191.101.26.67 A wikileaks.org
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 53887
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
...
;; ANSWER SECTION:
wikileaks.org. 400 IN A 127.0.0.1
This IP address, meaning
localhost, was
indeed seen by some DNSDB sensors:
;; bailiwick: wikileaks.org.
;; count: 1
;; first seen: 2017-08-31 09:17:29 -0000
;; last seen: 2017-08-31 09:17:29 -0000
wikileaks.org. IN A 127.0.0.1
Since the DNS heavily relies on caching, the information was still seen even after the configuration was fixed. Here, we use the RIPE Atlas probes with the atlas-resolve tool to see how many probes still saw the wrong value (pay attention to the date and time, all in UTC, which is the rule when analyzing Internet problems):
% atlas-resolve -r 1000 -t A wikileaks.org
[141.105.65.113 141.105.69.239 195.35.109.44 195.35.109.53 95.211.113.131 95.211.113.154] : 850 occurrences
[195.175.254.2] : 2 occurrences
[127.0.0.1] : 126 occurrences
Test #9261634 done at 2017-08-31T10:03:24Z
L'article seul
RFC 8216: HTTP Live Streaming
Date de publication du RFC : Août 2017
Auteur(s) du RFC : R. Pantos (Apple), W. May (Major
League Baseball Advanced Media)
Pour information
Première rédaction de cet article le 1 septembre 2017
Ce RFC décrit la version 7 du protocole HTTP Live Streaming, qui permet de distribuer des flux multimédia, typiquement de la vidéo.
Utiliser HTTP, c'est bien, ça passe
quasiment tous les pare-feux, et ça permet
de réutiliser l'infrastructure existante, comme les serveurs, et les caches. (Au contraire, un protocole
comme RTP, RFC 3550, a souvent du mal à passer les
différentes
middleboxes.) La manière triviale de distribuer une vidéo avec
HTTP est d'envoyer un fichier vidéo au bon
format, avec des méthodes HTTP standard, typiquement en réponse à
un GET. Mais cette méthode a des tas de
limites. Par exemple, elle ne permet pas de
s'adapter à une capacité variable du
réseau. Par contre, le protocole décrit dans ce RFC, quoique plus
compliqué qu'un simple GET, permet cet
ajustement (et plein d'autres).
HTTP Live Streaming (ou simplement Live Streaming, ou encore HLS) existe depuis longtemps, la première spécification a été publiée (par Apple) en 2009, mais c'est la première fois qu'il se retrouve dans un RFC, ce qui devrait permettre d'améliorer encore l'interopérabilité.
Donc, brève description de HTTP Live Streaming : une ressource multimédia qu'on veut diffuser est représentée par un URI. Ceui-ci désigne une playlist, qui est un fichier texte contenant les URI des données multimedia et diverses informations. Les données multimédia figurent dans plusieurs segments ; en jouant tous les segments successivement, on obtient la vidéo souhaitée. Le client n'a pas ainsi à tout charger, il peut récupérer les segments au fur et à mesure de ses besoins. (Au lieu de « segments », mmu_man suggère de parler d'un « émincé de fichiers ».) Voici l'exemple de playlist que donne le RFC :
#EXTM3U
#EXT-X-TARGETDURATION:10
#EXTINF:9.009,
http://media.example.com/first.ts
#EXTINF:9.009,
http://media.example.com/second.ts
#EXTINF:3.003,
http://media.example.com/third.ts
Ce format de playlist est dérivé du format
M3U et est généralement nommé « M3U étendu ».
On y trouve successivement l'identificateur du format (si ça
commence par #EXTM3U, c'est bien une
playlist de notre RFC), la durée maximale d'un
segment en secondes, puis les trois segments, avec la durée de
chacun. Cette durée, indiquée par l'étiquette
#EXTINF, est un des rares éléments
obligatoires dans une playlist. Il y a bien sûr plein d'autres choses qu'on peut mettre
dans un fichier playlist, la section 4 du RFC
en donne la liste complète. Ainsi,
#EXT-X-BYTERANGE permettra d'indiquer qu'on
ne veut jouer qu'une partie d'une vidéo. Des exemples plus
complets sont donnés dans la section 8 du RFC.
Ça, c'était la media playlist, qui se limite à lister des ressources multimédias. La master playlist, dont le format est le même, est plus riche, et permet de spécifier des versions alternatives d'un même contenu. Ces variantes peuvent être purement techniques (« variant stream », deux encodages d'une même vidéo avec différents formats) ou porter sur le fond : par exemple deux pistes audio dans des langues différentes, ou deux vidéos d'un même évènement filmé depuis deux points de vue distincts. Les variantes techniques servent au client à s'ajuster aux conditions réelles du réseau, les variantes de fond (nommées renditions) servent au client à donner à l'utilisateur ce qu'il préfère. Ici, par exemple, on a dans cette master playlist trois variantes techniques (trois résolutions, de la plus basse, à la plus élevée, qui va nécessiter une bonne capacité réseau), et trois « renditions », correspondant à trois points de vue (centerfield et dugout sont des termes de baseball, ce qui est logique vu l'employeur d'un des deux auteurs du RFC) :
#EXTM3U
#EXT-X-MEDIA:TYPE=VIDEO,GROUP-ID="low",NAME="Main", \
DEFAULT=YES,URI="low/main/audio-video.m3u8"
#EXT-X-MEDIA:TYPE=VIDEO,GROUP-ID="low",NAME="Centerfield", \
DEFAULT=NO,URI="low/centerfield/audio-video.m3u8"
#EXT-X-MEDIA:TYPE=VIDEO,GROUP-ID="low",NAME="Dugout", \
DEFAULT=NO,URI="low/dugout/audio-video.m3u8"
#EXT-X-STREAM-INF:BANDWIDTH=1280000,CODECS="...",VIDEO="low"
low/main/audio-video.m3u8
#EXT-X-MEDIA:TYPE=VIDEO,GROUP-ID="mid",NAME="Main", \
DEFAULT=YES,URI="mid/main/audio-video.m3u8"
#EXT-X-MEDIA:TYPE=VIDEO,GROUP-ID="mid",NAME="Centerfield", \
DEFAULT=NO,URI="mid/centerfield/audio-video.m3u8"
#EXT-X-MEDIA:TYPE=VIDEO,GROUP-ID="mid",NAME="Dugout", \
DEFAULT=NO,URI="mid/dugout/audio-video.m3u8"
#EXT-X-STREAM-INF:BANDWIDTH=2560000,CODECS="...",VIDEO="mid"
mid/main/audio-video.m3u8
#EXT-X-MEDIA:TYPE=VIDEO,GROUP-ID="hi",NAME="Main", \
DEFAULT=YES,URI="hi/main/audio-video.m3u8"
#EXT-X-MEDIA:TYPE=VIDEO,GROUP-ID="hi",NAME="Centerfield", \
DEFAULT=NO,URI="hi/centerfield/audio-video.m3u8"
#EXT-X-MEDIA:TYPE=VIDEO,GROUP-ID="hi",NAME="Dugout", \
DEFAULT=NO,URI="hi/dugout/audio-video.m3u8"
#EXT-X-STREAM-INF:BANDWIDTH=7680000,CODECS="...",VIDEO="hi"
hi/main/audio-video.m3u8
Si vous voulez le voir en vrai, et que vous êtes abonné à Free, la Freebox distribue sa playlist sous ce format (mais avec le mauvais type MIME) :
% curl -s http://mafreebox.freebox.fr/freeboxtv/playlist.m3u
#EXTM3U
#EXTINF:0,2 - France 2 (bas débit)
rtsp://mafreebox.freebox.fr/fbxtv_pub/stream?namespace=1&service=201&flavour=ld
#EXTINF:0,2 - France 2 (HD)
rtsp://mafreebox.freebox.fr/fbxtv_pub/stream?namespace=1&service=201&flavour=hd
#EXTINF:0,2 - France 2 (standard)
rtsp://mafreebox.freebox.fr/fbxtv_pub/stream?namespace=1&service=201&flavour=sd
#EXTINF:0,2 - France 2 (auto)
rtsp://mafreebox.freebox.fr/fbxtv_pub/stream?namespace=1&service=201
#EXTINF:0,3 - France 3 (standard)
rtsp://mafreebox.freebox.fr/fbxtv_pub/stream?namespace=1&service=202&flavour=sd
...
(On me dit qu'avec certaines Freebox, il faut ajouter
-L à curl, en raison d'une redirection HTTP.)
Un client comme vlc peut prendre comme
argument l'URI de la playlist, la télécharger et jouer ensuite les
vidéos.
(Tous les moyens sont bons pour télécharger la playlist, le RFC n'impose pas un
mécanisme particulier.)
Télécharger chacun des segments se fait a priori avec
HTTP, RFC 7230, mais
vous voyez plus haut que, sur la Freebox,
c'est RTSP, RFC 7826. Le serveur, lui, est un serveur HTTP
ordinaire. L'auteur a « juste » eu à découper sa vidéo en segments (ou
la garder en un seul morceau si elle est assez courte), à
fabriquer un fichier playlist, puis à le servir
avec le type MIME application/vnd.apple.mpegurl. (La
section 6 du RFC décrit plus en détail ce que doivent faire client
et serveur.)
Il est recommandé que chaque segment soit auto-suffisant, c'est-à-dire puisse être décodé sans avoir besoin des autres segments. Ainsi, si les segments sont en H.264, chacun doit avoir un Instantaneous Decoding Refresh (IDR).
Plusieurs formats sont évidemment possibles dans une playlist HTTP Live Streaming, MPEG-2, MPEG-4 fragmenté, WebVTT pour avoir les sous-titres, et un format pour l'audio (qui accepte entre autres MP3).
HTTP Live Streaming permet aussi de servir du direct. Prenons par exemple le flux vidéo de l'Assemblée Nationale, qui permet de suivre les débats parlementaires :
% curl -s http://videos-diffusion-live.assemblee-nationale.fr/live/live1/stream1.m3u8 #EXTM3U #EXT-X-VERSION:3 #EXT-X-ALLOW-CACHE:NO #EXT-X-TARGETDURATION:11 #EXT-X-MEDIA-SEQUENCE:382 #EXTINF:9.996, media_1_4805021_382.ts #EXTINF:11.483, media_1_4805021_383.ts ...
Un peu plus tard, les fichiers ont changé, le client HLS doit recharger la playlist régulièrement (section 6.2.2 du RFC), et charger de nouveaux fichiers vidéo :
% curl -s http://videos-diffusion-live.assemblee-nationale.fr/live/live1/stream1.m3u8 #EXTM3U #EXT-X-VERSION:3 #EXT-X-ALLOW-CACHE:NO #EXT-X-TARGETDURATION:11 #EXT-X-MEDIA-SEQUENCE:390 #EXTINF:10.039, media_1_4805021_390.ts #EXTINF:11.242, media_1_4805021_391.ts ...
(Notez également l'incrémentation du #EXT-X-MEDIA-SEQUENCE.)
Ainsi, l'utilisateur a l'impression d'une vidéo continue, alors
que le logiciel client passe son temps à charger des segments différents et à les
afficher à la suite.
Notez que HTTP Live Streaming n'est pas le seul mécanisme dans ce domaine, son principal concurrent est MPEG-DASH.
Si vous voulez lire davantage :
- Un article d'introduction, orienté vers l'auteur de vidéos,
- Un article plus technique d'Apple.
L'article seul
RFC 6844: DNS Certification Authority Authorization (CAA) Resource Record
Date de publication du RFC : Janvier 2013
Auteur(s) du RFC : P. Hallam-Baker (Comodo), R. Stradling
(Comodo)
Chemin des normes
Première rédaction de cet article le 31 août 2017
Dernière mise à jour le 26 octobre 2017
Ce RFC a quelques années mais n'avait connu que peu de déploiement effectif. Cela va peut-être changer à partir du 8 septembre 2017, où les AC ont promis de commencer à vérifier les enregistrements CAA (Certification Authority Authorization) publiés dans le DNS. Ça sert à quoi ? En gros, un enregistrement CAA publié indique quelles AC sont autorisées à émettre des certificats pour ce domaine. Le but est de corriger très partiellement une des plus grosses faiblesses de X.509, le fait que n'importe quelle AC peut émettre des certificats pour n'importe quel domaine, même si ce n'est pas un de ses clients. Notez qu'il a depuis été remplacé par le RFC 8659.
C'est donc une technique très différente de DANE (RFC 6698), les seuls points communs étant l'utilisation du DNS pour sécuriser les certificats. DANE est déployé chez le client TLS, pour qu'il vérifie le certificat utilisé, CAA est surtout dans l'AC, pour limiter le risque d'émission d'un certificat malveillant (par exemple, CAA aurait peut-être empêché le faux certificat Gmail du ministère des finances.) Disons que CAA est un contrôle supplémentaire, parmi ceux que l'AC doit (devrait) faire. Les clients TLS ne sont pas censés le tester (ne serait-ce que parce que l'enregistrement CAA a pu changer depuis l'émission du certificat, la durée de vie de ceux-ci étant en général de plusieurs mois). CAA peut aussi servir à des auditeurs qui veulent vérifier les pratiques d'une AC (même avertissement : le certificat a pu être émis alors que l'enregistrement CAA était différent.)
La section 3 de notre RFC présente l'enregistrement CAA (la syntaxe détaillée est en section 5). Il a été ajouté au registre des types d'enregistrements sous le numéro 257. Il comprend une série d'options (flags) et une propriété qui est sous la forme {clé, valeur}. Un nom peut avoir plusieurs propriétés. Pour l'instant, une seule option est définie (un registre existe pour les options futures), « issuer critical » qui indique que cette propriété est cruciale : si on ne la comprend pas, le test doit être considéré comme ayant échoué et l'AC ne doit pas produire de certificat.
Les propriétés possibles sont, à l'heure actuelle (d'autres pourront être ajoutée dans le registre IANA) :
issue, la principale, qui indique une AC autorisée à émettre des certificats pour ce domaine (l'AC est indiquée par son nom de domaine),issuewild, idem, mais avec en plus la possibilité pour l'AC d'émettre des certificats incluants des jokers,iodef, qui indique où l'AC doit envoyer d'éventuels rapports d'échec, pour que le titulaire du nom de domaine puisse les corriger. Un URL est indiqué pour cela, et le rapport doit être au format IODEF (RFC 7970).
Voici par exemple quel était l'enregistrement CAA de mon domaine personnel :
% dig CAA bortzmeyer.org ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 61450 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 3, AUTHORITY: 7, ADDITIONAL: 7 ... ;; ANSWER SECTION: bortzmeyer.org. 26786 IN CAA 0 issue "cacert.org" bortzmeyer.org. 26786 IN CAA 0 issuewild "\;" ...
Il indique que seule l'AC CAcert peut
créer un certificat pour ce domaine (et sans les jokers). Bon, c'est
un peu inutile car CAcert ne teste pas les enregistrements CAA, mais
c'était juste pour jouer. Je n'ai pas mis d'iodef
mais il aurait pu être :
bortzmeyer.org. CAA 0 iodef "mailto:security@bortzmeyer.org"
Et, dans ce cas, l'AC peut écrire à
security@bortzmeyer.org, avec le rapport IODEF
en pièce jointe.
Attention, l'enregistrement CAA est valable pour tous les
sous-domaines (et ce n'est pas une option,contrairement à, par
exemple, HSTS du RFC 6797, avec
son includeSubDomains). C'est pour cela que
j'ai dû retirer l'enregistrement ci-dessus, pour avoir des
certificats pour les sous-domaines, certificats faits par une autre
AC.
Des paramètres peuvent être ajoutés, le RFC cite l'exemple d'un numéro de client :
example.com. CAA 0 issue "ca.example.net; account=230123"
Une fois les enregistrements CAA publiés, comment sont-ils utilisés (section 4) ? L'AC est censée interroger le DNS pour voir s'il y a un CAA (on note que DNSSEC est recommandé, mais n'est pas obligatoire, ce qui réduit le service déjà faible qu'offre CAA). S'il n'y en a pas, l'AC continue avec ses procédures habituelles. S'il y a un CAA, deux cas : il indique que cette AC peut émettre un certificat pour le domaine, et dans ce cas-là, c'est bon, on continue avec les procédures habituelles. Second cas, le CAA ne nomme pas cette AC et elle doit donc renoncer à faire un certificat sauf s'il y a une exception configurée pour ce domaine (c'est la deuxième faille de CAA : une AC peut facilement passer outre et donc continuer émettre de « vrais/faux certificats »).
Notez que le RFC ne semble pas évoquer la possibilité d'imposer la présence d'un enregistrement CAA. C'est logique, vu le peu de déploiement de cette technique mais cela veut dire que « qui ne dit mot consent ». Pour la plupart des domaines, la vérification du CAA par l'AC ne changera rien.
Notez que, si aucun enregistrement CAA n'est trouvé, l'AC est
censé remonter l'arbre du DNS. (C'est pour cela que SSL [sic]
Labs trouve un enregistrement CAA pour
mercredifiction.bortzmeyer.org : il a utilisé
le CAA du domaine parent, bortzmeyer.org.) Si example.com
n'a pas de CAA, l'AC va tester
.com, demandant ainsi à
Verisign si son client peut avoir un
certificat et de qui. Cette erreur consistant à grimper sur l'arbre
avait déjà été dénoncée dans le RFC 1535, mais apparemment
la leçon n'a pas été retenue.
Enfin, la section 6 du RFC analyse les différents problèmes de sécurité que peut poser CAA :
- Le respect de l'enregistrement CAA dépend de la bonne volonté de l'AC (et CAA ne remplace donc pas DANE),
- Sans DNSSEC, le test CAA est vulnérable à des attaques par exemple par empoisonnement (le RFC conseille de ne pas passer par un résolveur normal mais d'aller demander directement aux serveurs faisant autorité, ce qui ne résout pas le problème : le programme de test peut se faire empoisonner, lui aussi, d'autant plus qu'il prend sans doute moins de précautions qu'un résolveur sérieux),
- Et quelques autres risques plus exotiques.
Comme indiqué au début, le CA/Browser Forum a décidé que le test des CAA serait obligatoire à partir du 8 septembre 2017. (Cf. la décision.) Parmi les rares enregistrements CAA dans la nature, on trouve celui de Google, qui autorise deux AC :
% dig CAA google.com ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 55244 ;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1 ... ;; ANSWER SECTION: google.com. 86400 IN CAA 0 issue "pki.goog" google.com. 86400 IN CAA 0 issue "symantec.com" ...
(Le TLD .goog est
apparemment utilisé par Google pour son infrastructure,
.google étant plutôt pour les choses publiques.)
Notez que gmail.com, lui, pourtant souvent
détourné par des gouvernements et des entreprises qui veulent
surveiller le trafic, n'a pas d'enregistrement CAA.
Le célèbre SSL [sic] Labs teste la présence d'un
enregistrement CAA. S'il affiche « DNS Certification Authority Authorization (CAA) Policy found for
this domain », c'est bon. Regardez le
cas de Google.
Le type CAA est relativement récent (quatre ans quand même), donc il crée des problèmes amusants avec les serveurs DNS bogués comme ceux de BNP Paribas, qui timeoutent lorsque le type demandé n'est pas A :
% dig CAA mabanqueprivee.bnpparibas
; <<>> DiG 9.10.3-P4-Debian <<>> CAA mabanqueprivee.bnpparibas
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 42545
^^^^^^^^
Quelques lectures et ressources pour finir :
- Un bon article de synthèse par SSL Labs.
- Une aide interactive pour fabriquer un enregistrement CAA. Si vous avez un très vieux serveur DNS, et qu'il refuse de charger les enregistrements CAA, vous allez devoir utiliser la syntaxe générique du RFC 3597. Comme elle est un peu compliquée, le service ci-dessus, ainsi que ce service en ligne peuvent vous aider, en affichant à l'ancienne syntaxe.
- Cet article détaillé écrit par une AC note un grand nombre de problèmes et de limites de CAA.
- Dès le lendemain du début des tests CAA par les AC, Comodo (la société des auteurs du RFC) avait déjà violé les règles et émis un certficat qui n'aurait pas dû l'être.
- Let's Encrypt
vérifie bien les enregistrements CAA. Si on a un CAA indiquant une
autre AC, même pour un
domaine parent du domaine pour lequel on veut un certificat, Let's
Encrypt refuse avec une erreur de type
urn:acme:error:caa, « CAA record for DOMAIN_NAME prevents issuance ».
L'article seul
RFC 8228: Guidance on Designing Label Generation Rulesets (LGRs) Supporting Variant Labels
Date de publication du RFC : Août 2017
Auteur(s) du RFC : A. Freytag
Pour information
Première rédaction de cet article le 23 août 2017
Le RFC 7940 définissait un langage, LGR (Label Generation Ruleset), pour exprimer des politiques d'enregistrement de noms écrits en Unicode, avec les éventuelles variantes. Par exemple, avec LGR, on peut exprimer une politique disant que les caractères de l'alphabet latin et eux seuls sont autorisés, et que « é » est considéré équivalent à « e », « ç » à « c », etc. Ce nouveau RFC donne quelques conseils aux auteurs LGR. (Personnellement, je n'ai pas trouvé qu'il apportait grand'chose par rapport au RFC 7940.)
LGR peut s'appliquer à tous les cas où on a des identificateurs en Unicode mais il a surtout été développé pour les IDN (RFC 5890). Les exemples de ce RFC 8228 sont donc surtout pris dans ce domaine d'application. Un ensemble de règles exprimées dans le langage du RFC 7940 va définir deux choses :
- Si un nom donné est acceptable ou pas (dans l'exemple donné plus haut, un registre de noms de domaine ouest-européen peut décider de n'autoriser que l'alphabet latin),
- Et quels noms sont des variantes les
uns des autres. Une variante est un nom composé de caractères
Unicode différents mais qui est considéré comme « le même » (la
définition de ce que c'est que « le même » n'étant pas
technique ; par exemple, un anglophone peut considérer que
theatre et theater sont
« le même » mot, alors que, du point de vue technique, ce sont
deux chaînes de caractère
différentes). Le RFC dit que deux noms sont « le même » s'ils
sont visuellement similaires (
googlevs.goog1e), mais c'est une notion bien trop floue, et qui dépend en outre de la police de caractères utilisée (avec Courier,googleetgoog1esont difficilement distinguables). Le RFC ajoute qu'il y a également le cas de la similarité sémantique (le cas de theatre vs. theater, ou bien celui des sinogrammes traditionnels vs. les simplifiés ou encore, mais c'est compliqué, le cas des accents en français, avec « café » et « cafe » mais aussi avec « interne » et « interné »).
L'idée est que le registre utilise ensuite ces règles pour accepter ou refuser un nom et, si le nom est accepté, pour définir quelles variantes deviennent ainsi bloquées, ou bien attribuées automatiquement au même titulaire. Notez une nouvelle fois qu'il s'agit d'une décision politique et non technique. Le RFC dit d'ailleurs prudemment dans la section 1 qu'il ne sait pas si ce concept de variante est vraiment utile à quoi que ce soit. (J'ajoute qu'en général ce soi-disant risque de confusion a surtout été utilisé comme FUD anti-Unicode, par des gens qui n'ont jamais digéré la variété des écritures humaines.)
J'ai dit qu'une variante était « le même » que le nom de
base. Du point de vue mathématique, la relation « est une
variante de » doit donc être symétrique et
transitive (section 2). « Est une variante
de » est noté avec un tiret donc
A - B signifie « A est une variante de B »
(et réciproquement, vu la symétrie). Notez que le RFC 7940 utilisait un langage fondé sur
XML alors que ce RFC 8228
préfère une notation plus compacte. La section 18 de notre RFC
indique la correspondance entre la notation du RFC 7940 et celle du nouveau RFC.
Mais toutes les relations entre noms « proches » ne sont pas forcément symétriques et transitives. Ainsi, la relation « ressemble à » (le chiffre 1 ressemble à la lettre l minuscule) est non seulement vague (cela dépend en effet de la police) mais également non transitive (deux noms ressemblent chacun à un nom dont la forme est quelque part entre eux, sans pour autant se ressembler entre eux).
Le RFC 7940 permet de définir des relations qui ne sont ni symétriques, ni transitives. Mais ce nouveau RFC 8228 préfère les relations d'équivalence.
Bon, et maintenant, comment on crée les variantes d'un nom ou d'un composant d'un nom (section 6) ? On remplace chaque caractère du nom originel par toutes ses variantes possibles (le fait qu'un caractère correspond à un autre est noté -->). Ainsi, si on a décidé que « e » et « é » étaient équivalents (é --> e), le nom « interne » aura comme variantes possibles « interné », « intérne » et « intérné » (oui, une seule de ces variantes a un sens en français, je sais). Une fois cette génération de variantes faites, le registre, selon sa politique, pourra l'utiliser pour, par exemple, refuser l'enregistrement d'« interné » si « interne » est déjà pris (je le répète parce que c'est important : ce RFC ne décrit pas de politique, l'exemple ci-dessus n'est qu'un exemple).
En pratique, travailler caractère par caractère n'est pas toujours réaliste. Il y a des cas où c'est un groupe de caractères qui poserait problème. La section 7 introduit une amélioration où on peut étiqueter les correspondances de manière asymétrique. Le caractère x veut dire que l'allocation du nom est interdite (détails en section 9), le a qu'elle est autorisée (détails en section 8). On pourrait donc avoir « e x--> é » et « é a--> e » ce qui veut dire que la réservation de « interne » bloquerait celle d'« interné » mais pas le contraire.
Le monde des identificateurs étant très riche et complexe, on ne s'étonnera pas que des règles trop simples soient souvent prises en défaut. Ainsi, la variante peut dépendre du contexte : dans certaines écritures (comme l'arabe), la forme d'un caractère dépend de sa position dans le mot, et un même caractère peut donc entrainer de la confusion s'il est à la fin d'un mot mais pas s'il est au début. Il faut donc étiqueter les relations avec ce détail (par exemple, « final: C --> D » si le caractère noté C peut se confondre avec le caractère D mais uniquement si C est en fin de mot, cf. section 15 du RFC).
Si vous développez du LGR, au moins deux logiciels peuvent aider, celui de Viagénie, lgr-crore et lgr-django et un logiciel de l'auteur de ce RFC, développé pour le « ICANN Integration Panel work » mais qui ne semble pas publié.
L'article seul
RFC 8193: Information Model for Large-Scale Measurement Platforms (LMAPs)
Date de publication du RFC : Août 2017
Auteur(s) du RFC : T. Burbridge, P. Eardley (BT), M. Bagnulo (Universidad Carlos III de Madrid), J. Schoenwaelder (Jacobs University Bremen)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF lmap
Première rédaction de cet article le 22 août 2017
Ce RFC est l'un de ceux du groupe de travail IETF nommé LMAP, pour « Large-Scale Measurement Platforms ». Ce groupe développe des normes pour les systèmes de mesure à grande échelle, ceux où des centaines ou des milliers de sondes quantifient l'Internet. Il décrit le modèle de données utilisé.
Le projet LMAP est décrit dans les RFC 7536 (qui explique à quoi sert LMAP, avec deux exemples concrets) et RFC 7594 (qui normalise le vocabulaire et le cadre général). Pour résumer très vite, LMAP prévoit un Measurement Agent (la sonde) qui parle à un contrôleur, qui lui dit quoi faire, et à un collecteur, qui ramasse les données. Ce nouveau RFC décrit le modèle de données abstrait utilisé dans ces deux communications.
Rappelons que, dans le cadre défini pour LMAP, chaque MA (Measurement Agent) parle à un et un seul contrôleur, qui lui dit ce qu'il doit mesurer. (LMAP sépare le rôle du contrôleur et du collecteur, rôles que beaucoup de systèmes déployés fusionnent.) Il y a donc trois protocoles en jeu, le protocole de contrôle, entre le contrôleur et les MA, le protocole de collecte, entre les collecteurs et les MA, et enfin les protocoles utilisés dans les tests (ICMP ECHO, par exemple, mais aussi HTTP, DNS…) Enfin, il y a aussi la configuration nécessaire dans tous ces équipements. Tous ces points peuvent faire l'objet d'un travail de normalisation, mais ce RFC 8193 présente uniquement un modèle de données adapté au protocole de collecte et au protocole de contrôle.
La notion de modèle de données est expliquée dans le RFC 3444. En gros, il s'agit d'un modèle abstrait (très abstrait) décrivant quel genre de données sont échangées. Il peut se formaliser de manière un peu plus concrète par la suite, par exemple en utilisant le langage YANG (c'est justement ce que fait le RFC d'accompagnement, le RFC 8194). Un tel modèle sert à guider la normalisation, à faciliter la traduction d'un protocole dans un autre s'ils utilisent le même modèle de données, et à définir les données que doit mesurer et conserver le MA.
Le modèle défini ici utilise une notation formelle, utilisant
des types de données classiques en programmation (section 3 du RFC) :
int (un entier),
boolean (une valeur
logique), string, mais aussi des
types plus riches comme datetime ou uri.
Le modèle lui-même est dans la section 4 du RFC. Je rappelle qu'il suit le cadre du RFC 7594. Il a six parties :
- Informations de pré-configuration du MA (celle qui est faite en usine),
- Informations de configuration du MA,
- Instructions reçues par le MA (« envoie telle requête DNS à tel serveur, de telle heure à telle heure »),
- Journal du MA, avec des évènements comme le redémarrage de la sonde,
- État général du MA (« je sais faire des tests IPv6 »),
- Et bien sûr, le résultat des mesures, ce qui est l'information la plus importante.
Le MA peut également avoir d'autres informations, par exemple des détails sur son type de connectivité.
Pour donner des exemples concrets, je vais souvent citer les
sondes RIPE
Atlas, même si ce système, conçu avant le RFC, ne suis pas
exactement ce modèle. C'est sans doute l'un des plus grands, voire le plus
grand réseau de points de mesure dans le monde, avec près de
10 000 sondes connectées. Par exemple, pour la configuration, les
informations de pré-configuration d'une sonde Atlas comprennent
une adresse MAC et un identificateur, qu'on
peut voir sur la sonde : 
Les sondes sont également pré-configurées avec le nom du
contrôleur (qui sert également de collecteur). Elles acquièrent le
reste de leur configuration par
DHCP et SLAAC. Regardons par exemple la sonde
d'identificateur #21660, installée à
Cochabamba, on voit les adresses IP obtenues : 
Les sondes Atlas disposent également d'étiquettes
(tags) décrivant plus précisement certaines de
leurs caractéristiques. Certaines des étiquettes sont attribuées
manuellement par leur propriétaire (en bleu sur l'image ci-dessous), d'autres, qui peuvent être
déterminées automatiquement, sont mises par le système (en vert
sur l'image), et rentrent donc dans le cadre de la partie « état
général de la sonde » du modèle :
Les classes utilisées dans le modèle sont, entre autres :
- Les agendas (schedules) qui indiquent quelle tâche doit être accomplie,
- Les canaux de communication (channels),
- les configurations (task configurations),
- Les évènements (events), qui détaillent le moment où une tâche doit être exécutée.
Première partie, la pré-configuration (section 4.1). On y trouve les informations dont le MA aura besoin pour accomplir sa mission. Au minimum, il y aura un identificateur (par exemple l'adresse MAC), les coordonnées de son contrôleur (par exemple un nom de domaine, mais le RFC ne cite que le cas où ces coordonnées sont un URL, pour les protocoles de contrôle de type REST), peut-être des moyens d'authentification (comme le certificat de l'AC qui signera le certificat du contrôleur). URL et moyens d'authentification, ensemble, forment un canal de communication.
Dans le langage formel de ce modèle, cela fait :
object {
[uuid ma-preconfig-agent-id;]
ma-task-obj ma-preconfig-control-tasks<1..*>;
ma-channel-obj ma-preconfig-control-channels<1..*>;
ma-schedule-obj ma-preconfig-control-schedules<1..*>;
[uri ma-preconfig-device-id;]
credentials ma-preconfig-credentials;
} ma-preconfig-obj;
Cela se lit ainsi : l'information de pré-configuration (type
ma-preconfig-obj) comprend
divers attributs dont un identificateur (qui est un
UUID, on a vu que les Atlas utilisaient un
autre type d'identificateurs), des canaux de communication avec le
contrôleur, et des lettres de créance à présenter pour
s'authentifier. Notez que l'identificateur est optionnel (entre
crochets).
Vous avez compris le principe ? On peut passer à la suite plus rapidement (je ne vais pas répéter les déclarations formelles, voyez le RFC). La configuration (section 4.2) stocke les informations volatiles (la pré-configuration étant consacrée aux informations plus stables, typiquement stockées sur une mémoire permanente).
Les instructions (section 4.3) sont les tâches que va accomplir la sonde, ainsi que l'agenda d'exécution, et bien sûr les canaux utilisé pour transmettre les résultats. La journalisation (section 4.4) permet d'enregistrer les problèmes (« mon résolveur DNS ne marche plus ») ou les évènements (« le courant a été coupé »).
Il ne sert évidemment à rien de faire des mesures si on ne transmet pas le résultat. D'où la section 4.6, sur la transmission des résultats de mesure au collecteur. La communication se fait via les canaux décrits en section 4.8.
Une dernière photo, pour clore cet article, une sonde RIPE
Atlas en fonctionnement, et une autre sonde, la SamKnows : 
Merci à André Sintzoff pour avoir trouvé de grosses fautes.
L'article seul
jq, traiter du JSON en ligne de commande
Première rédaction de cet article le 9 août 2017
Aujourd'hui, énormément de données sont distribuées dans le format JSON. La simplicité de ce format, normalisé dans le RFC 8259, et bien sûr son utilisation dans JavaScript expliquent ce succès. Pour le transport de données (celui du texte est une autre histoire), JSON a largement remplacé XML. Il existe donc des bibliothèques pour traiter le JSON dans tous les langages de programmation. Mais si on veut une solution plus simple, permettant de traiter du JSON depuis la ligne de commande ? C'est là qu'intervient jq, qui permet à la fois de faire des opérations simples en ligne de commande sur des données JSON, et de programmer des opérations complexes, si nécessaires.
jq est parfois présenté comme « l'équivalent de sed pour JSON ». Ce n'est pas faux, puisqu'il permet en effet des opérations simples depuis la ligne de commande. Mais c'est assez court, comme description : jq est bien plus que cela, il inclut même un langage de programmation complet.
Commençons par quelques exemples simples. On va utiliser le JSON produit en utilisant l'outil madonctl pour récupérer des messages (les pouètes) envoyées sur Mastodon. Si je fais :
% madonctl --output json timeline :afnic
[{"id":3221183,"uri":"tag:mastodon.social,2017-07-20:objectId=13220936:objectType=Status","url":"https://mastodon.soc
ial/users/afnic/updates/3830115","account":{"id":37388,"username":"afnic","acct":"afnic@mastodon.social","display_nam
e":"Afnic","note":"\u003cp\u003eLe registre des noms de domaine en .fr\u003cbr\u003eRdv sur \u003ca href=\"http://www
.afnic.fr/\" rel=\"nofollow noopener\" target=\"_blank\"\u003e ...
J'ai récupéré les pouètes qui parlent de l'AFNIC, sous forme d'une seule ligne de JSON, peu lisible. Alors qu'avec jq :
% madonctl --output json timeline :afnic | jq .
[
{
"id": 3221183,
"uri": "tag:mastodon.social,2017-07-20:objectId=13220936:objectType=Status",
"url": "https://mastodon.social/users/afnic/updates/3830115",
"account": {
"id": 37388,
"username": "afnic",
"acct": "afnic@mastodon.social",
"display_name": "Afnic",
"note": "<p>Le registre des noms de domaine en .fr<br>Rdv sur <a href=\"http://www.afnic.fr/\" rel=\"nofollow n
oopener\" target=\"_blank\"><span class=\"invisible\">http://www.</span><span class=\"\">afnic.fr/</span><span class=
\"invisible\"></span></a></p>",
"url": "https://mastodon.social/@afnic",
J'ai au contraire du beau JSON bien lisible. C'est la première utilisation de jq pour beaucoup d'utilisateurs, dans un monde où les services REST fabriquent en général du JSON très compact (peut-être pour gagner quelques octets), jq peut servir de pretty-printer.
Le point après la commande
jq est un filtre. jq
fonctionne par enchainement de filtres et, par défaut, produit des
données JSON joliment formatées. (Si, par contre, on ne veut pas
de pretty-printing, on lance jq avec l'option
--compact-output.)
Prenons un exemple où on veut sélectionner une seule information dans un fichier JSON. Mettons qu'on utilise RDAP (RFC 9082) pour trouver de l'information sur une adresse IP. RDAP produit du JSON :
% curl -s http://rdap.db.ripe.net/ip/2001:1470:8000:53::44
{
"handle" : "2001:1470:8000::/48",
"startAddress" : "2001:1470:8000::/128",
"endAddress" : "2001:1470:8000:ffff:ffff:ffff:ffff:ffff/128",
"ipVersion" : "v6",
"name" : "ARNES-IPv6-NET",
"type" : "ASSIGNED",
"country" : "SI",
...
Si on ne veut que le pays du titulaire d'un préfixe d'adresses
IP, c'est simple avec jq, avec le filtre
.country qui veut dire « le champ
country de l'objet JSON
(. étant le texte JSON de plus haut niveau,
ici un objet) » :
% curl -s http://rdap.db.ripe.net/ip/131.111.150.25 | jq .country "GB" % curl -s http://rdap.db.ripe.net/ip/192.134.1.1 | jq .country "FR"
On n'aurait pas pu utiliser les outils ligne de commande classiques comme grep ou sed car le format JSON n'est pas orienté ligne (et a trop de subtilités pour eux).
Et si on veut interroger son nœud Bitcoin pour connaitre à quel bloc il en est :
% bitcoin-cli getinfo | jq .blocks 478280
Cet exemple particulier n'est pas super-intéressant, on a déjà
bitcoin-cli getblockcount mais cela montre
bien qu'on peut utiliser jq très simplement, pour des tâches
d'administration système.
Au passage, pour trouver le filtre à utiliser, il faut connaitre la structure du fichier JSON. On peut lire la documentation (dans l'exemple RDAP ci-dessus, c'est le RFC 9083) mais c'est parfois un peu compliqué alors que JSON, étant un format texte, fournit une solution plus simple : afficher le début du fichier JSON et repérer les choses qui nous intéressent. (Un format binaire comme CBOR, RFC 8949, ne permet pas cela.) Cette méthode peut sembler du bricolage, mais l'expérience prouve que les services REST n'ont pas toujours de documentation ou, lorsqu'ils en ont, elle est souvent fausse. Donc, savoir explorer du JSON est utile.
Notez que jq produit du JSON, donc les chaînes de caractères
sont entre guillemets. Si on veut juste le
texte, on utilise l'option --raw-output :
% curl -s http://rdap.db.ripe.net/ip/2001:1470:8000:53::44 | jq --raw-output .country
SI
Et si on veut un membre d'un objet qui est lui-même un membre de l'objet de plus haut niveau ? On crée un filtre avec les deux clés :
% echo '{"foo": {"zataz": null, "bar": 42}}' | jq .foo.bar
42
Un exemple réel d'un tel « double déréférencement » serait avec l'API de GitHub, ici pour afficher tous les messages de commit :
% curl -s https://api.github.com/repos/bortzmeyer/check-soa/commits | \
jq --raw-output '.[].commit.message'
New rules for the Go linker (see <http://stackoverflow.com/questions/32468283/how-to-contain-space-in-value-string-of-link-flag-when-using-go-build>)
Stupid regression to bug #8. Fixed.
Timeout problem with TCP
Query the NN RRset with EDNS. Closes #9
Stupidest bug possible: I forgot to break the loop when we got a reply
TCP support
...
Et si le texte JSON était formé d'un tableau et pas d'un objet (rappel : un objet JSON est un dictionnaire) ? jq permet d'obtenir le nième élément d'un tableau (ici, le quatrième, le premier ayant l'indice 0) :
% echo '[1, 2, 3, 5, 8]' | jq '.[3]'
5
(Il a fallu mettre le filtre entre apostrophes car les crochets sont des caractère spéciaux pour le shell Unix.)
Revenons aux exemples réels. Si on veut le cours du Bitcoin en euros, CoinDesk nous fournit une API REST pour cela. On a juste à faire un triple accès :
% curl -s https://api.coindesk.com/v1/bpi/currentprice.json | jq .bpi.EUR.rate
"2,315.7568"
Notez que le cours est exprimé sous forme d'une chaîne de caractères, pas d'un nombre, et qu'il n'est pas à la syntaxe correcte d'un nombre JSON. C'est un des inconvénients de JSON : ce format est un tel succès que tout le monde en fait, et souvent de manière incorrecte. (Sinon, regardez une solution sans jq mais avec sed.)
Maintenant, on veut la liste des comptes
Mastodon qui ont pouèté au sujet de
l'ANSSI. Le résultat de la requête
madonctl --output json timeline :anssi est un
tableau. On va devoir
itérer sur ce tableau, ce qui se fait avec
le filtre [] (déjà utilisé plus haut dans l'exemple GitHub), et faire un double
déréférencement, le membre account puis le
membre acct :
% madonctl --output json timeline :anssi | jq '.[].account.acct'
"nschont@mastodon.etalab.gouv.fr"
"ChristopheCazin@mastodon.etalab.gouv.fr"
"barnault@mastodon.etalab.gouv.fr"
...
Parfait, on a bien notre résultat. Mais le collègue qui avait demandé ce travail nous dit qu'il faudrait éliminer les doublons, et trier les comptes par ordre alphabétique. Pas de problème, jq dispose d'un grand nombre de fonctions pré-définies, chaînées avec la barre verticale (ce qui ne déroutera pas les utilisateurs Unix) :
% madonctl --output json timeline :anssi | jq '[.[].account.acct] | unique | .[]' "ChristopheCazin@mastodon.etalab.gouv.fr" "G4RU" "Sangokuss@framapiaf.org" ...
Oulah, ça devient compliqué ! unique se comprend sans difficulté mais c'est
quoi, tous ces crochets en plus ? Comme
unique travaille sur un tableau, il a fallu en
fabriquer un : les crochets extérieurs dans l'expression
[.[].account.acct] disent à jq de faire un
tableau avec tous les .account.acct
extraits. (On peut aussi fabriquer un objet JSON et je rappelle que
objet = dictionnaire.) Une fois ce tableau
fait, unique
peut bien travailler mais le résultat sera alors un tableau :
% madonctl --output json timeline :anssi | jq '[.[].account.acct] | unique' [ "ChristopheCazin@mastodon.etalab.gouv.fr", "G4RU", "Sangokuss@framapiaf.org", ...
Si on veut « aplatir » ce tableau, et avoir juste une suite de
chaînes de caractères, il faut refaire une itération à la fin (le
.[]).
(Les Unixiens expérimentés savent qu'il existe
uniq et sort comme commandes Unix et
qu'on aurait aussi pu faire jq '.[].account.acct' | sort
| uniq. Chacun ses goûts. Notez aussi qu'il n'y a pas
besoin d'un tri explicite en jq : unique trie
le tableau avant d'éliminer les doublons.)
J'ai dit un peu plus haut que jq pouvait construire des textes
JSON structurés comme les tableaux. Ça marche aussi avec les
objets, en indiquant la clé et la valeur de chaque membre. Par
exemple, si je veux un tableau dont les éléments sont des objets
où la clé href désigne l'URL d'un pouète
Mastodon (ici, les pouètes ayant utilisé le
mot-croisillon « slovénie ») :
% madonctl --output json timeline :slovénie | jq "[.[] | { href: .url }]"
[
{
"href": "https://mastodon.gougere.fr/users/bortzmeyer/updates/40282"
},
{
"href": "https://mamot.fr/@Nighten_Dushi/3131270"
},
{
"href": "https://mastodon.cx/users/DirectActus/updates/29810"
}
]
Les accolades entourant la deuxième partie
du programme jq indiquent de construire un objet, dont on indique comme clé
href et comme valeur le membre
url de l'objet original.
Rappelez-vous, jq ne sert pas qu'à des filtrages ultra-simples
d'un champ de l'objet JSON. On peut écrire de vrais programmes et
il peut donc être préférable de les mettre dans un fichier. (Il
existe évidemment un mode Emacs pour éditer
plus agréablement ces fichiers source,
jq-mode.)
Si le fichier accounts.jq contient :
# From a Mastodon JSON file, extract the accounts [.[].account.acct] | unique | .[]
Alors, on pourra afficher tous les comptes (on se ressert de
--raw-output pour ne pas avoir d'inutiles
guillemets) :
% madonctl --output json timeline :anssi | jq --raw-output --from-file accounts.jq ChristopheCazin@mastodon.etalab.gouv.fr G4RU Sangokuss@framapiaf.org ...
Mais on peut vouloir formater des résultats sous une forme de
texte, par exemple pour inclusion dans un message ou un
rapport. Reprenons notre nœud Bitcoin et
affichons la liste des pairs (Bitcoin est un réseau
pair-à-pair), en les classant selon le
RTT décroissant. On met ça dans le fichier bitcoin.jq :
"You have " + (length | tostring) + " peers. From the closest (network-wise) to the furthest away",
([.[] | {"address": .addr, "rtt": .pingtime}] | sort_by(.rtt) |
.[] | ("Peer " + .address + ": " + (.rtt|tostring) + " ms"))
Et on peut faire :
% bitcoin-cli getpeerinfo | jq --raw-output --from-file bitcoin.jq
You have 62 peers. From the closest (network-wise) to the furthest away
Peer 10.105.127.82:38806: 0.00274 ms
Peer 192.0.2.130:8333: 0.003272 ms
Peer [2001:db8:210:5046::2]:33567: 0.014099 ms
...
On a utilisé des constructions de tableaux et d'objets, la
possibilité de trier sur un critère quelconque (ici la valeur de
rtt, en paramètre à sort_by) et des fonctions utiles pour l'affichage
de messages : le signe plus indique la
concaténation de chaînes, et la fonction
tostring transforme un entier en chaîne de
caractères (jq ne fait pas de conversion de type implicite).
jq a également des fonctions pré-définies pour faire de
l'arithmétique. Utilisons-les pour analyser les résultats de
mesures faites par des sondes
RIPE Atlas. Une fois une mesure lancée (par exemple la
mesure de RTT
#9211624,
qui a été créée par la commande atlas-reach -r 100 -t 1
2001:500:2e::1, cf. mon article « Using RIPE Atlas to Debug Network Connectivity Problems »),
les résultats peuvent être récupérés sous forme d'un fichier JSON
(à l'URL
https://atlas.ripe.net/api/v2/measurements/9211624/results/). Cherchons
d'abord le RTT maximal :
% jq '[.[].result[0].rtt] | max' < 9211624.json
505.52918
On a pris le premier élément du tableau car, pour cette mesure,
chaque sonde ne faisait qu'un test. Ensuite, on utilise les
techniques jq déjà vues, plus la fonction
max (qui prend comme argument un tableau, il
a donc fallu construire un tableau). La sonde la plus lointaine de l'amer est donc à plus de 500 millisecondes. Et le
RTT minimum ? Essayons la fonction min
% jq '[.[].result[0].rtt] | min' < 9211624.json
null
Ah, zut, certaines sondes n'ont pas réussi et on n'a donc pas de
RTT, ce que jq traduit en null. Il faut donc
éliminer du tableau ces échecs. jq permet de tester une valeur,
avec select. Par exemple,
(select(. != null) va tester que la valeur
existe. Et une autre fonction jq, map, bien
connue des programmeurs qui aiment le style fonctionnel, permet
d'appliquer une fonction à tous les éléments d'un tableau. Donc,
réessayons :
% jq '[.[].result[0].rtt] | map(select(. != null)) | min' < 9211624.json
1.227755
C'est parfait, une milli-seconde pour la sonde la plus
proche. Notez que, comme map prend un tableau
en entrée et rend un tableau, on aurait aussi pu l'utiliser au
début, à la place des crochets :
% jq 'map(.result[0].rtt) | map(select(. != null)) | min' < 9211624.json
1.227755
Et la moyenne des RTT ? On va utiliser
les fonctions
add (additionner tous les éléments du
tableau) et length (longueur du tableau) :
% jq '[.[].result[0].rtt] | add / length' < 9211624.json
76.49538228
(Il y a une faille dans le programme, les valeurs nulles auraient dû être exclues. Je vous laisse modifier le code.) La moyenne n'est pas toujours très utile quand on mesure des RTT. C'est une métrique peu robuste, que quelques outliers suffisent à perturber. Il est en général bien préférable d'utiliser la médiane. Une façon simple de la calculer est de trier le tableau et de prendre l'élément du milieu (ou le plus proche du milieu) :
% jq '[.[].result[0].rtt] | sort | .[length/2]' < 9211624.json 43.853845
On voit que la médiane est bien plus petite que la moyenne, quelques
énormes RTT ont en effet tiré la moyenne vers le haut. J'ai un peu
triché dans le filtre jq ci-dessus car il ne marche que pour des
tableaux de taille paire. Si elle est impaire,
length/2 ne donnera pas un nombre entier et on
récupérera null. Corrigeons, ce sera l'occasion
d'utiliser pour la première fois la structure de contrôle
if. Notez qu'une expression jq doit toujours
renvoyer quelque chose (les utilisateurs de langages
fonctionnels comme Haskell ne
seront pas surpris par cette règle), donc pas de if sans une
branche else :
% jq '[.[].result[0].rtt] | sort | if length % 2 == 0 then .[length/2] else .[(length-1)/2] end' < 9211624.json 43.853845
Et maintenant, si on veut la totale, les quatre métriques avec du texte, on mettra ceci dans le fichier source jq. On a utilisé un nouvel opérateur, la virgule, qui permet de lancer plusieurs filtres sur les mêmes données :
map(.result[0].rtt) | "Median: " + (sort |
if length % 2 == 0 then .[length/2] else .[(length-1)/2] end |
tostring),
"Average: " + (map(select(. != null)) | add/length | tostring),
"Min: " + (map(select(. != null)) | min | tostring),
"Max: " + (max | tostring)
Et cela nous donne :
% jq --raw-output --from-file atlas-rtt.jq < 9211624.json
Median: 43.853845
Average: 77.26806290909092
Min: 1.227755
Max: 505.52918
Peut-on passer des arguments à un programme jq ?
Évidemment. Voyons un exemple avec la base des « espaces blancs »
décrite dans le RFC 7545. On va chercher la
puissance d'émission maximale autorisée pour une fréquence
donnée, avec ce script jq, qui contient la variable
frequency, et qui cherche une plage de
fréquences (entre startHz et
stopHz) comprenant cette fréquence :
.result.spectrumSchedules[0].spectra[0].frequencyRanges[] |
select (.startHz <= ($frequency|tonumber) and .stopHz >= ($frequency|tonumber)) |
.maxPowerDBm
On l'appelle en passant la fréquence où on souhaite émettre :
% jq --from-file paws.jq --arg frequency 5.2E8 paws-chicago.json
15.99999928972511
(Ne l'utilisez pas telle quelle : par principe, les espaces blancs ne sont pas les mêmes partout. Celui-ci était pour Chicago en juillet 2017.)
Il est souvent utile, quand on joue avec des données, de les
grouper par une certaine caractéristique, par exemple pour compter
le nombre d'occurrences d'un certain phénomène, ou bien pour
classer. C'est le classique GROUP BY de
SQL, qui a son équivalent en jq. Revenons à
la liste des comptes Mastodon qui ont pouèté sur
l'ANSSI et affichons combien chacun a émis
de pouètes. On va grouper les pouètes par compte, fabriquer
un objet JSON dont les clés sont le compte, le trier, puis afficher le résultat. Avec ce code jq :
# Count the number of occurrences
[.[].account] | group_by(.acct) |
# Create an array of objects {account, number}
[.[] | {"account": .[0].acct, "number": length}] |
# Now sort
sort_by(.number) | reverse |
# Now, display
.[] | .account + ": " + (.number | tostring)
On obtiendra :
% madonctl --output json timeline :anssi | jq -r -f anssi.jq
gapz@mstdn.fr: 4
alatitude77@mastodon.social: 4
nschont@mastodon.etalab.gouv.fr: 2
zorglubu@framapiaf.org: 1
sb_51_@mastodon.xyz: 1
Voilà, on a bien avancé et je n'ai toujours pas donné
d'exemple avec le DNS. Un autre cas
d'utilisation de select va y pourvoir. Le
DNS Looking Glass peut produire
des résultats en JSON, par exemple ici le
SOA du TLD
.xxx : curl
-s -H 'Accept: application/json'
https://dns.bortzmeyer.org/xxx/SOA. Si je veux juste le
numéro de série de cet enregistrement SOA ?
% curl -s -H 'Accept: application/json' https://dns.bortzmeyer.org/xxx/SOA | \
jq '.AnswerSection[0].Serial'
2011210193
Mais il y a un piège. En prenant le premier élément de la
Answer Section, j'ai supposé qu'il s'agissait
bien du SOA demandé. Mais l'ordre des éléments dans les sections
DNS n'est pas défini. Par exemple, si une signature
DNSSEC est renvoyée, elle sera peut-être le
premier élément. Il faut donc être plus subtil, et utiliser
select pour ne garder que la réponse de type SOA :
% curl -s -H 'Accept: application/json' https://dns.bortzmeyer.org/xxx/SOA | \
jq '.AnswerSection | map(select(.Type=="SOA")) | .[0].Serial'
2011210193
Notre code jq est désormais plus robuste. Ainsi, sur un nom qui a plusieurs adresses IP, on peut ne tester que celles de type IPv6, ignorant les autres, ainsi que les autres enregistrements que le serveur DNS a pu renvoyer :
% curl -s -H 'Accept: application/json' https://dns.bortzmeyer.org/gmail.com/ADDR | \
jq '.AnswerSection | map(select(.Type=="AAAA")) | .[] | .Address'
"2607:f8b0:4006:810::2005"
Bon, on approche de la fin, vous devez être fatigué·e·s, mais encore deux exemples, pour illustrer des trucs et concepts utiles. D'abord, le cas où une clé dans un objet JSON n'a pas la syntaxe d'un identificateur jq. C'est le cas du JSON produit par le compilateur Solidity. Si je compile ainsi :
% solc --combined-json=abi registry.sol > abi-registry.json
Le JSON produit a deux défauts. Le premier est que certains utilisateurs ont une syntaxe inhabituelle (des points dans la clé, et le caractère deux-points) :
{"registry.sol:Registry": {"abi": ...
jq n'accepte pas cette clé comme filtre :
% jq '.contracts.registry.sol:Registry.abi' abi-registry.json jq: error: syntax error, unexpected ':', expecting $end (Unix shell quoting issues?) at <top-level>, line 1: .contracts.registry.sol:Registry.abi jq: 1 compile error
Corrigeons cela en mettant la clé bizarre entre guillemets :
% jq '.contracts."registry.sol:Registry".abi' abi-registry.json
On récupère ainsi l'ABI du
contrat.
Mais, et là c'est gravement nul de la part du compilateur, l'ABI est
une chaîne de caractères à évaluer pour en faire du vrai JSON !
Heureusement, jq a tout ce qu'il faut pour cette évaluation, avec la
fonction fromjson :
% jq '.contracts."registry.sol:Registry".abi | fromjson' abi-registry.json
Ce problème des clés qui ne sont pas des identificateurs à la
syntaxe traditionnelle se pose aussi si l'auteur du JSON a choisi,
comme la norme le lui permet, d'utiliser des caractères
non-ASCII pour les identificateurs. Prenons
par exemple le fichier JSON des verbes
conjugués du
français, en https://github.com/Drulac/Verbes-Francais-Conjugues
[{ "Indicatif" : { "Présent" : [ "abade", "abades", "abade", "abadons", "abadez", "abadent" ], "Passé composé" : [ "abadé", "abadé", "abadé", "abadé", "abadé", "abadé" ], "Imparfait" : [ "abadais", "abadais", "abadait", "abadions", "abadiez", "abadaient" ], "Plus-que-parfait" : [ "abadé", "abadé", "abadé", "abadé", "abadé", "abadé" ], "Passé simple" : [ "abadai", "abadas", "abada", "abadâmes", "abadâtes", "abadèrent" ], "Passé antérieur" : [ "abadé", "abadé", "abadé", "abadé", "abadé", "abadé" ], ...
Il faut donc mettre les clés non-ASCII entre guillemets. Ici, la conjugaison du verbe « reposer » :
% jq 'map(select(.Infinitif."Présent"[0] == "reposer"))' verbs.json
[
{
"Indicatif": {
"Présent": [
"repose",
"reposes",
"repose",
...
Notez toutefois que jq met tout en mémoire. Cela peut l'empêcher de lire de gros fichiers :
% ls -lh la-crime.json -rw-r--r-- 1 stephane stephane 798M Sep 9 19:09 la-crime.json % jq .data la-crime.json error: cannot allocate memory zsh: abort jq .data la-crime.json
Et un dernier exemple, pour montrer les manipulations de date en
jq, ainsi que la définition de fonctions. On va
utiliser l'API d'Icinga pour récupérer
l'activité de la supervision. La commande curl -k
-s -u operator:XXXXXXX -H 'Accept: application/json' -X POST
'https://ADRESSE:PORT/v1/events?types=StateChange&queue=operator'
va nous donner les changements d'état des machines et des services
supervisés. Le résultat de cette commande est du JSON : on souhaite
maintenant le formater de manière plus
compacte et lisible. Un des membres JSON est une date
écrite sous forme d'un nombre de secondes depuis une
epoch. On
va donc la convertir en jolie date avec la fonction
todate. Ensuite, les états Icinga
(.state) sont affichés
par des nombres (0 = OK, 1 = Avertissement, etc.), ce qui n'est pas
très agréable. On les
convertit en chaînes de caractères, et mettre cette conversion dans
une fonction, s2n :
def s2n(s):
if s==0 then "OK" else if s==1 then "Warning" else "Critical" end end;
(.timestamp | todate) + " " + .host + " " + .service + " " + " " + s2n(.state) +
" " + .check_result.output
Avec ce code, on peut désormais exécuter :
% curl -k -s -u operator:XXXXXXX -H 'Accept: application/json' -X POST 'https://ADRESSE:PORT/v1/events?types=StateChange&queue=operator' | \ jq --raw-output --unbuffered --from-file logicinga.jq ... 2017-08-08T19:12:47Z server1 example Critical HTTP CRITICAL: HTTP/1.1 200 OK - string 'Welcome' not found on 'http://www.example.com:80/' - 1924 bytes in 0.170 second response time
Quelques lectures pour aller plus loin :
- La page officielle de jq, avec son excellent manuel, une bonne FAQ et plein d'exemples d'utilisation de jq.
- En parlant de manuel, la man page de jq est très complète.
- On trouve aussi un tutoriel officiel mais très court, c'est juste un début d'introduction. Je préfère le tutoriel « Reshaping JSON with jq », avec ses exemples tirés du monde des musées.
- Autre application pratique de jq, pour la cartographie, un tutoriel par l'exemple.
- Il existe un logiciel proche de jq mais où le langage de programmation est Python, pjy.
- Un autre système spécialisé pour traiter du JSON est le langage JMESPath. Il dispose d'une mise en œuvre en ligne de commande, jp.
- Et une troisième alternative à jq est jshon.
- Enfin, il y a le langage JSONPath, normalisé dans le RFC 9535, mis en œuvre, par exemple dans le programme jpq.
- Un article en français sur l'utilisation de jq pour fouiller dans les données Twitter : l'analyse du hashtag #TelAvivSurSeine.
- Et bien sûr comme d'habitude l'incontournable StackOverflow.
Merci à Jean-Edouard Babin et Manuel Pégourié-Gonnard pour la correction d'une grosse bogue dans la première version de cet article.
L'article seul
RFC 8198: Aggressive Use of DNSSEC-Validated Cache
Date de publication du RFC : Juillet 2017
Auteur(s) du RFC : K. Fujiwara (JPRS), A. Kato
(Keio/WIDE), W. Kumari (Google)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 26 juillet 2017
Lorqu'un client DNS interroge un résolveur, celui-ci peut répondre très vite si l'information demandée est dans sa mémoire (son « cache ») mais cela peut être beaucoup plus lent s'il faut aller demander aux serveurs faisant autorité. Il est donc essentiel, pour les performances du DNS, d'utiliser le cache le plus possible. Traditionnellement, le résolveur n'utilisait le cache que si la question posée par le client avait une réponse exacte dans le cache. Mais l'arrivée de DNSSEC autorise un usage plus énergique et plus efficace du cache : ce nouveau RFC permet aux résolveurs de synthétiser des réponses à partir des informations DNSSEC.
Comment peut-il faire ? Eh bien prenons par exemple les
enregistrements NSEC. Ils indiquent une
plage où il n'y a pas de noms enregistrés. Ainsi, si une zone
example.com contient :
albatross IN AAAA 2001:db8:1028::a:1
elephant IN AAAA 2001:db8:1028::a:2
zebra IN AAAA 2001:db8:1028::a:3
Sa signature DNSSEC va ajouter des enregistrements NSEC, notamment :
albatross.example.com. IN NSEC elephant.example.com. AAAA
qui veut dire qu'il n'y a pas de nom entre
albatross et elephant. Si le
client interroge le résolveur à propos de
cat.example.com, le résolveur ira voir les
serveurs faisant autorité, il aura une réponse négative
(NXDOMAIN, ce nom n'existe pas) et l'enregistrement NSEC. Les deux
informations seront renvoyées au client, et pourront être mémorisées dans le cache. Maintenant,
si le client demande dog.example.com, les
résolveurs traditionnels retourneront demander aux serveurs faisant
autorité. Alors que les résolveurs modernes, conformes à ce nouveau
RFC 8198, pourront déduire du NSEC que
dog.example.com n'existe pas non plus, et
immédiatement générer un NXDOMAIN pour le client. Cela fera gagner du
temps et des efforts à tout le monde. (Les règles exactes sont
dans la section 5.1 de notre RFC.)
La règle (désormais dépassée) comme quoi le résolveur ne peut répondre immédiatement que s'il a l'information correspondant à la question exacte est spécifiée dans le RFC 2308, pour le cache négatif (mémoriser les réponses NXDOMAIN). Désormais, elle n'est plus obligatoire si (et seulement si, voir section 9) le résolveur valide avec DNSSEC, et si la zone est signée (aucun changement si elle ne l'est pas). Outre le cas simple de NSEC avec des réponses négatives, présenté plus haut, il y a deux cas plus complexes, les enregistrements NSEC3, et les jokers. Si la zone est signée avec NSEC3 au lieu de NSEC, les enregistrements NSEC3 indiqueront des condensats et pas des noms et le résolveur devra donc condenser le nom demandé, pour voir s'il tombe dans un NSEC3 connu, et si on peut synthétiser le NXDOMAIN. Les règles exactes sur les NSEC3 sont dans le RFC 5155 (attention, c'est compliqué), sections 8.4 à 8.7, et dans notre RFC, section 5.2. Évidemment, si la zone est signée avec l'option « opt-out » (c'est le cas de la plupart des TLD), le résolveur ne peut pas être sûr qu'il n'y a pas un nom non signé dans une plage indiquée par un enregistrement NSEC, et ne peut donc pas synthétiser. Tout aussi évidemment, toute solution qui empêchera réellement l'énumération des noms dans une zone signée (comme le projet, désormais abandonné, NSEC5) sera incompatible avec cette solution.
Si la zone inclut des jokers (RFC 1034,
section 4.3.3), par exemple example.org :
avocado IN A 192.0.2.1 * IN A 192.0.2.2 zucchini IN A 192.0.2.3
Alors, le résolveur pourra également synthétiser des réponses positives. S'il a
déjà récupéré et mémorisé le joker, et que le client lui demande
l'adresse IPv4 de
leek.example.org, le résolveur pourra tout de
suite répondre 192.0.2.2. (J'ai simplifié : le
résolveur doit aussi vérifier que le nom
leek.example.org n'existe pas, ou en tout cas n'a
pas d'enregistrement A. Le joker ne masque en effet pas les noms
existants. Détails en section 5.3 du RFC.)
Pour cette utilisation plus énergique de la mémoire d'un résolveur validant, il a fallu amender légèrement le RFC 4035, dont la section 4.5 ne permettait pas cette synthèse de réponses (la nouvelle rédaction est en section 7). Notez un inconvénient potentiel de cette synthèse : un nom ajouté ne sera pas visible tout de suite. Mais c'est de toute façon une propriété générale du DNS et de ses caches souvent appelée, par erreur, « durée de propagation ».
La durée exacte pendant laquelle le résolveur « énergique » pourra garder les informations qui lui servent à la synthèse des réponses est donnée par le TTL des NSEC.
Quel intérêt à cette synthèse énergique de réponses ? Comme indiqué plus haut, cela permet de diminuer le temps de réponse (section 6). Du fait de la diminution de nombre de questions à transmettre, cela se traduira également par une diminution de la charge, et du résolveur, et du serveur faisant autorité. Sur la racine du DNS, comme 65 % des requêtes entrainent un NXDOMAIN (voir par exemple les statistiques de A-root), le gain devrait être important. Un autre avantage sera pour la lutte contre les attaques dites « random QNAMEs » lorsque l'attaquant envoie plein de requêtes pour des noms aléatoires (générant donc des NXDOMAIN). Si l'attaquant passe par un résolveur, celui-ci pourra écluser la grande majorité des requêtes sans déranger le serveur faisant autorité.
Mais la synthèse énergique entraine aussi un gain en matière de vie privée (cf. RFC 7626) : les serveurs faisant autorité verront encore moins de questions.
Cette technique de « cache négatif énergique » avait été proposée pour la première fois dans la section 6 du RFC 5074. Elle s'inscrit dans une série de propositions visant à augmenter l'efficacité des caches DNS, comme le « NXDOMAIN cut » du RFC 8020. La synthèse énergique de réponses prolonge le RFC 8020, en allant plus loin (mais elle nécessite DNSSEC).
Il semble que Google Public DNS mette déjà en œuvre une partie (les réponses négatives) de ce RFC, mais je n'ai pas encore vérifié personnellement.
L'article seul
Conférence climagic sur la ligne de commande et ses beautés
Première rédaction de cet article le 20 juillet 2017
Le 19 juillet 2017, à Prague, Mark Krenz, le fondateur et animateur du fameux compte Twitter climagic (Command-Line interface magic), profitait de ses vacances en Europe pour faire un exposé sur la ligne de commande, ses beautés, et le projet climagic. Ça m'a fait rater la séance plénière de l'IETF 99 mais ça valait la peine. (Pour ce·ux·lles qui n'étaient pas à Prague, les pauvres, l'exposé est visible chez Google.)
L'exposé se tenait à la ČVUT (excellents locaux, vue magnifique sur la ville depuis le 14e étage). La grande salle était presque pleine. Comme on s'en doute, il n'y avait que trois ou quatre femmes.
La thèse centrale de Mark Krenz est que la ligne de commande n'est pas une survivance du passé, qu'on garde par habitude, ou par nostalgie. C'est toujours un outil puissant et efficace pour les professionnels (comme un de ses enfants lui avait dit une fois, lorsque le réseau était en panne, « open the black window and type text, to fix the network »). Le concept n'est en outre pas spécifique à Unix, Mark Krenz a cité l'ARexx d'Amiga. Une des preuves de cette pertinence de la ligne de commande est que désormais même Windows a une ligne de commandes de qualité raisonnable, Powershell. L'orateur a ensuite illustré ce point de vue de nombreux exemples.
Prévoyant que l'unixien moyen était pinailleur, il a
prévenu tout de suite que c'était ses exemples, qu'il y avait
plusieurs façons de faire, et que ce n'était pas la peine de lui
dire que tel exemple aurait pu être fait avec telle autre
méthode. Il a aussi précisé que la référence pour ses tweets était
Linux avec bash
(même s'il teste parfois sur une VM
FreeBSD) et
qu'il ne fallait pas l'embêter avec des « mais c'est pas
portable ». Effectivement, il utilise des exemples comme la
commande interne help (specifique à bash) ou
comme l'excellente et indispensable option -i
de sed (spécifique à GNU sed).
Mark Krenz (qui travaille au CACR et est l'auteur des
excellents num-utils) a d'abord résumé le projet climagic. Démarré en
2009, il consiste en un compte Twitter (il
y a aussi des
vidéos) où environ la moitié des tweets sont des commandes
Unix. Elles sont en général sous le format
commande # description (le
croisillon indiquant un commentaire). Par
exemple :
killall -USR1 dd # Force each dd command in the process table to output its current status (blocks written, etc). The USR1 signal does this.
(lisez les documentations de killall et dd si nécessaire.) Les autres tweets sont diverses réflexions, ou des blagues, par exemple sur Chuck Norris (« Chuck Norris once ran cd .. in / and it worked »).
Ah, et pourquoi le magic dans « climagic ». Précisement parce que cela n'a rien de magique, tout peut être appris. « Witchcraft to the ignorant, simple science for the learned one » (Leigh Brackett).
La force du shell
Unix est évidemment sa capacité à combiner
des commandes pour faire davantage que ce que ferait chaque
commande individuelle. Donc, lister des commandes et des options,
c'est bien, mais il faut surtout se rappeler qu'on peut les
combiner. Un exemple montré par l'auteur est une commande qui
énonce à voix haute les réseaux Wi-Fi
rencontrés : iwlist wlp2s0 scan | awk -F: '/ESSID/ {print $2}' | sort|uniq | espeak.
Je ne vais pas citer tous les trucs Unix qu'a montré l'orateur, uniquement ceux que je ne connaissais pas. Vous pourrez ainsi juger de la profondeur de mon ignorance d'Unix :
- Je n'utilise pas les opérateurs rigolos après les noms de
variables du shell. Si
ALPHABETvaut les lettres de l'alphabet (par exemple en faisantALPHABET=$(echo {a..z} | tr -d ' '), alorsecho ${ALPHABET:0:3}affichera les trois premières, etecho ${ALPHABET^^}affichera leurs versions majuscules (bash seulement). - Je ne connaissais pas certaines variables spéciales comme
SHLVL(pour voir si on est dans un sous-shell), ouCOLUMNS(qui était inutile sur un VT100 mais bien pratique sur un xterm). - J'ai découvert qu'après more et less, il y avait désormais une commande most (pas mal pour les fichiers binaires).
- column est cool pour formater joliment des commandes qui ne le font pas elle-même (comme mount).
- Il y a d'autres commandes que je ne connaissais pas mais qui ne m'ont pas convaincu comme comm, ou pee (analogue à tee mais envoie les données à un processus, pas à un fichier, il se trouve dans les moreutils).
- Certaines commandes classiques donnent des résultats
inattendus dans certains cas. Par exemple
cal 9 1752. Si vous vous demandez ce que sont devenus ces treize jours, ils ont disparu suite à l'application de la réforme grégorienne à l'empire britannique (les pays catholiques l'ont fait longtemps avant, ce dont on peut déduire qu'Unix n'est pas catholique). Comme tous les pays n'ont pas adopté cette réforme au même moment, logiquement, le résultat devrait dépendre de la valeur de la variable d'environnementLC_CTIMEmais ce n'est hélas pas le cas. - Je ne savais pas non plus que la barre
oblique après un joker ne
renvoyait que les répertoires. Parfait pour un
du -sh */(au fait, GNU sort peut trier ces tailles « human-readables », avec-h:du -sh */ | sort -rh | head -5permet de voir les cinq plus gros répertoires, avec un joli affichage des tailles.) - Parmi les autres options pratiques,
-Pdit à xargs d'effectuer les commandes en parallèle (comme le-jde make). Cela a permis à l'orateur de montrer un fping refait avec un ping ordinaire, l'expansion des séquences, et xargs.
Lors de la discussion qui a suivi, j'ai soulevé la question d'Unicode dans le shell Unix. Certaines commandes gèrent bien Unicode, par exemple awk :
% echo -n café | awk '{print length($1)}'
4
Il a bien indiqué la longueur en caractères, pas en octets (« café » fait cinq octets en UTF-8). wc, lui, permet d'avoir caractères ou octets au choix :
% echo -n café | wc -m
4
% echo -n café | wc -c
5
Cela montre que, même si le shell a la réputation d'être un vieux truc, il a su s'adapter à la modernité. Mais ce n'est pas le cas de toutes les commandes Unix. Au moins sur mon Ubuntu (il parait que ça marche sur d'autres Unix), cut semble insensible à l'internationalisation (il affiche les octets bêtement, malgré ce que prétend sa documentation) :
% echo caféthé | cut -c 3
f
% echo caféthé | cut -c 4
[Caractère Unicode +FFFD]
% echo caféthé | cut -c 5
[Caractère Unicode +FFFD]
% echo caféthé | cut -c 6
De même, l'expansion par le shell ne semble pas marcher avec les caractères non-ASCII :
% echo {a..c}
a b c
% echo {à..ç}
{à..ç}
(Et, oui, la variable d'environnement
LC_CTYPE était bien définie, sinon, grep ou
wc n'auraient pas marché.)
M. climagic a évidemment parlé de plein d'autres choses, mais je les connaissais. Et vous ?
- Il a bien sûr cité
man et ses options. Notez que
man -k deletene trouve pas la commande rm… - Il a longuement parlé de nombreux trucs du shell comme les
astuces de la commande cd (
cd -vous ramène au dernier répertoire), le job control (Control-Z, fg et bg), l'expansion des intervalles (echo {a..z},echo IMG_{3200..3300}.jpg, qui permet de faire unrsync -a -v IMG_{3200..3300}.jpg server:dir…, les fonctions (le plus bel exemple était une redéfinition de cd, pour accepter l'argument...pour dire « remonte de deux niveaux » :function cd(){ [[ "$1" == "..." ]] && builtin cd ../.. || builtin cd $@}, la redirection des seules erreurs (command 2> file), etc. - Mark Krenz a évidemment consacré du temps à awk et sed (tiens, lui non plus n'a pas l'air de gérer Unicode).
- Et enfin il a parlé de deux programmes géniaux qui méritent d'être plus connus, ngrep (comme grep mais pour le réseau), et socat (netcat en mieux).
Autre discussion à la fin de la réunion, je lui ai demandé pourquoi ne pas avoir également climagic sur le réseau social décentralisé Mastodon. Il n'est pas contre (surtout si on peut le faire depuis la ligne de commande, bien sûr, mais c'est possible avec madonctl), c'est surtout un problème de manque de temps. (À noter que climagic a existé sur identi.ca mais que cela ne lui a pas laissé de bons souvenirs.)
La vue depuis l'université : 
Le panneau sur la salle de réunion : 
L'article seul
RFC 8197: A SIP Response Code for Unwanted Calls
Date de publication du RFC : Juillet 2017
Auteur(s) du RFC : H. Schulzrinne (FCC)
Chemin des normes
Première rédaction de cet article le 18 juillet 2017
Voici un RFC qui n'est pas trop long à lire ou à comprendre : il ajoute un code de réponse au protocole SIP (utilisé surtout pour la téléphonie sur IP), le code 607 qui dit explicitement « je n'ai pas envie de répondre à cet appel ».
Sur certaines lignes téléphoniques, la majorité des appels entrants sont du spam (cf. RFC 5039), du genre salons de beauté ou remplacements de fenêtres, voire appels automatiques en faveur d'un candidat politicien. Toute méthode de lutte contre ce spam nécessite d'avoir un retour des utilisateurs, qui déclarent « je ne veux pas de cet appel ». Simplement raccrocher ne suffit pas, il faut permettre à l'utilisateur de déclarer explicitement la spamicité d'un appel. (Les codes de rejet existants comme 603 - RFC 3261, section 21.6.2 - ne sont pas assez spécifiques. 603 indique typiquement un rejet temporaire, du genre je suis à table, ne me dérangez pas maintenant.)
C'est désormais possible avec ce nouveau code de retour 607, enregistré à l'IANA. Le logiciel de l'utilisateur enverra ce code (il aura typiquement un bouton « rejet de ce spam » comme c'est le cas pour les logiciels de courrier), et il pourra être utilisé pour diverses techniques anti-spam (par exemple par un fournisseur SIP pour déterminer que tel numéro ne fait que du spam et peut donc être bloqué). La FCC (pour laquelle travaille l'auteur du RFC) avait beaucoup plaidé pour un tel mécanisme.
Notez que l'interprétation du code sera toujours délicate, car il peut y avoir usurpation de l'identité de l'appelant (section 6 de notre RFC, et aussi RFC 4474) ou tout simplement réaffectation d'une identité à un nouvel utilisateur, innocent de ce qu'avait fait le précédent. Au passage, dans SIP, l'identité de l'appelant peut être un URI SIP ou bien un numéro de téléphone, cf. RFC 3966.
Le code aurait dû être 666 (le nombre de la Bête) mais le code 607 a été finalement choisi pour éviter des querelles religieuses. (Le RFC 7999 n'a pas eu les mêmes pudeurs.)
L'action (ou l'inaction) suivant une réponse 607 dépendra de la politique de chaque acteur. (La discussion animée à l'IETF avait surtout porté sur ce point.) Comme toujours dans la lutte contre le spam, il faudra faire des compromis entre trop de faux positifs (on refuse des messages légitimes) et trop de faux négatifs (on accepte du spam). D'autant plus que l'utilisateur peut être malveillant (rejeter comme spam des appels légitimes dans l'espoir de faire mettre l'appelant sur une liste noire) ou simplement incompétent (il clique un peu au hasard). Les signalements sont donc à prendre avec des pincettes (section 6 du RFC).
L'article seul
Developing a dnstap to C-DNS converter at the IETF hackathon
First publication of this article on 17 July 2017
The weekend of 15-16 july 2017, I participated to the IETF 99 hackathon in Prague. The project was to develop a dnstap to C-DNS converter. This is a small documentation of the result and of the lessons learned.
First, a bit of background. Most DNS
operators these days gather a lot of data from the DNS traffic and
then analyze it. Events like DITL can fill many
hard disks with pcap files. pcap not being
very efficient (both in producing it, in storing it, and in
analyzing it), a work is under way at the
IETF to create a better format: C-DNS (for
"capture DNS"). C-DNS was specified at this time in an
Internet-Draft, draft-ietf-dnsop-dns-capture-format
(it is now RFC 8618). It
was only a draft, not yet a RFC. One of the
goals of IETF hackathons is
precisely to test drafts, to see if they are reasonable,
implementable, etc, before they are approved.
Note that C-DNS is based on CBOR (RFC 7049). There is already an implementation of C-DNS, available under a free software licence. Here, the idea was to write a second implementation, to test interoperability. The target was a C-DNS producer. Where to find the data to put in the file? I choosed dnstap since it is currently the best way to get data from a DNS server. dnstap relies on protocol buffers so it may be difficult to handle but there is already a good dnstap client, written in Go.
So, the decisions were:
- Get DNS data via dnstap from a Unbound resolver (the only resolver with dnstap support at this time),
- Use the dnstap client as a starting point (which means the hackathon project was to use Go),
- Test the C-DNS produced with the inspector from the first implementation.
First, compiling the first C-DNS implementation, which is in
C++ (I used a
not-up-to-date Ubuntu machine):
it requires several Boost libraries, and I'm
too lazy to check exactly which, so I installed everything
aptitude install libboost1.58-all-dev liblzma-dev lzma-dev
lzma. The C++ capture library libtins does not appear
to be in a Ubuntu "xenial" package (but there is a Debian one and it is
in some Ubuntu versions). The "trusty" package is too old, we install
the "yakkety" one manually:
./configure make
Then, we can produce C-DNS files from pcaps:
./compactor/compactor -o short.cdns -c /dev/null short.pcap
And read C-DNS files:
./compactor/inspector short.cdns
So, now, we can test the produced files.
Next, compiling Unbound with dnstap support (it is not done by default, probably because it add a lot of dependencies, coming from protocol buffers):
aptitude install libprotobuf-c-dev protobuf-c-compiler libfstrm-dev fstrm-bin ./configure --enable-dnstap make
We configure Unbound with:
dnstap:
dnstap-enable: yes
dnstap-socket-path: "/var/run/unbound/dnstap.sock" # "the dnstap socket won't appear in the filesystem until the dnstap listener is started."
dnstap-send-identity: yes
dnstap-send-version: yes
dnstap-log-resolver-response-messages: yes
dnstap-log-client-query-messages: yes
dnstap-log-resolver-query-messages: yes
dnstap-log-client-response-messages: yes
And we start it:
./unbound/unbound -d -c dnstap.conf
Then, when processing DNS queries and responses, Unbound sends a report to the dnstap socket. We just need a dnstap client to display it.
We forked
the dnstap client, created a c-dns branch, and started our copy. To
compile it:
aptitude install golang-dns-dev golang-goprotobuf-dev go get github.com/farsightsec/golang-framestream go install github.com/bortzmeyer/golang-dnstap go build dnstap/main.go
Then we can run it:
./main -y -u /var/run/unbound/dnstap.sock
And we can see the YAML output when Unbound receives or sends DNS messages. To store this output, I was not able to put the data in a file, so I just redirected the standard output.
Most of the hackathon work took place in the new file
CdnsFormat.go. First, producing
CBOR. I had a look at the various Go implementations of
CBOR. Most seem old and unmaintained and CBOR seemed to me simple
enough that it was faster to reimplement from scratch. This is the
code at the beginning of CdnsFormat.go, the
cborInteger() and similar functions. I also
developed a small Go program to read
CBOR files and display them as a tree, a tool which was very useful to
debug my C-DNS producer. The grammar of C-DNS
is specified in the CDDL language (currently specified in another
Internet-Draft). A validating tool exists,
taking CDDL and CBOR and telling if the CBOR file is correct, but this
tool's error messages are awful. It is just good to say if the file is
OK or not, afterwards, you have to examine the file manually.
Then, actually producing the C-DNS file. The C-DNS format is not
simple: it is intended for performance, and harsh
compression, not for ease of
implementation. The basic idea is to capture in tables most of what is
repeated, actual DNS messages being made mostly of references to these
tables. For instance, a DNS query for
www.sinodun.com won't include the string
www.sinodun.com. This FQDN
will be stored once, in the name-rdata table, and
a numeric index to an entry of this table will be used in the
message. For instance:
// Server address s.Write(cborInteger(0)) s.Write(cborInteger(2))
Here, we don't write the server IP address directly, we write an index to the table where the IP address is (2 is the second value of the table, C-DNS indexes start at 1, read later about the value zero). Note that the inspector crashed when meeting indexes going outside of an array, something that Jim Hague fixed during the hackathon.
Speaking of IP addresses, "client" and "server" in the C-DNS specification don't mean "source" and "destination". For a DNS query, "client" is the source and "server" the destination but, for a DNS response, it is the opposite (dnstap works the same way, easing the conversion).
Among the things that are not clear in the current version of the draft (version -03) is the fact that CBOR maps are described with keys that are strings, while in the CDNS format, they are actually integers. So when you read in the draft:
FilePreamble = {
major-format-version => uint,
minor-format-version => uint,
...
Read on: FilePreamble is indeed a CBOR map but
the actual keys are further away:
major-format-version = 0 minor-format-version = 1
So for a version number of 0.5 (the current one), you must write in Go the map as:
// Major version s.Write(cborInteger(0)) s.Write(cborInteger(0)) // Minor version s.Write(cborInteger(1)) s.Write(cborInteger(5))
Another choice to make: CBOR allow arrays and maps of indefinite of finite length. C-DNS does not specify which one to use, it is up to you, programmer, to choose. Of course, it is often the case that you don't know the length in advance, so sometimes you have no choice. An example of a finite length array:
s.Write(cborArray(3)) // Then write the three items
And an example of an indefinite length array:
s.Write(cborArrayIndef()) // Write the items s.Write(cborBreak())
Note that you need to checkpoint from time to time (for instance by
rotating the C-DNS file and creating a new one) otherwise a crash will
leave you with a corrupted file (no break at the end). The fact that
C-DNS (well, CBOR, actually), requires this break code at the end
forced us to modify the API of dnstap modules, to have a new function
finish (of type
TextFinishFunc, this function is a no-op
for the other formats).
Note there is a semantic mismatch between C-DNS and dnstap: C-DNS assumes all the data is mandatory while in dnstap, almost everything is optional. That means that we have to create dummy data in some places for instance:
s.Write(cborArray(2))
if m.QueryTimeSec != nil {
s.Write(cborInteger(int(*m.QueryTimeSec)))
} else {
s.Write(cborInteger(0))
}
Here, if we don't have the time of the DNS message, we write the dummy
value 0 (because earliest-time is not optional in
the C-DNS format). One possible evolution of the C-DNS draft could be
to have profiles of C-DNS, for instance a "Full" profile where
everything is mandatory and a "Partial" one where missing values are allowed.
The C-DNS specification is currently ambiguous about empty arrays. Most arrays are declared, in the grammar, as allowing to be empty. It raises some issues with the current tools (the inspector crashed when meeting these empty arrays, something that Jim Hague fixed during the hackathon). But it is also unclear in its semantics. For instance, the draft says that a value zero for an index mean "not found" but it does not appear to be supported by the current tools, forcing us to invent dummy data.
dnstap formats a part of the DNS messages but not everything. To get the rest, you need to parse the binary blob sent by dnstap. We use the excellent Go DNS package):
import ( ... "github.com/miekg/dns" ... msg = new(dns.Msg) err := msg.Unpack(m.QueryMessage)
This allows us to get information like the QNAME (name used in the question):
qname := make([]byte, 256) ... n, err = dns.PackDomainName(msg.Question[0].Name, qname, 0, nil, false) ... s.Write(cborByteString(qname[0:n]))
(Unpack leaves us with a domain
name in the presentation - text - format, but C-DNS
requires the label - binary - format, which we do with
PackDomainName.) Domain names are defined as CBOR
byte string and not strings 1) because you cannot be sure of their
encoding (strings have to be UTF-8) 2) and for
consistency reasons because the same tables can store other things
than domain names.
OK, now, we have everything, compile again and run (there is a Unbound running in another window):
go build dnstap/main.go ./main -c -u /var/run/unbound/dnstap.sock > test.cdns ../compactor/inspector test.cdns
And the inspector produced a pcap file, as well as a report. Let's try the pcap:
% tcpdump -n -r test.cdns.pcap reading from file test.cdns.pcap, link-type EN10MB (Ethernet) 13:02:02.000000 IP6 ::1.51834 > ::.0: UDP, length 25 13:02:02.000000 IP 0.0.0.0.0 > 193.0.14.129.53: 666 SOA? 142.com. (25) 13:02:02.000000 IP 193.0.14.129.53 > 0.0.0.0.0: 666- [0q] 0/0/0 (12) 13:02:02.000000 IP6 ::.0 > 2001:503:83eb::30.53: 666 AAAA? ns2.bodis.com. (31) 13:02:02.000000 IP 0.0.0.0.0 > 192.41.162.30.53: 666 AAAA? ns1.bodis.com. (31) 13:02:02.000000 IP6 2001:503:83eb::30.53 > ::.0: 666- [0q] 0/0/0 (12)
You immediately note the missing data. Most of the times, it was the lack of this data in dnstap (the IP addresses, for instance), sometimes it was my own lazyness (the microseconds in the time).
Sometimes, there are things that are available in dnstap but C-DNS offers no way to store them. This is the case with the bailiwick (the zone from which the DNS responses came) or with the fact thata the resolver cache experienced a hit or a miss.
This was the end of the IETF 99 hackathon. The code is available. An example C-DNS file produced by my converter is attached here. Other things would of course be possible:
- The biggest limit of the current dnstap-to-C-DNS tool is that it uses one C-DNS block per DNS message. This is simpler for the lazy programmer, but it defeats the most important requirments of C-DNS: compression. Compression is done py putting in tables information which is common to several DNS messages. This is the obvious next step.
- Test with an authoritative name server like Knot (which has dnstap support).
Thanks to Jim Hague for working with me throughout the hackathon (and fixing many things, and answering many questions) and to Sara Dickinson.
L'article seul
RFC 8200: Internet Protocol, Version 6 (IPv6) Specification
Date de publication du RFC : Juillet 2017
Auteur(s) du RFC : S. Deering (Retired), R. Hinden (Check Point Software)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF 6man
Première rédaction de cet article le 16 juillet 2017
Ce RFC est la nouvelle norme du protocole IPv6. IP est le protocole de base de l'Internet, la version 6 y est minoritaire mais est bien plus répandue qu'elle ne l'était lors de la sortie de la précédente norme, qui était le RFC 2460, norme que notre nouveau RFC remplace (et cela fait passer IPv6 au statut de norme Internet, la précédente étant officiellement une proposition de norme).
Pas de changements cruciaux, la norme est nouvelle, mais le protocole reste largement le même. Ce RFC 8200 continue à présenter IPv6 comme « a new version of the Internet Protocol (IP) ». Comme la première norme IPv6 est sortie en 1995, l'adjectif « new » n'est vraiment pas sérieux. Comme, malheureusement, la plupart des formations réseau ne parlent que d'IPv4 et traitent IPv6 de manière bâclée à la fin, le RFC présente IPv6 en parlant de ses différences par rapport à IPv4 (section 1 du RFC) :
- La principale est évidemment l'espace d'adressage bien plus grand. Alors qu'IPv4, avec ses adresses sur 32 bits, ne peut même pas donner une adresse IP à chaque habitant de la planète (ce qui serait déjà insuffisant), IPv6, avec ses 128 bits d'adresse, permet de distribuer une quantité d'adresses que le cerveau humain a du mal à se représenter. Cette abondance est la principale raison pour laquelle il est crucial de migrer vers IPv6. Les autres raisons sont plus discutables.
- IPv6 a sérieusement changé le format des options. En IPv4, les options IP étaient un champ de longueur variable dans l'en-tête, pas exactement ce qui est le plus facile à analyser pour un routeur. Le RFC dit qu'IPv6 a simplifié le format mais c'est contestable : une complexité a succédé à une autre. Désormais, le premier en-tête est de taille fixe, mais il peut y avoir un nombre quelconque d'en-têtes chaînés. Le RFC utilise malheureusement des termes publicitaires assez déconnectés de la réalité, en parlant de format plus efficace et plus souple.
- IPv6 a un mécanisme standard pour étiqueter les paquets appartenant à un même flot de données. Mais le RFC oublie de dire qu'il semble inutilisé en pratique.
- Et le RFC termine cette énumération par le plus gros pipeautage, prétendre qu'IPv6 aurait de meilleurs capacités d'authentification et de confidentialité. (C'est faux, elles sont les mêmes qu'en IPv4, et peu déployées, en pratique.)
Notez que ce RFC 8200 ne spécifie que le format des paquets IPv6. D'autres points très importants sont normalisés dans d'autres RFC, les adresses dans le RFC 4291, et ICMP dans le RFC 4443.
La section 3 présente le format des paquets IPv6 :
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|Version| Traffic Class | Flow Label |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Payload Length | Next Header | Hop Limit |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| |
+ +
| |
+ Source Address +
| |
+ +
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| |
+ +
| |
+ Destination Address +
| |
+ +
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
(D'ailleurs, si quelqu'un sait pourquoi l'adresse IP source est avant la destination ? Il me semblerait plus logique que ce soit l'inverse, puisque tous les routeurs sur le trajet doivent examiner l'adresse destination, alors qu'on n'a pas toujours besoin de l'adresse source.) Le numéro de version vaut évidemment 6, le « traffic class » est présenté en section 7, le « flow label » en section 6.
Le champ « Next header » remplace le « Protocol » d'IPv4. Il peut indiquer le protocole de transport utilisé (la liste figure dans un registre IANA et est la même pour IPv4 et IPv6) mais aussi les en-têtes d'extension, une nouveauté d'IPv6, présentée en section 4 de notre RFC.
Le champ « Hop limit » remplace le « Time to Live » d'IPv4. En fait, les deux ont exactement la même sémantique, qui est celle d'un nombre maximal de routeurs utilisés sur le trajet (le but est d'éviter les boucles infinies dans le réseau). Autrefois, dans IPv4, il était prévu que ce champ soit réellement une durée, mais aucune mise en œuvre d'IPv4 ne l'avait jamais utilisé comme ceci. Le renommage dans IPv6 fait donc correspondre la terminologie avec une réalité ancienne (cf. aussi la section 8.2). Notez que c'est ce champ qui est utilisé par traceroute.
Voici une simple connexion HTTP en IPv6,
vue avec tcpdump et
tshark. Le client a demandé
/robots.txt et a obtenu une réponse négative
(404). Si vous voulez, le pcap complet est
ipv6-http-connection.pcap. Voici d'abord avec
tcpdump avec ses options par défaut :
15:46:21.768536 IP6 2001:4b98:dc2:43:216:3eff:fea9:41a.37703 > 2605:4500:2:245b::42.80: Flags [S], seq 3053097848, win 28800, options [mss 1440,sackOK,TS val 1963872568 ecr 0,nop,wscale 7], length 0
On voit les deux adresses IPv6, tcpdump n'affiche rien d'autre de
l'en-tête de couche 3, tout le reste est du
TCP, le protocole de transport utilisé par HTTP. Avec l'option -v de tcpdump :
15:46:21.768536 IP6 (hlim 64, next-header TCP (6) payload length: 40) 2001:4b98:dc2:43:216:3eff:fea9:41a.37703 > 2605:4500:2:245b::42.80: Flags [S] [...]
Cette fois, on voit le « Hop limit » (64),
l'en-tête suivant (TCP, pas d'en-tête d'extension) et la longueur
(40 octets). Pour avoir davantage, il faut passer à
tshark (décodage complet en ipv6-http-connection.txt) :
Internet Protocol Version 6, Src: 2001:4b98:dc2:43:216:3eff:fea9:41a, Dst: 2605:4500:2:245b::42
0110 .... = Version: 6
.... 0000 0000 .... .... .... .... .... = Traffic class: 0x00 (DSCP: CS0, ECN: Not-ECT)
.... 0000 00.. .... .... .... .... .... = Differentiated Services Codepoint: Default (0)
.... .... ..00 .... .... .... .... .... = Explicit Congestion Notification: Not ECN-Capable Transport (0)
.... .... .... 0000 0000 0000 0000 0000 = Flow label: 0x00000
Payload length: 40
Next header: TCP (6)
Hop limit: 64
Source: 2001:4b98:dc2:43:216:3eff:fea9:41a
[Source SA MAC: Xensourc_a9:04:1a (00:16:3e:a9:04:1a)]
Destination: 2605:4500:2:245b::42
[Source GeoIP: France]
[Source GeoIP Country: France]
[Destination GeoIP: United States]
[Destination GeoIP Country: United States]
On a cette fois tout l'en-tête IPv6 : notons le « Flow Label » (j'avais bien dit que peu de gens s'en servaient, il est nul dans ce cas).
La section 4 de notre RFC est dédiée à une nouveauté d'IPv6, les en-têtes d'extension. Au lieu d'un champ « Options » de taille variable (donc difficile à analyser) comme en IPv4, IPv6 met les options IP dans des en-têtes supplémentaires, chaînés avec l'en-tête principal. Par exemple, si un paquet UDP a un en-tête « Destination Options », le champ « Next header » de l'en-tête principal vaudra 60 (pour « Destination Options »), il sera suivi de l'en-tête d'extension « Destination Options » qui aura, lui, un « Next header » de 17 pour indiquer que ce qui suit est de l'UDP. (Je rappelle que les valeurs possibles pour « Next Header » sont dans un registre IANA.) Il peut y avoir zéro, un ou davantage d'en-têtes d'extension chaînés entre eux.
Notez qu'analyser cette chaîne d'en-têtes est compliqué car les en-têtes n'ont pas tous le même format (le RFC 6564 a créé un format unique, mais cela ne concerne que les futurs en-têtes.) Il est donc exagéré de dire que la suppression du champ « Options » de taille variable a simplifié les choses.
Les différents en-têtes ne sont pas tous traités pareillement par les routeurs. Il existe notamment un en-tête, « Hop-by-hop Options » qui doit être examiné par tous les routeurs du trajet (cette obligation, jamais respectée, a de toute façon été relâchée par rapport au RFC 2460, puis re-spécifiée de manière plus réaliste dans le RFC 9673). C'est pour cela qu'il doit être placé au début des en-têtes, juste après l'en-tête principal. Les autres en-têtes d'extension doivent être ignorés par les routeurs.
Comme il est compliqué de rajouter un nouveau modèle d'en-tête (il faudrait modifier toutes les machines IPv6), une solution légère existe pour les options simples : utiliser les en-têtes d'options, « Hop-by-hop Options » et « Destination Options ». Tous les deux sont composés d'une série d'options encodées en TLV. En outre, le type de l'option indique, dans ses deux premiers bits, le traitement à appliquer au paquet si le système ne connait pas cette option. Si les deux premiers bits sont à zéro, on ignore l'option et on continue. Autrement, on jette le paquet (les trois valeurs restantes, 01, 10 et 11, indiquent si on envoie un message d'erreur ICMP et lequel). Ainsi, l'option pour la destination de numéro 0x07 (utilisée par le protocole de sécurité du RFC 5570) est facultative : elle a les deux premiers bits à zéro et sera donc ignorée silencieusement par les destinataires qui ne la connaissent pas (cf. registre IANA.)
« Destination Options », comme son nom l'indique, n'est examinée que par la machine de destination. Si vous voulez envoyer des paquets avec cet en-tête, regardez mon article.
Outre les en-têtes « Hop-by-hop Options » et « Destination Options », il existe des en-têtes :
- « Routing Header », qui permet de spécifier le routage depuis la source (un peu comme les options de « source routing » en IPv4). Il y a plusieurs types, et les valeurs possibles sont dans un registre IANA, géré suivant les principes du RFC 5871. (Le type 0 a été retiré depuis le RFC 5095.)
- « Fragment Header », qui permet de fragmenter les paquets de taille supérieure à la MTU.
- Les autres en-têtes sont ceux utilisés par IPsec, décrits dans les RFC 4302 et RFC 4303.
La fragmentation est différente de celle
d'IPv4. En IPv6, seule la machine émettrice peut fragmenter, pas
les routeurs intermédiaires. Si le paquet est plus grand que la
MTU, on le découpe en fragments, chaque
fragment portant un « Fragment Header ». Cet
en-tête porte une identification (un nombre sur 32 bits qui doit
être unique parmi les paquets qui sont encore dans le réseau),
un décalage (offset) qui indique à combien
d'octets depuis le début du paquet original se situe ce fragment
(il vaut donc zéro pour le premier fragment) et un bit qui indique
si ce fragment est le dernier. À la destination, le paquet est
réassemblé à partir des fragments. (Il est désormais interdit que
ces fragments se recouvrent, cf. RFC 5722.) Voici un exemple de fragmentation. La sonde Atlas n° 6271 a
interrogé un serveur DNS de la racine Yeti avec le type de
question ANY qui signifie « envoie-moi tout
ce que tu peux / veux ». La réponse, plus grande que la MTU (plus
de quatre kilo-octets !), a été
fragmentée en trois paquets (le pcap
complet est en ipv6-dns-frag.pcap) :
16:14:27.112945 IP6 2001:67c:217c:4::2.60115 > 2001:4b98:dc2:45:216:3eff:fe4b:8c5b.53: 19997+ [1au] ANY? . (28)
16:14:27.113171 IP6 2001:4b98:dc2:45:216:3eff:fe4b:8c5b > 2001:67c:217c:4::2: frag (0|1232) 53 > 60115: 19997*- 35/0/1 NS bii.dns-lab.net., NS yeti.bofh.priv.at., NS yeti.ipv6.ernet.in., NS yeti.aquaray.com., NS yeti.mind-dns.nl., NS dahu1.yeti.eu.org., NS dahu2.yeti.eu.org., NS yeti1.ipv6.ernet.in., NS ns-yeti.bondis.org., NS yeti-ns.ix.ru., NS yeti-ns.lab.nic.cl., NS yeti-ns.tisf.net., NS yeti-ns.wide.ad.jp., NS yeti-ns.conit.co., NS yeti-ns.datev.net., NS yeti-ns.switch.ch., NS yeti-ns.as59715.net., NS yeti-ns1.dns-lab.net., NS yeti-ns2.dns-lab.net., NS yeti-ns3.dns-lab.net., NS xn--r2bi1c.xn--h2bv6c0a.xn--h2brj9c., NS yeti-dns01.dnsworkshop.org., NS yeti-dns02.dnsworkshop.org., NS 3f79bb7b435b05321651daefd374cd.yeti-dns.net., NS ca978112ca1bbdcafac231b39a23dc.yeti-dns.net., RRSIG, NSEC, RRSIG[|domain]
16:14:27.113187 IP6 2001:4b98:dc2:45:216:3eff:fe4b:8c5b > 2001:67c:217c:4::2: frag (1232|1232)
16:14:27.113189 IP6 2001:4b98:dc2:45:216:3eff:fe4b:8c5b > 2001:67c:217c:4::2: frag (2464|637)
On note que tcpdump n'a interprété qu'un seul fragment comme étant
du DNS, la premier, puisque c'était le seul qui portait l'en-tête
UDP, avec le numéro de port 53 identifiant du DNS. Dans le
résultat de tcpdump, après le mot-clé frag,
on voit le décalage du fragment par rapport au début du paquet
original (respectivement 0, 1232 et 2464 pour les trois
fragments), et la taille du fragment (respectivement 1232, 1232 et
637 octets). Vu par tshark (l'analyse complète est en ipv6-dns-frag.txt), le premier fragment contient :
Type: IPv6 (0x86dd)
Internet Protocol Version 6, Src: 2001:4b98:dc2:45:216:3eff:fe4b:8c5b, Dst: 2001:67c:217c:4::2
Payload length: 1240
Next header: Fragment Header for IPv6 (44)
Fragment Header for IPv6
Next header: UDP (17)
Reserved octet: 0x00
0000 0000 0000 0... = Offset: 0 (0 bytes)
.... .... .... .00. = Reserved bits: 0
.... .... .... ...1 = More Fragments: Yes
Identification: 0xcbf66a8a
Data (1232 bytes)
On note le « Next Header » qui indique qu'un en-tête d'extension, l'en-tête « Fragmentation », suit l'en-tête principal. Le bit M (« More Fragments ») est à 1 (ce n'est que le premier fragment, d'autres suivent), le décalage (« offset ») est bien sûr de zéro. L'identificateur du paquet est de 0xcbf66a8a. Le dernier fragment, lui, contient :
Internet Protocol Version 6, Src: 2001:4b98:dc2:45:216:3eff:fe4b:8c5b, Dst: 2001:67c:217c:4::2
Payload length: 645
Next header: Fragment Header for IPv6 (44)
Fragment Header for IPv6
Next header: UDP (17)
Reserved octet: 0x00
0000 1001 1010 0... = Offset: 308 (2464 bytes)
.... .... .... .00. = Reserved bits: 0
.... .... .... ...0 = More Fragments: No
Identification: 0xcbf66a8a
Cette fois, le « Next Header » indique que c'est de l'UDP qui suit, le décalage est de 2464, et le bit M est à zéro (plus d'autres fragments). L'identificateur est le même, c'est celui du paquet original, et c'est grâce à lui que la machine de destination saura réassembler les fragments. Notez qu'à la fin de l'analyse par tshark figure un réassemblage complet du paquet, ce qui permet une analyse DNS complète.
Et si je ne suis pas satisfait des en-têtes d'extension existants et que je veux créer le mien ? C'est en général une mauvaise idée. La plupart des cas concrets devraient être résolus avec un des en-têtes déjà normalisés. Notamment, l'en-tête « Destination Options » est là pour la majorité des situations. C'est lui qu'il faut regarder en premier (ce qu'ont fait les RFC 6744, RFC 6788 ou RFC 7837, la liste complète figurant dans un registre IANA). Notre RFC 8200 exige donc que, si vous tenez à créer un nouvel en-tête, vous expliquiez bien pourquoi c'est indispensable, et pourquoi aucun des en-têtes existants ne convient.
Il est également déconseillé de créer de nouvelles options « hop-by-hop » (la liste actuelle est à l'IANA), car ces options doivent être traitées par tous les routeurs du trajet. Il y a un risque sérieux qu'ils laissent tomber les paquets ayant cet en-tête « Hop-by-hop Options », ou bien qu'ils le traitent plus lentement (logiciel du routeur et pas circuits matériels spécialisés). Là aussi, il faudra donc une justification sérieuse.
La section 5 de notre RFC se penche sur un problème délicat, la taille des paquets. IPv6 exige une MTU d'au moins 1 280 octets, mais les paquets sont souvent plus grands (par exemple 1 500 octets si on part d'un Ethernet). Beaucoup de liens ont, en pratique, une MTU de 1 500 octets mais IPv6 étant souvent porté par des tunnels (en raison de l'immobilisme de beaucoup de FAI, qui ne déploient toujours pas IPv6), un certain nombre de liens offrent moins de 1 500 octets. Normalement, l'émetteur d'un paquet IPv6 doit faire de la découverte de la MTU du chemin (RFC 8201) afin de pouvoir fragmenter, si nécessaire. Une mise en œuvre « paresseuse » d'IPv6 pourrait se dispenser de découverte de la MTU du chemin, et se limiter à 1 280 octets par paquet.
Le problème est que la découverte de la MTU du chemin dépend du bon fonctionnement d'ICMP. L'émetteur d'un paquet doit pouvoir recevoir les paquets ICMP « Packet too big » (RFC 4443, section 3.2). Or, un certain nombre de pare-feux, stupidement configurés par des amateurs, bloquent tout ICMP « pour des raisons de sécurité » (c'est d'ailleurs une bonne question pour les entretiens d'embauche d'un administrateur de réseaux : « filtrer ICMP en entrée ou pas ? » S'il répond Oui, on est sûr qu'il est incompétent.) Ne recevant pas les « Packet too big », l'émetteur risque de croire à tort que ses paquets sont passés. En outre, si l'émetteur décide de fragmenter (en général, quand la MTU du chemin est inférieure à la sienne, avec TCP, on réduit la MSS, avec UDP, on fragmente), il faut que les fragments passent à travers le réseau. Et, là encore, un certain nombre de pare-feux bêtement configurés bloquent les fragments. Donc, en pratique, découverte du chemin + fragmentation est un processus fragile, en raison de ce véritable sabotage par des middleboxes.
C'est certainement le plus gros problème pratique lors du déploiement d'IPv6. On peut même penser à prendre des mesures radicales et coûteuses, comme d'abaisser la MTU à 1 280 octets pour être tranquille. Moins violent, il est fréquent de voir des MTU à 1 480 octets. Voici par exemple la configuration de mon routeur Turris Omnia pour passer par l'IPv6 de Free (un tunnel) :
config interface 'lan'
option ip6assign '64'
option ip6addr '2001:db8:42::1:fe/64'
option ip6prefix '2001:db8:42::/64'
option ip6gw '2001:db8:42::1'
option mtu '1480'
Et le « flow label », dont j'avais parlé plus haut ? Il est décrit dans la (très courte) section 6, qui renvoie surtout au RFC 6437. En pratique, ce champ semble peu utilisé comme on l'a vu dans l'exemple décodé par tshark.
Même chose pour le « traffic class », en section 7 : pour son utilisation pour la différenciation de trafic, voir les RFC 2474 et RFC 3168.
Maintenant qu'IPv6, protocole de couche 3, a été bien défini, le RFC monte vers la couche 4, en consacrant sa section 8 aux problèmes des couches supérieures. Cela concerne notamment la somme de contrôle. Si vous avez fait attention au schéma de l'en-tête IPv6 de la section 3, vous avez noté qu'il n'y avait pas de champ « Header Checksum », contrairement à ce qui existait en IPv4. En IPv6, pas de somme de contrôle en couche 3, c'était une tâche supplémentaire pour les routeurs (pour citer le RFC 791, « Since some header fields change (e.g., time to live), this is recomputed and verified at each point that the internet header is processed. »), tâche dont ils sont désormais dispensés.
Par contre, la somme de contrôle existe pour les en-têtes de couche 4 et elle devient même obligatoire pour UDP (elle était facultative en IPv4, quoique très fortement recommandée). (Voir le RFC 1071, au sujet de cette somme de contrôle.)
Un gros changement de ce RFC par rapport à son prédécesseur, le RFC 2460, concerne la sécurité. La section sur la sécurité est passée d'une annexe de deux lignes (qui se contentait de passer le bébé à IPsec) à une analyse plus détaillée (section 10 du RFC). La question est délicate car la sécurité d'IPv6 a souvent fait l'objet de FUD, visant à justifier l'immobilisme de pas mal d'acteurs. Il est évidemment plus valorisant de dire « nous ne migrons pas vers IPv6 pour des raisons de sécurité » que de reconnaitre « nous sommes trop flemmards et paralysés par la peur du changement ». (Cf. mon exposé sur la sécurité d'IPv6 à l'ESGI.) S'il fallait synthétiser (la deuxième partie de cette synthèse ne figure pas dans le RFC), je dirais :
- La sécurité d'IPv6 est quasiment la même qu'en IPv4 (ce qui est logique, il ne s'agit après tout que de deux versions du même protocole). Les grandes questions de sécurité d'IPv4 (usurpation d'adresse source, relative facilité à faire des attaques par déni de service, pas d'authentification ou de confidentialité par défaut) sont exactement les mêmes en IPv6. (C'est une blague courante à l'IETF de dire que si IPv4, l'un des plus grands succès de l'ingéniérie du vingtième siècle, était présenté à l'IESG aujourd'hui, il serait rejeté pour sa trop faible sécurité.)
- Par contre, en pratique, les solutions techniques d'attaque et de défense, ainsi que les compétences des attaquants et des défenseurs, sont bien plus faibles en IPv6. Pas mal de logiciels « de sécurité » ne gèrent pas IPv6, bien des logiciels de piratage ne fonctionnent qu'en IPv4, les administrateurs système sont déroutés face à une attaque IPv6, et les pirates ne pensent pas à l'utiliser. (Faites l'expérience : configurez un pot de miel SSH en IPv4 et IPv6. Vous aurez plusieurs connexions par jour en IPv4 et jamais une seule en IPv6.) L'un dans l'autre, je pense que ces deux aspects s'équilibrent.
Bon, assez de stratégie, passons maintenant aux problèmes concrets que décrit cette section 10. Elle rappelle des risques de sécurité qui sont exactement les mêmes qu'en IPv4 mais qu'il est bon de garder en tête, ce sont des problèmes fondamentaux d'IP :
- Communication en clair par défaut, donc espionnage trop facile pour les États, les entreprises privées, les pirates individuels. (Cf. Snowden.)
- Possibilité de rejouer des paquets déjà passés, ce qui permet certaines attaques. Dans certains cas, on peut modifier le paquet avant de le rejouer, et ça passera.
- Possibilité de générer des faux paquets et de les injecter dans le réseau.
- Attaque de l'homme du milieu : une entité se fait passer pour l'émetteur auprès du vrai destinataire, et pour le destinataire auprès du vrai émetteur.
- Attaque par déni de service, une des plaies les plus pénibles de l'Internet.
En cohérence avec le RFC 2460 (mais pas avec la réalité du terrain), notre RFC recommande IPsec (RFC 4301) comme solution à la plupart de ces problèmes. Hélas, depuis le temps qu'il existe, ce protocole n'a jamais connu de déploiement significatif sur l'Internet public (il est par contre utilisé dans des réseaux privés, par exemple le VPN qui vous permet de vous connecter avec votre entreprise de l'extérieur utilise probablement une variante plus ou moins standard d'IPsec). Une des raisons de ce faible déploiement est la grande complexité d'IPsec, et la complexité pire encore de ses mises en œuvre. En pratique, même si le RFC ne le reconnait que du bout des lèvres, ce sont les protocoles applicatifs comme SSH ou TLS, qui sécurisent l'Internet.
Pour les attaques par déni de service, par contre, aucune solution n'est proposée : le problème ne peut pas forcément se traiter au niveau du protocole réseau.
La différence la plus spectaculaire entre IPv4 et IPv6 est
évidemment la taille des adresses. Elle rend le
balayage bien plus complexe (mais pas impossible), ce qui
améliore la sécurité (l'Internet IPv4 peut être exploré
incroyablement vite, par exemple avec masscan,
et, si on est trop flemmard pour balayer soi-même, on peut
utiliser des balayages déjà faits, par exemple par
Shodan ou https://scans.io/
Et qu'en est-il de la vie privée ? L'argument, largement FUDé, a été beaucoup utilisé contre IPv6. Le RFC note qu'IPv6 a entre autre pour but de rendre inutile l'usage du NAT, dont certaines personnes prétendent qu'il protège un peu les utilisateurs. L'argument est largement faux : le NAT (qui est une réponse à la pénurie d'adresses IPv4, pas une technique de sécurité) ne protège pas contre tout fingerprinting, loin de là. Et, si on veut empêcher les adresses IP des machines du réseau local d'être visibles à l'extérieur, on peut toujours faire du NAT en IPv6, si on veut, ou bien utiliser des méthodes des couches supérieures (comme un relais).
Autre question de vie privée avec IPv6, les adresses IP fondées sur l'adresse MAC. Cette ancienne technique, trop indiscrète, a été abandonnée avec les RFC 8981 et RFC 7721, le premier étant très déployé. Il est curieux de constater que cet argument soit encore utilisé, alors qu'il a perdu l'essentiel de sa (faible) pertinence.
Mais il y avait bien des problèmes de sécurité concrets avec le précédent RFC 2460, et qui sont réparés par ce nouveau RFC :
- Les « fragments atomiques » ne doivent désormais plus être générés (RFC 8021) et, si on en reçoit, doivent être « réassemblés » par une procédure spéciale (RFC 6946).
- Les fragments qui se recouvrent partiellement sont désormais interdits (cf. RFC 5722, le réassemblage des fragments en un paquet est déjà assez compliqué et sujet à erreur comme cela).
- Si le paquet est fragmenté, les en-têtes d'extension doivent désormais tous être dans le premier fragment (RFC 7112).
- L'en-tête de routage (Routing Header) de type 0, dit « RH0 », est abandonné, il posait trop de problèmes de sécurité (cf. RFC 5095 et RFC 5871).
L'annexe B de notre RFC résume les changements depuis le RFC 2460. Pas de choses révolutionnaires, les changements les plus importantes portaient sur la sécurité, comme listé un peu plus haut (section 10 du RFC). On notera comme changements :
- [Section 1] Clarification que IPv6 est gros-boutien, comme IPv4 (cf. l'annexe B du RFC 791).
- [Section 3] Clarification de l'utilisation du « hop limit », décrémenté de 1 à chaque routeur.
- [Section 4] Clarification du fait qu'un équipement intermédiaire ne doit pas tripoter les en-têtes d'extension (à part évidemment « Hop-by-hop Options »), ni les modifier, ni en ajouter ou retirer, ni même les lire.
- [Section 4] Le traitement de l'en-tête « Hop-by-hop Options par les routeurs sur le trajet n'est plus obligatoire. Si un routeur est pressé, il peut s'en passer (le RFC suit ainsi la pratique). Ceci dit, le RFC 9673 a, depuis, mieux défini le traitement de cet en-tête, dans l'espoir de le ressusciter.
- [Section 4.4] Suppression de l'en-tête de routage de type 0.
- [Section 4.5] Pas mal de changements sur la fragmentation (un processus toujours fragile !), notamment l'abandon des fragments atomiques.
- [Section 4.8] Intégration du format unique des éventuels futurs en-têtes d'extension, format initialement présenté dans le RFC 6564.
- [Section 6] Reconnaissance du fait que « Flow Label » n'était pas réellement bien défini, et délégation de cette définition au RFC 6437.
- [Section 8.1] Autorisation, dans certains cas bien délimités, d'omission de la somme de contrôle UDP (RFC 6935).
- Il y a eu également correction de diverses erreurs comme les 2541 (omission sur la définition du « Flow Label ») et 4279 (paquet entrant avec un « Hop Limit » déjà à zéro).
Le projet de mise à jour de la norme IPv6 avait été lancé en 2015 (voici les supports du premier exposé).
D'habitude, je termine mes articles sur les RFC par des informations sur l'état de mise en œuvre du RFC. Mais, ici, il y en a tellement que je vous renvoie plutôt à cette liste. Notez que des tests d'interopérabilité ont été faits sur les modifications introduites par ce nouveau RFC et que les résultats publiés n'indiquent pas de problème.
Parmi les publications récentes sur le déploiement d'IPv6, signalons :
- Le rapport de l'ARCEP au gouvernement français sur la transition vers IPv6 et les moyens de l'accélérer.
- Le rapport 2016 de l'l’Observatoire ANSSI/AFNIC de la résilience de l’Internet français a une section sur IPv6.
- Google publie d'intéressantes statistiques sur l'accès en IPv6 à ses services.
L'article seul
RFC 8201: Path MTU Discovery for IP version 6
Date de publication du RFC : Juillet 2017
Auteur(s) du RFC : J. McCann (Digital Equipment
Corporation), S. Deering
(Retired), J. Mogul (Digital Equipment
Corporation), R. Hinden (Check Point
Software)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF 6man
Première rédaction de cet article le 16 juillet 2017
Ce RFC est l'adaptation à IPv6 du protocole décrit dans le RFC 1191, protocole qui permet de découvrir la MTU du chemin entre deux machines reliées par Internet. Il remplace le RFC 1981.
Avec IPv4, déterminer la MTU maximale du chemin est très utile pour optimiser les performances. Mais elle devient presque indispensable en IPv6, où les routeurs n'ont pas le droit de fragmenter les paquets trop gros (toute fragmentation doit être faite dans la machine de départ). PMTU fait donc quasi-obligatoirement partie d'IPv6. Une alternative est de n'envoyer que des paquets suffisamment petits pour passer partout. C'est moins efficace (on ne tirera pas profit des MTU plus importantes), mais ça peut être intéressant pour des mises en œuvre légères d'IPv6, par exemple pour des objets connectés. (La section 4 du RFC précise en effet que mettre en œuvre cette découverte de la MTU du chemin n'est pas obligatoire.)
L'algorithme (section 3 de notre RFC) est le même qu'en v4, envoyer des paquets, et voir si on reçoit des paquets ICMP Packet too big (RFC 4443, section 3.2) qui contiennent en général la MTU maximale du lien suivant. (Pas de bit DF - Don't fragment - en IPv6 puisque la fragmentation n'est possible qu'à la source. L'annexe A détaille les différences avec l'algorithme IPv4 décrit dans le RFC 1191.)
Voici par exemple un de ces paquets ICMP, vu par
tcpdump (déclenché par une commande
ping -s 1500 …) :
18:18:44.813927 IP6 2a02:8400:0:3::a > 2605:4500:2:245b::bad:dcaf: ICMP6, packet too big, mtu 1450, length 1240
Il ne faut pas s'arrêter au premier paquet Packet too big reçu, car il peut y avoir des liens réseau avec une MTU encore plus basse plus loin. En outre, la MTU du chemin change avec le temps et il faut donc rester vigilant, on peut recevoir des Packet too big si le trafic passe désormais par un lien de MTU plus faible que la précédente MTU du chemin. Plus délicat, il faut aussi de temps en temps réessayer avec des paquets plus gros, pour voir si la MTU du chemin n'aurait pas augmenté. Comme cela va faire perdre des paquets, s'il n'y a pas eu d'augmentation, il ne faut pas le faire trop souvent. (Dix minutes, dit la section 5.)
La section 4 du RFC précise les exigences qu'il normalise. (Je
donne quelques exemples de leur mise en œuvre dans le noyau
Linux, dans net/ipv6/route.c.) Par
exemple, le nœud IPv6 doit vérifier le contenu
des paquets ICMP Packet Too
Big qu'il reçoit (le Message Body,
cf. RFC 4443, où le routeur émetteur est censé
placer des données du paquet original), pour éviter de croire des faux messages
ICMP envoyés par un attaquant (rien n'authentifie un paquet ICMP, à
part son contenu).
Nouveauté de ce RFC, par rapport à son prédecesseur, un nœud IPv6
doit ignorer les messages Packet Too
Big indiquant une MTU inférieur aux 1 280 octets minimum
d'IPv6 (le RFC 8021 explique pourquoi). C'est le
but de l'instruction mtu = max_t(u32, mtu,
IPV6_MIN_MTU); dans le code du noyau Linux, qui ne garde
pas la MTU indiquée si elle est inférieur au minimum.
Et la machine IPv6 ne doit jamais augmenter la
MTU du chemin suite à la réception d'un Packet Too
Big indiquant une MTU supérieure à l'actuelle. Un tel
message ne peut être qu'une erreur ou une attaque. Voir les
commentaires au début de la fonction
rt6_mtu_change_route dans le code Linux.
Comme avec IPv4, l'algorithme PMTU marche mal en pratique car beaucoup de sites filtrent stupidement tous les paquets ICMP et la machine qui tente de faire de la Path MTU discovery n'aura jamais de réponse. IPv6, comme IPv4, devra donc plutôt utiliser la technique du RFC 4821.
La section 5 du RFC rassemble diverses questions de mise en œuvre de cette découverte de la MTU du chemin. D'abord, il y a l'interaction entre IP (couche 3) et les protocoles au dessus, comme TCP mais aussi des protocoles utilisant UDP, comme le DNS. Ces protocoles de transport ont une MMS_S (maximum send transport-message size, voir le RFC 1122) qui est à l'origine la MTU moins la taille des en-têtes. Les protocoles de transport peuvent diminuer cette MMS_S pour ne pas avoir à faire de fragmentation.
Pour le DNS, par exemple, on peut diminuer l'usage de la découverte de la MTU du chemin en diminuant la taille EDNS. Par exemple, avec le serveur nsd, on mettrait :
ipv6-edns-size: 1460
Et, avec 1 460 octets possibles, on serait alors raisonnablement sûr de ne pas avoir de fragmentation donc, même si la découverte de la MTU du chemin marche mal, tout ira bien.
Une fois la découverte de la MTU du chemin faite, où faut-il garder l'information, afin d'éviter de recommencer cette découverte à chaque fois ? Idéalement, cette information est valable pour un chemin donné : si le chemin change (ou, a fortiori, si la destination change), il faudra découvrir à nouveau. Mais la machine finale ne connait pas en général tout le chemin suivi (on ne fait pas un traceroute à chaque connexion). Le RFC suggère donc (section 5.2) de stocker une MTU du chemin par couple {destination, interface}. Si on n'a qu'une seule interface réseau, ce qui est le cas de la plupart des machines terminales, on stocke la MTU du chemin par destination et on maintient donc un état pour chaque destination (même quand on ne lui parle qu'en UDP, qui n'a normalement pas d'état). Les deux exemples suivants concernent une destination où la MTU du chemin est de 1 450 octets. Pour afficher cette information sur Linux pour une adresse de destination :
% ip -6 route get 2a02:8428:46c:5801::4
2a02:8428:46c:5801::4 from :: via 2001:67c:1348:7::1 dev eth0 src 2001:67c:1348:7::86:133 metric 0
cache expires 366sec mtu 1450 pref medium
S'il n'y a pas de PMTU indiquée, c'est que le cache a expiré, réessayez (en UDP, car TCP se fie à la MSS). Notez que, tant qu'on n'a pas reçu un seul Packet Too Big, il n'y a pas de MTU affichée. Donc, pour la plupart des destinations (celles joignables avec comme PMTU la MTU d'Ethernet), vous ne verrez rien. Sur FreeBSD, cet affichage peut se faire avec :
% sysctl -o net.inet.tcp.hostcache.list | fgrep 2a02:8428:46c:5801::4 2a02:8428:46c:5801::4 1450 0 23ms 34ms 0 4388 0 0 23 4 3600
Pour d'autres systèmes, je vous recommande cet article.
Notez qu'il existe des cas compliqués (ECMP) où cette approche de stockage de la PMTU par destination peut être insuffisante. Ce n'est donc qu'une suggestion, chaque implémentation d'IPv6 peut choisir sa façon de mémoriser les MTU des chemins.
Si on veut simplifier la mise en œuvre, et la consommation mémoire, on peut ne mémoriser qu'une seule MTU du chemin, la MTU minimale de tous les chemins testés. Ce n'est pas optimal, mais ça marchera.
Si on stocke la MTU du chemin, comme l'Internet peut changer, il faut se préparer à ce que l'information stockée devienne obsolète. Si elle est trop grande, on recevra des Packet too big (il ne faut donc pas s'attendre à n'en recevoir que pendant la découverte initiale). Si elle est trop petite, on va envoyer des paquets plus petits que ce qu'on pourrait se permettre. Le RFC suggère donc (section 5.3) de ne garder l'information sur la MTU du chemin que pendant une dizaine de minutes.
Le RFC demande enfin (section 5.5) que les mises en œuvre d'IPv6 permettent à l'ingénieur système de configurer la découverte de la MTU du chemin : la débrayer sur certaines interfaces, fixer à la main la MTU d'un chemin, etc.
Il ne faut pas oublier les problèmes de sécurité (section 6 du RFC) : les Packet Too Big ne sont pas authentifiés et un attaquant peut donc en générer pour transmettre une fausse information. Si la MTU indiquée est plus grande que la réalité, les paquets seront jetés. Si elle est plus petite, on aura des sous-performances.
Autre problème de sécurité, le risque que certains administrateurs réseau incompétents ne filtrent tous les messages ICMP, donc également les Packet Too Big (c'est stupide, mais cela arrive). Dans ce cas, la découverte de la MTU du chemin ne fonctionnera pas (cf. RFC 4890 sur les recommandations concernant le filtrage ICMP). L'émetteur devra alors se rabattre sur des techniques comme celle du RFC 4821.
L'annexe B de notre RFC résume les changements faits depuis le RFC 1981. Rien de radical, les principaux portent sur la sécurité (ce sont aussi ceux qui ont engendré le plus de discussions à l'IETF) :
- Bien expliquer les problèmes créés par le blocage des messages ICMP,
- Formulations plus strictes sur la validation des messages ICMP,
- Et surtout, suppression des « fragments atomiques » (RFC 8021).
Le texte a également subi une actualisation générale, les références (pré-)historiques à BSD 4.2 ou bien à TP4 ont été supprimées.
Enfin, pour faire joli, un exemple de
traceroute avec recherche de la MTU du chemin
activée (option --mtu). Notez la réception d'un
Packet Too Big à l'étape 12, annonçant une MTU de
1 450 octets :
% sudo traceroute -6 --mtu --udp --port=53 eu.org traceroute to eu.org (2a02:8428:46c:5801::4), 30 hops max, 65000 byte packets ... 3 vl387-te2-6-paris1-rtr-021.noc.renater.fr (2001:660:300c:1002:0:131:0:2200) 2.605 ms 2.654 ms 2.507 ms 4 2001:660:7903:6000:1::4 (2001:660:7903:6000:1::4) 5.002 ms 4.484 ms 5.494 ms 5 neuf-telecom.sfinx.tm.fr (2001:7f8:4e:2::178) 4.193 ms 3.682 ms 3.763 ms 6 neuf-telecom.sfinx.tm.fr (2001:7f8:4e:2::178) 14.264 ms 11.927 ms 11.509 ms 7 2a02-8400-0000-0003-0000-0000-0000-1006.rev.sfr.net (2a02:8400:0:3::1006) 12.760 ms 10.446 ms 11.902 ms 8 2a02-8400-0000-0003-0000-0000-0000-1c2e.rev.sfr.net (2a02:8400:0:3::1c2e) 10.524 ms 11.477 ms 11.896 ms 9 2a02-8400-0000-0003-0000-0000-0000-1c2e.rev.sfr.net (2a02:8400:0:3::1c2e) 13.061 ms 11.589 ms 11.915 ms 10 2a02-8400-0000-0003-0000-0000-0000-117e.rev.sfr.net (2a02:8400:0:3::117e) 10.446 ms 10.420 ms 10.361 ms 11 2a02-8400-0000-0003-0000-0000-0000-000a.rev.sfr.net (2a02:8400:0:3::a) 10.460 ms 10.453 ms 10.517 ms 12 2a02-8428-046c-5801-0000-0000-0000-00ff.rev.sfr.net (2a02:8428:46c:5801::ff) 12.495 ms F=1450 12.102 ms 11.203 ms 13 2a02-8428-046c-5801-0000-0000-0000-0004.rev.sfr.net (2a02:8428:46c:5801::4) 12.397 ms 12.217 ms 12.507 ms
La question de la fragmentation en IPv6 a suscité d'innombrables articles. Vous pouvez commencer par celui de Geoff Huston.
Merci à Pierre Beyssac pour avoir fourni le serveur de test configuré comme il fallait, et à Laurent Frigault pour la solution sur FreeBSD.
L'article seul
RFC 8212: Default External BGP (EBGP) Route Propagation Behavior without Policies
Date de publication du RFC : Juillet 2017
Auteur(s) du RFC : J. Mauch (Akamai), J. Snijders
(NTT), G. Hankins (Nokia)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF grow
Première rédaction de cet article le 10 juillet 2017
Ce RFC est très court, mais concerne un problème fréquent sur l'Internet : les fuites de routes BGP. Traditionnellement, un routeur BGP acceptait par défaut toutes les routes, et annonçait par défaut à ses voisins toutes les routes qu'il connaissait. Il fallait une configuration explicite pour ne pas le faire. En cas d'erreur, ce comportement menait à des fuites (RFC 7908). Notre RFC normalise désormais le comportement inverse : un routeur BGP ne doit, par défaut, rien accepter et rien annoncer. Il faut qu'il soit configuré explicitement si on veut le faire.
Avec l'ancien comportement, la configuration de certains routeurs BGP, les plus imprudents, indiquait les pairs avec qui on échangeait de l'information, plus un certain nombre de routes qu'on n'envoyait pas. Si une erreur faisait qu'on recevait tout à coup des routes imprévues, on les acceptait, et on les renvoyait telles quelles, propageant la fuite (RFC 7908). Des cas fameux de fuites ne manquent pas (voir par exemple celle d'un opérateur malaisien). L'idée derrière ce comportement était d'assurer la connectivité du graphe de l'Internet. Aujourd'hui, on est plutôt plus sensibles aux risques de sécurité qu'à ceux de partitionnement du graphe, et les bonnes pratiques demandent depuis longtemps qu'on indique explicitement ce qu'on accepte et ce qu'on envoie. Voyez par exemple les recommandations de l'ANSSI.
En pratique, ce très court RFC ajoute juste deux paragraphes à la norme BGP, le RFC 4271. Dans sa section 9.1, les paragraphe en question disent désormais qu'il ne doit pas y avoir du tout d'exportation ou d'importation de routes, par défaut. Notez donc que cela ne change pas le protocole BGP, juste le comportement local.
Du moment qu'on change le comportement par défaut, il va y avoir un problème de transition (et ce point a soulevé des discussions à l'IETF). Si le logiciel du routeur s'adaptait au nouveau RFC, certains opérateurs seraient bien surpris que leurs routes ne soient tout coup plus annoncées. L'annexe A du RFC recommande une stratégie en deux temps :
- D'abord introduire une nouvelle option « BGP non sécurisé » qui serait à Vrai par défaut (mais que les opérateurs pourraient changer), ce qui garderait le comportement actuel mais avec un avertissement émis quelque part « attention, vous exportez des routes sans décision explicite »,
- Ensuite, dans la version suivante du logiciel, faire que cette option soit à Faux par défaut.
Et pour finir sur une note d'humour, à une réunion IETF (IETF 97), le projet qui a finalement mené à ce RFC était illustré… de photos de préservatifs. Pratiquez donc le BGP safe, l'Internet vous remerciera.
L'article seul
Les #MercrediFiction de Mastodon, techniques pour les traduire dans d'autres formats
Première rédaction de cet article le 9 juillet 2017
Une des pratiques les plus intéressantes de Mastodon est celle du #MercrediFiction. Le mercredi, des gens écrivent une fiction, a priori en moins de 500 caractères. Plusieurs personnes avaient demandé si on pouvait publier ces pouètes sous d'autres formats (la demande initiale était pour créer un « ebook »). J'ai donc fait un petit programme qui publie les pouètes #MercrediFiction en EPUB et HTML. Cet article, destiné à des programmeurs, explique les choix techniques et quelques problèmes rencontrés. Si vous n'êtes pas programmeur, n'hésitez pas à lire #MercrediFiction quand même !
Même moi, je m'y suis mis à en écrire. Et pour les récupérer ? Premier choix, j'ai décidé d'écrire le code en Python. J'ai utilisé la version 3 de Python (qui n'est pas compatible avec la précédente), la version 2 n'évoluant plus.
Comment récupérer les pouètes ayant le bon mot-croisillon ? La solution évidente est d'utiliser l'API de Mastodon, qui est bien documentée. Mais je la trouve trop compliquée pour mon goût, surtout question authentification (même si ce projet particulier n'a pas besoin d'authentification). J'ai donc décidé de déléguer cette tâche à l'excellent outil en ligne de commande madonctl. (On aurait pu utiliser toot.) Récupérer les pouètes ayant le mot-croisillon #MercrediFiction et les exporter au format JSON se fait simplement avec :
% madonctl --output json timeline :MercrediFiction
Je ne sais pas exactement jusqu'où madonctl, ou plutôt l'API de Mastodon qu'il utilise, remonte dans le temps. Je fais donc plusieurs récupérations par jour, et je supprime ensuite les doublons.
Quelle instance utiliser pour récupérer les pouètes ? Dans une fédération, rien ne garantit que deux instances (deux nœuds Mastodon) ont le même contenu. L'algorithme exact qui détermine dans quel cas une instance a reçu un pouète n'est pas, à ma connaissance, documenté (sauf dans le code source, feront remarquer les libristes). Il semble que ce soit à peu près « on récupère les pouètes des gens qui sont sur mon instance, ainsi que ceux repouètés par quelqu'un de mon instance, ainsi que ceux émis par quelqu'un suivi par quelqu'un de mon instance ». Dans ce cas, il est clairement évident qu'il vaut mieux récupérer les pouètes sur une grosse instance, avec plein d'utilisateurs et plein de connexions avec d'autres instances. J'ai choisi Mamot, qui a ces caractéristiques, et est en plus géré par des gens bien.
Une fois le compte
mercredifiction@mamot.fr créé, l'appel à
madonctl me donne donc les pouètes en JSON. Qu'en faire à la fin
de la journée ? (Au passage, le code est évidemment distribué sous
une licence libre, et il est visible en https://framagit.org/bortzmeyer/MercrediFiction
Les deux formats que je crée actuellement, EPUB et HTML, utilisent tous les deux XHTML. Il faut donc traduire le JSON en XHTML, ce qui est trivial. J'utilise la bibliothèque officielle de Python pour analyser le JSON et, pour produire le XHTML, le module Yattag, dont le gros intérêt est que le gabarit est lui-même en Python : on n'utilise donc qu'un seul langage. Voici un exemple du code Python+Yattag utilisé pour produire le XHTML :
with tag('head'):
with tag('link', rel = "stylesheet", type = "text/css", href = "mercredifiction.css"):
pass
with tag('title'):
text("Mercredi Fiction %s" % datestr)
with tag('body'):
with tag('h1'):
text("Mercredi Fiction du %s" % formatdate(datestr, short=True))
Et le contenu du pouète lui-même ? L'API le distribue en HTML. Mais il y a deux pièges : c'est du HTML et pas du XHTML, et surtout rien ne garantit que l'instance n'enverra que du HTML sûr. Il y a un risque d'injection si on copie ce HTML aveuglément dans le document EPUB ou dans une page Web. Si demain l'instance envoie du JavaScript, on sera bien embêté.
Donc, première chose, traduire le HTML en XHTML. C'est simple,
avec le module ElementTree (etree) de lxml :
from lxml import etree, html
...
tree = html.fromstring(content)
result = etree.tostring(tree, pretty_print=False, method="xml")
doc.asis(result.decode('UTF-8'))
(La fonction asis vient de Yattag et indique de
mettre le contenu tel quel dans le document HTML, sans, par exemple,
convertir les > en >.)
Et pour la sécurité ? On utilise un autre module de lxml, Cleaner :
from lxml.html.clean import Cleaner
...
cleaner = Cleaner(scripts=True, javascript=True, embedded=True, meta=True, page_structure=True,
links=False, remove_unknown_tags=True,
style=False)
Le code ci-dessus supprime de l'HTML le JavaScript, et plusieurs autres éléments HTML dangereux.
Voilà, on a désormais du XHTML propre et, espérons-le, sûr. Pour produire les pages Web, ça suffit. Mais, pour l'EPUB, c'est un peu plus compliqué. À ma connaissance, le format EPUB ne bénéficie pas d'une norme publique. J'ai donc dû me rabattre sur d'excellentes documentations comme le Epub Format Construction Guide qui explique bien la structure d'un fichier EPUB. Un fichier EPUB est un zip contenant entre autre des fichiers HTML. Le lecteur EPUB typique est bien plus strict que le navigateur Web typique, et il faut donc faire attention à l'HTML qu'on génère. Il faut aussi placer diverses métadonnées, en Dublin Core. En l'absence d'une norme disponible, certaines choses doivent être devinées (par exemple, mettre le fichier CSS dans l'EPUB et le manifeste ne suffit pas, il faut aussi le déclarer dans l'HTML, ou bien le fait que les compteurs du nombre de pages dans la table des matières semblent optionnels). Pour les programmeurs Python, il y a aussi cet exemple en Python.
Si vous écrivez un programme qui produit de l'EPUB, n'oubliez pas de valider l'EPUB produit. Cela peut se faire en ligne de commande avec le programme epubcheck :
% epubcheck mercredifiction-dernier.epub Validating using EPUB version 2.0.1 rules. No errors or warnings detected. epubcheck completed
Ou cela peut être vérifié en ligne, ce service utilisant le même programme.
Enfin, question EPUB, n'oubliez pas de servir les fichiers EPUB
avec le bon type MIME,
application/epub+zip, pour que le lecteur
d'ebooks soit lancé
automatiquement. Sur Apache, ça peut se faire
avec la directive AddType application/epub+zip
.epub.
Quelques petits détails amusants ou énervants, pour
terminer. D'abord, l'API de Mastodon, pour des raisons qui m'échappent
complètement (j'ai entendu des explications, mais toutes mauvaises),
lorsque le pouète contient des emojis (comme 🌸 ou 🌤),
renvoie non pas le caractère Unicode correspondant, mais du texte
entre deux-points, par exemple
:cherry_blossom: (ces textes viennent du système
commercial Emoji One). Il
n'y a absolument aucune raison d'utiliser ces séquences de texte. La
bogue a
été signalée mais pour l'instant sans résultat. J'avais
envisagé de faire la
conversion moi-même pour #MercrediFiction mais c'est trop
complexe, vu la taille de la base des emojis, à moins d'installer le
code très compliqué fourni par Emoji One.
Autre limite de la version actuelle de mon service, le fait que les images ne sont pas incluses. Rare sont les pouètes #MercrediFiction qui comportent des images, mais ce serait tout de même sympathique de les gérer proprement. L'EPUB et le HTML devraient sans doute être gérés différemment : dans le premier cas, le lecteur s'attend à un ebook autonome, fonctionnant sans connexion Internet, et il faut donc récupérer les images en local, et les mettre dans le fichier EPUB. Dans le second, il vaut sans doute mieux mettre un lien vers l'image originale (avec toutefois le risque que, si l'hébergement original disparait, on perde l'image).
Notez que récupérer les images présente quelques risques juridiques. En théorie, c'est pareil avec les textes (le droit d'auteur s'applique aux deux, et je dois avouer que je récolte les pouètes sans penser à ce problème) mais, en pratique, le risque de réclamation est plus élevé pour les images (demandez à n'importe quel hébergeur). Pour l'instant, je n'ai pas encore reçu de message d'un juriste me demandant de supprimer tel ou tel pouète.
Le résultat est visible ici. Sinon, il existe un autre service de distribution, dont les sources (également en Python) sont disponibles.
L'article seul
RFC 8195: Use of BGP Large Communities
Date de publication du RFC : Juin 2017
Auteur(s) du RFC : J. Snijders, J. Heasley
(NTT), M. Schmidt (i3D.net)
Pour information
Réalisé dans le cadre du groupe de travail IETF grow
Première rédaction de cet article le 1 juillet 2017
Le RFC 8092 a normalisé la notion de « grande communauté » BGP, des données attachées aux annonces de routes, plus grandes que les précédentes « communautés » et permettant donc de stocker davantage d'informations. Ce nouveau RFC explique à quoi peuvent servir ces grandes communautés et donne des exemples d'utilisation. Un document concret, qui ravira les opérateurs réseaux.
Le RFC original sur les communautés BGP était le RFC 1997, et il était accompagné d'un RFC 1998 présentant des cas concrets d'utilisation. C'est la même démarche qui est faite ici, de faire suivre le document de normalisation, le RFC 8092, d'un document décrivant des utilisations dans le monde réel (avec des expériences pratiques décrites à NANOG ou NLnog).
Un petit rappel des grandes communautés, d'abord (section 2 du RFC). Chaque communauté se compose de trois champs de quatre octets chacun. Le premier champ se nomme GA, pour Global Administrator, et sa valeur est le numéro de l'AS qui a ajouté cette communauté (rappelez-vous que les numéros d'AS font désormais quatre octets), ce qui assure l'unicité mondiale des communautés. Les deux autres champs portent les noms peu imaginatifs de Local Data Part 1 et Local Data Part 2. La plupart du temps, on se sert du premier pour identifier une fonction, et du second pour identifier les paramètres d'une fonction. Notez qu'il n'existe pas de standard pour ces deux champs locaux : comme leur nom l'indique, chaque AS les affecte comme il veut. Une même valeur peut donc avoir des significations différentes selon l'AS.
Le RFC contient plusieurs exemples, qui utilisent à chaque fois
la même topologie : un transitaire, l'AS 65551, avec un client,
l'AS 64497, qui est lui-même transitaire pour les AS 64498 et
64499, qui par ailleurs ont une relation de
peering (en épais sur
l'image)  :
:
Notre RFC classe les communautés en deux catégories : celles d'information et celles d'action. Les premières servent à distribuer des informations qui ne modifieront pas le comportement des routeurs, mais pourront être utiles pour le débogage, ou les statistiques. Un exemple est l'ajout d'une communauté pour indiquer dans quel pays on a appris telle route. Elles sont typiquement ajoutées par l'AS qui a défini ces informations, et il mettra donc son numéro d'AS dans le champ GA. Les secondes, les communautés d'action, servent à indiquer une action souhaitée. Elles sont définies par l'AS qui aura à agir, et mises dans le message BGP par un de ses pairs. Un exemple est une communauté pour indiquer à son pair quelle préférence on souhaite qu'il attribue à telle route.
La section 3 donne des exemples de communautés
d'information. Le premier est celui où l'AS 66497 marque les
routes qu'il a reçues avec une communauté qui indique le pays où
la route a été apprise (le code pays utilisé est celui de
ISO 3166-1). La fonction a reçu le numéro
1. Donc, la présence dans l'annonce
BGP de la communauté 64497:1:528 indique une
route apprise aux Pays-Bas, la communauté
64497:1:392 indique le
Japon, etc. Le même opérateur peut aussi
prévoir une fonction 2 pour indiquer la région (concept plus vaste
que le pays), en utilisant les codes M.49 :
64497:2:2 dit que la route a été apprise en
Afrique, 64497:2:150
en Europe et ainsi de suite. Rappelez-vous
bien que la signification d'une fonction (et donc des paramètres qui
suivent) dépend de l'AS (ou, plus rigoureusement, du champ GA). Il n'y a pas de standardisation des
fonctions. Si vous voyez une communauté
65551:2:2, cela ne signifie pas forcément que
la route vient d'Afrique : l'AS 65551 peut utiliser la fonction 2
pour tout à fait autre chose.
À part l'origine géographique d'une route, il est souvent utile
de savoir si la route a été apprise d'un pair ou d'un
transitaire. Le RFC donne l'exemple d'une fonction 3 où le
paramètre 1 indique une route interne, 2 une route apprise d'un
client, 3 d'un pair et 4 d'un transitaire. Ainsi, la communauté
64497:3:2 nous dit que la route vient d'un
client de l'AS 64497.
Une même annonce de route peut avoir plusieurs communautés. Une
route étiquetée 64497:1:528, 64497:2:150 et
64497:3:3 vient donc d'un pair aux Pays-Bas.
Et les communautés d'action (section 4 du
RFC) ? Un premier exemple est celui où on indique à son camarade
BGP de ne pas exporter inconditionnellement une route qu'on lui
annonce (ce qui est le comportement par défaut de BGP). Mettons
que c'est la fonction 4. (Vous noterez qu'il n'existe pas d'espace
de numérotation de fonctions distinct pour les communautés
d'information et d'action. On sait que la fonction 4 est d'action
uniquement si on connait la politique de l'AS en question.)
Mettons encore que l'AS 64497 a défini le paramètre comme étant un
numéro d'AS à qui il ne faut pas exporter la
route. Ainsi, envoyer à l'AS 64497 une route étiquetée
64497:4:64498 signifierait « n'exporte
pas cette route à l'AS 64498 ». De la même
façon, on peut imaginer une fonction 5 qui utilise pour cette
non-exportation sélective le code
pays. 64997:5:392 voudrait dire « n'exporte
pas cette route au Japon ». (Rappelez-vous que BGP est du routage
politique : son but principal est de permettre de faire respecter
les règles du business des opérateurs.)
Je me permets d'enfoncer le clou : dans les communautés d'action, l'AS qui ajoute une communauté ne met pas son numéro d'AS dans le champ GA, mais celui de l'AS qui doit agir.
Un autre exemple de communauté d'action serait un allongement
sélectif du chemin d'AS. On allonge le chemin d'AS en répétant le
même numéro d'AS lorsqu'on veut décourager l'utilisation d'une
certaine route. (En effet, un des facteurs essentiels d'une
décision BGP est la longueur du chemin d'AS : BGP préfère le plus
court.) Ainsi, l'exemple donné utilise la fonction 6 avec comme
paramètre l'AS voisin où appliquer cet allongement
(prepending). 64497:6:64498
signifie « ajoute ton AS quand tu exportes vers 64498 ».
Quand on gère un routeur BGP multihomé, influencer le trafic
sortant est assez simple. On peut par exemple mettre une
préférence plus élevée à la sortie vers tel
transitaire. Influencer le trafic entrant (par exemple si on veut
que le trafic vienne surtout par tel transitaire) est plus
délicat : on ne peut pas configurer directement la politique des
autres AS. Certains partenaires BGP peuvent permettre de définir
la préférence locale (RFC 4271, section
5.1.5), via une communauté. Ici, le RFC donne l'exemple d'une
fonction 8 qui indique « mets la préférence d'une route client [a
priori une préférence élevée] », 10 une route de
peering, 11 de transit
et 12 une route de secours, à n'utiliser qu'en dernier recours
(peut-être parce qu'elle passe par un fournisseur cher, ou bien de
mauvaise qualité). Le paramètre (le troisième champ de la
communauté) n'est pas utilisé. Alors, la communauté
64997:12:0 signifiera « AS 64997, mets à cette route la
préférence des routes de secours [a priori très basse] ».
Le RFC suggère aussi, si le paramètre est utilisé, de le
prendre comme indiquant la région où cette préférence spécifique
est appliquée. Par exemple 64997:10:5
demandera à l'AS 64997 de mettre la préférence des routes de
peering (10) à tous les routeurs en
Amérique du Sud (code 5 de la norme
M.49).
Attention, changer la préférence locale est une arme puissante, et sa mauvaise utilisation peut mener à des coincements (RFC 4264).
Dernier exemple donné par notre RFC, les souhaits exprimés à un
serveur de routes (RFC 7947). Ces serveurs parlent en
BGP mais ne sont pas des routeurs, leur seul rôle est de
redistribuer l'information aux routeurs. Par défaut, tout est
redistribué à tout le monde (RFC 7948), ce
qui n'est pas toujours ce qu'on souhaite. Si on veut une politique
plus sélective, certains serveurs de route documentent des
communautés que les clients du serveur peuvent utiliser pour
influencer la redistribution des routes. Notre RFC donne comme
exemple une fonction 13 pour dire « n'annonce pas » (alors que
cela aurait été le comportement normal) et une fonction 14 pour
« annonce quand même » (si le comportement normal aurait été de ne
pas relayer la route). Ainsi, 64997:13:0 est
« n'annonce pas cette route par défaut » et
64997:14:64999 est « annonce cette route à
l'AS 64999 ».
Vous voudriez des exemples réels ? Netnod avait annoncé que ces grandes communautés étaient utilisables sur leur AS 52005 :
52005:0:0Do not announce to any peer52005:0:ASxDo not announce to ASx52005:1:ASxAnnounce to ASx if 52005:0:0 is set52005:101:ASxPrepend peer AS 1 time to ASx52005:102:ASxPrepend peer AS 2 times to ASx52005:103:ASxPrepend peer AS 2 times to ASx
On trouve également ces communautés au IX-Denver, documentées ici (sous « Route Server B and C Communities ») ou au SIX (dans leur documentation). Il y a enfin cet exemple à ECIX. (Merci à Job Snijders et Pier Carlo Chiodi pour les exemples.)
Voilà, à vous maintenant de développer votre propre politique de communautés d'information, et de lire la documentation de vos voisins BGP pour voir quelles communautés ils utilisent (communautés d'action).
L'article seul
RFC 8190: Updates to Special-Purpose IP Address Registries
Date de publication du RFC : Juin 2017
Auteur(s) du RFC : R. Bonica (Juniper
Networks), M. Cotton
(ICANN), B. Haberman (Johns Hopkins
University), L. Vegoda (ICANN)
Première rédaction de cet article le 28 juin 2017
Le RFC 6890 avait créé un registre unique des préfixes d'adresses IP « spéciaux ». Ce nouveau RFC met à jour le RFC 6890, précisant et corrigeant quelques points.
Un préfixe « spécial » est juste un préfixe
IP dédié à un usage inhabituel, et qui peut
nécessiter un traitement particulier. Ainsi, les préfixes
203.0.113.0/24 et
2001:db8::/32 sont dédiés à la documentation,
aux cours et exemples et, bien que n'étant pas traités
différemment des autres préfixes par les routeurs, ne doivent normalement pas
apparaitre dans un vrai réseau. Le RFC 6890
spécifie les deux registres de préfixes spéciaux, un
pour IPv4 et un
pour IPv6. Mais il y avait une ambiguité dans ce RFC, dans
l'usage du terme « global ». Il n'est pas
évident à traduire en français. Dans le langage courant,
global/globalement, a surtout le sens de « le plus
souvent/généralement », alors que, dans le contexte de l'Internet,
ce serait plutôt dans le sens « valable pour tout point du
globe ». Même en anglais, le
terme est polysémique : il peut signifier que
l'adresse IP est unique au niveau mondial ou bien il peut
signifier que l'adresse est potentiellement joignable
mondialement, et qu'un routeur peut donc faire suivre le paquet en
dehors de son propre domaine. (La joignabilité effective, elle,
dépend évidemment de l'état de BGP.) Le
RFC 4291, dans sa section 2.5.4, n'est pas
plus clair.
Reprenons l'exemple des préfixes de documentation. Dans les trois
préfixes IPv4 de documentation (comme
203.0.113.0/24), les adresses ne sont pas
uniques (chacun les alloue comme il veut et, vu le faible nombre
d'adresses total, il y aura certainement des collisions) et, de
toute façon, n'ont pas de signification en dehors d'un domaine :
cela n'a pas de sens de transmettre des paquets ayant de telles
adresses à ses partenaires. Pour le préfixe de documentation IPv6,
2001:db8::/32, c'est un peu plus compliqué
car les adresses peuvent être quasi-uniques mondialement (si on
prend la précaution de les tirer au sort dans le préfixe) mais, de
toute façon, n'ont pas vocation à être joignables de partout et on
ne transmet donc pas ces paquets à ses voisins.
Bref, notre nouveau RFC choisit d'être plus précis, renommant l'ancien booléen « global » du RFC 6890 en « globally reachable ».
La nouvelle définition (section 2) est donc bien « le paquet ayant cette adresse comme destination peut être transmis par un routeur à un routeur d'un autre domaine (d'un autre opérateur, en pratique) ». La colonne Global du registre est donc remplacée par Globally reachable. Notez qu'il n'y a pas de colonne « Unicité » (une autre définition possible de global).
Cela a nécessité quelques changements supplémentaires dans le registre (toujours section 2), colonne Globally reachable :
L'article seul
Fiche de lecture : La face cachée d'Internet
Auteur(s) du livre : Rayna Stamboliyska
Éditeur : Larousse
978-2-03-593641-7
Publié en 2017
Première rédaction de cet article le 28 juin 2017
Vous allez peut-être vous dire, en prenant connaissance du sous-titre (« hackers, darkweb, Tor, Anonymous, WikiLeaks, bitcoins… ») et surtout en voyant la couverture un peu tape-à-l'œil, que c'est juste le Nième livre sur les gros méchants cyberaffreux des bas-fonds du réseau, ceux qui font sauter une centrale nucléaire en tapotant sur un smartphone, ceux que le gentil ministre va heureusement bientôt civiliser. Des livres de ce genre, sensationnalistes, bourrés d'erreurs qui amusent les geeks et égarent les lecteurs innocents, il y en a plein. Mais celui-ci est différent :
- Il est écrit par une auteure qui connait son (ou plutôt ses) sujets,
- Il ne contient pas d'erreurs (ou alors je ne les ai pas trouvées),
- Il essaie de tout expliquer sans simplifier et sans prendre le lecteur pour un ahuri.
Le cahier des charges était donc difficile. Les éditions Larousse font des livres à destination du grand public (le célèbre M. Michu). Souvent, « mais c'est pour le grand public » sert d'excuse pour bâcler le travail. Or, cela devrait être le contraire : comme M. Michu n'a pas les connaissances nécessaires pour corriger de lui-même les erreurs, il faut être plus rigoureux et plus précis quand on écrit pour le grand public. L'auteure n'a pas écrit pour toi, lecteur typique de mon blog ou, plutôt, pas que pour toi.
On trouve très peu de livres ayant un cahier des charges analogue. Soit on fait du purement technique, pour informaticiens, soit on fait du Paris Match. C'est ce que j'apprécie le plus dans le travail de Rayna Stamboliyska, l'effort pour être claire et pédagogue, sans être approximative et baratineuse.
Est-ce réussi ? Je vais laisser l·a·e lect·rice·eur en juger. Personnellement, je trouve que le livre est riche, plein d'informations, et que M. Michu va devoir faire un effort pour suivre ces nombreux personnages et ces rebondissements multiples (notamment dans le chapitre sur WikiLeaks). D'autant plus qu'on trouve dans ce livre des choses qu'on s'attend plus à voir dans un ouvrage universitaire (ma préférée est le double espace de numérotation des références, un en romain pour des notes de bas de page, un autre en italique pour la bibliographie à la fin) Mais, justement, je ne pense pas que M. Michu soit un imbécile et demander un travail au lecteur ne me choque pas.
Ah, et puisque j'ai parlé de la bibliographie : recopier à la main des URL est évidemment pénible et provoque souvent des erreurs. Donc, pour accéder aux nombreux textes cités, et pour d'autres raisons, je recommande que vous visitiez le site Web officiel attaché au livre. Quelques autres références :
- Un très intéressant interview de l'auteure sur le Framablog, sur le processus d'élaboration du livre,
- La première critique publiée sur le livre,
- Le très réussi livre d'Amaelle Guiton sur les hackers,
- Si vous voulez savoir ce qu'est vraiment un darknet (et qui n'a rien à voir avec le sens médiatique), et son copain le greynet, lisez le RFC 6018.
Avertissement : je suis l'auteur de la préface, et j'ai reçu un exemplaire gratuit. Je ne suis donc pas neutre.
Un dernier mot, pour les programmeurs : il y a deux fautes dans le code en C sur la couverture. Cherchez.
L'article seul
Les drôles de pratiques BGP d'un opérateur bulgare et d'une université colombienne
Première rédaction de cet article le 26 juin 2017
Aujourd'hui, nous allons un peu regarder un drôle de problème BGP, et en n'utilisant que des sources ouvertes. L'infrastructure de l'Internet est en effet largement ouverte aux investigations.
Alors, d'abord, le premier fait : l'opérateur bulgare Wireless Network
Solutions annonçait en BGP un grand
nombre de routes assez éloignées de ce qu'on attendrait de
lui. L'annonce a cessé le 7 juin mais on peut toujours voir les
anciennes annonces dans ce
fichier issu de RIPE stat ou directement sur
RIPE Stat :
Parmi les préfixes annoncés, on trouvait en effet des valeurs
comme 168.176.219.0/24. Or,
l'AS 34991 est situé en
Bulgarie (ici, les données complètes,
obtenues via whois). Alors que le préfixe
168.176.219.0/24 fait partie du
168.176.0.0/16 alloué à l'Université nationale de
Colombie (ici, les données complètes via
whois). Pourquoi donc un opérateur situé
dans une petite ville de
Bulgarie aurait-il comme client une université à
Bogota ? Les liens économiques,
historiques, linguistiques ou religieux, entre la Bulgarie et la
Colombie semblent faibles. Creusons.
L'Université nationale de Colombie dispose d'un préfixe IPv4 de longueur 16 (cf. les données citées plus haut) mais ne l'annonce pas en BGP. On ne le voit pas sur RIPE stat, ou sur le looking glass de Hurricane Electric. Des sous-préfixes sont annoncés mais pas le /16 complet. Voyons sur RouteViews en telnet :
% telnet route-views.routeviews.org
Trying 2001:468:d01:33::80df:3367...
Connected to route-views.routeviews.org.
...
User Access Verification
Username: rviews
route-views>show ip route 168.176.219.0
% Subnet not in table
route-views>show ip route 168.176.0.0
Routing entry for 168.176.0.0/16, 46 known subnets
Variably subnetted with 7 masks
B 168.176.0.0/18 [20/0] via 66.110.0.86, 2d02h
B 168.176.64.0/19 [20/0] via 66.110.0.86, 2d02h
B 168.176.72.0/22 [20/0] via 66.110.0.86, 2d02h
B 168.176.76.0/24 [20/0] via 66.110.0.86, 2d02h
...
Donc, l'université colombienne n'annonce qu'une petite partie de son
/16. À une époque où tout le monde souffre de la pénurie d'adresses IPv4, c'est
un peu curieux. L'annonce du sous-préfixe
168.176.219.0/24 par l'AS 34991 n'est donc
pas un détournement BGP classique comme
l'étaient ceux par Telekom Malaysia en
2015 ou bien lors du shunt de
2013. « Aucun préfixe BGP n'a été détourné pour le tournage de
ce film. » Néanmoins, il ne semble pas non plus que cette annonce,
qui n'a duré que dix jours, ait été légitime, à moins que le
campus de Medellín n'ait eu envie pendant
dix jours d'être connecté à l'Internet via la Bulgarie ? Une autre
hypothèse, qui ne peut être formulée que par des gens pratiquant
la méchanceté gratuite, serait que l'université a loué des /24 à des spammeurs
bulgares…
Certains ont émis l'hypothèse que l'AS bulgare avait été pris par des méchants, à l'occasion d'une attaque flamant. Une attaque flamant est l'enregistrement d'un domaine qui n'existait pas, pour récupérer le courrier, y compris les demandes d'autorisation, d'un objet dont les contacts utilisaient des domaines disparus, ou mal enregistrés. Un exemple d'attaque flamant pour des TLD est par exemple documentée ici. La (je crois) première description publique date de 2007.
Les contacts techniques et
administratifs de l'AS sont en
@wirelessnetbg.info. Ils ont été modifiés
juste avant les annonces bizarres, et le domaine créé peu de temps
avant ces annonces (cf. les données récupérées par
whois, le champ Creation Date). Mais
rien ne prouve (en tout cas avec des données ouvertes) qu'il y a
eu une attaque flamant contre l'AS, bien qu'elle soit possible. Notez
enfin que
l'entreprise derrière l'AS ne semble pas exister dans le registre
des entreprises en Bulgarie.
Merci à Ronald F. Guilmette pour avoir détecté le cas et l'avoir publié, et à Rayna Stamboliyska pour des investigations.
L'article seul
RFC 8126: Guidelines for Writing an IANA Considerations Section in RFCs
Date de publication du RFC : Juin 2017
Auteur(s) du RFC : M. Cotton (ICANN), B. Leiba (Huawei
Technologies), T. Narten (IBM
Corporation)
Première rédaction de cet article le 21 juin 2017
Un aspect peu connu du travail de normalisation est la nécessité de tenir des registres de certains paramètres, lorsque la liste de ces derniers n'est pas fixée dans un RFC. Par exemple, les algorithmes publiés dans le DNS pour IPsec ne sont pas définis de manière limitative dans le RFC 4025 mais sont enregistrés dans un registre public. Même chose pour les types de média du RFC 6838, qui ont leur propre registre. Pour les RFC, ces registres sont tenus par l'IANA. Celle-ci ne décide pas quels registres elle doit tenir ni à quelle condition un nouveau paramètre peut y rentrer, elle applique les décisions contenues dans la section IANA Considerations d'un RFC. C'est cette section qui est décrite ici. Ce RFC remplace l'ancien RFC 5226.
Prenons l'exemple du RFC 3315 (DHCP). Sa
section 24 contient le texte « This document defines several
new name spaces associated with DHCPv6 and DHCPv6 options: Message
types, Status codes, DUID and Option codes. IANA has established a
registry of values for each of these name spaces, which are described
in the remainder of this section. These name spaces will be managed
by the IANA and all will be managed separately from the name spaces
defined for DHCPv4. ». En application de ce texte,
l'IANA a créé le registre DHCPv6 and
DHCPv6 options qu'on peut consulter en ligne à https://www.iana.org/assignments/dhcpv6-parameters. Et comment
ajoute-t-on des entrées dans ce registre ? En suivant les règles
données dans ce même RFC : « New DHCP option codes are
tentatively assigned after the specification for the associated
option, published as an Internet Draft, has received expert review by
a designated expert [11]. The final assignment of DHCP option codes
is through Standards Action, as defined in RFC 2434.
».
L'intérêt d'avoir une section obligatoire IANA Considerations est de concentrer en un seul endroit les informations nécessaires à l'IANA pour faire son travail. Pour aider les auteurs de RFC à écrire correctement cette section IANA Considerations, notre RFC 8126, qui succède au RFC 5226, pose quelques règles.
La section 1 du RFC décrit le problème général de la gestion d'un espace de nommage (namespace). Tous ces espaces n'ont pas les mêmes caractéristiques. Certains sont très petits (le champ protocole, qui n'a que huit bits soit 256 valeurs possibles, cf. RFC 5237) et doivent donc être gérés avec prudence, certains sont hiérarchiques comme le DNS ou comme les OID et peuvent donc être délégués, certains sont immenses, et peuvent être gérés avec moins de précautions (mais nécessitent quand même des règles, comme expliqué dans la section 1).
Cette même section 1 résume les points essentiels que doit connaitre l'auteur d'un RFC, notamment d'avoir une section dédiée IANA Considerations, et de n'y mettre que ce qui est strictement nécessaire à l'IANA (pas de digressions, pas de détails techniques).
La section 2 est consacrée à la création d'un nouveau registre. Il y a bien des décisions à prendre à ce stade. Par exemple, notre RFC recommande de voir si on ne peut pas faire un registre arborescent, où l'action de l'IANA se limiterait à la racine de ce registre, diminuant ainsi sa charge de travail. (C'est le cas des URN du RFC 8141.)
Si un RFC doit demander une telle création, il doit préciser quelle politique d'enregistrement devra suivre l'IANA. C'est une des parties les plus intéressantes du RFC, notamment sa section 4 qui explique les politiques possibles :
- Premier Arrivé, Premier Servi (« First Come First Served »), où toute requête est
acceptable et est faite dans l'ordre d'arrivée. Les entrées dans le
préfixe OID
iso.org.dod.internet.private.enterprisesont un bon exemple (https://www.iana.org/assignments/enterprise-numbersmais attention, le registre est lourd à charger). C'est aussi le cas des plans d'URI provisoires (RFC 7595) ou des états de traitement du courrier (RFC 6729). C'est sans doute la plus « libérale » des politiques d'enregistrement. (Il n'y a pas de mécanisme explicite contre les vilains qui enregistreraient plein de valeurs inutiles, avait noté l'examen de sécurité.) - Examen par un expert (« Expert review »), comme détaillé plus bas (section 5 du RFC). C'est ainsi que sont gérés les plans des URI permanents du RFC 7595, ou bien les types de méthode d'EAP (RFC 3748, sections 6 et 7.2, notez que Expert review était appelé Designated expert à cette époque).
- Spécification nécessaire (« Specification required ») où un texte écrit et stable décrivant le paramètre souhaité est nécessaire (ce texte n'est pas forcément un RFC, il y a d'ailleurs une politique « RFC required »). Il faut en outre un examen par un expert, comme dans la politique ci-dessus, l'expert vérifiant que la spécification est claire. Les profils de ROHC (RFC 5795) sont enregistrées sous cette condition. Les utilisations de certificat de DANE (RFC 6698, section 7.2) sont « RFC nécessaire ».
- Examen par l'IETF (« IETF Review »), l'une des plus « lourdes », puisqu'il faut un RFC « officiel », qui soit passé par l'IESG ou par un groupe de travail IETF (tous les RFC ne sont pas dans ce cas, certains sont des contributions individuelles). C'est la politique des extensions TLS du RFC 6066 (cf. RFC 5246, section 12, qui utilisait encore l'ancien terme de « IETF Consensus »).
- Action de normalisation (« Standards Action »), encore plus difficile, le RFC doit être sur le chemin des normes et donc avoir été approuvé par l'IESG. C'est le cas par exemple des types de message BGP (RFC 4271, section 4.1), en raison de la faible taille de l'espace en question (un seul octet, donc un nombre de valeurs limité) et sans doute aussi en raison de l'extrême criticité de BGP. C'est aussi la politique pour les options DHCP données en exemple plus haut.
- Utilisation privée (« Private use ») est une politique possible, qui est en fait l'absence de registre, et donc l'absence de politique de registre : chacun utilise les valeurs qu'il veut. Par exemple, dans le protocole TLS (RFC 5246, section 12), les valeurs 224 à 255 des identifiants numériques du type de certificat sont à usage privé ; chacun s'en sert comme il veut, sans coordination.
- Utilisation à des fins expérimentales (« Experimental use »), est en pratique la même chose que l'utilisation privée. La seule différence est le but (tester temporairement une idée, cf. RFC 3692). C'est le cas des valeurs des en-têtes IP du RFC 4727.
- Et il existe encore l'approbation par l'IESG (« IESG approval ») qui est la politique de dernier recours, à utiliser en cas de cafouillage du processus.
- Et le cas un peu particulier de l'allocation hiérarchique (« Hierarchical allocation ») où l'IANA ne gère que le registre de plus haut niveau, selon une des politiques ci-dessus, déléguant les niveaux inférieurs à d'autres registres. C'est le cas par exemple des adresses IP ou bien sûr des noms de domaine.
Le choix d'une politique n'est pas évident : elle ne doit pas être trop stricte (ce qui ferait souffrir les auteurs de protocoles, confrontés à une bureaucratie pénible) mais pas non plus trop laxiste (ce qui risquerait de remplir les registres de valeurs inutiles, les rendant difficilement utilisables). En tout cas, c'est une des décisions importantes qu'il faut prendre lors de l'écriture d'une spécification.
Notre RFC conseille (sans l'imposer) d'utiliser une de ces politiques (« well-known policies »). Elles ont été testés en pratique et fonctionnent, concevoir une nouvelle politique fait courir le risque qu'elle soit incohérente ou insuffisamment spécifiée, et, de toute façon, déroutera les lecteurs et l'IANA, qui devront apprendre une nouvelle règle.
Parmi les autres points que doit spécifier le RFC qui crée un nouveau registre, le format de celui-ci (section 2.2 ; la plupart des registres sont maintenus en XML, mais même dans ce cas, des détails de syntaxe, comme les valeurs acceptables, peuvent devoir être précisés). Notez que le format n'est pas forcément automatiquement vérifié par l'IANA. Notre RFC recommande également de bien préciser si le registre accepte des caractères non-ASCII (cf. RFC 8264, section 10).
Autre choix à faire dans un registre, le pouvoir de changer les
règles (change control). Pour des normes IETF (RFC
sur le chemin des normes), c'est en général l'IETF qui a ce pouvoir,
mais des registres IANA peuvent être créés pour des protocoles qui ne sont
pas gérés par l'IETF et, dans ce cas, le pouvoir peut appartenir à une
autre organisation. C'est ainsi que les types de données
XML (RFC 7303), comme le
application/calendar+xml (RFC 6321) sont contrôlés par le W3C.
La section 3 couvre l'enregistrement de nouveaux paramètres dans un registre existant. C'est elle qui précise, entre autres, que l'IANA ne laisse normalement pas le choix de la valeur du paramètre au demandeur (mais, en pratique, l'IANA est sympa et a accepté beaucoup de demandes humoristiques comme le port TCP n° 1984 pour le logiciel Big Brother...)
La section 6 donne des noms aux différents états d'enregistrement d'une valeur. Le registre note l'état de chaque valeur, parmi ces choix :
- Réservé à une utilisation privée,
- Réservé à une utilisation expérimentale,
- Non affecté (et donc libre),
- Réservé (non alloué mais non libre, par exemple parce que la norme a préféré le garder pour de futures extensions),
- Affecté,
- Utilisation connue, mais non officiellement affecté, ce qui se produit parfois quand un malotru s'approprie des valeurs sans passer par les procédures normales, comme dans le cas du RFC 8093.
Par exemple, si on prend les types de messages
BGP, on voit dans le
registre que 0 est réservé, les valeurs à partir de 6 sont
libres, les autres sont affectées (1 = OPEN, etc).
La section 5 décrit le rôle des experts sur
lesquels doit parfois s'appuyer l'IANA. Certains registres nécessitent
en effet un choix technique avec l'enregistrement d'un nouveau
paramètre et l'IANA n'a pas forcément les compétences nécessaires pour
cette évaluation. Elle délègue alors cette tâche à un expert
(designated expert, leur nom est noté à côté de celui du registre). Par exemple, pour le registre des langues, défini par le RFC 5646, l'expert actuel est Michael Everson. Ce registre utilise également une autre
possibilité décrite dans cette section, une liste de discussion qui sert à un examen collectif des requêtes
(pour le registre des langues, cette liste est
ietf-languages@iana.org). La section 5.1 discute
des autres choix qui auraient pu être faits (par exemple un examen par le groupe de travail qui a
créé le RFC, ce qui n'est pas possible, les groupes de travail IETF
ayant une durée de vie limitée). Elle explique ensuite les devoirs de
l'expert (comme la nécessité de répondre relativement rapidement,
section 5.3, chose qui est loin d'être toujours faite).
Enfin, diverses questions sont traitées dans la section 9, comme la récupération de valeurs qui avaient été affectées mais qui ne le sont plus (le RFC 3942 l'avait fait mais c'est évidemment impossible dès que les paramètres en question ont une... valeur, ce qui est le cas entre autres des adresses IP).
Bien que la plupart des allocations effectuées par l'IANA ne sont guère polémiques (à l'exception des noms de domaine et des adresses IP, qui sont des sujets très chauds), notre RFC 8126 prévoit une procédure d'appel, décrite en section 10. Cela n'a pas suffit à régler quelques cas pénibles comme l'enregistrement de CARP.
Ce RFC 8126 remplace le RFC 5226. Les principaux changements sont détaillés dans la section 14.1 :
- Moins de texte normatif style RFC 2119, puisqu'il ne s'agit pas de la description d'un protocole,
- Meilleure description des registres hiérarchiques,
- Ajout d'une partie sur le pouvoir de changer les règles (change control),
- Ajout de la possibilité de fermer un registre,
- Ajout de la section 8 sur le cas de RFC qui remplacent un RFC existant,
- Etc.
Notez que notre RFC est également complété en ligne par des informations plus récentes.
Les relations entre l'IETF et l'IANA sont fixées par le MOU contenu dans le RFC 2860. À noter que tout n'est pas couvert dans ce RFC, notamment des limites aux demandes de l'IETF. Que se passerait-il par exemple si l'IETF demandait à l'IANA, qui ne facture pas ses prestations, de créer un registre de milliards d'entrées, très dynamique et donc très coûteux à maintenir ? Pour l'instant, l'IANA ne peut pas, en théorie, le refuser et la question s'est parfois posée à l'IETF de savoir si tel ou tel registre n'était pas trop demander.
Puisque l'IANA est un acteur important de l'Internet, rappelons aussi que, bien que la fonction de l'IANA soit actuellement assurée par l'ICANN, la tâche de gestion des protocoles et des registres n'a rien à voir avec les activités, essentiellement politiciennes, de l'ICANN. La « fonction IANA » (création et gestion de ces registres) est formellement nommée IFO (IANA Functions Operator) ou IPPSO (IANA Protocol Parameter Services Operator) mais tout le monde dit simplement « IANA ».
L'article seul
Sur une panne DNS, et sur les leçons à en tirer (BNP Paribas)
Première rédaction de cet article le 20 juin 2017
Dernière mise à jour le 22 juin 2017
Ce matin du 20 juin, plein de messages sur les réseaux sociaux pour se plaindre d'une impossibilité d'accéder aux services en ligne de BNP Paribas. Le CM a bien du mal à répondre à tout le monde. À l'origine de cette panne, un problème DNS. Que s'est-il passé et pourquoi ?
Les noms de
domaine utilisés par BNP
Paribas sont tous dans le TLD
.bnpparibas. On peut facilement vérifier que
ce TLD va bien (un seul serveur ne répond pas) :
% check-soa -i bnpparibas
a0.nic.bnpparibas.
2a01:8840:3e::9: OK: 1000002072 (241 ms)
65.22.64.9: OK: 1000002072 (91 ms)
a2.nic.bnpparibas.
65.22.67.9: OK: 1000002072 (3 ms)
2a01:8840:41::9: OK: 1000002072 (3 ms)
b0.nic.bnpparibas.
2a01:8840:3f::9: OK: 1000002072 (19 ms)
65.22.65.9: OK: 1000002072 (27 ms)
c0.nic.bnpparibas.
2a01:8840:40::9: OK: 1000002072 (21 ms)
65.22.66.9: ERROR: read udp 10.10.86.133:33849->65.22.66.9:53: i/o timeout
Mais c'est en dessous qu'il y a des problèmes. En raison de règles
ICANN absurdes, les noms publiés sont tous
des sous-domaines de .bnpparibas, délégués à
deux serveurs de noms :
% dig @a2.nic.bnpparibas. NS mabanqueprivee.bnpparibas
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 51136
...
;; AUTHORITY SECTION:
mabanqueprivee.bnpparibas. 86400 IN NS sns5.bnpparibas.net.
mabanqueprivee.bnpparibas. 86400 IN NS sns6.bnpparibas.net.
...
;; SERVER: 2a01:8840:41::9#53(2a01:8840:41::9)
;; WHEN: Tue Jun 20 09:55:22 CEST 2017
Et, de ces deux serveurs de noms, l'un n'existe pas, l'autre est en panne (ou bien victime d'une attaque par déni de service) :
% check-soa -i -ns sns5.bnpparibas.net\ sns6.bnpparibas.net mabanqueprivee.bnpparibas
sns5.bnpparibas.net.
159.50.249.65: ERROR: read udp 10.10.86.133:57342->159.50.249.65:53: i/o timeout
sns6.bnpparibas.net.
Cannot get the IPv4 address: NXDOMAIN
On peut aussi tester avec dig, si vous préférez :
% dig @sns5.bnpparibas.net. NS mabanquepro.bnpparibas
; <<>> DiG 9.10.3-P4-Debian <<>> @sns5.bnpparibas.net. NS mabanquepro.bnpparibas
; (1 server found)
;; global options: +cmd
;; connection timed out; no servers could be reached
% dig @sns6.bnpparibas.net. NS mabanquepro.bnpparibas
dig: couldn't get address for 'sns6.bnpparibas.net.': not found
C'est assez étonnant. Un des deux serveurs n'existe même pas dans
le DNS. D'après DNSDB, il n'a même jamais existé ! Tous les
noms de BNP Paribas
(mabanqueprivee.bnpparibas,
mabanquepro.bnpparibas, etc) dépendaient donc
d'un seul serveur, qui a défailli ce matin.
Résultat, les utilisateurs ne pouvaient pas résoudre le nom en adresse et donc pas accéder au site Web ou à l'API. On le voit avec les sondes RIPE Atlas :
% atlas-resolve -r 100 mabanqueprivee.bnpparibas.
[ERROR: SERVFAIL] : 48 occurrences
[TIMEOUT(S)] : 50 occurrences
Test #8925333 done at 2017-06-20T07:55:45Z
La reprise a été partielle (plusieurs serveurs anycastés ? Attaque par déni de service qui se calme ?), un peu plus tard, on voit que certaines sondes réussissaient :
% atlas-resolve -r 100 mabanquepro.bnpparibas. [159.50.188.21] : 3 occurrences [ERROR: SERVFAIL] : 51 occurrences [TIMEOUT(S)] : 40 occurrences Test #8925337 done at 2017-06-20T07:58:24Z
Pour le serveur inexistant, l'explication m'a été donnée par un
anonyme (que je remercie beaucoup) : le vrai nom est sns6.bnpparibas.FR
(et pas .NET). Ce serveur existe bien,
répond, et fait en effet autorité pour les zones de la
banque. Lors de la délégation de la plupart des sous-domaines,
c'est simplement un mauvais nom qui a été indiqué !
Tout ceci n'est pas très conforme aux bonnes pratiques (telles qu'elles sont régulièrement rappelées, par exemple, dans le rapport annuel sur la résilience de l'Internet français) :
- Deux serveurs DNS faisant autorité, ce n'est en général pas assez (surtout si un des deux n'existe en fait pas),
- Les serveurs doivent être supervisés. Icinga ou Zabbix auraient prévenu depuis longtemps qu'un des deux serveurs ne marchait pas.
- Les configurations DNS doivent être testées, par exemple avec Zonemaster.
- Le TTL renvoyé par le serveur, lorsqu'il marche, est de seulement 30 secondes. C'est très insuffisant. En cas de panne imprévue, il faut facilement plusieurs heures pour réparer (l'essentiel du temps étant consacré à paniquer en criant).
Notez que, deux jours après la panne, rien n'a été réparé :
- Les zones n'ont toujours qu'un seul serveur (celui inexistant ne comptant évidemment pas),
- En prime, l'unique serveur répond incorrectement (il accepte les requêtes DNS de type A mais pas celles de types NS ou SOA).
Ces erreurs sont clairement visible sur les programmes de test DNS comme Zonemaster ou bien DNSviz.
L'article seul
Sur la communication quantique (et les exagérations)
Première rédaction de cet article le 19 juin 2017
Dans un article publié dans Science, un groupe de chercheurs annonce avoir réussi à transporter des photons intriqués sur plus de mille kilomètres. Mais ce n'est pas cette avancée scientifique intéressante que je veux commenter, mais les grossières exagérations avec lesquelles elle a été annoncée, notamment la promesse ridicule que la communication quantique allait donner un Internet plus sûr, voire un « Internet inviolable » (comme dit dans l'article sensationaliste de l'Express).
L'article en question promet en effet, outre l'Internet inviolable, de la téléportation, des « ordinateurs dotés d'une puissance de calcul sans commune mesure avec les plus puissantes machines actuelles » et même « un Internet basé à l'avenir sur les principes de la physique quantique ». Revenons au monde réel. L'article originel est bien plus modeste. (Au passage, il n'est pas disponible en ligne, car où irait-on si tout le monde pouvait accéder facilement aux résultats scientifiques ? Heureusement, on le trouve sur Sci-Hub, qu'on ne remerciera jamais assez.) Les auteurs ont réussi à transmettre des photons intriqués sur une distance plus grande que ce qui avait été fait avant. Beau résultat (l'opération est très complexe, et est bien décrite dans leur article) mais en quoi est-ce que ça nous donne un Internet inviolable ? L'idée est que la communication quantique est à l'abri de l'écoute par un tiers, car toute lecture, même purement passive, casserait l'intrication et serait facilement détectée. Sa sécurité est donc physique et non plus algorithmique. La NSA serait donc réduite au chômage ? C'est en tout cas ce que promet l'Express…
Il y a plusieurs raisons pour lesquelles cette promesse est absurde. La plupart de ces raisons découlent d'un fait simple que le journaliste oublie complètement dans son article : la communication de point à point n'est qu'une partie du système technique complexe qui permet à Alice et Bob de s'envoyer des messages de manière sécurisée. Si on ne considère pas la totalité de ce système, on va se planter. D'abord, citons « l'argument de Schneier », écrit il y a plus de huit ans et toujours ignoré par les vendeurs de solutions quantiques : la communication quantique ne sert à rien, pas parce qu'elle ne marche pas (au contraire, les progrès sont importants) mais parce qu'elle sécurise ce qui était déjà le maillon le plus fort du système. Quant on veut surveiller les gens, la plupart du temps, on ne va pas casser la cryptographie qui les protège. On va faire plus simple : exploiter une faille du protocole de communication, ou une bogue du logiciel qui le met en œuvre, ou tout simplement récupérer l'information à une des deux extrêmités (il ne sert à rien de faire de la communication quantique avec Google si Google fournit toutes vos données à la NSA). Avant de remplacer la cryptographie classique, il faudrait déjà sécuriser tous ces points. Autrement, le surveillant et l'espion, qui sont des gens rationnels, continueront à attaquer là où la défense est faible. Déployer de la communication quantique, c'est comme utiliser un camion blindé pour transmettre de l'argent entre deux entrepôts dont les portes ne ferment pas à clé. (C'est d'autant plus important que la communication quantique n'est pas de bout en bout : elle n'arrive pas jusqu'aux PC d'Alice et Bob.)
Et ce n'est pas la seule faiblesse de la communication quantique. La plus importante, à mon avis, est qu'elle n'authentifie pas. Vos messages ne peuvent pas être interceptés mais vous ne pouvez pas être sûr de savoir à qui vous parlez. Vous avez une communication sécurisée avec… quelqu'un, c'est tout. Cela rend la communication quantique très vulnérable à l'attaque de l'Homme du Milieu. Il existe bien sûr des remèdes contre cette attaque, mais tous dépendent de la cryptographie classique, avec ses faiblesses.
En parlant de cryptographie classique, notons aussi que la communication quantique est limitée à la distribution de clés. Vous avez toujours besoin d'un algorithme classique (comme AES) pour chiffrer.
Autre limite de la communication quantique : elle protège le canal, pas les données. Une fois les données « au repos » (sur les disques durs des ordinateurs d'Alice et Bob), elles sont aussi vulnérables qu'avant. Un piratage avec fuite de données (comme Ashley Madison, Yahoo, Sony…) se ferait aussi bien avec communication quantique que sans.
Qu'y avait-il encore comme promesses dénuées de sens dans l'article de l'Express ? Ah, oui, « des ordinateurs dotés d'une puissance de calcul sans commune mesure avec les plus puissantes machines actuelles ». Ici, il semble que l'auteur ait confondu la communication quantique avec le calcul quantique, qui n'a rien à voir. Et quant à la téléportation, elle relève plus de la science-fiction : l'expérience décrite dans Science n'a rien à voir avec de la téléportation, même limitée.
Voilà, comme d'habitude, on a une avancée scientifique réelle, décrite dans un article sérieux mais que personne ne lira, sur-vendue dans un dossier de presse aguicheur, lui-même repris sans critique et sans vérification dans de nombreux médias. Vu l'information reçue par les citoyens ordinaires, il n'est pas étonnant que la sécurité informatique soit actuellement si mauvaise.
Depuis la parution de cet article, l'ANSSI a publié une bonne synthèse sur le sujet.
L'article seul
dnstap, un journal de l'activité d'un serveur DNS
Première rédaction de cet article le 8 juin 2017
Comment voir en temps réel l'activité d'un serveur DNS, les requêtes qu'il reçoit et les réponses qu'il envoie ? Il existe plusieurs méthodes, cet article présent rapidement la plus récente, dnstap.
Est-ce que je présente d'abord dnstap, ou d'abord les autres solutions, afin d'expliquer leurs faiblesses et de dire pourquoi dnstap a été développé ? Je choisis d'être positif et de commencer par les bonnes choses : dnstap, ce qu'il fait, et comment.
dnstap est un moyen d'obtenir un flux d'informations de la part d'un serveur DNS (qu'il s'agisse d'un résolveur ou bien d'un serveur faisant autorité). Le serveur doit être modifié pour journaliser son activité, et configuré ensuite pour émettre un flux dnstap. Typiquement, ce flux est envoyé vers une prise Unix, où un lecteur dnstap l'attendra pour stocker ce flux, ou pour le formater et l'afficher joliment. Ce flux est encodé en Protocol Buffers, eux-mêmes transportés dans des Frame Streams.
C'est pas assez concret ? OK, alors jouons un peu avec un résolveur DNS, Unbound. On le configure ainsi :
dnstap:
dnstap-enable: yes
dnstap-socket-path: "/var/run/unbound/dnstap.sock"
dnstap-send-identity: yes
dnstap-send-version: yes
dnstap-log-resolver-response-messages: yes
dnstap-log-client-query-messages: yes
(Les quatre dernières lignes sont optionnelles. Ici, avec les deux dernières lignes, on ne journalise qu'une partie des requêtes et des réponses.) Et on relance le serveur. Il va dire quelque chose comme :
[1496927690] unbound[32195:0] notice: attempting to connect to dnstap socket /var/run/unbound/dnstap.sock
[1496927690] unbound[32195:0] notice: dnstap identity field set to "gpd-01"
[1496927690] unbound[32195:0] notice: dnstap version field set to "unbound 1.5.10"
[1496927690] unbound[32195:0] notice: dnstap Message/RESOLVER_RESPONSE enabled
[1496927690] unbound[32195:0] notice: dnstap Message/CLIENT_QUERY enabled
Si on l'interroge (par exemple avec
dig), le serveur DNS va envoyer les messages
dnstap à la prise, ici
/var/run/unbound/dnstap.sock. Pour les lire,
on va utiliser le client en ligne de commande
dnstap :
% dnstap -q -u /var/run/unbound/dnstap.sock
...
15:17:09.433521 CQ ::1 UDP 41b "witches.town." IN A
...
15:18:23.050690 CQ ::1 UDP 52b "fete.lutte-ouvriere.org." IN A
15:18:23.055833 RR 2001:4b98:abcb::1 UDP 147b "fete.lutte-ouvriere.org." IN A
Pour la première requête, l'information était dans le cache (la
mémoire) du résolveur DNS. Il n'y a donc eu qu'une seule requête,
depuis dig vers le résolveur (CQ = Client Query). Dans le second cas, la réponse ne se
trouvait pas dans le cache, notre résolveur a dû aller demander à
un serveur faisant autorité pour le domaine (en l'occurrence le
serveur 2001:4b98:abcb::1, dont on voit la
réponse au résolveur).
Si le cache est froid (le résolveur vient de démarrer), on
verra que le résolveur devra faire plein d'autres requêtes
(« requêtes tertiaires », dit le RFC 7626), ici,
on a demandé www.sinodun.com, et le résolveur devra
trouver les adresses IP des serveurs de
.com (les
serveurs de la racine étaient déjà connus,
ici, c'est le serveur I.root-servers.net qui
a répondu) :
11:47:39.556098 CQ ::1 UDP 44b "www.sinodun.com." IN A
11:47:39.560778 RR 192.36.148.17 UDP 1097b "." IN NS
11:47:39.598590 RR 192.112.36.4 UDP 867b "www.sinodun.com." IN A
11:47:39.605212 RR 2001:500:9f::42 UDP 852b "m.gtld-servers.net." IN AAAA
11:47:39.611999 RR 2001:503:a83e::2:30 UDP 789b "m.gtld-servers.net." IN AAAA
11:47:39.611999 RR 199.7.91.13 UDP 852b "l.gtld-servers.net." IN AAAA
11:47:39.611999 RR 192.35.51.30 UDP 789b "j.gtld-servers.net." IN AAAA
11:47:39.616442 RR 192.35.51.30 UDP 771b "av4.nstld.com." IN A
11:47:39.618318 RR 192.12.94.30 UDP 771b "av1.nstld.com." IN A
11:47:39.619118 RR 192.26.92.30 UDP 517b "www.sinodun.com." IN A
11:47:39.620192 RR 192.82.134.30 UDP 286b "av4.nstld.com." IN A
11:47:39.625671 RR 192.82.134.30 UDP 115b "m.gtld-servers.net." IN AAAA
11:47:39.628389 RR 192.54.112.30 UDP 789b "f.gtld-servers.net." IN AAAA
11:47:39.628974 RR 192.54.112.30 UDP 789b "d.gtld-servers.net." IN AAAA
Et si je veux voir les réponses, pas seulement les questions ?
Demandons à dnstap d'être plus bavard :
% dnstap -y -u /var/run/unbound/dnstap.sock
type: MESSAGE
identity: "gpd-01"
version: "unbound 1.5.10"
message:
type: CLIENT_QUERY
query_time: !!timestamp 2017-06-08 13:24:56.664846
socket_family: INET6
socket_protocol: UDP
query_address: ::1
query_port: 52255
query_message: |
;; opcode: QUERY, status: NOERROR, id: 32133
;; flags: rd ad; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1
;; QUESTION SECTION:
;www.kancha.de. IN A
;; ADDITIONAL SECTION:
;; OPT PSEUDOSECTION:
; EDNS: version 0; flags: do; udp: 4096
---
type: MESSAGE
identity: "gpd-01"
version: "unbound 1.5.10"
message:
type: RESOLVER_RESPONSE
query_time: !!timestamp 2017-06-08 13:24:56.664838
response_time: !!timestamp 2017-06-08 13:24:56.697349
socket_family: INET
socket_protocol: UDP
response_address: 85.13.128.3
response_port: 53
query_zone: "kancha.de."
response_message: |
;; opcode: QUERY, status: NOERROR, id: 6700
;; flags: qr aa; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; QUESTION SECTION:
;www.kancha.de. IN A
;; ANSWER SECTION:
www.kancha.de. 7200 IN A 85.13.153.248
;; ADDITIONAL SECTION:
;; OPT PSEUDOSECTION:
; EDNS: version 0; flags: do; udp: 1680
---
(Eh oui, c'est du YAML.) Notons quelques points importants :
- C'est le client dnstap pas le résolveur DNS, qui formate ce résultat comme il veut. On peut donc écrire d'autres clients dnstap, qui feraient autre chose avec les données (calculer des résultats agrégés, présenter comme tcpdump, etc). C'est une propriété importante de dnstap : le serveur journalise, le client dnstap en fait ce qu'il veut.
- dnstap permet d'ajouter des informations qui
n'apparaissent à aucun moment dans la requête ou dans la
réponse. C'est le cas de
query_zone, qui indique le bailliage (la zone d'où vient l'information sur ce nom) ou des temps de réponse.
Bon, maintenant, quelques petits détails techniques sur ce
qu'il a fallu faire pour obtenir cela. D'abord,
Unbound, sur presque tous les systèmes, a
été compilé sans dnstap, probablement pour ne
pas ajouter une dépendance supplémentaire (vers les Protocol Buffers). Si vous essayez
de configurer Unbound pour dnstap, vous aurez un « fatal
error: dnstap enabled in config but not built with dnstap
support ». Il faut donc le
compiler soi-même, avec l'option
--enable-dnstap. Cela nécessite d'installer Protocol Buffers et Frame
Streams (paquetages
Debian
libprotobuf-c-dev et
libfstrm-dev).
Quant au client dnstap, celui utilisé est écrit en Go et nécessite d'installer le paquetage golang-dnstap :
% go get github.com/dnstap/golang-dnstap % go install github.com/dnstap/golang-dnstap/dnstap
Quelles sont les autres mises en œuvre dont on dispose ? Le
serveur DNS faisant autorité Knot a dnstap (mais ce n'est pas le cas du
résolveur du même nom). Le serveur BIND peut également
être compilé avec dnstap (testé avec la 9.11.1). Comme client, il existe aussi un client
fondé sur ldns (paquetage Debian
dnstap-ldns).
Enfin, pour terminer, voyons les autres solutions qui existent pour afficher ce que fait le serveur DNS. La plus évidente est de demander au serveur de journaliser lui-même. Avec le formatage des données, cela peut imposer une charge sévère au serveur, alors qu'un serveur DNS doit rester rapide, notamment en cas d'attaque par déni de service (avec dnstap, le formatage à faire est minime, vu l'efficacité des Protocol Buffers). Comme le note la documentation d'Unbound, « note that it takes time to print these lines which makes the server (significantly) slower ». Mais il y a une autre limite : on ne peut voir que les requêtes, pas les réponses, ni les requêtes tertiaires.
Avec Unbound, cela se configure ainsi :
log-queries: yes
Et, si on demande le MX de
sonic.gov.so, on obtient :
Jun 08 15:53:01 unbound[2017:0] info: ::1 sonic.gov.so. MX IN
Avec BIND, c'est :
08-Jun-2017 16:22:44.548 queries: info: client @0x7f71d000c8b0 ::1#39151 (sonic.gov.so): query: sonic.gov.so IN MX +E(0)D (::1)
Une autre solution pour voir le trafic DNS, et celle que je recommandais avant, est de sniffer le trafic réseau et de l'analyser. Il vaut mieux ne pas faire cela sur le serveur, que cela peut ralentir, mais sur une autre machine, avec du port mirroring pour envoyer une copie du trafic à la machine d'observation. Cette technique a le gros avantage de n'imposer absolument aucune charge au serveur. Mais elle a quatre défauts :
- Il faut réassembler les réponses fragmentées, phénomène relativement fréquent avec le DNS, où les données peuvent dépasser la MTU et où l'utilisation d'UDP fait que la couche transport ne découpe pas les données.
- Il faut reconstituer le trafic TCP, qui se retrouve réparti en plusieurs paquets. Avec le RFC 7766, l'utilisation de TCP deviendra sans doute de plus en plus fréquente pour le DNS.
- Enfin, si le trafic est chiffré (RFC 7858), le sniffer est aveugle.
- Certaines choses (comme la bailliage) ne se voient pas du tout dans le trafic, seul le serveur les connait.
Les trois premières raisons sont relativement récentes (autrefois, on ne chiffrait pas, on n'utilisait pas TCP, et les données étaient plus petites) et justifient le retour à un système où le serveur va devoir faire une partie du travail.
L'article seul
RFC 8179: Intellectual Property Rights in IETF Technology
Date de publication du RFC : Mai 2017
Auteur(s) du RFC : Scott Bradner (Harvard
University), Jorge Contreras (University of
Utah)
Première rédaction de cet article le 1 juin 2017
L'appropriation intellectuelle est partout et donc logiquement aussi dans les organismes de normalisation comme l'IETF. C'est l'objet de ce RFC, qui remplace les RFC 3979 et RFC 4879 sur les questions de brevets (nommées, à tort, questions de « propriété intellectuelle », alors que les brevets ne sont pas la même chose que les copyrights, traités dans le RFC 5378).
Donc, sur quels principes repose la politique de l'IETF au sujet des brevets ? L'idée de base est de s'assurer que l'IETF disposera d'information sur les brevets pouvant s'appliquer à une norme donnée, de façon à pouvoir prendre une décision en toute connaissance de cause. Il n'y a par contre pas de mécanisme automatique de décision, par exemple « Ne jamais normaliser des technologies brevetées ». En effet, compte-tenu du fait que l'écrasante majorité des brevets logiciels est futile, enregistrée uniquement parce que les organismes de brevetage ont un intérêt financier à accepter tout et n'importe quoi, une telle politique mènerait à ne rien pouvoir normaliser.
En pratique, tout ce RFC 8179 pourrait donc se résumer à « Tout participant à l'IETF qui connait ou devrait connaitre un brevet pouvant s'appliquer à une technique en cours de discussion doit en informer l'IETF ». C'est tout. Mais il y a quelques détails pratiques.
D'abord, il faut rappeler que ce sont officiellement des individus qui participent à l'IETF, pas des sociétés. Donc l'obligation s'applique à ces individus et ils ne peuvent pas y échapper en prétendant que leur compagnie leur interdit de réveler un brevet sous-marin (brevet sur lequel on fait peu de publicité, pour le ressortir une fois que la technique brevetée a été largement adoptée). Ensuite, le RFC définit ce que signifie contribuer à l'IETF (section 1). Par exemple, écrire sur une liste de diffusion d'un groupe de travail est une contribution. Cette règle est régulièrement rappelée par le fameux Note Well.
La section 1 définit formellement bien d'autres choses. Un concept essentiel mais souvent oublié est le Reasonably and personally known. Il désigne une information que le participant connait ou devrait connaitre, vu sa position dans l'entreprise qui l'emploie. L'idée est que le participant IETF n'est pas obligé de chercher activement dans le portefeuille de brevets de son entreprise, que l'obligation ne s'applique qu'à ce qu'il connait forcément, depuis son poste. Le but de l'ajout reasonably est d'éviter qu'une entreprise ne dissimule un brevet à ses propres employés.
Les principes sont donc :
- L'IETF ne va pas chercher à déterminer si un brevet est futile ou pas (cela peut être un très gros travail, la plupart des brevets étant rédigés en termes délibérement incompréhensibles),
- L'IETF peut normaliser ou pas une technique brevetée, il n'y a pas de refus systématique,
- Pour pouvoir néanmoins savoir où on va, l'IETF a besoin d'information et c'est de là que découle l'exigence de divulgation des brevets, la principale obligation concrète de ce RFC 8179.
La section 3 rentre dans le concret, même si elle commence par un bel exercice de langue de bois (« The intent is to benefit the Internet community and the public at large, while respecting the legitimate rights of others. »). C'est elle qui impose que le contributeur à l'IETF ait bien divulgué tous les brevets qu'il connaissait « raisonnablement ». Outre le brevet lui-même, il peut y avoir une licence associée (un droit d'utiliser la technologie brevetée, sous certaines conditions). Si le détenteur du brevet n'indique pas de licence, l'IETF peut poliment lui demander. La licence (RAND, FRAND, RANDZ - c'est-à-dire gratuite …) sera évidemment un des éléments sur lesquels les participants à l'IETF fonderont leur position (cf. RFC 6410).
La section 4
indique ce que l'IETF va en faire, de ces divulgations (nommées
« IPR [Intellectual Property Rights] disclosures ») : indication
du fait qu'il existe des brevets pouvant s'y appliquer et
publication de ces divulgations en http://www.ietf.org/ipr/. Par exemple,
Verisign a un brevet (brevet
états-unien 8,880,686,
et la
promesse de licence de Verisign)
qu'ils prétendent valable,
et dont ils affirment qu'il couvre la technique décrite dans le RFC 7816. (Sur la page officielle du
RCF, c'est le lien « Find IPR Disclosures from the IETF ».) L'IETF (ou
l'IAB, ou l'ISOC ou
autre) n'ajoutera aucune
appréciation sur la validité du brevet, ou sur les conditions de
licence. Une telle appréciation nécessiterait en effet
un long et coûteux travail juridique.
La note d'information n'est plus à inclure dans chaque RFC comme c'était autrefois le cas. Elle est désormais dans le IETF Trust Legal Provisions (version de 2015 : « The IETF Trust takes no position regarding the validity or scope of any Intellectual Property Rights or other rights that might be claimed to pertain to the implementation or use of the technology described in any IETF Document or the extent to which any license under such rights might or might not be available; nor does it represent that it has made any independent effort to identify any such rights. »). Comme exemple d'un brevet abusif, on peut citer la divulgation #1154, qui se réclame d'un brevet sur les courbes elliptiques qui s'appliquerait à tous les RFC parlant d'un protocole qui peut utiliser ces courbes, comme le RFC 5246.
Les divulgations ne sont pas incluses dans les RFC eux-mêmes
(section 10) car elles peuvent évoluer dans le temps alors que le RFC
est stable. Il faut donc aller voir ces « IPR
disclosures » en ligne sur http://www.ietf.org/ipr/.
Les divulgations sont-elles spécifiées plus en détail ? Oui, en
section 5. La 5.1 précise qui doit faire la
divulgation (le participant, en tant que personne physique), la
section 5.2 donne les délais (« aussi vite que possible »), la section
5.4.3 rappelle que la divulgation doit être précise et qu'un
contributeur ne peut pas se contenter de vagues généralités
(« blanket disclosure »). Le tout
est aussi mis en ligne, en http://www.ietf.org/ipr-instructions.
Et si un tricheur, comme la société RIM, ne respecte pas cette obligation de divulgation ? La section 6 ne prévoit aucune dérogation : si, par exemple, une société empêche ses employés de divulguer les brevets, ces employés ne doivent pas participer à l'IETF (« tu suis les règles, ou bien tu ne joues pas »). Tout participant à l'IETF est censé connaitre cette règle (section 3.3). Le RFC 6701 liste les sanctions possibles contre les tricheurs et le RFC 6702 expose comment encourager le respect des règles.
Bien, donc, arrivé là, l'IETF a ses informations et peut prendre ses décisions. Sur la base de quelles règles ? La section 7 rappelle le vieux principe qu'une technique sans brevets est meilleure ou, sinon, à la rigueur, une technique où le titulaire des brevets a promis des licences gratuites. Mais ce n'est pas une obligation, l'IETF peut choisir une technologie brevetée, même sans promesses sur la licence, si cette technologie en vaut la peine.
La seule exception concerne les techniques de sécurité obligatoires : comme tout en dépend, elles ne doivent être normalisées que s'il n'existe pas de brevet ou bien si la licence est gratuite.
Les règles de bon sens s'appliquent également : s'il s'agit de faire une nouvelle version normalisée d'un protocole très répandu, on évitera de choisir une technologie trop encombrée de brevets, s'il s'agit d'un tout nouveau protocole expérimental, on pourra être moins regardant.
Les changements depuis les RFC précédents, les RFC 3979 et RFC 4879, sont décrits dans la section 13. Pas de révolution, les principes restent les mêmes. Parmi les changements :
- Texte modifié pour permettre l'utilisation de ces règles en dehors de la voie IETF classique (par exemple par l'IRTF).
- La définition d'une « contribution IETF » a été élargie pour inclure, par exemple, les interventions dans les salles XMPP de l'IETF.
- Meilleure séparation des questions de brevets (traitées dans notre RFC) avec celles de droit d'auteur (traitées dans le RFC 5378). Le terme de « propriété intellectuelle » a plusieurs défauts, dont celui de mêler des choses très différentes (brevets, marques, droit d'auteur…)
- Il n'y a plus de boilerplate (qui était en section 5 du RFC 3979) à inclure dans les documents, il est désormais en ligne.
L'article seul
RFC 8112: Locator/ID Separation Protocol Delegated Database Tree (LISP-DDT) Referral Internet Groper (RIG)
Date de publication du RFC : Mai 2017
Auteur(s) du RFC : D. Farinacci (lispers.net), A. Jain
(Juniper
Networks), I. Kouvelas, D. Lewis
(cisco Systems)
Expérimental
Première rédaction de cet article le 27 mai 2017
Ce RFC concerne les utilisateurs de LISP (le protocole réseau, pas le langage de programmation). Il décrit un nouvel outil, rig, le Referral Internet Groper, qui permet d'interroger les tables de correspondance identificateur->localisateur.
Un point important de LISP (RFC 9300) est en effet cette séparation de l'EID (l'identificateur d'une machine) et du RLOC (le localisateur de cette machine, qui indique où envoyer les paquets). Tout système ayant cette séparation doit maintenir une correspondance (mapping) entre les deux : lorsque je veux écrire à telle machine dont je connais l'EID, il faut que je trouve le localisateur. LISP permet plusieurs mécanismes pour cette correspondance. L'outil rig, présenté dans ce RFC, est conçu pour le mécanisme DDT (RFC 8111), une base de données arborescente et répartie. rig est donc un client DDT de débogage, lig (RFC 6835) étant un autre outil, plus général (il peut interroger d'autres bases que DDT).
Un client DDT comme rig (ou comme un routeur LISP lors de son
fonctionnement normal) va donc
envoyer des Map-Request (RFC 9300, section 4.2, et aussi RFC 9301) aux serveurs DDT.
La section 4 de notre RFC résume le fonctionnement de rig. Il
envoie le Map-Request et affiche le
Map-Referral de réponse. Il peut ensuite suivre
cette référence jusqu'à arriver au Map Server
qui gère ce préfixe. (Notez que c'est le RLOC du Map
Server qu'on obtient, sinon, on aurait un intéressant
problème d'œuf et de poule si on avait
besoin de DDT pour utiliser DDT...)
rig a donc besoin d'au moins deux paramètres, l'EID (l'identificateur) qu'on cherche à résoudre, et le serveur DDT par lequel on va commencer la recherche. (Pour l'EID, rig accepte également un nom de domaine, qu'il va traduire en EID dans le DNS.) La syntaxe typique est donc :
rig <eid> to <ddt-node>
La section 5 décrit les mises en œuvres existantes, sur les routeurs Cisco. La syntaxe est un peu différente de ce que je trouve dans la doc' de Cisco mais, bon, tout ceci est expérimental et en pleine évolution. Voici un exemple tiré de la documentation officielle de Cisco (LISP DDT Configuration Commands) :
Device# lisp-rig 172.16.17.17 to 10.1.1.1
rig LISP-DDT hierarchy for EID [0] 172.16.17.17
Send Map-Request to DDT-node 10.1.1.1 ... replied, rtt: 0.007072 secs
EID-prefix [0] 172.16.17.16/28, ttl: 1, action: ms-not-registered, referrals:
10.1.1.1, priority/weight: 0/0
10.2.1.1, priority/weight: 0/0
10.3.1.1, priority/weight: 0/0
Et voilà, on sait que l'EID
172.16.17.17, il faut aller demander aux
serveurs 10.1.1.1,
10.2.1.1 et
10.3.1.1. Dans le RFC, on trouve un exemple
où rig suit ces références :
Router# rig 12.0.1.1 to 1.1.1.1
Send Map-Request to DDT-node 1.1.1.1 ... node referral, rtt: 4 ms
EID-prefix: [0] 12.0.0.0/16, ttl: 1440
referrals: 2.2.2.2
Send Map-Request to DDT-node 2.2.2.2 ... node referral, rtt: 0 ms
EID-prefix: [0] 12.0.1.0/24, ttl: 1440
referrals: 4.4.4.4, 5.5.5.5
Send Map-Request to DDT-node 4.4.4.4 ... map-server acknowledgement,
rtt: 0 ms
EID-prefix: [0] 12.0.1.0/28, ttl: 1440
referrals: 4.4.4.4, 5.5.5.5
Si vous voulez en savoir plus sur DDT et rig, vous pouvez aussi regarder l'exposé de Cisco ou celui de Paul Vinciguerra à NANOG, ou bien la page officielle de la racine DDT (qui semble peu maintenue).
L'article seul
RFC 8111: Locator/ID Separation Protocol Delegated Database Tree (LISP-DDT)
Date de publication du RFC : Mai 2017
Auteur(s) du RFC : V. Fuller, D. Lewis, V. Ermagan
(Cisco), A. Jain (Juniper
Networks), A. Smirnov (Cisco)
Expérimental
Réalisé dans le cadre du groupe de travail IETF lisp
Première rédaction de cet article le 27 mai 2017
Le protocole LISP (dont on ne rappelera jamais assez qu'il ne faut pas le confondre avec le langage de programmation du même nom) sépare les deux rôles de l'adresse IP, identificateur et localisateur. C'est très joli de séparer, cela permet plein de choses intéressantes, comme de lutter contre la croissance illimitée de la DFZ mais cela présente un défi : comment obtenir un localisateur quand on a un identificateur ? Dit autrement, « où est cette fichue machine que j'essaie de joindre ? » Ajouter une indirection, en informatique, oblige toujours à créer un système de correspondance permettant de passer par dessus le fossé qu'on vient juste de créer. LISP a plusieurs systèmes de correspondance possibles, tous expérimentaux, et ce nouveau DDT (Delegated Database Tree) vient les rejoindre. C'est le système qui est le plus proche du DNS dans ses concepts. Comme je connais un peu le DNS, j'utiliserai souvent dans cet article des comparaisons avec le DNS.
Pour résumer DDT en un paragraphe : dans LISP (RFC 9300), l'identificateur se nomme EID (Endpoint Identifier) et le localisateur RLOC (Routing Locator). Les EID ont une structure arborescente (leur forme syntaxique est celle d'adresses IP). Cet arbre est réparti sur plusieurs serveurs, les nœuds DDT. Un nœud DDT fait autorité pour un certain nombre de préfixes d'EID. Il délègue ensuite les sous-préfixes à d'autres nœuds DDT, ou bien à des Map Servers LISP (RFC 9301) quand on arrive en bas de l'arbre. (Une des différences avec le DNS est donc que les serveurs qui délèguent sont d'une nature distincte de ceux qui stockent les feuilles de l'arbre.)
LISP a une interface standard avec les serveurs qui font la
résolution d'EID en RLOC, décrite dans le RFC 9301. En gros, le client envoie un message
Map-Request et obtient une réponse
Map-Reply, ou bien une délégation
(Map-Referral) qu'il va devoir suivre en
envoyant le Map-Request suivant au RLOC
indiqué dans la délégation. Derrière cette interface, LISP ne spécifie pas
comment les serveurs obtiennent l'information. Plusieurs
propositions ont déjà été faites (comme ALT, dans le RFC 6836, ou NERD, dans le
RFC 6837…), auxquelles s'ajoute celle de
notre RFC. Un bon résumé est dans cette
image (mais qui ne montre qu'un seul niveau de délégation, il
peut y en avoir davantage.)
{kind=link}
DDT vise avant tout le passage à l'échelle, d'où la structuration hiérarchique de l'information. La notion de délégation (d'un préfixe général à un sous-préfixe plus spécifique) est centrale dans DDT. Un client (le routeur LISP qui a un paquet destiné à un EID donné et qui cherche à quel RLOC le transmettre, ou bien un résolveur, un serveur spécialisé agissant pour le compte de ce routeur) va donc devoir suivre cette délégation, descendant l'arbre jusqu'à l'information souhaitée.
La délégation est composée, pour un préfixe délégué, d'un ensemble de RLOC (pas d'EID pour éviter des problèmes d'œuf et de poule) désignant les nœuds qui ont une information sur le préfixe délégué. (Ce sont donc l'équivalent des enregistrements NS du DNS, mais avec une indirection en moins, comme si la partie droite d'un enregistrement NS stockait directement une adresse IP.)
J'ai écrit jusque là que la clé d'accès à l'information (rôle tenu par le nom de domaine dans le DNS) était l'EID mais c'est en fait un peu plus compliqué : la clé est le XEID (eXtended EID), qui est composé de plusieurs valeurs, dont l'EID (section 4.1 de notre RFC).
Pour indiquer au résolveur qu'il doit transmettre sa requête à
une autre machine, ce RFC crée un nouveau type de message LISP,
Map-Referral, type 6 (cf. le registre IANA)
détaillé en section 6,
envoyé en réponse à un Map-Request, quand le
nœud DDT ne connait pas la réponse. (Comme indiqué plus haut,
c'est l'équivalent d'une réponse
DNS avec uniquement une section Autorité contenant des
enregistrements NS.)
Continuons un peu la terminologie (section 3 du RFC) :
- Un client DDT est une machine qui interroge les nœuds DDT
(avec un
Map-Request, cf. RFC 9301) et suit lesMap-Referraljusqu'au résultat. C'est en général un résolveur (Map Resolver, RFC 9301) mais cela peut être aussi un routeur LISP (ITR, Ingress Tunnel Router). - Un résolveur est serveur d'un côté, pour les routeurs qui
envoient des
Map-Request, et client DDT de l'autre, il envoie des requêtes DDT. Il gère un cache (une mémoire des réponses récentes). Le résolveur maintient également une liste des requêtes en cours, pas encore satisfaites.
La base des données des serveurs DDT est décrite en section
4. Elle est indexée par XEID. Un XEID est un EID (identificateur
LISP) plus un AFI (Address Family Identifier,
1 pour IPv4, 2 pour IPv6, etc), un identificateur d'instance (voir RFC 9300, section 3, et RFC 8060, section 4.1) qui sert à avoir plusieurs espaces d'adressage, et quelques autres paramètres, pas
encore utilisés. Configurer un serveur DDT, c'est lui indiquer la
liste de XEID qu'il doit connaitre, avec les RLOC des serveurs qui
pourront répondre. Désolé, je n'ai pas de serveur DDT sous la main
mais on peut trouver un exemple, dans la
documentation de Cisco, où on délègue au Map
Server de RLOC 10.1.1.1 :
router lisp
ddt authoritative 2001:db8:eeee::/48
delegate 10.1.1.1 eid-prefix 172.16.0.0/16
delegate 10.1.1.1 eid-prefix 2001:db8:eeee::/48
Un autre exemple de délégation est l'actuelle liste des données dans la racine DDT.
Le DNS n'a qu'un type de serveurs faisant autorité, qu'ils soient essentiellement serveurs de délégation (ceux des TLD, par exemple) ou qu'ils soient serveurs « finaux » contenant les enregistrements autres que NS. Au contraire, LISP+DDT a deux types de serveurs, les nœuds DDT présentés dans ce RFC, qui ne font que de la délégation, et les traditionnels Map Servers, qui stockent les correspondances entre EID et RLOC (entre identificateurs et localisateurs). Dit autrement, DDT ne sert pas à trouver la réponse à la question « quel est le RLOC pour cet EID », il sert uniquement à trouver le serveur qui pourra répondre à cette question.
Comme pour le DNS, il existe une racine, le nœud qui peut
répondre (enfin, trouver une délégation) pour tout XEID. (Sur le
Cisco cité plus haut, la directive ddt root
permettra d'indiquer le RLOC des serveurs de la racine, voir aussi
la section 7.3.1 de notre RFC.) Une
racine expérimentale existe, vous trouverez ses RLOC en
http://ddt-root.org/.
La section 5 de notre RFC décrit en détail la modification au
message Map-Request que nécessite DDT. Ce
message était normalisé par le RFC 9300
(section 6.1.2) et un seul ajout est fait : un bit qui était
laissé vide sert désormais à indiquer que la requête ne vient pas
directement d'un routeur LISP mais est passée par des nœuds DDT.
La section 6, elle, décrit un type de message nouveau,
Map-Referral, qui contient les RLOC du nœud
DDT qui pourra mieux répondre à la question. Cette réponse contient un code
qui indique le résultat d'un Map-Request. Ce
résultat peut être « positif » :
NODE-REFERRAL, renvoi à un autre nœud DDT,MS-REFERRAL, renvoi à un Map Server (rappelez-vous que, contrairement au DNS, il y a une nette distinction entre nœud intermédiaire et Map Server final),MS-ACK, réponse positive d'un Map Server.
Mais aussi des résultats « négatifs » :
MS-NOT-REGISTERED, le Map Server ne connait pas cet EID,DELEGATION-HOLE, l'EID demandé tombe dans un trou (préfixe non-LISP dans un préfixe LISP),NOT-AUTHORITATIVE, le nœud DDT n'a pas été configuré pour ce préfixe.
Le fonctionnement global est décrit en détail dans la section 7
du RFC. À lire si on veut savoir exactement ce que doivent faire
le Map Resolver, le Map
Server, et le nouveau venu, le nœud DDT. La même
description figure sous forme de
pseudo-code dans la section 8. Par exemple,
voici ce que doit faire un nœud DDT lorsqu'il reçoit un
Map-Request (demande de résolution d'un EID
en RLOC) :
if ( I am not authoritative ) {
send map-referral NOT_AUTHORITATIVE with
incomplete bit set and ttl 0
} else if ( delegation exists ) {
if ( delegated map-servers ) {
send map-referral MS_REFERRAL with
ttl 'Default_DdtNode_Ttl'
} else {
send map-referral NODE_REFERRAL with
ttl 'Default_DdtNode_Ttl'
}
} else {
if ( eid in site) {
if ( site registered ) {
forward map-request to etr
if ( map-server peers configured ) {
send map-referral MS_ACK with
ttl 'Default_Registered_Ttl'
} else {
send map-referral MS_ACK with
ttl 'Default_Registered_Ttl' and incomplete bit set
}
} else {
if ( map-server peers configured ) {
send map-referral MS_NOT_REGISTERED with
ttl 'Default_Configured_Not_Registered_Ttl'
} else {
send map-referral MS_NOT_REGISTERED with
ttl 'Default_Configured_Not_Registered_Ttl'
and incomplete bit set
}
}
} else {
send map-referral DELEGATION_HOLE with
ttl 'Default_Negative_Referral_Ttl'
}
}
Un exemple complet et détaillé figure dans la section 9, avec description de tous les messages envoyés.
Question sécurité, je vous renvoie à la section 10 du RFC. DDT dispose d'un mécanisme de signature des messages (l'équivalent de ce qu'est DNSSEC pour le DNS). La délégation inclut les clés publiques des nœuds à qui on délègue.
Il existe au moins deux mises en œuvre de DDT, une chez Cisco et l'autre chez OpenLisp. (Le RFC ne sort que maintenant mais le protocole est déployé depuis des années.)
L'article seul
L'axe des Y doit partir de zéro !
Première rédaction de cet article le 22 mai 2017
Dernière mise à jour le 23 mai 2017
On voit souvent dans les infographies des graphiques où l'axe des Y (axe des ordonnées) ne part pas de zéro. Pourquoi faut-il appeler la malédiction de tous les démons connus et inconnus sur les auteurs de ces graphiques ?
Parce que cela sert à tromper. Mettre comme point de départ une valeur différente de zéro tend à amplifier artificiellement un phénomène. Imaginons une grandeur qui varie assez peu, disons entre (unités arbitraires) 650 et 660. Si on la représente sur un graphique qui part de 0, la variation semblera faible. Si l'axe des Y part de la valeur 650, on aura l'impression de grandes variations.
Un bon exemple est la dispositive n° 11 de cet
exposé : elle donne l'impression d'une envolée de la dette,
en laissant entendre qu'on partait de zéro, alors que
l'augmentation n'a été que de 30 % :
Un autre exemple est ce
graphique de la croissance de
l'ether, où le fait de ne pas partir de
zéro donne l'impression d'une croissance encore plus
spectaculaire : 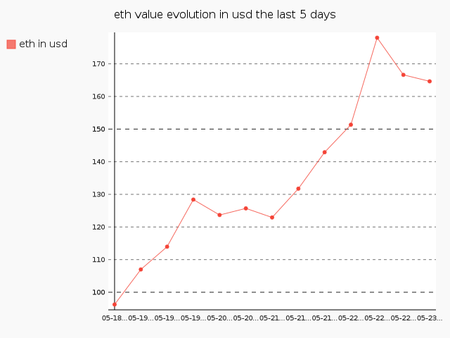
Même s'il y a une échelle sur l'axe des Y (certains graphiques n'en ont même pas), l'œil pressé n'y fait pas attention (on en voit, des graphiques, dans une journée…) et retient une fausse impression.
Cette tromperie est bien illustrée dans ce dessin de William Easterly :
Cette règle de partir de zéro est-elle absolue ? Non, évidemment. D'abord, évidemment, si l'échelle est logarithmique, elle ne va évidemment pas partir de zéro. Ensuite, il y a des cas où cela peut être logique, par exemple s'il existe une justification liée à la nature du phénomène mesuré. Si on fait un graphique de la température du corps humain, il est plus logique de partir de 35 ou 36° que de 0, puisque la température du corps ne va jamais se promener aussi bas. Et, bien sûr, on peut vouloir mettre en évidence des petites variations (qui seraient lissées si l'axe des Y partait de zéro) sans intention de tromper. Mais je soupçonne que de tels cas sont très minoritaires.
En supposant que les lecteurs deviennent méfiants vis-à-vis de cette manipulation, xkcd a fait un excellent dessin prévoyant une escalade dans la tromperie.
L'article seul
RFC 8174: RFC 2119 Key Words: Clarifying the Use of Capitalization
Date de publication du RFC : Mai 2017
Auteur(s) du RFC : B. Leiba (Huawei)
Première rédaction de cet article le 19 mai 2017
Dernière mise à jour le 20 mai 2017
Un très court RFC discutant un problème de procédure : dans le RFC 2119, qui décrit les termes précis à utiliser dans les normes, un doute subsistait sur la casse de ces termes.
Ce RFC 2119 est celui qui formalise les fameux MUST, SHOULD et MAY, les termes qu'il faut utiliser dans les normes pour être sûr d'indiquer le niveau exact d'exigence. Suivant l'exemple du RFC 2119, ils sont toujours écrits en CAPITALES pour les distinguer du sens courant en anglais, mais cet usage n'était pas explicite dans le RFC 2119 (qui a juste un vague « These words are often capitalized »). Un oubli que corrige notre RFC 8174. Désormais, MUST n'a le sens du RFC 2119 que s'il est en capitales.
Par exemple, dans le RFC 8120, dans le texte « The client SHOULD try again to construct a req-KEX-C1 message in this case », SHOULD est en capitales et a donc bien le sens précis du RFC 2119 (le client est censé ré-essayer de faire son message, sauf s'il a une très bonne raison), alors que dans le texte « This case should not happen between a correctly implemented server and client without any active attacks », should est en minuscules et a donc bien son sens plus informel qui est usuel en anglais.
Le texte qu'il est recommandé d'inclure dans les RFC qui font référence au RFC 2119 apporte désormais cette précision : « The key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "NOT RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in BCP 14 [RFC2119],[RFC 8174] when, and only when, they appear in all capitals, as shown here. » Plusieurs auteurs de RFC, conscients de l'ambiguité, avaient d'ailleurs déjà fait une telle modification dans leur référence au RFC 2119. Ainsi, le RFC 5724 dit « The _capitalized_ [souligné par moi] key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in [RFC2119]. »
Notez que le fait de faire une différence sémantique entre le mot en minuscules et le mot en capitales est assez typique des utilisateurs de l'alphabet latin, et déroute toujours beaucoup les utilisateurs d'écritures qui n'ont pas cette distinction, comme les Coréens.
L'article seul
RFC 8170: Planning for Protocol Adoption and Subsequent Transitions
Date de publication du RFC : Mai 2017
Auteur(s) du RFC : D. Thaler (Microsoft)
Pour information
Première rédaction de cet article le 18 mai 2017
L'Internet existe depuis de nombreuses années (le nombre exact dépend de la façon dont on compte…) et, pendant tout ce temps, les protocoles utilisés ne sont pas restés identiques à eux-mêmes. Ils ont évolué, voire ont été remplacés. Cela soulève un problème : la transition entre l'ancien et le nouveau (le cas le plus fameux étant évidemment le passage d'IPv4 à IPv6…) Beaucoup de ces transitions se sont mal passées, parfois en partie car l'ancien protocole ou l'ancienne version n'avait pas prévu son futur remplacement. Contrairement à ce qu'espèrent souvent les techniciens, il ne suffit pas d'incrémenter le numéro de version pour que tous les acteurs adoptent la nouvelle version. Ce nouveau RFC de l'IAB raconte les leçons tirées, et regarde comment on pourrait améliorer les futures transitions.
Ce RFC se focalise sur les transitions techniques. Ce ne sont évidemment pas les seules (il y a par exemple des transitions organisationnelles) mais ce sont celles qui comptent pour l'IAB et l'IETF. Une transition peut être aussi bien le déploiement d'un tout nouveau protocole, que le passage d'un protocole d'une version à une autre. Le thème de la transition d'un protocole à l'autre est fréquent, et de nombreux RFC ont déjà été consacrés à une transition. C'est le cas de :
- Le RFC 3424, qui parlait des techniques de contournement des NAT, en insistant sur le fait qu'elles devaient avoir un caractère provisoire, et ne pas ossifier encore plus l'Internet,
- Le RFC 4690 qui parlait de la transition d'une version d'Unicode à l'autre, dans le contexte des IDN,
- La déclaration de l'IAB sur NAT-PT, qui critiquait une méthode de transition vers IPv6.
Outre les transitions à proprement parler, l'IAB s'est déjà penché sur les principes qui faisaient qu'un protocole pouvait marcher ou pas. C'est notamment le cas de l'excellent RFC 5218 qui étudie les facteurs qui font d'un protocole un échec, un succès, ou un succès fou. Parmi les leçons tirées par ce RFC 5218, les concepteurs d'un protocole devraient s'assurer que :
- Les bénéfices sont pour celui qui assume les coûts. Dans un réseau, coûts et bénéfices ne sont pas forcément alignés. Par exemple, le déploiement de BCP 38 bénéficie aux concurrents de celui qui paie, ce qui explique le manque d'enthousiasme des opérateurs. Notez que coûts et bénéfices ne sont pas déterminés par les lois physiques, ils peuvent être changés par la loi (amendes pour ceux qui ne déploient pas BCP 38, ou à l'inverse code source gratuitement disponible et payé par l'argent public, comme cela avait été le cas pour encourager le déploiement de TCP/IP).
- Le protocole est déployable de manière incrémentale (dans un réseau comme l'Internet, qui représente des investissements énormes, toute solution qui nécessite de jeter tout l'existant d'un coup est condamnée d'avance).
- Le coût total est raisonnable. Il ne faut pas seulement regarder le prix des machines et d'éventuelles licences logicielles. Il faut aussi tenir compte de la formation, des changements de pratiques, des conséquences juridiques…
Le RFC 7305 discutait également des aspects économiques de la transition et notait l'importance de donner une carotte aux premiers à adopter le nouveau protocole, ceux qui font un pari risqué. C'est pour cela qu'il est parfaitement légitime que les premiers à avoir cru dans Bitcoin aient reçu une quantité importante de bitcoins à un prix très faible. Cette décision était une des meilleures prises par Satoshi Nakamoto. Ce RFC note aussi l'importance d'un partenariat avec des organisations qui peuvent aider ou contrarier la transition (comme les RIR ou l'ICANN).
La section 2 de notre RFC rappelle que, de toute façon, le terme « transition » risque d'être mal interprété. Il n'est plus possible depuis longtemps de faire un flag day dans l'Internet, un jour J où on change toutes les machines d'un coup de manière coordonnée. Les transitions sont donc forcément longues, avec une période de co-existence entre l'ancien et le nouveau.
Si l'ancien et le nouveau protocole ne peuvent pas interopérer directement (cas d'IPv4 et d'IPv6), il faudra parfois envisager un mécanisme de traduction (qui ne se situera pas forcément dans la même couche). Un tel traducteur, s'il est situé sur le chemin entre les deux machines, pose souvent d'ennuyeux problèmes de sécurité car il risque fort de casser le modèle de bout en bout.
La section 5 de notre RFC est consacrée aux plans de transition. Ah, les plans… Ils sont évidemment indispensables (on ne va pas se lancer dans une grande transition sans avoir planifié un minimum) mais ils sont aussi très fragiles (comme disent les militaires, « aucun plan ne survit à la première rencontre avec l'ennemi »), et ils terminent souvent au musée des mauvaises idées. Disons qu'il faut avoir un plan, mais ne pas en être esclave.
Quelles sont les qualités d'un bon plan de transition, en s'appuyant sur les expériences ratées et réussies ? D'abord, il faut bien connaitre l'existant. Par exemple, si l'ancien protocole a une fonction optionnelle qui n'a pas d'équivalent, ou un équivalent très différent dans le nouveau protocole, il est bon de savoir si cette fonction est utilisée en pratique (elle peut même ne pas être implémentée du tout, ce qui facilite les choses). De même, il est important de savoir si les logiciels existants mettent réellement en œuvre l'ancien protocole tel qu'il est spécifié, ou bien si, en pratique, ils en dévient, et ont des comportements qui vont poser des problèmes pendant la transition. (Un cas typique est celui de SSL où la plupart des programmes n'avaient pas mis en œuvre correctement le mécanisme de négociation, et plantaient donc lorsqu'une nouvelle version arrivait.)
Un autre élément important d'un plan de transition est d'avoir les idées claires sur les incitations à migrer. Les acteurs de l'Internet utilisent l'ancien protocole. Ça marche pour eux. Pourquoi feraient-ils l'effort de migrer vers un nouveau protocole, ce qui leur coûtera du temps et de l'argent ? Il faut donc des incitations (ou du marketing, qui arrive souvent à faire acheter un gadget inutile). Il n'y a pas que les coûts financiers directs, il faut aussi regarder d'autres problèmes à surmonter (par exemple l'hostilité de certains acteurs, ainsi le chiffrement a du mal à se répandre car les acteurs de l'Internet qui font de la surveillance ont intérêt à continuer à violer la vie privée).
Il y a ensuite le plan proprement dit : une liste des étapes, avec un vague calendrier. Le calendrier est certainement la partie la plus fragile du plan ; l'Internet n'ayant pas de chef, une transition va dépendre des efforts d'un grand nombre d'acteurs non coordonnés, et prédire leurs délais de réaction est à peu près impossible. (Voir le RFC 5211 pour un exemple.)
Un bon plan doit aussi comprendre un moyen de déterminer le succès (ou l'échec). Là aussi, ce n'est pas évident du tout. Certains protocoles sont surtout utilisés dans des réseaux locaux, donc difficiles à mesurer de l'extérieur (comment savoir combien de FAI proposent un résolveur DNS sécurisé par le RFC 7858 ?) Parfois, les critères quantitatifs ne sont pas évidents à établir. Prenons l'exemple d'IPv6 (lisez à ce sujet le rapport de l'ARCEP sur la transition IPv6, qui traite la question en détail). Comment mesure-t-on le succès d'IPv6 ? Le pourcentage de sites Web du Top N d'Alexa qui a une adresse IPv6 ? Le pourcentage d'utilisateurs finaux qui a IPv6 ? Le pourcentage d'octets IPv6 vs. IPv4 ? (Et où ? Chez Google ? Sur un point d'échange comme le France-IX ? Sur le réseau d'un transitaire ? Les valeurs seront très différentes.)
On l'a dit, les plans, même les meilleurs, survivent rarement à la rencontre avec le monde réel. Il faut donc un (ou plusieurs) « plan B », une solution de secours. Souvent, de facto, la solution de secours est la coexistence permanente de l'ancien et du nouveau protocole…
Et puis bien des acteurs de l'Internet ne suivent pas attentivement ce que fait l'IETF, voire ignorent complètement son existence, ce qui ajoute un problème supplémentaire : il faut communiquer le plan, et s'assurer qu'il atteint bien tous les acteurs pertinents (tâche souvent impossible). C'est le but d'opérations de communication comme le World IPv6 Launch Day.
Notre RFC rassemble ensuite (annexe A) quatre études de cas, illustrant des problèmes de transition différents. D'abord, le cas d'ECN. Ce mécanisme, normalisé dans le RFC 3168, permettait aux routeurs de signaler aux machines situées en aval de lui que la congestion menaçait. L'idée est que la machine aval, recevant ces notifications ECN, allait dire à la machine émettrice, située en amont du routeur, de ralentir, avant qu'une vraie congestion n'oblige à jeter des paquets. Les débuts d'ECN, vers 2000-2005, ont été catastrophiques. Les routeurs, voyant apparaitre des options qu'ils ne connaissaient pas, ont souvent planté. C'est un cas typique où une possibilité existait (les options d'IPv4 étaient normalisées depuis le début) mais n'était pas correctement implémentée en pratique. Toute transition qui se mettait à utiliser cette possibilité allait donc se passer mal. Pour protéger les routeurs, des pare-feux se sont mis à retirer les options ECN, ou bien à jeter les paquets ayant ces options, rendant ainsi très difficile tout déploiement ultérieur, même après correction de ces sérieuses failles dans les routeurs.
À la fin des années 2000, Linux et Windows ont commencé à accepter l'ECN par défaut (sans toutefois le réclamer), et la présence d'ECN, mesurée sur le Top Million d'Alexa, a commencé à grimper. De quasiment zéro en 2008, à 30 % en 2012 puis 65 % en 2014. Bref, ECN semble, après un très long purgatoire, sur la bonne voie (article « Enabling Internet-Wide Deployment of Explicit Congestion Notification »).
(Un autre cas, non cité dans le RFC, où le déploiement d'une possibilité ancienne mais jamais testé, a entrainé des conséquences fâcheuses, a été celui de BGP, avec la crise de l'attribut 99.)
L'exemple suivant du RFC est celui
d'IDN. L'internationalisation
est forcément un sujet chaud, vu les sensibilités existantes. Les
IDN résolvent enfin un problème très ancien, l'impossibilité
d'avoir des noms de
domaine dans toutes les écritures du monde. (Voir la
section 3 du RFC 6055, pour la longue et
compliquée histoire des IDN.) Une fois que la norme IDN était
disponible, il restait à effectuer la transition. Elle n'est pas
encore terminée aujourd'hui. En effet, de nombreuses applications
manipulent les noms de domaine et doivent potentiellement être
mises à jour. Bien sûr, elles peuvent toujours utiliser la forme
Punycode, celle-ci est justement conçue
pour ne pas perturber les applications traditionnelles, mais ce
n'est qu'un pis-aller (ஒலிம்பிக்விளையாட்டுகள்.சிங்கப்பூர் est
quand même supérieur à xn--8kcga3ba7d1akxnes3jhcc3bziwddhe.xn--clchc0ea0b2g2a9gcd).
Pire, IDN a connu une transition dans la transition, lors du passage de la norme IDN 2003 (RFC 3490) vers IDN 2008 (RFC 5890). IDN 2008 était conçu pour découpler IDN d'une version particulière d'Unicode mais l'un des prix à payer était le cassage de la compatibilité : certains caractères comme le ß étaient traités différemment entre IDN 2003 et IDN 2008.
Le cas d'IDN est aussi l'occasion, pour le RFC, de rappeler que tout le monde n'a pas forcément les mêmes intérêts dans la transition. IDN implique, outre l'IETF, les auteurs de logiciels (par exemple ceux des navigateurs), les registres de noms de domaine, les domaineurs, et bien sûr les utilisateurs. Tous ne sont pas forcément d'accord et le blocage d'une seule catégorie peut sérieusement retarder une transition (diplomatiquement, le RFC ne rappele pas que l'ICANN a longtemps retardé l'introduction d'IDN dans la racine du DNS, pour des pseudo-raisons de sécurité, et que leur introduction n'a pu se faire qu'en la contournant.)
Lorsqu'on parle transition douloureuse, on pense évidemment tout de suite à IPv6. Ce successeur d'IPv4 a été normalisé en 1995 (par le RFC 1833), il y a vingt-deux ans ! Et pourtant, il n'est toujours pas massivement déployé. (Il existe de nombreuses métriques mais toutes donnent le même résultat : IPv6 reste minoritaire, bien que ces dernières années aient vu des progrès certains. Notez que les réseaux visibles publiquement ne sont qu'une partie de l'Internet : plusieurs réseaux internes, par exemple de gestion d'un opérateur, sont déjà purement IPv6.) Il y avait pourtant un plan de transition détaillé (RFC 1933), fondé sur une coexistence temporaire où toutes les machines auraient IPv4 et IPv6, avant qu'on ne démantèle progressivement IPv4. Mais il a clairement échoué, et ce problème est maintenant un sujet de plaisanterie (« l'année prochaine sera celle du déploiement massif d'IPv6 », répété chaque année).
Là encore, un des problèmes était que tout le monde n'a pas les mêmes intérêts. Si les fabricants de routeurs et les développeurs d'applications bénéficient d'IPv6, c'est beaucoup moins évident pour les gérants de sites Web, ce qui explique que plusieurs sites à forte visibilité, comme Twitter, ou bien gérés par des gens pourtant assez branchés sur la technique, comme GitHub, n'aient toujours pas IPv6 (c'est également le cas de la totalité des sites Web du gouvernement français, qui pourtant promeut officiellement l'usage d'IPv6).
L'effet réseau a également joué à fond contre IPv6 : les pionniers n'ont aucune récompense, puisqu'ils seront tout seuls alors que, par définition, le réseau se fait à plusieurs. Bien sûr, IPv6 marche mieux que l'incroyable et branlante pile de techniques nécessaire pour continuer à utiliser IPv4 malgré la pénurie (STUN, TURN, port forwarding, ICE, etc). Mais tout le monde ne ressent pas ce problème de la même façon : le FAI, par exemple, ne supporte pas les coûts liés à la non-transition, alors qu'il paierait ceux de la transition. Ce problème de (non-)correspondance entre les coûts et les bénéfices est celui qui ralentit le plus les nécessaires transitions. Et puis, pour les usages les plus simples, les plus Minitel 2.0, IPv4 et ses prothèses marchent « suffisamment ».
La lenteur de la transition vers IPv6 illustre aussi la difficulté de nombreux acteurs à planifier à l'avance. C'est seulement lorsque l'IANA, puis les RIR sont l'un après l'autre tombés à court d'adresses IPv4 que certains acteurs ont commencé à agir, alors que le problème était prévu depuis longtemps.
Il n'y a évidemment pas une cause unique à la lenteur anormale de la transition vers IPv6. Le RFC cite également le problème de la formation : aujourd'hui encore, dans un pays comme la France, une formation de technicien ou d'ingénieur réseaux peut encore faire l'impasse sur IPv6.
Le bilan du déploiement d'IPv6 est donc peu satisfaisant. Si certains réseaux (réseaux internes d'entreprises, réseaux de gestion) sont aujourd'hui entièrement IPv6, le déploiement reste loin derrière les espérances. Ce mauvais résultat nécessite de penser, pour les futurs déploiements, à aligner les coûts et les bénéfices, et à essayer de fournir des bénéfices incrémentaux (récompenses pour les premiers adoptants, comme l'a fait avec succès Bitcoin).
Dernier cas de transition étudié par notre RFC, HTTP/2 (RFC 7540). Nouvelle version du super-populaire protocole HTTP, elle vise à améliorer les performances, en multiplexant davantage, et en comprimant les en-têtes (RFC 7541). HTTP/2 a vécu la discussion classique lors de la conception d'une nouvelle version, est-ce qu'on résout uniquement les problèmes les plus sérieux de l'ancienne version ou bien est-ce qu'on en profite pour régler tous les problèmes qu'on avait laissés ? HTTP/2 est très différent de HTTP/1. Ses règles plus strictes sur l'utilisation de TLS (algorithmes abandonnés, refus de la renégociation, par exemple) ont d'ailleurs entrainé quelques problèmes de déploiement.
Il y a même eu la tentation de supprimer certaines fonctions de HTTP/1 considérées comme inutiles ou néfastes (les réponses de la série 1xx, et les communications en clair, entre autres). Après un débat très chaud et très houleux, HTTP/2 n'impose finalement pas HTTPS : les communications peuvent se faire en clair même si, en pratique, on voit très peu de HTTP/2 sans TLS.
Et comment négocier l'ancien protocole HTTP/1 ou le nouveau HTTP/2 ? Ce problème du client (le même qu'avec les versions d'IP : est-ce que je dois tenter IPv6 ou bien est-ce que j'essaie IPv4 d'abord ?) peut être résolu par le mécanisme Upgrade de HTTP (celui utilisé par le RFC 6455), mais il nécessite un aller-retour supplémentaire avec le serveur. Pour éviter cela, comme presque toutes les connexions HTTP/2 utilisent TLS, le mécanisme privilégié est l'ALPN du RFC 7301.
Ce mécanisme marche tellement bien que, malgré le conseil du RFC 5218, HTTP/2 prévoit peu de capacités d'extensions du protocole, considérant qu'il vaudra mieux, si on veut l'étendre un jour, passer à un nouvelle version, négociée grâce à ALPN (cf. RFC 6709.)
En conclusion, on peut dire que la conception d'un nouveau protocole (ou d'une nouvelle version d'un protocole existant) pour que la transition se passe vite et bien, reste un art plutôt qu'une science. Mais on a désormais davantage d'expérience, espérons qu'elle sera utilisée dans le futur.
L'article seul
RFC 8164: Opportunistic Security for HTTP/2
Date de publication du RFC : Mai 2017
Auteur(s) du RFC : M. Nottingham, M. Thomson
(Mozilla)
Intérêt historique uniquement
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 16 mai 2017
Pendant la mise au point de la version 2 du protocole
HTTP (finalement normalisée dans le RFC 7540), un débat très vigoureux avait porté
sur la possibilité de chiffrer les échanges avec
TLS même si le plan de
l'URL demandé était
http: (et pas
https:). Certains demandaient le chiffrement
systématique (que l'URL commence par http: ou
https:), d'autres voulaient garder la même
sémantique que HTTP version 1 (TLS pour
https:, en clair pour
http:). Cette dernière décision l'avait
emporté à l'époque, en gardant la possibilité de permettre une
extension à HTTP/2. Ce RFC décrivait
justement une telle extension : en HTTP/2, on pouvait
utiliser TLS (et donc HTTPS) même pour un
URL de plan http:. Mais l'expérience a été
abandonnée en décembre 2021 (personne n'utilisait cette extension)
et le RFC reclassé comme d'intérêt historique seulement.
Le problème à résoudre est celui de la surveillance de masse, à laquelle procèdent un certain nombre d'acteurs (les États, bien sûr, mais pas uniquement, certains FAI, certains réseaux locaux, surveillent le trafic de leurs utilisateurs). Cette surveillance de masse est considérée, à juste titre, par l'IETF comme un problème de sécurité, et contre lequel il faut donc trouver des solutions ou au moins des mitigations (RFC 7258). Chiffrer massivement le trafic Web est évidemment indispensable pour diminuer l'efficacité de la surveillance.
Mais le modèle de HTTP version 1 rend cela difficile. En
HTTP/1, on accède à un URL de plan
http: avec du trafic en clair, passer à
TLS nécessite de changer les URL, donc les
pages Web qui les contiennent, les signets des utilisateurs,
etc. Des logiciels comme HTTPS Everywhere
aident à cela mais ne sont pas une solution parfaite
(rappelez-vous par exemple qu'une bonne partie du trafic HTTP
n'est pas due aux navigateurs
Web).
Il serait tentant de résoudre le problème en disant « le client
HTTP qui tente d'accéder à un URL de plan
http: n'a qu'à essayer en même temps
HTTPS. Si ça marche, tant mieux. Si ça
rate, au moins on aura essayé. » C'est ce qu'on nomme parfois le
« chiffrement opportuniste » (RFC 7435). Mais cela pose trois problèmes :
- Si on tente HTTPS d'abord, sur le port 443, et qu'un pare-feu sur le trajet absorbe ces paquets, on devra attendre l'expiration du délai de garde avant d'essayer avec succès sur le port 80. Ce problème est réel, mais soluble par l'algorithme des globes oculaires heureux, décrit dans le RFC 6555.
- Que faire si ça réussit en HTTPS mais que le
certificat du serveur ne peut pas être
validé ? La difficulté et/ou le coût d'un certificat sont après
tout les principales raisons pour lesquelles HTTPS n'est pas
davantage déployé. (Je ne publie pas des URL
https:pour mon blog car beaucoup de gens n'ont pas mon AC dans leur magasin d'autorités.) On note qu'aujourd'hui les alertes de sécurité des navigateurs Web sont souvent absurdes : si on se connecte en HTTPS mais avec un certificat expiré (qui a donc été parfaitement valable), on a des alertes plus effrayantes que si on se connecte en clair ! - Enfin, et c'est le plus gros problème, rien ne garantit qu'on obtiendra le même contenu en HTTP et en HTTPS : la plupart des serveurs HTTP permettent de configurer deux virtual host différents sur les deux ports 80 et 443. Pas question donc de jouer à ça sans une autorisation explicite du serveur.
Bref, pour le HTTP traditionnel, il semble qu'il n'y ait pas de solution.
Celle proposée par notre RFC est d'utiliser le mécanisme des services alternatifs
du RFC 7838. Le serveur va indiquer
(typiquement par un en-tête Alt-Svc:) qu'il
est accessible par un autre mécanisme (par exemple HTTPS). Cela a
également l'avantage d'éviter les problèmes de contenu
mixte qui surviendraient si on avait mis la page en HTTPS
mais pas tous ses contenus. Par contre, l'indication de service
alternatif n'étant pas forcément bien protégée, ce mécanisme
« opportuniste » reste vulnérable aux attaques actives. En
revanche, ce mécanisme devrait être suffisamment simple pour être
largement déployé assez vite.
Donc, maintenant, les détails concrets (section 2 du RFC). Le
serveur qui accepte de servir des URL http:
avec TLS annonce le service alternatif. Notez que les clients
HTTP/1 n'y arriveront pas, car ils ne peuvent pas indiquer l'URL
complet (avec son plan) dans la requête à un serveur
d'origine (section 5.3.1 du RFC 7230). Cette spécification est donc limitée à HTTP/2 (RFC 7540). Si le client le veut bien, il va alors
effectuer des requêtes chiffrées vers la nouvelle
destination. S'il ne veut pas, ou si pour une raison ou pour une
autre, la session TLS ne peut pas être établie, on se rabat sur du
texte en clair (chose qu'on ne ferai jamais avec un URL https:).
Si le client est vraiment soucieux de son intimité et ne veut même pas que la première requête soit en clair, il peut utiliser une commande HTTP qui ne révèle pas grand'chose, comme OPTIONS (section 4.3.7 du RFC 7231).
Le certificat client ne servirait à rien
dans ce chiffrement opportuniste et donc, même si on en a un, on
ne doit pas l'envoyer. Par contre, le serveur doit avoir un
certificat, et valide (RFC 2818) pour le
service d'origine (si le service d'origine était en
foo.example et que le service alternatif est
en bar.example, le certificat doit indiquer
au moins foo.example). Ce service
ne permet donc pas de se chiffrer sans authentification, par
exemple avec un certificat expiré, ou avec une
AC inconnue du client, et ne résout donc pas un des
plus gros problèmes de HTTPS. Mais c'est une exigence de la
section 2.1 du RFC 7838, qui exige que le renvoi à un service
alternatif soit « raisonnablement » sécurisé. (Notez que cette
vérification est délicate, comme l'a montré CVE-2015-0799.)
En outre, le client doit avoir fait une
requête sécurisée pour le nom bien connu (RFC 8615,
pour la notion de nom bien connu)
/.well-known/http-opportunistic. La réponse à
cette requête doit être positive, et doit être en
JSON, et contenir un tableau de chaînes de caractères
dont l'une doit être le nom d'origine (pour être sûr que ce
serveur autorise le service alternatif, car le certificat du serveur
effectivement utilisé prouve une autorisation du serveur
alternatif, et la signature d'une AC, ce qu'on peut trouver
insuffisant). Ce nouveau nom bien connu figure désormais dans
le registre IANA.
La section 4 de notre RFC rappelle quelques trucs de sécurité :
- L'en-tête
Alt-Svc:étant envoyé sur une liaison non sécurisée, il ne faut pas s'y fier aveuglément (d'où les vérifications faites ci-dessus). - Certaines applications tournant sur le serveur peuvent utiliser des drôles de moyens pour déterminer si une connexion était sécurisée ou pas (par exemple en regardant le port destination). Elles pourraient faire un faux diagnostic sur les connexions utilisant le service alternatif.
- Il est trivial pour un attaquant actif (un « Homme du Milieu ») de retirer cet en-tête, et donc de faire croire au client que le serveur n'a pas de services alternatifs. Bref, cette technique ne protège que contre les attaques passives. Ce point a été un des plus discutés à l'IETF (débat classique, vaut-il mieux uniquement la meilleure sécurité, ou bien accepter une sécurité « au mieux », surtout quand l'alternative est pas de sécurité du tout).
- Le client ne doit pas utiliser des indicateurs qui donneraient à l'utilisateur l'impression que c'est aussi sécurisé qu'avec du « vrai » HTTPS. Donc, pas de joli cadenas fermé et vert. (C'est une réponse au problème ci-dessus.)
Apparemment, Firefox est le seul client
HTTP à mettre
en œuvre ce nouveau service (mais avec une syntaxe
différente pour le JSON, pas encore celle du RFC). Notez que le serveur ne
nécessite pas de code particulier, juste une configuration
(envoyer l'en-tête Alt-Svc:, avoir le
/.well-known/http-opportunistic…) Les
serveurs de Cloudflare permettent
ce choix.
L'article seul
Fin du groupe de travail IETF dbound
Première rédaction de cet article le 15 mai 2017
L'IETF a annoncé le 24 avril 2017 la dissolution du groupe de travail DBOUND. Je n'écrirai donc pas d'article sur les RFC de ce groupe, il n'y en a eu aucun. Pourquoi cet échec ?
D'abord, voyons quel était le problème que voulait résoudre ce
groupe. DBOUND signifie Domain Boundaries et
il s'agissait en gros d'indiquer publiquement quelles étaient les
frontières organisationnelles dans les noms de domaine. Minute, vont se dire
certains lecteurs, c'est facile ! Dans
www.foobar.example, la frontière est
forcément entre foobar et le truc appelé à
tort « extension »
.example ? Mais c'est complètement faux, les
coupures (passage d'une organisation à une autre) peuvent être à
plein d'endroits différents et rien dans le nom de domaine ne
l'indique. (Cf. mon article sur « La terminologie des parties d'un nom
de domaine ».)
Et, au passage, pourquoi est-ce que c'est important de savoir
que signal.eu.org et
eahm.eu.org ne dépendent
pas de la même organisation ? Parce que
plusieurs services en dépendent. (Une liste partielle de raisons
figure dans mon article « Trouver le domaine
responsable ».) Par exemple, on pourrait vouloir, dans la
barre d'adresses du navigateur Web, colorier
différemment le domaine enregistré le plus haut dans l'arbre, pour
éviter certains trucs utilisés par le hameçonnage.
Aujourd'hui, comme il y a un vrai besoin, la plupart des utilisateurs se servent de la « Public Suffix List » de Mozilla. Cela marche « suffisamment » mais son principal inconvénient est qu'elle n'est pas administrée par les gérants de noms de domaine, et qu'elle n'est donc jamais à jour.
C'est là dessus que devait travailler le groupe
DBOUND. Il devait « développer une solution unique pour
déterminer les frontières organisationnelles ». Le travail a
commencé sur une liste de diffusion en
janvier
2014, et le groupe lui-même a été créé en avril
2015. Plusieurs documents ont
été proposés mais aucun n'a réuni même un début de
commencement de consensus. (Même pas le document de description du
problème, draft-sullivan-dbound-problem-statement.)
Suivant un principe général de l'IETF, qu'un groupe de travail est fait pour travailler et qu'il ne faut pas maintenir en vie artificiellement des groupes qui ne produiront manifestement rien d'utile, le groupe a donc été dissous.
Pourquoi cet échec ? Il n'y a sans doute pas une raison unique. Parmi les explications :
- Le problème est bien plus compliqué qu'il n'en a l'air (comme beaucoup de problèmes qu'on aborde avec des yakafokon), par exemple parce qu'il n'est pas évident qu'il faille les mêmes frontières pour toutes les applications,
- Il y a un désaccord de fond entre ceux qui disent que l'indication des frontières doit être faite par le domaine parent (au-dessus de la frontière), car c'est lui qui fixe les règles d'enregistrement, et ceux qui disent qu'elle doit être faite par le domaine fils (car c'est lui qui sait son propre statut),
- Et, tout simplement, intérêt insuffisant pour un problème dont la partie la plus urgente (les cookies) est déjà partiellement résolu. L'IETF étant une organisation de volontaires, s'il n'y a pas de volontaire, rien ne se passe.
L'article seul
Cours DNS au CNAM
Première rédaction de cet article le 14 mai 2017
Dernière mise à jour le 9 juillet 2018
Le 11 mai 2017, c'était la première édition de mon cours DNS de trois heures au CNAM. Pour l'anecdote, c'était dans le bâtiment où il y avait eu la première connexion UUCP/Usenet, et le premier serveur HTTP public, en France.
Voici les supports de l'exposé :
- Version adaptée à l'écran,
- Version adaptée à l'impression,
- Source LaTeX.
Une version un peu raccourcie (deux heures, tout de même) a été filmée mais la vidéo n'est plus en ligne.
J'ai fait aussi un cours BGP au même endroit.
Merci à Sami Taktak pour l'idée et l'organisation, et aux élèves pour avoir posé plein de questions pas toujours faciles.
L'article seul
RFC 8165: Design considerations for Metadata Insertion
Date de publication du RFC : Mai 2017
Auteur(s) du RFC : T. Hardie
Pour information
Première rédaction de cet article le 14 mai 2017
Ce court RFC déconseille l'insertion de métadonnées dans les paquets IP, si cette insertion est faite en route, par des intermédiaires. Pourquoi ? (Essentiellement pour des raisons de vie privée.)
Le problème de la surveillance de masse que pratiquent la plupart des États (en tout cas ceux qui en ont les moyens financiers) est maintenant bien documenté (par exemple dans les RFC 7258 et RFC 7624). Une solution fréquente pour limiter cette surveillance, la rendre plus coûteuse et moins efficace est de chiffrer ses communications. Dans l'éternelle lutte de l'épée et de la cuirasse, les surveillants réagissent au chiffrement en utilisant davantage les métadonnées, en général non protégées par le chiffrement. Qui met des métadonnées dans les paquets, affaiblissant ainsi l'effet du chiffrement ?
Certaines métadonnées sont absolument indispensables au fonctionnement de l'Internet. Par exemple, l'adresse IP de destination dans un paquet doit être en clair car tous les routeurs situés sur le trajet doivent la voir, pour prendre leurs décisions. Certaines métadonnées sont inutiles au fonctionement de l'Internet, mais difficiles à dissimuler, la taille des paquets, par exemple. (C'est également un exemple d'une métadonnée implicite : contrairement à l'adresse IP, elle n'apparait pas explicitement dans le paquet.) Normalement, pour gêner la surveillance, il faut envoyer le moins de métadonnées possible.
L'Internet est souvent décrit comme
reposant sur une liaison de bout en bout, où seules les deux
machines situées aux extrémités de la communication ont accès à
tout le contenu de la communication. Mais, en pratique, il existe
souvent des équipements intermédiaires qui ont accès à des
informations poour faire leur travail. Si ces
middleboxes ont la
mauvaise idée de mettre ces informations dans les métadonnées d'un
paquet, elles affaiblissent la confidentialité des
échanges. Imaginons par exemple (ce n'est pas forcément fait
aujourd'hui : le RFC met en garde contre une mauvaise idée, pas
toujours contre des pratiques existantes, voir à ce sujet l'examen
par la direction Sécurité), imaginons par exemple un VPN qui
déciderait d'indiquer l'adresse IP originale dans la
communication… Notre RFC mentionne deux exemples qui sont décrits
dans des RFC : le RFC 7239 qui décrit l'en-tête HTTP
Forwarded: qu'un relais
HTTP peut mettre pour indiquer l'adresse IP d'origine
du client, et bien sûr le RFC 7871, où un
résolveur DNS transmet aux serveurs faisant
autorité l'adresse IP du client original.
La section 4 du RFC est la recommandation concrète : les métadonnées ne doivent pas être mises par les intermédiaires. Si ces informations peuvent être utiles aux destinataires, c'est uniquement au client d'origine de les mettre. Autrement, on trahit l'intimité du client.
Le RFC 7871, par exemple, aurait dû spécifier un mécanisme où l'adresse IP est mise par le client DNS de départ, celui qui tourne sur la machine de l'utilisateur. Cela permettrait un meilleur contrôle de sa vie privée par l'utilisateur.
Et si cette machine ne connait pas sa propre adresse IP publique, par exemple parce qu'elle est coincée derrière un NAT? Dans ce cas, notre RFC 8165 dit qu'il faut utiliser une technique comme STUN (RFC 8489) pour l'apprendre.
Bon, la section 4, c'était très joli, c'était les bons conseils. Mais la cruelle réalité se met parfois sur leur chemin. La section 5 de notre RFC est le « reality check », les problèmes concrets qui peuvent empêcher de réaliser les beaux objectifs précédents.
D'abord, il y a le désir d'aller vite. Prenons l'exemple du
relais HTTP qui ajoute un en-tête
Forwarded: (RFC 7239), ce qui permet des choses positives (adapter le
contenu de la page Web servie au client) et négatives (fliquer les
clients). Certes, le client HTTP d'origine aurait pu le
faire lui-même, mais, s'il est derrière un routeur
NAT, il faut utiliser
STUN. Même si tous les clients
HTTP décidaient de la faire, cela ne serait pas instantané, et la
longue traine du déploiement des navigateurs Web ferait qu'un
certain nombre de clients n'aurait pas cette fonction. Alors que
les relais sont moins nombreux et plus susceptibles d'être
rapidement mis à jour.
En parlant d'adaptation du contenu au client, il faut noter que c'est une des principales motivations à l'ajout de tas de métadonnées. Or, comme dans l'exemple ci-dessus, si on demande au client de mettre les métadonnées lui-même, beaucoup ne le feront pas. De mon point de vue, ils ont bien raison, et le RFC note qu'une des motivations pour la consigne « ne pas ajouter de métadonnées en route » est justement de rendre le contrôle à l'utilisateur final : il pourra choisir entre envoyer des métadonnées lui permettant d'avoir un contenu bien adapté, et ne pas en envoyer pour préserver sa vie privée. Mais ce choix peut rentrer en conflit avec ds gens puissants, qui exigent, par exemple dans la loi, que le réseau trahisse ses utilisateurs, en ajoutant des informations qu'eux-mêmes ne voulaient pas mettre.
Enfin, il y a l'éternel problème de la latence. L'utilisation de STUN va certainement ralentir le client.
Un dernier point (section 7 du RFC) : si on passe par Internet pour contacter des services d'urgence (pompiers, par exemple, ou autre PSAP), ils ont évidemment besoin du maximum d'informations, et, dans ce cas, c'est peut-être une exception légitime à la règle de ce RFC.
L'article seul
RFC 8105: Transmission of IPv6 Packets over DECT Ultra Low Energy
Date de publication du RFC : Mai 2017
Auteur(s) du RFC : P. Mariager, J. Petersen (RTX A/S), Z. Shelby (ARM), M. Van de Logt (Gigaset Communications GmbH), D. Barthel (Orange Labs)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF 6lo
Première rédaction de cet article le 3 mai 2017
Tout le monde connait DECT, la technique utilisée, depuis vingt ans, entre votre téléphone sans fil à la maison, et sa base. DECT ne sert pas que pour la voix, il peut aussi être utilisé pour transmettre des données, par exemple de capteurs situés dans une « maison intelligente ». DECT a une variante « basse consommation », DECT ULE (pour Ultra Low Energy) qui est spécialement conçue pour des objets connectés ayant peu de réserves d'énergie. Elle vise donc la domotique, s'appuyant sur la vaste distribution de DECT, la disponibilité de composants bon marché et très diffusés, de fréquences dédiées, etc. Il ne restait donc plus qu'à faire passer IPv6 sur DECT ULE. C'est ce que normalise ce RFC, qui réutilise les techniques 6LoWPAN (RFC 4919).
DECT est normalisé par l'ETSI sous le numéro 300.175 (et la norme est en ligne). ULE s'appuie sur DECT pour le cas particulier des engins sans guère de réserves énergétiques. Il est normalisé dans les documents ETSI 102.939-1 et 102.939-2. Dans la terminologie DECT, le FP (Fixed Part) est la base, le PP (Portable Part) le téléphone sans fil (ou bien, dans le cas d'ULE, le capteur ou l'actionneur ). Le FP peut être connecté à l'Internet (et c'est évidemment là qu'IPv6 est important).
Un réseau DECT ULE typique serait une maison où des capteurs (les PP) mesureraient des informations et les transmettraient au FP qui, étant doté de capacités de calcul et de réserves d'énergie suffisantes, les traiterait, en ferait des jolis graphiques, aurait une interface Web, etc. Le RFC cite un autre exemple où une personne âgée serait munie d'un pendentif qui enverrait des signaux de temps en temps (consommant peu d'énergie) mais permettrait d'établir une liaison vocale avec le FP (et, de là, avec les services médicaux) en cas d'urgence.
Et IPv6 ? Il permettrait d'avoir une communication avec tous les équipements IP. IPv6 fonctionne déjà sur une autre technologie similaire, IEEE 802.15.4, avec le système 6LoWPAN (RFC 4944, RFC 6282 et RFC 6775). Comme DECT ULE ressemble à 802.15.4 (mais est un protocole différent, attention), ce RFC décrit comment faire passer de l'IPv6, en s'inspirant de ce qui marchait déjà pour 802.15.4.
La section 2 du RFC rappelle ce qu'il faut savoir de DECT et d'ULE. ULE permet le transport de la voix et des données mais ce RFC ne se préoccupe que des données. Le protocole utilise les bandes de fréquence entre 1880 et 1920 MHz, à 1,152 Mbauds. La topologie théorique est celle d'un réseau cellulaire mais, en pratique, DECT est la plupart du temps organisé en étoile, un FP (la base) au « centre » et des PP (téléphones et capteurs) qui lui sont rattachés. Toute session peut commencer à l'initiative du FP ou d'un PP mais attention : avec ULE, bien des PP seront des engins aux batteries limitées, qui dormiront pendant l'essentiel du temps. Au minimum, il y aura une sérieuse latence s'il faut les réveiller.
Comme, dans le cas typique, le FP est bien moins contraint que le PP (connecté au courant électrique, processeur plus puissant), ce sera le FP qui jouera le rôle de 6LBR (6LoWPAN Border Router, voir RFC 6775), et le PP celui de 6LN (6LoWPAN Node, même RFC). Contrairement à 802.15.4, DECT ULE ne permet que des liens directs, pour aller au delà, il faut un routeur (le FP). Tous les PP connectés à un FP forment donc un seul lien, leurs adresses seront dans le même préfixe IPv6.
Comment attribuer cette adresse ? Alors, là, faites attention, c'est un point délicat et important. Chaque PP a un IPEI (International Portable Equipment Identity) de 40 bits, qui est l'identifiant DECT. Les FP ont un RFPI (Radio Fixed Part Identity, également 40 bits). Les messages envoyés entre PP et FP ne portent pas l'IPEI mais le TPUI (Temporary Portable User Identity, 20 bits). Pas mal de mises en œuvre de DECT attribuent répétitivement le même TPUI à une machine, même si ce n'est pas obligatoire. Il peut donc être un identifiant stable, en pratique, comme le sont IPEI et RFPI.
L'adresse IPv6 est composée du préfixe du réseau et d'un identifiant d'interface, qu'on peut construire à partir de l'adresse MAC (les équipements DECT peuvent aussi avoir une adresse MAC, en sus des identificateurs déjà cités). Adresse MAC, IPEI, RFPI ou TPUI, tout ce qui est stable pose des problèmes de protection de la vie privée (RFC 8065), et n'est pas recommandé comme identifiant d'interface par défaut.
Un petit mot aussi sur la MTU : les paquets DECT ne sont que 38 octets, bien trop petit pour IP. Certes, DECT fournit un mécanisme de fragmentation et de réassemblage, qui fournit une MTU « virtuelle » qui est, par défaut, de 500 octets. La MTU minimum exigée par IPv6 étant de 1 280 octets (RFC 2460, section 5), il faudra donc reconfigurer le lien DECT pour passer à une MTU de 1 280. Ainsi, les paquets n'auront jamais besoin d'être fragmentés par IP. Évidemment, plus le paquet est gros, plus le coût énergétique de transmission est élevé, au détriment de la durée de vie de la batterie.
Place maintenant à la spécification elle-même, en section 3 du RFC. La base (alias FP, alias 6LBR) et l'objet (alias PP, alias 6LN) vont devoir se trouver et établir une session DECT classique. On aura alors une couche 2 fonctionnelle. Ensuite, on lancera IPv6, qui fournira la couche 3. La consommation de ressources, notamment d'énergie, étant absolument cruciale ici, il faudra s'appuyer sur les technologies IPv6 permettant de faire des économies, notamment RFC 4944 (IPv6 sur un autre type de réseau contraint, IEEE 802.15.4), RFC 6775 (optimisation des mécanismes de neighbor discovery pour les 6LoWPAN) et RFC 6282 (compression des paquets et notamment des en-têtes).
Comme indiqué plus haut, les PP ne peuvent parler qu'au FP, pas directement de l'un à l'autre. Si tous les PP d'un même FP (d'une même base) forment un sous-réseau IPv6 (choix le plus simple), le modèle sera celui d'un NBMA. Lorsqu'un PP écrira à un autre PP, cela sera forcément relayé par le FP.
Les adresses IPv6 des PP seront formées à partir du préfixe (commun à tous les PP d'un même FP) et d'un identifiant d'interface. Pour les adresses locales au lien, cet identifiant d'interface dérivera des identifiants DECT, les IPEI et RFPI, complétés avec des zéros pour atteindre la taille requise. Le bit « unique mondialement » sera à zéro puisque ces identifiants ne seront pas uniques dans le monde (ils ont juste besoin d'être uniques localement, ce fut un des points les plus chauds lors de l'écriture de ce RFC).
Pour les adresses globales des PP, pas question d'utiliser des identificateurs trop révélateurs (RFC 8065), il faut utiliser une technique qui préserve la vie privée comme les CGA (RFC 3972), les adresses temporaires du RFC 8981 ou les adresses stables mais opaques du RFC 7217.
Le FP, la base, a une connexion avec l'Internet, ou en tout cas avec d'autres réseaux IP, et routera donc les paquets, s'ils viennent d'un PP et sont destinés à une adresse extérieure au sous-réseau (idem avec les paquets venus de l'extérieur et destinés au sous-réseau.) Au fait, comment est-ce que la base, qui est un routeur IPv6, obtient, elle, le préfixe qu'elle va annoncer ? Il n'y a pas de méthode obligatoire mais cela peut être, par exemple, la délégation de préfixe du RFC 8415, ou bien le RFC 4193.
Question mises en œuvre, il semble que RTX et Gigaset en aient déjà, et que peut-être l'alliance ULE va produire une version en logiciel libre.
L'article seul
RFC 8141: Uniform Resource Names (URNs)
Date de publication du RFC : Avril 2017
Auteur(s) du RFC : P. Saint-Andre
(Filament), J. Klensin
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF urnbis
Première rédaction de cet article le 30 avril 2017
Dans la grande famille des URI, il y a (entre autres) les
URL, et les
URN, comme urn:ietf:params:xml:ns:iodef-2.0, normalisés
dans ce RFC, qui couvre aussi bien leur
syntaxe (qui était
auparavant dans le RFC 2141) que les
procédures d'enregistrement (autrefois dans le RFC 3406). Il remplace donc ces deux anciens RFC.
Le RFC 3986, qui normalise la syntaxe générique des URI, délègue les détails des familles particulières d'URI à d'autres RFC comme celui-ci. Notre RFC 8141 précise la syntaxe générique pour le cas des URN, des URI dont les propriétés sont a priori la persistence et la non-résolvabilité (donc, plutôt des noms que des adresses, pour reprendre le vocabulaire des RFC 1737 et RFC 3305).
La section 2, URN Syntax décrit à quoi
ressemblent les URN. Un URN est formé avec le plan
urn (enregistré à l'IANA), un NID (Namespace
IDentifier) qui indique l'organisme qui gère la fin de
l'URN, puis le NSS (Namespace Specific String), tous
séparés par des deux-points. Il existe de très nombreux NID déjà enregistrés, comme ceux du RFC 7207 (messagerie Eurosystem), RFC 7254 (IMEI),
RFC 5165 (normes OGC), RFC 9562 (UUID)… Deux idées essentielles des URN sont que la création de NID est
strictement gérée (il faut documenter précisément le pourquoi du
nouvel NID) et que, dans chaque espace de noms créé par un NID,
l'affectation des NSS est à son tour gérée, avec des règles
rigoureuses, que l'on suit soigneusement. Les URN sont conçus pour
du nommage « sérieux ». Il n'existe pas d'URN à enregistrement libre
et, donc, le fait d'être correct syntaxiquement ne suffit pas pour
qu'un URN soit un vrai URN : il doit en plus être passé par le
processus d'enregistrement.
Par exemple, si on prend les URN néo-zélandais du RFC 4350, le NID est nzl et un URN
ressemble donc à
urn:nzl:govt:registering:recreational_fishing:form:1-0. Attention,
le deux-points n'est un séparateur qu'au début,
entre le plan et le NID, puis entre le NID et le NSS. Après, c'est
juste un caractère comme un autre. Donc,
govt:registering:recreational_fishing:form:1-0
n'est pas forcément du nommage arborescent.
Notez que la syntaxe est moins
restrictive qu'elle ne l'était dans le RFC 2141.
Comme avec les autres URI, les caractères considérés comme
« spéciaux » doivent être protégés avec l'encodage pour
cent (cela ne concerne pas le NID qui doit être purement
en ASCII). On ne peut donc hélas pas faire de vrais URN
internationaux. Ainsi, urn:example:café doit en
fait s'écrire urn:example:caf%E9.
Notre RFC 8141 introduit un concept nouveau, qui n'était
pas dans le RFC 2141, celui de composants. Ils
sont de trois sortes, les r-components, les
q-components et les
f-components. Les premiers, les
r-components, servent à passer des paramètres à un
éventuel système de résolution. Ils commencent par un point
d'interrogation suivi d'un
plus. Ainsi, dans
urn:example:bar-baz-qux?+CCResolve:cc=fr, le
r-component est
CCResolve:cc=fr, indiquant probablement qu'on
souhaite une réponse adaptée à la France (CCResolve
= Country-Code Resolve). La syntaxe est définie
(ainsi que le fait que ces composants doivent être ignorés pour la
comparaison de deux URN) mais la sémantique est pour l'instant laissée
dans le flou.
Contrairement au r-component, prévu pour le
système de résolution, le q-component est prévu
pour la ressource à laquelle on accède. Il commence par un point
d'interrogation suivi d'un égal. Un exemple
pourrait être
urn:example:weather?=op=map&lat=39.56&lon=-104.85
(cherchez pas : c'est près de Denver).
Quant au f-component, introduit par un croisillon, il n'est destiné qu'au client (comme le classique identificateur de fragment des URI).
La section 3, consacrée à l'équivalence
lexicale de deux URN, explique comment on peut
déterminer si deux URN sont égaux ou pas, sans connaitre les règles
particulières de l'organisme qui les enregistre. (Déterminer
l'équivalence sert, par
exemple, pour savoir si un URN a déjà été visité.) Ainsi,
urn:foo:BAR et urn:FOO:BAR
sont lexicalement équivalents (le NID est insensible à la casse, cf. section 2.1) mais
urn:foo:BAR et urn:foo:bar
ne le sont pas, le NSS étant, lui, sensible à la casse (les deux URN
sont peut-être fonctionnellement équivalents mais cela dépend de la
politique d'enregistrement de l'organisme désigné par
foo). Il n'y a pas d'autre normalisation
appliquée avant la comparaison, notamment sur les caractères encodés
pour-cent.
Notez que la définition d'un espace de noms donné peut toujours rajouter des règles (par exemple que le NSS soit insensible à la casse) mais ces règles doivent uniquement créer de nouvelles équivalences, jamais séparer deux URN qui auraient été identiques dans une comparaison générique (par un logiciel qui ne connaissait pas les règles spécifiques de cet espace de noms, voir aussi la section 4.2).
Comme vu plus haut, il y a dans un URN, immédiatement après la
chaîne de caractères urn:, l'espace de
noms (namespace ou NID), une chaîne de caractères qui identifie le domaine d'une
autorité d'enregistrement. Notre RFC 8141 explique les
procédures de création d'un nouvel espace de noms dans le registre des espaces de noms que tient
l'IANA. Si vous voulez juste faire des exemples,
il existe un NID example specifié dans le RFC 6963 (oui, j'aurais dû l'utiliser au lieu de foo).
Comme expliqué dans la section 5, ce mécanisme d'espaces de noms suppose que, dans chaque espace, il existe une autorité d'enregistrement qui accepte (ou refuse) les enregistrements et que, d'autre part, il existe une autorité qui enregistre les espaces de noms (en l'occurrence l'IANA). La section 6 de notre RFC est consacrée aux procédures de cette dernière autorité et aux mécanismes pour enregistrer un identificateur d'espace de noms (NID pour namespace identifier). (La résolution des URN en autres identificateurs n'est par contre pas couverte, mais on peut toujours regarder le RFC 2483.) Des exemples d'autorité d'enregistrement dans un espace de noms donné sont le gouvernement néo-zélandais (RFC 4350) ou l'OGC (RFC 5165).
Notez que certains URN sont créés en partant de rien, alors que
d'autres sont juste une transcription en syntaxe URN d'identificateurs
déjà enregistrés par ailleurs. C'est le cas des
ISBN (RFC 8254) ou des
RFC eux-mêmes (RFC 2648, avec le NID
ietf, ce RFC est donc urn:ietf:rfc:8141).
Tiens, et où peut-on mettre des URN ? Syntaxiquement, un
URN est un URI, donc on peut en mettre partout où on peut mettre des
URI (section 4 du RFC). Par exemple, comme nom d'espace de
noms XML. Mais ce n'est pas une bonne idée de mettre des
URN partout. Par exemple, en argument d'un <a
href="…, c'est même certainement une mauvaise idée (car le
navigateur Web typique ne sait pas résoudre des URN).
Autre recommandation pratique de notre RFC, si un logiciel affiche
un URN, bien penser à l'afficher en complet (contrairement à ce que
font certains navigateurs Web qui, stupidement, tronquent l'URI, par
exemple en omettant le plan http://). En effet,
une abréviation peut ne pas avoir le résultat attendu. En effet, il
existe un NID urn:xmpp (RFC 4854) et un
plan d'URI xmpp: (RFC 5122). Si on n'affiche pas le plan
urn:, il y a un gros risque de confusion.
La section 5 du RFC détaille ce qu'est un espace de noms (un ensemble d'identificateurs uniques géré, c'est-à-dire que tous les noms syntaxiquements corrects n'en font pas partie, uniquement ceux qui ont été enregistrés). Par exemple, les ISBN forment un tel espace (dont l'utilisation dans des URN a fait l'objet du RFC 8254). À l'intérieur d'un espace de noms, les règles d'enregistrement et le travail quotidien du registre ne sont pas gérés par l'IETF ou l'IANA mais par l'autorité d'enregistrement de cet espace.
La section 5 introduit les différents types d'espaces de noms. Il y a les espaces informels (section 5.2),
dont le NID commence par urn- et est composé de
chiffres et les espaces formels (section 5.1)
dont le NID est composé de lettres et qui, contrairement aux
informels, sont censés fournir un bénéfice aux utilisateurs de
l'Internet (les espaces informels ont le droit
d'être réservés à une communauté déconnectée). Contrairement encore
aux informels, l'enregistrement des espaces formels fait l'objet d'un
examen par un expert (cf. RFC 5226)
et il est
recommandé que cet enregistrement fasse
l'objet d'une spécification écrite, par exemple un
RFC. L'organisation
qui gère un NID formel doit également démontrer sa stabilité et son
sérieux sur le long terme.
Un des principes des URN est la durabilité : un URN devrait être stable dans le temps (et, logiquement, jamais réaffecté si jamais il est supprimé). Mais cette stabilité dépend essentiellement de facteurs non-techniques, comme la permanence dans le temps du registre (une organisation privée et fermée comme l'IDF est, par exemple, typiquement un mauvais choix pour assurer la permanence). Toutefois, si on ne peut pas garantir la stabilité d'un espace de noms, on connait en revanche des facteurs qui diminuent la probabilité de permanence et l'IETF peut donc analyser les spécifications à la recherche de tels facteurs (c'est une variante du problème très riche mais bien connu de la stabilité des identificateurs). Au passage, la plupart des grandes questions liées aux URN (permanence, compromis entre facilité d'enregistrement et désir de ne pas permettre « n'importe quoi ») sont des questions bien plus anciennes que les URN, et même plus anciennes que l'Internet, et ne feront probablement pas l'objet d'un consensus de si tôt (cf. section 1.2).
Enfin, le processus d'enregistrement lui-même. Il faut en effet un
peu de bureaucratie pour s'assurer que le NID est bien enregistré et
que le registre des
NID soit lui-même stable. Les procédures sont différentes selon
le type d'espace de noms. Les informels, qui commencent par la chaîne
de caractères urn- suivie d'un nombre, ont leur
propre
registre, avec un processus d'enregistrement léger, mais très
peu utilisé.
Le gros morceau est constitué des espaces de noms formels. Cette
fois, le processus d'enregistrement est plus complexe, mais on obtient
un « vrai » NID comme mpeg (RFC 3614),
oasis (RFC 3121) ou
3gpp (RFC 5279).
Le formulaire d'enregistrement complet est disponible dans l'annexe
A du RFC. Bon courage aux futurs enregistreurs. N'oubliez pas de lire
tout le RFC. Notez par exemple qu'il faudra décrire les mécanismes
par lesquels vous allouerez des noms (si vous gérez
urn:example, et que je demande
urn:example:boycott-de-mcdo, que
répondrez-vous ?), et qu'il faudra une analyse de sécurité et aussi
(c'est une nouveauté par rapport au RFC 2141) de
vie privée.
Ce nouveau RFC remplace à la fois le RFC 2141
et le RFC 3406, et le processus fut long (six
ans) et difficile. L'annexe B indique les
principaux changements depuis le RFC 2141 :
alignement de la syntaxe sur le RFC 3986 (en
pratique, la nouvelle syntaxe est plus acceptante), introduction des
composants (pour pouvoir faire des choses comme les fragments, qui
marchaient avec tous les autres URI)… L'annexe C, elle, présente les
changements par rapport au RFC 3406 :
politique d'enregistrement d'un NID plus libérale (examen par un expert
au lieu d'examen par l'IETF), suppression des NID expérimentaux (nom
commençant par x-) en raison du RFC 6648…
L'article seul
RFC 8143: Using Transport Layer Security (TLS) with Network News Transfer Protocol (NNTP)
Date de publication du RFC : Avril 2017
Auteur(s) du RFC : J. Élie
Chemin des normes
Première rédaction de cet article le 25 avril 2017
Ce RFC concernant le protocole NNTP met à jour l'ancien RFC 4642 qui donnait des conseils TLS très spécifiques (activer la compression, utiliser RC4...), conseils qui n'ont pas résisté à l'évolution de la cryptographie. On arrête donc de donner des conseils TLS spécifiques, NNTP a un usage générique de TLS et doit donc se référer au RFC générique BCP 195 (actuellement RFC 7525).
NNTP, le protocole de transport des News, est normalisé dans le RFC 3977. Il peut utiliser TLS (RFC 5246) pour sécuriser la communication entre deux serveurs NNTP, ou bien entre serveur et client. Le RFC 4642, qui décrivait cet usage de TLS, faisait une erreur : il donnait des conseils de cryptographie. Or, d'une part, NNTP ne faisait pas un usage particulier de la cryptographie, et n'avait pas besoin de recommandations spécifiques et, d'autre part, la cryptographie est un domaine qui évolue. Ainsi, les fonctions de compression de données de TLS sont aujourd'hui considérées comme une mauvaise idée, dans la plupart des cas (attaque CRIME, cf. RFC 7525, section 3.3).
L'essentiel de notre nouveau RFC est dans sa section 3 : désormais, il faut suivre le RFC de bonnes pratiques TLS, BCP 195 (actuellement RFC 7525).
De même que le courrier électronique
peut préciser dans un en-tête Received: que
la connexion SMTP était protégée par TLS,
de même NNTP permet d'ajouter dans le champ
Path: (section 3.1.5 du RFC 5536) une indication que
le pair a été authentifié (deux points d'exclamation de suite).
La section 2 du RFC résume les changements par rapport au RFC 4642 (la liste complète est dans l'annexe
A). Comme dit plus haut, la compression TLS est désormais fortement déconseillée
(à la place, on peut utiliser l'extension de compression de NNTP,
normalisée dans le RFC 8054). Il est très
nettement recommandé d'utiliser du TLS implicite (connexion sur un
port dédié (le 563 pour les clients, non
spécifié pour les autres serveurs), au lieu de la
directive STARTTLS, qui est vulnérable à
l'attaque décrite dans la section 2.1 du RFC 7457). Il ne faut évidemment
plus utiliser RC4 (cf. RFC 7465), mais les algorithmes de chiffrement obligatoires
de TLS. Il faut utiliser
l'extension TLS Server Name Indication (RFC 6066, section 3). Et, pour authentifier, il
faut suivre les bonnes pratiques TLS des RFC 5280 et RFC 6125.
Comme la plupart des mises en oœuvre de NNTP-sur-TLS utilisent une bibliothèque TLS générique, elles suivent déjà une bonne partie des recommandations de ce RFC. Après, tout dépend des options particulières qu'elles appellent…
Merci à Julien Élie pour une relecture attentive (j'avais réussi à mettre plusieurs erreurs dans un article aussi court.)
L'article seul
RFC 8153: Digital Preservation Considerations for the RFC Series
Date de publication du RFC : Avril 2017
Auteur(s) du RFC : H. Flanagan (RFC Editor)
Pour information
Première rédaction de cet article le 25 avril 2017
La préservation, sur le long terme, des documents qui ne sont jamais passés par une forme papier, est un défi important de notre époque. Nous pouvons relire aujourd'hui toute la correspondance du ministère des affaires étrangères de Louix XV, pourrons-nous, dans un siècle ou deux, relire les documents numériques du vingtième siècle ? Pourrons-nous relire les RFC ? C'est le but de ce document que d'explorer les pistes permettant de donner aux RFC une meilleure chance de conservation.
Le RFC Editor (RFC 8728) est à la fois l'éditeur et l'archiviste des RFC. Les deux fonctions sont souvent contradictoires : l'éditeur voudrait utiliser les derniers gadgets pour publier des jolis trucs (multimédia, par exemple, ou contenus exécutables), l'archiviste est prudent et conservateur et voudrait des technologies simples. L'éditeur doit produire des documents clairs et lisibles. L'archiviste doit les conserver, et pour une durée potentiellement bien plus longue que les modes technologiques, durée qui peut atteindre des siècles (on est ravis, aujourd'hui, quand on retrouve les textes de lois d'un royaume depuis longtemps oublié, au fin fond de la Mésopotamie, même quand ces lois ont depuis longtemps cessé d'être applicables).
Notez que des organisations comme l'IETF produisent plein de documents (les discussions sur les listes de diffusion, par exemple), mais que ce RFC se focalise sur la préservation des RFC.
Historiquement, les RFC étaient en texte seul. Ce format avait des tas d'avantages. Simple, et auto-documenté (la seule spécification nécessaire pour le comprendre était ASCII), il convenait bien à l'archivage. Régulièrement, des naïfs demandaient que le RFC Editor passe à un format « plus moderne », en général une mode passagère, oubliée quelques années après. Le texte seul a donc tenu très longtemps, et à juste titre.
Mais la roue de l'histoire a fini par tourner et le RFC 6949 a pris acte du fait qu'on n'allait pas rester en texte seul éternellement. Le format officiel des RFC, décrit dans le RFC 7990 est désormais fondé sur XML, avec divers enrichissements comme le jeu de caractères Unicode (RFC 7997) ou les images en SVG (RFC 9896). Cela fait peser une pression plus forte sur l'archivage : si on est certain de pouvoir relire le texte brut en ASCII dans cent ans, qu'en est-il d'images SVG ? L'ancien système d'archivage des RFC ne va donc a priori pas suffire. (Le XML lui-même est relativement auto-documenté. Si on met des documents XML sous les yeux d'un programmeur qui n'en a jamais vu, il pourra probablement rétro-ingénierer l'essentiel. Ce n'est pas forcément le cas des vocabulaires qui utilisent XML, notamment le compliqué SVG.)
Le nouveau système d'archivage suivra le cadre conceptuel d'OAIS (norme ISO 14721, disponible en ligne). Sur OAIS, on peut lire la bonne introduction d'Emmanuelle Bermes. Il faut notamment distinguer deux tâches (section 1.1 de notre RFC) :
- Préservation des bits : archiver un fichier informatique et pouvoir le ressortir des dizaines d'années après, au bit près. Cela se fait, par exemple, en recopiant régulièrement le fichier sur de nouveaux supports physiques, et en vérifiant via une somme de contrôle ou une signature que rien n'a changé. Des classiques sauvegardes, vérifiées régulièrement, suffisent donc.
- Préservation du contenu : il ne suffit plus de stocker et de restituer les bits, il faut aussi présenter le contenu à l'utilisateur. Avoir une copie parfaite des bits d'un fichier WordPerfect de 1990 ne sert pas à grand'chose s'il n'existe plus aucun logiciel capable de lire le Wordperfect sur les machines et systèmes d'exploitation modernes. Assurer la préservation du contenu est plus complexe, et il existe plusieurs solutions, par exemple de garder une description du format (pour qu'on puisse toujours développer un outil de lecture), et/ou garder non seulement les fichiers mais aussi les outils de lecture, et tout l'environnement qui permet de les faire fonctionner.
Ceci dit, ce problème d'archivage à long terme des fichiers numériques n'est ni nouveau, ni spécifique aux RFC. Il a été largement étudié par de nombreuses organisations. On peut citer la BNF, le projet LIFE en Grande-Bretagne, ou l'étude du cycle de vie faite à la Bibliothèque du Congrès. Des processus pour maintenir sur le long terme les fichiers, avec recopies régulières et nombreuses vérifications, existent.
Les RFC bénéficient depuis un certain temps d'un mécanisme similaire de préservation des bits : les métadonnées (indispensables pour retrouver un document) sont créées et enregistrées. Les fichiers sont recopiés d'un ordinateur à l'autre au fur et à mesure que les anciennes technologies de stockage deviennent dépassées. En outre, depuis 2010, tous les RFC sont imprimés sur du papier, pour avoir « ceinture et bretelles ». Les RFC plus anciens que 2010 subissent également parfois ce traitement, mais il existe des trous (RFC perdus, ou, tout simplement, problèmes avec le droit d'auteur, avant que cette question ne soit explicitement traitée, cf. RFC 8179).
Cette copie papier s'est avérée utile au moins une fois, quand 800 RFC ont dû être été re-saisis à la main, suite à une panne informatique (et une insuffisance des sauvegardes). Un petit détail amusant au passage : le RFC Editor à une époque acceptait des documents qui n'étaient pas des RFC, et qu'il faut aussi sauvegarder, voir l'histoire antique des RFC.
Il n'y a pas actuellement de sauvegarde de l'environnement logiciel utilisé pour lire les RFC, l'idée est que cela n'est pas nécessaire : on pourra toujours lire du texte brut en ASCII dans cent ans (la preuve est qu'on n'a pas de mal à relire le RFC 1, vieux de quarante-huit ans). Le processus de sauvegarde préserve les bits, et on considère que la préservation du contenu ne pose pas de problème, avec un format aussi simple. (Par exemple, l'impression sur le papier ne garde pas les hyperliens mais ce n'est pas un problème puiqu'il n'y en a pas dans le format texte brut.)
Mais, puisque les RFC vont bientôt quitter ce format traditionnel et migrer vers un format plus riche, il faut reconsidérer la question. La section 2 de notre RFC explore en détail les conséquences de cette migration sur chaque étape du cycle de vie. Il faut désormais se pencher sur la préservation des contenus, pas seulement des bits.
Certaines caractéristiques du cycle de vie des RFC facilitent l'archivage. Ainsi, les RFC sont immuables. Même en cas d'erreur dans un RFC, il n'y a jamais de changement (au maximum, on publie un nouveau RFC, comme cela avait été fait pour le RFC 7396). Il n'y a donc pas à sauvegarder des versions successives. D'autres caractéristiques du cycle de vie des RFC compliquent l'archivage. Ainsi, ce n'est pas le RFC Editor qui décide d'approuver ou pas un RFC (RFC 5741). Il n'a donc pas le pouvoir de refuser un document selon ses critères à lui.
Le RFC Editor maintient une base de données (qui n'est pas
directement accessible de l'extérieur) des RFC, avec évidemment
les métadonnées associées (état, auteurs,
date, DOI, liens vers les éventuels errata
puisqu'on ne corrige jamais un RFC, etc). Les pages
d'information sur les RFC sont automatiquement tirées de cette
base (par exemple https://www.rfc-editor.org/info/rfc8153
Les RFC citent, dans la bibliographie à la fin, des références
dont certaines sont normatives (nécessaires pour comprendre le
RFC, les autres étant juste « pour en savoir plus »). Idéalement,
les documents ainsi référencés devraient également être archivés
(s'ils ne sont pas eux-même des RFC)
mais ce n'est pas le cas. Notre RFC suggère que l'utilisation de
Perma.cc serait peut-être une
bonne solution. C'est un mécanisme d'archivage des données
extérieures, maintenu par groupe de bibliothèques juridiques de
diverses universités. Pour un exemple, voici la sauvegarde Perma.cc
(https://perma.cc/E7QG-TG98) de mon article sur le hackathon de l'IETF.
Dans un processus d'archivage, une étape importante est la normalisation, qui va supprimer les détails considérés comme non pertinents. Elle va permettre la préservation du contenu, en évitant de garder des variantes qui ne font que compliquer la tâche des logiciels. Par exemple, bien que XML permette d'utiliser le jeu de caractères de son choix (en l'indiquant dans la déclaration, tout au début), une bonne normalisation va tout passer en UTF-8, simplifiant la tâche du programmeur qui devra un jour, écrire ou maintenir un logiciel de lecture du XML lorsque ce format sera à moitié oublié.
Or, au cours de l'histoire des RFC, le RFC Editor a reçu plein de formats différents, y compris des RFC uniquement sur papier. Aujourd'hui, il y a au moins le format texte brut, et parfois d'autres.
Maintenant qu'il existe un format canonique officiel (celui du RFC 7991), quelles solutions pour assurer la préservation du contenu ?
- Best effort, préserver les bits et espérer (ou compter sur les émulateurs, ce qui se fait beaucoup dans le monde du jeu vidéo vintage),
- Préserver un format conçu pour l'archivage (PDF/A-3 étant un candidat évident - voir le RFC 7995, d'autant plus que le XML original peut être embarqué dans le document PDF),
- Préserver le XML et tous les outils, production, test, visualisation, etc. (Ce que les mathématiciens ou les programmeurs en langages fonctionnels appeleraient une fermeture.)
La première solution, celle qui est utilisée aujourd'hui, n'est plus réaliste depuis le passage au nouveau format. Elle doit être abandonnée. La deuxième solution sauvegarde l'information dans le document, mais pas le document lui-même (et c'est embêtant que le format archivé ne soit pas le format canonique, mais uniquement un des rendus). Et l'avenir de PDF/A-3 est incertain, on n'a pas encore essayé de le lire trente ans après, et les promesses du marketing doivent être considérées avec prudence (d'autant plus qu'il y a toujours peu d'outils PDF/A, par exemple aucun logiciel pour vérifier qu'un document PDF est bien conforme à ce profil restrictif). Pour la troisième solution, cela permettrait de refaire un rendu des RFC de temps en temps, adapté aux outils qui seront modernes à ce moment. Mais c'est aussi la solution la plus chère. Si on imagine un futur où XML, HTML et PDF sont des lointains souvenirs du passé, on imagine ce que cela serait d'avoir préservé un environnement d'exécution complet, les navigateurs, les bibliothèques dont ils dépendent, le système d'exploitation et même le matériel sur lequel il tourne !
Une solution plus légère serait de faire (par exemple tous les ans) un tour d'horizon des techniques existantes et de voir s'il est encore possible, et facile, de visualiser les RFC archivés. Si ce n'est pas le cas, on pourra alors se lancer dans la tâche de regénérer des versions lisibles.
Au passage, il existe déjà des logiciels qui peuvent faciliter certains de ces activités (le RFC cite le logiciel libre de gestion d'archives ArchiveMatica).
Après cette analyse, la section 3 de notre RFC va aux recommandations : l'idée est de sauvegarder le format canonique (XML), un fichier PDF/A-3, le futur outil xml2rfc et au moins deux lecteurs PDF (qui doivent être capables d'extraire le XML embarqué). Les tâches immédiates sont donc :
- Produire les PDF/A-3 (à l'heure de la publication de ce RFC, l'outil n'est pas encore développé) avec le XML à l'intérieur, et l'archiver,
- Archiver le format canonique (texte seul pour les vieux RFC, XML pour les nouveaux),
- Archiver les versions majeures des outils, notamment xml2rfc,
- Archiver deux lecteurs PDF,
- Avoir des partenariats avec différentes institutions compétentes pour assurer la sauvegarde des bits (c'est déjà le cas avec la bibliothèque nationale suédoise). Un guide d'évaluation de ce ces archives est ISO 16363.
La version papier, par contre, ne sera plus archivée.
Conclusion (section 4) : les RFC sont des documents importants, qui ont un intérêt pour les générations futures, et qui valent la peine qu'on fasse des efforts pour les préserver sur le long terme.
L'article seul
Icinga notifications to Mastodon
First publication of this article on 23 April 2017
I use Icinga to monitor my hosts and services. Notification of problems, with Icinga, is not hardwired in the software, it is delegated to an external program. So, if you know how to send a message from a program, you can use this for notifications. Here, I explain how I did to toot (send) my Icinga notifications to Mastodon.
Mastodon is the latest trendy social network: unlike Twitter, Facebook, Slack or Instagram, it is decentralized, and does not depend on a given corporation. There is an API to perform Mastodon functions. I'm too lazy to write my own program, so I rely on the madonctl, written in Go. Let's install it. (If you use Debian like me, do note it does not compile on Debian stable, you'll need unstable, or a backport.)
% go get github.com/McKael/madonctl
Then, if the directory where go get installs
the binaries is in your PATH, you can use the command:
% madonctl
madonctl is a CLI tool for the Mastodon REST API.
You can use a configuration file to store common options.
...
Now, let's configure it with the name of your Mastodon instance, the user name at this instance, and your password:
% mkdir -p ~/.config/madonctl % madonctl config dump -i MY_INSTANCE -L MY_MASTODON_NAME -P MY_PASSWORD > ~/.config/madonctl/madonctl.yaml
Let's test that we can toot (post a message):
% madonctl toot "Writing a blog article" - Status ID: 310679 From: bortzmeyer Timestamp: 2017-04-23 18:56:59.141 +0000 UTC Contents: Writing a blog article URL: https://mastodon.gougere.fr/@bortzmeyer/310679
OK, now that the command-line tool works, let's configure
Icinga. First, decide if you want your Icinga notifications to be
public or not. In the first case, you'll simply send them without
anything specific, like I did with the test toot above. In the
second case, you'll probably use Mastodon "direct" option, as I
do. Your toots will be only visible to you. Let's start with the
users.conf file to configure the account that
will receive the notification toots:
object User "icingaadmin" {
...
email = "ME@MY.EMAIL.SITE"
vars.mastodon = "MY_MASTODON_NAME"
}
I would have preferred to name the variable simply
mastodon but Icinga does not let me create a
new attribute for users (one of the annoying things with Icinga is
to find out if a custom attribute is allowed or not; "it depends";
and it's not well documented.) So, I use the
vars dictionary.
Now, let's create the notification command itself. Based on
Icinga's email notification script, it will be a simple
shell script wrapper
around
madonctl. /mastodon-host-notification.sh will
be:
#!/bin/sh export HOME=/var/lib/nagios template=$(cat <<TEMPLATE @$USERMASTODON Icinga $NOTIFICATIONTYPE - $HOSTDISPLAYNAME is $HOSTSTATE Notification Type: $NOTIFICATIONTYPE Host: $HOSTALIAS Address: $HOSTADDRESS State: $HOSTSTATE Date/Time: $LONGDATETIME Additional Info: $HOSTOUTPUT Comment: [$NOTIFICATIONAUTHORNAME] $NOTIFICATIONCOMMENT TEMPLATE ) /usr/share/gocode/bin/madonctl toot --visibility direct $(/usr/bin/printf "%b" "$template")
And mastodon-service-notification.sh will be
almost identical:
#!/bin/sh export HOME=/var/lib/nagios template=$(cat <<TEMPLATE @$USERMASTODON Icinga $NOTIFICATIONTYPE - $HOSTDISPLAYNAME $SERVICEDISPLAYNAME is $SERVICESTATE Notification Type: $NOTIFICATIONTYPE Service: $SERVICEDESC Host: $HOSTALIAS Address: $HOSTADDRESS State: $SERVICESTATE Date/Time: $LONGDATETIME Additional Info: $SERVICEOUTPUT Comment: [$NOTIFICATIONAUTHORNAME] $NOTIFICATIONCOMMENT TEMPLATE ) /usr/share/gocode/bin/madonctl toot --visibility direct $(/usr/bin/printf "%b" "$template")
(And if you don't know the printf command, it's time to learn.)
Now, let's declare this notification command to Icinga, in
commands.conf:
object NotificationCommand "mastodon-host-notification" {
command = [ SysconfDir + "/icinga2/scripts/mastodon-host-notification.sh" ]
env = {
NOTIFICATIONTYPE = "$notification.type$"
HOSTALIAS = "$host.display_name$"
HOSTADDRESS = "$address$"
HOSTSTATE = "$host.state$"
LONGDATETIME = "$icinga.long_date_time$"
HOSTOUTPUT = "$host.output$"
NOTIFICATIONAUTHORNAME = "$notification.author$"
NOTIFICATIONCOMMENT = "$notification.comment$"
HOSTDISPLAYNAME = "$host.display_name$"
USERMASTODON = "$user.vars.mastodon$"
}
}
object NotificationCommand "mastodon-service-notification" {
command = [ SysconfDir + "/icinga2/scripts/mastodon-service-notification.sh" ]
env = {
NOTIFICATIONTYPE = "$notification.type$"
HOSTALIAS = "$host.display_name$"
HOSTADDRESS = "$address$"
SERVICESTATE = "$service.state$"
LONGDATETIME = "$icinga.long_date_time$"
SERVICEOUTPUT = "$service.output$"
NOTIFICATIONAUTHORNAME = "$notification.author$"
NOTIFICATIONCOMMENT = "$notification.comment$"
SERVICEDISPLAYNAME = "$service.display_name$"
USERMASTODON = "$user.vars.mastodon$"
}
}
We reference the scripts we just wrote. Note two things:
- The environment variable
USERMASTODONderives fromuser.vars.mastodon, not justuser.mastodon, becausemastodonis not a built-in attribute, - And we do not define the environment variable
HOMEin theenvarray above, since it seems ignored. Instead, we define it in the scripts (export HOME=/var/lib/nagios). Otherwise, madonctl cannot find the configuration file and complains "no instance provided".
Now, let's configure the notifications themselves, in
notifications.conf:
apply Notification "mastodon-icingaadmin" to Host {
import "mastodon-host-notification"
user_groups = host.vars.notification.mastodon.groups
users = host.vars.notification.mastodon.users
assign where host.vars.notification.mastodon
}
apply Notification "mastodon-icingaadmin" to Service {
import "mastodon-service-notification"
user_groups = host.vars.notification.mastodon.groups
users = host.vars.notification.mastodon.users
assign where host.vars.notification.mastodon
}
We can now define the required variables for each host we're
interested in, or in a general template if we want to be "tooted"
for all our hosts. In templates.conf:
template Host "generic-host" {
...
vars.notification["mastodon"] = {
groups = [ "icingaadmins" ]
}
}
And that's all. Restart Icinga and wait for the next problem to be "tooted". If you're impatient, break a host or a service to see what happens or, better, use the explicit notification function of Icinga (in the panel for a Host or a Service, near the top). You can see online an example of notification.
L'article seul
RFC 8145: Signaling Trust Anchor Knowledge in DNS Security Extensions (DNSSEC)
Date de publication du RFC : Avril 2017
Auteur(s) du RFC : D. Wessels (Verisign), W. Kumari
(Google), P. Hoffman (ICANN)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 19 avril 2017
L'utilisation de DNSSEC implique que le résolveur DNS ait une ou plusieurs clés de départ de la validation (trust anchors). Typiquement, le résolveur aura une clé pour la racine, les autres domaines étant validés en suivant l'arborescence du DNS (cela se configure, même si la plupart des résolveurs viennent avec une pré-configuration pour la clé ICANN de la racine). Seulement, parfois, les clés changent et le gérant d'un domaine aimerait bien savoir, avant de supprimer l'ancienne clé, si les résolveurs ont bien tous reçu la nouvelle. D'où cette nouvelle option EDNS où le résolveur signale au serveur faisant autorité la liste des clés qu'il utilise comme point de départ de la validation. (Le RFC décrit également une autre méthode, non fondée sur EDNS.)
En toute rigueur, il faut dire que le résolveur ne transmet pas les
clés mais les identificateurs courts (key tags
ou key IDs), qui sont un
condensat de 16 bits des clés (section 3.1.6 du RFC 4034, et notez dans l'annexe B du même RFC
que ce ne sont pas des condensats cryptographiques). On trouve cet
identificateur de clé si on utilise l'option
+multi de dig :
% dig +multi DNSKEY tf
...
;; ANSWER SECTION:
tf. 172800 IN DNSKEY 257 3 8 (
...
) ; KSK; alg = RSASHA256; key id = 12520
tf. 172574 IN DNSKEY 256 3 8 (
...
) ; ZSK; alg = RSASHA256; key id = 51793
...
tf. 172574 IN RRSIG DNSKEY 8 1 172800 (
20170524190422 20170325180422 12520 tf.
...
Il est utilisé pour la communication entre humains mais on le trouve aussi dans les enregistrements DS chez le parent :
% dig DS tf ... ;; ANSWER SECTION: tf. 86400 IN DS 12520 8 2 ( 2EC74274DD9AA7FFEA33E695EFF98F17F7C78ABD2D76 EDBBDE4EDD4630D68FA2 ) ...
Ainsi que dans les signatures :
% dig +dnssec SOA tf
...
;; ANSWER SECTION:
tf. 172800 IN SOA nsmaster.nic.fr. hostmaster.nic.fr. (
2222242731 ; serial
...
tf. 172800 IN RRSIG SOA 8 1 172800 (
20170531124004 20170401114004 51793 tf.
...
On voit ici que la clé de
.tf dans la racine est la 12520, qui signe la clé
51793, qui elle-même signe les enregistrements.
Si vous n'êtes pas parfaitement au point sur la terminologie DNSSEC, lisez la section 3 du RFC. Et, à titre d'exemple, voici la configuration d'un résolveur Unbound pour utiliser comme clés de départ de la validation celles de Yeti :
% cat /etc/unbound/unbound.conf
...
server:
...
auto-trust-anchor-file: "/var/lib/unbound/yeti.key"
...
% cat /var/lib/unbound/yeti.key
. 86400 IN DNSKEY 257 3 8 AwE...8uk= ;{id = 59302 (ksk), size = 2048b} ;;state=1 [ ADDPEND ] ;;count=67 ;;lastchange=1488474089 ;;Thu Mar 2 18:01:29 2017
. 86400 IN DNSKEY 257 3 8 AwE...y0U= ;{id = 19444 (ksk), size = 2048b} ;;state=2 [ VALID ] ;;count=0 ;;lastchange=1472139347 ;;Thu Aug 25 17:35:47 2016
On voit deux clés, d'identificateurs 59302 et 19444. Tout contenu signé avec une de ces deux clés sera accepté. (Le fait qu'il y ait deux clés alors qu'une suffirait est dû au fait qu'un changement est en cours, suivant le RFC 5011.)
Voyons maintenant la première façon de signaler ses clés dont
dispose un résolveur, la méthode EDNS
(section 4 de notre RFC, et voir le RFC 6891, pour les détails sur ce qu'est EDNS). On utilise
une nouvelle option EDNS, edns-key-tag
(code 14 dans le
registre IANA). Comme toutes les options EDNS, elle
comprend le code (14), la longueur, puis une suite
d'identificateurs de clés. Par exemple, le résolveur Unbound
montré plus haut enverrait une option {14, 4, 59302, 19444}
(longueur quatre
car il y a deux identificateurs, de deux octets chacun). Il est
recommandé d'utiliser cette option pour toutes les requêtes de
type DNSKEY (et jamais pour les autres).
Notez que le serveur qui reçoit une requête avec cette option n'a rien à faire : elle est juste là pour l'informer, la réponse n'est pas modifiée. S'il le souhaite, le serveur peut enregistrer les valeurs, permettant à son administrateur de voir, par exemple, si une nouvelle clé est largement distribuée (avant de supprimer l'ancienne).
La deuxième méthode de signalisation, celle utilisant le
QNAME (Query Name, le nom indiqué dans la
requête DNS) figure en section 5. La requête de signalisation
utilise le type NULL (valeur
numérique 10), et un nom de
domaine qui commence par « _ta- », suivi de la liste
des identificateurs en hexadécimal (dans cet article, ils
étaient toujours montré en décimal) séparés par des
traits. Le nom de la zone pour laquelle
s'applique ces clés est ajouté à la fin (la plupart du temps, ce
sera la racine, donc il n'y aura rien à ajouter). En reprenant
l'exemple du résolveur Unbound plus haut, la requête sera
_ta-4bf4-e7a6.. Comme ce nom n'existe pas,
la réponse sera certainement NXDOMAIN.
Le serveur utilise cette requête comme il utilise l'option EDNS : ne rien changer à la réponse qui est faite, éventuellement enregistrer les valeurs indiquées, pour pouvoir informer l'administrateur du serveur.
Voilà, comme vous voyez, c'est tout simple. Reste quelques petites questions de sécurité (section 7) et de vie privée (section 8). Pour la sécurité, comme, par défaut, les requêtes DNS passent en clair (RFC 7626), un écoutant indiscret pourra savoir quelles clés utilise un résolveur. Outre que cela peut permettre, par exemple, de trouver un résolveur ayant gardé les vieilles clés, la liste peut révéler d'autres informations, par exemple sur le logiciel utilisé (selon la façon dont il met en œuvre le RFC 5011). C'est donc un problème de vie privée également.
Notez aussi que le client peut mentir, en mettant de fausses valeurs. Par exemple, il pourrait envoyer de faux messages, avec une adresse IP source usurpée, pour faire croire que beaucoup de clients ont encore l'ancienne clé, de façon à retarder un remplacement.
(Au passage, si vous voulez des informations sur le remplacement des clés DNSSEC de la racine, voyez la page de l'ICANN, et la première expérimentation Yeti ainsi que la deuxième.)
Notez que le mécanisme utilisé a beaucoup varié au cours du développement de ce RFC (section 1.1, sur l'histoire). Au début, il n'y avait que l'option EDNS, en copiant sur le mécanisme du RFC 6975. Mais EDNS a quelques limites :
- Il n'est pas de bout en bout : si une requête passe par plusieurs résolveurs, les options EDNS ne sont pas forcément transmises,
- Il y a toujours le problème des stupides et bogués boitiers intermédiaires, qui bloquent parfois les paquets ayant une option EDNS qu'ils ne connaissent pas,
- Comme l'option n'est pas forcément envoyée à chaque requête DNS, un résolveur pourrait avoir besoin de mémoriser les valeurs envoyées par ses clients, afin de les transmettre, ce qui l'obligerait à garder davantage d'état.
L'approche concurrente, avec le QNAME, a aussi ses inconvénients :
- Elle ne permet pas de distinguer les clés connues du client, de celles connues par le client du client (si plusieurs résolveurs sont chaînés, via le mécanisme forwarder),
- Elle nécessite deux requêtes, une avec la demande normale, une avec le QNAME spécial : en cas de répartition de charge entre serveurs, par exemple avec l'anycast, ces deux requêtes peuvent même aboutir sur des serveurs différents,
- Enfin la requête avec le QNAME spécial peut ne pas être transmise du tout, en cas de mise en mémoire énergique des réponses négatives par un résolveur intermédiaire (cf. RFC 8020 and RFC 8198).
D'où le choix (chaudement discuté) de fournir les deux méthodes.
À l'heure actuelle, je ne connais qu'une seule mise en œuvre de ce RFC, introduite dans BIND 9.10.5 rc1 (« named now provides feedback to the owners of zones which have trust anchors configured by sending a daily query which encodes the keyids of the configured trust anchors for the zone. This is controlled by trust-anchor-telemetry »).
L'article seul
Premier essai (raté) de raccordement à la Fibre
Première rédaction de cet article le 18 avril 2017
Dernière mise à jour le 19 avril 2017
Comme tout le monde, je voudrais un accès au Très Haut Débit de la Mort qui Tue, grâce à la fibre optique (en fait, c'est plus la meilleure latence qui m'intéresse, mais la publicité ne rentre pas dans ces subtilités). Il y a quelques années, j'ai donc rempli le formulaire en ligne auprès de mon opérateur pour avoir accès à cette merveilleuse technologie. J'ai finalement eu un rendez-vous le 18 avril pour l'arrivée de la fibre chez moi. Mais ça n'a pas marché pas du premier coup.
D'abord, les faits. J'habite en « zone très dense », à
Paris, et je suis donc a priori du bon côté
de la fracture numérique. Il y a longtemps que je regarde avec envie
la fibre qui est dans le garage au sous-sol : 
Mais la faire monter dans les étages, et arriver dans les appartements, c'est autre chose. Ce sont les derniers mètres les plus durs. Les deux techniciens envoyés par Free sont arrivés à l'heure, mais sans reconnaissance préalable. Comme à chaque installation de fibre (d'après tous les témoignages que j'ai vu), ils découvrent le terrain à leur arrivée. Ils ont démonté la prise téléphonique, parce qu'il parait qu'elle abritait un fourreau (un tuyau en plastique) où glisserait la fibre. Sauf que… pas de fourreau visible. Même chose dans la prise libre à côté. Et dans la prise du câble, pas la place de faire glisser la fibre (et, apparemment, pas le droit d'arracher ce câble, qui ne sert pourtant à rien).
Problème : la fibre arrive bien sur le palier, mais comment la faire rentrer dans l'appartement s'il n'y a aucun fourreau qui arrive jusqu'aux prises ? Une solution évidente est de percer le mur et de faire une fibre à l'air, collée au mur pour gagner les prises. Outre le problème esthétique, cela impose de percer un mur qui ne m'appartient pas, puisqu'il fait l'interface avec les parties communes de l'immeuble. On va demander à la gardienne, qui explique que la société qui gère l'immeuble refuse absolument qu'on fasse cela, puisqu'il y a des fourreaux (soupir…). (Sur Mastodon, on m'a suggéré de percer sans demander l'autorisation, en espérant que cela ne se voit pas trop, mais une telle malhonnêté révulse ma conscience de citoyen.)
Bref, les techniciens repartent sans avoir pu résoudre le problème. Pas de fibre pour aujourd'hui.
Pourquoi est-ce si compliqué ? L'une des raisons est la multiplicité des acteurs (ah, les merveilles de la concurrence…) Il y a la propriétaire (la mairie), la société de gestion, le locataire (moi), le FAI (Free), la société qui fait les installations… Ces acteurs ne communiquent pas, et résoudre un problème prend donc beaucoup de temps, d'autant plus qu'il n'est pas facile de trouver un interlocuteur (j'avais demandé à Free si je pouvais parler avec les techniciens avant qu'ils viennent, pour discuter de deux ou trois problèmes que j'avais identifiés, mais ce n'est apparemment pas possible).
Ensuite, les documentations qu'on peut trouver en ligne semblent toutes faites pour un cas unique (on est propriétaire), qui n'est pas le mien (« vous devez soulever le problème en assemblée générale des copropriétaires »).
Bref, on est loin des discours. La connexion généralisée à la fibre optique fait partie des « grands sujets » sur lesquels on fait de nombreux colloques, des « Plan France Très Très Vraiment Très Haut Débit 2010-2020 », d'innombrables rapports, des promesses électorales (« je lancerai un plan fibre ambitieux doté de N millions de brouzoufs, pourqu'aucun de nos compatriotes ne reste tristement relié à l'ADSL ») et des déclarations ministérielles. Mais les problèmes concrets du terrain de base semblent largement ignorés.
Je ne suis pas le seul à avoir expérimenté des problèmes bêtes et pratiques lors de la pose de la fibre, voir l'excellent récit de Guigui ou bien celui de Tom.
Prochaine étape pour moi : appeler la société gestionnaire de l'immeuble, essayer d'y trouver quelqu'un qui comprenne mes questions, et demander pourquoi il n'y a pas de fourreaux, est-ce qu'on peut en faire poser, ou bien est-ce qu'on peut percer le mur sinon ?
Mise à jour : depuis la première parution de cet article, j'ai reçu d'innombrables conseils, notamment sur les réseaux sociaux. merci à tou·te·s pour les dits conseils, que je crois pouvoir classer en deux catégories. La première, ce sont les variantes autour de « on s'en fout des autorisations, perce, personne ne s'en apercevra et, s'ils râlent, envoie-les promener ». C'est radical, mais, outre l'aspect moral (violer les règles, c'est vilain, c'est comme télécharger du Johnny Hallyday sans l'autorisation des ayant-tous-les-droits), c'est risqué : un accident pendant l'opération et on a des ennuis.
Deuxième catégorie de conseils, les conseils techniques (« tirer le câble coaxial pour tirer une aiguille, et après se servir de cette aiguille pour retirer le câble et la fibre » ou bien « fais rentrer la fibre par le fourreau dans les parties communes, pousse-le et essaie de voir par où elle sort »). Ces conseils sont certainement très pertinents mais ils me font poser une question : pour avoir le Très Haut Débit de la Fibre chez soi, faut-il donc être à la fois juriste, entrepreneur en bâtiment, diplomate, et très bricoleur ? Le citoyen ordinaire qui ne sait pas faire grand'chose n'a-t-il pas droit lui aussi à la fibre ?
PS : j'ai finalement eu la fibre onze mois après.
L'article seul
Hackathon de l'IETF
Première rédaction de cet article le 29 mars 2017
Bon, les hackathons, c'est un sujet banal, la majorité (la totalité ?) de mes lect·eur·rice·s ont déjà participé à un hackathon mais, pour moi, c'était la première fois. Donc, en mode « Stéphane découvre les hackathons après tout le monde », voici celui de l'IETF qui s'est tenu les 25 et 26 mars à Chicago.
Le concept est à la mode, c'est sûr, mais il est aussi extrêmement galvaudé. Toute startup, tout gouvernement, toute organisation de powerpointeurs se doit aujourd'hui d'avoir son hackathon. La plupart du temps, il s'agit juste de vagues rassemblements qui commencent à 10 h, s'interrompent de 12 à 14 h, et se terminent par des pitches à 16 h. Il s'agit davantage de séances de remue-méninges, voire de purs évenements de communication, que de vrais hackathons.
Mais, alors, c'est quoi, un « vrai » hackathon ? C'est avant tout un rassemblement où on produit quelque chose. Pas forcément des programmes, mais c'est souvent le cas, puisque le concept vient du monde de l'informatique. Le hackathon, pour moi, c'est une occasion où on parle, certes, on échange, mais il y a un but concret, à la fin, on a quelque chose qui tourne. Et comme le vrai travail prend du temps, un hackathon ne peut pas se dérouler en seulement quelques heures.
Et celui de l'IETF, c'est un « vrai » ? La tâche principale de l'IETF n'est pas de développer des programmes, c'est d'écrire des normes. Certes, l'IETF a toujours tiré fierté de son caractère concret, de l'importance donnée au « running code », au code qui marche. Mais la production de logiciels n'était pas une activité organisée de l'IETF. C'est seulement en 2015, à la réunion de Dallas, que l'IETF a organisé un hackathon, le week-end précédent la réunion. Ce n'est donc pas une vieille tradition.
On travaille sur quoi, à un hackathon IETF ? L'idée est évidemment de travailler sur les techniques IETF, donc toute la famille TCP/IP. Mais la priorité est surtout donnée aux normes en cours de développement : une mise en œuvre précoce peut aider à détecter des problèmes dans la spécification, apprécier son réalisme, avoir une idée des performances. La plupart des développeurs présents travaillaient donc sur des idées documentées dans un Internet-Draft.
Nous étions 14 équipes, chacune travaillant sur un sujet spécifique de
l'IETF. La liste des équipes est disponible
sur le Wiki du hackathon. J'étais dans l'équipe
DNS (évidemment,
vont dire certains). Globalement, c'est très libre, chacun
travaille sur ce qu'il veut, et si on veut que les autres vous
suivent, il faut les convaincre. Comme
pour tout bon hackathon, on avait une salle de
l'hôtel, du courant électrique, du Wifi, du café à volonté et de temps en temps
des repas qui apparaissaient magiquement (non, je rigole, c'est
Mozilla et Ericsson
qui payaient les repas). 
Chacun avait évidemment son ordinateur portable mais quelques uns
avaient du matériel plus spécialisé comme l'équipe
multicast :

À partir de là, chaque équipe a fait ses plans (voici le projet
CAPPORT, le groupe de travail IETF qui essaie de nous sauver de ces
affreux portails captifs, voir par exemple le
RFC 7710) :
J'ai beaucoup aimé le concept. C'est très sympa de
passer un week-end à ne faire que programmer et discuter
d'informatique. L'ambiance était bonne (je craignais un peu que ce
soit assez viriliste, tendance piscine d'une école parisienne à la mode, mais non). En prime, j'ai pu terminer
mon sujet.
Tout programme informatique moderne dépend d'autres programmes et
bibliothèques et,
souvent, les difficultés viennent de ces autres programmes qui ne font
pas ce qu'on veut. Il faut alors prévenir le développeur, attendre
qu'il réagisse. Ici, j'utilisais surtout la bibliothèque de programmes
getdns et le développeur,
Willem Toorop, était assis juste à côté de moi, je
pouvais donc lui demander des trucs (« ya pas moyen de récupérer le
certificat X.509 du pair, dans la struct renvoyée par un call
reporting ? ») et il le faisait tout de suite (« j'ai mis ton truc,
c'est dans la branche devel/, attention, j'ai pas testé »).
Allez, une image de nourriture, pour finir, pour montrer qu'on ne
mangeait pas que des pizzas : 
L'article seul
RFC 8073: Coordinating Attack Response at Internet Scale (CARIS) Workshop Report
Date de publication du RFC : Mars 2017
Auteur(s) du RFC : K. Moriarty (Dell EMC
Corporation), M. Ford (Internet
Society)
Pour information
Première rédaction de cet article le 29 mars 2017
Ce nouveau RFC fait le bilan de l'atelier CARIS (Coordinating Attack Response at Internet Scale) qui s'est tenu à Berlin le 18 juin 2015. Cet atelier avait pour but d'explorer les problèmes de coordination entre les victimes et témoins d'une attaque portant sur l'Internet. Ce RFC est un compte-rendu, les positions exprimées ne sont pas forcément celles de l'IAB ou de l'Internet Society (organisateurs de l'atelier). D'autant plus que les participants ont mis les pieds dans le plat, expliquant très bien pourquoi il n'y a toujours pas de coordination globale des acteurs de l'Internet face aux attaques. (Un deuxième atelier sur ce thème a eu lieu en 2019, et son compte-rendu figure dans le RFC 8953.)
L'atelier avait été organisé pour que les participants à la réunion FIRST de Berlin puissent venir. Il rassemblait cinquante acteurs (c'était un atelier fermé, sur invitation seulement) de l'Internet, représentant une grande diversité d'organisations. La liste des participants figure dans l'annexe A du RFC. Chaque participant avait rempli un article de deux pages expliquant son point de vue et/ou les problèmes qu'il·elle souhaitait aborder. Tous ces documents sont disponibles en ligne (je vous encourage à les lire). Dans le reste du RFC, n'attendez pas d'attribution de tel discours à tel participant, l'atelier était tenu sous la règle de Chatham House, pour que les discussions restent libre.
L'atelier a vu cinq sessions (cf. section 2 du RFC) autour de ce thème des attaques, et de la coordination pour y faire face :
- Coordination entre les CSIRT, et avec ceux qui combattent directement l'attaque,
- Répondre aux dDoS et aux botnets, avec passage à l'échelle pour les attaques de grande ampleur que nous voyons aujourd'hui,
- Infrastructure de l'Internet, notamment les acteurs du DNS, et les RIR,
- Problèmes de confiance et de confidentialité dans les échanges entre acteurs de l'Internet (un très gros sujet lors de l'atelier),
- Conséquences des attaques sur l'architecture de l'Internet, et sur ses futures évolutions. (Peu de détails données dans le RFC sur cette dernière session.)
Parmi les organisations qui ont participé à la première session, on notait, entre autres :
- L'ENISA qui, quoiqu'elle fasse de la formation et de l'échange, n'a pas directement d'activité concernant les attaques pendant qu'elles se produisent (l'ENISA n'est pas « temps réel »).
- L'APWG, qui a un mécanisme d'échange entre acteurs (une clearing house).
- Le Ren-ISAC (si vous ne savez pas ce qu'est un ISAC, c'est le moment d'apprendre) qui sert de point de partage d'informations dans le monde académique états-unien. Cet organisme permet une mutualisation des efforts (bien des universités n'ont pas les moyens d'avoir une équipe à temps plein pour réagir aux attaques 24 heures sur 24).
- Le CERT brésilien, qui joue un rôle essentiel dans ce pays. Bien des pays, contrairement au Brésil, n'ont pas un CERT national mais plein de petits CERT limités à un groupe ou une entreprise.
Les principaux points mis en avant pendant cette session ont été :
- La surveillance de masse effectuée par les États a mis en danger les mécanismes de coordination, en réduisant la confiance. On note qu'au contraire de tant de colloques bavards et convenus sur la cybersécurité, l'atelier CARIS n'a pas pratiqué la langue de bois. Au lieu de répéter en boucle que la cybersécurité était importante, qu'elle reposait sur l'échange et la coordination, les participants ont directement pointé les vrais problèmes : les acteurs n'ont pas confiance dans l'État, et pour des très bonnes raisons, ce qui diminue l'éfficacité du travail en commun.
- Les tentatives des certains États d'encourager le partage d'informations (par exemple via une agence nationale) n'ont pas été des succès.
- Tout le monde veut que les autres partagent de l'information mais personne ne veut en donner. Ici encore, l'atelier pointe un problème que tout le monde connait, mais dont on ne parlait pas publiquement.
- Outre les simples problèmes d'ego, le partage d'informations est handicapé par les craintes des organisations pour leur réputation : si on dit la vérité sur une attaque qu'on n'a pas bien paré, on va paraitre faible.
- Les barrières de langue sont un gros problème. (Le RFC ne le dit pas, mais tout le monde pense aux immenses difficultés de communication avec les acteurs chinois. Des listes de diffusion comme celles de NANOG sont pleines de remarques amères « j'ai signalé le problème au FAI chinois et il n'a rien fait », sans que leur auteur se demande comment lui réagirait s'il recevait un rapport d'attaque écrit en mandarin. Contrairement à ce que pourrait laisser croire un certain discours globaliste, tout le monde ne parle pas anglais. Sans compter les problèmes culturels, encore plus difficiles.)
- Les règles de protection de la vie privée (comme le réglement européen sur la protection des données personnelles) peuvent gêner l'échange d'information (on n'envoie pas un fichier contenant des adresses IP aux USA). (Derrière cette remarque, on peut lire l'agacement des États-Unis - qui eux-même n'envoient pas de données - face aux lois européennes plus protectrices, mais aussi le regret des professionnels de la lutte contre les attaques informatiques, face à des lois prévues pour traiter d'autres problèmes que les leurs.)
Deuxième session, sur les mesures de lutte contre les dDoS et les botnets, notamment sur la question du passage à l'échelle de ces efforts. Les points essentiels abordé furent :
- Les mesures prises jusqu'à présent ont été plutôt efficaces. (C'était avant l'attaque contre Dyn, et le RFC ne mentionne pas le fait que la plupart de ces « mesures efficaces » ne sont accessibles qu'aux gros acteurs, ou à leurs clients, et que le petit hébergeur reste aussi vulnérable qu'avant.)
- La tension entre les réactions à court terme (stopper l'attaque en cours) et les exigences du long terme (éradiquer réellement le botnet, ce qui implique de le laisser « travailler » un certain temps pour l'étudier) reste entière. Sans compter, là aussi, le manque d'échanges entre pompiers de la lutte anti-dDoS et chasseurs de botnets.
- Il existe des groupes où règne une certaine confiance mutuelle comme le peu documenté CRAG.
- Trier le trafic entrant, puis le filtrer, est un problème soluble. (Je note personnellement que, pour l'instant, les seules solutions sont des boîtes noires fermées. Un problème pour les gens attachés à la liberté.)
- Il existe un groupe de travail IETF nommé DOTS qui travaille sur des mécanismes techniques facilitant l'échange de données pendant une attaque. Un effort précédant de l'IETF avait mené au RFC 6545. Les deux solutions sont conceptuellement proches mais DOTS est plus récent, devrait utiliser des techniques modernes et semble avoir davantage de soutiens de la part des acteurs.
- Il existe une certaine dose de confiance dans le milieu mais pas complète. On ne peut pas toujours faire confiance aux informations reçues. À cette session également, le problème des services d'espionnage étatiques a été mentionné, comme une grosse menace contre la confiance.
- La question brûlante des « arrêts automatiques » (automated takedowns) a été mentionnée. Certains cow-boys voudraient, compte-tenu de la rapidité des phénomènes en jeu, que certaines décisions puissent être automatiques, sans intervention humaine. Par exemple, un nom de domaine est utilisé pour une attaque « random QNAMEs », l'attaque est analysée automatiquement, signalée au registre et paf, le nom de domaine est supprimé. Inutile de dire que l'idée est très controversée.
Ensuite, troisième session, consacrée aux organisations de l'infrastructure DNS (par exemple les registres) et aux RIR. Les points étudiés :
- L'utilisation du passive DNS (par exemple DNSDB) pour analyser certaines attaques.
- Les données que détiennent les RIR, en raison de leur activité mais aussi suite à divers projets non directement liés à leur activité (comme l'observation des annonces BGP ou comme la gestion d'un serveur racine du DNS). Des participants ont regretté l'absence d'API standard pour accéder à ces données.
- Certains des RIR ont déjà une coordination active avec des organisations qui réagissent en cas d'attaques.
Quatrième session, les problèmes de confiance. Tout le monde est d'accord pour dire que c'est cool de partager les données, et que c'est indispensable pour lutter efficacement contre les attaques. Alors, pourquoi si peu d'organisations le font ? Il n'y a clairement pas une raison unique. C'est un mélange de crainte pour la vie privée, de contraintes juridiques, de problèmes techniques, de différences culturelles et de simples malentendus. Sans compter le pur égoïsme (« partager mes données avec nos concurrents ??? ») Enfin, il faut rappeler qu'il est impossible de s'assurer du devenir de données numériques : si on passe nos données à quelqu'un, pour aider pendant une attaque, que deviendront-elles après ? (Envoyer des données aux USA, c'est la certitude qu'elles seront vendues et revendues.) Le RFC note que tous les participants à l'atelier ont estimé que ces raisons étaient mauvaises ou, plus exactement, qu'on pouvait trouver des solutions. Les points précis discutés :
- La réputation est cruciale : il y a des gens à qui on envoie toutes les données qu'ils veulent et d'autres à qui on ne transmettra rien. (Sans la règle de Chatham House, on peut parier que personne n'aurait osé exprimer cette évidence pendant l'atelier.)
- L'utilisation du TLP (certains participants regrettent son manque de granularité, je pense personnellement que déjà trop de gens ont du mal avec ses quatre niveaux).
- Officielement, la confiance est entre organisations. En réalité, elle est entre individus (personne ne fait confiance à un machin corporate) et il faut donc développer des liens entre individus. En outre, la confiance est forcément limitée en taille : on ne fait confiance qu'à ceux qu'on connait et on ne peut pas connaître tout le monde. Comme le dit le RFC, « Social interaction (beer) is a common thread amongst sharing partners to build trust relationships ».
- Par analogie avec les marques déposées, certains se sont demandés s'il faudrait un mécanisme de labelisation de la confiance.
- Plusieurs participants ont remarqué que le travail réel ne se faisait pas dans les structures officielles, mais dans des groupes fondés sur des relations de confiance. (Le RFC utilise le terme classique des geeks pour parler de ces groupes : cabals.) Comme le dit le RFC pudiquement, « This was not disputed. » (autrement dit, tout le monde le savait bien mais ne le disait pas).
La section 4 du RFC concerne le « et maintenant ? ». Il y a eu un consensus sur la nécessité de la formation (au sens large). Par exemple, on trouve toujours des professionnels de l'Internet qui ne connaissent pas BCP 38. Du travail pour les pédagogues (et les auteurs de blogs...)
Plus technique, la question des mécanismes techniques d'échange d'information a suscité des débats animés. Le RFC 6545 date de plus de dix ans. Il ne semble pas être universellement adopté, loin de là. Le groupe de travail DOTS fera-t-il mieux ? D'autres techniques ont été discutées comme TAXII ou XMPP-Grid. Ce dernier, fondé sur XMPP (RFC 6120) semble prometteur et est déjà largement mis en œuvre. Le groupe de travail nommé MILE a aussi un protocole nommé ROLIE (pas encore de RFC).
L'article seul
Developing a monitoring plugin for DNS-over-TLS at the IETF hackathon
First publication of this article on 27 March 2017
The weekend of 25-26 march 2017, I participated to the IETF 98 hackathon in Chicago. The project was to develop a monitoring plugin for the DNS-over-TLS privacy protocol, standardized in RFC 7858. This is a small documentation of the result and of the lessons learned.
A bit of background, first. "Monitoring Plugins" is project to develop and maintain an excellent suite of testing programs to be used by many monitoring software like Icinga. Using their API was an obvious choice, allowing the plugin to be used in many places. And DNS-over-TLS? It's a way to improve privacy of DNS users by encrypting the DNS traffic (see RFC 7626 for the privacy issues of the DNS). DNS-over-TLS is described in RFC 7858, published less than one year ago. DNS-over-TLS is implemented in many DNS servers (such as Unbound) and there are several public DNS-over-TLS resolvers. All of them are experimental, "best effort" services and thus some monitoring is a good idea, so we can be sure they actually work most of the time. Existing monitoring plugins like check_dig cannot run with TLS.
The IETF hackathon is intended for development of IETF-related techniques. A monitoring plugin for this DNS-over-TLS service is a good fit for a hackathon: hard enough to require some work, but small enough to be reasonably completed in one weekend.
I prepared for the hackathon by setting up a Github repository and exploring the various possibilities. I saw two alternatives:
- Use Go because it has both a nice DNS library and a good TLS standard package. On the other hand, I'm not sure that the Monitoring Plugins project accept plugins written in Go (I did not find precise rules about that). And the command line arguments parsing package of Go may make difficult to follow exactly the rules of the API.
- Use C with the getdns package, which can do DNS over TLS (and many other things). Because most monitoring plugins are written in C, there was a lot of code to start with.
I choosed C and getdns for two reasons, the availability of getdns developers at the hackathon (that's the good thing with hackathons, working with people who are at the same table), and the problem of retrieving the PKIX certificate. Why did I need this certificate? Because I wanted to test things that are TLS-specific, such as a nearby expiration, by far the most common problem with TLS servers.
Using Go and the godns library, it is easy to do a DNS-over-TLS
request with the Exchange() function. It is
easy because it hides everything from the programmer. But it is
also what makes it unsuitable for my purpose, it hides the TLS
details and provides no way to retrieve the certificate. A
possible solution would be to use godns only to create and parse
DNS messages and to call directly the Go network and TLS libraries
to send messages and receive responses. Then, I would have the
certificate in the conn object. Certainly
doable, but more work. So, I used C and getdns.
At first glance, it was not better, getdns does not give access to
the certificate of the TLS connection. But this is what makes
hackathons great: the developer of the library you use is in the
same room and you can ask him "Willem, could you add this cool
feature?", and a few minutes after, the feature is available in a
git development
branch. Basically, the new stuff uses the
return_call_reporting getdns extension:
getdns_dict_set_int(extensions, "return_call_reporting",
GETDNS_EXTENSION_TRUE);
and then you have a dictionary member
call_reporting in the answer:
getdns_list *report_list;
getdns_dict *report_dict;
getdns_dict_get_list(this_response, "call_reporting", &report_list);
getdns_list_get_dict(report_list, 0, &report_dict);
The dictionary in the report has now a new member,
tls_peer_cert (it will appear in getdns 1.1):
getdns_bindata *cert; getdns_dict_get_bindata(report_dict, "tls_peer_cert", &cert);
To parse this certficate (which is in DER format), I use GnuTLS:
gnutls_datum_t raw_cert;
time_t expiration_time;
struct tm *f_time;
raw_cert.size = cert->size;
raw_cert.data = malloc(cert->size);
memcpy(raw_cert.data, cert->data, cert->size);
gnutls_x509_crt_import(parsed_cert, &raw_cert, GNUTLS_X509_FMT_DER);
expiration_time = gnutls_x509_crt_get_expiration_time(parsed_cert);
strftime(msgbuf, 1000, "%Y-%m-%d", f_time);
printf("Expires on %s\n", msgbuf);
Now, I can test things like an incoming expiration of the certificate.
Another touchy issue was authentication. RFC 7858 allows to authenticate the server by a
pinned cryptographic key. (Another authentication methods
are under development at the IETF, see
draft-ietf-dprive-dtls-and-tls-profiles.)
That's another problem for Go, by the way: authentication is
inflexible, and done by the TLS library. For getdns, on the
contrary, is easy: just provide the pinned keys and getdns does
the necessary checks:
keys = getdns_pubkey_pin_create_from_string(this_context, raw_keys); getdns_list *keys_list = getdns_list_create(); getdns_list_set_dict(keys_list, 0, keys); getdns_dict_set_list(this_resolver, "tls_pubkey_pinset", keys_list);
and the result of the authentication is reported in the "call reporting" dictionary we already saw:
getdns_bindata *auth_status;
getdns_dict_get_bindata(report_dict, "tls_auth_status", &auth_status);
printf("Authentication is %s\n", auth_status->data);
Now, let's put it all together, compile and test from the command line (the arguments are the standard ones for the monitoring plugins, the servers are public servers):
% ./check-dns-with-getdns -H 2620:ff:c000:0:1::64:25 -n www.ietf.org GETDNS OK - 121 ms, expiration date 2027-08-25, auth. Failed: Address 2400:cb00:2048:1::6814:55 Address 2400:cb00:2048:1::6814:155 Address 104.20.0.85 Address 104.20.1.85 % echo $? 0
(We ask the return code of the command but this is what the monitoring software uses to find out whether everything is fine or not.) The authentication status was "Failed" because the server uses a self-signed certificate (otherwise, we would have obtained "None"). Here, we did not require authentication, so the global result is still OK. Should we provide the pinned key, it would be better:
% ./check-dns-with-getdns -H 2620:ff:c000:0:1::64:25 -n www.afnic.fr -k pin-sha256=\"pOXrpUt9kgPgbWxBFFcBTbRH2heo2wHwXp1fd4AEVXI=\" GETDNS OK - 1667 ms, expiration date 2027-08-25, auth. Success: Address 2001:67c:2218:30::24 Address 192.134.5.24 % echo $? 0
If the key is wrong, it fails:
% ./check-dns-with-getdns -H 2620:ff:c000:0:1::64:25 -n www.afnic.fr -a -k pin-sha256=\"pOXrpUt9kgPgbWxBFFcBTbRI2heo2wHwXp1fd4AEVXI=\" GETDNS CRITICAL - 123 ms, expiration date 2027-08-25, auth. Failed: Address 2001:67c:2218:30::24 Address 192.134.5.24
And if the key is wrong and we require
authentication (-r), we get a fatal error:
% ./check-dns-with-getdns -H 2620:ff:c000:0:1::64:25 -n www.afnic.fr -r -k pin-sha256=\"pOXrpUt9kgPgbWxBFFcBTbRI2heo2wHwXp1fd4AEVXI=\" GETDNS CRITICAL - Error Generic error (1) when resolving www.afnic.fr at 2620:ff:c000:0:1::64:25 % echo $? 2
And of course, if the server has no DNS-over-TLS or if the server is down, or access to port 853 blocked, we also get an error:
% ./check-dns-with-getdns -H 8.8.8.8 -n www.afnic.fr GETDNS CRITICAL - Error Generic error (1) when resolving www.afnic.fr at 8.8.8.8 % echo $? 2
(You can also appreciate the lack of details in error messages…)
By the way, how do you find the key of an existing server?
Simplest way is with the gnutls-cli program,
shipped with GnuTLS:
% gnutls-cli -p 853 2001:4b98:dc2:43:216:3eff:fea9:41a
...
pin-sha256:pAhhaG82hLpW/qXpEIuCknyIYM5iWnbMKsX12rSGm54=
(Yes, I know, it works only when you are not using Diffie-Hellman.)
Once it is tested, we can put it in a monitoring program. I choosed Icinga. The configuration is:
object CheckCommand "dns_with_getdns" {
command = [ PluginContribDir + "/check_dns_with_getdns" ]
arguments = {
"-H" = "$address$",
"-n" = "$dns_with_getdns_lookup$",
"-a" = "$dns_with_getdns_authenticate$",
"-e" = "$dns_with_getdns_accept_errors$",
"-r" = "$dns_with_getdns_require_auth$",
"-k" = "$dns_with_getdns_keys$",
"-C" = "$dns_with_getdns_certificate$"
}
}
apply Service "dns-tls" {
import "generic-service"
check_command = "dns_with_getdns"
assign where (host.address || host.address6) && host.vars.dns_over_tls
vars.dns_with_getdns_lookup = "www.ietf.org"
vars.dns_with_getdns_certificate = "7,3"
vars.dns_with_getdns_accept_errors = false
}
object Host "oarc-dns" {
import "generic-host"
address = "2620:ff:c000:0:1::64:25"
vars.dns_over_tls = true
vars.dns_with_getdns_authenticate = true
vars.dns_with_getdns_keys = "pin-sha256=\"pOXrpUt9kgPgbWxBFFcBTbRH2heo2wHwXp1fd4AEVXI=\""
}
Then we get the goal of every hackathon project: a screenshot  .
.
Later, this code was used in the nice Project dnsprivacy-monitoring, which monitors all the public DNS-over-TLS resolvers.
Now, I'm not sure if I'll have time to continue to work on this project. There are several TODO in the code, and an ambitious goal: turn it into a proper plugin suitable for inclusion on the official Monitoring Plugins project. Even better would be to have a generic DNS checker based on getdns, replacing the existing plugins which depend on external commands such as dig. If you want to work on it, the code is at Github.
Many thanks to Willem Toorop for a lot of help and getdns additions, to Francis Dupont for debugging a stupid C problem with GnuTLS (garbage data, unaligned access, all the pleasures of C programming), and to Sara Dickinson for help, inspiration and animation of the DNS team.
L'article seul
Le transit Internet est-il vraiment mort ?
Première rédaction de cet article le 21 mars 2017
À la réunion APRICOT / APNIC du 20 février au 2 mars, à Hô-Chi-Minh-Ville, Geoff Huston a fait un exposé remarqué, au titre provocateur, « The death of transit ». A-t-il raison de prédire la fin du transit Internet ? Et pourquoi est-ce une question importante ?
Deux petits mots de terminologie, d'abord, s'inscrivant dans l'histoire. L'Internet avait été conçu comme un réseau connectant des acteurs relativement égaux (par exemple, des universités), via une épine dorsale partagée (comme NSFnet). Avec le temps, plusieurs de ces épines dorsales sont apparues, l'accès depuis la maison, l'association ou la petite entreprise est devenu plus fréquent, et un modèle de séparation entre les FAI et les transitaires est apparu. Dans ce modèle, le client se connecte à un FAI. Mais comment est-ce que les FAI se connectent entre eux, pour que Alice puisse échanger avec Bob, bien qu'ils soient clients de FAI différents ? Il y a deux solutions, le peering et le transit. Le premier est l'échange de trafic (en général gratuitement et informellement) entre des pairs (donc plus ou moins de taille comparable), le second est l'achat de connectivité IP, depuis un FAI vers un transitaire. Ces transitaires forment donc (ou formaient) l'épine dorsale de l'Internet. Le modèle de l'Internet a été un immense succès, au grand dam des opérateurs téléphoniques traditionnels et des experts officiels qui avaient toujours proclamé que cela ne marcherait jamais.
Mais une autre évolution s'est produite. Les utilisateurs ne se connectent pas à l'Internet pour le plaisir de faire des ping et des traceroute, ils veulent communiquer, donc échanger (des textes, des images, des vidéos…) À l'origine, l'idée était que l'échange se ferait directement entre les utilisateurs, ou sinon entre des serveurs proches des utilisateurs (ceux de leur réseau local). Le trafic serait donc à peu près symétrique, dans un échange pair-à-pair. Mais les choses se ne passent pas toujours comme ça. Aujourd'hui, il est de plus en plus fréquent que les communications entre utilisateurs soient médiées (oui, ce verbe est dans le Wiktionnaire) par des grands opérateurs qui ne sont pas des opérateurs de télécommmunication, pas des transitaires, mais des « plate-formes » comme les GAFA (Google, Apple, Facebook, Amazon). La communication entre utilisateurs n'est plus pair-à-pair mais passe par un intermédiaire. (On peut parler d'un Minitel 2.0.)
Bon, mais quel rapport avec l'avenir de l'Internet ? Mes lect·eur·rice·s sont très cultivé·e·s et savent bien que le Web, ce n'est pas l'Internet, et que le fait que deux utilisateurs de Gmail passent par Gmail pour communiquer alors qu'ils sont à 100 mètres l'un de l'autre n'est pas une propriété de l'Internet. (Les ministres et la plupart des journalistes n'ont pas encore compris cela, mais ça viendra.) L'Internet continue à fonctionner comme avant et on peut toujours faire du BitTorrent, et se connecter en SSH avec un Raspberry Pi situé à l'autre bout de la planète. (Notez qu'il s'agit de l'Internet en général : dans la quasi-totalité des aéroports et des hôtels, de nombreux protocoles sont interdits. Et ces malhonnêtes osent prétendre qu'ils fournissent un « accès Internet ».)
C'est là qu'on en arrive à l'exposé de Huston. Il note d'abord que les sites Web qui ne sont pas déjà chez un GAFA sont souvent hébergés sur un CDN. Ensuite, il fait remarquer que les GAFA, comme les CDN, bâtissent de plus en plus leur propre interconnexion. À ses débuts, Google était une entreprise comme une autre, qui achetait sa connectivité Internet à un fournisseur. Aujourd'hui, Google pose ses propres fibres optiques (ou achète des lambdas) et peere avec les FAI : encore un peu et Google n'aura plus besoin de transit du tout. Si tous les GAFA et tous les CDN en font autant (et la plupart sont déjà bien engagés dans cette voie), que deviendra le transit ? Qui pourra encore gagner sa vie en en vendant ? Et si le transit disparait, l'architecture de l'Internet aura bien été modifiée, par l'action de la minitélisation du Web. (Je résume beaucoup, je vous invite à lire l'exposé de Huston vous-même, ainsi que son article sur des thèmes proches.)
Notez que Huston n'est pas le premier à pointer du doigt cette évolution. Plusieurs articles moins flamboyants l'avaient déjà fait, comme les déjà anciens « The flattening internet topology: natural evolution, unsightly barnacles or contrived collapse? » ou « Internet Inter-Domain Traffic ». Mais Huston réussit toujours mieux à capter l'attention et à résumer de manière percutante un problème complexe.
Alors, si Huston a raison, quelles seront les conséquences de la disparition du transit ? Huston note qu'une telle disparition pourrait rendre inutile le système d'adressage mondial (déjà très mal en point avec l'épuisement des adresses IPv4 et la prévalence du NAT), voire le système de nommage mondial que fournit le DNS. Le pair-à-pair, déjà diabolisé sur ordre de l'industrie du divertissement, pourrait devenir très difficile, voire impossible. Aujourd'hui, même si 95 % des utilisateurs ne se servaient que des GAFA, rien n'empêche les autres de faire ce qu'ils veulent en pair-à-pair. Demain, est-ce que ce sera toujours le cas ?
Mais est-ce que Huston a raison de prédire la mort du transit ? D'abord, je précise que je suis de ceux qui ne croient pas à la fatalité : ce sont les humains qui façonnent l'histoire et les choses peuvent changer. Décrire la réalité, c'est bien, mais il faut toujours se rappeler que c'est nous qui la faisons, cette réalité, et que nous pouvons changer. Essayons de voir si les choses ont déjà changé. Huston aime bien provoquer, pour réveiller son auditoire. Mais il faut bien distinguer l'apparence et la réalité.
Les observateurs légers croient que tout l'Internet est à leur image. Comme eux-même ne se servent que de Gmail et de Facebook, ils expliquent gravement en passant à la télé que l'Internet, c'est Google et Facebook. Mais c'est loin d'être la totalité des usages. Des tas d'autres usages sont présents, par exemple dans l'échange de données entre entreprises (y compris via d'innombrables types de VPN qui transportent leurs données… sur Internet), les SCADA, BitTorrent, la recherche scientifique et ses pétaoctets de données, les réseaux spécialisés comme LoRa, les chaînes de blocs, et ces usages ne passent pas par les GAFA.
Peut-on quantifier ces usages, pour dire par exemple, qu'ils sont « minoritaires » ou bien « un détail » ? Ce n'est pas facile car il faudrait se mettre d'accord sur une métrique. Si on prend le nombre d'octets, c'est évidemment la vidéo qui domine et, à cause du poids de YouTube, on peut arriver à la conclusion que seuls les GAFA comptent. Mais d'autres critères sont possibles, quoique plus difficiles à évaluer (le poids financier, par exemple : un message d'une entreprise à une autre pour un contrat de centaines de milliers d'euros pèse moins d'octets qu'une vidéo de chat, mais représente bien plus d'argent ; ou bien le critère de l'utilité sociale). Bref, les opérateurs de transit sont loin d'être inutiles. L'Internet n'est pas encore réduit à un Minitel (ou à une télévision, l'exemple que prend Huston qui, en bon Australien, ne connait pas ce fleuron de la technologie française.)
Merci à Antoine Fressancourt, Jérôme Nicolle, Pierre Beyssac, Raphaël Maunier, Olivier Perret, Clément Cavadore et Radu-Adrian Feurdean pour leurs remarques intéressantes. Aucune de ces conversations avec eux n'est passée par un GAFA.
L'article seul
Suite de mes aventures avec le routeur Turris Omnia
Première rédaction de cet article le 19 mars 2017
Dans un précédent article, j'ai parlé du routeur Turris Omnia et de ce qu'on peut faire avec. Ce deuxième article est un assortiment de diverses choses que j'ai faites depuis avec ce routeur.
Il est connecté à Free en ADSL. Plus exactement, l'ADSL arrive sur une Freebox Révolution, configurée en bridge, à laquelle est relié le Turris Omnia, qui est le vrai routeur. À l'origine, j'avais laissé le Freebox Player connecté au Freebox Server, ce qui faisait que la télévision classique et le téléphone marchaient comme avant. Mais comme je voulais regarder les chaînes de télévision depuis un PC, avec VLC et le protocole RTSP (RFC 7826), il fallait connecter le Freebox Player au routeur. Je me suis beaucoup inspiré de cet excellent article. Donc, ce qu'il fallait faire :
- Connecter le câble Ethernet entre le Turris et le Freebox Player (celui-ci n'a donc plus de câble vers le Freebox Server),
- Configurer le commutateur du Turris pour utiliser le VLAN 100, celui sur lequel Freebox Player et Server communiquent.
Attention en jouant avec la configuration du commutateur interne du Turris : une erreur et on se retrouve vite avec des tempêtes de diffusion, qui peuvent aller jusqu'à rendre le routeur inaccessible en Ethernet. J'ai aussi eu un cas amusant où la plupart des paquets étaient bien transmis, sauf ceux de diffusion, ce qui cassait des protocoles comme ARP ou DHCP. Deux conseils : vérifier que le Wi-Fi fonctionne, il peut servir de mécanisme de secours pour se connecter au Turris, si l'Ethernet devient inutilisable. Et bien relire sa configuration avant de la confirmer. Dans le pire des cas, il faudra perdre toute la configuration en remettant le routeur aux réglages d'usine (pensez à garder cette documentation avant de vous couper votre accès Internet !)
Vu du côté Unix, le Turris a plein d'interfaces
réseau. eth0 rassemble la plupart des ports
physiques du commutateur, eth2 étant le
CPU (et le port 4 du commutateur, voir
cette
discussion sur le forum). Voici d'ailleurs un schéma : 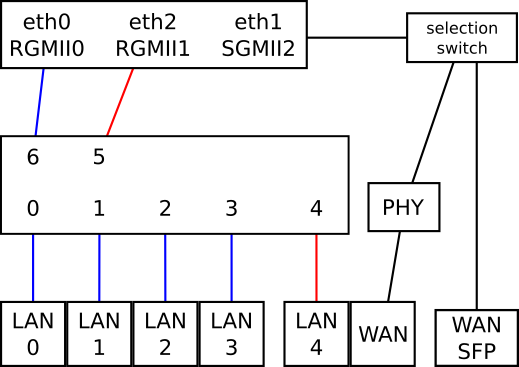
Ensuite,
des interfaces virtuelles regroupent plusieurs de ces
interfaces (sour l'interface LuCI, vous trouver cette
configuration en Network -> Interfaces, https://ROUTER/cgi-bin/luci/admin/network/network). Par
exemple, br-lan regroupe typiquement
eth0 et eth2. Et c'est
ainsi que les deux groupes communiquent (sur LuCI,
Network -> Interfaces puis
Edit puis Physical settings).
Et les VLAN ? Ils se
configurent/s'affichent avec LuCI en Network ->
Switch, https://ROUTER/cgi-bin/luci/admin/network/vlan. Par défaut, tous les ports sont non marqués
(untagged) ce qui veut dire que le commutateur
ne fait pas de VLAN. Si on branche le Freebox Player sur un port
où on active le marquage (tagged pour le VLAN
100, celui utilisé par les boitiers Freebox) et le Freebox Server
sur un autre port marqué 100, les deux boitiers peuvent
communiquer, la télévision marche mais, dans ce cas, le réseau
local, toujours non marqué, ne peut plus communiquer avec ces
boitiers et on n'a donc pas d'accès Internet. La configuration qui
marche est donc celle-ci : 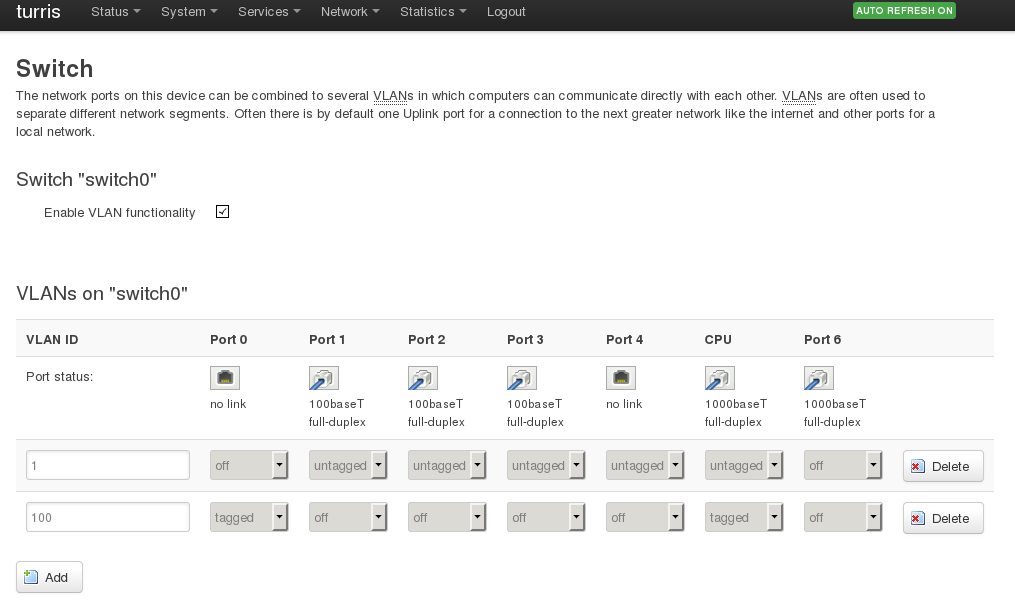 Le port marqué CPU dans LuCI est celui qui est marqué WAN sur le
boitier (je sais, c'est bizarre).
Le port marqué CPU dans LuCI est celui qui est marqué WAN sur le
boitier (je sais, c'est bizarre).
Vous n'aimez pas les copies d'écran, vous préférez des fichiers
de configuration ? Pas de problème, cela se configure dans
/etc/config/network (je n'ai montré que les
paramètres pertinents) :
config interface 'lan'
option type 'bridge'
option ifname 'eth0 eth2'
config interface 'Freebox'
option type 'bridge'
option proto 'static'
option ifname 'eth0.100 eth1.100'
config switch_vlan
option device 'switch0'
option vlan '1'
option vid '1'
option ports '1 2 3 4 5'
config switch_vlan
option device 'switch0'
option vlan '2'
option ports '0t 5t'
option vid '100'
Pour résumer cette configuration : on a deux VLANs, 1 et 100. 100
(deuxième directive config switch_vlan)
couvre le port 0 (qui est marqué, et où est connecté le Freebox Player)
et le port CPU/WAN/5 - connecté au Freebox Server - qui est le seul
à être sur deux VLAN (1 en non marqué et 100 en marqué). Le
t dans la liste des ports indique un marquage
(tagging). L'autre VLAN,
1 (première directive config switch_vlan), couvre
les autres ports. Pour que les interfaces physiques communiquent, on a
deux ponts, br-lan (directive config
interface 'lan') et br-Freebox, qui
fait communiquer les deux ports du VLAN 100 (qui arrivent sur des
commutateurs différents, regardez le schéma plus haut). Les ports
marqués correspondent aux interfaces comportant le numéro du VLAN
(comme eth0.100, les paquets du VLAN 100
arrivant sur eth0)
(Au passage, si vous utilisez LuCI pour configurer, vous devrez
cliquer sur Save and apply pour appliquer votre
configuration. Rappelez-vous de bien la vérifier avant. Si vous
avez au contraire édité le fichier de configuration à la main, ce
sera un /etc/init.d/network restart, avec les
mêmes précautions.)
Avec tout ça, tout le monde communique, la télé marche (si le
Freebox Player affiche au démarrage qu'il ne peut pas communiquer avec
le Freebox Server, c'est que vous avez un problème), l'Internet
fonctionne, etc. Mais on ne peut toujours pas regarder la télévision
avec VLC
(vlc http://mafreebox.freebox.fr/freeboxtv/playlist.m3u
affiche live555 demux error: no data received in 10s, aborting). La raison en est que RTSP est un
protocole un peu spécial (il n'est pas vraiment client/serveur) : certes, le PC se connecte à la Freebox mais
le flux vidéo lui-même n'est pas envoyé dans cette connexion, mais
séparement sous forme de paquets UDP. Le Turris
n'a apparemment pas de mécanisme de suivi des sessions RTSP
(conntracker, comme ce module) qui permettrait de transmettre
automatiquement ces paquets UDP à la bonne machine. J'ai donc choisi,
en suivant cette excellente
documentation, de configurer le Turris pour chaque machine. Sur
chaque PC du réseau local qui veut regarder des conneries à la télé, il
faut fixer le port dans VLC
Paramètres -> Préférences -> Input/Codecs->Demuxers ->
RTP/RTSP. Là on coche
la case Options avancées. On voit s'afficher un champ Client port,
avec la valeur -1, ce qui signfie que VLC choisit aléatoirement le
port d'entrée. On met la valeur de son choix (attention, elle doit
être paire), par exemple 31336. Il faut aussi
configurer le Turris pour transmettre ce port à la bonne
machine. (Oui, tout serait plus pratique si
mafreebox.free.fr avait une adresse
IPv6). Dans LuCI, c'est dans Network
-> Firewall puis Port forwards
ROUTER/cgi-bin/luci/admin/network/firewall/forwards :
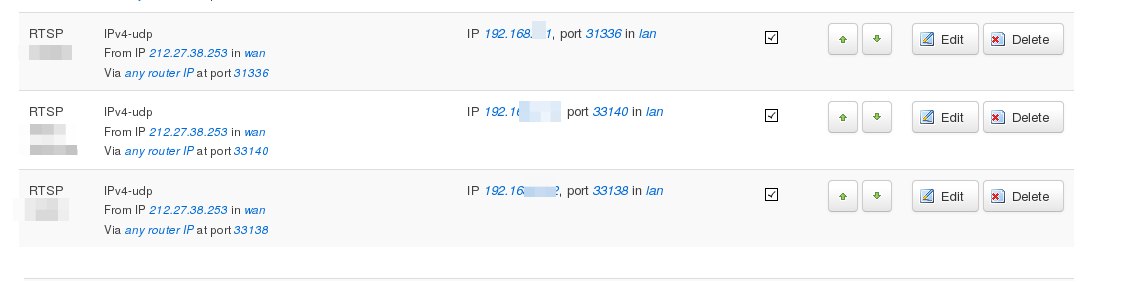 Et si vous préférez cette configuration en mode texte, c'est dans
Et si vous préférez cette configuration en mode texte, c'est dans
/etc/config/firewall :
config redirect option target 'DNAT' option name 'RTSP machine1' option proto 'udp' option src 'wan' option src_dport '31336' option dest 'lan' option dest_ip '192.168.X.Y' option dest_port '31336' option src_ip '212.27.38.253'
Une fois qu'on a ses VLAN comme on veut, on peut s'avachir devant la télé qu'on reçoit sur son PC, ou bien on peut passer à une autre tâche. Installer un disque dur supplémentaire dans l'Omnia et créer des machines virtuelles (les deux tâches sont liées, pour des raisons expliquées plus loin).
Pourquoi un disque supplémentaire, pourquoi ne pas se contenter de la Flash présente ? Cet espace de stockage est largement suffisant (8 Go) pour faire tourner les fonctions de base du routeur, mais il ne l'est plus si on veut installer des applications, par exemple de supervision ou de statistiques, qui vont stocker des données sur le long terme, ou bien si on veut mettre son serveur de messagerie sur le Turris. Ou encore si on veut s'en servir comme NAS. Si on veut réaliser la promesse de la page Web officielle, « More than just a router. The open-source [sic] center of your home », il faudra plus de huit gigas.
D'autant plus que la Flash a un autre problème, elle s'use vite
quand on écrit souvent. Voilà pourquoi, dans
OpenWrt, par défaut, /var
est en mémoire, et donc un équivalent de /tmp,
qui ne survit pas aux redémarrages. Autrement, des services comme
syslog démoliraient la Flash trop vite.
Donc, installons un disque supplémentaire. L'Omnia a un emplacement libre, au dessus de l'emplacement pour carte SIM, où on peut mettre un disque SSD via une interface mSATA. J'ai acheté un Kingston mS200 de 120 Go à 50 € TTC. Mais c'est ensuite que les ennuis commencent. L'emplacement libre dans l'Omnia n'est pas celui qui a le port combiné miniPCIexpress/mSATA, le bon emplacement est occupé par une des deux cartes Wi-Fi, il va donc falloir ouvrir le routeur, et déplacer la carte Wi-Fi. (On pourrait évidemment utiliser un disque externe, connecté en USB mais une de mes motivations pour tout mettre sur le Turris Omnia était de diminuer le nombre de boitiers et de prises de courant.)
La procédure nécessite donc tournevis et une
certaine habileté manuelle. Elle est très bien expliquée dans ce
film (les commentaires de la vidéo valent également d'être lus). Notez toutefois que dans mon cas, cela n'a pas suffi :
les vis du dessus des cartes Wi-Fi ne se défont pas et j'ai donc dû
démonter la carte Wi-Fi en l'attaquant de l'autre côté de la carte
mère. (Vous trouverez aussi sur le forum Turris des discussions sur
cette procédure, comme
ici.) Voici le Turris Omnia ouvert avant l'opération :
 Et le même après, la carte Wi-Fi qui était tout à droite ayant été
déplacée tout à gauche :
Et le même après, la carte Wi-Fi qui était tout à droite ayant été
déplacée tout à gauche :
 Vous pouvez aussi télécharger une image en haute
définition.
Attention notamment aux fils qui vont des cartes Wi-Fi aux antennes,
ils se défont facilement.
Vous pouvez aussi télécharger une image en haute
définition.
Attention notamment aux fils qui vont des cartes Wi-Fi aux antennes,
ils se défont facilement.
{kind=link}
(Notez que, depuis mon bricolage, la carte-mère de l'Omnia a un peu changé.)
Une fois le disque branché et bien branché, la carte mère replacée
et le capot fermé, on redémarre le routeur (en priant, si on est
croyant). On doit voir un disque en /dev/sda
(tapez dmesg | grep sda après le démarrage). On
le formate comme indiqué, par exemple, dans la documentation
d'OpenWrt. Chez moi, cela donne :
# fdisk -l /dev/sda Disk /dev/sda: 111.8 GiB, 120034123776 bytes, 234441648 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: gpt Disk identifier: 0263F4A2-3C22-4043-B2ED-32B962569924 Device Start End Sectors Size Type /dev/sda1 2048 121636863 121634816 58G Linux filesystem /dev/sda2 121636864 234441614 112804751 53.8G Linux filesystem # blkid /dev/mmcblk0p1: UUID="0eec9a72-3c0f-4222-ab9e-2147243a7c1e" UUID_SUB="6b8deab1-dff4-48fc-a522-395f67d59de8" TYPE="btrfs" PARTUUID="2cbb06e2-01" /dev/sda1: UUID="cb35ae3d-78f8-49f9-bbbb-efbab97b4a81" TYPE="ext4" PARTUUID="ab197dd0-71d2-446c-80e6-bf8810b86ebd" /dev/sda2: UUID="df1c2ed7-5728-4629-9d72-263bbf2b5939" TYPE="ext4" PARTUUID="3673e386-6636-40e8-bf08-b32899b6e7c3" /dev/mmcblk0: PTUUID="2cbb06e2" PTTYPE="dos"
On peut ensuite monter le disque de la manière OpenWrt
habituelle. Voici mon /etc/config/fstab :
config mount option enabled '1' option target '/srv' option uuid 'cb35ae3d-78f8-49f9-bbbb-efbab97b4a81' config mount option enabled '1' option uuid 'df1c2ed7-5728-4629-9d72-263bbf2b5939' option target '/var'
Pour compléter, notez que ce déplacement d'une carte Wi-Fi va
nécessiter de reconfigurer le service Wi-Fi (dans LuCI,
Network -> Wireless), la carte passant de
radio1 à radio2.
Une fois qu'on a son disque, on peut installer ses machines virtuelles ou plus exactements ses containers. Pourquoi ces machines supplémentaires alors qu'on a déjà un Unix qui tourne parfaitement sur le matériel ? Mon problème était surtout que le nombre de paquetages est très limité sur l'Omnia (cf. la liste). Il n'y a ainsi pas emacs. Les outils de développement sont absents (on peut éventuellement faire de la compilation croisée) et, de toute façon, il y a deux bonnes raisons pour ne pas installer plein de choses sur l'Unix OpenWrt de l'Omnia :
- Seuls les paquetages officiels bénéficients d'une fonction essentielle de l'Omnia (notamment pour la sécurité), la mise à jour automatique.
- Le routeur doit router dans tous les cas, et doit donc avoir un jeu de logiciels minimum. Tout ce qu'on rajoute peut créer des problèmes.
Donc, la méthode propre sur Omnia, si on veut des logiciels comme Icinga (pour la supervision) ou des petits utilitaires sympa comme uptimed ou comme check-soa (indispensable quand on joue souvent avec le DNS), la méthode propre, donc, est d'installer des machines virtuelles sur l'Omnia.
En fait, ce ne sont pas des machines virtuelles complètes, juste des containers, avec la technique LXC. Contrairement à des vraies machines virtuelles, ils ne fournissent pas une étanchéité complète. Tous utilisent le même noyau, qui ne s'exécute qu'une fois. (C'est d'ailleurs pour cela qu'uptimed dans un container marche bien : il enregistre l'uptime du routeur, pas celui du container.) Les containers n'ont pas non plus d'horloge propre et c'est pour cela qu'ils n'ont pas besoin de NTP, celui du routeur suffit.
Autre conséquence du modèle du container, les « machines » doivent tourner avec Linux, pas de FreeBSD sur le Turris Omnia. LXC sur cette machine est bien documenté. Voici le processus de création d'un container, avec le choix des systèmes d'exploitation :
# lxc-create -t download -n gandalf Setting up the GPG keyring Downloading the image index --- DIST RELEASE ARCH VARIANT BUILD --- Turris_OS stable armv7l default 2016-11-27 Turris_OS stable ppc default 2016-11-27 Alpine 3.4 armv7l default 2016-11-27 Debian Jessie armv7l default 2016-11-27 Gentoo stable armv7l default 2016-11-27 openSUSE 13.2 armv7l default 2016-11-27 openSUSE Tumbleweed armv7l default 2016-11-27 Ubuntu Xenial armv7l default 2016-11-27 Ubuntu Yakkety armv7l default 2016-11-27 --- Distribution: Debian Release: Jessie Architecture: armv7l Downloading the image index Downloading the rootfs Downloading the metadata The image cache is now ready Unpacking the rootfs --- Distribution Debian version Jessie was just installed into your container. Content of the tarballs is provided by third party, thus there is no warranty of any kind.
Pas d'Arch Linux, je le regrette, donc j'ai mis Debian.
Ensuite, on démarre le container :
# lxc-start -n gandalf
On s'y attache :
# lxc-attach -n gandlf
Et on peut configurer le mot de passe, le réseau (je n'ai pas réussi à
faire marcher le client DHCP sur les containers, j'ai tout configuré
en statique), SSH… (Notez qu'on
peut aussi faire tout cela depuis LuCI, Services -> LXC
containers.) La configuration du container
gandalf se retrouve dans
/srv/lxc/gandalf/config. On peut notamment
configurer l'adresse MAC du container
(attention, si ce n'est pas fait, le container change d'adresse MAC à
chaque démarrage, ce qui est excellent pour la vie
privée mais moins pour l'administration système, avec
arpwatch et NDPMon qui
voient une nouvelle machine à chaque fois) :
# cat /srv/lxc/gandalf/config ... # Network configuration lxc.network.type = veth lxc.network.link = br-lan lxc.network.flags = up lxc.network.name = eth0 lxc.network.script.up = /usr/share/lxc/hooks/tx-off lxc.network.hwaddr = 21:ae:a4:79:73:16
Une fois qu'on a un beau container qui tourne, on peut y installer ses logiciels favoris, comme Icinga (qui, avant, tournait chez moi sur un Raspberry Pi).
Le troisième grand dossier, après les VLAN et l'ajout du disque, c'était la configuration du résolveur DNS. Le Turris utilise par défaut kresd, alias Knot resolver. Intéressant logiciel, quoique ayant encore quelques défauts de jeunesse. Knot marche bien par défaut, et fournit notamment la validation DNSSEC :
% dig A www.afnic.fr ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 47317 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 6, AUTHORITY: 0, ADDITIONAL: 1 ... ;; ANSWER SECTION: www.afnic.fr. 133 IN CNAME www.nic.fr. www.nic.fr. 133 IN CNAME lb01-1.nic.fr. lb01-1.nic.fr. 133 IN A 192.134.5.24
Le AD (Authentic Data dans les flags) indique que le nom est signé et vérifié. Avec un nom pas signé, on n'a pas ce AD :
% dig A www.ssi.gouv.fr ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 16026 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ... ;; ANSWER SECTION: www.ssi.gouv.fr. 14400 IN A 213.56.166.109 ...
Et, si le nom est signé mais erroné, on récupère un
SERVFAIL (Server Failure) :
% dig A tsc.gov ... ;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 28366 ;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 0 ... % dig +cd A tsc.gov ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 25881 ;; flags: qr rd ra cd; QUERY: 1, ANSWER: 3, AUTHORITY: 0, ADDITIONAL: 1 ... ;; ANSWER SECTION: tsc.gov. 60 IN A 153.31.112.95
(Le +cd voulant dire Checking
Disabled, pour être sûr que le problème vient de
DNSSEC.)
Le premier changement que j'ai fait à sa configuration était de
couper la transmission (forwarding) aux résolveurs
du FAI (qui sont des résolveurs
menteurs) : option forward_upstream '0'
dans /etc/config/resolver. (Si, à l'inverse, on
veut transmettre à des serveurs aval spécifiques, voir cette
discussion sur le forum.)
Mais je voulais surtout une configuration spéciale pour utiliser la
racine Yeti. Cela nécessite la configuration suivante. D'abord,
/etc/config/resolver :
config resolver 'common'
...
option keyfile '/etc/kresd/yeti-root.keys'
config resolver 'kresd'
...
option include_config '/etc/kresd/custom.conf'
Le fichier des clés de Yeti, indispensable pour la validation DNSSEC,
se récupère chez
Yeti (et est réécrit ensuite par Knot, qui gère le RFC 5011). Ensuite, le
/etc/kresd/custom.conf contient :
hints.root({
['bii.dns-lab.net.'] = '240c:f:1:22::6',
['yeti-ns.tisf.net .'] = '2001:4f8:3:1006::1:4',
['yeti-ns.wide.ad.jp.'] = '2001:200:1d9::35',
['dahu1.yeti.eu.org.'] = '2001:4b98:dc2:45:216:3eff:fe4b:8c5b',
['dahu2.yeti.eu.org.'] = '2001:67c:217c:6::2',
...
})
(Pas grave s'il manque un ou deux serveurs, le priming - RFC 8109 - s'en occupe.)
Voilà, le résolveur utilise désormais la racine Yeti, comme on peut le vérifier facilement :
% dig NS . ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 46120 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 26, AUTHORITY: 0, ADDITIONAL: 1 ... ;; ANSWER SECTION: . 86400 IN NS bii.dns-lab.net. . 86400 IN NS dahu1.yeti.eu.org. . 86400 IN NS dahu2.yeti.eu.org. . 86400 IN NS yeti-ns.tisf.net. . 86400 IN NS yeti-ns.wide.ad.jp. ...
Notez que kresd peut être interrogé via une console CLI :
# socat - UNIX-CONNECT:/tmp/kresd/tty/$(pidof kresd) >
Et on a droit alors à plein d'informations amusantes (tapez
help() pour la liste ou bien regardez la
documentation) :
> cache.count()
61495
> cache.stats()
[hit] => 12259583
[delete] => 1
[miss] => 24413638
[insert] => 1542550
> stats.list()
[answer.nxdomain] => 775648
[answer.100ms] => 102752
[answer.1500ms] => 27366
[answer.slow] => 72019
[answer.servfail] => 354445
[answer.250ms] => 125256
[answer.cached] => 3062179
[answer.nodata] => 206878
[query.dnssec] => 80582
[answer.1ms] => 3054309
[predict.epoch] => 27
[query.edns] => 84111
[predict.queue] => 5946
[answer.total] => 4112245
[answer.10ms] => 77419
[answer.noerror] => 2775274
[answer.50ms] => 393935
[answer.500ms] => 205149
[answer.1000ms] => 47949
[predict.learned] => 447
> cache.get("google.com")
[clients2.google.com] => {
[CNAME] => true
}
[ghs.google.com] => {
[CNAME] => true
}
[clients6.google.com] => {
[CNAME] => true
}
[get.google.com] => {
[A] => true
}
[accounts-cctld.l.google.com] => {
[A] => true
[AAAA] => true
}
[gmail-imap.l.google.com] => {
[A] => true
}
[inputtools.google.com] => {
[CNAME] => true
}
[kh.google.com] => {
[CNAME] => true
}
...
Après ces trois « grands dossiers », voici plein de petits détails et de petits projets plus ou moins amusants.
Un des avantages d'un routeur qu'on contrôle complètement, où on est root, c'est qu'on peut tout configurer, y compris les diodes luminescentes, si indispensables à l'informatique. On peut par exemple changer la couleur des diodes selon le débit. La technique en Lua expliquée sur le forum marche très bien.
Par défaut, le Turris Omnia se gère en
HTTPS
avec un certificat
auto-signé. Même si ce n'est que sur le réseau
local, ce n'est pas satisfaisant (et ça empêche les navigateurs de
mémoriser les mots de passe, le site n'étant pas considéré comme sûr). Comme je suis utilisateur de CAcert, je voulais utiliser HTTPS avec un
certificat CAcert. On le crée (openssl req -new -nodes -newkey rsa:2048 -keyout server.key -out server.csr -days 1000), on le fait signer via l'interface Web du CAcert (tout est gratuit et automatique dans
CAcert) et on concatène clé privée et certificat (c'est le format
qu'attend le serveur HTTPS du Turris,
lighthttpd, cf. cet
article du forum) :
# cat server.key server.pem > /etc/lighttpd/tls/server.pem
Et on change la configuration HTTPS (/etc/lighttpd/conf.d/ssl-enable.conf) :
$SERVER["socket"] == ":443" {
ssl.engine = "enable"
ssl.pemfile = "/etc/lighttpd/tls/server.pem"
ssl.use-sslv2 = "disable"
ssl.use-sslv3 = "disable"
}
(Et idem avec $SERVER["socket"] == "[::]:443"
pour IPv6.) En prime, j'active
HSTS (RFC 6797) :
$HTTP["scheme"] == "https" {
# Add 'HTTP Strict Transport Security' header (HSTS) to sites
setenv.add-response-header += ( "Strict-Transport-Security" => "max-age=31536000; includeSubDomains" )
}
Et je mets une redirection en place depuis HTTP vers HTTPS, dans
/etc/lighttpd/conf.d/https-redirect.conf :
$HTTP["scheme"] == "http" {
# capture vhost name with regex conditiona -> %0 in redirect pattern
# must be the most inner block to the redirect rule
$HTTP["host"] =~ ".*" {
url.redirect = (".*" => "https://%0$0")
}
}
Tout marche bien, désormais.
Un problème fréquent des tunnels (comme
celui qu'utilise Free pour faire passer
l'IPv6 vers les clients
ADSL) est que, la MTU
ayant été diminuée, les paquets d'une taille proche de la MTU
traditionnelle de 1 500 octets ne passent plus. Cela se voit lorsque
ping (avec la taille par défaut) ou
openssl s_client passent mais que
HTTP n'arrive pas à faire passer des données. La
MTU configurée sur l'Omnia est de 1 480 octets :
config interface 'wan' option ifname 'eth1' option proto 'dhcp' option mtu '1480'
Désormais, tout passe, mais des machines du réseau local envoient toujours des paquets trop gros (je devrais peut-être diffuser la MTU réduite sur le réseau local). Le routeur note :
2016-11-02T07:47:14+00:00 err kernel[]: [ 437.388025] mvneta f1034000.ethernet eth1: bad rx status 8fa50000 (max frame length error), size=1504
Il y a aussi des problèmes que je n'ai pas réussi à résoudre comme
celui d'un accès
anonyme aux graphes de trafic. Notez que je n'ai guère utilisé
les forums génériques OpenWrt : les problèmes discutés sont souvent
très spécifiques à un modèle de routeur. Par contre, la documentation d'OpenWrt est très utile si le Turris Omnia est le premier
routeur OpenWrt que vous configurez sérieusement. Vous y trouverez
notamment des explications sur le système de configuration
/etc/config, qui peut être déroutant, si vous
venez d'un Unix classique.
Et il y a des problèmes qui sont résolus (le Turris Omnia est en plein développement, et, avec les mises à jour automatiques, on voit des solutions aux problèmes arriver seules). C'est ainsi que le « socat fou » qui avait fait perdre tant de temps et d'électricité au début de l'Omnia a été réparé sans que j'ai rien eu à faire.
Le routeur Turris permet d'afficher de jolis graphes de trafic (dans LuCI, Statistics -> Graphs). La configuration n'est pas évidente (Statistics -> Setup) : j'ai dû créer à la main les répertoites indiqués dans la configuration, puis faire :
/etc/init.d/luci_statistics enable /etc/init.d/collectd enable
Par défaut, toutes les données sont perdues à chaque démarrage (voir
plus haut la discussion sur la mémoire Flash). On peut changer les
répertoires de données pour le disque stable, mais cette modification
est perdue à chaque mise à jour du logiciel, hélas. Bref, ce n'est pas
encore satisfaisant.
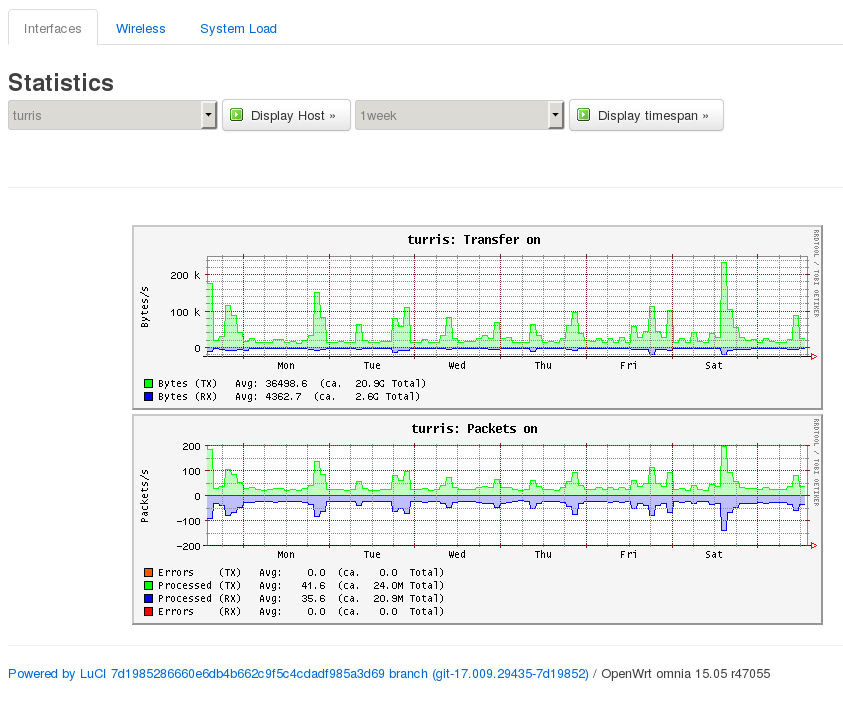
L'article seul
RFC 8118: The application/pdf Media Type
Date de publication du RFC : Mars 2017
Auteur(s) du RFC : M. Hardy, L. Masinter, D. Markovic (Adobe Systems), D. Johnson (PDF Association), M. Bailey (Global Graphics)
Pour information
Première rédaction de cet article le 18 mars 2017
Le format PDF, largement utilisé sur l'Internet, n'a sans doute pas besoin
d'être présenté ici. De toute façon, ce nouveau
RFC ne prétend pas décrire PDF, juste le
type de contenu
application/pdf. Ce RFC remplace l'ancien
RFC 3778, notamment pour tenir compte du fait
qu'officiellement, PDF n'est plus une spécification
Adobe mais une norme
ISO, 32000-1:2008.
Donc, si vous envoyez des documents PDF
via l'Internet, que ce soit par courrier ou par le
Web, vous êtes censé les étiqueter avec le
type MIME
application/pdf (le type de premier niveau
applicaton/ indiquant que c'est un format
binaire, non utilisable en dehors des applications
spécialisées). Ce type a été enregistré à l'IANA
(section 8 du RFC).
PDF avait été conçu pour le monde du papier (les commerciaux d'Adobe répétaient dans les années 90 que PDF permettait d'avoir « le même rendu partout » ce qui n'a pas de sens sur écran, où tous les écrans sont différents), ce qui se retrouve dans de nombreux concepts archaïques de PDF comme le découpage en pages. Un document PDF est un « rendu final », typiquement non modifiable, avec du texte utilisant différentes polices, des images… PDF permet également de représenter des liens hypertexte, une table des matières… On peut même inclure du JavaScript pour avoir des documents interactifs. PDF permet également le chiffrement et la signature, et a un mécanisme (en fait, plusieurs) pour placer des métadonnées, XMP. Bref, PDF est un format très complexe, ce qui explique les nombreuses failles de sécurité rencontrées par les programmes qui lisent du PDF.
La norme PDF est désormais déposée à l'ISO (ISO 32000-1) mais l'archaïque ISO ne distribue toujours pas librement ces documents. Si on veut apprendre PDF, il faut donc le télécharger sur le site d'Adobe.
Pour les protocoles où il y a une notion d'identificateur de
fragment (comme les URI, où cet
identificateur figure après le croisillon),
PDF permet d'indiquer une partie d'un document. Cela fera partie
de la future norme ISO, mais c'était déjà dans l'ancien RFC 3778. Cet identificateur prend la forme d'un ou plusieurs
couples clé=valeur, où la clé est, par exemple,
page=N (pour aller à la page n° N),
comment=ID (aller à l'endroit marqué par
l'annotation ID), zoom=S (agrandir d'un
facteur S), search=MOT (aller à la première
occurrence de MOT)… (Je n'ai pas réussi à faire fonctionner ces
identificateurs de fragments avec le lecteur PDF inclus dans
Chrome. Quelqu'un connait un logiciel où ça marche ?)
PDF a également des sous-ensembles. La norme est riche, bien
trop riche, et il est donc utile de la restreindre. Il y a eu
plusieurs de ces sous-ensembles de PDF normalisés (voir sections 2
et 4 du RFC). Ainsi, PDF/A, sous-ensemble
de PDF pour l'archivage à long terme (ISO 19005-3:2012), limite
les possibilités de PDF, pour augmenter la probabilité que le
document soit toujours lisible dans 50 ou 100 ans. Par exemple,
JavaScript y est interdit. PDF/X (ISO 15930-8:2008), lui, vise le
cas où on envoie un fichier à un imprimeur. Il restreint également
les possibilités de PDF, pour accroitre les chances que
l'impression donne exactement le résultat attendu. Enfin,
PDF/UA (ISO 14289-1:2014) vise
l'accessibilité, en insistant sur une
structuration sémantique (et non pas fondée sur l'apparence
visuelle) du document. Tous ces sous-ensembles s'étiquettent avec
le même type application/pdf. Ils ne sont pas
mutuellement exclusifs : un document PDF peut être à la fois PDF/A
et PDF/UA, par exemple.
Il existe d'innombrables mises en œuvre de PDF, sur toutes les plate-formes possible. Celle que j'utilise le plus sur Unix est Evince.
Un mot sur la sécurité (section 7 du RFC). On l'a dit, PDF est un format (trop) complexe, ce qui a des conséquences pour la sécurité. Comme l'impose la section 4.6 du RFC 6838, notre RFC inclut donc une analyse des risques. (Celle du RFC 3778 était trop limitée.) Notamment, PDF présente les risques suivants :
- Les scripts inclus, écrits en JavaScript,
- Le chargement de fichiers extérieurs, et les liens hypertexte vers l'extérieur,
- Les fichiers inclus, qui peuvent être absolument n'importe quoi, et qui viennent avec leurs propres dangers (sans compter le risque de leur exportation vers le système de fichiers local).
Et c'est sans compter sur les risques plus génériques, comme la complexité de l'analyseur. Il y a eu de nombreuses failles de sécurité dans les lecteurs PDF (au hasard, par exemple CVE-2011-3332 ou bien CVE-2013-3553). La revue de sécurité à l'IETF avait d'ailleurs indiqué que les premières versions du futur RFC étaient encore trop légères sur ce point, et demandait un mécanisme pour mieux étiqueter les contenus « dangereux ».
Vous avez peut-être noté (lien « Version PDF de cette page » en bas) que tous les articles de ce blog ont une version PDF, produite via LaTeX (mais elle n'est pas toujours complète, notamment pour les caractères Unicode). Une autre solution pour obtenir des PDF de mes articles est d'imprimer dans un fichier, depuis le navigateur.
La section 2 du RFC rappelle l'histoire de PDF. La première
version date de 1993. PDF a été un très
grand succès et est largement utilisé aujourd'hui. Si on
google
filetype:pdf, on trouve « Environ 2 500 000
000 résultats » (valeur évidemment très approximative, le chiffre
rond indiquant que Google n'a peut-être pas tout compté) . Si PDF a été créé et reste largement
contrôlé par Adobe, il en existe une
version ISO, la norme 32000-1, qui date
de 2008 (pas de mise à jour depuis, bien
qu'une révision soit attendue en 2017). ISO
32000-1:2008 est identique à la version PDF 1.7 d'Adobe.
Normalement, les anciens lecteurs PDF doivent pouvoir lire les versions plus récentes, évidemment sans tenir compte des nouveautés (section 5 du RFC).
Quels sont les changements depuis l'ancienne version, celle du RFC 3778 ? La principale est que le change controller, l'organisation qui gère la norme et peut donc demander des modifications au registre IANA est désormais l'ISO et non plus Adobe. Les autres changements sont :
- Une mise à jour de la partie historique,
- Une mise à jour de la partie sur les sous-ensembles de PDF, qui étaient moins nombreux autrefois,
- Une section sécurité bien plus détaillée.
L'article seul
RFC 8106: IPv6 Router Advertisement Options for DNS Configuration
Date de publication du RFC : Mars 2017
Auteur(s) du RFC : J. Jeong (Sungkyunkwan
University), S. Park (Samsung
Electronics), L. Beloeil (France Telecom
R&D), S. Madanapalli (iRam
Technologies)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF 6man
Première rédaction de cet article le 18 mars 2017
Il existe deux méthodes pour configurer une machine IPv6 automatiquement, DHCP (RFC 8415) et RA (Router Advertisement, RFC 4862). Toutes les deux peuvent indiquer d'autres informations que l'adresse IP, comme par exemple les adresses des résolveurs DNS. Notre RFC normalise cette possibilité pour les RA. Il remplace le RFC 6106, avec peu de changements.
Si on gère un gros réseau, avec de nombreuses machines dont
certaines, portables, vont et viennent, s'assurer que toutes ces
machines ont les adresses IP
des serveurs de noms à utiliser n'est pas trivial (section 1 du RFC). On ne peut évidemment pas utiliser le DNS, cela serait tenter de voler en tirant
sur les lacets de ses chaussures. Et configurer à la main les adresses
sur chaque machine (par exemple, sur Unix, en
les écrivant dans le fichier /etc/resolv.conf)
est bien trop difficile à maintenir. Se passer du DNS est hors de
question. Pour les machines bi-protocoles (IPv4
et IPv6), une solution possible était
d'utiliser un serveur de noms en v4. Mais pour une solution purement v6 ?
La solution la plus populaire était DHCP (RFC 8415 et RFC 3646). Son principal inconvénient est qu'elle est à état : le serveur DHCP doit se souvenir des baux qu'il a attribué. Sur un gros réseau local, le nombre de requêtes à traiter, chacune nécessitant une écriture dans une base de données, peut devenir très lourd.
Une autre solution est sans état et repose sur
une nouveauté d'IPv6, les RA (Router
Advertisements, cette méthode est aussi appelée ND, pour
Neighbor Discovery, les RA en étant un cas particulier), décrits dans le RFC 4862. Ce sont des messages envoyés à intervalles
réguliers par les routeurs et
qui informent les machines non-routeuses des caractéristiques
essentielles du réseau, comme le préfixe utilisé (par exemple
2001:db8:beef:42::/64). Le routeur diffuse ses
messages et n'a pas besoin d'écrire quoi que ce soit sur son disque,
ni de faire des traitements compliqués lors d'une sollicitation, il
répond toujours par le même message RA.
Ces RA peuvent diffuser diverses informations, par le biais d'un système d'options. Le principe de notre RFC est donc d'utiliser ces RA pour transporter l'information sur les serveurs de noms récursifs utilisables sur le réseau local, via des options notamment celle nommée RDNSS (le numéro 25 lui a été affecté par l'IANA).
La section 1.1 du RFC rappelle qu'il existe plusieurs choix, notre RFC 8106 n'étant qu'une possibilité parmi d'autres. Le RFC 4339 contient une discussion plus détaillée de ce problème du choix d'une méthode de configuration des serveurs de noms (notons qu'il existe d'autres méthodes comme l'anycast avec une adresse « bien connue »). La section 1.2 décrit ce qui se passe lorsque plusieurs méthodes (par exemple DHCP et RA) sont utilisées en même temps.
La méthode RA décrite dans notre RFC repose sur deux options, RDNSS, déjà citée, et DNSSL (section 4). La première permet de publier les adresses des serveurs de noms, la seconde une liste de domaine à utiliser pour compléter les noms courts (formés d'un seul composant). Les valeurs pour ces deux options doivent être configurées dans le routeur qui va lancer les RA. (Le routeur Turris Omnia le fait automatiquement. Si on veut changer les paramètres, voici comment faire. En général, pour OpenWrt, il faut lire cette documentation, l'ancien logiciel radvd n'étant plus utilisé.)
La première option, RDNSS, de numéro 25, est décrite en section 5.1. Elle indique une liste d'adresse IPv6 que le client RA mettra dans sa liste locale de serveurs de noms interrogeables.
La seconde option, DNSSL, de numéro 31, est en section 5.2 (les
deux options sont enregistrées dans le registre
IANA, cf. section 8). Elle
publie une liste de domaines, typiquement ceux qui, sur une machine
Unix, se retrouveront dans l'option
search de /etc/resolv.conf.
Sur Linux, le démon rdnssd permet de recevoir ces RA et de modifier la configuration DNS. Pour FreeBSD, on peut consulter une discussion sur leur liste. Les CPE de Free, les Freebox, émettent de telles options dans leurs RA (apparemment, la dernière fois que j'ai regardé, uniquement des RDNSS). Voici ce qu'affiche Wireshark :
...
Ethernet II, Src: FreeboxS_c3:83:23 (00:07:cb:c3:83:23),
Dst: IPv6mcast_00:00:00:01 (33:33:00:00:00:01)
...
Internet Control Message Protocol v6
Type: 134 (Router advertisement)
...
ICMPv6 Option (Recursive DNS Server)
Type: Recursive DNS Server (25)
Length: 40
Reserved
Lifetime: 600
Recursive DNS Servers: 2a01:e00::2 (2a01:e00::2)
Recursive DNS Servers: 2a01:e00::1 (2a01:e00::1)
et les serveurs DNS annoncés répondent correctement. (Vous pouvez récupérer le paquet entier sur pcapr.net.)
Autre mise en œuvre de ces options, dans radvd (ainsi que pour les logiciels auxiliaires). Wireshark, on l'a vu, sait décoder ces options.
La section 6 de notre RFC donne des conseils aux programmeurs qui voudraient mettre en œuvre ce document. Par exemple, sur un système d'exploitation où le client RA tourne dans le noyau (pour configurer les adresses IP) et où la configuration DNS est dans l'espace utilisateur, il faut prévoir un mécanisme de communication, par exemple un démon qui interroge le noyau régulièrement pour savoir s'il doit mettre à jour la configuration DNS.
RA pose divers problèmes de sécurité, tout comme DHCP, d'ailleurs. Le problème de ces techniques est qu'elles sont conçues pour faciliter la vue de l'utilisateur et de l'administrateur réseau et que « faciliter la vie » implique en général de ne pas avoir de fonctions de sécurité difficiles à configurer. La section 7 traite de ce problème, par exemple du risque de se retrouver avec l'adresse d'un serveur DNS méchant qui vous redirigerait Dieu sait où (les RA ne sont pas authentifiés). Ce risque n'a rien de spécifique aux options DNS, toute la technique RA est vulnérable (par exemple, avec un faux Neighbor Advertisement). Donc, notre RFC n'apporte pas de risque nouveau (cf. RFC 6104). Si on considère cette faiblesse de sécurité comme insupportable, la section 7.2 recommande d'utiliser le RA guard du RFC 6105, ou bien SEND (RFC 3971, mais il est nettement moins mis en avant que dans le précédent RFC).
Ce problème d'une auto-configuration simple des machines connectées à IPv6 est évidemment particulièrement important pour les objets connectés et c'est sans doute pour cela que le RFC contient la mention « This document was supported by Institute for Information & communications Technology Promotion (IITP) grant funded by the Korea government (MSIP) [10041244, Smart TV 2.0 Software Platform] ».
Les changements faits depuis le précédent RFC, le RFC 6106, figurent dans l'annexe A. On y trouve notamment :
- Une valeur par défaut plus élevée pour la durée de vie des
informations envoyées (qui passe de deux fois
MaxRtrAdvIntervalà trois fois sa valeur, soit 1 800 secondes avec la valeur par défaut de cette variable), pour diminuer le nombre de cas où l'information expire parce que le réseau perdait trop de paquets, - L'autorisation explicite des adresses locales au lien (celles
en
fe80::/10), comme adresses de résolveurs DNS, - Suppression de la limite de trois résolveurs DNS, qui était dans l'ancien RFC.
À noter que ce RFC n'intègre pas encore les résolveurs sécurisés du RFC 7858, car il se contente de réviser un RFC existant. Il n'y a donc pas de moyen de spécifier un résolveur sécurisé, pas de port 853.
Et pour finir, voici le RA émis par défaut par le routeur Turris, décodé par Wireshark :
Internet Protocol Version 6, Src: fe80::da58:d7ff:fe00:4c9e, Dst: ff02::1
0110 .... = Version: 6
.... 0000 0000 .... .... .... .... .... = Traffic class: 0x00 (DSCP: CS0, ECN: Not-ECT)
.... 0000 00.. .... .... .... .... .... = Differentiated Services Codepoint: Default (0)
.... .... ..00 .... .... .... .... .... = Explicit Congestion Notification: Not ECN-Capable Transport (0)
.... .... .... 0101 1110 1011 0100 0001 = Flow label: 0x5eb41
Payload length: 152
Next header: ICMPv6 (58)
Hop limit: 255
Source: fe80::da58:d7ff:fe00:4c9e
[Source SA MAC: CzNicZSP_00:4c:9e (d8:58:d7:00:4c:9e)]
Destination: ff02::1
[Source GeoIP: Unknown]
[Destination GeoIP: Unknown]
Internet Control Message Protocol v6
Type: Router Advertisement (134)
Code: 0
Checksum: 0x35ed [correct]
[Checksum Status: Good]
Cur hop limit: 64
Flags: 0x80
1... .... = Managed address configuration: Set
.0.. .... = Other configuration: Not set
..0. .... = Home Agent: Not set
...0 0... = Prf (Default Router Preference): Medium (0)
.... .0.. = Proxy: Not set
.... ..0. = Reserved: 0
Router lifetime (s): 1800
Reachable time (ms): 0
Retrans timer (ms): 0
ICMPv6 Option (Source link-layer address : d8:58:d7:00:4c:9e)
Type: Source link-layer address (1)
Length: 1 (8 bytes)
Link-layer address: CzNicZSP_00:4c:9e (d8:58:d7:00:4c:9e)
ICMPv6 Option (MTU : 1480)
Type: MTU (5)
Length: 1 (8 bytes)
Reserved
MTU: 1480
ICMPv6 Option (Prefix information : fde8:9fa9:1aba::/64)
Type: Prefix information (3)
Length: 4 (32 bytes)
Prefix Length: 64
Flag: 0xc0
1... .... = On-link flag(L): Set
.1.. .... = Autonomous address-configuration flag(A): Set
..0. .... = Router address flag(R): Not set
...0 0000 = Reserved: 0
Valid Lifetime: 7200
Preferred Lifetime: 1800
Reserved
Prefix: fde8:9fa9:1aba::
ICMPv6 Option (Prefix information : 2a01:e35:8bd9:8bb0::/64)
Type: Prefix information (3)
Length: 4 (32 bytes)
Prefix Length: 64
Flag: 0xc0
1... .... = On-link flag(L): Set
.1.. .... = Autonomous address-configuration flag(A): Set
..0. .... = Router address flag(R): Not set
...0 0000 = Reserved: 0
Valid Lifetime: 7200
Preferred Lifetime: 1800
Reserved
Prefix: 2a01:e35:8bd9:8bb0::
ICMPv6 Option (Route Information : Medium fde8:9fa9:1aba::/48)
Type: Route Information (24)
Length: 3 (24 bytes)
Prefix Length: 48
Flag: 0x00
...0 0... = Route Preference: Medium (0)
000. .000 = Reserved: 0
Route Lifetime: 7200
Prefix: fde8:9fa9:1aba::
ICMPv6 Option (Recursive DNS Server fde8:9fa9:1aba::1)
Type: Recursive DNS Server (25)
Length: 3 (24 bytes)
Reserved
Lifetime: 1800
Recursive DNS Servers: fde8:9fa9:1aba::1
ICMPv6 Option (Advertisement Interval : 600000)
Type: Advertisement Interval (7)
Length: 1 (8 bytes)
Reserved
Advertisement Interval: 600000
On y voit l'option RDNSS (l'avant-dernière) mais pas de DNSSL.
Merci à Alexis La Goutte pour ses informations.
L'article seul
RFC 8109: Initializing a DNS Resolver with Priming Queries
Date de publication du RFC : Mars 2017
Auteur(s) du RFC : P. Koch
(DENIC), M. Larson, P. Hoffman
(ICANN)
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 16 mars 2017
Un résolveur DNS ne connait au début, rien du contenu du DNS. Rien ? Pas tout à fait, il connait une liste des serveurs de noms faisant autorité pour la racine, car c'est par eux qu'il va commencer le processus de résolution de noms. Cette liste est typiquement en dur dans le code du serveur, ou bien dans un de ses fichiers de configuration. Mais peu d'administrateurs système la maintiennent à jour. Il est donc prudent, au démarrage du résolveur, de chercher une liste vraiment à jour, et c'est le priming (initialisation ?), opération que décrit ce RFC. Il a depuis été remplacé par le RFC 9609.
Le problème de départ d'un résolveur est un problème
d'œuf et de poule. Le résolveur doit interroger le DNS
pour avoir des informations mais comment trouve-t-il les serveurs
DNS à interroger ? La solution est de traiter la racine du DNS de
manière spéciale : la liste de ses serveurs est connue du résolveur
au démarrage. Elle peut être dans le code du serveur lui-même, ici
un Unbound qui contient les adresses IP des
serveurs de la racine (je ne montre que les trois premiers,
A.root-servers.net,
B.root-servers.net et C.root-servers.net) :
% strings /usr/sbin/unbound | grep -i 2001: 2001:503:ba3e::2:30 2001:500:84::b 2001:500:2::c ...
Ou bien elle est dans un fichier de configuration (ici, sur un Unbound) :
server: directory: "/etc/unbound" root-hints: "root-hints"
Ce fichier peut être téléchargé via
l'IANA, il peut être spécifique au logiciel résolveur, ou bien fourni
par le système d'exploitation (cas du
paquetage dns-root-data chez
Debian). Il contient la liste des serveurs
de la racine et leurs adresses :
. 3600000 NS A.ROOT-SERVERS.NET. . 3600000 NS B.ROOT-SERVERS.NET. ... A.ROOT-SERVERS.NET. 3600000 A 198.41.0.4 A.ROOT-SERVERS.NET. 3600000 AAAA 2001:503:ba3e::2:30 B.ROOT-SERVERS.NET. 3600000 A 192.228.79.201 B.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:84::b ...
Cette configuration initiale du résolveur est décrite dans la section 2.3 du RFC 1034, mais ce dernier ne décrit pas réellement le priming (quoi que dise notre nouveau RFC), priming que tous les résolveurs actuels mettent en œuvre. En effet, les configurations locales tendent à ne plus être à jour au bout d'un moment. (Sauf dans le cas où elles sont dans un paquetage du système d'exploitation, mis à jour avec ce dernier, comme dans le bon exemple Debian ci-dessus.)
Les changements des serveurs racines sont rares. Si on regarde sur le site des opérateurs des serveurs racine, on voit :
- 2016-12-02 Announcement of IPv6 addresses
- 2015-11-05 L-Root IPv6 Renumbering
- 2015-08-31 H-Root to be renumbered
- 2014-03-26 IPv6 service address for c.root-servers.net (2001:500:2::C)
- 2012-12-14 D-Root IPv4 Address to be Renumbered
- 2011-06-10 IPv6 service address for d.root-servers.net (2001:500:2D::D)
Bref, peu de changements. Ils sont en général annoncés sur les listes de diffusion opérationnelles (comme ici, là ou encore ici). Mais les fichiers de configuration ayant une fâcheuse tendance à ne pas être mis à jour et à prendre de l'âge, les anciennes adresses des serveurs racine continuent à recevoir du trafic des années après (comme le montre cette étude de J-root). Notez que la stabilité de la liste des serveurs racine n'est pas due qu'au désir de ne pas perturber les administrateurs système : il y a aussi des raisons politiques (aucun mécanisme en place pour choisir de nouveaux serveurs, ou pour retirer les « maillons faibles »). C'est pour cela que la liste des serveurs (mais pas leurs adresses) n'a pas changé depuis 1997 !
Notons aussi que l'administrateur système d'un résolveur peut changer la liste des serveurs de noms de la racine pour une autre liste. C'est ainsi que fonctionnent les racines alternatives comme Yeti. Si on veut utiliser cette racine expérimentale et pas la racine « officielle », on édite la configuration de son résolveur :
server:
root-hints: "yeti-hints"
Et le fichier, téléchargé chez Yeti, contient :
. 3600000 IN NS bii.dns-lab.net bii.dns-lab.net 3600000 IN AAAA 240c:f:1:22::6 . 3600000 IN NS yeti-ns.tisf.net yeti-ns.tisf.net 3600000 IN AAAA 2001:559:8000::6 . 3600000 IN NS yeti-ns.wide.ad.jp yeti-ns.wide.ad.jp 3600000 IN AAAA 2001:200:1d9::35 . 3600000 IN NS yeti-ns.as59715.net ...
Le priming, maintenant. Le principe du priming est, au démarrage, de faire une requête à un des serveurs listés dans la configuration et de garder sa réponse (certainement plus à jour que la configuration) :
% dig +bufsize=4096 +norecurse +nodnssec @k.root-servers.net NS . ; <<>> DiG 9.10.3-P4-Debian <<>> +norecurse +nodnssec @k.root-servers.net NS . ; (2 servers found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 42123 ;; flags: qr aa; QUERY: 1, ANSWER: 13, AUTHORITY: 0, ADDITIONAL: 27 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ;; QUESTION SECTION: ;. IN NS ;; ANSWER SECTION: . 518400 IN NS a.root-servers.net. . 518400 IN NS b.root-servers.net. . 518400 IN NS c.root-servers.net. . 518400 IN NS d.root-servers.net. . 518400 IN NS e.root-servers.net. . 518400 IN NS f.root-servers.net. . 518400 IN NS g.root-servers.net. . 518400 IN NS h.root-servers.net. . 518400 IN NS i.root-servers.net. . 518400 IN NS j.root-servers.net. . 518400 IN NS k.root-servers.net. . 518400 IN NS l.root-servers.net. . 518400 IN NS m.root-servers.net. ;; ADDITIONAL SECTION: a.root-servers.net. 518400 IN A 198.41.0.4 a.root-servers.net. 518400 IN AAAA 2001:503:ba3e::2:30 b.root-servers.net. 518400 IN A 192.228.79.201 b.root-servers.net. 518400 IN AAAA 2001:500:84::b c.root-servers.net. 518400 IN A 192.33.4.12 c.root-servers.net. 518400 IN AAAA 2001:500:2::c d.root-servers.net. 518400 IN A 199.7.91.13 d.root-servers.net. 518400 IN AAAA 2001:500:2d::d e.root-servers.net. 518400 IN A 192.203.230.10 e.root-servers.net. 518400 IN AAAA 2001:500:a8::e f.root-servers.net. 518400 IN A 192.5.5.241 f.root-servers.net. 518400 IN AAAA 2001:500:2f::f g.root-servers.net. 518400 IN A 192.112.36.4 g.root-servers.net. 518400 IN AAAA 2001:500:12::d0d h.root-servers.net. 518400 IN A 198.97.190.53 h.root-servers.net. 518400 IN AAAA 2001:500:1::53 i.root-servers.net. 518400 IN A 192.36.148.17 i.root-servers.net. 518400 IN AAAA 2001:7fe::53 j.root-servers.net. 518400 IN A 192.58.128.30 j.root-servers.net. 518400 IN AAAA 2001:503:c27::2:30 k.root-servers.net. 518400 IN A 193.0.14.129 k.root-servers.net. 518400 IN AAAA 2001:7fd::1 l.root-servers.net. 518400 IN A 199.7.83.42 l.root-servers.net. 518400 IN AAAA 2001:500:9f::42 m.root-servers.net. 518400 IN A 202.12.27.33 m.root-servers.net. 518400 IN AAAA 2001:dc3::35 ;; Query time: 3 msec ;; SERVER: 2001:7fd::1#53(2001:7fd::1) ;; WHEN: Fri Mar 03 17:29:05 CET 2017 ;; MSG SIZE rcvd: 811
(Les raisons du choix des trois options données à dig sont indiquées plus loin.)
La section 3 de notre RFC décrit en détail à quoi ressemblent les requêtes
de priming. Le type de données demandé
(QTYPE) est NS (Name Servers,
type 2) et le nom demandé (QNAME) est « . »
(oui, juste la racine). D'où le dig NS .
ci-dessus. Le bit RD (Recursion Desired) est
typiquement mis à zéro (d'où le +norecurse
dans l'exemple avec dig). La taille de la réponse dépassant les 512
octets (limite très ancienne du DNS), il faut utiliser
EDNS (cause du
+bufsize=4096 dans l'exemple). On peut
utiliser le bit DO (DNSSEC OK) qui indique qu'on
demande les signatures DNSSEC mais ce n'est pas habituel (d'où le
+nodnssec dans l'exemple). En effet, si la
racine est signée, permettant d'authentifier l'ensemble
d'enregistrements NS, la zone
root-servers.net, où se trouvent actuellement
tous les serveurs de la racine, ne l'est pas, et les
enregistrements A et AAAA ne peuvent donc pas être validés avec DNSSEC.
Cette requête de priming est envoyée lorsque le résolveur démarre, et aussi lorsque la réponse précédente a expiré (regardez le TTL dans l'exemple : six jours). Si le premier serveur testé ne répond pas, on essaie avec un autre. Ainsi, même si le fichier de configuration n'est pas parfaitement à jour (des vieilles adresses y trainent), le résolveur finira par avoir la liste correcte.
Et comment choisit-on le premier serveur qu'on interroge ? Notre RFC recommande un tirage au sort, pour éviter que toutes les requêtes de priming ne se concentrent sur un seul serveur (par exemple le premier de la liste). Une fois que le résolveur a démarré, il peut aussi se souvenir du serveur le plus rapide, et n'interroger que celui-ci, ce qui est fait par la plupart des résolveurs, pour les requêtes ordinaires (mais n'est pas conseillé pour le priming).
Et les réponses au priming ? Il faut bien
noter que, pour le serveur racine, les requêtes
priming sont des requêtes comme les autres, et
ne font pas l'objet d'un traitement particulier. Normalement, la
réponse doit avoir le code de retour NOERROR
(c'est bien le cas dans mon exemple). Parmi les
flags, il doit y avoir AA
(Authoritative Answer). La section de réponse
doit évidemment contenir les NS de la racine, et la section
additionnelle les adresses IP. Le résolveur garde alors cette
réponse dans son cache, comme il le ferait pour n'importe quelle
autre réponse. Notez que là aussi, il ne faut pas de traitement
particulier. Par exemple, le résolveur ne doit pas compter qu'il y
aura exactement 13 serveurs, même si c'est le cas depuis longtemps
(ça peut changer).
Normalement, le serveur racine envoie la totalité des adresses IP (deux par serveur, une en IPv4 et une en IPv6). S'il ne le fait pas (par exemple par manque de place parce qu'on a bêtement oublié EDNS), le résolveur va devoir envoyer des requêtes A et AAAA explicites pour obtenir les adresses IP :
% dig @k.root-servers.net A g.root-servers.net
; <<>> DiG 9.10.3-P4-Debian <<>> @k.root-servers.net A g.root-servers.net
; (2 servers found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 49091
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 13, ADDITIONAL: 26
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 4096
;; QUESTION SECTION:
;g.root-servers.net. IN A
;; ANSWER SECTION:
g.root-servers.net. 3600000 IN A 192.112.36.4
...
Vous pouvez voir ici les requêtes et réponses de priming d'un Unbound utilisant Yeti. D'abord, décodées par tcpdump :
20:31:36.226325 IP6 2001:4b98:dc2:43:216:3eff:fea9:41a.7300 > 2a02:cdc5:9715:0:185:5:203:53.53: 50959% [1au] NS? . (28) 20:31:36.264584 IP6 2a02:cdc5:9715:0:185:5:203:53.53 > 2001:4b98:dc2:43:216:3eff:fea9:41a.7300: 50959*- 26/0/7 NS bii.dns-lab.net., NS yeti.bofh.priv.at., NS yeti.ipv6.ernet.in., NS yeti.aquaray.com., NS yeti.mind-dns.nl., NS dahu1.yeti.eu.org., NS dahu2.yeti.eu.org., NS yeti1.ipv6.ernet.in., NS ns-yeti.bondis.org., NS yeti-ns.ix.ru., NS yeti-ns.lab.nic.cl., NS yeti-ns.tisf.net., NS yeti-ns.wide.ad.jp., NS yeti-ns.conit.co., NS yeti-ns.datev.net., NS yeti-ns.switch.ch., NS yeti-ns.as59715.net., NS yeti-ns1.dns-lab.net., NS yeti-ns2.dns-lab.net., NS yeti-ns3.dns-lab.net., NS xn--r2bi1c.xn--h2bv6c0a.xn--h2brj9c., NS yeti-dns01.dnsworkshop.org., NS yeti-dns02.dnsworkshop.org., NS 3f79bb7b435b05321651daefd374cd.yeti-dns.net., NS ca978112ca1bbdcafac231b39a23dc.yeti-dns.net., RRSIG (1225)
Et ici par tshark :
1 0.000000 2001:4b98:dc2:43:216:3eff:fea9:41a → 2a02:cdc5:9715:0:185:5:203:53 DNS 90 Standard query 0xc70f NS <Root> OPT 2 0.038259 2a02:cdc5:9715:0:185:5:203:53 → 2001:4b98:dc2:43:216:3eff:fea9:41a DNS 1287 Standard query response 0xc70f NS <Root> NS bii.dns-lab.net NS yeti.bofh.priv.at NS yeti.ipv6.ernet.in NS yeti.aquaray.com NS yeti.mind-dns.nl NS dahu1.yeti.eu.org NS dahu2.yeti.eu.org NS yeti1.ipv6.ernet.in NS ns-yeti.bondis.org NS yeti-ns.ix.ru NS yeti-ns.lab.nic.cl NS yeti-ns.tisf.net NS yeti-ns.wide.ad.jp NS yeti-ns.conit.co NS yeti-ns.datev.net NS yeti-ns.switch.ch NS yeti-ns.as59715.net NS yeti-ns1.dns-lab.net NS yeti-ns2.dns-lab.net NS yeti-ns3.dns-lab.net NS xn--r2bi1c.xn--h2bv6c0a.xn--h2brj9c NS yeti-dns01.dnsworkshop.org NS yeti-dns02.dnsworkshop.org NS 3f79bb7b435b05321651daefd374cd.yeti-dns.net NS ca978112ca1bbdcafac231b39a23dc.yeti-dns.net RRSIG AAAA 240c:f:1:22::6 AAAA 2a01:4f8:161:6106:1::10 AAAA 2001:e30:1c1e:1:
Et un décodage plus détaillé de tshark dans ce fichier.
Enfin, la section 5 de notre RFC traite des problèmes de sécurité du priming. Évidemment, si un attaquant injecte une fausse réponse aux requêtes de priming, il pourra détourner toutes les requêtes ultérieures vers des machines de son choix. À part le RFC 5452, la seule protection est DNSSEC : si le résolveur valide (et a donc la clé publique de la racine), il pourra détecter que les réponses sont mensongères. Cela a l'avantage de protéger également contre d'autres attaques, ne touchant pas au priming, comme les attaques sur le routage.
Notez que DNSSEC est recommandé pour valider les réponses
ultérieures mais, comme on l'a vu, n'est pas important pour valider
la réponse de priming elle-même, puisque
root-servers.net n'est pas signé. Si un
attaquant détournait, d'une manière ou d'une autre, vers un faux
serveur racine, servant de fausses données, ce ne serait qu'une
attaque par déni de
service, puisque le résolveur validant pourrait
détecter que les réponses sont fausses.
Ce RFC a connu une très longue gestation puisque le premier brouillon date de février 2007 (vous pouvez admirer la chronologie).
L'article seul
RFC 8117: Current Hostname Practice Considered Harmful
Date de publication du RFC : Mars 2017
Auteur(s) du RFC : C. Huitema (Private Octopus
Inc.), D. Thaler
(Microsoft), R. Winter (University of Applied
Sciences Augsburg)
Pour information
Réalisé dans le cadre du groupe de travail IETF intarea
Première rédaction de cet article le 12 mars 2017
« Je suis l'iPhone de Jean-Luc ! » Traditionnellement, les ordinateurs connectés à l'Internet ont un nom, et ce nom est souvent annoncé à l'extérieur par divers protocoles. Cette pratique très répandue, dont l'origine remonte à l'époque où on n'avait que quelques gros serveurs partagés, et fixes, est dangereuse pour la vie privée, dans un monde de mobilité et de machines individuelles. Comme le note ce nouveau RFC, « c'est comme si on se promenait dans la rue avec une étiquette bien visible portant son nom ». Ce RFC dresse l'état des lieux, fait la liste des protocoles problématiques, et suggère, lorsqu'on ne peut pas changer le protocole, d'utiliser des noms aléatoires, ne révélant rien sur la machine.
Pour illustrer le problème, voici un exemple du trafic WiFi pendant une réunion, en n'écoutant qu'un seul protocole, mDNS (RFC 6762). Et d'autres protocoles sont tout aussi bavards. Notez que cette écoute n'a nécessité aucun privilège particulier sur le réseau (cf. RFC 8386), ni aucune compétence. N'importe quel participant à la réunion, ou n'importe quelle personne située à proximité pouvait en faire autant avec tcpdump (j'ai changé les noms des personnes) :
% sudo tcpdump -n -vvv port 5353 tcpdump: listening on wlp2s0, link-type EN10MB (Ethernet), capture size 262144 bytes 15:03:16.909436 IP6 fe80::86a:ed2c:1bcc:6540.5353 > ff02::fb.5353: 0*- [0q] 2/0/3 0.4.5.6.C.C.B.1.C.2.D.E.A.6.8.0.0.0.0.0.0.0.0.0.0.0.0.0.0.8.E.F.ip6.arpa. (Cache flush) [2m] PTR John-Smiths-iPhone-7.local., [...] 15:03:17.319992 IP 172.25.1.84.5353 > 224.0.0.251.5353: 0*- [0q] 2/0/3 C.4.1.6.F.8.D.E.0.3.6.3.4.1.0.1.0.0.0.0.0.0.0.0.0.0.0.0.0.8.E.F.ip6.arpa. (Cache flush) [2m] PTR Jane-iPhone.local., [...] 15:03:20.699557 IP6 fe80::e2ac:cbff:fe95:da80.5353 > ff02::fb.5353: 0 [5q] [4n] [1au] PTR (QU)? _googlecast._tcp.local. ANY (QU)? info-mac-66._smb._tcp.local. [...]
On y voit que les noms des machines présentes sont annoncés à
tous (ff02::fb et
224.0.0.251 sont des adresses
multicast). Certains
noms sont très révélateurs (nom, prénom et type de la machine),
d'autres un peu moins (prénom et type), d'autres sont presques
opaques (juste un type de machine, très général). Un indiscret qui
regarde le trafic sur des réseaux publiquement accessibles peut
ainsi se faire une bonne idée de quelles machines sont présentes,
voire de qui est présent. Les deux exemples des noms
info-mac-66 et
John-Smiths-iPhone-7 illustrent les deux
risques. Dans le premier cas, si le nom est stable, il permet de
suivre à la trace une machine qui se déplacerait. Le second cas
est encore pire puisqu'on a directement le nom du propriétaire.
Le fait que les ordinateurs aient des noms est une tradition très ancienne (voir la définition de host name dans le RFC 8499). Un nom court (sans point à l'intérieur) combiné avec un suffixe forme un FQDN (Fully Qualified Domain Name, cf. RFC 1983). On utilise ces noms courts et ces FQDN à plein d'endroits. IP lui-même n'utilise pas de noms du tout mais plein de protocoles de la famille TCP/IP le font, comme mDNS montré plus haut.
Un nom court doit être unique dans un contexte donné mais n'est pas forcément unique mondialement. Le FQDN, lui, est unique au niveau mondial.
Je vous recommande l'excellent travail de M. Faath, F. Weisshaar et R. Winter, « How Broadcast Data Reveals Your Identity and Social Graph » à l'atelier TRAC 2016 (supports de leur exposé), montrant toutes les fuites d'information liées à cette utilisation des noms, et ce qu'un méchant peut en faire. (C'est ce groupe qui avait écouté le trafic WiFi lors d'une réunion IETF à Prague, déclenchant une grande discussion sur les attentes en matière de vie privée quand le trafic est diffusé.)
Pourquoi nomme-t-on les ordinateurs, au fait, à part la tradition ? Sur un réseau, bien des systèmes d'exploitation, à commencer par Unix et Windows tiennent pour acquis que les ordinateurs ont un nom, et ce nom peut être utilisé dans des tas de cas. Il existe plusieurs schémas de nommage (section 2 du RFC), du plus bucolique (noms de fleurs) au plus français (noms de vins) en passant par les schémas bien geeks comme les noms des personnages du Seigneur des Anneaux. Mais, parfois, c'est le système d'exploitation lui-même qui nomme l'ordinateur, en combinant le nom de l'utilisateur et les caractéristiques de l'ordinateur, comme on le voit avec les iPhones dans l'exemple tcpdump ci-dessus. (Sur les schémas de nommage, voir le RFC 1178, et, sur un ton plus léger, le RFC 2100. Il existe une excellente page Web pleine d'idées de noms. L'ISC fait des statistiques sur les noms vus sur Internet. Entre 1995 et 2017, vous pouvez constater la décroissance des noms sympas en faveur des noms utilitaires.)
Dans les environnements corporate, on ne
laisse pas l'utilisateur choisir et il y a un schéma officiel. Par
exemple, sur le réseau interne de
Microsoft, le nom est dérivé du nom de
login de l'utilisateur et un des auteurs du RFC
a donc une machine huitema-test-2.
Est-il nécessaire de donner des noms aux « objets », ces
machines à laver ou brosses à dents connectés, qui sont des
ordinateurs, mais ne sont en général pas perçus comme tels (ce qui
a des graves conséquences en terme de sécurité) ? Comme ces engins
n'offrent en général pas de services, ils ont moins besoin d'un
nom facile à retenir, et, lorsque les protocoles réseaux employés
forcent à utiliser un nom, c'est également un nom fabriqué à
partir du nom du fabricant, du modèle de l'appareil et de son
numéro de série (donc, un nom du genre
BrandX-edgeplus-4511-2539). On voit même
parfois la langue parlée par l'utilisateur utilisée dans ce nom,
qui est donc très « parlant ».
Même un identificateur partiel peut être révélateur (section 3
du RFC). Si on ordinateur se nomme
dthaler-laptop, on ne peut pas être sûr qu'il
appartienne vraiment au co-auteur du RFC Dave Thaler. Il y a
peut-être d'autres D. Thaler dans le monde. Mais si on
observe cet ordinateur faire une connexion au réseau interne de
Microsoft (pas besoin de casser le
chiffrement, les
métadonnées suffisent), on est alors
raisonnablement sûr qu'on a identifié le propriétaire.
Beaucoup de gens croient à tort qu'un identificateur personnel
doit forcément inclure le nom d'état civil de l'utilisateur. Mais
ce n'est pas vrai : il suffit que l'identificateur soit stable, et
puisse être relié, d'une façon ou d'une autre, au nom de
l'utilisateur. Par exemple, si un ordinateur
portable a le nom stable a3dafaaf70950 (nom
peu parlant) et que l'observateur ait pu voir une fois cette
machine faire une connexion à un compte
IMAP jean_dupont, on
peut donc associer cet ordinateur à Jean Dupont, et le suivre
ensuite à la trace.
Ce risque est encore plus important si l'attaquant maintient une base de données des identifications réussies (ce qui est automatisable), et des machines associées. Une ou deux fuites d'information faites il y a des mois, voire des années, et toutes les apparitions ultérieures de cette machine mèneront à une identification personnelle.
Donc, n'écoutez pas les gens qui vous parleront d'« anonymat »
parce que les noms de machine ne sont pas parlants (comme le
a3dafaaf70950 plus haut). Si quelqu'un fait
cela, cela prouve simplement qu'il ne comprend rien à la sécurité
informatique. Un nom stable, pouvant être observé (et on a vu que
bien des protocoles étaient très indiscrets), permet
l'observation, et donc la surveillance.
Justement, quels sont les protocoles qui laissent ainsi fuiter des noms de machine, que l'observateur pourra noter et enregistrer (section 4 du RFC) ? Il y a d'abord DHCP, où le message de sollicitation initial (diffusé à tous…) contient le nom de la machine en clair. Le problème de vie privée dans DHCP est analysé plus en détail dans les RFC 7819 et RFC 7824. Les solutions pour limiter les dégâts sont dans le RFC 7844.
Le DNS est également une cause de fuite,
par exemple parce qu'il permet d'obtenir le nom d'une machine à
partir de son adresse IP, avec les requêtes PTR dans
in-addr.arpa ou ip6.arpa, nom qui peut
réveler des détails. C'est le cas avec tout protocole conçu
justement pour distribuer des informations, comme celui du RFC 4620 (qui ne semble pas très déployé dans la nature).
Plus sérieux est le problème de mDNS (RFC 6762), illustré par le tcpdump montré plus haut. Les requêtes sont diffusées à tous sur le réseau local, et contiennent, directement ou indirectement, les noms des machines. Même chose avec le DNS Service Discovery du RFC 6763 et le LLMNR du RFC 4795 (beaucoup moins fréquent que mDNS).
Enfin, NetBIOS (quelqu'un l'utilise encore ?) est également une grande source d'indiscrétions.
Assez décrit le problème, comment le résoudre (section 5) ? Bien sûr, il faudra des protocoles moins bavards, qui ne clament pas le nom de la machine à tout le monde. Mais changer d'un coup des protocoles aussi répandus et aussi fermement installés que, par exemple, DHCP, ne va pas être facile. De même, demander aux utilisateurs de ne pas faire de requêtes DHCP lorsqu'ils visitent un réseau « non sûr » est difficile (déjà, comment l'utilisateur va-t-il correctement juger si le réseau est sûr ?), d'autant plus qu'ils risquent fort de ne pas avoir de connectivité du tout, dans ce cas. Certes, couper les protocoles non nécessaires est un bon principe de sécurité en général. Mais cet angle d'action semble quand même bien trop drastique. (Il faut aussi noter qu'il existe des protocoles privés, non-IETF, qui peuvent faire fuire des noms sans qu'on le sache. Le client Dropbox diffuse à la cantonade l'ID du client, et celui des shares où il se connecte. Il est facile de faire un graphe des utilisateurs en mettant ensemble ceux qui se connectent au même share.)
La suggestion de notre RFC est donc d'attaquer le problème d'une autre façon, en changeant le nom de la machine, pour lui substituer une valeur imprévisible (comme le fait le RFC 7844 pour les adresses MAC). Pour chaque nouveau réseau où est connectée la machine, on génère aléatoirement un nouveau nom, et c'est celui qu'on utilisera dans les requêtes DHCP ou mDNS. Ces protocoles fonctionneront toujours mais la surveillance des machines mobiles deviendra bien plus difficile. Bien sûr, pour empêcher toute corrélation, le changement de nom doit être coordonné avec les changements des autres identificateurs, comme l'adresse IP ou l'adresse MAC.
Windows a même un concept de « nom de machine par réseau », ce qui permet aux machines ayant deux connexions de présenter deux identités différentes (malheureusement, Unix n'a pas ce concept, le nom est forcément global).
Bien sûr, on n'a rien sans rien (section 6). Si on change les noms des machines, on rendra l'administration système plus difficile. Par exemple, l'investigation sur un incident de sécurité sera plus complexe. Mais la défense de la vie privée est à ce prix.
Pour l'instant, à ma connaissance, il n'y a pas encore de mise en œuvre de cette idée de noms imprévisibles et changeants. (Une proposition a été faite pour Tails. Notez qu'il existe d'autres possibilités comme d'avoir un nom unique partout.)
L'article seul
RFC 8128: IETF Appointment Procedures for the ICANN Root Zone Evolution Review Committee
Date de publication du RFC : Mars 2017
Auteur(s) du RFC : C. Morgan (AMS)
Pour information
Première rédaction de cet article le 11 mars 2017
Un petit RFC purement bureaucratique publié hier, il décrit les procédures par lesquelles l'IETF nomme un représentant dans un des innombrables comités de l'ICANN, le RZERC (Root Zone Evolution Review Committee), qui travaille sur la gestion de la zone racine du DNS.
Ce nouveau comité RZERC est chargé des mécanismes de publication de la zone racine, une zone évidemment cruciale puisque la nature arborescente du DNS fait que, si elle a des problèmes, plus rien ne marche. Notez que le RZERC ne s'occupe que de la création et de la publication de la zone racine, pas de servir cette zone. Cette tâche incombe en effet aux serveurs racines du DNS, qui sont indépendants de l'ICANN (contrairement à ce qu'on lit souvent dans des médias mal informés). L'actuelle charte du RZERC est en ligne et elle prévoit que le comité comprend entre autres « The Chair or delegate of the Internet Engineering Task Force ».
C'est l'IAB qui désigne le représentant IETF, le premier étant Jim Reid. Les qualités nécessaires sont citées en section 2 de notre RFC. Sans surprise, il faut être techniquement très compétent, et il faut pouvoir traduire des recommandations en des termes compréhensibles par la bureaucratie ICANN (« be able to articulate those technology issues such that the ICANN Board can be provided with sound technical perspectives »). Le RFC précise également qu'il faut comprendre l'articulation de la gouvernance Internet et les rôles des différents organismes, une tâche complexe, c'est sûr !
Suivant les procédures décrites en section 3 du RFC, un appel à volontaires avait été lancé le 25 mai 2016, il y avait quatre candidats (Marc Blanchet, Warren Kumari, Kaveh Ranjbar et Jim Reid), et Jim Reid a été nommé le 11 août 2016. Depuis, si on veut savoir ce que fait ce comité, il faut regarder sa page Web officielle. Son rôle n'est pas encore bien défini et fait l'objet de la plupart des discussions. En gros, il devrait intervenir uniquement lorsqu'une proposition de changement important est faite, pas pour la gestion quotidienne.
L'article seul
RFC 8078: Managing DS records from the Parent via CDS/CDNSKEY
Date de publication du RFC : Mars 2017
Auteur(s) du RFC : O. Gudmundsson
(CloudFlare), P. Wouters (Red Hat)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 11 mars 2017
Un problème fréquent avec DNSSEC est de transmettre à sa zone parente les clés publiques de signature de sa zone, pour que le parent puisse signer un lien qui va vers ces clés (l'enregistrement de type DS). Le RFC 7344 apportait une solution partielle, avec ses enregistrements CDS et CDNSKEY. Il y manquait deux choses : la création du premier DS (activation initiale de DNSSEC), et le retrait de tout les DS (on arrête de faire du DNSSEC). Ce nouveau RFC 8078 comble ces deux manques (et, au passage, change l'état du RFC 7344, qui passe sur le Chemin des Normes).
Avant le RFC 7344, tout changement des clés KSK (Key Signing Key) d'une zone nécessitait une interaction avec la zone parente, par le biais d'un mécanisme non-DNS (« out-of-band », par exemple un formulaire Web). La solution du RFC 7344, elle, n'utilise que le DNS (« in-band »). Ce nouveau RFC complète le RFC 7344 pour les configurations initiales et finales. (Le problème est complexe car il peut y avoir beaucoup d'acteurs en jeu. Par exemple, le BE n'est pas forcément l'hébergeur DNS. Ces difficultés ont certainement nui au déploiement de DNSSEC.)
Lorsqu'on change d'hébergeur DNS, la solution la plus propre est de faire un remplacement des clés, depuis celle de l'ancien hébergeur jusqu'à celle du nouveau. Cette solution préserve en permanence la sécurité qu'offre DNSSEC. Mais une des procédures mentionnées par notre RFC passe au contraire par un état non sécurisé, où la zone n'est pas signée. C'est dommage mais cela est parfois nécessaire si :
- Les logiciels utilisés ne permettent pas de faire mieux, ou l'un des deux hébergeurs ne veut pas suivre la procédure « propre »,
- Ou bien le nouvel hébergeur ne gère pas DNSSEC du tout, ou encore le titulaire de la zone ne veut plus de DNSSEC.
Une zone non signée vaut certainement mieux qu'une signature invalide. Mais le RFC oublie de dire que cela va casser certaines applications de sécurité qui exigent DNSSEC comme DANE (RFC 6698) ou SSHFP (RFC 4255).
Avant de lire la suite de ce RFC, deux conseils :
- Lisez bien le RFC 7344. Vraiment.
- Rappelez-vous qu'il y a des tas d'acteurs possibles dans le DNS. Le modèle RRR (Titulaire-BE-Registre, Registrant-Registrar-Registry) n'est pas le seul. Et il n'y a pas que les TLD qui délèguent des zones ! Le RFC parle donc uniquement de « parent » (responsable parental ?) pour désigner l'entité à laquelle on s'adresse pour obtenir des changements dans la zone parente.
Les enregistrements CDS (Client-side Delegation Signer) servent à trois choses (section 2 du RFC) :
- Installer le DS (Delegation Signer) initial dans la zone parente,
- Remplacer (rollover) la clé publique de signature des clés (KSK, Key-Signing Key) dans la zone parente,
- Supprimer le DS de la zone parente, débrayant ainsi la validation DNSSEC de la zone fille chez les résolveurs.
Avec le RFC 7344, seule la deuxième était possible (c'est la moins dangereuse, qui ne nécessite aucun changement dans les relations de confiance,notamment entre parente et fille). Notre RFC 8078 permet désormais les deux autres, plus délicates, car posant davantage de problèmes de sécurité.
La sémantique des enregistrements CDS (ou CDNSKEY) est donc désormais « la publication d'un ou plusieurs CDS indique un souhait de synchronisation avec la zone parente ; celle-ci est supposée avoir une politique en place pour accepter/refuser/vérifier ce ou ces CDS, pour chacune des trois utilisations notées ci-dessus ». Quand des CDS différents des DS existants apparaissent dans la zone fille, le responsable parental doit agir.
D'abord, l'installation initiale d'un DS alors qu'il n'y en avait pas avant (section 3 du RFC). La seule apparition du CDS ou du CDNSKEY ne peut pas suffire car comment le vérifier, n'ayant pas encore de chaîne DNSSEC complète ? Le responsable parental peut utiliser les techniques suivantes :
- Utiliser un autre canal, extérieur au DNS, par exemple l'API du responsable parental,
- Utiliser des tests de vraisemblance, du genre un message de confirmation envoyé au contact technique du domaine, ou bien regarder si la configuration du domaine est stable,
- Attendre un certain temps, de préférence vérifier depuis plusieurs endroits dans le réseau (pour éviter les empoisonnements locaux), puis considérer le CDS comme valable s'il est resté pendant ce temps (l'idée est qu'un piratage aurait été détecté, pendant ce délai),
- Envoyer un défi au titulaire de la zone fille, par exemple génerer une valeur aléatoire et lui demander de l'insérer sous forme d'un enregistrement TXT dans la zone (bien des applications qui veulent vérifier le responsable d'un domaine font cela, par exemple Keybase ou bien Google webmasters),
- Accepter immédiatement s'il s'agit d'une nouvelle délégation. Ainsi, le domaine sera signé et validable dès le début.
La deuxième utilisation des CDS, remplacer une clé est, on l'a vu, déjà couverte par le RFC 7344.
Et pour la troisième utilisation, la suppression de tous les DS chez le parent ? Elle fait l'objet de la section 4 du RFC. Pour demander cette suppression, on publie un CDS (ou un CDNSKEY) avec un champ « algorithme » à zéro. Cette valeur n'est pas affectée à un vrai algorithme dans le registre officiel, elle est réservée (cf. section 6 du RFC) pour dire « efface ». (Le RFC 4398 utilisait déjà le même truc.)
Pour éviter tout accident, le RFC est plus exigeant que cela et exige cette valeur spécifique pour ces enregistrements :
DOMAINNAME IN CDS 0 0 0 0
ou bien :
DOMAINNNAME IN CDNSKEY 0 3 0 0
(Le 3 étant l'actuel numéro de version de DNSSEC, voir le RFC 4034, section 2.1.2.)
Une fois le CDS (ou CDNSKEY) « zéro » détecté, et validé par DNSSEC, le parent retire le DS. Une fois le TTL passé, le fils peut « dé-signer » la zone.
À noter que ce RFC a été retardé par la question du déplacement du RFC 7344, de son état « pour information », au Chemin des Normes. La demande était discrète, et avait été raté par certains relecteurs, qui ont protesté ensuite contre ce « cavalier ». L'« élévation » du RFC 7344 est désormais explicite.
Cette possibilité est opérationnelle en .ch ou .cz. Jan-Piet Mens a fait un excellent article sur son utilisation dans .ch.
L'article seul
RFC 8095: Services Provided by IETF Transport Protocols and Congestion Control Mechanisms
Date de publication du RFC : Mars 2017
Auteur(s) du RFC : G. Fairhurst (University of Aberdeen), B. Trammell, M. Kuehlewind (ETH Zurich)
Pour information
Réalisé dans le cadre du groupe de travail IETF taps
Première rédaction de cet article le 10 mars 2017
Les protocoles de transport (couche 4 dans le modèle en couches traditionnel), comme le fameux TCP, fournissent certains services aux applications situées au-dessus d'eux. Mais quels services exactement ? Qu'attend-on de la couche de transport ? Le but de ce RFC de synthèse est de lister tous les services possibles de la couche 4, et d'analyser ensuite tous les protocoles existants pour voir lesquels de ces services sont offerts. Ce document ne normalise donc pas un nouveau protocole, il classe et organise les protocoles existants. (L'idée est de pouvoir ensuite développer une interface abstraite permettant aux applications d'indiquer quels services elles attendent de la couche transport au lieu de devoir, comme c'est le cas actuellement, choisir un protocole donné. Une telle interface abstraite permettrait au système d'exploitation de choisir le protocole le plus adapté à chaque environnement.)
C'est d'autant plus important qu'il n'y a pas que TCP mais aussi des protocoles comme SCTP, UDP, DCCP, les moins connus FLUTE ou NORM, et même HTTP, qui est devenu une couche de transport de fait. Toute évolution ultérieure de l'architecture de l'Internet, des middleboxes, des API offertes par le système d'exploitation, implique une compréhension détaillée de ce que fait exactement la couche transport.
Pour TCP, tout le monde connait (ou croit connaitre) : il fournit un service de transport de données fiable (les données qui n'arrivent pas sont retransmises automatiquement, l'application n'a pas à s'en soucier, la non-modification est - insuffisamment - contrôlée via une somme de contrôle), et ordonné (les octets arrivent dans l'ordre d'envoi même si, dans le réseau sous-jacent, un datagramme en a doublé un autre). TCP ne fournit pas par contre de service de confidentialité, ce qui facilite le travail de la NSA ou de la DGSI. Tout le monde sait également qu'UDP ne fournit aucun des deux services de fiabilité et d'ordre : si l'application en a besoin, elle doit le faire elle-même (et il est donc logique que la plupart des applications utilisent TCP).
Parfois, le service de transport offert aux applications est lui-même bâti sur un autre service de transport. C'est la raison pour laquelle ce RFC présente des protocoles qui ne sont pas « officiellement » dans la couche 4 (mais, de toute façon, le modèle en couches n'a toujours été qu'une vague indication ; en faire une classification rigide n'a aucun intérêt, et a été une des raisons de l'échec du projet l'OSI). Un exemple est TLS. Une application qui s'en sert ne voit pas directement le TCP sous-jacent, elle confie ses données à TLS qui, à son tour, fait appel à TCP. Le service de transport vu par l'application offre ainsi les fonctions de TCP (remise fiable et ordonnée des données) plus celles de TLS (confidentialité, authentification et intégrité). Il faudrait être particulièrement pédant pour s'obstiner à classer TLS dans les applications comme on le voit parfois.
Le même phénomène se produit pour UDP : comme ce protocole n'offre quasiment aucun service par lui-même, on le complète souvent avec des services comme TFRC (RFC 5348) ou LEDBAT (RFC 6817) qui créent ainsi un nouveau protocole de transport au-dessus d'UDP.
La section 1 de notre RFC liste les services possibles d'une couche de transport :
- Envoi des messages à un destinataire (unicast) ou à plusieurs (multicast ou anycast),
- Unidirectionnel (ce qui est toujours le cas avec le multicast) ou bidirectionnel,
- Nécessite un établissement de la connexion avant d'envoyer des données, ou pas,
- Fiabilité de l'envoi (par un mécanisme d'accusé de réception et de réémission) ou bien fire and forget (notez que cette fiabilité peut être partielle, ce que permet par exemple SCTP),
- Intégrité des données (par exemple via une somme de contrôle),
- Ordre des données (avec certains protocoles de transport comme UDP, le maintien de l'ordre des octets n'est pas garanti, un paquet pouvant en doubler un autre),
- Structuration des données (framing), certains protocoles découpent en effet les données en messages successifs (ce que ne fait pas TCP),
- Gestion de la congestion,
- Confidentialité,
- Authentification (TLS fournit ces deux derniers services).
La section 3 du RFC est le gros morceau. Elle liste tous les protocoles de transport possibles (au moins ceux normalisés par l'IETF), en donnant à chaque fois une description générale du protocole, l'interface avec les applications, et enfin les services effectivement offerts par ce protocole.
À tout seigneur, tout honneur, commençons par l'archétype des protocoles de transport, TCP. Normalisé dans le RFC 793, très largement répandu (il est difficile d'imaginer une mise en œuvre d'IP qui ne soit pas accompagnée de TCP), utilisé quotidiennement par des milliards d'utilisateurs. Le RFC originel a connu pas mal de mises à jour et, aujourd'hui, apprendre TCP nécessite de lire beaucoup de RFC (le RFC 7414 en donne la liste). Ainsi, la notion de données urgentes, qui était dans le RFC originel, a été supprimée par le RFC 6093.
TCP multiplexe les connexions en utilisant les numéros de port, comme beaucoup de protocoles de transport. Une connexion est identifiée par un tuple {adresse IP source, port source, adresse IP destination, port destination}. Le port de destination identifie souvent le service utilisé (c'est moins vrai aujourd'hui, où la prolifération de middleboxes stupides oblige à tout faire passer sur les ports 80 et 443). TCP fournit un service de données non-structurées, un flot d'octets, mais, en interne, il découpe ces octets en segments, dont la taille est négociée au début (en général, TCP essaie de faire que cette taille soit la MTU du chemin, en utilisant les RFC 1191, RFC 1981 et de plus en plus le RFC 4821). Chaque octet envoyé a un numéro, le numéro de séquence, et c'est ainsi que TCP met en œuvre la fiabilité et l'ordre. (Contrairement à ce que croient certaines personnes, c'est bien l'octet qui a un numéro, pas le segment.) Autrefois, si deux segments non contigus étaient perdus, il fallait attendre la réémission du premier pour demander celle du second, mais les accusés de réception sélectifs du RFC 2018 ont changé cela.
Quant au contrôle de congestion de TCP, il est décrit en détail dans le RFC 5681. TCP réagit à la perte de paquets (ou bien à leur marquage avec l'ECN du RFC 3168) en réduisant la quantité de données envoyées.
Les données envoyées par l'application ne sont pas forcément transmises immédiatement au réseau. TCP peut attendre un peu pour remplir davantage ses segments (RFC 896). Comme certaines applications (par exemple celles qui sont fortement interactives comme SSH) n'aiment pas les délais que cela entraine, ce mécanisme est typiquement débrayable.
Enfin, pour préserver l'intégrité des données envoyées, TCP utilise une somme de contrôle (RFC 793, section 3.1, et RFC 1071). Elle ne protège pas contre toutes les modifications possibles et il est recommandé aux applications d'ajouter leur propre contrôle d'intégrité (par exemple, si on transfère un fichier, via un condensat du fichier).
Et l'interface avec les applications, cruciale, puisque le rôle
de la couche transport est justement d'offrir des services aux
applications ? Celle de TCP est décrite de manière relativement
abstraite dans le RFC 793 (six commandes,
Open, Close,
Send, Receive, etc). Des
points comme les options TCP n'y sont pas spécifiés. Le RFC 1122 est un peu plus détaillé, mentionnant
par exemple l'accès aux messages ICMP qui
peuvent indiquer une erreur TCP. Enfin, une interface concrète est
celle des prises,
normalisées par POSIX (pas de RFC à ce sujet). Vous créez une prise
avec l'option SOCK_STREAM et hop, vous
utilisez TCP et tous ses services.
Quels services, justement ? TCP fournit :
- Établissement d'une connexion, et démultiplexage en utilisant les numéros de port,
- Transport unicast (l'anycast est possible, si on accepte le risque qu'un changement de routes casse subitement une connexion),
- Communication dans les deux sens,
- Données envoyées sous forme d'un flot d'octets, sans séparation (pas de notion de message, c'est à l'application de le faire, si elle le souhaite, par exemple en indiquant la taille du message avant le message, comme le font EPP et DNS), c'est aussi cela qui permet l'accumulation de données avant envoi (algorithme de Nagle),
- Transport fiable, les données arriveront toutes, et dans l'ordre,
- Détection d'erreurs (mais pas très robuste),
- Contrôle de la congestion, via les changements de taille de la fenêtre d'envoi (la fenêtre est l'ensemble des octets qui peuvent être envoyés avant qu'on ait reçu l'accusé de réception des données en cours), voir le RFC 5681.
Par contre, TCP ne fournit pas de confidentialité, et l'authentification se limite à une protection de l'adresse IP contre les attaquants situés hors du chemin (RFC 5961).
Après TCP, regardons le deuxième protocole de transport étudié, MPTCP (Multipath TCP, RFC 6824). C'est une extension de TCP qui permet d'exploiter le multi-homing. Pour échapper aux middleboxes intrusives, MPTCP fonctionne en créant plusieurs connexions TCP ordinaires depuis/vers toutes les adresses IP utilisées, et en multiplexant les données sur ces connexions (cela peut augmenter le débit, et cela augmente la résistance aux pannes, mais cela peut aussi poser des problèmes si les différents chemins ont des caractéristiques très différentes). La signalisation se fait par des options TCP.
L'interface de base est la même que celle de TCP, mais il existe des extensions (RFC 6897) pour tirer profit des particularités de MPTCP.
Les services sont les mêmes que ceux de TCP avec, en prime le multi-homing (il peut même y avoir des adresses IPv4 et IPv6 dans la même session MPTCP), et ses avantages notamment de résilience.
Après TCP, UDP est certainement le protocole de transport le plus connu. Il est notamment très utilisé par le DNS. Le RFC 8085 explique comment les applications peuvent l'utiliser au mieux. La section 3.3 de notre RFC lui est consacrée, pour décrire son interface et ses services.
Contrairement à TCP, UDP n'a pas la notion de connexion (on envoie directement les données, sans négociation préalable), UDP découpe les données en messages (voilà pourquoi les messages DNS en UDP ne sont pas précédés d'une longueur : UDP lui-même fait le découpage), n'a pas de contrôle de congestion, et ne garantit pas le bon acheminement. UDP dispose d'un contrôle d'intégrité, mais il est facultatif (quoique très recommandé) en IPv4, où on peut se contenter du contrôle d'intégrité d'IP. IPv6 n'ayant pas ce contrôle, UDP sur IPv6 doit activer son propre contrôle, sauf dans certains cas très précis (RFC 6936).
En l'absence de contrôle de congestion, l'application doit être prudente, veiller à ne pas surcharger le réseau, et ne pas s'étonner si l'émetteur envoie plus que ce que le récepteur peut traiter. D'une façon générale, il faut penser à lire le RFC 8085, qui explique en détail tout ce qu'une application doit faire si elle tourne sur UDP.
Il est d'ailleurs recommandé de bien se poser la question de l'utilité d'UDP, dans beaucoup de cas. Un certain nombre de développeurs se disent au début d'un projet « j'ai besoin de vitesse [sans qu'ils fassent bien la différence entre latence et capacité], je vais utiliser UDP ». Puis ils découvrent qu'ils ont besoin de contrôle de flux, d'ordre des données, de bonne réception des données, ils ajoutent à chaque fois des mécanismes ad hoc, spécifiques à leur application et, au bout du compte, ils ont souvent réinventé un truc aussi lourd que TCP, mais bien plus bogué. Attention donc à ne pas réinventer la roue pour rien.
L'interface d'UDP, maintenant. Le RFC 768 donne quelques indications de base, que le RFC 8085 complète. Bien qu'UDP n'ait
pas le concept de connexion, il est fréquent que les
API aient une opération
connect() ou analogue. Mais il ne faut pas
la confondre avec l'opération du même nom sur TCP : ce
connect() UDP est purement local, associant
la structure de données locale à une machine distante (c'est
ainsi que cela se passe avec les prises
Berkeley).
Et les services d'UDP ? La liste est évidemment bien plus courte que pour TCP. Elle comprend :
- Transport des données, unicast, multicast , anycast et broadcast (c'est le seul point où UDP en fournit davantage que TCP),
- Démultiplexage en utilisant les numéros de port,
- Unidirectionnel (ce qui est toujours le cas avec le multicast) ou bidirectionnel,
- Données structurées en messages,
- Aucune garantie, ou signalement, des pertes de message,
- Aucune garantie sur l'ordre de délivrance des messages.
Nettement moins connu qu'UDP est UDP-Lite, normalisé dans le RFC 3828. C'est une version très légèrement modifiée d'UDP, où la seule différence est que les données corrompues (détectées par la somme de contrôle) sont quand même données à l'application réceptrice, au lieu d'être jetées comme avec UDP. Cela peut être utile pour certains applications, notamment dans les domaines audio et vidéo.
Avec UDP-Lite, le champ Longueur de l'en-tête UDP change de sémantique : il n'indique plus la longueur totale des données mais la longueur de la partie qui est effectivement couverte par la somme de contrôle. Typiquement, on ne couvre que l'en-tête applicatif. Le reste est... laissé à la bienveillance des dieux (ou des démons). Pour tout le reste, voyez la section sur UDP.
Notez qu'il n'existe pas d'API spécifique pour UDP-Lite. Si quelqu'un parmi mes lecteurs a des exemples de code bien clairs...
Bien plus original est SCTP (RFC 4960). C'est un protocole à connexion et garantie d'acheminement et d'ordre des données, comme TCP. Mais il s'en distingue par sa gestion du multi-homing. Avec SCTP, une connexion peut utiliser plusieurs adresses IP source et destination, et passer de l'une à l'autre pendant la session, assurant ainsi une bonne résistance aux pannes. Plus drôle, cet ensemble d'adresses peut mêler des adresses IPv4 et IPv6.
Notez aussi qu'une connexion SCTP (on dit une association) comporte plusieurs flux de données, afin de minimiser le problème connu sous le nom de head of line blocking (un paquet perdu empêche la délivrance de toutes les données qui suivent tant qu'il n'a pas été réémis).
SCTP avait surtout été conçu pour la signalisation dans les réseaux téléphoniques. Mais on le trouve dans d'autres cas, comme ForCES (cf. RFC 5811) ou comme la signalisation WebRTC (RFC 8825).
Contrairement à TCP, SCTP utilise une quadruple poignée de mains pour établir la connexion, ce qui permet de ne négocier les options qu'une fois certain de l'identité du partenaire (les techniques anti-DoS de TCP sont incompatible avec l'utilisation des options, cf. RFC 4987, section 3.6). La somme de contrôle fait 32 bits (au lieu des 16 bits de TCP et UDP) et est donc normalement plus robuste.
SCTP est très extensible et plusieurs extensions ont déjà été définies comme l'ajout ou le retrait d'adresses IP pendant l'association (RFC 5061), ou bien la possibilité de n'accepter qu'une fiabilité partielle (RFC 3758). Pour la sécurité, on peut faire tourner TLS sur SCTP (RFC 3436) au prix de la perte de quelques fonctions, ou bien utiliser DTLS (RFC 6083), qui préserve quasiment toutes les fonctions de SCTP.
Victime fréquente des middleboxes stupides qui ne connaissent qu'UDP et TCP, SCTP peut tourner sur UDP (RFC 6951), au lieu de directement reposer sur IP, afin de réussir à passer ces middleboxes.
Contrairement à des protocoles de transport plus anciens, SCTP a une interface bien spécifiée. Le RFC 4960 définit l'interface abstraite, et une extension aux prises Berkeley, spécifiée dans le RFC 6458, lui donne une forme concrète. Cette API prévoit également certaines extensions, comme celle des reconfigurations dynamiques d'adresses du RFC 5061.
Les services fournis par SCTP sont très proches de ceux fournis par TCP, avec deux ajouts (la gestion du multi-homing et le multi-flux), et un changement (données structurées en messages, au lieu d'être un flot d'octets continu comme TCP).
Un autre protocole de transport peu connu, et ne fournissant pas, lui, de fiabilité de l'envoi des données, est DCCP (RFC 4340). DCCP est une sorte d'UDP amélioré, qui peut fournir des services supplémentaires à ceux d'UDP, tout en restant plus léger que TCP (la description du besoin figure dans le RFC 4336). DCCP est bien adapté aux applications multimédia ou aux jeux en ligne, où une faible latence est cruciale, mais où peut aimer avoir des services en plus. Sans DCCP, chaque application qui veut de l'« UDP amélioré » devrait tout réinventer (et ferait sans doute des erreurs).
DCCP a des connexions, comme TCP, qu'on établit avant de communiquer et qu'on ferme à la fin. Il offre une grande souplesse dans le choix des services fournis, choix qui peuvent être unilatéraux (seulement l'envoyeur, ou bien seulement le récepteur) ou négociés lors de l'ouverture de la connexion. Le paquet d'ouverture de connexion indique l'application souhaitée (RFC 5595), ce qui peut être une information utile aux équipements intermédiaires. S'il faut faire passer DCCP à travers des middleboxes ignorantes, qui n'acceptent qu'UDP et TCP, on peut, comme avec SCTP, encapsuler dans UDP (RFC 6773).
L'interface avec DCCP permet d'ouvrir, de fermer et de gérer une connexion. Il n'y a pas d'API standard. Les services fournis sont :
- Transport des données, uniquement unicast,
- Protocole à connexion, et démultiplexage fondé sur les numéros de port,
- Structuration des données en messages,
- Les messages peuvent être perdus (mais, contrairement à UDP, l'application est informée des pertes), et ils peuvent être transmis dans le désordre,
- Contrôle de la congestion (le gros avantage par rapport à UDP), et avec certains choix (optimiser la latence ou au contraire la gigue, par exemple) laissés à l'application.
Autre exemple de protocole de transport, même s'ils ne sont en général pas décrits comme tels, TLS (RFC 5246) et son copain DTLS (RFC 6347). Si on est un fanatique du modèle en couches, on ne met pas ces protocoles de sécurité en couche 4 mais, selon l'humeur, en couche 5 ou en couche 6. Mais si on est moins fanatique, on reconnait que, du point de vue de l'application, ce sont bien des protocoles de transport : c'est à eux que l'application confie ses données, comptant sur les services qu'ils promettent.
TLS tourne sur TCP et DTLS sur UDP. Du point de vue de l'application, TLS fournit les services de base de TCP (transport fiable d'un flot d'octets) et DTLS ceux d'UDP (envoi de messages qui arriveront peut-être). Mais ils ajoutent à ces services de base leurs services de sécurité :
- Confidentialité, éventuellement avec sécurité future,
- Authentification,
- Intégrité (souvent citée à part mais, à mon avis, c'est un composant indispensable de l'authentification).
Le RFC rappelle qu'il est important de se souvenir que TLS ne spécifie pas un mécanisme d'authentification unique, ni même qu'il doit y avoir authentification. On peut n'authentifier que le serveur (c'est actuellement l'usage le plus courant), le client et le serveur, ou bien aucun des deux. La méthode la plus courante pour authentifier est le certificat PKIX (X.509), appelé parfois par une double erreur « certificat SSL ».
DTLS ajoute également au service de base quelques trucs qui n'existent pas dans UDP, comme une aide pour la recherche de PMTU ou un mécanisme de cookie contre certaines attaques.
Il n'y a pas d'API standard de TLS. Si on a écrit une application avec l'API d'OpenSSL, il faudra refaire les appels TLS si on passe à WolfSSL ou GnuTLS. C'est d'autant plus embêtant que les programmeurs d'application ne sont pas forcément des experts en cryptographie et qu'une API mal conçue peut les entrainer dans des erreurs qui auront des conséquences pour la sécurité (l'article « The most dangerous code in the world: validating SSL certificates in non-browser software » en donne plusieurs exemples).
Passons maintenant à RTP (RFC 3550). Ce protocole est surtout utilisé pour les applications multimédia, où on accepte certaines pertes de paquet, et où le format permet de récupérer après cette perte. Comme TLS, RTP fonctionne au-dessus du « vrai » protocole de transport, et peut exploiter ses services (comme la protection de l'intégrité d'une partie du contenu, que fournissent DCCP et UDP-Lite).
RTP comprend en fait deux protocoles, RTP lui-même pour les données et RTCP pour le contrôle. Par exemple, c'est via RTCP qu'un émetteur apprend que le récepteur ne reçoit pas vite et donc qu'il faudrait, par exemple, diminuer la qualité de la vidéo.
RTP n'a pas d'interface standardisée offerte aux programmeurs. Il faut dire que RTP est souvent mis en œuvre, non pas dans un noyau mais directement dans l'application (comme avec libortp sur Unix). Ces mises en œuvre sont donc en général optimisées pour une utilisation particulière, au lieu d'être généralistes comme c'est le cas avec les implémentations de TCP ou UDP.
Autre cas d'un protocole de transport qui fonctionne au-dessus d'un autre protocole de transport, HTTP (RFC 7230 et suivants). Il n'était normalement pas conçu pour cela mais, dans l'Internet d'aujourd'hui, où il est rare d'avoir un accès neutre, où les ports autres que 80 et 443 sont souvent bloqués, et où hôtels, aéroports et écoles prétendent fournir un « accès Internet » qui n'est en fait qu'un accès HTTP, bien des applications qui n'ont rien à voir avec le Web en viennent à utiliser HTTP comme protocole de transport. (Même si le RFC 3205 n'encourage pas vraiment cette pratique puisque HTTP peut ne pas être adapté à tout. Mais, souvent, on n'a pas le choix.)
Outre cette nécessité de contourner blocages et limitations, l'utilisation de HTTP comme transport a quelques avantages : protocole bien connu, disposant d'un grand nombre de mises en œuvre, que ce soit pour les clients ou pour les serveurs, et des mécanismes de sécurité existants (RFC 2617, RFC 2817…). L'un des grands succès de HTTP est le style REST : de nombreuses applications sont conçues selon ce style.
Les applications qui utilisent HTTP peuvent se servir des
méthodes existantes (GET,
PUT, etc) ou bien en créer de nouvelles
(qui risquent de moins bien passer partout).
Je ne vais pas refaire ici la description de HTTP que contient le RFC (suivant le même plan que pour les autres protocoles de transport), je suppose que vous connaissez déjà HTTP. Notez quand même quelques points parfois oubliés : HTTP a un mécanisme de négociation du contenu, qui permet, par exemple, de choisir le format lorsque la ressource existe en plusieurs formats, HTTP a des connexions persistentes donc on n'est pas obligé de se taper un établissement de connexion TCP par requête, et HTTP a des mécanismes de sécurité bien établis, à commencer par HTTPS.
Il y a plein de bibliothèques qui permettent de faire de l'HTTP facilement (libcurl et neon en C, Requests en Python, etc). Chacune a une API différente. Le W3C a normalisé une API nommée XMLHttpRequest, très utilisée par les programmeurs JavaScript.
Les services que fournit HTTP quand on l'utilise comme protocole de transport sont :
- Transport unicast, bi-directionnel, fiable (grâce à TCP en dessous), et avec contrôle de congestion (idem),
- Négociation du format, possibilité de ne transférer qu'une partie d'une ressource,
- Authentification et confidentialité si on utilise HTTPS.
Beaucoup moins connus que les protocoles précédents sont deux des derniers de notre liste, FLUTE et NORM.
FLUTE (File Delivery over Unidirectional Transport/ Asynchronous Layered Coding Reliable Multicast) est normalisé dans le RFC 6726. Il est conçu pour un usage très spécifique, la distribution de fichiers à des groupes multicast de grande taille, où on ne peut pas demander à chaque récepteur d'accuser réception. Il est surtout utilisé dans le monde de la téléphonie mobile (par exemple dans la spécification 3GPP TS 26.346).
FLUTE fonctionne sur UDP, et le protocole ALC du RFC 5775. Il est souvent utilisé sur des réseaux avec une capacité garantie, et où on peut donc relativiser les problèmes de congestion. Il n'y a pas d'interface de programmation spécifiée.
Les services de FLUTE sont donc :
- Transport de fichiers (que FLUTE appelle « objets ») plutôt que d'octets,
- Fiable (heureusement, pour des fichiers).
Et NORM (NACK-Oriented Reliable Multicast ? Normalisé dans le RFC 5740, il rend à peu près les mêmes services que FLUTE (distribution massive de fichiers). À noter qu'il en existe une mise en œuvre en logiciel libre.
Reste un cas amusant, ICMP. Bien sûr, ICMP n'est pas du tout conçu pour être un protocole de transport, c'est le protocole de signalisation d'IP (RFC 792 pour ICMP sur IPv4 et RFC 4443 pour ICMP sur IPv6). Mais, bon, comme il est situé au-dessus de la couche 3, on peut le voir comme un protocole de transport.
Donc, ICMP est sans connexion, sans fiabilité, et unidirectionnel. Évidemment pas de contrôle de congestion. Pas vraiment d'interface standard, les messages ICMP ne sont signalés qu'indirectement aux applications (dans certains cas, une application peut demander à recevoir les messages ICMP). On ne peut pas tellement s'en servir comme protocole de transport, bien que des programmes comme ptunnel s'en servent presque ainsi.
Après cette longue section 3 qui faisait le tour de tous les protocoles de transport ou assimilés, la section 4 de notre RFC revient sur la question cruciale de la congestion. Sans contrôle de congestion, si chacun émettait comme ça lui chante, l'Internet s'écroulerait vite sous la charge. C'est donc une des tâches essentielles d'un protocole de transport que de fournir ce contrôle de congestion. Pour ceux qui ne le font pas, l'application doit le faire (et c'est très difficile à faire correctement).
À noter que la plupart des protocoles de transport tendent à ce que chaque flot de données utilise autant de capacité disponible que les autres flots. Au contraire, il existe des protocoles « décroissants » comme LEDBAT (RFC 6817) qui cèdent la place aux autres et n'utilise la capacité que lorsque personne n'est en concurrence avec eux.
La section 5 de notre RFC revient sur la notion de fonctions fournies par le protocole de transport, et classe sur un autre axe que la section 3. La section 3 était organisée par protocole et, pour chaque protocole, indiquait quelles étaient ses fonctions. La section 5, au contraire, est organisée par fonction et indique, pour chaque fonction, les valeurs qu'elle peut prendre, et les protocoles qui correspondent. Première catégorie de fonctions, celle du contrôle. Ainsi, une des fonctions de base d'un protocole de transport est l'adressage, celui-ci peut être unicast (TCP, UDP, SCTP, TLS, HTTP), multicast (UDP encore, FLUTE, NORM), broadcast (UDP toujours), anycast (UDP, quoique TCP puisse l'utiliser si on accepte le risque de connexions coupées lorsque le routage change).
Autre fonction, la façon dont se fait l'association entre les deux machines, et elle peut être avec connexion (TCP, SCTP, TLS) ou sans connexion (UDP). La gestion du multi-homing peut être présente (MPTCP, SCTP) ou pas. La signalisation peut être faite avec ICMP ou bien dans le protocole d'application (RTP).
Seconde catégorie de fonctions, la délivrance de données. Première fonction dans cette catégorie, la fiabilité, qui peut être complète (TCP, SCTP, TLS), partielle (RTP, FLUTE, NORM) ou inexistante (UDP, DCCP). Deuxième fonction, la détection d'erreurs, par une somme de contrôle qui couvre toutes les données (TCP, UDP, SCTP, TLS), une partie (UDP-Lite), et qui peut même être optionnelle (UDP en IPv4). Troisième fonction de délivrance, l'ordre des données, qui peut être maintenu (TCP, SCTP, TLS, HTTP, RTP) ou pas (UDP, DCCP, DTLS). Quatrième fonction, le découpage des données : flot sans découpage (TCP, TLS) ou découpage en messages (UDP, DTLS).
Troisième catégorie de fonctions, celles liées au contrôle de la transmission et notamment de la lutte contre la congestion.
Enfin, quatrième et dernière catégorie de fonctions, celles liées à la sécurité : authentification (TLS, DTLS) et confidentialité (les mêmes) notamment.
Voilà, armé de ce RFC, si vous êtes développeurs d'un nouveau protocole applicatif sur Internet, vous pouvez choisir votre protocole de transport sans vous tromper.
Une lecture recommandée est « De-Ossifying the Internet Transport Layer: A Survey and Future Perspectives », de Giorgos Papastergiou, Gorry Fairhurst, David Ros et Anna Brunström.
L'article seul
RFC 8086: GRE-in-UDP Encapsulation
Date de publication du RFC : Mars 2017
Auteur(s) du RFC : L. Yong (Huawei
Technologies), E. Crabbe
(Oracle), X. Xu (Huawei
Technologies), T. Herbert (Facebook)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tsvwg
Première rédaction de cet article le 9 mars 2017
Le protocole de tunnel GRE, normalisé dans les RFC 2784 et RFC 7676, tourne normalement directement sur IP (numéro de protocole 47, TCP étant 6 et UDP 17). Cela présente quelques inconvénients, notamment la difficulté à passer certaines middleboxes, et ce nouveau RFC propose donc une encapsulation de GRE dans UDP, et non plus directement dans IP. Un des autres avantages de cette encapsulation est que le port source UDP peut être utilisé comme une source d'entropie supplémentaire : sa vérification permet d'améliorer la (faible) sécurité de GRE. GRE sur UDP permet aussi l'utilisation de DTLS si on veut chiffrer (ce que ne fait pas GRE classiquement).
Un autre avantage est que l'encapsulation dans UDP peut améliorer les performances, dans le cas où il y a des répartiteurs de charge ECMP : ils pourront alors faire passer tous les paquets d'un même tunnel GRE par le même chemin, puisqu'ils prennent leurs décisions sur la base du tuple {protocole, adresse IP source, adresse IP destination, port source, port destination}.
Vu du réseau, un tunnel GRE sur UDP sera juste du trafic UDP normal. Attention, toutefois, le trafic UDP sur l'Internet public doit normalement obéir à certaines règles, notamment de contrôle de la congestion (ces règles figurent dans le RFC 8085). Avec TCP, c'est le protocole de transport qui s'en charge, avec UDP, c'est à l'application de le faire. Si on transporte du trafic quelconque, pas spécialement raisonnable, dans un tunnel GRE sur UDP, on viole les règles du RFC 8085. Il faut donc s'assurer que le trafic dans le tunnel a des mécanismes de contrôle de la congestion, ou bien réserver GRE sur UDP à des réseaux fermés, où on prend les risques qu'on veut. (Voir aussi la section 8 de notre RFC.)
Donc, on peut se servir de GRE sur UDP au-dessus d'IPv4 ou d'IPv6 (section 2 du RFC). La somme de contrôle UDP est très recommandée (elle est obligatoire en IPv6). On doit vérifier que le trafic transporté fera attention au contrôle de congestion. Le port source UDP doit être dans la plage des ports éphémères (de 49 152 à 65 535, voir aussi la section 3.2.1). Utiliser un port par flot encapsulé facilite la tâche des équipements comme les répartiteurs de trafic. Mais on peut aussi n'utiliser qu'un seul port pour tout ce qui passe dans le tunnel et, dans ce cas, il faut le choisir de manière imprévisible, pour des raisons de sécurité (RFC 6056). Et en IPv6, merci de penser à utiliser le flow label (RFC 6438).
Ce protocole GRE sur UDP a eu une histoire longue et compliquée, pris dans des efforts pour fournir des mécanismes génériques d'encapsulation dans UDP (projet GUE), efforts qui n'ont guère débouché (cf. le RFC 7510 pour un autre exemple que GRE).
Voilà, après ces grands principes, le format exact (section 3). Au-dessus de l'en-tête IP (v4 ou v6), on met un en-tête UDP (RFC 768) et un en-tête GRE (RFC 2784).
La section 5 du RFC couvre le cas de DTLS (RFC 6347), qui a l'avantage de donner à GRE les moyens de chiffrer le trafic, sans modifier GRE lui-même.
Évidemment, dans l'Internet réellement existant, le problème, ce sont les middleboxes (section 7 du RFC). C'est d'ailleurs parfois uniquement à cause d'elles qu'il faut utiliser GRE sur UDP et pas GRE tout court, car certaines se permettent de bloquer les protocoles qu'elles ne connaissent pas (typiquement, tout sauf UDP et TCP).
Même en mettant GRE dans UDP, tous les problèmes ne sont pas résolus. Le trafic GRE est unidirectionnel (il y a en fait deux tunnels différents, chacun à sens unique). Il n'y est pas censé avoir des réponses au port source du trafic. Mais certaines middleboxes vont insister pour que ce soit le cas. Une solution possible, pour ces middleboxes pénibles, est de n'utiliser qu'un seul port source.
Il existe des mises en œuvre de ce RFC pour
Linux et BSD. Les
tests suivants ont été faits sur des machines Linux,
noyaux 4.4 et 4.8. ip
tunnel ne fournit pas de choix pour « GRE sur
UDP ». Il faut passer par le système FOU
(Foo-over-UDP, cf. cet article de LWN),
qui a l'avantage d'être plus générique :
# modprobe fou
# lsmod|grep fou
fou 20480 0
ip_tunnel 28672 1 fou
ip6_udp_tunnel 16384 1 fou
udp_tunnel 16384 1 fou
La machine qui va recevoir les paquets doit configurer FOU pour indiquer que les paquets à destination de tel port UDP sont en fait du GRE :
# ip fou add port 4754 ipproto 47
(47 = GRE) La machine émettrice, elle, doit créer une interface GRE encapsulée grâce à FOU :
# ip link add name tun1 type gre \
remote $REMOTE local $LOCAL ttl 225 \
encap fou encap-sport auto encap-dport 4754
# ip link set tun1 up
Et il faut évidemment configurer une route passant par cette
interface tun1, ici pour le préfixe
172.16.0.0/24 :
# ip route add 172.16.0.0/24 dev tun1
Avec cette configuration, lorsque la machine émettrice
pingue
172.16.0.1, les paquets arrivent bien sur la
machine réceptrice :
12:10:40.138768 IP (tos 0x0, ttl 215, id 10633, offset 0, flags [DF], proto UDP (17), length 116)
172.19.7.106.46517 > 10.17.124.42.4754: [no cksum] UDP, length 88
On peut les examiner plus en détail avec Wireshark :
User Datagram Protocol, Src Port: 1121 (1121), Dst Port: 4754 (4754)
Source Port: 1121
Destination Port: 4754
Length: 96
Checksum: 0x0000 (none)
[Good Checksum: False]
[Bad Checksum: False]
[Stream index: 0]
Data (88 bytes)
0000 00 00 08 00 45 00 00 54 3e 99 40 00 40 01 ef 6f ....E..T>.@.@..o
...
Wireshark ne connait apparemment pas le GRE sur UDP. Mais, dans les données, on reconnait bien l'en-tête GRE (les quatre premiers octets où presque tous les bits sont à zéro, le bit C étant nul, les quatre octets suivants optionnels ne sont pas inclus, le 0x800 désigne IPv4, cf. RFC 2784), et on voit un paquet IPv4 ensuite. Pour que ce paquet soit correctement traité par la machine réceptrice, il faut le transmettre à GRE. Comme ce dernier n'a pas de mécanisme permettant de mettre plusieurs tunnels sur une même machine (l'en-tête GRE n'inclut pas d'identificateurs), il faut activer l'unique interface GRE :
# ip link set gre0 up
On voit bien alors notre ping qui arrive :
# tcpdump -vv -n -i gre0
tcpdump: listening on gre0, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
14:02:06.922367 IP (tos 0x0, ttl 64, id 47453, offset 0, flags [DF], proto ICMP (1), length 84)
10.10.86.133 > 172.16.0.1: ICMP echo request, id 13947, seq 17, length 64
Voilà, je vous laisse faire la configuration en sens inverse.
Si vous voulez en savoir plus sur la mise en œuvre de FOU, voyez cet excellent exposé d'un des auteurs, Tom Herbert, cet article du même, et enfin sa vidéo.
L'article seul
RFC 8085: UDP Usage Guidelines
Date de publication du RFC : Mars 2017
Auteur(s) du RFC : L. Eggert (NetApp), G. Fairhurst
(University of Aberdeen), G. Shepherd (Cisco
Systems)
Réalisé dans le cadre du groupe de travail IETF tsvwg
Première rédaction de cet article le 9 mars 2017
La grande majorité des applications Internet tourne sur le protocole de transport TCP. Mais son concurrent UDP, normalisé dans le RFC 768, prend de l'importance avec le multimédia et les jeux en ligne pour lesquels il est souvent bien adapté. Contrairement à TCP, UDP ne fournit aucun mécanisme de contrôle de la congestion. C'est donc aux applications de fournir ce contrôle, suivant les règles expliquées par ce RFC. (Qui parle surtout de congestion mais aussi d'autres sujets importants pour ceux qui utilisent UDP, comme la taille des messages ou comme les sommes de contrôle.) Il remplace le RFC 5405.
UDP est apprécié pour certaines applications car il est simple et léger et le fait qu'il ne garantisse pas l'acheminement de la totalité des paquets n'est pas forcément un problème dans les applications multimédia : si on perd quelques secondes d'une communication téléphonique RTP, il vaut mieux passer à la suite que de perdre du temps à la retransmettre comme le ferait TCP. Mais UDP ne fournit pas non plus de contrôle de la congestion. Une application UDP enthousiaste peut envoyer des paquets au débit maximum permis, saturant tous les liens situés en aval. (Il ne faut pas juste tenir compte de la capacité du lien auquel on est connecté, mais de celle du chemin complet. L'exemple du RFC, avec un chemin à seulement 56 kb/s, que cinq paquets UDP de 1 500 octets par seconde saturent, n'est pas invraisemblable.) Protéger le réseau de la congestion est pourtant nécessaire (RFC 2914 et RFC 7567), à la fois pour assurer que le réseau continue à être utilisable et également pour assurer une certaine équité entre les différents flux de données, pour éviter qu'une seule application gourmande ne monopolise le réseau pour elle. (Ceci concerne l'Internet public. Si on est dans un environnement fermé, utilisant TCP/IP mais où la capacité réseau, et son usage, sont contrôlés, le problème est évidemment différent. Voir notamment la section 3.6.)
UDP ne faisant pas ce contrôle de congestion, il faut bien que l'application le fasse et, pour cela, qu'elle mette en œuvre les conseils de ce RFC. (Notre RFC contient également des conseils pour d'autres aspects de l'utilisation d'UDP que le contrôle de congestion : mais c'est le plus important.)
Le gros du RFC est dans la section 3 qui détaille ces conseils (la
section 7 contient un excellent résumé sous forme d'un tableau des
conseils à suivre). Le
premier est qu'il vaut peut-être mieux ne pas utiliser UDP. Beaucoup
de développeurs d'applications pensent à UDP en premier parce qu'il
est simple et facile à comprendre et qu'il est « plus rapide que
TCP ». Mais, rapidement, ces développeurs se rendent compte qu'ils ont
besoin de telle fonction de TCP, puis de telle autre, ils les mettent
en œuvre dans leur application et arrivent à une sorte de TCP en
moins bien, davantage bogué et pas plus rapide. Notre RFC conseille
donc d'abord de penser aux autres protocoles de transport comme
TCP (RFC 793),
DCCP (RFC 4340) ou
SCTP (RFC 9260). Ces protocoles sont
d'autant plus intéressants qu'ils ont souvent fait l'objet de réglages
soigneux depuis de nombreuses années et qu'il est donc difficile à un
nouveau programme de faire mieux. D'autant plus qu'il existe souvent
des réglages spécifiques pour les adapter à un usage donné. Par
exemple, on peut dire à TCP de donner la priorité à la
latence (paramètre
TCP_NODELAY de setsockopt) ou bien au débit.
Si on ne suit pas ces sages conseils, et qu'on tient à se servir d'UDP, que doit-on faire pour l'utiliser intelligemment ? La section 3.1 couvre le gros morceau, le contrôle de congestion. Celui-ci doit être pris en compte dès la conception de l'application. Si cette dernière fait de gros transferts de données (section 3.1.2, c'est le cas de RTP, RFC 3550), elle doit mettre en œuvre TFRC, tel que spécifié dans le RFC 5348, donc faire à peu près le même travail que TCP. Et ce mécanisme doit être activé par défaut.
Si l'application transmet peu de données (section 3.1.3), elle doit quand même faire attention et le RFC demande pas plus d'un datagramme par RTT, où le RTT est un cycle aller-retour avec la machine distante (si le calcul n'est pas possible, le RFC demande une durée de trois secondes). L'application doit également détecter les pertes de paquet pour ralentir son rythme si ces pertes - signe de congestion - sont trop fréquentes.
Si l'application est bi-directionnelle (le cas de loin le plus fréquent), le contrôle de la congestion doit se faire indépendamment dans les deux directions.
Notez que se retenir d'envoyer des paquets n'est pas le seul moyen pour une application d'éviter la congestion. Elle peut aussi (si l'API utilisée le permet) se servir d'ECN (RFC 3168) pour transmettre l'information qui permettra de réguler le trafic.
Enfin, le RFC demande (section 3.1.10) un mécanisme de « disjoncteur » (circuit breaker, cf. RFC 8084 ou bien RFC 8083 pour l'exemple spécifique de RTP). C'est un mécanisme de dernier recours pour couper la communication en cas de risque d'effondrement du réseau.
Le cas où l'application est un tunnel au-dessus d'UDP est également couvert (section 3.1.11). C'est par exemple le cas du protocole GRE quand il tourne sur UDP (RFC 8086).
En suivant toutes ces règles, l'application gère proprement la congestion. Et le reste ? La section 3.2 fournit des pistes sur la gestion de la taille des paquets. La charge utile d'un paquet UDP peut théoriquement faire 65 507 octets en IPv4 et 65 527 en IPv6. Mais c'est théorique. En pratique, la fragmentation marche mal sur l'Internet, et notre RFC conseille de rester en dessous de la MTU, et d'utiliser la découverte de la MTU du chemin spécifiée dans des RFC comme les RFC 4821 et RFC 8899. (Aujourd'hui, la principale application qui envoie des paquets UDP plus gros que la MTU, et doit donc se battre avec la fragmentation, est le DNS ; voir par exemple l'étude de Geoff Huston sur les comportements très variés des serveurs de la racine.)
La section 3.3 explique la question de la fiabilité : par défaut, UDP ne retransmet pas les paquets perdus. Si c'est nécessaire, c'est l'application qui doit le faire. Elle doit aussi gérer l'eventuelle duplication des paquets (qu'UDP n'empêche pas). Le RFC note que les retards des paquets peuvent être très importants (jusqu'à deux minutes, normalise le RFC, ce qui me semble très exagéré pour l'Internet) et que l'application doit donc gérer le cas où un paquet arrive alors qu'elle croyait la session finie depuis longtemps.
La section 3.4 précise l'utilisation des sommes de contrôle (facultatives pour UDP sur IPv4 mais qui devraient être utilisées systématiquement). Si une somme de contrôle pour tout le paquet semble excessive, et qu'on veut protéger uniquement les en-têtes de l'application, une bonne alternative est UDP-Lite (RFC 3828), décrit dans la section 3.4.2. (Il y a aussi des exceptions à la règle « somme de contrôle obligatoire en IPv6 » dans le cas de tunnels.)
Beaucoup de parcours sur l'Internet sont encombrés de
« middleboxes », ces engins intermédiaires qui
assurent diverses fonctions (NAT,
coupe-feu, etc) et qui sont souvent de médiocre
qualité logicielle, bricolages programmés par un inconnu et jamais
testés. La section 3.5 spécifie les règles que devraient suivre les applications UDP pour passer au travers sans
trop de heurts. Notamment, beaucoup de ces « middleboxes »
doivent maintenir un état par flux qui les
traverse. En TCP, il est relativement facile de détecter le début et
la fin d'un flux en observant les paquets d'établissement (SYN) et de
destruction (FIN) de la connexion. En UDP, ces paquets n'ont pas
d'équivalent et la détection d'un flux repose en général sur des
heuristiques. L'engin peut donc se tromper et mettre fin à un flux qui
n'était en fait pas terminé. Si le DNS s'en
tire en général (c'est un simple protocole requête-réponse, avec la
lupart du temps moins d'une seconde entre l'une et l'autre), d'autres
protocoles basés sur UDP pourraient avoir de mauvaises
surprises. Ces protocoles doivent donc se préparer à de soudaines interruptions
de la communication, si le timeout d'un engin
intermédiaire a expiré alors qu'il y avait encore des paquets à
envoyer. (La solution des
keepalives est déconseillée
par le RFC car elle consomme de la capacité du réseau et ne dispense
pas de gérer les coupures, qui se produiront de toute façon.)
La section 5 fera le bonheur des
programmeurs qui y trouveront des conseils pour
mettre en œuvre les principes de ce RFC, via
l'API des prises
(sockets, RFC 3493). Elle est largement documentée mais en général plutôt
pour TCP que pour UDP, d'où l'intérêt du résumé qu'offre ce RFC, qui
ne dispense évidemment pas de lire le Stevens. Par exemple, en
l'absence de mécanisme de TIME_WAIT (la prise
reste à attendre d'éventuels paquets retardés, même après sa fermeture
par l'application), une application UDP peut ouvrir une prise... et
recevoir immédiatement des paquets qu'elle n'avait pas prévus, qui
viennent d'une exécution précédente.
Le RFC détaille également la bonne stratégie à utiliser pour les ports. Il existe un registre des noms et numéros de ports (RFC 6335), et le RFC 7605 explique comment utiliser les ports. Notre RFC conseille notamment de vérifier les ports des paquets reçus, entre autre pour se protéger de certaines attaques, où l'attaquant, qui ne peut pas observer le trafic et doit injecter des paquets aveuglément, ne connait pas les ports utilisés (en tout cas pas les deux). L'application devrait utiliser un port imprévisible, comme le fait TCP (RFC 6056). Pour avoir suffisamment d'entropie pour les répartiteurs de charge, le RFC rappelle qu'en IPv6, on peut utiliser le champ flow label (RFC 6437 et RFC 6438).
Le protocole ICMP fournit une aide utile, que les applications UDP peuvent utiliser (section 5.2). Mais attention, certains messages ICMP peuvent refléter des erreurs temporaires (absence de route, par exemple) et ne devraient pas entraîner de mesures trop drastiques. Autre piège, il est trivial d'envoyer des faux paquets ICMP. Une application doit donc essayer de déterminer, en examinant le contenu du message ICMP, s'il est authentique. Cela nécessite de garder un état des communications en cours, ce que TCP fait automatiquement mais qui, pour UDP, doit être géré par l'application. Enfin, il faut se rappeler que pas mal de middleboxes filtrent stupidement l'ICMP et l'application doit donc être prête à se débrouiller sans ces messages.
Après tous ces conseils, la section 6 est dédiée aux questions de sécurité. Comme TCP ou SCTP, UDP ne fournit en soi aucun mécanisme d'intégrité des données ou de confidentialité. Pire, il ne fournit même pas d'authentification de l'adresse IP source (authentification fournie, avec TCP, par le fait que, pour établir la connexion, il faut recevoir les réponses de l'autre). Cela permet, par exemple, les injections de faux trafic (contre lesquelles il est recommandé d'utiliser des ports source imprévisibles, comme le fait le DNS), ou bien les attaques par amplification.
L'application doit-elle mettre en œvre la sécurité seule ? Le RFC conseille plutôt de s'appuyer sur des protocoles existants comme IPsec (RFC 4301, dont notre RFC note qu'il est très peu déployé) ou DTLS (RFC 9147). En effet, encore plus que les protocoles de gestion de la congestion, ceux en charge de la sécurité sont très complexes et il est facile de se tromper. Il vaut donc mieux s'appuyer sur un système existant plutôt que d'avoir l'hubris et de croire qu'on peut faire mieux que ces protocoles ciselés depuis des années.
Pour authentifier, il existe non seulement IPsec et DTLS mais également d'autres mécanismes dans des cas particuliers. Par exemple, si les deux machines doivent être sur le même lien (un cas assez courant), on peut utiliser GTSM (RFC 3682) pour s'en assurer.
Enfin, notre RFC se termine (section 7) par un tableau qui synthétise les recommandations, indiquant à chaque fois la section du RFC où cette recommandation est développée. Développeu·r·se d'applications utilisant UDP, si tu ne lis qu'une seule section du RFC, cela doit être celle-ci !
Quels changements depuis le RFC précédent, le RFC 5405 ? Le fond des recommandations reste le même, la principale addition est celle de nombreuses recommandations spécifiques au multicast (dont je n'ai pas parlé ici) mais aussi à l'anycast, aux disjoncteurs, et aux tunnels. Il y a également l'introduction d'une différence entre l'Internet public (où il se faut se comporter en bon citoyen) et des réseaux privés et fermés utilisant les mêmes protocoles, mais où on a droit à des pratiques qui seraient jugées anti-sociales sur l'Internet public (comme d'envoyer des paquets sans tenir compte de la congestion). Ce RFC est donc bien plus long que son prédécesseur.
L'article seul
RFC 8094: DNS over Datagram Transport Layer Security (DTLS)
Date de publication du RFC : Février 2017
Auteur(s) du RFC : T. Reddy
(Cisco), D. Wing, P. Patil
(Cisco)
Expérimental
Réalisé dans le cadre du groupe de travail IETF dprive
Première rédaction de cet article le 2 mars 2017
Dernière mise à jour le 22 mai 2022
Le DNS fonctionne traditionnellement surtout sur UDP, notamment pour minimiser la latence : quand on veut une réponse DNS, on la veut rapidement. Dans le cadre du projet « DNS et vie privée », le choix avait été fait de chiffrer le trafic DNS avec TLS (RFC 7858), imposant ainsi l'usage de TCP. Certains pensaient quand même qu'UDP était bien adapté au DNS et, puisqu'il existe une version de TLS adaptée à UDP, DTLS, ce serait une bonne idée de l'utiliser pour chiffrer le DNS. C'est ce que décrit ce nouveau RFC (qui n'a pas eu un avenir brillant, peu de gens ont été intéressés, regardez plutôt le RFC 9250).
De toute façon, il est très possible que le DNS utilise de plus en plus TCP, et le RFC 7766 allait dans ce sens, demandant davantage de la part des mises en œuvre de DNS sur TCP. Mais, bon, il est toujours bon d'essayer des alternatives, d'où ce RFC, dans l'état « Expérimental ». Outre les RFC déjà cités, il est recommandé, avant de le lire, de prendre connaissance du RFC 7626, qui décrit les problèmes de vie privée que pose le DNS, et le RFC 9147, qui normalise DTLS (bien moins connu que son copain TLS, et peu utilisé jusqu'à présent, à part pour WebRTC).
Les motivations pour explorer une alternative au DNS-sur-TLS du RFC 7858 sont :
- TCP souffre du « head of line blocking » où la perte d'un seul paquet empêche de recevoir tous ceux qui suivent, même s'ils sont bien arrivés, tant que le paquet perdu n'est pas retransmis. DNS-sur-DTLS sera donc peut-être meilleur sur des réseaux qui perdent pas mal de paquets.
- Dans certaines conditions, l'établissement d'une session est plus rapide avec DTLS qu'avec TLS. (Rappelez-vous toutefois que le RFC 7766 exige des sessions TCP persistentes : pas question d'établir une session par requête DNS !) Reprendre une session TLS peut ne prendre qu'un aller-retour avec DTLS, alors que TLS devra attendre l'établissement de la connexion TCP (le RFC 7413 changera peut-être les choses, mais TLS et DTLS 1.3 obligeront également à réviser ce raisonnement.)
De même qu'un serveur et un client DNS ne peuvent pas se contenter d'UDP (pour pouvoir envoyer des données de grande taille, il faudra de toute façon passer à TCP), DNS-sur-DTLS ne peut pas suffire seul, et il faudra donc que les clients et serveurs aient également DNS-sur-TLS.
La spécification de DNS-sur-DTLS est dans la section 3 de notre
RFC. DNS-sur-DTLS va tourner, comme DNS-sur-TLS, sur le
port 853 (sauf accord préalable entre
client et serveur, s'ils sont adultes et consentants). Un client
peut déterminer si le serveur gère DNS-sur-DTLS en envoyant un
message DTLS ClientHello vers le port 853. En
l'absence de réponse, le client réessaie, puis laisse
tomber DTLS. Selon sa configuration (plus ou moins paranoïaque), le
client va alors tenter le DNS habituel en clair, ou bien
complètement renoncer. En tout cas, interdiction d'utiliser le
port 853 pour transmettre des messages DNS en clair. L'utilisation
de ce port sur UDP implique DTLS.
Si, par contre, le serveur répond et qu'une session DTLS est établie, le client DNS-sur-DTLS authentifie le serveur avec les mêmes méthodes que pour TLS, en suivant les bonnes pratiques de sécurité de TLS (RFC 7525) et les profils d'authentification de DNS-sur-TLS décrits dans le RFC 8310. Une fois que tout cela est fait, les requêtes et réponses DNS sont protégées et les surveillants sont bien embêtés, ce qui était le but.
DTLS tourne sur UDP et reprend sa sémantique. Notamment, il est parfaitement normal qu'une réponse arrive avant une autre, même partie plus tôt. Le client DNS-sur-DTLS ne doit donc pas s'étonner et, pour faire correspondre les requêtes et les réponses, il doit, comme avec le DNS classique sur UDP, utiliser le Query ID ainsi que la question posée (qui est répétée dans les réponses, dans la section Question).
Pour ne pas écrouler le serveur sous la charge, le client ne devrait créer qu'une seule session DTLS vers chaque serveur auquel il parle, et y faire passer tous les paquets. S'il y a peu de requêtes, et que le client se demande si le serveur est toujours là, il peut utiliser l'extension TLS du « battement de cœur » (RFC 6520), qui peut également servir à rafraichir l'état d'un routeur NAT éventuel. Le RFC recommande aux serveurs DNS-sur-DTLS un délai d'au moins une seconde en cas d'inutilisation de la session, avant de raccrocher. Le problème est délicat : si ce délai est trop long, le serveur va garder des ressources inutiles, s'il est trop court, il obligera à refaire le travail d'établissement de session trop souvent. En tout cas, le client doit être prêt à ce que le serveur ait détruit la session unilatéralement, et doit la réétablir s'il reçoit l'alerte DTLS qui lui indique que sa session n'existe plus.
Un petit mot sur les performances, maintenant, puisque rappelons-nous que le DNS doit aller vite (section 4). L'établissement d'une session DTLS peut nécessiter d'envoyer des certificats, qui sont assez gros et peuvent nécessiter plusieurs paquets. Il peut donc être utile d'utiliser les clés brutes (pas de certificat) du RFC 7250, ou bien l'extension TLS Cached Information Extension (RFC 7924).
Dans le cas d'un lien stub resolver vers résolveur, le serveur DNS parle à beaucoup de clients, chaque client ne parle qu'à très peu de serveurs. L'état décrivant les sessions DTLS doit donc plutôt être gardé chez le client (RFC 5077). Cela permettra de réétablir les sessions DTLS rapidement, sans pour autant garder d'état sur le serveur.
Le DNS est la principale application qui se tape les problèmes de PMTU (Path MTU, la MTU du chemin complet). Les réponses DNS peuvent dépasser les 1 500 octets magiques (la MTU d'Ethernet et, de facto, la PMTU de l'Internet). DTLS ajoute au moins 13 octets à chaque paquet, sans compter l'effet du chiffrement. Il est donc impératif (section 5) que clients et serveurs DNS-sur-DTLS gèrent EDNS (RFC 6891) pour ne pas être limité par l'ancien maximum DNS de 512 octets, et que les serveurs limitent les paquets DTLS à la PMTU (RFC 9147).
Contrairement au DNS classique, où chaque requête est indépendante, toute solution de cryptographie va nécessiter un état, l'ensemble des paramètres cryptographiques de la session. L'anycast, qui est répandu pour le DNS, ne pose donc pas de problème au DNS classique : si le routage change d'avis entre deux requêtes, et que la seconde requête est envoyée à un autre serveur, aucun problème. Avec DTLS, ce n'est plus le cas (section 6 du RFC) : le deuxième serveur n'a pas en mémoire la session cryptographique utilisée. Le serveur qui la reçoit va répondre avec une alerte TLS fatale (la méthode recommandée) ou, pire, ne pas répondre. Dans les deux cas, le client doit détecter le problème et réétablir une session cryptographique. (À noter que l'alerte TLS n'est pas authentifiée et ne peut donc pas être utilisée comme seule indication du problème. C'est d'ailleurs pareil pour d'éventuels messages d'erreur ICMP.) Le cas est donc proche de celui où le serveur ferme la session unilatéralement, et la solution est la même : le client doit toujours être prêt à recommencer l'ouverture de session DTLS.
Un point de sécurité, pour finir (section 9). Le RFC recommande l'utilisation de l'extension TLS « agrafage OCSP » (RFC 6066, section 8), notamment pour éviter la grosse fuite d'information que représente OCSP.
Il n'existe aucune mise en œuvre de DNS-sur-DTLS, et aucune n'est prévue. Cette expérimentation semble clairement un échec.
L'article seul
RFC 8098: Message Disposition Notification
Date de publication du RFC : Février 2017
Auteur(s) du RFC : T. Hansen (AT&T
Laboratories), A. Melnikov (Isode)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF appsawg
Première rédaction de cet article le 1 mars 2017
Une demande fréquente des utilisateurs du courrier électronique est d'avoir un mécanisme permettant de savoir si et quand le message a été lu par le destinataire. Comme toutes les demandes des utilisateurs, il ne faut pas forcément la satisfaire sans réfléchir (elle pose des gros problèmes de vie privée et, en outre, elle ne garantit pas que le message a été traité, juste que le logiciel l'a affiché). Ce n'est pas par hasard que cette fonction « accusé de réception » était souvent présente (et mise en avant par les vendeurs) pour les systèmes de messagerie conçus pour des environnements très bureaucratiques (le RFC cite l'antédiluvien X.400). Mais, bon, si les gens y tiennent, cette possibilité existe dans la norme : ce nouveau RFC spécifie un mécanisme permettant de signaler qu'on souhaite un tel accusé de réception, ainsi qu'un format structuré (lisible par un programme comme le MUA) pour les accusés de réception qui seront (peut-être) envoyés. Ces accusés de réception sont appelés MDN pour Message Disposition Notification. Ce RFC remplace son prédécesseur, le RFC 3798.
Donc, résumé général du fonctionnement de ce système :
l'émetteur d'un message qui veut un accusé de réception met un
en-tête Disposition-Notification-To: dans son
message. Le récepteur, s'il le désire,
répondra à cette demande lors de la lecture du message, en
envoyant un message de type MIME
message/disposition-notification (a priori
situé à l'intérieur d'un rapport plus général, de type
multipart/report, cf. RFC 6522). Tout ceci
est sous un format structuré, donc peut être traité par un
programme, typiquement le MUA. Voilà, vous
connaissez l'essentiel de ce RFC. Place aux
détails.
À quoi servent les MDN (Message Disposition Notification, un concept plus large que celui d'accusé de réception) ? Voici le cahier des charges proposé par notre RFC :
- Indiquer ce qu'il est advenu du message après la réception physique (lu, imprimé, détruit),
- Permettre d'associer un message à son devenir (le MDN contient les informations permettant la jointure avec les messages envoyés),
- Transmettre de l'information sur le devenir des messages entre systèmes de messagerie différents (un cas devenu rare aujourd'hui, mais qui était plus crucial lors de la sortie du premier RFC sur cette technique, en 1998, cf. la section 8 pour ces passerelles),
- Donner de l'information aux programmes, pas seulement aux humains (pas uniquement du texte non formaté, donc),
- Être indépendant de la langue naturelle utilisée par les humains,
- Être extensible, car on ne sait jamais.
Première partie de la norme, la demande
d'un MDN (section 2). L'émetteur le fait en ajoutant dans son message un
en-tête Disposition-Notification-To:
indiquant les adresses auxquelles envoyer le MDN. Par exemple :
Disposition-Notification-To: stephane+mdn@bortzmeyer.org
Le risque d'utilisation de ce truc pour bombarder de message un
tiers innocent est évident. C'est pour cela que le RFC recommande
d'ignorer cet en-tête si l'adresse indiquée ne coïncide pas avec
celle stockée dans l'en-tête
Return-Path: (voir section 6.4). Dans tous les cas,
rappelez-vous bien que le logiciel à la réception est libre de
faire ce qu'il veut. Il peut estimer que ces MDN ne servent à rien
et ignorer les Disposition-Notification-To:,
il peut demander une autorisation à l'utilisateur il peut envoyer le MDN de
manière totalement automatique (après les vérifications de
vraisemblance comme celle du
il peut envoyer le MDN de
manière totalement automatique (après les vérifications de
vraisemblance comme celle du Return-Path:), etc.
Deuxième partie de la norme, le format du MDN lui-même (section
3 du RFC). La réponse est dans un message de type
multipart/report (type défini dans le RFC 6522), avec le type de rapport (paramètre report-type)
disposition-notification. Le MDN lui-même a
deux ou trois parties : une première partie est du texte libre,
lisible par un humain, une deuxième est structurée, et de type
MIME message/disposition-notification, la
troisième partie est optionnelle et est le message auquel on
« répond ».
La deuxième partie du MDN est la plus intéressante. Son corps est
composé de plusieurs champs nom: valeur, dont
deux sont obligatoires, Final-Recipient: et
Disposition: qui indique ce qui est arrivé au
message. Parmi les autres champs, notez le
Reporting-UA:, indiquant le logiciel qui a
répondu, et dont le RFC recommande qu'il ne soit pas trop
détaillé, car il donne des informations qui peuvent être utiles à
un éventuel attaquant. Comme Reporting-UA:,
le champ Original-Message-ID: n'est pas
obligatoire mais il est très utile : c'est lui qui permet à
l'émetteur du message original de faire
la jointure entre ce qu'il a envoyé et le MDN reçu. (Il n'est pas
obligatoire car le message original n'a pas forcément un
Message-ID:. Mais, s'il en a un, il faut
inclure Original-Message-ID: dans le
MDN.)
Le champ le plus important est sans doute
Disposition:. Il indique ce qui est arrivé au
message original (disposition type) : a-t-il
été affiché à un utilisateur (displayed, ce
qui ne garantit pas du tout qu'il soit arrivé au cerveau de l'utilisateur), traité sans être montré à un
utilisateur (processed), effacé
(deleted) ? Ce champ
Disposition: indique aussi
(disposition mode) si le sort du
message a été décidé par un être humain ou bien automatiquement
(par exemple par Sieve),
et si le MDN a été généré suite à une autorisation explicite ou
bien automatiquement. Notez bien (et c'est la principale raison
pour laquelle les accusés de réception sont une fausse bonne idée)
que la seule façon d'être sûr que le message aura été traité par
son destinataire, est de recevoir une réponse explicite et
manuelle de sa part.
Enfin, le champ Error: sert à transporter
des messages... d'erreur.
Voici un exemple complet de MDN, tiré de la section 9 :
Date: Wed, 20 Sep 1995 00:19:00 (EDT) -0400
From: Joe Recipient <Joe_Recipient@example.com>
Message-Id: <199509200019.12345@example.com>
Subject: Re: First draft of report
To: Jane Sender <Jane_Sender@example.org>
MIME-Version: 1.0
Content-Type: multipart/report; report-type=disposition-notification;
boundary="RAA14128.773615765/example.com"
--RAA14128.773615765/example.com
Content-type: text/plain
The message sent on 1995 Sep 19 at 13:30:00 (EDT) -0400 to Joe
Recipient <Joe_Recipient@example.com> with subject "First draft of
report" has been displayed.
This is no guarantee that the message has been read or understood.
--RAA14128.773615765/example.com
Content-type: message/disposition-notification
Reporting-UA: joes-pc.cs.example.com; Foomail 97.1
Original-Recipient: rfc822;Joe_Recipient@example.com
Final-Recipient: rfc822;Joe_Recipient@example.com
Original-Message-ID: <199509192301.23456@example.org>
Disposition: manual-action/MDN-sent-manually; displayed
--RAA14128.773615765/example.com
Content-type: message/rfc822
[original message optionally goes here]
--RAA14128.773615765/example.com--
Notez la première partie, en langue naturelle (ici en
anglais), la seconde, avec les informations structurées (ici, le
destinataire a affiché le message - manual-action
... displayed - puis autorisé/déclenché manuellement
l'envoi du MDN - MDN-sent-manually), et la
présence de la troisième partie, qui est optionnelle.
Un peu de sécurité pour finir le RFC. D'abord, évidemment, il
ne faut pas accorder trop d'importance aux MDN. Ils peuvent être
fabriqués de toutes pièces, comme n'importe quel message sur
l'Internet. Ensuite, il faut faire attention à la vie
privée des utilisateurs. Le destinataire n'a pas
forcément envie qu'on sache si et quand il a lu un message ! Le
destinataire, ou son logiciel, ont donc parfaitement le droit de
refuser d'envoyer un MDN (ce qui diminue encore l'intérêt de cette
technique, qui était déjà très faible). Même des informations
inoffensives à première vue, comme le contenu du champ
Disposition: peuvent être considérées comme
sensibles. Si on configure Sieve pour
rejeter (RFC 5429) automatiquement tous les
messages d'une certaine personne, on n'a pas forcément envie
qu'elle le sache. Le RFC précise donc qu'on peut envoyer
manual-action/MDN-sent-manually dans ce cas,
pour cacher le fait que c'était automatique.
Quels sont les changements depuis le précédent RFC, le RFC 3798 ? Ils sont résumés dans l'annexe
A. Tout ce qui touche à la vie privée a été sérieusement renforcé
(les MDN sont très indiscrets). Les
champs commençant par un X- ont été supprimés
de la spécification, suivant le RFC 6648. La
grammaire a été corrigée (plusieurs bogues
et ambiguïtés).
En pratique, les MDN ne semblent guère utilisés dans l'Internet et ont peu de chance de marcher. Je note par exemple qu'aussi bien le MUA Unix mutt que le service Gmail semblent les ignorer complètement. Mais d'autres logiciels ont cette fonction.
L'article seul
RFC 8081: The "font" Top-Level Media Type
Date de publication du RFC : Février 2017
Auteur(s) du RFC : C. Lilley (W3C)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF justfont
Première rédaction de cet article le 1 mars 2017
Les types de contenu, servant
à indiquer le type des données envoyées (par le
Web, par le
courrier, etc) sont composés de deux
parties, un type de premier niveau (top level type, ou
type proprement dit, c'est la
catégorie des données) et un
sous-type (il indique le format des données). Type et sous-type
sont séparés par une barre
oblique. Par exemple, image/png
est un type MIME identifiant une image au format
PNG. Des nouveaux sous-types sont
enregistrés très souvent, c'est un événement banal. Mais des
nouveaux types de premier niveau sont bien plus rares. Ce
RFC en décrit un, le type
font/, qui sert à identifier les formats pour des
polices de caractères. Ainsi, on pourra
envoyer un fichier de polices au format TTF en
l'étiquetant font/ttf. (Notre RFC procède
également à l'enregistrement de plusieurs sous-types pour des
formats de polices particuliers.)
Une police de caractères, c'est une
description de comment représenter visuellement un ensemble de
caractères, description qu'un programme peut lire et comprendre.
Il existe bien des façons de faire cette représentation. Les
premiers formats de polices numériques étaient
matriciels mais on est depuis passés à des
formats vectoriels, qui permettent des
changements de taille à volonté. Ces descriptions de caractères
peuvent être distribuées via l'Internet et
la question se pose alors du type de média
à utiliser. En pratique, cela a souvent été
application, un type un peu fourre-tout. On
trouve ainsi enregistré, par exemple, un application/font-woff. Le
RFC 6838, sur l'enregistrement des types et
sous-types de contenus, permet (dans sa section 4.2.7, qui ajoute « Such cases are expected to be quite
rare »)
l'enregistrement d'un nouveau type de premier niveau. C'est ainsi
que ce RFC 8081 crée font/.
Le besoin provient entre autres de l'usage de plus en plus
important des Web
fonts. C'est ansi qu'HTTP
Archive a vu passer le pourcentage de sites Web utilisant cette
technique de 1 % en 2010 à 50 % en 2015. L'analyse de Kuetell montrait une
certaine confusion chez les utilisateurs quant au type MIME à
utiliser pour ces polices. Certains utilisaient le type de premier
niveau font/ avant même son enregistrement
officiel et on voyait donc déjà des
font/truetype pour le format
TrueType. D'autres se servaient
d'application/ pour des
application/octet-stream (fichier binaire
quelconque) ou des application/x-font-ttf
(utilisant le préfixe x-, pourtant abandonné
par le RFC 6648). On voit même des
text/plain pour des ressources pourtant
clairement binaires... Les rares types officiellement enregistrés,
comme application/font-woff, enregistré par un
groupe du W3C, sont peu utilisés.
Au fait, pourquoi est-ce qu'application/
est une mauvaise idée ? Une des principales raisons est qu'il est
regardé avec suspicion par les logiciels de filtrage, qui se
méfient de la capacité de ces fichiers à transporter du
logiciel malveillant. (Certains formats de police incluent un
langage de Turing, et peuvent donc offrir
des possibilités insoupçonnées…) Ensuite, en l'absence d'un type
de premier niveau, il n'était pas possible de définir un jeu
commun de paramètres précisant le type. Enfin, les polices de
caractères ne sont pas des logiciels et posent des problèmes
spécifiques, notamment de licence. Bref, il
fallait un type pour les formats de polices.
Ah, et puisque j'ai parlé de sécurité, la section 3 du RFC fait le point sur les problèmes que peuvent poser les polices de ce côté. Un fichier décrivant une police contient des données, mais aussi des programmes (hinting instructions) pour les opérations de rendu les plus sophistiquées. Par exemple, quand on agrandit un caractère, il ne faut pas agrandir uniformément selon toutes les dimensions ; ou bien certaines caractéristiques d'un caractère dépendent des caractères qui l'entourent. Bref, le rendu est une chose trop compliquée pour être spécifié sans un langage de programmation. C'est par exemple ce qu'on trouve dans les polices TrueType (cf. l'article de Wikipédia). Bien sûr l'exécution de ces « programmes » se fait en général dans un bac à sable, et ils n'ont pas accès à l'extérieur, mais certaines attaques restent possibles, par exemple des attaques par déni de service visant à bloquer le moteur de rendu. Les langages utilisés sont en général trop riches pour que des protections simples suffisent.
Et même si on se limite aux données, la plupart des formats (comme SFNT) sont extensibles et permettent l'ajout de nouvelles structures de données. Cette extensibilité est une bonne chose mais elle présente également des risques (par exemple, elle facilite la dissimulation de données dans les fichiers de polices).
Bon, je vous ai assez fait peur avec les risques de sécurité,
place à l'enregistrement de font/ à
l'IANA (section 4 du
RFC). font/ n'indique pas un format
particulier, mais une catégorie de contenu. Le format sera indiqué
dans le sous-type et c'est là seulement que le logiciel qui reçoit
ce contenu saura s'il peut en faire quelque chose d'utile. (Le RFC
suggère que les sous-types inconnus devraient être traités comme
du binaire quelconque, comme s'ils étaient
application/octet-stream.) Six
sous-types sont enregistrés par notre RFC.
On peut utiliser un identificateur de fragment (RFC 3986, section 3.5, cet identificateur est le truc après
le croisillon dans un URI), pour désigner
une police particulière au sein d'une collection présente dans les
données envoyées. L'identificateur est le nom
PostScript. Attention, certains caractères
peuvent être utilisés dans un nom PostScript mais interdits pour
un identificateur de fragment, et doivent donc être
échappés
avec la notation pour-cent. Par exemple, l'identificateur de
la police Caret^stick sera
#Caret%5Estick.
Le RFC enregistre plusieurs sous-types. Si on veut en ajouter au registre des polices, il faut suivre les procédures du RFC 6838. Il est recommandé que la spécification du format soit librement accessible (ce qui n'est pas évident dans ce milieu).
Le RFC se termine avec les six sous-types de
font/ officiellement enregistrés. D'abord,
sfnt pour le format générique
SFNT. Il prend des paramètres optionnels,
outlines (qui prend comme valeur
TTF, CFF ou
SVG) et layout
(valeurs OTL, AAT et
SIL). On pourra donc écrire, par exemple,
font/sfnt; layout=SIL. Ce
font/sfnt remplace l'ancien type enregistré,
application/font-sfnt. Notez que la
spécification de ce format est la norme ISO
ISO/IEC 14496-22, dite
« Open Font Format ».
SFNT est un format générique, qui sera sans doute rarement
utilisé tel quel. On verra plutôt ttf ou otf.
Un exemple d'un format spécifique est en effet
TrueType. Ce sera le sous-type
ttf. Il aura également un paramètre optionnel
layout (mêmes valeurs possibles). On pourra
donc voir dans une réponse HTTP
Content-Type: font/ttf.
Troisième sous-type enregistré, otf pour
OpenType.
On trouve aussi un sous-type collection
pour mettre plusieurs polices ensemble.
Viennent enfin WOFF versions 1
(woff) et 2 (woff2). Il
s'agit cette fois d'une norme W3C. Ce
nouveau type font/woff remplace l'ancien application/font-woff.
Voilà, c'est tout, le nouveau type de premier niveau
font est désormais inclus dans le registre
IANA des types de premier niveau, et les polices
enregistrées sont dans cet
autre registre IANA.
L'article seul
RFC 8033: Proportional Integral Controller Enhanced (PIE): A Lightweight Control Scheme to Address the Bufferbloat Problem
Date de publication du RFC : Février 2017
Auteur(s) du RFC : R. Pan, P. Natarajan, F. Baker (Cisco Systems), G. White (CableLabs)
Expérimental
Réalisé dans le cadre du groupe de travail IETF aqm
Première rédaction de cet article le 1 mars 2017
Mais c'est quoi, ce bufferbloat (obésité du tampon ?) et pourquoi est-ce mauvais ? Le bufferbloat désigne la tendance à mettre dans les routeurs des tampons d'entrée/sortie de plus en plus gros. Cette tendance vient de la baisse du prix des mémoires, et d'un désir de pouvoir encaisser les brusques pics de trafic (bursts) qui sont fréquents sur l'Internet. Mais le bufferbloat a une conséquence négative : la latence augmente, puisque le paquet risque de devoir attendre longtemps dans un tampon qui, une fois rempli, aura du mal à se vider. Ce RFC propose donc un mécanisme de gestion des files d'attente, PIE (Proportional Integral controller Enhanced) où le routeur surveille la latence des paquets dans les tampons d'entrée/sortie, et jette des paquets, même si le tampon n'est pas plein, pour limiter la latence. Le paquet perdu dira en effet aux émetteurs de ralentir.
La latence est particulièrement à surveiller dans le cas d'applications fortement interactives comme les jeux en ligne ou la vidéoconférence. On cherche donc à diminuer la latence, pour fournir une meilleure qualité de service aux utilisateurs. PIE a fait l'objet d'analyses théoriques, de simulations, puis de mise en œuvre dans le noyau Linux, et semble aujourd'hui une solution intéressante. PIE est une solution purement locale au routeur, et ne pose donc pas de problèmes d'interopérablité : les autres routeurs avec lesquels on parle n'ont pas besoin de participer.
L'un des problèmes centraux de l'Internet a toujours été la congestion. Les paquets arrivent quand ils veulent, et peuvent dépasser la capacité du réseau. Deux solutions pour un routeur, jeter les paquets (IP est prévu pour cela, il travaille en mode datagramme), et attendre que les couches supérieures comme TCP s'en aperçoivent et ralentissent, ou bien deuxième solution, mettre les paquets dans un tampon, en attendant de pouvoir les envoyer. Ce tampon va permettre de lisser un trafic Internet qui est très irrégulier. En pratique, les deux solutions doivent être déployées : le tampon a une taille finie et, s'il est plein, il faut bien se résigner à jeter des paquets.
Comme la perte de paquets entraine un ralentissement du transfert de données (TCP va automatiquement diminuer le débit), il existe une forte demande pour limiter cette perte. La baisse des prix des mémoires permet de satisfaire cette demande, en augmentant la taille des tampons. (Voir le site Web consacré au « bufferbloat », qui contient notamment une bonne introduction au problème.)
L'effet pervers de cette augmentation de taille est que les protocoles comme TCP, ne voyant pas de perte de paquets, vont continuer à augmenter leur débit, et envoyer plein de paquets jusqu'à ce que, le tampon étant plein, le routeur commence à jeter des paquets, calmant TCP. Mais, à ce moment, il est trop tard, le tampon est plein et risque de rester plein longtemps, l'émetteur continuant à envoyer des paquets, même si c'est à un rythme réduit. Les paquets vont donc patienter dans le tampon, augmentant la latence. Et plus le tampon est grand, plus on aggrave la latence. On est donc passé de Charybde en Scylla : pour éviter les pertes de paquets, qui diminuent le débit, on a augmenté la latence. (On voit d'ailleurs que la notion de performance, dans les réseaux, est une notion compliquée. C'est pour cela que des termes flous et passe-partout comme « vitesse » ne devraient pas être employés.)
Un système de gestion de la file d'attente (AQM) va permettre de mieux contrôler le problème, en essayant de faire en sorte que les pics soudains d'activité puissent passer, tout en limitant la latence pour les transferts de longue durée. Un exemple de mécanisme d'AQM est RED, initialement proposé dans le RFC 2309 il y a dix-huit ans. RED a deux limites, il nécessite un réglage manuel de ses paramètres, et il agit sur la longueur de la file d'attente, pas sur la latence. C'est entre autre pour cela que le RFC 7567 avait demandé à ce que de nouveaux mécanismes d'AQM soient développés.
L'algorithme de ce RFC, PIE, se veut, comme RED, simple et facile à mettre en œuvre. Comme RED, son principal moyen d'action est de jeter, de manière partiellement aléatoire, des paquets avant qu'ils ne soient mis dans la file d'attente. Contrairement à RED, il agit sur la latence, pas sur la longueur de la file d'attente.
Les objectifs de PIE sont décrits dans la section 3 du RFC :
- Contrôler la latence, le paramètre qui est réellement important pour les applications,
- Essayer d'utiliser le réseau au mieux de sa capacité (si on jette trop de paquets, TCP va tellement ralentir que, certes, les tampons seront vides et la latence excellente, mais le réseau ne sera plus utilisé à fond),
- Simple à programmer et déployer (pas de réglage manuel des paramètres).
La section 4 du RFC décrit PIE, et c'est la section à lire si vous voulez mettre en œuvre PIE dans un routeur, ou simplement le comprendre complètement. L'algorithme effectue trois tâches :
- Jeter des paquets aléatoirement, avec une certaine probabilité, lors de l'arrivée dans la file d'attente,
- Mettre à jour automatiquement en permanence cette probabilité,
- Calculer la latence (puisque c'est elle qu'on veut minimiser).
La description complète originale figure dans l'article de Pan, R., Natarajan, P. Piglione, C., Prabhu, M.S., Subramanian, V., Baker, F. Steeg et B. V., « PIE: A Lightweight Control Scheme to Address the Bufferbloat Problem » en 2013. Cet algorithme suit les principes de stabilité de théorie du contrôle.
Dans cette section 4, notre RFC présente l'algorithme PIE sous
forme de texte et de pseudo-code. La
première tâche (section 4.1), jeter les paquets entrants selon une certaine
probabilité (PIE->drop_prob_) va s'exprimer :
//Safeguard PIE to be work conserving
if ( (PIE->qdelay_old_ < QDELAY_REF/2 && PIE->drop_prob_ < 0.2)
|| (queue_.byte_length() <= 2 * MEAN_PKTSIZE) ) {
return ENQUE;
else
randomly drop the packet with a probability PIE->drop_prob_.
La première branche du if est là pour éviter
du travail inutile : si la probabilité de jeter un paquet est
faible, ou bien si la file d'attente est loin d'être pleine (moins
de deux paquets en attente), ou bien si la latence est bien plus
faible que la latence visée,
dans ces cas, on le jette rien. C'est le fonctionnement idéal du
routeur, lorsque la congestion n'est qu'une menace lointaine.
La deuxième tâche, calculer automatiquement la probabilité de
jeter un paquet, est plus délicate (section 4.2). Il faut
connaitre la latence mais aussi la tendance (est-ce que la latence
tend à diminuer ou bien à augmenter). C'est ce qu'on nomme le
contrôleur Proportional Integral qui a donné
son nom à l'algorithme PIE. La formule de base (voir le
pseudo-code complet dans le RFC, notamment dans l'annexe A) est que la probabilité est la
latence (current_qdelay) multipliée par un coefficient (alpha),
augmentée de la différence entre la latence actuelle et la latence
précédente (et, donc, si la latence diminue, la probabilité sera diminuée) :
p = alpha*(current_qdelay-QDELAY_REF) +
beta*(current_qdelay-PIE->qdelay_old_);
Et la troisième tâche, le calcul de la latence, est fait en suivant la loi de Little (section 4.3) :
current_qdelay = queue_.byte_length()/dequeue_rate;
Cette formule est une estimation de la latence. On peut aussi la mesurer directement (mais cela fait plus de travail pour le routeur), par exemple en ajoutant une estampille temporelle aux paquets entrants et en la lisant à la sortie.
Ce pseudo-code n'est encore qu'une approximation du vrai algorithme. L'un des gros problèmes de tout système de gestion de la file d'attente est que le trafic Internet est sujet à de brusques pics où un grand nombre de paquets arrive en peu de temps. Cela va remplir la file et augmenter la latence, mais cela ne veut pas dire qu'il faille subitement augmenter la probabilité d'abandon de paquets (section 4.4). Donc, la première tâche, jeter certains paquets, devient :
if PIE->burst_allowance_ > 0 enqueue packet;
else randomly drop a packet with a probability PIE->drop_prob_.
if (PIE->drop_prob_ == 0 and current_qdelay < QDELAY_REF/2 and PIE->qdelay_old_ < QDELAY_REF/2)
PIE->burst_allowance_ = MAX_BURST;
Et dans la seconde, le calcul de la probabilité d'abandon de paquets, on ajoute :
PIE->burst_allowance_ = max(0,PIE->burst_allowance_ - T_UPDATE);
Cette fois, on a un PIE complet. Mais on peut, optionnellement, y ajouter certains éléments (section 5 du RFC). Le plus évident est, au lieu de jeter le paquet, ce qui fait qu'il aura été émis et transmis par les routeurs amont pour rien, de marquer les paquets avec ECN (RFC 3168). La première tâche regarde donc si le flot de données gère ECN et utilise cette possibilité dans ce cas, au lieu de jeter aveuglément :
if PIE->drop_prob_ < mark_ecnth && ecn_capable_packet:
mark packet;
else:
drop packet;
Le trafic réseau varie beaucoup dans le temps. La plupart du temps, si le réseau est bien dimensionné, il n'y a pas de problème et il serait dommage que PIE jette au hasard des paquets quand on n'est dans cette phase heureuse. Un autre ajout utile à PIE est donc une désctivation automatique quand la file d'attente est peu remplie. Un des avantages de couper complètement PIE (par rapport à simplement décider de ne pas jeter les paquets) est de gagner du temps dans le traitement des paquets.
Pour réactiver PIE quand la congestion commence, c'est un peu plus compliqué. Si PIE est coupé, il n'y a plus de calcul de la latence, et on ne peut donc pas utiliser une augmentation de la latence pour décider de remettre PIE en marche. Le RFC suggère de remettre PIE en route dès qu'on passe au-dessus d'un tiers d'occupation de la file d'attente.
Autre question délicate, les problèmes que crée le hasard. Par défaut, PIE prend ses décisions en jetant les dés. Si la latence est importante, indiquant qu'on approche de la congestion, PIE jette des paquets au hasard. Mais le hasard n'est pas prévisible (évidemment). Et il ne mène pas à une répartition uniforme des pertes de paquets. Il se peut qu'aucun paquet ne soit jeté pendant longtemps, ce qui fait que le routeur ne réagira pas à l'augmentation de la latence. Mais il se peut aussi qu'un massacre de paquets se produise à certains moments. L'utilisation du hasard mène forcément à des « séries noires » (ou à des « séries blanches »). Notre RFC propose donc un mécanisme (optionnel) de « dé-hasardisation », où un nouveau paramètre augmente avec la probabilité d'abandon de paquet, et est remis à zéro lorsqu'on jette un paquet. La décision de laisser tomber un paquet n'est prise que lorsque ce paramètre est entre deux valeurs pré-définies.
La section 6 du RFC se penche sur les problèmes concrets de mise en œuvre (programmeurs, on pense à vous). PIE peut être mis en œuvre en logiciel ou bien en matériel (sur beaucoup de routeurs, la mise en file d'attente est typiquement « plus logicielle » que le retrait de la file). PIE est simple, et peut être programmé de manière très économique (ou plus coûteuse si on met une estampille temporelle à chaque paquet, ce qui permet de mieux mesurer la latence, mais nécessite davantage de mémoire).
La deuxième tâche de PIE, recalculer la probabilité d'abandon, se fait typiquement en parallèle avec le traitement de la file d'attente. Vu le rythme d'entrée et de sortie des paquets dans un routeur moderne, ce sont des milliers de paquets qui sont passés entre deux recalculs. Le routeur ne pourra donc pas réagir instantanément.
Comme tous les bons algorithmes, PIE est évidemment plombé par un brevet, en l'occurrence deux brevets de Cisco. Cette entreprise a promis une licence gratuite et sans obligations (mais avec la classique clause de représailles, annulant cette licence si quelqu'un essaie d'utiliser ses brevets contre Cisco).
Aujourd'hui, Linux, FreeBSD (voir la page Web du projet) et d'autres mettent en œuvre PIE.
L'article seul
Les conséquences techniques de l'interception HTTPS en entreprise
Première rédaction de cet article le 28 février 2017
Le 28 février 2017, à la conférence NDSS 17 à San Diego, Zakir Durumeric a présenté les conclusions de la recherche faite avec Zane Ma, Drew Springall, Richard Barnes, Nick Sullivan, Elie Bursztein, Michael Bailey, J. Alex Halderman et Vern Paxson, « The Security Impact of HTTPS Interception ». Ils montraient que la pratique, très répandue en entreprise, de l'interception (en fait, le détournement) des sessions HTTPS des utilisateurs, outre son côté immoral, a de graves conséquences pour la sécurité.
De quoi s'agit-il ? Normalement, la session HTTPS est protégée de bout en bout. Le client se connecte au serveur et le protocole TLS se fait directement entre client et serveur. Les intermédiaires (par exemple les routeurs) ne voient qu'un flux chiffré qu'ils ne peuvent pas comprendre (confidentialité via le chiffrement), ni modifier (intégrité). Dans un certain nombre d'entreprises et d'organisations, par exemple étatiques, la direction souhaite au contraire pouvoir examiner le trafic des employés, par exemple pour savoir qui écrit au Canard Enchaîné. La technique pour cela consiste à intercepter le trafic HTTPS, le déchiffrer, et le rechiffrer avec le serveur. Lorsqu'il sera en clair, dans l'équipement de surveillance, on pourra l'examiner.
Mais, attendez, dit la lectrice qui connait TLS (RFC 5246) : ça ne peut pas marcher. La session n'est pas juste chiffrée, elle est authentifiée. Le serveur doit présenter un certificat, et il chiffre avec la clé contenue dans ce certificat. L'équipement d'interception ne peut pas montrer un certificat qui convienne.
Le truc réside dans une énorme faille du système
X.509 : n'importe quelle
autorité de certification peut produire un
certificat pour n'importe quel nom de
domaine, même si le titulaire de ce nom a choisi une
autre AC. Il suffit donc d'avoir une AC à
sa disposition dans le magasin de certificat de la machine. C'est
ainsi par exemple que le
ministère des finances avait fait un vrai/faux
certificat pour gmail.com...
Je ne parlerai pas ici des aspects moraux, politiques ou
juridiques de la surveillance via interception HTTPS. L'article
des chercheurs qui a fait l'objet de l'exposé d'aujourd'hui se
focalisait sur les problèmes techniques. Ils ont étudié cette
interception des deux côtés : en observant le trafic chez certains
serveurs Web, et en étudiant certaines des boîtes noires qui
font cette interception. Côté serveur, pour voir si le trafic est
intercepté, ils regardaient surtout s'il y avait une différence
entre le User-Agent:
HTTP (RFC 7231,
section 5.5.3) annoncé et les paramètres
TLS. Si un navigateur se présente comme
étant Firefox mais annonce l'extension
« battement de cœur » du RFC 6520, on est
sûr qu'il s'agit d'une interception : Firefox n'a jamais mis en
œuvre cette extension. Des tas d'autres heuristiques peuvent être
utilisées, comme l'ordre des extensions TLS dans le
ClientHello du client.
Leur étude montre que plus de 10 % des sessions HTTPS vers Cloudflare (6 % pour des sites divers de commerce en ligne) sont interceptées, ce qui est assez inquiétant.
Mais il y a bien pire : le système d'interception, on l'a vu, termine la session TLS et en commence une autre avec le serveur. Ce faisant, la totalité des systèmes testés font d'énormes erreurs TLS : ils annoncent des algorithmes de chiffrement abandonnés (RC4, cf. RFC 7465), ou qui n'auraient jamais dû être utilisées (les algorithmes « exportation », délibérement affaiblis), acceptent des certificats expirés, et, parfois, ils ne valident même pas le certificat du serveur ! Ils sont en outre vulnérables à plusieurs attaques TLS connues. Cela est dû au fait que ces boîtes noires utilisent des versions anciennes de bibliothèques TLS, et qu'elles ne les configurent pas proprement. (Ce problème avait déjà été démontré avec les anti-virus.)
Rien d'étonnant à cela : ces boîtes noires sont achetées par des gens qui n'y connaissent rien, qui n'évaluent pas le logiciel, et pour qui la sécurité est un produit qu'on achète. (Je viens de lire un guide « L'essentiel de la sécurité numérique pour les dirigeants » qui recommande de dépenser « de 3 % à 10 % du budget informatique [pour la] cybersécurité », comme si la sécurité dépendait de l'argent dépensé !)
Autre point à noter : ces boîtes noires de surveillance sont toutes en logiciel privateur (et sont donc populaires auprès de dirigeants qui se disent « le logiciel libre, ce n'est pas professionnel et enterprise-grade ») mais utilisent très souvent du logiciel libre en dessous (sans prendre la peine d'utiliser des versions récentes).
Donc, employés, la prochaine fois que vous entendez dire qu'on a déployé l'interception HTTPS pour votre bien, « pour des raisons de sécurité », méfiez-vous : cette pratique diminue la sécurité.
Dans la série des bonnes lectures, notez que l'ANSSI a un guide sur l'interception HTTPS. Notez que le US-CERT a également sonné l'alarme contre ces interceptions HTTPS. La recherche présentée à NDSS portait sur le côté client des boîtiers intercepteurs mais leur côté serveur est tout aussi bogué comme le montre l'exemple BlueCoat.
L'article seul
RFC 8064: Recommendation on Stable IPv6 Interface Identifiers
Date de publication du RFC : Février 2017
Auteur(s) du RFC : F. Gont (SI6 Networks /
UTN-FRH), A. Cooper (Cisco), D. Thaler
(Microsoft), W. Liu (Huawei
Technologies)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF 6man
Première rédaction de cet article le 24 février 2017
Ce RFC parle de vie privée mais il est très court, car il se contente de changer une règle, la nouvelle étant déjà largement acceptée. Désormais, si une machine IPv6 configure son adresse par le système SLAAC, et que cette adresse doit être stable dans le temps, désormais, donc, la méthode recommandée est celle du RFC 7217 et non plus celle, mauvaise pour la vie privée, d'utiliser l'adresse MAC. (Si l'adresse n'a pas besoin d'être stable, aucun changement, la méthode recommandée reste celle du RFC 8981, les adresses temporaires.)
Que veut dire SLAAC, au fait ? Ce mécanisme de configuration d'une adresse IPv6 est normalisé dans le RFC 4862. L'idée est que la machine écoute sur le réseau les annonces faites par les routeurs, apprenant ainsi le·s préfixe·s IP du réseau. Elle ajoute ensuite à ce préfixe un terme, l'identificateur d'interface (IID, cf. RFC 4291), formant ainsi une adresse IPv6 mondiale, et unique (si l'IID est bien choisi). La méthode originelle était de dériver l'IID de l'adresse MAC. Celle-ci est en effet unique et, en prime, son utilisation présente certains avantages (compression des en-têtes du RFC 6775, par exemple). Mais s'en servir soulève plein de problèmes de sécurité et notamment de vie privée : traçabilité des utilisateurs dans le temps, et dans l'espace (si la machine se déplace, elle change de préfixe mais garde le même identificateur d'interface), facilitation du balayage des adresses dans le réseau, etc (cf. RFC 7721). D'une manière générale, réutiliser des identificateurs d'un autre « monde » est une fausse bonne idée, souvent dangereuse en matière de vie privée. Voilà pourquoi ce RFC dit clairement que, désormais, il est fortement déconseillé d'utiliser les adresses MAC. (Plusieurs mises en œuvre d'IPv6, comme celles de Microsoft, avaient déjà cessé, avant même que ce RFC ne soit publié.)
Et ce RFC 7217 qu'il faut désormais suivre, il dit quoi ? Il propose de fabriquer l'identificateur d'interface en condensat une concaténation du préfixe et de diverses valeurs stables. Si on change de réseau, on a une nouvelle adresse (on ne peut donc pas suivre à la trace une machine mobile). Mais, si on reste sur le même réseau, l'adresse est stable.
La section 1 de notre RFC rappelle aussi la différence entre les adresses stables et les autres. Toutes les adresses IP n'ont pas besoin d'être stables. La solution la meilleure pour la vie privée est certainement celle du RFC 8981, des adresses temporaires, non stables (pour de telles adresses, on peut aussi utiliser le système des adresses MAC si elles changent souvent par exemple avec macchanger). Toutefois, dans certains cas, les adresses stables sont souhaitables : l'administration réseaux est plus simple, les journaux sont plus faciles à lire, on peut mettre des ACL, on peut avoir des connexions TCP de longue durée, etc. Et, bien sûr, si la machine est un serveur, ses adresses doivent être stables. Il y a donc une place pour une solution différente de celle du RFC 8981, afin de fournir des adresses stables. C'est seulement pour ces adresses stables que notre RFC recommande désormais la solution du RFC 7217.
La nouvelle règle figure donc en section 3 de notre RFC : lorsqu'une machine veut utiliser SLAAC et avoir des adresses stables, qui ne changent pas dans le temps, tant que la machine reste sur le même réseau, alors, dans ce cas et seulement dans ce cas, la méthode à utiliser est celle du RFC 7217. L'ancienne méthode (qu'on trouve par exemple dans le RFC 2464) d'ajouter le préfixe à l'adresse MAC ne doit plus être utilisée.
Notez donc bien que ce RFC ne s'adresse pas à toutes les
machines IPv6. Ainsi, si vous configurez vos serveurs (qui ont
clairement besoin d'une adresse stable) à la main, avec des
adresses en leet comme
2001:db8::bad:dcaf, ce RFC 8064 ne
vous concerne pas (puisqu'il n'y a pas de
SLAAC).
Les RFC comme le RFC 4944, RFC 6282, RFC 6775 ou RFC 7428 devront donc être remplacés par des documents tenant compte de la nouvelle règles. (Cf. RFC 8065.)
Aujourd'hui, il semble que les dernières versions de Windows, MacOS, iOS et Android mettent déjà en œuvre la nouvelle règle.
L'article seul
RFC 8065: Privacy Considerations for IPv6 Adaptation-Layer Mechanisms
Date de publication du RFC : Février 2017
Auteur(s) du RFC : D. Thaler (Microsoft)
Pour information
Réalisé dans le cadre du groupe de travail IETF 6lo
Première rédaction de cet article le 24 février 2017
Entre la couche 3 (du modèle en couches) et la couche 2 (par exemple Ethernet) se trouve une adaptation, qui définit comment on va mettre les paquets IPv6 sur la couche sous-jacente. Certaines de ces adaptations posent des problèmes de protection de la vie privée. Ce RFC résume les problèmes existants. Chaque adaptation devra ensuite travailler à s'améliorer sur ce plan (le RFC donne des idées). L'idée est d'améliorer les normes actuelles et futures, pour mieux prendre en compte ce problème de vie privée.
Ce problème de la vie privée pour IPv6 a déjà été beaucoup discuté, notamment en raison d'un choix initial de privilégier une adaptation à Ethernet qui gardait une partie de l'adresse IPv6 constante, même quand la machine changeait de réseau. Ce problème est résolu depuis longtemps (RFC 8981) mais d'autres peuvent demeurer, surtout si la couche 2 a des contraintes qui empêchent de déployer certaines protections de la vie privée.
Les documents de référence à lire d'abord sont le RFC général sur la vie privée, RFC 6973 (sa section 5.2 est particulièrement utile ici), et, plus spécifique à IPv6, le RFC 7721. Le risque qui concerne l'adaptation est lié au mécanisme de génération des IID (identificateurs d'interface, cf. RFC 4291), puisque cet IID fait partie de l'adresse IPv6 (typiquement les 64 derniers bits) et va donc être potentiellement visible publiquement. Si l'IID est trop prévisible ou trop stable, il permettra notamment :
- De corréler des activités du même utilisateur au cours du temps,
- De suivre l'utilisateur à la trace s'il se déplace en gardant le même IID,
- De balayer plus facilement un réseau à la recherche de machines à attaquer (alors que, normalement, la taille élevée de l'espace d'adressage IPv6 rend ces balayages lents et pénibles).
Un concept important est celui d'entropie, c'est-à-dire du nombre de bits dans l'IID qui sont réellement imprévisibles. Idéalement, l'entropie devrait être de 64 bits (le préfixe IPv6 ayant typiquement une longueur de 64 bits pour un réseau, cf. RFC 7421).
Voilà pourquoi le RFC 8064 déconseille de créer un IID à partir d'une adresse « couche 2 » fixe, comme l'est souvent l'adresse MAC. Il recommande au contraire la technique du RFC 7217 si on veut des adresses stables tant qu'on ne se déplace pas, et celle du RFC 8981 si on veut être vraiment difficile à tracer (au prix d'une administration réseaux plus difficile). Le RFC sur la sélection des adresses source, RFC 6724 privilégie déjà par défaut les adresses temporaires du RFC 8981.
Revenons maintenant à cette histoire d'entropie (section 2 du
RFC). Combien de bits sont-ils nécessaires ? Prenons le cas le plus
difficile, celui d'un balayage du réseau local, avec des paquets
ICMP Echo Request ou bien avec des
TCP SYN. L'entropie minimum
est celle qui minimise les chances d'un attaquant de trouver une
adresse qui réponde. Quel temps faudra-t-il pour avoir une chance
sur deux de trouver une adresse ? (Notez que la capacité de
l'attaquant à trouver des machines dépend aussi du fait qu'elles
répondent ou pas. Si une machine ne répond pas aux ICMP
Echo Request, et n'envoie pas de
RST aux paquets TCP SYN,
la tâche de l'attaquant sera plus compliquée. Cf. RFC 7288, notamment sa section 5. Même si la machine répond,
un limiteur de trafic peut rendre la tâche de l'attaquant
pénible. Avec la valeur par défaut d'IOS de
deux réponses ICMP par seconde, il faut une année pour balayer un
espace de seulement 26 bits.)
Les formules mathématiques détaillées sont dans cette section 2 du RFC. L'entropie nécessaire dépend de la taille de l'espace d'adressage mais aussi de la durée de vie du réseau. Avec 2^16 machines sur le réseau (c'est un grand réseau !) et un réseau qui fonctionne pendant 8 ans, il faudra 46 bits d'entropie pour que l'attaquant n'ait qu'une chance sur deux de trouver une machine qui réponde (avec la même limite de 2 requêtes par seconde ; sinon, il faudra davantage d'entropie).
Et combien de bits d'entropie a-t-on avec les techniques actuelles ? La section 3 donne quelques exemples : seulement 48 bits en Bluetooth (RFC 7668), 8 (oui, uniquement 256 adresses possibles, mais c'est nécessaire pour permettre la compression des en-têtes) en G.9959 (RFC 7428) et le pire, 5 bits pour NFC (RFC pas encore paru).
Ces adaptations d'IPv6 à diverses couches 2 utilisent comme identificants d'interface des adresses IEEE (comme les adresses MAC) ou bien des « adresses courtes ». Commençons par les adresses reposant sur des adresses IEEE. Dans certains cas, la carte ou la puce qui gère le réseau dispose d'une adresse EUI-48 ou EUI-64 (comme l'adresse MAC des cartes Ethernet). On peut facilement construire une adresse IPv6 avec ces adresses, en concaténant le préfixe avec cette adresse IEEE utilisée comme identificateur d'interface (IID). L'entropie dépend du caractère imprévisible de l'adresse IEEE. L'IEEE a d'ailleurs des mécanismes (pas forcément déployés dans le vrai monde) pour rendre ces adresses imprévisibles. Même dans ce cas, la corrélation temporelle reste possible, sauf si on change les adresses de temps en temps (par exemple avec macchanger).
Un argument souvent donné en faveur des adresses MAC est leur unicité, qui garantit que les adresses IPv6 seront « automatiquement » distinctes, rendant ainsi inutile la détection d'adresses dupliquées (DAD, RFC 4862, section 5.4, et RFC 4429, annexe A). Sauf que ce n'est pas vrai, les adresses MAC ne sont pas forcément uniques, en pratique et les identificateurs d'interface aléatoires sont donc préférables, pour éviter les collisions d'adresses.
En dehors des adresses allouées par un mécanismes de l'IEEE, il y a les « adresses courtes » (16 bits, utilisées par IEEE 802.15.4, cf. RFC 4944), allouées localement, et uniques seulement à l'intérieur du réseau local. Vu leur taille, elles n'offrent évidemment pas assez d'entropie. Il faut donc les étendre avant de s'en servir comme identificateur d'interface. Le RFC cite par exemple un condensat de la concaténation de l'adresse courte avec un secret partagé par toutes les machines du réseau.
On peut aussi utiliser dans le condensat le numéro de version spécifié dans la section 4.3 du RFC 6775. Ainsi, un changement de numéro de version permettra une rénumérotation automatique.
Bien, après cette analyse, les recommandations (section 4) :
- La section Sécurité (Security Considerations) des RFC qui normalisent une adaptation à une couche 2 donnée devrait dire clairement comment on limite le balayage. Cela nécessite de préciser clairement la durée de vie des adresses, et le nombre de bits d'entropie.
- Il faut évidemment essayer de maximiser cette entropie. Avoir des identificateurs d'adresses aléatoires est une bonne façon de le faire.
- En tout cas, pas question de juste utiliser une adresse courte et stable avec quelques bits supplémentaires de valeur fixe et bien connue.
- Les adresses ne devraient pas être éternelles, pour limiter la durée des corrélations temporelles.
- Si une machine peut se déplacer d'un réseau à l'autre (ce qui est courant aujourd'hui), il faudrait que l'identifiant d'interface change, pour limiter les corrélations spatiales.
L'article seul
RFC 8089: The "file" URI Scheme
Date de publication du RFC : Février 2017
Auteur(s) du RFC : M. Kerwin (QUT)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF appsawg
Première rédaction de cet article le 20 février 2017
Vous connaissez le plan d'URI
file:, qui indique que la ressource se
trouve sur le système de fichiers local ? (Par exemple, ce fichier
que je suis en train d'éditer est
file:///home/stephane/Blog/RFC/8089.xml.) Ce plan avait été défini
très brièvement dans le RFC 1738 (section 3.10). Tellement
brièvement qu'il y manquait pas mal de choses. Ce nouveau
RFC remplace cette partie du RFC 1738 et fournit cette fois une description
complète du plan file:. Ce n'était pas une
tâche facile car les différents systèmes de fichiers ont des
syntaxes et des comportements très différents. Le RFC lui-même est
très court, mais il comporte plusieurs annexes plus longues,
discutant de points spécifiques parfois assez tordus.
Donc, d'abord, la définition (section 1 de notre RFC) : un fichier est un objet qui se trouve rangé dans un environnement structuré, qui fournit notamment un système de nommage, environnement qu'on nomme le système de fichiers. (Et le fichier contient des données mais ce point n'est pas crucial pour les URI et n'est donc pas mentionné.) Ensuite, les URI : ce sont les identificateurs standard du Web. Leur syntaxe générique est définie dans le RFC 3986 et ce nouveau RFC ne fait donc que spécialiser le RFC 3986. Normalement, ce RFC est parfaitement compatible avec l'ancienne syntaxe, celle du RFC 1738 mais, en pratique, comme l'ancienne définition était vraiment trop vague, il y aura forcément quelques différences. (L'annexe E donne quelques exemples de pratiques utilisées dans la nature et qui ne sont pas strictement alignées sur les nouvelles règles. Elle cite par exemple l'ajout d'un nom d'utilisateur dans l'URI. Un exemple des problèmes que ces différences posent aux navigateurs est bien expliqué dans cet article de Microsoft.)
Les URI file: ne supposent pas
l'utilisation d'un protocole particulier, ni d'un type
de média particulier.
Ce plan d'URI désigne des « fichiers locaux ». Un fichier local est accessible juste à partir de son nom, sans autre information (par exemple sans utiliser une adresse réseau explicite). Mais, en pratique (section 1.1), il peut être physiquement sur une autre machine, grâce à des techniques comme NFS ou SMB.
La syntaxe de ces URI figure en section 2 de notre RFC,
formalisée en ABNF (RFC 5234). S'appuyant sur la syntaxe générique du RFC 3986, elle diffère légèrement de celle du
RFC 1738 (l'annexe A liste les
différences). Le plan file: est référencé
dans le registre des plans d'URI. Je vous laisse découvrir sa
grammaire dans le RFC, je donne juste des
exemples qui illustrent certains points de la syntaxe :
- Commençons par un URI banal :
file:///tmp/toto.txt. Il désigne le fichier local/tmp/toto.txtde l'ordinateur sur lequel on travaille. La syntaxe du nom de fichier est celle d'Unix, même si ledit ordinateur n'utilise pas Unix. Ainsi, le fichierc:\machin\trucsur une machine Windows sera quand mêmefile:///c:/machin/truc(il existe plein de variantes non-standard, voir l'annexe E, et l'article cité plus haut, sur les problèmes que cela pose). Sur VMS,DISK1:[CS.JANE]PAPER.PSdeviendrafile:///disk1/cs/jane/paper.ps(cf. annexe D). - Le composant après les trois barres obliques doit être un chemin absolu dans le système de fichiers de la machine. Cela a l'air simple mais la notion de « chemin absolu » ne l'est pas, et l'annexe D cite quelques surprises possibles (comme le tilde de certains shells Unix).
- Après les deux premières barres obliques, il y a normalement un
champ nommé « Autorité » (en pratique un nom
de domaine), qui est optionnel. Pour les URI
file:, on peut mettre dans ce champlocalhost, voire n'importe quel nom qui désigne la machine locale (je ne suis pas sûr de l'intérêt que cela présente, mais c'est la norme qui, il est vrai, déconseille cet usage). Donc, l'URI cité au début aurait pu (mais ce n'est pas recommandé) êtrefile://localhost/tmp/toto.txt. (Voir aussi la section 3 du RFC.) - Si on ne met pas le nom de domaine, les deux premières
barres obliques sont facultatives (c'est une nouveauté de notre
RFC, par rapport au RFC 1738) et
file:/tmp/toto.txtest donc légal. - Certains systèmes de fichiers sont sensibles à
la casse et il faut donc faire attention, en
manipulant les URI, à ne pas changer la
casse.
file:///c:/machin/trucetfile:///c:/Machin/TRUCsont deux URI différents même si on sait bien que, sur une machine Windows, ils désigneront le même fichier.
Que peut-on faire avec un fichier ? Plein de choses (l'ouvrir,
lire les données, le détruire… La norme
POSIX peut donner des idées à ce sujet.) Le plan d'URI
file: ne limite pas les opérations
possibles.
Évidemment, l'encodage des caractères
utilisé va faire des histoires, puisqu'il varie d'une machine à
l'autre. C'est parfois UTF-8, parfois un
autre encodage et, parfois, le système de fichiers ne définit
rien, le nom est juste une suite d'octets, qui devra être
interprétée par les applications utilisées (c'est le cas
d'Unix). Notre RFC (section 4) recommande bien sûr
d'utiliser UTF-8, avant l'optionelle transformation
pour cent (RFC 3986,
section 2.5). Ainsi, le fichier
/home/stéphane/café.txt aura l'URI
file:/home/st%C3%A9phane/caf%C3%A9.txt, quel
qu'ait été son encodage sur la machine. Au passage, j'ai essayé
avec curl et
file:///tmp/café.txt,
file:/tmp/café.txt,
file:/tmp/caf%C3%A9.txt,
file://localhost/tmp/caf%C3%A9.txt et même
file://mon.adresse.ip.publique/tmp/caf%C3%A9.txt marchent tous.
Et la sécurité ? Toucher aux fichiers peut évidemment avoir des
tas de conséquences néfastes. Par exemple, si l'utilisateur charge
le fichier file:///home/michu/foobar.html,
aura-t-il la même origine (au sens de la sécurité du Web) que
file:///tmp/youpi.html ? Après tout, ils
viennent du même domaine (le domaine vide, donc la machine
locale). Le RFC note qu'au contraire l'option la plus sûre est de
considérer que chaque fichier est sa propre origine (RFC 6454).
Autre question de sécurité rigolote, les systèmes de fichiers
ont en général des caractères spéciaux (comme la barre
oblique ou un couple de points pour Unix). Accéder bêtement à un
fichier en passant juste le nom au système de fichiers peut
soulever des problèmes de sécurité (c'est évidemment encore pire
si on passe ces noms à des interpréteurs comme le
shell, qui rajoutent leur propre liste de
caractères spéciaux). Le RFC ne spécifie pas de liste de
caractères « dangereux » car tout nouveau système de fichiers peut
l'agrandir. C'est aux programmeurs qui font les logiciels de faire
attention, pour le système d'exploitation
pour lequel ils travaillent. (Un problème du même ordre existe
pour les noms de fichiers spéciaux, comme
/dev/zero sur Unix ou
aux et
lpt sur Windows.)
Une mauvaise gestion de la sensibilité à la casse ou de l'encodage des caractères peut aussi poser des problèmes de sécurité (voir par exemple le rapport technique UAX #15 d'Unicode.)
Notons qu'il existe d'autres définitions possibles d'un URI
file: (annexe C de notre RFC). Par exemple,
le WhatWG maintient une liste des plans d'URI, non synchronisée avec celle
« officielle », et dont l'existence a
fait pas mal de remous à l'IETF, certains
se demandant s'il fallait quand même publier ce RFC, au risque
d'avoir des définitions contradictoires (cela a sérieusement
retardé la sortie du RFC). En gros,
l'IETF se concentre plutôt sur la syntaxe,
et le WhatWG sur le comportement des navigateurs (rappelez-vous que les URI ne sont
pas utilisés que par des navigateurs…). Il y a aussi les
définitions Microsoft comme UNC
ou leurs
règles sur les noms de fichier.
Et, pour finir, je vous recommande cet autre article de Microsoft sur l'évolution du traitement des URI dans IE.
L'article seul
RFC 8092: BGP Large Communities Attribute
Date de publication du RFC : Février 2017
Auteur(s) du RFC : J. Heitz (Cisco), J. Snijders
(NTT), K. Patel (Arrcus), I. Bagdonas
(Equinix), N. Hilliard (INEX)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF idr
Première rédaction de cet article le 19 février 2017
Ce RFC normalise un nouvel attribut des annonces BGP, « Large Communities ». Les « communautés » BGP sont des courtes données collées aux annonces BGP et qui permettent d'indiquer certaines caractéristiques des routes. Les décisions des routeurs peuvent utiliser ces caractéristiques. Mais les communautés originales étaient trop courtes (seulement quatre octets) : le nouvel attribut permet des communautés de douze octets.
Les « communautés » sont définies dans le RFC 1997. On les apprend via les documentations des
opérateurs ou des points d'échange. Par
exemple, celle du point
d'échange irlandais (section « Community based prefix filtering »). Un attribut COMMUNITY
dans une annonce BGP peut comporter plusieurs
communautés. Traditionnellement, les quatre octets des
communautés initiales sont utilisées pour représenter le numéro
d'AS dans les deux premiers octets (ainsi,
une communauté est mondialement unique, par ce système
d'allocation à deux niveaux), et des données spécifiques à l'AS
dans les deux suivants. Évidemment, avec les numéros d'AS de
quatre octets du RFC 6793, ça ne marchait
plus. D'où cet attribut LARGE_COMMUNITY,
désormais stocké dans le registre
IANA sous le numéro (type code) 32. (Il
y a bien eu une autre tentative d'augmenter la taille des
communautés, dans le RFC 4360, mais pas
suffisamment pour que les AS à quatre octets puissent être
utilisés partout.) Comme pour les « petites » communautés, ces grandes
communautés dans une annonce forment un ensemble (donc, non
ordonné) : plusieurs routeurs auront pu ajouter une communauté à
cet ensemble.
Les communautés sont importantes car elles sont utilisées dans
la politique de routage. BGP ne cherche pas
à trouver le meilleur chemin : il fait du routage politique, où
les décisions sont prises en fonction de choix faits par les
opérateurs (privilégier tel ou tel lien pour le trafic entrant,
par exemple). Les informations contenues dans une annonce BGP
(section 4.3 du RFC 4271) habituelle ne sont pas toujours
suffisantes, et c'est pour cela que les communautés ont été
introduites par le RFC 1997, pour ajouter
des informations utiles, comme l'endroit où telle route a été
apprise.
L'attribut
COMMUNITY (numéro 8) est transitif (section
5 du RFC 4271), ce qui
veut dire qu'après réception d'une annonce, il est transmis aux autres routeurs (d'où
l'importance de marquer la communauté avec un numéro d'AS, pour
que les communautés soient uniques au niveau mondial, sans qu'il
existe un registre central des communautés).
Le nouvel attribut LARGE_COMMUNITY (numéro
32) est également optionnel et transitif (section 2 de notre RFC). Il se compose d'un
ensemble de grandes communautés, chacune étant stockée sur douze
octets. L'idée est qu'on utilise les quatre premiers octets pour
identifier l'AS (ce qui va bien avec les grands AS du du RFC 6793), ce qui va garantir l'unicité des
communautés. Le nombre de communautés dans un attribut
LARGE_COMMUNITY est donné par le champ
Longueur de l'attribut, les attributs BGP étant encodés en
TLV (cf. RFC 4271,
section 4.3).
En cas d'agrégation de routes (section 3 du RFC), il est recommandé d'utiliser comme communautés l'union des ensembles de communautés des différentes annonces.
Et comment on va représenter ces grandes communautés sous forme
texte ? (Sur le câble, entre les deux routeurs, c'est du binaire,
en gros boutien, cf. RFC 4271, section 4.) On note trois groupes de quatre
octets, séparés par un deux-points, par
exemple 2914:65400:38016 (section 4 de notre RFC), où le premier champ
est presque toujours l'AS. (On trouve plein d'exemples dans le RFC 8195.)
Comme toutes les grandes communautés font exactement douze octets, si le champ Longueur de l'attribut n'est pas un multiple de douze, l'attribut est invalide, et le routeur qui reçoit cette annonce doit la gérer comme étant un retrait de la route (RFC 7606).
Un point de sécurité important en section 6 du RFC ; en gros, les grandes communautés ont quasiment les mêmes propriétés de sécurité que les anciennes petites communautés. Notamment, elles ne sont pas protégées contre une manipulation en transit : tout AS dans le chemin peut ajouter des communautés (même « mensongères », c'est-à-dire indiquant un autre AS que le sien) ou retirer des communautés existantes. La section 11 du RFC 7454 donne quelques détails à ce sujet. Ce problème n'est pas spécifique aux communautés, c'est un problème général de BGP. L'Internet n'a pas de chef et il est donc difficile de concevoir un mécanisme permettant de garantir l'authenticité des annonces.
Il existe déjà de nombreuses mises en œuvre de BGP qui gèrent
ces grandes communautés. Par exemple IOS
XR, ExaBGP,
BIRD, OpenBGPD, GoBGP,
Quagga, bgpdump depuis la
version 1.5,
pmacct... Une liste plus complète figure
sur le
Wiki. Mais il y a aussi le site Web du projet,
où vous trouverez plein de choses. Si vous avez accès à un routeur
BGP, ou à un looking
glass qui affiche les grandes communautés
(c'est le cas de celui du
Ring de NLnog),
les deux préfixes 2001:67c:208c::/48 et
192.147.168.0/24 ont une grande communauté
(15562:1:1).
Si vous essayez sur un routeur qui a un vieux logiciel, ne
comprenant pas ces grandes communautés, vous verrez sans doute
quelque chose du genre « unknown attribute ». Ici
sur IOS à Route Views :
% telnet route-views.oregon-ix.net
...
Username: rviews
route-views> show ip bgp 192.147.168.0
BGP routing table entry for 192.147.168.0/24, version 37389686
Paths: (41 available, best #21, table default)
Not advertised to any peer
Refresh Epoch 1
3333 1273 2914 15562
193.0.0.56 from 193.0.0.56 (193.0.0.56)
Origin IGP, localpref 100, valid, external
Community: 1273:22000 2914:410 2914:1206 2914:2203 2914:3200
unknown transitive attribute: flag 0xE0 type 0x20 length 0xC
value 0000 3CCA 0000 0001 0000 0001
...
Ici sur un vieux IOS-XR (le test a été fait à l'époque où l'attribut avait le numéro 30 et pas 32, d'où le 0x1e) :
RP/0/RSP0/CPU0:Router# show bgp ipv6 unicast 2001:67c:208c::/48 unknown-attributes
BGP routing table entry for 2001:67c:208c::/48
Community: 2914:370 2914:1206 2914:2203 2914:3200
Unknown attributes have size 15
Raw value:
e0 1e 0c 00 00 3c ca 00 00 00 01 00 00 00 01
Et ici sur JunOS :
user at JunOS-re6> show route 2001:67c:208c::/48 detail
2001:67c:208c::/48 (1 entry, 1 announced)
AS path: 15562 I
Unrecognized Attributes: 15 bytes
Attr flags e0 code 1e: 00 00 3c ca 00 00 00 01 00 00 00 01
Notez que certaines configurations (parfois activées par défaut) du routeur peuvent supprimer l'attribut « grandes communautés ». Pour empêcher cela, il faut, sur JunOS :
[edit protocols bgp]
user at junos# delete drop-path-attributes 32
Et sur IOS-XR :
configure
router bgp YourASN
attribute-filter group ReallyBadIdea ! avoid creating bogons
no attribute 32
!
!
Trois lectures pour finir :
- Un bon article sur l'acceptation des grandes communautés dans la nature et
- Un outil (fondé sur Docker) pour expérimenter avec ces grandes communautés.
- Le RFC 8195 qui donne de nombreux exemples d'usage de ces grandes communautés.
L'article seul
RFC 1997: BGP Communities Attribute
Date de publication du RFC : Août 1996
Auteur(s) du RFC : Ravishanker Chandrasekeran (cisco Systems), Paul Traina (cisco Systems), Tony Li
Chemin des normes
Première rédaction de cet article le 17 février 2017
Il n'y a pas de rapport simple entre la longueur d'un RFC et l'importance de la norme technique qu'il spécifie. Ce RFC (vieux de plus de vingt ans) ne fait que cinq pages mais décrit une technique qui est essentielle au bon fonctionnement du routage sur l'Internet, la technique des communautés BGP.
Rien de plus simple que cette idée : une communauté est juste une étiquette numérique qu'on ajoute aux annonces de routes IP transportées par le protocole BGP. On peut ainsi « décorer » ses annonces comme on veut, et les autres routeurs BGP pourront ainsi prendre des décisions fondées sur cette information supplémentaire. Les communautés sont juste une syntaxe, on leur met la signification qu'on veut.
Un tout petit rappel sur BGP : c'est le protocole d'échange de routes entre les opérateurs Internet. Son principe est simple (RFC 4271) : quand une route apparait, on annonce à ses pairs BGP la route, sous la forme d'un préfixe d'adresses IP, avec un certain nombre d'attributs. Les attributs ont un format et une sémantique précise. Voici un exemple d'une annonce reçue par le service RouteViews, et affichée sous forme texte par le logiciel bgpdump :
TIME: 02/17/17 15:00:00 TYPE: BGP4MP/MESSAGE/Update FROM: 208.51.134.246 AS3549 TO: 128.223.51.102 AS6447 ORIGIN: IGP ASPATH: 3549 3356 2914 30259 NEXT_HOP: 208.51.134.246 MULTI_EXIT_DISC: 13920 ATOMIC_AGGREGATE AGGREGATOR: AS30259 10.11.1.1 COMMUNITY: 2914:410 2914:1001 2914:2000 2914:3000 3356:3 3356:86 3356:575 3356:666 3356:2011 3356:11940 3549:2011 3549:2017 3549:2521 3549:2582 3549:2950 3549:2991 3549:30840 3549:31826 3549:32344 3549:33036 3549:34076 WITHDRAW 93.181.192.0/19 ANNOUNCE 199.193.160.0/22
On y voit que le routeur 208.51.134.246,
appartenant à l'AS
3549 (Level
3, ex-Global Crossing) a
annoncé une route à destination du préfixe
199.193.160.0/22 (il a aussi retiré une autre
route mais on ne s'en soucie pas ici). Cette annonce avait plusieurs
attributs comme le chemin d'AS (ASPATH) emprunté.
Les communautés (au nombre de 21 ici) sont un attribut
COMMUNITY dont le
format est défini mais dont on fait ensuite ce qu'on
veut. L'utilisation la plus courante est d'indiquer l'origine d'une
route, pour d'éventuelles décisions ultérieures, en fonction de la
politique de routage. Les communautés sont donc un outil pour gérer
la complexité de ces politiques.
Le RFC définit d'ailleurs une communauté comme « un groupe de
destinations partageant une propriété commune ». Ainsi, dans le cas de
l'annonce ci-dessus, la lecture de la documentation des différents
opérateurs nous apprend que 3549:31826 indique
que la route a été apprise en Europe, au Royaume-Uni, que
2914:410 nous montre
qu'il s'agissait d'une route d'un client (et non pas d'un pair) de
NTT, etc.
L'exemple d'utilisation donné par le RFC date pas mal (NSFNET n'existe plus) mais ce genre de cas est toujours fréquent. NSFNET, financé par l'argent public, ne permettait pas d'utilisation purement commerciale. Une entreprise à but lucratif pouvait s'y connecter, mais seulement pour échanger avec les organismes de recherche ou d'enseignement (le RFC parle d'organismes respectant l'AUP, qui étaient les conditions d'utilisation de NSFNET). Une telle politique est facile à faire avec les communautés : on étiquette toutes les routes issues du monde enseignement/recherche avec une communauté signifiant « route AUP », et NSFNET pouvait annoncer les routes AUP à tous et les routes non-AUP (n'ayant pas cette communauté) seulement aux client AUP. Ainsi, deux entreprises commerciales ne pouvaient pas utiliser NSFNET pour communiquer entre elles. Sans les communautés, une telle politique aurait nécessité une base complexe de préfixes IP, base difficile à maintenir, d'autant plus que tous les routeurs de bord devaient y accéder. (Avant les communautés, c'était bien ainsi qu'on procédait, avec les retards et les erreurs qu'on imagine.)
Autre exemple d'utilisation donné par le RFC, l'agrégation de routes. Si on annonce à la fois un préfixe englobant et un sous-préfixe plus spécifique pour optimiser l'accès à un site particulier, on ne souhaite en général annoncer ce sous-préfixe qu'aux pairs proches (les autres n'ont pas de chemin meilleur vers ce site). On va donc étiqueter l'annonce faite à ces pairs proches avec une communauté indiquant « cette route est pour vous, mais ne la propagez pas ». D'autres exemples d'utilisation figurent dans les RFC 1998 et RFC 4384.
L'attribut COMMUNITY (le RFC le nomme
COMMUNITIES, ce qui est effectivement plus logique, mais il a bien été enregistré sous
le nom COMMUNITY) est donc un attribut
optionnel (certaines annonces BGP ne l'utiliseront pas) et transitif
(c'est-à-dire qu'il est conçu pour être transmis avec l'annonce
lorsqu'on la relaie à ses pairs). Il consiste en un ensemble (non
ordonné, donc) de communautés, chacune occupant quatre octets (ce
qui est bien insuffisant aujourd'hui). Son code de type d'attribut
est 8. Le nombre de communautés dans une annonce est très
variable. Par exemple, le LU-CIX voit une
moyenne de 10,5 communautés par route sur ses serveurs de routes.
Si un attribut COMMUNITY est mal formé, en
vertu du RFC 7606, la route annoncée sera
retirée. (À l'époque du RFC originel, une erreur aboutissait à
fermer toute la session BGP, retirant toutes les routes.)
Chaque communauté peut donc aller de 0x0000000 à 0xFFFFFFFF mais
les valeurs de 0x0000000 à
0x0000FFFF, et de 0xFFFF0000 à 0xFFFFFFFF sont réservées. D'autre
part, la convention recommandée est de mettre son numéro
d'AS dans les deux premiers octets, et une
valeur locale à l'AS dans les deux derniers. (Notez que ce système
ne marche plus avec les AS de quatre octets du RFC 6793, ce qui a mené aux RFC 4360 et
RFC 8092.) Prenons comme exemple de
communauté 0x0D1C07D1. On note les communautés sous forme de deux
groupes de deux octets chacun, séparés par un
deux-points. Cette communauté est donc
3356:2001 : AS 3356
(Level 3) et valeur locale 2001 (le choix des
valeurs locales est une décision... locale donc on ne peut savoir ce
que signifie 2001 qu'en regardant la documentation
de Level 3. Dit autrement, la valeur locale est opaque.)
Certaines valeurs sont réservées à des communautés « bien
connues ». C'est le cas par exemple de 0xFFFFFF01 (alias
NO_EXPORT : ne pas transmettre cette annonce en
dehors de son AS), de 0xFFFFFF02 (NO_ADVERTISE,
ne transmettre cette annonce à aucun autre routeur) ou bien de la
plus récente 0xFFFF029A (BLACKHOLE, RFC 7999). Rappelez-vous que chaque routeur est
maître de ses décisions : les communautés bien connues sont une
suggestion, mais on ne peut jamais être sûr que le pair va la suivre
(c'est ainsi que, malgré les NO_EXPORT que
mettent les nœuds anycast
qui veulent rester relativement locaux, on voit dans certains cas les annonces
se propager plus loin, parfois pour des bonnes et parfois pour des
mauvaises raisons.)
Enfin, le RFC précise qu'un routeur est libre d'ajouter ses propres communautés aux annonces qu'il relaie, voire de supprimer des communautés existantes (chacun est maître de son routage).
Quelques bonnes lectures sur les communautés BGP :
- Un gros effort de rassemblement des documentations de tous
les opérateurs sur leurs communautés. Si vous voulez savoir
ce que signifie
8308:60050, c'est là qu'il faut aller (réponse ici). - Un très bon cours du NSRC, très concret, avec plein de détails (avec exemples de configuration pour Cisco IOS).
- Toujours pour les possesseurs de Cisco, la documentation officielle.
- Un bon exposé à NANOG.
- Un excellent travail de recherche et de taxonomie sur les communautés.
- Un autre travail de recherche, pour extraire de l'information sur les clients des opérateurs, en utilisant leurs communautés (notez celles d'AT&T, bien détaillées).
- Un exemple de politique de communautés extrêmement complète, celle de NTT. Notez le European country origins (là où la route a été apprise), qui peut permettre de faire du routage Schengen.
- Une communauté bien connue qui a besoin d'une bonne
documentation est la
BLACKHOLEdu RFC 7999. Voyez par exemple celle de Hurricane Electric.
Certains looking glass affichent les communautés par exemple celui de Cogent :
BGP routing table entry for 129.250.0.0/16, version 3444371605
Paths: (1 available, best #1, table Default-IP-Routing-Table)
2914
130.117.14.250 (metric 10109031) from 38.28.1.83 (38.28.1.83)
Origin IGP, metric 4294967294, localpref 100, valid, internal, best
Community: 174:11102 174:20666 174:21100 174:22010
Originator: 38.28.1.32, Cluster list: 38.28.1.83, 38.28.1.67, 38.28.1.235
Les communautés sont souvent documentées dans l'objet AS stocké dans la base d'un RIR et accessible via whois (ou, aujourd'hui, RDAP). Ici, celle du France-IX (notez l'utilisation d'AS privés) :
% whois AS51706 ... aut-num: AS51706 as-name: FRANCE-IX-AS ... remarks: The following communities can be used by members: remarks: remarks: ***************************************************** remarks: ** Note: These communities are evaluated remarks: ** on a "first match win" basis remarks: ***************************************************** remarks: 0:peer-as = Don't send route to this peer as remarks: 51706:peer-as = Send route to this peer as remarks: 0:51706 = Don't send route to any peer remarks: 51706:51706 = Send route to all peers remarks: ***************************************************** remarks: ** Note: the community (51706:51706) is applied remarks: ** by default by the route-server remarks: ***************************************************** remarks: remarks: 65101:peer-as = Prepend 1x to this peer remarks: 65102:peer-as = Prepend 2x to this peer remarks: 65103:peer-as = Prepend 3x to this peer remarks: 65201:peer-as = Set MED 50 to this peer remarks: 65202:peer-as = Set MED 100 to this peer remarks: 65203:peer-as = Set MED 200 to this peer remarks: remarks: ----------------------------------------------------- remarks: BLACKHOLING, set the next-hop to the blackhole router remarks: can be use with the basic community (above) remarks: remarks: 65535:666 = BLACKHOLE [RFC7999] remarks: remarks: https://www.franceix.net/en/technical/blackholing/ remarks: remarks: ----------------------------------------------------- remarks: Set peer-as value as listed below for all IXP members: remarks: (Can't be used for 51706:peer-as) remarks: 64649 = FranceIX Marseille peers remarks: 64650 = FranceIX Paris peers remarks: 64651 = SFINX peers remarks: 64652 = LyonIX peers remarks: 64653 = LU-CIX peers remarks: 64654 = TOP-IX peers remarks: 64655 = TOUIX peers remarks: remarks: ----------------------------------------------------- remarks: Set peer-as value as listed below for 32 bits ASNs: remarks: AS197422 -> AS64701 (Tetaneutral) remarks: AS196689 -> AS64702 (Digicube) [...] remarks: remarks: Extended Communities are supported and usage is remarks: encouraged instead of 32b->16b mapping remarks: ----------------------------------------------------- remarks: Communities that are in the public range remarks: (1-64495:x) and (131072-4199999999:x) remarks: will be preserved by the route-servers remarks: ----------------------------------------------------- remarks: Well-known communities are not interpreted by the remarks: route-servers and are propagated to all peers remarks: ----------------------------------------------------- remarks: remarks: The following communities are applied by the route-server: remarks: remarks: ***************************************************** remarks: ** WARNING remarks: ** You should not set any of these by yourself remarks: ** (from 51706:64495 to 51706:64699) remarks: ** (and 51706:64800 to 51706:65535) remarks: ** If you do so, your routes will be rejected remarks: ***************************************************** remarks: remarks: 51706:64601 = Prefix received from a peer on RS1 Paris remarks: 51706:64602 = Prefix received from a peer on RS2 Paris remarks: 51706:64611 = Prefix received from a peer on RS1 Marseille remarks: 51706:64612 = Prefix received from a peer on RS2 Marseille remarks: remarks: 51706:64649 = Prefix received from a FranceIX Marseille peer remarks: 51706:64650 = Prefix received from a FranceIX Paris peer remarks: 51706:64651 = Prefix received from a SFINX peer remarks: 51706:64652 = Prefix received from a LyonIX peer remarks: 51706:64653 = Prefix received from a LU-CIX peer remarks: 51706:64654 = Prefix received from a TOP-IX peer remarks: 51706:64655 = Prefix received from a TOUIX peer remarks: remarks: 51706:64666 = Prefix with invalid route origin ...
L'article seul
RFC 8093: Deprecation of BGP Path Attribute Values 30, 31, 129, 241, 242, and 243
Date de publication du RFC : Février 2017
Auteur(s) du RFC : J. Snijders (NTT)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF idr
Première rédaction de cet article le 17 février 2017
Ce très court RFC ne fait pas grand'chose : il marque juste comme « à ne pas utiliser » (deprecated) un certain nombre d'attributs BGP.
BGP est le protocole de routage de l'Internet. En permanence, les routeurs s'envoient des annonces de routes, annonces portant certains attributs (RFC 4271, section 5) qui précisent des caractéristiques de la route. La liste de ces attributs figure dans un registre IANA. Les attributs cités dans ce RFC sont marqués comme officiellement abandonnés. Ce n'est pas qu'ils ne servaient pas : au contraire, ils étaient « squattés » en étant annoncés bien qu'ils n'aient jamais fait l'objet d'un enregistrement formel. Mieux valait donc les marquer dans le registre.
Mais pourquoi est-ce que des gens peuvent utiliser des attributs non enregistrés ? Parce qu'il n'y a pas de police de l'Internet (en dépit de raccourcis franchements abusifs, par exemple de certains journalistes qui écrivent que « l'ICANN est le régulateur de l'Internet »). Personne ne peut donner des ordres à tous les routeurs, et les faire appliquer.
Bref, il y a des mises en œuvre de BGP qui fabriquent des
annonces avec des attributs non enregistrés. C'est la vie. Mais
c'est ennuyeux car cela peut entrainer des collisions avec de
nouveaux attributs qui, eux, suivent les règles. C'est ainsi que
l'attribut LARGE_COMMUNITY du RFC 8092 avait d'abord reçu la valeur numérique 30 avant
qu'on s'aperçoive que cette valeur était squattée par un autre
attribut (merci, Huawei)... Résultat, les routeurs squatteurs, quand ils
recevaient des annonces avec un attribut
LARGE_COMMUNITY ne lui trouvaient pas la
syntaxe attendue et retiraient donc la route de leur table de
routage (conformément au RFC 7606). LARGE_COMMUNITY a donc dû
aller chercher un autre numéro (32), et 30 a été ajouté au
registre, pour indiquer « territoire dangereux, squatteurs ici
». Le même traitement a été appliqué aux attributs 31, 129, 241,
242 et 243, qui étaient également squattés.
Le groupe de travail à l'IETF s'est demandé s'il n'aurait pas mieux valu « punir » les squatteurs en allouant délibérement le numéro officiel pour un autre attribut que le leur mais cela aurait davantage gêné les utilisateurs de l'attribut légitime que les squatteurs, qui avaient déjà une base installée.
L'article seul
RFC 8080: Edwards-Curve Digital Security Algorithm (EdDSA) for DNSSEC
Date de publication du RFC : Février 2017
Auteur(s) du RFC : O. Sury (CZ.NIC), R. Edmonds
(Fastly)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF curdle
Première rédaction de cet article le 15 février 2017
Ce RFC (premier RFC du groupe CURDLE) spécifie comment utiliser les algorithmes de cryptographie à courbe elliptique Ed25519 et Ed448 dans DNSSEC.
Contrairement à ce qu'on a pu parfois lire sous la plume de trolls ignorants, DNSSEC, mécanisme d'authentification des enregistrements DNS, n'est en rien lié à RSA. Au contraire, comme tous les protocoles cryptographiques de l'IETF, il dispose d'une propriété nommée agilité cryptographique. Ce nom désigne un système utilisant la cryptographie qui n'est pas lié à un algorithme cryptographique particulier. Il peut donc en changer, notamment pour suivre les progrès de la cryptanalyse, qui rend l'abandon de certains algorithmes nécessaire. Aujourd'hui, par exemple, RSA semble bien démodé, et les courbes elliptiques ont le vent en poupe. Aucun problème pour DNSSEC : aussi bien les clés que les signatures disposent d'un champ numérique qui indique l'algorithme cryptographique utilisé. Les valeurs possibles de ce champ figurent dans un registre IANA, registre auquel viennent d'être ajoutés (cf. sections 5 et 7) 15 pour Ed25519 et 16 pour Ed448.
Notez que ces algorithmes ne sont pas les premiers algorithmes à courbes elliptiques normalisés pour DNSSEC : le premier avait été GOST R 34.10-2001 (RFC 5933), il y a six ans, et le second ECDSA (RFC 6605).
Les algorithmes cryptographiques Ed25519 et Ed448, instances de EdDSA, sont spécifiés dans le RFC 8032. Ils peuvent d'ailleurs servir à d'autres systèmes que DNSSEC (par exemple SSH, cf. RFC 7479).
Les détails pratiques pour DNSSEC, maintenant (section 3 du RFC). Notre nouveau RFC est court car l'essentiel était déjà fait dans le RFC 8032, il ne restait plus qu'à décrire les spécificités DNSSEC. Une clé publique Ed25519 fait 32 octets (section 5.1.5 du RFC 8032) et est encodée sous forme d'une simple chaîne de bits. Une clé publique Ed448 fait, elle, 57 octets (section 5.2.5 du RFC 8032).
Les signatures (cf. section 4 de notre RFC) font 64 octets pour Ed25519 et 114 octets pour Ed448. La façon de les générer et de les vérifier est également dans le RFC 8032, section 5.
Voici un exemple de clé publique Ed25519, et des signatures faites avec cette clé, extrait de la section 6 du RFC (attention, il y a deux erreurs, les RFC ne sont pas parfaits) :
example.com. 3600 IN DNSKEY 257 3 15 (
l02Woi0iS8Aa25FQkUd9RMzZHJpBoRQwAQEX1SxZJA4= )
example.com. 3600 IN DS 3613 15 2 (
3aa5ab37efce57f737fc1627013fee07bdf241bd10f3b1964ab55c78e79
a304b )
example.com. 3600 IN MX 10 mail.example.com.
example.com. 3600 IN RRSIG MX 3 3600 (
1440021600 1438207200 3613 example.com. (
Edk+IB9KNNWg0HAjm7FazXyrd5m3Rk8zNZbvNpAcM+eysqcUOMIjWoevFkj
H5GaMWeG96GUVZu6ECKOQmemHDg== )
Et, pour une vraie clé dans un vrai domaine, cette fois sans erreur :
% dig DNSKEY ed25519.monshouwer.eu ; <<>> DiG 9.9.5-9+deb8u9-Debian <<>> DNSKEY ed25519.monshouwer.eu ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 46166 ;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 4096 ;; QUESTION SECTION: ;ed25519.monshouwer.eu. IN DNSKEY ;; ANSWER SECTION: ed25519.monshouwer.eu. 3537 IN DNSKEY 257 3 15 ( 2wUHg68jW7/o4CkbYue3fYvGxdrd83Ikhaw38bI9dRI= ) ; KSK; alg = 15; key id = 42116 ed25519.monshouwer.eu. 3537 IN RRSIG DNSKEY 15 3 3600 ( 20170223000000 20170202000000 42116 ed25519.monshouwer.eu. Gq9WUlr01WvoXEihtwQ6r7t9AfkQfyETKTfm84WtcZkd M04KEe+4xu9jqhnG9THDAmV3FKASyWQ1LtCaOFr5Dw== ) ;; Query time: 0 msec ;; SERVER: 127.0.0.1#53(127.0.0.1) ;; WHEN: Wed Feb 15 13:13:27 CET 2017 ;; MSG SIZE rcvd: 215
Quelques questions de sécurité pour conclure ce RFC (section 8). Les clés Ed25519 font l'équivalent de 128 bits de sécurité (et 224 pour Ed448). Du fait de l'existence d'algorithmes efficaces pour les casser sur un ordinateur quantique, cela ne sera pas suffisant le jour où on disposera d'un tel ordinateur. Ce jour est probablement très lointain (bien que la NSA, organisme de confiance, dise le contraire).
Enfin, la même section 8 rappelle l'existence des attaques trans-protocoles : il ne faut pas utiliser une clé dans DNSSEC et dans un autre protocole.
À noter que ce RFC est un pas de plus vers une cryptographie 100 % Bernstein, avec cette adaptation des algorithmes utilisant Curve25519 à DNSSEC. Bientôt, l'ancien monopole de RSA aura été remplacé par un monopole de Curve25519.
Apparemment, le RFC est un peu en avance sur le logiciel, les systèmes DNSSEC existants ne gèrent pas encore Ed25519 ou Ed448 (à part, semble-t-il, PowerDNS et, bientôt, DNS Go. BIND a eu EdDSA à partir de la version 9.12.)
L'article seul
RFC 8063: Key Relay Mapping for the Extensible Provisioning Protocol
Date de publication du RFC : Février 2017
Auteur(s) du RFC : H.W. Ribbers, M.W. Groeneweg (SIDN), R. Gieben, A.L.J Verschuren
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF eppext
Première rédaction de cet article le 15 février 2017
Un des problèmes pratiques que pose DNSSEC est le changement d'hébergeur DNS. Si on sous-traite sa gestion des clés cryptographiques, et ses signatures à un tiers, que faire lors du changement de prestataire, pour ne pas casser la chaîne de confiance DNSSEC ? On ne peut évidemment pas demander à l'ancien hébergeur de transmettre la clé privée au nouveau ! Même pour les données non confidentielles, comme la clé publique, la transmission est difficile car les deux hébergeurs n'ont pas de canal de transmission sécurisé commun. Ce nouveau RFC propose d'utiliser comme canal sécurisé le registre de la zone parente et, plus concrètement, de définir une extension au protocole EPP, qui permet un mécanisme de « messagerie » électronique sécurisée, afin de l'utiliser entre deux clients du même registre.
Pour bien comprendre le problème et sa solution, il faut faire un peu de terminologie :
- Bureau d'enregistrement (BE) : l'entité par laquelle il faut passer pour toute opération sur le registre. À noter que tous les registres n'ont pas ce concept et c'est pour cela que notre RFC, comme les autres RFC sur EPP, ne parle pas de BE mais de client EPP.
- Hébergeur DNS (DNS operator dans le RFC) : l'entité qui gère les serveurs de nom du domaine. C'est souvent le BE mais ce n'est pas du tout obligatoire. Les serveurs DNS peuvent être gérés par une entreprise spécialisée, qui n'est pas BE, ou bien directement par l'utilisateur.
- EPP : protocole d'avitaillement (notamment de noms de domaine), normalisé dans le RFC 5730, entre un serveur (le registre) et un client (le BE, lorsque ce registre utilise des BE).
- DNSSEC : système d'authentification des informations récupérées via le DNS. Il repose sur la cryptographie asymétrique et il y a donc une clé publique (mise dans le DNS) et une clé privée (qui n'est... pas publique). DNSSEC utilise le DNS et doit donc faire attention au temps qui s'écoule ; par exemple, lorsqu'on publie une nouvelle clé (on l'ajoute à l'ensemble DNSKEY), elle ne va pas être visible tout de suite par tous les clients DNS, certains ont en effet mémorisé l'ancien ensemble de clés.
Dans le cas le plus fréquent, l'hébergeur DNS assure la gestion des clés (création, suppression, etc) et connait donc la clé privée, qu'il utilise pour signer les enregistrements. Si le titulaire du domaine veut changer d'hébergeur, pas question bien sûr de transmettre la clé privée. Le nouvel hébergeur (le « gagnant ») va donc créer des nouvelles clés et les utiliser pour signer. Le problème est qu'un résolveur DNS peut avoir des signatures de l'ancien hébergeur (le « perdant ») et des clés du nouveau (ou bien le contraire). Dans ces deux cas, la validation échouera, le domaine sera vu comme invalide.
Une solution à ce problème serait que l'ancien hébergeur mette à l'avance (rappelez-vous, le temps est crucial dès qu'on fait du DNS...) dans les clés qu'il publie la nouvelle clé du nouvel hébergeur. Mais cela suppose qu'il connaisse cette clé. Le titulaire du nom peut servir de relais mais il n'est pas forcément compétent pour cela (« M. Michu, votre nouvel hébergeur a dû vous remettre une clé cryptographique. C'est une série de lettres et de chiffres incompréhensiblles. Pouvez-nous nous la transmettre sans la moindre altération ? »). L'ancien hébergeur ne peut pas non plus utiliser le DNS puisque les serveurs du nouveau ne sont pas encore configurés et, même s'ils le sont, l'ancien hébergeur ne peut pas valider leur contenu avec DNSSEC. L'idée de notre RFC est donc d'utiliser le registre comme intermédiaire de confiance. Si les deux hébergeurs sont également BE, ils ont déjà un canal sécurisé avec le registre (la session EPP). Sinon, on peut espérer que le BE acceptera de servir de relais entre l'hébergeur et le registre.
Avec la solution de ce RFC, le nouvel hébergeur (on va suppose qu'il est également BE, ce sera plus simple) va créer ses clés, les transmettre (la clé publique seulement, bien sûr) au registre via l'extension EPP de notre nouveau RFC, l'ancien hébergeur va les lire (le registre ne sert que de boîte aux lettres sécurisée), les mettre dans la zone DNS. Au bout d'un temps déterminé par le TTL des enregistrements, tous les résolveurs auront l'ancienne et la nouvelle clé publique dans leur mémoire, et pourront valider aussi bien les anciennes que les nouvelles signatures.
Une autre façon de résoudre ce problème serait évidemment que chacun gère sa zone DNS lui-même, et donc ne change jamais d'« hébergeur » mais ce n'est évidemment pas souhaitable pour la plupart des titulaires.
Ce RFC ne spécifie qu'un mécanisme de messagerie, pas une
politique, ni une procédure détaillée. La politique est du ressort
du registre et de ses BE (via le contrat qui les lie, qui spécifie
typiquement des obligations comme « le BE perdant doit coopérer au
transfert du domaine, et mettre les nouvelles clés dans la zone
qu'il gère encore »). La procédure n'est pas décrite dans un
RFC. (Il y a eu une tentative via le
document draft-koch-dnsop-dnssec-operator-change,
mais qui n'a pas abouti. La lecture de ce document est quand même
très recommandée.) Le mécanisme de messagerie décrit dans notre RFC
est donc « neutre » : il ne suppose pas une politique
particulière. Une fois la clé transmise, sa bonne utilisation va
dépendre des règles en plus et de si elles sont obéies ou
pas. Comme le dit le RFC, « The
registry SHOULD have certain policies in place that require the
losing DNS operator to cooperate with this transaction, however this
is beyond this document. »
Les détails EPP figurent en section 2. Les clés publiques sont
dans un élément XML
<keyRelayData>. Il contient deux
éléments, <keyData>, avec la clé
elle-même (encodée en suivant la section 4 du RFC 5910), et <expiry> (optionnel) qui
indique combien de temps (en absolu ou bien en relatif) garder cette clé dans la zone. La syntaxe formelle complète figure en section 4,
en XML Schema.
Les commandes EPP liées à cette extension figurent en section
3. Certaines commandes EPP ne sont pas modifiées par cette
extension, comme check, info,
etc. La commande create, elle, est étendue
pour permettre d'indiquer la nouvelle clé (un exemple figure dans
notre RFC, section 3.2.1). Si le serveur EPP accepte cette
demande, il met la clé dans la file d'attente de messages du
client EPP qui gère le nom de domaine en question (typiquement le
BE « perdant »). Sinon, il répond pas le code de retour 2308.
La nouvelle clé apparaitra dans le système de « messagerie » d'EPP (poll queue), RFC 5730, section 2.9.2.3. Un exemple de réponse figure dans notre RFC, section 3.1.2.
Quelques points de sécurité pour finir (section 6). Un client
EPP méchant pourrait envoyer des clés à plein de gens juste pour
faire une attaque par déni de
service. C'est au serveur EPP de détecter ces abus et
d'y mettre fin. Le serveur EPP peut exiger un
authinfo correct dans le message de création,
pour vérifier que l'action a bien été autorisée par le
titulaire. Enfin, cette technique d'envoi des clés ne garantit
pas, à elle seule, que tout aura bien été fait de bout en
bout. Par exemple, le nouvel hébergeur a tout intérêt à vérifier,
par une requête DNS epxlicite, que l'ancien
a bien mis la nouvelle clé dans la zone.
Ce RFC a eu une histoire longue et compliquée, malgré une forte demande des utilisateurs. Il y a notamment eu un gros problème avec un brevet futile (comme la plupart des brevets logiciels) de Verisign, qui a fait perdre beaucoup de temps (la déclaration de Verisign est la n° 2393, le brevet lui-même est le US.201113078643.A, la décision de l'IETF de continuer malgré ce brevet, et malgré l'absence de promesses de licence, est enregistrée ici).
Question mise en œuvre, la bibliothèque Net::DRI gère déjà ce RFC. Combien de registres et de BE déploieront ce RFC ? Le coût pour le registre est probablement assez faible, puisqu'il a juste à relayer la demande, utilisant un mécanisme de « messagerie » qui existe déjà dans EPP. Mais, pour les BE, il y a certainement un problème de motivation. Ce RFC aidera le BE « gagnant », et le titulaire du domaine, mais pas le BE « perdant ». Il n'a donc pas de raison de faire des efforts, sauf contrainte explicite imposée par le registre (et l'expérience indique que ce genre de contraintes n'est pas toujours strictement respecté).
Comme bonne explication de ce RFC, vous pouvez aussi lire l'excellent explication de SIDN (avec une jolie image). En parlant de SIDN, vous pouvez noter que leur première mention d'un déploiement d'une version préliminaire de cette solution a eu lieu en 2013 (cf. leur rapport d'activité). Le même SIDN vient de publier un article de premier bilan sur ce projet.
Merci à Patrick Mevzek pour les explications, le code et les opinions.
L'article seul
Fiche de lecture : For all the tea in China
Auteur(s) du livre : Sarah Rose
Éditeur : Arrow Books
9780099493426
Publié en 2009
Première rédaction de cet article le 14 février 2017
Robert Fortune n'exerçait pas vraiment un métier qu'on associe aux aventures, à l'espionnage et à la mondialisation économique. Il était botaniste. S'il a désormais sa place comme héros de roman, c'est parce que ce Britannique a joué un rôle crucial dans le grand jeu qui a permis de prélever en Chine les plants de thé et le savoir nécessaire pour les faire pousser, avant de transplanter le tout en Inde, permettant à l'Empire de se passer d'un partenaire chinois difficile et de produire son propre thé, révolutionnant ainsi le breakfast.
C'est qu'il ne suffisait pas d'être bon botaniste pour, en 1848, faire pousser du thé en Inde. La Chine avait un monopole historique, et le défendait. Exporter les plants de thé, ou les méthodes permettant de transformer les feuilles, était strictement interdit. La Chine était certes à l'époque dominée militairement par l'Europe mais restait indépendante. Et très peu d'Européens avaient osé pénétrer à l'intérieur du pays. La plupart restait dans les ports protégés par les canonnières impérialistes.
Fortune, employé de l'East India Company, fut donc chargé de cette mission. Sarah Rose fait revivre de façon très vivante les aventures assez extraordinaires d'un homme qu'on imaginerait plutôt s'occuper d'un tranquille jardin anglais. Il part en Chine sans guide Lonely Planet, loin des zones où les armes européennes garantissent la sécurité des étrangers, dans des parties de la Chine où même le pouvoir de l'Empereur est assez théorique. Curieux, Fortune observe non seulement le thé, mais aussi plein d'autres plantes, ainsi que les Chinois et leur civilisation. (Il est moins curieux en politique, ne voyant pas venir la révolte des Taiping.) Et il réussit non seulement à survivre mais à mener à bien sa mission d'espionnage industriel (les ayant-droits d'aujourd'hui parleraient probablement de « piratage »). Le thé arrive à Calcutta, puis à Darjeeling et finira, après un ou deux faux départs, par s'épanouir en Inde.
Bref, voyages, thé, et aventures, tout ce qu'on attend d'un roman.
L'article seul
Fiche de lecture : Du yéti au calmar géant
Auteur(s) du livre : Benoit Grison
Éditeur : Delachaux et Niestlé
978-2-603-02409-6
Publié en 2016
Première rédaction de cet article le 13 février 2017
Un gros livre fascinant sur la cryptozoologie, l'étude des animaux... pas forcément imaginaires mais en tout cas qui se dérobent aux investigations scientifiques. 400 pages de voyages et d'aventures, avec de superbes illustrations, à la poursuite de tas de bestioles mystérieuses.
La cryptozoologie est plus compliquée qu'il ne parait. Si tous les récits de monstres marins mystérieux n'étaient que des racontars de vieux marins ivres au bistrot du port, si toutes les histoires d'animaux étranges au cœur de la jungle n'étaient que des inventions d'indigènes ignorants, forcément ignorants, tout serait plus simple. On classerait tout cela au rayonnage des mythes, amusants et distrayants sans doute, mais indignes d'une vraie étude scientifique. Mais la cryptozoologie peut apporter des surprises. Bien sûr, il est rare que la bestiole citée dans les légendes existe vraiment. Mais son étude scientifique peut mener à des découvertes bien réelles. Les pieuvres gigantesques n'existent pas, mais le calmar géant (bien moins cité dans les légendes) était réel. Les mystérieux hommes-singes perdus au fin fond de l'Afrique sont de « simples » chimpanzés, mais ces chimpanzés montrent une variété de physiques et de cultures bien plus grande que ce qu'on croyait.
En l'absence de données précises, la cryptozoologie doit faire feu de tout bois, et appeler des disciplines comme l'ethnologie à son aide. Pas mal de ces monstres vivent en effet dans la mémoire des peuples, à défaut de réellement peupler mers et forêts. Les mythes ont tous une justification. On croise aussi dans ce livre des militants aveuglés par leur passion, des latino-américains qui voient partout des grands singes dans les Andes car ils espèrent démontrer que l'homme (ou au moins certains hommes) est apparu en Amérique, comme des nazis qui espèrent relativiser l'unité de l'espèce humaine, en gaspillant l'argent du Troisième Reich à chercher le mystérieux « dremo » (ce qui vaut à Himmler de se retrouver dans l'index du livre, au milieu d'autres illuminés nettement plus sympathiques).
L'auteur couvre de nombreuses espèces d'animaux à l'existence non prouvée. S'il y a des vedettes comme le serpent de mer et le bigfoot, on y trouve aussi des tas d'animaux dont la réputation ne dépasse pas l'Office de Tourisme local : l'ucumar (le yéti argentin), le nikur (le « cheval des eaux » des légendes scandinaves), ou Memphré, le monstre lacustre québecois.
Il y a aussi des cas où l'animal n'est pas imaginaire, on a de nombreuses preuves de son existence mais on pense qu'il est éteint depuis lontemps, alors que des récits plus ou moins fiables indique une survivance... parfois jusqu'à nos jours. Pour ces mammouths, mastodontes et toxodons, est-on dans la presque cryptozoologie ?
Pour tant d'autres animaux, on ne sait pas encore. L'auteur a clairement ses préférences : le monstre du Loch Ness est rapidement exécuté comme invraisemblable, mon cryptoanimal favori, le mokélé-mbembé est traité en deux pages seulement, mais le yéti et l'almasty bénéficient de davantage d'indulgence. Et si...
L'article seul
Repenser la sécurité du routage Internet
Première rédaction de cet article le 8 février 2017
Ah, voilà une question qu'elle est bonne : comment améliorer la sécurité du routage Internet ? On sait qu'elle n'est pas bonne, on sait que n'importe qui ayant accès à un routeur de la DFZ peut annoncer les routes qu'il veut et ainsi détourner du trafic. On sait aussi qu'il existe plusieurs techniques pour limiter les dégâts. La question est : sont-elles bonnes, et ne perd-on pas du temps avec des techniques compliquées lorsque de plus simples marcheraient presque aussi bien ? C'est, en gros, l'argument des auteurs de cet excellent article de Robert Lychev, Michael Schapira et Sharon Goldberg, « Rethinking Security for Internet Routing ».
(Au passage, je n'ai pas trouvé cet article en ligne - le dinosaure ACM, pourtant censé être une association d'informaticiens, ne le permet pas - mais on peut le télécharger via l'excellent Sci-Hub. Encore merci à son auteure, pour cet indispensable apport à la science.)
Pour empêcher quelqu'un d'annoncer une route illégitime dans l'Internet, on a plusieurs solutions (qui ne sont pas incompatibles : on peut en déployer plusieurs, voir RFC 7454). On peut valider les annonces reçues de ses pairs BGP contre un IRR (prefix filtering, dans l'article ; sur les IRR, voir le RFC 7682). On peut utiliser les techniques qui reposent sur la RPKI comme les ROA (origin validation dans l'article) ou comme le futur BGPsec (path validation, dans l'article, les RFC sur BGPsec ne sont pas encore sortis). On peut même ne rien faire et corriger après coup quand une annonce anormale apparait. Ces techniques ont en commun de nécessiter qu'on connaisse bien ses adresses IP et sa connectivité (ne riez pas, certains opérateurs ont du mal ici !) La RPKI stocke à peu près 5 % des routes de l'Internet aujourd'hui.
Les auteurs de « Rethinking Security for Internet Routing » ont testé (enfin, simulé). Sur un banc de test représentant une partie de l'Internet, ils ont essayé plusieurs stratégies et les résultats ne sont pas ceux qu'on attendait. Si le filtrage des annonces des clients était complètement déployé, il bloquerait presque autant d'attaques que les techniques plus sophistiquées de ROA ou de BGPsec. Cela montre que les techniques simples et anciennes sont souvent très efficaces.
Évidemment, c'est irréaliste : on n'a jamais une technique de sécurité qui soit complètement déployée partout. Toute analyse doit tenir compte des « maillons faibles », qui ne vérifient rien. Mais, même dans ce cas, leur simulation montre que le filtrage à la source est efficace. Pensez à cela la prochaine fois que votre transitaire vous embêtera à exiger que vos routes apparaissent dans la base d'un RIR : c'est pénible, mais c'est efficace contre les détournements.
L'article seul
RFC 8060: LISP Canonical Address Format (LCAF)
Date de publication du RFC : Février 2017
Auteur(s) du RFC : D. Farinacci (lispers.net), D. Meyer
(Brocade), J. Snijders (NTT)
Expérimental
Réalisé dans le cadre du groupe de travail IETF lisp
Première rédaction de cet article le 3 février 2017
Le protocole LISP permet d'utiliser comme identificateur ou comme localisateur aussi bien des adresses IPv4 qu'IPv6. Pour rendre les mécanismes de résolution d'identificateur en localisateur aussi génériques que possibles, ce nouveau RFC décrit un format d'adresses qui permet de gérer les deux familles d'adresses (et davantage).
Il existait des méthodes partielles pour représenter ces deux
familles. Par exemple, on peut décider de tout mettre en
IPv6 et de représenter les adresses
IPv4 sous la forme
« IPv4-mapped » (RFC 4291, section 2.5.5.2, par exemple
::ffff:192.0.2.151). Ou on pourrait, comme
c'est le cas dans les URL, représenter les
adresses sous forme texte en utilisant les
crochets pour distinguer IPv4 et IPv6 (RFC 3986, section 3.2.2, par exemple
https://192.0.2.151/
vs. https://[2001:db8:3f:ae51::78b:ff1]/). Mais
le groupe de travail à l'IETF a choisi une
solution qui traite les deux familles sur un pied d'égalité, et
est parfaitement générique (elle intégre d'autres
familles que simplement IPv4 et IPv6). La solution finalement documentée dans ce RFC est très
souple et peut servir à bien d'autres que LISP, dès qu'on veut
représenter des requêtes ou réponses d'un système d'annuaire.
À propos de familles, un terme important à retenir est celui d'AFI (Address Family Identifier). C'est un nombre identifiant la famille d'adresses utilisée. Il avait été introduit dans le RFC 2453 puis précisé dans le RFC 4760, et peut prendre plusieurs valeurs, stockées dans un registre à l'IANA (1 pour IPv4, 2 pour IPv6, etc). 0 indique une famille non spécifiée.
Le format de ces adresses LCA (LISP Canonical Address) est décrit dans la section 3 de notre RFC. L'adresse LCAF commence par l'AFI de LISP (16387) suivi de divers champs notamment la longueur totale de l'adresse et son type. Une LCA peut en effet contenir plus que des adresses IP (type 1). Elle peut aussi servir à transporter des numéros d'AS (type 3), des coordonnées géographiques (type 5), etc. La liste des types possibles est enregistrée à l'IANA. La section 4 explique les différents types et l'encodage du contenu associé.
Lorsqu'une LCA indique des adresses IP, elle utilise le type 1 : son contenu est une série de couples {AFI, adresse}. Des adresses IPv4 (AFI 1) et IPv6 (AFI 2) peuvent donc apparaitre dans cette liste (mais aussi des adresses MAC, AFI 6, lorsqu'on crée des VPN de couche 2, ou bien des noms de domaine, AFI 16). Ce seront ces LCA qui seront sans doute les plus utilisées dans les systèmes de correspondance LISP comme DDT (RFC 8111) ou ALT (RFC 6836).
Pour les numéros d'AS (type 3), la LCA contient un numéro d'AS, puis un préfixe (IPv4 ou IPv6) affecté à cet AS. Quant aux coordonnées géographiques (type 5), elles sont indiquées sous forme de latitude, longitude et altitude dans le système WGS-84. Cela permet, dans une réponse du système de correspondance LISP, d'indiquer la position physique du réseau du préfixe encodé dans la LCA. (Attention, le RFC note bien que cela a des conséquences pour la vie privée.) On peut aussi stocker des clés cryptographiques (type 11) dans une LCA (voir RFC 8111 et RFC 8061).
Les mises en œuvre existantes de LISP utilisent déjà les LCA (mais ne gèrent pas forcément tous les types officiels).
L'article seul
RFC 8040: RESTCONF Protocol
Date de publication du RFC : Janvier 2017
Auteur(s) du RFC : A. Bierman (YumaWorks), M. Bjorklund
(Tail-f Systems), K. Watsen
(Juniper)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF netconf
Première rédaction de cet article le 1 février 2017
Pour configurer à distance un équipement réseau (par exemple un routeur ou bien un commutateur), il existait déjà le protocole NETCONF (RFC 6241). Fondé sur un échange de données en XML, il n'a pas convaincu tout le monde, qui aurait préféré un protocole REST. C'est désormais fait avec RESTCONF, décrit dans ce RFC.
RESTCONF est donc bâti sur HTTP (RFC 7230) et les opérations CRUD. Comme NETCONF, RESTCONF utilise des modèles de données décrits en YANG (RFC 7950). Il devrait donc permettre de configurer plus simplement les équipements réseau. (Les historiens noteront que l'ancêtre SNMP avait été prévu, non seulement pour lire des informations, mais également pour écrire, par exemple pour modifier la configuration d'un routeur. Cette possibilité n'a eu aucun succès. Cet échec est une des raisons pour lesquelles NETCONF a été développé.)
Les opérations CRUD sont donc faites
avec les méthodes classiques de HTTP (RFC 7231). Lire l'état de l'engin se fait
évidemment avec la méthode GET. Le modifier
se fait avec une des méthodes parmi
PUT, DELETE,
POST ou PATCH
(cf. section 4 du RFC). Les
données envoyées, ou bien lues, sont encodées, au choix, en
XML ou en JSON. À
noter que RESTCONF, conçu pour les cas relativement simples, est plus limité que NETCONF (il n'a pas de
fonction de verrou, par exemple). Il ne peut donc
pas complètement remplacer NETCONF (ainsi, si un client NETCONF a
mis un verrou sur une ressource, le client RESTCONF ne peut
pas y accéder, voir la section 1.4 du RFC). Mais le RFC fait quand
même plus de 130 pages, avec plein d'options.
La syntaxe des URL utilisés comme
paramètres de ces méthodes est spécifiée dans ce RFC en utilisant
le langage de gabarit du RFC 6570. Ainsi, dans ce langage, les URL de
Wikipédia sont décrits par
http://fr.wikipedia.org/wiki/{topic} ce qui
signifie « le préfixe
http://fr.wikipedia.org/wiki/ suivi d'une
variable (qui est le sujet de la page) ».
En connaissant le modèle de données YANG du serveur, le client peut ainsi générer les requêtes REST nécessaires.
Les exemples du RFC utilisent presque tous la configuration d'un... juke-box (le module YANG est décrit dans l'annexe A). Cet engin a une fonction « jouer un morceau » et voici un exemple de requête et réponse REST encodée en JSON où le client demande au serveur ce qu'il sait faire :
GET /top/restconf/operations HTTP/1.1
Host: example.com
Accept: application/yang-data+json
HTTP/1.1 200 OK
Date: Mon, 23 Apr 2016 17:01:00 GMT
Server: example-server
Cache-Control: no-cache
Last-Modified: Sun, 22 Apr 2016 01:00:14 GMT
Content-Type: application/yang-data+json
{ "operations" : { "example-jukebox:play" : [null] } }
L'opération play, elle, est décrite dans
l'annexe A, le modèle de données du juke-box :
rpc play {
description "Control function for the jukebox player";
input {
leaf playlist {
type string;
mandatory true;
description "playlist name";
}
leaf song-number {
type uint32;
mandatory true;
...
Autre exemple, où on essaie de redémarrer le juke-box (et,
cette fois, on encode en XML pour montrer la différence avec JSON
- notez les différents types
MIME, comme
application/yang-data+xml ou
application/yang-data+json, et le fait que la
racine est /restconf et plus /top/restconf) :
POST /restconf/operations/example-ops:reboot HTTP/1.1
Host: example.com
Content-Type: application/yang-data+xml
<input xmlns="https://example.com/ns/example-ops">
<delay>600</delay>
<message>Going down for system maintenance</message>
<language>en-US</language>
</input>
HTTP/1.1 204 No Content
Date: Mon, 25 Apr 2016 11:01:00 GMT
Server: example-server
(Le serveur a accepté - le code de retour commence par 2 - mais n'a rien à dire, d'où le corps de la réponse vide, et le code 204 au lieu de 200.)
Et voici un exemple de récupération d'informations avec
GET :
GET /restconf/data/example-jukebox:jukebox/library/artist=Foo%20Fighters/album=Wasting%20Light HTTP/1.1
Host: example.com
Accept: application/yang-data+xml
HTTP/1.1 200 OK
Date: Mon, 23 Apr 2016 17:02:40 GMT
Server: example-server
Content-Type: application/yang-data+xml
Cache-Control: no-cache
ETag: "a74eefc993a2b"
Last-Modified: Mon, 23 Apr 2016 11:02:14 GMT
<album xmlns="http://example.com/ns/example-jukebox"
xmlns:jbox="http://example.com/ns/example-jukebox">
<name>Wasting Light</name>
<genre>jbox:alternative</genre>
<year>2011</year>
</album>
Pour éviter les collisions d'édition (Alice lit une variable,
tente de l'incrémenter, Bob tente de la multiplier par deux, qui
va gagner ?), RESTCONF utilise les mécanismes classiques de HTTP,
If-Unmodified-Since:,
If-Match:, etc.
Allez, encore un exemple, je trouve qu'on comprend mieux avec des exemples, celui-ci est pour modifier une variable :
PUT /restconf/data/example-jukebox:jukebox/library/artist=Foo%20Fighters/album=Wasting%20Light HTTP/1.1
Host: example.com
Content-Type: application/yang-data+json
{
"example-jukebox:album" : [
{
"name" : "Wasting Light",
"genre" : "example-jukebox:alternative",
"year" : 2011
}
]
}
HTTP/1.1 204 No Content
Date: Mon, 23 Apr 2016 17:04:00 GMT
Server: example-server
Last-Modified: Mon, 23 Apr 2016 17:04:00 GMT
ETag: "b27480aeda4c"
Et voici un exemple utilisant la méthode
PATCH, qui avait été introduite dans le RFC 5789, pour changer l'année de l'album :
PATCH /restconf/data/example-jukebox:jukebox/library/artist=Foo%20Fighters/album=Wasting%20Light HTTP/1.1
Host: example.com
If-Match: "b8389233a4c"
Content-Type: application/yang-data+xml
<album xmlns="http://example.com/ns/example-jukebox">
<year>2011</year>
</album>
HTTP/1.1 204 No Content
Date: Mon, 23 Apr 2016 17:49:30 GMT
Server: example-server
Last-Modified: Mon, 23 Apr 2016 17:49:30 GMT
ETag: "b2788923da4c"
Et on peut naturellement détruire une ressource :
DELETE /restconf/data/example-jukebox:jukebox/library/artist=Foo%20Fighters/album=Wasting%20Light HTTP/1.1
Host: example.com
HTTP/1.1 204 No Content
Date: Mon, 23 Apr 2016 17:49:40 GMT
Server: example-server
L'URL utilisé dans la requête comprend les différentes parties habituelles d'un URL (RFC 3986) : le chemin, la requête, l'identificateur, etc. (Dans les exemples précédents, je n'ai pas mis de requête ou d'identificateur.)
Notre RFC impose HTTPS, puisque modifier la configuration d'un équipement réseau est évidemment une opération sensible. Pour la même raison, le serveur RESTCONF doit évidemment authentifier le client. La méthode recommandée est le certificat client (section 7.4.6 du RFC 5246) mais on peut aussi utiliser une autre méthode d'authentification HTTP.
L'article seul
RFC 8058: Signaling One-Click Functionality for List Email Headers
Date de publication du RFC : Janvier 2017
Auteur(s) du RFC : J. Levine (Taughannock
Networks), T. Herkula (optivo)
Chemin des normes
Première rédaction de cet article le 31 janvier 2017
Le RFC 2369 décrit des en-têtes du
courrier électronique qui indiquent, entre
autres, comment se désabonner d'une liste de
diffusion (en-tête
List-Unsubscribe:, qui indique des
URI à activer pour se désabonner). Cela peut permettre des
désabonnements sans interaction explicite avec l'utilisateur : le
MUA voit cette en-tête, propose un bouton
« Désabonnement » à l'utilisateur, et le MUA effectue la requête
(par exemple HTTP) tout
seul. L'inconvénient est que certains logiciels (par exemple des
anti-spam) visitent automatiquement tous
les liens hypertexte présents dans les
messages, et risquent alors de désabonner l'abonné
accidentellement. Pour éviter cela, la page pointée par l'URI
présent dans List-Unsubscribe: n'est en
général pas « one-click » : il faut une action
explicite une fois cette page affichée. Ce nouveau
RFC propose des ajouts à
List-Unsubscribe: pour indiquer qu'un
désabonnement one-click est possible.
Voici un exemple de cet en-tête traditionnel
List-Unsubscribe: dans une liste de
diffusion IETF :
List-Unsubscribe: <https://www.ietf.org/mailman/options/ietf>,
<mailto:ietf-request@ietf.org?subject=unsubscribe>
La page indiquée dans l'URI HTTPS est une landing page : elle ne désabonne pas directement, il faut indiquer son adresse et sélectionner le bouton Unsubscribe. C'est acceptable quand l'utilisateur est un humain, mais pas dans les cas où il n'y a pas d'interaction possible. Imaginons un logiciel qui traite automatiquement les messages après le départ ou le décès d'un utilisateur, et qui veut donc le désabonner proprement de toutes les listes où il était abonné avec cette adresse désormais invalide. Ce logiciel doit pouvoir fonctionner sans intervention humaine, donc sans analyser une page HTML compliquée.
À noter que l'en-tête List-Unsubscribe:
ci-dessus, comme dans la plupart des cas, propose également un URI
de plan mailto:, déclenchant l'envoi d'un
message par courrier électronique. La
plupart des services qui envoient de grosses quantités de message
(les hébergeurs de listes de diffusion à grand volume) ont du mal
à gérer le flot de messages de désinscription (ils sont optimisés
pour envoyer beaucoup, pas pour recevoir beaucoup), et ce
RFC ne prend donc en compte que les URI de
plan https:.
La section 1 résume le cahier des charges de la solution présentée ici :
- Permettre aux émetteurs de courrier de signaler de manière standard et non-ambigüe qu'on peut se désabonner en un seul clic (« one-click »),
- Permettre aux auteurs de MUA de fournir une interface simple (par exemple un bouton « Désabonnement immédiat », lorsque le message lu est signalé comme le permettant),
- Permettre aux utilisateurs de se désabonner sans quitter leur MUA, sans avoir à basculer vers une page Web avec des instructions spécifiques (et, notre RFC oublie de le dire, page Web qui est souvent conçue pour décourager le désabonnement de la newsletter à la con).
La section 3 du RFC spécifie la solution retenue. Elle consiste
dans l'ajout d'un nouvel en-tête,
List-Unsubscribe-Post:, dont le contenu est un
couple clé=valeur,
List-Unsubscribe=One-Click. (Ce nouvel
en-tête a été ajouté dans le
registre IANA.) Par exemple,
l'en-tête montré plus haut deviendrait :
List-Unsubscribe: <https://www.ietf.org/mailman/options/ietf?id=66fd1aF64>,
<mailto:ietf-request@ietf.org?subject=unsubscribe>
List-Unsubscribe-Post: List-Unsubscribe=One-Click
Cela indiquerait clairement que le désabonnement en un clic est
possible. Le MUA, s'il désire effectuer le désabonnement, va alors
faire une requête HTTPS de méthode POST, en
mettant dans le corps de la requête le contenu de l'en-tête
List-Unsubscribe-Post:. Le serveur HTTPS,
s'il voit ce List-Unsubscribe=One-Click dans
la requête, doit
exécuter la requête sans poser de questions supplémentaires (le
but étant de faire un désabonnement en un seul clic).
Notez qu'il faut indiquer quelque part l'adresse à désabonner,
le serveur HTTP ne peut pas la deviner autrement. Pour rendre plus
difficile la création de fausses instructions de désabonnement,
cela se fait indirectement, via une donnée opaque, comprise
seulement du serveur (le id dans l'exemple
hypothétique ci-dessus).
Les données contenues dans le List-Unsubscribe-Post:
doivent idéalement être envoyées avec le type MIME
multipart/form-data (RFC 7578), et, sinon, en
application/x-www-form-urlencoded, comme le
ferait un navigateur Web. Bien sûr, le MUA
doit avoir la permission de l'utilisateur pour effectuer ce
désabonnement (on est en « un seul clic », pas en « zéro clic »).
Au fait, pourquoi la méthode POST ?
GET ne peut pas modifier l'état du serveur et
PUT ou DELETE sont
rarement accessibles.
Le courrier électronique n'étant pas vraiment sécurisé, il y a
un risque de recevoir des messages avec un
List-Unsubscribe-Post: mensonger. C'est
pourquoi le RFC demande (section 4) qu'il y ait un minimum
d'authentification du message. La seule
méthode d'authentification décrite est DKIM
(RFC 6376), avec une étiquette
d= identifiant le domaine. La signature DKIM
doit évidemment inclure dans les en-têtes signés les
List-Unsubscribe: et
List-Unsubscribe-Post: dans l'étiquette DKIM h=.
Avec l'exemple plus haut, la requête HTTP POST
ressemblerait à :
POST /mailman/options/ietf?id=66fd1aF64 HTTP/1.1
Host: www.ietf.org
Content-Type: multipart/form-data; boundary=---FormBoundaryjWmhtjORrn
Content-Length: 124
---FormBoundaryjWmhtjORrn
Content-Disposition: form-data; name="List-Unsubscribe"
One-Click
---FormBoundaryjWmhtjORrn--
La section 6 de notre RFC décrit les éventuels problèmes de
sécurité. En gros, il en existe plusieurs, mais tous sont en fait
des problèmes génériques du courrier électronique, et ne sont pas
spécifiques à cette nouvelle solution. Par exemple, un spammeur pourrait envoyer plein de
messages ayant l'en-tête
List-Unsubscribe-Post:, pour faire générer
plein de requêtes POST vers le pauvre
serveur. Mais c'est déjà possible aujourd'hui en mettant des URI
dans un message, avec les logiciels qui vont faire des
GET automatiquement.
Je n'ai pas encore vu cet en-tête
List-Unsubscribe-Post: apparaitre dans de
vrais messages.
Un des auteurs du RFC a écrit un bon résumé de son utilité, article qui explique bien comment fonctionne le courrier aujourd'hui.
L'article seul
RFC 8067: Updating When Standards Track Documents May Refer Normatively to Documents at a Lower Level
Date de publication du RFC : Janvier 2017
Auteur(s) du RFC : B. Leiba (Huawei)
Première rédaction de cet article le 29 janvier 2017
Un très (vraiment très court) RFC purement bureaucratique, pour un très léger (vraiment très léger) changement des règles concernant les références d'un RFC à un autre RFC.
Le problème était simple : un RFC situé sur le Chemin des Normes est dans une étape donnée. Au nombre de trois au début (RFC 2026), ces étapes sont désormais deux (RFC 6410) : Proposition de norme et Norme. D'autre part, un RFC a des références à d'autres RFC, dans sa bibliographie, et ces références peuvent être normatives (il faut avoir lu et compris les RFC cités) ou informatives (elles sont juste là pour compléter et éclairer). Une règle de l'IETF est qu'un RFC ne peut pas avoir de référence normative à un RFC situé à une étape inférieure. Le but était d'éviter qu'une norme ne dépende d'un texte de maturité et d'adoption inférieurs.
Le RFC 3967 introduisait une exception à cette règle, mais en imposant un processus jugé désormais trop rigide. On pouvait donc, quand c'était nécessaire, déroger à la règle « pas de références vers le bas [du chemin des normes, downward reference en anglais] » mais il fallait le documenter dans le Last Call (dernier appel avant adoption). Si quelque chose changeait dans les références d'un RFC, il pouvait donc y avoir à refaire le Last Call.
C'était d'autant plus gênant que la question se pose plus souvent maintenant. En effet, les groupes de travail de l'IETF qui bossent sur un sujet compliqué font souvent un document « de base », définissant les concepts, la terminologie, etc, et ces documents ne sont pas sur le chemin des normes (ils sont juste « pour information »). Impossible donc de mettre une référence « vers le bas ».
La nouvelle règle figure en section 2 du RFC : le RFC 3967 est légèrement mis à jour. Désormais, il n'est plus nécessaire de mentionner l'existence d'une référence « vers le bas » au moment du dernier appel. En cas de changement des références, il ne sera donc plus obligatoire de répéter le dernier appel. C'est donc entièrement à l'IESG de déterminer si une référence à un RFC « inférieur » est acceptable ou non.
L'article seul
RFC 8054: Network News Transfer Protocol (NNTP) Extension for Compression
Date de publication du RFC : Janvier 2017
Auteur(s) du RFC : K. Murchison (Carnegie Mellon
University), J. Élie
Chemin des normes
Première rédaction de cet article le 26 janvier 2017
Ce nouveau RFC définit un mécanisme standard de compression des news échangées en NNTP, sur Usenet.
NNTP, normalisé dans le RFC 3977 est un protocole gourmand en débit. Comprimer les données transmises est donc très souhaitable. C'est aussi un protocole très ancien, ce qui se voit dans certaines références du RFC, comme l'allusion à la compression PPP du RFC 1962 ou bien à la compression par modem comme V42bis :-)
Mais, malgré ce besoin de compression, il n'y avait pas encore
de solution standard en NNTP. Un certain nombre de mécanismes
non-standards avaient été déployés avec des noms comme XZVER,
XZHDR, XFEATURE COMPRESS,
ou MODE COMPRESS. Outre l'absence de
normalisation, ils souffraient de ne comprimer que les réponses
du serveur de news.
Compte-tenu du déploiement de plus en plus fréquent de TLS, pour assurer la confidentialité des échanges, il avait été envisagé à une époque de compter sur le mécanisme de compression de TLS (RFC 4642, remis en cause par le RFC 8143). Celui-ci présente malheureusement des dangers, qui fait que son usage est déconseillé dans beaucoup de cas (section 3.3 du RFC 7525, section 2.6 du RFC 7457, et RFC 8143). En outre, la solution de ce RFC bénéficie de davantage de souplesse : elle peut par exemple n'être activée qu'une fois l'authentification faite, pour éviter les attaques comme CRIME (voir aussi les sections 2.2.2 et 7 de notre RFC, pour tous les détails de sécurité).
Pour assurer l'interopérabilité maximale, un seul algorithme de compression est défini, et il est, logiquement, obligatoire. Cela garantit qu'un client et un serveur NNTP auront toujours cet algorithme en commun. Il s'agit de Deflate, normalisé dans le RFC 1951.
(Un petit point qui n'a rien à voir avec NNTP et la compression : comme le demandait l'Internet-Draft qui a donné naissance à notre RFC, j'ai mis un accent à la première lettre du nom d'un des auteurs, ce qui n'est pas possible dans le RFC original, cela ne le sera que lorsque le RFC 7997 sera mis en œuvre.)
Maintenant, les détails techniques (section 2 du RFC). Le
serveur doit annoncer sa capacité à comprimer en réponse à la
commande CAPABILITIES. Par exemple (C =
client, S = serveur) :
[C] CAPABILITIES
[S] 101 Capability list:
[S] VERSION 2
[S] READER
[S] IHAVE
[S] COMPRESS DEFLATE SHRINK
[S] LIST ACTIVE NEWSGROUPS
[S] .
L'annonce de la capacité est suivie de la liste des algorithmes
gérés. On trouve évidemment l'algorithme obligatoire
DEFLATE mais aussi un
algorithme non-standard (imaginaire, ce n'est qu'un exemple)
SHRINK.
Le client peut alors utiliser la commande
COMPRESS, suivie du nom d'un algorithme
(cette commande a été ajoutée
au registre IANA des commandes NNTP). Voici un exemple où
le serveur accepte la compression :
[C] COMPRESS DEFLATE
[S] 206 Compression active
(À partir de là, le trafic est comprimé)
Attention à ne pas confondre la réponse du serveur à une demande
de ses capacités, et la commande envoyée par le client (dans les
deux cas, ce sera une ligne COMPRESS DEFLATE).
Et voici un exemple où le serveur refuse, par exemple parce que la compression a déjà été activée :
[C] COMPRESS DEFLATE
[S] 502 Command unavailable
Si on utilise TLS, ce qui est évidemment recommandé pour des raisons de confidentialité et d'authentification, l'envoyeur doit d'abord comprimer, puis (si SASL est activé) appliquer SASL (RFC 4422), puis seulement à la fin chiffrer avec TLS. À la réception, c'est bien sûr le contraire, on déchiffre le TLS, on analyse SASL, puis on décomprime.
Voici un exemple d'un dialogue plus détaillé, avec TLS et compression :
[C] CAPABILITIES [S] 101 Capability list: [S] VERSION 2 [S] READER [S] STARTTLS [S] AUTHINFO [S] COMPRESS DEFLATE [S] LIST ACTIVE NEWSGROUPS [S] . [C] STARTTLS [S] 382 Continue with TLS negotiation (Négociation TLS) (Désormais, tout est chiffré) [C] CAPABILITIES [S] 101 Capability list: [S] VERSION 2 [S] READER [S] AUTHINFO USER [S] COMPRESS DEFLATE [S] LIST ACTIVE NEWSGROUPS [S] . [C] AUTHINFO USER michu [S] 381 Enter passphrase [C] AUTHINFO PASS monsieur [S] 281 Authentication accepted [C] CAPABILITIES [S] 101 Capability list: [S] VERSION 2 [S] READER [S] POST [S] COMPRESS DEFLATE [S] LIST ACTIVE NEWSGROUPS [S] . [C] COMPRESS DEFLATE [S] 206 Compression active (Désormais, toutes les données envoyées sont comprimées, puis chiffrées) [C] CAPABILITIES [S] 101 Capability list: [S] VERSION 2 [S] READER [S] POST [S] LIST ACTIVE NEWSGROUPS [S] .
Et voici deux exemples où le serveur refuse la compression. D'abord parce qu'il ne peut pas (manque de mémoire, par exemple) :
[C] COMPRESS DEFLATE [S] 403 Unable to activate compression
Et ici parce que le client essaie d'utiliser un algorithme que le serveur ne connait pas :
[C] COMPRESS SHRINK [S] 503 Compression algorithm not supported
La liste des algorithmes standards (pour l'instant réduite à un seul) est dans un registre IANA.
NNTP est un protocole dont les spécificités posent des
problèmes amusants lorsqu'on veut comprimer son trafic (section 3
du RFC). Les messages sont très divers, ce qui peut être contrariant pour une
compression fondée sur un dictionnaire. Les réponses à certaines
commandes (DATE, GROUP,
NEXT, et le CHECK du
RFC 4644) sont peu comprimables. Par contre, les réponses
à LIST, LISTGROUP ou
NEWNEWS sont facilement réduites à 25 à 40 %
de la taille originale
avec zlib.
En outre, les news envoyées sont dans des formats différents. Un article sera parfois du texte seul, relativement court (et souvent uniquement en ASCII) et se comprimera bien. Les textes plus longs sont souvent envoyés sous un format déjà comprimé et, là, le compresseur NNTP va s'essouffler pour rien. Mais il y a aussi souvent des données binaires (images, par exemple), encodées en Base64 ou uuencode. On peut souvent les réduire à 75 % de l'original. (Deflate marche bien sur des données en 8 bits mais l'encodage lui dissimule la nature 8-bitesque de ces données.) Si les données sont encodées en yEnc, elles seront moins compressibles.
Il y a apparemment au moins un logiciel serveur (INN) et un client (flnews) qui gèrent cette compression.
Merci à Julien Élie pour sa relecture attentive (et pour avoir trouvé au moins une grosse faute.)
L'article seul
RFC 8032: Edwards-curve Digital Signature Algorithm (EdDSA)
Date de publication du RFC : Janvier 2017
Auteur(s) du RFC : S. Josefsson (SJD AB), I. Liusvaara (Independent)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF cfrg
Première rédaction de cet article le 25 janvier 2017
Ce RFC est la description IETF de l'algorithme de signature cryptographique EdDSA. EdDSA est en fait une famille, il prend un certain nombre de paramètres, comme la courbe elliptique Edwards utilisée et ce RFC décrit son utilisation avec les courbes Edwards25519 et Edwards448.
EdDSA n'avait apparemment été décrit auparavant que dans des publications scientifiques, ce RFC sert à la fois à avoir une référence IETF, et également à décrire EdDSA dans des termes plus familiers aux programmeurs. Pourquoi faire de l'EdDSA, d'ailleurs ? Parce que cet algorithme (ou plutôt cette famille d'algorithmes) a plusieurs avantages, notamment :
- Rapide,
- Ne nécessite pas un nombre aléatoire différent par signature (un problème qui a souvent frappé les mises en œuvres de DSA, par exemple avec la Sony Playstation),
- Clés et signatures de taille réduite.
Un site Web sur EdDSA a été créé par ses auteurs. La référence officielle d'EdDSA est l'article « High-speed high-security signatures » de D. Bernstein, N. Duif, T. Lange, P. Schwabe, P., et B. Yang. Une extension à d'autres courbes est décrite dans « EdDSA for more curves ». Sur les courbes elles-mêmes, on peut consulter le RFC 7748.
La section 3 du RFC décrit l'algorithme générique d'EdDSA. Comme il laisse ouvert pas moins de onze paramètres, on voit qu'on peut créer une vaste famille d'algorithmes se réclamant d'EdDSA. Mais, évidemment, toutes les combinaisons possibles pour ces onze paramètres ne sont pas sérieuses du point de vue de la sécurité cryptographique, et notre RFC ne décrira que cinq algorithmes spécifiques, dont ed25519 et ed448. L'algorithme générique est surtout utile pour la culture générale.
C'est parce que EdDSA est un algorithme générique (au contraire
de ECDSA) que les programmes qui
l'utilisent ne donnent pas son nom mais celui de l'algorithme
spécifique. Ainsi, OpenSSH vous permet de
générer des clés Ed25519 (ssh-keygen -t
ed25519) mais pas de clés EdDSA (ce qui ne voudrait
rien dire).
La section 4 du RFC décrit en détail un des paramètres importants de EdDSA : le choix de la fonction prehash. Celle-ci peut être l'identité (on parle alors de Pure EdDSA) ou bien une fonction de condensation cryptographique (on parle alors de Hash EdDSA).
La section 5, elle, spécifie EdDSA avec les autres paramètres, décrivant notamment Ed25519 et Ed448. Ainsi, Ed25519 est EdDSA avec la courbe Edwards25519, et une fonction prehash qui est l'identité. (Pour les autres paramètres, voir le RFC.) L'algorithme Ed25519ph est presque identique sauf que sa fonction prehash est SHA-512.
Comme tout algorithme de cryptographie, il faut évidemment beaucoup de soin quand on le programme. La section 8 du RFC contient de nombreux avertissements indispensables pour le programmeur. Un exemple typique est la qualité du générateur aléatoire. EdDSA n'utilise pas un nombre aléatoire par signature (la plaie de DSA), et est déterministe. La sécurité de la signature ne dépend donc pas d'un bon ou d'un mauvais générateur aléatoire. (Rappelons qu'il est très difficile de faire un bon générateur aléatoire, et que beaucoup de programmes de cryptographie ont eu des failles de sécurité sérieuses à cause d'un mauvais générateur.) Par contre, la génération des clés, elle, dépend de la qualité du générateur aléatoire (RFC 4086).
Il existe désormais pas mal de mises en œuvre d'EdDSA, par
exemple dans OpenSSH cité plus haut. Sinon,
les annexes A et B du RFC contiennent une mise en œuvre en
Python d'EdDSA. Attention, elle est conçue
pour illustrer l'algorithme, pas forcément pour être utilisée en
production. Par exemple, elle n'offre aucune protection contre les
attaques exploitant la différence de temps de calcul selon les
valeurs de la clé privée (cf. la section 8.1). J'ai extrait ces deux
fichiers, la bibliothèque eddsalib.py et le
programme de test eddsa-test.py (ils nécessitent
Python 3). Le programme de test prend comme entrée un fichier
composé de plusieurs vecteurs de test,
chacun comprenant quatre champs, séparés par des
deux-points, clé secrète, clé publique, message et
signature. La section 7 du RFC contient des vecteurs de
test pour de nombreux cas. Par exemple, le test 2 de la section 7.1 du RFC s'écrit
4ccd089b28ff96da9db6c346ec114e0f5b8a319f35aba624da8cf6ed4fb8a6fb:3d4017c3e843895a92b70aa74d1b7ebc9c982ccf2ec4968cc0cd55f12af4660c:72:92a009a9f0d4cab8720e820b5f642540a2b27b5416503f8fb3762223ebdb69da085ac1e43e15996e458f3613d0f11d8c387b2eaeb4302aeeb00d291612bb0c00
et l'exécution du programme de test affiche juste le numéro de
ligne quand tout va bien :
% python3 eddsa-test.py < vector2.txt
1
On peut aussi utiliser des tests plus détaillés comme ce fichier de vecteurs de test :
% python3 eddsa-test.py < sign.input 1 2 3 ... 1024
Si on change le message, la signature ne correspond évidemment plus et le programme de test indique une assertion erronée :
% python3 eddsa-test.py < vector2-modified.txt
1
Traceback (most recent call last):
File "eddsa-test.py", line 30, in <module>
assert signature == Ed25519.sign(privkey, pubkey, msg)
AssertionError
L'article seul
RFC 8056: Extensible Provisioning Protocol (EPP) and Registration Data Access Protocol (RDAP) Status Mapping
Date de publication du RFC : Janvier 2017
Auteur(s) du RFC : J. Gould (Verisign)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 18 janvier 2017
Deux protocoles utilisés dans l'industrie des noms de domaine, EPP et RDAP, ont la notion d'état d'un nom de domaine, indiquant, par exemple, que ce nom est verrouillé et ne doit pas être modifié. Mais les états de EPP et de RDAP sont différents, et pas toujours évidents à rapprocher. Ce nouveau RFC précise la correspondance entre les états EPP et les états RDAP, établissant la liste comparée.
EPP (protocole d'avitaillement d'objets dans un registre, par exemple un registre de noms de domaine) est normalisé dans divers RFC (STD 69), ceux qui décrivent les états sont les RFC 5731 (section 2.3), RFC 5732 (section 2.3), RFC 5733 (section 2.2) et RFC 3915 (section 3.1). Les états RDAP (protocole d'information sur les objets d'un registre, qui vise à remplacer whois) sont normalisés dans le RFC 9083 (section 10.2) qui crée un registre IANA des états possibles. Pourquoi des états différents dans ces deux protocoles ? Disons qu'ils ont été conçus pour des buts différents, et que la nécessité de faire correspondre les états de l'un avec ceux de l'autre n'est devenue évidente qu'après. Le but de ce nouveau RFC est justement d'établir une correspondance univoque entre les états d'EPP et de RDAP.
La section 2 de notre RFC commence par une liste des états
EPP, avec leur équivalent RDAP (quand il existe). Par exemple, il
est assez évident que le pendingDelete d'EPP
(RFC 5731) correspond au pending
delete de RDAP. De même, le ok
d'EPP est clairement l'équivalent du active
de RDAP. Mais les addPeriod (RFC 3915, durée après l'enregistrement d'un nom de domaine
pendant laquelle on peut annuler l'enregistrement gratuitement) ou
clientHold (RFC 5731,
le client a demandé que ce nom de domaine ne soit pas publié dans
le DNS)
d'EPP n'ont pas d'équivalent RDAP. L'inverse existe aussi, le
delete prohibited de RDAP n'a pas un
équivalent simple en EPP, qui a deux états pour cela, selon que
l'interdiction a été posée par le client EPP ou par le
serveur.
La section 2 du RFC se continue donc avec ce qui est désormais
la liste officielle des correspondances, en tenant compte des
nouveaux états ajoutés, par exemple dans le registre
RDAP. C'est ainsi qu'un add period et
un client hold ont été ajoutés (section 3 du RFC), ainsi qu'un
client delete prohibited et un
server delete prohibited, pour préciser le
delete prohibited.
L'article seul
Utiliser un résolveur DNS public ?
Première rédaction de cet article le 15 janvier 2017
Après la censure administrative en France via des DNS menteurs, puis une panne spectaculaire des résolveurs DNS d'Orange, au moins trois pannes analogues de ceux de Free, et enfin un détournement accidentel de Google et Wikipédia vers le Ministère de l'Intérieur, pas mal d'utilisat·eur·rice·s de l'Internet se demandent si on peut vraiment faire confiance au résolveur DNS de son FAI. Et beaucoup se mettent alors à utiliser un résolveur DNS public, le plus célèbre étant Google Public DNS. Mais est-ce une bonne idée ?
D'abord, recadrons un peu la terminologie. Le protocole
DNS a deux sortes de serveurs, qui n'ont
pas grand'chose à voir, les serveurs faisant
autorité et les
résolveurs. Confondre les deux (par exemple
en parlant du vague « serveur DNS ») ne va pas aider
l'utilisat·eur·rice à comprendre, et donc à faire des choix
corrects. Les serveurs faisant autorité sont ceux qui connaissent
les informations sur le contenu des domaines. Par exemple, ceux de
l'AFNIC connaissent le contenu de
.fr et ceux de
CloudFlare, hébergeur utilisé par
Next INpact, connaissent le contenu de
nextinpact.com, par exemple l'adresse du site Web
(104.25.248.21 et
104.25.249.21 aujourd'hui). Les résolveurs
(on dit aussi serveurs récursifs, ou bien serveurs caches),
eux, ne connaissent rien, à part l'adresse des serveurs
de la racine, où ils commencent leurs
interrogations. Les serveurs faisant autorité sont gérés par des
hébergeurs DNS spécialisés (comme Dyn), ou bien directement par le titulaire
du nom de domaine. Les résolveurs sont typiquement gérés par le
service informatique du réseau où vous vous connectez, ou bien par
le FAI, pour les accès grand public. Ces
résolveurs sont une partie cruciale du service d'accès à
l'Internet : sans DNS, il n'y a quasiment rien qui marche. S'ils
sont en panne, plus d'Internet. S'ils mentent, on est détourné vers un mauvais site.
On voit depuis des années apparaître des résolveurs DNS publics, qui ne dépendent ni du FAI, ni du réseau local d'accès. Ce sont Google Public DNS, Cisco OpenDNS, FDN, OpenNIC, Verisign, Yandex, etc. Attention à ne pas confondre ces résolveurs publics avec ce qu'on nomme les résolveurs ouverts. Tous ont en commun qu'ils acceptent de répondre à des requêtes DNS, quelle que soit leur source. Mais les résolveurs ouverts le sont par accident, par erreur de configuration, et ne sont pas gérés. Les résolveurs publics, eux, le sont déliberement, ils sont (normalement...) gérés par des gens sérieux. La différence est importante car un résolveur ouvert est un outil utile dans de nombreuses attaques comme les attaques par amplification ou comme certains empoisonnements. C'est pour cette raison que le RFC 5358 demande que les résolveurs DNS ne soient pas ouverts.
Après ce long préambule, retour aux pannes de résolveurs DNS. Aujourd'hui, dès qu'un problème Internet survient, et quelle que soit la cause réelle du problème, la réponse fuse sur tous les rézosocios : « utilise Google DNS » (ou bien, version libriste, « utilise FDN »). Un exemple, pris au hasard lors de la dernière panne Free est ce tweet. (Et voici une documentation plus élaborée.)
Ce genre de conseils ne tient pas compte de plusieurs inconvénients sérieux des résolveurs publics. Je vais commencer par les inconvénients communs à tous les résolveurs publics. Le principal est que le lien entre vous et le résolveur public est long et non sécurisé. Même si vous avez une confiance aveugle dans le résolveur public et ceux qui le gèrent, sur le trajet, des tas de choses peuvent aller mal. D'abord, le trafic peut être écouté trivialement (les seuls résolveurs publics qui proposent une solution à ce problème sont Cisco OpenDNS et OpenNIC, avec DNSCrypt). Comme le rappelle le RFC 7626, le trafic DNS est très bavard (trop), circule en clair, passe par des réseaux supplémentaires (en plus du trafic « normal »), et peut donc poser des problèmes de vie privée. Avec un résolveur DNS habituel, le problème est limité car le résolveur est proche de vous, limitant le nombre de gens qui peuvent écouter. Avec un résolveur public, le nombre d'écoutants potentiels augmente.
Mais il y a pire : la plupart des résolveurs publics n'offre aucune authentification (là encore, la seule exception est Cisco OpenDNS et OpenNIC, mais où cette authentification est facultative, et je ne sais pas combien d'utilisateurs s'en servent réellement). Même les mesures les plus triviales comme le NSID du RFC 5001 ne sont pas mises en œuvre (NSID ne fait pas une réelle authentification, mais il permet de détecter certains problèmes). Si vous utilisez des résolveurs publics pour contourner la censure, c'est un sérieux problème. Des censeurs ont déjà effectué des détournements de résolveurs DNS public (comme en Turquie, mais aussi dans d'autres pays). Donc, même si le résolveur public est géré par des gens biens, et que vous connaissez, cela ne suffit pas, car vous n'avez aucun moyen de savoir si vous parlez bien à ce résolveur, et pas à un usurpateur (le DNS utilise UDP, qui n'offre aucune protection contre l'usurpation d'adresse).
Il est amusant (et révélateur du manque de connaissances sur le fonctionnement de l'Internet) que les débats sur les résolveurs ouverts se focalisent souvent sur la confiance que l'on peut accorder (ou pas) au serveur, et jamais sur celle qu'on peut accorder (ou pas) au réseau qui y mène !
Il y a aussi des inconvénients qui sont spécifiques à certains des résolveurs publics souvent recommandés :
- Je soupçonne que certains ne sont pas si bien gérés que cela (normalement, ils doivent faire de la limitation de trafic, être supervisés 24 heures sur 24, etc) et peuvent être utilisés pour des attaques par réflexion, avec amplification,
- Google, Cisco et Verisign sont situés aux États-Unis, pays qui n'a aucune protection des données personnelles, même théorique (argument bien développé chez Shaft),
- Yandex est en Russie, si vous voulez donner vos informations au FSB plutôt qu'à la NSA,
- OpenNIC est une racine alternative, ce qui veut dire qu'ils ajoutent des TLD « bidons », qui ne marcheront que chez eux,
- Certains services sont peu fiables, souvent en panne, très lents, ou disparaissant sans laisser de nouvelles.
Alors, si utiliser les résolveurs publics est une mauvaise idée, quelle est la bonne ? Le mieux serait évidemment de pouvoir utiliser les résolveurs DNS de son FAI. Un résolveur DNS correct fait partie (ou devrait faire partie) de l'offre Internet de base. Les utilisateurs devraient réclamer un tel service, fiable et rapide. Les pannes récentes, ou bien les horreurs des résolveurs DNS des points d'accès Wi-Fi des hôtels et des aéroports, et enfin le problème de la censure étatique (qu'un service de qualité chez le FAI ne résoudra pas) font qu'il n'y a plus guère le choix, il faut utiliser d'autres résolveurs que ceux du FAI. La solution la plus propre est d'avoir son propre résolveur DNS, pas forcément sur chaque machine de son réseau local, mais plutôt dans une machine unique, typiquement le routeur d'accès. Avant qu'on ne me dise « mais ce n'est pas Michu-compatible, M. Michu ne vas quand même pas installer OpenBSD sur un Raspberry Pi pour avoir un résolveur sur son réseau », je dis tout de suite qu'évidemment, cela ne doit pas être fait directement par M. Michu mais une fois pour toutes dans un paquet logiciel et/ou matériel qu'il n'y a plus qu'à brancher. (Un truc du genre de la Brique Internet.)
Parfois, il est difficile ou peu pratique d'avoir son propre résolveur. En outre, un résolveur à soi sur le réseau local protège bien contre la censure, ou contre les pannes, mais peu contre la surveillance, puisqu'il va lui-même émettre des requêtes en clair aux serveurs faisant autorité. Il est donc utile d'avoir des résolveurs publics accessibles en DNS-sur-TLS (RFC 7858), ce qui protège la confidentialité et permet l'authentification du résolveur. Ces résolveurs publics (comme par exemple celui de LDN ou bien celui de Yeti) peuvent être utilisés directement, ou bien servir de relais pour le résolveur local. Attention, la plupart sont encore très expérimentaux. Vous trouverez une liste sur le portail DNS Privacy. (Pour la solution non normalisée DNScrypt, on trouve, outre le site Web officiel, la doc de malekalmorte ou bien celle-ci.)
Pour se prémunir contre la censure (mais pas contre les pannes, ni contre la surveillance), une autre technologie utile est DNSSEC. Le résolveur local doit donc valider avec DNSSEC. Notez que, malheureusement, peu de domaines sont signés.
La meilleure solution est donc un résolveur DNS validant avec DNSSEC et tournant sur une machine du réseau local (la « box » est l'endroit idéal). Cela assure un résolveur non-menteur et sécurisé. Si on veut en plus de la vie privée, il faut lui faire suivre les requêtes non-résolues à un résolveur public de confiance (donc pas Google ou Verisign) et accessible par un canal chiffré (DNS sur TLS).
Si votre box est fermée et ne permet pas ce genre de manips, remplacez-la par un engin ouvert, libre et tout ça, comme le Turris Omnia qui a par défaut un résolveur DNSSEC.
L'article seul
RFC 8021: Generation of IPv6 Atomic Fragments Considered Harmful
Date de publication du RFC : Janvier 2017
Auteur(s) du RFC : F. Gont (SI6 Networks /
UTN-FRH), W. Liu (Huawei
Technologies), T. Anderson (Redpill
Linpro)
Pour information
Première rédaction de cet article le 7 janvier 2017
C'est quoi, un « fragment atomique » ? Décrits dans le RFC 6946, ces charmants objets sont des datagrammes IPv6 qui sont des fragments... sans en être. Ils ont un en-tête de fragmentation sans être fragmentés du tout. Ce RFC estime qu'ils ne servent à rien, et sont dangereux, et devraient donc ne plus être générés.
Le mécanisme de fragmentation d'IPv6 (assez différent de celui d'IPv4) est décrit dans le RFC 2460, sections 4.5 et 5. Que se passe-t-il si un routeur génère un message ICMP Packet Too Big (RFC 4443, section 3.2) en indiquant une MTU inférieure à 1 280 octets, qui est normalement la MTU minimale d'IPv6 ? (Le plus beau, c'est que ce routeur n'est pas forcément en tort, cf. RFC 6145, qui décrivait leur utilisation pour être sûr d'avoir un identificateur de datagramme.) Eh bien, dans ce cas, l'émetteur du datagramme trop gros doit mettre un en-tête « Fragmentation » dans les datagrammes suivants, même s'il ne réduit pas sa MTU en dessous de 1 280 octets. Ce sont ces datagrammes portant un en-tête « Fragmentation » mais pas réellement fragmentés (leur bit M est à 0), qui sont les fragments atomiques du RFC 6946.
Malheureusement, ces fragments atomiques permettent des attaques contre les machines IPv6 (section 2 du RFC). Il existe des attaques liées à la fragmentation (RFC 6274 et RFC 7739). Certaines nécessitent que les datagrammes soient réellement fragmentés mais ce n'est pas le cas de toutes : il y en a qui marchent aussi bien avec des fragments atomiques. Un exemple d'une telle attaque exploite une énorme erreur de certaines middleboxes, jeter les datagrammes IPv6 ayant un en-tête d'extension, quel qu'il soit (y compris, donc, l'en-tête Fragmentation). Ce comportement est stupide mais hélas répandu (cf. RFC 7872). Un attaquant peut exploiter cette violation de la neutralité du réseau pour faire une attaque par déni de service : il émet des faux messages ICMP Packet Too Big avec une MTU inférieur à 1 280 octets, la source se met à générer des fragments atomiques, et ceux-ci sont jetés par ces imbéciles de middleboxes.
Le RFC décrit aussi une variante de cette attaque, où deux pairs BGP jettent les fragments reçus (méthode qui évite certaines attaques contre le plan de contrôle du routeur) mais reçoivent les ICMP Packet Too Big et fabriquent alors des fragments atomiques. Il serait alors facile de couper la session entre ces deux pairs. (Personnellement, le cas me parait assez tiré par les cheveux...)
Ces attaques sont plus faciles à faire qu'on ne pourrait le croire car :
- Un paquet ICMP peut être légitimement émis par un routeur intermédiaire et l'attaquant n'a donc pas besoin d'usurper l'adresse IP de la destination (donc, BCP 38 ne sert à rien).
- Certes, l'attaquant doit usurper les adresses IP contenues dans le message ICMP lui-même mais c'est trivial : même si on peut en théorie envisager des contrôles du style BCP 38 de ce contenu, en pratique, personne ne le fait aujourd'hui.
- De toute façon, pas mal de mises en œuvres d'IP ne font aucune validation du contenu du message ICMP (malgré les recommandations du RFC 5927).
- Un seul message ICMP suffit, y compris pour plusieurs connexions TCP, car la MTU réduite est typiquement mémorisée dans le cache de l'émetteur.
- Comme la seule utilisation légitime connue des fragments atomiques était celle du RFC 6145 (qui a depuis été remplacé par le RFC 7915), on pourrait se dire qu'il suffit de limiter leur génération aux cas où on écrit à un traducteur utilisant le RFC 6145. Mais cela ne marche pas, car il n'y a pas de moyen fiable de détecter ces traducteurs.
Outre ces problèmes de sécurité, le RFC note (section 3) que les fragments atomiques ne sont de toute façon pas quelque chose sur lequel on puisse compter. Il faut que la machine émettrice les génère (elle devrait, mais la section 6 du RFC 6145 note que beaucoup ne le font pas), et, malheureusement, aussi bien les messages ICMP Packet Too Big que les fragments sont souvent jetés par des machines intermédiaires.
D'ailleurs, il n'est même pas certain que la méthode du RFC 6145 (faire générer des fragments atomiques afin d'obtenir un identificateur par datagramme) marche vraiment, l'API ne donnant pas toujours accès à cet identificateur de fragment. (Au passage, pour avoir une idée de la complexité de la mise en œuvre des fragments IP, voir cet excellent article sur le noyau Linux.)
En conclusion (section 4), notre RFC demande qu'on abandonne les fragments atomiques :
- Les traducteurs du RFC 7915 (la seule utilisation légitime connue) devraient arrêter d'en faire générer.
- Les machines IPv6 devraient désormais ignorer les messages ICMP Packet Too Big lorsqu'ils indiquent une MTU inférieure à 1 280 octets.
L'article seul
Articles des différentes années : 2026 2025 2024 2023 2022 2021 2020 Précédentes années
Syndication : Flux Atom avec seulement les résumés et Flux Atom avec tout le contenu.
{kind=link}