
Ce blog n'a d'autre prétention que de me permettre de mettre à la disposition de tous des petits textes que j'écris. On y parle surtout d'informatique mais d'autres sujets apparaissent parfois.
Fiche de lecture : Cryptographie par la pratique avec Python et OpenSSL
Auteur(s) du livre : Rémi Boulle
Éditeur : Dunod
978-2-10-087133-9
Publié en 2024
Première rédaction de cet article le 26 décembre 2024
Vous le savez tous et toutes, la cryptographie est une composante essentielle de la sécurité de l'Internet. Si tout le monde ne va pas devenir expert·e en cryptographie, en revanche, il est utile de connaitre les principes de base. Ce livre, destiné à des étudiant·es plutôt qu'au grand public, est une approche très concrète de la cryptographie, avec des exemples pratiques. J'ai beaucoup apprécié cette approche terre-à-terre.
Le livre commence par rappeler l'enjeu de la cryptographie, indispensable pour protéger l'utilisateurice de l'Internet des nombreuses activités de surveillance qui s'exercent contre lui ou elle. Les révélations d'Edward Snowden, par exemple, ont montré que la surveillance massive par les États est une réalité. La cryptographie soulève de nombreuses questions politiques, ce livre les mentionne mais parle surtout de technique.
Vous aurez en effet ensuite une explication des principes de la cryptographie, puis des différents algorithmes. Il faudra accepter un peu de mathématique, mais c'est nécessaire dans ce domaine.
Pour les exemples de code, le livre utilise Python, et commence par une
introduction (ou un rappel) de ce langage, si vous ne le connaissez
pas bien. Il dépend ensuite de plusieurs bibliothèques qu'il
présente, dont cryptography et,
comme le titre l'indique, OpenSSL. La
cryptographie nécessite des opérations de bas niveau, comme des
décalages de bits mais ne vous inquiétez pas, tout cela est
rappelé.
On commence par un exemple trivial et d'intérêt purement historique, l'algorithme de César :
import sys
KEY=3
def chiffre_Cesar_texte(texte_clair, k):
texte_chiffre = ""
for lettre in texte_clair:
code_lettre = ord(lettre)-65
chiffre = (code_lettre + k) % 26
lettre_chiffre = chr(chiffre + 65)
texte_chiffre = texte_chiffre + lettre_chiffre
return texte_chiffre
for texte in sys.argv[1:]:
print(chiffre_Cesar_texte(texte, KEY))
Mais vous aurez d'innombrables exemples de codes plus sérieux, utilisant des services réels, par exemple récupérer des données sur la chaine de blocs Bitcoin, l'analyser, la vérifier et même faire du minage de bitcoins. Même un·e connaisseur·se en cryptographie y découvrira certainement quelque chose, par exemple qu'il existe une courbe elliptique souveraine en France.
Conçu comme livre de classe, il contient de nombreux exercices. Si vous voulez récupérer l'intégralité des exemples et des solutions, allez sur le site officiel (on vous demande votre adresse de courrier mais mettez n'importe quoi, ça marche).
Le livre ne se contente pas de généralités sur la cryptographie mais explique aussi les détails de certains protocoles de communication sécurisés, très utilisés sur l'Internet, comme HTTPS et SSH, ou bien dans le contexte de l'Internet des objets, comme LoRaWAN, avec décorticage de paquets. Bref, si vous êtes prêt à vous plonger dans la cryptographie, voici un excellent guide.
La photo du livre, ci-dessous, contient une autre image,
cachée. Lisez le chapitre sur la
stéganographie et vous pourrez récupérer
cette image cachée (les quatre bits de poids faible contiennent les
bits de poids fort de l'image cachée, cf. section 4.5.2, p. 43 et
44). 
L'article seul
La robustesse de la connectivité Internet, l'exemple du Pakistan
Première rédaction de cet article le 22 décembre 2024
Si vous êtes en vacances dans les prochains jours, cela peut être l'occasion de lire des articles scientifiques riches. Par exemple, si vous voulez en apprendre davantage sur la robustesse des connexions Internet face aux coupures de câbles, regardez le cas du Pakistan dans cet article (en anglais).
Régulièrement, la question de la vulnérabilité des câbles qui forment l'infrastructure physique de l'Internet est posée. Souvent, elle est traitée de manière sensationnaliste (« les russechinoicoréeniraniens vont couper notre Internet, on ne pourra plus voir Netflix »), par exemple par des politiciens qui veulent jouer au chef de temps de guerre. Si on veut traiter le sujet plus sérieusement, il faut analyser en détail, et ça prend davantage de temps que de faire un titre putaclic. C'est ce que font Nowmay Opalinski, Zartash Uzmi et Frédérick Douzet pour le cas du Pakistan. Leur article « The Quest for a Resilient Internet Access in a Constrained Geopolitical Environment » étudie en détail la connectivité d'un pays. Combien de câbles vers l'extérieur ? Par où passent-ils ? (Je vous laisse lire l'article pour voir leur méthodologie, mais notez qu'il ne suffit pas d'étudier l'infrastructure physique, leur article décortique aussi l'infrastructure logicielle.) Cela donne une bonne idée de la robustesse de la connectivité d'un pays, de ses chances de résister à des coupures de câble, qu'elles soient volontaires ou accidentelles (et je rappelle qu'il y a davantage de maladroits que de malveillants).
Si vous regardez la carte, vous pouvez vous dire que le Pakistan n'a pas trop besoin de câbles sous-marins, il peut passer par des connexions terrestres avec ses voisins. Mais la question n'est évidemment pas purement technique, il faut prendre en question la géopolitique. Pas question de passer par l'Inde, par exemple. Et, avec l'Iran, ce n'est pas beaucoup mieux. Il reste l'Afghanistan… Et il y a même un lien avec la Chine, avec qui les relations sont bien plus cordiales, mais, ici, c'est la géographie qui n'est pas d'accord (le câble, dont l'utilisation n'est pas claire, passe par un col difficile).
Bref, les connexions internationales du Pakistan passent pour l'essentiel par des liaisons sous-marines depuis Karachi, vers des pays plus lointains. Une panne dans cette région met donc en péril toute la connectivité extérieure du pays.
Ce ne serait pas trop grave si les Pakistanais·es pouvaient encore dialoguer entre ielles. Mais, comme dans beaucoup de pays, les communications, même locales, sont souvent médiées par les GAFA. Et ceux-ci n'ont souvent pas d'infrastructure dans le pays, suggérant parfois de passer par l'Inde, ce qui est évidemment irréaliste vu les relations entre les deux pays. Une coupure des liens avec l'extérieur pourrait donc avoir de sérieuses conséquences. Si on utilisait davantage les liaisons pair-à-pair et l'auto-hébergement, il y aurait davantage de robustesse.
Un exemple (j'ai pris le DNS parce que c'est ce que je connais mais lisez l'article, il y aura d'autres exemples), l'instance de Google Public DNS qu'on peut joindre depuis le Pakistan, vue par les sondes RIPE Atlas, est aux Émirats, de l'autre côté du golfe :
% blaeu-resolve --requested 100 --country PK --nameserver 8.8.8.8 \
--nsid --type A lums.edu.pk
Nameserver 8.8.8.8
[110.93.234.24 111.68.103.174 203.135.62.24 NSID: gpdns-fjr;] : 3 occurrences
Test #85285321 done at 2024-12-22T13:48:31Z
(Voir mon autre article sur l'utilisation des sondes Atlas. Regardez le NSID - RFC 5001 de l'instance, qui pointe vers les EAU.)
En parlant d'histoire-géographie, notez aussi que l'article met en évidence que les liaisons intérieures du pays sont très concentrées dans la vallée de l'Indus. La technologie moderne utilise la même voie de communication qu'il y a cinq mille ans.
Quelques autres références :
- Un bon résumé (en anglais) par un des auteurs.
- Les transparents d'un exposé (en anglais) par ce même auteur à une réunion SANOG (très détaillés, avec cartes et photos).
- Le blog d'Anurag Bhatia (en anglais) est une des meilleures sources sur la connectivité Internet de la région (voir par exemple son « Pakistan-Europe connectivity via China » sur le lien à travers le col de Khunjerab).
- Loin du Pakistan, un exemple d'analyse sérieuse de coupure de câbles, loin de tout sensationnalisme, « Does the Internet Route Around Damage? - Baltic Sea Cable Cuts » et « A Deep Dive Into the Baltic Sea Cable Cuts ».
L'article seul
RFC 9639: Free Lossless Audio Codec
Date de publication du RFC : Décembre 2024
Auteur(s) du RFC : M.Q.C. van
Beurden, A. Weaver
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF cellar
Première rédaction de cet article le 19 décembre 2024
Le format FLAC, normalisé dans ce RFC, permet de stocker et de transmettre du son sans perte (contrairement à des mécanismes de compression comme MP3). Il est donc utile, par exemple pour l'archivage à long terme (mais aussi pour la haute fidélité).
Le multimédia, c'est compliqué. Le RFC fait près de 100 pages, pour un format audio qui se veut pourtant simple. FLAC fait de la compression pour limiter l'espace de stockage nécessaire mais en prenant soin de permettre une décompression qui redonne exactement le fichier originel (d'où le « sans perte » dans son nom, qu'il partage avec d'autres formats, comme le FFV1 du RFC 9043). Je ne connais pas assez le domaine de l'audio pour faire un résumé intelligent du RFC donc je vous invite à le lire si vous voulez comprendre comment FLAC fonctionne (les sections 4 à 6 vous font une description de haut niveau).
Si on prend un fichier FLAC, un programme comme file peut le comprendre :
% file Thélème.flac Thélème.flac: FLAC audio bitstream data, 24 bit, stereo, 44.1 kHz, length unknown
Le fait que l'échantillonage soit à 44,1 kHz est encodé dans les métadonnées (cf. section 9.1.2 du RFC), que file a pu lire (section 9.1.3 pour le fait que le fichier soit en stéréo).
Il y a quelques fichiers FLAC sur Wikimedia Commons. Mais un bon exemple de l'utilisation de FLAC est donné par l'enregistrement des Variations Goldberg par Kimiko Ishizaka, que vous pouvez télécharger en FLAC et sous une licence libre (CC0).
La mise en œuvre de référence de FLAC est en logiciel libre et se nomme libFLAC. Mais il existe beaucoup d'autres programmes qui savent gérer FLAC (j'ai écouté plusieurs fichiers FLAC avec vlc pour cet article), le lire, l'écrire, l'analyser, etc. Une liste est disponible sur le site du groupe de travail IETF. Il faut dire que FLAC, bien qu'il vienne seulement d'être normalisé, est un format ancien, dont le développement a commencé en 2000, et il n'est donc pas étonnant que les programmeur·ses aient eu le temps de travailler.
Si vous voulez ajouter du code à cette liste, lisez bien la section 11 du RFC, sur la sécurité. Un programme qui lit du FLAC doit être paranoïaque (comme avec n'importe quel autre format, bien sûr) et se méfier des cas pathologiques. Ainsi, le RFC note qu'on peut facilement créer un fichier FLAC de 49 octets qui, décomprimé, ferait 2 mégaoctets, ce qui pourrait dépasser la mémoire qui avait été réservée. Ce genre de surprises peut arriver à plusieurs endroits. L'annexe D du RFC contient plusieurs fichiers FLAC intéressants (et vous pouvez les retrouver en ligne) et il existe également une collection de fichiers FLAC, dont certains sont délibérément anormaux, pour que vous puissiez tester la robustesse de votre programme. Autre piège (mais lisez toute la section 11, il y en a beaucoup), FLAC permet de mettre des URL dans les fichiers, URL qu'il ne faut évidemment pas déréférencer bêtement.
Ce RFC est également la documentation pour l'enregistrement
du type MIME audio/flac
(section 12.1).
Pour une analyse technique de la prétention « sans perte » de FLAC, voir cet article de Guillaume Seznec.
L'article seul
RFC 9300: The Locator/ID Separation Protocol (LISP)
Date de publication du RFC : Octobre 2022
Auteur(s) du RFC : D. Farinacci (lispers.net), V. Fuller (vaf.net Internet Consulting), D. Meyer (1-4-5.net), D. Lewis (Cisco Systems), A. Cabellos (UPC/BarcelonaTech)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF lisp
Première rédaction de cet article le 14 décembre 2024
Le protocole LISP (qui n'a rien à voir avec le langage de programmation du même nom), vise à résoudre un problème documenté dans le RFC 4984 : les difficultés que rencontre le système de routage de l'Internet devant les pressions imposées par la croissance du réseau et par le désir des utilisateurs de ne pas être lié à un unique fournisseur d'accès. Actuellement, tout changement de routage sur n'importe quel site se propage à tous les autres routeurs de la DFZ. Un tel système ne passe pas réellement à l'échelle (il ne peut pas croitre indéfiniment). LISP propose une solution, dans un ensemble de RFC dont ce RFC 9300 (qui succède au RFC 6830) est le principal. LISP n'est désormais plus considéré comme expérimental et ce nouveau RFC est sur le chemin des normes (Standards Track) mais, en pratique, le projet LISP semble plutôt en panne.
Avant de plonger dans ce RFC, voyons les motivations pour LISP et ses principes essentiels (si vous préférez les lire dans le RFC et pas dans mon article, c'est en section 4 mais la lecture recommandée est le RFC 9299). Aujourd'hui, les adresses IP ont deux rôles, localisation (où suis-je connecté au réseau) et identité (qui suis-je). Une adresse IP est un localisateur car changer de point d'attachement (par exemple parce qu'on change de FAI) vous fait changer d'adresse IP, et c'est un identificateur car c'est ce qui est utilisé par les protocoles de transport comme TCP pour identifier une session en cours : changer d'adresse IP casse les connexions existantes.
Le principal problème de cette approche concerne le routage. Un routage efficace nécessiterait une cohérence entre les adresses et la topologie du réseau, par exemple que deux sites proches sur le réseau aient des adresses proches. Mais on n'a pas cette cohérence actuellement. On notera qu'IPv6 ne résolvait pas ce problème, et délibérément (le cahier des charges d'IPv6 ne prévoyait pas de changer le modèle de routage).
Résultat, les routeurs doivent gérer bien plus de routes que nécessaire, augmentant leur prix (en attendant le jour où, même en payant, on n'arrivera pas à manipuler autant de routes, avec leurs changements fréquents). Le RFC 4984 insistait sur ce problème en affirmant que « The workshop participants believe that routing scalability is the most important problem facing the Internet today and must be solved, although the time frame in which these problems need solutions was not directly specified. »
Cette croissance de la table de routage peut être suivie sur le célèbre site de Geoff Huston. Notez que la taille n'est pas le seul aspect, le rythme de changement (le nombre d'updates BGP par seconde) est au moins aussi important.
LISP vise donc à résoudre ce problème par une technique connue sous le nom de séparation du localisateur et de l'identificateur (son nom, « Locator/ID Separation Protocol », en dérive d'ailleurs, bien qu'il soit loin d'être le seul protocole dans cette catégorie). Au lieu que tous les préfixes IP aillent dans la DFZ, seuls les localisateurs, les RLOC (Routing LOCators) y iront. Les identificateurs, les EID (Endpoint IDentifiers) sont dans un nouveau système, le système de correspondance (mapping, RFC 9301), qui permettra de trouver un RLOC à partir d'un EID. LISP est donc l'application d'un vieux principe de l'informatique : « Tout problème peut être résolu en ajoutant un niveau d'indirection. »
À quoi ressemblent RLOC et EID ? Physiquement, ce sont juste des adresses IP (v4 ou v6), avec une nouvelle sémantique. Le RFC 8060 décrit plus en détail comment représenter les EID.
Par rapport aux autres solutions de séparation de l'identificateur et du localisateur (la plus achevée étant HIP), LISP s'identifie par les points suivants :
- Solution dans le réseau, pas dans les machines terminales. Seuls des routeurs (mais pas tous les routeurs de l'Internet) seront modifiés pour gérer LISP.
- Déployable de manière incrémentale (il n'est pas nécessaire que tout le monde passe à LISP).
- Pas de cryptographie (et donc pas plus de sécurité que l'IP d'aujourd'hui).
- Indépendant de la famille IP utilisée (v4 ou v6).
- Outre une solution au problème du passage à l'échelle du système de routage, LISP se veut aussi utilisable pour la mobilité et la virtualisation de réseaux (imaginez une machine virtuelle migrant d'un centre d'hébergement à un autre sans changer d'identificateur...).
Comment se passe l'envoi d'un paquet avec LISP ? Supposons qu'une machine
veuille écrire à www.example.com. Elle utilise
le DNS comme
aujourd'hui, pour trouver que l'adresse est
2001:db8:110:2::e9 (c'est un EID, un
identificateur, mais la machine n'a pas besoin de le savoir, les
machines terminales ne connaissent pas LISP et ne savent même pas
qu'elles l'utilisent). Elle envoie le paquet à son routeur
habituel. À un moment dans le réseau, le paquet va arriver dans un
routeur LISP (qui, lui, a été modifié pour gérer LISP). Il va alors
chercher le RLOC (le localisateur). Il demande au système de
correspondance (l'équivalent LISP du DNS) qui va lui dire « le RLOC de
2001:db8:110:2::e9 est
198.51.100.178 » (notez au passage que RLOC et
EID peuvent être des adresses v4 ou v6). (L'information est stockée
dans un cache du
routeur, pour le prochain paquet.) Le paquet est alors encapsulé dans un paquet
LISP qui est transmis en UDP (port 4341) à
198.51.100.178. (En raison de ces deux étapes,
correspondance puis encapsulation, LISP fait partie des protocoles
nommés Map and Encap.)
198.51.100.178 décapsule et le paquet suit
ensuite un chemin normal vers la machine
2001:db8:110:2::e9. Pendant le trajet dans le
tunnel,
le paquet aura donc deux en-têtes, l'interne
(celui placé par la machine d'origine et qui utilise des EID dans
les champs « Adresse IP source » et « Adresse IP destination ») et
l'externe (celui placé par le routeur d'entrée du tunnel, et qui
utilise des RLOC).
Si le système de correspondance avait répondu négativement « Ce
n'est pas un EID, je n'ai pas de RLOC pour
2001:db8:110:2::e9 » (Negative map
reply) ? Cela aurait voulu dire que le site cible
n'utilise pas LISP et, dans ce cas, on lui transmet le paquet par
les mécanismes habituels d'IP.
Ainsi, pour prendre le scénario d'usage principal de LISP, un site qui veut être multi-homé n'aura pas besoin de BGP et d'annoncer ses routes dans la DFZ. Il aura ses identificateurs, ses EID, et les paquets entrant ou sortant de son réseau seront encapsulés en LISP (le système de correspondance peut renvoyer plusieurs RLOC pour un EID, avec des préférences différentes, pour faire de l'ingénierie de trafic). Pour les routeurs de la DFZ, ce seront juste des paquets IP ordinaires. Seules les deux extrémités du tunnel sauront que LISP est utilisé.
Le système de correspondance de LISP n'est pas unique : plusieurs choix sont possibles comme ALT (RFC 6836). Comme le DNS, il fonctionne en tirant les informations nécessaires (pas en les poussant vers tout le monde, comme le fait BGP), ce qui devrait lui donner une bonne capacité de croissance. De toute façon, LISP spécifie une interface vers le système de correspondance (RFC 9301) et les différents systèmes ont juste à mettre en œuvre cette interface pour qu'on puisse en changer facilement. Ainsi, ALT pourra être remplacé par un de ses concurrents, CONS, EMACS ou NERD (leurs noms sont des références au langage de programmation). NERD est documenté dans le RFC 6837.
Ce RFC est un gros morceau (d'autant plus que d'autres parties de LISP sont dans d'autres RFC). Je ne vais pas le couvrir en entier. Mais quelques points méritent d'être gardés en tête :
- Un paquet dont l'adresse de destination est un EID ne peut être acheminé que via LISP. L'EID n'est pas routé sur l'Internet habituel. (Les EID peuvent être des adresses RFC 1918, par exemple.)
- Pour éviter que la base des EID ne pose les mêmes problèmes de croissance que la DFZ d'aujourd'hui, les EID seront agrégés, mais cela sera fait de manière indépendante de la topologie : si on change de FAI, cette agrégation ne changera pas.
Pour les fanas de format de paquets, la section 5 décrit l'encapsulation. LISP est indépendant de la famille d'adresses, donc on peut avoir un paquet IP où les EID sont IPv4 qui soit tunnelé avec des RLOC IPv6 ou bien le contraire. Devant le paquet normal, LISP va ajouter un en-tête IP standard pour les RLOC, où la source sera l'ITR (routeur d'entrée du tunnel) et la destination l'ETR (routeur de sortie du tunnel), puis un en-tête UDP (l'UDP a davantage de chances de passer les middleboxes que de l'IP mis directement dans l'IP, des protocoles comme QUIC ont le même problème), avec le port de destination à 4341, puis un en-tête spécifique à LISP et enfin le paquet original. Donc, pour résumer :
- En-tête du paquet original (inner header en terminologie LISP) : les adresses IP source et destination sont des identificateurs, des EID,
- En-tête vu par les routeurs situés entre l'ITR et l'ETR (outer header) : les adresses IP source et destination sont des localisateurs, des RLOC.
L'en-tête spécifique à LISP contient notamment (section 5 si vous voulez tout connaître) :
- Cinq bits de contrôle, nommés N, L, E, V et I
- Si le bit N est à 1, un champ Nonce (section 10.1). Il s'agit d'un nombre tiré au hasard : si le destinataire d'un paquet peut le renvoyer, cela prouve qu'il avait reçu le message original (et qu'on parle donc bien au bon destinataire : ce numnique sert à éviter les attaques en aveugle).
- Si le bit L est à 1, un champ Locator Status Bits, qui indique l'état (joignable ou pas) des machines situées sur le site de départ du paquet. (À ne pas utiliser sur l'Internet public, cf. section 4.1.)
Comme toutes les solutions à base de tunnel, LISP va souffrir de la mauvaise gestion de la PMTUD dans l'Internet d'aujourd'hui (cf. RFC 4459), l'en-tête LISP supplémentaire réduisant la MTU (cf. section 7 pour des solutions possibles).
La section 5 décrivait les paquets de données, ceux encapsulant les données envoyées par le site original. La section 6 couvre les paquets de contrôle, utilisés par LISP pour ses propres besoins, notamment le système de correspondance (cf. RFC 9301 pour les détails). On y retrouve l'utilisation d'UDP :
- Map Requests, où le port de destination est 4342,
- Map Replies,
- et quelques autres qui partagent des formats proches.
Il est évidemment essentiel qu'on sache si son correspondant est joignable ou pas. Comment cette « joignabilité » est-elle vérifiée ? La section 6.3 énumère les mécanismes disponibles. Entre autres :
- Les Locator Status Bits où un ITR (le routeur LISP à l'entrée du tunnel) indique si les sites qu'il contrôle sont joignables. Si on souhaite répondre à un message transmis en LISP, c'est une information cruciale. (Ils ne doivent pas être utilisés sur l'Internet public, voir la section 4.1 pour les détails.)
- Les classiques messages ICMP comme Host Unreachable. Comme ils ne sont pas authentifiés, les croire aveuglément est dangereux. Mais les ignorer totalement serait dommage.
- La réception récente d'un message Map Reply est une bonne indication que le site à l'autre bout fonctionne.
Mais on peut aussi tester explicitement, par le mécanisme Echo Nonce de la section 10.1. Le testeur émet un message LISP avec les bits N (numnique présent) et E (écho demandé), met le numnique à une valeur aléatoire (RFC 4086), et envoie le paquet. (La section 4.1 précise toutefois que cela ne doit pas être utilisé sur l'Internet public.) L'ETR à l'autre bout doit normalement renvoyer ce numnique dans son prochain paquet. Notons que cela teste la bidirectionnalité de la connexion. Si on n'obtient pas de réponse, cela peut signifier que la connexion est complètement coupée ou tout simplement qu'elle ne marche que dans un seul sens. Mais, surtout, l'absence de réponse peut indiquer le cas où l'ETR qui reçoit le trafic pour un site n'est pas le même routeur que l'ITR qui génère le trafic sortant. Dans ce cas, l'absence de réponse n'est pas un problème. Enfin, le routeur en face peut tout simplement être configuré pour ignorer les demandes d'écho.
Une autre solution pour tester est donc d'utiliser les messages du système de correspondance EID->RLOC, les Map Request et Map Reply. Ces messages ont un bit P (pour probe) qui indique que le demandeur est intéressé par la joignabilité du site demandé.
LISP impose donc des traitements supplémentaires, par rapport à ceux de l'IP classique. Est-ce que cela ne ralentit pas trop les routeurs ? La section 15 explore le problème et explique pourquoi LISP ne nécessite pas de changement du matériel de forwarding (les ASIC du routeur). La plupart des routeurs ont déjà du code prévu pour gérer des tunnels (encapsuler et décapsuler) rapidement.
Comment sera déployé LISP ? Le RFC 7215 décrit plusieurs scénarios possibles et les détails. Principal problème : combien d'ITR et d'ETR pour un opérateur ? Grâce aux tunnels, on peut n'avoir qu'un seul ITR et un seul ETR pour tout le trafic. Cela poserait évidemment des problèmes de redondance et de performance. Mais avoir beaucoup de xTR peut poser des problèmes d'administration. Si les ITR sont largement automatiques (leur cache des correspondance EID->RLOC est bâti dynamiquement), avoir beaucoup d'ETR risque d'être compliqué à maintenir (car l'ETR doit avoir dans sa configuration une liste des EID qu'il va gérer).
Un des gros problèmes que pose la séparation de l'identificateur et du localisateur est la sécurité : nouvelles attaques (par exemple contre le système de correspondance), nouveaux pièges (une machine qui utiliserait le vrai RLOC mais mentirait sur l'EID, par exemple). La section 16 du RFC examine les risques théoriquement présents dans LISP, mais lisez aussi les RFC 7835 et RFC 9303.
Comme avec toutes les techniques de tunnel, un émetteur peut facilement tricher sur l'adresse source interne (celle qui sera utilisée après décapsulation par l'ETR). Pour se protéger, un ITR devrait n'encapsuler un paquet que si l'adresse source est un EID qu'il contrôle. Et un ETR ne devrait transmettre un paquet que si la destination est un EID sous sa responsabilité.
Le test de la réversibilité (via les numniques, cf. section 3) est essentiel contre ces risques. Sans ce test, un ETR pirate pourrait par exemple envoyer un Map Reply en réponse aveugle à un Map Request, et le voir accepté, avec des données mensongères (naturellement, l'ITR n'accepte que des Map Replies qui sont en réponse à un Map Request de sa part). Avec ce système de numnique que le récepteur doit mettre dans sa réponse, un attaquant aveugle (qui n'est pas situé sur le chemin des paquets et ne peut donc pas les observer) aura donc peu de chances de réussir à faire accepter ses paquets.
En revanche, un attaquant situé sur le chemin, et qui peut observer les paquets qui passent, a la possibilité de commettre bien plus de dégâts. Mais c'est déjà le cas avec les protocoles actuels (par exemple, les numéros de séquence difficiles à deviner du RFC 6528 ne protègent pas TCP contre des attaquants situés sur le chemin).
Les attaques par déni de service sont évidemment possibles avec LISP : une des précautions recommandées est de limiter le trafic des Map Requests et Map Replies. Autre attaque par déni de service, un ITR peut être victime d'une machine qui essaie de remplir la table des correspondances EID->RLOC du routeur. Il est donc important d'envisager ce cas, par exemple en permettant de garder dans le cache les entrées les plus fréquemment accédées (pour éviter qu'elles ne soient retirées automatiquement pour faire de la place). Mais il n'existe pas de solution miracle contre ce problème d'envahissement de cache.
Le fonctionnement de LISP est schématisé sur ce dessin : Alice a l'identificateur (EID)
2001:db8:1::1 et veut écrire à Bob qui a le
2001:db8:2::42 (dans la plupart des cas, Alice
aura trouvé l'adresse de Bob dans le DNS, comme aujourd'hui). Ni Alice, ni Bob n'ont
à connaître LISP, chacun croit utiliser de l'IP normal. Alice envoie
donc un paquet standard, à destination de
2001:db8:2::42. Mais, sur le trajet, il y a un
ITR, un routeur LISP. Celui-ci va chercher (dans le système de
correspondance, non montré ici) le RLOC (le localisateur) de Bob
(ou, plus exactement, de son site). Une fois qu'il a trouvé
2001:db8:ff::666, il encapsule le paquet
derrière un en-tête LISP et envoie ce paquet à l'ETR, l'autre
routeur LISP en face, 2001:db8:ff::666. Les
routeurs de l'Internet, entre l'ITR et l'ETR, ne connaissent pas
LISP non plus et routent ce qui leur semble un paquet IP
normal. Arrivé à l'ETR, le paquet est décapsulé et poursuit son
chemin par du routage IP classique. Sur tout le schéma, seuls l'ITR
et l'ETR sont des nouveautés LISP.
Modifions légèrement le schéma pour y mettre le système de
correspondance : On y voit l'ITR
demander à son résolveur « Quel est le localisateur de
2001:db8:2::42 ? » et son résolveur lui
répondre. Le résolveur avait demandé au serveur qui avait reçu de
l'ETR un enregistrement disans « Le localisateur de
2001:db8:2::42 est
2001:db8:ff::666 ». Entre le résolveur et le
serveur se trouve le cœur du système de correspondance. LISP
en a plusieurs possibles, comme le ALT du RFC 6836.
Où trouve-t-on du code LISP aujourd'hui ?
- Bien sûr dans IOS puisque LISP est l'enfant de Cisco.
- FreeBSD avait OpenLISP, qui semble abandonné (ou intégré dans le système ? Quelqu'un sait ?).
- Pour Linux, je ne connais que LispMob, qui traite un besoin spécifique (la mobilité).
- Il parait qu'un code Cisco mettant en œuvre LISP tourne sur Android.
Comme pour tous les protocoles fondés sur le principe de la séparation de l'identificateur et du localisateur, il est toujours utile, si on veut en comprendre les principes, de (re)lire l'article fondateur de Chiappa, « Endpoints and Endpoint names: A Proposed Enhancement to the Internet Architecture ». Autres articles à lire :
- Le RFC 9299, une introduction à LISP et ses concepts,
- Un bon résumé de LISP.
- Le premier article pratique sur le protocole. Avec instructions, commandes, et résultat (sur des routeurs Cisco). Parfait pour les ingénieurs qui ont du mal à se taper les RFC LISP mais veulent quand même comprendre comment ça marche. Très détaillé. Le même auteur a d'autres articles sur LISP comme celui expliquant comment tunneler IPv6 sur IPv4.
- Le compte-rendu de la connexion de Facebook à LISP (Facebook a été le premier gros site à sauter le pas mais je ne sais pas si cela fonctionne toujours aujourd'hui).
La section 18 de notre RFC décrit les changements depuis le RFC 6830. Le principal est bien sûr que LISP n'est plus considéré comme expérimental, on peut le déployer sur l'Internet public, modulo les précautions de la section 4.1. Sinon :
- Les trois bits qui étaient réservés dans l'en-tête ont été alloués par le RFC 8061,
- La récolte automatique d'informations de correspondance entre EID et RLOC (gleaning) est désormais optionnelle,
- Sur la forme, notons que bien des points, notamment le mécanisme de contrôle (et pas seulement d'acheminement de données) ont été déplacés vers le RFC 9301.
La section 4.1 décrit ce qu'il faut faire et ne pas faire lorsqu'on déploie LSIP « en vrai » sur l'Internet public. Quand on n'est plus expérimental, il faut faire attention. Bien des techniques de LISP (comme la mise à jour automatique des données des routeurs juste en regardant un paquet qui passe, le gleaning, clairement dangereux) ne sont sûres que dans un environnement fermé.
L'article seul
RFC 9549: Internationalization Updates to RFC 5280
Date de publication du RFC : Mars 2024
Auteur(s) du RFC : R. Housley (Vigil Security)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF lamps
Première rédaction de cet article le 22 novembre 2024
Ce court RFC ajoute aux certificats PKIX du RFC 5280 la possibilité de contenir des adresses de courrier électronique dont la partie locale est en Unicode. Et il modifie légèrement les règles pour les noms de domaine en Unicode dans les certificats. Il remplace le RFC 8399, avec peu de changements.
Les certificats sur
l'Internet sont normalisés dans le RFC 5280, qui décrit un profil de
X.509 nommé PKIX
(définir un profil était nécessaire car la norme X.509 est bien trop
riche et complexe). Ce RFC 5280 permettait des
noms de domaine en
Unicode (sections 4.2.1.10 et 7 du RFC 5280) mais il suivait l'ancienne norme IDN, celle des
RFC 3490 et suivants. Depuis, les IDN sont
normalisés dans le RFC 5890 et suivants, et
notre nouveau RFC 9549 modifie très légèrement le RFC 5280 pour s'adapter à cette nouvelle norme de
noms de domaines en Unicode. Les noms de domaine dans un certificat
peuvent être présents dans les champs Sujet (titulaire du
certificat) et Émetteur (AC ayant signé le certificat) mais aussi
dans les contraintes sur le nom (une autorité de certification peut être
limitée à des noms se terminant en example.com,
par exemple).
Notez que, comme avant, ces noms sont exprimés dans le certificat
en Punycode (RFC 3492,
xn--caf-dma.fr au lieu de
café.fr), appelé A-label
dans notre RFC. C'est un bon exemple du fait que les
limites qui rendaient difficiles d'utiliser des noms de domaine en
Unicode n'avaient rien à voir avec le DNS (qui n'a jamais été limité à
ASCII, contrairement à ce qu'affirme une légende
courante). En fait, le problème venait des applications (comme
PKIX), qui ne s'attendaient pas à des noms en
Unicode. Un logiciel qui traite des certificats aurait été bien
étonné de voir des noms de domaines non-ASCII, et
aurait peut-être planté. D'où ce choix du
Punycode (A-label) par opposition à la forme plus
lisible du U-label.
Nouveauté plus importante du RFC 8399, mis à jour par notre RFC 9549, les adresses de courrier électronique en Unicode (EAI pour Email Address Internationalization). Elles étaient déjà permises par la section 7.5 du RFC 5280, mais seulement pour la partie domaine (à droite du @). Désormais, elles sont également possibles dans la partie locale (à gauche du @). Le RFC 8398 donne tous les détails sur ce sujet.
Reste à savoir quelles AC acceptent
Unicode. En 2018, j'avais testé avec
Let's Encrypt (avec le
client Dehydrated, en
mettant le Punycode dans domains.txt) et ça
marchait, regardez le certificat de https://www.potamochère.fr/
% gnutls-cli www.potamochère.fr
...
- subject `CN=www.xn--potamochre-66a.fr', issuer `CN=R10,O=Let's Encrypt,C=US', serial 0x03a34cfc017b4311da0b21797cd250ebd3c0, RSA key 4096 bits, signed using RSA-SHA256, activated `2024-11-01 05:26:59 UTC', expires `2025-01-30 05:26:58 UTC', pin-sha256="6y…
D'autres AC acceptent ces noms en Unicode : Gandi le fait aussi, par exemple. On
notera que le célèbre service de test de la qualité des
configurations TLS, SSLlabs, gère bien les IDN :
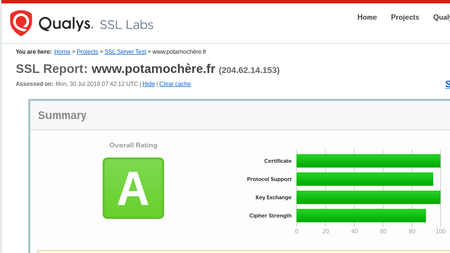
Enfin, le registre du
.ru a participé au développement de
logiciels pour traiter l'Unicode dans les certificats.
La section 1.2 résume les changements depuis le RFC 8399. Notamment :
- Le RFC 8399 ne les mentionnait pas
mais les emojis ne sont pas
autorisés dans les noms de domaine (ils appartiennent à la
catégorie Unicode So, « Autres symboles », que le RFC 5890 n'inclut pas). Comme le rappelle notre RFC 9549, un nom comme
♚.examplene serait pas légal. Ce point est désormais explicite. - Si le RFC 8399 prescrivait certains
traitements à faire sur la forme Unicode
(U-label) des noms, désormais, tout se fait sur
la forme en Punycode (A-label, donc
xn--potamochre-66a.fret paspotamochère.fr). Cela permet d'éviter de déclencher certaines failles de sécurité.
L'article seul
RFC 9649: WebP Image Format
Date de publication du RFC : Novembre 2024
Auteur(s) du RFC : J. Zern, P. Massimino, J. Alakuijala
(Google)
Pour information
Première rédaction de cet article le 19 novembre 2024
Un RFC sur un
format d'image : il décrit le format WebP et
enregistre officiellement le type image/webp.
Bon, des images au format WebP, vous en avez forcément vu un peu partout sur le Web. Mais le format n'était pas encore documenté par un organisme de normalisation. C'est désormais fait. WebP s'appuie sur le format RIFF. Plus précisément, RIFF est un cadre générique qui peut se décliner en divers formats. C'est pour cela que les fichiers WebP commencent par les quatre codes ASCII correspondant à "RIFF".
WebP permet de la compression avec perte ou sans perte, et, d'une manière générale, tout ce qu'on attend d'un format graphique. C'est donc un concurrent de JPEG, PNG (RFC 2083), GIF… L'encodage lors de la compression avec perte est celui de VP8 (RFC 6386), produisant des images plus petites que ses prédécesseurs, ce qui est bon pour le réseau. La compression sans perte est faite en LZ77 et Huffman. WebP permet également le stockage de métadonnées codées en EXIF ou en XMP. Ah, et WebP permet des animations.
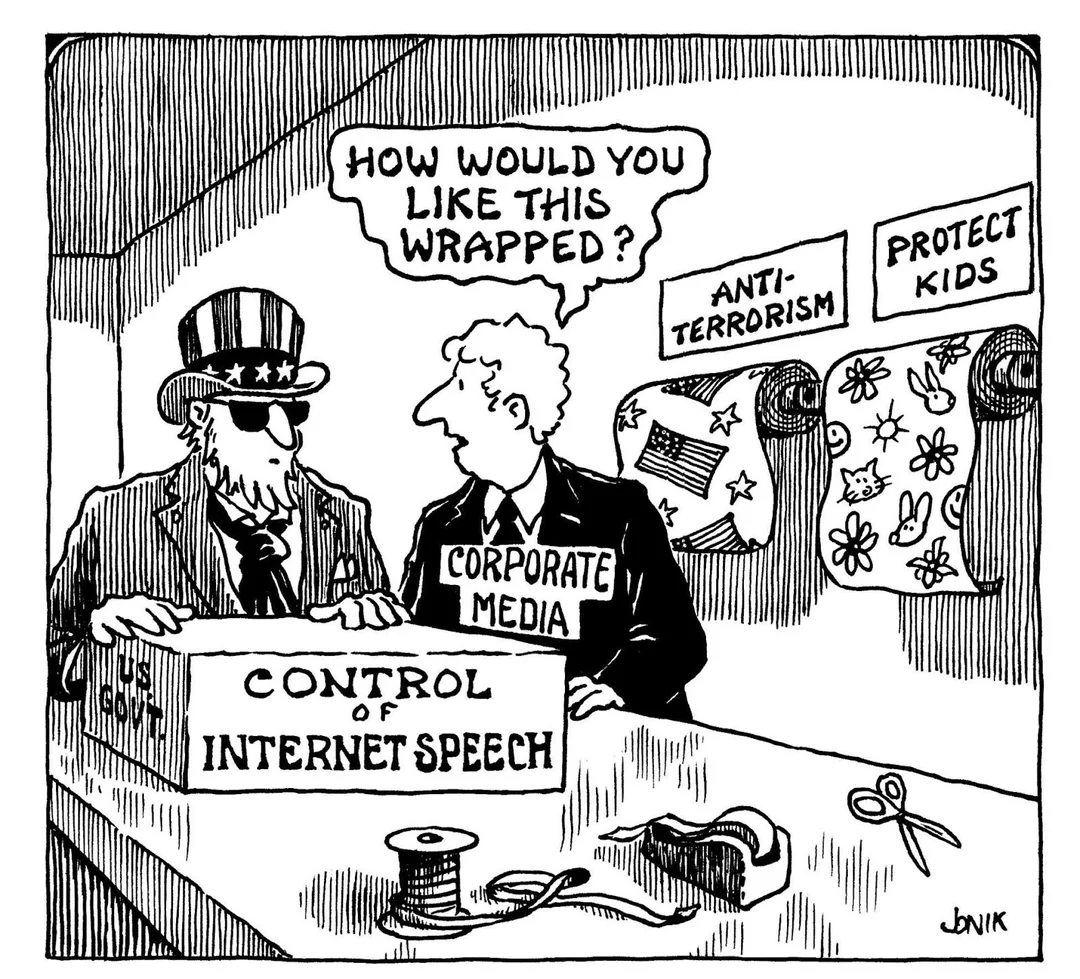
Cette image, sur un sujet politique qui est toujours d'actualité,
est au format WebP :
La section 2 du RFC décrit le format en détail. Les trois premiers champs sont la chaine "RIFF", la taille du fichier en binaire et la chaine "WEBP", chacun sur quatre octets. Affichons ces trois champs :
% dd if=how-do-you-like-it-wrapped.webp bs=4 count=3 RIFFXWEBP 3+0 records in 3+0 records out 12 bytes copied…
La section 3 décrit ensuite le stockage des pixels sans perte.
Comme avec tout format, les logiciels qui lisent les fichiers WebP (qu'on télécharge souvent depuis l'Internet, via des sources pas forcément de confiance) doivent être prudents dans l'analyse des fichiers. Les fichiers peuvent être invalides, par accident ou délibérément, et mener le logiciel négligent à lire en dehors d'un tableau ou déréférencer un pointeur invalide. La paranoïa est recommandée quand on lit ces fichiers. Plusieurs failles ont touché la libwebp, l'implémentation de référence, dont la grave CVE-2023-4863 en 2023 qui avait fait, à juste titre, beaucoup de bruit.
Toujours question sécurité, WebP n'a pas de contenu exécutable (contrairement à, par exemple, TrueType). Mais les métadonnées EXIF ou en XMP peuvent poser des problèmes de sécurité et doivent donc être interprétées avec prudence.
Le type
image/webp est désormais dans
le registre des types de médias (cf. le
formulaire rempli).
Si on regarde des fichiers WebP, on a ce genre d'informations :
% file resolution-dns.webp resolution-dns.webp: RIFF (little-endian) data, Web/P image % file --mime-type resolution-dns.webp resolution-dns.webp: image/webp
Pour finir, produisons un peu d'images WebP pour voir. Si on utilise Asymptote, c'est facile :
% asy -f webp -o resolution-dns.webp resolution-dns.asy
On peut aussi convertir depuis les formats existants, ici avec ImageMagick :
% convert -verbose resolution-dns.png resolution-dns.webp resolution-dns.png PNG 823x508 823x508+0+0 8-bit sRGB 31713B 0.020u 0:00.011 resolution-dns.png=>resolution-dns.webp PNG 823x508 823x508+0+0 8-bit sRGB 16580B 0.040u 0:00.047
Si on fait des graphiques depuis ses programmes en Python avec Matplotlib, il suffit, depuis la version 3.6, de :
plot.savefig(fname="test.webp") # No need to indicate the format, it
# is taken from the file extension.
(Voir aussi ce beau résultat sur Wikimedia Commons.)
L'article seul
RFC 9682: Updates to the CDDL grammar of RFC 8610
Date de publication du RFC : Novembre 2024
Auteur(s) du RFC : C. Bormann (Universität Bremen
TZI)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF cbor
Première rédaction de cet article le 19 novembre 2024
Voici une légère mise à jour de la grammaire du langage de description de schéma CDDL (Concise Data Definition Language), originellement normalisé dans le RFC 8610. Pas de gros changement.
Il y avait juste quelques errata à traiter, et des ambiguités concernant notamment les chaines de caractères. Il était devenu nécessaire de modifier l'ABNF. CDDL a été décrit dans le RFC 8610, puis étendu par le RFC 9165. Il vise à décrire un schéma pour des fichiers CBOR ou JSON. Depuis quatre ans qu'il est normalisé, plusieurs erreurs ont été relevées dans la norme. (Dont une, c'est amusant, causée par le traitement du source du RFC, traitement qui avait fait disparaitre accidentellement des barres obliques inversées.)
Donc, notre RFC 9682 modifie l'ABNF qui décrit les littéraux pour les chaines de caractères, ABNF qui était trop laxiste (section 2 du RFC). Il change également la grammaire générale (section 3) pour autoriser (au niveau syntaxique) des schémas vides (ils restent interdits au niveau sémantique). Ainsi, l'ancienne règle :
cddl = S 1*(rule S)
devient :
cddl = S *(rule S)
L'article seul
Le cas du serveur DNS qui ne se mettait plus à jour
Première rédaction de cet article le 11 novembre 2024
La semaine dernière, 26 TLD africains avaient des problèmes DNS. Pourquoi ? Parce qu'une machine quelque part ne se mettait plus à jour et servait des données erronées.
Le problème semble s'être déclenché autour du 29 octobre. Des signalements ont été faits sur les réseaux
sociaux comme quoi certain·es utilisateurices n'arrivaient pas à
résoudre des noms en
.mg. On voit ici un test
fait avec les sondes RIPE
Atlas et le logiciel Blaeu :
% blaeu-resolve --requested 100 --displayvalidation --type NS mg [dns-tld.ird.fr. ns-mg.afrinic.net. ns-mg.malagasy.com. ns.dts.mg. ns.nic.mg. pch.nic.mg.] : 39 occurrences [ (Authentic Data flag) dns-tld.ird.fr. ns-mg.afrinic.net. ns-mg.malagasy.com. ns.dts.mg. ns.nic.mg. pch.nic.mg.] : 52 occurrences [ERROR: SERVFAIL] : 5 occurrences [ERROR: NXDOMAIN] : 2 occurrences Test #81689686 done at 2024-11-08T15:45:06Z
Cinq sondes ont un résolveur qui
répond SERVFAIL (Server Failure). On peut
soupçonner un problème DNSSEC et on voit en effet avec DNSviz que
des signatures expirées sont reçues par
certains clients DNS. Le fait que la plupart des utilisateurices ne
voient pas de problème laisse entendre que tous les serveurs faisant
autorité pour .mg ne sont pas également
affectés. Examinons-les tous :
% for ns in ns.dts.mg. ns-mg.malagasy.com. dns-tld.ird.fr. pch.nic.mg. ns.nic.mg. ns-mg.afrinic.net.; do for> echo $ns for> dig @$ns mg. NS for> done ns.dts.mg. … ;; ANSWER SECTION: mg. 7200 IN NS ns.nic.mg. mg. 7200 IN NS ns-mg.afrinic.net. mg. 7200 IN NS ns.dts.mg. mg. 7200 IN NS ns-mg.malagasy.com. mg. 7200 IN NS pch.nic.mg. mg. 7200 IN NS dns-tld.ird.fr. mg. 7200 IN RRSIG NS 8 1 7200 ( 20241113113756 20241030045734 18 mg. ExrGRrWttb4umpOtW2d8gbW2J1p68LENdw3X409lP1hm … ;; Query time: 193 msec ;; SERVER: 196.192.32.2#53(ns.dts.mg.) (UDP) ;; WHEN: Fri Nov 08 16:46:03 CET 2024 ;; MSG SIZE rcvd: 548 ns-mg.afrinic.net. … ;; ANSWER SECTION: mg. 7200 IN NS ns.dts.mg. mg. 7200 IN NS ns.nic.mg. mg. 7200 IN NS dns-tld.ird.fr. mg. 7200 IN NS ns-mg.malagasy.com. mg. 7200 IN NS pch.nic.mg. mg. 7200 IN NS ns-mg.afrinic.net. mg. 7200 IN RRSIG NS 8 1 7200 ( 20241101171148 20241018111647 18 mg. UIIoFCD8kaXyqTIVsrgBdiwQZxwHOXsnZjpPky5p5dRa … ; Query time: 156 msec ;; SERVER: 2001:43f8:120::35#53(ns-mg.afrinic.net.) (UDP) ;; WHEN: Fri Nov 08 16:46:04 CET 2024 ;; MSG SIZE rcvd: 504
Je n'ai gardé que la réponse de deux des serveurs. Celle de
ns.dts.mg ne montre aucun problème particulier
mais celle de ns-mg.afrinic.net montre une
signature expirée (20241101171148 = 1 novembre alors que le test a
été fait le 8). Pas étonnant que les résolveurs qui valident avec
DNSSEC soient mécontents. Mais pourquoi ce serveur fait-il cela ? En
testant avec le logiciel
check-soa, on voit :
% check-soa mg dns-tld.ird.fr. 13.39.116.127: OK: 2024110815 ns-mg.afrinic.net. 2001:43f8:120::35: OK: 2024102913 196.216.168.35: OK: 2024102913 ns-mg.malagasy.com. 51.178.182.212: OK: 2024110815 ns.dts.mg. 196.192.32.2: OK: 2024110815 ns.nic.mg. 196.192.42.153: OK: 2024110815 pch.nic.mg. 2001:500:14:6121:ad::1: OK: 2024110815 204.61.216.121: OK: 2024110815
Aïe, le numéro de série est en retard (2024102913 alors que les autres serveurs sont à 2024110815). Donc, ce serveur ne se met plus à jour avec son serveur maitre, il continue à distribuer de vieilles données.
Mais attention, ce serveur ns-mg.afrinic.net
est anycasté. Ce ne sont peut-être
pas toutes les instances anycast qui ont le
problème. D'ailleurs, check-soa depuis d'autres machines ne montre
pas de problème. Utilisons encore les sondes RIPE Atlas pour
interroger uniquement ce serveur, en demandant son NSID (RFC 5001) :
% blaeu-resolve --requested 100 --nameserver ns-mg.afrinic.net. --nsid --type SOA mg Nameserver ns-mg.afrinic.net. [NSID: s03-ns2.iso; ns.nic.mg. ramboa.nic.mg. 2024110815 14400 3600 604800 3600] : 41 occurrences [NSID: s01-ns2.pkl; ns.nic.mg. ramboa.nic.mg. 2024102913 14400 3600 604800 3600] : 28 occurrences [NSID: s01-ns2.pkl; ns.nic.mg. ramboa.nic.mg. 2024110815 14400 3600 604800 3600] : 24 occurrences [NSID: s04-ns2.jnb; ns.nic.mg. ramboa.nic.mg. 2024110815 14400 3600 604800 3600] : 4 occurrences [NSID: None; ns.nic.mg. ramboa.nic.mg. 2024110815 14400 3600 604800 3600] : 1 occurrences [TIMEOUT] : 2 occurrences Test #81689801 done at 2024-11-08T15:54:11Z
On voit ici que l'instance s01-ns2.pkl est
celle qui a le problème : le numéro de série est vieux. (Pour
compliquer les choses, notons qu'il y a deux instances ayant le même
NSID, ce qui ne facilite pas le déboguage.)
Une partie des clients DNS (ceux qui ont la malchance de tomber sur cette instance) reçoivent donc de la vieille information. Les domaines créés récemment, par exemple, ne sont pas connus de cette instance. Et, comme vu plus haut, elle sert des signatures expirées, ce qui peut planter DNSSEC. (Normalement, le résolveur validant, en recevant ces signatures expirées, devrait réessayer auprès d'un autre serveur du domaine mais, apparemment, certains ne le font pas.)
Et le problème n'affectait pas que .mg. Ce
serveur secondaire, géré par Afrinic, sert 26
TLD en
tout. (Les gérants de ces TLD ont été notifiés. Si vous voulez en
parler à Afrinic, c'est leur ticket [DNS
#924626]. Si vous connaissez l'Internet, vous ne serez pas surpris
d'apprendre que, dans deux cas, l'adresse de contact était invalide
et générait un message d'erreur.) Voici par exemple ce que cela
donnait pour .td :
% blaeu-resolve --requested 100 --nameserver ns-td.afrinic.net. --nsid --type SOA td Nameserver ns-td.afrinic.net. [NSID: s01-ns2.pkl; pch.nic.td. hostmaster.nic.td. 2024110815 21600 3600 604800 7200] : 20 occurrences [NSID: s01-ns2.pkl; pch.nic.td. hostmaster.nic.td. 2024102914 21600 3600 604800 7200] : 25 occurrences [NSID: s03-ns2.iso; pch.nic.td. hostmaster.nic.td. 2024110815 21600 3600 604800 7200] : 47 occurrences [NSID: None; pch.nic.td. hostmaster.nic.td. 2024110815 21600 3600 604800 7200] : 1 occurrences [NSID: s04-ns2.jnb; pch.nic.td. hostmaster.nic.td. 2024110815 21600 3600 604800 7200] : 5 occurrences Test #81691145 done at 2024-11-08T16:55:58Z
Le problème a finalement été réparé le 10 novembre. Afrinic a
retiré du service l'instance invalide. Ici, on voit qu'elle n'est
plus présente (test avec le .mz) :
% blaeu-resolve --requested 100 --displayvalidation --nsid --nameserver ns-mz.afrinic.net --type SOA mz Nameserver ns-mz.afrinic.net [NSID: s03-ns2.iso; anyns.uem.mz. hostmaster.nic.mz. 2024111106 480 300 259200 21600] : 48 occurrences [NSID: s01-ns2.jinx; anyns.uem.mz. hostmaster.nic.mz. 2024111106 480 300 259200 21600] : 13 occurrences [TIMEOUT] : 33 occurrences [NSID: s04-ns2.jnb; anyns.uem.mz. hostmaster.nic.mz. 2024111106 480 300 259200 21600] : 4 occurrences [NSID: None; anyns.uem.mz. hostmaster.nic.mz. 2024111106 480 300 259200 21600] : 1 occurrences Test #81847650 done at 2024-11-11T06:14:08Z
Les leçons à en tirer :
- Des cas similaires, voire très proches, avaient déjà existé (voir par exemple le problème de .com à Singapour et sa vision par Cloudflare).
- L'Internet, c'est compliqué, le DNS aussi,
- Du fait du caractère décentralisé de l'Internet et du DNS, deux clients différents placés à des endroits différents ne verront pas la même chose. Il ne faut pas donc déboguer depuis un seul point de mesure (tests avec dig et check-soa) mais depuis plusieurs, ce que permettent justement les sondes Atlas,
- Le DNS résiste beaucoup mieux aux pannes franches (câble coupé) qu'aux serveurs qui servent des réponses erronées ou dépassées. En cas de panne franche, un autre des serveurs faisant autorité aurait été interrogé. Si vous supervisez vos serveurs DNS (et vous le faites, j'en suis sûr), ne regardez pas seulement s'ils répondent mais aussi s'ils répondent avec les bonnes données.
Annexe : la liste des domaines africains servis par la machine d'Afrinic pendant la panne :
.bi .bj .bw .ci .cm .dz .gm .gn .ke .km .lr .ls .ly .mg .mr .mz .ne .rw .sd .ss .td .tn .ug .zm .موريتانيا .تونس
L'article seul
IETF 121 hackathon: greasing DNS answers
First publication of this article on 10 November 2024
On November 2 and 3 was the IETF hackathon in Dublin. I worked on the greasing of DNS answers from an authoritative name server. What is greasing? Continue reading.
One of the big technical problems of the Internet is its ossification: software is written by people who did not read the technical standards, or did not understand them, specially software in the middleboxes (load balancers, firewalls, etc). As a result, some things that are possible according to the technical specification are de facto forbidden by broken software. This makes difficult to deploy new things. For instance, TLS 1.3 had to pretend to be 1.2 (and add an extension to say "I am actually 1.3") because too many middleboxes prevented the establishement of TLS sessions if the version was 1.3 (see RFC 8446, section 4.1.2). This problem is widespread in the Internet, specially since there is typically no way to talk to the middlebox software authors and these boxes are popular among managers.
A way to fight ossification is greasing. Basically, the idea is to exercise all the features and options of a protocol from day one, not waiting that you really need them. This way, broken software will be detected immediately, not many years after, when it is entrenched. TLS was the first protocol to go that way (see RFC 8701) and it proved effective. QUIC also uses greasing (RFC 9287).
The DNS could
benefit from greasing as well, since it is often difficult to deploy
new features, because they sometimes break bad software (it was the
case with the cookies of RFC 7873). Hence the current
Internet Draft draft-ietf-dnsop-grease.
OK, so, let's grease the rusted parts of the Internet but where exactly, and how? DNS servers are basically of two kinds: resolver and authoritative servers. The version -00 of the draft only mentions resolvers because they are in the best place to test greasing and to report what broke. The general idea is that the resolver sends its queries with "unexpected" values (unallocated EDNS options, unallocated EDNS flags, etc, all of them "legal" according to the RFC). If it receives no reply from the authoritative server (or a bad one such as FORMERR), and, if retrying without greasing work, the resolver knows there is a problem in the path to this authoritative name server and can log it and/or report it (for instance through RFC 9567). The remaining question is: what we can grease? We need options that are legal to send but new and unexpected. For plain DNS, there is no hope: there is only one remaining (unallocated) bit in the flags (RFC 1035, section 4.1.1) of the DNS query. So, it means we can grease only with EDNS stuff: EDNS version number, EDNS options, and EDNS flags. For instance, unknown EDNS options are supposed to be ignored (otherwise, it would never be possible to deploy new options). Now, how to choose the unallocated values to send? TLS decided to reserve ranges of values for which to choose randomly. The risk is that some bad software will treat this range in a special way but, at least, it guarantees there will be no collision with a future allocation.
This is the current version (-00) of the draft. Now, the work at the hackahton. First, I decided to work on an authoritative server. A priori, it is less useful than a resolver, because, unlike the resolver, the authoritative name server cannnot know if its reply was accepted or not, or created problems. But it could be useful on test zones, to see (for instance through the use of RIPE Atlas probes) if they have resolution issues. The work was done on the software Drink.
First test, sending back in the reply two EDNS records. Sending two OPT records in a response does not seem forbidden by the RFC (which prohibit it only in a query, RFC 6891, section 6.1.1) but dig does not like it:
% dig +norec grease.courbu.re SOA @31.133.134.59 ;; Warning: Message parser reports malformed message packet.
It creates problems with many other programs and it is not clear if it is legitimate so let's stop here.
Second test, sending an EDNS reply with a version number which is higher than the one requested. This is legal, the last paragraph of Section 6.1.3 of RFC 6891 says that a responder can respond with a higher EDNS version than what was requested by the requestor. (And it explains why, and the limits, for instance to keep the same format.) I tried that for DNS greasing and typical resolvers seem to be happy with it. But DNS testing tools (very useful tools, do not forget to tests your zones with them!) disagree. ednscomp says "expect: OPT record with version set to 0" (not greater-or-equal, stricly equal). DNSviz says "The server responded with EDNS version 1 when a request with EDNS version 0 was sent, instead of responding with RCODE BADVERS. See RFC 6891, Sec. 6.1.3." (We obviously do not read this section in the same way. To me, it mentions BADVERS only in a different context.) And Zonemaster also disagrees with me. So, there is a debate: when a responder knows both version 0 and some higher version (say, version 1), can it reply to a EDNS=0 query with a EDNS=1 response? Can we use that for greasing?
Less controversial, adding EDNS options and flags. You can see the result here:
% dig @192.168.41.237 grease.courbu.re SOA
; <<>> DiG 9.18.28-0ubuntu0.24.04.1-Ubuntu <<>> @192.168.41.237 grease.courbu.re SOA
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 61647
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 1, flags:; MBZ: 0x0072, udp: 1440
; OPT=16282: 58 ("X")
; OPT=17466: 58 58 58 58 58 58 58 58 58 ("XXXXXXXXX")
; OPT=18095: 58 58 58 58 58 58 58 58 58 58 58 58 58 58 58 58 58 58 58 ("XXXXXXXXXXXXXXXXXXX")
; OPT=16375: 58 58 58 58 58 58 58 58 58 58 58 58 58 58 58 58 ("XXXXXXXXXXXXXXXX")
; OPT=18: 06 72 65 70 6f 72 74 07 65 78 61 6d 70 6c 65 03 63 6f 6d 00 (".report.example.com.")
; COOKIE: db279863745c8e7198d4274c54233c48 (good)
;; QUESTION SECTION:
;grease.courbu.re. IN SOA
;; ANSWER SECTION:
grease.courbu.re. 0 IN SOA dhcp-863b.meeting.ietf.org. root.invalid. (
2024111007 ; serial
1800 ; refresh (30 minutes)
300 ; retry (5 minutes)
604800 ; expire (1 week)
86400 ; minimum (1 day)
)
;; Query time: 1 msec
;; SERVER: 192.168.41.237#53(192.168.41.237) (UDP)
;; WHEN: Sun Nov 10 07:33:30 GMT 2024
;; MSG SIZE rcvd: 224
Here, the authoritative name server (a recent version of Drink,using
the --greasing option at startup), sent:
- A EDNS response with version 1 (remember current version is 0),
- Four EDNS options with unallocated codes, with varying length and values (the last two options have allocated codes, even if dig knows only one, these two options are not greasing),
- Unallocated EDNS flags set (the "0x0072").
Apparently, from tests with various resolver software and through RIPE Atlas probes, it does not break anything, thus paving the way for future allocations. Note that option codes, flags and the number of options are choosen at random, following the draft.
If you want to see the changes it required in the name server, this is this pull request.
Thanks to Shumon Huque and Mark Andrews for code, conversation and explanations.
L'article seul
Fiche de lecture : L'avenir d'Internet - unité ou fragmentation ?
Auteur(s) du livre : Clément Perarnaud, Julien
Rossi, Francesca Musiani, Lucien
Castex
Éditeur : Le bord de l'eau
9782385190682
Publié en 2024
Première rédaction de cet article le 9 novembre 2024
La fragmentation d'Internet est un sujet complexe, et souvent mal traité. Ce court livre fait le point sur les différentes questions que soulève ce débat et d'abord « qu'est-ce que c'est que la fragmentation ? » J'en recommande la lecture.
Le terme de fragmentation a en effet souvent été utilisé dans un but politique. Des influenceurs étatsuniens ont dit que le RGPD (ou le DSA), avec son application extra-territoriale, menait à une fragmentation de l'Internet. D'autres influenceurs étatsuniens (ou les mêmes) dénoncent toute activité de souveraineté numérique (imposer le stockage des données dans le pays, imposer que les échanges entre entités du pays restent dans le pays, etc) comme de la fragmentation. On entend souvent dire que les Chinois ou les Russes auraient « leur propre Internet » (ce qui n'a aucun sens). On se demande souvent si les gens qui répètent avec gourmandise qu'il y a fragmentation de l'Internet avec les actions russes ou chinoises le déplorent, ou bien s'ils voudraient que d'autres pays fassent pareil… Enfin, le débat est souvent marqué par l'hypocrisie comme lorsque les USA dénoncent le fait que le gouvernement chinois veuille empêcher ses citoyens d'aller sur Facebook alors que lui-même fait tout pour bloquer TikTok. En paraphrasant OSS 117, on pourrait dire « non, mais la fragmentation, c'est seulement quand les gens ont des manteaux gris et qu'il fait froid ».
Bref, le débat est mal parti. D'où l'importance de ce livre, qui est tiré d'un rapport au Parlement européen des mêmes auteurs, et qui étudie sérieusement les différents aspects de la question.
Déjà, première difficulté, définir la fragmentation. Est-ce lorsque une machine ne peut plus envoyer un paquet IP à une autre ? (La traduction d'adresses est-elle un facteur de fragmentation ?) Est-ce lorsque le résolveur DNS par défaut ne résout pas certains noms ? (Et si on peut en changer ?) Est-ce quand les Chinois n'utilisent pas les mêmes réseaux sociaux ou moteurs de recherche que nous ? (Ne riez pas, j'ai déjà entendu cette affirmation.) Bien des participant·es au début ne connaissent pas le B.A. BA du modèle en couches et n'essaient même pas de définir rigoureusement la fragmentation. Les auteur·es du livre s'attachent à examiner les définitions possibles. Non, ielles ne fournissent pas « la bonne définition », le problème est trop complexe pour cela. Il est sûr que tout·e utilisateurice de l'Internet ne voit pas la même chose et n'a pas le même vécu. Mais enfermer cette observation évidente dans une définition rigoureuse reste difficile.
D'un côté, disent les auteure·es, il y a bien des tendances centrifuges. De l'autre, non, l'Internet n'est pas fragmenté, malgré les affirmations de ceux qui tentent des prophéties auto-réalisatrices (comme le notent les auteur·es, le thème de la fragmentation et l'utilisation de termes journalistiques comme « splinternet » est souvent simplement une arme rhétorique). Mais est-ce que cela durera ?
Le livre détaille l'action des États qui pousse à la fragmentation, le jeu des lois du marché qui peut mener à la création de silos fermés (la fameuse « minitélisation de l'Internet »), etc.
Bon, une critique, quand même. Tout débat sur la politique Internet est forcément complexe car il faut à la fois comprendre la politique et comprendre Internet. Et, s'agissant de l'Internet, des faits de base (comme le pourcentage d'utilisateurs qui utilisent un résolveur DNS public) sont souvent difficiles à obtenir. Néanmoins, prétendre que dix sociétés résolvent la moitié des requêtes DNS au niveau mondial est impossible à croire. Le chiffre, cité p. 73, est tiré d'un article grossièrement anti-DoH qui ne cite pas ses sources. (Pour voir à quel point ce chiffre est invraisemblable, pensez simplement que toutes les études montrent que les résolveurs DNS publics sont une minorité des usages, et surtout que cela dépend des pays, les Chinois n'utilisant pas les mêmes que les Français et ielles sont nombreux.) L'usage de chiffres « au doigt mouillé » est malheureusement fréquent dans les débats de politique Internet.
Mais, bon, je l'ai dit, la question est très complexe, les données souvent dures à obtenir et cette critique ne doit pas vous empêcher d'apprendre tout sur le débat « fragmentation » dans cet excellent livre. Et rappelez-vous, l'avenir de l'Internet dépend aussi de vous.
L'article seul
RFC 9687: Border Gateway Protocol 4 (BGP-4) Send Hold Timer
Date de publication du RFC : Novembre 2024
Auteur(s) du RFC : J. Snijders
(Fastly), B. Cartwright-Cox (Port
179), Y. Qu (Futurewei)
Chemin des normes
Première rédaction de cet article le 8 novembre 2024
Que doit faire un routeur BGP lorsque le pair en face ne traite manifestement plus ses messages ? Ce n'était pas précisé avant mais la réponse est évidente : raccrocher (mettre fin à la communication).
Un problème classique lors d'une connexion réseau, par exemple sur TCP, est de détecter si la machine en face est toujours là. Par défaut, TCP ne fournit pas ce service : s'il n'y a aucun trafic, vous ne pouvez pas savoir si votre partenaire est mort ou simplement s'il n'a rien à dire. Une coupure de réseau, par exemple, ne sera pas détectée tant que vous n'avez pas de trafic à transmettre (avec attente d'une réponse). Et BGP ne transmet que les changements donc l'absence de trafic ne signale pas forcément un problème. Il existe des solutions, comme d'envoyer périodiquement des messages même quand on n'a rien à dire (RFC 4271, section 4.4), mais aucune n'est parfaite : un programme qui utilise TCP ne sait typiquement pas immédiatement si ses messages sont vraiment partis (et l'alarme actuelle ne couvre que la réception des messages, pas leur envoi). Et BGP n'a pas de fonction « ping », qui exigerait une réponse.
Quand la coupure est franche et détectée, aucun problème, la session BGP (RFC 4271) s'arrête et les routes correspondantes sont retirées de la table de routage. Mais ce RFC traite le cas de où le routeur BGP d'en face a un problème mais qu'on ne détecte pas. Un exemple : si ce routeur en face a complètement fermé sa fenêtre TCP de réception (RFC 9293, notamment la section 3.8.6), on ne pourra pas lui envoyer de messages, mais la session BGP ne sera pas coupée et les paquets continueront à être transmis selon des annonces de routage dépassées, alors qu'ils finiront peut-être dans un trou noir (le problème des « zombies BGP »).
La solution (section 3 de notre RFC) est de modifier
l'automate de BGP (RFC 4271, section 8), en ajoutant une alarme (RFC 4271, section 10),
SendHoldTimer. Quand elle expire, on coupe la
connexion TCP et on retire les routes qu'avait annoncé le pair dont
on n'a plus de nouvelles. Le RFC recommande une configuration par
défaut de huit minutes de patience avant de déclencher l'alarme.
L'erreur « Send Hold Timer Expired » est désormais dans le registre IANA des erreurs BGP et tcpdump sait l'afficher. Il existe plusieurs mises en œuvre de ce RFC :
- Celle d'OpenBGPD (son source),
- Celle de FRRouting (son source),
- Celle de BIRD (son source).
Si les processus IETF vous passionnent, il y a une documentation des discussions autour de ce RFC.
L'article seul
RFC 9669: BPF Instruction Set Architecture (ISA)
Date de publication du RFC : Octobre 2024
Auteur(s) du RFC : D. Thaler
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF bpf
Première rédaction de cet article le 1 novembre 2024
On a souvent envie de faire tourner des programmes à soi dans le noyau du système d'exploitation, par exemple à des fins de débogage ou d'observation du système. Cela soulève plein de problèmes (programmer dans le noyau est délicat) et la technique eBPF permet, depuis de nombreuses années, de le faire avec moins de risques. Ce RFC spécifie le jeu d'instructions eBPF. Programmeureuses en langage d'assemblage, ce RFC est pour vous.
eBPF désigne ici un jeu d'instructions (comme ARM ou RISC-V). Programmer en eBPF, c'est donc programmer en langage d'assemblage et, en général, on ne le fait pas soi-même, on écrit dans un langage de plus haut niveau (non spécifié ici mais c'est souvent un sous-ensemble de C) et on confie à un compilateur le soin de générer les instructions. Ce jeu d'instructions a plusieurs particularités. Notamment, il est délibérément limité, puisque toute bogue dans le noyau est particulièrement sérieuse, pouvant planter la machine ou pire, permettre son piratage. Vous ne pouvez pas faire de boucles générales, par exemple. eBPF est surtout répandu dans le monde Linux (et c'est là où vous trouverez beaucoup de ressources) où il est une alternative aux modules chargés dans le noyau. Pas mal du code réseau d'Android est ainsi en eBPF. Normalisé ici, eBPF peut être mis en œuvre sur d'autres noyaux (il tourne sur Windows, par exemple). Le monde eBPF est très riche, il y a plein de logiciels (pas toujours faciles à utiliser), plein de tutoriels (pas toujours à jour et qui ne correspondent pas toujours à votre système d'exploitation) mais cet article se focalise sur le sujet du RFC : le jeu d'instructions.
On trouve de nombreux exemples d'utilisation en production par exemple le répartiteur de charge Katran chez Facebook, via lequel vous êtes certainement passé, si vous utilisez Facebook. En plus expérimental, j'ai trouvé amusant qu'on puisse modifier les réponses DNS en eBPF.
Passons tout de suite à la description de ce jeu
d'instructions (ISA = Instruction Set
Architecture). D'abord, les types (section 2.1) :
u32 est un entier non
signé sur 32 bits, s16, un signé
sur 16 bits, etc. eBPF fournit des fonctions de conversions utiles
(section 2.2) comme be16 qui convertit en
gros boutien (le RFC cite IEN137…). Au
passage, une mise en œuvre d'eBPF n'est pas obligée de tout fournir
(section 2.4). La norme décrit des groupes de conformité et une
implémentation d'eBPF doit lister quels groupes elle met en
œuvre. Le groupe base32 (qui n'a rien à voir
avec le Base32 du RFC 4648) est le minimum requis dans tous les cas. Par
exemple, divmul32 ajoute multiplication et
division. Tous ces groupes figurent dans un registre IANA.
Les instructions eBPF sont encodées en 64 ou 128 bits (section
3). On y trouve les instructions classiques de tout jeu, les
opérations arithmétiques (comme ADD), logiques
(comme AND), les sauts
(JA, JEQ et autrs), qui se
font toujours vers l'avant, pour, je suppose, ne pas permettre de boucles
(souvenez-vous du problème de l'arrêt, qui n'a
pas de solution avec un jeu
d'instructions plus étendu), l'appel de fonction, etc.
En parlant de fonctions, eBPF ne peut pas
appeler n'importe quelle fonction. Il y a deux sortes de fonctions
utilisables, les fonctions d'aide (section 4.3.1), pré-définies par
la plateforme utilisée, et non normalisées (pour celles de Linux,
voir la
documentation, qui est sous
Documentation/bpf si vous avez les sources du
noyau). Il y a aussi les fonctions locales (section 4.3.2), définies
par le programme eBPF.
Il y a enfin des instructions pour lire et écrire dans la mémoire
(LD, ST, etc). Pour
mémoriser plus facilement, eBPF utilise
des dictionnaires (maps,
cf. section 5.4.1).
La section 6 concerne la sécurité, un point évidemment crucial puisque les programmes eBPF tournent dans le noyau, où les erreurs ne pardonnent pas. Un programme eBPF malveillant peut provoquer de nombreux dégâts. C'est pour cela que, sur Linux, seul root peut charger un tel programme dans le noyau. Le RFC recommande de faire tourner ces programmes dans un environnement limité (bac à sable), de limiter les ressources dont ils disposent et de faire tourner des vérifications sur le programme avant son exécution (par exemple, sur Linux, regardez cette documentation ou bien l'article « Simple and Precise Static Analysis of Untrusted Linux Kernel Extensions »).
Enfin, section 7, les registres (pas les registres du processeur, ceux où on enregistre les codes utilisés). Deux registres IANA sont créés, celui des groupes de conformité et celui du jeu d'instructions. L'annexe A du RFC donne les valeurs actuelles. Les registres sont extensibles et la politique d'enregistrement est « Spécification nécessaire » et « Examen par un expert », cf. RFC 8126. (J'avoue ne pas savoir pourquoi, si les opcodes sont enregistrés, les mnémoniques ne le sont pas, cela rend les registres difficiles à lire.)
Un peu d'histoire, au passage. eBPF est dérivé de BPF, ce qui voulait dire Berkeley Packet Filter, et était spécifique au filtrage des paquets réseau. Cet usage a été notamment popularisé par tcpdump. D'ailleurs, ce programme a une option pour afficher le code BPF produit :
% sudo tcpdump -d port 53 (000) ldh [12] (001) jeq #0x86dd jt 2 jf 10 (002) ldb [20] (003) jeq #0x84 jt 6 jf 4 (004) jeq #0x6 jt 6 jf 5 (005) jeq #0x11 jt 6 jf 23 (006) ldh [54] … (021) jeq #0x35 jt 22 jf 23 (022) ret #262144 (023) ret #0
Si vous voulez vous mettre à eBPF (attention, la courbe
d'apprentissage va être raide), man 4 bpf est
utile. Typiquement, vous écrirez vos programmes dans un
sous-ensemble de C et vous
compilerez en eBPF, par exemple avec clang,
après avoir installé tous les outils et bibliothèques nécessaires
(il faut souvent des versions assez récentes) :
% cat count.c
…
int count_packets(struct __sk_buff *skb) {
__u32 key = 0;
__u64 *counter;
counter = bpf_map_lookup_elem(&pkt_counter, &key);
if (counter) {
(*counter)++;
}
return 0;
}
…
% clang -target bpf -c count.c
% file count.o
count.o: ELF 64-bit LSB relocatable, eBPF, version 1 (SYSV), not stripped
% objdump -d count.o
…
0000000000000000 <count_packets>:
0: 7b 1a f8 ff 00 00 00 00 stxdw [%r10-8],%r1
8: b7 01 00 00 00 00 00 00 mov %r1,0
10: 63 1a f4 ff 00 00 00 00 stxw [%r10-12],%r1
18: 18 01 00 00 00 00 00 00 lddw %r1,0
20: 00 00 00 00 00 00 00 00
28: bf a2 00 00 00 00 00 00 mov %r2,%r10
30: 07 02 00 00 f4 ff ff ff add %r2,-12
(Notez l'utilisation du désassembleur objdump.) Vous pouvez alors charger le code eBPF dans votre noyau, par exemple avec bpftool (et souvent admirer de beaux messages d'erreur comme « libbpf: elf: legacy map definitions in 'maps' section are not supported by libbpf v1.0+ »). Si tout fonctionne, votre code eBPF sera appelé par le noyau lors d'événements particuliers que vous avez indiqués (par exemple la création d'un processus, ou bien l'arrivée d'un paquet par le réseau) et fera alors ce que vous avez programmé. Comme me le fait remarquer Pierre Lebeaupin, il y a une bogue dans le source ci-dessus : l'incrémentation du compteur n'est pas atomique et donc, si on a plusieurs CPU, on risque de perdre certaines incrémentations. La solution de ce problème est laissé à la lectrice.
Un exemple d'utilisation d'eBPF pour observer ce que fait le noyau (ici avec un outil qui fait partie de bcc), on regarde les exec :
% sudo /usr/sbin/execsnoop-bpfcc PCOMM PID PPID RET ARGS check_disk 389622 1628 0 /usr/lib/nagios/plugins/check_disk -c 10% -w 20% -X none -X tmpfs -X sysfs -X proc -X configfs -X devtmpfs -X devfs -X check_disk 389623 1628 0 /usr/lib/nagios/plugins/check_disk -c 10% -w 20% -X none -X tmpfs -X sysfs -X proc -X configfs -X devtmpfs -X devfs -X check_swap 389624 1628 0 /usr/lib/nagios/plugins/check_swap -c 25% -w 50% check_procs 389625 1628 0 /usr/lib/nagios/plugins/check_procs -c 400 -w 250 ps 389627 389625 0 /bin/ps axwwo stat uid pid ppid vsz rss pcpu etime comm args sh 389632 389631 0 /bin/sh -c [ -x /usr/lib/php/sessionclean ] && if [ ! -d /run/systemd/system ]; then /usr/lib/php/sessionclean; fi sessionclean 389633 1 0 /usr/lib/php/sessionclean sort 389635 389633 0 /usr/bin/sort -rn -t: -k2,2 phpquery 389638 389634 0 /usr/sbin/phpquery -V expr 389639 389638 0 /usr/bin/expr 2 - 1 sort 389642 389638 0 /usr/bin/sort -rn
Le code eBPF est interprété par une machine virtuelle ou bien traduit à la volée en code natif.
Même ChatGPT peut écrire de l'eBPF (les tours de Hanoi et un serveur DNS).
De nombreux exemples se trouvent dans le répertoire
samples/bpf des sources du noyau Linux. (Le
fichier README.rst explique comment compiler
mais seulement dans le cadre de la compilation d'un noyau. En gros,
c'est make menuconfig , cd
samples/bpf puis make -i.) Un bon
exemple, relativement simple, pour commencer avec le réseau est
tcp_clamp_kern.c.
Si vous préférez travailler en Go (là aussi, avec un Go récent…), il existe un bon projet. Si vous suivez bien la documentation, vous pourrez compiler des programmes et les charger :
% go mod init ebpf-test % go mod tidy % go get github.com/cilium/ebpf/cmd/bpf2go % go generate % go build % sudo ./ebpf-test 2024/08/20 15:21:43 Counting incoming packets on veth0.. … 2024/08/20 15:22:03 Received 25 packets 2024/08/20 15:22:04 Received 26 packets 2024/08/20 15:22:05 Received 27 packets 2024/08/20 15:22:06 Received 502 packets <- ping -f 2024/08/20 15:22:07 Received 57683 packets 2024/08/20 15:22:08 Received 75237 packets ^C2024/08/20 15:22:09 Received signal, exiting..
Vous trouverez beaucoup de ressources eBPF sur https://ebpf.io/
Ce RFC avait fait l'objet de pas mal de débats à l'IETF car, normalement, l'IETF ne normalise pas de langages de programmation ou de jeux d'instructions. (La première réunion était à l'IETF 116 en mars 2023 donc c'est quand même allé assez vite.)
L'article seul
RFC 9673: IPv6 Hop-by-Hop Options Processing Procedures
Date de publication du RFC : Octobre 2024
Auteur(s) du RFC : R. Hinden (Check Point
Software), G. Fairhurst (University of
Aberdeen)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF 6man
Première rédaction de cet article le 31 octobre 2024
Parmi les différentes options qui peuvent être placées dans un en-tête d'un paquet IPv6, certaines sont à traiter par chaque routeur situé sur le trajet. On les appelle les options « par saut » (hop-by-hop). Elles sont très peu utilisées en pratique, entre autres parce que leur traitement, tel que spécifié dans le RFC 8200, est trop contraignant pour les routeurs. Ce nouveau RFC change donc les règles, dans le sens d'un plus grand pragmatisme.
À part l'en-tête « Hop-by-hop Options » (RFC 8200, section 4.3), tous les en-têtes IPv6 ne concernent que les machines terminales. « Hop-by-hop Options », lui, concerne les routeurs et, avant le RFC 8200, tous les routeurs sur le trajet avaient l'obligation de le lire et d'agir en fonction des options qu'il contenait (la liste complète des options possibles est dans un registre IANA). Bien trop coûteuse pour les routeurs, cette obligation a été supprimée par le RFC 8200. Ce nouveau RFC 9673 modifie le traitement des options de cet en-tête (et donc le RFC 8200) dans l'espoir qu'il voit enfin un vrai déploiement dans l'Internet (actuellement, cet en-tête par saut - hop-by-hop - est quasiment inutilisé). Si vous concevez des routeurs, et êtes pressé·e, sautez directement à la section 5 du RFC, qui décrit les nouvelles règles, mais ce serait dommage.
Petite révision sur l'architecture des routeurs (section 3 du RFC). Les routeurs de haut de gamme ont une voie rapide (fast path) pour le traitement des paquets, lorsque ceux-ci n'ont pas de demande particulière. Mise en œuvre en dehors du processeur principal du routeur, cette voie rapide est traitée par des circuits spécialisés, typiquement des ASIC. Si le paquet nécessite des opérations plus complexes, on passe par une voie plus lente, utilisant des méthodes et du matériel plus proches de ceux d'un ordinateur classique. (Les RFC 6398 et RFC 6192 sont des lectures recommandées ici.) D'autre part, on distingue souvent, dans le routeur, la transmission (forwarding plane) et le contrôle (control plane). La transmission est le travail de base du routeur (transmettre les paquets reçus sur une interface via une autre interface, et le plus vite possible), le contrôle regroupe notamment les opérations de manipulation de la table de routage, par exemple lors de mises à jour reçues via des protocoles comme OSPF ou BGP. Contrairement à la transmission, le contrôle n'est pas en « temps réel ».
Aujourd'hui, un paquet IPv6 utilisant des options par saut risque fort de ne même pas arriver à destination, sacrifié par des routeurs qui ne veulent pas le traiter. (Voir le RFC 7872, l'exposé « Internet Measurements: IPv6 Extension Header Edition » ou l'article « Is it possible to extend IPv6? ».)
Que disent donc les nouvelles procédures (section 5) ?
- Un routeur ne devrait pas jeter un paquet uniquement parce que celui-ci contient l'en-tête par saut (voir aussi RFC 9288). Même si le routeur ne traite pas les options de cet en-tête, il devrait transmettre le paquet.
- Il est très recommandé que les routeurs disposent d'une option de configuration permettant d'indiquer s'il faut ou non traiter les options par saut. Et d'une autre pour indiquer quelles options dans l'en-tête doivent être gérées, que cela ne soit pas du tout ou rien.
- IPv6 dispose de deux bits dans chaque option par saut pour indiquer le traitement souhaité du paquet si le routeur ne connait pas l'option. La nouvelle procédure permet d'être plus indulgent et, par exemple, de ne pas jeter un paquet même si l'émetteur le demandait, si le routeur ne veut pas traiter cette option (cf. le premier item de cette liste de règles).
- Les émetteurs qui mettent l'en-tête par saut dans les paquets doivent être bien conscients que tous les routeurs ne le traiteront pas (c'est le cas depuis longtemps, le RFC ne fait que décrire cet état de fait).
- Les machines terminales devraient examiner cet en-tête et le traiter, il ne concerne pas que les routeurs.
Pour faciliter la tâche des routeurs, et toujours dans l'espoir que les options par saut deviennent enfin une possibilité réaliste, la section 6 du RFC encadre la définition de nouveaux en-têtes (le RFC 8200 recommandait carrément de ne plus en définir, tant qu'on n'avait pas mieux défini leur utilisation). Les éventuelles futures options doivent être simples à traiter et conçues en pensant au travail qu'elles imposeront au routeur. Le protocole qui les utilise doit intégrer le fait que le routeur est autorisé à ignorer cette option, voire qu'il puisse jeter le paquet.
Ah, et un mot sur la sécurité (section 8). Plusieurs RFC ont déjà documenté les problèmes de sécurité que peuvent poser les options par saut, notamment le risque qu'elles facilitent une attaque par déni de service sur le routeur : RFC 6398, RFC 6192, RFC 7045 et RFC 9098.
Est-ce que le déploiement de ce RFC va améliorer les choses pour l'en-tête par saut, qui est jusqu'à présent un exemple d'échec ? Je suis assez pessimiste, étant donné la difficulté à changer des comportements bien établis.
Un peu d'histoire pour terminer (section 4 du RFC) : les
premières normes IPv6 (RFC 1883, puis RFC 2460) imposaient à tous les routeurs d'examiner
et de traiter les options par saut. Le RFC 7045 avait été le premier à constater que cette règle
n'était pas respectée et ne pouvait pas l'être vu l'architecture des
routeurs modernes. Le problème de performance dans le traitement des
options était d'autant plus grave que les options n'avaient pas
toutes le même format (cela a été résolu par le RFC 6564, qui imposait un format unique). Le résultat, comme
vu plus haut, était que les routeurs ignoraient les options par saut
ou, pire, jetaient le paquet qui les contenait. (Le RFC 9288 et l'article « Threats
and Surprises behind IPv6 Extension Headers »
expliquent pourquoi c'est une mauvaise
idée. L'Internet Draft
draft-ietf-v6ops-hbh discute également cette
question.)
L'article seul
RFC 9680: Antitrust Guidelines for IETF Participants
Date de publication du RFC : Octobre 2024
Auteur(s) du RFC : J. M. Halpern (Ericsson), J. Daley
(IETF Administration LLC)
Pour information
Première rédaction de cet article le 31 octobre 2024
Les normes publiées par l'IETF ne sont pas que des documents techniques à seule destination des techniciens. L'Internet et, de manière plus générale, les protocoles TCP/IP sont aussi une grosse industrie qui brasse beaucoup d'argent. Il y a donc un risque que des acteurs de cette industrie essaient d'influencer les normes à leur profit, par exemple en formant des alliances qui, dans certains pays, seraient illégales au regard des lois antitrust. Ce court RFC administratif explique aux participant·es IETF ce que sont ces lois et comment éviter de les violer.
En effet, les organisations, notamment les entreprises à but lucratif, qui participent à l'IETF peuvent être concurrentes sur leurs marchés. Or, le développement de normes nécessite de la collaboration entre ces concurrents. Pour maintenir une concurrence et pour éviter les ententes, plusieurs pays ont des lois, dites « antitrust », lois que des participant·es à l'IETF ne connaissent pas forcément bien. La justification idéologique de ces lois est rappelée par le RFC, dans le cas étatsunien mais d'autres pays capitalistes ont des principes similaires : « Competition in a free market benefits consumers through lower prices, better quality and greater choice. Competition provides businesses the opportunity to compete on price and quality, in an open market and on a level playing field, unhampered by anticompetitive restraints. » Que ce soit vrai ou pas, peu importe, les lois antitrust doivent être respectées. Ce RFC n'édicte pas de règles pour l'IETF (« respectez la loi » est de toute façon déjà obligatoire), mais il explique des subtilités juridiques aux participant·es à l'IETF.
Il y a en effet deux risques pour l'IETF, qu'un·e représentant officiel de l'IETF soit accusé de comportement anti-concurrentiel, engageant la responsabilité de l'organisation, ou que des participant·es soient accusés de comportement anti-concurrentiel, ce qui n'engagerait pas la responsabilité de l'IETF mais pourrait affecter sa réputation.
Les participant·es à l'IETF sont censés suivre des règles dont certaines limitent déjà le risque de comportement anti-concurrentiel, entre autres :
- Suivre les procédures officielles (RFC 2026, RFC 2418 et plusieurs autres),
- Agir en tant qu'individu (RFC 7154) et non pas en tant que représentant de son employeur (ce qui est assez théorique, il faut bien le dire…), voir aussi cet article de l'administration de l'IETF,
- Respecter les règles concernant la propriété intellectuelle (RFC 5378 et RFC 8179),
- Et les règles sur le conflit d'intérêt (il y a celle de l'IESG, celle de l'IAB et enfin celle de l'organisation administrative de l'IETF ; mais les trois politiques sont très semblables).
Maintenant, s'y ajoutent les questions spécifiques au respect des lois sur la concurrence. La section 4, le cœur de ce RFC, attire l'attention sur :
- La nécessité d'éviter de parler de certains sujets comme les prix des produits, les marges bénéficiaires, les accords avec des tiers, les analyses marketing, bref tout ce qui concerne le business, auquel le RFC ajoute les salaires et avantages divers (allez au bistrot le plus proche si vous voulez en parler librement). Des discussions sur ces sujets ne violent pas forcément les lois antitrust mais, dans le doute, mieux vaut être prudent.
- L'importance de consulter un·e expert·e juridique en cas de doute. (L'IETF ne fournit pas de conseils juridiques.)
- Le fait que les problèmes peuvent être signalés à l'équipe
juridique de l'IETF (
legal@ietf.org) ou via le service spécifique pour les lanceurs d'alerte.
L'article seul
RFC 9311: Running an IETF Hackathon
Date de publication du RFC : Septembre 2022
Auteur(s) du RFC : C. Eckel (Cisco Systems)
Pour information
Réalisé dans le cadre du groupe de travail IETF shmoo
Première rédaction de cet article le 31 octobre 2024
L'IETF, l'organisation qui normalise les protocoles de l'Internet a toujours prôné le pragmatisme et le réalisme : ce n'est pas tout d'écrire des normes, il faut encore qu'elles fonctionnent en vrai. Un des outils pour cela est le hackathon qui se déroule traditionnellement le week-end avant les réunions physiques de l'IETF. Ce RFC, écrit par le responsable de ces hackathons, décrit l'organisation de ces événements.
La salle (en cours d'installation) du hackathon à
Yokohama en 2023 :

Paradoxalement, alors que cette ambition de réalisme (« we believe in rough consensus and running code ») est ancienne à l'IETF, les hackathons sont relativement récents. Le premier était en 2015 à Dallas. Mais les hackathons font désormais partie de la culture IETF et on n'imagine plus de réunion sans eux. Ils accueillent désormais systématiquement plusieurs centaines de participant·es (cf. section 6 du RFC). (Mon premier était à Chicago.) Au passage, si vous êtes programmeur·se et que vous allez à une réunion IETF, ne ratez pas le hackathon, il en vaut la peine. Le prochain commence ce samedi, le 2 novembre 2024, à Dublin.
Donc, le but du hackathon à l'IETF (section 1 du RFC) est de tester les normes en cours d'élaboration, de voir si la future spécification est claire et réaliste, et de faire en sorte que les gens qui écrivent les normes (qui ne sont pas forcément des développeur·ses) interagissent avec ceux et celles qui mettent en œuvre les normes. (Cela peut paraitre étonnant, mais beaucoup de SDO ne fonctionnent pas comme cela ; la norme est écrite par des gens qui sont très loin du terrain et qui se moquent du caractère réaliste et effectif de leurs textes.) Le code qui tourne est souvent plus significatif qu'une opinion exprimée pendant la réunion. Et le hackathon est aussi l'occasion de travailler en commun (surtout si on est présent·e physiquement), ce qui fait avancer les projets.
Ah, et puisqu'on parle de collaboration, contrairement à certains hackathons, ceux de l'IETF n'ont plus aucune forme de compétition : pas de classement, pas de prix. (Voir la section 7.6 sur le rôle qu'avaient les juges de la compétition et pourquoi cela a été vite supprimé.) En outre, la plupart du code écrit pendant les hackathons est sous une licence libre (la principale exception concerne les gens qui ont modifié un logiciel privateur, par exemple le code de certains routeurs). Du point de vue « juridique », notez que le hackathon est un événement de l'IETF et donc soumis aux règles IETF (voir aussi la section 5.3).
Les hackathons de l'IETF sont gratuits (et il n'est pas forcément nécessaire de payer son voyage, on peut le faire à distance, voir plus loin) et ouverts à tous (cf. section 5.3). On s'inscrit en ligne puis on y va. Si vous êtes débutant·e, ne vous inquiétez pas, on a tous été débutant·es et les hackathons sont justement l'occasion de mêler étudiant·es, expert·es, etc. Une large participation est encouragée.
Comment organise t-on un tel événement ? Charles Eckel, l'auteur du RFC, est pour l'instant le pilier de ces hackathons. Le RFC a été écrit, entre autres, pour transmettre son expérience et permette à d'autres de le seconder ou de lui succéder. La section 2 du RFC détaille les choix effectués. Le hackathon se tient le week-end pour faciliter la participation des gens qui travaillent, notamment de ceux et celles qui ne viennent pas à la réunion IETF la semaine suivante. Et puis ça renforce le côté informel.
Questions horaires, le hackathon de l'IETF n'essaie pas de faire travailler les gens 24 heures sur 24 tout le week-end. La majorité des participant·es au hackathon viennent à l'IETF ensuite et doivent donc rester frai·ches. Le hackathon dure typiquement le samedi de 09:00 à 22:00 et le dimanche de 09:00 à 16:00 (il y a déjà des réunions IETF le dimanche en fin d'après-midi). Si des gens veulent travailler toute la nuit, ielles doivent le faire dans leur chambre.
La nourriture est fournie sur place pour éviter qu'on doive sortir (mais on a évidemment le droit de sortir, les participant·es ne sont pas attaché·es et peuvent estimer plus important d'aller discuter avec d'autres participant·es en dehors du hackathon). Et, comme le note le RFC, c'est une motivation supplémentaire pour faire venir les gens (on mange bien).
Et pour les gens qui sont à distance ? Le problème avait commencé à se poser pour la réunion IETF 107 prévue à Vancouver et annulée au dernier moment pour cause de Covid. Il y avait eu un effort pour maintenir un hackathon en distanciel mais cela n'avait pas intéressé grand'monde. (Un des plus gros problèmes du distanciel est le décalage horaire. Les gens qui n'étaient pas en PST n'avaient montré aucun enthousiasme pour le hackathon.) Cela s'est mieux passé par la suite, avec des réunions entièrement en ligne pendant la pandémie. Aujourd'hui, les réunions ont repris en présentiel mais une partie des participant·es, aussi bien à l'IETF qu'au hackathon, sont à distance. (Mon opinion personnelle est que c'est peu utile ; l'intérêt du hackathon est la collaboration intense avec les gens qui sont juste là. En travaillant à distance, on perd cette collaboration. Autant travailler tout seul dans son coin.) Une approche intermédiaire, très utilisée à Maurice, est d'avoir une réunion en présentiel locale, où les gens travaillent à distance sur le hackathon. Cela permet de garder un côté collectif sympa.
Tout cela (à commencer par les repas, et bien sûr la salle, mais elle est parfois incluse dans le contrat global de l'IETF pour sa réunion) coûte de l'argent. La section 3 décrit les sources de financement, qui permettent de garder le hackathon gratuit pour les participant·es. Il y a, comme souvent dans les conférences techniques, des sponsors. (Pour le prochain hackathon, ce seront Ericsson, Meta et l'ICANN.) Mais il y a aussi un financement par l'IETF elle-même (car on ne trouve pas toujours des sponsors). Le RFC précise même quels repas seront sacrifiés s'il n'y a pas assez d'argent (le diner du samedi est considéré comme moins important que les déjeuners, car les participant·es pourront toujours diner en rentrant).
Ah, et les T-shirts ? Pas de hackathon sans T-shirt. Le RFC donne des statistiques intéressantes, comme la répartition par taille aux précédents hackathons.
La participation à distance dispense du coût des repas mais il faut ajouter celle des systèmes de communication utilisés, notamment Meetecho et Gather. (Avant de proposer un autre système, rappelez-vous qu'il y a des centaines de participant·es actif·ves au hackathon et qu'il faut une solution qui tienne la charge.)
À la fin du hackathon, les participant·es présentent leur travail, les résultats obtenus et les conclusions qu'on peut en tirer pour les normes en cours de développement (section 4). Au début, il y avait également une session de présentation des projets au début du hackathon mais elle a dû être abandonnée au fur et à mesure que le hackathon grossissait. La présentation initiale se fait désormais sur le Wiki (voir par exemple la prochaine et la page où on peut aller si on cherche une équipe ou bien des volontaires). C'est sur ce Wiki que les champions (les gens qui ont une idée et organisent une activité particulière au hackathon, cf section 7.4) essaient de recruter. Quant aux présentations finales, elles sont publiées sur Github. C'est aussi là qu'on trouvera le code produit lorsqu'il n'est pas sur un dépôt extérieur (section 5.6).
La liste des projets affichés dans la salle du hackathon de
Yokohama en 2023 :

On a parlé des outils utilisés, lors de la section sur le financement. La section 5 dresse une liste plus complète des outils logiciels qui servent pour le hackathon. Il y a évidemment, comme pour tout travail IETF, le Datatracker (qui a une section sur le hackathon). Tout aussi évidemment, puisque l'IETF travaille largement avec des listes de diffusion, il y a une liste des participant·es au hackathon.
Pour profiter de tous ces outils, il faut un réseau à forte capacité, fiable, et évidemment sans aucun filtrage. Lors de la réunion de Beijing, les négociations avec les autorités avaient été serrées et l'accord final imposait un contrôle d'accès aux salles de l'IETF, pour éviter que des citoyens chinois n'en profitent. (Normalement, il n'y a aucun contrôle à l'entrée de l'IETF, personne ne vérifie les badges.) Le groupe qui s'occupe de monter et de démonter le réseau de l'IETF a donc en plus la charge du réseau du hackathon. Celui-ci peut en outre nécessiter des services spéciaux, afin de tester en présence de tels services (NAT64, prefix delegation, etc). Il y a même un accès VPN, pour celles et ceux qui travaillent à distance.
L'article seul
RFC 9636: The Time Zone Information Format (TZif)
Date de publication du RFC : Octobre 2024
Auteur(s) du RFC : A.D. Olson, P. Eggert
(UCLA), K. Murchison (Fastmail)
Chemin des normes
Première rédaction de cet article le 31 octobre 2024
Ce nouveau RFC
documente un format déjà ancien et largement déployé, TZif, un
format de description des fuseaux
horaires. Il définit également des types MIME pour ce format,
application/tzif et
application/tzif-leap. Il remplace le premier
RFC de normalisation de ce format, le RFC 8536, mais il y a très peu de changements. Bienvenue donc
à la version 4 du format, spécifiée dans ce RFC.
Ce format existe depuis quarante ans (et a pas mal évolué pendant ce temps) mais n'avait apparemment jamais fait l'objet d'une normalisation formelle avant le RFC 8536 en 2019. La connaissance des fuseaux horaires est indispensable à toute application qui va manipuler des dates, par exemple un agenda. Un fuseau horaire se définit par un décalage par rapport à UTC, les informations sur l'heure d'été, des abréviations pour désigner ce fuseau (comme CET pour l'heure de l'Europe dite « centrale ») et peut-être également des informations sur les secondes intercalaires. Le format iCalendar du RFC 5545 est un exemple de format décrivant les fuseaux horaires. TZif, qui fait l'objet de ce RFC, en est un autre. Contrairement à iCalendar, c'est un format binaire.
TZif vient à l'origine du monde Unix et est apparu dans les années 1980, quand le développement de l'Internet, qui connecte des machines situées dans des fuseaux horaires différents, a nécessité que les machines aient une meilleure compréhension de la date et de l'heure. Un exemple de source faisant autorité sur les fuseaux horaires est la base de l'IANA décrite dans le RFC 6557 et dont l'usage est documenté à l'IANA. Pour la récupérer, voir par exemple le RFC 7808.
La section 2 de notre RFC décrit la terminologie du domaine :
- Temps Universel Coordonné (UTC est le sigle officiel) : la base du temps légal. Par exemple, en hiver, la France métropolitaine est en UTC + 1. (GMT n'est utilisé que par les nostalgiques de l'Empire britannique.)
- Heure d'été (le terme français est incorrect, l'anglais DST - Daylight Saving Time est plus exact) : le décalage ajouté ou retiré à certaines périodes, pour que les activités humaines, et donc la consommation d'énergie, se fassent à des moments plus appropriés (cette idée est responsable d'une grande partie de la complexité des fuseaux horaires).
- Temps Atomique International (TAI) : contrairement à UTC, qui suit à peu près le soleil, TAI est déconnecté des phénomènes astronomiques. Cela lui donne des propriétés intéressantes, comme la prédictibilité (alors qu'on ne peut pas savoir à l'avance quelle sera l'heure UTC dans un milliard de secondes) et la monotonie (jamais de sauts, jamais de retour en arrière, ce qui peut arriver à UTC). Cela en fait un bon mécanisme pour les ordinateurs, mais moins bon pour les humains qui veulent organiser un pique-nique. Actuellement, il y a 37 secondes de décalage entre TAI et UTC.
- Secondes intercalaires : secondes ajoutées de temps en temps à UTC pour compenser les variations de la rotation de la Terre.
- Correction des secondes intercalaires : TAI - UTC - 10 (lisez le RFC pour savoir pourquoi 10). Actuellement 27 secondes.
- Heure locale : l'heure légale en un endroit donné. La différence avec UTC peut varier selon la période de l'année, en raison de l'heure d'été. En anglais, on dit aussi souvent « le temps au mur » (wall time) par référence à une horloge accrochée au mur. Quand on demande l'heure à M. Toutlemonde, il donne cette heure locale, jamais UTC ou TAI ou le temps Unix.
- Epoch : le point à partir duquel on compte le temps. Pour Posix, c'est le 1 janvier 1970 à 00h00 UTC.
- Temps standard : la date et heure « de base » d'un fuseau horaire, sans tenir compte de l'heure d'été. En France métropolitaine, c'est UTC+1.
- Base de données sur les fuseaux horaires : l'ensemble des informations sur les fuseaux horaires (cf. par exemple RFC 7808). Le format décrit dans ce RFC est un des formats possibles pour une telle base de données.
- Temps universel : depuis 1960, c'est équivalent à UTC, mais le RFC préfère utiliser UT.
- Temps Unix : c'est ce qui est renvoyé
par la fonction
time(), à savoir le nombre de secondes depuis l'epoch, donc depuis le 1 janvier 1970. Il ne tient pas compte des secondes intercalaires, donc il existe aussi un « temps Unix avec secondes intercalaires » (avertissement : tout ce qui touche au temps et aux calendriers est compliqué). C'est ce dernier qui est utilisé dans le format TZif, pour indiquer les dates et heures des moments où se fait une transition entre heure d'hiver et heure d'été.
La section 3 de notre RFC décrit le format lui-même. Un fichier TZif est composé d'un en-tête (taille fixe de 44 octets) indiquant entre autres le numéro de version de TZif. La version actuelle est 4. Ensuite, on trouve les données. Dans la version 1 de TZif, le bloc de données indiquait les dates de début et de fin des passages à l'heure d'été sur 32 bits, ce qui les limitait aux dates situées entre 1901 et 2038. Les versions ultérieures de TZif sont passées à 64 bits, ce qui permet de tenir environ 292 milliards d'années mais le bloc de données de la version 1 reste présent, au cas où il traine encore des logiciels ne comprenant que la version 1. Notez que ces 64 bits permettent de représenter des dates antérieures au Big Bang, mais certains logiciels ont du mal avec des valeurs situées trop loin dans le passé.
Les versions 2, 3 et 4 ont un second en-tête de 44 octets, et un bloc de données à elles. Les vieux logiciels arrêtent la lecture après le premier bloc de données et ne sont donc normalement pas gênés par cet en-tête et ce bloc supplémentaires. Les logiciels récents peuvent sauter le bloc de données de la version 1, qui ne les intéresse a priori pas (voir section 4 et annexe A). C'est au créateur du fichier de vérifier que les blocs de données destinés aux différentes versions sont raisonnablement synchrones, en tout cas pour les dates antérieures à 2038.
Nouveauté apparue avec la version 2, il y a aussi un pied de page à
la fin. Les entiers sont stockés en gros boutien, et en complément à deux. L'en-tête
commence par la chaîne magique « TZif » (U+0054 U+005A U+0069
U+0066), et comprend la longueur du bloc de données (qui dépend du
nombre de transitions, de secondes intercalaires et d'autres
informations à indiquer). Le bloc de données contient la liste des
transitions, le décalage avec UT, le nom du fuseau horaire, la liste des
secondes intercalaires, etc. Vu par le mode hexadécimal
d'Emacs, voici le début d'un fichier Tzif
version 2 (pris sur une Ubuntu, dans
/usr/share/zoneinfo/Europe/Paris). On voit bien
la chaîne magique, puis le numéro de version, et le début du bloc de
données :
00000000: 545a 6966 3200 0000 0000 0000 0000 0000 TZif2...........
00000010: 0000 0000 0000 000d 0000 000d 0000 0000 ................
00000020: 0000 00b8 0000 000d 0000 001f 8000 0000 ................
00000030: 9160 508b 9b47 78f0 9bd7 2c70 9cbc 9170 .`P..Gx...,p...p
00000040: 9dc0 48f0 9e89 fe70 9fa0 2af0 a060 a5f0 ..H....p..*..`..
...
Avec od, ça donnerait :
% od -x -a /usr/share/zoneinfo/Europe/Paris
0000000 5a54 6669 0032 0000 0000 0000 0000 0000
T Z i f 2 nul nul nul nul nul nul nul nul nul nul nul
0000020 0000 0000 0000 0d00 0000 0d00 0000 0000
nul nul nul nul nul nul nul cr nul nul nul cr nul nul nul nul
0000040 0000 b800 0000 0d00 0000 1f00 0080 0000
nul nul nul 8 nul nul nul cr nul nul nul us nul nul nul nul
0000060 6091 8b50 479b f078 d79b 702c bc9c 7091
dc1 ` P vt esc G x p esc W , p fs < dc1 p
...
Des exemples détaillés et commentés de fichiers TZif figurent en annexe B. À lire si vous voulez vraiment comprendre les détails du format.
Le pied de page indique notamment les extensions à la variable d'environnement TZ. Toujours avec le mode hexadécimal d'Emacs, ça donne :
00000b80: 4345 542d 3143 4553 542c 4d33 2e35 2e30 CET-1CEST,M3.5.0
00000b90: 2c4d 3130 2e35 2e30 2f33 0a ,M10.5.0/3.
On a vu que le format TZif avait une histoire longue et compliquée. La section 4 du RFC est entièrement consacrée aux problèmes d'interopérabilité, liés à la coexistence de plusieurs versions du format, et de beaucoup de logiciels différents. Le RFC conseille (sections 4 et 5) :
- De ne plus générer de fichiers suivant la version 1, qui ne marchera de toute façon plus après 2038.
- Les logiciels qui en sont restés à la version 1 doivent faire attention à arrêter leur lecture après le premier bloc (dont la longueur figure dans l'en-tête).
- La version 4 n'apporte pas beaucoup par rapport à la 2 et à la 3 et donc, sauf si on utilise les nouveautés spécifiques de la 4, il est recommandé de produire plutôt des fichiers conformes à la version 2 ou 3.
- Un fichier TZif transmis via l'Internet devrait être
étiqueté
application/tzif-leapouapplication/tzif(s'il n'indique pas les secondes intercalaires). Ces types MIME sont désormais dans le registre officiel (cf. section 9 du RFC).
L'annexe A du RFC en rajoute, tenant compte de l'expérience accumulée ; par exemple, certains lecteurs de TZif n'acceptent pas les noms de fuseaux horaires contenant des caractères non-ASCII et il peut donc être prudent de ne pas utiliser ces caractères. Plus gênant, il existe des lecteurs assez bêtes pour planter lorsque des temps sont négatifs. Or, les entiers utilisant dans TZif sont signés, afin de pouvoir représenter les moments antérieurs à l'epoch. Donc, attention si vous avez besoin de données avant le premier janvier 1970, cela perturbera certains logiciels bogués.
En parlant des noms de fuseaux horaires, le RFC rappelle (section 5) que le sigle utilisé dans le fichier Tzif (comme « CET ») est en anglais et que, si on veut le traduire, cela doit être fait dans l'application, pas dans le fichier. Le RFC donne comme exemple CST, qui peut être présenté comme « HNC », pour « Heure Normale du Centre ».
Autre piège avec ces sigles utilisés pour nommer les fuseaux horaires : ils sont ambigus. PST peut être la côte Ouest des USA mais aussi l'heure du Pakistan ou des Philippines.
La section 7 du RFC donne quelques conseils de sécurité :
- L'en-tête indique la taille des données mais le programme qui lit le fichier doit vérifier que ces indications sont correctes, et n'envoient pas au-delà de la fin du fichier.
- TZif, en lui-même, n'a pas de mécanisme de protection de l'intégrité, encore moins de mécanisme de signature. Il faut fournir ces services extérieurement (par exemple avec curl, en récupérant via HTTPS).
Enfin, l'annexe C du RFC liste les changements depuis le RFC 8536, changements qui mènent à cette nouvelle version, la 4. Rien de crucial mais :
- Formalisation de l'ancienne convention comme quoi un décalage de « - 0 » avec UTC indique qu'on ne connait pas le vrai décalage.
- Correction de plusieurs erreurs.
Une bonne liste de logiciels traitant ce format figure à l'IANA.
L'article seul
RFC 9536: Registration Data Access Protocol (RDAP) Reverse Search
Date de publication du RFC : Avril 2024
Auteur(s) du RFC : M. Loffredo, M. Martinelli (IIT-CNR/Registro.it)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 28 octobre 2024
Ce RFC normalise une extension au protocole d'accès à l'information RDAP pour permettre des recherches inversées, des recherches par le contenu (« quels sont tous les noms de domaine de cette personne ? »).
Alors, tout d'abord, un avertissement. L'extension normalisée dans ce RFC est dangereuse pour la vie privée. Je détaille ce point plus loin mais ne réclamez pas tout de suite le déploiement de cette extension : lisez tout d'abord. C'est dès sa section 1 que le RFC met en garde contre un déploiement hâtif !
RDAP (normalisé dans les RFC 9082 et RFC 9083), comme son prédécesseur whois, permet d'obtenir des informations dites sociales (nom, adresse, numéro de téléphone, etc) sur les personnes (morales ou physiques) associées à une ressource Internet réservée, comme un nom de domaine ou un adresse IP. Une limite importante de ces deux protocoles est qu'il faut connaitre l'identifiant (nom de domaine, adresse IP) de la ressource. Or, certaines personnes seraient intéressés à faire l'inverse, découvrir les ressources à partir d'informations sociales. C'est le cas par exemple de juristes cherchant le portefeuille de noms de domaine de quelqu'un qu'ils soupçonnent de menacer leur propriété intellectuelle. Ou de chercheurs en sécurité informatique étudiant toutes les adresses IP utilisées par le C&C d'un botnet et voulant en découvrir d'autres. Ce RFC normalise justement un moyen de faire des recherches inverses. whois n'avait jamais eu une telle normalisation, à cause des risques pour la vie privée, risques qui sont peut-être moins importants avec RDAP.
(Notez quand même que le RFC 9082, section 3.2.1, prévoyait déjà certaines recherches inverses, d'un domaine à partir du nom ou de l'adresse d'un de ses serveurs de noms.)
Passons aux détails techniques (section 2). L'URL
d'une requête inverse va inclure dans son chemin
/reverse_search et, bien sûr, des critères de
recherche. Par exemple,
/domains/reverse_search/entity?fn=Jean%20Durand&role=registrant
donnera tous les domaines dont le titulaire
(registrant) se nomme Jean Durand
(fn est défini dans la section 6.2.1 du RFC 6350). Le terme après
/reverse_search indique le type des données
auxquelles s'appliquent les critères de recherche (actuellement,
c'est forcément entity, une personne morale ou
physique).
La plupart des recherches inverses porteront sans doute sur quelques champs comme l'adresse de courrier électronique ou le handle (l'identifiant d'une entité). La section 8 décrit les possibilités typiques mais un serveur RDAP choisit de toute façon ce qu'il permet ou ne permet pas.
La sémantique exacte d'une recherche inverse est décrite en
JSONPath (RFC 9535). Vous trouvez le JSONPath dans la réponse (section
5 du RFC), dans le membre
reverse_search_properties_mapping. Par exemple :
"reverse_search_properties_mapping": [
{
"property": "fn",
"propertyPath": "$.entities[*].vcardArray[1][?(@[0]=='fn')][3]"
}
]
L'expression JSONPath
$.entities[*].vcardArray[1][?(@[0]=='fn')][3]
indique que le serveur va faire une recherche sur le membre
fn du tableau vCard
(RFC 7095). Oui, elle est compliquée, mais
c'est parce que le format vCard est compliqué. Heureusement, on
n'est pas obligé de connaitre JSONPath pour utiliser les recherches
inverses, uniquement pour leur normalisation (section 3).
Pour savoir si le serveur RDAP que vous interrogez gère cette
extension et quelles requêtes il permet, regardez sa réponse à la
question help (RFC 9082,
section 3.1.6, et RFC 9083, section 7) ; s'il
accepte les requêtes inverses, vous y trouverez la valeur
reverse_search dans le membre
rdapConformance (section 9), par exemple :
"rdapConformance": [
"rdap_level_0",
"reverse_search"
]
Pour les recherches acceptées, regardez le membre
reverse_search_properties. Par exemple :
"reverse_search_properties": [
{
"searchableResourceType": "domains",
"relatedResourceType": "entity",
"property": "fn"
}
]
Ici, le serveur indique qu'il accepte les requêtes inverses pour trouver des noms de domaine en fonction d'un nom d'entité (ce que nous avons fait dans l'exemple plus haut). Voir la section 4 pour les détails. Si vous tentez une requête inverse sur un serveur, et que le serveur n'accepte pas les requêtes inverses, ou tout simplement n'accepte pas ce type particulier de recherche inverse que vous avez demandé, il répondra avec le code de retour HTTP 501 (section 7). Vous aurez peut-être aussi un 400 si votre requête déplait au serveur pour une raison ou l'autre.
L'extension est désormais placée dans le registre des extensions RDAP. En outre, deux nouveaux registres sont créés, RDAP Reverse Search, pour les recherches possibles et RDAP Reverse Search Mapping pour les règles JSONPath. Pour y ajouter des valeurs, la politique (RFC 8126) est « spécification nécessaire ».
Revenons maintenant aux questions de vie privée (RFC 6973), que je vous avais promises. La section 12 du RFC détaille le problème. La puissance des recherches inverses les rend dangereuses. Une entreprise concurrente pourrait regarder vos noms de domaine et ainsi se tenir au courant, par exemple, d'un nouveau projet ou d'un nouveau produit. Un malveillant pourrait regarder les noms de domaine d'une personne et identifier ainsi des engagements associatifs que la personne ne souhaitait pas forcément rendre très visibles. Les données stockées par les registres sont souvent des données personnelles et donc protégées par des lois comme le RGPD. Le gestionnaire d'un serveur RDAP doit donc, avant d'activer la recherche inverse, bien étudier la sécurité du serveur (section 13) mais aussi (et ce point n'est hélas pas dans le RFC) se demander si cette activation est vraiment une bonne idée.
En théorie, RDAP pose moins de problème de sécurité que whois pour ce genre de recherches, car il repose sur HTTPS (le chiffrement empêche un tiers de voir questions et réponses) et, surtout, il permet l'authentification ce qui rend possible, par exemple, de réserver les recherches inverses à certains privilégiés, avec un grand choix de contrôle d'accès (cf. annexe A). Évidemment, cela laisse ouvertes d'autres questions comme « qui seront ces privilégiés ? » et « comment s'assurer qu'ils n'abusent pas ? » (là, les journaux sont indispensables pour la traçabilité, cf. l'affaire Haurus).
Notons qu'outre les problèmes de vie privée, la recherche inverse pose également des problèmes de performance (section 10). Attention avant de la déployer, des requêtes apparemment innocentes pourraient faire ramer sérieusement le serveur RDAP. Si vous programmez un serveur RDAP ayant des recherches inverses, lisez bien les recommandations d'optimisation de la section 10, par exemple en ajoutant des index dans votre SGBD. Et le serveur ne doit pas hésiter, en cas de surcharge, à répondre seulement de manière partielle (RFC 8982 ou RFC 8977).
Je n'ai pas trouvé de code public mettant en œuvre ces recherches inverses. De même, je ne connais pas encore de serveur RDAP déployé qui offre cette possibilité.
L'article seul
Fiche de lecture : Online virality - Spread and Influence
Auteur(s) du livre : Valérie Schafer, Fred
Pailler
Éditeur : De Gruyter
978-3-11-131035-0
Publié en 2024
Première rédaction de cet article le 28 octobre 2024
Dans le contexte du Web, la viralité est un terme emprunté, évidemment, à l'épidémiologie, pour désigner une propagation rapide, de proche en proche, d'une information. En tant que phénomène social, elle peut être étudiée et c'est ce que fait ce livre collectif sur la viralité.
Bien des commerciaux et des politiciens se demandent tous les jours comment atteindre cet objectif idéal, la viralité, ce moment où les messages que vous envoyez sont largement repris et diffusés sans que vous ayiez d'effort à faire. Cela intéresse aussi évidemment les chercheur·ses en sciences humaines, d'où ce livre. (Et le projet HIVI, et le colloque qui aura lieu du 18 au 20 novembre 2024 à l'université du Luxembourg.) La version papier du livre coûte cher mais vous pouvez le télécharger légalement (le lien pour avoir tout le livre, et pas chapitre par chapitre, peut être difficile à voir : regardez en haut à droite).
Il y a de nombreux points à discuter dans la viralité et vous trouverez certainement dans ces études des choses intéressantes. Par exemple, le rôle des outils. Dans quelle mesure les programmes avec lesquels vous interagissez encouragent ou découragent la viralité ? Et, si le débat politique tourne en général exclusivement autour du rôle des GAFA et des mythifiés « algorithmes », il ne faut pas oublier que les médias traditionnels jouent aussi un rôle dans la viralité, en validant que telle ou telle information est « virale ».
N'oublions pas non plus que la viralité des informations n'est pas arrivée avec l'Internet. Le Kilroy was here des soldats étatsuniens de la deuxième guerre mondiale est un bon exemple de viralité avant les réseaux informatiques.
Mon chapitre préféré, dans ce livre, a été celui de Gastón Arce-Pradenas sur le succès viral et, souvent, la chute, de personnalités du mouvement chilien de 2019. Comme souvent dans un mouvement peu organisé (on pense évidemment aux gilets jaunes français, qui ont également vu ce genre de phénomène), des personnalités émergent sans mandat particulier, choisies par les médias, et/ou bénéficiant d'un succès viral, aidé par des techniques de communication spectaculaires, avant de trébucher rapidement. Ne ratez pas l'histoire du dinosaure bleu, par exemple, une des plus fascinantes. Vous aurez d'ailleurs d'autres perspectives internationales, par exemple du Brésil avec l'étude de Nazaré Confusa. La viralité ne concerne pas que les sujets étatsuniens.
Un peu de critique, toutefois : le livre est inégal, et certaines contributions n'ont pas de rapport direct avec la notion de viralité.
Et si le sujet vous fascine :
- Une fresque chronologique d'informations virales fameuses et une version spécialisée dans les chats (what else?).
- À propos de chats, une des auteures du livre a donné un bon interview sur la viralité féline.
- La viralité concerne souvent un mème,
un point de départ qu'on peut décliner donc, si vous voulez tout
savoir sur un mème particulier, il faut aller voir
knowyourmeme.com. - L'excellente série télévisée Le dessous des images parle souvent d'images virales.
L'article seul
Fiche de lecture : Quand les travailleurs sabotaient
Auteur(s) du livre : Dominique Pinsolle
Éditeur : Agone
978-2-7489-0563-2
Publié en 2024
Première rédaction de cet article le 28 octobre 2024
Aujourd'hui, le terme de « sabotage » renvoie uniquement à des activités sournoises et clandestines, non revendiquées officiellement. Mais, à une époque, le terme était ouvertement discuté dans certaines organisations ouvrières, et considéré par certains comme un moyen de lutte parmi d'autres. Ce livre revient sur l'histoire du concept de sabotage, notamment à propos des débats qu'il avait suscité dans le mouvement ouvrier.
C'est difficile de parler du sabotage aujourd'hui car le concept a été brouillé par les médias qui l'ont présenté systématiquement comme un acte destructeur, voire meurtrier. Or, lorsque le terme a été popularisé en France à la fin du XIXe siècle, c'était dans un sens triplement différent : il n'était pas forcément destructeur (le simple ralentissement de la cadence était inclus dans le sabotage), il était revendiqué publiquement et, surtout, il faisait l'objet de nombreuses discussions ayant pour but d'en fixer les limites (notamment le tabou de la violence contre les personnes). Car, à la Belle Époque, un syndicat comme la CGT pouvait ouvertement inscrire le sabotage dans ses résolutions votées au congrès.
Le livre se focalise sur deux moments de cette politisation du sabotage. L'acte lui-même est certainement bien plus ancien mais la nouveauté, due notamment à Pouget, était d'en faire un moyen de lutte collective, assumé comme tel.
Après la période française, la revendication publique du sabotage a connu une deuxième période, aux États-Unis, où l'IWW en faisait un de ses moyens d'action. (Le livre rappelle, et c'est très important, le contexte de la lutte de classes aux USA, marqué par une extrême violence patronale, avec utilisation fréquente de milices privées qui, elles, n'avaient aucun scrupule à utiliser la violence contre les personnes, et en toute impunité.) Le livre détaille ces deux périodes, et met l'accent sur les innombrables discussions politiques au sein du mouvement ouvrier autour du sabotage, de sa légitimité, de ses liens avec les autres formes de lutte et avec les travailleurs, des limites qu'on s'impose, et des risques, qu'ils soient d'accident, de débordement par des irresponsables, ou de difficulté à empêcher la diabolisation par les médias et les politiciens. À la fin, aussi bien la CGT que l'IWW ont renoncé à mentionner le sabotage, en partie à cause des difficultés qu'il y avait à l'expliquer aux travailleurs. (Et aussi à le contrôler : l'auteur cite Jaurès qui disait que le sabotage était la forme de lutte qu'il fallait le plus contrôler, alors qu'elle était aussi la plus difficile à contrôler.) Cela n'a pas mis fin au sabotage : l'auteur note qu'en France, il y a même eu davantage de sabotages après que la CGT l'ait retiré de son programme.
J'ai noté que l'auteur parlait très peu de la Résistance, un autre moment où le sabotage était assumé et glorifié. Mais c'est sans doute que, là, il n'y avait pas de débat : aucun résistant ne discutait la légitimité du sabotage sans limite. L'OSS les aidait même, avec son fameux « manuel du sabotage » (qui, il faut le rappeler, incluait aussi des méthodes non destructrices comme de ralentir le travail).
Pour d'autres périodes, l'auteur expose les différentes façons de pratiquer le sabotage, incluant par exemple la grève du zèle. Il cite l'exemple du « sabotage de la bouche ouverte » chez les serveurs de restaurant au début du XXe siècle : on sert le client mais on lui dit tout ce qu'il y a vraiment dans le plat servi. De nombreuses idées astucieuses de ce genre ont surgi dans le débat.
Le sabotage, qui était bien plus ancien que le livre de Pouget, reste toujours d'actualité, comme on l'a vu dans l'affaire de Tarnac (jamais élucidée, notamment en raison du comportement des enquêteurs qui, certains de tenir les coupables, ont bâclé l'enquête) ou dans les récentes attaques contre les liaisons Internet, là aussi non revendiquées. (Il y en avait eu aussi en avril 2022, cf. article de Numérama et article du Nouvel Obs.) On est à l'opposé des théories des « syndicalistes révolutionnaires » du XIXe siècle puisqu'on atteint le degré zéro de la politique : aucune idée sur les auteurs de ces coupures et leur but.
L'article seul
RFC 9558: Use of GOST 2012 Signature Algorithms in DNSKEY and RRSIG Resource Records for DNSSEC
Date de publication du RFC : Avril 2024
Auteur(s) du RFC : B. Makarenko (The Technical center of Internet, LLC), V. Dolmatov (JSC "NPK Kryptonite")
Pour information
Première rédaction de cet article le 21 octobre 2024
Ce RFC marque l'arrivée d'un nouvel algorithme de signature dans les enregistrements DNSSEC, algorithme portant le numéro 23. Bienvenue au GOST R 34.10-2012 (alias ECC-GOST12), algorithme russe, spécifié en anglais dans le RFC 7091, une légère mise à jour de GOST R 34.10-2001.
La liste des algorithmes DNSSEC est un registre à l'IANA, https://www.iana.org/assignments/dns-sec-alg-numbers/dns-sec-alg-numbers.xml#dns-sec-alg-numbers-1. Elle
comprend désormais GOST R 34.10-2012 (qui succède au R 34.10-2001 du
RFC 5933). Notez que GOST désigne en fait une
organisation de
normalisation, le terme correct serait donc de ne jamais
dire « GOST » tout court, mais plutôt « GOST R 34.10-2012 » pour
l'algorithme de signature et « GOST R 34.11-2012 » pour celui de
condensation,
décrit dans le RFC 6986 (voir la section 1 de notre RFC 9558).
La section 2 décrit le format des enregistrements
DNSKEY avec GOST, dans lequel
on publie les clés GOST R 34.10-2012. Le champ Algorithme vaut 23,
le format de la clé sur le réseau suit le RFC 7091. GOST
est un algorithme à courbes elliptiques, courbes décrites par Q
= (x,y). Les 32 premiers octets de la clé sont x et les 32 suivants
y (en petit-boutien,
attention, contrairement à la majorité des protocoles Internet).
Parmi les bibliothèques cryptographiques existantes, au moins OpenSSL met en œuvre GOST R 34.10-2012 (testé avec la version 3.3.2). Voir RFC 9215 pour de l'aide à ce sujet. Sinon, on trouve parfois seulement l'ancienne version dans certains logiciels et certaines bibliothèques.
La section 2.2 donne un exemple de clé GOST publiée dans le DNS,
je n'ai pas trouvé d'exemple réel dans la nature, même en
.ru.
La section 3 décrit le format des enregistrements RRSIG, les signatures (avec un
exemple). On suit les RFC 5958 et RFC 7091.
Attention, une particularité de GOST fait que deux signatures des
mêmes données peuvent donner des résultats différents, car un
élément aléatoire est présent dans la signature.
La section 4
décrit le format des enregistrements DS pour GOST. La clé publique de
la zone fille est condensée par GOST R 34.11-2012, algorithme de
numéro
5.
Les sections 5 et 6 couvrent des questions pratiques liées au développement et au déploiement de systèmes GOST, par exemple un rappel sur la taille de la clé (512 bits) et sur celle du condensat cryptographique (256 bits).
GOST peut se valider avec Unbound si la bibliothèque de cryptographie utilisée gère GOST. Et, comme indiqué plus haut, ce ne sera sans doute que l'ancienne version, celle du RFC 5933. Pour les programmeurs Java, DNSjava a le dernier GOST depuis la version 3.6.2. Pour le statut (recommandé ou non) de l'algorithme GOST pour DNSSEC, voir le RFC 8624. En Python, dnspython en version 2.7.0 n'a que l'ancien algorithme.
L'article seul
RFC 9559: Matroska Media Container Format Specification
Date de publication du RFC : Octobre 2024
Auteur(s) du RFC : S. Lhomme, M. Bunkus, D. Rice
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF cellar
Première rédaction de cet article le 15 octobre 2024
Matroska est un format de conteneur pour du contenu multimédia (son, image, sous-titres, etc). Ce n'est pas un format de données (format utilisé par un codec), mais un moyen de regrouper de manière structurée des données différentes.
Je vous préviens tout de suite, le RFC fait 167 pages, et, en prime, le multimédia n'est pas ma spécialité. Donc, je vais faire court. Matroska est fondé sur un langage qui utilise le modèle de données XML, EBML (normalisé dans le RFC 8794). Notre nouveau RFC 9559 est donc surtout une très longue liste des éléments XML qu'on peut y trouver (Matroska est riche !), encodés en binaire. Matroska n'est pas nouveau (il en est à la version 4), mais c'est sa première normalisation. Notez que vous trouverez de l'information sur la page Web du projet.
Le caractère hiérarchique d'un fichier Matroska (des éléments dans d'autres éléments) est bien rendu par cet outil (qui fait partie de MKVToolNix, cité plus loin) :
% mkvinfo ./format/matroska/testdata/sweep-with-DC.mkvmerge13.mka
+ EBML head
|+ EBML version: 1
|+ EBML read version: 1
|+ Maximum EBML ID length: 4
|+ Maximum EBML size length: 8
|+ Document type: matroska
|+ Document type version: 4
|+ Document type read version: 2
+ Segment: size 18507
|+ Seek head (subentries will be skipped)
|+ EBML void: size 4031
|+ Segment information
| + Timestamp scale: 22674
| + Multiplexing application: libebml v1.4.2 + libmatroska v1.6.2
| + Writing application: mkvmerge v52.0.0 ('Secret For The Mad') 64-bit
| + Duration: 00:00:02.607714066
| + Date: 2022-08-28 18:32:21 UTC
| + Segment UID: 0x3b 0x9f 0x28 0xc7 0xc4 0x90 0x8a 0xe0 0xcd 0x66 0x8f 0x11 0x8f 0x7c 0x2f 0x54
|+ Tracks
| + Track
| + Track number: 1 (track ID for mkvmerge & mkvextract: 0)
| + Track UID: 3794791294650729286
| + Track type: audio
| + Codec ID: A_FLAC
| + Codec's private data: size 133
| + Default duration: 00:00:00.040634920 (24.609 frames/fields per second for a video track)
| + Language: und
| + Language (IETF BCP 47): und
| + Audio track
| + Sampling frequency: 44100
| + Bit depth: 16
|+ EBML void: size 1063
|+ Cluster
On voit un document de la version 4 (celle du RFC), commençant
(forcément, cf. section 4.5 du RFC) par un en-tête EBML, et
comportant une seule piste (l'élément
Tracks est décrit en section 5.1.4), un son au
format FLAC
(RFC 9639). L'extension
.mka est souvent utilisée pour des conteneurs
n'ayant que de l'audio (et .mkv s'il y a de la
vidéo). La piste audio est dans une langue indéterminée,
und. Plusieurs éléments existent pour noter la
langue car Matroska n'utilisait autrefois que la norme
ISO 639 mais la version 4 recommande les bien
plus riches étiquettes de langue IETF (RFC 5646, alias « IETF BCP 47 »).
Un autre document a deux pistes, le son et l'image :
% mkvinfo ~/Videos/2022-01-22\ 13-17-28.mkv … |+ Tracks | + Track | + Track number: 1 (track ID for mkvmerge & mkvextract: 0) | + Track UID: 1 | + "Lacing" flag: 0 | + Language: und | + Codec ID: V_MPEG4/ISO/AVC | + Track type: video | + Default duration: 00:00:00.033333333 (30.000 frames/fields per second for a video track) | + Video track | + Pixel width: 852 | + Pixel height: 480 | + Display unit: 4 | + Codec's private data: size 41 (H.264 profile: High @L3.1) | + Track | + Track number: 2 (track ID for mkvmerge & mkvextract: 1) | + Track UID: 2 | + "Lacing" flag: 0 | + Name: simple_aac_recording | + Language: und | + Codec ID: A_AAC | + Track type: audio | + Audio track | + Channels: 2 | + Sampling frequency: 44100 | + Bit depth: 16 | + Codec's private data: size 5
L'arborescence des fichiers Matroska peut être très profonde et ça se reflète dans la numérotation des sections du RFC (il y a une section 5.1.4.1.28.18 !).
Les types MIME à utiliser sont audio/matroska
et video/matroska
(section 27.3 du RFC).
Il existe plusieurs mises en œuvre de Matroska en logiciel libre comme MKVToolNix, qui sait faire beaucoup de choses (comme afficher les éléments Matroska comme vu plus haut) et qui existe en ligne de commande ou GUI. Et VLC sait évidemment jouer les fichiers Matroska. OBS, quant à lui, permet d'en produire. Par exemple, cette vidéo sans intérêt a été faite avec OBS.
L'article seul
RFC 9660: The DNS Zone Version (ZONEVERSION) Option
Date de publication du RFC : Octobre 2024
Auteur(s) du RFC : H. Salgado (NIC Chile), M. Vergara (DigitalOcean), D. Wessels (Verisign)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 13 octobre 2024
Cette nouvelle option du DNS permet au client d'obtenir du serveur le numéro de version de la zone servie. (Et, non, le numéro de série dans l'enregistrement SOA ne suffit pas, lisez pour en savoir plus.)
Cela permettra de détecter les problèmes de mise à jour des serveurs faisant autorité si, par exemple, un des secondaires ne se met plus à jour. C'est surtout important pour l'anycast, qui complique le déboguage. En combinaison avec le NSID du RFC 5001, vous trouverez facilement le serveur qui a un problème. Cette nouvelle option ressemble d'ailleurs à NSID et s'utilise de la même façon.
Vous le savez, le DNS ne garantit pas que tous les serveurs faisant
autorité d'une zone servent la même version de la zone au
même moment. Si je regarde la zone
.com à cet instant (14
juillet 2024, 09:48 UTC) avec check-soa, je
vois :
% check-soa com a.gtld-servers.net. 2001:503:a83e::2:30: OK: 1720950475 192.5.6.30: OK: 1720950475 b.gtld-servers.net. 192.33.14.30: OK: 1720950475 2001:503:231d::2:30: OK: 1720950475 c.gtld-servers.net. 2001:503:83eb::30: OK: 1720950475 192.26.92.30: OK: 1720950475 d.gtld-servers.net. 2001:500:856e::30: OK: 1720950475 192.31.80.30: OK: 1720950475 e.gtld-servers.net. 2001:502:1ca1::30: OK: 1720950475 192.12.94.30: OK: 1720950475 f.gtld-servers.net. 2001:503:d414::30: OK: 1720950475 192.35.51.30: OK: 1720950475 g.gtld-servers.net. 192.42.93.30: OK: 1720950475 2001:503:eea3::30: OK: 1720950475 h.gtld-servers.net. 192.54.112.30: OK: 1720950475 2001:502:8cc::30: OK: 1720950475 i.gtld-servers.net. 2001:503:39c1::30: OK: 1720950460 192.43.172.30: OK: 1720950475 j.gtld-servers.net. 2001:502:7094::30: OK: 1720950475 192.48.79.30: OK: 1720950475 k.gtld-servers.net. 192.52.178.30: OK: 1720950460 2001:503:d2d::30: OK: 1720950475 l.gtld-servers.net. 192.41.162.30: OK: 1720950475 2001:500:d937::30: OK: 1720950475 m.gtld-servers.net. 2001:501:b1f9::30: OK: 1720950475 192.55.83.30: OK: 1720950475
On observe que, bien que le numéro de série dans l'enregistrement SOA soit 1720950475, certains serveurs sont restés à 1720950460. Le DNS est « modérement cohérent » (RFC 3254, sur ce concept).
Dans l'exemple ci-dessus, check-soa a simplement fait une requête pour le type de données SOA (section 4.3.5 du RFC 1034). Une limite de cette méthode est que, si on observe des données d'autres types qui ne semblent pas à jour et que, pour vérifier, on fait une requête de type SOA, on n'a pas de garantie de tomber sur le même serveur, notamment en cas d'utilisation d'anycast (RFC 4786) ou bien s'il y a un répartiteur de charge avec plusieurs serveurs derrière. (D'ailleurs, dans l'exemple ci-dessus, vous avez remarqué que vous n'avez pas la même réponse en IPv4 et IPv6, probablement parce que vous arriviez sur deux instances différentes du nuage anycast.) Il faut donc un mécanisme à l'intérieur même de la requête qu'on utilise, comme pour le NSID. C'est le cas du ZONEVERSION de ce RFC, qui permet d'exprimer la version sous forme d'un numéro de série (comme avec le SOA) ou par d'autres moyens dans le futur, puisque toutes les zones n'utilisent pas le mécanisme de synchronisation habituel du DNS. On peut par exemple avoir des zones entièrement dynamiques et tirées d'une base de données, ou bien d'un calcul.
Notez aussi que certaines zones, comme
.com, changent très
vite, et que donc, même si on tombe sur le même serveur, le numéro
de série aura pu changer entre une requête ordinaire et celle pour
le SOA. C'est une raison supplémentaire pour avoir le mécanisme
ZONEVERSION.
Bref, le nouveau mécanisme (section 2 du RFC), utilise EDNS (section 6.1.2 du RFC 6891). La nouvelle option EDNS porte le numéro 19. Encodée en TLV comme toutes les options EDNS, elle comprend une longueur et une chaine d'octets qui est la version de la zone. La longueur vaut zéro dans une requête (le client indique juste qu'il souhaite connaitre la version de la zone) et, dans la réponse, une valeur non nulle. La version est elle-même composée de trois champs :
- Le nombre de composants dans le nom de domaine pour la zone
concernée. Si la requête DNS portait sur le nom de domaine
foo.bar.example.orget que le serveur renvoie la version de la zoneexample.org, ce champ vaudra deux. - Le type de la version. Différents serveurs faisant autorité utiliseront différentes méthodes pour se synchroniser et auront donc des types différents. Pour l'instant, un seul est normalisé, le 0 (alias SOA-SERIAL), qui est le numéro de série, celui qu'on trouverait dans le SOA, cf. section 3.3.13 du RFC 1035. La longueur sera donc de 6, les 4 octets de ce numéro, le type et le nombre de composants, un octet chacun. Un nouveau registre IANA accueillera peut-être d'autres types dans le futur, suivant la procédure « spécification nécessaire » du RFC 8126. (Cette procédure nécessite un examen par un expert, et la section 7.2.1 guide l'expert pour ce travail.)
- La valeur à proprement parler.
Si vous voulez voir dans un pcap, regardez
zoneversion.pcap
L'option ZONEVERSION n'est renvoyée au client qui si celui-ci l'avait demandé, ce qu'il fait en mettant une option ZONEVERSION vide dans sa requête (section 3 du RFC). Si le serveur fait autorité pour la zone concernée (ou une zone ancêtre), et qu'il gère cette nouvelle option, il répond avec une valeur. Même si le nom demandé n'existe pas (réponse NXDOMAIN), l'option est renvoyée dans la réponse.
Comme les autres options EDNS, elle n'est pas signée par DNSSEC (section 8). Il n'y a donc pas de moyen de vérifier son authenticité et elle ne doit donc être utilisée qu'à titre informatif, par exemple pour le déboguage. (En outre, elle peut être modifiée en route, sauf si on utilise un mécanisme comme DoT - RFC 7858.)
Question mises en œuvre de cette option, c'est surtout du code expérimental pour l'instant, voir cette liste (pas très à jour ?). Personnellement, j'ai ajouté ZONEVERSION à Drink, et écrit un article sur l'implémentation d'options EDNS (mais notez que l'option a changé de nom et de format depuis). Notez que, contrairement à presque toutes les options EDNS, ZONEVERSION est par zone, pas par serveur, ce qui est une contrainte pour le ou la programmeureuse, qui ne peut pas choisir la valeur avant de connaitre le nom demandé. Du côté des autres logiciels, NSD a vu un patch (mais apparemment abandonné). Voici ce que voit dig actuellement (en attendant une intégration officielle de l'option) :
% dig +ednsopt=19 @ns1-dyn.bortzmeyer.fr dyn.bortzmeyer.fr SOA
…
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 64655
;; flags: qr aa rd; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1
…
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 1440
; OPT=19: 03 00 78 a5 08 cc ("..x...")
…
;; ANSWER SECTION:
dyn.bortzmeyer.fr. 0 IN SOA ns1-dyn.bortzmeyer.fr. stephane.bortzmeyer.org. (
2024081612 ; serial
…
Vous noterez que "03" indique trois composants
(dyn.bortzmeyer.fr), "00" le SOA-SERIAL, et "78
a5 08 cc" égal 2024081612. Vous pouvez aussi tester ZONEVERSION avec
le serveur de test 200.1.122.30 (un NSD
modifié), avec le domaine example.com.
L'article seul
Un peu de terminologie de la gouvernance Internet : multipartieprenantisme
Première rédaction de cet article le 6 octobre 2024
Quand on suit des débats sur la gouvernance de l'Internet, et qu'on débute dans ce secteur, on est parfois dérouté par des termes nouveaux. Quand des gens sont en désaccord sur le « multilatéralisme » et le « multipartieprenantisme », de quoi s'agit-il ?
Il y a réellement des concepts différents, derrière ce qui pourrait sembler du jargon creux. En fait, c'est très simple :
- Un·e partisan·e du multilatéralisme préfère que la gouvernance de l'Internet (la politique, pour parler normalement) soit du ressort des États, négociant entre eux (multilatéralement), au sein d'une instance comme l'ONU ou ses annexes comme l'UIT,
- alors que celui ou celle qui préfère le multipartieprenantisme (doctrine qui est en général désignée par un mot en anglais, multistakeholderism), choisirait plutôt qu'on implique ensemble les États, les entreprises privées (enfin, leur direction, uniquement, pas les travailleurs), les associations (on dit parfois « société civile » mais c'est un terme qui inclut dans certains cas tout ce qui n'est pas l'État), les universités, etc. La plupart du temps, ces personnes vont dire que l'ICANN représente le multipartieprenantisme.
Bien sûr, les choses sont toujours plus compliquées que cela : les partisan·es des États mettent souvent sous le tapis des questions gênantes pour eux et elles (par exemple celle de la légitimité des gouvernements, notamment dans les pays qui sont de franches dictatures), et ceux et celles du multipartieprenantisme exagèrent fréquemment la représentativité des organisations qui y participent. Tout lobby qui dit « représenter les utilisateurs » ou carrément « la société civile » ne dit pas forcément la vérité.
L'article seul
RFC 9651: Structured Field Values for HTTP
Date de publication du RFC : Septembre 2024
Auteur(s) du RFC : M. Nottingham
(Cloudflare), P-H. Kamp (The Varnish Cache
Project)
Chemin des normes
Première rédaction de cet article le 6 octobre 2024
Plusieurs en-têtes HTTP sont structurés,
c'est-à-dire que le contenu n'est pas juste une suite de caractères
mais est composé d'éléments qu'un logiciel peut analyser. C'est par
exemple le cas de Accept-Language: ou de
Content-Disposition:. Mais chaque en-tête ainsi
structuré a sa propre syntaxe, sans rien en commun avec les autres
en-têtes structurés, ce qui en rend l'analyse pénible. Ce nouveau
RFC (qui
remplace le RFC 8941) propose donc
des types de données et des algorithmes que les futurs en-têtes qui
seront définis pourront utiliser pour standardiser un peu l'analyse
d'en-têtes HTTP. Les en-têtes structurés anciens ne sont pas
changés, pour préserver la compatibilité. De nombreux RFC utilisent
déjà cette syntaxe (RFC 9209, RFC 9211, etc).
Imaginez : vous êtes un concepteur ou une conceptrice d'une extension au protocole HTTP qui va nécessiter la définition d'un nouvel en-tête. La norme HTTP, le RFC 9110, section 16.3.2, vous guide en expliquant ce à quoi il faut penser quand on conçoit un en-tête HTTP. Mais même avec ce guide, les pièges sont nombreux. Et, une fois votre en-tête spécifié, il vous faudra attendre que tous les logiciels, serveurs, clients, et autres (comme Varnish, pour lequel travaille un des auteurs du RFC) soient mis à jour, ce qui sera d'autant plus long que le nouvel en-tête aura sa syntaxe spécifique, avec ses amusantes particularités. Amusantes pour tout le monde, sauf pour le programmeur ou la programmeuse qui devra écrire l'analyse.
La solution est donc que les futurs en-têtes structurés réutilisent les éléments fournis par notre RFC, ainsi que son modèle abstrait, et la sérialisation proposée pour envoyer le résultat sur le réseau. Le RFC recommande d'appliquer strictement ces règles, le but étant de favoriser l'interopérabilité, au contraire du classique principe de robustesse, qui mène trop souvent à du code compliqué (et donc dangereux) car voulant traiter tous les cas et toutes les déviations. L'idée est que s'il y a la moindre erreur dans un en-tête structuré, celui-ci doit être ignoré complètement.
La syntaxe est malheureusement spécifiée sous forme d'algorithmes d'analyse. L'annexe C fournit toutefois aussi une grammaire en ABNF (RFC 5234).
Voici un exemple fictif d'en-tête structuré très simple
(tellement simple que, si tous étaient comme lui, on n'aurait sans
doute pas eu besoin de ce RFC) :
Foo-Example: est défini comme ne prenant qu'un
élément comme valeur, un entier compris entre 0 et 10. Voici à quoi
il ressemblera en HTTP :
Foo-Example: 3
Il accepte des paramètres après un
point-virgule, un seul paramètre est défini,
foourl dont la valeur est un URI. Cela pourrait
donner :
Foo-Example: 2; foourl="https://foo.example.com/"
Donc, ces solutions pour les en-têtes structurés ne serviront que pour les futurs en-têtes, pas encore définis, et qui seront ajoutés au registre IANA. Imaginons donc que vous soyez en train de mettre au point une norme qui inclut, entre autres, un en-tête HTTP structuré. Que devez-vous mettre dans le texte de votre norme ? La section 2 de notre RFC vous le dit :
- Inclure une référence à ce RFC 9651.
- J'ai parlé jusqu'à présent d'en-tête structuré mais en fait ce RFC 9651 s'applique aussi aux pieds (trailers) (RFC 9110, section 6.5 ; en dépit de leur nom, les pieds sont des en-têtes eux aussi). La norme devra préciser si elle s'applique seulement aux en-têtes classiques ou bien aussi aux pieds.
- Spécifier si la valeur sera une liste, un dictionnaire ou
juste un élément (ces termes sont définis en section 3). Dans
l'exemple ci-dessus
Foo-Example:, la valeur était un élément, de type entier. - Penser à définir la sémantique.
- Et ajouter les règles supplémentaires sur la valeur du
champ, s'il y en a. Ainsi, l'exemple avec
Foo-Example:imposait une valeur entière entre 0 et 10.
Une spécification d'un en-tête structuré ne peut que rajouter des contraintes à ce que prévoit ce RFC 9651. S'il en retirait, on ne pourrait plus utiliser du code générique pour analyser tous les en-têtes structurés.
Rappelez-vous que notre RFC est strict : si une erreur est présente
dans l'en-tête, il est ignoré. Ainsi, s'il était spécifié que la
valeur est un élément de type entier et qu'on trouve une chaîne de
caractères, on ignore l'en-tête. Idem dans l'exemple ci-dessus si on
reçoit Foo-Example: 42, la valeur excessive
mène au rejet de l'en-tête.
Les valeurs peuvent inclure des paramètres (comme le
foourl donné en exemple plus haut), et le RFC
recommande d'ignorer les paramètres inconnus, afin de permettre
d'étendre leur nombre sans tout casser.
On a vu qu'une des plaies du Web était le laxisme trop grand dans l'analyse des données reçues (c'est particulièrement net pour HTML). Mais on rencontre aussi des cas contraires, des systèmes (par exemple les pare-feux applicatifs) qui, trop fragiles, chouinent lorsqu'ils rencontrent des cas imprévus, parce que leurs auteurs avaient mal lu le RFC. Cela peut mener à l'ossification, l'impossibilité de faire évoluer l'Internet parce que des nouveautés, pourtant prévues dès l'origine, sont refusées. Une solution récente est le graissage, la variation délibérée des messages pour utiliser toutes les possibilités du protocole. (Un exemple pour TLS est décrit dans le RFC 8701.) Cette technique est recommandée par notre RFC.
La section 3 du RFC décrit ensuite les types qui sont les briques de base avec lesquelles on va pouvoir définir les en-têtes structurés. La valeur d'un en-tête peut être une liste, un dictionnaire ou un élément. Les listes et les dictionnaires peuvent à leur tour contenir des listes. Une liste est une suite de termes qui, dans le cas de HTTP, sont séparés par des virgules :
ListOfStrings-Example: "foo", "bar", "It was the best of times."
Et si les éléments d'une liste sont eux-mêmes des listes, on met ces listes internes entre parenthèses (et notez la liste vide à la fin, et l'espace comme séparateur) :
ListOfListsOfStrings-Example: ("foo" "bar"), ("baz"), ("bat" "one"), ()
Un en-tête structuré dont la valeur est une liste a toujours une valeur, la liste vide, même si l'en-tête est absent.
Un dictionnaire est une suite de termes nom=valeur. En HTTP, cela donnera :
Dictionary-Example: en="Applepie", fr="Tarte aux pommes"
Et nous avons déjà vu les éléments simples dans le premier
exemple. Les éléments peuvent être de type
entier,
chaîne de
caractères, booléen,
identificateur, valeur binaire, date, et un dernier type plus exotique
(lisez le RFC pour en savoir plus). L'exemple avec
Foo-Example: utilisait un entier. Les exemples
avec listes et dictionnaires se servaient de chaînes de
caractères. Ces chaînes sont encadrées de
guillemets (pas
d'apostrophes).
Compte-tenu des analyseurs HTTP
existants, les chaînes de caractères ordinaires
doivent être en ASCII (RFC 20). Si on veut envoyer de l'Unicode, il faut utiliser
un autre type, Display String. Quant aux booléens, notez qu'il faut
écrire 1 et 0 (pas true et
false), et préfixé d'un point
d'interrogation.
Toutes ces valeurs peuvent prendre des paramètres, qui sont eux-mêmes une suite de couples clé=valeur, après un point-virgule qui les sépare de la valeur principale (ici, on a deux paramètres) :
ListOfParameters: abc;a=1;b=2
J'ai dit au début que ce RFC définit un modèle abstrait, et une sérialisation concrète pour HTTP. La section 4 du RFC spécifie cette sérialisation, et son inverse, l'analyse des en-têtes (pour les programmeur·ses seulement).
Ah, et si vous êtes fana de formats structurés, ne manquez pas l'annexe A du RFC, qui répond à la question que vous vous posez certainement depuis plusieurs paragraphes : pourquoi ne pas avoir tout simplement décidé que les en-têtes structurés auraient des valeurs en JSON (RFC 8259), ce qui évitait d'écrire un nouveau RFC, et permettait de profiter du code JSON existant ? Le RFC estime que le fait que les chaînes de caractères JSON soient de l'Unicode est trop risqué, par exemple pour l'interopérabilité. Autre problème de JSON, les structures de données peuvent être emboîtées indéfiniment, ce qui nécessiterait des analyseurs dont la consommation mémoire ne peut pas être connue et limitée. (Notre RFC permet des listes dans les listes mais cela s'arrête là : on ne peut pas poursuivre l'emboîtement.)
Une partie des problèmes avec JSON pourrait se résoudre en se limitant à un profil restreint de JSON, par exemple en utilisant le RFC 7493 comme point de départ. Mais, dans ce cas, l'argument « on a déjà un format normalisé, et mis en œuvre partout » tomberait.
Enfin, l'annexe A note également qu'il y avait des considérations d'ordre plutôt esthétiques contre JSON dans les en-têtes HTTP.
Toujours pour les programmeur·ses, l'annexe B du RFC donne quelques conseils pour les auteur·es de bibliothèques mettant en œuvre l'analyse d'en-têtes structurés. Pour les aider à suivre ces conseils, une suite de tests est disponible. Quant à une liste de mises en œuvre du RFC, vous pouvez regarder celle-ci.
Actuellement, il y a dans le registre
des en-têtes plusieurs en-têtes structurés, comme le
Accept-CH: du RFC 8942 (sa valeur est une liste d'identificateurs), le
Cache-Status: du RFC 9211
ou le Client-Cert: du RFC 9440.
Si vous voulez un exposé synthétique sur ces en-têtes structurés, je vous recommande cet article par un des auteurs du RFC.
Voyons maintenant un peu de pratique avec une des mises en œuvre citées plus haut, http_sfv, une bibliothèque Python. Une fois installée :
% python3 >>> import http_sfv >>> my_item=http_sfv.Item() >>> my_item.parse(b"2") >>> print(my_item) 2
On a analysé la valeur « 2 » en déclarant que cette valeur devait être un élément et, pas de surprise, ça marche. Avec une valeur syntaxiquement incorrecte :
>>> my_item.parse(b"2, 3")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/stephane/.local/lib/python3.12/site-packages/http_sfv/util.py", line 61, in parse
raise ValueError("Trailing text after parsed value")
ValueError: Trailing text after parsed value
Et avec un paramètre (il sera accessible après l'analyse, via le
dictionnaire Python params) :
>>> my_item.parse(b"2; foourl=\"https://foo.example.com/\"")
>>> print(my_item.params['foourl'])
https://foo.example.com/
Avec une liste :
>>> my_list=http_sfv.List()
>>> my_list.parse(b"\"foo\", \"bar\", \"It was the best of times.\"")
>>> print(my_list)
"foo", "bar", "It was the best of times."
Et avec un dictionnaire :
>>> my_dict=http_sfv.Dictionary()
>>> my_dict.parse(b"en=\"Applepie\", fr=\"Tarte aux pommes\"")
>>> print(my_dict)
en="Applepie", fr="Tarte aux pommes"
>>> print(my_dict["fr"])
"Tarte aux pommes"
L'annexe D résume les principaux changements depuis le RFC 8941. Rien de trop crucial, à part le fait que l'ABNF est reléguée à une annexe. Sinon, il y a deux nouveaux types de base, pour les dates et les chaines de caractères en Unicode (Display Strings).
L'article seul
Bien maitriser ses chaines de dépendance DNS
Première rédaction de cet article le 24 septembre 2024
Le DNS repose
sur un système de délégation, avec des
dépendances qui ne sont pas toujours
maitrisées. (Si vous êtes responsables d'un nom de domaine, veillez à connaitre ces
dépendances et à les examiner !) Un exemple concret aujourd'hui avec
telehouse.fr.
Ce nom de domaine est utilisé par le gérant de centres de données pour certains services à destination des clients (un portail clients, par exemple). Ce matin, il ne répond pas (dans l'après-midi, tout remarchait) :
% dig telehouse.fr … ;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 44602 ;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1 … ;; Query time: 4000 msec ;; SERVER: 127.0.0.1#53(127.0.0.1) (UDP) ;; WHEN: Tue Sep 24 11:13:46 CEST 2024 ;; MSG SIZE rcvd: 41
SERVFAIL signifie SERVer FAILure et, comme ce nom l'indique, c'est mauvais. Si on demande à un autre résolveur DNS qui met en œuvre les rapports d'erreur détaillés (RFC 8914), on a :
% dig @1.1.1.1 telehouse.fr … ;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 20599 ;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 1232 ; EDE: 22 (No Reachable Authority): (at delegation telehouse.fr.) … ;; Query time: 4256 msec ;; SERVER: 1.1.1.1#53(1.1.1.1) (UDP) ;; WHEN: Tue Sep 24 11:14:37 CEST 2024 ;; MSG SIZE rcvd: 74
L'EDE (Extended DNS Error) nous dit que le
résolveur n'a pu joindre aucun des serveurs faisant
autorité. On va donc devoir creuser. D'abord, quels sont ces
serveurs faisant autorité pour telehouse.fr ?
Demandons à un des serveurs du domaine parent
.fr :
% dig @d.nic.fr telehouse.fr
…
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 21940
;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 6, ADDITIONAL: 1
;; WARNING: recursion requested but not available
…
;; AUTHORITY SECTION:
telehouse.fr. 3600 IN NS ns1.fr.kddi.com.
telehouse.fr. 3600 IN NS ns2.fr.kddi.com.
Bien, nous avons les noms de ces serveurs, interrogeons-les :
% dig ns1.fr.kddi.com.
…
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 20153
;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1
…
;; Query time: 12 msec
;; SERVER: 127.0.0.1#53(127.0.0.1) (UDP)
;; WHEN: Tue Sep 24 11:15:12 CEST 2024
;; MSG SIZE rcvd: 44
Ah, raté, on ne peut pas résoudre le nom du serveur de noms. Le serveur est toujours là et, si on connait son adresse IP (par exemple parce qu'elle est encore dans la mémoire du résolveur), on peut l'interroger :
% dig @85.90.48.10 telehouse.fr … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 15119 ;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 2, ADDITIONAL: 3 … ;; ANSWER SECTION: telehouse.fr. 900 IN A 85.90.40.15
Bon, et si on n'a pas cette adresse IP ? Demandons au domaine parent :
% dig kddi.com NS
…
;; ANSWER SECTION:
kddi.com. 85645 IN NS dnsa01.kddi.ne.jp.
kddi.com. 85645 IN NS dnsa02.kddi.ne.jp.
kddi.com. 85645 IN NS dns103.kddi.ne.jp.
kddi.com. 85645 IN NS dns104.kddi.ne.jp.
;; Query time: 0 msec
;; SERVER: 127.0.0.1#53(127.0.0.1) (UDP)
;; WHEN: Tue Sep 24 11:15:33 CEST 2024
;; MSG SIZE rcvd: 131
Et interrogeons-les :
% dig @dnsa01.kddi.ne.jp. fr.kddi.com NS
…
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 43194
;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 2, ADDITIONAL: 1
;; WARNING: recursion requested but not available
…
;; AUTHORITY SECTION:
fr.kddi.com. 86400 IN NS ns1.kddi-telehouse.eu.
fr.kddi.com. 86400 IN NS ns2.kddi-telehouse.eu.
;; Query time: 216 msec
;; SERVER: 54.64.39.199#53(dnsa01.kddi.ne.jp.) (UDP)
;; WHEN: Tue Sep 24 11:15:57 CEST 2024
;; MSG SIZE rcvd: 121
Et suivons cette délégation :
% dig ns1.kddi-telehouse.eu. … ;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 48644 ;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1 … ;; Query time: 0 msec ;; SERVER: 127.0.0.1#53(127.0.0.1) (UDP) ;; WHEN: Tue Sep 24 11:16:11 CEST 2024 ;; MSG SIZE rcvd: 50
Bon, même problème, le nom du serveur de noms ne peut pas être
résolu. Poursuivons notre quête auprès des serveurs de
.eu :
% dig @w.dns.eu. kddi-telehouse.eu. NS … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 26571 ;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 6, ADDITIONAL: 1 ;; WARNING: recursion requested but not available … ;; AUTHORITY SECTION: kddi-telehouse.eu. 86400 IN NS ns2.validname.com. kddi-telehouse.eu. 86400 IN NS ns1.validname.com.
Et demandons :
% dig @ns1.validname.com kddi-telehouse.eu.
;; communications error to 2a01:c8:ff00:200::219#53: timed out
;; communications error to 2a01:c8:ff00:200::219#53: timed out
;; communications error to 2a01:c8:ff00:200::219#53: timed out
;; communications error to 2a01:c8:ff00:200::220#53: timed out
;; communications error to 185.65.56.219#53: timed out
;; communications error to 185.65.56.220#53: timed out
Ah, cette fois, les choses ont changé : on arrive bien à trouver
l'adresse IP de ces
serveurs, le nom peut être résolu, mais le serveur ne répond pas
(idem pour ns2.validname.com).
Arrivé là, il est temps de faire un bilan :
le domaine telehouse.fr dépend du domaine
fr.kddi.com qui dépend du domaine
kddi-telehouse.eu qui dépend de deux serveurs
(ns1.validname.com et
ns2.validname.com) qui sont en panne. Vu en
sens inverse, la panne des validname.com a
entrainé celle du domaine
kddi-telehouse.eu qui a entrainé celle du domaine
fr.kddi.com qui a entrainé celle du
domaine telehouse.fr.
La morale ? Soyez attentifs aux dépendances. Si le domaine
X.example a tous ses serveurs de noms dans
Y.example, une panne de ce dernier sera fatale
à X.example. Et cette dépendance est
transitive : si
Y.example dépend de
Z.example, une panne de ce dernier cassera
X.example. Pour afficher les dépendances d'un
domaine, vous pouvez utiliser l'outil
ns-tree :
% ./ns-tree.py telehouse.fr
telehouse.fr
telehouse.fr.
└─ fr.kddi.com. ← { ns2.fr.kddi.com., ns1.fr.kddi.com. }
├─ kddi-telehouse.eu. ← { ns2.kddi-telehouse.eu., ns1.kddi-telehouse.eu. }
│ └─ validname.com. ← { ns1.validname.com., ns2.validname.com. }
│ └─ namebay.com. ← { ns1.namebay.com., ns2.namebay.com. }
│ └─ namebay.com. ← { ns1.namebay.com., ns2.namebay.com. }
└─ fr.kddi.com. ← { ns2.fr.kddi.com., ns1.fr.kddi.com. }
Autre solution, en ligne : https://trans-trust.verisignlabs.com/
Une note finale : validname.com est géré par
Namebay qui a annoncé sur sa page d'accueil
une panne DNS : 
Cette panne DNS était peut-être liée au passage d'un
rançongiciel trois jours auparavant
(cf. cet
article) :

L'article seul
RFC 9620: Guidelines for Human Rights Protocol and Architecture Considerations
Date de publication du RFC : Septembre 2024
Auteur(s) du RFC : G. Grover, N. ten Oever (University of Amsterdam)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF hrpc
Première rédaction de cet article le 17 septembre 2024
Voici un RFC explicitement politique, puisqu'il documente la façon dont les concepteur·rices de protocoles à l'IETF devraient examiner les conséquences de leurs protocoles sur l'exercice des droits humains. Si vous concevez un protocole réseau (IETF ou pas), c'est une lecture recommandée.
Les protocoles ne sont pas neutres puisqu'ils ont des conséquences concrètes sur les utilisateurices, conséquences positives ou négatives. S'ils n'en avaient pas, on ne passerait pas du temps à les développer, et on ne dépenserait pas d'argent à les déployer. Ces conséquences ne sont pas forcément faciles à déterminer, surtout avant tout déploiement effectif, mais ce RFC peut guider la réflexion et permettre d'identifier les points qui peuvent avoir des conséquences néfastes. Il comprend de nombreux exemples tirés de précédents RFC. Il met à jour partiellement le RFC 8280, dont il reprend la section 6, et s'inspire de la méthode du RFC 6973, qui documentait les conséquences des protocoles sur la vie privée.
La question est évidemment complexe. Les protocoles n'ont pas forcément un pouvoir direct sur ce que les utilisateurices peuvent faire ou pas (c'est l'argument central de ceux qui estiment que les techniques sont neutres : HTTP transférera aussi bien un article de la NASA qu'un texte complotiste sur les extra-terrestres). Leur rôle est plutôt indirect, en ce qu'ils encouragent ou découragent certaines choses, plutôt que d'autoriser ou interdire. Et puis, comme le note le RFC, cela dépend du déploiement. Par exemple, pour le courrier électronique, des faits politiques importants ne s'expliquent pas par le protocole. Ce ne sont pas les particularités de SMTP (RFC 5321) qui expliquent la domination de Gmail par exemple. Il ne faut en effet pas tomber dans le déterminisme technologique (comme le font par exemple les gens qui critiquent DoH) : l'effet dans le monde réel d'un protocole dépend de bien d'autres choses que le protocole.
Ah, et autre point dans l'introduction, la définition des droits humains. Notre RFC s'appuie sur la déclaration universelle des droits humains et sur d'autres documents comme le International Covenant on Economic, Social and Cultural Rights.
Parmi les droits humains cités dans cette déclaration universelle, nombreux sont ceux qui peuvent être remis en cause sur l'Internet : liberté d'expression, liberté d'association, droit à la vie privée, non-discrimination, etc. L'absence d'accès à l'Internet mène également à une remise en cause des droits humains, par exemple parce que cela empêche les lanceurs d'alerte de donner l'alerte. Les atteintes aux droits humains peuvent être directes (censure) ou indirectes (la surveillance des actions peut pousser à l'auto-censure, et c'est souvent le but poursuivi par les acteurs de la surveillance ; cf. « Chilling Effects: Online Surveillance and Wikipedia Use »). Et les dangers pour les individus ne sont pas seulement « virtuels », ce qui se passe en ligne a des conséquences physiques quand, par exemple, une campagne de haine contre des gens accusés d'attaques contre une religion mène à leur assassinat, ou quand un État emprisonne ou tue sur la base d'informations récoltées en ligne.
C'est pour cela que, par exemple, le conseil des droits humains de l'ONU mentionne que les droits qu'on a dans le monde physique doivent aussi exister en ligne. [La propagande des médias et des politiciens en France dit souvent que « l'Internet est une zone de non-droit » et que « ce qui est interdit dans le monde physique doit aussi l'être en ligne », afin de justifier des lois répressives. Mais c'est une inversion complète de la réalité. En raison des particularités du numérique, notamment la facilité de la surveillance de masse, et de l'organisation actuelle du Web, avec un petit nombre d'acteurs médiant le trafic entre particuliers, les droits humains sont bien davantage menacés en ligne.] Sur la question de l'application des droits humains à l'Internet, on peut aussi lire les « 10 Internet Rights & Principles> » et le « Catalog of Human Rights Related to ICT Activities ».
Comme les droits humains sont précieux, et sont menacés sur l'Internet, l'IETF doit donc veiller à ce que son travail, les protocoles développés, n'aggravent pas la situation. D'où la nécessité, qui fait le cœur de ce RFC, d'examiner les protocoles en cours de développement. Ces examens (reviews, section 3 du RFC) devraient être systématiques et, évidemment, faits en amont, pas une fois le protocole déployé. [En pratique, ces examens ont assez vite été arrêtés, et ce RFC ne reflète donc pas la situation actuelle.]
Vu la façon dont fonctionne l'IETF, il n'y a pas besoin d'une autorité particulière pour effectuer ces examens. Tout·e participant·e à l'IETF peut le faire. Ce RFC 9620 vise à guider les examinateurs (reviewers). L'examen peut porter sur le contenu d'un Internet Draft mais aussi être complété, par exemple, avec des interviews d'experts de la question (les conséquences de tel ou tel paragraphe dans un Internet Draft ne sont pas forcément évidentes à la première lecture, ou même à la seconde) mais aussi des gens qui seront affectés par le protocole en question. Si un futur RFC parle d'internationalisation, par exemple, il ne faut pas interviewer que des anglophones, et pas que des participants à l'IETF, puisque l'internationalisation concerne tout le monde.
Une grosse difficulté, bien sûr, est que le protocole n'est pas tout. Les conditions effectives de son déploiement, et son évolution dans le temps, sont cruciales. Ce n'est pas en lisant le RFC 5733 (ou le RFC 9083) qu'on va tout comprendre sur les enjeux de la protection des données personnelles des titulaires de noms de domaine ! Le RFC 8980 discute d'ailleurs de cette importante différence entre le protocole et son déploiement.
La plus importante section de notre RFC est sans doute la section 4, qui est une sorte de check-list pour les auteur·es de protocoles et les examinateurices. Idéalement, lors de la phase de conception d'un protocole, il faudrait passer toutes ces questions en revue. Bien évidemment, les réponses sont souvent complexes : la politique n'est pas un domaine simple.
Premier exemple (je ne vais pas tous les détailler, rassurez-vous), les intermédiaires. Est-ce que le protocole permet, voire impose, des intermédiaires dans la communication ? C'est une question importante car ces intermédiaires, s'ils ne sont pas sous le contrôle des deux parties qui communiquent, peuvent potentiellement surveiller la communication (risque pour la confidentialité) ou la perturber (risque pour la liberté de communication). Un exemple est l'interception HTTPS (cf. « The Security Impact of HTTPS Interception »). Le principe de bout en bout (RFC 1958 ou bien « End-to-End Arguments in System Design ») promeut plutôt une communication sans intermédiaires, mais on trouve de nombreuses exceptions dans les protocoles IETF (DNS, SMTP…) ou en dehors de l'IETF (ActivityPub), car les intermédiaires peuvent aussi rendre des services utiles. En outre, ces intermédiaires tendent à ossifier le protocole, en rendant plus difficile le déploiement de tout changement (cf. RFC 9846 pour les problèmes rencontrés par TLS 1.3).
Le RFC fait aussi une différence entre intermédiaires et services. Si vous êtes utilisateurice de Gmail, Gmail n'est pas un intermédiaire, mais un service car vous êtes conscient·e de sa présence et vous l'avez choisi. [L'argument me semble avoir des faiblesses : ce genre de services pose exactement les mêmes problèmes que les intermédiaires et n'est pas forcément davantage maitrisé.]
Un bon moyen de faire respecter le principe de bout en bout est de chiffrer au maximum. C'est pour cela que QUIC (RFC 9000) chiffre davantage de données que TLS. C'est aussi pour cela que l'IETF travaille au chiffrement du SNI (RFC 9849).
Autre exemple, la connectivité (section 4.2). Car, si on n'a pas accès à l'Internet du tout, ou bien si on y a accès dans des conditions très mauvaises, tout discussion sur les droits humains sur l'Internet devient oiseuse. L'accès à l'Internet est donc un droit nécessaire (cf. la décision du Conseil Constitutionnel sur Hadopi, qui posait le principe de ce droit d'accès à l'Internet). Pour le protocole, cela oblige à se pencher sur son comportement sur des liens de mauvaise qualité : est-ce que ce protocole peut fonctionner lorsque la liaison est mauvaise ?
Un sujet délicat (section 4.4) est celui des informations que le protocole laisse fuiter (l'« image vue du réseau » du RFC 8546). Il s'agit des données qui ne sont pas chiffrées, même avec un protocole qui fait de la cryptographie, et qui peuvent donc être utilisées par le réseau, par exemple pour du traitement différencié (de la discrimination, pour dire les choses franchement). Comme recommandé par le RFC 8558, tout protocole doit essayer de limiter cette fuite d'informations. C'est pour cela que TCP a tort d'exposer les numéros de port, par exemple, que QUIC va au contraire dissimuler.
L'Internet est mondial, on le sait. Il est utilisé par des gens qui ne parlent pas anglais et/ou qui n'utilisent pas l'alphabet latin. Il est donc crucial que le protocole fonctionne pour tout le monde (section 4.5). Si le protocole utilise des textes en anglais, cela doit être de manière purement interne (le GET de HTTP, le Received: de l'IMF, etc), sans être obligatoirement montré à l'utilisateurice. Ce principe, formulé dans le RFC 2277, dit que tout ce qui est montré à l'utilisateur doit pouvoir être traduit. (En pratique, il y a des cas limites, comme les noms de domaine, qui sont à la fois éléments du protocole, et montrés aux utilisateurs.)
Si le protocole sert à transporter du texte, il doit évidemment utiliser Unicode, de préférence encodé en UTF-8. S'il accepte d'autres encodages et/ou d'autres jeux de caractère (ce qui peut être dangereux pour l'interopérabilité), il doit permettre d'étiqueter ces textes, afin qu'il n'y ait pas d'ambiguité sur leurs caractéristiques. Pensez d'ailleurs à lire le RFC 6365.
Un contre-exemple est le vieux protocole whois (RFC 3912), qui ne prévoyait que l'ASCII et, si on peut l'utiliser avec d'autres jeux de caractères, comme il ne fournit pas d'étiquetage, le client doit essayer de deviner de quoi il s'agit. (Normalement, whois n'est plus utilisé, on a le Web et RDAP, mais les vieilles habitudes ont la vie dure.)
Toujours question étiquetage, notre RFC rappelle l'importance de pouvoir, dans le protocole, indiquer explicitement la langue des textes (RFC 5646). C'est indispensable afin de permettre aux divers logiciels de savoir quoi en faire, par exemple en cas de synthèse vocale.
Le RFC parle aussi de l'élaboration des normes techniques (section 4.7). Par exemple, sont-elles dépendantes de brevets (RFC 8179 et RFC 6701) ? [Personnellement, je pense que c'est une question complexe : les brevets ne sont valables que dans certains pays et, en outre, la plupart des brevets logiciels sont futiles, brevetant des technologies banales et déjà connues. Imposer, comme le proposent certains, de ne normaliser que des techniques sans brevet revient à donner un doit de veto à n'importe quelle entreprise qui brevète n'importe quoi. Par exemple, le RFC 9156 n'aurait jamais été publié si on s'était laissé arrêter par le brevet.]
Mais un autre problème avec les normes techniques concerne leur disponibilité. Si l'IETF, le W3C et même l'UIT publient leurs normes, ce n'est pas le cas de dinosaures comme l'AFNOR ou l'ISO, qui interdisent même la redistribution de normes qu'on a légalement acquises. Si les normes IETF sont de distribution libre, elles dépendent parfois d'autres normes qui, elles, ne le sont pas.
Un peu de sécurité informatique, pour continuer. La section 4.11 traite de l'authentification des données (ce que fait DNSSEC pour le DNS, par exemple). Cette possibilité d'authentification est évidemment cruciale pour la sécurité mais le RFC note qu'elle peut aussi être utilisée négativement, par exemple avec les menottes numériques.
Et il y a bien sûr la confidentialité (section 4.12 mais aussi RFC 6973), impérative depuis toujours mais qui était parfois sous-estimée, notamment avant les révélations Snowden. Les auteur·es de protocoles doivent veiller à ce que les données soient et restent confidentielles et ne puissent pas être interceptées par un tiers. Il y a longtemps que tout RFC doit contenir une section sur la sécurité (RFC 3552), exposant les menaces spécifiques à ce RFC et les contre-mesures prises, entre autre pour assurer la confidentialité. L'IETF refuse, à juste titre, toute limitation de la cryptographie, souvent demandée par les autorités (RFC 1984). Les exigences d'accès par ces autorités (en invoquant des arguments comme la lutte contre le terrorisme ou la protection de l'enfance) ne peuvent mener qu'à affaiblir la sécurité générale puisque ces accès seront aussi utilisés par les attaquants, ou par un État qui abuse de son pouvoir.
Le modèle de menace de l'Internet, depuis longtemps, est que tout ce qui est entre les deux machines situées aux extrémités de la communication doit être considéré comme un ennemi. Pas parce que les intermédiaires sont forcément méchants, loin de là, mais parce qu'ils ont des possibiliés techniques que certains exploiteront et il faut donc protéger la communication car on ne sait jamais ce que tel ou tel intermédiaire fera (RFC 7258 et RFC 7624). Bref, tout protocole doit chiffrer le contenu qu'il transporte (RFC 3365). Aujourd'hui, les principales exceptions à ce principe sont le très vieil whois (RFC 3912) et surtout le DNS qui a, certes, des solutions techniques pour le chiffrement (RFC 7858 et RFC 8484) mais qui sont loin d'être universellement déployées.
Ce chiffrement doit évidemment être fait de bout en bout, c'est-à-dire directement entre les deux machines qui communiquent, afin d'éviter qu'un intermédiaire n'ait accès à la version en clair. Cela pose un problème pour les services store-and-forward comme le courrier électronique (RFC 5321). De même, chiffrer lorsqu'on communique en HTTPS avec Gmail ne protège pas la communication contre Google, seulement contre les intermédiaires réseau ! Relire le RFC 7624 est recommandé.
Question vie privée, le RFC recommande également de faire attention aux métadonnées et à l'analyse de trafic. Les conseils du RFC 6973, section 7, sont ici utiles.
Un sujet encore plus délicat est celui de l'anonymat et du pseudonymat. On sait qu'il n'y a pas réellement d'anonymat sur l'Internet (quoiqu'en disent les politiciens malhonnêtes et les journalistes avides de sensationnalisme), le numérique permettant au contraire de récolter et de traiter beaucoup de traces de la communication. Néanmoins, le protocole doit permettre, autant que possible, de s'approcher de l'anonymat. Par exemple, les identificateurs persistents sont évidemment directement opposés à cet objectif puisqu'ils rendent l'anonymat impossible (rappel important : anonymat ≠ pseudonymat). Au minimum, il faudrait permettre à l'utilisateur de changer facilement et souvent ces identificateurs. Et, bien sûr, ne pas imposer qu'ils soient liés à l'identité étatique. Des exemples d'identificateurs qui sont parfois utilisés sur le long terme sont les adresses IP, les Connection ID de QUIC (un bon exemple d'un protocole qui permet leur changement facilement), les biscuits de HTTP, et les adresses du courrier électronique, certainement très difficiles à changer. Comme le montre l'exemple de ces adresses, les identificateurs stables sont utiles et on ne peut pas forcément les remplacer par des identificateurs temporaires. Ici, le souci de vie privée rentre en contradiction avec l'utilité des identificateurs, une tension courante en sécurité. Le fait qu'on ne puisse en général pas se passer d'identificateurs, à relativement longue durée de vie, est justement une des raisons pour lesquelles il n'y a pas de vrai anonymat sur l'Internet.
Notons que les politiciens de mauvaise foi et les journalistes incompétents parlent parfois d'anonymat dès qu'un identificateur stable n'est pas l'identité étatique (par exemple quand je crée un compte Gmail « anonymous652231 » au lieu d'utiliser le nom qui est sur ma carte d'identité). Mais tout identificateur stable peut finir par se retrouver lié à une autre identité, peut-être aussi à l'identité étatique, par exemple si deux identificateurs sont utilisés dans le même message. Et certains identificateurs sont particulièrement communs, avec plusieurs usages, ce qui les rend encore plus dangereux pour la vie privée. Le numéro de téléphone, que certaines messageries instantanées imposent, est particulièrement sensible et est donc déconseillé.
Donc, s'il faut utiliser des identificateurs stables, ils doivent au moins pouvoir être des pseudonymes.
D'autres façons de désanonymiser existent, par exemple quand les gens ont bêtement cru que condenser un identificateur n'était pas réversible (cf. l'article « Four cents to deanonymize: Companies reverse hashed email addresses »).
Notre RFC rappelle ainsi les discussions animées qu'avait connu l'IETF en raison d'un mécanisme d'allocation des adresses IPv6, qui les faisaient dériver d'un identificateur stable, l'adresse MAC, qui permettait de suivre à la trace un utilisateur mobile. Depuis, le RFC 8981 (et le RFC 7217 pour les cas où on veut une stabilité limitée dans l'espace) ont résolu ce problème (le RFC 7721 résume le débat). À noter que l'adresse MAC peut aussi devenir variable (RFC 9724).
Autre exemple où un protocole IETF avait une utilisation imprudente des identificateurs, DHCP, avec ses identificateurs stables qui, certes, n'étaient pas obligatoires mais, en pratique, étaient largement utilisés (RFC 7844).
Une autre question très sensible est celle de la censure. Le protocole en cours de développement a-t-il des caractéristiques qui rendent la censure plus facile ou au contraire plus difficile (section 4.16) ? Par exemple, si le protocole fait passer par des points bien identifiés les communications, ces points vont certainement tenter les censeurs (pensez aux résolveurs DNS et à leur rôle dans la censure…). Les RFC 7754 et RFC 9505 décrivent les techniques de censure. Elles sont très variées. Par exemple, pour le Web, le censeur peut agir sur les résolveurs DNS mais aussi bloquer l'adresse IP ou bien, en faisant du DPI, bloquer les connexions TLS en regardant le SNI. Certains systèmes d'accès au contenu, comme Tor, ou de distribution du contenu, comme BitTorrent, résistent mieux à la censure que le Web mais ont d'autres défauts, par exemple en termes de performance. L'exemple du SNI montre en tout cas très bien une faiblesse de certains protocoles : exposer des identificateurs aux tierces parties (qui ne sont aucune des deux parties qui communiquent) facilite la censure. C'est pour cela que l'IETF développe ECH (cf. RFC 9849).
Le protocole, tel que normalisé dans un RFC, c'est bien joli, mais il faut aussi tenir compte du déploiement effectif. Comme noté au début, ce n'est pas dans le RFC 5321 qu'on trouvera les causes de la domination de Gmail ! Les effets du protocole dans la nature sont en effet très difficiles à prévoir. La section 4.17 se penche sur cette question et demande qu'on considère, non seulement le protocole mais aussi les effets qu'il aura une fois déployé. [Ce qui, à mon avis, relève largement de la boule de cristal, surtout si on veut tenir compte d'effets économiques. Et les exemples du RFC ne sont pas géniaux, comme de reprocher au courrier sa gratuité, qui encourage le spam. L'exemple de l'absence de mécanisme de paiement sur le Web, qui pousse à développer des mécanismes néfastes comme la publicité, est meilleur.] La section 4.21 traite également ce sujet des conséquences, parfois inattendues, du déploiement d'un protocole.
Le RFC a aussi un mot (section 4.18) sur les questions d'accessibilité, notamment aux handicapés. Cette question, très présente dans les discussions autour des couches hautes du Web (cf. les réunions Paris Web) semble plus éloignée de ce que fait l'IETF mais le RFC cite quand même l'exemple du RFC 9071, sur l'utilisation de RTP dans des réunions en ligne, avec une alternative en texte pour les personnes malentendantes.
L'Internet est aujourd'hui très, trop, centralisé, notamment pour ce qui concerne les services (la connectivité, quoique imparfaitement répartie, est moins dépendante d'un petit nombre d'acteurs). Il est donc utile, lors de la conception d'un protocole, de réfléchir aux caractéristiques du protocole qui risquent d'encourager la centralisation (par exemple par la création d'un, ou d'un petit nombre de points de contrôle). Le RFC 3935 donne explicitement à l'IETF un objectif de promotion de la décentralisation.
En conclusion, même si l'activité organisée d'examen des futurs RFC n'a pas pris, ce RFC reste utile pour réfléchir à l'impact de nos protocoles sur les droits des humains.
L'article seul
Version 16 d'Unicode
Première rédaction de cet article le 14 septembre 2024
Le 10 septembre est sortie la version 16 d'Unicode. Une description officielle des principaux changements est disponible mais voici ceux qui m'ont intéressé particulièrement. (Il n'y a pas de changement radical.)
Pour explorer plus facilement la grande base Unicode, j'utilise un programme qui la convertit en SQL et permet ensuite de faire des analyses variées. Faisons quelques requêtes SQL :
ucd=> SELECT count(*) AS Total FROM Characters; total -------- 155063
Combien de caractères sont arrivés avec la version 16 ?
ucd=> SELECT version,count(version) FROM Characters GROUP BY version ORDER BY version::float; ... 13.0 | 5930 14.0 | 838 15.0 | 4489 15.1 | 627 16.0 | 5185
5 185 nouveaux caractères, c'est pas mal, la plus grosse addition depuis la version 13.0. Quels sont ces nouveaux caractères ?
ucd=> SELECT To_U(codepoint) AS Code_point, name FROM Characters WHERE version='16.0' ORDER BY Codepoint; code_point | name -----------+---------------------------------------------------------------------------- U+A7CB | LATIN CAPITAL LETTER RAMS HORN U+A7CC | LATIN CAPITAL LETTER S WITH DIAGONAL STROKE … U+10D50 | GARAY CAPITAL LETTER A U+10D51 | GARAY CAPITAL LETTER CA U+10D52 | GARAY CAPITAL LETTER MA … U+11BC2 | SUNUWAR LETTER EKO U+11BC3 | SUNUWAR LETTER IMAR U+11BC4 | SUNUWAR LETTER REU … U+1346E | EGYPTIAN HIEROGLYPH-1346E U+1346F | EGYPTIAN HIEROGLYPH-1346F U+13470 | EGYPTIAN HIEROGLYPH-13470 … U+1CC15 | LOGIC GATE OR U+1CC16 | LOGIC GATE AND … U+1CC4A | FLYING SAUCER WITH BEAMS U+1CC4B | FLYING SAUCER WITHOUT BEAMS … U+1CC4E | ALIEN SQUID OPEN TENTACLES U+1CC4F | ALIEN SQUID CLOSED TENTACLES … U+1CC60 | LEFT-POINTING ATOMIC BOMB U+1CC61 | UP-POINTING ATOMIC BOMB … U+1CE20 | LARGE TYPE PIECE CROSSBAR WITH LOWER STEM U+1CE21 | LARGE TYPE PIECE UPPER HALF VERTEX OF M U+1CE22 | LARGE TYPE PIECE DIAGONAL LOWER LEFT …
Cette version amène en effet plusieurs nouvelles écritures. C'est le
cas du Sunuwar, par exemple. On voit aussi arriver le
Garay. Cette dernière
écriture ne semble d'ailleurs pas avoir tellement eu de succès, le
nom de domaine du site
officiel, garay-ecriture.com a disparu en 2012.
Parmi les nouveautés, beaucoup d'hiéroglyphes
égyptiens, et l'habituelle arrivée
d'emojis comme les différentes variantes
d'extra-terrestres, avec ou sans tentacules (bon, d'accord, ceux-là ne
sont pas officiellement des emojis, ils ont été enregistrés via une
autre voie mais ils seront sans doute utilisés comme des emojis).
Revenu du passé, le jeu de caractères des machines Sharp MZ est désormais inclus. Cela apporte notamment les symboles des circuits électroniques.
Si vous avez les bonnes polices de caractères, vous allez pouvoir voir quelques exemples (sinon, le lien mène vers Uniview). Voici par exemple le grand S barré , la première lettre de l'alphabet garay , celle du sunuwar , un des nouveaux et nombreux hiéroglyphes , une diode et un extra-terrestre .
Sur le même sujet, je vous recommande l'article d'Ysabeau sur LinuxFr.
L'article seul
RFC 9616: Delay-based Metric Extension for the Babel Routing Protocol
Date de publication du RFC : Septembre 2024
Auteur(s) du RFC : B. Jonglez (ENS Lyon), J. Chroboczek (IRIF, Université Paris Cité)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF babel
Première rédaction de cet article le 14 septembre 2024
Voici un RFC sur le protocole de routage Babel. Il normalise une extension au protocole pour tenir compte du RTT, le temps d'aller-retour sur un segment du réseau. C'est l'occasion de revenir sur ce critère de routage, souvent cité mais rarement utilisé (et pour de bonnes raisons).
On lit parfois des affirmations rapides comme « les routeurs Internet choisissent la route la plus rapide ». Outre que « rapide » n'a pas de définition précise (parle-t-on de la latence ? De la capacité ?), la phrase est fausse : le routage se fait sur des critères nettement moins dynamiques. Dans le cas de BGP, ce sont en bonne partie des critères de business. Das le cas d'un IGP, des critères de performance sont pris en compte, mais en se limitant à des critères assez statiques. En effet, si on prend en compte naïvement une variable très dynamique, qui change souvent, comme l'est le RTT, on risque d'avoir un routage très instable : un lien est peu utilisé, ses performances sont bonnes, les routeurs vont y envoyer tout le trafic, ses performances vont chuter, les routeurs vont tout envoyer ailleurs, les performances vont remonter, les routeurs vont encore changer d'avis, etc. Tenir compte des performances immédiates du lien est donc une fausse bonne idée ou, plus précisément, ne doit pas être fait naïvement.
C'est justement ce que fait ce RFC qui explique comment utiliser intelligemment un critère très mouvant, le RTT (la latence, mais mesurée en aller-retour), pour le choix des routes dans Babel. Babel est un protocole de routage de type IGP, normalisé dans le RFC 8966, surtout prévu pour des réseaux sans administration centrale.
Si par exemple (section 1 du RFC), une machine A à Paris a deux moyens de joindre une machine D également à Paris, une des routes passant par un routeur B à Paris et une autre par un routeur C à Tokyo, il est assez évident qu'il vaut mieux rester à Paris. Mais ce n'est pas forcément ce que feront les mises en œuvre de Babel, qui se disent simplement que les deux routes ont le même nombre de segments (deux). Bien sûr, attribuer manuellement des préférences aux segments résoudrait le problème (un lien vers le Japon est plus « cher ») mais l'un des buts de Babel est de ne pas requérir de configuration manuelle par un administrateur réseaux.
Utiliser le RTT, qui est relativement facile à évaluer (mais continuez la lecture : il y a des pièges) semble une solution évidente. Mais, comme dit plus haut, cela peut mener à de violentes instabilités du routage. Il faut donc évaluer le RTT, puis le traiter avant de l'utiliser, pour éviter des oscillations du routage. Et attention, la latence n'est pas toujours le meilleur critère de choix, d'autres, comme le coût monétaire, peuvent être pris en compte, par exemple pour privilégier un lien WiFi sur un lien 5G. Babel n'impose pas de critère unique de choix des routes.
Cette extension ne nécessite pas que les différents routeurs aient une horloge synchronisée (ce qui serait difficile à faire dans un réseau sans administration), juste que les horloges ne dérivent pas trop vite l'une par rapport à l'autre. D'autre part, comme l'algorithme essaie de limiter les oscillations de routes, il ne s'ajustera pas instantanément aux changements, et ne sera donc pas optimal dans tous les cas.
Commençons par l'évaluation du RTT. Il ne suffit pas de soustraire le temps de départ d'une question au temps d'arrivée d'une réponse, entre autre parce que la génération de la réponse peut prendre du temps (et puis un routeur Babel n'est pas obligé de répondre à tous les messages Hello). Et rappelez-vous que cette extension n'impose pas une synchronisation des horloges. L'algorithme est donc un peu plus compliqué, c'est celui créé par Mills et utilisé entre autres pour NTP. Un routeur nommé Alice qui envoie un message Hello (RFC 8966, section 3.4.1) ajoute à ces messages le temps de départ, appelé t1. Le routeur nommé Bob le reçoit à un temps t1'. Comme les horloges ne sont pas forcément synchronisées, on ne peut pas comparer directement t1 et t1'. Au lieu de cela, Bob, quand il enverra un message Babel IHU (I Heard yoU) indiquera à la fois t1 et t1' dans ce message, ainsi que le temps t2' d'émission. Alice, recevant ce message, n'aura qu'à calculer (t2 - t1) - (t2' - t1') et aura ainsi le RTT, même si les horloges sont différentes (tant qu'elles ne dérivent pas trop dans l'intervalle entre t1 et t2). Bon, j'ai simplifié, mais vous avez tous les détails dans le RFC, section 3.2.
Notez que cet algorithme impose aux deux routeurs de garder des informations supplémentaires sur leurs voisins, dans la table documentée dans la section 3.2.4 du RFC 8966. Celle-ci devra stocker les estampilles temporelles reçues.
Ces estampilles étant stockées sur 32 bits et ayant une
résolution en microsecondes, elles reviendront à zéro toutes les 71
minutes. Le routeur doit donc prendre garde à ignorer les
estampilles situées dans son futur (par exemple s'il a redémarré et
perdu la notion du temps) ou trop éloignées. Sur un système
POSIX, le routeur peut donc utiliser
clock_gettime(CLOCK_MONOTONIC).
Bon, désormais, nous avons le RTT. Qu'en faire ? Comme indiqué plus haut, il ne faut pas l'utiliser tel quel comme critère de sélection des routes, sous peine d'osccilations importantes des tables de routage. Il y a plusieurs opérations à faire (section 4). D'abord, il faut lisser le RTT, éliminant ainsi les cas extrêmes. Ainsi, on va utiliser la formule RTT ← α RTT + (1 - α) RTTn, où RTTn désigne la mesure qu'on vient juste de faire, et où la constante α a une valeur recommandée de 0,836. (Les détails figurent dans l'article « A delay-based routing metric ».)
Ensuite, pour nourrir l'algorithme de choix des routes, il faut convertir ce RTT en un coût. La fonction est simple : de 0 à une valeur rtt-min, le coût est constant, il augmente ensuite linéairement vers une valeur maximale, atteinte pour un RTT égal à rtt-max, et constante ensuite. Les valeurs par défaut recommandées sont de 10 ms pour rtt-min et 150 ms pour rtt-max. En d'autres termes, sur l'Internet, tout RTT inférieur à 10 ms est bon, tout RTT supérieur à 150 ms est à éviter autant que possible.
Enfin, car il reste encore des variations, la section 4 sur les traitements du RTT se termine en demandant l'application d'un mécanisme d'hystérésis, comme celui du RFC 8966, annexe A.3.
Le format des paquets, maintenant. Rappelons que Babel encode les données en TLV et permet des sous-TLV (la valeur d'un TLV est elle-même un TLV). Un routeur doit ignorer les sous-TLV qu'il ne comprend pas, ce qui permet d'ajouter des nouvelles informations sans risque (section 5).
Donc, notre RFC normalise le sous-TLV Timestamp (type 3), qui permet de stocker les estampilles temporelles, et peut apparaitre sous les sous-TLV Hello et IHU. Dans le premier cas, il stockera juste une valeur (t1 ou t2' dans l'exemple plus haut), dans le second, deux valeurs (t1 et t1' dans l'exemple plus haut).
La mise en œuvre « officielle » de Babel a, dans sa version de
développement, la capacité de déterminer ces RTT (option
enable-timestamps dans la configuration).
L'article seul
Le problème du serveur whois du .mobi
Première rédaction de cet article le 12 septembre 2024
Des chercheurs en sécurité ont publié un
article sur un problème causé par le serveur
whois du TLD
.mobi. Le problème est
réel et le travail des chercheurs excellent, mais je souhaiterais
ajouter quelques points.
D'abord, les faits : beaucoup de TLD (notamment la totalité de ceux qui
sont sous contrat avec l'ICANN, au moins jusqu'en
janvier 2025) ont un serveur whois, pour
permettre d'obtenir des informations sur le titulaire et les
contacts des noms de
domaine. Ce protocole, whois, est normalisé dans le RFC 3912. C'est un protocole très simple, voire
simpliste, qui présente de nombreuses limites (on reparlera plus
loin de son ou ses successeurs). Notamment, il n'existe pas de
mécanisme normalisé pour découvrir le serveur pertinent pour un nom
de domaine donné. Chaque logiciel client whois développe donc ses
propres heuristiques. Par exemple, GNU whois, qui est
probablement celui que vous trouverez sur une machine
Debian ou Fedora,
utilise une liste de TLD et de leurs serveurs, qui est « en dur »
dans le programme mais peut être surpassée par un fichier de
configuration, /etc/whois.conf. D'autres clients whois utilisent d'autres
méthodes pour récupérer une information analogue. Notons qu'il
existe beaucoup de clients whois et, contrairement à ce qu'écrivent
parfois les ignorants, ils ne sont pas forcément en ligne
de commande. (Sinon, pour les TLD, la source faisant
autorité est la
base IANA des TLD.) Vous voyez bien le problème : cette liste
de TLD et de leurs serveurs évolue et le logiciel peut avoir une
liste dépassée. Comme beaucoup d'utilisateurices et
d'administrateurices système ne tiennent pas à jour leurs logiciels
et les configurations, le risque d'avoir une vieille information sur
les serveurs whois est non négligeable.
Et c'est justement ce qu'ont constaté
Benjamin Harris et Aliz Hammond, les chercheurs en sécurité
dont je parlais. Constatant que le TLD
.mobi (TLD qui est par
ailleurs une
mauvaise idée, mais c'est une autre histoire) avait changé son
serveur whois, de whois.dotmobiregistry.net à
whois.nic.mobi,
et que le nom de domaine
dotmobiregistry.net, non renouvelé, avait
expiré et était donc libre, les chercheurs ont enregistré le nom
dotmobiregistry.net, mis en place un serveur
whois (je rappelle que le protocole est très simple et que n'importe
quel·le étudiant·e peut programmer un serveur whois en un quart
d'heure) et récolté d'innombrables requêtes provenant de clients
whois qui n'avaient pas mis leur base à jour.
Les chercheurs ont ensuite creusé qui
envoyait ces requêtes à un serveur qui normalement n'existait
plus. Sans surprise, une bonne partie provenait de relais, de
passerelles entre Web et whois. Comme certains utilisateurs de whois
n'ont pas de client whois sur leur machine, ils passent par des
passerelles dont rien ne garantit l'honnêteté, l'intégrité… ou la
tenue à jour de leur liste. C'est ainsi que
who.is ou whois.ru
allaient visiter le serveur whois « pirate ». (Je découvre à cette
occasion qu'il y a apparemment des gens qui sont dans la
cybersécurité et qui, au lieu de contacter le serveur whois faisant
autorité, se servent de whois.ru. Des gens qui
sont dans la cybersécurité…) Donc, un rappel : on ne doit pas
utiliser ces passerelles mais toujours interroger
directement un serveur qui fait autorité.
Mieux (ou pire), parmi les clients qui contactaient le serveur « pirate » se trouvaient des AC ! Pour découvrir les adresses de courrier électronique des contacts, ces « Autorités » de « Certification » (la liste figure dans l'article) utilisaient une information plus à jour… Cela a de quoi faire réfléchir sur la valeur ajoutée de ces AC en sécurité.
Au passage, le fait d'enregistrer un domaine qui est libre, mais toujours référencé quelque part, pour capter du trafic, souvent à des fins malveillantes, est nommé une attaque flamant (l'oiseau, pas la région de la Belgique dont le nom des habitants se termine par un D, pas un T). C'est une catégorie d'attaques qu'on retrouve de temps en temps. Pour s'en prémunir, faites attention avant de supprimer un domaine dont vous croyez qu'il ne sert plus. (Vous êtes sûr·e ? Vous avez vérifié tous les endroits en dehors de vos machines où ce nom est cité ?)
L'article des chercheurs ne le mentionne pas mais, si on veut
faire les choses proprement, on ne doit plus utiliser whois mais son
successeur RDAP (RFC 9082 et RFC 9083) qui a notamment
l'avantage d'avoir un mécanisme standard de découverte du serveur
(spécifié dans le RFC 9224), qui évite ces
listes codées en dur, trop susceptibles d'erreurs, comme l'a bien
montré l'affaire du .mobi. Bref, la solution
technique existe depuis de nombreuses années, mais on sait qu'il est
difficile de faire abandonner une vieille technique mauvaise pour
une moderne qui marche ; whois s'accroche.
(Pour les programmeureuses : un exemple de script Python pour trouver le serveur RDAP est disponible en ligne. Il est documenté dans un article sur RDAP.)
Sinon, Ars Technica a fait un article résumant l'affaire. L'article est bien mais reste purement factuel et ne met pas assez en perspective.
L'article seul
Des services de DNS secondaires gratuits
Première rédaction de cet article le 30 août 2024
Dernière mise à jour le 24 juillet 2026
Pour des raisons de robustesse, il est fortement recommandé d'avoir plusieurs serveurs faisant autorité pour une zone DNS. Mais ce n'est pas tout : il faut aussi de la diversité, pour éviter que la même cause ne rende plusieurs serveurs injoignables. Il est donc très souhaitable d'avoir des serveurs secondaires en dehors de son réseau habituel. Si on est une grosse organisation, il existe des offres commerciales pour cela. Et si on est une petite organisation, avec peu de moyens ? Des solutions existent quand même.
Un nombre important de serveurs faisant autorité est certes souhaitable (la résolution doit toujours fonctionner même si un serveur est en panne) mais il vaut encore mieux qu'ils soient divers. Si on a quatre serveurs (un bon nombre) mais qu'ils sont dans la même armoire, ou alimentés par le même système électrique, ou routés ensemble par le même AS, ces quatre serveurs vivent sous la menace d'un SPOF : une panne peut les planter tous les quatre.
La solution est donc d'avoir des serveurs secondaires, qui iront récupérer les données sur le serveur primaire (d'où le terme de serveurs esclaves, que l'on trouve par exemple dans les fichiers de configuration de certains logiciels). Mais pour avoir le maximum de diversité, il vaut mieux qu'ils soient routés via des AS différents, et même qu'ils soient gérés par des organisations différentes. On peut toujours demander à des copains ou copines d'héberger de tels secondaires (le DNS fonctionnait souvent comme cela au début). Mais si on n'a pas de copines ou copains qui fournissent ce service ? Alors, il y a plusieurs solutions gratuites :
- puck.nether.net.
- NS-Global. L'utilisation est originale : vous n'avez pas de compte, vous configurez votre primaire et demandez ensuite le service.
- 1984 Hosting.
- Hurricane Electric.
- FreeDNS 42.
- FreeDNS (sans lien avec le précédent) : je trouve l'utilisation très peu claire (heureusement que Jean-Philippe Pick m'a aidé). Il faut aller dans la section Backup DNS et suivre les instructions.
- FediNS.
- Hetzner (je ne l'ai pas testé, il faut un compte chez eux, envoyer des données personnelles et les informations sur sa carte de paiement, même si c'est gratuit).
- Certains bureaux d'enregistrement fournissent un service de secondaire mais uniquement si le domaine est enregistré chez eux.
Pour tous ces services, quelques points à garder en tête :
- Cela va de soi mais je le répète quand même : il faut avoir un serveur primaire que vous gérez vous-même. Cet article ne parle que de trouver des secondaires.
- Il s'agit à chaque fois de services gratuits, qui font au mieux, mais qui ne peuvent pas fournir une fiabilité de 100 % (mais, comme souvent avec les services créés par des passionné·es, cela marche souvent mieux que les services commerciaux et le support répond plus vite et plus sérieusement). Soyez gentil·les avec leurs administrateurices.
- Si vous vous inquiétez pour l'intégrité de vos données DNS (qui nous dit que ces administrateurices ne vont pas subrepticement modifier les enregistrements ?), signez avec DNSSEC. De toute façon, signez avec DNSSEC.
- Tous ces services fournissent ce qu'il faut pour DNSSEC mais vérifiez quand même. Et, bien sûr, c'est vous qui êtes responsable de la supervision.
- Si vous vous inquiétez pour la confidentialité des requêtes (pas des données, qui sont publiques, mais des requêtes), vous avez raison de vous inquiéter. Si vous ne vous inquiétez pas, lisez le RFC 7626. DNSSEC ne traite pas ce problème.
Outre les copains et copines, outre les services gratuits comme ceux cités ici, on peut aussi recourir aux services de gens de son écosystème professionnel ou associatif. Ainsi, les services publics ne devraient pas hésiter à échanger des services de DNS secondaire (ils ne sont pas concurrents, après tout), mais on constate que ce n'est pas le cas, les rendant vulnérables aux pannes et aux attaques par déni de service.
L'article seul
Pour se protéger de l'étranger, bloquons les accès de l'extérieur
Première rédaction de cet article le 29 août 2024
Dernière mise à jour le 31 août 2024
On le sait, les attaques par déni de service sont une des plaies de l'Internet, très difficiles à contrer. Quand elles sont motivés géopolitiquement, on peut souvent les lier à des pays étrangers (pas toujours à juste titre). Il est donc tentant de bloquer les attaques en bloquant l'étranger, ce que vient de faire la Cour de Cassation. Intéressant cas de géopolitique Internet.
Tout a commencé par une remarque d'une internaute vivant à
l'étranger et qui s'étonnait de ne pas pouvoir accéder au site Web
de la Cour de Cassation, https://www.courdecassation.fr/
D'abord, voyons comment tester. Depuis une machine qui peut joindre le site Web de la Cour, on teste ping :
% ping -c 3 www.courdecassation.fr PING www.courdecassation.fr.direct.cdn.anycast.me (80.87.226.23) 56(84) bytes of data. --- www.courdecassation.fr.direct.cdn.anycast.me ping statistics --- 3 packets transmitted, 0 received, 100% packet loss, time 2055ms
Raté, l'hébergeur bloque ICMP echo. C'est bête mais c'est fréquent. Il va donc falloir tester uniquement en HTTPS. Sur ma machine, curl est content :
% curl -v https://www.courdecassation.fr/ |& more
…
* Connected to www.courdecassation.fr (80.87.226.23) port 443 (#0)
…
* SSL connection using TLSv1.2 / ECDHE-RSA-AES256-GCM-SHA384
* ALPN: server accepted http/1.1
…
> GET / HTTP/1.1
> Host: www.courdecassation.fr
> User-Agent: curl/7.88.1
…
< HTTP/1.1 200 OK
< Server: nginx
…
<!DOCTYPE html>
<html lang="fr" dir="ltr" prefix="og: https://ogp.me/ns#">
<head>
<meta charset="utf-8" />
<script>var _paq = _paq || [];(function(){var u …
Mais depuis une machine aux États-Unis, ça échoue :
% curl -v https://www.courdecassation.fr/ * Trying 80.87.226.23:443... * connect to 80.87.226.23 port 443 failed: Connection timed out * Failed to connect to www.courdecassation.fr port 443 after 131838 ms: Couldn't connect to server * Closing connection 0 curl: (28) Failed to connect to www.courdecassation.fr port 443 after 131838 ms: Couldn't connect to server
Sachant que les institutions françaises (et la Cour de Cassation avait été explicitement citée sur certains réseaux sociaux) ont été victimes dans les jours précédents d'attaques par déni de service politiquement motivées (apparemment en lien avec l'arrestation de Pavel Durov), on peut commencer à se douter que le résultat va dépendre du pays.
Il faudrait tester depuis davantage de points : l'Internet est vaste. Utilisons les sondes RIPE Atlas, via le logiciel Blaeu. Comme les sondes Atlas ne permettent de l'HTTP que dans des conditions très limitées, on va juste attaquer en TLS :
% blaeu-cert -r 100 -4 www.courdecassation.fr 73 probes reported [/CN=www.courdecassation.fr] : 5 occurrences [FAILED TO GET A CERT: connect: timeout] : 68 occurrences Test #78156324 done at 2024-08-29T08:35:23Z
OK, certaines sondes peuvent récupérer le certificat, d'autres pas. On soupçonne déjà que ça dépend du pays donc utilisons la possibilité d'Atlas de sélectionner le pays :
% blaeu-cert --requested 100 -4 --country FR www.courdecassation.fr 93 probes reported [FAILED TO GET A CERT: connect: timeout] : 1 occurrences [/CN=www.courdecassation.fr] : 92 occurrences Test #78157154 done at 2024-08-29T09:18:36Z % blaeu-cert --requested 100 -4 --country IT www.courdecassation.fr 94 probes reported [FAILED TO GET A CERT: timeout reading hello] : 3 occurrences [FAILED TO GET A CERT: connect: timeout] : 91 occurrences Test #78157186 done at 2024-08-29T09:19:28Z
Bref, pas de problème pour les résidents français, c'est juste l'étranger qui est bloqué. Notons toutefois que les DROM semblent exclus de la France :
% blaeu-cert -4 --requested 10 --country GP www.courdecassation.fr 2 probes reported [FAILED TO GET A CERT: connect: timeout] : 2 occurrences Test #78167255 done at 2024-08-29T11:41:39Z % blaeu-cert -4 --requested 10 --country NC www.courdecassation.fr 5 probes reported [FAILED TO GET A CERT: connect: timeout] : 5 occurrences Test #78167664 done at 2024-08-29T11:50:46Z
Globalping permet des requêtes HTTP. Si on lui envoie ce code JSON :
{
"limit": 100,
"locations": [{"country": "FR"}],
"target": "www.courdecassation.fr",
"type": "http",
"measurementOptions": {
"protocol": "HTTPS",
"request": {
"path": "/"
}
}
}
On teste en France et cela confirme le résultat des sondes Atlas ; tout marche (ou presque : la géolocalisation n'est jamais parfaite). En demandant un autre pays, tout échoue.
L'accès depuis, apparemment, le monde entier a été rétabli le 30 ou le 31 août. Tout remarche désormais.
En conclusion, il est clair que l'hébergeur de la Cour a choisi de se retrancher derrière les frontières nationales, suite aux attaques subies. Un intéressant exemple de géopolitique. Mais, par delà la question de bloquer l'accès aux gens situés à l'étranger, il n'est pas sûr que cela soit efficace du point de vue opérationnel : les attaquants professionnels n'attaquent pas depuis la machine qui est sur le bureau, ils utilisent un botnet, dont certaines machines sont en France… En outre, le blocage est fait en couche 3 (IP), contrairement aux sites de vidéo à la demande ou de commerce en ligne, qui, pour des raisons juridiques, le font en couche 7. Cela a pour conséquence l'absence de message d'erreur clair pour l'utilisateurice.
Merci à Marie-Odile Morandi pour le signalement de ce cas intéressant.
L'article seul
Essais du système de déboguage des réseaux Globalping
Première rédaction de cet article le 28 août 2024
Si vous lisez ce blog régulièrement, vous savez que j'insiste souvent pour que, lorsqu'on teste un service réseau, on ne le fasse pas que depuis un seul point de mesure. L'Internet est vaste, et varié ! Il faut donc utiliser plusieurs points de mesure. Si on ne travaille pas chez Google, on n'a probablement à sa disposition qu'un petit nombre de points à sa disposition et on utilise donc un système réparti de mesure. Vous le savez, je suis un grand fan des sondes RIPE Atlas mais il est toujours bon de regarder les alternatives comme Globalping, qui fait l'objet de cet article.
Alors, je ne vais pas arrêter d'utiliser le système des sondes RIPE Atlas, qui a bien plus de points de mesure et, surtout, qui est géré par une organisation sans but lucratif, contrôlée par ses membres. Mais la diversité sur l'Internet est une bonne chose, et il faut connaitre les autres possibilités. Donc, Globalping est un réseau de points de mesures actives, utilisant l'infrastructure du CDN jsDelivr, mesures qu'on peut déclencher soi-même. Je vous laisse regarder le site Web pour en savoir plus, je vais juste tester un peu.
Les mesures peuvent être déclenchées par l'interface Web, par
un programme qu'on installe localement (n'étant pas fan de
curl install.sh | sudo bash, je ne l'ai pas testé) ou par une API. Celle-ci semble bien fichue et bien
documentée donc je vais faire les essais avec elle. Dans tous
les cas, c'est gratuit et il n'y a pas besoin de se créer un compte,
ce qui est très rafraichissant dans un monde où les marketeux
insistent pour que vous laissiez vos données personnelles pour tout
et n'importe quoi. Je suppose que ces accès « anonymes » ont des
limites, par exemple en nombre de mesures déclenchées, mais je n'ai
pas étudié la question en profondeur.
Donc, commençons avec l'API. On fait une requête HTTP à
api.globalping.io et la requête est évidemment
un petit bout de JSON. Voici un exemple d'un script
shell qui appelle curl pour demander une mesure
IPv6 vers ce blog :
#!/bin/sh
curl --compressed --write-out '\nReturn code: %{http_code}\n' \
--data-binary @- \
--header "Content-Type: application/json" \
https://api.globalping.io/v1/measurements \
<<EOF
{
"limit": 5,
"locations": [],
"target": "www.bortzmeyer.org",
"type": "ping",
"measurementOptions": {
"packets": 3,
"ipVersion": 6
}
}
EOF
Le script va vous afficher l'identificateur de cette mesure, vous
pouvez la récupérer en ajoutant
https://api.globalping.io/v1/measurements/
devant. Ce sera du JSON, qu'on peut traiter avec les moyens
classiques, par exemple jq, comme avec
les sondes Atlas :
% jq '"Average: " + (.results[].result.stats.avg | tostring) + " ms"' chDqJ8xB9HxCrpCe.json "Average: 225.948 ms" "Average: 223.1 ms" "Average: 139.932 ms" "Average: 35.985 ms" "Average: 2.802 ms"
Ici, on affiche le temps d'aller-retour moyen pour chaque sonde. Je ne crois pas que le JSON produit soit documenté mais il est assez clair comme cela.
J'aime bien les éventuels messages d'erreur, très précis :
{
"error": {
"type": "validation_error",
"message": "Parameter validation failed.",
"params": {
"measurementOptions.protocole": "\"measurementOptions.protocole\" is not allowed"
}
},
"links": {
"documentation": "https://www.jsdelivr.com/docs/api.globalping.io#post-/v1/measurements"
}
}
On peut aussi faire des mesures DNS, par exemple avec cette demande en JSON :
{
"limit": 5,
"locations": [],
"target": "qwant.com",
"type": "dns",
"measurementOptions": {
}
}
Et si on demande dans le fichier résultant les données obtenues :
% jq '.results[].result.answers[].value' eghOnwP7HffbmGVa.json "54.38.0.163" "141.95.150.143" "141.94.211.182" "54.38.0.163" "141.94.211.182" …
Mais, apparemment, on ne peut pas récupérer la réponse DNS complète, seulement les parties analysées par leur logiciel.
Et avec HTTP ? Demandons :
{
"limit": 5,
"locations": [],
"target": "www.aemarielle.com",
"type": "http",
"measurementOptions": {
"protocol": "HTTPS",
"request": {
"path": "/"
}
}
}
Et on obtient un beau fichier JSON dont on peut extraire, par exemple :
% jq '"Total time: " + (.results[].result.timings.total | tostring) + " ms"' iLBZu1TOiyqXzQF1.json "Total time: 1481 ms" "Total time: 1157 ms" "Total time: 421 ms" "Total time: 1512 ms" "Total time: 888 ms"
Et si on veut participer et avoir sa propre sonde ? (J'ai oublié de dire que tout est apparemment en logiciel libre.) La solution suggérée est d'installer une sonde logicielle via Docker ou Podman. Bon, pour être franc, avec la commande indiquée, je n'ai pas réussi à le faire avec Podman :
WARN[0000] Using cgroups-v1 which is deprecated in favor of cgroups-v2 with Podman v5 and will be removed in a future version. Set environment variable `PODMAN_IGNORE_CGROUPSV1_WARNING` to hide this warning. Error: failed to get new shm lock manager: failed to create 2048 locks in /libpod_lock: no such file or directory
Ou bien, sur une autre machine :
Error: short-name "globalping/globalping-probe" did not resolve to an alias and no unqualified-search registries are defined in "/etc/containers/registries.conf"
On peut aussi demander une sonde matérielle mais il faut payer dix dollars par mois ce qui m'a semblé excessif.
L'article seul
RFC 9637: Expanding the IPv6 Documentation Space
Date de publication du RFC : Août 2024
Auteur(s) du RFC : G. Huston (APNIC), N. Buraglio (Energy Sciences Network)
Pour information
Réalisé dans le cadre du groupe de travail IETF v6ops
Première rédaction de cet article le 28 août 2024
Le préfixe IPv6 normalisé pour les
documentations, 2001:db8::/32 était trop petit
pour vous ? Vous aviez du mal à exprimer des architectures réseau
complexes, avec beaucoup de préfixes ? Ne pleurez plus, un nouveau
préfixe a été alloué, c'est désormais un /20, le 3fff::/20.
Ce RFC modifie
légèrement le RFC 3849, qui normalisait ce
préfixe de documentation. Le but d'un préfixe IP de documentation est
d'éviter que les auteur·es de ces documentations ne prennent des
adresses IP qui existent
par ailleurs, au risque que des administrateurices
réseaux maladroit·es ne copient ces adresses IP (songez
au nombre d'articles qui parlent d'IPv4 en
utilisant des exemples comme les adresses
1.1.1.1 ou 1.2.3.4, qui
existent réellement). On doit donc utiliser les noms de domaine du RFC 2606, les adresses IPv4 du RFC 5737, et les numéros d'AS du RFC 5398. Pour IPv6, l'espace de
documentation est désormais 3fff::/20 (l'ancien
préfixe 2001:db8::/32
reste réservé et valable donc pas besoin de modifier les
documentations existantes).
Cette nouvelle taille permet de documenter des réseaux réalistes,
par exemple où deux /32 se parlent.
Si ce préfixe est désormais dans le registre des adresses spéciales, il ne semble pas (encore ?) décrit dans la base d'un RIR, contrairement à son prédécesseur.
L'article seul
RFC 9276: Guidance for NSEC3 Parameter Settings
Date de publication du RFC : Août 2022
Auteur(s) du RFC : W. Hardaker (USC/ISI), V. Dukhovni
(Bloomberg)
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 26 août 2024
Si vous êtes responsable d'une zone DNS, et que vous la testez régulièrement avec des outils comme Zonemaster ou DNSviz (ce que font tous les responsables sérieux), vous avez peut-être eu des avertissements comme quoi vos « paramètres NSEC3 » n'étaient pas ceux conseillés. C'est parce que les recommandations en ce sens ont changé avec ce RFC. Lisez-le donc si vous voulez comprendre les recommandations actuelles.
D'abord, un peu de contexte. Ce RFC concerne les zones qui sont
signées avec DNSSEC
et qui utilisent les enregistrements NSEC3 du
RFC 5155. Aujourd'hui, par exemple, c'est le
cas de .fr,
.com mais aussi de
bortzmeyer.org grâce à qui vous êtes arrivés
sur cet article. Mais ce n'est pas le cas de la racine des
noms de domaine, qui
utilise NSEC (RFC 4035). Pour comprendre la
dfifférence entre les deux, je vous renvoie à mon article sur le
RFC 5155.
Un exemple où Zonemaster proteste, sur
icann.org :

Ce RFC 5155 donnait des conseils de sécurité cryptographiques qui, avec le recul et l'expérience se sont avérés sous-optimaux. Ce nouveau RFC 9276 les modifie donc et suggère fortement de ne plus utiliser de sel, ni d'itérations successives, dans le calcul des condensats pour NSEC3.
Lorsqu'une zone est signée avec utilisation de NSEC3, elle comprend un enregistrement de type NSEC3PARAM qui indique quatre choses :
- L'algorithme de condensation utilisé (presque toujours SHA-1, aujourd'hui, c'est le seul normalisé). Il n'est pas discuté ici (voir le RFC 8624 sur le choix des algorithmes).
- Les options, notamment celle nommée
opt-out et qui est un avantage souvent oublié
de NSEC3 par rapport à NSEC : la possibilité de ne pas avoir un
enregistrement NSEC3 par nom mais seulement par nom signé. C'est
un peu moins sûr (les noms non signés, typiquement les délégations
DNS, ne sont pas protégés) mais ça fait une grosse économie de
mémoire pour les zones qui comprennent beaucoup de délégations non
signées (et cela évite de passer trop de temps à modifier les
chaines NSEC3 dans des zones qui changent souvent). C'est
typiquement la cas des gros TLD et cela explique pourquoi
.frou.comutilisent NSEC3, même s'il n'y a pas de problème avec l'énumération des noms (.frdistribue la liste). (Notez que si l'option est à 0 dans le NSEC3PARAM, cela ne signifie pas qu'il n'y a pas d'opt-out, celui-ci est typiquement indiqué uniquement dans les enregistrements NSEC3.) - Le nombre d'itérations supplémentaires (RFC 5155, sections 3.1.3 et 4.1.3) faites lorsqu'on condense un nom.
- Le sel utilisé.
Voici par exemple l'enregistrement de icann.org
en août 2024 :
% dig +short icann.org NSEC3PARAM 1 0 5 A4196F45E2097176
Utilisation de SHA-1 (le 1 est le code de SHA-1), pas
d'opt-out (mais prudence, son utilisation n'est
pas obligatoirement signalée dans les options, voir plus haut), cinq
itérations supplémentaires (donc six au total) et un sel apparemment
aléatoire, A4196F45E2097176.
La première recommandation du RFC concerne le nombre
d'itérations. Comme le sel, le but est de rendre plus difficile
l'utilisation de tables calculées à l'avance par un attaquant. Sans
sel et avec une seule itération, un attaquant qui a à l'avance
calculé tout un dictionnaire et sait donc que le condensat de
foobar est
8843d7f92416211de9ebb963ff4ce28125932878 pourra
donc facilement inverser le condensat dans un enregistrement
NSEC3. C'est pour cela que le RFC 5155
recommandait un nombre variable d'itérations, indiqué par
l'enregistrement NSEC3PARAM. Mais, en pratique, la protection contre
l'énumération n'est pas si solide que ça. Bien des noms peuvent être
devinés (www étant le plus évident mais il y a
aussi les mots d'un dictionnaire de la langue), d'autant plus qu'on
choisit en général un nom de domaine pour être simple
et facilement mémorisable. Et que ces noms se retrouvent à
plein d'endroits comme les journaux Certificate
Transparency (RFC 9162). L'opinion
d'aujourd'hui est que le jeu (la protection contre l'énumération)
n'en vaut pas la chandelle (le coût de signature
et de validation). Notez aussi une externalité négative : les résolveurs aussi devront effectuer ces
itérations et sont donc concernés. Bon, en prime, les techniques
modernes rendent la protection peu efficace de toute façon
(cf. « GPU-Based NSEC3 Hash
Breaking »). La recommandation du RFC
est donc de ne pas avoir d'itérations supplémentaires, donc de
mettre ce nombre à zéro.
Et la deuxième recommandation concerne le sel. Il y a dans NSEC3 un sel implicite, c'est le nom de domaine (RFC 5155, section 5). D'ailleurs, mon exemple de condensat de foobar était faux, puisque j'avais omis cette étape. Si on l'inclut, le sel supplémentaire indiqué dans l'enregistrement NSEC3PARAM perd de son intérêt. En outre, en pratique, on change rarement le sel (cela nécessite de modifier toute la chaine NSEC3) ce qui diminue la protection qu'il offre. La recommandation actuelle est donc de ne pas utiliser de sel (ce qui se note avec un tiret, pas avec une chaine vide).
Si on suit les recommandations du RFC, le NSEC3PARAM aura cette allure :
% dig +short fr NSEC3PARAM 1 0 0 -
Et un des NSEC3 sera du genre :
% dig nexistesurementpas.fr
qu7kmgn3e….fr. 594 IN NSEC3 1 1 0 - (
QU7MMK1…
NS DS RRSIG )
Notez aussi que le RFC recommande (section 3), avant de réfléchir
aux paramètres de NSEC3, de réfléchir à NSEC3 lui-même. Sur une
grosse zone de délégation, changeant souvent, comme
.fr, NSEC3 est tout à fait justifié en raison
des avantages de l'opt-out. Mais sur la zone DNS
typique d'une petite organisation, qui ne compte souvent que des
noms prévisibles (l'apex, www et
mail), NSEC3 peut avantageusement être remplacé
par NSEC, qui consomme moins de ressources. (NSEC3, ou d'ailleurs
les couvertures minimales du RFC 4470, peut, dans le
pire des cas, faciliter certaines attaques par déni de
service.)
Les recommandations précédentes s'appliquaient aux signeurs de zone (côté serveurs faisant autorité, donc). Mais la section 3 a aussi des recommandations pour les résolveurs : compte-tenu du coût que représente pour eux les itérations NSEC3, ils ont le droit d'imposer un maximum, et de le diminuer petit à petit. Ces résolveurs peuvent refuser de répondre (réponse SERVFAIL) ou bien traiter la zone come n'étant pas signée (cf. section 6). Un nouveau code d'erreur étendu (RFC 8914), le numéro 27, Unsupported NSEC3 iterations value, a été réservé pour qu'ils puissent informer leurs clients.
Revenons aux serveurs faisant autorité : le RFC précise aussi qu'un hébergeur DNS devrait informer clairement ses utilisateurs des paramètres NSEC3 qu'il accepte. Il ne faudrait pas qu'on choisisse N itérations et qu'on s'aperçoive au déploiement qu'un des secondaires n'accepte pas d'en faire autant.
Aujourd'hui, la grande majorité des zones utilisant NSEC3 est
passée aux recommandations de ce RFC (comme par
exemple .fr en 2022). Notons que .org a
un sel mais pas d'itérations supplémentaires.
% dig +short org NSEC3PARAM 1 0 0 332539EE7F95C32A
Si vous utilisez OpenDNSSEC pour automatiser les opérations DNSSEC sur vos zones, voici la configuration conforme au RFC que j'utilise :
<Denial>
<NSEC3>
<!-- <OptOut/> -->
<Resalt>P100D</Resalt>
<Hash>
<Algorithm>1</Algorithm>
<Iterations>0</Iterations>
<Salt length="0"/>
</Hash>
</NSEC3>
</Denial>
L'article seul
Fiche de lecture : Le triomphe et le règne des mammifères
Auteur(s) du livre : Steve Brusatte
Éditeur : Quanto
978-288915-554-5
Publié en 2023
Première rédaction de cet article le 26 août 2024
Vous qui me lisez, vous êtes probablement un mammifère. Sans une météorite complaisante, vous seriez toujours un genre de petite souris qui n'a même pas inventé l'Internet et vous ne pourriez pas lire ce blog. Heureusement pour vous et malheureusement pour les dinosaures, la météorite a frappé, dégageant le terrain pour « le triomphe et le règne des mammifères », que raconte ce livre.
L'auteur avait justement écrit avant sur les dinosaures mais je n'ai pas lu ce précédent livre. Ici, il décrit en détail toute l'histoire de ces bestioles à poils et à mamelles dont nous faisons partie. C'est un livre de vulgarisation mais il faut s'accrocher quand même, l'auteur ne se contente pas d'images d'animaux mignons, il rentre bien dans les détails techniques, mais c'est très vivant, très bien écrit, une lecture recommandée si vous voulez vous tenir au courant du passé.
L'auteur ne parle pas que des bestioles, une part importante du livre est consacrée aux paléontologues, à leur parcours personnel et professionnel souvent surprenant, à leur travail et à leurs découvertes. (Vous y lirez, par exemple, une rencontre avec Zofia Kielan-Jaworowska.)
(J'ai lu la traduction en français, l'original en anglais avait été publié en 2022.)
L'article seul
RFC 9301: Locator/ID Separation Protocol (LISP) Control-Plane
Date de publication du RFC : Octobre 2022
Auteur(s) du RFC : D. Farinacci (lispers.net), F. Maino (Cisco Systems), V. Fuller (vaf.net Internet Consulting), A. Cabellos (UPC/BarcelonaTech)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF lisp
Première rédaction de cet article le 23 août 2024
Comme pour tous les protocoles de séparation de l'identificateur et du localisateur, le protocole LISP, normalisé dans le RFC 9300, doit faire face au problème de la correspondance (mapping) entre les deux informations. Comment trouver un localisateur, en ne connaissant que l'identificateur ? LISP n'a pas de solution unique et plusieurs protocoles de correspondance peuvent être utilisés. La stabilité du logiciel des routeurs imposait une interface stable avec le système de résolution des identificateurs en localisateurs. C'est ce que fournit notre RFC 9301, qui spécifie l'interface, vue du routeur, et qui ne devrait pas changer, même si de nouveaux systèmes de correspondance/résolution apparaissent. Ce RFC remplace le RFC 6833. L'interface change assez peu mais le texte est sérieusement réorganisé, et la spécification a désormais le statut de norme et plus simplement d'expérimentation.
LISP prévoit deux sortes de machines impliquées dans la résolution d'identificateurs (les EID, Endpoint ID) en localisateurs (les RLOC, Routing Locator). Ces deux machines sont les Map-Resolver et les Map-Server. Pour ceux qui connaissent le DNS, on peut dire que le Map-Server est à peu près l'équivalent du serveur faisant autorité et le Map-Resolver joue quasiment le même rôle que celui du résolveur. Toutefois, il ne faut pas pousser la comparaison trop loin, LISP a ses propres règles. Pour résumer en deux phrases, un routeur LISP d'entrée de tunnel (un ITR, Ingress Tunnel Router), ayant reçu un paquet à destination d'une machine dont il connait l'identificateur (l'EID), va interroger un Map-Resolver pour connaître le localisateur (le RLOC, auquel l'ITR enverra le paquet). Pour accomplir sa tâche, le Map-Resolver fera suivre les requêtes au Map-Server, qui la transmettra finalement au routeur de sortie du tunnel (l'ETR, Egress Tunnel Router), qui est la vraie source faisant autorité.
C'est entre le Map-Resolver et le Map-Server que se trouvent les détails du système de correspondance. Ils peuvent être connectés par ALT (RFC 6836), par CONS (RFC jamais publié), par NERD (RFC 6837), par DDT (RFC 8111) ou bien par tout autre système de résolution, existant ou encore à créer (ils ne peuvent pas être connectés avec simplement LISP, puisqu'on aurait alors un problème d'œuf et de poule, LISP ayant besoin de ALT qui aurait besoin de LISP… cf. section 8.1). Rappelez-vous que notre RFC 9301 ne décrit qu'une interface, celle des ITR et ETR avec les Map-Resolver et Map-Server. Il est donc relativement court.
Comme avec toute technique nouvelle, il est prudent d'apprendre
le vocabulaire (section 3, puis section 4 pour un survol général du
système). Il y a deux types d'acteurs, les
Map-Server et les Map-Resolver
que nous avons déjà vu, et trois types
importants de messages, Map-Register (un
ETR l'envoie au Map-Server pour indiquer les RLOC
des EID dont il est responsable), Map-Request
(un ITR l'envoie à un Map-Resolver pour obtenir
les RLOC ; le Map-Resolver fait suivre jusqu'au
Map-Server, puis à l'ETR) et enfin
Map-Reply, la réponse au précédent. Notons que
ces types de messages ont leur description complète (avec leur
format) dans le RFC 9300. Notez aussi
que Map-Resolver et Map-Server
sont des fonctions, et que les deux peuvent être assurés par la même
machine, qui serait à la fois Map-Resolver et
Map-Server (dans le DNS, un tel mélange est
déconseillé).
Schéma général du système de correspondance LISP :
La section 8 de notre RFC plonge dans les
détails. Accrochez-vous. Voyons d'abord le premier routeur LISP que
rencontrera le paquet. On le nomme ITR pour Ingress Tunnel
Router. Les routeurs précédents traitaient l'adresse de
destination du paquet comme une adresse IP
ordinaire. L'ITR, lui, va la traiter comme un identificateur (EID
pour Endpoint IDentification). L'EID n'est pas
routable sur l'Internet. Il faut donc encapsuler le paquet en LISP
pour l'envoyer dans le tunnel. La nouvelle adresse IP de destination
est le localisateur (RLOC pour Routing
LOCator). Pour trouver le localisateur, l'ITR va demander
à un ou plusieurs Map-Resolver. Il a été
configuré (typiquement, à la main) avec leurs adresses IP (qui
doivent être des localisateurs, pour éviter un amusant problème
d'œuf et de poule; notez que plusieurs
Map-Resolver peuvent avoir la même adresse, grâce
à l'anycast). L'ITR ne
connait que le protocole de résolution, envoi d'une
Map-Request et récupération d'une
Map-Reply (en termes DNS, l'ITR est un
stub resolver). L'ITR ne connait donc
pas les protocoles utilisés en interne par le
système de correspondance, il ne connait pas ALT (ou ses
concurrents). Cette communication avec le
Map-Resolver peut être testée et déboguée avec
l'outil lig (RFC 6835).
La réponse du Map-Resolver ne sera pas
forcément positive. L'ITR recevra peut-être une
negative Map-Reply, envoyée
en réponse si un Map-Resolver ne trouve pas de
localisateur pour l'identificateur qu'on lui a passé. Cela veut dire
que le site final n'utilise pas LISP, et qu'il faut alors router le
paquet avec les méthodes habituelles d'IP. (Il n'est évidemment pas prévu que tout
l'Internet passe à LISP du jour au lendemain, le routeur LISP doit
donc aussi pouvoir joindre les sites non-LISP.)
Si la réponse est positive, l'ITR peut alors encapsuler le paquet et le transmettre. Comment le Map-Resolver a-t-il trouvé la réponse qu'il a envoyé ? Contrairement aux routeurs LISP comme l'ITR, le Map-Resolver et le Map-Server connaissent le système de correspondance utilisé (si c'est ALT, ils sont tous les deux routeurs ALT) et c'est celui-ci (non traité dans ce RFC) qu'ils utilisent pour savoir s'il y a une réponse et laquelle.
Et, à l'autre bout du tunnel, que s'était-il passé ? Le routeur
de fin de tunnel (l'ETR, pour Egress Tunnel
Router), avait été configuré par un administrateur réseaux
avec une liste d'EID dont il est responsable. Pour que le reste du
monde connaisse ces EID, il les publie auprès d'un
Map-Server en envoyant à ce dernier des messages
Map-Register. Pour d'évidentes raisons de
sécurité, ces messages doivent être authentifiés (champ
Authentication Data du message
Map-Register, avec clés gérées à la main pour
l'instant, avec SHA-256 au minimum), alors
que les Map-Request ne l'étaient pas (la base
de données consultée par les routeurs LISP est publique, pas besoin
d'authentification pour la lire, seulement pour y écrire). Ces
Map-Request sont renvoyés périodiquement (le
RFC suggère toutes les minutes) pour que le
Map-Server sache si l'information est toujours à
jour. Ainsi, si un ETR est éteint, l'information obsolète dans les
Map-Server disparaîtra en trois minutes maximum
(des messages peuvent être perdus, le RFC demande donc de patienter
un peu en cas de non-réception). Cela veut aussi dire que LISP ne
convient pas forcément tel quel pour les situations où on exige une
mobilité très rapide.
Notez que je ne décris pas tous les détails (comme la possibilité pour un ETR de demander un accusé de réception au Map-Server, chose que ce dernier ne fait pas par défaut), voyez le RFC si vous êtes curieux.
Arrivés là, nous avons un Map-Server qui
connait les EID que gère l'ETR. Désormais, si ce
Map-Server reçoit une demande
Map-Request, il peut la faire suivre à l'ETR
(si vous connaissez le DNS, vous avez vu que le
Map-Register n'est pas tout à fait l'équivalent
des mises à jour dynamiques du RFC 2136 : avec
ces dernières, le serveur de noms qui a reçu la mise à jour répondra
ensuite lui-même aux requêtes). Le Map-Server ne
sert donc que de relais, il ne modifie pas la requête
Map-Request, il la transmet telle quelle à
l'ETR. Le rôle des Map-Resolver et des
Map-Server est donc simplement de trouver l'ETR
responsable et de lui faire suivre (sans utiliser l'encapsulation
LISP) les requêtes, pas de répondre à sa place. Cela se fera
peut-être dans le futur lorsque des mécanismes de
cache seront ajoutés. Pour le moment, les
Map-Resolver n'ont pas de cache, de mémoire
(section 4), une
grosse différence avec le DNS (section 1).
La section 9 fait le tour des questions de sécurité liées au service de résolution. Comme les requêtes sont faites avec le format de paquets de LISP, elles héritent des services de sécurité de LISP comme le nonce qui permet de limiter les risques d'usurpation ou comme la sécurité LISP du RFC 9303. Par contre, comme pour les protocoles utilisés dans l'Internet actuel, il n'y a pas de vraie protection contre les annonces faites à tort (un Map-Server qui annoncerait un EID qui n'est pas à lui). C'est un problème très proche de celui de la sécurité de BGP et qui utilisera peut-être le même genre de solutions.
Notez qu'en théorie, l'interface spécifiée dans ce RFC pourrait servir à d'autres protocoles que celui du RFC 9300, comme par exemple GRE (RFC 2890) ou VXLAN (RFC 7348). Mais, pour l'instant, ce n'est pas le cas.
Il y a apparemment trois mises en œuvre. Outre l'outil de débogage lig (RFC 6835), il y a celle de Cisco pour ses routeurs, mais je ne connais pas les autres, sans doute dans des Unix.
Et les changements depuis le précédent RFC ? Ils sont résumés dans la section 11 :
- Ajout du type de message
Map-Notify-Ack, un accusé de réception, - Plein de bits supplémentaires dans les en-têtes des messages,
- Dans les actions qu'un routeur peut prendre lorsqu'un paquet arrive, ajout de possibilités de rejet du paquet (section 5.4).
L'article seul
Fiche de lecture : La souveraineté numérique
Auteur(s) du livre : Brunessen Bertrand, Guillaume Le
Floch
Éditeur : Bruylant
978-2-8027-7134-0
Publié en 2024
Première rédaction de cet article le 19 août 2024
Cet ouvrage collectif rassemble les articles liés aux interventions lors d'un intéressant colloque sur la souveraineté numérique tenu à la fac de droit de Rennes en 2022.
(Curieusement, le livre ne mentionne apparemment pas du tout le colloque.)
Comme tous les ouvrages collectifs, personne ne sera d'accord avec tout. Personnellement, j'ai trouvé qu'il y avait une variété de positions qui permet de bien se rendre compte de la difficulté de cerner le concept de souveraineté numérique et ses conséquences. Je trouve quand même que plusieurs articles sont excessivement pro-État, considérant que l'État agit forcément dans l'intérêt des citoyens, que la loi de l'État est toujours parfaite et que le remède à tous les problèmes de l'Internet est davantage de lois formelles (rappelez-vous que ce colloque est organisé par des juristes). Heureusement, certaines interventions comme celle de Pauline Türk (« L'exercice des fonctions de l'État à l'ère numérique ») sont plus critiques vis-à-vis de cette conception.
Une section particulièrement riche et originale est celle consacrée aux différentes conceptions nationales de la souveraineté numérique. Elle permet d'échapper à une vision étroite de la souveraineté et essayant de se placer à la place des autres. Ainsi, Paul-Alain Zibi Fama (qui n'avait pas pu être présent au colloque) parle de la souveraineté numérique, vue d'Afrique, continent régulièrement oublié dans les débats sur l'Internet. L'idée est très bonne mais gâchée par des erreurs comme de parler de blockchain « chiffrée », alors que justement la chaîne de blocs repose sur la transparence, pas sur la confidentialité. D'autre part, il met l'accent sur le manque de cadre juridique en Afrique, comme si c'était le principal problème (encore un biais de juriste). J'ai par contre apprécié l'analyse détaillé de l'état actuel de dépendance de l'Afrique, et l'accent mis sur l'importance de l'éducation.
J'ai aussi noté l'article de Mathilde Velliet sur « La conception américaine [sic] de la souveraineté numérique » à propos de l'extrême hypocrisie de la position de Washington (aussi bien le gouvernement que les influenceurs) pour qui « souveraineté numérique » est un gros mot, uniquement utilisé pour critiquer les efforts d'indépendance technologique des autres pays, notamment l'Europe, alors que les nombreuses interventions de l'État pour aider les entreprises étatsuniennes, qui ont exactement les mêmes objectifs, ne sont jamais critiquées.
Mais lisez le reste du livre : vous y trouverez plein de choses, sur ce thème souvent abordé de manière simpliste dans les médias et les réseaux sociaux. (Oui, je sais, il est cher. Demandez à votre employeur.)
Des vidéos du colloque sont disponibles en ligne.
L'article seul
RFC 9606: DNS Resolver Information
Date de publication du RFC : Juin 2024
Auteur(s) du RFC : T. Reddy.K (Nokia), M. Boucadair
(Orange)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF add
Première rédaction de cet article le 18 août 2024
Traditionnellement, tous les résolveurs DNS fournissaient un service équivalent. Le client avait un résolveur configuré, soit statiquement, soit via DHCP, et ne se souciait pas vraiment du résolveur ainsi désigné, tous étaient pareils. Aujourd'hui, ce n'est plus vraiment le cas : les résolveurs fournissent des services très différents, par exemple en matière de chiffrement, ou de blocage de certains noms. Il est donc utile que le client puisse se renseigner sur son résolveur, ce que permet cette nouvelle technique, le type de données RESINFO, que le client va récupérer dans le DNS.
Voici une liste (non-limitative !) des caractéristiques d'un résolveur et qui peuvent être présentes ou pas :
- Chiffrement des requêtes, avec DoT, DoH ou DoQ.
- Blocage de certains noms, par exemple la publicité, ou le porno, ou bien les noms qui gênent le gouvernement, ou encore les noms des services qui osent enfreindre la propriété intellectuelle sacrée.
- Protection de la vie privée via la minimisation des requêtes (RFC 9156) et/ou l'absence de stockage de l'historique des requêtes.
Avant la solution de ce RFC, la seule manière pour le client DNS de savoir ce que son résolveur proposait était manuelle, en lisant des documentations (cf. par exemple celle de mon résolveur). Ce n'est pas pratique quand la configuration du résolveur est automatique ou semi-automatique, via DHCP, ou avec les solutions des RFC 9462 et RFC 9463.
Ce nouveau RFC propose donc un mécanisme qui permet au client de découvrir les caractéristiques d'un résolveur et de les analyser, avant de décider quel résolveur choisir. (Un point important est que ce RFC se veut neutre : il ne dit pas quelles sont les bonnes caractéristiques d'un résolveur, le client reçoit une information, il est libre de l'utiliser comme il veut.)
Place à la technique (section 3 du RFC) : un nouveau type de
données DNS est défini, RESINFO (code
261). Son contenu est l'information recherchée, sous forme de
couples clé=valeur. Le nom de domaine auquel il est rattaché est le
nom du résolveur, récupéré par les méthodes des RFC 9462 et RFC 9463, ou manuellement
configuré. Ce nom est désigné par le sigle ADN, pour
Authentication Domain Name (RFC 9463, section 3.1.1). Si on a utilisé le nom spécial
resolver.arpa (RFC 9462,
section 4), on peut lui demander son RESINFO.
Le format du RESINFO (section 4 du RFC) est copié sur celui des enregistrements TXT. Chaque chaine de caractères suit le modèle clé=valeur du RFC 6763, section 6.3. Les clés inconnues doivent être ignorées, ce qui permettra dans le futur d'ajouter de nouvelles clés au registre des clés. Un exemple d'enregistrement RESINFO :
resolver IN RESINFO "qnamemin" "exterr=15,17" "infourl=https://resolver.example.com/guide"
Il indique (section 5, sur la signification des clés) que ce résolveur fait de la minimisation des requêtes (RFC 9156), et notez que cette clé n'a pas de valeur, c'est juste un booléen dont la présence indique la QNAME minimisation. L'enregistrement continue en donnant les codes EDE (Extended DNS Errors, RFC 8914) que peut renvoyer le résolveur. C'est surtout utile pour indiquer ce qu'il bloque (15 = bloqué par décision de l'administrateurice du résolveur, 17 = bloqué par demande de l'utilisateurice). Et enfin il donne un URL où on peut aller chercher davantage d'information en langue naturelle.
La section 7 du RFC donne quelques conseils de sécurité : avoir
un lien sécurisé avec le résolveur qu'on interroge (par exemple avec
DoT), pour éviter qu'un méchant ne modifie le
RESINFO, et valider la réponse avec DNSSEC (sauf pour
resolver.arpa, qui est un cas spécial).
La section 8 précise le registre
des clés disponibles. Pour ajouter des clés (on note qu'à
l'heure actuelle, il n'y en a pas pour indiquer la disponibilité de
DoT ou DoH, ou pour la politique de conservation des
requêtes), la procédure est « spécification nécessaire » (RFC 8126). Si on veut des clés non normalisées, on
doit les préfixer par temp-.
RESINFO est récent et donc pas forcément mis en œuvre dans tous les logiciels DNS que vous utilisez. Un dig récent fonctionne :
% dig dot.bortzmeyer.fr RESINFO … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 34836 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1 … ;; ANSWER SECTION: dot.bortzmeyer.fr. 86369 IN CNAME radia.bortzmeyer.org. radia.bortzmeyer.org. 86369 IN RESINFO "qnamemin" "infourl=https://doh.bortzmeyer.fr/policy" ;; Query time: 0 msec ;; SERVER: 192.168.2.254#53(192.168.2.254) (UDP) ;; WHEN: Sun Aug 18 08:15:55 UTC 2024 ;; MSG SIZE rcvd: 142
Si vous avez un dig plus ancien, il faudra demander TYPE261 et pas RESINFO. Notez que, physiquement, un RESINFO est juste un TXT, ce qui facilite sa mise en œuvre (dans le futur dnspython, la classe RESINFO hérite simplement de TXT).
Trouve-t-on beaucoup de RESINFO dans la nature ? La plupart des grands résolveurs DNS publics ne semblent pas en avoir. Une exception est DNS4ALL :
% dig +short dot.dns4all.eu RESINFO "qnamemin exterr=0-1,3,5-12,18,20 infourl=https://dns4all.eu"
Et, comme vous le voyez plus haut, j'en ai mis un dans mon résolveur. Le logiciel du serveur primaire ne connaissant pas encore ce type, j'ai utilisé la technique des types inconnus du RFC 3597 :
; Pour le résolveur public : ; Type RESINFO (RFC 9606), enregistré à l'IANA mais pas encore connu des logiciels radia IN TYPE261 \# 50 08716e616d656d696e 28696e666f75726c3d68747470733a2f2f646f682e626f72747a6d657965722e66722f706f6c696379
Cette série de chiffres hexadécimaux ayant été produite à partir de
la version texte et du programme text-to-unknown-txt-type.py
L'article seul
RFC 9581: Concise Binary Object Representation (CBOR) Tags for Time, Duration, and Period
Date de publication du RFC : Août 2024
Auteur(s) du RFC : C. Bormann (Universität Bremen TZI), B. Gamari (Well-Typed), H. Birkholz (Fraunhofer SIT)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF cbor
Première rédaction de cet article le 17 août 2024
Ce RFC ajoute au format de données binaire CBOR la possibilité de stocker des données temporelles plus détaillées, incluant par exemple l'échelle utilisée (UTC ou TAI), ou bien ayant une précision supérieure.
Petit rappel : CBOR est normalisé dans le RFC 8949, il incluait deux étiquettes pour les données temporelles, permettant d'indiquer date et heure en format lisible par un humain, et sous forme d'un nombre de secondes depuis l'epoch, avec une résolution d'une seconde. Le RFC 8943 y ajoute les dates (sans indication de l'heure). Au passage, le concept d'étiquette en CBOR est normalisé dans la section 3.4 du RFC 8949.
Notre nouveau RFC 9581 ajoute :
- Une étiquette, 1001, pour un temps étendu, sous forme d'un dictionnaire CBOR. La clé 1 doit être présente, pour indiquer le temps de base, des clés négatives servent pour indiquer des fractions de seconde, la clé -1 sert pour l'échelle (UTC ou TAI, notamment).
- Une étiquette, 1002, pour indiquer une durée. C'est également un dictionnaire CBOR.
- Une étiquette, 1003, pour indiquer une période, représentée par une date de début et une date de fin.
Ces nouvelles étiquettes ont été ajoutées au registre des étiquettes CBOR. Les clés possibles pour les dictionnaires indiquant les temps étendus sont dans un nouveau registre à l'IANA. Ajouter une entrée à ce registre nécessite un RFC et un examen par un expert.
Un service sur ce blog, https://www.bortzmeyer.org/apps/date-in-cbor
% curl -s https://www.bortzmeyer.org/apps/date-in-cbor | cbor2diag.rb
["Current date in CBOR, done with Python 3.11.2 (main, Mar 13 2023, 12:18:29) [GCC 12.2.0] and the flunn library <https://github.com/funny-falcon/flunn>",
0("2024-04-17T14:21:07Z"),
1(1713363667),
100(19830),
1004("2024-04-17"),
1001({1: 1713363667, -1: 0, -9: 193986759}),
1001({1: 1713363704, -1: 1}),
"Duration since boot: ",
1002({1: 1742903})]
On voit alors successivement :
- Les deux valeurs étiquetées 0 et 1 du RFC 8949 et les deux valeurs étiquetées 100 et 1004 du RFC 8943.
- Puis les nouveautés de notre RFC.
- D'abord, un temps étendu étiqueté 1001. Le dictionnaire a trois éléments, celui de clé 1 est la date et heure, celui de clé -1 indique qu'il s'agit d'un temps UTC, celui de clé -9 indique qu'il s'agit de nanosecondes (-3 : millisecondes, -6 : microsecondes, etc). On a ainsi une meilleure résolution.
- Un autre temps étendu est en TAI (la clé -1 a la valeur 1) et vous voyez qu'il est situé 37 secondes dans le futur (l'actuel décalage entre UTC et TAI).
- Une durée, qui est le temps écoulé (en secondes) depuis le démarrage de la machine.
- On n'indique pas des informations comme la qualité de l'horloge car, franchement, je n'ai pas vraiment compris comment elle était représentée.
Question programmation, le service a été écrit en
Python. Ce langage a une fonction
time_ns,
qui permet d'obtenir les nanosecondes. Pour le TAI, cela a été un
peu plus difficile, la machine doit être configurée spécialement.
L'article seul
Fiche de lecture : De l'écran à l'émotion
Auteur(s) du livre : Emmanuelle Bermès
Éditeur : École nationale des chartes
978-2-35723-187-0
Publié en 2024
Première rédaction de cet article le 5 août 2024
« Quand le numérique devient patrimoine » est le sous-titre de ce livre consacré à un tour d'horizon complet de la question de la gestion patrimoniale des documents numériques. L'auteure s'appuie notamment sur son importance expérience à la BnF. Aucune nostalgie du papier dans ce livre tourné vers l'avenir.
Le patrimoine, pour une bibliothèque du début du XXe siècle, c'était facile à définir. C'étaient des objets physiques, notamment des livres, qu'il fallait cataloguer, stocker, préserver du feu ou de l'eau, et mettre à la disposition des lecteurices. Mais le numérique a bouleversé le travail des bibliothèques. Il faut récolter et stocker ces « objets » numériques, les préserver des changements technologiques qui risquent de les rendre illisibles, les cataloguer, les mettre à disposition. Leur nombre, à lui seul, pose un sacré défi. Et la définition même d'objet est difficile. Par exemple, archiver cet article que vous êtes en train de lire, c'est quoi ? Archiver le code HTML (c'est assez loin du vécu de la lectrice ou du lecteur de ce blog) ? L'image que montre le navigateur (non structurée et difficile à analyser, par exemple à des fins de cataloguage) ? Et si je modifie cet article, faut-il garder toutes les versions, même quand je n'ai changé qu'une virgule ? Emmanuelle Bermès, l'auteure du fameux Figoblog, expose toutes ces questions et les choix à faire.
Si on a pu s'agacer au début du « retard à l'allumage » de certains institutions, notamment en France, face au numérique, si on a pu ricaner des déclarations enflammées d'intellectuels médiatiques proclamant, par exemple, qu'on ne pouvait pas ressentir d'émotion en lisant sur écran, cela fait quand même longtemps que les bibliothèques nationales, spécialistes de la conservation à très long terme de toute sorte de documents, ont pris à bras-le-corps la question du patrimoine numérique. C'est cette prise de conscience, ces débats, et les actions qui ont suivi, que raconte Emmanuelle Bermès dans ce passionnant livre. Si vous vous souvenez de la diatribe de Jean-Noël Jeanneney dans Le Monde contre le projet de numérisation des livres par Google, vous retrouverez avec intérêt les débats de l'époque. Et, si vous ne les avez pas vécu, vous aurez un excellent résumé des étapes par lesquelles la BnF est passée (par exemple au sujet de Gallica ou du dépôt légal). L'actuelle BnF est assez loin de certains projets qui avaient été conçus à l'époque du Minitel !
Bref, contrairement à ce qu'on lit parfois sous le clavier de gens qui ne se sont pas renseignés, le patrimoine numérique existe, et de nombreuses personnes travaillent à le gérer et à le préserver. C'est bien sûr le cas de l'excellent service Internet Archive (l'auteure mentionne les attaques d'éditeurs comme Hachette contre ce service). Mais c'est aussi le cas du dépôt légal en France et dans de nombreux autres pays. En parlant de dépôt légal, ce blog est archivé de longue date par la BnF, et on voit ici dans le journal du serveur HTTP, une des visites du ramasseur de la BnF :
194.199.7.22:10401 - - [03/Jul/2024:14:36:57 +0000] "GET /opendns-quitte-france.html HTTP/1.0" 200 18036 \
"https://next.ink/wp-json/wp/v2/posts/142507" \
"Mozilla/5.0 (compatible; bnf.fr_bot; +https://www.bnf.fr/fr/capture-de-votre-site-web-par-le-robot-de-la-bnf)" \
www.bortzmeyer.org TLS
On notera le suivi des liens (à partir d'un article de Next), et le fait que le ramasseur se présente, et indique où obtenir tous les détails sur l'activité du robot. Bref, toutes les bêtises que je peux écrire ici sont archivées, sinon pour l'éternité, du moins pour longtemps. (Après tout, les historiens actuels sont ravis quand ils trouvent une tablette sumérienne avec une liste de commissions à faire.)
L'auteure se penche également sur les émotions que suscite le patrimoine (avec hommage à Aaron Swartz) et sur les techniques futures. L'IA aidera t-elle à cataloguer tous les documents sauvegardés ? Pas tant qu'un logiciel classera un tableau comme « femme ayant un bébé dans les bras » (exact, mais sans intérêt) au lieu de « Vierge à l'enfant »…
L'article seul
Le résolveur DNS public de Wikimédia
Première rédaction de cet article le 2 août 2024
Encore un résolveur DNS public ? Oui, mais c'est une bonne chose, il en faut le plus possible, pour éviter de dépendre d'un petit nombre d'acteurs. Et celui-ci est géré par la fondation Wikimédia.
Rien n'est plus agaçant que les gens qui croient s'y connaitre et
qui, à chaque panne, censure ou autre problème mettant en jeu
(croient-ils) le DNS, répondent tout de suite qu'il faut utiliser
8.8.8.8 (Google) ou
parfois un autre résolveur étatsunien comme
1.1.1.1 ou 9.9.9.9. Non
seulement il est mauvais, pour la vie privée, d'envoyer toutes ses
requêtes DNS aux USA mais il y a aussi un problème plus
stratégique. Si tout le monde dépend d'un petit nombre d'acteurs,
nous devenons tous vulnérables à des changements de politique, de
tarification, ou à une offensive de la censure (qui a d'ailleurs
commencé à frapper les résolveurs
publics). Il faut au contraire une grande diversité de
résolveurs DNS. Saluons donc le travail de la fondation
Wikimédia, qui a un résolveur
public, « Wikimedia DNS ».
Je vous recommande la documentation très claire et très détaillée de ce service. Ce résolveur est bien noté comme expérimental et sans garantie, mais, si vous lisez les petites lettres des CGU, c'est pareil pour tous les autres. Au moins, il est géré par une association et pas par une personne unique (comme l'est le mien) donc il est moins dépendant d'un individu.
Notez aussi qu'il n'est accessible qu'en DoT et DoH, ce qui est raisonnable techniquement, et normal pour un service surtout destiné à contourner la censure (qui aurait beau jeu de tripoter des réponses envoyés en clair). En traditionnel UDP en clair, on n'aura donc pas de réponse :
% dig @185.71.138.138 ratzeburg.de ;; communications error to 185.71.138.138#53: timed out ;; communications error to 185.71.138.138#53: timed out ;; communications error to 185.71.138.138#53: timed out ; <<>> DiG 9.18.28-0ubuntu0.22.04.1-Ubuntu <<>> @185.71.138.138 ratzeburg.de ; (1 server found) ;; global options: +cmd ;; no servers could be reached
Mais le serveur marche bien, ici en DoT :
% dig +tls @185.71.138.138 ratzeburg.de ; <<>> DiG 9.18.28-0ubuntu0.22.04.1-Ubuntu <<>> +tls @185.71.138.138 ratzeburg.de ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 16221 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 512 ;; QUESTION SECTION: ;ratzeburg.de. IN A ;; ANSWER SECTION: ratzeburg.de. 3600 IN A 213.178.85.153 ;; Query time: 56 msec ;; SERVER: 185.71.138.138#853(185.71.138.138) (TLS) ;; WHEN: Fri Aug 02 13:29:26 CEST 2024 ;; MSG SIZE rcvd: 57
On peut donc l'utiliser directement depuis les systèmes qui peuvent utiliser DoT (Android, par exemple) ou indirectement via un résolveur local comme Unbound qui fera suivre à Wikimédia DNS. Voici un exemple de configuration de Unbound pour cela :
forward-zone:
name: "."
# Wikimedia DNS. On authentifie le nom dans le certificat
# (émis par Let's Encrypt) donc, sur Debian/Ubuntu, ne pas
# oublier le "tls-system-cert: yes" dans le bloc "server:".
forward-addr: 185.71.138.138#wikimedia-dns.org
forward-tls-upstream: yes
On notera que, comme tous les résolveurs sérieux, il valide avec DNSSEC :
% dig +tls @185.71.138.138 denic.de
…
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 30888
;; flags: qr rd ra ad; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
^^
Authentic Data
…
;; ANSWER SECTION:
denic.de. 3578 IN A 81.91.170.12
…
Et la répartition des instances de ce serveur dans le monde ? Regardons avec les sondes RIPE Atlas :
% blaeu-resolve --nameserver 2001:67c:930::1 --nsid --type A --tls \
--requested 200 ratzeburg.de
Nameserver 2001:67c:930::1
[213.178.85.153 NSID: doh3004;] : 45 occurrences
[213.178.85.153 NSID: doh1001;] : 10 occurrences
[213.178.85.153 NSID: doh3003;] : 52 occurrences
[213.178.85.153 NSID: doh2001;] : 6 occurrences
[TIMEOUT] : 7 occurrences
[213.178.85.153 NSID: doh6001;] : 14 occurrences
[213.178.85.153 NSID: doh1002;] : 11 occurrences
[213.178.85.153 NSID: doh6002;] : 16 occurrences
[213.178.85.153 NSID: doh5002;] : 12 occurrences
[213.178.85.153 NSID: doh5001;] : 8 occurrences
[213.178.85.153 NSID: doh7002;] : 2 occurrences
[213.178.85.153 NSID: doh4002;] : 5 occurrences
[213.178.85.153 NSID: doh4001;] : 6 occurrences
[213.178.85.153 NSID: doh7001;] : 1 occurrences
[TUCONNECT (may be a TLS negotiation error or a TCP connection issue)] : 1 occurrences
Test #76486532 done at 2024-08-02T11:40:00Z
On voit qu'on a plusieurs NSID (RFC 5001), ce qui indique que le résolveur est anycasté, sur l'infrastructure de la fondation (qui héberge notamment Wikipédia). Les pros de l'administration système noteront que la configuration Puppet est disponible. Sinon, une meilleure preuve de la répartition anycastée est donnée en regardant la latence depuis divers pays : qu'on soit en Europe ou en Amérique, on obtient des RTT très courts, ce qui n'arriverait pas s'il existait une seule instance physique du serveur.
L'article seul
RFC 9580: OpenPGP
Date de publication du RFC : Juillet 2024
Auteur(s) du RFC : P. Wouters (Aiven), D. Huigens
(Proton AG), J. Winter
(Sequoia-PGP), Y. Niibe (FSIJ)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF openpgp
Première rédaction de cet article le 1 août 2024
Dernière mise à jour le 4 janvier 2025
Le logiciel PGP est synonyme de cryptographie pour beaucoup de gens. Un des plus anciens et des plus utilisés pour les fonctions de confidentialité mais aussi d'authentification. Le format de PGP, OpenPGP, est normalisé dans ce RFC, qui remplace le RFC 4880 (il n'y a pas de changement crucial, juste une mise à jour longtemps attendue).
PGP a vu son
format de données normalisé pour la première fois en août 1996, dans
le RFC 1991. Cette norme a été révisée par la suite, dans
le RFC 2440, puis le RFC 4880, puis par des RFC ponctuels (comme les RFC 5581 et RFC 6637, désormais inclus)
et notre RFC est la dernière version, qui synthétise tout. Sa
gestation a été longue et douloureuse et a suscité des controverses,
menant à un projet concurrent, LibrePGP (qui prévoit son propre
RFC, actuellement draft-koch-librepgp,
que j'avoue n'avoir pas lu).
Cette normalisation permet à diverses mises en œuvre de PGP d'interopérer. La plus connue aujourd'hui est le logiciel libre, GNU Privacy Guard (qui n'existait pas encore au moment de la publication du premier RFC) mais il y en a d'autres comme Sequoia (qui a annoncé qu'il suivrait notre récent RFC). Il ne faut donc pas confondre le logiciel PGP, écrit à l'origine par Phil Zimmermann, et qui est non-libre, avec le format OpenPGP que décrit notre RFC (cf. section 1.1) et que des logiciels autres que PGP peuvent lire et écrire.
Le principe du chiffrement avec PGP est simple. Une clé de session (le terme est impropre puisqu'il n'y a pas de session au sens de TLS mais c'est celui utilisé par le RFC) est créée pour chaque destinataire, elle sert à chiffrer le message et cette clé est chiffrée avec la clé publique du destinataire (section 2.1 du RFC).
Pour l'authentification, c'est aussi simple conceptuellement. Le message est condensé et le condensé est chiffré avec la clé privée de l'émetteur (section 2.2 du RFC).
Le format OpenPGP permet également la compression (qui améliore la sécurité en supprimant les redondances) et l'encodage en Base64 (RFC 4648), baptisé ASCII armor, pour passer à travers des logiciels qui n'aiment pas le binaire (la section 6 détaille cet encodage).
La section 3 explique les éléments de base utilisés par le format PGP. L'un des plus importants est le concept d'entier de grande précision (MPI pour Multi-Precision Integers), qui permet de représenter des entiers de très grande taille, indispensables à la cryptographie, sous forme d'un doublet longueur + valeur.
Enfin les sections 4 et 5 expliquent le format lui-même. Un message PGP est constitué de paquets (rien à voir avec les paquets réseau). Chaque paquet a un type, une longueur et un contenu. Par exemple, un paquet de type 1 est une clé de session chiffrée, un paquet de type 2 une signature, un paquet de type 9 du contenu chiffré, etc.
La section 7 du RFC décrit un type de message un peu particulier, qui n'obéit pas à la syntaxe ci-dessus, les messages en clair mais signés. Ces messages ont l'avantage de pouvoir être lus sans avoir de logiciel PGP. Ils nécessitent donc des règles spéciales.
On notera que gpg
permet d'afficher les paquets présents dans un message PGP, ce qui
est pratique pour l'apprentissage ou le débogage. Voyons un exemple
avec un fichier test.txt de 17 octets, signé
mais non chiffré (j'ai un peu simplifié la sortie du logiciel) :
% gpg --list-packets test.gpg :compressed packet: algo=2 :onepass_sig packet: keyid 3FA836C996A4A254 version 3, sigclass 0x00, digest 10, pubkey 1, last=1 :literal data packet: mode b (62), created 1721800388, name="test.txt", raw data: 17 bytes :signature packet: algo 1, keyid 3FA836C996A4A254 version 4, created 1721800388, md5len 0, sigclass 0x00 digest algo 10, begin of digest 2b d9 hashed subpkt 33 len 21 (issuer fpr v4 C760CAFC6387B0E8886C823B3FA836C996A4A254) hashed subpkt 2 len 4 (sig created 2024-07-24) subpkt 16 len 8 (issuer key ID 3FA836C996A4A254) data: [4096 bits]
Malheureusement, gpg n'affiche pas les valeurs numériques des types, telles que listées par le RFC. Mais les noms qu'il utilise sont les mêmes que dans le RFC, on peut donc facilement trouver la section qui explique ce qu'est un "onepass_sig packet" (section 5.4).
Avec un message chiffré, on obtient :
% gpg --list-packets test.txt.gpg
gpg: encrypted with 4096-bit RSA key, ID 9045E02757F02AA1, created 2014-02-09
"Stéphane Bortzmeyer (Main key) <stephane@bortzmeyer.org>"
gpg: encrypted with 2048-bit RSA key, ID 516CB37B336525BB, created 2009-12-15
"ISC Security Officer <security-officer@isc.org>"
gpg: decryption failed: No secret key
:pubkey enc packet: version 3, algo 1, keyid 516CB37B336525BB
data: [2046 bits]
:pubkey enc packet: version 3, algo 1, keyid 9045E02757F02AA1
data: [4096 bits]
:encrypted data packet:
length: 78
mdc_method: 2
Conformément au principe d'agilité cryptographique (RFC 7696), le format OpenPGP n'est pas lié à un algorithme cryptographique particulier, et permet d'en ajouter de nouveaux. La section 15 détaille comment demander à l'IANA d'ajouter de nouveaux paramètres dans les registres PGP.
L'annexe B, quant à elle, énumère les principaux changements depuis le RFC 4880. Ce dernier RFC a été publié il y a plus de seize ans mais son remplacement par notre nouveau RFC 9580 a été une opération longue et difficile, et les changements se sont accumulés (Daniel Huigens en a fait un bon résumé). Ceci dit, le format OpenPGP ne change pas radicalement, et l'interopérabilité avec les anciens programmes est maintenue. Parmi les principales modifications :
- des nouveaux algorithmes cryptographiques de signature comme Ed25519, ou bien ECDSA avec les courbes Brainpool (RFC 5639),
- des nouveaux algorithmes cryptographiques de chiffrement, comme X25519 ; comme pour ceux de signature, ils étaient parfois mentionnés dans le RFC 4880 sans que leur utilisation dans OpenPGP soit complètement spécifiée, et parfois avaient été intégrés via un RFC spécifique, comme le RFC 6637, sur certains algorithmes à courbe elliptique,
- des nouveaux modes pour le chiffrement intègre, comme GCM (nouveaux pour OpenPGP, mais anciens en cryptographie),
- des nouvelles fonctions de dérivation de clé comme Argon2 (RFC 9106) ou de condensation comme SHA-3,
- au contraire, certains algorithmes sont désormais marqués comme dépassés et ne devant plus être utilisés pour de nouveaux messages ; c'est le cas de DSA, ElGamal, MD5, SHA-1… (rappelez-vous que PGP peut avoir à lire des messages anciens et qu'on ne peut donc pas retirer purement et simplement ces algorithmes, d'autant plus qu'autrefois ils étaient parfois les seuls obligatoires pour une mise en œuvre standard d'OpenPGP),
- nouvelle version (version 6) pour plusieurs types de paquets,
- réduction de l'en-tête de la protection ASCII des messages (OpenPGP est du binaire mais peut être transcrit en ASCII armor, par exemple pour le courrier électronique) ; vous ne verrez plus le « Version: » dans cet en-tête,
- redressement de la terminologie, qui était parfois trop floue.
Enfin, un grand nombre d'errata ont été traités (la liste complète est dans l'annexe D).
L'article seul
Fiche de lecture : Des Martiens au Sahara
Auteur(s) du livre : Jean-Loïc Le Quellec
Éditeur : Édition du Détour
979-10-97079-23-9
Publié en 2023
Première rédaction de cet article le 31 juillet 2024
Des Martiens sont venus au Sahara pour se faire dessiner sur des parois rocheuses, tout le monde sait cela. Et des squelettes de géants ont été trouvés en Arabie saoudite, confirmant le Coran. De l'autre côté du globe, des astronautes extra-terrestres chassaient le dinosaure avec des haches au Pérou, en prenant le temps de construire des monuments, les peuples indigènes étant jugés incapables d'avoir réalisé de telles constructions. Vous y croyez ? Alors, c'est peut-être une bonne idée de lire ce livre, recueil d'articles sur les plus beaux mensonges et illusions en archéologie.
Il s'agit d'une réédition de l'ouvrage, avec mise à jour (lorsque l'auteur parle du scientifique-génial-qui-trouve-tout-seul-le-remède-mais-les-méchants-ne-veulent-pas-en-entendre-parler, les exemples du sida et du cancer ont été rejoints par la covid …). Il signale aussi le récent et scandaleux « documentaire » Netflix « À l'aube de notre histoire », que Netflix ose présenter comme un vrai documentaire alors qu'il s'agit du délire complotiste et raciste d'un menteur connu (la moitié du documentaire, que j'ai regardé, est faite de scènes où ce menteur se met en scène sur des sites archéologiques, alors qu'il n'a fait aucune recherche et rien découvert). La « thèse » de l'escroc est que tous les monuments antiques du monde ont été construits par une civilisation avancée et disparue. Si le documentaire reste prudent sur cette civilisation, dans ses livres, l'escroc n'hésite pas à dire qu'il s'agissait de Blancs, et insiste que ces monuments n'ont pas pu être construits par les indigènes. (Netflix a fait d'autres « documentaires » mensongers et complotistes comme celui sur le MH370.)
J'avais découvert Le Quellec avec son excellent livre détaillant la façon dont ignorance et racisme s'étaient conjugués pour produire une analyse erronée de la Dame Blanche (livre très recommandé !). Ici, il donne de nombreux autres exemples.
Il y a des escroqueries délibérées, faites pour des raisons monétaires ou politiques. Mais il y a aussi de nombreux cas où on se demande si le découvreur n'était pas sincère, s'auto-illusionnant, à la fois par manque de connaissances scientifiques et par désir d'arriver à tout prix au résultat voulu (confirmer ses préjugés, par exemple). On retrouvera donc dans ce livre les crânes de cristal, les pierres d'Ica, le livre de Mormon ou les interprétations délirantes sur les bâtisseurs de tertres (ces bâtisseurs sont bien réels, mais ils ne sont ni atlantes, ni extra-terrestres). Mais on n'aura pas les momies tridactyles, on ne peut pas tout traiter. Chaque cas est analysé en détail, son histoire, le contexte, le rôle des différentes personnes impliquées, chacune abordant la question avec son passé et ses préjugés.
Bref, un livre à lire pour creuser la variété des tromperies, mensonges, et dérapages. Je suis quand même un peu triste de découvrir qu'il y a peu d'innovation dans le pipeautage, les faux archéologues reprennent très souvent des légendes qui avaient déjà été analysées et démenties au XIXe siècle…
L'article seul
RFC 9619: In the DNS, QDCOUNT is (usually) One
Date de publication du RFC : Juillet 2024
Auteur(s) du RFC : R. Bellis (ISC), J. Abley
(Cloudflare)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 25 juillet 2024
Dans un message DNS, il y a quatre sections qui peuvent prendre un nombre variable d'enregistrements (resource records). Chaque section est précédée d'un chiffre qui indique ce nombre d'enregistrements. L'une de ces sections indique la question posée. Est-ce que cela a un sens de mettre plusieurs questions dans un message ? Non, répond, ce très court RFC, qui clarifie le RFC 1035 sur ce point.
Regardons une requête DNS avec tshark :
% tshark -V -r dns.pcap
…
Domain Name System (query)
Transaction ID: 0x0dfd
Flags: 0x0120 Standard query
0... .... .... .... = Response: Message is a query
.000 0... .... .... = Opcode: Standard query (0)
…
Questions: 1
Answer RRs: 0
Authority RRs: 0
Additional RRs: 1
Queries
wylag.de: type A, class IN
Name: wylag.de
[Name Length: 8]
[Label Count: 2]
Type: A (Host Address) (1)
Class: IN (0x0001)
Additional records
<Root>: type OPT
Name: <Root>
Type: OPT (41)
UDP payload size: 4096
Higher bits in extended RCODE: 0x00
EDNS0 version: 0
Z: 0x8000
1... .... .... .... = DO bit: Accepts DNSSEC security RRs
.000 0000 0000 0000 = Reserved: 0x0000
Data length: 12
Option: COOKIE
Option Code: COOKIE (10)
Option Length: 8
Option Data: 93c545f2aaf3f12c
Client Cookie: 93c545f2aaf3f12c
Server Cookie: <MISSING>
Il s'agit d'une requête, pas d'une réponse, donc il est normal que
les sections Answer et Authority soient vides (taille à zéro). La
section Additional n'est pas vide car elle contient l'enregistrement
EDNS. Et la section Question contient un seul
enregistrement, la question (« quelle est l'adresse IPv4 de
wylag.de ? »).
Tout le problème traitée par ce RFC est : que se passe t-il si la section Question d'une requête contient plus d'un enregistrement ? Je divulgâche tout de suite : c'est interdit, il ne faut pas. (Pour le cas des requêtes/réponses ordinaires, avec l'opcode 0 ; d'autres messages DNS peuvent avoir des règles différentes.) La principale raison pour cette interdiction est que, dans la réponse, certains champs sont globaux à toute la réponse (comme le code de réponse, le rcode) et on ne peut donc pas se permettre d'accepter des questions qui risqueraient de nécessiter des réponses différentes. Désormais, un serveur DNS qui voit passer une requête avec un nombre de questions supérieur à 1 doit répondre avec le code de retour FORMERR (format error).
Le RFC 1035, la norme originelle, traitait ce point mais restait flou.
Il y avait une autre façon de régler le problème, en imposant que, s'il y a plusieurs questions, toutes portent sur le même nom de domaine. Cela aurait réglé le doute sur le code de retour et aurait pu être pratique pour des cas comme la demande simultanée de l'adresse IPv4 et IPv6. Mais cette solution a été écartée au profit de la solution plus simple qui était d'interdire les questions multiples. (Et, de toute façon, on ne peut pas garantir que le code de retour sera le même pour tous les types, même si le nom est le même. Pensez aux serveurs DNS générant dynamiquement les données.)
L'article seul
Le nouveau type de données DNS WALLET
Première rédaction de cet article le 19 juillet 2024
Contrairement au cliché mille fois répété (mais faux), le DNS ne sert pas qu'à « traduire des noms de domaine en adresses IP ». Il est d'un usage général et permet de récupérer, indexées par un nom de domaine, diverses informations. Un nouveau type d'information vient d'être officiellement enregistré, WALLET, pour indiquer l'adresse d'un portefeuille de cryptomonnaie.
La capacité du DNS à résoudre un nom de domaine en divers types d'informations vient d'un champ des requêtes et réponses DNS, le type (ou, en plus long, le RR type, pour Resource Record type). Décrit dans la section 3.2.2 du RFC 1035, ce type peut prendre des valeurs diverses : AAAA pour les adresses IP, SVCB pour les serveurs d'un service donné, LOC pour une position, TXT pour du texte libre, etc.
Il est important de noter que cette liste des types possibles n'est pas figée. Elle est enregistrée dans un registre IANA et on peut ajouter des types à ce registre, en suivant la procédure décrite dans le RFC 6895. Cette procédure est délibérement très légère : le demandeur documente le nouveau type, envoie la demande à l'IANA, celle-ci la fait examiner par un expert (actuellement Ólafur Guðmundsson) et s'il n'y a pas de problèmes, le nouveau type est enregistré. Bien que la procédure soit libérale, on ne peut pas dire qu'il y ait eu une bousculade depuis la sortie du RFC 6895, la plupart des types enregistrés ayant suivi un chemin plus classique de normalisation.
Mais le nouveau WALLET, désormais ajouté au registre IANA, a utilisé le chemin simple ; une documentation, un examen par l'expert et hop, c'est enregistré. Comme les types ont un numéro en plus de leur nom (c'est ce numéro qui figure dans les paquets DNS), le 262 a été alloué. Que contient un enregistrement DNS de type WALLET ? Deux champs, une chaine de caractères qui identifie la cryptomonnaie utilisée (BTC pour Bitcoin, ETH pour Ethereum, etc) et une autre chaine de caractères qui contient l'adresse d'un compte.
L'encodage dans les paquets est identique à celui des enregistrements de type TXT : une suite de chaines de caractères est encodée en un octet qui indique la longueur de la chaine puis la suite d'octets de la chaine. Ainsi, "BTC" (pour Bitcoin) sera encodé {3, 66, 84, 67}, les trois derniers octets étant les codes ASCII.
J'ai ainsi ajouté au DNS mon adresse
Bitcoin, sous bortzmeyer.fr. Mais
attention, comme le type WALLET est récent (créé le 21 juin 2024),
la plupart des logiciels ne le connaissent pas. Pour le mettre dans
le fichier de zone du serveur primaire, j'ai dû utiliser la méthode
des « types inconnus » du RFC 3597 :
@ IN TYPE262 \# 39 03425443 223148744E4A365A465563397975397532714177423474476447775051617351476178
(39 octets, le premier groupe fait trois octets, les trois lettres
de "BTC", regardez la table ASCII. Vous pouvez utiliser le script
Python text-to-unknown-txt-type.py
% dig bortzmeyer.fr TYPE262 … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 26302 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1 … ;; ANSWER SECTION: bortzmeyer.fr. 86400 IN TYPE262 \# 39 ( 03425443223148744E4A365A46556339797539753271 4177423474476447775051617351476178 ) …
Pour le formater plus joliment, en attendant que dig soit mis à jour, j'ai écrit un petit script en Python (utilisant la bibliothèque dnspython) :
% wallet-dns.py bortzmeyer.fr bortzmeyer.fr Code: BTC ; Address: 1HtNJ6ZFUc9yu9u2qAwB4tGdGwPQasQGax
Et voilà, l'adresse est joliment affichée. (Une gestion assez minimale de ce type est en cours de développement dans dnspython.)
PS : il existe aussi cette alternative.
L'article seul
RFC 9537: Redacted Fields in the Registration Data Access Protocol (RDAP) Response
Date de publication du RFC : Mars 2024
Auteur(s) du RFC : J. Gould, D. Smith (VeriSign), J. Kolker, R. Carney (GoDaddy)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 14 juillet 2024
RDAP est le protocole recommandé pour accéder aux données sociales sur un nom de domaine, comme le nom du titulaire ou son adresse postale. Pour d'évidentes raisons de vie privée, certains registres ne renvoient pas la totalité de l'information dont ils disposent. Que doit-on mettre dans RDAP dans ce cas ? La question n'était pas tranchée et chaque registre faisait différemment. Désormais, il existe une solution normalisée.
Au passage, oui, d'accord, il n'y a pas que
RDAP pour obtenir les données sociales (cet
article vous en indiquera d'autres). Mais c'est le service le
plus moderne et le plus adapté
aux programmeur·ses. Contacté en HTTPS, le serveur RDAP va
renvoyer du JSON que le client n'aura plus qu'à filtrer et
formatter. Voici par exemple une partie de la réponse RDAP obtenue
en se renseignant sur
nouveaufrontpopulaire.fr :
% curl -s https://rdap.nic.fr/domain/nouveaufrontpopulaire.fr | jq
…
[
"fn",
{},
"text",
"Parti Socialiste"
],
[
"org",
{},
"text",
"Parti Socialiste"
],
[
"adr",
{},
"text",
[
"",
"",
"99 Rue Moliere",
"Ivry-sur-Seine",
"",
"94200",
"FR"
]
],
…
Ici, il s'agit d'une personne morale donc les données sont toutes envoyées. Et s'il s'agissait d'une personne physique, pour laquelle la loi Informatique & et Libertés s'applique, depuis 1978 ? La solution évidente est de ne pas envoyer les données qu'on ne veut pas diffuser mais attention, il y a un piège, il ne faut pas casser la syntaxe JSON. Par exemple, RDAP utilise (c'est en cours de changement, cf. RFC 9553) jCard pour formater les adresses (RFC 7095) et les champs dans jCard ne sont pas étiquetés, c'est leur position dans le tableau qui indique leur rôle (c'est un des nombreux inconvénients de jCard). On ne peut donc pas supprimer, par exemple, la rue, en indiquant :
[
"adr",
{},
"text",
[
"",
"",
"Ivry-sur-Seine",
"",
"94200",
"FR"
]
],
[
"email",
{},
"text",
"e5d92838d5f0268143ac47d86880b5f7-48916400@contact.gandi.net"
],
Car, alors, on ne saurait plus si "Ivry-sur-Seine" est la rue ou bien la ville.
Le principe de notre RFC est donc : si on peut, retirer le membre
JSON. Si on ne peut pas (cas du tableau de taille fixe), mettre une
valeur vide ou null.
Petit point de terminologie : comment traduire le redacted du titre ? « Censuré » est inadapté (l'intervention ne vient pas d'un tiers mais d'une des deux parties). Je vais dire « élidé », mais « caviardé », « biffé » et « expurgé » sont également de bonnes solutions. Le nom correspondant est « élision ». Évidemment, il ne faut surtout pas dire « anonymisé », il n'y a rien d'anonyme ici, puisque le registre connait toute l'information, il refuse simplement de la diffuser.
La section 1 du RFC expose les grands principes de
l'élision. Elle explique notamment qu'en cas d'élision, il faut
ajouter un membre (nommé redacted) à la réponse
JSON, expliquant les raisons et utilisant le langage
JSONPath (RFC 9535)
pour désigner de manière formelle la partie élidée.
Compte-tenu des contraintes sur la syntaxe de la réponse JSON (RFC 9083), le RFC normalise quatre façons d'élider (section 3) :
- Suppression d'un champ, si possible (c'est la méthode préférée). Cela marche dans la plupart des cas. Par exemple, si on ne veut pas publier le titulaire d'un domaine, on ne l'inclut pas dans la réponse, point.
- Mettre une valeur vide. Quand les contraintes de syntaxe empêchent de supprimer complètement un champ, on lui met une valeur vide. C'est notamment nécessaire pour les tableaux que jCard utilise abondamment : le retrait d'un champ casserait le tableau, qui est censé avoir un nombre d'élements fixe.
- Une valeur trop détaillée peut être remplacée par une
valeur partielle. L'adresse
"label":"123 Maple Ave\nSuite 901\nVancouver BC\nCanada"(un exemple du RFC 7095) peut être remplacée par une valeur moins précise comme"label":"Vancouver\nBC\nCanada\n". - Enfin, la dernière méthode est de remplacer une valeur par
une autre, par exemple une adresse de courrier par une adresse qui masque la
vraie, comme
e5d92838d5f0268143ac47d86880b5f7-48916400@contact.gandi.netdans l'exemple plus haut.
Et le RFC insiste qu'il ne faut pas utiliser de texte bidon (« XXX », « lorem ipsum dolor » ou « Ano Nymous ») car ce texte ne correspond pas forcément aux règles de syntaxe du champ (et, j'ajoute, peut être difficile à identifier pour le lecteur, qui peut ne pas avoir la référence).
Pour la première méthode, la suppression d'un champ, si on
supprime le titulaire, on aura un membre nommé
redacted (élidé) ajouté ainsi :
"redacted": [
{
"name": {
"description": "Remove registrant"
},
"prePath": "$.entities[?(@.roles[0]=='registrant')]",
"method": "removal"
}
]
Notez le (difficile à lire) code JSONPath
$.entities[?(@.roles[0]=='registrant')].
Le deuxième cas, celui d'une valeur vide, donnerait, pour le cas où on supprime juste le nom du titulaire (qui est en position 1 dans le jCard, et son nom en position 3 - sachant qu'on part de 0) :
[
"fn",
{},
"text",
""
]
…
"redacted": [
{
"name": {
"description": "Registrant Name"
},
"postPath": "$.entities[?(@.roles[0]=='registrant')].
vcardArray[1][?(@[0]=='fn')][3]",
"pathLang": "jsonpath",
"method": "emptyValue",
"reason": {
"description": "Server policy"
}
}
]
Troisième technique d'élision, réduire une valeur. Le
redacted devient :
"redacted": [
{
"name": {
"description": "Home Address Label"
},
"postPath": "$.vcardArray[1][?(@[0]=='adr')][1].label",
"pathLang": "jsonpath",
"method": "partialValue",
"reason": {
"description": "Server policy"
}
}
]
Et pour finir, la quatrième et dernière méthode, le remplacement :
"redacted": [
{
"name": {
"description": "Registrant Email"
},
"postPath": "$.entities[?(@.roles[0]=='registrant')].
vcardArray[1][?(@[0]=='email')][3]",
"pathLang": "jsonpath",
"method": "replacementValue",
}
]
Ce membre appelé redacted est spécifié en
détail dans la section 4 du RFC. (Et il est enregistré à l'IANA parmi les extensions RDAP.) Pour signaler qu'il peut
apparaitre, le membre rdapConformance de la
réponse JSON va l'indiquer :
{
"rdapConformance": [
"itNic",
"redacted",
"rdap_level_0"
],
…
Dès qu'il y a élision, redacted doit être
ajouté. Il contient un tableau JSON d'objets, dont les membres
peuvent être (seul le premier est obligatoire) :
name: un terme qui décrit le champ élidé,prePathetpostPath: des expressions JSONPath (RFC 9535) qui dénotent le membre retiré ou modifié,method: la technique d'élision utilisée (suppression, nettoyage, remplacement, etc),reason: texte libre décrivant la raison de l'élision.
L'article seul
Passage de mes zones DNS à des signatures à courbes elliptiques
Première rédaction de cet article le 6 juillet 2024
Vous l'avez peut-être remarqué, mes zones DNS personnelles (comme
bortzmeyer.org, que vous utilisez pour lire
ce blog) viennent de changer d'algorithme de
signature cryptographique. RSA a été remplacé par
ECDSA.
Pourquoi ce grand remplacement ? Les signatures DNSSEC
faites avec ECDSA (RFC 6605) sont
plus petites, ce qui peut présenter des avantages dans certains cas
(mais ne va évidemment pas diminuer l'empreinte environnementale de
mes zones). Mais, surtout, l'avis de la grande majorité des experts
en cryptographie (je ne fais pas partie de
ces experts, très loin de là, donc je leur fais confiance) est que
la cryptographie sur courbes elliptiques, qui
est à la base d'ECDSA, est plus sûre, surtout face aux futures
évolutions de la cryptanalyse, que le
traditionnel RSA. Vous noterez d'ailleurs que beaucoup de
zones DNS
importantes ont changé, par exemple
.com. De même,
.fr a migré il
y a plusieurs années et c'est uniquement la paresse qui
m'avait jusque là empêché d'en faire autant. (La racine du DNS,
elle, est toujours en RSA, car il est bien plus compliqué de changer
une clé que tous les résolveurs
de la planète doivent connaitre, et ce malgré le RFC 5011.)
J'ai un peu hésité à passer à ECDSA car il dépend d'une courbe elliptique, la P-256, conçue par la NSA et normalisée par le NIST, et à utiliser plutôt EdDSA (RFC 8080). Mais, autant tous les résolveurs DNSSEC acceptent aujourd'hui aussi bien ECDSA que RSA, autant Ed25519 reste moins répandu.
Une fois la décision prise, comment faire ? Comme toujours avec le DNS, il faut tenir compte du fait que la réjuvénation n'est pas instantanée. Si on change brutalement les clés qu'on publie, on risque que certains résolveurs aient encore dans leur mémoire des clés qui ne valideront pas les signatures récentes (ou bien le contraire). Que l'on change les clés ou, comme ici, les algorithmes, il faut procéder à ce remplacement (rollover) en intégrant les contraintes temporelles (RFC 6781 et RFC 7583).
Suivre manuellement ces contraintes (ajouter la nouvelle clé, attendre le TTL, ajouter l'enregistrement DS dans la zone parente, attendre qu'il soit publié, attendre le TTL, retirer l'ancien DS, attendre, retirer l'ancienne clé…) est pénible et le risque d'erreur est très élevé. Il faut donc automatiser, ce que j'ai fait. Mes zones DNS personnelles sont gérées avec OpenDNSSEC et c'est donc lui qui a fait tout le travail.
Prenons l'exemple de la zone
cyberstructure.fr. DNSviz va nous montrer ses
différents états (l'archivage des anciennes mesures et la facilité
de navigation dans cet historique font partie des grandes forces de
DNSviz). Elle était signée
uniquement avec RSA. (Les erreurs signalées par DNSviz sont
dues au non-respect du RFC 9276, j'y
reviendrai.) Le 17 juin 2024, je change la configuration
OpenDNSSEC. Dans ce logiciel, chaque zone gérée l'est selon une
politique choisie par l'administrateur
système. La politique utilisée, nommée
default était d'utilise RSA. Je crée une
nouvelle politique, nommée, sans imagination,
new. Dans la syntaxe XML du fichier de
configuration d'OpenDNSSEC, le fichier kasp.xml
contient :
<Policy name="new">
<Description>A new policy with ECDSA</Description>
…
<Keys>
…
<!-- Parameters for KSK only -->
<KSK>
<Algorithm length="512">13</Algorithm>
<Lifetime>P3Y</Lifetime>
<Repository>SoftHSM</Repository>
<ManualRollover/>
</KSK>
<!-- Parameters for ZSK only -->
<ZSK>
<Algorithm length="512">13</Algorithm>
<Lifetime>P90D</Lifetime>
<Repository>SoftHSM</Repository>
<!-- <ManualRollover/> -->
</ZSK>
</Keys>
…
L'algorithme de numéro 13 est ECDSA (RSA est le numéro 8, cf. le registre IANA). On change ensuite la
configuration de la zone (dans zonelist.xml) :
<Zone name="cyberstructure.fr">
<Policy>new</Policy>
…
On recharge alors OpenDNSSEC :
% sudo ods-enforcer zonelist import … Updated zone cyberstructure.fr successfully
Les nouvelles clés ECDSA (rappel : algorithme 13) sont alors créées par OpenDNSSEC :
% sudo ods-enforcer key list --verbose --zone cyberstructure.fr Keys: Zone: Keytype: State: Date of next transition: Size: Algorithm: CKA_ID: Repository: KeyTag: cyberstructure.fr KSK active 2024-06-18 10:53:01 2048 8 2d63a8cc9f68602d5b98f2bcb2714119 SoftHSM 63130 cyberstructure.fr ZSK active 2024-06-18 10:53:01 1024 8 b8e16f9a3aad96676ae36cd6fdb955ad SoftHSM 11668 cyberstructure.fr KSK publish 2024-06-18 10:53:01 512 13 02e0ddf994431d5fa3d89cdc12f7addd SoftHSM 10825 cyberstructure.fr ZSK ready 2024-06-18 10:53:01 512 13 cebc635b489780d2fddf5efabeba5b81 SoftHSM 54500
Elles n'apparaissent pas dans le DNS immédiatement, il faut attendre
leur passage en état ready (regardez la colonne
Date of next transition). Une fois que c'est
fait, DNSviz nous montre le
nouvel état, avec pour l'instant les clés ECDSA publiées mais qui ne
seront pas utilisées pour la validation. 
Pensez aussi à recharger le signeur d'OpenDNSSEC
(ods-signer update --all). Dans le DNS, on
note que les deux ZSK (Zone-signing key) signent
(même si, pour l'instant, les signatures ECDSA ne servent à rien) :
% dig @ns4.bortzmeyer.org. cyberstructure.fr SOA … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 18279 ;; flags: qr aa rd; QUERY: 1, ANSWER: 3, AUTHORITY: 8, ADDITIONAL: 1 … ;; ANSWER SECTION: cyberstructure.fr. 7200 IN SOA ns4.bortzmeyer.org. hostmaster.bortzmeyer.org. ( 2024061703 ; serial 7200 ; refresh (2 hours) 3600 ; retry (1 hour) 604800 ; expire (1 week) 3600 ; minimum (1 hour) ) cyberstructure.fr. 7200 IN RRSIG SOA 13 2 7200 ( 20240701143938 20240617155301 54500 cyberstructure.fr. CW/V6zSkMn/cC8E2hUHYlaSparKbOgc03CRcbOecTOMY HxMTavaExj9fvvkH3srNrP9Kx/VYRQsi4YrjMFH6DA== ) cyberstructure.fr. 7200 IN RRSIG SOA 8 2 7200 ( 20240701143938 20240617155301 11668 cyberstructure.fr. UCskHbeGjx20Bqo+9IyczDaHrEZ83uBYQsjDy/Etqngy QeCH1gADMbsl3VaBPHiLDd8MIVkzH2I73/jEUo2R22wq KPtSTsGHQ8I2vPff5ylplqJFXVUitiyGcEYVaAtI3hAk eijaGI6J3nAdcYuAxFo9Gi+WRCEmTRcL8RZAjCo= )
On voit notamment que la signature ECDSA est plus petite, ce qui était une des motivations pour ce remplacement. Et les clés ?
% dig @ns4.bortzmeyer.org. cyberstructure.fr DNSKEY … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 51884 ;; flags: qr aa rd; QUERY: 1, ANSWER: 6, AUTHORITY: 0, ADDITIONAL: 1 … ;; ANSWER SECTION: cyberstructure.fr. 7200 IN DNSKEY 257 3 8 ( AwEAAddHCFxVIpXyRRVCBh4zHt22o3ReQzk+Avi5J+c2 hLnB2zSB7obXWsxj0fZSeyYE4VAClJ5/7TF687gRjVRW 3cNTsJ9mrQzbLbuxL3nnIKWZRrVKWg9RpKHDul9QL1EC trgum18SK9QpRnywZx8kM0zFviu75Df2636wT1YcQZUz KDXRE0IGg6r9qGMcq6PXL3woDPoVmv3H7SvXZjlj/2zI nMvQo15Y0Y7kO6Epng9qgnJaZeTrTo4OtzIPMSOahFMJ YD8AxlsT5yN7lQZSRMJDYjJ1HC+PgyLMnz7y+iwvVLMZ 6IVr1yeYbCp+inTHi+qn9fRJSIjirWJWb/7sHdk= ) ; KSK; alg = RSASHA256 ; key id = 63130 cyberstructure.fr. 7200 IN DNSKEY 256 3 8 ( AwEAAcGW9K353z/T1ZKstnQ4Y0ricKlmb2DyVEE0Dcrc St/fNVdB3g2Y9tlXh9oQH0RzNK2UqIAm2PxmAleeWOZp 8qzYdtWZj5O/4VXtLkjAwOUuinjaYIfDskcuue/pg+cT ilQhXnh/sKktyci4wtFIDZLBL7gYyiZSFrR4DCwcpITr ) ; ZSK; alg = RSASHA256 ; key id = 11668 cyberstructure.fr. 7200 IN DNSKEY 257 3 13 ( zyVnEtBlrgWpNtDUnhPIikEIUaAj+/VwHfC7j1jpWeqa fAE04Mx9nXDFhznhDD0uvIFpY3se9wefPddNZJDVCA== ) ; KSK; alg = ECDSAP256SHA256 ; key id = 10825 cyberstructure.fr. 7200 IN DNSKEY 256 3 13 ( s+HVObz03Vzug26yX3KjlyXbpMcCzoD/8CblfTR2zQsi e35hf2DBwLarHOCcMpu6X5+FgHMsOwmvaSJH/AzZCA== ) ; ZSK; alg = ECDSAP256SHA256 ; key id = 54500 cyberstructure.fr. 7200 IN RRSIG DNSKEY 13 2 7200 ( 20240701061231 20240617155301 10825 cyberstructure.fr. EbgfiMIxj2zhVgnAD2MPf4fZ6PZjCT4iZMhMgUb6EK/m o8foczgd9PFotvcaaQxaE6rybMiOvhRETbIrX9IeCA== ) cyberstructure.fr. 7200 IN RRSIG DNSKEY 8 2 7200 ( 20240701061231 20240617155301 63130 cyberstructure.fr. qTI+5RbOnuWfpkXgTSiYEv04An19XjxP1vGyYEnD5ao0 zaexw3yh1xhNGlsqFU1XLkADTilpt1w60qO/9lshE3kD eA73s6u03hsrLxL71YjvUEU68pO/iT4LxhpYY0P1gCPX rdiM50mYauiSQROnt5UeQ0wJ/Q4NSl4fQrko1cHcymcD 05JeCS4e2gq7HlCQsn2rTQTwP2A0d9ccYBe02rPziTP4 HnyEAcBqATHPU1U+yqd5OZLYkJh+mGJTFFHoXfxYSqKu 6C86KVV5wtrX+bCxcNGrdRiyGI0FSDioXQG7p1+/oLYf j6vQnfns9INHEH2uY6P6LdJX4GTFKq3gpg== ) ;; Query time: 0 msec ;; SERVER: 2001:4b98:dc0:41:216:3eff:fe27:3d3f#53(ns4.bortzmeyer.org.) (UDP) ;; WHEN: Mon Jun 17 18:53:46 CEST 2024 ;; MSG SIZE rcvd: 1048
Ouf, ça en fait, des données à envoyer. Mais ce n'est que transitoire.
À la prochaine étape (tout se déroule automatiquement et est géré par OpenDNSSEC), la clé ECDSA est prête :
% sudo ods-enforcer key list --verbose --zone cyberstructure.fr Keys: Zone: Keytype: State: Date of next transition: Size: Algorithm: CKA_ID: Repository: KeyTag: cyberstructure.fr KSK retire waiting for ds-gone 2048 8 2d63a8cc9f68602d5b98f2bcb2714119 SoftHSM 63130 cyberstructure.fr ZSK active 2024-09-15 18:53:01 1024 8 b8e16f9a3aad96676ae36cd6fdb955ad SoftHSM 11668 cyberstructure.fr KSK ready waiting for ds-seen 512 13 02e0ddf994431d5fa3d89cdc12f7addd SoftHSM 10825 cyberstructure.fr ZSK active 2024-09-15 18:53:01 512 13 cebc635b489780d2fddf5efabeba5b81 SoftHSM 54500
Maintenant, il va falloir travailler, l'étape suivante ne peut pas
être automatisée. Il faut prévenir la zone parente (dans le cas de
.fr, via le BE) et indiquer à
OpenDNSSEC (qui ne sait pas faire de requête DNS lui-même) quand
l'enregistrement DS arrivera. On lui demande d'exporter la clé :
% sudo ods-enforcer key export --zone cyberstructure.fr
(Si votre BE et/ou votre registre demande le
DS et pas le DNSKEY, il faudra ajouter --ds à
la commande.) On indique alors la nouvelle clé dans l'interface du
BE (Web ou API). Attention à soigner cette
étape : cette clé va désormais être utilisée pour la validation, il
ne faut pas se tromper. On patiente ensuite le temps que le
registre ait bien mis à jour la zone parente et, lorsque notre DS
est dans le DNS, on prévient OpenDNSSEC :
% sudo ods-enforcer key ds-seen --keytag 10825 --zone cyberstructure.fr 1 KSK matches found. 1 KSKs changed. % sudo ods-enforcer key list --verbose --zone cyberstructure.fr Keys: Zone: Keytype: State: Date of next transition: Size: Algorithm: CKA_ID: Repository: KeyTag: cyberstructure.fr KSK retire waiting for ds-gone 2048 8 2d63a8cc9f68602d5b98f2bcb2714119 SoftHSM 63130 cyberstructure.fr ZSK active 2024-06-21 14:06:08 1024 8 b8e16f9a3aad96676ae36cd6fdb955ad SoftHSM 11668 cyberstructure.fr KSK active 2024-06-21 14:06:08 512 13 02e0ddf994431d5fa3d89cdc12f7addd SoftHSM 10825 cyberstructure.fr ZSK active 2024-06-21 14:06:08 512 13 cebc635b489780d2fddf5efabeba5b81 SoftHSM 54500
Parfait, la KSK (Key-signing key) ECDSA est
désormais active. La KSK RSA va être retirée. Regardons d'abord
le
nouvel état. Il y a deux DS et deux clés actives. 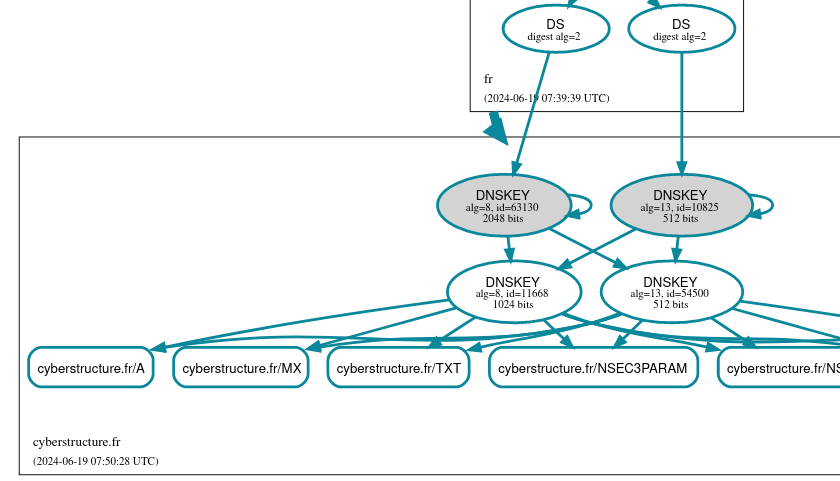
On va maintenant retirer l'ancien DS. On le supprime via l'interface du BE puis, lorsque le registre a mis la zone à jour :
% sudo ods-enforcer key ds-gone --keytag 63130 --zone cyberstructure.fr 1 KSK matches found. 1 KSKs changed. % sudo ods-enforcer key list --verbose --zone cyberstructure.fr Keys: Zone: Keytype: State: Date of next transition: Size: Algorithm: CKA_ID: Repository: KeyTag: cyberstructure.fr KSK retire 2024-06-21 14:06:08 2048 8 2d63a8cc9f68602d5b98f2bcb2714119 SoftHSM 63130 cyberstructure.fr ZSK active 2024-06-21 14:06:08 1024 8 b8e16f9a3aad96676ae36cd6fdb955ad SoftHSM 11668 cyberstructure.fr KSK active 2024-06-21 14:06:08 512 13 02e0ddf994431d5fa3d89cdc12f7addd SoftHSM 10825 cyberstructure.fr ZSK active 2024-06-21 14:06:08 512 13 cebc635b489780d2fddf5efabeba5b81 SoftHSM 54500
Plus qu'un
seul DS, mais l'ancienne clé RSA est toujours là, pour les
résolveurs qui auraient des anciennes informations dans leur
mémoire. 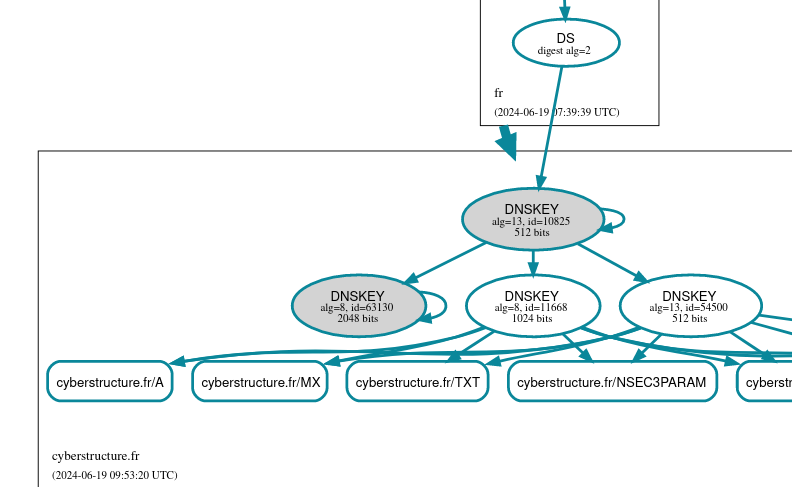
Enfin, les clés et signatures RSA seront automatiquement supprimées du DNS lorsqu'elles sont devenues inutiles, ce qui nous mène au dernier état, lorsque le remplacement est terminé. Les clés disparaitront ensuite du trousseau d'OpenDNSSEC (mais cela prendra davantage de temps).
% sudo ods-enforcer key list --verbose --zone cyberstructure.fr Keys: Zone: Keytype: State: Date of next transition: Size: Algorithm: CKA_ID: Repository: KeyTag: cyberstructure.fr KSK retire 2024-07-06 08:09:09 2048 8 2d63a8cc9f68602d5b98f2bcb2714119 SoftHSM 63130 cyberstructure.fr ZSK retire 2024-07-06 08:09:09 1024 8 b8e16f9a3aad96676ae36cd6fdb955ad SoftHSM 11668 cyberstructure.fr KSK active 2024-07-06 08:09:09 512 13 02e0ddf994431d5fa3d89cdc12f7addd SoftHSM 10825 cyberstructure.fr ZSK active 2024-07-06 08:09:09 512 13 cebc635b489780d2fddf5efabeba5b81 SoftHSM 54500
Voici le résultat : 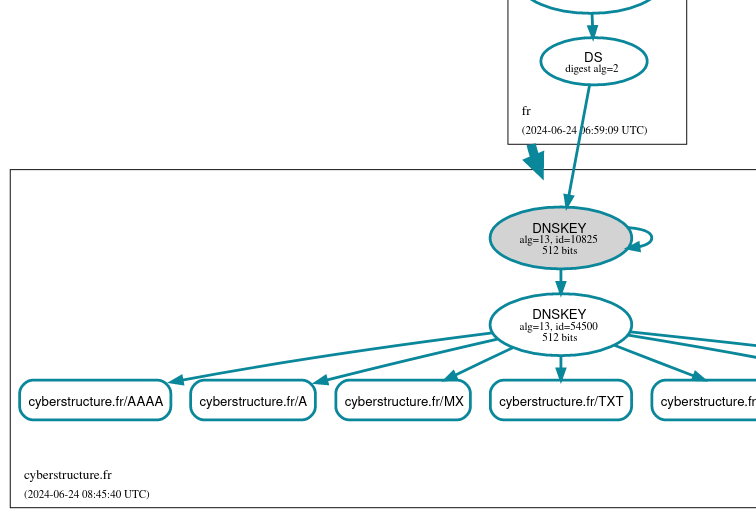
Ah, et j'avais dit qu'il y avait des erreurs dues au non-respect du RFC 9276, qui a changé les paramètres recommandés pour les enregistrements NSEC3 (RFC 5155). C'est exact, donc il a fallu également modifier cela dans notre politique :
<!-- Régime sans sel, et sans itérations -->
<NSEC3>
…
<Hash>
<Algorithm>1</Algorithm>
<Iterations>0</Iterations>
<Salt length="0"/>
</Hash>
</NSEC3>
Quelques liens intéressants :
- Le wiki d'OpenDNSSEC,
- Le remplacement d'algorithme qu'avait fait le RIPE (manuellement…),
- Un autre récit de remplacement utilisant OpenDNSSEC,
L'article seul
OpenDNS plus accessible depuis la France
Première rédaction de cet article le 28 juin 2024
Dernière mise à jour le 3 juillet 2024
Le résolveur DNS public OpenDNS ne répond désormais plus aux adresses IP situées en France, se pliant aux exigences des ayant-tous-les-droits.
OpenDNS a fait un communiqué sur ces exigences. Voici le résultat, avec dig, depuis une adresse chez Free :
% dig @208.67.222.222 www.bortzmeyer.org
; <<>> DiG 9.18.24-0ubuntu0.22.04.1-Ubuntu <<>> @208.67.222.222 www.bortzmeyer.org
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: REFUSED, id: 102
;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 2
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 1410
; EDE: 16 (Censored)
;; QUESTION SECTION:
;www.bortzmeyer.org. IN A
;; ADDITIONAL SECTION:
www.bortzmeyer.org. 0 IN TXT "Due to a court order in France issued under Article L.333-10 of the French Sport code the OpenDNS service is not currently available to users in France and certain French territories."
;; Query time: 4 msec
;; SERVER: 208.67.222.222#53(208.67.222.222) (UDP)
;; WHEN: Fri Jun 28 17:39:19 CEST 2024
;; MSG SIZE rcvd: 249
Notez le status: REFUSED et l'enregistrement de type TXT qui explique. La loi en question est vouée à défendre les intérêts du sport-spectacle, qui passent avant tout, et est lisible ici (et le jugement qui a contraint OpenDNS semble être celui-ci, vous y trouverez la liste des noms concernés, ça vient de cet article de l'Informé). Les défenseurs de l'appropriation intellectuelle affirment souvent qu'elle sert à « protéger les créateurs » mais, comme on le voit ici, elle sert surtout à enrichir les clubs de rugby ou de football. Les personnes qui utilisaient OpenDNS le faisaient sans doute pour contourner une censure qui bénéficie surtout aux ayant-droits.
Ce n'est pas spécifique au nom de domaine demandé, tous donnent le même résultat. En outre, on peut vérifier, par exemple avec les sondes RIPE Atlas, que c'est pareil depuis quasiment tous les FAI français :
% blaeu-resolve --requested 200 --country FR --nameserver 208.67.222.222 --type A www.bortzmeyer.org Nameserver 208.67.222.222 [ERROR: REFUSED] : 180 occurrences [80.77.95.49] : 4 occurrences [TIMEOUT] : 2 occurrences Test #74529588 done at 2024-06-28T15:43:35Z
(Et inutile d'essayer en IPv6, c'est pareil.)
Celles et ceux qui avaient configuré leur réseau pour utiliser le résolveur OpenDNS n'avaient donc plus d'accès réseau (sans résolveur DNS, on ne peut quasiment rien faire, et cela bloquait un certain nombre d'équipements). C'est sans doute pour cela qu'OpenDNS a fait une exception (notée par David Ponzone) pour un service critique, la synchronisation d'horloges avec NTP :
% dig @208.67.222.222 ntp.org … ;; ->>HEADER<<- opcode: QUERY, status: REFUSED, id: 6126 ;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 2 … ;; ADDITIONAL SECTION: ntp.org. 0 IN TXT "Due to a court order in France issued under Article L.333-10 of the French Sport code the OpenDNS service is not currently available to users in France and certain French territories." ;; Query time: 8 msec ;; SERVER: 208.67.222.222#53(208.67.222.222) (UDP) ;; WHEN: Wed Jul 03 09:57:37 CEST 2024 ;; MSG SIZE rcvd: 238 % dig @208.67.222.222 pool.ntp.org … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 47543 ;; flags: qr rd ra; QUERY: 1, ANSWER: 4, AUTHORITY: 0, ADDITIONAL: 1 … ;; ANSWER SECTION: pool.ntp.org. 130 IN A 185.123.84.51 pool.ntp.org. 130 IN A 51.15.182.163 pool.ntp.org. 130 IN A 51.38.113.118 pool.ntp.org. 130 IN A 51.255.141.76 ;; Query time: 48 msec ;; SERVER: 208.67.222.222#53(208.67.222.222) (UDP) ;; WHEN: Wed Jul 03 09:57:41 CEST 2024 ;; MSG SIZE rcvd: 105
Notez qu'on observe la même chose au Portugal, pays également cité dans le communiqué d'OpenDNS :
% blaeu-resolve --requested 200 --country PT --nameserver 208.67.222.222 --type A www.bortzmeyer.org Nameserver 208.67.222.222 [ERROR: REFUSED] : 168 occurrences [80.77.95.49] : 1 occurrences Test #74532654 done at 2024-06-28T18:07:19Z
OpenDNS n'est qu'un des nombreux résolveurs DNS publics (et pas forcément le plus sympathique, par exemple, pendant longtemps, ils remplaçaient les réponses négatives par des publicités à eux). Par exemple, en Europe, il y a dns.sb, DNS4ALL, en France, il y a celui de FDN et il y en a même un à moi. Si on utilise un résolveur public (ce qui n'est pas forcément une bonne idée), le choix est vaste et les alternatives nombreuses (aucune raison de tous aller sur le résolveur d'une grosse entreprise capitaliste étatsunienne). Mais il n'est pas évident de choisir.
Un de ces gros résolveurs étatsuniens est celui de Google, qui est cité dans le jugement et qui, contrairement à OpenDNS, n'a pas bloqué tout service mais censure seulement les domaines demandés par la justice. (OpenDNS a sans doute jugé plus simple de bloquer tout accès depuis la France.)
% dig @8.8.8.8 volkastream.xyz A ; <<>> DiG 9.18.24-0ubuntu0.22.04.1-Ubuntu <<>> @8.8.8.8 volkastream.xyz A ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: REFUSED, id: 18572 ;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 512 ; EDE: 16 (Censored): (The requested domain is on a court ordered copyright piracy blocklist for FR (ISO country code). To learn more about this specific removal, please visit https://lumendatabase.org/notices/41939614.) ;; QUESTION SECTION: ;volkastream.xyz. IN A ;; Query time: 4 msec ;; SERVER: 8.8.8.8#53(8.8.8.8) (UDP) ;; WHEN: Fri Jun 28 20:10:16 CEST 2024 ;; MSG SIZE rcvd: 246
Notez l'EDE (Extended DNS Error), concept normalisé dans le RFC 8914. Le code 16 pour indiquer la censure est très rarement observé dans la nature, la plupart des censeurs étant hypocrites.
En parlant de ce domaine, volkastream.xyz,
voyons sa censure par les résolveurs DNS des
FAI français :
% ./blaeu-resolve --country FR --requested 100 --ede --type A volkastream.xyz [104.21.38.55 172.67.219.135] : 68 occurrences [127.0.0.1] : 18 occurrences [ERROR: NXDOMAIN] : 2 occurrences [EDE 16 (Censored): The requested domain is on a court ordered copyright piracy blocklist for FR (ISO country code). To learn more about this specific removal, please visit https://lumendatabase.org/notices/41939614. ERROR: REFUSED] : 2 occurrences Test #74533089 done at 2024-06-28T18:26:58Z
Ce domaine n'est pas bloqué par le résolveur DNS public de Cloudflare mais, comme Cloudflare est son hébergeur Web, il a pu quand même le censurer, et renvoie désormais le code de statut HTTP 451 (normalisé dans le RFC 7725) :
% curl -v https://volkastream.xyz … * Connected to volkastream.xyz (2606:4700:3037::6815:2637) port 443 (#0) … > GET / HTTP/2 > Host: volkastream.xyz > user-agent: curl/7.81.0 > accept: */* … < HTTP/2 451 < date: Sat, 29 Jun 2024 17:52:55 GMT < content-type: text/html
Merci à capslock pour le signalement.
L'article seul
Problème DNSSEC au Libéria
Première rédaction de cet article le 13 juin 2024
Dernière mise à jour le 16 juin 2024
Le 12 juin, une panne (partielle ?) a touché
le TLD
.lr. Il s'agit
d'un problème DNSSEC (qui a fait l'objet d'un
retex détaillé par le gestionnaire technique.
L'alerte a été donné sur la liste de l'OARC. Au matin du 13 juin, on constate :
- Que Zonemaster voit un problème. Et que DNSviz est d'accord que ça ne va pas.
- Que la plupart des résolveurs
DNS, même ceux qui valident avec
DNSSEC, n'ont pas de problème avec
.lr. Principale exception : celui de Cloudflare,1.1.1.1.
Les sondes RIPE Atlas sont d'accord pour dire que ça marche mais pas parfaitement :
% blaeu-resolve --requested 200 --type SOA --displayvalidation lr [ (Authentic Data flag) rip.psg.com. hostmaster.psg.com. 1718251170 345600 3600 2592000 14400] : 88 occurrences [rip.psg.com. hostmaster.psg.com. 1718251170 345600 3600 2592000 14400] : 85 occurrences [ERROR: SERVFAIL] : 13 occurrences [ERROR: NXDOMAIN] : 11 occurrences [ (Authentic Data flag) rip.psg.com. hostmaster.psg.com. 1718225894 345600 3600 2592000 14400] : 1 occurrences [] : 1 occurrences Test #73322645 done at 2024-06-13T07:39:43Z
L'explication technique est probablement la suivante : en
interrogeant tous les serveurs faisant
autorité pour .lr, avec la requête
lr/DNSKEY, on voit que certains envoient deux
signatures (ayant le même identificateur de clé, 29984) :
lr. 86400 IN DNSKEY 257 3 8 ( AwEAAbdBaOsz0xNn+L+8+GopcC0w9NneWhKl9GJyCR5d … ) ; KSK; alg = RSASHA256 ; key id = 29984 lr. 86400 IN DNSKEY 256 3 8 ( AwEAAci9weuAQKBbKsqkOYnm1H0C5a7ZX/8xoQDmNp8Y … ) ; ZSK; alg = RSASHA256 ; key id = 42940 lr. 86400 IN RRSIG DNSKEY 8 1 86400 ( 20240626012025 20240611235025 29984 lr. YeZQ3KiSsDQD3jizNHXnTUYxRtzJwXl0aoctrgqDqajW … lr. 86400 IN RRSIG DNSKEY 8 1 86400 ( 20240626205813 20240612192813 29984 lr. lDt9P1RZtcs+/SDilJZ6tNRsZr+F5EdisfmsNw7E62+1 …
Cela ne se voit pas à l'œil nu mais une des deux signatures est invalide (cf. les rapports de DNSviz et Zonemaster). Les résolveurs qui réussissent sont ceux qui sont tombés sur le serveur faisant autorité qui ne servait que la bonne signature, ou bien testaient les deux signatures (d'où l'importance de tester plus qu'une signature, malgré KeyTrap). Notez que, malgré cette différence des réponses, tous les serveurs faisant autorité ont le même numéro de série :
% check-soa lr fork.sth.dnsnode.net. 77.72.229.254: OK: 1718251170 2a01:3f0:0:306::53: OK: 1718251170 ns-lr.afrinic.net. 196.216.168.61: OK: 1718251170 2001:43f8:120::61: OK: 1718251170 rip.psg.com. 2001:418:1::39: OK: 1718251170 147.28.0.39: OK: 1718251170
La commande pour interroger tous les serveurs est :
% for server in 77.72.229.254 2a01:3f0:0:306::53 2001:43f8:120::61 196.216.168.61 2001:418:1::39 147.28.0.39; do echo $server dig +dnssec @$server lr DNSKEY done > lr.txt
Comme elle est faite depuis un seul point de mesure (mon bureau), elle a ses limites, notamment, elle ne détectera pas les différences entre instances d'un même nuage anycast.
Y avait-il collision des identificateurs de clé comme en Russie en début d'année ? Comme vu plus loin, le problème était autre. Un indice : le Liban, qui a le même gestionnaire technique, avait le même problème.
Bref, les explications techniques complètes figurent dans cet article très détaillé ; une attaque par déni de service a déclenché une bogue assez bizarre dans le signeur, Knot.
L'article seul
Encore un résolveur DNS public européen, DNS4ALL
Première rédaction de cet article le 7 juin 2024
Utiliser un résolveur DNS public est souvent nécessaire pour contourner la censure faite, notamment, au profit des ayant-tous-les-droits. Mais il ne faut pas que tout le monde se concentre sur deux ou trois gros résolveurs, surtout s'ils sont gérés depuis un pays qui se moque de la protection des données personnelles. Il faut au contraire une multiplicité de résolveurs DNS publics, et gérés depuis des pays divers. D'où l'intérêt de ce nouveau résolveur public géré aux Pays-Bas, DNS4ALL.
Merci donc à SIDN, registre de
.nl, pour cette
contribution au pluralisme et à la diversité. (Il y a peu de
résolveurs DNS publics européens mais on peut citer celui de FDN ou celui de DNS.sb.) Peut-être que cela fera
enfin taire la propagande qui essaie de s'opposer à ces résolveurs
publics en faisant semblant de croire qu'il n'y a que ceux de
Google et
Cloudflare ?
Commençons par le commencement, est-ce qu'il marche ? Regardons avec dig :
% dig @2001:678:8::3 www.bortzmeyer.org ; <<>> DiG 9.18.24-1-Debian <<>> @2001:678:8::3 www.bortzmeyer.org ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 20893 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 1232 ;; QUESTION SECTION: ;www.bortzmeyer.org. IN A ;; ANSWER SECTION: www.bortzmeyer.org. 86397 IN A 80.77.95.49 ;; Query time: 4 msec ;; SERVER: 2001:678:8::3#53(2001:678:8::3) (UDP) ;; WHEN: Fri Jun 07 11:05:20 CEST 2024 ;; MSG SIZE rcvd: 63
OK, il fonctionne (« status: NOERROR »), il donne bien la bonne réponse, et il valide avec DNSSEC (« flags: ad », ce qui veut dire Authentic Data). Ici, on a utilisé du DNS classique sur UDP, en clair, testons avec du DNS chiffré via TLS (kdig nous donne un peu plus de détails que dig, mais ce dernier marche aussi pour DNS sur TLS) :
% kdig +tls @2001:678:8::3 www.bortzmeyer.org
;; TLS session (TLS1.3)-(ECDHE-SECP256R1)-(RSA-PSS-RSAE-SHA256)-(AES-256-GCM)
;; ->>HEADER<<- opcode: QUERY; status: NOERROR; id: 57888
;; Flags: qr rd ra ad; QUERY: 1; ANSWER: 1; AUTHORITY: 0; ADDITIONAL: 1
;; EDNS PSEUDOSECTION:
;; Version: 0; flags: ; UDP size: 1232 B; ext-rcode: NOERROR
;; QUESTION SECTION:
;; www.bortzmeyer.org. IN A
;; ANSWER SECTION:
www.bortzmeyer.org. 86259 IN A 80.77.95.49
;; Received 63 B
;; Time 2024-06-07 11:07:37 CEST
;; From 2001:678:8::3@853(TCP) in 94.9 ms
Parfait, là aussi, on s'est connecté en TLS (authentifié par RSA, clés échangées par ECDHE, chiffré par AES). On peut donc utiliser ce résolveur de manière sécurisée. (Il a également DoH mais pas encore DoQ.)
Que se passe-t-il avec les domaines qui ont un problème technique, nous donne-t-il des détails ?
% dig +tls @2001:678:8::3 servfail.nl … ;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 40616 … ; EDE: 9 (DNSKEY Missing): (validation failure <servfail.nl. A IN>: signatures from unknown keys from 96.126.104.187 for <servfail.nl. SOA IN>) …
C'est à juste titre qu'il échoue (« status: SERVFAIL donc Server Failure) et il nous explique pourquoi en utilisant les EDE (Extended DNS Errors) du RFC 8914 : « signatures from unknown keys » (ce domaine sert à des tests et ses signatures DNSSEC sont délibérement cassées).
Bon, on utilise souvent les résolveurs publics pour contourner la censure mais certains peuvent aussi censurer. Je dois dire que j'ai été trop paresseux pour lire leur politique de censure et je me suis contenté de tester Sci-Hub (il n'est pas possible de tout vérifier, mais, si vous connaissez un nom censuré, vous pouvez le tester) :
% dig +tls @2001:678:8::3 sci-hub.se … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 20416 … ;; ANSWER SECTION: sci-hub.se. 60 IN A 186.2.163.219
Au moins Sci-Hub fonctionne (c'est l'adresse IP légitime).
Les gérants de ce service disent qu'il est anycasté, ce qui est une bonne chose mais vérifions avec les sondes Atlas :
% blaeu-resolve --requested 200 --nsid --tls --nameserver 2001:678:8::3 www.gouda.nl Nameserver 2001:678:8::3 [2001:9a8:a6:0:87:233:198:3 NSID: america-mex1;] : 24 occurrences [2001:9a8:a6:0:87:233:198:3 NSID: asia-sin1;] : 60 occurrences [2001:9a8:a6:0:87:233:198:3 NSID: eur-fra1;] : 106 occurrences [TIMEOUT] : 5 occurrences [NO RESPONSE FOR UNKNOWN REASON at probe 1006022] : 1 occurrences [TUCONNECT (may be a TLS negotiation error or a TCP connection issue)] : 1 occurrences [NO RESPONSE FOR UNKNOWN REASON at probe 62742] : 1 occurrences Test #73149926 done at 2024-06-07T09:18:33Z
On notera :
- Quelques problèmes techniques (combiner IPv6 et TLS, je cherchais la difficulté, mais on voit à peu près la même chose en IPv4, et ce n'est pas forcément la faute de l'opérateur du résolveur, le port 853 peut être bloqué sur le réseau local),
- Apparemment trois serveurs, si on se fie aux NSID (RFC 5001), un sur chaque continent. Un article des opérateurs du projet dit qu'il y a 30 nœuds anycast, qui envoient vers 3 résolveurs, ce que nous avons pu vérifier.
L'article cité mentionne que les nœuds utilisent dnsdist (qui a sa propre mémoire, donc n'envoie pas forcément aux résolveurs) et les résolveurs utilisent Unbound. (C'est amusant, c'est pareil pour mon propre résolveur public.)
Terminons avec un exemple de configuration où on utilise sur son réseau local ou sur sa machine un résolveur Unbound qui fait suivre les requêtes dont les réponses ne lui sont pas connues à DNS4ALL. On notera qu'on indique le nom du serveur, ce qui permet à Unbound de vérifier le certificat (dont le titulaire est « CN=*.dns4all.eu,O=Stichting Internet Domeinregistratie Nederland,ST=Gelderland,C=NL ») :
forward-zone: name: "." # DNS4ALL forward-addr: 2001:678:8::3#dot.dns4all.eu forward-tls-upstream: yes
En tout cas, voici un nouveau résolveur public (alors que le projet officiel de la Commission, DNS4EU, est toujours inexistant, des années après son annonce), ce qui contribue à accroitre la diversité des offres.
L'article seul
Les Journées du Logiciel Libre à Lyon (et avec du Zig et du RDDS)
Première rédaction de cet article le 27 mai 2024
Les 25 et 26 mai 2024, à Lyon, c'étaient les Journées du Logiciel Libre. Comme toujours, deux jours passionnants avec plein de gens bien. J'y ai fait une conférence « Trouver de l'information sur un nom de domaine » et un atelier « Initiation à la programmation en Zig ».
La conférence « Trouver de l'information sur un nom de domaine » venait de l'observation que beaucoup d'internautes ont du mal à naviguer dans le monde, effectivement très complexe, des noms de domaine et, par exemple, à trouver de l'information correcte sur les données associées à un nom (comme l'identité du titulaire). Les outils pour cela sont parfois nommés collectivement RDDS (pour Registration Data Directory Services) et, si leur utilisation est parfois simple, l'interprétation de leurs résultats ne l'est pas. Voici les supports de la conférence (et leur source). Je n'ai pas compté le nombre de personnes présentes mais il m'a semblé que ce sujet suscitait l'intérêt.
Pour ce qui est de l'atelier sur le langage de programmation Zig, la forme choisie avait été celle d'une session où les participants (pas d'écriture inclusive ici, il n'y avait que des hommes) suivaient un support en ligne, faisaient les exercices et éventuellement posaient des questions. (Le source du support et l'ensemble des fichiers est disponible). À ma grande surprise, alors que je m'attendais à une participation très réduite, puisque le langage est peu connu, la salle était pleine comme un œuf (16 personnes) et avec tous ces humains et tous ces ordinateurs portables, plus les fixes pour ceux qui n'avaient pas apporté le leur, ça chauffait.
Parmi les autres activités du week-end (je n'ai pas tout fait, le programme était riche !), il y avait :
- Une intéressante conférence d'altercarto sur les données ouvertes à partir de leur situation dans trois pays, France, Tunisie et Burkina Faso. Le point important était que les données ouvertes, c'est très bien, ça incite à bosser sur ce qui est publié (ce qui est bien le but) mais il y a aussi ce qui n'est pas publié et c'est à cela qu'il faut prêter attention. On manque ainsi de données sur les droits sociaux, la santé, l'éducation… Par exemple, en France : les données d'actes de soin remboursés par la Sécurité Sociale par ville ne sont pas disponibles. Cela serait pourtant utile pour étudier les inégalités. En Tunisie, des organisations comme Cartographie Citoyenne ne peuvent plus travailler car la dictature fait qu'il y a de moins en moins de données (par exemple sur la pollution à Gabès, sujet polémique), sous prétexte de « diffusion de fausses nouvelles ». (Comme en France, le discours sur les fake news est toujours un prétexte à censure.) Au Burkina Faso depuis le coup d'État pro-russe, les acteurs de la donnée ouverte se taisent et ont arrêté leur activité qui, il est vrai, aboutissait parfois à montrer les défauts et les faiblesses de l'action publique (par exemple en publiant les points d'eau qui fonctionnaient, pas uniquement ceux qui existaient).
- Une conférence
portait sur les noms de
domaine, partant d'une explication sur le
fonctionnement de l'Internet et aboutissant
au projet d'un bureau d'enregistrement
coopératif (puisque tous les BE ouverts au public sont désormais
des entreprises commerciales, qui ne correspondent pas forcément
aux besoins des particuliers et associations ; et ce alors qu'il
existe des FAI et des hébergeurs sans but
lucratif). L'orateur rappelait par exemple que les
registres ont des règles d'enregistrement,
parfois différentes. Ainsi,
.coopest réservé aux coopératives et aux organismes qui en font la promotion. Le BE est l'intermédiaire qui, par exempe pour un.fr, paie 5,07 € au registre (l'Afnic) chaque année par nom. Le futur bureau d'enregistrement nommé Le Bureau, devrait être sous forme d'une coopérative. (Pour l'instant, le projet semble largement porté par Hashbang.) Pour être BE de.coop, il faut l'accréditation ICANN (3500 $ + 4000/an, « cinq salariés à temps plein suffisent », dit l'ICANN), l'accréditation auprès du registre (qui n'est pas une copérative…) et un contrat avec l'OTR (l'opérateur technique du registre). C'est très lourd et, a priori, le futur BE commencera comme BE dans certains TLD, comme.frmais sera sans doute au début simple revendeur d'un BE pour.coop,.com, etc. Notez que je ne suis pas d'accord avec certains points de la présentation, comme les pouvoirs excessifs prêtés à l'ICANN (« L'organisation qui a le plus de pouvoir sur l'Internet est l'ICANN » ou des phrases percutantes mais fausses comme « Si les États-Unis veulent couper une zone géographique d'Internet ils peuvent. »). Une beta privée du futur BE pourrait apparaitre à l'automne. - Une autre conférence venait des Restos du Cœur et détaillait leur infrastructure informatique pour gérer les applications métier comme le contenu des réfrigérateurs ou la flotte de véhicules. C'était assez stupéfiant car, avec six administrateurs système, tous bénévoles donc travaillant le soir ou le week-end, les Restos du Cœur ont une infrastructure matérielle et logicielle qui rendrait jalouses la grande majorité des entreprises spécialisées en informatique. On trouve dans les logiciels utilisés Ansible, Passbolt, Maas, Ceph, Ruddder, Unbound, PowerDNS, MariaDB, PostgreSQL, un bastion SSH, mais aussi OpenStack et Kubernetes. Cela donne quand même l'impression d'un excès d'ingéniérie. (Mais l'orateur estimait que cela correspondait aux besoins des Restos, qui ont des applications locales, et pour lesquelles il faut offrir un service « cloud ».) Le tout tourne sur du matériel donné aux Restos, pour des raisons financières, les services comme AWS ne sont pas trop utilisés. Une conférence très déroutante, qui a bien étonné les administrateurs système présents.
- Alexis Kauffmann a énuméré les « 42 raisons de croire au logiciel libre » dans l'Éducation nationale française. Parmi les 41 (« la 42e va vous étonner »), le fait qu'il y a des libristes au ministère, des services comme Éducajou, des profs qui font des paquetages LaTeX, des profs de philo qui font du Markdown, Tchap, des belles paroles du ministère, Papillon, un concurrent libre de Pronote (qui les a menacé juridiquement), etc. Une coupure de courant a obligé l'orateur à continuer sans slides et sans micro. Une préparation au monde futur post-effondrement ?
- Il y avait une conférence
sur les outils libres pour les langues. Des langues, il y en a
beaucoup, dans les 7 000 (ou à peu près, ça se discute), dans les
1 500 écrites (environ), et pour 50 écritures (tiens, j'aurais cru
qu'il y en avait davantage). Il existe plusieurs efforts de
classification comme celui de SIL, organisation missionnaire
chrétienne qui catalogue les langues pour traduire la Bible (et
qui gère Ethnologue), celui de Glottolog, etc. (Et j'ajoute le registre de
langues IETF, normalisé dans le RFC 5646, qui est celui utilisé par HTTP et HTML. On peut aussi y
accéder via mon site Web
https://www.langtag.net/ - Enfin, un atelier permettait de réfléchir à l'IA en jouant les rôles de personnes fanatiquement pour (« Oui, Laurent Alexandre est si inspirant »), plutôt pour, plutôt contre ou fanatiquement contre. Une expérience intéressante pour moi (mais trop courte).
- Par contre, la conférence sur la situation en prison a été annulée. Dommage.
Ah, et j'ai découvert aux JDLL l'existence du syndicat de la cybersécurité.
Cette année, le lieu historique des JDLL n'a pas accueilli
l'événement. Il a fallu trouver rapidement un lieu alternatif et les
JDLL se sont tenues à l'ENS. Le parc intérieur est superbe, et entretenu
par des animaux
consciencieux, dont la position est même donnée
sur OpenStreetMap, avec l'émoji qui va bien 🐑 dans la
description : 
Et bien sûr mille mercis aux nombreux·ses bénévoles qui ont travaillé pour cette édition des JDLL, très réussie comme d'habitude.
Autre(s) compte-rendu(s) des JDLL publié(s) :
L'article seul
Les retards du serveur racine C
Première rédaction de cet article le 22 mai 2024
Dernière mise à jour le 23 mai 2024
On fait souvent remarquer que c'est pendant les pannes qu'on peut le mieux observer comment un système marche. Les perturbations qui affectent le serveur racine du DNS identifié par la lettre C sont donc l'occasion d'apprendre comment fonctionne ce système des serveurs racine.
À la racine du DNS, se trouvent treize serveurs (« serveur » au
sens virtuel car cela fait évidemment bien plus que treize
machines), chacun identifié par une lettre de A à M, et nommés dans
le domaine root-servers.net. Un programme comme
check-soa
permet de les voir en action (l'option -i
permet d'avoir le temps de réponse), ici le 22 mai à 08:47:24
UTC :
% check-soa -i . a.root-servers.net. 2001:503:ba3e::2:30: OK: 2024052200 (14 ms) 198.41.0.4: OK: 2024052200 (15 ms) b.root-servers.net. 2801:1b8:10::b: OK: 2024052200 (14 ms) 170.247.170.2: OK: 2024052200 (14 ms) c.root-servers.net. 2001:500:2::c: OK: 2024052101 (25 ms) 192.33.4.12: OK: 2024052101 (25 ms) d.root-servers.net. 2001:500:2d::d: OK: 2024052200 (4 ms) 199.7.91.13: OK: 2024052200 (5 ms) e.root-servers.net. 192.203.230.10: OK: 2024052200 (6 ms) 2001:500:a8::e: OK: 2024052200 (6 ms) f.root-servers.net. 2001:500:2f::f: OK: 2024052200 (6 ms) 192.5.5.241: OK: 2024052200 (6 ms) g.root-servers.net. 2001:500:12::d0d: OK: 2024052200 (52 ms) 192.112.36.4: OK: 2024052200 (65 ms) h.root-servers.net. 2001:500:1::53: OK: 2024052200 (11 ms) 198.97.190.53: OK: 2024052200 (14 ms) i.root-servers.net. 192.36.148.17: OK: 2024052200 (10 ms) 2001:7fe::53: OK: 2024052200 (10 ms) j.root-servers.net. 2001:503:c27::2:30: OK: 2024052200 (15 ms) 192.58.128.30: OK: 2024052200 (14 ms) k.root-servers.net. 2001:7fd::1: OK: 2024052200 (8 ms) 193.0.14.129: OK: 2024052200 (14 ms) l.root-servers.net. 199.7.83.42: OK: 2024052200 (15 ms) 2001:500:9f::42: OK: 2024052200 (14 ms) m.root-servers.net. 2001:dc3::35: OK: 2024052200 (4 ms) 202.12.27.33: OK: 2024052200 (5 ms)
(Le point désigne la racine.)
Avez-vous remarqué le problème ? L'un des serveurs,
C.root-servers.net, est en retard. Le numéro de
série dans l'enregistrement SOA est
2024052101 alors que tous les autres sont à 2024052200. Dans le cas
de la racine (c'est une convention courante mais pas du tout
obligatoire), le numéro de série indique la date de modification, on
voit donc qu'il est resté à hier, 21 mai.
C'était pire avant : du 18 au 21 mai, ce serveur est resté en 2024051801, ignorant donc tout changement qui aurait pu avoir lieu dans le contenu de la racine (heureusement, il n'y en a eu aucun pendant cette période) :
% date -u Tue 21 May 20:03:11 UTC 2024 % check-soa -i . a.root-servers.net. 198.41.0.4: OK: 2024052101 (23 ms) 2001:503:ba3e::2:30: OK: 2024052101 (96 ms) b.root-servers.net. 170.247.170.2: OK: 2024052101 (23 ms) 2801:1b8:10::b: OK: 2024052101 (84 ms) c.root-servers.net. 192.33.4.12: OK: 2024051801 (22 ms) 2001:500:2::c: OK: 2024051801 (22 ms) d.root-servers.net. 199.7.91.13: OK: 2024052101 (16 ms) 2001:500:2d::d: OK: 2024052101 (16 ms) e.root-servers.net. 192.203.230.10: OK: 2024052101 (16 ms) 2001:500:a8::e: OK: 2024052101 (16 ms) f.root-servers.net. 192.5.5.241: OK: 2024052101 (22 ms) 2001:500:2f::f: OK: 2024052101 (96 ms) g.root-servers.net. 2001:500:12::d0d: OK: 2024052101 (54 ms) 192.112.36.4: OK: 2024052101 (66 ms) h.root-servers.net. 198.97.190.53: OK: 2024052101 (23 ms) 2001:500:1::53: OK: 2024052101 (96 ms) i.root-servers.net. 192.36.148.17: OK: 2024052101 (23 ms) 2001:7fe::53: OK: 2024052101 (23 ms) j.root-servers.net. 192.58.128.30: OK: 2024052101 (23 ms) 2001:503:c27::2:30: OK: 2024052101 (96 ms) k.root-servers.net. 2001:7fd::1: OK: 2024052101 (23 ms) 193.0.14.129: OK: 2024052101 (22 ms) l.root-servers.net. 199.7.83.42: OK: 2024052101 (16 ms) 2001:500:9f::42: OK: 2024052101 (22 ms) m.root-servers.net. 2001:dc3::35: OK: 2024052101 (16 ms) 202.12.27.33: OK: 2024052101 (16 ms)
Le serveur C est anycasté donc le test ci-dessus laisse ouverte la possibilité d'un problème spécifique à l'instance à laquelle je parle. Mais une mesure faite avec les sondes RIPE Atlas montre que non, le problème touche presque toutes les instances :
% blaeu-resolve --requested 200 --nsid --type SOA --nameserver c.root-servers.net . Nameserver c.root-servers.net [NSID: lax1a.c.root-servers.org; … 2024051801 1800 900 604800 86400] : 10 occurrences [NSID: fra1b.c.root-servers.org; … 2024051801 1800 900 604800 86400] : 37 occurrences [NSID: mad1a.c.root-servers.org; … 2024051801 1800 900 604800 86400] : 5 occurrences [NSID: rio1a.c.root-servers.org; … 2024051801 1800 900 604800 86400] : 2 occurrences [NSID: fra1a.c.root-servers.org; … 2024051801 1800 900 604800 86400] : 37 occurrences [NSID: iad1b.c.root-servers.org; … 2024051801 1800 900 604800 86400] : 10 occurrences [NSID: lax1b.c.root-servers.org; … 2024052101 1800 900 604800 86400] : 8 occurrences [NSID: sin1b.c.root-servers.org; … 2024051801 1800 900 604800 86400] : 3 occurrences [NSID: par1b.c.root-servers.org; … 2024051801 1800 900 604800 86400] : 20 occurrences [NSID: par1a.c.root-servers.org; … 2024051801 1800 900 604800 86400] : 20 occurrences [TIMEOUT] : 9 occurrences [NSID: mad1b.c.root-servers.org; … 2024051801 1800 900 604800 86400] : 1 occurrences [NSID: iad1a.c.root-servers.org; … 2024051801 1800 900 604800 86400] : 7 occurrences [NSID: sin1a.c.root-servers.org; … 2024051801 1800 900 604800 86400] : 1 occurrences [NSID: bts1a.c.root-servers.org; … 2024051801 1800 900 604800 86400] : 4 occurrences [NSID: ord1a.c.root-servers.org; … 2024051801 1800 900 604800 86400] : 9 occurrences [NSID: jfk1b.c.root-servers.org; … 2024051801 1800 900 604800 86400] : 1 occurrences [NSID: bts1b.c.root-servers.org; … 2024051801 1800 900 604800 86400] : 6 occurrences [NSID: ord1b.c.root-servers.org; … 2024051801 1800 900 604800 86400] : 3 occurrences [NSID: jfk1a.c.root-servers.org; … 2024051801 1800 900 604800 86400] : 2 occurrences [… 2024052100 1800 900 604800 86400] : 1 occurrences Test #72103734 done at 2024-05-21T20:15:03Z
Quelles sont les conséquences pratiques pour les
utilisateurices ? Si leur résolveur interroge C (ce qui dépend
d'un certain nombre de facteurs, dont le temps de réponse des
différents serveurs
faisant autorité), ledit résolveur aura des informations
peut-être dépassées. Ainsi, ce matin du 22 mai, on voit que le
TLD
.int a publié hier un nouvel
enregistrement DS (dans le cadre de sa
migration vers la cryptographie en courbes
elliptiques) mais le serveur C ne le voit toujours pas :
% dig +short @a.root-servers.net int DS 59895 13 2 10C789F286599316D3A74C2C513434C3F8A33B9238976D5DE2A178E5 4DA353F3 27433 7 2 5864812D4DF2A4A455D905AF311389F479AFCD96FD369060941C7E17 0B40CA4F % dig +short @c.root-servers.net int DS 27433 7 2 5864812D4DF2A4A455D905AF311389F479AFCD96FD369060941C7E17 0B40CA4F
Un problème identique se pose pour
.gov qui planifiait la
même transition vers ECDSA et a dû la
retarder. Cela sera encore pire si un TLD était redélégué ou
si les signatures DNSSEC servies par C
finissaient par expirer.
Que peut-on faire ? Pas grand'chose. Le gestionnaire du serveur C, Cogent va peut-être réparer mais on ne sait pas quand et on n'a pas d'informations. Techniquement, il serait possible de retirer C de la liste des serveurs racine ou bien de confier C à un autre opérateur, mais personne n'a le droit et/ou l'autorité de supprimer ou de réaffecter un serveur racine. Contrairement à ce qu'écrivent les journalistes, l'ICANN n'est pas régulateur du DNS, encore moins de l'Internet et ne peut donc pas agir. (La liste des serveurs et de leurs opérateurs est disponible en ligne.)
Le problème a finalement été réparé vers le 23 mai, d'abord sans explications et sans communication de la part de Cogent, puis finalement par un court texte sur leur site Web : « 2024‑05‑23 - On May 21 at 15:30 UTC the c-root team at Cogent Communications was informed that the root zone as served by c-root had ceased to track changes from the root zone publication server after May 18. Analysis showed this to have been caused by an unrelated routing policy change whose side effect was to silence the relevant monitoring systems. No production DNS queries went unanswered by c-root as a result of this outage, and the only impact was on root zone freshness. Root zone freshness as served by c-root was fully restored on May 22 at 16:00 UTC. ».
À noter qu'à peu près au même moment (mais nous ne savons pas
s'il s'agit d'une coïncidence ou bien si les deux problèmes sont
liés), le site Web d'information sur le serveur C, https://c.root-servers.org/.org alors que le
serveur DNS est en .net)
avait cessé de fonctionner vers le 17 mai. Il utilisait l'adresse IP
38.230.3.4, allouée à
Orange Côte d'Ivoire
et, depuis le 17 mai, annoncée
par eux dans BGP.
% whois 38.230.3.4 ... Found a referral to rwhois.cogentco.com:4321. %rwhois V-1.5:0010b0:00 rwhois.cogentco.com (CGNT rwhoisd 1.2.0) network:ID:NET4-26E6000011 network:Network-Name:NET4-26E6000011 network:IP-Network:38.230.0.0/17 network:Org-Name:Orange Cote d'Ivoire network:Street-Address:CABLE SAT3 CLS, RUA AMÉLIA FRADE network:City:SESIMBRA network:Country:PT network:Postal-Code:2970 – 712 network:Tech-Contact:ZC108-ARIN network:Updated:2024-05-10 16:33:20
Orange Côte d'Ivoire est un client de Cogent
et, manifestement, Cogent avait délégué ce préfixe à son client sans
remarquer qu'ils l'utilisaient pour
C.root-servers.org. Ou bien ils ne s'étaient
pas aperçus du problème car, en interne, cela marchait, en
raison d'une route plus spécifique. (Quand j'ai signalé le
problème à Cogent, l'employé avait répondu que ça marchait pour
lui. De manière très peu professionnelle, il testait le service
depuis sa machine, sur le réseau interne de son employeur.)
Il n'y avait donc aucun détournement BGP, contrairement à ce qui
a parfois été écrit, l'annonce d'Orange Côte d'Ivoire est
parfaitement légitime. Le service Web a désormais une autre
adresse IP et qui fonctionne, ce qui permet de voir le site
et de constater qu'il n'y avait aucune information publiée avant le
23 mai : 
(Merci à Bert Hubert pour avoir détecté le problème de
synchronisation du serveur DNS racine C, à Jan-Piet Mens pour avoir
détecté le problème avec le serveur Web
C.root-servers.org et à Alarig Le Lay pour ses
explications sur le routage dans Cogent.)
L'article seul
Fiche de lecture : La ronde des bêtes
Auteur(s) du livre : François Jarrige
Éditeur : La Découverte
9782-348-07671
Publié en 2023
Première rédaction de cet article le 17 mai 2024
Autrefois, on utilisait des « moteurs » animaux pour les travaux pénibles, puis on est passé aux moteurs à combustion interne, qui ont pris le dessus parce que, plus récents, ils étaient forcément meilleurs. Dans ce livre, François Jarrige montre que le remplacement des animaux par les machines aux 18e et 19e siècles a été plus compliqué que cela. Le « moteur animal » avait des avantages et le processus n'a pas été simple. C'est donc aussi un livre d'histoire des techniques et de leur déploiement.
Les chiffres indiquent en effet que c'est au 19e siècle et non pas au Moyen Âge qu'il y avait le plus d'animaux au travail dans les campagnes françaises. La révolution industrielle a d'abord conduit à une augmentation du travail animal, pour suivre l'évolution de la demande. Et puis l'auteur, à travers l'analyse de nombreux documents du passé, montre que le « progrès » n'est pas unilatéral. Les machines ont des défauts : le risque d'incendie (un risque sérieux dans une ferme en bois où on stocke du foin, ou dans une usine où on produit de l'alcool), le coût, notamment en capital, la nécessité de disposer de techniciens qualifiés pour soigner ces merveilleuses machines souvent en panne. De même qu'aujourd'hui, les gens qui travaillent dans un bureau vont souvent parcourir les couloirs à la recherche du sorcier informaticien qui va pouvoir remettre en service l'ordinateur mécontent, au 19e siècle, la machine à vapeur ou, plus tard, à pétrole, rendait les paysans ou les artisans dépendants de spécialistes rares et chers (alors que tout le monde savait s'occuper des animaux). Bref, si les animaux sont restés utilisés longtemps après l'arrivée des machines, ce n'était pas par conservatisme stupide des paysans (contrairement à ce qu'écrivaient des experts urbains méprisants dans des journaux) mais c'était souvent un choix rationnel.
Au bout du compte, les animaux effectuant un travail ont peu à peu disparu. Le 19e siècle a été également marqué par une plus grande sensibilité aux souffrances des animaux (qui travaillaient dans des conditions éprouvantes, comme les humains à l'époque, d'ailleurs). Est-il légitime de faire travailler les animaux ? Les promoteurs des machines, engins chers et difficiles à vendre, ont en tout cas saisi l'occasion de devenir défenseurs de la cause animale pour promouvoir leurs produits. Et les animaux de trait n'existent plus.
L'article seul
Fiche de lecture : Chaudun - La montagne blessée
Auteur(s) du livre : Luc Bronner
Éditeur : Seuil
978.2.02.143954.0
Publié en 2020
Première rédaction de cet article le 13 mai 2024
Chaudun est un village en France. Ou plutôt un ex-village. Lassés de la dureté de la vie à Chaudun, tous ses habitants sont partis en 1895, après avoir vendu tout le village et ses terrains à l'État. Luc Bronner, dans ce livre très prenant, fait revivre ces habitants. Qui étaient-ils et comment vivaient-ils ? Partons pour une plongée dans les archives.
L'auteur a fait un travail extraordinaire, collectant les archives de l'état civil (Félicie Marin, décédée le 30 avril 1877, à l'âge de 17 ans), celles de l'Église (étonnant questionnaire envoyé aux curés de tout le département, écrit en français sauf une question en latin, je vous laisse lire pour trouver laquelle), celles de l'armée (descriptions détaillées du physique et de la taille des conscrits mais aussi beaucoup d'insoumis, marqués « parti en Amérique »), celles du conseil municipal (faut-il vraiment utiliser l'argent destiné aux « indigents » pour rembourser le mulet du facteur ?), celles de l'Éducation nationale (Chaudun était un « territoire perdu de la République » où on ne nommait que les enseignants qu'on voulait sanctionner), remontant aux cahiers de doléance… La misère du village se voit partout (mortalité infantile, émigration, lettres des curés et des instituteurs à leur supérieur demandant une mutation…). Il manque évidemment les témoignages des habitants, qui s'exprimaient peu, et dont l'auteur essaie de deviner les pensées, en marchant dans les ruines du village, ou en épluchant des vieux documents. Est-ce que vraiment les habitants continuaient à rendre un culte païen au Soleil, comme le prétend un religieux ?
À la fin du livre, on passe aux archives des Eaux & Forêts, qui ont pris les commandes et planté des arbres.
J'ai été très touché par ce livre, qui raconte tant d'histoires sur la France pauvre de l'époque. Au moins, toutes ces bureaucraties qui notaient et enregistraient ont un avantage : les habitants de Chaudun ne sont pas complètement oubliés et le travail minutieux du journaliste-historien permet de faire revivre une partie de leur vie. On saura ainsi les noms et la carrière des quatre curés qui ont exercé à Chaudun pendant la vie de Félicie Marin.
(Le livre décrit plusieurs photos de l'époque, qui ne sont pas reproduites mais qu'on peut trouver en ligne, avec également des photos récentes des ruines. Et si vous voulez randonner jusqu'aux ruines, suivez cette fiche.)
L'article seul
RFC 9562: Universally Unique IDentifiers (UUIDs)
Date de publication du RFC : Mai 2024
Auteur(s) du RFC : K. Davis (Cisco Systems), B. Peabody (Uncloud), P. Leach (University of Washington)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF uuidrev
Première rédaction de cet article le 12 mai 2024
Ce RFC normalise les UUID, une famille d'identificateurs uniques, obtenus sans registre central. Il remplace l'ancienne norme, le RFC 4122, avec pas mal de nouveautés et un RFC complètement refait.
Les UUID, également connus autrefois sous le nom de GUID (Globally Unique IDentifiers), sont issus à l'origine du système des Apollo, adopté ensuite dans la plate-forme DCE. Les UUID ont une taille fixe, 128 bits, et sont obtenus localement, par exemple à partir d'un autre identificateur unique comme un nom de domaine, ou bien en tirant au hasard, la grande taille de leur espace de nommage faisant que les collisions sont très improbables (section 6.7 du RFC). Ce RFC reprend la spécification (bien oubliée aujourd'hui) de DCE de l'Open Group (ex-OSF) et ajoute la définition d'un espace de noms pour des URN (sections 4 et 7). (Il existe aussi une norme ITU sur les UUID et un registre des UUID, pour ceux qui y tiennent.)
Les UUID peuvent donc convenir pour identifier une entité sur le réseau, par exemple une machine mais aussi, vu leur nombre, comme identificateur unique pour des transactions (ce qui était un de leurs usages dans DCE). En revanche, ils ne sont pas résolvables, contrairement aux noms de domaine. Mais ils sont présents dans beaucoup de logiciels (Windows, par exemple, les utilise intensivement). On les utilise comme clé primaire dans les bases de données, comme identificateur de transaction, comme nom de machine, etc.
Les UUID peuvent se représenter sous forme d'un nombre binaire de
128 bits (la section 5 du RFC décrit les différents champs qui
peuvent apparaitre) ou bien sous forme texte. Sur
Unix, on peut fabriquer un UUID avec la
commande uuidgen, qui affiche la représentation
texte standard que normalise notre RFC (section 4) :
% uuidgen 317e8ed3-1428-4ef1-9dce-505ffbcba11a % uuidgen ec8638fd-c93d-4c6f-9826-f3c71436443a
Sur Linux, vous pouvez aussi simplement
faire cat /proc/sys/kernel/random/uuid. Sur une machine FreeBSD, un UUID de la
machine est automatiquement généré (par le script
/etc/rc.d/hostid) et stocké dans le fichier
/etc/hostid.
Pour l'affichage sous forme d'URN (RFC 8141), on ajoute
juste l'espace uuid par exemple
urn:uuid:ec8638fd-c93d-4c6f-9826-f3c71436443a. Il
a été ajouté au registre
IANA des espaces de noms des URN.
La section 4 du RFC détaille le format de l'UUID. En dépit des apparences, l'UUID n'est pas plat, il a une structure, mais il est très déconseillé aux applications de l'interpréter (section 6.12). Un des champs les plus importants est le champ Version (qui devrait plutôt s'appeler Type) car il existe plusieurs types d'UUID :
- UUID version 1, fondé sur le temps (notez tout de suite que les versions 6 et 7 sont recommandées à sa place).
- UUID version 2, réservé, non utilisé.
- UUID version 3, fondé sur un espace de noms (par exemple le DNS) et un nom qui est condensé en MD5 (la version 5 est préférable).
- UUID version 4, aléatoire.
- UUID version 5, fondé sur un espace de noms et un nom qui est condensé en SHA-1.
- UUID version 6, fondé sur le temps, avec les mêmes champs que la version 1, mais avec un format différent.
- UUID version 7, fondé sur le temps, avec une autre définition, et des champs différents.
- UUID version 8, pour les usages expérimentaux, si vous voulez jouer localement avec un nouveau mécanisme de génération.
Ces différents types / versions figurent dans un registre IANA. Ce registre ne peut être modifié que par une action de normalisation (cf. RFC 8126).
uuidgen, vu plus haut, peut générer des UUID de
version 1 option -t, de version 3
(-m), de version 4 (c'est son comportement par
défaut, mais on peut utiliser l'option -r si on
veut être explicite) ou de version 5 (-s). Ici,
on voit les UUID fondés sur une estampille temporelle (version 1)
augmenter petit à petit :
% uuidgen -t 42ff1626-0fc7-11ef-8162-49e9505fb2f3 % uuidgen -t 4361fae8-0fc7-11ef-8162-49e9505fb2f3 % uuidgen -t 45381d02-0fc7-11ef-8162-49e9505fb2f3
Ici, dans le cas d'un UUID fondé sur un nom (version 3), l'UUID est stable (essayez chez vous, vous devriez obtenir le même résultat que moi), une propriété importante des UUID de version 3 et 5 :
% uuidgen -m -n @dns -N foobar.example 8796bf1a-793c-3c44-9ec5-a572635cd3d4 % uuidgen -m -n @dns -N foobar.example 8796bf1a-793c-3c44-9ec5-a572635cd3d4
Les espaces de noms sont enregistrés dans un
registre IANA, d'autres peuvent être ajoutés si on écrit une spécification
(cf. RFC 8126). Notez que chaque espace a son
UUID (6ba7b810-9dad-11d1-80b4-00c04fd430c8 pour
l'espace DNS).
Les UUID de version 6 et 7, nouveautés de ce RFC 9562, ne sont pas mis en œuvre par uuidgen, ni d'ailleurs par beaucoup d'autres programmes.
Les sections 6.1 et 6.2, elles, décrivent le processus de génération d'un UUID à base temporelle. Idéalement, il faut utiliser une graine enregistrée sur le disque (pour éviter de générer des UUID identiques) ainsi que l'instant de la génération. Mais lire sur le disque prend du temps (alors qu'on peut vouloir générer des UUID rapidement, par exemple pour identifier des transactions) et l'horloge de la machine n'a pas toujours une résolution suffisante pour éviter de lire deux fois de suite le même instant. Ces sections contiennent donc également des avis sur la génération fiable d'UUID, par exemple en gardant en mémoire le nombre d'UUID générés, pour les ajouter à l'heure.
La section 8, consacrée à la sécurité, rappelle qu'un UUID ne doit pas être utilisé comme capacité (car il est trop facile à deviner) et qu'il ne faut pas demander à un humain de comparer deux UUID (ils se ressemblent trop pour un œil humain).
Il est évidemment recommandé d'utiliser les UUID de version 5 plutôt que de version 3 (RFC 6151) mais SHA-1 a aussi ses problèmes (RFC 6194) et, de toute façon, pour la plupart des utilisations des UUID, les faiblesses cryptographiques de MD5 et de SHA-1 ne sont pas gênantes.
La section 2.1 du RFC détaille les motivations pour la mise à jour du RFC 4122 et quels sont les changements effectués. Certaines utilisations des UUID ont remis en cause des suppositions originales. Ainsi, les UUID sont souvent utilisés dans un contexte réparti, où leur capacité à être uniques sans registre central est très utile. Mais quelques points manquaient au RFC 4122 :
- UUID version 4 (aléatoire) avait une mauvaise localité : deux UUID créés l'un après l'autre en un temps très court n'ont aucun rapport, ce qui est gênant pour certains usages (par exemple comme étiquette dans un B-tree).
- UUID version 1 (fondé entre autre sur le temps écoulé depuis l'epoch) utilise un incrément peu pratique (cent nanosecondes).
- Certaines méthodes fabrication des UUID posaient des gros problèmes de vie privée, par exemple l'utilisation des adresses MAC dans UUID version 1, désormais déconseillée.
- Le RFC 4122 descendait trop dans les détails de mise en œuvre.
- Le RFC 4122 ne séparait pas les exigences pour la génération d'UUID et celles pour leur stockage.
Seize mises en œuvre des UUID ont été étudiées pour préparer le nouveau RFC (vous avez la liste dans la section 2.1), menant aux constations suivantes :
- Beaucoup d'errata dans le RFC 4122.
- Spécification du format qui mélangeait trop les diverses versions d'UUID.
- Absence de vecteurs de test (ils figurent désormais dans l'annexe A).
En Python, il existe un module UUID qui offre des fonctions de génération d'UUID de différentes versions (mais pas les plus récentes) :
import uuid
myuuid = uuid.uuid1() # Version 1, Time-based UUID
heruuid = uuid.uuid3(uuid.NAMESPACE_DNS, "foo.bar.example") # Version
# 3, Name-based ("hash-based") UUID, a name hashed by MD5
otheruuid = uuid.uuid4() # Version 4, Random-based UUID
yetanotheruuid = uuid.uuid5(uuid.NAMESPACE_DNS,
"www.example.org")
# Version 5, a name hashed by SHA1
if (myuuid == otheruuid or \
myuuid == heruuid or \
myuuid == yetanotheruuid or \
otheruuid == yetanotheruuid):
raise Exception("They are equal, PANIC!")
print(myuuid)
print(heruuid) # Will always be the same
print(otheruuid)
print(yetanotheruuid) # Will always be the same
Et comme le dit la documentation, Note that uuid1() may compromise privacy since it creates a UUID containing the computer’s network address. (méthode de génération des UUID version 1 qui est désormais déconseillée).
Le SGBD PostgreSQL inclut un type UUID. Cela évite de stocker les UUID sous leur forme texte, ce qui est techniquement absurde et consomme 288 bits au lieu de 128 (section 6.13 du RFC).
essais=> CREATE TABLE Transactions (id uuid, value INT);
CREATE TABLE
essais=> INSERT INTO Transactions VALUES
('74738ff5-5367-5958-9aee-98fffdcd1876', 42);
INSERT 0 1
essais=> INSERT INTO Transactions VALUES
('88e6441b-5f5c-436b-8066-80dca8222abf', 6);
INSERT 0 1
essais=> INSERT INTO Transactions VALUES ('Pas correct', 3);
ERROR: invalid input syntax for type uuid: "Pas correct"
LINE 1: INSERT INTO Transactions VALUES ('Pas correct', 3);
^
-- PostgreSQL peut seulement générer la version 4, les aléatoires
essais=> INSERT INTO Transactions VALUES (gen_random_uuid () , 0);
INSERT 0 1
essais=> SELECT * FROM Transactions;
id | value
--------------------------------------+-------
74738ff5-5367-5958-9aee-98fffdcd1876 | 42
88e6441b-5f5c-436b-8066-80dca8222abf | 6
41648aef-b123-496e-8a4c-52e573d17b6a | 0
(3 rows)
Attention, le RFC (section 6.13) déconseille l'utilisation des UUID fondés sur un nom pour servir de clé primaire dans la base de données, sauf si on est absolument certain (mais c'est rare) que les noms ne changeront pas.
Il existe plusieurs exemples d'utilisation des UUID. Par exemple,
Linux s'en sert pour identifier les disques
attachés à la machine, de préférence à l'ancien système où l'ajout
d'un nouveau disque pouvait changer l'ordre des numéros sur le bus et
empêcher le système de trouver un disque. Un
/etc/fstab typique sur Linux contient donc
des :
UUID=da8285a0-3a70-413d-baed-a1f48d7bf7b2 /home ext3 defaults ...
plutôt que les anciens :
/dev/sda3 /home ext3 defaults
car sda3 n'est pas un identificateur
stable. L'UUID, lui, est dans le système de fichiers et ne changera
pas avec les changements sur le bus. On peut
l'afficher avec dumpe2fs :
# dumpe2fs -h /dev/sda3 ... Filesystem UUID: da8285a0-3a70-413d-baed-a1f48d7bf7b2 ...
Un exemple d'utilisation de la nouvelle version 7 est décrit dans l'excellent article « Goodbye integers. Hello UUIDv7! ». Une mise en œuvre de cette version 7 apparait dans « UUIDv7 in 20 languages ».
La section 6 décrit les bonnes pratiques de génération d'un UUID. Ainsi :
- Pour tous les UUID fondés sur le temps, si vous avez besoin d'unicité des UUID, attention aux cas où l'horloge peut changer, en raison d'une modification manuelle, d'une seconde intercalaire ou d'un ajustement fait par NTP.
- Si vous générez des UUID de manière répartie, sur plusieurs machines, ce qui est un des points forts des UUID, mais que vous voulez quand même de l'unicité, vous pouvez préfixer vos UUID avec un identificateur de la machine, ou bien compter sur un registre central (mais, en général, c'est justement ce qu'on veut éviter avec des UUID).
- UUID rend les collisions (génération de deux UUID identiques) peu probables mais pas impossibles. Lorsque vous concevez une application, demandez-vous si une collision est juste un petit inconvénient ou bien si elle est inacceptable (le RFC cite l'exemple fictif d'un système de contrôle aérien où chaque avion serait identifié par un UUID ; l'attribution du même UUID à deux avions différents serait clairement catastrophique). Dans ce cas, vous devez trouver un moyen de ne pas avoir de collision.
- Si vous voulez des UUID qui ne soient pas prévisibles par un observateur extérieur, utilisez la version 4 et assurez vous que votre générateur de nombres aléatoires suit bien les prescriptions des RFC 4086 et RFC 8937, ainsi que « Random Number Generator Recommendations for Applications ».
- Les versions 6 et 7 (nouveautés de ce RFC 9562) sont prévues pour que les UUID soient triables chronologiquement, sans avoir besoin d'analyse, uniquement en triant la version binaire. Un des avantages est que des UUID générés à des moments proches ont des valeurs proches, ce qui peut être utile dans certaines applications.
L'article seul
RFC 9490: Report from the IAB Workshop on Management Techniques in Encrypted Networks (M-TEN)
Date de publication du RFC : Janvier 2024
Auteur(s) du RFC : M. Knodel, W. Hardaker, T. Pauly
Pour information
Première rédaction de cet article le 9 mai 2024
Aujourd'hui, l'essentiel du trafic sur l'Internet est chiffré, et pour d'excellentes raisons. Pas question de revenir là-dessus, mais, ceci dit, il va falloir adapter certaines pratiques de gestion des réseaux. L'IAB a organisé en 2022 un atelier sur ce sujet, dont ce RFC est le compte-rendu.
Comme les autres ateliers de l'IAB, il s'agit de faire s'exprimer diverses personnes, pas forcément d'arriver à une position commune (surtout sur un sujet… sensible). Tenu entièrement en ligne, cet atelier commençait par la soumission d'articles, qui devaient être lus d'abord, et discutés lors de l'atelier. La liste des articles figure dans l'annexe A du RFC, et les articles sont disponibles en ligne.
D'abord, notre RFC réaffirme que la cryptographie est absolument nécessaire à la protection de la vie privée. Les difficultés réelles qu'elle peut poser ne doivent jamais être un prétexte pour réduire ou affaiblir le chiffrement. Qu'il y ait une tension entre l'impératif du chiffrement et certaines méthodes de gestion du réseau, OK, mais la priorité reste la lutte contre la surveillance (RFC 7258).
Ensuite (section 1), le RFC pose le paysage : le trafic étant largement chiffré, des méthodes traditionnelles de gestion du réseau ne fonctionnent plus. tcpdump ne montre plus les données, on ne peut donc pas distinguer différentes méthodes HTTP, par exemple. Avec QUIC (RFC 9000), c'est même une partie de la couche transport qui est chiffrée donc un observateur extérieur ne peut plus, par exemple, évaluer le RTT d'une session qu'il observe (ce qui était possible avec TCP). Il va donc falloir s'adapter notamment en coopérant davantage avec les applications qui, elles, ont accès à tout. Pour l'instant, on a vu surtout passer des récriminations d'acteurs habitués à surveiller le trafic et qui se plaignent que le chiffrement les en empêchent (le RFC 8404 est un bon exemple de ces récriminations). Au contraire, il faut chercher à résoudre une contradiction : permettre aux réseaux d'appliquer leur politique sans céder d'un millimètre sur le principe du chiffrement.
Outre le cas des opérateurs réseau qui veulent examiner le trafic, à des fins louables (améliorer le réseau) ou critiquables (défavoriser certains usages), on peut aussi citer, parmi les intermédiaires qui voudraient observer et/ou interférer avec le trafic réseau, les réseaux d'entreprise qui veulent, par exemple, empêcher les employés d'accéder à certains services, ou bien les mécanismes de contrôle des enfants (appelés à tort « contrôle parental », alors que leur but est justement de remplacer les parents).
Trois thèmes importants étaient discutés à l'atelier : la situation actuelle, les futures techniques et la façon dont on pourrait arriver à déployer ces futures techniques.
Pour la situation actuelle, on sait que, depuis longtemps, les administrateurices réseau comptent sur de l'observation passive, par exemple pour classer le trafic (tant de HTTP, tant de SSH, etc). C'est à la base de techniques comme IPFIX (RFC 7011), qui permet de produire de beaux camemberts. Outre la production de rapports, cette observation passive peut (mais n'est pas forcément) être utilisée pour prévoir les évolutions futures, prioriser certains types de trafic, détecter des comportements malveillants, etc. Les protocoles Internet étaient en effet traditionnellement trop bavards, faisant fuiter des informations vers des observateurs passifs (cf. le concept de « vue depuis le réseau », RFC 8546).
La lutte
de l'épée et de la cuirasse étant éternelle, il y a évidemment eu
des travaux sur des mécanismes pour empêcher ce genre d'analyses
comme l'article soumis pour l'atelier « WAN
Traffic Obfuscation at Line Rate ». (Au passage,
sur cette idée d'obfuscation, je recommande le
livre de Brunton et Nissenbaum.)
Le RFC mentionne aussi une discussion sur l'idée d'exiger une
permission explicite des utilisateurs pour les analyses du trafic
(je ne vous dis pas les difficultés pratiques…). Voir
l'Internet-Draft
draft-irtf-pearg-safe-internet-measurement.
Dans un monde idéal, le réseau et les applications coopéreraient (et, dans un monde idéal, licornes et bisounours s'embrasseraient tous les jours) mais on voit plutôt une lutte, le réseau essayant d'en savoir plus, les applications de préserver leur intimité. Pourtant, le RFC note qu'une coopération pourrait être dans leur intérêt réciproque. Bien sûr, des applications comme Tor refuseraient certainement toute coopération puisque leur but est de laisser fuiter le moins d'information possible, mais d'autres applications pourraient être tentées, par exemple en échange d'informations du réseau sur la capacité disponible. Après tout, certaines techniques sont justement conçues pour cela, comme ECN (RFC 3168).
OK, maintenant, quelles sont les techniques et méthodes pour résoudre le problème de la gestion des réseaux chiffrés (section 2.2) ? Le RFC exprime bien le fait que le but du chiffrement est d'empêcher tout tiers d'accéder aux informations. Donc, sauf faille de sécurité, par exemple suite à une faiblesse du chiffrement, tout accès à l'information impose la coopération d'une des deux parties qui communiquent. Cette question du consentement est cruciale. Si on n'a pas le consentement d'une des deux extrémités de la communication, on n'a pas le droit d'accéder aux données, point. Cf. la contribution « What’s In It For Me? Revisiting the reasons people collaborate ». Comme le répète souvent Eric Rescorla « Sur l'Internet, tout ce qui n'est pas une des extrémités est un ennemi. » (Cela inclut donc tous les équipements réseaux et les organisations qui les contrôlent.) Bref, les utilisateurs doivent pouvoir donner un consentement éclairé, et juger si les bénéfices de la visibilité l'emportent sur les risques. Évidemment, ce principe correct va poser de sérieuses difficultés d'application, car il n'est pas évident d'analyser proprement les bénéfices, et les risques (songez aux bandeaux cookies ou aux permissions des application sur votre ordiphone). Développer des nouveaux mécanismes de communication avec l'utilisateurice sont nécessaires, sinon, comme le note le RFC, « les ingénieurs devront choisir pour les utilisateurs ». Le RFC estime que les utilisateurs donneront toujours la priorité à leur vie privée (notamment parce qu'ils ne comprennent pas l'administration de réseaux et ses exigences), mais cela ne me semble pas si évident que cela. Personnellement, il me semble que le choix par défaut est crucial, car peu d'utilisateurices le modifieront.
Une des techniques qui permettent d'avoir accès à de l'information sans avoir toute l'information est celle des relais (cf. « Relying on Relays: The future of secure communication ». Le principe est de séparer les fonctions : l'utilisateur parle à un relais qui parle au serveur final. Le relais ne connait pas le contenu de la demande, le serveur ne connait pas le demandeur. C'est utilisé dans des techniques comme Oblivious HTTP (RFC 9458) ou Oblivious DNS (RFC 9230). La préservation de la vie privée est donc bien meilleure qu'avec, par exemple, un VPN, où l'opérateur du VPN voit tout, le demandeur et la demande (contrairement à ce que prétendent les publicités pour NordVPN que de nombreux youtubeurs transmettent avec leurs vidéos). Le relais permet donc un accès à une information limitée, ce qui permet d'assurer certaines fonctions (comme le filtrage de contenu malveillant) sans avoir un accès complet.
Un exemple souvent cité par les opérateurs de l'intérêt d'accéder à la communication et de la modifier est celui de l'optimisation des flux TCP. Des PEP (Performance Enhancing Proxies) violant le modèle en couches (car, normalement, TCP est de bout en bout) sont souvent déployés, notamment sur les liaisons satellites, dont les performances sont plus mauvaises, et les caractéristiques techniques très spéciales. (Cf. l'exposé de Nicolas Kuhn, « QUIC for satellite communications » à la Journée du Conseil Scientifique de l'Afnic en 2021.) Le PEP va modifier les en-têtes TCP, voire parfois boucler la connexion TCP et en faire une autre lui-même. Cette technique ne marche évidemment plus avec QUIC, qui chiffre même la couche transport. Et elle mène à l'ossification de l'Internet puisqu'elle rend plus difficile de faire évoluer TCP, car toute évolution risque de perturber les PEP. QUIC avait en partie été explicitement développé pour empêcher ces intermédiaires de bricoler la session. Une autre approche est celle proposée dans « The Sidecar: "Opting in" to PEP Functions ».
Bon, maintenant, comment arriver à déployer de meilleures méthodes ? Dans un environnement fermé ou semi-fermé, cela doit être possible de faire en sorte que, par exemple, toutes les machines mettent en œuvre telle fonction (cf. RFC 8520 pour un exemple). Mais cela ne marche clairement pas pour l'Internet.
Parmi les moyens proposés de résolution de la contradiction entre visibilité par le réseau et protection de la vie privée, le RFC mentionne les Zero-Knowledge Middleboxes. Décrites dans l'article du même nom, cette méthode utilise les preuves à divulgation nulle de connaissance pour prouver à l'intermédiaire qui fait le filtrage qu'on a bien respecté sa politique de filtrage, sans lui dire ce qu'on a fait. L'article détaille par exemple comment cela peut s'appliquer au DNS, qui est le principal outil de censure de l'Internet dans l'Union européenne. Ces preuves à divulgation nulle de connaissance ayant toujours été mystérieuses pour moi, je ne vous expliquerai pas comment elles marchent, mais notez que les auteurs ont fait un article pédagogique.
Enfin, le RFC mentionne la proposition Red Rover, qui propose encore un arrangement bisounours où les utilisateurs et les opérateurs collaboreraient pour un filtrage géré en commun. Les auteurs disent que ça marcherait car les utilisateurs « ne veulent probablement pas violer les CGU » (ben si : ils veulent utiliser Sci-Hub même si c'est censuré).
En conclusion, le RFC note en effet qu'on peut être sceptique quant aux chances d'une solution négociée. Mais il met aussi en avant le fait qu'il va être très difficile de trouver une solution qui marche pour toute la variété des réseaux. Et que l'expérience prouve largement que toute nouvelle technique va avoir des effets inattendus et que, par exemple, une solution qui visait à donner aux opérateurs des informations utiles pour la gestion de réseaux, va parfois être détournée pour d'autres buts.
Sinon, sur la question du déboguage des applications dans un monde où tout est chiffré, j'avais fait un exposé à Capitole du Libre.
L'article seul
RFC 9499: DNS Terminology
Date de publication du RFC : Mars 2024
Auteur(s) du RFC : P. Hoffman (ICANN), K. Fujiwara
(JPRS)
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 3 mai 2024
Comme beaucoup de protocoles très utilisés sur l'Internet, le DNS est ancien. Très ancien (la première norme, le RFC 882, date de 1983). Les normes techniques vieillissent, avec l'expérience, on comprend mieux, on change les points de vue et donc, pour la plupart des protocoles, on se lance de temps en temps dans une révision de la norme. Mais le DNS est une exception : la norme actuelle reste fondée sur des textes de 1987, les RFC 1034 et RFC 1035. Ces documents ne sont plus à jour, modifiés qu'ils ont été par des dizaines d'autres RFC. Bref, aujourd'hui, pour comprendre le DNS, il faut s'apprêter à lire de nombreux documents. En attendant qu'un courageux et charismatique participant à l'IETF se lance dans la tâche herculéenne de faire un jeu de documents propre et à jour, ce RFC 9499, successeur du RFC 8499 (il y a peu de modifications), se limite à une ambition plus modeste : fixer la terminologie du DNS. Ce n'est pas un tutoriel : vous n'y apprendrez pas le DNS. C'est plutôt une encyclopédie.
En effet, chacun peut constater que les discussions portant sur le DNS sont difficiles : on manque de terminologie standard, et celle des RFC officielles ne suffit pas, loin de là. Souvent, le DNS a tellement changé que le RFC officiel est même trompeur : les mots ne veulent plus dire la même chose. D'autres protocoles ont connu des mises à jour de la norme. Cela a été le cas de SMTP, passé successivement du RFC 772 à l'actuel RFC 5321, en passant par plusieurs révisions successives. Ou de XMPP, qui a vu sa norme originale mise à jour dans le RFC 6120. Et bien sûr de HTTP, qui a connu plusieurs toilettages complets (cf. RFC 9110). Mais personne n'a encore osé faire pareil pour le DNS. Au moins, ce RFC 9499, comme son prédécesseur RFC 8499, traite l'un des problèmes les plus criants, celui du vocabulaire. Le RFC est évidemment en anglais, les traductions proposées dans cet article, et qui n'ont pas de valeur « officielle » sont de moi seul.
Notre RFC 9499 rassemble donc des définitions pour des termes qui étaient parfois précisément définis dans d'autres RFC (et il fournit alors un lien vers ce RFC original), mais aussi qui n'étaient définis qu'approximativement ou parfois qui n'étaient pas définis du tout (et ce RFC fournit alors cette définition). Du fait du flou de certains RFC anciens, et des changements qui ont eu lieu depuis, certaines définitions sont différentes de l'original. Le document a fait l'objet d'un consensus relatif auprès des experts DNS mais quelques termes restent délicats. Notez aussi que d'autres organisations définissent des termes liés au DNS par exemple le WHATWG a sa définition de ce qu'est un domaine, et le RSSAC a développé une terminologie.
Ironiquement, un des termes les plus difficiles à définir est
« DNS » lui-même (section 1 de notre RFC). D'accord, c'est le sigle
de Domain Name System mais ça veut dire quoi ?
« DNS » peut désigner le schéma de nommage (les noms de domaine comme
signal.eu.org, leur syntaxe, leurs
contraintes), la base de données répartie (et faiblement cohérente)
qui associe à ces noms des informations (comme des certificats, des
adresses IP, etc), ou le
protocole
requête/réponse (utilisant le port 53) qui permet d'interroger cette
base. Parfois, « DNS » désigne uniquement le protocole, parfois,
c'est une combinaison des trois éléments indiqués plus haut
(personnellement, quand j'utilise « DNS », cela désigne uniquement
le protocole, un protocole relativement simple, fondé sur l'idée
« une requête => une réponse »).
Bon, et ces définitions rigoureuses et qui vont mettre fin aux discussions, ça vient ? Chaque section du RFC correspond à une catégorie particulière. D'abord, en section 2, les noms eux-même, ces fameux noms de domaine. Un système de nommage (naming system) a plusieurs aspects, la syntaxe des noms, la gestion des noms, le type de données qu'on peut associer à un nom, etc. D'autres systèmes de nommage que celui présenté dans ce RFC existent, et sont distincts du DNS sur certains aspects. Pour notre système de nommage, le RFC définit :
- Nom de domaine (domain
name) : la définition est différente de celle du RFC 7719, qui avait simplement repris celle du
RFC 1034, section 3.1. Elle est désormais
plus abstraite, ce qui permet de l'utiliser pour d'autres systèmes
de nommage. Un nom de domaine est désormais simplement une liste
(ordonnée) de composants (labels). Aucune
restriction n'est imposée dans ces composants, simplement formés
d'octets (tant pis pour la
légende comme quoi le DNS serait limité à ASCII). Comme on peut représenter les
noms de domaine sous forme d'un arbre (la racine de l'arbre étant à la fin
de la liste des composants) ou bien sous forme texte
(
www.madmoizelle.com), le vocabulaire s'en ressent. Par exemple, on va dire quecomest « au-dessus demadmoizelle.com» (vision arborescente) ou bien « à la fin dewww.madmoizelle.com» (vision texte). Notez aussi que la représentation des noms de domaine dans les paquets IP n'a rien à voir avec leur représentation texte (par exemple, les points n'apparaissent pas). Enfin, il faut rappeler que le vocabulaire « standard » n'est pas utilisé partout, même à l'IETF, et qu'on voit parfois « nom de domaine » utilisé dans un sens plus restrictif (par exemple uniquement pour parler des noms pouvant être résolus avec le DNS, pour lesquels il avait été proposé de parler de DNS names). - FQDN (Fully Qualified Domain
Name, nom de domaine complet) : apparu dans le RFC 819, ce terme désigne un nom de domaine où tous les
composants sont cités (par exemple,
ldap.potamochère.fr.est un FQDN alors queldaptout court ne l'est pas). En toute rigueur, un FQDN devrait toujours s'écrire avec un point à la fin (pour représenter la racine) mais ce n'est pas toujours le cas. (Notre RFC parle de « format de présentation » et de « format courant d'affichage » pour distinguer le cas où on met systématiquement le point à la fin et le cas où on l'oublie.) - Composant
(label) : un nœud de l'arbre des noms de
domaine, dans la chaîne qui compose un FQDN. Dans
www.laquadrature.net, il y a trois composants,www,laquadratureetnet. - Nom de machine (host
name) : ce n'est pas la
même chose qu'un nom de domaine. Utilisé dans de nombreux
RFC (par exemple RFC 952) mais jamais défini, un nom de
machine est un nom de domaine avec une syntaxe plus
restrictive, définie dans la section 3.5 du RFC 1035 et amendée par la section 2.1 du RFC 1123 : uniquement des lettres, chiffres, points et le
tiret. Ainsi,
brienne.tarth.got.examplepeut être un nom de machine maiswww.&#$%?.examplene peut pas l'être. Le terme de « nom de machine » est parfois aussi utilisé pour parler du premier composant d'un nom de domaine (briennedansbrienne.tarth.got.example). - TLD (Top Level
Domain, domaine de premier niveau ou domaine de
tête) : le dernier composant d'un nom de domaine, celui juste
avant (ou juste en dessous) de la racine. Ainsi,
frounamesont des TLD. N'utilisez surtout pas le terme erroné d'« extension ». Et ne dites pas que le TLD est le composant le plus à droite, ce n'est pas vrai dans l'alphabet arabe. La distinction courante entre gTLD, gérés par l'ICANN, et ccTLD, indépendants de l'ICANN, est purement politique et ne se reflète pas dans le DNS. - DNS mondial (Global DNS), nouveauté du RFC 8499, désigne l'ensemble des noms qui obéissent aux règles plus restrictives des RFC 1034 et RFC 1035 (limitation à 255 octets, par exemple). En outre, les noms dans ce « DNS mondial » sont rattachés à la racine officiellement gérée par l'ICANN, via le service Public Technical Identifiers (PTI). Une racine alternative, si elle sert un contenu différent de celui de PTI, n'est donc pas le « DNS mondial » mais ce que le RFC nomme « DNS privé » (private DNS). Évidemment, un système de nommage qui n'utilise pas le DNS du tout mais qui repose, par exemple, sur le pair-à-pair, ne doit pas être appelé DNS (« DNS pair-à-pair » est un oxymore, une contradiction dans les termes.)
- IDN (Internationalized Domain Name, nom de domaine internationalisé) : un nom de domaine en Unicode, normalisé dans le RFC 5890, qui définit des termes comme U-label (le nom Unicode) et A-label (sa représentation en Punycode). Sur l'internationalisation des noms, vous pouvez aussi consulter le RFC de terminologie RFC 6365.
- Sous-domaine
(subdomain) : domaine situé sous un autre,
dans l'arbre des noms de domaines. Sous forme texte, un domaine
est sous-domaine d'un autre si cet autre est un suffixe. Ainsi,
www.cl.cam.ac.ukest un sous-domaine decl.cam.ac.uk, qui est un sous-domaine decam.ac.uket ainsi de suite, jusqu'à la racine, le seul domaine à n'être sous-domaine de personne. Quand le RFC parle de suffixe, il s'agit d'un suffixe de composants, pas de caractères :foo.example.netn'est pas un sous-domaine deoo.example.net. - Alias (alias) :
attention, il y a un piège. Le DNS permet à un nom d'être un
alias d'un autre, avec le type d'enregistrement CNAME (voir la
définition suivante). L'alias est le terme de gauche de
l'enregistrement CNAME. Ainsi, si on met dans un fichier de zone
vader IN CNAME anakin, l'alias estvader(et c'est une erreur de dire que c'est « le CNAME »). - CNAME (Canonical
Name, nom canonique, le « vrai » nom) : le membre
droit dans l'enregistrement CNAME. Dans l'exemple de la
définition précédente,
anakinest le CNAME, le « nom canonique ».
Fini avec les noms, passons à l'en-tête des messages DNS et aux codes qu'il peut contenir. Cet en-tête est défini dans le RFC 1035, section 4.1. Il donne des noms aux champs mais pas forcément aux codes. Ainsi, le code de réponse 3 indiquant qu'un domaine demandé n'existe pas est juste décrit comme name error et n'a reçu son mnémonique de NXDOMAIN (No Such Domain) que plus tard. Notre RFC définit également, dans sa section 3 :
- NODATA : un mnémonique pour une réponse où le nom de domaine demandé existe bien mais ne contient aucun enregistrement du type souhaité. Le code de retour est 0, NOERROR, et le nombre de réponses (ANCOUNT pour Answer Count) est nul.
- Réponse négative (negative answer) : le terme recouvre deux choses, une réponse disant que le nom de domaine demandé n'existe pas (code de retour NXDOMAIN), ou bien une réponse indiquant que le serveur ne peut pas répondre (code de retour SERVFAIL ou REFUSED). Voir le RFC 2308.
- Renvoi (referral) : le DNS étant décentralisé, il arrive qu'on pose une question à un serveur qui ne fait pas autorité pour le domaine demandé, mais qui sait vous renvoyer à un serveur plus proche. Ces renvois sont indiqués dans la section Authority d'une réponse.
Voici un renvoi depuis la racine vers .fr :
% dig @l.root-servers.net A blog.imirhil.fr
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 16572
;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 5, ADDITIONAL: 11
...
;; AUTHORITY SECTION:
fr. 172800 IN NS d.ext.nic.fr.
fr. 172800 IN NS d.nic.fr.
fr. 172800 IN NS e.ext.nic.fr.
fr. 172800 IN NS f.ext.nic.fr.
fr. 172800 IN NS g.ext.nic.fr.
La section 4 s'intéresse aux transactions DNS. Un des termes définis est celui de QNAME (Query NAME), nouveauté du RFC 8499. Il y a trois sens possibles (le premier étant de très loin le plus commun) :
- Le sens original, le QNAME est la question posée (le nom de domaine demandé),
- Le sens du RFC 2308, la question finale (qui n'est pas la question posée s'il y a des CNAME sur le trajet),
- Un sens qui n'apparait pas dans les RFC mais est parfois présent dans les discussions, une question intermédiaire (dans une chaîne de CNAME).
Le RFC 2308 est clairement en tort ici. Il aurait dû utiliser un terme nouveau, pour le sens nouveau qu'il utilisait.
Passons maintenant aux enregistrements DNS, stockés dans cette base de données répartie (section 5 du RFC) :
- RR (Resource Record) : un enregistrement DNS.
- Enregistrements d'adresses (Address records) : enregistrements DNS A (adresses IPv4) et AAAA (adresses IPv6). Beaucoup de gens croient d'ailleurs que ce sont les seuls types d'enregistrements possibles (« le DNS sert à traduire les noms en adresses IP » est une des synthèses erronées du DNS les plus fréquentes).
- Ensemble d'enregistrements (RRset pour Resource Record set) : un ensemble d'enregistrements ayant le même nom (la même clé d'accès à la base), la même classe, le même type et le même TTL. Cette notion avait été introduite par le RFC 2181. Notez que la définition originale parle malheureusement de label dans un sens incorrect. La terminologie du DNS est vraiment compliquée !
- Fichier maître (master file) : un fichier texte contenant des ensembles d'enregistrement. Également appelé fichier de zone, car son utilisation la plus courante est pour décrire les enregistrements que chargera le serveur maître au démarrage. (Ce format peut aussi servir à un résolveur quand il écrit le contenu de sa mémoire sur disque.)
- EDNS (Extension for DNS, également appelé EDNS0) : normalisé dans le RFC 6891, EDNS permet d'étendre l'en-tête du DNS, en spécifiant de nouvelles options, en faisant sauter l'antique limitation de taille de réponses à 512 octets, etc.
- OPT (pour Option) : une astuce d'EDNS pour encoder les informations de l'en-tête étendu. C'est un enregistrement DNS un peu spécial, défini dans le RFC 6891, section 6.1.1.
- Propriétaire (owner ou owner name) : le nom de domaine d'un enregistrement. Ce terme est très rarement utilisé, même par les experts.
- Champs du SOA (SOA field names) : ces noms des enregistrements SOA (comme MNAME ou RNAME) sont peu connus et malheureusement peu utilisés (RFC 1035, section 3.3.13). Notez que la sémantique du champ MINIMUM a complètement changé avec le RFC 2308.
- TTL (Time To Live) : la durée de vie maximale d'un enregistrement dans les caches des résolveurs. C'est un entier non signé (même si le RFC 1035 dit le contraire), en secondes.
Voici un ensemble d'enregistrements (RRset), comptant ici deux enregistrements :
rue89.com. 600 IN MX 50 mx2.typhon.net.
rue89.com. 600 IN MX 10 mx1.typhon.net.
(Depuis, ça a changé.)
Et voici un pseudo-enregistrement OPT, tel qu'affiché par dig, avec une indication de la taille maximale et l'option client subnet (RFC 7871) :
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 512
; CLIENT-SUBNET: 13.176.144.0/24/0
Ensuite, un sujet chaud où le vocabulaire est particulièrement peu défini, et très mal utilisé (voir les forums grand public sur le DNS où les discussions prennent un temps fou car les gens utilisent mal les mots) : les différents types de serveurs et clients DNS (section 6). Pour commencer, il est crucial de se méfier quand un texte parle de « serveur DNS » tout court. Si le contexte ne permet pas de savoir de quel genre de serveur DNS on parle, cela indique un manque de compréhension du DNS par l'auteur du texte. Serveurs faisant autorité et serveurs résolveurs, quoique utilisant le même protocole, sont en effet très différents.
- Résolveur (resolver) : un client DNS qui va produire une réponse finale (pas juste un renvoi, pas juste une information ponctuelle comme le fait dig). Il existe plusieurs types de résolveurs (voir ci-dessous) et, en pratique, quand on dit « résolveur » tout court, c'est en général un « résolveur complet ».
- Résolveur minimum (stub
resolver) : un résolveur qui ne sait pas suivre les
renvois et qui dépend donc d'un ou de plusieurs résolveurs
complets pour faire son travail. Ce type est défini dans la
section 6.1.3.1 du RFC 1123. C'est ce
résolveur minimum qu'appellent les applications lorsqu'elles font
un
getaddrinfo()ougetnameinfo(). Sur Unix, le résolveur minimum fait en général partie de la libc et trouve l'adresse du ou des résolveurs complets dans/etc/resolv.conf. - Résolveur complet (full resolver) : un résolveur qui sait suivre les renvois et donc fournir un service de résolution complet. Des logiciels comme Unbound ou PowerDNS Resolver assurent cette fonction. Le résolveur complet est en général situé chez le FAI ou dans le réseau local de l'organisation où on travaille, mais il peut aussi être sur la machine locale. On le nomme aussi « résolveur récursif ». Notez que « résolveur complet » fait partie de ces nombreux termes qui étaient utilisés sans jamais avoir été définis rigoureusement.
- Resolveur complet avec mémoire (full-service resolver) : un résolveur complet, qui dispose en plus d'une mémoire (cache) des enregistrements DNS récoltés.
- Serveur faisant autorité
(authoritative server et traduire ce terme
par « serveur autoritaire » montre une grande ignorance de
l'anglais ; un adjudant est autoritaire,
un serveur DNS fait autorité) : un serveur DNS qui connait une
partie des données du DNS (il « fait autorité » pour une ou
plusieurs zones) et peut donc y répondre (RFC 2182,
section 2). Ainsi, au moment de l'écriture de cet article,
f.root-servers.netfait autorité pour la racine,d.nic.frfait autorité pourpm, etc. Des logiciels comme NSD ou Knot assurent cette fonction. Les serveurs faisant autorité sont gérés par divers acteurs, les registres, les hébergeurs DNS (qui sont souvent en même temps bureaux d'enregistrement), mais aussi parfois par M. Michu. La commandedig NS $ZONEvous donnera la liste des serveurs faisant autorité pour la zone$ZONE. Ou bien vous pouvez utiliser un service sur le Web en visitanthttps://dns.bortzmeyer.org/DOMAIN/NSoù DOMAIN est le nom de domaine qui vous intéresse. - Serveur mixte : ce terme n'est pas dans ce RFC. Autrefois, il était courant que des serveurs DNS fassent à la fois résolveur et serveur faisant autorité. Cette pratique est fortement déconseillée depuis de nombreuses années (entre autres parce qu'elle complique sérieusement le débogage, mais aussi pour des raisons de sécurité parce qu'elle mène à du code plus complexe) et n'est donc pas dans ce RFC.
- Initialisation
(priming) : le processus par lequel un
résolveur complet vérifie l'information sur les serveurs de la
racine. Ce concept est décrit en détail dans le RFC 9609. Au démarrage, le résolveur ne sait rien. Pour
pouvoir commencer la résolution de noms, il doit demander aux
serveurs de la racine. Il a donc dans sa configuration leur
liste. Mais ces configurations ne sont pas forcément mises à
jour souvent. La liste peut donc être trop vieille. La première
chose que fait un résolveur est donc d'envoyer une requête
«
NS .» à un des serveurs de sa liste. Ainsi, tant qu'au moins un des serveurs de la vieille liste répond, le résolveur est sûr d'apprendre la liste actuelle. - Indications de la racine (root hints) : la liste des noms et adresses des serveurs racine, utilisée pour l'initialisation. L'administrateur d'un résolveur utilisant une racine alternative changera cette liste.
- Mémorisation des négations (negative caching, ou « cache négatif ») : mémoriser le fait qu'il n'y a pas eu de réponse, ou bien une réponse disant qu'un nom de domaine n'existe pas.
- Serveur primaire (primary
server mais on dit aussi serveur maître, master
server) : un serveur faisant autorité qui a accès à la
source des données (fichier de zone, base de données,
etc). Attention, il peut y avoir plusieurs serveurs
primaires (autrefois, ce n'était pas clair et beaucoup de gens
croient qu'il y a un serveur primaire, et qu'il est indiqué dans
l'enregistrement SOA). Attention bis, le terme ne s'applique qu'à des
serveurs faisant autorité, l'utiliser pour les résolveurs (« on
met en premier dans
/etc/resolv.confle serveur primaire ») n'a pas de sens. - Serveur secondaire (secondary server mais on dit aussi « serveur esclave », slave server) : un serveur faisant autorité qui n'est pas la source des données, qui les a prises d'un serveur primaire (dit aussi serveur maître), via un transfert de zone (RFC 5936).
- Serveur furtif (stealth server) : un serveur faisant autorité mais qui n'apparait pas dans l'ensemble des enregistrements NS. (Définition du RFC 1996, section 2.1.)
- Maître caché (hidden master) : un serveur primaire qui n'est pas annoncé publiquement (et n'est donc accessible qu'aux secondaires). C'est notamment utile avec DNSSEC : s'il signe, et donc a une copie de la clé privée, il vaut mieux qu'il ne soit pas accessible de tout l'Internet (RFC 6781, section 3.4.3).
- Transmission (forwarding) : le fait, pour un résolveur, de faire suivre les requêtes à un autre résolveur (probablement mieux connecté et ayant un cache partagé plus grand). On distingue parfois (mais ce n'est pas forcément clair, même dans le RFC 5625) la transmission, où on émet une nouvelle requête, du simple relayage de requêtes sans modification.
- Transmetteur
(forwarder) : le terme est parfois utilisé
confusément. Il désigne tantôt la machine qui transmet une
requête et tantôt celle vers laquelle on transmet (c'est dans
ce sens qu'il est utilisé dans la configuration de
BIND, avec la directive
forwarders). La définition de notre RFC est le premier sens. - Résolveur politique (policy-implementing resolver) : un résolveur qui modifie les réponses reçues, selon sa politique. On dit aussi, moins diplomatiquement, un « résolveur menteur ». C'est ce que permet, par exemple, le système RPZ. Sur l'utilisation de ces « résolveurs politiques » pour mettre en œuvre la censure, voir entre autres mon article aux RIPE Labs. Notez que le résolveur politique a pu être choisi librement par l'utilisateur (par exemple comme élément d'une solution de blocage des publicités) ou bien qu'il lui a été imposé.
- Résolveur ouvert (open resolver) : un résolveur qui accepte des requêtes DNS depuis tout l'Internet. C'est une mauvaise pratique (cf. RFC 5358) et la plupart de ces résolveurs ouverts sont des erreurs de configuration. Quand ils sont délibérement ouverts, comme Google Public DNS ou Quad9, on parle plutôt de résolveurs publics.
- Collecte DNS passive (passive DNS) : désigne les systèmes qui écoutent le trafic DNS, et stockent tout ou partie des informations échangées. Le cas le plus courant est celui où le système de collecte ne garde que les réponses (ignorant donc les adresses IP des clients et serveurs), afin de constituer une base historique du contenu du DNS (c'est ce que font DNSDB ou le système de PassiveDNS.cn).
- Serveur protégeant la vie privée (privacy-enabled server) : ce terme désigne un serveur, typiquement un résolveur, qui permet les requêtes DNS chiffrées, avec DNS-sur-TLS (RFC 7858) ou avec DoH (RFC 8484).
- Anycast : le fait d'avoir un service en plusieurs sites physiques, chacun annonçant la même adresse IP de service (RFC 4786). Cela résiste mieux à la charge, et permet davantage de robustesse en cas d'attaque par déni de service. Les serveurs de la racine, ceux des « grands » TLD, et ceux des importants hébergeurs DNS sont ainsi « anycastés ». Chaque machine répondant à l'adresse IP de service est appelée une instance.
- DNS divisé (split
DNS) : le fait de donner des réponses différentes
selon que le client est interne à une organisation ou
externe. Le but est, par exemple, de faire en sorte que
www.organisation.exampleaille sur le site public quand on vient de l'Internet mais sur un site interne de la boîte quand on est sur le réseau local des employés.
Voici, vu par tcpdump, un exemple d'initialisation d'un résolveur BIND utilisant la racineYeti (RFC 8483) :
15:07:36.736031 IP6 2a01:e35:8bd9:8bb0:21e:8cff:fe76:29b6.35721 > 2001:6d0:6d06::53.53: \
21476% [1au] NS? . (28)
15:07:36.801982 IP6 2001:6d0:6d06::53.53 > 2a01:e35:8bd9:8bb0:21e:8cff:fe76:29b6.35721: \
21476*- 16/0/1 NS yeti-ns.tisf.net., NS yeti-ns.lab.nic.cl., NS yeti-ns.wide.ad.jp., NS yeti.ipv6.ernet.in., NS yeti-ns.as59715.net., NS ns-yeti.bondis.org., NS yeti-dns01.dnsworkshop.org., NS dahu2.yeti.eu.org., NS dahu1.yeti.eu.org., NS yeti-ns.switch.ch., NS bii.dns-lab.net., NS yeti.bofh.priv.at., NS yeti-ns.conit.co., NS yeti.aquaray.com., NS yeti-ns.ix.ru., RRSIG (619)
La question était « NS . » (quels sont les
serveurs de la racine) et la réponse contenait les noms des seize
serveurs racine qu'avait Yeti à l'époque.
Voici aussi des exemples de résultats avec un résolveur ou bien avec un serveur faisant autorité. Si je demande à un serveur faisant autorité (ici, un serveur racine), avec mon client DNS qui, par défaut, demande un service récursif (flag RD, Recursion Desired) :
% dig @2001:620:0:ff::29 AAAA www.iab.org
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 54197
;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 9, ADDITIONAL: 13
;; WARNING: recursion requested but not available
...
;; AUTHORITY SECTION:
org. 172800 IN NS b0.org.afilias-nst.org.
...
C'est pour cela que dig affiche WARNING: recursion requested but not available. Notez aussi que le serveur, ne faisant autorité que pour la racine, n'a pas donné la réponse mais juste un renvoi aux serveurs d'Afilias. Maintenant, interrogeons un serveur récursif (le service de résolveur public Yandex DNS) :
% dig @2a02:6b8::feed:0ff AAAA www.iab.org
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 63304
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
...
;; ANSWER SECTION:
www.iab.org. 1800 IN AAAA 2001:1900:3001:11::2c
Cette fois, j'ai obtenu une réponse, et avec le
flag RA, Recursion
Available. Si je pose une question sans le
flag RD (Recursion Desired,
avec l'option +norecurse de dig) :
% dig +norecurse @2a02:6b8::feed:0ff AAAA www.gq.com
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 59438
;; flags: qr ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
...
;; ANSWER SECTION:
www.gq.com. 293 IN CNAME condenast.map.fastly.net.
J'ai obtenu ici une réponse car l'information était déjà dans le cache (la mémoire) de Yandex DNS (on le voit au TTL, qui n'est pas un chiffre rond, il a été décrémenté du temps passé dans le cache). Si l'information n'est pas dans le cache :
% dig +norecurse @2a02:6b8::feed:0ff AAAA blog.keltia.net
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 19893
;; flags: qr ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 0
...
Je n'obtiens alors pas de réponse (ANSWER: 0, donc NODATA). Si je demande au serveur faisant autorité pour cette zone :
% dig +norecurse @2a01:e0d:1:3:58bf:fa61:0:1 AAAA blog.keltia.net
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 62908
;; flags: qr aa; QUERY: 1, ANSWER: 2, AUTHORITY: 6, ADDITIONAL: 15
...
;; ANSWER SECTION:
blog.keltia.net. 86400 IN AAAA 2a01:240:fe5c:1::2
...
J'ai évidemment une réponse et, comme il s'agit d'un serveur faisant autorité, elle porte le flag AA (Authoritative Answer, qu'un résolveur ne mettrait pas). Notez aussi le TTL qui est un chiffre rond (et qui ne change pas si on rejoue la commande).
Passons maintenant à un concept relativement peu connu, celui de zones, et le vocabulaire associé (section 7) :
- Zone : un groupe de domaines contigus
dans l'arbre des noms, et gérés ensemble, par le même ensemble
de serveurs de noms (ma définition, celle du RFC étant très
abstraite). Beaucoup de gens croient que tout domaine est une
zone, mais c'est faux. Ainsi, au moment de la publication de ce
RFC,
gouv.frn'est pas une zone séparée, il est dans la même zone quefr(cela se teste facilement :gouv.frn'a pas d'enregistrement NS ou de SOA). - Parent : le domaine « du
dessus ». Ainsi, le parent de
wikipedia.orgestorg, le parent de.orgest la racine. - Apex : le sommet d'une zone, là où on trouve les enregistrements NS et SOA. Si la zone ne comprend qu'un domaine, l'apex est ce domaine. Si la zone est plus complexe, l'apex est le domaine le plus court. (On voit parfois des gens utiliser le terme erroné de racine pour parler de l'apex.)
- Coupure de zone (zone cut) : l'endroit où on passe d'une zone à l'autre. Au-dessus de la coupure, la zone parente, en dessous, la zone fille.
- Délégation (delegation) : un concept évidemment central dans le DNS, qui est un système décentralisé. En ajoutant un ensemble d'enregistrements NS pointant vers les serveurs de la zone fille, une zone parente délègue une partie de l'arbre des noms de domaine à une autre entité. L'endroit où se fait la délégation est donc une coupure de zone.
- Colle (glue
records) : lorsqu'une zone est déléguée à des serveurs
dont le nom est dans la zone fille, la résolution DNS se heurte
à un problème d'œuf et de poule. Pour trouver l'adresse de
ns1.mazone.example, le résolveur doit passer par les serveurs demazone.example, qui est déléguée àns1.mazone.exampleet ainsi de suite... On rompt ce cercle vicieux en ajoutant, dans la zone parente, des données qui ne font pas autorité sur les adresses de ces serveurs (RFC 1034, section 4.2.1). Il faut donc bien veiller à les garder synchrones avec la zone fille. (Tanguy Ortolo me suggère d'utiliser « enregistrement de raccord » plutôt que « colle ». Cela décrit bien leur rôle, en effet.) - Délégation boiteuse (lame delegation) : un ou plusieurs des serveurs à qui la zone est déléguée ne sont pas configurés pour servir cette zone. La délégation peut avoir été boiteuse depuis le début (parce que le titulaire a indiqué des noms un peu au hasard) ou bien l'être devenue par la suite. C'est certainement une des erreurs techniques les plus courantes. Mais le RFC note que l'usage du terme a dérivé et qu'aujourd'hui, il est devenu plus flou, désignant hélas des erreurs très variées.
- Dans le bailliage (in bailiwick) : terme absent des textes DNS originaux et qui peut désigner plusieurs choses. (La définition du RFC 8499, embrouillée, a été heureusement remplacée.) « Dans le bailliage » est (très rarement, selon mon expérience) parfois utilisé pour parler d'un serveur de noms dont le nom est dans la zone servie (et qui nécessite donc de la colle, voir la définition plus haut), mais le sens le plus courant désigne des données pour lesquelles le serveur qui a répondu fait autorité, soit pour la zone, soit pour un ancêtre de cette zone. L'idée est qu'il est normal dans la réponse d'un serveur de trouver des données situées dans le bailliage et, par contre, que les données hors-bailliage sont suspectes (elles peuvent être là suite à une tentative d'empoisonnement DNS). Un résolveur DNS prudent ignorera donc les données hors-bailliage.
- ENT (Empty
Non-Terminal pour nœud non-feuille mais vide) : un
domaine qui n'a pas d'enregistrements mais a des
sous-domaines. C'est fréquent, par exemple, sous
ip6.arpaou sous les domaines très longs de certains CDN. Cela se trouve aussi avec les enregistrements de service : dans_sip._tcp.example.com,_tcp.example.comest probablement un ENT. La réponse correcte à une requête DNS pour un ENT est NODATA (code de réponse NOERROR, liste des répoonses vide) mais certains serveurs bogués, par exemple, à une époque, ceux d'Akamai, répondaient NXDOMAIN. - Zone de délégation (delegation-centric zone) : zone composée essentiellement de délégations vers d'autres zones. C'est typiquement le cas des TLD et autres suffixes publics. Il est amusant de noter que les RFC 4956 et RFC 5155 utilisaient ce terme sans le définir.
- Changement rapide (fast flux) : une technique notamment utilisée par les botnets pour mettre leur centre de commande à l'abri des filtrages ou destructions. Elle consiste à avoir des enregistrements d'adresses IP avec des TTL très courts et à en changer fréquemment.
- DNS inverse (reverse DNS) : terme qui désigne en général les requêtes pour des enregistrements de type PTR, permettant de trouver le nom d'une machine à partir de son adresse IP. À ne pas confondre avec les vraies requêtes inverses, qui avaient été normalisées dans le RFC 1035, avec le code IQUERY, mais qui, jamais vraiment utilisées, ont été abandonnées dans le RFC 3425.
Voyons ici la colle retournée par un serveur faisant autorité (en
l'occurrence un serveur de .net) :
% dig @a.gtld-servers.net AAAA labs.ripe.net
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 18272
;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 8, ADDITIONAL: 9
...
;; AUTHORITY SECTION:
ripe.net. 172800 IN NS ns3.nic.fr.
ripe.net. 172800 IN NS sec1.apnic.net.
ripe.net. 172800 IN NS sec3.apnic.net.
ripe.net. 172800 IN NS tinnie.arin.net.
ripe.net. 172800 IN NS sns-pb.isc.org.
ripe.net. 172800 IN NS pri.authdns.ripe.net.
...
;; ADDITIONAL SECTION:
sec1.apnic.net. 172800 IN AAAA 2001:dc0:2001:a:4608::59
sec1.apnic.net. 172800 IN A 202.12.29.59
sec3.apnic.net. 172800 IN AAAA 2001:dc0:1:0:4777::140
sec3.apnic.net. 172800 IN A 202.12.28.140
tinnie.arin.net. 172800 IN A 199.212.0.53
tinnie.arin.net. 172800 IN AAAA 2001:500:13::c7d4:35
pri.authdns.ripe.net. 172800 IN A 193.0.9.5
pri.authdns.ripe.net. 172800 IN AAAA 2001:67c:e0::5
On notera :
- La section ANSWER est vide, c'est un renvoi.
- Le serveur indique la colle pour
pri.authdns.ripe.net: ce serveur étant dans la zone qu'il sert, sans son adresse IP, on ne pourrait jamais le joindre. - Le serveur envoie également les adresses IP d'autres
machines comme
sec1.apnic.net. Ce n'est pas strictement indispensable (on pourrait l'obtenir par une nouvelle requête), juste une optimisation. - Les adresses de
ns3.nic.fretsns-pb.isc.orgne sont pas renvoyées. Le serveur ne les connait probablement pas et, de toute façon, elles seraient hors-bailliage, donc ignorées par un résolveur prudent.
Voyons maintenant, un ENT,
gouv.fr (notez que, depuis, ce domaine n'est
plus un ENT) :
% dig @d.nic.fr ANY gouv.fr
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 42219
;; flags: qr aa rd; QUERY: 1, ANSWER: 0, AUTHORITY: 2, ADDITIONAL: 1
Le serveur fait bien autorité pour ce domaine (flag AA dans la réponse), le domaine existe (autrement, le status aurait été NXDOMAIN, pas NOERROR) mais il n'y a aucun enregistrement (ANSWER: 0).
Et, ici, une délégation boiteuse, pour
.ni :
% check-soa ni
dns.nic.cr.
2001:13c7:7004:1::d100: ERROR: SERVFAIL
200.107.82.100: ERROR: SERVFAIL
ns.ideay.net.ni.
186.1.31.8: OK: 2013093010
ns.ni.
165.98.1.2: ERROR: read udp 10.10.86.133:59569->165.98.1.2:53: i/o timeout
ns.uu.net.
137.39.1.3: OK: 2013093010
ns2.ni.
200.9.187.2: ERROR: read udp 10.10.86.133:52393->200.9.187.2:53: i/o timeout
Le serveur dns.nic.cr est déclaré comme
faisant autorité pour .ni mais il ne le sait
pas, et répond donc SERVFAIL.
Les jokers ont une section à eux, la section 8 du RFC. S'appuyant sur le RFC 4592, elle définit, entre autres :
- Joker
(wildcard) : une source de confusion
considérable depuis les débuts du DNS. Si on pouvait refaire le
DNS en partant de zéro, ces jokers seraient la première chose à
supprimer. Pour les résumer, le nom
*dans une zone déclenche la synthèse automatique de réponses pour les noms qui n'existent pas dans la zone. Si la zonefoo.examplecontientbar.foo.exampleet*.foo.example, une requête pourthing.foo.examplerenverra le contenu de l'enregistrement avec le joker, une requête pourbar.foo.exampledonnera les données debar.foo.example. Attention, l'astérisque n'a son rôle particulier que s'il est le composant le plus spécifique (le premier). Dansfoo.*.bar.example, il n'y a pas de joker. - Ancêtre le plus proche
(closest encloser) : c'est le plus long
ancêtre existant d'un nom. Si
foo.bar.baz.examplen'existe pas, quebar.baz.examplen'existe pas non plus, mais quebaz.exampleexiste, alorsbaz.exampleest l'ancêtre le plus proche defoo.bar.baz.example. Ce concept est nécessaire pour le RFC 5155.
Allez courage, ne faiblissons pas, il reste encore la question de l'enregistrement des noms de domaine (section 9) :
- Registre
(registry) : l'organisation ou la personne
qui gère les délégations d'une zone. Le terme est parfois
employé uniquement pour les gérants de grandes zones de
délégation, mais ce n'est pas obligatoire. Je suis à moi tout
seul le registre de
bortzmeyer.org😁. C'est le registre qui décide de la politique d'enregistrement, qui peut être très variable selon les zones (sauf dans celles contrôlées par l'ICANN, où une certaine uniformité est imposée). Mes lecteurs français noteront que, comme le terme « registre » est court et largement utilisé, le gouvernement a inventé un nouveau mot, plus long et jamais vu auparavant, « office d'enregistrement ». - Titulaire (registrant, parfois holder) : la personne ou l'organisation qui a enregistré un nom de domaine.
- Bureau d'enregistrement (registrar) : dans le modèle RRR (Registry-Registrar-Registrant, mais ce modèle n'est pas obligatoire et pas universel), c'est un intermédiaire entre le titulaire et le registre.
- Hébergeur DNS (DNS operator) : la personne ou l'organisation qui gère les serveurs DNS. Cela peut être le titulaire, son bureau d'enregistrement, ou encore un acteur spécialisé dans cette gestion.
- Suffixe public (public
suffix) : ce terme pas très officiel est parfois
utilisé pour désigner un suffixe de noms de domaine qui est
contrôlé par un registre public (au sens où il accepte des
enregistrements du public). Mais le terme est trompeur car, par
exemple,
.aquarellese trouve dans la Public Suffix List alors qu'il s'agit d'un «.marque», un de ces TLD où une seule entreprise peut enregistrer des noms. Le terme est ancien mais est apparu pour la première fois dans un RFC avec le RFC 6265, section 5.3.com,co.uketeu.orgsont des suffixes publics. Rien dans la syntaxe du nom n'indique qu'un nom de domaine est un suffixe public, puisque ce statut ne dépend que d'une politique d'enregistrement (qui peut changer). Il est parfaitement possible qu'un domaine, et un de ses enfants, soient tous les deux un suffixe public (c'est le cas de.orgeteu.org). - EPP (Extensible Provisioning Protocol) : normalisé dans le RFC 5730, c'est le protocole standard entre bureau d'enregistrement et registre. Ce protocole n'a pas de lien avec le DNS, et tous les registres ne l'utilisent pas.
- Whois (nommé d'après la question Who Is?) : un protocole réseau, sans lien avec le DNS, normalisé dans le RFC 3912. Il permet d'interroger les bases de données du registre pour trouver les informations dites « sociales », informations qui ne sont pas dans le DNS (comme le nom du titulaire, et des moyens de le contacter). Les termes de « base Whois » ou de « données Whois » sont parfois utilisés mais ils sont erronés puisque les mêmes bases peuvent être interrogées par d'autres protocoles que Whois, comme RDAP (voir définition suivante).
- RDAP (Registration Data Access Protocol) : un protocole concurrent de Whois, mais plus moderne. RDAP est décrit notamment dans les RFC 9082 et RFC 9083.
Prenons par exemple le domaine eff.org. Au
moment de la publication du RFC :
Enfin, pour terminer, les sections 10 et 11 de notre RFC couvrent DNSSEC. Pas grand'chose de nouveau ici, DNSSEC étant plus récent et donc mieux défini.
L'annexe A de notre RFC indique quelles définitions existaient dans de précédents RFC mais ont été mises à jour par le nôtre. (C'est rare, puisque le but de ce RFC de terminologie est de rassembler les définitions, pas de les changer.) Par exemple, la définition de QNAME du RFC 2308 est corrigée ici.
L'annexe B liste les termes dont la première définition formelle se trouve dans ce RFC (ou dans un de ses prédécesseurs, les RFC 7719 et "RFC 8499). Cette liste est bien plus longue que celle de l'annexe A, vu le nombre de termes courants qui n'avaient jamais eu l'honneur d'une définition stricte.
Notre RFC ne contient pas une liste exhaustive des changements depuis son prédécesseur, le RFC 8499, mais ils sont peu importants. Parmi les changements sérieux :
- DoT (RFC 7858), DoH (RFC 8484) et DoQ (RFC 9250) ont maintenant une définition complète.
- Par contraste, le DNS traditionnel (Classic DNS), celui qui tourne directement sur UDP ou TCP, et en clair, a sa définition.
- L'importance de TLS se traduit aussi par l'arrivée des définitions de DoT vers le résolveur (RDoT, pour Recursive DNS over TLS), de DoT vers le serveur faisant autorité (ADoT pour Authoritative DNS over TLS) et XoT (zone transfer over TLS, normalisé dans le RFC 9103).
- Le RFC prend également acte du fait que le terme désignant les délégations invalides, lame delegation, a beaucoup dérivé.
L'article seul
Exposé « Normalisation technique, qui décide ? » aux journées FedeRez
Première rédaction de cet article le 29 avril 2024
FedeRez est la fédération nationale des associations d'étudiants qui gèrent des réseaux informatiques. Elle tient des journées annuelles et, à celles de 2024 dans un endroit éloigné de tout transport en commun, j'ai fait un exposé sur le thème « Normalisation technique, qui décide ? ».
Voici les transparents de mon exposé :
- Format adapté à l'écran,
- Format adapté à l'impression,
- Source (LaTeX/Beamer),
L'enregistrement vidéo n'est pas encore disponible.
L'article seul
RFC 9557: Date and Time on the Internet: Timestamps with Additional Information
Date de publication du RFC : Avril 2024
Auteur(s) du RFC : U. Sharma (Igalia, S.L.), C. Bormann (Universität Bremen TZI)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF sedate
Première rédaction de cet article le 29 avril 2024
Ce RFC modifie légèrement le format des estampilles temporelles du RFC 3339, changeant à la marge une définition et, surtout, permettant d'y attacher des informations supplémentaires.
Le RFC 3339 décrit un des formats d'estampilles temporelles possibles sur l'Internet (car, malheureusement, toutes les normes Internet ne l'utilisent pas). Un exemple, sur Unix :
% date --rfc-3339=seconds 2024-04-29 06:22:33+00:00
Le format du RFC 3339 est du type « YYYY-MM-DD HH:MM:SS » avec, à la fin, ajout d'une information sur le décalage avec le temps de référence (on verra que notre nouveau RFC 9557 change un peu cette dernière information). Un format gros boutien, donc, qui permet notamment de trier les dates-et-heures uniquement en suivant l'ordre lexicographique des caractères.
Mais certaines applications voudraient en savoir plus, et ajouter
à ce format des détails. D'ailleurs, c'est déjà fait dans des
solutions non normalisées, comme le
format de Java, très populaire, qui permet des estampilles
comme 2011-12-03T10:15:30+01:00[Europe/Paris]
(fuseau horaire, ajouté après la date au
format du RFC 3339 ; lisez le RFC 6557 pour en savoir davantage sur les fuseaux
horaires).
Ce nouveau RFC prévoit donc une extension optionnelle (les dates-et-heures qui suivaient le format de l'ancien RFC restent parfaitement valdies), compatible avec celle de Java, et généraliste (on pourra indiquer autre chose que le fuseau horaire). Ce format étendu est baptisé IXDTF pour Internet Extended Date/Time Format. En revanche, le nouveau format ne gère pas des cas compliqués (la gestion du temps en informatique est toujours compliquée) comme les dates futures lorque la définition du fuseau horaire changera, par exemple en supprimant l'heure d'été, ou des échelles de temps différentes, comme TAI (le format IXDTF ne marche que pour l'échelle d'UTC).
Donc, concrètement, notre RFC commence par changer un peu la définition du décalage à la fin des estampilles. Dans le RFC 3339, il y avait trois cas subtilement différents pour une estampille indiquant l'absence de décalage :
- Une lettre Z indiquait qu'on utilisait UTC comme référence,
- Un
+00:00indiquait qu'on utilisait UTC comme référence (identique au cas précédent), - Un
-00:00indiquait qu'on n'avait aucune idée sur la référence (typiquement parce qu'on voudrait connaitre l'heure locale mais qu'on ne la connait pas).
(Au passage, si vous ne connaissiez pas ces trois cas et leurs
différences, ne vous inquiétez pas, vous n'étiez pas seul·e.) Notre
RFC change cela (section 2) en décidant que Z est désormais synonyme
de -00:00 plutôt que de
+00:00, un changement qui aura sans doute peu
d'importance en pratique.
L'autre nouveauté de ce RFC 9557 est plus marquante, c'est le format étendu IXDTF (section 3). Il consiste à ajouter à la fin de l'estampille une série (facultative) de couples {clé, valeur}, entre crochets. Si la clé est absente, c'est que la valeur est un fuseau horaire, suivant la syntaxe de la base TZ. Voici un exemple :
2022-07-08T12:14:37+02:00[Europe/Paris][u-ca=hebrew]
Cet exemple indique que le fuseau horaire était celui de
Paris (cf. le format de
ces noms de fuseaux) et que le calendrier préféré (clé
u-ca), pour afficher cette date, serait le
calendrier hébreu (ce qui indiquera 9 Tammouz
5782, sauf erreur).
Un point d'exclamation avant la clé indiquerait que la clé doit être comprise par le lecteur, sinon, il faut qu'il ignore l'estampille temporelle (la plupart du temps, l'application peut ignorer les clés et leurs valeurs). Un trait bas indique une clé expérimentale, non officiellement enregistrée.
Car notre RFC crée aussi un registre
des clés. Pour l'instant, il ne compte qu'une seule clé,
u-ca, pour indiquer le calendrier préféré. Pour
enregistrer une nouvelle clé, il faut une spécification écrite
(cf. RFC 8126), mais il y a aussi des
enregistrements temporaires, plus légers.
Et on termine par un petit mot sur la sécurité (section 7). Le RFC rappelle que plus on donne d'informations, plus on risque d'en donner trop. Ainsi, l'indication du calendrier préféré peut indiquer une origine ethnique ou religieuse, qui peut être considérée comme privée, surtout s'il y a des risques d'attaques racistes.
L'article seul
RFC 9567: DNS Error Reporting
Date de publication du RFC : Avril 2024
Auteur(s) du RFC : R. Arends (ICANN), M. Larson
(ICANN)
Chemin des normes
Première rédaction de cet article le 27 avril 2024
Lorsqu'un résolveur DNS détecte un problème avec une zone, l'empêchant de résoudre les noms dans cette zone, il n'avait pas de moyen simple et automatique de prévenir les gérants des serveurs faisant autorité pour cette zone. Leur envoyer un message en utilisant l'information dans l'enregistrement SOA ou les adresses classiques du RFC 2142 ? Mais, justement, si la zone ne marche pas, le courrier ne partira pas forcément. Ce nouveau RFC propose un nouveau système. Les serveurs faisant autorité annoncent un domaine (qui marche, espérons-le), qui acceptera des requêtes DNS spéciales signalant le problème.
Cela dépend évidemment du problème pratique qui se pose. Si la zone n'a aucun serveur faisant autorité qui marche, il n'y a évidemment rien à faire. Mais s'ils marchent, tout en servant des données problématiques (par exemple des signatures DNSSEC expirées), alors, le résolveur pourra agir. Les serveurs faisant autorité mettent dans leurs réponses une option EDNS qui indique le domaine qui recevra les rapports (cela doit être un autre domaine, qui n'a pas de problème), le résolveur fera alors une requête DNS se terminant par le nom du domaine de signalement, et encodant le problème. L'agent, le domaine de signalement, pourra alors récolter ces requêtes et savoir qu'il y a un problème. Cela ne traite pas tous les cas (il faudra toujours utiliser RDAP ou whois pour récolter des informations sur les contacts du domaine erroné, puis leur écrire depuis un autre réseau) mais c'est simple, léger et automatisable. Les gérants de domaine sérieux, qui prennent au sérieux les signalements de problèmes techniques (soit 0,00001 % des domaines) pourront alors agir. (Note si vous gérez un résolveur et que vous constatez un problème avec un domaine et que les contacts ne répondent pas : un message méchant sur Twitter est souvent plus efficace.)
Donc, les détails techniques : le domaine qui veut recevoir les éventuels signalements va devoir configurer ses serveurs faisant autorité pour renvoyer une option EDNS, de numéro 18 (section 5 du RFC), indiquant l'agent, c'est-à-dire le domaine qui va recevoir les signalements (il faut évidemment veiller à ce qu'il n'ait pas de point de défaillance commun avec le domaine surveillé). Notez que cette option est systématiquement envoyée, le client (le résolveur) n'a pas à dire quoi que ce soit (la question avait fait l'objet d'un sérieux débat à l'IETF).
En cas de problème, notamment DNSSEC, le résolveur qui a noté le problème va alors construire un nom de domaine formé, successivement (section 6.1.1) par :
- Le composant
_er, - Le type de données qui posait problème (adresse IP, enregistrement de service, etc),
- Le nom de domaine qui était initialement demandé par le résolveur,
- L'erreur étendue (EDE, RFC 8914),
- Le composant
_er(oui, encore), - Le nom de domaine de l'agent.
Par exemple, si le domaine dyn.bortzmeyer.fr
annonce comme agent report.dyn.sources.org, et
qu'un résolveur découvre des signatures DNSSEC expirées (EDE 7) en
cherchant à résoudre hello.dyn.bortzmeyer.fr /
TXT (TXT a la valeur 16), la
requête de signalement du résolveur sera
_er.16.hello.dyn.bortzmeyer.fr.7._er.report.dyn.sources.org
(ouf). Le type demandé est TXT. Lorsque cette requête
arrivera au serveur faisant autorité pour
report.dyn.sources.org, il pourra enregistrer
qu'il y a eu un problème, et mettre cette information à la
disposition de son administrateur système.
Ce serveur faisant autorité est censé répondre au signalement avec une réponse de type TXT comme ici :
% dig _er.16.hello.dyn.bortzmeyer.fr.7._er.report.dyn.sources.org TXT … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 12032 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1 … ;; ANSWER SECTION: _er.16.hello.dyn.bortzmeyer.fr.7._er.report.dyn.sources.org. 30 IN TXT "Thanks for the report of error 7 on hello.dyn.bortzmeyer.fr" …
L'agent peut ensuite être interrogé, par des méthodes propres à la mise en œuvre utilisée :
% echo report | socat - UNIX-CONNECT:/home/drink/drink.sock REPORT state: hello.dyn.bortzmeyer.fr, 7 ip.dyn.bortzmeyer.fr, 7
Ici, on voit que deux domaines ont été signalés comme ayant des signatures expirées (rassurez-vous, c'était juste des tests). Le nombre de signalements n'est pas indiqué, ni la source des signalements (travail futur).
Quelques petits points de sécurité à garder en tête (section 9 du RFC) :
- Le fait de signaler va, par définition, donner au serveur faisant autorité des informations sur le résolveur (par exemple, un résolveur menteur qui signalerait les blocages informerait sur sa politique, ce que les censeurs ne font en général pas).
- Il en donnera aussi aux serveurs des zones parentes du domaine agent, et il est donc très recommandé de minimiser le nom (RFC 9156).
- Il n'y a pas spécialement d'authentification donc tous ces rapports doivent être traités avec prudence. Un méchant peut facilement fabriquer de faux rapports, de toute façon. Ils doivent donc toujours être vérifiés.
Cette technique a été mise en œuvre dans Drink lors d'un hackathon IETF. Drink peut à la fois signaler un domaine agent, et être serveur pour un domaine agent.
Un exemple de signalisation EDNS de cette option, vu la version
de développement de Wireshark (merci à Alexis La Goutte) : 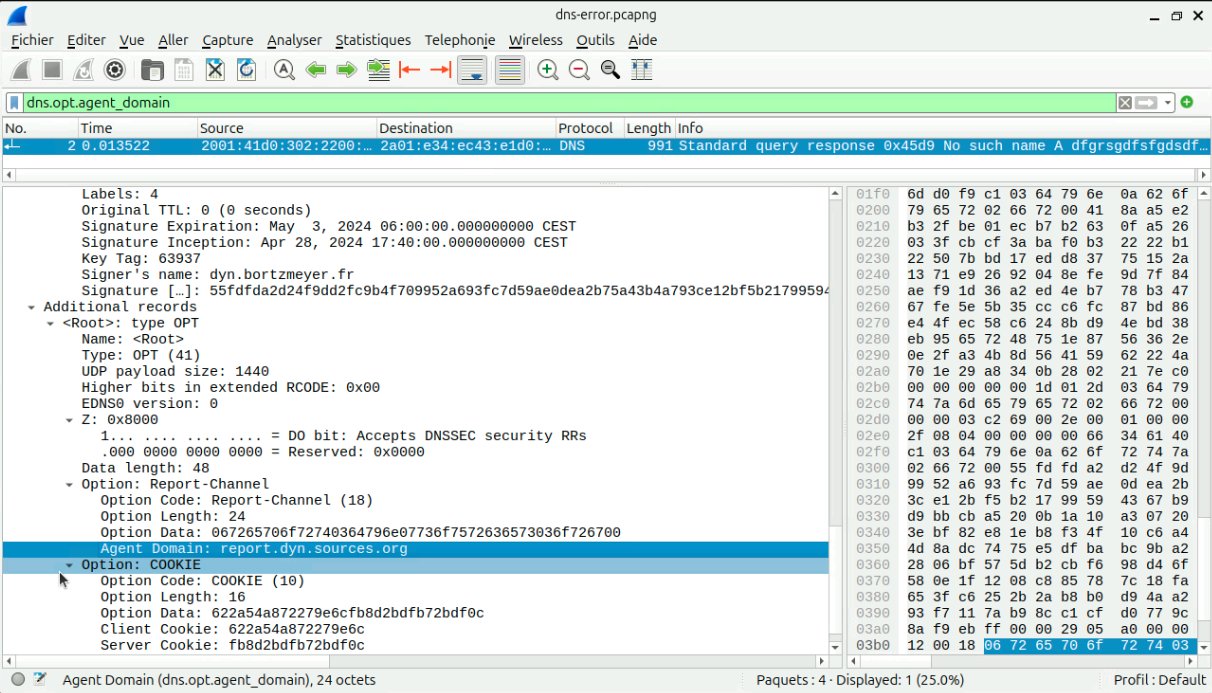
L'article seul
RFC 9547: Report from the IAB Workshop on Environmental Impact of Internet Applications and Systems, 2022
Date de publication du RFC : Février 2024
Auteur(s) du RFC : J. Arkko, C. S. Perkins, S. Krishnan
Pour information
Première rédaction de cet article le 24 avril 2024
La question de l'empreinte environnementale du numérique suscite beaucoup de débats. L'IAB avait organisé en décembre 2022 un atelier sur le cas de l'empreinte environnementale de l'Internet dont ce RFC est le compte-rendu (tardif, oui, je sais, mais mon propre article de résumé du RFC est aussi en retard).
Le sujet est très complexe, relativement nouveau, et surtout noyé sous beaucoup d'approximations, voire de franches bêtises (l'ADEME s'en est fait une spécialité, avec des chiffres tirés du chapeau et à la méthodologie inconnue). Il y a donc du travail sur la planche. L'IAB commence par estimer que l'Internet a certes une empreinte environnementale mais peut aussi servir à diminuer l'empreinte environnementale globale, ce qui n'est franchement pas étayé (le RFC cite l'exemple de réunions physiques remplacées par des réunions en ligne, sans citer de calcul détaillé qui permettrait de voir s'il y a vraiment un gain, et en oubliant que de toute façon une réunion en ligne ne rend pas les mêmes services). Mais l'IAB note aussi que l'Internet a des effets indirects, et pas forcément positifs : il cite l'exemple de l'augmentation de la consommation de biens matériels que produit le commerce en ligne.
Clairement, l'Internet n'est pas virtuel, contrairement à ce que prétend le marketing qui abuse de termes comme cloud pour faire croire que le numérique est immatériel. A contrario, l'Internet dépend de machines, de l'électricité (et des humains qui font fonctionner ces machines). Que peut-on faire pour diminuer l'empreinte environnementale de l'Internet ? (Sans pour autant suivre les conseils débiles de l'ADEME, comme de supprimer ses messages.)
Comme tous les ateliers de l'IAB, celui-ci a fonctionné en demandant aux participants des position papers expliquant leur point de vue. Ne participent à l'atelier que des gens ayant écrit un de ces articles, ce qui garantit que tout le monde a dû travailler le sujet. Ces articles sont disponibles en ligne, plus exactement à cet endroit. (Tous les documents liés à cet atelier sont également disponibles.) Parmi les papiers acceptés :
- « Extending IPv6 to support Carbon Aware Networking », où comment rendre les équipements réseau plus conscients des conséquences environnementales,
- « Frugal Computing », sur la sobriété numérique,
- « Internet Infrastructure and Climate Justice », qui se focalise davantage sur l'aspect politique (il y a d'autres prises de position de l'auteure, et une collection de liens utiles),
- Et de nombreux autres, souvent très intéressants.
La section 2 du RFC détaille les sujets qui étaient dans le programme de l'atelier :
- Les impacts environnementaux directs de l'Internet (consommation électrique des machines, des routeurs aux serveurs en passant par les machines terminales, refroidissement, fabrication des machines, et leur traitement final, souvent oublié dans les études),
- Les impacts indirects de l'Internet, provenant des effets qu'il a sur la société,
- Les métriques (souvent très maltraitées dans les artcles parlant de l'empreinte environnementale du numérique, par exemple en confondant énergie et puissance), un sujet crucial puisqu'on ne peut pas améliorer ce qu'on ne peut pas mesurer,
- Les questions non techniques, comme les enjeux financiers ou comme la régulation,
- Les questions techniques où l'IETF pourrait travailler pour améliorer les choses (par exemple, mais non cité par le RFC, annoncer dans les réponses HTTP le coût environnemental de la requête),
- Mais aussi les questions liées aux usages et aux utilisateurices, qui sont souvent sollicités, mais en général de manière culpabilisatrice (« regardez les vidéos en basse définition et pas de porno »).
Ah et, si vous vous le demandez, l'atelier a été entièrement en ligne (section 2.1 du RFC).
La première des quatre sessions de l'atelier essayait d'aborder le problème de manière générale. Le problème du réchauffement climatique est évidemment bien plus vaste que l'Internet seul et n'a pas de solution simple et unique. Et les solutions ne sont pas toutes techniques, donc il y a des limites à ce que l'IETF peut faire (ce qui ne veut pas dire qu'il ne faut rien faire !). Même la publicité est mentionnée dans cette section du RFC, avec un très prudent « davantage d'études sont nécessaires » (opinion personnelle : son attitude au sujet de la publicité est un bon moyen de savoir si votre interlocuteur veut sérieusement lutter contre le réchauffement climatique, ou bien s'il veut juste faire des discours).
Ensuite, deuxième session sur les mesures et la récolte des faits. Par exemple, où sont les gros postes de consommation électrique dans le numérique ? Les serveurs ? Les routeurs ? Les terminaux ? C'est d'autant plus important que le RFC note la quantité de fausses informations qui circulent (citant par exemple un article qui confondait MB/s et Mb/s, soit un facteur 8 de différence). De même, contrairement à ce qui est encore souvent dit, la session a mis en évidence le fait que la consommation électrique n'est pas du tout proportionnelle au trafic. Des phrases comme « envoyer un courrier dégage autant de dioxyde de carbone qu'un vol Paris-Quelquepart » n'ont donc aucun sens. (Un des papiers acceptés, « Towards a power-proportional Internet » expliquait pourquoi il fallait changer cela et comment le faire.) Par contre, les usages impactent la consommation car ils peuvent nécessiter des mises à jour du réseau.
La troisième session regardait du côté des pistes d'amélioration,
plus précisement de celles sur lesquelles l'IETF pouvait agir. Le
premier point est celui des mesures (insuffisantes et parfois
contradictoires). Le deuxième point concernait l'influence de
phénomènes comme la gigue (RFC 4689) ou l'élongation du
trajet (RFC 7980) sur la consommation énergétique (si on
réduit ces phénomènes grâce à de meilleurs protocoles, est-ce qu'on
diminue la consommation ?). Parmi les autres optimisations
possibles, le choix de meilleurs formats, plus optimisés
(CBOR - RFC 8949 - est
cité). Notez qu'un des articles acceptés pour l'atelier faisait le
point sur toutes les activités de l'IETF liées à l'énergie,
draft-eckert-ietf-and-energy-overview.
Et la quatrième et dernière session portait sur les étapes suivantes du travail ; en résumé, il y a du travail et, même si l'IETF ne peut pas tout, elle doit en prendre sa part. Il faut toujours garder en tête que le but n'est pas de réduire l'empreinte environnementale de l'Internet mais de réduire celle de l'ensemble de la société. Éteindre l'Internet diminuerait certainement son empreinte environnementale mais pourrait avoir des effets négatifs sur d'autres secteurs, comme les transports. Pour améliorer l'Internet sans le supprimer, plusieurs axes ont été mis en avant :
- Mesurer, toujours mesurer, on manque d'informations,
- Pouvoir diminuer la consommation quand il n'y a pas de travail en cours, voire hiberner, serait utile (comme dans beaucoup de cas, le problème est complexe : un routeur ne peut pas hiberner car il ne sait pas quand arrivera le prochain paquet, et il ne peut pas se réveiller instantanément),
- Adopter de meilleurs formats de données. Comme le disait un des articles présentés, « CBOR est plus vert ».
Et les actions concrètes (section 2.4.3) ?
- Faut-il imposer dans chaque RFC une section Environmental considerations comme il y a déjà une Security considerations obligatoire ? (La question s'était déjà posée pour une éventuelle Human rights considerations.) Pour l'instant, ce n'est pas prévu notamment parce que, dans l'état actuel des choses, la plupart des auteurs de RFC n'ont pas de connaissances suffisamment approfondies ur le sujet pour écrire une section utile.
- Plusieurs groupes à l'IETF sont déjà au travail sur ce sujet environnemental : NMRG travaille sur les métriques (et a, par exemple, un Internet-Draft « Challenges and Opportunities in Management for Green Networking »), même chose à OPSAWG et le nouveau groupe TVR (Time-Variant Routing), comme il travaille sur le routage intermittent, a également un rôle, par exemple lorsqu'on coupe des liens pour économiser de l'énergie. Là, on est pile dans le rôle de l'IETF.
- Curieusement, le RFC parle aussi d'éviter les NFT, qui ne sont pourtant plus guère à la mode (et n'ont jamais suscité beaucoup d'intérêt à l'IETF, de toute façon). En outre, la plupart d'entre eux tournent sur Ethereum, qui n'utilise plus la preuve de travail et n'est donc pas crucial du point de vue environnemental.
Si vous voulez participer au nouveau programme de l'IAB E-IMPACT, tout est là.
Puisqu'on parlait de la section sur la sécurité qui est obligatoire dans les RFC, notre RFC en a une, qui rappelle que :
- Tout mécanisme par lequel on donne des pénalités (financières ou bien en terme de diminution des ressources allouées) en fonction de métriques d'empreinte environnementale doit se préparer à ce qu'il y ait des tricheurs (cf. P. McDaniel, « Sustainability is a Security Problem », à la conférence SIGSAC en 2022), qui faussent les mesures pour échapper à ces pénalités.
- De même, tout mécanisme qui va agir sur le réseau, par exemple pour diminuer l'empreinte environnementale, peut être détourné pour une attaque par déni de service, et doit donc prévoir le problème.
L'article seul
Fiche de lecture : Députée pirate - comment j'ai infiltré la machine européenne
Auteur(s) du livre : Leïla Chaibi
Éditeur : Les liens qui libèrent
979-10-209-2405-6
Publié en 2024
Première rédaction de cet article le 22 avril 2024
Ce petit livre résume l'expérience de l'auteure au Parlement européen, notamment à travers ses tentatives pour faire reconnaitre le statut de salarié aux employés d'Uber (ou d'entreprises équivalentes).
Le titre et le sous-titre sont trompeurs : l'auteure n'est pas députée Pirate mais LFI, et elle n'a rien infiltré, elle a été élue au Parlement européen. Ce sous-titre ridicule fait penser à cette journaliste de droite qui avait fait un livre disant qu'elle était infiltrée chez les wokes, alors qu'elle était juste allé à quelques réunions. Mais, bon, on sait que ce n'est pas l'auteure qui fait la couverture du livre.
Donc, Leïla Chaibi raconte son expérience au Parlement européen. Elle ne surprendra pas les amateurs de l'excellente série télé Parlement, on y retrouve l'incroyable complexité du machin, le poids des lobbys, les arrangements divers, même entre partis opposés. Sauf qu'au lieu de légiférer sur le finning, comme dans la série télé, elle essaie de faire en sorte que les employés des entreprises comme Deliveroo, officiellement sous-traitants, soient reconnus pour ce qu'ils sont, des salariés.
Et ce n'est pas facile. Dans l'ambiance feutrée du Parlement, où les bruits et la réalité du monde extérieur ne pénètrent pas, intéresser les collègues à des choses concrètes n'est pas facile. Et une fois un texte voté par le Parlement, il n'est pas adopté pour autant, puisque le Parlement européen ne sert à rien. Il n'a pas l'initiative législative et ses textes ne valent que si le Conseil et la Commission le veulent bien (le fameux trilogue). Les politiciens et les journalistes qui regrettent que les électeurs ne s'intéressent pas aux élections du Parlement européen devraient se demander pourquoi (ma réponse : parce que ce Parlement n'est qu'une coquille vide, dénuée de pouvoir, il en a encore moins que le Parlement français, ce qui n'est pas peu dire).
En outre, pour cette question particulière du salariat des employés d'Uber ou de Deliveroo, l'auteure a eu à faire face à un lobbying intense du gouvernement français, très soumis à Uber, et qui a tout essayé pour saboter le projet.
Le livre est bien écrit, très vivant (malgré l'aridité du sujet), très pédagogique. Je ne voterais quand même pas LFI aux prochaines élections européennes, vu leurs positions sur l'Ukraine ou l'islamisme, mais si vous voulez comprendre le Parlement européen avant d'aller voter le 9 juin, c'est une bonne source.
L'article seul
Getting TAI time on a Debian machine
First publication of this article on 16 April 2024
Last update on of 17 April 2024
It should work by default but, apparently, on some operating systems like Debian, it does not: to get the TAI time, you need a small configuration change. I document it here for myself or for people which will use a search engine and find this page.
TAI is useful because, unlike UTC, it never adds an extra second, neither it misses one (UTC does, because of leap seconds). This makes it convenient, for instance for Internet servers. But how to get TAI time on a Debian machine?
The official answer is that when you use
clock_gettime in a C
program or time.clock_gettime in a
Python one, you need to pass the option
CLOCK_TAI. One can easily check that, on a
Debian stable machine (version 12.5), it does not work: you get the
same value with CLOCK_TAI or
CLOCK_REALTIME (the typical clock, set on
UTC). Unfortunately, no error code will tell you that something was
wrong.
It seems that the kernel (which manages
the clock and answers to clock_gettime) knows
only UTC and, to convert to TAI,
it needs to know the offset (currently 37 seconds). Debian has a
file to do so, a leap seconds table, in
/usr/share/zoneinfo/leap-seconds.list. This
file contains all the information necessary to get TAI from
UTC. But someone has to read it and to inform the kernel. This is
typically done by ntpd. But it is not done by
default, this is why the above test failed.
So, the system administrator needs to
configure ntpd to load this file. This is done in
/etc/ntpsec/ntp.conf (or
/etc/ntp.conf depending on the version of ntpd
you use) by adding this line:
leapfile /usr/share/zoneinfo/leap-seconds.list
and restarting ntpd and waiting some time for the kernel to synchronize, it is not instantaneous.
If you see in the log file (for instance
with journalctl -n 10000 -t ntpd | grep -i
leap) something like:
Apr 16 08:25:39 mymachine ntpd[29050]: CLOCK: leapsecond file ('/var/lib/ntp/leap-seconds.list'): open failed: Permission denied
(note the file name, which is not the default one), it means you need
to check the permissions of the file and that
systemd or AppArmor
are not adding some restrictions (the default AppArmor profile of
ntpd on Debian includes
/usr/share/zoneinfo/leap-seconds.list but may
be you changed something).
You can check that the kernel now knows the truth, for instance with a simple Python session:
% python Python 3.11.2 (main, Mar 13 2023, 12:18:29) [GCC 12.2.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import time >>> time.clock_gettime(time.CLOCK_TAI) 1713284374.8322737 >>> time.clock_gettime(time.CLOCK_REALTIME) 1713284337.8329697
You can see that there is indeed 37 seconds of difference (plus a small value because of the delay between the two commands).
That's all. You can now use TAI in your programs. The file
/usr/share/zoneinfo/leap-seconds.list is
automatically managed by Debian (it is part of the package
tzdata,
and the reference version is https://data.iana.org/time-zones/tzdb/leap-seconds.listhttps://hpiers.obspm.fr/iers/bul/bulc/ntp/leap-seconds.listntpleapfetch which are necessary on other
operating systems.
For instance, on a Slackware system, the
file leap-seconds.list is not provided by
default (there is a file named
/usr/share/zoneinfo/leapseconds, with a
different format, and that ntpd cannot use), so you will need to
configure cron to download the proper file.
An alternative is to handle time through a library that will do it for you, such as hifitime for Rust and Python.
Thanks to Nicolas Sapa, Matthieu Herrb and Kim Minh Kaplan for the useful help.
L'article seul
Fiche de lecture : Des élèves à la conquête du passé
Auteur(s) du livre : Magali Jacquemin
Éditeur : Libertalia
978-2-9528292
Publié en 2023
Première rédaction de cet article le 15 avril 2024
Ce livre raconte les dix ans d'expérience de l'auteure, professeure des écoles, à enseigner l'histoire à des élèves du primaire, en essayant de ne pas se limiter à un récit venu d'en haut.
C'est tout à fait passionnant. L'auteure, partisane des méthodes Freinet (mais avec nuance et sans en faire un dogme), essaie de ne pas se contenter de parler d'histoire aux enfants mais de les faire pratiquer un peu, en partant de sources. Évidemment, vu leur âge, ielles ne feront pas de recherche vraiment originale (et ne travailleront pas forcément sur des sources primaires) mais le but est qu'ielles comprennent que l'histoire, ce ne sont pas juste des dates qu'on assène d'en haut.
Et que l'histoire ne concerne pas que des rois et des généraux. Par exemple, lorsque l'auteure enseigne dans le quartier de La Villette, elle fait travailler ses élèves sur les anciennes usines du quartier, usine à gaz ou sucrerie, avec recherche d'informations sur les conditions de travail des différentes époques.Elle les emmène même voir des archives et comprendre ainsi avec quel matériau les historiens travaillent.
La difficulté est bien sûr de laisser les élèves assez libres (principes de Freinet) tout en les cadrant pour qu'ils aient les connaissances de base. Elle note que les élèves manquent souvent de contexte et, par exemple, lors d'un travail sur les lettres entre les soldats et leurs femmes et fiancées pendant la Première Guerre mondiale, un élève a demandé pourquoi ils ne s'appelaient pas par téléphone. Il faut donc fixer les époques et leurs caractéristiques dans l'esprit des élèves.
Une autre question émouvante portait sur la guerre d'Algérie, un certain nombre de ses élèves étant issu·es de l'immigration algérienne. Faut-il parler de la torture, sachant que le grand-père d'une des élèves l'a fait ? Comment concilier l'importance de la vérité avec le souci de ne pas traumatiser les élèves ? L'auteure ne se contente en effet pas de gentilles généralités « les élèves sont créatifs, il faut les laisser faire », elle détaille les difficultés, les nombreuses questions soulevées par cet objectif de liberté, et les solutions trouvées.
Bref, je recommande ce livre à celles et ceux qui s'intéressent à l'histoire et à l'éducation.
L'article seul
Printing on a Xerox AltaLink from Debian
First publication of this article on 11 April 2024
This is a very short article documenting how I managed to configure a Xerox AltaLink C8130 printer on a Debian machine. No rocket science, it is just that it could have been easier so I document it for the benefits of the people finding this artcle via a search engine, and also for my own benefit if I have to do it again.
I use CUPS for printing on my
Debian machine and, without anything special,
it worked with the Xerox AltaLink C8130. But without any option
(double-sided, stapling, etc). To have the full set of options, I
deleted the printer through CUPS' Web interface (the one which is
by default at http://localhost:631/) and added
it from scratch (Administration → Add a printer). I then choosed
"LPD/LPR printer" (I assume it should work as well with
IPP but I did not try), then used
socket://192.0.2.43/ as connection parameter
(the IP address being of
course the printer's address; the easiest way to get it is by
printing a test page from the front panel of the printer).
Then, I added the PPD file. This is the
important step and it is not easy to find the PPD file on
Xerox Web site (a "site:support.xerox.com ppd
altalink" in your favorite search engine helps, searching for
"drivers" or "download" is useless). The file is labeled "Generic
PPD" and its name is
AltaLink_C8130-C8170_5.709.0.0_PPD.zip.
You can then upload it to CUPS through its Web interface and it's done.
L'article seul
RFC 9460: Service Binding and Parameter Specification via the DNS (SVCB and HTTPS Resource Records)
Date de publication du RFC : Novembre 2023
Auteur(s) du RFC : B. Schwartz (Meta Platforms), M. Bishop, E. Nygren (Akamai Technologies)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 8 avril 2024
Dernière mise à jour le 31 mars 2025
Ces deux nouveaux types d'enregistrement DNS, SVCB et sa variante HTTPS, permettent de donner des informations supplémentaires à un client réseau avant qu'il ne tente de se connecter à un serveur. On peut envoyer ainsi des indications sur les versions des protocoles gérées, des clés cryptographiques ou des noms de serveurs supplémentaires.
Un client d'un service réseau a en effet plein de questions à se poser avant de tenter une connexion. Quelle adresse IP utiliser ? Quel port ? Chiffrement ou pas ? Les anciens mécanismes traitent la question de l'adresse IP (on la trouve par une requête DNS) et celle du port, si on se limite aux ports bien connus (comme 43 pour whois). Mais cela ne dit pas, par exemple, si le serveur HTTP distant accepte ou non HTTP/3 (RFC 9114). Par contre, cet enregistrement HTTPS de Cloudflare va bien nous dire que ce serveur accepte HTTP/2 et 3 :
% dig cloudflare.com HTTPS … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 28399 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1 … ;; ANSWER SECTION: cloudflare.com. 300 IN HTTPS 1 . alpn="h3,h2" ipv4hint=104.16.132.229,104.16.133.229 ipv6hint=2606:4700::6810:84e5,2606:4700::6810:85e5 … ;; WHEN: Mon Apr 08 09:27:01 CEST 2024 ;; MSG SIZE rcvd: 226
Bon, en quoi consiste cet enregistrement SVCB ? Il a deux modes de fonctionnement, alias et service. Le premier mode sert à faire d'un nom une version canonique d'un autre, un peu comme le CNAME mais en étant utilisable à l'apex d'une zone. Le second mode sert à indiquer les paramètres techniques de la connexion. Un enregistrement SVCB (ou HTTPS) a trois champs dans ses données :
SvcPriority: quand il vaut zéro, il indique le mode alias. Autrement (par exemple dans le cas ci-dessus), il indique la priorité de ces paramètres.TargetName: en mode alias, il indique le nom canonique, ou autrement un nom alternatif (pour un service accessible via plusieurs noms). Dans l'exemple Cloudflare ci-desssus, il valait la racine (un point) ce qui indique l'absence de nom alternatif (section 2.5).SvcParams: une liste de couples {clé,valeur} pour les paramètres de connexion (uniquement en mode service). Dans le cas avec Cloudflare, c'étaitalpn="h3,h2" ipv4hint=104.16.132.229,104.16.133.229 ipv6hint=2606:4700::6810:84e5,2606:4700::6810:85e5. (Si vous vous intéressez aux débats à l'IETF, la question de la syntaxe de ces paramètres avait suscité une longue discussion.)
Les enregistrements SVCB ont le type 64 (enregistré à l'IANA) et les HTTPS, qui ont la même syntaxe et le même contenu, mais sont spécifiques à HTTP, ont le 65 (SVCB est générique). Les enregistrements HTTPS (et de futurs enregistrements pour d'autres protocoles) sont dits « compatibles avec SVCB » car ils ont la même syntaxe et la même sémantique.
Notre RFC définit (section 7) une liste de paramètres possibles mais d'autres peuvent être ajoutés dans un registre IANA, via la procédure « Examen par un expert » (RFC 8126). Pour l'instant, il y a, entre autres :
L'enregistrement peut (cela dépend des protocoles qui
l'utilisent, HTTP ne le fait pas) être placé sur un sous-domaine
indiquant le service, par exemple
_8765._baz.api.example.com (section
10.4.5).
Idéalement, un serveur faisant autorité devrait renvoyer les SVCB et les HTTPS, s'ils sont présents, dans la section additionnelle de la réponse, lorsque le type demandé était une adresse IP. Mais ceux de Cloudflare ne semblent pas le faire actuellement. (PowerDNS le fait.)
Si vous vous intéressez aux questions opérationnelles, et que vous voulez mettre des enregistrements SVCB/HTTPS dans votre zone, la section 10 du RFC est faite pour vous. J'ai des enregistrements HTTPS pour ce blog :
# Un alias à l'apex (la priorité 0 indique le mode alias) % dig +short +nodnssec bortzmeyer.org HTTPS 0 www.bortzmeyer.org. # J'ai HTTP/2 (mais pas encore HTTP/3) % dig +short +nodnssec www.bortzmeyer.org HTTPS 1 . alpn="h2"
Pour cela, j'ai mis dans le fichier de zone :
; Enregistrements SVCB (HTTPS). ; HTTP/2 (mais pas encore - au 2024-04-08 - de HTTP/3) www IN HTTPS 1 . alpn="h2" ; alias @ IN HTTPS 0 www.bortzmeyer.org.
Les clients HTTP récents, qui gèrent SVCB/HTTPS vont alors se
connecter directement en HTTP/2 à
https://www.bortzmeyer.org/ même si
l'utilisateur demandait originellement
http://bortzmeyer.org/ (le type
d'enregistrement HTTPS, comme son nom l'indique, sert aussi à
annoncer qu'on accepte HTTPS, ce qui permettra d'abandonner HSTS). Les clients
HTTP plus anciens, évidemment, ne connaissent pas le système
SVCB/HTTPS et il faut donc garder une configuration pour eux (par
exemple des adresses IP à l'apex). Il y a aussi les autres méthodes,
comme le Alt-Svc: du RFC 7838. La section 9.3 du RFC décrit le comportement attendu
lorsque les différentes méthodes coexistent.
Faites attention toutefois, lorsque vous mettez ce type d'enregistrements dans votre zone, je ne connais pas encore d'outils de test permettant de vérifier la syntaxe des enregistrements, encore moins leur correspondance avec la réalité (par exemple, SSLLabs ne semble pas le faire). C'est un problème général de la signalisation sur l'Internet, quand on signale (notamment via le DNS) les capacités d'un serveur : le logiciel client doit de toute façon être prêt à tout, car il ne peut jamais être sûr que le signal est conforme aux faits.
En parlant d'anciens logiciels (clients et serveurs), vous pouvez trouver une liste de mises en œuvre de SVCB/HTTPS. Attention, elle est incomplète et pas à jour. Notez qu'il y a parfois des contraintes particulières, ainsi, il semble que Firefox ne demande des enregistrements HTTPS que s'il utilise DoH. iOS envoie des requêtes HTTPS depuis iOS 14, publié en septembre 2020, ce qui avait étonné, à l'époque.
En parlant de Firefox, s'il est assez
récent, et s'il est configuré
pour faire du DoH, vous pouvez tester le SVCB/HTTPS en allant dans
about:networking#dnslookuptool. En entrant un
nom de domaine, le champ « RR HTTP » doit renvoyer l'enregistrement
HTTPS.
curl utilise désormais le type HTTPS mais il faut le compiler avec une certaine option.
Avec un tcpdump récent, voici le trafic
DNS utilisant le nouvel enregistrement DNS, qu'on peut observer sur
un serveur faisant autorité pour
bortzmeyer.org :
09:49:23.354974 IP6 2a04….31362 > 2001:4b98:dc0:41:216:3eff:fe27:3d3f.53: 13024% [1au] HTTPS? www.bortzmeyer.org. (47) 09:52:06.094314 IP6 2a00….56551 > 2001:4b98:dc0:41:216:3eff:fe27:3d3f.53: 40948% [1au] HTTPS? wWw.bOrTZmEyER.ORg. (62) 10:06:21.501437 IP6 2400….11624 > 2001:4b98:dc0:41:216:3eff:fe27:3d3f.53: 59956 [1au] HTTPS? doh.bortzmeyer.fr. (46) 10:06:21.999608 IP6 2400….36887 > 2001:4b98:dc0:41:216:3eff:fe27:3d3f.53: 17231 [1au] HTTPS? radia.bortzmeyer.org. (49) 10:25:53.947096 IP6 2001….54476 > 2001:4b98:dc0:41:216:3eff:fe27:3d3f.53: 26123% [1au] HTTPS? www.bortzmeyer.org. (47)
Si votre tcpdump est plus ancien, vous verrez Type65 au lieu de HTTPS.
Sinon, si vous aimez les bricolages (et celui-ci sera de moins en moins utile avec le temps, au fur et à mesure que les serveurs géreront ce type), pour fabriquer les enregistrements, vous pouvez utiliser cet outil, qui va fabriquer la forme binaire, directement chargeable par les serveurs faisant autorité :
% perl type65_https.pl 'example.net HTTPS 1 . alpn="h3,h2" ipv4hint="192.0.2.42" ipv6hint="2001:db8::42"' example.net. TYPE65 ( \# 41 00010000010006026833026832000400 04c000022a0006001020010db8000000 000000000000000042 )
(Il faut un Net::DNS
récent sinon « unknown type "HTTPS" at /usr/share/perl5/Net/DNS/RR.pm line 671.
in new Net::DNS::RR( www.bortzmeyer.org HTTPS 1 . alpn="h2" )
at type65_https.pl line 30. ».)
Quelques articles pas mal :
- Simple HTTPS Records par Kal Feher.
- Use of HTTPS Resource Records avec le résultat de mesures sur le déploiement effectif.
- Autres mesures dans le monde, l'article Deciphering the Digital Veil: Exploring the Ecosystem of DNS HTTPS Resource Records.
L'article seul
Un résolveur DNS public en Inde
Première rédaction de cet article le 7 avril 2024
J'avais raté l'information : il y a désormais un résolveur
DNS public en
Inde, dns.nic.in.
Il ne semble pas y avoir eu beaucoup de communication publique sur
ce service mais il fonctionne. Un résolveur DNS
public est un résolveur qui est ouvert à toustes
et accepte donc des requêtes DNS de n'importe quelle adresse
IP. (Un résolveur ouvert fait pareil mais c'est une
erreur de configuration ; un résolveur public résulte d'une action
volontaire.) Les plus connus sont ceux de grosses entreprises
étatsuniennes comme Google (avec son
8.8.8.8) ou Cloudflare
(avec son 1.1.1.1). Si on ne veut pas, et avec
raison, contribuer à nourrir ces entreprises d'encore plus de données
personnelles, sans compter les risques de centralisation de la
résolution DNS, on a le choix : on peut avoir son propre résolveur, ou
bien utiliser d'autres résolveurs publics comme celui de Yandex (si on veut
envoyer ses données personnelles au FSB
plutôt qu'à la NSA), celui d'une
entreprise allemande ou d'une association
française. (Il y en a même un que je gère.)
Cette offre importante et variée s'est enrichie (mais je ne sais
pas trop quand) d'un résolveur indien. Il est accessible en UDP et TCP avec plusieurs adresses
IP. Prenons l'une des plus jolies,
2409::.
% dig @2409:: mastodon.gougere.fr AAAA ; <<>> DiG 9.18.18-0ubuntu0.22.04.2-Ubuntu <<>> @2409:: mastodon.gougere.fr AAAA ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 33859 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 1232 ; COOKIE: d5d69e457527742201000000661296ca11b1e6683393ded2 (good) ;; QUESTION SECTION: ;mastodon.gougere.fr. IN AAAA ;; ANSWER SECTION: mastodon.gougere.fr. 900 IN AAAA 2001:bc8:1202:ce00::1 mastodon.gougere.fr. 900 IN RRSIG AAAA 13 3 900 ( 20240522050147 20240323042710 18689 gougere.fr. YUzJqyzLVFbndBhaFPtxcQZPoFgVynD9BpxukCuYKJzP PtSzNK/lY3xFvHi44Txda+/KrZiRIr7LvuU46s0RhQ== ) ;; Query time: 304 msec ;; SERVER: 2409::#53(2409::) (UDP) ;; WHEN: Sun Apr 07 14:51:22 CEST 2024 ;; MSG SIZE rcvd: 210
OK, tout fonctionne, et on peut voir (flag AD, pour Authentic Data) que ce résolveur valide avec DNSSEC. Le temps de réponse n'est pas extraordinaire depuis ma machine en France mais il est probable que les gérants de ce serveur ont privilégié leur présence en Inde.
Testons cette hypothèe avec les sondes RIPE Atlas :
% blaeu-resolve --nameserver 2409:: --displayvalidation --displayrtt --requested 100 \
--country IN --old_measurement 69708749 --type AAAA geoponum.com
…
[ (Authentic Data flag) 2001:41d0:301::28] : 33 occurrences Average RTT 27 ms
[TIMEOUT] : 11 occurrences
Test #69708785 done at 2024-04-07T13:01:15Z
% blaeu-resolve --nameserver 2409:: --displayvalidation --displayrtt --requested 100 \
--country JP --old_measurement 69708763 --type AAAA geoponum.com
…
[ (Authentic Data flag) 2001:41d0:301::28] : 98 occurrences Average RTT 134 ms
[2001:41d0:301::28] : 1 occurrences Average RTT 897 ms
[TIMEOUT] : 1 occurrences
Test #69708813 done at 2024-04-07T13:03:37Z
(On réutilise les sondes d'une mesure précédente, pour augmenter la probabilité que tout soit dans la mémoire du résolveur.) On voit que la latence moyenne est plus basse en Inde qu'au Japon, ce qui est logique. Ce résolveur n'est donc peut-être pas la solution idéale si vous vivez en dehors de l'Inde.
Je l'ai dit, l'offre en matière de résolveurs publics est très diverse et donc les arguments des contempteurs de DoH comme quoi DoH pousserait à la centralisation sont bien à côté de la plaque. Notez aussi que, bien qu'il existe de nombreux résolveurs publics de qualité opérationnels, celui annoncé en fanfare par la Commission Européenne il y a déjà plusieurs années, DNS4EU, ne fonctionne toujours pas (Thierry Breton est plus doué pour les annonces que pour l'opérationnel, ce qui était déjà le cas lorsqu'il dirigeait Atos).
Ah, mais j'ai dit que le résolveur était accessible en UDP et en TCP. Et avec des protocoles chiffrés comme DoT (RFC 7858) ou DoH (RFC 8484) ?
% kdig +tls @2409:: geoponum.com ;; WARNING: can't connect to 2409::@853(TCP) ;; ERROR: failed to query server 2409::@853(TCP)
Ah, zut, pas encore de chiffrement. Mais, en fait, c'est plus compliqué que cela. Il semble que certaines instances du nuage anycast (cf. plus loin) aient du chiffrement, mais pas les autres. Donc, selon l'adresse IP de service qu'on utilise et l'endroit où on est, on verra du chiffrement ou pas :
% kdig +nsid +https=/dns-query @1.10.10.10 geoponum.com ;; TLS session (TLS1.3)-(ECDHE-SECP256R1)-(RSA-PSS-RSAE-SHA256)-(AES-256-GCM) ;; HTTP session (HTTP/2-POST)-(1.10.10.10/dns-query)-(status: 200) ;; ->>HEADER<<- opcode: QUERY; status: NOERROR; id: 0 ;; Flags: qr rd ra; QUERY: 1; ANSWER: 1; AUTHORITY: 0; ADDITIONAL: 1 ;; EDNS PSEUDOSECTION: ;; Version: 0; flags: ; UDP size: 1232 B; ext-rcode: NOERROR ;; NSID: 696E2D626F6D2D7331 "in-bom-s1" ;; QUESTION SECTION: ;; geoponum.com. IN A ;; ANSWER SECTION: geoponum.com. 3600 IN A 51.91.236.193 ;; Received 70 B ;; Time 2024-04-07 16:49:26 CEST ;; From 1.10.10.10@443(TCP) in 613.4 ms
Ici, l'instance de Bombay a bien répondu en DoH (son certificat, sans surprise, est un Let's Encrypt).
En demandant le NSID (RFC 5001, on voit que le résolveur est manifestement anycasté :
% blaeu-resolve --nameserver 2409:: --nsid --requested 200 --type AAAA geoponum.com Nameserver 2409:: [TIMEOUT] : 12 occurrences [2001:41d0:301::28 NSID: in-amd-s1;] : 134 occurrences [2001:41d0:301::28 NSID: in-blr-s1;] : 32 occurrences [2001:41d0:301::28 NSID: in-maa-s1;] : 6 occurrences [2001:41d0:301::28 NSID: in-maa-s2;] : 3 occurrences [2001:41d0:301::28 NSID: in-bom-s1;] : 1 occurrences [2001:41d0:301::28 NSID: in-gau-s1;] : 6 occurrences [2001:41d0:301::28 NSID: None;] : 3 occurrences [2001:41d0:301::28 NSID: in-bom-s2;] : 3 occurrences Test #69708899 done at 2024-04-07T13:10:50Z
On voit au moins sept instances différentes. Le schéma de nommage semble être le classique code IATA des aéroports (AMD = Ahmedabad, BLR = Bangalore, etc).
Si on essaie d'obtenir le nom du serveur à partir de son adresse
IP, on voit que la zone 0.0.0.9.0.4.2.ip6.arpa
est bien cassée (regardez l'EDE - RFC 8914) :
% dig -x 2409:: … ;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 9388 ;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 1232 ; EDE: 7 (Signature Expired): (6GJV) ;; QUESTION SECTION: ;0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.9.0.4.2.ip6.arpa. IN PTR ;; Query time: 4296 msec ;; SERVER: 192.168.2.254#53(192.168.2.254) (UDP) ;; WHEN: Sun Apr 07 10:40:34 CEST 2024 ;; MSG SIZE rcvd: 111
Outre les signatures DNSSEC expirées, cette zone a plein d'autres problèmes DNS.
Et les adresses IP sortantes, à partir desquelles le résolveur
indien pose des questions aux serveurs faisant
autorité ? Testons avec le service
ip.dyn.bortzmeyer.fr, qui renvoie l'adresse IP de son
client (du résolveur, donc) :
% blaeu-resolve --nameserver 2409:: --nsid --requested 200 --type TXT ip.dyn.bortzmeyer.fr Nameserver 2409:: ["160.202.194.2" NSID: in-amd-s1;] : 140 occurrences [TIMEOUT] : 10 occurrences ["160.202.198.2" NSID: in-blr-s1;] : 5 occurrences ["2409:e:e7::3" NSID: in-maa-s2;] : 4 occurrences ["240a:eff6::2" NSID: in-blr-s1;] : 23 occurrences ["160.202.200.2" NSID: in-gau-s1;] : 1 occurrences ["180.250.245.54" NSID: None;] : 1 occurrences ["2409:e:e7::2" NSID: in-maa-s1;] : 2 occurrences ["45.249.124.2" NSID: in-maa-s1;] : 1 occurrences ["240a:eff8::2" NSID: in-gau-s1;] : 7 occurrences ["2409:e:e4::2" NSID: in-bom-s1;] : 2 occurrences ["2409:e:e4::3" NSID: in-bom-s2;] : 2 occurrences ["99.212.0.7" NSID: None;] : 1 occurrences ["121.46.96.2" NSID: in-bom-s1;] : 1 occurrences Test #69709105 done at 2024-04-07T13:26:34Z
On voit une grande variété de préfixes, tous enregistrés en Inde, à divers organismes publics.
L'article seul
RFC 9340: Architectural Principles for a Quantum Internet
Date de publication du RFC : Mars 2023
Auteur(s) du RFC : W. Kozlowski, S. Wehner
(QuTech), R. Van Meter (Keio
University), B. Rijsman, A. S. Cacciapuoti, M. Caleffi
(University of Naples Federico II), S. Nagayama
(Mercari)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF qirg
Première rédaction de cet article le 3 avril 2024
Voici un RFC assez futuriste qui explore à quoi pourrait ressembler un futur « Internet » quantique. Je divulgâche tout de suite : ce ne sera pas de si tôt.
Quelques avertissements s'imposent d'abord. Avant tout, rappelez-vous que la quantique produit des résultats qui sont parfaitement cohérents théoriquement et très bien vérifiés expérimentalement mais qui sont hautement non-intuitifs. Avant d'aborder le monde merveilleux de la quantique, n'oubliez pas d'oublier tout ce que vous croyez savoir sur le monde physique. Et ne comptez pas trop sur moi comme guide, on sort nettement ici de mon domaine de compétence. Ensuite, « quantique » est un terme à très forte charge marketing (moins que « IA » mais davantage que « métavers » ou même « blockchain », qui semblent bien passés de mode). Il faut donc être prudent chaque fois qu'un commercial ou un éditorialiste va dire que « c'est quantique » ou que « la quantique va bouleverser tel ou tel domaine ». Enfin, il y a loin de la coupe aux lèvres : de même qu'on n'a pas encore d'ordinateur quantique utile, on n'a pas encore de réseau quantique. Le RFC est à juste titre prudent, pointant les différents obstacles qui restent sur le chemin de l'Internet quantique.
Bon, ces précautions étant posées, qu'est-ce qu'un réseau quantique et pourquoi y consacrer un RFC ? La section 1 du RFC le résume : un réseau quantique est un réseau qui ferait communiquer des dispositifs quantiques pour faire des choses inimaginables avec un réseau classique. Il s'appuierait sur des propriétés spécifiques au monde quantique, notamment l'intrication, propriétés qui n'ont pas d'équivalent dans le monde classique. Attention, et le RFC insiste bien là-dessus, personne n'envisage de remplacer l'Internet classique par un Internet quantique (de la même façon que les futurs ordinateurs quantiques, étant loin d'être généralistes, ne remplaceront pas les ordinateurs classiques). Au contraire, le scénario envisagé est celui d'un réseau hybride, partiellement quantique. (Une lecture recommandée par le RFC est « The quantum internet ».)
Un exemple typique qui ne serait pas possible avec un réseau classique est celui de la distribution quantique de clés (parfois appelée du terme erroné de « cryptographie quantique »), dont l'utilité pratique est douteuse mais qui est assez spectaculaire et, contrairement à d'autres applications, est assez avancée techniquement. D'autres applications sont envisageables à plus long terme. C'est le cas par exemple du blind quantum computation, qui n'a pas encore d'article Wikipédia mais est expliqué dans cet article.
En laboratoire, beaucoup de résultats ont été obtenus. Les chercheurs et chercheuses ont déjà mis au point bien des dispositifs physiques étonnants. Mais à l'échelle du réseau, il n'y a pas encore eu beaucoup de travaux. Le RFC compare cette situation à celle d'un réseau classique où on aurait des fibres optiques et des lasers pour les illuminer mais aucun protocole de transport, aucun mécanisme de routage, encore moins de moyens de gérer le réseau. Développer une application pour un réseau quantique revient à toucher directement au matériel, comme, pour un réseau classique, s'il fallait que chaque application parle aux interfaces physiques, sans avoir d'interface de plus haut niveau comme les prises.
La section 2 du RFC est un rappel sur la quantique. Comme dit plus haut, c'est un domaine riche et complexe, où l'intuition ordinaire ne sert pas à grand'chose. Donc, lire ce rappel est une bonne idée mais n'espérez pas tout comprendre si vous n'êtes pas spécialiste de la question. Cette section est conçue pour des gens qui ne connaissent rien à la physique quantique, elle recommande, pour aller plus loin, le livre de Sutor Dancing with Qubits ou bien celui de Nielsen et Chuang, Quantum Computation and Quantum Information.
Le rappel commence avec la notion d'état quantique. Vous avez sans doute déjà entendu dire qu'un bit classique peut prendre deux valeurs, 0 ou 1, alors que son équivalent quantique, le qubit, a un état qui est une superposition de valeurs possibles, avec des probabilités. Lorsqu'on le mesure, on trouve un 0 ou un 1. (Oui, comme le célèbre chat qui est à la fois vivant et mort.) Attention, ces non-certitudes ne sont pas la conséquence d'un manque d'information mais sont une propriété fondamentale du monde quantique (Alain Aspect a eu un prix Nobel pour avoir prouvé cela). Notez que les versions HTML ou PDF du RFC sont recommandées ici, car il y a quelques équations. Comme un qubit est dans un état qui superpose les deux valeurs possibles, les opérations quantiques agissent sur tout l'état, par exemple l'équivalent quantique d'une porte NOT va inverser les probabilités du 0 et du 1 mais pas transformer un 0 en 1.
Le terme « qubit » (et cette distinction revient souvent dans le RFC) peut désigner aussi bien le concept abstrait que le truc physique qui va le mettre en œuvre (il existe plusieurs techniques pour fabriquer un engin qui gérera des qubits).
On peut ensuite assembler des qubits et, très vite, le nombre de possibilités croît. Mais l'intérêt de mettre des qubits ensemble est qu'on peut les intriquer et ce concept est au cœur de beaucoup de solutions quantiques, notamment du réseau quantique. Une fois intriqués, les deux qubits verront leur sort lié. Une mesure sur l'un affectera l'autre. (Rappel : la quantique n'est pas intuitive et l'intrication n'a pas d'équivalent dans le monde non-quantique, celui sur lequel a été bâtie notre intuition.) La mesure, comme toujours en quantique, est « destructive » au sens où elle ramène à un système classique (le qubit vaut 0 ou 1 quand on le mesure, pas un mélange des deux, et le chat est vivant ou mort quand on ouvre la boite).
Cette intrication est au cœur des réseaux quantiques (section 3 du RFC). Tous les projets de réseaux quantiques utilisent cette propriété (qui, rappelons-le, n'a pas d'équivalent non-quantique). L'intrication permet de corréler deux nœuds du réseau. Par exemple, pour se mettre d'accord sur une valeur, deux machines n'ont pas besoin de faire tourner des algorithmes de consensus, elles peuvent utiliser deux qubits intriqués, chacune en gardant un. Quand une machine lira la valeur de son qubit, elle sera certaine de la valeur lue par l'autre. Et l'intrication ne peut pas être partagée : un tiers ne peut pas s'intriquer avec une intrication existante, ce qui peut avoir des applications en sécurité.
Un réseau quantique est donc défini par notre RFC comme un ensemble de nœuds qui peuvent échanger des qubits intriqués.
Bon, tout ça, c'est très joli, mais comment on le réalise, ce réseau quantique ? La section 4 se penche sur les défis :
- Comme toute mesure détruit le caractère quantique du qubit et le transforme en un bit ordinaire, des opérations banales dans le monde classique, comme la copie d'un bit, deviennent non triviales.
- Et copier un qubit sans le mesurer ? On ne peut pas (c'est le théorème d'impossibilité du clonage).
- Tout cela rend très difficile la correction d'erreurs. Un réseau réel, reposant sur des objets physiques, va forcément voir des erreurs (un rayon cosmique passe et paf, un 0 est transformé en 1) et de nombreuses techniques existent pour gérer ce problème dans le monde classique. Mais elles ne peuvent en général pas s'appliquer dans le monde quantique, qui va donc avoir un problème de fidélité : la fidélité est la conformité à ce qu'on souhaitait (elle va de 0 à 1), et les applications doivent en tenir compte.
Distribuer sur le réseau des qubits quelconques n'est pas forcément facile, donc le RFC suggère de plutôt distribuer des paires de Bell. On peut alors plus facilement (tout est relatif) faire de la téléportation, c'est-à-dire « transporter » un qubit d'un point à un autre. Ce n'est pas une violation du théorème d'impossibilité du clonage puisque le qubit n'est pas copié (il disparait de son point de départ). Notez que le terme de « téléportation » est surtout marketing : vous ne pourrez pas déplacer votre chat ou vous-même de cette façon.
Dernier problème, amplifier le signal (sans le copier !) pour tenir compte de sa dégradation avec la distance. Il existe une astuce, l'échange d'intrication, que je ne vais pas essayer d'expliquer, mais qui permet des réseaux quantiques sur des distances importantes.
Revenons à la correction d'erreurs. Les réseaux quantiques ne sont pas complètement démunis, et ont des solutions possibles, comme les codes quantiques.
OK, on a vu que le monde quantique était très spécial. Donc, le réseau quantique va être bizarre aussi, aux yeux de quelqu'un qui a l'habitude des réseaux classiques (section 5 du RFC). Par exemple, il fera face à ces problèmes :
- C'est bien joli, les paires de Bell, mais ce n'est pas l'équivalent d'un paquet portant une charge utile. Il n'y a pas l'équivalent de l'en-tête du paquet, et le réseau quantique va donc devoir utiliser un réseau classique pour l'information de contrôle. On ne fera pas un réseau purement quantique.
- Toute action sur des qubits intriqués doit être coordonnée entre les nœuds puisque l'action sur un qubit va déterminer le résultat d'une action sur les autres (il faut donc que chaque nœud sache contacter les autres).
Répétons-le, chaque nœud du réseau quantique devra également être relié à un réseau classique. Le réseau sera donc complexe et son administration pas évidente.
Une fois qu'on a accepté cela, le réseau classique pourra s'occuper d'opérations comme la construction des tables de routage, pour laquelle les algorithmes et méthodes classiques semblent suffire. On n'aura donc peut-être qu'un seul plan de contrôle (le classique) mais deux plans de données, le classique et le quantique.
Que faut-il construire comme machines pour le plan de données quantique ? D'abord, des répéteurs quantiques qui vont pouvoir créer les intrications, les échanger et contrôler la fidélité. Ensuite :
- Des routeurs quantiques, qui, en plus des fonctions ci-dessus, participeront au routage.
- Les nœuds ordinaires, des répéteurs qui ne participent pas au routage.
- Les nœuds terminaux, qui pourront émettre et recevoir des qubits mais pas faire d'échange d'intrication. C'est là que tourneront les applications.
Facile, me direz-vous ? Non, construire ces machines va nécessiter de s'attaquer à quelques problèmes physiques :
- Stocker un qubit est un défi ! Le monde classique n'aime pas les objets quantiques et essaie régulièrement de les rappeler à ses lois. Les bruits divers de l'environnement font rapidement perdre aux qubits leurs propriétés quantiques. (C'est d'ailleurs pour cela que vous ne rencontrez pas de chats de Schrödinger dans la vraie vie.) Cela se nomme la décohérence et c'est l'un des principaux obstacles sur la route des réseaux quantiques (ou des calculateurs quantiques). Les durées de vie qu'on atteint étaient, lors de la rédaction du RFC, de l'ordre de la seconde (ou de la minute si on n'est pas connecté au réseau, source de perturbations).
- La capacité des liens quantiques est un autre problème. Générer des qubits intriqués prend du temps. Quand on en fabrique dix par seconde, on est contents. Bien sûr, la technique progresse sans cesse (pas mal des références du RFC sont un peu datées, car il a mis du temps à sortir) mais pas assez.
- On l'a dit, on peut réaliser des qubits intriqués par différentes méthodes physiques, avec des performances différentes selon la métrique utilisée. Mais ces méthodes ne communiquent pas entre elles, ce qui veut dire que tous les nœuds du réseau doivent utiliser la même.
Si vous n'êtes pas découragé·e (mais il ne faut pas l'être : même si les difficultés sont colossales, le chemin est rigolo), il faut maintenant, en supposant qu'on aura les composants de base d'un réseau, les assembler. (À moins que le choix décrit dans le RFC des paires de Bell et de l'échange d'intrication ne soit remis en cause par les futurs progrès…) La section 6 se penche sur la question. Elle démarre par un bel excès d'optimisme, en expliquant que, contrairement à ce qui s'est passé avec l'Internet classique, on a de l'expérience sur la construction de réseau, et qu'on pourra donc ne pas faire d'erreur comme la taille trop réduite des adresses IPv4.
Des services essentiels pour un réseau réel seront difficiles à assurer sur un réseau quantique. Par exemple, l'impossibilité du clonage interdira d'utiliser un logiciel équivalent à tcpdump (remarquez, pour la sécurité, c'est un plus). Le RFC liste les principes de base d'un réseau quantique :
- Le service de base sera l'intrication.
- La fidélité est aussi un service (contrairement au réseau classique où on peut espérer une fidélité parfaite).
- Le temps va être un facteur crucial, compte tenu de la décohérence. Pas question de faire patienter des qubits trop longtemps dans une file d'attente, par exemple.
- Il faudra être flexible, notamment parce que le matériel va continuer à évoluer.
Et le RFC se termine par une exploration d'une architecture de réseau quantique possible, inspirée de MPLS. Dans ce réseau (pour l'instant) imaginaire, tout fonctionne en mode connecté (comme MPLS) : on doit d'abord créer un circuit virtuel (car créer les paires de Bell et les utiliser va nécessiter de la coordination, donc il vaut mieux établir d'abord une connexion). Ce QVC (Quantum Virtual Circuit) a des caractéristiques comme une qualité de service choisie, qui se décline en, par exemple, une capacité mesurée en nombre de paires de Bell par seconde et bien sûr une fidélité (toutes les applications des réseaux quantiques n'ont pas les mêmes exigences en terme de fidélité). La signalisation peut être décentralisée (comme avec RSVP) ou centralisée (comme avec OpenFlow). Comme vous le verrez en lisant cette conclusion du RFC, les détails sont encore approximatifs.
Ce RFC a mis longtemps à être écrit, vous pouvez trouver une description ancienne du projet sur le blog de l'IETF. Notez que l'écriture de ce RFC a été en partie financée par la Quantum Internet Alliance européenne.
N'hésitez pas à vous plonger dans la bibliographie très détaillée de ce RFC, vous y trouverez beaucoup de lectures passionnantes. Il y a même déjà des livres entiers sur les réseaux quantiques comme celui de Van Meter.
L'article seul
Fiche de lecture : L'animal médiatique (Le temps des médias)
Auteur(s) du livre : Ouvrage collectif
Éditeur : Nouveau monde
978-2-38094-393-1
Publié en 2023
Première rédaction de cet article le 3 avril 2024
Ce numéro de la revue d'histoire « Le temps des médias » est consacré à la place des animaux dans les médias et il y a beaucoup à dire !
Tous les articles sont passionnants mais, parmi ceux qui m'ont particulièrement instruit :
- L'histoire de l'« ours Martin » (qui n'était pas un ours unique, mais un nom générique) au Jardin des plantes, par Olivier Vayron. Si les médias de l'époque adoraient les récits (presque tous imaginaires) d'agressions commises par Martin sur les visiteurs, la réalité est plus glauque : ce sont les humains qui agressaient l'ours du zoo, souvent de manière lâche et ignoble.
- L'analyse de la place de l'animal sauvage dans les récits d'aventure bon marché du XIXe siècle, par Sophie Bros. Peu de souci de véracité ou même de vraisemblance dans ces récits conçus pour de la production et de la distribution de masse. Dans le train de l'époque, tiré par une locomotive à vapeur, on avait le temps de se délecter d'histoires toutes pareilles, où le courageux explorateur européen venait à bout de toute une ménagerie de bêtes féroces et exotiques.
- Plus actuel, un article de Félix Patiès détaille la polémique au sein de la Fédération Anarchiste sur une émission « antispéciste » de Radio Libertaire. Difficile équilibre entre un désir d'ouverture à d'autres courants (d'autant plus importante que l'ARCOM exige une production minimum de contenus originaux) et nécessité, pour une organisation politique, de ne pas accepter n'importe quoi sur son antenne, notamment lorsque cela s'oppose directement à sa ligne politique.
- Toujours dans une actualité plus récente, une étude détaillée de Michel Dupuy sur la construction de l'image de l'oiseau mazouté, comme symbole des destructions que la société industrielle inflige à l'environnement. Ce malheureux oiseau a également été utilisé pour de la propagande de guerre pendant la guerre du Golfe.
- Les fanas de géopolitique trouveront aussi de quoi les intéresser, avec l'article de Zhao Alexandre Huang, Mylène Hardy et Rui Wang sur l'utilisation des pandas par la propagande chinoise. Derrière la mignoncitude, Beijing tire les ficelles.
- Et bien sûr un article sur le rôle des chats sur l'Internet et un sur celui des chiens dans les films de Disney (article que j'ai trouvé extrêmement pro-Disney…)
On peut se procurer ce numéro sous forme papier chez l'éditeur et sous forme numérique (paradoxalement bien plus chère) sur cairn.info. PS : oui, le site Web officiel de la revue n'est pas à jour et est plein de mojibake.
L'article seul
RFC 9432: DNS Catalog Zones
Date de publication du RFC : Juillet 2023
Auteur(s) du RFC : P. van Dijk (PowerDNS), L. Peltan
(CZ.NI), O. Sury (Internet Systems
Consortium), W. Toorop (NLnet
Labs), C.R. Monshouwer, P. Thomassen
(deSEC, SSE - Secure Systems
Engineering), A. Sargsyan (Internet Systems
Consortium)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 29 mars 2024
L'idée de base de ces « zones catalogue » est d'automatiser la configuration d'une nouvelle zone DNS sur les serveurs secondaires, en publiant dans le DNS les caractéristiques des zones qu'ils devront servir. Cela concerne donc surtout les gros hébergeurs qui ont beaucoup de zones.
Petit rappel : une zone, dans le DNS, est une partie contigüe de l'arbre des
noms de domaine, gérée
comme un tout (mêmes serveurs faisant
autorité). Ainsi, si vous venez de louer le nom
machin.example, un hébergeur DNS va configurer
ses serveurs pour faire autorité pour ce nom. Par exemple, avec le
logiciel NSD, sur
le primaire (serveur maitre) :
zone:
name: "machin.example"
zonefile: "primary/machin.example"
# Les serveurs secondaires :
notify: 2001:db8:1::53
provide-xfr: 2001:db8:1::53
…
Et, sur un serveur secondaire (serveur esclave), qui transférera la zone depuis le primaire (RFC 5936) :
zone: name: "machin.example" # Le primaire : allow-notify: 2001:db8:cafe::1 NOKEY request-xfr: AXFR 2001:db8:cafe::1 NOKEY
Si on gère beaucoup de zones, avec des ajouts et des retraits tout le temps, l'avitaillement manuel est long et risqué (et si on oublie un serveur ?). Éditer ces fichiers sur tous les serveurs secondaires devient vite pénible. Et si les logiciels sur les secondaires sont différents les uns des autres (ce qui est recommandé, pour la robustesse), il faut se souvenir des différentes syntaxes. Pourquoi faire manuellement ce qu'on peut automatiser ? C'est le principe des zones catalogue.
Le principe est simple : une zone catalogue est une zone comme
une autre, produite par les mêmes mécanismes (par exemple
emacs) et qui sera servie par un serveur
primaire à tous les secondaires, qui changeront alors
automatiquement leur configuration en fonction du contenu de la zone
catalogue. Chaque zone à configurer est un enregistrement de type
PTR, dont la partie gauche est une étiquette interne et la partie
droite indique le nom de la zone. Ici, on configure la zone
rutaba.ga, l'étiquette (qui doit être unique)
label1 est à usage interne (section 4.1 du RFC) :
label1.zones.catalog.example. IN PTR rutaba.ga.
Le reste est listé sous forme de propriétés (section 4.2). Une
propriété évidente est l'adresse IP du primaire. Pour l'instant,
elle doit être indiquée via le composant ext
qui désigne les propriétés pas encore normalisées :
primaries.ext.catalog.example. IN AAAA 2001:db8:bad:dcaf::42
La liste des propriétés figure dans un registre IANA.
À l'heure actuelle, de nombreux logiciels gèrent ces zones catalogues. Le site Web du projet (pas mis à jour depuis très longtemps) en liste plusieurs.
Voici un exemple complet de zone catalogue :
; -*- zone -*-
catalog.example. IN SOA ns4.bortzmeyer.org. stephane.bortzmeyer.org. 2023120902 900 600 86400 1
catalog.example. IN NS invalid. ; Le NS est inutile mais
; obligatoire et "invalid" est la valeur
; recommandée (section 4).
version.catalog.example. IN TXT "2" ; Obligatoire, section 4.2.1
label1.zones.catalog.example. IN PTR rutaba.ga.
primaries.ext.catalog.example. IN AAAA 2001:db8:bad:dcaf::42
La configuration de BIND pour l'utiliser :
# La zone catalogue se charge comme n'importe quelle zone. Ceci dit,
# vu le caractère critique de la zone catalogue, la section 7 du RFC
# insiste sur l'importance de sécuriser ce transfert, par exemple avec
# TSIG (RFC 8945) :
zone "catalog.example" {
type slave;
file "catalog.example";
masters {
2001:db8:666::;
};
};
# Et, ici, on la désigne comme spéciale :
options {
...
catalog-zones {
zone "catalog.example"
in-memory no;
};
};
Naturellement, comme toujours lorsque on automatise, on risque le syndrome de l'apprenti sorcier. Attention donc en générant la zone catalogue. Comme le note le RFC (section 6) : « Great power comes with great responsibility. Catalog zones simplify zone provisioning by orchestrating zones on secondary name servers from a single data source: the catalog. Hence, the catalog producer has great power and changes must be treated carefully. For example, if the catalog is generated by some script and this script generates an empty catalog, millions of member zones may get deleted from their secondaries within seconds, and all the affected domains may be offline in a blink of an eye. »
L'article seul
Fiche de lecture : La baleine, une histoire culturelle
Auteur(s) du livre : Michel Pastoureau
Éditeur : Seuil
978-2-02-151688-3
Publié en 2023
Première rédaction de cet article le 29 mars 2024
Michel Pastoureau continue son exploration de l'histoire culturelle des animaux avec la baleine.
D'abord, une précision, c'est un livre d'histoire des mentalités, pas un livre de zoologie. Le terme « baleine », dans le passé, pouvait désigner beaucoup d'animaux qu'on n'appelerait pas « baleine » aujourd'hui. L'idée est de faire le tour, de l'Antiquité à nos jours, sur la vision que les humains ont de la baleine. C'est un animal qui, par sa taille, par le milieu jugé hostile où il vit et par le fait qu'il était très mal connu jusqu'au XIXe siècle, est un parfait support de fantasmes. En gros, jusqu'au XXe siècle, la baleine est monstrueuse, inquiétante, incarnation du Mal, puis elle change tout à coup ou, plutôt, la vision qu'on en a change et on se met à la considérer comme gentille, menacée, et digne d'être protégée (elle est, avec le panda, un des animaux iconiques des campagnes de protection de la nature).
Ce retournement est récent. Le christianisme voyait plutôt la baleine négativement (cf. l'aventure de Jonas, même si la Bible ne dit pas clairement si c'était une baleine, ou un très gros poisson). Les marins aimaient décrire les dangers terribles, et imaginaires, qu'elle faisait courir aux bateaux. Et bien sûr, Moby-Dick n'est pas un modèle de gentillesse, même si son chasseur ne vaut pas mieux. On l'a dit, ce livre est une histoire culturelle d'humains, donc toutes les projections n'ont pas grand'chose à voir avec les baleines réelles.
Ah, et le livre est magnifiquement illustré, les dessins médiévaux sont très bien reproduits, en grand et avec de belles couleurs (vous trouverez celui-ci p. 59). Inutile de rappeler que le réalisme n'était pas le principal souci des auteurs de ces dessins…
(Tiens, j'ai terminé ce livre juste avant de commencer la série télé danoise Trom, où la chasse à la baleine aux iles Féroé et les polémiques que cela suscite sont la toile de fond de l'intrigue policière.)
L'article seul
Fiche de lecture : ENIAC in action
Auteur(s) du livre : Thomas Haig, Mark
Priestley, Crispin Rope
Éditeur : MIT Press
978-0-262-53517-5
Publié en 2016
Première rédaction de cet article le 25 mars 2024
Un passionnant livre détaillant l'histoire de l'ENIAC, l'un des premiers ordinateurs. Contrairement à beaucoup d'autres textes sur l'ENIAC, celui-ci est très détaillé techniquement et ne vous épargne pas les informations précises sur le fonctionnement de cette bête, notamment de ses débuts où la programmation se faisait en soudant et désoudant.
L'ENIAC a été largement traité dans de nombreux ouvrages et articles. De nombreux mythes et légendes ont été développés, malgré le fait qu'on dispose d'une quantité énorme d'informations de première main, accessible aux historiens (beaucoup plus que pour le Colossus, secret militaire et dont beaucoup de documents ont été détruits). Mais depuis ses débuts, l'ENIAC a été un objet médiatique, très publicisé (pendant la guerre, il n'était que confidentiel, pas secret, encore moins très secret, et il a été déclassifié tout de suite après la guerre). Résultat, tout le monde avait quelque chose à dire sur l'ENIAC.
Par exemple, alors que les premières histoires sur l'ENIAC ne mentionnaient que des hommes, on a vu plus récemment des histoires affirmer en sens inverse que tout avait été fait par des femmes, les six de l'ENIAC. Le récit désormais classique est qu'elles faisaient la programmation de l'ENIAC, les « inventeurs » classiques, Eckert et Mauchly ne s'occupant « que » du matériel. Écoutant pour la Nième fois cette affirmation lors d'un exposé au FOSDEM, je me suis demandé « mais ça voulait dire quoi, au juste, programmer sur l'ENIAC » et j'ai lu ce livre.
Plusieurs facteurs rendent compliqué de répondre à cette question : d'abord, comme le notent bien les auteurs du livre, l'ENIAC, qui a eu une durée de vie très longue (de 1945 à 1955, bien plus qu'un smartphone d'aujourd'hui), a beaucoup évolué, cet ordinateur unique, qui ne faisait pas partie d'une fabrication en série, était modifié en permanence. Ainsi, la question de savoir si l'ENIAC était une machine à programme enregistré (plutôt qu'une « simple » calculatrice où le programme était à l'extérieur) a plusieurs réponses possibles (« plutôt non » au début de sa carrière, « plutôt oui » à la fin). Et la façon de « programmer » l'ENIAC a donc beaucoup changé.
Ensuite, bien que l'ENIAC ait laissé une énorme pile de documentation (comme les journaux d'exploitation, qui étaient bien sûr entièrement papier) pour les historiens, tout n'a pas été décrit. Des interactions informelles entre les membres de l'équipe n'ont pas forcément laissé de trace. Plusieurs couples mari-femme travaillaient sur l'ENIAC (comme Adele et Herman Goldstine) et il n'est pas facile de séparer leurs contributions (à chaque époque, on a mis en valeur les contributions de l'une ou de l'autre, selon la sensibilité de l'époque).
Enfin, comme tout était nouveau dans cette machine, même les acteurs et les actrices du projet n'avaient pas toujours une vision claire. Même une distinction comme celle entre matériel et logiciel était loin d'être évidente à cette époque. Et la notion même de « programme » était floue. Les « six de l'ENIAC » avaient été embauchées comme « opératrices », plutôt à déboguer des programmes existants (la machine avait mauvais caractère et les bogues étaient souvent d'origine matérielle, un composant qui brûlait, et le déboguage nécessitait donc de fouiller dans les entrailles de la bête) avant que leur travail n'évolue vers quelque chose qui ressemblait beaucoup plus à la programmation actuelle (sans que leurs fiches de poste ne suivent cette évolution).
Et cette programmation, sur une machine qui était loin d'être bâtie sur un modèle en couches bien propre, nécessitait des compétences variées. Ainsi, à un moment, l'ENIAC a reçu des nouvelles mémoires, dites « lignes à retard », où une onde sonore était envoyée dans un tube de mercure. La lenteur des ondes sonores, comparée à la vitesse de l'électronique, faisait que cela permettait de mémoriser (mais pas pour toujours) une information. Comme la ligne à retard stockait plusieurs informations, et était strictement FIFO, l'optimisation du programme nécessitait de bien soigner l'ordre dans lequel on mettait les variables : il fallait qu'elles arrivent à la fin du tube pile au moment où le programme allait en avoir besoin. Le programmeur ou la programmeuse avait donc besoin d'une bonne connaissance du matériel et de la physique ! En lisant ce livre, on comprend mieux les exploits quotidiens que faisaient les « six de l'ENIAC » et leurs collègues.
Il y avait plein d'autres différences entre la programmation de l'époque et celle d'aujourd'hui. Par exemple, l'ENIAC manipulait des nombres décimaux (son successeur, l'EDVAC passera au binaire). Les débats étaient très vivants au sein de l'équipe sur la meilleure façon de dompter ces nouvelles machines. Ainsi, une discussion récurrente était de savoir s'il valait mieux une machine complexe sachant faire beaucoup de choses ou bien une machine simple, ne faisant que des choses triviales, mais optimisée et plus générale. La deuxième possibilité nécessitait évidemment que la complexité soit prise en charge par les programmes. Bref, un débat qui évoque beaucoup celui CISC contre RISC. Au milieu de tous ces débats, il peut être difficile de distinguer la contribution de chacun ou de chacune. Ainsi, on présente souvent von Neumann comme l'inventeur de l'ordinateur moderne à programme enregistré (et où le code est donc traité comme une donnée), dans son fameux first draft. mais d'autres témoins relativisent son rôle en estimant que le first draft ne faisait que documenter par écrit les idées qui circulaient dans l'équipe. Les auteurs du livre se gardent de trancher (la vérité peut aussi être quelque part entre les deux). Les éventuels désaccords de personnes compliquent aussi les choses, par exemple Adele Goldstine et les six de l'ENIAC n'ont pas vraiment les mêmes souvenirs sur la création de cette équipe et son rôle. (Contrairement à ce qui est parfois raconté, les six de l'ENIAC n'étaient pas des victimes passives du sexisme, et ont largement fait connaitre leurs souvenirs et leurs opinions, contrairement à ceux et celles de Bletchley Park, tenu·es à un secret militaire rigoureux, même longtemps après la guerre.)
Point amusant, l'ENIAC est entré en service à une époque où les concepts de la cybernétique étaient à la mode et cela a influencé le vocabulaire de l'informatique. Si le terme de « cerveau électronique », par lequel était souvent désigné l'ENIAC, n'est pas resté, c'est avec l'ENIAC qu'on a commencé à utiliser une autre métaphore humaine, « mémoire » pour parle des dispositifs de stockage de l'information et, là, ce terme a perduré.
Outre les passions humaines, l'histoire de l'ENIAC a aussi été brouillée par des conflits motivés par l'argent. Eckert et Mauchly avaient tenté d'obtenir un brevet sur les concepts de base de l'ENIAC et le long conflit juridique sur ce brevet (finalement refusé) a été marqué par de nombreux témoignages officiels devant les tribunaux, témoignages qui ont pu figer certains souvenirs en fonction d'intérêts financiers.
En tout cas, le débat sur le rôle des six de l'ENIAC a occulté le rôle d'une autre catégorie, bien oubliée (on ne connait même pas leurs noms), les Rosie qui ont bâti le monstre, un engin qui occupait une immense pièce et avait nécessité beaucoup de travail manuel, peu reconnu.
Les auteurs notent d'ailleurs que bien des débats en histoire ne peuvent pas avoir de réponse simple. Ainsi, la recherche effrénée du « premier » (l'ENIAC était-il le premier ordinateur ?) n'a pas forcément, notent-ils, de sens. Déjà, cela dépend de la définition qu'on donne d'« ordinateur », ensuite, certains concepts émergent petit à petit, sans qu'il y ait un « moment Eurêka » où tout se révèle d'un coup. (Pour prendre l'exemple d'une autre polémique classique dans l'histoire de l'informatique, se demander qui a inventé le datagramme n'a pas plus de sens. Le concept est apparu progressivement, sans qu'on puisse citer, par exemple, l'article ou la conférence qui l'aurait exposé en premier.)
Le livre se termine d'ailleurs par une « histoire de l'histoire » de l'ENIAC, qui montre les nombreuses évolutions qu'il y a eu, et qu'il continuera à y avoir, sur cette machine. Comme souvent l'histoire suit le présent (les motivations de son époque) plutôt que le passé.
Merci à Valérie Schafer pour le conseil de lire ce livre, tout à fait ce qu'il faut pour comprendre ce que voulait dire « programmer l'ENIAC ».
L'article seul
Fiche de lecture : The Bomber Mafia
Auteur(s) du livre : Malcolm Gladwell
Éditeur : Penguin Books
978-0-141-99840-4
Publié en 2021
Première rédaction de cet article le 22 mars 2024
Le court livre « The Bomber Mafia » est l'histoire de la controverse technico-politique au sein de l'armée de l'air des USA, juste avant la Deuxième Guerre mondiale et pendant celle-ci : comment utiliser le mieux possible les bombardiers, peut-on forcer un ennemi à capituler en le bombardant et comment ?
Ce n'est pas une étude historique, plutôt un récit journalistique, centré sur deux personnes, Haywood Hansell et Curtis LeMay. Pour simplifier, le premier était un représentant d'un groupe surnommé The Bomber Mafia, qui avait une confiance illimitée dans les capacités des bombardiers à atteindre leur objectif, à le toucher avec précision, et ainsi à contraindre l'ennemi à capituler. Avant la deuxième guerre mondiale, leurs idées n'avaient pas vraiment été testées, et les adversaires de la Bomber Mafia lui reprochaient justement sa tendance à aborder les problèmes sous un angle trop théorique. LeMay, d'un autre côté, tout aussi convaincu de la puissance des bombardiers, et qui allait faire une belle carrière après la guerre, était plus pragmatique. Tous les deux s'opposaient sur la question de l'utilisation des B-17 et des B-29 mais, à ce conflit, se superposait aussi celui de tous les aviateurs (dont Hansell et LeMay) contre les autres branches de l'armée qui estimaient que ces jouets très chers ne gagneraient pas la guerre à eux seuls (« aucun soldat ne s'est jamais rendu à un avion »).
Au débat entre les « théoriciens » de la Bomber Mafia et les « praticiens », qui voyaient bien que les bombardements ne se passaient pas aussi bien que dans les théories d'avant-guerre, se superposait un débat moral, la Bomber Mafia estimant que le progrès technique permettait au bombardier de frapper avec une précision absolue, ce qui limitait les dégâts collatéraux, alors que ses adversaires, voyant bien la difficulté à mettre les bombes en plein sur l'objectif, dans un monde réel plein de nuages, d'appareils déréglés, et de vents puissants en altitude, voulaient plutôt bombarder largement, sans se soucier des conséquences, notamment sur les civils, voire en les ciblant délibérement.
Le livre détaille (c'est sa meilleure partie) le cas d'un appareil présenté comme magique, le viseur Norden, une incroyable merveille d'ingéniosité et de précision, contenant un calculateur analogique et qui devait permettre à l'homme chargé de déclencher le largage des bombes de mettre en plein dans le mille. Malgré les promesses boursouflées de l'inventeur (un classique de l'innovation technologique), malgré la fascination de beaucoup d'aviateurs pour cette très haute technologie, coûteuse et très secrète (l'équipage avait ordre de tout faire pour détruire le viseur si le bombardier tombait), le viseur Norden n'a jamais tenu ses promesses. Spectaculaire en laboratoire, il marchait nettement moins bien à plusieurs milliers de mètres d'altitude, dans le froid et la condensation, à bord d'un avion en mouvement. Son échec a beaucoup contribué à décrédibiliser la Bomber mafia et à donner raison à LeMay et à sa pratique d'un bombardement très étendu, d'autant plus que LeMay ne s'encombrait pas d'arguments moraux. Mais la Bomber Mafia n'a apparemment jamais admis que les faits étaient plus forts que sa théorie, trouvant toujours des moyens de dire que, cette fois, ça allait marcher comme ils le disaient.
L'auteur, qui a nettement tendance à présenter Hansell comme le bon et LeMay comme le méchant, alors que tous les deux étaient dans la même armée et poursuivaient le même but, estime que le temps a donné raison à la Bomber Mafia, puisque, le numérique ayant remplacé l'analogique, le drone moderne peut frapper avec une précision parfaite. Est-ce que les militaires d'aujourd'hui peuvent vraiment, en plein dans le brouillard de la guerre, frapper pile où ils veulent, sans dégâts collatéraux ?
L'article seul
Fiche de lecture : Eaten by the Internet
Auteur(s) du livre : Ouvrage collectif, piloté par Corinne
Cath
Éditeur : Meatspace Press
978-1-913824-04-4
Publié en 2023
Première rédaction de cet article le 22 mars 2024
Ce court livre en anglais rassemble plusieurs textes sur les questions politiques liées à l'Internet comme la défense de la vie privée, le chiffrement, la normalisation, etc.
Le livre est disponible gratuitement en ligne mais vous pouvez préférer l'édition papier, qui a une curieuse mise en page, avec une couverture qui se tourne dans un sens inhabituel et les appels des notes de bas de page joliment décorés.
Vous y trouverez de nombreux articles, tous écrits par des spécialistes de l'Internet (et j'ai bien dit l'Internet, pas les GAFA, vous n'aurez pas le Nième article sur les turpitudes de Facebook, encore moins sur les derniers exploits de l'IA). C'est très intéressant et couvre beaucoup de sujets, dont certains sont rarement traités (comme l'article de Shivan Kaul Sahib sur les conséquences politiques des CDN). Mais, vu la taille du livre et le nombre de contributions, cela reste peu approfondi, donc ce livre vise plutôt un public de débutant·es. (Si vous suivez ces questions depuis quelques années, vous avez certainement déjà rencontré ces auteur·es et leurs textes.)
L'article seul
La faille DNSSEC KeyTrap
Première rédaction de cet article le 19 mars 2024
Le 16 février a été publiée la faille de sécurité DNSSEC KeyTrap. Je sais, c'est un peu tard pour en parler mais c'est quand même utile, non ?
KeyTrap est une faille qui permet un déni de service contre des résolveurs DNS validants, c'est-à-dire qui vérifient les signatures cryptographiques de DNSSEC. Avec peu de messages DNS, parfois un seul, elle permet de stopper toute résolution de noms pendant des minutes, voire des heures. Comme souvent, hélas, en sécurité informatique, les découvreurs de la faille ont sérieusement abusé des grands mots dans leur communication (que les médias, comme d'habitude, ont bien relayés sans esprit critique) mais la faille est réelle et ils ont fait un bon travail pour la cerner exactement, et la reproduire afin de tester des remèdes.
Comment fonctionne KeyTrap ? Le point de départ est d'observer qu'un résolveur validant ne cherche pas à échouer dans la résolution de noms, il cherche à trouver, si nécessaire en insistant, un enregistrement correctement signé. Par exemple, si un des serveurs faisant autorité ne renvoie pas de signatures (il devrait), le résolveur va demander à un autre. Si une signature est invalide, le résolveur va en essayer d'autres. Cela part d'une bonne intention, éviter un échec des requêtes des clients. Mais cela ouvre la possibilité, pour un client malveillant, de donner beaucoup de travail au résolveur.
Le résolveur va essayer, pour chaque signature trouvée, toutes les clés cryptographiques présentes. En temps normal, il n'y a qu'une signature et une clé. Lors d'opérations comme le remplacement d'une clé, il peut y en avoir deux. Mais, et c'est le point important, ces nombres sont contrôlés par l'attaquant. S'il envoie dix clés et dix signatures, le résolveur aura cent vérifications à faire. Et si l'attaquant arrive à faire tenir cent clés et cent signatures dans le message, il faudra dix mille vérifications… Elles retiendront le résolveur pendant longtemps, l'empêchant de répondre aux autres requêtes (voire le bloquant complètement si ces vérifications ne sont pas réellement parallélisées).
Voyons maintenant quelques détails pratiques. D'abord, le résolveur ne va pas tester toutes les clés mais uniquement toutes celles qui ont l'identificateur, le keytag indiqué dans la signature. Si on trouve cette signature :
% dig +multi +dnssec brisbane.now.weather.dyn.bortzmeyer.fr TXT … ;; ANSWER SECTION: brisbane.now.weather.dyn.bortzmeyer.fr. 1800 IN TXT "Brisbane" "Partly cloudy" "27.0 C" "precipitation 0.17 mm" "wind 11.2 km/h" "cloudiness 25 %" "humidity 70 %" brisbane.now.weather.dyn.bortzmeyer.fr. 1800 IN RRSIG TXT 8 6 1800 ( 20240323040000 20240318154000 63937 dyn.bortzmeyer.fr. gUXD/SnFywfzQVRstRH9t5k6DIGXLHUeuSgM8ShNfTUx …
Alors, il n'est pas nécessaire d'essayer toutes les clés mais seulement celle(s) qui ont un identificateur (keytag ou key id) de 63937 (il est indiqué dans la signature, après les dates). Ce système est censé limiter le travail du résolveur. Si un attaquant envoie cent clés, une seule sera utilisée. Mais, car il y a un mais, ce keytag ne fait que deux octets (donc les collisions sont relativement fréquentes) et surtout, ce n'est pas un condensat cryptographique sûr, comme par exemple SHA-256. Il est facile pour un attaquant de générer cent clés ayant le même keytag et celui-ci ne sert alors plus à rien, le malheureux résolveur doit essayer toutes les clés.
Autre problème, pour l'attaquant (qui veut évidemment faire le plus de mal possible), la taille de la réponse. En UDP, un client DNS typique ne va pas accepter des réponses de plus de 4 096 octets, voire souvent 1 460 octets. Comme l'attaquant veut fourrer le plus grand nombre possible de clés et de signatures dans sa réponse, il a intérêt à utiliser les algorithmes à courbes elliptiques, comme ECDSA, dont les clés et les signatures sont bien plus petites qu'avec RSA.
Maintenant, quelles sont les solutions ? Le rapport sur KeyTrap est plein de phrases boursouflées comme « Solving these issues fundamentally requires to reconsider the basics of the design philosophy of the Internet. » C'est évidemment faux. Il faut simplement limiter le nombre d'opérations et/ou le temps passé. C'est une nécessité général du DNS, bien antérieure à KeyTrap. Le RFC 1035, en 1987, disait déjà « The amount of work which a resolver will do in response to a client request must be limited to guard against errors in the database, such as circular CNAME references, and operational problems, such as network partition which prevents the resolver from accessing the name servers it needs. While local limits on the number of times a resolver will retransmit a particular query to a particular name server address are essential, the resolver should have a global per-request counter to limit work on a single request. ». L'oubli de ce paragraphe a déjà mené à des possibilités d'attaque par déni de service comme l'attaque infinie, iDNS. La solution est donc évidente, limiter le nombre de vérifications. Il y a une part d'arbitraire dans cette limite (stopper au bout de trois clés ? de quatre ?) mais il est clair qu'il n'y a aucune raison légitime de vérifier cent clés. C'est la modification qui a été faite dans tous les résolveurs.
Noter que, pour l'exploitation de cette faille, il faut pouvoir parler au résolveur, pour lui demander de résoudre un nom dans le domaine contrôlé par l'attaquant, domaine qu'il aura rempli de clés et de signatures. C'est évidemment facile pour un résolveur public, et pas trop difficile pour les gros FAI, mais plus compliqué pour des petits résolveurs locaux. Donc, tout résolveur validant était plus ou moins menacé. Ceci dit, tous les logiciels ont été patchés très vite et tous les administrateurs système sérieux ont déjà appliqué les patches.
Notez que cette attaque ne remet pas en cause l'importance de DNSSEC. Toute technique de sécurité peut être (plus ou moins facilement) détournée pour en faire une attaque par déni de service.
Quelques lectures :
- Le rapport originel. Très bon travail, très détaillé, sa lecture est recommandée, il faut juste ignorer les nombreuses exagérations dramatiques. Idem dans ce résumé d'une des auteures.
- Un bon résumé de Geoff Huston.
- L'attaque avait été documentée des années auparavant mais sans être médiatisée, et était donc passé inaperçue.
- Coïncidence, le TLD
.rua connu au même moment une grande panne liée à une collision de keytags
L'article seul
IETF 119 hackathon: compact denial of existence for DNSSEC
First publication of this article on 18 March 2024
Last update on of 22 March 2024
On March 16 and 17 was the IETF hackathon in Brisbane. I worked on a DNSSEC feature called "compact denial of existence", and implemented it successfully (which was easy). It later became RFC 9824.
Compact Denial of Existence (CDE) was originally called "black lies". The name was changed, probably because of some typical US issue with every adjective of color, but also because there was a risk of confusion with lying DNS resolvers, which are something quite different. What is its purpose? For DNSSEC, you have to sign your records. You can do it offline, on a primary name server (the records and the signatures are then transferred to other authoritative name servers), or online, in every authoritative name server. The first method is more secure (you don't need the private key on every authoritative name server) and uses less CPU resources but it is not usable if you have very dynamic content, generated at every request. For this kind of content, you need online signing.
Online signing of records does not raise any particular issue. The difficulty starts with denial of existence, when you want to sign a statement that a name, or a specific record type does not exist. In that case, you have no data to sign. DNSSEC has several ways to deal with that and the simplest is NSEC records. They are records created to say "there is no name between this one and that one". Let's query a root name server to see these NSEC records:
% dig +dnssec @d.root-servers.net doesnotexist
…
;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 26586
…
;; AUTHORITY SECTION:
doctor. 86400 IN NSEC dog. NS DS RRSIG NSEC
doctor. 86400 IN RRSIG NSEC 8 1 86400 20240330170000 20240317160000 30903 . hZ08T19claSr8ZkU
…
You get a NXDOMAIN (No Such Domain), obviously, and a NSEC record
(more than one, actually, but I make things simple, but see later),
which says that there is no TLD between .doctor and
.dog. This NSEC record is signed, proving that
.doesnotexist does not exist.
When signing a complete zone, creating the NSEC records is easy. But if we generate DNS content dynamically, it is more tricky. The DNS server, when signing, does not always know the previous name and the next name, it may not have a complete view of the zone. A trick for dynamic signing was named "white lies" and documented in RFC 4470. The idea is to generate dynamically a NSEC with a previous name and a next name both very close from the requested name. Something like (this is a real domain, you can try it yourself):
% dig +multi +dnssec +noidnout doesnotexist.dyn.bortzmeyer.fr … ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 61681 … ;; AUTHORITY SECTION: ~.doesnotexiss~.dyn.bortzmeyer.fr. 0 IN NSEC doesnotexist!.dyn.bortzmeyer.fr. RRSIG NSEC ~.doesnotexiss~.dyn.bortzmeyer.fr. 0 IN RRSIG NSEC 8 5 0 ( …
The names ~.doesnotexiss~.dyn.bortzmeyer.fr and
doesnotexist!.dyn.bortzmeyer.fr were choosen to
be close enough of the requested name. This is not the exact
algorithm of RFC 4470 because I had problems with some
resolvers but the general idea is the same. (Also,
+noidnout was added because dig has some ideas
about what is a displayable domain name. There are no
IDN involved.) Here is how Drink, the
dynamic name server used in the hackathon, written in
Elixir, did the
"white lies" trick:
previous = Drink.Dnssec.previous_name(domain)
nsec = %DNS.Resource{class: :in,
domain: to_charlist(DomainName.name(previous)),
type: @nsec,
data: Drink.Dnssec.nsec(domain, is_base)}
Now, what is the problem with this way of generating dynamic NSEC records? I said before that you actually need two (and sometimes three) NSEC records because you also need to prove that the name could not have been generated by a wildcard. Each NSEC will require computation for its signature and, since all of this is done in real-time, we wish to minimize the number of computations (and the size of the response). Hence the Compact Denial of Existence (CDE, formerly known as "black lies"). The idea is to have a NSEC record which does not go from "a name just before" to "a name just after" but from "the requested name" to "a name just after". This way, you no longer need to prove there was no wildcard since you do not claim the name does not exist. (And this could be called a lie, but, since it is done by the authoritative name server which, by definition, tells the truth, the term is better left unused.) But it has an important consequence, the response code must now be NOERROR and not NXDOMAIN, obscuring the fact that the name does not "really" exist (something that some people at the IETF did not like). Here is the result, as produced by Cloudflare name servers:
% dig +multi +dnssec @ns4.cloudflare.com doesnotexist.cloudflare.com … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 43367 … ;; AUTHORITY SECTION: doesnotexist.cloudflare.com. 300 IN NSEC \000.doesnotexist.cloudflare.com. RRSIG NSEC TYPE65283 cloudflare.com. 300 IN RRSIG SOA 13 2 300 ( …
As you can see, the left-hand part of the record (the "owner name",
doesnotexist.cloudflare.com) is now set to the
requested name. And the return code is NOERROR, with no data
returned in the Answer section. The response says that the name
exists, but only with RRSIG, NSEC and TYPE65283 - more on this one
later - records.
It should be noted that any ordinary, unmodified, validating resolver will have no problem with this response. It will be validated. CDE does not require any change to the resolver. Also, checking tools like DNSviz and Zonemaster will see no problem. CDE can be deployed unilaterally, and this is exactly what Cloudflare did.
So, as we saw, CDE is not new, even if it is not described in any
RFC. It is
already deployed (remember that the Internet is permissionless: you
do not need a RFC to implement and deploy a technology). But what
IETF
is currently working one is precisely a specification of this
technique. The project is currently an
Internet-Draft, draft-ietf-dnsop-compact-denial-of-existence
(it was later standardised in RFC 9824,
with several changes). This
draft describes the basic technique for generating the unique NSEC
record and adds:
- In the list of record types that are present at the requested name (the "NSEC bitmap"), a pseudo-type NXNAME, signaling that the NOERROR return code is actually a NXDOMAIN. It is not officially allocated today and implementations use a value reserved for experimentations, 65283 (hence the TYPE65283 above). This can be used by resolvers to restore the NXDOMAIN from the response so that their clients will have a proper error code.
- EDNS signaling that the client understands compact answers and can receive a NXDOMAIN, it won't be surprised to see the NSEC claiming that the name does not exist. This signaling is done with a bit called CO (for Compact OK).
During the IETF hackathon, two authoritative name servers were modified to generate CDE:
- adns_server, written in Python.
- Drink, written in
Elixir. The code is currently in a separate
branch,
compact-denial(if you retrieved the code with git,git diff -u -r master -r compact-denialwill give you the code written during the hackathon).
In both cases, the work was simple and fast: once you have dynamic signing (it was already in Drink), CDE is simpler than white lies. The two servers also implemented the NXNAME reporting and accept the signaling via the CO bit. Here is the result with Drink (this test domain was created for the hackathon, and no longer works):
% dig +dnssec +multi nonono.ietf.bortzmeyer.fr TXT
…
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 49495
;; flags: qr rd ra ad; QUERY: 1, ANSWER: 0, AUTHORITY: 4, ADDITIONAL: 1
…
nonono.ietf.bortzmeyer.fr. 0 IN NSEC \000.nonono.ietf.bortzmeyer.fr. \
RRSIG NSEC TYPE65283
nonono.ietf.bortzmeyer.fr. 0 IN RRSIG NSEC 8 4 0 (
20240321040000 20240316154000 43304
ietf.bortzmeyer.fr. …
…
As of today, no real resolver has been modified to implement
NXDOMAIN restoration and/or EDNS wignaling with CO. This is not
mandatory, but would be cool. Zonemaster was
happy and so
was DNSviz : 
As usual, the hackathon pinpointed some issues that were not always noticed before:
- Since the draft says that explicit requests for a NXNAME record are forbidden, which error code should be returned and, if using EDE (Extended DNS Errors, RFC 8914), which EDE? (Actually, the problem is larger than just CDE since it seems that the replies to requests of pseudo-types - those between 128 and 255 - are underspecified. May be another work to start.)
- When a DNS client does not set the DO bit, indicating it does not know about DNSSEC, should we return NXDOMAIN, forgetting about CDE, like most implementations do, or should we return NOERROR, as if the DO bit were set?
- This is not only about the non-DNSSEC clients: some people are not happy that, by conflating NXDOMAIN and NOERROR, we lose information, and that will make debugging more difficult (unless you have a NXDOMAIN-restoring resolver, which does not exist today). It is important to remember that it is not because something is simple to implement and works, that it is a good idea.
Thanks to Shumon Huque for code, conversation and explanations.
L'article seul
Fiche de lecture : Le libre pensée dans le monde arabo-musulman
Auteur(s) du livre : Ouvrage collectif
Éditeur : Fédération de la Libre Pensée
978-2-916801-23-0
Publié en 2023
Première rédaction de cet article le 22 février 2024
En France en 2024, le discours politique sur le monde arabo-musulman est souvent fondé sur une assignation identitaire, qui suppose que toute personne élevée dans un milieu musulman est forcément croyante, voire bigote, ou même islamiste. La réalité est différente et le monde arabo-musulman a lui aussi ses libres penseurs qui n'acceptent pas aveuglément les dogmes religieux, et encore moins les humains qui les utilisent pour assoir leur pouvoir. Cet ouvrage rassemble un certain nombre de contributions, très diverses, sur des libres penseurs dans l'histoire du monde arabo-musulman.
Tout le monde a entendu parler d'Omar Khayyam, bien sûr. Mais la plupart des autres libres penseurs décrits dans l'ouvrage sont nettement moins connus en Occident. Ils ne forment pas un groupe homogène : certains sont athées, d'autres simplement méfiants vis-à-vis de la religion organisée. Il faut aussi noter que le livre couvre treize siècles d'histoire et une aire géographique très étendue ; il n'est pas étonnant que la diversité de ces libres penseurs soit grande. Le livre contient aussi des textes qui remettent en perspective ces penseurs, par exemple en détaillant le mouvement de la Nahda ou bien en critiquant le mythe de la tolérance religieuse qui aurait régné en al-Andalus.
Le livre est assez décousu, vu la variété des contributeurs. On va de textes plutôt universitaires à des articles davantage militants (et certains sont assez mal écrits, je trouve, et auraient bénéficié d'une meilleure relecture). Mais tous ont le même mérite : tirer de l'oubli des libres penseurs souvent invisibilisés comme Tahar Haddad ou Ibn al-Rawandi. Et vous apprendrez de toute façon plein de choses (je ne connaissais pas le mutazilisme).
L'article seul
Fiche de lecture : Atlas du numérique
Auteur(s) du livre : Ouvrage collectif
Éditeur : Les presses de SciencesPo
978-2-7246-4150-9
Publié en 2023
Première rédaction de cet article le 21 février 2024
Cet atlas illustre (au sens propre) un certain nombre d'aspects du monde numérique (plutôt axé sur l'Internet). Beaucoup de données et d'infographies sous les angles économiques, sociaux et politiques.
L'ouvrage est très graphique, et riche. Tout le monde y trouvera des choses qui l'intéressent comme le spectaculaire tableau des systèmes d'exploitation p. 18 ou bien la représentation astucieuse de l'alternance des modes en IA p. 33 ou encore la visualisation de la censure en Russie p. 104 (tirée des travaux de Resistic). Les résultats ne sont pas forcément surprenants (p. 61, les youtubeurs les plus populaires sur les sujets de la voiture ou de la science sont des hommes, sur les sujet animaux, style et vie quotidienne, ce sont des femmes). Mais plusieurs articles mettent aussi en cause certaines analyses traditionnelles comme p. 82 celui qui dégonfle le mythe « fake news » (ou plus exactement leur instrumentalisation par les détenteurs de la parole officielle).
Les utilisations de l'Internet (en pratique, surtout les réseaux sociaux centralisés) sont très détaillées, par contre l'infrastructure logicielle est absente (la matérielle est présente via des cartes de câbles sous-marins et des articles sur l'empreinte environnementale).
Les infographies sont magnifiques mais souvent difficiles à lire, en raison de leur petite taille (sur la version papier de l'ouvrage) et du fait que chacune est le résultat de choix de présentation différents. D'autre part, les couleurs sont parfois difficiles à distinguer (p. 31 par exemple). Et l'axe des X ou celui des Y manque parfois, comme dans l'article sur la viralité p. 56 qui n'a pas d'ordonnées. Il faut dire que certaines réalités sont très difficiles à capturer comme la gouvernance de l'Internet p. 101, sujet tellement complexe qu'il n'est pas sûr qu'il aurait été possible de faire mieux.
Plus gênantes sont les bogues comme p. 31 la Quadrature du Net et FFDN classées dans « Secteur économique et start-ups ». Ou bien p. 37 LREM considéré comme plus à gauche que le PS…
L'article seul
Fiche de lecture : The Wager
Auteur(s) du livre : David Grann
Éditeur : Simon & Schuster
976-1-47118367-6
Publié en 2023
Première rédaction de cet article le 20 février 2024
Si vous aimez les histoires de bateau à voile, avec naufrages, mutineries, iles désertes et tout ça, ce roman vous emballera. Sauf que ce n'est pas un roman, le navire « The Wager » a vraiment existé et vraiment fait vivre toutes ces aventures à son équipage.
Le livre a été écrit par David Grann, connu comme l'auteur de « Killers of the flower moon ». En attendant que Scorsese en fasse un film, comme il l'a fait de « Killers of the flower moon », je recommande fortement la lecture du livre. « The Wager », navire de guerre anglais, n'a eu que des malheurs pendant la guerre de l’oreille de Jenkins. Départ retardé, épidémies à bord alors même qu'il était encore à quai, problèmes divers en route, une bonne partie de l'équipage mort alors même que le Wager n'a pas échangé un seul coup de canon avec les Espagnols. Le bateau finit par faire naufrage en Patagonie. À cette époque, sans radio, sans GPS, sans même de mesure de longitude correcte, de tels naufrages n'étaient pas rares. (Le livre parle aussi d'une escadre espagnole qui a tenté d'intercepter celle où se trouvait le Wager, et n'a pas été plus heureuse.)
Ce qui est plus original dans le cas du Wager est que des survivants sont rentrés séparement en Angleterre et qu'ils ont raconté des histoires très différentes sur le naufrage et la mutinerie qui a suivi. Chacun (en tout cas ceux qui savaient écrire ou bien trouvaient quelqu'un pour le faire pour eux) a publié sa version et l'auteur de ce livre essaie de rendre compte des différents points de vue.
Donc, pas un roman mais autant de rebondissements que dans un roman. Vous feriez comment, vous, pour rentrer en Angleterre si vous étiez coincé sur une des iles les plus inhospitalières d'une des régions les plus inhospitalières du monde ? Le plus extraordinaire est que plusieurs groupes de survivants y sont arrivés, par des moyens différents.
Sinon, les informaticien·nes noteront que l'arrière-grand-père d'Ada Lovelace était à bord (il fait partie de ceux qui ont écrit un livre sur le voyage du Wager). Les fans de Patricio Guzmán verront que cela se passe au même endroit que son film « Le bouton de nacre » (et on croise dans le livre les mêmes Kawésqars).
L'article seul
Fiche de lecture : Penser la transition numérique
Auteur(s) du livre : Ouvrage collectif
Éditeur : Les éditions de l'atelier
978-2-7082-5410-7
Publié en 2023
Première rédaction de cet article le 19 février 2024
Comme les lecteurices de ce blog le savent sûrement, je pense que la place prise par le numérique dans nos vies justifie qu'on réfléchisse sérieusement à cette transition que nous vivons. Donc, ce livre est une bonne idée. Mais, comme beaucoup d'ouvrages collectifs, il souffre d'un manque évident de coordination entre les auteurices, dont les différentes contributions sont de niveaux très inégaux.
On y croise ainsi des baratineurs classiques comme Luc Ferry, personnage qu'on aurait pu penser définitivement démonétisé. Sans surprise, il parle d'un sujet cliché, le transhumanisme (le mannequin de paille classique de beaucoup d'« intellectuels » français). Sans aller aussi loin dans la vacuité, on trouve aussi dans ce livre des articles par des auteurs dont on peut se demander s'ils maitrisent leur sujet. Ainsi une auteure présentée comme spécialiste des questions bancaires déplore que l'IA a des biais quand elle décide d'accorder un prêt ou pas (un exemple, typique de la sur-utilisation de la notion de biais ; évidemment qu'un outil d'aide à la décision en matière de prêts va être mal disposé envers les gens ayant des revenus faibles et irréguliers). Le texte de présentation de chaque contribution a aussi sa part de responsabilité, comme celui de l'article sur la chaine de blocs qui dit que les données sont cryptées (et, non, le problème n'est pas l'utilisation de cet terme, « chiffrées » n'aurait pas été mieux). Enfin lisant un livre qui se veut de réflexion sur le numérique, je vois la phrase « les technologies digitales sont des technologies qui sont faciles à prendre en main », et je me demande si l'auteur l'a fait exprès.
Bon, assez critiqué, il y a aussi des analyses intéressantes (j'ai dit intéressantes, pas forcément que j'étais 100 % d'accord) : Pauline Türk réfléchit sur l'utilisation du numérique pour améliorer le processus démocratique, Ophélie Coelho traite de géopolitique et détaille les risques liés à la dépendance vis-à-vis d'entreprises ou d'États, Lionel Maurel plaide pour l'ouverture des résultats des recherches scientifiques, mais aussi (avec nuances) pour l'ouverture des données de recherche, Philippe Bihouix explique concrètement comment réduire l'empreinte environnementale, Jessica Eynard questionne l'identité numérique (même si je la trouve bien trop optimiste sur le projet d'identité numérique étatique au niveau de l'UE), Amine Smihi décrit la vidéosurveillance vue de son rôle d'élu local, etc.
Bref, un tour d'horizon de beaucoup de questions que pose la place du numérique dans notre société.
L'article seul
Panne du domaine national russe
Première rédaction de cet article le 30 janvier 2024
Dernière mise à jour le 8 février 2024
Aujourd'hui, une panne a affecté le domaine de premier
niveau russe,
.ru. Que sait-on ?
(Quand cet article a été initialement publié, on ne savait pas
exactement ce qui s'était passé. Voir à la fin pour des explications vraisemblables.)
La panne a duré à peu près de 15:20 UTC à
19:00 UTC (avec une réparation partielle à 17:50 UTC).
Pour l'instant, il semble certain que le problème était lié à
DNSSEC et qu'il s'agissait probablement
d'une panne, pas d'une action volontaire de la Russie ou de ses
ennemis (hypothèse parfois citée, vu le contexte de
guerre). Un petit rappel : DNSSEC est une technique de
sécurité visant à garantir l'intégrité des noms de domaine. DNSSEC, comme toutes les
techniques de sécurité, peut, en cas de fausse manœuvre, aboutir à
un déni de service ; si vous perdez les clés de votre maison, vous
ne pourrez plus rentrer chez vous. Ici, les signatures des domaines de
.ru étaient invalides,
menant les résolveurs DNS à les
rejeter et donc à ne pas réussir à résoudre les noms de domaine sous
.ru. Deux points sont notamment à noter :
- Du fait du caractère arborescent du
DNS, une panne de
.ruaffecte tous les noms situés sous.ru. La gestion d'un TLD est quelque chose de critique ! Il est donc faux de dire que tel ou tel site Web russe était en panne ; en fait, son nom de domaine ne fonctionnait plus. - Comme tous les résolveurs DNS ne valident pas les signatures DNSSEC, la résolution marchait encore pour certains.
Compte-tenu des observations faites sur le moment, il semble bien
que le communiqué du
ministère russe était correct (à un point près, détaillé plus
loin). Le problème était bien dans le
registre du .ru et était
sans doute le résultat d'une erreur de leur côté. La traduction du
communiqué par DeepL : « Ministère russe de
la numérisation \ L'accès aux sites de la zone .RU sera bientôt
rétabli \ La zone .RU a été affectée par un problème technique lié à
l'infrastructure DNSSEC* mondiale. Des spécialistes du Centre
technique de l'internet et de MSC-IX travaillent à son
élimination. \ Actuellement, le problème a été résolu pour les
abonnés du système national de noms de domaine. Les travaux de
restauration sont en cours. Nous vous tiendrons au courant de
l'évolution de la situation. \ *DNSSEC est un ensemble d'extensions
du protocole DNS, grâce auxquelles l'intégrité et la fiabilité des
données sont garanties. » Et le communiqué original sur
Telegram : 
Notons que les TLD
.su et
.рф ne semblent pas
avoir été affectés, alors qu'ils sont gérés par le même registre.
Un peu plus de technique, maintenant. Avec dig, voyons la résolution DNS, via un résolveur validant :
% date -u ; dig ru. NS Tue 30 Jan 17:12:05 UTC 2024 ; <<>> DiG 9.18.18-0ubuntu0.22.04.1-Ubuntu <<>> ru. NS ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 32950 ;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 1232 ; EDE: 6 (DNSSEC Bogus): (NXJA) ;; QUESTION SECTION: ;ru. IN NS ;; Query time: 2384 msec ;; SERVER: 192.168.2.254#53(192.168.2.254) (UDP) ;; WHEN: Tue Jan 30 18:12:07 CET 2024 ;; MSG SIZE rcvd: 41
Le SERVFAIL indique un échec. Notez l'EDE (Extended DNS Error, RFC 8914), qui indique que l'échec est lié à DNSSEC.
Ensuite, vérifions que tout
marchait, à part DNSSEC. En coupant la validation
DNSSEC (option +cd, Checking
Disabled), on avait bien une réponse :
% date -u ; dig +cd ru. NS Tue 30 Jan 17:15:06 UTC 2024 ; <<>> DiG 9.18.18-0ubuntu0.22.04.1-Ubuntu <<>> +cd ru. NS ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 5673 ;; flags: qr rd ra cd; QUERY: 1, ANSWER: 6, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 1232 ;; QUESTION SECTION: ;ru. IN NS ;; ANSWER SECTION: ru. 344162 IN NS b.dns.ripn.net. ru. 344162 IN NS d.dns.ripn.net. ru. 344162 IN NS e.dns.ripn.net. ru. 344162 IN NS f.dns.ripn.net. ru. 344162 IN NS a.dns.ripn.net. ru. 344162 IN RRSIG NS 8 1 345600 ( 20240305102631 20240130141847 52263 ru. kw9oqgvi/l0MZp/6FY0Ha+VZDWRR3+iDUCYqAY5W7D2w CfIXXdOOvdd58nNY7z/3b4fRK6tlTF3wQpCDSpeKrmkW mric4kcUptaj1rp71lC0GHXHmGwDsx8Zi/lvo6sJEk0g uBbJYBJkzKqeseD4u1Pw29jkRHhQEJKk2seP+Zk= ) ;; Query time: 8 msec ;; SERVER: 192.168.2.254#53(192.168.2.254) (UDP) ;; WHEN: Tue Jan 30 18:15:06 CET 2024 ;; MSG SIZE rcvd: 285
Les serveurs de nom faisant autorité répondaient bien :
% dig @b.dns.ripn.net. ru NS ; <<>> DiG 9.18.18-0ubuntu0.22.04.1-Ubuntu <<>> @b.dns.ripn.net. ru NS ; (2 servers found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 37230 ;; flags: qr aa rd; QUERY: 1, ANSWER: 6, AUTHORITY: 0, ADDITIONAL: 11 ;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 4096 ;; QUESTION SECTION: ;ru. IN NS ;; ANSWER SECTION: RU. 345600 IN NS a.dns.ripn.net. RU. 345600 IN NS e.dns.ripn.net. RU. 345600 IN NS b.dns.ripn.net. RU. 345600 IN NS f.dns.ripn.net. RU. 345600 IN NS d.dns.ripn.net. ru. 345600 IN RRSIG NS 8 1 345600 ( 20240305102631 20240130141847 52263 ru. kw9oqgvi/l0MZp/6FY0Ha+VZDWRR3+iDUCYqAY5W7D2w CfIXXdOOvdd58nNY7z/3b4fRK6tlTF3wQpCDSpeKrmkW mric4kcUptaj1rp71lC0GHXHmGwDsx8Zi/lvo6sJEk0g uBbJYBJkzKqeseD4u1Pw29jkRHhQEJKk2seP+Zk= ) ;; ADDITIONAL SECTION: a.dns.RIPN.net. 1800 IN AAAA 2001:678:17:0:193:232:128:6 b.dns.RIPN.net. 1800 IN AAAA 2001:678:16:0:194:85:252:62 d.dns.RIPN.net. 1800 IN AAAA 2001:678:18:0:194:190:124:17 e.dns.RIPN.net. 1800 IN AAAA 2001:678:15:0:193:232:142:17 f.dns.RIPN.net. 1800 IN AAAA 2001:678:14:0:193:232:156:17 a.dns.RIPN.net. 1800 IN A 193.232.128.6 b.dns.RIPN.net. 1800 IN A 194.85.252.62 d.dns.RIPN.net. 1800 IN A 194.190.124.17 e.dns.RIPN.net. 1800 IN A 193.232.142.17 f.dns.RIPN.net. 1800 IN A 193.232.156.17 ;; Query time: 268 msec ;; SERVER: 2001:678:16:0:194:85:252:62#53(b.dns.ripn.net.) (UDP) ;; WHEN: Tue Jan 30 17:56:45 CET 2024 ;; MSG SIZE rcvd: 526
{kind=link}
{kind=link}
{kind=link}
Comme le note DNSviz, les signatures étaient invalides :
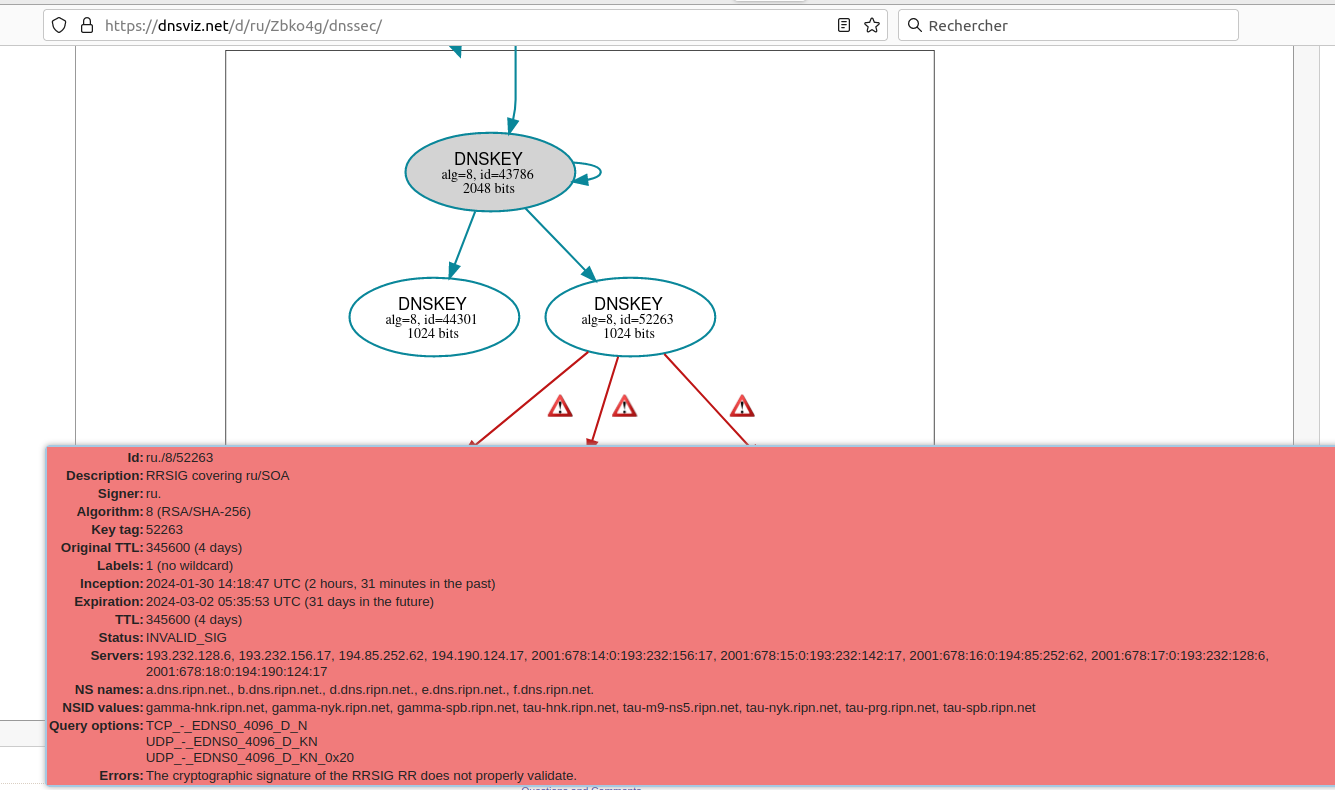
Il ne s'agissait pas de problèmes locaux. En demandant aux sondes RIPE Atlas, on voit beaucoup d'échecs de résolution (SERVFAIL, SERVer FAILure) :
% blaeu-resolve -r 200 --type NS ru [ERROR: SERVFAIL] : 79 occurrences [a.dns.ripn.net. b.dns.ripn.net. d.dns.ripn.net. e.dns.ripn.net. f.dns.ripn.net.] : 66 occurrences [ERROR: NXDOMAIN] : 13 occurrences Test #66905129 done at 2024-01-30T16:59:57Z
(Notez les NXDOMAIN - No Such Domain, qui sont des mensonges de résolveurs qui censurent la Russie, en raison de son agression de l'Ukraine.)
Une fois que tout était réparé, la validation se passait bien :
% blaeu-resolve -r 200 --type DNSKEY --displayvalidation --ednssize 1450 ru … [ERROR: NXDOMAIN] : 19 occurrences [ (Authentic Data flag) 256 3 8 awea…] : 93 occurrences [256 3 8 aweaa…] : 64 occurrences [ERROR: SERVFAIL] : 9 occurrences [] : 1 occurrences [ (TRUNCATED - EDNS buffer size was 1450 ) ] : 1 occurrences Test #66910201 done at 2024-01-30T18:20:56Z
Notez que la phrase du ministre « le problème a été résolu pour les abonnés du système national de noms de domaine » était fausse. Le problème a été résolu pour tout le monde (ce « système national de noms de domaine » est l'objet de beaucoup de propagande et de fantasme et il n'est pas du tout sûr qu'il ait une existence réelle). La situation actuelle :
% dig ru DNSKEY ; <<>> DiG 9.18.18-0ubuntu0.22.04.1-Ubuntu <<>> ru DNSKEY ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 6401 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 4, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 1232 ;; QUESTION SECTION: ;ru. IN DNSKEY ;; ANSWER SECTION: ru. 39023 IN DNSKEY 256 3 8 ( AwEAAcBtr/w2hP6OQjiCacPFzK6xh0pR7QsHV9lxprIX G9WBoBB5XWPVc5q17F3yt3wpJ7xmedt80gxVMaicPYNY Aa8YUFyMxTGVBDVQlz5gCmXQKlr0yImI78sdwzWNmgKH ap0BLypTBVxAKxpcvuwTmqXQUSONkjq9werHvogrvkUb ) ; ZSK; alg = RSASHA256 ; key id = 44301 ru. 39023 IN DNSKEY 257 3 8 ( AwEAAfcMZekGvFYkmt18Q8KIS+XX/7UBbpmIJ4hK3FNz ErkJmiNPxq+sbM00NYJwY725QxoDwHPeK0JIybKW6s+U 2+I7aBGJus/bvDklw0CMTDsG7HoJG+4sjq/jRPUQNwkO A/cNoiYjroqw7/GnB8DEAGE03gyxdZcxxU3BJKPZfds8 DJYPBaDUO35g9I6+dLPXxHK6LFUFprkBtpqj13tJ/ptL yMSaivvi3xrvJMqu/FWN6piMzu7uYmrSdv6s01y+0x62 29sZ7ufSQ6E66gdTmXebDx8S8q70B4BmMZosrsHlf3uX VMMY72LnrQzbere2ecd95q+1VDMDXcXB/pT1/C0= ) ; KSK; alg = RSASHA256 ; key id = 43786 ru. 39023 IN DNSKEY 256 3 8 ( AwEAAbjj3GP0TUwaNI7BIIw/fvwKTmdR+oZsEPk64pl8 VYn4dfdbGHWpYIooxcgEbuBEYrnC/oqnKhad38nTxrZ9 SAK3qV5qShntFdgozS5IKs5m1ebNmg2sotlhXRhJ4vqg H+BQh/lw6T4vdB8FE5tHGE1vwPs9Vhj0vLTBhX8TwB6/ ) ; ZSK; alg = RSASHA256 ; key id = 52263 ru. 39023 IN RRSIG DNSKEY 8 1 345600 ( 20240213000000 20240124000000 43786 ru. rgqGAFvlWoGzSGrKaaMUqpNkOGyKQS+MOwvrwy3+A4nh FiioZ610H9GlN/fh3kUjiFrRJ7T1sKiW9AVekkpdZk/Q T5vRGqWi+PLyuRtfL7ZtJKVgUPV+jGVOc0A9AZA0dVgx qX54L+mbMY6OGCcMeTHwUpg6J2UR0MmB3TCyHPhg0Z/L VHWf/E9hHO4dqdePwKvlVeA7txcXemiJE6C1/mgFvtQl uQsot9eDOqKZt9oUpqzi63gsw835+h6fiKNbMJf4SEPw 5enbdQqcubSWwwY/SbeoW74qgPgPgJrmiP8UxT6DEAZc W5UO9CsMcyfgifsL0zy5SMba4kS0izp4rQ== ) ;; Query time: 4 msec ;; SERVER: 192.168.2.254#53(192.168.2.254) (UDP) ;; WHEN: Tue Jan 30 21:04:05 CET 2024 ;; MSG SIZE rcvd: 893
Plusieurs personnes ont noté une lenteur, ou même parfois une
absence de réponse, de la part de certains des serveurs faisant
autorité pour .ru. Il s'agit
probablement d'un effet dû aux efforts des résolveurs DNS qui, recevant des
signatures invalides, réessayaient (éventuellement vers d'autres
serveurs faisant autorité) dans l'espoir de récupérer enfin des
signatures correctes. En tout cas, rien n'indique qu'il y ait eu une
attaque externe contre .ru.
Mais peut-on savoir ce qui s'est passé ? Pas exactement, mais on peut
toujours poursuivre l'analyse. DNSviz nous donne également accès
aux numéros de série, stockés dans l'enregistrement SOA de la zone
.ru. On peut donc reconstituer une
chronologie (elle a été faite par Phil Kulin et vérifiée par moi) :
- 2024-01-30 12:29:44 UTC : dernier test où tout était correct. Le numéro de série était 4058855, la clé signant les enregistrements (ZSK, Zone Signing Key) était la 44301, la ZSK 52263 était déjà publiée (remplacement de ZSK en cours).
- 2024-01-30 15:27:27 UTC : premier test avec la panne, qui a donc dû commencer quelques minutes plus tôt (en cas de problème DNSSEC, il y a toujours quelqu'un qui se précipite pour faire un test DNSviz). Le numéro de série est le 4058857. La clé signante est désormais la 52263, et les signatures sont invalides.
- Il y aura une zone de numéro 4058858, mais le problème continue.
- 2024-01-30 17:59:46 UTC : la réparation commence. L'ancienne zone de numéro 4058856 est republiée, signée par l'ancienne clé 44301. Notez que, pendant plus d'une heure, plusieurs versions de la zone coexisteront (avec trois numéros de série différents, 4058856, 4058857 et 4058858).
- 2024-01-30 19:07:29 UTC : réparation terminée, on est revenu à la situation d'avant la panne.
- À un moment dans la journée du 31 janvier : la zone bouge à nouveau (le numéro de série augmente, la zone est signée par la clé 52263).
Enfin, on notera que le numéro de série ne bougeait plus (il changeait toutes les deux heures environ auparavant), ce qui fait penser que le problème n'était pas tant dans la clé 52263 que dans un système de signature désormais cassé.
% dig ru SOA ; <<>> DiG 9.18.19-1~deb12u1-Debian <<>> ru SOA ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 44285 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 2, AUTHORITY: 6, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 4096 ;; QUESTION SECTION: ;ru. IN SOA ;; ANSWER SECTION: ru. 86400 IN SOA a.dns.ripn.net. hostmaster.ripn.net. ( 4058856 ; serial 86400 ; refresh (1 day) 14400 ; retry (4 hours) 2592000 ; expire (4 weeks 2 days) 3600 ; minimum (1 hour) ) ru. 86400 IN RRSIG SOA 8 1 345600 ( 20240313163045 20240130121923 44301 ru. dAGkfXQSmGCwwUuzxIfNeIgd+/BbAYt0whh3JcqvKi6x z6N8a7KGBHkfBCbg19xzx6b+LQBJgK4yVtvTQLqLNo8P fxg5J8S/JUw2EHgPUMJw0CjsrqH85biJqkv+5TVoN9dG PFnFIjaTPLP0DRscR3ps5NP8lJstDwBYQmg/i68= ) ;; AUTHORITY SECTION: ru. 86400 IN NS e.dns.ripn.net. ru. 86400 IN NS d.dns.ripn.net. ru. 86400 IN NS a.dns.ripn.net. ru. 86400 IN NS f.dns.ripn.net. ru. 86400 IN NS b.dns.ripn.net. ru. 86400 IN RRSIG NS 8 1 345600 ( 20240304113906 20240126101933 44301 ru. KthCG9ahQ3UyFl1aakpJRiXI0GXH6TNB6i+uY+920a93 DQgCgkokpsYAHCCzqJl0VXiAmcaEK1yLFHxfJzDbjsel 0xz8IJi3CIuzEtBfBbedXUfBzE/64HmJ9xHVgc5fdLDA 6AfIAmw0oeHCgssUTdZ67IlZO90nzeEHu6PHj2k= ) ;; Query time: 32 msec ;; SERVER: 127.0.0.1#53(127.0.0.1) (UDP) ;; WHEN: Wed Jan 31 10:45:15 CET 2024 ;; MSG SIZE rcvd: 580
Il n'a repris sa progression que dans la journée du 31 janvier, et la clé 52263 était à nouveau utilisée :
% dig ru SOA
; <<>> DiG 9.18.19-1~deb12u1-Debian <<>> ru SOA
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 37102
;; flags: qr rd ra ad; QUERY: 1, ANSWER: 2, AUTHORITY: 6, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 4096
;; QUESTION SECTION:
;ru. IN SOA
;; ANSWER SECTION:
ru. 86397 IN SOA a.dns.ripn.net. hostmaster.ripn.net. (
4058871 ; serial
86400 ; refresh (1 day)
14400 ; retry (4 hours)
2592000 ; expire (4 weeks 2 days)
3600 ; minimum (1 hour)
)
ru. 86397 IN RRSIG SOA 8 1 345600 (
20240306211526 20240201082001 52263 ru.
trZgMG6foXNX+ZotfA11sPGSCJwVpdSzobvrPbMfagIj
pToI2+W9fa3HIW5L3GSliQHbWDnaTp0+dhMs/v3UFnFs
UtCoTy00F/d1FysBtQP2uPZLwPTI3rXJSE2U5/Xxout/
2hSCsIxQE5CxksPzb9bazp63Py0AfbWY56b1/FE= )
;; AUTHORITY SECTION:
ru. 86397 IN NS e.dns.ripn.net.
ru. 86397 IN NS f.dns.ripn.net.
ru. 86397 IN NS a.dns.ripn.net.
ru. 86397 IN NS b.dns.ripn.net.
ru. 86397 IN NS d.dns.ripn.net.
ru. 86397 IN RRSIG NS 8 1 345600 (
20240303133621 20240131134337 52263 ru.
MD8EOMQtjhr08qt3I890qHE+E0HBvhdbtUkasjez+1zd
8zsxH0GCPz5zD0db/HQr9o0hDUMd3xZLHaDvlS/PjLti
6dEVOT7SYHHC2yF7Ypu97alFpEHpGEcchEhMx3rSUBZF
Jik3JVG9yqOxF4m0r+QgVotU4PMIejFGjPdvZ0w= )
;; Query time: 16 msec
;; SERVER: 127.0.0.1#53(127.0.0.1) (UDP)
;; WHEN: Thu Feb 01 11:27:06 CET 2024
;; MSG SIZE rcvd: 580
Merci à John Shaft, et Paul Ó Duḃṫaiġ pour les analyses expertes et les discussions. J'ai fait à la réunion FOSDEM du 3 février 2024 un exposé rapide sur la question (supports et vidéo sont en ligne).
Vous pouvez lire le premier communiqué officiel du registre (dont les affirmations sont conformes aux observations). Contrairement à ce qui a été affirmé sans preuves, il n'y a aucune indication que cette panne soit liée aux projets russes de renforcement du contrôle étatique sur la partie russe de l'Internet.
L'explication technique officielle et détaillée a finalement été
donnée le 7 février dans un message aux
BE. Il s'agirait donc bien d'une bogue
logicielle dans le système de signature, qui se déclenchait lorsque
deux clés avaient le même key tag (ce qui est
possible, vu la taille de ce key tag, mais
n'aurait pas dû provoquer de faille.) Cette explication officielle
colle très bien aux observations qui ont été faites au moment de la
panne. Notez aussi que cette explication confirme bien que
.рф
et .su n'ont
pas été affectés (conformément à ce qui a été observé, et au
contraire de ce qu'ont affirmé plusieurs articles écrits sans
vérifier) alors que deux TLD peu connus,
.дети
et .tatar
l'ont été.
L'article seul
Jouons et sécurisons avec une clé FIDO2/WebAuthn
Première rédaction de cet article le 29 janvier 2024
Je viens de me lancer dans l'utilisation d'une clé de sécurité (une Nitrokey) pour les protocoles d'authentification FIDO2 et WebAuthn. Regardons cela.
Un peu de contexte d'abord. Lorsqu'on veut s'authentifier auprès d'un service en ligne (un serveur SSH, un site Web, etc), la solution la plus ancienne est le couple identificateur (login) / mot de passe. Ce système pose plusieurs problèmes :
- La difficulté d'avoir des mots de passe à la fois solides (résistant aux attaques par force brute) et mémorisables par l'utilisateurice.
- Le risque de hameçonnage, lorsque l'utilisateurice se laisse convaincre d'aller sur un service qui n'est pas le vrai, à qui ielle donnera le mot de passe, que le hameçonneur pourra ensuite utiliser.
- Plus généralement, la trop grande facilité avec laquelle un mot de passe se partage, par exemple suite à de l'ingénierie sociale.
Tous ces problèmes ont des solutions. Par exemple, le premier se résout très bien par l'utilisation d'un gestionnaire de mots de passe, solution très recommandée. Mais, évidemment, aucune des solutions n'est parfaite.
On cherche donc à renforcer la sécurité, en ajoutant un deuxième facteur d'authentification, par exemple un code à usage restreint, généré sur une machine distincte, qui peut être un ordinateur (rappel : un ordiphone est un ordinateur) ou un périphérique matériel spécialisé, souvent nommé « clé ». Des protocoles normalisés existent comme HOTP (RFC 4226, le code est alors à usage unique) ou TOTP (RFC 6238, le code étant alors à usage limité dans le temps). Il existe aussi des solutions non normalisées, spécifiques à un seul vendeur, qu'il faut bien sûr fuir. Aujourd'hui, lorsqu'on veut accéder à un service sensible (l'interface de gestion de ses noms de domaine, par exemple), cette authentification à deux facteurs doit être considérée comme impérative.
Je vais essayer ici une technique qui permet, soit de remplacer le couple identificateur / mot de passe par une authentification à un seul facteur, mais plus sûre, soit d'utiliser comme deuxième facteur une méthode plus sûre que HOTP ou TOTP. Il s'agit de FIDO2/WebAuthn. C'est en fait un ensemble de plusieurs protocoles. Pour les expliquer, un peu de terminologie (tout en se rappelant qu'en français, il n'y a souvent pas de terminologie standard et répandue pour une bonne partie du vocabulaire de l'informatique). Il y a quatre entités, humaines et non-humaines, qui interviennent
- L'utilisateurice, M. ou Mme Toutlemonde.
- Le service auquel ielle veut se connecter (par exemple un site Web).
- Le logiciel client de l'utilisateurice (par exemple un navigateur Web).
- L'authentificateur, qui est un dispositif à la disposition de l'utilisateurice (par exemple une clé physique comme ma Nitrokey).
Le protocole entre l'authentificateur (relayé par le logiciel client) et le service utilise la classique cryptographie asymétrique. Le service génère des données à usage unique qu'il chiffre avec la clé publique de l'authentificateur, celui-ci les déchiffrera et les enverra, prouvant ainsi qu'il connait la clé privée. Le service n'apprend donc jamais aucun secret (contrairement à ce qui se passe avec le mot de passe), ce qui protège contre le hameçonnage. Les clés privées ne quittent pas l'authentificateur, le logiciel client ne les voit jamais. FIDO2 désigne la communication avec l'authentificateur, WebAuthn l'API JavaScript exposée aux services.
Voyons en pratique ce que cela donne, avec le service de test
https://webauthn.io/
Je sors ensuite ma clé, une Nitrokey 3A NFC : 
Je la mets dans le port USB de la machine et j'appuie sur le bouton de la clé (une lumière sur la clé clignote pour vous le rappeler) et je suis authentifié. Ici, on n'a qu'un seul facteur (la possession de la clé). Avec la version de Firefox sur mon système, on ne peut pas ajouter de code PIN à la clé (mais ça marche avec Chrome, sur la même machine ; dans le monde FIDO2 / WebAuthn, vous rencontrerez souvent ce genre de problèmes d'interopérabilité ; sur Android, Fennec n'a tout simplement pas WebAuthn). Notez aussi que, la première fois, il faudra s'enregistrer auprès du service pour être reconnu par la suite.
La Nitrokey 3A NFC que je possède peut aussi, comme son nom
l'indique, être « connectée » en NFC (testé
avec succès sur mon Fairphone, bien qu'il
faille un peu chercher où la placer sur l'ordiphone, et avec un
Samsung, même problème). 
Une fois que vous avez testé votre clé sur ce service et que tout
marche, vous pouvez commencer à activer son utilisation sur divers
services réels (mais lisez cet article jusqu'au bout : il y a des
pièges). Ici, par exemple, sur Proton Mail :
Sans la configuration d'un code PIN sur la clé, le vol de la clé permet au voleur de se faire passer pour vous. Il ne faut donc l'utiliser qu'en combinaison avec un autre facteur. Certaines clés, plus coûteuses, peuvent reconnaitre leur utilisateurice par biométrie mais ne vous fiez pas aux promesses des commerciaux : la biométrie est très loin d'être la solution miracle. Non seulement un attaquant peut reproduire des caractéristiques biométriques (vous laissez vos empreintes digitales un peu partout) mais inversement, vos propres doigts ne sont pas forcément reconnus (les empreintes s'usent avec l'âge et vous aurez de plus en plus de problèmes).
Quand à la perte de la clé, elle doit être anticipée. Sans la clé, vous ne pourrez plus vous connecter. Comme le dit la FAQ, il faut avoir un plan B. Par exemple, lorsqu'on active la sécurité FIDO2/WebAuthn sur Cloudflare, le service fournit une longue série de chiffres secrets qui permettront de récupérer son compte, et suggère très fortement de les stocker dans un endroit sécurisé (à la fois contre le vol et contre la perte). Il n'y a pas de mécanisme de sauvegarde de la clé (c'est délicat à concevoir pour un dispositif dont le but est d'empêcher les clés privées de sortir). La solution la plus simple semble être d'avoir deux clés et d'enregistrer les deux auprès des services qui le permettent.
Pour gérer ma clé, j'utilise l'utilitaire en ligne de
commande nitropy. La
documentation en ligne n'est pas terrible (sauf pour la partie sur
l'installation sur une machine Linux, où il
faut configurer
udev). Mais le logiciel a une aide avec
--help. Voici quelques exemples d'utilisation :
% nitropy list Command line tool to interact with Nitrokey devices 0.4.45 :: 'Nitrokey FIDO2' keys :: 'Nitrokey Start' keys: :: 'Nitrokey 3' keys /dev/hidraw3: Nitrokey 3 522A… % nitropy nk3 status Command line tool to interact with Nitrokey devices 0.4.45 UUID: 522A… Firmware version: v1.5.0 Init status: ok Free blocks (int): 60 Free blocks (ext): 478 Variant: LPC55
Pour finir, des liens utiles :
- Les documentations officielles de Nitrokey.
- Une des raisons de mon choix pour la Nitrokey est son caractère ouvert.
- Un autre service de test et un troisième (bien qu'il soit fait par la société Yubi, il marche avec la Nitrokey).
- Plusieurs services ont la possibilité de s'authentifier via FIDO2 / WebAuthn : outre Proton Mail et Cloudflare, déjà cités, il y a GitHub, PyPi et bien d'autres (cf. aussi cette seconde liste).
- Les autres modèles de clé similaires à la Nitrokey : Yubikey, Thetis, Google Titan, Winkeo Fido2 de Néowave…
L'article seul
Gestion de son serveur de courrier électronique
Première rédaction de cet article le 8 janvier 2024
Je gère depuis longtemps mon propre serveur de courrier électronique. Cet article va présenter quelques observations issues de cette expérience. Si vous êtes pressé·e, voici un résumé : 1) ça marche et je peux envoyer du courrier y compris aux grosses plateformes 2) c'est compliqué et ça fait du travail.
Je commence par des explications générales, si vous vous intéressez aux détails techniques, ils sont à la fin. Si vous n'êtes pas familier·ère avec le monde du courrier électronique, quelques notions. Un élément essentiel du cahier des charges du courrier est la possibilité d'envoyer des messages non sollicités, à quelqu'un avec qui on n'a jamais échangé. Les cas d'usage de cette fonction sont nombreux (candidature spontanée à une entreprise, demande d'un devis à une entreprise, remarques sur un article de blog, etc.). Cet élément est une des raisons du succès du courrier électronique, qui reste aujourd'hui le principal moyen de contact universel. Mais il y a un côté négatif, le spam, puisque les spammeurs, eux aussi, utilisent cette possibilité pour nous envoyer leurs messages sans intérêt. La lutte contre le spam est un sujet complexe mais le point qui nous intéresse ici est que, comme pour toute question de sécurité, il y a forcément des faux négatifs (des coupables qui s'en tirent) et des faux positifs (des innocents frappés à tort). Ceux qui vous diraient le contraire et prétendraient qu'on peut avoir des solutions sans faux positifs ni faux négatifs sont des menteurs ou des commerciaux.
Des organisations qui gèrent des grandes plateformes de
courrier, comme Google avec
gmail.com ou Microsoft
avec outlook.com et
hotmail.com, déploient diverses techniques pour
lutter contre le spam. Un effet de bord de ces techniques, dit-on
souvent, est de bloquer les petits hébergeurs ou les
auto-hébergeurs, les petites structures ou les particuliers qui,
comme moi, gèrent leur propre serveur. Une accusation courante est
qu'il ne s'agit pas de difficultés techniques, mais d'une politique
délibérée, que ces grandes entreprises essaient volontairement de
tuer cet auto-hébergement. Il n'y a pourtant aucune raison
technique, ni dans les normes techniques du
courrier électronique (RFC 5321 et RFC 5322), ni dans des règles légales, qui impose
que le courrier ne passe que par un oligopole de grandes
entreprises ; une personne ou une petite organisation peut
parfaitement gérer son propre serveur. Sans le spam, ce serait même
plutôt simple techniquement. Mais, avec le spam et ses conséquences,
les choses se compliquent.
(Point philosophico-politique au passage : la délinquance ou l'incivilité a des conséquences directes, si on vous vole votre vélo, vous n'avez plus de vélo mais aussi, et c'est trop souvent oublié, des conséquences indirectes et qui sont souvent plus coûteuses : déploiement de mesures de sécurité chères et gênantes, perte de confiance qui délite la société, etc.)
Voyons maintenant la légitimité des plateformes de courrier électronique à prendre des mesures anti-spam qui m'empêcheront parfois de joindre mon correspondant. Le gestionnaire d'un service de messagerie est maître chez lui. Il ou elle peut déployer les techniques qu'il veut, même si cela bloque certains émetteurs, de même que vous n'êtes pas obligés de prendre le tract qu'on vous tend dans une manifestation. Google n'est pas obligé d'accepter vos messages, rien ne l'y force. Toutefois, la situation n'est pas la même que celle de la personne qui ne veut pas prendre un tract. Ici, il y a un intermédiaire, qui va décider pour ses utilisateurs. Ceux-ci et celles-ci ne sont jamais informé·es de la politique de lutte anti-spam de leur hébergeur. Mieux, la propagande des grandes plateformes affirme en général que, si le message n'arrive pas, c'est de la faute de l'émetteur. Beaucoup d'utilisateurs ou d'utilisatrices croient sur parole ce discours.
J'ai ainsi été étonné de voir que des gens, ne recevant pas mes
messages, ne voulaient pas se plaindre auprès de leurs fournisseurs,
me demandant de le faire. Pourtant, n'étant pas client de
outlook.com, j'avais certainement beaucoup
moins de poids sur Microsoft que des utilisateurs de leur
service.
(Si vous utilisez le fédivers comme réseau social, vous aurez noté que c'est pareil, et pour cause, le courrier électronique était un réseau social décentralisé bien avant le fédivers. C'est pareil car le gestionnaire d'une instance peut refuser qui il veut. En soi, ce n'est pas un problème, mais cela se complique quand le petit chef qui dirige une instance le fait pour le compte de ses utilisateurices.)
Donc, le petit hébergeur de courrier part avec un sérieux
désavantage : Google ou Microsoft se fichent pas mal de lui, et
leurs utilisateurs et utilisatrices font une confiance aveugle à ces
GAFA, davantage qu'à leurs propres
correspondant·es. Google, Microsoft, Orange,
laposte.net, etc, se satisferaient certainement
d'un oligopole où tout se passerait entre eux. Heureusement, le
monde du courrier électronique n'en est pas là. On va voir qu'il
n'est pas exact de dire que les gros hébergeurs bloquent
déliberement les petits. D'une part, ils ne sont pas les seuls à
poser problème, d'autre part, ils ne sont pas acharnés à bloquer les
petits, c'est plutôt qu'ils s'en foutent.
(Au passage, les politiques anti-spam des grosses plateformes de courrier peuvent rejeter le message directement, ce qui donne à l'expéditeur un message d'erreur, ou bien escamoter le message sans avertissement, ou encore le mettre dans la boite Spam du destinataire. Je vais traiter tous ces cas ensemble.)
Parmi les problèmes que j'ai rencontrés, le fait d'être listé de temps en temps dans une liste de blocage de Spamhaus. Mon serveur n'a jamais envoyé de spam, il n'héberge même pas de liste de diffusion (héberger une liste est bien plus difficile, puisque, par construction, elles envoient en masse, ce que certains récepteurs considèrent comme du spam). La communication avec Spamhaus n'a jamais donné de résultat, notamment lorsque je leur ai demandé les spams que j'avais soi-disant envoyés, pour que je puisse les étudier et comprendre un éventuel problème (jamais de réponse). Le rejet du courrier via l'utilisation de cette liste est loin d'être spécifique aux gros méchants GAFA. Pas mal de libristes utilisent la liste de Spamhaus et se montrent assez agressifs quand on leur suggère que c'est peut-être une mauvaise idée (Spamhaus a beaucoup de fanboys).
Autre problème, avec Microsoft, qui gère
des services comme outlook.com et
hotmail.com. Tous les services Microsoft
rejetaient mon courrier par intermittence :
<DESTINATAIRE@outlook.com>: host
outlook-com.olc.protection.outlook.com[52.101.73.31] said: 550 5.7.1
Unfortunately, messages from [92.243.4.211] weren't sent. Please contact
your Internet service provider since part of their network is on our block
list (S3150). You can also refer your provider to
http://mail.live.com/mail/troubleshooting.aspx#errors.
[AMS0EPF000001AE.eurprd05.prod.outlook.com 2023-10-07T10:03:08.034Z
08DBBB93AD81129F] (in reply to MAIL FROM command)
Résoudre le problème est très chronophage. Il faut essayer un des
innombrables moyens de contact avec Microsoft comme https://sender.office.com/https://sendersupport.olc.protection.outlook.com/snds/https://olcsupport.office.com/outlook.com et hotmail.com
(pour l'instant, en tout cas). Mais on se doute bien que toustes les
administrateurices de serveurs de messagerie n'ont pas envie de
dépenser autant de temps et d'effort avec cette entreprise.
Concrètement, ma plateforme actuelle est composée d'un serveur de messagerie, qui est un VPS sous Debian. (Vous pouvez trouver son nom, tout est forcément public, pour que ça fonctionne, ce qui peut avoir des conséquences en terme de vie privée.) Ce serveur est situé chez Gandi. J'aurais pu l'héberger à la maison (mon FAI bloque le port 25 - celui de SMTP - par défaut mais permet de l'ouvrir gratuitement simplement en un clic sur l'interface client) mais je n'avais pas envie de gérer l'alimentation électrique permanente, certains opérateurs qui refusent le courrier provenant d'adresses IP « résidentielles », etc. Sur cette machine tournent Postfix et les autres logiciels utiles (comme OpenDKIM).
Bien sûr, j'utilise SPF (mon enregistrement), DKIM (la clé actuelle) et même DMARC (avec une politique laxiste car DMARC casse les listes de diffusion, ce que je trouve inacceptable). Et j'ai un enregistrement inverse (de l'adresse IP vers le nom) dans le DNS. J'ai testé toutes ces configurations avec divers auto-répondeurs. Et, pour me protéger moi-même contre le spam, je valide les assertions SPF, DKIM et DMARC, ce qui ajoute au courrier des informations (RFC 8601) comme :
Authentication-Results: mail.bortzmeyer.org;
dkim=pass (2048-bit key; unprotected) header.d=mailchimpapp.net
header.i=rayna=rs-strategy.consulting@mailchimpapp.net header.a=rsa-sha256 header.s=k2 header.b=Gr+4sGal;
dkim-atps=neutral
Authentication-Results: mail.bortzmeyer.org; spf=pass (sender SPF authorized) smtp.mailfrom=mail198.atl221.rsgsv.net
(client-ip=198.2.139.198; helo=mail198.atl221.rsgsv.net;
envelope-from=bounce-mc.us5_165546418.9420482-fccde11058@mail198.atl221.rsgsv.net)
Comme SPF et DKIM ne font que de l'authentification (et qu'un spammeur peut lui aussi s'authentifier), j'ajoute du greylisting (RFC 6647), avec Greyfix, SpamAssassin (comme tout le monde…) et surtout bogofilter, qui est particulièrement efficace, les faux positifs sont en nombre infime.
Quelques lectures :
- Vous ne devriez pas faire tourner votre serveur de mail parce que c'est dur (le titre n'est pas à prendre au premier degré).
- Être un géant du mail, c’est faire la loi… (sans défendre les GAFA - qui n'ont pas besoin de moi pour ça, je trouve l'article trop unilatéral ; mes messages ont souvent été bloqués par des petits serveurs mal gérés).
En conclusion, si vous m'avez écrit et que vous n'avez pas eu de réponse, c'est peut-être que votre hébergeur de courrier fait n'importe quoi et bloque mes messages. Dirigez vos reproches vers eux, pas vers moi.
L'article seul
Du nouveau dans la (l'in)sécurité de l'Internet ?
Première rédaction de cet article le 5 janvier 2024
Le 3 janvier 2024, une partie du trafic IP à destination de la filiale espagnole d'Orange n'a pas été transmis, en raison d'un problème BGP, le système dont dépend tout l'Internet. Une nouveauté, par rapport aux nombreux autres cas BGP du passé, est qu'il semble que le problème vienne du piratage d'un compte utilisé par Orange. Quelles leçons tirer de cette apparente nouveauté ?
D'abord, les faits. Le 3 janvier 2024, vers 14:30 UTC, le trafic avec
l'AS 12479,
celui d'Orange
Espagne chute brutalement. Cela se voit par
exemple sur Radar, le tableau
de bord de Cloudflare, recopié ici :
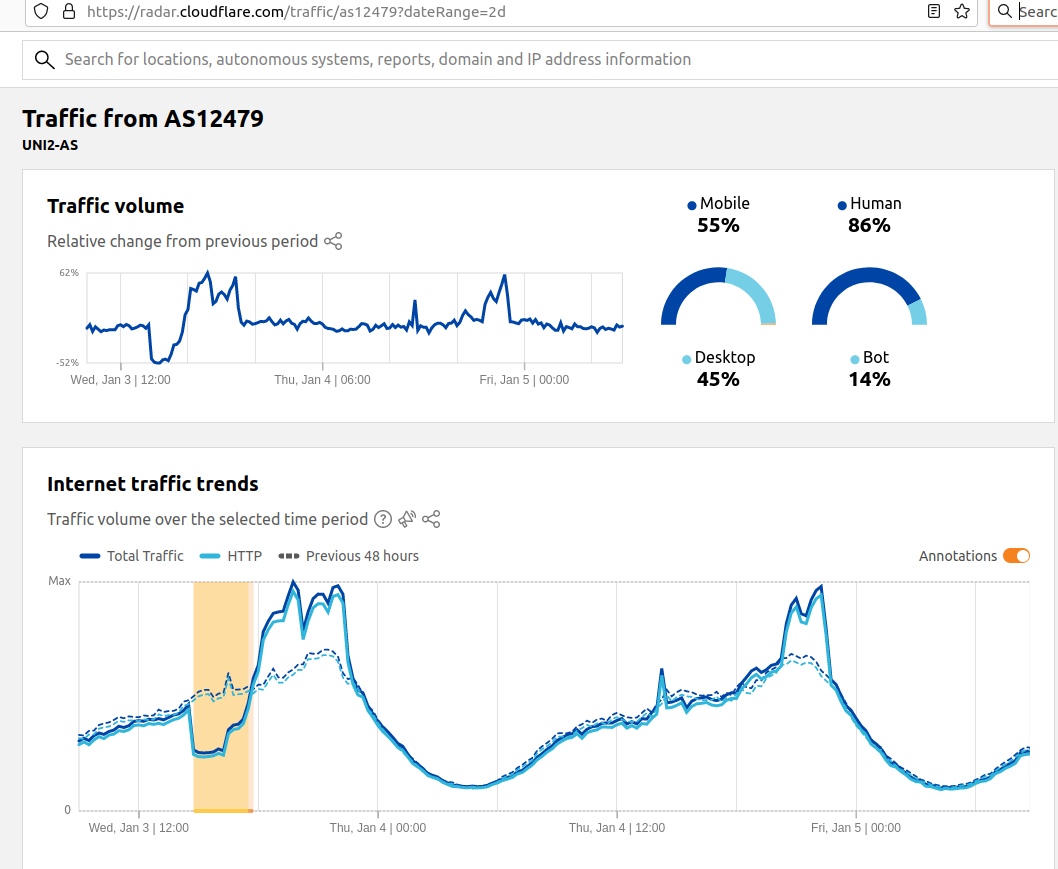
Pourquoi ? Le problème est lié à BGP, ce qui est logique puisque ce
protocole de routage
est la vraie infrastructure de
l'Internet. C'est BGP qui permet à tous les
routeurs de savoir par où envoyer les
paquets IP. On voit l'augmentation importante du
trafic BGP de cet AS sur RIPE
stat : 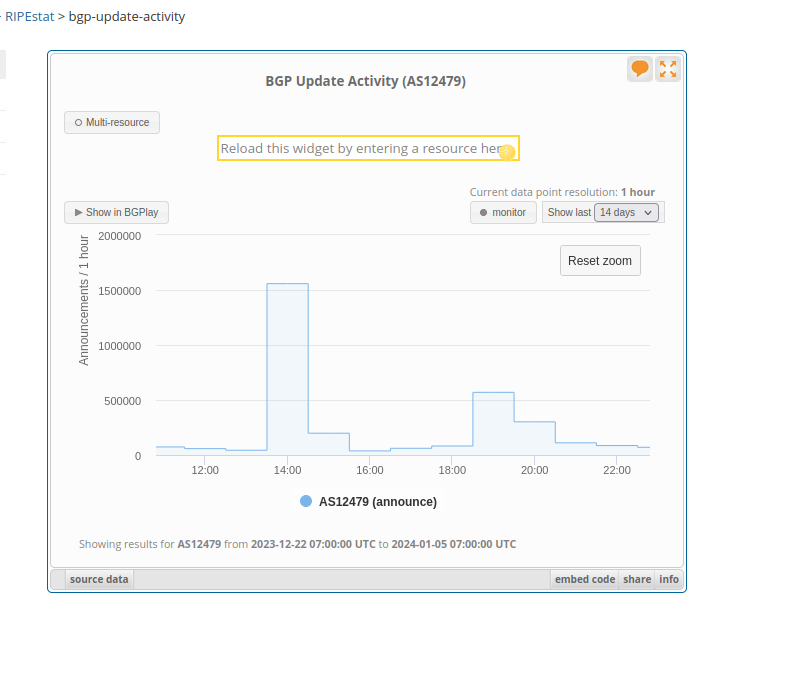
Mais il ne s'agit pas d'un détournement par le biais d'une
annonce BGP mensongère comme on l'a vu de nombreuses fois. Ici, le
problème était plus subtil. Si on regarde l'archive des annonces BGP
à RouteViews, on ne trouve
pas une telle annonce « pirate ». Prenons le fichier d'annonces BGP
https://archive.routeviews.org/route-views3/bgpdata/2024.01/UPDATES/updates.20240103.1400.bz2
(attention, il est gros) et convertissons les données (qui étaient
au format MRT du RFC 6396), avec l'outil bgpdump : on trouve
des retraits massifs d'annonces des préfixes d'Orange Espagne
comme :
TIME: 01/03/24 14:13:17.792524 TYPE: BGP4MP_ET/MESSAGE/Update FROM: 208.94.118.10 AS40630 TO: 128.223.51.108 AS6447 WITHDRAW 85.50.0.0/22 85.51.12.0/22 85.53.56.0/22 85.53.100.0/22 85.54.36.0/22 ...
Mais pas d'annonce usurpatrice. Le problème est très différent et semble venir d'un détournement d'un mécanisme de sécurité de BGP.
En effet, BGP est, par défaut, très vulnérable. N'importe quel
routeur de la DFZ peut annoncer une route vers n'importe quel
préfixe et ainsi capter du trafic (un grand classique, on l'a
dit). Rassurez-vous, il existe plusieurs mécanismes de sécurité pour
limiter ce risque. Mais comme rien n'est parfait en ce bas monde,
ces mécanismes peuvent à leur tour créer des problèmes. En
l'occurrence, le problème semble avoir été avec la
RPKI. Ce système, normalisé dans le RFC 6480, permet de signer
les ressources Internet, notamment les préfixes d'adresses IP (comme
85.50.0.0/22 et les autres cités plus haut). Un
des objets que permet la RPKI est le ROA (Route Origination
Authorization, RFC 6482), qui
déclare quel(s) AS
peuvent être à l'origine d'une annonce d'un préfixe. Il y a
normalement un ROA pour les préfixes d'Orange Espagne (il se voit,
ainsi que sa validité, sur le service de
Hurricane Electric, ou bien sur
RIPE stat). Mais, pendant le problème, ce ROA avait disparu,
remplacé par un autre qui donnait comme origine l'AS
49581 (qui, j'insiste sur ce point, est apparemment
totalement innocent dans cette affaire et semble avoir été choisi au
hasard). Les annonces BGP d'Orange Espagne étaient donc refusés par
les routeurs validants, ce qui explique les retraits de route comme
celui montré plus haut, d'où l'agitation BGP, et la chute du trafic,
bien des routeurs ne sachant plus comment joindre les préfixes
d'Orange Espagne.
S'agissait-il d'une erreur d'Orange ? Apparemment pas. Une
personne identifiée comme « Ms_Snow_OwO » s'est vantée sur
Twitter
d'avoir provoqué le problème. Le message a depuis disparu mais voici
une copie d'écran : 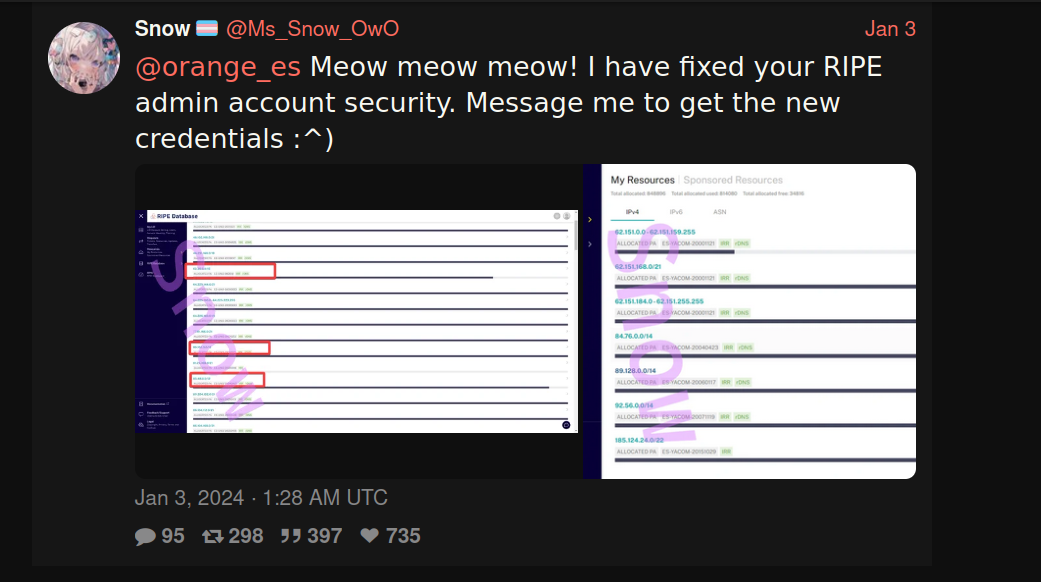
Notez aussi les copies d'écran envoyées par « Ms_Snow_OwO »,
montrant bien l'interface du RIPE-NCC avec les ressources (notamment
les préfixes IP) d'Orange Espagne : 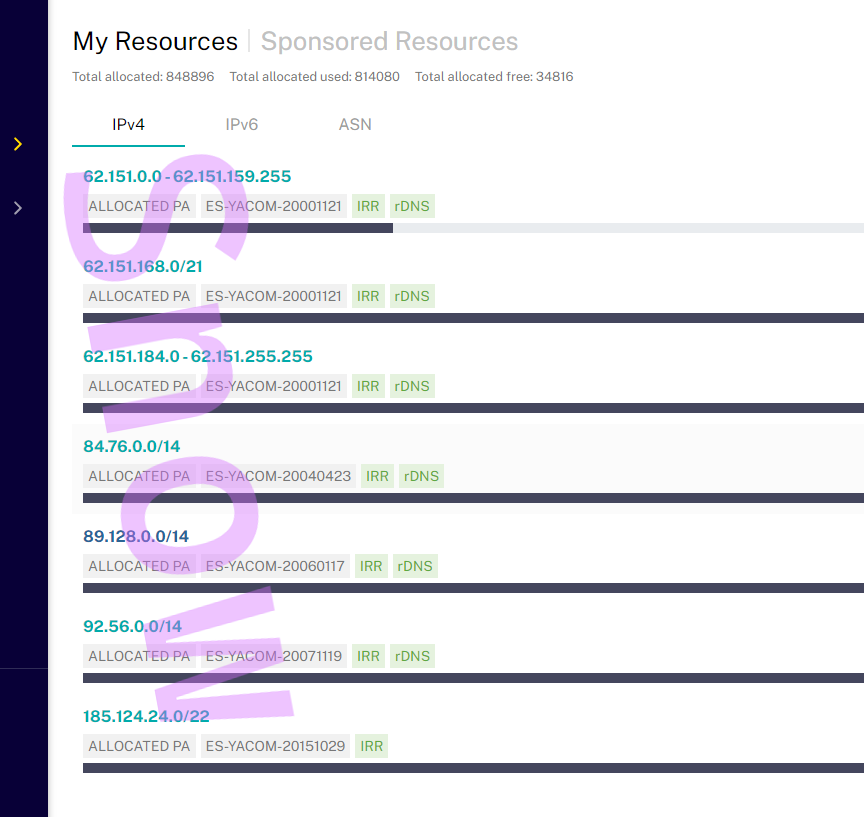
En Europe, la très grande majorité des opérateurs qui créent des ROA ne le font pas sur une machine à eux (ce que la RPKI permet, puisqu'elle est décentralisée) mais sous-traitent cette opération au RIR, le RIPE-NCC. L'opérateur se connecte à une interface Web, le LIR Portal, s'authentifie et indique les préfixes qu'il veut voir signés. On voit donc qu'un maillon nécessaire à la sécurité est l'authentification sur le portail qui sert aux opérateurs Internet. Le RIPE-NCC permet une authentification à deux facteurs, via le protocole TOTP (normalisé dans le RFC 6238), mais ce n'est pas obligatoire (ça l'est devenu le 27 mars 2024, suite à ce problème) et, selon « Ms_Snow_OwO », le mot de passe était bien trop simple. L'attaquant a pu alors s'authentifier auprès du RIPE-NCC et changer le ROA, cassant ainsi le routage.
C'est un problème courant en sécurité : toute technique qui vise à empêcher l'accès aux méchants peut être détournée pour faire un déni de service. Ainsi, par exemple, si vous bloquez un compte au bout de N tentatives d'accès infructueuses (une très mauvaise idée, mais qu'on voit parfois), il est trivial pour un attaquant de bloquer le compte, juste en tapant n'importe quel mot de passe. Ici, on peut s'indigner de ce qu'une technique anti-usurpation mène à un déni de service mais c'est un problème bien plus vaste que la RPKI.
Comme des informations ont montré que le mot de passe d'Orange Espagne était bien trop faible (juste « ripeadmin »), beaucoup de gens ont ricané, parfois bêtement, sur cette faiblesse. En fait, comme l'attaquant a apparemment utilisé un logiciel malveillant installé sur l'ordinateur d'un employé d'Orange Espagne, il aurait pu avoir le meilleur mot de passe du monde (« 45cf*b2b44cfA7🦕f64ccç302617F! »), cela n'aurait rien changé. Plutôt que de se focaliser sur ce mot de passe, effectivement trop faible, il vaudrait mieux insister sur l'importance d'activer l'authentification à deux facteurs, comme le recommande le RIPE.
Quelques lectures sur cette attaque, presque toutes en anglais car je n'ai rien trouvé en français :
- L'article de Lawrence Abrams sur BleepingComputer, le plus détaillé,
- L'analyse de HudsonRock, montrant comment l'attaquant a obtenu le mot de passe (pas en devinant !),
- Sur Twitter, l'analyse en temps réel de bgp.tools (excellent service, d'ailleurs),
- L'annonce d'Orange sur Twitter (en espagnol).
- Bon article de l'expert Doug Madory, avec notamment des détails sur les ROA vus (idem sur le blog de Kentik et sur celui de l'APNIC),
- La synthèse de Benjojo.
L'article seul
Articles des différentes années : 2026 2025 2024 2023 2022 2021 2020 Précédentes années
Syndication : Flux Atom avec seulement les résumés et Flux Atom avec tout le contenu.
{kind=link}