
Ce blog n'a d'autre prétention que de me permettre de mettre à la disposition de tous des petits textes que j'écris. On y parle surtout d'informatique mais d'autres sujets apparaissent parfois.
Fiche de lecture : Counting on computers
Auteur(s) du livre : Carmen Flury
Éditeur : De Gruyter
978-3-11-144763-6
Publié en 2025
Première rédaction de cet article le 26 juillet 2026
Ce livre d'histoire de l'informatique se penche sur la politique d'éducation à l'informatique dans l'ancienne Allemagne de l'Est.
Le plus curieux est de voir qu'une bonne partie des débats concernant l'introduction de l'informatique dans l'enseignement n'étaient pas différents de ce qu'il y avait à l'Ouest : faut-il enseigner l'utilisation des ordinateurs ou la compréhension de leur fonctionnement ? Quelles techniques faire étudier exactement, dans un secteur où tout change vite ? (Comme à l'Ouest, les ordinateurs conçus pour l'école étaient périmés à peine arrivés dans les classes.) Faut-il enseigner l'informatique à tous car tous utiliseront les ordinateurs, ou bien seulement aux futurs professionnels du secteur ? Faut-il utiliser des logiciels existants ou bien des logiciels spécifiquement développés pour l'éducation ? Faut-il même étudier l'informatique dès l'école, ne serait-il pas préférable d'enseigner les savoirs supposés fondamentaux ? La RDA a hésité, essayé plusieurs choix mais finalement la chute du mur a mis fin aux débats, qui ne sont plus désormais que du matériau pour historiens.
Il y avait aussi des différences avec l'Ouest : le rôle d'une dictature qui jugeait tout à l'aune de sa propre survie, les débats pseudo-idéologiques du genre « l'informatique est-elle une science capitaliste à rejeter entièrement, ou bien peut-elle être utile au régime ? », le retard technique qui fait que les ordinateurs produits localement étaient toujours derrière leurs homologues occidentaux… Rapidement, l'informatique a été considérée comme importante pour l'avenir et le discours dominant sera toujours techno-optimiste. Le livre ne mentionne pas de pressions venues d'URSS pour influencer les débats pédagogiques.
Il y avait des ordinateurs locaux, fabriqués
par des sociétés comme Robotron. Curieusement, il n'y avait
aucune coopération entre les pays de l'Est,
l'Union Soviétique refusant même toute aide à ses
colonies, l'informatique y étant un domaine réservé des
militaires. La photo
de couverture du livre montre une étonnante parade à Berlin
où les ouvrières de Robotron défilent avec les ordinateurs
fabriqués : 
{kind=link}
Ces ordinateurs locaux n'ont jamais été assez nombreux, ni assez perfectionnés mais ils ont été utilisés dans les écoles, ou dans des clubs de passionnés, étroitement surveillés par la police. Au fait, je n'ai pas utilisé d'écriture inclusive ici mais l'auteure note que, malgré le discours officiel comme quoi en RDA, il n'y avait pas de discrimination sexuelle, les femmes étaient, comme à l'Ouest, peu représentées dans l'informatique.
Comme dans l'autre Allemagne, il y avait beaucoup de magazines pour enfants et pour jeunes, avec une présence importante de la science et de la technologie, donc l'éducation à l'informatique se faisait aussi en dehors de l'école, avec ces lectures.
L'auteure a fait un énorme travail pour suivre l'évolution du débat dans la RDA, des années 1960 à la réunification. Je regrette juste que le développement logiciel soit peu mentionné (par exemple, le seul langage de programmation cité est BASIC, avec un interpréteur apparemment fait sur place).
Le livre est en anglais et coûte 75 € en version papier mais vous pouvez aussi le télécharger gratuitement sur le site de l'éditeur (la licence est une Creative Commons non libre, pas de dérivé et pas d'utilisation commerciale).
Allez, un vieux
Robotron pour terminer : 
_02.jpg){kind=link}
L'article seul
Polymarket bloqué par certains FAI français
Première rédaction de cet article le 20 juillet 2026
L'autorité nationale des jeux a annoncé qu'elle demandait le blocage de Polymarket. J'ai déjà parlé de censure via résolveur DNS menteur à propos d'autres sources de blocage mais je n'avais pas encore parlé de l'ANJ.
Cette ANJ (ex-ARJEL) fait en effet partie
des quelques organismes à qui la loi française permet d'édicter des
mesures de blocage de noms de
domaine. (La documentation de
l'ANJ parle d'URL mais c'est une erreur ; un résolveur DNS ne voit que les noms de
domaine et ne peut bloquer que sur cette base.) Une originalité de
cet organisme est qu'il est le seul à publier la liste complète des
domaines bloqués. Vous la trouvez sous forme d'un fichier CSV en
https://ressources.anj.fr/blocage_sites_illegaux/blocage_sites_illegaux.csv.
Le fichier comporte aujourd'hui 4747 noms mais cela fait moins
que ça de domaines enregistrés auprès d'un
registre car le fichier inclut le domaine
enregistré et son sous-domaine www.
Un FAI doit donc télécharger ce fichier et le traduire dans les règles de filtrage de ses résolveurs DNS. Il serait techniquement préférable que l'ANJ serve ce fichier en RPZ mais cela n'est pas fait.
Notez qu'aujourd'hui, le serveur HTTP de l'ANJ dit que ce fichier n'a pas été modifié depuis le 16 juin et, bien que le blocage de Polymarket soit officiellement annoncé, leur domaine n'y figure pas.
L'ANJ ne décide pas du mécanisme technique de la censure. Mais, en pratique, tous les FAI français qui la déploient utilisent un résolveur DNS menteur. Regardons avec les sondes RIPE Atlas, d'abord en Allemagne pour comparer :
% blaeu-resolve --requested 200 --country DE --type A polymarket.com [104.18.34.205 172.64.153.51] : 199 occurrences Test #191944198 done at 2026-07-20T13:55:35Z
OK, ça fonctionne, toutes les sondes Atlas germaniques trouvent la bonne adresse IP (chez Cloudflare). Et en France ?
% blaeu-resolve --requested 200 --country FR --type A polymarket.com [104.18.34.205 172.64.153.51] : 116 occurrences [] : 37 occurrences [145.239.225.117] : 44 occurrences [0.0.0.0] : 1 occurrences Test #191929487 done at 2026-07-20T12:52:56Z
Là, on voit la censure en action. Certains résolveurs n'ont pas
renvoyé d'adresse du tout (la liste vide), d'autres une adresse qui
est dans le préfixe IP de l'ANJ (la
145.239.225.117), probablement pour rediriger
vers une page d'explication (ce qui fait que l'ANJ peut récolter
l'adresse IP de votre
machine et d'autres informations). Si vous y tenez, vous pouvez voir cette page.
Notez que Polymarket semble également partiellement censuré en Espagne (et dans d'autres pays) :
% blaeu-resolve --requested 200 --country ES --type A polymarket.com [104.18.34.205 172.64.153.51] : 53 occurrences [192.187.20.203] : 6 occurrences Test #191943716 done at 2026-07-20T13:53:30Z
(192.187.20.203 semble être chez le régulateur
espagnol.)
Comme le mécanisme technique utilisé par les FAI est un résolveur menteur, on peut échapper à la censure en changeant de résolveur. (C'est une des raisons pour lesquelles on voit que de nombreuses sondes Atlas ne voient pas le blocage. Chez moi, j'ai mon propre résolveur et je peux donc voir Polymarket) Mais attention à ne pas tomber de Charybde en Scylla. (D'ailleurs, Scylla est très réussi graphiquement dans le dernier film de Nolan contre lequel l'extrême-droite fait campagne en ce moment.) Les résolveurs des GAFA, par exemple, ne se soucient guère de vie privée et vos données filent chez beaucoup de monde. Choisissez bien votre résolveur et n'écoutez pas les conseils de Jean-Kevin sur Twitter.
L'article seul
Les limites de la métrique « nombre d'octets » sur les réseaux informatiques
Première rédaction de cet article le 17 juillet 2026
La présentation, le 16 juillet 2026, du rapport annuel de l'ARCEP sur l'état de l'Internet en France a été l'occasion de se poser la question : quand on compare quantitativement des choses sur l'Internet, par exemple l'appairage public et le transit, on utilise presque toujours comme métrique le nombre d'octets. Est-ce une bonne idée ?
Ainsi, le rapport de l'ARCEP dit que « 49 % du trafic à destination des utilisateurs finals [est dû à] le fournisseur de CDN (Akamai) et les quatre plus grands fournisseurs de contenus et d’applications (Netflix, Amazon, Google, Meta) ». Le point important est que ces 49 % sont le pourcentage du nombre d'octets qui viennent de ces cinq gros. Mais une autre métrique aurait donné un autre pourcentage.
Car le fait de compter en octets n'a rien d'évident : c'est une métrique parmi d'autres. Elle est couramment utilisée car :
- Elle est relativement facile à obtenir, les équipements réseau donnent accès à cette information. C'est le problème bien connu de la recherche sous le lampadaire : on regarde là où on peut facilement regarder, pas là où se trouvent les choses importantes.
- Elle a une réelle importance pour les opérateurs du réseau, car le dimensionnement des équipements en dépend. La métrique « nombre d'octets » n'est pas la seule, ni même forcément la meilleure mais elle est certainement utile.
L'inconvénient de tout baser sur cette métrique est que, pour
certaines analyses, elle n'est pas pertinente. Prenons l'exemple du
problème de la robustesse de l'Internet face aux pannes et aux
attaques (non, je n'ai pas encore lu le
rapport de la commission d’enquête parlementaire sur nos
vulnérabilités et dépendances numériques). Il est assez
évident qu'il serait plus grave de ne pas pouvoir joindre
https://www.impots.gouv.fr/ que d'être dans
l'impossibilité de regarder TikTok. Le second
envoie pourtant bien plus d'octets. Ainsi, le chiffre de 49 % donné
plus haut semble énorme mais il ne reflète pas forcément une
dépendance critique, ces 49 % mêlant des contenus d'importance très
variable. De même, si on compare l'appairage
public via les points d'échange (1,5 % du
trafic total) à l'appairage privé (43,2 % du trafic), en octets, le
premier peut sembler négligeable. Mais il joue un rôle stratégique
important.
Il n'y a pas de métrique idéale. Dans la famille des métriques « techniques », on pourrait envisager le nombre de flots par seconde (pour TCP et QUIC, un flot = une connexion, pour UDP, on essaie de reconstituer des flots mais c'est plus difficile ; IPFIX - RFC 7011 - existe déjà pour récolter cette information).
Une autre métrique possible, plus axée sur l'économie, serait de compter en euros. Le document échangé entre deux entreprises et qui concerne un contrat de plusieurs millions péserait davantage que la vidéo YouTube qui va rapporter quelques centimes à Google, des poussières au créateur et sans doute pas grand'chose au spectateur. Mais les difficultés pratiques d'une telle métrique sont grandes.
Alors, quelle métrique choisir ? Il n'y a pas de métrique parfaite qui couvrirait tous les cas. Celle que j'ai cité, de l'« importance » du trafic est évidemment très subjective. Je pense que retransmettre sur l'Internet le championnat organisé par les ultra-pourris de la FIFA n'est pas important, mais ce n'est pas une opinion consensuelle.
Je propose donc de continuer à utiliser les métriques qu'on veut mais d'être conscient de leurs limites et de ne pas croire que l'information est uniquement dans le nombre d'octets qui circulent.
L'article seul
RFC 9852: New Protocols Using TLS Must Require TLS 1.3
Date de publication du RFC : Juillet 2026
Auteur(s) du RFC : R. Salz (Akamai
Technologies), N. Aviram
Réalisé dans le cadre du groupe de travail IETF uta
Première rédaction de cet article le 17 juillet 2026
Si vous concevez des protocoles réseau utilisant la cryptographie, vous utiliserez souvent TLS. Dans ce cas, pour un nouveau protocole, n'ayant pas à gérer l'existant, l'IETF vous conseille fortement, dans ce RFC, d'exiger dans la définition du protocole qu'il faut au moins la version 1.3 de TLS.
TLS 1.3 (RFC 9846) est largement déployé (vous trouverez difficilement un serveur Internet qui n'ait que la version précédente, la 1.2, normalisée dans le RFC 5246), a de meilleures preuves de sécurité, et protège mieux. Il est donc raisonnable de le définir comme version minimum. Attention, ce RFC est destiné aux gens qui conçoivent des protocoles réseau, par exemple à l'IETF, pas à l'administrateur réseaux de terrain. Celui-ci ou celle-ci peut continuer à utiliser TLS 1.2.
La section 6 de notre RFC détaille les faiblesses de TLS 1.2, en remarquant qu'on peut configurer TLS 1.2 de manière sûre (couper la renégociation, désactiver les algorithmes de cryptographie faibles, etc) mais que ce n'est pas toujours fait en pratique. Et bien des failles de sécurité ont frappé 1.2, alors que 1.3 n'y était pas vulnérable (on parle bien d'une faille du protocole, pas d'un programme particulier mettant en œuvre ce protocole). C'était par exemple le cas de Beast.
Certains protocoles ont déjà pris cette décision d'exiger TLS 1.3, par exemple QUIC (RFC 9001), qui impose de couper tout de suite la connexion si l'autre partie ne fait pas de 1.3. D'autres n'ont pas encore sauté le pas, ainsi, DoT (RFC 8310) permet encore TLS 1.2. Notez que le RFC 9325, que notre RFC met à jour, ne donnait TLS 1.3 que comme « recommandé » (section 5).
La plupart des bibliothèques TLS permettent au programmeur d'imposer une version minimale de TLS donc respecter cette exigence « au moins 1.3 » ne devrait pas poser de problème (section 4).
Le RFC note (section 3) qu'à l'heure actuelle, le monde de la cryptographie est occupé à préparer une transition vers des algorithmes post-quantiques (RFC 9958). Comme TLS 1.2 est gelé (cf. RFC 9851), les solutions post-quantiques n'y seront pas intégrées et, si un CRQC (Cryptographically Relevant Quantum Computer) finit par apparaitre un jour, TLS 1.2 ne sera plus sûr.
Notez enfin que cette exigence d'avoir la version 1.3 s'applique à TLS, mais pas à DTLS.
L'article seul
RFC 9851: TLS 1.2 is in Feature Freeze
Date de publication du RFC : Juillet 2026
Auteur(s) du RFC : R. Salz (Akamai
Technologies), N. Aviram
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 16 juillet 2026
Vous pouvez toujours utiliser la version 1.2 de TLS mais ne demandez pas des ajouts, des extensions, etc. Elle est désormais gelée, aucune nouvelle fonction ne sera ajoutée, tout le travail se fait désormais sur la meilleure version, la 1.3, normalisée dans le RFC 9846.
TLS 1.3 (RFC 9846) a en effet plusieurs avantages : il chiffre une plus grande proportion de la négociation au début de la session et, surtout, il a fait l'objet d'une analyse de sécurité formelle, donc il est considéré comme plus sûr. Dans ces conditions, continuer à travailler sur la version 1.2 (RFC 5246) n'a plus guère de sens. TLS 1.2 n'est pas abandonné (ne paniquez pas si vous l'utilisez encore), mais il n'évoluera plus.
Il y aura quand même quelques nouveautés permises : les identificateurs ALPN, les exporter labels, et, bien sûr, des éventuels changements nécessaires en urgence si une faille de sécurité était découverte dans la version 1.2.
Sinon, vous avez certainement entendu parler de cryptographie post-quantique, qui remplacera les bons vieux RSA et ECDSA si un calculateur quantique futur le nécessite. Les algorithmes sont déjà normalisés mais il reste à les intégrer dans TLS. Celui-ci va permettre d'utiliser ces nouveaux algorithmes mais cela ne concernera que la version 1.3 (section 2 du RFC), la 1.2 étant gelée. La 1.2 ne survivra donc pas aux CRQC (Cryptographically Relevant Quantum Computers). (Le RFC rappelle que la première discussion sérieuse à l'IETF sur ce sujet était en 2016. La normalisation prend du temps.)
L'article seul
RFC 9973: TLS 1.3 Extension for Using Certificates with an External Pre-Shared Key
Date de publication du RFC : Juillet 2026
Auteur(s) du RFC : R. Housley (Vigil Security)
Chemin des normes
Première rédaction de cet article le 16 juillet 2026
L'authentification dans TLS se fait typiquement soit à partir d'un certificat, soit par une clé partagée à l'avance. Ce RFC spécifie une extension de TLS qui permet d'utiliser certificat et clé partagée à l'avance. Il remplace le RFC 8773 mais ne change pas grand'chose, la principale modification étant que ce nouveau RFC a le statut de norme (au lieu d'être considéré comme expérimental).
Rappelons d'abord qu'il y a deux sortes de clés partagées à l'avance (PSK, pour Pre-Shared Key) : celles qui ont été négociées dans une session précédente (resumption PSK) et celles qui ont été négociées par un mécanisme extérieur (envoi par pigeon voyageur sécurisé…), les external PSK. Ce RFC ne concerne que les secondes. Les certificats et les clés partagées à l'avance ont des avantages et des inconvénients. Les certificats ne nécessitent pas d'arrangement préalable entre client et serveur, ce qui est pratique. Mais il faut se procurer un certificat auprès d'une AC. Et les certificats, comme ils reposent sur des algorithmes comme RSA ou ECDSA, sont vulnérables aux progrès de la cryptanalyse, par exemple en utilisant un (futur) ordinateur quantique (enfin, un CRQC, un Cryptographically Relevant Quantum Computer). Utiliser une clé partagée à l'avance n'est pas forcément commode (par exemple quand on veut la changer) mais cela peut être plus sûr. Or, la norme TLS (RFC 9846) ne permettait d'utiliser qu'une seule des deux méthodes d'authentification. Si on les combinait ? L'ajout d'une clé externe permettrait de rendre la sécurité plus solide.
Le principe est simple : notre RFC spécifie une extension à TLS,
tls_cert_with_extern_psk (valeur
33). Le client TLS l'envoie dans son
ClientHello. Elle indique la volonté de
combiner certificat et PSK. Elle est accompagnée d'extensions
indiquant quelle est la clé partagée à utiliser. Si le serveur TLS
est d'accord, il met l'extension
tls_cert_with_extern_psk dans son message
ServerHello. (Le serveur ne peut pas décider
seul de l'utilisation de cette extension, il faut que le client ait
demandé d'abord.)
Les clés ont une identité, une série d'octets sur lesquels client
et serveur se sont mis d'accord avant (PSK = Pre-Shared
Key, clé partagée à l'avance). C'est cette identité qui
est envoyée dans l'extension pre_shared_key,
qui accompagne tls_cert_with_extern_psk. La clé
elle-même est bien sûr un secret, connu seulement du client et du
serveur (et bien protégée : ne la mettez pas sur un fichier lisible
par tous). Voyez la section 7 du RFC pour une discussion plus
détaillée de la gestion de la PSK.
Une fois que client et serveur sont d'accord pour utiliser l'extension, et ont bien une clé en commun, l'authentification se fait via le certificat (sections 4.4.2 et 4.4.3 du RFC 9846) et on utilise ensuite, non pas seulement la clé générée (typiquement par Diffie-Hellman), mais la combinaison de la clé générée et de la PSK. L'entropie de la PSK s'ajoute donc à celle de la clé générée de manière traditionnelle.
Du point de vue de la sécurité, on note donc que cette technique de la PSK est un strict ajout à la sécurité actuelle, donc on peut garantir que son utilisation ne diminuera pas la sécurité.
L'annexe A du RFC liste les changements depuis l'ancien RFC 8773 :
- Le principal est le changement de statut, d'Expérimental à Norme. La technique spécifiée dans ce RFC est désormais considérée comme stable et validée.
- La menace des calculateurs quantiques est un peu relativisée. (Elle ne semble pas se rapprocher.)
- Autre relativisation, le RFC insiste désormais sur le fait que la PSK ne va pas servir à l'authentification (mon article sur le RFC 8773 était confus sur ce point).
- Une erreur a été corrigée (mélange entre client et serveur).
- Le terme de master secret a été remplacé par le plus gentillet main secret.
L'article seul
RFC 9954: Hybrid key exchange in TLS 1.3
Date de publication du RFC : Juillet 2026
Auteur(s) du RFC : D. Stebila (University of
Waterloo), S. Fluhrer (Cisco
Systems), S. Gueron (U. Haifa &
Meta)
Pour information
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 16 juillet 2026
Dans le monde merveilleux de la cryptographie post-quantique (RFC 9958), un problème se pose : si en voulant éviter le Charybde des calculateurs quantiques, on tombe dans le Scylla d'un algorithme, certes post-quantique, mais pour lequel une attaque cryptanalytique est trouvée ? N'aurait-on pas lâché la proie pour l'ombre ? La solution, que ce RFC décrit pour le cas de l'échange de clés dans TLS, est la cryptographie hybride : on utilise à la fois un algorithme traditionnel et un post-quantique (RFC 9794). Un éventuel attaquant devrait alors casser les deux pour réussir.
Si vous n'êtes pas à l'aise avec la terminologie de la cryptographie post-quantique, la section 1.2 de notre RFC la rappelle. Notamment, un algorithme traditionnel est un de ceux qu'on utilisait avant la menace des calculateurs quantiques, comme par exemple RSA ou ECDH. Un algorithme post-quantique est un algorithme dont on a de bonnes raisons de penser qu'il résistera aux futurs CRQC (Cryptographically-Relevant Quantum Computer, les calculateurs quantiques capables de traiter des problèmes de cryptographie réels). Un algorithme de nouvelle génération est un de ceux récemment créés et dont on n'est pas complètement sûrs de la sécurité. Cela inclut certains algorithmes post-quantiques, par exemple ML-KEM. Un algorithme hybride combine un traditionnel et un post-quantique. On parle de clé composée quand elle est faite de deux clés, une traditionnelle et une post-quantique, gérées ensemble comme un seul algorithme. Mais les termes ne sont pas universellement adoptés : comme « hybride » a un autre sens en cryptographie (un protocole qui utilise à la fois la cryptographie symétrique et l'asymétrique, comme TLS ou OpenPGP), certains préfèrent dire « composé » pour tout système PQ/T (post-quantique et traditionnel).
« Nouvelle génération » pour parler (entre autres) des algorithmes post-quantiques est inhabituel mais le but est de montrer que la technique décrite dans ce RFC ne se limite pas au post-quantique : elle s'applique dès qu'on n'a aucun algorithme parfait et qu'on en compose deux, que ces algorithmes soient post-quantiques ou pas.
Et puisqu'on pinaille sur le terminologie, le RFC note que TLS utilise le terme de « groupe » pour parler des algorithmes d'échange de clé alors que tous ces algorithmes ne font pas référence à un groupe. Mais l'habitude s'est prise.
Pourquoi créer des systèmes hybrides, PQ/T, plutôt que, par exemple, attendre tranquillement que les algorithmes post-quantiques soient mieux testés, et qu'on leur fasse autant confiance qu'à, par exemple, RSA ? Avoir un seul algorithme serait plus simple. Mais le but des hybrides est de permettre aux adopteurs précoces de se lancer tout de suite dans le post-quantique, en étant sûrs de ne pas diminuer leur sécurité actuelle. (D'autant plus que l'utilisation des algorithmes traditionnels peut être une obligation réglementaire, par exemple pour respecter FIPS.) Ces adopteurs précoces peuvent être motivés, entre autres, par la crainte d'un décryptage rétroactif, lorsqu'un attaquant qui n'a pas de CRQC aujourd'hui enregistre quand même les communications, pour les décrypter dès qu'il pourra acheter un CRQC sur AliExpress. Si vous gérez des secrets qui ont une longue durée de vie (secrets d'État…), vous ne devez pas attendre qu'un CRQC existe réellement, même s'il n'arrive que dans 20 ans, certains secrets durent plus longtemps que ça.
Bon, maintenant, au boulot ; ce RFC sur les échanges de clé hybrides dans TLS 1.3 (RFC 9846) ne va pas vous dire quel algorithme post-quantique utiliser, et il ne va pas parler d'authentification (vu la façon dont fonctionne TLS, le risque d'attaque rétroactive n'existe pas, donc on a le temps de voir venir). Par contre, il va dire comment faire que les deux parties aient la clé (clé pour la cryptographie symétrique, celle qui va chiffrer la communication une fois la session TLS établie) avec une configuration hybride, PQ/T. Parmi ses objectifs, il y a évidemment la compatibilité avec le TLS existant (un client récent doit interopérer avec un serveur ancien et réciproquement, sans compter les exaspérantes middleboxes entre les deux), et de préférence sans exiger des aller-retours supplémentaires, car il ne faut pas dégrader la latence. Il faut aussi être rapide (ne pas imposer des calculs démesurés, voir « Benchmarking Post-Quantum Cryptography in TLS » et « Post-quantum confidentiality for TLS »). Et il ne faut pas trop augmenter la taille des paquets : bien sûr, TLS fonctionne sur TCP et n'a pas les problèmes que la fragmentation des paquets pose à UDP mais quand même. Or, les algorithmes post-quantiques ont souvent des clés et des signatures bien plus grosses que les algorithmes traditionnels.
Plus spécifiquement qu'un général échange de clés, ce RFC parle de KEM (Key Encapsulation Mechanism). Si vous ne vous souvenez pas bien de ce qu'est un KEM, la section 2 du RFC vous le résume. Un KEM est utilisé lorsque la clé est générée par une seule des deux parties, et communiquée à l'autre. Le but d'un KEM est que les deux parties qui communiquent utilisent la même clé secrète pour le chiffrement en cryptographie symétrique. Un KEM permet de communiquer de manière sécurisée même face à un attaquant actif qui peut modifier les paquets à sa guise (au pire, il fera un déni de service mais ne pourra jamais lire les messages).
Maintenant, les détails pratiques, en section 3. Le nom du
mécanisme hybride va être annoncé au début de la session TLS (dans
l'extension supported_groups et rappelez-vous
que ce ne sont pas forcément des groupes). Le nom, même si on y
retrouve les noms des deux algorithmes (le traditionnel et le
post-quantique) désigne le mécanisme hybride, quand on fera du
post-quantique pur, il y aura un autre nom. Un exemple de nom (RFC pas encore publié) est X25519MLKEM768 (le
traditionnel X25519 et le post-quantique
ML-KEM). Ensuite, on fait simple : on fait un
double échange de clefs (un traditionnel et un post-quantique) et on
dérive ensuite les clefs de session à partir des deux. Plus
précisément, on concatène les messages traités avec chacun des deux
algorithmes du mécanisme hybride. Même chose pour le secret généré
par chacun des deux algorithmes. La concaténation de ces secrets
sera le point d'entrée du calcul de la clé.
La sécurité du système (section 6) vient du fait qu'un attaquant devrait réussir à casser les deux algorithmes : il lui faudrait un CRQC et une attaque (aujourd'hui inconnue) contre l'algorithme quantique. C'est l'avantage de ces systèmes hybrides. Mais si vous voulez creuser la cryptographie qui est derrière ces mécanismes hybrides, le RFC recommande « KEM Combiners » et « Hybrid Key Encapsulation Mechanisms and Authenticated Key Exchange ». Et si vous voulez en apprendre plus sur le calcul quantique, l'annexe A du RFC cite quelques bonnes lectures.
La section 4 discute quelques problèmes avec cette approche (ou, parfois, avec la cryptographie post-quantique en général). Par exemple, les clés sont grandes. Bon, qu'on fasse de l'hybride ou du post-quantique pur, ça ne change pas grand'chose, c'est la clé post-quantique qui est responsable de la grande majorité des octets : Classic McEliece a des clés d'au moins 200 kilo-octets ! Une telle taille se heurterait à des limites de TLS (65 536 octets pour la clé publique) mais heureusement les algorithmes post-quantiques normalisés par le NIST ont des clés plus petites, et qui tiennent dans les messages TLS (mais pas forcément dans un seul paquet IP). L'encodage de notre RFC aggrave les choses si on annonce deux hybrides, chacun utilisant la même clé post-quantique, qui sera alors envoyée deux fois.
Les noms des mécanismes hybrides seront mis dans le
registre IANA (X25519MLKEM768 et
quelques autres y sont déjà) au fur et à mesure de leur spécification.
Côte mises en œuvre, les expérimentations sont anciennes : CECPQ2 ou OQS, par exemple, et des tests de performance ont été faits. Aujourd'hui, le mécanisme hybride est possible avec Chrome, Firefox, OpenSSL, wolfSSL, Cloudflare, Google, BoringSSL, Rustls…(Je n'ai pas testé Firefox.)
L'article seul
RFC 9850: The SSLKEYLOGFILE Format for TLS
Date de publication du RFC : Juillet 2026
Auteur(s) du RFC : M. Thomson (Mozilla), Y. Rosomakho
(Zscaler), H. Tschofenig (H-BRS)
Pour information
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 16 juillet 2026
Déboguer une application réseau qui utilise le chiffrement est difficile. Le but du chiffrement est justement d'empêcher un tiers (par exemple l'analyseur de paquets) de regarder ce qui se passe. Une approche possible est de demander gentiment à l'application d'exporter ses clés de chiffrement dans un fichier que l'analyseur pourra importer pour ensuite déchiffrer la communication. Ce RFC décrit le format le plus répandu pour exporter ses clés, connu sous le nom de SSLKEYLOGFILE et très commun aujourd'hui.
Le nom est trompeur car SSL est abandonné depuis
longtemps (RFC 7568), ce format est en fait
pour TLS mais
l'ancien nom est resté. Il vient d'une convention courante, définir
une variable
d'environnement nommée
SSLKEYLOGFILE, qui va indiquer à l'application
qu'on demande à recevoir les clés dans un fichier dont le nom est la
valeur de la variable SSLKEYLOGFILE. Mais ce
RFC n'indique pas
comment activer cette fonction d'exportation de clés, il documente
juste le format résultant.
Un petit rappel de cryptographie telle
qu'elle est faite dans TLS (RFC 8446) :
l'authentification est faite avec de la
cryptographie
asymétrique puis un échange de clés a lieu, permettant aux deux parties
de se mettre d'accord sur des clés utilisés en cryptographie
symétrique. Ce sont ces clés, qui sont évidemment
secrètes (seules les deux parties qui communiquent les connaissent)
qui nous intéressent ici. Sans elles, l'analyseur de paquets ne peut
que baisser les bras et dire « ici, il y a des données chiffrées
mais je ne peux pas te les montrer ». Ici, par exemple,
Wireshark peut juste dire que c'est du TLS et
que c'est chiffré : 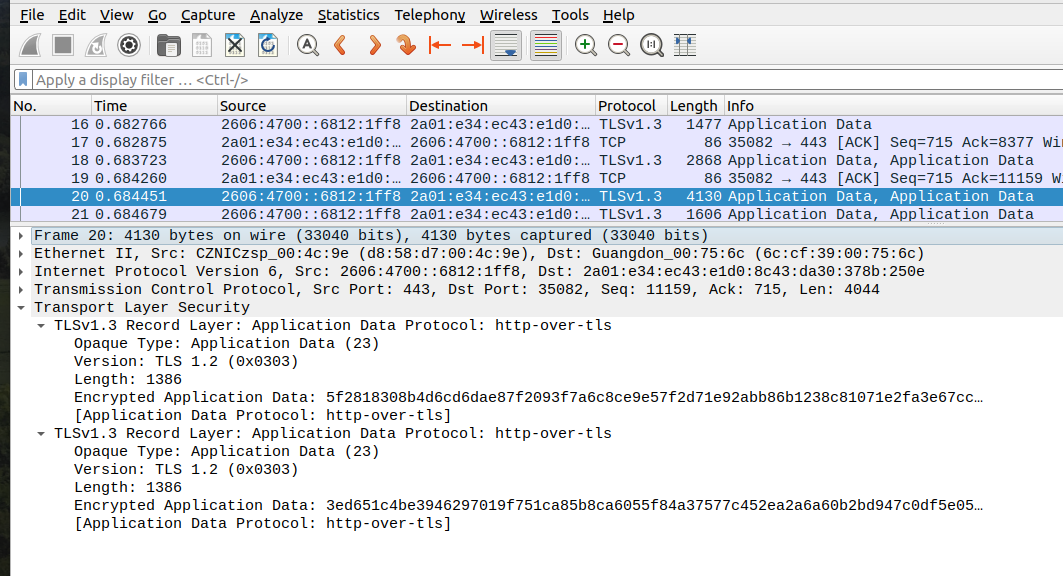
Donc, le format du fichier des clés est simple (section 2 du RFC) : un fichier texte en UTF-8 (la partie signifiante est forcément en ASCII mais il peut y avoir des commentaires qui n'ont pas cette restriction). La fin de ligne n'est pas normalisée (on aurait pu exiger le respect du RFC 5198 mais, bon, ces fichiers ne sont typiquement pas échangés entre machines différentes). Les commentaires commencent par le croisillon. Chaque secret enregistré tient sur une ligne, le nom du secret, la valeur d'un champ TLS aléatoire qui permet d'identifier la connexion (il peut y avoir des secrets de plusieurs connexions distinctes dans le fichier) et enfin la valeur du secret, en hexadécimal. Ces trois champs sont séparés par des espaces. Par contre, aucune indication sur les paramètres cryptographiques de la connexion, comme l'algorithme de cryptographie utilisé donc, si on n'a pas le début de la session TLS, le fichier peut être inutilisable. Le RFC suggère d'être indulgent dans l'analyse du fichier et d'ignorer les lignes incorrectes, ce qui permet d'extraire des secrets d'un fichier abimé.
Le RFC liste ensuite les noms possibles pour les secrets. Ils dépendent de la version de TLS. Essayons avec curl et une connexion TLS 1.3 :
% export SSLKEYLOGFILE=./keys.sslkeylogfile % curl https://www.example.com % cat keys.sslkeylogfile SERVER_HANDSHAKE_TRAFFIC_SECRET 09d… 2d7d2e4090c6… EXPORTER_SECRET 09d… 21cbb457ee72aa… SERVER_TRAFFIC_SECRET_0 09d… 7e0027e87… CLIENT_HANDSHAKE_TRAFFIC_SECRET 09d… 7ef813bf0… CLIENT_TRAFFIC_SECRET_0 09d… f4a7ab14e…
Lisez le RFC et la norme TLS pour avoir des explications sur chaque secret. Un registre IANA des valeurs possibles a été créé et de nouveaux noms pourront y être ajoutés en suivant la procédure « Spécification nécessaire » du RFC 8126.
De toute façon, ce n'est pas vous qui allez le lire mais un
logiciel comme Wireshark. En parlant de
Wireshark, si on le configure pour lire ce fichier de secrets (dans
le fichier ~/.config/wireshark/preferences,
mettre tls.keylog_file:
/some/where/tmp/keys.sslkeylogfile), Wireshark saura
déchiffrer la session TLS vue plus haut (même
pcap). Vous voyez les requêtes HTTP complètes, qui
étaient masquées par le chiffrement : 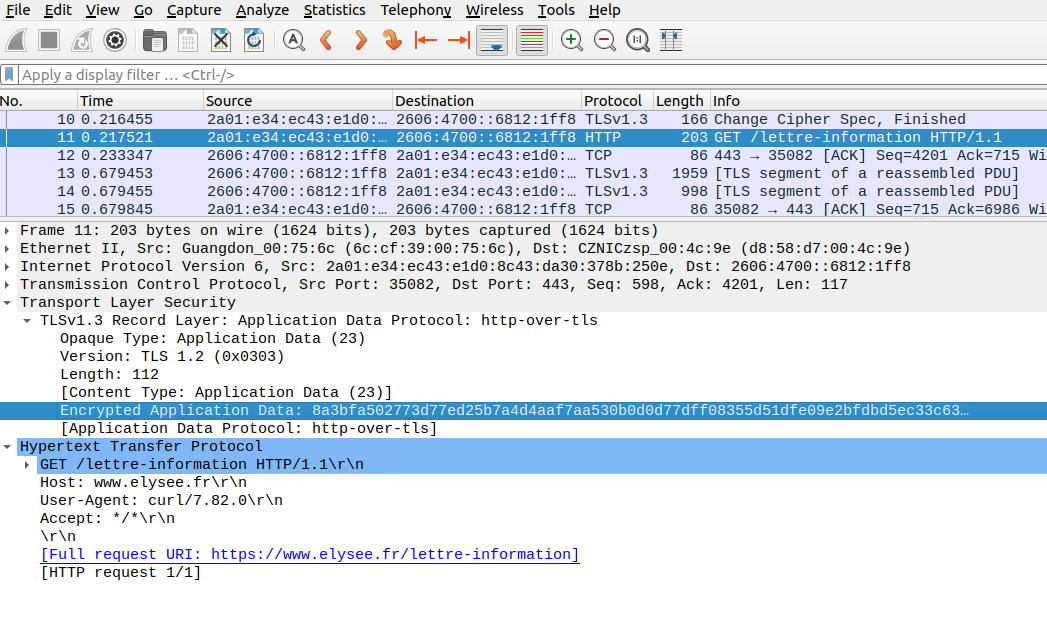
L'ordre des secrets dans le fichier n'est pas pertinent. Ah et, sinon, les noms de secret se terminant par un tiret bas et un chiffre sont là pour le cas où TLS génère plusieurs clés pendant une session (RFC 8446, section 7.2). « nomDuSecret_0 » est la première.
Évidemment, l'usage de cette possibilité d'écrire les clés secrètes annule tout l'intérêt de TLS. La section 3 du RFC insiste sur ce point. Cette possibilité est très pratique pour le débogage mais ne doit surtout pas être utilisée avec des vraies sessions TLS sensibles. La lecture du fichier permet de tout déchiffrer et même la confidentialité persistante est compromise si on a ce fichier. Il faut faire attention à ce que les fichiers SSLKEYLOGFILE ne circulent pas et ne soient pas accessibles par tout le monde (bien des programmes les créent avec les autorisations d'accès par défaut, qui peuvent être assez laxistes). Et, de manière tout aussi évidente, un programme ne doit pas écrire ces secrets s'il n'est pas certain que la demande vient du vrai utilisateur. (L'utilisation d'une variable d'environnement dans l'exemple avec curl satisfait cette condition.) Le RFC suggère aussi une option de compilation permettant de compiler l'application sans gestion de SSLKEYLOGFILE.
Une note amusante : si la session TLS est de longue durée, un attaquant qui mettrait la main sur le fichier SSLKEYLOGFILE pourrait non seulement lire les données chiffrées mais également interférer avec la session tant qu'elle est en cours.
Le format ainsi normalisé peut marcher avec diverses versions de TLS, y compris dépassées (RFC 8996). Il fonctionne avec d'autres protocoles, s'ils utilisent le mécanisme de génération de clés de TLS, ce qui est le cas de DTLS (RFC 9147) ou de QUIC (RFC 9000).
Le type de média
application/sslkeylogfile
a été ajouté au registre
IANA.
Ce format SSLKEYLOGFILE est largement adopté par de nombreuses applications depuis des années, par exemple tous les navigateurs Web. (J'ai bien dit des applications ; contrairement à ce qu'on lit parfois, ce ne sont pas les bibliothèques TLS comme OpenSSL qui le mettent en œuvre. Certains programmes utilisant OpenSSL ont cette fonction d'exportation de clés et d'autres pas.) Un exemple avec mon client Gemini Agunua :
% export SSLKEYLOGFILE=./keys.sslkeylogfile % agunua gemini.bortzmeyer.org % cat keys.sslkeylogfile SERVER_HANDSHAKE_TRAFFIC_SECRET 724f8f07224… 8bcf43772bc21b45ad… …
Agunua est écrit en Python et activer cette fonction est simple, on s'appuie sur le fait qu'OpenSSL fournit une fonction pour demander à recevoir notification de la génération des clés :
def write_keys(conn, keys):
keylogfile.write(keys.decode() + "\n")
if "SSLKEYLOGFILE" in os.environ:
keylogfile = open(os.environ["SSLKEYLOGFILE"], "a")
context.set_keylog_callback(write_keys)
(Pour curl, cité plus haut, regarde le fichier
lib/vtls/keylog.c.)
La question plus générale du débogage des applications dans un monde où tout est chiffré avait fait l'objet de mon exposé à Capitole du Libre 2022 dont voici mes supports.
L'article seul
Sentinelle, un outil pour analyser le routage de votre réseau
Première rédaction de cet article le 14 juillet 2026
Vous gérez un AS ou, tout simplement, vous êtes curieux du routage d'un réseau que vous utilisez ? Il existe plusieurs outils d'analyse de la configuration et de la sécurité du routage, aujourd'hui, voyons un des plus récents, Sentinelle.
Le principe est simple : vous indiquez un numéro d'AS et Sentinelle vous produit
un joli rapport sur la configuration BGP de cet AS et notamment sa sécurité, via la
RPKI. Prenons l'exemple d'une des machines
qui porte ce blog, chez
Gandi, AS 29169. 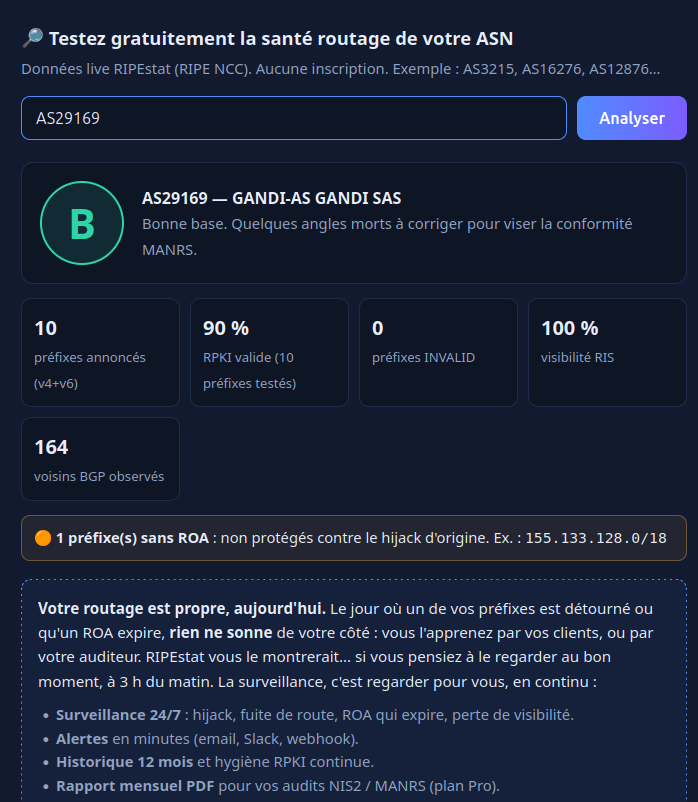
On y voit une situation raisonnable (note B), que cet AS annonce
dix préfixes, tous visibles dans le RIS, et que tous les préfixes
sont protégés par la RPKI (sauf
155.133.128.0/18). Si vous voulez voir une bien
plus mauvaise note (D), testez l'AS 1… Si vous voulez voir des
annonces invalides (contraires à la RPKI), regardez le 132203.
Voilà ce qu'on obtient avec l'offre gratuite. L'offre payante offre d'autres possibilités comme la production de jolis PDF pour votre auditeur sécurité (en supposant qu'il s'intéresse au routage) ou comme l'alerte en temps réel mais je n'ai pas testé.
Sentinelle se base sur le service RIPEstat mais en étant plus léger et plus lisible, pour une synthèse rapide à lire. Sinon, vous avez aussi d'autres outils BGP comme BGPtools.
L'article seul
Un domaine important de Telegram suspendu
Première rédaction de cet article le 14 juillet 2026
Dernière mise à jour le 15 juillet 2026
Si vous utilisez le service de messagerie instantanée Telegram, vous avez sans doute vu aujourd'hui 14 juillet 2026, que des services ne marchaient pas, notamment les liens vers des ressources diverses (images, etc). C'est parce que le registre de noms de domaine du Monténégro l'avait décidé. Voyons les détails.
D'abord, les faits. Telegram utilise le
nom de domaine
t.me pour des liens courts, par exemple vers
des documents partagés par les utilisateurices du
service. Aujourd'hui, ce nom ne fonctionnait plus. Testons avec
dig :
% dig t.me … ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 60053 ;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 1 … ;; AUTHORITY SECTION: me. 1909 IN SOA a0.nic.me. hostmaster.donuts.email. 1784020434 7200 900 1209600 3600 … ;; WHEN: Tue Jul 14 11:47:03 CEST 2026
NXDOMAIN signifie No Such Domain, ce nom n'existe pas dans le DNS. Ce n'est pas juste mon résolveur qui dit cela, comme on peut le vérifier avec les sondes RIPE Atlas :
% blaeu-resolve --requested 100 --type A t.me [ERROR: NXDOMAIN] : 97 occurrences Test #189950980 done at 2026-07-14T09:48:55Z
Bon, personne n'avait accès à ce domaine. Est-ce que ça veut dire qu'il a été supprimé et que, par exemple, quelqu'un pourrait l'enregistrer ? Non, on le voyait avec whois (mais on pourrait utiliser d'autres moyens) :
% whois t.me Domain Name: t.me … Updated Date: 2026-07-13T19:24:55Z Registrar: GoDaddy.com, LLC … Domain Status: serverHold https://icann.org/epp#serverHold … Name Server: ns-cloud-b1.googledomains.com Name Server: ns-cloud-b2.googledomains.com Name Server: ns-cloud-b3.googledomains.com Name Server: ns-cloud-b4.googledomains.com
Le domaine existe bien, son Bureau
d'Enregistrement est GoDaddy, il
a des serveurs de
noms. Mais il n'était plus publié dans le DNS comme l'indique la ligne
serverHold. (Si
vous voulez, vous pouvez en
apprendre davantage sur les états possibles des noms de
domaine.)
Ce retrait, comme indiqué dans le résultat de whois, a été fait
le 13 juillet 2026, vers 19h30 UTC. Si on regarde avec DNSDB, on voit que la dernière réponse pour
t.me est le 14 juillet, vers 01h30
UTC. (Diverses raisons font qu'un nom de domaine continue de
fonctionner après sa suppression, notamment les mémoires des résolveurs.) Le domaine a été réactivé
le 14 juillet vers 12h20 UTC :
% blaeu-resolve --requested 100 --type A t.me [ERROR: NXDOMAIN] : 16 occurrences [149.154.167.99] : 80 occurrences [149.154.167.220] : 1 occurrences [146.112.250.215 146.112.250.222 146.112.47.152 146.112.47.169 146.112.47.225 146.112.47.3] : 1 occurrences Test #190041253 done at 2026-07-14T12:44:39Z
Comme on le voit, certains résolveurs avaient encore en mémoire la non-existence du domaine.
Telegram avait changé son logiciel pour utiliser
telegram.me au lieu de
t.me. Je suppose qu'il vont re-changer
maintenant que t.me remarche.
Qui a décidé de cette non-publication ? L'état nous l'indique,
c'est le serveur, ce qui, dans
le contexte du protocole EPP, désigne le
registre (le client étant le
Bureau d'Enregistrement, pas le client
final). C'est donc le registre de
.me qui a suspendu le
domaine.
Mais c'est quoi, .me ? Comme l'indique le
fait qu'il comporte deux lettres, c'est un domaine
national, en l'occurrence celui du
Monténégro. Ces domaines nationaux ne
dépendent pas de l'ICANN (contrairement à ce
qu'on lit souvent dans les articles pas informés) et ont leurs
propres règles d'enregistrement et de gestion des litiges. Je n'ai
pas vérifié ces règles d'enregistrement (vous savez, ce que vous
acceptez en cochant la case « je n'ai rien lu mais je suis
d'accord ») mais il est possible qu'elles indiquent la primauté des
lois et des tribunaux monténégrins. Après, certains pays vendent sur
le marché international des noms et, pour des raisons géopolitiques
et commerciales, suivent des règles venues des États-Unis. Et
l'infrastructure technique de .me est largement
gérée par des organisations étatsuniennes, ce qui n'aide pas.
Voilà, ça, c'était les faits. Maintenant, les raisons derrière la
décision du registre ? Je ne les connais pas mais, apparemment,
c'était une exigence des autorités étatsuniennes, que les Monténégrins
n'ont pas osé contester. (Souvenir : une tentative de censure de
Telegram en France avait bloqué ce nom dans certains
résolveurs français.)
Depuis, le registre du .me a officiellement
reconnu qu'il censurait sur ordre venant des USA :
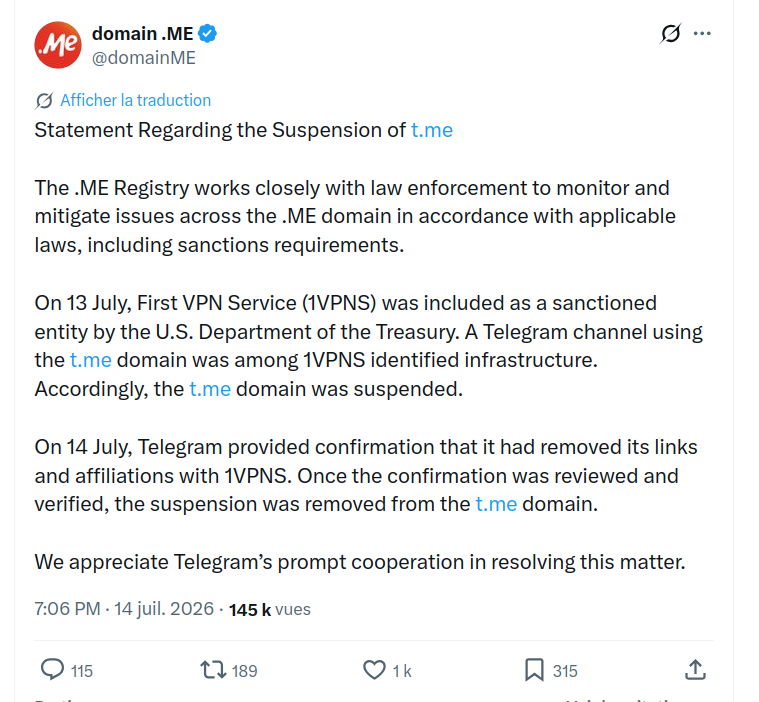
Autres articles sur la question :
- Sur IT-connect (en français).
- Une discussion sur Ycombinator.
L'article seul
RFC 9846: The Transport Layer Security (TLS) Protocol Version 1.3
Date de publication du RFC : Juillet 2026
Auteur(s) du RFC : E. Rescorla (Independent)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 12 juillet 2026
Ce RFC met à jour la norme de la version 1.3 du protocole de cryptographie TLS. Il n'y a pas de grand changement par rapport à son prédécesseur, le RFC 8446.
Regardons un peu en détail le protocole TLS 1.3. Revenons d'abord sur les fondamentaux : TLS est un mécanisme permettant aux applications client/serveur de communiquer au travers d'un réseau non sûr (par exemple l'Internet) tout en empêchant l'écoute et la modification des messages. TLS suppose un mécanisme sous-jacent pour acheminer les bits dans l'ordre, et sans perte. En général, ce mécanisme est TCP (mais une partie de TLS est aussi utilisée pour QUIC). Avec ce mécanisme de transport, et les techniques cryptographiques mises en œuvre par dessus, TLS garantit :
- L'authentification du serveur (celle du client est facultative), authentification qui permet d'empêcher l'attaque de l'intermédiaire, et qui se fait en général via la cryptographie asymétrique,
- La confidentialité des données (mais attention, TLS ne masque pas la taille des données, permettant certaines analyses de trafic),
- L'intégrité des données (qui est inséparable de l'authentification : il ne servirait pas à grand'chose d'être sûr de l'identité de son correspondant, si les données pouvaient être modifiées en route).
Ces propriétés sont vraies même si l'attaquant contrôle complètement le réseau entre le client et le serveur (le modèle de menace est détaillé dans la section 3 - surtout la 3.3 - du RFC 3552, et dans l'annexe F de notre RFC).
TLS est un protocole gros et compliqué (ce qui n'est pas forcément optimum pour la sécurité). Le RFC fait 161 pages. Pour dompter cette complexité, TLS est séparé en deux composants :
- Le protocole de salutation (handshake protocol), chargé d'organiser les échanges du début, qui permettent de choisir les paramètres de la session (c'est un des points délicats de TLS, et plusieurs failles de sécurité ont déjà été trouvées dans ce protocole pour les anciennes versions de TLS),
- Et le protocole des enregistrements (record protocol), au plus bas niveau, chargé d'acheminer les données chiffrées.
Pour comprendre le rôle de ces deux protocoles, imaginons un protocole fictif simple, qui n'aurait qu'un seul algorithme de cryptographie symétrique, et qu'une seule clé, connue des deux parties (par exemple dans leur fichier de configuration). Avec un tel protocole, on pourrait se passer du protocole de salutation, et n'avoir qu'un protocole des enregistrements, indiquant comment encoder les données chiffrées. Le client et le serveur pourraient se mettre à communiquer immédiatement, sans salutation, poignée de mains et négociation, réduisant ainsi la latence. Un tel protocole serait très simple, donc sa sécurité serait bien plus facile à analyser, ce qui est une bonne chose. Mais il n'est pas du tout réaliste : changer la clé utilisée serait complexe (il faudrait synchroniser exactement les deux parties), remplacer l'algorithme si la cryptanalyse en venait à bout (comme c'est arrivé à RC4, cf. RFC 7465) créerait un nouveau protocole incompatible avec l'ancien, communiquer avec un serveur qu'on n'a jamais vu serait impossible (puisque on ne partagerait pas de clé commune), etc. D'où la nécessité du protocole de salutation, où les partenaires :
- S'authentifient avec leur clé publique (ou, si on veut faire comme dans le protocole fictif simple, avec une clé secrète partagée),
- Sélectionnent l'algorithme de cryptographie symétrique qui va chiffrer la session, ainsi que ses paramètres divers,
- Choisissent la clé de la session TLS (et c'est là que se sont produites les plus grandes bagarres lors de la conception de TLS 1.3).
Notez que TLS n'est en général pas utilisé tel quel mais via un protocole de haut niveau, comme HTTPS pour sécuriser HTTP. TLS ne suppose pas un usage particulier : on peut s'en servir pour HTTP, pour SMTP (RFC 7672), pour le DNS (RFC 7858), etc. Cette intégration dans un protocole de plus haut niveau pose parfois elle-même des surprises en matière de sécurité, par exemple si l'application utilisatrice ne fait pas attention à la sécurité (Voir mon exposé à Devoxx, et ses transparents.)
TLS 1.3 est plutôt un nouveau protocole qu'une nouvelle version, et il n'est pas directement compatible avec son prédécesseur, TLS 1.2 (une application qui ne connait que 1.3 ne peut pas parler avec une application qui ne connait que 1.2). En pratique, les bibliothèques qui mettent en œuvre TLS incluent en général les différentes versions, et un mécanisme de négociation de la version utilisée permet normalement de découvrir la version maximum que les deux parties acceptent (historiquement, plusieurs failles sont venues de ce point, avec des pare-feux stupidement configurés qui interféraient avec la négociation).
La section 1.3 de notre RFC liste les différences importantes entre TLS 1.2 (qui était normalisé dans le RFC 5246) et 1.3 :
- La liste des algorithmes de cryptographie symétrique acceptés a été violemment réduite. Beaucoup trop longue en TLS 1.2, offrant trop de choix, comprenant plusieurs algorithmes faibles, elle ouvrait la voie à des attaques par repli. Les « survivants » de ce nettoyage sont tous des algorithmes à chiffrement intègre.
- Un nouveau service apparait, 0-RTT (zero round-trip time, la possibilité d'établir une session TLS avec un seul paquet, en envoyant les données tout de suite), qui réduit la latence du début de l'échange. Attention, rien n'est gratuit en ce monde, et 0-RTT présente des nouveaux dangers, et ce nouveau service a été un des plus controversés lors de la mise au point de TLS 1.3, entrainant de nombreux débats à l'IETF.
- Désormais, la sécurité future est systématique, la compromission d'une clé secrète ne permet plus de déchiffrer les anciennes communications. Plus de clés publiques statiques, tout se fera par clés éphémères. C'était le point qui a suscité le plus de débats à l'IETF, car cela complique sérieusement la surveillance (ce qui est bien le but) et le débogage. L'ETSI, représentante du patronat, a même normalisé son propre TLS délibérément affaibli,eTLS (depuis disparu de leur site Web, ils ont dû avoir honte).
- Plusieurs messages de négociation qui étaient auparavant en clair sont désormais chiffrés. Par contre, l'indication du nom du serveur (SNI, section 3 du RFC 6066) reste en clair, sauf si on utilise le tout nouveau ECH (Encrypted Client Hello), normalisé en même temps que ce RFC, dans le RFC 9849 (cf. son cahier des charges dans le RFC 8744.)
- Les fonctions de dérivation de clé ont été refaites.
- La machine à états utilisée pour l'établissement de la connexion également (elle est détaillée dans l'annexe A du RFC).
- Les algorithmes asymétriques à courbes elliptiques font maintenant partie de la définition de base de TLS (cf. RFC 7748), et on voit arriver des nouveaux comme ed25519 (cf. RFC 8422).
- Par contre, DSA a été retiré.
- Le mécanisme de négociation du numéro de version (permettant à deux machines n'ayant pas le même jeu de versions TLS de se parler) a changé. L'ancien était très bien mais, mal implémenté, il a suscité beaucoup de problèmes d'interopérabilité. Le nouveau est censé mieux gérer les innombrables systèmes bogués qu'on trouve sur l'Internet (la bogue ne provenant pas tant de la bibliothèque TLS utilisée que des pare-feux mal programmés et mal configurés qui sont souvent mis devant). J'en profite pour vous recommander l'article « HTTPS : de SSL à TLS 1.3 », sur ce sujet de la négociation de version.
- La reprise d'une session TLS précédente fait l'objet désormais d'un seul mécanisme, qui est le même que celui pour l'usage de clés pré-partagées. La négociation TLS peut en effet être longue, en terme de latence, et ce mécanisme permet d'éviter de tout recommencer à chaque connexion. Deux machines qui se parlent régulièrement peuvent ainsi gagner du temps.
Un bon résumé de ce protocole est dans l'article de Mark Nottingham.
Ce RFC concerne TLS 1.3 mais il contient aussi quelques changements pour la version 1.2 (section 1.4 du RFC), comme un mécanisme pour limiter les attaques par repli portant sur le numéro de version, et des mécanismes de la 1.3 « portés » vers la 1.2 sous forme d'extensions TLS.
Et les changements depuis le RFC 8446, le
premier qui avait normalisé TLS 1.3 ? Ils sont peu importants, le
plus spectaculaire étant le remplacement de toutes les occurrences de
master par main dans les noms
de variable. Ainsi, resumption_master_secret
est devenu resumption_secret et le
extended_master_secret du RFC 7627 est
devenu extended_main_secret. Il s'agissait de
répondre à une obsession étatsunienne mais je ne sais pas si ce
changement sera propagé dans les programmes qui mettent en œuvre
TLS (noms des variables et texte affiché, regardez l'exemple
Wireshark plus bas). Tous ces changements depuis le RFC 8446
sont résumés dans la section 1.2 mais il s'agit surtout de détails
et de précisions : la version 1.3 du protocole ne change pas.
La section 2 du RFC est un survol général de TLS 1.3 (le RFC fait 161 pages, et peu de gens le liront intégralement). Au début d'une session TLS, les deux parties, avec le protocole de salutation, négocient les paramètres (version de TLS, algorithmes cryptographiques) et définissent les clés qui seront utilisées pour le chiffrement de la session. En simplifiant, il y a trois phases dans l'établissement d'une session TLS :
- Définition des clés de session, et des paramètres
cryptographiques, le client envoie un
ClientHello, le serveur répond avec unServerHello, - Définition des autres paramètres (par exemple
l'application utilisée au-dessus de TLS, ou bien la demande
CertificateRequestd'un certificat client), cette partie est chiffrée, contrairement à la précédente, - Authentification du serveur, avec le message
Certificate(qui ne contient pas forcément un certificat, cela peut être une clé brute - RFC 7250 ou une clé d'une session précédente - RFC 7924).
Un message Finished termine cette ouverture
de session.
(Si vous êtes fana de futurisme, notez que seule la première étape
pourrait être remplacée par la distribution quantique
de clés, les autres resteraient
indispensables. Contrairement à ce que promettent ses promoteurs,
la QKD ne dispense pas d'utiliser les protocoles existants.)
Comment les deux parties se mettent-elles d'accord sur les clés ? Trois méthodes :
- Diffie-Hellman sur courbes elliptiques qui sera sans doute la plus fréquente,
- Clé pré-partagée,
- Clé pré-partagée avec Diffie-Hellman,
- Et la méthode RSA, elle, disparait de la norme (mais RSA peut toujours être utilisé pour l'authentification, autrement, cela ferait beaucoup de certificats à jeter…)
Si vous connaissez la cryptographie, vous savez que les PSK, les clés partagées, sont difficiles à gérer, puisque devant être transmises de manière sûre avant l'établissement de la connexion. Mais, dans TLS, une autre possibilité existe : si une session a été ouverte sans PSK, en n'utilisant que de la cryptographie asymétrique, elle peut être enregistrée, et resservir, afin d'ouvrir les futures discussions plus rapidement. TLS 1.3 utilise le même mécanisme pour des « vraies » PSK, et pour celles issues de cette reprise de sessions précédentes (contrairement aux précédentes versions de TLS, qui utilisaient un mécanisme séparé, celui du RFC 5077, désormais abandonné).
Si on a une PSK (gérée manuellement, ou bien via la reprise de session), on peut même avoir un dialogue TLS dit « 0-RTT ». Le premier paquet du client peut contenir des données, qui seront acceptées et traitées par le serveur. Cela permet une importante diminution de la latence, dont il faut rappeler qu'elle est souvent le facteur limitant des performances. Par contre, comme rien n'est idéal dans cette vallée de larmes, cela se fait au détriment de la sécurité :
- Plus de confidentialité persistante, si la PSK est compromise plus tard, la session pourra être déchiffrée,
- Le rejeu devient possible, et l'application doit donc savoir gérer ce problème.
La section 8 du RFC et l'annexe F.5 détaillent ces limites, et les mesures qui peuvent être prises.
Le protocole TLS est décrit avec un langage spécifique, décrit de manière relativement informelle dans la section 3 du RFC. Ce langage manipule des types de données classiques :
- Scalaires
(
uint8,uint16), - Tableaux, de taille fixe -
Datum[3]ou variable, avec indication de la longueur au début -uint16 longer<0..800>, - Énumérations (
enum { red(3), blue(5), white(7) } Color;), - Enregistrements structurés, y compris avec variantes (la présence de certains champs dépendant de la valeur d'un champ).
Par exemple, tirés de la section 4 (l'annexe B fournit la liste complète), voici, dans ce langage, la liste des types de messages pendant les salutations, une énumération :
enum {
client_hello(1),
server_hello(2),
new_session_ticket(4),
end_of_early_data(5),
encrypted_extensions(8),
certificate(11),
certificate_request(13),
certificate_verify(15),
finished(20),
key_update(24),
message_hash(254),
(255)
} HandshakeType;
Et le format de base d'un message du protocole de salutation :
struct {
HandshakeType msg_type; /* handshake type */
uint24 length; /* bytes in message */
select (Handshake.msg_type) {
case client_hello: ClientHello;
case server_hello: ServerHello;
case end_of_early_data: EndOfEarlyData;
case encrypted_extensions: EncryptedExtensions;
case certificate_request: CertificateRequest;
case certificate: Certificate;
case certificate_verify: CertificateVerify;
case finished: Finished;
case new_session_ticket: NewSessionTicket;
case key_update: KeyUpdate;
};
} Handshake;
La section 4 fournit tous les détails sur le protocole de
salutation, notamment sur la délicate négociation des paramètres
cryptographiques. Notez que la renégociation en cours de session a
disparu, donc un ClientHello ne peut
désormais plus être envoyé qu'au début.
Un problème auquel a toujours dû faire face TLS est celui de la
négociation de version, en présence de mises en œuvre boguées, et,
surtout, en présence de boitiers intermédiaires encore plus
bogués (pare-feux ignorants, par exemple, que
des DSI ignorantes placent un peu
partout). Le modèle original de TLS pour un client était d'annoncer
dans le ClientHello le plus grand numéro de
version qu'on gère, et de voir dans ServerHello
le maximum imposé par le serveur. Ainsi, un client TLS 1.2 parlant à
un serveur qui ne gère que 1.1 envoyait
ClientHello(client_version=1.2) et, en recevant
ServerHello(server_version=1.1), se repliait
sur TLS 1.1, la version la plus élevée que les deux parties
gèraient. En pratique, cela ne marche pas aussi bien. On voyait par
exemple des serveurs (ou, plus vraisemblablement, des pare-feux
bogués) qui raccrochaient brutalement en présence d'un numéro de
version plus élevé, au lieu de suggérer un repli. Le client n'avait
alors que le choix de renoncer, ou bien de se lancer dans une série
d'essais/erreurs (qui peut être longue, si le serveur ou le pare-feu
bogué ne répond pas).
TLS 1.3 change donc complètement le
mécanisme de négociation. Le client annonce toujours la version 1.2
(en fait 0x303, pour des raisons historiques), et la vraie version
est mise dans une extension, supported_versions
(section 4.2.1), dont on espère qu'elle sera ignorée par les
serveurs mal gérés. (L'annexe D du RFC détaille ce problème de la
négociation de version.) Dans la réponse
ServerHello, un serveur 1.3 doit inclure cette
extension, autrement, il faut se rabattre sur TLS 1.2.
En
parlant d'extensions, concept qui avait été introduit originellement
dans le RFC 4366, notre RFC reprend des
extensions déjà normalisées, comme le SNI (Server Name
Indication) du RFC 6066, le
battement de cœur du RFC 6520, le remplissage
du ClientHello du RFC 7685, et en ajoute dix, dont
supported_versions. Certaines de ces extensions
doivent être présentes dans les messages Hello,
car la sélection des paramètres cryptographiques en dépend, d'autres
peuvent être uniquement dans les messages
EncryptedExtensions, une nouveauté de TLS 1.3,
pour les extensions qu'on n'enverra qu'une fois le chiffrement
commencé. Le RFC en profite pour rappeler que les messages
Hello ne sont pas protégés cryptographiquement,
et peuvent donc être modifiés (le message
Finished résume les décisions prises et peut
donc protéger contre ce genre d'attaques).
Autrement, parmi les autres nouvelles extensions :
- Le petit gâteau (cookie), pour tester la joignabilité,
- Les données précoces (early data), extension qui permet d'envoyer des données dès le premier message (« 0-RTT »), réduisant ainsi la latence, un peu comme le fait le TCP Fast Open du RFC 7413,
- Liste des AC (certificate authorities), qui, en indiquant la liste des AC connues du client, peut aider le serveur à choisir un certificat qui sera validé (par exemple en n'envoyant le certificat CAcert que si le client connait cette AC).
La section 5 décrit le protocole des enregistrements (record protocol). C'est ce sous-protocole qui va prendre un flux d'octets, le découper en enregistrements, les protéger par le chiffrement puis, à l'autre bout, déchiffrer et reconstituer le flux… Notez que « protégé » signifie à la fois confidentialité et intégrité puisque TLS 1.3, contrairement à ses prédécesseurs, impose AEAD (RFC 5116).
Les enregistrements sont typés et marqués handshake (la salutation, vue dans la section précédente), change cipher spec, alert (pour signaler un problème) et application data (les données elle-mêmes) :
enum {
invalid(0),
change_cipher_spec(20),
alert(21),
handshake(22),
application_data(23),
(255)
} ContentType;
Le contenu des données est évidemment incompréhensible, en raison du chiffrement (voici un enregistrement de type 23, données, vu par tshark) :
TLSv1.3 Record Layer: Application Data Protocol: http-over-tls
Opaque Type: Application Data (23)
Version: TLS 1.2 (0x0303)
Length: 6316
Encrypted Application Data: eb0e21f124f82eee0b7a37a1d6d866b075d0476e6f00cae7...
Et décrite par la norme dans son langage formel :
struct {
ContentType opaque_type = application_data; /* 23 */
ProtocolVersion legacy_record_version = 0x0303; /* TLS v1.2 */
uint16 length;
opaque encrypted_record[TLSCiphertext.length];
} TLSCiphertext;
(Oui, le numéro de version reste à TLS 1.2 pour éviter d'énerver les stupides middleboxes.) Notez que des extensions à TLS peuvent introduire d'autres types d'enregistrements.
Une faiblesse classique de TLS est que la taille des données chiffrées n'est pas dissimulée. Si on veut savoir à quelle page d'un site Web un client HTTP a accédé, on peut parfois le déduire de l'observation de cette taille. D'où la possibilité de faire du remplissage pour dissimuler cette taille (section 5.4 du RFC). Notez que le RFC ne suggère pas de politique de remplissage spécifique (ajouter un nombre aléatoire ? Tout remplir jusqu'à la taille maximale ?), c'est un choix compliqué. Il note aussi que certaines applications font leur propre remplissage, et qu'il n'est alors pas nécessaire que TLS le fasse.
La section 6 du RFC est dédiée au cas des alertes. C'est un des types d'enregistrements possibles, et, comme les autres, il est chiffré, et les alertes sont donc confidentielles. Une alerte a un niveau et une description :
struct {
AlertLevel level;
AlertDescription description;
} Alert;
Le niveau indiquait si l'alerte est fatale mais n'est plus utilisé en TLS 1.2, où il faut se fier uniquement à la description, une énumération des problèmes possibles (message de type inconnu, mauvais certificat, enregistrement non décodable - rappelez-vous que TLS 1.3 n'utilise que du chiffrement intègre -, problème interne au client ou au serveur, extension non acceptée, etc). La section 6.2 donne une liste des erreurs fatales, qui doivent mener à terminer immédiatement la session TLS.
La section 8 du RFC est entièrement consacrée à une nouveauté délicate, le « 0-RTT ». Ce terme désigne la possibilité d'envoyer des données dès le premier paquet, sans les nombreux échanges de paquets qui sont normalement nécessaires pour établir une session TLS. C'est très bien du point de vue des performances, mais pas forcément du point de vue de la sécurité puisque, sans échanges, on ne peut plus vérifier à qui on parle. Un attaquant peut réaliser une attaque par rejeu en envoyant à nouveau un paquet qu'il a intercepté. Un serveur doit donc se défendre en se souvenant des données déjà envoyées et en ne les acceptant pas deux fois. (Ce qui peut être plus facile à dire qu'à faire ; le RFC contient une bonne discussion très détaillée des techniques possibles, et de leurs limites. Il y en a des subtiles, comme d'utiliser des systèmes de mémorisation ayant des faux positifs, comme les filtres de Bloom, parce qu'ils ne produiraient pas d'erreurs, ils rejetteraient juste certains essais 0-RTT légitimes, cela ne serait donc qu'une légère perte de performance.)
La section 9 de notre RFC se penche sur un problème difficile, la
conformité des mises en œuvres de TLS. D'abord, les algorithmes
obligatoires. Afin de permettre l'interopérabilité,
toute mise en œuvre de TLS doit avoir la suite
de chiffrement TLS_AES_128_GCM_SHA256
(AES en
mode GCM avec
SHA-256). D'autres suites sont recommandées
(cf. annexe B.4). Pour l'authentification, RSA avec SHA-256
et ECDSA sont obligatoires. Ainsi, deux
programmes différents sont sûrs de pouvoir trouver des algorithmes
communs. La possibilité
d'authentification par certificats PGP du RFC 6091 a été
retirée.
De plus, certaines extensions à TLS sont obligatoires, un pair TLS 1.3 ne peut pas les refuser :
supported_versions, nécessaire pour annoncer TLS 1.3,cookie,signature_algorithms,signature_algorithms_cert,supported_groupsetkey_share,server_name, c'est à dire SNI (Server Name Indication), souvent nécessaire pour pouvoir choisir le bon certificat (cf. section 3 du RFC 6066).
La section 9 précise aussi le comportement attendu des équipements intermédiaires. Ces dispositifs (pare-feux, par exemple, mais pas uniquement) ont toujours été une plaie pour TLS. Alors que TLS vise à fournir une communication sûre, à l'abri des équipements intermédiaires, ceux-ci passent leur temps à essayer de s'insérer dans la communication, et souvent la cassent. Normalement, TLS 1.3 est conçu pour que ces interférences ne puissent pas mener à un repli (le repli est l'utilisation de paramètres moins sûrs que ce que les deux machines auraient choisi en l'absence d'interférence).
Il y a deux grandes catégories d'intermédiaires, ceux qui tripotent la session TLS sans être le client ou le serveur, et ceux qui terminent la session TLS de leur côté. Attention, dans ce contexte, « terminer » ne veut pas dire « y mettre fin », mais « la sécurité TLS se termine ici, de manière à ce que l'intermédiaire puisse accéder au contenu de la communication ». Typiquement, une middlebox qui « termine » une session TLS va être serveur TLS pour le client et client TLS pour le serveur, s'insérant complètement dans la conversation. Normalement, l'authentification vise à empêcher ce genre de pratiques, et l'intermédiaire ne sera donc accepté que s'il a un certificat valable. C'est pour cela qu'en entreprise, les machines officielles sont souvent installées avec une AC contrôlée par le vendeur du boitier intermédiaire, de manière à permettre l'interception.
Le RFC ne se penche pas sur la légitimité de ces pratiques, uniquement sur leurs caractéristiques techniques. (Les boitiers intermédiaires sont souvent programmés avec les pieds, et ouvrent de nombreuses failles.) Le RFC rappelle notamment que l'intermédiaire qui termine une session doit suivre le RFC à la lettre (ce qui devrait aller sans dire…)
Depuis le RFC 4346, il existe plusieurs registres IANA pour TLS, décrits en section 11, avec leurs nouveautés. En effet, plusieurs choix pour TLS ne sont pas « câblés en dur » dans le RFC mais peuvent évoluer indépendamment. Par exemple, le registre de suites cryptographiques a une politique d'enregistrement « spécification nécessaire » (cf. RFC 8126, sur les politiques d'enregistrement). La cryptographie fait régulièrement des progrès, et il faut donc pouvoir modifier la liste des suites acceptées (par exemple lorsqu'il faudra y ajouter les algorithmes post-quantiques) sans avoir à toucher au RFC (l'annexe B.4 donne la liste actuelle). Le registre des types de contenu, lui, a une politique d'enregistrement bien plus stricte, « action de normalisation ». On crée moins souvent des types que des suites cryptographiques. Même chose pour le registre des alertes ou pour celui des salutations.
L'annexe C du RFC plaira aux programmeurs, elle donne plusieurs conseils pour une mise en œuvre correcte de TLS 1.3 (ce n'est pas tout d'avoir un protocole correct, il faut encore qu'il soit programmé correctement). Pour aider les développeurs à déterminer s'ils ont correctement fait le travail, le RFC 8448 fournit des vecteurs de test.
Un des conseils les plus importants est évidemment de faire
attention au générateur de nombres aléatoires, source de
tant de failles de sécurité en cryptographie. TLS utilise des
nombres qui doivent être imprévisibles à un attaquant pour générer
des clés de session. Si ces nombres sont prévisibles, toute la
cryptographie s'effondre. Le RFC conseille fortement d'utiliser un
générateur existant (comme /dev/urandom sur les
systèmes Unix) plutôt que d'écrire le sien,
ce qui est bien plus difficile qu'il ne semble. (Si on tient quand
même à le faire, le RFC 4086 est une lecture
indispensable.)
Le RFC conseille également de vérifier le certificat du partenaire par défaut (quitte à fournir un moyen de débrayer cette vérification). Si ce n'est pas le cas, beaucoup d'utilisateurs du programme ou de la bibliothèque oublieront de le faire. Il suggère aussi de ne pas accepter certains certificats trop faibles (clé RSA de seulement 1 024 bits, par exemple).
Il existe plusieurs moyens avec TLS de ne pas avoir d'authentification du serveur : les clés brutes du RFC 7250 (à la place des certificats), ou bien les certificats auto-signés. Dans ces conditions, une attaque de l'homme du milieu est parfaitement possible, et il faut donc prendre des précautions supplémentaires (par exemple DANE, normalisé dans le RFC 6698, que le RFC oublie malheureusement de citer).
Autre bon conseil de cryptographie, se méfier des attaques fondées sur la mesure du temps de calcul, et prendre des mesures appropriées (par exemple en vérifiant que le temps de calcul est le même pour des données correctes et incorrectes).
Il n'y a aucune bonne raison d'utiliser certains algorithmes faibles (comme RC4, abandonné depuis le RFC 7465), et le RFC demande que le code pour ces algorithmes ne soit pas présent, afin d'éviter une attaque par repli (annexes C.3 et D.5 du RFC). De la même façon, il demande de ne jamais accepter SSL v3 (RFC 7568).
L'expérience a prouvé que beaucoup de mises en œuvre de TLS ne réagissaient pas correctement à des options inattendues, et le RFC rappelle donc qu'il faut ignorer les suites cryptographiques inconnues (autrement, on ne pourrait jamais introduire une nouvelle suite, puisqu'elle casserait les programmes), et ignorer les extensions inconnues (pour la même raison).
L'annexe D, elle, est consacrée au problème de la communication
avec un vieux partenaire, qui ne connait pas TLS 1.3. Le mécanisme
de négociation de la version du protocole à utiliser a complètement
changé en 1.3. Dans la 1.3, le champ version du
ClientHello contient 1.2, la vraie version
étant dans l'extension supported_versions. Si
un client 1.3 parle avec un serveur <= 1.2, le serveur ne
connaitra pas cette extension et répondra sans l'extension,
avertissant ainsi le client qu'il faudra parler en 1.2 (ou plus
vieux). Ça, c'est si le serveur est correct. S'il ne l'est pas ou,
plus vraisemblablement, s'il est derrière une middlebox
boguée, on verra des problèmes comme par exemple le refus de
répondre aux clients utilisant des extensions inconnues (ce qui sera
le cas pour supported_versions), soit en
rejettant ouvertement la demande soit, encore pire, en
l'ignorant. Arriver à gérer des
serveurs/middleboxes incorrects est un problème
complexe. Le client peut être tenté de re-essayer avec d'autres
options (par exemple tenter du 1.2, sans l'extension
supported_versions). Cette méthode n'est pas
conseillée. Non seulement elle peut prendre du temps (attendre
l'expiration du délai de garde, re-essayer…) mais surtout, elle
ouvre la voie à des attaques par repli : l'attaquant bloque les
ClientHello 1.3 et le client, croyant bien
faire, se replie sur une version plus ancienne et sans doute moins
sûre de TLS.
En parlant de compatibilité, le « 0-RTT » n'est évidemment pas
compatible avec les vieilles versions. Le client qui envoie du
« 0-RTT » (des données dans le ClientHello)
doit donc savoir que, si la réponse est d'un serveur <= 1.2,
la session ne pourra pas être établie, et il faudra donc réessayer
sans 0-RTT.
Naturellement, les plus gros problèmes ne surviennent pas avec
les clients et les serveurs mais avec les
middleboxes. Plusieurs études ont montré leur
caractère néfaste (cf. présentation
à l'IETF 100, mesures
avec Chrome (qui indique également que certains serveurs TLS
sont gravement en tort, comme celui installé dans les imprimantes
Canon), mesures
avec Firefox, et encore
d'autres mesures). Le RFC suggère qu'on limite les risques en
essayant d'imiter le plus possible une salutation de TLS 1.2, par
exemple en envoyant des messages
change_cipher_spec, qui ne sont plus utilisés
en TLS 1.3, mais qui peuvent rassurer la
middlebox (annexe D.4).
Enfin, le RFC se termine par l'annexe E, qui énumère les propriétés de sécurité de TLS 1.3 : même face à un attaquant actif (RFC 3552), le protocole de salutation de TLS garantit des clés de session communes et secrètes, une authentification du serveur (et du client si on veut), et une sécurité persistante, même en cas de compromission ultérieure des clés (sauf en cas de 0-RTT, un autre des inconvénients sérieux de ce service, avec le risque de rejeu). De nombreuses analyses détaillées de la sécurité de TLS sont listées dans l'annexe E.1.6. À lire si vous voulez travailler ce sujet.
Quant au protocole des enregistrements, celui de TLS 1.3 garantit confidentialité et intégrité (RFC 5116).
TLS 1.3 a fait l'objet de nombreuses analyses de sécurité par des chercheurs, avant même sa normalisation, ce qui est une bonne chose (et qui explique en partie les retards). Notre annexe E pointe également les limites restantes de TLS :
- Il est vulnérable à l'analyse de trafic. TLS n'essaie pas de cacher la taille des paquets, ni l'intervalle de temps entre eux. Ainsi, si un client accède en HTTPS à un site Web servant quelques dizaines de pages aux tailles bien différentes, il est facile de savoir quelle page a été demandée, juste en observant les tailles. (Voir « I Know Why You Went to the Clinic: Risks and Realization of HTTPS Traffic Analysis », de Miller, B., Huang, L., Joseph, A., et J. Tygar et « HTTPS traffic analysis and client identification using passive SSL/TLS fingerprinting », de Husak, M., Čermak, M., Jirsik, T., et P. Čeleda). TLS fournit un mécanisme de remplissage avec des données bidon, permettant aux applications de brouiller les pistes. Certaines applications utilisant TLS ont également leur propre remplissage (par exemple, pour le DNS, c'est le RFC 7830). De même, une mise en œuvre de TLS peut retarder les paquets pour rendre l'analyse des intervalles plus difficile. On voit que dans les deux cas, taille des paquets et intervalle entre eux, résoudre le problème fait perdre en performance (c'est pour cela que ce n'est pas intégré par défaut).
- TLS peut être également vulnérable à des attaques par canal auxiliaire. Par exemple, la durée des opérations cryptographiques peut être observée, ce qui peut donner des informations sur les clés. TLS fournit quand même quelques défenses : l'AEAD facilite la mise en œuvre de calculs en temps constant, et format uniforme pour toutes les erreurs, empêchant un attaquant de trouver quelle erreur a été déclenchée.
Le 0-RTT introduit un nouveau risque, celui de rejeu. (Et 0-RTT a sérieusement contribué aux délais qu'a connu le projet TLS 1.3, plusieurs participants à l'IETF protestant contre cette introduction risquée.) Si l'application est idempotente, ce n'est pas très grave. Si, par contre, les effets d'une requête précédentes peuvent être rejoués, c'est plus embêtant (imaginez un transfert d'argent répété…) TLS ne promet rien en ce domaine, c'est à chaque serveur de se défendre contre le rejeu (la section 8 donne des idées à ce sujet). Voilà pourquoi le RFC demande que les requêtes 0-RTT ne soient pas activées par défaut, mais uniquement quand l'application au-dessus de TLS le demande. (Cloudflare, par exemple, n'active pas le 0-RTT par défaut.)
Voilà, vous avez maintenant fait un tour complet du RFC, mais vous savez que la cryptographie est une chose difficile, et pas seulement dans les algorithmes cryptographiques (TLS n'en invente aucun, il réutilise des algorithmes existants comme AES ou ECDSA), mais aussi dans les protocoles cryptographiques, un art complexe. N'hésitez donc pas à lire le RFC en détail, et à vous méfier des résumés forcément toujours sommaires, comme cet article.
À part le 0-RTT, le plus gros débat lors de la création de TLS
1.3 avait été autour du concept que ses partisans nomment
« visibilité » et ses adversaires « surveillance ». C'est l'idée
qu'il serait bien pratique si on (on : le patron, la police, le
FAI…)
pouvait accéder au contenu des communications TLS. « Le chiffrement,
c'est bien, à condition que je puisse lire les données quand même »
est l'avis des partisans de la visibilité. Cela avait été proposé
dans les Internet-Drafts draft-green-tls-static-dh-in-tls13
et draft-rhrd-tls-tls13-visibility. Je
ne vais pas ici pouvoir capturer la totalité du débat, juste noter
quelques points qui sont parfois oubliés dans la discussion. Côté
partisans de la visibilité :
- Dans une entreprise capitaliste, il n'y pas de citoyens, juste un patron et des employés. Les ordinateurs appartiennent au patron, et les employés n'ont pas leur mot à dire. Le patron peut donc décider d'accéder au contenu des communications chiffrées.
- Il existe des règles (par exemple PCI-DSS dans le secteur financier ou HIPAA dans celui de la santé) qui requièrent de certaines entreprises qu'elles sachent en détail tout ce qui circule sur le réseau. Le moyen le plus simple de le faire est de surveiller le contenu des communications, même chiffrées. (Je ne dis pas que ces règles sont intelligentes, juste qu'elles existent. Notons par exemple que les mêmes règles imposent d'utiliser du chiffrement fort, sans faille connue, ce qui est contradictoire.)
- Enregistrer le trafic depuis les terminaux est compliqué en pratique : applications qui n'ont pas de mécanisme de journalisation du trafic, systèmes d'exploitation fermés, boîtes noires…
- TLS 1.3 risque de ne pas être déployé dans les entreprises qui tiennent à surveiller le trafic, et pourrait même être interdit dans certains pays, où la surveillance passe avant les droits humains.
Et du côté des adversaires de la surveillance :
- La cryptographie, c'est compliqué et risqué. TLS 1.3 est déjà assez compliqué comme cela. Lui ajouter des fonctions (surtout des fonctions délibérement conçues pour affaiblir ses propriétés de sécurité) risque fort d'ajouter des failles de sécurité. D'autant plus que TLS 1.3 a fait l'objet de nombreuses analyses de sécurité avant son déploiement, et qu'il faudrait tout recommencer.
- Contrairement à ce que semblent croire les partisans de la « visibilité », il n'y a pas que HTTPS qui utilise TLS. Ils ne décrivent jamais comment leur proposition marcherait avec des protocoles autres que HTTPS.
- Pour HTTPS, et pour certains autres protocoles, une solution simple, si on tient absolument à intercepter tout le trafic, est d'avoir un relais explicite, configuré dans les applications, et combiné avec un blocage dans le pare-feu des connexions TLS directes. Les partisans de la visibilité ne sont en général pas enthousiastes pour cette solution car ils voudraient faire de la surveillance furtive, sans qu'elle se voit dans les applications utilisées par les employés ou les citoyens.
- Les partisans de la « visibilité » disent en général que l'interception TLS serait uniquement à l'intérieur de l'entreprise, pas pour l'Internet public. Mais, dans ce cas, tous les terminaux sont propriété de l'entreprise et contrôlés par elle, donc elle peut les configurer pour copier tous les messages échangés. Et, si certains de ces terminaux sont des boîtes noires, non configurables et dont on ne sait pas bien ce qu'ils font, eh bien, dans ce cas, on se demande pourquoi des gens qui insistent sur leurs obligations de surveillance mettent sur leur réseau des machines aussi incontrôlables.
- Dans ce dernier cas (surveillance uniquement au sein d'une entreprise), le problème est interne à l'entreprise, et ce n'est donc pas à l'IETF, organisme qui fait des normes pour l'Internet, de le résoudre. Après tout, rien n'empêche ces entreprises de garder TLS 1.2.
Revenons maintenant aux choses sérieuses, avec les mises en œuvre de TLS 1.3. Il y en existe au moins une dizaine à l'heure actuelle et la version 1.3 est désormais largement déployée.
Par exemple, avec un GnuTLS récent, on peut utiliser le
programme en ligne de commande gnutls-cli avec
un serveur qui accepte TLS 1.3 :
% gnutls-cli -V gmail.com ... - Description: (TLS1.3-X.509)-(ECDHE-SECP256R1)-(ECDSA-SECP256R1-SHA256)-(AES-256-GCM) - Ephemeral EC Diffie-Hellman parameters - Using curve: SECP256R1 - Curve size: 256 bits - Version: TLS1.3 - Server Signature: ECDSA-SECP256R1-SHA256 - Cipher: AES-256-GCM - MAC: AEAD ...
Et ça marche, on fait du TLS 1.3. Si vous préférez écrire le
programme vous-même, regardez ce petit
programme. Si GnuTLS est en /local, il
se compilera avec cc -I/local/include -Wall -Wextra -o
test-tls13 test-tls13.c -L/local/lib -lgnutls et
s'utilisera avec :
% ./test-tls13 www.ietf.org TLS connection using "TLS1.3 AES-256-GCM" % ./test-tls13 gmail.com TLS connection using "TLS1.3 AES-256-GCM" % ./test-tls13 blog.cloudflare.com TLS connection using "TLS1.3 AES-256-GCM" % ./test-tls13 cr.yp.to TLS connection using "TLS1.2 CHACHA20-POLY1305"
Cela vous donne une petite idée des serveurs qui acceptent TLS 1.3 (le dernier testé ne l'accepte pas).
Un pcap d'une session TLS 1.3 est
disponible en tls13-2.pcap. Regardez le numéro de
version de TLS dans l'extension (0x304), qui identifie TLS 1.3. Voici la
session vue par tshark :
1 0.000000 2001:41d0:302:2200::180 → 2606:4700::6810:7b60 TCP 94 56462 → 443 [SYN] Seq=0 Win=64800 Len=0 MSS=1440 SACK_PERM TSval=2022119812 TSecr=0 WS=1024
2 0.005516 2606:4700::6810:7b60 → 2001:41d0:302:2200::180 TCP 94 443 → 56462 [SYN, ACK] Seq=0 Ack=1 Win=65535 Len=0 MSS=1360 SACK_PERM TSval=4271324975 TSecr=2022119812 WS=8192
3 0.005539 2001:41d0:302:2200::180 → 2606:4700::6810:7b60 TCP 86 56462 → 443 [ACK] Seq=1 Ack=1 Win=65536 Len=0 TSval=2022119818 TSecr=4271324975
4 0.005837 2001:41d0:302:2200::180 → 2606:4700::6810:7b60 TLSv1 492 Client Hello (SNI=www.cloudflare.com)
5 0.011387 2606:4700::6810:7b60 → 2001:41d0:302:2200::180 TCP 86 443 → 56462 [ACK] Seq=1 Ack=407 Win=131072 Len=0 TSval=4271324981 TSecr=2022119818
6 0.013523 2606:4700::6810:7b60 → 2001:41d0:302:2200::180 TLSv1.3 1434 Server Hello, Change Cipher Spec
7 0.013523 2606:4700::6810:7b60 → 2001:41d0:302:2200::180 TCP 520 [TCP Previous segment not captured] 443 → 56462 [PSH, ACK] Seq=2697 Ack=407 Win=131072 Len=434 TSval=4271324983 TSecr=2022119818 [TCP segment of a reassembled PDU]
8 0.013523 2606:4700::6810:7b60 → 2001:41d0:302:2200::180 TCP 1434 [TCP Out-Of-Order] 443 → 56462 [ACK] Seq=1349 Ack=407 Win=131072 Len=1348 TSval=4271324983 TSecr=2022119818
9 0.013543 2001:41d0:302:2200::180 → 2606:4700::6810:7b60 TCP 86 56462 → 443 [ACK] Seq=407 Ack=1349 Win=68608 Len=0 TSval=2022119826 TSecr=4271324983
10 0.013555 2001:41d0:302:2200::180 → 2606:4700::6810:7b60 TCP 98 [TCP Dup ACK 9#1] 56462 → 443 [ACK] Seq=407 Ack=1349 Win=68608 Len=0 TSval=2022119826 TSecr=4271324983 SLE=2697 SRE=3131
11 0.013560 2001:41d0:302:2200::180 → 2606:4700::6810:7b60 TCP 86 56462 → 443 [ACK] Seq=407 Ack=3131 Win=68608 Len=0 TSval=2022119826 TSecr=4271324983
12 0.013799 2001:41d0:302:2200::180 → 2606:4700::6810:7b60 TLSv1.3 92 Change Cipher Spec
13 0.028771 2001:41d0:302:2200::180 → 2606:4700::6810:7b60 TLSv1.3 160 Application Data
14 0.034250 2606:4700::6810:7b60 → 2001:41d0:302:2200::180 TCP 86 443 → 56462 [ACK] Seq=3131 Ack=488 Win=131072 Len=0 TSval=4271325004 TSecr=2022119826
15 0.035800 2606:4700::6810:7b60 → 2001:41d0:302:2200::180 TCP 86 443 → 56462 [FIN, ACK] Seq=3131 Ack=488 Win=131072 Len=0 TSval=4271325005 TSecr=2022119826
16 0.035821 2001:41d0:302:2200::180 → 2606:4700::6810:7b60 TCP 86 56462 → 443 [ACK] Seq=488 Ack=3132 Win=69632 Len=0 TSval=2022119848 TSecr=4271325005
Et, complètement décodée par tshark :
Transport Layer Security
TLSv1 Record Layer: Handshake Protocol: Client Hello
Content Type: Handshake (22)
Version: TLS 1.0 (0x0301)
Length: 401
Handshake Protocol: Client Hello
Handshake Type: Client Hello (1)
Length: 397
Version: TLS 1.2 (0x0303)
Cipher Suites Length: 58
Cipher Suites (29 suites)
Cipher Suite: TLS_AES_256_GCM_SHA384 (0x1302)
Cipher Suite: TLS_CHACHA20_POLY1305_SHA256 (0x1303)
…
Compression Methods Length: 1
Compression Methods (1 method)
Compression Method: null (0)
Extensions Length: 266
Extension: ec_point_formats (len=2)
Type: ec_point_formats (11)
Length: 2
EC point formats Length: 1
Elliptic curves point formats (1)
EC point format: uncompressed (0)
Extension: key_share (len=107) secp256r1, x25519
Type: key_share (51)
Length: 107
Key Share extension
Client Key Share Length: 105
Key Share Entry: Group: secp256r1, Key Exchange length: 65
Group: secp256r1 (23)
Key Exchange Length: 65
Key Exchange: 04baaae9e5261e75a052917c5266e92491905e012c8403dacdb3ae5cd4edc025d87d6d1131fb01e1c71d031cd5c1e4eaa49a8db64dceea2238a2f459206f5e592a
Key Share Entry: Group: x25519, Key Exchange length: 32
Group: x25519 (29)
Key Exchange Length: 32
Key Exchange: 81f6e52c0e771d320529cdff1729c1c290842a68044f86223a80cf608926be5d
Extension: server_name (len=23) name=www.cloudflare.com
Type: server_name (0)
Length: 23
Server Name Indication extension
Server Name list length: 21
Server Name Type: host_name (0)
Server Name length: 18
Server Name: www.cloudflare.com
Extension: status_request (len=5)
Type: status_request (5)
Length: 5
Certificate Status Type: OCSP (1)
Responder ID list Length: 0
Request Extensions Length: 0
Extension: session_ticket (len=0)
Type: session_ticket (35)
Length: 0
Session Ticket: <MISSING>
Extension: supported_groups (len=22)
Type: supported_groups (10)
Length: 22
Supported Groups List Length: 20
Supported Groups (10 groups)
Supported Group: secp256r1 (0x0017)
Supported Group: secp384r1 (0x0018)
Supported Group: secp521r1 (0x0019)
Supported Group: x25519 (0x001d)
Supported Group: x448 (0x001e)
Supported Group: ffdhe2048 (0x0100)
Supported Group: ffdhe3072 (0x0101)
Supported Group: ffdhe4096 (0x0102)
Supported Group: ffdhe6144 (0x0103)
Supported Group: ffdhe8192 (0x0104)
Extension: record_size_limit (len=2)
Type: record_size_limit (28)
Length: 2
Record Size Limit: 16385
Extension: encrypt_then_mac (len=0)
Type: encrypt_then_mac (22)
Length: 0
Extension: supported_versions (len=9) TLS 1.3, TLS 1.2, TLS 1.1, TLS 1.0
Type: supported_versions (43)
Length: 9
Supported Versions length: 8
Supported Version: TLS 1.3 (0x0304)
Supported Version: TLS 1.2 (0x0303)
Supported Version: TLS 1.1 (0x0302)
Supported Version: TLS 1.0 (0x0301)
Extension: psk_key_exchange_modes (len=3)
Type: psk_key_exchange_modes (45)
Length: 3
PSK Key Exchange Modes Length: 2
PSK Key Exchange Mode: PSK with (EC)DHE key establishment (psk_dhe_ke) (1)
PSK Key Exchange Mode: PSK-only key establishment (psk_ke) (0)
Extension: extended_master_secret (len=0)
Type: extended_master_secret (23)
Length: 0
Extension: signature_algorithms (len=40)
Type: signature_algorithms (13)
Length: 40
Signature Hash Algorithms Length: 38
Signature Hash Algorithms (19 algorithms)
Signature Algorithm: Unknown SM2 (0x0904)
Signature Hash Algorithm Hash: Unknown (9)
Signature Hash Algorithm Signature: SM2 (4)
Signature Algorithm: Unknown Unknown (0x0905)
Signature Hash Algorithm Hash: Unknown (9)
Signature Hash Algorithm Signature: Unknown (5)
…
Extension: renegotiation_info (len=1)
Type: renegotiation_info (65281)
Length: 1
Renegotiation Info extension
Renegotiation info extension length: 0
Le texte complet est en tls13-2.txt. Notez bien que la négociation est
en clair. D'autres exemples de traces TLS 1.3 figurent dans le RFC 8448.
Quelques autres articles à lire :
- L'annonce officielle de l'IETF,
- Le bon résumé de Cloudflare sur la version 1.3,
- Liste complète des réponses aux partisans de la visbilité,
- Bon article historique très détaillé sur l'histoire de TLS, jusqu'à la version 1.3,
- Un exemple d'un des ateliers où a été étudié la sécurité de TLS 1.3 à San Diego en 2016,
- Bon article sur la question des middleboxes, expliquant notamment les extensions « inutiles », mais permettant de tromper ces middleboxes pour ressembler à TLS 1.2.
L'article seul
Réseau « avec connexion » ou « sans connexion », un peu d'histoire et de technique
Première rédaction de cet article le 7 juillet 2026
Dans les débats sur la conception d'un réseau informatique de grande taille, on entend souvent des références à une discussion « commutation de paquets » vs. « commutation de circuits ». Cela revient souvent, par exemple, quand on parle en France des choix de Transpac par rapport à l'Internet. Mais la discussion est parfois mal informée sur la réalité de ces architectures et elle oublie une autre discussion, « commutation de paquets » vs. « datagramme pur ».
Comme toute création humaine, l'Internet a son « roman national ». Dans la version la plus simpliste, les gens des télécommunications se seraient cramponnés trop longtemps à la « commutation de circuits » et l'Internet, grâce à l'invention par les informaticiens de la « commutation de paquets » se serait imposé en raison de cette supériorité technique. Bon, peu de gens vont défendre une version aussi caricaturale mais ce récit a quand même laissé des traces. Alors, approfondissons. D'abord, c'est quoi, la différence entre « commutation de paquets » et « commutation de circuits » ?
La commutation de circuits vient effectivement du monde de la téléphonie. À l'époque où une standardiste manipulait des connexions physiques, chaque coup de téléphone avait un circuit physique, un fil de cuivre continu, rien que pour lui. Ce système manquait évidemment de souplesse, et a fini par être remplacé par des circuits virtuels. On était toujours en commutation de circuits (il fallait établir le circuit avant de pouvoir échanger un mot, et le circuit était ensuite entièrement dédié) mais cette fois on n'avait plus de lien physique. Par exemple, les liens physiques étaient partagés temporellement.
La commutation de circuits est relativement simple à réaliser. Par exemple, si on l'applique à l'informatique, l'émetteur n'a rien d'autre à faire que d'envoyer les bits sur le circuit obtenu (c'est ainsi que ça fonctionnait avec les modems). Mais elle a des limites, notamment un certain gaspillage des ressources : le circuit est établi, et des ressources réservées, même si les deux participants n'ont rien à dire. Comme cette technique est celle de la téléphonie, elle est longtemps restée populaire dans le monde des télécommunications (entre autres car elle collait bien à leur modèle de facturation à la durée).
Et la commutation de paquets ? Cette fois, le flux de données est découpé en petites unités, les paquets, et chaque paquet est transmis « indépendamment ». Si des participants n'ont rien à dire, les commutateurs peuvent consacrer leur temps à traiter des paquets d'autres participants. Chaque paquet comporte des informations d'adressage (qui étaient absentes en commutation de circuits puisque chaque conversation avait son propre circuit), permettant au commutateur de savoir quoi faire du paquet. Un tel système a traditionnellement plutôt la faveur des informaticiens, dont les ordinateurs ont un trafic réseau très irrégulier.
Mais c'est ensuite que les choses se compliquent. car « commutation de paquets » peut signifier deux choses différentes. On peut imposer la création d'un circuit virtuel avant tout échange, ou bien on peut utiliser des datagrammes, des paquets de données complètement autonomes, qui ne dépendent pas d'une connexion. (La terminologie dans ce domaine est souvent variable, et parfois floue. Le terme « datagramme » a pu être utilisé pour des paquets non autonomes et on parle alors de « datagramme pur » pour les paquets réellement autonomes. Ne vous lancez pas dans un débat sur ces techniques sans qu'il y ait auparavant un accord sur des définitions précises de tous les termes.)
Lorsqu'on crée un circuit virtuel, l'établissement préalable d'une connexion est nécessaire, exactement comme dans la commutation de circuits. La différence avec celle-ci est que les données seront ensuite découpées en paquets, et que chaque paquet portera une information d'adressage. Typiquement, un identifiant sera attribué à la connexion, lors de l'établissement initial de celle-ci, et cet identifiant sera mis dans chaque paquet. Les commutateurs sur le trajet sauront alors quoi faire du paquet.
Comme avec la commutation de circuits, cette commutation de paquets nécessite un établissement de connexion initial (et donc ne satisfait pas les applications qui veulent une très courte latence), et surtout nécessite un état dans tous les équipements intermédiaires : si un commutateur redémarre et perd son état, les connexions en cours seront coupées.
Par compte, avec le datagramme, chaque paquet est complètement auto-suffisant. Il porte l'adresse de destination de l'autre machine et peut être acheminé par les routeurs sans avoir à faire partie d'une connexion. Si un routeur redémarre, ou bien si le routage change et qu'on passe par d'autres routeurs, cela n'a pas de conséquences fâcheuses, puisqu'il n'y a pas d'état dans le réseau.
Comme souvent avec les choix d'ingénierie, il n'y a pas de solution idéale. Chacune de ces trois architectures (commutation de circuits, commutation de paquets, datagramme) a ses avantages et ses inconvénients. Ainsi, le datagramme permet un meilleur passage à l'échelle, ce qui est important pour un gros réseau mondial comme l'Internet, puisque les routeurs n'ont pas besoin de mémoriser un état. Il est une des raisons du succès de l'Internet. Mais en revanche, il impose que chaque paquet porte une information d'adressage complète, pas une simple étiquette attribuée à la connexion, ce qui utilise davantage d'octets et, surtout, impose des adresses de taille fixe, puisqu'on ne peut pas demander à un routeur qui traite des centaines de millions de paquets par seconde de faire des analyses trop compliquées. Ce choix des adresses de taille fixe a à son tour la conséquence que, si on a mal calculé la taille nécessaire, augmenter celle-ci nécessite de changer le format des paquets et donc tous les routeurs.
Et puis, bien sûr, un autre inconvénient du datagramme est que son modèle (on envoie chaque paquet indépendamment) ne colle pas avec les demandes de la plupart des applications. La très grande majorité des applications préfère envoyer des octets dans l'ordre et qu'ils arrivent tous, et dans l'ordre. Les applications ont davantage besoin d'un modèle de circuit. C'est pour cela que, dans l'Internet, les applications utilisent en général TCP (RFC 9293) ou QUIC (RFC 9000), qui recréent un circuit virtuel au-dessus des datagrammes.
Si on fait un peu d'histoire, il est intéressant de se rappeler qu'Arpanet, l'ancêtre de l'Internet, était à commutation de circuits, tout comme X.25. L'Internet n'est devenu complètement « à datagrammes » qu'en 1983 avec l'arrivée d'IPv4. (Notons aussi que les protocoles utilisés par les machines terminales, aussi bien avec l'Arpanet qu'avec X.25, ne sont pas ceux utilisés à l'intérieur du réseau. C'est une des innovations d'IP d'avoir utilisé le même protocole partout. Pour Arpanet, vous pouvez lire par exemple le RFC 33.) Par contre, Cyclades a utilisé le datagramme mais il est très difficile de trouver des articles techniques détaillés sur le fonctionnement de Cyclades.
Sur ce sujet, vous pouvez aussi consulter l'article de Valérie Schafer, « Circuits virtuels et datagrammes : une concurrence à plusieurs échelles ».
L'article seul
Exposition sur l'histoire du CD-ROM et conférence Technostalgia
Première rédaction de cet article le 3 juillet 2026
Du 18 au 20 juin 2026, à Luxembourg, se tenait une exposition scientifique sur l'histoire du CD-ROM et la conférence Technostalgia.
L'exposition sur l'histoire du CD-ROM
montrait des CD-ROM divers, des explications, des exemples de
technologies proches, qui n'ont pas été le même succès, des livres
et journaux qui rappellent que c'était tout un écosystème très
dynamique. 

On voyait des CD-ROM de Flight Simulator
(puisque les jeux, à
l'époque, étaient distribués sur CD-ROM), et bien sûrs les kits de
connexion Internet  .
.
Mais le mieux, dans
l'exposition, était la possibilité de faire fonctionner les
programmes sur de vraies machines de l'époque avec
Windows 95 ou 98. On pouvait insérer le
CD-ROM, répondre à plein de questions (comme le type de
Sound Blaster présent dans le PC) et jouer. Et
retrouver le plaisir des plantages. 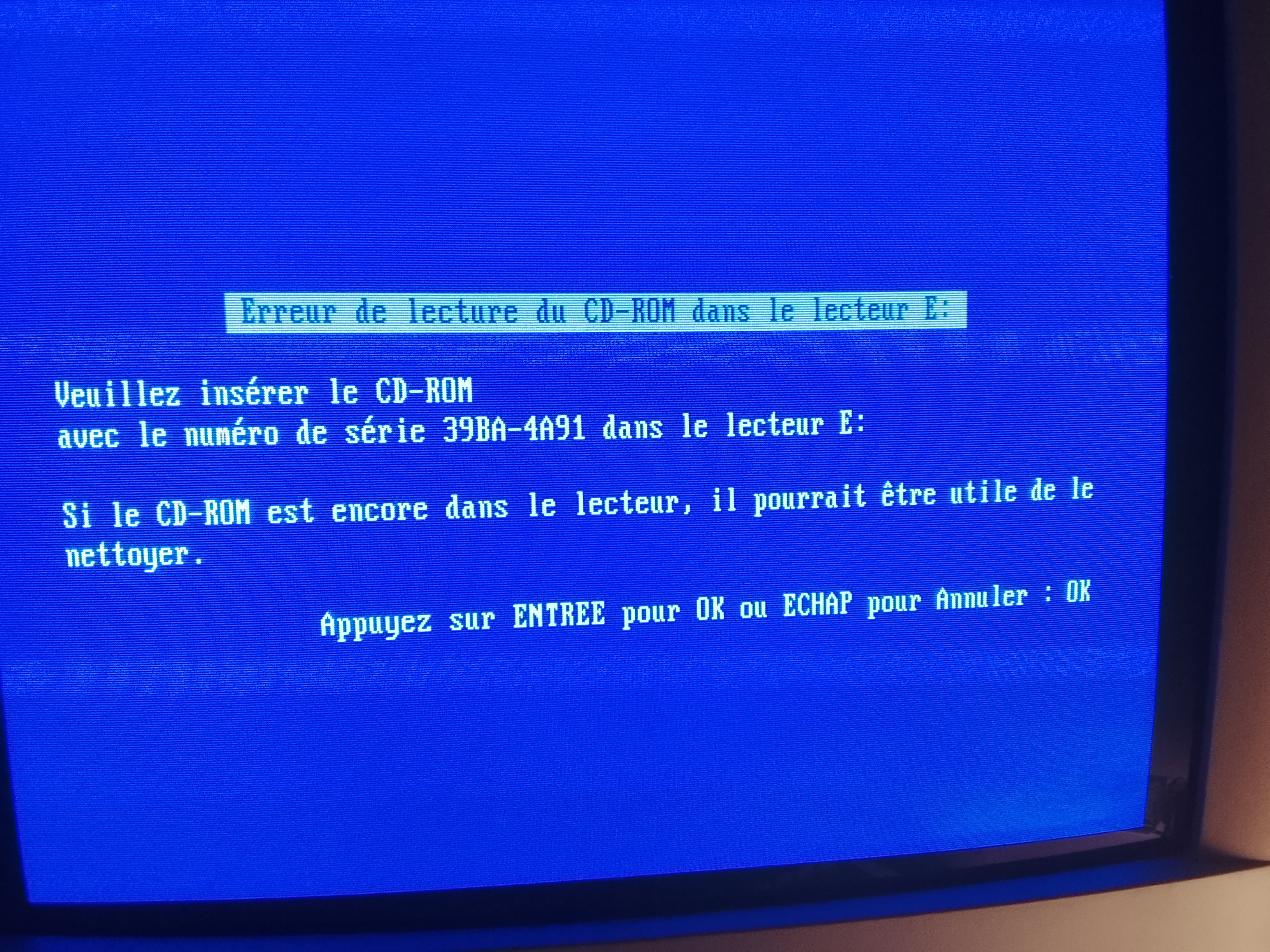
Et il y avait de l'art, aussi

La conférence Technostalgia était une conférence scientifique dédiée au phénomène de technostalgie, le souvenir agréable de technologies anciennes… qui n'étaient pas forcément si agréables sur le moment ! D'ailleurs, Jesper Verhoef a commencé par une dénonciation du mythe « c'était mieux avant », en expliquant que les technologies du passé, comme celles du présent, avaient des problèmes. Par exemple, le walkman promouvait l'individualisme, et le fax avait commencé à effacer la frontière entre temps de travail (au bureau) et repos (à la maison). Et le Minitel, que des passionnés continuent à faire vivre aujourd'hui, était un gouffre financier pour ses utilisateurs, et un système centralisé et fermé.
Till Heilmann a parlé de l'histoire du format GIF, qui a été
pendant longtemps le principal format de distribution d'images
(beaucoup de CD-ROM étaient des collections d'images GIF). Il a
insisté sur le fait que regarder aujourd'hui ces images ne nous
donne pas une bonne idée de ce qu'on voyait à l'époque, les
logiciels et les écrans ayant changé. Sa démonstration utilisait
d'ailleurs un émulateur
MS-DOS, un logiciel de
CompuServe (Compushow alias
CSHOW.EXE) et le CD-ROME
CARRS pour le contenu. À l'époque, utiliser un CD-ROM
nécessitait de savoir répondre à des questions comme « avez-vous du
VGA ? ». Pour ses recherches, il a dû écrire
son propre analyseur GIF (inutile de dire que
ni les logiciels de l'époque, ni les images, ne suivaient
correctement la spécification, pourtant largement disponible).
Johanna Arnesson et Evelina Liliequist ont parlé de l'introduction de l'Internet au grand public en Suède au début des années 1990. L'une des chercheuses avait même relu son journal intime d'adolescente de l'époque « aujourd'hui, j'ai surfé sur Internet, c'était super ». Pourtant, il fallait noter sur le papier les adresses des sites Web intéressants, et les faire circuler au lycée. Mais cette soudaine ouverture sur le monde semblait extraordinaire. Et, comme souvent en technostalgie, un son ennuyeux à l'époque (le long sifflement du modem) réveille aujourd'hui de bons souvenirs.
Julien Mailland et Kevin Driscoll, eux, faisaient revivre des services Minitel (« vous envoyez beaucoup d'argent et vous recevez du contenu ; exactement comme l'App Store »). Certes, le PAVI n'existe plus (encore que des passionnés ont, curieusement, re-créé un équivalent de ce symbole du réseau contrôlé et pompe à fric) mais les Minitels ont toujours pu parler directement aux serveurs via le réseau téléphonique et cette possibilité est encore utilisée aujourd'hui. Par contre, les auteurs ont critiqué les limites de la reconstitution (re-enactment) : elle n'est jamais parfaitement réaliste, tout n'est pas reconstitué (certaines technologies sont privilégiées) et surtout la reconstitution est déconnectée des conditions politico-économiques de l'époque.
Dans la séance finale, Benjamin Thierry a également mentionné ce fait que la technostalgie est sélective et qu'elle ne garde que les aspects sympathiques du passé. La technostalgie est aussi une technamnésie. En outre, elle est souvent élitiste « ah, c'était mieux avant que tous ces idiots ne débarquent ».
Merci à Valérie Schafer, à tous ceux et toutes celles qui ont
contribué à cette exposition et cette conférence 
L'article seul
RFC 9998: Report from the IAB/W3C Workshop on Age-Based Restrictions on Content Access
Date de publication du RFC : Juin 2026
Auteur(s) du RFC : M. Nottingham, M. Thomson
Pour information
Première rédaction de cet article le 3 juillet 2026
En octobre 2025, l'IAB et le W3C ont organisé un atelier à Londres sur la restriction d'accès à des services Internet en fonction de l'âge. Ce RFC est le compte-rendu de l'atelier. En tant que compte-rendu, il n'exprime donc pas une position officielle de l'IAB.
Le sujet est d'actualité, avec de nombreux politiciens qui proposent d'interdire les réseaux sociaux ou la pornographie aux mineurs. Des lois sont déjà votées, comme en Australie. L'UE a un plan en cours et un projet de logiciel. Vous pouvez consulter le site du projet logiciel. En France, où l'une des questions secondaires était la compatibilité d'un éventuel contrôle avec le droit européen, un arrêt du 16 juin 2026 de la Cour de justice de l’Union européenne a estimé que la France pouvait obliger des sociétés basées dans un État membre à mettre en place une vérification d’âge.
L'atelier
devait explorer les différents techniques et choix
d'architecture liés à ce désir de restriction. Comment combiner
cette exigence de restriction aux mineurs tout en préservant les
principes d'universalité et de décentralisation de l'Internet, ainsi
que la vie privée ? Comment le faire sans mettre en place un
système de contrôle qui fera le bonheur de gouvernements
autoritaires voire dictatoriaux ? Et faut-il déléguer la sécurité
des enfants aux opérateurs Internet, plutôt qu'aux adultes qui s'en
occupent (parents, enseignants, etc) ? Les politiciens qui réclament
des restrictions d'âge « pour protéger les enfants » ne se posent
évidemment jamais ces questions (et les avertissements
des experts sont systèmatiquement ignorés). Un exemple
non technique : ces restrictions peuvent servir à un gouvernement
religieux et/ou réactionnaire pour bloquer l'accès à des sites Web
LGBT, au détriment des mineurs en
questionnement qui voudraient s'informer (notez que le RFC ne
mentionne pas ce point). L'atelier n'a pas essayé de traiter les
problèmes politiques, mais uniquement d'analyser les techniques
existantes et de pointer leurs caractéristiques et leurs
conséquences. Comme indiqué au début, cet atelier a été l'occasion
d'exprimer des points de vue variés (sous la règle de
Chatham House), ce RFC ne prétend pas en faire un synthèse, ni
donner La Bonne Réponse. Le RFC inclut notamment une liste des
propriétés attendues d'une « bonne » solution, dans l'annexe D. Ce
point de départ d'un vrai cahier des charges manque dans la plupart
des discours politiciens, où on ne fait que répéter des slogans,
sans dire clairement quels sont les avantages attendus et les
inconvénients acceptables. (L'annexe C est une intéressante liste
des impacts - positifs ou négatifs - possibles du contrôle d'âge.)
L'agenda complet de l'atelier figure dans l'annexe A du RFC, la liste des participants dans l'annexe B. Passons maintenant au contenu.
Les « solutions » techniques peuvent être mises en œuvre dans le
terminal de l'utilisateurice, dans le réseau (par exemple dans le
résolveur DNS) ou bien dans le
service (regardez https://fr.pornhub.com/
depuis la France, pour voir ; n'hésitez pas, c'est
SFW). Dans le terminal ? Cela donne du
pouvoir à Microsoft ou
Google et encourage les systèmes
privateurs sur lesquels l'utilisateurice n'a
aucun contrôle. (Encore que le logiciel libre
peut aussi, par souci de conformité et pour se faire bien voir des
politiciens, mettre en œuvre
ces contrôles.) Dans le réseau ? Cela met en danger le cœur
de l'Internet. Et cela donne du pouvoir aux acteurs de
l'infrastructure. Et ce n'est pas très précis (pensez au cas d'un
foyer où il y a adultes et enfants mais une seule adresse IP). Dans
les services ? Cela met le problème sur le dos de chaque
webmestre.
L'atelier a examiné quelques technologies « miracle » censées permettre de vérifier l'âge tout en préservant la vie privée (comme les ZKP). Même si elles résolvaient parfaitement le problème de vie privée, elles laissent ouverts les autres problèmes. Et ces technologies sont souvent récentes et leur sécurité n'est pas toujours testée en profondeur.
Bref, l'atelier n'a pas débouché sur une « solution » ni même sur un plan de travail pour l'IETF. La question reste très ouverte.
Le RFC pointe en section 3 les aspects les plus importants de ce sujet. D'abord, le fait que l'atelier a été utile car, alors que le sujet a bénéficié de nombreux articles dans la presse généraliste, et de nombreux discours politiciens, les discussions techniques ont été rares, de même que les forums impliquant toutes les parties prenantes. Et quand des techniciens étaient consultés, c'était toujours du point de vue des services, jamais de celui de l'infrastructure.
Ensuite, les discussions sont souvent peu productives car il y a eu peu d'efforts pour identifier les différentes rôles impliqués (cf. la présentation d'Hanson) :
- Le vérificateur qui doit tester si une personne donnée a plus que l'âge requis,
- Le contrôleur qui doit empêcher une personne qui a « raté » le test précédent d'accéder au service,
- Le sélecteur de politique, qui définit la politique à appliquer (elle dépend en général du pays de résidence du client, qui est difficile à déterminer sur l'Internet),
- Et le classificateur qui doit déterminer si un contenu donné ou un certain service doit être restreint d'accès.
Cette question est aussi liée à celle de la terminologie, souvent peu définie. (Tiens, j'apprends dans le RFC qu'il existe une norme ISO sur la vérification d'âge, ISO/IEC 27566-1:2025, évidemment pas accessible aux mineurs - il faut laisser plein de données personnelles pour l'obtenir.)
Autre sujet mis en évidence à l'atelier, l'importance de la préservation de la vie privée. Cette exigence est largement méprisée par les défenseurs du contrôle d'âge, le record de connerie ayant récemment été battu par une parlementaire canadienne qui affirmait que la reconnaissance faciale respectait l'anonymat puisque le logiciel ne connaissait pas le nom de la personne. Une partie des acteurs cités plus haut va connaitre des informations personnelles sur les clients des services, et ces acteurs ne sont pas forcément connus de ces clients. Imaginez que vous alliez sur un site Web de contenu pour adultes puis soudainement vous êtes redirigé vers le site Web du vérificateur qui va vous demander de prouver votre âge. Si vous êtes raisonnablement prudent, vous refusez. Si vous tenez à voir le contenu, vous répondez et voilà : on a habitué les utilisateurs à faire confiance à des sites inconnus et inattendus. Une vraie aide au hameçonnage.
En parlant de confiance, un des points difficiles de toute solution technique au problème du contrôle d'âge est la nécessité de faire confiance à de nouveaux acteurs. Certes, il existe des méthodes mathématiques pour prouver quelque chose sans divulguer d'information mais elles sont récentes, peu testées, et sont loin d'épuiser le problème de la confiance. Le fait que beaucoup de techniques proposées ne soient pas en logiciel libre n'arrange rien. (Le RFC ne mentionne pas ce point, sauf pour enfoncer une porte ouverte en rappelant que le logiciel libre ne résout pas tous les problèmes de confiance.)
Les participants à l'atelier ont aussi noté qu'il y avait peu de chances qu'une seule technique suffise : toutes ont des défauts graves. Les techniques reposant sur des documents étatiques écartent les gens qui n'en ont pas, ou ceux qui ont des documents non reconnus. Les techniques probabilistes d'estimation de l'âge (par exemple par examen du visage) ont beaucoup de faux positifs et de faux négatifs (et, pire, cela dépend de la couleur de peau). Une approche possible serait d'essayer successivement plusieurs techniques, en commençant par les moins invasives (mais cela créerait une discrimination envers les catégories de population qui échouent à ces premières techniques).
L'imperfection de toutes ces techniques a des conséquences sérieuses : exclusion de certaines personnes, contournement par d'autres (certains utilisateurs de contenu « pour adultes » n'ont pas l'âge mais sont motivés, techniquement compétents et ont du temps libre).
La plupart des architectures proposées ajoutent des parties à la relation traditionnelle entre le visiteur d'un site Web et le site en question, notamment le vérificateur et le contrôleur. On complique donc l'architecture du Web en ajoutant de nouvelles dépendances.
Et, bien sûr, la technique n'est pas tout. La sécurité des mineurs ne doit pas dépendre uniquement de techniques dont l'atelier a largement montré la fragilité. Le problème, il est vrai, est très difficile puisqu'il faut à la fois protéger les mineurs contre les dangers bien réels, tout en les préparant à leur future vie de majeur, où il n'y aura pas de restrictions techniques. Les contrôles techniques sont forcément grossiers et binaires, et ne prennent pas en compte toutes les nuances du monde. Il ne faudrait surtout pas déléguer des tâches aussi complexes et délicates que l'éducation à des « solutions » techniques.
Quelques autres ressources :
- La vidéo de présentation de l'atelier.
- Les documents présentés à l'atelier.
- La prise de position de l'Internet Society.
- Un précédent Internet-Draft sur les conséquences d'une restriction d'âge pour l'Internet.
L'article seul
RFC 9943: An Architecture for Trustworthy and Transparent Digital Supply Chains
Date de publication du RFC : Juin 2026
Auteur(s) du RFC : H. Birkholz (Fraunhofer SIT), A. Delignat-Lavaud, C. Fournet (Microsoft Research), Y. Deshpande (ARM), S. Lasker
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF scitt
Première rédaction de cet article le 1 juillet 2026
Des attaques sur la chaine d'approvisionnement du logiciel, il y en a tout le temps. L'attaquant arrive à glisser du code malveillant dans un logiciel, en amont de son installation par la victime et, quand celle-ci fait tourner le logiciel, le code de l'attaquant est exécuté et paf. Il n'y a pas de solution miracle à ce problème mais on peut au moins essayer de fournir une traçabilité forte des logiciels, qui permet d'être sûr de ce qu'on fait tourner sur ses machines, et, dans le cas d'une enquête postérieure, de mieux comprendre ce qui s'est passé. Ce RFC décrit une architecture, très inspirée du Certificate Transparency du RFC 9162.
Vous voulez des exemples d'attaques contre la chaine d'approvisionnement du logiciel ? Deux cas récents sont la faille Trivy/Aqua Security, annoncée le 1er avril de cette année mais qui n'est pas une blague (tout juste de l'ironie car le logiciel Trivy servait à détecter les problèmes de sécurité…). Cette attaque a notamment permis l'accès aux données de la Commission Européenne. Et il y a aussi, encore plus récente, l'attaque contre le paquetage Python litellm. Mais le cas le plus fameux, quoique un peu moins récent, est celui du détournement de la bibliothèque XZ. (Olivier Poncet en a fait une conférence.)
Les attaquants peuvent frapper à de nombreux endroits différents dans la chaine d'approvisionnement d'un logiciel. Cela peut être en modifiant une bibliothèque utilisée par le logiciel, en modifiant directement le code source, en modifiant l'environnement de compilation (de manière à produire un code exécutable malveillant à partir d'un code source intact), en remplaçant le code exécutable dans un magasin d'applications, etc. La figure 1 dans la section 2.1 du RFC donne une liste complète. Le choix va dépendre des capacités de l'attaquant, de ses choix de discrétion, et des solutions de sécurité déployées.
Je l'ai dit au début, il n'y a pas de solution parfaite au problème, qui est complexe. Dans le cas de XZ, le mainteneur a eu tort de faire confiance à un inconnu mais, si on arrêtait d'accepter des volontaires inconnus, tout le logiciel libre s'effondrerait. Et le logiciel privateur a d'autres failles, comme l'opacité, qui empêche de savoir quels sont les composants logiciels intégrés.
Que propose le groupe de travail SCITT, auteur de ce RFC ? L'approche choisie est celle de la transparence et de la traçabilité. Il faut qu'on puisse vérifier de quels logiciels on dépend. La principale source d'inspiration est le Certificate Transparency du RFC 9162 et l'architecture SCITT peut être vue comme une généralisation de Certificate Transparency au logiciel. Il repose sur une structure de données ordonnée, et qui garantit que seul l'ajout de données est possible, et que tout dans cette structure de données est signé. (Si vous criez « chaine de blocs » ici, vous avez tort : une chaine de blocs fournit en effet ce service mais elle n'est pas nécessaire, d'autres mécanismes existent depuis longtemps, tels que ceux utilisés par le RFC 9162.) D'autre part, il est important de se souvenir que notre RFC ne présente qu'une architecture, pas un protocole complet. Les programmeurs et programmeuses ne peuvent donc pas se mettre au travail tout de suite. L'architecture SCITT est conçue pour les chaines d'approvisionnement de logiciel mais peut a priori être étendue plus tard pour d'autres usages.
Le mécanisme de base consiste en des données en CBOR (RFC 8949), dont la structure est spécifiée en CDLL (RFC 8610), signées avec COSE (RFC 9052) et récupérable via des arbres de Merkle (RFC 9942). Grâce à cela, celui ou celle qui veut vérifier des informations sur un logiciel peut les récupérer facilement et efficacement, puis les vérifier (là encore, comme avec Certificate Transparency). C'est par exemple ce que le NIST appelle DevSecOps.
La section 2.2 du RFC fournit trois cas d'usages de cette technologie. L'un d'eux concerne l'assemblage du logiciel pour un véhicule. (Dans le monde réel, les gens qui assemblent le logiciel pour une voiture ou pour n'importe quel objet connecté ne se soucient guère de sécurité ; comme il y a zéro conséquence négative pour eux en cas de bogue, ou même de faille de sécurité, ils utilisent des versions antédiluviennes de logiciels non testés.) La chaine de dépendance est longue car une voiture est faite de plusieurs composants, chacun apportant du logiciel qui, à son tour, dépend de diverses bibliothèques. SCITT permettrait au moins d'avoir des idées claires sur les composants logiciels utilisés, chacun ayant fait l'objet d'un ajout dans la structure de données de traçabilité.
Bon, maintenant, si on veut être un peu plus précis et comprendre ce qu'est l'architecture SCITT, par quoi on commence ? Par le vocabulaire, peut-être. Découvrons-le dans la section 3 du RFC :
- Déclaration (statement) : une information portant sur un fait (par exemple « la version actuelle est la 3.14 » ou bien « ce logiciel dépend de libfoobar et de grutzbaum-plus »). Les logiciels peuvent être identifiés par un grand nombre d'identificateurs, notre RFC cite entre autres CoSWID (RFC 9393), in-toto, SPDX, SWID, etc.
- Enveloppe (envelope) : les méta-données comme l'identité de l'émetteur.
- Émetteur (issuer) : l'entité qui déclare quelque chose, et qui a une clé privée pour signer cette déclaration.
- Utilisateur (relying party) : l'entité qui va utiliser les déclarations.
- Équivoque (equivocation, quoiqu'il me semble que le terme soit moins fort en français) : déclarations contradictoires (ce qui est clairement mauvais).
- Reçu (receipt) : preuve comme quoi une
déclaration signée a bien été incluse dans la structure de
données. Si on les distribue sur l'Internet, le type de
média à utiliser est
application/scitt-receipt+cose - Déclaration signée (signed statement) :
ce sont elles qui sont encodées en COSE
(RFC 9052). Si on les distribue sur
l'Internet, le type de média à utiliser est
application/scitt-statement+cose. - Structure de données vérifiable (verifiable data structure) : là où on met les déclarations. Cette structure de données doit être à ajout seul (et, je me répète, une chaine de blocs a cette propriété mais les chaines de blocs ne sont nullement indispensables pour cela), doit empêcher l'équivoque (cf. section 5.1.3) et doit permettre l'examen complet (peut-être après autorisation) pour vérifier sa cohérence. Le RFC 9942 donne des détails techniques.
Armé de ces termes, nous pouvons décrire l'architecture SCITT (mais regardez aussi la figure 2 du RFC) :
- Des émetteurs produisent des déclarations signées et les envoient à des services de transparence,
- ces services de transparence authentifient l'émetteur, vérifient les signatures, vérifient la conformité des déclarations à leur politique (cf. section 5.2.1), mettent la déclaration dans la structure de données vérifiable et produisent un reçu (suivant le RFC 9942),
- des utilisateurs vont accéder à ces informations pour vérifier les informations (« est-ce que je dépend ou pas de libfoobar ? », sachant que la dépendance peut être transitive), ou bien pour vérifier la cohérence du service de transparence, par exemple lors d'un audit (c'est une propriété importante d'un service de transparence, on doit pouvoir vérifier son intégrité).
Il peut y avoir plusieurs services de transparence (comme c'est le cas pour Certificate Transparency), personne n'envisage évidemment d'avoir un unique point de dépôt des déclarations.
Le format des déclarations signées et des reçus figure (en CDDL, cf. RFC 8610) en section 6.1.
La section 9 du RFC est vraiment à lire car c'est celle consacrée à l'analyse de sécurité de l'architecture SCITT. D'abord, il faut être bien conscient que SCITT fournit de la transparence et de la traçabilité mais pas de la vérité. Si un émetteur signe que son logiciel tourne avec toutes les versions de libfrobnicate mais qu'en fait il lui faut au moins la version 2, le service de transparence ne va pas regarder les sources du logiciel pour vérifier. C'est vrai pour les erreurs des émetteurs et encore plus pour leurs malhonnêtetés. « Transparency does not prevent dishonest or compromised Issuers, but it holds them accountable ».
Un émetteur grognon ou négligent peut aussi ne pas enregistrer toutes les informations qu'il a. Un utilisateur ne doit donc pas utiliser une déclaration signée sans vérifier le reçu, qui seul prouvera que la déclaration a été enregistrée.
Il existe apparemment au moins trois mises en œuvre de cette technique, chez deux entreprises spécialisées dans la traçabilité des chaines d'approvisionnement, Datatrails et Tradeverifyd, mais aussi chez Microsoft (cf. leur article).
Enfin, une bonne lecture sur ces structures de données vérifiables est « Attested Append-Only Memory: Making Adversaries Stick to their Word ».
L'article seul
RFC 9980: Post-Quantum Cryptography in OpenPGP
Date de publication du RFC : Juin 2026
Auteur(s) du RFC : S. Kousidis
(BSI), J. Roth, F. Strenzke (MTG
AG), A. Wussler (Proton AG)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF openpgp
Première rédaction de cet article le 1 juillet 2026
Vous le savez, le jour où des CRQC (Cryptographically Relevant Quantum Computer, un calculateur quantique capable de calculs non triviaux, contrairement aux modèles d'aujourd'hui) seront disponibles, la cryptographie sera sérieusement secouée. Il est donc important de travailler dès maintenant sur des algorithmes pour l'après-quantique, et de les intégrer dans les protocoles et les formats utilisés sur l'Internet. Ce RFC documente l'utilisation des algorithmes normalisés par le NIST dans le format OpenPGP.
Le format OpenPGP, utilisé par de nombreux logiciels de cryptographie, est normalisé dans le RFC 9580. La liste des algorithmes de chiffrement n'est pas figée et de nouveaux algorithmes peuvent être disponibles pour ce format. C'est le cas de ceux pour la cryptographie post-quantique, un sujet d'actualité. Les messages chiffrés et/ou signés au format OpenPGP peuvent avoir besoin de résister à la décryption et/ou à l'usurpation pendant de nombreuses années. Aujourd'hui, ces messages utilisent typiquement RSA ou des algorithmes à courbes elliptiques, tous étant vulnérables aux calculateurs quantiques. C'est notamment en raison de cette nécessité de sécurité sur une longue période qu'il ne faut pas attendre que les CRQC soient disponibles pour intégrer les algorithmes post-quantiques à OpenPGP. Il y a peut-être des attaquants qui stockent aujourd'hui des messages OpenPGP, en attendant d'avoir un CRQC pour les lire (ou pour imiter des signatures).
(Rappelons au passage qu'OpenPGP n'est pas utilisé que dans le courrier électronique. Il sert, par exemple, à authentifier le code avec git, ou les paquetages compilés, avec apt et rpm.)
Il ne suffit pas d'ajouter les nouveaux algorithmes aux registres IANA. Il y a des problèmes spécifiques, comme les clés hybrides (une PQ et une classique) et composées (hybrides, mais présentées d'une manière unifiée). En effet, il ne servirait à rien de déployer des algorithmes post-quantiques si ceux-ci étaient cassables par de la cryptanalyse classique. Rien ne dit que ces « nouveaux » algorithmes soient incassables. Et comme ils sont relativement récents, on ne peut pas avoir le même degré de confiance qu'avec RSA ou ECDSA. L'approche la plus courante aujourd'hui, et que ce RFC suit, est d'utiliser une technique hybride : combinaison d'un algorithme traditionnel et d'un algorithme post-quantique. On n'abandonne donc pas RSA ou ECDSA, on les flanque d'un collègue, ce qu'on appelle le PQ/T (post-quantique/traditionnel, cf. section 1.1.1).
Plus précisément, notre RFC utilise des composés, des hybrides PQ/T mais où les deux clés, la post-quantique et la traditionnelle, sont gérées comme une seule. Le RFC 9794 est la bonne lecture, si vous voulez approfondir ces notions d'hybride et de composé et vous avez aussi intérêt à lire le RFC 9958, « Post-Quantum Cryptography for Engineers ».
Quels sont ces nouveaux algorithmes ? La section 1.2 les résume :
- ML-KEM, normalisé dans la norme FIPS-203, pour l'échange de clés préalable au chiffrement,
- ML-DSA, normalisé dans FIPS-204, pour la signature,
- SLH-DSA, normalisé dans FIPS-205, également pour la signature.
Notez que l'algorithme SLH-DSA, lui, est considéré suffisamment sûr pour se passer de l'assistance d'un algorithme traditionnel (il utilise des problèmes mathématiques complètement différents de ceux utilisés par ML-KEM ou ML-DSA). Les deux autres vont être utilisés par OpenPGP avec de la cryptographie traditionnelle, en l'occurrence ECDH avec les courbes X25519 et X448 (RFC 7748) et EdDSA (RFC 8032). Pour la vérification d'une signature, les deux (post-quantique et traditionnelle) signatures doivent être valides (cf. sections 3 et 5.2.3). Pour le chiffrement, les deux clés obtenues doivent être utilisées.
Le format OpenPGP permet d'avoir plusieurs signatures dans un message mais ces signatures parallèles sont différentes des clés composées utilisées pour le PQ/T car le succès d'une seule signature suffit à la validation. (Idem pour le chiffrement, cf. section 3.) Évidemment, le système n'est résistant aux CRQC que si toutes les signatures utilisent un algorithme PQ ou PQ/T. Si ces signatures multiples, incluant au moins une clé T (traditionnelle, sans post-quantique) sont moins sûres, elles ont par contre l'avantage d'assurer la compatibilité avec les vieilles versions des logiciels OpenPGP (section 5.2.5 du RFC 9580).
La section 2 du RFC donne la liste exhaustive des algorithmes qui viennent d'être officiellement ajoutés. À partir des trois cités plus haut, il y a quelques variantes, fondées sur la taille de certains paramètres ou sur la courbe elliptique utilisée dans le composé. Ainsi, SLH-DSA a trois variantes, SLH-DSA-SHAKE-128f (f pour fast car il optimise la vitesse), SLH-DSA-SHAKE-128s (s pour short car il optimise la taille) et SLH-DSA-SHAKE-256s. ML-KEM a deux variantes, ML-KEM-768+X25519 et ML-KEM-1024+X448, avec des courbes différentes.
Notez enfin que les clés PQ/T ne doivent être utilisées qu'avec des données OpenPGP des versions 4 ou 6 (et même uniquement version 6 pour ML-KEM-1024+X448 et ML-DSA). Ici, par exemple, GnuPG montre un paquet OpenPGP de version 3, trop vieux pour gérer le post-quantique :
% gpg --list-packets review.txt.gpg … :pubkey enc packet: version 3, algo 1, keyid XXXXXXXXX data: [4096 bits]
Les sections 4, 5 et 6 du RFC expliquent en détail le format des nouvelles clés et comment les utiliser. La section 7 donne des conseils sur les algorithmes de cryptographie symétrique, par exemple qu'il est nécessaire de mettre en œuvre AES-256 (la version à 128 bits est possiblement cassable grâce à l'algorithme de Grover).
Et la migration depuis les anciens algorithmes ? Tous les logiciels qui mettent en œuvre OpenPGP ne vont pas passer au post-quantique en même temps. On aura des messages qui vont passer d'un logiciel récent à un ancien, qui ne pourra pas les lire. La section 8 ajoute des conseils pour bien réussir sa migration. Déjà, un logiciel récent, qui pense que les récepteurs de ses messages seront pré-quantiques peut chiffrer ses messages avec une clé PQ (ou PQ/T) et une clé traditionnelle (chiffrement en parallèle, où une seule clé est nécessaire, et pas en série, comme c'est le cas ave les solutions hybrides citées plus haut, où les deux clés sont nécessaires). Bien sûr, s'il fait cela, le message sera déchiffrable par un calculateur quantique. Il faut donc choisir entre sécurité et interopérabilité (avec les vieux logiciels). PGP étant conçu pour des communications asynchrones (comme le courrier électronique), il n'est pas possible de savoir à l'avance les capacités du récepteur.
Le même problème se pose pour les signatures. Lors d'une vérification de signature, n'importe laquelle des deux signatures sera acceptée (là encore, on parle de signatures séparées, qui ont toujours existé dans OpenPGP, pas des hybrides du PQ/T). Le RFC permet toutefois à un vérificateur paranoïaque, ou simplement un vérificateur qui sait que l'émetteur a une clé PQ ou PQ/T, d'ignorer les signatures traditionnelles.
Enfin, la section 9 du RFC discute un certain nombre de questions de sécurité. Par exemple, elle explique comment les signatures composites du PQ/T ne sont pas vulnérables aux attaques par suppression d'une des signatures (les métadonnées indiquent l'identificateur de l'algorithme hybride).
Quelles sont les mises en œuvre de ces nouveaux algorithmes ? Malheureusement, il semble que GnuPG ne suive pas les récents RFC sur le format OpenPGP (sur cette affaire, lire le point de vue de Debian ou celui d'Arch Linux), entre autre (mais pas uniquement) sur le post-quantique. On va donc tester avec les autres (il existe une liste).
Si vous voulez écrire votre propre programme OpenPGP (ce que je ne conseillerai pas : la cryptographie, c'est difficile, et les bogues ne se voient pas forcément), l'annexe A du RFC, qui fait la grande majorité du RFC, est composée de vecteurs de test.
Les programmes testés sont conformes au
projet de standard SOP et ont donc à
peu près la même interface utilisateur (actuellement en projet, dans
draft-dkg-openpgp-stateless-cli). Souvent, le post-quantique
n'est pas encore intégré dans les versions officielles et il va
falloir changer de branche et compiler.
Commençons avec rsop, écrit en
Rust. Après le
cargo install pgp :
% rsop list-profiles generate-key default: v4 key using Curve25519 (alias: draft-koch-eddsa-for-openpgp-00) compatibility: v4 key using RSA (alias: rfc4880) performance: v6 key using Ed25519/X25519 (alias: rfc9580) security: v6 key using Ed448/X448 (alias: rfc9580-curve448)
Je vous l'avais bien dit : pas de post-quantique. Mais la FAQ dans le code nous le dit « ### Is rPGP adding support for Post Quantum Cryptography (PQC)? Yes, rPGP implements the IETF draft [Post-Quantum Cryptography in OpenPGP](https://datatracker.ietf.org/doc/draft-ietf-openpgp-pqc/), gated behind the feature `draft-pqc`. ». Ah, c'est planqué dans une feature. Compilons :
% cargo install --features draft-pqc rsop % rsop list-profiles generate-key default: v4 key using Curve25519 (alias: draft-koch-eddsa-for-openpgp-00) compatibility: v4 key using RSA (alias: rfc4880) performance: v6 key using Ed25519/X25519 (alias: rfc9580) security: v6 key using Ed448/X448 (alias: rfc9580-curve448) draft-ietf-openpgp-pqc-14-v4-ed25519-mlkem768x25519: TESTING ONLY draft-ietf-openpgp-pqc-14-v6-ed25519-mlkem768x25519: TESTING ONLY draft-ietf-openpgp-pqc-14-v6-mldsa65ed25519-mlkem768x25519: TESTING ONLY draft-ietf-openpgp-pqc-14-v6-mldsa87ed448-mlkem1024x448: TESTING ONLY draft-ietf-openpgp-pqc-14-v6-slhdsashake128s-mlkem768x25519: TESTING ONLY draft-ietf-openpgp-pqc-14-v6-slhdsashake128f-mlkem768x25519: TESTING ONLY draft-ietf-openpgp-pqc-14-v6-slhdsashake256s-mlkem1024x448: TESTING ONLY
Ça marche, on a du post-quantique, utilisons-le :
% rsop generate-key --profile draft-ietf-openpgp-pqc-14-v6-ed25519-mlkem768x25519 > key.asc
OK, on a une clé hybride (ML-KEM et Ed25519). Créeons la clé publique :
% cat key.asc | rsop extract-cert > cert.asc
Et maintenant, on peut chiffrer un fichier avec la clé publique :
% cat hello.txt | rsop encrypt cert.asc > hello.asc
Et le déchiffrer avec la clé privée :
% cat hello.asc | rsop decrypt key.asc Hello, world
Bon, on a tout fait avec le même programme, mais le but d'OpenPGP est l'interopérabilité. Essayons avec un deuxième programme, Sequoia, pour lequel il y a des instructions détaillées pour le compiler avec gestion du post-quantique :
% sudo apt install libsqlite3-dev % git clone https://gitlab.com/sequoia-pgp/sequoia-sq.git % git checkout pqc % cargo build --release --locked --no-default-features --features crypto-openssl
Et utilisons-le pour regarder les fichiers produits par rsop :
% sq inspect key.asc
key.asc: Transferable Secret Key.
Fingerprint: AC7FD6CBD09E90C928C2ED5796A69001B5F0535CE6BF09C227DFE71063006BD0
Public-key algo: Ed25519
Public-key size: 256 bits
Secret key: Unencrypted
Creation time: 2026-02-09 17:36:25 UTC
Key flags: certification, signing
Subkey: 91BED065B7E654656D3354CA16E901D8F8B192874385EB6C325421055AFB5B9E
Public-key algo: ML-KEM-768+X25519
Secret key: Unencrypted
Creation time: 2026-02-09 17:36:25 UTC
Key flags: transport encryption, data-at-rest encryption
Joli, non ? rsop avait bien fabriqué une clé hybride et sq arrive à la lire.
% cat hello.asc | sq decrypt --recipient-file key.asc Encrypted and protected using AES-256/OCB Hello, world Decrypted by AC7FD6CBD09E90C928C2ED5796A69001B5F0535CE6BF09C227DFE71063006BD0, unknown 0 authenticated signatures.
Et Sequoia peut déchiffrer les messages chiffrés par rsop.
% sq inspect --cert-file cert.asc < hello.asc
OpenPGP Certificate.
Fingerprint: AC7FD6CBD09E90C928C2ED5796A69001B5F0535CE6BF09C227DFE71063006BD0
Public-key algo: Ed25519
Public-key size: 256 bits
Creation time: 2026-02-09 17:36:25 UTC
Key flags: certification, signing
Subkey: 91BED065B7E654656D3354CA16E901D8F8B192874385EB6C325421055AFB5B9E
Public-key algo: ML-KEM-768+X25519
Creation time: 2026-02-09 17:36:25 UTC
Key flags: transport encryption, data-at-rest encryption
Et examiner ses clés. rsop et sq étaient tous les deux écrits en Rust donc testons l'interopérabilité avec un programme en Go :
% git clone https://github.com/ProtonMail/gosop.git % cd gosop % git checkout gosop-gopenpgp-v3-pqc % go build % ./gosop list-profiles generate-key default: Generate v4 keys using Curve25519 compatibility: Generate v4 keys using 3072-bit RSA (alias: rfc4880) performance: Generate v6 keys using Ed25519/X25519 (alias: rfc9580) security: Generate v6 keys using Ed448/X448 draft-ietf-openpgp-pqc-09: ML-KEM-768 and ML-DSA-65 draft-ietf-openpgp-pqc-09-high-security: ML-KEM-1024 and ML-DSA-87 draft-ietf-openpgp-persistent-symmetric-keys-00: AEAD and HMAC % ./gosop/gosop decrypt key.asc < hello.asc Hello, world
Et tout se passe bien.
L'article seul
RFC 9958: Post-Quantum Cryptography for Engineers
Date de publication du RFC : Juin 2026
Auteur(s) du RFC : A. Banerjee, T. Reddy, D. Schoinianakis
(Nokia), T. Hollebeek
(DigiCert), M. Ounsworth (Entrust)
Pour information
Réalisé dans le cadre du groupe de travail IETF pquip
Première rédaction de cet article le 20 juin 2026
Tout le monde parle des calculateurs quantiques et du risque qu'ils font peser sur la cryptographie traditionnelle. La solution ? Remplacer ces algorithmes par des algorithmes post-quantiques, c'est-à-dire résistant aux calculateurs quantiques. Ces algorithmes existent déjà, plusieurs sont normalisés et beaucoup ont déjà été mis en œuvre dans des programmes. Mais les intégrer dans les protocoles de l'Internet n'est pas trivial. Ce RFC vise à guider les ingénieur·es qui vont appliquer ces algorithmes post-quantiques à des logiciels et des protocoles du monde de l'Internet.
Il ne s'agit pas ici d'expliquer le fonctionnement des algorithmes de cryptographie post-quantiques. Le RFC les considère acquis et se demande comment on va les utiliser. (Note personnelle : de toute façon, je ne comprends rien à la cryptographie, post-quantique ou pas. Mais ce n'est pas forcément grave, ce RFC est conçu pour des ingénieur·es normaux·les, le doctorat en cryptographie n'est pas indispensable.) Notez aussi, question terminologie, que « post-quantique » ne fait pas l'unanimité. On pourrait dire (section 2 du RFC), « après quantique » ou bien « résistant au quantique » ou encore « prêt pour le quantique ». Chaque terme a ses qualités et ses défauts : « résistant au quantique » serait inapproprié si, finalement, on trouvait un algorithme quantique pour casser un algorithme qui se prétendait sûr face aux calculateurs quantiques.
D'abord, résumons le problème : la
quantique est aujourd'hui un domaine très
bien connu et dont les bases théoriques sont solides et établies. Un
calculateur quantique peut effectuer
certains calculs plus vite qu'un ordinateur
classique. Parmi ces calculs, il y a les problèmes mathématiques
sous-jacents aux algorithmes de cryptographie courants, comme
RSA et
ECDSA. Aujourd'hui, certes, les calculateurs
quantiques sont très loin de pouvoir être utilisés en pratique
contre la cryptographie. Il faudrait des millions de
qubits physiques ou des milliers de qubits
logiques (ceux qui ont un système de correction d'erreurs). On n'en
est qu'à quelques centaines de qubits physiques (malgré certaines
annonces sensationnalistes), et la difficulté de fabrication et de
fonctionnement augmente très vite avec le nombre de qubits. Mais, à
force de progrès, on aura peut-être un jour des CRQC
(Cryptographically Relevant Quantum Computer,
prononcez « cric », cf. section 2 du RFC), des calculateurs
quantiques utilisables dans le monde réel. 
Ce jour-là, on pourra, par exemple, trouver une clé privée RSA ou ECDSA à partir de la clé publique, cassant ainsi effectivement ces algorithmes. Et, comme le déploiement des algorithmes post-quantiques va prendre du temps, il ne faut pas attendre que des CRQC soient disponibles pour commencer.
On pourrait croire que le problème, pour les protocoles IETF, est simple : tous ont la propriété d'agilité cryptographique (RFC 7696), qui permet de remplacer un algorithme par un autre sans changer le protocole et le code. Mais ça serait trop simple : les algorithmes post-quantiques ont des propriétés qui font qu'il n'est pas toujours possible de les utiliser tels quels, sans adaptation du protocole. Par exemple, leurs clés et signatures sont souvent bien plus grandes, et ne rentrent pas dans les protocoles existants.
Donc, quelques points à garder en tête (j'ai déjà lu des erreurs sur ces sujets, dans divers articles) :
- Un algorithme post-quantique n'a rien de quantique, et ne nécessite pas de calculateur quantique pour tourner. Nous travaillons sur la défense (la cryptographie post-quantique), pas sur l'attaque (les calculateurs quantiques). Pas besoin donc de s'y connaitre en quantique pour comprendre ces algorithmes.
- Les algorithmes « quantiques » ne sont pas 100 % quantiques. Ils ont tous une partie classique et un calculateur quantique ne sera donc pas utilisé seul, mais comme une partie d'un ordinateur mixte (section 3 du RFC).
- Un calculateur quantique n'est pas un ordinateur : il n'est rapide que pour certains problèmes, et c'est cela qui permet de concevoir des algorithmes dont on pense qu'ils ne seront pas vulnérables aux futurs CRQC. (Le RFC fait une analogie avec les GPU qui ne sont pas plus rapides que les CPU dans l'absolu, seulement plus rapides pour certains problèmes.)
- Un algorithme post-quantique peut, si on trouve une faille dans sa conception ou dans sa mise en œuvre, être cassé par un ordinateur classique. C'est d'autant plus gênant que ces algorithmes sont plus récents que RSA ou ECDSA, et ont été moins testés au feu.
Donc (section 1 du RFC), aujourd'hui, des gens construisent des calculateurs quantiques et ceux-ci sont de plus en plus perfectionnés, capable d'attaquer des problèmes plus gros. Pas mal d'argent et d'efforts sont investis dans ces travaux. Mais on reste loin du CRQC (Cryptographically Relevant Quantum Computer), les calculateurs connus du public ne peuvent casser que des clés RSA ou ECDSA ridiculement courtes. Il est très difficile de prévoir quand on aura un CRQC. (Lorsque j'ai fait mon exposé à Pas Sage En Seine, plusieurs personnes m'ont dit que les CRQC seraient disponibles « bientôt ». C'était en 2018 et on ne les a toujours pas.) Le problème est difficile et il ne suffit pas d'extrapoler les prototypes actuels, le monde quantique est difficile et, plus on rassemble de composants, plus il est difficile de maintenir les propriétés quantiques qui nous intéressent. Des prédictions sensationnalistes sur l'arrivée « prochaine » de calculateurs quantiques ont déjà été faites et se sont montrées fausses. Ceci dit, il faut noter qu'il n'y a pas que la recherche publique : on peut toujours imaginer que, dans la zone 51, la NSA fait tourner un CRQC utilisant des technologies obtenues auprès des extra-terrestres…
Mais le fait que les CRQC n'arrivent pas n'est pas une raison pour attendre : le déploiement effectif des algorithmes post-quantiques va prendre beaucoup de temps (il s'agit d'une migration très complexe) et il ne faut donc pas rester les bras croisés en attendant qu'un CRQC soit réellement disponible (d'autant plus qu'il existe toujours la possibilité de percées soudaines dans la recherche scientifique). Mais, en raison de l'incertitude, la question est délicate (cf. mon exposé à NetGouv 26).
Euclide concevait des algorithmes bien avant qu'on ait des ordinateurs et Lovelace écrivait des programmes alors que l'ordinateur à qui ils étaient destinés n'existait pas (et n'a finalement pas existé). De même, des chercheurs écrivent des algorithmes pour les calculateurs quantiques sans avoir de calculateurs quantiques. C'est notamment le cas de l'algorithme de Shor, qui résout le problème de la décomposition en facteurs premiers qui est à la base de RSA. Et une variante de l'algorithme résout le problème du logarithme discret qui est à la base des algorithmes à courbes elliptiques comme ECDSA (RFC 6090).
Il existe aussi un algorithme, l'algorithme de Grover, qui permet de s'attaquer aux clés utilisées en cryptographie symétrique mais il est loin de l'efficacité spectaculaire de l'algorithme de Shor et notre RFC estime donc (section 3.1 pour les détails) que les éventuels futurs calculateurs quantiques n'auront que peu d'impact sur la cryptographie symétrique, notamment parce que cet algorithme n'est pas facilement parallélisable. Et il y a des raisons de penser que Grover ne sera sans doute pas amélioré. Un algorithme comme AES-128 est donc a priori sûr (et c'est encore plus vrai pour AES-256). Le RFC se concentre donc sur l'asymétrique.
Pour la cryptographie asymétrique, la situation est moins rose (section 3.2). Des algorithmes très courants comme RSA et les algorithmes à courbes elliptiques, mais aussi des algorithmes moins connus comme ElGamal (RFC 6090) ou Schnorr (RFC 8235) seront cassables dès qu'on aura un CRQC. En quelques heures, voire en quelques secondes, celui-ci pourra casser une clé RSA de 2 048 bits, comme étudié dans « Circuit for Shor’s algorithm using 2n+3 qubits », « How to factor 2048 bit RSA integers in 8 hours using 20 million noisy qubits » ou bien « Breaking RSA Encryption - an Update on the State-of-the-Art ». (Rappel : tous ces articles supposent l'existence d'un CRQC, et on n'en a pas encore.) Bon, après, vous pouvez toujours faire des clés RSA d'un téra-octet mais ça ne serait pas pratique.
La section 4 du RFC détaille les services pour lesquels on utilise de la cryptographie asymétrique :
- Transport de clé symétrique. C'était la façon traditionnelle de chiffrer. Pour des raisons de performance, on ne chiffre pas avec les algorithmes de cryptographie asymétrique, qui sont trop lents. Une des parties génère une clé de cryptographie symétrique, qui doit donc être connue des deux parties, et on la chiffre avec l'algorithme de cryptographie asymétrique avant de l'envoyer à l'autre partie. Cette méthode ne fournit pas de confidentialité persistante donc on ne l'utilise plus beaucoup.
- Accord sur une clé. C'est la façon la plus courante aujourd'hui pour que les deux parties aient la même clé de chiffrement symétrique. Un exemple pour réaliser cet accord est la méthode Diffie-Hellman.
- Signature de documents et authentification d'une autre partie.
Les algorithmes courants utilisés en cryptographie asymétrique sont vulnérables aux futurs éventuels CRQC. Ce problème étant connu depuis longtemps, plusieurs algorithmes pour lesquels on ne connait pas d'algorithme quantique susceptible de les casser ont été développés. On peut donc les qualifier de « post-quantiques ». Suite à un concours lancé en 2016, le NIST a normalisé plusieurs de ces algorithmes (et d'autres le seront dans le futur). Mais, en général, ces algorithmes ne peuvent pas tout simplement remplacer les algorithmes traditionnels. Par exemple, RSA et ECDSA peuvent servir de KEM (Key Encapsulation Mechanism, cf. section 9) et faire des signatures alors que les algorithmes post-quantiques existants ne savent faire qu'un des deux. Et puis ils ne s'utilisent pas de la même façon et la transition vers ces algorithmes sera donc plus complexe que l'a été celle depuis RSA vers ECDSA.
Quels sont ces algorithmes normalisés par le NIST (section 5) ? Pour le KEM, ce sont :
- ML-KEM (autrefois nommé Kyber), normalisé dans la norme FIPS-203.
- HQC, approuvé mais pas encore normalisé.
Et pour les signatures :
- ML-DSA (autrefois nommé Dilithium), normalisé dans FIPS-204. (Voir aussi la section 10.2.)
- SLH-DSA (autrefois nommé SPHINCS+), normalisé dans FIPS-205.
- FN-DSA (autrefois nommé Falcon), qui sera apparemment normalisé dans FIPS-206.
D'autres algorithmes sont en cours de normalisation à l'ISO (section 6) :
- FrodoKEM.
- ClassicMcEliece.
- NTRU.
OK, on a plein d'algorithmes résistants aux calculateurs quantiques. Maintenant, de quel délai dispose t-on pour faire la transition, avant que les CRQC ne fichent toute la cryptographie traditionnelle en l'air ? La section 7 de notre RFC explore cette difficile question. Je divulgâche tout de suite : on ne sait pas. Le progrès des calculateurs quantiques ne dépend pas de progrès d'ingénierie relativement prévisibles mais de percées scientifiques encore inconnues. Mais d'un autre côté, attendre n'est pas non plus une bonne solution. Il y a sans doute des attaquants qui enregistrent des messages aujourd'hui, dans l'espoir qu'un CRQC permettra de les décrypter un jour (ce qu'on nomme HNDL pour Harvest Now, Decrypt Later). Si certains secrets sont à courte durée de vie, d'autres peuvent être encore sensibles dans des dizaines d'années (la France ne publie toujours pas complètement les archives étatiques sur la guerre d'Algérie). Pour de tels secrets, il serait peut-être plus prudent de passer au post-quantique tout de suite.
Pour les signatures, le RFC prend l'exemple de l'authentification : les signatures utilisées dans l'établissement d'une connexion TLS ne sont sensibles que pendant le très court temps entre leur génération et leur vérification. Par contre, la signature du microcode d'un objet connecté peut rester critique pendant toute la durée de vie de l'objet.
Pour analyser le délai dont on dispose, on utilise souvent le
modèle de Mosca. Dans ce modèle, X est le temps pendant lequel les secrets
doivent rester secrets (rappelez-vous que, pour certains secrets,
cela peut être de nombreuses années), Y est la durée de la
transition (rappelez-vous qu'en informatique, les transitions complètes
prennent toujours beaucoup
plus de temps que prévu, la publication par le NIST d'une norme ne
suffit pas) et Z est le temps qu'il nous reste avant que les CRQC
soient disponibles (c'est la durée la plus incertaine des trois,
d'autant plus qu'on ne peut pas exclure la possibilité de progrès soudains). Si
Z > X + Y, tout va bien. Sinon, on a un trou pendant lequel
certains usages vont être vulnérables. Notons aussi que Z va être
plus court pour les États (qui ont sans doute quelques années
d'avance sur la recherche publique en matière de calculateurs
quantiques) que pour le pirate de base, qui doit attendre qu'un CRQC
soit en vente sur AliExpress. 
Quant à Y, son estimation varie beaucoup. S'il faut juste faire une mise à jour d'un logiciel, cela peut être rapide. Mais de la cryptographie est aussi présente dans bien des matériels, qu'on ne remplace pas du jour au lendemain, comme les puces accélératrices des opérations de cryptographie ou les HSM. Et certaines clés doivent rester stables pendant longtemps comme la clé DNSSEC de la racine du DNS. Et il y a aussi le temps de programmer, de tester, de faire valider, de déployer, etc. Bref, entre la publication d'une norme comme FIPS-203 et sa généralisation, il faut compter de nombreuses années. C'est une des raisons qui justifie que le travail de transition vers la cryptographie post-quantique n'ait pas attendu la sortie du premier CRQC.
Si vous voulez apprendre un peu de cryptographie, vous pouvez aussi lire la section 8 du RFC, qui expose les principales catégories d'algorithmes post-quantiques :
- Réseaux euclidiens (non, ne me demandez pas d'expliquer) : c'est la technique sous-jacente à ML-KEM, ML-DSA et FrodoKEM, donc la technique « principale » à l'heure actuelle. Clés et surtout signatures sont bien plus grandes qu'avec ECDSA ou même RSA mais quand même plus courtes qu'avec les autres catégories. (La cryptographie post-quantique n'est pas écologique.)
- Condensation : c'est la technique derrière SLH-DSA. Il y a même des algorithmes spécifiés dans un RFC, les RFC 8391 et RFC 8554. Attention : bien des algorithmes de cette catégorie sont à état (il ne faut pas signer deux fois avec le même état) et sont donc difficiles à utiliser de manière sûre (et pas du tout adapté aux protocoles comme DNSSEC, qui sont habitués à un environnement sans état).
- Codes correcteurs : c'est là qu'on trouve HQC et ClassicMcEliece.
La façon la plus courante d'utiliser la cryptographie sur l'Internet est de combiner de la cryptographie symétrique, avec une clé générée pour chaque utilisation, et de la cryptographie asymétrique, qui sert à authentifier et à faire en sorte que la clé de cryptographie symétrique soit partagée par les deux parties (cf. RFC 9180 mais attention au fait que le terme « hybride » peut désigner autre chose en cryptographie post-quantique). La façon la plus simple (mais pas la plus sûre !) de réaliser ce partage est qu'une des deux parties génère la « clé de session », celle utilisée pour la cryptographie symétrique, puis la chiffre en cryptographie asymétrique avec la clé publique de l'autre partie. (On combine cryptographie symétrique et asymétrique, alors qu'on pourrait assurer le même service uniquement avec l'asymétrique, car, si l'asymétrique est souple, la symétrique est beaucoup plus rapide.) Ce transport de la clé d'une partie à l'autre est une des façons de faire en sorte que les deux parties aient la même clé, mais il en existe d'autres (ne me demandez pas un exposé détaillé, et encore moins un avis !). Et ces différentes façons ont typiquement des API différentes, ce qui complique le remplacement d'une façon par une autre. La section 9, consacrée aux KEM, détaille cette question. Après l'avoir lue, vous comprendrez les concepts d'AKE et de NIKE ☺.
La section 10 du RFC, consacrée aux signatures, intéressera entre autres les gens qui font du DNSSEC, comme moi. Un point amusant (section 10.4) et qui illustre bien qu'on ne peut pas toujours remplacer purement et simplement un algorithme traditionnel par un post-quantique : ML-DSA incorpore dans son calcul la condensation de la donnée à signer, ce qui le rend plus résistant à certaines attaques. Les protocoles qui calculent un condensat eux-mêmes avant de signer (comme DNSSEC) ne bénéficient donc pas de cette sécurité accrue et, idéalement, devraient être modifiés.
Un autre exemple du fait qu'on ne peut pas brancher un algorithme post-quantique et espérer que tout soit pareil qu'avant est le problème des performances. Ce n'est pas juste que les algorithmes post-quantiques sont plus lents, c'est qu'ils sont parfois tellement lents et avec des clés tellement grosses qu'il faut changer sa façon de travailler. Les tableaux de la section 12 donnent une idée du problème. Alors que des clés traditionnelles font, par exemple, 65 et 32 octets (pour la clé publique et la clé privée), les plus petites clés ML-KEM font respectivement 800 et 1632 octets (et c'est pire pour ML-DSA). Pour des protocoles comme TLS, qui fonctionne sur des connexions TCP ou QUIC, ce n'est pas très grave, OK, ce n'est pas écologique, mais l'augmentation de données due aux clés n'est probablement qu'une faible partie de ce que transportera la connexion. À part avec des middleboxes boguéees qui auraient une limite stupide à la taille des paquets TLS, ça devrait marcher (mais elles ont d'autres problèmes). Mais pour des protocoles comme IKE ou le DNS, qui tournent sur UDP et ont des limites bien plus strictes, c'est ennuyeux. Et le même problème se pose pour les objets contraints et leurs protocoles spécifiques (cf. section 14, qui leur est dédiée). Il existe bien des solutions (cf. RFC 9242 et RFC 9370 pour IKE) mais qui compliquent et ralentissent le protocole.
Autre problème, la sécurité des algorithmes post-quantiques face
aux ordinateurs traditionnels. C'est bien joli,
de résister aux CRQC mais, si l'algorithme peut être cassé par de la
cryptanalyse traditionnelle, cela ne sert à
rien (cf. sections 15.1 et 15.4 du RFC). Lors de la dernière grande
transition cryptographique sur l'Internet, celle depuis RSA vers
ECDSA, il y avait de très bonnes raisons de penser que le nouvel
algorithme était plus sûr et qu'on pouvait donc simplement remplacer
l'ancien par le nouveau.
Ce n'est pas le cas avec les algorithmes post-quantiques,
dont on ne peut pas être certains de leur résistance (regardez par
exemple l'attaque KyberSide, contre
ML-KEM). C'est d'autant plus vrai que les programmes qui les
mettent en œuvre sont, eux aussi, récents et pas forcément testés
longuement au feu. Et, comme les algorithmes traditionnels sont
vulnérables aux CRQC, que faire ? Que choisir ? L'idée dominante
aujourd'hui est d'avoir les deux, un système
hybride (ou « PQ/T », pour « Post-quantique et
Traditionnel », cf. RFC 9794). Par exemple,
lors d'un échange de clé symétrique, on va créer la clé en
concaténant deux clés qui ont été obtenues, l'une par un algorithme
traditionnel, l'autre par un post-quantique (c'est ce que fait le
RFC 9954). Ainsi,
la défaillance d'un des deux algorithmes ne permettra pas à
l'attaquant d'obtenir la clé. On peut aussi appliquer la
fonction de dérivation autant de fois qu'on a
de clés dans la structure hybride (RFC 9370). Pour
l'authentification, on peut authentifier avec les deux algorithmes
et exiger que les deux donnent le même résultat (draft-ietf-lamps-pq-composite-sigs).
Pour faciliter la tâche des programmeur·ses, il vaut mieux que
les deux clés (la PQ et la T) soient manipulées ensemble, dans une
seule structure de données (composite). On
évitera ainsi de compliquer le protocole comme cela serait le cas
si, par exemple, on exigeait qu'il y ait deux
certificats. Un travail de normalisation va
être nécessaire pour le format de ces clés composées
(cf. draft-bonnell-lamps-chameleon-certs). Il
faudra aussi définir quelles paires PQ/T ont du sens, question
sécurité, et ne pas juste accepter n'importe quel algorithme
post-quantique avec n'importe quel algorithme traditionnel.
Voilà, maintenant, si vous voulez sérieusement apprendre la cryptographie post-quantique, le RFC recommande le livre « Serious Cryptography » (la deuxième édition), de Jean-Philippe Aumasson (qui a aussi une traduction française). Si vous voulez voir du code post-quantique, il y a le projet OQS (avec une très bonne FAQ pour les débutants et un dépôt Github). Et si vous vous demandez ce que fait l'IETF en matière de normalisation de la cryptographie post-quantique dans ses protocoles, il y a une liste maintenue à jour. Je rajoute « awesome-post-quantum », qui maintient une liste de ressources sur la cryptographie post-quantique, Cloudflare avait fait un article détaillé sur les finalistes du concours NIST, qui expliquait bien les différentes questions techniques, et enfin lisez le texte de position de l'ANSSI.
Bon, mais je vais quand même vous montrer des exemples d'utilisation d'algorithmes post-quantiques dans des protocoles Internet. D'abord, avec SSH :
% ssh -v autre-machine-debian … debug1: kex: algorithm: mlkem768x25519-sha256
Oui, OpenSSH sait faire du ML-KEM pour l'échange de clés, depuis la version 10. Celui-ci ne permet pas de faire de l'authentification donc OpenSSH ne sait apparemment pas générer des clés de machines avec des algorithmes post-quantiques.
Pour TLS, voici un échange de clés hybride (ML-KEM et
traditionnel) vu par Firefox (« Outils de
développement Web » puis « Réseau » puis « Sécurité », tout au
bout) : 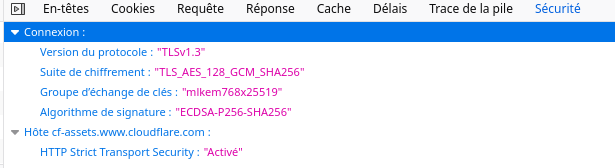 .
.
Pour DNSSEC, il existe une zone d'exemple expérimentale signée avec ML-DSA :
% dig +dnssec dilithium2.pdns.pq-dnssec.dedyn.io DNSKEY
;; Truncated, retrying in TCP mode.
…
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 55771
;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1
…
;; ANSWER SECTION:
dilithium2.pdns.pq-dnssec.dedyn.io. 3598 IN DNSKEY 257 3 18 (
XVrPO18btCpMLjXFiZYJNyMbQLXB7oOwk6ZXEmxhm8PP
EKiKP1+t/j7pwBUNYXp3s0U+3AFp3moviOf4cnl4K4MH
…
) ; KSK; alg = 18 ; key id = 47389
dilithium2.pdns.pq-dnssec.dedyn.io. 3598 IN RRSIG DNSKEY 18 5 3600 (
20260129000000 20260108000000 47389 dilithium2.pdns.pq-dnssec.dedyn.io.
aGU3rLJ8vb1AYln+y3bxcOO0RHboWfh03i8H1XhLd9f/
TxhGJNwsTCoRGOnJPjdB2ZDHMB7EnfUfgOitDjvcvcsd
…
;; Query time: 0 msec
;; SERVER: 127.0.0.1#53(127.0.0.1) (TCP)
;; WHEN: Tue Jan 20 15:16:45 CET 2026
;; MSG SIZE rcvd: 3877
Notez la taille de la réponse, et la nécessité de se rabattre sur TCP. D'autre part, l'algorithme de numéro 18, utilisé ici, n'est pas enregistré. Aujourd'hui, le monde du DNS semble plutôt attentiste, il n'y a pas d'algorithme de signature post-quantique qui convienne vraiment au DNS. Une synthèse de l'ICANN est relativement sceptique.
Et merci à Magali Bardet pour sa relecture attentive. (Et, naturellement, les erreurs restantes en crypto sont de moi, pas d'elle.)
L'article seul
RFC 10008: The HTTP QUERY Method
Date de publication du RFC : Juin 2026
Auteur(s) du RFC : J. Reschke (greenbytes), J.M. Snell
(Cloudflare), M. Bishop (Akamai)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 16 juin 2026
Ce n'est pas tous les jours qu'on normalise une nouvelle méthode HTTP. Bienvenue, donc, à QUERY, qui rejoint des méthodes bien plus anciennes comme GET et POST. QUERY peut être décrit comme « GET mais avec un corps dans la requête ». Comme GET, elle est idempotente et donc sûre à répéter.
L'idée est de pouvoir interroger, par exemple, un service de recherche (vous verrez un exemple plus loin sur mon blog). Sans QUERY, on envoyait quelque chose du genre :
GET /feed?q=foo&limit=10&sort=published HTTP/1.1
On est donc obligés de mettre les paramètres dans l'URL. Cela peut poser problème si les paramètres sont nombreux et de grande taille, cela oblige à les pourcent-encoder et cela peut poser des problèmes de vie privée (l'URL demandé a des chances d'être enregistré dans un journal).
Des gens utilisent donc POST pour une recherche, bien qu'il n'ait pas la bonne sémantique :
POST /feed HTTP/1.1
q=foo&limit=10&sort=published
Mais on ne voit plus que la requête est idempotente. Un navigateur Web n'osera pas la répéter ou bien demandera confirmation à l'utilisateur. Et on ne pourra pas facilement mémoriser le résultat (puisque le client ne sait pas si la requête n'a pas d'effets de bord). QUERY résout le problème :
QUERY /feed HTTP/1.1
q=foo&limit=10&sort=published
La méthode est idempotente, le résultat peut être mémorisé.
La section 2 du RFC décrit avec précision QUERY. À lire si vous écrivez des clients ou des serveurs qui l'utilisent. Par exemple, puisque QUERY, contrairement à GET, inclut un corps dans la requête, le client doit indiquer le type de média utilisé, et sans se tromper, sinon le serveur lui renverra un 400. (Et un 415 si le type est bien là mais que le serveur ne le connait pas.) Autre chose à noter : en cas de redirection, le client ne doit pas changer de méthode (alors qu'on pouvait changer un POST en GET si la redirection était faite avec 301 ou 302). Autrement, QUERY ressemble beaucoup dans son comportement à GET. QUERY est désormais enregistré dans le registre des méthodes HTTP.
Un serveur HTTP qui met en œuvre QUERY n'accepte pas forcément
n'importe quel format en entrée. Pour documenter ce qu'il accepte
comme corps de la requête, notre RFC introduit un nouveau
champ HTTP, Accept-Query: (section 3)
qui est la liste des types de média
acceptés.
Vous avez plein d'exemples de requêtes et de réponses dans l'annexe A.
Il y a une mise en œuvre de QUERY sur ce blog, pour fournir un
moteur de recherche des
articles. L'URL est
https://www.bortzmeyer.org/methodquery et voici
un exemple d'utilisation avec curl :
% curl --request QUERY --data query=framasoft https://www.bortzmeyer.org/methodquery
Query of "framasoft" OK
https://www.bortzmeyer.org/capitole-du-libre-2023.html "Capitole du Libre 2023, et mon exposé sur la censure de l'Internet"
…
Vous pouvez avoir une documentation plus détaillée de ce service
au début de son code source (en Python),
method-query.pytest-http-query.py
En parlant de curl, notez que, lorsqu'il suit
une redirection HTTP (option --location), il ne
transmet pas actuellement le
corps de la requête, ce qui casse ce service. Il faut de toute façon
utiliser
--follow.
La création de cette nouvelle méthode (ce qui est rare, je crois que la précédente avait été PATCH dans le RFC 5789 il y a quinze ans) a pris du temps. Le premier projet avait été rédigé en 2015 et le travail a connu plusieurs interruptions. Une des discussions avait porté sur le nom de la méthode, qui aurait pu s'appeler SEARCH (réutilisant une méthode normalisée dans le RFC 5323). L'annexe B du RFC discute le choix qui a été fait.
Une autre discussion portait sur le code de retour HTTP, un problème classique de tous les services tournant sur HTTP : si la requête est bien transmise et traitée mais qu'on n'a pas de résultat, doit-on quand même renvoyer le 200, qui signifie que tout s'est bien passé ? Avec GET, on utilise souvent 404 dans ce cas, mais c'est parce que le terme de recherche est dans l'URL, ce qui n'est plus le cas ici. On aurait pu aussi avoir un nouveau code commençant par 2. Finalement, le choix a été de renvoyer 200 quand la requête est bien arrivée et que le moteur de recherche a fonctionné, même s'il n'a rien trouvé. (Une discussion analogue avait eu lieu pendant le développement de DoH. Le RFC 8484 avait finalement décidé de répondre 200 même si le nom de domaine demandé n'existait pas.)
Ah, et si vous voulez superviser votre service HTTP utilisant QUERY, le programme check_http des monitoring plugins le permet. Voici un exemple de configuration pour Icinga :
vars.http_vhosts["query"] = {
http_uri = "/methodquery"
http_vhost = "www.bortzmeyer.org"
http_ssl = true
http_sni = true
http_method = "QUERY"
# Notez que le nom de la variable n'est pas très heureux.
http_post = "query=foobar"
http_content_type = "application/x-www-form-urlencoded"
http_string = "foobar\" OK"
http_timeout = 15
}
Sinon, si vous voulez d'autres lectures, il y a un bon article de Tykok.
L'article seul
RFC 9975: Clarifications on CDS/CDNSKEY and CSYNC Consistency
Date de publication du RFC : Mai 2026
Auteur(s) du RFC : P. Thomassen (SSE - Secure Systems
Engineering)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 28 mai 2026
Pour compléter un processus de sécurisation des noms de domaine avec DNSSEC, il faut transmettre au domaine parent votre clé publique. Le faire manuellement via l'interface Web du BE n'est pas pratique donc il existe un moyen d'automatiser cela, les CDS/CDNSKEY, moyen décrit dans le RFC 7344. Mais attention à la sécurité ! Ce moyen n'est sûr que si on suit quelques précautions, décrites dans ce nouveau RFC.
Bon, je sais, j'ai simplifié, on ne transmet pas forcément au domaine parent sa clé publique mais parfois un condensat de celle-ci. (Le domaine parent publiera ensuite un enregistrement DS, contenant un condensat que vous aurez donné ou bien qu'il aura calculé à partir de la clé.) Ça ne change pas grand'chose en pratique. Le RFC 7344 décrit comment automatiser le changement de clé en publiant dans son domaine des enregistrements CDS et/ou CDNSKEY, qui informent le parent. (Et le RFC 9615 permet de le faire pour la configuration initiale, pas juste pour un changement.) Avec une technique proche, les enregistrements CSYNC du RFC 7477, on peut aussi automatiser le changement des serveurs de noms faisant autorité.
À partir de là, le gestionnaire du domaine parent (typiquement un registre de noms de domaine) va récupérer ces enregistrements et agir (modifier les enregistrements DS et NS dans son domaine). La façon la plus simple de récupérer les CDS, CDNSKEY et CSYNC est de faire une bête requête DNS classique, donc via son résolveur par défaut :
% dig turris.cz CDS … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 16850 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 … ;; ANSWER SECTION: turris.cz. 5 IN CDS 53148 13 2 9A0E997A2992D4089CE39C1976DC65C00C9D20A6C36187F897E71D6E 23368E6E ;; Query time: 24 msec ;; SERVER: 192.168.2.254#53(192.168.2.254) (UDP) ;; WHEN: Fri Jan 09 11:15:20 CET 2026 ;; MSG SIZE rcvd: 86 % dig alatienne.fr CDNSKEY … ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 53877 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 … ;; ANSWER SECTION: alatienne.fr. 3600 IN CDNSKEY 257 3 13 ( mdsswUyr3DPW132mOi8V9xESWE8jTo0dxCjjnopKl+Gq JxpVXckHAeF+KkxLbxILfDLUT0rAK9iUzy1L53eKGQ== ) ; KSK; alg = ECDSAP256SHA256 ; key id = 2371 ;; Query time: 52 msec ;; SERVER: 127.0.0.1#53(127.0.0.1) (UDP) ;; WHEN: Thu Feb 05 16:35:32 CET 2026 ;; MSG SIZE rcvd: 229
Mais cette méthode n'est pas très sûre et nous allons voir pourquoi, et comment arranger les choses.
Ici, la réponse CDS était signée par DNSSEC (le
flag ad, pour
Authentic Data). Mais ce n'est pas toujours le
cas (avec les CSYNC, ou tout simplement lors de la configuration
initiale de DNSSEC, cf. RFC 8078). Le fond du
problème est que les serveurs faisant
autorité pour le domaine qui publie CDS, CDNSKEY ou CSYNC
peuvent être en désaccord. (Ou bien, mais le RFC ne semble pas le
mentionner, il y a eu empoisonnement de la mémoire du résolveur.) Ce
désaccord peut être dû à un piratage d'un des serveurs (ou à une
malveillance de ses opérateurs) mais il peut être aussi le résultat
d'un cafouillage technique
(un serveur ne se synchronisant plus) ou organisationnel, les
serveurs n'étant pas forcément gérés par la même entité. Sans
compter le risque d'une délégation boiteuse (lame
delegation) où un des serveurs listés dans l'ensemble NS
n'est pas censé être serveur pour ce domaine. D'ailleurs, même
DNSSEC ne protège pas dans tous les cas, s'il y a plusieurs signeurs
(RFC 8901), ils peuvent aussi déconner
séparement. Avec le comportement par défaut du résolveur typique
(accepter la réponse du premier serveur faisant autorité qui
répond), un seul des serveurs faisant autorité peut déclencher un
changement de configuration dans le domaine parent. Le cœur de notre
nouveau RFC est
de dire que le logiciel qui récupère CDS/CDNSKEY/CSYNC doit
s'assurer que les serveurs faisant autorité sont
cohérents, qu'ils renvoient tous la même
réponse.
Cela ne peut pas se faire via un résolveur typique, je n'en connais pas qu'on puisse configurer pour faire cela, il faut donc interroger directement les serveurs faisant autorité. Par exemple, pour la requête dig ci-dessus, un moyen de le faire serait, par exemple en shell :
% for ns in $(dig +short turris.cz NS); do dig @$ns +short turris.cz CDS done 53148 13 2 9A0E997A2992D4089CE39C1976DC65C00C9D20A6C36187F897E71D6E 23368E6E 53148 13 2 9A0E997A2992D4089CE39C1976DC65C00C9D20A6C36187F897E71D6E 23368E6E 53148 13 2 9A0E997A2992D4089CE39C1976DC65C00C9D20A6C36187F897E71D6E 23368E6E
Et il faudrait ensuite s'assurer que toutes les réponses sont identiques. Sinon, le domaine parent s'abstient d'agir. (Comme les lecteurs et lectrices de ce blog sont très fort·es en réseau, ielles ont certainement remarqué que j'avais simplifié : comme un serveur peut avoir plusieurs adresses IP, il faudrait les tester toutes. Des exemples de programmes plus perfectionnés figurent par la suite.)
Ces nouvelles règles amènent à mettre à jour quelques RFC, qui ne les spécifiaient pas : les RFC 7344 et la section 3.1 du RFC 7477, qui conseillait de ne demander qu'à un seul serveur faisant autorité (ce que fait le résolveur typique mais qui n'est pas assez sûr).
La section 3 du RFC liste plus formellement les nouvelles exigences :
- Tester la présence et le contenu des CDS/CDNSKEY/CSYNC via toutes les adresses IP des serveurs faisant autorité.
- Toutes les réponses doivent être identiques.
- On peut arrêter le test dès qu'au moins une des réponses correspond au DS/NS existant. Cela veut dire qu'au moins un des serveurs faisant autorité ne veut pas qu'on change.
Si et seulement si toutes les réponses sont identiques, et différentes de la situation actuelle, le gestionnaire du domaine parent peut envisager de modifier NS et DS.
Notez que, si les serveurs faisant autorité utilisent l'anycast, le test ne sera pas complet, le vérificateur de cohérence ne testera qu'une seule instance d'un nuage anycast. Dans ce cas, il peut être intéressant de tester la cohérence depuis plusieurs points de mesure, pour avoir des chances de contacter plusieurs instances anycast.
La même règle s'applique aux enregistrements CSYNC du RFC 7477. La section 3.2 de notre RFC détaille comment traiter ces enregistrements, qui permettent notamment de synchroniser les enregistrements NS du domaine parent (et la colle) avec ceux du domaine fils. Il y a une petite nuance pour le numéro de série de la zone que contient l'enregistrement CSYNC (il doit être identique à celui du SOA du même serveur, pas forcément à ceux des CSYNC des autres serveurs faisant autorité).
La section 5 de notre RFC discute les conséquences pour la sécurité. Si on ne fait pas les vérifications décrites ici, il y a un risque de copier dans la zone parente des données incorrectes, voire créées par un attaquant, par exemple parce qu'il a réussi à pirater un des serveurs faisant autorité ou bien parce qu'il gérait un de ces serveurs mais agissant sans autorisation du gérant de la zone (cas courant si on sous-traite certains de ses serveurs secondaires). Ce RFC privilégie donc l'intégrité des données, au risque, on peut le remarquer, qu'un changement souhaité prenne davantage de temps, si un des serveurs faisant autorité a des problèmes. Que faire si un de ces serveurs ne veut vraiment pas jouer le jeu et, par exemple, ne se synchronise plus et ne publie pas le nouveau CDS/CDNSKEY/CSYNC ? La section 5 dit qu'il faut donc maintenir un canal traditionnel (via le BE, par exemple), pour pouvoir changer quand même les données publiées par la zone parente. C'est par exemple le rôle d'EPP (RFC 5730).
Cette vérification de la cohérence a déjà été mise en œuvre dans les logiciels de TANGO et CORE, ainsi que déployée par le registre suisse. Zonemaster fait ce test.
Enfin, l'annexe A du RFC décrit plus en détail des scénarios où l'incohérence entre les serveurs faisant autorité pour un domaine a eu des conséquences fâcheuses. Par exemple, si un domaine a une délégation boiteuse, vers un serveur qui n'existe pas, un malveillant peut créer le serveur en question, mettre un CSYNC en indiquant uniquement des serveurs qu'il contrôle et transformer une simple délégation boiteuse en un détournement complet du nom. Si le serveur non existant était dans un nom de domaine non enregistré, l'attaquant n'a qu'à enregistrer ce nom (attaque flamant). Si le serveur non existant était sur une adresse IP libre chez un hébergeur public, l'attaquant n'a qu'à créer des machines chez cet hébergeur jusqu'à tomber sur l'adresse en question (une variante de l'attaque des sous-domaines). Ce genre d'attaques est décrit dans des articles comme « Unresolved Issues: Prevalence, Persistence, and Perils of Lame Delegations » ou « Risky BIZness: risks derived from registrar name management ». Bon, si le domaine est signé avec DNSSEC, il est protégé, non ? Oui, sauf si l'attaquant peut changer la clé avec un CDS… D'où l'importance de la vérification de cohérence de ce RFC.
Autre exemple d'accident possible (et qui n'est pas dû à une attaque délibérée), dans le cas où un domaine a plusieurs signeurs DNSSEC (RFC 8901), si un des serveurs faisant autorité ne publie que ses propres clés dans un CDS. Sans vérification de cohérence, au lieu d'avoir plusieurs DS comme prévu, on n'en aura qu'une partie.
Et si vous cherchez un programme simple qui fait à peu près ce
que demande le RFC, vous avez cds-consistency.py
% ./cds-consistency.py knot-resolver.cz knot-resolver.cz is consistent, data is "None" % ./cds-consistency.py àlacon.fr àlacon.fr is consistent, data is "7177 13 2 fa99827c7aca1681b8905285e7fa33ec5adccb430393b4fa1e9f9aa3d9263709"
L'article seul
RFC 9982: JSContact Version 2.0: A JSON Representation of Contact Data
Date de publication du RFC : Mai 2026
Auteur(s) du RFC : R. Stepanek (Fastmail)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF calext
Première rédaction de cet article le 28 mai 2026
Voici la version 2 du format de représentation d'entités
(personnes ou organisations) JSContact (RFC 9553). En fait, ce numéro de version est trompeur, il n'y
a qu'un seul changement, le membre uid qui
était obligatoire devient facultatif. Mais ce petit changement, qui
casse la compatibilité, oblige à changer de numéro de version.
Dans la section 2.1.9 du RFC 9553,
l'uid (User IDentifier)
était obligatoire. Alors que le vieux format
vCard (RFC 6350) le
disait facultatif, ce qui rendait difficile toute traduction
automatique de vCard vers JSContact. En outre, s'il était cool
d'avoir la garantie d'un identificateur unique pour chaque carte de
visite au format JSContact, cela ne convenait pas dans tous les
cas. Ainsi, RDAP (RFC 9083)
n'utilise pas du tout cette propriété uid.
Donc, seul changement entre les versions 1 et 2, l'attribut
uid devient optionnel. On passe de :
uid: String (mandatory)
à :
*uid: String (optional).*
Mais c'est suffisant pour obliger à changer le numéro de version de JSContact (RFC 9553, section 1.9).
Par exemple, cet object JSContact (qui n'a pas
d'uid) est désormais légal :
{
"@type": "Card",
"version": "2.0",
"name": {"components": [{"kind": "given","value": "Jean"},
{"kind": "surname","value": "Durand"}]},
"emails": {
"email": {
"address": "jean.durand@example.com"
}
}
}
(Avec la version 1, il aurait fallu quelque chose comme
"uid": "a73c940e-b1d3-4f3c-aa50-c9749352c253"
après la version.)
L'article seul
Articles des différentes années : 2026 2025 2024 2023 2022 2021 2020 Précédentes années
Syndication : Flux Atom avec seulement les résumés et Flux Atom avec tout le contenu.
{kind=link}