
Ce blog n'a d'autre prétention que de me permettre de mettre à la disposition de tous des petits textes que j'écris. On y parle surtout d'informatique mais d'autres sujets apparaissent parfois.
Migration de tous mes dépôts de développement vers un Gitlab
Première rédaction de cet article le 29 décembre 2019
Je viens de terminer la migration de tous mes dépôts de développement logiciel actifs (et quelques inactifs) vers un GitLab, suite au rachat de GitHub par Microsoft, en 2018.
Quand j'avais commencé à mettre des dépôts sur une forge publique, c'était sur SourceForge, en 2000. Après que SourceForge ait sombré, techniquement et politiquement, je suis passé à GitHub, à l'époque une petite entreprise sympa et techniquement pointue. Puis GitHub a grandi, devenant le « Facebook des geeks ». Et, en juin 2018, Microsoft annonce le rachat de GitHub, le sort fréquent des petites entreprises cools. Il n'était évidemment pas question pour moi de rester chez Microsoft, l'entreprise symbole du logiciel privateur. Même si de nombreux Microsoft fanboys s'étaient à l'époque succédé sur les réseaux sociaux pour répéter les éléments de langage « Microsoft a changé », « Maintenant, c'est une entreprise sympa », « Il y a eu quelques erreurs mais maintenant, Microsoft ne traite plus le logiciel libre de cancer communiste », je n'ai jamais avalé ces arguments. D'ailleurs, Microsoft lui-même ne s'est jamais réclamé du logiciel libre, juste d'un vague « open source », qui veut tout et rien dire, et qu'on utilise quand le mot « liberté » fait peur.
Bon, c'est bien joli, cela, mais cela fait bien plus d'un an que le rachat a eu lieu, c'était pas rapide comme fuite hors de l'étreinte de Microsoft ? C'est vrai, il m'a fallu du temps, la paresse a longtemps été la plus forte, mais j'ai fini par le faire.
Et la destination ? La solution techniquement la plus proche de
GitHub est un GitLab. Attention, beaucoup de
gens confondent un
GitLab (une instance spécifique d'un service
utilisant le logiciel) et le GitLab.com géré par la
société du même nom. Migrer vers GitLab.com
n'aurait qu'un intérêt limité : ce serait abandonner une entreprise
pour une autre, qui connaitra peut-être le même sort si elle a du
succès. Au contraire, le logiciel GitLab est
libre et peut donc
être installé par de nombreux acteurs. Je ne sais pas s'il existe
quelque part une liste d'instances GitLab ouvertes, mais je connais
Framasoft et j'ai donc choisi la leur, FramaGit. Je
sais que Framasoft est lancé dans une entreprise de « déframasofisation »
et qu'il faudra peut-être une autre migration dans un an ou deux
mais le sort de FramaGit ne semble pas clairement fixé. Si vous
connnaissez un GitLab (ou équivalent) chez un CHATON sympa…
Passons maintenant à la pratique. Il faut récupérer les données. L'utilisation d'un VCS décentralisé comme git résout automatiquement une grande partie du problème. Chaque copie locale contient non seulement tout le code mais également tout l'historique. Il ne reste plus qu'à récupérer les tickets et les pull requests. Personne ne migrerait depuis GitHub si cela signifiait de perdre ces importantes informations. Pour tout récupérer, GitLab a fait une excellente documentation. J'en résume les principaux points :
- La mise en correspondance des auteurs des commits entre GitHub et la nouvelle forge se fait sur la base d'une connexion utilisant GitHub ou bien sur celle de l'adresse de courrier. Sans correspondance, commits et tickets seront attribués à la personne faisant l'importation.
- L'administrateur de la forge GitLab utilisée doit avoir activé l'intégration GitHub. (C'est le cas de FramaGit.)
- Ensuite, il n'y a plus qu'à faire (vous noterez que la traduction en français de GitLab est incomplète) Nouveau projet → Import project → [depuis] Github → [Accepter l'autorisation OAuth] Authenticate with GitHub → [Sélectionner le projet à importer]. Le plus long est évidemment de tout vérifier, mettre à jour ses dépôts locaux, documenter sur l'ancien dépôt (je n'ai pas détruit les anciens dépôts, juste mis à jour la documentation) et sur le nouveau.
Comme mon adresse de courrier n'était pas la même sur GitHub et
sur FramaGit, je ne pouvais pas compter sur une bonne
correspondance. Je me suis donc une fois connecté à FramaGit en
utilisant mon compte GitHub, créant ainsi un compte « fantôme » qui
allait recevoir les anciens commits. (J'aurais pu
m'en passer, ce qui aurait réaffecté ces commits au compte FramaGit
habituel.) Ensuite, tout s'est bien passé,
commits, pull requests et
tickets sont bien importés. (Attention à ne pas trop en mettre,
FramaGit semble avoir une limite à 50 projets.)
Notez que, politiquement, c'est évidemment une excellente idée que de migrer depuis un service centralisé comme GitHub vers plein de petits GitLab partout. Mais, techniquement, cela peut rendre la coopération difficile, puisqu'il faut un compte sur chaque instance pour participer. C'est d'autant plus absurde que git est lui-même décentralisé (et a des mécanismes pour contribuer sans compte.) Il faudrait donc qu'on puisse avoir un dépôt complètement décentralisé, par exemple en mettant les tickets dans git lui-même. (On me dit que ce serait possible avec le logiciel SourceHut, qui a déjà un service d'hébergement, mais je n'ai pas testé. Ou bien avec Fossil ou encore git-bug. Et il y a une liste de projets similaires.) Une autre approche (qui ne me convainc pas, mais qui peut être utile pour certains services) serait de fédérer les GitLab, par exemple avec ActivityPub. Voir par exemple le ticket #4013 de GitLab.
L'article seul
Analyse technique du résolveur DNS public chinois 114dns
Première rédaction de cet article le 29 décembre 2019
Dernière mise à jour le 6 janvier 2020
Aujourd'hui, nous allons regarder de près un résolveur
DNS public, le
114.114.114.114, qui présente la particularité
d'être géré en Chine. Il y a de nombreuses
choses étranges sur ce service, qui distrairont les techniciens
Internet.
Des résolveurs DNS publics, il y en a plein : Google Public DNS, Quad9, et plusieurs autres. Je ne discuterai pas ici des inconvénients qu'ils présentent, je veux juste faire quelques expériences avec un de ces résolveurs, et montrer par la même occasion quelques outils utiles pour explorer les entrailles de l'infrastructure de l'Internet.
Donc, depuis pas mal d'années, il existe un résolveur public
chinois. Il a l'adresse
IPv4 114.114.114.114 et
il a un site Web
(uniquement en chinois, il semble). Je l'ai
dit, il n'est pas nouveau, mais il a fait l'objet d'un renouveau
d'intérêt fin 2019 car il serait le résolveur DNS par défaut dans
certains objets connectés fabriqués en Chine. Testons d'abord s'il
existe et répond. Nous allons utiliser divers outils en
ligne de commande qu'on trouve sur
Unix. Commençons par le client DNS
dig :
% dig +dnssec @114.114.114.114 cyberstructure.fr AAAA
; <<>> DiG 9.11.5-P4-5.1-Debian <<>> @114.114.114.114 cyberstructure.fr AAAA
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 33037
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;cyberstructure.fr. IN AAAA
;; ANSWER SECTION:
cyberstructure.fr. 86399 IN AAAA 2001:4b98:dc0:41:216:3eff:fe27:3d3f
;; Query time: 3113 msec
;; SERVER: 114.114.114.114#53(114.114.114.114)
;; WHEN: Sun Dec 29 16:31:54 CET 2019
;; MSG SIZE rcvd: 63
On note d'abord qu'il est lent (depuis la France) et qu'on a souvent des délais de garde dépassés. Mais il marche. Notez que l'utilisation de ping montre que c'est bien le résolveur qui est lent, pas le réseau : les paquets envoyés par ping ont une réponse bien plus rapide :
% ping -c 10 114.114.114.114 ... 10 packets transmitted, 10 received, 0% packet loss, time 24ms rtt min/avg/max/mdev = 95.508/96.107/98.871/1.031 ms
Le RTT est bien inférieur à ce qu'on obtient quand on va en Chine, indiquant que ce résolveur a des instances en d'autres endroits, probablemement grâce à l'anycast. C'est confirmé par un ping depuis une machine aux États-Unis, qui montre des RTT qui sont encore moins compatibles avec la durée d'un aller-retour en Chine :
% ping -c 10 114.114.114.114 ... --- 114.114.114.114 ping statistics --- 10 packets transmitted, 10 received, +1 duplicates, 0% packet loss, time 20ms rtt min/avg/max/mdev = 19.926/20.054/20.594/0.226 ms
Qui gère ce résolveur ? whois nous dit que c'est bien en Chine :
% whois 114.114.114.114 % [whois.apnic.net] ... inetnum: 114.114.0.0 - 114.114.255.255 netname: XFInfo descr: NanJing XinFeng Information Technologies, Inc. descr: Room 207, Building 53, XiongMao Group, No.168 LongPanZhong Road descr: Xuanwu District, Nanjing, Jiangsu, China country: CN ... source: APNIC
Ce service n'est apparemment pas un résolveur menteur. Les noms
censurés en Chine, comme facebook.com
fonctionnent. Si on le souhaite, la documentation semble indiquer
(je n'ai pas testé) que d'autres adresses abritent des résolveurs
menteurs, par exemple 114.114.114.119 filtre
le logiciel malveillant et
114.114.114.110 filtre le porno.
Quelles sont les caractéristiques techniques du service ? D'abord, notons
qu'il ne valide pas avec
DNSSEC, ce qui est dommage. On le voit car
il n'y a pas le flag AD (Authentic
Data) dans la réponse au dig plus
haut (alors que le domaine visé est signé avec DNSSEC). Une autre
façon de voir qu'il n'a pas DNSSEC est de demander des noms
délibérement invalides comme
servfail.nl. 114.114.114.114
donne une réponse alors qu'il ne devrait pas.
Pendant qu'on est sur DNSSEC, notons une bizarrerie du résolveur : il renvoie parfois une section EDNS (RFC 6891) et parfois pas. Dans l'exemple dig ci-dessus, il n'y en avait pas, mais parfois si :
% dig +dnssec @114.114.114.114 afnic.fr
; <<>> DiG 9.11.5-P4-5.1-Debian <<>> +dnssec @114.114.114.114 afnic.fr
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 59581
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 4096
; COOKIE: c46f830f4a12bfab (echoed)
;; QUESTION SECTION:
;afnic.fr. IN A
;; ANSWER SECTION:
afnic.fr. 579 IN A 192.134.5.25
;; Query time: 20 msec
;; SERVER: 114.114.114.114#53(114.114.114.114)
;; WHEN: Sun Dec 29 17:00:19 CET 2019
;; MSG SIZE rcvd: 65
Ce comportement est tout à fait anormal, et il se peut qu'il y ait plusieurs machines derrière un répartiteur de charge, avec des configurations différentes.
Autre chose qui manque : il n'a pas de NSID (Name Server IDentifier, RFC 5001), cette indication du nom du serveur, très pratique lorsqu'on analyse un service anycasté, c'est-à-dire composé de plusieurs instances. (NSID peut également indiquer si une machine qui répond est la vraie, au cas, fréquent, où un détourneur n'ait pas eu l'idée de faire un faux NSID.)
% dig +dnssec +nsid @114.114.114.114 framagit.org ; <<>> DiG 9.11.5-P4-5.1-Debian <<>> +dnssec +nsid @114.114.114.114 framagit.org ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 745 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 4096 ; NSID ; COOKIE: 7f99ae3cb5e63ad1 (echoed) ;; QUESTION SECTION: ;framagit.org. IN A ;; ANSWER SECTION: framagit.org. 10779 IN A 144.76.206.42 ;; Query time: 20 msec ;; SERVER: 114.114.114.114#53(114.114.114.114) ;; WHEN: Sun Dec 29 17:05:40 CET 2019 ;; MSG SIZE rcvd: 73
Le NSID est vide, ce qui est bizarre. Normalement, quand un serveur DNS ne veut pas répondre à la question NSID, il ne renvoie pas l'option EDNS dans la OPT pseudo-section. Ici, ce zèbre étrange renvoie l'option, mais vide.
Le service n'a apparemment pas d'adresse IPv6, ce qui est étonnant en 2019. En tout cas, il n'y a pas d'enregistrement de type AAAA pour le nom :
% dig +dnssec public1.114dns.com. AAAA ; <<>> DiG 9.11.5-P4-5.1-Debian <<>> public1.114dns.com. AAAA ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 4421 ;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 4096 ; COOKIE: 0d4b4b8dd9fc8613c831aa085e08cf5e9b2e8073e1d6741d (good) ;; QUESTION SECTION: ;public1.114dns.com. IN AAAA ;; AUTHORITY SECTION: 114dns.com. 600 IN SOA ns1000.114dns.com. dnsadmin.114dns.com. ( 20120510 ; serial 3600 ; refresh (1 hour) 300 ; retry (5 minutes) 604800 ; expire (1 week) 300 ; minimum (5 minutes) ) ;; Query time: 114 msec ;; SERVER: 127.0.0.1#53(127.0.0.1) ;; WHEN: Sun Dec 29 17:07:58 CET 2019 ;; MSG SIZE rcvd: 127
(Au fait, j'ai trouvé ce nom
public1.114dns.com en faisant une résolution
« inverse », avec dig -x 114.114.114.114.)
Enfin, ce résolveur n'a que le DNS traditionnel, sur UDP. Pas de TCP, pourtant normalisé dès les débuts du DNS, au même titre que UDP, et surtout pas de chiffrement pour sécuriser la communication, ce résolveur n'a pas DoT (DNS sur TLS, RFC 7858) ou DoH (DNS sur HTTPS, RFC 8484). On peut tester ces deux protocoles avec Homer :
% homer https://114.114.114.114/ cyberstructure.fr ... pycurl.error: (7, 'Failed to connect to 114.114.114.114 port 443: Connection timed out') % homer --dot 114.114.114.114 cyberstructure.fr timeout
Tester depuis un seul point de mesure, ou même deux, est évidemment insuffisant pour un résolveur anycasté, donc nous allons utiliser les sondes RIPE Atlas via l'outil Blaeu. Ici, on demande à mille sondes RIPE Atlas, réparties sur toute la planète, d'interroger le résolveur public :
% blaeu-resolve -r 1000 --nameserver 114.114.114.114 --displayrtt --dnssec --nsid --displayvalidation write.as Nameserver 114.114.114.114 [2001:4800:7812:514:500b:b07c:ff05:694d NSID: b''] : 909 occurrences Average RTT 129 ms [2001:4800:7812:514:500b:b07c:ff05:694d] : 31 occurrences Average RTT 430 ms [TIMEOUT] : 42 occurrences Average RTT 0 ms Test #23727649 done at 2019-12-29T15:54:15Z
On voit le nombre relativement élevé de timeout
(comme je l'ai noté plus haut, ce service est lent), et le fait que
parfois, on n'a pas de réponse EDNS (et donc pas de NSID, même
vide). Plus drôle, en répétant le test, les sondes Atlas trouvent
plusieurs détournements de ce résolveur public. Une des grosses
faiblesses d'un résolveur public sans authentification (ce qui est le
cas de tous ceux qui n'offrent ni DoT, ni
DoH) est qu'on ne peut
pas les authentifier. Il est donc trivial de faire un faux serveur,
en jouant avec le routage, comme le font souvent les censeurs. J'ai
ainsi vu une sonde Atlas détecter un NSID « CleanBrowsing v1.6a -
dns-edge-usa-east-dc-c », manifestement un outil de filtrage qui se
faisait passer pour 114.114.114.114 et qui
l'assumait, en affichant un NSID à lui.
Puisqu'on a parlé de routage, c'est l'occasion de tester traceroute. Un traceroute ordinaire ne donne rien, ses paquets étant manifestement jetés dans le réseau du résolveur. On va donc utiliser traceroute avec TCP vers le port 53, celui du DNS, depuis la machine états-unienne de tout à l'heure :
% tcptraceroute 114.114.114.114 53 traceroute to 114.114.114.114 (114.114.114.114), 30 hops max, 60 byte packets 1 88.214.240.4 (88.214.240.4) 2.518 ms 2.613 ms 2.699 ms 2 be5893.rcr51.ewr04.atlas.cogentco.com (38.122.116.9) 0.485 ms 1.009 ms 1.014 ms 3 be3657.rcr21.ewr03.atlas.cogentco.com (154.24.33.169) 1.021 ms 0.986 ms 1.091 ms 4 be2495.rcr24.jfk01.atlas.cogentco.com (154.54.80.193) 1.350 ms be2390.rcr23.jfk01.atlas.cogentco.com (154.54.80.189) 2.468 ms 1.268 ms 5 be2897.ccr42.jfk02.atlas.cogentco.com (154.54.84.213) 1.631 ms 1.669 ms be2896.ccr41.jfk02.atlas.cogentco.com (154.54.84.201) 1.749 ms 6 be2890.ccr22.cle04.atlas.cogentco.com (154.54.82.245) 13.427 ms 13.581 ms be2889.ccr21.cle04.atlas.cogentco.com (154.54.47.49) 13.587 ms 7 be2718.ccr42.ord01.atlas.cogentco.com (154.54.7.129) 20.108 ms 21.048 ms 20.062 ms 8 be3802.rcr21.ord07.atlas.cogentco.com (154.54.47.38) 20.992 ms 154.54.89.2 (154.54.89.2) 20.794 ms be3802.rcr21.ord07.atlas.cogentco.com (154.54.47.38) 20.925 ms 9 * * * 10 23.237.126.230 (23.237.126.230) 22.188 ms 22.502 ms 22.331 ms 11 23.237.136.242 (23.237.136.242) 24.471 ms 23.732 ms 24.089 ms 12 * * * 13 public1.114dns.com (114.114.114.114) <syn,ack> 19.963 ms 20.631 ms 20.658 ms
On y voit que la machine répond bien en TCP (bien qu'elle refuse d'assurer un service DNS en TCP, encore une bizarrerie). On note aussi que le RTT confirme celui de ping. (Ce qui ne va pas de soi : le réseau peut traiter différemment différents protocoles.)
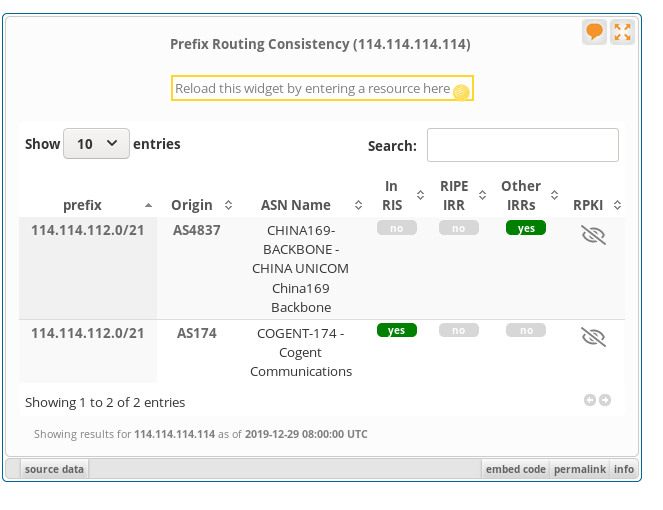
Il y a une dernière chose très étrange avec ce service. Son
adresse fait partie d'un préfixe IP annoncé en BGP,
114.114.112.0/21. Vous pouvez le trouver auprès
d'un service comme RIPE
Stat, ou bien en utilisant curl pour interroger une API publique :
% curl https://bgp.bortzmeyer.org/114.114.114.114 114.114.112.0/21 174
Après le préfixe (114.114.112.0/21), on voit
le numéro d'AS, 174. Or, cet AS est
l'opérateur étatsunien Cogent :
% whois AS174 ... # Copyright 1997-2019, American Registry for Internet Numbers, Ltd. ASNumber: 174 ASName: COGENT-174 ASHandle: AS174 Ref: https://rdap.arin.net/registry/autnum/174 OrgName: Cogent Communications OrgId: COGC Address: 2450 N Street NW City: Washington StateProv: DC PostalCode: 20037 Country: US Ref: https://rdap.arin.net/registry/entity/COGC
A priori, pourquoi pas, une organisation chinoise a bien le droit de faire appel à un opérateur étatsunien pour annoncer son préfixe. Mais il y a des choses étranges. D'abord, la route enregistrée dans l'IRR d'APNIC ne mentionne pas Cogent, mais l'AS 4837, China Unicom :
% whois 114.114.114.114 ... route: 114.114.112.0/21 descr: China Unicom Shandong Province network descr: Addresses from CNNIC country: CN origin: AS4837 mnt-by: MAINT-CNCGROUP-RR last-modified: 2011-04-12T07:52:02Z source: APNIC
Il n'y a pas de ROA (Route Origin Authorizations, RFC 6482) pour ce préfixe :
% whois -h whois.bgpmon.net 114.114.114.114 % This is the BGPmon.net whois Service ... RPKI status: No ROA found ...
(On pourrait avoir le même résultat en consultant
RIPE stat.) La seule information quant à la validité de
l'annonce BGP est donc l'objet route, qui
exclut Cogent. Notez qu'en fouillant un peu plus, on trouve des
annonces du préfixe 114.114.112.0/21 par
d'autres AS, 4837 (ce qui est conforme à l'objet
route ci-dessous), et 4134
(ChinaNet). Mais la plupart des routeurs BGP de la planète ne voient que l'annonce de
Cogent.
Que faut-il déduire de ce dernier cafouillage ? La situation est certes anormale (l'IRR n'annonce qu'un seul AS d'origine possible, mais c'est un autre qu'on voit presque partout), mais est-ce le résultat d'une attaque délibérée, comme les détournements BGP dont on parle souvent (RFC 7464), en général en les attribuant aux… Chinois ? Probablement pas : la situation générale de la sécurité du routage est médiocre, les IRR ne sont pas maintenus à jour, l'opérateur Cogent n'est pas connu pour sa rigueur (il ne devrait pas annoncer des préfixes sans qu'ils soient marqués comme tel dans un IRR) et il s'agit sans doute plus de négligence que de malveillance.
Et pour finir la partie sur le routage, une copie d'écran de RIPE stat montrant
l'incohérence des annonces :
Revenons un peu à ping. Manuel Ponce a fort justement observé qu'il y avait un problème intéressant dans les réponses à ping :
% ping -c 10 114.114.114.114 PING 114.114.114.114 (114.114.114.114) 56(84) bytes of data. 64 bytes from 114.114.114.114: icmp_seq=1 ttl=63 time=94.0 ms 64 bytes from 114.114.114.114: icmp_seq=2 ttl=56 time=93.8 ms 64 bytes from 114.114.114.114: icmp_seq=3 ttl=81 time=93.9 ms 64 bytes from 114.114.114.114: icmp_seq=4 ttl=84 time=94.1 ms 64 bytes from 114.114.114.114: icmp_seq=5 ttl=62 time=94.2 ms 64 bytes from 114.114.114.114: icmp_seq=6 ttl=66 time=94.0 ms 64 bytes from 114.114.114.114: icmp_seq=7 ttl=80 time=93.9 ms 64 bytes from 114.114.114.114: icmp_seq=8 ttl=69 time=93.9 ms 64 bytes from 114.114.114.114: icmp_seq=9 ttl=72 time=94.2 ms 64 bytes from 114.114.114.114: icmp_seq=10 ttl=59 time=94.1 ms --- 114.114.114.114 ping statistics --- 10 packets transmitted, 10 received, 0% packet loss, time 9011ms rtt min/avg/max/mdev = 93.801/94.045/94.285/0.342 ms
Prenez cinq minutes pour regarder et voyez si vous trouvez le problème…
C'est bon, vous avez trouvé ? Moi, je n'avais pas vu : le TTL change à chaque paquet. Normalement, il devrait être à peu près constant, sauf si le routage se modifie subitement pendant le test (ce qui est rare). Ici, c'est un mystère de plus de ce curieux service. Personne n'a trouvé d'explication certaine de ce phénomène mais Baptiste Jonglez suggère cette commande Netfilter si vous voulez faire pareil sur vos serveurs (Non testé ! Ne l'essayez pas en production comme ça !) :
for ttl in {0..31}
do
iptables -t mangle -A OUTPUT -p icmp --icmp-type echo-reply -m statistic --mode nth --every 32 --packet $ttl -j TTL --ttl-set $((ttl+72))
done
Cela donne des TTL dans l'ordre. Pour les avoir aléatoires, Paul
Rolland suggère de remplacer --mode nth --every 32
--packet $ttl par --mode random --probability 0.03125.
L'article seul
RFC 8700: Fifty Years of RFCs
Date de publication du RFC : Décembre 2019
Auteur(s) du RFC : H. Flanagan (RFC Editor)
Pour information
Première rédaction de cet article le 24 décembre 2019
Ce nouveau RFC marque le cinquantième anniversaire des RFC. Le RFC 1 avait en effet été publié le 7 avril 1969. Ce RFC 8700, publié avec un certain retard, revient sur l'histoire de cette exceptionnelle série de documents.
Il y avait déjà eu des RFC faisant le bilan de la série, à l'occasion d'anniversaires, comme le RFC 2555 pour le trentième RFC, et le RFC 5540 pour le quarantième. La série a évidemment commencé avec le RFC 1, cinquante ans auparavant, et donc dans un monde très différent. À l'époque, les RFC méritaient leur nom, ils étaient été en effet des « appels à commentaires », prévus non pas comme des références stables, mais comme des étapes dans la discussion. En cinquante ans, les choses ont évidemment bien changé, et les RFC sont devenus des documents stables, intangibles, et archivés soigneusement. Logiquement, le processus de création des RFC a également évolué, notamment vers un plus grand formalisme (on peut même dire « bureaucratie »).
Plus de 8 500 RFC ont été publiés (il existe quelques trous dans la numérotation ; ainsi, le RFC 26 n'a jamais existé…) Les plus connus sont les normes techniques de l'Internet. La description précise de HTTP, BGP ou IP est dans un RFC. Mais d'autres RFC ne normalisent rien (c'est le cas du RFC 8700, sujet de cet article), ils documentent, expliquent, suggèrent… Tous les RFC ont en commun d'être publiés puis soigneusement gardés par le RFC Editor, une fonction assurée par plusieurs personnes, et aujourd'hui animée par Heather Flanagan, auteure de ce RFC 8700, mais qui a annoncé son départ.
Cette fonction a elle aussi une histoire : le premier RFC Editor était Jon Postel. À l'époque c'était une fonction informelle, tellement informelle que plus personne ne sait à partir de quand on a commencé à parler du (ou de la) RFC Editor (mais la première mention explicite est dans le RFC 902). Postel assurait cette fonction en plus de ses nombreuses autres tâches, sans que cela n'apparaisse sur aucune fiche de poste. Petit à petit, cette fonction s'est formalisée.
Les changements ont affecté bien des aspects de la série des RFC, pendant ces cinquante ans. Les premiers RFC étaient distribués par la poste ! Au fur et à mesure que le réseau (qui ne s'appelait pas encore Internet) se développait, ce mécanisme de distribution a été remplacé par le courrier électronique et le FTP anonyme. Autre changement, les instructions aux auteurs, données de manière purement orales, ont fini par être rédigées. Et l'équipe s'est étoffée : d'une personne au début, Postel seul, le RFC Editor a fini par être une tâche assurée par cinq à sept personnes. Autrefois, la fonction de RFC Editor était liée à celle de registre des noms et numéros, puis elle a été séparée (le registre étant désormais PTI). Puis la fonction de RFC Editor a été structurée, dans le RFC 4844, puis RFC 5620, enfin dans le RFC 6635. Et l'évolution continue, par exemple en ce moment avec le changement vers le nouveau format des documents (voir RFC 7990). Dans le futur, il y aura certainement d'autres changements, mais le RFC Editor affirme son engagement à toujours prioriser la stabilité de la formidable archive que représentent les RFC, et sa disponibilité sur le long terme (RFC 8153).
La section 2 du RFC rappelle les grands moments de l'histoire des RFC (je n'ai pas conservé toutes ces étapes dans la liste) :
- Avril 1969, premier RFC, le RFC 1,
- 1971, premier RFC distribué via le réseau, le RFC 114,
- 1977, premier RFC publié le premier avril, le RFC 748,
- 1986, création de l'IETF,
- 1998, début du projet de récupération et de restauration des vieux RFC perdus,
- 1998, mort de Jon Postel, le « père de la série des RFC » (cf. RFC 2441),
- 2009, publication du RFC 5620, qui décrit à peu près le modèle d'aujourd'hui,
- 2010, les RFC ne sont plus gérés à l'ISI, mais chez une organisation spécialisée,
- 2011, une des nombreuses réformes des RFC, l'abandon des trois niveaux de normalisation, documenté dans le RFC 6410,
- 2013, début du projet de changement du format (RFC 6949) et d'abandon du texte brut,
- 2017, passage au zéro papier (RFC 8153).
Dans la section 3 de ce RFC, plusieurs personnes ayant vécu de l'intérieur l'aventure des RFC écrivent. Steve Crocker, dans la section 3.1, rappelle les origines des RFC (qu'il avait déjà décrites dans le RFC 1000). Il insiste sur le fait que les débuts étaient… peu organisés, et que la création de la série des RFC n'était certainement pas prévue dés le départ. Elle doit beaucoup aux circonstances. Le réseau qui, après bien des évolutions, donnera naissance à l'Internet a été conçu vers 1968 et a commencé à fonctionner en 1969. Quatre machines, en tout et pour tout, le constituaient, un Sigma 7, un SDS 940, un IBM 360/75 et un PDP-10. Le point important est qu'il s'agissait de machines radicalement différentes, un des points distinctifs de l'Internet, qui a toujours dû gérer l'hétérogénéité. Un byte n'avait pas la même taille sur toutes ces machines. (Le terme français octet est apparu bien plus tard, lorsque la taille de huit bits était devenue standard.)
Crocker décrit la première réunion de ce qui allait devenir le Network Working Group puis, très longtemps après l'IETF. Rien n'était précisement défini à part « il faut qu'on fasse un réseau d'ordinateurs » et persone ne savait trop comment le faire. La principale conclusion de la réunion avait été « il faudrait faire une autre réunion ». Dès le début, le réseau qui allait permettre de travailler à distance était donc un prétexte à des réunions AFK. (L'ironie continue aujourd'hui, où l'IETF réfléchit à avoir des réunions entièrement en ligne.)
L'espoir des étudiants comme Crocker était qu'un monsieur sérieux et expérimenté vienne expliquer ce qu'on allait devoir faire. Mais cet espoir ne s'est pas matérialisé et le futur Network Working Group a donc dû se débrouiller.
Parmi les idées les plus amusantes, le groupe avait réfléchi à la création d'un langage portable permettant d'envoyer du code sur une autre machine qui l'exécuterait. Ce lointain prédécesseur de JavaScript se nommait DEL (pour Decode-Encode Language) puis NIL (Network Interchange Language). Mais en attendant le travail matériel avançait, la société BBN ayant obtenu le contrat de construction des IMP (à peu près ce qu'on appelerait plus tard routeurs). La répartition des tâches entre le NWG et BBN n'était pas claire et le groupe a commencé de son côté à documenter ses réflexions, créant ainsi les RFC. Le nom de ces documents avait fait l'objet de longs débats. Le Network Working Group n'avait aucune autorité officielle, aucun droit, semblait-il, à édicter des « normes » ou des « références ». D'où ce titre modeste de Request for Comments ou « Appel à commentaires ». Cette modestie a beaucoup aidé au développement du futur Internet : personne ne se sentait intimidé par l'idée d'écrire des documents finaux puisque, après tout, ce n'était que des appels à commentaires. C'était d'autant plus important que certains des organismes de rattachement des participants avaient des règles bureaucratiques strictes sur les publications. Décréter les RFC comme de simples appels à commentaires permettait de contourner ces règles.
Le premier « méta-RFC » (RFC parlant des RFC) fut le RFC 3, qui formalisait cette absence de formalisme. De la même façon, il n'existait pas encore vraiment de RFC Editor, même si Crocker attribuait les numéros, et que le SRI gardait une archive non officielle. Mais deux principes cardinaux dominaient, et sont toujours vrais aujourd'hui : tout le monde peut écrire un RFC, nul besoin de travailler pour une grosse entreprise, ou d'avoir un diplôme ou un titre particulier, et tout le monde peut lire les RFC (ce qui n'a rien d'évident : en 2019, l'AFNOR ne distribue toujours pas librement ses normes.)
Dans la section 3.2, Vint Cerf décrit les changements ultérieurs. En 1971, Jon Postel est devenu RFC Editor (titre complètement informel à cette époque). Cette tâche était à l'époque mélée à celle d'attribution des numéros pour les protocoles, désormais séparée. Postel s'occupait à la fois du côté administratif du travail (donner un numéro aux RFC…) et de l'aspect technique (relecture et révision), tâche aujourd'hui répartie entre diverses organisations comme l'IESG pour les RFC qui sont des normes. C'est pendant cette « période Postel » que d'autres personnes sont venues rejoindre le RFC Editor comme Joyce Reynolds ou Bob Braden. Jon Postel est décédé en 1998 (cf. RFC 2468).
Leslie Daigle, dans la section 3.3 de notre RFC, rappelle la longue marche qu'a été la formalisation du rôle de RFC Editor, le passage de « bon, qui s'en occupe ? » à un travail spécifié par écrit, avec plein de règles et de processus. (Daigle était présidente de l'IAB au moment de la transition.) Le travail était devenu trop important en quantité, et trop critique, pour pouvoir être assuré par deux ou trois volontaires opérant « en douce » par rapport à leurs institutions. Une des questions importantes était évidemment la relation avec l'IETF. Aujourd'hui, beaucoup de gens croient que « les RFC, c'est l'IETF », mais c'est faux. Les RFC existaient bien avant l'IETF, et, aujourd'hui, tous les RFC ne sont pas issus de l'IETF.
Parmi les propositions qui circulaient à l'époque (début des années 2000) était celle d'une publication complètement automatique. Une fois le RFC approuvé par l'IESG, quelqu'un aurait cliqué sur Publish, et le RFC se serait retrouvé en ligne, avec un numéro attribué automatiquement. Cela aurait certainement fait des économies, mais cela ne réglait pas le cas des RFC non-IETF, et surtout cela niait le rôle actif du RFC Editor en matière de contenu du RFC. (Témoignage personnel : le RFC Editor a joué un rôle important et utile dans l'amélioration de mes RFC. C'est vrai même pour les RFC écrits par des anglophones : tous les ingénieurs ne sont pas des bons rédacteurs.) D'un autre côté, cela résolvait le problème des modifications faites de bonne foi par le RFC Editor mais qui changeaient le sens technique du texte.
La solution adoptée est décrite dans le RFC 4844, le premier à formaliser en détail le rôle du RFC Editor, et ses relations complexes avec les autres acteurs.
Nevil Brownlee, lui, était ISE, c'est-à-dire Independent Submissions Editor, la personne chargée de traiter les RFC de la voie indépendante (ceux qui ne viennent ni de l'IETF, ni de l'IAB, ni de l'IRTF.) Dans la section 3.4, il revient sur cette voie indépendante (d'abord décrite dans le RFC 4846). En huit ans, il a été responsable de la publication de 159 RFC… Avant, c'était le RFC Editor qui décidait quoi faire des soumissions indépendantes. Comme le rappelle Brownlee, le logiciel de gestion de cette voie indépendante était un simple fichier texte, tenu par Bob Braden.
Le principal travail de l'ISE est de coordonner les différents acteurs qui jouent un rôle dans ces RFC « indépendants ». Il faut trouver des relecteurs, voir avec l'IANA pour l'allocation éventuelle de numéros de protocoles, avec l'IESG pour s'assurer que ce futur RFC ne rentre pas en conflit avec un travail de l'IETF (cf. RFC 5742), etc. Ah, et c'est aussi l'ISE qui gère les RFC du premier avril.
Puis c'est la RFC Editor actuelle, Heather Flanagan qui, dans la section 3.5, parle de son expérience, d'abord comme simple employée. La charge de travail atteignait de tels pics à certains moments qu'il a fallu recruter des personnes temporaires (au nom de l'idée que la publication des RFC devait être un processus léger, ne nécessitant pas de ressources permanentes), ce qui a entrainé plusieurs accidents quand des textes ont été modifiés par des employés qui ne comprenaient pas le texte et introduisaient des erreurs. L'embauche d'employés permanents a résolu le problème.
Mais il a fallu aussi professionnaliser l'informatique. Le RFC Editor qui travaillait surtout avec du papier (et un classeur, le fameux « classeur noir ») et quelques outils bricolés (la file d'attente des RFC était un fichier HTML édité à la main), a fini par disposer de logiciels adaptés à la tâche. Finies, les machines de Rube Goldberg !
Dans le futur, bien sûr, les RFC vont continuer à changer ; le gros projet du moment est le changement de format canonique, du texte brut à XML. Si l'ancien format avait de gros avantages, notamment en terme de disponibilité sur le long terme (on peut toujours lire les anciens RFC, alors que les outils et formats à la mode au moment de leur écriture sont depuis longtemps oubliés), il avait aussi des inconvénients, comme l'impossibilité d'utiliser d'autres caractères que l'ASCII. Le RFC 7990 décrit le nouveau format, actuellement en cours de déploiement.
Autres lectures :
- Pour ce cinquantième anniversaire, Darius Kazemi commente un RFC par jour et c'est passionnant,
- Article de Dan York.
L'article seul
Fiche de lecture : The box
Auteur(s) du livre : Marc Levinson
Éditeur : Max Milo
9782315002986
Publié en 2011
Première rédaction de cet article le 16 décembre 2019
C'est une banalité que de choisir le conteneur comme symbole de la mondialisation. Mais comment en est-on arrivé là ? Qui a inventé le conteneur et pourquoi ? Comment s'est-il imposé ? Je trouve que Marc Levinson a fait un excellent travail d'histoire de la conteneurisation dans ce gros livre.
Donc, le conteneur, c'est la grosse boîte en acier qu'on voit déborder sur le pont des navires. Permettant d'abaisser le coût de transport international jusqu'au point qu'il devient souvent négligeable, le conteneur a permis aux baskets fabriquées au Viêt Nam, aux T-shirts du Bangladesh et aux téléphones montés en Chine d'arriver partout dans le monde. Plus besoin de mettre les usines près des futurs clients, on peut les installer là où les travaileurs ne sont pas syndiqués et donc pas chers. Mais malgré son rôle économique crucial, le conteneur ne fait pas rêver. On écrit plein de livres sur les avions, sur les bateaux, sur de nombreuses machines, mais pas sur cette grosse boîte disgracieuse, peinte de couleurs vulgaires, qu'est le conteneur. C'est là que Marc Levinson est intervenu pour écrire ce livre touffu et très détaillé. (L'original est en anglais mais j'ai lu la traduction en français.)
Levinson retrace l'histoire du conteneur, en insistant sur le rôle de Malcom McLean, qui n'est pas « l'inventeur » du conteneur (comme beaucoup d'inventions, le conteneur a de nombreux pères), mais celui qui l'a promu et développé depuis le début. L'histoire de l'homme seul luttant contre les conservatismes pour révolutionner le transport de marchandises aurait pu être fait en style « légende étatsunienne » classique, avec le courageux entrepreneur qui, parti de rien, devient riche par son travail personnel, mais, heureusement, Levinson ne donne pas dans ce travers. Il explique bien le rôle de McLean, mais aussi ses erreurs et ses défauts, et le rôle de nombreuses autres personnes.
C'est que le conteneur a eu une histoire difficile. Il n'y a que dans les légendes que l'inventeur conçoit un objet et qu'après de courtes difficultés initiales, l'objet conquiert le monde par la seule force de ses qualités intrinsèques. En fait, le conteneur ne s'est pas imposé tout de suite. Il a rencontré de nombreuses difficultés, du conservatisme des acteurs déjà installés aux problèmes politiques et légaux, en passant par la difficulté d'adapter toute la chaîne du transport. Sans oublier des problèmes techniques bien concrets, pour faire une boîte solide, mais pas chère et facile à manipuler.
Levinson ne cache pas que l'effondrement des coûts du transport international n'est pas uniquement dû au conteneur, objet magique. Il a fallu refaire toute la logistique, et cela a pris de nombreuses années. En cela, ce livre est un excellent modèle d'analyse d'un système socio-technique. Contrairement à beaucoup d'études sur un objet technique, celle-ci ne considère pas le conteneur comme isolé, mais bien comme un des maillons d'un système complexe. Avec le recul, on dit que c'est le conteneur, par la baisse des coûts qu'il a engendrée, qui a permis l'actuelle mondialisation. Mais pendant de nombreuses années, il fallait vraiment avoir la foi, le conteneur coûtait aussi cher, voire plus cher que les systèmes qu'il voulait remplacer. Et il fallait remplir cette grosse boîte, pour qu'elle ne voyage pas à moitié vide et cela au retour comme à l'aller. C'est seulement quand tout le système socio-technique du transport s'est adapté à ces exigences que les coûts ont réellement baissé. En attendant, il a fallu financer l'adaptation des bateaux et des ports à ce nouvel objet et, contrairement à la légende des entrepreneurs privés qui risquent leur argent et, si ça marche, en retirent des bénéfices bien mérités, ici, une bonne partie des ports et même des navires ont été financés pendant des années par l'argent public, McLean ayant réussi à convaincre beaucoup de monde que l'avenir était au conteneur. C'est d'ailleurs la guerre du Viêt Nam qui a marqué le vrai décollage du conteneur, vu les énormes besoins en matériel de l'armée étatsunienne et l'argent dont elle disposait.
Comme tous les changements socio-techniques, le conteneur a fait des gagnants et des perdants. Levinson ne joue pas la partition de la « mondialisation heureuse » et analyse qui a gagné et qui a perdu. Parmi les perdants, les marins : la rapidité de chargement et de déchargement, un des buts de la conteneurisation, a réduit à quelques heures la durée des escales. On ne voit plus du pays quand on est marin, seulement les gigantesques terminaux à conteneurs, toujours situés, vu leur taille, très loin de la ville, contrairement au port traditionnel. Toujours parmi les perdants, les dockers, le but du conteneur étant entre autres de nécessiter moins de personnel pour charger et décharger les bateaux. Les pages consacrées aux questions sociales sont très intéressantes, mais le livre est évidemment très centré sur les États-Unis et ce pays présente quelques particularités, comme les liens de certains syndicats avec le crime organisé (même si l'auteur note que le film Sur les quais n'est pas toujours réaliste), ou comme la concurrence entre syndicats (celui des dockers et celui des camionnneurs qui s'allient chacun avec son patronat, contre l'autre syndicat…)
Mais les principaux perdants n'ont pas forcément été du côté des professionnels du transport maritime : ce sont tous les travailleurs qui se trouvent désormais en compétition avec des pays sans lois sociales, sans syndicats, sans droit du travail.
La normalisation est un sujet peu abordé dans les analyses des systèmes socio-techniques mais, ici, elle a la place qu'elle mérite. Le conteneur n'est en effet intéressant que si n'importe quel navire, train ou camion peut l'embarquer. Cela nécessite une normalisation de la taille, des caractéristiques physiques (résistance à l'écrasement) et du système de verrouillage des conteneurs. C'est un des meilleurs chapitres du livre, introduisant le lecteur à ce monde feutré des négociations autour de la normalisation, sachant que des détails apparemment sans importance, comme la largeur exacte du conteneur, peuvent faire perdre beaucoup d'argent aux premiers investisseurs, qui risquent de devoir refaire leurs ports et leurs navires, si la taille initialement retenue n'est pas celle choisie par ces premiers arrivés. Et les décisions de normalisation ne sont pas purement arbitraires, la technique a son mot à dire, par exemple sur le système de verrouillage (sinon, on perd des conteneurs en mer.)
Pour résumer, c'est un très bon exemple d'analyse socio-technique, à lire même si vous ne travaillez pas dans le domaine du transport de marchandises. On voudrait que tous les systèmes socio-techniques complexes fassent l'objet d'aussi bonnes synthèses.
Et de jolies photos de conteneurs, prises à l'exposition
Playmobil à Calais :
 (Version en taille originale.)
(Version en taille originale.)
 (Version en taille originale.)
(Version en taille originale.)
{kind=link}
{kind=link}
L'article seul
Vérifier le nom dans un certificat : pas trivial
Première rédaction de cet article le 15 décembre 2019
J'ai récemment eu à écrire un programme qui se connecte en TLS à un serveur et devait donc vérifier le certificat. La bibliothèque TLS utilisée ne vérifie pas que le nom dans le certificat correspond au nom demandé, c'est au programmeur de le faire, et ce n'est pas trivial, avec de nombreux pièges.
Un peu de contexte pour comprendre : le programme était un client DoT (DNS sur TLS, normalisé dans le RFC 7858). Il ne s'agit pas d'un client HTTP (qui ont tous des mécanismes de vérification du certificat). Au début, je me suis dit « pas de problème, je ne vais pas programmer TLS moi-même, de toute façon, cela serait très imprudent, vu mes compétences, je vais utiliser une bibliothèque toute faite, et, avantage en prime, j'aurais moins de travail ». Le client étant écrit en Python, j'utilise la bibliothèque pyOpenSSL, qui repose sur la bien connue OpenSSL.
Je prends bien soin d'activer la vérification du certificat et,
en effet, les certificats signés par une AC
inconnue, ou bien les certificats expirés, sont rejetés. Mais,
surprise (pour moi), si le nom dans le certificat ne correspond
pas au nom demandé, le certificat est quand même accepté. Voici un
exemple avec le client OpenSSL en ligne de commande, où j'ai mis
badname.example dans mon
/etc/hosts pour tester (une autre solution
aurait été d'utiliser l'adresse IP et pas le nom, pour se
connecter, ou bien un alias du nom) :
% openssl s_client -connect badname.example:853 -x509_strict
...
Certificate chain
0 s:CN = dot.bortzmeyer.fr
i:C = US, O = Let's Encrypt, CN = Let's Encrypt Authority X3
...
Et aucun message d'erreur, tout se passe bien, alors que le
certificat ne contenait pas du tout
badname.example.
Notez que c'est précisé. La documentation d'OpenSSL nous dit « You must confirm a match between the hostname you contacted and the hostnames listed in the certificate. OpenSSL prior to 1.1.0 does not perform hostname verification, so you will have to perform the checking yourself. ». Pourquoi cette absence de vérification ? Et comment faire la vérification ?
En fait, le problème n'est pas spécifique à OpenSSL. Le système de sécurité autour des certificats est un empilement complexe de normes. À la base, se trouve une norme UIT nommée X.509. Elle était disponible en ligne (depuis, l'UIT l'a fait disparaitre, où irions-nous si tout le monde pouvait lire les normes) et fait, aujourd'hui, 236 pages. Elle décrit le format des certificats, le rôle des AC, et plein d'autres choses, mais ne parle pas de la vérification des noms (on dit « sujets » et pas « noms », dans la terminologie X.509), et pour cause : X.509 permet de très nombreuses façons d'indiquer le sujet, ce n'est pas forcément un nom de domaine. Comme le dit sa section 9.3.1, « public-key certificates need to be usable by applications that employ a variety of name forms ». Une convention aussi banale que d'utiliser une astérisque comme joker n'est même pas mentionnée. Bref, X.509 ne va pas répondre à nos questions. Mais l'Internet n'utilise pas X.509. Il utilise la plupart du temps le protocole TLS, normalisé dans le RFC 9846. TLS utilise comme méthode d'authentification principale un certificat, décrit par un profil, une variation de X.509, ne gardant pas toutes les posssibilités de X.509, et en ajoutant d'autres. Ce profil est souvent nommé PKIX, pour Public-Key Infrastructure X.509 et est normalisé dans le RFC 5280. PKIX est plus précis que X.509 mais reste encore loin de tout spécifier, renvoyant souvent aux applications telle ou telle question. Par exemple, les jokers, déjà mentionnés, sont laissés à l'appréciation des applications. On comprend donc que les développeurs de OpenSSL n'aient pas inclus une vérification par défaut.
Pour compléter cette revue des normes, il faut citer surtout le RFC 6125, qui, lui, décrit précisément la vérification des sujets, quand ce sont des noms de domaine. C'est la principale source d'information quand on veut programmer une vérification du nom.
Ah, et, quand on teste, bien penser à séparer bibliothèque et
programme utilisant cette bibliothèque. Ce n'est pas parce que la
commande openssl peut tester le nom que la
bibliothèque le fait par défaut. L'option pertinente se nomme
-verify_hostname :
% openssl s_client -connect badname.example:853 -x509_strict -verify_hostname badname.example ... verify error:num=62:Hostname mismatch ...
Si on avait utilisé le bon nom (celui présent dans le
certificat,ici dot.bortzmeyer.fr),
on aurait eu :
Verification: OK
Verified peername: dot.bortzmeyer.fr
Notez bien que c'est une option. Si elle est mise sur la ligne de
commande, openssl demandera à la bibliothèque
OpenSSL de faire la vérification, mais cela ne sera pas fait
autrement. OpenSSL dispose d'un sous-programme
X509_check_host qui fait la vérification,
mais il n'est pas appelé par défaut, et il n'est pas présent
dans pyOpenSSL, la bibliothèque Python.
Par contre, avec la bibliothèque GnuTLS, le programme en ligne de commande fait cette vérification, par défaut :
% gnutls-cli --port 853 badname.example
...
Connecting to '2001:41d0:302:2200::180:853'...
...
- Certificate[0] info:
- subject `CN=dot.bortzmeyer.fr', issuer `CN=Let's Encrypt Authority X3,O=Let's Encrypt,C=US', serial 0x042ab817dad761f36920a3f2b3e7b780986f, RSA key 2048 bits, signed using RSA-SHA256, activated `2019-11-26 08:34:11 UTC', expires `2020-02-24 08:34:11 UTC', pin-sha256="eHAFsxc9HJW8QlJB6kDlR0tkTwD97X/TXYc1AzFkTFY="
...
- Status: The certificate is NOT trusted. The name in the certificate does not match the expected.
*** PKI verification of server certificate failed...
*** Fatal error: Error in the certificate.
Le sous-programme dans GnuTLS qui fait la vérification se nomme
gnutls_x509_crt_check_hostname.
Et si vous voulez faire cette vérification vous-même (ce qui n'est pas prudent mais on va dire qu'on veut vivre dangereusement) ? Il faut penser à plein de choses. Prenons l'exemple d'un programme en Python. Le test de base, où on compare le nom de serveur donné au « common name » (CN) dans le certificat :
if hostname == cert.get_subject().commonName:
est non seulement insuffisant (il ne tient pas compte des jokers, ou des « subject alternative name », ou SAN) mais il est en outre incorrect, le RFC 6125 disant bien, dans sa section 6.4.4, qu'il ne faut tester le « common name » que si tous les autres tests ont échoué. Il faut en fait tenir compte des SAN (Subject Alternative Names) contenus dans le certificat. Il faut examiner tous ces SAN :
for alt_name in get_certificate_san(cert).split(", "):
if alt_name.startswith("DNS:"):
(start, base) = alt_name.split("DNS:")
if hostname == base:
...
Rappelez-vous qu'un sujet, en X.509, n'est pas forcément un nom de domaine. Cela peut être une adresse IP, un URL, ou même du texte libre. Traitons le cas des adresses IP. Le certificat de Quad9 utilise de telles adresses :
% openssl s_client -connect 9.9.9.9:853 -showcerts | openssl x509 -text
...
X509v3 Subject Alternative Name:
DNS:*.quad9.net, DNS:quad9.net, IP Address:9.9.9.9, IP Address:9.9.9.10, IP Address:9.9.9.11, IP Address:9.9.9.12, IP Address:9.9.9.13, IP Address:9.9.9.14, IP Address:9.9.9.15, IP Address:149.112.112.9, IP Address:149.112.112.10, IP Address:149.112.112.11, IP Address:149.112.112.12, IP Address:149.112.112.13, IP Address:149.112.112.14, IP Address:149.112.112.15, IP Address:149.112.112.112, IP Address:2620:FE:0:0:0:0:0:9, IP Address:2620:FE:0:0:0:0:0:10, IP Address:2620:FE:0:0:0:0:0:11, IP Address:2620:FE:0:0:0:0:0:12, IP Address:2620:FE:0:0:0:0:0:13, IP Address:2620:FE:0:0:0:0:0:14, IP Address:2620:FE:0:0:0:0:0:15, IP Address:2620:FE:0:0:0:0:0:FE, IP Address:2620:FE:0:0:0:0:FE:9, IP Address:2620:FE:0:0:0:0:FE:10, IP Address:2620:FE:0:0:0:0:FE:11, IP Address:2620:FE:0:0:0:0:FE:12, IP Address:2620:FE:0:0:0:0:FE:13, IP Address:2620:FE:0:0:0:0:FE:14, IP Address:2620:FE:0:0:0:0:FE:15
Voici une première tentative pour les tester :
elif alt_name.startswith("IP Address:"):
(start, base) = alt_name.split("IP Address:")
if hostname == base:
...
Mais ce code n'est pas correct, car il compare les adresses IP
comme si c'était du texte. Or, les adresses peuvent apparaitre
sous différentes formes. Par exemple, pour
IPv6, le RFC 5952
spécifie un format canonique mais les certificats dans le monde
réel ne le suivent pas forcément. Le certificat de Quad9 ci-dessus
utilise par exemple 2620:FE:0:0:0:0:FE:10
alors que cela devrait être 2620:fe::fe:10
pour satisfaire aux exigences du RFC 5952. Il faut donc convertir les adresses IP en binaire
et comparer ces binaires, ce que je fais ici en Python avec la
bibliothèque
netaddr :
elif alt_name.startswith("IP Address:"):
(start, base) = alt_name.split("IP Address:")
host_i = netaddr.IPAddress(hostname)
base_i = netaddr.IPAddress(base)
if host_i == base_i:
...
Ce problème du format des adresses IP illustre un piège général lorsqu'on fait des comparaisons avec les certificats, celui de la canonicalisation. Les noms (les sujets) peuvent être écrits de plusieurs façons différentes, et doivent donc être canonicalisés avant comparaison. Pour les noms de domaine, cela implique par exemple de les convertir dans une casse uniforme. Plus subtil, il faut également tenir compte des IDN (RFC 5891). Le RFC 6125, section 6.4.2, dit qu'il faut comparer les « A-labels » (la forme en Punycode), on passe donc tout en Punycode (RFC 3492) :
def canonicalize(hostname):
result = hostname.lower()
result = result.encode('idna').decode()
return result
Vous pouvez tester avec www.potamochère.fr,
qui a un certificat pour le nom de domaine en
Unicode.
Ensuite, il faut tenir compte du fait que le certificat peut
contenir des jokers, indiqués par
l'astérisque. Ainsi,
rdap.nic.bzh présente un certificat avec un
joker :
% gnutls-cli rdap.nic.bzh ... - Certificate[0] info: - subject `CN=*.nic.bzh', issuer `CN=RapidSSL TLS RSA CA G1,OU=www.digicert.com,O=DigiCert Inc,C=US', serial 0x0a38b84f1a0b01c9a8fbc42854cbe6f6, RSA key 4096 bits, signed using RSA-SHA256, activated `2018-09-03 00:00:00 UTC', expires `2020-07-30 12:00:00 UTC', pin-sha256="2N9W5qz35u4EgCWxbdPwmWvf/Usz2gk5UkUYbAqabcA=" ...
Il faut donc traiter ces jokers. Attention, comme le précise le
RFC 6125 (rappelez-vous que la norme
X.509 ne parle pas des jokers), il ne faut
accepter les jokers que sur le premier composant du nom de domaine
(*.nic.bzh marche mais
rdap.*.bzh non), et le joker ne peut
correspondre qu'à un seul composant
(*.nic.bzh accepte
rdap.nic.bzh mais pas
foo.bar.kenavo.nic.bzh.) Cela se traduit
par :
if possibleMatch.startswith("*."): # Wildcard
base = possibleMatch[1:] # Skip the star
(first, rest) = hostname.split(".", maxsplit=1)
if rest == base[1:]:
return True
if hostname == base[1:]:
return True
return False
else:
return hostname == possibleMatch
Un point amusant : le RFC 6125 accepte
explicitement des astérisques au milieu d'un
composant, par exemple un certificat pour
r*p.nic.bzh accepterait
rdap.nic.bzh. Mon code ne gère pas ce cas
vraiment tordu, mais les développeurs d'OpenSSL l'ont prévu (si
l'option X509_CHECK_FLAG_NO_PARTIAL_WILDCARDS
n'est pas activée) :
/* Only full-label '*.example.com' wildcards? */
if ((flags & X509_CHECK_FLAG_NO_PARTIAL_WILDCARDS)
&& (!atstart || !atend))
return NULL;
/* No 'foo*bar' wildcards */
Autre cas amusant, le code de curl, quand il vérifie que le nom du
serveur correspond au contenu du certificat, refuse les jokers si
le nom dans le certificat n'a que deux composants. Le but est sans
doute d'éviter qu'un certificat pour *.com ne
permette de se faire passer pour n'importe quel nom en
.com mais cette règle,
qui ne semble pas être dans le RFC 6125,
n'est sans doute pas adaptée aux récents TLD
.BRAND, limités à une entreprise.
Au passage, j'avais dit au début que mon but initial était de tester un serveur DoT (DNS-over-TLS, RFC 7858). Le RFC original sur DoT ne proposait pas de tester le nom, estimant qu'un résolveur DoT serait en général configuré via son adresse IP, pour éviter un problème d'œuf et de poule (on a besoin du résolveur pour trouver l'adresse IP du résolveur…) La solution était d'authentifier via la clé publique du résolveur (l'idée a été développée dans le RFC 8310.)
Voilà, vous avez un exemple de programme Python qui met en
œuvre les techniques données ici (il est plus complexe, car il y a
des pièges que je n'ai pas mentionnés), en tls-check-host.py. Une autre solution, n'utilisant que la
bibliothèque standard de Python, est tls-check-host-std-lib.py, mais, attention, ladite
bibliothèque standard ne gère pas les IDN, donc ça ne marchera pas
avec des noms non-ASCII. (Mais son
utilisation évite de recoder la vérification.)
En conclusion, j'invite les programmeurs qui utilisent TLS à bien s'assurer que la bibliothèque TLS qu'ils ou elles utilisent vérifie bien que le nom de serveur donné corresponde au contenu du certificat. Et, si ce n'est pas le cas et que vous le faites vous-même, attention : beaucoup d'exemples de code source de validation d'un nom qu'on trouve au hasard de recherches sur le Web sont faux, par exemple parce qu'ils oublient les jokers, ou bien les traitent mal. Lisez bien le RFC 6125, notamment sa section 6, ainsi que cette page OpenSSL.
Merci à Patrick Mevzek et KMK pour une intéressante discussion sur cette question. Merci à Pierre Beyssac pour le rappel de ce que peut faire la bibliothèque standard de Python.
L'article seul
RFC 8674: The "safe" HTTP Preference
Date de publication du RFC : Décembre 2019
Auteur(s) du RFC : M. Nottingham
Pour information
Première rédaction de cet article le 5 décembre 2019
Ce nouveau RFC
définit une nouvelle préférence qu'un client HTTP peut envoyer au
serveur. « safe » (sûr) indique que le client
ne souhaite pas recevoir du contenu qu'il trouve contestable.
Je vous arrête tout de suite : vous allez me demander « mais qui
définit du contenu contestable ? Ça dépend des gens » et, je vous
rassure, l'auteur du RFC a bien vu le
problème. La préférence safe est juste une
possibilité technique, le RFC ne définit pas ce qui est sûr et ce
qui ne l'est pas, cela devra se faire dans un autre cadre, une
discussion à ce sujet serait bien trop casse-gueule pour
l'IETF. En pratique, le résultat de
l'utilisation de cette préférence dépendra de bien des choses, comme
la politique du serveur (le RFC dit « the cultural context
of the site »), et une éventuelle relation pré-existante
entre le serveur et un utilisateur particulier. Le RFC donne quand
même une indication : safe peut vouloir dire
« adapté aux mineurs ».
Il y a manifestement une demande, puisque bien des
sites Web ont un mode « sûr », où on peut
sélectionner « je ne veux pas voir des choses que je n'aime
pas ». Notez que, dans ces cas, la définition de ce qui est sûr ou
pas dépend du site Web. S'ils est géré aux
États-Unis, « sûr » sera sans doute « aucune
nudité humaine », en Arabie saoudite,
« aucune femme visible », etc. Ce mode « sûr » des sites Web n'est
pas pratique pour l'utilisateurice, car il nécessite de sélectionner
l'option pour chaque site, et de se créer un compte, soit explicite,
soit implicite via les
cookies (RFC 6265). À moins que le mode « sûr » soit le mode par défaut
et, dans ce cas, ce sont les gens qui n'en voudront pas qui auront
du travail. D'où l'idée, très controversée à l'IETF, de
configurer cela dans le navigateur Web (ou
bien dans le système d'exploitation, pour que
tous les clients HTTP le fassent), qui va indiquer au serveur
les préférences (un peu comme le Do Not
Track, dont on sait qu'il est largement ignoré
par les sites Web). La technique utilisée est celle des préférences
HTTP, normalisées dans le RFC 7240,
préférences dont je rappelle que leur respect par le serveur est
optionnel. La préférence safe envoyée par le
client est donc à prendre comme un appel à « faire au mieux » et
« je te fais confiance pour la définition de "sûr" », pas plus.
La section 2 de notre RFC est plus concrète, présentant la
syntaxe exacte de safe. Voici un exemple de
requête HTTP exprimant cette préférence :
GET /foo.html HTTP/1.1 Host: www.example.org User-Agent: ExampleBrowser/1.0 Prefer: safe
La préférence est enregistrée
à l'IANA. Le RFC impose que les requêtes « sûres » soient
faites en HTTPS, pour éviter la surveillance spécifique
des gens qui demandent du safe (et qui peuvent
être des enfants), et pour éviter qu'un intermédiaire ne bricole la
requête, ajoutant ou enlevant cette préférence. Une réponse possible
à la requête ci-dessus serait :
HTTP/1.1 200 OK Transfer-Encoding: chunked Content-Type: text/html Preference-Applied: safe Server: ExampleServer/2.0 Vary: Prefer
Le Vary: (RFC 7231,
section 7.1.4) indique aux relais/caches intermédiaires qu'ils
doivent tenir compte de la valeur de Prefer:
avant de renvoyer la page mémorisée à un autre client.
Si vous voulez tester en vrai, la page https://www.bortzmeyer.org/apps/pornPrefer: safe ou pas. Voici un exemple avec
curl :
% curl --header "Prefer: safe" https://www.bortzmeyer.org/apps/porn
Le code est du Python/WSGI et se résume à :
def porn(start_response, environ):
# Apache/WSGI always give us one Prefer: header even if the client sent several.
preferences = re.split("\s*,\s*", environ['HTTP_PREFER'])
safe = False
for pref in preferences:
if pref.lower() == 'safe':
safe = True
break
begin = """<html><head>..."""
end = """</body></html>"""
safe_content = """<p>Safe ..."""
unsafe_content = """<p>Unsafe ..."""
if safe:
output = begin + safe_content + end
else:
output = begin + unsafe_content + end
status = '200 OK'
response_headers = [('Content-type', 'text/html'),
('Content-Length', str(len(output)))]
start_response(status, response_headers)
return [output]
Cette préférence semble répondre à une forte demande, puisqu'elle est déjà reconnue :
- Dans Internet Explorer (cf. la documentation),
- Dans Bing (cf. Bing),
- Dans les boitiers Cisco (cf. la documentation).
La section 3 du RFC rassemble quelques informations de sécurité :
- HTTPS est indispensable, sinon un
intermédiaire pourra ajouter (ou retirer) la préférence
safe, - Paradoxalement,
safepeut être dangereux puisqu'il transmet une information supplémentaire au serveur, aidant au fingerprinting, - On n'a évidemment aucune garantie que le serveur a bien
adapté le niveau du contenu à ce qu'on voulait. Le RFC fait même
remarquer qu'un serveur sadique pourrait envoyer du contenu
« pire » lorsque la préférence
safeest présente.
Enfin, l'annexe A donne quelques conseils aux auteurs de
navigateurs quant à la mise en œuvre de cette
préférence. L'UI n'est pas évidente. Il est
crucial de ne pas donner à l'utilisateur ou l'utilisatrice
l'impression que cette préférence fournirait des garanties. Le RFC
suggère un texte plus prudent pour une case à
cocher « Demander du contenu "sûr" aux sites Web ». Et
l'annexe B a des conseils pour les gérants de sites Web comme, par
exemple, ne pas permettre aux utilisateurs de demander (via leur
profil, par exemple) d'ignorer la préférence
safe puisqu'elle a pu être placée par un
logiciel de contrôle parental.
Ce RFC a le statut « pour information » et a été publié sur la voie indépendante (cf. RFC 5742) puisqu'il n'a pas fait l'objet d'un consensus à l'IETF (euphémisme…) Les principales objections étaient :
- « Sûr » n'a pas de définition précise et universelle, le terme est vraiment trop vague,
- Les navigateurs Web envoient déjà beaucoup trop d'informations aux serveurs, en ajouter une, qui pourrait, par exemple, permettre de cibler les mineurs, n'est pas forcément une bonne idée.
L'article seul
RFC 8689: SMTP Require TLS Option
Date de publication du RFC : Novembre 2019
Auteur(s) du RFC : J. Fenton (Altmode Networks)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF uta
Première rédaction de cet article le 28 novembre 2019
Ah, la sécurité, c'est toujours compliqué. Pour le courrier électronique, par exemple, SMTP peut être fait sur TLS, pour garantir la confidentialité et l'intégrité du message. Mais TLS est optionnel. Cela entraine deux problèmes : si la politique du MTA est laxiste, le message risque de passer en clair à certains moments, et si elle est stricte, le message risque d'être rejeté alors que l'expéditeur aurait peut-être préféré qu'il passe en clair. Ce nouveau RFC fournit deux mécanismes, un pour exiger du TLS à toutes les étapes, un au contraire pour demander de la bienveillance et de la tolérance et d'accepter de prendre des risques.
SMTP
(RFC 5321) a une option nommée
STARTTLS (normalisée dans le RFC 3207), qui permet, si le pair en face l'accepte, de passer
la session SMTP sur TLS, assurant ainsi sa
sécurité. STARTTLS a plusieurs problèmes,
notamment son caractère optionnel. Même avec des sessions SMTP
entièrement TLS (sans STARTTLS, cf. RFC 8314), le problème demeure. Que doit faire un
MTA s'il ne peut
pas lancer TLS, parce que le MTA en face ne l'accepte pas, ou parce
que son certificat est invalide (RFC 6125) ou
encore car DANE (RFC 7672) est
utilisé et que le certificat ne correspond pas ? Jusqu'à présent, la
décision était prise par chaque MTA et, comme SMTP repose sur le
principe du relayage, l'émetteur original ne pouvait pas exprimer
ses préférences, entre « je suis parano, j'ai lu le bouquin de Snowden, j'exige du TLS
tout le temps » et « je m'en fous, je suis inconscient, je crois que
je n'ai rien à cacher, je
veux que le message soit envoyé, même en clair ». La politique des
serveurs SMTP était typiquement de privilégier la distribution du
message plutôt que sa sécurité. Désormais, il possible pour
l'émetteur de donner ses préférences : l'option SMTP
REQUIRETLS permet d'exiger du TLS tout le
temps, et l'en-tête TLS-Required: (bien mal
nommé) permet d'indiquer qu'on préfère au contraire la délivrance du
message à sa sécurité.
En général, aujourd'hui, les MTA acceptent d'établir la session TLS, même si
le certificat est invalide. En effet, dans le
cas contraire, peu de messages seraient livrés, les certificats dans
le monde du courrier étant fréquemment
invalides, à l'opposé de ce qui se passe dans le monde du Web, où les navigateurs sont bien plus
stricts. Pour durcir cette politique par défaut, et aussi parce
qu'un attaquant actif peut retirer l'option
STARTTLS et donc forcer un passage en clair, il existe
plusieurs mécanismes permettant de publier une politique, comme
DANE (RFC 7672) et
MTA-STS (RFC 8461). Mais elles sont contrôlées par le récepteur, et on
voudrait permettre à l'émetteur de donner son avis.
Commençons par REQUIRETLS, l'extension
SMTP. (Désormais dans le registre IANA des
extensions SMTP.) Il s'agit pour l'émetteur d'indiquer qu'il
ne veut pas de laxisme : il faut du TLS du début à la fin, et,
évidemment, avec uniquement des certificats valides. En utilisant
cette extension, l'émetteur indique qu'il préfère que le message ne
soit pas distribué, plutôt que de l'être dans de mauvaises
conditions de sécurité. Cette extension peut être utilisée entre
deux MTA, mais aussi quand un MUA se connecte au premier MTA, pour une
soumission de message (RFC 6409). Voici un
exemple (« C: » = envoyé par le client, « S: » = envoyé par le
serveur) :
S: 220 mail.example.net ESMTP C: EHLO mail.example.org S: 250-mail.example.net Hello example.org [192.0.2.1] S: 250-SIZE 52428800 S: 250-8BITMIME S: 250-REQUIRETLS C: MAIL FROM:<roger@example.org> REQUIRETLS S: 250 OK C: RCPT TO:<editor@example.net> S: 250 Accepted C: DATA S: 354 Enter message, ending with "." on a line by itself (Le message) C: . S: 250 OK C: QUIT
(Le lecteur ou la lectrice astucieux aura remarqué qu'il y a un
piège, le risque qu'un attaquant actif ne retire le
REQUIRETLS du client ou bien du serveur. Ce cas
est traité plus loin.)
Dans l'exemple ci-dessus, le serveur a annoncé qu'il savait faire
du REQUIRETLS, et le client a demandé à ce que
l'envoi depuis roger@example.org soit protégé
systématiquement par TLS. Cela implique que pour toutes les sessions
SMTP suivantes :
- L'enregistrement MX soit résolu en utilisant DNSSEC (ou alors on utilise MTA-STS, RFC 8461),
- Le certificat soit valide et soit authentifié par une AC ou par DANE,
- Le serveur suivant doit accepter la consigne REQUIRETLS (on veut une chaîne complète, de l'émetteur au récepteur).
Puisque l'idée est d'avoir du TLS partout, cela veut dire qu'un MTA
qui reçoit un message marqué REQUIRETLS doit
noter cette caractéristique dans sa base et s'en souvenir, puisqu'il
devra passer cette exigence au serveur suivant.
Si le serveur en face ne sait pas faire de
REQUIRETLS (ou, pire, pas de TLS), l'émetteur
va créer une erreur
commençant par 5.7 (les erreurs SMTP étendues sont décrites dans le
RFC 5248) :
REQUIRETLS not supported by server: 5.7.30 REQUIRETLS needed
Et l'en-tête TLS-Required: ? (Ajouté dans le
registre IANA des en-têtes.) Il fait
l'inverse, il permet à l'émetteur de spécifier qu'il préfère la
distribution du message à la sécurité, et qu'il faut donc débrayer
les tests qu'on pourrait faire. Ce nom de
TLS-Required: est mal choisi, car cet en-tête
ne peut prendre qu'une seule valeur, no (non),
comme dans cet exemple amusant du RFC :
From: Roger Reporter <roger@example.org>
To: Andy Admin <admin@example.com>
Subject: Certificate problem?
TLS-Required: No
Date: Fri, 18 Jan 2019 10:26:55 -0800
Andy, there seems to be a problem with the TLS certificate
on your mail server. Are you aware of this?
Roger
Si l'en-tête est présent, le serveur doit être plus laxiste que
d'habitude et accepter d'envoyer le message même s'il y a des
problèmes TLS, même si la politique normale du serveur serait de
refuser. Bien sûr, TLS-Required: no n'interdit
pas d'utiliser TLS, si possible, et l'émetteur doit quand même
essayer. Notez aussi que les MTA sont libres de leur politique et qu'on peut
parfaitement tomber sur un serveur SMTP qui refuse de tenir compte
de cette option, et qui impose TLS avec un certificat correct, même
en présence de TLS-Required: no.
(Le lecteur ou la lectrice astucieux aura remarqué qu'il y a un
piège, le risque qu'un attaquant actif n'ajoute
TLS-Required: no. Ce cas est traité plus
loin.)
Ah, et si on a les deux, REQUIRETLS et
TLS-Required: no ? La section 4.1 du RFC couvre
ce cas, en disant que la priorité est à la sécurité (donc,
REQUIRETLS).
La section 5 de notre RFC couvre le cas des messages d'erreur
générés par un MTA lorsqu'il ne peut pas ou ne veut pas envoyer le
message au MTA suivant (ou au MDA). Il
fabrique alors un message envoyé à l'expéditeur
(bounce, en anglais, ou message de non-distribution). Ce message contient
en général une bonne partie, voire la totalité du message
original. Sa confidentialité est donc aussi importante que celle du
message original. Si celui-ci était protégé par
REQUIRETLS, le courrier d'erreur doit l'être
aussi. Le MTA qui génère ce courrier d'erreur doit donc lui-même
activer l'extension REQUIRETLS. (Notez que,
comme le chemin que suivra cet avis de non-remise ne sera pas
forcément le même que celui suivi par le message originel, s'il y a
un serveur non-REQUIRETLS sur le trajet, le
courrier d'erreur ne sera pas reçu.)
Si un logiciel ré-émet un message (par exemple un gestionnaire de
liste de diffusion transmettant aux membres
de la liste, cf. RFC 5598), il devrait,
idéalement, appliquer également le REQUIRETLS
sur le message redistribué. Le RFC ne l'impose pas car, en pratique,
cela risquerait d'empêcher la réception du message par beaucoup.
Notre RFC se termine par une longue
section 8 sur la sécurité, car les problèmes qu'essaie de résoudre
ces solutions sont complexes. Le cas des attaques
passives est facile : TLS protège presque parfaitement
contre elles. Mais les attaques actives
soulèvent d'autres questions. REQUIRETLS mènera
à un refus des connexions SMTP sans TLS, protégeant ainsi contre
certaines attaques actives comme le SSL
stripping ou comme une attaque de
l'Homme du Milieu avec un mauvais
certificat. (Cette dernière attaque est facile aujourd'hui dans le
monde du courrier, où bien des serveurs SMTP
croient aveuglément tout certificat présenté.)
REQUIRETLS protège également contre beaucoup
d'attaques via le DNS, en exigeant
DNSSEC (ou, sinon,
MTA-STS).
Par contre, REQUIRETLS ne protège pas contre
un méchant MTA qui prétendrait gérer REQUIRETLS
mais en fait l'ignorerait. De toute façon, SMTP sur TLS n'a jamais
protégé des MTA intermédiaires, qui ont le texte du message en
clair. Si on veut se protéger contre un tel MTA, il faut utiliser
PGP (RFC 9580) ou
équivalent. (Par contre, le risque de l'ajout d'un
TLS-Required: no par un MTA malveillant ne
semble pas traité dans le RFC ; PGP ne protège pas contre cela.)
Il peut y avoir un conflit entre TLS-Required:
no et la politique du MTA, qui tient absolument à
vérifier les certificats des serveurs auxquels il se connecte, via
PKIX ou via DANE. Le RFC laisse
entendre que le dernier mot devrait revenir à l'expéditeur, au moins
si le message a été envoyé via TLS et donc pas modifié en route. (Le
cas d'un message reçu en clair - donc pas sécurisé - et demandant de
ne pas exiger TLS reste ouvert…)
Et pour finir, l'exemple de session SMTP où le serveur annonçait
qu'il gérait REQUIRETLS (en disant
250-REQUIRETLS) était simplifié. Si la session
commençait en clair, puis passait à TLS après, avec la commande
STARTTLS, le client doit recommencer la session
une fois TLS activé, pour être sûr que ce qu'annonce le serveur est réel.
Bien qu'il y ait déjà des programmeurs ayant travaillé sur ce RFC, je ne trouve encore rien du tout dans le source de Postfix, le MTA que j'utilise, même dans la version expérimentale.
L'article seul
Pourquoi ne pas mélanger résolveur DNS et serveur DNS faisant autorité ?
Première rédaction de cet article le 22 novembre 2019
Je donne souvent le conseil de ne pas configurer un serveur DNS à la fois en résolveur et en serveur faisant autorité. Mais pourquoi, au juste ?
D'abord, fixons la terminologie. Parler de « serveur DNS » tout
court (ou, encore pire de « DNS » pour désigner un serveur, du genre
« pour être sûr que la NSA ait mes données, j'utilise 8.8.8.8 comme DNS ») est
générateur de confusion. En effet, les deux types de serveurs DNS,
résolveurs et serveurs faisant
autorité sont très différents, posent des questions bien
diverses, et il est rare qu'on ait besoin de parler des deux
ensemble. Quand quelqu'un écrit ou dit « serveur DNS », il s'agit
en général de l'un ou de l'autre type, et cela vaudrait donc la
peine de le préciser. Les termes de résolveur
et de serveur faisant autorité sont bien
définis dans le RFC 9499 mais il est sans
doute utile de rappeler ces définitions et quelques explications
ici :
- Un résolveur (en anglais resolver) est un serveur DNS qui ne connait presque rien au démarrage, mais qui va interroger, pour le compte du client final, d'autres serveurs jusqu'à avoir une réponse qu'il transmettra au client final. Dans une configuration typique, le résolveur que vous utilisez est géré par votre FAI ou bien par le service informatique de l'organisation où vous travaillez. (Il existe aussi des résolveurs publics, comme ceux de Cloudflare ou de Quad9.)
- Un serveur faisant autorité (en anglais authoritative server, parfois bêtement traduit par « serveur autoritaire ») connait (« fait autorité pour ») une ou plusieurs zones DNS et il sert l'information sur ces zones aux résolveurs qui l'interrogeront. Il est typiquement géré par un hébergeur DNS ou par le bureau d'enregistrement ou directement par le titulaire du nom de domaine.
Par exemple, au moment de la rédaction de cet article, je suis dans
un train, avec le Wi-Fi, et le résolveur annoncé est
10.26.0.4, une machine gérée par la
SNCF. Si je veux me connecter à
celsa.fr, ma machine demandera au résolveur
10.26.0.4, qui relaiera aux deux serveurs
faisant autorité, ns0.idianet.net et
ns1.idianet.net (Idianet étant l'hébergeur DNS
choisi par le CELSA), puis me retransmettra
leur réponse.
La plupart des logiciels permettant de faire un serveur DNS ne permettent de faire qu'un résolveur, ou bien qu'un serveur faisant autorité. Comme je l'ai dit, c'est logique puisque ce sont deux fonctions très différentes, avec des problèmes bien distincts :
- Le serveur faisant autorité est public (s'il est interne à une organisation, la question de la séparation entre résolveur et serveur faisant autorité est différente), donc il doit faire face à un Internet pas toujours sympathique,
- Le résolveur, lui, est privé (il est déconseillé d'avoir des résolveurs ouverts, sauf si on est Google et qu'on sait ce qu'on fait, cf. RFC 5358),
- Le serveur faisant autorité a des temps de réponse connus, et une consommation de mémoire stable,
- Le résolveur, lui, ne sait pas à l'avance combien de temps prendront les requêtes, et il peut avoir à allouer des ressources variables,
- Et, bien sûr, le serveur faisant autorité connait exactement les données, alors que le résolveur les obtient de l'extérieur, ce qui diminue la confiance qu'on peut leur accorder.
Mais certains logiciels (comme BIND) permettent d'assurer les deux fonctions, et en même temps. Certains administrateurs système ont donc configuré une machine où le même démon est résolveur et serveur faisant autorité. C'est une mauvaise idée, et ces administrateurs système ont tort. Pourquoi ?
Le principal problème pratique est de débogage. En effet, si le même serveur DNS est à la fois résolveur et serveur faisant autorité, les réponses reçues par un client DNS peuvent être issues du résolveur ou directement des zones DNS gérées. Normalement, avec un logiciel bien fait, les données faisant autorité auront toujours priorité (c'est bien ce que veut dire « faire autorité ») et les données issues de la résolution ne les remplaceront jamais. C'est ainsi que se comporte BIND aujourd'hui, mais cela n'a pas toujours été le cas, et ce n'est toujours pas le cas pour d'autres logiciels. On voit ainsi parfois des données récupérées lors du processus de résolution (et donc moins fiables, surtout lors d'attaques type empoisonnement de cache) masquer les données faisant autorité.
La seconde raison pour laquelle le mélange est une mauvaise idée est plus abstraite : les deux fonctions, résolveur et autorité, sont très différentes conceptuellement, et beaucoup de problèmes pratiques avec le DNS viennent d'une ignorance des acteurs (pas seulement les utilisateurs, même les administrateurs systèmes et réseaux) de ces deux fonctions, de leur rôle respectif, et des problèmes pratiques auxquelles elles font face.
Enfin, pour les programmeurs, on notera que, si ces deux fonctions ont du code en commun (encodage et décodage des requêtes et réponses, par exemple, et qui peut donc avoir intérêt à être dans une bibliothèque commune), l'essentiel du programme est différent. Ainsi, un serveur faisant autorité est sans état : il peut répondre aux questions immédiatement, il ne dépend de personne d'autre, et peut donc travailler de manière synchrone. Le résolveur, lui, est forcément avec état car il doit mémoriser les requêtes en cours de résolution, résolution dont la durée dépend des serveurs faisant autorité extérieurs. Si vous voulez essayer, notez qu'écrire un serveur faisant autorité est un projet relativement simple, alors qu'un résolveur est beaucoup plus compliqué (notamment du point de vue de la sécurité). Contrairement au serveur faisant autorité, il dépend fortement de serveurs extérieurs. (Comme une partie du code est quand même commune, une bonne architecture est celle de Knot : le serveur faisant autorité et le résolveur partagent la même bibliothèque libknot pour certaines fonctions de base mais, autrement, ce sont deux logiciels très différents.)
Pour finir, voici un exemple de la différence entre les réponses
fournies par un résolveur (127.0.0.1, ma
machine locale, je ne suis plus dans le train), et celles fournies
par un serveur faisant autorité pour la zone en question
(ns0.idianet.net). D'abord, le résolveur :
% dig A celsa.fr
; <<>> DiG 9.11.5-P4-5.1-Debian <<>> A celsa.fr
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 53605
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 4096
;; QUESTION SECTION:
;celsa.fr. IN A
;; ANSWER SECTION:
celsa.fr. 83049 IN A 195.154.244.151
;; Query time: 0 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: Tue Nov 19 20:09:28 CET 2019
;; MSG SIZE rcvd: 53
La réponse ne fait pas autorité (il n'y a pas de flag AA - Authoritative Answer), et le TTL a été décrémenté depuis sa valeur originale (l'information a été tirée de la mémoire du résolveur). Maintenant, la réponse d'un serveur faisant autorité :
% dig @ns0.idianet.net A celsa.fr
; <<>> DiG 9.11.5-P4-5.1-Debian <<>> @ns0.idianet.net A celsa.fr
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 3519
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 2, ADDITIONAL: 3
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 4096
;; QUESTION SECTION:
;celsa.fr. IN A
;; ANSWER SECTION:
celsa.fr. 86400 IN A 195.154.244.151
;; AUTHORITY SECTION:
celsa.fr. 86400 IN NS ns0.idianet.net.
celsa.fr. 86400 IN NS ns1.idianet.net.
;; ADDITIONAL SECTION:
ns0.idianet.net. 86400 IN A 195.154.201.10
ns1.idianet.net. 86400 IN A 195.154.244.138
;; Query time: 4 msec
;; SERVER: 195.154.201.10#53(195.154.201.10)
;; WHEN: Tue Nov 19 20:09:34 CET 2019
;; MSG SIZE rcvd: 132
Cette fois, la réponse fait autorité (flag AA) et le TTL est la valeur originale (ici, une journée). On notera également le temps de réponse plus court du résolveur, puisqu'ici, l'information était déjà dans sa mémoire. Si le résolveur avait été « froid » (pas d'information en mémoire), le temps de réponse aurait été plus long, et le TTL aurait eu sa valeur originale (car l'information venait juste d'être récupérée).
En conclusion, il est recommandé de séparer les deux fonctions, de résolveur et de serveur faisant autorité. Même si ça semble marcher lors de la mise en service, mélanger les deux fonctions vous vaudra des maux de tête plus tard, lorsqu'un problème surviendra.
L'article seul
RFC 8659: DNS Certification Authority Authorization (CAA) Resource Record
Date de publication du RFC : Novembre 2019
Auteur(s) du RFC : P. Hallam-Baker, R. Stradling (Sectigo), J. Hoffman-Andrews (Let's Encrypt)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF lamps
Première rédaction de cet article le 22 novembre 2019
Ce RFC décrit un mécanisme pour renforcer un peu la sécurité des certificats. Il normalise les enregistrements CAA (Certification Authority Authorization), qui sont publiés dans le DNS, et indiquent quelles AC sont autorisées à émettre des certificats pour ce domaine. Le but est de corriger très partiellement une des plus grosses faiblesses de X.509, le fait que n'importe quelle AC peut émettre des certificats pour n'importe quel domaine, même si ce n'est pas un de ses clients. Ce RFC remplace l'ancienne définition de CAA, qui était dans le RFC 6844.
CAA est donc une technique très différente de DANE (RFC 6698), les seuls points communs étant l'utilisation du DNS pour sécuriser les certificats. DANE est déployé chez le client TLS, pour qu'il vérifie le certificat utilisé, CAA est surtout dans l'AC, pour limiter le risque d'émission d'un certificat malveillant (par exemple, CAA aurait peut-être empêché le faux certificat Gmail du ministère des finances.) Disons que CAA est un contrôle supplémentaire, parmi ceux que l'AC doit (devrait) faire. Les clients TLS ne sont pas censés le tester (ne serait-ce que parce que l'enregistrement CAA a pu changer depuis l'émission du certificat, la durée de vie de ceux-ci étant en général de plusieurs mois). CAA peut aussi servir à des auditeurs qui veulent vérifier les pratiques d'une AC (même avertissement : le certificat a pu être émis alors que l'enregistrement CAA était différent.)
La section 4 de notre RFC présente l'enregistrement CAA. Il a été ajouté au registre des types d'enregistrements sous le numéro 257. Il comprend une série d'options (flags) et une propriété qui est sous la forme {clé, valeur}. Un nom peut avoir plusieurs propriétés. Pour l'instant, une seule option est définie (un registre existe pour les options futures), « issuer critical » qui indique que cette propriété est cruciale : si on ne la comprend pas, le test doit être considéré comme ayant échoué et l'AC ne doit pas produire de certificat.
Les principales propriétés possibles sont (la liste complète est dans le registre IANA) :
issue, la principale, qui indique une AC autorisée à émettre des certificats pour ce domaine (l'AC est indiquée par son nom de domaine),issuewild, idem, mais avec en plus la possibilité pour l'AC d'émettre des certificats incluants des jokers,iodef, qui indique où l'AC doit envoyer d'éventuels rapports d'échec, pour que le titulaire du nom de domaine puisse les corriger. Un URL est indiqué pour cela, et le rapport doit être au format IODEF (RFC 7970).
Voici par exemple quel était l'enregistrement CAA de mon domaine personnel :
% dig CAA bortzmeyer.org ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 61450 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 3, AUTHORITY: 7, ADDITIONAL: 7 ... ;; ANSWER SECTION: bortzmeyer.org. 26786 IN CAA 0 issue "cacert.org" bortzmeyer.org. 26786 IN CAA 0 issuewild "\;" ...
Il indique que seule l'AC CAcert peut
créer un certificat pour ce domaine (et sans les jokers). Bon, c'est
un peu inutile car CAcert ne teste pas les enregistrements CAA, mais
c'était juste pour jouer. Je n'ai pas mis d'iodef
mais il aurait pu être :
bortzmeyer.org. CAA 0 iodef "mailto:security@bortzmeyer.org"
Et, dans ce cas, l'AC peut écrire à
security@bortzmeyer.org, avec le rapport IODEF
en pièce jointe.
Attention, l'enregistrement CAA est valable pour tous les
sous-domaines (et ce n'est pas une option,contrairement à, par
exemple, HSTS du RFC 6797, avec
son includeSubDomains). C'est pour cela que
j'avais dû retirer l'enregistrement ci-dessus, pour avoir des
certificats pour les sous-domaines, certificats faits par une autre
AC. (Depuis, j'ai mis deux enregistrements CAA, pour les deux AC
utilisées, les autorisations étant additives, cf. section 4.2 du RFC.)
Des paramètres peuvent être ajoutés, le RFC cite l'exemple d'un numéro de client :
example.com. CAA 0 issue "ca.example.net; account=230123"
Une fois les enregistrements CAA publiés, comment sont-ils utilisés (section 3) ? L'AC est censée interroger le DNS pour voir s'il y a un CAA (on note que DNSSEC est très recommandé, mais n'est pas obligatoire, ce qui réduit le service déjà faible qu'offre CAA). S'il n'y en a pas, l'AC continue avec ses procédures habituelles. S'il y a un CAA, deux cas : il indique que cette AC peut émettre un certificat pour le domaine, et dans ce cas-là, c'est bon, on continue avec les procédures habituelles. Second cas, le CAA ne nomme pas cette AC et elle doit donc renoncer à faire un certificat sauf s'il y a une exception configurée pour ce domaine (c'est la deuxième faille de CAA : une AC peut facilement passer outre et donc continuer émettre de « vrais/faux certificats »).
Notez que le RFC ne semble pas évoquer la possibilité d'imposer la présence d'un enregistrement CAA. C'est logique, vu le peu de déploiement de cette technique mais cela veut dire que « qui ne dit mot consent ». Pour la plupart des domaines, la vérification du CAA par l'AC ne changera rien.
Notez que, si aucun enregistrement CAA n'est trouvé, l'AC est
censé remonter l'arbre du DNS. (C'est pour cela que SSL [sic] Labs trouvait un
enregistrement CAA pour
mercredifiction.bortzmeyer.org : il avait utilisé
le CAA du domaine parent, bortzmeyer.org.) Si
example.com n'a pas de CAA, l'AC va tester
.com, demandant ainsi à
Verisign si son client peut avoir un
certificat et de qui. Cette erreur consistant à grimper sur l'arbre
avait déjà été dénoncée dans le RFC 1535, mais apparemment
la leçon n'a pas été retenue. Au moins, ce RFC corrige une grosse
erreur du RFC 6844, en limitant cette montée
de l'arbre au nom initialement cherché, et pas aux alias
(enregistrements DNS CNAME) éventuels.
Enfin, la section 5 du RFC analyse les différents problèmes de sécurité que peut poser CAA :
- Le respect de l'enregistrement CAA dépend de la bonne volonté de l'AC (et CAA ne remplace donc pas DANE),
- Sans DNSSEC, le test CAA est vulnérable à des attaques par exemple par empoisonnement (le RFC conseille de ne pas passer par un résolveur normal mais d'aller demander directement aux serveurs faisant autorité, ce qui ne résout pas le problème : le programme de test peut se faire empoisonner, lui aussi, d'autant plus qu'il prend sans doute moins de précautions qu'un résolveur sérieux),
- Et quelques autres risques plus exotiques.
Le CA/Browser Forum avait décidé que le test des CAA serait obligatoire à partir du 8 septembre 2017. (Cf. la décision.) Comme exemple, parmi les enregistrements CAA dans la nature, on trouve celui de Google, qui autorise deux AC :
% dig CAA google.com ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 55244 ;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1 ... ;; ANSWER SECTION: google.com. 86400 IN CAA 0 issue "pki.goog" google.com. 86400 IN CAA 0 issue "symantec.com" ...
(Le TLD
.goog est apparemment utilisé par Google pour
son infrastructure, .google étant plutôt pour
les choses publiques.) Notez que gmail.com,
souvent détourné par des gouvernements et des entreprises qui
veulent surveiller le trafic, a également un enregistrement CAA. Le
célèbre SSL [sic] Labs
teste la présence d'un enregistrement CAA. S'il affiche
« DNS Certification Authority Authorization (CAA) Policy
found for this domain », c'est bon. Regardez le
cas de Google.
Quelques lectures et ressources pour finir :
- Un bon article de synthèse par SSL Labs.
- Une aide interactive pour fabriquer un enregistrement CAA. Si vous avez un très vieux serveur DNS, et qu'il refuse de charger les enregistrements CAA, vous allez devoir utiliser la syntaxe générique du RFC 3597. Comme elle est un peu compliquée, le service ci-dessus, ainsi que ce service en ligne peuvent vous aider, en affichant à l'ancienne syntaxe.
- Cet article détaillé écrit par une AC note un grand nombre de problèmes et de limites de CAA.
- Dès le lendemain du début des tests CAA par les AC, Comodo (la société des auteurs du RFC) avait déjà violé les règles et émis un certificat qui n'aurait pas dû l'être.
- Let's Encrypt
vérifie bien les enregistrements CAA. Si on a un CAA indiquant une
autre AC, même pour un
domaine parent du domaine pour lequel on veut un certificat, Let's
Encrypt refuse avec une erreur de type
urn:acme:error:caa, « CAA record for DOMAIN_NAME prevents issuance ». Le monde étant cruel, et les logiciels souvent bogués, cela a d'ailleurs entrainé un amusant problème.
La section 7 de ce RFC décrit les changements depuis le RFC 6844. Sur la forme, le RFC a été profondément
réorganisé. Sur le fond, le principal changement est que la
procédure de montée dans l'arbre du DNS, très dangereuse, a été
légèrement sécurisée en la limitant au nom lui-même, et pas aux
alias. En effet, le RFC 6844 prévoyait que, si
on cherchait le CAA de something.example.com,
qu'on ne le trouvait pas,
et que something.example.com était en fait un
alias vers other.example.net, on remonte
également l'arbre en partant de
example.net. Cette idée a été heureusement
abandonnée (mais, pour something.example.com,
on testera quand même example.com et
.com, donc le registre
de .com garde la possibilité de mettre un CAA
qui s'appliquera à tous les sous-domaines…)
Autre changement, la section 6, sur les questions de déploiement, qui intègre l'expérience pratique obtenue depuis le RFC 6844. Notamment :
- Certaines middleboxes boguées (pléonasme) bloquent les requêtes des types DNS inconnus et, apparemment, ne sont mises à jour que tous les vingt ans donc CAA est encore considéré comme inconnu,
- Certains serveurs faisant autorité sont programmés avec les pieds et répondent mal pour les types de données DNS qu'ils ne connaissent pas (ce n'est évidemment pas le cas des logiciels libres sérieux comme BIND, NSD, Knot, PowerDNS, etc.)
Le reste des changements depuis le RFC 6844
porte sur des points de détails comme une clarification de la
grammaire, ou bien des précisions sur la sémantique des
enregistrements CAA lorsque des propriétés comme
issue sont absentes.
L'article seul
Capitole du Libre 2019
Première rédaction de cet article le 18 novembre 2019
Le 16 et le 17 novembre 2019, c'était Capitole du Libre à Toulouse, un rassemblement libriste à ne pas manquer. Plein de rencontres, d'ateliers et de conférences intéressantes.
C'était aussi le premier anniversaire du mouvement des Gilets jaunes, marqué par de nombreuses manifestations.
J'y ai fait une séance dédicace de mon livre
« Cyberstructure », qui avait été annoncé pour la première fois
publiquement au Capitole du Libre de l'année dernière. La
séance était organisée par la librairie
« Les petits ruisseaux ». J'étais à côté de David Revoy, l'auteur de Pepper et Carrot, qui faisait
de superbes dessins. 
J'ai fait un exposé sur le protocole QUIC,
qui était en cours de normalisation à
l'IETF
(il a depuis été normalisé et les RFC publiés). Voici la version en PDF
pour présentation, la version en
PDF pour impression et le source en
LaTeX/Beamer. La vidéo est
disponible (et également sur GoogleTube). Il y a aussi d'excellentes
sketchnotes (par Kevin Ottens, merci à lui.) Version complète 
{kind=link}
Le programme de Capitole du Libre était très riche. J'ai beaucoup aimé la présentation de Marina Fernández de Retana (alias Kaoseto), l'auteure du « Cycle de Shaedra ». (Sa présentation sur YouTube.) Ses romans ne sont pas écrits avec un gros logiciel WYSIWYG comme LibreOffice (a fortiori pas en Word), mais dans un langage de balisage, du WYSIWYM. Un des gros avantages des outils WYSIWYM est l'intégration aux outils externes comme grep ou git (là où l'obésiciel doit réinventer en moins bien tous ces outils externes.) Après avoir essayé LaTeX (messages d'erreur insupportables) et Markdown (pas de balisage sémantique, on ne peut pas créer ses propres balises, encore qu'il existe des extensions utiles pour l'écrivain comme Manuskript ou Crowbook), l'auteure a finalement choisi Frundis. Frundis permet notamment de créer ses propres balises sémantiques, même pour la poésie, et de produire ensuite facilement du bon PDF (pour l'impression) et du du bon EPUB (pour lire sur écran). (Au passage, j'ai suivi une démarche du même genre pour mon livre, mais c'est plus rare chez un·e romanci·er·ère.) À noter qu'elle tape le Frundis avec vim sur un clavier Bépo.
Question Frundis, si vous voulez un exemple ultra-court (Frundis peut faire bien mieux), voici :
.X set lang fr .X set document-title "Quel beau titre" .Ch Test Comment ça va ? .P Début, puis un lien : .Lk https://cyberstructure.fr/ "Mon livre" .P Suite, lorem, ipsum, dolor, et tout ça.
J'ai installé le logiciel en suivant les instructions dans le README et ça marche :
% frundis -T latex -s -o test1.tex test1.frundis
produit un fichier LaTeX à partir duquel on peut faire un PDF.
% frundis -T xhtml -s -o test1.html test1.frundis
produit de l'HTML. Notez que Frundis corrige certaines erreurs, comme de mettre un espace ordinaire (au lieu de l'espace insécable) avant un point d'interrogation :
frundis: test1.frundis:3:Ch: incorrect regular space before '?'
Je n'ai pas aussi bien réussi avec EPUB, il faudra que je regarde ça.
Dans la conférence « Rien à cacher ? Vous devriez. », Julien Osman a expliqué très clairement les enjeux actuels de la protection des données personnelles, face aux capacités modernes du machine learning. « Le machine learning est à la data ce que sont les raffineries au pétrole. [Ça transforme un truc qui, brut, n'a aucun intérêt, en un truc qui rapporte.] » Ainsi, cette technique permet d'identifier les points sensibles d'un individu, ceux où une publicité ciblée sera efficace (comme dans le cas de Cambridge Analytica.) « Aujourd'hui, notre gouvernement est plutôt bienveillant. Il installe des caméras de vidéo-surveillance partout, pour que la Mère Michel arrête de perdre son chat. Mais, demain, avec la reconnaissance faciale et un gouvernement moins bienveillant, cela donnera quoi ? »
Taziden est revenu sur « Censure de sites imposée aux
FAI : où en est on ? ». Il a notamment noté
qu'on n'avait pas de liste consolidée de tous les noms de domaine censurés par
l'autorité judiciaire. Certes, les décisions de justice sont
publiques, mais il n'existe pas de liste de synthèse, rendant
difficile l'évaluation de l'ampleur de la censure. Pour mesurer le
degré d'application de cette censure, Taziden suggérait
OONI mais aussi les sondes RIPE Atlas (le programme Blaeu permet de voir la
censure de Sci-Hub aujourd'hui en France). La censure
administrative (par la police) est évidemment encore plus opaque, on
a seulement un rapport annuel agrégé. En 2018, il y a eu 879
demandes de blocage. Notez que des sites Web ont retiré des
contenus, par peur de se retrouver dans la liste de blocage
(cf. lettre de menace affichée pendant l'exposé). Les blocages
effectivement faits ne montrent donc qu'une partie de la censure
administrative. L'orateur a rappelé que la
CNIL est censée garder un œil sur cette
censure administrative. Suite à la demande de retrait et de blocage
d'Indymedia Grenoble & Nantes, l'orateur a fait une demande afin
d'obtenir des documents et il les a eu. Ils montraient que la police
et la CNIL n'étaient pas d'accord. Le tribunal
administratif de Cergy a d'ailleurs annulé les décisions
de blocage des sites Indymedia le 1 septembre 2019. Pour contourner
cette censure, Taziden a cité les résolveurs
DNS publics. Attention : si on y accède en
UDP (le cas le plus courant), on n'a aucune authentification, aucune intégrité, et aucune
confidentialité. Utilisez plutôt DoT
(DNS sur TLS) ou DoH
(DNS sur HTTPS). Ainsi, le résolveur DNS
public de LDN,
80.67.188.188 a DoT (voir
ce test avec le client DoT Homer).
Un mot aussi sur deux activités d'aide au développement avec du logiciel libre, « Le logiciel libre au service de l'éducation en Guinée » par Kovann Ly (association EDA - Enfants De l'Aïr) et « Afrikalan : rendre les logiciels libres éducatifs accessibles hors des pays du nord » par l'association Bilou Toguna. EDA a de nombreuses activités (santé, éducation, agriculture) mais la partie qui intéresse plus directement le Capitole du Libre, c'est l'accès au numérique dans l'éducation. Un des problèmes dans la zone des mines d'or est que certains parents mettent leurs enfants à la mine plutôt qu'à l'école. Pour encourager la scolarisation, l'école doit être « sexy » et c'est là que l'informatique joue un rôle. Mais installer vingt PC normaux dans une salle dépasse les capacités du groupe électrogène (il n'y a pas de réseau électrique), d'où le choix des Raspberry Pi. Les Raspberry Pi sont connectés entre eux en WiFi mais les établissements scolaires n'ont pas d'accès Internet (notez que l'administration scolaire n'est pas chaude, par peur de l'Internet). Une copie de Wikipédia est donc disponible sur le serveur (qui est dans un très beau boitier en bois fait par le menuisier local.) Pas mal de logiciels libres sont installés sur les postes des élèves, dont Scratch. L'expérience avec les Raspberry Pi est positive : matériel très robuste, malgré l'électricité déconnante, et faible consommation électrique (ce sont les écrans qui consomment l'essentiel). Par contre, il faut fréquemment dépoussiérer, pour enlever la latérite. L'autre conférence, « Afrikalan : rendre les logiciels libres éducatifs accessibles hors des pays du nord » ou « Pourquoi les pingouins devraient plus souvent aller dans les écoles d'Afrique » portait, en dépit de son titre, plutôt sur le périscolaire. En effet, une des difficultés dans l'enseignement au Mali, où intervient l'association, est que les enseignants sont peu autonomes. Ils ne créent pas leur propre contenu pédagogique, ils appliquent. Cela rend difficile de créer des variantes (logiciel libre au lieu de privateur). D'où le choix d'Afrikalan de travailler plutôt dans un cadre périscolaire. Entre autres, Afrikalan utilise les nombreuses activités conçues par des enseignants pour des enfants d'âge très divers par Pepit. Souvent, les adultes dans l'école s'approprient les ordinateurs qui avaient été installés pour les enfants, l'ordinateur étant un objet de prestige, et les adultes n'en ayant pas pour leur travail. Il faut donc des objets qui ne soient pas considérés comme des ordinateurs. Et, comme EDA, Afrikalan utilise le Raspberry Pi, qui n'est pas moins cher (compte-tenu du prix de son écran), mais qui fait l'objet de moins de convoitises.
Et sur les réseaux sociaux décentralisés ? J'ai été moins convaincu par « Zot : aux frontières des réseaux fédérés avec Hubzilla et Zap » d'Ale Abdo mais il est vrai qu'il a manqué de temps pour présenter ces systèmes pas évidents. Hubzilla (qui a changé de nom plusieurs fois) utilise le protocole Zot pour fournir un réseau social décentralisé. (Il y a une passerelle vers ActivityPub, pour parler aux fédiversiens.) Une des originalités est que l'identité (et les contacts) peuvent se promener d'une instance (« hub ») à l'autre, en copiant sa clé privée et son profil. Quant à Zap, c'est une scission de Hubzilla, qui se concentre sur l'aspect réseau social (Hubzilla peut faire plein d'autres choses).
Mille mercis à Toulibre et à tous les
organisateurs (vous pouvez suivre un
interview de ceux-ci.) Photo de Matthieu Herrb : 
Autre(s) lecture(s) sur cette édition de Capitole du Libre :
L'article seul
Fiche de lecture : Grandir connectés
Auteur(s) du livre : Anne Cordier
Éditeur : C&F Éditions
978-2-915825-49-7
Publié en 2015
Première rédaction de cet article le 5 novembre 2019
Les discours sur les pratiques numériques des « jeunes » ne manquent pas, allant de « ielles sont digital natives, ielles sont complètement à l'aise dans l'environnement numérique, les adultes n'ont rien à leur apprendre » à « ielles sont bêtes, ielles ont la capacité d'attention d'un poisson rouge, ielles gobent toutes les fake news, ielles ne lisent plus rien, c'était mieux avant [surtout qu'il n'y avait pas d'écriture inclusive] ». Les deux positions ont en commun d'être énoncées sans avoir sérieusement étudié les pratiques effectives de jeunes réels… Au contraire, dans ce livre, Anne Cordier regarde des vrais jeunes et, sans juger a priori, analyse ce qu'ielles font sur l'Internet.
Le livre date de 2015 (et le travail de recherche semble avoir été fait un certain temps avant), mais les choses n'ont pas forcément énormément changé depuis. Il y a sans doute moins de Facebook et davantage d'Instagram chez les jeunes, et MSN, cité dans le livre, a probablement disparu. Mais les fondamentaux demeurent, à savoir une grande… déconnexion entre l'existence connectée quasiment en permanence, et la difficulté à comprendre ce qui se passe derrière l'écran. (Et comme le note l'auteure, cette déconnexion n'est pas spécifique aux jeunes. Bien des adultes, même en milieu professionnel, ne comprennent pas non plus les dessous du numérique.)
La méthodologie suivie par l'auteure était d'observer, dans un CDI, collègiens et lycéens dans leurs aventures connectées, et de les interroger, de façon aussi neutre que possible, sur ce qu'ielles en pensaient, sur leurs analyses de l'Internet. Il est important de ne pas juger. Par exemple, ceux et celles qui ont des difficultés avec les outils de l'Internet ont souvent du mal à en parler aux enseignant·e·s ou aux parents. Et d'autant plus que le discours sur les mythiques digital natives, ces jeunes qui sauraient absolument tout sur le numérique et n'auraient rien à apprendre à ce sujet, est très présent, y compris dans leurs têtes. Si une personne de 70 ans peut avouer « moi, ces machines modernes, je n'y comprends rien », un tel aveu est bien plus difficile à 11 ans, quand on est censé tout maitriser de l'Internet. Les expressions du genre « si j'avouais que je ne sais pas faire une recherche Google, ce serait la honte » reviennent souvent.
Alors, que font et disent ces jeunes ? D'abord, ielles sont divers, et il faut se méfier des généralisations. D'autant plus que l'auteure a travaillé avec des classes différentes, dans des établissements scolaires différents. La première chose qui m'a frappé a été le manque de littératie numérique (et je ne pense pas que ce se soit beaucoup amélioré depuis 2015). Oui, ils et elles savent se servir avec rapidité des équipements électroniques, et de certains logiciels (comme, aujourd'hui, WhatsApp). Mais cela n'implique pas de compréhension de ce qui se passe derrière, et cela conduit à des comportements stéréotypés, par exemple d'utiliser toujours le même moteur de recherche. Le livre contient beaucoup de déclarations des jeunes participant à l'étude, et, p. 215, l'auteure leur demande pourquoi avoir choisi le moteur de recherche de Google : « on n'a que ça à la maison ». Sans compter celles et ceux qui affirment bien fort que « Google, c'est le meilleur », avant d'admettre qu'ielles n'en connaissent pas d'autres. Là encore, ne rions pas d'eux et elles : bien des adultes ne sont pas plus avancés, même s'ielles sont à des postes importants dans le monde professionnel.
En parlant de Google, il est frappant, en lisant le livre, à quel point Google occupe une « part d'esprit », en sus de sa part de marché. Et, là, ça n'a certainement pas changé depuis la sortie du livre. Les services de Google/Alphabet sont la référence pour tout, et plus d'un collègien ou lycéen lui attribue des pouvoirs quasi-magiques. À l'inverse, les échecs ne sont que rarement correctement analysés (p. 115). Cela va de l'auto-culpabilisation « j'ai fait une erreur, je suis nulle », au déni « je suis super-fort en Internet, ce n'est pas moi qui ai fait une erreur, je suis un boss » en passant par la personnalisation « il n'a pas compris ce que je lui demandais ». Notez quand même qu'à part quelques vantards, beaucoup des jeunes interrogés sont assez lucides sur leur manque de littératie numérique « on ne nous a jamais appris, les profs disent qu'on est censés tout savoir, mais en fait, on ne sait pas ».
Le plus grave, je trouve, c'est l'absence de compréhension de ce qu'ielles font (p. 244), qui se manifeste notamment par l'absence de terminologie. Beaucoup des jeunes interrogés ne savent pas raconter ce qu'ielles font sur l'Internet, à part en décrivant des gestes (« je clique sur le E bleu »). Une telle absence de modélisation, de conceptualisation, ne permet certainement pas de comprendre ce qui se passe, et d'avoir une attitude active et critique.
Les jeunes sont souvent en compétition les uns avec les autres, et cela se manifeste aussi dans les usages numériques. Lors d'un travail scolaire impliquant le montage d'un film, les utilisateurices de Movie Maker se sont ainsi fait vertement reprendre, comme quoi il ne s'agissait que d'un outil pour bricoleurs, pas pour vrais pros.
Par contre, ielles parlent beaucoup d'entraide, surtout de la part des grandes sœurs (les grands frères sont plus rarement mentionnés) et même des parents (les mères, surtout, les pères semblent moins souvent cités par les jeunes.)
Bref, un livre que je recommande beaucoup, pour avoir une bonne idée de l'état de la « culture numérique » chez les jeunes. Normalement, vous en sortez avec moins de certitudes et de généralisations qu'au départ.
Comme l'auteure a été professeur documentaliste, j'en profite pour signaler l'existence des APDEN, les associations de professeurs documentalistes, qui font d'excellentes réunions. Et puisqu'on a parlé d'éducation au numérique, je vous suggère la lecture du programme de SNT, qui commence en 2019. Mon avis est que ce programme est ambitieux, peut-être trop, vu les moyens concrets alloués, mais qu'il va dans la bonne direction : c'est justement ce niveau d'exigence qu'il faudrait pour le numérique.
Je vous recommande également cet excellent interview de l'auteure à l'émission 56Kast.
L'article seul
RFC 8642: Policy Behavior for Well-Known BGP Communities
Date de publication du RFC : Août 2019
Auteur(s) du RFC : J. Borkenhagen (AT&T), R. Bush (IIJ & Arrcus), R. Bonica (Juniper Networks), S. Bayraktar (Cisco Systems)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF grow
Première rédaction de cet article le 3 novembre 2019
Le protocole d'annonces de routes BGP permet d'attacher aux annonces des étiquettes, les communautés, qui sont des métadonnées pour les routes. Certaines valeurs sont réservées pour des communautés « bien connues » qui sont censées donner le même résultat partout. Mais ce n'est pas vraiment le cas, comme l'explique ce RFC, qui demande qu'on améliore la situation.
Les communautés sont normalisées dans le RFC 1997, qui décrit par la même occasion le concept de communauté bien connue. Celles-ci sont enregistrées à l'IANA. Voici un exemple d'annonce BGP avec des communautés :
TIME: 11/03/19 09:14:47 TYPE: BGP4MP/MESSAGE/Update FROM: 89.149.178.10 AS3257 TO: 128.223.51.102 AS6447 ASPATH: 3257 8966 17557 136030 138368 NEXT_HOP: 89.149.178.10 COMMUNITY: 3257:4000 3257:8102 3257:50001 3257:50110 3257:54900 3257:54901 65535:65284 ANNOUNCE 103.131.214.0/24
Cette annonce du préfixe 103.131.214.0/24
contient sept communautés, dont une bien connue,
65535:65284 (0xFFFFFF04 en
hexadécimal), NOPEER, normalisée dans le RFC 3765.
Le RFC estime que le RFC 1997 était un peu trop flou, et que cela explique partiellement les différences que nous observons aujourd'hui.
Ainsi, le changement d'une communauté par la politique
locale d'un AS. Un routeur
BGP qui reçoit une annonce avec des
communautés peut évidemment modifier ces communautés (typiquement en
ajouter, mais parfois aussi en enlever). Tous les modèles de
routeurs permettent donc de modifier les communautés, entre autres
en fournissant une commande, appelée
set ou un nom de ce genre, qui remplace les communautés
par un autre ensemble de communautés. Toutes les communautés ? Non,
justement, c'est là qu'est le problème : sur certains routeurs, les
communautés bien connues sont épargnées par cette opération, mais pas
sur d'autres routeurs.
(Personnellement, cela me semble un problème d'interface utilisateur, qui ne concerne pas vraiment le protocole. Mais je cite l'opinion du RFC, qui trouve cette différence de comportement ennuyeuse, par exemple parce qu'elle peut créer des problèmes si un technicien, passant sur un nouveau type de routeur, suppose qu'une commande ayant le même nom va avoir la même sémantique.)
La section 4 du RFC liste les comportements constatés sur les routeurs :
- Sur Junos OS,
community setremplace toutes les communautés, bien connues ou pas, - Sur les Brocade NetIron,
set communitya le même effet, - Même chose sur VRP de Huawei,
avec
community set, - Idem sur SR OS,
avec
replace, - Sur IOS XR,
set communityremplace toutes les communautés sauf certaines communautés bien connues, commeNO_EXPORT, ces communautés doivent être retirées explicitement si on veut un grand remplacement ; la liste des communautés ainsi préservées n'est même pas la liste enregistrée à l'IANA, - Sur OpenBGPD,
set communityne supprime aucune des communautés existantes, qu'elles soient bien connues ou pas.
La section 5 de notre RFC souhaite donc que, pour les futures communautés spécifiées dans de futurs RFC, le comportement (remplaçable ou pas) soit précisé par l'IETF.
À destination, cette fois, des gens qui font le logiciel des routeurs, la section 6 suggère :
- De ne pas changer le comportement actuel, même pour améliorer la cohérence, même si une communauté change de statut (devenant bien connue) car ce changement serait trop perturbant,
- Mais de documenter soigneusement (apparemment, ce n'est pas
fait) le comportement des commandes de type
set; que font-elles aux communautés bien connues ?
Quant aux opérateurs réseau, le RFC leur rappelle qu'on ne peut
jamais être sûr de ce que vont faire les AS
avec qui on s'appaire, et qu'il vaut mieux vérifier avec eux ce
qu'ils font des NO_EXPORT ou autres communautés
bien connues qu'on met dans les annonces qu'on leur envoie.
L'article seul
A Fediverse/Mastodon bot for BGP queries
First publication of this article on 2 November 2019
Last update on of 11 January 2025
I created a bot to answer BGP queries over the fediverse (decentralized social network, best known implementation being Mastodon). What for? Well, mostly for the fun, but also because I need from time to time to find out the origin AS for an IP address or prefix, and I don't have a direct access to a DFZ router. This article is to document this project.
The idea was originally suggested during my lightning talk at RIPE 76 meeting in Marseille.
First, how to use it. Once you have a
Fediverse account (for Mastodon, see
https://joinmastodon.org/@bgp@mastodon.gougere.fr. You just tell it
the IP address (or IP prefix) you want to know about and it
replies with the actually announced prefix and the origin
AS. There are also links to the RIPE Stat
service, for more details. Here is an example, with the answer:
The bot replies with the same level of confidentiality as the query. So, if you want the request to be private, use the "direct" mode. Note that the bot itself is very indiscreet: it logs everything, and I read it. So, your direct messages will be private only from third parties, not from the bot administrator.
If you are a command-line fan, you can use the madonctl tool to send the query to the bot:
% madonctl toot "@bgp@mastodon.gougere.fr 2a01:e34:ec2a:94a0::4"
You can even make a shell function:
# Definition (in a startup file)
whichasn() {
madonctl toot --visibility direct "@bgp@mastodon.gougere.fr $1"
}
# Usage
% whichasn 2001:67c:2218:e::51:41
You can also, instead of an IP address, just send "info" and the bot will reply with details about the number of prefixes and AS it knows.
There is also a more classical (non-fediverse) Web interface, at
https://bgp.bortzmeyer.org/IPADDRESS. For
instance, with curl :
% curl https://bgp.bortzmeyer.org/159.89.230.222
159.89.224.0/20 1406
Note that, unlike the fediverse interface, the Web interface is not really necessary, you could use other online services such as RIPE Stat. Here is an example with RIPE Stat (we use jq to parse the resulting JSON):
% curl -s https://stat.ripe.net/data/routing-status/data.json\?resource=185.49.140.0 | jq .data.resource "185.49.140.0/22"
Now, the implementation of the bot. (You can get all the files
at https://framagit.org/bortzmeyer/fediverse-bgp-bot/
The bot backend could call directly the RIPE stat API mentioned above. But there is a limit in the number of requests and, if the bot is popular, it could be blacklisted. Same thing for other online services. Hence my choice of getting the raw RIS dumps. Parsing them and serving them to the bot is done by the WhichASN daemon.
Other useful services and readings for the BGP fans:
- We rely on the excellent RIS (Routing Information Service), which collects and stores BGP information, before making them available to the public.
- There are other ways to access RIS data, such as RIPE Stat or RIS Live.
- The RouteViews project has several useful tools, such as a DNS interface. It would solve the rate-limiting issue but, unfortunately, it works only with IPv4.
- I also like the Qrator API (but you need to register).
- I could also have used BGPstream.
- There are also several whois
servers distributing BGP information such as
whois.cymru.comorwhois.bgpmon.net. - You can access BGP data and registry data over the DNS
with
ipasn.net. - Many tools available also at TeamCymru.
L'article seul
RFC 8633: Network Time Protocol Best Current Practices
Date de publication du RFC : Juillet 2019
Auteur(s) du RFC : D. Reilly (Orolia USA), H. Stenn
(Network Time Foundation), D. Sibold
(PTB)
Réalisé dans le cadre du groupe de travail IETF ntp
Première rédaction de cet article le 27 octobre 2019
Le protocole NTP, qui sert à synchroniser les horloges sur l'Internet, est probablement un des plus vieux protocoles encore en service. Il est normalisé dans le RFC 5905. Ce nouveau RFC ne change pas la norme, il rassemble simplement un ensemble de bonnes pratiques pour l'utilisation de NTP. Sa lecture est donc très recommandée à toutes les personnes qui gèrent la synchronisation d'horloges dans leur organisation.
Bien sûr, tout dépend des niveaux d'exigence de cette organisation. Quel écart entre les horloges acceptez-vous ? Quel est le risque d'une attaque délibérée contre les serveurs de temps que vous utilisez ? À vous de lire ces bonnes pratiques et de les adapter à votre cas.
Le RFC commence par un conseil de sécurité réseau général (section 2). NTP est fondé sur UDP, ce qui signifie que le protocole de transport ne protège pas contre les usurpations d'adresses. Et comme les réponses NTP sont souvent bien plus grosses (en octets) que les questions, des attaques par réflexion et amplification sont possibles, et effectivement observées dans la nature. (Le RFC recommande également la lecture de « Technical Details Behind a 400Gbps NTP Amplification DDoS Attack », de « Taming the 800 Pound Gorilla: The Rise and Decline of NTP DDoS Attacks » et de « Attacking the Network Time Protocol ».) Il est donc nécessaire que les opérateurs réseau déploient les mesures « BCP 38 » contre les usurpations d'adresses IP.
Après ce conseil général, qui concerne également d'autres protocoles, comme DNS ou SNMP, la section 3 du RFC se penche sur les bonnes pratiques de configuration de NTP. Évidemment, il faut maintenir les logiciels à jour (ce qu'on oublie plus facilement lorsqu'il s'agit d'un protocole d'infrastructure, comme NTP).
Moins évidente, la nécessité d'avoir plusieurs sources de
temps. Une source donnée peut être malveillante, ou tout
simplement incorrecte. Or, NTP peut utiliser plusieurs sources, et
trouver le temps correct à partir de ces sources (les détails sont
dans le RFC 5905, et dans le livre de
D. Mills, « Computer network time synchronization: the
Network Time Protocol ».) Trois sources sont le minimum,
quatre sont recommandées, si, bien sûr, elles sont suffisamment
diverses, et dignes de confiance. (Au passage,
Renater gère une liste de
serveurs NTP en France mais elle ne semble pas à jour,
chronos.cru.fr n'existe plus, il y manque le serveur de
l'AFNIC, ntp.nic.fr, etc.)
Ce conseil de chercher plusieurs serveurs suppose évidemment
que ces serveurs sont indépendants : s'ils prennent tous le temps
depuis une même source et que celle-ci est déréglée ou
malveillante, avoir plusieurs serveurs ne suffira pas. Il est donc
également nécessaire de veiller à la diversité des horloges
sous-jacentes. Avoir plusieurs serveurs mais connectés à des
horloges du même vendeur fait courir le risque d'un problème
commun à toutes. La diversité doit aussi s'appliquer au choix du
type d'horloge : si on utilise plusieurs horloges, mais toutes
fondées sur des constellations de
satellites, une tache solaire va les perturber tous en même
temps. Autre risque : un problème DNS
supprimant le nom de
domaine, comme c'était arrivé à
usno.navy.mil (l'USNO), en
décembre 2018 et surtout à ntp.org en janvier
2017 (cf. cette
discussion ou bien celle-ci).
Autre question, les messages de contrôle de NTP. Introduits
dans l'annexe B du RFC 1305, qui normalisait
la version 3 de NTP, ils n'ont pas été conservés pour la version 4
(RFC 5905). (Un projet existe à
l'IETF pour les remettre,
cf. draft-ietf-ntp-mode-6-cmds.) Utiles à l'administrateur
système pour la gestion de ses serveurs, ces messages
peuvent être dangereux, notamment en permettant des attaques par réflexion, avec
amplification. La bonne pratique est donc de ne pas les
ouvrir au monde extérieur, seulement à son réseau. Des exemples de
configurations restrictives figurent à la fin de cet article.
Il est évidemment nécessaire de superviser ses serveurs NTP, afin de s'assurer qu'ils sont en marche, et, surtout, du fait qu'ils soient bien synchronisés. Des exemples, utilisant Icinga, figurent à la fin de cet article.
Un serveur NTP qui sert des dizaines de milliers de clients
peut nécessiter beaucoup de ressources réseau. Il est donc
important de n'utiliser comme serveur que des serveurs qu'on est
autorisé à questionner (ce qui est le cas des serveurs publics
comme ntp.nic.fr). Il existe hélas de
nombreux exemples d'abus de serveurs NTP, le
plus célèbre étant sans doute celui du serveur de
Poul-Henning Kamp par
D-Link.
Pour permettre à tous et toutes de synchroniser leurs horloges, le projet « NTP Pool » a été créé. De nombreux volontaires mettent à la disposition de tous leurs serveurs NTP. L'heure ainsi distribuée est en général de bonne qualité mais, évidemment, le projet ne peut fournir aucune garantie. Il convient bien pour les configurations par défaut distribuées avec les logiciels, ou pour des machines non critiques. Autrement, il faut utiliser des serveurs « de confiance ».
Pour l'utiliser, il faut regarder les
instructions (elles existent aussi en
français). En gros, on doit indiquer comme serveurs NTP des
noms pris sous pool.ntp.org et ces noms
pointeront, au hasard, vers des machines différentes, de manière à
répartir la charge. Voici un exemple (avec un serveur français) :
% dig +short A 0.fr.pool.ntp.org 5.196.192.58 51.15.191.239 92.222.82.98 162.159.200.123
Mais quelque temps après, les adresses IP auront changé.
% dig +short A 0.fr.pool.ntp.org 80.74.64.2 212.83.154.33 94.23.99.153 37.187.5.167
Voici un
exemple de configuration avec le serveur NTP habituel, dans son
ntp.conf :
pool 0.fr.pool.ntp.org iburst
pool 1.fr.pool.ntp.org iburst
pool 2.fr.pool.ntp.org iburst
pool 3.fr.pool.ntp.org iburst
Ainsi, on aura quatre serveurs, pointant vers des adresses réparties dans le lot. Avec OpenNTPd, ce serait :
servers fr.pool.ntp.org
L'administrateur système ne pense pas
toujours à ajuster la configuration, donc beaucoup de fournisseurs
de logiciels ont un
sous-domaine de pool.ntp.org, utilisé
dans les configurations livrées avec leurs serveurs NTP. Par
exemple, pour OpenWrt, le fichier de
configuration par défaut contiendra :
server 0.openwrt.pool.ntp.org iburst
server 1.openwrt.pool.ntp.org iburst
server 2.openwrt.pool.ntp.org iburst
server 3.openwrt.pool.ntp.org iburst
Un problème récurrent des horloges sur
l'Internet est celui des
secondes intercalaires. La
Terre étant imparfaite, il faut de temps en
temps corriger le temps
universel avec ces secondes intercalaires. Jusqu'à
présent, on a toujours ajouté des secondes, puisque la Terre
ralentit, mais, en théorie, on pourrait avoir à en
retirer. Il existe un temps qui n'a pas ce problème,
TAI, mais, outre qu'il s'éloigne petit à
petit du temps astronomique, il n'a pas été retenu dans les normes
comme POSIX (ou NTP,
qui ne connait qu'UTC…) Il faut donc gérer les soubresauts d'UTC,
et c'est une source de bogues sans fin. Les secondes intercalaires
ne sont pas prévisibles longtemps à l'avance (je vous avait dit
que la Terre est imparfaite) et il faut donc lire
les bulletins de l'IERS (en l'occurrence le bulletin C)
pour se tenir au courant. Notez que ce bulletin n'est pas écrit
sous une forme structurée, lisible par un programme, donc on
pourra préférer le leap-seconds.list,
disponible en plusieurs endroits. Pour un
serveur NTP, une autre solution est d'utiliser des horloges qui
distribuent de l'information sur les secondes intercalaires
prévues. C'est le cas du GPS ou de
DCF77. Dans ce cas, le serveur NTP peut se
préparer un peu à l'avance (ce qui n'évite pas les bogues…)
Autre problème amusant, noté par le RFC, le leap smearing, qui consiste à lisser l'arrivée d'une seconde intercalaire au lieu de brutalement décaler l'horloge d'une seconde. Lors de la seconde intercalaire de juin 2015, certains serveurs NTP faisaient du leap smearing et pas d'autres, ce qui semait la confusion chez les clients qui avaient un mélange de ces deux types de serveurs. Le leap smearing n'est pas conforme à la norme NTP et ne doit donc pas être utilisé sur des serveurs NTP publics, d'autant plus que le protocole ne permet pas de savoir si le serveur utilise ce smearing ou pas. Dans un environnement fermé, par contre, on fait évidemment ce qu'on veut.
Concernant ce leap smearing, le RFC note qu'il peut poser des problèmes juridiques : l'horloge de la machine ne sera pas en accord avec l'heure légale, ce qui peut créer des histoires en cas, par exemple, d'accès des autorités aux journaux.
Passons maintenant aux mécanismes de sécurité de NTP (section 4
du RFC). L'analyse des risques a été faite dans le RFC 7384, notre RFC rappelle les moyens de faire face à ces
risques. Il y a bien sûr les clés partagées (la directive
keys /etc/ntp/ntp.keys dans le serveur NTP
classique). NTP n'a pas de mécanisme de distribution de ces clés,
il faut le faire en dehors de NTP (copier
/etc/ntp/ntp.keys…), ce qui ne marche donc
pas pour des serveurs publics. (Comme il y a toujours des lecteurs
qui me disent « mais c'est pas pratique de recopier les clés à la
main sur toutes les machines », je rappelle l'existence
d'Ansible, et autres outils analogues.) À
noter que le seul algorithme de
condensation normalisé pour l'utilisation
de ces clés est MD5, clairement dangereux
(RFC 6151). Ceci dit, d'autres algorithmes
sont parfois acceptés par les mises en œuvre de NTP, cf. RFC 8573. (Opinion
personnelle : MD5 vaut mieux que pas de sécurité du tout.)
Et… c'est tout. Il n'existe pas actuellement d'autre mécanisme de sécurité pour NTP. Le système Autokey, normalisé dans le RFC 5906 a été abandonné, en raison de ses vulnérabilités. Un travail était en cours à l'époque pour lui concevoir un successeur, ce qui a donné le RFC 8915.
La section 5 de notre RFC résume les bonnes pratiques en matière de sécurité NTP :
- Éviter les fuites d'information que permettent les requêtes de contrôle. Les articles de Malhotra, A., Cohen, I., Brakke, E., et S. Goldberg, « Attacking the Network Time Protocol », de Van Gundy, M. et J. Gardner, « Network Time Protocol Origin Timestamp Check Impersonation Vulnerability » (CVE-2015-8138) et de Gardner, J. et M. Lichvar, « Xleave Pivot: NTP Basic Mode to Interleaved » (CVE-2016-1548) documentent des attaques rendues possibles par ce côté trop bavard de NTP. C'est ainsi par exemple que Shodan se permettait de repérer des adresses IPv6 à analyser, pour compenser le fait que l'espace d'adressage IPv6 est trop gros pour le balayer systématiquement (RFC 7707).
- Surveiller les attaques connues, par exemple avec Suricata.
- NTP a un mécanisme de répression des requêtes, le KoD (Kiss-o'-Death, RFC 5905, section 7.4), qui permet de calmer les clients qui suivent la norme (un attaquant l'ignorera, bien sûr).
- La diffusion des informations NTP à
tout le réseau local, pratique pour diminuer l'activité NTP
(directives
broadcastetbroadcastclientdans le serveur NTP), ne devrait se faire que si ledit réseau est de confiance et que les informations sont authentifiées. - Même chose pour le mode symétrique (entre pairs qui
s'échangent les informations NTP, directive
peer).
Enfin, la section 6 du RFC couvre le cas particulier des systèmes embarqués. Par exemple, les objets connectés ont une fâcheuse tendance à rester en service des années sans mise à jour. S'ils ont été configurés en usine avec une liste de serveurs NTP, et que certains de ces serveurs disparaissent ensuite, l'objet risque de ne plus pouvoir se synchroniser ou, pire, il va matraquer une machine innocente qui a récupéré l'adresse d'un serveur NTP (cf. RFC 4085). Il est donc important que les clients NTP puissent mettre à jour la liste de leurs serveurs. D'autre part, la liste doit évidemment être correcte dès le début, et ne pas inclure des serveurs NTP, même publics, sans leur autorisation. Une solution simple est de passe par le le projet « NTP Pool ».
L'annexe A de notre RFC rassemble des conseils qui sont
spécifiques à une mise en œuvre de NTP, celle de la Network Time
Foundation, le « code NTP original »
(paquetage ntp sur
Debian ou ArchLinux).
Pour obtenir une variété de sources, le
démon « ntpd » fourni a la directive
pool, qui permet de désigner un ensemble de
serveurs :
pool 0.debian.pool.ntp.org iburst
pool 1.debian.pool.ntp.org iburst
pool 2.debian.pool.ntp.org iburst
pool 3.debian.pool.ntp.org iburst
NTP a la possibilité de recevoir des messages de contrôle (annexe B du RFC 1305). Cela peut être dangereux, et il est recommandé d'en restreindre l'accès. Avec le serveur habituel ntpd, c'est bien documenté (mais cela reste complexe et pas intuitif du tout). Voici un exemple :
restrict default noquery nopeer nomodify notrap
restrict ::1
restrict 2001:db8:b19:3bb0:: mask ffff:ffff:ffff:ffff:: notrust
restrict 2001:db8:2fab:e9d0:d40b:5ff:fee8:a36b nomodify
Dans cet exemple, la politique par défaut (première ligne) est de
ne rien autoriser. Toute machine qui tenterait de parler au
serveur NTP serait ignorée. Ensuite, la machine locale
(::1, deuxième ligne) a tous les droits
(aucune restriction). Entre les deux (troisième ligne), les
machines du réseau local
(2001:db8:b19:3bb0::/64) ont le droit de
parler au serveur seulement si elles sont authentifiées
cryptographiquement. Enfin, la machine
2001:db8:2fab:e9d0:d40b:5ff:fee8:a36b a le
droit de lire le temps chez nous mais pas de le modifier.
On avait parlé plus haut de l'importance de superviser ses services de temps. Voici une configuration avec Icinga pour faire cela :
apply Service "ntp-time" {
import "generic-service"
check_command = "ntp_time"
assign where (host.address || host.address6) && host.vars.ntp
}
...
object Host "foobar" {
...
vars.ntp = true
Avec cette configuration, la machine foobar sera
supervisée. On peut tester depuis la ligne de commande que le
monitoring plugin arrive bien à lui parler :
% /usr/lib/nagios/plugins/check_ntp_time -H foobar NTP OK: Offset 7.331371307e-06 secs|offset=0.000007s;60.000000;120.000000;
Si la réponse avait été CRITICAL - Socket timeout after 10
seconds, on aurait su que le serveur refuse de nous parler.
Ah, et puisqu'on a parlé de sécurité et de protéger (un peu) NTP par la cryptographie, voici un exemple (non, ce ne sont pas mes vrais clés, je vous rassure) :
% cat /etc/ntp/ntp.keys ... 13 SHA1 cc5b2e7c400e778287a99b273b19dc68369922b9 # SHA1 key % cat /etc/ntp.conf ... keys /etc/ntp/ntp.keys trustedkey 13
Avec cette configuration (le fichier ntp.keys
peut être généré avec la commande ntp-keygen), le serveur NTP acceptera les messages
protégés par la clé numéro 13. Sur le client, la configuration sera :
keys /etc/ntp/ntp.keys server SERVERNAME key 13
Quelques petits trucs pour finir. Avec ntpd, comment voir l'état des pairs avec qui ont est connectés ? Ici, on a configuré l'utilisation du pool :
% ntpq -pn
remote refid st t when poll reach delay offset jitter
==============================================================================
0.debian.pool.n .POOL. 16 p - 64 0 0.000 0.000 0.000
1.debian.pool.n .POOL. 16 p - 64 0 0.000 0.000 0.000
2.debian.pool.n .POOL. 16 p - 64 0 0.000 0.000 0.000
3.debian.pool.n .POOL. 16 p - 64 0 0.000 0.000 0.000
-162.159.200.123 10.19.11.58 3 u 25 128 377 1.381 -2.439 0.199
-164.132.45.112 43.13.124.203 3 u 8 128 377 5.507 -1.423 0.185
+212.83.145.32 193.200.43.147 2 u 4 128 377 1.047 -1.823 0.455
+5.196.160.139 145.238.203.14 2 u 12 128 377 5.000 -0.981 0.291
-163.172.61.210 145.238.203.14 2 u 8 128 377 1.037 -0.888 0.246
*82.64.45.50 .GPS. 1 u 71 128 377 11.116 -1.178 0.549
-178.249.167.0 193.190.230.65 2 u 3 128 377 6.233 -1.026 0.145
-194.57.169.1 145.238.203.14 2 u 2 128 377 10.660 -0.931 0.233
-151.80.124.104 193.204.114.232 2 u 16 128 377 4.888 -1.414 0.354
Autre commande utile, pour comparer l'heure locale avec les serveurs NTP :
% ntpdate -q ntp.nic.fr server 2001:67c:2218:2::4:12, stratum 2, offset 0.000520, delay 0.03194 server 2001:67c:2218:2::4:13, stratum 2, offset 0.000746, delay 0.03175 server 192.134.4.12, stratum 2, offset 0.000509, delay 0.03127 server 192.134.4.13, stratum 2, offset 0.000596, delay 0.04376 28 Oct 10:54:08 ntpdate[18996]: adjust time server 192.134.4.12 offset 0.000509 sec
Et avec un serveur NTP complètement différent ? Essayons avec OpenNTPD :
% cat /etc/ntpd.conf
# No way to restrict per IP address :-( Use a firewall
listen on *
servers fr.pool.ntp.org
sensor *
Avec cette configuration, la machine va se synchroniser au
pool, cequ'on pourra vérifier avec ntpctl :
% sudo ntpctl -s all
4/4 peers valid, clock synced, stratum 4
peer
wt tl st next poll offset delay jitter
162.159.200.123 from pool fr.pool.ntp.org
1 10 3 23s 30s -2.270ms 4.795ms 0.027ms
193.52.136.2 from pool fr.pool.ntp.org
1 10 2 32s 34s -1.904ms 18.058ms 1.788ms
91.121.96.146 from pool fr.pool.ntp.org
* 1 10 3 0s 31s -1.147ms 1.872ms 0.069ms
62.210.213.21 from pool fr.pool.ntp.org
1 10 2 1s 34s -0.367ms 4.989ms 0.067ms
L'article seul
Fiche de lecture : (Cyber) harcèlement
Auteur(s) du livre : Bérengère Stassin
Éditeur : C&F Éditions
978-2-915825-94-7
Publié en 2019
Première rédaction de cet article le 27 octobre 2019
Le sujet du harcèlement dans l'enseignement est douloureux mais il est quand même nécessaire de l'étudier. Il ne se réduit pas au cyberharcèlement, et il n'est même pas sûr que le cyberharcèlement soit si différent que cela du harcèlement classique, comme l'indique le titre de ce livre, qui met « cyber » entre parenthèses. En outre, ce sujet se prête au sensationnalisme, et les articles sur quelques cas spectaculaires masquent souvent la réalité du phénomène. On peut donc féliciter l'auteure d'avoir abordé le sujet sous un angle plus scientifique, en s'appuyant sur des faits, et en étudiant le phénomène sous tous ses aspects, afin de mieux pouvoir le combattre.
C'est d'autant plus important que les exagérations et les approximations qui sont fréquentes lorsqu'on parle du cyberharcèlement ont souvent des but cachés. Par exemple, les politiciens français dénoncent souvent l'anonymat sur l'Internet comme étant lié au harcèlement, et réclament son abolition, alors que Bérengère Stassin fait remarquer que, dans la plupart des affaires de harcèlement scolaire, la victime sait parfaitement qui sont ses harceleurs. Mais la vérité ne compte pas quand on veut faire passer une nouvelle loi.
Et, si les médias et les autorités parlent si souvent du cyberharcèlement (et très peu du harcèlement tout court), c'est que cela sert aussi à diaboliser les outils de communication modernes, qui les concurrencent. On voit ainsi des campagnes de sensibilisation anxiogènes, qui ne présentent l'Internet que comme un outil de harcèlement.
Revenons au livre. L'auteure commence par recadrer le problème dans l'ensemble des phénomènes de harcèlement à l'école, malheureusement fréquents. (Elle fait aussi remarquer que les cas les plus dramatiques, se terminant parfois par un suicide de la victime, font parfois oublier qu'il existe un harcèlement de masse, pas aussi grave mais beaucoup plus fréquent.) Le harcèlement scolaire a été étudié depuis longtemps par les spécialistes, même s'il n'existe évidemment pas de solution miracle. Le harcèlement massif est difficile à mesurer car il consiste en beaucoup de micro-agressions. Chaque agresseur a l'impression de ne pas avoir fait grand'chose, alors que c'est leur nombre qui fait la gravité du phénomène. Et le harcèlement est inégalement réparti entre les genres, les filles en étant plus souvent victimes.
Comme toutes les activités humaines, le harcèlement s'est ensuite adapté à l'Internet et diverses formes de cyberharcèlement sont apparues, que l'auteure passe en revue en détail avec, pour chacune, ce que dit la loi. Mais la presse et les politiciens, toujours prêts à diaboliser le nouveau système de communication, ont rapidement entonné le discours « c'est la faute d'Internet et des écrans, les jeunes étaient mieux avant », quitte à inventer les faits, comme dans l'affaire du soi-disant Momo challenge. La réalité est pourtant bien assez grave comme cela, et plusieurs personnalités ont dénoncé publiquement le cyberharcèlement dirigé contre elles, par exemple Marion Seclin ou Nadia Daam. Ces trois premiers chapitres du livre sont difficiles à lire, car parlant de choses extrêmement douloureuses (même si les agresseurs les considèrent toujours avec légèreté) mais indispensables, pour avoir une idée claire du phénomène. Le livre détaille notamment les nombreuses études qui ont été faites, analysant les motivations des harceleurs (inutile de rappeler que comprendre, ce n'est pas excuser, n'est-ce pas ?)
Une fois qu'on a étudié le harcèlement, reste à lutter contre lui. C'est l'objet du dernier chapitre. Au moins, maintenant, le problème est nommé et reconnu (ce n'était pas le cas il y a cent ans.) L'État s'en empare, le ministère fait des campagnes, et sensibilise, plusieurs associations sont actives (comme l'APHEE, Marion, la main tendue ou e-Enfance, cette dernière étant spécialisée dans la lutte contre le cyberharcèlement et, au passage, le livre contient énormément d'URL de ressources utiles pour lutter contre le harcèlement).
Le livre ne fournit bien sûr pas de solution simple et magiquement efficace. Il liste de nombreuses initiatives, de nombreux endroit où trouver des informations et des idées. Les personnes impliquées dans la lutte contre le harcèlement, les enseignant·e·s par exemple, y trouveront des armes contre ces affreuses pratiques. Ne manquez pas également de visiter le blog de l'auteure.
Autre compte-rendu de ce livre : celui de Didier Epsztajn.
L'article seul
Il n'existe pas de TLD interne standard
Première rédaction de cet article le 25 octobre 2019
Dans beaucoup d'organisations, les noms de domaine locaux sont attribués dans un
TLD, un
domaine de tête, non normalisé, comme .loc ou
.lan. Pourquoi n'y a t-il pas de domaine de
premier niveau normalisé pour ces usages « internes » ?
Un certain nombre de personnes, sans avoir vérifié, croient
savoir qu'il y a un domaine de premier niveau
prévu pour cela. On cite parfois à tort
.local (qui est en fait
affecté à autre chose par le RFC 6762). Parfois, le .loc, plus court,
est utilisé. La plupart du temps, on ne se pose pas la question, et
on utilise un TLD non affecté, sans réfléchir.
Alors, peut-on répondre aux administrateurs
réseaux de ces organisations « vous auriez dû utiliser
le TLD standard prévu pour cela » ? Après tout, il y a des TLD
standards pour des usages spécifiques, comme
.test pour les essais et
le développement ou comme
.example pour les
exemples dans la documentation. Ils sont normalisés dans le RFC 2606 et, depuis, a été créé un registre IANA, peuplé selon des règles définies dans
le RFC 6761, pour stocker tous ces noms
« spéciaux ». (Le RFC 8244 peut être aussi une
bonne lecture, mais à lire avec son sens critique allumé.)
Mais, parmi eux, il n'y a pas de TLD réservé comme « usage
interne des organisations ». Ce n'est pas faute d'avoir essayé,
plusieurs tentatives ont été faites pour normaliser un tel nom, mais
sans résultat. Pour comprendre, il faut d'abord revenir sur la
question « pourquoi ne pas prendre un nom un peu au hasard et
l'utiliser ? » Imaginons une organisation nommée « Foobar » et qui
nommerait ses ressources internes sous le TLD non-existant
.foobar. (Il y a de nombreux exemples
réels. Par exemple, la société Belkin livrait
des produits pré-configurés avec le TLD
.belkin.) Quel(s) problème(s) cela poserait ?
Ils sont au nombre de trois :
- Pendant longtemps, il semblait que la liste des TLD ne
changeait pas et qu'un nom libre le resterait longtemps. Les
indépendances suite à la fin de la guerre
froide, et la création par l'ICANN de
centaines de nouveaux TLD à partir de 2013 ont mis fin à cette légende. Si demain,
l'ICANN ouvre un nouveau cycle d'enregistrement de TLD, et que
quelqu'un demande et obtient
.foobar, notre entreprise sera bien embêtée, il y aura de nombreuses collisions entre ses noms internes et les noms externes. Le résultat de la résolution DNS dépendra de beaucoup de choses. Cela avait par exemple posé des problèmes pour .dev. - Quand on utilise un nom assez répandu comme, aujourd'hui,
.loc,.homeou.corp, un autre danger se présente, celui lié aux fusions/acquisitions. Si une organisation fusionne avec une autre, par exemple une entreprise se fait acheter, et que les deux organisations utilisaient le même TLD interne, on retombe dans le même problème de collisions. La DSI aura bien du mal à gérer ce choc entre les deux utilisations du même nom. Utiliser un nom aléatoire tel que.fa43h7hiowxa3lk9aiocomme TLD interne rendrait ce risque peu vraisemblable, mais ça ne serait pas très pratique. - Et enfin il y a le problème des fuites. Lorsqu'on crée un
TLD interne, c'est pour qu'il reste interne, d'autant plus qu'il
recense des ressources privées, mais, en pratique, il est très
difficile de s'assurer qu'il n'y aura pas de fuites. Un employé
oublie qu'il n'a pas lancé le VPN de l'entreprise, et cherche à accéder à
des ressources internes. Ou bien il rapporte le portable chez lui
et ses logiciels tentent automatiquement de résoudre ces noms
internes. Dans tous ces cas, les noms internes vont fuiter vers
les serveurs faisant autorité, et la racine du DNS voit une part
significative de requêtes pour des TLD n'existant pas. (Vous
pouvez regarder vous-même ces requêtes pour des TLD non existants,
par exemple sur la page
de statistiques du serveur C-root.) Les fuites ne se
produisent d'ailleurs pas que vers la racine du DNS. Le
ministère de l'intérieur utilise
.mien interne et a déjà publié des appels d'offres, des offres d'emploi ou des communiqués de presse en indiquant un URL en.mi.
Pour ces trois raisons, utiliser un TLD imaginaire n'est pas une bonne idée. Notez qu'un certain nombre d'administrateurs réseau s'en moquent : ils se disent que le problème n'arrivera que dans plusieurs années, qu'ils auront changé d'entreprise à ce moment et que ce sera leur successeur ou successeuse qui devra gérer les conséquences de leurs décisions erronnées.
Mais alors, puisque ce n'est pas une bonne idée de prendre un TLD
au pifomètre, pourquoi est-ce que l'IETF, qui a déjà enregistré
plusieurs TLD spéciaux, n'enregistre
pas un .internal (ou un autre nom) en le
marquant comme « Usage interne seulement » ? Ce serait en gros
l'analogue pour le DNS de ce que sont les adresses IP privées du RFC 1918. L'opération a été tentée, et pas qu'une seule
fois. Le dernier essai était
l'Internet-Draft
draft-wkumari-dnsop-internal, qui
réservait .internal.
Le brouillon draft-wkumari-dnsop-internal
examinait également les autres possibilités, alternatives au
.internal :
- Le TLD
.alta finalement été adopté longtemps après (RFC 9476) mais, de toute façon, il est réservé aux cas où la résolution de noms ne se faisait pas via le DNS mais, par exemple, via GNUnet. - L'IETF a déjà un TLD quasiment à sa disposition,
.arpa. On aurait pu envisager unquelquechose.arpa. Mais le sigle ARPA n'est pas parlant à M. Toutlemonde, et un suffixe de nom de domaine à deux composants est jugé moins pratique qu'un suffixe à un seul composant, le TLD. - Les noms déjà réservés comme
spéciaux comme
.localou.invalidont tous une sémantique bien précise, et restrictive. Bref, ils servent déjà à autre chose.
D'où le choix du .internal par l'auteur du document.
À noter qu'une question intéressante, lorsqu'on décide de
réserver un pseudo-TLD pour les sites locaux, est celle de
DNSSEC. Si le TLD n'est pas délégué par la
racine, les résolveurs validants rejetteront ce nom, puisque la
racine est signée. Ce n'est peut-être pas trop grave puisqu'ils
auront de toute façon besoin d'une configuration spécifique pour
l'utiliser. Un exemple ? Ici, avec Unbound, on délègue
.internal à deux serveurs internes :
server:
domain-insecure: "internal" # Only necessary if there is no
# insecure delegation from the root.
forward-zone:
name: "internal"
forward-addr: 10.42.1.68
forward-addr: fd9d:ebf3:dd41:6094::1:53
Et si on délègue le nom
(par exemple au nouvel AS112 du RFC 7535) ?
Pas moyen de signer cette délégation (puisqu'il faudrait distribuer
publiquement la clé privée, pour que chacun signe sa zone locale). La
seule solution est donc une délégation non signée (des
enregistrements NS mais pas de DS). Notez que
.alt, s'il avait été accepté, n'aurait pas eu
ce problème, puisqu'il était réservé aux usages non-DNS.
Mais le brouillon
draft-wkumari-dnsop-internal note que c'est
bien joli de choisir un joli nom, encore faut-il, si on a décidé
qu'il était mieux de le déléguer, convaincre l'ICANN de le faire. Et, là, on est partis pour
dix ans de multistakeholder bottom-up decision
process et d'innombrables réunions. C'est en partie ce qui
explique le manque d'intérêt qui a finalement
coulé le projet .internal. Le marécage
de la gouvernance Internet est difficile à
traverser.
De toute façon, .internal n'aurait résolu
que le premier problème (risque de délégation d'un vrai TLD du même
nom). Il aurait un peu aggravé le second (collision lors d'une
fusion/acquisition) puisque tout le monde utiliserait le même
nom. Et il aurait un peu aidé pour le troisième (les fuites)
puisqu'il aurait été plus facile de prendre des mesures standard
pour gérer les fuites d'un TLD standard. Bref, l'idée n'est pas
forcément excellente, la motivation principale pour le
.internal était « c'est une mauvaise idée mais
il y a une demande donc on donne ce TLD aux administrateurs réseau
pour qu'ils arrêtent de râler ». On a vu que cette motivation
n'avait pas été suffisante et que, finalement, on n'a pas de TLD (ou
de suffixe) standard pour les noms internes.
Que doit faire l'administrateur réseau,
alors ? Le plus simple, étant donné que toute organisation a (ou
devrait avoir) un nom de domaine à soi, est de prendre un
sous-domaine de ce domaine. Si l'organisation Foobar citée plus haut
a foobar.com, qu'elle nomme ses ressources
internes en internal.foobar.com. Du fait de la
nature arborescente des noms de domaine, aucun risque que ce nom
soit attribué à un autre, aucun risque de collision en cas de
fusion/acquisition, et aucun risque de fuites.
L'article seul
Journée de l'APDEN (professeur·e·s documentalistes) sur l'enseignement de l'informatique
Première rédaction de cet article le 22 octobre 2019
Le 16 octobre 2019, les APDEN (association de professeur·e·s documentalistes de l'éducation nationale) franciliennes tenaient une journée d'études au lycée Janson-de-Sailly. Le thème était l'enseignement de l'informatique au lycée, notamment suite à la nouvelle option SNT (Sciences Numériques et Technologie) au lycée. Je parlais quant à moi de l'enseignement de l'Internet.
Les professeur·e·s documentalistes ne sont pas une espèce très connue. Pas mal d'élèves, et de parents d'élèves, ignorent que la « dame du CDI » est une professeure comme les autres. Pour le nouvel enseignement SNT, comme une bonne partie du programme porte sur la recherche d'informations, les professeur·e·s documentalistes sont aussi bien équipés que les autres pour l'enseigner. Si vous souhaitez connaitre le programme, il est disponible en ligne (et le PDF est là.) Tout le monde dans cette journée était d'accord pour dire qu'il est ambitieux. Voici deux manuels de cet enseignement, consultables en ligne : celui de Nathan, et celui d'Hachette.
Commençons par un café : 
Bon, je vais utiliser le féminin dans le reste de cet article, pour parler des professeures documentalistes car, en pratique, c'est un métier essentiellement féminin.
J'ai parlé de ma vision de ce qu'il fallait enseigner sur l'Internet. Voici les supports (et leur source).
Autrement, Véronique Bonnet, professeure de philosophie et militante de l'APRIL nous a parlé de philosophie du document (Montaigne disait qu'il fallait pilloter les livres comme les abeilles pillotaient les fleurs…). Elle nous a également fait réfléchir sur les représentations visuelles d'Ada Lovelace. Sur ses portraits, elle n'a pas l'air d'une nerd, est-ce une bonne ou une mauvaise chose ? Est-ce que ça encourage à l'imiter ? (On n'a que des portraits officiels d'elle. On ne sait pas à quoi elle ressemblait quand elle travaillait dans son bureau.)
Tristan Nitot a ensuite parlé de souveraineté numérique, notamment avec l'exemple de Qwant. Qwant ne mémorise pas ses visiteurs : « c'est un guichetier amnésique ». Il y a de la publicité, mais purement liée à la recherche en cours, pas aux recherches précédentes. Plusieurs enseignantes ont fait remarquer que leurs élèves ne semblaient pas sensibles au flicage fait par les GAFA, estimant que la publicité ciblée était même une bonne chose. D'autres ont fait remarquer que le sevrage n'était pas facile : « J'ai essayé d'abandonner Google, j'ai tenu 10 jours. » (Et je rajoute que c'est d'autant plus vrai que les résultats de Qwant sont bien plus mauvais que ceux de Google.) Quant aux objets connectés, notamment aux assistants vocaux, Tristan Nitot a noté que « nous sommes plus crétins que les Troyens, car nous payons les caméras et les micros connectés que nous introduisons dans nos salons. Au moins, les Troyens n'avait pas payé pour le cheval. »
Nous avons eu aussi une présentation par Thierry Bayoud de son documentaire « LOL ; le logiciel libre, une affaire sérieuse », qui cherche actuellement un distributeur. (Le documentaire n'est pas distribué librement. Certains festivals exigent, pour envisager la possible remise d'un prix, d'être en première. Si le film a été diffusé avant, même accidentellement, c'est fichu.).
La journée se terminait avec une table ronde sur l'enseignement SNT (Sciences Numériques et Technologie) : quelle perspective pour les professeurs documentalistes ? Il y avait deux excellents récits d'expériences concrètes, sur le terrain. Céline Caminade a raconté son expérience avec l'implémentation du programme de SNT en lycée. Parmi les difficultés pratiques : les profs sont censés enseigner la programmation en Python mais ne savent pas forcément programmer (et ça ne s'apprend pas en deux semaines). Mais j'ai bien aimé qu'il y ait eu une sortie au théâtre pour voir la pièce « La Machine de Turing », de Benoit Solès, avec la prof d'anglais et la prof de maths. Amélie Chaumette, elle, avait fait une expérience (en dehors de l'enseignement SNT, qui n'existait pas encore) d'enseignement de la cryptographie en classe de première. Histoire (de César à Enigma, en passant par Vigenère) puis protection des données personnelles puis travaux divers pour les élèves.
Merci à Habib pour m'avoir invité, et à toutes les intervenantes et participantes, c'était passionnant, et j'ai appris plein de choses.
Ah, et le plaisir de se retrouver dans un vieux lycée parisien pittoresque… 
L'article seul
Unicode à ses débuts
Première rédaction de cet article le 20 octobre 2019
Sur le site Web du consortium Unicode, consortium qui pilote l'évolution de cette norme, on trouve une très intéressante page d'histoire, rassemblant un certain nombre de documents sur le passé d'Unicode. Parmi eux, « Unicode 88 » qui, en 1988, était le premier document à exposer les bases de ce qui allait devenir la norme Unicode. Il est amusant de voir aujourd'hui ce qui a été gardé de ce projet, et ce qui a été changé.
Ce document « Unicode 88 » était un projet : tout n'était pas encore défini. Mais on y trouve déjà quelques principes importants qui ont été conservés :
- Encodage de caractères abstraits, et pas de glyphes (la représentation graphique du caractère),
- Utilisation pour le texte brut, sans caractères de formatage (ce qui n'a pas été complètement respecté).
D'autres principes étaient absents, comme la séparation de l'affectation des points de code et leur encodage en bits. Il y a aussi des principes qui ont été gardés mais qu'on regrette aujourd'hui comme l'unification Han.
Le plus frappant, avec le recul, est l'insistance sur un principe qui n'a pas été conservé, l'encodage de taille fixe (proche du futur UCS-2), en 16 bits (dérivé de XCCS). On sait qu'en fait c'est un encodage de taille variable, UTF-8 (RFC 3629), qui s'est imposé (pour les protocoles Internet, ce choix en faveur d'UTF-8 est formalisé dans les RFC 2277 et RFC 5198.) L'article « Unicode 88 » accuse son âge lorsqu'il écrit que 16 bits seront suffisants dans tous les cas (16 bits permettent d'encoder 65 536 caractères, or il en existe aujourd'hui 137 994). « Unicode 88 » note que cela implique d'abandonner les écritures du passé, qui sont au contraire aujourd'hui une part importante d'Unicode.
À l'époque, un certain nombre de gens critiquaient Unicode en raison de l'augmentation de taille des textes (un caractère sur deux octets au lieu d'un). L'argument a toujours été faible, compte tenu de la rapide augmentation des capacités des processeurs et des disques durs mais, à cette époque où la disquette de trois pouces et demi était une invention récente, il avait du poids. D'ailleurs, encore aujourd'hui, à une époque de documents Word de plusieurs dizaines de mégaoctets, sans même parler des vidéos haute définition, on entend parfois des critiques d'UTF-32 (un autre encodage de taille fixe…) sur la base de la taille des fichiers de texte brut. Le document estime que le problème de la taille est mieux réglé par la compression.
Autre point où le document accuse son âge, le curieux tableau qui mesure l'importance des écritures en fonction du PNB des pays qui les utilisent. Cela rappele qu'Unicode a été conçu par des entreprises capitalistes qui cherchaient le profit, et donc les marchés rentables.
Le choix d'un encodage de taille fixe (qui n'a donc pas été retenu par la suite) était stratégique, et le document revient plusieurs fois sur l'importance de ce choix, en raison de la simplification des programmes qu'il permet. L'argument de la simplicité des programmes a finalement cédé face à l'argument choc d'UTF-8 : la compatibilité avec ASCII (tout document en ASCII est automatiquement un document en UTF-8).
Et l'unification Han ? Cette idée de considérer les caractères chinois et japonais comme équivalents, en raison de leur origine commune, et malgré leurs apparences différentes (mais rappelez-vous qu'Unicode encode des caractères, pas des glyphes), est à peine discutée dans l'article, alors qu'elle est certainement le concept Unicode le plus critiqué depuis.
L'article seul
Fiche de lecture : Twitter & les gaz lacrymogènes
Auteur(s) du livre : Zeynep Tufekci
Éditeur : C&F Éditions
978-2-915825-95-4
Publié en 2019
Première rédaction de cet article le 10 octobre 2019
Beaucoup de textes ont été écrits sur le rôle de l'Internet, et des réseaux sociaux centralisés, comme Facebook ou Twitter, dans des évènements politiques. Ce fut le cas, par exemple, du printemps arabe. L'auteure explore, dans ce livre très riche et très rigoureux, tous les aspects de cette relation entre les militants et les techniques d'information et de communication. Twitter peut-il battre les gaz lacrymogènes ?
(Le livre a été écrit en anglais, Zeynep Tufekci étant étatsunienne - d'origine turque. Il a été publié dans sa langue originale en 2017. Je l'ai lu dans la traduction française, tout à fait correcte, à part une certaine tendance à utiliser le mot anglais en français, comme traduire activist par activiste ou devastated par dévasté.)
Une grande partie des articles et messages écrits au sujet de l'utilisation de l'Internet par les militants des quatre coins du globe sont assez excessifs dans un sens ou dans l'autre. Soit on estime que l'Internet change tellement de choses qu'il ouvre une façon toute nouvelle de faire de la politique, et rend donc dépassées les méthodes traditionnelles, soit on se moque des « révolutions Twitter » et on affirme que le pouvoir se prend dans la rue, comme avant. La vérité est évidemment plus complexe : l'arrivée de l'Internet n'a pas supprimé les lois de la politique, les questions posées aux militants et aux révolutionnaires restent les mêmes, ainsi que les problèmes auxquels ils et elles font face. Mais l'Internet n'est pas non plus un épiphénomène : comme d'autres techniques avant lui (l'imprimerie est l'exemple canonique, d'ailleurs analysé de façon originale par l'auteure), l'Internet a changé les moyens dont les gens disposent, a créé de nouvelles affordances (là, je ne critiquerai pas la traduction : il n'y a pas de bon terme en français), c'est-à-dire de nouvelles potentialités, des encouragements à aller dans de nouvelles directions. Sur la question récurrente de la neutralité de la technique, Zeynep Tufekci cite à juste titre la citation classique de Melvin Kranzberg : « La technologie n'est ni bonne, ni mauvaise ; et n'est pas neutre non plus. »
Une des raisons pour lesquelles bien des discours sur les mouvements politiques utilisant l'Internet sont très unilatéraux est que beaucoup de leurs auteurs sont des férus de technique qui ne connaissent pas grand'chose à la politique, et qui découvrent comme s'ils étaient les premiers à militer, ou bien ils sont des connaisseurs de la politique, mais complètement ignorants de la technique, dont ils font un tout, animé d'une volonté propre (les fameux « algorithmes »), et pas des outils que les gens vont utiliser. L'auteure, au contraire, informaticienne, puis chercheuse en sciences politiques, connait bien les deux aspects. Elle a étudié en profondeur de nombreux mouvements, les zapatistes au Mexique, Occupy Wall Street, l'occupation du parc Gezi, Black Lives Matter, les révolutions tunisienne et égyptienne, en étant souvent sur le terrain, à respirer les gaz lacrymogènes. (Les gilets jaunes n'y sont pas, bien que ce mouvement mériterait certainement d'être étudié dans son rapport à Facebook, mais le livre a été publié avant.) Et elle analyse le rôle de l'Internet, en chercheuse qui le connait bien, en voit les forces et les limites.
En contraste, elle étudie également le mouvement des droits civiques aux États-Unis. Voici un mouvement de très grande importance, qui a tout fait sans disposer de l'Internet. Alors qu'aujourd'hui, deux ou trois messages sur Facebook peuvent être le point de départ d'une manifestation très importante, et très rapidement prête, le mouvement des droits civiques a dû ramer pendant de nombreux mois pour, par exemple, organiser sa grande manifestation à Washington. L'auteure ne dit pas que c'était mieux à l'époque ou mieux aujourd'hui : elle insiste plutôt sur les permanences de l'action politique. Mais elle note aussi les différences : si l'organisation était bien plus laborieuse à l'époque (pas question de coordonner les aspects matériels avec une feuille de calcul mise en ligne et partagée), cela avait également des avantages. Les militants apprenaient à se connaitre, à se faire confiance, même des activités a priori sans intérêt politique, comme l'organisation pratique des voyages pour aller sur le lieu de la manifestation, avaient l'avantage de créer des liens, qui allaient permettre au mouvement de rester solide dans les tempêtes, face à la répression, et surtout face aux choix tactiques et stratégiques nécessaires lorsque la situation évolue.
Au contraire, l'Internet permet de se passer de cette organisation, au moins au début. Un individu seul peut se créer son blog et s'exprimer là où, auparavant, il aurait dû mendier un espace d'expression aux médias officiels, ou bien rejoindre un parti ou un mouvement critique, pour pouvoir faire relayer ses idées. C'est un énorme avantage et un des grands succès de l'Internet. Mais cela entraine de nouveaux risques, comme le fait qu'on n'a plus besoin de supporter les difficultés du travail collectif, ce qui peut rendre plus compliquée la traduction des idées en actions qui changent les choses.
Parmi les affordances de l'Internet, il y a le fait que beaucoup de choses sont possibles sans organisation formelle. Des mouvements très forts (comme celui du parc Gezi) ont été possibles sans qu'un parti traditionnel ne les structure et ne les dirige. Mais, bien sûr, cet avantage a aussi une face négative : puisque la nécessité d'une organisation n'est pas évidente, on peut se dire qu'on peut s'en passer. Au début, ça se passe effectivement bien, sans les lourdeurs bureaucratiques exaspérantes. Mais, ensuite, les problèmes surgissent : le pouvoir en place fait des ouvertures. Comment y répondre ? Ou bien il change de tactique, et le mouvement doit s'adapter. Et, là, l'absence d'un mécanisme de prise de décision commun se fait sentir, et beaucoup de mouvements s'affaiblissent alors, permettant à la répression de disperser ce qui reste. J'avais été frappé, sur les ronds-points, par la fréquence du discours « ah non, surtout pas de partis, surtout pas de syndicats, surtout pas d'organisations et de porte-paroles », chez des gilets jaunes qui n'avaient sans doute pas étudié les théoriciens de l'anarchisme. Mais c'est que le débat est aussi ancien que la politique. L'Internet le met en évidence, en rendant possible des fonctionnements moins centralisés, mais il ne l'a pas créé.
Léger reproche à l'auteure : elle ne discute pas ce qui pourrait arriver avec d'autres outils que les gros réseaux centralisés étatsuniens comme Facebook ou Twitter. Il est vrai qu'on manque encore d'exemples détaillés à utiliser, il n'y a pas encore eu de révolution déclenchée sur le fédivers ou via Matrix.
Je n'ai donné qu'une idée très limitée de ce livre. Il est très riche, très nuancé, l'auteure a vraiment tenu à étudier tout en détail, et aucun résumé ne peut donc suffire. En conclusion, un livre que je recommande à toutes celles et tous ceux qui veulent changer le monde et se demandent comment faire. Il n'est ni optimiste, ni pessimiste sur le rôle de l'Internet dans les révolutions : « ni rire, ni pleurer, mais comprendre » (Spinoza, il semble).
Autre(s) article(s) en français sur ce livre :
- Celui de Matthieu Demory.
Petit avertissement : j'ai reçu un exemplaire gratuit de ce livre.
L'article seul
Version 12 d'Unicode
Première rédaction de cet article le 8 octobre 2019
En mars dernier est sortie la version 12 d'Unicode. Une description officielle des principaux changements est disponible mais voici ceux qui m'ont intéressé particulièrement. (Il n'y a pas de changement radical.)
Pour explorer plus facilement la grande base Unicode, j'utilise un programme qui la convertit en SQL et permet ensuite de faire des analyses variées. Faisons quelques requêtes SQL :
ucd=> SELECT count(*) AS Total FROM Characters; total -------- 137994
Combien de caractères sont arrivés avec la version 12 ?
ucd=> SELECT version,count(version) FROM Characters GROUP BY version ORDER BY version::float; ... 10.0 | 8518 11.0 | 684 12.0 | 554 12.1 | 1
554 nouveaux, cette version 12 est très modérée. Quels sont ces nouveaux caractères ?
ucd=> SELECT To_U(codepoint) AS Codepoint, name FROM Characters WHERE version='12.0'; codepoint | name -----------+---------------------------------------------------------------------------- ... U+1FA70 | BALLET SHOES ... U+2E4F | CORNISH VERSE DIVIDER ... U+A7C3 | LATIN SMALL LETTER ANGLICANA W ... U+10FE0 | ELYMAIC LETTER ALEPH U+10FE1 | ELYMAIC LETTER BETH U+10FE2 | ELYMAIC LETTER GIMEL ... U+1E100 | NYIAKENG PUACHUE HMONG LETTER MA U+1E101 | NYIAKENG PUACHUE HMONG LETTER TSA U+1E102 | NYIAKENG PUACHUE HMONG LETTER NTA ... U+1F6D5 | HINDU TEMPLE U+1F6FA | AUTO RICKSHAW ... U+1F97B | SARI ... U+1F9A7 | ORANGUTAN ... U+1F9BB | EAR WITH HEARING AID U+1F9BC | MOTORIZED WHEELCHAIR U+1F9BD | MANUAL WHEELCHAIR ... U+1FA30 | WHITE CHESS KNIGHT ROTATED TWO HUNDRED TWENTY-FIVE DEGREES U+1FA31 | BLACK CHESS KNIGHT ROTATED TWO HUNDRED TWENTY-FIVE DEGREES
Parmi les emojis de cette version, beaucoup concernent l'Inde, comme le sari ou le rickshaw. Beaucoup de caractères liés au handicap ont été créés, ainsi, mais c'est plus anecdotique, que beaucoup de caractères pour le jeu d'échecs. On trouve aussi des caractères étonnants comme U+2E4F, qui ne sert apparemment qu'à la poésie cornouaillaise. Et il y a bien sûr de nouvelles écritures comme l'élymaïque ou le nyiakeng puachue hmong. Même l'alphabet latin voit arriver de nouveaux caractères comme le U+A7C3.
Au fait, l'unique caractère de la version 12.1, c'était quoi ?
ucd=> SELECT To_U(codepoint) AS Codepoint, name FROM Characters WHERE version='12.1'; codepoint | name -----------+----------------------- U+32FF | SQUARE ERA NAME REIWA
Une version d'Unicode uniquement pour introduire un caractère japonais permettant de noter l'ère Reiwa… (Merci à John Shaft pour avoir repéré celui-là.)
Tiens, d'ailleurs, combien de caractères Unicode sont des symboles (il n'y a pas que les emojis parmi eux, mais Unicode n'a pas de catégorie « emoji ») :
ucd=> SELECT count(*) FROM Characters WHERE category IN ('Sm', 'Sc', 'Sk', 'So');
count
-------
7564
Ou, en plus détaillé, et avec les noms longs des catégories :
ucd=> SELECT description,count(category) FROM Characters,Categories WHERE Categories.name = Characters.category AND category IN ('Sm', 'Sc', 'Sk', 'So') GROUP BY category, description;
description | count
-----------------+-------
Modifier_Symbol | 123
Other_Symbol | 6431
Math_Symbol | 948
Currency_Symbol | 62
L'article seul
Fiche de lecture : Une histoire populaire de la France
Auteur(s) du livre : Gérard Noiriel
Éditeur : Agone
978-2-7489-0301-0
Publié en 2018
Première rédaction de cet article le 7 octobre 2019
Excellent (vraiment excellent) livre d'histoire de la France, vu sous un angle différent de l'habituel : moins de rois et de princes, et d'avantage de gens du peuple.
Le titre fait référence à un livre très connu d'histoire des États-Unis. L'idée de départ est la même : les livres d'histoire traditionnels privilégient les gens importants, les « premiers de cordée », comme dirait Macron, et oublient les « 99 % ». On voit ainsi des historiens écrire sans sourciller que « Louis XIV a construit le château de Versailles », sans tenir compte des ouvriers.
Si les historiens tendent à privilégier ces « gens d'en haut », ça n'est pas forcément par conviction politique aristocratique, ou par mépris du peuple. C'est aussi parce que c'est plus facile. On dispose de tas de textes sur Louis XIV, de sa main, de celle de ses courtisans, de celle de ses ennemis, tout est bien documenté. Les nobles et les bourgeois de l'époque ont aussi parlé de leur classe sociale respective. Mais que sait-on des travailleurs de base ? Ils ne savaient en général pas écrire et, même quand c'était le cas, leurs textes ont rarement été gardés. On a des traces matérielles, mais peu de choses sur ce qu'ils ressentaient, leurs opinions, la vie quotidienne.
Et l'auteur ne résout pas complètement ce problème : il reconnait dès le début que l'historien manque de matériaux sur lesquels s'appuyer pour une histoire des classes populaires. Son livre est donc plutôt une histoire de France, en gardant sans cesse comme perspective que la France ne se limitait pas au roi et à la cour.
Le plan est classique, chronologique, de la guerre de Cent Ans à nos jours, soit 800 pages bien tassées. La question des débuts de la France est étudiée en détail ; à partir de quand les gens se disaient-ils français ? L'histoire traditionnelle est souvent anachronique, en qualifiant par exemple Jeanne d'Arc de patriote française, notion qui lui était bien étrangère. Les questions religieuses occupent ensuite beaucoup de place : au Moyen-Âge, tout conflit interne était présenté comme religieux, même quand ses causes profondes étaient politiques. L'auteur explique d'ailleurs que les guerres de religion ne méritaient que partiellement leur nom, et qu'elles avaient des racines qui n'étaient pas toujours religieuses.
L'esclavage et le colonialisme sont largement traités. Ils sont parfois absents des « histoires de la France », soit parce que ce n'était pas très glorieux, soit parce que les pays qui en furent victimes n'étaient pas la France. Ici, au contraire, ces questions sont vues en détail. Ces peuples n'avaient pas voulu faire partie de l'histoire de France, mais ils en sont devenus une composante importante. Comme l'accent du livre est mis sur le peuple, pas seulement comme sujet mais aussi comme acteur, les révoltes d'esclaves et les luttes anti-colonialistes jouent un rôle important.
Comme le peuple s'obstine à ne pas comprendre que les dirigeants veulent son bien, et qu'il se révolte de temps en temps, et de diverses manières, l'État développe ses moyens de contrôle. Noiriel explique ainsi le développement successif de la notion d'identité (comme dans « carte d'identité »), et le contrôle qu'elle permet.
La révolution industrielle fait franchir une nouvelle étape à ces processus, avec la création du prolétariat de masse, et la prise de conscience qui a suivi, permettant les nombreuses révoltes du 19e siècle. Mais l'articulation entre l'appartenance de classe et les opinions politiques est restée compliquée. Le parti communiste, par exemple, n'a jamais hésité à jouer la carte de la culpabilisation, écartant toutes les critiques de sa politique d'un « nous sommes un parti ouvrier, donc nous avons forcément raison ». Lorsque l'opposant était en effet né dans une famille bourgeoise, l'argument avait du poids. Comme le note Noiriel, « la culpabilité est mauvaise conseillère ». (Et elle continue à l'être.)
Par la suite, les changements dans l'organisation de la société, et une offensive idéologique importante, ont remis en cause cette conscience de classe. Aujourd'hui, l'idéologie dominante est identitaire et racialiste, faisant croire au prolétaire que sa nationalité, sa couleur de peau ou sa religion sont les choses importantes, niant les classes sociales. Cette méthode est efficace pour limiter le risque de révolte contre les dominants. Mais l'histoire n'est jamais terminée et les choses vont continuer à changer, peut-être en mieux, peut-être pas.
Je recommande fortement la lecture de ce livre, si vous voulez une histoire de France très complète, très documentée, et qui ne cherche pas à faire des raccourcis au milieu des chemins souvent complexes que cette histoire a empruntés.
L'article seul
Documentation technique de mon résolveur DoH
Première rédaction de cet article le 30 septembre 2019
Dernière mise à jour le 28 septembre 2021
Vous voulez connaitre tous les détails techniques du
fonctionnement d'un résolveur public DoH (DNS sur HTTPS) ? Voici
comment fonctionne le service https://doh.bortzmeyer.fr/.
L'article complet
Fiche de lecture : Permanent record
Auteur(s) du livre : Edward Snowden
Éditeur : MacMillan
9781529035667 90100
Publié en 2019
Première rédaction de cet article le 29 septembre 2019
Tout le monde connait bien sûr Edward Snowden, le héros grâce à qui les citoyens ordinaires ont des informations précises et étayées sur la surveillance de masse qu'exercent les États sur les citoyens. S'il a fait plusieurs interventions à distance, depuis son exil, il n'avait pas encore raconté de manière détaillée son parcours. C'est ce qu'il fait dans ce livre.
(J'ai lu ce livre en anglais car le titre de la traduction française m'avait semblé bizarre. Permanent record, c'est « Dossier qui vous suivra toute la vie » ou « Fiché pour toujours », certainement pas « Mémoires vives ».)
Je n'étais pas sûr de l'intérêt de ce livre : on peut être un héros sans savoir écrire, un informaticien compétent sans capacités pédagogiques, un lanceur d'alerte sans avoir guère de connaissances politiques. Mais j'ai été agréablement surpris : le livre est très bien écrit (Snowden remercie à la fin ceux qui ont lui ont appris à faire un livre intéressant), souvent drôle, malgré la gravité des faits, et Snowden explique très bien les questions informatiques comme le fonctionnement des services de surveillance étatiques.
Une partie du livre, surtout au début, est plutôt personnelle : enfance, jeunesse, débuts dans l'informatique. L'auteur décrit très bien la passion qu'est l'informatique, comment le hacker veut savoir comment ça marche, comment les erreurs aident à progresser. Tout informaticien se reconnaitra sans peine. (Si vous croisez quelqu'un qui dit « je ne comprends pas comment on peut être passionné par l'informatique », faites-lui lire ce livre.) Après commence la vie professionnelle, et Snowden démonte très bien le mécanisme pervers de recrutement des agences gouvernementales étatsuniennes : plutôt que d'avoir des fonctionnaires, on fait appel à des sous-traitants, qui facturent cher et font vivre un certain nombre de boites parasites, qui se contentent de mettre en rapport les informaticiens et l'État. Toute personne qui a travaillé dans une SSII reconnaitra ce monde, où on n'est jamais dans l'entreprise qui vous a embauché, et où on est parfois sous-traitant du sous-traitant. La majorité des gens qui conçoivent et font fonctionner le système de surveillance de masse sont des employés du privé…
Les amateurs de récits d'espionnage, même s'il n'y a évidemment aucun secret militaire dans ce livre, seront ravis des explications sur le fonctionnement interne des services de sécurité étatsuniens, monde très opaque et très complexe, qui est ici bien décortiqué.
La divergence entre Snowden et ses collègues a lieu après : la plupart des passionnés d'informatique accepteront sans problème de travailler pour Palantir, pour Facebook, pour Criteo ou pour la NSA. Ils ne se poseront pas de questions, se disant « de toute façon, c'est comme ça, on ne peut rien y faire » ou bien « la technique est neutre, je ne suis pas responsable de ce que les chefs font de mes programmes ». C'est là que Snowden suit une autre voie : il s'interroge, il se pose des questions, il lit, au grand étonnement de ses collègues de la CIA ou de la NSA, le texte de la constitution, et il finit par décider d'alerter le public sur le système d'espionnage qui avait été mis en place de manière complètement illégale (et qui l'est toujours).
Les amateurs de sécurité informatique pratique liront avec intérêt les réflexions d'Edward Snowden qui, sans pouvoir en parler avec personne, a dû concevoir un mécanisme pour sortir des locaux de la NSA, les innombrables documents qui ont fait les « révélations Snowden ». Je vous divulgue tout de suite un truc : les cartes SD (surtout microSD) sont bien plus discrètes que les clés USB, ne font pas sonner les détecteurs de métaux, et peuvent être avalées plus rapidement en cas d'urgence. Pendant qu'on en est aux conseils techniques, Snowden insiste sur l'importance du chiffrement, la principale protection technique sérieuse (mais pas à 100 %) contre la surveillance. Un des intérêts de ce livre est de revenir sur des points sur lesquels les discussions suite aux révélations de Snowden avaient parfois été brouillées par du FUD, où des gens plus ou moins bien intentionnés avaient essayé de brouiller le message en disant « mais, le chiffrement, ça ne protège pas vraiment », ou bien « mais non, PRISM, ce n'est pas une récolte directement auprès des GAFA ». Snowden explique clairement les programmes de la NSA, aux noms pittoresques, et les mécanismes de protection existants, au lieu de pinailler pour le plaisir de pinailler comme cela se fait parfois en matière de sécurité informatique.
Puis, une fois les documents sortis, c'est le départ pour Hong Kong et l'attente dans la chambre d'hôtel avant la rencontre avec Glen Greenwald et Laura Poitras, qui a filmé ces journées pour son remarquable documentaire « Citizenfour » (si vous ne l'avez pas vu, arrêtez de lire ce blog et allez voir ce documentaire).
Le livre n'a pas vraiment de conclusion : c'est à nous désormais de l'écrire.
L'article seul
Le protocole DoH et pourquoi il y a tant de discussions
Première rédaction de cet article le 24 septembre 2019
Le 6 septembre dernier, Mozilla a annoncé l'activation du protocole DoH par défaut dans leur navigateur Firefox. (Et, même si ce n'est pas explicite, il est prévu que ce soit par défaut avec le résolveur de Cloudflare.) Cette annonce a suscité beaucoup de discussions, souvent confuses et mal informées. Cet article a pour but d'expliquer la question de DoH, et de clarifier le débat.
DoH veut dire « DNS sur HTTPS ». Ce protocole, normalisé dans le RFC 8484, permet l'encapsulation de requêtes et de réponses DNS dans un canal cryptographique HTTPS menant au résolveur. Le but est double : empêcher un tiers de lire les requêtes DNS, qui sont souvent révélatrices (cf. RFC 7626), et protéger les réponses DNS contre des modifications, faites par exemple à des fins de censure. Le statu quo (laisser le DNS être le seul protocole important qui ne soit pas protégé par la cryptographie) n'est pas tolérable, et il faut donc féliciter Mozilla d'avoir agi. Mais cela ne veut pas dire que tout soit parfait dans leur décision. Notamment, DoH, comme toutes les solutions reposant sur TLS, ne fait que sécuriser le canal de communication contre la surveillance et la manipulation par un tiers. Il ne garantit pas que le partenaire à l'autre bout du canal est gentil. Faire du DoH vers un méchant résolveur ne serait donc pas très utile, et le choix du résolveur est donc crucial.
Voyons maintenant les principales critiques qui ont été faites contre DoH et/ou contre la décision de Mozilla (si j'en ai oublié, écrivez-moi). Rappelez-vous bien que le débat est très confus, en partie par mauvaise foi de certains, en partie par ignorance (du DNS ou de la sécurité). Notamment, certaines des critiques formulées contre DoH n'ont rien à voir avec DoH mais, par exemple, avec un aspect spécifique de la décision de Mozilla. Et, parfois, d'autres protocoles, comme DoT (DNS sur TLS, RFC 7858), présentent exactement les mêmes propriétés.
- DoH empêche (en réalité : rend plus difficile) d'appliquer une politique, par exemple de censurer Sci-Hub. Aucun doute à ce sujet, c'est même le but explicite. Ceux qui le présentent comme un inconvénient avouent franchement que leur but est le contrôle des utilisateurs. L'IETF, qui a normalisé le protocole, travaille pour un Internet ouvert. Si vous voulez utiliser les technologies TCP/IP dans un réseau fermé, vous avez le droit, mais c'est à vous de trouver des solutions. Cette critique n'est pas spécifique à DoH, DoT offre exactement le même avantage (ou le même inconvénient, si on est du côté des censeurs).
- DoH empêche (en réalité : rend plus difficile) la surveillance des utilisateurs. L'examen des requêtes DNS peut être très révélateur (cf. RFC 7626) et être utilisé pour le bien (détection de l'activité de logiciels malveillants) ou pour le mal (repérer qui visite tel ou tel site Web). Là encore, c'est le but explicite de DoH (comme de TLS en général) de rendre plus difficile la surveillance (cf. RFC 7258). Cette critique n'est pas spécifique à DoH, DoT offre exactement le même avantage (ou le même inconvénient, si on est du côté des surveillants).
- On a souvent lu que DoH aggravait la centralisation (déjà bien trop importante) de l'Internet et notamment du Web. C'est une drôle de façon de poser le problème que de l'attribuer à DoH. Lorsque Gmail rassemble la majorité du courrier électronique (oui, même si vous n'êtes pas client de Gmail, et n'avez pas accepté leurs conditions d'utilisation, une bonne partie de votre courrier est chez Gmail), est-ce qu'on décrit ce problème comme étant de la faute de SMTP ? (Notez que la relation entre les protocoles et les résultats de leurs déploiements est une question complexe, cf. RFC 8280.) Je suis personnellement d'accord que ce n'est pas une bonne idée d'envoyer tout le trafic DNS à Cloudflare, mais la solution n'est pas de supprimer DoH, ou de le limiter à parler aux résolveurs des FAI, précisément ceux auxquels on ne fait pas forcément confiance. La solution est au contraire de multiplier les serveurs DoH, de même que la solution aux réseaux sociaux centralisés est d'avoir plein d'instances décentralisées. C'est ce que je fais avec mon résolveur DoH personnel, c'est ce que font, en plus sérieux, les CHATONS. Bref, la centralisation du Web autour d'une poignée de GAFA est un vrai problème, mais pas lié à DoH. Les résolveurs DNS publics, comme Google Public DNS posent le même problème.
- On a lu parfois que DoH diminuait la vie privée car
HTTP est
bavard, très bavard. Ainsi, une requête DNS contient très peu
d'informations sur le client, alors que HTTP transmet plein
d'informations inutiles et dangereuses comme
Accept-Language:ouUser-Agent:, qui peuvent servir à identifier un utilisateur. Sans compter bien sûr les très dangereux biscuits (RFC 6265). Il s'agit là d'un vrai problème. Des solutions ont été proposées (cf. l'Internet-Draftdraft-dickinson-doh-dohpe) mais n'ont guère suscité d'intérêt. C'est probablement l'une des deux seules critiques de DoH qui soit réellement spécifique à DoH (DoT n'a pas ce problème), le reste étant confusion et mauvaise foi. - Un reproche plus conceptuel et abstrait qui a été fait à DoH (par exemple par Paul Vixie) est d'ordre architectural : selon cette vision, le DNS fait partie du plan de contrôle et pas du plan de données, ce qui fait qu'il doit être contrôlé par l'opérateur réseau, pas par l'utilisateur. Le positionnement du DNS ne fait pas l'objet d'un consensus : protocole situé dans la couche Application, il fait pourtant partie de l'infrastructure de l'Internet. Disons que cette ambiguïté est consubstantielle à l'Internet : plusieurs protocoles d'infrastructure (c'est aussi le cas de BGP) tournent dans la couche 7. Dans tous les cas, le DNS ne peut pas être vu comme purement technique (comme, par exemple, ARP), son utilisation massive pour la censure montre bien qu'il est aussi un protocole de contenu, et devrait donc être protégé contre la censure. Si les gens qui clament que le DNS fait partie de l'infrastructure et que l'utilisateur ne devrait pas pouvoir bricoler sa résolution DNS étaient cohérents, ils réclameraient également que les FAI s'engagent à ne jamais interférer (ce que suggérait l'IAB dans une récente déclaration). Mais cela semble peu réaliste à court terme.
- Un autre reproche de nature architecturale a été fait à DoH : tout faire passer sur HTTPS n'est pas « propre ». Ce reproche est justifié du point de vue technique (l'Internet n'a pas été conçu pour fonctionner comme cela, normalement, les applications doivent tourner sur SCTP, TCP, UDP, pas sur HTTPS). Mais, en pratique, « le bateau a déjà quitté le port », comme disent les anglophones. De plus en plus de réseaux bloquent tous les ports sauf 80 et 443 et, si on veut faire un protocole qui passe partout, il doit utiliser HTTPS. Si cela vous déplait, plaignez-vous aux gérants des points d'accès WiFi, pas à DoH. Notez que cette remarque est une des rares à être effectivement spécifique à DoH.
- Tel qu'il est mis en œuvre dans Firefox, DoH est fait par l'application, pas
par le système d'exploitation (ce qu'on
nomme parfois ADD, pour Applications Doing
DNS). Ce n'est pas du tout une propriété de DoH, juste
un choix de Firefox. Les nombreux schémas où on voit « avec DoH,
c'est l'application qui fait les requêtes DNS » révèlent qu'ils
ont été faits par des gens qui ne comprennent pas ce qu'est un
protocole. DoH peut parfaitement être
utilisé par les couches basses du système d'exploitation (par
exemple, sur les systèmes qui ont le malheur d'utiliser
systemd, par
systemd-resolveou, plus sérieusement, par un démon comme Stubby). Le choix de Mozilla est à mon avis erroné, mais n'a rien à voir avec DoH. Là encore, rien de spécifique à DoH, une application a toujours pu faire des requêtes DNS directement avec UDP, ou utiliser DoT, ou avoir son propre protocole privé de résolution de noms (ce que font souvent les logiciels malveillants). - Enfin, on lit parfois que DoH poserait des problèmes lorsque la réponse DNS dépend de la localisation du client (ce qui est courant avec les CDN). C'est un effet déplorable de la centralisation du Web : comme l'essentiel du trafic est concentré sur un petit nombre de sites, ces sites doivent se disperser sur la planète et utiliser des bricolages dans le DNS pour diriger le client vers « le plus proche », estimé en fonction de l'adresse IP du client. Si le résolveur est loin de l'utilisateur, on sera renvoyé vers un endroit sous-optimal. Il existe une solution technique (RFC 7871) mais elle est très dangereuse pour la vie privée, et c'est pour cela que Cloudflare, contrairement à Google, ne l'utilise actuellement pas. Ceci dit, cela n'a rien de spécifique à DoH, tout résolveur DNS public (notez que ce terme est défini dans le RFC 9499) soulève les mêmes questions (c'est également le cas si vous avez des noms de domaine privés, spécifiques à une organisation).
Articles intéressants sur le sujet :
Et pour finir, une petite image (prise sur
Wikimedia Commons) du détroit de
Messine où, selon les légendes, les marins qui tentaient
d'éviter Scylla
tombaient sur Charybde. Bref, ce n'est pas
parce qu'on n'aime pas Cloudflare qu'il faut maintenir le statu-quo
et continuer à envoyer ses requêtes DNS au résolveur fourni par le
réseau d'accès 
{kind=link}
L'article seul
Assises régionales de la cyber-sécurité à Bordeaux
Première rédaction de cet article le 24 septembre 2019
À Bordeaux, le 23 septembre 2019, se sont tenues les RSSIA, « Assises régionales de la cyber-sécurité », organisées par le CLUSIR Aquitaine. J'y ai parlé de choix politiques en matière de sécurité informatique.
Je suis parti de mon livre, « Cyberstructure », qui parle des relations entre l'infrastructure technique et la politique. Comme le sujet de cette réunion était la sécurité, je me suis focalisé sur les questions liées à la « cybersécurité ». Voici les supports de ma présentation : au format PDF et le source LaTeX/Beamer. Désolé pour celles et ceux qui n'étaient pas présents, il n'y a pas eu de captation vidéo.
Comme dans la plupart des événements du même genre, il y avait également une exposition avec de nombreux stands. Sur l'un d'eux, une boite annonçait sur ses kakemonos qu'elle fournissait un « cryptage renforcé » qui m'a laissé perplexe.
Lors du discours de bienvenue en séance plénière, le président du conseil régional, Alain Rousset, a plaisanté sur le futur « campus de cybersecurité » aquitain en proposant qu'il soit baptisé Lisbeth Salander.
Dans les conférences techniques, Renaud Lifchitz a parlé de calculateurs quantiques, résumant l'état de l'art et ses conséquences pour la cryptographie (voir à ce sujet mon exposé à Pas Sage En Seine). J'y ai appris que le nombre de vrais calculateurs quantiques accessibles gratuitement sur l'Internet augmentait. Il n'y a pas que celui d'IBM, même Alibaba en propose un. L'auteur a également rappelé que, trois jours plus tôt, Google avait annoncé (puis retiré l'article) avoir atteint la « suprématie quantique », ce moment où un calculateur quantique va plus vite qu'un ordinateur classique émulant le calculateur quantique.
Et Rayna Stamboliyska a fait le bilan de son livre « La face cachée
d'Internet ». Depuis sa parution il y a deux ans, la
cybersécurité a-t-elle progressé ? Pas tellement, par rapport à
l'ampleur de la menace. Il y a eu des changements : la
quasi-disparition de l'« hacktivisme »
indépendant, le progrès des attaques menées par des groupes
proches de l'État, comme en Russie (tel que
CyberBerkut) ou en
Chine, le développement de
l'Internet des objets, catastrophique pour
la sécurité. Mais on voit toujours des machines connectées à
l'Internet avec un RabbitMQ grand ouvert,
laissant lire tous les messages, voire permettant d'en
injecter. L'auteure est également revenue sur le mythe
journalistique du « darknet » en notant qu'il n'y a guère que
50 000 domaines en
.onion, la plupart
avec un niveau de fiabilité très bas (« vu
l'uptime des
.onion, heureusement
qu'ils ne signent pas de SLAs »), alors que les opérations et
ventes illégales se font plutôt sur
Instagram, WhatsApp,
etc.
L'article seul
La politique du serveur DoH doh.bortzmeyer.fr et ce qu'il faut savoir
Première rédaction de cet article le 22 septembre 2019
Dernière mise à jour le 7 novembre 2023
Ce texte est la politique suivie par le résolveur DoH
doh.bortzmeyer.fr et par le résolveur
DoT
dot.bortzmeyer.fr. Il explique ce qui est
garanti (ou pas), ce qui est journalisé (ou pas), etc. (Vous
pouvez également accéder à ce texte par
l'URL
https://doh.bortzmeyer.fr/policy .)
[If you don't read French, sorry, no translation is planned. But there are many other DoH resolvers available (or DoT), sometimes with policies in English.]
- Nouveauté du 7 novembre 2023 : le service DNS-over-QUIC.
- Nouveauté du 28 septembre 2021 : le service
.onion. - Nouveauté du 25 octobre 2020 : engagement de couper ECS.
- Nouveauté du 14 août 2020 : mention des statistiques agrégées.
Les protocoles DoH (DNS sur HTTPS), normalisé dans le RFC 8484, et DoT (DNS sur TLS), normalisé dans le RFC 7858, permettent d'avoir un canal sécurisé (confidentialité et intégrité) avec un résolveur DNS qu'on choisit. DoH est mis en œuvre dans plusieurs clients comme Mozilla Firefox. Ce texte n'est pas un mode d'emploi (qui dépend du client) mais une description de la politique suivie. La sécurisation du canal (par la cryptographie) vous protège contre un tiers mais évidemment pas contre le gérant du résolveur DoH ou DoT. C'est pour cela qu'il faut évaluer le résolveur DoH qu'on utilise, juger de la confiance à lui accorder, à la fois sur la base de ses déclarations, et sur la base d'une évaluation du respect effectif de ces déclarations. Cette politique suit à peu près les principes du RFC 8932.
Le résolveur DoH doh.bortzmeyer.fr et le
résolveur DoT dot.bortzmeyer.fr sont
gérés par moi. C'est un projet individuel, avec ce
que cela implique en bien ou en mal.
Ce résolveur :
- Est public (au sens du RFC 9499), ce qui veut dire que tout le monde peut l'utiliser,
- Est authentifiable par le nom dans le certificat, ou bien
par DANE (RFC 6698)
ou encore par l'épinglage de la clé qui vaut, pour le serveur
DoT,
eHAFsxc9HJW8QlJB6kDlR0tkTwD97X/TXYc1AzFkTFY=(en SHA-256/Base64, comme spécifié par le RFC 7858), - Outre les noms
doh.bortzmeyer.fretdot.bortzmeyer.fr, le serveur est accessible par les adresses IP193.70.85.11et2001:41d0:302:2200::180, que j'essaierai de ne pas changer (vous pouvez de toute façon les vérifier dans le DNS, la zone est signée avec DNSSEC) et est aussi accessible via un service.onion(Tor),lani4a4fr33kqqjeiy3qubhfx2jewfd3aeaepuwzxrx6zywp2mo4cjad.onion, - Est également accessible avec DoQ (DNS over
QUIC, RFC 9250), via le nom
doq.bortzmeyer.fr, mais c'est très expérimental et pas garanti, - N'offre aucune garantie de bon fonctionnement. Il est supervisé mais les ressources humaines et financières disponibles ne permettent pas de s'engager sur sa stabilité, comme l'a montré la panne des 13 et 14 août 2024. (Mais vous êtes bien sûr encouragé·e·s à signaler tous les problèmes ou limites que vous rencontreriez.)
- Accepte tous les clients gentils, mais avec une limitation de trafic (actuellement cent requêtes par seconde mais cela peut changer sans préavis). Les clients méchants pourraient se retrouver bloqués.
- N'enregistre pas du tout les requêtes DNS reçues. Elles ne
sont jamais mises en mémoire stable. Notez que la liste des
adresses IP des
clients (sauf si vous utilisez Tor), et celle des noms de
domaines demandés est gardée en mémoire
temporaire, et ne survit donc pas à un redémarrage du logiciel
serveur (ou a fortiori de la machine). Les deux listes sont
stockées séparément donc je peux voir que
2001:db8:99:fa4::1a fait une requête, ou que quelqu'un a demandétoto.example, mais je ne sais pas si c'est la même requête. - Et les requêtes complètes ne sont pas copiées vers un autre serveur. (Certaines politiques de serveurs disent « nous ne gardons rien » mais sont muettes sur l'envoi de copies à un tiers.) Notez que, pour faire son travail, le résolveur DoH doit bien transmettre une partie de la requête aux serveurs faisant autorité, mais cette partie est aussi minimisée que possible (RFC 9156), et ECS (RFC 7871) est coupé.
- Des statistiques fortement agrégées (comme « nombre total de requêtes de la semaine » ou bien « les TLD les plus demandés ») pourront être produites et publiées. Elles seront toujours suffisamment agrégées pour qu'il ne soit pas possible de retrouver les requêtes individuelles ou leur origine.
- Le résolveur ne ment pas, il transmet telles quelles les
réponses reçues des serveurs faisant autorité. Même des domaines
dangereux pour la vie privée comme
google-analytics.comsont traités de manière neutre. - Je suis sincère (si, si, faites-moi confiance) mais ce serveur dépend d'autres acteurs. C'est une simple machine virtuelle et l'hébergeur peut techniquement interférer avec son fonctionnement. C'est d'autant plus vrai que la machine est en France et donc soumise à diverses lois liberticides comme la loi Renseignement.
Comme indiqué plus haut, il s'agit d'un projet individuel, donc sa gouvernance est simple : c'est moi qui décide (mais, en cas de changement des règles, je modifierai cet article, et en changeant la date pour que les utilisateurices de la syndication aient la nouvelle version). Si cela ne vous convient pas, je vous suggère de regarder les autres serveurs DoH disponibles (plus il y en a, mieux c'est). Voyez aussi les serveurs DoT. En français, il existe aussi le serveur public de Shaft, avec une politique et une documentation utilisateur détaillée.
Et si vous êtes technicien·ne, j'ai également publié sur la mise en œuvre de ce résolveur.
L'article seul
Using the CowBoy HTTP server from an Elixir program
First publication of this article on 17 September 2019
Among the people who use the CowBoy HTTP server, some do it from an Erlang program, and some from an Elixir program. The official documentation only cares about Erlang. You can find some hints online about how to use CowBoy from Elixir but they are often outdated (CowBoy changed a lot), or assume that you use CowBoy with a library like Plug or a framework like Phoenix. Therefore, I document here how I use plain CowBoy, from Elixir programs, because it may help. This is with Elixir 1.9.1 and CowBoy 2.6.3.
I do not find a way to run CowBoy without the mix tool. So, I start with mix:
% mix new myserver
...
Your Mix project was created successfully.
I then add CowBoy dependencies to the mix.exs
file:
defp deps do
[
{:cowboy, "~> 2.6.0"}
]
end
(Remember that CowBoy changes a lot, and a lot of CowBoy examples you find online are for old versions. Version number is important. I used 2.6.3 for the examples here.) Then, get the dependencies:
% mix deps.get
...
cowboy 2.6.3
cowlib 2.7.3
ranch 1.7.1
...
We can now fill lib/myserver.ex with the main
code:
defmodule Myserver do
def start() do
dispatch_config = build_dispatch_config()
{ :ok, _ } = :cowboy.start_clear(:http,
[{:port, 8080}],
%{ env: %{dispatch: dispatch_config}}
)
end
def build_dispatch_config do
:cowboy_router.compile([
{ :_,
[
{"/", :cowboy_static, {:file, "/tmp/index.html"}}
]}
])
end
end
And that's all. Let's test it:
% iex -S mix
Erlang/OTP 22 [erts-10.4.4] [source] [64-bit] [smp:4:4] [ds:4:4:10] [async-threads:1]
Compiling 1 file (.ex)
Interactive Elixir (1.9.1) - press Ctrl+C to exit (type h() ENTER for help)
iex(1)> Myserver.start()
{:ok, #PID<0.197.0>}
iex(2)>
If you have HTML code in
/tmp/index.html, you can now use any
HTTP client such as
curl, lynx or
another browser, to visit
http://localhost:8080/.
The start_clear routine (which was
start_http in former versions) starts HTTP
(see its
documentation.) If you want explanation about the behaviour
:cowboy_static and its parameters like :file, see the CowBoy
documentation. If you are interested in routes (the
argument of :cowboy_router.compile, directives
for CowBoy telling it "if the request is for
/this, then do that"),
see also the
documentation. There are many other possibilities, for
instance, we could serve an entire directory:
def build_dispatch_config do
:cowboy_router.compile([
{ :_,
[
# Serve a single static file on the route "/".
{"/", :cowboy_static, {:file, "/tmp/index.html"}},
# Serve all static files in a directory.
# PathMatch is "/static/[...]" -- string at [...] will be used to look up the file
# Directory static_files is relative to the directory where you run the server
{"/static/[...]", :cowboy_static, {:dir, "static_files"}}
]}
])
end
You can now start from this and improve:
- Use
start_tlsinstead ofstart_clear, to provide security through HTTPS, - Replace
def start() dobydef start(_type, _args) do(ordef start(type, args) doif you want to use the parameters) to follow OTP conventions, in order for instance to run the HTTP server under a supervisor (see this example - untested), or simply to create a standalone application, - Serve dynamic content by using Elixir (or Erlang) modules to produce content on the fly.
L'article seul
IPv6 sur un VPS Arch Linux chez OVH
Première rédaction de cet article le 16 septembre 2019
Dernière mise à jour le 30 septembre 2019
L'hébergeur OVH a une offre nommée « VPS » (pour Virtual Private Server ») qui permet de disposer d'une machine virtuelle connectée à l'Internet, par exemple pour y héberger ses serveurs. Par défaut, on n'a que de l'IPv4 mais IPv6 est possible. Comme je n'ai pas trouvé de documentation qui marche pour le cas où la machine virtuelle tourne sous Arch Linux, je documente ici ma solution, pour que les utilisateurs des moteurs de recherche la trouvent.
Donc, le problème est le suivant. Soit un VPS OVH utilisant le système d'exploitation Arch Linux. Configuré et démarré, il n'a qu'une adresse IPv4 ce qui, en 2019, est inacceptable. OVH permet de l'IPv6, mais ce n'est pas configuré automatiquement par leur système « Cloud Init ». Il faut donc le faire soi-même. OVH documente la façon de faire mais Arch Linux n'y est pas mentionné. Du côté de ce système d'exploitation, IPv6 est documenté (il faut utiliser NetCtl). A priori, c'est simple, en utilisant les deux documentations, on devrait y arriver. Sauf que cela n'a pas marché, la machine, après redémarrage, n'a toujours pas d'adresse IPv6, et qu'il n'y a pas d'information de débogage disponible. Pas moyen de savoir où je me suis trompé.
Après une heure d'essais infructueux, je suis donc passé à une méthode simple et qui marche immédiatement : écrire un script shell de deux lignes et le faire exécuter au démarrage de la machine. Le script était simplement :
ip -6 addr add 2001:41d0:302:2200::180/128 dev eth0
ip -6 route add 2001:41d0:302:2200::1 dev eth0
ip -6 route add default via 2001:41d0:302:2200::1
Cette façon de faire est un peu bizarre, avec ce préfixe de longueur 128 (normalement, cela devrait être 64), qui oblige à mettre une route vers… le routeur, mais c'est cohérent avec ce qui est fait par défaut pour IPv4. Une solution plus propre aurait été :
ip -6 addr add 2001:41d0:5fa1:b49::180/64 dev eth0
ip -6 route add default via 2001:41d0:5fa1:b49::1
Et cela marche mais je ne suis pas sûr que cela permette de joindre les machines du même réseau.
Les adresses IP à utiliser (votre machine, et le routeur par défaut) sont obtenues via l'espace client (manager) de votre compte OVH, rubrique Serveur → VPS → IP.
Une fois ce script écrit, stocké en /usr/local/sbin/start-ipv6, et rendu exécutable, il reste à le
lancer au démarrage. Pour cela, je me sers de
systemd. Je crée un fichier
/etc/systemd/system/ipv6.service. Il
contient :
[Unit]
Description=Starts IPv6
After=systemd-networkd.service
Before=network.target
[Service]
ExecStart=/bin/true
ExecStartPost=/usr/local/sbin/start-ipv6
[Install]
WantedBy=multi-user.target
J'active ce service avec systemctl enable ipv6
et, au redémarrage de la machine, tout va bien et on a IPv6.
Sinon, Gilles Hamel me dit que ça marche pour lui avec Netplan (qui est en paquetage sur ArchLinux) et une configuration du genre :
% cat /etc/netplan/99-ipv6.yaml
network:
version: 2
ethernets:
eth0:
addresses:
- 2001:41d0:5fa1:b49::180/64
gateway6: 2001:41d0:5fa1:b49::1
Mais je n'ai pas testé.
L'article seul
« Entrée libre » à Quimper
Première rédaction de cet article le 12 septembre 2019
Du 27 au 29 août, à Quimper, s'est tenu l'évènement libriste « Entrée Libre ».
À cette occasion, j'avais préparé un exposé sur « Qu'est-ce qu'Internet ? ». Bien sûr, tout le monde connait l'Internet, mais sans savoir en général ce qui se passe derrière l'écran. Or, ce système pas directement visible peut avoir de sérieuses conséquences sur ce que l·e·a citoyen·ne peut faire sur l'Internet. Voici les supports de cet exposé, et leur source (en LaTeX). La vidéo, quant à elle, se trouve sur PennarWeb et sur Vimeo. (Oui, je sais, il faudrait aussi les mettre sur PeerTube.)
Il y avait également plein d'activités intéressantes, notamment des ateliers interactifs, et d'autres exposés passionnants (les vidéos sont sur Vimeo). Citons, entre autres, celle sur les données de santé, celle sur les logiciels libres pour les professionnels de la santé, celle sur Exodus Privacy.
Merci mille fois à Brigitte et à tous les bénévoles et salariés du Centre Social des Abeilles. (Et j'avais déjà eu le plaisir de venir à ce Centre des Abeilles.)
L'article seul
L'avenir de Salto
Première rédaction de cet article le 10 septembre 2019
Le 12 août dernier, les médias ont annoncé en fanfare le lancement de Salto, le « Netflix français », lancement déjà annoncé en juin 2018. En réalité, une étape (purement bureaucratique) a été franchie. Mais quel avenir attend Salto ?
Les réseaux sociaux ont déjà fait d'innombrables blagues sur ce projet caricatural : décisions d'en haut, ignorance abyssale de ce qui existe, mépris pour les problèmes concrets, Salto cumule en effet de quoi faire ricaner. Mais de quoi s'agit-il et quelles sont les chances de réussite de Salto ?
Autrefois, il y a bien longtemps, la télévision était diffusée par ondes hertziennes, captées par tous. Il n'y avait qu'une seule chaîne de télévision, dirigée par l'État. Le ministre de l'information officielle et gaulliste y dictait les sujets (« la télévision est la voix de la France »), et tout le monde obéissait. Paradoxalement, dans cet environnement si contrôlé, des échappées étaient possibles et quelques émissions créatives (comme les Shadoks) ont quand même pu éclore. Pas d'enregistrement possible, ni de télévision à la demande des anciennes émissions, la France s'asseyait donc aux heures imposées devant l'unique écran de la maison, et regardait. Puis le magnétoscope est arrivé, d'autres chaînes sont apparues, puis les entreprises privées en ont créé ou bien ont mis la main sur d'ex-chaînes publiques, et il y a eu beaucoup de choix, enfin au moins en apparence.
Après l'Internet s'est répandu et, logiquement, on s'est mis à diffuser de la télévision via l'Internet, même si tous les experts français de l'expertise étaient d'accord au début des années 1990 pour dire que cela ne serait jamais possible, qu'il fallait plutôt utiliser les technologies françaises. Le nombre d'écrans par foyer a explosé, comme le choix, plus réel cette fois, puisque, avec l'Internet, M. Michu peut non seulement « accéder à du contenu » mais en produire.
Comme d'habitude, les élites dirigeantes françaises ont mis du temps à comprendre et, plutôt que de se féliciter de ces nouvelles possibilités, ont tout fait pour les contrôler et les limiter. La création de la HADOPI est sans doute le plus bel exemple de cet aveuglement, partagé par tous les partis politiques officiels, et par les médias dominants. Entre autres, on a diabolisé le pair-à-pair, c'est-à-dire les techniques qui exploitaient le mieux les caractéristiques techniques de l'Internet. En voulant ainsi défendre les intérêts de l'industrie du divertissement nationale, on a donc laissé se développer des GAFA centralisés comme YouTube et, plus tard, Netflix. Aujourd'hui, les gens qui regardent « la télévision », le font en général via ces plate-formes Internet, sur un écran d'ordinateur ou d'ordiphone, et plus en s'asseyant devant « la télévision ». (Notez qu'il existe un gros fossé générationnel : TF1 reste très regardé, chez la frange la plus âgée de la population, ce qui fait du monde. Les chaînes de télévision traditionnelles déclinent, mais il faudra de nombreuses années pour qu'elles disparaissent complètement.)
Ajoutons aussi que, déconnecté des demandes des utilisateurs, on a également ajouté de plus en plus de publicité à la télé, comme si on cherchait à encourager la migration vers Netflix…
Là, des gens dans les sphères d'en haut ont fini par se dire qu'il y avait un problème. Netflix, qui repose sur un système d'abonnement, croît continuellement, et se fait « un pognon de dingue », et les jeunes ne savent même plus ce que c'est que de lire Télé 7 jours pour savoir à quelle heure commence le film. C'est là qu'est né le projet Salto, baptisé « le Netflix français ».
Bien sûr, la comparaison avec Netflix est absurde. Salto n'aura jamais un budget comparable, et même les plus optimistes ne le voient pas prendre une part non-microscopique de la part de marché de Netflix. Mais l'enflure verbale est souvent appréciée des politiques et des journalistes, transformant un projet peu enthousiasmant (les télévisions du passé s'unissent pour mourir un peu moins vite…) en une croisade tricolore contre la sous-culture yankee.
Une grande partie des critiques contre Salto ont porté sur le catalogue : c'est la grande force de Netflix, la disponibilité d'une étonnante quantité de contenus, très souvent d'origine étrangère aux États-Unis. (Quelle chaîne de télévision française aurait diffusé une série comme « 3 % » ?) Face à cette offre surabondante, les catalogues des créateurs de Salto, TF1, France Télévisions et M6 paraissent en effet bien pâles… (D'autant plus qu'il semble bien qu'on n'aura sur Salto qu'une petite partie du catalogue des membres du projet.) Je ne vais donc pas insister sur cette question du catalogue, bien qu'elle soit en effet cruciale. Et je vais plutôt parler de l'opérationnel, et de la gouvernance.
Il me semble qu'il y a un sérieux problème pratique : une plate-forme comme celle de Netflix est un défi permanent pour l'ingéniérie. Il faut distribuer la vidéo, qui est très gourmande et prend énormément de capacité, il va falloir d'innombrables serveurs pour héberger ces vidéos, du devops pour lier le tout et une interface humaine adaptée à des millions d'utilisateurs qui veulent juste que ça marche, et se détourneront vite de Salto s'il y a des problèmes techniques. C'est d'autant plus sérieux que Netflix a de nombreuses années d'avance, et a déjà beaucoup innové en ce domaine (comme avec leur célèbre - à juste titre - singe du chaos.) Jusqu'à présent, les responsables de Salto ont fait preuve d'une légèreté inquiétante dans ce domaine. Ils ne communiquent que sur des succès bureaucratiques (la signature de l'accord initial, l'approbation de l'Autorité de la concurrence…) et jamais sur le travail concret qui sera colossal. Affirmer que le projet avance alors que pas une seule ligne de code n'a été écrite est révélateur d'une certaine vision : celle qui ne connait que les réunions au sommet, et jamais les considérations opérationnelles. Le Monde parlait de l'« accouchement » du projet. Mais l'accouchement de quoi, puisque rien n'a encore été produit, il n'y a eu que réunions et paperasses. Le plus dur, avoir une plateforme technique qui fonctionne, reste à faire.
On peut être d'autant plus inquiet pour Salto que la France a vécu plusieurs mauvaises expériences de projets informatique comparables. On fait des réunions, on signe des papiers, et on oublie complètement la réalisation concrète. Des années après, le projet est une catastrophe et il faut fermer boutique. On se souvient de l'escroquerie qu'avait été le « cloud souverain », définitivement clos en juillet 2019 après des années de gaspillage. Ou bien le « Google européen » lancé par Chirac, Quaero. Citons aussi le ridicule projet « OS souverain » qui, lui, a heureusement sombré vite, avant de coûter trop cher. Et concernant la distribution de vidéos, la liste des échecs est longue. A priori, un des scénarios les plus probables pour Salto était que des millions de lignes de Java seraient écrites par une grosse ESN habituée des contrats, et que rien ne marcherait jamais vraiment techniquement. Un gros projet informatique est quelque chose de complexe, qui ne se fait pas juste en signant des papiers et en sous-traitant à une entreprise importante. Souvent, il vaut mieux faire appel à une petite équipe, ayant une vision claire et ne dépendant pas de cahiers des charges de milliers de pages.
Selon certaines sources (non officielles, on ne trouve rien sur https://www.salto.fr/https://www.6play.fr/
(Ce n'est pas un problème avec cette vidéo particulière, ça le fait pour toutes.)
Mais à part ces considérations pratiques, Salto a deux autres gros défauts, qui mettent sérieusement en danger le projet. L'un est son côté peu disruptif : il s'agit uniquement de copier Netflix, en plus petit et en moins bien. Battre un mastodonte comme Netflix, sans parler des autres entreprises qui vont tenter de faire la même chose comme Disney ou Warner, qui ont des projets similaires (Disney+ et HBO Max), est impossible si on se place sur le même terrain. Quand on n'a pas les moyens de Netflix (moyens financiers et humains), on n'essaie pas de lutter dans la même catégorie : on change de terrain. La distribution de vidéo depuis un service centralisé, comme Netflix ou Salto, est de toute façon une mauvaise façon d'utiliser l'Internet. Elle mène à des déséquilibres dans la répartition du trafic qui, à leur tour, mènent à des attaques contre la neutralité de l'Internet. La bonne solution, pour distribuer un contenu lourd en nombre de gigaoctets, est au contraire le pair-à-pair. Au lieu de laisser les ayant-trop-de-droits diaboliser ce mécanisme, il faudrait au contraire décentraliser au maximum la distribution, utilisant des petits services un peu partout au lieu de chercher à se faire aussi gros que le bœuf Netflix. Et ça tombe bien, il existe des solutions techniques pour cela, notamment le logiciel libre PeerTube, qui permet l'installation de plein de petits services partout, eux-même distribuant en pair-à-pair (grâce à WebTorrent) les vidéos. C'est ce genre de services, fondés sur le logiciel libre et le pair-à-pair que les pouvoirs publics devraient encourager et aider !
Certaines personnes qui défendent Salto estiment que toutes les critiques sont du « french bashing », de la critique systématique et masochiste de ce qui vient de France. Cet argument aurait plus de poids si Salto n'utilisait pas, pour son propre hébergement, un étranger (AWS) plutôt qu'un hébergeur français. Et PeerTube, que j'ai cité, est développé en France donc, si on veut vraiment faire du nationalisme, Salto n'est pas la bonne voie.
Outre ce problème technique, et ce manque d'intérêt pour les questions concrètes, Salto souffre d'un autre problème : il est entièrement conçu d'en haut, dans un entre-soi complet. Les gens qui connaissent vraiment Netflix, et/ou qui connaissent vraiment l'Internet, n'ont pas été consultés. (Tous et toutes auraient pu dire que le projet n'avait aucun sens.) Au lieu de discuter avec les personnes qui ont une expérience de l'Internet, Salto a été conçu dans des bureaux fermés, entre des dirigeants qui ne connaissent que la télé d'autrefois. Cela n'augure pas bien de son avenir.
En conclusion, mon pronostic est clair : Salto est fichu. Dans le meilleur des cas, il coulera vite. Dans le pire, cela durera des années, en engloutissant diverses aides et subventions pour « soutenir la création française » ou bien parce que « on ne peut pas laisser Netflix en numéro un ». Déjà, le gouvernement en est à menacer d'utiliser la contrainte (« S'ils ne le font pas, ils ne pourront plus être disponibles en France »), en annonçant que Netflix pourrait être censuré en France, ce qui montre bien que je ne suis pas le seul à être sceptique quant aux capacités de Salto.
Je ne changerai pas cet article dans le futur, vous pourrez donc voir en 2020 ou 2021 si j'avais raison…
Notez toutefois qu'une autre possibilité existe : derrière les rodomontades ridicules reprises en boucle par les médias (« faire un Netflix français »), il y a peut-être de tout autres projets, moins ambitieux. Par exemple, il est parfaitement possible que le vrai but de Salto soit de concurrencer Molotov plutôt que Netflix. Ou bien tout bêtement de remplacer l'accès aux émissions précédentes (replay) gratuit par un accès payant via Salto. Ce serait un objectif moins glorieux mais plus réaliste. Dans ce cas, le discours sur Netflix serait juste un écran de fumée.
Bon, j'ai fini cet article, je retourne regarder Arte.
L'article seul
RFC 8620: The JSON Meta Application Protocol (JMAP)
Date de publication du RFC : Juillet 2019
Auteur(s) du RFC : N. Jenkins (Fastmail), C. Newman (Oracle)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF jmap
Première rédaction de cet article le 6 septembre 2019
Le protocole JMAP, JSON Meta Application Protocol, permet de bâtir des mécanismes d'accès à des objets distants (par exemple des boîtes aux lettres, ou des agendas), en envoyant et recevant du JSON au dessus de HTTPS. Son principal « client » est le protocole « JMAP for mail », un concurrent d'IMAP normalisé dans le RFC 8621.
Au début, JMAP était même conçu uniquement pour l'accès au courrier, comme l'indique son nom, qui évoque IMAP. Mais, dans le cadre de la normalisation de JMAP, est apparu le désir de séparer le protocole générique, adapté à toutes sortes d'objets distants, du protocole spécifique du courrier. D'où les deux RFC : ce RFC 8620 normalise le protocole générique, alors que le RFC 8621 normalise « JMAP for mail ». Dans le futur, d'autres protocoles fondés sur JMAP apparaitront peut-être, par exemple pour l'accès et la synchronisation d'un agenda (en concurrence avec le CalDAV du RFC 4791, donc).
Parmi les concepts techniques importants de JMAP, notons :
- Utilisation de JSON (RFC 8259) pour encoder les données, parce que tout le monde utilise JSON aujourd'hui,
- Transport sur HTTPS (RFC 2818 et RFC 7230), là encore comme tout le monde aujourd'hui, avec toutes les propriétés de sécurité de HTTPS (notamment, le client JMAP doit authentifier le serveur, typiquement via un certificat),
- Possibilité de regrouper (batching) les requêtes en un seul envoi, pour les cas où la latence est élevée,
- Possibilité de notification par le serveur (push), pour éviter l'interrogation répétée par le client (polling),
- Un mécanisme de transfert incrémental des objets, pour limiter le débit sur le réseau.
Du fait de l'utilisation de JSON, il est bon de réviser le vocabulaire JSON, notamment le fait qu'un objet (object) JSON est en fait un dictionnaire.
Outre les types de données de base de JSON, comme les booléens,
les chaînes de caractères
et les entiers, JMAP définit quelques types à lui, notamment le
type Id, qui stocke l'identificateur d'un
objet. Syntaxiquement, c'est une chaîne de caractères
LDH (Letter-Digit-Hyphen, lettres ASCII, chiffres et trait d'union). Par exemple, dans le RFC 8621, la première boîte aux lettres mentionnée a comme
identificateur MB23cfa8094c0f41e6. Notre RFC
crée aussi le type Date, puisque JSON ne
normalise pas les dates. Ce type utilise le format du RFC 3339.
À ce stade, je peux avouer que j'ai fait un abus de langage. J'ai parlé de JSON mais en fait JMAP utilise un sous-ensemble de JSON, nommé I-JSON, et décrit dans le RFC 7493, afin d'éviter certaines ambiguités de JSON (section 8.4 de notre RFC). Tout le contenu échangé en JMAP doit être du I-JSON. D'ailleurs, si vous connaissez un logiciel libre qui vérifie qu'un texte JSON est du I-JSON, je suis preneur.
JMAP nécessite que le client se connecte au serveur (section 2 du RFC, sur la session). Pour cela, il lui faut l'URL du serveur (rappelez-vous que JMAP tourne sur HTTPS), qui peut être obtenu manuellement, ou par un processus de découverte décrit plus loin. Et il faut évidemment les moyens d'authentification (par exemple nom et phrase de passe), ceux-ci n'étant pas précisés dans notre RFC. Un mécanisme unique avait été prévu mais avait suscité trop de controverses à l'IETF. Finalement, les mécanismes utilisables sont ceux habituels de HTTPS (enregistrés à l'IANA). Lors de la connexion, le serveur va envoyer un objet JSON décrivant entre autres ses capacités, comme la taille maximale des objets téléversés, ou comme les extensions gérées (comme le « JMAP for mail » du RFC 8621). Voici un exemple (tiré du RFC, car je n'ai pas trouvé de serveur JMAP où je pouvais avoir facilement un compte pour tester, si vous en avez un, n'hésitez pas à m'écrire) :
{
"capabilities": {
"urn:ietf:params:jmap:core": {
"maxSizeUpload": 50000000,
"maxSizeRequest": 10000000,
...
"collationAlgorithms": [
"i;ascii-numeric",
"i;ascii-casemap",
"i;unicode-casemap"
]
},
"urn:ietf:params:jmap:mail": {}
"urn:ietf:params:jmap:contacts": {},
"https://example.com/apis/foobar": {
"maxFoosFinangled": 42
}
},
"accounts": {
"A13824": {
"name": "john@example.com",
"isPersonal": true,
"isReadOnly": false,
"accountCapabilities": {
"urn:ietf:params:jmap:mail": {
"maxMailboxesPerEmail": null,
"maxMailboxDepth": 10,
...
},
"urn:ietf:params:jmap:contacts": {
...
}
...
"apiUrl": "https://jmap.example.com/api/",
...
Notez que ce serveur annonce qu'il sait faire du JMAP pour le
courrier (RFC 8621, cf. la ligne
urn:ietf:params:jmap:mail) et qu'il a
également une extension privée,
https://example.com/apis/foobar. Les
capacités publiques sont dans un registre
IANA. On peut ajouter des capacités par la procédure
(cf. RFC 8126) « Spécification nécessaire »
pour les capacités marquées « fréquentes »
(common), et par la procédure « Examen par un
expert » pour les autres.
La méthode standard pour découvrir le serveur JMAP, si on n'en
connait pas l'URL, est d'utiliser un enregistrement
SRV (RFC 2782, mais voir aussi
le RFC 6186) puis un URL bien
connu. Imaginons que le domaine soit
example.net. On cherche le SRV pour
_jmap._tcp.example.net. (jmap
a donc été ajouté au registre des
services.) On récupère alors le
nom du serveur et le port (a priori, ce
sera 443, le port standard de HTTPS). Et on n'a plus qu'à se
connecter à l'URL bien connu (RFC 8615), à
https://${hostname}[:${port}]/.well-known/jmap.
jmap figure à cet effet dans le registre des URL bien connus. (Notez
que l'étape SRV est facultative, certains clients iront
directement au /.well-known/jmap.) Ainsi, si vous utilisez JMAP pour le courrier, et que votre
adresse est gerard@example.net, vous partez
du domaine example.net et vous suivez
l'algorithme ci-dessus. (Je ne sais pas pourquoi JMAP n'utilise
pas plutôt le WebFinger du RFC 7033.)
Puisqu'on utilise le DNS pour récupérer ces enregistrements SRV, il est évidemment recommandé de déployer DNSSEC.
Une fois qu'on a récupéré le premier objet JSON décrit plus
haut, on utilise la propriété (le membre, pour parler JSON) apiUrl de cet
objet pour faire les requêtes suivantes (section 3 du RFC). On utilise la méthode
HTTP POST, le type
MIME application/json, et on
envoie des requêtes en JSON, qui seront suivies de réponses du
serveur, également en JSON. Les méthodes JMAP (à ne pas confondre
avec les méthodes HTTP comme GET ou
POST) sont écrites sous la forme
Catégorie/Méthode. Il existe une catégorie
Core pour les méthodes génériques de JMAP et
chaque protocole utilisant JMAP définit sa (ou ses) propre(s)
catégorie(s). Ainsi, le RFC 8621 définit les
catégories Mailbox,
Email (un message), etc. Comme
Core définit une méthode
echo (section 4, le ping de
JMAP), qui ne fait que renvoyer les données, sans les comprendre, un exemple de requête/réponse peut
être :
[[ "Core/echo", {
"hello": true,
"high": 5
}, "b3ff" ]]
[[ "Core/echo", {
"hello": true,
"high": 5
}, "b3ff" ]]
(Oui, la réponse - le second paragraphe - est identique à la question.)
En cas d'erreur, le serveur devrait renvoyer un objet décrivant le problème, en utilisant la syntaxe du RFC 7807. Une liste des erreurs connues figure dans un registre IANA.
Il existe des noms de méthodes standard qu'on retrouve dans
toutes les catégories, comme get. Si on a une
catégorie Foo décrivant un certain type
d'objets, le client sait qu'il pourra récupérer les objets de ce
type avec la méthode Foo/get, les modifier
avec Foo/set et récupérer uniquement les
modifications incrémentales avec
Foo/changes. La section 5 du RFC décrit ces
méthodes standard.
Une méthode particulièrement utile est
query (section 5.5). Elle permet au client de demander au
serveur de faire une recherche et/ou un tri des objets. Au lieu de
tout télécharger et de faire recherche et tri soi-même, le client
peut donc sous-traiter cette opération potentiellement
coûteuse. Cette méthode est une de celles qui permet de dire que
JMAP est bien adapté aux machines clientes disposant de faibles
ressources matérielles, et pas très bien connectées. Le RFC cite
(section 5.7) un type (imaginaire) Todo
décrivant des tâches à accomplir, et l'exemple avec
query permet d'illustrer le membre
filter de la méthode, pour indiquer les
critères de sélection :
[[ "Todo/query", {
"accountId": "x",
"filter": {
"operator": "OR",
"conditions": [
{ "hasKeyword": "music" },
{ "hasKeyword": "video" }
]
}
}
]]
Comme beaucoup de méthodes JMAP, query peut
imposer un travail important au serveur. Un client maladroit, ou
cherchant déliberement à créer une attaque par déni de
service pourrait planter un serveur trop léger. Les
serveurs JMAP doivent donc avoir des mécanismes de protection,
comme une limite de temps passé sur chaque requête.
On l'a dit, un des intérêts de JMAP est la possibilité d'obtenir des notifications du serveur, sans obliger le client à vider sa batterie en interrogeant périodiquement le serveur. La section 7 du RFC détaille ce mécanisme. Deux alternatives pour le client : garder la connexion HTTPS ouverte en permanence, pour y recevoir ces notifications, ou bien utiliser un service tiers comme celui de Google. Notons que ces notifications, par leur seule existence, même si le canal est chiffré, peuvent révéler des informations. Comme noté dans la revue du protocole par la direction Sécurité à l'IETF "I.e., if someone can see that wikileaks smtp server sends email to corporate smtp server, but the smtp traffic is encrypted so they do not know the recipient of the email, but then few seconds later see push event notification stream going to the Joe's laptop indicating something has happened in his mail box, they can find out the who the recipient was.".
Il existe une page « officielle » présentant le protocole et plusieurs mises en oeuvre (actuellement, la plupart sont, expérimentales et/ou en cours de développement). C'est une des raisons pour lesquelles je ne présente pas ici d'essais réels. Notez toutefois que Fastmail a du JMAP en production.
L'article seul
RFC 8618: Compacted-DNS (C-DNS): A Format for DNS Packet Capture
Date de publication du RFC : Septembre 2019
Auteur(s) du RFC : J. Dickinson (Sinodun), J. Hague (Sinodun), S. Dickinson (Sinodun), T. Manderson (ICANN), J. Bond (ICANN)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 4 septembre 2019
Lorsque l'opérateur d'un service DNS veut conserver les données de trafic, il peut demander au serveur d'enregistrer requêtes et réponses (mais, la plupart du temps, le serveur n'écrit qu'une petite partie des informations) ou bien écouter le trafic réseau et enregistrer le pcap. Le problème est que le format pcap prend trop de place, est de trop bas niveau (une connexion TCP, par exemple, va être éclatée en plusieurs paquets), et qu'il est difficile de retrouver les informations spécifiquement DNS à partir d'un pcap. D'où la conception de ce format de stockage, spécifique au DNS, et qui permet d'enregistrer la totalité de l'information, dans un format optimisé en taille et de plus haut niveau. C-DNS s'appuie sur CBOR pour cela.
Le DNS est un service d'infrastructure absolument critique. Il est donc nécessaire de bien le connaitre et de bien l'étudier. Cela passe par une récolte de données, en l'occurrence le trafic entrant et sortant des serveurs DNS, qu'ils soient des résolveurs ou bien des serveurs faisant autorité. Ce genre de récolte peut être coordonnée par l'OARC pour des projets comme DITL (« un jour dans la vie de l'Internet »). Un exemple d'une telle récolte, faite avec le classique tcpdump (qui, en dépit de son nom, ne fait pas que du TCP) :
% tcpdump -w /tmp/dns.pcap port 53
Le fichier produit (ici, sur un serveur faisant autorité pour
eu.org), au format
pcap, contient les requêtes DNS et les
réponses, et peut être analysé avec des outils comme tcpdump
lui-même, ou comme Wireshark. Il y a aussi
des outils spécifiques au DNS comme PacketQ ou comme
dnscap. Ici,
avec tcpdump :
% tcpdump -n -r /tmp/dns.pcap
15:35:22.432746 IP6 2001:db8:aa:101::.40098 > 2400:8902::f03c:91ff:fe69:60d3.53: 41209% [1au] A? tracker.torrent.eu.org. (51)
15:35:22.432824 IP6 2400:8902::f03c:91ff:fe69:60d3.53 > 2001:db8:aa:101::.40098: 41209- 0/4/5 (428)
Au lieu des outils tous faits, on peut aussi développer ses propres programmes en utilisant les nombreuses bibliothèques qui permettent de traiter du pcap (attention si vous analysez du trafic Internet : beaucoup de paquets sont mal formés, par accident ou bien délibérément, et votre analyseur doit donc être robuste). C'est ce que font en général les chercheurs qui analysent les données DITL.
Le problème du format pcap (ou pcapng) est qu'il y a à la fois trop de données et pas assez. Il y a trop de données car il inclut des informations probablement rarement utiles, comme les adresses MAC et car il ne minimise pas les données. Et il n'y en a pas assez car il ne stocke pas les informations qui n'étaient pas visibles sur le réseau mais qui l'étaient uniquement dans la mémoire du serveur DNS. Ainsi, on ne sait pas si la réponse d'un résolveur avait été trouvée dans le cache ou pas. Ou bien si les données étaient dans le bailliage ou pas (cf. RFC 8499, section 7). Les captures DNS peuvent être de très grande taille (10 000 requêtes par seconde est banal, 100 000, ça arrive parfois) et on désire les optimiser autant que possible, pour permettre leur rapatriement depuis les serveurs éloignés, puis leur stockage parfois sur de longues périodes. (Les formats « texte » comme celui du RFC 8427 ne conviennent que pour un message isolé, ou un tout petit nombre de messages.)
Le cahier des charges du format C-DNS (Compacted DNS) est donc :
- Minimiser la taille des données,
- Minimiser le temps de traitement pour compacter et décompacter.
La section du RFC détaille les scénarios d'usage de C-DNS. En effet, la capture de données DNS peut être faite dans des circonstances très différentes. Le serveur peut être une machine physique, une virtuelle, voire un simple conteneur. La personne qui gère le capture peut avoir le contrôle des équipements réseau (un commutateur, par exemple, pour faire du port mirroring), le serveur peut être surdimensionné ou, au contraire, soumis à une attaque par déni de service qui lui laisse peu de ressources. Le réseau de collecte des données capturées peut être le même que le réseau de service ou bien un réseau différent, parfois avec une capacité plus faible. Bref, il y a beaucoup de cas. C-DNS est optimisé pour les cas où :
- La capture des données se fait sur le serveur lui-même, pas sur un équipement réseau,
- Les données seront stockées localement, au moins temporairement, puis analysées sur une autre machine.
Donc, il est crucial de minimiser la taille des données récoltées. Mais il faut aussi faire attention à la charge que représente la collecte : le serveur de noms a pour rôle de répondre aux requêtes DNS, la collecte est secondaire, et ne doit donc pas consommer trop de ressources CPU.
Compte-tenu de ces contraintes, C-DNS a été conçu ainsi (section 4 du RFC) :
- L'unité de base d'un fichier C-DNS est le couple R/R, {requête DNS, réponse DNS} (Q/R data item), ce qui reflète le fonctionnement du protocole DNS, et permet d'optimiser le stockage, puisque bien des champs ont des valeurs communes entre une requête et une réponse (par exemple le nom de domaine demandé). Notez qu'un couple R/R peut ne comporter que la requête, ou que la réponse, si l'autre n'a pas pu être capturée, ou bien si on a décidé délibérément de ne pas le faire.
- C-DNS est optimisé pour les messages DNS syntaxiquement corrects. Quand on écrit un analyseur de paquets DNS, on est frappés du nombre de messages incorrects qui circulent sur le réseau. C-DNS permet de les stocker sous forme d'un « blob » binaire, mais ce n'est pas son but principal, il ne sera donc efficace que pour les messages corrects.
- Pratiquement toute les données sont optionnelles dans C-DNS. C'est à la fois pour gagner de la place, pour tenir compte du fait que certains mécanismes de capture ne gardent pas toute l'information, et pour permettre de minimiser les données afin de préserver la vie privée.
- Les couples R/R sont regroupés en blocs, sur la base d'élements communs (par exemple l'adresse IP source, ou bien la réponse, notamment les NXDOMAIN), qui permettent d'optimiser le stockage, en ne gardant cet élément commun qu'une fois par bloc. (Par contre, cela complexifie les programmes. On n'a rien sans rien.)
C-DNS repose sur CBOR (RFC 8949). La section 5 du RFC explique pourquoi :
- Format binaire, donc prenant moins d'octets que les formats texte comme JSON (l'annexe C discute des autres formats binaires),
- CBOR est un format normalisé et répandu,
- CBOR est simple et écrire un analyseur peut se faire facilement, si on ne veut pas dépendre d'une bibliothèque extérieure,
- CBOR a désormais un langage de schéma, CDDL (RFC 8610), qu'utilise notre RFC.
Avec la section 6 du RFC commence la description du
format. Classiquement, un fichier C-DNS commence par un en-tête,
puis une série de blocs. Chaque bloc comprend un certain nombre de
tables (par exemple une table d'adresses IP pour les adresses
apparaissant dans le bloc), suivies des éléments R/R. Ceux-ci
référencent les tables. Ainsi, une requête de
2001:db8:1::cafe à
2001:db8:ffff::beef pour le nom
www.example.org contiendra des pointeurs vers
les entrées 2001:db8:1::cafe et
2001:db8:ffff::beef de la table des adresses
IP, et un pointeur vers l'entrée
www.example.org de la table des noms de
domaine. S'il n'y a qu'un seul élément R/R dans le bloc, ce serait
évidemment une complication inutile, mais l'idée est de factoriser
les données qui sont souvent répétées.
On l'a vu, dans C-DNS, plein de choses sont optionnelles, car deux dispositifs de capture différents ne récoltent pas forcément les mêmes données. Ainsi, par exemple, un système de capture situé dans le logiciel serveur n'a pas forcément accès à la couche IP et ne peut donc pas enregistrer le nombre maximal de sauts (hop limit). Cela veut dire que, quand on lit un fichier C-DNS :
- Il faut déterminer si une donnée est présente ou pas, et ne pas supposer qu'elle l'est forcément,
- Il peut être utile de déterminer si une donnée manquante était absente dès le début, ou bien si elle a été délibérément ignorée par le système de capture. Si un message ne contient pas d'option EDNS (RFC 6891), était-ce parce que le message n'avait pas cette option, ou simplement parce qu'on ne s'y intéressait pas et qu'on ne l'a pas enregistrée ?
C-DNS permet donc d'indiquer quels éléments des données initiales ont été délibérément ignorés. Cela permet, par exemple, à un programme de lecture de fichiers C-DNS de savoir tout de suite si le fichier contient les informations qu'il veut.
Ces indications contiennent aussi des informations sur un
éventuel échantillonnage (on n'a gardé que
X % des messages), sur une éventuelle normalisation (par exemple
tous les noms de domaine passés en caractères minuscules) ou sur
l'application de techniques de minimisation, qui permettent de
diminuer les risques pour la vie
privée. Par exemple, au lieu de stocker les adresses IP complètes, on peut ne
stocker qu'un préfixe (par exemple un /32 au lieu de l'adresse
complète), et il faut alors l'indiquer dans le fichier C-DNS
produit, pour que le lecteur comprenne bien que
2001:db8:: est un préfixe, pas une
adresse.
La section 7 du RFC contient ensuite le format détaillé. Quelques points sont à noter (mais, si vous écrivez un lecteur C-DNS, lisez bien tout le RFC, pas juste mon article !) Ainsi, toutes les clés des objets (maps) CBOR sont des entiers, jamais des chaînes de caractère, pour gagner de la place. Et ces entiers sont toujours inférieurs à 24, pour tenir sur un seul octet en CBOR (lisez le RFC 8949 si vous voulez savoir pourquoi 24). On peut aussi avoir des clés négatives, pour les extensions au format de base, et elles sont comprises entre -24 et -1.
La syntaxe complète, rédigée dans le format CDDL du RFC 8610, figure dans l'annexe A de notre RFC.
On peut reconstruire un fichier pcap à partir de C-DNS. Une des difficultés est qu'on n'a pas forcément toutes les informations, et il va donc falloir être créatif (section 9). Une autre raison fait qu'on ne pourra pas reconstruire au bit près le fichier pcap qui aurait été capturé par un outil comme tcpdump : les noms de domaines dans les messages DNS étaient peut-être comprimés (RFC 1035, section 4.1.4) et C-DNS n'a pas gardé d'information sur cette compression. (Voir l'annexe B pour une discussion détaillée sur la compression.) Pareil pour les informations de couche 3 : C-DNS ne mémorise pas si le paquet UDP était fragmenté, s'il était dans un ou plusieurs segments TCP, s'il y avait des messages ICMP liés au trafic DNS, etc.
Si vous voulez écrire un lecteur ou un producteur de C-DNS, la section 11 du RFC contient des informations utiles pour la programmeuse ou le programmeur. D'abord, lisez bien le RFC 8949 sur CBOR. C-DNS utilise CBOR, et il faut donc connaitre ce format. Notamment, la section 3.9 du RFC 7049 donne des conseils aux implémenteurs CBOR pour produire un CBOR « canonique ». Notre RFC en retient deux, représenter les entiers, et les types CBOR, par la forme la plus courte possible (CBOR en permet plusieurs), mais il en déconseille deux autres. En effet, la section 3.9 du RFC 7049 suggérait de trier les objets selon la valeur des clés, et d'utiliser les tableaux de taille définie (taille indiquée explicitement au début, plutôt que d'avoir un marqueur de fin). Ces deux conseils ne sont pas réalistes pour le cas de C-DNS. Par exemple, pour utiliser un tableau de taille définie, il faudrait tout garder en mémoire jusqu'au moment où on inscrit les valeurs, ce qui augmenterait la consommation mémoire du producteur de données C-DNS. (D'un autre côté, le problème des tableaux de taille indéfinie est qu'ils ont un marqueur de fin ; si le programme qui écrit du C-DNS plante et ne met pas le marqueur de fin, le fichier est du CBOR invalide.)
Le RFC a créé plusieurs registres IANA pour ce format, stockant notamment les valeurs possibles pour le transport utilisé, pour les options de stockage (anonymisé, échantillonné...), pour le type de réponse (issue de la mémoire du résolveur ou pas).
Bien sûr, récolter des données de trafic DNS soulève beaucoup de problèmes liés à la vie privée (cf. RFC 7626). Il est donc recommander de minimiser les données, comme imposé par des réglements comme le RGPD, ou comme demandé dans le rapport « Recommendations on Anonymization Processes for Source IP Addresses Submitted for Future Analysis ».
Les passionnés de questions liées aux formats regarderont l'annexe C, qui liste des formats alternatifs à CBOR, qui n'ont finalement pas été retenus :
- Apache Avro, trop complexe car on ne peut lire les données qu'en traitant le schéma,
- Protocol Buffers, qui a le même problème,
- JSON (RFC 8259), qui n'est pas un format binaire, mais qui a été ajouté pour compléter l'étude.
Cette annexe décrit également le résultat de mesures sur la compression obtenue avec divers outils, sur les différents formats. C-DNS n'est pas toujours le meilleur, mais il est certainement, une fois comprimé, plus petit que pcap, et plus simple à mettre en œuvre qu'Avro ou Protocol Buffers.
Notez que j'ai travaillé sur ce format lors d'un hackathon de l'IETF, mais le format a pas mal changé depuis (entre autres en raison des problèmes identifiés lors du hackathon).
Voyons maintenant une mise en œuvre de ce format, avec l'outil DNS-STATS plus exactement son Compactor (source sur Github, et documentation). Je l'ai installé sur une machine Debian :
aptitude install libpcap-dev libboost1.67-all-dev liblzma-dev libtins-dev
git clone https://github.com/dns-stats/compactor.git
cd compactor
sh autogen.sh
autoconf
automake
./configure
make
Et après, on peut l'utiliser pour transformer du C-DNS en pcap et
réciproquement. J'ai créé un fichier pcap d'un million de paquets
avec tcpdump sur un serveur faisant autorité, avec tcpdump -w
dns.pcap -c 1000000 port 53. Puis :
% ./compactor -o /tmp/dns.cdns /tmp/dns.pcap
Et en sens inverse (reconstituer le pcap) :
% ./inspector /tmp/dns.cdns
Cela nous donne :
% ls -lth /tmp/dns*
-rw-r--r-- 1 stephane stephane 98M Jul 31 08:13 /tmp/dns.cdns.pcap
-rw-r--r-- 1 stephane stephane 3.2K Jul 31 08:13 /tmp/dns.cdns.pcap.info
-rw-r--r-- 1 stephane stephane 27M Jul 31 07:27 /tmp/dns.cdns
-rw-r--r-- 1 root root 339M Jul 30 20:05 /tmp/dns.pcap
Notez que dns.cdns.pcap est le pcap reconstitué, on
remarque qu'il est plus petit que le pcap original, certaines
informations ont été perdues, comme les adresses MAC. Mais il reste bien plus gros que la même
information stockée en C-DNS. Le
/tmp/dns.cdns.pcap.info nous donne quelques informations :
% cat /tmp/dns.cdns.pcap.info CONFIGURATION: Query timeout : 5 seconds Skew timeout : 10 microseconds Snap length : 65535 Max block items : 5000 File rotation period : 14583 Promiscuous mode : Off Capture interfaces : Server addresses : VLAN IDs : Filter : Query options : Response options : Accept RR types : Ignore RR types : COLLECTOR: Collector ID : dns-stats-compactor 0.12.3 Collection host ID : ns1.example STATISTICS: Total Packets processed : 1000000 Matched DNS query/response pairs (C-DNS) : 484407 Unmatched DNS queries (C-DNS) : 98 Unmatched DNS responses (C-DNS) : 69 Malformed DNS packets : 68 Non-DNS packets : 0 Out-of-order DNS query/responses : 1 Dropped C-DNS items (overload) : 0 Dropped raw PCAP packets (overload) : 0 Dropped non-DNS packets (overload) : 0
L'article seul
RFC 8615: Well-Known Uniform Resource Identifiers (URIs)
Date de publication du RFC : Mai 2019
Auteur(s) du RFC : M. Nottingham
Chemin des normes
Première rédaction de cet article le 3 septembre 2019
Plusieurs normes du Web s'appuient sur l'existence d'un fichier à un
endroit bien connu d'un site. Les deux exemples les plus connus sont
robots.txt et
favicon.ico. Autrefois, ces
endroits « bien connus » étaient alloués sans schéma
central. Depuis le RFC 5785, c'est mieux
organisé, avec tous ces fichiers « sous »
/.well-known/. Notre
RFC remplace le RFC 5785 (et le RFC 8307), avec peu de
changements significatifs.
Prenons l'exemple le plus connu,
robots.txt, fichier
stockant la politique d'autorisation des robots qui fouillent le Web. Si un robot examine le site
Web http://www.example.org/, il va tenter de
trouver ledit fichier en
http://www.example.org/robots.txt. Même chose
pour, par exemple, sitemap.xml ou P3P (section 1
du RFC). Ce système avait plusieurs inconvénients, notamment le
risque de collision entre deux noms (puisqu'il n'y avait pas de
registre de ces noms) et, pire, le risque de collision entre un de
ces noms et une ressource normale du site. D'où l'importance d'un
« rangement » de ces ressources bien connues. Elles doivent
dorénavant être préfixées de
/.well-known/. Ainsi, si le protocole
d'autorisation des robots était normalisé aujourd'hui, on
récupérerait la politique d'autorisation en
http://www.example.org/.well-known/robots.txt.
À noter que le RFC spécifie uniquement un
préfixe pour le chemin de la ressource,
/.well-known/ n'est pas forcément un
répertoire sur le disque du serveur (même si
c'est une mise en œuvre possible).
Le RFC 8615 note aussi qu'il existe déjà des mécanismes de récupération de métadonnées par ressource (comme les en-têtes de HTTP ou les propriétés de WebDAV) mais que ces mécanismes sont perçus comme trop lourds pour remplacer la ressource unique située en un endroit bien connu.
Le nom .well-known avait été choisi
(cf. annexe A de notre RFC) car il
avait peu de chances de rentrer en conflit avec un nom existant
(traditionnellement, sur Unix,
système d'exploitation le plus utilisé sur
les serveurs Web, les fichiers dont le nom commencent par un point
ne sont pas affichés).
Bref, passons à la section 3 qui donne les détails
syntaxiques. Le préfixe est donc /.well-known/,
les noms en « dessous » doivent être enregistrés (cf. section
5.1), et ils doivent se conformer à la production
segment-nz du RFC 3986
(en clair, cela veut dire qu'ils doivent être une suite de
caractères ASCII imprimables, avec quelques
exclusions comme la barre oblique). Du
point de vue sémantique, ils doivent être précis, pour éviter
l'appropriation de termes génériques (par exemple, l'application
Toto qui veut stocker ses métadonnées
devrait utiliser toto-metadata et pas juste
metadata.) À noter que l'effet d'une requête
GET /.well-known/ (tout court, sans nom de
ressource après), est indéfini (sur mon blog, cela donne ça ; devrais-je le configurer pour
renvoyer autre chose ? Sur Mastodon, ça donne 404.)
Quelques conseils de sécurité pour le webmestre (section 4) : ces ressources « bien connues » s'appliquent à une origine (un « site Web ») entière, donc attention à contrôler qui peut les créer ou les modifier, et d'autre part, dans le contexte d'un navigateur Web, elles peuvent être modifiées par du contenu, par exemple JavaScript.
La section 5 décrit les conditions d'enregistrement des noms bien connus à l'IANA. Le registre contient par exemple les métadonnées du RFC 6415. Y mettre des noms supplémentaires nécessite un examen par un expert et une description publiée (pas forcément un RFC). Dans les termes du RFC 8126, ce sera Spécification Nécessaire et Examen par un Expert. Il y a un mini-formulaire à remplir (section 3.1 du RFC) et hop, le nom bien connu sera enregistré (mais lisez les conseils avant). Plusieurs existent désormais.
Notez qu'il est très difficile de savoir combien de sites ont
des ressources /.well-known. Bien sûr,
Google
le sait, mais ne
donne pas accès à cette information (une requête
inurl:/.well-known ou
inurl:"/.well-known" ignore hélas le point
initial et trouve donc surtout des faux positifs). Si on n'a pas
accès à la base de Google, il faudrait donc faire soi-même une
mesure active avec un client HTTP qui aille visiter de nombreux
sites.
Les changements depuis le RFC 5785 sont résumés dans l'annexe B du RFC :
- Les plans d'URI pour WebSocket, du RFC 8307, ont été intégrés,
- D'ailleurs, le préfixe
/.well-known/n'est plus réservé au Web, il peut être utilisé pour d'autres plans d'URI, ce qui a modifié le registre des plans pour y ajouter une colonne indiquant s'ils permettent ce préfixe (section 5.2), - Les instructions pour l'enregistrement d'un nouveau nom ont été légèrement assouplies,
- La section sur la sécurité est nettement plus détaillée.
L'article seul
RFC 8624: Algorithm Implementation Requirements and Usage Guidance for DNSSEC
Date de publication du RFC : Juin 2019
Auteur(s) du RFC : P. Wouters (Red Hat), O. Sury (Internet Systems Consortium)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 2 septembre 2019
Quel algorithme de cryptographie choisir pour mes signatures DNSSEC, se demande l'ingénieur système. Lesquels doivent être reconnus par le logiciel que j'écris, s'interroge la programmeuse. Il y a bien un registre IANA des algorithmes normalisés mais c'est juste une liste non qualifiée, qui mêle des algorithmes de caractéristiques très différentes. Ce nouveau RFC vise à répondre à cette question en disant quels sont les algorithmes recommandés. Il remplace l'ancien RFC 6944, qui est modifié considérablement. Notamment, il marque l'avantage désormais donné aux courbes elliptiques par rapport à RSA. Et il a depuis été remplacé par le RFC 9904.
La précédente liste d'algorithmes possibles datait donc du RFC 6944. D'autres algorithmes ont été ajoutés par la suite. Certains sont devenus populaires. Par exemple, ECDSA est maintenant suffisamment répandu pour qu'un résolveur validant ne puisse plus raisonnablement l'ignorer. D'autres algorithmes ont été peu à peu abandonnés, par exemple parce que les progrès de la cryptanalyse les menaçaient trop.
Aujourd'hui, le développeur qui écrit ou modifie un signeur (comme ldns, utilisé par OpenDNSSEC) ou un logiciel résolveur validant (comme Unbound ou Knot) doit donc se taper pas mal de RFC mais aussi pas mal de sagesse collective distillée dans plusieurs listes de diffusion pour se faire une bonne idée des algorithmes que son logiciel devrait gérer et de ceux qu'il peut laisser tomber sans trop gêner ses utilisateurs. Ce RFC vise à lui simplifier la tâche, en classant ces algorithmes selon plusieurs niveaux.
Notre RFC 8624 détermine pour chaque algorithme s'il est indispensable (MUST, nécessaire pour assurer l'interopérabilité), recommandé (RECOMMENDED, ce serait vraiment bien de l'avoir, sauf raison contraire impérieuse), facultatif (MAY, si vous n'avez rien d'autre à faire de vos soirées que de programmer) ou tout simplement déconseillé (NOT RECOMMENDED), voire à éviter (MUST NOT, pour le cas de faiblesses cryptographiques graves et avérées). Il y a deux catégorisations, une pour les signeurs (le cas de l'administratrice système cité au début), et une pour les résolveurs qui valideront. Par exemple, un signeur ne devrait plus utiliser RSA avec SHA-1, vu les faiblesses de SHA-1, mais un résolveur validant doit toujours le traiter, car des nombreux domaines sont ainsi signés. S'il ignorait cet algorithme, bien des zones seraient considérées comme non signées.
La liste qualifiée des algorithmes se trouve dans la section 3 : ECDSA avec la courbe P-256, et RSA avec SHA-256, sont les seuls indispensables pour les signeurs. ED25519 (RFC 8080) est recommandé (et sera probablement indispensable dans le prochain RFC). Plusieurs algorithmes sont à éviter, comme DSA, GOST R 34.10-2001 (RFC 5933) ou RSA avec MD5 (RFC 6151). Tous les autres sont facultatifs.
Pour les résolveurs validants, la liste des indispensables et des recommandés est un peu plus longue. Par exemple, ED448 (RFC 8080) est facultatif pour les signeurs mais recommandé pour les résolveurs.
La même section 3 justifie ces choix : RSA+SHA-1 est l'algorithme de référence, celui qui assure l'interopérabilité (tout logiciel compatible DNSSEC doit le mettre en œuvre) et c'est pour cela qu'il reste indispensable pour les résolveurs, malgré les faiblesses de SHA-1. RSA+SHA-256 est également indispensable car la racine et la plupart des TLD l'utilisent aujourd'hui. Un résolveur qui ne comprendrait pas ces algorithmes ne servirait pas à grand'chose. RSA+SHA-512 ne pose pas de problème de sécurité, mais a été peu utilisé, d'où son statut « non recommandé » pour les signeurs.
D'autre part, le RFC insiste sur le fait qu'on ne peut pas changer le statut d'un algorithme trop vite : il faut laisser aux ingénieurs système le temps de changer leurs zones DNS. Et les résolveurs sont forcément en retard sur les signeurs : même si les signeurs n'utilisent plus un algorithme dans leurs nouvelles versions, les résolveurs devront continuer à l'utiliser pour valider les zones pas encore migrées.
Depuis le RFC 6944, ECDSA a vu son utilisation augmenter nettement. Les courbes elliptiques sont clairement l'avenir, d'où leur statut mieux placé. Ainsi, une zone DNS qui n'était pas signée et qui va désormais l'être devrait choisir un algorithme à courbes elliptiques, comme ECDSA ou EdDSA (RFC 8032 et RFC 8080). Avec ECDSA, il est recommandé d'utiliser l'algorithme déterministe du RFC 6979 pour générer les signatures. Les zones actuellement signées avec RSA devraient migrer vers les courbes elliptiques. Une chose est sûre, la cryptographie évolue et ce RFC ne sera donc pas éternel.
Le RFC note d'ailleurs (section 5) que le remplacement d'un algorithme cryptographique par un autre (pas juste le remplacement d'une clé) est une opération complexe, à faire avec prudence et après avoir lu les RFC 6781 et RFC 7583.
Ah, et parmi les algorithmes à courbes elliptiques, GOST (RFC 5933) régresse
car l'ancien algorithme R 34.10-2001 a été remplacé par un nouveau qui n'est
pas, lui, normalisé pour DNSSEC. L'algorithme venant du GOST avait été
normalisé pour DNSSEC car les gérants du
.ru disaient qu'ils ne
pouvaient pas signer avec un algorithme étranger mais, finalement,
ils ont utilisé RSA, ce qui diminue sérieusement l'intérêt des
algorithmes GOST.
Outre les signeurs et les résolveurs, le RFC prévoit le cas des registres, qui délèguent des zones signées, en mettant un enregistrement DS dans leur zone. Ces enregistrements DS sont des condensats de la clé publique de la zone fille, et, ici, SHA-1 est à éviter et SHA-256 est indispensable.
Aujourd'hui, les mises en œuvre courantes de DNSSEC sont en général compatibles avec ce que demande le RFC. Elles sont parfois trop « généreuses » (RSA+MD5 encore présent chez certains), parfois un peu trop en retard (ED448 pas encore présent partout).
L'article seul
RFC 8605: vCard Format Extensions: ICANN Extensions for the Registration Data Access Protocol (RDAP)
Date de publication du RFC : Mai 2019
Auteur(s) du RFC : S. Hollenbeck (Verisign Labs), R. Carney (GoDaddy)
Pour information
Première rédaction de cet article le 1 septembre 2019
Dernière mise à jour le 4 septembre 2019
Ce RFC décrit des extensions au format vCard afin d'ajouter dans les réponses RDAP deux informations exigées par l'ICANN. Il concerne donc surtout registres et utilisateurs des TLD ICANN.
Le protocole RDAP (RFC 9083) sert à récupérer des informations sur un objet
enregistré, par exemple un nom de
domaine. Une partie des informations, par exemple les
adresses et numéros de téléphone, est au format
vCard (RFC 6350). Mais l'ICANN a des exigences
supplémentaires, décrites dans la Specification
for gTLD Registration Data. Par exemple, l'ICANN
exige (cf. leur
politique) que, si les informations sur un contact ne sont
pas publiées (afin de préserver sa vie privée), le
registre fournisse au moins un URI indiquant un
moyen de contact (section 2.7.5.2 de la politique ICANN), par
exemple un formulaire Web (comme https://www.afnic.fr/fr/resoudre-un-litige/actions-et-procedures/joindre-le-contact-administratif-d-un-domaine/CONTACT-URI est désormais dans
le
registre IANA. (Si vous voulez réviser les notions de
propriété et de paramètre en vCard, plus exactement
jCard, cf. RFC 7095.)
D'autre part, la norme vCard, le RFC 6350, précise dans sa section 6.3.1, que le nom du
pays doit être spécifié en langue
naturelle, alors que l'ICANN exige (section 1.4 de leur politique) un code à deux
lettres tiré de la norme ISO 3166. (Notez
qu'à l'heure actuelle, certains registres mettent le nom du pays,
d'autres le code à deux lettres…) Le
paramètre CC, qui va indiquer le code, est désormais dans
le
registre IANA.
Ainsi, une réponse vCard suivant notre RFC pourrait indiquer (je ne peux pas vous montrer d'exemples réels d'un registre, aucun n'a apparemment déployé ces extensions, mais, si vous êtes curieux, lisez jusqu'à la fin) :
% curl -s https://rdap.nic.example/domain/foobar.example | jq .
...
[
"contact-uri", <<< Nouveauté
{},
"uri",
"https://rds.nic.example/get-in-touch"
]
...
[
"adr",
{"cc": "US"}, <<< Nouveauté
"text",
["", "", "123 Main Street", "Any Town", "CA", "91921-1234", "U.S.A."]
]
...
J'ai parlé jusqu'à présent des registres, mais l'ICANN impose
également RDAP aux bureaux d'enregistrement. Cela a en
effet un sens pour les registres minces, comme
.com, où les données
sociales sont chez les bureaux en question. La liste
des bureaux d'enregistrement ICANN contient une colonne
indiquant leur serveur RDAP. Testons avec Blacknight, qui est
souvent à la pointe :
% curl https://rdap.blacknight.com/domain/blacknight.com | jq .
...
[
"fn",
{},
"text",
"Blacknight Internet Solutions Ltd."
],
[
"adr",
{
"cc": "IE"
},
...
[
"contact-uri",
{},
"uri",
"https://whois.blacknight.com/contact.php?fqdn=blacknight.com&contact_type=owner"
]
On a bien un usage de ces extensions dans le monde réel (merci à Patrick Mevzek pour ses remarques et ajouts).
L'article seul
RFC 8612: DDoS Open Threat Signaling (DOTS) Requirements
Date de publication du RFC : Mai 2019
Auteur(s) du RFC : A. Mortensen (Arbor Networks), T. Reddy (McAfee), R. Moskowitz (Huawei)
Pour information
Réalisé dans le cadre du groupe de travail IETF dots
Première rédaction de cet article le 22 août 2019
Les attaques par déni de service, et notamment les dDoS (distributed Denial of Service), sont une des principales plaies de l'Internet. Le projet DOTS (DDoS Open Threat Signaling) à l'IETF vise à développer un mécanisme de signalisation permettant à des acteurs de la lutte anti-dDoS d'échanger des informations et de se coordonner, même lorsque l'attaque fait rage. Par exemple, un mécanisme DOTS permettra à un client d'un service de traitement des attaques de demander à son fournisseur d'activer le filtrage anti-dDoS. Ce RFC est le premier du projet : il décrit le cahier des charges.
Ces attaques par déni de service (décrites dans le RFC 4732) peuvent être utilisées à des fins financières (racket), lors d'affrontements inter-étatiques (comme dans le cas estonien souvent cité), à des fins de censure contre des opposants politiques. Le risque est particulièrement élevé pour les « petits ». En effet, beaucoup d'attaques par déni de service reposent sur la taille : par exemple, l'attaquant envoie tellement d'octets qu'il sature la ou les connexions Internet de sa victime. La seule solution est alors de louer un tuyau plus gros, ce qui n'est pas toujours financièrement possible. Les attaques dDoS favorisent donc les plus riches. Aujourd'hui, par exemple, un petit hébergeur Web a le plus grand mal à faire face à d'éventuelles attaques, ce qui rend difficile l'hébergement associatif et/ou décentralisé. Les attaques par déni de service ont donc des conséquences bien au-delà des quelques heures d'indisponibilité du service : elles encouragent la centralisation des services, puisqu'il faut être gros pour encaisser le choc. C'est ainsi qu'aujourd'hui beaucoup d'organisations sont chez Cloudflare, dépendant de cette société privée étatsunienne pour leur « protection ». On est dans l'équivalent moderne de la relation féodale au Moyen-Âge : le paysan seul, ou même le village, est trop vulnérable, il doit chercher la protection d'un seigneur, en échange de sa soumission.
Il est très difficile de se protéger contre les attaques par déni de service. Et le projet DOTS ne va pas proposer de solution magique, uniquement des mécanismes de cooordination et d'échange en cas d'attaque. La réponse à une attaque dDoS consiste typiquement à examiner les paquets entrants, et à jeter ceux qui semblent faire partie de l'attaque. (Voir par exemple mon article sur le filtrage.) Il faut bien sûr le faire le plus tôt possible. Si vous êtes connecté à l'Internet par un lien de capacité 1 Gb/s, et que l'attaquant arrive à le saturer par les paquets qu'il envoie, trier les paquets de votre côté ne servira à rien, cela serait trop tard ; ils doivent être triés en amont, par exemple chez votre opérateur. Et, évidemment, trier n'est pas trivial, les paquets ne sont pas marqués comme participant à l'attaque (sauf si on utilise le RFC 3514, mais regardez sa date de publication). Il y aura donc toujours des faux positifs, des paquets innocents jetés. (Pour un exemple de solution anti-dDoS, voir le VAC d'OVH, et les nombreux articles qui lui ont été consacrés.) En 2019, beaucoup d'organisations ne font plus ce tri elles-mêmes (par manque de moyens financiers, et surtout humains) mais sous-traitent à un fournisseur spécialisé (comme Arbor, pour lequel travaille un des auteurs du RFC). On envoie le trafic vers ce fournisseur, par des astuces DNS ou BGP, il le trie, et vous renvoie ce qui lui semble inoffensif. Ce tri se nomme en anglais scrubbing. Ces fournisseurs sont donc un élement critique, par exemple parce qu'ils voient passer tout votre trafic. En général, on active ce service à la demande, et cette activation est un des scénarios d'utilisation de DOTS les plus cités dans le RFC.
Actuellement, l'activation du service de scrubbing se fait via des interfaces privatrices, fournies par le « protecteur », ce qui contribue à enfermer le client dans sa relation avec le fournisseur. Et puis, parfois, il faut que plusieurs acteurs participent à la réponse à attaque. D'où l'idée du projet DOTS (dDoS Open Threat Signaling) qui va développer une interface normalisée, au sein du groupe de travail du même nom à l'IETF.
La section 1.2 du RFC précise le terminologie employée : DOTS sera client/serveur, le client DOTS étant chez la victime, qui cherche une solution, et le serveur DOTS étant chez le protecteur (mitigator dans le RFC). Rappelez-vous que DOTS ne normalise pas les méthodes de protection (elles évoluent vite, même si le motif « tri puis poubellisation des paquets » reste dominant), mais uniquement la communication entre les acteurs impliqués. Les différents acteurs communiquent avec deux sortes de canaux, les canaux de signalisation et les canaux de données. Les premiers sont prévus pour des messages assez courts (« jette tous les paquets à destination du port NNN ») mais qui doivent arriver à tout prix, même en cas d'attaque intense ; ils sont le cœur du système DOTS, et privilégient la survivabilité. Les seconds, les canaux de données, sont prévus pour de grandes quantités de données, par exemple pour envoyer des informations de configuration, comme la liste des préfixes IP à protéger.
L'essentiel du RFC est la section 2, qui décrit les exigences auxquelles devra se soumettre le futur protocole DOTS. (Notez que le travail est déjà bien avancé. Depuis, un RFC d'architecture générale du systéme, le RFC 8811, a été publié, et les RFC 8782 et RFC 8783 ont normalisé le protocole.) Il s'agit d'exigences techniques : ce RFC ne spécifie pas d'exigences business ou de politique. Par exemple, il ne dit pas à partir de quand un client DOTS a le droit de demander une action au serveur, ni dans quels cas le client a le droit d'annuler une demande.
Le protocole DOTS a des exigences difficiles ; compte-tenu du caractère très sensible des échanges entre le client et le serveur, il faut absolument fournir authentification, intégrité, confidentialité et protection contre le rejeu par un tiers. Autrement, le protocole DOTS, comme la plupart des techniques de sécurité, pourrait en fait fournir un nouveau moyen d'attaque. Mais, d'un autre côté, le protocole doit être très robuste, puisqu'il est précisément conçu pour fonctionner face à un hostile, qui va essayer de perturber les communications. Combiner toutes ces demandes n'est pas trivial. DOTS fournira de la robustesse en utilisant des messages de petite taille (qui auront donc davantage de chances de passer), asynchrones, et qui pourront être répétés sans dommage (en cas de doute, les acteurs DOTS n'hésiteront pas à envoyer de nouveau un message).
Je ne vais pas répéter ici la longue liste des exigences, vous les trouverez dans la section 2. Elles sont réparties en plusieurs catégories. Il y a d'abord les exigences générales :
- Le protocole doit être extensible, car les attaques par déni de service vont évoluer, ainsi que les solutions (la lutte de l'épée et de la cuirasse est éternelle),
- Comme rappelé ci-dessus, le protocole doit être robuste, la survivabilité doit être sa principale qualité puisqu'il est prévu pour fonctionner en situation très perturbée,
- Un message qui a du mal à passer ne ne doit pas bloquer le suivant (pas de head-of-line blocking),
- Le client doit pouvoir donner des indications sur les actions souhaitées, puisqu'il dispose parfois d'informations, par exemple issues du renseignement sur les menaces.
Il y a ensuite les exigences sur le canal de signalisation :
- Il doit utiliser des protocoles existants comme UDP (TCP est possible mais, en cas d'attaque, il peut être difficile, voir impossible, d'établir une connexion),
- La taille des messages doit être faible, à la fois pour augmenter les chances de passer malgré l'attaque, et pour éviter la fragmentation,
- Le canal doit être bidirectionnel, entre autres pour détecter une éventuelle coupure du lien (un serveur peut être configuré pour activer les solutions anti-dDoS précisément quand il ne peut plus parler au client, des messages de type battement de cœur sont donc nécessaires, mais pas évidents à faire correctement, cela avait été une des plus grosses discussions à l'IETF),
- Le client doit pouvoir demander au serveur des actions (c'est le but principal du protocole), et doit pouvoir aussi solliciter des informations sur ce que voit et fait le serveur DOTS (« j'ai jeté 98 % des paquets » ou « je jette actuellement 3,5 Gb/s »),
- Le client doit pouvoir tenir le serveur au courant de l'efficacité perçue des actions effectuées (« ça marche pas, je reçois toujours autant »),
- Le client doit pouvoir indiquer une durée pour les actions du serveur, y compris une durée infinie (si le client préfère que tout son trafic soit examiné et filtré en permanence),
- Le client doit pouvoir demander un filtrage fin, en
indiquant une portée
(« uniquement ce qui vient de
192.0.2.0/24» ou « seulement les paquets à destination de2001:db8:a:b::/64», voire « seulement les paquets pourwww.example.com», et le serveur DOTS doit alors faire la résolution de nom).
Il y a aussi des exigences pour l'autre canal, celui des données. Rappelons que, contrairement au canal de signalisation, il n'est pas indispensable qu'il puisse fonctionner pendant l'attaque. La principale exigence est la transmission fiable des données.
Vu le contexte de DOTS, il y a évidemment des exigences de sécurité :
- Authentification mutuelle (du serveur par le client et du client par le serveur), un faux serveur ou un faux client pourraient faire des catastrophes, cf. section 4 du RFC,
- Confidentialité et intégrité, vu le caractère critique des données (imaginez si un attaquant pouvait modifier les messages DOTS…)
La section 3 du RFC se penche sur le problème de la congestion. Le protocole DOTS ne doit pas ajouter à l'attaque en noyant tout le monde sous les données, alors qu'il utilisera sans doute un transport qui ne gère pas lui-même la congestion, UDP (au moins pour le canal de signalisation). Il faudra donc bien suivre les règles du RFC 8085.
À noter qu'Arbor a un brevet sur les mécanismes analogues à DOTS (brevet 20130055374, signalé à l'IETF ici.) Arbor promet des licences RF et RAND. Même les attaques créent du business…
L'article seul
RFC 8576: Internet of Things (IoT) Security: State of the Art and Challenges
Date de publication du RFC : Avril 2019
Auteur(s) du RFC : O. Garcia-Morchon (Philips IP&S), S. Kumar (Philips Research), M. Sethi (Ericsson)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF t2trg
Première rédaction de cet article le 16 août 2019
Une blague très courante dit que, dans IoT (Internet of Things, l'Internet des Objets), le S veut dire sécurité… C'est peu dire que la sécurité de l'Iot est mauvaise. Elle est en fait catastrophique, comme l'analyse bien Schneier dans son livre « Click here to kill everybody ». C'est en grande partie dû à des raisons politico-économiques (les fabriquants se moquent de la sécurité notamment, parce que les failles de sécurité n'ont aucune conséquence négative pour eux) et en petite partie aux réelles difficultés techniques qu'il y a à sécuriser des objets qui sont parfois contraints en ressources (énergie électrique limitée, par exemple.) Ce nouveau RFC du groupe de recherche T2T (Thing to Thing) de l'IRTF se penche sur la question et essaie d'identifier les questions à long terme. À lire absolument, si vous vous intéressez à la sécurité des objets connectés. Et à lire également si vous ne vous y intéressez pas car, que vous le vouliez ou non, la sécurité des objets connectés va vous toucher.
On ne part pas de zéro pourtant. Contrairement à ce que disent parfois les vendeurs d'objets connectés pour justifier l'insécurité abyssale de leurs produits, des solutions techniques ont été développées. (Voir par exemple cet article qui parle de la sécurité des sondes Atlas.) Il existe des protocoles adaptés aux objets, comme CoAP (RFC 7252), une alternative légère à HTTP, qu'on peut sécuriser avec DTLS (RFC 9147). Mais il reste à les déployer.
Notre RFC suit un plan classique : il étudie d'abord le cycle de vie des objets connectés (section 2 du RFC), examine ensuite les risques (section 3), l'état de l'art (section 4), puis les défis pour sécuriser les objets (section 5), et enfin les prochaines étapes du travail nécessaire (section 6).
Le terme d'Internet des Objets fait partie de ces termes pipeau qui ne veulent pas dire grand'chose. Les « objets » n'ont pas grand'chose à voir, allant d'un ordiphone plus puissant que certains ordinateurs, à des étiquettes RFID, en passant par des voitures connectées qui disposent d'électricité et de puissance de calcul considérables, et des capteurs industriels qui sont au contraire très contraints. Quant à leur connexion, elle se limite parfois au réseau local et, parfois, à envoyer toutes leurs données, aussi privées qu'elles soient, vers leur maitre dans le mythique cloud. C'est le consortium privé Auto-Id qui a popularisé ce terme à la fin des années 1990, pour de simples raisons marketing. À l'époque, c'était limité à des étiquettes RFID n'ayant qu'une connexion très limitée, sans rapport avec l'Internet. Certains ont suggéré de réserver le terme d'« Internet des Objets » aux objets connectés en IP mais ces appels à la rigueur terminologique n'ont en général que peu d'impact. Bref, chercher des solutions pour l'« Internet des Objets » en général n'a que peu de chances d'aboutir, vu la très grande variété de situations que ce terme recouvre.
Mais revenons au début, au cycle de vie de nos objets connectés (section 2 du RFC). Comme la variété des objets connectés est très grande, le RFC choisit de partir d'un exemple spécifique, un système de gestion de bâtiment. Ce système contrôle la climatisation, le chauffage, la ventilation, l'éclairage, la sécurité, etc. Un tel système représente de nombreux objets, dont certains, notamment les capteurs installés un peu partout, peuvent être très contraints en ressource (processeur lent, énergie fournie uniquement par des batteries, etc). Pire, du point de vue des protocoles réseau, certains de ces objets vont passer beaucoup de temps à dormir, pour économiser l'énergie, et ne répondront pas aux autres machines pendant ce temps. Et les objets seront sans doute fabriqués par des entreprises différentes, ce qui soulèvera des questions amusantes d'interopérabilité.
La figure 1 du RFC représente un cycle de vie simplifié. Je le simplifie encore ici. L'objet est successivement :
- fabriqué,
- il peut rester assez longtemps sur l'étagère, attendant un acheteur (ce qui contribue à l'obsolescence de son logiciel),
- installé et configuré (probablement par différents sous-traitants),
- mis en service,
- il va fonctionner un certain temps puis verra des évenements comme une mise à jour logicielle,
- ou des changements de sa configuration,
- à un moment, il cessera d'être utilisé,
- puis sera retiré du bâtiment (à moins qu'il soit oublié, et reste actif pendant des années sans qu'on s'en occupe),
- mais il aura peut-être droit à une reconfiguration et une remise en service à un autre endroit, recommençant le cycle,
- sinon, il sera jeté.
Les différents objets présents dans le bâtiment ne seront pas aux mêmes étapes au même moment.
Le RFC remarque que le cycle de vie ne commence pas forcément à la fabrication de l'objet physique, mais avant. Pour des objets comportant du logiciel, le cycle de vie commence en fait lorsque la première bibliothèque qui sera utilisée est écrite. Les logiciels des objets connectés ont une forte tendance à utiliser des versions anciennes et dépassées des bibliothèques, notamment de celles qui assurent des fonctions de sécurité. Les bogues ont donc une longue durée de vie.
La sécurité est une question cruciale pour les objets connectés, car ils sont en contact avec le monde physique et, si ce sont des actionneurs, ils agissent sur ce monde. Comme le note Schneier, une bogue sur un objet connecté, ce n'est plus seulement un programme qui plante ou un fichier qu'on perd, cela peut être des atteintes physiques aux humains. Et les objets sont nombreux : pirater une machine ne donne pas beaucoup de pouvoir à l'attaquant, mais s'il arrive à trouver une faille lui permettant de pirater via l'Internet tous les objets d'un vendeur donné, il peut se retrouver à la tête d'un botnet conséquent (c'est exactement ce qui était arrivé avec Mirai).
Quels sont les risques exactement ? La section 3 du RFC décrit les différentes menaces, une liste longue et un peu fourre-tout. Avant tout, le code peut être incorrect, bogué ou mal conçu. C'est le cas de tout logiciel (ne croyez pas un instant les commerciaux qui assurent, sans rien en savoir eux-mêmes, que « le logiciel est conforme à l'état de l'art et aux préconisations de [insérer ici le nom d'un organisme quelconque] »). Mais comme vu plus haut, les conséquences sont plus graves dans le cas des objets connectés. En outre, il y a deux problèmes logiciels qui sont davantage spécifiques aux objets connectés : les mises à jour, pour corriger les bogues, sont plus difficiles, et rarement faites, et le logiciel est globalement négligé, n'étant pas le « cœur de métier » de l'entreprise vendeuse. On voit ainsi des failles de sécurité énormes, qui n'arrivent plus dans l'informatique plus classique.
Autre raison pour laquelle la sécurité des objets connectés est difficile à assurer, le fait que l'attaquant peut avoir un accès physique aux objets (par exemple s'il s'agit d'un type d'objet vendu publiquement). Il peut le démonter, l'étudier, et acquérir ainsi des informations utiles pour le piratage d'autres objets du même type. Si, par exemple, tous les objets d'un même type partagent une clé cryptographique privée, elle pourrait être récupérée ainsi (l'objet connecté typique n'est pas un HSM). Un modèle de sécurité comme celui de la boite noire ne s'applique donc pas. Dans le futur, peut-être que les PUF seront une solution ?
La sécurité impose de mettre à jour le logiciel de l'objet régulièrement. Mais cette mise à jour ouvre elle-même des failles de sécurité. Si le processus de mise à jour n'est pas sécurisé (par exemple par une signature du logiciel), un malveillant pourra peut-être y glisser sa version du logiciel.
Ensuite, l'objet, même s'il fonctionne comme prévu, peut faire fuiter des informations privées. S'il envoie des informations à des tiers (c'est le cas de presque tous les objets conçus pour l'usage domestique) ou s'il transmet en clair, il permet la surveillance de son propriétaire. Le chiffrement est évidemment indispensable, mais il ne protège pas contre les extrémités de la communication (le sextoy connecté qui envoie les informations sur son usage au vendeur de l'objet) et, s'il n'est pas accompagné d'une authentification du partenaire avec qui on communique, ile ne protège pas contre l'homme du milieu. Une des difficultés de l'authentification est qu'il faut bien, avant la communication, avitailler l'objet en informations (par exemple les clés publiques de ses correspondants), un défi pour des objets fabriqués en masse. Avitailler une fois l'objet sur le terrain est tout aussi difficile : ces objets n'ont souvent pas d'interface utilisateur. Cela impose des solutions comme le TOFU (faire confiance la première fois, puis continuer avec le même correspondant) ou bien l'appairage (on approche deux objets, on appuie sur un bouton et ils sont désormais appairés, ils ont échangé leurs clés).
Les objets ont souvent une histoire compliquée, étant composée de l'assemblage de divers composants matériels et logiciels, parfois promenés sur de longues distances, entre beaucoup d'entreprises différentes. Une des attaques possibles est de s'insérer quelque part dans cette chaîne d'approvisionnement et d'y glisser du logiciel ou du matériel malveillant. Est-ce que quelqu'un sait vraiment ce que fait cette puce dont on a acheté des dizaines de milliers d'exemplaires à un revendeur ? Dans le cas extrême, c'est l'objet entier qui peut être remplacé par un objet apparemment identique, mais malveillant.
Les objets connectés sont souvent dans des lieux qui ne sont pas physiquement protégés. Par exemple, les capteurs sont placés un peu partout, et parfois accessibles à un attaquant. Une fois qu'on peut mettre la main sur un objet, il est difficile d'assurer sa sécurité. Des informations confidentielles, comme une clé privée, peuvent alors se retrouver entre les mains de l'attaquant. Transformer chaque objet connecté en un coffre-fort inviolable n'est évidemment pas réalistes.
Les objets communiquent entre eux, ou bien avec des passerelles les connectant à l'extérieur. Cela ouvre de nouvelles possibilités d'attaque via le routage. Les objets connectés se servent souvent de protocoles de routage non sécurisés, permettant au malveillant d'injecter de fausses routes, permettant ainsi, par exemple, de détourner le trafic vers une machine contrôlée par ce malveillant.
Enfin, il y a la menace des attaques par déni de service. Les objets sont souvent contraints en ressources et sont donc particulièrement vulnérables aux attaques par déni de service, même légères. Et les objets ne sont pas forcément victimes, ils peuvent être aussi devenir zombies et, recrutés par un logiciel malveillant comme Mirai, être complices d'attaques par déni de service comme cela avait été le cas en octobre 2016. (Un outil comme Shodan permet de trouver facilement des objets vulnérables et/ou piratés.)
Bon, ça, c'étaient les menaces. Mais on n'est pas resté les bras ballants, on a déjà des mécanismes possibles pour faire face à ces attaques. La section 4 de notre RFC décrit l'état de l'art en matière de connexion des objets connectés, et de leur sécurisation.
Déjà, il existe plusieurs protocoles pour les objets connectés, comme ZigBee, BACnet ou DALI. Mais l'IETF se focalise évidemment sur les objets qui utilisent IP, le seul cas où on puisse réellement parler d'« Internet des Objets ». IP tel qu'il est utilisé sur les ordinateurs classiques n'est pas forcément bien adapté, et des groupes ont développé des adaptations pour les réseaux d'objets (voir par exemple le RFC 4944). De même, il existe des normes pour faire tourner IP sur des tas de couches physiques différentes, comme Bluetooth (RFC 7668), DECT (RFC 8105) ou NFC (RFC pas encore publié). Au-dessus d'IP, le protocole CoAP (RFC 7252) fournit un protocole applicatif plus adapté aux objets que le HTTP classique.
Questions formats, on a également le choix. On a JSON (RFC 8259), mais aussi CBOR (RFC 8949) qui, lui, est un format binaire, sans doute plus adapté aux objets contraints. Tous les deux ont des solutions de sécurité, par exemple la famille JOSE pour signer et chiffrer les documents JSON, et son équivalent pour CBOR, CORE (RFC 8152).
Le problème de la sécurité de l'IoT est connu depuis longtemps, et ce ne sont pas les solutions techniques qui manquent, que ce soit pour protéger les objets connectés, ou pour protéger le reste de l'Internet contre ces objets. Certains de ces protocoles de sécurité ne sont pas spécifiques aux objets connectés, mais peuvent être utilisés par eux, c'est le cas de TLS (RFC 9846). Une excuse classique des fabricants d'objets connectés pour ne pas sécuriser les communications avec TLS est le caractère contraint de l'objet (manque de ressources matérielles, processeur, mémoire, énergie, etc). Cet argument peut jouer pour des objets vraiment contraints, des capteurs bon marché disséminés dans l'usine et ne fonctionnant que sur leur batterie mais beaucoup d'objets connectés ne sont pas dans ce cas, et ont largement les moyens de faire tourner TLS. Quand on entend des fabriquants de télévisions connectées ou de voitures connectées expliquer qu'ils ne peuvent pas utiliser TLS car ce protocole est trop coûteux en ressources, on rit ou on s'indigne car c'est vraiment un argument ridicule ; une télévision ou une voiture ont largement assez de ressources pour avoir un processeur qui fait tourner TLS. (Je n'utilise que TLS et SSH pour communiquer avec un Raspberry Pi 1, avec son processeur à 700 MHz et sa consommation électrique de 2 W.)
Outre les protocoles, la sécurité repose sur des règles à suivre. La section 4.3 liste les règles formalisées existantes. Ainsi, GSMA a publié les siennes, BITAG également, le DHS étatsunien s'y est mis, l'ENISA aussi et notre RFC liste de nombreux autres documents. Si les fabriquants d'objets connectés ne sont pas au courant, ce n'est pas faute d'information, c'est bien de la mauvaise volonté !
C'est d'autant plus grave que, comme l'a illustré le cas de Mirai, les objets connectés non-sécurisés ne sont pas un problème que pour le propriétaire de l'objet, mais peuvent également toucher tout l'Internet. Il est donc logique que beaucoup de voix s'élèvent pour dire qu'il faut arrêter de compter sur la bonne volonté des fabricants d'objets connectés, qui ont largement démontré leur irresponsabilité, et commencer à réguler plus sévèrement. (C'est par exemple une demande du régulateur étatsunien FCC.)
Cette disponibilité de très nombreuses solutions techniques ne veut pas dire que tous les problèmes sont résolus. La section 5 du RFC fait ainsi le point sur les défis qui nous restent, et sur lesquels chercheu·r·se·s et ingénieur·e·s devraient se pencher. D'abord, certains objets sont contraints en ressources (pas tous, on l'a vu), comme détaillé dans le RFC 7228. L'Internet est un monde très hétérogène, connectant des machines ayant des ressources très diverses, via des réseaux qui ont des capacités hautement variables. Pour ces objets contraints (qui sont une partie seulement des « objets », une caméra de vidéo-surveillance n'est pas un objet contraint), il est raisonnable de chercher à optimiser, par exemple la cryptographie. Ainsi, la cryptographie à courbes elliptiques (RFC 9846) demande en général moins de ressources que RSA.
Les attaques par déni de service sont un autre défi pour les objets connectés, qui disposent de peu de ressources pour y faire face. Des protocoles qui permettent de tester qu'il y a une voie de retour (return routability ou returnability) peuvent aider à éviter certaines attaques que des protocoles sans ce test (comme le DNS ou comme d'autres protocoles fondés sur UDP) rendent facile. C'est pour cela que DTLS (RFC 9147) ou HIP (RFC 7401) intègrent ce test de réversibilité. Évidemment, cela n'aide pas pour les cas de la diffusion, ou bien lorsque le routage est contrôlé par l'attaquant (ce qui est souvent le cas dans les réseaux « mesh ».) Autre protection, qui existe par exemple dans HIP : forcer l'initiateur d'une connexion à résoudre un problème, un « puzzle », afin d'éviter que les connexions soient « gratuites » pour l'initiateur. La principale limite de cette solution est qu'elle marche mal si les machines impliquées ont des capacités de calcul très différentes (un objet contraint contre un PC). Il y a également le cas, non mentionné par le RFC, où l'attaquant dispose d'un botnet et ne « paie » donc pas les calculs.
L'architecture actuelle de l'Internet n'aide pas au déploiement de certaines solutions de sécurité. Ainsi, un principe de base en sécurité est d'avoir une sécurité de bout en bout, afin de ne pas dépendre d'intermédiaires malveillants ou piratés, mais c'est rendu de plus en plus difficile par l'abus de middleboxes, qui interfèrent avec beaucoup de comunications. On est donc forcés d'adapter la sécurité à la présence de ces middleboxes, souvent en l'affaiblissant. Par exemple :
- Il faut parfois partager les clés avec les middleboxes pour qu'elles puissent modifier les paquets, ce qui est évidemment une mauvaise pratique,
- Le chiffrement homomorphe peut aider, en permettant d'effectuer certaines opérations sur des données chiffrées, mais toutes les opérations ne sont pas possibles ainsi, et les bibliothèques existantes, comme SEAL, n'ont pas les performances nécessaires,
- Remonter la sécurité depuis le niveau des communications (ce que fait TLS) vers celui des données échangées pourrait aider. C'est ce que font COSE (RFC 8152), JOSE (RFC 7520) ou CMS (RFC 5652).
Une fois déployés, les objets connectés vont rester en fonctionnement des années, voire des décennies. Il est donc crucial d'assurer les mises à jour de leur logiciel, ne serait-ce que pour réparer les failles de sécurité qui ne manqueront pas d'être découvertes, qu'elles soient dans le code ou dans les algorithmes utilisés. Par exemple, si les promesses des ordinateurs quantiques se concrétisent un jour, il faudra jeter RSA et les courbes elliptiques (section 5.8 du RFC).
Mais assurer des mises à jour sûres n'est pas facile, comme le note Bruce Schneier. C'est que le processus de mise à jour, s'il est insuffisamment sécurisé, peut lui-même servir pour une attaque, par exemple en envoyant du code malveillant à un objet trop naïf. Et puis comment motiver les vendeurs à continuer à fournir des mises à jour logicielles des années après que le dernier exemplaire de ce modèle ait été vendu ? Capitalisme et sécurité ne vont pas bien ensemble. Et il se peut tout simplement que le vendeur ait disparu, que le code source de l'objet ne soit plus disponible, et qu'il soit donc impossible en pratique de développer une mise à jour. (D'où l'importance, même si le RFC ne le dit pas, du logiciel libre.) Enfin, si la mise à jour doit être effectuée manuellement, il est probable qu'elle ne sera pas faite systématiquement. (Un rapport de la FTC états-unienne détaille également ce problème.)
Mais les mises à jour automatiques posent également des tas de problèmes. Par exemple, pour des ampoules connectées (une idée stupide, mais le monde de l'IoT est plein d'idées stupides), il vaut mieux mettre à jour leur logiciel le jour que la nuit. Et il vaut mieux que toutes les ampoules ne soient pas mises à jour en même temps. Et les mises à jour supposent que le système ait été conçu pour cela. Par exemple, en cryptographie, il est souvent nécessaire de remplacer les algorithmes cryptographiques qui ont été cassés avec le temps, mais beaucoup d'objets connectés utilisent des systèmes cryptographiques mal conçus, qui n'ont pas d'agilité cryptographique. (Au passage, la section 5.8 du RFC traite le cas des possibles futurs ordinateurs quantiques, et des conséquences qu'ils auront pour la cryptographie. Les objets connectés peuvent rester actifs de nombreuses années, et il faut donc penser loin dans le futur.) Ces points, et beaucoup d'autres, avaient été traités dans un atelier de l'IAB, qui avait fait l'objet du RFC 8240. À l'IETF, le groupe de travail SUIT développe des mécanismes pour aider les mises à jour (mais qui ne traiteront qu'une petite partie du problème).
Rapidement dépassés, les objets connectés posent également des problèmes de gestion de la fin de vie. Au bout d'un moment, le vendeur va arrêter les différentes fonctions, comme les mises à jour du logiciel ou, plus radicalement, comme les serveurs dont dépend l'objet. Cet arrêt peut être volontaire (l'objet n'intéresse plus le vendeur, qui est passé à d'autres gadgets) ou involontaire (vendeur en faillite). Le RFC note qu'une des voies à explorer est la continuation de l'objet avec du logiciel tiers, qui ne dépend plus de l'infrastructure du vendeur. Bien des ordiphones ont ainsi vu leur vie prolongée par CyanogenMod, et bien des routeurs ont bénéficié d'OpenWrt. (D'où l'importance de pouvoir installer ce logiciel tiers, ce qu'interdisent beaucoup de vendeurs.)
Une autre question intéressante de sécurité posée par les objets connectés est la vérification de leurs capacités réelles et de leur comportement effectif. L'acheteur peut avoir l'impression qu'il est le propriétaire de l'objet acheté mais cet objet est suffisamment complexe pour que l'acheteur ne soit pas au courant de tout ce que l'objet fait dans son dos. Le vrai maitre de l'objet est alors le vendeur, qui continue à communiquer avec l'engin connecté. C'est ainsi que des malhonnêtes comme Lidl ou Google avaient installé des micros dans des objets qu'on installe chez soi, et évidemment sans le dire à l'acheteur. Et encore, un micro est un appareil physique, qu'un examen attentif (avez-vous vérifié tous les objets connectés chez vous ?) peut détecter. Mais savoir ce que raconte l'objet connecté à son maitre est plus difficile. Peu d'utilisateurs ont envie de configurer un routeur local, et d'y faire tourner tcpdump pour voir le trafic. Et encore, ce trafic peut être chiffré et l'acheteur (qui, rappelons-le, n'est pas le véritable propriétaire de l'objet, puisqu'il n'a quasiment aucun contrôle, aucune information) n'a pas les clés.
Le problème de fournir des informations à l'utilisateur n'est pas trivial techniquement. Beaucoup d'objets connectés n'ont pas d'interface utilisateur où afficher « je suis en train d'envoyer plein de données sur vous à mon maitre ». Une solution partielle serait une description des capacités de l'engin, et de ses communications, dans un fichier MUD (Manufacturer Usage Description, RFC 8520). Ceci dit, vu le niveau d'éthique dans le monde de l'IoT, gageons que ces fichiers MUD mentiront souvent, notamment par omission.
Puisqu'on a parlé de vie privée, c'est l'occasion de rappeler que l'IoT est une grave menace pour cette vie privée. Le RFC note que, dans le futur, nous serons peut-être entourés de centaines d'objets connectés. (Malheureusement, le RFC parle surtout des risques dus à des tiers qui observeraient le trafic, et très peu des risques dus aux vendeurs qui récoltent les données.) L'IoT permet une intensification considérable du capitalisme de surveillance.
Bref, la situation est mauvaise et, s'il y a en effet quelques progrès (on voit moins souvent des mots de passe identiques pour tous les objets d'un type), ils sont largement annulés par de nouveaux déploiements.
L'article seul
RFC 8621: The JSON Meta Application Protocol (JMAP) for Mail
Date de publication du RFC : Août 2019
Auteur(s) du RFC : N. Jenkins (FastMail), C. Newman
(Oracle)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF jmap
Première rédaction de cet article le 14 août 2019
Ce nouveau RFC décrit un remplaçant pour le traditionnel protocole IMAP, remplaçant fondé sur le cadre JMAP (JSON Meta Application Protocol, RFC 8620).
Le protocole décrit dans ce RFC fournit les mêmes services qu'IMAP (RFC 9051) : accéder aux boîtes aux lettres de courrier, chercher dans ces boîtes, gérer les messages (détruire les inutiles, par exemple), etc. Par rapport à IMAP, outre l'utilisation du format JSON, l'accent est mis sur la synchronisation rapide, l'optimisation pour les clients mobiles, et sur la possibilité de notifications. JMAP est sans état (pas besoin de connexion permanente). Ce « JMAP pour le courrier » s'appuie sur JMAP, normalisé dans le RFC 8620. JMAP est un protocole générique, qui peut servir à synchroniser bien des choses entre un client et un serveur (par exemple un agenda, ou bien une liste de contacts). Par abus de langage, je vais souvent dire « JMAP » dans cet article alors que je devrais normalement préciser « JMAP pour le courrier », premier « utilisateur » du JMAP générique.
JMAP manipule différents types d'objets. Le plus important est
sans doute Email (section 4 du RFC), qui
modélise un message. Il s'agit d'une représentation de haut
niveau, le client JMAP n'a pas à connaitre tous les détails de
l'IMF (Internet Message Format, RFC 5322), de
MIME (RFC 2045),
etc. Un objet de type Email a une liste
d'en-têtes et un corps, et JMAP fournit des méthodes pour accéder
aux différentes parties du corps. Il y a même plusieurs
représentations d'un message, pour s'adapter aux différents
clients. Par exemple, un message MIME est normalement un
arbre, de profondeur quelconque, mais un
client JMAP peut décider de demander une représentation aplatie,
avec juste une liste d'attachements. (La plupart des MUA présentent à
l'utilisateur une vue aplatie de l'objet MIME.) Voilà pourquoi
l'objet Email a plusieurs propriétés, le
client choisissant à laquelle il accède :
bodyStructure: l'arbre MIME, c'est la représentation la plus « authentique »,textBody: une liste des parties MIME à afficher quand on préfère du texte,htmlBody: une liste des parties MIME à afficher quand on préfère de l'HTML,attachments: la liste des « pièces jointes » (rappelez-vous que le concept de « pièces jointes » a été créé pour l'interface avec l'utilisateur ; il n'a pas de sens en MIME, qui ne connait qu'un arbre avec des feuilles de différents types).
Les en-têtes doivent pouvoir être internationaux (RFC 6532).
Un message a évidemment des métadonnées, parmi lesquelles :
id, un identifiant du message (ce n'est pas leMessage-ID:, c'est attribué par le serveur JMAP), contrairement à IMAP, l'identificateur d'un message ne change pas, même quand le message change de boîte, et il peut apparaitre dans plusieurs boîtes à la foisblobIf, un identifiant du message représenté sous la forme d'une suite d'octets, à analyser par le client, par opposition à l'objet de haut niveau identifié parid,size, la taille du message,keywords, des mots-clés, parmi lesquels certains, commençant par un dollar, ont une signification spéciale.
En IMAP, les mots-clés spéciaux sont précédés d'une
barre inverse. En JMAP, c'est le
dollar. Parmi ces mots-clés,
$seen indique que le message a été lu,
$answered, qu'on y a répondu,
$junk, que le serveur l'a classé comme
spam, etc. Ces mots-clés sont dans un
registre IANA.
Et quelles opérations sont possibles avec les objets de type
Email ? Ce sont les opérations génériques de
JMAP (RFC 8620, section 5). Ainsi,
on peut récupérer un message avec
Email/get. Cette requête :
[[ "Email/get", {
"ids": [ "f123u456", "f123u457" ],
"properties": [ "threadId", "mailboxIds", "from", "subject",
"receivedAt", "header:List-POST:asURLs",
"htmlBody", "bodyValues" ],
"bodyProperties": [ "partId", "blobId", "size", "type" ],
"fetchHTMLBodyValues": true,
"maxBodyValueBytes": 256
}, "#1" ]]
peut récupérer, par exemple, cette valeur :
[[ "Email/get", {
"accountId": "abc",
"state": "41234123231",
"list": [
{
"id": "f123u457",
"threadId": "ef1314a",
"mailboxIds": { "f123": true },
"from": [{ "name": "Joe Bloggs", "email": "joe@example.com" }],
"subject": "Dinner on Thursday?",
"receivedAt": "2013-10-13T14:12:00Z",
"header:List-POST:asURLs": [
"mailto:partytime@lists.example.com"
],
"htmlBody": [{
"partId": "1",
"blobId": "B841623871",
"size": 283331,
"type": "text/html"
}, {
"partId": "2",
"blobId": "B319437193",
"size": 10343,
"type": "text/plain"
}],
"bodyValues": {
"1": {
"isTruncated": true,
"value": "<html><body><p>Hello ..."
},
"2": {
"isTruncated": false,
"value": "-- Sent by your friendly mailing list ..."
}
}
}
],
"notFound": [ "f123u456" ]
}, "#1" ]]
Notez que le client a demandé deux messages, mais qu'un seul, le
f123u457, a été trouvé.
Tout aussi indispensable, Email/query
permet de demander au serveur une recherche, selon de nombreux
critères comme la date, les mots-clés, ou bien le contenu du corps
du message.
Email/set permet de modifier un message,
ou d'en créer un (qu'on pourra ensuite envoyer avec
EmailSubmission, décrit plus loin). Notez qu'il n'y a pas de
Email/delete. Pour détruire un message, on
utilise Email/set en changeant la propriété
indiquant la boîte aux lettres, pour mettre la boîte aux lettres
spéciale qui sert de poubelle (rôle = trash).
Comme IMAP, JMAP pour le courrier a la notion de boîte aux lettres (section 2 du RFC). Une boîte (vous pouvez appeler ça un dossier ou un label si vous voulez) est un ensemble de messages. Tout message est dans au moins une boîte. Les attributs importants d'une boîte :
- Un nom unique (par exemple Vacances ou Personnel), en Unicode (RFC 5198),
- Un identificateur attribué par le serveur (et a priori moins lisible par des humaines que ne l'est le nom),
- Un rôle, optionnel, qui indique à quoi sert la boîte, ce
qui est utile notamment si le serveur peut être utilisé en JMAP
et en IMAP. Ainsi, le rôle
inboxidentifie la boîte où le courrier arrive par défaut. (Les rôles figurent dans un registre IANA créé par le RFC 8457.) - Certains attributs ne sont pas fixes, par exemple le nombre total de messages contenus dans la boîte, ou bien le nombre de messages non lus.
- Les droits d'accès (ACL, cf. RFC 4314.) Les permissions sont par boîte, pas par message.
Ensuite, on utilise les méthodes JMAP pour accéder aux boîtes
(révisez donc le RFC 8620, qui décrit
le JMAP générique). Ainsi, pour accéder à une boîte,, on utilise
la méthode JMAP Mailbox/get, qui utilise le
/get JMAP (RFC 8620, section 5.1). Le paramètre
ids peut être nul, cela indique alors qu'on
veut récupérer tous les messages (c'est ce qu'on fait dans
l'exemple ci-dessous).
De même, pour effectuer une recherche sur le serveur, JMAP
normalise la méthode /query (RFC 8620, section 5.5) et JMAP pour le courrier peut
utiliser Mailbox/query.
Par exemple, si on veut voir toutes les boîtes existantes, le client JMAP envoie le JSON :
[[ "Mailbox/get", {
"accountId": "u33084183",
"ids": null
}, "0" ]]
et reçoit une réponse du genre (on n'affiche que les deux premières boîtes) :
[[ "Mailbox/get", {
"accountId": "u33084183","state": "78540",
"state": "78540",
"list": [{
"id": "MB23cfa8094c0f41e6",
"name": "Boîte par défaut",
"role": "inbox",
"totalEmails": 1607,
"unreadEmails": 15,
"myRights": {
"mayAddItems": true,
...},
{
"id": "MB674cc24095db49ce",
"name": "Personnel",
...
Notez que state est l'identificateur d'un
état de la boîte. Si on veut ensuite récupérer les changements, on
pourra utiliser Mailbox/changes avec comme
paramètre "sinceState": "88540".
Dans JMAP, les messages peuvent être regroupés en fils de discussion (threads, section 3 du RFC). Tout message est membre d'un fil (parfois membre unique). Le RFC n'impose pas de méthode unique pour constituer les fils mais suggère :
- D'utiliser les en-têtes du RFC 5322
(
In-Reply-To:ouReferences:indiquant leMessage-Id:d'un autre message). - Et de vérifier que les messages ont le même sujet (après avoir supprimé des préfixes comme « Re: »), pour tenir compte des gens qui volent les fils. Cette heuristique est imparfaite (le sujet peut avoir changé sans pour autant que le message soit sans rapport avec le reste du fil).
On peut ensuite accéder aux fils. Le client envoie :
[[ "Thread/get", {
"accountId": "acme",
"ids": ["f123u4", "f41u44"]
}, "#1" ]]
Et récupère les fils f123u4 et
f41u44 :
[[ "Thread/get", {
"accountId": "acme",
"state": "f6a7e214",
"list": [
{
"id": "f123u4",
"emailIds": [ "eaa623", "f782cbb"]
},
{
"id": "f41u44",
"emailIds": [ "82cf7bb" ]
}
...
Un client qui vient de se connecter à un serveur JMAP va
typiquement faire un Email/query sans
conditions particulières, pour recevoir la liste des messages (ou
alors en se limitant aux N messages les plus récents),
puis récupérer les fils de discussion correspondants avec
Thread/get, récupérer les messages
eux-mêmes. Pour diminuer la latence, JMAP permet au client
d'envoyer toutes ces requêtes en une seule fois (batching), en disant pour
chaque requête qu'elle doit utiliser le résultat de la précédente
(backreference, membre JSON resultOf).
JMAP permet également d'envoyer des messages. Un client JMAP
n'a donc besoin que d'un seul protocole, contrairement au cas
courant aujourd'hui
où il faut IMAP et
SMTP,
configurés séparement, avec, trop souvent, l'un qui marche et l'autre pas. Cela simplifie
nettement les choses pour l'utilisateur. Cela se fait avec le type
EmailSubmission (section 7 du RFC). Deux
importantes propriétés d'un objet de type
EmailSubmission sont
mailFrom, l'expéditeur, et
rcptTo, les destinataires. Rappel important
sur le courrier électronique : il y a les adresses indiquées dans
le message (champs To:,
Cc:, etc, cf. RFC 5322), et les adresses indiquées dans l'enveloppe
(commandes SMTP comme MAIL
FROM et RCPT TO, cf. RFC 5321). Ces adresses ne sont pas forcément
identiques. Lorsqu'on apprend le fonctionnement du courrier
électronique, la distinction entre ces deux catégories d'adresses
est vraiment cruciale.
Un EmailSubmission/set va créer l'objet
EmailSubmission, et
envoyer le message. Ici, on envoie à
john@example.com et
jane@example.com un message (qui avait été créé
par Email/set et qui avait l'identificateur
M7f6ed5bcfd7e2604d1753f6c) :
[[ "EmailSubmission/set", {
"accountId": "ue411d190",
"create": {
"k1490": {
"identityId": "I64588216",
"emailId": "M7f6ed5bcfd7e2604d1753f6c",
"envelope": {
"mailFrom": {
"email": "john@example.com",
"parameters": null
},
"rcptTo": [{
"email": "jane@example.com",
"parameters": null
},
...
]
}
}
},
"onSuccessUpdateEmail": {
"#k1490": {
"mailboxIds/7cb4e8ee-df87-4757-b9c4-2ea1ca41b38e": null,
"mailboxIds/73dbcb4b-bffc-48bd-8c2a-a2e91ca672f6": true,
"keywords/$draft": null
}
}
}, "0" ]]
Anecdote sur l'envoi de courrier : les premières versions de
« JMAP pour le courrier » utilisaient une boîte aux lettres
spéciale, nommée Outbox, où on mettait les
messages à envoyer (comme dans ActivityPub).
JMAP a d'autres types d'objets amusants, comme
VacationResponse (section 8), qui permet de
faire envoyer un message automatiquement lorsqu'on est absent
(l'auto-répondeur du serveur doit évidemment suivre le RFC 3834, pour éviter de faire des bêtises comme
de répondre à une liste de diffusion). On
crée un objet avec VacationResponse/set et
hop, l'auto-répondeur est amorcé.
Et je n'ai pas parlé de tout, par exemple JMAP permet de pousser des changements depuis le serveur vers le client, si la boîte aux lettres est modifiée par un autre processus (RFC 8620, section 7).
JMAP a le concept de
capacités (capabilities),
que le serveur annonce au client, dans un objet JSON (rappel :
JSON nomme « objets » les
dictionnaires), et sous la forme d'un URI. JMAP pour le courrier
ajoute trois capacités au registre des
capacités JMAP,
urn:ietf:params:jmap:mail pour dire qu'on
sait gérer le courrier,
urn:ietf:params:jmap:submission, pour dire
qu'on sait en envoyer (cf. RFC 6409, sur ce
concept de soumission d'un message), et
urn:ietf:params:jmap:vacationresponse pour
dire qu'on sait gérer un auto-répondeur.
Le courrier électronique pose plein de problèmes de sécurité
intéressants. La section 9 de notre RFC les détaille. Par exemple,
les messages en HTML sont particulièrement dangereux. (Il
est toujours amusant de voir des entreprises de sécurité
informatique envoyer leur newsletter en HTML,
malgré les risques associés, qui sont aujourd'hui bien connus.) Le
RFC rappelle donc aux clients JMAP (mais c'est valable pour tous
les MUA) que du
JavaScript dans le message peut changer son
contenu, qu'un message en HTML peut récupérer du contenu sur
l'Internet (via par exemple un <img
src=…), ce qui trahit le
lecteur et fait fuiter des données privées, que
CSS,
quoique moins dangereux que JavaScript, permet également des trucs
assez limites, que les liens en HTML ne pointent pas toujours vers
ce qui semble (<a
href="http://evil.example/">cliquez ici pour aller sur le site
de votre banque https://good-bank.example</a>),
etc. Pour faire face à tous ces dangers du courrier en HTML, le
RFC suggère de nettoyer le HTML avant de l'envoyer au
client. Attention, outre que c'est une modification du contenu, ce
qui est toujours délicat politiquement, le faire proprement est
difficile, et le RFC recommande fortement d'utiliser une
bibliothèque bien testée, de ne pas le faire soi-même à la main
(il y a trop de pièges). Par exemple, en
Python, on peut utiliser lxml, et son module
Cleaner, ici en mode extrémiste qui retire
tout ce qui peut être dangereux :
from lxml.html.clean import Cleaner
...
cleaner = Cleaner(scripts=True, javascript=True, embedded=True, meta=True, page_structure=True,
links=True, remove_unknown_tags=True,
style=True)
Mais il est probablement impossible de complètement sécuriser HTML dans le courrier. Le RFC explique à juste titre que HTML augmente beaucoup la surface d'attaque. Une organisation soucieuse de sécurité ne devrait pas traiter le HTML dans le courrier.
La soumission du courrier (cf. RFC 6409) pose également des problèmes de sécurité. Imaginez un client JMAP piraté et qui serve ensuite à envoyer du spam de manière massive, utilisant le compte de l'utilisateur ignorant de ce piratage. Les MTA qui acceptent du courrier ont des mécanismes de défense (maximum N messages par heure, avec au plus M destinataires par message…) mais ces mécanismes marchent d'autant mieux que le serveur a davantage d'information. Si la soumission via JMAP est mise en œuvre par un simple relais vers un serveur SMTP de soumission, certaines informations sur le client peuvent être perdues. De tels relais doivent donc veiller à transmettre au serveur SMTP toute l'information disponible, par exemple via le mécanisme XCLIENT.
JMAP a été développé essentiellement au sein de FastMail, qui le met en œuvre sur ses serveurs. Il existe une page « officielle » présentant le protocole, qui explique entre autres les avantages de JMAP par rapport à IMAP. Vous y trouverez également des conseils pour les auteurs de clients, très bien faits et qui donnent une bonne idée de comment le protocole marche. Ce site Web est un passage recommandé.
On y trouve également une liste de mises en œuvre de JMAP. Ainsi, le serveur IMAP bien connu Cyrus a déjà JMAP en expérimental. Le MUA K-9 Mail a, quant à lui, commencé le travail.
L'article seul
Fiche de lecture : Cyberattaque
Auteur(s) du livre : Angeline Vagabulle
Éditeur : Les funambulles
978-2-9555452-7-0
Publié en 2018
Première rédaction de cet article le 8 août 2019
Des livres parlant de « cyberattaques » ou de « cybersécurité », il y en a plein. C'est un thème à la mode et les historiens du futur, lorsqu'ils étudieront la littérature du passé, noteront sans doute que les années 2010 étaient marquées par l'importance de ce thème. Mais ce livre a un angle original : ni un roman, ni un « reportage » sensationnaliste, ni une pseudo-réflexion sur la « cyberguerre », c'est un récit vu de l'intérieur d'une grosse perturbation, le passage de NotPetya dans l'entreprise où travaille l'auteure. Derrière le passionnant récit « sur le terrain », c'est peut-être l'occasion de se poser quelques questions sur l'informatique et la sécurité.
J'avoue ne pas savoir dans quelle mesure ce récit est authentique. L'auteure raconte à la première personne ce qu'a vécu l'entreprise où elle travaillait. Angeline Vagabulle est un pseudonyme, soit parce que l'entreprise ne souhaitait pas que ses cafouillages internes soient associés à son nom, soit parce que l'auteure a fait preuve d'imagination et romancé la réalité. Mais le récit est très réaliste et, même si cette entreprise particulière n'existe pas, les évènements relatés dans ce livre ont tous bien eu lieu dans au moins une grande entreprise dans le monde.
Ceux et celles qui ont vécu un gros problème informatique dans une grande entreprise multinationale les reconnaitront : le DSI qui se vante dans des messages verbeux et mal écrits que l'entreprise est bien protégée et que cela ne pourrait pas arriver, les conseils absurdes (« ne cliquez pas sur un lien avant d'être certain de son authenticité »), l'absence de communication interne une fois que le problème commence (ou bien son caractère contradictoire « éteignez tout de suite vos ordinateurs » suivi de « surtout n'éteignez pas vos ordinateurs »), la langue de bois corporate (« nous travaillons très dur pour rétablir la situation »), la découverte de dépendances que personne n'avait sérieusement étudié avant (« ah, sans les serveurs informatiques, on ne peut plus téléphoner ? »), l'absence de moyens de communications alternatifs. Il faut dire que l'entreprise décrite ici a fait fort : non seulement les postes de travail sur le bureau mais tous les serveurs étaient sous Windows, évidemment pas tenus à jour, et donc vulnérables à la faille EternalBlue. Au passage de NotPetya, tous les fichiers sont détruits et plus rien ne marche, on ne peut plus envoyer de propositions commerciales aux clients, on ne peut plus organiser une réunion, on ne peut même plus regarder le site Web public de la boîte (qui, lui, a tenu, peut-être était-il sur Unix ?) Et cela pendant plusieurs semaines.
Le ton un peu trop « léger », et le fait que l'héroïne du livre surjoue la naïve qui ne comprend rien peuvent agacer mais ce livre n'est pas censé être un guide technique du logiciel malveillant, c'est un récit par une témoin qui ne comprend pas ce qui se passe, mais qui décrit de manière très vivante la crise. (En italique, des encarts donnent des informations plus concrètes sur la cybersécurité. Mais celles-ci sont parfois non vérifiés, comme les chiffres de cyberattaques, a fortiori comme leur évaluation financière.)
(Le titre est clairement sensationnaliste : il n'y a pas eu d'attaque, cyber ou pas, NotPetya se propageait automatiquement et ne visait pas spécialement cette entreprise.)
En revanche, j'ai particulièrement apprécié les solutions que mettent en place les employés, pour faire face à la défaillance de l'informatique officielle. Comme les ordiphones ont survécu, WhatsApp est largement adopté, et devient l'outil de communication de fait. (Ne me citez pas les inconvénients de WhatsApp, je les connais, et je connais l'entreprise qui est derrière. Mais, ici, il faut se rappeler que les différents sites de la boîte n'avaient plus aucune communication.) Il reste à reconstituer les carnets d'adresses, ce qui occupe du monde (« C'est John, du bureau de Dublin, qui demande si quelqu'un a le numéro de Kate, à Bruxelles, c'est pour pouvoir contacter Peter à Dubaï. ») Beaucoup de débrouillardise est déployée, pour pallier les conséquences du problème. Une nouvelle victoire du shadow IT, et la partie la plus passionnante du livre.
Ce livre peut aussi être lu comme une critique de l'entreprise. Avant même le problème informatique, l'auteure note que sa journée se passait en réunion « sans même le temps d'aller aux toilettes ». On peut se demander s'il est normal qu'une journée de travail se passe exclusivement en réunions et en fabrication de reportings, sans rien produire. Il est symptomatique, d'ailleurs, qu'on ne sait pas exactement quel travail fait l'héroïne dans son entreprise, ni dans quel service elle travaille, ni d'ailleurs ce que fait l'entreprise.
L'auteure s'aventure à supposer que le problème est partiellement de la faute des informaticiens. « Ils feraient mieux de se concentrer sur leur boulot, en l'occurrence le développement d'applications et de systèmes sans failles. » C'est non seulement très yakafokon (développer un système sans faille est vraiment difficile) mais surtout bien à côté de la plaque. On sait, sinon faire des applications sans faille, du moins faire des applications avec moins de failles. On sait sécuriser les systèmes informatiques, pas parfaitement, bien sûr, mais en tout cas bien mieux que ce qu'avait fait l'entreprise en question. On le sait. Il n'y a pas de problème d'ignorance. En revanche, savoir n'est pas tout. Encore faut-il appliquer et c'est là que le bât blesse. Les solutions connues ne sont pas appliquées, à la fois pour de bonnes et de mauvaises raisons. Elles coûtent trop cher, elles ne plaisent pas aux utilisateurs (« le système que tu nous dis d'utiliser, j'ai essayé, il est peut-être plus sécurisé, mais qu'est-ce qu'il est moche ») et/ou aux décideurs (« ce n'est pas enterprise-grade » ou bien « on n'a pas le temps, il faut d'abord finir le reporting du trimestre précédent »). D'ailleurs, après une panne d'une telle ampleur, est-ce que l'entreprise en question a changé ses pratiques ? Gageons qu'elle aura continué comme avant. Par exemple, au moment du passage de NotPetya, l'informatique était sous-traitée au Portugal et en Inde. Aucun informaticien compétent dans les bureaux. Est-ce que ça a changé ? Probablement pas. L'expérience ne sert à rien, surtout en matière de cybersécurité.
Déclaration de potentiel conflit d'intérêt : j'ai reçu un exemplaire gratuitement.
L'article seul
Fiche de lecture : Programming Elixir
Auteur(s) du livre : Dave Thomas
Éditeur : The Pragmatic Programmers
978-1-68050-299-2
Publié en 2018
Première rédaction de cet article le 6 août 2019
Ce livre présente le langage de programmation Elixir, un langage, pour citer la couverture, « fonctionnel, parallèle, pragmatique et amusant ».
Elixir est surtout connu dans le monde des programmeurs Erlang, car il réutilise la machine virtuelle d'Erlang pour son exécution, et reprend certains concepts d'Erlang, notamment le parallélisme massif. Mais sa syntaxe est très différente et il s'agit bien d'un nouveau langage. Les principaux logiciels libres qui l'utilisent sont Pleroma (c'est via un travail sur ActivityPub que j'étais venu à Pleroma et donc à Elixir) et CertStream.
Comme tous les livres de cet éditeur, l'ouvrage est très concret, avec beaucoup d'exemples. Si vous voulez vous lancer, voici un exemple, avec l'interpréteur iex :
% iex
Erlang/OTP 22 [erts-10.4.4] [source] [64-bit] [smp:1:1] [ds:1:1:10] [async-threads:1] [hipe]
Interactive Elixir (1.8.2) - press Ctrl+C to exit (type h() ENTER for help)
iex(1)> "Hello"
"Hello"
iex(2)> 2 + 2
4
Mais on peut aussi bien sûr mettre du Elixir dans un fichier et l'exécuter :
% cat > test.exs
IO.puts 2+2
% elixir test.exs
4
Elixir a évidemment un mode Emacs, elixir-mode (site de référence sur Github). On peut l'utiliser seul, ou bien intégré dans l'environnement général alchemist. J'ai utilisé MELPA pour installer elixir-mode. Une fois que c'est fait, on peut se lancer dans les exercices du livre.
Quelles sont les caractéristiques essentielles d'Elixir ? Comme indiqué sur la couverture du livre, Elixir est fonctionnel, parallèle, pragmatique et amusant. Voici quelques exemples, tirés du livre ou inspirés par lui, montrés pour la plupart en utilisant l'interpréteur iex (mais Elixir permet aussi de tout mettre dans un fichier et de compiler, chapitre 1 du livre).
Contrairement à un langage impératif classique, les variables ne sont pas modifiées (mais on peut lier une variable à une nouvelle valeur, donc l'effet est proche de celui d'un langage impératif) :
iex(1)> toto = 42
42
iex(2)> toto
42
iex(3)> toto = 1337
1337
iex(4)> ^toto = 1
** (MatchError) no match of right hand side value: 1
(stdlib) erl_eval.erl:453: :erl_eval.expr/5
(iex) lib/iex/evaluator.ex:249: IEx.Evaluator.handle_eval/5
(iex) lib/iex/evaluator.ex:229: IEx.Evaluator.do_eval/3
(iex) lib/iex/evaluator.ex:207: IEx.Evaluator.eval/3
(iex) lib/iex/evaluator.ex:94: IEx.Evaluator.loop/1
(iex) lib/iex/evaluator.ex:24: IEx.Evaluator.init/4
iex(4)> ^toto = 1337
1337
Dans les deux derniers tests, le caret avant le nom de la variable indique qu'on ne veut pas que la variable soit redéfinie (chapitre 2 du livre).
Elixir compte sur le pattern matching (chapitre 2 du livre) et sur les fonctions beaucoup plus que sur des structures de contrôle comme le test ou la boucle. Voici la fonction qui calcule la somme des n premiers nombres entiers. Elle fonctionne par récurrence et, dans un langage classique, on l'aurait programmée avec un test « si N vaut zéro, c'est zéro, sinon c'est N plus la somme des N-1 premiers entiers ». Ici, on utilise le pattern matching :
iex(1)> defmodule Test do
...(1)> def sum(0), do: 0
...(1)> def sum(n), do: n + sum(n-1)
...(1)> end
iex(2)> Test.sum(3)
6
(On ne peut définir des functions nommées que dans un module, d'où
le defmodule.)
Naturellement, comme dans tout langage fonctionnel, on peut
passer des fonctions en paramètres (chapitre 5 du livre). Ici, la traditionnelle
fonction map (qui est dans le module standard
Enum)
prend en paramètre une fonction anonyme qui multiplie par deux :
iex(1)> my_array = [1, 2, 8, 11]
[1, 2, 8, 11]
iex(2)> Enum.map my_array, fn x -> x*2 end
[2, 4, 16, 22]
Cela marche aussi si on met la fonction dans une variable :
iex(3)> my_func = fn x -> x*2 end
#Function<7.91303403/1 in :erl_eval.expr/5>
iex(4)> Enum.map my_array, my_func
[2, 4, 16, 22]
Notez qu'Elixir a une syntaxe courante mais moins claire pour les programmeurs et programmeuses venu·e·s d'autres langages, si on veut définir une courte fonction :
iex(5)> Enum.map my_array, &(&1*2)
[2, 4, 16, 22]
(Et notez aussi qu'on ne met pas forcément de parenthèses autour des appels de fonction.)
Évidemment, Elixir gère les types de données de base (chapitre 4) comme les entiers, les booléens, les chaînes de caractères… Ces chaînes sont en Unicode, ce qui fait que la longueur n'est en général pas le nombre d'octets :
iex(1)> string = "Café"
"Café"
iex(2)> byte_size(string)
5
iex(3)> String.length(string)
4
Il existe également des structures de
données, comme le
dictionnaire (ici, le dictionnaire a deux
élements, nom et
ingrédients, le deuxième ayant pour valeur une
liste) :
defmodule Creperie do
def complète do
%{nom: "Complète", ingrédients: ["Jambon", "Œufs", "Fromage"]}
end
À propos de types, la particularité la plus exaspérante d'Elixir (apparemment héritée d'Erlang) est le fait que les listes de nombres sont imprimées comme s'il s'agissait de chaînes de caractères, si ces nombres sont des codes ASCII plus ou moins imprimables :
iex(2)> [78, 79, 78]
'NON'
iex(3)> [78, 79, 178]
[78, 79, 178]
iex(4)> [78, 79, 10]
'NO\n'
iex(5)> [78, 79, 7]
'NO\a'
iex(6)> [78, 79, 6]
[78, 79, 6]
Les explications complètes sur cet agaçant problème figurent dans la documentation des charlists. Pour afficher les listes de nombres normalement, plusieurs solutions :
- Pour l'interpréteur iex, mettre
IEx.configure inspect: [charlists: false]dans~/.iex.exs. - Pour la fonction
IO.inspect, lui ajouter un second argument,charlists: :as_lists. - Un truc courant est d'ajouter un entier nul à la fin de la
liste,
[78, 79, 78] ++ [0]sera affiché[78, 79, 78, 0]et pasNON.
À part cette particularité pénible, tout cela est classique dans les langages fonctionnels. Ce livre va nous être plus utile pour aborder un concept central d'Elixir, le parallélisme massif (chapitre 15). Elixir, qui hérite en cela d'Erlang, encourage les programmeuses et les programmeurs à programmer en utilisant un grand nombre d'entités s'exécutant en parallèle, les processus (notons tout de suite qu'un processus Elixir, exécuté par la machine virtuelle sous-jacente, ne correspond pas forcément à un processus du système d'exploitation). Commençons par un exemple trivial, avec une machine à café et un client :
defmodule CoffeeMachine do
def make(sugar) do
IO.puts("Coffee done, sugar is #{sugar}")
end
end
CoffeeMachine.make(true)
spawn(CoffeeMachine, :make, [false])
IO.puts("Main program done")
Le premier appel au sous-programme
CoffeeMachine.make est classique, exécuté
dans le processus principal. Le second appel lance par contre un
nouveau processus, qui va exécuter
CoffeeMachine.make avec la liste d'arguments
[false].
Les deux processus (le programme principal et celui qui fait le café) sont ici séparés, aucun message n'est échangé. Dans un vrai programme, on demande en général un minimum de communication et de synchronisation. Ici, le processus parent envoie un message et le processus fils répond (il s'agit de deux messages séparés, il n'y a pas de canal bidirectionnel en Elixir, mais on peut toujours en bâtir, et c'est ce que font certaines bibliothèques) :
defmodule CoffeeMachine do
def make(sugar) do
pid = self() # PID pour Process IDentifier
IO.puts("Coffee done by #{inspect pid}, sugar #{sugar}")
end
def order do
pid = self()
receive do
{sender, msg} ->
send sender, {:ok, "Order #{msg} received by #{inspect pid}"}
end
end
end
pid = spawn(CoffeeMachine, :order, [])
IO.puts("Writing to #{inspect pid}")
send pid, {self(), "Milk"}
receive do
{:ok, message} -> IO.puts("Received \"#{message}\"")
{_, message} -> IO.puts("ERROR #{message}")
after 1000 -> # Timeout after one second
IO.puts("No response received in time")
end
On y notera :
- Que l'identité de l'émetteur n'est pas automatiquement ajoutée, c'est à nous de le faire,
- L'utilisation du pattern matching pour
traiter les différentes types de message (avec clause
afterpour ne pas attendre éternellement), - Que contrairement à d'autres langages à parallélisme, il n'y a pas de canaux explicites, un processus écrit à un autre processus, il ne passe pas par un canal. Là encore, des bibliothèques de plus haut niveau permettent d'avoir de tels canaux. (C'est le cas avec Phoenix, présenté plus loin.)
spawn crée un processus complètement
séparé du processus parent. Mais on peut aussi garder un lien avec
le processus créé, avec spawn_link, qui lie
le sort du parent à celui du fils (si une exception se produit
dans le fils, elle tue aussi le parent) ou
spawn_monitor, qui transforme les exceptions
ou la terminaison du fils en un message envoyé au parent :
defmodule Multiple do
def newp(p) do
send p, {self(), "I'm here"}
IO.puts("Child is over")
# exit(:boom) # exit() would kill the parent
# raise "Boom" # An exception would also kill it
end
end
child = spawn_link(Multiple, :newp, [self()])
Et avec spawn_monitor :
defmodule Multiple do
def newp(p) do
pid = self()
send p, {pid, "I'm here"}
IO.puts("Child #{inspect pid} is over")
# exit(:boom) # Parent receives termination message containing :boom
# raise "Boom" # Parent receives termination message containing a
# tuple, and the runtime displays the exception
end
end
{child, _} = spawn_monitor(Multiple, :newp, [self()])
Si on trouve les processus d'Elixir et leurs messages de trop bas niveau, on peut aussi utiliser le module Task, ici un exemple où la tâche et le programme principal ne font pas grand'chose à part dormir :
task = Task.async(fn -> Process.sleep Enum.random(0..2000); IO.puts("Task is over") end)
Process.sleep Enum.random(0..1000)
IO.puts("Main program is over")
IO.inspect(Task.await(task))
Vous pouvez trouver un exemple plus réaliste, utilisant le parallélisme pour lancer plusieurs requêtes réseau en évitant qu'une lente ne bloque une rapide qui suivrait, dans cet article.
Les processus peuvent également être lancés sur une autre machine du réseau, lorsqu'une machine virtuelle Erlang y tourne (chapitre 16 du livre). C'est souvent présenté par les zélateurs d'Erlang ou d'Elixir comme un bon moyen de programmer une application répartie sur l'Internet. Mais il y a deux sérieux bémols :
- Ça ne marche que si les deux côtés de l'application (sur la machine locale et sur la distante) sont écrits en Elixir ou en Erlang,
- Et, surtout, surtout, la sécurité est très limitée. La seule protection est une série d'octets qui doit être la même sur les deux machines. Comme elle est parfois fabriquée par l'utilisateur (on trouve sur le Web des exemples de programmes Erlang où cette série d'octets est une chaîne de caractères facile à deviner), elle n'est pas une protection bien solide, d'autant plus que la machine virtuelle la transmet en clair sur le réseau. (Chiffrer la communication semble difficile.)
Bref, cette technique de création de programmes répartis est à réserver aux cas où toutes les machines virtuelles tournent dans un environnement très fermé, complètement isolé de l'Internet public. Autrement, si on veut faire de la programmation répartie, il ne faut pas compter sur ce mécanisme.
Passons maintenant à des exemples où on utilise justement le réseau. D'abord, un serveur echo (je me suis inspiré de cet article). Echo est normalisé dans le RFC 862. Comme le programme est un peu plus compliqué que les Hello, world faits jusqu'à présent, on va commencer à utiliser l'outil de compilation d'Elixir, mix (chapitre 13 du livre, il existe un court tutoriel en français sur Mix).
Le plus simple, pour créer un projet qui sera géré avec mix, est :
% mix new echo
Le nouveau projet est créé, on peut l'ajouter à son VCS favori, puis aller dans le répertoire du projet et le tester :
% cd echo % mix test
Les tests ne sont pas très intéressants pour l'instant, puisqu'il
n'y en a qu'un seul, ajouté automatiquement par Mix. Mais ça
prouve que notre environnement de développement
marche. Maintenant, on va écrire du vrai code, dans
lib/echo.ex (vous pouvez voir le résultat complet).
Les points à noter :
- Le livre de Dave Thomas ne parle pas du tout de programmation réseau, ou des prises réseau,
- J'ai utilisé une bibliothèque Erlang.gen_tcp,
puisqu'on peut appeler les bibliothèques Erlang depuis Elixir
(rappelez-vous que les deux langages utilisent la même machine
virtuelle, Beam.) Les bibliothèques Erlang
importées dans Elixir ont leur nom précédé d'un
deux-points donc, ici,
:gen_tcp. - Une fois un client accepté avec
:gen_tcp.accept, la fonctionloop_acceptorlance un processus séparé puis s'appelle elle-même. Comme souvent dans les langages fonctionnels, on utilise la récursion là où, dans beaucoup de langages, on aurait utilisé une boucle. Cette appel récursif ne risque pas de faire déborder la pile, puisque c'est un appel terminal. - La fonction
serveutilise l'opérateur|>, qui sert à emboiter deux fonctions, le résultat de l'une devenant l'argument de l'autre (comme le tube pour le shell Unix.) Et elle s'appelle elle-même, commeloop_acceptor, pour traiter tous les messages envoyés. - La fonction
write_lineest définie en utilisant le pattern matching (deux définitions possibles, une pour le cas normal, et une pour le cas où la connexion TCP est fermée.) - Le code peut sembler peu robuste, plusieurs cas ne sont
pas traités (par exemple, que se passe-t-il si
:gen_tcp.recv, et doncread_line, renvoie{:error, :reset}? Aucune définition dewrite_linene prévoit ce cas.) Mais cette négligence provient en partie du d'un style de développement courant en Elixir : on ne cherche pas à faire des serveurs qui résistent à tout, ce qui complique le code (la majorité du programme servant à gérer des cas rares). On préfère faire tourner le programme sous le contrôle d'un superviseur (et l'environnement OTP fournit tout ce qu'il faut pour cela, cf. chapitres 18 et 20 dans le livre), qui redémarrera le programme le cas échéant. Au premier atelier Elixir que j'avais suivi, au BreizhCamp, le formateur, Nicolas Savois, m'avait dit que mon code était trop robuste et que je vérifiait trop de choses. Avec Elixir, c'est Let it crash, et le superviseur se chargera du reste. (Dans mon serveur echo, je n'ai pas utilisé de superviseur, mais j'aurais dû.)
Et pour lancer le serveur ? Un programme
start-server.exs contient simplement :
import Echo
Echo.accept(7)
(7 étant le port standard d'echo) Et on le démarre ainsi :
% sudo mix run start-server.exs
18:54:47.410 [info] Accepting connections on port 7
...
18:55:10.807 [info] Serving #Port<0.6>
La ligne « Serving #Port » est affichée lorsqu'un client apparait. Ici, on peut tester avec telnet :
% telnet thule echo
Trying 10.168.234.1...
Connected to thule.
Escape character is '^]'.
toto
toto
^]
telnet> quit
Connection closed.
Ou bien avec un client echo spécialisé, comme echoping :
% echoping -v thule ... Trying to send 256 bytes to internet address 10.168.234.1... Connected... TCP Latency: 0.000101 seconds Sent (256 bytes)... Application Latency: 0.000281 seconds 256 bytes read from server. Estimated TCP RTT: 0.0001 seconds (std. deviation 0.000) Checked Elapsed time: 0.000516 seconds
Et si on veut faire un serveur HTTP,
parce que c'est quand même plus utile ? On peut utiliser le même
gen_tcp
comme dans l'exemple qui figure au début de cet
article. Si vous voulez tester, le code est en http-serve.exs, et ça se lance avec :
% elixir server.exs
15:56:29.721 [info] Accepting connections on port 8080
...
On peut alors l'utiliser avec un client comme
curl, ou bien un
navigateur visitant
http://localhost:8080/. Mais ce serveur
réalisé en faisant presque tout soi-même est très limité (il ne
lit pas le chemin de l'URL, il ne traite
qu'une requête à la fois, etc) et, en pratique, la plupart des
programmeurs vont s'appuyer sur des cadriciels existants comme Phoenix ou Plug. Par défaut, tous les deux utilisent le
serveur HTTP Cowboy, écrit en
Erlang (cf. le site Web de
l'entreprise qui développe Cowboy, et la documentation.) Pour avoir des exemples concrets, regardez cet
article ou bien, avec Plug, celui-ci.
Mix permet également de gérer les dépendances d'une application (les bibliothèques dont on a besoin), via Hex, le système de gestion de paquetages commun à Erlang et Elixir (chapitre 13 du livre). Voyons cela avec une bibliothèque DNS, Elixir DNS. On crée le projet :
% mix new test_dns * creating README.md * creating .formatter.exs * creating .gitignore * creating mix.exs * creating lib * creating lib/test_dns.ex * creating test * creating test/test_helper.exs * creating test/test_dns_test.exs ... % mix test Compiling 1 file (.ex) Generated test_dns app .. Finished in 0.04 seconds 1 doctest, 1 test, 0 failures
On modifie le fichier mix.exs, créé par Mix,
pour y ajouter la bibliothèque qu'on veut, avec son numéro de
version minimal :
# Run "mix help deps" to learn about dependencies.
defp deps do
[
{:dns, "~> 2.1.2"},
]
end
Et on peut alors installer les dépendances. (Pour utiliser Hex, sur Debian, il faut
installer le paquetage erlang-inets, sinon on obtient
(UndefinedFunctionError) function :inets.stop/2 is
undefined (module :inets is not available).)
% mix deps.get Could not find Hex, which is needed to build dependency :dns Shall I install Hex? (if running non-interactively, use "mix local.hex --force") [Yn] y * creating /home/stephane/.mix/archives/hex-0.20.1
Le message Could not find Hex [...] Shall I install Hex n'apparaitra que la première fois. Après :
% mix deps.get Resolving Hex dependencies... Dependency resolution completed: New: dns 2.1.2 socket 0.3.13 * Getting dns (Hex package) * Getting socket (Hex package)
Notez qu'Hex a également installé la dépendance de la dépendance
(dns dépend de socket.) On
peut maintenant exécuter nos programmes :
% cat example.exs
IO.inspect(DNS.resolve("github.com", :a))
% mix run ./example.exs
{:ok, [{140, 82, 118, 4}]}
En conclusion, je trouve le livre utile. Il est en effet très pratique, très orienté vers les programmeuses et programmeurs qui veulent avoir du code qui tourne dès les premiers chapitres. Concernant le langage, je réserve mon opinion tant que je n'ai pas écrit de vrais programmes avec.
Qui, d'ailleurs, écrit des vrais programmes avec Elixir ? Parmi les logiciels connus :
- Une mise en œuvre du fédivers, Pleroma.
- L'excellent serveur de suivi des journaux Certificate Transparency (RFC 6962) CertStream (journaux qu'il est indispensable de surveiller automatiquement pour détecter des faux certificats utilisant votre nom).
- Le système Nerves de développement de code embarqué.
- Toujours pour l'IoT, il y a Astarte.
- Le système de communication audio/vidéo Discord (non libre, contrairement aux trois précédents) l'utilise. Ils publient d'intéressants articles sur les questions de passage à l'échelle, comme celui-ci ou bien cet autre, qui mentionne les limites d'Elixir.
- Le système de curation de contenu éducatif Moodle.
- Et le futur système de coordination d'actions Mobilizon sera en Elixir.
Si vous cherchez des ressources supplémentaires sur Elixir, voici quelques idées :
- La bibliothèques standard est documentée en
https://hexdocs.pm/elixir/ - Sur la notion de superviseur, cruciale en Elixir pour écrire des serveurs non-expérimentaux, voir la documentation officielle. (Mais on les utilise typiquement via l'orchestrateur OTP.)
- Pour créer un serveur HTTP supervisé, et avec l'aide de Mix, Cowboy et Plug, voir cet article.
- Une bonne introduction à Plug.
- Pour essayer en pratique un langage de programmation, on utilise souvent l'API CRUD TODO Backend, qui permet de gérer une liste de choses à faire (ajouter une chose à faire, la voir, la modifier, avoir la liste, la détruire). Parmi les innombrables réalisations de cette API qu'on trouve sur leur site, il y en a trois en Elixir, une avec Phoenix, une avec Plug, et une avec un autre cadriciel, Maru.
- Une bonne ressource pour les débutants, le site Elixir School.
- J'avais mentionné l'atelier de Nicolas Savois au BreizhCamp, les documents de cet atelier sont en ligne.
L'article seul
ILNP DNS processing at the IETF 105 hackathon
First publication of this article on 23 July 2019
The weekend of 20-21 July 2019, in Montréal, was the hackathon preceding the IETF 105 meeting. During this hackathon, I helped to improve the DNS support for the ILNP protocol, in the Knot DNS resolver.
ILNP is an identifier/locator
separation network protocol. Each machine has at least
one identifier such as
0:0:c:1, which is stable (never changes), and
at least one locator such as
2001:8b0:d3:cc22, which may vary often, for
instance when the machine moves from one network to another, or
when the network is renumbered. The idea is to give stable
identities to the machine, while keeping locators for efficient
routing. If the locator looks like an
IPv6 address, it is not a coincidence, it
is because you can use ILNP locators everywhere you would use an
IP address (more on that later). Each identifier/locator
separation system requires a mapping service
to get the locator from the identifier. With ILNP, this mapping
service is the old and proven DNS. As the
saying goes, "you can solve every problem in computer science just
by adding one level of indirection".
ILNP is described in RFC 6740 and the DNS resource
records on RFC 6742. These resource records
are NID (find the identifier from the
domain name) and L64
(find the locator from the domain name). I simplify, there are
other records but here are the two I worked with. You can see them
online yourself:
% dig NID ilnp-aa-test-c.bhatti.me.uk
...
;; ANSWER SECTION:
ilnp-aa-test-c.bhatti.me.uk. 10 IN NID 10 0:0:c:1
ilnp-aa-test-c.bhatti.me.uk. 10 IN NID 20 0:0:c:2
ilnp-aa-test-c.bhatti.me.uk. 10 IN NID 30 0:0:c:3
...
% dig L64 ilnp-aa-test-c.bhatti.me.uk
...
;; ANSWER SECTION:
ilnp-aa-test-c.bhatti.me.uk. 10 IN L64 10 2001:8b0:d3:cc11
ilnp-aa-test-c.bhatti.me.uk. 10 IN L64 20 2001:8b0:d3:cc22
...
ILNP could work just like that. RFC 6742, section
3.2, just recommends that the name servers do some additional
processing, and return other possibly useful ILNP records when
queried. For instance, if NID records are
asked for, there is a good chance L64 records
will be needed soon, so the server could as well find them and
return them in the additional section of the DNS response (in the
two examples above, there is only the answer section).
Current name servers don't do this additional
processing. Anyway, this weekend, we went a bit further,
implementing an option which is not in the RFC. Following an idea
by Saleem Bhatti, the goal was to have the DNS resolver return
ILNP records when queried for an AAAA record
(IPv6 address). This would allow unsuspecting applications to use
ILNP without being modified. The application would ask the IP
address of another machine, and a modified name resolution library
would get the ILNP records and, if they exist, return to the
application the locator instead of the "normal" IP address
(remember they have the same syntax).
Now, let's see how to do that in the Knot
resolver. Knot has a system of modules that allow to
define specific processing for some requests, without modifying
the main code. (I already used that at the
previous hackathon.) Modules can be written in
Lua or C. I choosed
C. We will therefore create a
ilnp module in
modules/ilnp. A module can be invoked at
several "layers" during the processing of a DNS request. We will
use the consume layer, where the request has
been received but not all the answers are known yet:
static int ilnp_consume(kr_layer_t *ctx, knot_pkt_t *pkt) {
...
}
KR_EXPORT
int ilnp_init(struct kr_module *module) {
static kr_layer_api_t layer = {
.consume = &ilnp_consume,
};
The entire module is 83 lines, including test of return values,
logging, comments and empty lines.
Now, if the module is loaded, Knot will invoke
consume() for every DNS request. We need to
act only for AAAA requests:
struct kr_request *req = ctx->req;
if (req->current_query->stype == KNOT_RRTYPE_AAAA) {
...
}
/* Otherwise, do nothing special, let Knot continue. */
And what do we do when we see the AAAA requests? We ask Knot to
add a sub-request to the current requests (two, actually, for
NID and L64). And we
need also to check if the request is a sub-request or not. So we
add some flags in lib/rplan.h:
struct kr_qflags {
...
bool ILNP_NID_SUB : 1; /** NID sub-requests for ILNP (ilnp module) */
bool ILNP_L64_SUB : 1; /** L64 sub-requests for ILNP (ilnp module) */
And we modify the code to add the sub-requests
(kr_rplan_push(), here I show only the
NID one) and to test them
(req->options.ILNP_..._SUB):
if (req->current_query->stype == KNOT_RRTYPE_AAAA && !req->options.ILNP_NID_SUB && !req->options.ILNP_L64_SUB)
{
next_nid = kr_rplan_push(&req->rplan, req->current_query,
req->current_query->sname, req->current_query->sclass,
KNOT_RRTYPE_NID);
next_nid->flags.ILNP_NID_SUB = true;
next_nid->flags.DNSSEC_WANT = true;
next_nid->flags.AWAIT_CUT = true;
}
And, when the sub-request returns, we add its answers to the
additional section (array_push(), again, I
show only for NID):
else if (req->current_query->stype == KNOT_RRTYPE_NID && req->current_query->flags.ILNP_NID_SUB) {
for (i=0; i<req->answ_selected.len; i++) {
if (req->answ_selected.at[i]->rr->type == KNOT_RRTYPE_NID) {
array_push(req->additional, req->answ_selected.at[i]->rr);
}
}
}
To test that, we have to load the module (people not interested in ILNP will not run this code, which is good for them, because the extra queries take time):
modules = {'hints', 'view', 'nsid', 'ilnp'}
And Knot now gives us the ILNP records in the additional section:
% dig @MY-RESOLVER AAAA ilnp-aa-test-c.bhatti.me.uk
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 53906
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 6
...
;; ANSWER SECTION:
ilnp-aa-test-c.bhatti.me.uk. 10 IN AAAA 2001:8b0:d3:1111::c
;; ADDITIONAL SECTION:
ilnp-aa-test-c.bhatti.me.uk. 10 IN L64 10 2001:8b0:d3:cc11
ilnp-aa-test-c.bhatti.me.uk. 10 IN L64 20 2001:8b0:d3:cc22
ilnp-aa-test-c.bhatti.me.uk. 10 IN NID 10 0:0:c:1
ilnp-aa-test-c.bhatti.me.uk. 10 IN NID 20 0:0:c:2
ilnp-aa-test-c.bhatti.me.uk. 10 IN NID 30 0:0:c:3
;; Query time: 180 msec
;; MSG SIZE rcvd: 194
A possible option would have been to return the ILNP records only if they are already in the cache, improving performances. (Today, most machines have no ILNP records, so querying them takes time for nothing.) But, as far as I know, Knot does not provide an easy way to peek in the cache to see what's in it.
I also worked on the Unbound
resolver. Unbound is not modular so modifications are more
tricky, and I was unable to complete the work. Unbound, unlike
Knot, allows you to see what is in the cache (added in daemon/worker.c):
rrset_reply = rrset_cache_lookup(worker->env.rrset_cache, qinfo.qname,
qinfo.qname_len,
LDNS_RR_TYPE_NID, LDNS_RR_CLASS_IN, 0, *worker->env.now, 0);
if (rrset_reply != NULL) {
/* We have a NID for sldns_wire2str_dname(qinfo.qname,
256)) */
lock_rw_unlock(&rrset_reply->entry.lock); /* Read the
documentation in the source: it clearly says it is locked
automatically and you have to unlock when done. *
}
But NID and other ILNP records are not put into the cache. This
is because Unbound does not follow the caching model described
in RFC 1034. For performance reasons, it has two caches, one for entire DNS messages and
one for resource records. The first one is used for "normal" DNS
queries (for instance a TXT record), the
second for information that may be needed to answer queries,
such as the IP addresses of name servers. If you query an
Unbound resolver for a TXT record, the answer will be only in
the message cache, not in the resource record cache. This allows
Unbound to reply much faster: no need to construct an answer,
just copy the one in the cache. But it makes retrieval of data
more difficult, hence the resource record cache. A possible
solution would be to put ILNP records in the resource record
cache (in iterator/iter_scrub.c):
#ifdef ILNP
if (rrset->type == LDNS_RR_TYPE_NID || rrset->type == LDNS_RR_TYPE_L64 ||
rrset->type == LDNS_RR_TYPE_L32 || rrset->type == LDNS_RR_TYPE_LP) {
store_rrset(pkt, msg, env, rrset);
}
#endif
But, as I said, I stopped working on Unbound, lack of time and lack of brain.
Many thanks to Ralph Dolmans and Petr Špaček for their help while I struggled with Unbound and Knot Resolver.
L'article seul
RFC 8631: Link Relation Types for Web Services
Date de publication du RFC : Juillet 2019
Auteur(s) du RFC : E. Wilde
Pour information
Première rédaction de cet article le 21 juillet 2019
Le Web, ce sont les pages auxquelles on accède depuis son navigateur, avec les textes à lire et les images à regarder. Mais ce sont aussi de nombreuses applications, avec une API, prévues pour être utilisées depuis un programme spécifique, pas depuis le navigateur Web. Ces Web services ont un ou plusieurs URL pour les appeler, et des ressources supplémentaires comme la documentation. Ce nouveau RFC décrit un type de liens hypertextes permettant de trouver l'URL de la documentation d'un service.
Normalement, on peut interagir avec un service Web sans connaitre les détails à l'avance. La négociation de contenu, par exemple (RFC 7231, sections 3.4 et 5.3) permet de choisir dynamiquement le type de données. En combinant les outils de l'architecture Web (URI, HTTP, etc), on peut créer des services plus simples que les anciennes méthodes compliquées, type CORBA. (Le terme de service REST est souvent utilisé pour ces services modernes et simples.) Mais cela ne dispense pas complètement de documentation et de description des services. (La documentation est du texte libre, conçue pour les humains, la description est sous un format structuré, et conçue pour les programmes.) Il faut donc, pour accéder à un service, trouver documentation et description. C'est ce que propose ce RFC, avec de nouveaux types de liens (les types de liens sont décrits dans le RFC 8288).
Notez bien que ce RFC ne dit pas comment doit être écrite la documentation, ou sous quel format structurer la description. Un format de description courant aujourd'hui est OpenAPI, fondé sur JSON. Mais il en existe d'autres comme RAML (fondé sur YAML) ou RSDL, si vous avez des expériences concrètes sur ces langages, ou des opinions sur leurs avantages et inconvénients, je suis intéressé. (Dans le passé, on utilisait parfois WSDL). Ce RFC fournit juste un moyen de trouver ces descriptions. (En prime, il permet également de trouver l'URL d'un service décrivant l'état actuel d'un service, permettant d'informer, par exemple, sur des pannes ou sur des opérations de maintenance.)
Parfois, documentation et description sont fusionnées en un seul ensemble de ressources. Dans ce cas, on n'est pas obligé d'utiliser notre RFC, on peut se contenter du type de lien décrit dans le RFC 5023.
Les quatre nouveaux types de liens (section 4 du RFC) sont :
service-docpour indiquer où se trouve la documentation (écrite pour des humains),service-descpour donner accès à la description (conçue pour des programmes),service-metapour l'URI des méta-informations diverses sur le service, comme des informations à caractère juridique (politique « vie privée » du service, par exemple),statuspour l'état actuel du service.
Ces types sont notés dans le registre IANA des types de liens (section 6 du RFC).
Un exemple dans un document HTML serait, pour indiquer la documentation :
<link rel="service-doc" type="text/html" title="My documentation"
href="https://api.example.org/documentation.html"/>
Et dans les en-têtes HTTP, ici pour indiquer la description :
Link: <https://api.example.org/v1/description.json> rel="service-desc";
type="application/json"
Si vous voulez voir un exemple réel, il y en a un dans le DNS Looking Glass. Les en-têtes HTTP, et le code HTML contiennent un lien vers la documentation.
La section 5 est consacrée à
status, qui permet d'indiquer une ressource
sur le Web donnant des informations sur l'état du
service. On peut voir par exemple la page de Github ou
bien celle de
CloudFlare. (Évidemment, il est recommandé qu'elle soit hébergée sur
une infrastructure différente de celle du service dont elle
indique l'état de santé, pour éviter que le même problème
DNS, BGP ou autre ne
plante le service et son bulletin de santé en même temps. C'est ce
que ne fait pas la page
de Framasoft, qui utilise le même nom de domaine.) Aucune obligation sur le contenu
auquel mène le lien, cela peut être un texte conçu pour un humain
ou pour un programme.
Quelques considérations de sécurité pour finir (section 7 du RFC). D'abord, toute documentation peut être utilisée par les gentils utilisateurs, mais aussi par les méchants attaquants. Il peut donc être prudent de ne donner dans la documentation que ce qui est nécessaire à l'utilisation du service. D'autre part, la description (ce qui est en langage formel, analysable par un programme) peut permettre davantage d'automatisation. C'est bien son but, mais cela peut aider les attaquants à automatiser les attaques. Sans même parler d'attaque délibérée, le RFC note aussi que cette automatisation, utilisée par un programme client mal écrit, peut mener à une charge importante du service si, par exemple, le client se met à utiliser sans limitation toutes les options qu'il découvre.
Enfin, tout programmeur et toute programmeuse sait bien que les documentations ne sont pas toujours correctes. (Ou, plus charitablement, qu'elles ne sont pas toujours à jour.) Le programme client ne doit donc pas faire une confiance aveugle à la documentation ou à la description et doit se préparer à des comportements imprévus de la part du service.
À part le DNS Looking Glass, je n'ai pas encore trouvé de service Web qui utilise ces types de liens. Si vous en voyez un, vous me prévenez ?
L'article seul
La vente d'une partie du réseau 44
Première rédaction de cet article le 19 juillet 2019
Dernière mise à jour le 20 juillet 2019
Hier, une partie du préfixe IPv4
44.0.0.0/8 a été vendue à
Amazon. Comment ? Pourquoi ? Et c'est quoi
cette histoire de ventes d'adresses
IP ? Nous allons plonger dans le monde de la
gouvernance de l'Internet pour en savoir
plus.
D'abord, les faits. Le préfixe vendu est le
44.192.0.0/10 et on peut vérifier, par
exemple avec whois, qu'il « appartient »
(les juristes hésitent pour savoir s'il s'agit réellement de propriété) à
Amazon :
% whois 44.192.0.0
...
NetRange: 44.192.0.0 - 44.255.255.255
CIDR: 44.192.0.0/10
...
Parent: NET44 (NET-44-0-0-0-0)
Organization: Amazon.com, Inc. (AMAZO-4)
RegDate: 2019-07-18
Updated: 2019-07-18
Comme l'indique la date de mise à jour, cela a été fait hier. Le
reste du préfixe 44.0.0.0/8 « appartient » à
ARDC (Amateur Radio Digital Communications),
une organisation créée pour représenter les intérêts des
radioamateurs. En effet, ce préfixe
44.0.0.0/8, comportant 16 777 216 adresses
IPv4 avait historiquement été alloué au
réseau de radioamateurs, AMPR. (Le site Web officiel de l'ARDC
est dans le domaine ampr.org.)
% whois 44.0.0.0
NetRange: 44.0.0.0 - 44.191.255.255
CIDR: 44.128.0.0/10, 44.0.0.0/9
NetName: AMPRNET
Parent: NET44 (NET-44-0-0-0-0)
Organization: Amateur Radio Digital Communications (ARDC)
RegDate: 1992-07-01
Updated: 2019-07-18
Pour les amateurs de BGP, notez que le préfixe entier était annoncé par l'UCSD il y a un peu plus d'un mois. Depuis le 4 juin 2019, ce n'est plus le cas, comme le montre RIPE stat, Amazon annoncera sans doute « son » préfixe dans le futur (pour l'instant, ce n'est pas fait).
Les addresses IPv4 sont de plus en plus rares et, logiquement, valent de plus en plus cher. Amazon, avec son épais portefeuille, peut donc en acheter, seule la loi du marché compte. On peut acheter et vendre des adresses IP, comme des bananes ou des barils de pétrole, elles ne sont pas considérées comme des biens communs, et ne sont pas soustraites au marché. Pour diminuer cette pression liée à la pénurie, la bonne solution est évidemment de déployer IPv6 mais beaucoup d'acteurs trainent la patte, voire nient le problème.
Le préfixe 44.0.0.0/8 dépend du
RIR ARIN et ARIN
estime que la transaction a suivi ses règles : le titulaire du
préfixe était d'accord, et le nouveau titulaire était éligible (il
pouvait démontrer un besoin d'adresses, ce qui est assez évident
pour AWS). Mais quelles questions cela
pose-t-il ?
D'abord, je précise que je ne suis pas radioamateur moi-même et que je ne peux donc pas donner une opinion intelligente sur les relations (apparemment pas toujours idylliques) au sein d'ARDC et entre ARDC et les radioamateurs en général.
Car l'une des premières questions posées concernait justement
la légitimité d'ARDC. À l'époque où le
44.0.0.0/8 a été alloué, en 1986, assez loin
dans le passé de l'Internet (la date de 1992 que donne ARIN est la
date de l'entrée dans une nouvelle base de données, pas la date
originelle), ARDC n'existait pas. À l'époque, les allocations de
préfixes se faisaient de manière non bureaucratique, assez
souplement, et sur la base de relations de confiance
mutuelle. ARDC a été créé par la suite, en 2011, justement pour
gérer les ressources communes, et certains se demandent si cette
responsabilité d'ARDC va jusqu'à lui permettre de vendre une
partie des ressources communes, même si cet argent (« plusieurs
millions de dollars », ce qui est bon marché au cours actuel des
adresses IPv4, mais, comme beaucoup de choses dans cette affaire,
le montant exact n'est pas public) reviendra au bout du compte à
la communauté des radioamateurs. Ce problème de vente d'un bien
commun est d'autant plus crucial que l'ARDC est une organisation
purement états-unienne, alors qu'il y a des radioamateurs dans le
monde entier (et qu'ils ont une
fédération internationale qui les représente.)
Il y a aussi des débats, internes à ce monde des radioamateurs, quand au mécanisme de prise de décision, et à l'information envoyée par les décideurs (apparemment inexistante, avant la vente). Mais, comme je l'ai dit, je ne suis pas radioamateur donc je ne peux pas juger.
On peut aussi se poser la question de l'applicabilité des
règles d'ARIN. Au moment de la délégation
du préfixe 44.0.0.0/8, ARIN n'existait même
pas (il n'a été créé qu'en 1997). Comme les autres préfixes du
« marais »,
44.0.0.0/8 a été récupéré par un RIR, qui a
ensuite imposé ses règles. ARIN n'a pas voulu dire si ARDC avait
ou non signé un accord - nommé RSA (Registration Services
Agreement) ou LRSA (Legacy Registration
Services Agreement) selon le cas - pour cette soumission
aux règles ARIN.
Notez que cette acceptation des règles de l'ARIN est obligatoire si on veut mettre ses préfixes dans la RPKI. (L'argument d'ARIN étant que la RPKI, elle, a été créé après ARIN.) Ce n'est pas forcément très important en pratique, les réglementations internationales font que le réseau des radioamateurs n'est pas un réseau critique, de toute façon. (Par exemple, le chiffrement est interdit.)
Certains ont défendu la vente en disant que le préfixe vendu
n'était pas utilisé (et ne le serait probablement jamais,
l'activité de radioamateur ne grossissant pas tant que ça) mais
le site Web de l'ARDC montre que
44.224.0.0/15, qui fait partie du préfixe
vendu, était bien prévu pour être utilisé (en pratique,
l'Allemagne semble ne pas s'en être servi beaucoup).
Toute cette histoire illustre bien le fait que la gestion des
adresses IP est tout aussi politique (et business) que celle des
noms de domaine, pour lesquels tant (trop) de gens s'excitent. La
gouvernance de l'Internet ne se limite pas
à la création (ou non) du .gay, du
.vin ou du .amazon !
Quelques autres lectures :
- Si vous voulez le point de vue de la direction d'ARDC sur cette vente, il figure sur leur site Web.
- Cette vente avait été prévue dans un poisson d'avril il y a quelques années.
L'article seul
RFC 8569: Content Centric Networking (CCNx) Semantics
Date de publication du RFC : Juillet 2019
Auteur(s) du RFC : M. Mosko (PARC), I. Solis (LinkedIn), C. Wood (University of California Irvine)
Expérimental
Réalisé dans le cadre du groupe de recherche IRTF icnrg
Première rédaction de cet article le 16 juillet 2019
Certaines personnes trouvent une utilité au réseau centré sur le contenu, où adressage et nommage ne désignent que du contenu, des ressources numériques auxquelles on accède via le réseau. (Cette idée est souvent nommée ICN, pour Information-Centric Networking ou NDN pour Named Data Networking.) Le groupe de recherche ICNRG développe des spécifications pour normaliser certains aspects de ce réseau centré sur le contenu, un projet nommmé CCNx (pour Content Centric Networking). Ce nouveau RFC décrit les concepts de base de CCNx. CCNx est le premier protocole conçu par le groupe ICNRG.
Précisons tout de suite : ce point de vue comme quoi le socle du réseau devrait être l'accès au contenu est très contestable. Il évoque fortement le raccourci de certains journalistes, décideurs, et opérateurs de télécommunication traditionnels comme quoi le seul usage de l'Internet fait par M. Michu serait « accéder à du contenu ». Mais j'ai déjà développé ces critiques dans un autre article il y a huit ans, donc je ne les reprendrai pas ici.
Les acteurs du réseau centré sur le contenu sont notamment :
- Le producteur (producer ou publisher) qui crée du contenu. Il peut avoir une clé qui lui permet de signer ce contenu.
- Le consommateur (consumer) qui veut accéder à du contenu.
(Vous noterez qu'il n'y a pas de pair à pair dans ce réseau, ce qui limite certains usages.)
Le protocole CCnx repose sur deux types de messages :
Interest, par lequel on signale qu'on
aimerait bien récupérer tel contenu, et Content
Object, qui transporte un contenu. En général, la
machine de l'utilisateur, du consommateur demandeur, enverra un
Interest et, si tout va bien, récupérera en
échange un ou plusieurs Content Object. Si
tout va mal, on aura à la place un
InterestReturn, qui signale un
problème. Comment sont désignés les contenus ? Par des noms
hiérarchiquement organisés, comme dans les
URL d'aujourd'hui (section 3 du RFC). Un nom est donc composé
d'une série de segments, et la correspondance entre un nom demandé
et une entrée de la table de routage est toujours faite de manière exacte, bit
à bit. (Pas
d'insensibilité à la casse, pas de
recherche floue.) Le nom est opaque. Il n'est donc pas forcément lisible par un
humain. Comme les noms sont hiérarchiques, un nom peut être exact
(le nom entier) ou être un préfixe (correspondant à plusieurs
noms). On dit aussi qu'un nom est complet quand il inclut un
condensat du contenu (comme dans les
magnets de
BitTorrent). Le condensat est expliqué plus
en détail dans les sections 5 et 7 du RFC. La syntaxe est décrite
dans l'Internet
Draft draft-mosko-icnrg-ccnxurischeme, qui met
les noms CCNx sous forme d'URI. Par
exemple, un nom possible est
ccnx:/NAME=foo/APP:0=bar. Il n'y a pas de
registre de tels noms pour l'instant. Si on veut trouver des noms,
le protocole lui-même ne le permet pas, il faudra bâtir des
solutions (par exemple un moteur de recherche) au-dessus de CCNx.
CCNx fonctionne en
relayant les messages (aussi bien Interest
que Content Object) d'une machine à
l'autre. Du fait de ce modèle de relayage systématique, il faut
ajouter un troisième acteur au producteur et au consommateur, le
relayeur (forwarder), qui
est toute machine intermédiaire, un peu comme un
routeur sauf que le relayeur fait bien plus
de choses qu'un routeur. Par exemple, contrairement au routeur
IP, le relayeur a un état. Chaque demande
d'objet qui passe est mémorisée par le relayeur (dans une
structure de données nommée la PIT, pour Pending Interest
Table), qui saura donc où
renvoyer la réponse. CCNx est sourceless,
contrairement à IP : l'adresse source n'est pas indiquée dans la demande.
La FIB (Forwarding Information Base) est la table de routage de CCNx. Si elle contient une entrée pour le contenu convoité, cette entrée indique où envoyer la requête. Sinon, la requête ne peut aboutir. Notez que ce RFC ne décrit pas le protocole par lequel cette FIB sera construite. Il n'existe pas encore d'OSPF ou de BGP pour CCNx.
Comme le contenu peut être récupéré après un passage par pas mal d'intermédiaires, il est crucial de vérifier son intégrité. CCNx permet plusieurs méthodes, de la signature au HMAC. Ainsi, l'intégrité dans CCNx est une protection des objets (du contenu), pas uniquement du canal comme c'est le cas avec HTTPS. CCNX permet également de signer des listes d'objets (des manifestes), la liste contenant un SHA ou un CRC des objets, ce qui permet d'assurer l'intégrité de ceux-ci.
Ces concepts avaient été décrits dans les RFC 7476 et RFC 7927. Le vocabulaire est expliqué dans le RFC 8793. Maintenant, voyons les détails, sachant que le format précis des messages a été délégué à un autre RFC, le RFC 8609. La section 2 du RFC décrit précisement le protocole.
On a vu que le consommateur commençait l'échange, en envoyant
un message de type Interest. Ce message
contient le nom de l'objet qui intéresse le consommateur, et
éventuellement des restrictions sur le contenu, par exemple qu'on ne veut que des objets signés, et avec tel
algorithme, ou bien ayant tel
condensat cryptographique de l'objet (le
tuple regroupant nom et restrictions se nomme le lien, cf. section
6). Un nombre maximal de
sauts restants est indiqué dans le message. Décrémenté par chaque
relayeur, il sert à empêcher les boucles (lorsqu'il atteint zéro,
le message est jeté). Le producteur, lui,
stocke le contenu, indexé par les noms, et signale ces noms sur le
réseau pour que les relayeurs peuplent leur FIB (on a vu que le
protocole permettant ce signalement n'était pas encore défini,
bien que plusieurs propositions existent). Enfin, le relayeur, le
troisième type d'acteur, fait suivre les
Interest dans un sens (en consultant sa FIB)
et les Content Object en sens inverse (en
consultant sa PIT).
Le relayeur a également une mémoire (un
cache), qui sert notamment à accélérer l'accès au contenu le
plus populaire (section 4 du RFC). Il existe des moyens de
contrôler l'utilisation de cette mémoire, par exemple deux champs
dans un Content Object, la date d'expiration,
après laquelle il ne faut plus garder l'objet dans le cache, et la
date de fin d'intérêt, après laquelle il n'est sans doute plus
utile de garder l'objet (mais on peut quand même si on veut).
La validation des objets, leur vérification, est un composant crucial de CCNx. Elle est spécifiée dans la section 8 du RFC, avec ses trois catégories, la validation utilisant un simple condensat (pas forcément cryptographique), un HMAC ou bien une signature.
On a vu que le troisième type de message de CCNx, après
Interest et Content
Object, était
Interest Return. Il est décrit en détail dans
la section 10 de notre RFC. Notez tout de suite qu'il peut ne pas
y avoir de réponse du tout, un relayeur n'étant pas forcé
d'envoyer un Interest Return s'il ne peut
acheminer un Interest. S'il y a un
Interest Return, il indique l'erreur, par
exemple No Route (aucune entrée dans la FIB
pour ce nom), No Resources (le relayeur manque
de quelque chose, par exemple de place disque pour son cache),
Malformed Interest (un problème dans la demande),
Prohibited (le relayeur n'a pas envie de
relayer), etc.
Enfin, sur la question cruciale de la sécurité, la section 12 du RFC revient sur quelques points sensibles. Par exemple, j'ai dit plus haut que les objets pouvaient être validés par une signature numérique. Mais où trouve-t-on les clés publiques des producteurs, pour vérifier leur signature ? Eh bien ce point n'est pas actuellement traité. Notez que les relayeurs, eux, ne sont pas obligés de valider et un cache peut donc contenir des données invalides. Les RFC 7927 et RFC 7945 sont des bonnes ressources à lire sur la sécurité des réseaux centrés sur le contenu.
Il existait une version précédente du protocole CCNx,
identifiée « 0.x », et décrite dans « Networking Named
Content ». Dans 0.x, la correspondance entre le
nom demandé dans un Interest et celui obtenu
était hiérarchique : le nom demandé pouvait être un préfixe du nom
obtenu. La version décrite dans ce RFC, « 1.0 », est plus
restrictive ; le nom obtenu doit être exactement le nom
demandé. Les fonctions de recherche ne sont pas dans CCNx, elles
doivent être dans un protocole de couche supérieure, un Google ou
Pirate Bay du réseau CCN. Un exemple d'un tel protocole est décrit
dans l'Internet Draft draft-mosko-icnrg-selectors.
Et questions mise en œuvre du protocole CCNx ? Il en existe au moins deux, Community ICN, et CCN-Lite (cette dernière, tournant sur RIOT, visant plutôt l'Internet des objets).
L'article seul
RFC 8610: Concise Data Definition Language (CDDL): A Notational Convention to Express Concise Binary Object Representation (CBOR) and JSON Data Structures
Date de publication du RFC : Juin 2019
Auteur(s) du RFC : H. Birkholz (Fraunhofer SIT), C. Vigano (Universitaet Bremen), C. Bormann (Universitaet Bremen TZI)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF cbor
Première rédaction de cet article le 13 juin 2019
Le format de données binaire CBOR, normalisé dans le RFC 8949, commence à avoir un certain succès. Il lui manquait juste un langage de schéma, permettant de décrire les données acceptables (comme Relax NG ou XML Schema pour XML, ou comme le projet - abandonné - JCR (« JSON Content Rules ») pour JSON). C'est désormais fait dans ce RFC, qui normalise le langage CDDL, « Concise Data Definition Language ». (Il a par la suite été légèrement modifié dans le RFC 9682.)
La section 1 de notre RFC résume le cahier des charges : CDDL
doit permettre de décrire sans ambiguïté un fichier CBOR
acceptable pour un usage donné, il doit être lisible et rédigeable
par un humain, tout en étant analysable par un programme, et doit
permettre la validation automatique d'un fichier CBOR. Autrement
dit, étant donné une description en CDDL en
schema.cddl et un fichier CBOR en
data.cbor, il faut qu'on puisse développer un
outil validator qui permettra de lancer la
commande validator data.cbor schema.cddl et
qui dira si le fichier CBOR est conforme au schéma ou pas. (Un tel
outil existe effectivement, il est présenté à la fin de cet
article.) Comme CBOR utilise un modèle de données très proche de
celui de JSON, CDDL peut (même si ce n'est pas son but principal)
être utilisé pour décrire des fichiers JSON, ce que détaille
l'annexe E du RFC, consacrée à l'utilisation de CDDL avec JSON (il
y a quelques subtilités à respecter).
(Attention, il ne faut pas confondre notre CDDL avec la licence ayant le même acronyme.)
La section 2 de notre RFC explique les éléments de base d'un schéma CDDL. On y trouve les classiques nombres, booléens, chaînes de caractères, correspondant aux éléments identiques en CBOR. Pour les structures plus compliquées (tableaux et maps, c'est-à-dire dictionnaires, ce qu'on nomme objets en JSON), CDDL ne fournit qu'un seul mécanisme, le groupe. Un groupe est une liste de doublets {nom, valeur}, le nom pouvant être omis si on décrit un tableau. Avec ce concept de groupe, CDDL permet également de décrire ce que dans d'autres langages, on appelerait struct ou enregistrement.
La liste est encadrée par des parenthèses. Chaque donnée
décrite en CDDL a un type, par exemple bool
pour un booléen, uint pour un entier non
signé ou tstr pour une chaîne de
caractères. La définition indique également quel type majeur CBOR
(RFC 8949, section 3.1) va être utilisé pour
ce type CDDL. uint est évidemment le type
majeur 0, bool est le type majeur 7,
etc. (D'ailleurs, vous pouvez aussi créer des types en indiquant
le type majeur CBOR, ce qui donne une grande liberté, et la
possibilité d'influencer la sérialisation.) Une liste des types et
valeurs prédéfinies (comme false et
true) figure dans l'annexe D de notre
RFC.
Voici un groupe à qui on donne le nom
pii :
pii = (
age: uint,
name: tstr,
employer: tstr
)
Et ici une donnée person est définie avec ce
groupe :
person = {
pii
}
Comme person est défini avec des
accolades, ce sera un
dictionnaire (map). Le même groupe
pii aurait pu être utilisé pour définir un
tableau, en mettant entre crochets (et, dans ce cas, les noms seraient ignorés, seule la
position compte).
On peut définir une donnée en utilisant un groupe et d'autres
informations, ici, person et
dog ont les attributs de
identity et quelques uns en plus :
person = {
identity,
employer: tstr
}
dog = {
identity,
leash-length: float
}
identity = (
age: 0..120, ; Ou "uint" mais, ici, on utilise les intervalles
name: tstr
)
La syntaxe nom: valeur est en fait un cas
particulier. La notation la plus générale est clé =>
valeur. Comme CBOR (contrairement à JSON) permet
d'avoir des clés qui ne sont pas des chaînes de caractères, la
notation avec le deux-points est là pour ce
cas particulier, mais courant, où la clé est une chaîne de
caractères. (age: int et "age"
=> int sont donc équivalents.)
Un autre exemple permet d'illustrer le fait que l'encodage CBOR en tableau ou en dictionnaire va dépendre de la syntaxe utilisée en CDDL (avec en prime les commentaires, précédés d'un point-virgule) :
Geography = [
city : tstr,
gpsCoordinates : GpsCoordinates,
]
GpsCoordinates = {
longitude : uint, ; multiplied by 10^7
latitude : uint, ; multiplied by 10^7
}
Dans le fichier CBOR, GpsCoordinates sera un
dictionnaire (map) en raison de l'utilisation des
accolades, et Geography sera un tableau (les
noms city et
gpsCoordinates seront donc ignorés).
Un champ d'un groupe peut être facultatif, en le faisant précéder d'un point d'interrogation, ou bien répété (avec une astérisque ou un plus) :
apartment = {
kitchen: size,
+ bedroom: size,
? bathroom: size
}
size = float
Dans cet appartement, il y a exactement une cuisine, au moins une chambre et peut-être une salle de bains. Notez que l'outil cddl, présenté plus loin, ne créera pas d'appartements avec plusieurs chambres. C'est parce que CBOR, contrairement à JSON (mais pas à I-JSON, cf. RFC 7493, section 2.3), ne permet pas de clés répétées dans une map. On a ici un exemple du fait que CDDL peut décrire des cas qui ne pourront pas être sérialisés dans un format cible donné.
Revenons aux types. On a également le droit aux énumérations, les valeurs étant séparées par une barre oblique :
attire = "bow tie" / "necktie" / "Internet attire" protocol = 6 / 17
C'est d'ailleurs ainsi qu'est défini le type booléen (c'est prédéfini, vous n'avez pas à taper cela) :
bool = false / true
On peut aussi choisir entre groupes (et pas seulement entre types), avec deux barres obliques.
Et l'élement racine, on le reconnait comment ? C'est simplement le premier défini dans le schéma. À part cette règle, CDDL n'impose pas d'ordre aux définitions. Le RFC préfère partir des structures de plus haut niveau pour les détailler ensuite, mais on peut faire différemment, selon ses goûts personnels.
Pour les gens qui travaillent avec des protocoles réseau, il
est souvent nécessaire de pouvoir fixer exactement la
représentation des données. CDDL a la notion de contrôle, un
contrôle étant une directive donnée à CDDL. Elle commence par un
point. Ainsi, le contrôle .size indique la
taille que doit prendre la donnée. Par exemple
(bstr étant une chaîne d'octets) :
ip4 = bstr .size 4
ip6 = bstr .size 16
Un autre contrôle, .bits, permet de placer
les bits exactement, ici pour
l'en-tête TCP :
tcpflagbytes = bstr .bits flags
flags = &(
fin: 8,
syn: 9,
rst: 10,
psh: 11,
ack: 12,
urg: 13,
ece: 14,
cwr: 15,
ns: 0,
) / (4..7) ; data offset bits
Les contrôles existants figurent dans un registre IANA, et d'autres pourront y être ajoutés, en échange d'une spécification écrite (cf. RFC 8126).
La section 3 du RFC décrit la syntaxe formelle de CDDL. L'ABNF (RFC 5234) complet est en annexe B. CDDL lui-même ressemble à ABNF, d'ailleurs, avec quelques changements comme l'autorisation du point dans les noms. Une originalité plus fondamentale, documentée dans l'annexe A, est que la grammaire utilise les PEG et pas le formalisme traditionnel des grammaires génératives.
La section 4 de notre RFC couvre les différents usages de CDDL. Il peut être utilisé essentiellement pour les humains, une sorte de documentation formelle de ce que doit contenir un fichier CBOR. Il peut aussi servir pour écrire des logiciels qui vont permettre une édition du fichier CBOR guidée par le schéma (empêchant de mettre des mauvaises valeurs, par exemple, mais je ne connais pas de tels outils, à l'heure actuelle). CDDL peut aussi servir à la validation automatique de fichiers CBOR. (Des exemples sont donnés plus loin, avec l'outil cddl.) Enfin, CDDL pourrait être utilisé pour automatiser une partie de la génération d'outils d'analyse de fichiers CBOR, si ce format continue à se répandre.
Un exemple réaliste d'utilisation de CDDL est donné dans
l'annexe H, qui met en œuvre les « reputons » du RFC 7071. Voici le schéma
CDDL. Un autre exemple en annexe H est de réécrire des
règles de l'ancien projet JCR (cf. Internet
draft draft-newton-json-content-rules)
en CDDL.
Quels sont les RFC et futurs RFC qui se servent de CDDL ? CDDL est utilisé par le RFC 8007 (son annexe A), le RFC 8152 et le RFC 8428. Il est également utilisé dans des travaux en cours comme le format C-DNS (RFC 8618), sur lequel j'avais eu l'occasion de travailler lors d'un hackathon. Autre travail en cours, le système GRASP (RFC 8990) et dans OSCORE (RFC 8613). En dehors du monde IETF, CDDL est utilisé dans Web Authentication.
Un outil, décrit dans l'annexe F du RFC, a été développé pour générer des fichiers CBOR d'exemple suivant une définition CDDL, et pour vérifier des fichiers CBOR existants. Comme beaucoup d'outils modernes, il faut l'installer en utilisant les logiciels spécifiques d'un langage de programmation, ici Ruby :
% gem install cddl
Voici un exemple, pour valider un fichier JSON (il peut évidemment aussi valider du CBOR, rappelez-vous que c'est presque le même modèle de données, et que CDDL peut être utilisé pour les deux) :
% cddl person.cddl validate person.json
%
Ici, c'est bon. Quand le fichier de données ne correspond pas au
schéma (ici, le membre foo n'est pas prévu) :
% cat person.json
{"age": 1198, "foo": "bar", "name": "tic", "employer": "tac"}
% cddl person.cddl validate person.json
CDDL validation failure (nil for {"age"=>1198, "foo"=>"bar", "name"=>"tic", "employer"=>"tac"}):
["tac", [:prim, 3], nil]
C'est surtout quand le schéma lui-même a une erreur que les messages d'erreur de l'outil cddl sont particulièrement mauvais. Ici, pour un peu d'espace en trop :
% cddl person.cddl generate
*** Look for syntax problems around the %%% markers:
%%%person = {
age: int,
name: tstr,
employer: tstr,%%% }
*** Parse error at 0 upto 69 of 93 (1439).
Et pour générer des fichiers de données d'exemple ?
% cat person.cddl
person = {
"age" => uint, ; Or 'age: uint'
name: tstr,
employer: tstr
}
% cddl person.cddl generate
{"age": 3413, "name": "tic", "employer": "tac"}
Ce format est du JSON mais c'est en fait le profil « diagnostic »
de CBOR, décrit dans la section 8 du RFC 8949. (cddl person.cddl
json-generate fabriquerait du JSON classique.)
On peut avoir du CBOR binaire après une conversion avec
les outils
d'accompagnement :
% json2cbor.rb person.json > person.cbor
CBOR étant un format binaire, on ne peut pas le regarder directement, donc on se sert d'un outil spécialisé (même dépôt que le précédent) :
% cbor2pretty.rb person.cbor
a3 # map(3)
63 # text(3)
616765 # "age"
19 0d55 # unsigned(3413)
64 # text(4)
6e616d65 # "name"
63 # text(3)
746963 # "tic"
68 # text(8)
656d706c6f796572 # "employer"
63 # text(3)
746163 # "tac"
Et voilà, tout s'est bien passé, et le fichier CBOR est valide :
% cddl person.cddl validate person.cbor %
L'article seul
Fiche de lecture : Qu'est-ce qu'une archive du Web ?
Auteur(s) du livre : Francesca Musiani, Camille
Paloque-Bergès, Valérie
Schafer, Benjamin Thierry
Éditeur : OpenEdition Press
979-10-365-0368-9
Publié en 2019
Première rédaction de cet article le 10 juin 2019
Ce très court livre décrit ce qu'est une archive du Web, et les diverses questions que soulève le problème « faut-il conserver tout ce qui a été un jour publié sur le Web et, si oui, comment, notamment compte-tenu de la taille de ces données et de leur rapidité de changement ? ».
Le Web a un peu plus de trente ans et déjà d'innombrables pages Web ont changé voire disparu. Bien des gens seraient intéressés à voir l'état passé du Web : historiens (cf. le précédent livre d'une des auteures, « En construction »), journalistes (qui voudraient par exemple vérifier le texte qu'un politicien a changé après son élection), simples curieux… Mais cela soulève des difficultés techniques et politiques.
Ces difficultés ne sont pas insurmontables : Internet Archive existe et est
très utilisé. Ainsi, l'URL http://web.archive.org/web/19970606063341/http://www.nic.fr/
D'abord, voyons les difficultés techniques : le Web est gros et grossit en permanence. Il n'existe aucune estimation sérieuse du nombre de pages Web (d'autant plus qu'il n'y a pas de définition claire de ce qu'est une page) mais il ne fait pas de doute que c'est beaucoup. Vouloir stocker tous les états passés de toutes ces pages ne se fait pas avec trois disques durs dans son garage. Mais la principale difficulté technique réside dans la rapidité du changement de ces pages. Certaines pages changent en permanence (la page d'accueil d'un site d'informations, par exemple). Faut-il donc passer toutes les minutes voir cette page ?
Et, ensuite, comment s'assurer que les pages sauvegardées seront encore visibles dans vingt, trente, quarante ans ? Même si on a les données, un site Web en Flash sauvegardé en 2000 sera-t-il encore lisible en 2040 ? Faut-il sauvegarder les données (qu'on ne saura peut-être plus interpréter), ou bien juste une image de la page, rendue par les logiciels existants ?
Un autre problème est celui de la cohérence des pages. Une page Web est constituée de plusieurs élements, par exemple une ressource en HTML, deux en CSS, trois images, et un programme en JavaScript. Toutes ces ressources n'ont pas été récoltées au même moment et peuvent être incohérentes. Les aut·rice·eur·s citent ainsi le cas du site Web du CNRS dont la version « BNF » d'août 2015 montre un bandeau noir lié aux attentats djihadistes de novembre.
Ces difficultés techniques font que l'archivage du Web n'est pas du ressort du bricoleur dans son coin. Il faut de grosses organisations, bien financées, et assurées d'une certaine pérénnité (comme les bibliothèques nationales). Les questions techniques liées à la récolte sont peu mentionnées dans ce livre. Car il y a bien d'autres difficultés, notamment politiques.
D'abord, qui a le droit de récolter ainsi toutes ces pages ? On
pourrait se dire qu'elles sont publiques, et qu'il n'y a donc pas de
problème. Mais les lois sur la protection des données ne sont pas de
cet avis : ce n'est pas parce que quelque chose est public qu'on a
le droit de le récolter et de le traiter. Internet Archive considère
qu'il est admissible de récolter ces pages publiques, en respectant
simplement le
robots.txt. La BNF
s'appuie sur une
obligation légale (le dépôt légal est créé
par une loi) et ne
suit donc pas ce robots.txt.
La question peut être sensible dans certains cas. Le livre cite
l'exemple des sites Web en
.ao, récoltés par une
organisation portugaise. Bien
sûr, ces sites étaient publiquement disponibles et tout le monde
pouvait les récolter, mais cela peut être vu ici comme une
manifestation de néo-colonialisme tout en sachant que, sans cette
récolte de l'ancien colonisateur, rien ne serait récolté.
Ensuite, que peut-on publier de ce qui a été récolté ? Cela soulève des questions liées au droit d'auteur. Pour éviter de froisser les ayant-tous-les-droits, la BNF ne rend pas publique les pages archivées. Internet Archive, par contre, le fait. (Mais l'Internet Archive a déjà retiré des contenus, par exemple sur ordre de la toute-puissante Scientologie.) Le livre détaille pays par pays les solutions adoptées.
Outre les questions légales liées au droit d'auteur, il peut y avoir des questions éthiques. Par exemple, que penseraient les gens qui avaient contribué à GeoCities si leurs pages de l'époque (publiques, rappelons-le) étaient décortiquées aujourd'hui, alors qu'ils ne s'attendaient pas certainement à ce qu'elles fassent un jour l'objet de tant d'attention.
Et il y a de très nombreuses autres questions à étudier lorsqu'on archive le Web. Bref, un excellent livre, trop court pour tous les sujets à couvrir, mais qui vous fera réfléchir sur une question très riche, ayant plein de conséquences.
Ah, et le livre est disponible gratuitement en EPUB et PDF.
L'article seul
RFC 8601: Message Header Field for Indicating Message Authentication Status
Date de publication du RFC : Mai 2019
Auteur(s) du RFC : M. Kucherawy
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dmarc
Première rédaction de cet article le 8 juin 2019
Il existe plusieurs techniques pour authentifier les courriers
électroniques. Certaines peuvent nécessiter des
calculs un peu compliqués et on voudrait souvent les centraliser
sur une machine de puissance raisonnable, dotée de tous les
logiciels nécessaires. Dans cette hypothèse, le MUA ne recevra qu'une
synthèse (« Ce message vient bien de
example.com ») et pourra alors prendre une
décision, basée sur cette synthèse. C'est le but de l'en-tête
Authentication-Results:, normalisé originellement dans le RFC 5451 dix ans plus tôt, auquel ont succédés les RFC 7001 puis RFC 7601, que
ce nouveau RFC met légèrement à jour (il y a peu de
changements, le principal concernant l'ajout de la gestion du courrier
électronique internationalisé, avec davantage d'Unicode).
Avec des techniques d'authentification comme DKIM (RFC 6376) ou SPF (RFC 7208), les
calculs à faire pour déterminer si un message est authentique
peuvent être complexes (DKIM utilise la cryptographie) et
nécessiter la présence de bibliothèques non-standard. Les installer
et les maintenir à jour sur chaque machine, surtout en présence
d'éventuelles failles de sécurité qu'il faudra boucher en urgence,
peut être trop pénible pour l'administrateur système. L'idée de ce
RFC est donc de séparer l'opération en deux :
l'authentification est faite sur un
serveur, typiquement le premier MTA du site (cf. annexe C pour une discussion
de ce choix), celui-ci ajoute au message un en-tête indiquant le
résultat de ladite authentification et le MUA (ou bien le
MDA, voir la
section 1.5.4 pour un bon rappel sur ces concepts) peut ensuite,
par exemple par un langage de filtrage comme
procmail ou
Sieve, agir sur la base de ce
résultat. L'idée n'est donc pas de montrer la valeur de cet
en-tête à M. Michu (voir la section 4.1 pour quelques risques que
cela poserait), mais d'en faire une donnée pour un programme. Cet
en-tête marche pour tous les protocoles d'authentification et
surpasse donc les en-têtes spécifiques comme le
Received-SPF: de SPF (section 1 du RFC). Le
filtrage des messages non authentifiés n'est
pas obligatoire (section 1.4) : agir - ou
pas - sur la base de l'en-tête Authentication-Results: est une décision politique
locale.
J'ai utilisé le terme de « site » pour désigner un ensemble de
machines gérées par la même organisation mais le RFC a un terme
plus rigoureux, ADMD (ADministrative Management
Domain). La frontière d'un ADMD est la « frontière de
confiance » (trust boundary), définie en
section 1.2. Un domaine administratif de gestion est un groupe de
machines entre lesquelles il existe une relation de confiance,
notamment du fait que, à l'intérieur de l'ADMD, l'en-tête Authentication-Results: ne
sera pas modifié ou ajouté à tort (section 1.6 : l'en-tête n'est
pas protégé, notamment il n'est pas signé). Il existe de
nombreuses variantes organisationnelles du concept d'ADMD. Un ADMD
inclus typiquement une organisation (ou un département de
celle-ci) et d'éventuels sous-traitants. Il a un nom,
l'authserv-id, défini en section 2.2. Bien
sûr, la décision de faire confiance ou pas à telle entité, telle
machine ou tel ADMD est une décision locale, le RFC ne précise pas
comment elle est prise.
L'en-tête Authentication-Results: lui-même est formellement défini en section
2. Il appartient à la catégorie des en-têtes de « trace » (RFC 5322, section 3.6.7 et RFC 5321, section 4.4) comme Received:
qui doivent être ajoutés en haut des en-têtes et jamais
modifiés. La syntaxe de Authentication-Results: est en section 2.2. L'en-tête est
composé du authserv-id, le nom de l'ADMD et
d'une série de doublets (méthode, résultat), chacun indiquant une
méthode d'authentification et le résultat obtenu. L'annexe B
fournit une série d'exemples. Elle commence (annexe B.1) par un
message sans Authentication-Results: (eh oui, il n'est pas obligatoire). Puis (tiré
de l'annexe B.3), une authentification SPF réussie, au sein de
l'ADMD example.com, donnera :
Authentication-Results: example.com;
spf=pass smtp.mailfrom=example.net
Received: from dialup-1-2-3-4.example.net
(dialup-1-2-3-4.example.net [192.0.2.200])
by mail-router.example.com (8.11.6/8.11.6)
with ESMTP id g1G0r1kA003489;
Wed, Mar 14 2009 17:19:07 -0800
From: sender@example.net
Date: Wed, Mar 14 2009 16:54:30 -0800
To: receiver@example.com
Rappelez-vous qu'il peut y avoir plusieurs authentifications. Voici un cas (annexe B.4) avec SPF et l'authentification SMTP du RFC 4954 :
Authentication-Results: example.com;
auth=pass (cram-md5) smtp.auth=sender@example.net;
spf=pass smtp.mailfrom=example.net
Received: from dialup-1-2-3-4.example.net (8.11.6/8.11.6)
(dialup-1-2-3-4.example.net [192.0.2.200])
by mail-router.example.com (8.11.6/8.11.6)
with ESMTP id g1G0r1kA003489;
Fri, Feb 15 2002 17:19:07 -0800
Date: Fri, Feb 15 2002 16:54:30 -0800
To: receiver@example.com
From: sender@example.net
L'une des authentifications peut réussir et l'autre échouer. Un
exemple (annexe B.6) avec deux signatures DKIM, une bonne et une
qui était correcte au départ (regardez le premier Authentication-Results:) mais plus
à l'arrivée, peut-être parce qu'un gestionnaire de liste de
diffusion a modifié le message :
Authentication-Results: example.com;
dkim=pass reason="good signature"
header.i=@mail-router.example.net;
dkim=fail reason="bad signature"
header.i=@newyork.example.com
Received: from mail-router.example.net
(mail-router.example.net [192.0.2.250])
by chicago.example.com (8.11.6/8.11.6)
for <recipient@chicago.example.com>
with ESMTP id i7PK0sH7021929;
Fri, Feb 15 2002 17:19:22 -0800
DKIM-Signature: v=1; a=rsa-sha256; s=furble;
d=mail-router.example.net; t=1188964198; c=relaxed/simple;
h=From:Date:To:Message-Id:Subject:Authentication-Results;
bh=ftA9J6GtX8OpwUECzHnCkRzKw1uk6FNiLfJl5Nmv49E=;
b=oINEO8hgn/gnunsg ... 9n9ODSNFSDij3=
Authentication-Results: example.net;
dkim=pass (good signature) header.i=@newyork.example.com
Received: from smtp.newyork.example.com
(smtp.newyork.example.com [192.0.2.220])
by mail-router.example.net (8.11.6/8.11.6)
with ESMTP id g1G0r1kA003489;
Fri, Feb 15 2002 17:19:07 -0800
DKIM-Signature: v=1; a=rsa-sha256; s=gatsby;
d=newyork.example.com;
t=1188964191; c=simple/simple;
h=From:Date:To:Message-Id:Subject;
bh=sEu28nfs9fuZGD/pSr7ANysbY3jtdaQ3Xv9xPQtS0m7=;
b=EToRSuvUfQVP3Bkz ... rTB0t0gYnBVCM=
From: sender@newyork.example.com
Date: Fri, Feb 15 2002 16:54:30 -0800
To: meetings@example.net
La liste complète des méthodes figure dans un registre IANA (section 6). De nouvelles méthodes peuvent être enregistrées en utilisant la procédure « Examen par un expert » du RFC 5226. Des méthodes sont parfois abandonnées comme la tentative de Microsoft d'imposer son Sender ID (RFC 4406.)
L'en-tête Authentication-Results: inclut également les valeurs de certaines
propriétés (RFC 7410. Ainsi, dans :
Authentication-Results: example.com;
auth=pass (cram-md5) smtp.auth=sender@example.net;
spf=pass smtp.mailfrom=example.net
La propriété smtp.auth (authentification
SMTP) a la valeur
sender@example.net (l'identité qui a été validée).
La section 2.5 détaille
l'authserv-id. C'est un texte qui identifie
le domaine, l'ADMD. Il doit donc être unique dans tout
l'Internet. En général, c'est un nom de
domaine comme laposte.net. (Il
est possible d'être plus spécifique et d'indiquer le nom d'une
machine particulière mais cette même section du RFC explique
pourquoi c'est en général une mauvaise idée : comme les MUA du
domaine n'agissent que sur les Authentication-Results: dont ils reconnaissent
l'authserv-id, avoir un tel identificateur
qui soit lié au nom d'une machine, et qui change donc trop
souvent, complique l'administration système.)
La section 2.7 explique les résultats possibles pour les
méthodes d'authentification (en rappelant que la liste à jour des
méthodes et des résultats est dans le registre
IANA). Ainsi, DKIM (section 2.7.1) permet des résultats comme
pass (authentification réussie) ou
temperror (erreur temporaire au cours de
l'authentification, par exemple liée au DNS). Des résultats similaires sont
possibles pour SPF (section 2.7.2).
Notons la normalisation d'une méthode traditionnelle
d'authentification faible, le test DNS du chemin « adresse IP du
serveur -> nom » et retour. Baptisée iprev,
cette méthode, bien que bâtie sur la pure superstition
(cf. section 7.11) est utilisée couramment. Très injuste (car les
arbres des résolutions inverses du
DNS, in-addr.arpa et
ip6.arpa, ne sont pas sous le contrôle du
domaine qui envoie le courrier), cette méthode discrimine les
petits FAI, ce qui est sans doute un avantage pour les gros, comme
AOL qui
l'utilisent. Attention aux implémenteurs : aussi bien la
résolution inverse d'adresse IP en nom que la résolution droite de
nom en adresse IP peuvent renvoyer plusieurs résultats et il faut
donc comparer des ensembles. (Cette méthode qui,
contrairement aux autres, n'avait jamais été exposée dans un RFC
avant le RFC 5451, est décrite en détail
dans la section 3, avec ses sérieuses limites.)
Autre méthode mentionnée, auth (section
2.7.4) qui repose sur l'authentification SMTP du RFC 4954. Si un MTA (ou plutôt MSA) a authentifié un
utilisateur, il peut le noter ici.
Une fois le code d'authentification exécuté, où mettre le
Authentication-Results: ? La section 4 fournit tous les détails, indiquant
notamment que le MTA doit placer l'en-tête en haut du message, ce
qui facilite le repérage des Authentication-Results: à qui on peut faire confiance
(en examinant les en-têtes Received: ; en
l'absence de signature, un Authentication-Results: très ancien, situé au début du
trajet, donc en bas des en-têtes, ne signifie pas grand'chose). On
se fie a priori aux en-têtes mis par les MTA de l'ADMD, du domaine
de confiance. L'ordre est donc important. (La section 7 revient en
détail sur les en-têtes Authentication-Results: usurpés.)
Ce n'est pas tout de mettre un Authentication-Results:, encore faut-il
l'utiliser. La section 4.1 s'attaque à ce problème. Principe
essentiel pour le MUA : ne pas agir sur la base d'un Authentication-Results:, même
si ce n'est que pour l'afficher, sans l'avoir validé un
minimum. Comme le Authentication-Results: n'est pas signé, n'importe qui a pu en
insérer un sur le trajet. Le RFC précise donc que les MUA doivent,
par défaut, ne rien faire. Et qu'ils doivent ne regarder les Authentication-Results:
qu'après que cela ait été activé par l'administrateur de la
machine, qui indiquera quel authserv-id est
acceptable.
Naturellement, le MTA d'entrée du domaine devrait supprimer les
Authentication-Results: portant son propre authserv-id qu'il
trouve dans les messages entrants : ils sont forcément frauduleux
(section 5). (Le RFC accepte aussi une solution plus simpliste,
qui est de supprimer tous les Authentication-Results: des messages entrants, quel
que soit leur authserv-id.)
Arrivé à ce stade de cet article, le lecteur doit normalement
se poser bien des questions sur la valeur du Authentication-Results:. Quel poids lui
accorder alors que n'importe quel méchant sur le trajet a pu
ajouter des Authentication-Results: bidons ? La section 7, consacrée à l'analyse
générale de la sécurité, répond à ces inquiétudes. 7.1 détaille le
cas des en-têtes usurpés. Les principales lignes de défense ici
sont le fait que le MUA ne doit faire confiance aux Authentication-Results: que
s'ils portent le authserv-id de son ADMD
et le fait que le MTA entrant doit filtrer
les Authentication-Results: avec son authserv-id. Comme
l'intérieur de l'ADMD, par définition, est sûr, cela garantit en
théorie contre les Authentication-Results: usurpés. Le RFC liste néanmoins d'autres
méthodes possibles comme le fait de ne faire confiance qu'au
premier Authentication-Results: (le plus récent), si on sait
que le MTA en ajoute systématiquement un (les éventuels Authentication-Results:
usurpés apparaîtront après ; mais certains serveurs les
réordonnent, cf. section 7.3). Pour l'instant, il n'y a pas de
méthode unique et universelle de vérification du Authentication-Results:, le RFC
propose des pistes mais ne tranche pas.
Comme toujours en sécurité, il faut bien faire la différence
entre authentification et
autorisation. Un spammeur a pu insérer un Authentication-Results: légitime
pour son
authserv-id. Même authentifié, il ne doit pas
être considéré comme une autorisation (section 7.2).
De nombreuses mises en œuvre de ce système existent déjà comme dans MDaemon, sendmail (via sid-milter), Courier, OpenDKIM, etc. Des logiciels comme Zimbra permettent également de le faire :
Authentication-Results: zimbra.afnic.fr (amavisd-new); dkim=pass (2048-bit key) header.d=cfeditions.com header.b=hGHP51iK; dkim=pass (2048-bit key) header.d=cfeditions.com header.b=go30DQO8
Si on veut analyser les en-têtes Authentication-Results: en Python, on a le module authres. Parmi
les grosses usines à courrier centralisées,
Gmail met systématiquement cet en-tête, par
exemple :
Authentication-Results: mx.google.com; spf=pass \
(google.com: domain of stephane@sources.org designates 217.70.190.232 \
as permitted sender) smtp.mail=stephane@sources.org
Outre Gmail, à la date de publication du RFC, des services comme
Yahoo et Outlook ajoutaient cet
en-tête. Évidemment, ces en-têtes ne sont pas toujours
corrects. Outlook ne met pas le authserv-id et
n'affiche pas l'adresse IP dans les tests SPF :
authentication-results: spf=none (sender IP is ) smtp.mailfrom=abo@charliehebdo.fr;
Mon serveur de messagerie utilise
Postfix et j'y fais des tests
SPF, dont le résultat est affiché sous
forme d'un en-tête Authentication-Results:. Pour cela, j'ai installé pypolicyd-spf via
le paquetage Debian :
% sudo aptitude install postfix-policyd-spf-python
Puis on configure pypolicyd-spf (dans
/etc/postfix-policyd-spf-python/policyd-spf.conf,
la documentation est dans
/usr/share/doc/postfix-policyd-spf-python/policyd-spf.conf.commented.gz). Par
défaut, pypolicyd-spf met l'ancien en-tête
Received-SPF:. Pour avoir Authentication-Results:, il faut
dire :
Header_Type = AR
Et ajouter l'authserv-id (le nom de
l'ADMD) :
Authserv_Id = mail.bortzmeyer.org
Il reste à configurer Postfix, dans
master.cf :
# SPF
policyd-spf unix - n n - 0 spawn
user=policyd-spf argv=/usr/bin/policyd-spf
Et dans main.cf :
smtpd_recipient_restrictions = [...] check_policy_service unix:private/policyd-spf
Postfix va alors mettre ceci dans les messages (ici, un test réussi) :
Authentication-Results: mail.bortzmeyer.org; spf=pass (mailfrom)
smtp.mailfrom=nic.fr (client-ip=2001:67c:2218:2::4:12; helo=mx4.nic.fr;
envelope-from=bortzmeyer@nic.fr; receiver=<UNKNOWN>)
Les changements depuis le RFC 7601 sont
peu nombreux (annexe D pour une liste complète). On y trouve notamment
l'ajout du courrier électronique internationalisé
(EAI, pour Email Address
Internationalization, voir RFC 6530, RFC 6531 et RFC 6532) et quelques petits détails de forme. Et le registre
IANA est légèrement modifié, entre autres
pour y ajouter deux possibilités DKIM, a
(algorithme utilisé) et
s (sélecteur).
L'article seul
RFC 6238: TOTP: Time-Based One-Time Password Algorithm
Date de publication du RFC : Mai 2011
Auteur(s) du RFC : D. M'Raihi (Verisign), S. Machani
(Diversinet), M. Pei
(Symantec), J. Rydell (Portwise)
Pour information
Première rédaction de cet article le 7 juin 2019
Ce RFC documente le protocole TOTP, utilisé pour bâtir des systèmes d'authentification à deux facteurs. TOTP est une amélioration du protocole HOTP du RFC 4226, remplaçant le simple compteur par l'heure. Ainsi, il n'est plus nécessaire que les deux machines mémorisent la même séquence.
Mais d'abord, qu'est-ce que l'authentification à deux facteurs ? Imaginons que vous vous connectiez à une interface Web, d'un établissement financier comme Paymium ou PayPal, d'un bureau d'enregistrement de noms de domaines, ou de tout autre service important. La méthode la plus courante d'authentification est le couple {identificateur, mot de passe}. Elle est simple, et facilement expliquable aux utilisat·rice·eur·s. Mais elle pose des problèmes de sécurité : le mot de passe choisi est souvent trop faible, et les utilisat·rice·eur·s le communiquent parfois à des tiers, par exemple suite à une attaque par ingéniérie sociale. On dit traditionnellement qu'il existe trois voies d'authentification : ce qu'on est, ce qu'on a, ou bien ce qu'on sait. La biométrie utilise la première voie, et le mot de passe la troisième. TOTP, décrit dans ce RFC, va permettre d'utiliser la deuxième voie. Mais on n'utilise pas TOTP seul. Le principe de l'authentification à deux facteurs est d'avoir… deux facteurs. Par exemple, sur le Web, le cas le plus courant est un mot de passe classique, plus un code produit par TOTP. Les deux facteurs doivent évidemment être indépendants. Si on se connecte à sa banque depuis son ordiphone et que le générateur TOTP est sur le même ordiphone, il n'y a pas réellement d'indépendance (si le téléphone est volé ou piraté, les deux facteurs peuvent être compromis en même temps). Une solution est d'avoir mot de passe sur l'ordinateur et générateur TOTP sur l'ordiphone, ou bien mot de passe sur l'ordiphone et générateur TOTP sur un dispositif auxiliaire, genre YubiKey.
Pour prendre un exemple récent, lors de l'attaque de 2018 contre de nombreux noms de domaine moyen-orientaux, l'absence d'authentification à deux facteurs avait certainement joué, rendant relativement facile le piratage en masse.
Mais comment fonctionne TOTP ? L'idée de base est qu'on part d'un secret partagé entre les deux parties, le client et le serveur, secret qui n'est pas envoyé pour l'authentification (et donc moins vulnérable qu'un mot de passe). Ce secret sert à générer un code à usage limité dans le temps (donc, si vous l'avez envoyé au pirate par erreur, ce n'est pas forcément grave). Dans l'ancien protocole HOTP (RFC 4226), la génération du code était contrôlée par le nombre de connexions au service (et il fallait donc que les deux parties communicantes gardent trace du nombre de connexions, et soient bien synchrones sur ce point), dans le nouveau protocole TOTP, objet de ce RFC, c'est l'heure qui gouverne le code généré (et les deux parties doivent donc avoir des horloges à peu près correctes).
Voici ce que voit l'utilisateur avec le logiciel andOTP sur
Android. On voit la liste des comptes de
l'utilisateur (j'ai masqué les identifiants de l'utilisateur, bien
qu'ils ne soient pas totalement secrets), et le code courant (je
l'ai partiellement masqué mais notez que ce n'est pas nécessaire :
ils ne sont utilisables que pendant le bon intervalle). 
Un petit rappel sur HOTP : HOTP, normalisé dans le RFC 4226, le code à usage unique était généré en condensant avec SHA-1 la concaténation d'un secret partagé et d'un compteur, chaque partie incrémentant le compteur lors d'une connexion. Il y a donc un risque de désynchronisation si une partie incrémente le compteur alors que l'autre a eu un hoquet et a raté cette incrémentation (RFC 4226, section 7.4).
TOTP, au contraire, utilise un condensat du secret partagé et de l'heure. Il est en effet plus facile d'avoir deux machines ayant une horloge à peu près correcte que d'avoir deux machines restant en accord sur un compteur partagé. (D'autre part, TOTP peut utiliser SHA-2 et plus seulement SHA-1.)
La section 3 du RFC résume quel était le cahier des charges de TOTP : dépendance vis-à-vis de l'heure (plus précisement du temps Unix), avec un intervalle de validité partagé, dépendance vis-à-vis d'un secret partagé entre les deux parties (et avec personne d'autre), secrets qui doivent être bien gardés par les deux parties.
L'algorithme exact (j'ai beaucoup simplifié ici) est en section 4. Un code TOTP est la
condensation avec SHA-2 de la concaténation
du secret partagé et de l'heure, plus exactement du nombre de
secondes depuis l'epoch, divisée par
l'intervalle. Ainsi, pour un même couple client/serveur, deux
demandes de code très rapprochées donneront le même code,
contrairement à HOTP où les codes n'étaient pas réutilisés. Notez
que les valeurs de l'epoch et de l'intervalle ne
sont pas spécifiées dans le protocole, elle sont communiquées en
dehors du protocole. On ne peut donc pas utiliser TOTP seul et
espérer que cela va marcher, il faut ajouter des informations. Cela peut se faire via des cadres de
référence comme OATH ou bien dans
l'URI fabriqué par le serveur (par exemple
otpauth://totp/ACME%20Co:john.doe@example.com?secret=HXDMVJECJJWSRB3HWIZR4IFUGFTMXBOZ&issuer=ACME%20Co&period=60
pour mettre un intervalle à soixantes secondes, le format exact de
ces URI est
documenté
par Google.)
La section 5, sur la sécurité, est évidement très détaillée. Elle rappelle par exemple que la transmission du secret initial doit être faite sur un canal sécurisé, par exemple avec TLS. D'autre part, ce secret, cette clé, doit être stockée de manière sûre. Si on utilise un ordiphone pour générer les codes, ce qui est fréquent, il faut tenir compte du fait qu'un ordiphone se perd ou se vole facilement. Il ne doit pas divulguer le secret simplement parce qu'un voleur a l'appareil en main. Le RFC recommande que le secret soit chiffré, et de manière à ce que la possession physique de la machine ne permettre pas de le déchiffrer. (Dans andOTP, la base de données est chiffrée avec un mot de passe choisi par l'utilisateur. À l'usage, il est assez pénible de taper ce mot de passe - forcément long et compliqué - très souvent, mais c'est le prix de la sécurité.)
TOTP repose sur l'heure et non seulement les deux horloges ne sont pas parfaitement synchrones mais en outre les délais de transmission du réseau ajoutent une incertitude. On pourrait mettre un intervalle important (la valeur recommandée est de 30 secondes) pour limiter le risque de rejet d'un code mais, d'une part, cela augmente le risque qu'un code volé puisse être réutilisé (il reste valable pendant tout l'intervalle) et d'autre part on peut jouer de malchance, par exemple si un code est généré juste avant la fin d'un intervalle. Le RFC recommande donc d'accepter les codes de l'intervalle précédent l'intervalle courant.
L'annexe A du RFC contient une mise en œuvre de TOTP en Java (avec au moins une bogue).
Pour envoyer, lors de l'enrôlement initial, le secret partagé qui
servira de base au calcul, la méthode la plus courante est que le
serveur auprès duquel on s'authentifiera la génère, puis l'affiche
sous forme d'un QR-code à lire, ou sous une
forme texte. Voilà comment ça se passe chez le bureau
d'enregistrement Gandi. On active
l'authentification à deux facteurs : 
Puis on fait lire à son ordiphone le secret (j'ai masqué QR-code
et secret en texte, puisqu'ils doivent rester secrets) :  )
)
Bien d'autres services sur le Web acceptent l'authentification à deux facteurs. C'est le cas entre autres de GitLab (et donc de l'excellent service Framagit) dans la rubrique « Compte », des places de marché Bitcoin comme Kraken (qui le documente très bien) ou Paymium (qui, stupidement, ne le documente que comme imposant l'utilisation de Google Authenticator, ce qui est faux, ça a marché avec andOTP, remarquez, Mastodon commet presque la même faute), des registres comme le RIPE (qui documente également très bien), etc. En revanche, les banques, comme le Crédit mutuel ou la Banque postale, imposent un outil privateur, sous forme d'une application fermée, exigeant trop de permissions, et contenant des pisteurs. (Alors que le but des normes comme TOTP est justement de permettre le libre choix du logiciel. Mais un tel mépris du client est classique chez les banques.)
Côté client, j'ai choisi andOTP sur mon
ordiphone mais il y a aussi Aegis, FreeOTP, Google
Authenticator, etc. Si vous êtes fana de la ligne
de commande, vous pouvez même directement utiliser
l'outil oathtool présenté plus loin, comme décrit
dans cet article (avec un astucieux script pour analyser les
URI otpauth:). Il y a aussi des mises en œuvre
privatrices dans du matériel spécialisé comme la YubiKey (à partir de 35 € à l'heure actuelle.)
TOTP est à l'origine issu du projet OATH (ne pas confondre avec OAuth.) Une de leurs initiatives est le développement d'outils logiciels pour faciliter le déploiement de techniques d'authentification fortes. C'est par exemple le cas de l'outil libre oathtool et des autres logiciels du OATH Toolkit. Voici une utilisation sur une Debian (le paramètre à la fin est la clé, le secret partagé) :
% oathtool --totp=sha256 123456789abcde 839425
Si on le lance plusieurs fois de suite, il affichera le même code, jusqu'à la fin de l'intervalle en cours :
% oathtool --totp=sha256 123456789abcde 839425 % oathtool --totp=sha256 123456789abcde 839425 % oathtool --totp=sha256 123456789abcde 839425 % oathtool --totp=sha256 123456789abcde 963302
Par défaut, oathtool utilise l'horloge courante. On peut lui indiquer une autre heure (cf. sa documentation mais attention à ne pas copier/coller les exemples, ça ne marchera pas, les tirets ayant été remplacés par des caractères typographiquement plus jolis, menant à un « hex decoding of secret key failed » incompréhensible). Essayons avec les vecteurs de test indiqués dans l'annexe B de notre RFC :
% oathtool --totp=sha256 --digits=8 3132333435363738393031323334353637383930313233343536373839303132 62307269 % oathtool --totp=sha256 --digits=8 --now "1970-01-01 00:00:59 UTC" 3132333435363738393031323334353637383930313233343536373839303132 46119246
(Et, oui, les valeurs de la clé secrète indiquées dans le RFC sont fausses.)
Notez aussi que oathtool fait par défaut du HOTP (ici, au démarrage, puis au bout de cinq connexions) :
% oathtool 123456789abcde 725666 % oathtool --counter=5 123456789abcde 030068
Pour configurer un serveur ssh avec TOTP et l'outil de gestion de configuration Salt, vous pouvez utiliser la recette de Feth Arezki.
Si on veut déveloper des services utilisant TOTP, il existe plein d'autres mises en œuvre comme ROTP pour Ruby, onetimepass ou otpauth pour Python, etc. Pour apprendre à utiliser TOTP depuis Python, j'ai apprécié cette transcription de session.
Il ne faut pas croire que l'authentification à deux facteurs est une solution magique. Comme toujours en sécurité, elle vient avec ses propres inconvénients. (Ils sont très bien expliqués dans l'excellent article « Before You Turn On Two-Factor Authentication… ».) Le risque le plus sérieux est probablement le risque de s'« enfermer dehors » : si on perd l'ordiphone ou la clé physique, ou bien s'il tombe en panne, tout est fichu, on ne peut plus se connecter sur aucun des services où on a activé l'authentification à deux facteurs. Une seule solution : les sauvegardes. Avec andOTP, par exemple, on peut exporter la liste des comptes et leurs secrets dans un fichier en clair (ce qui est évidemment déconseillé), chiffré avec AES et le mot de passe d'andOTP, ou bien chiffré avec PGP, la solution la plus pratique. J'ai installé openKeychain sur mon Android, récupéré ma clé PGP et tout marche, les sauvegardes, une fois exportées, sont copiées sur d'autres machines. Si je déchiffre et regarde en quoi consiste la sauvegarde, on y trouve un fichier JSON contenant les informations dont nous avons déjà parlé (la clé secrète), le type d'algorithme, ici TOTP, l'algorithme de condensation, l'intervalle (period), etc :
{
"secret": "K...",
"label": "framagit.org - framagit.org:stephane+frama@bortzmeyer.org",
"digits": 6,
"type": "TOTP",
"algorithm": "SHA1",
"thumbnail": "Default",
"last_used": 1559836187528,
"period": 30,
"tags": []
}
Si on veut utiliser ces sauvegardes depuis l'outil en ligne de commande présentée plus haut, il faut prendre note de l'algorithme de condensation (ici SHA-1), du nombre de chiffres (ici 6) et de la clé (qui est encodée en base32) :
% oathtool --totp=sha1 --digits 6 --base32 K...
Sinon, je recommande cet article en anglais très détaillé : « Understanding TOTP Two-Factor Authentication: An ELI5 », avec une mise en œuvre en Python.
L'article seul
RFC 8558: Transport Protocol Path Signals
Date de publication du RFC : Avril 2019
Auteur(s) du RFC : T. Hardie
Pour information
Première rédaction de cet article le 6 juin 2019
Ce nouveau RFC de l'IAB examine les signaux envoyés par un protocole de transport aux couches supérieures. Par exemple, la machine à états de TCP est observable de l'extérieur, on peut déduire son état de l'examen des paquets envoyés. Certains de ces signaux sont explicites, prévus pour être lus par les routeurs, d'autres sont implicites, déduits de certains comportements. Le RFC recommande de compter plutôt sur les signaux explicites, documentés et fiables. Attention, la tendance actuelle est, pour protéger la vie privée et pour limiter les interférences du réseau avec les communications, de limiter les signaux envoyés. Ainsi, QUIC envoie nettement moins de signaux que TCP.
Le principe de bout en bout dit que les éléments du réseau ne devraient pas avoir besoin de ces signaux du tout (RFC 1958). Ils devraient transporter les datagrammes, point. Mais en pratique, des raisons plus ou moins légitimes font que des équipements intermédiaires ont besoin d'accéder à des informations sur le transport. C'est par exemple le cas des routeurs NAT (RFC 3234).
Comme exemple de signaux implicites, on peut citer ceux de TCP (RFC 793). Les messages échangés (SYN, RST, FIN…) sont destinés aux extrémités, pas aux boitiers intermédiaires mais, comme ils sont visibles (sauf utilisation d'IPsec), le réseau peut être tenté de s'en servir comme signaux implicites. C'est ce que fait un pare-feu à état quand il utilise ces messages pour déterminer si la connexion a été demandée depuis l'intérieur (auquel cas elle est souvent autorisée) ou de l'extérieur (auquel cas elle est souvent interdite).
Cette observation des signaux implicites a souvent pour but une action (blocage des connexions entrantes, dans l'exemple ci-dessus, ou bien déni de service en envoyant des faux RST). Il est donc logique que les protocoles cherchent à se protéger en chiffrant la communication. TLS ou SSH ne chiffrent que l'application, et restent donc vulnérables aux attaques visant la couche 4. D'où le développement de protocoles comme QUIC, qui chiffrent l'essentiel de la machinerie de transport.
La section 2 de notre RFC liste les signaux qui peuvent être déduits de l'observation de la couche transport en action :
- Découvrir l'établissement d'une session, et le fait que tel paquet appartienne à telle session (identifiée typiquement par un tuple {adresse IP source, adresse IP destination, protocole de transport, port source, port destination}), font partie des signaux les plus utilisés. (Pensez à l'exemple du pare-feu plus haut, ou bien à celui d'un répartiteur de charge qui veut envoyer tous les paquets d'une même session au même serveur.)
- Vérifier que la section est à double sens (les deux machines peuvent communiquer et le veulent) est également possible, et important. Par exemple, si le pare-feu détecte qu'une machine a initié la session, on peut supposer qu'elle veut recevoir les réponses, ce qui justifie qu'on fasse un trou dans le pare-feu pour laisser passer les paquets de cette session. (Pour le NAT, cf. RFC 7857.)
- Mesurer des caractéristiques quantitatives de la session est aussi possible. L'observation passive de TCP, par exemple, peut indiquer la latence (en mesurant le temps écoulé entre le passage des données et l'accusé de réception correspondant), ou le taux de perte de paquets (en regardant les retransmissions).
On le voit, les signaux implicites sont utilisés (pas forcément pour de bonnes raisons). Si on chiffre la couche transport, comme le fait QUIC, on perd certains de ces signaux. Que faut-il faire ? La section 3 du RFC liste, sans en recommander une particulière, plusieurs possibilités. La première est évidemment de ne rien faire. Si on chiffre, c'est justement pour assurer la confidentialité ! Le transport étant une fonction de bout en bout, les intermédiaires ne sont pas censés regarder son fonctionnement. Cette approche a quand même quelques inconvénients. Par exemple, un routeur NAT ne sait plus quand les connexions commencent et quand elles finissent, il peut donc être nécessaire d'ajouter du trafic « battement de cœur » pour maintenir l'état dans ce routeur.
On peut aussi se dire qu'on va remplacer les signaux implicites de la couche transport par des signaux explicites, conçus précisement pour une utilisation par des boitiers intermédiaires. C'est le cas du connection ID de QUIC, qui permet par exemple aux répartiteurs de charge d'envoyer tous les paquets d'une connexion QUIC donnée au même serveur. Ou du spin bit du même protocole, pour permettre certaines mesures par les intermédiaires (un bit qui a été très controversé dans la discussion à l'IETF). Le RFC note que ces signaux explicites pourraient être transportés par les en-têtes hop-by-hop d'IPv6 (RFC 7045) mais que leur capacité à être déployés sans perturber les équipements intermédiaires ne va pas de soi.
Ces signaux explicites pourraient être placés dans une mince couche intermédiaire entre UDP (qui sert de base à plusieurs protocoles de transport, comme QUIC ou comme SCTP désormais), et cette normalisation d'une couche intermédiaire avait, par exemple, été proposée dans le projet PLUS (Transport-Independent Path Layer State Management).
Après cette étude, quelles recommandations ? La section 4 du RFC recommande évidemment que les nouveaux protocoles fournissent de la confidentialité par défaut (TCP expose trop de choses), ce qui implique le chiffrement systématique. Les signaux implicites font fuiter de l'information et devraient être évités. L'approche de QUIC est donc la bonne. Par contre, comme il peut être utile d'envoyer certaines informations aux différents équipements intermédiaires situés sur le réseau, l'IAB recommande de mettre quelques signaux explicites.
Cela nécessite de suivre les principes suivants :
- Tout ce qui est destiné aux machines terminales doit être chiffré pour empêcher les middleboxes d'y accéder. Par exemple, le message de fin d'une connexion n'a pas à être public (c'est parce qu'il l'est que TCP est vulnérable aux attaques avec des faux RST).
- Les signaux explicites, destinés aux équipements intermédiaires, doivent être protégés. Que le réseau puisse les lire, d'accord, mais il n'y a aucune raison qu'il puisse les modifier.
- Les signaux explicites doivent être séparés des informations et messages destinés aux machines terminales.
- Les machines intermédiaires ne doivent pas ajouter de signaux (le RFC cite le RFC 8164 mais je trouve le RFC 8165 plus pertinent). Les machines terminales ont intérêt à protéger l'intégrité du paquet, pour éviter ces ajouts.
Notez que cette intégrité ne peut être vérifiée que par les machines terminales, les machines du réseau n'ayant pas le matériau cryptographique (les clés) nécessaires.
Reste enfin les questions de sécurité (section 6 du RFC). Le modèle de menace classique sur l'Internet est qu'on ne peut pas faire confiance aux intermédiaires : sur le trajet entre Alice et Bob, il est trop fréquent qu'au moins un des intermédiaires soit bogué, ou simplement malveillant. Tous les signaux envoyés implicitement sont dangereux, car ils peuvent donner de l'information à celui qui est peut-être un attaquant, lui facilitant certaines attaques. D'où l'importance de diminuer ces signaux implicites.
Naturellement, ce n'est pas une solution miracle ; les attaquants vont trouver d'autres méthodes et la lutte entre attaquant et défenseur ne sera donc jamais finie.
Publier des signaux explicites présente aussi des risques ; en voulant donner au réseau des informations qui peuvent lui être utiles, on peut menacer la vie privée. Ceci explique la vigueur des débats à l'IETF au sujet du spin bit de QUIC. Le spin bit n'a pas d'utilité pour les machines terminales, seulement pour les équipements intermédiaires. Ses partisans disaient qu'il était important que ces équipements puissent accéder à des informations sur le RTT. Ses adversaires (qui n'ont pas eu gain de cause complet, le spin bit est optionnel, on n'est pas forcé de l'envoyer) estimaient que faire fuiter volontairement de l'information, même assez inoffensive, ouvrait un risque potentiel.
Enfin, comme les signaux explicites sont déconnectés des messages échangés entre les deux machines qui communiquent, il faut se poser la question de leur authenticité. Un tiers peut les modifier pour tromper les machines suivantes sur le trajet. Les protections cryptographiques ne sont pas utilisables puisqu'il n'y a aucune chance que les équipements intermédiaires disposent des clés leur permettant de vérifier ces protections. Plus drôle, si un opérateur réseau agit sur la base de ces signaux explicites, et, par exemple, favorise certaines sessions au détriment d'autres, on pourrait voir des machines terminales décider de « tricher » en envoyant délibérement de faux signaux. (Ce qui n'est pas possible avec les signaux implicites, qui sont de véritables messages, interprétés par la machine située en face.)
L'article seul
RFC 8517: An Inventory of Transport-centric Functions Provided by Middleboxes: An Operator Perspective
Date de publication du RFC : Février 2019
Auteur(s) du RFC : D. Dolson, J. Snellman, M. Boucadair, C. Jacquenet (Orange)
Pour information
Première rédaction de cet article le 26 mai 2019
À l'IETF, ou, d'une manière générale, chez les gens qui défendent un réseau neutre, les boitiers intermédiaires, les middleboxes, sont mal vus. Ces boitiers contrarient le modèle de bout en bout et empêchent souvent deux machines consentantes de communiquer comme elles le veulent. Des simples routeurs, OK, qui ne font que transmettre les paquets, mais pas de middleboxes s'arrogeant des fonctions supplémentaires. Au contraire, ce RFC écrit par des employés d'Orange, défend l'idée de middlebox et explique leurs avantages pour un opérateur. Ce n'est pas par hasard qu'il est publié alors que les discussions font toujours rage à l'IETF autour du protocole QUIC, qui obscurcira délibérement une partie de son fonctionnement, pour éviter ces interférences par les middleboxes.
Le terme de middlebox est défini dans le RFC 3234. Au sens littéral, un routeur IP est une middlebox (il est situé entre les deux machines qui communiquent, et tout le trafic passe par lui) mais, en pratique, ce terme est utilisé uniquement pour les boitiers qui assurent des fonctions en plus de la transmission de paquets IP. Ces fonctions sont par exemple le pare-feu, la traduction d'adresses, la surveillance, etc. (Le RFC parle de advanced service functions, ce qui est de la pure publicité.) Ces boitiers intermédiaires sont en général situés là où on peut observer et contrôler tout le trafic donc en général à la connexion d'un réseau local avec l'Internet, par exemple dans la box qu'imposent certains FAI, ou bien, dans les réseaux pour mobiles, là où le GGSN se connecte au PDN (RFC 6459, section 3.1.) Mais, parfois, ces boitiers sont en plein milieu du réseau de l'opérateur.
L'Internet suit normalement un modèle de bout en bout (RFC 1958.) Ce modèle dit que les équipements intermédiaires entre deux machines qui communiquent ne doivent faire que le strict minimum, laissant aux deux machines terminales l'essentiel des fonctions. Cela assure la capacité de changement (il est plus facile de modifier les extrémités que le réseau), ainsi le Web a pu être déployé sans avoir besoin de demander la permission aux opérateurs, contrairement à ce qui se passe dans le monde des télécommunications traditionnelles. Et, politiquement, ce modèle de bout en bout permet la neutralité du réseau. Il n'est donc pas étonnant que les opérateurs de télécommunication traditionnels, dont les PDG ne ratent jamais une occasion de critiquer cette neutralité, n'aiment pas ce modèle. Truffer l'Internet de middleboxes de plus en plus intrusives est une tentative de revenir à un réseau de télécommunications comme avant, où tout était contrôlé par l'opérateur. Comme le RFC 8404, ce RFC est donc très politique.
Et, comme le RFC 8404, cela se manifeste par des affirmations outrageusement publicitaires, comme de prétendre que les opérateurs réseaux sont « les premiers appelés quand il y a un problème applicatif ». Faites l'expérience : si vlc a du mal à afficher une vidéo distante, appelez votre FAI et regardez si vous aurez réellement de l'aide… C'est pourtant ce que prétend ce RFC, qui affirme que l'opérateur veut accéder aux informations applicatives « pour aider ».
Le RFC note aussi que certaines des fonctions assurées par les boitiers intermédiaires ne sont pas réellement du choix de l'opérateur : contraintes légales (« boîtes noires » imposées par l'État) ou bien réalités de l'Internet (manque d'adresses IPv4 - cf. RFC 6269, fonctions liées aux attaques par déni de service, par exemple).
Les middleboxes travaillent parfois avec les informations de la couche 7 (ce qu'on nomme typiquement le DPI) mais le RFC se limite au travail sur les fonctions de la couche 4, une sorte de « DPI léger ».
Voyons maintenant ces utilisations des middleboxes, et commençons par les mesures (section 2 du RFC), activité passive et qui ne modifie pas les paquets, donc n'entre pas forcément en conflit avec le principe de neutralité. Par exemple, mesurer le taux de perte de paquets (RFC 7680) est certainement quelque chose d'intéressant : s'il augmente, il peut indiquer un engorgement quelque part sur le trajet (pas forcément chez l'opérateur qui mesure). Chez l'opérateur, qui ne contrôle pas les machines terminales, on peut mesurer ce taux en observant les réémissions TCP (ce qui indique une perte en aval du point d'observation), les trous dans les numéros de séquence (ce qui indique une perte en amont), ou bien les options SACK (RFC 2018). Cela marche avec TCP, moins bien avec QUIC, où ces informations sont typiquement chiffrées. Comme l'observation des options ECN (RFC 3168), le taux de pertes permet de détecter la congestion.
Et le RTT (RFC 2681) ? Il donne accès à la latence, une information certainement intéressante. L'opérateur peut le mesurer par exemple en regardant le délai avant le passage d'un accusé de réception TCP. Plusieurs autres mesures sont possibles et utiles en étant « au milieu » et le RFC les détaille. Arrêtons-nous un moment sur celles liées à la sécurité : l'observation du réseau peut permettre de détecter certaines attaques, mais le RFC note (et déplore) que l'évolution des protocoles réseau tend à rendre cela plus difficile, puisque les protocoles annoncent de moins en moins d'information au réseau (en terme du RFC 8546, ils réduisent la vue depuis le réseau). Cela se fait par la diminution de l'entropie pour éviter le fingerprinting et par le chiffrement (cf. RFC 8404, qui critiquait déjà le chiffrement de ce point de vue). Évidemment, les utilisateurs diront que c'est fait exprès : on souhaite en effet réduire les possibilités de surveillance. Mais tout le monde n'a pas les mêmes intérêts.
Le RFC parle également des mesures effectuées au niveau applicatif. Ainsi, il note que les opérateurs peuvent tirer des conclusions de l'analyse des temps de réponse DNS.
Il y a bien sûr plein d'autres choses que les boitiers intermédiaires peuvent faire, à part mesurer. La section 3 du RFC les examine, et c'est le gros de ce RFC. L'une des plus connues est la traduction d'adresses. Celle-ci est souvent un grave obstacle sur le chemin des communications, malgré les recommandations (pas toujours suivies) des RFC 4787 et RFC 7857.
Après la traduction d'adresses, la fonction « pare-feu » est sans doute la plus connue des fonctions assurées par les middleboxes. Par définition, elle est intrusive : il s'agit de bloquer des communications jugées non souhaitées, voire dangereuses. La question de fond est évidemment « qui décide de la politique du pare-feu ? » Du point de vue technique, le RFC note qu'il est très fréquent de différencier les communications initiées depuis l'intérieur de celles initiées depuis l'extérieur. Cela nécessite d'observer la totalité du trafic pour détecter, par exemple, quel paquet avait commencé la session.
Les autres fonctions des middleboxes citées par ce RFC sont moins connues. Il y a le « nettoyage » (dDoS scrubbing) qui consiste à classifier les paquets en fonction de s'ils font partie d'une attaque par déni de service ou pas, et de les jeter si c'est le cas (cf. par exemple RFC 8811). Le RFC explique que c'est une action positive, puisque personne (à part l'attaquant) n'a intérêt à ce que le réseau soit ralenti, voire rendu inutilisable, par une telle attaque. Le cas est compliqué, comme souvent en sécurité. Bien sûr, personne ne va défendre l'idée que le principe de neutralité va jusqu'à laisser les attaques se dérouler tranquillement. Mais, d'un autre côté, toutes les classifications (un préalable indispensable au nettoyage) ont des faux positifs, et la sécurité peut donc avoir des conséquences néfastes (le RFC regrette que la protection de la vie privée a pour conséquence qu'il est plus difficile de reconnaitre les « paquets honnêtes »). La vraie question, ici comme ailleurs est « qui va décider ? ».
Autre utilisation, cette fois franchement problématique, l'identification implicite. Il s'agit d'identifier un utilisateur donné sans qu'il ait d'action explicite à faire, par exemple en ajoutant à ses requêtes HTTP un élément d'identification (comme expliqué dans un article fameux) ou bien en jouant avec les options TCP (RFC 7974). Il s'agit là clairement de prise de contrôle par le boitier intermédiaire, qui se permet non seulement de modifier les données pendant qu'elles circulent, mais également prétend gérer l'identification des utilisateurs.
Autre fonction des boitiers intermédiaires, l'amélioration des performances en faisant assurer par ces middleboxes des fonctions qui étaient normalement assurées par les machines terminales, mais où l'opérateur estime qu'il est mieux placé pour le faire. Ces PEP (Performance-Enhancing Proxies) sont notamment courants dans les réseaux pour mobiles (cf. RFC 3135, notamment sa section 2.1.1 ou bien cet exposé). Cette fonction nécessite de pouvoir tripoter les en-têtes TCP.
Bien sûr, comme ce RFC exprime le point de vue des gros intermédiaires, il reprend l'élément de langage courant comme quoi il est nécessaire de prioriser certains types de trafic par rapport à d'autres. On aurait une voie rapide pour certains et des lentes pour les autres. Tout le monde est d'accord que la prioritisation est utile (la vidéo YouTube est moins importante que mon courrier professionnel) mais la question est encore « qui décide de ce qu'on priorise, et donc de ce qu'on ralentit ? » Ici, le RFC dit sans hésiter que c'est aux middleboxes de décider, après examen du trafic. L'exemple donné est amusant « on peut ainsi décider de donner la priorité aux jeux en ligne sur les mises à jour de logiciels ». Les gens de la sécurité, qui essaient toujours d'obtenir que les mises à jour de sécurité soient déployées plus rapidement, apprécieront…
On peut prioriser sans avoir accès à toutes les données (par exemple, en se basant uniquement sur les adresses IP) mais le RFC estime que, sans cet accès à tout, les décisions seront forcément moins efficaces.
Les auteurs du RFC sont manifestement conscients que beaucoup de leurs propositions vont énerver les utilisateurs. Alors, ils tentent de temps en temps d'expliquer que c'est pour leur bien qu'on viole la neutralité du réseau. Ainsi, le RFC cite l'exemple d'un réseau qui ralentirait le téléchargement d'une vidéo, pour épargner à l'abonné l'épuisement de son « forfait » « illimité ». Après tout, la vidéo ne sera peut-être pas regardée en entier, donc il n'est pas nécessaire de la charger tout de suite…
Voilà, nous sommes arrivés au bout de la liste des fonctions assurées par les boitiers intermédiaires (je ne les ai pas toutes citées dans ce court article). Il reste à voir les conséquences de ces fonctions pour la sécurité, et c'est le rôle de la section 5 du RFC. Elle estime d'abord que les fonctions décrites ne violent pas forcément la vie privée (RFC 6973) mais note quand même que même les champs « purement techniques » comme l'en-tête TCP, peuvent poser des risques pour la confidentialité des communications.
Et cette section 5 note aussi que l'information observée dans les en-têtes de couche 4 peuvent rendre certaines attaques plus faciles, par exemple en fabriquant un paquet TCP qui sera accepté par la machine terminale. On peut alors mener une attaque par déni de service en envoyant un faux RST (qui coupe la connexion, une attaque que les opérateurs ont déjà pratiquée.) La solution citée est l'utilisation du RFC 5925, qui protège l'intégrité de la connexion TCP mais pas sa confidentialité…
L'article seul
RFC 8548: Cryptographic Protection of TCP Streams (tcpcrypt)
Date de publication du RFC : Mai 2019
Auteur(s) du RFC : A. Bittau (Google), D. Giffin
(Stanford University), M. Handley (University College
London), D. Mazieres (Stanford
University), Q. Slack
(Sourcegraph), E. Smith (Kestrel
Institute)
Expérimental
Réalisé dans le cadre du groupe de travail IETF tcpinc
Première rédaction de cet article le 23 mai 2019
Aujourd'hui, il n'est plus acceptable d'avoir des communications non chiffrées. États, entreprises et délinquants surveillent massivement les réseaux publics et toute communication effectuée en clair peut être espionnée, voire modifiée. Il est donc nécessaire de continuer les efforts pour chiffrer ce qui ne l'est pas encore. Ce RFC décrit un mécanisme expérimental pour TCP, nommé tcpcrypt, permettant de chiffrer les communications sans participation de l'application située au-dessus, sans authentification obligatoire. (Mais le projet semble mal en point donc je ne suis pas optimiste quant à son déploiement.)
La section 2 du RFC est le cahier des charges de « tcpcrypt », ce nouveau mécanisme de protection de TCP :
- Pouvoir être mis en œuvre conjointement à TCP. Cela implique de pouvoir tourner dans le noyau, où on ne peut pas charger des bibliothèques comme OpenSSL. Et certaines piles TCP tournent sur des machines contraintes (Internet des Objets), donc le protocole doit être léger.
- Ne pas trop augmenter la latence lors de la négociation cryptographique.
- Tolérer certains intermédiaires qui se permettent de modifier l'en-tête TCP.
- Ne pas faire de liaison avec l'adresse IP : une session tcpcrypt doit pouvoir reprendre si l'adresse IP a changé.
tcpcrypt est très différent des classiques TLS et SSH. Il est conçu pour ne pas impliquer l'application, qui peut ignorer qu'on chiffre dans les couches inférieures. tcpcrypt est prévu pour être une solution simple, ne nécessitant pas de modifier protocoles ou applications, changeant le moins de chose possible pour être déployable. Il est également intéressant de voir le « non-cahier des charges », ce qui n'est pas obligatoire dans tcpcrypt :
- Aucune authentification n'est faite par tcpcrypt,
- En cas de problème, on se replie sur du TCP non sécurisé.
Ces deux points rendent tcpcrypt vulnérable aux attaquants actifs.
Pendant la longue et douloureuse gestation de ce protocole, TLS avait été envisagé comme alternative. Après tout, pourquoi inventer un nouveau protocole de cryptographie, activité longue et délicate (les failles de sécurité sont vite arrivées) ? Il y avait deux propositions sur la table à l'IETF, le futur tcpcrypt, et une solution fondée sur TLS. C'est pour essayer de faire fonctionner les deux solutions que la négociation des paramètres avait été traitée à part (option ENO, RFC 8547). Mais, depuis, la proposition TLS a été de facto abandonnée, en partie parce que la communauté TLS était occupée par le travail sur la version 1.3.
tcpcrypt s'appuie sur l'option TCP ENO (Encryption Negotiation Option) pour la négociation de l'utilisation du chiffrement. Ce RFC 8548 décrit comment chiffrer, une fois les paramètres négociés.
La section 3 décrit le protocole en détail. Je ne vais pas la reprendre ici (la cryptographie n'est pas mon point fort). On est dans le classique, de toute façon, avec cryptographie asymétrique pour se mettre d'accord sur une clé et cryptographie symétrique pour chiffrer ; tcpcrypt utilise trois types d'algorithmes cryptographiques :
- Un mécanisme de négociation de clé pour, à partir d'une clé publique temporaire, se mettre d'accord sur un secret partagé (qui servira, après traitement, à chiffrer la session),
- une fonction d'extraction pour tirer de ce secret partagé une clé,
- une fonction pseudo-aléatoire pour tirer de cette clé les clés de chiffrement symétrique.
La fonction d'extraction et la fonction pseudo-aléatoire sont celles de HKDF (RFC 5869), elle-même fondée sur HMAC (RFC 2104). Une fois qu'on a la clé, on chiffre avec un algorithme de chiffrement intègre.
Comme vous avez vu, les clés publiques utilisées dans le protocole tcpcrypt sont temporaires, jamais écrites sur disque et renouvellées fréquemment. Ce ne sont pas des clés permanentes, indiquant l'identité de la machine comme c'est le cas pour SSH. tcpcrypt n'authentifie pas la machine en face (la section 8 détaille ce point).
La négociation du protocole, pour que les deux parties qui font du TCP ensemble se mettent d'accord pour chiffrer, est faite avec l'option TCP ENO (Encryption Negotiation Option), décrite dans le RFC 8547. La négociation complète peut nécessiter un aller-retour supplémentaire par rapport à du TCP habituel, ce qui augmente la latence d'établissement de connexion. Un mécanisme de reprise des sessions permet de se passer de négociation, si les deux machines ont déjà communiqué, et gardé l'information nécessaire.
Une fois la négociation terminée, et le chiffrement en route, tcpcrypt génère (de manière imprévisible, par exemple en condensant les paramètres de la session avec un secret) un session ID, qui identifie de manière unique cette session tcpcrypt particulière. Ce session ID est mis à la disposition de l'application via une API, qui reste à définir et l'application peut, si elle le souhaite, ajouter son mécanisme d'authentification et lier une authentification réussie au session ID. Dans ce cas, et dans ce cas seulement, tcpcrypt est protégé contre l'Homme du Milieu.
Notez que seule la charge utile TCP est chiffrée, et donc protégée. L'en-tête TCP ne l'est pas (pour pouvoir passer à travers des boitiers intermédiaires qui tripotent cet en-tête, et tcpcrypt ne protège donc pas contre certaines attaques comme les faux paquets RST (terminaison de connexion, les détails figurent en section 8). Toutefois, certains champs de l'en-tête (mais pas RST) sont inclus dans la partie chiffrée (cf. section 4.2). C'est par exemple le cas de FIN, pour éviter qu'une troncation des données passe inaperçue.
L'option TCP ENO (RFC 8547) crée le
concept de TEP (TCP Encryption Protocol). Un
TEP est un mécanisme cryptographique particulier choisi par les
deux machines qui communiquent. Chaque utilisation de l'option ENO
doit spécifier son ou ses TEP. Pour tcpcrypt, c'est fait dans la
section 7 de notre RFC, et ces TEP sont placés dans un
registre IANA. On y trouve, par exemple,
TCPCRYPT_ECDHE_Curve25519 (le seul qui soit
obligatoire pour toutes les mises en œuvre de tcpcrypt, cf. RFC 7696) qui veut dire « création des clés avec
du Diffie-Hellman sur courbes
elliptiques avec la courbe
Curve25519 ». Pour le chiffrement lui-même,
on a vu qu'il ne fallait utiliser que du chiffrement intègre, et le seul algorithme
obligatoire pour tcpcrypt est
AEAD_AES_128_GCM (« AES en mode
GCM »). Les autres sont également dans
un
registre IANA.
Le but de tcpcrypt est la sécurité donc la section 8, consacrée à l'analyse de la sécurité du protocole, est très détaillée. D'abord, tcpcrypt hérite des propriétés de sécurité de l'option ENO (RFC 8547). Ainsi, il ne protège pas contre un attaquant actif, qui peut s'insérer dans le réseau, intercepter les paquets, les modifier, etc. Un tel attaquant peut retirer l'option ENO des paquets et il n'y a alors plus grand'chose à faire (à part peut-être épingler la connaissance du fait qu'une machine donnée parlait tcpcrypt la dernière fois qu'on a échangé, et qu'il est bizarre qu'elle ne le fasse plus ?) Si l'application a son propre mécanisme d'autentification, situé au-dessus de tcpcrypt, et qui lie l'authentification au session ID, alors, on est protégé contre les attaques actives. Sinon, seul l'attaquant passif (qui ne fait qu'observer) est bloqué par tcpcrypt. Une analyse plus détaillée figure dans l'article fondateur du projet tcpcrypt, « The case for ubiquitous transport-level encryption », par Bittau, A., Hamburg, M., Handley, M., Mazieres, D., et D. Boneh.. tcpcrypt fait donc du chiffrement opportuniste (RFC 7435).
tcpcrypt ne protège pas la plus grande partie des en-têtes TCP. Donc une attaque active comme l'injection de faux RST (RFC 793, et aussi RFC 5961) reste possible.
Comme la plupart des techniques cryptographiques, tcpcrypt dépend fortement de la qualité du générateur de nombres pseudo-aléatoires utilisé. C'est d'autant plus crucial qu'un des cas d'usage prévus pour tcpcrypt est les objets contraints, disposant de ressources matérielles insuffisantes. Bref, il faut relire le RFC 4086 quand on met en œuvre tcpcrypt. Et ne pas envoyer l'option ENO avant d'être sûr que le générateur a acquis assez d'entropie.
On a dit que tcpcrypt ne protégeait pas les « métadonnées » de la connexion TCP. Ainsi, les keepalives (RFC 1122) ne sont pas cryptographiquement vérifiables. Une solution alternative est le mécanisme de renouvellement des clés de tcpcrypt, décrit dans la section 3.9 de notre RFC.
Ce RFC 8548 est marqué comme « Expérimental ». On n'a en effet que peu de recul sur l'utilisation massive de tcpcrypt. La section 9 liste les points qui vont devoir être surveillés pendant cette phase expérimentale : que deux machines puissent toujours se connecter, même en présence de boitiers intermédiaires bogués et agressifs (tcpcrypt va certainement gêner la DPI, c'est son but, et cela peut offenser certains boitiers noirs), et que l'implémentation dans le noyau ne soulève pas de problèmes insurmontables (comme le chiffrement change la taille des données, le mécanisme de gestion des tampons va devoir s'adapter et, dans le noyau, la gestion de la mémoire n'est pas de la tarte). C'est d'autant plus important qu'il semble qu'après l'intérêt initial, l'élan en faveur de ce nouveau protocole se soit sérieusement refroidi (pas de commit depuis des années dans le dépôt initial).
Et les mises en œuvre de tcpcrypt (et de l'option ENO, qui lui est nécessaire) ? Outre celle de référence citée plus haut, qui est en espace utilisateur, et qui met en œuvre ENO et tcpcrypt, il y a plusieurs projets, donc aucun ne semble prêt pour la production :
- Une mise en œuvre dans le noyau Linux.
- Une autre pour FreeBSD.
- Et encore une autre pour MacOS.
- Une extension Firefox (apparemment ancienne et pas maintenue) pour afficher le session ID.
- Un module Apache, également
apparemment abandonné, pour accéder au session
ID et le fournir aux programmes tournant sur le serveur
(dans la variable d'environnement
TCP_CRYPT_SESSID, donc du code PHP, par exemple, peut lire$_SERVER['TCP_CRYPT_SESSID']).
Il y avait un site « officiel » pour le projet, http://tcpcrypt.org/
L'article seul
RFC 8547: TCP-ENO: Encryption Negotiation Option
Date de publication du RFC : Mai 2019
Auteur(s) du RFC : A. Bittau (Google), D. Giffin (Stanford University), M. Handley (University College London), D. Mazieres (Stanford University), E. Smith (Kestrel Institute)
Expérimental
Réalisé dans le cadre du groupe de travail IETF tcpinc
Première rédaction de cet article le 23 mai 2019
Ce RFC, tout juste sorti des presses, décrit une extension de TCP nommée ENO, pour Encryption Negotiation Option. Elle permet d'indiquer qu'on souhaite chiffrer la communication avec son partenaire TCP, et de négocier les options. Elle sert au protocole tcpcrypt, décrit, lui, dans le RFC 8548.
Malgré le caractère massif de la surveillance exercée sur les
communications Internet, il y a encore des
connexions TCP dont le contenu n'est pas chiffré. Cela peut être
parce que le protocole applicatif ne fournit pas de moyen (genre une
commande STARTTLS) pour indiquer le passage
en mode chiffré, ou simplement parce que les applications ne sont
plus guère maintenues et que personne n'a envie de faire le
travail pour, par exemple, utiliser TLS. Pensons à
whois (RFC 3912), par
exemple. La nouvelle option ENO va permettre de chiffrer ces
protocoles et ces applications, en agissant uniquement dans la
couche transport, au niveau
TCP.
Le but de cette nouvelle option TCP est de permettre aux deux pairs TCP de se mettre d'accord sur le fait d'utiliser le chiffrement, et quel chiffrement. Ensuite, tcpcrypt (RFC 8548) ou un autre protocole utilisera cet accord pour chiffrer la communication. En cas de désaccord, on se rabattra sur du TCP « normal », en clair.
Le gros de la spécification est dans la section 4 du RFC. ENO est une option TCP (cf. RFC 793, section 3.1). Elle porte le numéro 69 (qui avait déjà été utilisé par des protocoles analogues mais qui étaient restés encore plus expérimentaux) et figure dans le registre des options TCP. (0x454E a été gardé pour des expériences, cf. RFC 6994.) Le fait d'envoyer cette option indique qu'on veut du chiffrement. Chaque possibilité de chiffrement, les TEP (TCP Encryption Protocol) est dans une sous-option de l'option ENO (section 4.1 pour les détails de format). Si la négociation a été un succès, un TEP est choisi. Les TEP sont décrits dans d'autres RFC (par exemple, le RFC 8548, sur tcpcrypt, en décrit quatre). Les TEP sont enregistrés à l'IANA.
À noter que TCP est symétrique : il n'y a pas de « client » ou de « serveur », les deux pairs peuvent entamer la connexion simultanément (BGP, par exemple, utilise beaucoup cette possibilité). ENO, par contre, voit une asymétrie : les deux machines qui communiquent sont nommées A et B et ont des rôles différents.
A priori, c'est A qui enverra un SYN (message de demande d'établissement de connexion). Ce SYN inclura l'option ENO, et ce sera de même pour les trois messages de la triple poignée de mains TCP. La section 6 du RFC donne quelques exemples. Ainsi :
- A > B : SYN avec ENO (X, Y) - TEP X et Y,
- A < B : SYN+ACK avec ENO (Y)
- A > B : ACK avec ENO vide
Cet échange mènera à un chiffrement fait avec le TEP Y, le seul que A et B avaient en commun. Par contre, si B est un vieux TCP qui ne connait pas ENO :
- A > B : SYN avec ENO (X, Y) - TEP X et Y,
- A < B : SYN+ACK sans ENO
- A > B : ACK sans ENO
Ne voyant pas de ENO dans le SYN+ACK, A renonce au chiffrement. La connexion TCP ne sera pas protégée.
Et les TEP (TCP Encryption Protocol), qu'est-ce qu'ils doivent définir ? La section 5 détaille les exigences pour ces protocols. Notamment :
- Ils doivent chiffrer (évidemment) avec un algorithme de chiffrement intègre (cf. RFC 5116),
- définir un session ID, un identificateur de session unique et imprévisible (pour les applications qui souhaiteraient faire leur authentification et la lier à une session particulière),
- ne pas accepter d'algorithmes de chiffrement trop faibles, ou, bien sûr, nuls (cela parait drôle mais certaines protocoles autorisaient explicitement un chiffrement sans effet),
- fournir de la confidentialité persistante.
Si, à ce stade, vous vous posez des questions sur les choix faits par les concepteurs d'ENO, et que vous vous demandez pourquoi diable ont-ils décidé ceci ou cela, il est temps de lire la section 8, qui explique certains choix de conception. D'abord, une décision importante était qu'en cas de problème lors de la négociation, la connexion devait se replier sur du TCP classique, non chiffré, et surtout ne pas échouer. En effet, si un problème de négociation empêchait la connexion de s'établir, personne n'essayerait d'utiliser ENO. Donc, si on n'a pas d'option ENO dans les paquets qu'on reçoit, on n'insiste pas, on repasse en TCP classique. Et ceci, que les options n'aient jamais été mises, ou bien qu'elles aient été retirées par un intermédiaire trop zélé. On trouve de tout dans ces machines intermédiaires, y compris les comportements les plus délirants. Le RFC note ainsi que certains répartiteurs de charge renvoient à l'expéditeur les options TCP inconnues. L'émetteur pourrait alors croire à tort que son correspondant accepte ENO même quand ce n'est pas vrai. Un bit nommé b, mis à 0 par la machine A et à 1 par la machine B, permet de détecter ce problème, et de ne pas tenter de chiffrer avec un correspondant qui ne sait pas faire.
Cette asymétrie (une machine met le bit b à 1 mais pas l'autre) est un peu ennuyeuse, car TCP est normalement symétrique (deux machines peuvent participer à une ouverture simultanée de connexion, cf. RFC 793, section 3.4). Mais aucune meilleure solution n'a été trouvée, d'autant plus qu'une machine ne sait qu'il y a eu ouverture simultanée qu'après avoir envoyé son SYN (et si le message SYN de l'autre machine est perdu, elle ne saura jamais qu'une ouverture simultanée a été tentée).
Les protocoles utilisant ENO, comme tcpcrypt, sont conçus pour fonctionner sans la participation de l'application. Mais si celle-ci le souhaite, elle peut s'informer de l'état de sécurisation de la connexion TCP, par exemple pour débrayer un chiffrement au niveau applicatif, qui n'est plus nécessaire. Le bit a dans l'option ENO sert à cela. Mis à 1 par une application, il sert à informer l'application en face qu'on peut tenir compte du chiffrement, par exemple pour activer des services qui ont besoin d'une connexion sécurisée. (Notez qu'il n'existe pas d'API standard pour lire et modifier le bit a, ce qui limite les possibilités.)
La section 7 de notre RFC explique quelques développements futurs qui pourraient avoir lieu si des améliorations futures à TCP se répandent. Ainsi, si de nouvelles API, plus perfectionnées que celles du RFC 3493, permettent à TCP de connaitre non seulement l'adresse IP de la machine où on veut se connecter mais également son nom, on pourrait imaginer une authentification fondée sur le nom, par exemple avec DANE (RFC 6394). On pourrait aussi imaginer qu'ENO permette de sélectionner et de démarrer TLS même sans que l'application soit au courant.
Dans l'Internet très ossifié d'aujourd'hui, il est difficile de déployer quelque chose de nouveau, comme l'option ENO (d'où le statut expérimental de ce RFC.) On risque toujours de tomber sur un intermédiaire qui se croit autorisé à modifier ou jeter des paquets dont la tête ne lui revient pas. La section 9 du RFC analyse deux risques :
- Le rique de repasser en TCP classique, non chiffré, par exemple si un intermédiaire supprime l'option ENO,
- le risque de ne pas pouvoir se connecter du tout, par exemple si un intermédiaire jette les paquets contenant l'option ENO.
Le premier risque n'est pas trop sérieux, ENO était prévu pour du déploiement incrémental, de toute façon (on ne peut pas espérer que toutes les machines adoptent ENO en même temps.) Le deuxième est plus grave et, s'il s'avère trop commun, il faudra des heuristiques du genre « si pas de réponse en N millisecondes, réessayer sans ENO ».
Outre ces risques, il est toujours possible, lorsqu'on touche à un protocole aussi crucial que TCP, que d'autres choses aillent mal, et il est donc nécessaire d'expérimenter. Il y a aussi des inconnues du genre « les applications vont-elles tirer profit d'ENO ? » (ce qui n'est pas nécessaire mais pourrait être utile).
La section 10 du RFC étudie les questions de sécurité soulevées par ENO. Comme ENO vise à permettre, entre autres, le chiffrement opportuniste (on chiffre si on peut, sinon on passe en clair, et on n'impose pas d'authentification, cf. RFC 7435), il faut être bien conscient des limites de ce modèle. Le chiffrement opportuniste protège bien contre un surveillant purement passif, mais pas contre un attaquant actif qui pourrait, par exemple, supprimer toutes les options ENO des paquets TCP, ou bien se mettre en position de terminaison TCP, avant de relayer vers le vrai destinataire, agissant ainsi en homme du milieu. Il ne faudrait donc pas prétendre à l'utilisateur que sa connexion est sûre.
Une solution est l'authentification, et c'est bien à cela que sert le session ID. Si l'application peut authentifier, elle doit lier cette authentification au session ID, pour être bien sûr qu'un attaquant ne va pas profiter d'une authentification réussie dans une session pour abuser d'une autre. Par exemple, si l'authentification est faite par une méthode analogue à celle du RFC 7616, le session ID peut être ajouté aux éléments qui seront condensés. Et si la méthode d'authentification ressemble à SCRAM (RFC 5802), le session ID peut être utilisé comme channel binding.
ENO n'est pas lié à un algorithme cryptographique particulier, en application du principe d'agilité (RFC 7696). Mais cela implique qu'un algorithme faible peut affaiblir la sécurité de tout le système. Les mises en œuvre d'ENO doivent donc faire attention à ne pas accepter des algorithmes cryprographiques faibles.
Pour les mises en œuvre d'ENO, voir la fin de mon article sur le RFC 8548 ; pour l'instant, ce sont les mêmes que celles de tcpcrypt.
L'article seul
RFC 8589: The 'leaptofrogans' URI Scheme
Date de publication du RFC : Mai 2019
Auteur(s) du RFC : A. Tamas (OP3FT), B. Phister (OP3FT), J-E. Rodriguez (OP3FT)
Pour information
Première rédaction de cet article le 23 mai 2019
Ce nouveau RFC documente un nouveau plan
d'URI, leaptofrogans,
qui permettra de construire des URI pour le système
Frogans, comme par exemple
leaptofrogans:example*test.
Le système Frogans est un système, conçu il y a vingt ans, de publication de contenu sur l'Internet. Il ne semble pas avoir jamais décollé et je suis sceptique quant à ses chances. Mais l'enregistrement d'un plan d'URI (le plan est la première partie d'un URI, avant le deux-points, cf. RFC 3986) ne signifie pas approbation ou encouragement, il indique juste que les formes ont bien été respectées.
Le système Frogans (section 1 du RFC) contient plusieurs composants, un langage de
description des « sites Frogans »,
des adresses Frogans qu'on reconnait à l'astérisque (comme par exemple
example*test), un logiciel
non-libre, le Frogans
Player, un registre des
adresses, une organisation qui pilote la
technologie, etc.
Pourquoi un nouveau plan d'URI ? (Section 2.) L'idée est de permettre au
navigateur, quand il voit un lien du genre
<a href="leaptofrogans:example*test">Contenu
intéressant</a> de lancer le Frogans
Player lorsque ce lien est sélectionné par l'utilisateur.
Le nom un peu long du nouveau plan, leaptofrogans, a
été choisi pour éviter des confusions avec les adresses Frogans,
qui commencent souvent par frogans avant
l'astérisque (section 3 du RFC pour les détails.)
Quelques détails de syntaxe maintenant (section 4). Les
adresses Frogans peuvent utiliser tout
Unicode. Il faut donc utiliser le nouveau
plan leaptofrogans dans des
IRI (RFC 3987) ou
bien encoder avec les pour-cent. Ainsi,
l'adresse Frogans
网络名*站名
sera l'IRI
leaptofrogans:网络名*站名
ou bien l'URI
leaptofrogans:%E7%BD%91%E7%BB%9C%E5%90%8D*%E7%AB%99%E5%90%8D.
Les procédures du RFC 7595 ayant été
suivies, le plan leaptofrogans est désormais dans
le
registre IANA (enregistrement permanent, un enregistrement
temporaire avait été envisagé à un moment).
L'article seul
RFC 8594: The Sunset HTTP Header Field
Date de publication du RFC : Mai 2019
Auteur(s) du RFC : E. Wilde
Pour information
Première rédaction de cet article le 22 mai 2019
Dernière mise à jour le 27 février 2025
Un nouvel en-tête HTTP (et un nouveau
type de lien) fait son
apparition avec ce RFC :
Sunset: (coucher de soleil) sert à indiquer la date où la
ressource Web cessera probablement d'être servie. Le but est,
lorsque le webmestre sait à l'avance qu'il retirera une ressource,
de prévenir les utilisateurs.
Normalement, bien sûr, cela ne devrait pas arriver. Les URL doivent être stables. Mais dans certains cas, il peut y avoir une raison légitime de retirer une ressource qui avait été publiée sur le Web. Et, si on le sait à l'avance, c'est plus gentil si on prévient les utilisateurs qui accèdent à cette ressource. Donc, en pratique, ce nouvel en-tête servira peu (et sans doute surtout pour les API) mais il sera utile dans des cas précis. Par exemple (ce sont les cas cités par le RFC, personnellement, je ne les trouve pas tous pertinents) :
- Certaines ressources sont par nature temporaires. Par exemple, une page correspondant à une commande en cours sur un site Web de commerce en ligne. (À mon avis, il vaudrait mieux qu'elle soit permanente, pour pouvoir accéder à des informations même une fois la commande exécutée.)
- Lorsqu'une migration vers de nouveaux URL est envisagée dans le futur.
- Lorsque la loi ou un réglement quelconque l'exige. Par exemple, le RGPD, comme les lois de protection des données personnelles qui l'ont précédé, exige la suppression de ces données lorsque la raison pour laquelle elles avaient été collectées n'est plus d'actualité. Si on les détruit au bout d'un mois, on peut annoncer cette suppression à l'avance.
- Si la ressource fait partie d'une
API, il est possible que l'API soit
remplacée par une nouvelle version et que la date de retrait de
l'ancienne soit connue à l'avance, permettant d'informer les
utilisateurs. (Notez qu'une API comprend en général plusieurs
ressources, donc plusieurs URL. L'en-tête
Sunset:ne permet pas de traiter ce cas, cf. section 5 du RFC, mais le type de liensunsetpermet d'indiquer une page Web documentant l'API et ses changements.)
Pour ces usages, ce RFC introduit
(section 3)
donc l'en-tête HTTP Sunset: (coucher de
soleil). Il contient une seule valeur, la date et l'heure de la
suppression, au format HTTP classique de la section 7.1.1.1 du
RFC 7231. Par exemple, pour indiquer qu'une
ressource disparait à la fin de cette année (celle de parution du
RFC) :
Sunset: Tue, 31 Dec 2019 23:59:59 GMT
Et c'est tout. L'en-tête ne donne aucune information sur ce qui arrivera après (réponse 404, 410, redirection 3xx vers une autre ressource…). Cet en-tête figure désormais dans le registre IANA des en-têtes.
Notre RFC introduit, en plus de l'en-tête HTTP, un type de
lien (cf. RFC 8288), sunset, qui peut être mis dans d'autres contextes que celui des
en-têtes HTTP, par exemple dans du HTML
(section 6 de notre RFC). Il
permet d'indiquer des détails sur la future suppression
de la ressource, à la page Web indiquée. Ainsi, en
HTML, cela donnerait :
<link rel="sunset" href="https://example.org/why-sunset-and-when">
Ce type de lien figure dans le registre IANA de ces types.
Le RFC ne précise pas ce que des applications comme les navigateurs doivent faire exactement avec cette information. C'est un choix des auteurs des applications. Ils peuvent choisir, par exemple, d'alerter l'utilisateur. Notez que la date indiquée n'est qu'une indication. Le serveur Web reste libre de garder la ressource plus longtemps, ou au contraire de la supprimer avant.
J'ai mis un champ Sunset: sur ce blog pour
voir. Regardez
https://www.bortzmeyer.org/apps/limit :
% curl -i https://www.bortzmeyer.org/apps/limit
HTTP/1.1 200 OK
…
Sunset: Fri, 1 Jan 2100 00:00:00 GMT
Link: <https://www.bortzmeyer.org/8594.html>; rel="sunset"; type="text/html"
…
Will be deprecated on 2038-01-19T03:14:08Z and removed on 2100-01-01T00:00:00Z.
Pour traiter ce champ, et le
Deprecation: du RFC 9745 (qui est moins « dur » que
Sunset:, il indique un abandon, pas forcément
un retrait), regardez ce
script en Python.
Sinon, quelques logiciels utilisent ou génèrent l'information sur le
coucher de soleil :
- Guzzle
peut examiner les en-têtes
Sunset:dans les réponses, - Idem pour Faraday,
- Un outil
pour les programmeurs Ruby-on-Rails afin d'indiquer la
future suppression en utilisant l'en-tête
Sunset:.
L'article seul
Financement du logiciel de coordination d'actions Mobilizon
Première rédaction de cet article le 21 mai 2019
Une campagne de financement est en cours pour le logiciel Mobilizon. Ce logiciel doit permettre de créer des services Internet de coordination d'actions. Que l'action soit une manifestation, un pique-nique, une soutenance de thèse, une réunion ou bien un goûter d'anniversaire, Mobilizon permettra de la préparer et de le faire connaître.
Aujourd'hui, ce genre de service est rendu par des grosses sociétés privées, à but lucratif, capteuses de données personnelles, et qui censurent à leur guise les événements qui ne leur plaisent pas. Il est paradoxal d'organiser, par exemple, une réunion sur le thème de la défense de la vie privée, en utilisant un service qui la viole régulièrement ! Trop d'associations, de syndicats ou de partis politiques dépendent exclusivement de gros silos de données pour des actions citoyennes.
Mobilizon sera développé par l'association Framasoft, qui a déjà piloté des projets similaires comme PeerTube. Mobilizon sera évidemment un logiciel libre. Mais Framasoft a besoin d'argent pour cela, d'où cet appel au financement. Le projet Mobilizon prévoit trois paliers :
- 20 000 € pour les fonctions de base. Ce montant a déjà été atteint.
- 35 000 € pour la fédération. Ce point est très important. Il ne s'agit pas de créer un nouveau service centralisé, il en existe déjà trop ! Au contraire, Mobilizon permettra à chaque personne, à chaque organisation, de créer son propre service avec le logiciel Mobilizon. Mais avoir un service isolé est d'une utilité limitée : ce qui est important est de pouvoir se connecter au reste du fédivers, des autres services décentralisés. C'est actuellement là qu'il faut aider le projet et le financer.
- 50 000 € pour la prochaine étape, avec par exemple des service de communication et de travail en groupe.
Loin des salons commerciaux où des startups plus ou moins bidons font assaut de services dangereux pour la démocratie ou pour la vie privée, Mobilizon vise à changer le monde en mieux. Son financement dépend de vous, il n'y a pas de business model pour de tels projets, c'est à vous de jouer.
L'article seul
Sur l'Internet, citoyen ou simple consommateur ?
Première rédaction de cet article le 9 mai 2019
Si vous regardez la télévision, ou écoutez les discours officiels, vous avez l'impression que l'Internet sert uniquement au commerce en ligne, et à nourrir Facebook et YouTube en leur laissant le plus de données personnelles possibles. Le débat politique au sujet de l'Internet est très pauvre, réduit à des discussions sur la répartition exacte du pouvoir entre ces GAFA et le gouvernement. Le citoyen et la citoyenne sont complètement absents. GAFA et gouvernement, derrière les polémiques qu'ils mettent en scène, sont en fait d'accord : l'internaute doit la fermer et consommer.
Il est donc urgent de re-politiser
l'Internet. Un système technique par lequel passe l'essentiel de
nos échanges ne doit pas être géré sans les citoyennes et
citoyens. D'où le débat le 5 juin prochain, à la Fonderie de
l'Image à Bagnolet, « Réinventer la citoyenneté à
l'heure d'internet ». (Ce débat rassemble notamment des
auteurs publiés chez C&F
Éditions.) Venez nombreuses et nombreux ! (Si vous utilisez
OpenAgenda, les informations sont par ici.) 
On parlera aussi d'alternatives. Car un autre point sur lesquels gouvernement et GAFA sont d'accord, c'est qu'il n'y a pas d'alternative : on discute de Facebook comme si aucun autre moyen de communication n'existait. De nombreuses entreprises, et plus encore d'associations ne communiquent publiquement que via Facebook. C'est cette position dominante qu'il faut remettre en cause. Quand on a une place aussi importante que Facebook, on en abuse forcément (pour la plus grande joie du gouvernement, qui ne demande pas mieux que de sous-traiter la censure à Facebook). Il est donc urgent de développer et de populariser des alternatives, comme les réseaux sociaux décentralisés mais aussi, par exemple, la syndication.
Les sites Web des autres intervenants :
- Le Standblog de Tristan Nitot,
- L'association Vecam, où intervient Valérie Peugeot.
L'article seul
RFC 8415: Dynamic Host Configuration Protocol for IPv6 (DHCPv6)
Date de publication du RFC : Novembre 2018
Auteur(s) du RFC : T. Mrugalski, M. Siodelski (ISC), B. Volz, A. Yourtchenko (Cisco), M. Richardson (SSW), S. Jiang (Huawei), T. Lemon (Nibbhaya Consulting), T. Winters (UNH-IOL)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dhc
Première rédaction de cet article le 3 mai 2019
IPv6 dispose de trois mécanismes principaux pour l'allocation d'une adresse IP à une machine. L'allocation statique, « à la main », le système d'« autoconfiguration » SLAAC du RFC 4862 et DHCP. DHCP pour IPv6 avait été normalisé pour la première fois dans le RFC 3315, que notre RFC met à jour. Le protocole n'a guère changé mais le texte du RFC a été sérieusement revu (DHCP est un protocole compliqué). Une mise à jour a eu lieu par la suite, remplaçant ce RFC par le RFC 9915.
DHCP permet à une machine (qui n'est pas forcément un ordinateur) d'obtenir une adresse IP (ainsi que plusieurs autres informations de configuration) à partir d'un serveur DHCP du réseau local. C'est donc une configuration « avec état », du moins dans son mode d'utilisation le plus connu. (Notre RFC documente également un mode sans état.) DHCP nécessite un serveur, par opposition à l'autoconfiguration du RFC 4862 qui ne dépend pas d'un serveur (cette autoconfiguration sans état peut être utilisée à la place de, ou bien en plus de DHCP). Deux utilisations typiques de DHCP sont le SoHo où le routeur ADSL est également serveur DHCP pour les trois PC connectés et le réseau local d'entreprise où deux ou trois machines Unix distribuent adresses IP et informations de configuration à des centaines de machines.
Le principe de base de DHCP (IPv4 ou IPv6) est simple : la nouvelle machine annonce à la cantonade qu'elle cherche une adresse IP, le serveur lui répond, l'adresse est allouée pour une certaine durée, le bail, la machine cliente devra renouveler le bail de temps en temps.
L'administrateur d'un réseau IPv6 se pose souvent la question « DHCP ou SLAAC » ? Notez que les deux peuvent coexister, ne serait-ce que parce que certaines possibilités n'existent que pour un seul des deux protocoles. Ainsi, DHCP seul ne peut indiquer l'adresse du routeur par défaut. Pour le reste, c'est une question de goût.
Le DHCP spécifié par notre RFC ne fonctionne que pour IPv6, les RFC 2131 et RFC 2132 traitant d'IPv4. Les deux protocoles restent donc complètement séparés, le RFC 4477 donnant quelques idées sur leur coexistence. Il a parfois été question de produire une description unique de DHCPv4 et DHCPv6, ajoutant ensuite les spécificités de chacun, mais le projet n'a pas eu de suite (section 1.2 de ce RFC), les deux protocoles étant trop différents. De même, l'idée de permettre l'envoi d'informations spécifiques à IPv4 (par exemple l'adresse IPv4, proposée dans le RFC 3315, section 1) au-dessus de DHCPv6 a été abandonnée (mais voyez quand même le RFC 7341).
DHCP fonctionne par diffusion
restreinte. Un client DHCP,
c'est-à-dire une machine qui veut obtenir une adresse, diffuse
(DHCP fonctionne au-dessus d'UDP, RFC 768, le
port source est 546, le port de destination,
où le serveur écoute, est 547) sa demande à l'adresse
multicast locale au lien
ff02::1:2. Le serveur se reconnait et lui
répond. S'il n'y a pas de réponse, c'est, comme dans le DNS, c'est au client de réémettre
(section 15). L'adresse IP source du client est également une
adresse locale au lien.
(Notez qu'une autre adresse de diffusion restreinte est
réservée, ff05::1:3 ; elle inclut également
tous les serveurs DHCP mais, contrairement à la précédente, elle
exclut les relais, qui transmettent les requêtes DHCP d'un réseau
local à un autre.)
Le serveur choisit sur quels critères il alloue les adresses IP. Il peut les distribuer de manière statique (une même machine a toujours la même adresse IP) ou bien les prendre dans un pool d'adresses et chaque client aura donc une adresse « dynamique ». Le fichier de configuration du serveur DHCP ISC ci-dessous montre un mélange des deux approches.
Il faut bien noter (et notre RFC le fait dans sa section 22) que DHCP n'offre aucune sécurité. Comme il est conçu pour servir des machines non configurées, sur lesquelles on ne souhaite pas intervenir, authentifier la communication est difficile. Un serveur DHCP pirate, ou, tout simplement, un serveur DHCP accidentellement activé, peuvent donc être très gênants. Les approches de sécurité suggérées dans le RFC 3315 se sont avérées peu pratiques et plusieurs ont été retirées dans notre nouveau RFC.
Outre l'adresse IP, DHCP peut indiquer des options comme les adresses des serveurs DNS à utiliser (RFC 3646).
Notre version IPv6 de DHCP est assez différente de la version IPv4 (et le RFC est plus de trois fois plus long). Par exemple, l'échange « normal » entre client et serveur prend quatre paquets IP (section 5) et non pas deux. (Il y a aussi un échange simplifié à deux paquets, cf. section 5.1.) L'encodage des messages est très différent, et il y a des différences internes comme l'IA (Identity Association) de la section 12. Il y a aussi des différences visibles à l'utilisateur comme le concept de DUID (DHCP Unique IDentifier), section 11, qui remplace les anciens client identifier et server identifier de DHCP v4. Les différences sont telles que le RFC précise que leur intégration avec DHCP pour IPv4 n'est pas envisagée.
À l'heure actuelle, il existe plusieurs mises en œuvre de DHCPv6, Dibbler (client et serveur, mais qui n'est plus maintenu), celle de l'Institut Leibniz à Dresde (serveur seulement), celles de l'ISC, l'ancien DHCP et le nouveau, nommé Kea (dans les deux cas, serveur seulement) et dhcpcd (client seulement). Pour celles et ceux qui utilisent une Freebox comme serveur DHCP, il semble qu'elle ait DHCPv6 depuis 2018 (je n'ai pas testé). Il parait que la Livebox le fait également. Je n'ai pas non plus essayé pour la Turris Omnia mais cela devrait marcher puisqu'elle utilise le serveur odhcpd, qui sait faire du DHCPv6. Et il y a bien sûr des implémentations non-libres dans des équipements comme les Cisco. Notez que ces mises en œuvre de DHCPv6 n'ont pas forcément déjà intégré les modifications de notre RFC 8415.
Voici un exemple d'utilisation de Dibbler, qui nous affiche les
quatre messages (Solicit - Advertise -
Request - Reply) :
% sudo dibbler-client run ... 2019.05.02 11:35:15 Client Notice Unable to open DUID file (client-duid), generating new DUID. 2019.05.02 11:35:15 Client Notice DUID creation: Generating 14-bytes long link-local+time (duid-llt) DUID. 2019.05.02 11:35:15 Client Info My DUID is 00:01:00:01:24:5d:76:53:00:1e:8c:76:29:b6. ... 2019.05.02 12:12:38 Client Info Creating SOLICIT message with 1 IA(s), no TA and 0 PD(s) on eth1/2 interface. 2019.05.02 12:12:38 Client Info Received ADVERTISE on eth1/2,trans-id=0x614722, 4 opts: 1 2 3 23 2019.05.02 12:12:39 Client Info Processing msg (SOLICIT,transID=0x614722,opts: 1 3 8 6) 2019.05.02 12:12:39 Client Info Creating REQUEST. Backup server list contains 1 server(s). 2019.05.02 12:12:39 Client Info Received REPLY on eth1/2,trans-id=0x634881, 4 opts: 1 2 3 23 2019.05.02 12:12:39 Client Notice Address fde8:9fa9:1aba:0:fafa::2/128 added to eth1/2 interface. 2019.05.02 12:12:39 Client Notice Setting up DNS server 2001:db8:2::dead:beef on interface eth1/2.
Le serveur en face était un Kea ainsi configuré :
"subnet6": [
{
"interface": "eth0",
"subnet": "fde8:9fa9:1aba:0::/64",
"pools": [ { "pool": "fde8:9fa9:1aba:0:fafa::/80" } ],
...
Pour que Kea puisse écouter sur le port DHCP, il a aussi fallu :
% sudo setcap 'cap_net_bind_service=+ep' /usr/sbin/kea-dhcp6
(Sinon, c'est le Permission denied.) Si vous
voulez, le pcap de l'échange est disponible (capture faite avec tcpdump -w /tmp/dhcpv6.pcap udp and port 546 or port 547).
tcpdump voit le trafic ainsi :
12:17:44.531859 IP6 fe80::21e:8cff:fe76:29b6.546 > ff02::1:2.547: dhcp6 solicit 12:17:44.555202 IP6 fe80::d40b:5ff:fee8:a36b.547 > fe80::21e:8cff:fe76:29b6.546: dhcp6 advertise 12:17:45.559247 IP6 fe80::21e:8cff:fe76:29b6.546 > ff02::1:2.547: dhcp6 request 12:17:45.567875 IP6 fe80::d40b:5ff:fee8:a36b.547 > fe80::21e:8cff:fe76:29b6.546: dhcp6 reply
On voit bien les quatre messages (Solicit - Advertise -
Request - Reply). Avec l'option
-vvv, tcpdump est plus bavard et montre qu'il
analyse bien DHCPv6 :
12:17:44.531859 IP6 (flowlabel 0x90d05, hlim 1, next-header UDP (17) payload length: 58) fe80::21e:8cff:fe76:29b6.546 > ff02::1:2.547: [udp sum ok] dhcp6 solicit (xid=aecc66 (client-ID hwaddr/time type 1 time 610104915 001e8c7629b6) (IA_NA IAID:1 T1:4294967295 T2:4294967295) (elapsed-time 0) (option-request DNS-server)) 12:17:44.555202 IP6 (flowlabel 0xa6d2a, hlim 64, next-header UDP (17) payload length: 128) fe80::d40b:5ff:fee8:a36b.547 > fe80::21e:8cff:fe76:29b6.546: [udp sum ok] dhcp6 advertise (xid=aecc66 (client-ID hwaddr/time type 1 time 610104915 001e8c7629b6) (server-ID hwaddr/time type 1 time 610105065 d60b05e8a36b) (IA_NA IAID:1 T1:1000 T2:2000 (IA_ADDR fde8:9fa9:1aba:0:fafa::4 pltime:3000 vltime:4000)) (DNS-server 2001:db8:2::dead:beef 2001:db8:2::cafe:babe)) 12:17:45.559247 IP6 (flowlabel 0x90d05, hlim 1, next-header UDP (17) payload length: 104) fe80::21e:8cff:fe76:29b6.546 > ff02::1:2.547: [udp sum ok] dhcp6 request (xid=dc7ba (client-ID hwaddr/time type 1 time 610104915 001e8c7629b6) (IA_NA IAID:1 T1:4294967295 T2:4294967295 (IA_ADDR fde8:9fa9:1aba:0:fafa::4 pltime:3000 vltime:4000)) (option-request DNS-server) (server-ID hwaddr/time type 1 time 610105065 d60b05e8a36b) (elapsed-time 0)) 12:17:45.567875 IP6 (flowlabel 0xa6d2a, hlim 64, next-header UDP (17) payload length: 128) fe80::d40b:5ff:fee8:a36b.547 > fe80::21e:8cff:fe76:29b6.546: [udp sum ok] dhcp6 reply (xid=dc7ba (client-ID hwaddr/time type 1 time 610104915 001e8c7629b6) (server-ID hwaddr/time type 1 time 610105065 d60b05e8a36b) (IA_NA IAID:1 T1:1000 T2:2000 (IA_ADDR fde8:9fa9:1aba:0:fafa::4 pltime:3000 vltime:4000)) (DNS-server 2001:db8:2::dead:beef 2001:db8:2::cafe:babe))
Mais si vous préférez tshark, l'analyse de cet échange est également disponible.
Quant au fichier de configuration du traditionnel serveur ISC (celui avant Kea), il ressemble beaucoup à ce qu'il est en v4 :
subnet6 2001:db8:dead:babe::/64 {
range6 2001:db8:dead:babe::100 2001:db8:dead:babe::FFF;
# On peut aussi utiliser préfixe/longueur au lieu d'indiquer les
# adresses de début et de fin de la plage
}
On doit lancer le serveur avec l'option -6 (le même démon ne peut pas servir le v4 et le v6 en même temps, les deux protocoles étant trop différents) :
# dhcpd -6 -d -f Internet Systems Consortium DHCP Server 4.0.0 ... Listening on Socket/eth0/2001:db8:dead:babe::/64 Sending on Socket/eth0/2001:db8:dead:babe::/64 [Puis arrive une requête] Solicit message from fe80::219:b9ff:fee4:25f9 port 546, transaction ID 0x4BB14F00 Picking pool address 2001:db8:dead:babe::fbb Sending Advertise to fe80::219:b9ff:fee4:25f9 port 546 Request message from fe80::219:b9ff:fee4:25f9 port 546, transaction ID 0x46B10900 Sending Reply to fe80::219:b9ff:fee4:25f9 port 546
(Le concept de transaction ID est décrit
sections 8 et 16.1.) La requête est émise depuis une adresse
lien-local (ici
fe80::219:b9ff:fee4:25f9) pas depuis une
adresse « tout zéro » comme en IPv4 (section 17 du RFC). Vu avec
tcpdump, la requête est :
15:07:43.455918 IP6 fe80::219:b9ff:fee4:25f9.546 > ff02::1:2.547: dhcp6 solicit 15:07:43.456098 IP6 fe80::219:b9ff:fee4:2987.547 > fe80::219:b9ff:fee4:25f9.546: dhcp6 advertise 15:07:44.512946 IP6 fe80::219:b9ff:fee4:25f9.546 > ff02::1:2.547: dhcp6 request 15:07:44.513233 IP6 fe80::219:b9ff:fee4:2987.547 > fe80::219:b9ff:fee4:25f9.546: dhcp6 reply
On note que l'échange a été celui à quatre messages
(Solicit - Advertise - Request - Reply),
décrit section 5.2 (et la liste des types possibles est en section 7.3). Le serveur n'a pas répondu directement avec un
Reply, parce que le client n'a pas inclus
l'option Rapid Commit (section 21.14). Cette
option n'est pas actuellement gérée par le client DHCP utilisé
(l'option dhcp6.rapid-commit existe mais la
documentation précise qu'elle est ignorée). Dans l'échange à quatre
messages, le client demande à tous (Solicit),
un(s) serveur(s) DHCP répond(ent) (Advertise), le client
envoie alors sa requête au serveur choisi
(Request), le serveur donne (ou pas) son
accord (Reply).
L'échange à deux messages (Solicit- Reply)
est, lui, spécifié dans la section 5.1. Il s'utilise si le client
n'a pas besoin d'une adresse IP, juste d'autres informations de
configuration comme l'adresse du serveur
NTP, comme décrit dans le RFC 4075. Même si le client demande une adresse IP, il est
possible d'utiliser l'échange à deux messages, via la procédure
rapide avec l'option Rapid Commit.
Actuellement, l'attribution d'adresses statiques à une machine,
en la reconnaissant, par exemple, à son adresse
MAC est plus délicate avec le serveur de l'ISC (merci à
Shane Kerr pour son aide). Il faut trouver le client
identifier (section 21.2 du RFC, deux méthodes possibles
pour le trouver sont expliquées plus loin) et le mettre dans
dhcpd.conf :
host lilith {
host-identifier option dhcp6.client-id 0:1:0:1:47:96:21:f7:0:19:b9:e4:25:f9;
fixed-address6 2001:db8:dead:babe::2;
}
et cette adresse IP fixe est donnée au client.
Pour trouver le client identifier, une
méthode spécifique au client DHCP de l'ISC est de regarder dans le
fichier des baux du client (typiquement
/var/db/dhclient6.leases) :
... option dhcp6.client-id 0:1:0:1:47:96:21:f7:0:19:b9:e4:25:f9;
Il suffit alors de le copier-coller.
Une autre méthode, plus complexe, mais qui marche avec tous les clients DHCP est de lancer tcpdump en mode bavard :
# tcpdump -n -vvv ip6 and udp and port 547 12:24:15.084006 IP6 (hlim 64, next-header UDP (17) payload length: 60) fe80::219:b9ff:fee4:25f9.546 > ff02::1:2.547: dhcp6 solicit (xid=4323ac (client ID hwaddr/time type 1 time 1201021431 0019b9e425f9) (option request DNS DNS name)[|dhcp6ext])
Tout client ou serveur DHCP v6 a un DUID (DHCP Unique
Identifier, décrit en section 11). Le DUID est opaque et
ne devrait pas être analysé par la machine qui le reçoit. La seule
opération admise est de tester si deux DUID sont égaux (indiquant
qu'en face, c'est la même machine). Il existe plusieurs façons de
générer un DUID (dans l'exemple plus haut, Dibbler avait choisi la
méthode duid-llt, adresse locale et heure) et de nouvelles pourront apparaitre dans le
futur. Par exempe, un DUID peut être fabriqué à partir d'un
UUID (RFC 6355).
Le client identifier de l'exemple avec le serveur de l'ISC ci-dessus, le DUID, a été fabriqué, comme pour Dibbler, en concaténant le type de DUID (ici, 1, Link-layer Address Plus Time, section 11.2 du RFC), le type de matériel (1 pour Ethernet), le temps (ici 1201021431, notons que ce client DHCP violait le RFC en comptant les secondes à partir de 1970 et pas de 2000) et l'adresse MAC, ce qui redonne le même résultat au prix de quelques calculs avec bc.
Mais l'utilisation exclusive du DUID, au détriment de l'adresse MAC, n'est pas une obligation du RFC (le RFC, section 11, dit juste « DHCP servers use DUIDs to identify clients for the selection of configuration parameters », ce qui n'interdit pas d'autres méthodes), juste un choix des développeurs de l'ISC. Le serveur de Dresde, dhcpy6d, permet d'utiliser les adresses MAC, comme on le fait traditionnellement en IPv4. En combinaison avec des commutateurs qui filtrent sur l'adresse MAC, cela peut améliorer la sécurité.
La section 6 de notre RFC décrit les différentes façons d'utiliser DHCPv6. On peut se servir de DHCPv6 en mode sans état (section 6.1), lorsqu'on veut juste des informations de configuration, ou avec état (section 6.2, qui décrit la façon historique d'utiliser DHCP), lorsqu'on veut réserver une ressource (typiquement l'adresse IP) et qu'il faut alors que le serveur enregistre (et pas juste dans sa mémoire, car il peut redémarrer) ce qui a été réservé. On peut aussi faire quelque chose qui n'a pas d'équivalent en IPv4, se faire déléguer un préfixe d'adresses IP entier (section 6.3). Un client DHCP qui reçoit un préfixe, mettons, /60, peut ensuite redéléguer des bouts, par exemple ici des /64. (Le RFC 7084 est une utile lecture au sujet des routeurs installés chez M. Toutlemonde.)
Le format détaillé des messages est dans la section 8. Le début des messages est toujours le même, un type d'un octet (la liste des types est en section 7.3) suivi d'un identificateur de transaction de trois octets. Le reste est variable, dépendant du type de message.
On a déjà parlé du concept de DUID plus haut, donc sautons la section 11 du RFC, qui parle du DUID, et allons directement à la section 12, qui parle d'IA (Identity Association). Une IA est composée d'un identifiant numérique, l'IAID (IA IDentifier) et d'un ensemble d'adresses et de préfixes. Le but du concept d'IA est de permettre de gérer collectivement un groupe de ressources (adresses et préfixes). Pour beaucoup de clients, le concept n'est pas nécessaire, on n'a qu'une IA, d'identificateur égal à zéro. Pour les clients plus compliqués, on a plusieurs IA, et les messages DHCP (par exemple d'abandon d'un bail) indiquent l'IA concernée.
Comme pour DHCPv4, une bonne partie des informations est transportée dans des options, décrites dans la section 21. Certaines options sont dans ce RFC, d'autres pourront apparaitre dans des RFC ultérieurs. Toutes les options commencent par deux champs communs, le code identifiant l'option (deux octets), et la longueur de l'option. Ces champs sont suivis par des données, spécifiques à l'option. Ainsi, l'option Client Identifier a le code 1, et les données sont un DUID (cf. section 11). Autre exemple, l'option Vendor Class (code 16) permet d'indiquer le fournisseur du logiciel client (notez qu'elle pose des problèmes de sécurité, cf. RFC 7824, et section 23 de notre RFC). Notez qu'il peut y avoir des options dans les options, ainsi, l'adresse IP (code 5) est toujours dans les données d'une option IA (les IA sont décrites en section 12).
Puisqu'on a parlé de sécurité, la section 22 du RFC détaille les questions de sécurité liées à DHCP. Le fond du problème est qu'il y a une profonde incompatibilité entre le désir d'une autoconfiguration simple des clients (le but principal de DHCP) et la sécurité. DHCP n'a pas de chiffrement et tout le monde peut donc écouter les échanges de messages, voire les modifier. Et, de toute façon, le serveur n'est pas authentifié, donc le client ne sait jamais s'il parle au serveur légitime. Il est trivial pour un méchant de configurer un serveur DHCP « pirate » et de répondre à la place du vrai, indiquant par exemple un serveur DNS que le pirate contrôle. Les RFC 7610 et RFC 7513 décrivent des solutions possibles à ce problème.
Des attaques par déni de service sont également possibles, par exemple via un client méchant qui demande des ressources (comme des adresses IP) en quantité. Un serveur prudent peut donc limiter la quantité de ressources accessible à un client.
Nouveauté de ce RFC (elle était quasiment absente du RFC 3315), les questions de vie privée. La section 23 rappelle que DHCP est très indiscret. Le RFC 7824 décrit les risques que DHCP fait courir à la vie privée du client (et le RFC 7844 des solutions possibles).
Les registres IANA ne changent pas par rapport à l'ancien RFC. Les différents paramètres sont en ligne.
L'annexe A de notre RFC décrit les changements depuis le vieil RFC 3315. Ils sont nombreux mais en général pas cruciaux. On notera :
- beaucoup de changements dans le texte, pour clarifier certains points, ou mieux expliquer des questions complexes,
- une section 6 sur les questions d'utilisation de DHCP, toute neuve,
- l'option Option Request devient obligatoire dans certains messages,
- une nouvelle section sur la vie privée,
- les références à IPsec (jamais déployé) ont été retirées,
- le protocole d'« authentification retardée » (jamais déployé, et probablement pas déployable) a été retiré (cf. section 25),
- la possibilité pour le client d'indiquer la durée d'un bail souhaitée a été retirée,
- plusieurs RFC séparés ont été fusionnés avec ce nouveau RFC, comme la délégation de préfixe, initialement séparée dans le RFC 3633 (l'implémenteur de DHCPv6 aura donc désormais une vue unifiée du protocole, et moins de RFC à lire),
- le mode « sans état », qui était dans le RFC 3736, a été intégré,
- le mécanisme de ralentissement des clients lorsque le serveur ne répond pas (ex-RFC 7083), le relayage des messages de type inconnu (remplaçant donc le RFC 7283), et le fonctionnement des différents modes (au revoir, le RFC 7550) sont également intégrés,
- une bonne douzaine de bogues relevées dans le RFC 3315 et ses RFC proches, ont été corrigées.
L'article seul
RFC 8546: The Wire Image of a Network Protocol
Date de publication du RFC : Avril 2019
Auteur(s) du RFC : B. Trammell, M. Kuehlewind (ETH Zurich)
Pour information
Première rédaction de cet article le 29 avril 2019
Ce nouveau RFC de l'IAB décrit le très important concept de vue depuis le réseau (wire image), une abstraction servant à modéliser ce que voit, sur le réseau, une entité qui ne participe pas à un protocole, mais peut en observer les effets. Cela peut être un routeur, un boitier de surveillance, etc. Le concept n'était pas nécessaire autrefois, où tout le trafic était en clair. Maintenant qu'une grande partie est (heureusement) chiffrée, il est important d'étudier ce qui reste visible à ces entités extérieures.
Un protocole de communication, c'est un ensemble de règles que les participants doivent respecter, le format des messages, qui doit envoyer quoi et comment y répondre, etc. Par exemple, si on prend le protocole HTTP, il y a au moins deux participants, le client et le serveur, parfois davantage s'il y a des relais. Ces participants (par exemple le navigateur Web et le serveur HTTP) connaissent le protocole, et le suivent. (Du moins on peut l'espérer.) Mais, en plus des participants, d'autres entités peuvent observer le trafic. Cela va des couches basses de la machine (TCP, IP, Ethernet) aux équipements intermédiaires. Même si le routeur ne connait pas HTTP, et n'en a pas besoin pour faire son travail, il voit passer les bits et peut techniquement les décoder, en suivant le RFC. C'est ainsi que des applications comme Wireshark peuvent nous afficher une compréhension d'un dialogue auxquelles elles ne participent pas.
Cette fuite d'informations vers d'autres entités n'est pas explicite dans la spécification d'un protocole. Autrefois, avec le trafic en clair, elle allait de soi (« bien sûr que le routeur voit tout passer ! »). Aujourd'hui, avec le chiffrement, il faut se pencher sur la question « qu'est-ce que ces entités voient et comprennent du trafic ? » C'est la vue depuis le réseau qui compte, pas la spécification du protocole, qui ne mentionne pas les fuites implicites.
Prenons l'exemple de TLS (RFC 9846). TLS chiffre le contenu de la connexion TCP. Mais il reste des informations visibles : les couches inférieures (un observateur tiers voit le protocole TCP en action, les retransmissions, le RTT, etc), les informations sur la taille (TLS ne fait pas de remplissage, par défaut, ce qui permet, par exemple, d'identifier la page Web regardée), la dynamique des paquets (délai entre requête et réponse, par exemple). Tout ceci représente la vue depuis le réseau.
Le RFC prend un autre exemple, le protocole QUIC. Cette fois, la mécanique du protocole de transport est largement cachée par le chiffrement. QUIC a donc une « vue depuis le réseau » réduite. C'est le premier protocole IETF qui essaie délibérement de réduire cette vue, de diminuer le « rayonnement informationnel ». Cela a d'ailleurs entrainé de chaudes discussions, comme celles autour du spin bit, un seul bit d'information laissé délibérement en clair pour informer les couches extérieures sur le RTT. En effet, diminuer la taille de la vue depuis le réseau protège la vie privée mais donne moins d'informations aux opérateurs réseau (c'est bien le but) et ceux-ci peuvent être frustrés de cette décision. Le conflit dans ce domaine, entre sécurité et visibilité, ne va pas cesser de si tôt.
Après cette introduction, la section 2 du RFC décrit formellement cette notion de « vue depuis le réseau ». La vue depuis le réseau (wire image) est ce que voit une entité qui ne participe pas aux protocoles en question. C'est la suite des paquets transmis, y compris les métadonnées (comme l'heure de passage du paquet).
La section 3 de notre RFC discute ensuite en détail les propriétés de cette vue. D'abord, elle ne se réduit pas aux « bits non chiffrés ». On l'a vu, elle inclut les métadonnées comme la taille des paquets ou l'intervalle entre paquets. Ces métadonnées peuvent révéler bien des choses sur le trafic. Si vous utilisez OpenVPN pour chiffrer, et que vous faites ensuite par dessus du SSH ou du DNS, ces deux protocoles présentent une vue très différente, même si tout est chiffré. Mais un protocole chiffré, contrairement aux protocoles en clair (où la vue est maximale) peut être conçu pour changer volontairement la vue qu'il offre (la section 4 approfondira cette idée).
La cryptographie peut aussi servir à garantir l'intégrité de la vue (empêcher les modifications), même si on ne chiffre pas. En revanche, toutes les parties de la vue qui n'utilisent pas la cryptographie peuvent être non seulement observées mais encore changées par des intermédiaires. Ainsi, un FAI sans scrupules peut changer les en-têtes TCP pour ralentir certains types de trafic. (Beaucoup de FAI ne respectent pas le principe de neutralité.)
Notez que la vue depuis le réseau dépend aussi de
l'observateur. S'il ne capture qu'un seul paquet, il aura une vue
réduite. S'il observe plusieurs paquets, il a accès à des
informations supplémentaires, et pas seulement celles contenues
dans ces paquets, mais également celles liées à l'intervalle entre
paquets. De même, si l'observateur ne voit que les paquets d'un
seul protocole, il aura une vue limitée de ce qui se passe alors
que, s'il peut croiser plusieurs protocoles, sa vue s'élargit. Un
exemple typique est celui du DNS : très
majoritairement non chiffré, contrairement à la plupart des
protocoles applicatifs, et indispensable à la très grande majorité
des transactions Internet, il contribue beaucoup à la vue depuis le
réseau (RFC 7626). Si vous voyez une requête DNS
pour imap.example.net juste avant un soudain
trafic, il est facile de suspecter que le protocole utilisé était
IMAP. Élargissons encore la perspective :
outre le trafic observé, le surveillant peut disposer d'autres
informations (le résultat d'une reconnaissance faite avec
nmap, par exemple), et cela augmente encore
les possibilités d'analyse de la vue dont il dispose.
Puisqu'on parle de vue (image), le RFC note également que le terme n'est pas uniquement une métaphore, et qu'on pourrait utiliser les techniques de reconnaissance d'images pour analyser ces vues.
Notez que, du point de vue de l'IETF, l'Internet commence à la couche 3. Les couches 1 et 2 contribuent également à la vue depuis le réseau, mais sont plus difficiles à protéger, puisqu'elles n'opèrent pas de bout en bout.
Pour un protocole, il est difficile de réduire la vue qu'il offre au réseau. On ne peut pas rendre les paquets plus petits, ni diminuer l'intervalle entre deux paquets. Une des solutions est d'envoyer volontairement des informations fausses, pour « noyer » les vraies. (Voir le livre de Finn Brunton et Helen Nissenbaum, « Obfuscation », chez C&F Éditions en français.) On ne peut pas réduire les paquets, mais on peut les remplir, par exemple. Ou bien on peut ajouter de faux paquets pour brouiller les pistes. Mais il n'y a pas de miracle, ces méthodes diminueront la capacité utile du réseau, ou ralentiront les communications. (Par exemple, utiliser le Web via Tor est bien plus lent.) Bref, ces méthodes ne sont vraiment acceptables que pour des applications qui ne sont pas trop exigeantes en performance.
J'ai dit plus haut qu'on pouvait assurer l'intégrité de certains champs du protocole, sans les chiffrer. Cela permet d'avoir des informations fiables, non modifiables, mais visibles, ce qui peut être utile pour certains équipements intermédiaires. Notez que cette protection a ses limites : on ne peut protéger que des bits, pas des données implicites comme l'écart entre deux paquets. Et la protection est forcément par paquet puisque, dans un réseau à commutation de paquets, comme l'Internet, on ne peut pas garantir l'arrivée de tous les paquets, ou leur ordre.
Enfin, la dernière section de notre RFC, la section 4, explore les moyens par lesquels un protocole peut tromper un éventuel surveillant, en modifiant la vue qu'il offre au réseau. Une fois qu'on a ce concept de vue depuis le réseau, on peut bâtir des choses utiles sur ce concept. Par exemple, il aide à comprendre des questions d'ossification (la difficulté à déployer de nouveaux services ou protocoles, et qui rend, par exemple, nécessaire de faire passer même le DNS sur HTTPS, comme spécifié dans le RFC 8484). En effet, tout ce qui est visible sera regardé, tout ce qui n'est pas protégé sera modifié. Les boitiers intermédiaires, ou plutôt les entreprises et les États qui les conçoivent et les déploient, n'ont aucun scrupule et ne connaissent aucune restriction. Cela veut dire que si un protocole laisse une information visible, celle-ci sera utilisée par les boitiers intermédiaires et donc il sera difficile de changer sa sémantique par la suite, même si toutes les machines terminales sont d'accord.
Prenons l'exemple de TCP (normalisé dans le RFC 793). TCP envoie un certain nombre de signaux involontaires et implicites. Par exemple, l'observation des numéros de séquence permet de mesurer le RTT. Et TCP permet également de modifier ces signaux. Comme l'explique le RFC 8558, des équipements sont vendus aujourd'hui avec des fonctions de surveillance et tripotage des en-têtes TCP. Le RFC fournit deux exemples d'utilisation de cette surveillance :
- Déterminer la joignabilité et le consentement. Si on voit des réponses respectant le protocole TCP (notamment les numéros de séquences, cf. RFC 6528), cela indique que les deux machines sont d'accord pour communiquer, l'une n'est pas en train d'attaquer l'autre. Cette conclusion peut être utilisée par un pare-feu.
- Mesurer la latence et le taux de pertes de paquets. Cela peut se faire, comme indiqué plus haut, en regardant les numéros de séquence dans les paquets et les accusés de réception, et ou en regardant ECN (RFC 3168) et l'estampillage (RFC 7323).
Dans le cas de TCP, cette exposition d'information est « involontaire ». Le but de TCP n'est pas que tout le monde sur le trajet puisse regarder, et encore moins modifier, ces informations. Mais c'est quand même ce qui arrive. Avec un protocole qui réduit consciemment la vue, comme QUIC, ne serait-ce pas une bonne idée que de donner un peu à manger aux équipements intermédiaires, afin qu'ils puissent optimiser leurs décisions ? Ce fut tout le débat dans le groupe de travail QUIC à l'IETF sur le spin bit, un bit uniquement conçu pour agrandir un peu la vue dont disposent les équipements du réseau, mais qui était un peu en conflit avec le principe d'en dire le moins possible, et ossifiait un peu le protocole (une fois QUIC déployé avec le spin bit, on ne peut plus le supprimer, sous peine de mettre en colère les middleboxes.)
Les informations accessibles dans la vue sont en pratique difficiles à changer puisque les boitiers intermédiaires vont s'habituer à compter dessus. Au moins, on pourrait les rendre explicites plutôt qu'implicites, et documenter clairement ces invariants, ces informations présentes dans la vue et que les concepteurs du protocole s'engagent à garder dans les évolutions futures. Typiquement, les invariants sont des données stables, et simples. Pour un protocole qui a la notion de version, et de négociation de version, cette négociation a intérêt à être déclarée invariante (RFC 8999 pour le cas de QUIC). Mais attention : une fois qu'on a figé certaines parties de la vue, en les déclarant invariantes, il ne faut pas s'imaginer que les équipements du réseau vont s'arrêter là : ils vont sans doute utiliser d'autres parties de la vue pour prendre leur décision, et ces autres parties risquent donc de devenir des invariants de fait. Le RFC recommande donc que toutes les parties qui ne sont pas explicitement listées comme invariantes soient chiffrées, pas pour la confidentialité, mais pour éviter qu'elles ne deviennent invariantes du fait de leur utilisation par les intermédiaires.
Enfin, le RFC rappelle que les équipements intermédiaires ne peuvent pas savoir ce que les deux parties qui communiquent ont décidé entre elles, et que la véracité de la vue depuis le réseau n'est jamais garantie.
L'article seul
Le logiciel Pleroma, pour communiquer sur le fédivers
Première rédaction de cet article le 25 avril 2019
Le fédivers (ou fediverse, ou fédiverse) est l'ensemble des systèmes qui communiquent sur l'Internet en échangeant des messages typiquement assez courts, dans une logique de microblogging et en utilisant en général le format Activity Streams et le protocole ActivityPub. Il existe plusieurs logiciels qui permettent de participer au fédivers, et cet article va parler de mon expérience avec Pleroma.
Mon résumé du fédivers vous a semble bien vague et bien nébuleux ? C'est normal, le fédivers n'a pas de définition claire. Beaucoup de gens le confondent avec Mastodon, qui n'est qu'un des logiciels permettant l'accès au fédivers. En pratique, il est vrai que « fédivers » est souvent défini de facto comme « tout ce qui peut échanger des messages avec Mastodon ».
Mon compte fédivers personnel, bortzmeyer@mastodon.gougere.fr,
est sur Mastodon, mais je pense qu'il est crucial d'avoir un
pluralisme des logiciels utilisés. Ce serait triste de fuir les
rézosocios centralisés des
GAFA pour retrouver un monopole dans le
logiciel, même si c'est un logiciel libre. Et puis, je voulais gérer ma
propre instance (ma propre machine connectée
au fédivers) et l'installation et l'administration de Mastodon me
faisaient un peu peur, surtout sur une petite machine. Donc, je me
suis tourné vers le logiciel des pauvres,
Pleroma.
Un mot d'abord pour les utilisateurs, et je parlerai des
administrateurs système par la suite. Si
vous voulez expérimenter avec Pleroma, il existe au moins une
instance publique en France, https://pleroma.fr/bortzmeyer@pleroma.fr,
même si je m'en sers peu). Contrairement à Mastodon, où le serveur
et l'interface utilisateur sont développés et distribués ensemble,
Pleroma sépare les deux. L'interface Web par défaut est nommée
Pleroma FE (FE pour FrontEnd) mais on peut en
utiliser d'autres, y compris celle de Mastodon (Mastodon FE). Bon,
mais on ne va parler que de Pleroma FE.
Contrairement à Mastodon FE, tous les pouètes sont sur une seule colonne, et on utilise les liens à gauche pour afficher les messages des gens qu'on suit, les messages qui nous mentionnent, les messages privées, ou bien tous les messages connus de l'instance.
Pour écrire, on tape son pouète (son message, son toot) dans la fenêtre (celle avec le choix par défaut « Just landed in L.A. », je n'ai pas encore trouvé comment le modifier…) Le protocole ActivityPub laisse plein de choses non décidées. Ainsi, il n'y a aucune règle sur la taille maximale des pouètes. Mastodon la limite à 500 caractères par défaut (mais l'administrateurice de l'instance peut le changer), Pleroma à 5 000 (également modifiable). Le format des pouètes n'est pas non plus normalisé et Pleroma permet (ce n'est pas activé par défaut) de mettre du gras, de l'italique… (Les utilisateurices les plus avancé·e·s noteront qu'on peut utiliser la syntaxe Markdown.)
Comme Pleroma est par défaut mono-colonne et Mastodon par défaut multi-colonnes, cela déroute parfois ceux et celles qui viennent de Mastodon. Quelques petites particularités de l'interface Pleroma FE, listées par lord :
- Sur n’importe quel pouète qui est une réponse, tu peux survoler une petite flèche en haut à gauche pour voir le pouète d’origine, sans ouvrir tout le fil.
- En parlant de fil, le petit signe plus permet d’afficher tout le fil tout en restant là où tu en étais dans ta colonne (ça insère le contenu à partir du pouète que tu as cliqué, donc une fois refermé, tu es de nouveau là où tu étais, tu ne perds pas le fil).
- Tu peux cliquer sur l'avatar d'un utilisateur pour faire apparaitre son profil sans changer la vue, juste en insérant le profil au milieu de la colonne.
- Tu peux mettre des signes distinctifs sur les gens ; par exemple, sur telle personne tu peux rajouter un liseré de la couleur que tu veux pour faire ressortir ses pouètes plus distinctement. (Je me suis amusé à mettre un fond rouge vif pour tous les gens de gauche que je suis.)
Autre avantage de Pleroma par rapport à Mastodon : le moteur de recherche cherche dans tous les messages, pas seulement ceux marqués avec un croisillon.
Outre l'instance https://pleroma.fr/https://pleroma.bortzmeyer.fr/priv/static/static/terms-of-service.html pour
indiquer les CGU.)
Le reste de cet article concerne plutôt les administrateurs système, qui voudraient installer une instance Pleroma sur leur machine.
Un des principaux intérêts de Pleroma par rapport à Mastodon est d'être très léger et de pouvoir tourner sur une petite machine. Dans mon cas, il s'agit d'un container LXC sur une Turris Omnia. J'ai installé Alpine Linux dessus, car c'est un système peu consommateur de ressources (et qui n'a pas systemd, chic).
Comme je n'ai qu'une seule adresse IPv4,
le container n'a pas d'adresse IPv4 publique. Donc, j'ai
configuré un relais sur la machine ayant
l'adresse publique. Ce relais utilise nginx
et sa configuration est celle proposée par Pleroma
(installation/pleroma.nginx dans les sources
de Pleroma), notamment :
server {
listen 443 ssl http2;
listen [::]:443 ssl http2;
ssl_certificate /var/lib/dehydrated/certs/pleroma.bortzmeyer.fr/fullchain.pem;
ssl_certificate_key /var/lib/dehydrated/certs/pleroma.bortzmeyer.fr/privkey.pem;
server_name pleroma.bortzmeyer.fr;
# Redirection vers le container qui porte Pleroma
location / {
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_set_header Host $http_host;
proxy_pass http://LE.CONTAINER.À.MOI:4000;
}
Cela a également l'avantage de permettre de gérer les certificats Let's Encrypt (ce que Pleroma ne sait pas faire seul).
Pleroma n'est apparemment distribué que sous forme de
code source. Il faut donc le compiler. Il
est écrit en Elixir et il faut donc un
compilateur Elixir (cf. mon
article à propos d'Elixir). Sur Alpine, Elixir est dans la section
community et pas
main. Il faut donc ajouter
l'URL de community à /etc/apk/repositories.
Ensuite, on télécharge les sources. Le site de référence est
https://git.pleroma.social/pleroma/pleroma
% git clone https://git.pleroma.social/pleroma/pleroma.git
Une fois que c'est fait, il n'y a plus qu'à suivre les instructions
d'installation. (Si vous vous demandez ce qu'est ce
mix, c'est l'outil de gestion de tâches
d'Elixir. Un peu comme
make pour C. Il
permet entre autres d'installer les
dépendances.)
% mix deps.get
% mix pleroma.instance gen
What domain will your instance use? (e.g pleroma.soykaf.com) [] pleroma.bortzmeyer.fr
What is the name of your instance? (e.g. Pleroma/Soykaf) [] Unsafe
What is your admin email address? [] stephane+pleroma@bortzmeyer.org
What is the hostname of your database? [localhost]
What is the name of your database? [pleroma_dev] pleroma
What is the user used to connect to your database? [pleroma]
What is the password used to connect to your database? [autogenerated]
Writing config to config/generated_config.exs. You should rename it to config/prod.secret.exs or config/dev.secret.exs.
Writing config/setup_db.psql.
To get started:
1. Verify the contents of the generated files.
2. Run `sudo -u postgres psql -f 'config/setup_db.psql'`.
3. Run `mv 'config/generated_config.exs' 'config/prod.secret.exs'`.
Arrivé à ce stade, le SGBD PostgreSQL doit être installé, et tourner, pour faire la suite.
% sudo -u postgres psql -f 'config/setup_db.psql'
% mv 'config/generated_config.exs' 'config/prod.secret.exs'
On peut alors lancer à la main Pleroma (le code va être compilé par mix) :
% mix phx.server
Et voilà, votre Pleroma tourne. Essayez de vous connecter sur
https://MON-INSTANCE/ pour voir. Si vous
n'avez pas fait proprement la redirection depuis le relais nginx,
vous aurez des choses bizarres, comme des boutons présents mais inactifs.
Pour activer Pleroma sur Alpine, avec OpenRC, on copie le script proposé,
installation/init.d/pleroma en
/etc/init.d/pleroma et on peut alors indiquer
que Pleroma doit être lancé au démarrage, avec rc-update
add pleroma. Si on veut le démarrer tout de suite,
c'est rc-service pleroma start.
Notez que Pleroma permet de gérer facilement deux
environnements, de production et de développement, en fonction de
la variable d'environnement
MIX_ENV. Comme je n'ai qu'un environnement,
j'ai défini MIX_ENV=prod dans mes fichiers de
configuration. Sinon, il faut y penser à chaque commande :
% MIX_ENV=prod mix phx.server
Bon, Pleroma est maintenant démarré. Créons un·e utilisateurice :
% mix pleroma.user new dominique dominique@example.net --password toto
Et voilà, dominique peut désormais se
connecter via l'interface Web, et envoyer des pensées profondes et
des photos de chats à tout le fédivers.
Vous trouvez que le mot de passe mis est vraiment trop nul ? Laissons l'utilisateur le changer mais on peut aussi l'aider :
% mix pleroma.user reset_password dominique
Où ai-je trouvé ces commandes ? Sur l'ancien
Wiki, plus mis à jour mais qui contient des informations que
je ne trouve pas facilement dans la
documentation officielle (Haelwenn me signale que toutes ces
tâches mix sont documentées
ici.) On peut aussi voir toutes les commandes avec
mix help pleroma.user. Et il y a bien sûr
l'examen du source
(lib/mix/tasks/pleroma/user.ex)… Maintenant
qu'ielle a un bon mot de passe, dominique peut être nommé·e
administrateurice :
% mix pleroma.user set dominique --admin
Ou bien « modérateurice » (censeur) :
% mix pleroma.user set dominique --moderator
Il n'y a pas à ma connaissance de page Web pour l'administrateur
d'une instance Pleroma. On édite le fichier de configuration
(config/prod.secret.exs, qui est du code
Elixir) et on
tape des commandes comme celles ci-dessus. Pour changer l'apparence
de son instance Pleroma, par exemple, on regarde cette
page. Pour contrôler le robots.txt,
voir
cette documentation.
Qu'est-ce que Pleroma va afficher lors de son exécution ? Cela se règle également dans le fichier de configuration :
config :logger, level: :info
(Si vous êtes curieu·x·se, le deux-points indique un atome Elixir.) Et si on veut tous les détails (vraiment tous) :
config :logger, level: :debug
Un des intérêts d'avoir sa propre instance, est qu'on peut fouiller dans la base de données, au-delà de ce que permet l'interface, ce qui est pratique, les capacités de recherche de pouètes de Mastodon et de Pleroma étant limitées. On se connecte à la base PostgreSQL :
% sudo -u postgres psql pleroma
Et on peut alors taper les requêtes SQL de son choix (ici, émetteur et date d'arrivée du message) :
pleroma=# SELECT actor,inserted_at FROM activities ORDER BY inserted_at DESC LIMIT 10;
actor | inserted_at
----------------------------------------------+---------------------
https://hostux.social/users/R1Rail | 2019-04-24 15:30:38
https://hostux.social/users/R1Rail | 2019-04-24 15:27:30
https://mastodon.gougere.fr/users/bortzmeyer | 2019-04-24 15:25:02
https://hostux.social/users/R1Rail | 2019-04-24 15:25:02
https://mastodon.social/users/jpmens | 2019-04-24 15:21:20
https://mamot.fr/users/Shaft | 2019-04-24 15:21:20
https://mastodon.host/users/federationbot | 2019-04-24 15:18:58
https://mastodon.host/users/federationbot | 2019-04-24 15:18:12
https://misskey.io/users/7rmk7gm7ew | 2019-04-24 15:18:12
https://mastodon.host/users/federationbot | 2019-04-24 15:16:55
(10 rows)
Et si on veut tout le contenu en Activity Streams du pouète (ici, je restreins aux messages que j'ai envoyé) :
pleroma=# SELECT actor,inserted_at,data FROM activities WHERE actor LIKE 'https://pleroma.bortzmeyer.fr/%' ORDER BY inserted_at DESC LIMIT 10;
https://pleroma.bortzmeyer.fr/users/stephane | 2019-04-24 10:04:20 | {"cc": ["https://pleroma.bortzmeyer.fr/users/stephane/followers"], "id": "https://pleroma.bortzmeyer.fr/activities/586a3505-d8e7-4bb9-958c-18c18e098e7b", "to": ["https://www.w3.org/ns/activitystreams#Public"], "type": "Create", "actor": "https://pleroma.bortzmeyer.fr/users/stephane", "object": {"cc": ["https://pleroma.bortzmeyer.fr/users/stephane/followers"], "id": "https://pleroma.bortzmeyer.fr/objects/207538f4-759d-4126-bb0a-a41fcbe60129", "to": ["https://www.w3.org/ns/activitystreams#Public"], "tag": ["pleroma"], "type": "Note", "actor": "https://pleroma.bortzmeyer.fr/users/stephane", "emoji": {}, "content": "As an user, I can change the <a class='hashtag' data-tag='pleroma' href='https://pleroma.bortzmeyer.fr/tag/pleroma' rel='tag'>#Pleroma</a> theme at will but changing the default theme in the secret.exs file seems ignored. Why?", "context": "https://pleroma.bortzmeyer.fr/contexts/cd07dc37-4472-4e87-b157-90df23a00e8e", "summary": null, "published": "2019-04-24T10:04:20.185186Z", "attachment": [], "context_id": 174350, "announcements": ["https://mastodon.gougere.fr/users/bortzmeyer", "https://pleroma.fr/users/bortzmeyer"], "announcement_count": 2}, "context": "https://pleroma.bortzmeyer.fr/contexts/cd07dc37-4472-4e87-b157-90df23a00e8e", "published": "2019-04-24T10:04:20.177118Z", "context_id": 174350, "directMessage": false}
...
La colonne data contient l'objet
Activity Streams, en JSON.
J'ai indiqué que j'utilisais la version de développement de
Pleroma. Il y a donc du nouveau régulièrement et, après un
git pull, il faut penser à charger les
dépendances nouvelles :
% mix deps.get
Si le schéma de la base de données a changé, il faut également mettre à jour votre base :
% mix ecto.migrate
(Ecto est l'interface aux bases de données utilisé par Elixir.) Si vous avez un doute sur la nécessité de ces deux commandes, n'hésitez pas, lancez-les, elles sont inoffensives si le travail est déjà fait. Vous trouverez davantage d'informations sur la mise à jour de votre instance sur l'ancien Wiki (pas encore trouvé où c'était sur la documentation officielle).
Et si je veux hacker Pleroma sérieusement ? Voyez ce bon article, avec explications sur Elixir, Ecto, Mix, etc. Au passage, vous devrez apprendre Elixir donc les documentations sont là (dont une pour débutants.) Sinon, il y a le livre de Dave Thomas. Si vous trouvez des bogues dans Pleroma, signalez-les.
Enfin, pour finir, quelques articles et informations sur l'administration d'un serveur Pleroma :
- Un article d'introduction à Pleroma, plutôt pour les utilisateurs. C'est une traduction de l'article du développeur principal.
- On peut avoir de l'aide sur le canal
#pleromadu réseau IRC Freenode. - Ou bien en utilisant une pièce
Matrix,
https://matrix.heldscal.la/#/room/#freenode_#pleroma:matrix.org - Je n'ai pas trouvé d'instance Pleroma dédiée à
l'administration ou au développement de Pleroma, ni de
mot-croisillon spécifique (à part bien sûr
#Pleroma). - L·a·e développeu·se·r principal·e de Pleroma est bien sûr joignable
sur le fédivers :
lain@pleroma.soykaf.com(mais, comme vous vous en doutez, ielle est assez occupé·e). - Il y a la documentation officielle.
- On trouve des choses utiles sur l'ancien Wiki.
- Installation sur une Debian, avec nginx en frontal. Également dans la documentation officielle.
- Installation pour Alpine. Également dans la documentation officielle.
- If you read english and want to run Pleroma in a FreeBSD jail instead of a container, see Jacques' article.
L'article seul
RFC 8553: DNS Attrleaf Changes: Fixing Specifications That Use Underscored Node Names
Date de publication du RFC : Mars 2019
Auteur(s) du RFC : D. Crocker (Brandenburg InternetWorking)
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 19 avril 2019
Autrefois, de nombreux services et protocoles Internet avaient
« réservé » de manière informelle, et sans enregistrement de cette
réservation, des noms préfixés par un tiret
bas, comme _submission._tcp.example.net (cf. RFC 6186 pour cet exemple). Comme le RFC 8552 a mis fin à cette activité en créant un
registre officiel des noms préfixés, il fallait réviser les normes
existantes pour s'aligner sur les nouvelles règles. C'est le but
de ce RFC 8553 qui modifie pas moins de trente-trois
RFC !
Dans le nouveau registre, les
entrées sont indexées par un couple {type d'enregistrement DNS,
nom}. Par exemple, {TXT, _dmarc} pour
DMARC (RFC 9989).
Les enregistrements SRV (RFC 2782) et URI (RFC 7553) posent un problème supplémentaire puisqu'ils utilisent un autre registre de noms, celui des noms de protocoles et services (dit aussi registre des numéros de ports) décrit dans le RFC 6335.
La section 2 du RFC décrit les usages actuels des noms préfixés par le tiret bas. Les enregistrements de type TXT, par exemple, sont utilisés dans sept RFC différents, comme le RFC 5518. Et les SRV dans bien davantage.
Enfin la section 3 du RFC contient le texte des changements qui est fait aux différentes spécifications utilisant les noms préfixés. (Il s'agit essentiellement de faire référence au nouveau registre du RFC 8552, il n'y a pas de changement technique.)
L'article seul
RFC 8552: Scoped Interpretation of DNS Resource Records through "Underscored" Naming of Attribute Leaves
Date de publication du RFC : Mars 2019
Auteur(s) du RFC : D. Crocker (Brandenburg InternetWorking)
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 19 avril 2019
Une convention répandue pour les noms de domaine est de préfixer les services
par un tiret bas, par exemple
_xmpp-client._tcp.jabber.ietf.org. Cette
pratique n'avait jamais été documentée mais c'est désormais
fait. Et il existe désormais un registre
IANA des noms ainsi préfixés.
Bien sûr, on peut mettre des ressources sous n'importe quel
nom. Le DNS
n'impose aucune restriction pour cela, et vous pouvez décider que
le service X sera sous le nom $X%.example.com
(si vous ne me croyez pas, relisez le RFC 1035 et RFC 2181). Mais les
humains aiment les conventions, par exemple pour les machines,
comme www comme préfixe d'un serveur
Web (préfixe
d'ailleurs contesté, souvent
pour de mauvaises
raisons) ou
mail pour un serveur de messagerie. Ce ne sont
que des conventions, le DNS s'en moque, et on peut mettre un
serveur Web en mail.example.com si on veut,
cela ne perturbera que les humains. D'autant plus qu'on peut
utiliser n'importe quel type de données avec n'importe quel nom
(par exemple un enregistrement MX pour
www.example.org).
La convention du tiret bas initial est répandue, notamment parce qu'elle évite toute confusion avec les noms de machines, qui ne peuvent pas comporter ce caractère (RFC 952). Elle est donc très commune en pratique. Cette convention permet de restreindre explicitement une partie de l'arbre des noms de domaine pour certains usages. Comme ce RFC ne fait que documenter une convention, il ne nécessite aucun changement dans les logiciels.
Une
alternative au tiret bas serait d'utiliser un type de données
spécifique. Quant aux types « généralistes » comme
TXT, ils ont l'inconvénient qu'on récupère,
lors de la résolution DNS, des informations inutiles, par exemple
les TXT des autres services. Bref, vous créez un nouveau service,
mettons X, vous avez le choix, pour le cas du domaine parent
example.org, entre :
- Un nouveau type d'enregistrements DNS, nommons-le par exemple
TYPEX(en pratique, c'est long et compliqué, et sans déploiement garanti, cf. RFC 5507), - Un type d'enregistrement générique comme TXT cité plus haut ou bien le URI du RFC 7553, menant à des ensembles d'enregistrements (RRset) potentiellement assez gros, problème détaillé en section 1.2,
- Une convention de nommage comme
x.example.org, - Une convention de nommage avec un tiret bas
(
_x.example.org), l'objet de ce RFC 8552.
Un exemple d'un service réel utilisant la convention avec le tiret
bas est DKIM (RFC 6376), avec le préfixe _domainkey :
% dig +short TXT mail._domainkey.gendarmerie.interieur.gouv.fr
"v=DKIM1; k=rsa; t=y; p=MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQDIgwhYZeeZgM94IofX9uaGAwQ+tynFX7rYs/igs+d1afqrrjMaoKay11IMprRyqhcVurQtJwGfk7PAWrXRjB+KpdySH9lqzvbisB3GrSs1Sf4uWscAbZ+saapw3/QD8YFyfYbsXunc6HROJQuQHM+U56OOcoiAiPHpfepAmuQyFQIDAQAB"
Comme beaucoup de choses, la convention « tiret bas » s'entend
mal avec les jokers du DNS. D'abord, on ne peut pas utiliser les
jokers entre le préfixe et le reste du nom
(_x.*.example.net ne marche pas), ensuite, un
joker couvre également les noms avec tiret bas donc
*.example.net va répondre positivement pour
_x.example.net même si on ne le voulait
pas.
La section 1.5 de notre RFC détaille l'histoire de la convention « tiret bas au début ». Beaucoup de services utilisaient cette convention mais sans coordination, et sans qu'il existe une liste complète. Du fait de l'existence de plusieurs choix possibles (énumérés plus haut), ce RFC n'a pas obtenu de consensus immédiatement et les débats ont été longs et compliqués.
La section 2 du RFC explique comment remplir le nouveau
registre des noms à tiret bas. On ne met dans ce registre que le
nom le plus proche de la racine du DNS. Si un service mène à des
noms comme _foo._bar.example.org, seul le
_bar sera mis dans le registre. C'est
particulièrement important pour le cas des
enregistrements SRV qui ont souvent deux niveaux de
noms préfixés (par exemple _sip._tcp.cisco.com). Seul
le nom le plus proche de la racine, ici _tcp,
est enregistré (ici, _sip est quand même
enregistré car il peut en théorie être utilisé sans le
_tcp mais il me semble que c'est rare en pratique).
Les règles
pour les noms plus spécifiques sous le _bar
(ou _tcp)
sont spécifiées lors de la description du service en question. Par
exemple, pour DKIM, le RFC 6376 précise que que sous le nom
_domainkey, on trouve un sélecteur dont
l'identificateur apparait dans le courrier signé. Donc, pour un
message envoyé avec s=mail et
d=gendarmerie.interieur.gouv.fr, on cherche
les informations DKIM en mail._domainkey.gendarmerie.interieur.gouv.fr.
Le formulaire pour demander l'enregistrement d'un nouveau nom préfixé par un tiret bas figure en section 3 du RFC. Il faut indiquer le type de données DNS (un enregistrement n'est valable que pour un certain type, donc la clé du registre est un couple {type, nom}), le nom et la référence du document décrivant le service en question. Le registre est décrit en section 4 du RFC. L'ajout dans ce registre se fait selon la politique « examen par un expert » (RFC 8126, section 4.5). La section 5 de notre RFC donne quelques indications à l'IANA sur cet examen.
Un ensemble d'entrées à ajouter pour initialiser ce nouveau
registre est indiqué. On y trouve par exemple {TXT,
_domainkey} pour DKIM, {TLSA,
_tcp} pour DANE (RFC 6698), {TXT,
_acme-challenge} pour
ACME (RFC 8555),
etc. Deux cas particuliers : le nom _example
est réservé pour tous les types d'enregistrement, lorsqu'on a
besoin de donner un exemple, sans spécifier un cas réel, et le nom
_ta, qui sert au mécanisme de signalement des
clés DNSSEC du RFC 8145, désigne en fait tous les noms commençant par _ta.
L'article seul
Cours HTTP au CNAM
Première rédaction de cet article le 18 avril 2019
Dernière mise à jour le 21 avril 2022
Le 17 avril 2019, c'était la première édition de mon cours HTTP de deux heures au CNAM. Pour l'anecdote, c'était dans le bâtiment où il y avait eu l'un des premiers serveurs HTTP publics en France.
Voici les supports de l'exposé :
- Version adaptée à l'écran,
- Version adaptée à l'impression,
- Source LaTeX.
Tout a été filmé et la vidéo est disponible (mais, attention, c'est une version du cours plus ancienne, avant HTTP/3) :
- Sur PeerTube, voyez ici,
- Et ici au CNAM.
Merci à Éric Gressier pour l'idée et l'organisation, et aux élèves pour avoir posé plein de questions pas toujours faciles.
L'article seul
RFC 8574: cite-as: A Link Relation to Convey a Preferred URI for Referencing
Date de publication du RFC : Avril 2019
Auteur(s) du RFC : H. Van de Sompel (Data Archiving and Networked Services), M. Nelson (Old Dominion University), G. Bilder (Crossref), J. Kunze (California Digital Library), S. Warner (Cornell University)
Pour information
Première rédaction de cet article le 18 avril 2019
Ce RFC décrit un nouveau type de liens hypertexte permettant d'indiquer l'URI sous lequel on préfère qu'une ressource soit accédée, à des fins de documentation ou de citation précise.
Imaginons que vous accédez à un article scientifique en ligne. Vous utilisez un URI qui identifie cet article. Vous voulez ensuite citer cet article dans un de vos textes. Allez-vous utiliser l'URI d'accès ? Ce n'est pas forcément le meilleur, par exemple ce n'est pas forcément le plus stable sur le long terme. Le lien « cite avec » permet au serveur d'indiquer l'URI le plus pertinent pour une citation.
Ce RFC s'appuie sur la formalisation du concept de lien faite dans le RFC 8288. « Contexte » et « cible » sont donc utilisés comme dans cette norme, le contexte d'un lien étant le point de départ et la cible l'arrivée. En prime, notre RFC 8574 définit deux termes, l'URI d'accès, celui utilisé pour accéder à une ressource (par exemple une page Web) et l'URI de référence, celui qu'il faudrait utiliser pour la citation.
La section 3 du RFC décrit quelques scénarios d'usage. Le premier est celui des identificateurs stables. Normalement, lorsque le ou la webmestre est compétent(e) et sérieux(se), les URI sont stables, comme précisé dans l'article « Cool URIs don't change. Mais, en pratique, beaucoup de webmestres sont incompétents ou paresseux. Cela a mené à des « solutions » fondées sur la redirection, où il apparait une différence entre URI d'accès et URI de référence. C'est le cas avec des techniques comme les DOI (« use the Crossref DOI URL as the permanent [reference] link »), PURL ou ARK. Dans les trois cas, au lieu de gérer proprement les URI, on utilise un redirecteur supposé plus stable (alors que rien ne le garantit) et on souhaite utiliser comme URI de référence l'URI du redirecteur (donnant ainsi des pouvoirs démesurés à des organisations privées comme l'IDF, qui matraque régulièrement l'importance de n'utiliser que leurs identificateurs).
Un autre scénario d'usage est celui des ressources
versionnées. C'est par exemple le cas de Wikipédia. La page Wikipédia sur
l'incendie de Notre-Dame de Paris change souvent en ce
moment. Comme toutes les pages Wikipédia, chaque version à un
identificateur, et on peut se référer à une version
particulier. Si https://fr.wikipedia.org/wiki/Incendie_de_Notre-Dame_de_Parishttps://fr.wikipedia.org/w/index.php?title=Incendie_de_Notre-Dame_de_Paris&oldid=158468007https://fr.wikipedia.org/w/index.php?title=Incendie_de_Notre-Dame_de_Paris&oldid=158478416
Souvent, quand on veut citer un article de Wikipédia, on veut se mettre à l'abri de changements ultérieurs, pas forcément positifs, et on souhaite donc citer exactement une version particulière. On clique donc sur « Lien permanent » (ou bien « Voir l'historique » puis sur la date la plus récente) pour avoir l'URI de la version qu'on vient de regarder. (Notez aussi le très utile lien « Citer cette page ».)
Troisième cas d'usage cité, celui des identifiants sur les
réseaux sociaux. M. Toutlemonde a
typiquement plusieurs pages le décrivant sur ces réseaux (dans mon
cas, https://mastodon.gougere.fr/@bortzmeyerhttps://twitter.com/bortzmeyerhttps://www.linkedin.com/in/sbortzmeyer/https://seenthis.net/people/stephane
Enfin, un dernier cas d'usage est celui d'une publication composée de plusieurs ressources (par exemple un livre où chaque chapitre est accessible séparement, avec son propre URI). On souhaite alors que l'accès à chaque ressource indique, à des fins de citation, l'URI de référence (par exemple la page d'accueil).
La section 4 du RFC présente la solution : un nouveau type de
lien, cite-as, qui permet de dire quel est
l'URI de référence. (Le RFC recommande d'ailleurs que cet URI soit
un URL : le but est d'accéder à la
ressource !) Il est évidemment recommandé qu'il n'y ait qu'un seul
lien de type cite-as. Ce lien n'interdit pas
d'utiliser d'autres URI, il indique seulement quel est l'URI
que le webmestre souhaite voir utilisé dans les références
webographiques. cite-as est désormais dans
le
registre IANA des types de liens.
La section 6 du RFC donne des exemples concrets, puisque les
liens peuvent se représenter de plusieurs façons. Par exemple,
l'article de PLOS One auquel vous accédez en https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0171057rel="cite-as" :
<link rel="cite-as"
href="https://doi.org/10.1371/journal.pone.0171057" />
Cela indiquerait que les auteurs préfèrent être cités par le DOI (une mauvaise idée, mais c'est une autre histoire).
Autre exemple de syntaxe concrète pour les liens, imaginé pour
arXiv, pour des
articles avec versionnement, un lien dans un en-tête
HTTP pour https://arxiv.org/abs/1711.03787
HTTP/1.1 200 OK
Date: Sun, 24 Dec 2017 16:12:43 GMT
Content-Type: text/html; charset=utf-8
Link: <https://arxiv.org/abs/1711.03787v1> ; rel="cite-as"
Comme arXiv garde les différentes versions successives d'un article, cela permettrait de récupérer la version actuelle tout en sachant comment la référencer.
Revenons au HTML pour l'exemple des profils sur les réseaux sociaux, imaginons un utilisateur, John Doe, qui place dans le code HTML de sa page personnelle un lien vers son profil FOAF en Turtle :
<html>
<head>
...
<link rel="cite-as" href="http://johndoe.example.com/foaf"
type="text/turtle"/>
...
</head>
<body>
...
Et un dernier exemple, celui d'une publication composée de
plusieurs ressources. Ici, l'exemple est Dryad une base de données scientifiques qui
permet l'accès à des fichiers individuels, mais où chaque jeu de données a un
identificateur canonique. En HTTP, cela donnerait, lorsqu'on accès
à https://datadryad.org/bitstream/handle/10255/dryad.98509/PIPFIL_M_BCI.csv
HTTP/1.1 200 OK
Date: Tue, 12 Jun 2018 19:19:22 GMT
Last-Modified: Wed, 17 Feb 2016 18:37:02 GMT
Content-Type: text/csv;charset=ISO-8859-1
Link: <https://doi.org/10.5061/dryad.5d23f> ; rel="cite-as"
Le fichier CSV est membre d'un jeu de données plus général, dont
l'URI de référence est https://doi.org/10.5061/dryad.5d23f
Ainsi, dans un monde idéal, un logiciel qui reçoit un lien
cite-as pourrait :
- Lorsqu'il garde un signet, utiliser l'URI de référence,
- Identifier plusieurs URI d'accès comme ayant le même URI de référence, par exemple à des fins de comptage,
- Indexer les ressources par plusieurs URI.
D'autres solutions avaient été proposées pour résoudre ce
problème de l'URI de référence. La section 5 de notre RFC les
énumère. Il y avait notamment cinq autres types de liens qui
auraient peut-être pu convenir, alternate,
duplicate, related, bookmark et
canonical.
Les trois premiers sont vite
éliminés. alternate (RFC 4287) décrit une autre représentation de la même
ressource (par exemple la même vidéo mais encodée
différemment). duplicate (RFC 6249) désigne une reproduction identique (et cela ne
traite donc pas, par exemple, le cas d'une publication composée de
plusieurs ressources). Quant à related (RFC 4287), sa
sémantique est bien trop vague. Un article des auteurs du RFC
décrit
en détail les choix de conceptions et explique bien le
problème. (Je trouve cet article un peu gâché par les affirmations
sans preuves comme quoi les DOI seraient « permanents ». Si le
registre disparait ou fait n'importe quoi, il y aura le même
problème avec les DOI qu'avec n'importe quelle autre famille d'identificateurs.)
Le cas de bookmark (normalisé par le W3C) est plus
compliqué. Il est certainement proche en sémantique de
cite-as mais ne peut pas être présent dans
les en-têtes HTTP ou dans la tête d'une page HTML, ce qui en réduit
beaucoup l'intérêt. Le cas compliqué de
bookmark est décrit dans
un autre article des auteurs du RFC.
Enfin, le cas de canonical (RFC 6596). Ce dernier semble trop restreint
d'usage pour les utilisations prévues pour
cite-as. Et il n'a pas vraiment la même
sémantique. Par exemple, pour les ressources versionnées,
canonical indique la plus récente, exactement
le contraire de ce qu'on voudrait avec
cite-as. Et c'est bien ainsi que l'utilise
Wikipédia. Si je récupère https://fr.wikipedia.org/w/index.php?title=Incendie_de_Notre-Dame_de_Paris&oldid=158478416
<link rel="canonical" href="https://fr.wikipedia.org/wiki/Incendie_de_Notre-Dame_de_Paris"/>
On voit que canonical renvoie à la dernière
version. Le cas de canonical fait lui aussi
l'objet
d'un article détaillé.
Je n'ai pas mis de tels liens sur ce blog, ne voyant pas de cas où ils seraient utiles.
L'article seul
RFC 8509: A Root Key Trust Anchor Sentinel for DNSSEC
Date de publication du RFC : Décembre 2018
Auteur(s) du RFC : G. Huston, J. Damas (APNIC), W. Kumari (Google)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 14 avril 2019
On le sait, le premier changement de la clé DNSSEC de la racine du DNS s'est déroulé sans encombre le 11 octobre dernier. Ce qu'on sait moins est que ce changement a été précédé par des nombreuses études, pour tenter de prévoir les conséquences du changement. Une question importante était « combien de résolveurs DNS n'ont pas vu la nouvelle clé, depuis sa publication, et vont donc avoir des problèmes lorsque l'ancienne sera retirée du service ? » Ce RFC décrit une des techniques qui avaient été développées pour répondre à cette question, technique qui continuera à être utile pour les discussions actuellement en cours sur une éventuelle systématisation et accélération du rythme des changements de clé.
La question de cette systématisation a fait par exemple l'objet
d'un débat à la dernière réunion IETF à
Prague le 28
mars. L'idée est de voir si on peut passer de changements
exceptionnels et rares à des changements réguliers,
banalisés. Pour cela, il faut avoir une idée de ce que voient les
résolveurs DNS,
du moins ceux qui valident avec DNSSEC, technique dont
l'importance avait encore été démontré par les attaques récentes. Mais comment
savoir ce que voient les résolveurs et, notamment, quelle(s)
clé(s) de départ de la validation (trust
anchor) ils utilisent ? La solution de la
sentinelle, spécifiée dans ce nouveau
RFC, peut
permettre de répondre à cette question. L'idée est que les
résolveurs reconnaitront une requête « spéciale », dont le nom
commence par root-key-sentinel-is-ta ou
root-key-sentinel-not-ta, nom qui sera suivi
de l'identificateur (key tag) de la clé (ta =
Trust Anchor). La réponse du résolveur dépendra
de s'il utilise cette clé ou pas comme point de départ de la
validation. Un logiciel client pourra alors tester si son
résolveur a bien vu le changement de clé en cours, et est
prêt. L'utilisateur peut alors savoir si ce résolveur fonctionnera
lors du changement. (Cela peut aussi aider
l'administrateurice système mais celui-ci
ou celle-là a d'autres moyens pour cela, comme d'afficher le
fichier contenant la clé de départ de la validation. Par contre,
les sentinelles sont utiles pour les chercheurs qui récoltent des
données automatiquement, comme dans l'article de Huston cité à la
fin.)
Ce mécanisme de sentinelle est complémentaire de celui du RFC 8145, où le résolveur signale aux serveurs faisant autorité les clés qu'il utilise comme trust anchor. Ici, la cible est le client du résolveur, pas les serveurs faisant autorité que contacte le résolveur. Ce mécanisme de sentinelle permet à tout utilisateur de savoir facilement la(es) clé(s) utilisée(s) par son résolveur DNS.
Petit rappel sur DNSSEC d'abord : comme le DNS, DNSSEC est arborescent. La validation part en général de la racine, et, via les enregistrements DS, arrive à la zone qu'on veut valider. Les clés sont identifiées par un key tag qui est un condensat de la clé. La clé qui est le point de départ de la validation se nomme le trust anchor et est stockée par le résolveur. Si on a la mauvaise clé, la validation échouera. Le trust anchor est géré manuellement par l'administrateur système en charge du résolveur, ou peut être mise à jour automatiquement en suivant la technique du RFC 5011. Aujourd'hui, le résolveur sur la machine où j'écris cet article utilise la trust anchor ayant le key tag 20326, la clé publique de la racine IANA (le résolveur est un Unbound) :
% cat /var/lib/unbound/root.key
...
. 172800 IN DNSKEY 257 3 8 AwEAAaz/tAm8y...1AkUTV74bU= ;{id = 20326 (ksk), size = 2048b} ;;state=2 [ VALID ] ;;count=0 ;;lastchange=1502474052 ;;Fri Aug 11 19:54:12 2017
Le id = 20326 indique l'identificateur de la
clé.
La section 2 expose le cœur du RFC. Un résolveur DNS, validant
avec DNSSEC (RFC 4035) et qui met en œuvre
ce RFC, doit reconnaitre comme spéciaux, les noms de domaine
demandés qui commencent
par root-key-sentinel-is-ta-NNNNN et
root-key-sentinel-not-ta-NNNNN où NNNNN est
un identificateur de clé. Voyons un exemple avec un domaine de
test, dans lequel on trouve
root-key-sentinel-is-ta-20326.ksk-test.net
et
root-key-sentinel-not-ta-20326.ksk-test.net
(20326 est l'identificateur de la clé actuelle de la racine). Tout
résolveur validant qui utilise la clé 20326 va pouvoir récupérer
et valider le premier nom :
% dig root-key-sentinel-is-ta-20326.ksk-test.net
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 23817
;; flags: qr rd ra ad; QUERY: 1, ANSWER: 2, AUTHORITY: 3, ADDITIONAL: 1
...
;; ANSWER SECTION:
root-key-sentinel-is-ta-20326.ksk-test.net. 30 IN A 204.194.23.4
Ici, le ad dans les résultats indique que
l'enregistrement a bien été validé (AD = Authentic
Data). Si le résolveur ne valide pas, on n'aura
évidemment pas le ad. Maintenant, que se
passe-t-il avec le second nom, celui avec
not-ta ? Un résolveur validant, mais qui ne
met pas en œuvre notre RFC 8509 va récupérer et valider
ce nom :
% dig root-key-sentinel-not-ta-20326.ksk-test.net
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 20409
;; flags: qr rd ra ad; QUERY: 1, ANSWER: 2, AUTHORITY: 3, ADDITIONAL: 1
...
;; ANSWER SECTION:
root-key-sentinel-not-ta-20326.ksk-test.net. 30 IN A 204.194.23.4
En revanche, un résolveur validant et qui met en œuvre ce RFC 8509 (ici, le résolveur Knot) va renvoyer un SERVFAIL (Server Failure) :
% dig root-key-sentinel-not-ta-20326.ksk-test.net
...
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 37396
;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 0
On voit comment on peut utiliser le mécanisme de ce RFC pour découvrir si le résolveur utilise ou pas la clé 20326. Avec un client DNS, et une zone qui dispose des sentinelles :
- Si on peut récupérer
root-key-sentinel-not-ta-20326et qu'on n'a pas le bitad, c'est que le résolveur ne valide pas, - Si on peut récupérer et valider
root-key-sentinel-not-ta-20326, c'est que le résolveur valide mais ne gère pas le mécanisme des sentinelles, - Si on peut récupérer et valider
root-key-sentinel-is-ta-20326mais pasroot-key-sentinel-not-ta-20326, c'est que le résolveur valide, gère le mécanisme des sentinelles, et utilise la clé 20326, - Si on peut récupérer et valider
root-key-sentinel-not-ta-20326mais pasroot-key-sentinel-is-ta-20326, c'est que le résolveur valide, gère le mécanisme des sentinelles, et n'utilise pas la clé 20326. (Ce test ne marche pas forcément, cela dépend de comment est configurée la zone de test.)
L'annexe A de notre RFC détaille comment on utilise le mécanisme de sentinelle.
La beauté du mécanisme est qu'on peut l'utiliser sans client
DNS, depuis une page Web. On crée une page qui essaie de charger
trois images, une depuis invalid.ZONEDETEST
(enregistrement mal signé), une depuis
root-key-sentinel-is-ta-20326.ZONEDETEST et une depuis
root-key-sentinel-not-ta-20326.ZONEDETEST. On teste en
JavaScript si les images se sont chargées :
- Si toutes se chargent, c'est que le résolveur de l'utilisateur ne valide pas,
- Si la première (
invalid) ne charge pas mais que les deux autres chargent, c'est que le résolveur ne connait pas les sentinelles, on ne peut donc pas savoir quelle(s) clé(s) il utilise, - Si la première (
invalid) et la troisième (root-key-sentinel-not-ta-20326) ne se chargent pas mais que la deuxième (root-key-sentinel-is-ta-20326) se charge, c'est que le résolveur connait les sentinelles, et utilise la clé 20326. - Si la première (
invalid) et la deuxième (root-key-sentinel-is-ta-20326) ne se chargent pas mais que la troisième (root-key-sentinel-not-ta-20326) se charge, c'est que le résolveur connait les sentinelles, et n'utilise pas la clé 20326. Soit il utilise une autre racine que celle de l'ICANN, soit il a gardé une ancienne clé et aura des problèmes lors du remplacement.
Notez que le choix des préfixes avait été chaudement discuté à
l'IETF. À un moment, l'accord s'était fait
sur les préfixes _is-ta
ou _not-ta, le tiret
bas convenant bien à ces noms spéciaux. Mais comme ce
même tiret bas rendait ces noms ilégaux comme noms de machine, cela rendait
difficile certains tests. Autant _is-ta
ou _not-ta étaient utilisables depuis
dig, autant on ne pouvait pas les tester
depuis un navigateur Web, ce qui rendait
difficile des tests semi-automatisés, sous formes d'images qu'on
charge depuis une page Web et de JavaScript
qui regarde le résultat. D'où les noms root-key-sentinel-is-ta-NNNNN et
root-key-sentinel-not-ta-NNNNN. Ce n'est pas
une solution satisfaisante que de prendre des noms ne commençant
pas par un tiret bas, mais cela a semblé le meilleur compromis
possible. Le nom est suffisamment long et alambiqué pour que le
risque de collisions avec des noms existants soit faible.
Donc, que doit faire le résolveur quand on l'interroge pour un
nom commençant par root-key-sentinel-is-ta-NNNNN ou
root-key-sentinel-not-ta-NNNNN ? Si et
seulement si le type demandé est A (adresse IPv4) ou AAAA (adresse
IPv6), et que la réponse est validée par DNSSEC, le résolveur doit
extraire le key tag du nom et déterminer s'il
corresponde à une des clés de départ de la validation pour la
racine. (Les serveurs faisant autorité, eux, n'ont rien de
particulier à faire, ils fonctionnent comme aujourd'hui.)
- Si le nom demandé commençait par
root-key-sentinel-is-taet que l'identificateur de clé est celui d'une trust anchor, alors on renvoie la réponse originale, - Si le nom demandé commençait par
root-key-sentinel-is-taet que l'identificateur n'est pas celui d'une trust anchor, alors on renvoie le code d'erreur SERVFAIL, - Si le nom demandé commençait par
root-key-sentinel-not-taet que l'identificateur est celui d'une trust anchor, alors on renvoie le code d'erreur SERVFAIL, - Si le nom demandé commençait par
root-key-sentinel-not-taet que l'identificateur n'est pas celui d'une trust anchor, alors on renvoie la réponse originale.
Le principe est simple, les sections suivantes du RFC décrivent comment déduire
l'état du résolveur avec ce principe. Par exemple, la section 3
décrit le cas où on n'a qu'un seul résolveur. Si on veut connaitre
la situation de la clé 12345, et que les noms nécessaires sont
présents dans le domaine xxx.example, que le domaine broken.xxx.example est
cassé, question DNSSEC, on cherche à résoudre les
noms root-key-sentinel-is-ta-12345.xxx.example,
root-key-sentinel-not-ta-12345.xxx.example et
broken.xxx.example. Pour un résolveur validant, et
qui met en œuvre ce RFC, seule la première requête doit
réussir. Si la troisième réussit, c'est que le résolveur ne valide
pas. Si la deuxième réussit, c'est qu'il ne connait pas le système
sentinelle de notre RFC 8509. (L'algorithme détaillé est
dans la section 3 du RFC, il y a quelques cas vicieux.)
Notez bien qu'on n'a pas besoin d'un client DNS complet pour ces tests. Une résolution de nom en adresse normale suffit, ce qui permet de faire ces tests depuis un navigateur Web, ce qui était bien le but. Par exemple en HTML :
<ul>
<li><a href="http://invalid.ksk-test.net/invalid.gif">"http://invalid.ksk-test.net/invalid.gif"</a></li>
<li><a href="http://root-key-sentinel-is-ta-20326.ksk-test.net/is-ta.gif">"http://root-key-sentinel-is-ta-20326.ksk-test.net/is-ta.gif"</a></li>
<li><a href="http://root-key-sentinel-not-ta-20326.ksk-test.net/not-ta.gif">"http://root-key-sentinel-not-ta-20326.ksk-test.net/not-ta.gif"</a></li>
</ul>
Et avec du JavaScript pour vérifier :
if (img_invalid.height === 0) {invalid = false;}
if (img_is_ta.height === 0) {is_ta = false;}
if (img_not_ta.height === 0) {not_ta = false;}
switch (true) {
case invalid === true:
result="You are not DNSSEC validating, and so will be fine!";
break;
case (is_ta === true && not_ta === true):
result="You are using a legacy resolver (or updated resolvers, with some new and some old), we cannot determine your fate!";
break;
case (not_ta === true):
result="WARNING!: Your resolvers do not have the new KSK. Your Internet access will break!";
break;
case (is_ta === true):
result="Congratulations, you have the new key. You will be fine.";
break;
}
Si la machine a plusieurs résolveurs, le cas est plus compliqué par la bibliothèque qui fait la résolution de noms va typiquement passer au résolveur suivant en cas de réponse SERVFAIL. La section 4 décrit un algorithme qui peut permettre, sinon de déterminer la situation exacte de chacun des résolveurs utilisés, en tout cas de voir si une clé donnée a des chances de fonctionner avec cet ensemble de résolveurs.
Quels résolveurs ont ce mécanisme de sentinelle ? BIND l'a depuis la version 9.13, Knot a également ce mécanisme, activé par défaut, depuis la version 2.0 (et le documente), Unbound en dispose depuis la version 1.7.1 et c'est activé par défaut. Parmi les résolveurs DNS publics, Cloudflare et Quad9 ne gèrent apparemment pas les sentinelles de notre RFC 8509.
Côté client, on peut tester son résolveur avec dig, ou
bien avec les
services Web http://www.ksk-test.nethttp://test.kskroll.dnssec.lab.nic.cl/http://sentinel.research.icann.org/http://www.bellis.me.uk/sentinel/ksk-test.net). La lecture des sources
de ces pages est recommandée.
On peut aussi regarder, parmi les sondes RIPE Atlas, lesquelles utilisent un résolveur avec sentinelles :
% blaeu-resolve --displayvalidation --type A --requested 100 --dnssec root-key-sentinel-not-ta-20326.ksk-test.net [ (Authentic Data flag) 204.194.23.4] : 30 occurrences [ERROR: SERVFAIL] : 12 occurrences [ (Authentic Data flag) (TRUNCATED - EDNS buffer size was 4096 ) 204.194.23.4] : 1 occurrences [204.194.23.4] : 52 occurrences Test #20692175 done at 2019-04-13T16:32:15Z % blaeu-resolve --displayvalidation --type A --requested 100 --old_measurement 20692175 --dnssec root-key-sentinel-is-ta-20326.ksk-test.net [ERROR: SERVFAIL] : 1 occurrences [ (Authentic Data flag) 204.194.23.4] : 38 occurrences [204.194.23.4] : 56 occurrences Test #20692176 done at 2019-04-13T16:33:56Z
Le premier test montre 52 sondes utilisant un résolveur non validant, 30 utilisant un validant sans sentinelles (ou bien utilisant une autre clé que 20326), et 12 utilisant un résolveur validant avec sentinelles. Le second test, effectué avec exactement les mêmes sondes, montre que les sondes utilisant un résolveur validant à sentinelles utilisent bien la clé 20326 (sauf une, qui a un SERVFAIL). Notez que les nombres ne coïncident pas parfaitement (30 + 12 - 1 ne fait pas 38), sans doute parce que certaines sondes ont plusieurs résolveurs DNS configurés, ce qui complique sérieusement l'analyse.
Un exemple d'utilisation de ce mécanisme de sentinelles figure dans cet article de Geoff Huston et cet autre.
L'article seul
RFC 8544: Organization Extension for the Extensible Provisioning Protocol (EPP)
Date de publication du RFC : Avril 2019
Auteur(s) du RFC : L. Zhou (CNNIC), N. Kong (Consultant), J. Wei, J. Yao (CNNIC), J. Gould (Verisign)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 12 avril 2019
Le RFC 8543 étendait le format utilisé par le protocole d'avitaillement EPP, afin d'ajouter le concept d'« organisation », une entreprise, association ou agence qui joue un rôle dans la création et gestion d'objets enregistrés, notamment les noms de domaine. Ce RFC 8544 ajoute une extension au protocole EPP pour affecter ces organisations à un domaine, contact ou autre objet enregistré.
Prenons l'exemple le plus connu (quoique EPP puisse servir à d'autres), celui de l'industrie des noms de domaine. Souvent, le registre reçoit des demandes d'un BE, via le protocole EPP. Mais d'autres organisations peuvent jouer un rôle, en plus du BE. Il y a par exemple l'hébergeur DNS (qui n'est pas forcément le BE) ou bien un revendeur du BE, ou bien un « anonymisateur » qui, pour protéger la vie privée des participants, est placé entre le participant et le monde extérieur. Ces différents acteurs (cf. RFC 8499, section 9, pour la terminologie) sont décrits par les nouvelles classes d'objets du RFC 8543. Notre RFC 8544 permet d'utiliser ces classes. Une fois les objets « organisation » créés au registre, on peut les attacher à un nom de domaine ou à un contact, par exemple pour dire « ce nom de domaine a été acheté via le revendeur X ».
L'espace de noms
XML est
urn:ietf:params:xml:ns:epp:orgext-1.0 (et est
enregistré dans le
registre IANA). L'extension à EPP est notée dans le
registre des extensions EPP. Dans les exemples qui suivent,
l'espace de noms est abrégé orgext. Les
organisations ont un identificateur (le
<org:id> du RFC 8543), et cet identificateur sera un attribut
<orgext:id> des objets comme par
exemple le domaine. Pour chaque rôle (revendeur, hébergeur DNS,
etc, cf. RFC 8543, section 7.3), le domaine
a au plus un attribut identifiant une organisation.
La section 4 du RFC décrit les ajouts aux commandes et réponses EPP. Par
exemple, pour <info>, la commande ne
change pas mais la réponse a désormais en plus des attributs
<orgext:id>. Voici un exemple :
<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
<response>
<result code="1000">
<msg lang="en-US">Command completed successfully</msg>
</result>
<resData>
<domain:infData
xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
<domain:name>example.com</domain:name>
...
</resData>
<extension>
<orgext:infData
xmlns:orgext="urn:ietf:params:xml:ns:epp:orgext-1.0">
<orgext:id role="reseller">reseller1523</orgext:id>
<orgext:id role="privacyproxy">proxy2935</orgext:id>
</orgext:infData>
</extension>
<trID>
<clTRID>ngcl-IvJjzMZc</clTRID>
<svTRID>test142AWQONJZ</svTRID>
</trID>
</response>
</epp>
Ici, le domaine a été avitaillé via le revendeur « reseller1523 » et est protégé par l'« anonymisateur » « proxy2935 ».
Bien sûr, la commande EPP <create>
est également modifiée, pour pourvoir créer un domaine avec les
organisations associées. Ici, le revendeur « reseller1523 » crée
un domaine :
<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
<command>
<create>
<domain:create
xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
<domain:name>example.com</domain:name>
<domain:period unit="y">3</domain:period>
...
</create>
<extension>
<orgext:create
xmlns:orgext="urn:ietf:params:xml:ns:epp:orgext-1.0">
<orgext:id role="reseller">reseller1523</orgext:id>
</orgext:create>
</extension>
</command>
</epp>
De le même façon, on peut mettre à jour les organisations
associées à un objet, avec
<update>. Ici, on ajoute un « anonymiseur » :
<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
<command>
<update>
<domain:update
xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
<domain:name>example.com</domain:name>
</domain:update>
</update>
<extension>
<orgext:update
xmlns:orgext="urn:ietf:params:xml:ns:epp:orgext-1.0">
<orgext:add>
<orgext:id role="privacyproxy">proxy2935</orgext:id>
</orgext:add>
</orgext:update>
</extension>
</command>
</epp>
Et ici on retire le revendeur (pas besoin d'indiquer son identificateur, rappelez-vous qu'il ne peut y avoir qu'une seule organisation par rôle) :
<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
<command>
<update>
<domain:update
xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
<domain:name>example.com</domain:name>
</domain:update>
</update>
<extension>
<orgext:update
xmlns:orgext="urn:ietf:params:xml:ns:epp:orgext-1.0">
<orgext:rem>
<orgext:id role="reseller"/>
</orgext:rem>
</orgext:update>
</extension>
</command>
</epp>
La syntaxe complète (au format XML Schema) figure dans la section 5 du RFC.
Question mise en œuvre, cette extension est dans le SDK de Verisign, accessible avec leurs autres logiciels pour registres. CNNIC a également inclus cette extension, dans leur code interne.
L'article seul
RFC 8543: Extensible Provisioning Protocol (EPP) Organization Mapping
Date de publication du RFC : Mars 2019
Auteur(s) du RFC : L. Zhou (CNNIC), N. Kong (Consultant), G. Zhou, J. Yao (CNNIC), J. Gould (Verisign)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 12 avril 2019
L'industrie des noms de domaine est d'une grande complexité. Les utilisateurs s'y perdent facilement entre registres, bureaux d'enregistrement, hébergeurs DNS, revendeurs divers, sociétés qui développent des sites Web, prête-noms pour protéger la vie privée, etc. Cette complexité fait qu'il est difficile de savoir qui est responsable de quoi. Dans le contexte d'EPP, protocole d'avitaillement de noms de domaine (création, modification, suppression de noms), il n'y avait jusqu'à présent pas de moyen de décrire ces acteurs. Par exemple, l'ajout d'un enregistrement DS dépend d'actions de l'hébergeur DNS, qui n'est pas forcément le BE. Mais ces hébergeurs DNS n'étaient pas définis et connus. Désormais, avec ce nouveau RFC, on peut utiliser EPP pour l'avitaillement d'objets « organisation ».
EPP (RFC 5730) est le protocole standard d'avitaillement de noms de domaine, permettant à un client (en général le BE) de créer des objets dans un registre, en parlant au serveur EPP. EPP permettait déjà des objets de type « contact » RFC 5733, identifiant les personnes ou les organisations qui assuraient certaines fonctions pour un nom de domaine. Par exemple, le contact technique était la personne ou l'organisation à contacter en cas de problème technique avec le nom de domaine.
Désormais, avec notre nouveau RFC 8543, une nouvelle catégorie (mapping) d'objets est créée, les organisations. On peut ainsi utiliser EPP pour enregistrer l'hébergeur DNS d'un domaine (qui peut être le titulaire du domaine, mais ce n'est pas toujours le cas, ou qui peut être le BE, mais ce n'est pas systématique). Ce nouveau RFC décrit donc une extension à EPP, qui figure désormais dans le registre des extensions (cf. RFC 7451).
EPP utilise XML et tout ici va donc être spécifié en
XML, avec un nouvel espace de
noms XML,
urn:ietf:params:xml:ns:epp:org-1.0, abrégé en
org dans le RFC (mais rappelez-vous que le
vrai identificateur d'un espace de noms XML est l'URI, pas
l'abréviation). Le nouvel espace de noms est désormais dans
le registre des espaces de noms.
La section 3 de notre RFC décrit les attributs d'une organisation (notez que le vocabulaire est trompeur : ils s'appellent attributs mais ne sont pas des attributs XML). Mais commençons par un exemple, décrivant le BE nommé « Example Registrar Inc. » :
<org:infData
xmlns:org="urn:ietf:params:xml:ns:epp:org-1.0">
<org:id>registrar1362</org:id>
<org:roid>registrar1362-REP</org:roid>
<org:role>
<org:type>registrar</org:type>
<org:status>ok</org:status>
<org:status>linked</org:status>
<org:roleID>1362</org:roleID>
</org:role>
<org:status>ok</org:status>
<org:postalInfo type="int">
<org:name>Example Registrar Inc.</org:name>
<org:addr>
<org:street>123 Example Dr.</org:street>
<org:city>Dulles</org:city>
<org:sp>VA</org:sp>
<org:cc>US</org:cc>
</org:addr>
</org:postalInfo>
<org:voice x="1234">+1.7035555555</org:voice>
<org:email>contact@organization.example</org:email>
<org:url>https://organization.example</org:url>
<org:contact type="admin">sh8013</org:contact>
<org:contact type="billing">sh8013</org:contact>
<org:contact type="custom"
typeName="legal">sh8013</org:contact>
<org:crID>ClientX</org:crID>
<org:crDate>1999-04-03T22:00:00.0Z</org:crDate>
<org:upID>ClientX</org:upID>
<org:upDate>1999-12-03T09:00:00.0Z</org:upDate>
</org:infData>
Voyons maintenant quelques-uns des attributs possibles.
Une organisation a un identificateur,
indiqué par l'élément XML <org:id>,
attribué par le registre (c'est registrar1362
dans l'exemple). Il a aussi un ou plusieurs
rôles, dans l'élement XML
<org:role>. Un même acteur peut avoir
plusieurs rôles (par exemple il est fréquent que les BE soient
également hébergeurs DNS). Le rôle inclut un
type, qui peut valoir :
registrar: BE, comme dans le cas ci-dessus,reseller: revendeur, par exemple l'organisation à laquelle le titulaire du nom de domaine achète un domaine n'est pas toujours un « vrai » BE, ce peut être un revendeur,privacyproxy: un prête-nom qui, en se mettant devant l'utilisateur, permet de protéger sa vie privée,- et enfin
dns-operator, l'hébergeur DNS.
D'autres types pourront apparaitre dans le futur, ils sont indiqués dans un registre IANA, des nouveaux types seront ajoutés en suivant la procédure « Examen par un expert » du RFC 8126.
Notez qu'au début du travail à l'IETF sur cette extension, seul le cas des revendeurs était prévu. Après des discussions sur l'importance relative des différents acteurs, il a été décidé de prévoir d'autres types que les seuls revendeurs.
Il y a aussi dans l'objet un ou plusieurs état(s),
<org:status>, qui peut valoir notamment :
ok, l'état normal, celui du BE dans l'exemple ci-dessus,terminated, quand l'organisation va être retirée de la base et ne peut plus être utilisée (c'est le cas d'un BE qui n'est plus accrédité),linked, qui indique que cette organisation est liée à d'autres objets, et ne doit donc pas être supprimée.
Il existe également un attribut
<org:parent>, qui indique une relation
avec une autre organisation. Par exemple, un revendeur aura une
relation <org:parent> vers le BE dont
il est revendeur. (Dans l'exemple plus haut, il n'y a pas de <org:parent>.)
La section 4 du RFC présente ensuite les commandes EPP qui
peuvent être appliquées à ces objets
« organisation ». <check> permet au
client EPP de
savoir s'il pourra créer un objet,
<info> lui donnera les moyens de
s'informer sur une oranisation (l'exemple en XML ci-dessus était
le résultat d'une commande EPP
<info>) et bien sûr une commande
<create> et une
<delete>. Voici
<create> en action, pour créer un objet
de rôle « revendeur » (notez que, cette fois, il a un parent) :
<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
<command>
<create>
<org:create
xmlns:org="urn:ietf:params:xml:ns:epp:org-1.0">
<org:id>res1523</org:id>
<org:role>
<org:type>reseller</org:type>
</org:role>
<org:parentId>1523res</org:parentId>
<org:postalInfo type="int">
<org:name>Example Organization Inc.</org:name>
<org:addr>
<org:street>123 Example Dr.</org:street>
<org:city>Dulles</org:city>
<org:sp>VA</org:sp>
<org:cc>US</org:cc>
</org:addr>
</org:postalInfo>
<org:voice x="1234">+1.7035555555</org:voice>
<org:email>contact@organization.example</org:email>
<org:url>https://organization.example</org:url>
<org:contact type="admin">sh8013</org:contact>
<org:contact type="billing">sh8013</org:contact>
</org:create>
</create>
</command>
</epp>
Le schéma complet, en syntaxe XML Schema, figure dans la section 5 du RFC.
Question mise en œuvre de cette extension EPP, Verisign l'a ajouté dans son SDK, disponible en ligne. CNNIC a une implémentation, mais non publique.
L'article seul
RFC 8555: Automatic Certificate Management Environment (ACME)
Date de publication du RFC : Mars 2019
Auteur(s) du RFC : R. Barnes (Cisco), J. Hoffman-Andrews (EFF), D. McCarney (Let's Encrypt), J. Kasten (University of Michigan)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF acme
Première rédaction de cet article le 11 avril 2019
Une grande partie de la sécurité du Web, et d'ailleurs de plein d'autres chose sur l'Internet, repose sur des certificats où une Autorité de Certification (AC) garantit que vous êtes bien ce que vous prétendez être. Traditionnellement, l'émission d'un certificat se faisait selon un processus manuel, lent et coûteux, à part dans quelques AC automatisées et gratuites comme CAcert. Mais il n'existait pas de mécanisme standard pour cette automatisation. (Et CAcert n'a pas d'API, même non-standard.) Un tel mécanisme standard existe désormais, avec le protocole ACME, normalisé dans ce RFC. Son utilisateur le plus connu est l'AC Let's Encrypt.
Pour comprendre ACME, il faut d'abord revenir aux utilisations des certificats. La norme technique pour les certificats utilisés sur l'Internet se nomme PKIX et est normalisée dans le RFC 5280. PKIX est un profil (une restriction d'une norme beaucoup plus large - et bien trop large, comme le sont souvent les normes des organismes comme l'UIT ou l'ISO) de X.509. Un certificat PKIX comprend, entre autres :
- Une clé cryptographique publique, le titulaire du certificat étant supposé conserver avec soin et précaution la clé privée correspondante,
- Le nom du titulaire du certificat (X.509 l'appelle le sujet),
- Une signature de l'émetteur du certificat (l'AC).
- Des métadonnées dont notamment la date d'expiration du certificat, qui sert à garantir qu'en cas de copie de la clé privée, le copieur ne pourra pas profiter du certificat éternellement.
On note que le certificat est public. N'importe qui peut récupérer
le certificat de, par exemple, un site Web. Voici un exemple avec
OpenSSL et
www.labanquepostale.fr pour un certificat de
type EV :
% openssl s_client -connect www.labanquepostale.fr:443 -showcerts | openssl x509 -text
Certificate:
Data:
Version: 3 (0x2)
Serial Number:
0d:8f:ec:dd:d8:7b:83:b8:a0:1e:eb:c2:a0:2c:10:9b
Signature Algorithm: sha256WithRSAEncryption
Issuer: C = US, O = DigiCert Inc, OU = www.digicert.com, CN = DigiCert SHA2 Extended Validation Server CA
Validity
Not Before: Sep 5 00:00:00 2018 GMT
Not After : Sep 4 12:00:00 2020 GMT
Subject: businessCategory = Private Organization, jurisdictionC = FR, serialNumber = 421 100 645, C = FR, L = PARIS, O = LA BANQUE POSTALE SA, OU = DISFE, CN = www.labanquepostale.fr
...
et un avec GnuTLS
pour un certificat DV (Domain Validation), mamot.fr :
% gnutls-cli mamot.fr - subject `CN=mamot.fr', issuer `CN=Let's Encrypt Authority X3,O=Let's Encrypt,C=US', serial 0x035516154ab9120c186e9211d0da6296af62, RSA key 2048 bits, signed using RSA-SHA256, activated `2019-01-13 23:00:32 UTC', expires `2019-04-13 23:00:32 UTC', key-ID `sha256:ef62c4aae2a9a99c00c33f2bbac9c40b980c70400a056e2a8042885e501ce283' ...
D'ailleurs, des services comme Certificate
Transparency (RFC 6962), accessible entre autres en https://crt.sh/
Du fait que seul le titulaire connait la clé privée, la capacité à signer des messages vérifiables avec la clé publique permet d'authentifier le partenaire avec lequel on communique. Grâce à la signature de l'AC, quiconque fait confiance à cette AC particulière peut être sûr que le certificat appartient bien au titulaire. Dans l'exemple avec OpenSSL, le certificat de la Banque Postale était signé par DigiCert, si on fait confiance à DigiCert, on sait qu'on est bien connecté à la Banque Postale.
Qui sont les AC ? Ce sont la plupart du temps des entreprises
commerciales qui sont payées par les titulaires de certificat, et
elles sont censées vérifier la sincérité de leurs clients. Cette
vérification peut être manuelle, partiellement ou totalement
automatique. Normalement, les certificats de type EV
(Extended Validation), comme celui de la Banque
Postale plus haut, font l'objet d'une vérification manuelle. Cela
permet de vérifier l'identité officielle (celle gérée par l'État)
du titulaire. Les certificats DV (Domain
Validation), comme celui de
mamot.fr, eux, peuvent être validés
automatiquement, ils assurent uniquement le fait que le titulaire
contrôle bien le nom de
domaine utilisé comme sujet. (Pour avoir tous les
horribles détails, y compris les certificats OV - Organization Validated - dont je n'ai pas
parlé, on peut consulter les « Baseline
Requirements for the Issuance and Management of Publicly-Trusted
Certificates » du CA/Browser
Forum.) Ainsi, pour CAcert, on doit prouver le contrôle du
domaine en répondant aux courriers envoyés aux adresses publiques
de contact pour le domaine.
Les certificats peuvent servir à de nombreux protocoles de sécurité mais le plus connu est TLS (normalisé dans le RFC 8446). Comme il n'est pas le seul protocole pour lequel on a des certificats, il est erroné de parler de « certificats TLS » ou, pire encore, de « certificats SSL ». TLS est un protocole client/serveur, où le client authentifie le serveur mais où le serveur authentifie rarement le client. Il est à la base de la sécurisation d'un grand nombre de services sur l'Internet, à commencer par le Web avec HTTPS (RFC 2818). L'authentification du serveur par le client est faite en vérifiant (attention, je vais simplifier) :
- Que le partenaire avec qui on parle a la clé privée (il peut signer des messages) correspondant au certificat présenté,
- Que le certificat n'a pas expiré,
- Que le certificat est signé par une AC connue du client (la clé publique de l'AC est dans le magasin du client),
- Que le nom indiqué par le client correspond à un des noms disponibles dans le certificat. Dans le cas du Web, c'est le nom de domaine dans l'URL choisi (RFC 6125).
Une fois cette authentification faite, TLS assure l'intégrité et la confidentialité de la communication.
Attention, on parle bien d'authentification, pas de
confiance. Malgré ce que vous pourrez lire dans les « La sécurité
pour les nuls », le fameux « cadenas vert » ne signifie pas du
tout que vous pouvez faire vos achats en ligne en toute
sécurité. Il indique seulement que le partenaire a bien le nom que
vous avez demandé, et qu'un tiers ne pourra pas écouter ou
modifier la conversation. Il n'indique pas
que le partenaire soit digne de confiance ; l'AC ne peut pas
vérifier cela ! Ainsi, dans l'exemple plus haut, TLS et
l'authentification par certificat garantissent bien qu'on se
connecte au serveur HTTPS de la Maison-Blanche,
www.whitehouse.gov, mais pas que
Trump dise la vérité !
J'ai parlé du magasin où se trouvent les clés des AC à qui on fait confiance. Qui décide du contenu de ce magasin ? C'est une question complexe, il n'y a pas une liste d'AC faisant autorité. La plupart des systèmes d'exploitation ont une liste à eux, créée en suivant des critères plus ou moins opaques. Les applications (comme le navigateur Web) utilisent ce magasin global du système ou, parfois, ont leur propre magasin, ce qui aggrave encore la confusion. Les utilisateurs peuvent (c'est plus ou moins facile) ajouter des AC ou bien en retirer.
Et comment obtient-on un certificat ? Typiquement, on crée d'abord une demande de certificat (CSR pour Certificate Signing Request, cf. RFC 2986). Avec OpenSSL, cela peut se faire avec :
% openssl req -new -nodes -newkey rsa:2048 -keyout server.key -out server.csr
On se connecte ensuite au site Web de l'AC choisie, et on lui
soumet le CSR. Ici, un exemple avec CAcert :
L'AC doit alors faire des vérifications, plus ou moins rigoureuses. Par exemple, l'AC fait une requête whois, note l'adresse de courrier du domaine, envoie un message contenant un défi et le client de l'AC doit y répondre pour prouver qu'il a bien accès à cette adresse et contrôle donc bien le domaine. L'AC crée ensuite le certificat qu'elle vous renvoie. Il faut alors l'installer sur le serveur (HTTPS, par exemple). L'opération est complexe, et beaucoup d'utilisateurs débutants cafouillent.
C'est ce processus non-standard et compliqué que le protocole ACME vise à normaliser et à automatiser. Ce RFC a une longue histoire mais est déjà déployé en production par au moins une AC.
Le principe d'ACME est simple : l'AC fait tourner un serveur
ACME, qui attend les requêtes des clients. Le client ACME (un
logiciel comme dehydrated ou
certbot) génère la
CSR, se connecte au serveur, et demande un certificat signé pour
un nom donné. Le serveur va alors renvoyer un
défi qui va permettre au client de prouver
qu'il contrôle bien le nom de domaine demandé. Il existe plusieurs
types de défis, mais le plus simple est un nom de fichier
que le serveur ACME choisit, demandant au client ACME de mettre un
fichier de ce nom sur son site Web. Si le nom de fichier était
Vyzs0Oqkfa4gn4skMwszORg6vJaO73dvMLN0uX38TDw,
le serveur ACME va devenir client HTTP et chercher à récupérer
http://DOMAIN/.well-known/acme-challenge/Vyzs0Oqkfa4gn4skMwszORg6vJaO73dvMLN0uX38TDw. S'il
y réussit, il considère que le client ACME contrôle bien le nom de
domaine, et il signe alors le certificat, qui est renvoyé au
client lorsque celui-ci soumet la CSR.
Le modèle idéal d'utilisation d'ACME est présenté dans la section 2. (En pratique, il n'est pas vraiment réalisé, notamment parce qu'il n'existe pratiquement qu'une seule AC utilisant ACME, Let's Encrypt. Il n'y a donc pas encore beaucoup de diversité.) L'espoir est qu'un jour, on puisse faire comme suit :
- On installe un serveur Web (avec des services comme le CMS),
- La procédure d'installation vous demande le nom de domaine à utiliser (ce point là n'est pas automatisable, sans même parler de la procédure de location du nom de domaine),
- Le logiciel vous propose une liste d'AC parmi lesquelles choisir (on a vu qu'il n'y en avait qu'une actuellement ; dans le futur, s'il y en a plusieurs, l'utilisateur aura sans doute autant de mal à choisir qu'il ou elle en a aujourd'hui à choisir un BE),
- Le logiciel fait tout le reste automatiquement : requête à l'AC choisie en utilisant le protocole ACME normalisé dans notre RFC, réponse au défi de l'AC via le serveur HTTP installé, récupération du certificat et configuration de TLS,
- Par la suite, c'est le logiciel qui effectuera automatiquement les demandes de renouvellement de certificat (aujourd'hui, avec les logiciels existants, c'est le point qui est le plus souvent oublié ; combien de sites Web ont annoncé fièrement qu'ils étaient désormais protégés par HTTPS, pour afficher un certificat expiré trois mois après…)
Ainsi, une procédure manuelle et pénible pourra devenir assez simple, encourageant une présence en ligne plus sécurisée. Cela pourrait devenir aussi simple que d'avoir un certificat auto-signé.
La section 4 du RFC expose de manière générale le protocole ACME (le RFC complet fait 94 pages, car il y a beaucoup de détails à spécifier). Rappelez-vous avant de la lire que, pour ACME, le client est celui qui demande le certificat (c'est donc typiquement un serveur Internet, par exemple un serveur HTTPS) et le serveur ACME est l'AC. Quand je dirais « client » ou « serveur » tout court, il s'agira du client et du serveur ACME.
ACME encode ses messages en JSON (RFC 8259). Le client doit d'abord avoir un compte auprès du serveur (avec Let's Encrypt, cela peut être fait automatiquement sans que l'utilisateur s'en rende compte). Par exemple, avec dehydrated, cela se fait ainsi :
% dehydrated --register --accept-terms + Generating account key... + Registering account key with ACME server... + Done!
Et on trouve dans le répertoire accounts/ la
clé privée du compte, et les informations du compte :
% cat accounts/aHR0cHM6Ly9...9yeQo/registration_info.json
{
"id": 5...1,
"key": {
"kty": "RSA",
"n": "wv...HCk",
"e": "AQAB"
},
"contact": [],
"initialIp": "2001:4b98:dc0:41:216:3eff:fe27:3d3f",
"createdAt": "2019-03-12T19:32:20.018154799Z",
"status": "valid"
}
Pour certbot, on peut le faire tourner avec l'option
-v pour avoir les mêmes informations. certbot
affiche également des messages d'ordre administratif comme :
Enter email address (used for urgent renewal and security notices) (Enter 'c' to
cancel): stephane+letsencrypt@bortzmeyer.org
...
Please read the Terms of Service at
https://letsencrypt.org/documents/LE-SA-v1.2-November-15-2017.pdf. You must
agree in order to register with the ACME server at
https://acme-v02.api.letsencrypt.org/directory
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
(A)gree/(C)ancel: A
JWS payload:
b'{\n "contact": [\n "mailto:stephane+letsencrypt@bortzmeyer.org"\n ],\n "termsOfServiceAgreed": true,\n "resource": "new-reg"\n}'
{
"id": 53367492,
"key": { ...
"contact": [
"mailto:stephane+letsencrypt@bortzmeyer.org"
],
"createdAt": "2019-03-15T16:07:58.29914038Z",
"status": "valid"
}
Reporting to user: Your account credentials have been saved in your Certbot configuration directory at /etc/letsencrypt. You should make a secure backup of this folder now. This configuration directory will also contain certificates and private keys obtained by Certbot so making regular backups of this folder is ideal.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Would you be willing to share your email address with the Electronic Frontier
Foundation, a founding partner of the Let's Encrypt project and the non-profit
organization that develops Certbot? We'd like to send you email about our work
encrypting the web, EFF news, campaigns, and ways to support digital freedom.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
(Y)es/(N)o: No
...
Le compte sera authentifié en utilisant une biclé (clé privée et clé publique). Il y aura ensuite quatre étapes :
- Demander un certificat,
- Répondre au défi (notez bien qu'ACME permet plusieurs types de défis possibles),
- Envoyer le CSR,
- Récupérer le certificat signé.
Mais comment transporte-t-on ces messages en JSON ? La section 6 du RFC répond à cette question : on utilise HTTPS. En prime, les messages sont signés avec JWS (RFC 7515), en utilisant la clé privée du client pour les requêtes. Voici par exemple la réponse d'un serveur ACME lorsqu'on l'interroge sur un défi en cours :
{
"type": "http-01",
"status": "pending",
"url": "https://acme-v02.api.letsencrypt.org/acme/challenge/7TAkQBMmFqm8Rhs6Sn8SFCne2MoZXoEHCz0Px7f0dpE/13683685175",
"token": "mMXGXjEijKBZXl2RuL0rjlektPPpy-ozJpZ2vB4w6Dw"
}
Les messages d'erreur utilisent le RFC 7807. En voici un exemple :
{
"type": "http-01",
"status": "invalid",
"error": {
"type": "urn:acme:error:unauthorized",
"detail": "Invalid response from http://mercredifiction.bortzmeyer.org/.well-known/acme-challenge/rE-rIfjjCfMlivxLfoJmMbRyspwmld97Xnxmy7K0-JA: \"\u003c!DOCTYPE HTML PUBLIC \"-//IETF//DTD HTML 2.0//EN\"\u003e\n\u003chtml\u003e\u003chead\u003e\n\u003ctitle\u003e404 Not Found\u003c/title\u003e\n\u003c/head\u003e\u003cbody\u003e\n\u003ch1\u003eNot Found\u003c/h1\u003e\n\u003cp\"",
"status": 403 ...
[Le message d'erreur indique également typiquement l'URL demandé,
et les adresses IP utilisées, ce qui est crucial si le serveur HTTP
a plusieurs adresses IP, par exemple une en IPv4 et une en IPv6. Il
faut donc bien lire tout le message d'erreur.]
Une liste des erreurs possibles est enregistrée à l'IANA. Voici par exemple une erreur CAA (RFC 8659) :
"error": {
"type": "urn:acme:error:caa",
"detail": "CAA record for mercredifiction.bortzmeyer.org prevents issuance",
"status": 403
},
Comment un client ACME trouve-t-il les
URL pour les différentes opérations ? Il y
a un URL à connaitre, le répertoire
(directory). Une requête à cet URL (par exemple
curl
https://acme-v02.api.letsencrypt.org/directory va renvoyer
un objet JSON qui contient la liste des autres URL (section 7, une
des plus cruciales du RFC). Voici un exemple chez Let's
Encrypt :
{ ...
"meta": {
"caaIdentities": [
"letsencrypt.org"
],
"termsOfService": "https://letsencrypt.org/documents/LE-SA-v1.2-November-15-2017.pdf",
"website": "https://letsencrypt.org"
},
"newAccount": "https://acme-v02.api.letsencrypt.org/acme/new-acct",
"newNonce": "https://acme-v02.api.letsencrypt.org/acme/new-nonce",
"newOrder": "https://acme-v02.api.letsencrypt.org/acme/new-order",
"revokeCert": "https://acme-v02.api.letsencrypt.org/acme/revoke-cert"
}
On peut ensuite créer un compte (le champ
newAccount dans l'exemple ci-dessus) puis demander
des certificats (champ newOrder dans
l'exemple ci-dessus), ici (Let's Encrypt) en écrivant à
https://acme-v02.api.letsencrypt.org/acme/new-order :
{
"payload": "ewogICJpZGVudGlmaWVycyI6IFsKICAgIHsKICAgICAgInR5cGUiOiAiZG5zIiwKICAgICAgInZhbHVlIjogInRlc3QtYWNtZS5ib3J0em1leWVyLmZyIgogICAgfQogIF0KfQ",
"protected": "eyJhbGciOiAiUlMyNTYiLCAidXJsIjogImh0dHBzOi8vYWNtZS12MDIuYXBpLmxldHNlbmNyeXB0Lm9yZy9hY21lL25ldy1vcmRlciIsICJraWQiOiAiaHR0cHM6Ly9hY21lLXYwMi5hcGkubGV0c2VuY3J5cHQub3JnL2FjbWUvYWNjdC81MzE3NzA1MCIsICJub25jZSI6ICJyZXNXTXFtQkJYbVZrZ2JfSnVQU3VEcmlmQzhBbDZrTm1JeDZuNkVwRDFZIn0",
"signature": "MP9rXTjX4t1Be-y6dhPOP7JE3B401wokydUlG8gJGWqibTM_gydkUph1smtrUZ5W4RXNTEnlmiFwoiU4eHLD-8MzN5a3G668VbgzKd0VN7Y1GxQBGtsj9fShx4VMjSGLzVq1f7bKCbdX3DYn0LaiRDApgNXiMfoEnPLltu5Ud7RBNOaWY8zE0yAV7e3NFlF9Wfaii5Ff9OT1ZCD8LusOHP-gA4VkimQ9ofYr32wZYgsUFu6G--QflP0tjc5eKYMe1cKlgpyKZsDtBurWwvKlj2cU_PUdOZvjXSBbHX18jVlwglzfFnu0xTaDGTTvOuMBfjnWJCWpr-oA7Ih48dL-Jg"
}
Eh oui, tout est signé, en JWS (RFC 7515) et base64isé (cf. section 7.4 du RFC). Ici, le décodage Base64 nous dira que la requête était :
{
{
"identifiers": [
{
"type": "dns",
"value": "test-acme.bortzmeyer.fr"
}
]
}
, {"alg": "RS256", "url":
"https://acme-v02.api.letsencrypt.org/acme/new-order", "kid":
"https://acme-v02.api.letsencrypt.org/acme/acct/53177050", "nonce":
"resWMqmBBXmVkgb_JuPSuDrifC8Al6kNmIx6n6EpD1Y"}
}
Donc, une demande de certificat pour test-acme.bortzmeyer.fr.
Les autres opérations possibles avec un serveur ACME sont enregistrées à l'IANA. Par exemple, on peut révoquer un certificat.
La réponse sera :
{
"status": "pending",
"expires": "2019-03-19T19:50:41.434669372Z",
"identifiers": [
{
"type": "dns",
"value": "test-acme.bortzmeyer.fr"
}
],
"authorizations": [
"https://acme-v02.api.letsencrypt.org/acme/authz/FVMFaHS_oWjqfR-rWd6eBKMlt1EWfIcf6i7D4wU_swM"
],
"finalize": "https://acme-v02.api.letsencrypt.org/acme/finalize/53177050/352606317"
}
Le client ACME va alors télécharger l'autorisation à l'URL
indiqué, récupérant ainsi les défis qu'il devra affronter (section
7.5 du RFC). Une fois qu'il a fait ce qui lui était demandé par le
serveur, il utilise l'URL donné dans le champ
finalize pour indiquer au serveur que c'est
bon, que le serveur peut vérifier. La commande
certbot avec l'option -v
vous permettra de voir tout ce dialogue.
Le protocole ACME peut être utilisé par d'autres AC que Let's
Encrypt. Avec le client dehydrated, il suffira, quand de telles AC
seront disponibles, de mettre CA=URL dans le
fichier de configuration (l'URL par défaut est
https://acme-v02.api.letsencrypt.org/directory). Un exemple d'autre AC utilisant ACME est BuyPass (pas testé).
Mais en quoi consistent exactement les
défis, dont j'ai déjà parlé plusieurs fois ?
La section 8 les explique. L'idée de base d'un défi ACME est de
permettre de prouver qu'on contrôle réellement un identificateur,
typiquement un nom de
domaine. ACME ne normalise pas un type de défi
particulier. Le cadre est ouvert, et de nouveaux défis pourront
être ajoutés dans le futur. Le principe est toujours le même :
demander au client ACME de faire quelque chose que seul le vrai
titulaire de l'identificateur pourrait faire. Un défi, tel
qu'envoyé par le serveur ACME, a un type (le plus utilisé
aujourd'hui, est de loin, est le défi
http-01), un état (en attente ou bien, au
contraire, validé) et un texte d'erreur, au cas où la validation
ait échoué. Plusieurs défis, comme http-01
ont également un jeton, un cookie, un texte
généré par le serveur, et non prévisible par le client ou par le
reste du monde, et qu'il faudra placer quelque part où le serveur
pourra le vérifier. Le serveur ACME ne testera que lorsque le
client lui aura dit « c'est bon, je suis prêt, j'ai fait tout ce
que tu m'as défié de faire ». Le RFC demande également au serveur
de réessayer après cinq ou dix secondes, si la vérification ne
marche pas du premier coup, au cas où le client ait été trop
rapide à se dire prêt.
Le plus connu et le plus utilisé des défis, à l'heure actuelle,
est http-01. Le client ACME doit configurer
un serveur HTTP où une page (oui, je sais,
le terme correct est « ressource ») a comme nom le contenu du
jeton. Le serveur ACME va devenir client HTTP pour récupérer cette
page et, s'il y arrive, cela prouvera que le client contrôlait
bien le nom de domaine qu'il avait indiqué. De manière
surprenante, et qui déroute beaucoup de débutants, le défi se fait
bien sur HTTP et pas HTTPS, parce que beaucoup d'hébergements Web
partagés ne donnent pas suffisamment de contrôle à l'hébergé.
Le jeton est une chaîne de caractères utilisant le jeu de caractères de Base64, pour passer partout. Voici un exemple de défi HTTP envoyé par le serveur :
{
"identifier": {
"type": "dns",
"value": "test-acme.bortzmeyer.fr"
},
"status": "pending",
"expires": "2019-03-19T19:50:41Z",
"challenges": [
{
"type": "http-01",
"status": "pending",
"url": "https://acme-v02.api.letsencrypt.org/acme/challenge/FVMFaHS_oWjqfR-rWd6eBKMlt1EWfIcf6i7D4wU_swM/13574068498",
"token": "4kpeqw7DVMrY6MI3tw1-tTq9oySN2SeMudaD32IcxNM"
} ...
L'URL qu'utilisera le serveur est
http://DOMAINE-DEMANDÉ/.well-known/acme-challenge/JETON
(ou, en syntaxe du RFC 6570,
http://{domain}/.well-known/acme-challenge/{token}). Comme
expliqué plus haut, c'est bien http:// et pas
https://. Les URL avec
.well-known sont documentés dans le RFC 8615 et acme-challenge
est désormais dans
le registre.
Imaginons qu'on utilise le serveur HTTP Apache et qu'on veuille répondre à ce défi. Le plus simple est de configurer le serveur ainsi :
<VirtualHost *:80>
Alias /.well-known/acme-challenge /var/lib/dehydrated/acme-challenges
<Directory /var/lib/dehydrated/acme-challenges>
Options None
AllowOverride None
...
Cela indique à Apache que les réponses aux défis seront dans le
répertoire
/var/lib/dehydrated/acme-challenges,
répertoire où le client ACME dehydrated va mettre ses
fichiers. Avec le serveur HTTP Nginx, le
principe est le même :
server {
location ^~ /.well-known/acme-challenge {
alias /var/lib/dehydrated/acme-challenges;
}
}
Bien sûr, de nombreuses autres solutions sont possibles. Le serveur HTTP peut intégrer le client ACME, par exemple. Autre exemple, le client ACME certbot inclut son propre serveur HTTP, et peut donc répondre aux défis tout seul, sans Apache.
Ensuite, on lance le client ACME, éventuellement en lui spécifiant où il doit écrire la réponse aux défis :
% certbot certonly --webroot -w /usr/share/nginx/html -d MONDOMAINE.eu.org
certbot va mettre le certificat généré et signé dans son
répertoire, typiquement
/etc/letsencrypt/live/MONDOMAINE.eu.org/fullchain.pem. Et
on programme son système (par exemple avec
cron) pour relancer le client ACME tous les
jours (les clients ACME typique vérifient la date d'expiration du
certificat, et n'appellent l'AC que si cette date est proche.)
Notez bien qu'il est crucial de superviser l'expiration des
certificats. On voit fréquemment des sites Web utilisant
Let's Encrypt devenir inaccessibles parce que le certificat a été
expiré. Beaucoup d'administrateurs système
croient que parce que Let's Encrypt est « automatique », il n'y a
aucun risque. Mais ce n'est pas vrai : non seulement la commande
de renouvellement peut ne pas être exécutée, ou bien mal se passer
mais, même si le certificat est bien renouvellé, cela ne garantit
pas que le serveur HTTP soit rechargé.
Petite anecdote personnelle : pour le blog que vous êtes en train de lire, cela avait été un peu plus compliqué. En effet, le blog a deux copies, sur deux machines différentes. J'ai donc du rediriger les vérifications ACME sur une seule des deux machines. En Apache :
ProxyRequests Off
ProxyPass /.well-known/acme-challenge/ http://MACHINE-DE-RÉFÉRENCE.bortzmeyer.org/.well-known/acme-challenge/
ProxyPreserveHost On
À noter qu'un serveur HTTP paresseux qui se contenterait de
répondre 200 (OK) à chaque requête sous
/.well-known/acme-challenge n'arriverait pas à répondre
avec succès aux défis HTTP. En effet, le fichier doit non
seulement exister mais également contenir une chaîne de caractères
faite à partir d'éléments fournis par le serveur ACME (cf. section 8.3).
Un autre type de défi répandu est le défi
dns-01, où le client doit mettre dans le
DNS un enregistrement
TXT
_acme-challenge.DOMAINE-DEMANDÉ contenant le jeton. Cela nécessite donc un serveur
DNS faisant autorité qui permette les mises à jour dynamiques, via
le RFC 2136 ou bien via une
API. Notez que le RFC recommande (section
10.2) que l'AC fasse ses requêtes DNS via un résolveur qui valide
avec DNSSEC. (Le serveur ACME ne demande pas
directement aux serveurs faisant autorité, il passe par un
résolveur. Attention donc à la mémorisation par les résolveurs des
réponses, jusqu'au TTL.)
On peut utiliser le défi DNS avec des jokers (pour avoir un
certificat pour *.MONDOMAINE.fr) mais c'est
un peu plus compliqué (section 7.1.3 si vous voulez vraiment les détails).
D'autres types de défis pourront être ajouté dans le futur. Un
registre
IANA en garde la liste. Notez que des types de défis
peuvent également être supprimés comme
tls-sni-01 et tls-sni-02, jugés à l'usage pas assez sûrs.
Le but de ce RFC est la sécurité, donc toute faiblesse d'ACME dans ce domaine serait grave. La section 10 du RFC se penche donc sur la question. Elle rappelle les deux objectifs de sécurité essentiels :
- Seul·e l·e·a vrai·e titulaire d'un identificateur (le nom de domaine) peut avoir une autorisation pour un certificat pour cet identificateur,
- Une fois l'autorisation donnée, elle ne peut pas être utilisée par un autre compte.
Le RFC 3552 décrit le modèle de menace typique de l'Internet. ACME a deux canaux de communication, le canal ACME proprement dit, utilisant HTTPS, et le canal de validation, par lequel se vérifient les réponses aux défis. ACME doit pouvoir résister à des attaques passives et actives sur ces deux canaux.
ACME n'est qu'un protocole, il reçoit des demandes, envoie des
requêtes, traite des réponses, mais il ne sait pas ce qui se passe
à l'intérieur des machines. Les défis, par exemple, peuvent être
inutiles si la machine testée est mal gérée (section 10.2). Si, par exemple, le
serveur HTTP est sur un serveur avec plusieurs utilisateurs, et où
tout utilisateur peut bricoler la configuration HTTP, ou bien
écrire dans le répertoire .well-known, alors
tout utilisateur sur ce serveur pourra avoir un certificat. Idem
évidemment si le serveur est piraté. Et, si on sous-traite le
serveur de son organisation à l'extérieur, le sous-traitant peut
également faire ce qu'il veut et obtenir des certificats pour son
client (« il n'y a pas de
cloud, il y a juste
l'ordinateur de quelqu'un d'autre »).
ACME permet d'obtenir des certificats DV et ceux-ci dépendent évidemment des noms de domaine et du DNS. Un attaquant qui peut faire une attaque Kaminsky, par exemple, peut envoyer les requêtes du serveur ACME chez lui. Plus simple, même si le RFC n'en parle guère (il se focalise sur les attaques DNS, pas sur celles portant sur les noms de domaine), un attaquant qui détourne le nom de domaine, comme vu fin 2018 au Moyen-Orient, peut évidemment obtenir les certificats qu'il veut, contrairement à la légende répandue comme quoi TLS protègerait des détournements.
Comment se protéger contre ces attaques ? Le RFC recommande d'utiliser un résolveur DNS validant (vérifiant les signatures DNSSEC) ce que peu d'AC font (Let's Encrypt est une exception), de questionner le DNS depuis plusieurs points de mesure, pour limiter l'efficacité d'attaques contre le routage (cf. celle contre MyEtherWallet en avril 2018), et pourquoi pas d'utiliser TCP plutôt qu'UDP pour les requêtes DNS (ce qui présente l'avantage supplémentaire de priver de certificat les domaines dont les serveurs de noms sont assez stupides pour bloquer TCP). Voir aussi la section 11.2, qui revient sur ces conseils pratiques. Par exemple, une AC ne doit évidemment pas utiliser le résolveur DNS de son opérateur Internet, encore moins un résolveur public.
ACME est un protocole, pas une politique. L'AC reste maitresse de sa poltique d'émission des certificats. ACME ne décrit donc pas les autres vérifications qu'une AC pourrait avoir envie de faire :
- Acceptation par le client d'un contrat,
- Restrictions supplémentaires sur le nom de domaine,
- Autorisation ou pas des jokers dans le nom demandé,
- Liste noire de noms considérés comme sensibles, par exemple parce désignant telle ou telle marque puissante,
- Tests avec la PSL,
- Tests techniques sur la cryptographie (par exemple rejeter les clés pas assez fortes, ou bien utilisant des algorithmes vulnérables),
- Présence d'un enregistrement CAA (RFC 8659).
Les certificats DV (ceux faits avec ACME) sont sans doute moins fiables que les EV (les DV n'ont qu'une vérification automatique, avec peu de sécurité puisque, par exemple, DNSSEC n'est pas obligatoire) et il est donc prudent de limiter leur durée de validité. Let's Encrypt fait ainsi des certificats à courte durée de vie, seulement trois mois, mais ce n'est pas trop grave en pratique, puisque le renouvellement peut être complètement automatisé.
Quels sont les mises en œuvre disponibles d'ACME ? Comme le RFC
est publié longtemps après les premiers déploiements, il y en a
déjà pas mal. Let's Encrypt maintient une
liste de clients. Personnellement, j'ai pratiqué certbot et dehydrated
mais il en existe d'autres, comme acme-tiny, qui
semble simple et compréhensible. Un avantage que je trouve à
dehydrated est qu'il est bien plus simple de garde sa clé lors des
renouvellements, par exemple pour
DANE : il suffit de mettre
PRIVATE_KEY_RENEW="no" dans le fichier de
configuration. En revanche, dehydrated est à la fois pas assez et
trop bavard. Pas assez car il n'a pas d'option permettant de voir
la totalité du dialogue en JSON avec le serveur (contrairement à
certbot) et trop car il affiche des messages même quand il n'a rien
fait (parce que le certificat était encore valide pour assez
longtemps). Pas moyen de le faire taire, et rediriger la sortie
standard ne marche pas car on veut savoir quand il y a eu
renouvellement effectif.
On dispose également de bibliothèques
permettant au programmeur ou à la programmeuse de développer plus
facilement un client ACME. (Par exemple
Protocol::ACME
(encore que j'ai l'impression qu'il n'est plus maintenu, un
programmeur Perl disponible pour évaluer ce
qui existe ?). Pour les programmeures
Python, il y a le module
acme qui est celui utilisé par le client
certbot, mais qui est aussi distribué indépendamment. En
Go, il y a LeGo. Mais on peut aussi
mettre le client ACME dans le serveur HTTP, comme le permet
Apache
Et les serveurs ACME ? Évidemment, peu de gens monteront une AC mais, si vous voulez le faire, le serveur de Let's Encrypt, Boulder, est en logiciel libre.
Notez que ce RFC ne parle que de la validation de noms de domaines mais ACME pourra, dans le futur, être utilisé pour valider la « possession » d'une adresse IP (RFC 8738), ou d'autres identifiants.
Et si vous voulez un résumé rapide d'ACME par ses auteurs, allez lire cet article sur le blog de l'IETF. Ou bien vous préférez une histoire détaillée d'ACME ?
L'article seul
Deux « bots » de plus pour le fédivers
Première rédaction de cet article le 7 avril 2019
Je viens de mettre en service deux « bots », sur le réseau social « fédivers ». Ce court article est là pour documenter les techniques utilisées, si vous voulez vous-même réaliser un tel « agent logiciel autonome » sur ce réseau.
Un « bot », dans le contexte des réseaux sociaux, est simplement un logiciel qui, sans intervention humaine, va écrire sur le réseau social, parfois en réponse à des demandes des humains. C'est un concept très ancien (il y en avait déjà sur IRC) mais je vais me focaliser ici sur des bots participant au fédivers (également écrit fedivers, fediverse, féediverse, etc). J'avais déjà documenté en anglais un bot qui répondait à des requêtes DNS, les deux bots décrits ici en français sont plus simples, ils n'écoutent pas les messages, ils ne font qu'écrire. Cela permet de ne pas avoir un démon tournant en permanence (et qu'il faut superviser, redémarrer, etc) mais juste de les lancer de temps en temps depuis cron : ils écrivent puis retournent se coucher.
Ces deux bots sont balladependus, qui écrit le texte du
poème « La ballade des pendus », de
François Villon, et voirapp, qui récite la chanson
« Voir » de Jacques Brel. À quoi ça sert
d'envoyer des poèmes sur le fédivers ? À rien, mais plusieurs bots
le font déjà, comme LInternationale qui
nous réveille avec les paroles de
l'Internationale (une version préliminaire,
pas les paroles les plus connues).
Les deux bots sont hébergés par
l'instance fédivers botsin.space, spécialisée dans les
bots.
Le premier, balladependus, est écrit en
shell, le second, voirapp, en
Python. Voyons d'abord le premier.
Le code source de balladependus est distribué ici. Il repose sur l'excellent
programme madonctl, qui permet d'accéder
au fédivers depuis la ligne de
commande. madonctl utilise
l'API du serveur
Mastodon (botsin.space
est un Mastodon). Normalement, Pleroma gère
également cette API et donc madonctl devrait marcher avec Pleroma,
mais je n'ai jamais essayé. Autrement, que fait le programme ? En
commençant du début :
- Il récupère sur la ligne de commande ses deux arguments, le fichier contenant le poème, et le nom du fichier de configuration (le même programme peut être utilisé pour plusieurs poèmes et plusieurs comptes).
- Il lit un fichier de configuration, contenant les
paramètres spécifiques à un compte fédivers, notamment le jeton
d'autorisation ; ce fichier a été créé avec
madonctl config dump -i YOURINSTANCE -L YOURID -P YOURPASSWORD > ~/.config/madonctl/YOURCONFIG.yml. Il faut donc s'être créé un compte sur l'instance préalablement (en n'oubliant pas de cocher, dans le profil, la case « Je suis un bot »). - Il lit ensuite un fichier d'état
(
$checkpoint) qui indique à quelle strophe du poème on en est. Le logiciel ne tourne pas en permanence et c'est donc ce fichier d'état qui lui permettra de ne pas partir de zéro à chaque fois. Le même fichier contient un identificateur du pouète (message sur le fédivers) précédemment envoyé, de façon à organiser toutes les strophes du poème en un seul fil. - Ensuite, il lit le fichier contenant le poème, une ligne vide indique le passage au pouète suivant. (Le fichier a été créé manuellement avec un éditeur.)
- Le bot attend ensuite un nombre aléatoire de secondes, pour mettre un peu de variété dans les messages. Notez qu'il n'existe pas de moyen standard en shell de faire des nombres aléatoires.
- Enfin, on écrit le pouète avec madonctl, qui prend en
argument le fichier de configuration de ce compte (paramètre
--config) et, sauf pour la première strophe, l'identificateur du pouète précédent (paramètre--in-reply-to). On note en retour l'identificateur (Status ID) du pouète. - Enfin, il n'y a plus qu'à écrire identificateur du pouète et numéro de la strophe dans le fichier d'état.
Le programme est lancé automatiquement par cron, envoyant une strophe toutes les trois heures :
# Ballade des pendus 35 0,3,6,9,12,15,18,21 * * * ballade-pendus.sh ballade-pendus.txt ballade
Et l'autre programme, celui derrière voirapp ? Il
est écrit en Python, pour le plaisir de la
variété. Il dépend de la bibliothèque Mastodon.py. Il
est plus court que la version shell, en partie parce que Python
offre des possibilités supérieures, mais également parce qu'il lui
manque certaines fonctions. Par exemple, il est moins générique,
le nom du poème est en dur dans le code. Le source est également disponible.
Comment fonctionne ce programme ? Il ressemble beaucoup au
précédent. Il ouvre le fichier d'état
(CHECKPOINT), y lit l'identificateur du pouète
précédent et le numéro de la strophe. Il lit le fichier contenant
la chanson (même formatage que pour le script en shell), et attend
une durée aléatoire avant d'envoyer, et enfin écrit le nouveau
fichier d'état. Pour envoyer, il se connecte à
une instance Mastodon (mastodon =
Mastodon(...)) et
envoie le pouète via
mastodon.status_post(...). Avant cela, il aura
fallu s'enregistrer auprès de l'instance, pour fabriquer les
fichiers contenant les lettres de créance
(voirapp_clientcred.secret et
voirapp_usercred.secret). Cet enregistrement
peut également se faire en Python (une fois suffit, les lettres de
créance seront enregistrées) :
Mastodon.create_app(
'voirapp',
api_base_url = 'https://botsin.space/',
to_file = 'voirapp_clientcred.secret'
)
mastodon = Mastodon(
client_id = 'voirapp_clientcred.secret',
api_base_url = 'https://botsin.space/'
)
mastodon.log_in(
USER,
PASSWORD,
to_file = 'voirapp_usercred.secret'
)
Le programme est ensuite lancé depuis cron, comme le précédent.
L'article seul
Exposé sur DoH (DNS sur HTTPS) aux JDLL
Première rédaction de cet article le 7 avril 2019
Dernière mise à jour le 9 avril 2019
Comme chaque année, les Journées du Logiciel Libre à Lyon ont été passionnantes et très bien organisées. J'y ai fait un petit exposé sur une technique qui a fait un peu de bruit récemment, DoH (DNS sur HTTPS).
DoH a été normalisé dans le RFC 8484. Cette technique permet de chiffrer le trafic DNS, afin d'échapper à la surveillance et à la modification du trafic. (DNSSEC permet de détecter ces modifications mais pas d'y échapper.) Elle suscite donc les réactions de ceux qui avaient pris l'habitude de regarder le trafic DNS, voire de changer les réponses.
Mais le déploiement de DoH soulève une autre question. Un acteur important, Mozilla, a choisi de configurer DoH par défaut dans son navigateur Firefox (ce qui se défend) mais également de désigner comme résolveur par défaut celui d'un GAFA, Cloudflare. Question vie privée, passer d'une surveillance et d'une censure par le FAI à une surveillance et peut-être demain une censure, par une entreprise capitaliste états-unienne n'est pas forcément un progrès… Il est donc important et urgent que des résolveurs DoH vraiment libres soient déployés par des acteurs non-GAFA, par exemple des chatons.
Les supports de mon exposé sont disponibles ici (ainsi que leur source). La conférence a été filmée et la vidéo est sur PeerTube chez Benzo (cf. son article) et chez GoogleTube.
La démonstration de DoH a été faite avec un serveur DoH écrit
en Python lors d'un hackathon à l'IETF, tournant sur
https://doh.bortzmeyer.fr/. Attention :
non seulement ce serveur DoH est purement expérimental, et
toujours en panne, mais en outre il n'offre aucune vie privée, je
regarde tout le trafic. Voici par exemple ce qui s'affiche
lorsqu'un client DoH a fait une requête pour
jdll.org :
INFO: id 0
opcode QUERY
rcode NOERROR
flags RD
;QUESTION
jdll.org. IN A
;ANSWER
;AUTHORITY
;ADDITIONAL
[2019-04-09 18:55:36,513] 10.251.62.29:35552 GET / 2 200 42 870793
Le client DoH de test utilisé (développé au même hackathon, utilisait la
méthode HTTP
GET. curl, lui,
utilise POST. La requête curl
--doh-url https://doh.bortzmeyer.fr/ https://jdll.org/
provoque :
INFO: id 0
opcode QUERY
rcode NOERROR
flags RD
;QUESTION
jdll.org. IN AAAA
;ANSWER
;AUTHORITY
;ADDITIONAL
INFO: id 0
opcode QUERY
rcode NOERROR
flags RD
;QUESTION
jdll.org. IN A
;ANSWER
;AUTHORITY
;ADDITIONAL
[2019-04-09 19:01:51,750] 82.251.62.29:35610 POST / 2 200 91 8403
[2019-04-09 19:01:51,750] 82.251.62.29:35608 POST / 2 200 42 6703
Notez également que curl a fait deux requêtes, A et AAAA. Voici ce qu'affiche curl de son activité :
% curl --doh-url https://doh.bortzmeyer.fr/ https://jdll.org/
* Hostname 'doh.bortzmeyer.fr' was found in DNS cache
* Connected to doh.bortzmeyer.fr (193.70.85.11) port 443 (#1)
* ALPN, offering h2
* ALPN, offering http/1.1
* ALPN, server accepted to use h2
* Server certificate:
* subject: CN=doh.bortzmeyer.fr
* start date: Apr 5 12:54:32 2019 GMT
* expire date: Jul 4 12:54:32 2019 GMT
* subjectAltName: host "doh.bortzmeyer.fr" matched cert's "doh.bortzmeyer.fr"
* issuer: C=US; O=Let's Encrypt; CN=Let's Encrypt Authority X3
* SSL certificate verify ok.
* Using HTTP2, server supports multi-use
* Connection state changed (HTTP/2 confirmed)
* Copying HTTP/2 data in stream buffer to connection buffer after upgrade: len=0
* Using Stream ID: 1 (easy handle 0x56448a35af30)
> POST / HTTP/2
Host: doh.bortzmeyer.fr
Accept: */*
Content-Type: application/dns-message
Content-Length: 26
* SSL connection using TLSv1.3 / TLS_AES_256_GCM_SHA384
< HTTP/2 200
< content-type: application/dns-message
< content-length: 42
< cache-control: no-cache
< date: Tue, 09 Apr 2019 17:03:48 GMT
< server: hypercorn-h2
...
<!DOCTYPE html>
<html lang="">
<head>
<meta charset="utf-8" />
<title>Accueil | JdLL</title>
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<meta property="og:image" content="/user/themes/jd-ll/images/favicon.ico"/>
<meta name="generator" property="og:description" content="GravCMS" />
Sur Firefox, il faut configurer DoH dans un
onglet about:config. Le mot-clé est TRR pour
Trusted Recursive Resolver. On voit ici les
réglages disponibles (2 veut dire « utiliser DoH mais se rabattre
sur le DNS normal en cas de problème », 3 serait « uniquement
DoH » et 0 « pas de DoH du tout ») : 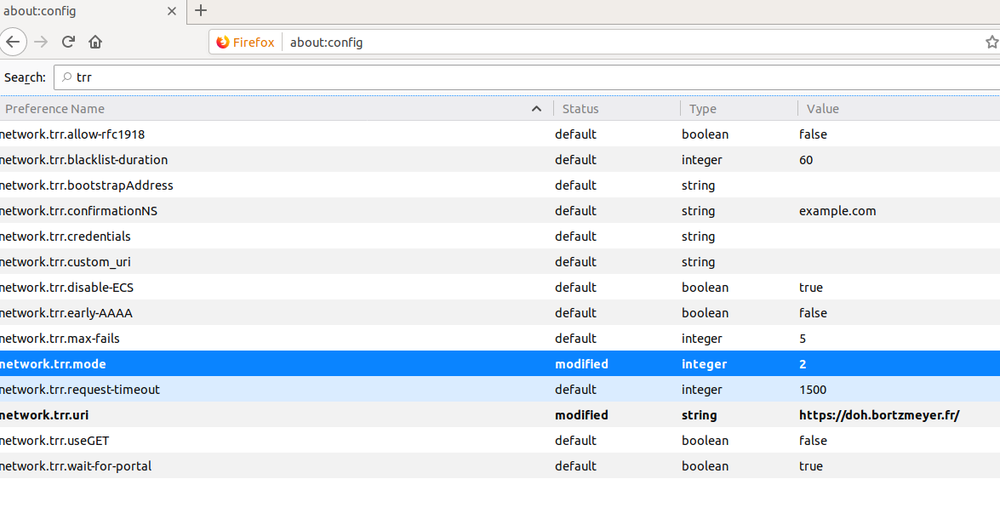
Merci aux organisat·eur·rice·s. On peut trouver de jolies photos des JDLL. Merci à Syst et Marne pour leur excellent exposé sur « Le vrai coût écologique de la publicité en ligne ». J'ai modestement contribué à la lutte contre les panneaux de surveillance publicitaire en installant une copie de la page de désinscription. Autre exposé très utile, celui d'Oriane sur « La Fédération FDN et la fibre optique. Enjeux et perspectives de l'Internet associatif en haut débit. » analysant les chances pour un opérateur Internet « alternatif » de pouvoir utiliser la fibre optique des RIP (Réseaux d'initiative publique). L'énorme travail de récolte d'informations fait par la FFDN montre que ce n'est pas gagné…
{kind=link}
L'article seul
DNS Extended Error reporting at the IETF hackathon
First publication of this article on 25 March 2019
On 23 and 24 March 2019 took place the now traditional hackathon of the IETF. I worked on a mechanism to report more detailed errors for DNS requests.
This IETF meeting was located in Prague (a very common city for IETF meetings). As we now do at each meeting, there is a hackathon the weekend before. This one was the biggest ever, with more than 350 persons coding in the room.
One of the projects (involving four people, Shane Kerr, Ralph Dolmans, Vladimír Čunát and myself) was to implement the "Extended DNS Errors" Internet-Draft. (It was later published as RFC 8914.) A long-time problem of the DNS is the fact there is little error reporting to the client. Most standardized return codes are rare or useless and one, SERVFAIL (Server Failure), is used to report almost every possible error. Therefore this draft, which adds a EDNS option to be returned by the server, adding to the normal return code:
- An "info-code", an integer giving details,
- Optional "extra-text", a human-readable character string,
- The "retry" bit, indicating to the clients if it makes sense to retry to another server or not.
My choice for the hackathon was to add this extended reporting system to the Knot resolver, with Vladimír Čunát (Shane Kerr worked on dnsdist and Ralph Dolmans on Unbound). Knot is written in C but a part of the extra modules is in Lua.
Adding an extra EDNS option in the reply is quite simple (the real difficulty is after that, don't stop reading!). I choose a code for the option, 65500, from the range dedicated to experimentations:
#define KNOT_EDNS_OPTION_EXTENDED_ERROR 65500
Of course, in the future, this definition will be in libknot, the general DNS library of the Knot authoritative server, library which is also used by the Knot resolver.
I then created a new module for Knot (many functions are not
done by the core but by modules),
extended_error, with the usual data
structures (code is available, you'll see it later). Extended
errors are defined as:
struct extended_error_t {
bool valid; /* Do we have something to report? */
bool retry;
uint16_t response_code;
uint16_t info_code;
const char *extra_text; /* Can be NULL. Allocated on the kr_request::pool or static. */
};
One small issue: serializing such a data
structure in the layout decided by the draft (one bit for retry,
four for response_code, matching RFC 1035, section
4.1.1, twelve for the info_code), required me
to re-learn bit manipulations in C:
uint32_t serialize(struct extended_error_t err) {
uint32_t result = 0;
result = (u_int32_t)err.retry << 31;
result = result + ((err.response_code & 0x0000000F) << 12);
result = result + (err.info_code & 0x00000FFF);
return(htonl(result));
}
(Je sais, ce n'est pas beau d'utiliser les opérateurs arithmétiques comme le plus, pour des opérations sur des bits. Cela a été corrigé par la suite.)
Now, once the module is done (modules/extended_error/), compiled (Knot uses
Meson) and ran, we indeed get the new EDNS
option in dig output. (We did not develop a
client using extended error codes, just used dig or
Wireshark to see what the server returned.)
But the real difficulty of the project was not here: it is to
extract the correct information from the depths of the DNS
resolver. On some resolvers (at least on Knot), the place where
the error is noticed can be quite far from the place where the
answer is built, with its EDNS options. In practice, we had to add
data to the request object kr_request, for
the extended error information to be carried to the module that
emits the extended error code EDNS option. So, the real difficulty
is not in the draft, but in knowing and understanding your
resolver.
First example, the case where all the authoritative name
servers for a zone are down (or reply wrongly). This is in
lib/resolve.c after some search in the code
to see where the resolver decided it is time to give in:
if (qry->ns.score > KR_NS_MAX_SCORE) {
request->extended_error.valid = true;
if (kr_zonecut_is_empty(&qry->zone_cut)) {
request->extended_error.retry = true;
request->extended_error.response_code = KNOT_RCODE_SERVFAIL;
request->extended_error.info_code = KNOT_EXTENDED_ERROR_SERVFAIL_NO_AUTHORITY;
request->extended_error.extra_text = "no NS with an address"; /* Also used when all authoritative nameservers timeout */
Younger C programmers would use the syntax:
request->extended_error = (struct extended_error_t){
.valid = true,
.retry = true,
.response_code = KNOT_RCODE_SERVFAIL,
.info_code = KNOT_EXTENDED_ERROR_SERVFAIL_NO_AUTHORITY,
.extra_text = "no NS with an address",
};
Another example is with DNSSEC, because
DNSSEC is a very important use case for extended errors since it
is important to know if the error is local to the resolver, or due
to a broken DNS zone. This is in
lib/layer/validate.c and, again, the
difficulty was not to write the code but to find where to put it:
if (ret != 0) {
if (ret != kr_error(DNSSEC_INVALID_DS_ALGORITHM) &&
ret != kr_error(EAGAIN)) {
req->extended_error.valid = true;
req->extended_error.retry = false;
req->extended_error.response_code = KNOT_RCODE_SERVFAIL;
if (vctx.rrs_counters.expired > 0) {
req->extended_error.info_code = KNOT_EXTENDED_ERROR_SERVFAIL_DNSSEC_EXPIRED;
req->extended_error.extra_text = "DNSSEC expired signatures";
One last example, using Knot's policy module. "Policy" means
the ability to lie, for instance to block domains used in
advertising and tracking (or to implement state
censorship). Most Knot modules are in
Lua. This one is in
modules/policy/policy.lua, and it shows that
extended error codes are not only useful for SERVFAIL but here for
NXDOMAIN, to allow the lying resolver to explain why it lied:
function policy.DENY_MSG(msg) -- TODO: customizable extended error info code
return function (_, req)
...
req.extended_error.valid = true
req.extended_error.retry = true
req.extended_error.response_code = kres.rcode.NXDOMAIN
req.extended_error.info_code = 1 -- "Blocked" TODO KNOT_EXTENDED_ERROR_NXDOMAIN_BLOCKED
With this code, we can configure the resolver to load the "extended error" module, and we block a domain, to check the policy module. Here is the configuration (itself a Lua file):
modules = {
'hints', 'nsid', 'extended_error'
}
...
policy.add(policy.suffix(policy.DENY_MSG("No tracking"), {todname('googleanalytics.com.')}))
Let's try it with dig:
% dig @::1 A brk.internautique.fr
...
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 15368
;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 4096
; OPT=65500: 80 00 20 07 6e 6f 20 4e 53 20 77 69 74 68 20 61 6e 20 61 64 64 72 65 73 73 (".. .no NS with an address")
;; QUESTION SECTION:
;brk.internautique.fr. IN A
...
We get a SERVFAIL, which is expected for this broken zone, plus an extended error code, displayed in hexadecimal by dig. We get the retry bit (such error might be temporary, or it may be server-dependent, for instance because of a local routing problem), and the "info code" 7 ("SERVFAIL Extended DNS Error Code 7 - No Reachable Authority").
Another example, with a zone which has a DNSSEC problem (in that case, deliberately introduced, for testing):
% dig @::1 A expired.caatestsuite-dnssec.com
...
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 38360
;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 4096
; OPT=65500: 00 00 20 02 44 4e 53 53 45 43 20 65 78 70 69 72 65 64 20 73 69 67 6e 61 74 75 72 65 73 (".. .DNSSEC expired signatures")
;; QUESTION SECTION:
;expired.caatestsuite-dnssec.com. IN A
...
This time, no "retry" bit (using another resolver won't help) and
info code 2, KNOT_EXTENDED_ERROR_SERVFAIL_DNSSEC_EXPIRED.
One last example, showing the effect of the policy declared in the configuration file:
% dig @::1 -p 9053 A googleanalytics.com
...
;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 46242
;; flags: qr aa rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 2
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 4096
; OPT=65500: 80 00 30 01 4e 6f 20 74 72 61 63 6b 69 6e 67 ("..0.No tracking")
;; QUESTION SECTION:
;googleanalytics.com. IN A
;; AUTHORITY SECTION:
googleanalytics.com. 10800 IN SOA googleanalytics.com. nobody.invalid. (
1 ; serial
3600 ; refresh (1 hour)
1200 ; retry (20 minutes)
604800 ; expire (1 week)
10800 ; minimum (3 hours)
)
;; ADDITIONAL SECTION:
explanation.invalid. 10800 IN TXT "No tracking"
Note the retry bit (if you don't approve the lie, you may go to another resolver), the forged SOA record, and the extra text which contains the message indicated in the configuration file.
If you want to see the full code, it is on
the public site, in Git branch
extended_error. A
merge has
been requested.
Thanks to Vladimír Čunát for a nice collaboration and for answering my (not always clever) questions, to Sara Dickinson for presenting the results, and to the organisers of the hackathon: a useful event!
L'article seul
« Keynote » sur Internet et les droits humains à BreizhCamp
Première rédaction de cet article le 22 mars 2019
Le 21 mars 2019, j'ai eu le plaisir et l'honneur et tout ça de faire la keynote d'ouverture à la conférence de développeurs BreizhCamp à Rennes. Le thème était « Internet et droits humains, il y a vraiment un rapport ? ».
Si vous voulez consulter les transparents, les voici, et vous avez droit également à leur source. La keynote a été filmée et la vidéo devrait donc être disponible un de ces jours, par exemple sur le canal YouTube de BreizhCamp. J'ai un peu parlé de mon livre « Cyberstructure », et pu faire une intéressante séance de dédicace après.
Et Pierre
Tibulle a fait une excellente
sketchnote de mon
exposé : 
Même chose de la part de Sarah : 
J'ai également suivi :
- L'atelier de Nicolas Savois sur le langage de
programmation Elixir. Ce n'était pas
juste un cours magistral mais également un apprentissage par la
pratique, les matériaux de l'atelier sont en
ligne. J'ai apprécié cette formule, où on a le temps de
pratiquer. Très convaincant, cela donnait envie de faire de
l'Elixir. Comme on est en Bretagne, les
exemples du formateur utilisaient un module nommé
Creperie. - Les bricolages d'enfer de Xavier Moulet, qui construit une console de jeu en partant de zéro, avec le fer à souder, et qui termine par sa programmation (« il n'y a pas de système d'exploitation donc ça démarre plus vite »). Voyez la page Web du projet. Les plans étant disponibles, environ cinquante consoles de ce modèle ont été construites par des passionnés. « La gestion de la mémoire est simple : la mémoire est là, on l'utilise. »
- L'intéressant exposé de Marc Audefroy et Éric Vergne sur
le projet humoristique de créer un TLD
.breizhcamp. Évidemment, il s'agissait d'une plaisanterie, mais le but était d'introduire le monde des noms de domaines (premier exemple,crepe-saucisse.bzh…), et la création de nouveaux TLD par l'ICANN. Environ 300 000 € pour votre TLD, selon l'estimation des orateurs (le dépôt initial n'est qu'une partie des frais). C'est bien plus cher s'il y a plusieurs candidatures et qu'il faut faire des enchères : 6,7 M$ pour.tech, 19 M$ pour.blog, 25 M$ pour.app, 41 M$ pour.shopet 135 M$ pour.web. - L'exposé d'Antoine Cailly sur Scuttlebutt. Le monde des réseaux sociaux décentralisés est bouillonnant, avec plein de nouveautés tout le temps. Dans Scuttlebutt, l'identité est une clé cryptographique. Et tous les messages sont signés. Pas très convivial mais sûr. Les données sont stockées sur sa machine et sur les machines des relations. Pour trouver un correspondant à partir de sa clé publique, on utilise des machines spéciales, les « pubs ». Si elles sont injoignables, Scuttlebutt peut encore fonctionner en échangeant les données sur le réseau local, ou même via une clé USB.
- Les exposés avec démonstration à vif, ce qui est toujours
courageux, de Jérôme Marchand sur le système de vérification
d'identité Keycloak et de Sébastien
Lecacheur sur le processeur JSON jq (au
passage, j'ai fait un article sur ce
logiciel). Avec comme exemple un gros
JSON décrivant tous les personnages de
Star Wars. La démo de
group_bypermet de voir qu'il y a beaucoup plus d'hommes que de femmes. - J'ai dû partir le vendredi matin et je n'ai donc pas pu voir les exposés du dernier jour.
Merci à Marc Audefroy pour m'avoir proposé de faire cette keynote, et merci à toute l'équipe d'organisation qui a fait un énorme travail bénévole. N'hésitez pas à venir à la prochaine édition, tout est très bien organisé ! (Et on a bien mangé.)
L'article seul
RFC 8490: DNS Stateful Operations
Date de publication du RFC : Mars 2019
Auteur(s) du RFC : R. Bellis (ISC), S. Cheshire (Apple), J. Dickinson (Sinodun), S. Dickinson (Sinodun), T. Lemon (Nibbhaya Consulting), T. Pusateri
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 18 mars 2019
Autrefois, le DNS était toujours cité comme exemple d'un protocole sans état. On envoie une requête, on reçoit une réponse, et le client et le serveur oublient aussitôt qu'ils ont échangé, ils ne gardent pas de trace de cette communication. Mais, dans certains cas, maintenir un état sur une durée plus longue qu'un simple échange requête/réponse peut être utile. Ce nouveau RFC propose un mécanisme pour des sessions DNS, le mécanisme DSO (DNS Stateful Operations). Il introduit donc une nouvelle notion dans le DNS, la persistance des sessions.
Ne pas avoir d'état a de nombreux avantages : cela simplifie les programmes, cela augmente les performances considérablement (pas besoin de chercher dans une table l'état actuel d'un dialogue, le contenu de la requête est suffisant pour donner une réponse, on peut répondre à la vitesse de l'éclair) et cela permet de résister aux DoS, qui réussissent souvent lorsqu'elles arrivent à épuiser le système qui dépend d'un état. (C'est pour cela que c'est souvent une mauvaise idée de mettre un pare-feu à état devant un serveur Internet, et c'est même franchement absurde quand il s'agit d'un serveur DNS.) Le DNS « habituel », tournant sur UDP et sans maintenir d'état, doit une partie de son succès à son caractère sans état.
Mais ne pas avoir d'état a aussi des inconvénients : toutes les options, tous les choix doivent être répétés dans chaque requête. Et cela rend impossible de négocier des paramètres entre les deux parties, par exemple dans le cas d'une session cryptographiquement protégée. Bref, dans certains cas, on aimerait bien avoir une vraie session, de durée relativement longue (plusieurs secondes, voire plusieurs minutes). Le DNS a un mécanisme de connexion de longue durée, en utilisant TCP (RFC 7766), et peut utiliser TLS pour sécuriser cette communication (DoT, « DNS over TLS », RFC 7858) mais les requêtes à l'intérieur de cette connexion n'en profitent pas, elles ne savent pas qu'elles sont liées par le fait qu'elles sont dans la même connexion. D'où ce nouveau système.
Le principe de DSO (DNS Stateful Operations) est de permettre à une requête DNS de créer une session, avec des paramètres communs à toute la session (comme la durée maximale d'inactivité). La session est balisée par des requêtes DNS utilisant l'opcode DSO, de numéro 6 (la création d'un nouvel opcode est très rare). Les paramètres sont encodés en TLV (une nouveauté dans le monde DNS ; les traditionnels Query count et Answer count, avec les sections correspondantes, ne sont pas utilisés). La longueur du message DSO est indiquée par les deux premiers octets du message. Les messages DSO peuvent solliciter une réponse (même si c'est un simple accusé de réception) ou pas. Cette sollicitation est faite par un Message ID différent de zéro. Si, par contre, le Message ID DNS est à zéro, il s'agit d'un message DSO unidirectionnel (retenez ce terme, il va souvent servir dans ce RFC), qui n'attend pas de réponse. (Rappelez-vous que le Message ID sert à faire correspondre requêtes et réponses DNS. Si on n'attend pas de réponse, pas besoin d'un Message ID. Si par contre le message est bidirectionnel, il doit mettre un Message ID non nul.)
DSO (DNS Stateful Operations, sessions - avec état, donc - pour le DNS) ne s'applique qu'avec certains transports sous-jacents (section 4 du RFC). UDP est évidemment exclu, car il faut maintenir l'ordre des messages, et il faut qu'il y ait une connexion à gérer. Cela peut être TCP (RFC 1035, section 4.2.2 et RFC 7766) ou DoT (DNS sur TLS, RFC 7858). DoH (DNS sur HTTPS, RFC 8484) est par contre exclu car HTTP a ses propres mécanimes de gestion de session. (D'autre part, la section 9.2 décrit les conséquences que cela a pour l'anycast.)
Deux importantes utilisations de DSO sont prévues :
- Gestion de sessions et des paramètres associés : DSO va permettre de définir des paramètres comme les durées maximales d'inactivité avant qu'on ne coupe la connexion de transport sous-jacente. Dans ce cas, DSO est une alternative au RFC 7828.
- Abonnements de longue durée à des services comme la découverte (RFC 6763).
La section 5 est le gros du RFC, elle décrit tous les détails du protocole. Pour établir une session DSO, il faut :
- Établir une connexion avec un protocole comme TCP ; on est alors connecté (on peut envoyer des messages DNS et recevoir des réponses) mais sans session DSO,
- On envoie une demande DSO,
- Si le correspondant est d'accord, on reçoit une réponse DSO, et la session est établie, et les paramètres comme la durée d'inactivité maximale sont désormais contrôlés par DSO ; on peut envoyer des messages DSO unidirectionnels (non sollicités, et ne demandant pas de réponse),
- Si par contre le correspondant refuse DSO, on continue avec une connexion normale.
Si on sait à l'avance que le correspondant gère DSO, on peut se considérer comme en session dès l'établissement de la connexion. Mais, souvent on ne sait pas ou on n'est pas sûr et il faut donc explicitement ouvrir une session. Cela se fait avec un message DSO (un message où l'opcode DNS vaut 6 ; ces opcodes sont décrits dans le RFC 1035, section 4.1.1). L'acceptation prend la forme d'un message DSO avec un Message ID qui correspond et un code de réponse 0 (rcode = NOERROR). Si le code de réponse est autre chose que NOERROR (par exemple 4, NOTIMP, « type de requête inconnu » ou 5, REFUSED, « je connais peut-être DSO mais je n'ai pas envie d'en faire »), c'est que notre correspondant ne peut pas ou ne veut pas établir une session.
Il n'y a pas de message DSO dédié à l'ouverture de session. On envoie un message DSO de n'importe quel type (par exemple Keepalive). Il peut donc arriver que le copain en face connaisse DSO mais pas ce type particulier. Dans ce cas, il va répondre DSOTYPENI (DSO Type Not Implemented, code 11, une nouveauté dans le registre). La session n'est pas établie et le client doit recommencer avec un autre type (comme Keepalive, qui a l'avantage d'être normalisé depuis le début et d'être obligatoire, donc il marchera partout).
Il y a des cas plus gênants : un serveur qui couperait la connexion de transport sous-jacente, ou bien qui ne répondrait pas aux messages DSO. Ce cas risque de se produire si un boitier intermédiaire bogué est sur le trajet. Il peut être alors nécessaire d'adopter des mesures de contournement comme celles qu'utilisaient les résolveurs DNS avec les serveurs ne gérant pas bien EDNS, mesures de contournement qui ont été abandonnées récemment avec le DNS Flag Day.
Si, par contre, tout se passe bien, la session DSO est établie, et des paramètres comme le délai d'inactivité doivent désormais suivre les règles de DSO et plus celles de normes précédentes comme le RFC 7766 (c'est pour cela que notre RFC met à jour le RFC 7766).
La section 5 détaille également le format des messages DSO. Ce sont des messages DNS ordinaires, commençant par le Message ID sur deux octets, avec l'opcode qui vaut DSO (code numérique 6). Les champs qui indiquent le nombre d'enregistrements dans les différentes sections doivent tous être mis à zéro. Les données DSO sont situées après l'en-tête DNS standard, et sont sous forme de TLV. Le logiciel peut donc analyser ces données même s'il ne connait pas un type DSO spécifique. Dans une requête DSO, il y a toujours au moins un TLV, le « TLV primaire », qui indique le type d'opérations. Les autres éventuels TLV (« TLV additionnels ») sont là pour préciser le message. Rappelons qu'il y a deux sortes de messages DSO, les unidirectionnels et les autres. Les unidirectionnels ont le Message ID à zéro et n'ont jamais de réponse. (Avec le Message ID à zéro, on ne saurait de toute façon pas à quelle demande correspond une réponse.)
Chaque TLV comprend trois champs :
- Le type, sur deux octets (la liste des types possibles figure dans un registre IANA créé par ce RFC),
- La longueur des données, sur deux octets,
- Les données.
Notez que la définition de chaque type doit préciser s'il est censé être utilisé en TLV primaire ou additionnel. Pour une réponse, il peut n'y avoir aucun TLV présent.
Toutes les sections « normales » d'un message DNS sont vides, y
compris la section additionnelle qu'utilise
EDNS (le champ ARCOUNT
doit être à zéro). Il ne peut donc pas y avoir d'options
EDNS dans un message DSO (pour éviter la confusion qui se
produirait si une option EDNS et un message DSO donnaient des
valeurs différentes au même service). Si on veut le service équivalent à une
option EDNS, il faut créer un nouveau type DSO (section 10.3 du
RFC pour les détails)
et le faire enregistrer.
Combien de temps durent les sessions DSO ? D'un côté, il faut qu'elles soient aussi longues que possible, pour amortir le coût de créer et de maintenir des sessions sur un grand nombre de requêtes, d'un autre, il ne faut pas gaspiller des ressorces à maintenir une session ouverte si elle ne sert plus à rien. La section 6 du RFC discute cette question. DSO a un délai maximal d'inactivité et, quand le délai est dépassé sans activité, le client DSO est censé couper la connexion. (S'il ne le fait pas, le serveur le fera, après un délai plus long.) Le client a évidemment le droit de couper la session avant l'expiration du délai, s'il sait qu'il n'en aura plus besoin.
Le délai maximal d'inactivité est fixé par les messages DSO de type 1. Deux cas spéciaux : zéro indique qu'on doit fermer la connexion immédiatement après la première requête, et 0xFFFFFFFF indique que la session peut être gardée ouverte aussi longtemps qu'on le souhaite.
DSO permet également de spécifier l'intervalle de génération des messages keepalives, messages envoyés périodiquement uniquement pour que les boitiers de traduction d'adresse gardent leur état et ne suppriment pas une correspondance adresse interne <-> adresse externe en pensant qu'elle ne sert plus. Si on sait qu'il n'y a pas de NAT sur le trajet, on peut mettre un intervalle très élevé. Le client peut aussi se dire « j'ai une adresse RFC 1918, le serveur a une adresse IP publique, il y a donc sans doute un machin NAT sur le trajet, je demande des keepalives fréquents ».
Enfin, le client doit être préparé à ce que le serveur ferme la session à sa guise, parce que le serveur estime que le client exagère (il ne ferme pas la session alors que le délai d'inactivité est dépassé, et qu'il n'envoie pas de requêtes), ou bien parce que le serveur va redémarrer. Normalement, c'est le client DSO qui ferme la session mais, dans certains cas, le serveur peut décider de le faire.
La section 7 du RFC décrit les trois TLV de base qui doivent être présents dans toutes les mises en œuvre de DSO : keepalive, délai avant de réessayer, et remplissage. La section 8.2 indique dans quels cas ils peuvent être utilisés par le client ou par le serveur.
Le TLV keepalive contrôle l'envoi de messages servant uniquement à indiquer que la session est toujours ouverte, afin notamment de rassurer les routeurs NAT. Ce même TLV sert également à indiquer le délai d'inactivité maximal. Comme ce type de TLV est obligatoire, c'est un bon candidat pour le message initial d'ouverture de session (il n'y a pas de message particulier pour cette ouverture : on envoie juste un message ordinaire). Il a le type 1 et comprend deux champs de données, le délai maximal d'inactivité, en millisecondes, sur quatre octets, et l'intervalle d'émission des keepalives, également en millisecondes, et sur quatre octets. Il peut être utilisé comme TLV primaire, et il requiert une réponse, le Message ID doit donc être différent de zéro. La valeur du délai maximal d'inactivité émise par le client est un souhait, la valeur à utiliser est celle qui figure dans la réponse du serveur. Si le client ne la respecte pas par la suite, le serveur aura le droit de fermer la session. Notez qu'EDNS avait déjà un mécanisme équivalent, pour définir une durée d'inactivité maximale dans les connexions TCP, normalisé dans le RFC 7828. Mais les limites d'EDNS, comme le fait que les options EDNS ne s'appliquent normalement qu'au message en cours, rendent cette solution peu satisfaisante. Cet ancien mécanisme ne doit donc pas être utilisé avec DSO, qui dispose, d'un autre système, celui utilisant les valeurs spécifiées par un message portant le TLV Keepalive.
Une fois la durée d'émission des keepalives fixée, les messages de keepalive seront des messages unidirectionnels (pas de réponse) et donc envoyés avec un Message ID nul.
Deuxième type de TLV obligatoire, le délai avant de réessayer de se connecter, qui a le code 2. C'est un message unidirectionnel, envoyé par le serveur pour indiquer qu'il va couper et qu'il ne faut pas réessayer avant la durée indiquée en valeur du TLV.
Et enfin, le troisième type (code 3) qui doit être présent dans toute mise en œuvre de DSO est le remplissage. Le but est d'améliorer la protection de la vie privée en insérant des données bidon dans les messages DNS, pour rendre plus difficile l'analyse des données chiffrées. Il n'a évidemment de sens que si la session sous-jacente est chiffrée, par exemple avec le RFC 7858. Pour la longueur du remplissage à choisir, voir le RFC 8467.
Comme toujours sur l'Internet, une grande partie des problèmes opérationnels viendront des middleboxes. Le RFC rappelle à juste titre que la meilleure solution serait de ne pas avoir de middleboxes mais, comme c'est un idéal lointain, en attendant, il faut se pencher sur ce que font ces fichus boitiers intermédiaires, qui se permettent parfois d'intercepter automatiquement le trafic DNS et de le modifier. Si le boitier gère DSO et répond correctement aux spécifications de ce RFC, tout va bien. Si le boitier ne comprend pas DSO et renvoie un NOTIMP ou équivalent, cela empêche d'utiliser DSO mais, au moins, cela ne viole pas la norme : le client réagira comme si le serveur ne connait pas DSO. Si le boitier ne connait pas le DNS, et n'essaie pas de le comprendre, ça devrait marcher si, bien sûr, il établit bien une connexion et une seule pour chaque connexion entrante (c'est ce que fait un routeur NAT qui ne regarde pas les couches supérieures).
Dès que le boitier ne respecte pas ces règles, on peut prévoir des ennuis, et qui seront très difficiles à déboguer. Par exemple si un répartiteur de charge DNS reçoit des connexions TCP, les ouvre, et envoie chaque requête DNS qu'elles contenaient à un serveur différent, le client DSO va certainement souffrir. Il croira avoir une session alors qu'il n'en est rien.
Autre problème pratique qui se posera peut-être : les optimisations de TCP. Deux d'entre elles ont des chances sérieuses de créer des ennuis, l'algorithme de Nagle et les accusés de réception retardés (on attend un peu de voir si un autre segment arrive, pour pouvoir accuser réception des deux avec un seul paquet, RFC 1122, section 4.2.3.2). Pour les messages DSO bidirectionnels, pas de problème. Pour les unidirectionnels, en revanche, le retard de l'accusé de réception pourra atteindre 200 millisecondes, ce qui est énorme dans un centre de données typique, avec des liens qui peuvent débiter plus d'un gibabit par seconde. L'algorithme de Nagle fera qu'on n'enverra pas de données tout de suite, attendant s'il n'y a pas quelque chose à transmettre et, avec l'accusé de réception retardé, la combinaison des deux retardera sérieusement l'envoi.
Débrayer l'algorithme de Nagle, ou bien les accusés de réception retardés, résoudrait le problème mais ferait perdre d'utiles optimisations. En fait, la seule solution propre serait que les API permettent aux applications de dire à TCP « il n'y aura pas de réponse à ce message, envoie l'accusé de réception tout de suite ».
Enfin, un petit mot sur la sécurité pour finir. DSO nécessite des connexions permanentes et, potentiellement, cela peut consommer pas mal de ressources sur le serveur. Pour se protéger, le serveur a donc parfaitement le droit de limiter le nombre de connexions maximal, et de fermer des sessions quand ça lui chante.
Toujours sur la sécurité, DSO permet des établissements de connexion sans aller-retour, avec TCP Fast Open (RFC 7413) et TLS 1.3 (RFC 8446). C'est très rapide, c'est très bien mais les données envoyées avec le premier paquet (early data) ne sont pas forcément bien sécurisées et la définition de chaque type de TLV doit donc indiquer s'il est sûr ou pas de l'utiliser dans le premier paquet.
Il semble qu'à l'heure actuelle, il n'y a pas encore de mise en œuvre de cette technique DSO.
L'article seul
Conférence « Vie privée et Internet : derrière les derniers scandales » à la bibliothèque de Limoges
Première rédaction de cet article le 9 mars 2019
Aujourd'hui, conférence sur la vie privée à Limoges, à la bibliothèque francophone multimédia.
Splendide bibliothèque, pleine de livres dans un cadre exceptionnel. On a envie d'y passer ses journées à lire. Mais je n'étais pas là pour ça mais, dans le cadre du Mois du Logiciel Libre, je venais parler de la vie privée sur l'Internet. Il y a régulièrement des scandales liés à une fuite de données personnelles, ou à une utilisation dégueulasse des données, par exemple dans l'affaire Cambridge Analytica. Qu'est-ce que ces scandales nous apprennent ? Quel est l'état de la protection des données personnelles ? Quand se décidera-t-on enfin à minimiser les données collectées ? Va-t-il falloir brouiller délibérement les données ? (Réponse : oui.)
Voici les transparents utilisés : d'abord une version
PDF, vie-privee-bfm-limoges.pdf, puis le source en
LaTeX, vie-privee-bfm-limoges.tex. La conférence a été filmée
donc il y a des chances que la vidéo apparaisse un jour sur
l'Internet.
Merci à Guillaume Lair pour l'organisation de la conférence, et à tou·te·s les libristes qui sont venus au bistrot après. Grâce à vous, la liberté finira par gagner.
L'article seul
Détails techniques sur les récentes attaques contre les noms de domaine
Première rédaction de cet article le 27 février 2019
Au cours du dernier trimestre 2018, mais peut-être depuis plus longtemps, un certain nombre d'attaques contre les noms de domaine ont eu lieu, apparemment toutes perpétrées par le même groupe. Dans un autre article, j'ai essayé d'expliquer à un public assez large ce qu'étaient ces attaques et leurs conséquences. Dans l'article que vous êtes en train de lire, je détaille un certain nombre de points techniques. Au contraire du premier, cet article est fait pour un public de technicien·ne·s.
Quelques avertissements sont sans doute utiles :
- L'auteur de cet article (moi) ne sait pas tout. Autant que possible, j'ai essayé de ne parler que de ce qui était public, et que chacun pouvait vérifier mais, en sécurité, ça n'est pas toujours possible. Et, évidemment, vous ne trouverez pas ici d'informations confidentielles.
- Les gens qui savent quelque chose, et qui connaissent le sujet sont presque toujours employés par une organisation qui ne leur permet pas de tout raconter à l'extérieur.
- Le monde de la cybersécurité est très fermé, les informations ne circulent que dans des cercles restreints. Ce qui est publié n'est souvent que de vagues résumés, parfois délibérement déformés à des fins commerciales ou politiques. C'est une des raisons pour lesquelles la cybersécurité progresse si lentement, et pourquoi les légendes ont la vie dure : le baratin est libre alors que la vérité a les mains liées.
Cet article est basé en grande partie sur les rares articles techniques sérieux publiés sur le sujet (dans l'ordre chronologique) :
- L'article de Talos, qui fut apparemment le premier, à un moment où l'ampleur de la campagne n'était pas encore évidente,
- Celui de Fireye (que je trouve peu détaillé, et dont les explications DNS sont confuses),
- Celui de CrowdStrike qui, sauf erreur, a été le premier à donner des IOC (élements précis qu'on peut vérifier, les adresses IP utilisées, par exemple), IOC que j'utilise par la suite,
- L'article de Brian Krebs, le plus complet.
Cet article sera malheureusement assez décousu, sautant d'un sujet à l'autre. l'idée est d'expliquer en français quelques points techniques subtils sur ces attaques.
Donc, d'abord, un résumé. La série d'attaques qui a eu lieu au
moins d'octobre à décembre 2018 reposait en grande partie sur le
détournement de noms de domaine. Le
détournement (hijacking, d'ailleurs un collègue
me dit que ça peut s'écrire highjacking) de
noms de domaine consiste à usurper l'identité d'un titulaire ou
d'un autre responsable d'un nom
de domaine pour changer les informations associées à
un nom. Voici par exemple le panneau de contrôle Web de
Gandi : 
Ce panneau est protégé par un mot de passe, auquel on peut ajouter un deuxième facteur d'authentification. Si quelqu'un peut mettre la main sur ces mécanismes d'authentification, il peut se faire passer pour le vrai responsable du nom, et changer les informations. On voit que cette attaque n'est pas une attaque DNS, le protocole DNS n'y ayant joué aucun rôle. Il s'agit d'une attaque contre le système d'avitaillement des noms de domaine (leur création et modification). Par contre, elle va avoir des conséquences sur le DNS. Et c'est encore plus vrai si le nom détourné est le nom d'un serveur de noms faisant autorité. On voit également que cette attaque n'était pas de haute technologie, et reposait probablement sur des méthodes de hameçonnage et d'ingénierie sociale classiques.
Les attaques par détournement de nom de domaine sont classiques et anciennes. Sur ce blog, j'avais déjà parlé en détail de celle contre le New York Times en 2013 et de celle contre Wikileaks en 2017. Il y en a eu d'autres commes celles contre Canal + et Météo France en 2016. La nouveauté des attaques de 2018, si nouveauté il y a, est dans leur caractère plus systématique et professionnel, probablement au sein d'un groupe unique. (Ne me demandez pas qui ; je n'en sais rien.)
Je m'aperçois que je m'emballe, j'ai déjà parlé du DNS alors que je voulais garder cela pour plus tard. Le DNS est à la fois une technologie indispensable de l'Internet, et une des plus mal connues. La lecture des articles qui parlent de DNS est souvent déprimante, en raison du nombre d'erreurs. Donc, pour lire la suite de cet article, il vaut mieux être au courant du vocabulaire des noms de domaine et du DNS, tel que compilé dans le RFC 8499. Il est notamment crucial de noter que parler de « serveur DNS » tout court est fortement déconseillé. Il y a les résolveurs et il y a les serveurs faisant autorité et ce sont deux choses très différentes. Dans le RFC 8499, vous allez également devoir réviser les notions de bailliage et de colle.
Après les préliminaires, lançons-nous dans les attaques de 2018. D'abord, peut-on vérifier les faits mentionnés dans les articles cités plus haut, ou bien devons-nous faire une confiance aveugle ? L'article de Crowdstrike ou celui de Krebs donnent des détails techniques précis, qu'on peut vérifier. (Je classe automatiquement les articles qui ne donnent aucun nom, aucune adresse IP, dans la catégorie « pas sérieux ».) Comme ces articles concernent des événements passés, on ne peut pas utiliser les clients DNS comme dig aujourd'hui, il faut faire appel à des outils historiques comme DNSDB, qui ne sont pas toujours accessibles publiquement. Prenons l'exemple du ministère des affaires étrangères égyptien. DNSDB nous montre :
;; bailiwick: gov.eg.
;; count: 3
;; first seen: 2018-11-14 18:41:30 -0000
;; last seen: 2018-11-14 20:05:40 -0000
mail.mfa.gov.eg. IN A 188.166.119.57
On y voit que le 14 novembre 2018, et peut-être également avant et
après (DNSDB ne voit pas tout le trafic DNS, loin de là),
mail.mfa.gov.eg avait comme adresse IP
188.166.119.57, une des adresses listées dans
les IOC de CrowdStrike. (L'adresse IP
habituelle de ce serveur, avant et après, est
41.191.80.13.) L'adresse IP utilisée par les
attaquants est hébergée chez DigitalOcean, ce qu'on peut voir avec
whois.
DNSDB permet également de chercher par le contenu. On peut voir ainsi les autres noms pointant (ou ayant pointé, parfois longtemps avant) vers cette adresse :
mail.mfa.gov.eg. IN A 188.166.119.57
sm2.mod.gov.eg. IN A 188.166.119.57
mail.mod.gov.eg. IN A 188.166.119.57
mail.noc.ly. IN A 188.166.119.57
embassy.ly. IN A 188.166.119.57
egypt.embassy.ly. IN A 188.166.119.57
...
Si nous faisons ce même exercice de recherche avec une autre adresse trouvée dans la liste de CrowdStrike :
ns0.idm.net.lb. IN A 139.59.134.216 sa1.dnsnode.net. IN A 139.59.134.216 fork.sth.dnsnode.net. IN A 139.59.134.216 plinkx.info. IN A 139.59.134.216 ...
On trouve de vieilles informations
(plinkx.info n'existe plus depuis 2017) mais
aussi d'autres noms comme
ns0.idm.net.lb, au Liban. Comme son nom l'indique,
c'est un serveur DNS, et on voit qu'il fait autorité pour le domaine :
% dig @ns0.idm.net.lb NS idm.net.lb
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 54194
;; flags: qr aa rd; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 4
...
;; ANSWER SECTION:
idm.net.lb. 3600 IN NS sf.idm.net.lb.
idm.net.lb. 3600 IN NS ns0.idm.net.lb.
...
;; SERVER: 2a00:1590:3c::2#53(2a00:1590:3c::2)
;; WHEN: Tue Feb 26 20:40:26 CET 2019
;; MSG SIZE rcvd: 134
DNSDB nous indique que cette adresse a changé pendant le moment où l'attaque était à son maximum :
;; bailiwick: lb. ;; count: 2 ;; first seen: 2018-12-18 15:00:27 -0000 ;; last seen: 2018-12-18 15:00:27 -0000 ns0.idm.net.lb. IN A 139.59.134.216
Cela illustre un point important de cette attaque : elle ne visait pas que des serveurs « finaux » (serveur HTTP ou SMTP) mais aussi des serveurs DNS, afin de pouvoir envoyer de fausses réponses aux requêtes DNS.
Notez aussi la ligne marquée bailiwick
(bailliage). L'information mensongère n'était pas dans la zone
elle-même, mais dans la zone parente
(.lb pour
ns0.idm.net.lb). Cela montre que l'attaquant
est bien passé par le bureau
d'enregistrement et pas par l'hébergeur DNS, puisqu'il
a pu modifier les informations au registre
« du dessus ».
Et si vous n'avez pas accès à DNSDB ou pas confiance dans leurs résultats ? Vous pouvez essayer aussi avec PassiveDNS.cn, qui nous trouve :
mail.mfa.gov.eg A In rrset
-------
Record times: 2018-10-22 17:27:09 -- 2019-02-26 18:45:45
Count: 807
mail.mfa.gov.eg A 41.191.80.13
Record times: 2014-08-19 13:08:27 -- 2018-10-22 11:27:47
Count: 1398
mail.mfa.gov.eg A 41.191.80.12
Record times: 2017-11-21 00:39:59 -- 2018-10-21 10:42:56
Count: 951
mail.mfa.gov.eg A 41.191.80.12
mail.mfa.gov.eg A 41.191.80.13
Ah, oui, le monde est cruel. Le service chinois de passive
DNS a beaucoup moins
de points de mesure, et n'a pas vu le court moment du
détournement. Même problème avec circl.lu, qui, pour le
serveur de noms libanais, voit juste :
{"count": 1724, "origin": "https://www.circl.lu/pdns/", "time_first": 1477641718, "rrtype": "A", "rrname": "ns0.idm.net.lb", "rdata": "194.126.10.18", "time_last": 1538114779}
Bref, difficile de se passer de DNSDB.
Si vous avez bien regardé plus haut les noms qui ont pointé
vers 139.59.134.216, vous avez peut-être
remarqué fork.sth.dnsnode.net. C'est encore
un serveur de noms, appartenant à un hébergeur important,
Netnod. Cette société a publiquement
communiqué à propos de cette attaque. La machine en
question est également un serveur de noms, et c'est une nouvelle
illustration de l'utilisation de serveurs de noms pour une attaque
très indirecte, où le pirate change l'adresse IP du serveur de
noms pour ensuite pouvoir répondre ce qu'il
veut. fork.sth.dnsnode.net est utilisé par
des TLD comme
.ps ou
.lb (mais aussi par
des TLD sans lien avec le Moyen-Orient comme
.aq). DNSDB montre au
moins deux détournements :
;; bailiwick: net.
;; count: 9308
;; first seen: 2018-12-14 12:09:32 -0000
;; last seen: 2018-12-24 12:17:24 -0000
fork.sth.dnsnode.net. IN A 82.196.11.127
;; bailiwick: dnsnode.net.
;; count: 63
;; first seen: 2018-12-24 15:21:49 -0000
;; last seen: 2018-12-27 19:24:23 -0000
fork.sth.dnsnode.net. IN A 139.59.134.216
Outre les adresses IP, l'article de CrowdStrike nous apprend
que les attaquants ont également utilisé des
noms comme cloudnamedns.com. Si le domaine
n'existe plus, on retrouve son nom dans le détournement des
services de renseignement jordanien :
;; bailiwick: gov.jo.
;; count: 67
;; first seen: 2017-02-07 08:17:10 -0000
;; last seen: 2017-02-12 23:27:29 -0000
gid.gov.jo. IN NS ns1.cloudnamedns.com.
gid.gov.jo. IN NS ns2.cloudnamedns.com.
(Notez la date : c'était bien avant que l'affaire soit publique.)
Ce cas illustre le fait que les attaquants ont tantôt changé des
adresses IP (enregistrements DNS de type A), tantôt des listes de
serveurs de noms (enregistrements DNS de type NS). Dans le cas de
gov.eg, on ne trouve pas de trace de
changement des NS, alors que, pour
gid.gov.jo, on voit ci-dessus le changement
de NS. Changer les NS
dans la zone parente nécessite d'avoir accès au bureau
d'enregistrement. Changer les adresses IP nécessite un
accès à l'hébergeur DNS, ou bien au bureau d'enregistrement s'il
s'agit d'enregistrements dits de colle. (Notez que l'hébergeur DNS
peut être également le bureau d'enregistrement, ou bien être le
titulaire lui-même, ou encore être un tiers.)
DNSSEC a souvent été mentionné comme une technique à déployer, voire comme une solution qui aurait empêché cette attaque. Ce sont en fait deux questions distinctes. Oui, DNSSEC, normalisé dans le RFC 4033 et suivants, est une bonne solution, et devrait être déployé partout depuis longtemps. (Vous pouvez voir l'arborescence DNSSEC du domaine de ce blog sur DNSviz.) Mais, comme toutes les techniques de sécurité, DNSSEC ne résout pas tous les problèmes. DNSSEC signe les enregistrements DNS. Un résolveur DNS validant (qui vérifie les signatures) peut alors détecter les enregistrements modifiés et les rejeter. DNSSEC protège, par exemple, contre un serveur secondaire faisant autorité qui serait malhonnête ou piraté. Il protège également contre les attaques de type Kaminsky.
Normalisé depuis longtemps (le RFC 4033
date de quatorze ans) et déployé dans la racine du DNS et dans les
TLD importants comme
.fr et
.com depuis 2009-2011,
DNSSEC devrait aujourd'hui être présent partout. Les zones DNS
importantes devraient être signées, et les résolveurs devraient
valider. Bien sûr, mieux vaut tard que jamais. Si, suite aux
attaques du moment, davantage d'organisations déploient DNSSEC,
c'est parfait.
Mais DNSSEC aurait-il aidé dans ces cas précis ? DNSSEC, on l'a vu, permet de s'assurer que les données n'ont pas été modifiées entre l'origine (l'endroit où sont gérées les données) et le résolveur validant. Mais si les données sont fausses dès l'origine ? Le bon sens nous dit qu'il ne sert à rien de signer des données fausses. Si l'attaquant a le contrôle de l'origine (par exemple le serveur DNS maître), il peut modifier les données et signer des données mensongères. Ou bien il peut simplement retirer l'enregistrement DS dans la zone parente, indiquant ainsi que la zone n'est pas signée. Pour citer Paul Ebersman, « DNSSEC isn't useless but it solves one specific problem ».
Ça, c'est la théorie, mais la pratique est plus compliquée. D'abord, les attaquants ne sont pas parfaits. Il y a des amateurs, des professionnels, et des professionnels compétents. Et même ces derniers font des erreurs. Lors de détournements de noms signés avec DNSSEC, il a déjà été observé que les attaquants, bien qu'ils ont acquis le pouvoir de changer également les informations DNSSEC, n'y pensent pas toujours. Et même s'ils y pensent, le temps n'est pas sous leur contrôle, ce qui peut rendre DNSSEC efficace, même en cas de piratage d'un registre. L'article de Krebs cité plus haut donne d'ailleurs le témoignage de l'hébergeur PCH, qui explique comment DNSSEC a partiellement empêché l'exploitation par le pirate de ses succès antérieurs. Il faut faire très attention, en sécurité, à ne pas se braquer exclusivement sur des solutions théoriquement parfaites. Ce qu'on cherche à faire, ce n'est pas à rendre impossible toute attaque (c'est irréaliste), mais à gêner le plus possible l'attaquant. La plupart des serrures ne résistent pas longtemps à un cambrioleur professionnel, équipé de matériel de qualité. Mais on ne renonce pas à mettre des serrures pour autant : elles bloquent le cambrioleur amateur, et elles gênent même les plus compétents, ce qui peut les empêcher d'aller jusqu'au bout. Pour citer Paul Ebersman, « we are in a world now where every layer of security we can add is probably a good idea and having a day to notice could be handy ».
Bref, attaques du moment ou pas, ce serait une bonne chose que pousser le déploiement de DNSSEC. Comme DNSSEC consiste en la signature des zones et leur validation, deux catégories d'acteurs doivent agir : les gérants des zones (cela peut être l'hébergeur DNS, ou bien le titulaire de la zone), et les gérants des résolveurs (typiquement le FAI ou le service informatique de votre organisation). Pourquoi n'ont-ils pas encore agi ? Les raisons sont variées, mais c'est l'occasion de rappeler que la sécurité, ce n'est pas juste pousser des cris quand une attaque spectaculaire est révélée. Cela nécessite du temps, et des efforts constants. Une des raisons du déploiement insuffisant est peut-être l'étonnante quantité de nimportequoi qu'on trouve dans les médias au sujet de DNSSEC. Comme quand un article explique que DNS chiffre (non) et « rend les données illisibles » (certainement pas).
Arrivé·es là, mes lecteurices, qui sont très compétent·e·s, se disent probablement : « mais on s'en moque du détournement DNS, tout est protégé par TLS de nos jours, donc le détournement ne servira à rien ». Précisons : ce n'est pas tant TLS qui pourrait permettre de détecter un détournement, mais l'authentification fournie par PKIX/X.509 (ce que les médias appellent « certificat SSL », même si SSL est officiellement abandonné depuis trois ans - RFC 7568 - et que, de toute façon, ces certificats peuvent servir à d'autres usages). Normalement, en cas de détournement DNS, les visiteurs du serveur pirate auraient dû se heurter à un mauvais certificat, et la communication être coupée, non ?
Eh bien non, comme l'ont montré ces attaques. D'abord, il y a des services qui n'utilisent pas TLS ou une technique équivalente (c'est le cas du DNS, malgré le RFC 7858). Ensuite, il n'y a pas que les navigateurs Web. Les autres applications clientes oublient parfois de vérifier les certificats, ou bien ne coupent pas la communication si le certificat est invalide. Mais, surtout, ce qui relativise sérieusement la protection offerte par PKIX, c'est que, si on contrôle un nom de domaine, on peut avoir un certificat. Cela n'est certes pas vrai pour les certificats EV mais les DV, eux, peuvent être obtenus dès qu'on contrôle le domaine.
Et c'est bien ce qu'ont fait les pirates ! On peut le savoir
grâce au fait qu'il existe plusieurs
journaux stockant les certificats émis, et
accessibles publiquement (RFC 6962). Prenons
crt.sh pour y
accéder, et un domaine égyptien cité plus haut :
;; bailiwick: gov.eg. ;; count: 3 ;; first seen: 2018-11-14 18:41:30 -0000 ;; last seen: 2018-11-14 20:05:40 -0000 mail.mfa.gov.eg. IN A 188.166.119.57
Pendant cette courte période, l'attaquant a obtenu un certificat via Let's Encrypt, le 03:d9:d3:e5:a6:2c:dc:87:1c:b8:0f:1f:fd:e5:fa:eb:2c:b7. L'attaquant avait donc un certificat parfaitement valable et reconnu par beaucoup de logiciels. TLS, PKIX et X.509 ne protégeaient plus.
Un autre exemple est celui d'un domaine albanais. DNSDB montre le détournement :
;; bailiwick: asp.gov.al.
;; count: 8
;; first seen: 2018-11-08 09:49:18 -0000
;; last seen: 2018-11-08 10:06:17 -0000
mail.asp.gov.al. IN A 199.247.3.191
Et l'attaquant a eu un certificat. On notera que, contrairement à ce qui a parfois été écrit, il n'y a pas que Let's Encrypt qui a été utilisé par les pirates, ce dernier certificat venait d'une autre AC, Comodo. Puisqu'on parlait de DNSSEC, on notera que Comodo ne valide pas les domaines à travers un résolveur DNS validant… Pire, Comodo n'a pas révoqué les certificats émis pendant les détournements, alors qu'ils sont valables un an. (Ceux de Let's Encrypt, d'une durée de validité de trois mois, sont pour la plupart expirés.)
Une autre technique qui aurait pu aider est celle du verrouillage. L'idée est de demander au registre de ne pas accepter les modifications (changement des serveurs de noms, par exemple), sans une procédure additionnelle de déverrouillage (envoi de SMS à N contacts, auxquels au moins M d'entre eux doivent répondre, par exemple). La plupart des registres offrent cette possibilité (par exemple .fr), mais elle reste peu utilisée. Notez que vous ne pouvez pas voir, de l'extérieur, si un domaine est ainsi verrouillé. whois ne l'affiche pas, par exemple.
Outre DNSSEC et le verrouillage, un autre outil de sécurité important, mais souvent négligé, est la supervision. On a vu plus haut que les certificats émis étaient publics, et il est donc utile de superviser l'émission de certificats pour ses noms de domaine, pour voir si un méchant n'a pas réussi à en obtenir un.
Dommage,
crt.sh n'a apparemment pas d'API mais, comme me le conseille
Valentin Robineau, on peut utiliser celle
de CertStream. Ici, j'utilise leur
bibliothèque Python avec un
petit script qui n'affiche que les certificats pour des
noms en .fr (le flux
complet est évidemment très bavard) :
[2019-02-28T08:35:30] www.ilovemypet.fr (SAN: )
[2019-02-28T08:35:34] www.manaturopatheetmoi.fr (SAN: )
[2019-02-28T08:35:34] cdns.nicolaschoquet.fr (SAN: )
[2019-02-28T08:35:36] bmv-verre.fr (SAN: www.bmv-verre.fr)
[2019-02-28T08:35:36] www.armand-martin-osteo.fr (SAN: )
[2019-02-28T08:35:37] www.chiropracteur-thiais-nabe.fr (SAN: )
[2019-02-28T08:35:37] hekafrance.fr (SAN: www.hekafrance.fr)
[2019-02-28T08:35:50] mail.topocad-tech.fr (SAN: )
[2019-02-28T08:35:53] cherchons-trouvons.fr (SAN: cherchons-trouvons.odazs.com, cpanel.cherchons-trouvons.fr, mail.cherchons-trouvons.fr, webdisk.cherchons-trouvons.fr, webmail.cherchons-trouvons.fr, www.cherchons-trouvons.fr, www.cherchons-trouvons.odazs.com)
(Dans la réalité, bien sûr, on ne regarderait que les noms de ses domaines.)
Mais il n'y a pas que les certificats qu'on peut superviser. On peut aussi regarder son domaine avec whois et/ou avec le DNS pour être prévenu immédiatement d'un changement. C'est assez facile à programmer soi-même, pour intégration dans un système de supervision comme Icinga. Pour le DNS, il existe même des services tout faits comme l'excellent DNSspy (si vous en connaissez d'autre, merci de me les signaler).
La supervision ne peut que détecter le détournement, pas l'empêcher. À la base, le problème principal est de suivre les bonnes pratiques de sécurité, ce qui est toujours plus facile à dire qu'à faire. On peut déjà éviter de mettre le mot de passe de l'interface Web du BE sur un Post-It affiché dans l'open space. (Ne riez pas : ça existe.) Au-delà, il faut envisager de durcir tous les mécanismes d'authentification. Lors des débats suivant cette attaque, pas mal de gens ont cité l'authentification à deux facteurs. C'est une bonne idée dans l'absolu mais son déploiement est freiné par la variété des solutions fermées et incompatibles. Si on n'avait à protéger que l'interface du BE ou de l'hébergeur DNS, ce serait simple, mais l'administrateur réseaux typique gère beaucoup de choses et, s'il activait l'authentification à deux facteurs partout, il devrait se trimbaler avec un grand nombre de dispositifs matériels. Il existe bien un protocole ouvert, décrit dans le RFC 6238, mais ce n'est pas celui qui est utilisé par tout le monde. Il ne suffit pas de crier « il faut faire du 2FA ! », il faut aussi accepter de discuter les problèmes pratiques de déploiement.
Quelques lectures qui peuvent vous intéresser, outre les articles techniques sérieux cités au début de cet article :
- De bons textes, plein de sages avis, sur la sécurisation de vos noms de domaine : le guide des bonnes pratiques de l'ANSSI et le dossier de l'AFNIC sur la même question.
- Le communiqué de l'ICANN.
- Un bon
communiqué de SIDN, le registre de
.nl, décrivant calmement le problème (avec de bons conseils dans l'avant-dernier paragraphe.) - Un court
communiqué du registre de
.com. - Pour les gens pressés, Ars Technica a fait un résumé pas trop mauvais.
- Des semaines après, Talos a publié un rapport avec peu d'informations nouvelles, et des grosses erreurs sur la notion de registre.
- Beaucoup d'articles sensationnalistes, voire ridicules, ont été publiés. Un exemple est cet article mais il est loin d'être le seul ; méfiez-vous des médias.
- Beaucoup d'articles contiennent des erreurs, parfois sérieuses. C'est le cas de cet article, qui invente que l'ICANN aurait été « reconnue d'utilité publique » (par qui ???), qui cite une attaque dDoS sans aucun rapport avec l'attaque actuelle, et qui mélange détournement de noms de domaine et attaques par réflexion. De même, cet autre article prétend qu'on ne peut pas utiliser TCP pour le DNS (les auteurs auraient dû lire le RFC 7766), prétend que DNSSEC « introduit de l'aléatoire dans les requêtes » (!!!), ajoute que DNSSEC chiffre (!!!) et finit par ajouter des certificats imaginaires dans DNSSEC. Un autre exemple est cet autre article : contrairement à ce qu'il dit, l'ICANN n'a pas été piratée (et n'a pas signalé un tel piratage, le gestionnaire de mots de passe n'a absolument rien à voir avec ce piratage, utiliser Cisco OpenDNS n'aurait protégé, puisque l'attaque portait sur le domaine lui-même, et la publicité pour le VPN à la fin est non seulement indication de malhonnêteté mais est absurde : utiliser un VPN n'aurait rien changé ici. La médiocrité de l'information que reçoit le lecteur ou la lectrice ordinaire a de quoi inquiéter, car on n'améliorera pas la sécurité de l'Internet sans un minimum de compréhension du problème.
- En français, plusieurs articles ont présenté une vue plus informée du problème : l'article de Next Inpact, celui du Monde ou cet interview sur France TV info.
L'article seul
Attaques récentes contre les noms de domaine, que se passe-t-il ?
Première rédaction de cet article le 25 février 2019
Le week-end des 23 et 24 février a vu beaucoup d'articles dans les médias à propos d'une campagne d'attaques Internet menées via les noms de domaine. Que s'est-il passé ?
Cet article se veut pédagogique et prévu pour des gens qui ne sont pas des experts en noms de domaine. (Les experts qui veulent plein de détails techniques devront lire un autre article.)
Donc, commençons par un avertissement : la cybersécurité est un domaine compliqué, et qui n'est pas facile à résumer et à vulgariser. Je vais être obligé de simplifier (rappelez-vous que cet article n'est pas pour les experts) tout en restant rigoureux. Il n'est pas possible de résumer ce qu'on sait de ces attaques discutées récemment en un seul paragraphe. Et tout n'a pas encore été découvert, il est possible que des investigations ultérieures nuancent, voire annulent, ce que j'écris ici. D'autre part, un point important de la cybersécurité est que tout n'est pas public, loin de là. Il y a des tas de choses que je ne sais pas, et d'autres dont je ne peux pas forcément parler. Comme le dit l'adage, « ceux qui savent ne parlent pas, ceux qui parlent ne savent pas ». Donc, prudence.
Commençons par les certitudes : au dernier trimestre de l'année 2018, plusieurs attaques informatiques ont eu lieu, en utilisant des méthodes similaires, et visant notamment des objectifs gouvernementaux. On voit déjà qu'il ne s'agit pas du tout d'une attaque en cours, qui aurait commencé le 22 ou le 23 février, mais d'un problème déjà passé. Ces attaques avaient en commun le détournement des noms de domaine. Avant de continuer, il faut donc s'arrêter sur les noms de domaine et sur leur utilité.
Un nom de domaine est un identificateur pour un service ou une
machine sur l'Internet. Il se présente sous
la forme de chaînes de caractères séparées par des points. Par
exemple, www.bortzmeyer.org est un nom de
domaine, tout comme brexit.gouv.fr ou
réussir-en.fr. Des informations techniques,
utiles uniquement pour les machines, sont associées à ces
noms. Ces informations sont cruciales pour faire en sorte que
vous, utilisateur ordinaire de l'Internet, arriviez bien au bon
endroit. Par exemple, si votre banque est accessible en ligne et
que vous utilisez le nom de domaine
client.mabanque.example, votre ordinateur ou
ordiphone va obtenir, en échange de ce nom,
les informations dont il a besoin pour se connecter au site
Web de la banque. (Il s'agit entre autres de
l'adresse IP.) Si, par malheur, ces
informations étaient incorrectes, vous n'arriveriez pas sur le
site de votre banque mais sur un autre.
Et c'est précisement le cœur de l'attaque qui a fait tant de bruit depuis quelques jours : les pirates informatiques ont réussi à prendre le contrôle d'un certain nombre de noms de domaine, et à y associer d'autres informations techniques. Ainsi, les utilisateurs, croyant se connecter à tel ou tel service, allaient en fait sur un autre. Lorsque le service est un site Web, l'attaquant copiait le site Web original, faisait quelques modifications, et le plaçait sur le serveur qu'il contrôlait. Une telle attaque n'a pas d'équivalent dans le monde physique. Si vous voulez vous rendre à la Tour Eiffel et qu'on vous donne une mauvaise adresse pour ce monument, vous vous rendrez bien compte que vous n'êtes pas au bon endroit. (Des lecteurs érudits de ce blog me font remarquer qu'une attaque très similaire est pourtant montrée dans le film Ocean 11 ou dans la série The Blacklist.) Mais, sur l'Internet, vous ne voyez pas la distance (vous ne savez pas facilement si vous vous connectez à un site Web situé au Maroc ou au Japon) et vous ne voyez pas du premier coup que le site a été copié.
Et il n'y a pas que le Web. Les attaquants avaient également détourné des serveurs de messagerie, ce qui est encore plus facile, car l'utilisateur ne « voit » pas le serveur de messagerie, connexion et échange de messages se font de manière automatique.
Avec le détournement de sites Web, l'attaquant peut capter des informations confidentielles, comme le mot de passe, qu'il pourra ensuite utiliser avec le vrai site Web. Avec le détournement d'un serveur de messagerie, l'attaquant pourra capter du courrier, possiblement confidentiel (rappelez-vous que les attaquants en question visaient surtout des noms de domaine de gouvernements).
Par exemple, l'un des noms de domaine détournés était
webmail.finance.gov.lb. C'est l'interface Web
du service de courrier électronique au ministère des finances
libanais
(.lb indique le
Liban). Il est normalement connecté par l'opérateur libanais
TerraNet. Le 6 novembre 2018 (et peut-être
davantage), en essayant de se connecter via ce nom de domaine, on
arrivait chez l'hébergeur ukrainien DeltaHost. L'utilisateur qui ne se méfiait pas entrait donc le mot de
passe de son compte sur un serveur contrôlé par le pirate.
La force de ce type d'attaques particulier est son caractère indirect. Au lieu de pirater le site Web, ou le serveur de messagerie, probablement bien défendus, l'attaquant pirate les informations qui indiquent comment s'y rendre. La gestion des noms de domaine est souvent le maillon faible de la cybersécurité. Les attaquants appartenant à ce groupe de pirates particulier n'ont pourtant pas innové. Ils n'ont trouvé aucune faille de sécurité nouvelle, ils n'ont pas réalisé une percée technologique. Ils n'ont même pas été les premiers à comprendre l'intérêt des attaques indirectes, via le nom de domaine. Un exemple fameux d'une telle attaque avait été le détournement du nom de domaine du New York Times en 2013. Mais ces attaquants de 2018 ont attaqué un grand nombre de noms de domaine.
Bon, mais si c'est si facile, pourquoi est-ce que tout le monde ne
le fait pas ? Pourquoi est-ce que je ne détourne pas le nom de
domaine du RN pour pointer vers un site Web
servant un contenu anti-raciste ? Bon, d'abord, c'est parce que je
suis un citoyen respectueux des lois. Mais il n'y a pas que
ça. Pour comprendre, voyons comment fonctionne la gestion de noms
de domaine, vue, par exemple, du
webmestre. Je vais reprendre un exemple
utilisé dans mon
livre : « suivons M. Michu, pizzaiolo, qui habite à
Soissons et gère un restaurant nommé "Au
soleil de Soissons". Il n'a pas de compétence spéciale en
informatique mais voudrait un site Web pour sa pizzeria. Il va
alors contacter une entreprise locale, mettons "Aisne Web", qui
réalise des sites Web. Aisne Web réserve le nom de domaine
au-soleil-de-soissons.fr auprès d'un
bureau d'enregistrement, qui sert également
d'hébergeur des serveurs de noms de domaine. Aisne Web indiquera,
via une interface Web, l'adresse IP du serveur Web hébergeant le
site et réalisera le contenu qui apparaitra sous forme de pages
Web. Dès qu'Aisne Web aura terminé ce site Web, les visiteurs
pourront alors se connecter à
au-soleil-de-soissons.fr. »
Mais supposons qu'Aisne Web ne soit pas une entreprise très attentive en matière de sécurité. Pour s'authentifier auprès du bureau d'enregistrement de noms de domaine, ils ont choisi le mot de passe « toto12345 ». Un tel mot de passe est facile à deviner, surtout pour un logiciel qui peut faire de nombreux essais sans s'en fatiguer. Même avec un mot de passe plus difficile, peut-être qu'un employé d'Aisne Web est crédule et que, quand quelqu'un prétendant être « un technicien de Microsoft » (ou d'Apple, ou d'Orange…) appelera, l'employé acceptera de communiquer le mot de passe. (C'est ce qu'on nomme l'ingénierie sociale et c'est beaucoup plus efficace qu'on ne le croit.)
Une fois le mot de passe connu, le pirate peut alors se connecter à l'interface Web du bureau d'enregistrement, en se faisant ainsi passer pour l'utilisateur légitime. Il va alors modifier les informations techniques, par exemple l'adresse IP du site Web. Et voilà, en croyant se connecter à la pizzeria, les visiteurs iront sur le site du pirate. Bien sûr, pour une pizzeria, ce n'est pas forcément très grave. Mais des noms de domaine bien plus sensibles peuvent être détournés ainsi. Et ces attaques forment un véritable bruit de fond sur l'Internet. Les attaques comme celles perpétrées dans l'affaire qui fait du bruit en ce moment ne sont ni les premières, ni les seules.
Comme souvent en sécurité, il n'y a pas de solution magique unique et simple à ce problème, et à ces vulnérabilités. Ce n'est pas spécifique à la cybersécurité. Pour d'autres questions de sécurité, on voudrait aussi une solution immédiate et qui résolve tout, et les politiciens sont particulièrement rapides à passer à la télé, après un fait divers, pour réclamer de telles solutions magiques. Mais la sécurité ne marche pas comme cela. Elle nécessite des efforts sur le long terme, faits avec sérieux et constance. Par exemple, un tout premier élément serait de choisir des mots de passe forts (difficiles à deviner) et de ne pas les communiquer à quelqu'un à la voix chaleureuse et qui inspire confiance. Ces mesures simples et peu spectaculaires, l'hygiène numérique, empêcheraient déjà un certain nombre d'attaques.
Comme dit plus haut, on ne sait pas tout sur cette campagne d'attaques. Il y a beaucoup d'incertitudes. Par exemple, quand les détournements ont-ils commencé ? En octobre 2018 ou avant ? Les attaquants ont-ils renoncé après la publication, de novembre 2018 à février 2019, de plusieurs articles détaillant leurs opérations ? Nous ne le savons pas.
Et il y a bien sûr la question de l'attribution. Qui a effectué ces attaques ? Beaucoup des objectifs étaient au Moyen-Orient, ce qui fait qu'on peut spéculer que l'attaquant était impliqué dans un conflit du Moyen-Orient (je ne dis pas le conflit du Moyen-Orient, car il y en a plusieurs, parfois entremêlés). Mais ça fait beaucoup de suspects. La lecture de la BD « Cyberfatale » vous donnera une idée de la difficulté de l'attribution des cyberattaques…
Enfin, si vous vous intéressez aux questions de la cybersécurité, je vous encourage à lire le livre « La face cachée d'Internet ».
L'article seul
RFC 8492: Secure Password Ciphersuites for Transport Layer Security (TLS)
Date de publication du RFC : Février 2019
Auteur(s) du RFC : D. Harkins (HP Enterprise)
Pour information
Première rédaction de cet article le 22 février 2019
Ce nouveau RFC décrit un mécanisme permettant une authentification lors de l'utilisation de TLS sans utiliser de cryptographie à clé publique, mais avec un mot de passe.
Au passage, l'auteur réhabilite la notion de mot de passe, souvent considérée comme une méthode d'authentification dépassée. Il estime que « un mot de passe est plus naturel qu'un certificat » car « depuis l'enfance, nous avons appris la sémantique d'un secret partagé ».
Experts en sécurité, ne jetez pas tout de suite ce RFC à la poubelle. Rassurez-vous, le mot de passe n'est pas utilisé tel quel, mais via un protocole nommé TLS-PWD, dont la principale partie s'appelle Dragonfly. Dragonfly était déjà utilisé dans le RFC 5931.
D'abord, pourquoi ce nouveau mécanisme (section 1 du RFC) ? TLS (RFC 5246) utilise traditionnellement de la cryptographie à clé publique pour l'authentification. La machine qui veut être authentifiée (en général, c'est le serveur, mais le client peut le faire aussi) présente un certificat, contenant la clé publique et diverses métadonnées plus ou moins utiles (date d'expiration, signature d'une AC). Le protocole vérifie ensuite que la machine peut signer des données avec la clé privée correspondante, prouvant ainsi qu'elle connait cette clé privée. Ce mécanisme est bien connu mais, estime le RFC, a quelques défauts. Notamment, obtenir un certificat n'est pas trivial, et certainement bien plus compliqué que de configurer un mot de passe, opération qui est familière (le RFC dit « naturelle », ce qui est exagéré) à beaucoup. La quantité de certificats auto-signés (les plus simples à obtenir) qu'on trouve (surtout sur les MTA) en est la preuve. (Sans compter les autres problèmes comme les certificats expirés, qui montrent bien que l'avitaillement en certificats est un problème non résolu.) Et puis s'authentifier pour obtenir le premier certificat est un problème d'œuf et de poule qu'on pourrait résoudre avec ce nouveau protocole, authentifiant simplement un échange, quitte à obtenir le certificat par la suite, sur le lien sécurisé (méthode décrite dans le RFC 7030). Autre scénario d'usage pour ce nouveau protocole, le cas d'un lecteur qui transmet le PIN à la carte à puce en clair : il serait trop compliqué d'utiliser un certificat dans ce cas, alors qu'une authentification par mot de passe serait plus simple.
Les solutions sans certificat ont des vulnérabilités comme la possibilité d'attaques par dictionnaire. Un attaquant essaie plein de mots de passe possibles (par exemple, le recrutement de Mirai fonctionne ainsi) et tombe forcément juste de temps en temps. Une solution souvent proposée est d'avoir un mot de passe à forte entropie, qui a peu de chances d'être dans les essais effectués par l'attaquant. Par exemple un mot de passe choisi aléatoirement oblige l'attaquant à essayer toutes les possibilités (puisque toutes les combinaisons sont également possibles). Si le mot de passe fait N bits, cela imposera à l'attaquant 2^(N-1) essais en moyenne.
Mais la faiblesse de ce raisonnement est qu'il ne marche que si l'attaquant peut faire autant d'essais qu'il veut, sans conséquences négatives pour lui (par exemple parce qu'il a mis la main sur un fichier de mots de passe condensés, et qu'il peut à loisir tester hors-ligne s'il en trouve un). D'autres solutions sont pourtant possibles. Ainsi, le PIN d'une carte Visa ne fait que quatre chiffres, ce qui est très peu (5 000 essais suffisent, en moyenne) sauf que la carte se bloque au bout de trois essais échoués. (Notez que sur les très anciennes cartes, il était parfois possible de remettre le compteur d'essais à zéro, annulant cette sécurité.) Ce qui compte, ce ne sont pas les 10 000 possibilités théoriques, ce sont les trois essais. Le RFC généralise cette observation : « la résistance à une attaque par dictionnaire doit être une fonction du nombre d'interactions avec un participant honnête, pas une fonction de la quantité de calculs effectués ». En effet, le nombre d'interactions avec le participant honnête ne croîtra guère dans le futur (l'attaquant est détecté avant) alors que la quantité de calculs réalistiquement possibles croîtra à coup sûr. Comme dans le cas du code PIN, il n'est pas forcément nécessaire d'avoir un mot de passe à forte entropie, il faut juste empêcher l'adversaire d'essayer à volonté, et pour cela le forcer à des attaques actives, interagissant réellement avec sa victime. La section 7 du RFC détaille cette analyse, notant que ce protocole peut se contenter de mots de passe relativement « faibles ». Ainsi, note le RFC, un mot de passe de quatre lettres ASCII peut être suffisant (sans les consignes « votre mot de passe doit comporter au moins douze caractères, dont une lettre minuscule, une lettre majuscule, un chiffre, un emoji et un hiéroglyphe ») puisqu'il offre 459 976 possibilités. Un attaquant qui tenterait la force brute devrait essayer des dizaines de milliers de fois, ce qui sera certainement détecté (par exemple par des logiciels du genre de fail2ban, ou par des IDS).
Désolé, mais je ne vais pas vous exposer le protocole Dragonfly. Il dépasse mes maigres connaissances en cryptographie. La section 3 du RFC expose le minimum qu'il faut savoir en cryptographie pour comprendre la suite (vous aurez besoin de réviser la cryptographie sur courbes elliptiques, par exemple via le RFC 6090 et ça vaut aussi la peine de relire le RFC 8422 sur les extensions TLS spécifiques aux courbes elliptiques). La section 3 rappelle aussi qu'il faut saler les mots de passe avant de les stocker, côté serveur, au cas où le fichier des mots de passe se fasse voler (voir aussi la section 7, qui détaille ce risque et ses conséquences). Le résultat se nomme la base. Plus précisement, la base est le résultat de l'application de HMAC-SHA256 à un sel et à la concaténation du nom de l'utilisateur et du mot de passe. Par exemple, si vous voulez le faire avec OpenSSL, que l'utilisateur est "fred" et le mot de passe "barney", avec un sel (tiré aléatoirement) "57ff4d5abdfe2ff3d849fb44848b42f2c41fd995", on fera :
% echo -n fredbarney | openssl dgst -sha256 -hmac "57ff4d5abdfe2ff3d849fb44848b42f2c41fd995" -binary \
| openssl enc -base64
4m9bv5kWK6t3jUFkF8qk96IuixhG+C6CY7NxsOGrlPw=
Comme le mot de passe peut inclure de l'Unicode, il doit être traité selon les règles du RFC 8265. Le serveur va stocker le nom de l'utilisateur, le sel et la base.
C'est la base qui est présentée par le client (après que le serveur lui ait envoyé le sel), pas le mot de passe, et le fichier des bases est donc aussi sensible qu'un fichier de mots de passe en clair (cf. section 7).
La section 4 du RFC décrit le protocole. L'échange de clés utilisé, Dragonfly, est décrit dans le RFC 7664. Utiliser Dragonfly en clair serait sûr du point de vue de l'authentification, mais pas du point de vue de la vie privée puisque le nom d'utilisateur passerait en clair. TLS-PWD, le protocole complet (dont Dragonfly n'est qu'une partie), offre un mécanisme pour protéger contre l'écoute de ce nom, une paire de clés cryptographiques étant générée et utilisée juste pour chiffrer ce bout de la session.
Le protocole TLS-PWD nécessite l'utilisation d'extensions
TLS (RFC 5246,
notamment la section 7.4.1.2). Elles sont au nombre de trois, notamment
PWD_protect (protection du nom) et
PWD_clear (nom d'utilisateur en clair). Elles
figurent désormais dans le registre IANA. Une
fois le nom reçu et trouvé dans le fichier côté serveur, le client
peut s'authentifier avec le mot de passe (c'est plus compliqué que
cela : voir la section 4 pour tous les détails).
Dans TLS, la suite complète des algorithmes utilisés dans une
session est indiquée dans une variable nommée cipher
suite (RFC 5246, sections 7.4.1.2, 9 et annexe
C). Les nouvelles suites permettant l'authentification par mot de
passe sont listées dans la section 5 : ce sont
TLS_ECCPWD_WITH_AES_128_GCM_SHA256,
TLS_ECCPWD_WITH_AES_256_GCM_SHA384,
TLS_ECCPWD_WITH_AES_128_CCM_SHA256 et
TLS_ECCPWD_WITH_AES_256_CCM_SHA384. Elles
sont indiquées dans le registre IANA.
La section 7 du RFC contient de très nombreux détails sur la sécurité du protocole. Elle note par exemple qu'un attaquant qui essaierait tous les mots de passe d'un même utilisateur serait facilement détecté mais qu'un attaquant pourrait aussi essayer un seul mot de passe avec beaucoup d'utilisateurs, échappant ainsi à la détection. Le RFC recommande donc de compter toutes les tentatives de connexion ensemble, quel que soit l'utilisateur. (Cela traite aussi partiellement le cas d'un IDS extérieur, qui ne verrait pas le nom d'utilisateur, celui-ci étant protégé. L'IDS pourrait néanmoins compter les problèmes de connexion et donner l'alarme.) D'autre part, les mesures contre les attaques par dictionnaire (forcer l'attaquant à interagir avec le serveur, et donc à se signaler) ne sont évidemment pas efficaces si un utilisateur a le même mot de passe sur plusieurs serveurs et que l'un est compromis. La consigne d'utiliser des mots de passe différents par service reste donc valable. (Et, même si le RFC n'en parle pas, il ne faut évidemment pas noter ces mots de passe sur un post-it collé sous le clavier. La relativisation de la règle des mots de passe compliqués permet d'utiliser des mots de passe courts et mémorisables, donc plus d'excuses pour noter sur le post-it.) Sinon, les fanas de cryptographie qui voudraient étudier la sécurité du protocole Dragonfly sont invités à lire l'article de Lancrenon, J. et M. Skrobot, « On the Provable Security of the Dragonfly Protocol ».
Une curiosité : ce RFC est apparemment le premier à avoir une section « Droits Humains » (Human Rights Considerations, section 8). Une telle section, analysant les conséquences du protocole décrit dans le RFC sur les droits humains était suggérée (mais non imposée) par le RFC 8280. Mais, en l'occurrence, celle-ci se réduit à une défense des armes à feu, sans trop de rapport avec le sujet du RFC. On note également une vision très personnelle et très états-unienne des droits humains « le premier des droits est celui de se protéger », ce qui ne figure dans aucun des textes fondateurs des droits humains.
L'article seul
RIS Live, un flux de messages BGP en temps réel
Première rédaction de cet article le 19 février 2019
Les annonces du protocole de routage BGP sont publiques, comme beaucoup de choses sur l'Internet. Mais si on ne gère pas soi-même un routeur connecté à la DFZ, comment récupère-t-on ces annonces ? Plusieurs systèmes vous donnent accès à ces annonces, mais pas en temps réel. Désormais, grâce à RIS Live, tu peux, toi aussi, internaute ordinaire, accéder à cette information immédiatement.
Quel est l'intérêt de voir ces annonces ? Petit détour pour
expliquer ce que fait BGP :
l'Internet, et c'est sa principale
caractéristique, est d'être un réseau de
réseaux. Aucune organisation n'est en charge de
l'Internet dans sa globalité. Chacun (entreprise, association,
particulier) gère un des réseaux qui, connectés ensemble,
constitue l'Internet. Comment, dans ces conditions, un réseau
situé en France sait à qui envoyer les paquets lorsqu'un de ses utilisateurs
veut écrire en Mongolie ? C'est tout simple
(dans le principe) : chaque opérateur réseau prévient ses voisins
(ceux à qui il est directement connecté) des adresses IP qu'il gère. Le voisin
prévient ensuite son voisin, et ainsi de suite. Au bout d'un
moment, l'opérateur français recevra l'information sur les
adresses IP de son collègue mongol, et va donc savoir à qui transmettre les
paquets, qui suivront un chemin à peu près réciproque (oui, je
simplifie…) de celui
suivi par les annonces. Ces annonces sont manuelles lorsqu'un
petit acteur se connecte à un gros, mais les gros opérateurs
utilisent entre eux le protocole BGP,
normalisé dans le RFC 4271. En permanence,
les opérateurs connectés à la DFZ (et
quelques autres) s'échangent ces annonces : « j'ai désormais une
route vers 2c0f:fe30::/32 », « je n'ai plus
ma route vers 208.65.144.0/24 ». Ces annonces
sont les battements de cœur de l'Internet. Notez que BGP n'informe
que des nouveautés : il n'a pas d'envoi périodique, contrairement
à ce que font certains protocoles de routage
intérieurs. Néanmoins, comme il y a toujours quelque chose qui
bouge ou qui change dans l'Internet, en pratique, l'activité BGP
est importante.
Ces annonces sont traitées automatiquement par les routeurs qui ajoutent les nouvelles routes, retirent les anciennes et décident, au vu des routes disponibles, à quel voisin envoyer les paquets. Mais il y a aussi des humains qui regardent ces annonces. Il y a les opérationnels, les gens qui dans les NOC surveillent le réseau et interviennent en cas de problèmes. (Ils utilisent par exemple des systèmes d'alerte pour savoir si quelqu'un n'a pas annoncé leurs préfixes IP.) Il y a les chercheurs, qui publient d'intéressantes études sur les dynamiques à l'œuvre dans l'Internet. Il y a les étudiants qui veulent apprendre. Et il y a les curieux qui aiment regarder ce qui se passe. Comme exemple des travaux qui résultent de l'observation de BGP, notons par exemple le rapport sur la résilience de l'Internet français, édité par l'ANSSI.
Passons maintenant au sujet principal de cet article, RIS Live. Il s'agit d'un service du RIPE-NCC, s'appuyant sur un réseau de routeurs BGP, le RIS. Les routeurs du RIS ont des sessions BGP avec un grand nombre d'opérateurs et voient donc une grande partie du trafic BGP. (Avec BGP, contrairement à des protocoles comme OSPF, les routeurs ne voient pas tous la même chose, et aucun routeur ne connait tout. Observer BGP nécessite donc plusieurs routeurs, placés à différents endroits de l'Internet et, même dans ce cas, on ne voit pas tout.) Les données récoltées par le RIS sont accessibles via divers moyens comme RIPE stat, mais toujours avec un certain retard.
Au contraire, RIS Live est temps réel. Regardez la page Web, on y voit le
trafic actuel, rafraichi en permanence (tant que cette page reste
ouverte, votre machine reçoit les informations de RIS Live).

Mais vous n'êtes pas obligé d'utiliser le Web, RIS Live est accessible via une API (la page Web utilise d'ailleurs cette API, via du code JavaScript chargé avec la page). Cette API repose sur WebSocket (RFC 6455) et est bien documentée.
J'ai écrit un petit programme Python
d'exemple avec cette API, ris-live.py
% ./ris-live.py
{"type":"ris_message","data":{"timestamp":1550561936.88,"peer":"198.32.176.14","peer_asn":"2914","id":"198.32.176.14-1550561936.88-24139764","host":"rrc14","type":"UPDATE","withdrawals":["140.16.144.0/23"]}}
{"type":"ris_message","data":{"timestamp":1550561936.88,"peer":"2001:504:d::6","peer_asn":"2914","id":"2001:504:d::6-1550561936.88-14277506","host":"rrc14","type":"UPDATE","path":[2914,1299,7473,3758,9911,9890],"community":[[2914,420],[2914,1008],[2914,2000],[2914,3000]],"origin":"igp","med":12,"announcements":[{"next_hop":"2001:504:d::6","prefixes":["2a00:ad87:4600::/48"]},{"next_hop":"fe80::4255:39ff:fe47:5237","prefixes":["2a00:ad87:4600::/48"]}]}}
{"type":"ris_message","data":{"timestamp":1550561936.88,"peer":"2001:504:d::6","peer_asn":"2914","id":"2001:504:d::6-1550561936.88-14277507","host":"rrc14","type":"UPDATE","path":[2914,1299,7473,4804],"community":[[2914,420],[2914,1008],[2914,2000],[2914,3000]],"origin":"incomplete","med":12,"announcements":[{"next_hop":"2001:504:d::6","prefixes":["2405:dc00:35d::/48"]},{"next_hop":"fe80::4255:39ff:fe47:5237","prefixes":["2405:dc00:35d::/48"]}]}}
{"type":"ris_message","data":{"timestamp":1550561936.91,"peer":"27.111.228.6","peer_asn":"18106","id":"27.111.228.6-1550561936.91-103597777","host":"rrc23","type":"UPDATE","path":[18106,6939,37100,24757],"community":[[6939,2000]],"origin":"igp","announcements":[{"next_hop":"27.111.228.6","prefixes":["197.156.81.0/24"]}]}}
Je vous avais prévenu qu'il y en avait du trafic BGP, à tout instant ! Les messages de RIS Live sont en JSON. Voyons une annonce complète :
{
"timestamp": 1550562092.12, (le moment de l'annonce, le 19
février 2019 à 07:41:32 UTC,
comme on peut le voir avec 'date -u --date=@1550562092.12')
"peer": "2001:7f8:20:101::208:223", (le voisin BGP du routeur RIS)
"peer_asn": "20764", (le numéro de système autonome
dudit voisin)
"host": "rrc13", (l'identité du routeur RIS qui a
vu l'annonce)
"type": "UPDATE",
"path": [ (le chemin d'AS - Autonomous
System, système autonome - : l'AS d'origine est le 33047)
20764,
8359,
6327,
16696,
33047
],
"community": [ (les communautés BGP attachées
à l'annonce)
[
6327,
1405
],
[
6327,
41030
]
],
"origin": "igp",
"announcements": [ (l'annonce elle-même, pour le
préfixe d'adresses IP 2a03:8160:14::/48)
{
"next_hop": "2001:7f8:20:101::208:223",
"prefixes": [
"2a03:8160:14::/48"
]
}
}
}
(La notion - cruciale - de système autonome ou AS est expliquée sur Wikipédia. Les communautés BGP sont normalisées dans le RFC 1997.)
RIS Live offre de nombreuses options pour ne pas être noyé sous
l'afflux des annonces, et pour ne sélectionner que celles qui vous
intéressent. Le programme ris-live.py permet
d'en sélectionner certaines. Ici, par exemple, on ne demande que
ce qui concerne l'AS 2484 (utilisé par
l'AFNIC) :
% ./ris-live.py --path 2484 -v
Trying to connect, to send {"type": "ris_subscribe", "data": {"path": "2484"}}
Connected, {"type": "ris_subscribe", "data": {"path": "2484"}} sent
Trying to receive
Waking up, it is 2019-02-18T17:00:05Z
Waking up, it is 2019-02-18T17:01:05Z
{"type":"ris_message","data":{"timestamp":1550509323.73,"peer":"2001:7f8::514b:0:1","peer_asn":"20811","id":"2001:7f8::514b:0:1-1550509323.73-471074217","host":"rrc12","type":"UPDATE","path":[20811,2484],"origin":"igp","announcements":[{"next_hop":"2001:7f8::9b4:0:1","prefixes":["2001:678:c::/48"]}]}}
Trying to receive
Waking up, it is 2019-02-18T17:02:05Z
...
Waking up, it is 2019-02-18T17:27:05Z
Waking up, it is 2019-02-18T17:28:05Z
{"type":"ris_message","data":{"timestamp":1550510896.29,"peer":"2001:7f8::514b:0:1","peer_asn":"20811","id":"2001:7f8::514b:0:1-1550510896.29-471090283","host":"rrc12","type":"UPDATE","path":[20811,2484],"origin":"igp","announcements":[{"next_hop":"2001:7f8::9b4:0:1","prefixes":["2001:678:c::/48"]}]}}
On peut aussi ne demander que les informations d'un seul routeur RIS. Pour avoir la liste de ces routeurs :
% ./ris-live.py -l
{"type":"ris_rrc_list","data":["rrc00","rrc01","rrc03","rrc04","rrc05","rrc06","rrc07","rrc10","rrc11","rrc12","rrc13","rrc14","rrc15","rrc16","rrc18","rrc19","rrc20","rrc21","rrc22","rrc23","rrc24"]}
À ma connaissance, tous ne sont pas sur la DFZ et n'ont donc pas un flux complet, certains sont sur des points d'échange et ne voient que le trafic BGP au point d'échange.
Pour avoir un flux BGP en temps réel, je suppose qu'on peut utiliser l'alternative bgpstream mais je n'ai pas encore testé.
L'article seul
Fiche de lecture : Manuel d'auto-défense contre le harcèlement en ligne (« Dompter les trolls »)
Auteur(s) du livre : Stéphanie de Vanssay
Éditeur : Dunod
978-2100-787944
Publié en 2019
Première rédaction de cet article le 17 février 2019
Dernière mise à jour le 11 mars 2019
La question du harcèlement en ligne est maintenant bien connue et, à juste titre, souvent mise sur le devant de la scène, mais cela ne veut pas dire que ceux et celles qui en parlent en parlent intelligemment. C'est donc une excellente chose que Stéphanie de Vanssay, qui connait très bien le monde du numérique, s'attaque à cette question, dans un très bon livre.
L'auteure sait hélas de quoi elle parle : comme la grande majorité des femmes qui s'expriment publiquement, avec des opinions affirmées, elle a été victime de plusieurs campagnes de harcèlement. (Un exemple est décrit ici.) Je dis bien de harcèlement, pas juste de critiques (qui seraient parfaitement légitimes) de son engagement ou de ses idées politiques, mais des insultes sur son physique, des menaces de viol ou de torture, etc. La publication de son livre ne va évidemment pas faire changer les harceleurs, qui critiquent déjà sur les réseaux sociaux sa « position victimaire » (les victimes qui dénoncent les agressions cherchent toutes à augmenter leur nombre de followers Twitter, c'est bien connu). Et le harcèlement n'est pas uniquement le fait de déséquilibrés isolés, mais il est fréquemment commis en bandes organisées, ayant des objectifs précis (souvent de faire taire les femmes).
Ayant été témoin des déchainements contre Stéphanie de Vanssay, j'ai noté que le point de départ était souvent une question pédagogique. Car l'auteur est enseignante et parle souvent de questions d'éducation. Apparemment, cela ne plait pas à une horde vindicative qui dénonce les « pédagogistes » (et, à leurs yeux, est « pédagogiste » quiconque estime que l'enseignant n'a pas toujours raison et que les méthodes d'enseignement n'ont pas forcément à rester ce qu'elles étaient dans un lycée militaire au 19e siècle). Bref, cette horde est composée en partie d'enseignants et, en tant qu'ex-parent d'élève, je ne peux pas m'empêcher de trouver inquiétant le fait que certaines personnes chargées de l'éducation des enfants soient aussi agressifs en ligne (et, je le souhaite, seulement en ligne). En tout cas, il est sûr que le harcèlement en ligne n'est pas seulement pratiqué par des islamistes et des bas-du-front votant Trump, des bac+quelquechose le font aussi, hélas.
Je l'ai dit au début, la question du harcèlement en ligne est, heureusement, aujourd'hui reconnue comme une question politique importante. Mais cela ne veut pas dire que toutes les réponses suggérées soient bonnes. Ainsi, comme c'est souvent le cas pour les questions de sécurité, le harcèlement en ligne est souvent utilisé comme prétexte pour rogner les libertés. C'est par exemple le cas en France en ce moment avec le projet présidentiel d'interdire l'anonymat en ligne. Ce projet ne tient pas compte du fait qu'il existe déjà des tas de possibilités légales de lutter contre la « haine en ligne » mais qu'ils ne sont pas utilisés par manque de moyens matériels et manque de réelle volonté. On voit aussi des politiciens sans scrupules qui soutiennent la lutte anti-anonymat en s'appuyant sur les actions de la ligue du LOL… alors que les membres de la dite ligue agissaient souvent sous leur nom officiel. Sans compter les gens qui ne comprennent rien au monde de l'Internet et se contentent d'affirmations sommaires comme « il faudrait que Facebook demande une carte d'identité » (comme si Facebook n'avait pas déjà trop de données personnelles).
Mais assez parlé du contexte, parlons du livre de Stéphanie de Vanssay, plutôt. Elle connait très bien le sujet et ne propose donc pas de ces pseudo-solutions répressives et à l'emporte-pièce. D'abord, l'auteure est modeste : il s'agit d'aider les victimes de harcèlement à se défendre, sans prétendre régler tous les cas de harcèlement, notamment les plus graves (comme, par exemple, celui dont avait été victime la journaliste Nadia Daam). Dans ce cas, l'auteure note à juste titre qu'il faut envisager des recours, par exemple à la justice, et elle donne quelques indications pratiques à ce sujet. Mais même le harcèlement moins radical est dur pour les victimes, et peut mener la victime à ne plus s'exprimer publiquement (ce qui est souvent le but des harceleurs). L'auteure rejette l'idée (qui est aussi celle des trolls, et un des leurs arguments de défense favoris) « en ligne, c'est pas grave ».
L'essentiel du livre parle de ce que les victimes peuvent faire elles-mêmes et eux-mêmes. La force du troll ou du harceleur est que la victime se croit impuissante. Stéphanie de Vanssay montre que ce n'est pas complètement le cas, et qu'il existe diverses stratégies pour lutter contre les trolls.
La plus évidente est le fameux « ne nourrissez pas les trolls » (ne leur répondez pas, ignorez-les en espérant que le problème disparaitra de lui-même), conseil souvent donné mais avec lequel l'auteure n'est pas trop d'accord. D'abord, si le troll dit des choses vraiment inacceptables (des propos racistes, par exemple), cela ne doit pas être ignoré mais combattu. Et, dans certains cas, le troll peut être neutralisé par l'humour et la solidarité (des autres participants : l'auteure insiste que la victime doit être consciente qu'elle n'est pas seule). Mais dans certains cas, cette tactique d'ignorer le harceleur peut être préférable. Voir par exemple dans le livre le témoignage de Florence Porcel (le « petit groupe de potes » dont elle parle est la ligue du LOL, pas encore connue publiquement à l'époque de la rédaction du livre). Globalement, l'auteure est prudente : il n'y a pas de méthode magique anti-troll, pas de solution universelle au harcèlement.
Stéphanie de Vanssay tord le cou à pas mal d'idées reçues. Contrairement au discours médiatique dominant, elle fait remarquer que le harcèlement n'est pas apparu avec Facebook (elle cite Usenet, qui avait déjà permis d'observer pas mal de comportements scandaleux). Elle critique également une autre tarte à la crème du discours anti-numérique, la « bulle de filtres » qui ferait qu'en ligne, on ne serait exposé qu'à ce à quoi on croit déjà. L'auteur note au contraire qu'autrefois, quelqu'un qui ne partageait pas les opinions politiques du Figaro ne lisait jamais ce journal alors que, sur l'Internet, en un clic, on peut accéder à un de leurs articles, et on le fait bien plus souvent qu'hors-ligne.
Stéphanie de Vanssay explique aussi que pour protéger les enfants des dangers qui les menacent en ligne, les solutions simplistes souvent assénées ne sont pas idéales. Ne pas leur permettre un accès à l'Internet, solution souvent citée, revient à les boucler à la maison pour les protéger des dangers de la rue. Et cela les rendra encore plus vulnérables quand ils finiront par y accéder.
Peu de mentions des GAFA dans ce livre, à part pour noter que le signalement des trolls aux GAFA a peu d'effets, voire des effets négatifs (le troll chasse en bande, et eux aussi peuvent signaler, ce qui fait que la bureaucratie va fermer le compte de la victime plutôt que celui du harceleur).
Je vous laisse lire le livre pour voir les stratégies de défense que conseille l'auteur, toujours avec nuance et en sachant bien qu'aucune n'est parfaite. Personnellement, je ne suis pas tellement d'accord avec l'approche (revendiquée) « développement personnel », comme si la lutte contre les harceleurs consistait essentiellement à s'améliorer soi-même mais la question est délicate de toute façon : il faut à la fois aider les victimes à se défendre, sans pour autant les culpabiliser si elles n'y arrivent pas. Globalement, je trouve que ce livre se tire bien de cet exercice très difficile, et je souhaite qu'il serve à de nombreuses victimes à être plus fortes.
Quelques lectures en plus :
- Le site Web d'accompagnement du livre,
- Le moment Twitter des gens qui parlent du livre,
- Sur le site de l'éditeur,
- L'avis de Marie Rachedi,
- Le récit par l'auteure du processus d'écriture.
Et l'habituel instant « déclaration de conflit d'intérêt » : j'ai reçu un exemplaire de ce livre gratuitement, en tant que blogueur.
L'article seul
RFC 8536: The Time Zone Information Format (TZif)
Date de publication du RFC : Février 2019
Auteur(s) du RFC : A. Olson, P. Eggert (UCLA), K. Murchison (FastMail)
Chemin des normes
Première rédaction de cet article le 13 février 2019
Ce nouveau RFC (depuis remplacé par le RFC 9636) documente un format déjà
ancien et largement déployé, TZif, un
format de description des fuseaux
horaires. Il définit également des types
MIME pour ce format,
application/tzif et
application/tzif-leap.
Ce format existe depuis bien trente ans (et a pas mal évolué pendant ce temps) mais n'avait apparemment jamais fait l'objet d'une normalisation formelle (notre RFC 8536 a depuis été remplacé par le RFC 9636). La connaissance des fuseaux horaires est indispensable à toute application qui va manipuler des dates, par exemple un agenda. Un fuseau horaire se définit par un décalage par rapport à UTC, les informations sur l'heure d'été, des abréviations pour désigner ce fuseau (comme CET pour l'heure de l'Europe dite « centrale ») et peut-être également des informations sur les secondes intercalaires. Le format iCalendar du RFC 5545 est un exemple de format décrivant les fuseaux horaires. TZif, qui fait l'objet de ce RFC, en est un autre. Contrairement à iCalendar, c'est un format binaire.
TZif vient à l'origine du monde Unix et est apparu dans les années 1980, quand le développement de l'Internet, qui connecte des machines situées dans des fuseaux horaires différents, a nécessité que les machines aient une meilleure compréhension de la date et de l'heure. Un exemple de source faisant autorité sur les fuseaux horaires est la base de l'IANA décrite dans le RFC 6557 et dont l'usage est documenté à l'IANA.
La section 2 de notre RFC décrit la terminologie du domaine :
- Temps Universel Coordonné (UTC est le sigle officiel) : la base du temps légal. Par exemple, en hiver, la France métropolitaine est en UTC + 1. (GMT n'est utilisé que par les nostalgiques de l'Empire britannique.)
- Heure d'été (le terme français est incorrect, l'anglais DST - Daylight Saving Time est plus exact) : le décalage ajouté ou retiré à certaines périodes, pour que les activités humaines, et donc la consommation d'énergie, se fassent à des moments plus appropriés (cette idée est responsable d'une grande partie de la complexité des fuseaux horaires).
- Temps Atomique International (TAI) : contrairement à UTC, qui suit à peu près le soleil, TAI est déconnecté des phénomènes astronomiques. Cela lui donne des propriétés intéressantes, comme la prédictibilité (alors qu'on ne peut pas savoir à l'avance quelle sera l'heure UTC dans un milliard de secondes) et la monotonie (jamais de sauts, jamais de retour en arrière, ce qui peut arriver à UTC). Cela en fait un bon mécanisme pour les ordinateurs, mais moins bon pour les humains qui veulent organiser un pique-nique. Actuellement, il y a 37 secondes de décalage entre TAI et UTC.
- Secondes intercalaires : secondes ajoutées de temps en temps à UTC pour compenser les variations de la rotation de la Terre.
- Correction des secondes intercalaires : TAI - UTC - 10 (lisez le RFC pour savoir pourquoi 10). Actuellement 27 secondes.
- Heure locale : l'heure légale en un endroit donné. La différence avec UTC peut varier selon la période de l'année, en raison de l'heure d'été. En anglais, on dit aussi souvent « le temps au mur » (wall time) par référence à une horloge accrochée au mur. Quand on demande l'heure à M. Toutlemonde, il donne cette heure locale, jamais UTC ou TAI ou le temps Unix.
- Epoch : le point à partir duquel on compte le temps. Pour Posix, c'est le 1 janvier 1970 à 00h00 UTC.
- Temps standard : la date et heure « de base » d'un fuseau horaire, sans tenir compte de l'heure d'été. En France métropolitaine, c'est UTC+1.
- Base de données sur les fuseaux horaires : l'ensemble des informations sur les fuseaux horaires (cf. par exemple RFC 7808). Le format décrit dans ce RFC est un des formats possibles pour une telle base de données.
- Temps universel : depuis 1960, c'est équivalent à UTC, mais le RFC préfère utiliser UT.
- Temps Unix : c'est ce qui est
renvoyé par la fonction
time(), à savoir le nombre de secondes depuis l'epoch, donc depuis le 1 janvier 1970. Il ne tient pas compte des secondes intercalaires, donc il existe aussi un « temps Unix avec secondes intercalaires » (avertissement : tout ce qui touche au temps et aux calendriers est compliqué.) C'est ce dernier qui est utilisé dans le format TZif, pour indiquer les dates et heures des moments où se fait une transition entre heure d'hiver et heure d'été.
La section 3 de notre RFC décrit le format lui-même. Un fichier TZif est composé d'un en-tête (taille fixe de 44 octets) indiquant entre autres le numéro de version de TZif. La version actuelle est 3. Ensuite, on trouve les données. Dans la version 1 de TZif, le bloc de données indiquait les dates de début et de fin des passages à l'heure d'été sur 32 bits, ce qui les limitait aux dates situées entre 1901 et 2038. Les versions ultérieures de TZif sont passées à 64 bits, ce qui permet de tenir environ 292 milliards d'années mais le bloc de données de la version 1 reste présent, au cas où il traine encore des logiciels ne comprenant que la version 1. Notez que ces 64 bits permettent de représenter des dates antérieures au Big Bang, mais certains logiciels ont du mal avec des valeurs situées trop loin dans le passé.
Les versions 2 et 3 ont un second en-tête de 44 octets, et un bloc de données à elles. Les vieux logiciels arrêtent la lecture après le premier bloc de données et ne sont donc normalement pas gênés par cette en-tête et ce bloc supplémentaires. Les logiciels récents peuvent sauter le bloc de données de la version 1, qui ne les intéresse a priori pas (voir section 4 et annexe A). C'est au créateur du fichier de vérifier que les blocs de données destinés aux différentes versions sont raisonnablement synchrones, en tout cas pour les dates antérieures à 2038.
Nouveauté apparue avec la version 2, il y aussi un pied de page
à la fin. Les entiers sont stockés en gros
boutien, et en complément à
deux. L'en-tête commence par la chaîne magique
« TZif » (U+0054 U+005A U+0069 U+0066), et comprend la longueur du
bloc de données (qui dépend du nombre de transitions, de secondes
intercalaires et d'autres informations à indiquer). Le bloc de
données contient la liste des transitions, le décalage avec
UT, le nom du fuseau horaire, la liste des
secondes intercalaires, etc. Vu par le mode
hexadécimal d'Emacs, voici le
début d'un fichier Tzif version 2 (pris sur une
Ubuntu, dans
/usr/share/zoneinfo/Europe/Paris). On voit
bien la chaîne magique, puis le numéro de version, et le début du
bloc de données :
00000000: 545a 6966 3200 0000 0000 0000 0000 0000 TZif2...........
00000010: 0000 0000 0000 000d 0000 000d 0000 0000 ................
00000020: 0000 00b8 0000 000d 0000 001f 8000 0000 ................
00000030: 9160 508b 9b47 78f0 9bd7 2c70 9cbc 9170 .`P..Gx...,p...p
00000040: 9dc0 48f0 9e89 fe70 9fa0 2af0 a060 a5f0 ..H....p..*..`..
...
Avec od, ça donnerait :
% od -x -a /usr/share/zoneinfo/Europe/Paris
0000000 5a54 6669 0032 0000 0000 0000 0000 0000
T Z i f 2 nul nul nul nul nul nul nul nul nul nul nul
0000020 0000 0000 0000 0d00 0000 0d00 0000 0000
nul nul nul nul nul nul nul cr nul nul nul cr nul nul nul nul
0000040 0000 b800 0000 0d00 0000 1f00 0080 0000
nul nul nul 8 nul nul nul cr nul nul nul us nul nul nul nul
0000060 6091 8b50 479b f078 d79b 702c bc9c 7091
dc1 ` P vt esc G x p esc W , p fs < dc1 p
...
Un exemple détaillé et commenté de fichier TZif figure en annexe B. À lire si vous voulez vraiment comprendre les détails du format.
Le pied de page indique notamment les extensions à la variable d'environnement TZ. Toujours avec le mode hexadécimal d'Emacs, ça donne :
00000b80: 4345 542d 3143 4553 542c 4d33 2e35 2e30 CET-1CEST,M3.5.0
00000b90: 2c4d 3130 2e35 2e30 2f33 0a ,M10.5.0/3.
On a vu que le format TZif avait une histoire longue et compliquée. La section 4 du RFC est entièrement consacré aux problèmes d'interopérabilité, liés à la coexistence de plusieurs versions du format, et de beaucoup de logiciels différents. Le RFC conseille :
- De ne plus générer de fichiers suivant la version 1, qui ne marchera de toute façon plus après 2038.
- Les logiciels qui en sont restés à la version 1 doivent faire attention à arrêter leur lecture après le premier bloc (dont la longueur figure dans l'en-tête).
- La version 3 n'apporte pas beaucoup par rapport à la 2 et donc, sauf si on utilise les nouveautés spécifiques de la 3, il est recommandé de produire plutôt des fichiers conformes à la version 2.
- Un fichier TZif transmis via l'Internet devrait être
étiqueté
application/tzif-leapouapplication/tzif(s'il n'indique pas les secondes intercalaires). Ces types MIME sont désormais dans le registre officiel (cf. section 8 du RFC).
L'annexe A du RFC en rajoute, tenant compte de l'expérience accumulée ; par exemple, certains lecteurs de TZif n'acceptent pas les noms de fuseaux horaire contenant des caractères non-ASCII et il peut donc être prudent de ne pas utiliser ces caractères. Plus gênant, il existe des lecteurs assez bêtes pour planter lorsque des temps sont négatifs. Or, les entiers utilisant dans TZif sont signés, afin de pouvoir représenter les moments antérieurs à l'epoch. Donc, attention si vous avez besoin de données avant le premier janvier 1970, cela perturbera certains logiciels bogués.
La section 6 du RFC donne quelques conseils de sécurité :
- L'en-tête indique la taille des données mais le programme qui lit le fichier doit vérifier que ces indications sont correctes, et n'envoient pas au-delà de la fin du fichier.
- TZif, en lui-même, n'a pas de mécanisme de protection de l'intégrité, encore moins de mécanisme de signature. Il faut fournir ces services extérieurement (par exemple avec curl, en récupérant via HTTPS).
Une bonne liste de logiciels traitant ce format figure à l'IANA.
L'article seul
Fiche de lecture : Habemus Piratam
Auteur(s) du livre : Pierre Raufast
Éditeur : Alma
978-2-36279-283-0
Publié en 2018
Première rédaction de cet article le 8 février 2019
Voici un roman policier que je recommande, dans le monde de la cybersécurité, « Habemus Piratam ».
C'est très bien écrit, drôle (enfin, pour le lecteur, pas pour les victimes), l'histoire est curieuse, pleine de rebondissements, et on est surpris jusqu'au bout.
Les livres à destination du grand public et parlant de sécurité informatique sont souvent remplis d'absurdités techniques. Ce n'est pas forcément grave lorsqu'il s'agit de romans, qui ne prétendent pas être une documentation correcte. L'auteur a heureusement le droit de ne pas laisser les faits se mettre sur le chemin de son imagination. Mais, ici, l'auteur s'est bien documenté et presque tout sonne vrai (à part la légende habituelle des tueurs à gage sur le darknet). Les « piratages » sont vraisemblables (sauf un, à mon avis, je vous laisse lire le livre). Il y a plein de clins d'œil (« CERT Baobab ») qui amuseront le lecteur qui connait un peu. La description de la conférence Botconf m'a beaucoup fait rire. Mais le polar est très agréable à lire même pour les personnes non expertes en sécurité informatique.
Il n'y a pas que la technique qui est réaliste, l'environnement humain l'est également ; « J'ai l'habitude de ces audits [de sécurité]. En général, la direction à qui je présente les résultats est horrifiée. Elle exige un plan de correction immédiat, fait tomber quelques têtes et ça s'arrête là. Quelques jours plus tard, les vicissitudes de la marche courante reprennent le dessus, le devis nécessaire à la correction des failles est annoncé. Au vu du montant astronomique, les travaux de colmatage sont repoussés au budget de l'année suivante. »
L'article seul
Fiche de lecture : Sur les pas de Lucy
Auteur(s) du livre : Raymonde Bonnefille
Éditeur : Odile Jacob
978-2-7381-4164-4
Publié en 2018
Première rédaction de cet article le 8 février 2019
Depuis la découverte de Lucy en 1974, tous les protagonistes, quelle que soit l'importance de leur participation réelle, ont écrit sur les expéditions qui ont mené à cette découverte. Ici, Raymonde Bonnefille nous fait revivre ce qu'était le travail de terrain en Éthiopie, dans les années 1960 et 1970. Un récit très vivant, centré surtout sur les conditions pratiques de ce travail.
L'auteure était l'une des rares femmes présentes dans ces expéditions. Comme elle le note, ce n'est pas toujours facile d'être dans cette situation quand on est au milieu de dizaines de jeunes mâles bien testostéronés. D'autant que c'est à elle et à elle seule que le chef de l'expédition reproche d'affoler les chercheurs masculins, ou les soldats éthiopiens qui escortent l'expédition.
Les multiples expéditions auxquelles elle a participé se sont tenues dans deux régions, dans la vallée de l'Omo et dans les environs d'Hadar, où a été retrouvée Lucy. La situation géopolitique était bien différente de celle d'aujourd'hui, on était en pleine guerre froide, dans une Éthiopie fidèle alliée des États-Unis et toujours dirigée par un empereur. Plusieurs expéditions occidentales exploraient la région, connue pour sa richesse en fossiles depuis les années 1930. (Le livre contient des témoignages émouvants sur Camille Arenbourg, revenu à 83 ans sur le terrain qu'il avait exploré à l'époque.) Certaines de ces expéditions étaient françaises, d'autres états-uniennes et l'auteure a participé aux deux, ce qui lui permet de comparer des styles bien différents (les États-uniens ne comprenant pas que les Français s'arrêtent pour le déjeuner, et mettent une nappe sur la table).
Bonnefille est palynologue, un métier peu connu mais sur lequel on n'apprendra pas beaucoup de détails, à part que l'étude des pollens est cruciale pour reconstituer le paysage de l'époque de Lucy, et ses ressources alimentaires. C'est un métier moins spectaculaire que de chasser des fossiles humains (ou des dinosaures !) et l'exercer diminue sérieusement vos chances de devenir une vedette médiatique comme Yves Coppens. Plutôt que d'expliquer en détail la palynologie, l'auteure a donc choisi un angle plutôt « aventure ». Une expédition dans l'Omo ne s'improvise pas, on ne trouve pas de garage ou d'épicerie facilement, et les imprévus sont nombreux. On emporte donc beaucoup de matériel (bien davantage évidemment dans les expéditions états-uniennes) et on doit se débrouiller avec les moyens du bord quand le 4x4 est embourbé, quand on tombe malade, ou simplement quand il faut prendre une douche. (Ce qui n'est pas un luxe scandaleux : il fait très chaud en Éthiopie.)
Je recommande donc ce livre à tous les amateurs et toutes les amateures de voyages, d'expéditions, et d'interactions humaines (pas facile, le travail en équipe !)
À lire aussi, le récit de John Kalb sur les mêmes expéditions.
L'article seul
RFC 8522: Looking Glass Command Set
Date de publication du RFC : Février 2019
Auteur(s) du RFC : M. Stubbig
Pour information
Première rédaction de cet article le 6 février 2019
Avec plusieurs systèmes de routage, et notamment avec le protocole standard de l'Internet, BGP, un routeur donné n'a qu'une vue partielle du réseau. Ce que voit votre routeur n'est pas forcément ce que verront les autres routeurs. Pour déboguer les problèmes de routage, il est donc souvent utile de disposer d'une vue sur les routeurs des autres acteurs. C'est fait par le biais de looking glasses qui sont des mécanismes permettant de voir l'état d'un routeur distant, même géré par un autre acteur. Il n'y a aucun standard pour ces mécanismes, il faut donc tout réapprendre pour chaque looking glass, et il est difficile d'automatiser la collecte d'informations. Ce RFC propose une solution (surtout théorique aujourd'hui) : une norme des commandes à exécuter par un looking glass, utilisant les concepts REST.
Voyons d'abord deux exemples de looking glass. Le premier, au
France-IX, utilise une interface Web :
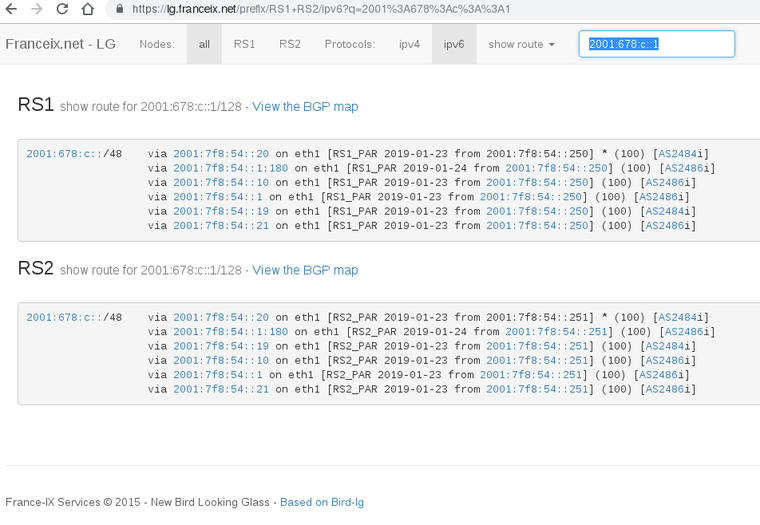
Le second, chez Route Views, utilise telnet :
% telnet route-views3.routeviews.org
...
route-views3.routeviews.org> show bgp 2001:678:c::1
BGP routing table entry for 2001:678:c::/48
Paths: (8 available, best #4, table Default-IP-Routing-Table)
Not advertised to any peer
39351 2484
2a03:1b20:1:ff01::5 from 2a03:1b20:1:ff01::5 (193.138.216.164)
Origin IGP, localpref 100, valid, external
AddPath ID: RX 0, TX 179257267
Last update: Mon Jan 28 15:22:29 2019
46450 6939 2484
2606:3580:fc00:102::1 from 2606:3580:fc00:102::1 (158.106.197.135)
Origin IGP, localpref 100, valid, external
AddPath ID: RX 0, TX 173243076
Last update: Sat Jan 26 08:26:39 2019
...
Notez que le premier looking glass n'affichait que les routes locales
au point d'échange alors que le second voit
toute la DFZ. Les looking glasses jouent un rôle
essentiel dans l'Internet, en permettant d'analyser les problèmes
réseau chez un autre opérateur. (On peut avoir une liste, très
partielle et pas à jour, des looking glasses existants en http://traceroute.org/#Looking%20Glass
La section 2 de notre RFC décrit le fonctionnement de ce looking glass normalisé. Il y a trois acteurs, le client, le serveur et le routeur. Le client est le logiciel utilisé par l'administrateur réseaux qui veut des informations (par exemple curl), le serveur est le looking glass, le routeur est la machine qui possède les informations de routage. (Le RFC l'appelle « routeur » mais ce n'est pas forcément un routeur, cela peut être une machine spécialisée qui récolte les informations en parlant BGP avec les routeurs.) Entre le client et le serveur, on parle HTTP ou, plus exactement, HTTPS. Le client ne parle pas directement au routeur. La communication entre le serveur et le routeur se fait avec le protocole de leur choix, il n'est pas normalisé (cela peut être SSH, NETCONF, etc).
La requête se fera toujours avec la méthode HTTP
GET, puisqu'on ne modifie rien sur le
serveur. Si le serveur est lg.op.example, la
requête sera vers l'URL
https://lg.op.example/.well-known/looking-glass/v1
(le préfixe bien connu est décrit dans le RFC 8615, et ce looking-glass figure
désormais dans le registre
IANA). L'URL est complété avec le nom de la commande
effectuée sur le routeur. Évidemment, on ne peut pas exécuter de
commande arbitraire sur le routeur, on est limité au jeu défini
dans ce RFC, où on trouve les grands classiques comme ping ou bien l'affichage de la
table de routage. La commande peut être suivie de détails, comme
l'adresse IP visée, et de paramètres. Parmi ces paramètres :
protocolqui indique notamment si on va utiliser IPv4 ou IPv6,routerqui va indiquer l'identité du routeur qui exécutera la commande, pour le cas, fréquent, où un même serveur looking glass donne accès à plusieurs routeurs.vrf(Virtual Routing and Forwarding), une table de routage spécifique, pour le cas où le routeur en ait plusieurs,format, qui indique le format de sortie souhaité sous forme d'un type MIME ; par défaut, c'esttext/plain. Attention, c'est le format des données envoyées par le routeur, pas le format de l'ensemble de la réponse, qui est forcément en JSON.
Le code de retour est un code HTTP classique (RFC 7231, section 6), la réponse est de type
application/json, suivant le profil
JSend, rappelé dans l'annexe A. Ce profil
impose la présence d'un champ success, ainsi
que d'un champ data en cas de succès. Voici un
exemple où tout s'est bien passé :
HTTP/1.1 200 OK
Content-Type: application/json
{
"status" : "success",
"data" : {
"router" : "route-server.lg.op.example"
"performed_at" : "2019-01-29T17:13:11Z",
"runtime" : 2.63,
"output" : [
"Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
2001:67c:16c8:18d1::1 4 206479 80966 79935 0 0 0 01w2d14h 2
2401:da80::2 4 63927 12113237 79918 0 0 0 07w6d13h 62878
2405:3200:0:23:: 4 17639 0 0 0 0 0 never Connect"
],
"format" : "text/plain"
}
}
JSend impose un champ status qui, ici,
indique le succès. Le champ data contient la
réponse. output est la sortie littérale du routeur, non
structurée (le type est
text/plain). router est
le nom du routeur utilisé (rappelez-vous qu'un serveur looking glass peut
donner accès à plusieurs routeurs).
Ici, par contre, on a eu une erreur (une erreur sur le routeur, le serveur, lui, a bien fonctionné, d'où le code de retour 200, cf. section 4 sur les conséquences de ce choix) :
HTTP/2.0 200 OK
Content-Type: application/json
{
"status" : "fail",
"data" : {
"performed_at" : "2019-01-29T17:14:51Z",
"runtime" : 10.37,
"output" : [
"Sending 5, 100-byte ICMP Echos to 2001:db8:fa3::fb56:18e",
".....",
"Success rate is 0 percent (0/5)"
],
"format" : "text/plain",
"router" : "route-server.lg.op.example"
}
}
Le fail indique que la commande exécutée sur
le routeur a donné un résultat négatif, mais, autrement, tout
allait bien. Si le serveur looking glass ne peut même pas faire exécuter la
commande par le routeur, il faut utiliser
error et mettre un code de retour HTTP
approprié :
HTTP/1.1 400 Bad Request
{
"status" : "error",
"message" : "Unrecognized host or address."
}
La section 3 du RFC donne la liste des commandes
possibles (un looking glass peut toujours en ajouter d'autres). La syntaxe
suivie pour les présenter est celle des gabarits d'URL du RFC 6570. La première est évidemment ce brave
ping, avec le gabarit https://lg.op.example/.well-known/looking-glass/v1/ping/{host} :
GET /.well-known/looking-glass/v1/ping/2001:db8::35?protocol=2
Host: lg.op.example
HTTP/1.1 200 OK
{
"status" : "success",
"data" : {
"min" : 40,
"avg" : 41,
"max" : 44,
"rate" : 100,
"output" : [
"Sending 5, 100-byte ICMP Echos to 2001:db8::35",
"!!!!!",
"Success rate is 100 percent (5/5)"
],
"format" : "text/plain",
"performed_at" : "2019-01-29T17:28:02Z",
"runtime" : 0.77,
"router" : "c2951.lab.lg.op.example"
}
}
Notez que le RFC ne décrit pas les champs possibles (comme
min ou avg), ni les
unités utilisées (probablement la milliseconde).
Autre commande traditionnelle,
traceroute :
GET /.well-known/looking-glass/v1/traceroute/192.0.2.8
Host: lg.op.example
HTTP/1.1 200 OK
{
"status": "success",
"data": {
"output": [
"Tracing the route to 192.0.2.8",
"",
" 1 198.51.100.77 28 msec 28 msec 20 msec",
" 2 203.0.113.130 52 msec 40 msec 40 msec",
" 3 192.0.2.8 72 msec 76 msec 68 msec"
],
"format": "text/plain",
"performed_at": "2018-06-10T12:09:31Z",
"runtime": 4.21,
"router": "c7206.lab.lg.op.example"
}
}
Notez une des conséquences du format non structuré de
output : ce sera au client de l'analyser. Le
RFC permet d'utiliser des formats structurés (par exemple, pour
traceroute, on peut penser à celui du RFC 5388) mais ce n'est pas obligatoire car on ne peut pas
forcément exiger du serveur qu'il sache traiter les formats de
sortie de tous les routeurs qu'il permet d'utiliser. L'analyse
automatique des résultats reste donc difficile.
D'autres commandes permettent d'explorer la table de
routage. Ainsi, show route affiche le route
vers un préfixe donné (ici, le routeur est un
Cisco et affiche donc les données au format Cisco) :
GET /.well-known/looking-glass/v1/show/route/2001:db8::/48?protocol=2,1
Host: lg.op.example
HTTP/1.1 200 OK
{
"status": "success",
"data": {
"output": [
"S 2001:DB8::/48 [1/0]",
" via FE80::C007:CFF:FED9:17, FastEthernet0/0"
],
"format": "text/plain",
"performed_at": "2018-06-11T17:13:39Z",
"runtime": 1.39,
"router": "c2951.lab.lg.op.example"
}
}
Une autre commande, show bgp, affiche les
informations BGP :
GET /.well-known/looking-glass/v1/show/bgp/192.0.2.0/24
Host: lg.op.example
HTTP/1.1 200 OK
{
"status": "success",
"data": {
"output": [
"BGP routing table entry for 192.0.2.0/24, version 2",
"Paths: (2 available, best #2, table default)",
" Advertised to update-groups:",
" 1",
" Refresh Epoch 1",
" Local",
" 192.0.2.226 from 192.0.2.226 (192.0.2.226)",
" Origin IGP, metric 0, localpref 100, valid, internal",
"[...]"
],
"format": "text/plain",
"performed_at": "2018-06-11T21:47:17Z",
"runtime": 2.03,
"router": "c2951.lab.lg.op.example"
}
}
Les deux précédentes commandes avaient un argument, le préfixe
IP sur lequel on cherche des informations (avec la syntaxe des
gabarits, cela s'écrit
https://lg.op.example/.well-known/looking-glass/v1/show/bgp/{addr}). Mais
certaines commandes n'ont pas d'argument. Par exemple,
show bgp summary affiche la liste des pairs
BGP :
GET /.well-known/looking-glass/v1/show/bgp/summary?protocol=2&routerindex=3
Host: lg.op.example
HTTP/1.1 200 OK
{
"status": "success",
"data": {
"output": [
"BGP router identifier 192.0.2.18, local AS number 64501",
"BGP table version is 85298, main routing table version 85298",
"50440 network entries using 867568 bytes of memory",
"[...]",
"Neighbor V AS MsgRcvd MsgSent TblVer Up/Down",
"2001:DB8:91::24 4 64500 481098 919095 85298 41w5d"
],
"format": "text/plain",
"performed_at": "2018-06-11T21:59:21Z",
"runtime": 1.91,
"router": "c2951.lab.lg.op.example"
}
}
D'autres commandes (« organisationnelles ») sont destinées à aider le client à formuler
sa question. C'est le cas de show router
list, qui affiche la liste des routeurs auquel ce
serveur looking glass donne accés :
GET /.well-known/looking-glass/v1/routers
...
{
"status" : "success",
"data" : {
"routers" : [
"route-server.lg.op.example",
"customer-edge.lg.op.example",
"provider-edge.lg.op.example"
],
"performed_at" : "2018-10-19T12:07:23Z",
"runtime" : 0.73
}
}
Autre exemple de commande organisationnelle,
cmd, qui permet d'obtenir la liste des
commandes acceptées par ce serveur (curieusement, ici, la syntaxe
des gabarits du RFC 6570 n'est plus utilisée
intégralement) :
GET /.well-known/looking-glass/v1/cmd
...
{
"status" : "success",
"data" : {
"commands" : [
{
"href" : "https://lg.op.example/.well-known/looking-glass/v1/show/route",
"arguments" : "{addr}",
"description" : "Print records from IP routing table",
"command" : "show route"
},
{
"href" : "https://lg.op.example/.well-known/looking-glass/v1/traceroute",
"arguments" : "{addr}",
"description" : "Trace route to destination host",
"command" : "traceroute"
}
]
}
}
La liste des commandes données dans ce RFC n'est pas exhaustive, un looking glass peut toujours en ajouter (par exemple pour donner de l'information sur les routes OSPF en plus des BGP).
La section 6 du RFC décrit les problèmes de sécurité envisageables. Par exemple, un client malveillant ou maladroit peut abuser de ce service et il est donc prudent de prévoir une limitation de trafic. D'autre part, les informations distribuées par un looking glass peuvent être trop détaillées, révéler trop de détail sur le réseau et ce qu'en connaissent les routeurs, et le RFC note qu'un serveur peut donc limiter les informations données.
Et question mises en œuvre de ce RFC ? Il existe Beagle mais qui, à l'heure où ce RFC est publié, ne semble pas à jour et concerne encore une version antérieure de l'API. Peut-être RANCID va t-il fournir une API compatible pour son looking glass. Periscope, lui, est un projet différent, avec une autre API.
L'article seul
RFC 8410: Algorithm Identifiers for Ed25519, Ed448, X25519, and X448 for Use in the Internet X.509 Public Key Infrastructure
Date de publication du RFC : Août 2018
Auteur(s) du RFC : S. Josefsson (SJD AB), J. Schaad (August Cellars)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF curdle
Première rédaction de cet article le 2 février 2019
Ce RFC spécifie l'utilisation des
courbes elliptiques
Curve25519 et
Curve448 dans PKIX,
c'est-à-dire dans les certificats utilisés notamment pour
TLS. Il réserve des identifiants pour les
algorithmes, comme Ed25519.
Les courbes elliptiques Curve25519 et Curve448 sont normalisées dans le RFC 7748. Elles sont utilisées pour diverses opérations cryptographiques comme la signature. L'algorithme EdDSA, utilisant ces courbes, est, lui, dans le RFC 8032. Quand on écrit « Ed25519 », cela veut dire « EdDSA avec la courbe Curve25519 ». D'autre part, quand on écrit « X25519 », cela signifie « échange de clés Diffie-Hellman avec la courbe Curve25519 ».
Un certificat suivant le profil
PKIX du RFC 5280
contient une clé publique, pour un algorithme cryptographique
donné. Il faut donc un identificateur formel pour cet
algorithme. Sa syntaxe est celle d'un OID,
par exemple 1.2.840.113549.1.1.1 (cf. RFC 8017) pour
RSA. Notre
RFC définit
(section 3) quatre nouveaux identificateurs :
id-X25519:1.3.101.110(ou, en détaillé,{iso(1) identified-organization(3) thawte(101) id-X25519(110)}) ; notez qu'il avait été enregistré par Thawte, depuis racheté par Symantec, ce qui explique pourquoi le RFC remercie Symantec,id-X448:1.3.101.111,id-Ed25519:1.3.101.112,id-Ed448:1.3.101.113.
Le RFC recommande aussi des noms plus sympathiques que les OID, OID qu'on ne peut vraiment pas montrer aux utilisateurs. Ces noms sont ceux décrits plus haut, comme Ed25519 pour EdDSA avec Curve25519. Si on ne sait pas quelle courbe est utilisée, on dit simplement « EdDSA » pour la signature, et « ECDH » pour l'échange de clés Diffie-Hellman.
Les nouveaux identificateurs et OID sont désormais dans le le registre IANA.
Le RFC fournit aussi des structures ASN.1, avec des exemples en section 10.
Notez qu'OpenSSL, avec openssl
x509 -text, ou GnuTLS, avec
certtool --certificate-info, n'affichent pas
les OID, seulement les identificateurs texte.
L'article seul
Aujourd'hui, le « DNS flag day »
Première rédaction de cet article le 1 février 2019
Je vois dans le journal du moteur de recherche de ce blog que des gens cherchent des informations sur le DNS Flag Day. Donc, je mets cet article pour qu'on puisse trouver l'information sur ce jour de la vie du DNS.
Donc, de quoi s'agit-il ? Pas la peine que je l'explique, cela a déjà été fait, je donne juste des pointeurs :
- L'article
(en français)
de Vincent Levigneron sur le blog de
l'AFNIC, avec une excellente explication, et des
statistiques sur les domaines en
.fr, - Le site
officiel, avec l'outil de test de votre zone, pour savoir
si elle survivra aux conséquences de ce jour (et si vous testez
bortzmeyer.org, oui, un des serveurs déconne, il a changé d'adresse IP en urgence hier et l'ancienne adresse, qui ne répond plus, est toujours dans la mémoire de certains résolveurs), - Zonemaster peut également tester votre zone,
- Un autre outil de test utile,
- Pour les hispanophones, une explication par
Hugo Salgado, du
.cl, - Utilisez le whois de l'AFNIC aujourd'hui et vous verrez un bandeau spécial.
Voici un exemple de test réussi :
Et un test avec quelques problèmes :
Puis un test avec des gros problèmes :
Certains domaines sont dans un état tellement catastrophique
que le test ne peut même pas être fait (ici, c'est parce que les
serveurs de noms faisant autorité pour ce domaine ne répondent pas
- du tout - aux requêtes de type NS, Name
Server) : 
L'article seul
RFC 8504: IPv6 Node Requirements
Date de publication du RFC : Janvier 2019
Auteur(s) du RFC : T. Chown (Jisc), J. Loughney (Intel), T. Winters (UNH-IOL)
Réalisé dans le cadre du groupe de travail IETF 6man
Première rédaction de cet article le 31 janvier 2019
Il existe des tas de RFC qui concernent IPv6 et le programmeur qui met en œuvre ce protocole dans une machine risque fort d'en rater certains, ou bien d'implémenter certains qu'il aurait pu éviter. Ce RFC est donc un méta-RFC, chargé de dresser la liste de ce qui est indispensable dans une machine IPv6. Pas de changements spectaculaires par rapport au précédent RFC mais beaucoup de détails.
Ce document remplace son prédécesseur, le RFC 6434. Il vise le même but, servir de carte au développeur qui veut doter un système de capacités IPv6 et qui se demande s'il doit vraiment tout faire (réponse : non). Ce RFC explique clairement quels sont les points d'IPv6 qu'on ne peut pas négliger, sous peine de ne pas pouvoir interagir avec les autres machines IPv6. Le reste est laissé à l'appréciation du développeur, ou à celle de profils spécifiques à un usage ou à une organisation (comme dans le cas du « Profile for IPv6 in the U.S. Government »). La section 1 résume ce but.
Ce RFC s'applique à tous les nœuds IPv6, aussi bien les routeurs (ceux qui transmettent des paquets IPv6 reçus qui ne leur étaient pas destinés) que les machines terminales (toutes les autres).
Bien, maintenant, voyons les obligations d'une machine IPv6, dans l'ordre. D'abord, la couche 2 (section 4 du RFC). Comme IPv4, IPv6 peut tourner sur des tas de couches de liaison différentes et d'autres apparaîtront certainement dans le futur. En attendant, on en a déjà beaucoup, Ethernet (RFC 2464), 802.16 (RFC 5121), les réseaux pour objets connectés LowPAN 802.15.4 (RFC 4944), PPP (RFC 5072) et bien d'autres, sans compter les tunnels.
Ensuite, la couche 3 (section 5 du RFC) qui est évidemment le gros morceau puisque c'est la couche d'IP. Le cœur d'IPv6 est normalisé dans le RFC 8200 et ce dernier RFC doit donc être intégralement implémenté.
Comme IPv6, contrairement à IPv4, ne permet pas aux routeurs intermédiaires de fragmenter les paquets, la découverte de la MTU du chemin est particulièrement cruciale. La mise en œuvre du RFC 8201 est donc recommandée. Seules les machines ayant des ressources très limitées (du genre où tout doit tenir dans la ROM de démarrage) sont dispensées. Mais le RFC se doit de rappeler que la détection de la MTU du chemin est malheureusement peu fiable dans l'Internet actuel, en raison du grand nombre de pare-feux configurés avec les pieds et qui bloquent tout l'ICMP. Il peut être donc nécessaire de se rabattre sur les techniques du RFC 4821. Le RFC recommande également de ne pas trop fragmenter les paquets, pour ne pas tenter le diable, un certain nombre de machines intermédiaires bloquant les fragments. Cela concerne notamment les protocoles utilisant UDP, comme le DNS, qui n'ont pas de négociation de la taille des messages, contrairement à TCP.
En parlant de fragmentation, notre RFC rappelle également qu'on ne doit pas générer de fragments atomiques (un datagramme marqué comme fragmenté alors que toutes les données sont dans un seul datagramme), pour les raisons expliquées dans le RFC 8021. Et il ne faut pas utiliser d'identificateurs de fragment prévisibles (RFC 7739), afin d'empêcher certaines attaques comme l'attaque Shulman sur le DNS.
Le RFC 8200 décrit le format des paquets et leur traitement. Les adresses y sont simplement mentionnées comme des champs de 128 bits de long. Leur architecture est normalisée dans le RFC 4291, qui est obligatoire. (Une tentative de mise à jour de ce RFC 4291 avait eu lieu mais a été abandonnée sous les protestations.) La règle actuelle (RFC 7421) est que le réseau local a une longueur de préfixe de 64 bits (mais il y a au moins une exception, cf. RFC 6164.)
Également indispensable à toute machine IPv6, l'autoconfiguration sans état du RFC 4862 (SLAAC, StateLess Address AutoConfiguration), ainsi que ses protocoles auxiliaires comme la détection d'une adresse déjà utilisée. D'autre part, il est recommandé d'accepter l'allocation d'un préfixe entier à une machine (RFC 8273).
Les en-têtes d'extension (RFC 8200, section 4) sont un élément de base d'IPv6 et doivent donc être acceptés et traités par toutes les machines terminales. Notez que la création de nouveaux en-têtes est désormais déconseillée donc qu'une mise en œuvre d'IPv6 a des chances de ne pas voir apparaitre de nouveaux en-têtes. Même si c'était le cas, ils devront suivre le format générique du RFC 6564, ce qui devrait faciliter leur traitement.
ICMP (RFC 4443) est évidemment obligatoire, c'est le protocole de signalisation d'IP (une des erreurs les plus courantes des administrateurs réseaux incompétents est de bloquer ICMP sur les pare-feux).
Dernier protocole obligatoire, la sélection de l'adresse source selon les règles du RFC 6724, pour le cas où la machine aurait le choix entre plusieurs adresses (ce qui est plus fréquent en IPv6 qu'en IPv4).
Le reste n'est en général pas absolument obligatoire mais recommandé (le terme a un sens précis dans les RFC, définie dans le RFC 2119 : ce qui est marqué d'un SHOULD doit être mis œuvre, sauf si on a une bonne raison explicite et qu'on sait exactement ce qu'on fait). Par exemple, la découverte des voisins (NDP, RFC 4861) est recommandée. Toutes les machines IPv6 en ont besoin, sauf si elles utilisent les liens ne permettant pas la diffusion.
Moins générale, la sélection d'une route par défaut s'il en existe plusieurs, telle que la normalise le RFC 4191. Elle est particulièrement importante pour les environnements SOHO (RFC 7084). Et si la machine IPv6 a plusieurs adresses IP, et qu'il y a plusieurs routeurs, elle doit choisir le routeur en fonction de l'adresse source (RFC 8028).
On a vu que l'autoconfiguration sans état (sans qu'un serveur doive se souvenir de qui a quelle adresse) était obligatoire. DHCP (RFC 9915), lui, n'est que recommandé. Notez que DHCP ne permet pas d'indiquer le routeur à utiliser, cette information ne peut être obtenue qu'en écoutant les RA (Router Advertisements).
Une extension utile (mais pas obligatoire) d'IP est celle des adresses IP temporaires du RFC 8981, permettant de résoudre certains problèmes de protection de la vie privée. Évidemment, elle n'a pas de sens pour toutes les machines (par exemple, un serveur dans son rack n'en a typiquement pas besoin). Elle est par contre recommandée pour les autres. Le RFC 7721 fait un tour d'horizon plus général de la sécurité d'IPv6.
Encore moins d'usage général, la sécurisation des annonces de route (et des résolutions d'adresses des voisins) avec le protocole SEND (RFC 3971). Le déploiement effectif de SEND est très faible et le RFC ne peut donc pas recommander cette technique pour laquelle on n'a pas d'expérience, et qui reste simplement optionnelle.
L'une des grandes questions que se pose l'administrateur réseaux avec IPv6 a toujours été « autoconfiguration SLAAC - StateLess Address AutoConfiguration - / RA - Router Advertisement - ou bien DHCP ? » C'est l'un des gros points de ce RFC et la section 8.4 le discute en détail. Au début d'IPv6, DHCP n'existait pas encore pour IPv6 et les RA utilisés par SLAAC ne permettaient pas encore de transmettre des informations pourtant indispensables comme les adresses des résolveurs DNS (c'est maintenant possible, cf. RFC 8106). Aujourd'hui, les deux protocoles ont à peu près des capacités équivalentes. RA a l'avantage d'être sans état, DHCP a l'avantage de permettre des options de configuration différentes par machine. Mais DHCP ne permet pas d'indiquer le routeur à utiliser. Alors, quel protocole choisir ? Le problème de l'IETF est que si on en normalise deux, en laissant les administrateurs du réseau choisir, on court le risque de se trouver dans des situations où le réseau a choisi DHCP alors que la machine attend du RA ou bien le contraire. Bref, on n'aurait pas d'interopérabilité, ce qui est le but premier des normes Internet. Lorsque l'environnement est très fermé (un seul fournisseur, machines toutes choisies par l'administrateur réseaux), ce n'est pas un gros problème. Mais dans un environnement ouvert, par exemple un campus universitaire ou un hotspot Wifi, que faire ? Comme l'indiquent les sections 6.3 et 6.5, seul RA est obligatoire, DHCP ne l'est pas. RA est donc toujours la méthode recommandée si on doit n'en choisir qu'une, c'est la seule qui garantit l'interopérabilité.
Continuons à grimper vers les couches hautes. La section 7 est
consacrée aux questions DNS. Une machine IPv6 devrait pouvoir suivre le
RFC 3596 et donc avoir la possibilité de
gérer des enregistrements DNS de type AAAA (les adresses IPv6) et
la résolution d'adresses en noms grâce à des enregistrements PTR dans
ip6.arpa.
À noter qu'une machine IPv6, aujourd'hui, a de fortes chances de se retrouver dans un environnement où il y aura une majorité du trafic en IPv4 (c'est certainement le cas si cet environnement est l'Internet). La section 10 rappelle donc qu'une machine IPv6 peut avoir intérêt à avoir également IPv4 et à déployer des techniques de transition comme la double-pile du RFC 4213.
Encore juste une étape et nous en sommes à la couche 7, à laquelle la section 11 est consacrée. Si elle parle de certains détails de présentation des adresses (RFC 5952), elle est surtout consacrée à la question des API. En 2019, on peut dire que la très grande majorité des machines a IPv6, côté couche 3 (ce qui ne veut pas dire que c'est activé, ni que le réseau le route). Mais les applications sont souvent en retard et beaucoup ne peuvent tout simplement pas communiquer avec une autre machine en IPv6. L'IETF ne normalise pas traditionnellement les API donc il n'y a pas d'API recommandée ou officielle dans ce RFC, juste de l'insistance sur le fait qu'il faut fournir une API IPv6 aux applications, si on veut qu'elles utilisent cette version d'IP, et qu'il en existe déjà, dans les RFC 3493 (fonctions de base) et RFC 3542 (fonctions avancées).
La sécurité d'IPv6 a fait bouger beaucoup d'électrons, longtemps avant que le protocole ne soit suffisamment déployé pour qu'on puisse avoir des retours d'expérience. Le RFC note donc bien que la sécurité est un processus complexe, qui ne dépend certainement pas que d'une technique magique et qu'aucun clair gagnant n'émerge de la liste des solutions de sécurité (IPsec, TLS, SSH, etc). D'autant plus qu'IPv6 vise à être déployé dans des contextes comme « l'Internet des Trucs » où beaucoup de machines n'auront pas forcément les ressources nécessaires pour faire de l'IPsec.
Toutes les règles et recommandations précédentes étaient pour tous les nœuds IPv6. La section 14 expose les règles spécifiques aux routeurs. Ils doivent évidemment router les paquets (cf. RFC 7608). Ils doivent aussi être capables d'envoyer les Router Advertisement et de répondre aux Router Solicitation du RFC 4861 et on suggère aux routeurs SOHO d'envisager sérieusement d'inclure un serveur DHCP (RFC 7084) et aux routeurs de réseaux locaux de permettre le relayage des requêtes DHCP.
Nouveauté de ce RFC, la section 15 se penche sur le cas des objets contraints, ces tout petits ordinateurs avec peu de ressources, pour lesquels il a parfois été dit qu'IPv6 n'était pas réaliste. Le groupe de travail de l'IETF 6LowPAN a beaucoup travaillé pour faire en sorte qu'IPv6 tourne bien sur ces objets contraints (RFC 4919). Pour la question de la consommation énergétique, voir le RFC 7772.
Enfin, la section 16 se penche sur la gestion des réseaux IPv6 en notant qu'au moins deux MIB sont recommandées, celle du RFC 4292 sur la table de routage, et celle du RFC 4293 sur IP en général. SNMP n'est plus le seul protocole cité, Netconf (RFC 6241) et Restconf (RFC 8040) apparaissent.
Les changements par rapport au RFC 6434 sont résumés dans l'annexe A. Pas mal de changements pendant les sept ans écoulés depuis le RFC 6434 mais aucun n'est dramatique :
- Ajout des objets contraints, et des questions liées à la consommation eléctrique,
- L'indication du résolveur DNS par les RA, devient obligatoire (section 8.3),
- Ajout de Netconf et Restconf pour la gestion des réseaux,
- Les questions liées à la vie privée sont plus nombreuses, avec par exemple le profil DHCP du RFC 7844,
- Les jumbograms du RFC 2675, peu déployés, ont été abandonnés,
- Autre abandon, celui d'ATM, un échec complet,
- Conseils sur la fragmentation, notamment pour le DNS.
L'article seul
RFC 8501: Reverse DNS in IPv6 for Internet Service Providers
Date de publication du RFC : Novembre 2018
Auteur(s) du RFC : L. Howard (Retavia)
Pour information
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 28 janvier 2019
Le DNS permet d'avoir des
enregistrements de type PTR, dans un sous-arbre spécifique sous
.arpa, permettant
d'associer un nom à
une adresse IP. Les
FAI et autres fournisseurs peuplent souvent
ce sous-arbre afin que tous les clients aient un PTR, et donc que
la « résolution inverse » (mal nommée, mais tant pis) rende un
résultat. Avec IPv4, c'est facile. Si on
gère un préfixe /22, on a 1 024 PTR à mettre, ce qui fait encore
une assez petite zone DNS. Mais en IPv6 ?
La zone ainsi pré-peuplée serait de taille colossale, bien au-delà
des capacités des serveurs de noms. Il faut donc trouver d'autres
solutions, et c'est ce que décrit ce
RFC.
Deux exemples d'enregistrement PTR en IPv6, pour commencer, vus avec dig :
% dig +short -x 2a00:1450:4007:816::2005
par10s33-in-x05.1e100.net.
(1E100 = Google). Et un autre, avec tous les détails :
% dig -x 2001:67c:2218:e::51:41
...
;; QUESTION SECTION:
;1.4.0.0.1.5.0.0.0.0.0.0.0.0.0.0.e.0.0.0.8.1.2.2.c.7.6.0.1.0.0.2.ip6.arpa. IN PTR
;; ANSWER SECTION:
1.4.0.0.1.5.0.0.0.0.0.0.0.0.0.0.e.0.0.0.8.1.2.2.c.7.6.0.1.0.0.2.ip6.arpa. 600 IN PTR epp.nic.fr.
Et les mêmes, vus avec le DNS looking
glass : https://dns.bortzmeyer.org/2a00:1450:4007:816::2005?reverse=1https://dns.bortzmeyer.org/2001:67c:2218:e::51:41?reverse=1
Pourquoi mettre ces enregistrements PTR ? Le RFC 1912, section 2.1, dit que ce serait bien de le faire (« For every IP address, there should be a matching PTR record in the in-addr.arpa domain ») mais ne donne pas de raison, à part que certains services risquent de vous refuser si vous n'avez pas ce PTR. En fait, il y a deux sortes de vérification que peut faire un service distant auquel vous vous connectez :
- Vérifier que votre adresse IP, celle du client, a un PTR, et refuser l'accès distant sinon. C'est relativement rare (et, à mon avis, assez bête).
- Vérifier que, s'il y a un PTR, il
pointe vers un nom qui à son tour pointe vers l'adresse IP du
client (et attention si vous programmez cela : on peut avoir
plusieurs PTR, et les noms qu'ils indiquent peuvent avoir
plusieurs adresses IP). Ce test est plus fréquent et bien plus
justifié (vous n'êtes pas obligé d'avoir un PTR mais, si vous en
avez un, il doit être cohérent). Notez que, par exemple,
Postfix fait ce test (on obtient des
messages du genre « postfix/smtpd[818]: warning: hostname
ppp-92-39-138-98.in-tel.ru does not resolve to address
92.39.138.98: Name or service not known », et de tels messages
sont fréquents, indiquant que beaucoup
d'administrateurs réseaux sont
négligents) et que ce test n'est apparemment pas
débrayable. Pour configurer les conséquences de ce test, voyez
les paramètres
reject_unknown_client_hostnameetreject_unknown_reverse_client_hostname. Pour OpenSSH, c'est l'optionUseDNSqui décide des conséquences du test.
La deuxième vérification peut se faire ainsi (en pseudo-code sur le serveur) :
if is_IPv4(client_IP_address) then
arpa_domain = inverse(client_IP_address) + '.in-addr.arpa'
else
arpa_domain = inverse(client_IP_address) + '.ip6.arpa'
end if
names = PTR_of(arpa_domain) # Bien se rappeler qu'il peut y avoir plusieurs PTR
for name in names loop
if is_IPv4(IP_address) then
addresses = A_of(name) # Bien se rappeler qu'il peut y avoir plusieurs A ou AAAA
else
addresses = AAAA_of(name)
end if
if client_IP_address in addresses then
return True
end if
end loop
return False
Est-ce une bonne idée d'exiger un enregistrement PTR ? Le RFC 1912 le fait, mais il est vieux de 22 ans et
est nettement dépassé sur ce point. Cette question des
enregistrements PTR, lorsqu'elle est soulevée dans les forums
d'opérateurs ou bien à l'IETF, entraine toujours des débats
passionnés. Un projet de RFC avait été développé (draft-ietf-dnsop-reverse-mapping-considerations)
mais n'avait jamais abouti. Mais ce qui est sûr est que ces PTR
sont parfois exigés par des serveurs Internet, et qu'il faut donc
réfléchir à la meilleure façon de les fournir.
En IPv4, comme indiqué dans le
paragraphe introductif, c'est simple. On écrit un petit programme
qui génère les PTR, on les met dans un fichier de zone, et on
recharge le serveur DNS faisant
autorité. Si le FAI
example.net gère le préfixe IP
203.0.113.0/24, la zone DNS correspondante
est 113.0.203.in-addr.arpa, et on met dans le
fichier de zone quelque chose comme :
1 IN PTR 1.north.city.example.net.
2 IN PTR 2.north.city.example.net.
3 IN PTR 3.north.city.example.net.
4 IN PTR 4.north.city.example.net.
...
Et, si on est un FAI sérieux, on vérifie qu'on a bien les enregistrements d'adresse dans la
zone example.net :
1.north.city IN A 203.0.113.1
2.north.city IN A 203.0.113.2
3.north.city IN A 203.0.113.3
4.north.city IN A 203.0.113.4
...
Mais en IPv6 ? Un PTR a cette forme (dans
le fichier de zone de
a.b.b.a.2.4.0.0.8.b.d.0.1.0.0.2.ip6.arpa) :
1.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0 IN PTR 1.north.city.example.net.
Et l'enregistrement d'adresse :
1.north.city IN AAAA 2001:db8:42:abba::1
Mais il faudrait autant de PTR que d'adresses possibles. Générer automatiquement la multitude de PTR qu'il faudrait, même pour un simple /64, est inenvisageable. Même si un programme arrivait à le faire (comme le note le RFC, en écrivant 1 000 entrées par seconde, il faudrait presque 600 millions d'années pour un pauvre /64), le serveur de noms ne pourrait pas charger une zone aussi grosse.
La section 2, le gros du RFC, décrit les solutions possibles. Elles n'ont pas les mêmes propriétés en terme de passage à l'échelle, conformité aux normes et disponibilité dans les logiciels existants, et, disons-le tout de suite, aucune n'est parfaite.
Première solution, la plus brutale, répondre NXDOMAIN (« ce nom n'existe pas »). C'est simple à faire et ça marche bien, quelle que soit la taille du préfixe. Il suffit d'un fichier de zone vide (juste les enregistrements SOA et NS) pour mettre en œuvre cette solution.
Après tout, c'est la réponse la plus honnête : pas d'information disponible. (Attention, on parle bien de répondre NXDOMAIN, et surtout pas de ne pas répondre. Ne pas répondre va laisser le client DNS attendre, peut-être très longtemps, alors qu'un NXDOMAIN va tout de suite lui dire qu'il n'y a pas de réponse.) Cela ne suit pas le RFC 1912, mais dont on a vu qu'il est très contestable sur ce point. Par contre, certains services seront refusés (à tort, je pense, mais la légende « s'il n'a pas de PTR, c'est un méchant » est très répandue) au client qui n'a pas de PTR.
Deuxième solution, profiter des jokers du DNS (RFC 4592) pour avoir une réponse identique pour toutes les adresses IP (cf. RFC 4472). C'est simple à faire et ça passe bien à l'échelle. Le fichier de zone va être :
* IN PTR one-host.foo.bar.example.
Le principal inconvénient est que la requête en sens inverse (du
nom - ici one-host.foo.bar.example - vers
l'adresse IP) ne donnera pas un bon résultat, puisqu'il n'y a
qu'un seul nom, ce qui plantera les programmes qui vérifient la
cohérence des PTR et des A/AAAA.
Troisième solution, laisser les machines mettre à jour elle-mêmes le DNS, pour y mettre le PTR. La machine qui vient d'obtenir une adresse IP (que ce soit par SLAAC, DHCP ou un autre moyen), va mettre à jour enregistrements AAAA et PTR dans un serveur DNS dynamique. Cette fois, c'est compliqué à réaliser. Pour un gros FAI, il y aura plusieurs serveurs DNS, à des fins de redondance, il faudra que les machines clientes s'adressent au bon (il n'y a pas de mécanisme standard pour cela), s'il y a beaucoup de clients DNS, le serveur va souffrir, authentifier ces requêtes de mise à jour du DNS va être compliqué… Sans compter le risque qu'un utilisateur facétieux ne mette un PTR… « créatif » ou tout simplement un nom déjà utilisé.
Notez que, à la maison ou dans au autre petit réseau local, ce n'est pas forcément la machine terminale qui pourrait faire la mise à jour DNS. Cela pourrait se centraliser au niveau du routeur CPE (la box).
Dans ce cas, on pourrait même imaginer que le FAI délègue deux
noms de domaine à ce routeur CPE, un nom pour les requêtes
d'adresses (mettons
customer-7359.city.example.net) et un pour
les requêtes inverses (mettons
6.a.2.1.6.a.a.b.8.b.d.0.1.0.0.2.ip6.arpa). Dans
ce cas, ce serait de la responsabilité du routeur CPE de répondre
pour ces noms, d'une manière configurable par l'utilisateur. Si le
FAI fournit la box, comme c'est courant en
France, il peut s'assurer qu'elle est capable de fournir ce
service. Autrement, il faut ne faire cette délégation que si
l'utilisateur a cliqué sur « oui, j'ai un serveur DNS bien
configuré, déléguez-moi », ou bien en utilisant une heuristique
(si un client demande une délégation de préfixe IP, on peut
estimer qu'il s'agit d'un routeur et pas d'une machine terminale,
et elle a peut-être un serveur DNS inclus). Notez que le RFC 6092 dit qu'un routeur CPE ne doit pas avoir,
par défaut, de serveur DNS accessible de l'extérieur, mais cet
avis était pour un résolveur, pas pour un serveur faisant
autorité.
Enfin, la mise à jour dynamique du DNS peut aussi être faite par le serveur DHCP du FAI, par exemple en utilisant le nom demandé par le client (RFC 4704). Ou par le serveur RADIUS.
Quatrième solution, déjà partiellement évoquée plus haut, déléguer le DNS à l'utilisateur. Cela ne marche pas en général avec l'utilisateur individuel typique, qui n'a pas de serveur DNS, ni le temps ou l'envie d'en installer un. Une solution possible serait d'avoir une solution toute prête dans des offres de boitiers faisant tout comme le Turris Omnia.
Enfin, cinquième et dernière possibilité, générer des réponses
à la volée, lors de la requête DNS. Un exemple d'algorithme
serait, lors de la réception d'une requête DNS de type PTR, de
fabriquer un nom (mettons
host-56651.customers.example.net), de le
renvoyer et de créer une entrée de type AAAA
pour les requêtes portant sur ce nom. Ces deux entrées pourraient
être gardées un certain temps, puis nettoyées. Notez que cela ne
permet pas à l'utilisateur de choisir son nom. Et que peu de
serveurs DNS savent faire cela à l'heure actuelle. (Merci à Alarig
Le Lay pour m'avoir signalé le
module qui va bien dans Knot.)
Cette technique a deux autres inconvénients. Si on utilise DNSSEC, elle impose de générer également les signatures dynamiquement (ou de ne pas signer cette zone, ce qui est raisonnable pour de l'information non-critique). Et l'algorithme utilisé doit être déterministe, pour donner le même résultat sur tous les serveurs de la zone.
La section 3 de notre RFC discute la possibilité d'un
avitaillement du DNS par l'utilisateur final, via une interface
dédiée, par exemple une page Web (évidemment authentifiée). Voici par exemple
l'interface de Linode :
Notez qu'on ne peut définir un PTR qu'après avoir testé que la
recherche d'adresses IP pour ce nom fonctionne, et renvoie une des
adresses de la machine. Chez Gandi, on ne
peut plus changer ces enregistrements depuis le passage à la
version 5 de l'interface, hélas. Mais ça fonctionne encore tant
que la version 4 reste en service :
L'interface
de Free (qui ne gère qu'IPv4) est boguée : elle affiche le nom
choisi mais une requête PTR donne quand même le nom automatique
(du genre lns-bzn-x-y-z.adsl.proxad.net,
d'autant plus drôle qu'il concerne un abonnement via la
fibre).
La section 4 tente de synthétiser le problème et les solutions. Considérant qu'il y a six utilisations typiques des enregistrements PTR :
- Accepter ou rejeter du courrier, dans le cadre de la lutte anti-spam,
- Servir des publicités, en utilisant le PTR comme source de géolocalisation,
- Accepter ou rejeter des connexions SSH (en supposant, ce qui est très contestable, qu'un PTR avec validation de l'adresse est un bon indicateur d'un client SSH « sérieux »),
- La journalisation, en notant aussi
bien le nom que l'adresse IP du client ; attention, noter le nom
seul serait une erreur, puisqu'il est entièrement contrôlé du
côté du client (l'administrateur de
2001:db8:42::1peut, via son contrôle de2.4.0.0.8.b.d.0.1.0.0.2.ip6.arpa, mettre un PTR indiquantwww.google.com), - traceroute (à mon avis l'une des rares utilisations vraiment valables des enregistrements PTR),
- La découverte de services, suivant le RFC 6763.
Considérant ces usages, la meilleure solution serait la délégation du DNS à l'utilisateur, pour qu'il ait un contrôle complet, mais comme c'est actuellement irréaliste la plupart du temps, le NXDOMAIN est parfois la solution la plus propre. Évidemment, comme toujours, « cela dépend » et chaque opérateur doit faire sa propre analyse (rappelez-vous qu'il n'y a pas de consensus sur ces enregistrements PTR). Personnellement, je pense que tout opérateur devrait fournir à ses utilisateurs un moyen (formulaire Web ou API) pour mettre un enregistrement PTR.
Et pour terminer, la section 5 de notre RFC décrit les questions de sécurité et de vie privée liées à ces questions de résolution « inverse ». Parmi elles :
- Certaines personnes affirment bien fort que la présence d'un enregistrement PTR signifie quelque chose (par exemple que l'administrateur réseaux est sérieux/qualifié) mais c'est contestable.
- Ces enregistrements PTR, en l'absence de DNSSEC, n'ont qu'une valeur limitée pour la sécurité, puisqu'ils peuvent être manipulés, ajoutés ou détruits par un tiers ; tester ces enregistrements via un résolveur non-validant n'est pas très sérieux,
- Attention à la vie privée : trop d'information dans un PTR peut poser des problèmes (cf. RFC 8117),
- Lorsque l'utilisateur peut choisir la chaîne de caractères
mise dans le PTR, son inventivité peut poser des problèmes
(
le-ministre-machin-est-un-voleur.example.net, ce qui peut valoir des ennuis juridiques au FAI).
Et si vous préférez lire en espagnol, Hugo Salgado l'a fait ici.
L'article seul
RFC 8482: Providing Minimal-Sized Responses to DNS Queries that have QTYPE=ANY
Date de publication du RFC : Janvier 2019
Auteur(s) du RFC : J. Abley (Afilias), O. Gudmundsson, M. Majkowski (Cloudflare), E. Hunt (ISC)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 11 janvier 2019
Lorsqu'un client DNS envoie une requête à un serveur DNS, le client indique le type de données souhaité. Contrairement à ce qu'on lit souvent, le DNS ne sert pas à « traduire des noms de domaine en adresses IP ». Le DNS est une base de données généraliste, qui sert pour de nombreux types de données. Outre les types (AAAA pour les adresses IP, SRV pour les noms de serveurs assurant un service donné, SSHFP ou TLSA pour les clés cryptographiques, etc), le DNS permet de demander tous les types connus du serveur pour un nom de domaine donné ; c'est ce qu'on appelle une requête ANY. Pour différentes raisons, l'opérateur du serveur DNS peut ne pas souhaiter répondre à ces requêtes ANY. Ce nouveau RFC spécifie ce qu'il faut faire dans ce cas.
Les requêtes comme ANY, qui n'utilisent pas un type spécifique, sont souvent informellement appelées « méta-requêtes ». Elles sont spécifiées (mais de manière un peu ambigüe) dans le RFC 1035, section 3.2.3. On note que le terme « ANY » n'existait pas à l'époque, il est apparu par la suite.
Pourquoi ces requêtes ANY défrisent-elles certains
opérateurs de serveurs DNS ? La section 2 de notre RFC explique
ce choix. D'abord, quelle était l'idée derrière ces requêtes
ANY ? La principale motivation était de débogage : ANY n'est pas
censé être utilisé dans la cadre du fonctionnement normal du DNS,
mais lorsqu'on veut creuser un problème, vérifier l'état d'un
serveur. Voici un exemple de requête ANY envoyée au serveur
faisant autorité pour le nom de domaine
anna.nic.fr :
% dig +nodnssec @ns1.nic.fr ANY anna.nic.fr
...
;; flags: qr aa rd; QUERY: 1, ANSWER: 3, AUTHORITY: 5, ADDITIONAL: 10
...
;; ANSWER SECTION:
anna.nic.fr. 600 IN A 192.134.5.10
anna.nic.fr. 172800 IN TXT "EPP prod"
anna.nic.fr. 600 IN AAAA 2001:67c:2218:e::51:41
...
;; Query time: 2 msec
;; SERVER: 2001:67c:2218:2::4:1#53(2001:67c:2218:2::4:1)
...
Le serveur 2001:67c:2218:2::4:1 a renvoyé
les données pour trois types, A (adresse IPv4), AAAA (adresse
IPv6) et TXT (un commentaire).
Certains programmeurs comprenant mal le DNS ont cru qu'ils pouvaient utiliser les requêtes ANY pour récupérer à coup sûr toutes les données pour un nom (ce fut par exemple une bogue de qmail). Voyons d'abord si ça marche, en essayant le même nom avec un autre serveur DNS :
% dig @::1 ANY anna.nic.fr
...
;; flags: qr rd ra ad; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
...
;; ANSWER SECTION:
anna.nic.fr. 595 IN AAAA 2001:67c:2218:e::51:41
...
;; Query time: 0 msec
;; SERVER: ::1#53(::1)
On n'a cette fois récupéré que l'adresse IPv6 et pas les trois enregistrements. C'est parce que cette fois, le serveur interrogé était un résolveur, pas un serveur faisant autorité. Il a bien répondu en donnant toutes les informations qu'il avait. Simplement, il ne connaissait pas tous les types possibles. Ce comportement est le comportement normal de ANY ; ANY (n'importe lesquelles) ne veut pas dire ALL (toutes). Il veut dire « donne-moi tout ce que tu connais ». Il n'y a jamais eu de garantie que la réponse à une requête ANY contiendrait toutes les données (c'est la bogue fondamentale de l'usage DNS de qmail). Si la réponse, comme dans l'exemple précédent, n'a pas de données de type A, est-ce que cela veut dire qu'il n'y a pas de telles données, ou simplement que le serveur ne les connaissait pas ? On ne peut pas savoir. Bref, il ne faut pas utiliser les requêtes ANY vers un résolveur ou, plus exactement, il ne faut pas compter sur le fait que cela vous donnera toutes les données pour ce nom. ANY reste utile pour le débogage (savoir ce que le résolveur a dans le cache) mais pas plus.
Et vers un serveur faisant autorité, est-ce que là, au moins, on a une garantie que cela va marcher ? Même pas car certains serveurs faisant autorité ne donnent qu'une partie des données, voire rien du tout, pour les raisons exposées au paragraphe suivant.
En effet, les requêtes ANY ont des inconvénients. D'abord, elles peuvent être utilisées pour des attaques par réflexion, avec amplification. La réponse, si le serveur envoie toutes les données possibles, va être bien plus grosse que la question, assurant une bonne amplification (cf. RFC 5358, et section 8 de notre nouveau RFC). Bien sûr, ANY n'est pas le seul type de requête possible pour ces attaques (DNSKEY ou NS donnent également de « bons » résultats.)
Ensuite, les requêtes ANY peuvent permettre de récupérer facilement toutes les données sur un nom de domaine, ce que certains opérateurs préféreraient éviter. C'est à mon avis l'argument le plus faible, le même effet peut être obtenu avec des requêtes multiples (il y a 65 536 types possibles, mais beaucoup moins en pratique) ou via le passive DNS.
Enfin, avec certaines mises en œuvre des serveurs DNS, récupérer toutes les informations peut être coûteux. C'est par exemple le cas si le dorsal du serveur est un SGBD où les données sont accessibles uniquement via la combinaison {nom, type}.
Bref, il est légitime que le gérant d'un serveur DNS veuille bloquer les requêtes ANY. Mais que doit-il répondre dans ce cas ? Ne pas répondre du tout, comme le font certains pare-feux programmés et configurés avec les pieds n'est pas une solution, le client réémettra, gaspillant des ressources chez tout le monde. Notre RFC suggère un choix de trois méthodes (section 4) :
- Envoyer un sous-ensemble non-vide des données connues. Le client ne saura jamais si on lui a envoyé toutes les données, seulement celles connues du serveur, ou bien un sous-ensemble. Mais rappelez-vous qu'il n'y a jamais eu aucune garantie qu'ANY renvoie tout. Cette technique ne change donc rien pour le client.
- Variante du précédent, essayer de deviner ce que veut le client et le lui envoyer. Par exemple, en renvoyant tous les A, AAAA, MX et CNAME qu'on a et en ignorant les autres types d'enregistrement, on satisfera sans doute la grande majorité des clients.
- Envoyer un enregistrement HINFO, solution décrite en détail plus loin.
Toutes ces réponses sont compatibles avec le protocole existant. Le RFC 1035, section 3.2.3, est relativement clair à ce sujet : ANY n'est pas la même chose que ALL (section 7 de notre RFC). Notez que notre nouveau RFC n'impose pas une politique particulière ; ce RFC ne dit pas qu'il faut renvoyer la réponse courte, il dit « si vous le faites, faites-le avec une des trois méthodes indiquées ».
Notez que le comportement du serveur peut dépendre de si la question était posée sur UDP ou sur TCP (section 4.4 du RFC). En effet, avec TCP, le risque d'attaque par réflexion est très faible.
Voici un exemple chez Cloudflare, la société qui a le plus « poussé » pour ce RFC :
% dig +nodnssec @ns5.cloudflare.com. ANY cloudflare.com
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 54605
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
...
;; ANSWER SECTION:
cloudflare.com. 3789 IN HINFO "ANY obsoleted" "See draft-ietf-dnsop-refuse-any"
;; Query time: 4 msec
;; SERVER: 2400:cb00:2049:1::a29f:209#53(2400:cb00:2049:1::a29f:209)
;; WHEN: Wed Dec 19 16:05:12 CET 2018
;; MSG SIZE rcvd: 101
Le client recevant ces réponses les mémorise de la manière classique. S'il trouve un HINFO, il peut décider de l'utiliser pour répondre aux requêtes ANY ultérieures. (C'est un changement de la sémantique du type HINFO mais pas grave, ce type étant très peu utilisé.)
Mais pourquoi HINFO, type qui était normalement prévu pour donner des informations sur le modèle d'ordinateur et sur son système d'exploitation (RFC 1035, section 3.3.2) ? La section 6 du RFC traite cette question. Le choix de réutiliser (en changeant sa sémantique) un type existant était dû au fait que beaucoup de boitiers intermédiaires bogués refusent les types DNS qu'ils ne connaissent pas (un nouveau type NOTANY avait été suggéré), rendant difficile le déploiement d'un nouveau type. HINFO est très peu utilisé, donc considéré comme « récupérable ». Ce point a évidemment fait l'objet de chaudes discussions à l'IETF, certains étant choqués par cette réutilisation sauvage d'un type existant. Le type NULL avait été proposé comme alternative mais l'inconvénient est qu'il n'était pas affiché de manière lisible par les clients DNS actuels, contrairement à HINFO, qui permet de faire passer un message, comme dans l'exemple Cloudflare ci-dessus.
Un HINFO réel dans une réponse peut être mémorisé par le résolveur et empêcher certaines requêtes ANY ultérieures. De la même façon, le HINFO synthétique généré en réponse à une requête ANY peut masquer des vrais HINFO. Attention, donc, si vous avez des HINFO réels dans votre zone, à ne pas utiliser ce type dans les réponses aux requêtes ANY.
Mais les HINFO réels sont rares. En janvier 2017, en utilisant
la base DNSDB, je n'avais trouvé que
54 HINFO sur les trois millions de noms de
.fr, et la plupart
n'étaient plus dans le DNS. Les meilleurs
étaient :
iiel.iie.cnam.fr. IN HINFO "VS3100" "VMS-6.2"
wotan.iie.cnam.fr. IN HINFO "AlphaServer-1000" "OSF"
Il y a peu de chance qu'une VaxStation 3100 soit encore en service en 2017 :-) Autres HINFO utilisés de façon créative :
www-cep.cma.fr. IN HINFO "bat. B" ""
syndirag.dirag.meteo.fr. IN HINFO "VM Serveur Synergie 1 operationnel" "RHEL 5.4"
www.artquid.fr. IN HINFO "Artquid" "ArtQuid, La place de marche du Monde de l'Art (Antiquites, Objets d'art, Art contemporain et Design)"
Le HINFO de syndirag.dirag.meteo.fr est
toujours en ligne et illustre très bien une raison pour laquelle
les HINFO sont peu utilisés : il est pénible de les maintenir à
jour (la machine n'est probablement plus en
RHEL 5.4).
Notons que d'autres solutions avaient été étudiées à l'IETF pendant la préparation de ce RFC (section 3) :
- Créer un nouveau code de retour (au lieu de l'actuel NOERROR). Le nommer, par exemple, NOTALL. Mais les résolveurs actuels, recevant un code inconnu, auraient simplement renvoyé la question à d'autres serveurs.
- Utiliser une option EDNS, mais l'expérience prouve que les options EDNS inconnues ont du mal à passer les boitiers intermédiaires.
- Simplement décider que ANY devenait un type d'enregistrement comme les autres, au lieu de rester un « méta-type » avec traitement spécial. Dans ce cas, comme il n'y a pas de données de type ANY dans la zone, la réponse aurait été NODATA (code de retour NOERROR mais une section de réponse vide). Cela s'intégre bien avec DNSSEC par exemple. Mais cela casserait les attentes des logiciels clients, et cela ne leur laisserait rien à mémoriser (à part la réponse négative).
Le choix a donc été fait de renvoyer quelque chose, afin que le client s'arrête là, et qu'il puisse garder quelque chose dans sa mémoire (cache).
On notera que cela laisse entier le problème du client qui voudrait récupérer, par exemple, adresse IPv4 (A) et IPv6 (AAAA) avec une seule requête. Plusieurs approches ont été proposées à l'IETF mais aucune adoptée.
Les techniques de ce RFC sont-elles disponibles ?
NSD avait depuis sa
version 4.1 une option
refuse-any, mais pas conforme au RFC (elle répond avec le bit TC indiquant la troncature, ce que le
RFC refuse explicitement). Cela semble s'être amélioré avec la
version 4.1.27 publiée en mars 2019. BIND a depuis la
version 9.11 une option
minimal-any qui, elle, est conforme. En
mettant minimal-any yes; dans la
configuration, BIND répondre aux requêtes ANY avec un seul
enregistrement. BIND n'utilise donc pas la solution « HINFO » mais
le RFC permet ce choix.
L'article seul
RFC 8461: SMTP MTA Strict Transport Security (MTA-STS)
Date de publication du RFC : Septembre 2018
Auteur(s) du RFC : D. Margolis, M. Risher (Google), B. Ramakrishnan (Oath), A. Brotman (Comcast), J. Jones (Microsoft)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF uta
Première rédaction de cet article le 9 janvier 2019
La question de la sécurité du courrier électronique va probablement amener à la publication de nombreux autres RFC dans les années qui viennent… Ce nouveau RFC traite du problème de la sécurisation de SMTP avec TLS ; c'est très bien d'avoir SMTP-sur-TLS, comme le font aujourd'hui tous les MTA sérieux. Mais comment le client SMTP qui veut envoyer du courrier va-t-il savoir si le serveur en face gère TLS ? Et si on peut compter dessus, refusant de se connecter si TLS a un problème ? Notre RFC apporte une solution, publier dans le DNS un enregistrement texte qui va indiquer qu'il faut télécharger (en HTTP !) la politique de sécurité TLS du serveur. En la lisant, le client saura à quoi s'attendre. Ne cherchez pas de déploiement de cette technique sur le serveur qui gère mon courrier électronique, je ne l'ai pas fait, pour les raisons expliquées plus loin.
Cette solution se nomme STS, pour Strict Transport Security. La section 1 du RFC explique le modèle de menace auquel répond cette technique. Sans TLS, une session SMTP peut être facilement écoutée par des espions et, pire, interceptée et modifiée. TLS est donc indispensable pour le courrier, comme pour les autres services Internet. À l'origine (RFC 3207), la méthode recommandée pour faire du TLS était dite STARTTLS et consistait, pour le MTA contacté, à annoncer sa capacité TLS puis, pour le MTA qui appelle, à démarrer la négociation TLS s'il le souhaitait, et si le serveur en face avait annoncé qu'il savait faire. Une telle méthode est très vulnérable aux attaques par repli, ici connues sous le nom de SSL striping ; un attaquant actif peut retirer l'indication STARTTLS du message de bienvenue du MTA contacté, faisant croire au MTA appelant que TLS ne sera pas possible.
D'autre part, un très grand nombre de serveurs SMTP ont des certificats expirés, ou auto-signés, qui ne permettent pas d'authentifier sérieusement le MTA qu'on appelle. En cas de détournement BGP ou DNS, on peut se retrouver face à un mauvais serveur et comment le savoir, puisque les serveurs authentiques ont souvent un mauvais certificat. Le MTA qui se connecte à un autre MTA est donc confronté à un choix difficile : si le certificat en face est auto-signé, et donc impossible à évaluer, est-ce parce que l'administrateur de ce MTA est négligent, ou bien parce qu'il y a un détournement ? Pour répondre à cette question, il faut un moyen indépendant de connaitre la politique du MTA distant. C'est ce que fournit notre RFC (c'est aussi ce que fournit DANE, en mieux).
À noter que ce RFC concerne les communications entre MTA. Pour celles entre MUA et MTA, voyez le RFC 8314, qui utilise un mécanisme assez différent, fondé sur le TLS implicite (au contraire du TLS explicite de STARTSSL).
Donc, la technique décrite dans ce RFC, STS, vise à permettre l'expression d'une politique indiquant :
- Si le receveur a TLS ou pas,
- Ce que devrait faire l'émetteur si TLS (chiffrement ou authentification) échoue.
D'abord, découvrir la politique du serveur distant (section 3
du RFC). Cela se fait en demandant un enregistrement
TXT. Si le domaine de courrier est
example.com, le nom où chercher
l'enregistrement TXT est
_mta-sts.example.com. Regardons chez
Gmail :
% dig TXT _mta-sts.gmail.com
...
;; ANSWER SECTION:
_mta-sts.gmail.com. 300 IN TXT "v=STSv1; id=20171114T070707;"
On peut aussi utiliser le DNS Looking Glass.
Cet enregistrement TXT contient des paires clé/valeur, deux clés sont utilisées :
vqui indique la version de STS utilisée, aujourd'huiSTSv1,- et
idqui indique un numéro de série (ici 20171114T070707) ; si la politique TLS change, on doit penser à modifier ce numéro. (Rappelons que la politique est accessible via HTTP. Dans beaucoup d'organisations, ce n'est pas la même équipe qui gère le contenu DNS et le contenu HTTP, et je prévois donc des difficultés opérationnelles.)
La présence de cet enregistrement va indiquer qu'une politique TLS pour le MTA est disponible, à récupérer via HTTP.
D'autres clés pourront être créées dans le futur, et mises dans le registre IANA, en suivant la politique « Examen par un expert » du RFC 8126.
Cette politique doit se trouver en (toujours en supposant que
le domaine est example.com)
https://mta-sts.example.com/.well-known/mta-sts.txt,
et avoir le type text/plain. (Le
.well-known est décrit dans le RFC 8615.) Le nom
mta-sts.txt a été ajouté dans le
registre IANA. Essayons de récupérer la politique de Gmail,
puisqu'ils ont l'enregistrement TXT :
% curl https://mta-sts.gmail.com/.well-known/mta-sts.txt
version: STSv1
mode: testing
mx: gmail-smtp-in.l.google.com
mx: *.gmail-smtp-in.l.google.com
max_age: 86400
On voit que les politiques sont également décrites sous formes de
paires clé/valeur, mais avec le deux-points
au lieu du égal. On voit aussi que
l'utilisation de STS (Strict Transport
Security) nécessite un nom spécial
(mta-sts, qui n'a pas de
tiret bas car il s'agit d'un nom de machine) ce qui peut entrer en conflit avec
des politiques de nommages locales, et est en général mal
perçu. (Cela a fait râler.) L'utilisation des
enregistrements de service aurait évité
cela mais ils n'ont pas été retenus.
Les clés importantes sont :
version: aujourd'huiSTSv1,mode: indique au MTA émetteur ce qu'il doit faire si TLS échoue. Il y a le choix entrenone(continuer comme si de rien n'était),testing(signaler les problèmes - cf. section 6 - mais continuer, c'est le choix de Gmail dans la politique ci-dessus) etenforce(refuser d'envoyer le message en cas de problème, c'est le seul mode qui protège contre les attaques par repli).max_age: durée de vie de la politique en question, on peut la mémoriser pendant ce nombre de secondes (une journée pour Gmail),mx: les serveurs de messagerie de ce domaine.
D'autres clés pourront être ajoutées dans le même registre IANA, avec la politique d'examen par un expert (cf. RFC 8126.) Un exemple de politique figure dans l'annexe A du RFC.
(Notez qu'au début du processus qui a mené à ce RFC, la politique était décrite en JSON. Cela a été abandonné au profit d'un simple format « clé: valeur » car JSON n'est pas habituel dans le monde des MTA, et beaucoup de serveurs de messagerie n'ont pas de bibliothèque JSON incluse.)
La politique doit être récupérée en
HTTPS (RFC 2818)
authentifié (RFC 6125), le serveur doit donc
avoir un certificat valide pour
mta-sts.example.com. L'émetteur doit utiliser
SNI (Server Name Indication, RFC 6066), et parler au moins TLS 1.2. Attention, le client
HTTPS ne doit pas suivre les redirections, et ne doit pas utiliser
les caches Web du RFC 9111.
Notez bien qu'une politique ne s'applique qu'à un domaine, pas
à ses sous-domaines. La politique récupérée en
https://mta-sts.example.com/ ne nous dit rien
sur les serveurs de messagerie du domaine
something.example.com.
Une fois que l'émetteur d'un courrier connait la politique du récepteur, il va se connecter en SMTP au MTA du récepteur et vérifier (section 4) que :
- Le MX correspond à un des serveurs listés
sous la clé
mxdans la politique, - Le serveur accepte de faire du TLS et a un certificat valide. Le certificat ne doit évidemment pas être expiré (ce qui est pourtant courant) et doit être signé par une des AC connues de l'émetteur (ce qui garantit bien des problèmes, puisque chaque émetteur a sa propre liste d'AC, qui n'est pas connue du récepteur). Le certificat doit avoir un SAN (Subject Alternative Name, cf. RFC 5280) avec un DNS-ID (RFC 6125) correspond au nom du serveur.
L'exigence que le certificat soit signé par une
AC connue de l'émetteur est la raison pour
laquelle je ne déploie pas STS sur mon domaine
bortzmeyer.org ; ses serveurs de messagerie
utilisent des certificats signés par CAcert, et beaucoup de MTA n'ont pas CAcert
dans le magasin qu'ils utilisent. Exiger un certificat signé par
une AC connue de l'émetteur pousse à la concentration vers
quelques grosses AC, puisque c'est la seule façon d'être
raisonnablement sûr qu'elle soit connue partout. Une meilleure
solution que STS, et celle que j'utilise, est d'utiliser
DANE (RFC 7672). Mais STS est issu
de chez Google, qui pousse toujours aux
solutions centralisées, avec un petit nombre d'AC
officielles. (Cf. annonce
initiale où Google dit clairement « nous avons une
solution, nous allons la faire normaliser ».)
Et si les vérifications échouent ? Tout dépend de la valeur
liée à la clé mode dans la politique. Si elle
vaut enforce, l'émetteur renonce et le
message n'est pas envoyé, si le mode est
testing ou none, on
envoie quand même. Dans le cas testing,
l'émetteur tentera de signaler au récepteur le problème (section
6), en utilisant le RFC 8460. C'est donc le
récepteur, via la politique qu'il publie, qui décide du sort du
message. L'annexe B du RFC donne, en
pseudo-code, l'algorithme complet.
La section 8 de notre RFC rassemble quelques considérations
pratiques pour celles et ceux qui voudraient déployer cette
technique STS. D'abord, le problème du changement de
politique. Lorsqu'on modifie sa politique, il y a deux endroits à
changer, les données envoyées par le serveur HTTP, et
l'enregistrement TXT dans le DNS (pour modifier la valeur associée
à id). Deux changements veut dire qu'il y a
du potentiel pour une incohérence, si on modifie un des endroits
mais pas l'autre, d'autant plus que ces deux endroits peuvent être
sous la responsabilité d'équipes différentes. Et l'enregistrement
TXT est soumis au TTL du DNS. Donc,
attention à changer la politique publiée en HTTPS avant de changer
l'enregistrement DNS. Et il faut faire en sorte que les deux
politiques fonctionnent car certains envoyeurs auront l'ancienne.
Un cas courant en matière de courrier électronique est la
délégation de l'envoi du courrier massif à un « routeur » (rien à
voir avec les routeurs
IP). Ainsi, les newsletters, dont le
service marketing croit qu'elles servent à quelque chose, sont
souvent déléguées à un spammeur professionnel, le
« routeur ». Dans ce cas, il faut aussi leur déléguer la
politique, et le _mta-sts dans le DNS doit
donc être un alias pointant vers un nom du routeur. Idem pour le
nom mta-sts qui pointe vers le serveur HTTP
où récupérer la politique. Cela doit être un alias DNS, ou bien un
reverse proxy HTTP (pas une redirection HTTP,
prohibée par le RFC).
Notre RFC se termine par la section 10, qui détaille quelques points de sécurité. Comme toute la sécurité de STS dépend du certificat PKIX qui est présenté à l'émetteur du courrier (cf. RFC 6125), la sécurité de l'écosystème X.509 est cruciale. Si une AC délivre un faux certificat (comme c'est arrivé souvent), l'authentification TLS ne protégera plus.
Autre problème potentiel, le DNS. Sans DNSSEC, il est trop facile de tromper un résolveur DNS et, par exemple, de lui dire que l'enregistrement TXT n'existe pas et qu'il n'y a donc pas de politique STS. La bonne solution est évidemment de déployer DNSSEC, mais le RFC donne également quelques conseils pratiques pour ceux et celles qui s'obstinent à ne pas avoir de DNSSEC. (Celles et ceux qui ont DNSSEC ont de toute façon plutôt intérêt à utiliser DANE.) Notamment, il est recommandé que le serveur émetteur mémorise ce que faisait le récepteur et se méfie si la politique disparait (une forme de TOFU).
STS n'est pas la première technique qui vise à atteindre ces
buts. La section 2 de notre RFC en présente d'autres. La
principale est évidemment DANE (RFC 7672), celle que j'ai choisi de déployer pour
le service de courrier de
bortzmeyer.org. DANE nécessite
DNSSEC, et le RFC présente comme un
avantage que la solution qu'il décrit ne nécessite pas DNSSEC
(c'est une erreur car, sans DNSSEC, la solution de ce RFC marche
mal puisqu'un attaquant pourrait prétendre que l'enregistrement
texte n'existe pas, ou bien lui donner une autre valeur). Par
contre, il est exact que STS permet un mode « test
seulement » que ne permet pas DANE.
Mais ce n'est pas un argument suffisant pour moi.
Qui met en œuvre STS aujourd'hui ? On a vu que Gmail le faisait. Yahoo a également une politique STS :
% dig +short TXT _mta-sts.yahoo.com "v=STSv1; id=20161109010200Z;"
Elle est en testing, comme celle de Gmail (je
n'ai encore rencontré aucun domaine qui osait utiliser
enforce). Comme illustration du fait que la
publication de la politique nécessitant deux
endroits (DNS et HTTP) est casse-gueule, regardons chez
Microsoft :
% dig +short TXT _mta-sts.outlook.com "v=STSv1; id=20180321T030303;"
Mais en HTTP, on récupère un 404 (ressource non existante) sur la politique…
ProtonMail n'a rien, pour l'instant STS semble uniquement sur les gros silos centralisés :
% dig TXT _mta-sts.protonmail.com ; <<>> DiG 9.11.3-1ubuntu1.3-Ubuntu <<>> TXT _mta-sts.protonmail.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 12470 ...
Et question logiciels libres de MTA, qu'est-ce qui existe ? Voyons Postfix ; il y a deux cas à distinguer :
- Pour le courrier entrant, où Postfix n'est pas concerné, il suffit d'activer TLS sur Postfix, puis de publier sa politique (rappelez-vous : DNS et HTTP).
- Pour le courrier sortant, il faudrait que Postfix regarde la politique du serveur distant. Il n'est pas évident que ce code doive être dans le démon Postfix lui-même (trop de code n'est pas une bonne idée). Comme le note Venema, « Like DKIM/DMARC I do not think that complex policies like STS should be built into core Postfix SMTP components ». Une meilleure solution est sans doute un programme externe comme postfix-mta-sts-resolver, qui met en œuvre une partie de ce RFC (la possibilité d'envoi de rapports est absente, par exemple), et communique ensuite les résultats à Postfix, via le système socketmap. Vous pouvez lire cet article d'exemple. Ne me demandez pas des détails, comme expliqué plus haut, j'utilise DANE et pas STS.
Une fois tout cela configuré, il existe un bon
outil de test en
ligne pour voir si votre politique STS est
correcte. Essayez-le avec outlook.com pour
rire un peu.
Quelques articles sur STS :
- Keltia n'a pas aimé.
- Shaft non plus.
- Le service de tests de sécurité en ligne Hardenize a fait un bon article de synthèse.
- Une autre solution pour connaitre la politique TLS d'un domaine : la liste maintenue par l'EFF (je n'y suis pas non plus, puisque l'AC que j'ai choisie n'est pas acceptée par l'EFF).
L'article seul
Les limites de la déGAFAisation individuelle
Première rédaction de cet article le 5 janvier 2019
Il y a aujourd'hui une certaine prise de conscience des dangers divers associés à l'utilisation trop exclusive des GAFA. (Si vous ne la partagez pas, je vous conseille le livre de Tristan Nitot, surveillance://.) Cette prise de conscience a comme résultat l'apparition de nombreux articles donnant des conseils de déGAFAisation (par exemple), « faites ceci », « ne faites pas cela », conseils sur les logiciels et les services à utiliser… Même le gouvernement français s'y met. C'est une excellente chose et je m'en félicite. Mais, en même temps, il faut être conscient des limites de cette approche individuelle.
En effet, l'idée sous-jacente des mesures suggérées est que le problème est individuel. « Les gens », « M. Michu », ont tort de dépendre des GAFA, ils devraient changer, se déGAFAiser, avoir une meilleure « hygiène numérique » et ainsi contribuer à diminuer le poids de ces GAFA. Moi-même, j'ai souvent donné ce genre de conseils et je ne le regrette pas. Mais, si la déGAFAisation individuelle est certainement une bonne chose, si l'application de ces conseils va en effet améliorer la situation de ce·lles·ux qui les suivent (notamment la vie privée), elle ne suffit pas.
D'abord, une remarque pratique : les solutions proposées à la place des GAFA ne sont pas toujours de qualité, et pérennes. Recommander des services sympas, mais gérés par un bénévole, et qui ne dureront peut-être pas longtemps, n'est pas forcément une bonne idée. Ceci dit, les solutions commerciales ne sont pas éternelles non plus (Google a déjà abandonné plusieurs services).
Toujours du côté pratique, certaines alternatives peuvent être réellement compliquées. Demander aux gens de lire les conditions d'utilisation ou autres codes de conduite avant de s'inscrire à un service est une farce. Ces textes sont délibérement incompréhensibles et, en prime, se terminent toujours par « de toute façon, l'administrateur de la plate-forme fait ce qu'il veut ».
L'argument « les gens utilisent les GAFA parce que c'est simple et ça marche » a une part de vérité. Mais une part seulement : après tout, Signal n'est pas plus dur à utiliser que Messenger, ou Mastodon plus difficile que Twitter. Certains succès de GAFA sont essentiellement dus au marketing (Slack, par exemple). D'autres tiennent en effet en partie à la difficulté de déploiement des solutions alternatives. Installer et gérer un serveur de messagerie ou un serveur XMPP est clairement trop complexe à l'heure actuelle. Et ce n'est pas seulement une question de compétence : même l'administrateur système professionnel peut estimer qu'il a autre chose à faire pour communiquer. Politiquement, il est clair que la vie privée et le contrôle de sa présence en ligne ne devraient pas être réservés à ce·lles·eux qui sont informaticien·ne·s et ont du temps libre en abondance. M. Michu a droit à sa vie privée même s'il est complètement largué face à l'informatique.
Ensuite, il y a une question psychologique : les conseils de déGAFAisation individuelle sont souvent présentés de façon culpabilisatrice, « Ne soyez pas une poire, arrêtez d'utiliser les GAFA », voire en blamant les victimes « Oui, Facebook a vendu vos données personnelles à Cambridge Analytica, mais c'est de votre faute aussi, pourquoi n'utilisiez-vous pas Diaspora ? ». Je plaide coupable, au passage, car j'utilise moi-même parfois ce genre d'arguments. Ils ont l'avantage de sortir les utilisateurs d'une position victimaire, de les traiter en citoyens, et de leur rappeler qu'ils peuvent agir, mais ils ont aussi l'inconvénient de leur demander un travail parfois difficile, et qu'ils ne devraient pas avoir à faire eux-mêmes. Être complètement déGAFAisé nécessite un investissement important ! Pensez simplement aux ridicules avertissements cookies, délibérement conçus pour être pénibles afin de s'assurer que les utilisateurs cliquent sur OK tout de suite, pour en être débarrassés. Trouver l'option pour ne pas être fliqué prend en général bien plus de temps que de lire la page Web elle-même.
Même pour des militants très actifs, la partie est inégale. Il n'y a que dans la BD « V pour Vendetta » que le héros solitaire arrive à tenir tête au système, et même à le détruire. Dans la réalité, les changements de société nécessitent d'avantage que des milliers de changements de comportement individuels, avec « M. Michu contre la World Company » (ou Thursday Next contre Goliath ?)
Notez que le même problème existe en écologie, où les conseils écologistes sont souvent également culpabilisateurs et individualistes « arrête de consommer de l'huile de palme ou bien c'est toi qui est responsable de la disparition des orang-outans ». Le mouvement des gilets jaunes a montré la difficulté d'allier préoccupations écologiques (l'étalement de l'habitat est une grosse erreur, qui ne peut aboutir qu'à augmenter la dépendance vis-à-vis de l'automobile, donc la pollution et le réchauffement planétaire) et considérations sociales (celui ou celle qui prend une voiture pour aller au bureau de poste n'est pas responsable des choix des technocrates qui ont décidé qu'on allait fermer les bureaux de poste pas rentables, ainsi que les lignes de chemin de fer, pendant qu'on y est).
Enfin, d'un point de vue plus politique, il est important de rappeler qu'une addition de changements individuels ne change pas forcément la société. Le système en place peut parfaitement digérer une opposition minoritaire, et laisser quelques geeks être libres et indépendants des GAFA, tant que la grande majorité de la population reste sur les systèmes de surveillance massive.
Bon, assez critiqué, que faudrait-il faire ? D'abord, je ne dis pas qu'il faut arrêter de donner des conseils de déGAFAisation, ou bien ne pas faire de listes comme celle du gouvernement citée au début. Informer les utilisateurs, c'est toujours bien, et la lutte pour la littératie numérique est importante.
Mais il faut connaitre les limites de cette approche et également chercher plus loin. D'abord et avant tout, il faut aussi travailler sur les solutions collectives, dont la loi. Cela n'a pas de sens de demander à chaque utilisateur de Facebook d'être un Max Schrems qui va se lancer dans une croisade contre le géant. Le RGPD, malgré ses nombreuses faiblesses, est un bon premier pas : c'est à la collectivité, en l'occurrence l'État, d'affronter les entreprises qui collectent des données personnelles. Il faut d'autres lois, plus strictes, contre cette collecte. Et comme l'État n'est pas le dernier à surveiller, il faut également des changements politiques. (Ce qui va être difficile, je le sais, puisqu'il y a un consensus des partis officiels en faveur de la surveillance.)
Outre les lois, les actions collectives peuvent aussi passer par le soutien aux logiciels libres (par exemple pour faire des logiciels toujours plus simples à déployer) et aux coopératives et associations qui les déploient (car, si simple que soit le logiciel, tout le monde n'a pas envie d'assurer les tâches d'un·e administrat·eur·rice système, même si on lui fournit une jolie interface graphique conviviale, il est donc nécessaire d'avoir des services tout prêts).
22Décembre me fait remarquer qu'entre les injonctions culpabilisantes à l'action purement individuelle, et des actions collectives qui peuvent être perçues comme lointaines et difficiles à faire mettre en route, il y a de la place pour dire que chacun a une partie de la solution. On ne peut pas changer le monde tout seul, on ne doit pas attendre une action d'un collectif en restant immobile en attendant, on peut, à son niveau faire ce qu'on peut. Le choix n'est pas uniquement entre « faire toute la route tout·e seul·e » et « attendre un bus hypothétique ».
Et pour finir, un point qui me tient à cœur en tant qu'informaticien : les alternatives aux GAFA qui sont présentées sont souvent des alternatives non-innovantes. Aucun changement, juste le remplacement d'un méchant par un autre acteur, qu'on espère plus gentil. On propose Qwant à la place de Google, ou Salto à la place de Netflix, et on se dit que le problème est résolu. Bien sûr, comme me le fait remarquer Guillaume Betous, c'est quand même une amélioration, si cela aboutit à répartir les risques. Le plus grave problème, avec Google, est la concentration de toutes les données dans une seule entreprise. Desserrer cette concentration est une bonne idée. Mais c'est insuffisant. Souvent, la vraie rupture ne viendra pas du remplacement d'un acteur par un autre, mais d'un changement de paradigme. Plutôt que de remplacer un moteur de recherche par un autre, apprendre aux utilisateurs que le moteur de recherche n'est pas indispensable pour tout (combien de fois ai-je vu des gens qui, pour aller sur le site Web de leur entreprise, utilisaient Google ?), qu'on peut utiliser signets, noms de domaine, et auto-complétion de l'URL par le navigateur ? Plutôt que de remplacer un distributeur de vidéos centralisé par un autre, passer à un système décentralisé, contrôlé par personne (et c'est exactement ce que fait PeerTube).
L'article seul
RFC 8445: Interactive Connectivity Establishment (ICE): A Protocol for Network Address Translator (NAT) Traversal
Date de publication du RFC : Juillet 2018
Auteur(s) du RFC : A. Keranen, C. Holmberg (Ericsson), J. Rosenberg (jdrosen.net)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF ice
Première rédaction de cet article le 5 janvier 2019
Le problème de la traversée des routeurs NAT est traité dans plusieurs RFC, de façon à réparer la grossière erreur qu'avait été le déploiement massif du NAT plutôt que celui de IPv6. ICE est un « méta-protocole », orchestrant plusieurs protocoles comme STUN et TURN pour arriver à découvrir un canal de communication malgré le NAT. ICE avait été normalisé il y a huit ans et le RFC 5245, que notre nouveau RFC remplace. Le protocole ne change guère, mais sa description normalisée est sérieusement modifiée.
L'objectif principal est la session multimédia, transmise entre deux terminaux, en général en UDP. ICE est donc utilisé, par exemple, par les solutions de téléphonie sur IP. Ces solutions ont déjà dû affronter le problème du NAT (RFC 3235) et ont développé un certain nombre de techniques, dont la bonne utilisation est l'objet principal de notre RFC.
En effet, les protocoles de téléphonie sur IP, comme SIP (RFC 3261) ont en commun d'avoir une session de contrôle de la connexion, établie par l'appelant en TCP (et qui passe en général assez bien à travers le NAT, si l'appelé utilise un relais public) et une session de transport des données, en général au-dessus d'UDP. C'est cette session qui est en général perturbée par le NAT. La session de contrôle (signaling session) transmet au partenaire SIP l'adresse IP de son correspondant mais, s'il y a deux domaines d'adressage séparés (par exemple un partenaire sur le domaine public et un autre dans le monde des adresses privées du RFC 1918), cette adresse IP ainsi communiquée ne sert pas à grand'chose.
On voit donc que le non-déploiement d'IPv6, qui aurait permis de se passer du NAT, a coûté très cher en temps de développement. Notre RFC fait 100 pages (et d'autres RFC doivent être lus en prime comme ceux de STUN, TURN, et le futur RFC décrivant l'utilisation de ICE par SIP et SDP), et se traduira par du code réseau très complexe, uniquement pour contourner une mauvaise décision.
Des solutions au NAT, soit standard comme STUN (RFC 8489) soit purement spécifiques à un logiciel fermé comme Skype ont été développées. Mais aucune n'est parfaite, car tous les cas sont spécifiques. Par exemple, si deux machines sont sur le même réseau local, derrière le même routeur NAT, faire appel à STUN est inutile, et peut même échouer (si le routeur NAT ne supporte pas le routage en épingle à cheveux, où un paquet d'origine interne retourne vers le réseau interne). Le principe d'ICE est donc de décrire comment utiliser plusieurs protocoles de traversée de NAT, pour trouver la solution optimale pour envoyer les paquets de la session de données. Et ceci alors que les machines qui communiquent ne savent pas en général si elles sont derrière un NAT, ni, si oui, de quel type de NAT il s'agit.
Le principe d'ICE, exposé dans la section 2 et détaillé dans les sections 5 et suivantes, est donc le suivant : chaque partenaire va déterminer une liste de paires d'adresses de transport candidates (en utilisant leurs adresses IP locales, STUN et TURN), les tester et se mettre d'accord sur la « meilleure paire ». Une fois ces trois étapes passées, on va pouvoir communiquer. Une adresse de transport est un couple (adresse IP, port).
La première étape (section 5) est donc d'établir la liste des paires, et de la trier par ordre de priorité. La section 5.1.2.1 recommande une formule pour calculer la priorité, formule qui fait intervenir une préférence pour le type d'adresses IP (une adresse locale à la machine sera préférée à une adresse publique obtenue par STUN, et celle-ci sera préférée à l'adresse d'un serveur relais TURN, puisque STUN permettra ensuite une communication directe, sans relais, donc plus rapide) et une préférence locale, par exemple pour les adresses IPv6 par rapport à IPv4.
La deuxième étape est de tester les paires (sections 2.2 et 7) pour déterminer celles qui marchent. (Les paires ont d'abord été triées par priorité à l'étape précédente.) ICE poursuit les tests, même en cas de succès, pour voir si un meilleur RTT peut être trouvé (c'est un sérieux changement par rapport au précédent RFC).
Pour ces tests, ICE utilise STUN, mais avec des extensions spécifiques à ICE (sections 7.1 et 16).
La troisième et dernière étape d'ICE (section 8) est de sélectionner la meilleure paire (en terme de priorité) parmi celles qui ont fonctionné. Les couples (adresse IP, port) de celles-ci seront alors utilisées pour la communication.
Des exemples détaillés d'utilisation d'ICE, avec tous les messages échangés, figurent dans la section 15 du RFC.
L'ensemble du processus est relativement compliqué et nécessite de garder un état sur chaque partenaire ICE, alors qu'ICE est inutile pour des machines qui ont une adresse IP publique. La section 2.5 introduit donc la possibilité de mises en œuvre légères (lite implementation) d'ICE, qui peuvent interagir avec les autres machines ICE, sans avoir à gérer tout le protocole (cf. aussi section 8.2).
Tous ces tests prennent évidemment du temps, d'autant plus de temps qu'il y a de paires d'adresse de transport « nominées ». C'est le prix à payer pour la plus grande souplesse d'ICE : il sera toujours plus lent que STUN seul.
Les protocoles de téléphonie sur IP ayant eu leur part de vulnérabilités, la section 19, sur la sécurité, est très détaillée. Par exemple, une attaque classique est d'établir une communication avec un partenaire, puis de lui demander d'envoyer le flux de données vers la victime. C'est une attaque par amplification classique, sauf que l'existence d'une session de données séparée de la session de contrôle fait qu'elle ne nécessite même pas de tricher sur son adresse IP (et les techniques du RFC 2827 sont donc inefficaces). Cette attaque, dite « attaque du marteau vocal », peut être combattue grâce à ICE, puisque le test de connectivité échouera, la victime ne répondant pas (puisqu'elle n'a rien demandé). Si tout le monde utilise ICE, cette attaque peut donc complètement disparaitre.
Notez que le lien direct entre participants est excellent pour les performances, mais est mauvais pour la vie privée (voir la section 19.1) puisqu'il révèle les adresses IP de son correspondant à chaque participant. (WebRTC - RFC 8825 - a le même problème.)
D'innombrables détails compliquent les choses et expliquent en partie la taille de ce RFC. Par exemple, la section 11 décrit l'obligation d'utiliser des keepalives, des paquets inutiles mais qui ont pour seul but de rappeler au routeur NAT que la session sert toujours, afin que les correspondances entre une adresse IP interne et une adresse externe restent ouvertes (le flux de données ne suffit pas forcément, car il peut y avoir des périodes d'inactivité).
Enfin, une intéressante section 17 décrit les problèmes pratiques du déploiement. Par exemple, la planification de la capacité des serveurs est discutée en 17.2.1. Un serveur STUN n'a pas besoin de beaucoup de capacité, mais un serveur TURN, oui, puisqu'il relaie tous les paquets, y compris ceux de la session de données.
La première version d'ICE ne gérait que l'UDP mais, depuis la publication du RFC 6544, TCP est également accepté.
La section 18 discute de la sortie, que le RFC 3424 impose à toutes les propositions concernant le NAT : est-ce que le contournement du NAT pourra être supprimé par la suite, ou bien sera-t-il lui-même un élément d'ossification ? En fait, ICE est utile même dans un Internet sans NAT (par exemple grâce à IPv6), pour tester la connectivité.
La section 21 décrit, mais de façon sommaire, les changements depuis le RFC 5245. Le RFC a été pas mal réorganisé et a un plan différent de celui du RFC 5245. Les principaux changements techniques :
- Suppression de la possibilité d'arrêter les tests dès la découverte d'une paire possible,
- Protocole de contrôle (signaling protocol) désormais déplacé dans un RFC à part, le RFC 8839.
Pour celles et ceux qui veulent creuser vraiment le RFC, et comprendre tous les choix techniques effectués, l'annexe B est là pour cela.
Il existe plusieurs mises en œuvres d'ICE en logiciel libre, comme pjnath, qui fait partie de la bibliothèque PJSIP, ou comme Nice.
L'article seul
RFC 8439: ChaCha20 and Poly1305 for IETF Protocols
Date de publication du RFC : Mai 2018
Auteur(s) du RFC : Y. Nir (Dell EMC), A. Langley (Google)
Pour information
Première rédaction de cet article le 4 janvier 2019
Les algorithmes de cryptographie ChaCha20 et Poly1305 avaient fait l'objet d'une spécification stable, permettant leur référencement pour les protocoles IETF, dans le RFC 7539, que notre RFC remplace, avec très peu de changements. Ce RFC normalise aussi bien leur utilisation isolée (ChaCha20 seul ou Poly1305 seul) que leur combinaison, qui fournit du chiffrement intègre (AEAD).
Pendant longtemps, la référence en matière de chiffrement symétrique était AES, entre autres en raison de ses performances très élevées sur du matériel dédié. AES est quatre à dix fois plus rapide que 3DES, qui était la précédente référence. Il est donc logique que AES soit utilisé partout, et notamment qu'il chiffre sans doute encore la majorité des sessions TLS. Le problème alors est qu'on dépend trop d'AES : si une faille est découverte par la cryptanalyse, on est fichu (AES est par exemple vulnérable dans certains cas). Il serait plus rassurant d'avoir des alternatives sérieuses à AES (n'obligeant pas à revenir à 3DES), pour que d'éventuelles percées en cryptanalyse ne cassent pas toute la crypto d'un coup. D'autant plus qu'AES a un défaut : rapide sur du matériel spécialisé, il l'est moins sur du matériel généraliste.
D'où les algorithmes décrits formellement dans ce RFC. Inventés par Bernstein, ils ont déjà fait l'objet d'un certain nombre d'analyses de sécurité (« New Features of Latin Dances: Analysis of Salsa, ChaCha, and Rumba » et « Latin Dances Revisited: New Analytic Results of Salsa20 and ChaCha »). ChaCha20 est un algorithme de chiffrement symétrique, plus rapide qu'AES sur un matériel générique (mise en œuvre purement en logiciel), Poly1305 est un MAC, et les deux peuvent être combinés pour faire du chiffrement intègre (et cela figure désormais dans le registre sur AEAD).
La section 2 du RFC décrit les algorithmes (je ne la reprends pas ici, la crypto, c'est trop fort pour moi), et ajoute du pseudo-code, des exemples et des vecteurs de test (il y en a d'autres dans l'annexe A). À l'origine, Poly1305 était décrit comme lié à AES, pour obtenir, par chiffrement du numnique, une chaîne de bits unique et secrète. Mais, en fait, n'importe quelle fonction de chiffrement convient, pas uniquement AES.
En cryptographie, ce sont plus souvent les mises en œuvre que les algorithmes qui ont une faille. La section 3 est donc consacrée aux avis aux programmeurs, pour éviter qu'une erreur de leur part n'affaiblisse ces beaux algorithmes. Poly1305 nécessite de travailler avec des grands nombres et le RFC déconseille d'utiliser la plupart des bibliothèques existantes de gestion des grands nombres comme celle d'OpenSSL. Celles-ci sont trop souvent vulnérables à des attaques par mesure du temps écoulé et le RFC conseille d'utiliser uniquement des bibliothèques qui font leur travail en un temps constant, comme NaCl. Un exemple de mise en œuvre de Poly1305 est poly1305-donna.
La section 4, sur la sécurité, détaille les points importants à suivre pour ne pas se faire casser sa jolie crypto. Pour ChaCha20, avant tout, il faut utiliser un numnique (numnique ?) vraiment unique. On peut utiliser un compteur, on peut utiliser un LFSR, mais il doit être unique.
ChaCha20 et Poly1305 n'utilisent que des opérations simples,
normalement faciles à implémenter en un temps constant, qui ne
permettront pas à l'attaquant de déduire quoi que ce soit de la
mesure des temps de réponse. Attention, programmeurs, certaines
fonctions comme la classique
memcmp() ne s'exécutent pas en un
temps constant, et, si elles sont utilisées, permettent certaines
attaques.
Ces algorithmes sont dans le registre IANA des algorithmes TLS. Notez aussi un bon article d'explication de CloudFlare.
Comme indiqué au début, il n'y a que peu de changements depuis le RFC 7539, à part la correction de plusieurs erreurs techniques.
L'article seul
RFC 8499: DNS Terminology
Date de publication du RFC : Janvier 2019
Auteur(s) du RFC : P. Hoffman (ICANN), A. Sullivan, K. Fujiwara (JPRS)
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 3 janvier 2019
Comme beaucoup de protocoles très utilisés sur l'Internet, le DNS est ancien. Très ancien (la première norme, le RFC 882, date de 1983). Les normes techniques vieillissent, avec l'expérience, on comprend mieux, on change les points de vue et donc, pour la plupart des protocoles, on se lance de temps en temps dans une révision de la norme. Mais le DNS est une exception : la norme actuelle reste fondée sur des textes de 1987, les RFC 1034 et RFC 1035. Ces documents ne sont plus à jour, modifiés qu'ils ont été par des dizaines d'autres RFC. Bref, aujourd'hui, pour comprendre le DNS, il faut s'apprêter à lire de nombreux documents. En attendant qu'un courageux et charismatique participant à l'IETF se lance dans la tâche herculéenne de faire un jeu de documents propre et à jour, ce RFC 8499, successeur du RFC 7719, se limite à une ambition plus modeste : fixer la terminologie du DNS. Ce n'est pas un tutoriel : vous n'y apprendrez pas le DNS. C'est plutôt une encyclopédie. Il a depuis été remplacé par le RFC 9499, mais avec peu de changements.
En effet, chacun peut constater que les discussions portant sur le DNS sont difficiles : on manque de terminologie standard, et celle des RFC officielles ne suffit pas, loin de là. Souvent, le DNS a tellement changé que le RFC officiel est même trompeur : les mots ne veulent plus dire la même chose. D'autres protocoles ont connu des mises à jour de la norme. Cela a été le cas de SMTP, passé successivement du RFC 772 à l'actuel RFC 5321, en passant par plusieurs révisions successives. Ou de XMPP, qui a vu sa norme originale mise à jour dans le RFC 6120. Et bien sûr de HTTP, qui a connu un toilettage complet. Mais personne n'a encore osé faire pareil pour le DNS. Au moins, ce RFC 8499, comme son prédécesseur RFC 7719, traite l'un des problèmes les plus criants, celui du vocabulaire. Le RFC est évidemment en anglais, les traductions proposées dans cet article, et qui n'ont pas de valeur « officielle » sont de moi seul.
Notre RFC 8499 rassemble donc des définitions pour des termes qui étaient parfois précisément définis dans d'autres RFC (et il fournit alors un lien vers ce RFC original), mais aussi qui n'étaient définis qu'approximativement ou parfois qui n'étaient pas définis du tout (et ce RFC fournit alors cette définition). Du fait du flou de certains RFC anciens, et des changements qui ont eu lieu depuis, certaines définitions sont différentes de l'original. Le document a fait l'objet d'un consensus relatif auprès des experts DNS mais quelques termes restent délicats. Notez aussi que d'autres organisations définissent des termes liés au DNS par exemple le WHATWG a sa définition de ce qu'est un domaine, et le RSSAC a développé une terminologie.
Ironiquement, un des termes les plus difficiles à définir est
« DNS » lui-même (section 1 de notre RFC). D'accord, c'est le sigle de Domain Name
System mais ça veut dire quoi ? « DNS » peut désigner le
schéma de nommage (les noms de
domaine comme signal.eu.org, leur
syntaxe, leurs contraintes), la base de données répartie (et
faiblement cohérente) qui associe à ces noms des informations
(comme des certificats, des adresses IP, etc), ou le protocole
requête/réponse (utilisant le port 53) qui permet d'interroger cette
base. Parfois, « DNS » désigne uniquement le protocole, parfois,
c'est une combinaison des trois éléments indiqués plus haut
(personnellement, quand j'utilise « DNS », cela désigne uniquement
le protocole, un protocole relativement simple, fondé sur l'idée « une requête => une réponse »).
Bon, et ces définitions rigoureuses et qui vont mettre fin aux discussions, ça vient ? Chaque section du RFC correspond à une catégorie particulière. D'abord, en section 2, les noms eux-même, ces fameux noms de domaine. Un système de nommage (naming system) a plusieurs aspects, la syntaxe des noms, la gestion des noms, le type de données qu'on peut associer à un nom, etc. D'autres systèmes de nommage que celui présenté dans ce RFC existent, et sont distincts du DNS sur certains aspects. Pour notre système de nommage, le RFC définit :
- Nom de domaine (domain
name) : la définition est différente de celle du RFC 7719, qui avait simplement repris celle du
RFC 1034, section 3.1. Elle est désormais
plus abstraite, ce qui permet de l'utiliser pour d'autres
systèmes de nommage. Un nom de domaine est désormais simplement
une liste (ordonnée) de composants
(labels). Aucune restriction n'est imposée
dans ces composants, simplement formés
d'octets (tant pis pour la légende comme
quoi le DNS serait limité à ASCII). Comme on
peut représenter les noms de domaine sous forme d'un arbre (la racine de l'arbre
étant à la fin de la liste des composants) ou bien sous forme
texte (
www.madmoizelle.com), le vocabulaire s'en ressent. Par exemple, on va dire quecomest « au-dessus demadmoizelle.com» (vision arborescente) ou bien « à la fin dewww.madmoizelle.com» (vision texte). Notez aussi que la représentation des noms de domaine dans les paquets IP n'a rien à voir avec leur représentation texte (par exemple, les points n'apparaissent pas). Enfin, il faut rappeler que le vocabulaire « standard » n'est pas utilisé partout, même à l'IETF, et qu'on voit parfois « nom de domaine » utilisé dans un sens plus restrictif (par exemple uniquement pour parler des noms pouvant être résolus avec le DNS, pour lesquels il avait été proposé de parler de DNS names.) - FQDN (Fully Qualified Domain
Name, nom de domaine complet) : apparu dans le RFC 819, ce terme désigne un nom de domaine où tous les
composants sont cités (par exemple,
ldap.potamochère.fr.est un FQDN alors queldaptout court ne l'est pas). En toute rigueur, un FQDN devrait toujours s'écrire avec un point à la fin (pour représenter la racine) mais ce n'est pas toujours le cas. (Notre RFC parle de « format de présentation » et de « format courant d'affichage » pour distinguer le cas où on met systématiquement le point à la fin et le cas où on l'oublie.) - Composant
(label) : un nœud de l'arbre des noms de domaine, dans la chaîne
qui compose un FQDN. Dans
www.laquadrature.net, il y a trois composants,www,laquadratureetnet. - Nom de machine (host
name) : ce n'est pas la
même chose qu'un nom de domaine. Utilisé dans de nombreux
RFC (par exemple RFC 952) mais jamais défini, un nom de
machine est un nom de domaine avec une syntaxe plus
restrictive, définie dans la section 3.5 du RFC 1035 et amendée par la section 2.1 du RFC 1123 : uniquement des lettres, chiffres, points et le
tiret. Ainsi,
brienne.tarth.got.examplepeut être un nom de machine maiswww.&#$%?.examplene peut pas l'être. Le terme de « nom de machine » est parfois aussi utilisé pour parler du premier composant d'un nom de domaine (briennedansbrienne.tarth.got.example). - TLD (Top Level
Domain, domaine de premier niveau ou domaine de
tête) : le dernier composant d'un nom de domaine, celui juste
avant (ou juste en dessous) de la racine. Ainsi,
frounamesont des TLD. N'utilisez surtout pas le terme erroné d'« extension ». Et ne dites pas que le TLD est le composant le plus à droite, ce n'est pas vrai dans l'alphabet arabe. La distinction courante entre gTLD, gérés par l'ICANN, et ccTLD, indépendants de l'ICANN, est purement politique et ne se reflète pas dans le DNS. - DNS mondial (Global DNS), nouveauté de notre RFC, désigne l'ensemble des noms qui obéissent aux règles plus restrictives des RFC 1034 et RFC 1035 (limitation à 255 octets, par exemple). En outre, les noms dans ce « DNS mondial » sont rattachés à la racine officiellement gérée par l'ICANN, via le service PTI. Une racine alternative, si elle sert un contenu différent de celui de PTI, n'est donc pas le « DNS mondial » mais ce que le RFC nomme « DNS privé » (private DNS). Évidemment, un système de nommage qui n'utilise pas le DNS du tout mais qui repose, par exemple, sur le pair-à-pair, ne doit pas être appelé DNS (« DNS pair-à-pair » est un oxymore, une contradiction dans les termes.)
- IDN (Internationalized Domain Name, nom de domaine internationalisé) : un nom de domaine en Unicode, normalisé dans le RFC 5890, qui définit des termes comme U-label (le nom Unicode) et A-label (sa représentation en Punycode). Sur l'internationalisation des noms, vous pouvez aussi consulter le RFC de terminologie RFC 6365.
- Sous-domaine
(subdomain) : domaine situé sous un autre,
dans l'arbre des noms de domaines. Sous forme texte, un domaine
est sous-domaine d'un autre si cet autre est un suffixe. Ainsi,
www.cl.cam.ac.ukest un sous-domaine decl.cam.ac.uk, qui est un sous-domaine decam.ac.uket ainsi de suite, jusqu'à la racine, le seul domaine à n'être sous-domaine de personne. Quand le RFC parle de suffixe, il s'agit d'un suffixe de composants, pas de caractères :foo.example.netn'est pas un sous-domaine deoo.example.net. - Alias (alias) :
attention, il y a un piège. Le DNS permet à un nom d'être un
alias d'un autre, avec le type d'enregistrement CNAME (voir la
définition suivante). L'alias est le terme de gauche de
l'enregistrement CNAME. Ainsi, si on met dans un fichier de zone
vader IN CNAME anakin, l'alias estvader(et c'est une erreur de dire que c'est « le CNAME »). - CNAME (Canonical
Name, nom canonique, le « vrai » nom) : le membre
droit dans l'enregistrement CNAME. Dans l'exemple de la
définition précédente,
anakinest le CNAME, le « nom canonique ».
Fini avec les noms, passons à l'en-tête des messages DNS et aux codes qu'il peut contenir. Cet en-tête est défini dans le RFC 1035, section 4.1. Il donne des noms aux champs mais pas forcément aux codes. Ainsi, le code de réponse 3 indiquant qu'un domaine demandé n'existe pas est juste décrit comme name error et n'a reçu son mnémonique de NXDOMAIN (No Such Domain) que plus tard. Notre RFC définit également, dans sa section 3 :
- NODATA : un mnémonique pour une réponse où le nom de domaine demandé existe bien mais ne contient aucun enregistrement du type souhaité. Le code de retour est 0, NOERROR, et le nombre de réponses (ANCOUNT pour Answer Count) est nul.
- Réponse négative (negative answer) : le terme recouvre deux choses, une réponse disant que le nom de domaine demandé n'existe pas (code de retour NXDOMAIN), ou bien une réponse indiquant que le serveur ne peut pas répondre (code de retour SERVFAIL ou REFUSED). Voir le RFC 2308.
- Renvoi (referral) : le DNS étant décentralisé, il arrive qu'on pose une question à un serveur qui ne fait pas autorité pour le domaine demandé, mais qui sait vous renvoyer à un serveur plus proche. Ces renvois sont indiqués dans la section Authority d'une réponse.
Voici un renvoi depuis la racine vers .fr :
% dig @l.root-servers.net A blog.imirhil.fr
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 16572
;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 5, ADDITIONAL: 11
...
;; AUTHORITY SECTION:
fr. 172800 IN NS d.ext.nic.fr.
fr. 172800 IN NS d.nic.fr.
fr. 172800 IN NS e.ext.nic.fr.
fr. 172800 IN NS f.ext.nic.fr.
fr. 172800 IN NS g.ext.nic.fr.
La section 4 s'intéresse aux transactions DNS. Un des termes définis est celui de QNAME (Query NAME). Nouveauté de ce RFC, il a suscité bien des débats. Il y a en effet trois sens possibles (le premier étant de très loin le plus commun) :
- Le sens original, le QNAME est la question posée (le nom de domaine demandé),
- Le sens du RFC 2308, la question finale (qui n'est pas la question posée s'il y a des CNAME sur le trajet),
- Un sens qui n'apparait pas dans les RFC mais est parfois présent dans les discussions, une question intermédiaire (dans une chaîne de CNAME).
Le RFC 2308 est clairement en tort ici. Il aurait dû utiliser un terme nouveau, pour le sens nouveau qu'il utilisait.
Passons maintenant aux enregistrements DNS, stockés dans cette base de données répartie (section 5 du RFC) :
- RR (Resource Record) : un enregistrement DNS.
- Enregistrements d'adresses (Address records) : enregistrements DNS A (adresses IPv4) et AAAA (adresses IPv6). Beaucoup de gens croient d'ailleurs que ce sont les seuls types d'enregistrements possibles (« le DNS sert à traduire les noms en adresses IP » est une des synthèses erronées du DNS les plus fréquentes).
- Ensemble d'enregistrements (RRset pour Resource Record set) : un ensemble d'enregistrements ayant le même nom (la même clé d'accès à la base), la même classe, le même type et le même TTL. Cette notion avait été introduite par le RFC 2181. Notez que la définition originale parle malheureusement de label dans un sens incorrect. La terminologie du DNS est vraiment compliquée !
- Fichier maître (master file) : un fichier texte contenant des ensembles d'enregistrement. Également appelé fichier de zone, car son utilisation la plus courante est pour décrire les enregistrements que chargera le serveur maître au démarrage. (Ce format peut aussi servir à un résolveur quand il écrit le contenu de sa mémoire sur disque.)
- EDNS (Extension for DNS, également appelé EDNS0) : normalisé dans le RFC 6891, EDNS permet d'étendre l'en-tête du DNS, en spécifiant de nouvelles options, en faisant sauter l'antique limitation de taille de réponses à 512 octets, etc.
- OPT (pour Option) : une astuce d'EDNS pour encoder les informations de l'en-tête étendu. C'est un enregistrement DNS un peu spécial, défini dans le RFC 6891, section 6.1.1.
- Propriétaire (owner ou owner name) : le nom de domaine d'un enregistrement. Ce terme est très rarement utilisé, même par les experts.
- Champs du SOA (SOA field names) : ces noms des enregistrements SOA (comme MNAME ou RNAME) sont peu connus et malheureusement peu utilisés (RFC 1035, section 3.3.13). Notez que la sémantique du champ MINIMUM a complètement changé avec le RFC 2308.
- TTL (Time To Live) : la durée de vie maximale d'un enregistrement dans les caches des résolveurs. C'est un entier non signé (même si le RFC 1035 dit le contraire), en secondes.
Voici un ensemble d'enregistrements (RRset), comptant ici deux enregistrements :
rue89.com. 600 IN MX 50 mx2.typhon.net.
rue89.com. 600 IN MX 10 mx1.typhon.net.
(Depuis, ça a changé.)
Et voici un pseudo-enregistrement OPT, tel qu'affiché par dig, avec une indication de la taille maximale et l'option client subnet (RFC 7871) :
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 512
; CLIENT-SUBNET: 13.176.144.0/24/0
Ensuite, un sujet chaud où le vocabulaire est particulièrement peu défini, et très mal utilisé (voir les forums grand public sur le DNS où les discussions prennent un temps fou car les gens utilisent mal les mots) : les différents types de serveurs et clients DNS (section 6). Pour commencer, il est crucial de se méfier quand un texte parle de « serveur DNS » tout court. Si le contexte ne permet pas de savoir de quel genre de serveur DNS on parle, cela indique un manque de compréhension du DNS par l'auteur du texte. Serveurs faisant autorité et serveurs résolveurs, quoique utilisant le même protocole, sont en effet très différents.
- Résolveur (resolver) : un client DNS qui va produire une réponse finale (pas juste un renvoi, pas juste une information ponctuelle comme le fait dig). Il existe plusieurs types de résolveurs (voir ci-dessous) et, en pratique, quand on dit « résolveur » tout court, c'est en général un « résolveur complet ».
- Résolveur minimum (stub
resolver) : un résolveur qui ne sait pas suivre les
renvois et qui dépend donc d'un ou de plusieurs résolveurs
complets pour faire son travail. Ce type est défini dans la
section 6.1.3.1 du RFC 1123. C'est ce
résolveur minimum qu'appelent les applications lorsqu'elles font
un
getaddrinfo()ougetnameinfo(). Sur Unix, le résolveur minimum fait en général partie de la libc et trouve l'adresse du ou des résolveurs complets dans/etc/resolv.conf. - Résolveur complet (full resolver) : un résolveur qui sait suivre les renvois et donc fournir un service de résolution complet. Des logiciels comme Unbound ou PowerDNS Resolver assurent cette fonction. Le résolveur complet est en général situé chez le FAI ou dans le réseau local de l'organisation où on travaille, mais il peut aussi être sur la machine locale. On le nomme aussi « résolveur récursif ». Notez que « résolveur complet » fait partie de ces nombreux termes qui étaient utilisés sans jamais avoir été définis rigoureusement.
- Resolveur complet avec mémoire (full-service resolver) : un résolveur complet, qui dispose en plus d'une mémoire (cache) des enregistrements DNS récoltés.
- Serveur faisant autorité
(authoritative server et traduire ce terme
par « serveur autoritaire » montre une grande ignorance de
l'anglais ; un adjudant est autoritaire,
un serveur DNS fait autorité) : un serveur DNS qui connait une
partie des données du DNS (il « fait autorité » pour une ou
plusieurs zones) et peut donc y répondre (RFC 2182,
section 2). Ainsi, au moment de l'écriture de cet article,
f.root-servers.netfait autorité pour la racine,d.nic.frfait autorité pourpm, etc. Des logiciels comme NSD ou Knot assurent cette fonction. Les serveurs faisant autorité sont gérés par divers acteurs, les registres, les hébergeurs DNS (qui sont souvent en même temps bureaux d'enregistrement), mais aussi parfois par M. Michu. La commandedig NS $ZONEvous donnera la liste des serveurs faisant autorité pour la zone$ZONE. Ou bien vous pouvez utiliser un service sur le Web en visitanthttps://dns.bortzmeyer.org/DOMAIN/NSoù DOMAIN est le nom de domaine qui vous intéresse. - Serveur mixte : ce terme n'est pas dans ce RFC. Autrefois, il était courant que des serveurs DNS fassent à la fois résolveur et serveur faisant autorité. Cette pratique est fortement déconseillée depuis de nombreuses années (entre autres parce qu'elle complique sérieusement le débogage, mais aussi pour des raisons de sécurité parce qu'elle mène à du code plus complexe) et n'est donc pas dans ce RFC.
- Initialisation
(priming) : le processus par lequel un
résolveur complet vérifie l'information sur les serveurs de la
racine. Ce concept est décrit en détail dans le RFC 8109. Au démarrage, le résolveur ne sait rien. Pour
pouvoir commencer la résolution de noms, il doit demander aux
serveurs de la racine. Il a donc dans sa configuration leur
liste. Mais ces configurations ne sont pas forcément mises à
jour souvent. La liste peut donc être trop vieille. La première
chose que fait un résolveur est donc d'envoyer une requête
«
NS .» à un des serveurs de sa liste. Ainsi, tant qu'au moins un des serveurs de la vieille liste répond, le résolveur est sûr d'apprendre la liste actuelle. - Indications de la racine (root hints, terme défini dans ce nouveau RFC, et qui n'était pas dans son prédécesseur) : la liste des noms et adresses des serveurs racine, utilisée pour l'initialisation. L'administrateur d'un résolveur utilisant une racine alternative changera cette liste.
- Mémorisation des négations (negative caching, ou « cache négatif ») : mémoriser le fait qu'il n'y a pas eu de réponse, ou bien une réponse disant qu'un nom de domaine n'existe pas.
- Serveur primaire (primary
server mais on dit aussi serveur maître, master
server) : un serveur faisant autorité qui a accès à la
source des données (fichier de zone, base de données,
etc). Attention, il peut y avoir plusieurs serveurs
primaires (autrefois, ce n'était pas clair et beaucoup de gens
croient qu'il y a un serveur primaire, et qu'il est indiqué dans
l'enregistrement SOA). Attention bis, le terme ne s'applique qu'à des
serveurs faisant autorité, l'utiliser pour les résolveurs (« on
met en premier dans
/etc/resolv.confle serveur primaire ») n'a pas de sens. - Serveur secondaire (secondary server mais on dit aussi « serveur esclave », slave server) : un serveur faisant autorité qui n'est pas la source des données, qui les a prises d'un serveur primaire (dit aussi serveur maître), via un transfert de zone (RFC 5936).
- Serveur furtif (stealth server) : un serveur faisant autorité mais qui n'apparait pas dans l'ensemble des enregistrements NS. (Définition du RFC 1996, section 2.1.)
- Maître caché (hidden master) : un serveur primaire qui n'est pas annoncé publiquement (et n'est donc accessible qu'aux secondaires). C'est notamment utile avec DNSSEC : s'il signe, et donc a une copie de la clé privée, il vaut mieux qu'il ne soit pas accessible de tout l'Internet (RFC 6781, section 3.4.3).
- Transmission (forwarding) : le fait, pour un résolveur, de faire suivre les requêtes à un autre résolveur (probablement mieux connecté et ayant un cache partagé plus grand). On distingue parfois (mais ce n'est pas forcément clair, même dans le RFC 5625) la transmission, où on émet une nouvelle requête, du simple relayage de requêtes sans modification.
- Transmetteur
(forwarder) : le terme est confus (et a
suscité plein de débats dans le groupe de travail DNSOP lors de
la mise au point du précédent RFC, le RFC 7719). Il désigne parfois la machine qui transmet une
requête et parfois celle vers laquelle on transmet (c'est dans
ce sens qu'il est utilisé dans la configuration de
BIND, avec la directive
forwarders). - Résolveur politique (policy-implementing resolver) : un résolveur qui modifie les réponses reçues, selon sa politique. On dit aussi, moins diplomatiquement, un « résolveur menteur ». C'est ce que permet, par exemple, le système RPZ. Sur l'utilisation de ces « résolveurs politiques » pour mettre en œuvre la censure, voir entre autres mon article aux RIPE Labs. Notez que le résolveur politique a pu être choisi librement par l'utilisateur (par exemple comme élément d'une solution de blocage des publicités) ou bien qu'il lui a été imposé.
- Résolveur ouvert (open resolver) : un résolveur qui accepte des requêtes DNS depuis tout l'Internet. C'est une mauvaise pratique (cf. RFC 5358) et la plupart de ces résolveurs ouverts sont des erreurs de configuration. Quand ils sont délibérement ouverts, comme Google Public DNS ou Quad9, on parle plutôt de résolveurs publics.
- Collecte DNS passive (passive DNS) : désigne les systèmes qui écoutent le trafic DNS, et stockent tout ou partie des informations échangées. Le cas le plus courant est celui où le système de collecte ne garde que les réponses (ignorant donc les adresses IP des clients et serveurs), afin de constituer une base historique du contenu du DNS (c'est ce que font DNSDB ou le système de PassiveDNS.cn).
- Serveur protégeant la vie privée (privacy-enabled server) : nouveauté de ce RFC; ce terme désigne un serveur, typiquement un résolveur, qui permet les requêtes DNS chiffrées, avec DNS-sur-TLS (RFC 7858) ou avec DoH (RFC 8484).
- Anycast : le fait d'avoir un service en plusieurs sites physiques, chacun annonçant la même adresse IP de service (RFC 4786). Cela résiste mieux à la charge, et permet davantage de robustesse en cas d'attaque par déni de service. Les serveurs de la racine, ceux des « grands » TLD, et ceux des importants hébergeurs DNS sont ainsi « anycastés ». Chaque machine répondant à l'adresse IP de service est appelée une instance.
- DNS divisé (split
DNS) : le fait de donner des réponses différentes
selon que le client est interne à une organisation ou
externe. Le but est, par exemple, de faire en sorte que
www.organisation.exampleaille sur le site public quand on vient de l'Internet mais sur un site interne de la boîte quand on est sur le réseau local des employés.
Voici, vu par tcpdump, un exemple d'initialisation d'un résolveur BIND utilisant la racineYeti (RFC 8483) :
15:07:36.736031 IP6 2a01:e35:8bd9:8bb0:21e:8cff:fe76:29b6.35721 > 2001:6d0:6d06::53.53: \
21476% [1au] NS? . (28)
15:07:36.801982 IP6 2001:6d0:6d06::53.53 > 2a01:e35:8bd9:8bb0:21e:8cff:fe76:29b6.35721: \
21476*- 16/0/1 NS yeti-ns.tisf.net., NS yeti-ns.lab.nic.cl., NS yeti-ns.wide.ad.jp., NS yeti.ipv6.ernet.in., NS yeti-ns.as59715.net., NS ns-yeti.bondis.org., NS yeti-dns01.dnsworkshop.org., NS dahu2.yeti.eu.org., NS dahu1.yeti.eu.org., NS yeti-ns.switch.ch., NS bii.dns-lab.net., NS yeti.bofh.priv.at., NS yeti-ns.conit.co., NS yeti.aquaray.com., NS yeti-ns.ix.ru., RRSIG (619)
La question était « NS . » (quels sont les
serveurs de la racine) et la réponse contenait les noms des seize
serveurs racine qu'avait Yeti à l'époque.
Voici aussi des exemples de résultats avec un résolveur ou bien avec un serveur faisant autorité. Si je demande à un serveur faisant autorité (ici, un serveur racine), avec mon client DNS qui, par défaut, demande un service récursif (flag RD, Recursion Desired) :
% dig @2001:620:0:ff::29 AAAA www.iab.org
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 54197
;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 9, ADDITIONAL: 13
;; WARNING: recursion requested but not available
...
;; AUTHORITY SECTION:
org. 172800 IN NS b0.org.afilias-nst.org.
...
C'est pour cela que dig affiche WARNING: recursion requested but not available. Notez aussi que le serveur, ne faisant autorité que pour la racine, n'a pas donné la réponse mais juste un renvoi aux serveurs d'Afilias. Maintenant, interrogeons un serveur récursif (le service de résolveur public Yandex DNS) :
% dig @2a02:6b8::feed:0ff AAAA www.iab.org
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 63304
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
...
;; ANSWER SECTION:
www.iab.org. 1800 IN AAAA 2001:1900:3001:11::2c
Cette fois, j'ai obtenu une réponse, et avec le
flag RA, Recursion
Available. Si je pose une question sans le
flag RD (Recursion Desired,
avec l'option +norecurse de dig) :
% dig +norecurse @2a02:6b8::feed:0ff AAAA www.gq.com
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 59438
;; flags: qr ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
...
;; ANSWER SECTION:
www.gq.com. 293 IN CNAME condenast.map.fastly.net.
J'ai obtenu ici une réponse car l'information était déjà dans le cache (la mémoire) de Yandex DNS (on le voit au TTL, qui n'est pas un chiffre rond, il a été décrémenté du temps passé dans le cache). Si l'information n'est pas dans le cache :
% dig +norecurse @2a02:6b8::feed:0ff AAAA blog.keltia.net
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 19893
;; flags: qr ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 0
...
Je n'obtiens alors pas de réponse (ANSWER: 0, donc NODATA). Si je demande au serveur faisant autorité pour cette zone :
% dig +norecurse @2a01:e0d:1:3:58bf:fa61:0:1 AAAA blog.keltia.net
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 62908
;; flags: qr aa; QUERY: 1, ANSWER: 2, AUTHORITY: 6, ADDITIONAL: 15
...
;; ANSWER SECTION:
blog.keltia.net. 86400 IN AAAA 2a01:240:fe5c:1::2
...
J'ai évidemment une réponse et, comme il s'agit d'un serveur faisant autorité, elle porte le flag AA (Authoritative Answer, qu'un résolveur ne mettrait pas). Notez aussi le TTL qui est un chiffre rond (et qui ne change pas si on rejoue la commande).
Passons maintenant à un concept relativement peu connu, celui de zones, et le vocabulaire associé (section 7) :
- Zone : un groupe de domaines contigus
dans l'arbre des noms, et gérés ensemble, par le même ensemble
de serveurs de noms (ma définition, celle du RFC étant très
abstraite). Beaucoup de gens croient que tout domaine est une
zone, mais c'est faux. Ainsi, au moment de la publication de ce
RFC,
gouv.frn'est pas une zone séparée, il est dans la même zone quefr(cela se teste facilement :gouv.frn'a pas d'enregistrement NS ou de SOA). - Parent : le domaine « du
dessus ». Ainsi, le parent de
wikipedia.orgestorg, le parent de.orgest la racine. - Apex : le sommet d'une zone, là où on trouve les enregistrements NS et SOA. Si la zone ne comprend qu'un domaine, l'apex est ce domaine. Si la zone est plus complexe, l'apex est le domaine le plus court. (On voit parfois des gens utiliser le terme erroné de racine pour parler de l'apex.)
- Coupure de zone (zone cut) : l'endoit où on passe d'une zone à l'autre. Au-dessus de la coupure, la zone parente, en dessous, la zone fille.
- Délégation (delegation) : un concept évidemment central dans le DNS, qui est un système décentralisé. En ajoutant un ensemble d'enregistrements NS pointant vers les serveurs de la zone fille, une zone parente délègue une partie de l'arbre des noms de domaine à une autre entité. L'endroit où se fait la délégation est donc une coupure de zone.
- Colle (glue
records) : lorsqu'une zone est déléguée à des serveurs
dont le nom est dans la zone fille, la résolution DNS se heurte
à un problème d'œuf et de poule. Pour trouver l'adresse de
ns1.mazone.example, le résolveur doit passer par les serveurs demazone.example, qui est déléguée àns1.mazone.exampleet ainsi de suite... On rompt ce cercle vicieux en ajoutant, dans la zone parente, des données qui ne font pas autorité sur les adresses de ces serveurs (RFC 1034, section 4.2.1). Il faut donc bien veiller à les garder synchrones avec la zone fille. (Tanguy Ortolo me suggère d'utiliser « enregistrement de raccord » plutôt que « colle ». Cela décrit bien leur rôle, en effet.) - Délégation boiteuse (lame delegation) : un ou plusieurs des serveurs à qui la zone est déléguée ne sont pas configurés pour servir cette zone. La délégation peut avoir été boiteuse depuis le début (parce que le titulaire a indiqué des noms un peu au hasard) ou bien l'être devenue par la suite. C'est certainement une des erreurs techniques les plus courantes.
- Dans le bailliage (in bailiwick) : terme absent des textes DNS originaux et qui peut désigner plusieurs choses. (La définition du RFC 7719, embrouillée, a été heureusement remplacée.) « Dans le bailliage » est (très rarement, selon mon expérience) parfois utilisé pour parler d'un serveur de noms dont le nom est dans la zone servie (et qui nécessite donc de la colle, voir la définition plus haut), mais le sens le plus courant désigne des données pour lesquelles le serveur qui a répondu fait autorité, soit pour la zone, soit pour un ancêtre de cette zone. L'idée est qu'il est normal dans la réponse d'un serveur de trouver des données situées dans le bailliage et, par contre, que les données hors-bailliage sont suspectes (elles peuvent être là suite à une tentative d'empoisonnement DNS). Un résolveur DNS prudent ignorera donc les données hors-bailliage.
- ENT (Empty
Non-Terminal pour nœud non-feuille mais vide) : un
domaine qui n'a pas d'enregistrements mais a des
sous-domaines. C'est fréquent, par exemple, sous
ip6.arpaou sous les domaines très longs de certains CDN. Cela se trouve aussi avec les enregistrements de service : dans_sip._tcp.example.com,_tcp.example.comest probablement un ENT. La réponse correcte à une requête DNS pour un ENT est NODATA (code de réponse NOERROR, liste des répoonses vide) mais certains serveurs bogués, par exemple ceux d'Akamai, répondent NXDOMAIN. - Zone de délégation (delegation-centric zone) : zone composée essentiellement de délégations vers d'autres zones. C'est typiquement le cas des TLD et autres suffixes publics. Il est amusant de noter que les RFC 4956 et RFC 5155 utilisaient ce terme sans le définir.
- Changement rapide (fast flux) : une technique notamment utilisée par les botnets pour mettre leur centre de commande à l'abri des filtrages ou destructions. Elle consiste à avoir des enregistrements d'adresses IP avec des TTL très courts et à en changer fréquemment.
- DNS inverse (reverse DNS) : terme qui désigne en général les requêtes pour des enregistrements de type PTR, permettant de trouver le nom d'une machine à partir de son adresse IP. À ne pas confondre avec les vraies requêtes inverses, qui avaient été normalisées dans le RFC 1035, avec le code IQUERY, mais qui, jamais vraiment utilisées, ont été abandonnées dans le RFC 3425.
Voyons ici la colle retournée par un serveur faisant autorité (en
l'occurrence un serveur de .net) :
% dig @a.gtld-servers.net AAAA labs.ripe.net
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 18272
;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 8, ADDITIONAL: 9
...
;; AUTHORITY SECTION:
ripe.net. 172800 IN NS ns3.nic.fr.
ripe.net. 172800 IN NS sec1.apnic.net.
ripe.net. 172800 IN NS sec3.apnic.net.
ripe.net. 172800 IN NS tinnie.arin.net.
ripe.net. 172800 IN NS sns-pb.isc.org.
ripe.net. 172800 IN NS pri.authdns.ripe.net.
...
;; ADDITIONAL SECTION:
sec1.apnic.net. 172800 IN AAAA 2001:dc0:2001:a:4608::59
sec1.apnic.net. 172800 IN A 202.12.29.59
sec3.apnic.net. 172800 IN AAAA 2001:dc0:1:0:4777::140
sec3.apnic.net. 172800 IN A 202.12.28.140
tinnie.arin.net. 172800 IN A 199.212.0.53
tinnie.arin.net. 172800 IN AAAA 2001:500:13::c7d4:35
pri.authdns.ripe.net. 172800 IN A 193.0.9.5
pri.authdns.ripe.net. 172800 IN AAAA 2001:67c:e0::5
On notera :
- La section ANSWER est vide, c'est un renvoi.
- Le serveur indique la colle pour
pri.authdns.ripe.net: ce serveur étant dans la zone qu'il sert, sans son adresse IP, on ne pourrait jamais le joindre. - Le serveur envoie également les adresses IP d'autres
machines comme
sec1.apnic.net. Ce n'est pas strictement indispensable (on pourrait l'obtenir par une nouvelle requête), juste une optimisation. - Les adresses de
ns3.nic.fretsns-pb.isc.orgne sont pas renvoyées. Le serveur ne les connait probablement pas et, de toute façon, elles seraient hors-bailliage, donc ignorées par un résolveur prudent.
Voyons maintenant, un ENT,
gouv.fr (notez que, depuis, ce domaine n'est
plus un ENT) :
% dig @d.nic.fr ANY gouv.fr
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 42219
;; flags: qr aa rd; QUERY: 1, ANSWER: 0, AUTHORITY: 2, ADDITIONAL: 1
Le serveur fait bien autorité pour ce domaine (flag AA dans la réponse), le domaine existe (autrement, le status aurait été NXDOMAIN, pas NOERROR) mais il n'y a aucun enregistrement (ANSWER: 0).
Et, ici, une délégation boiteuse, pour
.ni :
% check-soa ni
dns.nic.cr.
2001:13c7:7004:1::d100: ERROR: SERVFAIL
200.107.82.100: ERROR: SERVFAIL
ns.ideay.net.ni.
186.1.31.8: OK: 2013093010
ns.ni.
165.98.1.2: ERROR: read udp 10.10.86.133:59569->165.98.1.2:53: i/o timeout
ns.uu.net.
137.39.1.3: OK: 2013093010
ns2.ni.
200.9.187.2: ERROR: read udp 10.10.86.133:52393->200.9.187.2:53: i/o timeout
Le serveur dns.nic.cr est déclaré comme
faisant autorité pour .ni mais il ne le sait
pas, et répond donc SERVFAIL.
Les jokers ont désormais une section à eux, la section 8 du RFC. S'appuyant sur le RFC 4592, elle définit, entre autres :
- Joker
(wildcard) : une source de confusion
considérable depuis les débuts du DNS. Si on pouvait refaire le
DNS en partant de zéro, ces jokers seraient la première chose à
supprimer. Pour les résumer, le nom
*dans une zone déclenche la synthèse automatique de réponses pour les noms qui n'existent pas dans la zone. Si la zonefoo.examplecontientbar.foo.exampleet*.foo.example, une requête pourthing.foo.examplerenverra le contenu de l'enregistrement avec le joker, une requête pourbar.foo.exampledonnera les données debar.foo.example. Attention, l'astérisque n'a son rôle particulier que s'il est le composant le plus spécifique (le premier). Dansfoo.*.bar.example, il n'y a pas de joker. - Ancêtre le plus proche
(closest encloser) : c'est le plus long
ancêtre existant d'un nom. Si
foo.bar.baz.examplen'existe pas, quebar.baz.examplen'existe pas non plus, mais quebaz.exampleexiste, alorsbaz.exampleest l'ancêtre le plus proche defoo.bar.baz.example. Ce concept est nécessaire pour le RFC 5155.
Allez courage, ne faiblissons pas, il reste encore la question de l'enregistrement des noms de domaine (section 9) :
- Registre
(registry) : l'organisation ou la personne
qui gère les délégations d'une zone. Le terme est parfois
employé uniquement pour les gérants de grandes zones de
délégation, mais ce n'est pas obligatoire. Je suis à moi tout
seul le registre de
bortzmeyer.org😁. C'est le registre qui décide de la politique d'enregistrement, qui peut être très variable selon les zones (sauf dans celles contrôlées par l'ICANN, où une certaine uniformité est imposée). Mes lecteurs français noteront que, comme le terme « registre » est court et largement utilisé, le gouvernement a inventé un nouveau mot, plus long et jamais vu auparavant, « office d'enregistrement ». - Titulaire (registrant, parfois holder) : la personne ou l'organisation qui a enregistré un nom de domaine.
- Bureau d'enregistrement (registrar) : dans le modèle RRR (Registry-Registrar-Registrant, mais ce modèle n'est pas obligatoire et pas universel), c'est un intermédiaire entre le titulaire et le registre.
- Hébergeur DNS (DNS operator) : la personne ou l'organisation qui gère les serveurs DNS. Cela peut être le titulaire, son bureau d'enregistrement, ou encore un acteur spécialisé dans cette gestion.
- Suffixe public (public
suffix) : ce terme pas très officiel est parfois
utilisé pour désigner un suffixe de noms de domaine qui est
contrôlé par un registre public (au sens où il accepte des
enregistrements du public). Le terme est ancien mais est apparu
pour la première fois dans un RFC avec le RFC 6265, section 5.3.
com,co.uketeu.orgsont des suffixes publics. Rien dans la syntaxe du nom n'indique qu'un nom de domaine est un suffixe public, puisque ce statut ne dépend que d'une politique d'enregistrement (qui peut changer). Il est parfaitement possible qu'un domaine, et un de ses enfants, soient tous les deux un suffixe public (c'est le cas de.orgeteu.org). - EPP (Extensible Provisioning Protocol) : normalisé dans le RFC 5730, c'est le protocole standard entre bureau d'enregistrement et registre. Ce protocole n'a pas de lien avec le DNS, et tous les registres ne l'utilisent pas.
- Whois (nommé d'après la question Who Is?) : un protocole réseau, sans lien avec le DNS, normalisé dans le RFC 3912. Il permet d'interroger les bases de données du registre pour trouver les informations dites « sociales », informations qui ne sont pas dans le DNS (comme le nom du titulaire, et des moyens de le contacter). Les termes de « base Whois » ou de « données Whois » sont parfois utilisés mais ils sont erronés puisque les mêmes bases peuvent être interrogées par d'autres protocoles que Whois, comme RDAP (voir définition suivante).
- RDAP (Registration Data Access Protocol) : un protocole concurrent de Whois, mais plus moderne. RDAP est décrit notamment dans les RFC 9082 et RFC 9083.
Prenons par exemple le domaine eff.org. Au
moment de la publication du RFC :
Enfin, pour terminer, les sections 10 et 11 de notre RFC couvrent DNSSEC. Pas grand'chose de nouveau ici, DNSSEC étant plus récent et donc mieux défini.
L'annexe A de notre RFC indique quelles définitions existaient dans de précédents RFC mais ont été mises à jour par le nôtre. (C'est rare, puisque le but de ce RFC de terminologie est de rassembler les définitions, pas de les changer.) Par exemple, la définition de QNAME du RFC 2308 est corrigée ici.
L'annexe B liste les termes dont la première définition formelle se trouve dans ce RFC (ou dans son prédécesseur le RFC 7719). Cette liste est bien plus longue que celle de l'annexe A, vu le nombre de termes courants qui n'avaient jamais eu l'honneur d'une définition stricte.
Notre RFC ne contient pas une liste exhaustive des changements depuis son prédécesseur, le RFC 7719, alors qu'il y a quelques modifications substantielles. Parmi les gros changements :
- La description des autres systèmes de nommage ; on peut penser à Namecoin ou à ENS (Ethereum Name Service, cf. leur site Web). La section 2 donne une définition de naming system qui n'existait pas avant.
- La définition d'un nom de domaine a complètement changé, pour être plus générale, moins liée au DNS, de façon à pouvoir la conserver avec d'autres systèmes de nommage. Ce sujet a toujours été sensible à l'IETF. À une époque, il avait été proposé de différencier domain name et DNS name (ces seconds étant un sous-ensemble des premiers, utilisés dans le contexte du DNS) mais cela n'a pas été retenu.
- Des définitions ont été sérieusement changées, comme celle de bailiwick.
- Et plein de nouveaux termes ont été introduits comme « instance » (pour l'anycast), split DNS, reverse dns, indications de la racine (root hints), etc.
L'article seul
RFC 8387: Practical Considerations and Implementation Experiences in Securing Smart Object Networks
Date de publication du RFC : Mai 2018
Auteur(s) du RFC : M. Sethi, J. Arkko, A. Keranen (Ericsson), H. Back (Nokia)
Pour information
Réalisé dans le cadre du groupe de travail IETF lwig
Première rédaction de cet article le 2 janvier 2019
On le sait, la sécurité de l'Internet des Objets est absolument catastrophique. Les objets vendus au grand public, par exemple, non seulement envoient toutes vos données personnelles quelque part chez le vendeur de l'objet, mais en outre permettent en général facilement à des tiers de copier ces données. Ce RFC décrit les défis que pose la sécurisation de réseaux d'objets connectés, spécialement pour ceux qui disposent de ressources (comme l'électricité) limitées.
Le problème n'est pas purement technique : si les innombrables objets connectés que vous avez reçus comme cadeau de Noël cette année ont une sécurité abyssalement basse, c'est parce que les vendeurs sont totalement incompétents, et qu'ils ne font aucun effort pour apprendre. Cela n'a la plupart du temps rien à voir avec le manque de ressources (processeur, électricité) de l'objet. Les télévisions connectées ou voitures connectées n'ont pas une meilleure sécurité, alors qu'elles disposent de bien plus de ressources qu'un Raspberry Pi 1, qui peut pourtant faire du SSH ou TLS sans problème. Mais les vendeurs agissent dans une impunité totale, et ne sont donc pas motivés pour améliorer les choses. Aucun vendeur d'objets connectés n'a jamais eu à subir les conséquences (légales ou commerciales) d'une faille de sécurité. Les objets à la sécurité pourrie se vendent aussi bien que les autres. Et la loi ne protège pas le client. Les mêmes qui s'indignent contre la vente de bitcoins à des particuliers sans expérience financière ne protestent jamais contre la vente d'objets espions facilement piratables.
Mais comme la plupart des RFC, ce document se focalise sur l'aspect technique du problème, et suggère des solutions techniques. Je suis pessimiste quant aux chances de déploiement de ces solutions, en raison de l'absence de motivations (cf. ci-dessus). Mais il est vrai que ce RFC vise plutôt les objets utilisés en milieu industriel que ceux destinés au grand public.
D'abord, les défis auxquels font face les objets connectés (section 3 du RFC). D'abord, il y a le fait que, dans certains objets, les ressources sont limitées : le processeur est très lent, la mémoire est réduite, et la batterie n'a pas des réserves infinies. On a vu que ces ressources limitées sont parfois utilisées comme excuses pour ne pas mettre en œuvre certaines techniques de sécurité (une télévision connectée qui utilise HTTP et pas HTTPS avec l'argument que la cryptographie est trop coûteuse !) Mais, pour certaines catégories d'objets, l'argument est réel : un capteur industriel peut effectivement ne pas avoir autant de ressources que l'expert en sécurité le souhaiterait. Certains objets sont vendus à des prix individuels très bas et doivent donc être fabriqués à faible coût. Conséquences : il faut utiliser CoAP et non pas HTTP, les clés cryptographiques ne peuvent pas être trop longues, l'engin ne peut pas être allumé en permanence et n'est donc pas forcément joignable, son interface utilisateur très réduite ne permet pas de définir un mot de passe, etc.
Outre le fait que ces ressouces limitées sont souvent un faux prétexte pour justifier la paresse des vendeurs, le RFC note que le développement de ces objets se fait souvent dans le mauvais ordre : on conçoit le matériel puis, bien après, on cherche les solutions de sécurité qui arriveraient à tourner sur ce matériel. Pour sortir de l'état catastrophique de la sécurité des objets connectés, il faudrait procéder en sens inverse, et intégrer la sécurité dès le début, concevant le matériel en fonction des exigences de sécurité.
Deuxième défi pour le concepteur d'un objet connecté, l'avitaillement (provisioning). Comment mettre dans l'objet connectés les informations nécessaires, mots de passe, clés et autres données ? Par exemple, si une technique de sécurité utilise un mot de passe, mettre le même dans chaque objet lors de sa fabrication est facile, mais évidemment très mauvais pour la sécurité. Mais demander à M. Michu, qui a acheté un gadget connecté, de rentrer un mot de passe avec une interface à deux boutons et un minuscule écran n'est pas évident. Et si une entreprise a acheté une centaine de capteurs, faut-il une intervention manuelle sur chacun, pour mettre le mot de passe ? Le RFC considère que c'est sans doute le principal défi pour la sécurité des objets connectés. Le problème est difficile à résoudre car :
- L'interface utilisateur des objets connectés est minimale, voire inexistante.
- Les utilisateurs typiques ne sont pas compétents en ce domaine, et la plupart du temps ne sont même pas conscients du fait qu'ils ont désormais une responsabilité d'administrateur système. C'est d'ailleurs une des raisons pour lesquelles le terme d'« objet » est dangereux : il empêche de percevoir cette responsabilité. Ces engins sont des ordinateurs, avec les risques associés, et devraient être traités comme tels.
- Ces objets sont souvent livrés en très grande quantité ; toute solution d'avitaillement doit passer à l'échelle.
Résultat, les objets connectés sont souvent vendus avec des informations statiques, et une identité stable, qui facilite certes des aspects de l'administration du réseau, comme le suivi d'un objet donné, mais met sérieusement en danger la sécurité.
En outre, troisième défi, chaque objet ayant souvent des capacités limitées, la communication est fréquemment relayée par des passerelles. Même lorsque l'objet a une visibilité directe, il faut souvent passer par une passerelle car l'objet peut passer la majorité de son temps endormi, donc injoignable, afin d'économiser l'électricité. Les modèles traditionnels de sécurité, fondés sur le principe de bout en bout, ne fonctionnent pas bien dans ce contexte.
Pour affronter ces défis, notamment celui de l'avitaillement, la section 4 de notre RFC décrit un modèle de déploiement, où les identités des objets sont dérivées de clés cryptographiques, auto-générées sur chaque objet, comme les CGA du RFC 3972 ou les HIT du RFC 7401. Dans ce modèle, chaque objet génère une paire de clés. L'opération de génération de l'identité consiste typiquement à appliquer une fonction de condensation cryptographique à la concaténation d'une clé publique de l'engin et d'une information locale. Une fois qu'on connait l'identité d'une machine, on peut communiquer avec elle de manière sûre, puisqu'elle peut signer ses messages avec sa clé privée, qui n'est jamais communiquée.
Avec ce modèle, il n'y a plus de mots de passe définis en usine et identiques sur toutes les machines. Mais cela impose, au moment du déploiement, de récolter ces identités (par exemple via un code QR affiché par l'objet, ou bien via NFC) pour les enregistrer dans la base de données qui sera utilisée par le, la ou les administrateurs du réseau. Ce mécanisme permettra d'authentifier les objets, mais pas aux objets d'authentifier un éventuel partenaire, par exemple celui qui leur envoie des ordres. Pour cela, il faudra en autre indiquer la clé publique de ce partenaire au moment de l'installation, ce qui nécessitera un mécanisme de communication, par exemple via le port USB. On ne pourra pas sortir les objets du carton et aller les poser sur le terrain sans autre formalité. Mais la sécurité est à ce prix.
Ces identités stables posent potentiellement un problème de vie privée. Il faut donc prévoir leur renouvellement, soit périodiquement, soit lorsque l'objet change de propriétaire. Un bouton ou autre mécanisme « oublie tout et crée une nouvelle identité » est donc nécessaire.
Une fois qu'on a ces identités, on peut les utiliser de plusieurs façons, de bout en bout ou bien via des intermédiaires. Plusieurs architectures et protocoles sont possibles. Ce serait par exemple le cas de HIP. Mais les auteurs du RFC privilégient une solution qui se situerait au niveau des applications, bâtie sur CoAP (RFC 7252) car cela permettrait :
- aux machines intermédiaires de servir de caches pour les objets qui dorment,
- à ces mêmes machines d'effectuer des tâches de filtrage ou d'agrégation sans remettre en cause la sécurité,
- à cette solution de fonctionner même en présence de ces middleboxes qui empêchent souvent tout déploiement d'une solution dans les couches plus basses.
S'agit-il d'une idée en l'air, d'un vague projet ? Non, les auteurs du RFC ont déjà identifié plusieurs bibliothèques logicielles qui peuvent permettre de mettre en œuvre ces idées en fournissant des opérations cryptographiques nécessaires à cette architecture, même à des machines peu gonflées :
- AvrCryptolib, pour AVR,
- Relic, portable, car écrit en C (d'autres bibliothèques utilisent totalement ou partiellement le langage d'assemblage), inclut RSA et Curve25519,
- TinyECC, écrit en nesC pour TinyOS,
- Wiselib en C++, et qui a été testé avec succès sur Arduino Uno,
- MatrixSSL (rebaptisé depuis « TLS Toolkit »), conçu pour des objets mieux dotés (processeur de 32 bits).
Certains systèmes d'exploitation sont spécialement conçus pour des objets contraints, et disposent des bibliothèques nécessaires. C'est le cas par exemple de mbed, qui tourne sur plusieurs membres de la famille ARM Cortex.
Ce n'est pas tout d'avoir du code, encore faut-il qu'il tourne de manière efficace. La section 6 de notre RFC est dédiée aux tests de performance, notamment lors des opérations de signature. C'est ainsi que RSA avec une clé de 2 048 bits et le code d'AvrCryptolib prend vraiment trop de temps (sur une machine apparemment non spécifiée) pour être utilisable.
ECDSA avec TinyECC sur un Arduino Uno tourne par contre en un temps supportable. Sans utiliser le code en langage d'assemblage qui est disponible dans cette bibliothèque, la consommation de RAM reste la même mais le temps d'exécution augmente de 50 à 80 %. D'autres mesures figurent dans cette section, avec diverses bibliothèques, et divers algorithmes. La conclusion est la même : la cryptographie asymétrique, sur laquelle repose l'architecture de sécurité proposée dans notre RFC est réaliste sur des objets très contraints mais probablement uniquement avec les courbes elliptiques. Les courbes recommandées sont celles du RFC 7748, bien plus rapides que celles du NIST (tests avec la bibliothèque NaCl).
Les problèmes concrets ne s'arrêtent pas là. Il faut aussi voir que certains objets contraints, comme l'Arduino Uno, n'ont pas de générateur aléatoire matériel. (Contrairement à, par exemple, le Nordic nRF52832.) Ces engins n'ayant pas non plus d'autres sources d'entropie, générer des nombres aléatoires de qualité (RFC 4086), préliminaire indispensable à la création des clés, est un défi.
La section 7 du RFC décrit une application développée pour illustrer les principes de ce RFC. Il s'agit de piloter des capteurs qui sont éteints pendant l'essentiel du temps, afin d'économiser leur batterie, et qui se réveillent parfois pour effectuer une mesure et en transmettre le résultat. Des machines sont affectées à la gestion de la communication avec les capteurs et peuvent, par exemple, conserver un message lorsque le capteur est endormi, le distribuant au capteur lorsqu'il se réveille. Plus précisément, il y avait quatre types d'entités :
- Les capteurs, des Arduino Mega (un processeur de seulement 8 bits) utilisant Relic, soit 29 ko dans la mémoire flash pour Relic et 3 pour le client CoAP,
- Le courtier, qui est allumé en permanence, et gère la communication avec les capteurs, selon un modèle publication/abonnement,
- L'annuaire, où capteurs et courtier peuvent enregistrer des ressources et les chercher,
- L'application proprement dite, tournant sur un ordinateur généraliste avec Linux, et communiquant avec l'annuaire et avec les courtiers.
Le modèle de sécurité est TOFU ; au premier démarrage, les capteurs génèrent les clés, et les enregistrent dans l'annuaire, suivant le format du RFC 6690. (L'adresse IP de l'annuaire est codée en dur dans les capteurs, évitant le recours au DNS.) Le premier enregistrement est supposé être le bon. Ensuite, chaque fois qu'un capteur fait une mesure, il l'envoie au courtier en JSON signé en ECDSA avec JOSE (RFC 7515). Il peut aussi utiliser CBOR avec COSE (RFC 8152). La signature peut alors être vérifiée. On voit qu'il n'y a pas besoin que la machine de vérification (typiquement celle qui porte l'application) soit allumée en même temps que le capteur. Ce prototype a bien marché. Cela montre comment on peut faire de la sécurité de bout en bout bien qu'il y ait au moins un intermédiaire (le courtier).
La question de la faisabilité de l'architecture décrite dans ce RFC est discutée plus en détail dans la section 8.1. On entend souvent que les objets connectés n'ont pas de vraie sécurité car « la cryptographie, et surtout la cryptographie asymétrique, sont bien trop lentes sur ces objets contraints ». Les expériences faites ne donnent pas forcément un résultat évident. La cryptographie asymétrique est possible, mais n'est clairement pas gratuite. RSA avec des clés de tailles raisonnables pourrait mettre plusieurs minutes à signer, ce qui n'est pas tolérable. Heureusement, ce n'est pas le seul algorithme. (Rappelons que cela ne s'applique qu'aux objets contraints. Il n'y a aucune bonne raison de ne pas utiliser la cryptographie pour des objets comme une télévision ou une caméra de surveillance.) La loi de Moore joue ici en notre faveur : les microcontrôleurs de 32 bits deviennent aussi abordables que ceux de 8 bits.
Quant aux exigences d'énergie électrique, il faut noter que le plus gourmand, et de loin, est la radio (cf. Margi, C., Oliveira, B., Sousa, G., Simplicio, M., Paulo, S., Carvalho, T., Naslund, M., et R. Gold, « Impact of Operating Systems on Wireless Sensor Networks (Security) Applications and Testbeds », à WiMAN en 2010). Signer et chiffrer, ce n'est rien, par rapport à transmettre.
L'ingénierie, c'est toujours faire des compromis, particulièrement quand on travaille avec des systèmes aussi contraints en ressources. La section 8 du RFC détaille certains de ces compromis, expliquant les choix à faire. Ainsi, la question de la fraîcheur des informations est délicate. Quand on lit le résultat d'une mesure sur le courtier, est-on bien informé sur l'ancienneté de cette mesure ? Le capteur n'a en général pas d'horloge digne de ce nom et ne peut pas se permettre d'utiliser NTP. On peut donc être amené à sacrifier la résolution de la mesure du temps aux contraintes pratiques.
Une question aussi ancienne que le modèle en couches est celle de la couche où placer la sécurité. Idéalement, elle devrait être dans une seule couche, pour limiter le code et le temps d'exécution sur les objets contraints. En pratique, elle va sans doute se retrouver sur plusieurs couches :
- Couche 2 : c'est la solution la plus courante aujourd'hui (pensez à une carte SIM et aux secrets qu'elle stocke). Mais cela ne sécurise que le premier canal de communications, ce n'est pas une sécurité de bout en bout. Peu importe que la communication de l'objet avec la base 4G soit signée et chiffrée si le reste du chemin est non authentifié, et en clair !
- Couche 3 : c'est ce que fait IPsec, solution peu déployée en pratique. Cette fois, c'est de bout en bout mais il est fréquent qu'un stupide intermédiaire bloque les communications ainsi sécurisées. Et les systèmes d'exploitation ne fournissent en général pas de moyen pratique permettant aux applications de contrôler cette sécurité, ou même simplement d'en être informé.
- Couche 4 ou Couche 7 : c'est l'autre solution populaire, une grande partie de la sécurité de l'Internet repose sur TLS, par exemple. (Ou, pour les objets contraints, DTLS.) C'est évidemment la solution la plus simple à contrôler depuis l'application. Par contre, elle ne protège pas contre les attaques dans les couches plus basses (un paquet TCP RST malveillant ne sera pas gêné par TLS) mais ce n'est peut-être pas un gros problème, cela fait juste un déni de service, qu'un attaquant pourrait de toute façon faire par d'autres moyens.
- On peut aussi envisager de protéger les données et pas la communication, en signant les données. Cela marche même en présence d'intermédiaires divers mais cette solution est encore peu déployée en ce moment, par rapport à la protection de la couche 2 ou de la couche 7.
Enfin, dernière étude sur les compromis à faire, le choix entre la cryptographie symétrique et la cryptographie asymétrique, bien plus gérable en matière de distribution des clés, mais plus consommatrice de ressources. On peut faire de la cryptographie symétrique à grande échelle mais, pour la cryptographie asymétrique, il n'y a pas encore de déploiements sur, disons, des centaines de millions d'objets. On a vu que dans certains cas, la cryptographie asymétrique coûte cher. Néanmoins, les processeurs progressent et, question consommation énergétique, la cryptographie reste loin derrière la radio. Enfin, les schémas de cryptographie des objets connectés n'utiliseront probablement la cryptographie asymétrique que pour s'authentifier au début, utilisant ensuite la cryptographie symétrique pour l'essentiel de la communication.
Enfin, la section 9 de notre RFC résume les points importants :
- Il faut d'abord établir les exigences de sécurité puis seulement après choisir le matériel en fonction de ces exigences,
- La cryptographie à courbes elliptiques est recommandée,
- La qualité du générateur de nombres aléatoires, comme toujours en cryptographie, est cruciale pour la sécurité,
- Si on commence un projet aujourd'hui, il vaut mieux partir directement sur des microcontrôleurs de 32 bits,
- Il faut permettre la génération de nouvelles identités, par exemple pour le cas où l'objet change de propriétaire,
- Et il faut prévoir les mises à jour futures (un objet peut rester en service des années) par exemple en terme de place sur la mémoire flash (le nouveau code sera plus gros).
La section 2 de notre RFC décrit les autres travaux menés en matière de sécurité, en dehors de ce RFC. Ainsi, la spécification du protocole CoAP, le « HTTP du pauvre objet » (RFC 7252) décrit comment utiliser CoAP avec DTLS ou IPsec. Cette question de la sécurité des objets connectés a fait l'objet d'un atelier de l'IAB en 2011, atelier dont le compte-rendu a été publié dans le RFC 6574.
L'article seul
Articles des différentes années : 2026 2025 2024 2023 2022 2021 2020 Précédentes années
Syndication : Flux Atom avec seulement les résumés et Flux Atom avec tout le contenu.
{kind=link}