
Ce blog n'a d'autre prétention que de me permettre de mettre à la disposition de tous des petits textes que j'écris. On y parle surtout d'informatique mais d'autres sujets apparaissent parfois.
Un modeste avis sur ChatGPT
Première rédaction de cet article le 14 décembre 2022
Tout le monde aujourd'hui utilise ChatGPT et envoie sur les réseaux sociaux les résultats les plus amusants ou les plus spectaculaires. La plupart des retours sont admiratifs devant les performances de ce système d'« Intelligence Artificielle » (IA) pour répondre à des questions et générer des textes. Mais il faut nuancer un peu.
Tout d'abord, un sérieux avertissement : je n'ai pas essayé ChatGPT moi-même, en raison de leur demande excessive de données personnelles (il faut indiquer une adresse de courrier et un numéro de téléphone, et les deux sont vérifiées par envoi d'un code à retourner ensuite ; on ne peut donc pas tricher). J'ai seulement lu les résultats de ChatGPT tels que publiés par ses utilisateurs. Si vous pensez que cela rend cet article sans valeur, arrêtez votre lecture tout de suite et allez faire autre chose, par exemple regarder les belles aquarelles d'Aemarielle.
Maintenant, revenons à ChatGPT. On lui pose des questions et il répond. Le résultat est souvent étonnant, par exemple lorsqu'on lui demande des textes « écrits dans le style de [telle personne] » ou lorsqu'on l'interroge sur des questions techniques complexes. Cela illustre de manière publique les progrès importants des techniques connues sous le nom commercial d'IA (Intelligence Artificielle), ainsi que la quantité vraiment colossale de données que ChatGPT a lues et assimilées. Il est par exemple à noter que ChatGPT écrit des textes bien meilleurs que ce que font beaucoup d'humains, y compris dans un environnement professionnel (« écris un communiqué de presse se félicitant de l'augmentation de X % du chiffre d'affaires de la société Machin » donnera un résultat indistinguable du « vrai »). Notamment, il ne fait aucune faute d'orthographe ou de grammaire.
Est-ce que cela signifie qu'on peut réellement parler d'intelligence et que les humains sont désormais inutiles ? Pas si vite. D'abord, l'intelligence, ce n'est pas de savoir exécuter une tâche, c'est de savoir quelle tâche exécuter. De ce point de vue, ChatGPT est loin de l'intelligence. Plusieurs personnes ont pu constater qu'on pouvait lui demander des textes contradictoires (« explique pourquoi il est important d'augmenter les impôts » puis « explique pourquoi il faut baisser les impôts », et ChatGPT s'exécutera).
Ensuite, ce que révèle ChatGPT, ce ne sont pas tellement les progrès de l'IA que le creux et l'absence de contenu de beaucoup de textes produits par des humains. ChatGPT sait faire des devoirs d'étudiants de première année, écrire des communiqués de presse, du reporting et produire les discours des ministres. Grâce à ce système, on voit bien que ces textes n'ont pas tellement de fond et ne nécessitent pas beaucoup d'intelligence, uniquement la lecture et le traitement d'une grande quantité d'informations, tâche où les humains sont certainement inférieurs aux ordinateurs. ChatGPT ne remplacera donc pas les humains mais lui ou ses successeurs pourront prendre en charge des tâches qui étaient considérées à tort comme nécessitant de l'intelligence. Comme le note Stéphane Mouton, ChatGPT est toujours « correct mais superficiel ».
Cela va certainement « disrupter » certains secteurs, comme celui des rédacteurs sous-payés qui écrivent vite et mal. Pour prendre un autre exemple, j'ai vu des étudiants de master produire des notes qui ne valaient pas ce que fait ChatGPT. L'enseignement devra donc s'adapter. Mais cela poussera à réfléchir à ce que nous voulons que les humains fassent. Écrire des synthèses fades et sans originalité ou bien travailler de manière plus créative ?
Mais, diront certains, ChatGPT et l'IA en général vont continuer à progresser. Les limites actuelles seront forcément dépassées. Eh bien non, ou plus exactement, c'est plus compliqué que cela. La marche du progrès technique peut faire croire que le progrès est forcément linéaire, chaque année marquant une amélioration technique. Des observations comme la loi de Moore vont en ce sens. Mais ce n'est pas une règle générale du progrès. Il y a également des techniques qui stagnent, ou qui ne progressent que par bonds imprévisibles. L'IA en est un bon exemple : depuis ses débuts (qui sont à peu près ceux de l'informatique), elle alterne des bonds spectaculaires avec de longues périodes de repos, le bond spectaculaire ayant été suivi d'une constatation qu'on n'arrivait pas à l'améliorer. Peut-être que ChatGPT va progresser, ou peut-être qu'il ne dépassera pas son stade actuel avant longtemps, mais on ne peut pas affirmer qu'il fera forcément mieux dans le futur.
Et sinon, non, petits coquins, cet article n'a pas été écrit par ChatGPT, Bruce Schneier a fait la blague avant moi (et je suis d'accord avec la plupart des commentaires à son article ; l'article est sans erreur mais enfonce des portes ouvertes et ne fait preuve d'aucune réflexion).
L'article seul
RFC 8521: Registration Data Access Protocol (RDAP) Object Tagging
Date de publication du RFC : Novembre 2018
Auteur(s) du RFC : S. Hollenbeck (Verisign Labs), A. Newton (ARIN)
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 23 novembre 2022
Contrairement à son lointain prédécesseur
whois, le protocole d'accès aux informations
des registres RDAP a un mécanisme standard de
découverte du serveur faisant autorité. Ce mécanisme est prévu pour
des données organisées de manière
arborescente comme les noms de domaine ou les adresses IP. Pour des objets qui n'ont
pas cette organisation, comment faire ? Ce RFC fournit une solution pour des objets
quelconques, s'ils obéissent à une convention de nommage
simple. C'est le cas des handles, ces
identificateurs d'entités (titulaires de noms de domaine, contacts
pour un préfixe IP, etc) ; s'ils sont de la forme
QUELQUECHOSE-REGISTRE, on pourra trouver le
serveur responsable.
Le mécanisme habituel de découverte du serveur est normalisé dans
le RFC 9224. En gros, l'IANA garde un
registre des serveurs, indexé par un nom de domaine ou par un
préfixe IP. Ce registre est au format JSON. Un client
RDAP est juste censé télécharger ce fichier,
trouver le serveur faisant autorité, puis le contacter. Pour pouvoir
faire la même chose avec des objets non structurés, il faut leur
imposer une convention de nommage. Si on interroge avec RDAP (ou
whois) l'adresse IP 88.198.21.14, on voit que
son contact technique est HOAC1-RIPE. Cette
convention de nommage est « d'abord un identifiant unique au sein du
registre, puis un tiret, puis le nom du registre, ici le RIPE-NCC ». L'IANA a juste à garder un registre de ces
registres qui nous dira, par exemple, que
RIPE a comme serveur RDAP
https://rdap.db.ripe.net/. On peut ensuite
l'interroger en RDAP :
% curl https://rdap.db.ripe.net/entity/HOAC1-RIPE
"vcardArray" : [ "vcard", [ [ "version", { }, "text", "4.0" ], [ "fn", { }, "text", "Hetzner Online GmbH - Contact Role" ], [ "kind", { }, "text", "group" ], [ "adr", {
"label" : "Hetzner Online GmbH\nIndustriestrasse 25\nD-91710 Gunzenhausen\nGermany"
}, "text", [ "", "", "", "", "", "", "" ] ], [ "tel", {
"type" : "voice"
}, "text", "+49 9831 505-0" ], [ "tel", {
...
Petit piège, la partie du début peut elle-même comporter des tirets donc lorsqu'on coupe en deux un handle, il faut le faire sur le dernier tiret (section 2 du RFC). Pourquoi le tiret, d'ailleurs ? Parce qu'il est couramment utilisé comme séparateur, et parce que son utilisation dans un URL ne pose pas de problème particulier (RDAP utilise HTTPS et donc des URL).
Le registre des serveurs RDAP est géré à l'IANA comporte un tableau JSON des services, chaque entrée étant composée de trois tableaux, la liste des adresses de courrier du responsable, la liste des suffixes (en général, un seul par registre) et la liste des serveurs RDAP. Par exemple, pour l'ARIN, on aura :
[
[
"andy@arin.net"
],
[
"ARIN"
],
[
"https://rdap.arin.net/registry/",
"http://rdap.arin.net/registry/"
]
]
Les entrées dans le registre sont ajoutées selon la politique « Premier Arrivé, Premier Servi » du RFC 8126.
Comme ce RFC décrit une
extension à RDAP, le serveur RDAP doit ajouter à sa réponse,
dans l'objet rdapConformance,
rdap_objectTag_level_0. (Apparemment, personne
ne le fait.)
Vous voulez du code ? La bibliothèque
ianardap.py, qui est disponible
en ligne, peut récupérer la base et l'analyser. Cela permet
ensuite de faire des requêtes pour des objets :
% ./dump-object.py F11598-FRNIC | jq .
...
[
"",
"",
"Association Framasoft c/o Locaux Motiv",
"Lyon",
"",
"69007",
"FR"
]
...
Le programme dump-object.py étant simplement :
#!/usr/bin/env python3
import ianardap
import requests
import sys
rdap = ianardap.IanaRDAPDatabase(category="objects")
for object in sys.argv[1:]:
url = rdap.find(object)
if url is None:
print("No RDAP server for %s" % object, file=sys.stderr)
continue
response = requests.get("%sentity/%s" % (url[0], object))
print(response.text)
L'article seul
Capitole du Libre 2022
Première rédaction de cet article le 21 novembre 2022
Dernière mise à jour le 21 février 2023
Les 19 et 20 novembre 2022, c'était Capitole du Libre à Toulouse, un rassemblement libriste important, qui reprenait après l'interruption Covid-19. Il y avait beaucoup de rencontres, d'ateliers et de conférences intéressantes. (En tout, 118 orateurs, 97 conférences, 16 ateliers et 39 stands au village associatif.)
J'ai fait deux exposés. Le premier, un peu plus politique, portait sur une question de programmation. Maintenant que tout est chiffré, comment déboguer les applications réseau alors qu'on ne peut plus utiliser Wireshark comme avant ? Il existe plusieurs solutions, de la lutte pour limiter le chiffrement, comme le font encore certains réactionnaires, à la coopération de l'application, qui est l'avenir. Voici la version en PDF, et le source en LaTeX/Beamer.
Le second exposé tirait les leçons du développement de Drink, un serveur DNS faisant autorité voué aux réponses dynamiquement générées. Voici la version en PDF, et le source en LaTeX/Beamer. Le code de Drink est disponible en ligne.
J'ai aussi participé à une table ronde sur le thème de la « souveraineté numérique », avec Gaël Duval, Philippe Latombe, et Amandine Le Pape, table ronde animée par Étienne Gonnu.
J'ai également participé à une séance dédicace de mon livre « Cyberstructure », qui avait été annoncé pour la première fois publiquement au Capitole du Libre il y a quatre ans. La séance était organisée par la librairie « Les petits ruisseaux ». J'étais à côté de David Revoy, l'auteur de Pepper et Carrot, qui faisait de superbes dessins.
Le programme de Capitole du Libre était très riche. J'ai beaucoup aimé « Introduction à Rust embarqué » de Sylvain Wallez, avec des belles démonstrations (l'inévitable diode clignotante) de ce langage en direct, sur un ATtiny85 (0,5 ko de RAM, 8 ko de flash) et un plus gros microcontrôleur ESP32. Également très technique, la descente en profondeur dans les entrailles des composants Ethernet « Plongée au coeur d'Ethernet, et son support dans Linux », de Maxime Chevallier.
Des enregistrements vidéo ont été faits et sont disponibles en ligne (dont les miens, le serveur DNS Drink et le déboguage d'applications chiffrées).
L'article seul
Survey of the DNS servers in the fediverse
First publication of this article on 18 November 2022
The fediverse is supposed to be decentralized. But the fact that the network has a decentralized architecture does not mean that it is perfectly decentralized in practice. We survey here the DNS authoritative servers for the domains used by the fediverse instances. Unfortunately, yes, they are too concentrated.
Mostly because of the incredibly childish behaviour of
Elon Musk, the current wave of migration from
Twitter to the
fediverse is much larger than the previous
ones. As a result, there is a renewed interest in the
fediverse, a system which is far from
recent. The fediverse is made of various
instances, each one being independently
administered, both from a technical point of view, and from a
political one. Nothing new or extraordinary, this is how the
Internet was architectured, and how its
services worked, before a few centralized US-based giants distorted
the vision of many people, making them believe that centralization
is normal. Each fediverse instance has a domain
name and this domain name is hosted on a set of
authoritative name servers, which will reply to
the DNS requests of
the clients, the DNS resolvers. As an example, the instance I use,
mastodon.gougere.fr is in the domain
gougere.fr, whose set of authoritative name
servers is currently composed of three
servers. Unix users can for instance
display them with dig :
% dig +short NS gougere.fr nsb.bookmyname.com. nsa.bookmyname.com. nsc.bookmyname.com.
Note you can also perform DNS queries on the fediverse itself, as explained here (see the current result).
A domain "works", for the users, only if the authoritative name servers reply, and reply properly. This makes them critical infrastructure for an instance. If your DNS authoritative servers fail, or lie, the instance is unusable, even if the Pleroma, Mastodon or other server still works fine. So, what are the DNS servers used for this critical role in the current fediverse?
To get data, I started from a list of current instances. I got one
from instances.social. Note
that, on a decentralized network like the fediverse, you cannot get
an official and complete list of all instances. All lists are
imperfect. But I have to start from somewhere (other possibilities:
http://demo.fedilist.com/instance or the public
list of peers of a big instance such as https://mastodon.social/api/v1/instance/peers). So, I created an
authentication token on instances.social, and
retrieved a list with curl:
% curl -s -H "Authorization: Bearer MY-TOKEN" https://instances.social/api/1.0/instances/list\?count=10000\&include_down=false > list.json
I included only live instances
(include_down=false) but, still, some instance
names already were missing from the DNS.
The resulting list was in the JSON format and processed by two Python scripts (see the code later). The first one queried the DNS (with the excellent dnspython library) to get information such as the list of authoritative name servers and their IP addresses. The second script processed the JSON data of the first to output meaningful statistics. Of course, like with any quantitative survey, the hard problem is often which questions to ask, rather than the answers.
Let's start with the actual numbers:
%./nameservers-fediverse-analyze.py There are 1596 instances
Remember that the list is incomplete (no one knows how many instances
really live). Some of these instances are grouped into the same
registered domain (the domain you bought from a
registry, may be through a
registrar). I choosed to group the instance
names in the DNS zones (a set of contiguous names hosted on the same
set of name servers). For instance,
medievalist.masto.host and
piano.masto.host are in the same zone,
masto.host, they have the same servers. There
are a bit less zones than instance names:
There are 1596 instances in 1540 zones. The largest zone, masto.host., encompasses 10 instances
Except masto.host, there are few fediverse
hosters with such subdomains, so no sign of
concentration/centralisation here. There is no giant fediverse
hoster.
Now, the name servers themselves:
There are 2062 nameservers. The largest one, dns2.registrar-servers.com., hosts 85 instances.
Some name servers are more common, such as this
dns2.registrar-servers.com, used by a big DNS
hoster. But it is still only for a small minority of instances.
But wait, name servers come in groups, called sets. The instance administrator, except if he or she is a DNS fan, typically does not cherry-pick his or her name servers, they use a set indicated by the DNS hoster. Let's study sets instead:
There are 951 nameserver sets. The largest one, dns1.registrar-servers.com.;dns2.registrar-servers.com., hosts 85 instances. The top 10 % hosts 677 instances.
There are less sets than instances (a sign of a small centralisation) but not by a large margin. The biggest set is not so big but we note that the top tenth of the sets hosts more than a third of the instances. There are not so many DNS providers.
But there is a catch. Some DNS hosters use a lot of names so you
may think there are many various sets but they actually depend on
one company, a bad thing for decentralisation. The typical example
is Cloudflare, with a lot of cool names
depending on the domain they host
(eleanor.ns.cloudflare.com,
sue.ns.cloudflare.com, etc). So, we have to
group the name servers by company. One of the simplest ways is to find
the registered domain of the name servers' names. To do so, we use
the Public Suffix List,
which is not authoritative and not perfect but sufficient for us. It
will put all the Cloudflare names into one bucket, the registered
domain cloudflare.com:
There are 667 nameserver's domains. The largest one, cloudflare.com, hosts 366 instances. The top 10 % hosts 1324 instances
This time, we have a clear sign of centralisation. A lot of seemingly independent instances have a shared provider, Cloudflare. If Cloudflare breaks, or does evil things, it will affect many instances. And the top 10 % of hosters serves the overwhelming majority of fediverse instances. For your information, the biggest ones are:
cloudflare.com: 366registrar-servers.com: 91gandi.net: 90domaincontrol.com: 55googledomains.com: 49digitalocean.com: 48linode.com: 39inwx.de: 23inwx.eu: 23
(It can be noticed that, unlike the fediverse itself, which uses a
lot of "new TLDs" such as
.social, the name servers are faithful to the
old TLDs.) Playing with names, as seen in the Cloudflare case,
complicated things. We have also the case of
AWS which does not appear on the above list
but they should; they use a lot of registered domains
(awsdns-46.co.uk,
awsdns-20.com, etc) so they appear as many
different hosters. Also, about Cloudflare, remember that this
survey is only about the DNS: I did not try to
see where the server instance is hosted. I repeat: just DNS, no HTTP
was used or considered here. (One also could note that some
authoritative name servers are installed at one big machine hoster,
which gives Cloudflare an even
more prominent place.)
So, as you can see, but this is hardly a surprise, the fediverse is not perfect and there are signs of centralisation, at least as far as DNS is concerned.
The two programs used for this article are:
nameservers-fediverse-gather.py: it gathers information from the DNS and produces a JSON file storing, for each instance, its DNS zone, the name servers and their IP addresses (which were not used for this article). To find the DNS zone, it just climbs the DNS tree until it founds name server records.nameservers-fediverse-analyze.py: it reads the JSON file produced by the first program and displays statistics.
Among the weaknesses of this analysis, you'll note that our
instances are considered equal. But there are very small and very big
instances. It could be useful to tweak results depending on the size
of the instance. instances.social gives us this
information but it has to be handled with care, it is just a declaration
from the instance (and many accounts may be inactive, anyway).
L'article seul
Peut-on censurer tout en respectant la vie privée ?
Première rédaction de cet article le 10 novembre 2022
C'était le thème d'une réunion pendant l'IETF 115 à Londres. Pour censurer sur l'Internet, le censeur doit regarder ce à quoi l'utilisateur voulait accéder, ce qui pose des problèmes de vie privée évidents. Peut-on censurer sans violer la vie privée ?
Le problème était posé sous la forme d'une question technique
mais, évidemment, c'est plus compliqué que cela. Avant de détailler
tous les aspects, voyons comment fonctionne un mécanisme de censure
simple : l'utilisateur veut visiter
https://truc-interdit.example/, les équipements
intermédiaires sur le réseau voient cette demande, la comparent à
une liste de choses interdites et bloquent éventuellement la
visite. On peut réaliser cela de plusieurs façons, par exemple par
un résolveur DNS menteur ou par un relais
HTTP qui regarde les URL. Peu importe : dans tous les cas, des
équipements intermédiaires apprendront qu'on voulait accéder à telle
ou telle ressource. C'est ennuyeux pour les droits
humains et ça rentre en conflit avec des techniques
comme DoT ou HTTPS, qui sont justement là
pour empêcher ce genre d'interceptions.
Mes lectrices et lecteurs informaticien·nes peuvent faire une pause ici et se demander comment techniquement réaliser une telle interception sans apprendre l'identité de la ressource à laquelle on voulait accéder. C'est un exercice intellectuellement stimulant. Mais, je le dis tout de suite, le problème n'est pas purement technique. En attendant d'élargir la question, je vous laisse quelques minutes pour réfléchir à une solution technique.
C'est bon, les quelques minutes sont écoulées ? Une solution possible serait, pour le cas du Web, que votre navigateur condense l'URL et envoie cet URL condensé à un service de filtrage qui répond Oui ou Non. Cela préserverait la vie privée, tout en permettant le filtrage. (Oui, il y a quelques détails techniques à prendre en compte, il faut saler pour éviter la constitution de dictionnaires, et il faut canonicaliser pour éviter qu'un malin ne fasse varier les URL pour éviter la détection, etc. Mais ne laissez pas ces détails techniques vous absorber trop longtemps.)
Le vrai problème de cette technique ? Elle nécessite la coopération de l'utilisateur (plus exactement de ses logiciels). C'était le point soigneusement dissimulé par le groupe qui avait organisé cette réunion, l'Internet Watch Foundation. (Au passage, cette réunion était un side meeting, réunion qui utilise les salles de l'IETF mais qui n'est pas forcément approuvée par l'IETF.) Le titre officiel de la réunion était « Is Privacy preserving Web Filtering Possible? » alors qu'en fait le désir n'était pas de filtrer mais de censurer (le filtrage se fait avec le consentement de l'utilisateur, la censure contre son gré). Le présentateur avait introduit la réunion en disant que le but était d'éviter qu'un internaute innocent ne soit exposé contre son gré à des images pédo-pornographiques. Si c'était vraiment le cas, le problème serait simple : un logiciel de filtrage sur la machine de l'utilisateur, comme on fait avec les bloqueurs de publicité. Le cas de la pédo-pornographie est un peu plus complexe car, contrairement aux bloqueurs de publicité, on ne souhaite pas distribuer les listes d'URL bloqués (des pédophiles pourraient les utiliser pour aprendre de nouvelles ressources). Mais ce n'est pas un gros problème, la solution du service qu'on interroge en lui envoyant un condensat de l'URL suffit.
Non, le vrai problème, c'est le consentement de l'utilisaeur. Si vraiment, on veut rendre un service à l'utilisateur, le problème est relativement simple. Si on veut censurer sans l'accord de l'utilisateur, cela devient effectivement plus compliqué. L'argument comme quoi on voulait protéger l'utilisateur contre une exposition accidentelle ne tient donc pas.
L'Internet Watch Foundation a présenté le problème comme purement technique, sachant très bien que les participant·es à l'IETF sont passionné·es de technique et vont sauter sur l'occasion, cherchant des solutions complexes et intéressantes (par exemple du côté du chiffrement homomorphique, la solution miracle souvent citée). Mais on est là dans un cas où la question n'est pas technique, mais politique. Il n'y a aucun moyen magique de censurer sans le consentement de l'utilisateur et en respectant sa vie privée. Le but de l'IWF était probablement justement de montrer qu'il n'y avait pas de solution technique (« on a été de bonne volonté on a soumis, la question à l'IETF ») et qu'il fallait donc censurer sans se soucier de vie privée.
Notons aussi qu'une infrastructure de censure, une fois en place, sert à beaucoup de choses. La pédo-pornographie, par l'horreur qu'elle suscite, sert souvent à couper court aux débats et à mettre en place des systèmes de censure, qui seront ensuite utilisés pour bien d'autres choses.
L'article seul
IETF 115 Hackathon, DNS error reporting
First publication of this article on 8 November 2022
Remember that IETF develops the
standards for the
Internet, roughly from layer
3 to some parts of layer 7. One
of the most important technologies at IETF is of course the
DNS. The role of
the IETF hackathons, that take place the
weekend just before the IETF meeting, is to try to implement new
ideas (not yet standardized) to see if it works (IETF prides itself
on relying on "running code"). This time, we were four persons
working on DNS error reporting. This technique is currently
specified in an Internet Draft
draft-ietf-dnsop-dns-error-reporting. The
problem it tries to solve is the one of informing the managers of a
zone that there is some technical problem detected by a DNS
resolver. Today, if you don't test your zone thoroughly with tools
like DNSviz or Zonemaster, you'll know that
there is a problem only when users will complain on
Twitter. It would be better to be told by
your clients, the resolvers, before that.
The way it works is a follows:
- The authoritative server for the zone returns in its replies an EDNS option indicating a report receiving domain.
- The resolver, when it detects a problem, such as a wrong DNSSEC key, sees this indication and creates a DNS query encoding the problem and appending the report receiving domain.
- The servers for the report receiving domain receives the query, processes it and stores it.
- The zone administrator reads about the problem and acts accordingly.
You can see there are three actors and therefore three programs to modify (the last ones, the servers for the report receiving domain, could be unmodified authoritative name servers). I worked on the authoritative side, using the experimental name server Drink. Willem Toorop worked on the Unbound resolver and Shane Kerr on another (proprietary) authoritative server. Roy Arends helped, replied and modified the draft with our feedback.
The draft is quite simple and straightforward. Drink was modified to emit a new EDNS option:
report_to = Binary.from_list(encode(config()["reporting-agent"])) length = byte_size(report_to) Binary.append(<<Drink.EdnsCodes.reporting::unsigned-integer-size(16), length::unsigned-integer-size(16)>>, report_to)
And then to process the reports (the query type for the reports is TXT):
"report" ->
if config()["services"]["report"] do
case qtype do
:txt ->
result = Drink.Reports.post(Enum.join(qname, "."))
%{:rcode => Drink.RCodes.noerror,
:data => [result],
:ttl => @report_ttl}
:any -> @any_hinfo
_ -> %{:rcode => Drink.RCodes.noerror}
end
Reports are stored in a separate agent. Note that we check they are
properly formed, with the label _er at the
beginning and at the end:
def post(value) do
labels = String.split(value, ".")
if List.last(labels) == "report" do
labels = List.delete_at(labels, length(labels)-1) # Remove report
if List.first(labels) == "_er" and List.last(labels) == "_er" do
labels = List.delete_at(List.delete_at(labels, length(labels)-1), 0) # Remove _er
error_code = List.last(labels)
qtype = List.first(labels)
qname = Enum.join(List.delete_at(List.delete_at(labels, length(labels)-1), 0), ".")
Agent.update(__MODULE__,
fn state ->
[{error_code, qtype, qname} | state]
end)
"Thanks for the report of error #{error_code} on #{qname}"
else
# Else do nothing, probably QNAME minimization (or may be broken report)
"Invalid report"
end
end
end
From the outside, this looks like this:
% dig _er.1.foobar.example.9._er.report.dyn.courbu.re TXT ... ;; ANSWER SECTION: _er.1.foobar.example.9._er.report.dyn.courbu.re. 24 IN TXT "Thanks for the report of error 9 on foobar.example" ;; AUTHORITY SECTION: dyn.courbu.re. 15 IN NS dhcp-80f2.meeting.ietf.org. ...
Since Drink is fully dynamic, it allows us to send a response depending on the analysis of the report (but the draft says you can return anything, you can use a static TXT record). If the report is invalid:
% dig _er.1.foobar.example.9.missing-end.report.dyn.courbu.re TXT
...
;; ANSWER SECTION:
_er.1.foobar.example.9.missing-end.report.dyn.courbu.re. 30 IN TXT "Invalid report"
One can then retrieve the report, by asking the name server:
% echo report | socat - UNIX-CONNECT:/home/stephane/.drink.sock
REPORT state:
foobar.example, 9
funny.example, 9;2
Lessons from the hackathon? Drink is well suited for rapid exprimentation (it was one of its goals), the draft is clear and simple and interoperability is fine. By querying the modified Unbound resolver, we see report queries arriving and being accepted. Here, a DNSSEC error:
% dig @2a04:b900:0:100::28 www.bogus.bortzmeyer.fr
...
;; OPT PSEUDOSECTION:
...
; EDE: 9 (DNSKEY Missing): (validation failure <www.bogus.bortzmeyer.fr. A IN>: key for validation bogus.bortzmeyer.fr. is marked as invalid because of a previous validation failure <www.bogus.bortzmeyer.fr. A IN>: No DNSKEY record from 2001:41d0:302:2200::180 for key bogus.bortzmeyer.fr. while building chain of trust)
...
(Errors are the errors specified in RFC 8914.) And Drink saw:
nov. 08 18:17:14 smoking Drink[365437]: [info] 185.49.141.28 queried for _er.1.www.bogus.bortzmeyer.fr.9._er.report.dyn.courbu.re/txt
% echo report | socat - UNIX-CONNECT:/home/stephane/.drink.sock
REPORT state:
foobar.example, 9
funny.example, 9;2
www.bogus.bortzmeyer.fr, 9
So, it is a success. You can see all the reports made at the end
of the hackathon (ours is
"IETF115-DNS-Hackathon-Results.pdf "). Outside of that, there is
a Wireshark implementation of the EDNS
option: 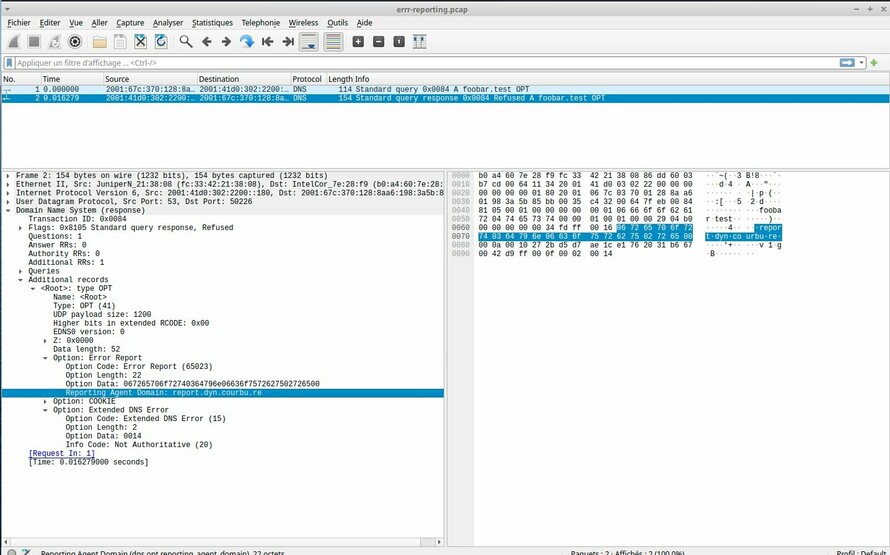
Because it is a work in progress, note that there were changes before, during and after the hackathon. The query type for the reports changed from NULL to TXT (the code for NULL was tested and works), the EDNS option is now returned only when the resolver asks for it (this is not yet done in Drink), the format of the query report changed, etc. The goal is to test, not to make stable code.
The code, written in Elixir, is available
online. It is not yet merged in the master, you have to use
the git branch
error-reporting.
L'article seul
An IPC server (with Unix sockets) in Elixir
First publication of this article on 7 November 2022
While adding IPC support to an Internet server written in Elixir, I did not find a lot of documentation or examples about Unix sockets with Elixir. So, here it is.
Unix sockets (also mentioned as "domain" or "local") are a way to communicate between processes (hence IPC = Inter-Process Communication) on the same machine. As such, they are less general than TCP/IP sockets but they are more secure (you cannot connect from the outside, and you can retrieve the process identifier, user identity, etc of the client) and you can finely control access through normal file permissions since the socket appears as a file.
To have the server written in Elixir listen on such a socket, we first clean (we use the standard module File):
sockname = System.get_env("HOME") <> "/.test-ipc.sock"
File.rm(sockname) # We don't test the results, since we are not interested
# if the file existed or not.
Then we can open the socket, using the Erlang
socket library, indicating the type
:local :
{:ok, s} = :socket.open(:local, :stream, %{})
:ok = :socket.bind(s, %{family: :local, path: sockname})
# You can add File.chmod here to set permissions
:ok = :socket.listen(s)
Note that we use pattern matching to be sure the operations succeeded (we would have better error messages with a code testing the different cases).
If you get an ErlangError
{:invalid, {:protocol, %{}}}, this is probably
because your Elixir (actually, OTP) is too
old. We need at least version 12 of Elixir (OTP 24). You can always
catch the error to produce a better error message (see the complete
source code).
Now, we can accept connections (the rest of the code is not specific to Unix local sockets):
{:ok, client} = :socket.accept(socket)
And read from the clients, and write to them (here, we just echo the message), like we would do with more common TCP/IP sockets:
{:ok, result} = :socket.recv(socket, 0)
msg = String.trim(result)
Logger.info("Received \"#{msg}\"")
:ok = :socket.send(socket, msg <> "\r\n")
A complete echo server using these techniques is ipc-server.exs
% elixir server.exs Listening on /home/stephane/.test-ipc.sock
Clients can be netcat:
% netcat -U ~/.test-ipc.sock allo allo Tu es là? Tu es là?
Or socat:
% echo foobar | socat - UNIX-CONNECT:/home/stephane/.test-ipc.sock foobar
Or of course a client you write yourself.
L'article seul
RFC 9299: An Architectural Introduction to the Locator/ID Separation Protocol (LISP)
Date de publication du RFC : Octobre 2022
Auteur(s) du RFC : A. Cabellos
(UPC-BarcelonaTech), D. Saucez
(INRIA)
Pour information
Réalisé dans le cadre du groupe de travail IETF lisp
Première rédaction de cet article le 3 novembre 2022
Le protocole réseau LISP (Locator/ID Separation Protocol, rien à voir avec le langage de programmation du même nom) est normalisé dans le RFC 6830 et plusieurs autres qui l'ont suivi. Ce RFC 6830 est un peu long à lire et ce nouveau RFC propose donc une vision de plus haut niveau, se focalisant sur l'architecture de LISP. Cela peut donc être un bon point de départ vers les RFC LISP.
L'idée de base de LISP est de séparer l'identificateur du localisateur, comme recommandé par le RFC 4984. Un identificateur désigne une machine, un localisateur sa position dans l'Internet. Aujourd'hui, les adresses IP servent pour les deux, ne satisfaisant parfaitement aucun des deux buts : les identificateurs devraient être stables (une machine qui change de réseau ne devrait pas en changer), les localisateurs devraient être efficaces et donc être liés à la topologie, et agrégeables.
LISP a donc deux classes : les identificateurs, ou EID (End-host IDentifier) et les localisateurs, ou RLOC (Routing LOCators). Les deux ont la syntaxe des adresses IP (mais pas leur sémantique). Un système de correspondance permet de passer de l'un à l'autre (par exemple, je connais l'EID de mon correspondant, je cherche le RLOC pour lui envoyer un paquet). LISP est plutôt prévu pour être mis en œuvre dans les routeurs, séparant un cœur de l'Internet qui n'utilise que les RLOC, d'une périphérie qui utiliserait les EID (avec, entre les deux, les routeurs LISP qui feraient la liaison).
En résumé (accrochez-vous, c'est un peu compliqué) :
- LISP peut être vu comme un réseau virtuel (overlay) au-dessus de l'Internet existant (underlay),
- Les RLOC n'ont de sens que dans le réseau sous-jacent, l'underlay,
- Les EID n'ont de sens que dans le réseau virtuel overlay,
- Entre les deux, le système de correspondance,
- Dans le réseau sous-jacent, les RLOC servent de localisateur et d'identificateur,
- Dans un site à la périphérie, les EID servent d'identificateur et de localisateur pour les autres machines du site.
C'est ce côté « solution dans les routeurs » et donc le fait que les machines terminales ne savent même pas qu'elles font du LISP, qui distingue LISP des autres solutions fondées sur la séparation de l'identificateur et du localisateur, comme ILNP (RFC 6740).
Au passage, pourquoi avoir développé LISP ? Quel était le problème à résoudre ? Outre la beauté conceptuelle de la chose (il n'est pas esthétique de mêler les fonctions d'identificateur et de localisateur), le principal problème à traiter était celui du passage à l'échelle du système de routage de l'Internet, décrit dans le RFC 4984. En gros, le nombre de routes distinctes augmente trop vite et menace la stabilité des routeurs de la DFZ. Le but était donc, par une nouvelle architecture, de rendre inutile certains choix qui augmentent la taille de la table de routage (comme la désagrégation des préfixes IP, afin de faire de l'ingénierie de trafic). Le RFC 7215 décrit comment LISP aide dans ce cas.
La section 7 du RFC décrit les différents scénarios d'usage de LISP :
- Ingénierie de trafic : aujourd'hui, dans l'Internet classique BGP, quand on veut orienter le trafic entrant, le faire passer par un chemin donné, on utilise souvent la désagrégation des préfixes. Comme indiqué plus haut, cela aggrave la pression sur la table de routage globale. L'indirection que permet LISP dispense de cette solution : on peut publier dans le système de correspondance les RLOC qu'on veut.
- Transition vers IPv6 : les EID et les RLOC ont la forme syntaxique d'une adresse IP, v4 ou v6, et il n'y a pas d'obligation qu'EID et RLOC aient la même version. On peut avoir des EID IPv6 et des RLOC IPv4, et cela fournit un mécanisme de tunnel permettant de connecter deux sites LISP IPv6 au-dessus de réseaux qui seraient purement IPv4. L'avantage par rapport aux techniques de transition actuelles est l'intégration dans une solution plus générale et plus « propre ».
- LISP permet également de faire des VPN, ou de gérer la mobilité de réseaux entiers (un réseau qui se déplace, et donc change de RLOC, c'est juste la correspondance dans le sous-système de contrôle qu'il faut changer, et tout les partenaires routeront vers les nouveaux RLOC).
La section 3 du RFC décrit en détail l'architecture de LISP (après, vous serez mûr·e·s pour lire les RFC LISP eux-mêmes, en commençant par le RFC 6830). Elle repose sur quatre principes :
- La séparation entre l'identificateur (le EID) et le localisateur (le RLOC),
- Deux sous-systèmes différents, le contrôle et les données, utilisant des protocoles différents, et pouvant évoluer séparement (enfin, dans une certaine mesure),
- Une architecture overlay : LISP est déployé sur un réseau virtuel au-dessus de l'Internet existant, ce qui évite les approches « table rase », qui ont une probabilité de déploiement à peu près nulle,
- Un protocole déployable de manière incrémentale, pas besoin d'attendre que tout le monde s'y mette, il y a des avantages à déployer LISP même pour les premiers à l'adopter (ce problème de déploiement est une des plaies de l'Internet actuel, comme on le voit avec IPv6).
La séparation entre identificateur et localisateur n'est pas faite au niveau de la machine individuelle, comme avec ILNP, mais à la frontière entre la périphérie de l'Internet (the edge) et son cœur (the core, en gros, la DFZ et quelques routeurs en plus). La périphérie travaille avec des EID (elle ne sait même pas que LISP est utilisé), le cœur avec des RLOC. Contrairement à ILNP, il n'y a donc pas une stricte séparation entre identificateurs et localisateurs : ils ont la même syntaxe (qui est celle d'une adresse IP, v4 ou v6) et, à part les routeurs d'entrée et de sortie des tunnels LISP, personne ne sait s'il utilise un EID ou un RLOC : les machines terminales manipulent des EID, les routeurs du cœur des RLOC, tout en croyant que ce sont des adresses IP ordinaires. Seuls les routeurs à la frontière entre les deux mondes connaissent LISP (et auront donc besoin d'un logiciel adapté).
Un Internet LISP est donc une série de « sites LISP » (des
réseaux de périphérie accessibles par LISP) connectés par des
tunnels entre eux, au-dessus du cœur
actuel. Le routeur d'entrée du tunnel se nomme ITR (pour
Ingress Tunnel Router) et celui de sortie ETR
(pour Egress Tunnel Router). Le terme de xTR
(pour « ITR ou bien ETR ») est parfois utilisé pour désigner un
routeur LISP, qu'il soit d'entrée ou de sortie
Le sous-système des données (data plane) se charge d'encapsuler et de décapsuler les paquets, puis de les transmettre au bon endroit. (Sa principale qualité est donc la rapidité : il ne faut pas faire attendre les paquets.) Les ITR encapsulent un paquet IP qui vient d'un site LISP (dans un paquet UDP à destination du port 4341), puis l'envoient vers l'ETR. À l'autre bout du tunnel, les ETR décapsulent le paquet. Dans le tunnel, les paquets ont donc un en-tête intérieur (un en-tête IP normal, contenant les EID source et destination), qui a été placé par la machine d'origine, et un en-tête extérieur (contenant le RLOC source, celui de l'ITR, et le RLOC de destination, celui de l'ETR puis, après l'en-tête UDP, l'en-tête spécifique de LISP). Rappelez-vous que les routeurs du cœur ne connaissent pas LISP, ils font suivre ce qui leur semble un paquet IP ordinaire. Les routeurs LISP utilisent des tables de correspondance entre EID et RLOC pour savoir à quel ETR envoyer un paquet.
Ces tables ont été apprises du sous-système de contrôle (control plane, qui contient la fonction de correspondance - mapping), le routeur ayant un cache des correspondances les plus récentes. Cette fonction de correspondance, un des points les plus délicats de LISP (comme de tout système de séparation de l'identificateur et du localisateur) est décrite dans le RFC 6833. Son rôle peut être comparé à celui du DNS et de BGP dans l'Internet classique.
Une correspondance est une relation entre un préfixe d'identificateurs (rappelez-vous que les EID sont, syntaxiquement, des adresses IP ; on peut donc utiliser des préfixes CIDR) et un ensemble de localisateurs, les RLOC des différents routeurs possibles pour joindre le préfixe convoité.
Le RFC 6833 normalise une interface avec ce système de correspondance. Il y a deux sortes d'entités, le Map Server, qui connait les correspondances pour certains préfixes (car les ETR lui ont raconté les préfixes qu'ils servent), et le Map Resolver, qui fait les requêtes (il est typiquement dans l'ITR, ou proche). Quatre messages sont possibles (les messages de contrôle LISP sont encpasulés en UDP, et vers le port 4342) :
Map-Register: un ETR informe son Map Server des préfixes EID qu'il sait joindre,Map-Notify: la réponse de l'ETR au message précédent,Map-Request: un ITR (ou bien un outil de débogage comme lig, cf. RFC 6835) cherche les RLOC correspondant à un EID,Map-Reply: un Map Server ou un ETR lui répond.
Un point important de LISP est qu'il peut y avoir plusieurs mécanismes de correspondance EID->RLOC, du moment qu'ils suivent les messages standard du RFC 6833. On pourra donc, dans le cadre de l'expérience LISP, changer de mécanisme pour voir, pour tester des compromis différents. Notre RFC rappele l'existence du système ALT (RFC 6836, fondé, comme BGP sur un graphe. Mais aussi celle d'un mécanisme utilisant une base « plate » (NERD, RFC 6837), un mécanisme arborescent nommé DDT (RFC 8111), des DHT, etc. On pourrait même, dans des déploiements privés et locaux, avoir une base centralisée avec un seul serveur.
ALT, normalisé dans le RFC 6836, est le système de correspondance « historique » de LISP, et il est souvent présenté comme le seul dans les vieux documents. Il repose sur BGP, protocole bien maitrisé par les administrateurs de routeurs, ceux qui auront à déployer LISP. L'idée de base est de connecter les serveurs ALT par BGP sur un réseau virtuel au-dessus de l'Internet.
DDT, dans le RFC 8111, lui, ressemble beaucoup plus au DNS, par sa structuration arborescente des données, et sa racine.
Évidemment, tout l'Internet ne va pas migrer vers LISP instantanément. C'est pour cela que notre RFC mentionne les problèmes de communication avec le reste du monde. Les EID ne sont typiquement pas annoncés dans la table de routage globale de l'Internet. Alors, comment un site pourra-t-il communiquer avec un site LISP ? Le mécanisme décrit dans le RFC 6832 utilise deux nouvelles sortes de routeurs : les PITR (Proxy Ingress Tunnel Router) et les PETR (Proxy Egress Tunnel Router). Le PITR annonce les EID en BGP vers l'Internet, en les agrégeant le plus possible (l'un des buts de LISP étant justement d'éviter de charger la table de routage globale). Il recevra donc les paquets envoyés par les sites Internet classiques et les fera suivre par les procédures LISP normales. A priori, c'est tout : le site LISP peut toujours envoyer des paquets vers l'Internet classiques en ayant mis un EID en adresse IP source. Mais cela peut échouer pour diverse raisons (uRPF, par exemple) donc on ajoute le PETR : il recevra le paquet du site LISP et le transmettra.
Voici pour les principes de LISP. Mais, si vous travaillez au quotidien comme administrateur d'un réseau, vous avez sans doute à ce stade plein de questions concrètes et opérationnelles. C'est le moment de lire la section 4 de ce RFC. Par exemple, la gestion des caches : un routeur LISP ne peut pas faire appel au système de correspondance pour chaque paquet qu'il a à transmettre. Le sous-système des données tuerait complètement le sous-système de contrôle, si un routeur s'avisait de procéder ainsi. Il faut donc un cache, qui va stocker les réponses aux questions récentes. Qui dit cache dit problèmes de cohérence des données, puisque l'information a pu changer entre la requête, et l'utilisation d'une réponse mise en cache. Pour gérer cette cohérence, LISP dispose de divers mécanismes, notamment un TTL (Time To Live) : l'ETR le définit, indiquant combien de temps les données peuvent être utilisées (c'est typiquement 24 h, aujourd'hui).
Autre problème pratique cruciale, la joignabilité des
RLOC. C'est bien joli de savoir que telle machine a tel RLOC mais
est-ce vrai ? Peut-on réellement lui parler ou bien tous les
paquets vont-ils finir dans un trou noir ? Un premier mécanisme
pour transporter l'information de joignabilité est les LSB
(Locator Status Bits). Transportés dans les
paquets LISP, ces bits indiquent si un RLOC donné est joignable
par l'ETR qui a envoyé le paquet. Évidemment, eux aussi peuvent
être faux, donc, s'il existe une communication bi-directionnelle,
il est préférable d'utiliser le mécanisme des numniques. Quand un ITR écrit à un ETR, il
met un numnique dans le paquet, que l'ETR renverra dans son
prochain paquet. Cette fois, plus de doute, l'ETR est bien
joignable. Si l'ITR est impatient et veut une réponse tout de
suite, il peut tester activement la joignabilité, en envoyant des Map-Request.
LISP est souvent présenté avec un modèle simplifié où chaque site est servi par un seul ETR, qui connait les EID du site et les annonce au Map Server. Mais, dans la réalité, les sites sérieux ont plusieurs ETR, pour des raisons de résilience et de répartition de charge. Cela soulève le problème de leur synchronisation : ces ETR doivent avoir des configurations compatibles, pour annoncer les mêmes RLOC pour leurs EID. Pour l'instant, il n'existe pas de protocole pour cela, on compte sur une synchronisation manuelle par l'administrateur réseaux.
Enfin, comme LISP repose sur des tunnels, il fait face à la malédiction habituelle des tunnels, les problèmes de MTU. Du moment qu'on encapsule, on diminue la MTU (les octets de l'en-tête prennent de la place) et on peut donc avoir du mal à parler avec les sites qui ont une MTU plus grande, compte-tenu de la prévalence d'erreurs grossières de configuration, comme le filtrage d'ICMP. La section 4.4 de notre RFC décrit le traitement normal de la MTU dans LISP et ajoute que des mécanismes comme celui du RFC 4821 seront peut-être nécessaires.
Dans l'Internet d'aujourd'hui, une préoccupation essentielle est bien sûr la sécurité : d'innombrables menaces pèsent sur les réseaux (section 8 du RFC). Quelles sont les problèmes spécifiques de LISP en ce domaine ? Par exemple, certains systèmes de correspondance, comme DDT, sont de type pull : on n'a pas l'information à l'avance, on va la chercher quand on en a besoin. Cela veut dire qu'un paquet de données (sous-système des données) peut indirectement déclencher un événement dans le sous-système de contrôle (par la recherche d'une correspondance EID->RLOC afin de savoir où envoyer le paquet). Cela peut affecter la sécurité.
D'autant plus que le sous-système de contrôle sera typiquement
mis en œuvre dans le processeur généraliste des routeurs, beaucoup
moins rapide que les circuits électroniques spécialisés qui
servent à la transmission des données. Un attaquant qui enverrait
des tas de paquets vers des EID différents pourrait, à un coût
très faible pour lui, déclencher plein de demandes à DDT,
ralentissant ainsi sérieusement les routeurs LISP. Une mise en œuvre naïve de LISP où toute requête pour
un EID absent du cache déclencherait systématiquement une
MAP-Request serait très vulnérable. Une
limitation du trafic est donc
nécessaire.
En parlant du système de correspondance, il représente évidemment un talon d'Achille de LISP. Si son intégrité est compromise, si des fausses informations s'y retrouvent, les routeurs seront trahis et enverront les paquets au mauvais endroit. Et si le système de correspondance est lent ou en panne, par exemple suite à une attaque par déni de service, le routage ne se fera plus du tout (à part pour les EID encore dans les caches des routeurs). On peut donc comparer ce système de correspondance au DNS dans l'Internet classique, par son côté crucial pour la sécurité.
Il faut donc des « bons » Map Server, qui suivent bien le RFC 6833 (notamment sa section 6) et, peut-être dans le futur, des Map Servers qui gèrent l'extension de sécurité LISP-Sec (si son RFC est publié un jour).
Dernier point de sécurité, le fait que LISP puisse faire du routage asymétrique (le chemin d'Alice à Bob n'est pas le même que celui de Bob à Alice). Rien d'extraordinaire à cela, c'est pareil pour lee routage Internet classique, mais il faut toujours se rappeler que cela a des conséquences de sécurité : par exemple, un pare-feu ne verra, dans certains cas, qu'une partie du trafic.
On trouvera plus de détails sur les attaques qui peuvent frapper LISP dans le RFC 7835.
Pour ceux qui sont curieux d'histoire des technologies, l'annexe A du RFC contient un résumé de LISP. Tout avait commencé à Amsterdam en octobre 2006, à l'atelier qui avait donné naissance au RFC 4984. Un groupe de participants s'était alors formé, avait échangé, et le premier Internet-Draft sur LISP avait été publié en janvier 2007. En même temps, et dans l'esprit traditionnel de l'Internet (running code), la programmation avait commencé et les premiers routeurs ont commencé à gérer des paquets LISP en juin 2007.
Le groupe de travail IETF officiel a été ensuite créé, en mars 2009. Les premiers RFC sont enfin sortis en 2013.
LISP n'a pas toujours été comme aujourd'hui ; le protocole initial était plutôt une famille de protocoles, désignés par des numéros, chacun avec des variantes sur le concept de base. Cela permettait de satisfaire tous les goûts mais cela compliquait beaucoup le protocole. On avait LISP 1, où les EID étaient routables dans l'Internet normal (ce qui n'est plus le cas), LISP 1.5 où ce routage se faisait dans un réseau séparé, LISP 2 où les EID n'étaient plus routables, et où la correspondance EID->RLOC se faisait avec le DNS, et enfin LISP 3 où le système de correspondance était nouveau (il était prévu d'utiliser une DHT...). Le LISP final est proche de LISP 3.
L'article seul
Il y a des cas où la chaine de blocs n'est pas utile
Première rédaction de cet article le 21 octobre 2022
La chaine de blocs, malgré quelques soubresauts et critiques, reste aujourd'hui un puissant argument marketing. On voit par exemple une université se vanter d'attester ses diplômes sur cette chaine, et son service de la communication pense apparemment que cela va jouer en sa faveur. Il est vrai que la chaine de blocs résout élégamment des problèmes auparavant considérés comme difficiles, voire impossibles, par exemple le triangle de Zooko. Mais, comme tous les outils, la chaine de blocs ne résout pas tous les problèmes. Voyons un cas où elle n'apporte rien, qui est justement le cas d'usage de l'université citée plus haut.
La chaine de blocs n'est pas simplement une liste chainée de données. Si c'était le cas, elle n'aurait rien d'intéressant, cette structure de données étant une des plus anciennes qui soit. De même, le fait que les transactions contenues dans le bloc soient signées est assez banal, les signatures numériques sont un concept ancien et répandu bien avant l'invention de la chaine de blocs. L'intérêt de la chaine de blocs est ailleurs : dans le fait qu'elle est pair-à-pair, que n'importe qui puisse y écrire, et qu'un consensus émerge entre des entités qui ne se font pas mutuellement confiance. C'est ainsi que fonctionne son utilisation la plus emblématique, les cryptomonnaies. Les gens qui acquièrent et dépensent les jetons de la cryptomonnaie utilisée ne se font pas confiance et ne se connaissent même pas. Il faut pourtant arriver à un consensus sur le fait qu'Alice ait trois jetons et, qu'après en avoir donné un à Bob, elle n'en a plus que deux (alors qu'Alice préfererait qu'on croit qu'elle en a toujours trois). C'est cela que permet la chaine de blocs et, dans ce cas d'usage, elle est irremplaçable. (Le tout est bien expliqué dans l'article de Satoshi Nakamoto qui décrit le Bitcoin, et qui a intoduit le concept de chaine de blocs. Ironiquement, le terme de blockchain n'apparait pas dans cet article.)
Le but affiché des cryptomonnaies est justement de réaliser une monnaie qui ne dépende pas d'une autorité extérieure, par exemple une banque centrale. Mais si on a une telle autorité et qu'on lui fait confiance, la chaine de blocs devient inutile. Elle fonctionne toujours mais n'est pas l'utilisation la plus intelligente des ressources informatiques.
Or, c'est justement le cas de l'université citée plus haut. Pour valider des diplômes, on ne veut pas du pair-à-pair, bien au contraire. Il y a une autorité, l'université, et c'est elle, et elle seule, qui peut dire si j'ai une maitrise de physique ou pas (mon diplôme universitaire le plus élevé). Si on met les diplômes sur une chaine de blocs, on ne souhaite certainement pas que tout le monde puisse y écrire. Le cas est donc très différent de celui des cryptomonnaies, ou d'autres utilisations de la chaine de blocs comme la réservation de noms. Notons en outre qu'aucun détail n'est donné sur la chaine utilisée par l'université : laquelle est-ce, qui la contrôle, son logiciel est-il publié, etc. En l'absence de tous ces éléments, la chaine de blocs n'apporte aucune confiance supplémentaire. L'université aurait tout aussi bien publier les diplômes sur son site Web… (Avec quelques techniques de sécurité comme HTTPS.) Et si on veut un système commun à toutes les universités, il existe déjà.
Les défenseurs de ces utilisations inutiles de la chaine de blocs citent parfois l'argument de la signature, qui permet d'authentifier le diplôme, y compris si l'information circule et n'est pas récupérée sur le site d'origine. C'est vrai, les signatures numériques sont une très bonne idée, mais elles sont bien antérieures aux chaines de blocs et peuvent être utilisées dans ce cas (par exemple en publiant des documents signés sur le site Web). Là encore, la chaine de blocs n'apporte rien. Notez que le responsable du projet est parfaitement conscient de cette inutilité puisque, dans les commentaires à un article de NextInpact, il dit ouvertement « j'assume que le mot blockchain a un peu été un prétexte ».
Une faiblesse courante avec les chaines de blocs est que peu de gens vérifient directement sur la chaine, pourtant la seule source fiable. Ils passent en général par un système centralisé. L'entreprise privée qui a été payée par l'université le dit d'ailleurs dans les commentaires à l'article de Next Inpact déjà cité : « Techniquement, tout est fait dans BCdiploma pour que la lecture des attestations soit la plus simple possible en masquant la complexité de la blockchain. Par exemple, les certificats sont ici lus depuis le site de l’université, augmentant ainsi la confiance. » (un exemple de ce que ça donnerait). Ça annule une bonne partie de l'intérêt du projet.
Pour les mêmes raisons, tous les projets de « chaines de blocs privées » ou de « chaines à permission » sont des non-sens, en raison de leur inutilité. (À l'exception peut-être de chaines pas publiques mais pas complètement privées, entre un petit nombre d'acteurs qui ne se font qu'une confiance limitée.) Évidemment, cette inutilité n'empêche pas les projets (par exemple au niveau européen), car il y a beaucoup de consultants et d'ESN à nourrir.
Mais attention, dit la lectrice attentive de cet article : l'université peut publier des diplômes signés sur son site Web, d'accord, mais elle peut aussi arrêter de les publier. Si on fait confiance à l'université pour certifier les diplômes, mais qu'on craint qu'elle n'essaie de réécrire le passé en prétendant qu'un diplôme n'a jamais existé, la publication sur le site Web n'aide pas. Bonne remarque, et il faut donc aller plus loin que la simple publication de documents signés sur un site Web. Mais on n'a pas besoin de chaine de blocs, il suffit d'utiliser des journaux publics à ajout seul (append-only logs).
Le principe de ces journaux est de publier l'information sous une forme qui rend toute altération ultérieure détectable. Il existe plusieurs solutions pour cela, mais la plus simple conceptuellement (mais pas la plus rapide) est de numéroter chaque document publié. La suppression d'un document peut ainsi être détectée. Si on a le document 67 et qu'on ne trouve pas le 66, le problème est visible. (Ce système de numérotation des documents pour assurer l'intégrité est un très vieux système, antérieur à l'informatique, avec les journaux papier utilisés par exemple dans les commissariats. Comme le dit Wikipédia, « Il est strictement interdit de modifier ou même de raturer une inscription en main courante sous peine de la rendre caduque, c'est pourquoi les pages d'une main courante papier sont toujours numérotées. ») En dehors du monde papier, un tel système est simple à faire : l'autorité numérote les documents, les signe et les publie. Les données étant publiques, n'importe qui peut facilement vérifier leur intégrité. Un tel système est par exempe décrit dans l'article « How to time-stamp a digital document » (à télécharger ici). Un des systèmes les plus anciens à être effectivement déployé est Stamper (cf. son historique), qui publiait ses signatures (faites avec PGP)… sur Usenet.
Depuis, bien d'autres systèmes de journaux à ajout seul sont apparus et sont utilisés. L'un des plus connus est le Certificate Transparency (normalisé dans le RFC 9162). Pas du tout besoin d'une chaine de blocs pour cette tâche cruciale, puisqu'il n'y a qu'un petit nombre d'émetteurs faisant autorité (les AC).
Au passage, j'ai dit qu'un tel système permettait de détecter les modifications. Or il y a des modifications légitimes, par exemple le retrait d'un diplôme obtenu à tort. Il faut donc prévoir la possibiité qu'un document annule un précédent (mais on ne supprime pas le précédent, on le remplace). La vérification publique est contradictoire avec la possibilité d'oubli, ce qui peut être une bonne ou une mauvaise chose.
L'article seul
Des leçons à tirer du problème du .coin
Première rédaction de cet article le 20 octobre 2022
Le 18 octobre 2022, la société Unstoppable Domains a annoncé
qu'elle arrêtait de vendre des noms sous
.coin. Il y a des leçons intéressantes à en
tirer.
Ces noms ont la syntaxe de noms de domaine mais ne « fonctionnent » pas, au sens où un nom de domaine habituel fonctionne, via une résolution par le DNS. Ils sont enregistrés, oui, dans une chaine de blocs, mais ne fonctionnent pas avec vos logiciels classiques. En pratique, ils sont très peu utilisés, ceux qui les achètent sont plutôt dans une démarche d'investissement, espérant qu'ils prendront de la valeur plus tard, plutôt que dans une démarche de présence en ligne, comme lorsqu'on achète un nom de domaine plus classique pour recevoir du courrier électronique ou afficher un site Web.
Plusieurs services analogues existent, certains commerciaux (on peut vendre des noms, des identificateurs), d'autres pas. C'est aussi un monde où on rencontre de tout, du marketing boursouflé (Web3 !), à certains vendeurs qui induisent en erreur leurs clients, par exemple en leur faisant croire que ces noms auront le même usage qu'un nom classique, utilisable via le DNS. Et il y a aussi de purs escrocs. L'intérêt, en théorie, d'enregistrer des noms dans une chaine de blocs, plutôt que via un registre traditionnel, est que la chaine fonctionne automatiquement, sans intervention humaine une fois lancée, et qu'on peut donc rester titulaire de son nom de domaine, sans risque de le voir saisi ou censuré (d'où le nom de la société Unstoppable Domains). L'idée est très ancienne (elle avait commencé avec Namecoin en 2010) mais a pris de l'ampleur ces dernières années, avec l'apparition d'intermédiaires comme Unstoppable Domains, ENS, Emercoin, etc. La vogue récente des NFT a mené certains à renommer leurs produits « NFT » mais il n'y a pas de changement de fond.
Un point important de toute cette offre est qu'il n'y a pas de coordination. Tout le monde (et son chat) peut créer une chaine de blocs ou, si on est moins ambitieux, un service de création de noms sur une chaine de blocs existante (la façon de réaliser un tel service avait été détaillée lors de la JCSA 2016). L'Internet est « sans permission » ce qui veut dire, et heureusement, qu'une innovation peut être créée et déployée sur l'Internet, sans l'autorisation de personne. Cela a permis Bitcoin (qui a créé le concept de chaine de blocs), BitTorrent mais aussi le Web (si Tim Berners-Lee avait dû patienter jusqu'à l'autorisation d'un comité, on attendrait toujours le Web). La contrepartie de cette liberté est qu'il y a aussi de mauvaises idées et des concurrences dommageables. Comme chacun (et son hamster) peut lancer un service de création et de vente de noms sur une chaine de blocs, si ces noms ont une syntaxe compatible, il y a des risques de collision. Une collision, c'est quand deux noms identiques sont enregistrés via des services différents. C'est inévitable si deux services vendent des noms avec le même suffixe.
Et c'est justement ce qui s'est produit ici : Unstoppable Domains
vendait du .coin mais Emercoin le faisait
également. Les collisions étaient donc inévitables. Finalement,
Unstoppable Domains a décidé d'arrêter, notant qu'Emercoin était
présent avant (mais qu'ils ne
le savaient pas). Notons l'ironie du nom Unstoppable Domains
puisque cette entreprise peut supprimer un nom à sa guise…
Ces problèmes de collision sont inévitables dès que plusieurs
organisations créent des noms sans aucune coordination. C'est une
des raisons pour lesquelles les racines DNS alternatives n'ont
jamais décollé. Leurs promoteurs évacuent souvent le problème des
collisions avec de vagues promesses « on s'arrangera ». Ici, un des
deux acteurs impliqués dans la collision a décidé d'arrêter mais il
n'y a aucune garantie que cela se passera toujours bien. C'est pour
cela que le RFC 2826 insiste sur l'importance
d'une coordination formelle. Dit autrement, il ne faut qu'un seul
registre pour .coin (ou
.nimporte-quoi).
J'ai dit plus haut qu'Unstoppable Domains avait supprimé les noms
en .coin. En fait, c'est plus compliqué que
cela. Les noms sont toujours dans la chaine de blocs (dont l'un des
buts est justement d'empêcher l'effacement du passé) et Unstoppable
Domains peut donc expliquer qu'en fait, ils n'ont pas supprimé les
noms. Mais, comme indiqué précédemment, presque aucune application
ne va regarder directement dans la chaine de blocs. Elles passent
quasiment toutes par des passerelles diverses, utilisant des
protocoles normalisés comme HTTP ou DNS. Ce qu'Unstoppable Domains
a coupé, comme
ils l'indiquent, ce sont ces
passerelles. C'est en effet une malhonnêteté intellectuelle
fréquente chez certains services se présentant comme
pair-à-pair : le support (ici, la chaine de
blocs) est bien pair-à-pair, mais en pratique presque tout le monde
y accède via une passerelle qui, elle, est centralisée. Lorsque
cette passerelle est fermée, vous perdez tout. (Le problème est loin
d'être spécifique à Unstoppable Domains ; regardez comme les
ressources IPFS, service censément pair-à-pair sont
toujours annoncées sous forme d'un URL passant par une passerelle
centralisée. C'est en partie dû au fait que le logiciel est très
complexe à compiler et installer.)
Cette dépendance de nombreux services pair-à-pair vis-à-vis de passerelles centralisées, donc vulnérables à la censure ou à des décisions business, est un des gros problèmes, à l'heure actuelle, de beaucoup de solutions pair-à-pair.
Quelques bonnes lectures pour finir :
- Unstoppable Domains a fait une FAQ sur l'affaire du .coin.
- Un article
de Domain Name Wire estime qu'Unstoppable Domains n'a pas agi
par gentillesse mais parce qu'eux-mêmes étaient dans un litige au
sujet du
.wallet. - Un article plutôt polémique, sur "Web 3 is going great".
L'article seul
Valider du XML : exemple EPP
Première rédaction de cet article le 20 octobre 2022
Dernière mise à jour le 21 octobre 2022
Cet article n'aura probablement pas beaucoup de lecteurs car peu de gens utilisent le protocole EPP. Ce dernier sert uniquement à la communication entre registres et bureaux d'enregistrement. Il utilise le format XML, et est décrit via un langage de schéma, ce qui permet sa validation par un programme. Comme ce n'est pas tout à fait évident, je montre ici comment on peut faire cette validation.
EPP est normalisé dans le RFC 5730. Mais attention, cela ne normalise que le cœur du protocole. EPP est un protocole d'avitaillement d'objets et il peut manipuler différents types d'objets, par exemple des noms de domaine. Il faut donc ajouter un RFC par type d'objet (pour les noms de domaine, c'est le RFC 5731) et à chaque fois un nouvel espace de noms. Et EPP a diverses extensions, avec à chaque fois un espace de noms. Tout cela est formellement décrit en XML Schema. Avantage : on peut valider un document EPP automatiquement et s'assurer qu'il est conforme à ce qu'on attend, avant de le traiter.
On va utiliser ici xmllint, qu'on trouve
dans tous les bons systèmes d'exploitation. xmllint exige qu'on lui
passe un fichier unique pour le schéma, donc je vous ai fait un joli
fichier XML Schema qui inclut toutes les extensions auxquelles j'ai
pensé, epp-wrapper.xsd.xsd concernant
les différents schémas qu'on utilise. Cela peut se faire avec le
script Python
extract-xsd.py
for schema in $(./extract-xsd.py epp-wrapper.xsd); do
wget https://www.iana.org/assignments/xml-registry/schema/${schema}
done
On peut ensuite valider un document EPP. Prenons celui-ci comme exemple :
<?xml version="1.0" encoding="utf-8"?>
<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
<command>
<create>
<domain:create
xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
<domain:name>example.com</domain:name>
<domain:authInfo>
<domain:pw>2fooBAR</domain:pw>
</domain:authInfo>
</domain:create>
</create>
<clTRID>ABC-12345</clTRID>
</command>
</epp>
Cela donne :
% xmllint --noout --schema epp-wrapper.xsd test.xml test.xml validates
Parfait. Un programme qui va traiter les données peut, s'il a
validé, être tranquille. Il sait par exemple qu'il aura une et une
seule commande dans l'élément <epp>.
Notez que c'est en écrivant cet article qu'une faille a été trouvée dans le RFC 9167.
Si maintenant on prend un document EPP invalide (ajout d'un
<foobar>) :
% xmllint --noout --schema epp-wrapper.xsd test-invalid.xml
test-invalid.xml:12: element foobar: Schemas validity error : Element '{urn:ietf:params:xml:ns:epp-1.0}foobar': This element is not expected.
test-invalid.xml fails to validate
Parfait encore, le document invalide est rejeté.
Si on utilise une extension à EPP comme celle pour DNSSEC du RFC 5910 :
<?xml version="1.0" encoding="utf-8"?>
<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
<command>
<update>
<domain:update
xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
<domain:name>example.com</domain:name>
</domain:update>
</update>
<extension>
<secDNS:create xmlns:secDNS="urn:ietf:params:xml:ns:secDNS-1.1">
<secDNS:dsData>
<secDNS:keyTag>12345</secDNS:keyTag>
<secDNS:alg>3</secDNS:alg>
<secDNS:digestType>1</secDNS:digestType>
<secDNS:digest>49FD46E6C4B45C55D4AC</secDNS:digest>
<!-- <secDNS:keyData>, la clé elle-même, est *facultatif* -->
</secDNS:dsData>
</secDNS:create>
</extension>
<clTRID>ABC-12345</clTRID>
</command>
</epp>
La validation sera possible grâce à tous les schémas chargés :
% xmllint --noout --schema epp-wrapper.xsd test-dnssec.xml test-dnssec.xml validates
L'article seul
Version 15 d'Unicode
Première rédaction de cet article le 15 septembre 2022
Le mardi 13 septembre est sortie la version 15 d'Unicode. Une description officielle des principaux changements est disponible mais voici ceux qui m'ont intéressé particulièrement. (Il n'y a pas de changement radical.)
Pour explorer plus facilement la grande base Unicode, j'utilise un programme qui la convertit en SQL et permet ensuite de faire des analyses variées. Faisons quelques requêtes SQL :
ucd=> SELECT count(*) AS Total FROM Characters; total -------- 149251
Combien de caractères sont arrivés avec la version 15 ?
ucd=> SELECT version,count(version) FROM Characters GROUP BY version ORDER BY version::float; ... 12.0 | 554 12.1 | 1 13.0 | 5930 14.0 | 838 15.0 | 4489
4489 nouveaux caractères, c'est pas mal (la version 14 était plus calme). Quels sont ces nouveaux caractères ?
ucd=> SELECT To_U(codepoint) AS Code_point, name FROM Characters WHERE version='15.0' ORDER BY Codepoint; code_point | name -----------+---------------------------------------------------------------------------- ... U+1D2C0 | KAKTOVIK NUMERAL ZERO ... U+1E4D4 | NAG MUNDARI LETTER ONG ... U+1F776 | LUNAR ECLIPSE ... U+1F77C | MAKEMAKE U+1F77D | GONGGONG ... U+1FACF | DONKEY
Cette version amène en effet des écritures nouvelles comme le Nag Mundari, ou les chiffres de Kaktovik.
Si vous avez les bonnes polices de caractères, vous allez pouvoir voir quelques exemples (sinon, le lien mène vers Uniview). Voici par exemple la lettre ETT du Nag Mundari 𞓩 et le chiffre de Kaktovik 2 𝋂 Il y a également de nouveaux symboles, notamment liés à l'astronomie, comme l'occultation 🝵 ou la petite planète Orcus 🝿. En plus anecdotique, on a le sans-fil 🛜, les maracas 🪇 ou l'élan 🫎. Ce dernier a d'ailleurs eu droit au point de code, U+1FACE, une utilisation amusante de l'hexadécimal.
Tiens, d'ailleurs, combien de caractères Unicode sont des symboles (il n'y a pas que les emojis parmi eux, mais Unicode n'a pas de catégorie « emoji ») :
ucd=> SELECT count(*) FROM Characters WHERE category IN ('Sm', 'Sc', 'Sk', 'So');
count
-------
7770
Ou, en plus détaillé, et avec les noms longs des catégories :
ucd=> SELECT description,count(category) FROM Characters,Categories WHERE Categories.name = Characters.category AND category IN ('Sm', 'Sc', 'Sk', 'So') GROUP BY category, description;
description | count
-----------------+-------
Modifier_Symbol | 125
Other_Symbol | 6634
Math_Symbol | 948
Currency_Symbol | 63
L'article seul
RFC 9267: Common Implementation Anti-Patterns Related to Domain Name System (DNS) Resource Record (RR) Processing
Date de publication du RFC : Juillet 2022
Auteur(s) du RFC : S. Dashevskyi, D. dos Santos, J. Wetzels, A. Amri (Forescout Technologies)
Pour information
Première rédaction de cet article le 14 septembre 2022
Comme chacun·e sait, l'Internet est une jungle (les politiciens ajouteraient « une jungle Far-West de non-droit qu'il faut civiliser »). Par exemple, les logiciels qui parlent avec les vôtres ne sont pas toujours correctement écrits, voire ils sont franchement malveillants. Le code de votre côté doit donc être robuste, voire paranoïaque, et penser à tout. Ce RFC décrit quelques problèmes qui ont été observés dans des logiciels mettant en œuvre le DNS et explique comment ne pas refaire la même erreur.
Le RFC ne parle pas de failles DNS mais de failles dans les programmes DNS, ce qui est très différent (mais la différence est souvent oubliée dans les médias). Le protocole lui-même n'était pas en cause dans ces cas, ce sont juste les logiciels qui avaient des bogues. Les cas sont nombreux, par exemple SIGRed (CVE-2020-1350) ou DNSpooq (CVE-2020-25681 à CVE-2020-25687). Ces problèmes frappent notamment souvent dnsmasq (personnellement, je n'ai jamais compris pourquoi ce logiciel était si utilisé, mais c'est une autre histoire).
Plusieurs vulnérabilités ont concerné l'analyse des
enregistrements DNS (RR = Resource Record). Les
risques lors de cette analyse devraient être bien connus, la
première faille documentée l'ayant été en 2000 (CVE-2000-0333) !
Tout logiciel qui analyse des enregistrements DNS (client, serveurs,
mais aussi pare-feux, IDS, etc) peut
tomber dans ces pièges, d'où l'importance de les documenter. C'était
déjà fait dans
l'Internet-Draft
draft-ietf-dnsind-local-compression
et dans le RFC 5625 mais c'était perdu au
milieu d'autres choses donc notre RFC choisit d'enfoncer le
clou.
Il commence par le grand classique des bogues de logiciels DNS : le traitement des pointeurs de compression. Pour gagner quelques octets, à l'époque où ça comptait, le DNS prévoit (RFC 1035, section 4.1.4) qu'on peut, dans un enregistrement DNS, remplacer tout ou partie d'un nom de domaine par un pointeur vers un autre endroit du paquet. Ainsi, si on a tous ses serveurs qui se terminent par les mêmes composants (comme c'est le cas, par exemple, de la racine), on peut ne mettre ces composants qu'une fois, et pointer vers eux partout ailleurs. Évidemment, si vous êtes programmeuse ou programmeur, vous avez déjà vu le piège : les pointeurs, c'est dangereux. Ils peuvent pointer en dehors du paquet, ou pointer vers eux-même, par exemple. Si on suit aveuglément un pointeur, un déni de service est possible, si on tape en dehors de la mémoire allouée ou bien si on se lance dans une boucle sans fin.
Rentrons dans les détails. Le RFC 1035 nous dit que l'octet qui indique la longueur d'un composant doit valoir moins de 64 (la taille maximale d'un composant), donc avoir les deux bits de plus fort poids à zéro. S'ils sont tous les deux à un, cela indique qu'on a un pointeur. Cet octet et le suivant (privés des deux bits de plus fort poids) sont alors un pointeur, le nombre d'octets depuis le début du message. On voit qu'on peut atteindre 16 383 octets (2 ** 14 - 1), largement assez pour sortir de la mémoire allouée pour le paquet, avec les conséquences qu'on imagine. Cela s'est produit en vrai (CVE-2020-25767, CVE-2020-24339 et CVE-2020-24335).
Autre exemple amusant cité par le RFC, le cas d'un pointeur pointant sur lui-même. Soit un message DNS minimal. Le premier composant est à 12 octets du début du message. Si on y met les octets 0xC0 et 0x0C, on aura un pointeur (0xC0 = 11000000, les deux bits de plus fort poids à un) qui vaut 12 (0xC0 0x0C moins les deux bits les plus significatifs = 0000000000001100 = 12). Le pointeur pointera alors sur lui-même, entrainant le logiciel DNS imprudent dans une boucle sans fin. Ça aussi, ça s'est déjà produit (CVE-2017-9345).
Dernier exemple amusant avec des pointeurs, le pointeur qui va
mener à un nombre infini de composants. L'attaquant (ou le
programmeur maladroit) met dans le message un composant suivi d'un
pointeur qui revient au début de ce composant. Si le composant était
test, un analyseur DNS imprudent va créer le
nom de domaine test.test.test.test… avant de
tomber à court de mémoire, ou bien, dans un langage de programmation
comme C, d'écrire dans une
autre zone de la mémoire, ce qui peut mener à un
RCE. Notez que les pointeurs ne devraient pas
pointer vers un pointeur : ça n'a aucun intérêt pratique et c'est
dangereux, mais le RFC 1035 ne l'interdit pas
explicitement. Une alternative est de tester le nombre de fois qu'on
a suivi un pointeur ou, encore mieux, de vérifier que le pointeur ne
pointe qu'en avant de lui-même.
Notez que le problème de la répétition infinie d'un composant pourrait également être évité en s'assurant que le nom de domaine reste en dessous de sa taille maximale, 255 octets (section 3 du RFC).
Mais il n'y a pas que les pointeurs. Un nom de domaine doit être
terminé par un octet nul, indiquant la racine. Ainsi, le nom
afnic.fr est encodé 0x05 0x61 0x66 0x6E 0x69
0x63 ("afnic") 0x02 0x66 0x72 ("fr") 0x00 (la racine). Que se
passe-t-il si l'octet nul final manque ? Certains programmes en
C ont été assez imprudents
pour tenter de traiter le nom de domaine avec des routines comme
strlen, qui comptent sur un octet nul pour
terminer les données (section 4 de notre RFC). Le développeur qui ne
veut pas refaire des failles comme CVE-2020-25107, CVE-2020-17440,
CVE-2020-24383 ou CVE-2020-27736 devrait utiliser
strnlen ou une autre méthode sûre.
On n'a pas terminé. Lorsqu'on traite une réponse DNS, les
enregistrements incluent des données. Leur longueur est donné par un
champ RDLENGTH de deux octets, qui précède les données (section
5). Si un analyseur DNS ne fait pas attention, la longueur indiquée
peut être supérieure à la taille du paquet. Un programme qui,
bêtement, lirait RDLENGTH puis ferait un read()
de la longueur indiquée aurait de fortes chances de taper en dehors
de la mémoire accessible (CVE-2020-25108, CVE-2020-24336 et
CVE-2020-27009).
Ah, et le RFC n'en parle pas, mais l'analyse des options EDNS (RFC 6891) offre également ce genre de pièges. Une option est encodée en TLV et une longueur invalide peut mener à lire les valeurs en dehors du paquet.
Un problème du même genre est décrit dans la section 6 du RFC. Un message DNS comprend plusieurs sections (Question, Réponse, Autorité, Additionnelle) et le nombre d'enregistrements par section est indiqué au début du message DNS. Ces nombres (count) peuvent également être faux et ne doivent pas être utilisés aveuglément, sinon, on aura des malheurs du genre CVE-2020-25109, CVE-2020-24340, CVE-2020-24334 ou CVE-2020-27737.
C'est en raison de tous ces risques qu'il faut tester que ses
programmes résistent bien à des messages DNS mal formés. Par
exemple, le serveur faisant autorité
Drink, écrit en Elixir, a dans ses jeux de tests de tels
messages. Regardez par exemple drink_parsing_test.exs. Un
exemple d'un tel test, pour le problème de boucle sans fin sur des
pointeurs, décrit en section 2 du RFC, est :
test "pointerloop1" do # RFC 9267, section 2
result = Drink.Parsing.parse_request(<<@id::unsigned-integer-size(16),
@request::unsigned-integer-size(16),
1::unsigned-integer-size(16), # QDcount
0::unsigned-integer-size(16), # ANcount
0::unsigned-integer-size(16), # NScount
0::unsigned-integer-size(16), # ARcount
0xc0::unsigned-integer-size(8), # First label of the question
# section starts with a
# compression pointer to itself.
0x0c::unsigned-integer-size(8),
@mx::unsigned-integer-size(16),
@in_class::unsigned-integer-size(16)
>>,
false)
assert result == {:error, :badDNS}
end
On fabrique un paquet DNS avec le pointeur invalide, et on
l'analyse. Le sous-programme parse_request ne
doit pas tourner sans fin, et doit renvoyer une erreur.
Un test du même genre en Python, où on envoie un message DNS avec un pointeur pointant sur lui-même (et on espère que ça n'aura pas tué le serveur qui le reçoit) :
id = 12345
misc = 0 # opcode 0, all flags zero
data = struct.pack(">HHHHHHBB", id, misc, 1, 0, 0, 0, 0xc0, 0x0c)
s.sendto(data, sockaddr)
L'article seul
RFC 9309: Robots Exclusion Protocol
Date de publication du RFC : Septembre 2022
Auteur(s) du RFC : M. Koster, G. Illyes, H. Zeller, L. Sassman
(Google)
Chemin des normes
Première rédaction de cet article le 14 septembre 2022
Quand vous gérez un serveur Internet (pas forcément un serveur
Web) prévu pour des humains, une bonne partie du trafic, voire la
majorité, vient de robots. Ils ne sont pas
forcément malvenus mais ils peuvent être agaçants, par exemple s'ils
épuisent le serveur à tout ramasser. C'est pour cela qu'il existe
depuis longtemps une convention, le fichier
robots.txt, pour dire aux robots gentils ce
qu'ils peuvent faire et ne pas faire. La spécification originale
était très limitée et, en pratique, la plupart des robots comprenait
un langage plus riche que celui du début. Ce nouveau RFC documente plus ou moins
le format actuel.
L'ancienne spécification, qui date de
1996, est toujours en ligne
sur le site de
référence (qui ne semble plus maintenu, certaines
informations ont des années de retard). La réalité des fichiers
robots.txt d'aujourd'hui est différente, et
plus riche. Mais, comme souvent sur
l'Internet, c'est assez le désordre, avec
différents robots qui ne comprennent pas la totalité du langage
d'écriture des robots.txt. Peut-être que la
publication de ce RFC aidera à uniformiser les choses.
Donc, l'idée de base est la suivante : le
robot qui veut ramasser des ressources sur un
serveur va d'abord télécharger un fichier situé sur le chemin
/robots.txt. (Au passage, si cette norme était
faite aujourd'hui, on utiliserait le
/.well-known du RFC 8615.) Ce fichier va contenir des instructions pour le
robot, lui disant ce qu'il peut récupérer ou pas. Ces instructions
concernent le chemin dans l'URI (et robots.txt n'a
donc de sens que pour les serveurs utilisant ces URI du RFC 3986, par exemple les serveurs Web). Un exemple très simple
serait ce robots.txt :
User-Agent: * Disallow: /private
Il dit que, pour tous les robots, tout est autorisé sauf les chemins
d'URI commençant par /private. Un robot qui
suit des liens (RFC 8288) doit donc ignorer
ceux qui mènent sous /private.
Voyons maintenant les détails pratiques (section 2 du RFC). Un
robots.txt est composé de
groupes, chacun s'appliquant à un robot ou un
groupe de robots particulier. Les groupes sont composés de
règles, chaque règle disant que telle partie de
l'URI est interdite ou autorisée. Par défaut, tout est autorisé
(même chose s'il n'y a pas de robots.txt du
tout, ce qui est le cas de ce blog). Un groupe commence par une
ligne User-Agent qui va identifier le robot (ou
un astérisque pour désigner tous les
robots) :
User-Agent: GoogleBot
Le robot va donc chercher le ou les groupes qui le concernent. En
HTTP,
normalement, l'identificateur que le robot cherche dans le
robots.txt est une sous-chaine de
l'identificateur envoyé dans le champ de l'en-tête HTTP
User-Agent (RFC 9110,
section 10.1.5).
Le robot doit combiner tous les groupes qui s'appliquent à lui,
donc on voit parfois plusieurs groupes avec le même
User-Agent.
Le groupe est composé de plusieurs règles, chacune commençant par
Allow ou Disallow (notez
que la version originale de la spécification n'avait pas
Allow). Si plusieurs règles correspondent, le
robot doit utiliser la plus spécifique, c'est-à-dire celle dont le
plus d'octets correspond. Par exemple, avec :
Disallow: /private Allow: /private/notcompletely
Une requête pour /private/notcompletely/foobar
sera autorisée. L'ordre des règles ne compte pas (mais certains
robots sont bogués sur ce point). C'est du fait de cette notion de
correspondance la plus spécifique qu'on ne peut pas compiler un
robots.txt en une simple expression
rationnelle, ce qui était possible avec la
spécification originelle. Si une règle Allow
et une Disallow correspondent, avec le même
nombre d'octets, l'accès est autorisé.
Le robot a le droit d'utiliser des instructions supplémentaires, par exemple pour les sitemaps.
En HTTP, le robot peut rencontrer une redirection
lorsqu'il essaie de récupérer le robots.txt
(code HTTP 301, 302, 307 ou 308). Il devrait dans ce cas la suivre
(mais pas infinement : le RFC recommande cinq essais au
maximum). S'il n'y a pas de robots.txt (en
HTTP, code de retour 404), tout est autorisé (c'est le cas de mon
blog). Si par contre il y a une erreur (par exemple 500 en HTTP), le
robot doit attendre et ne pas se croire tout permis. Autre point
HTTP : le robot peut suivre les instructions de mémorisation du
robots.txt données, par exemple, dans le champ
Cache-control de l'en-tête.
Avant de passer à la pratique, un peu de sécurité. D'abord, il
faut bien se rappeler que le respect du
robots.txt dépend de la bonne volonté du
robot. Un robot malveillant, par exemple, ne tiendra certainement
pas compte du robots.txt. Mais il peut y avoir
d'autres raisons pour ignorer ces règles. Par exemple, l'obligation
du dépôt légal fait que la
BNF
annonce explicitement qu'elle ignore ce
fichier. (Et un programme comme wget a
une option, -e robots=off, pour débrayer la vérification
du robots.txt.) Bref, un robots.txt ne remplace pas
les mesures de sécurité, par exemple des règles d'accès aux
chemins définies dans la configuration de votre serveur HTTP. Le
robots.txt peut même diminuer la sécurité, en
indiquant les fichiers « intéressants » à un éventuel attaquant.
Passons maintenant à la pratique. On trouve plein de mises en
œuvre de robots.txt un peu partout mais en
trouver une parfaitement conforme au RFC est bien plus
dur. Disons-le clairement, c'est le bordel, et l'auteur d'un
robots.txt ne peut jamais savoir comment il va
être interprété. Il ne faut donc pas être trop subtil dans son
robots.txt et en rester à des règles
simples. Du côté des robots, on a un problème analogue : bien des
robots.txt qu'on rencontre sont bogués. La
longue période sans spécification officielle est largement
responsable de cette situation. Et tout n'est pas clarifié par le
RFC. Par exemple, la grammaire en section 2.2 autorise un
Disallow ou un Allow à
être vide, mais sans préciser clairement la sémantique associée.
Pour Python, il y a un module standard, mais qui est loin de suivre le RFC. Voici un exemple d'utilisation :
import urllib.robotparser
import sys
if len(sys.argv) != 4:
raise Exception("Usage: %s robotstxt-file user-agent path" % sys.argv[0])
input = sys.argv[1]
ua = sys.argv[2]
path = sys.argv[3]
parser = urllib.robotparser.RobotFileParser()
parser.parse(open(input).readlines())
if parser.can_fetch(ua, path):
print("%s can be fetched" % path)
else:
print("%s is denied" % path)
Et, ici, on se sert de ce code :
% cat ultra-simple.txt User-Agent: * Disallow: /private % python test-robot.py ultra-simple.txt foobot /public/test.html /public/test.html can be fetched % python test-robot.py ultra-simple.txt foobot /private/test.html /private/test.html is denied
Mais ce module ne respecte pas la précédence des règles :
% cat precedence.txt User-Agent: * Disallow: / Allow: /bar.html % python3 test-robot.py precedence.txt foobot /bar.html /bar.html is denied
En application de la règle la plus spécifique,
/bar.html aurait dû être autorisé. Si on
inverse Allow et Disallow,
on obtient le résultat attendu. Mais ce n'est pas normal, l'ordre
des règles n'étant normalement pas significatif.
Autre problème du module Python, il ne semble pas gérer les
jokers, comme l'exemple *.gif$ du
RFC. Il existe des modules Python alternatifs pour traiter les
robots.txt mais aucun ne semble vraiment mettre
en œuvre le RFC.
La situation n'est pas forcément meilleure dans les autres langages de programmation. Essayons avec Elixir. Il existe un module pour cela. Écrivons à peu près le même programme qu'en Python :
usage = "Usage: test robotstxtname useragent path"
filename =
case Enum.at(System.argv(), 0) do
nil -> raise RuntimeError, usage
other -> other
end
content =
case File.read(filename) do
{:ok, data} -> data
{:error, reason} -> raise RuntimeError, "#{filename}: #{reason}"
end
ua =
case Enum.at(System.argv(), 1) do
nil -> raise RuntimeError, usage
other -> other
end
statuscode = 200
{:ok, rules} = :robots.parse(content, statuscode)
path =
case Enum.at(System.argv(), 2) do
nil -> raise RuntimeError, usage
other -> other
end
IO.puts(
case :robots.is_allowed(ua, path, rules) do
true -> "#{path} can be fetched"
false -> "#{path} can NOT be fetched"
end)
Et testons-le :
% mix run test-robot.exs ultra-simple.txt foobot /public/test.html /public/test.html can be fetched % mix run test-robot.exs ultra-simple.txt foobot /private/test.html /private/test.html can NOT be fetched
Il semble avoir moins de bogues que le module Python mais n'est quand même pas parfait.
Comme dit plus haut, le robots.txt n'est pas
réservé au Web. Il est utilisé par exemple pour
Gemini. Ainsi, le robot de
collecte Lupa lit les robots.txt et ne
va pas ensuite récupérer les URI interdits. En septembre 2022, 11 %
des capsules Gemini avaient un robots.txt.
L'article seul
RFC 9297: HTTP Datagrams and the Capsule Protocol
Date de publication du RFC : Août 2022
Auteur(s) du RFC : D. Schinazi (Google), L. Pardue (Cloudflare)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF masque
Première rédaction de cet article le 8 septembre 2022
Ce RFC est le premier du groupe de travail MASQUE qui développe des techniques pour relayer du trafic IP. Dans ce RFC, il s'agit de faire passer des datagrammes sur HTTP.
Pourquoi, sur HTTP ? Parce que c'est le seul protocole dont on est raisonnablement sûr qu'il passera partout. En bâtissant un service de datagrammes sur HTTP (et non pas directement sur IP), on arrivera à le faire fonctionner à tous les endroits où HTTP fonctionne.
En fait, ce RFC décrit deux mécanismes assez différents, mais qui visent le même but, la transmission de datagrammes sur HTTP. Le premier mécanisme est le plus simple, utiliser HTTP juste pour lancer une session qui utilisera les datagrammes de QUIC, normalisés dans le RFC 9221. (QUIC seul ne passe pas partout, d'où la nécessité d'insérer une couche HTTP.) Ce premier mécanisme dépend de QUIC donc ne marche qu'avec HTTP/3 (RFC 9114). Un second mécanisme est normalisé, dans notre RFC ; nommé Capsule, il permet de faire passer des datagrammes (ou à peu près) sur HTTP/2 (RFC 9113) et HTTP/1 (RFC 9112). Capsule est plus général, mais moins efficace.
Ces mécanismes ne sont pas vraiment prévus pour des utilisations par des applications, mais plutôt pour des extensions à HTTP (RFC 9110, section 16). Par exemple, le service CONNECT (RFC 9110, section 9.3.6) pourrait être doublé par un service équivalent, mais utilisant des datagrammes, au lieu du transfert fiable que fait CONNECT (cf. RFC 9298). Même chose pour les Web sockets du RFC 6455.
La section 2 de notre RFC explique de quels datagrammes on parle. Il s'agit de
paquets de données dont l'ordre
d'arrivée et l'acheminement ne sont pas garantis, et qui vont sans
doute consommer moins de ressources. Sur HTTP/3 (qui utilise QUIC),
ils vont utiliser les trames QUIC de type
DATAGRAM (RFC 9221). Ce
sont les « meilleurs » datagrammes HTTP, ceux qui collent le plus à
la sémantique des datagrammes. Sur HTTP/2, tout acheminement de
données est garanti. Si on veut faire des datagrammes, il va falloir
utiliser le protocole Capsule, décrit dans la
section 3. (Notez que HTTP/2 ne garantit pas l'ordre d'arrivée si
les datagrammes sont transportés dans des ruisseaux différents.) Et
pour HTTP/1 ? Le protocole ne convient guère puisqu'il garantit
l'ordre d'arrivée et l'acheminement, justement les propriétés
auxquelles on était prêt à renoncer. Là aussi, on se servira de
Capsule.
HTTP utilise différentes méthodes pour faire ses requêtes (les deux plus connues sont GET et POST). Les datagrammes ne sont utilisables qu'avec des méthodes qui les acceptent explicitement. Donc, pas de GET ni de POST, plutôt du CONNECT.
Sur HTTP/3, le champ de données du datagramme QUIC aura le format :
HTTP/3 Datagram {
Quarter Stream ID (i),
HTTP Datagram Payload (..),
}
Le quarter stream ID est l'identificateur du ruisseau QUIC du client où a été envoyée la requête HTTP, divisé par 4 (ce qu'on peut toujours faire, vu la façon dont sont générés ces identificateurs, RFC 9000, section 2.1).
Ah, et comme les datagrammes ne sont pas acceptés par défaut en
HTTP/3, il faudra envoyer au début de la session un paramètre
SETTINGS_H3_DATAGRAM (enregistré à
l'IANA).
Les capsules, maintenant. Inutiles en HTTP/3, elles sont la seule
façon de faire du datagramme en HTTP/1 et HTTP/2. Le protocole
Capsule permet d'envoyer des données encodées en
TLV sur une connexion HTTP. On indique qu'on
va l'utiliser, en HTTP/1 avec le champ Upgrade:
(RFC 9110, section 7.8) et en HTTP/2 avec un
CONNECT étendu (cf. RFC 8441). Les
upgrade tokens (les identificateurs de protocoles
utilisés, enregistrés à
l'IANA) sont décrits dans la section 16.7 du RFC 9110.
Le format des capsules est décrit en section 3.2 :
Capsule {
Capsule Type (i),
Capsule Length (i),
Capsule Value (..),
}
Les différents types possibles de capsules figurent dans un registre IANA. Une fois le protocole Capsule sélectionné via un upgrade token, on passe du HTTP classique au protocole Capsule. Un premier type de capsule est DATAGRAM (type 0) dont le nom indique bien la sémantique. D'autres types pourront être ajoutés en suivant la procédure « spécification nécessaire » du RFC 8126, sauf les valeurs basses du type (de 0 à 63) qui exigent une action de normalisation, ou bien une approbation par l'IESG.
Si on utilise Capsule, la requête HTTP est accompagnée du champ
Capsule-Protocol (un champ structuré, cf. RFC 9651), champ désormais enregistré
à l'IANA.
Il existe plusieurs mises en œuvre de ces datagramms HTTP. En logiciel libre, on a :
Notez que le protocole Capsule n'est a priori pas accessible au code JavaScript chargé dans le navigateur Web (il faut pouvoir accéder aux upgrade tokens). Mais rappelez-vous que tout ce mécanisme de datagrammes sur HTTP est conçu pour des extensions de HTTP, pas pour l'application finale.
L'article seul
Fiche de lecture : Petite histoire du compagnonnage
Auteur(s) du livre : François Icher
Éditeur : Cairn
978-2-35068-753-7
Publié en 2019
Première rédaction de cet article le 8 septembre 2022
Vous connaissez le compagnonnage ? Probablement de nom, puisque ce système de formation et d'entraide dans le monde du travail manuel est ancien et souvent cité, par exemple lorsqu'on a parlé des réparations de Notre-Dame de Paris après l'incendie. Mais en dehors de généralités, le compagnonnage n'est pas forcément bien connu, alors qu'il a une longue histoire, résumée dans ce livre.
Le travail de l'historien sur ce sujet est à la fois facile (de nombreux documents sont disponibles) et difficile car il y a tout un folklore compagnonnique, avec ses légendes (les racines du compagnonnage au temps du roi Salomon…) et que les compagnons ne sont pas forcément ravis de voir un historien extérieur documenter leur mouvement. L'auteur se concentre évidemment sur les faits établis, qui font remonter les sources du compagnonnage, non pas au temple de Jérusalem, mais au Moyen Âge, ce qui n'est déjà pas mal. En rupture avec le système médiéval des corporations, devenu figé, voire « aristocratique », le compagnonnage est né de la volonté de certaines catégories de travailleurs manuels de s'entraider et de se former entre eux, par l'échange et le voyage (le fameux « Tour de France »). Ces compagnons ont ensuite développé un certain nombre de traditions (parfois confondues, à tort, avec celles des francs-maçons, mouvement nettement plus bourgeois) et de règles, notamment d'entraide et de fraternité.
On croit souvent qu'il n'y a qu'une sorte de compagnon mais en fait, depuis longtemps, les compagnons sont divisés entre plusieurs obédiences qui, à certaines époques, réglaient leurs divergences par la violence. Le chemin du Tour de France n'était pas un long fleuve tranquille. Les chansons de marche que les compagnons entonnaient pour se donner du courage sur la route étaient fréquemment des chants guerriers dirigés contre les autres obédiences. (Le même auteur a fait le scénario d'une BD sur Agricol Perdiguier, un compagnon du XIXe siècle resté célèbre par sa lutte incessante contre ces affrontements fratricides. Une de ses actions a été d'écrire des chansons pour les marches et les fêtes, qui ne soient pas un appel à la violence. Un feuilleton célèbre de l'ORTF avait son scénario fondé sur ces violences.) Le compagnonnage n'a évidemment jamais échappé aux problèmes politiques de son temps : catholiques stricts contre laïcs au XIXe siècle, par exemple. Mais il y avait aussi des rivalités de boutique (monopole d'accès à certains travaux) et du simple sectarisme.
Le compagnonnage a ensuite été ébranlé par la révolution industrielle, qui a semblé un moment condamner l'artisan qualifié qu'était le compagnon, par le socialisme, qui rejetait ce mouvement qui se voulait souvent élitiste, par les divers soubresauts du XXe siècle (ah, la malheureuse tentative de rénovation du compagnonnage sous le patronage de… Pétain).
Le livre décrit toutes ces aventures du mouvement compagnonnique, et son état actuel. Toujours divisé, avec trois importantes obédiences et plusieurs plus petites, le mouvement existe toujours. L'auteur explique les divergences entre ces obédiences mais je dois dire que ce n'est pas forcément facile à décrypter pour un lecteur situé à l'extérieur du mouvement compagnonnique. Ce mouvement s'est parfois adapté au monde moderne (admission des femmes à partir de 2004), mais reste également fidèle à ses origines, notamment la valorisation du travail manuel, et l'importance de la transmission du savoir.
L'article seul
Fiche de lecture : Néandertal nu
Auteur(s) du livre : Ludovic Slimak
Éditeur : Odile Jacob
978-2-7381-5723-2
Publié en 2022
Première rédaction de cet article le 1 septembre 2022
L'homme de Néandertal fait l'objet de nombreux travaux de « réhabilitation » depuis des années, le présentant comme l'égal en tout de l'Homo Sapiens moderne que nous sommes. Dans ce livre, Slimak questionne cette vision et se demande si elle n'a pas tendance à considérer l'Homo Sapiens moderne comme la référence absolue.
Ce pauvre Néandertal était, au XIXe siècle
et au début du XXe, présenté comme une brute stupide, sans
sentiments religieux ou artistiques, et cannibale, pendant qu'on y
était. Les reconstitutions le montraient plutôt comme un singe que
comme un homme. Depuis un certain temps, cette vision est
contestée, et la tendance est plutôt à dire que Néandertal, s'il
vivait aujourd'hui, serait notre égal en presque tout et devrait
avoir le droit de vote. Trouvée sur
Wikimedia Commons, une image moderne (et qui fait écho au
titre du livre) :  .
.
{kind=link}
Ludovic Slimak reprend la question dans ce court livre. Il fait d'abord remarquer que beaucoup de théories sur les humains du passé sont fragiles, reposant sur peu de données, et de datations parfois délicates. Le risque de raisonnement circulaire est important ; on trouve un certain type d'artefacts avec des squelettes d'Homo Sapiens moderne, puis on trouve des artefacts analogues en un autre endroit, sans squelettes associés, on en déduit que des Homo Sapiens les ont réalisés et finalement que Néandertal n'a rien fait. Alors qu'il était peut-être l'auteur du second jeu d'artefacts.
Mais, surtout, l'auteur s'interroge sur cette tendance à vouloir réhabiliter Néandertal en insistant sur le fait qu'il était comme nous. Est-ce que cela n'indique pas un certain refus de la différence, si Néandertal n'était acceptable que s'il était plus ou moins identique à nous ? Slimak estime qu'on n'a pas de vraies preuves que Néandertal ait eu une activité artistique. Mais est-ce que cela veut dire qu'il n'est qu'une brute sans intérêt ? L'auteur appelle à analyer ce qu'on sait de Néandertal en essayant de ne pas nous prendre comme le mètre-étalon. Par exemple, sur le cannibalisme, Slimak fait remarquer qu'il n'y a guère de doute que Néandertal était cannibable (ce qui lui a souvent été reproché), mais que certains Homo Sapiens modernes l'étaient aussi et que de toute façon ce n'est pas forcément un signe d'animalité, ce cannibalisme étant fortement ritualisé et chargé de sens divers.
Le livre est agréable à lire, avec beaucoup d'exemples concrets et de dissertations intéressantes. Je le recommande pour comprendre la complexité du débat.
Et sinon, du côté des romans, il y a des personnages intéressants de Néandertals dans le cycle de Jean Auel « Les enfants de la Terre » et, en moins documenté scientifiquement, dans la série de Jasper Fforde sur Thursday Next. Dans les deux cas, Néandertal n'est pas un singe abruti, mais il n'est pas non plus un simple clone d'Homo Sapiens.
L'article seul
RFC 9287: Greasing the QUIC bit
Date de publication du RFC : Août 2022
Auteur(s) du RFC : M. Thomson (Mozilla)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF quic
Première rédaction de cet article le 30 août 2022
Dans un monde idéal, nos flux de données sur l'Internet passeraient sans problème et sans être maltraitées par les éléments intermédiaires du réseau. Mais dans le monde réel, de nombreuses middleboxes examinent le trafic et interfèrent avec lui. Les machines émettrices de trafic doivent donc se protéger et une des techniques les plus courantes est le chiffrement : si la middlebox ne peut pas comprendre ce qui est envoyé, elle ne pourra pas interférer. Le protocole de transport QUIC chiffre donc le plus possible. Mais une partie du trafic reste non chiffrée. Une des techniques pour empêcher que les middleboxes ne le lisent et ne prennent des décisions déplorables fondées sur ces informations transmises en clair est le graissage : on fait varier les données le plus possible. Ce RFC normalise une possibilité de graisser un bit de l'en-tête QUIC qui était fixe auparavant.
L'un des principes de conception de QUIC est de diminuer le plus possible la vue depuis le réseau (RFC 8546) ; les éléments intermédiaires, comme les routeurs ne doivent avoir accès qu'à ce qui leur est strictement nécessaire, le reste étant chiffré, pour leur éviter toute tentation. QUIC définit (dans le RFC 8999) des invariants, des informations qui seront toujours vraies même pour les futures versions de QUIC (le RFC 9000 définit QUIC version 1, pour l'instant la seule version). En dehors de ces invariants, tout peut… varier et les équipements intermédiaires du réseau ne doivent pas en tenir compte. Si tous suivaient ce principe, on préserverait la neutralité du réseau, et on éviterait l'ossification (cf. RFC 9170). Mais, en pratique, on sait que ce n'est pas le cas et que toute information visible depuis le réseau sera utilisée par les middleboxes, ce qui peut rendre difficile les évolutions futures (TLS a par exemple beaucoup souffert de ce problème, d'où le RFC 8701, le premier à avoir formalisé ce concept de graissage).
Or, QUIC a un bit qui n'est pas cité dans les invariants du RFC 8999 mais qui est fixe et peur servir à différencier QUIC d'autres protocoles. On l'appele d'ailleurs souvent le « bit QUIC » (même si ça n'est pas son nom officiel, qui est fixed bit, cf. RFC 9000, sections 17.2 et 17.3). Si les middleboxes s'en servent pour appliquer un traitement particulier à QUIC, les futures versions de QUIC ne pourront pas utiliser ce bit pour autre chose (rappelez-vous qu'il ne fait pas partie des invariants).
Notre RFC
ajoute donc à QUIC une option pour graisser ce bit, c'est-à-dire
pour le faire varier au hasard, décourageant ainsi les
middleboxes d'en tenir compte. Un nouveau
paramètre de transport QUIC (ces paramètres sont définis dans le
RFC 9000, section 7.4) est créé,
grease_quic_bit (et ajouté au registre
IANA). Lorsqu'il est annoncé à l'ouverture de la connexion
QUIC, il indique que ce bit est ignoré et que le pair à tout intérêt
à le faire varier.
Les paquets initiaux de la connexion
(Initial et Handshake)
doivent garder le bit QUIC à 1 (puisqu'on n'a pas encore les
paramètres de la connexion), sauf si on reprend une ancienne
connexion (en envoyant un jeton, cf. RFC 9000,
section 19.7).
Tout le but de ce graissage est de permettre aux futures versions
de QUIC (v2, 3, etc) d'utiliser ce bit qui était originellement
fixe. Ces futures versions, ou tout simplement des extensions à QUIC
négociées au démarrage de la connexion, pourront donc utiliser ce
bit (lui donner une sémantique). Le RFC leur recommande d'annoncer
quand même le paramètre grease_quic_bit, ce qui
permettra de graisser même si la future extension n'est pas gérée
par le partenaire.
Le RFC note enfin que ce graissage rend plus difficile d'identifier les flux de données QUIC au milieu de tout le trafic. C'est bien sûr le but, mais cela peut compliquer certains activités d'administration réseau. Un futur RFC explique plus en détail cette situation.
Apparemment, plusieurs mises en œuvre de QUIC gèrent déjà ce graissage.
L'article seul
RFC 9293: Transmission Control Protocol (TCP)
Date de publication du RFC : Août 2022
Auteur(s) du RFC : W. Eddy (MTI Systems)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tcpm
Première rédaction de cet article le 20 août 2022
Le protocole de transport TCP est l'un des piliers de l'Internet. La suite des protocoles Internet est d'ailleurs souvent appelée TCP/IP, du nom de ses deux principaux protocoles. Ce nouveau RFC est la norme technique de TCP, remplaçant l'antique RFC 793, qui était vieux de plus de quarante ans, plus vieux que la plupart des lecteurices de ce blog. Il était temps de réviser et de rassembler en un seul endroit tous les détails sur TCP.
TCP est donc un protocole de transport. Rappelons brièvement ce qu'est un protocole de transport et à quoi il sert. L'Internet achemine des paquets IP de machine en machine. IP ne garantit pas leur arrivée : les paquets peuvent être perdus (par exemple parce qu'un routeur n'avait plus de place dans ses files d'attente), peuvent être dupliqués, un paquet peut passer devant un autre, pourtant envoyé avant, etc. Pour la grande majorité des applications, ce n'est pas acceptable. La couche de transport est donc chargée de remédier à cela. Première (en partant du bas) couche à être de bout en bout (les routeurs et autres équipements intermédiaires n'y participent pas, ou plus exactement ne devraient pas y participer), elle se charge de suivre les paquets, de les remettre dans l'ordre, et de demander aux émetteurs de ré-émettre si un paquet s'est perdu. C'est donc un rôle crucial, puisqu'elle évite aux applications de devoir gérer ces opérations très complexes. (Certaines applications, par exemple de vidéo, n'ont pas forcément besoin que chaque paquet arrive, et n'utilisent pas TCP.) Le RFC 8095 contient une comparaison détaillée des protocoles de transport de l'IETF.
Avant de décrire TCP, tel que spécifié dans ce RFC 9293, un petit mot sur les normes techniques de l'Internet. TCP avait originellement été normalisé dans le RFC 761 en 1980 (les couches 3 - IP et 4 étaient autrefois mêlées en une seule). Comme souvent sur l'Internet, le protocole existait déjà avant sa normalisation et était utilisé. La norme avait été rapidement révisée dans le RFC 793 en 1981. Depuis, il n'y avait pas eu de révision générale, et les RFC s'étaient accumulés. Comprendre TCP nécessitait donc de lire le RFC 793 puis d'enchainer sur plusieurs autres. Un RFC, le RFC 7414, avait même été écrit dans le seul but de fournir un guide de tous ces RFC à lire. Et il fallait également tenir compte de l'accumulation d'errata. Désormais, la situation est bien plus simple, tout TCP a été consolidé dans un RFC central, notre RFC 9293. (Notez que ce travail de consolidation a été aussi fait pour HTTP et SMTP, qui ne sont plus décrits par les RFC d'origine mais par des versions à jour, mais pas pour le DNS, qui reste le principal ancien protocole qui aurait bien besoin d'une remise à jour complète des documents qui le spécifient.) Ne vous faites toutefois pas d'illusion : malgré ses 114 pages, ce RFC 9293 ne couvre pas tout, et la lecture d'autres RFC reste nécessaire. Notamment, TCP offre parfois des choix multiples (par exemple pour les algorithmes de contrôle de la congestion, une partie cruciale de TCP), qui ne sont pas décrits intégralement dans la norme de base. Voyez par exemple le RFC 7323, qui n'a pas été intégré dans le RFC de base, et reste une extension optionnelle.
Attaquons-nous maintenant à TCP. (Bien sûr, ce sera une présentation très sommaire, TCP est forcément plus compliqué que cela.) Son rôle est de fournir aux applications un flux d'octets fiable et ordonné : les octets que j'envoie à une autre machine arriveront dans l'ordre et arriveront tous (ou bien TCP signalera que la communication est impossible, par exemple en cas de coupure du câble). TCP découpe les données en segments, chacun voyageant dans un datagramme IP. Chaque octet est numéroté (attention : ce sont bien les octets et pas les segments qui sont numérotés) et cela permet de remettre dans l'ordre les paquets, et de détecter les pertes. En cas de perte, on retransmet. Le flux d'octets est bidirectionnel, la même connexion TCP permet de transmettre dans les deux sens. TCP nécessite l'établissement d'une connexion, donc la mémorisation d'un état, par les deux pairs qui communiquent. Outre les tâches de fiabilisation des données (remettre les octets dans l'ordre, détecter et récupérer les pertes), TCP fournit du démultiplexage, grâce aux numéros de port. Ils permettent d'avoir plusieurs connexions TCP entre deux machines, qui sont distinguées par ces numéros de port (un pour la source et un pour la destination) dans l'en-tête TCP. Le bon fonctionnement de TCP nécessite d'édicter un certain nombre de règles et le RFC les indique avec MUST-n où N est un entier. Par exemple, MUST-2 et MUST-3 indiqueront que la somme de contrôle est obligatoire, aussi bien en envoi qu'en vérification à la réception.
Après ces concepts généraux, la section 3 de notre RFC rentre dans les détails concrets, que je résume ici. D'abord, le format de cet en-tête que TCP ajoute derrière l'en-tête IP et devant les données du segment. Il inclut les numéros de port, le numéro de séquence (le rang du premier octet dans les données), celui de l'accusé de réception (le rang du prochain octet attendu), un certain nombre de booléens (flags, ou bits de contrôle, qui indiquent, par exemple, s'il s'agit d'une connexion déjà établie, ou pas encore, ou la fin d'une connexion), la taille de la fenêtre (combien d'octets peuvent être envoyés sans accusé de réception, ce qui permet d'éviter de surcharger le récepteur), une somme de contrôle, et des options, de taille variable (l'en-tête contient un champ indiquant à partir de quand commencent les données). Une option de base est MSS (Maximum Segment Size) qui indique quelle taille de segment on peut gérer. Il existe d'autres options comme les accusés de réception sélectifs du RFC 2018 ou comme le facteur multiplicatif de la taille de fenêtre du RFC 7323.
Avant d'expliquer la dynamique de TCP, le RFC définit quelques
variables indispensables, qui font partie de l'état de la connexion
TCP. Pour l'envoi de données, ce sont par exemple
SND.UNA (ces noms sont là pour comprendre le
RFC, mais un programme qui met en œuvre TCP peut évidemment nommer
ces variables comme il veut), qui désigne le numéro de séquence du
début des données envoyées, mais qui n'ont pas encore fait l'objet
d'un accusé de réception, ou SND.NXT, le numéro
de séquence du début des données pas encore envoyées ou encore
SND.WND, la taille de la fenêtre
d'envoi. Ainsi, on ne peut pas envoyer d'octets dont le rang serait
supérieur à SND.UNA +
SND.WND, il faut attendre des accusés de
réception (qui vont incrémenter SND.UNA) ou une
augmentation de la taille de la fenêtre. Pour la réception, on a
RCV.NXT, le numéro de séquence des prochains
paquets si tout est normal, et RCV.WND, la
taille de la fenêtre de réception.
TCP est un protocole à état et il a donc une machine à
états, décrite en section 3.3.2. Parmi les états,
LISTEN, qui indique un TCP en train d'attendre
un éventuel pair, ESTAB
(ou ESTABLISHED), où TCP envoie et reçoit des
données, et plusieurs états qui apparaissent lors de l'ouverture ou
de la fermeture d'une connexion.
Et les numéros de séquence ? Un point important de TCP est qu'on ne numérote pas les segments mais les octets. Chaque octet a son numéro et les accusés de réception référencent ces numéros. On n'accuse évidemment pas réception de chaque octet individuel. Les accusés de réception sont cumulatifs ; ils désignent un octet et, implicitement, tous les octets précédents. Quand un récepteur prévient qu'il a bien reçu l'octet N, cela veut dire que tous ceux avant N ont aussi été reçus.
Les numéros ne partent pas de 1 (ni de zéro), ils sont relatifs à un ISN (Initial Sequence Number, rappelez-vous qu'il y a un glossaire, en section 4 du RFC) qui est choisi aléatoirement (pour des raisons de sécurité, cf. RFC 6528) au démarrage de la session. Des logiciels comme Wireshark savent cela et peuvent calculer puis afficher des numéros de séquence qui partent de 1, pour faciliter la lecture.
Les numéros de séquence sont stockés sur 32 bits et il n'y a donc que quatre milliards (et quelques) valeurs possibles. C'était énorme quand TCP a été créé mais cela devient de plus en plus petit, relativement aux capacités des réseaux modernes. Comme TCP repart de zéro quand il atteint le numéro de séquence maximum, il y a un risque qu'un « vieux » paquet soit considéré comme récent. À 1 Gb/s, cela ne pouvait se produire qu'au bout de 34 secondes. Mais à 100 Gb/s, il suffit d'un tiers de seconde ! Les extensions du RFC 7323 deviennent alors indispensables.
Tout le monde sait bien que TCP est un protocole orienté connexion. Cela veut dire qu'il faut pouvoir créer, puis supprimer, les connexions. La section 3.5 de notre RFC décrit cet établissement de connexion, via la fameuse « triple poignée de mains ». En gros, un des TCP (TCP n'est pas client-serveur, et la triple poignée de mains marche également quand les deux machines démarrent la connexion presque en même temps) envoie un paquet ayant l'option SYN (pour synchronization), le second répond avec un paquet ayant les options ACK (accusé de réception du SYN) et SYN, le premier TCP accuse réception. Avec trois paquets, les deux machines sont désormais d'accord qu'elles sont connectées. En d'autres termes (ici, machine A commence) :
- Machine A ⇒ Machine B : je veux te parler,
- B ⇒ A : j'ai noté que tu voulais me parler et je veux te parler aussi,
- A ⇒ B : j'ai noté que tu voulais me parler.
Pour mettre fin à la connexion, un des deux TCP envoie un paquet ayant l'option FIN (pour finish), auquel l'autre répond de même.
Conceptuellement, TCP gère un flux d'octets sans séparation. TCP
n'a pas la notion de message. Si une application envoie (en appelant
print, write ou autre
fonction du langage de programmation utilisé) les octets "AB" puis
"CD", TCP transmettra puis livrera à l'application distante les
quatre octets "ABCD" dans l'ordre, sans indiquer qu'il y avait eu
deux opérations d'écriture sur le réseau. Mais, pour envoyer les
données, TCP doit les segmenter en paquets IP distincts. La
fragmentation IP n'étant pas bonne pour les
performances, et étant peu fiable de toute façon, l'idéal est que
ces paquets IP aient une taille juste inférieure à la MTU du chemin. Cela
nécessite de découvrir cette MTU (section 3.7.2), ou bien d'adopter
la solution paresseuse de faire des paquets de 1 280 octets (la MTU
minimum, en IPv6). Comme la solution paresseuse ne serait pas
optimale en performances, les mises en œuvre de TCP essaient toutes
de découvrir la MTU du chemin. Cela peut se faire avec la méthode
PMTUD, décrite dans les RFC 1191 et RFC 8201, mais qui a l'inconvénient de nécessiter
qu'ICMP ne soit pas bloqué. Or, beaucoup de
middleboxes programmées
avec les pieds, ou configurées par des incompétents, bloquent ICMP,
empêchant le fonctionnement de PMTUD. Une alternative est PLPMTUD,
normalisée dans le RFC 4821, qui ne dépend
plus d'ICMP.
Une fois la connexion établie, on peut envoyer des données. TCP va les couper en segments, chaque segment voyageant dans un paquet IP.
Une mise en œuvre de TCP
n'envoie pas forcément immédiatement les octets qu'on lui a
confiés. Envoyer des petits paquets n'est pas efficace : s'il y a
peu de données, les en-têtes du paquet forment la majorité du trafic
et, de toute façon, le goulet d'étranglement dans le réseau n'est
pas forcément lié au nombre d'octets, il peut l'être au nombre de
paquets. Un des moyens de diminuer le nombre de paquets contenant
peu d'octets est l'algorithme de Nagle. Le
principe est simple : quand TCP reçoit un petit nombre d'octets à
envoyer, il ne les transmet pas tout de suite mais attend un peu
pour voir si l'application ne va pas lui confier des octets
supplémentaires. Décrit dans le RFC 896, et
recommandé dans le RFC 1122, cet algorithme
est aujourd'hui présent dans la plupart des mises en œuvres de
TCP. Notre RFC 9293 le recommande, mais en ajoutant que les
applications doivent pouvoir le débrayer. C'est notamment
indispensable pour les applications interactives, qui n'aiment pas
les délais, même courts. (Sur Unix, cela se
fait avec l'option TCP_NODELAY passée à
setsockopt.)
Un des rôles les plus importants de TCP est de lutter contre la congestion. Il ne faut pas envoyer le plus d'octets possible, ou alors on risque d'écrouler le réseau (RFC 2914). Plusieurs mécanismes doivent être déployés : démarrer doucement (au début de la connexion, TCP ne connait pas le débit que peut supporter le réseau et doit donc être prudent), se calmer rapidement si on constate que des paquets sont perdus (cela peut être un signe de congestion en aval), etc. Ces mesures pour éviter la congestion sont absolument obligatoires (comme tous les biens communs, l'Internet est vulnérables aux parasites, un TCP égoïste qui ne déploierait pas ces mesures anti-congestion serait un mauvais citoyen du réseau). Elles sont décrites plus précisément dans les RFC 1122, RFC 2581, RFC 5681 et RFC 6298. Notez qu'ils énoncent des principes, mais pas forcément les algorithmes exacts à utiliser, ceux-ci pouvant évoluer (et ils l'ont fait depuis la sortie du RFC 793, voir les RFC 9743 et RFC 8961).
Un point qui surprend souvent les programmeur·ses qui écrivent
des applications utilisant TCP est que rien n'indique qu'une
connexion TCP est coupée, par exemple si un câble est
sectionné. C'est seulement lorsqu'on essaie d'écrire qu'on
l'apprendra (ce comportement est une conséquence de la nature sans
connexion d'IP ; pourquoi prévenir d'une coupure alors qu'IP va
peut-être trouver un autre chemin ?). Si on veut être mis au courant
tout de suite, on peut utiliser des keep-alives,
des segments vides qui seront envoyés de temps en temps juste pour
voir s'ils arrivent. Cette pratique est contestée (entre autre parce
qu'elle peut mener à abandonner une connexion qui n'est que
temporairement coupée, et aussi parce que, même si les
keep-alives passent, cela ne garantit pas que la
prochaine écriture de données passera). Notre RFC demande donc que
les keep-alives soient désactivés par défaut, et
que l'application puisse contrôler leur activation (sur Unix, c'est
l'option SO_KEEPALIVE à utiliser avec
setsockopt).
Pendant les quarante ans écoulés depuis la sortie du RFC 793, bien des choses ont changé. Des options ont été ajoutées mais on a vu aussi certaines options qui semblaient être des bonnes idées être finalement abandonnées. C'est le cas du mécanisme de données urgentes, qui n'a jamais vraiment marché comme espéré. Une mise en œuvre actuelle de TCP doit toujours le gérer, pour pouvoir parler avec les anciennes, mais on ne peut pas compter dessus (RFC 6093).
On a parlé plusieurs fois de l'utilisation de TCP par les applications. Pour cela, il faut que TCP offre une API à ces applications. Notre RFC ne décrit pas d'API concrète (cela dépend de toute façon du langage de programmation, et sans doute du système d'exploitation). Il se contente d'une description fonctionnelle de l'interface : les services qu'elle doit offrir à l'application. On y trouve :
- L'ouverture de la connexion, en indiquant l'adresse et le port distant, mais aussi l'adresse locale (MUST-43), pour pouvoir choisir l'adresse si la machine en a plusieurs.
- L'envoi de données, dont TCP garantit qu'elles arriveront toutes et dans l'ordre.
- La lecture de données. Rappelez-vous que TCP fournit un
flot continu d'octets, deux envois de données feront peut-être une
seule lecture ou bien un envoi deux lectures. C'est une des
erreurs les plus courante des programmeurs débutants que de penser
que s'ils font un write d'un côté, un
read de l'autre lira tout ce que le
writea écrit et seulement cela. - La fermeture propre (avec envoi, et réémission si nécessaire, des données écrites) de la connexion.
- Et quelques autres services auxiliaires que je ne détaille pas ici (voir la section 3.9.1).
Rappelez-vous que l'API « socket » n'est qu'un des moyens pour l'application de parler à TCP. Et, à propos de cette API, notez que le RFC utilise le terme de socket avec un sens très différent (cf. le glossaire en section 4).
Et l'autre interface, « sous » TCP, l'interface avec la couche réseau (section 3.9.2) ? TCP peut fonctionner avec des couches réseau variées mais, en pratique, c'est toujours IP, dans une de ses deux versions, v4 ou v6. Un des points délicats est le traitement des messages ICMP que TCP peut recevoir. Au minimum, ils doivent être assignés à une connexion existante. Mais cela ne veut pas dire qu'il faut systématiquement agir lors de la réception d'un de ces messages (RFC 5461). Par exemple, il faut ignorer les messages ICMP de répression de la source (RFC 6633). Et il ne faut pas fermer la connexion juste parce qu'on a reçu une erreur ICMP (MUST-56), car elles peuvent être temporaires.
TCP étant un protocole orienté connexion, la connexion va avoir
un état, représenté par un automate
fini. Ainsi, l'ouverture d'une connexion par le premier
TCP va le faire passer
par les états CLOSED, SYN-SENT puis enfin ESTABLISHED. Récupérée
sur
Wikimedia Commons, voici une représentation de cet automate :
{kind=link}
La section 5 de notre RFC décrit les changements depuis le RFC 793. TCP reste le même et des TCP d'« avant » peuvent interopérer avec ceux qui suivent notre RFC récent. Les principaux changements sont :
- La résolution d'un grand nombre d'errata accumulés depuis quarante ans.
- La « démobilisation » du mécanisme de données urgentes (cf. RFC 6093).
- L'incorporation d'une bonne partie des RFC comme le RFC 1011 ou le RFC 1122.
Le RFC 793 avait été écrit par Jon Postel (comme tant de RFC de cette époque), et notre nouveau RFC 9293 lui rend hommage, en estimant que la longue durée de vie du RFC 793 montre sa qualité.
En application des changements de ce nouveau RFC sur TCP, un registre IANA, celui des bits de l'en-tête comme URG (dont on a vu qu'il était désormais démobilisé), a été mis à jour.
La section 7 de notre nouveau RFC 9293 n'avait pas d'équivalent dans l'ancien RFC 793. Elle concerne la sécurité de TCP. TCP, par lui-même, fournit peu de sécurité (il protège quand même un peu contre l'usurpation d'adresse IP et l'injection de trafic, surtout contre un attaquant qui n'est pas sur le chemin, cf. RFC 5961). Par exemple, il ne fournit pas de services cryptographiques, donc pas de confidentialité ou de vraie garantie d'intégrité. (Son concurrent QUIC, lui, intègre systématiquement la cryptographie.) Si on veut davantage de sécurité pour TCP, il faut mettre IPsec en dessous de TCP ou bien TLS au-dessus. TCP a aussi des mécanismes de sécurité qui lui sont propres, comme AO, normalisé dans le RFC 5925 (mais très peu déployé en pratique). Autre expérience qui n'a pas été un succès, tcpcrypt (RFC 8548).
Il reste des attaques contre lesquelles la cryptographie ne fournit pas vraiment de solution. C'est le cas du SYN flooding, ou d'autres attaques par déni de service.
Mëme si on chiffre les données applicatives avec TLS, TCP expose quand même au réseau tout son fonctionnement. Cette vue depuis le réseau (RFC 8546) soulève plusieurs problèmes (elle peut par exemple faciliter des actions contraires à la neutralité du réseau) et c'est pour cela que le plus récent QUIC masque une grande partie de son fonctionnement (ce qui n'a pas été sans entrainer des polémiques). Toujours côté vie privée, le comportement des mises en œuvre de TCP est suffisamment différent pour qu'il soit possible dans certains cas d'identifier le système d'exploitation d'une machine à distance (ce n'est pas forcément grave, mais il faut le savoir).
Pour les programmeurs et programmeuses, l'annexe A du RFC contient différentes observations utiles pour la mise en œuvre concrète de TCP. Par exemple, cette annexe explique que la validation des numéros de séquence des segments TCP entrants, validation qui est nécessaire pour empêcher un grand nombre d'attaques, peut rejeter des segments légitimes. Ce problème n'a pas de solution idéale.
Un autre point intéressant concerne l'algorithme de
Nagle. Cet algorithme représente un compromis entre la
réactivité de l'application (qui nécessite d'envoyer les données le
plus vite possibles) et l'optimisation de l'occupation du réseau
(qui justifie d'attendre un peu pour voir si on ne va pas recevoir
de nouvelles données à envoyer). Une modification de l'algorithme de
Nagle, décrite dans le document
draft-minshall-nagle peut rendre le choix moins
douloureux.
Enfin, l'annexe B résume sous forme d'un tableau quelles sont les parties de la norme TCP qui doivent être mises en œuvre et quelles sont celles qu'on peut remettre à plus tard.
Si vous voulez sérieusement apprendre TCP, vous pouvez bien sûr lire le RFC en entier, mais il est sans doute plus sage de commencer par un bon livre comme le CNP3.
Un pcap d'une connexion TCP typique est
utilisé ici pour illustrer le fonctionnement de TCP (fichier tcp-typique.pcap). Vu par tshark, cela donne :
8.445772 2a01:4f8:c010:7eb7::106 → 2605:4500:2:245b::42 TCP 94 33672 → 443 [SYN] Seq=0 Win=64800 Len=0 MSS=1440 SACK_PERM=1 TSval=285818465 TSecr=0 WS=128 8.445856 2605:4500:2:245b::42 → 2a01:4f8:c010:7eb7::106 TCP 94 443 → 33672 [SYN, ACK] Seq=0 Ack=1 Win=64260 Len=0 MSS=1440 SACK_PERM=1 TSval=3778761402 TSecr=285818465 WS=128 8.534636 2a01:4f8:c010:7eb7::106 → 2605:4500:2:245b::42 TCP 86 33672 → 443 [ACK] Seq=1 Ack=1 Win=64896 Len=0 TSval=285818554 TSecr=3778761402 8.534897 2a01:4f8:c010:7eb7::106 → 2605:4500:2:245b::42 SSLv3 236 Client Hello 8.534989 2605:4500:2:245b::42 → 2a01:4f8:c010:7eb7::106 TCP 86 443 → 33672 [ACK] Seq=1 Ack=151 Win=64128 Len=0 TSval=3778761491 TSecr=285818554 8.548101 2605:4500:2:245b::42 → 2a01:4f8:c010:7eb7::106 TLSv1.2 1514 Server Hello 8.548111 2605:4500:2:245b::42 → 2a01:4f8:c010:7eb7::106 TCP 1514 443 → 33672 [PSH, ACK] Seq=1429 Ack=151 Win=64128 Len=1428 TSval=3778761504 TSecr=285818554 [TCP segment of a reassembled PDU] 8.548265 2605:4500:2:245b::42 → 2a01:4f8:c010:7eb7::106 TLSv1.2 887 Certificate, Server Key Exchange, Server Hello Done 8.636922 2a01:4f8:c010:7eb7::106 → 2605:4500:2:245b::42 TCP 86 33672 → 443 [ACK] Seq=151 Ack=2857 Win=63616 Len=0 TSval=285818656 TSecr=3778761504 8.636922 2a01:4f8:c010:7eb7::106 → 2605:4500:2:245b::42 TCP 86 33672 → 443 [ACK] Seq=151 Ack=3658 Win=62848 Len=0 TSval=285818656 TSecr=3778761504 8.649899 2a01:4f8:c010:7eb7::106 → 2605:4500:2:245b::42 TCP 86 33672 → 443 [FIN, ACK] Seq=151 Ack=3658 Win=64128 Len=0 TSval=285818669 TSecr=3778761504 8.650160 2605:4500:2:245b::42 → 2a01:4f8:c010:7eb7::106 TCP 86 443 → 33672 [FIN, ACK] Seq=3658 Ack=152 Win=64128 Len=0 TSval=3778761606 TSecr=285818669 8.739117 2a01:4f8:c010:7eb7::106 → 2605:4500:2:245b::42 TCP 86 33672 → 443 [ACK] Seq=152 Ack=3659 Win=64128 Len=0 TSval=285818758 TSecr=3778761606
Ici, 2a01:4f8:c010:7eb7::106 (une sonde RIPE Atlas) veut faire du
HTTPS (donc, port 443)
avec le serveur 2605:4500:2:245b::42. Tout
commence par la triple poignée de mains (les trois premiers paquets,
SYN, SYN+ACK, ACK). Une fois la connexion établie, tshark reconnait
que les machines font du TLS mais, pour TCP, ce ne sont que des données
applicatives (contrairement à QUIC, TCP sépare connexion et
chiffrement). On note qu'il n'y a pas eu
d'optimisation des accusés de réception. Par exemple, l'accusé de
réception du ClientHello TLS voyage dans un paquet séparé, alors
qu'il aurait pu être inclus dans la réponse applicative (le
ServerHello), probablement parce que celle-ci a mis un peu trop de
temps à être envoyée. À la fin de la connexion, chaque machine
demande à terminer (FIN). Une analyse automatique plus complète, avec
tshark -V figure dans tcp-typique.txt.
Ah, au fait, si vous avez pu lire cet article, c'est certainement grâce à TCP… (Ce blog ne fait pas encore de HTTP sur QUIC…).
L'article seul
RFC 9285: The Base45 Data Encoding
Date de publication du RFC : Août 2022
Auteur(s) du RFC : P. Faltstrom (Netnod), F. Ljunggren (Kirei), D. van Gulik (Webweaving)
Pour information
Première rédaction de cet article le 10 août 2022
Ce RFC décrit un encodage en texte de données binaires, l'encodage Base45. Proche conceptuellement d'encodages comme Base64, il est, par exemple, beaucoup utilisé pour le code QR.
Ces codes QR ne permettent pas de stocker directement des données binaires quelconques car le contenu sera toujours interprété comme du texte. Il est donc nécessaire d'encoder et c'est le rôle de Base45. Il existe bien sûr d'innombrables autres mécanismes d'encodage en texte, comme Base16, Base32 et Base64, spécifiés dans le RFC 4648 mais Base45 est plus efficace pour les codes QR, qui réencodent ensuite.
Base45 utilise un sous-ensemble d'ASCII, de 45 caractères (d'où son nom). Deux octets du contenu binaire sont encodés en trois caractères de ce sous-ensemble. Par exemple, deux octets nuls donneront la chaine de caractères "000". Regardons tout de suite avec le module Python base45 :
% pip3 install base45 % python3 >>> import base45 >>> base45.b45encode(b'Bonjour, tout le monde') b'.H86/D34ENJES4434ESUETVDL44-3E6VC' >>>
Et décodons avec le module Elixir base45 :
% iex -S mix
iex(1)> Base45.decode(".H86/D34ENJES4434ESUETVDL44-3E6VC")
"Bonjour, tout le monde"
C'est parfait, tout le monde est d'accord. Ici, évidemment, la chaine originale n'avait pas vraiment besoin d'être encodée donc on va essayer avec du binaire, les trois octets 42, 1 et 6, encodage en Elixir, décodage en Python :
iex(1)> Base45.encode(<<42, 1, 6>>)
"/D560"
>>> base45.b45decode("/D560")
b'*\x01\x06'
Encore une fois, tout va bien, Elixir a encodé les trois octets du binaire en quatre caractères, que Python a su décoder (l'astérisque est affiché car son code ASCII est 42).
Je vous laisse découvrir l'algorithme complet (il est assez simple) dans la section 3 du RFC. Si vous le programmez vous-même (ce qui n'est sans doute pas une bonne idée, il existe déjà de nombreuses mises en œuvre), attention aux cas limites comme un binaire d'un seul octet, ou comme une chaine à décoder qui compte des caractères invalides. Ici, un essai avec un caractère invalide, le signe égal :
% python3
>>> import base45
>>> base45.b45decode("AAAA=")
Traceback (most recent call last):
File "/home/stephane/.local/lib/python3.8/site-packages/base45/__init__.py", line 30, in b45decode
buf = [BASE45_DICT[c] for c in s.rstrip("\n")]
File "/home/stephane/.local/lib/python3.8/site-packages/base45/__init__.py", line 30, in <listcomp>
buf = [BASE45_DICT[c] for c in s.rstrip("\n")]
KeyError: '='
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/stephane/.local/lib/python3.8/site-packages/base45/__init__.py", line 54, in b45decode
raise ValueError("Invalid base45 string")
ValueError: Invalid base45 string
Pensez à tester votre code avec de nombreux cas variés. Le RFC cite
l'exemple des chaines "FGW" (qui se décode en une paire d'octets
valant chacun 255) et "GGW" qui, quoique proche de la précédente et
ne comportant que des caractères de l'encodage Base45 est néanmoins
invalide (testez-la avec votre décodeur). Le code de test dans le module Elixir
donne des idées de tests utiles (certains viennent de bogues
détectées pendant le développement). Regardez
test/base45_test.exs.
Et, comme toujours, lorsque vous recevez des données venues de l'extérieur, soyez paranoïaques dans le décodage ! Un code QR peut être malveillant et chercher à activer une bogue dans le décodeur (section 6 du RFC).
Enfin, le RFC rappelle qu'une chaine encodée n'est pas forcément directement utilisable comme URL, elle peut comporter des caractères qui ne sont pas sûrs, il faut donc encore une étape d'encodage si on veut en faire un URL.
Compte tenu de l'importance des codes QR, on trouve des mises en œuvre de Base45 un peu partout. J'ai par exemple cité celle en Python. Si vous programmez en Elixir, il y a une bibliothèque sur Hex (écrite en Erlang) mais aussi ma bibliothèque (aux performances très basses).
Sinon, si vous cherchez un bon article d'explication sur Base45, je recommande celui-ci.
L'article seul
Fiche de lecture : Le Puy du Faux
Auteur(s) du livre : Florian Besson, Pauline
Ducret, Guillaume Lancereau, Mathilde
Larrère
Éditeur : Les Arènes
979-10-375-0590-3
Publié en 2022
Première rédaction de cet article le 5 août 2022
Le parc d'attractions du Puy du Fou est un grand succès commercial, qui attire de nombreux visiteurs. Bon, d'accord, mais le Parc Astérix aussi, et on n'écrit pas des livres à son sujet, pourtant. Mais le Puy du Fou a une autre caractéristique : ses promoteurs prétendent qu'il est historiquement fondé, et qu'on peut non seulement s'y amuser mais en plus apprendre l'histoire. Quatre historiens se sont donc associés pour aller au parc d'attraction et vérifier.
Il y a plusieurs écueils si on veut avoir un regard critique sur l'histoire tendance Puy du Fou. Il y a le risque d'une critique élitiste, faisant fi du succès populaire du parc, méprisant la vulgarisation, et estimant que l'histoire ne doit se traiter que dans de gros livres ennuyeux pour universitaires. Il y a aussi le risque du pinaillage, pointant des erreurs de détails, par exemple sur les dates, et oubliant que le Puy du Fou a une cohérence dans sa vision de l'histoire, et que c'est elle qu'il faut étudier.
C'est ce qu'ont fait les quatre auteur·es, dont au moins deux sont activement engagés dans la vulgarisation de l'histoire, notamment sur les réseaux sociaux (les deux autres aussi, peut-être, mais je ne les connais pas). Ils sont allés au Puy du Fou, ils ont apprécié les spectacles, ils ont pris des notes et ils analysent la représentation historique. S'il y a en effet d'innombrables erreurs factuelles dans les spectacles du Puy du Fou, le plus gros problème est la vision peu historique du parc : une France éternelle, gardant son identité inchangée à travers les siècles, mélange de l'idéologie de l'Ancien Régime et du roman national du XIXe siècle. Par exemple, le spectacle se déroulant en Gaule romaine présente les seuls Gaulois comme ancêtres des Français, comme si la France d'aujourd'hui n'était pas tout autant héritière des Romains. (En prime, le spectacle montre les Gaulois chrétiens et les Romains païens, ce qui ne correspond pas à la réalité de l'époque.) Les auteur·es analysent de nombreux spectacles et la plupart (je vous laisse découvrir les exceptions) présentent la même vision d'une France mythique, qui a peu de rapport avec la réalité et avec les vrais Français des différentes époques.
Critiquer, c'est facile, mais proposer est plus difficile, pourront dire les défenseurs du parc. Mais un des chapitres les plus intéressants du livre est justement celui où les auteur·es se font scénaristes et imaginent quatre spectacles qui gardent ce qu'il y a de bien au Puy du Fou (des animations de qualité et spectaculaires, avec pyrotechnie obligatoire) tout en étant plus rigoureux historiquement. Ainsi celui de l'Antiquité montre les débats et divergences entre premiers chrétiens, alors que le Puy du Fou montre le christianisme, comme il le fait de la France, comme une entité éternelle et figée.
Faut-il aller au Puy du Fou ? Là n'est pas la question. Personnellement, je n'y suis jamais allé mais le livre peut donner envie, les spectacles semblant passionnants et bien faits. Le tout est d'y aller comme à Disneyland, pour la distraction, et pas en prétendant qu'on suit un cours d'histoire.
L'article seul
Fiche de lecture : Cyber-attaques : l'Amérique désigne ses ennemis
Auteur(s) du livre : Mark Corcoral
Éditeur : L'Harmattan
978-2-343-22452-7
Publié en 2021
Première rédaction de cet article le 4 août 2022
On le sait, l'attribution d'une cyber-attaque (« c'est les Chinois ! ») est un exercice difficile. Il faut analyser l'attaque, parvenir à une certitude et, ensuite, assumer de révéler publiquement l'origine. Comme le répète souvent Guillaume Poupard « L'attribution, c'est politique ». Le livre de Mark Corcoral étudie cette question de l'attribution notamment sous l'angle des accusations par les États-Unis : comment se fait l'attribution publique et suivant quels méandres politiques ?
La phrase de Guillaume Poupard, citée plus haut, a un amusant double sens. Elle dit que ce n'est pas à une agence technique comme l'ANSSI d'attribuer une attaque ; cette attribution publique peut avoir des conséquences et c'est donc au pouvoir politique de prendre ses responsabilités. Mais la phrase dit aussi qu'accuser publiquement tel ou tel pays est aussi un choix politique. Plus cyniquement, on pourrait reprendre la phrase d'un collègue de Topaze : « les coupables, il vaut mieux les choisir que les chercher ». Eh oui, quand un État en accuse un autre, l'accusation n'est pas forcément sincère…
Déjà, se faire une opinion est difficile : contrairement à une attaque physique qui va forcément laisser pas mal d'indices, une cyber-attaque ne laisse pas beaucoup de traces, et celles-ci peuvent facilement être imitées (une chaine de caractères en hébreu dans un logiciel malveillant ne signifie pas forcément que c'est un coup du Mossad, il est trivial d'en copier/coller une). Et l'interprétation de ces IOC peut être délicate. J'ai entendu des analystes expliquer que, comme les opérations de la cyber-attaque étudiée prenaient place entre 9 h et 17 h, heure de Beijing, cela menait à soupçonner les Chinois, comme si l'APL était tenue aux horaires de bureau. Et même une fois qu'on a acquis une conviction, il n'est pas facile d'en convaincre des tiers puisque, presque toujours, ceux qui font l'attribution d'une attaque ne donnent aucune information concrète sur les preuves récoltées (pour ne pas donner d'informations aux ennemis, mais aussi parfois pour cacher la faiblesse des preuves).
Et une fois qu'on a son intime conviction, l'attribution publique n'est pas automatique, elle relève de choix politiques, qui peuvent évoluer. C'est ainsi qu'avant, en gros, 2014, les États-Unis ne se livraient pas à des attributions publiques, avant de changer de politique et de multiplier les accusations. (La Russie et la Chine continuent à ne pas faire d'attribution publique pour des attaques précises, même si ces deux pays dénoncent de façon très générale les cyber-attaques dont ils sont victimes. Ils insistent beaucoup sur la difficulté à produire des preuves convaincantes.) Et à partir de 2017, les attributions faites par les États-Unis ne sont plus unilatérales mais impliquent parfois des pays alliés. Le choix dépend de la culture politique de chaque pays, et de sa conviction que l'attribution publique servira à quelque chose, par exemple en terme de propagande, ou bien pour faire avancer des négociations internationales sur une certaine régulation des attaques ou encore pour intimider un adversaire (« je t'ai vu ! »). Le choix est complexe et l'auteur explique très bien les innombrables questions géopolitiques qui sont liées à l'utilisation (ou pas) de l'attribution publique. Cette analyse des raisons qui poussent à attribuer publiquement est le gros du livre.
Un ouvrage que je recommande beaucoup, pour comprendre la complexité des questions de cyber-attaques et la difficulté des décisions à prendre.
(En plus léger, l'excellente BD « Cyberfatale » tourne essentiellement autour d'une question d'attribution, comment savoir qui a fait le coup et, une fois qu'on le sait, que faire de cette information.)
L'article seul
Fiche de lecture : Frontières.com
Auteur(s) du livre : Nicolas Arpagian
Éditeur : L'observatoire
979-10-329-2134-0
Publié en 2022
Première rédaction de cet article le 3 août 2022
Vous trouvez que la situation géopolitique sur l'Internet est compliquée ? Au moins, le livre d'Arpagian vous permettra d'avoir un tour d'horizon complet d'un certain nombre d'enjeux importants.
Ne lisez pas le quatrième de couverture, qui abuse de sensationnalisme (« les geeks-soldats de la cyber guérilla précèdent désormais les chars d'assaut »), voire d'erreurs (« la Russie construit son propre Internet »). Le livre est plus sérieux. Centré sur le rôle des frontières (pas seulement les frontières entre États, mais aussi celles qu'on s'était imaginées entre des activités que le numérique redéfinit), il a l'avantage de contenir de nombreux faits et données. Il passe en revue beaucoup de questions (sans doute trop, vu sa taille, et sans que ces questions aient de relation claire) : la privatisation, la censure, le pouvoir des GAFA, les mensonges, la cybersécurité, le succès de Léna Situations… C'est sérieux, l'auteur connait son sujet, et il ne prend pas pour agent comptant les clichés, par exemple sur le soi-disant anonymat de l'Internet.
Un livre qui peut être utile pour celle ou celui qui débute son exploration de la politique sur Internet. Vous pouvez aussi vous en faire une idée avec cet interview vidéo de l'auteur.
PS : le titre est un nom de domaine, réservé mais qui ne semble pas utilisé.
L'article seul
Fiche de lecture : Petite histoire de la mondialisation à l'usage des amateurs de chocolat
Auteur(s) du livre : Frédéric Amiel
Éditeur : Les éditions de l'Atelier
978-2-7082-5375-9
Publié en 2021
Première rédaction de cet article le 3 août 2022
Si, comme moi, vous abusez du chocolat, ce livre va peut-être vous être désagréable : il explique l'évolution de la mondialisation pour le cas particulier du chocolat. Ce n'est pas toujours très rose.
On commence évidemment au Mexique, où les conquérants européens découvrent le chocolat (que les Aztèques consommaient sans sucre mais avec du piment) et le rapportent en Europe. La substance suit le parcours de beaucoup d'autres produits rapportés d'Amérique : méfiance (médicale, mais aussi religieuse, quelque chose d'aussi bon doit être une création du diable), engouement, snobisme (rare et cher, le chocolat pouvait être un marqueur de distinction sociale). Puis la faible production mexicaine ne suffit plus et les Européens vont commencer à cultiver le chocolat de manière plus massive. D'abord aux Antilles puis en Amérique du Sud. Mais si on veut produire beaucoup de chocolat, il ne faut pas seulement avoir beaucoup de cacaoyers, il faut aussi traiter les fèves et, à la main, c'est long et difficile. Le parcours du chocolat croise donc celui de James Watt : ses machines à vapeur permettent de commencer à mécaniser le traitement. On n'est plus à la production artisanale, le chocolat est devenu une industrie. On croise dans le livre des entrepreneurs variés, comme Menier, un des promoteurs du paternalisme.
Puis la production de chocolat passe en Afrique. Le livre suit le développement d'une production de plus en plus importante, notamment sur l'ile de São Tomé, puis sur le continent. Un nouveau problème se pose alors : la production, grâce à la mondialisation de la production et à l'industrialisation, est devenue abondante et bon marché. Il faut donc convaincre de nouveaux consommateurs, pour faire du chocolat un produit de masse. Au 19e siècle, l'industrie chocolatière est donc une des plus friandes de publicité. L'exemple le plus connu de publicité pour le chocolat est, en France, le tirailleur sénégalais de Banania.
Et dans les pays producteurs ? Les cours du cacao sur les marchés mondiaux ne sont pas stables et ces pays connaissent des alternances de prospérité et de vaches maigres. Bien des gouvernements, après l'indépendance des colonies, ont cherché à stabiliser la situation, avec des succès variables. Car, entre temps, le cacao était passé des marchés de produits physiques aux marchés financiers. Désormais, au lieu de vendre et d'acheter du cacao, on achète et on vend des titres ayant un rapport plus ou moins lointain avec le cacao. (Note au passage : quand des gens, en 2022, reprochent aux cryptomonnaies d'être « virtuelles » et « déconnectées de l'économie réelle », ils ont quelques dizaines d'années de retard. Cela fait bien longtemps que les échanges sur les marchés sont déconnectés des produits et services.)
L'auteur se penche ensuite sur les alternatives : est-ce que du chocolat bio ou équitable (ou, soyons fous, les deux à la fois) permettrait au consommateur d'avoir de meilleurs produits et aux producteurs de vivre mieux ? La question des labels est compliquée ; certains n'ont guère de valeur car ils sont spécifiques à une entreprise, qui décide des critères et fait leur « vérification ». Difficile pour le consommateur de s'y retrouver !
Bref, un livre très lisible et très pédagogique, expliquant en détail tous les aspects de la production d'une marchandise, dans un monde où c'est devenu très compliqué.
L'article seul
[Histoire] Le protocole finger et la vie privée
Première rédaction de cet article le 2 août 2022
Sur le fédivers, jonny a attiré l'attention sur une discussion un peu oubliée, qualifiée avec une certaine exagération de « une des premières polémiques sur Internet ». Il s'agissait d'un débat en 1979 sur un changement technique fait dans des serveurs finger pour protéger un peu la vie privée, changement qui n'avait pas fait consensus. Un sujet toujours d'actualité, même dans l'Internet très différent que nous avons aujourd'hui.
Pour comprendre le débat, il faut passer un paragraphe à expliquer finger. Normalisé (mais bien après les faits) dans le RFC 1288, finger était un service d'information très populaire, qui permettait de trouver des informations sur un utilisateur d'une machine distante, son numéro de téléphone, son adresse postale, s'il était connecté en ce moment, etc. Avec les yeux d'aujourd'hui, on voit bien les questions de vie privée que cela peut poser. Le changement qui avait été fait dans un serveur finger (à l'université Carnegie-Mellon) était de ne pas diffuser l'information la plus sensible (dernière connexion, et dernière lecture du courrier électronique) par défaut (mais l'utilisateur avait une option pour activer cette diffusion).
Et c'est là que la polémique, en 1979, a commencé. Vous pouvez lire l'archive de la liste de diffusion msggroup de l'époque et voir la discussion de nos jours suite au pouète de jonny. Quel était le problème avec le changement fait à Carnegie Mellon ? C'était que ne pas diffuser l'information semblait à beaucoup anti-social. Le débat semble assez surréaliste aujourd'hui, avec une forte pression sociale pour tout diffuser par défaut. Mais, comme le notent Arne Babenhauserheide et Antoine-Frédéric dans la discussion, les mécanismes permettant d'indiquer qu'un message a été lu (qui sont déployés par exemple par WhatsApp) posent presque les mêmes problèmes (l'information n'est pas publique toutefois).
La loi Informatique & Libertés existait déjà, pourtant, mais on peut penser qu'elle n'était pas connue du petit groupe qui faisait alors fonctionner l'Internet, et au sein duquel tout le monde était à la fois utilisateur et acteur.
Il y a plein de choses à remarquer dans cette discussion. D'abord, que des choix apparemment très techniques (deux bits dans la configuration pour indiquer si on diffuse ces deux informations) sont en fait politiques. La passion déclenchée par ce simple changement (qui concernait un seul serveur finger : ceux qui n'étaient pas d'accord n'étaient pas obligés de modifier le leur) montre bien que tout le monde était conscient de l'importance de la question. Notons toutefois que des opposants au changement fait par l'université affirmaient que c'était un changement « politique », manifestement en considérant que ce terme était une insulte.
Ensuite, on peut noter bien sûr que les mentalités ont changé : on n'imagine plus aujourd'hui affirmer que garder ces informations privées est anti-social. Mais les changements ne sont pas si importants que cela ; encore aujourd'hui, lorsqu'on dénonce des atteintes à la vie privée, il y a toujours quelqu'un pour dire « si vous ne faites rien de mal, vous n'avez pas de raison d'avoir une vie privée ».
À propos de mentalité, il y a un cliché courant aujourd'hui qui est de dire que l'Internet n'avait pas été conçu pour la sécurité, c'est parce que, à l'époque, ses utilisateurs/acteurs étaient tous des hippies barbus et universitaires qui vivaient dans un monde de bisounours et se faisaient confiance. Il est vrai que ce monde était assez restreint, avec une forte homogénéité de classe sociale, de pays (uniquement des étatsuniens), de profession et de mentalité. Et l'espoir était en effet qu'une mentalité d'ouverture, de franche discussion et de confiance allait se généraliser. Ce n'était bien sûr pas réaliste, un tel climat pouvait se maintenir dans un petit groupe cohérent, mais avait peu de chance de passer à l'échelle, dans un Internet aux dimensions du monde. (Ceci dit, je préfère l'optimisme, même erroné, au cynisme « de toute façon, c'est la nature humaine, la loi de la jungle, la société sera toujours violente, et il faut mettre des barbelés partout ».)
Mais si les acteurs de l'Internet de l'époque sous-estimaient les questions de sécurité, ils ne les ignoraient pas. Sur bien des points où on reproche aux pionniers de l'Internet de n'avoir pas pris en compte la sécurité dès le début, il faut remarquer que, d'abord, il y a des bonnes raisons pour ne pas encombrer un nouveau système avec de la sécurité, si on veut qu'il soit un succès (RFC 5218). Ensuite, même aujourd'hui, avec l'expérience et le recul, on serait bien en peine de déployer un système sécurisé à l'échelle mondiale, avec le cahier des charges de l'Internet, qui est notamment de permettre à toute Alice de parler à tout Bob. Bref, les questions de 1979 n'appartiennent pas à un passé définitivement révolu, elles se posent toujours aujourd'hui.
Et un autre point à noter : l'importance de la valeur par défaut. Le changement fait à Carnegie Mellon impactait tous les utilisateurs (je n'utilise pas l'écriture inclusive ici car je soupçonne qu'il y avait peu d'utilisatrices), à part la minorité qui change les réglages. Ce problème est toujours d'actualité, par exemple lorsque Facebook se défend des reproches sur son manque de protection de la vie privée en disant que les utilisateurices peuvent toujours changer les réglages (tout en sachant que très peu le feront).
L'article seul
Fiche de lecture : Manual for survival
Auteur(s) du livre : Kate Brown
Éditeur : Penguin Books
978-0-141-98854-2
Publié en 2019
Première rédaction de cet article le 23 juillet 2022
Ce livre est une analyse des conséquences à long terme de la catastrophe nucléaire de Tchernobyl. Que se passe-t-il dans une région profondément irradiée ? L'auteure explore en détail le traitement de la catastrophe dans les années qui ont suivi l'explosion du réacteur, en ne se fiant pas uniquement aux déclarations officielles. Un ouvrage évidemment plutôt douloureux à lire, mais qui ne laisse aucun détail de côté.
Tout le monde connait la catastrophe qui a vu l'explosion d'un réacteur nucléaire à Tchernobyl le 26 avril 1986. On ne mentionne souvent que ses conséquences à court terme (la mort des « liquidateurs », qui sert à des affirmations trompeuses comme « la catastrophe n'a fait que 31 [le chiffre varie] morts ») mais le livre de Brown se concentre sur des conséquences à plus long terme, moins spectaculaires. Et il n'est pas facile de mesurer ces conséquences à long terme. Prenons l'exemple du cancer de la thyroïde. On en observe chez des enfants dans la région. Mais il y a aussi des cancers de ce type en l'absence de contamination radioactive. Sont-ils plus fréquents après l'accident de la centrale ? La statistique est une science difficile. (Comme on l'a vu récemment avec la pandémie de Covid-19, qui a vu le retour de déclarations anti-statistiques du genre « mon beau-frère n'est pas vacciné, et bien il n'est pas tombé malade ».)
Et il est d'autant plus difficile de répondre à la question que l'accident s'est produit dans un pays où le système de santé était loin d'être parfait, avec une collecte peu fiable des données (et le cancer de la thyroïde est apparemment délicat à diagnostiquer). En outre, il y avait sur place une radioactivité artificielle qui n'était pas due à cet accident, mais qui provenait des essais nucléaires atmosphériques et d'autres accidents (l'URSS traitait la sécurité nucléaire avec beaucoup de légèreté). Bref, le traitement de ces données n'est pas évident. Toutefois, il est clair que la radioactivité sur place est plus importante que ce qui avait parfois été raconté par les autorités, et que les maladies sont bien en augmentation.
Une autre difficulté statistique que décrit bien l'auteure est que la radioactivité est très variable d'un endroit à l'autre, et ne s'en tient pas aux traits tracés sur la carte (« ici, évacuation nécessaire, ici, ça peut aller »). Un jardin portager peut être contaminé et celui d'à côté rester peu touché. Un exemple particulièrement frappant est donné par l'auteure où des cueilleuses vont récolter des myrtilles dans une forêt et où chaque panier est mesuré pour déterminer sa contamination radioactive. Bien que récoltés dans la même forêt, ils sont très différents. Et, pour rester en deçà des normes de radioactivité acceptable, l'organisateur décide de mélanger les myrtilles des paniers relativement sains avec celle des paniers contaminés, diluant ainsi la radioactivité jusqu'à ce qu'elle reste en dessous du seuil…
Le livre décrit également longuement les réactions des autorités dans les années ayant suivi la catastrophe. Tchernobyl est en Ukraine mais proche de la Biélorussie. Dès l'accident, avant même la fin de l'URSS, les autorités ukrainiennes et biélorusses avaient traité le problème très différemment, la Biélorussie choisissant de largement nier le problème, y compris en confisquant les compteurs Geiger (pas de mesures, pas de problème…). La controverse n'est évidemment pas purement scientifique et Brown décrit longuement toutes les manœuvres des autorités pour cacher, ou relativiser, les faits gênants. Et Moscou s'en mêlait également, mais pas de façon uniforme : dans ces années de perestroïka, l'État soviétique partait déjà à vau-l'eau et tout le monde n'avait pas, et de loin, les mêmes idées sur comment faire face au problème. (À un moment, ce sont des médecins du KGB qui mettent en évidence les mensonges rassurants des autorités : vu les privilèges du KGB, ils avaient une meilleure clinique et du meilleur matériel, et savaient donc bien ce qu'il en était.)
Ah, et en parlant de géopolitique, l'auteure met aussi en évidence une curieuse complicité entre l'URSS et les USA. Malgré le fait que la guerre froide n'était pas finie, pas mal d'intervenants étatsuniens sur place soutenaient le discours officiel soviétique comme quoi les conséquences de l'accident n'étaient pas si graves que ça. Ce n'était pas forcément par confiance aveugle dans leurs collègues soviétiques, mais aussi peut-être par crainte que l'image de marque des filières nucléaires (civiles et militaires) ne souffrent trop de l'accident.
Bref, un livre à lire, pour celui ou celle qui veut approfondir les controverses politico-scientifiques, et apprécier la complexité des faits.
L'article seul
Les paquets IP passent-ils vraiment là où on leur dit ?
Première rédaction de cet article le 22 juillet 2022
La lecture d'une excellente étude faite à l'université de Twente m'a motivé pour faire un court article sur une question qu'on se pose trop rarement : sur un réseau comme l'Internet, les paquets IP passent-il vraiment là où le protocole de routage, typiquement BGP, leur a dit de passer ?
Je vous divulgâche tout de suite la fin : non. Comme répètent souvent les administrateurs réseau anglophones, « The data plane does not always follow the control plane ». Qu'est-ce que cela veut dire ?
Expliquons un peu le routage, dans un
réseau comme l'Internet : les routeurs se parlent entre eux et
échangent des informations (du genre « Tu sais quoi ? Je sais
comment joindre 2001:db8:fa9:aa3::/64. ») et
ces informations échangées leur servent à construire leur
table de routage, une structure de données qui
associe aux préfixes IP (comme ce
2001:db8:fa9:aa3::/64), l'adresse du routeur
suivant, celui qui rapprochera le paquet du
but. Ensuite, lorsqu'un routeur reçoit un paquet, il consulte sa
table de routage et envoie le paquet au routeur suivant, via la
bonne interface. Deux choses sont à noter :
- Il y a deux processus distincts, le routage (routing en anglosaxonien, construire la table avec les informations reçues par des protocoles de routage comme Babel - RFC 8966), et la transmission (forwarding dans la langue de Perlman, envoyer le paquet). Ces deux processus utilisent des protocoles très différents, n'ont pas les mêmes contraintes (par exemple, la transmission est temps-réel, avec des contraintes très serrées) et, dans un routeur haut de gamme, ces deux processus sont accomplis par des composants du routeur qui sont très différents.
- La responsabilité du routeur s'arrête une fois qu'il a transmis le paquet. Il ne peut pas indiquer au routeur suivant ce qu'il doit faire, et ne peut même pas connaitre la décision de celui-ci. C'est ce qu'on nomme le routage par étapes indépendantes (hop by hop).
Sur l'Internet, le protocole de routage standard est BGP (RFC 4271). Les annonces BGP ont la forme « je sais joindre
2001:db8:fa9::/48 et je le sais parce que
l'AS 64500 me l'a
dit et il le tenait de l'AS 65539 ». Mais, du fait du routage par
étapes indépendantes, rien ne dit qu'un paquet envoyé au routeur qui
a fait cette annonce ira bien à l'AS 64500 puis à l'AS 65539. Chaque
AS (en pratique, un
AS = un opérateur) est indépendant et a sa propre politique de
routage. Par exemple, l'administratrice du routeur suivant a
parfaitement pu configurer des routes statiques prioritaires, qui
seront utilisées avant celles apprises via BGP. C'est le sens de la
phrase « The data plane does not always follow the control
plane ». « The data plane », c'est IP,
c'est la transmission. « The control plane »,
c'est le protocole de routage, par exemple BGP.
L'étude
de Koen van Hove citée plus haut est une illustration
pratique de ce point (je vous en recommande vraiment la
lecture). L'auteur travaille sur la validation de l'origine des
routes (ROV, pour Route Origin Validation), via
la RPKI
(Resource Public Key Infrastructure). Les
titulaires de préfixes IP publient (et
signent) des ROA (Route Origin
Authorization) qui indiquent quel AS peut être à l'origine
d'une route (dans l'exemple plus haut, 65539 était l'origine). Les
routeurs connectés à l'Internet peuvent utiliser ces ROA pour
valider les annonces. Si on trouve un ROA correctement signé qui dit
« 2001:db8:fa9::/48 doit avoir comme AS
d'origine 65539 » et qu'une annonce
« 2001:db8:fa9::/48 passe par moi et ça vient
de l'AS 65500, qui en est l'origine », une telle annonce, invalide,
peut être rejetée.
Est-ce que cela suffit à garantir la sécurité du routage ? Non,
car, montre l'étude, même si on rejette cette annonce invalide, les
paquets qu'on émet sont transmis à des AS différents et ceux-ci
peuvent avoir d'autres règles et, par exemple, ne pas valider. Donc,
le malheureux paquet destiné à
2001:db8:fa9:b3:551::12:af8 sera peut-être
finalement transmis au méchant AS 65500. C'est ennuyeux, mais c'est
logique, chaque AS étant maitre de sa politique de routage.
Mais est-ce qu'on ne pourrait pas changer cela et « forcer » les AS à respecter des décisions prises par l'émetteur du paquet ? (Ce qu'on nomme le routage par la source.) Non, on ne peut pas, et le problème n'est pas technique (il existe plusieurs mécanismes pour représenter de telles décisions dans les paquets), mais d'ordre commercial et politique. En termes simples, les autres opérateurs font ce qu'ils veulent, et ils n'ont pas de raison de vous obéir. (Il faut se rappeler que l'Internet est une fédération de réseaux, pas un réseau unique.) Ils ont d'autant moins de raisons d'obéir à d'éventuelles consignes de l'émetteur que celles-ci permettraient des attaques contre la sécurité, par exemple en forçant le passage par un chemin qu'un attaquant sait moins contrôlé.
L'article seul
Le NIST a choisi ses algorithmes de cryptographie post-quantiques
Première rédaction de cet article le 6 juillet 2022
Dernière mise à jour le 16 août 2024
Ce mardi 5 juillet 2022, l'organisme de normalisation étatsunien NIST a annoncé qu'il avait choisi les algorithmes de cryptographie post-quantiques qu'il allait maintenant normaliser. Ce sont Kyber pour l'échange de clés et Dilithium pour les signatures.
L'annonce était prévue plus tôt mais a été retardée, selon certains par des problèmes liés aux nombreux brevets qui grèvent ces algorithmes (l'annonce du NIST prévoit des négociations), selon d'autres par la difficulté qu'avait la NSA à attaquer les algorithmes proposés . Il est difficile de le savoir puisque le NIST, même s'il avait fait un effort d'ouverture à cette occasion, reste assez opaque. En tout cas, désormais, c'est fait.
Pour comprendre l'importance de cette annonce, il faut revenir sur celle de la cryptographie. On sait que cet ensemble de techniques est absolument indispensable à la sécurité de l'utilisateur sur l'Internet. Ne croyez pas les politiciens ou les éditorialistes qui vont vous expliquer que si vous ne faites rien de mal, vous n'avez rien à cacher et pas besoin de cryptographie. Cet argument a été réfuté d'innombrables fois depuis des années mais continue à être parfois utilisé pour pousser les citoyen·nes à communiquer en public. Ignorez-le, et chiffrez l'intégralité de vos communications, c'est indispensable dans le monde d'aujourd'hui.
Mais aucune technique de sécurité n'est parfaite, que cela soit la cryptographie ou une autre. Il y a des questions non-techniques mais aussi des limites techniques de la cryptographie. Notamment, dans l'ordre d'importance décroissante :
- La cryptographie protège contre des tiers qui écoutent et/ou modifient les communications, mais pas contre le destinataire.
- Les logiciels de cryptographie, comme les autres, ont des bogues.
- Et les algorithmes utilisés en cryptographie peuvent ne pas être aussi solides qu'on le pense ; la cryptanalyse peut parfois en venir à bout. (Voyez par exemple le RFC 7465.)
Ce dernier risque est le plus spectaculaire et celui que les geeks préfèrent mentionner. Mais, en pratique, il est sans doute le moins sérieux. Vous avez bien plus de chances de voir vos secrets percés suite à une imprudence ou une maladresse de votre correspondant·e ou de vous-même que suite à une découverte mathématique fondamentale résolvant le problème du logarithme discret et cassant ainsi ECDSA. Certes, un problème mathématique comme la décomposition en facteurs premiers, qui est à la base de RSA, reste un problème ouvert et on n'a jamais démontré qu'il était insoluble. Néanmoins, vu le nombre de gens qui l'ont attaqué depuis des dizaines d'années, on peut être raisonnablement confiant : le problème est manifestement très difficile, et RSA reste donc sûr. La seule méthode connue pour attaquer des algorithmes comme ECDSA ou RSA reste donc la force brute, l'examen systématique de toutes les possibilités, ce qui prend quelques milliards d'années avec les machines existantes. (Je simplifie : on dispose en fait d'algorithmes meilleurs que la pure force brute mais ils ne font pas de miracles non plus.) En outre, la difficulté augmente exponentiellement avec la taille de la clé, et un progrès dans les processeurs ou bien certaines optimisations des programmes de cryptanalyse peuvent facilement être annulés en agrandissant la clé.
Mais les calculateurs quantiques pourraient changer les choses. Je ne vais pas détailler ici le fonctionnement de ces machines. Je dirais juste que, reposant directement sur la quantique, ils permettent de faire tourner des algorithmes radicalement différents (et pas évidents du tout à programmer !) de ceux qui sont utilisés actuellement, sur les ordinateurs classiques. Ainsi, l'algorithme de Shor permet de décomposer un nombre en ses facteurs premiers, en un temps linéaire, et donc de trouver une clé privée RSA à partir de la clé publique, tâche qui était impossible aux ordinateurs classiques. L'algorithme de Shor ne tournant que sur des calculateurs quantiques, si on dispose d'un tel calculateur, on a cassé RSA (et, avec un algorithme proche, ECDSA et les autres algorithmes à courbes elliptiques). Ce serait une catastrophe pour la sécurité de l'Internet, puisque les communications confidentielles pourraient toutes être décryptées, et les signatures toutes imitées. (Notez que cela serait pareil, même sans calculateur quantique, si un·e mathématicien·ne génial·e découvrait demain un moyen simple de décomposer un nombre en facteurs premiers. Comme indiqué plus haut, c'est peu probable mais pas impossible.)
Mais attention, le « si on dispose d'un calculateur quantique » est un gros « si ». De même qu'Euclide avait développé des algorithmes et qu'Ada Lovelace avait écrit des programmes longtemps avant qu'un ordinateur ne soit disponible pour les exécuter, Shor a développé son algorithme sans avoir de calculateur quantique. On a progressé depuis et des calculateurs quantiques existent, et on peut faire tourner l'algorithme de Shor dessus. Le problème est qu'ils sont très expérimentaux, très peu existent dans le monde et leurs plus grands exploits sont très loin de ce qui serait nécessaire pour casser les clés d'aujourd'hui. Les optimistes parient que ce n'est qu'une question de temps et que, dans quelques années, les calculateurs quantiques (dont les enthousiastes prédisent depuis des années qu'ils sont presque au point) s'attaqueront facilement à nos algorithmes cryptographiques. Les pessimistes font remarquer que les difficultés pratiques qui se présentent face aux calculateurs quantiques sont colossales et que les résoudre n'est pas un simple travail d'ingéniérie prévisible mais est souvent plus proche de la recherche fondamentale et de ses incertitudes. Bref, il n'y a pas actuellement de consensus sur le temps dont nous disposons encore face à la « menace quantique ».
Comme il faut s'y prendre à l'avance pour développer, tester et déployer de nouveaux algorithmes dits post-quantiques, les cryptographes n'ont pas attendu de voir les calculateurs quantiques en vente chez Darty pour réagir. Le travail sur des algorithmes post-quantiques a commencé il y a longtemps. Ces nouveaux algorithmes doivent résister aux calculateurs quantiques. Plus exactement, il faut qu'on ne connaisse pas d'algorithme quantique pour les attaquer. Mais il faut aussi qu'ils résistent à la cryptanalyse classique (voir par exemple cette attaque contre Rainbow, un des finalistes du concours). Et il faut aussi qu'ils soient réalistes en performance, en taille de clés, etc. Plusieurs candidats prometteurs ont été développés, et les cryptanalystes se sont déjà fait les dents à essayer de les casser.
Sur l'Internet, mais aussi en général dans le monde numérique, la normalisation est essentielle. Avoir des protocoles et des algorithmes, notamment de cryptographie, communs, permet l'interopérabilité, qui garantit liberté de choix, et bon fonctionnement du réseau. Pour qu'Alice puisse envoyer un message à Bob, il faut bien qu'Alice chiffre avec un algorithme que Bob puisse déchiffrer. Le rôle des organisations de normalisation est donc crucial. C'est pour cela que le NIST étatsunien a lancé en 2016 un grand concours pour choisi le meilleur algorithme à normaliser. Plutôt que de faire travailler ensemble des cryptologues à développer en commun ce meilleur algorithme, ce qui risquait d'amener à un compromis qui ne satisferait personne, le NIST a choisi le concours : de nombreuses équipes proposent leur algorithme, chacun essaie de casser celui des concurrents et que le meilleur gagne. C'est ce concours qui vient de franchir une étape décisive, avec l'annonce du choix de :
- Kyber pour l'échange de clés (aussi nommé KEM pour key encapsulation mechanism cf. RFC 9180), préalable au chiffrement effectué ensuite avec un algorithme symétrique classique comme AES. Kyber utilise les réseaux euclidiens.
- Dilithium (oui, ça vient de Star Trek) pour les signatures. Dilithium utilise également les réseaux euclidiens.
- Deux autres algorithmes de signature ont été également retenus, pour des usages spécifiques, Sphincs+ et Falcon, et plusieurs autres algorithmes seront examinés pour fournir un algorithme de secours, au cas où des problèmes apparaissent avec ceux sélectionnés (rappelons que, contrairement à, par exemple, RSA, ils n'ont pas bénéficié d'années de recherches de failles). Sphincs+ est le seul à ne pas utiliser les réseaux euclidiens, mais des fonctions de condensation.
Maintenant que ces algorithmes ont été choisis, verra-t-on dès demain TLS, SSH, DNSSEC et les autres utiliser des algorithmes post-quantiques ? Non, car il reste plusieurs étapes à franchir. D'abord, le NIST doit finir le travail de normalisation : il faut spécifier rigoureusement l'algorithme et publier la spécification officielle. (Cela a été fait deux ans après, le 14 août 2024, avec la parution de FIPS-203, FIPS-204 et FIPS-205.) Cela implique, comme le note l'annonce officielle, une négociation réussie sur les brevets qui plombent le champ de la cryptographie post-quantique (cf. par exemple le problème avec le CNRS et l'accord ultérieur). Ensuite, la plupart des utilisations de la cryptographie se fait au sein d'un protocole de cryptographie comme TLS. Les protocoles sérieux disposent tous de la propriété d'agilité (RFC 7696), ce qui veut dire qu'ils ne sont pas lié à un algorithme de cryptographie particulier. Mais il faudra quand même spécifier l'utilisation du nouvel algorithme pour ce protocole (par exemple, pour DNSSEC, il faudra l'ajouter au registre IANA, ce qui nécessitera la publication d'un RFC). (Cet article donne une première idée du travail à faire.) Ensuite, les programmeur·ses devront programmer ces algorithmes post-quantiques (une tâche à effectuer soigneusement ; on a vu que les bogues sont à l'origine de bien des problèmes de cryptographie). Même s'il existe déjà plusieurs mises en œuvre de ces algorithmes, des programmes dignes d'être utilisés en production sont une autre affaire. Et il faudra ensuite déployer ces programmes dans le monde réel.
Pour la partie de normalisation dans les protocoles TCP/IP, ce qui relève de l'IETF, on peut noter que quelques RFC parlent déjà de post-quantique. C'est le cas par exemple des RFC 8784, RFC 8696, RFC 8773 et RFC 8784, mais c'est exagéré, ils décrivent simplement des clés de cryptographie symétrique pré-partagées. Plus sérieusement, le RFC 8032 discute les risques que les calculateurs quantiques posent à l'algorithme EdDSA, et le RFC 8391 le fait pour XMSS, tandis que le RFC 9180 (section 9.1.3) a une vision plus générale. Même discussion pour les RFC 8240 et RFC 8576, dans le contexte de l'Internet des objets. Le RFC 9021 doit être un des rares qui repose déjà sur un algorithme post-quantique mais on voit que la prise de conscience était ancienne.
Il faudra donc compter de nombreuses années avant d'avoir les algorithmes post-quantiques massivement déployés. C'est d'ailleurs pour cela qu'il faut commencer tout de suite le processus, alors même que la menace des calculateurs quantiques est lointaine. (On peut aussi se rappeler que la cryptographie sert parfois à protéger des secrets de longue durée. Si les fichiers que vous chiffrez actuellement seront toujours sensibles dans trente ans, dites-vous bien que les calculateurs quantiques capables de casser les clés utilisées seront peut-être une réalité dans trente ans.)
Le mot « quantique » est parfois mis à toutes les sauces. Il faut notamment signaler que les questions discutées ici n'ont rien à voir avec ce qu'on nomme parfois la « cryptographie quantique » (et qui serait mieux appelée « distribution quantique de clés »), une technique dont l'intérêt n'est pas du tout évident (voir aussi le démontage de cette idée par Dan Bernstein et l'avis de l'ANSSI, en anglais seulement). De même, la question de la cryptographie post-quantique n'a pas de lien direct avec les projets d'« Internet quantique » (où les routeurs sont quantiques), sur lesquels travaille entre autres l'IRTF dans son groupe QIRG.
Sinon, question mises en œuvre, Kyber et Dilithium sont dans la bibliothèque de Cloudflare (écrite en Go). Elle n'a apparemment aucune documentation et son utilisation semble difficile. (La bibliothèque de Microsoft avait fait le choix d'autres algorithmes.)
Quelques bonnes lectures sur cette question des algorithmes de cryptographie post-quantiques :
- Les algorithmes post-quantiques ont été le sujet de la Journée du Conseil scientifique de l’Afnic en 2019.
- Un bon article d'introduction au CNRS.
- J'avais fait un exposé sur le post-quantique à Pas Sage En Seine en 2018.
- L'ANSSI a produit un avis détaillé. (Voir aussi l'article de l'ANSSI sur l'annonce du NIST.)
- Sur les conséquences du post-quantique sur le DNS, notamment DNSSEC, on peut regarder le rapport de l'ICANN de 2022 (en anglais).
- Un article en anglais d'Hilarie Orman, « Internet Security and Quantum Computing », faisait en 2021 le point sur les conséquences des calculateurs quantiques pour la sécurité de l'Internet.
- Il semble qu'il y ait eu un autre concours de sélection d'algorithmes post-quantiques, organisé en Chine, mais je n'ai pas beaucoup de détails.
- Sur la quantique en général (pas seulement sur la cryptographie post-quantique), la députée Paula Forteza a sorti le 10 janvier 2020 un intéressant rapport.
Et merci à Manuel Pégourié-Gonnard et Damien Stehlé pour leur relecture attentive. Évidemment, les erreurs restantes sont de moi.
L'article seul
Fiche de lecture : La folle histoire des virus
Auteur(s) du livre : Tania Louis
Éditeur : humenSciences
978-2-3793-1194-9
Publié en 2020
Première rédaction de cet article le 26 juin 2022
Je recommande ce passionnant livre de Tania Louis qui fait le tour de la question des virus, un sujet d'actualité (mais le livre a été largement écrit avant la pandémie de Covid-19, dont il ne parle pas).
Première chose que j'ai apprise dans ce livre : la virologie, c'est compliqué, d'autant plus que, régulièrement, des découvertes remettent en cause ce qu'on croyait avoir bien établi. Ainsi, la règle que les virus soient plus petits que les bactéries ne tient plus depuis la découverte des mimivirus.
Deuxième chose, la question de savoir si les virus sont vivants ou pas. L'auteure estime que, oui, plutôt, on peut dire qu'ils sont vivants, mais cela dépend évidemment de la définition exacte qu'on donne de la vie, et les virus, comme vu plus haut, ont tendance à défier les classifications trop rigides (j'ai d'ailleurs été surpris par la première partie de ce livre, qui ne parle pas avant longtemps de biologie, mais qui explique cette question de la classification). Au moins, les virus obligent à se poser des questions sur ce que l'on croit savoir de la vie. L'auteure note, par exemple, qu'on se focalise peut-être trop sur la particule virale, alors que le « vrai » virus est plutôt ce qui est actif dans la cellule.
Troisième découverte (pour moi), les virus ne sont pas forcément néfastes. On a bien sûr surtout étudié ce qui causaient du mal aux humains ou à l'agriculture. Mais il existe de nombreux virus, qui ne sont pas forcément dangereux.
Mais cela ne veut pas dire qu'ils sont inactifs. Les virus sont bien équipés pour faire passer des gènes d'un organisme à un autre et c'est un puissant coup de main à l'évolution. Un organe comme le placenta, si utile à nous autres mammifères placentaires, semble bien devoir son existence à des virus.
Les virus peuvent aussi aider les humains par l'action qu'ils ont contre certains de nos ennemis. Des virus infectent et tuent des bactéries dangereuses, par exemple. Ces bactériophages ont été au début du vingtième siècle considérés comme un moyen prometteur de lutter contre les infections bactériennes (travaux de Félix d'Hérelle, personnage passionnant). La mise au point des antibiotiques a fait un peu oublier les virus bactériophages, sauf dans le bloc de l'Est que la guerre froide tenait un peu à l'écart des exportations étatsunienne, comme le Coca-Cola ou les antibiotiques. L'apparition des résistances aux antibiotiques redonne leur chance aux bactériophages qui seront peut-être d'utiles alliés.
Le livre détaille plusieurs aventures où la science est faite par des êtres humains, avec leurs qualités, mais aussi leurs défauts. À propos de Rosalind Franklin, par exemple, l'auteure explique bien le processus compliqué de la recherche scientifique et pourquoi il est faux de présenter Franklin comme ayant fait tout le travail sur l'ADN seule (légende courante aujourd'hui), tout comme il était erroné de l'avoir complètement oubliée pendant de nombreuses années.
Comme le note l'auteure, la virologie évolue sans cesse, dépêchez-vous donc de lire ce livre avant qu'il ne soit plus d'actualité.
L'article seul
RFC 9255: The 'I' in RPKI Does Not Stand for Identity
Date de publication du RFC : Juin 2022
Auteur(s) du RFC : R. Bush (Arrcus & IIJ Research), R. Housley (Vigil Security)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF sidrops
Première rédaction de cet article le 15 juin 2022
Un très court RFC pour un simple rappel, qui ne devrait même pas être nécessaire : les identités utilisées dans la RPKI, la base des identités qui sert aux techniques de sécurisation de BGP, n'ont pas de lien avec les identités attribuées par l'État et ne doivent pas être utilisées pour, par exemple, signer des documents « officiels » ou des contrats commerciaux.
Le RFC 6480 décrit cette RPKI : il s'agit d'un ensemble de certificats et de signatures qui servent de base pour des techniques de sécurité du routage comme les ROA du RFC 6482 ou comme le BGPsec du RFC 8205. Les objets de la RPKI servent à établir l'autorité sur des ressources Internet (INR, Internet Number Resources, comme les adresses IP et les numéros d'AS). Le RFC 6480, section 2.1, dit clairement que cela ne va pas au-delà et que la RPKI ne prétend pas être la source d'identité de l'Internet, ni même une source « officielle ».
Prenons un exemple concret, un certificat
choisi au hasard dans les données du RIPE-NCC (qu'on peut récupérer avec
rsync en
rsync://rpki.ripe.net/repository). Il est au
format DER donc ouvrons-le :
% openssl x509 -inform DER -text -in ./DEFAULT/ztLYANxsM7afpHKR4vFbM16jYA8.cer
Certificate:
Data:
...
Serial Number: 724816122963 (0xa8c2685453)
Validity
Not Before: Jan 1 14:04:04 2022 GMT
Not After : Jul 1 00:00:00 2023 GMT
Subject: CN = ced2d800dc6c33b69fa47291e2f15b335ea3600f
...
X509v3 extensions:
...
sbgp-ipAddrBlock: critical
IPv4:
51.33.0.0/16
...
sbgp-autonomousSysNum: critical
Autonomous System Numbers:
206918
...
Je n'ai pas tout montré, mais seulement les choses importantes :
- Il n'y a pas de vraie identité dedans, le sujet a manifestement été généré automatiquement,
- Il couvre un certain nombre de ressources (INR,
Internet Number Resources), comme le préfixe IP
51.33.0.0/16, utilisant les extensions du RFC 3779.
Ce certificat dit simplement que l'entité qui a la clé privée (RFC 5280) correspondante (une administration britannique, dans ce cas) a autorité sur des ressources comme l'AS 206918. Rien d'autre.
Mais, apparemment, certaines personnes n'avaient pas bien lu le RFC 6480 et croyaient que cet attirail PKIesque leur permettait également de signer des documents sans lien avec les buts de la RPKI, voire n'ayant rien à voir avec le routage. Et d'autant plus que des gens croient que le I dans RPKI veut dire Identity (il veut en fait dire Infrastructure). Il a ainsi été suggéré que les clés de la RPKI pouvaient être utilisées pour signer des LOA demandant l'installation d'un serveur dans une baie.
Pourquoi est-ce que cela serait une mauvaise idée ? Il y a
plusieurs raisons mais la principale est qu'utiliser la RPKI pour
des usages en dehors du monde restreint du routage Internet est que
cela exposerait les AC de cette RPKI à des
risques juridiques qu'elles n'ont aucune envie d'assumer. Et cela
compliquerait les choses, obligeant sans doute ces AC à déployer des
processus bureaucratiques bien plus rigides. Si on veut connaitre
l'identité officielle (que le RFC nomme à tort « identité dans le
monde réel ») d'un titulaire de ressources Internet, on a les bases
des RIR,
qu'on interroge via RDAP ou autres
protocoles. (C'est ainsi que j'ai trouvé le titulaire de
51.33.0.0/16.) Bien sûr, il y a les
enregistrements Ghostbusters du RFC 6493 mais ils sont uniquement là pour aider à trouver un
contact opérationnel, pas pour indiquer l'identité étatique du
titulaire. Même les numéros d'AS ne sont pas l'« identité » d'un acteur de
l'Internet (certains en ont plusieurs).
Notons qu'il y a d'autres problèmes avec l'idée de se servir de la RPKI pour signer des documents à valeur légale. Par exemple, dans beaucoup de grandes organisations, ce ne sont pas les mêmes personnes qui gèrent le routage et qui gèrent les commandes aux fournisseurs. Et, au RIPE-NCC, les clés privées sont souvent hébergées par le RIPE-NCC, pas par les titulaires, et le RIPE-NCC n'a évidemment pas le droit de s'en servir pour autre chose que le routage.
Bref, n'utilisez pas la RPKI pour autre chose que ce pour quoi elle a été conçue.
L'article seul
RFC 9209: The Proxy-Status HTTP Response Header Field
Date de publication du RFC : Juin 2022
Auteur(s) du RFC : M. Nottingham (Fastly), P. Sikora (Google)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 14 juin 2022
Le protocole HTTP, qui est à la base du Web, n'est pas forcément de bout
en bout, entre client et serveur. Il y a souvent passage par un
relais et ce relais a
parfois des choses à signaler au client HTTP, notamment en cas
d'erreur. Ce RFC
spécifie le champ d'en-tête Proxy-Status pour
cela.
La norme HTTP, le RFC 9110 décrit ces relais, ces intermédiaires, dans sa section 3.7. On en trouve fréquemment sur le Web. Il y a depuis longtemps des codes d'erreur pour eux, comme 502 si le serveur d'origine répond mal et 504 pour les cas où il ne répond pas du tout. Mais ce n'est pas forcément assez précis, d'où le nouveau champ dans l'en-tête (ou dans le pied). Il utilise la syntaxe des champs structurés du RFC 9651. Voici un exemple :
Proxy-Status: proxy.example.net; error="http_protocol_error"; details="Malformed response header: space before colon", "Example CDN"
Cet exemple se lit ainsi : le premier (en partant du serveur
d'origine) s'identifie comme proxy.example.net
et il signale que le serveur d'origine n'avait pas bien lu le RFC 9112. Puis la réponse est passée par un autre
intermédiaire, qui s'identifie comme "Example
CDN" (l'identificateur n'est pas forcément un
nom de domaine), et n'a rien de particulier à
raconter. Le champ Proxy-Status est désormais
dans
le registres des champs d'en-tête (ou de pied).
Vous avez vu dans l'exemple ci-dessus le paramètre
error. Il peut s'utiliser, par exemple, avec le
code de retour 504 :
HTTP/1.1 504 Gateway Timeout Proxy-Status: foobar.example.net; error=connection_timeout
Ici, le relais foobar.example.net n'a eu aucune
réponse du serveur d'origine (ou, plus rigoureusement, du serveur
qu'il essayait de contacter, qui peut être un autre
intermédiaire).
Mais il existe d'autres paramètres possibles, comme :
next-hop: nom ou adresse du serveur contacté, par exempleProxy-Status: cdn.example.org; next-hop=backend.example.org:8001.next-protocol: protocole (ALPN, RFC 7301) utilisé avec le serveur, par exempleProxy-Status: "proxy.example.org"; next-protocol=h2pour du HTTP/2 (RFC 9113).received-status: le code de retour du serveur, comme dansProxy-Status: ExampleCDN; received-status=200, pour un cas où tout s'est bien passé.
Et on peut définir de nouveaux paramètres par la procédure d'examen par un expert (RFC 8126).
Le paramètre error prend comme valeur un
type d'erreur. Il en existe
plusieurs, chacun avec un code de retour recommandé dont (je
ne les indique pas tous, ils sont très nombreux !) :
dns_timeout(pour le code de retour 504) etdns_error(code 502) : c'est la faute du DNS. Le second type permet en outre d'indiquer le paramètrercode(code de retour DNS, commeNXDOMAIN) et le paramètreinfo-code, le code étendu du RFC 8914.connection_timeoutouconnection_refused.destination_ip_prohibited: le pare-feu ne veut pas.tls_protocol_error: là, c'est TLS qui ne veut pas.tls_certificate_error: certificat du serveur problématique, par exemple expiré.http_protocol_error: la réponse du serveur n'était pas du bon HTTP.proxy_internal_error: le relais a un problème interne.
Là aussi, on peut enregistrer de nouveaux types avec la procédure d'examen par un expert du RFC 8126.
La section 4 du RFC détaille les questions de sécurité. Comme
toute information, Proxy-Status peut aider un
attaquant, par exemple en lui donnant des idées sur comment joindre
directement un intermédiaire. Pour cette raison, les logiciels
doivent fournir un moyen de contrôler l'ajout (ou pas) de
Proxy-Status, qu'on peut aussi n'inclure que
dans certains cas. Notez aussi qu'un intermédiaire peut mentir (ou
se tromper) et que le Proxy-Status ne vaut donc
que ce que vaut l'intermédiaire.
Je n'ai pas de liste des logiciels qui mettent en œuvre ce champ Proxy-Status.
L'article seul
RFC 9205: Building Protocols with HTTP
Date de publication du RFC : Juin 2022
Auteur(s) du RFC : M. Nottingham
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 10 juin 2022
Aujourd'hui, la grande majorité des API accessibles via le réseau fonctionnent au-dessus de HTTP. Ce nouveau RFC, qui remplace le RFC 3205, décrit les bonnes pratiques pour la conception de telles API, notamment pour les protocoles IETF bâtis sur HTTP, comme DoH ou RDAP.
Il y a plein d'applications qui fonctionnent au-dessus de HTTP. Ce nouveau RFC se concentre sur celles qui sont d'usage général et qui ont plusieurs mises en œuvre et déploiements. (Si vous faites un service centralisé qui n'a qu'un seul déploiement de son API spécifique, ce RFC ne va pas forcément être pertinent pour vous.) Si vous avez déjà lu le RFC 3205, il faudra tout recommencer, les changements sont nombreux. Ces applications utilisant HTTP sont parfois qualifiées de REST mais, en toute rigueur, toutes ne suivent pas rigoureusement les principes de REST. Notez aussi un sous-ensemble, CRUD, pour les applications dont l'essentiel du travail est de créer/supprimer/gérer des objets distants.
Normalement, HTTP avait été conçu pour le Web et ses usages. Mais on voit aujourd'hui de très nombreuses API réseau être fondées sur HTTP pour diverses raisons :
- Parce que le développeur ou la développeuse ne connait que ça,
- parce qu'il existe un très grand nombre de bibliothèques pour faire les clients (comme l'excellente Requests pour le langage Python, qui sera utilisée ici dans plusieurs exemples), et de cadriciels pour les serveurs,
- parce que dans certains cas, il sera même possible d'utiliser un navigateur Web pour y accéder, et que tout le monde a un navigateur Web et est familier avec ce logiciel,
- parce que certains services comme l'authentification sont déjà disponibles dans les logiciels existants,
- parce que HTTP est le seul protocole dont on peut être sûr qu'il passera même dans les réseaux les plus coincés comme les hotspots des hôtels et des aéroports.
Mais tout n'est pas forcément rose et HTTP peut ne pas être bien adapté à ce qu'envisage le développeur de l'API. Et cette développeuse peut faire des erreurs lors de la conception de l'API, erreurs que ce RFC vise à éviter.
En effet, quand on développe une API sur HTTP, il y a plusieurs décisions à prendre :
La section 2 précise l'applicabilité de ce RFC. Il concerne les
protocoles qui utilisent HTTP (ports 80 ou
443, plans d'URI http: ou
https:). Ceux qui utiliseraient une version
modifiée de HTTP ne comptent pas, et cette pratique est d'ailleurs
déconseillée, puisque ces versions modifiées feraient probablement
perdre les avantages d'utiliser HTTP, notamment la réutilisation des
logiciels et infrastructures existants.
Section 3, maintenant. Quelles sont les caractéristiques
importantes de HTTP, qui gouvernent ce que peuvent faire les
applications qui l'utilisent ? D'abord, sa sémantique très
générale : on peut tout faire avec HTTP. Notammment, HTTP est
indépendant du type de ressources sur lesquelles il agit. Ainsi, des
composants HTTP génériques (bibliothèques, serveurs, relais) peuvent
être développés et déployés pour des applications très différentes,
même des applcations qui n'existent pas encore. (Voilà d'alleurs
pourquoi la section précédente insistait sur le fait q'il ne faut
pas modifier HTTP.) Plus subtile serait l'erreur qui consisterait à
spécifier un certain profil de HTTP, en restreignant ce que HTTP
peut faire ou pas (« la réponse à un POST doit
être 201 »). Une telle restriction, là encore, empêcherait
d'utiliser cerrtains composants génériques, en faisant perdre à HTTP
de sa généralité.
Une autre erreur courante est de s'attribuer tout ou partie de
l'espace de nommage fourni par les liens
hypertextes. C'est par exemple le cas lorsqu'une
application estime qu'elle peut contrôler tout le chemin dans l'URI
et décider que /truc/machin est forcément à
elle (RFC 8820). Cela complique le
déploiement, par exemple si on veut installer cette application sous
/chose et excusivement sous ce chemin
(cf. section 4.4). L'application devrait au contraire permettre de
la souplesse et utiliser les possibilités qu'offre le système de
liens (RFC 8288).
Enfin, HTTP dispose de nombreuses possibilités comme le multiplexage que permettent HTTP/2 (RFC 9113) et HTTP/3 (RFC 9114), l'intégration avec TLS, la possibilité de relayage, la négociation de contenu, la disponibilité de nombreux clients, et l'application qui utilise HTTP doit donc veiller à ne pas casser cet écosystème, et en tout cas à ne pas réinventer la roue, alors que HTTP offre déjà de nombreuses solutions éprouvées.
Bref, compte-tenu de tout cela, comment faire pour bien utiliser HTTP dans sa nouvelle application ? La section 4 est là pour répondre à cette question.
D'abord, bien définir la dépendance de l'application à HTTP, en donnant comme référence RFC 9110 (et surtout pas une version spécifique de HTTP, toujours afin de profiter au maximum de l'écosystème existant). On notera quand même que DoH (RFC 8484) impose (section 5.2 de son RFC) au moins HTTP/2, pour être sûr d'avoir du multiplexage. Notre RFC permet explicitement ce genre d'exceptions.
Le RFC recommande également, quand on montre un dialogue HTTP
titre d'exemple, d'utiliser plutôt les conventions de HTTP/1 (RFC 9112), plus lisibles. Donc, par exemple,
GET /truc HTTP/1.1 plutôt que le
:method = GET :path = /resource de
HTTP/2. C'est ce que fait curl :
% curl -v http://www.example > GET / HTTP/2 > Host: www.example > user-Agent: curl/7.68.0 > accept: */* > < HTTP/2 200 < content-Type: text/plain < content-Length: 13
On l'a dit, il ne faut pas modifier le comportement de base de HTTP. Ce qu'on peut faire, par contre :
- Spécifier le type des données (RFC 6838), par exemple JSON (qu'utilise RDAP),
- spécifier des champs dans l'en-tête,
- spécifier comment on trouve les ressources via des liens (RFC 8288).
Et le client ? L'application qui utilise HTTP ne devrait pas exiger de comportement trop spécifique du client ; idéalement, un navigateur Web normal devrait pouvoir interagir avec l'application. On peut par exemple s'appuyer sur les principes FETCH. Il est également préférable que l'application qui va utiliser HTTP soit claire sur le traitement attendu pour les redirections HTTP, ou pour les cookies (RFC 6265), et rappeler que la vérification des certificats doit se faire selon les principes de la section 4.3.4 du RFC 9110.
Le client doit, idéalement, pouvoir se configurer avec uniquement
un URL. (Par exemple, un serveur DoH est annoncé ainsi, comme
https://doh.bortzmeyer.fr/, la seule
information dont vous avez besoin pour l'utiliser.) Et si on ne
connait qu'un nom de domaine ? La solution du chemin d'URL fixe
qu'on s'alloue
(« obligatoirement /app ») étant interdite (RFC 8820), il y a le choix :
Et le plan d'URI (le premier composant de l'URI) ?
http: et surtout https:
sont évidemment recommandés mais on peut aussi choisir un plan
spécifique. Cela va évidemment rendre l'application inutilisable
par un navigateur Web ordinaire. Certains navigateurs permettent
d'enregistrer un mécanisme de gestion de ces plans non standards
(comme le registerProtocolHandler() du WHATWG) mais cela ne
marche pas partout. Et on aura le même problème avec tout
l'écosystème logiciel de HTTP. Bref, utiliser un plan autre que
http: ou https: fera
perdre une bonne partie des avantages qu'il y avait à utiliser le
protocole HTTP. D'autres problèmes se poseront comme l'impossibilité
d'utiliser le concept d'origine (RFC 6454) par
exemple dans la Same Origin
Policy, ou comme d'autres fonctions utiles
de HTTP (cookies, authentification, mémorisation
- RFC 9111, HSTS - RFC 6797, etc). Si vous tenez encore, après tout ça, à créer
un plan à vous, consultez le RFC 7595.
Et les ports ? HTTP utilise par défaut les
ports 80 pour le trafic en clair et 443 pour le traffic
chiffré. Utiliser un autre port est possible
(https://machin.example:666) mais rend le
trafic de l'application distinguable, ce qui peut être gênant pour
la vie privée. (C'est un des choix de conception de DoH que d'utiliser HTTPS sur le
port 443, pour ne pas être distinguable, et donc être plus difficile
à filtrer.) Le RFC 7605 donne des détails sur
ce choix des ports.
Maintenant, quelles méthodes HTTP utiliser ? Le RFC exige que les
applications utilisant HTTP se servent uniquement des méthodes enregistrées,
comme GET ou PUT. Certes,
une procédure existe pour enregistrer de nouvelles méthodes mais
l'IETF
insiste que ces nouvelles méthodes doivent être génériques, et non
pas limitées aux besoins d'une seule application. (Le RFC 4791 avait créé des méthodes spécifiques, mais c'était
avant. C'est maintenant interdit.)
Donc, pas de méthodes nouvelles. Mais quelle(s) méthode(s)
utiliser ? GET est le choix le plus
évident. Cette méthode est idempotente (et
permet donc, entre autres, la mémorisation), et a une sémantique
simple et compréhensible. Elle a quelques limites (comme le fait que
tous les éventuels paramètres doivent être dans l'URL, ce qui peut
nécessiter un encodage spécial, et peut empêcher des paramètres de
grande taille) mais rien de bien grave. Si c'est trop gênant pour
une application donnée, il ne reste plus qu'à utiliser
POST.
Et pour récupérer des métadonnées sur le
service ? Le RFC note que la méthode OPTIONS
n'est pas très pratique, par exemple parce qu'elle ne permet pas de
donner comme documentation un simple URL (la méthode par défaut
étant GET). Il recommande plutôt un URL dans
/.well-known (RFC 8615),
en créant un nouveau nom, ou
bien avec les URL host-meta (RFC 6415). Pour des métadonnées sur une ressource particulière,
il est recommandé d'utiliser les liens (RFC 8288). Le RFC
note que, dans ce dernier cas, l'en-tête Link:
marche même avec la méthode HEAD donc pas
besoin de récupérer la ressource pour avoir des informations sur ses
métadonnées.
Et les codes de retour HTTP comme 403 ou 404, comment les utiliser ? D'abord, une application qui utilise HTTP n'a pas forcément un complet contrôle sur ces codes de retour, qui peuvent être générés par des composants logiciels différents. Donc, le client HTTP doit se méfier, le code reçu n'est pas forcément significatif de l'application. Ensuite, une application peut avoir davantage de messages différents qu'il n'existe de codes de retour HTTP, ce qui peut pousser à de mauvaises pratiques, comme l'utilisation de codes de retour non standard, ou commme l'utilisation de codes certes standard mais utilisés d'une manière très éloignée de ce qui était prévu. Bref, le RFC conseille de découpler les erreurs applicatives des erreurs HTTP, de ne pas chercher à tout prix un code de retour HTTP pour chaque erreur applicative, et de ne pas hésiter à utiliser les codes de retour génériques (comme 500, pour « quelque chose ne va pas dans le serveur »). Pour envoyer des informations plus détaillées sur l'erreur, il est préférable d'utiliser les techniques du RFC 7807. Autre avertissement du RFC, les raisons envoyées par le serveur après un code de retour (404 File not found) ne sont pas significatives. Dans certains cas (message HTTP dans un message HTTP), elles ne sont pas transmises du tout, contrairement au code de retour, la seule information sur laquelle on peut compter. L'application ne doit donc pas espérer que le client recevra ces raisons.
Autre difficulté pour le concepteur ou la conceptrice
d'applications utilisant HTTP, les redirections. Il y a quatre
redirections différentes en HTTP, chacune pouvant être temporaire ou
définitive, et permettant de changer de méthode ou pas (une requête
POST indiquant une redirection suivie d'une
requête GET par le client). On a donc :
- 301, définitive et permettant de changer de méthode,
- 302, temporaire et permettant de changer de méthode,
- 307, temporaire et ne permettant pas de changer de méthode,
- 308, définitive et ne permettant pas de changer de méthode.
Et il faut donc réfléchir un peu avant de choisir un code de redirection (le RFC privilégie 301 et 302, plus souples).
Et les champs dans l'en-tête ? Une application a souvent envie d'en ajouter, que ce soit dans la requête ou dans la réponse. Mais le RFC n'est pas très chaud, demandant qu'on mette les informations plutôt dans l'URL ou dans le corps du message HTTP. Si on crée de nouveaux en-têtes, en théorie (c'est très théorique…), il faut les enregistrer à l'IANA (RFC 9110, section 16.3). Si ces en-têtes ont une structure, il est très recommandé qu'elles suivent les règles du RFC 9651.
Et le corps du message, justement ? L'application doit spécifier quel format est attendu. C'est souvent JSON (RFC 8259) mais cela peut être aussi XML, CBOR (RFC 8949), etc.
Une des grandes forces d'HTTP est la possibilité de mémorisation,
décrite en détail dans le RFC 9111. La
mémorisation améliore les performances, rend le service moins
sensible aux perturbations, et permet le passage à
l'échelle. Les applications qui utilisent HTTP ont donc
tout intérêt à permettre et à utiliser cette mémorisation. Il est
donc recommandé d'indiquer dans la réponse une durée de vie, de
préférence avec Cache-Control: max-age=… ou
bien, si c'est nécessaire, d'indiquer explicitement que la réponse
ne doit pas être mémorisée (Cache-Control:
no-store).
Un autre avantage pour une application d'utiliser HTTP est l'existence d'un cadre général pour l'authentification (RFC 9110, section 11). Attention, certains mécanismes ne doivent être utilisés qu'au-dessus d'HTTPS, comme la basic authentication du RFC 7617. HTTPS permet également d'utiliser les certificats client pour l'authentification. (Attention, avec TLS ≤ 1.2, ces certificats, qui contiennent des données personnelles, sont transmis en clair.)
Conséquence de l'utilisation de HTTP, l'application est
utilisable via un navigateur Web. Cela peut
être vu comme un avantage (tout le monde a un navigateur Web sous la
main) ou comme un inconvénient (si la sémantique de l'application ne
permet pas réellement un usage pratique depuis un navigateur). Mais
quoi qu'on en pense, l'application sera accessible aux navigateurs,
et il est donc important de s'assurer que cela ne provoquera pas de
problème. Par exemple, si on peut changer un état avec une requête
POST, l'application pourrait être attaquée
assez facilement par CSRF. Si l'application
tire une partie des données qu'elle renvoie en réponse d'une source
que l'attaquant peut contrôler, on risque le XSS. Il est donc recommandé,
même si l'application n'est pas prévue pour être utilisée par un
navigateur, de suivre les mêmes règles de développement sécurisé que
si elle devait être accédée depuis un navigateur, notamment :
- utiliser des champs dans l'en-tête comme
X-Content-Type-Options: nosniff, - utiliser CSP,
- utiliser
Referrer-Policy:, - utiliser l'option
HttpOnlysur les cookies (RFC 6265, section 5.2.6).
Voici un exemple d'une réponse suivant ces principes :
HTTP/1.1 200 OK Content-Type: application/example+json X-Content-Type-Options: nosniff Content-Security-Policy: default-src 'none' Cache-Control: max-age=3600 Referrer-Policy: no-referrer
Il reste à régler la question des frontières de l'application. Le plus simple pour l'application est d'avoir son propre nom de domaine et donc une origine (RFC 6454) unique. Cela simplifie par exemple des problèmes comme les cookies. Mais cela complique le déploiement, empêchant de mettre plusieurs applications derrière le même nom. Le RFC conseille donc plutôt de concevoir des applications pouvant coexister avec d'autres applications sous le même nom (RFC 8820).
Un mot sur la sécurité pour finir (section 6
du RFC). D'abord, une application qui utilise HTTP va évidemment
hériter des questions de sécurité générale de HTTP, comme détaillées
dans la section 17 du RFC 9110. Vu le
caractère sensible des données traitées par beaucoup d'applications,
le RFC recommande l'utilisation de HTTPS. Mais il développe aussi
la question de la vie
privée. HTTP est très bavard et le serveur en apprend
beaucoup, souvent beaucoup trop, sur son client. Ainsi, les
cookies, l'adresse
IP source, les ETags, les tickets
de session TLS sont très utiles au serveur qui voudrait
suivre un client. Et le RFC rappelle que HTTP donne assez
d'informations « auxiliaires » pour pouvoir reconnaitre un client
(ce qu'on nomme le fingerprinting). Bref, le
maintien de son intimité va être aussi difficile que sur le Web.
Ce RFC remplace l'ancien RFC 3205. Comme le note l'annexe A de notre RFC, il y a trop de changements pour les lister ; ce document est très différent de son prédécesseur (qui date de 2002 !).
Voyons maintenant quelques exemples d'application utilisant
HTTP. Dans le monde IETF, il y a évidemment
RDAP (RFC 7480, RFC 9082 et RFC 9083). RDAP
suit bien les principes de ce RFC. Par exemple, les chemins d'URL
comme /domain ou /ip ne
sont pas forcément à la « racine » du serveur HTTP. Autre exemple,
DoH (RFC 8484), également fidéle (heureusement !) aux
recommandations de l'IETF. Notez que ces recommandations laissent
des choix. Ainsi, lorsque le nom de domaine cherché n'est pas
trouvé, RDAP renvoie le code 404 (RFC 7480,
section 5.3) alors que DoH préfère renvoyer un 200 (le serveur HTTP
a bien été joignable et a bien répondu), gardant le signal de
non-existence uniquement dans la réponse DNS (RFC 8484,
section 4.2.1) transportée sur HTTP (l'argument est que DoH ne fait
que transporter les requêtes d'un autre protocole, contrairement à
RDAP).
J'ai parlé plus haut de la possibilité d'utilisation d'un
navigateur Web ordinaire pour accéder aux applications utilisant
HTTP. Mais comme ces applications envoient souvent des données
structurées en JSON, il faut un navigateur qui gère bien le
JSON. Et c'est justement ce que fait Firefox, qui sait l'afficher de manière
pratique : 
Terminons avec quelques exemples d'API « finales » (donc pas le sujet
principal du RFC,
qui parle de protocoles IETF).
Commençons modestement par l'API du DNS
looking glass. A priori, elle suit tous les
principes de ce RFC. En tout cas, elle essaie. Mais si vous
constatez des différences avec le RFC, n'hésitez pas à faire un
rapport.
Autre API intéressante, celle des sondes RIPE Atlas. Elle utilise
toutes les possibilités de HTTP, notamment les multiples méthodes
(DELETE pour supprimer une mesure en cours, par
exemple). J'aurais juste trouvé plus logique d'utiliser
PUT au lieu de POST pour
créer une mesure. L'API de Mastodon
(cf. sa
documentation) est
encore plus incohérente, utilisant POST pour
créer un pouète, mais PUT pour le mettre à jour.
L'article seul
RFC 9230: Oblivious DNS over HTTPS
Date de publication du RFC : Juin 2022
Auteur(s) du RFC : E. Kinnear (Apple), P. McManus (Fastly), T. Pauly (Apple), T. Verma, C.A. Wood (Cloudflare)
Expérimental
Première rédaction de cet article le 9 juin 2022
Des protocoles de DNS sécurisés comme DoH protègent la liaison entre un client et un résolveur DNS. Mais le résolveur, lui, voit tout, aussi bien le nom de domaine demandé que l'adresse IP du client. Ce nouveau RFC décrit un mécanisme expérimental de relais entre le client et le serveur DoH, permettant de cacher l'adresse IP du client au serveur, et la requête au relais. Une sorte de Tor minimum.
Normalement, DoH (normalisé dans le RFC 8484) résout le problème de la surveillance des requêtes DNS. Sauf qu'évidemment le serveur DoH lui-même, le résolveur, voit le nom demandé, et la réponse faite. (Les utilisateurices de l'Internet oublient souvent que la cryptographie, par exemple avec TLS, protège certes contre le tiers qui écoute le réseau mais pas du tout contre le serveur avec qui on parle.) C'est certes nécessaire à son fonctionnement mais, comme il voit également l'adresse IP du client, il peut apprendre pas mal de choses sur le client. Une solution possible est d'utiliser DoH (ou DoT) sur Tor (exemple plus loin). Mais Tor est souvent lent, complexe et pas toujours disponible (cf. annexe A du RFC). D'où les recherches d'une solution plus légère, Oblivious DoH, décrit dans ce nouveau RFC. L'idée de base est de séparer le routage des messages (qui nécessite qu'on connaisse l'adresse IP du client) et la résolution DNS (qui nécessite qu'on connaisse la requête). Si ces deux fonctions sont assurées par deux machines indépendantes, on aura amélioré la protection de la vie privée.
Les deux machines vont donc être :
- L'Oblivious Proxy, le relais qui connait l'adresse IP du client mais ne voit passer qu'une requête DNS chiffrée ; ce n'est pas un relais HTTP complet, il est spécialisé dans DoH.
- Et l'Oblivious Target, le serveur DoH (le résolveur, donc) ; il a une clé publique avec laquelle le client chiffrera les requêtes à envoyer.
Un schéma simplifié :
Il est important de répéter que, si le relais et le serveur sont complices, Oblivious DoH perd tout intérêt. Ils doivent donc être gérés par des organisations différentes.
La découverte du relais, et de la clé publique du serveur, n'est pas traité dans ce RFC. Au moins au début, elle se fera « manuellement ».
Le gros morceau du RFC est sa section 4. Elle explique les
détails du protocole. Le client qui a une requête DNS à faire doit
la chiffrer avec la clé publique du serveur. Ce client a été
configuré avec un gabarit d'URI (RFC 6570) et avec
l'URL du
serveur DoH, serveur qui doit connaitre le mécanisme
Oblivious DoH. Le gabarit doit contenir deux
variables, targethost (qui sera incarné avec le
nom du serveur DoH) et targetpath (qui sera
incarné avec le chemin dans l'URL du serveur DoH). Par exemple, un
gabarit peut être
https://dnsproxy.example/{targethost}/{targetpath}. Le
client va ensuite faire une requête (méthode HTTP
POST) vers le relais. La requête aura le
type application/oblivious-dns-message
(la réponse également, donc le client a intérêt à indiquer
Accept: application/oblivious-dns-message).
En supposant un serveur DoH d'URL
https://dnstarget.example/dns, la requête sera
donc (en utilisant la syntaxe de description de HTTP/2 et 3) :
:method = POST :scheme = https :authority = dnsproxy.example :path = /dnstarget.example/dns accept = application/oblivious-dns-message content-type = application/oblivious-dns-message content-length = 106 [La requête, chiffrée]
Le relais enverra alors au serveur :
:method = POST :scheme = https :authority = dnstarget.example :path = /dns accept = application/oblivious-dns-message content-type = application/oblivious-dns-message content-length = 106 [La requête, chiffrée]
Le relais ne doit pas ajouter quelque chose qui permettrait
d'identifier le client, ce qui annulerait tout l'intérêt
d'Oblivious DoH. Ainsi, le champ
forwarded (RFC 7239) est
interdit. Et bien sûr, on n'envoie pas de
cookies, non plus.
La réponse utilise le même type de médias :
:status = 200 content-type = application/oblivious-dns-message content-length = 154 [La réponse, chiffrée]
Le relais, en la transmettant, ajoutera un champ
proxy-status (RFC 9209).
Les messages de type
application/oblivious-dns-message sont encodés
ainsi (en utilisant le langage de description de TLS, cf. RFC 9846, section 3) :
struct {
opaque dns_message<1..2^16-1>;
opaque padding<0..2^16-1>;
} ObliviousDoHMessagePlaintext;
Bref, un message DNS binaire, et du remplissage. Le remplissage est nécessaire car TLS, par défaut, n'empêche pas l'analyse de trafic. (Lisez le RFC 8467.) Le tout est ensuite chiffré puis mis dans :
struct {
uint8 message_type;
opaque key_id<0..2^16-1>;
opaque encrypted_message<1..2^16-1>;
} ObliviousDoHMessage;
Le key_id servant à identifier ensuite le
matériel cryptographique utilisé.
J'ai parlé à plusieurs reprises de chiffrement. Le client doit connaitre la clé publique du serveur DoH pour pouvoir chiffrer. (Le RFC ne prévoit pas de mécanisme pour cela.) Comme avec la plupart des systèmes de chiffrement, le chiffrement sera en fait réalisé avec un algorithme symétrique. La transmission ou la génération de la clé de cet algorithme utlisera le mécanisme HPKE (Hybrid Public Key Encryption, spécifié dans le RFC 9180).
Outre l'analyse de trafic, citée plus haut, une potentielle faille d'Oblivious DoH serait le cas d'un serveur indiscret qui essaierait de déduire des informations de l'établissement des connexions DoH vers lui. Le RFC recommande que les relais établissent des connexions de longue durée et les réutilisent pour plusieurs clients, rendant cette éventuelle analyse plus complexe.
Notez aussi que le relais est évidemment libre de sa politique. Les relais peuvent par exemple ne relayer que vers certains serveurs DoH connus.
Le serveur DoH ne connait pas l'adresse IP du client (c'est le but) et ne peut donc pas transmettre aux serveurs faisant autorité les informations qui peuvent leur permettre d'envoyer une réponse adaptée au client final. Si c'est un problème, le client final peut toujours utiliser ECS (EDNS Client Subnet, RFC 7871), en indiquant un préfixe IP assez générique pour ne pas trop en révéler. Mais cela fait évidemment perdre une partie de l'intérêt d'Oblivious DoH.
Bon, et questions mises en œuvre de ce RFC ? Il y en a une dans DNScrypt (et ils publient une liste de serveurs et de relais).
Oblivious DoH est en travaux depuis un certain temps (voyez par exemple cet article de Cloudflare). Notez que la technique de ce RFC est spécifique à DoH. Il y a aussi des travaux en cours à l'IETF pour un mécanisme plus général, comme par exemple un Oblivious HTTP, qui serait un concurrent « low cost » de Tor.
À propos de Tor, j'avais dit plus haut qu'on pouvait évidemment, si on ne veut pas révéler son adresse IP au résolveur DoH, faire du DoH sur Tor. Voici un exemple de requête DoH faite avec le client kdig et le programme torsocks pour faire passer les requêtes TCP par Tor :
% torsocks kdig +https=/ @doh.bortzmeyer.fr ukraine.ua ;; TLS session (TLS1.3)-(ECDHE-SECP256R1)-(RSA-PSS-RSAE-SHA256)-(AES-256-GCM) ;; HTTP session (HTTP/2-POST)-(doh.bortzmeyer.fr/)-(status: 200) ... ;; ANSWER SECTION: ukraine.ua. 260 IN A 104.18.7.16 ukraine.ua. 260 IN A 104.18.6.16 ... ;; Received 468 B ;; Time 2022-06-02 18:45:15 UTC ;; From 193.70.85.11@443(TCP) in 313.9 ms
Et ce résolveur DoH ayant un service
.onion, on peut même :
% torsocks kdig +https=/ @lani4a4fr33kqqjeiy3qubhfx2jewfd3aeaepuwzxrx6zywp2mo4cjad.onion ukraine.ua ;; TLS session (TLS1.3)-(ECDHE-SECP256R1)-(RSA-PSS-RSAE-SHA256)-(AES-256-GCM) ;; HTTP session (HTTP/2-POST)-(lani4a4fr33kqqjeiy3qubhfx2jewfd3aeaepuwzxrx6zywp2mo4cjad.onion/)-(status: 200) ... ;; ANSWER SECTION: ukraine.ua. 212 IN A 104.18.6.16 ukraine.ua. 212 IN A 104.18.7.16 ... ;; Received 468 B ;; Time 2022-06-02 18:46:00 UTC ;; From 127.42.42.0@443(TCP) in 1253.8 ms
Pour comparer les performances (on a dit que la latence de Tor était franchement élevée), voici une requête non-Tor vers le même résolveur :
% kdig +https=/ @doh.bortzmeyer.fr ukraine.ua ;; TLS session (TLS1.3)-(ECDHE-SECP256R1)-(RSA-PSS-RSAE-SHA256)-(AES-256-GCM) ;; HTTP session (HTTP/2-POST)-([2001:41d0:302:2200::180]/)-(status: 200) ... ;; ANSWER SECTION: ukraine.ua. 300 IN A 104.18.6.16 ukraine.ua. 300 IN A 104.18.7.16 ... ;; Received 468 B ;; Time 2022-06-02 18:49:44 UTC ;; From 2001:41d0:302:2200::180@443(TCP) in 26.0 ms
L'article seul
RFC 9211: The Cache-Status HTTP Response Header Field
Date de publication du RFC : Juin 2022
Auteur(s) du RFC : M. Nottingham (Fastly)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 9 juin 2022
Ce RFC normalise enfin un en-tête HTTP pour permettre aux relais HTTP qui mémorisent les réponses reçues, les caches, d'indiquer au client comment ils ont traité une requête et si, par exemple, la réponse vient de la mémoire du relais ou bien s'il a fallu aller la récupérer sur le serveur HTTP d'origine.
Il existait déjà des en-têtes de débogage analogues mais
non-standards, variant aussi bien dans leur syntaxe que dans leur
sémantique. Le nouvel en-tête standard,
Cache-Status: va, espérons-le, mettre de
l'ordre à ce sujet. Sa syntaxe suit les principes des en-têtes
structurés du RFC 9651. Sa valeur est donc une
liste de relais qui ont traité la requête, séparés par des
virgules, dans l'ordre des traitements. Le
premier relais indiqué dans un Cache-Status:
est donc le plus proche du serveur d'origine et le dernier relais
étant le plus proche de l'utilisateur. Voici un exemple avec un seul
relais, nommé cache.example.net :
Cache-Status: cache.example.net; hit
et un exemple avec deux relais, OriginCache
puis CDN Company Here :
Cache-Status: OriginCache; hit; ttl=1100, "CDN Company Here"; hit; ttl=545
La description complète de la syntaxe figure dans la section 2 de notre RFC. D'abord, il faut noter qu'un relais n'est pas obligé d'ajouter cet en-tête. Il le fait selon des critères qui lui sont propres. Le RFC déconseille fortement d'ajouter cet en-tête si la réponse a été générée localement par le relais (par exemple un 400 qui indique que le relais a détecté une requête invalide). En tout cas, le relais qui s'ajoute à la liste ne doit pas modifier les éventuels relais précédents. Chaque relais indique son nom, par exemple par un nom de domaine mais ce n'est pas obligatoire. Ce nom peut ensuite être suivi de paramètres, séparés par des point-virgules.
Dans le
premier exemple ci-dessus, hit était un
paramètre du relais cache.example.net. Sa
présence indique qu'une réponse était déjà mémorisée par le relais
et qu'elle a été utilisée (hit : succès, on a
trouvé), le serveur d'origine n'ayant pas été contacté. S'il y
avait une réponse stockée, mais qu'elle était rassise (RFC 9111, section 4.2) et qu'il a fallu la
revalider auprès du serveur d'origine, hit ne
doit pas être utilisé.
Le deuxième paramètre possible est fwd (pour
Forward) et il indique qu'il a fallu contacter le
serveur HTTP d'origine. Plusieurs raisons sont possibles pour cela,
entre autres :
bypass, quand le relais a été configuré pour que cette requête soit systématiquement relayée,methodparce que la méthode HTTP utilisée doit être relayée (c'est typiquement le cas d'unPUT, cf. RFC 9110, section 9.3.4),miss, un manque, la ressource n'était pas dans la mémoire du relais (notez qu'il existe aussi deux paramètres plus spécifiques,uri-missetvary-miss),stale, car la ressource était bien dans la mémoire du relais mais, trop ancienne et rassise, a dû être revalidée (RFC 9111, section 4.3) auprès du serveur d'origine.
Ainsi, cet en-tête :
Cache-Status: ExampleCache; fwd=miss; stored
indique que l'information n'était pas dans la mémoire de
ExampleCache et qu'il a donc dû faire suivre au
serveur d'origine (puis qu'il a stocké cette information dans sa
mémoire, le paramètre stored).
Autre paramètre utile, ttl, qui indique
pendant combien de temps l'information peut être gardée (cf. RFC 9111, section 4.2.1), selon les
calculs du relais. Quant à detail,
il permet de donner des informations supplémentaires, de manière non
normalisée (la valeur de ce paramètre ne peut être interprétée que
si on connait le programme qui l'a produite).
Les paramètres sont enregistrés à l'IANA, dans un nouveau registre, et de nouveaux paramètres peuvent y être ajoutés, suivant la politique « Examen par un expert » du RFC 8126. La recommandation est de n'enregistrer que des paramètres d'usage général, non spécifiques à un programme particulier, sauf à nommer le paramètre d'une manière qui identifie clairement sa spécificité.
Questions mises en œuvre, Squid sait
renvoyer cet en-tête (cf. le code qui commence à SBuf
cacheStatus(uniqueHostname()); dans le fichier
src/client_side_reply.cc). Ce code n'est pas
encore présent dans la version 5.2 de Squid, qui n'utilise encore que
d'anciens en-têtes non-standards, il faut attendre de nouvelles versions :
< X-Cache: MISS from myserver < X-Cache-Lookup: NONE from myserver:3128 < Via: 1.1 myserver (squid/5.2)
Je n'ai pas regardé les autres logiciels.
L'article seul
RFC 9204: QPACK: Header Compression for HTTP/3
Date de publication du RFC : Juin 2022
Auteur(s) du RFC : C. Krasic (Netflix), M. Bishop (Akamai Technologies), A. Frindell (Facebook)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF quic
Première rédaction de cet article le 7 juin 2022
QPACK, normalisé dans ce RFC est un mécanime de compression des en-têtes HTTP, prévu spécifiquement pour HTTP/3. Il est proche du HPACK de HTTP/2, mais adapté aux particularités de QUIC.
Car le HPACK du RFC 7541 a un défaut qui n'était pas un problème en HTTP/2 mais le devient avec HTTP/3 : il supposait que les trames arrivent dans l'ordre d'émission, même si elles circulent sur des ruisseaux différents. Ce n'est plus vrai en HTTP/3 qui, grâce à son transport sous-jacent, QUIC, a davantage de parallélisme, et où une trame peut en doubler une autre (si elles n'étaient pas dans le même ruisseau). QPACK ressemble à HPACK, mais en ayant corrigé ce problème. (Au fait, ne cherchez pas ce que veut dire QPACK, ce n'est pas un acronyme.)
Donc, le principe de QPACK. Comme HPACK, on travaille avec deux
tables, qui vont associer aux en-têtes HTTP un nombre (appelé
index). L'une des tables est statique, définie dans ce RFC (annexe
A) et donc identique pour tout le monde. L'autre est dynamique et
construite par un échange de messages transmis dans des ruisseaux
QUIC. Le fonctionnement avec la table statique est simple :
l'encodeur regarde si ce qu'il veut écrire est dans la table, si
oui, il le remplace par l'index. Le décodeur, recevant un index, le
remplace par le contenu de la table. Par exemple, l'en-tête HTTP
if-none-match (RFC 7232,
section 3.2) est dans la table, index 9. L'encodeur remplacera donc
un if-none-match par 9 (12 octets de gagnés si
tout était sous forme de caractères de 8 bits, mais peut-être un peu
plus ou un peu moins, avec l'encodage de QPACK), et le décodeur fera
l'inverse.
J'ai un peu simplifié en supposant que la table ne contenait que
les noms des en-têtes. Elle peut aussi contenir leur valeur si
celle-ci est très courante. Ainsi, accept:
application/dns-message est dans la table, index 30, vu
son utilisation intensive par DoH (RFC 8484). Même chose
pour content-type: text/html;charset=utf-8 à
l'index 52.
La table dynamique est évidemment bien plus complexe. Encodeur (celui qui comprime) et décodeur doivent cette fois partager un état. En outre, le parallélisme inhérent à QUIC fait qu'un message d'ajout d'une entrée dans la table pourrait arriver après le message utilisant cette entrée. QPACK fonctionne de la façon suivante :
- L'encodeur peut envoyer (sur un ruisseau QUIC dédié) des instructions de construction de la table dynamique, notamment pour insérer une nouvelle entrée (mais pas en supprimer).
- Le décodeur accuse réception de ces instructions.
- L'encodeur envoie l'index le plus élevé de sa table, ce qui permet au décodeur, en regardant sa propre table, de savoir s'il est synchronisé ou pas. S'il ne l'est pas, le décodeur se bloque en attendant les instructions d'insertion qui vont faire grandir sa table.
QUIC a un système de contrôle de flux, et des inconvénients peuvent en résulter, par exemple un blocage des messages de contrôle de la table. Pour éviter tout blocage, un encodeur peut n'utiliser que des entrées de la table qui ont déjà fait l'objet d'un accusé de réception. Il comprimera moins mais ne risquera pas d'être bloqué.
Le RFC détaille les précautions à prendre pour éviter l'interblocage. Ainsi, les messages modifiant la table risquent d'être bloqués par ce système alors que le récepteur n'autorise pas de nouvelles trames tant qu'il n'a pas traité des trames qui ont besoin de ces nouvelles entrées dans la table dynamique. L'encodeur a donc pour consigne de ne pas tenter de modifier la table s'il ne lui reste plus beaucoup de « crédits » d'envoi de données. (D'une manière générale, quand il y a des choses compliquées à faire, QPACK demande à l'encodeur de les faire, le décodeur restant plus simple.)
L'encodage des messages QPACK est spécifié dans la section 4. QPACK utilise deux ruisseaux QUIC unidirectionnels, un dans chaque direction. Ils sont enregistrés à l'IANA.
Notez aussi qu'il y a deux instructions d'ajout d'une entrée dans
la table dynamique, une qui ajoute une valeur litérale (comme « ajoute
accept-language: fr ») et une qui ajoute une
valeur exprimée sous forme d'une référence à une entrée d'une table
(qui peut être la statique ou la dynamique). Par exemple, comme
accept-language est dans la table statique, à
l'index 72, on
peut dire simplement « ajoute 72: fr ». Encore quelques octets
gagnés.
Dans la trame SETTINGS de HTTP/3, deux
paramètres concernent spécialement QPACK, pour indiquer la taille
maximale de la table dynamique, et le nombre maximal de ruisseaux
bloqués. Ils sont placés dans un registre IANA.
Quelques mots sur la sécurité : dans certaines conditions, un observateur peut obtenir des informations sur l'état des tables (cf. l'attaque CRIME) même s'il ne peut déchiffrer les données protégées par TLS, celui-ci ne masquant pas la taille. Bien sûr, on pourrait remplir avec des données bidons mais cela annulerait l'avantage de la compression. La section 7 du RFC donne quelques idées sur des mécanismes de limitation du risque.
L'annexe A du RFC spécifie la table statique et ses 98
entrées. Elle a été composée à partir de l'analyse de trafic HTTP en
2018. L'ordre des entrées n'est pas arbitraire : vu comment sont
représentés les entiers, donc les index, dans QPACK, les entrées les
plus fréquentes sont en premier, car QPACK utilise moins de bits pour
les nombres les plus petits. Notez aussi que cette table comprend
les en-têtes HTTP « classiques », comme
content-length ou
set-cookie mais aussi ce que
HTTP/2 appelle les « pseudo-en-têtes », qui
commencent par deux-points. C'est par exemple
le cas de la méthode HTTP (GET,
PUT, etc), notée :method
ou, dans les réponses, du code de retour, noté
:status (tiens, la table statique a une entrée
pour le code 403 mais pas pour le 404).
Si vous envisagez de programmer QPACK, l'annexe B contient des exemples de dialogue entre encodeur et décodeur, et l'annexe C du pseudo-code pour l'encodeur.
L'article seul
RFC 9110: HTTP Semantics
Date de publication du RFC : Juin 2022
Auteur(s) du RFC : R. Fielding (Adobe), M. Nottingham (Fastly), J. Reschke (greenbytes)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 7 juin 2022
Que voilà une épaisse lecture (252 pages). Mais c'est parce qu'il s'agit de réécrire complètement la totalité des normes de HTTP. Pas le protocole lui-même, je vous rassure, HTTP ne change pas. Mais la rédaction de ses normes est profondément réorganisée, avec un RFC (notre RFC 9110) qui décrit une vision de haut niveau de HTTP, puis un autre RFC par version majeure de HTTP, décrivant les détails de syntaxe de chaque version.
Par exemple, HTTP/1 (RFC 9112) a un
encodage en texte alors que HTTP/2 (RFC 9113)
a un encodage binaire. Pourtant, tous les deux suivent les mêmes
principes, décrits dans ce RFC 9110 (méthodes comme
GET, en-têtes de la requête et de la réponse,
codes de retour à trois chiffres…) mais avec des encodages
différents, chacun dans son propre RFC. Notre RFC 9110 est donc la vision de haut niveau de HTTP, commune à
toutes les versions, et d'autres RFC vous donneront les
détails. Inutile de dire que cette réorganisation a été un gros
travail, commencé en 2018.
Les trois versions de HTTP actuellement en large usage (1.1, 2 et 3) reposent toutes sur des concepts communs. Par exemple, les codes d'erreur (comme le fameux 404) sont les mêmes. Il n'est pas prévu, même à moyen terme, que les versions les plus anciennes soient abandonnées (HTTP/1.1 reste d'un usage très courant, et souvent pour de bonnes raisons). D'où cette réorganisations des normes HTTP, avec notre RFC 9110 qui décrit ce qui est commun aux trois versions, d'autres RFC communs aux trois versions, et un RFC par version :
Vous connaissez certainement déjà HTTP, mais notre RFC ne présuppose pas de connaissances préalables et explique tout en partant du début, ce que je fais donc également ici. Donc, HTTP est un protocole applicatif, client/serveur, sans état, qui permet l'accès et la modification de ressources distantes (une ressource pouvant être du texte, une image, et étant générée dynamiquement ou pas, le protocole est indépendant du format de la ressource ou de son mode de création, le RFC insiste bien sur ce point). Le client se connecte, envoie une requête, le serveur répond. HTTP ne fonctionne pas forcément de bout en bout, il peut y avoir des relais sur le trajet, et leur présence contribue beaucoup à certaines complexités de la norme.
S'il fallait résumer HTTP rapidement, on pourrait dire qu'il décrit un moyen d'interagir avec une ressource distante (la ressource peut être un fichier, un programme…). Il repose sur l'échange de messages, avec une requête du client vers le serveur et une réponse en sens inverse. Outre la méthode qui indique ce que le client veut faire avec la ressource, HTTP permet de transporter des métadonnées.
La section 3 du RFC décrit les concepts centraux de ce protocole,
comme celui de ressource présenté plus haut. (Qui est parfois appelé
« page » ou « fichier » mais ces termes ne sont pas assez
génériques. Une ressource n'est pas forcément une page HTML !) HTTP identifie
les ressources par des URI. Une représentation
est la forme concrète d'une ressource, les bits qu'on reçoit ou
envoie. (Du fait de la négociation de contenu et d'autres facteurs,
récupérer une ressource en utilisant le même URI ne donnera pas
forcément les mêmes bits, même s'ils sont censés être sémantiquement
équivalents.) La ressource n'est pas non plus forcément un fichier, pensez à une ressource qui indique l'heure qu'il est,
ou le temps qu'il fait, par exemple. Ou à l'URI
https://www.bortzmeyer.org/apps/random qui vous
renvoie une page choisie aléatoirement de ce blog. HTTP agit
sur une ressource (dont le type n'est pas forcément connu) via une
méthode qui va peut-être retourner une représentation de cette
ressource. C'est ce qu'on nomme le principe REST et de
nombreuses API se réclament de ce principe.
HTTP est un protocole client/serveur. Le serveur attend le client. (Le client est parfois appelé user agent.) Entre les deux, HTTP utilisera un protocole de transport fiable, comme TCP (HTTP/1 et 2) ou QUIC (HTTP/3). Par défaut, HTTP est sans état : une fois une requête servie, le serveur oublie tout. Les clients sont très variés : il y a bien sûr les navigateurs Web, mais aussi les robots, des outils en ligne de commande comme wget, des objets connectés, des programmes vite faits en utilisant une des zillions de bibliothèques qui permettent de développer rapidement un client HTTP, des applications sur un ordiphone, etc. Notamment, il n'y a pas forcément un utilisateur humain derrière le client HTTP. (Pensez à cela si vous mettez des éléments d'interfaces qui demandent qu'un humain y réponde ; le client ne peut pas forcément faire de l'interactivité.)
Les messages envoyés par le client au serveur sont des requêtes et ceux envoyés par le serveur des réponses.
La section 2 du RFC explique ce qu'on attend d'un client ou d'un serveur HTTP conforme. Un point important et souvent ignoré est que HTTP ne donne pas de limites quantitatives à beaucoup de ses éléments. Par exemple, la longueur maximale de la première ligne de la requête (celle qui contient le chemin de la ressource) n'est pas spécifiée, car il serait trop difficile de définir une limite qui convienne à tous les cas, HTTP étant utilisé dans des contextes très différents. Comme les programmes ont forcément des limites, cela veut dire qu'on ne peut pas toujours compter sur une limite bien connue.
Une mise en œuvre conforme pour HTTP doit notamment bien gérer la notion de version de HTTP. Cette version s'exprime par deux chiffres séparés par un point, le premier chiffre étant la version majeure (1, 2 ou 3) et le second la mineure (il est optionnel, valant 0 par défaut, donc HTTP/2 veut dire la même chose que HTTP/2.0). Normalement, au sein d'une même version majeure, on doit pouvoir interopérer sans trop de problème alors qu'entre deux versions majeures, il peut y avoir incompatibilité totale. La sémantique est forcément la même (c'est du HTTP, après tout) mais la syntaxe peut être radicalement différente (pensez à l'encodage texte de HTTP/1 vs. le binaire de HTTP/2 et 3). Donc, être conforme à HTTP/1.1 veut dire lire ce RFC 9110 mais aussi le RFC 9112, qui décrit la syntaxe spécifique de HTTP/1.1.
Comme, dans la nature, des programmes ne sont pas corrects, le
RFC autorise du bout des lèvres à utiliser le contenu des champs
User-Agent: ou Server: de
l'en-tête pour s'ajuster à des bogues connues (mais, normalement, ce
doit être uniquement pour contourner des bogues, pas pour servir un
contenu différent).
De même qu'un client HTTP n'est pas forcément un navigateur Web, un serveur HTTP n'est pas forcément une grosse machine dans un centre de données chez un GAFA. Le serveur HTTP peut parfaitement être une imprimante, un petit objet connecté, une caméra de vidéosurveillance, un Raspberry Pi dans son coin… Le RFC parle de « serveur d'origine » pour le serveur qui va faire autorité pour les données servies. Pourquoi ce concept ? Parce que HTTP permet également l'insertion d'un certain nombre d'intermédiaires, les relais (proxy ou gateway en anglais), entre le client et le serveur d'origine. Leurs buts sont très variés. Par exemple, un relais (proxy, pour le RFC) dans le réseau local où se trouve le client HTTP peut servir à mémoriser les ressources Web les plus souvent demandées, pour améliorer les performances. Un relais (gateway ou reverse proxy, pour le RFC) qui est au contraire proche du serveur d'origine peut servir à répartir la charge entre diverses instances. Revenons à la mémorisation des ressources (caching en anglais). La mémoire (cache en anglais) est un stockage de ressources Web déjà visitées, prêtes à être envoyées aux clients locaux pour diminuer la latence. La mémorisation est un sujet suffisamment fréquent et important pour avoir son propre RFC, le RFC 9111.
On a vu que HTTP servait à agir sur des ressources distantes. Des
ressources, il y en a beaucoup. Comment les identifier ? Le Web va
utiliser des URI comme
identificateurs. Ces URI sont normalisés dans
le RFC 3986, mais qui ne spécifie qu'une
syntaxe générique. Chaque plan d'URI (la chaine
de caractères avant le deux-points, souvent
appelée à tort protocole) doit spécifier un certain nombre de
détails spécifique à ce plan. Pour les plans
http et https, cette
spécification est la section 4 de notre RFC. (Tous les plans sont
dans un
registre IANA.) Un URI de plan http ou
https indique forcément une autorité (un
identificateur du serveur d'origine, en pratique un nom de machine)
et un chemin (identificateur de la ressource à l'intérieur d'un
autorité. Ainsi, dans
https://www.afnic.fr/observatoire-ressources/consultations-publiques/,
le plan est https, l'autorité
www.afnic.fr et le chemin
/observatoire-ressources/consultations-publiques/. Le
port par défaut est 80 pour
http et 443 pour
https (tous les deux sont enregistrés
à l'IANA). La différence entre les deux plans est que
https implique l'utilisation du protocole de
sécurité TLS
(RFC 9846), pour assurer notamment la
confidentialité des requêtes.
En théorie, un URI de plan http et un autre
identique, sauf pour l'utilisation de https,
sont complètement distincts. Ils ne représentent pas la même origine
(l'origine est un triplet {plan, machine, port}) et les deux
ressources peuvent être complètement différentes. Mais notre RFC
note que certaines normes violent ce principe, notamment celle sur
les cookies (RFC 6265),
avec parfois des conséquences fâcheuses pour la sécurité.
En HTTPS, puisque ce protocole s'appuie sur TLS, le serveur présente un certificat, que le client doit vérifier (section 4.3.4), en suivant les règles du RFC 6125.
Pour expliquer plusieurs des propriétés de HTTP, je vais beaucoup
utiliser le logiciel curl, un
client HTTP en ligne de commande, dont
l'option -v permet d'afficher tout le dialogue
HTTP. Si vous voulez faire des essais vous aussi, interrompez
momentanément votre lecture pour installer curl. […] C'est fait ? On
peut reprendre ?
% curl -v http://www.hambers.mairie53.fr/ ... > GET / HTTP/1.1 > Host: www.hambers.mairie53.fr > User-Agent: curl/7.68.0 > Accept: */* > < HTTP/1.1 200 OK < Date: Wed, 02 Mar 2022 16:25:02 GMT < Server: Apache ... < Content-Length: 61516 < Content-Type: text/html; charset=UTF-8 < <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> ...
Nous avons vu que la requête et la réponse HTTP contenaient des métadonnées dans un en-tête composé de champs. (Il peut aussi y avoir un pied, une sorte de post-scriptum, mais c'est peu utilisé.) Chaque champ a un nom et une valeur. La section 5 du RFC détaille cet important concept. Les noms de champs sont insensibles à la casse. Ils sont enregistrés dans un registre IANA spécifique à HTTP (ils étaient avant dans le même registre que les champs du courrier électronique). Un client, un serveur ou un relais HTTP doivent ignorer les champs qu'ils ne connaissent pas, ce qui permet d'introduire de nouveaux champs sans tout casser. Le même champ peut apparaitre plusieurs fois. Comme pour d'autres éléments du protocole HTTP, la norme ne fixe pas de limite de taille. La valeur d'un champ peut donc être très grande.
La valeur d'un champ obéit à des règles qui dépendent du champ. Les caractères doivent être de l'ASCII, une limite très pénible de HTTP. Si on veut utiliser Unicode (ou un autre jeu de caractères), il faut l'encoder comme indiqué dans le RFC 8187. Le RFC rappelle qu'autrefois Latin-1 était autorisé (avec l'encodage du RFC 2047 pour les autres jeux) mais cela ne devrait normalement plus être le cas (mais ça se rencontre parfois encore). Si une valeur comprend plusieurs termes, ils doivent normalement être séparés par des virgules (et on met entre guillemets les valeurs qui comprennent des virgules). Les valeurs peuvent inclure des paramètres, écrits sous la forme nom=valeur. Certaines valeurs ont leur propre structure (RFC 9651). Ainsi, plusieurs champs peuvent inclure une estampille temporelle. La syntaxe pour celles-ci n'est hélas pas celle du RFC 3339 mais celle de l'IMF (RFC 5322), plus complexe et plus ambigüe. (Sans compter, vu l'âge de HTTP, qu'on rencontre parfois de vieux formats comme celui du RFC 850.) Voici des exemples de champs vus avec curl :
% curl -v http://confiance-numerique.clermont-universite.fr/
...
> GET / HTTP/1.1
> Host: confiance-numerique.clermont-universite.fr
> User-Agent: curl/7.68.0
> Accept: */*
< HTTP/1.1 200 OK
< Date: Fri, 28 Jan 2022 17:21:38 GMT
< Server: Apache/2.4.6 (CentOS)
< Last-Modified: Tue, 01 Sep 2020 13:29:41 GMT
< ETag: "1fbc1-5ae4082ec730d"
< Accept-Ranges: bytes
< Content-Length: 129985
< Content-Type: text/html; charset=UTF-8
<
<!DOCTYPE HTML SYSTEM>
<html>
<head>
<title>Séminaire Confiance Numérique</title>
Le client HTTP (curl) a envoyé trois champs,
Host: (le serveur qu'on veut contacter),
User-Agent: (une chaine de caractères décrivant
le client) et Accept: (les formats acceptés,
ici tous). Le serveur a répondu avec divers champs comme
Server: (l'équivalent du
User-Agent:) et
Content-Type: (le format utilisé, ici
HTML). Et voici ce qu'envoie le navigateur Firefox :
Host: localhost:8080 User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:96.0) Gecko/20100101 Firefox/96.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8 Accept-Language: en-US,en;q=0.5 Accept-Encoding: gzip, deflate Connection: keep-alive Upgrade-Insecure-Requests: 1 Sec-Fetch-Dest: document Sec-Fetch-Mode: navigate Sec-Fetch-Site: none Sec-Fetch-User: ?1
On notera surtout un Accept: plus complexe
(curl accepte tout car il ne s'occupe pas de l'affichage).
Maintenant, les messages (requêtes et réponses). La façon exacte dont ils sont transmis dépend de la version de HTTP. Par exemple, la version 1 les encode en texte alors que les versions 2 et 3 préfèrent le binaire. Autre exemple, la version 3 ne prévoit pas de mécanisme de début et de fin d'un message car chaque ruisseau QUIC ne porte qu'un seul message, un peu comme les versions 0 de HTTP, avec le ruisseau QUIC au lieu de la connexion TCP (notez qu'avec TCP sans TLS, le client peut ne pas savoir s'il a bien reçu toutes les données). La section 6 de notre RFC ne donne donc qu'une description abstraite. Un message comprend donc une information de contrôle (la première ligne, dans le cas de HTTP/1, un « pseudo en-tête » avec des noms de champs commençant par un deux-points pour les autres versions), un en-tête, un corps (optionnel) et un pied (également optionnel). L'information de contrôle donne plusieurs informations nécessaires pour la suite, comme la version de HTTP utilisée. Le contenu (le corps) est juste une suite d'octets, que HTTP transporte sans l'interpréter (ce n'est pas forcément de l'HTML). Dans la réponse, l'information de contrôle comprend notamment un code numérique de trois chiffres, qui indique comment la requête a été traitée (ou pas).
Beaucoup moins connu que l'en-tête, un message peut aussi comporter un pied, également composé de champs « nom: valeur ». Il est nécessaire de les utiliser dans les cas où l'information est générée dynamiquement et que certaines choses ne peuvent être déterminées qu'après coup (une signature numérique, par exemple).
Dans le cas le plus simple, le client HTTP parle directement au
serveur d'origine et il n'y a pas de complications de routage du
message. Le serveur traite le message reçu, point. Mais HTTP permet
d'autres cas, par exemple avec un relais qui
reçoit le message avant de le transmettre au « vrai » serveur
(section 7 du RFC). Ainsi, dans une requête, l'information de
contrôle n'est pas forcément un simple chemin
(/publications/cahiers-soutenabilites) mais
peut être un URL complet
(https://www.strategie.gouv.fr/publications/cahiers-soutenabilites). C'est
ce que fait le client HTTP s'il est configuré pour utiliser un
relais, par exemple pour mémoriser les réponses des requêtes (RFC 9111), ou bien parce que l'accès direct aux
ports 80 et 443 est
bloqué et qu'on est obligé d'utiliser un relais. Dans le cas où la
ressource demandées est identifiée par un URL complet, le relais
doit alors se transformer en client HTTP et faire une requête vers
le serveur d'origine (ou bien vers un autre relais…).
La section 8 de notre RFC s'attaque à une notion cruciale en
HTTP, celle de représentation. La
représentation d'une ressource est la suite d'octets qu'on obtient
en réponse à une requête HTTP (« représentation » est donc plus
concret que « ressource »). Une même ressource peut avoir plusieurs
représentations, par exemple selon les métadonnées que le client a
indiqué dans sa requête. Le type de la représentation est indiqué par le champ
Content-Type: de l'en-tête (et aussi par
Content-Encoding:). Sa valeur est un
type MIME (RFC 2046). Voici par exemple le type de la page que vous êtes
en train de lire :
Content-Type: text/html; charset=UTF-8
(Notez que le paramètre charset est mal nommé,
c'est en fait un encodage, pas un
jeu de caractères. L'erreur vient du fait que
dans les vieilles normes comme ISO-8859-1, les
deux concepts étaient confondus.)
Normalement, du fait de ce Content-Type:, le
client HTTP n'a pas à deviner le type de la représentation, il se
fie à ce que le serveur raconte. Ceci dit, certains clients ont la
mauvaise idée de chercher à deviner le
type. Cette divination est toujours incertaine (plusieurs
types de données peuvent se ressembler) et ouvre même la possibilité
de failles de sécurité.
Un autre champ, Content-Language:, indique
la langue de la représentation récupérée. Sa
valeur est une étiquette de langue, au sens
du RFC 5646. Si le texte est multilingue, ce
champ peut prendre plusieurs valeurs. Le RFC illustre cela avec le
traité de Waitangi, qui est en
maori et en anglais :
Content-Language: mi, en
Attention, la seule présence de différentes langues ne signifie pas qu'il faut mettre plusieurs étiquettes de langue. Un cours d'introduction à l'arabe écrit en français, pour un public francophone, sera :
Content-Language: fr
Les étiquettes de langue peuvent être plus complexes que l'indication de la seule langue, mais il me semble que c'est rarement utilisé sur le Web.
La taille de la représentation, elle, est exprimée avec
Content-Length:, un champ très pratique pour le
client HTTP qui sait ainsi combien d'octets il va devoir lire (avant
HTTP/1, c'était facile, on lisait jusqu'à la fin de la connexion
TCP ;
mais ça ne marche plus depuis qu'il y a des connexions persistentes
et, de toute façon, en l'absence de TLS, cela ne permettait pas de
détecter des coupures prématurées). Évidemment, le client doit
rester paranoïaque et supposer que l'information puisse être
fausse. curl (avec -v) avertit ainsi, si la
taille indiquée est trop faible :
* Excess found in a read: excess = 1, size = 12, maxdownload = 12, bytecount = 0
Si la taille indiquée est trop grande, curl attend pour essayer de lire davantage sur le connexion qui reste ouverte. Autre raison d'être paranoïaque, la taille indiquée peut être énorme, menant par exemple un client imprudent, qui allouerait la mémoire demandée à épuiser celle-ci. Sans compter l'éventualité d'un débordement d'entier si la taille ne peut pas être représentée dans les entiers utilisés par le client HTTP.
Ensuite vient un autre point pas forcément très connu : les
validateurs. HTTP permet d'indiquer des pré-conditions à la
récupération d'une ressource, pour épargner le réseau. Un client
HTTP peut ainsi demander « donne-moi cette ressource, si elle n'a
pas changé ». Pour cela, HTTP repose sur ces validateurs, qui sont
des métadonnées qui accompagnent la requête (avec des champs qui
expriment la requête conditionnelle, comme
If-Modified-Since:, et qui sont détaillés en
section 13) et que le serveur vérifiera. Il existe deux sortes de
validateurs, les forts et les faibles. Les faibles sont faciles à
générer mais ne garantissent pas une comparaison réussie, les forts
sont plus difficiles à faire mais sont plus fiables. Par exemple, un
condensat du contenu est fort. Il changera
forcément (sauf malchance inouïe) dès qu'on changera un seul bit du
contenu. Si le contenu est géré par un VCS, celui-ci fournit également des
validateurs forts : l'identificateur de
commit. Au contraire, une
estampille temporelle est un validateur faible. Si sa résolution est
d'une seconde, deux modifications dans la même seconde ne seront pas
détectées et le serveur croira à tort que le contenu n'a pas
changé.
Pour connaitre la valeur actuelle d'un futur validateur, le
client HTTP dispose de champs comme
Last-Modified: (une estampille temporelle) ou
ETag: (Entity Tag,
l'étiquette de la ressource, une valeur opaque, qui peut s'utiliser
avec des requêtes conditionnelles comme
If-None-Match:). Voici un exemple :
Last-Modified: Mon, 07 Feb 2022 12:20:20 GMT ETag: "5278-5d76c9fc1c9f4"
(Le serveur utilisé était un Apache. Par
défaut, Apache génère des étiquettes qui sont un
condensat de divers attributs du fichier
comme l'inœud, la taille et la date de
modification. Apache permet de configurer
cet algorithme. Rappelez-vous que l'étiquette est opaque, le
serveur peut donc la générer comme il veut, il doit juste s'assurer
qu'elle change à chaque modification de la ressource. Le serveur peut par
exemple utiliser un SHA-1 du contenu de la ressource.)
A priori, l'étiquette de la ressource est un validateur fort,
autrement, le serveur doit la préfixer par W/
(W pour Weak).
Passons maintenant aux méthodes (section 9
du RFC). Il y a très longtemps, HTTP n'avait qu'une seule méthode
pour agir sur les ressources, la méthode
GET. Désormais, il y a nettement plus de
méthodes, chacune agissant sur la ressource indiquée d'une manière
différente et ayant donc une sémantique différente. Par exemple,
GET va récupérer une représentation de la
ressource, alors que PUT va au contraire écrire
le contenu envoyé, remplaçant celui de la ressource et que
DELETE va… détruire la ressource. La liste
complète des méthodes figure dans un
registre IANA.
Certaines des méthodes sont dites sûres car elles ne modifient
pas la ressource et ne casseront donc rien. Bien sûr, une méthode
sûre peut avoir des effets de bord (comme d'écrire une ligne dans le
journal du serveur, mais ce n'est pas la
faute du client). GET, HEAD
et les moins connues OPTIONS et
TRACE sont sûres. Du fait de cette garantie de
sûreté, un programme qui ne fait que des requêtes sûres a moins
d'inquiétudes à avoir, notamment s'il agit sur la base
d'informations qu'il ne contrôle pas. Ainsi, le
ramasseur d'un moteur de
recherche ne fait a priori que des requêtes sûres, pour
éviter qu'une page Web malveillante ne l'entraine à effectuer des
opérations qui peuvent changer le contenu des sites Web visités.
Une autre propriété importante d'une méthode est d'être
idempotente ou pas. Une méthode idempotente a
le même effet qu'on l'exécute une ou N fois. Les méthodes sûres sont
toutes idempotentes mais l'inverse n'est pas vrai :
PUT et DELETE sont
idempotentes (qu'on détruise une ressource une ou N fois donnera le
même résultat : la ressource est supprimée) mais pas
sûres. L'intérêt de cette propriété d'idempotence est qu'elles
peuvent être répétées sans risque, par exemple si le réseau a eu un
problème et qu'on n'est pas certain que la requête ait été
exécutée. Les méthodes non-idempotentes ne doivent pas, par contre,
être répétées aveuglément.
La méthode la plus connue et sans doute la plus utilisée,
GET, permet de récupérer une représentation
d'une ressource. La syntaxe avec laquelle s'exprime le chemin de
cette ressource fait penser à l'arborescence d'un système
de fichiers et c'est en effet souvent ainsi que c'est
mis en œuvre dans les serveurs (par exemple dans Apache, où le chemin, mettons
/foo/bar, est ajouté à la fin de la variable de
configuration DocumentRoot, avant d'être
récupéré sur le système de fichiers : si
DocumentRoot vaut
/var/www, le fichier demandé sera
/var/www/foo/bar). Mais ce n'est pas une
obligation de HTTP, qui ne normalise que le protocole entre le client
et le serveur, pas la façon dont le serveur obtient les
ressources.
La méthode HEAD fait la même chose que
GET mais sans renvoyer la représentation de la
ressource.
POST est plus compliquée. Contrairement à
GET, la requête contient des données qui vont
être envoyés au serveur. Celui-ci va les
traiter. POST est souvent utilisé pour
soumettre le contenu d'un formulaire Web, par
exemple pour envoyer un texte qui sera le contenu d'un commentaire
lors d'une discussion sur un forum Web. Avec
GET, POST est probablement
la méthode la plus souvent vue sur le Web.
PUT, lui, est également accompagné de
données qui vont être écrites à la place de la ressource
désignée. On peut donc mettre en œuvre un serveur de fichiers
distant avec des PUT et des
GET. On peut y ajouter
DELETE pour supprimer les ressources devenues
inutiles.
La méthode CONNECT est plus complexe. Elle
n'agit pas sur une ressource mais permet d'établir une connexion
avec un service distant. Sa principale utilité est de permettre
d'établir un tunnel au-dessus de
HTTP. Ainsi :
CONNECT server.example.com:80 HTTP/1.1 Host: server.example.com
va établir une connexion avec
server.example.com et les octets envoyés par la
suite sur cette connexion HTTP seront relayés aveuglément vers
server.example.com.
Quant à la méthode OPTIONS, elle permet
d'obtenir des informations sur les options gérées par le
serveur. curl permet d'indiquer une méthode avec son option
--request (ou -X) :
% curl -v --request OPTIONS https://www.bortzmeyer.org/ ... > OPTIONS / HTTP/2 > Host: www.bortzmeyer.org > user-agent: curl/7.68.0 > accept: */* > ... < HTTP/2 200 < permissions-policy: interest-cohort=() < allow: POST,OPTIONS,HEAD,GET ...
La section 10 du RFC est ensuite une longue section qui décrit le contexte des messages HTTP, c'est-à-dire les métadonnées qui accompagnent requêtes et réponses. Je ne vais évidemment pas en reprendre toute la liste ici. Juste quelques exemples de champs intéressants :
From:permet d'indiquer l'adresse de courrier du responsable du logiciel. Il est surtout utilisé par les bots (par exemple ceux qui ramassent les pages pour le compte d'un moteur de recherche) pour indiquer qui contacter si le bot se comporte mal, par exemple en faisant trop de requêtes. Comme le rappelle le RFC, un navigateur ordinaire ne doit évidemment pas transmettre une telle donnée personnelle à tous les sites Web visités !Referer:(oui, avec une faute d'orthographe) sert à indiquer l'URL d'où vient le client HTTP. Le Web étant fondé sur l'idée d'hypertexte, l'utilisateur est peut-être venu ici en suivant un lien, et il peut ainsi indiquer où il a trouvé ce lien, ce qui peut permettre au webmestre de voir d'où viennent ses visiteurs. Lui aussi pose des problèmes de vie privée, et j'ai toujours été surpris que le Tor Browser l'envoie.User-Agent:indique le type du client HTTP. À part s'amuser en regardant le genre de visiteurs qu'on a, il n'a pas de vraie utilité, le Web reposant sur des normes, et précisant une structure et pas une présentation, il ne devrait pas y avoir besoin de changer une ressource en fonction du logiciel du visiteur. Mais c'est quand même ce que font certains serveurs HTTP, poussant les clients à mentir pour obtenir un certain résultat, ce qui donne des champsUser-Agent:ridicules comme (vu sur ce blog)Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36(probablement le navigateur Safari indiquant autant de logiciels que possible ; le RFC dit qu'il ne faut pas le faire mais c'est courant, pour tenir compte de serveurs qui interprètent ce champ). Là encore, on a une métadonnée qui contribue puissamment à la fuite d'information si commune sur le Web (votre client HTTP est certainement trop bavard). LeUser-Agent:est très utile pour le fingerprinting, l'identification d'un visiteur particulier, comme le démontre le Panopticlick.Server:est l'équivalent deUser-Agent:mais pour le serveur.
Jusqu'à présent, on a supposé que les ressources servies étaient
accessibles à tous et toutes. Mais en pratique, on souhaite parfois
servir du contenu à accès restreint et on veut donc n'autoriser que certains visiteurs. Il
faut donc disposer de mécanismes
d'authentification, exposés dans la section
11 du RFC. HTTP n'a pas un mécanisme unique
d'authentification. Chaque mécanisme est identifié par un nom (et
les possibilités sont dans un
registre IANA). Le serveur indique le mécanisme à utiliser
dans un champ WWW-Authenticate: de sa première
réponse. Par exemple, basic, normalisé dans le
RFC 7617, est un mécanisme simple de
mot de passe, alors que
digest (normalisé dans le RFC 7616) permet de s'authentifier via un
défi/réponse. Le mécanisme est spécifique à
un royaume, une information donnée par le serveur pour le cas où le
même serveur gérerait des types d'authentification différents selon
la ressource.
Voici un exemple d'authentification (avec le service
d'administration d'un serveur
dnsdist, celui utilisé pour mon résolveur
public) où l'identificateur est admin et
le mot de passe 2e12 :
% curl -v --user admin:2e12 https://doh.bortzmeyer.fr:8080/ > GET / HTTP/1.1 > Host: doh.bortzmeyer.fr:8080 > Authorization: Basic YWRtbW...OTcyM= > User-Agent: curl/7.68.0 > Accept: */* > ... < HTTP/1.1 200 OK ...
La représentation renvoyée peut dépendre du client, c'est ce
qu'on nomme la négociation de contenu (section 12 du RFC). La
méthode officielle est que le client annonce avec le champ
Accept: les types
de données qu'il accepte, et le serveur lui envoie de
préférence ce qu'il a demandé. (C'est utilisé sur ce blog pour les
images. En pratique, ça ne se passe pas toujours bien.)
La demande du client n'est pas strictement binaire « je veux du
format WebP ». Elle peut s'exprimer de
manière plus nuancée, via le système de qualité. Ainsi :
Accept: text/plain; q=0.5, text/html
signifie que le client comprend le texte brut et l'HTML mais préfère ce dernier (le poids par défaut est 1, supérieur, donc, au 0,5 du texte brut).
La négociation de contenu ne s'applique pas qu'au format des
représentations, elle peut aussi s'appliquer à la
langue, avec le champ
Accept-Language:. Ainsi, en disant :
Accept-Language: da, en;q=0.8
veut dire « je préfère le danois (poids de 1 par défaut), mais j'accepte l'anglais ». En pratique, ce n'est pas très utile sur le Web car cela ne permet pas d'indiquer la qualité de la traduction. Si on indique qu'on préfère le français, mais qu'on peut lire l'anglais, en visitant des sites Web d'organisations internationales, on se retrouve avec un texte français mal traduit, alors qu'on aurait préféré la version originale. En outre, comme beaucoup de champs de l'en-tête de la requête, il contribue à identifier le client (fingerprinting). C'est d'autant plus gênant que l'indication des langues préférées peut vous signaler à l'attention de gens peu sympathiques, si ces langues sont celles d'une minorité opprimée.
Comme la représentation envoyée peut dépendre de ces demandes du
client, le serveur doit indiquer dans sa réponse s'il a effectivement
tenu compte de la négociation de contenu. C'est notamment important
pour les relais Web qui mémorisent le contenu des réponses (RFC 9111). Le champ Vary:
permet d'indiquer de quoi a réellement dépendu la réponse. Ainsi :
Vary: accept-language
indique que la réponse ne dépendait que de la langue. Si un client d'un relais Web demande la même ressource mais avec une autre langue, il ne faut pas lui donner le contenu mémorisé.
HTTP permet d'exprimer des requêtes conditionnelles. Un client HTTP peut par exemple demander une ressource « sauf si elle n'a pas été modifiée depuis 08:00 ». Cela permet d'économiser des ressources, notamment dans les relais qui mémorisent RFC 9111. C'est également utile aux clients de syndication, qui récupèrent régulièrement (polling) le flux Atom pour voir s'il a changé. Les requêtes conditionnelles permettent, la plupart du temps, d'éviter tout téléchargement de ce flux.
Un autre scénario d'utilisation des requêtes conditionnelles est
le cas de la mise à jour perdue (lost
update). Prenons un client qui met à jour une ressource,
en récupérant d'abord son état actuel (avec un
GET), en la modifiant, puis en téléversant la
version modifiée (avec par exemple un PUT). Si
deux clients font l'opération à peu près en même temps, il y a un
risque d'une séquence :
- Client 1 fait un
GET, - Client 2 fait pareil,
- Client 1 fait un
PUTavec sa version modifiée, - Client 2 en fait autant,
- La mise à jour de Client 1 est perdue
Les mises à jour conditionnelles résoudraient ce problème : si
Client 2 fait sa mise à jour en ajoutant « seulement si la ressource
n'a pas changé », son PUT sera refusé, il devra
refaire un GET et il récupérera alors les
changeements de Client 1 avant d'appliquer les siens.
En pratique, les requêtes conditionnelles se font avec des champs
comme If-Modified-Since: dont la valeur est une
date. Par exemple, le client de syndication qui a récupéré une page
le 24 février à 18:11, va envoyer un If-Modified-Since:
Thu, 24 Feb 2022 18:11:00 GMT et le serveur ne lui
enverra la ressource Atom ou
RSS que si elle est plus récente (il recevra
un code de retour 304 dans le cas contraire). Autre exemple de
champ d'en-tête pour les requêtes conditionnelles,
If-Match:. Ce champ demande que la requête ne
soit exécutée que si la ressource correspond à la valeur du
If-Match:. La valeur est un validateur, comme
expliqué plus haut. If-Match: permet ainsi de
résoudre le problème de la mise à jour perdue.
Les ressources chargées en HTTP peuvent être de grande
taille. Parfois, le réseau a un hoquet et le transfert s'arrête. Il
serait agréable de pouvoir ensuite reprendre là où on s'était
arrêté, au lieu de tout reprendre à zéro. HTTP le permet via les
requêtes d'un intervalle (section 14). Le client indique par le
champ Range: quel intervalle de la ressource il
souhaite. Cet intervalle peut se formuler en plusieurs unités, le
champ Accept-Ranges: permettant au serveur
d'indiquer qu'il gère ces demandes, et dans quelles unités. En
pratique, seuls les octets
marchent réellement. Par exemple, ici, j'utilise curl pour récupérer
50 octets d'un article :
% curl -v --range 3100-3150 https://www.bortzmeyer.org/1.html ... > GET /1.html HTTP/2 > Host: www.bortzmeyer.org > range: bytes=3100-3150 ... ocuments, qui forme l'ossature de la <b><a class="
Passons maintenant aux codes de retour HTTP (section 15). Il y en a au moins un qui est célèbre, 404, qui indique que la ressource demandée n'a pas été trouvée sur ce serveur et qui est souvent directement visible par l'utilisateur humain (pensez aux « pages 404 » d'erreur). Ces codes sont composés de trois chiffres, le premier indiquant la classe :
- 1 indique que l'opération n'est pas terminée,
- 2 indique que l'opération a été finie et avec succès,
- 3 indique que l'opération n'a pas été faite mais il ne s'agit pas pour autant d'une erreur (contrairement à ce que dit le RFC, ce n'est pas forcément une redirection, plutôt « la vérité est ailleurs », ainsi 304 signifie, en réponse à une requête conditionnelle, que la ressource n'a pas été modifiée),
- 4 indique une erreur due au client, et qu'il n'est donc pas utile que celui-ci réessaie à l'identique,
- 5 indique une erreur due au serveur et le client peut donc avoir intérêt à réessayer plus tard.
Les deux autres chiffres fournissent des détails mais un client HTTP simple peut se contenter de comprendre la classe et d'ignorer les deux autres chiffres. Par exemple, 100 signifie que le serveur a compris la requête mais qu'il faut encore attendre pour la vraie réponse, 200 veut dire qu'il n'y a rien à dire, que tout s'est bien passé comme demandé, 308 indique qu'il faut aller voir à un autre URL, 404, comme signalé plus haut, indique que le serveur n'a pas trouvé la ressource, 500 est une erreur générique du serveur, en général renvoyée quand le serveur a eu un problème imprévu. Peut-être connaissez-vous également :
- 201 qui indique que la ressource a été créée (en réponse à
un
PUT), - 304, pour répondre à une requête conditionnelle, qui veut dire que le contenu n'ayant pas été modifié, le serveur n'envoie pas de réponse (si votre serveur a un flux de syndication, vous trouverez souvent cette réponse dans vos journaux),
- 400 qui signifie que la requête était syntaxiquement incorrecte,
- 401, pour demander que le client s'authentifie avant d'accéder à cette ressource, et 403 qui lui refuse purement et simplement l'accès,
- 410 qui veut dire la même chose que 404 mais en ajoutant que la ressource a bien existé dans le passé mais a été retirée (utilisé par exemple dans un article de ce blog),
- 409 indique un conflit entre l'état de la ressource et une modification demandée par le client (lorsqu'on se sert de HTTP pour éditer des ressources),
- 414 pour un URL trop long pour ce serveur (la norme HTTP ne met pas de limite quantitative à la taille des URL mais chaque serveur, lui, a une telle limite),
- 418 n'est pas réellement dans le registre IANA mais il avait été utilisé dans un RFC du premier avril et il apparait souvent dans les blagues,
- 503 que le serveur utilise quand il est temporairement à bout de moyens (surcharge, par exemple),
De nouveaux codes sont créés de temps en temps, et mis dans le registre IANA.
curl -v vous affichera entre autres ce code
de retour. Si vous ne voulez que le code, et pas tous les messages
que l'utilisation de -v entrainera, l'option
--write-out est bien pratique :
% curl --silent --write-out "%{http_code}\n" --output /dev/null https://www.bortzmeyer.org/1.html
200
% curl --silent --write-out "%{http_code}\n" --output /dev/null https://www.bortzmeyer.org/2.html
404
Sinon, pour rire avec les codes de statut HTTP, il existe des photos de chats et une proposition d'illustrer ces codes par des émojis.
Beaucoup de choses dans HTTP peuvent être étendues (section 16). On peut créer de nouvelles méthodes, de nouveaux codes de retour, etc. Un logiciel client ou serveur ne doit donc pas s'étonner de voir apparaitre des questions ou des réponses qui n'existaient pas quand il a été programmé.
Ainsi, des nouvelles méthodes, en sus des traditionnelles
GET, POST,
PUT, etc , peuvent être créées, comme l'avait
été PATCH par le RFC 5789. La liste à jour des méthodes est dans un
registre IANA. Si vous programmez côté serveur, et que vous utilisez l'interface
CGI, la méthode est indiquée dans la variable
REQUEST_METHOD et vous pouvez la tester, par
exemple ici en Python :
if environ["REQUEST_METHOD"] == "FOOBAR": ... Do something useful else: return unsupported(start_response, environ["REQUEST_METHOD"])
Des codes de retour peuvent également être ajoutés, comme le 451 (censure) du RFC 7725. Là aussi, la liste faisant autorité est le registre IANA.
Bien sûr, le registre le plus dynamique, celui qui voit le plus
d'ajouts, est celui des champs de
l'en-tête. Mais attention : du fait qu'il bouge beaucoup, les
nouveaux champs ne seront pas compris et utilisés par une bonne
partie des logiciels. (Au passage, notre RFC rappelle que l'ancienne
convention de préfixer les noms de champs non officiels par un
X- a été abandonnée, par le RFC 6648.)
Et enfin, on peut étendre les listes de mécanismes d'authentification, et plusieurs autres.
Très utilisé, HTTP a évidemment connu sa part de problèmes de sécurité. La section 17 du RFC analyse les principaux risques. (Certains risques spécifiques sont traités dans d'autres RFC. Ainsi, les problèmes posés par l'analyse de l'encodage textuel de HTTP/1 sont étudiés dans le RFC 9112. Ceux liés aux URL sont dans le RFC 3986.) D'autre part, beaucoup de problème de sécurité du Web viennent :
- du code qui tourne sur le serveur ; notre RFC ne va pas parler de la sécurité de WordPress,
- des failles du client (par exemple si en exécutant du code JavaScript, il permet un accès excessif à la machine cliente),
- de l'Internet lui-même (comme la divulgation de l'adresse IP source).
Cette section 17 se concentre sur les problèmes de sécurité de HTTP, ce qui est déjà pas mal. Le RFC recommande la lecture des documents OWASP pour le reste.
Bon, premier problème, la notion d'autorité. Une réponse fait
autorité si elle vient de l'origine, telle
qu'indiquée dans l'URL. Le client HTTP va donc dépendre du mécanisme
de résolution de nom. Si, par exemple, la machine du client utilise
un résolveur DNS menteur, tout est
fichu. On croit aller sur http://pornhub.com/
et on se retrouve sur une page Web de
l'ARCOM. Il est donc crucial que cette
résolution de noms soit sécurisée, par exemple en utilisant un
résolveur DNS de confiance, et qui valide les réponses avec
DNSSEC. HTTPS protège partiellement. Une des
raisons pour lesquelles sa protection n'est pas parfaite est qu'il
est compliqué de valider proprement (cf. RFC 7525). Et puis les problèmes sont souvent non techniques,
par exemple la plupart des tentatives
d'hameçonnage ne vont pas viser l'autorité
mais la perception que l'utilisateur en a. Une page Web copiée sur
celle d'une banque peut être prise pour celle de la banque même si,
techniquement, il n'y a eu aucune subversion des techniques de
sécurité. Le RFC recommande qu'au minimum, les navigateurs Web
permettent d'examiner facilement l'URL vers lequel va un lien, et de
l'analyser (beaucoup d'utilisateurs vont croire, en voyant
https://nimportequoi.example/banque-de-confiance.com
que le nom de domaine est
banque-de-confiance.com…).
On a vu qu'HTTP n'est pas forcément de bout en bout et qu'il est même fréquent que des intermédiaires se trouvent sur le trajet. Évidemment, un tel intermédaire est idéalement placé pour certaines attaques. Bref, il ne faut utiliser que des intermédiaires de confiance et bien gérés. (De nombreuses organisations placent sur le trajet de leurs requêtes HTTP des boites noires au logiciel privateur qui espionnent le trafic et font Dieu sait quoi avec les données récoltées.)
HTTP est juste un protocole entre le client et le serveur. Le
client demande une ressource, le serveur lui envoie. D'où le serveur
a-t-il tiré cette ressource ? Ce n'est pas l'affaire de HTTP. En
pratique, il est fréquent que le serveur ait simplement lu un
fichier pré-existant sur ses disques et, en outre, que le chemin
menant à ce fichier vienne d'une simple transformation de l'URL. Par
exemple, Apache,
avec la directive DocumentRoot valant
/var/doc/mon-beau-site et une requête HTTP
GET /toto/tata.html va chercher un fichier
/var/www/mon-beau-site/toto/tata.html. Dans ce
cas, attention, certaines manipulations sur le chemin donné en
paramètre à GET peuvent donner au client
davantage d'accès que ce qui était voulu. Ainsi, sans précautions
particulières, une requête GET
/../toto/tata.html serait traduite en
/var/www/mon-beau-site/../toto/tata.html, ce
qui, sur Unix, équivaudra à
/var/www/toto/tata.html, où il n'était
peut-être pas prévu que le client puisse se promener. Les auteurs de
serveurs doivent donc être vigilants : ce qui vient du client n'est
pas digne de confiance.
Autre risque lorsqu'on fait une confiance aveugle aux données envoyées par le client, l'injection. Ces données, par exemple le chemin dans l'URL, sont traitées par des langages qui ont des règles spéciales pour certains caractères. Si un de ces caractères se retrouve dans l'URL, et qe le programme, côté serveur, n'est pas prudent avec les données extérieures, le ou les caractères spéciaux seront interprétés, avec parfois d'intéressantes failles de sécurité à la clé. (Mais, attention, tester la présence de « caractères dangereux » n'est en général pas une bonne idée.)
La liste des questions de sécurité liées à HTTP ne s'arrête pas là. On a vu que HTTP ne mettait pas de limite de taille à des éléments comme l'URL. Un analyseur imprudent, côté serveur, peut se faire attaquer par un client qui enverrait un chemin d'URL très long, déclenchant par exemple un débordement de tableau.
HTTP est un protocole très bavard, et un client HTTP possède
beaucoup d'informations sur l'utilisateur humain qui est
derrière. Le client doit donc faire très attention à ne pas envoyer
ces données. Le RFC ne donne pas d'exemple précis mais on peut par
exemple penser au champ Referer qui indique
l'URL d'où on vient. Si le client l'envoie systématiquement, et que
l'utilisateur visitait un site Web interne de l'organisation avant de
cliquer vers un lien externe, son navigateur enverra des détails sur
le site Web interne. Autre cas important,
un champ comme Accept-Language, qu'on peut
estimer utile dans certains cas, est dangereux pour la vie privée,
transmettant une information qui peut être sensible, par exemple si
on a indiqué une langue minoritaire et mal vue dans son pays. Et
User-Agent facilite le ciblage d'éventuelles
attaques du serveur contre le client.
Du fait de ce caractère bavard, et aussi parce que, sur l'Internet, il y a des choses qu'on ne peut pas dissimuler facilement (comme l'adresse IP source), ce que le serveur stocke dans ses journaux est donc sensible du point de vue de la vie privée. Des lois comme la loi Informatique & Libertés encadrent la gestion de telles bases de données personnelles. Le contenu de ces journaux doit donc être protégé contre les accès illégitimes.
Comme HTTP est bavard et que le client envoie beaucoup de choses
(comme les Accept-Language et
User-Agent cités plus haut), le serveur peut
relativement facilement faire du
fingerprinting,
c'est-à-dire reconnaitre un client HTTP parmi des dizaines ou des
centaines de milliers d'aures. (Vous ne me croyez pas ? Regardez le
Panopticlick.) Un serveur peut ainsi suivre un client
à la trace, même sans
cookies (voir
« A
Survey on Web Tracking: Mechanisms, Implications, and
Defenses »).
Voilà, et encore je n'ai présenté ici qu'une partie des questions de sécurité liées à l'utilisation de HTTP. Lisez le RFC pour en savoir plus. Passons maintenant aux différents registres IANA qui servent à stocker les différents éléments du protocole HTTP. Je les ai présenté (au moins une partie d'entre eux !) plus haut mais je n'ai pas parlé de la politique d'enregistrement de nouvaux éléments. En suivant la terminologie du RFC 8126, il y a entre autres le registre des méthodes (pour ajouter une nouvelle méthode, il faut suivre la politique « Examen par l'IETF », une des plus lourdes), le registre des codes de retour (même politique), le registre des champs (désormais séparé de celui des champs du courrier, politique « Spécification nécessaire »), etc.
Ah, et si vous voulez la syntaxe complète de HTTP sous forme d'une grammaire formelle, lisez l'ABNF en annexe A.
Et avec un langage de programmation ? Vu le succès de HTTP et sa présence partout, il n'est pas étonnant que tous les langages de programmation permettent facilement de faire des requêtes HTTP. HTTP, en tout cas HTTP/1, est suffisamment simple pour qu'on puisse le programmer soi-même en appelant les fonctions réseau de bas niveau, mais pourquoi s'embêter ? Utilisons les bibliothèques prévues à cet effet et commençons par le langage Python. D'abord avec la bibliothèque standard http.client :
conn = http.client.HTTPConnection(HOST)
conn.request("GET", PATH)
result = conn.getresponse()
body = result.read().decode()
Et hop, la variable body contient une
représentation de la ressource demandée (le programme complet est en
sample-http-client.py). En pratique, la plupart des
programmeurs Python utiliseront sans doute une autre
bibliothèque standard, qui n'est pas spécifique à HTTP et
permet de traiter des URL quelconques (cela
donne le programme sample-http-urllib.py). D'encore
plus haut niveau (mais pas incluse dans la bibliothèque standard, ce
qui ajoute une dépendance à votre programme) est la bibliothèque
Requests, souvent utilisée (voir par exemple sample-http-requests.py).
Ensuite, avec le langage Go. Là aussi, il dispose de HTTP dans sa bibliothèque standard :
response, err := http.Get(Url) defer response.Body.Close() body, err := ioutil.ReadAll(response.Body)
Le programme complet est sample-http.go.
Et ici un client en Elixir, utilisant la bibliothèque HTTPoison :
HTTPoison.start()
{:ok, result} = HTTPoison.get(@url)
La version longue est en sample-http.ex
L'annexe B de notre RFC fait la liste des principaux changements depuis les précédents RFC. Je l'ai dit, le protocole ne change pas réellement mais il y a quand même quelques modifications, notamment des clarifications de textes trop ambigus (par exemple la définition des intervalles). Et bien sûr le gros changement est qu'il y a désormais une définition abstraite de ce qu'est un message HTTP, séparée des définitions concrètes pour les trois versions de HTTP en service. En outre, il y a désormais des recommandations explicites de taille minimale à accepter pour certains élements (par exemple 8 000 octets pour les URI).
HTTP est, comme vous le savez, un immense succès, dû à la place prise par le Web, dont il est le protocole de référence. Le RFC résume l'histoire de HTTP :
- Publié pour la première fois en
1990, au début un protocole ultra-simple,
réduit à la méthode
GET, et qui n'a été documenté qu'après, - HTTP/1.0 (RFC 1945 en 1996 mais le protocole existait bien avant le RFC) en a fait un protocole bien plus riche (en-tête, plusieurs méthodes), avec indication du type des ressources, et virtual hosting,
- HTTP/1.1 en 1995 (normalisé dans le RFC 2068 à l'origine, et aujourd'hui RFC 9112), au moment de l'explosion de l'usage du Web, a apporté beaucoup d'améliorations, comme le fait que les connexions sont persistentes par défaut,
- HTTP/2 a marqué plusieurs ruptures en 2015 (RFC 7540), avec son parallélisme (les réponses n'arrivent plus forcément dans l'ordre des requêtes) et son encodage binaire, rompant avec la tradition textuelle de beaucoup de protocoles IETF,
- Et enfin HTTP/3 (RFC 9114, en 2022) a abandonné TCP pour QUIC,
L'article seul
RFC 9113: HTTP/2
Date de publication du RFC : Juin 2022
Auteur(s) du RFC : M. Thomson (Mozilla), C. Benfield (Apple)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 7 juin 2022
Le protocole HTTP, à la base des échanges sur le Web, a plusieurs versions, 1, 2 et 3. Toutes ont en commun la même sémantique, décrite dans le RFC 9110. Mais l'encodage sur le câble est différent. HTTP/2 a un encodage binaire et un transport spécifique (binaire, multiplexé, avec possibilité de push). Fini de déboguer des serveurs HTTP avec telnet. En échange, cette version promet d'être plus rapide, notamment en diminuant la latence lors des échanges. Ce RFC remplace l'ancienne norme HTTP/2 (RFC 7540), mais le protocole ne change pas, il s'agit surtout d'une réécriture pour suivre le nouveau cadre de normalisation, où un RFC générique, le RFC 9110 spécifie la sémantique de HTTP et où il y a un RFC spécifique par version.
La section 1 de notre RFC résume les motivations derrère cette version 2, et notamment les limites de HTTP/1.1, normalisé dans le RFC 9112 :
- Une seule requête au plus en attente sur une connexion TCP donnée. Cela veut dire que, si on a deux requêtes à envoyer au même serveur, et que l'une est lente et l'autre rapide, il faudra faire deux connexions TCP (la solution la plus courante), ou bien se résigner au risque que la lente bloque la rapide. (La section 9.3.2 du RFC 9112 permet d'envoyer la seconde requête tout de suite mais les réponses doivent être dans l'ordre des requêtes, donc pas moyen pour une requête rapide de doubler une lente.)
- Un encodage des en-têtes inefficace, trop bavard et trop redondant.
Au contraire, HTTP/2 n'utilise toujours qu'une seule connexion TCP, de longue durée (ce qui sera plus sympa pour le réseau). L'encodage étant entièrement binaire, le traitement par le récepteur est normalement plus rapide. Le RFC note toutefois que HTTP/2, qui dépend de TCP et n'utilise qu'une seule connexion TCP, ne résout pas le problème du head-of-line blocking. (Pour cela, il faudrait HTTP/3, normalisé dans le RFC 9114.)
La section 2 de notre RFC résume l'essentiel de ce qu'il faut
savoir sur HTTP/2. Il garde la sémantique générale de HTTP (donc,
par exemple, un GET de
/cetteressourcenexistepas fait un 404). La
norme HTTP/2 ne normalise que le transport des messages, pas les
messages ou leurs réponses (qui sont décrits par le RFC 9110). Notez que HTTP/2 s'appelait il y a très longtemps
SPDY (initialement lancé par
Google).
Avec HTTP/2, l'unité de base de la communication est la
trame (frame, et, dans
HTTP/2, vous pouvez oublier la définition traditionnelle qui en fait
l'équivalent du paquet, mais pour la couche 2). Chaque trame a un type et, par exemple,
les échanges HTTP traditionnels se feront avec simplement une trame
HEADERS en requête et une
DATA en réponse. Certains types sont
spécifiques aux nouvelles fonctions de HTTP/2, comme
SETTINGS ou
PUSH_PROMISE.
Les trames voyagent ensuite dans des ruisseaux
(streams), chaque ruisseau hébergeant un et un
seul échange requête/réponse. On crée donc un ruisseau à chaque fois
qu'on a un nouveau GET ou
POST à faire. Les petits ruisseaux sont ensuite
multiplexés dans une grande rivière, l'unique connexion TCP entre un
client HTTP et un serveur. Les ruisseaux ont des mécanismes de
contrôle du trafic (ils avaient aussi un mécanisme de prioritisation
entre eux, que notre RFC abandonne).
Les en-têtes sont comprimés, en favorisant le cas le plus courant, de manière à s'assurer, par exemple, que la plupart des requêtes HTTP tiennent dans un seul paquet de la taille des paquets Ethernet.
Bon, maintenant, les détails pratiques (le RFC fait 90
pages). D'abord, l'établissement de la connexion. HTTP/2 tourne
au-dessus de TCP. Comment on fait pour savoir si le serveur
accepte HTTP/2 ? C'est marqué dans l'URL ? Non, les URL sont les mêmes,
avec les plans http: et
https:. On utilise un nouveau port, succédant au 80 de HTTP ?
Non. Les ports sont les mêmes, 80 et 443. On regarde dans le
DNS ou ailleurs si
le serveur sait faire du HTTP/2 ? Pas encore, bien que le futur
type de données DNS HTTPS permettra cela. Aujourd'hui, les
méthodes pour savoir si le client doit tenter HTTP/2 sont :
- Une configuration explicite (comme l'option
--http2de curl dans les exemples plus loin), - L'en-tête
Alt-Svc:du RFC 7838, qui nécessite de tenter en HTTP/1 d'abord, - Si on fait du HTTPS et donc du TLS, on peut utiliser ALPN (RFC 7301), en indiquant l'identificateur
h2(HTTP/2 sur TLS). Le serveur, recevant l'extension ALPN avech2, saura ainsi qu'on fait du HTTP/2 et on pourra tout de suite commencer l'échange de trames HTTP/2. (h2est dans le registre IANA. Dans le RFC 7540, il y avait aussi unh2cdont l'usage est maintenant abandonné.) - L'en-tête
HTTP
Upgrade:qui était dans la section 6.7 du RFC 7230 est désormais abandonné.
Une fois qu'un client aura réussi à établir une connexion avec un serveur en HTTP/2, il sait que le serveur gère ce protocole. Il peut s'en souvenir, pour les futures connexions (mais attention, ce n'est pas une indication parfaite : un serveur peut abandonner HTTP/2, par exemple).
Maintenant, c'est parti, on s'envoie des trames (il y a d'abord
une préface, un nombre magique qui permet de
s'assurer que tout le monde comprend bien HTTP/2, mais je n'en
parlerai pas davantage). À quoi
ressemblent ces trames (section 4) ? Elles commencent par un en-tête
indiquant leur longueur, leur type (comme
SETTINGS, HEADERS,
DATA… cf. section 6), des options (comme
ACK qui sert aux trames de type
PING à distinguer requête et réponse) et
l'identificateur du ruisseau auquel la trame appartient (un nombre
sur 31 bits). Le format complet est en section 4.1.
Les en-têtes HTTP sont comprimés selon la méthode normalisée dans le RFC 7541.
Les ruisseaux (streams), maintenant. Ce sont donc des suites ordonnées de trames, bi-directionnelles, à l'intérieur d'une connexion HTTP/2. Une connexion peut comporter plusieurs ruisseaux, chacun identifié par un stream ID (un entier de quatre octets, pair si le ruisseau a été créé par le serveur et impair autrement). Les ruisseaux sont ouverts et fermés dynamiquement et leur durée de vie n'est donc pas celle de la connexion HTTP/2. Contrairement à TCP, il n'y a pas de « triple poignée de mains » : l'ouverture d'un ruisseau est unilatérale et peut donc se faire très vite (rappelez-vous que chaque échange HTTP requête/réponse nécessite un ruisseau qui lui est propre ; pour vraiment diminuer la latence, il faut que leur création soit rapide). Les identificateurs ne sont jamais réutilisés (si on tombe à cours, la seule solution est de fermer la connexion TCP et d'en ouvrir une autre).
Un mécanisme de contrôle du flot s'assure que les ruisseaux se
partagent pacifiquement la connexion. C'est donc une sorte de TCP
dans le TCP, réinventé pour les besoins de HTTP/2 (section 5.2 et
relire aussi le RFC 1323). Le récepteur
indique (dans une trame WINDOWS_UPDATE) combien
d'octets il est prêt à recevoir (64 Kio par défaut) et l'émetteur
s'arrête dès qu'il a rempli cette fenêtre d'envoi. (Plus exactement,
s'arrête d'envoyer des trames DATA : les
autres, les trames de contrôle, ne sont pas soumises au contrôle du
flot).
Comme si ce système des connexions dans les connexions n'était pas assez compliqué comme cela, il y a aussi des dépendances entre ruisseaux. Un ruisseau peut indiquer qu'il dépend d'un autre et, dans ce cas, les ressources seront allouées d'abord au ruisseau dont on dépend. Par exemple, le code JavaScript ne peut en général commencer à s'exécuter que quand toute la page est chargée, et on peut donc le demander dans un ruisseau dépendant de celle qui sert à charger la page. On peut dépendre d'un ruisseau dépendant, formant ainsi un arbre de dépendances.
Il peut bien sûr y avoir des erreurs dans la
communication. Certaines affectent toute la connexion, qui devra
être abandonnée, mais d'autres ne concernent qu'un seul
ruisseau. Dans le premier cas, celui qui détecte l'erreur envoie une
trame GOAWAY (dont on ne peut pas garantir
qu'elle sera reçue, puisqu'il y a une erreur) puis coupe la
connexion TCP. Dans le second cas, si le problème ne concerne qu'un
seul ruisseau, on envoie la trame RST_STREAM
qui arrête le traitement du ruisseau.
HTTP/2 avait (RFC 7540, section 5.3) un mécanisme de priorité entre trames, qui permettait d'éviter, par exemple, que la récupération d'une grosse image ne ralentisse le chargement d'une feuille de style. Mais il était trop complexe, et a été peu mis en œuvre, la plupart des serveurs ignoraient les demandes de priorité des clients. Un nouveau mécanisme est décrit dans le RFC 9218.
Notre section 5 se termine avec des règles qui indiquent comment gérer des choses inconnues dans le dialogue. Ces règles permettent d'étendre HTTP/2, en s'assurant que les vieilles mises en œuvre ne pousseront pas des hurlements devant les nouveaux éléments qui circulent. Par exemple, les trames d'un type inconnu doivent être ignorées et mises à la poubelle directement, sans protestation.
On a déjà parlé plusieurs fois des trames, la section 6 du RFC détaille leur définition. Ce sont aux ruisseaux ce que les paquets sont à IP et les segments à TCP. Les trames ont un type (un entier d'un octet). Les types possibles sont enregistrés à l'IANA. Les principaux types actuels sont :
DATA(type 0), les trames les plus nombreuses, celles qui portent les données, comme les pages HTML (elles peuvent aussi contenir du remplissage, pour éviter qu'un observateur ne déduise de la taille des réponses la page qu'on regardait, cf. section 10.7),HEADERS(type 1), qui portent les en-têtes HTTP, dûment comprimés selon le RFC 7541,PRIORITY(type 2) indiquait la priorité que l'émetteur donne au ruisseau qui porte cette trame, mais ce type de trame n'est désormais plus utilisé,RST_STREAM(type 3), dont j'ai parlé plus haut à propos des erreurs, permet de terminer un ruisseau (filant la métaphore, on pourrait dire que cela assèche le ruisseau ?),SETTINGS(type 4), permet d'envoyer des paramètres, commeSETTINGS_HEADER_TABLE_SIZE, la taille de la table utilisée pour la compression des en-têtes,SETTINGS_MAX_CONCURRENT_STREAMSpour indiquer combien de ruisseaux est-on prêt à gérer, etc (la liste des paramètres est dans un registre IANA),PUSH_PROMISE(type 5) qui indique qu'on va transmettre des données non sollicitées (push), du moins si le paramètreSETTINGS_ENABLE_PUSHest à 1,PING(type 6) qui permet de tester le ruisseau (le partenaire va répondre avec une autre tramePING, ayant l'optionACKà 1),GOAWAY(type 7) que nous avons déjà vu plus haut, sert à mettre fin proprement (le pair est informé de ce qui va se passer) à une connexion,WINDOW_UPDATE(type 8) sert à faire varier la taille de la fenêtre (le nombre d'octets qu'on peut encore accepter, cf. section 6.9.1),CONTINUATION(type 9), indique la suite d'une trame précédente. Cela n'a de sens que pour certains types commeHEADERS(ils peuvent ne pas tenir dans une seule trame) ouCONTINUATIONlui-même. Mais une trameCONTINUATIONne peut pas être précédée deDATAou dePING, par exemple.
Dans le cas vu plus haut d'erreur entrainant la fin d'un ruisseau
ou d'une connexion entière, il est nécessaire d'indiquer à son
partenaire en quoi consistait l'erreur en question. C'est le rôle
des codes d'erreur de la section 7. Stockés sur quatre octets (et
enregistrés dans un
registre IANA), ils sont transportés par les trames
RST_STREAM ou GOAWAY qui
terminent, respectivement, ruisseaux et connexions. Parmi ces
codes :
NO_ERROR(code 0), pour les cas de terminaison normale,PROTOCOL_ERROR(code 1) pour ceux où le pair a violé une des règles de HTTP/2, par exemple en envoyant une trameCONTINUATIONqui n'était pas précédée deHEADERS,PUSH_PROMISEouCONTINUATION,INTERNAL_ERROR(code 2), un malheur est arrivé,ENHANCE_YOUR_CALM(code 11), qui ravira les amateurs de spam et de Viagra, demande au partenaire en face de se calmer un peu, et d'envoyer moins de requêtes.
Toute cette histoire de ruisseaux, de trames, d'en-têtes
comprimés et autres choses qui n'existaient pas en HTTP/1 est bien
jolie mais HTTP/2 n'a pas été conçu comme un remplacement de TCP,
mais comme un moyen de faire passer des dialogues HTTP. Comment met-on
les traditionnelles requêtes/réponses HTTP sur une connexion
HTTP/2 ? La section 8 répond à cette question. D'abord, il faut se
rappeler que HTTP/2 est du HTTP. La sémantique est donc celle du
RFC 9110. Il y a quelques différences comme le
fait que certains en-têtes disparaissent, par exemple
Connection: (section 8.2.2) qui n'est plus
utile en HTTP/2 ou Upgrade: (section 8.6).
HTTP est requête/réponse. Pour envoyer une requête, on utilise un
nouveau ruisseau (envoi d'une trame avec un numéro de ruisseau non
utilisé), sur laquelle on lira la réponse (les ruisseaux ne sont pas
persistents). Dans le cas le plus fréquent, la requête sera composée
d'une trame HEADERS contenant les en-têtes
(comme User-Agent: ou
Host:, cf. RFC 9110,
section 10.1) et les « pseudo-en-têtes » comme la méthode
(GET, POST, etc), avec
parfois des trames DATA (cas d'un
POST). La réponse comprendra une trame
HEADERS avec les en-têtes (comme
Content-Length:) et les pseudo-en-têtes comme
le code de retour HTTP (200, 403, 500, etc) suivie de plusieurs
trames DATA contenant les données (HTML, CSS, images,
etc). Des variantes sont possibles (par exemple, les trames
HEADERS peuvent être suivies de trames
CONTINUATION). Les en-têtes ne sont pas
transportés sous forme texte (ce qui était le cas en HTTP/1, où on
pouvait utiliser telnet comme client HTTP)
mais encodés en binaire, et comprimés selon
le RFC 7541. À noter que cet encodage implique
une mise du nom de l'en-tête en minuscules.
J'ai parlé plus haut des pseudo-en-têtes : c'est le mécanisme
HTTP/2 pour traiter des informations qui ne sont pas des en-têtes
en HTTP (section 8.3). Ces informations sont mises dans les
HEADERS HTTP/2, précédés d'un
deux-points. C'est le cas de la méthode (RFC 9110, section 9.3), donc GET
sera encodé :method GET. L'URL sera éclaté dans
les pseudo-en-têtes :scheme,
:path, etc. Idem pour la réponse HTTP, le
fameux code à trois lettres est désormais un pseudo-en-tête,
:status.
Le RFC met en garde les programmeur·ses : certains caractères peuvent être dangereux car profitant des faiblesses de certains analyseurs ou bien utilisant le fait que HTTP n'est pas toujours de bout en bout et qu'un message peut être traduit de HTTP/1 en HTTP/2 (ou réciproquement). Un deux-points dans le nom d'un champ, par exemple, pourrait produire un message dont l'interprétation ne serait pas celle attendue (ce qu'on nomme le request smuggling).
Voici des exemples de requêtes HTTP (mais vous ne le verrez pas ainsi si vous espionnez le réseau, en raison de la compression du RFC 7541) :
### HTTP/1, pas de corps dans la requête ### GET /resource HTTP/1.1 Host: example.org Accept: image/jpeg ### HTTP/2 (une trame HEADERS) :method = GET :scheme = https :path = /resource host = example.org accept = image/jpeg
Puis une réponse qui n'a pas de corps :
### HTTP/1 ### HTTP/1.1 304 Not Modified ETag: "xyzzy" Expires: Thu, 23 Jan ... ### HTTP/2, une trame HEADERS ### :status = 304 etag = "xyzzy" expires = Thu, 23 Jan ...
Une réponse plus traditionnelle, qui inclut un corps :
### HTTP/1 ###
HTTP/1.1 200 OK
Content-Type: image/jpeg
Content-Length: 123
{binary data}
### HTTP/2 ###
# trame HEADERS
:status = 200
content-type = image/jpeg
content-length = 123
# trame DATA
{binary data}
Plus compliqué, un cas où les en-têtes de la requête ont été mis dans deux trames, et où il y avait un corps dans la requête :
### HTTP/1 ###
POST /resource HTTP/1.1
Host: example.org
Content-Type: image/jpeg
Content-Length: 123
{binary data}
### HTTP/2 ###
# trame HEADERS
:method = POST
:path = /resource
:scheme = https
# trame CONTINUATION
content-type = image/jpeg
host = example.org
content-length = 123
# trame DATA
{binary data}
Nouveauté introduite par HTTP/2, la possibilité pour le serveur
de pousser (push, section 8.4 de notre RFC) du
contenu non sollicité vers le client (sauf si cette possibilité a
été coupée par le paramètre
SETTINGS_ENABLE_PUSH). Pour cela, le serveur
(et lui seul) envoie une trame de type
PUSH_PROMISE au client, en utilisant le
ruisseau où le client avait fait une demande originale (donc, la
sémantique de PUSH_PROMISE est « je te promets
que lorsque le moment sera venu, je répondrai plus longuement à ta
question »). Cette trame contient une requête HTTP. Plus tard,
lorsque le temps sera venu, le serveur tiendra sa promesse en
envoyant la « réponse » de cette « requête » sur le ruisseau qu'il
avait indiqué dans le PUSH_PROMISE.
Et enfin, à propos des méthodes HTTP/1 et de leur équivalent en
HTTP/2, est-ce que CONNECT (RFC 9110, section 9.3.6) fonctionne toujours ? Oui, on peut
l'utiliser pour un tunnel sur un
ruisseau. (Un tunnel sur un ruisseau... Beau défi pour le
génie civil.)
La section 9 de notre RFC rassemble quelques points divers. Elle rappelle que, contrairement à HTTP/1, toutes les connexions sont persistentes et que le client n'est pas censé les fermer avant d'être certain qu'il n'en a plus besoin. Tout doit passer à travers une connexion vers le serveur et les clients ne doivent plus utiliser le truc d'ouvrir plusieurs connexions HTTP avec le serveur. De même, le serveur laisse les connexions ouvertes le plus longtemps possible, mais a le droit de les fermer s'il doit économiser des ressources.
À noter qu'on peut utiliser une connexion prévue pour un autre
nom, du moment que cela arrive au même serveur (même adresse IP). Le
pseudo-en-tête :authority sert à départager les
requêtes allant à chacun des serveurs. Mais attention si la session
utilise TLS !
L'utilisation d'une connexion avec un autre
:authority (host + port)
n'est possible que si le certificat serveur qui a été utilisé est
valable pour tous (par le biais des
subjectAltName, ou bien d'un joker).
À propos de TLS, la section
9.2 prévoit quelques règles qui n'existaient pas en HTTP/1 (et dont
la violation peut entrainer la coupure de la connexion avec l'erreur
INADEQUATE_SECURITY) :
- TLS 1.2 (RFC 5246), minimum,
- Gestion de SNI (RFC 6066) obligatoire,
- Compression coupée (RFC 3749), comme indiqué dans le RFC 7525 (permettre la compression de données qui mêlent informations d'authentification comme les cookies, et données contrôlées par l'attaquant, permet certaines attaques comme BREACH) ce qui n'est pas grave puisque HTTP a de meilleures capacités de compression (voir aussi la section 10.6),
- Renégociation coupée, ce qui empêche de faire une renégociation en réponse à une certaine requête (pas de solution dans ce cas) et peut conduire à couper une connexion si le mécanisme de chiffrement sous-jacent ne permet pas d'encoder plus de N octets sans commencer à faire fuiter de l'information.
- Très sérieuse limitation du nombre d'algorithmes de chiffrement acceptés (voir l'annexe A pour une liste complète), en éliminant les algorithmes trop faibles cryptographiquement (comme les algorithmes « d'exportation » utilisés dans la faille FREAK). Peu d'algorithmes restent utilisables après avoir retiré cette liste !
Puisqu'on parle de sécurité, la section 10 traite un certain nombre de problèmes de sécurité de HTTP/2. Elle rappelle que TLS est fortement recommandé (mais il n'est devenu obligatoire qu'avec HTTP/3, HTTP/2 permettant toutefois une utilisation « opportuniste », cf. RFC 8164). Parmi les problèmes qui sont spécifiques à HTTP/2, on note que ce protocole demande plus de ressources que HTTP/1, ne serait-ce que parce qu'il faut maintenir un état pour la compression. Il y a donc potentiellement un risque d'attaque par déni de service. Une mise en œuvre prudente veillera donc à limiter les ressources allouées à chaque connexion.
Enfin, il y a la question de la vie privée, un sujet chaud dans le monde HTTP depuis longtemps. Les options spécifiques à HTTP/2 (changement de paramètres, gestion du contrôle de flot, traitement des innombrables variantes du protocole) peuvent permettre d'identifier une machine donnée par son comportement. HTTP/2 facilite donc le fingerprinting.
En outre, comme une seule connexion TCP est utilisée pour toute une visite sur un site donné, cela peut rendre explicite une information comme « le temps passé sur un site », information qui était implicite en HTTP/1, et qui devait être reconstruite.
Comme on le voit, HTTP/2 est bien plus complexe que HTTP/1. On ne peut pas espérer programmer un client ou un serveur en quelques heures, comme on le fait avec HTTP/1. C'est en partie pour cela que personne ne prévoit un abandon de HTTP/1, qui continuera à coexister avec HTTP/2 (et HTTP/3 !) pendant très longtemps encore.
Question mises en œuvre, HTTP/2 est désormais présent dans la quasi-totalité des clients, serveurs et bibliothèques HTTP. Ici, avec curl, en forçant l'utilisation de HTTP/2 dès le début :
% curl -v --http2 https://www.bortzmeyer.org/7540.html * Trying 2001:4b98:dc0:41:216:3eff:fe27:3d3f:443... * Connected to www.bortzmeyer.org (2001:4b98:dc0:41:216:3eff:fe27:3d3f) port 443 (#0) * ALPN, offering h2 * ALPN, offering http/1.1 ... * ALPN, server accepted to use h2 * Server certificate: * subject: CN=www.bortzmeyer.org ... * Using HTTP2, server supports multiplexing * Copying HTTP/2 data in stream buffer to connection buffer after upgrade: len=0 * h2h3 [:method: GET] * h2h3 [:path: /7540.html] * h2h3 [:scheme: https] * h2h3 [:authority: www.bortzmeyer.org] * h2h3 [user-agent: curl/7.82.0] * h2h3 [accept: */*] * Using Stream ID: 1 (easy handle 0x5639a5d10cf0) > GET /7540.html HTTP/2 > Host: www.bortzmeyer.org > user-agent: curl/7.82.0 > accept: */* ... < HTTP/2 200 ... < etag: "b4b0-5de09d5830d11" < content-type: text/html; charset=UTF-8 < date: Thu, 05 May 2022 13:07:08 GMT < server: Apache/2.4.53 (Debian) < <?xml version="1.0" ?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xml:lang="fr" lang="fr" xmlns="http://www.w3.org/1999/xhtml"> <head> ...
Vous voulez voir un joli pcap de HTTP/2 ? La plupart des sites accessibles en HTTP/2 (et parfois des clients) imposent TLS. Il faut donc, si on veut voir « à l'intérieur » des paquets, utiliser la technique classique d'exportation de la clé :
% export SSLKEYLOGFILE=/tmp/http2.key % curl --http2 https://www.bortzmeyer.org/7540.html
Puis vérifiez que dans les préférences de
Wireshark, on a cette clé (par exemple dans
~/.config/wireshark/preferences, une ligne
tls.keylog_file: /tmp/http2.key). On peut alors
regarder le pcap en détail. Voici un tel
pcap et la clé
correspondante. Cela permet de regarder le contenu des
messages avec Wireshark :
Cela permet aussi, avec une commande comme
tshark -V -r http2.pcap > http2.txt, de
produire un joli fichier
d'analyse. Notez les identificateurs de ruisseaux
(Stream ID) : il n'y en a que deux, 0 et 1, car
on n'a chargé qu'une ressource (il y a un ruisseau dans chaque direction). Je
vous laisse faire vous-même l'opération pour le cas de deux
ressources, avec une commande comme curl -v --http2
https://www.bortzmeyer.org/7540.html
https://www.bortzmeyer.org/9116.html. Vous verrez alors
le parallélisme de HTTP/2 et les multiples ruisseaux.
Et, sinon, si vous voulez activer HTTP/2 sur un serveur
Apache, c'est aussi
simple que de charger le module http2 et de
configurer :
Protocols h2 http/1.1
Sur Debian, la commande a2enmod
http2 fait tout cela automatiquement. Pour vérifier que
cela a bien été fait, vous pouvez utiliser curl
-v comme vu plus haut, ou bien un site de test (comme
KeyCDN) ou
encore la fonction Inspect element (clic droit
sur la page, puis onglet Network puis
sélectionner une des ressources chargées) de Firefox :
L'annexe B liste les principaux changements depuis le RFC 7540, notamment :
- L'abandon du mécanisme de priorité entre ruisseaux, trop complexe, remplacé par celui du RFC 9218.
- L'abandon de l'utilisation de
Upgrade:pour passer de HTTP/1 en HTTP/2, - Obligation plus strictes de valider la syntaxe des en-têtes,
- Meilleure description des en-têtes spécifiques à la gestion de la connexion, et qui ne doivent plus être utilisés,
- Et bien sûr un certain nombre de changements pour s'aligner avec le nouveau cadre générique du RFC 9110 et notamment sa terminologie.
Et, sinon, si vous voulez vous instruire sur HTTP/2 sans lire tout le RFC, il y a évidemment le livre de Daniel Stenberg.
L'article seul
RFC 9114: Hypertext Transfer Protocol Version 3 (HTTP/3)
Date de publication du RFC : Juin 2022
Auteur(s) du RFC : M. Bishop (Akamai)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF quic
Première rédaction de cet article le 7 juin 2022
Le protocole de transport QUIC, bien que permettant plusieurs protocoles applicatifs au-dessus de lui, a été surtout conçu pour HTTP. Il est donc logique que le premier protocole applicatif tournant sur QUIC et normalisé soit HTTP. Voici donc HTTP/3, la nouvelle version d'HTTP, et la première qui tourne sur QUIC, les précédentes tournant sur TCP (et, souvent, sur TLS sur TCP). À part l'utilisation de QUIC, HTTP/3 est très proche de HTTP/2.
Un petit point d'histoire sur HTTP : la version 1.1 (dont la norme précédente datait de 2014) utilise du texte, ce qui est pratique pour les humains (on peut se servir de netcat ou telnet comme client HTTP), mais moins pour les programmes. En outre, il n'a aucun multiplexage, encourageant les auteurs de navigateurs à ouvrir plusieurs connexions TCP simultanées avec le serveur, connexions qui ne partagent pas d'information entre elles et sont donc inefficaces. La version 2 de HTTP (RFC 9113) est binaire et donc plus efficace, et elle inclut du multiplexage. Par contre, les limites de TCP (une perte de paquet va affecter toutes les ressources en cours de transfert, une ressource lente peut bloquer une rapide, etc) s'appliquent toujours. D'où le passage à QUIC pour HTTP/3. QUIC améliore la latence, notamment grâce à la fusion avec TLS, et fournit du « vrai » multiplexage. Autrement, HTTP/3 est très proche de HTTP/2, mais il est plus simple, puisque le multiplexage est délégué à la couche transport.
QUIC offre en effet plusieurs fonctions très pratiques pour HTTP/3, notamment le multiplexage (complet : plus de head-of-line blocking), le contrôle de débit par ruisseau et pas par connexion entière, et l'établissement de connexion à faible latence. QUIC a été conçu en pensant à HTTP et aux problèmes spécifiques du Web.
Nous avons maintenant toute une panoplie de versions de HTTP, du HTTP/1.1 du RFC 9112 et suivants, au HTTP/2 du RFC 9113, puis désormais à notre HTTP/3. De même que HTTP/2 n'a pas supprimé HTTP/1, HTTP/3 ne supprimera pas HTTP/2, ne serait-ce que parce qu'il existe encore beaucoup de réseaux mal gérés et/ou restrictifs, où QUIC ne passe pas. Toutes ces versions de HTTP ont en commun les mêmes sémantiques, décrites dans le RFC 9110.
La section 2 du RFC fait un panorama général de HTTP/3. Quand le
client HTTP sait (on verra plus tard comment il peut savoir) que le
serveur fait du HTTP/3, il ouvre une connexion QUIC avec ce
serveur. QUIC fera le gros du travail. À l'intérieur de chaque
ruisseau QUIC, il y aura un seul couple requête/réponse HTTP. La
requête et la réponse seront placées dans des trames
QUIC de type STREAM (les trames de
contenu dans QUIC). À l'intérieur des trames QUIC, il y aura des
trames
HTTP, dont deux types sont particulièrement importants,
HEADERS et DATA. QUIC
étant ce qu'il est, chaque couple requête/réponse est séparé et, par
exemple, la lenteur à envoyer une réponse n'affectera pas les autres
requêtes, mêmes envoyées après celle qui a du mal à avoir une
réponse. (Il y a aussi la possibilité pour le serveur d'envoyer des
données spontanément, avec les trames HTTP de type
PUSH_PROMISE et quelques autres.) Les requêtes
et les réponses ont un encodage binaire comme en HTTP/2, et sont
comprimées avec QPACK (RFC 9114), alors que HTTP/2 utilisait HPACK (qui nécessitait
une transmission ordonnées des octets, qui n'existe plus dans une
connexion QUIC).
Après cette rapide présentation, voyons les détails, en
commençant par le commencement, l'établissement des connexions entre
client et serveur. D'abord, comment savoir si le serveur veut bien
faire du HTTP/3 ? Le client HTTP a reçu consigne de l'utilisateur
d'aller en
https://serveur-pris-au-hasard.example/,
comment va t-il choisir entre HTTP/3 et des versions plus classiques
de HTTP ? Il n'y a rien dans l'URL qui indique que QUIC est possible mais il y
a plusieurs méthodes de découverte, permettant au client une grande
souplesse. D'abord, le client peut simplement tenter sa chance : on
ouvre une connexion QUIC vers le port 443 et
on voit bien si ça marche ou si on reçoit un message ICMP nous
disant que c'est raté. Ici, un exemple vu avec
tcpdump :
11:07:20.368833 IP6 (hlim 64, next-header UDP (17) payload length: 56) 2a01:e34:ec43:e1d0:554:492d:1a13:93e4.57926 > 2001:41d0:302:2200::180.443: [udp sum ok] UDP, length 48 11:07:20.377878 IP6 (hlim 52, next-header ICMPv6 (58) payload length: 104) 2001:41d0:302:2200::180 > 2a01:e34:ec43:e1d0:554:492d:1a13:93e4: [icmp6 sum ok] ICMP6, destination unreachable, unreachable port, 2001:41d0:302:2200::180 udp port 443
Si ça rate, on se rabat en une version de HTTP sur TCP (les premiers tests menés par Google indiquaient qu'entre 90 et 95 % des utilisateurs avaient une connectivité UDP correcte et pouvaient donc utiliser QUIC). Mais le cas ci-dessus était le cas idéal où on avait reçu le message ICMP et où on avait pu l'authentifier. Comme il est possible qu'un pare-feu fasciste et méchant se trouve sur le trajet, et jette silencieusement les paquets UDP, sans qu'on reçoive de réponse, même négative, il faut que le client soit plus intelligent que cela, et essaie très vite une autre version de HTTP, suivant le principe des globes oculaires heureux (RFC 8305). L'Internet est en effet farci de middleboxes qui bloquent tout ce qu'elles ne connaissent pas, et le client HTTP ne peut donc jamais être sûr qu'UDP passera. C'est même parfois un conseil explicite de certains vendeurs.
Sinon, le serveur
peut indiquer explicitement qu'il gère HTTP/3 lors d'une connexion
avec une vieille version de HTTP, via l'en-tête
Alt-Svc: (RFC 7838). Le
client essaie d'abord avec une vieille version de HTTP, puis est
redirigé, et se souviendra ensuite de la redirection. Par exemple,
si la réponse HTTP contient :
Alt-Svc: h3=":443"
Alors le client sait qu'il peut essayer HTTP/3 sur le port
443. Il peut y avoir plusieurs services alternatifs dans un
Alt-Svc: (par exemple les versions
expérimentales de HTTP/3).
Dernière possibilité, celle décrite dans le RFC 8164. (Par contre, l'ancien mécanisme
Upgrade: et sa réponse 101 n'est plus utilisé
par HTTP/3.)
À propos de port, j'ai cité jusqu'à
présent le 443 car c'est le port par défaut, mais on peut évidemment
en utiliser un autre, en l'indiquant dans
l'URL, ou via
Alt-Svc:. Quant aux URL de plan
http: (tout court, sans le S), ils ne sont pas
utilisables directement (puisque QUIC n'a pas de mode en clair, TLS
est obligatoire) mais peuvent quand même rediriger vers du HTTP/3,
via Alt-Svc:.
Le client a donc découvert le serveur, et il se connecte. Il doit
utiliser l'ALPN TLS (RFC 7301,
qui est quasi-obligatoire avec QUIC, et indiquer comme application
h3 (cf. le registre
IANA des applications). Les réglages divers qui
s'appliqueront à toute la connexion (la liste des réglages possibles
est dans un
registre IANA) sont envoyés dans une trame HTTP de type
SETTINGS. La connexion QUIC peut évidemment
rester ouverte une fois les premières requêtes envoyées et les
premières réponses reçues, afin d'amortir le coût de connexion sur
le plus grand nombre de requêtes possible. Évidemment, le serveur
est autorisé à couper les connexions qui lui semblent inactives (ce
qui se fait normalement en envoyant une trame HTTP de type
GOAWAY), le client doit donc être prêt à les
réouvrir.
Voilà pour la gestion de connexions. Et, une fois qu'on est
connecté, comment se font les requêtes (section 4 du RFC) ? Pour
chaque requête, on envoie une trame HTTP de type
HEADERS contenant les en-têtes HTTP (encodés,
je le rappelle, en binaire) et la méthode utilisée
(GET, POST, etc), puis une
trame de type DATA si la requête contient des
données. Puis on lit la réponse envoyée par le serveur. Le ruisseau
est fermé ensuite, chaque ruisseau ne sert qu'à un seul couple
requête/réponse. (Rappelez-vous que, dans QUIC, envoyer une trame
QUIC de type STREAM suffit à créer le ruisseau
correspondant. Tout ce qui nécessite un état a été fait lors de la
création de la connexion QUIC.)
Comme expliqué plus haut, les couples requête/réponse se font sur un ruisseau, qui ne sert qu'une fois. Ce ruisseau est bidirectionnel (section 6), ce qui permet de corréler facilement la requête et la réponse : elles empruntent le même ruisseau. C'est celui de numéro zéro dans l'exemple plus loin, qui n'a qu'un seul couple requête/réponse. La première requête se fera toujours sur le ruisseau 0, les autres seront que les ruisseaux 4, 8, etc, selon les règles de génération des numéros de ruisseau de QUIC.
Voici,
un exemple, affiché par tshark d'un échange HTTP/3. Pour
pouvoir le déchiffrer, on a utilisé la méthode classique, en
définissant la variable
d'environnement SSLKEYLOGFILE avant
de lancer le client HTTP (ici, curl), puis en disant à Wireshark d'utiliser
ce fichier contenant la clé (tls.keylog_file:
/tmp/quic.key dans
~/.config/wireshark/preferences). Cela donne :
% tshark -n -r /tmp/quic.pcap 1 0.000000 10.30.1.1 → 45.77.96.66 QUIC 1294 Initial, DCID=94b8a6888cb47e3128b13d875980b557d9e415f0, SCID=57e2ce80152d30c1f66a9fcb3c3b49c81c98f329, PKN: 0, CRYPTO, PADDING 2 0.088508 45.77.96.66 → 10.30.1.1 QUIC 1242 Handshake, DCID=57e2ce80152d30c1f66a9fcb3c3b49c81c98f329, SCID=3bd5658cf06b1a5020d44410ab9682bcf277610f, PKN: 0, CRYPTO[Malformed Packet] 3 0.088738 10.30.1.1 → 45.77.96.66 QUIC 185 Handshake, DCID=3bd5658cf06b1a5020d44410ab9682bcf277610f, SCID=57e2ce80152d30c1f66a9fcb3c3b49c81c98f329, PKN: 0, ACK 4 0.089655 45.77.96.66 → 10.30.1.1 QUIC 1239 Handshake, DCID=57e2ce80152d30c1f66a9fcb3c3b49c81c98f329, SCID=3bd5658cf06b1a5020d44410ab9682bcf277610f, PKN: 1, CRYPTO 5 0.089672 10.30.1.1 → 45.77.96.66 QUIC 114 Handshake, DCID=3bd5658cf06b1a5020d44410ab9682bcf277610f, SCID=57e2ce80152d30c1f66a9fcb3c3b49c81c98f329, PKN: 1, ACK, PING 6 0.090740 45.77.96.66 → 10.30.1.1 QUIC 931 Handshake, DCID=57e2ce80152d30c1f66a9fcb3c3b49c81c98f329, SCID=3bd5658cf06b1a5020d44410ab9682bcf277610f, PKN: 2, CRYPTO 7 0.091100 10.30.1.1 → 45.77.96.66 HTTP3 257 Protected Payload (KP0), DCID=3bd5658cf06b1a5020d44410ab9682bcf277610f, PKN: 0, NCI, STREAM(2), SETTINGS, STREAM(10), STREAM(6) 8 0.091163 10.30.1.1 → 45.77.96.66 HTTP3 115 Protected Payload (KP0), DCID=3bd5658cf06b1a5020d44410ab9682bcf277610f, PKN: 1, STREAM(0), HEADERS 9 0.189511 45.77.96.66 → 10.30.1.1 HTTP3 631 Protected Payload (KP0), DCID=57e2ce80152d30c1f66a9fcb3c3b49c81c98f329, PKN: 0, ACK, DONE, CRYPTO, STREAM(3), SETTINGS 10 0.190684 45.77.96.66 → 10.30.1.1 HTTP3 86 Protected Payload (KP0), DCID=57e2ce80152d30c1f66a9fcb3c3b49c81c98f329, PKN: 1, STREAM(7) 11 0.190792 10.30.1.1 → 45.77.96.66 QUIC 85 Protected Payload (KP0), DCID=3bd5658cf06b1a5020d44410ab9682bcf277610f, PKN: 2, ACK 12 0.192047 45.77.96.66 → 10.30.1.1 HTTP3 86 Protected Payload (KP0), DCID=57e2ce80152d30c1f66a9fcb3c3b49c81c98f329, PKN: 2, STREAM(11) 13 0.193299 45.77.96.66 → 10.30.1.1 HTTP3 604 Protected Payload (KP0), DCID=57e2ce80152d30c1f66a9fcb3c3b49c81c98f329, PKN: 3, STREAM(0), HEADERS, DATA 14 0.193421 10.30.1.1 → 45.77.96.66 QUIC 85 Protected Payload (KP0), DCID=3bd5658cf06b1a5020d44410ab9682bcf277610f, PKN: 3, ACK
On y voit au début l'ouverture de la connexion QUIC. Puis, à partir
du datagramme 7 commence HTTP/3, avec la création des ruisseaux
nécessaires et l'envoi de la trame SETTINGS
(ruisseau 3) et de HEADERS (ruisseau 0). Pas de
trame DATA, c'était une simple requête HTTP
GET, sans corps. Le serveur répond par son
propre SETTINGS, une trame
HEADERS et une DATA (la
réponse est de petite taille et tient dans un seul datagramme). Vous
avez l'analyse complète et détaillée de cette session QUIC dans le fichier
http3-get-request.txt.
La section 7 décrit les différents types de trames définis pour
HTTP/3 (rappelez-vous que ce ne sont pas les mêmes que les trames
QUIC : toutes voyagent dans des trames QUIC de type
STREAM), comme :
HEADERS(type 1), qui transporte les en-têtes HTTP, ainsi que les « pseudo en-têtes » comme la méthode HTTP. Ils sont comprimés avec QPACK (RFC 9114).DATA(type 0) qui contient le corps des messages. Une requêteGETne sera sans doute pas accompagnée de ce type de trames mais la réponse aura, dans la plupart des cas, un corps et donc une ou plusieurs trames de typeDATA.SETTINGS(type 4), qui définit des réglages communs à toute la connexion. Les réglages possibles figurent dans un registre IANA.GOAWAY(type 7) sert à dire qu'on s'en va.
Les différents types de trames QUIC sont dans un registre IANA. Ce registre est géré selon les politiques (cf. RFC 8126) « action de normalisation » pour une partie, et « spécification nécessaire » pour une autre partie de l'espace des types, plus ouverte. Notez que les types de trame HTTP/3 ne sont pas les mêmes que ceux de HTTP/2, même s'ils sont très proches. Des plages de types sont réservées (section 7.2.8) pour le graissage, l'utilisation délibérée de types non existants pour s'assurer que le partenaire respecte bien la norme, qui commande d'ignorer les types de trame inconnus. (Le graissage et ses motivations sont expliqués dans le RFC 8701.)
Wireshark peut aussi analyser graphiquement les données et vous
pouvez voir ici une trame QUIC de type STREAM
(ruisseau 0) contenant une trame HTTP/3 de type
HEADERS. Notez que cette version de Wireshark
ne décode pas encore la requête HTTP (ici, un simple
GET) : 
Et une fois qu'on a terminé ? On ferme la connexion (section 5), ce qui peut arriver pour plusieurs raisons, par exemple :
- La connexion n'a pas été utilisée depuis longtemps (« longtemps » étant défini par les paramètres de la connexion) et une des deux parties décide de la fermer,
- une des deux parties décide de fermer une connexion car son
travail est terminé, et envoie donc une trame de type
GOAWAY, - une erreur a pu se produire, empêchant de continuer la connexion, par exemple parce que le réseau est coupé.
Bien sûr, des tas de choses peuvent aller mal pendant une connexion HTTP/3. La section 8 du RFC définit donc un certain nombre de codes d'erreurs pour signaler les problèmes. Ils sont stockés dans un registre IANA.
L'un des buts essentiels de QUIC était d'améliorer la
sécurité. La section 10 du RFC discute de ce qui a été fait. En
gros, la sécurité de HTTP/3 est celle de HTTP/2 quand il est combiné
avec TLS, mais il y a quelques points à garder en tête. Par exemple,
HTTP/3 a des fonctions, comme la compression d'en-têtes (RFC 9114) ou comme le
contrôle de flux de chaque ruisseau qui, utilisées sans précaution,
peuvent mener à une importante allocation de ressources. Les
réglages définis dans la trame SETTINGS servent
entre autres à mettre des limites strictes à la consommation de
ressources.
Autre question de sécurité, liée cette fois à la protection de la
vie privée, la taille des
données. Par défaut, TLS ne cherche pas à dissimuler la taille des
paquets. Si on ne sait pas quelle page a chargé un client HTTPS,
l'observation de la taille des données reçues, comparée à ce qu'on
obtient en se connectant soi-même au serveur, permet de trouver avec
une bonne probabilité les ressources demandées (c'est ce qu'on nomme
l'analyse de trafic). Pour contrer cela, on peut utiliser le
remplissage. HTTP/3 peut utiliser celui de
QUIC (avec les trames QUIC de type PADDING) ou
bien faire son propre remplissage avec des trames HTTP utilisant des
types non alloués, mais dont l'identificateur est réservé (les
trames HTTP de type inconnu doivent être ignorées par le
récepteur).
Toujours question sécurité, l'effort de QUIC et de HTTP/3 pour diminuer la latence, avec notamment la possibilité d'envoyer des données dès le premier paquet (early data), a pour conséquences de faciliter les attaques par rejeu. Il faut donc suivre les préconisations du RFC 8470.
La possibilité qu'offre QUIC de faire migrer une session d'une
adresse IP vers une autre (par exemple quand un ordiphone passe de
4G en WiFi ou réciproquement) soulève également des questions de
sécurité. Ainsi, journaliser l'adresse IP du
client (le access_log d'Apache…) n'aura plus forcément le même
sens, cette adresse pouvant changer en cours de route. Idem pour les
ACL.
Ah, et question vie privée, le fait que HTTP/3 et QUIC encouragent à utiliser une seule session pour un certain nombre de requêtes peut permettre de corréler entre elles des requêtes. Sans cookie, on a donc une traçabilité des utilisateurs.
HTTP/3 a beaucoup de ressemblances avec HTTP/2. L'annexe A de
notre RFC détaille les différences entre ces deux versions et
explique comment passer de l'une à l'autre. Ainsi, la gestion des
ruisseaux qui, en HTTP/2, était faite par HTTP, est désormais faite
par QUIC. Une des conséquences est que l'espace des identificateurs
de ruisseau est bien plus grand, limitant le risque qu'on tombe à
cours. HTTP/3 a moins de types de trames que HTTP/2 car une partie
des fonctions assurées par HTTP/2 le sont par QUIC et échappent donc
désormais à HTTP (comme PING ou WINDOW_UPDATE).
HTTP/3 est en plein déploiement actuellement et vos logiciels
favoris peuvent ne pas encore l'avoir, ou bien n'avoir qu'une
version expérimentale de HTTP/3 et encore pas par défaut. Par
exemple, pour Google
Chrome, il faut le lancer google-chrome
--enable-quic --quic-version=h3-24
(h3-24 étant une version de développement de
HTTP/3). Pour Firefox, vous pouvez suivre
cet article ou celui-ci. Quand vous lirez ces lignes, tout sera
peut-être plus simple, avec le HTTP/3 officiel dans beaucoup de
clients HTTP.
J'ai montré plus haut quelques essais avec curl. Pour avoir HTTP/3 avec curl, il faut actuellement quelques bricolages, HTTP/3 n'étant pas forcément compilé dans le curl que vous utilisez. Déjà, il faut utiliser un OpenSSL spécial, disponible ici. Sinon, vous aurez des erreurs à la compilation du genre :
openssl.c:309:7: warning: implicit declaration of function ‘SSL_provide_quic_data’ [-Wimplicit-function-declaration]
309 | if (SSL_provide_quic_data(ssl, from_ngtcp2_level(crypto_level), data,
| ^~~~~~~~~~~~~~~~~~~~~
ngtcp2 peut se compiler avec GnuTLS et pas le
OpenSSL spécial, mais curl ne l'accepte pas (configure:
error: --with-ngtcp2 was specified but could not find
ngtcp2_crypto_openssl pkg-config file.). Ensuite, il
faut les bibliothèques ngtcp2 et nghttp3. Une fois
celles-ci prêtes, vous configurez curl :
% ./configure --with-ngtcp2 --with-nghttp3 ... HTTP2: enabled (nghttp2) HTTP3: enabled (ngtcp2 + nghttp3) ...
Vérifiez bien que vous avez la ligne HTTP3
indiquant que HTTP3 est activé. De même, un curl
--version doit vous afficher HTTP3
dans les protocoles gérés. Vous pourrez enfin faire du HTTP/3 :
% curl -v --http3 https://quic.tech:8443 * Trying 45.77.96.66:8443... * Connect socket 5 over QUIC to 45.77.96.66:8443 * Connected to quic.tech () port 8443 (#0) * Using HTTP/3 Stream ID: 0 (easy handle 0x55879ffd4c40) > GET / HTTP/3 > Host: quic.tech:8443 > user-agent: curl/7.76.1 > accept: */* > * ngh3_stream_recv returns 0 bytes and EAGAIN * ngh3_stream_recv returns 0 bytes and EAGAIN * ngh3_stream_recv returns 0 bytes and EAGAIN < HTTP/3 200 < server: quiche < content-length: 462 < <!DOCTYPE html> <html> ...
Pour davantage de lecture sur HTTP/3 :
- La référence est bien sûr le livre libre et gratuit de Daniel Stenberg (l'auteur de curl), HTTP/3 explained. Il a une traduction en français. Le source du livre est en ligne.
- Rob Graham a fait un bon résumé de HTTP/3.
- Et on en trouve un autre sur le blog de Cloudflare.
- Et il y a une étude détaillée de Robin Marx.
- C'est en 2018 que HTTP/3 a reçu son nom, suite à cette annonce
Si vous utilisez Tor, notez que QUIC et HTTP/2 (j'ai bien dit HTTP/2, puisque Tor ne gère pas UDP et donc pas QUIC) peuvent mettre en cause la protection qu'assure Tor. Une analyse sommaire est disponible En gros, si QUIC, grâce à son chiffrement systématique, donne moins d'infos au réseau, il en fournit peut-être davantage au serveur.
Ah, sinon j'ai présenté HTTP/3
à ParisWeb et
les supports sont disponibles en parisweb2021-http3-bortzmeyer.pdf. Et Le blog de curl est désormais accessible
en HTTP/3. Voici d'autres parts quelques articles
intéressants annonçant la publication de HTTP/3 :
- Celui de Cloudflare, avec d'intéressantes statistiques sur l'utilisation des différentes versions de HTTP,
- Celui d'Akamai,
- Celui de Mark Nottingham.
L'article seul
RFC 9111: HTTP Caching
Date de publication du RFC : Juin 2022
Auteur(s) du RFC : R. Fielding (Adobe), M. Nottingham (Fastly), J. Reschke (greenbytes)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 7 juin 2022
Le protocole HTTP transporte énormément de données tous les
jours et consomme donc à lui seul une bonne partie des ressources de
l'Internet. D'où l'importance de
l'optimiser. Une des méthodes les plus efficaces pour cela est le
cache (terme anglais qui
fait très bizarre en français : pour mieux accéder à une ressource,
on la cache...). Ce RFC spécifie le modèle de cachage (de
mémorisation ?) de HTTP et comment les clients et les serveurs
peuvent l'utiliser. Il remplace le RFC 7234
avec peu de modifications importantes (la plus spectaculaire étant
l'abandon du champ Warning: dans
l'en-tête).
Un cache Web est un espace de stockage local où on peut conserver la représentation d'une ressource qu'on a récupérée. Si la même ressource est à nouveau désirée, on pourra la récupérer depuis cette mémoire, le cache, plus proche et donc plus rapide que le serveur d'origine. Outre le temps d'accès, le cachage a l'avantage de diminuer la consommation de capacité réseau. Un cache peut être partagé entre plusieurs utilisateurs, augmentant ainsi les chances qu'une ressource désirée soit présente, ce qui améliore l'efficacité. (S'il n'a qu'un seul utilisateur, on parle de cache privé.) Comme tous les caches, les caches Web doivent gérer le stockage, l'accès et la place disponible, avec un mécanisme pour gérer le cas du cache plein. Comme tous les caches, les caches Web doivent aussi veiller à ne servir que de l'information fraîche. Cette fraîcheur peut être vérifiée de différentes façons, y compris par la validation (vérification auprès du serveur d'origine). Donc, même si l'information stockée dans le cache n'est pas garantie fraîche, on pourra quand même l'utiliser, si le serveur d'origine confirme qu'elle est toujours utilisable (dans ce cas, on aura quand même un accès réseau distant à faire, mais on évitera de transférer une ressource qui peut être de grande taille).
Le cache est optionnel pour HTTP, mais recommandé, et utiliser un cache devrait être le comportement par défaut, afin d'épargner le réseau, pour lequel HTTP représente une bonne part du trafic.
On peut garder en cache plusieurs sortes de réponses HTTP. Bien
sûr, le résultat d'une récupération après un
GET (code 200, cf. RFC 9110) est cachable et représente l'utilisation la plus
courante. Mais on peut aussi conserver dans le cache le résultat de
certaines redirections, ou bien des résultats négatifs (un code 410,
indiquant que la ressource est définitivement partie), ou même le
résultat de méthodes autres que GET (bien que
cela soit plus rare en pratique).
Ici, un exemple où une page a été stockée par un cache
Squid, et récupérée ensuite. L'argument de
GET est l'URI complet, pas juste le chemin :
% curl -v http://www.w3.org/WAI/
...
> GET http://www.w3.org/WAI/ HTTP/1.1
> User-Agent: curl/7.26.0
> Host: www.w3.org
...
< HTTP/1.0 200 OK
< Last-Modified: Thu, 12 Jun 2014 16:39:11 GMT
< ETag: "496a-4fba6335209c0"
< Cache-Control: max-age=21600
< Expires: Sun, 15 Jun 2014 15:39:30 GMT
< Content-Type: text/html; charset=utf-8
< Age: 118
< X-Cache: HIT from cache.example.org
< X-Cache-Lookup: HIT from cache.example.org:3128
< Via: 1.1 cache.example.org:3128 (squid/2.7.STABLE9)
...
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
Le client HTTP curl suit la
variable d'environnement
http_proxy et contacte donc le relais/cache
Squid en cache.example.org en HTTP. À son tour,
celui-ci se connectera au serveur d'origine si nécessaire (ce ne
l'était pas ici, l'information a été trouvée dans le cache, comme
l'indique la mention HIT.)
Les données stockées dans le cache sont identifiées par une
clé (section 2 de notre RFC). Pour un cache
simple, qui ne gère que GET, la clé principale
est l'URI
de la ressource convoitée. On verra plus loin que la clé peut en
fait être plus complexe que cela, en raison de certaines fonctions
du protocole HTTP, comme la négociation de contenu, qui
impose d'utiliser comme clé certains en-têtes de la requête. A
priori, un cache ne mémorise que les réponses positives (codes de
retour 200) mais certains mémorisent des réponses négatives comme le
404 (ressource non trouvée).
La section 3 du RFC normalise les cas où le cache a le droit de stocker une réponse, pour réutilisation ultérieure. Le RFC définit ces cas négativement : le cache ne doit pas stocker une réponse sauf si toutes ces conditions sont vraies :
- La méthode est cachable (c'est notamment le cas de
GET), - Le code de retour est compris du cache (200 est le cas évident),
- Il n'y a pas de directive dans la réponse qui interdise le
cachage (en-tête
Cache-Control:, voir plus loin), - L'accès à la ressource n'était pas soumis à autorisation (cf. RFC 9110, section 11), dans le cas d'un cache partagé entre plusieurs utilisateurs,
- La réponse contient des indications permettant de calculer la
durée de vie pendant laquelle elle restera fraîche (comme l'en-tête
Expires:).
Un cache peut stocker des réponses partielles, résultat de requêtes avec intervalles (cf. RFC 9110, section 14), si lui-même comprend ces requêtes. Il peut concaténer des réponses partielles pour ensuite envoyer une ressource complète.
Une fois la ressource stockée, le cache ne doit pas la renvoyer sauf si (là encore, la norme - section 4 - est formulée de manière négative, ce qui est déroutant) toutes ces conditions sont vraies :
- Les URI correspondent,
- Les en-têtes désignés par l'en-tête
Vary:correspondent (cela concerne surtout le cas où il y a négociation du contenu), - La requête ne contient pas de directive interdisant de la servir avec des données stockées dans le cache,
- La ressource stockée est encore fraîche, ou bien a été re-validée avec succès.
L'exigence sur la clé secondaire (les en-têtes sur lesquels se fait
la négociation de contenu) est là pour s'assurer qu'on ne donnera
pas à un client une ressource variable et correspondant aux goûts
d'un autre client. Si le client dont la requête a déclenché la mise
en cache avait utilisé l'en-tête Accept-Language:
fr indiquant qu'il voulait du français, et que le second
client du cache demande la même ressource, mais avec
Accept-Language: en, il ne faut évidemment pas
donner la copie du premier client au second. Si la réponse avait
l'en-tête Vary: accept-language indiquant
qu'elle dépend effectivement de la langue, le cache ne doit la
donner qu'aux clients ayant le même
Accept-Language:.
Et la fraîcheur, elle se définit comment (section 4.2, une des
plus importantes du RFC) ? Le cas le plus simple est celui où le
serveur d'origine envoie un en-tête Expires (ou
une directive max-age), par exemple
Expires: Mon, 15 Jun 2015 09:33:06 GMT. Dans ce
cas, la ressource gardée en cache est fraîche jusqu'à la date
indiquée. Attention : les formats de date de HTTP sont compliqués
et il faut être prudent en les analysant. Si le
Expires: indique une date syntaxiquement
incorrecte, le cache doit supposer le pire et considérer que la
ressource a déjà expiré. En pratique, bien des serveurs HTTP ne
fournissent pas cet en-tête Expires: et le
cache doit donc compter sur des heuristiques. La plus courante est
d'utiliser le champ Last-Modified: et de
considérer que, plus le document est ancien, plus il restera frais
longtemps (section 4.2.2). (La FAQ
de Squid explique bien l'heuristique de ce
logiciel de cache.) Le RFC ne normalise pas une heuristique
particulière mais met des bornes à l'imagination des programmeurs :
ces heuristiques ne doivent être employées que s'il n'y a pas de
date d'expiration explicite, et la durée de fraîcheur doit être
inférieure à l'âge du document (et le RFC suggère qu'elle ne soit
que 10 % de cet âge).
Dans sa réponse, le cache inclut un en-tête
Age:, qui peut donner au client une idée de la
durée depuis la dernière validation (auprès du serveur
d'origine). Par exemple, Age: 118, dans le
premier exemple, indiquait que la page était dans le cache depuis
presque deux minutes.
Une réponse qui n'est pas fraîche peut quand même être renvoyée
au client dans certains cas, notamment lorsque le cache est
déconnecté du réseau et ne peut pas donc valider que sa copie est
toujours bonne. Le client peut empêcher l'envoi de ces réponses
rassises avec Cache-Control: must-revalidate ou
no-cache.
Comment se fait cette validation dont on a déjà parlé plusieurs
fois ? Lorsque le serveur a une copie d'une ressource, mais que sa
date maximum de fraîcheur est dépassée, il peut demander au serveur
d'origine. Cela se fait typiquement par une requête conditionnelle
(cf. RFC 9110, section 13.1) : si le serveur a une copie
plus récente, il l'enverra, autrement, il répondra par un 304,
indiquant que la copie du cache est bonne. La requête conditionnelle
peut se faire avec un If-Modified-Since: (RFC 9110, section 8.8.2) en
utilisant comme date celle qui avait été donnée dans le
Last-Modified:. Ou bien elle peut se faire avec
l'entity tag (RFC 9110,
section 8.8.3) et un
If-None-Match: :
% telnet cache 3128 ... GET http://www.w3.org/WAI/ HTTP/1.1 Host: www.w3.org If-None-Match: "496a-4fba6335209c0" HTTP/1.0 304 Not Modified Date: Sun, 15 Jun 2014 09:39:30 GMT Content-Type: text/html; charset=utf-8 Expires: Sun, 15 Jun 2014 15:39:30 GMT Last-Modified: Thu, 12 Jun 2014 16:39:11 GMT ETag: "496a-4fba6335209c0" Age: 418 X-Cache: HIT from cache.example.org X-Cache-Lookup: HIT from cache.example.org:3128 Via: 1.0 cache.example.org:3128 (squid/2.7.STABLE9) Connection: close
Le cache peut aussi utiliser la méthode HEAD
pour tester sa copie locale auprès du serveur d'origine, par exemple
pour invalider la copie locale, sans pour autant transférer la
ressource. Et s'il voit passer un URL connu avec des méthodes qui ont
de fortes chances de changer la ressource, comme
PUT ou POST, le cache doit
invalider la ressource stockée.
La section 5 liste tous les en-têtes des requêtes et des réponses
qui sont utilisés pour le bon fonctionnement des caches, comme
Age: (en secondes), Expires:, etc. Ils
sont enregistrés à
l'IANA, dans le registre des en-têtes (désormais séparé du registre
utilisé pour les en-têtes du courrier électronique).
Parmi ces en-têtes, Cache-Control: permet de
spécifier des directives concernant le cache. Un client d'un cache
peut spécifier l'âge maximum qu'il est prêt à accepter (directive
max-age), une fraîcheur minimum (directive
min-fresh), que la ressource ne doit pas être
stockée dans le cache (directive no-store, qui
est là pour des raisons de vie privée mais,
bien sûr, est loin de suffire pour une véritable confidentialité),
ou bien qu'elle peut être stockée mais ne doit pas être servie à un
client sans revalidation (directive no-cache),
etc. Il y a aussi l'opposé de no-cache,
only-if-cached, qui indique que le client ne
veut la ressource que si elle est stockée dans le cache. (Attention,
dans un cache partagé, cela peut permettre à un client de voir ce que
les autres clients ont demandé, ce qu'on nomme le cache
snooping.) L'ensemble des directives possibles sont
stockées dans un
registre IANA. Ainsi, le RFC 8246 avait
ajouté une valeur possible à Cache-Control:, pour
indiquer l'immuabilité d'une ressource.
L'en-tête
Cache-Control: peut aussi être utilisé dans des
réponses. Un serveur peut lui aussi indiquer
no-cache, typiquement parce que ce qu'il envoie
change fréquemment et doit donc être revalidé à chaque fois,
private s'il veut insister sur le fait que la
réponse n'était destinée qu'à un seul utilisateur et ne doit donc
pas être transmise à d'autres (le RFC insiste que c'est une
protection vraiment minimale de la vie privée), etc.
À noter qu'un cache HTTP n'est pas forcément un serveur spécialisé. Tous les navigateurs Web ont des fonctions d'historique (comme le bouton Back). Est-ce que celles-ci nécessitent des précautions analogues à celles des caches, pour éviter que le navigateur ne serve des données dépassées ? Pas forcément, dit le RFC, qui autorise un navigateur à afficher une page peut-être plus à jour lorsqu'on utilise le retour en arrière dans l'historique (mais lisez la section 6 du RFC : cette autorisation vient avec des limites).
La section 7 détaille les problèmes de sécurité qui peuvent affecter les caches. Un cache, par exemple, peut permettre d'accéder à une information qui n'est plus présente dans le serveur d'origine, et donc de rendre plus difficile la suppression d'une ressource. Un cache doit donc être géré en pensant à ces risques. Plus grave, l'empoisonnement de cache : si un malveillant parvient à stocker une fausse représentation d'une ressource dans un cache (avec une longue durée de fraîcheur), tous les utilisateurs du cache recevront cette information au lieu de la bonne.
Un cache peut aussi avoir des conséquences pour la vie privée : en demandant une ressource à un cache partagé, un utilisateur peut savoir, à partir du temps de chargement et d'autres informations envoyées par le cache, si un autre utilisateur avait déjà consulté cette page. Et si un cache est privé (restreint à un·e seule·e utilisateurice), les données qu'il a stocké permettent d'avoir un panorama complet des activités Web de l'utilisateur.
L'annexe B liste les différences depuis le texte précédent, celui du RFC 7234 :
- Clarification de certaines parties de la norme,
- Quelques légers changements dans les obligations et interdictions que le logiciel de mémorisation doit respecter,
- Nouvelle directive
must-understand, qui permet au serveur d'indiquer que la ressource ne doit être mémorisée que si le cache connait et comprend le code de retour indiqué, - Et le plus spectaculaire, le
Warningdans les réponses est abandonné, car il était peu utilisé et souvent redondant avec l'information déjà présente dans la réponse.
Question mise en œuvre, notez qu'il existe un projet de tests des caches pour vérifier leur conformité.
L'article seul
RFC 9112: HTTP/1.1
Date de publication du RFC : Juin 2022
Auteur(s) du RFC : R. Fielding (Adobe), M. Nottingham (Fastly), J. Reschke (greenbytes)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 7 juin 2022
Ce nouveau RFC normalise HTTP/1.1, la plus ancienne version de HTTP encore en service. Il décrit les détails de comment les messages sont représentés sur le réseau, la sémantique de haut niveau étant désormais dans un document séparé, le RFC 9110. Ensemble, ces deux RFC remplacent le RFC 7230.
HTTP est certainement le protocole Internet le plus connu. Il en existe plusieurs versions, ayant toutes en commun la sémantique normalisée dans le RFC 9110. Les versions les plus récentes, HTTP/2 et HTTP/3 sont loin d'avoir remplacé la version 1, plus précisément 1.1, objet de notre RFC et toujours largement répandue. Un serveur HTTP actuel doit donc gérer au moins cette version. (Par exemple, en octobre 2021, les ramasseurs de Google et Baidu utilisaient toujours exclusivement HTTP/1.1.)
Un des avantages de HTTP/1, et qui explique sa longévité, est que c'est un protocole simple, fondé sur du texte et qu'il est donc relativement facile d'écrire clients et serveurs. D'ailleurs, pour illustrer cet article, je vais prendre exemple sur un simple serveur HTTP/1 que j'ai écrit (le code source complet est disponible ici). Le serveur ne gère que HTTP/1 (les autres versions sont plus complexes) et ne vise pas l'utilisation en production : c'est une simple démonstration. Il est écrit en Elixir. Bien sûr, Elixir, comme tous les langages de programmation sérieux, dispose de bibliothèques pour créer des serveurs HTTP (notamment Cowboy). Le programme que j'ai écrit ne vise pas à les concurrencer : si on veut un serveur HTTP pour Elixir, Cowboy est un bien meilleur choix ! C'est en référence à Cowboy que mon modeste serveur se nomme Indian.
Commençons par le commencement, la section 1 de notre RFC rappelle les bases de HTTP (décrites plus en détail dans le RFC 9110).
La section 2 attaque ce qui est spécifique à la version 1 de
HTTP. Avec les URL de plan http:, on
commence par établir une connexion TCP avec le serveur. Ensuite, un
message en HTTP/1 commence par une ligne de démarrage, suivie d'un
CRLF (fin de ligne sous la forme des deux octets Carriage
Return et Line Feed), d'une série
d'en-têtes ressemblant à celui de l'IMF du
RFC 5322 (par exemple Accept:
text/*), d'une ligne vide et peut-être d'un corps du
message. Les requêtes du client au serveur et les réponses du
serveur au client sont toutes les deux des messages, la seule
différence étant que, pour la requête, la ligne de démarrage est une
ligne de requête et, pour la réponse, c'est une ligne d'état. (Le
RFC note qu'on pourrait réaliser un logiciel HTTP qui soit à la fois
serveur et client, distinguant requêtes et réponses d'après les
formats distincts de ces deux lignes. En pratique, personne ne
semble l'avoir fait.)
Pour une première démonstration de HTTP, on va utiliser le module http.server du langage Python, qui permet d'avoir un serveur HTTP opérationnel facilement :
% python3 -m http.server Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ...
Hop, nous avons un serveur HTTP qui tourne sur le
port 8000. On va utiliser
curl et son option -v,
qui permet de voir le dialogue (le > indique ce qu'envoie curl,
le < ce qu'il reçoit du serveur en Python) :
% curl -v http://localhost:8000/
> GET / HTTP/1.1
> Host: localhost:8000
> User-Agent: curl/7.68.0
> Accept: */*
>
< HTTP/1.0 200 OK
< Server: SimpleHTTP/0.6 Python/3.8.10
< Date: Thu, 06 Jan 2022 17:24:13 GMT
< Content-type: text/html; charset=utf-8
< Content-Length: 660
<
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
<html>
<head>
...
La ligne qui commence par GET est la ligne de
démarrage, ici une requête, curl a envoyé trois lignes d'en-tête. La
ligne qui commence par HTTP/1.0 est la ligne de
démarrage de la réponse, et elle est suivie par quatre lignes
d'en-tête. La requête n'avait pas de corps, mais la réponse en a un
(il commence par <!DOCTYPE HTML PUBLIC), ici
au format HTML. En dépit du H de son nom, HTTP n'a pas
grand'chose de spécifiquement lié à
l'hypertexte, et peut être utilisé pour tout
type de données (le serveur Indian ne renvoie que du texte
brut).
Pour le corps des messages, HTTP utilise certains concepts de MIME (RFC 2045). Mais HTTP n'est pas MIME : l'annexe B détaille les différences.
Le client est censé lire la réponse, commençant par la ligne
d'état, puis tout l'en-tête jusqu'à une ligne vide, puis le corps,
dont la taille est indiquée par le champ
Content-Length:, ici 660 octets. (Sans ce
champ, le client va lire jusqu'à la fin de la connexion TCP sous-jacente.)
Notez qu'Indian ne fait pas cela bien : il fait une seule opération
de lecture et analyse ensuite le résultat (alors qu'il faudra
peut-être plusieurs opérations, et que, si on utilise les connexions
persistentes, on ne peut découvrir la fin du corps que si on tient
compte de Content-Length:, ou des délimiteurs
de Transfer-Encxoding: chunked). Ce choix a été
fait pour simplifier l'analyse syntaxique
(qui devrait normalement être incrémentale,
contrairement à ce que fait Indian, mais la bibliothèque
utilisée ne le permet pas, contrairement à, par exemple tree-sitter). Rappelez-vous que
ce n'est qu'un programme de démonstration.
Quand la réponse est du texte, le client ne doit pas supposer un encodage particulier, il doit lire des octets, quitte à les convertir dans des concepts de plus haut niveau (comme les caractères) plus tard.
Notez tout de suite qu'on trouve de tout dans le monde HTTP, et que beaucoup de clients et de serveurs ne suivent pas forcément rigoureusement la norme dans ses moindres détails. En général, Indian est plutôt strict et colle à la norme, sauf dans les cas où il était absolument nécessaire d'être plus tolérant pour pouvoir être testé avec les clients que j'ai utilisé. Comme souvent sur l'Internet, ces déviations par rapport à la norme permettent des attaques rigolotes comme le request smuggling (section 11.2 du RFC) ou le response splitting (section 11.1).
La réponse du serveur indique un numéro de version, sous la forme de deux chiffres séparés par un point. Ce RFC spécifie la version 1.1 de HTTP (Indian peut aussi gérer la version 1.0).
Commençons par la requête (section 3 du RFC). Elle commence par
une ligne qui comprend la méthode, le chemin et la version de
HTTP. Elles sont séparées par un espace. Pour analyser les requêtes,
Indian utilise la combinaison
d'analyseurs syntaxiques avec NimbleParsec, l'analyseur de la
requête est donc : method |> ignore(string(" ")) |>
concat(path) |> ignore(string(" ")) |>
concat(version). (La norme ne prévoit qu'un seul espace,
autrement, on aurait pu prévoir une répétition de string("
"). Le RFC suggère que cette version plus laxiste est
acceptable mais peut être dangereuse.) La méthode indique ce
que le client veut faire à la ressource désignée. La plus connue des
méthodes est
GET (récupérer la ressource) mais il en existe
d'autres, et la
liste peut changer. Indian ne met donc pas un choix limitatif
mais accepte tout nom de méthode (method =
ascii_string([not: ?\ ], min: 1)), quitte à vérifier plus
tard. La ressource sur laquelle le client veut agir est indiquée par
un chemin (ou, dans certains cas par l'URL complet). Ainsi, un client qui
veut récupérer
http://www.example.org/truc?machin va envoyer
au serveur au moins :
GET /truc?machin HTTP/1.1 Host: www.example.org
Il existe d'autres formes pour la requête mais je ne les présente pas ici (lisez le RFC).
La première ligne de la requête est suivie de l'en-tête, composée
de plusieurs champs (cf. section 5). Voici la requête que génère
wget pour récupérer
https://cis.cnrs.fr/a-travers-les-infrastructures-c-est-la-souverainete-numerique-des-etats-qui-se-joue/ :
% wget -d https://cis.cnrs.fr/a-travers-les-infrastructures-c-est-la-souverainete-numerique-des-etats-qui-se-joue/ ... GET /a-travers-les-infrastructures-c-est-la-souverainete-numerique-des-etats-qui-se-joue/ HTTP/1.1 User-Agent: Wget/1.20.3 (linux-gnu) Accept: */* Accept-Encoding: identity Host: cis.cnrs.fr Connection: Keep-Alive
Une particularité souvent oubliée de HTTP est qu'il n'y a pas de limite de taille à la plupart des éléments du protocole. Les programmeurs se demandent souvent « quelle place dois-je réserver pour tel élément ? » et la réponse est souvent qu'il n'y a pas de limite, juste des indications. Par exemple, notre RFC dit juste qu'il faut accepter des lignes de requête de 8 000 octets au moins.
Le serveur répond avec une ligne d'état et un autre en-tête (section 4). La ligne d'état comprend la version de HTTP, un code de retour formé de trois chiffres, et un message facultatif (là encore, avec un espace comme séparateur). Voici par exemple la réponse d'Indian :
HTTP/1.1 200 Content-Type: text/plain Content-Length: 18 Server: myBeautifulServerWrittenInElixir
Le message est d'autant plus facultatif (Indian n'en met pas) qu'il n'est pas forcément dans la langue du destinataire et qu'il n'est pas structuré, donc pas analysable. Le RFC recommande de l'ignorer.
Beaucoup plus important est le code de retour. Ces trois chiffres indiquent si tout s'est bien passé ou pas. Ils sont décrits en détail dans le RFC 9110, section 15. Bien qu'il s'agisse normalement d'éléments de protocole, certains sont bien connus des utilisatrices et utilisateurs, comme le célèbre 404. Et ils ont une représentation en chats et on a proposé de les remplacer par des émojis.
L'en-tête, maintenant (section 5 du RFC). Il se compose de
plusieurs lignes, chacune comportant le nom du champ, un
deux-points (pas d'espace avant ce
deux-points, insiste le RFC), puis la valeur du champ. Cela
s'analyse dans Indian avec header_line = header_name |>
ignore(string(":")) |> ignore(repeat(string(" "))) |>
concat(header_value) |> ignore(eol). Les noms de champs
possibles sont dans un
registre IANA (on peut noter qu'avant ce RFC, ils étaient
mêlés aux champs du courrier électronique dans un même registre).
Après les en-têtes, le corps. Il est en général absent des
requêtes faites avec la méthode GET mais il est
souvent présent pour les autres méthodes, et il est en général dans
les réponses. Ici, une réponse d'un serveur avec le corps en
JSON :
% curl -v https://atlas.ripe.net/api/v2/measurements/34762605/results/
...
< HTTP/1.1 200 OK
< Server: nginx
< Date: Tue, 11 Jan 2022 20:19:31 GMT
< Content-Type: application/json
< Transfer-Encoding: chunked
...
[{"fw":5020,"mver":"2.2.0","lts":4,"resultset":[{"time":1641657433,"lts":4,"subid":1,"submax":1,"dst_addr":"127.0.0.1","dst_port":"53","af":4,"src_addr":"127.0.0.1","proto":"UDP","result":{"rt":487.455,"size":127,"abuf":"9+SBgAABA ...
Le champ Content-Length: est normalement
obligatoire dans la réponse, sauf s'il y a un champ
Transfer-Encoding:, comme ici. Il permet au
client de gérer sa mémoire, et de savoir s'il a bien tout
récupéré. (Avec TLS, si on reçoit un signal de fin de
l'application, on sait qu'on a toute les données mais, sans TLS, on
ne pourrait pas être sûr, s'il n'y avait ce
Content-Length:.)
HTTP/1.1 est un protocole simple (quoiqu'il y ait un certain nombre de pièges pour une mise en œuvre réelle) et on peut donc se contenter de telnet comme client HTTP :
% telnet evil.com 80 Trying 66.96.146.129... Connected to evil.com. Escape character is '^]'. GET / HTTP/1.1 Host: evil.com HTTP/1.1 200 OK Date: Sun, 16 Jan 2022 11:31:05 GMT Content-Type: text/html Content-Length: 4166 Connection: keep-alive Server: Apache/2 Last-Modified: Sat, 15 Jan 2022 23:21:33 GMT Accept-Ranges: bytes Cache-Control: max-age=3600 Etag: "1046-5d5a72e24309e" Expires: Sun, 16 Jan 2022 12:14:45 GMT Age: 980 <HTML> <HEAD> <meta content="Microsoft FrontPage 6.0" name="GENERATOR"> <meta content="FrontPage.Editor.Document" name="ProgId">
Les lignes GET / HTTP/1.1 et Host:
evil.com ont été tapées à la main, une fois telnet
connecté. HTTP/1.1 (contrairement aux versions 2 et 3) fait partie
de ces protocoles en texte, qu'on peut déboguer à la main avec
telnet.
En plus perfectionné que telnet, il y a netcat :
% echo -n "GET /hello HTTP/1.1\r\nConnection: close\r\n\r\n" | nc ip6-localhost 8080 HTTP/1.1 200 Content-Type: text/plain Content-Length: 12 Server: myBeautifulServerWrittenInElixir Hello, ::1!
On a dit plus haut que HTTP/1.1 fonctionnait au-dessus d'une connexion TCP. La section 9 de notre RFC décrit la gestion de cette connexion. (En HTTP 0.9, c'était simple, une transaction = une connexion, mais ça a changé avec HTTP 1.) HTTP n'a pas forcément besoin de TCP (d'ailleurs, HTTP/3 fonctionne sur QUIC), il lui faut juste une liaison fiable faisant passer les octets dans l'ordre et sans perte. Dans HTTP/1.1, c'est TCP qui fournit ce service. (Avec TLS si on fait du HTTPS.) L'établissement d'une connexion TCP prend du temps, et la latence est un des plus gros ennemis de HTTP. Il est donc recommandé de ne pas établir une connexion TCP par transaction HTTP, mais de réutiliser les connexions. Le problème est délicat car le serveur peut avoir envie de supprimer des connexions pour récupérer des ressources. Clients et serveurs doivent donc s'attendre à des comportements variés de la part de leur partenaire.
HTTP/1 n'a pas d'identificateur de requête (comme
a, par exemple, le DNS). Les transactions doivent donc se faire
dans l'ordre : si on envoie une requête A puis une requête B sur la
même connexion TCP, on recevra forcément la réponse A puis la
B. (HTTP/2 et encore plus HTTP/3 ont par contre une certaine dose de
parallélisme.) Les connexions sont persistentes par défaut dans
HTTP/1.1 (ce n'était pas le cas en HTTP/1.0) et des champs de
l'en-tête servent à contrôler cette persistence
(Connection: close indique qu'on ne gardera pas
la connexion ouverte, et un client poli qui ne fait qu'une requête
doit envoyer ce champ). Dans le code source d'Indian, les accès à
context["persistent-connection"] vous
montreront la gestion de connexion.
Si le client et le serveur gère les connexions persistentes, le client peut aussi envoyer plusieurs requêtes à la suite, sans attendre les réponses (ce qu'on nomme le pipelining). Les réponses doivent parvenir dans le même ordre (puisqu'il n'y a pas d'identificateur de requête, qui permettrait de les associer à une requête), donc HTTP/1.1 ne permet pas un vrai parallélisme.
Pour économiser les ressources du serveur, un client ne devrait pas ouvrir « trop » de connexions vers un même serveur. (Le RFC 2616, section 8.1.4, mettait une limite de 2 connexions mais cette règle a disparu par la suite.)
Jusqu'à présent, on a parlé de HTTP tournant directement sur
TCP. Mais cela fait passer toutes les données en clair, ce qui est
inacceptable du point de vue sécurité, dans un monde de surveillance
massive. Aujourd'hui, la grande majorité des connexions HTTP passent
sur TLS, un
mécanisme cryptographique qui assure
notamment la confidentialité et
l'authentification du serveur. HTTPS (HTTP
sur TLS) était autrefois normalisé dans le RFC 2818 mais qui a désormais été abandonné au profit du RFC 9110 et de notre RFC 9112. Le principe
pour HTTP/1.1 est simple : une fois la connexion TCP établie, le
client HTTP démarre une session TLS (RFC 9846)
par dessus et voilà. (L'ALPN à utiliser est
http/1.1.) Lors de la fermeture de la connexion, TLS envoie normalement
un message qui permet de différencier les coupures volontaires et
les pannes (close_notify, RFC 9846, section 6.1). (Indian ne gère pas TLS, si on veut
le sécuriser - mais ce n'est qu'un programme de démonstration, il
faut le faire tourner derrière stunnel ou
équivalent.)
Pour tester HTTPS à la main, on peut utiliser un programme
distribué avec GnuTLS, ici pour récupérer https://fr.wikipedia.org/wiki/Hunga_Tonga :
% gnutls-cli fr.wikipedia.org
...
Connecting to '2620:0:862:ed1a::1:443'...
- subject `CN=*.wikipedia.org,O=Wikimedia Foundation\, Inc.,L=San Francisco,ST=California,C=US', issuer `CN=DigiCert ...
...
- Simple Client Mode:
GET /wiki/Hunga_Tonga HTTP/1.1
Host: fr.wikipedia.org
Connection: close
HTTP/1.1 200 OK
Date: Sun, 16 Jan 2022 20:41:56 GMT
Content-Type: text/html; charset=UTF-8
Content-Length: 79568
...
<!DOCTYPE html>
<html class="client-nojs" lang="fr" dir="ltr">
<head>
<meta charset="UTF-8"/>
<title>Hunga Tonga — Wikipédia</title>
...
Les trois lignes commençant par GET ont été
tapées à la main par l'utilisateur.
La section 10 de notre RFC traite d'une fonction plus rare :
l'inclusion d'un message HTTP comme donnée d'un protocole (qui peut
être HTTP ou un autre). Un tel message est étiqueté avec le
type MIME application/http.
Quelques mots sur la sécurité pour finir (section 11) : en raison de la complexité du protocole (qui est moins simple qu'il n'en a l'air !) et des mauvaises mises en œuvre qu'il faut quand même gérer car elles sont largement présentes sur le Web, deux programmes peuvent interpréter la même session HTTP différemment. Cela permet par exemple l'attaque de response splitting (cf. l'article de Klein « Divide and Conquer - HTTP Response Splitting, Web Cache Poisoning Attacks, and Related Topics »). Autre attaque possible, le request smuggling (cf. l'article de Linhart, Klein, Heled et Orrin, « HTTP Request Smuggling »).
Notre section 11 rappelle aussi que HTTP tout seul ne fournit pas de mécanisme pour assurer l'intégrité et la confidentialité des communications. Il dépend pour cela d'un protocole sous-jacent, en pratique TLS (HTTP+TLS étant appelé HTTPS).
L'annexe C décrit les changements de HTTP jusqu'à cette version
1.1. Ainsi, HTTP/1.0 a introduit la notion d'en-têtes, qui a permis,
entre autres, le virtual
hosting, grâce au champ
Host:. HTTP/1.1 a notamment changé la
persistence par défaut des connexions (de non-persistente à
désormais persistente). Et notre RFC, par rapport à la précédente
norme de HTTP/1.1, le RFC 7230 ? Le plus gros
changement est éditorial, toutes les parties indépendantes du numéro
de version de HTTP ont été déplacées vers le RFC 9110, notre RFC ne gardant que ce qui est spécifique à
HTTP/1.1. S'il y a beaucoup de changements de détail, le protocole
n'est pas modifié, un client ou un serveur HTTP/1.1 reste
compatible.
Vous noterez que j'ai fait un cours HTTP au CNAM, dont les supports et la vidéo sont disponibles. HTTP/1 est un protocole simple, très simple, et trivial à programmer. Cela en fait un favori des enseignants en informatique car on peut écrire un client (ou même un serveur) HTTP très facilement, et il peut être utilisé contre des serveurs (ou des clients) réels, ce qui est motivant pour les étudiant·es.
L'article seul
RFC 9260: Stream Control Transmission Protocol
Date de publication du RFC : Juin 2022
Auteur(s) du RFC : R. Stewart (Netflix), M. Tüxen
(Münster Univ. of Appl. Sciences), K. Nielsen (Kamstrup A/S)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF twvwg
Première rédaction de cet article le 6 juin 2022
Une des particularités du protocole IP est que vous avez plusieurs protocoles de transport disponibles. TCP et UDP sont les plus connus mais SCTP, normalisé dans notre RFC, est également intéressant. C'est un protocole déjà ancien (il date de 2000) et ce RFC remplace son prédécesseur, le RFC 4960. Beaucoup de changements de détails, mais rien de crucial.
SCTP ressemble plutôt à TCP, notamment par le fait qu'il fournit un transport fiable. Mais il a plusieurs différences :
- il ne gère pas un flot d'octets continu mais une série de messages, bien séparés,
- il gère plusieurs flux de données séparés, qui partagent le même contrôle de congestion mais gèrent à part les pertes et retransmissions (un peu comme QUIC),
- il gère le cas où la machine a plusieurs adresses IP, ce qui lui fournit normalement plus de redondance, si on est connecté à plusieurs réseaux.
Cette dernière possibilité le rapproche des protocoles qui séparent l'identificateur et le localisateur et lui permet de gérer proprement le multihoming. Cela se fait en indiquant, au début du contact, toutes les adresses IP (autrefois, il y avait même les noms de domaines, cf. la section 3.3.2.1.4) de la machine.
SCTP tient également compte de l'expérience acquise avec TCP. par exemple, l'établissement d'une connexion (que SCTP nomme association) se fait avec un échange de quatre paquets (et non pas trois comme avec TCP), pour offrir une meilleure protection contre les dénis de service. Les SYN cookies, un ajout plus ou moins bancal en TCP, sont ici partie intégrante du protocole.
SCTP est surtout issu des demandes du monde de la téléphonie sur IP, qui avait besoin d'un tel protocole pour la signalisation mais il peut être aussi utilisé dans d'autres domaines.
Un excellent article du Linux Journal explique bien SCTP.
SCTP est depuis longtemps mis en œuvre dans Linux et dans FreeBSD. De même, des programmes de débogage comme Wireshark sont capables de décoder et d'afficher le SCTP. Voici par exemple un pcap entre deux machines dont l'une a envoyé (trame 3) la chaîne de caractères « toto ». (Vous avez également la version texte de ce dialogue.) Des exemples de programmes de tests SCTP se trouvent dans mon article sur le RFC 3286.
Comme tout « nouveau » protocole de transport, SCTP est handicapé par des coupe-feux mal programmés et/ou mal configurés. L'Internet s'ossifiant de plus en plus, il devient très difficile de déployer un nouveau protocole de transport. D'où le RFC 6951, pour faire tourner SCTP sur UDP (comme ce que fait QUIC).
Les changements qu'introduit ce nouveau RFC ne modifient pas en profondeur le protocole mais corrigent les nombreux problèmes survenus pendant ses premières années d'utilisation. Le RFC 8540 donne la liste complète des problèmes corrigés.
L'article seul
A dynamic experimental DNS server, just for fun
First publication of this article on 31 May 2022
Last update on of 25 February 2024
Let me introduce you to a new program, an experimental
authoritative DNS
server intended for dynamic answers (answers depending, for
instance, on the client). It is just for fun and it does not pretend
to replace existing programs. But you may want to read its source
code, or use its online demo, at
dyn.bortzmeyer.fr.
My main goal was to have fun. A secondary goal was to have a service to get the IP address used by resolvers to query authoritative name servers. So, as said above, this program is not intended for mission-critical uses.
The program is named Drink, for no special reason. Its source code is available online, under a free-software licence. It uses the Elixir programming language and I'll talk about it later.
Let's first use the program. An instance is installed on the
domain dyn.bortzmeyer.fr. The tests are done
with dig,
the links in this article are through the DNS looking glass. You can send TXT queries
to get help:
% dig dyn.bortzmeyer.fr TXT ... ;; ANSWER SECTION: dyn.bortzmeyer.fr. 0 IN TXT "Possible queries: " "hello/TXT to have a greeting. " "ip/TXT,A,AAAA to have the IP address of the client. ...
A query for the subdomain hello will produce
a
greeting and the version numbers of the programs used:
% dig hello.dyn.bortzmeyer.fr TXT ... ;; ANSWER SECTION: hello.dyn.bortzmeyer.fr. 0 IN TXT "Hello, this is the Drink DNS server, version 0.1.0 and I use the dns library version 2.3.0, running on Elixir 1.13.2"
The most useful service today, in my opinion, is at the subdomain
ip, returning the IP address of the DNS client:
% dig ip.dyn.bortzmeyer.fr AAAA ... ;; ANSWER SECTION: ip.dyn.bortzmeyer.fr. 0 IN AAAA 2001:860:de02:102::d2
Two important things about this service:
- If you do A (IPv4) or AAAA (IPv6) requests, and your resolver uses the other address family, you'll get a response but not of the queried type, and it will be put in the Additional section of the DNS message. Some resolvers will filter out this unexpected response. Use TXT requests if you want to avoid this.
- The IP address returned is not your IP address, nor it is the one you use to talk to your resolver.
Here, we query through Quad9:
% dig @2620:fe::9 ip.dyn.bortzmeyer.fr A ... ;; ANSWER SECTION: ip.dyn.bortzmeyer.fr. 0 IN A 66.185.123.250
As you can see, we queried Quad9 over IPv6 but Quad9 queried our dynamic server over IPv4, using one of PCH addresses.
If you want to know the ECS option sent by your resolver, you can query
the ecs service (TXT query).
You can get the date and time of the DNS server, in RFC 3339 syntax:
% dig TXT date.dyn.bortzmeyer.fr ... ;; ANSWER SECTION: date.dyn.bortzmeyer.fr. 0 IN TXT "2022-05-31T11:05:36.507343Z"
(Obviously, it is less efficient to synchronize clocks than NTP.) You can also get a random number, or IP address:
% dig A random.dyn.bortzmeyer.fr ... ;; ANSWER SECTION: random.dyn.bortzmeyer.fr. 0 IN A 149.154.12.82
It's probably a useless service but you can use it to explore
randomly the Internet, with commands such as whois $(dig
+short random.dyn.bortzmeyer.fr
A). Beware, there is a security
weakness in this command. Can you spot it? If you are the sort of person
who does curl http://random-site.example/something.sh |
sudo bash, don't worry, this is not worse. Also, this
command is less fun with IPv6, since a great part of the IPv6 address
space is unallocated.
Drink has EDNS (RFC 6891) and recognizes a few options, such as the maximum size of the answer:
% dig @ns1-dyn.bortzmeyer.fr +bufsize=50 date.dyn.bortzmeyer.fr TXT
;; Truncated, retrying in TCP mode.
...
;; ANSWER SECTION:
date.dyn.bortzmeyer.fr. 0 IN TXT "2022-05-31T11:24:09.318345Z"
...
;; MSG SIZE rcvd: 91
As you can see from the "Truncated, retrying in TCP mode.", Drink returned a response with the truncation flag, and dig retried with TCP (which is of course supported by Drink). Another thing you can do with EDNS, is to query NSID (Name Server Identifier, RFC 5001):
% dig @ns1-dyn.bortzmeyer.fr +nsid date.dyn.bortzmeyer.fr TXT
...
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 1200
; NSID: 6e 73 31 2d 64 79 6e 2e 62 6f 72 74 7a 6d 65 79 65 72 2e 66 72 ("ns1-dyn.bortzmeyer.fr")
...
;; ANSWER SECTION:
date.dyn.bortzmeyer.fr. 0 IN TXT "2022-05-31T11:31:43.240583Z"
As you can see, the name server identifier is returned (not terribly useful in that case, but much more interesting if you use anycast). Drink also properly manage cookies (RFC 7873) and EDE (Extended DNS Errors, RFC 8914).
If you want not only the IP address of the machine querying
Drink, but also the port and the
transport protocol used (currently almot
always UDP), you can query the
subdomain connection :
% dig connection.dyn.bortzmeyer.fr TXT ... ;; ANSWER SECTION: connection.dyn.bortzmeyer.fr. 0 IN TXT "80.77.95.49:58931 over UDP"
Another service is at the subdomain
bgp, returning not only the IP address of the DNS client, but also the IP
prefix announced in the DFZ, and the
AS number which originates this prefix:
% dig bgp.dyn.bortzmeyer.fr TXT ... ;; ANSWER SECTION: bgp.dyn.bortzmeyer.fr. 3597 IN TXT "2605:4500:2:245b::bad:dcaf" "2605:4500::/32" "46636"
(It uses the bgp.bortzmeyer.org
HTTPS service.)
Here, the resolver 2605:4500:2:245b::bad:dcaf
is part of the prefix 2605:4500::/32, announced
by AS
46636. This is specially interesting when you ask many
separate machines to query this name. For instance, with RIPE Atlas probes and the Blaeu
program, we can ask 20 probes to do a DNS resolution:
% blaeu-resolve --requested 20 --type TXT bgp.dyn.bortzmeyer.fr ["195.211.77.68" "195.211.76.0/23" "49825"] : 1 occurrences ["162.158.85.93" "162.158.84.0/22" "13335"] : 1 occurrences ["173.194.169.12" "173.194.0.0/16" "15169"] : 1 occurrences ["2001:610:1:40ba:145:100:185:17" "2001:610::/29" "1103"] : 1 occurrences ["192.87.106.106" "192.87.0.0/16" "1103"] : 1 occurrences ["45.32.149.90" "45.32.144.0/21" "20473"] : 1 occurrences ["185.73.24.170" "185.73.24.0/22" "201454"] : 1 occurrences ["66.96.115.242" "66.96.112.0/20" "715"] : 1 occurrences ["2a02:908:2:110b::24" "2a02:908::/33" "3209"] : 1 occurrences ["2404:4408:5::b9" "2404:4400::/28" "9790"] : 1 occurrences ["2607:fb90:c13e:fff0:b77b:5ed3:0:aaaa" "2607:fb90:c13e::/48" "22140"] : 1 occurrences ["2001:1438:2:14::11" "2001:1438::/32" "8881"] : 1 occurrences ["2a04:e4c0:14::69" "2a04:e4c0:14::/48" "36692"] : 1 occurrences ["195.121.117.200" "195.121.64.0/18" "8737"] : 1 occurrences ["66.185.123.252" "66.185.123.0/24" "42"] : 1 occurrences ["185.22.47.150" "185.22.44.0/22" "60294"] : 1 occurrences ["162.158.201.67" "162.158.200.0/22" "13335"] : 1 occurrences ["212.142.48.77" "212.142.32.0/19" "6830"] : 1 occurrences ["184.83.74.52" "184.83.0.0/16" "11232"] : 1 occurrences ["213.13.28.71" "213.13.0.0/16" "3243"] : 1 occurrences Test #41687133 done at 2022-06-11T10:17:45Z
Which gives us a glimpse of the resolvers they use (AS 12335 is Cloudflare and AS 15169 is Google, both operating public DNS resolvers used by some probes).
Another service? country gives you the
country of your DNS resolver, as a ISO 3166
two-letter code:
% dig TXT country.dyn.bortzmeyer.fr ... ;; ANSWER SECTION: country.dyn.bortzmeyer.fr. 3600 IN TXT "FR"
Two warnings: geolocation is far from perfect
(it relies on databases which are not always up-to-date; by the way,
we currently use ipinfo). And
remember that it typically indicates the country of the machine, not
the country of the company controlling it. For instance, currently,
in France, users of Google
Public DNS see their resolver in
Belgium because this is where Google
machines reside. (A similar service for geolocation of the resolver
is _country.pool.ntp.org.)
Note that requesting the full service will
give you all the informations given by bgp and
country:
% dig TXT full.dyn.bortzmeyer.fr ... ;; ANSWER SECTION: full.dyn.bortzmeyer.fr. 3600 IN TXT "185.49.141.27" "185.49.140.0/23" "8587" "NL"
The list of funny and useful (?) services is long: there is also
unit which will give you access to unit
conversions. See here
a conversion of bars to
kilopascals. Or you prefer to convert
kilobytes to kibis?
% dig 150KB.KiB.unit.dyn.bortzmeyer.fr TXT ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 20561 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ... ;; ANSWER SECTION: 150KB.KiB.unit.dyn.bortzmeyer.fr. 86400 IN TXT "146.48 KiB"
If you still live in the 19th century and want to convert from/to the old english units to the international ones, you can do it, too:
% dig 15000ft.m.unit.dyn.bortzmeyer.fr TXT ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 32635 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ... ;; ANSWER SECTION: 15000ft.m.unit.dyn.bortzmeyer.fr. 86393 IN TXT "4571.78 m"
To get an idea of all the possible unit conversions, see the documentation of the library we use. A big warning, though: some unit names are case-sensitive but the DNS is supposed to be case-INsensitive. If you go through a resolver/forwarder which changes the case (which it is entitled to do), you may get errors such as "undetermined conversion".
Let's see another service, op, to perform arithmetic (a
good opportunity to remind everyone that domain names are
not limited to letters, digits and hyphen):
% dig 2+2.op.dyn.bortzmeyer.fr TXT ... 2+2.op.dyn.bortzmeyer.fr. 86400 IN TXT "4" % dig 2+3\*4-\(5-2\).op.dyn.bortzmeyer.fr TXT ... 2+3*4-\(5-2\).op.dyn.bortzmeyer.fr. 86400 IN TXT "11"
Note that some characters were special for the Unix shell (not for the DNS) and had to be
escaped. Some were special both for the shell and for the zone file
format, this is why dig escaped them. (A similar service, but
requiring RPN, is at
rp.secret-wg.org. See its
documentation.)
Not more useful, but funny, the number formatting service. You indicate a number and a language (as a language tag) and you get the number spelled in words:
% dig +short 42.en.number.dyn.bortzmeyer.fr TXT "forty-two" % dig +short 42.fr.number.dyn.bortzmeyer.fr TXT "quarante-deux" % dig +short 65656734.ca.number.dyn.bortzmeyer.fr TXT "seixanta-cinc milions sis-cent cinquanta-sis mil set-cent trenta-quatre"
Not all languages are represented, for disk space and memory
reasons. We currently have arabic
(ar), catalan (ca), german (de),
english
(en), french (fr) and
dutch
(nl). Note also that, for some languages
(surprinsingly, not for french), the answer may be not
ASCII but full
UTF-8. This will require a DNS client able to
display it, something that typical traditional DNS clients cannot
do. (Note that there is no standard for the
character set and
encoding of the
characters strings in a TXT record value. No way to tag them as
« UTF-8 ». This explains the lack of clients.) An example of such a
client is the DNS
Looking Glass, another is the fediverse
DNS bot.
And a last service, weather reports. You query for a city (here, Quimper) and whether you want current weather:
% dig quimper.now.weather.dyn.bortzmeyer.fr TXT ... ;; ANSWER SECTION: quimper.now.weather.dyn.bortzmeyer.fr. 1800 IN TXT "Quimper" "Sunny" "25.0 C" "precipitation 0.0 mm" "wind 15.1 km/h" "cloudiness 0 %" "humidity 44 %"
Or the weather for the next day (here, in La Paz):
% dig la-paz.tomorrow.weather.dyn.bortzmeyer.fr TXT ... ;; ANSWER SECTION: la-paz.tomorrow.weather.dyn.bortzmeyer.fr. 1800 IN TXT "La Paz" "Sunny" "9.2 C" "precipitation 0.0 mm" "wind 7.6 km/h" "cloudiness 0 %" "humidity 20 %"
Finally, note that Drink, unlike all (most?) other dynamic DNS services, is fully protected with DNSSEC. Responses are dynamically signed and can therefore be authenticated by the resolver:
% dig +dnssec random.dyn.bortzmeyer.fr LOC
...
;; flags: qr rd ra ad; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1
...
;; ANSWER SECTION:
random.dyn.bortzmeyer.fr. 10 IN LOC 38 5 56.000 N 179 42 40.000 E 5741.00m 0.00m 0.00m 0.00m
random.dyn.bortzmeyer.fr. 10 IN RRSIG LOC 8 4 10 (
20230216040000 20230211154000 63937 dyn.bortzmeyer.fr.
NaOD0XqTdT7L3b2QmuyzpW3ATDppIRdWq9YvGc97TRlW
...
;; Query time: 48 msec
;; WHEN: Sun Feb 12 10:51:08 CET 2023
;; MSG SIZE rcvd: 290
(See the 'ad' flag? It means "Authenticated Data".) You can check
the DNSSEC configuration with DNSviz if you want:
Drink can also report statistics about the traffic it saw. For that, you have to activate its IPC interface and the statistics service. Then, you can query it (here, formatting the JSON with jq):
% echo statistics | socat - UNIX-CONNECT:/var/run/drink/drink.sock | jq .
{
"protocols": {
"tcp": 342,
"udp": 15047
},
"qnames": {
"1/0.op.dyn.bortzmeyer.fr": 1,
"2 + 2 * 5 - 10 - 1.op.dyn.bortzmeyer.fr": 1,
"2+2.op.dyn.bortzmeyer.fr": 1,
"32mb.kib.unit.dyn.bortzmeyer.fr": 1,
"OTHER NAME": 8556,
"bgp.dyn.bortzmeyer.fr": 1,
"bogus.bortzmeyer.fr": 1,
"date.dyn.bortzmeyer.fr": 1,
"dyn.bortzmeyer.fr": 1918,
"ecs.dyn.bortzmeyer.fr": 3,
"hello.dyn.bortzmeyer.fr": 5,
"ip.dyn.bortzmeyer.fr": 10,
"random.dyn.bortzmeyer.fr": 4383
},
"qtypes": {
"A": 10656,
"AAAA": 2218,
"ANY": 7,
"AXFR": 2,
"CNAME": 3,
"DNSKEY": 856,
"DS": 1,
"LOC": 2,
"MX": 8,
"NS": 18,
"PTR": 9,
"SOA": 1013,
"SRV": 2,
"TXT": 54,
"URI": 2
},
"rcodes": {
"NOERROR": 6326,
"NXDOMAIN": 14,
"REFUSED": 8542
},
"running-seconds": 59316,
"running-time": "16 hours 28 minutes 36 seconds",
"server-start": "2023-04-25T15:15:54.585281Z",
"when": "2023-04-26T07:44:30.314052Z"
}
OK, let's assume you're convinced and you want to install Drink
on your machines. Since it is written in the Elixir
programming language, which requires a
runtime, you need to install Elixir, and also
the Erlang sources, to compile the DNS
library (on Debian, this is apt
install elixir erlang-dev erlang-src, on
Arch, pacman -S elixir
erlang-nox). Then, get the code with
git and just type mix
deps.get then mix run drink.exs (see
the README.md file for details). You will
probably need to create a configuration file or to provide options
on the command line, see again README.md for
details.
For the ip service, you can find similar
existing services:
resolver.00f.net(A and AAAA, if the request is over IPv4, it creates an IPv4-mapped IPv6 address, see RFC 4291, section 2.5.5.2); besides Drink, it seems to be one of the few whose source code is available,dns.toysis a bit different, it is not a zone in the usual DNS tree, you need to query the authoritative server directly (and so you need a clean DNS path, something which is not always available, for instance at WiFi hotspots, and you won't learn the IP address of your resolver); trydig ip @dns.toys(and see their other funny services); its source code (in Go) is available,_country.pool.ntp.org(TXT queries) displays the IP address of the client, its port, the country, and ECS information.whoami.v4.powerdns.organdwhoami.v6.powerdns.org(TXT, A and AAAA),o-o.myaddr.l.google.com(only TXT queries, does also ECS),whoami.fastly.netandwhoami6.fastly.net(A, AAAA, and TXT queries, the TXT queries also give you ECS information).whoami.akamai.net(A and AAAA),resolver-identity.cloudfront.net(A and AAAA),whoami.ultradns.net(only A requests, even if the servers have IPv6),
If you know other similar DNS services on the Internet, don't hesitate to report them. (They tend to be short-lived, many old ones no longer work, or return broken results.)
If you have ideas about services implemented on Drink, or bugs to report, please create a ticket.
Now, a few words about the source code. One of the reasons of the choice of the programming language Elixir is its excellent support of parallelism (or, rather, the excellent support of parallelism by the Erlang virtual machine). This is priceless for Internet servers. One process (an Elixir process, not an operating system process) is created for each connection (a connection being an UDP request or a "real" connection, with TCP) and the parallelism between clients is efficiently handled by the virtual machine. This isolation of processes (they share nothing, not even memory) also protects the server against malicious or broken clients, that can wait for a long time sending anything, or can send badly crafted DNS messages (something which is quite common on the Internet). A process may crash (for instance when attempting to decode a malformed DNS message) but the server will continue to serve the other clients.
The Drink server handles, of course, UDP and TCP (which is mandatory, see RFC 7766 and RFC 9210, but often forgotten in "custom" DNS servers). This is also something that is relatively easy with Elixir parallelism.
The DNS library I used saved me a lot of work, thanks to its author. But it also has some limitations. For instance, it has no support for EDNS options so I had to add it (not a big deal, but still annoying).
If you know Elixir, and its culture, you may be surprised to see that Drink does not use many things common in the Elixir world, such as OTP supervisors or protocols like GenServer. This is because, for this specific case, it seems to me they were not adding a lot of value. I may change my mind later.
One word about performance, testing with the excellent dnsperf tool. On a PC with two 2.6 Ghz cores, running dnsperf with one hundred parallel sending threads yields 10,000 requests per second and zero failure. (This is with Drink's logging and DNSSEC disabled, if you log each query, the DNS server will be much slower, and if you sign answers as well.)
% cat data ip.test A hello.test TXT test SOA % ./src/dnsperf -n 10000 -c 100 -s 127.0.0.1 -p 3553 -d data DNS Performance Testing Tool Version 2.9.0 [Status] Command line: dnsperf -n 10000 -c 100 -s 127.0.0.1 -p 3553 -d data [Status] Sending queries (to 127.0.0.1:3553) [Status] Started at: Tue May 31 21:12:09 2022 [Status] Stopping after 10000 runs through file [Status] Testing complete (end of file) Statistics: Queries sent: 30000 Queries completed: 30000 (100.00%) Queries lost: 0 (0.00%) Response codes: NOERROR 30000 (100.00%) Average packet size: request 25, response 90 Run time (s): 2.974810 Queries per second: 10084.677677 Average Latency (s): 0.009701 (min 0.000258, max 0.028758) Latency StdDev (s): 0.002650 Latency StdDev (s): 0.022502
Otherwise, Drink implementation has been the subject of a talk at OARC meeting #40 in Atlanta (february 2023), centered about its usage (slides are available online), and at FOSDEM (february 2023), mostly focused on internal implementation, slides and video are available online.
L'article seul
RFC 9234: Route Leak Prevention and Detection Using Roles in UPDATE and OPEN Messages
Date de publication du RFC : Mai 2022
Auteur(s) du RFC : A. Azimov (Qrator Labs & Yandex), E. Bogomazov (Qrator Labs), R. Bush (IIJ & Arrcus), K. Patel (Arrcus), K. Sriram (USA NIST)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF idr
Première rédaction de cet article le 25 mai 2022
Vous savez sans doute que l'Internet repose sur le protocole de routage BGP et que ce protocole a été cité dans des accidents (voire des attaques) spectaculaires, par exemple lorsqu'un routeur BGP annonçait ou réannonçait des routes qu'il n'aurait pas dû annoncer (ce qu'on nomme une fuite de routes). Si BGP lui-même est pair-à-pair, en revanche, les relations entre les pairs ne sont pas forcément symétriques et des règles sont largement admises ; par exemple, on n'est pas censé annoncer à un transitaire des routes apprises d'un autre transitaire. Ce RFC étend BGP pour indiquer à l'ouverture de la session le type de relations qu'on a avec son pair BGP, ce qui permet de détecter plus facilement certaines fuites de routes.
La solution proposée s'appuie sur un modèle des relations entre opérateurs, le modèle « sans vallée » (valley-free, même si ce terme n'est pas utilisé dans le RFC). On le nomme aussi modèle Gao-Rexford. Ce modèle structure ces relations de telle façon à ce que le trafic aille forcément vers un opérateur aussi ou plus important (la « montagne »), avant de « redescendre » vers la destination ; le trafic ne descend pas dans une « vallée », sauf si elle est la destination finale. Le but est de permettre un routage optimum et d'éviter boucles et goulets d'étranglement, mais ce modèle a aussi une conséquence politico-économique, maintenir la domination des gros acteurs (typiquement les Tier-1). Les relations entre participants à une session BGP sont de type Client-Fournisseur ou Pair-Pair, et le trafic va toujours dans le sens du client vers le fournisseur, sauf pour les destinations finales (on n'utilise donc pas un pair pour du transit, c'est-à-dire pour joindre d'autres réseaux que ceux du pair).
En raison de ce modèle, un routeur BGP n'est pas censé annoncer à un transitaire des routes apprises d'un autre transitaire, ou annoncer à un pair des routes apprises d'un transitaire, ou bien apprises d'un autre pair (RFC 7908). Une fuite de routes est une annonce qui viole cette politique (qu'elle soit explicite ou implicite).
Traditionnellement, on empêche ces fuites par des règles dans la configuration du routeur. Par exemple, le client d'un transitaire va bloquer l'exportation par défaut, puis lister explicitement les routes qu'il veut annoncer. Et le transitaire va bloquer l'importation par défaut, et lister ensuite les routes qu'il acceptera de son client. Ce nouveau RFC ajoute un autre mécanisme, où la relation entre les deux partenaires BGP est explicitement marquée comme Client-Fournisseur ou Pair-Pair, facilitant la détection des fuites. Un concept qui était auparavant purement business, le type de relation entre acteurs BGP, passe ainsi dans le protocole.
Le RFC utilise donc ces termes, pour désigner la place d'un acteur BGP dans le processus de routage :
- Fournisseur (Provider) : peut envoyer n'importe quelle route (un transitaire est un Fournisseur).
- Client (Customer) : ne peut envoyer que ses propres routes, ou bien celles apprises d'un de ses clients (l'opérateur qui est Client pour une relation BGP peut être Fournisseur pour une autre).
- Serveur de routes (Route Server) : peut envoyer toutes les routes qu'il connait à ses clients.
- Client d'un serveur de routes (Route Server Client) : ne peut envoyer au serveur de routes que ses propres routes, ou bien celles apprises d'un de ses clients.
- Pair (Peer) : ne peut envoyer à un de ses pairs que ses propres routes, ou bien celles apprises d'un de ses clients.
Une violation de ces règles est une fuite de routes (RFC 7908). Le RFC précise qu'il s'agit de relations « techniques », qu'elles n'impliquent pas forcément une relation business mais, en pratique, l'échange entre pairs est souvent gratuit et la relation Client-Fournisseur payante. Le RFC précise aussi qu'il peut exister des cas plus complexes, comme une relation Client-Fournisseur pour certains préfixes IP et Pair-Pair pour d'autres.
Bon, assez de politique et de business, place à la technique et au protocole. Le RFC définit une nouvelle capacité (RFC 5492) BGP, Role, code 9 et dont la valeur, stockée sur un octet, indique un des rôles listés ci-dessus (0 pour Fournisseur, 3 pour Client, 4 pour Pair, etc). D'autres rôles pourront être ajoutés dans le futur (politique « Examen par l'IETF », cf. RFC 8126). Ce rôle indique la place de l'AS et est configuré avec la session BGP (rappelez-vous qu'un AS peut être Client d'un côté et Fournisseur de l'autre). À l'ouverture de la connexion, les routeurs vérifient la compatibilité des rôles (si tous les deux annoncent qu'ils sont Fournisseur, c'est un problème, d'où un nouveau code d'erreur BGP, Role mismatch).
Une fois que les deux routeurs sont d'accord sur les rôles respectifs de leurs AS, les routes annoncées peuvent être marquées avec un nouvel attribut, OTC (Only To Customer, code 35), dont la valeur est un numéro d'AS. Une route ainsi marquée ne sera acceptée que si elle vient d'un Fournisseur, ou d'un pair dont le numéro d'AS coïncide. Autrement, elle sera considérée comme résultant d'une fuite.
Ah, et pour les cas compliqués dont on a parlé plus haut, comme les rôles différents pour chaque préfixe ? Dans ce cas-là, le mécanisme des rôles de ce RFC n'est pas adapté et ne doit pas être utilisé.
Ce système des rôles est apparemment mis en œuvre dans des patches (non encore intégrés ?) pour FRRouting et BIRD. Par exemple, pour FRRouting, on configurerait :
neighbor 2001:db8:999::1 local-role customer
Pour BIRD, cela serait :
configuration
...
protocol bgp {
...
local_role customer;
}
Et la gestion des rôles devrait être bientôt
dans BGPkit. Et une version antérieure à la sortie du RFC
tourne sur les routeurs MikroTik (voir leur
documentation, local.role ebgp-customer…).
Par contre, je ne sais pas pour Cisco ou
Juniper. Si quelqu'un a des informations…
L'article seul
Fiche de lecture : Concealing for freedom
Auteur(s) du livre : Ksenia Ermoshina, Francesca Musiani
Éditeur : Mattering Press
Publié en 2022
Première rédaction de cet article le 25 mai 2022
Le chiffrement est depuis longtemps un sujet de controverses. Indispensable pour assurer la sécurité des communications sur les réseaux informatiques (donc, tous les réseaux, y compris le téléphone), il est régulièrement attaqué par des politiciens qui l'accusent de permettre aux délinquants et aux criminels de dissimuler leurs communications. Mais il n'y a pas que ces attaques grossières, il y a aussi beaucoup de débats autour du chiffrement et de la meilleure façon de protéger les communications de M. et Mme Toutlemonde. Ce livre de deux chercheuses en sociologie explore de manière très claire mais aussi très approfondie ces débats. En bref, le chiffrement est nécessaire mais pas forcément suffisant. Ce livre est très recommandé à toutes les personnes qui veulent comprendre ce difficile problème.
Notez tout de suite avant d'acheter la version papier du livre qu'il est également gratuitement disponible en ligne. Même si vous achetez la version papier, la version numérique vous intéressera peut-être, par exemple pour rechercher un mot, ou pour copier-coller une citation.
Les informaticien·nes ont parfois tendance à avoir une approche strictement technique du chiffrement. On chiffre, et on est protégé, et les seuls débats concernent des points tels que « dois-je utiliser ECDSA ou EdDSA ? ». Mais les auteures montrent bien que bien d'autres questions se posent, et peuvent affecter la sécurité des communications. Par exemple, le livre contient une analyse du modèle de menaces. On veut se cacher de qui ? Le problème d'une militante féministe en Russie n'est pas forcément le même que celui d'un journaliste qui couvre des manifestations aux États-Unis ou que celui d'une femme qui veut se protéger d'un mari violent. L'adversaire n'a pas les mêmes moyens, et le niveau de risque est différent à chaque fois. Ainsi, de manière peut-être contre-intuitive, il peut être plus prudent d'utiliser un logiciel moins sûr, mais plus répandu, pour ne pas attirer l'attention. (Ce chapitre, comme d'autres dans le livre, est repris d'un précédent article des auteures.)
Le livre s'appuie sur beaucoup d'ateliers et de formations où les
auteures ont participé. Ici, un dessin du modèle de menaces par une
militante russe lors d'un de ces ateliers, montrant les différents
ennemis : 
Dans bien des cas, le choix du système le plus sûr n'a pas de solution évidente, d'autant plus que bien des critères de choix se bousculent. Un chapitre est ainsi consacré au débat centralisation/décentralisation. Un système de communication centralisé est-il plus sûr ? La réponse n'est pas simple. Un système décentralisé a l'avantage de ne pas avoir de point de contrôle unique, susceptible d'être piraté, corrompu, ou soumis à des pressions financières ou juridiques. Utilisant des techniques standardisées, il est indépendant de tout fournisseur. Il règle de manière élégante la question du pouvoir et de ses abus en limitant la quantité de pouvoir dont dispose chaque acteur. Mais il a aussi des inconvénients : difficulté à faire évoluer techniquement (exemple du courrier électronique, réseau social décentralisé bien antérieur aux réseaux centralisés des GAFA, mais qui a du mal à déployer massivement des techniques de sécurité nouvelles), difficulté pour les utilisateurs à comprendre à qui il faut faire confiance (l'administrateur d'un serveur décentralisé n'est pas forcément « meilleur » que Gmail), risque d'invasion par des parasites contre lesquels il sera difficile de lutter (pensez au spam). Les auteures ne disent évidemment pas qu'il faut préférer les systèmes centralisés, simplement que le choix de la sécurité n'est pas toujours simple. (Une bonne partie du chapitre est consacrée aux controverses autour de Signal et du discours très pro-centralisation de son créateur, mais il parle aussi de systèmes moins connus comme Briar.) Et les arguments techniques cachent souvent des volontés de contrôle. Et parfois c'est la technique qui rend certaines solutions difficiles (faire du chiffrement de bout en bout est plus difficile si on veut des communications de groupe, faire de la distribution de message sans serveur est plus difficile si on veut épargner les batteries, etc).
La fédération (telle qu'utilisée par le fédivers) est souvent présentée comme la solution au problème du contrôle de la communication par quelques géants. Mais elle aussi pose ses propres problèmes, comme l'ont montré les difficultés de XMPP et Matrix à vaincre les messageries instantanées privatrices.
En parlant de messageries instantanées, un des chapitres les plus intéressants concerne l'analyse qu'avait publiée l'EFF pour aider les utilisateurices à choisir une messagerie instantanée sûre. La première version avait suscité de nombreuses critiques (pas toutes innocentes, et pas toutes intelligentes), portant par exemple sur la prépondérance excessive de critères purement techniques, ou s'inquiétant du fait de résumer un choix aussi complexe à un simple tableau de critères. Les auteurs détaillent longuement ces débats, et comment ils ont mené à une sérieuse réflexion sur la meilleure manière d'informer les utilisateurices.
Le livre est clairement écrit, et les auteures connaissent leur sujet (j'ai apprécié que le fédivers ne soit pas juste appelé Mastodon et que Pleroma soit aussi cité). Si vous croyez que le problème est simple, et que vous vous exprimez sèchement à ce sujet sur les réseaux sociaux, c'est le livre à lire d'abord.
L'article seul
RFC 9250: DNS over Dedicated QUIC Connections
Date de publication du RFC : Mai 2022
Auteur(s) du RFC : C. Huitema (Private Octopus), S. Dickinson (Sinodun IT), A. Mankin (Salesforce)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dprive
Première rédaction de cet article le 22 mai 2022
Ce nouveau RFC complète la série des mécanismes de protection cryptographique du DNS. Après DoT (RFC 7858) et DoH (RFC 8484), voici DoQ, DNS sur QUIC. On notera que bien que QUIC ait été conçu essentiellement pour les besoins de HTTP, c'est le DNS qui a été la première application normalisée de QUIC.
Fonctionnellement, DoQ est très proche de ses prédécesseurs, et offre les mêmes services de sécurité, confidentialité, grâce au chiffrement, et authentification du serveur, via le certificat de celui-ci. L'utilisation du transport QUIC permet quelques améliorations, notamment dans le « vrai » parallélisme. Contrairement à DoT (RFC 7858) et DoH (RFC 8484), DoQ peut être utilisé pour parler à un serveur faisant autorité aussi bien qu'à un résolveur.
Notez que le terme de DoQ (DNS over QUIC) n'apparait pas dans le RFC de terminologie DNS, le RFC 8499. Il sera normalement dans son successeur.
Logiquement, DoQ devrait faire face aux mêmes problèmes politiques que ceux vécus par DoH (voir aussi mon article dans Terminal) mais cela n'a pas été encore le cas. Il faut dire qu'il y a peu de déploiements (ne comptez pas installer DoQ comme serveur ou client tout de suite, le code est loin d'être disponible partout).
Le cahier des charges de DoQ est (sections 1 et 3 du RFC) :
- Protection contre les attaques décrites dans le RFC 9076.
- Même niveau de protection que DoT (RFC 7858, avec notamment les capacités d'authentification variées du RFC 8310). Rappelez-vous que QUIC est toujours chiffré (actuellement avec TLS, cf. RFC 9001).
- Meilleure validation de l'adresse IP source qu'avec le classique DNS sur UDP, grâce à QUIC.
- Pas de limite de taille des réponses, quelle que soit la MTU du chemin.
- Diminution de la latence, toujours grâce à QUIC et notamment ses possibilités de connexion 0-RTT (RFC 9000, section 5), ses procédures de récupération en cas de perte de paquets (RFC 9002) et la réduction du head-of-line blocking, chaque couple requête/réponse étant dans son propre ruisseau.
En revanche, DoQ n'esssaie pas de :
- Contourner le blocage de QUIC que font certaines middleboxes (DoH est meilleur, de ce point de vue). La section 3.3 du RFC détaille cette limitation de DoQ : il peut être filtré trop facilement, son trafic se distinguant nettement d'autres trafics.
- Ou de permettre des messages du serveur non sollicités (pour cela, il faut utiliser le RFC 8490).
DoQ utilise QUIC. QUIC est un protocole de transport généraliste, un concurrent de TCP. Plusieurs protocoles applicatifs peuvent utiliser QUIC et, pour chacun de ces protocoles, cela implique de définir comment sont utilisés les ruisseaux (streams) de QUIC. Pour HTTP/3, cela a été fait dans le RFC 9113, publié plus tard. Ironiquement, le DNS est donc le premier protocole à être normalisé pour une utilisation sur QUIC. Notez qu'une autre façon de faire du DNS sur QUIC est de passer par DoH et HTTP/3 (c'est parfois appelé DoH3, terme trompeur) mais cette façon n'est pas couverte dans notre RFC, qui se concentre sur DoQ, du DNS directement sur QUIC, sans HTTP.
La spécification de DoQ se trouve en section 4. Elle est plutôt
simple, DoQ étant une application assez directe de QUIC. Comme DoQ
utilise QUIC, il y a forcément un ALPN, en l'occurrence via
l'identificateur doq.
Le port, quant à lui, est par défaut 853,
également nommé domain-s. C'est donc le même
que DoT, et aussi le même que le DNS sur DTLS (RFC 8094, protocole expérimental, jamais vraiment mis en œuvre
et encore moins déployé, et qui est de toute façon distinguable du
trafic QUIC, cf. section 17.2 du RFC 9000). Bien sûr, un client et un serveur DNS majeurs et
vaccinés peuvent toujours se mettre d'accord sur un autre port (mais
pas 53, réservé au DNS classique). Cette utilisation d'un port
spécifique à DoQ est un des points qui le rend vulnérable au
filtrage, comme vu plus haut. Utiliser 443 peut aider. (Le point a
été chaudement discuté à l'IETF, entre
défenseurs de la vie privée et gestionnaires de réseau qui voulaient
pouvoir filtrer facilement les protocoles de leur choix. Si on
utilise le port 443, il faut se rappeler que l'ALPN est pour
l'instant en clair (ça a été corrigé dans le RFC 9849), la lutte de l'épée et de la cuirasse va donc continuer.)
Plus important, la question de la correspondance entre les messages DNS et les ruisseaux QUIC. La règle est simple : pour chaque requête DNS, un ruisseau est créé. La première requête sur une connexion donnée sera donc sur le ruisseau 0 (RFC 9000, section 2.1), la deuxième sur le ruisseau 4, etc. Si les connexions QUIC sont potentiellement de longue durée, en revanche, les ruisseaux ne servent qu'une fois. Le démultiplexage des réponses est assuré par QUIC, pas par le DNS (et l'identificateur de requête DNS est donc obligatoirement à zéro, puisqu'inutile). Le parallélisme est également fourni par QUIC, client et serveur n'ont rien de particulier à faire. Il est donc recommandé de ne pas attendre une réponse pour envoyer les autres questions. Les messages DNS sont précédés de deux octets indiquant leur longueur, comme avec TCP.
Comme avec TCP, client et serveur ont le droit de garder un œil sur les ruisseaux et les connexions inactifs, et de les fermer d'autorité. La section 5.5 donne des détails sur cette gestion de connexion, mais le RFC 7766 est également une bonne lecture (voir aussi le RFC 9103 pour le cas des transferts de zones).
DoQ introduit quelques codes
d'erreur à lui (RFC 9000, section
20.2), comme DOQ_INTERNAL_ERROR (quelque chose
s'est mal passé), DOQ_PROTOCOL_ERROR (quelqu'un
n'a pas lu le RFC, par exemple l'identificateur de requête était
différent de zéro) ou DOQ_EXCESSIVE_LOAD (trop
de travail tue le travail).
Un des gros avantages de QUIC est le 0-RTT, où des données sont envoyées dès le premier paquet, ce qui réduit nettement la latence. Cela implique que le client ait déjà contacté le serveur avant, mémorisant les informations qui seront données au serveur pour qu'il retrouve la session à reprendre. C'est cool, mais cela pose d'évidents problèmes de vie privée (ces informations mémorisées sont une sorte de cookie, et permettent le suivi à la trace d'un client). D'ailleurs, en parlant de vie privée, le RFC signale aussi (section 5.5.4) que la possibilité de migrer une connexion QUIC d'une adresse IP à l'autre a également des conséquences pour la traçabilité.
Autre piège avec le 0-RTT, il ne protège pas contre le rejeu et
il ne faut donc l'utiliser que pour des requêtes DNS
idempotentes comme QUERY
(le cas le plus courant) ou NOTIFY (qui change
l'état du serveur, mais est idempotent). Bon, de toute façon, un
serveur peut toujours être configuré pour ne pas accepter de 0-RTT,
et répondre alors REFUSED (avec un code
d'erreur étendu - RFC 8914 - Too
Early).
La section 5 du RFC liste les exigences auxquelles doivent se soumettre les mises en œuvre de DoQ. Le client doit authentifier le serveur (cf. RFC 7858 et RFC 8310, mais aussi RFC 8932, sur les bonnes pratiques). Comme tous les serveurs ne géreront pas DoQ, en tout cas dans un avenir prévisible, les clients doivent être préparés à ce que ça échoue et à réessayer, par exemple en DoT.
QUIC ne dissimule pas forcément la taille des messages échangés, et celle-ci peut être révélatrice. Malgré le chiffrement, la taille d'une requête ou surtout d'une réponse peut donner une idée sur le nom demandé. Le RFC impose donc l'utilisation du remplissage, soit par la méthode QUIC générique de la section 19.1 du RFC 9000, soit par la méthode spécifique au DNS du RFC 7830. La première méthode est en théorie meilleure car elle dissimule d'autres métadonnées, et qu'elle tient compte de davantage d'éléments, mais les bibliothèques QUIC n'exposent pas forcément dans leur API de moyen de contrôler ce remplissage. Le RFC recommande donc aux clients et serveurs DoQ de se préparer à faire le remplissage eux-mêmes (en relisant bien le RFC 8467 avant).
Un petit retour sur la protection de la vie privée en section 7. Cette section rappele l'importance de lire et suivre le RFC 8932 si vous gérez un service de résolution DNS sécurisé (DoQ ou pas DoQ). Et elle insiste sur le fait que des fonctions de QUIC très pratiques pour diminuer la latence à l'établissement de la connexion, notamment le 0-RTT, ont des conséquences pour la vie privée, en permettant de suivre un même utilisateur (plus exactement une même machine). Et cela marche même si la machine a changé d'adresse IP entretemps. On peut aussi dire que le problème de QUIC est de permettre des sessions de très longue durée (que ce soit une vraie session unique, ou bien une « session virtuelle », formée en reprenant une session existante avec le 0-RTT) et que de telles sessions longues, excellentes pour les performances, le sont forcément moins pour l'intimité.
Les mises en œuvre de DoQ, maintenant. La société AdGuard a produit du code, dont un serveur et un client en Go, dnslookup. (Regardez l'exposé du directeur technique de cette société à l'OARC.) Voici un exemple de compilation, puis d'utilisation de dnslookup :
% git clone https://github.com/ameshkov/dnslookup.git % cd dnslookup % make % ./dnslookup www.bortzmeyer.org quic://dns.adguard.com
On utilisait le serveur DoQ public d'AdGuard. Officiellement, NextDNS en a également un mais je n'arrive pas à l'utiliser :
% ./dnslookup www.bortzmeyer.org quic://3e4935.dns.nextdns.io ... 2022/05/22 08:16:33 Cannot make the DNS request: opening quic session to quic://3e4935.dns.nextdns.io:853: timeout: no recent network activity
Notez que si vous voulez utiliser dnslookup avec un serveur dont le
certificat n'est pas valide, il faut mettre la variable
d'environnement VERIFY à 0 (cela ne semble pas documenté).
Il existe une autre mise en œuvre de DoQ, quicdoq, écrite en C. Elle dépend de la bibliothèque QUIC picoquic qui, à son tour, dépend de picotls, dont la compilation n'est pas toujours évidente. D'une manière générale, les bibliothèques QUIC sont souvent récentes, parfois expérimentales, et ne marchent pas toujours du premier coup. Mais si vous arrivez à compiler les dépendances de quicdoq, vous pouvez lancer le serveur ainsi :
% ./quicdoq_app -p 8053 -d 9.9.9.9
Puis le client :
% ./quicdoq_app ::1 8053 foobar:SOA bv:NS www.bortzmeyer.org:AAAA
Le logiciel de test de performances Flamethrower, écrit en C++ a une branche DoQ en cours de développement.
Le logiciel en Python aioquic ne semble pouvoir interagir qu'avec lui-même. Vu les messages d'erreur (quelque chose à propos de not enough bytes), je soupçonne qu'il utilise l'encodage des débuts de DoQ, quand il n'y avait pas encore le champ de deux octets au début des messages. Même avec lui-même, il a des exigences pénibles en matière de certificat (pas de certificats auto-signés, obligation que le nom du serveur soit dans le SAN - Subject Alternative Name, pas seulement dans le sujet).
Pour PowerDNS, il n'y a pour l'instant qu'un ticket. Et pour Unbound, c'est en cours, ainsi que pour Knot.
Dans les bibliothèques DNS, un travail est en cours pour go-dns.
Pour finir, vous pouvez regarder la présentation de DoQ par une des auteures du RFC au RIPE 84. Et un des premiers articles de recherche sur DoQ est « One to Rule them All? A First Look at DNS over QUIC ».
L'article seul
Métavers… où ?
Première rédaction de cet article le 14 mai 2022
J'ai eu le plaisir aujourd'hui de donner une conférence au sujet du métavers à la médiathèque Marc Ferro à Saint-Germain-en-Laye.
Voici les supports de la conférence en PDF (ou son source en LaTeX).
Merci à Kim-Minh Kaplan pour avoir retrouvé et numérisé le vieux numéro de Clone (journal tellement oublié qu'il n'a pas de page Wikipédia). Et à Marc Fontana pour l'invitation et l'organisation (belle médiathèque, avec beaucoup d'animations, n'hésitez pas à venir ; c'est le mai numérique).
L'annonce de Facebook citée est visible en ligne. Quelques liens intéressants :
- Le blog Binaire avait fait un bon article,
- Une réflexion à la CNIL,
- Bonne vidéo historique sur Second Life,
- Le fondateur de Deuxième monde avait récidivé avec Cryopolis,
- Sur la (mauvaise) idée du métavers européen,
- Le sondage sur le métavers.
Les tweets copiés sur les supports sont :
L'article seul
RFC 9229: IPv4 Routes with an IPv6 Next Hop in the Babel Routing Protocol
Date de publication du RFC : Mai 2022
Auteur(s) du RFC : J. Chroboczek (IRIF, University of Paris)
Expérimental
Réalisé dans le cadre du groupe de travail IETF babel
Première rédaction de cet article le 11 mai 2022
Voici une extension sympathique qui réjouira tous les amateurs de routage IP. Elle permet à un routeur qui parle le protocole de routage Babel d'annoncer un préfixe IPv4 où le routeur suivant pour ce préfixe n'a pas d'adresse IPv4 sur cette interface.
Un petit rappel de routage : les annonces
d'un routeur qui parle un protocole de
routage dynamique comme Babel (RFC 8966) comprennent un préfixe IP (comme
2001:db8:543::/48) et l'adresse IP du routeur suivant
(next hop dans la langue de Radia
Perlman). Traditionnellement, le préfixe et l'adresse du
routeur suivant étaient de la même version (famille) : tous les deux
en IPv4 ou tous les deux en
IPv6. Mais, si on veut router IPv6
et IPv4, cela consomme une adresse IP par
interface sur chaque routeur, or les adresses IPv4 sont désormais
une denrée très rare. D'où la proposition de ce RFC : permettre des annonces
d'un préfixe IPv4 avec une adresse de routeur suivant en
IPv6. (Notez que cela ne concerne pas que Babel, cela pourrait être
utilisé pour d'autres protocoles de routage dynamique.)
La section 1 du RFC résume ce que fait un protocole de routage. Son but est de construire des tables de routage, où chaque entrée de la table est indexée par un préfixe d'adresses IP et a une valeur, l'adresse du routeur suivant. Par exemple :
destination next hop 2001:db8:0:1::/64 fe80::1234:5678%eth0 203.0.113.0/24 192.0.2.1
Lorsqu'un routeur doit transmettre un paquet, il regarde dans cette table et trouve l'adresse du routeur suivant. Il va alors utiliser un protocole de résolution d'adresses (ARP - RFC 826 - pour IPv4, ND - RFC 4861 - pour IPv6) pour trouver l'adresse MAC du routeur suivant. Rien dans cette procédure n'impose que le préfixe de destination et l'adresse du routeur suivant soient de la même version d'IP. Un routeur qui veut transmettre un paquet IPv4 vers un routeur dont il ne connait que l'adresse IPv6 procède à la résolution en adresse MAC, puis met simplement le paquet IPv4 dans une trame portant l'adresse MAC en question (l'adresse IPv6 du routeur suivant n'apparait pas dans le paquet).
En permettant des annonces de préfixes IPv4 avec un routeur suivant en IPv6, on économise des adresses IPv4. Un réseau peut fournir de la connectivité IPv4 sans avoir d'adresses IPv4, à part au bord. Et comme les adresses IPv6 des routeurs sont des adresses locales au lien allouées automatiquement (cf. RFC 7404), on peut avoir un réseau dont le cœur n'a aucune adresse statique, ce qui peut faciliter sa gestion.
Notre RFC documente donc une extension au protocole Babel (qui
est normalisé dans le RFC 8966), nommée
v4-via-v6. (Comme dit plus haut, le principe
n'est pas spécifique à Babel, voir le RFC 5549 pour son équivalent pour BGP.)
Bon, le concret, maintenant. Les préfixes annoncés en Babel sont précédés de l'AE (Address Encoding), un entier qui indique la version (famille) du préfixe. Ce RFC crée un nouvel AE, portant le numéro 4, qui a le même format que l'AE 1 qui servait à IPv4. Une annonce d'un préfixe ayant l'AE 4 devra donc contenir un préfixe IPv4 et un routeur suivant en IPv6. Un routeur qui sait router IPv4 mais n'a pas d'adresse IPv4 sur une de ses interfaces peut donc quand même y annoncer les préfixes connus, en les marquant avec l'AE 4 et en mettant comme adresse l'adresse IPv6 pour cette interface. (Cet AE est uniquement pour les préfixes, pas pour l'indication du routeur suivant.)
Les routeurs qui ne gèrent pas l'extension
v4-via-v6 ignoreront cette annonce, comme ils
doivent ignorer toutes les annonces portant un AE inconnu (RFC 8966). Pour
cette raison, si un routeur a une adresse IPv4 sur une interface, il
faut qu'il utilise des annonces traditionnelles, avec l'AE 1, pour
maximiser les chances que son annonce soit acceptée.
Arrivé ici, mes lectrices et mes lecteurs, qui sont très malins, se demandent depuis longtemps « mais un routeur doit parfois émettre des erreurs ICMP (RFC 792), par exemple s'il n'a pas d'entrée dans sa table pour cette destination ». Comment peut-il faire s'il n'a pas d'adresse sur l'interface où il a reçu le paquet coupable ? Ne rien émettre n'est pas acceptable, certains protocoles en dépendent. C'est par exemple le cas de la découverte de la MTU du chemin, documentée dans le RFC 1191, qui a besoin des messages ICMP Packet too big. Certes, il existe un algorithme de découverte de cette MTU du chemin qui est entièrement de bout en bout, et ne dépend donc pas des routeurs et de leurs messages (RFC 4821). Mais ICMP sert à d'autres choses, on ne peut pas y renoncer.
Si le routeur Babel a une adresse IPv4 quelque part, sur une de
ses interfaces, il peut l'utiliser comme adresse IP source pour ses
messages ICMP. S'il n'en a pas, il peut toujours utiliser
192.0.0.8 comme suggéré par la section 4.8 du
RFC 7600. Bien sûr, si tout le monde le fait, des outils
d'administration du réseau très pratiques comme
traceroute seront moins utiles.
La nouvelle extension peut soulever des questions de sécurité (section 6 du RFC). Par exemple, si l'administrateur réseaux croyait que, parce que les routeurs n'avaient pas d'adresse IPv4 sur une interface, les paquets IPv4 ne seraient pas traités sur cette interface, cette supposition n'est plus vraie. Ainsi, une île de machines IPv4 qui se croyaient séparées de l'Internet IPv4 par un ensemble de routeurs qui n'avaient pas d'adresse IPv4 de leur côté peut se retrouver subitement connectée. Si ce n'est pas ce qu'on veut, il faut penser à ne pas se contenter du protocole de routage pour filtrer, mais aussi à filtrer explicitement IPv4.
Question mise en œuvre, cette extension figure dans babeld (voir ici un compte-rendu d'expérience) à partir de la version 1.12, ainsi que dans BIRD.
L'article seul
RFC 9239: Updates to ECMAScript Media Types
Date de publication du RFC : Mai 2022
Auteur(s) du RFC : M. Miller, M. Borins (GitHub), M. Bynens (Google), B. Farias
Pour information
Réalisé dans le cadre du groupe de travail IETF dispatch
Première rédaction de cet article le 11 mai 2022
Ce RFC
documente les types de médias pour le langage
de programmation JavaScript (dont le nom
officiel est ECMAScript, qu'on retrouve dans le titre de ce RFC). Il
remplace le RFC 4329 et le principal
changement est que le type recommandé est désormais
text/javascript et non plus
application/javascript.
Si vous voulez vous renseigner en détail sur
JavaScript, notre RFC recommande de lire la norme
ECMA, en https://262.ecma-international.org/12.0/text/javascript. D'autres types existent,
application/ecmascript,
application/javascript, etc, mais ils sont
maintenant considérés comme dépassés.
Il existe plusieurs versions de la norme JavaScript et d'autres
apparaitront peut-être dans le futur. Mais le type officiel
n'indique pas de version (il a existé des propositions comme
text/javascript1.4) et compte que toutes ces
versions sont suffisamment compatibles pour qu'on ne gère pas la
complexité d'avoir plusieurs types. Normalement,
ECMA s'engage à ne pas bouleverser le
langage.
Le choix de text/ est contestable car la
définition originale de text/ dans le RFC 2045 prévoyait plutôt
application/ pour les programmes. Le RFC 4329 enregistrait les types
text/javascript et
application/javascript, et recommandait le
application/javascript (en accord avec ce que
dit le RFC 6838). Aujourd'hui, c'est le
contraire, text/javascript est le
préféré. D'une manière générale, application/
n'a guère été utilisé (pas seulement dans le cas de
JavaScript). (Personnellement, cela me convient très bien : pour
moi, si ça peut s'afficher avec cat et
s'éditer avec vi, c'est du texte.)
JavaScript est donc officiellement du texte, et la section 4 de
notre RFC précise : du texte en UTF-8. Le
paramètre charset est donc facultatif (même si
le RFC 6838 dit le contraire). Si vous aimez
les détails d'encodage, la section 4 vous ravira (c'est l'un des
points qui a suscité le plus de discussion à l'IETF).
Le type text/javascript est enregistré
à l'IANA ; les types comme
application/javascript sont marqués
comme dépassés. Même chose pour
text/ecmascript. Le nom officiel de JavaScript
est ECMAscript, puisque normalisé à l'ECMA
mais personne n'utilise ce terme. (Il faut quand même noter que
JavaScript est un terme publicitaire mensonger puisqu'il avait été
choisi par le marketing pour profiter de la popularité - à
l'époque - de Java, un
langage avec lequel il n'a rien à voir.) Enfin, les types comme
text/x-javascript qu'on voit parfois trainer
datent d'avant le RFC 6648, qui abandonnait
les identificateurs semi-privés commençant par
x-.
La section 5 couvre les questions de sécurité. Elle est très longue car l'envoi de JavaScript à un programme qui l'exécutera (ce qui est très courant sur le Web) pose plein de problèmes de sécurité. Le RFC rappelle que l'exécution automatique d'un programme fourni par un tiers est évidemment intrinsèquement dangereuse, et doit se faire dans un bac à sable. Parmi les dangers (mais il y en a beaucoup d'autres !) le déni de service puisque JavaScript est un langage de Turing et permet donc, par exemple, des boucles infinies.
L'annexe B du RFC résume les changements depuis le RFC 4329 : le principal est bien sûr l'abandon de
application/javascript au profit de
text/javascript. Il y a aussi l'ajout de
quelques détails comme une faille de sécurité nouvelle, et le cas
des modules JavaScript.
Ah, un point de détail cité au détour d'un paragraphe du RFC : il
n'y a pas de norme pour les identificateurs de fragments dans un
URI
pointant vers une ressource de type
text/javascript. Si
https://code.example/js/foreach.js#l23 pointe
vers du JavaScript, la signification du #l23
(l'identificateur de fragment) n'est pas spécifiée.
L'article seul
RFC 9116: A File Format to Aid in Security Vulnerability Disclosure
Date de publication du RFC : Avril 2022
Auteur(s) du RFC : E. Foudil, Y. Shafranovich (Nightwatch Cybersecurity)
Pour information
Première rédaction de cet article le 28 avril 2022
Lorsqu'on repère un problème de sécurité sur un site Web ou, plus
généralement, dans l'informatique d'une organisation, de deux choses
l'une : soit on est un méchant et on exploite l'information à son
profit, soit on fait partie des bons et on va essayer de faire en
sorte que le problème soit résolu. Une solution évidente est de
signaler le problème à l'organisation qui gère le site Web. Mais
comment ? Entre le formulaire de contact cassé qui refuse votre
adresse de courrier en prétendant qu'elle est illégale, et le
message envoyé à un humain sous-payé et sous-qualifié qui cliquera
tout de suite sur « Problème résolu » pour faire grimper ses
chiffres de résolution, prévenir quelqu'un de compétent et de
responsable est souvent un parcours du combattant ! D'où le choix de
ce RFC de
proposer encore une nouvelle méthode : un fichier à un endroit bien
connu sur le site Web, au format structuré, et contenant les
informations essentielles, le security.txt.
Comme beaucoup de techniques utilisées sur l'Internet, ce format a été déployé bien avant d'être officiellement décrit dans un RFC. On trouve aujourd'hui de tels fichiers sur plusieurs sites, y compris sur ce blog (regardez-le tout de suite si vous voulez avoir une idée de ce qu'on y met).
La section 1 du RFC décrit plus en détail le problème. Toute personne qui a déjà essayé de signaler un problème de sécurité à une organisation reconnaitra ses propres mésaventures. Le RFC commence par rappeler que trouver un contact, quoique très difficile, n'est pas tout : il faut aussi s'informer sur la politique de traitement des signalements de cette organisation, car plus d'un citoyen ayant voulu signaler une vulnérabilité s'est retrouvé accusé d'être un vilain pirate, et a parfois réellement été poursuivi en justice. Et enfin il faut s'informer sur les moyens de communications sécurisés puisque, par définition, on va transmettre des informations délicates. Est-ce qu'on peut utiliser PGP (RFC 9580), par exemple ? Pour ce qui est des contacts, il existe en théorie plusieurs solutions :
- Le RFC 2142 exige un certain nombre
d'adresses de courrier pour chaque domaine, comme
security@LE-DOMAINEpour les signalements de sécurité. Il y a peu d'organisations où cette adresse fonctionne techniquement et, même quand c'est le cas, elle n'est pas forcément lue. - Les RFC 3013 (section 2), RFC 2350 (section 3.2) et RFC 2196 (section 5.2) prévoient des adresses de contact pour différents types d'acteurs. (Même remarque que sur le point précédent.)
- Les bases des registres (de noms de domaine et d'adresses IP) contiennent également des adresses de contacts, en général accessibles via whois (cf. RFC 7485) ou RDAP. (Même remarque que sur le point précédent, en ajoutant que ces bases sont purement déclaratives, que leur exactitude est faible et baisse avec le temps.)
- Aucune de ces solutions ne donne facilement accès à la politique de divulgation de l'organisation. Et, surtout, même si le RFC garde un silence poli sur la question, toute personne qui a essayé de contacter une organisation sait bien que ces adresses de contact sont souvent erronées, dépassées, ou bien arrivent chez des gens qui s'en f...ent.
Le dernier point est à la fois une motivation important pour créer
une nouvelle solution et une des principales critiques qui avaient
été formulées à l'encontre du projet
security.txt lors de la discussion à
l'IETF : pourquoi est-ce que ça serait mieux avec
un nouveau format ? Si une organisation est assez négligente pour ne
pas tenir à jour les informations présentes chez le registre de son
nom de domaine, comment
espérer qu'elle tienne à jour son
security.txt ? Il n'y a évidemment pas de
certitude à ce sujet, juste l'espoir qu'un autre format, et surtout
un autre mécanisme de mise à jour augmentera les chances que
l'information soit correcte.
Le
security.txt est un fichier analysable par un
programme (mais quand même lisible par un humain), et qui permet
d'indiquer tout ce qui est nécessaire, par exemple au chercheur de
vulnérabilités qui a trouvé quelque chose. Il vise à signaler les
vulnérabilités (pas encore exploitées), pas les
incidents (car un attaquant qui a réussi a
peut-être modifié le fichier security.txt).
La spécification, maintenant (section 2 du
RFC). Le security.txt est un simple fichier
texte qui doit être déposé à un endroit précis du site Web,
/.well-known (RFC 8615,
et security.txt a été enregistré dans le registre
des URL bien connus). Son type doit être text/plain et
il doit être accessible en HTTPS, pour d'évidentes raisons de
sécurité. Il doit être en Unicode, utilisant
le profil du RFC 5198. Analysable par un
programme, il doit se conformer à la
grammaire spécifiée dans le RFC. Il comporte
plusieurs champs, chacun sur une ligne, et ayant un nom et une
valeur. La plupart des champs sont optionnels. Le champ le plus
connu est Contact, qui est obligatoire, et
voici un exemple :
Contact: mailto:stephane%2Bsecurity@bortzmeyer.org
(Vous avez reconnu l'encodage de l'URI spécifié dans la section 2.1 du RFC 3986. %2B est le signe
plus.) Les
lignes commençant par un croisillon sont des
commentaires.
Le RFC recommande que les security.txt
soient signés avec
OpenPGP (RFC 9580). Naturellement, comme avec n'importe quelle
signature, sa valeur dépend de si le vérificateur connait de manière
certaine la clé publique qui a été utilisée.
Un certain nombre de champs sont définis aujourd'hui, la plupart optionnels. Parmi eux :
Acknowledgments: un lien vers une page des remerciements, pour que la personne ayant l'intention de signaler un problème sache qu'elle pourra être remerciée publiquement. Question carotte pour les chercheurs de vulnérabilités, il y a aussi un champHiring☺.Canonical: l'URL officiel de cesecurity.txt. Cela peut permettre de détecter certaines erreurs de configuration (security.txtcopié sur le mauvais site).Contact: sans doute le champ le plus important, et un des rares qui soit obligatoire. Il contient un URI indiquant comment contacter quelqu'un de responsable, à qui confier le problème de sécurité. L'intérêt de définir la valeur de ce champ comme un URI est que cela permet de ne pas se limiter à une méthode de contact particulière. Puisque c'est un URI, les adresses de courrier électronique doivent être mises sous forme d'URImailto:(RFC 6068). Pareil pour les numéros de téléphone (RFC 3966). Le champContactpeut être répété, afin d'avoir plusieurs mécanismes de signalement (dans ce cas, l'ordre est important, la méthode recommandée est la première).Encryption: indique la clé de chiffrement à utiliser pour contacter. C'est encore un URI (qui peut être un URI de plandns:, pour les clés stockées dans le DNS du RFC 7929).Expires: ce champ est obligatoire et indique (au format du RFC 3339) la date limite d'utilisation de cesecurity.txt(pour éviter que de vieux fichiers pas maintenus restent utilisés).Policy: un lien vers la page décrivant la politique de l'organisation en matière de signalement de vulnérabilités. Rappelez-vous qu'un problème de beaucoup de personnes qui ont détecté une vulnérabilité est le risque que le signalement de celle-ci leur vaille des ennuis juridiques, en raison de la politique de beaucoup d'organisations qui est de nier les problèmes et de poursuivre devant les tribunaux ceux qui les signalent.Preferred-Languages: des étiquettes de langue (RFC 5646) indiquant dans quelles langues on préfère recevoir les rapports (et là, je pense à cet informaticien étatsunien qui s'était étonné publiquement qu'un webmestre chinois ne répondait pas à ses signalements de vulnérabilité faits en anglais…).
Les champs figurent dans un
registre IANA. D'autres champs pourront être rajoutés à ce
registre dans le futur, en suivant la politique « Examen par un
expert » (RFC 8126). Pour faciliter ces futurs
ajouts, il faut ignorer les champs qu'on ne connait pas. Un exemple
réel de security.txt ? Regardez celui de ce blog.
Le security.txt est publié via le site Web
mais ne s'applique pas forcément qu'au Web, il peut aussi servir
pour l'organisation en général. Par contre, il ne s'applique pas aux
sous-domaines : un security.txt sur
eu.org n'est pas valable pour
exodus-privacy.eu.org.
Vu le but de ce security.txt, il n'est pas
étonnant que la section 5 du RFC, consacrée à la
sécurité, soit si détaillée, d'autant plus qu'elle a fait l'objet de
vigoureuses discussions à l'IETF. Je n'en cite ici qu'une partie,
n'hésitez pas à lire toute cette section 5. D'abord,
l'objection la plus évidente : si le site Web a été piraté, le
security.txt ne peut plus être considéré comme
digne de confiance. Les signalements risquent d'être perdus ou même
envoyés à l'attaquant qui aura mis son adresse dans le
security.txt. C'est vrai, mais c'est le cas de
toutes les informations de contact. Par exemple, si le compte de
l'organisation auprès du BE a été piraté (comme dans l'attaque moyen-orientale
de 2018), les informations attachées au nom de domaine, et
récupérées par whois ou RDAP, sont également suspectes. Le RFC
recommande que les organisations qui ont un
security.txt le supervisent automatiquement et
vérifient notamment le champ Canonical. Et,
bien sûr, que le security.txt soit signé. Les
personnes qui signalent une vulnérabilité ont tout intérêt à
vérifier le security.txt. Et puis surtout,
security.txt est conçu pour la
réponse à vulnérabilité, pas la
réponse à incident. L'utiliser pour signaler
« vous avez une faille » est raisonnable, s'en servir pour signaler
« vous êtes piraté » l'est moins.
Comme toutes les informations mises en ligne (cf. l'exemple des
informations sociales sur un nom de domaine…), le
security.txt peut être faux, soit dès le début,
soit parce qu'il n'a pas été maintenu correctement. En tapant cet
article, je regardais le security.txt d'une
entreprise française de sécurité informatique et le champ
Encryption contenait un URL qui pointait… vers
un 404. Dans une très grosse entreprise française travaillant sur de
la haute technologie, notamment en sécurité, un URL dans le
security.txt donne… 403 ! Au même endroit, la
signature du security.txt est incorrecte… Le champ Expires permet de détecter les
security.txt trop vieux et pas maintenus mais
le problème est vaste et on peut s'attendre à se casser souvent le
nez sur des informations incorrectes. Comme pour toutes les
informations en ligne, les organisations qui publient un
security.txt devraient s'assurer, dans leurs
procédures, qu'il est maintenu à jour.
Certains croient qu'ils ont le droit de se livrer à des
tests d'attaques sur tout
site Web trouvé sur l'Internet. C'est évidemment faux, de même qu'on
n'a pas le droit dans le rue de tenter de crocheter toutes les
serrures pour voir lesquelles sont vulnérables. Même l'existence
d'un security.txt ne vaut pas autorisation de
tester le site. Le champ Policy peut indiquer
si des tests d'attaque sont autorisés et dans quelles
conditions. Sinon, on doit se limiter aux failles découvertes dans
le cours de l'utilisation normale du site (ceci n'est pas un conseil
juridique : la loi est compliquée et dépend du pays).
Naturellement, comme toujours lorsqu'on publie une adresse de
courrier, elle va recevoir du spam. Plus
gênant, le fait que le security.txt soit
analysable par un programme pourrait amener certains
bots qui font des soi-disant tests de
sécurité à envoyer des messages automatiques de faible
valeur. (Par exemple, j'ai vu un bot qui regardait la version
d'Apache et
envoyait automatiquement un courrier si la version lui semblait trop
vieille. Ce genre d'avertissements mécaniques n'a aucune valeur,
notamment parce que certains systèmes d'exploitation bouchent les
failles de sécurité sans changer la version et, surtout, parce qu'il
y a peu de chance qu'un logiciel puisse faire avec succès quelque
chose d'aussi délicat qu'une analyse de sécurité ; les logiciels
sont utiles pour une première reconnaissance, mais il ne faut pas
envoyer de message d'avertissement avant qu'un humain compétent
n'ait vérifié.)
Voilà, nous avons fait le tour du RFC. Si vous êtes responsable
de la sécurité d'une organisation, à vous de vous mettre au travail
pour concevoir et documenter une politique de signalement des
failles de sécurité (c'est le gros du travail), de rédiger un
security.txt (c'est trivial) et de faire en
sorte qu'il soit maintenu (ce n'est pas évident). Si vous avez
trouvé une faille de sécurité dans un site Web ou ailleurs chez une
organisation, pensez à regarder si elle a un
security.txt mais ne l'utilisez pas
aveuglément, comparez avec d'autres sources d'information. Pour vous
instruire, vous pouvez regarder le site Web du projet. Il
comprend notamment un bon formulaire pour aider à fabriquer son
security.txt (mais rappelez-vous que ce qui est
difficile, c'est l'élaboration de la politique). Ce site contient
également une liste de
logiciels qui peuvent aider. Le moteur de recherche
Shodan lit les
security.txt et les affiche proprement mais,
avec le virtual hosting,
comme Shodan travaille par adresse IP, ça ne marche pas
souvent. Sinon, YesWeHack fournit une extension
aux navigateurs Web pour afficher le
security.txt (pas très utile, je trouve, elle
se contente d'afficher le fichier tel quel, sans vraie valeur
ajoutée).
Le security.txt est-il obligatoire ? Cela
dépend de votre environnement. Le DHS
étatsunien le
recommande pour les organismes qui dépendent de lui. En
France, l'arrêté
du 18 septembre 2018 portant approbation du cahier des clauses
simplifiées de cybersécurité, dans son article 6.4, dit que
« Afin que ces signalements soient effectifs et efficaces, les
conventions d'usage en cybersécurité sont respectées (security.txt,
abuse@). Dans tous les cas, il faut moins d'une minute pour trouver
le point d'entrée approprié du signalement. ».
Terminons par un tour des security.txt
existants (mes commentaires concernent l'état de ce fichier en août 2021 ;
il a pu changer depuis). Commençons par un exemple très simple, mais correct,
celui de la société
Cyberzen :
% curl https://www.cyberzen.com/.well-known/security.txt Contact: contact@cyberzen.com Expires: Sun, 31 Dec 2023 23:59 +0200 Preferred-Languages: fr, en
Ensuite le registre de
.be a un très bon
security.txt, très complet, avec commentaires :
% curl https://www.dnsbelgium.be/.well-known/security.txt # Our security address Contact: mailto:csirt@dnsbelgium.be?subject=rdp_dnsbelgium.be # Our OpenPGP key Encryption: https://www.dnsbelgium.be/.well-known/pgp-key.txt # Canonical URL Canonical: https://www.dnsbelgium.be/.well-known/security.txt # Our security policy Policy: https://www.dnsbelgium.be/responsible-disclosure-policy Preferred-Languages: en, nl, fr Expires: Mon, 1 Nov 2021 00:00:00 +0100
Autre exemple, Google a un
security.txt :
Contact: https://g.co/vulnz Contact: mailto:security@google.com Encryption: https://services.google.com/corporate/publickey.txt Acknowledgements: https://bughunter.withgoogle.com/ Policy: https://g.co/vrp Hiring: https://g.co/SecurityPrivacyEngJobs
Le champ Expires, pourtant obligatoire, manque
encore (il a été ajouté dans les dernières révisions du projet de
spécification).
En France, la Sécu en a un et, contrairement à celui de Google, il est signé avec OpenPGP :
% curl https://www.ameli.fr/.well-known/security.txt -----BEGIN PGP SIGNED MESSAGE----- Hash: SHA512 Contact: mailto:abuse@assurance-maladie.fr Encryption: https://raw.githubusercontent.com/AssuranceMaladieSec/abuse/master/abuse-gpg-public-key.txt Policy: https://assurancemaladiesec.github.io/abuse/reporting/ Acknowledgments: https://assurancemaladiesec.github.io/abuse/thanks/ Preferred-Languages: fr,en -----BEGIN PGP SIGNATURE----- iQIzBAEBCgAdFiEEDSx9bqnSlmkiIRXbSDqGYCymPFIFAl4V9/cACgkQSDqGYCym PFIB7Q/9EI7fNOfyoCqnEH4chiTIW8fx32ldnlaE6WTgdMeQJmkyJrhd2osPAV/j ...
Ah, profitons-en pour vérifier la signature (la clé publique, curieusement, est hébergé chez un tiers, GitHub) :
% wget https://www.ameli.fr/.well-known/security.txt ... 2020-04-08 18:41:10 (6.87 MB/s) - ‘security.txt’ saved [1189] % wget https://raw.githubusercontent.com/AssuranceMaladieSec/abuse/master/abuse-gpg-public-key.txt ... 2021-08-12 09:03:52 (11,1 MB/s) - ‘abuse-gpg-public-key.txt’ saved [3159/3159] % gpg --import abuse-gpg-public-key.txt gpg: key 483A86602CA63C52: public key "Abuse Assurance Maladie <abuse@assurance-maladie.fr>" imported gpg: Total number processed: 1 gpg: imported: 1 % gpg --verify security.txt gpg: Signature made Wed Jan 8 16:40:39 2020 CET gpg: using RSA key 0D2C7D6EA9D29669222115DB483A86602CA63C52 gpg: Good signature from "Abuse Assurance Maladie <abuse@assurance-maladie.fr>" [unknown] gpg: WARNING: This key is not certified with a trusted signature! gpg: There is no indication that the signature belongs to the owner. Primary key fingerprint: 0D2C 7D6E A9D2 9669 2221 15DB 483A 8660 2CA6 3C52
C'est parfait, tout fonctionne (et c'est documenté).
Autre exemple en France, le service Flus, dont le
security.txt est décrit dans un bon article. Voici le fichier :
% curl https://flus.fr/.well-known/security.txt Contact: https://flus.fr/contact Contact: security@flus.io Expires: Fri, 01 Apr 2022 00:00 +0000 Policy: https://flus.fr/securite Acknowledgments: https://flus.fr/securite Canonical: https://flus.fr/.well-known/security.txt Preferred-Languages: fr, en
OpenSSL
a bien sûr un security.txt. À une époque, la
signature PGP était incorrecte…
% gpg --verify security.txt.asc security.txt gpg: Signature made Thu Jan 4 04:22:26 2018 CET gpg: using RSA key EFC0A467D613CB83C7ED6D30D894E2CE8B3D79F5 gpg: BAD signature from "OpenSSL OMC <openssl-omc@openssl.org>" [unknown]
Cela illustre un problème commun à tous les mécanismes de publication d'information de contact : l'information n'est pas facile à maintenir et tend à se dégrader avec le temps.
Quelques lectures supplémentaires qui peuvent être intéressantes :
- Si vous êtes prêt à payer, la norme ISO ISO.29147.2018 parle de « Security techniques - Vulnerability disclosure ».
- CMU a un « CERT Guide to Coordinated Vulnerability Disclosure ».
- Le projet
https://disclose.io/ - Autres articles en français sur le
security.txt: celui de Bruno Kerouanton et celui de y0no. - Et un article de l'ANSSI sur le signalement de vulnérabilités.
L'article seul
RFC 9151: Commercial National Security Algorithm (CNSA) Suite Profile for TLS and DTLS 1.2 and 1.3
Date de publication du RFC : Avril 2022
Auteur(s) du RFC : D. Cooley (NSA)
Pour information
Première rédaction de cet article le 26 avril 2022
Le choix est vaste parmi les algorithmes de cryptographie. Des protocoles comme TLS offrent de l'agilité cryptographique, c'est-à-dire la possibilité d'avoir différents algorithmes pour un même protocole. Pour l'administrateur système qui n'est pas un ou une expert en cryptographie, lesquels choisir ? Pour l'aider, les agences de sécurité nationales font souvent des documents synthétisant leur analyse des bons algorithmes du moment. C'est le cas du RGS en France, par exemple. Ce RFC définit le profil TLS de CNSA (Commercial National Security Algorithm), les bons algorithmes recommandés par la NSA.
C'est d'ailleurs le deuxième RFC écrit par un employé de cette agence étatsunienne, après le RFC 5903 mais il est évidemment possible que certains auteurs aient été discrets sur leur affiliation.
Ce profil CNSA (Commercial National Security Algorithm) est destiné à être utilisé dans le cadre de TLS, plus exactement ses versions 1.2 (RFC 5246) et 1.3 (RFC 9846). Le cadre réglementaire étatsunien est SP 80059. Un rappel : il s'agit d'un profil, une restriction des algorithmes possibles, il ne définit pas de nouvel algorithme, il liste juste ceux à utiliser, par exemple ceux des RFC 5288 et RFC 5289. C'est en effet une de missions de la NSA que de conseiller l'État et les entreprises en matière de cryptographie. (La NSA a également une mission offensive, qui va en sens inverse, les encourageant par exemple à garder secrètes des vulnérabilités, pour qu'elle puisse les exploiter.) Cette suite CNSA n'a rien de très novateur, elle est dans la continuation des précédentes, le prochain grand changement, estime la NSA, sera le passage aux algorithmes post-quantiques. (Notez que l'analyse de la NSA sur les mesures à prendre en attendant les calculateurs quantiques est très discutée.)
Après ces préliminaires, la suite CNSA elle-même (section 4). Elle inclut les grands classiques, Diffie-Hellman avec les corps finis, les courbes elliptiques du NIST et encore RSA, les signatures avec les courbes elliptiques (ECDSA seulement) et RSA, et l'algorithme de chiffrement symétrique AES en intègre avec GCM (ChaCha - RFC 8439, sans doute pas assez officiel, n'est pas cité). CNSA impose des tailles minimales de clés, par exemple 3 072 bits pour une signature avec RSA. Pour la condensation, c'est SHA-384 seulement (j'ignore pourquoi SHA-256 et les autres ne sont pas cités).
Pour la version de TLS, la section 5 de notre RFC impose au minimum 1.2 (c'est un des points où le blog que vous êtes en train de lire n'est pas conforme aux recommandations de la NSA…). Si on utilise une courbe elliptique (cf. RFC 8422), cela doit être la P-384 du NIST. (Saviez-vous d'ailleurs qu'il existe une courbe elliptique française, « FRP256 », publiée au Journal officiel ?) Et au passage, les certificats doivent suivre le profil du RFC 8603.
Pour TLS 1.3 (RFC 9846), CNSA impose de
tirer profit de certaines nouveautés de cette version, comme
l'extension signature_algorithms. Par contre,
il faut refuser early_data (les raisons sont
dans la section 2.3 du RFC 9846).
L'article seul
RFC 9224: Finding the Authoritative Registration Data Access Protocol (RDAP) Service
Date de publication du RFC : Mars 2022
Auteur(s) du RFC : M. Blanchet (Viagenie)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 25 avril 2022
Le protocole RDAP d'accès à l'information
sur les objets (noms de
domaines, adresses
IP, etc) stockés dans un registre fonctionne en
interrogeant le serveur en HTTP. Encore faut-il trouver le serveur à
interroger. Comment le client RDAP qui veut des informations sur
2001:67c:288::2 sait-il à quel serveur
demander ? Ce RFC
décrit le mécanisme choisi. En gros, l'IANA gère des
« méta-services » qui donnent la liste de serveurs RDAP, mais il
peut aussi y avoir redirection d'un serveur RDAP vers un autre. Ce
RFC remplace le premier RFC sur le sujet, le RFC 7484, avec très peu de changements.
Le protocole RDAP est décrit entre autres dans le RFC 7480 qui précise comment utiliser HTTP pour transporter les requêtes et réponses RDAP. Comme indiqué plus haut, il ne précise pas comment trouver le serveur RDAP responsable d'un objet donné. Le prédécesseur de RDAP, whois, avait exactement le même problème, résolu par exemple en mettant en dur dans le logiciel client tous les serveurs whois connus. En pratique, beaucoup de gens font simplement une requête Google et accordent une confiance aveugle auu premier résultat venu, quel que soit sa source. Au contraire, ce RFC vise à fournir un mécanisme pour trouver la source faisant autorité.
Avant d'exposer la solution utilisée, la section 1 de notre RFC rappelle comment ces objets (noms de domaine, adresses IP, numéros d'AS, etc) sont alloués et délégués. L'IANA délégue les TLD aux registres de noms de domaines, des grands préfixes IP et les blocs de numéros d'AS aux RIR. Il est donc logique que RDAP suive le même chemin : pour trouver le serveur responsable, on commence par demander à l'IANA, qui a déjà les processus pour cela, et maintient les registres correspondants (adresses IPv4, adresses IPv6, numéros d'AS et domaines).
Pour permettre à RDAP de fonctionner, ce RFC demande donc à l'IANA quelques fichiers supplémentaires, au format JSON (RFC 8259), dont le contenu dérive des registres cités plus haut. Et l'IANA doit aussi prévoir des serveurs adaptés à servir ces fichiers, nommés RDAP Bootstrap Service, à de nombreux clients RDAP.
Le format de ces fichiers JSON est décrit dans la section 3 de
notre RFC. Chaque bootstrap service contient des
métadonnées comme un numéro de version et une date de publication,
et il contient un membre nommé services qui
indique les URL où aller chercher l'information (la syntaxe
formelle figure en section 10). Voici un extrait d'un des fichiers
actuels :
% curl https://data.iana.org/rdap/ipv4.json
"description": "RDAP bootstrap file for IPv4 address allocations",
"publication": "2019-06-07T19:00:02Z",
"services": [
[
[
"41.0.0.0/8",
"102.0.0.0/8",
"105.0.0.0/8",
"154.0.0.0/8",
"196.0.0.0/8",
"197.0.0.0/8"
],
[
"https://rdap.afrinic.net/rdap/",
"http://rdap.afrinic.net/rdap/"
]
],
...
On voit que le contenu est un tableau donnant, pour des objets
donnés, les URL des serveurs RDAP à contacter pour ces objets
indiqués, par exemple pour l'adresse IP
154.3.2.1, on ira demander au serveur RDAP
d'AfriNIC en
https://rdap.afrinic.net/rdap/.
Le membre publication indique la date de
parution au format du RFC 3339. Les URL
indiqués se terminent par une barre oblique,
le client RDAP a juste à leur ajouter une requête formulée selon la
syntaxe du RFC 9082. Ainsi, cherchant des
informations sur 192.0.2.24, on ajoutera
ip/192.0.2.24 à l'URL de base.
Pour les adresses IP (section 5), les entrées sont des préfixes, comme dans le premier exemple montré plus haut et la correspondance se fait avec le préfixe le plus spécifique (comme pour le routage IP). Les préfixes IPv4 suivent la syntaxe du RFC 4632 et les IPv6 celle du RFC 5952. Voici un exemple IPv6 (légèrement modifié d'un cas réel) :
[
[
"2001:200::/23",
"2001:4400::/23",
"2001:8000::/19",
"2001:a000::/20",
"2001:b000::/20",
"2001:c00::/23",
"2001:e00::/23",
"2400::/12"
],
[
"https://rdap.apnic.net/"
]
],
[
[
"2001:200:1000::/36"
],
[
"https://example.net/rdaprir2/"
]
Si on cherche de l'information sur le préfixe
2001:200:1000::/48, il correspond à deux
entrées dans le tableau des services
(2001:200::/23 et
2001:200:1000::/36) mais la règle du préfixe le
plus long (le plus spécifique) fait qu'on va utiliser
2001:200:1000::/36, et la requête finale sera
donc
https://example.net/rdaprir2/ip/2001:200:1000::/48.
Pour les domaines (section 4), les entrées des services sont des noms de domaine :
...
"services": [
[
["net", "com", "org"],
[
"https://registry.example.com/myrdap/"
]
],
[
["foobar.org", "mytld"],
[
"https://example.org/"
]
],
...
L'entrée sélectionnée est la plus longue (en nombre de composants du
nom, pas en nombre de caractères) qui correspond. Dans l'exemple
ci-dessus, si on cherche des informations sur
foobar.org, on ira voir le serveur RDAP en
https://example.org/, si on en cherche sur
toto.org, on ira en
https://registry.example.com/myrdap/. (En
pratique, aujourd'hui, le tableau des serveurs RDAP ne contient que
des TLD.)
Pour les numéros d'AS (section 5.3), on se sert d'intervalles de numéros et de la syntaxe du RFC 5396 :
"services": [
[
["2045-2045"],
[
"https://rir3.example.com/myrdap/"
]
],
[
["10000-12000", "300000-400000"],
[
"http://example.org/"
]
],
...
Les entités (section 6 de notre RFC) posent un problème particulier, elles ne se situent pas dans un espace arborescent, contrairement aux autres objets utilisable avec RDAP. (Rappel : les entités sont les contacts, les titulaires, les BE…) Il n'existe donc pas de bootstrap service pour les entités (ni, d'ailleurs, pour les serveurs de noms, cf. section 9). En pratique, si une requête RDAP renvoie une réponse incluant un handle pour une entité, il n'est pas idiot d'envoyer les requêtes d'information sur cette entité au même serveur RDAP mais il n'est pas garanti que cela marche.
Notez (section 7) que le tableau services ne
sera pas forcément complet et que certains objets peuvent ne pas s'y
trouver. Par exemple, dans un tableau pour les TLD, les registres n'ayant pas
encore de serveur RDAP ne seront logiquement pas cités. On peut
toujours tenter un autre serveur, en espérant qu'il utilisera les
redirections HTTP. Par exemple, ici, on demande au serveur RDAP de
l'APNIC pour une adresse RIPE. On est bien redirigé
avec un code 301 (RFC 7231, section 6.4.2) :
% curl -v http://rdap.apnic.net/ip/2001:67c:288::2 ... > GET /ip/2001:67c:288::2 HTTP/1.1 > User-Agent: curl/7.38.0 > Host: rdap.apnic.net > Accept: */* > < HTTP/1.1 301 Moved Permanently < Date: Wed, 01 Apr 2015 13:07:00 GMT < Location: http://rdap.db.ripe.net/ip/2001:67c:288::2 < Content-Type: application/rdap+json ...
La section 8 couvre quelques détails liés au déploiement de ce
service. C'est que le Bootstrap Service est
différent des autres registres IANA. Ces autres registres ne sont
consultés que rarement (par exemple, lors de l'écriture d'un
logiciel) et jamais en temps réel. Si le serveur HTTP de l'IANA
plante, ce n'est donc pas trop grave. Au contraire, le
Bootstrap Service doit marcher en permanence, car
un client RDAP en a besoin. Pour limiter la pression sur les
serveurs de l'IANA, notre RFC recommande que les clients RDAP ne
consultent pas ce service à chaque requête RDAP, mais qu'au
contraire ils mémorisent le JSON récupéré, en utilisant le champ
Expires: de HTTP (RFC 7234, section 5.3) pour déterminer combien de temps doit
durer cette mémorisation. Néanmoins, l'IANA a dû ajuster ses
serveurs HTTP et louer les services d'un CDN pour assurer ce rôle relativement
nouveau.
Le client RDAP doit d'autre part être conscient que le registre n'est pas mis à jour instantanément. Par exemple, si un nouveau TLD est ajouté par le gouvernement états-unien, via Verisign, TLD dont le registre a un serveur RDAP, cette information ne sera pas disponible immédiatement pour tous les clients RDAP.
Comme son ancêtre whois, RDAP soulève plein de questions de sécurité intéressantes, détaillées plus précisement dans le RFC 7481.
La section 12 de notre RFC détaille les processus IANA à l'œuvre. En effet, et c'est une autre différence avec les registres IANA habituels, il n'y a pas de mise à jour explicite des registres du bootstrap service, ils sont mis à jour implicitement comme effet de bord des allocations et modifications d'allocation dans les registres d'adresses IPv4, adresses IPv6, numéros d'AS et domaines. Il a juste fallu modifier les procédures de gestion de ces registres existants, pour permettre d'indiquer le serveur RDAP. Ainsi, le formulaire de gestion d'un TLD par son responsable a été modifié pour ajouter un champ "serveur RDAP" comme il y avait un champ "serveur Whois".
Aujourd'hui, les fichiers de ce service sont :
https://data.iana.org/rdap/dns.jsonhttps://data.iana.org/rdap/ipv4.jsonhttps://data.iana.org/rdap/ipv6.jsonhttps://data.iana.org/rdap/asn.json
Voici, par exemple, celui d'IPv6 (notez le champ
Expires: dans la réponse) :
% curl -v https://data.iana.org/rdap/ipv6.json
...
* Connected to data.iana.org (2606:2800:11f:bb5:f27:227f:1bbf:a0e) port 80 (#0)
> GET /rdap/ipv6.json HTTP/1.1
> Host: data.iana.org
> User-Agent: curl/7.68.0
> Accept: */*
>
< HTTP/1.1 200 OK
< Expires: Tue, 26 Apr 2022 12:30:52 GMT
< Last-Modified: Wed, 06 Nov 2019 19:00:04 GMT
...
{
"description": "RDAP bootstrap file for IPv6 address allocations",
"publication": "2019-11-06T19:00:04Z",
"services": [
[
[
"2001:4200::/23",
"2c00::/12"
],
[
"https://rdap.afrinic.net/rdap/",
"http://rdap.afrinic.net/rdap/"
...
Et celui des TLD :
% curl -v http://data.iana.org/rdap/dns.json
...
"description": "RDAP bootstrap file for Domain Name System registrations",
"publication": "2022-04-22T16:00:01Z",
"services": [
[
[
"nowruz",
"pars",
"shia",
"tci",
"xn--mgbt3dhd"
],
[
"https://api.rdap.agitsys.net/"
]
],
Testons si cela marche vraiment :
% curl -v https://api.rdap.agitsys.net/domain/www.nowruz
...
"nameservers": [
{
"objectClassName": "nameserver",
"ldhName": "ns1.aftermarket.pl.",
"unicodeName": "ns1.aftermarket.pl."
},
{
"objectClassName": "nameserver",
"ldhName": "ns2.aftermarket.pl.",
"unicodeName": "ns2.aftermarket.pl."
}
]
Parfait, tout marche.
Il y a très peu de changements depuis le RFC précédent, le RFC 7484, quelques nettoyages seulement, et un changement de statut sur le chemin des normes.
Si vous aimez lire des programmes, j'ai fait deux mises en œuvre
de ce RFC, la première en Python est incluse dans le code utilisé pour
mon article « Récupérer la date
d'expiration d'un domaine en RDAP ». Le code principal est
ianardap.pyExpires:. La deuxième, en
Elixir, est plus correcte et est disponible
dans find-rdap-elixir.tar@verbose est vraie, le programme affiche les
étapes. S'il n'a pas mémorisé de données :
% mix run find_rdap.exs quimper.bzh
Starting
No expiration known
Retrieving from https://data.iana.org/rdap/dns.json
Updating the cache
RDAP bootstrap file for Domain Name System registrations published on 2022-04-22T16:00:01Z
RDAP server for quimper.bzh is https://rdap.nic.bzh/
Retrieving RDAP info at https://rdap.nic.bzh/domain/quimper.bzh
{"rdapConformance":["rdap_level_0","...
S'il en a mémorisé :
% mix run find_rdap.exs quimper.bzh
Starting
Expiration is 2022-04-26 12:44:48Z
Using the cache ./iana-rdap-bootstrap.json
RDAP bootstrap file for Domain Name System registrations published on 2022-04-22T16:00:01Z
RDAP server for quimper.bzh is https://rdap.nic.bzh/
Retrieving RDAP info at https://rdap.nic.bzh/domain/quimper.bzh
{"rdapConformance":["rdap_level_0", ...
Mais il existe évidemment une mise en œuvre de ce RFC dans tous les clients RDAP comme :
- L'application de Viagenie,
- Celle de l'ICANN (application Web),
- L'ARIN a un service de redirection,
https://rdap-bootstrap.arin.net/bootstrap, qui lit la base IANA et envoie les redirections appropriées, quand un client RDAP l'interroge.
L'article seul
RFC 9233: IDNA2008 and Unicode 12.0.0
Date de publication du RFC : Mars 2022
Auteur(s) du RFC : P. Faltstrom (Netnod)
Chemin des normes
Première rédaction de cet article le 24 avril 2022
La norme pour les noms de domaine en Unicode, dite « IDNA 2008 », prévoit une révision à chaque nouvelle version d'Unicode pour éventuellement s'adapter à des changements dus à ces nouvelles versions. Ce processus de révision a pas mal cafouillé (euphémisme), et ce RFC doit donc traiter d'un coup les versions 6 à 12 d'Unicode.
Le fond du problème est que l'ancienne norme sur les IDN (RFC 3490) était strictement liée à une version donnée d'Unicode et qu'il fallait donc une nouvelle norme pour chacune des versions annuelles d'Unicode. Vu le processus de publication d'une norme à l'IETF, ce n'était pas réaliste. La seconde norme IDN, « IDN 2 » ou « IDN 2008 » (bien qu'elle soit sortie en 2010) remplaçait les anciennes tables fixes de caractères autorisés ou interdits par un algorithme, à faire tourner à chaque sortie d'une version d'Unicode pour produire les tables listant les caractères qu'on peut accepter dans un nom de domaine internationalisé (le mécanisme exact, utilisant les propriétés des caractères listées dans la norme Unicode, figure dans le RFC 5892). En théorie, c'était très bien. En pratique, malgré les règles de stabilité d'Unicode, il se produisait parfois des problèmes. Comme le documente le RFC 8753, un caractère peut ainsi passer d'interdit à autorisé, ce qui n'est pas grave mais aussi dans certains cas d'autorisé à interdit ce qui est bien plus embêtant : que faire des noms déjà réservés qui utilisent ce caractère ? En général, il faut ajouter une exception manuelle, ce qui justifie un mécanisme de révision de la norme IDN, mis en place par ce RFC 8753. Ce nouveau RFC 9233 est le premier RFC de révision. Heureusement, cette fois, aucune exception manuelle n'a été nécessaire.
La précédente crise était due à Unicode version 6 qui avait créé trois incompatibilités (RFC 6452). Une seule était vraiment gênante, le caractère ᧚, qui, autorisé auparavant, était devenu interdit suite au changement de ses propriétés dans la norme Unicode. Le RFC 6452 avait documenté la décision de ne rien faire pour ce cas, ce caractère n'ayant apparemment jamais été utilisé. Unicode 7 a ajouté un autre problème, le ࢡ, qui était un cas différent (la possibilité de l'écrire de plusieurs façons), et la décision a été prise de faire désormais un examen formel de chaque nouvelle version d'Unicode. Mais cet examen a été souvent retardé et voilà pourquoi, alors qu'Unicode 13 est sorti (ainsi qu'Unicode 14 depuis), ce nouveau RFC ne traite que jusqu'à la version 12.
Passons maintenant à l'examen des changements apportés par les versions 7 à 12 d'Unicode, fait en section 3 du RFC :
- À part le cas du ࢡ cité plus haut, Unicode 7 n'a pas apporté de changements gênants pour IDN (par exemple, U+17B4 (caractère non visible) a changé de propriétés mais il était interdit pour IDN et le reste),
- Unicode 8, Unicode 9 et Unicode 10 n'ont appporté aucun changement gênant,
- Unicode 11 a changé les propriétés de certains caractères existants mais le résultat pour IDN ne change pas (par exemple, 𑨇, qui était autorisé, le reste),
- Et Unicode 12 ? Rien de problématique.
En Unicode 11, 𑇉 qui passe d'interdit à autorisé, était un cas peu gênant. Le RFC prend donc la décision de ne pas ajouter d'exception pour ce caractère peu commun.
Voilà, arrivé ici, vous pensez peut-être que cela fait beaucoup de bruit pour rien puisque finalement les différentes versions d'Unicode n'ont pas créé de problème. Mais c'est justement pour s'assurer de cela que cet examen était nécessaire.
Pour compliquer davantage les choses, on notera qu'il existe encore sans doute (section 2.3 du RFC) des déploiements d'IDN qui en sont restés à la première version (celle du RFC 3490) voire qui sont un mélange des deux versions d'IDN, en ce qui concerne l'acceptation ou le refus des caractères.
En avril 2022, le travail pour Unicode 13 ou Unicode 14 n'a apparemment pas encore commencé…
L'article seul
RFC 9150: TLS 1.3 Authentication and Integrity-Only Cipher Suites
Date de publication du RFC : Avril 2022
Auteur(s) du RFC : N. Cam-Winget (Cisco Systems), J. Visoky (ODVA)
Pour information
Première rédaction de cet article le 22 avril 2022
Ce nouveau RFC normalise des algorithmes pour le protocole de sécurité TLS, qui ne fournissent pas de chiffrement (seulement authentification et intégrité). C'est évidemment une option très contestée et l'IETF ne suggère pas d'utiliser ces algorithmes mais, bon, certaines personnes y voient une utilité.
La section 1 du RFC décrit des scénarios d'usage (souvent tirés du monde de l'IoT) où cela peut avoir un sens de ne pas chiffrer. Le premier exemple est celui d'un bras robotique commandé via un protocole TCP/IP. L'authentification est importante mais la confidentialité ne l'est peut-être pas, ce qui rendrait acceptable l'absence de chiffrement. Autre exemple, des rapports météo, ou bien l'envoi de signaux d'horloges, qu'il faut évidemment authentifier mais qui ne sont pas secrets. Le RFC cite aussi des exemples de communication avec des trains ou des avions, où l'intégrité des données est cruciale, mais pas leur confidentialité. Mais attention avant de jeter le chiffrement à la poubelle, le RFC dit bien qu'il faut faire une analyse soignée de la menace. Pour reprendre l'exemple du bras robotique, l'écoute des messages pourrait permettre la rétro-ingénierie, ce qu'on ne souhaite pas forcément.
Mais pourquoi se passer de chiffrement, d'ailleurs, alors qu'il est plus simple de l'utiliser systématiquement ? Parce que dans certains cas, il coûte cher, notamment en latence. En outre, certains équipements, notamment du genre objets connectés, ont des capacités de calcul très limitées. Bref, si le chiffrement systématique et par défaut reste la politique de l'IETF, ce RFC présente quelques façons de s'en passer, si on sait ce qu'on fait (si vous ne savez pas, continuez à chiffrer !).
Les algorithmes sans chiffrement sont présentés dans la section
4. Ils se nomment TLS_SHA256_SHA256 et
TLS_SHA384_SHA384, et sont évidemment dans
le
registre IANA. Ils utilisent une fonction de
condensation comme SHA-256 pour
faire du HMAC, protégeant ainsi l'intégrité des
communications.
Rappelez-vous bien : aucun chiffrement n'est fourni. Les certificats client, par exemple, qui sont normalement chiffrés depuis TLS 1.3, seront envoyés en clair.
Publier un tel RFC n'a pas été facile, la crainte de beaucoup étant que des gens qui ne comprennent pas bien les conséquences utilise ces algorithmes sans mesurer les risques. Le RFC demande (section 9) donc qu'ils ne soient pas utilisés par défaut et qu'ils requièrent une configuration explicite. Et rappelez-vous que ce RFC n'est que « pour information » et ne fait pas l'objet d'un consensus à l'IETF.
L'article seul
RFC 9147: The Datagram Transport Layer Security (DTLS) Protocol Version 1.3
Date de publication du RFC : Avril 2022
Auteur(s) du RFC : E. Rescorla (RTFM), H. Tschofenig (Arm Limited), N. Modadugu (Google)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 22 avril 2022
Pour sécuriser vos applications TCP sur l'Internet, vous utilisez TLS, pas vrai ? Et si vos applications préfèrent UDP, par exemple pour faire de la voix sur IP ? La solution est alors DTLS, dont la nouvelle version, la 1.3, est normalisée dans ce RFC 9147. Elle a vocation à remplacer l'ancienne version 1.2, qui était dans le RFC 6347.
DTLS fournit normalement les mêmes services de sécurité que TLS, notamment la confidentialité (via un chiffrement du trafic) et l'authentification (via une signature). Les seuls services TLS que DTLS ne peut pas rendre sont la protection de l'ordre des messages (ce qui est logique pour UDP) et, selon les options choisies, la protection contre le rejeu. DTLS a été conçu pour être aussi proche que possible de TLS, pour pouvoir réutiliser le code et s'appuyer sur des propriétés de sécurité déjà établies. DTLS 1.0 et 1.2 (il n'y a jamais eu de 1.1) avaient été normalisés sous forme de différences avec la version de TLS correspondante. De même, DTLS 1.3, objet de notre RFC, est défini en décrivant les différences avec TLS 1.3. Il faut donc lire le RFC 9846 avant. À propos de lectures, il faut aussi lire le RFC 9146, pour le concept d'identificateur de connexion (Connection ID).
La section 3 du RFC pose le problème : on veut un truc comme TLS mais qui marche sur un service de datagrammes, en général UDP (RFC 768). Un service de datagrammes ne garantit pas l'ordre d'arrivée, ni même que les datagrammes arrivent. DTLS ajoute de la sécurité au service de datagrammes mais ne change pas ses propriétés fondamentales : une application qui utilise DTLS ne doit pas s'étonner que les messages n'arrivent pas tous, ou bien arrivent dans le désordre. C'est un comportement connu des applications de diffusion vidéo ou de jeu en ligne, qui préfèrent sauter les parties manquantes plutôt que de les attendre.
Pourquoi un protocole distinct, DTLS, plutôt que de reprendre TLS ? C'est parce que TLS ne marche que si le service de transport sous-jacent garantit certaines propriétés qu'UDP ne fournit pas. TLS a besoin de :
- Une numérotation croissante des données. Ces numéros ne sont pas explicites dans TLS, ils sont déduits de l'ordre d'arrivée. DTLS les rend explicites.
- L'établissement d'une association TLS nécessite un échange fiable, où les messages arrivent dans l'ordre d'émission. Là aussi, DTLS doit ajouter des numéros de séquence explicites pour pouvoir remettre dans l'ordre les messages d'établissement d'association (cf. section 4.2).
- Certains messages TLS n'ont pas d'accusé de réception explicite, TLS compte sur les messages suivants pour savoir si son message a été reçu. Avec DTLS, ces messages doivent avoir un accusé de réception puisque la couche transport ne nous dit plus si le message a été perdu.
- Certains messages TLS peuvent être de grande taille (chaines de certificats, par exemple), supérieure à celle du datagramme (qui est typiquement de 1 500 octets) et DTLS doit donc être capable de les fragmenter et de les réassembler (la fragmentation IP étant hélas souvent bloquée par des équipements réseau mal programmés et/ou mal configurés).
- Tout protocole utilisant les datagrammes doit se méfier des attaques par réflexion, où l'attaquant ment sur son adresse IP. TCP protège contre cela, mais DTLS, ne pouvant compter sur TCP, doit avoir son propre mécanisme de test de réversibilité.
La section 4 présente la couche Enregistrements de DTLS, c'est-à-dire le format des paquets sur le réseau. Les messages sont transportés dans des enregistrements (record) TLS, et il peut y avoir plusieurs messages dans un seul datagramme UDP. Le format des messages est différent de celui de TLS (ajout d'un numéro de séquence) et de celui de DTLS 1.2 :
struct {
ContentType type;
ProtocolVersion legacy_record_version;
uint16 epoch = 0
uint48 sequence_number;
uint16 length;
opaque fragment[DTLSPlaintext.length];
} DTLSPlaintext;
struct {
opaque unified_hdr[variable];
opaque encrypted_record[length];
} DTLSCiphertext;
La première structure est en clair, la seconde
contient des données chiffrées. Un message dans un datagramme est,
soit un DTLSPlaintext (ils sont notamment
utilisés pour l'ouverture de connexion, quand on ne connait pas
encore le matériel cryptographique à utiliser) ou bien un
DTLSCiphertext.
La partie chiffrée du
DTLSCiphertext est composée d'un :
struct {
opaque content[DTLSPlaintext.length];
ContentType type;
uint8 zeros[length_of_padding];
} DTLSInnerPlaintext;
Comme pour TLS 1.3, le champ
legacy_record_version est ignoré (il n'est là
que pour tromper les middleboxes). Le
unified_hdr contient notamment l'identificateur
de connexion (Connection ID), concept expliqué
dans le RFC 9146 (comme avec QUIC, ils peuvent augmenter la
traçabilité). Les détails de la structure des messages
figurent dans l'annexe A du RFC.
À l'arrivée d'un datagramme, c'est un peu compliqué, vu la
variété de formats. La section 4.1 suggère un mécanisme de
démultiplexage, permettant de déterminer rapidement si le message
était du DTLSPlaintext, du
DTLSCipherext, ou une erreur. Un datagramme
invalide doit être silencieusement ignoré (c'est peut-être une
tentative d'un méchant pour essayer d'injecter des données ; couper
la connexion au premier datagramme invalide ouvrirait une facile
voie d'attaque par déni de service).
Qui dit datagramme dit problèmes de MTU, une des plaies de l'Internet. Normalement, c'est l'application qui doit les gérer, après tout le principe d'un service de datagrammes, c'est que l'application fait tout. Mais DTLS ne lui facilite pas la tâche, car le chiffrement augmente la taille des données, « dans le dos » de l'application. Et, avant même que l'application envoie ses premières données, la poignée de main DTLS peut avoir des datagrammes dépassant la MTU, par exemple en raison de la taille des certificats. Et puis dans certains cas, le système d'exploitation ne transmet pas à l'application les signaux indispensables, comme les messages ICMP Packet Too Big. Bref, pour aider, DTLS devrait transmettre à l'application, s'il la connait, la PMTU (la MTU du chemin complet, que la couche Transport a peut-être indiqué à DTLS). Et DTLS doit gérer la découverte de la PMTU tout seul pour la phase initiale de connexion.
La section 5 du RFC décrit le protocole d'établissement de l'association entre client et serveur (on peut aussi dire connexion, si on veut, mais pas session, ce dernier terme devrait être réservé au cas où on reprend une même session sur une connexion différente). Il est proche de celui de TLS 1.3 mais il a fallu ajouter tout ce qu'UDP ne fournit pas, la détection de la MTU (Path MTU, la MTU du chemin complet), des accusés de réception explicites et la gestion des cas de pertes de paquets. Voici l'allure d'un message DTLS d'établissement de connexion :
enum {
client_hello(1),
server_hello(2),
new_session_ticket(4),
end_of_early_data(5),
encrypted_extensions(8),
certificate(11),
certificate_request(13),
certificate_verify(15),
finished(20),
key_update(24),
message_hash(254),
(255)
} HandshakeType;
struct {
HandshakeType msg_type; /* handshake type */
uint24 length; /* bytes in message */
uint16 message_seq; /* DTLS-required field */
uint24 fragment_offset; /* DTLS-required field */
uint24 fragment_length; /* DTLS-required field */
select (msg_type) {
case client_hello: ClientHello;
case server_hello: ServerHello;
case end_of_early_data: EndOfEarlyData;
case encrypted_extensions: EncryptedExtensions;
case certificate_request: CertificateRequest;
case certificate: Certificate;
case certificate_verify: CertificateVerify;
case finished: Finished;
case new_session_ticket: NewSessionTicket;
case key_update: KeyUpdate;
} body;
} Handshake;
Le message ClientHello, comme en TLS 1.3, a un
champ legacy_version qui sert à faire croire
aux middleboxes (et aux
serveurs bogués qui ne gèrent pas correctement la négociation de
version) qu'il
s'agit d'un TLS ancien.
Un établissement de connexion DTLS typique est :
- Le client envoie un
ClientHello, - le serveur répond avec un
HelloRetryRequestqui contient le cookie, - le client renvoie le
ClientHello, cette fois avec le cookie (le serveur est désormais certain que le client ne ment pas sur son adresse IP), - le serveur peut alors transmettre son
ServerHello, - le client peut alors envoyer un message
Finishedet transmettre des données.
Il existe également, comme en TLS 1.3, un mode rapide, quand le client a déjà contacté ce serveur et obtenu du matériel cryptographique qu'il peut ré-utiliser. (C'est ce qu'on appelle aussi le « 0-RTT » ou la « reprise de session », et ça existe aussi dans des protocoles comme QUIC.) Tous les paquets pouvant se perdre, DTLS doit avoir un mécanisme de réémission.
Les risques d'attaques par déni de service sont très élevés dans le cas où on utilise des datagrammes. Un méchant peut envoyer des demandes de connexion répétées, pour forcer le serveur à faire des calculs cryptographiques et surtout à allouer de la mémoire pour les connexions en attente. Pire, il peut utiliser un serveur DTLS pour des attaques par réflexion où le méchant ment sur son adresse IP pour que le serveur dirige ses réponses vers une victime innocente. Les attaques par réflexion sont encore pires lorsqu'elles sont combinées à une amplification, quand la réponse est plus grosse que la question.
Pour éviter ces attaques, DTLS reprend, comme vu plus haut, le principe des cookies sans état de Photuris (RFC 2522) et IKE (RFC 7296).
L'extension connection_id (cf. RFC 9146) peut être mise
dans le ClientHello. Notez qu'une nouveauté par
rapport au RFC 9146 est la possibilité de
changer les identifiants de connexion pendant une association.
En section 7, une nouveauté de DTLS 1.3, et qui n'a pas
d'équivalent dans TLS, les accusés de réception
(ACK), nécessaires puisqu'on fonctionne
au-dessus d'un service de datagrammes, qui ne garantit pas l'arrivée
de tous les paquets. Un ACK permet d'indiquer
les numéros de séquence qu'on a vu. Typiquement, on envoie des
ACK quand on a l'impression que le partenaire
est trop silencieux (ce qui peut vouloir dire que ses messages se
sont perdus). Ces accusés de réception sont facultatifs, on peut
décider que la réception des messages (par exemple un
ServerHello quand on a envoyé un
ClientHello) vaut accusé de réception. Ils
servent surtout à exprimer son impatience « allô ? tu ne dis
rien ? »
Dans sa section 11, notre RFC résume les points importants, question sécurité (en plus de celles communes à TLS et DTLS, qui sont traitées dans le RFC 9846). Le principal risque, qui n'a pas vraiment d'équivalent dans TLS, est celui de déni de service via une consommation de ressources déclenchée par un partenaire malveillant. Les cookies à la connexion ne sont pas obligatoires mais fortement recommandés. Pour être vraiment sûrs, ces cookies doivent dépendre de l'adresse IP du partenaire, et d'une information secrète pour empêcher un tiers de les générer.
À noter d'autre part que, si DTLS garantit plusieurs propriétés de sécurité identiques à celle de TLS (confidentialité et authentification du serveur), il ne garantit pas l'ordre d'arrivée des messages (normal, on fait du datagramme…) et ne protège pas parfaitement contre le rejeu (sections 3.4 et 4.5.1 du RFC si vous voulez le faire).
Les sections 12 et 13 résument les principaux changements depuis DTLS 1.2 (seulement les principaux car DTLS 1.3 est très différent de 1.2) :
- n'accepte désormais que du chiffrement intègre,
- le mécanisme de reprise de session est différent, et la terminologie a changé (on parle désormais de PSK, Pre-Shared Key pour désigner les données stockées chez le client),
- la négociation de version a changé, pour tenir compte des nombreuses middleboxes boguées,
- les numéros de séquence sont chiffrées (sans cela, corréler deux échanges utilisant des adresses IP différentes serait trivial). En fait, c'est plus compliqué que cela, il y a le numéro de séquence complet dans la partie chiffrée, et un numéro réduit à ses derniers bits en clair.
Si jamais vous vous lancez dans la programmation d'une bibliothèque DTLS, lisez l'annexe C, qui vous avertit sur quelques pièges typiques de DTLS.
En octobre 2021, il n'y avait pas encore de DTLS 1.3 dans GnuTLS (ticket en cours), BoringSSL ou dans OpenSSL (ticket en cours).
Merci à Manuel Pégourié-Gonnard pour sa relecture attentive.
L'article seul
Qu'est-ce que l'Internet et quand est-on « coupé de l'Internet » ?
Première rédaction de cet article le 20 avril 2022
Mais c'est vrai, ça, c'est quoi, l'Internet ? Pour M. Toutlemonde, ça semble évident, c'est le truc auquel on se connecte via son FAI. Mais pour un pays, que veut dire « être connecté à l'Internet » ? Par exemple, si tous les câbles sous-marins entre l'Europe et l'Amérique étaient soudainement mis hors service, qui serait « coupé de l'Internet » ? Cet article de recherche « What Is The Internet? (Considering Partial Connectivity) » examine la question et tente de lui donner une réponse quantitative.
J'avais regardé cette question dans le contexte militaro-géopolitique dans mon article « Quelles conséquences si les câbles avec les USA étaient coupés ? ». Le point de départ était l'apparition d'articles médiatiques sensationalistes sur l'hypothèse d'une attaque russe contre les câbles sous-marins. Une erreur commune à tous ces médiocres articles était de ne rien comprendre à l'Internet. Ce dernier n'est pas un service auquel on se connecte, c'est un réseau de réseaux. Si les câbles transatlantiques sont attaqués, l'Europe n'est pas « coupée de l'Internet », elle continue à faire fonctionner ses réseaux pendant que l'Amérique le fait de son côté. Mais, alors, où est l'Internet, puisque ce n'est pas un objet physique situé à un endroit précis ? La décentralisation de l'Internet rend la question difficile. Pour reprendre une vieille blague britannique, en cas de coupure de la navigation sur la Manche, c'est l'Europe qui est isolée. 🤣
John Heidemann et Guillermo Baltra s'attaquent à cette question dans un article de 2021, « What Is The Internet? (Considering Partial Connectivity) » (arXiv:2107.11439v1). Ils notent qu'évidemment il y a plusieurs définitions possibles de l'Internet (après tout, certains utilisateurs disent bien que l'Internet est en panne lorsque c'est juste Facebook qui est arrêté). Les débats très confus (comme souvent en politique) sur le thème de la « fragmentation de l'Internet » (ou « Splinternet » pour faire chic) achoppent souvent sur ce point ; par exemple, à partir de quel niveau de filtrage / censure / problèmes techniques est-on réellement déconnecté de l'Internet ? Est-ce qu'une machine qui n'a pas d'adresse IP publique et est donc forcée de passer par un système de traduction d'adresses est bien « connectée à l'Internet » ? Et, s'il y a fragmentation en N morceaux, quel morceau est « l'Internet » ?
Les auteurs tranchent clairement la question : ils proposent de dire que l'Internet est l'ensemble connecté des adresses IP publiques qui peuvent joindre plus de la moitié des adresses IP publiques actives. Il y a, en plus de l'Internet ainsi défini, des iles (des réseaux connectés entre eux mais qui ne peuvent pas joindre l'Internet) et des péninsules (des réseaux qui peuvent joindre certaines des machines de l'Internet mais pas toutes).
La définition des auteurs fait qu'il n'y aura pas d'ambiguité : si un réseau a plus de 50 % des adresses IP publiques actives, il sera l'Internet. Si aucun réseau n'atteint ce seuil, on considérera qu'il n'y a plus d'Internet.
Les auteurs notent qu'aucun pays n'a à lui seul plus de la moitié des adresses IP publiques (même les États-Unis en sont loin) et que toute sécession d'un pays le laisserait donc en dehors de l'Internet ainsi défini. Ah, et en cas de coupure de tous les câbles sous-marins laissant d'un côté un bloc Amérique et de l'autre un bloc Eurasie, c'est ce dernier qui serait l'Internet, il aurait bien la majorité des adresses.
Les problèmes de joignabilité, qui créent iles et péninsules, peuvent avoir de nombreuses causes. Il peut s'agir d'une panne (et l'ile ou la péninsule sont alors temporaires), d'un conflit commercial entre deux opérateurs qui refusent de s'appairer (et cela peut durer longtemps) ou bien d'une action délibérée, par exemple d'un État qui veut priver sa population d'information. (Mais attention à ce qu'on lit dans les médias, c'est souvent plus compliqué que ce qu'ils racontent.)
L'article d'Heidemann et Baltra va ensuite partir à la recherche de ces iles et péninsules en utilisant les données de Trinocular. Trinocular a plusieurs points de mesure (VP, pour vantage point), ce qui est évidemment essentiel pour les mesures Internet, puisqu'une machine peut être joignable depuis certains endroits mais pas d'autres. Mais il ne couvre pas tout et peut donc prendre une péninsule pour une ile, par exemple. L'article décrit ensuite les iles et péninsules observées, et leur durée.
Bref, un excellent article, très concret et détaillé, apportant de l'information précise au débat.
L'article seul
Fiche de lecture : Une auberge dans la tempête
Auteur(s) du livre : Gee
Éditeur : Ptilouk.net
9-782493-727008
Publié en 2022
Première rédaction de cet article le 18 avril 2022
Vous connaissez peut-être Gee pour ses dessins pour Framasoft. Mais il fait aussi des romans comme ce livre à mystère.
Il y a en effet une grosse énigme (que se passe-t-il dans cette curieuse auberge où Nathalie est arrivée par hasard ?) et plein d'autres questions qui viennent successivement. L'héroïne est informaticienne mais ce n'est pas pour cela que j'ai aimé, c'est pour le style, l'humour, les innombrables choses bizarres à comprendre et le dénouement. Pas de sang ni de violence, cela repose de certains polars.
Le livre est sous une licence libre et vous pouvez le télécharger (ou bien acheter l'édition papier).
L'article seul
RFC 9210: DNS Transport over TCP - Operational Requirements
Date de publication du RFC : Mars 2022
Auteur(s) du RFC : J. Kristoff (Dataplane.org), D. Wessels (Verisign)
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 15 avril 2022
Ce nouveau RFC décrit les exigences opérationnelles pour le DNS, plus précisement pour son protocole de transport TCP. Le RFC 7766 décrivait la norme technique, et s'imposait donc aux programmeur·ses, ce RFC 9210 est plus opérationnel et concerne donc ceux et celles qui installent et configurent les serveurs DNS et les réseaux qui y mènent.
Les messages DNS sont historiquement surtout transportés sur UDP. Mais le DNS a toujours permis TCP et, de nos jours, il est fréquemment utilisé notamment en conjonction avec TLS (cf. RFC 7858). Il est d'autant plus important que TCP marche bien qu'il est parfois nécessaire pour certains usages, par exemple pour des enregistrements de grande taille (ce qui arrive souvent avec DNSSEC). Une mise en œuvre du DNS doit donc inclure TCP, comme clarifié par le RFC 7766 (les RFC précédents n'étaient pas sans ambiguité). Mais cela ne signifiait pas forcément que les serveurs DNS avaient activé TCP ou que celui-ci marchait bien (par exemple, une stupide middlebox pouvait avoir bloqué TCP). Ce nouveau RFC 9210 ajoute donc que l'obligation d'avoir TCP s'applique aussi aux serveurs effectifs, pas juste au logiciel.
DNS sur TCP a une histoire compliquée (section 2 du RFC). Franchement, le fait que le DNS marche sur TCP aussi bien que sur UDP n'a pas toujours été clairement formulé, même dans les RFC. Et, en dehors de l'IETF, beaucoup de gens ont raconté n'importe quoi dans des articles et des documentations, par exemple que TCP n'était utile qu'aux transferts de zone, ceux normalisés dans le RFC 5936. Cette légende a été propagée par certains auteurs (comme Cheswick et Bellovin dans leur livre Firewalls and Internet Security: Repelling the Wily Hacker) ou par des gens qui ne mesuraient pas les limites de leurs compétences DNS comme Dan Bernstein. Pourtant, TCP a toujours été nécessaire, par exemple pour transporter des données des grande taille (que DNSSEC a rendu bien plus fréquentes). Le RFC 1123, en 1989, insistait déjà sur ce rôle. Certes, EDNS (RFC 6891) permettait déjà des données de taille supérieure aux 512 octets de la norme originelle. Mais il ne dispense pas de TCP. Par exemple, des données de taille supérieure à 1 460 octets (le maximum qui peut tenir avec le MTU typique) seront fragmentées et les fragments, hélas, ne passent pas partout sur l'Internet. (Cf. le « DNS Flag Day » de 2020 et lire « DNS XL » et « Dealing with IPv6 fragmentation in the DNS ».) Et la fragmentation pose également des problèmes de sécurité, voir par exemple « Fragmentation Considered Poisonous ».
Bon, en pratique, la part de TCP reste faible mais elle augmente. Mais, trop souvent, le serveur ne répond pas en TCP (ou bien ce protocole est bloqué par le réseau), ce qui entraine des tas de problèmes, voir par exemple le récit dans « DNS Anomalies and Their Impacts on DNS Cache Servers ».
Notons enfin que TCP a toujours permis que plusieurs requêtes se succèdent sur une seule connexion TCP, même si les premières normes n'étaient pas aussi claires qu'il aurait fallu. L'ordre des réponses n'est pas forcément préservé (cf. RFC 5966), ce qui évite aux requêtes rapides d'attendre le résultat des lentes. Et un client peut envoyer plusieurs requêtes sans attendre les réponses (RFC 7766). Par contre, la perte d'un paquet va entrainer un ralentissement de toute la connexion, et donc des autres requêtes (QUIC résout ce problème et il y a un projet de DNS sur QUIC).
Vous pouvez tester qu'un serveur DNS accepte de faire passer
plusieurs requêtes sur une même connexion TCP avec
dig et son option
+keepopen (qui n'est pas activée par
défaut). Ici, on demande à ns4.bortzmeyer.org
les adresses IP de www.bortzmeyer.org et
mail.bortzmeyer.org :
% dig +keepopen +tcp @ns4.bortzmeyer.org www.bortzmeyer.org AAAA mail.bortzmeyer.org AAAA
Vous pouvez vérifier avec tcpdump qu'il n'y
a bien eu qu'une seule connexion TCP, ce qui ne serait pas le cas
sans +keepopen.
Les exigences opérationnelles pour le DNS sur TCP figurent dans la section 3 du RFC. Il est désormais obligatoire non seulement d'avoir la possibilité de TCP dans le code mais en outre que cela soit activé partout. (En termes du RFC 2119, on est passé de SHOULD à MUST.)
La section 4 discute de certaines considérations opérationnelles que cela pourrait poser. D'abord, certains serveurs ne sont pas joignables en TCP. C'était déjà mal avant notre RFC mais c'est encore pire maintenant. Mais cela arrive (ce n'est pas forcément la faute du serveur, cela peut être dû à une middlebox boguée sur le trajet). Les clients doivent donc être préparés à ce que TCP échoue (de toute façon, sur l'Internet, tout peut toujours échouer). D'autre part, diverses attaques par déni de service sont possibles, aussi bien contre le serveur (SYN flooding, contre lequel la meilleure protection est l'utilisation de cookies, cf. RFC 4987), que contre des machines tierces, le serveur étant utilisé comme réflecteur.
Aussi bien le client DNS que le serveur n'ont pas des ressources illimitées et doivent donc gérer les connexions TCP. Dit plus brutalement, il faut être prêt à couper les connexions qui semblent inutilisées. Bien sûr, il faut aussi laisser les connexions ouvertes suffisamment longtemps pour amortir leur création sur le plus grand nombre de requêtes possibles, mais il y a des limites à tout. (Le RFC suggère une durée maximale dans les dizaines de secondes, pouvant être abaissée à quelques secondes pour les serveurs très chargés.)
TCP est particulièrement intéressant pour le DNS quand TLS est inséré (RFC 7858). Mais il va alors consommer davantage de temps de CPU et, dans certains cas, l'établissement de connexion sera plus lent.
Le RFC donne quelques conseils quantitatifs (à ne pas appliquer aveuglément, bien sûr). Un maximum de 150 connexions TCP simultanées semble raisonnable pour un serveur ordinaire, avec un maximum de 25 par adresse IP source. Un délai de garde après inactivité de 10 secondes est suggéré. Par contre, le RFC ne propose pas de valeur maximale au nombre de requêtes par connexion TCP, ni de durée maximale à une connexion.
Les fanas des questions de sécurité noteront que les systèmes de journalisation et de surveillance peuvent ne pas être adaptés à TCP. Par exemple, un méchant pourrait mettre la requête DNS dans plusieurs segments TCP et donc plusieurs paquets IP. Un système de surveillance qui considérerait qu'une requête = un paquet serait alors aveugle. Notez qu'un logiciel comme dnscap a pensé à cela, et réassemble les paquets. Mais il est sans doute préférable, de nos jours, de se brancher sur le serveur, par exemple avec dnstap, notamment pour éviter de faire le réassemblage deux fois. (Ceux qui lisent mes articles depuis longtemps savent que je donnais autrefois le conseil inverse. Mais le déploiement de plus en plus important de TCP et surtout de TLS impose de changer de tactique.)
L'article seul
Implementation of the bioctal number format
First publication of this article on 14 April 2022
I just wrote an implementation of the bioctal number format, which is specified in RFC 9226 (RFC published on 1st April 2022).
The RFC standardizes a number format
called "bioctal". I let you read the RFC to understand the rationale
of this format. The implementation is written in the
Elixir programming language and is available
in the file bioctal.ex. It provides:
- Sigils (Elixir's way to use literals in various formats; sigils start with a tilde) for input,
- A formatting of numbers in bioctal for output.
An example of input:
IO.puts(~b{23cj}) # Thanks to the sigil ~b, "23cj" will be read as 9097
And an example of output:
IO.puts(format(9097)) # Will print "23cj"
L'article seul
RFC 9228: Delivered-To Email Header Field
Date de publication du RFC : Avril 2022
Auteur(s) du RFC : D. Crocker (Brandenburg InternetWorking)
Expérimental
Première rédaction de cet article le 14 avril 2022
Le courrier électronique est souvent plus
compliqué et plus varié que ne le croient certains utilisateurs. Par
exemple, rien ne garantit que l'adresse à laquelle un message est
livré soit listée dans les champs de l'en-tête (RFC 5322) comme To: ou
Cc:. Cette adresse de destination est en effet
séparément gérée, dans le protocole SMTP (RFC 5321)
et ses comandes RCPT TO. Et puis un message
peut être relayé, il peut y avoir plusieurs livraisons
successives. Bref, quand on a un message dans sa boite aux lettres,
on ne sait pas forcément quelle adresse avait servi. D'où ce
RFC expérimental
qui propose d'élargir le rôle du champ
Delivered-To: pour en faire un bon outil
d'information.
Ce champ existe déjà et on le voit parfois apparaitre dans les en-têtes, par exemple dans un message que je viens de recevoir :
Delivered-To: monpseudo@sources.org
Mais il n'est pas vraiment normalisé, son contenu exact peut varier et, en pratique, lorsqu'il y a eu plusieurs délivrances successives suivies de transmissions à une autre adresse, il ne reste parfois qu'une occurrence de ce champ, la plus récente. Difficile donc de compter dessus.
Mais c'est quoi, la livraison d'un message ? Comme définie par le RFC 5598, dans sa section 4.3.3, c'est un transfert de responsabilité d'un MTA vers un MDA comme procmail. Il peut y avoir plusieurs délivrances successives par exemple si le MDA, au lieu de simplement écrire dans la boite aux lettres de l'utilisateur, fait suivre le message à une autre adresse. Un exemple typique est celui d'une liste de diffusion, où le message va être délivré à la liste puis, après transmission par le logiciel de gestion de listes, à chaque utilisateur (dont les MDA renverront peut-être le message, créant de nouvelles livraisons).
Pourquoi est-il utile d'avoir de l'information sur ces livraisons successives ? Outre la curiosité, une motivation importante est le débogage. S'il y a des problèmes de livraison, la traçabilité est essentielle à l'analyse. Une autre motivation est la détection automatique de boucles, un problème souvent compliqué.
On l'a dit, Delivered-To: existe déjà, même
s'il n'était normalisé dans aucun RFC, bien qu'il soit cité dans des exemples,
comme dans le RFC 5193. Ce RFC 9228 enregistre le champ (selon la
procédure du RFC 3864), et prévoit d'étendre son
application. (Une tentative de normalisation est en cours dans
draft-duklev-deliveredto.) Du fait de cette
absence de normalisation, il existe de nombreuses variations dans
l'utilisation de Delivered-To:. Par exemple, si
la plupart des logiciels mettent comme valeur une adresse de
courrier et rien d'autre, certains ajoutent des commentaires. Notons
que le champ Received: est souvent utilisé de
la même façon, via sa clause for. On peut ainsi
trouver (regardez le for) :
Received: from bendel.debian.org (bendel.debian.org [82.195.75.100])
(using TLSv1.3 with cipher TLS_AES_256_GCM_SHA384 (256/256 bits)
key-exchange X25519 server-signature RSA-PSS (2048 bits) server-digest SHA256)
(No client certificate requested)
by ayla.bortzmeyer.org (Postfix) with ESMTPS id 6D245A00D9
for <monpseudo@sources.org>; Wed, 16 Feb 2022 13:22:03 +0100 (CET)
Là encore, il n'y a pas de normalisation et il semble qu'on ne
puisse pas compter sur cette clause for. Par
exemple, elle n'indique pas forcément une livraison mais peut être
utilisée pour une simple transmission d'un serveur à un autre.
Venons-en à la définition de l'utilisation de
Delivered-To: proposée par notre RFC dans sa
section 4 :
- Le champ
Delivered-To:est ajouté uniquement lors d'une livraison, - sa valeur est l'adresse de courrier utilisée pour cette livraison (une adresse unique, jamais de liste),
- si une réécriture de l'adresse est faite, on rajoute un
Delivered-To:avec l'adresse réécrite, - comme il peut y avoir plusieurs
Delivered-To:(en cas de livraisons multiples), le logiciel qui en ajoute un doit le mettre en haut (comme pour les autres champs de trace de l'en-tête, par exempleReceived:, cf. RFC 5321, section, 4.1.1.4), l'ordre chronologique desDelivered-To:sera donc de bas en haut, - et donc les logiciels ne doivent pas réordonner les
Delivered-To:ou en supprimer, sous peine de casser cette chronologie.
En conséquence, si un logiciel qui va ajouter un
Delivered-To: avec une certaine adresse voit un
Delivered-To: avec la même adresse, il peut
être sûr qu'il y a une boucle. Voici un exemple de deux
Delivered-To: différents, en raison du passage
par une liste de diffusion (le message comportait évidemment bien
d'autres champs dans son en-tête). La liste a été la première à
traiter le message, la livraison finale ayant eu lieu après (donc
plus haut dans le message, cf. section 5 du RFC) :
Delivered-To: monpseudo@sources.org Delivered-To: lists-debian-user-french@bendel.debian.org
Le RFC donne un exemple imaginaire mais plus détaillé (j'ai
raccourci les exemples du RFC, référez-vous à lui pour avoir les
Received: et autres détails). D'abord, le
message est émis par Ann :
From: Ann Author <aauthor@com.example> Date: Mon, 25 Jan 2021 18:29:00 -0500 To: list@org.example Subject: Sending through a list and alias Sender: Ann Author <aauthor@com.example>
Ce message a été envoyé à une liste de diffusion. Il est donc désormais :
Delivered-To: list@org.example From: Ann Author <aauthor@com.example> Date: Mon, 25 Jan 2021 18:29:06 -0500 To: list@org.example Subject: Sending through a list and alias
Un des abonnés à la liste est
alumn@edu.example. Chez lui, le
message sera :
Delivered-To: alumn@edu.example Delivered-To: list@org.example From: Ann Author <aauthor@com.example> Date: Mon, 25 Jan 2021 18:29:06 -0500 To: list@org.example Subject: Sending through a list and alias
Et cet abonné fait suivre automatiquement son courrier à
theRecipient@example.net. Le message, dans son
état final, sera :
Delivered-To: theRecipient@example.net Delivered-To: alumn@edu.example Delivered-To: list@org.example From: Ann Author <aauthor@com.example> Date: Mon, 25 Jan 2021 18:29:06 -0500 To: list@org.example Subject: Sending through a list and alias
Voilà, vous savez tout désormais sur l'extension proposée de
l'utilisation de Delivered-To:. La section 6
attire toutefois notre attention sur quelques
risques. Delivered-To: a comme valeur une
donnée personnelle. Donc, attention, cela
peut poser des questions de vie
privée. Par exemple, la liste des adresses par
lesquelles est passé un message peut en révéler plus que ce que le
destinataire connaissait. Le problème risque surtout de se poser si
quelqu'un fait suivre manuellement un message en incluant tous les
en-têtes.
Autre problème potentiel, certains systèmes stockent les messages
identiques en un seul exemplaire. Si on écrit à
alice@example.com et
bob@example.com, le serveur
d'example.com pourrait décider de ne stocker
qu'un seul exemplaire du message, avec des liens depuis les boites
aux lettres d'Alice et Bob. Ce serait évidemment incompatible avec
Delivered-To: (et pas question de mettre deux
Delivered-To:, on ne veut pas révéler à Alice
que Bob a reçu le message et réciproquement).
L'article seul
Mon atelier Elixir aux JDLL
Première rédaction de cet article le 3 avril 2022
Dernière mise à jour le 2 avril 2023
Le 2 avril, j'ai eu le plaisir d'animer un atelier de découverte du langage de programmation Elixir aux JDLL. Voici le support de cet atelier.
C'était bien un atelier et pas un cours magistral. Les participant·es utilisaient les PC pré-configurés et installés de la salle, ou bien leur propre ordinateur portable qu'ielles avaient apporté, je leur donnais l'URL de l'atelier et je répondais aux questions, c'est tout. Le support contenait quelques indications, des liens vers des documentations, les exercices et une solution proposée. Ce système, à l'usage, me semble avoir très bien marché, notamment parce qu'il permettait à chacun·e d'avancer à son rythme (les niveaux en programmation étaient très différents), sans être frustré·e par un cours trop lent ou trop rapide.
Le support de l'atelier. Notez qu'il est évidemment bien trop long pour les deux heures de l'atelier, le but était que les participant·es puissent continuer par eux et elles-mêmes ensuite.
Merci aux organisateurices des JDLL pour un évènement toujours passionnant, et aux participant·es de mon atelier pour leur enthousiasme. Parmi les autres sujets que j'ai noté aux JDLL :
- Une très intéressante conférence de l'association InfoClimat, l'OpenStreetMap des données météorologiques. Ils récoltent des données météo un peu partout, en partie de leurs propres stations (1 000 € pour une station météo sérieuse), en partie de stations gérées par d'autres (mais pas de Météo-France, qui ne donne pas grand'chose, au contraire) et publient le tout librement. Activité évidemment très utile vu l'importance de la météo. En outre, ils ne font pas que publier des données brutes mais fournissent également des logiciels pour les manipuler. Et il y a une base de photos météo. Leur exposé ne portait pas que sur le résultat de leur activité mais aussi sur les conditions du processus de production des données. Il faut notamment gérer des humains. Comment faire avec un bénévole qui avait installé une station dans un coin où il y avait peu de données mais qui, tout à coup, la déplace à l'ombre, faussant les mesures ? Diplomatie et pédagogie sont nécessaires. Ils ont beaucoup insisté sur le fait que le qualité des mesures est plus importante que leur quantité. Une station avec des instruments grand public, ou bien placée près d'arbres dont le feuillage, en dehors de l'hiver, gène les mesures, ne sert pas à grand'chose. Ils ont maintenant un peu d'argent et vont embaucher leur premier permanent, notamment pour s'occuper du logiciel (pas distribué publiquement car trop… trop illisible). Un excellent article de NextInpact détaille les activités de l'association, ainsi qu'un article sur le Framablog.
- Une autre conférence passionnante de l'UCL sur les rapports entre le librisme et le courant libertaire. Leur conférence a couvert plein de sujets comme l'achat de publicité ciblée sur Facebook pour un parti politique, ou comme le problème de la présence en ligne pour des organisations libertaires. Si une seule personne a le mot de passe du WordPress, est-ce bien conforme aux principes d'horizontalité et d'action collective ? Si on choisit de s'auto-héberger plutôt que d'aller chez les GAFA, est-ce qu'on n'accroit pas la verticalité puisque peu de gens dans l'organisation auront les compétences nécessaires ?
- Plus technique, il y a eu une excellente présentation de l'association 42l sur leurs serveurs et comment ils fonctionnent. 42l est un CHATON et gère quelques services, parfois publics, parfois réservés aux adhérents, sur deux VPS (l'association n'a pas encore le moyen d'avoir ses propres locaux avec ses machines dedans). Il y a entre autres un service DoH et un service Nitter (qui a un trafic nettement supérieur à celui de DoH). Chaque service est dans son propre conteneur Docker. Le service le plus gourmand en temps humain est le raccourcisseur de liens, en raison de liens de hameçonnage, qu'il faut supprimer.
- L'équipe de l'Établi numérique a parlé de l'accompagnement émancipateur au numérique. L'idée de base est qu'il ne suffit pas d'être compétent et techniquement correct quand on accompagne des personnes au numérique, encore faut-il que cet accompagnement débouche sur un enpouvoirement (émancipation) de la personne accompagnée. Les orateurs prennent l'exemple de quelqu'un qui demande à ce qu'on l'aide à résoudre un problème Windows. Lui dire sèchement « Windows, c'est nul, il faudrait utiliser Linux » n'aide pas la personne (surtout, évidemment, si c'est formulé de manière méprisante). Si elle ne suit pas ce conseil, elle n'aura pas progressé. Si elle le suit, elle risque de se retrouver fort désarmée si un autre problème survient alors qu'elle n'a pas forcément de compétences Linux disponibles. Les orateurs estiment qu'il faut répondre aux demandes des utilisateurs. Cela semble de pur bon sens mais je ne suis que partiellement d'accord avec cet argument. En effet, il y a bien des questions inadaptées ou fausses, qui méritent une analyse critique. Lorsqu'un webmestre débutant demande comment améliorer son SEO, lui donner quelques trucs pour gagner un peu de place dans le classement de Google ne va pas l'aider, par rapport à une critique de sa section et du danger d'une course à l'audience fondée sur ce qu'on croit savoir de l'algorithme de Google. (Cas réel, où la personne m'avait reproché de ne pas l'aider.) Pour reprendre l'exemple des orateurs, s'il est en effet préférable d'aider l'utilisateurice Windows (j'aurais personnellement du mal, vu mes compétences, mais je peux, comme suggéré par les orateurs, chercher avec elle), c'est quand même une marque de respect que de lui expliquer que certains problèmes n'ont pas de solution satisfaisante avec Windows. Lui cacher son opinion, sous couvert d'aide, ne serait pas honnête.
Et il y a plein de photos sympas en ligne.
L'article seul
RFC 9221: An Unreliable Datagram Extension to QUIC
Date de publication du RFC : Mars 2022
Auteur(s) du RFC : T. Pauly, E. Kinnear (Apple), D. Schinazi (Google)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF quic
Première rédaction de cet article le 1 avril 2022
Le protocole QUIC fournit, comme son
concurrent TCP, un canal fiable d'envoi de données. Mais
certaines applications n'ont pas impérativement besoin de cette
fiabilité et se contenteraient très bien d'un service de type
datagramme. Ce nouveau RFC ajoute donc un nouveau
type de trame QUIC, DATAGRAM, pour fournir un
tel service.
Dit comme cela, évidemment, ça semble drôle, de bâtir un service non fiable au-dessus du service fiable que rend QUIC. Mais cela permet plusieurs choses très intéressantes, notamment si deux machines qui communiquent ont besoin des deux types de service : elles pourront utiliser une seule session QUIC pour les deux.
Un petit rappel (mais relisez le RFC 9000
pour les détails) : dans une connexion QUIC sont envoyés des paquets
et chaque paquet QUIC contient une ou plusieurs trames. Chaque trame
a un type et ce type indique si la trame sera retransmise ou non en
cas de perte. Le service habituel (utilisé par exemple par
HTTP/3) se sert de trames de type
STREAM, qui fournissent un service fiable (les
données perdues sont retransmises par QUIC). Mais toutes les
applications ne veulent pas d'une telle fiabilité ou, plus
précisement, ne sont pas prêtes à en payer le coût en termes de
performance. Ces applications sont celles qui préféraient utiliser
UDP (RFC 768) plutôt que TCP. Pour rajouter de la sécurité,
elles utilisaient DTLS (RFC 6347). Si
QUIC remplace TCP, comment remplacer
UDP+DTLS ?
D'ailleurs, faut-il le remplacer ? La section 2 du RFC donne les raisons suivantes :
- Les applications qui ont besoin à la fois d'un canal fiable et d'un canal qui ne l'est pas (par exemple une application de communication qui veut un canal fiable pour la signalisation et un pas forcément fiable pour les données multimédia) peuvent avec QUIC n'avoir qu'une seule session (et donc ne « payer » l'établissement de la session qu'une fois, ce qui diminuera la latence),
- QUIC a un meilleur mécanisme de récupération des pertes que DTLS, lors de l'établissement de la connexion,
- contrairement à UDP+DTLS, QUIC a un mécanisme de contrôle de la congestion, ce qui simplifie la tâche de l'application (cf. RFC 8085).
Ces raisons sont particulièrement importantes pour le streaming audio/vidéo, pour les jeux en ligne, etc. Les datagrammes dans QUIC peuvent aussi être utiles pour un service de VPN. Là aussi, le VPN a besoin à la fois d'un canal fiable pour la configuration de la communication, mais peut se satisfaire d'un service de type datagramme ensuite (puisque les machines connectées via le VPN auront leur propre mécanisme de récupération des données perdues). Permettre la création de VPN au-dessus de QUIC est le projet du groupe de travail MASQUE.
Bien, normalement, maintenant, vous êtes convaincu·es de
l'intérêt des datagrammes au-dessus de QUIC. Pour en envoyer, il
faut toutefois que les deux parties qui communiquent soient
d'accord. C'est le rôle du paramètre de transport QUIC
max_datagram_frame_size, à utiliser lors de
l'établissement de la session. (Ce paramètre est enregistré
à l'IANA.) S'il est absent, on ne peut pas envoyer de
datagrammes (et le partenaire coupe la connexion si on le fait quand
même). S'il est présent, il indique la taille maximale acceptée,
typiquement 65 535 octets. Sa valeur peut être stockée dans la
mémoire d'une machine, de façon à permettre son utilisation lors du
0-RTT (commencer une session QUIC directement sans perdre du temps
en négociations). Un paquet QUIC 0-RTT peut donc inclure des trames
de type DATAGRAM.
Ah, justement, ce type DATAGRAM. Désormais
enregistré
à l'IANA parmi les types de trames QUIC, il sert à indiquer
des trames qui seront traitées comme des datagrammes, et qui ont la
forme suivant :
DATAGRAM Frame {
Type (i) = 0x30..0x31,
[Length (i)],
Datagram Data (..),
}
Le champ de longueur est optionnel, sa présence est indiquée par le dernier bit du type (0x30, pas de champ Longueur, 0x31, il y en a un). S'il est absent, la trame va jusqu'au bout du paquet QUIC (rappelons qu'un paquet QUIC peut contenir plusieurs trames).
Maintenant qu'on a des datagrammes comme QUIC, comment les
utilise-t-on (section 5 du RFC) ? Rien d'extraordinaire,
l'application envoie une trame DATAGRAM et
l'application à l'autre bout la recevra. Si la trame n'est pas
arrivée, l'émetteur ne le saura pas. La trame peut se retrouver avec
d'autres trames (du même type ou pas) dans un même paquet QUIC (et
plusieurs paquets QUIC peuvent se retrouver dans un même datagramme
IP). La notion de
ruisseau (stream) n'existe pas pour les
trames-datagrammes, si on veut pouvoir les démultiplexer, c'est à
l'application de se débrouiller. (Une version préliminaire de cette
extension à QUIC prévoyait un mécanisme de démultiplexage,
finalement abandonné.) Comme toutes les trames QUIC, les trames
DATAGRAM sont protégées par la
cryptographie. Le service est donc équivalent à celui d'UDP+DTLS,
pas UDP seul.
Un service de datagrammes est non fiable, des données peuvent se
perdre. Mais si les trames de type DATAGRAM ne
sont pas réémises (pas par QUIC, en tout cas), elles entrainent
néanmoins l'émission d'accusés de réception (RFC 9002, sections 2 et 3). Une bibliothèque QUIC peut ainsi
(mais ce n'est pas obligatoire) notifier l'application des
pertes. De la même façon, elle a la possibilité de dire à
l'application quelles données ont été reçues par le QUIC à l'autre
bout (ce qui ne garantit pas que l'application à l'autre bout les
aient bien reçues, si on a besoin d'informations sûres, il faut le
faire au niveau applicatif).
Comme l'émetteur n'estime pas
crucial que toutes les données arrivent, une optimisation possible
pour QUIC est que l'accusé de réception d'un paquet ne contenant que
des trames DATAGRAM ne soit pas émis tout de
suite, il peut attendre le paquet suivant.
Cette extension existe déjà dans plusieurs mises en œuvre de QUIC, mais je ne l'ai pas testée.
L'article seul
Un cas rigolo d'oubli d'un nom de domaine
Première rédaction de cet article le 30 mars 2022
Il est fréquent qu'une organisation utilise un sous-domaine de son domaine principal pour mettre une adresse IP qui est celle d'un hébergeur plus ou moins distant. Pas de problème avec cela. Sauf que, parfois, lorsqu'on arrête d'utiliser le serveur chez l'hébergeur, on oublie de supprimer le nom de domaine. Et cela peut ouvrir des failles de sécurité.
Le cas a été détecté par
Thomas Citharel. Le nom de
domaine
societaires.caisse-epargne.fr pointe vers une
adresse IP qui semble être
utilisée par un particulier sans lien avec la Caisse
d'Épargne. Regardons :
% dig A societaires.caisse-epargne.fr ; <<>> DiG 9.16.1-Ubuntu <<>> A societaires.caisse-epargne.fr ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 2803 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 4096 ;; QUESTION SECTION: ;societaires.caisse-epargne.fr. IN A ;; ANSWER SECTION: societaires.caisse-epargne.fr. 86400 IN A 5.39.72.65 ;; Query time: 183 msec ;; SERVER: 127.0.0.1#53(127.0.0.1) ;; WHEN: Fri Mar 25 07:50:02 CET 2022 ;; MSG SIZE rcvd: 74
L'adresse IP est 5.39.72.65 (au fait, vous
pouvez regarder vous-même si cela a changé depuis cet article, avec
dig, ou
bien via
le DNS Looking Glass). L'adresse en question indique une
machine chez OVH (vu avec
whois). Rien d'extraordinaire à ce que la
Caisse d'Épargne utilise des machines dans le
cloud. Ce qui est plus
curieux, c'est que le serveur HTTP sur la machine renvoie un code de retour
403 (accès interdit) :
% curl -v societaires.caisse-epargne.fr * Trying 5.39.72.65:80... * Connected to societaires.caisse-epargne.fr (5.39.72.65) port 80 (#0) > GET / HTTP/1.1 > Host: societaires.caisse-epargne.fr ... < HTTP/1.1 403 Forbidden < Server: nginx < Date: Wed, 30 Mar 2022 07:54:37 GMT ... <html> <head><title>403 Forbidden</title></head> ...
Pourquoi avoir ce nom de domaine si ça ne marche pas ? En fait, le serveur HTTP répond à un autre nom. Une façon de le trouver est dans le certificat. Réessayons en HTTPS :
% curl -v https://societaires.caisse-epargne.fr * Trying 5.39.72.65:443... ... * Server certificate: * subject: CN=cloud.sevenn.fr ...
Donc, la machine indique plutôt cloud.sevenn.fr
comme identité. Et, là, ça marche, ce nom
pointe vers la meme adresse IP :
% dig A cloud.sevenn.fr ... ;; ANSWER SECTION: cloud.sevenn.fr. 300 IN CNAME sevenn.fr. cloud.sevenn.fr. 300 IN RRSIG CNAME 13 3 300 ( 20220326075016 20220324055016 34505 sevenn.fr. YZKUrmJudhUmG/iOu1GKsei510JBZVS2Bn+2z2pmO8fC aXJbbgb66XTJsyCkMZ7oaPzaKdgJI8UldHhZ/1ErHg== ) sevenn.fr. 300 IN A 5.39.72.65 sevenn.fr. 300 IN RRSIG A 13 2 300 ( 20220326075016 20220324055016 34505 sevenn.fr. gk3v1r2/dJTc0/jqL4ZQqH6xQh7xvYLcCSNhQNq5yrvM ubQ3WYuv3Pu1Yw7MoxVrJjNOqP9NlVdzmo3L/FK8ag== ) ...
En visitant le site Web, on voit un service Nextcloud. (On notera que le domaine du particulier est signé avec DNSSEC, alors que celui de l'établissement financier ne l'est pas…)
Le plus probable est donc qu'à une époque, la Caisse d'Épargne
avait un serveur chez OVH. Elle a supprimé le serveur, mais a gardé
le nom de domaine. Plus tard, un particulier a loué un serveur chez
OVH, et récupéré l'adresse IP. Il contrôle donc une machine vers
laquelle pointe un nom de la Caisse d'Épargne. Quelles conséquences
cela peut avoir ? Il peut y avoir des problèmes de sécurité. Par
exemple, le locataire de la machine pourrait désormais obtenir un
certificat pour le nom
societaires.caisse-epargne.fr (et peut-être
pour le nom au-dessus). Il pourrait également placer des
cookies pour ce nom. C'est pour cela que j'ai
évidemment écrit aux adresses de contact du domaine
caisse-epargne.fr (obtenues via
whois) avant de publier cet article. Inutile
de dire que, comme pour la plupart des signalements de sécurité, je
n'ai jamais eu de réponse, et que rien n'a été fait.
Bien sûr, ici, il ne s'agit pas d'une attaque, le nouveau titulaire de l'adresse IP est parfaitement de bonne foi. Mais de telles attaques sont possibles : on parle d'« attaque par le sous-domaine ». Le principe est de repérer un sous-domaine de votre cible qui pointe vers une adresse IP d'un hébergeur et qui n'est plus affectée, puis de créer des serveurs chez l'hébergeur en question jusqu'à tomber sur la bonne adresse. Avec les API, cela s'automatise et peut donc être rapide et pas trop coûteux.
Un dernier détail : si vous visitez l'URL
http://societaires.caisse-epargne.fr avec
certaines versions de Firefox (et peut-être d'autres navigateurs),
cela « marchera » car le navigateur, recevant le code d'erreur 403,
ré-essaiera ensuite avec
www.societaires.caisse-epargne.fr (qui est
associé à une toute autre adresse IP, chez
Online). Cela rappelle qu'il ne faut
pas déboguer les problèmes de réseau avec un
navigateur Web, logiciel compliqué et qui fait plein de choses qu'on
ne lui a pas demandé.
(Ces problèmes d'« attaque » par sous-domaine ne sont pas nouveaux, Marc Framboisier m'a retrouvé un article de 2009 touchant un tribunal de la même façon.)
L'article seul
Fiche de lecture : Information security essentials
Auteur(s) du livre : Susan McGregor
Éditeur : Columbia University Press
9-780231-192330
Publié en 2021
Première rédaction de cet article le 28 mars 2022
Un livre très utile pour les personnes non expertes en cybersécurité mais qui veulent se protéger un peu plus. L'auteure vise essentiellement les journalistes (le sous-titre est « A guide for reporters, editors and newsroom leaders ») mais une bonne partie du livre s'applique à tous ceux et à toutes celles qui courent des risques dans le monde numérique (c'est-à-dire à peu près à tout le monde).
Je préviens mes lecteurs et lectrices qui travaillent dans la cybersécurité : ce livre n'est pas prévu pour vous. Il ne s'agit pas de devenir expert·e en sécurité informatique, mais d'améliorer sa protection. Et l'auteure ne parle pas que de technique, vous ne trouverez pas de comparaison détaillée de la sécurité de RSA et d'ECDSA, ce n'est pas le sujet.
Susan McGregor part de nombreux cas concrets de problèmes rencontrés par des journalistes, de la confiscation de l'ordiphone par la police pendant une manifestation de Black Lives Matter aux risques de fouille de l'ordinateur qu'on a laissé dans sa chambre pendant un reportage dans un pays peu regardant sur les droits humains. Les risques informatiques sont très nombreux, et certains ne menacent pas que le ou la journaliste mais aussi ses contacts. Et il y a également le risque d'être victime de faux, et de contribuer involontairement à diffuser des mensonges.
McGregor cite de nombreux professionnels des médias, ainsi que des responsables de la sécurité informatique dans divers médias (comme Runa Sandvik). La première partie du livre est une très bonne explication, très pédagogique, du monde numérique. Elle parle ensuite de la délicate mais indispensable modélisation de la menace (oui, vous pouvez être menacé·e, même si vous ne faites pas un reportage sur les djihadistes ou sur les proxénètes). Cette modélisation dépend, l'auteure insiste sur ce point, de la personne concernée : couvrir une manifestation contre les violences policières n'entraine pas les mêmes risques si le journaliste est noir ou blanc.
L'auteure continue avec des conseils pratiques. Pas les ridicules « n'ouvrez pas les pièces jointes provenant d'inconnus » (il serait pratique, le travail journalistique, si ce conseil était suivi) mais plutôt des conseils concrets et réalistes, qui peuvent faire une différence tout de suite (séparez vos comptes personnels et professionnels sur les réseaux sociaux, utilisez un gestionnaire de mots de passe, sauvegardez, chiffrez tout, utilisez l'authentification à deux facteurs, etc). Et elle explique bien qu'aucune solution technique n'est parfaite, il n'y a pas de sécurité absolue, il faut juste pouvoir être capable de déterminer si une solution de sécurité en vaut la peine ou pas.
Le livre détaille la question du reportage à l'étranger, en suggérant de ne pas laisser grand'chose sur son ordinateur, de tout mettre chez des prestataires externes. Cela suppose que ceux-ci soient de confiance. Bien qu'elle soit bien consciente que les États-Unis ne soient pas un pays parfait pour le respect des droits des journalistes, elle ne rappelle hélas pas les risques associés à ces prestataires. Mais il est clair qu'il n'y a pas de solution parfaite. Si on est en reportage en Chine, les fichiers qui restent sur le PC portable sont à la merci de la police chinoise, si on envoie tout chez les GAFA, les fichiers sont à la merci des services étatsuniens. Tout dépend de qui est le plus menaçant, pour un reportage donné.
Ensuite, McGregor étudie comment développer une culture de sécurité, c'est-à-dire comment faire que les bons conseils soient réellement appliqués. Elle est bien consciente que la sécurité, c'est pénible, et que bien des personnes en danger vont prendre des risques alors qu'elles sont informées de ces risques. Le livre couvre donc aussi ces questions plus psychologiques qu'informatiques.
Un chapitre est consacré aux freelances, une catégorie fréquente dans les médias, et qui posent des problèmes de sécurité particulièrement aigus puisqu'ielles ne bénéficient pas forcément des outils de l'organisation qui les emploie, et qu'ielles sont prêt·es à prendre beaucoup de risques déraisonnables, par exemple pour décrocher un scoop. L'auteure insiste donc sur la responsabilité du média, qui ne doit surtout pas encourager cette prise de risques.
Je ne suis pas d'accord avec tout (l'encadré sur logiciel libre vs. privateur est très contestable) mais c'est un livre que je recommande fortement si vous êtes journaliste, ou si vous exercez un autre métier incluant un risque informatique.
(Et, sinon, vous avez un interview de l'auteure en français, datant d'avant la parution de son livre.)
L'article seul
RFC 9199: Considerations for Large Authoritative DNS Servers Operators
Date de publication du RFC : Mars 2022
Auteur(s) du RFC : G.C.M. Moura (SIDN Labs/TU Delft), W. Hardaker, J. Heidemann (USC/Information Sciences Institute), M. Davids (SIDN Labs)
Pour information
Première rédaction de cet article le 22 mars 2022
On sait que le DNS est un des services d'infrastructure les plus essentiels de l'Internet. Il est, par exemple, crucial que les serveurs DNS faisant autorité soient correctement gérés, et robustes face aux problèmes qui peuvent survenir. Ce RFC donne un certain nombre de conseils (juste des conseils, il ne s'agit pas d'une norme) aux opérateurs de ces serveurs.
Il n'est pas obligatoire de suivre ces conseils mais il faut noter qu'ils sont tous fondés sur des articles publiés dans des revues techniques avec examen par les pairs. Donc, c'est quand même sérieux, même si ce RFC n'a pas le statut de norme. Le RFC vise surtout les « gros » serveurs faisant autorité, par exemple les serveurs de TLD importants. Ces serveurs sont typiquement anycastés (RFC 1546 et RFC 4786). Si le vôtre est unicast et ne sert qu'à trois visiteurs de temps en temps, vous n'êtes pas forcément concerné·e.
Au passage, cette distinction entre serveurs faisant autorité et résolveurs est cruciale dès qu'on parle du DNS. La section 2 du RFC commence d'ailleurs par un rappel de cette distinction. D'autre part, cette même section insiste sur l'importance du DNS pour le vécu de l'utilisatrice. Par exemple la latence perçue par celle-ci dépend en bonne partie du DNS. Voici un exemple :
% curl-timing https://www.nic.af/ DNS: 0,920891 s TCP connect: 1,124164 s TLS connect: 1,455578 s Start transfer: 1,598288 s Total: 1,735741 s
On voit que la résolution DNS a pris plus de la moitié du temps
total. (La commande curl-timing est définie par
alias curl-timing='curl --silent --output /dev/null
--write-out "DNS: %{time_namelookup} s\nTCP connect: %{time_connect}
s\nTLS connect: %{time_appconnect} s\nStart transfer:
%{time_starttransfer} s\nTotal: %{time_total} s\n"'.) Sur
ce sujet de la latence, voir aussi l'article « The
Internet at the Speed of Light ». La latence dépend
en grande partie de la distance géographique, et la réduire impose
donc une présence mondiale.
Et ces performances, et cette robustesse sont menacées, entre autres, par les nombreuses attaques par déni de service qui visent le DNS, comme celle décrite dans l'article « Anycast vs. DDoS: Evaluating the November 2015 Root DNS Event ».
La section 3 est le cœur du RFC, contenant les recommandations, numérotées de C1 à C6. Commençons par C1, le conseil de n'avoir que des serveurs anycast. L'anycast est indispensable pour répartir très largement les serveurs, assurant la performance et la robustesse de la résolution DNS. Bien sûr, on peut se contenter d'avoir plusieurs enregistrements NS mais cela ne suffit pas : diverses raisons font qu'on ne peut pas avoir des centaines d'enregistrements dans un ensemble NS, alors que certains nuages anycast atteignent cette taille. Donc, avoir plusieurs enregistrements NS est nécessaire mais cela ne dispense pas de l'anycast.
C'est d'autant plus vrai que, parmi les enregistrements NS, la
sélection de celui utilisé est faite par le résolveur. Les
résolveurs corrects mesurent la latence et choisissent le serveur
faisant autorité le plus rapide. Mais il y a d'autres résolveurs qui
n'utilisent pas de bons algorithmes de sélection
(cf. « Recursives
in the Wild: Engineering Authoritative DNS
Servers »). Avec l'anycast, la
sélection de l'instance utilisée est faite par le réseau, via
BGP, et peut
donc être meilleure. Du fait de ces résolveurs sous-performants, un
opérateur a donc intérêt à ce que tous les serveurs faisant autorité
soient anycastés. S'il y a un « maillon faible »,
unicast et mal connecté, il sera quand même
consulté par certains résolveurs, et dégradera donc la latence dans
certains cas. Par exemple, le TLD
.nl est passé en tout
anycast en 2018.
Maintenant, C2, le conseil de travailler son
routage. Une fois qu'on a décidé de mettre de
l'anycast partout, il reste à
optimiser. BGP
ne garantit pas du tout, contrairement à ce qu'on lit parfois, que
la route la plus rapide sera choisie. BGP fait ce que les
administrateurs réseau lui demandent de faire. On voit régulièrement
des traceroute qui montrent qu'on ne va pas à
l'instance anycast la plus proche. Certains
opérateurs DNS compensent en ajoutant davantage d'instances mais
l'article « Anycast
Latency: How Many Sites Are Enough? » montre, en
testant des serveurs de la racine depuis des
sondes RIPE Atlas, que le
nombre d'instances compte moins que le soin apporté au routage. (On
ne parle ici que de performances ; pour la résistance aux attaques
par déni de service, le nombre d'instances reste essentiel.) Ici, le
temps de réponse des serveurs faisant autorité pour
.fr, depuis une machine
en France (il y a une instance proche pour chaque serveur) :
% check-soa -i fr d.nic.fr. 2001:678:c::1: OK: 2230506452 (4 ms) 194.0.9.1: OK: 2230506452 (0 ms) e.ext.nic.fr. 193.176.144.22: OK: 2230506434 (15 ms) 2a00:d78:0:102:193:176:144:22: OK: 2230506434 (15 ms) f.ext.nic.fr. 194.146.106.46: OK: 2230506434 (6 ms) 2001:67c:1010:11::53: OK: 2230506452 (11 ms) g.ext.nic.fr. 2001:678:4c::1: OK: 2230506434 (2 ms) 194.0.36.1: OK: 2230506434 (2 ms)
Le conseil C3 porte sur un concept très important lorsqu'on fait de l'anycast, celui de bassin d'attraction. Ce terme désigne l'ensemble des réseaux qui vont envoyer leurs paquets vers une instance donnée. Si toutes les instances ont à peu près les mêmes capacités de traitement des requêtes, on souhaite en général placer les instances et configurer BGP de manière à ce que toutes les instances reçoivent à peu près la même quantité de requêtes. Mais en pratique c'est rarement le cas : le réseau est une chose compliquée. Il existe des méthodes pour améliorer les choses (cf. l'article « Broad and Load-Aware Anycast Mapping with Verfploeter », qui décrit l'outil Verfploeter) mais ce n'est jamais parfait. Au moins, un outil comme Verfploeter permet de procéder plus scientifiquement qu'au pifomètre, et d'avoir une idée de ce que produiront des changements de configuration BGP pour faire du traffic engineering (par exemple, allonger le chemin d'AS dans les annonces, pour diminuer le trafic d'une instance).
Le conseil C4, quant à lui, porte sur les attaques par déni de service (comme celle décrite dans « Anycast vs. DDoS: Evaluating the November 2015 Root DNS Event ») et sur le comportement des serveurs soumis à un stress intense. Que peut faire l'opérateur lorsque Mirai ou un de ses semblables attaque ?
- Essayer de diminuer le trafic entrant, soit en faisant du traffic engineering BGP pour envoyer le trafic vers une autre instance, si certaines ont davantage de capacité, ou bien ne sont pas attaquées, voire, si on n'a pas de réserves, en arrêtant complètement d'annoncer les routes (ce qui arrête le service - ce qui était le but de l'attaquant - mais cela peut être nécessaire s'il y a d'autres services au même endroit et qu'on veut les épargner),
- Ou bien encaisser en silence, sachant qu'on perdra des requêtes et qu'on ne pourra pas répondre à tout. Si l'attaque ne frappait que certaines instances, cela peut permettre d'épargner les instances non attaquées.
Le conseil C4 est donc d'avoir des plans prêts à l'avance, permettant de prendre une décision en cas de crise, et de l'appliquer.
Et les TTL ? Ils ne sont pas oubliés. La mémorisation des réponses, pendant une durée maximale égale au TTL, est un point essentiel du DNS, et un facteur de performance crucial. Même si un serveur faisant autorité répond souvent en moins de 50 ms, la réponse de la mémoire d'un résolveur, qui peut arriver en 1 ms, sera encore préférable. Ce rôle a été largement étudié (voir par exemple « Modeling TTL- based Internet Caches » ou, plus récemment, « When the Dike Breaks: Dissecting DNS Defenses During DDoS »). Une étude des conséquences du choix du TTL sur les performances est la base du conseil C5, l'étude « Cache Me If You Can: Effects of DNS Time-to- Live ». Elle montre que :
- Des TTL plus longs diminuent le temps de réponse (puisque
les données sont conservées plus longtemps dans la mémoire des
résolveurs), cf. par exemple l'expérience faite sur
.uycitée dans l'article ci-dessus, - Ces TTL plus longs diminuent le trafic DNS, pour la même raison, (logiquement, les gens qui s'inquiètent de l'empreinte environnementale du numérique devraient mettre des TTL longs sur leurs domaines),
- Et ils améliorent la robustesse face aux attaques par déni de service (même si tous les serveurs faisant autorité ont du mal à répondre, les résolveurs pourront continuer à servir les données),
- D'un autre côté, et comme il n'existe pas de solution parfaite, juste des choix et des compromis, des TTL plus longs empêchent de changer rapidement sa configuration ; si le changement était planifié, ce n'est pas grave (on abaisse le TTL avant le changement et on le remonte après), mais si on veut le faire en urgence, c'est plus gênant,
- C'est d'autant plus gênant que certains services d'atténuation des attaques par déni de service fonctionnent en utilisant le DNS pour envoyer le trafic vers l'atténuateur ; des TTL longs limitent cette possibilité (et la planification ne change rien dans ce cas, puisque les attaquants ne se signalent pas forcément à l'avance),
- Même problème avec la répartition de charge utilisant le DNS.
Bref, on ne peut pas faire une recommandation quantitative appliquable à tous les cas. Le conseil C5 est donc plus complexe :
- Pour un domaine ordinaire, des TTL d'au moins une heure, et de préférence d'au moins huit heures sont recommandés,
- Pour les gros registres (par exemple registres de TLD), la plupart des résolveurs utiliseront de toute façon les TTL indiqués dans la zone fille ; pour le bien des autres résolveurs, le RFC recommande un TTL d'au moins une heure,
- Pour les zones « terminales » qui utilisent des répartiteurs de charge ou des services d'atténuation d'attaques qui reposent sur le DNS, on peut se contenter de TTL de 5 minutes, mais le RFC recommande quand même au moins 15 minutes.
Et si les TTL entre la zone parente et la zone fille diffèrent ?
La question se pose typiquement pour les enregistrements
NS. Par exemple, les enregistrements NS dans la zone
racine ont un TTL de 48 heures, alors que dans les zones des TLD,
l'ensemble NS a presque toujours un TTL plus faible (une heure pour
.cl, par exemple). Selon
que le résolveur est parent-centric (une
minorité) ou child-centric (la grande majorité),
il utilisera le TTL de la zone parente ou bien celui de la zone
fille. Le conseil C6 : on ne peut pas compter que le TTL qu'on a mis
soit respecté partout, si l'enregistrement existe aussi dans la zone
parente avec des TTL différents. Attention donc lorsqu'on veut
changer quelque chose, à intégrer le TTL de la zone parente.
Un bon résumé en anglais de ce RFC a été écrit par un des auteurs. Il inclut un récit de la création du RFC et du processus suivi.
L'article seul
RFC 9146: Connection Identifiers for DTLS 1.2
Date de publication du RFC : Mars 2022
Auteur(s) du RFC : E. Rescorla (RTFM), H. Tschofenig, T. Fossati (Arm Limited), A. Kraus (Bosch.IO)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 20 mars 2022
Ce RFC ajoute au protocole de sécurité DTLS 1.2 la possibilité d'identificateurs de connexion (connection ID), permettant de relier entre eux des paquets d'une même session DTLS, même si l'adresse IP source change. C'est une solution simple et minimale, DTLS 1.3 (RFC 9147) l'utilise (avec quelques ajouts).
Dans le DTLS habituel, version de TLS qui tourne sur UDP et qui est normalisée dans le RFC 6347, lorsqu'un paquet arrive à une machine, celle-ci trouve l'association de sécurité appropriée (ce qui permet de trouver le matériel crptographique qui permettra de déchiffrer et de vérifier les signatures) en regardant le tuple {protocole, adresse IP source, adresse IP destination, port source, port destination}. Mais si la machine avec qui on correspond a changé d'adresse IP, par exemple parce qu'il s'agit d'un malinphone qui est passé de WiFi à 4G ? Ou bien si elle a changé de port car un routeur NAT a trouvé intelligent de considérer la session terminée, effaçant une entrée dans sa table de correspondance ? Dans ce cas, le paquet entrant va être considéré comme une nouvelle session, il faudra reprendre la négociation TLS, et c'est du temps perdu (la poignée de main cryptographique est coûteuse, et on souhaite amortir ce coût sur la plus longue durée possible).
Le RFC note que le problème est particulièrement sérieux pour les déploiements type Internet des Objets, où les objets peuvent se mettre souvent en sommeil pour économiser leur batterie, amenant le routeur NAT à oublier la session en cours.
Notez aussi qu'outre l'identificateur de connexion, notre RFC apporte quelques changements supplémentaires, notamment pour permettre le remplissage.
La section 3 du RFC spécifie l'extension DTLS
connection_id (numéro 54 dans le
registre IANA) qui permet de spécifier des identifiants des
connexions DTLS, et donc ainsi de construire une connexion qui
résistera aux changements d'adresses IP et de ports. Dans son
ClientHello, le client DTLS indiquera
l'identifiant qu'il utilisera (idem pour le serveur DTLS dans son
ServerHello). Par contre, on ne peut pas
changer d'identifiant de connexion en cours de connexion
(contrairement à ce que permettent, par exemple, QUIC ou, tout simplement, DTLS 1.3). Une fois
l'utilisation de connection IDs négociée, les
données sont envoyées dans une nouvelle structure, de type
tls12_cid (numéro 25 dans le
registre IANA). (Pour DTLS 1.3, il faudra regarder le RFC qui
lui sera consacré.) On peut
ajouter des zéros avant le chiffrement, à des
fins de remplissage. Voici la structure de
données avant le chiffrement :
struct {
opaque content[length];
ContentType real_type;
uint8 zeros[length_of_padding];
} DTLSInnerPlaintext;
Et une fois chiffrée, on envoie ça sur le réseau :
struct {
ContentType outer_type = tls12_cid;
ProtocolVersion version;
uint16 epoch;
uint48 sequence_number;
opaque cid[cid_length]; // L'identifiant de
// connexion est là.
uint16 length;
opaque enc_content[DTLSCiphertext.length];
} DTLSCiphertext;
Que se passe-t-il quand on reçoit un message pour un identifiant
de connexion connu mais une nouvelle adresse IP ? Il ne faut pas lui
faire une confiance aveugle (des méchants ont pu usurper l'adresse
IP) et envoyer immédiatement des réponses à
la nouvelle adresse IP. Il faut d'abord vérifier que le message est
correctement signé, qu'il a une epoch plus
récente que le précédent message (dans certains cas, comme l'ordre
des messages n'est pas garanti, cela peut mener à ignorer un message
valide), et l'application doit tester que le pair est toujours
d'accord (la méthode dépend de l'application).
Les identifiants de connexion posent évidemment des questions de vie privée (section 8 du RFC). Ils doivent être en clair (puisqu'ils servent au récepteur à découvrir le matériel cryptographique de la connexion, qui servira au déchiffrement) et sont donc observables par quiconque est situé sur le trajet, ce qui améliore la traçabilité (ce qui est mauvais pour la vie privée). Et, contrairement à QUIC, on n'a qu'un identifiant, on ne peut pas en changer (c'est mieux en DTLS 1.3).
L'article seul
Quelles conséquences si les câbles avec les USA étaient coupés ?
Première rédaction de cet article le 13 mars 2022
Une vidéo au titre sensationnaliste, « La Russie peut-elle couper le réseau internet en France et en Europe en s'attaquant aux câbles sous-marins ? » a été publiée par France Info hier. Ce titre montre une incompréhension sérieuse de ce qu'est l'Internet. Couper les câbles est une chose. Couper l'Internet une autre. Ce n'est pas parce qu'on ne peut plus communiquer avec les USA qu'on n'a plus d'Internet. Quelques explications.
Cette vidéo (depuis complétée par un article de même contenu) fait partie des classiques productions médiatiques qui jouent sur la peur « La menace est observée par Orange France et jugée "crédible" par la Marine Nationale ». (Un autre exemple, quoique un peu moins sensationnaliste est dans un article de The Conversation.) Mais elle est erronée à plusieurs niveaux.
Commençons par le risque d'une attaque de la Russie contre les câbles sous-marins. Comme je ne passe pas sur C8 avec le titre « expert en tout », je ne vais pas jouer au spécialiste militaire. Je ne saurais donc pas évaluer ce risque. Ce ne sont évidemment pas les scrupules moraux ou légaux qui arrêteront Poutine qui, en Tchétchénie, en Syrie ou en Ukraine, bombarde les hôpitaux et massacre les civils. La réalisation concrète, par contre, est plus difficile mais admettons. Plaçons-nous dans l'hypothèse que les Russes ont coupé tous les câbles sous-marins qui relient la France et l'Europe aux États-Unis. Que se passerait-il ?
Certaines personnes ont surtout fait porter leur critique de cette vidéo en mettant l'accent sur la possibilité d'un re-routage des communications par d'autres endroits (via l'Asie et le Pacifique, par exemple ou alors par des liaisons satellite). Certes, les protocoles de routage, comme BGP, sont conçus pour cela (c'est la jolie histoire de l'Internet conçu pour résister à une guerre nucléaire). Mais il n'est pas sûr que la capacité disponible soit suffisante (pour les satellites, il est sûr qu'elle ne l'est pas). Je vais donc supposer, pour le reste de la discussion, qu'il n'y a pas d'alternative disponible : les États-Unis sont injoignables.
Quelles seraient les conséquences ? FranceInfo dit sans hésiter que ce serait une coupure de l'Internet. Mais ils confondent le point de vue de M. Toutlemonde chez lui qui, quand sa fibre est coupée, est effectivement déconnecté de l'Internet, avec la situation d'un pays ou a fortiori d'un continent comme l'Europe. Pour un pays ou un continent, l'Internet n'est pas un service auquel on se connecte. C'est une interconnexion de réseaux qui ont du trafic externe mais aussi du trafic interne. Une grande partie des flux de données en Europe reste en Europe et ne serait pas affectée par une coupure d'avec les États-Unis. L'Europe est en effet largement autonome. (La vidéo donne le chiffre, non sourcé et invraisemblable, de 80 % du trafic qui serait avec les USA. Compte tenu de la capacité des liens européens, il en faudrait des câbles sous-marins si 80 % du trafic traversait l'océan.)
Le cas relativement favorable de l'Europe est assez rare ; beaucoup de pays dans le reste du monde n'ont pas de liaison même avec leurs voisins immédiats, et doivent passer par les USA. Parfois, ce sont les FAI d'un même pays qui n'ont pas de liaison locale et doivent passer par Miami ou New York, pour des communications purement nationales. C'est pour cela que le cas vietnamien cité par la vidéo n'est pas pertinent pour l'analyse de la situation européenne.
Donc, en cas de coupure transatlantique, les Européens pourraient continuer à communiquer. Bien sûr, ils ne pourraient pas échanger avec les étatsuniens, donc une telle coupure serait très gênante, mais ce ne serait pas une « coupure de l'Internet ».
Cette relative autonomie de l'Internet en Europe est due au fait que les infrastructures de base, aussi bien l'interconnexion (via par exemple les points d'échange) que le DNS (via l'hébergement de nombreuses instances des serveurs racine) sont disponibles en Europe. Un pays qui n'aurait pas ces infrastructures aurait certainement bien davantage de problèmes.
Arrivé là, certains me disent « mais on n'aurait plus accès à Google donc ce serait bien la fin de l'Internet ». C'est évidemment une vision incorrecte de l'Internet ; l'Internet est un réseau, pas un service et tout ne passe pas par Google. Mais analysons cette objection.
D'abord, en cas de coupure totale de la liaison avec les USA, il n'est pas du tout sûr que des services comme Google Search ou YouTube soient inaccessibles. Google connait son métier et il est probable que ces services soient capables de fonctionner sans traverser l'Atlantique (ce qui, de toute façon, aurait entrainé une latence insupportable à l'utilisateur). À lire certaines discussions sur les réseaux sociaux, on a l'impression que certains croient que YouTube est une machine située aux USA et que toutes les requêtes doivent passer par elle ! Il s'agit en fait d'un très grand nombre de serveurs répartis sur toute la planète. (Même ce modeste blog est sur deux machines, situées des deux côtés de l'Atlantique.) Bien sûr, il existe peut-être des dépendances cachées, par exemple ces serveurs contactent de temps en temps leur maitre aux États-Unis et, s'ils n'y arrivent pas, peut-être cessent-ils de fonctionner. On ne le sait pas, et Google ne communique pas sur ce sujet. Mon estimation est que ce n'est pas le cas et que ces serveurs peuvent fonctionner seuls pendant un certain temps.
Bon, ça, c'était Google, une entreprise sérieuse et qui sait ce qu'elle fait. Mais un certain nombre de services disponibles via l'Internet ne sont pas gérés par des entreprises sérieuses. Entrainés entre autres par le terme marketing de serverless, des services dépendent de services extérieurs et ne font pas forcément attention à ces dépendances, qu'ils découvrent seulement lors des pannes. Donc, en cas de coupure de la liaison transatlantique, il est certain qu'il y aura un certain nombre de services supposés européens qui, en raison d'une dépendance mal analysée vis-à-vis de quelque chose hébergé chez une région étatsunienne d'AWS auront des problèmes. En théorie, les services sérieux ont des plans pour résister aux problèmes (les PCA) et d'autres pour se redresser en cas de panne (les PRA). Mais ces plans sont souvent purement théoriques et n'ont jamais été testés. Donc, oui, là, une coupure des câbles transatlantiques aura des conséquences en cascade pour certains, les moins préparés.
Cette discussion sur les services ne portait que sur les services à administration centralisée, les plus vulnérables. Les services pair-à-pair sont évidemment plus robustes mais, en pratique, ils sont peu nombreux, en partie en raison de la lutte menée contre eux par les ayant-droits et les États, au détriment de la robustesse (comme on l'a vu pendant le confinement de 2020).
Voilà, nous avons vu que la vidéo de FranceInfo était très décalée par rapport à la réalité. Toutefois, le risque d'une action contre les câbles sous-marins peut être une bonne occasion de réfléchir aux dépendances plus ou moins visibles de nos outils numériques et à travailler à s'en affranchir, et éventuellement à changer nos usages (nul besoin d'un moteur de recherche pour aller sur le site Web de son employeur, comme le font tant de gens). La dépendance n'est pas une fatalité ou une loi physique, elle dépend de choix, qu'on peut changer.
L'article seul
La Russie et la « déconnexion de l'Internet »
Première rédaction de cet article le 7 mars 2022
Le régulateur russe des télécommunications, Roskomnadzor, vient d'édicter de nouvelles règles pour certains acteurs de l'Internet en Russie. Cela a entrainé une floraison de titres sensationnalistes du genre « La Russie se déconnecte de l'Internet ». Qu'en est-il ?
Le tout se passant dans le contexte de l'agression (non provoquée) russe contre l'Ukraine, on n'est pas étonné des nombreuses exagérations et affirmations erronées. La guerre n'est jamais favorable aux discussions sérieuses et aux vérifications prudentes. Néanmoins, dans le cadre de ce blog, on va quand même essayer de garder la tête froide (oui, je sais bien que c'est impossible, mais je vais essayer quand même) et d'analyser ce qui se passe dans l'Internet en Russie. Entre l'ignorance technique et la propagande de guerre, on lit en effet pas mal de bêtises sur cette situation.
Donc, Roskomnadzor annonce des nouvelles règles (pas si nouvelles puisque beaucoup sont répétées par Roskomnadzor depuis des années). Le texte a été publié sur Twitter mais je ne lis pas le russe, donc je me fie à des traductions pas forcément exactes. Donc, prudence.
Ces règles sont apparemment uniquement pour les services officiels et leur imposent entre autres de :
- Avoir les serveurs de nom des
domaines en Russie et
plus précisément sous le TLD
.ru, - Ne pas avoir sur les sites Web de code qui charge des ressources hébergées à l'étranger.
Si c'est exact, c'est loin d'une « déconnexion russe de l'Internet ». Un utilisateur de l'Internet (ici, le gouvernement russe) peut parfaitement édicter des règles concernant ses propres ressources (noms de domaines et sites Web). L'Internet est bâti sur les principes de connectivité universelle et de liberté de décision locale. Une décision par un utilisateur donné n'est pas la même chose qu'une coupure de l'accès Internet.
Bien sûr, les choses sont plus compliquées que cela. Les nouvelles règles seront peut-être, en pratique, de facto applicables à tout le monde, pas seulement aux sites officiels (la Russie n'est pas un état de droit, et la loi n'est pas tout). Mais il est important de ne pas relayer des informations fausses : la Russie ne vient pas de se déconnecter.
Notons d'ailleurs qu'il y a parfois une certaine hypocrisie dans
les discours entendus en dehors de la Russie. Aucun domaine dans le
TLD du
gouvernement étatsunien,
.gov, n'utilise de serveurs de noms en
dehors de ceux contrôlés par des organisations étatsuniennes. Et
personne n'accuse le gouvernement des États-Unis de se déconnecter
d'Internet. Il applique juste des principes de sécurité
(contestables, mais pas absurdes), en évitant les dépendances vers
des acteurs extérieurs au pays. Au passage, s'il faut trouver un
mérite aux édits de Roskomnadzor, c'est de faire réfléchir sur les
dépendances de nos services Internet. (Dépendance que le discours
marketing sur le
serverless tente de faire
oublier, mais dont on se rappele à chaque panne
d'un CDN.)
Et en parlant de propagande, notons que des défenseurs des GAFA ont déclaré que les déclarations de la CNIL sur le service de surveillance Google Analytics contribuaient à la « fragmentation de l'Internet ». Je ne compare évidemment pas la CNIL à Roskomnadzor mais je veux insister sur le fait qu'on n'est pas dans un monde de Bisounours : parmi les gens qui affirment des choses erronées, il y a des gens qui se trompent, mais aussi des lobbyistes et des propagandistes, qui ne cherchent pas la vérité.
Évidemment, mon analyse ne vaut que pour aujourd'hui. Demain, les choses vont certainement changer. Cela fait des années que le gouvernement russe va dans la direction d'un contrôle de plus en plus strict sur l'Internet (et, d'ailleurs, sur toute la société). On verra peut-être donc demain une vraie déconnexion, mais, pour l'instant, on en est très loin.
Cela fait d'ailleurs au moins dix ans qu'il est très à la mode de crier bien fort que « la Russie se déconnecte de l'Internet » ou que « la Russie a maintenant un Internet souverain ». C'est tout à fait faux (ce n'est même pas vrai pour la Chine, mais qui est un cas différent dont on reparlera une autre fois). La répétition de ce thème me fait parfois penser qu'il est mis en avant par des souverainistes qui admirent secrètement Poutine, et voudraient bien que la Russie montre l'exemple, permettant à d'autres pays de contrôler, censurer, etc.
L'article seul
Programmeur·ses, méfiez-vous des données contenues dans le DNS
Première rédaction de cet article le 3 mars 2022
Vous êtes programmeuse ou programmeur ? Vous écrivez des programmes qui reçoivent et traitent des données en provenance du grand méchant Internet ? Alors, vous savez certainement qu'il ne faut pas se fier à ces données, qu'elles peuvent être malveillantes, conçues pour créer des problèmes ? Vous le savez, non ? Vous ne passez pas ces données au shell sans précautions ? Ah, zut, d'après cet article, tout le monde ne le sait pas.
L'article met en avant le rôle du DNS. Mais, en fait, contrairement à ce que prétendent les auteur·es, le problème n'a pas forcément de rapport avec le DNS. Les failles de sécurité découvertes par les auteur·es de cet intéressant article sont dans deux catégories :
- Certaines viennent simplement d'une utilisation imprudente des données par une application. Que ces données aient été reçues via le DNS est un détail.
- D'autres sont davantage liées à l'utilisation du DNS.
Commençons par les premières. La plus spectaculaire affecte un
logiciel très utilisé pour Eduroam, radsecproxy. Pour faire
des requêtes DNS,
il passe, dans certains cas, des données obtenues via le DNS à un
script shell sans
aucune précaution particulière. Si ces données contiennent
une injection shell (example.com ; rm
-rf /…, regardez very-nasty.shaftinc.fr), le code est exécuté. C'est évidemment très grave
et heureusement que les auteur·es de l'article ont découvert cette
faille. Mais, répétons-le, contrairement à la présentation
sensationnaliste de l'article, ce n'est pas un problème DNS. Un
programme qui reçoit des données de l'extérieur (que ce soit par le
DNS, par HTTP, par LDAP ou
d'autres) et les passe à un script shell sans précautions est mal
écrit, point.
L'article affirme que la reponsabilité du DNS est engagée car le DNS passe des données sans les vérifier (sa « transparence »). C'est volontaire (RFC 3597) car c'est la seule solution pour pouvoir étendre le protocole et ajouter de nouveaux types de données. Si on écoutait les chercheurs en sécurité, on ne pourrait jamais déployer des nouveautés. Les auteur·es vont jusqu'à reprocher au DNS de ne pas tripoter les données ! (Un résumé de l'article est sur le blog de l'APNIC.)
Mais il y a une deuxième catégorie de failles dans l'article,
cette fois liées au fonctionnement du DNS. Certains programmes
analysent de manière incorrecte les données
reçues. Par exemple, les noms de
domaine ont une représentation texte (les classiques
jolinom.example.com) et une représentation
binaire sur le câble qui est très
différente (elle est de type {longueur, données} donc par
exemple {7, jolinom} {7, example} {3, com} {0}). Passer de l'une à
l'autre peut créer des surprises. Un nom de domaine peut inclure un
point au milieu d'un composant (regardez le nom à droite du
CNAME en
dot-in-label.bortzmeyer.org), et un nom peut
inclure un caractère nul (oui, un octet valant zéro, regardez le nom
à droite du CNAME en
nul-in-label.bortzmeyer.org) qui sera
interprété par certaines bibliothèques comme une fin de chaine. En
jouant avec ces subtilités, le gérant d'une zone peut envoyer des
données qui seront mal interprétées, et mémorisées à tort par
certains résolveurs.
Dans ce cas et dans ce cas seulement, cela pourrait être
intéressant, comme le note l'article, que les bibliothèques valident
un peu plus les données. Par exemple, la partie droite d'un
enregistrement MX comporte le nom d'un
serveur de courrier. Ce nom est un nom de machine et les noms de
machines sont soumis à une syntaxe bien plus
restrictive que les noms de domaine. Un sous-programme comme
getaddrinfo pourrait donc refuser les noms
illégaux. Les auteur·es montrent que la GNU
libc le fait bien, mais hélas pas la uClibc.
L'article seul
À propos des coupures des réseaux Internet en Russie
Première rédaction de cet article le 2 mars 2022
Dernière mise à jour le 3 mars 2022
Suite à l'invasion de l'Ukraine par les troupes de Poutine, on a entendu, d'un côté, plusieurs appels à couper d'une manière ou d'une autre les réseaux russes de l'Internet et, d'un autre côté, des annonces comme quoi la Russie allait procéder à de telles coupures. Cet article explore la question uniquement sous l'angle technique (avec toutefois quelques incursions dans la gouvernance de l'Internet). Je ne parle que de l'infrastructure logicielle de l'Internet, laissant de côté les services comme les réseaux sociaux.
D'abord, deux avertissements. Je ne suis pas neutre face à cette guerre, dont la responsabilité revient à 99,9 % à la Russie. Vouloir mettre sur un pied d'égalité l'agresseur et l'agressé (par exemple en refusant de livrer des armes à l'agressé afin qu'il se défende) n'est pas de la neutralité, c'est du soutien à l'agresseur. Il est donc important d'aider l'Ukraine (et pas seulement via l'aide humanitaire mais aussi directement en aidant l'Ukraine à faire face). Ensuite, cet article explore les aspects techniques des éventuelles coupures, ce qui ne veut pas dire que je pense qu'elles seraient une bonne idée. (Je vous donne tout de suite mon opinion : non, ce ne serait pas une bonne idée.)
Ah, un troisième avertissement quand même : beaucoup de choses qu'on lit sur les réseaux sociaux au sujet de l'Internet en Russie sont fausses (par exemple lorsqu'on reprend la propagande russe d'un test de déconnexion qui n'a jamais été observé indépendamment). Donc, prudence.
Si vous n'êtes pas familier·e avec la gouvernance de l'Internet, il faudra se rappeler, tout au long de cet article, qu'il n'y a pas de chef ou de président de l'Internet (si dans un article vous tombez sur des phrases comme « l'ICANN, régulateur de l'Internet », vous pouvez arrêter votre lecture tout de suite, elle prouve que l'auteur ne connait pas son sujet). Chaque acteur a son autonomie de décision (dans les limites des lois et de la politique de son pays). Personne n'a, par exemple, l'autorité technique ou politique de couper effectivement toutes les communications avec la Russie, même s'il le voulait.
Commençons par les noms de
domaine. On a vu par exemple le gouvernement ukrainien
appeler à retirer de la racine du DNS les TLD russes
.ru,
.su et
.рф. Est-ce possible ?
Il faut bien discerner la possibilité technique et la possibilité
politique. Techniquement, il n'y a guère de difficulté. La copie
maitresse de la racine est géré par un sous-traitant du gouvernement
étatsunien, Verisign (oui, il y a aussi un
rôle de l'ICANN mais, techniquement, ce n'est pas
l'ICANN qui édite le fichier de zone de
la racine). Il serait techniquement trivial de retirer des
TLD de cette zone, comme cela avait été fait pour le .yu. Cela ne signifierait pas
forcément que le .ru et les autres cessent de
fonctionner. Le gérant d'un résolveur
DNS peut toujours configurer son logiciel pour transmettre
(on parle de forwarding) les requêtes pour les
noms sous .ru directement aux serveurs faisant
autorité. Il est probable que beaucoup de résolveurs en
Russie sont déjà configurés ainsi, pour des raisons de
souveraineté. Si le .ru était retiré de la
racine, d'autres le feraient. On aurait donc une situation
compliquée, où le .ru marcherait à certains
endroits et pas à d'autres, aggravant la « bordélisation » de
l'Internet (qui est déjà assez élevée).
Mais bien sûr la principale question face à cette idée de
supprimer les TLD russes est politique : en admettant que
l'ICANN et le gouvernement étatsunien décident de
le faire (rappelons que même
.ir n'a jamais été
supprimé, malgré de nombreuses demandes aux États-Unis), cela
signifierait la fin immédiate de la racine unique du DNS (RFC 2826). Les Russes monteraient une autre racine,
probablement avec les Chinois, qui seraient ravis du prétexte, et
avec d'autres pays qui, jusqu'à présent, supportaient la gestion de
la racine par les États-Unis puisque cette gestion restait
relativement raisonnable. (Au passage, rappelez-vous que la majorité
des informations sur l'Internet dans les médias sont fausses. Il est
ainsi inexact de prétendre que Russie ou Chine, avant le 24 février
2022, utilisaient une racine alternative. Des discussions ont eu
lieu, des projets ont été montés, mais rien de concret n'a été
appliqué.) Comme attendu, l'ICANN a refusé
d'agir.
Plutôt que de demander la suppression de ces TLD de la racine,
une autre solution serait de configurer les résolveurs pour refuser de résoudre ces
noms. Ces résolveurs DNS menteurs sont largement utilisés en Europe
pour la censure, par exemple de Sci-Hub. Ils
contribuent eux aussi à fragmenter l'Internet. Contrairement aux
actions sur la racine, la configuration des résolveurs est très
décentralisée : chaque gérant de résolveur peut bloquer
.ru de sa propre initiative. En France, ce
refus frappe par exemple
la chaine RT.
Mais il n'y a pas que le DNS dans la vie. Les techniciens réseau
purs et durs diraient même que l'Internet, c'est IP, le DNS n'étant qu'une
application, dont on peut se passer. Je ne suis pas vraiment
d'accord avec ce point de vue (sans le DNS, on ne va pas très loin),
mais cela vaut quand même la peine de regarder ce qu'il en est de la
connectivité IP. Sur les listes de discussion
RIPE, beaucoup d'intervenants ont réclamé un
blocage des adresses IP russes, voire que le RIPE-NCC retire les
allocations de préfixes IP et de numéros de systèmes
autonomes de la Russie (ou, parfois, seulement du
gouvernement russe).
(Vu sur le
site Web du RIPE-NCC, un exemple d'un préfixe d'adresses IP
alloué à un organisme russe.) 
Comme pour le DNS, commençons par ce qui se fait au niveau « central » avant de voir les décisions des acteurs décentralisés. Le RIPE-NCC est le RIR européen et le territoire sous sa responsabilité inclut la Russie (mais aussi l'Iran). Comme l'ICANN, il ne bénéficie d'aucun statut international particulier, c'est juste une organisation de droit néerlandais, qui doit donc obéir aux lois de son pays. C'est par exemple le cas lors des sanctions décidées par l'Union Européenne. Techniquement, le RIPE-NCC peut en effet modifier sa base de données pour retirer les allocations de ressources russes (pour l'instant, ce n'est pas prévu).
Toutefois, comme pour le DNS, ce retrait ne se traduirait pas forcément par un effet concret dans les câbles. Chaque opérateur reste maitre de son routage, décide quels préfixes router et quels préfixes bloquer. Certes, beaucoup d'opérateurs filtrent automatiquement les annonces de routage (en général reçues via le protocole BGP) sur la base des bases de données des RIR (ce qu'on nomme l'IRR). Dans l'hypothèse d'une désallocation des ressources russes, ces opérateurs seraient donc coupés de la Russie. C'est d'ailleurs pour cela que Roskomnadzor a demandé aux opérateurs russes (traduction en anglais) de ne plus utiliser comme IRR celui du RIPE-NCC. Mais d'autres opérateurs n'appliquent pas aveuglément les IRR, surtout si ceux-ci étaient trop clairement utilisés pour mettre en œuvre des décisions géopolitiques. Il n'est donc pas du tout sûr que le routage soit coupé, seulement pertubé (encore un cas de « bordélisation » de l'Internet).
Notez bien que les adresses IP éventuellement désallouées ne pourraient pas être réaffectées à d'autres : comme les anciens titulaires russes continueraient certainement à les utiliser, ces adresses ne fonctionneraient pas réellement aux mains de leurs nouveaux titulaires, en raison des nombreux conflits que cela générerait.
L'effet d'une désallocation serait plus fort si le routage était uniformément sécurisé via la RPKI. Mais ce n'est pas partout le cas.
Là encore, la principale conséquence néfaste pour l'Internet viendrait de la fin du système actuel de gestion des ressources : au lieu de RIR internationaux, on verrait différents pays monter des registres concurrents, des adresses être attribuées deux fois et autres désordres.
Là aussi, comme pour le DNS, il peut y avoir des décisions locales. Un opérateur peut refuser les paquets IP venant d'adresses russes ou bien refuser les annonces BGP contenant des AS russes. On verra sans doute dans les prochaines semaines un paysage compliqué, où certaines communications marcheront à certains endroits.
Jusqu'à présent, j'ai parlé de la possibilité que des gens à l'extérieur de la Russie coupent les communications avec la Russie. Mais la coupure peut aussi se faire suite à une initiative russe, par exemple pour empêcher les citoyens russes de s'informer librement. Pour l'instant, cela ne semble pas être le cas (et on peut regarder RT).
Enfin, le texte du gouvernement ukrainien qui appelait à couper
.ru mentionnait également les AC. Elles ne dépendent
pas de l'ICANN ou des RIR, et prennent leurs décisions de leur côté,
selon les lois du pays dont elles dépendent. Si elles décidaient de
révoquer les certificats russes, on se retrouverait
avec des problèmes analogues : une communication partielle, la
Russie qui monterait ses propres AC, et, d'une manière générale, un
affaiblissement de la sécurité.
L'article seul
Fiche de lecture : Alexandria
Auteur(s) du livre : Quentin Jardon
Éditeur : Gallimard
978-2-0728-5287-9
Publié en 2019
Première rédaction de cet article le 2 mars 2022
Il y a certainement plein d'histoires de la création du Web qui ont été publiées, mais ce livre a un angle original, au plus près des différents acteurs (notamment du peu connu Robert Cailliau) et est très fidèle à la réalité historique.
Ce n'est pas l'œuvre d'un historien, mais il m'a été recommandé par une historienne, et j'ai personnellement suivi deux ou trois des choses citées donc je peux dire que c'est bien raconté et que l'auteur ne reprend pas la plupart des clichés sur l'invention du Web (comme le cliché journalistique courant de dire que Mosaic était le premier navigateur graphique). L'auteur a choisi de centrer son livre sur une quête : un interview de Robert Cailliau qui, normalement, les refuse systématiquement (je ne vous divulgâche pas la fin du livre…). Il y a eu beaucoup de controverses autour de Cailliau et de son rôle exact dans la création du Web. Certains enthousiastes l'ont présenté comme co-inventeur du Web, aux côtés de Tim Berners-Lee, alors que d'autres réduisaient son rôle à presque rien. Il est d'autant plus difficile de trancher que la propagande a joué son rôle (après le départ de Berners-Lee du CERN, le CERN a eu tendance à mettre en avant le rôle de Cailliau qui, lui, était resté) : les différents témoins de l'époque ont tous plus ou moins réécrit l'histoire. Notez que le livre de Jardon fait aussi sortir de l'ombre des personnes encore moins connues que Cailliau comme Nicola Pellow, l'auteure du client Web LineMode.
Mais, surtout, et je vais donner là mon opinion personnelle, la discussion sur le rôle de Cailliau est faussée par une conception erronée de l'invention et des inventeurs. On présente en général l'invention comme jaillie d'une traite d'un cerveau unique, sans préparation initiale et sans participation collective. Mais ce n'est pas ainsi que les choses se passent. Ainsi, je trouve tout à fait vain de chercher « l'inventeur du datagramme », comme s'il y en avait un, alors que c'est un concept qui a mûri lentement et dans de nombreux esprits. Autre problème, on oublie complètement l'importance de la mise en œuvre et du déploiement. L'idée n'est pas grand'chose, c'est la réalisation qui compte. C'est pour cela qu'il est tout à fait faux de dire que les escrocs Winklevoss ont « co-inventé » Facebook ; une idée de réseau social, ce n'est pas un réseau social. Bref, Cailliau n'a pas eu l'idée originale du Web mais a joué un grand rôle dans la maturation et la diffusion de l'idée.
Ah, et pourquoi « Alexandria » ? Parce que c'était le nom d'un projet de Cailliau d'une grande bibliothèque (en référence à la bibliothèque d'Alexandrie) créée au-dessus du Web pour lui donner le contenu nécessaire. Le projet avait été soumis notamment aux instances de l'Union Européenne, qui n'avaient évidemment jamais donné suite (les mêmes instances qui se plaignent aujourd'hui de la domination étatsunienne sur le Web). Finalement, le projet a été réalisé par la base, avec Wikipédia.
Le livre parle longuement des nombreuses polémiques autour du lent déploiement du Web, du rôle du NCSA (les médias étatsuniens allaient jusqu'à gommer complètement le rôle de Berners-Lee), et de la création douloureuse du W3C. Il rappelle que l'Internet n'est pas un monde de Bisounours, et que les enjeux étaient importants. Une lecture très recommandée pour comprendre le processus de l'innovation.
L'auteur du livre est un des participants au podcast de France-Culture sur l'histoire de l'Internet, dans l'épisode 5 (ne vous fiez pas au titre, l'émission est bien plus subtile).
L'article seul
Trois très très simples résolveurs DNS
Première rédaction de cet article le 22 février 2022
Dernière mise à jour le 24 février 2022
Inspiré par un excellent article de Julia Evans, voici trois très simples (vraiment très simples !) résolveurs DNS en Python, en Elixir et en Rust. Ne les utilisez pas en production, leur but est purement pédagogique.
Comme dans l'article
originel, l'idée est de montrer, via un programme, le
fonctionnement d'un résolveur
DNS, notamment la délégation d'un
domaine vers un sous-domaine, l'un des principes fondamentaux du
DNS. Voici par exemple le déroulé de la résolution du nom
www.st-cyr.terre.defense.gouv.fr (choisi pour
son nombre de composants) :
% ./tiny-resolver.py www.st-cyr.terre.defense.gouv.fr A
Querying www.st-cyr.terre.defense.gouv.fr./A at 2001:7fd::1, depth 0
Querying www.st-cyr.terre.defense.gouv.fr./A at 2001:678:c::1, depth 1
Querying www.st-cyr.terre.defense.gouv.fr./A at 84.96.147.1, depth 2
Value of www.st-cyr.terre.defense.gouv.fr./A is ('OK', <DNS IN A rdata: 77.129.200.34>)
Trois serveurs faisant autorité ont été interrogés successivement, un de la racine, un de l'Afnic et un de SFR.
Ces deux résolveurs ont beaucoup de limites : ils ne prennent que le premier serveur faisant autorité pour chaque délégation (un vrai résolveur essaie au hasard, puis mémorise le serveur le plus rapide à répondre), par exemple. Et ils sont peu robustes face aux imprévus. Le deuxième résolveur ne gère même pas les alias (mais celui de Julia Evans non plus).
Le premier résolveur est écrit en Python. Il est téléchargeable en tiny-resolver.py. Il dépend de la bibliothèque dnspython. Si vous ne
connaissez pas Python, cette bibliothèque peut s'installer avec, au
choix, le système de paquetage de votre
système d'exploitation (apt install
python3-dnspython sur Debian) ou
bien avec l'outil pip (pip3 install
dnspython).
Le deuxième résolveur est écrit en
Elixir. Il est téléchargeable en tiny-resolver-elixir.tar. Elixir ne permet pas facilement
de produire un exécutable avec un seul fichier dès qu'on utilise des
bibliothèques extérieures comme elixir-dns. La
marche à suivre est donc (ne pas oublier d'installer les sources
d'Erlang - erlang-src
sur Debian - pour pouvoir compiler la
bibliothèque DNS) :
tar xvf tiny-resolver-elixir.tar cd tiny-resolver-elixir mix deps.get # Et accepter l'installation de Hex, la source des paquetages mix run resolver.exs domain-name
Quant au troisième, écrit par Kim Minh Kaplan, il est en
Rust. Il est téléchargeable en tiny-resolver.rs. Vous devez avoir un Rust très
récent et ajouter ce manifeste décrivant les dépendances, dans Cargo.toml :
[package] name = "tiny-resolver" version = "0.1.0" edition = "2021" [dependencies] trust-dns-client = "0.20.4"
Ensuite, un cargo build, et vous trouverez le
programme exécutable en
./target/debug/tiny-resolver :
% ./target/debug/tiny-resolver www.afnic.fr dig -r @198.41.0.4 www.afnic.fr d.nic.fr. 172800 IN A 194.0.9.1 dig -r @194.0.9.1 www.afnic.fr ns3.nic.fr. 172800 IN A 192.134.0.49 dig -r @192.134.0.49 www.afnic.fr www.afnic.fr. 600 IN A 91.188.78.66 Result: 91.188.78.66
Bonne lecture de code source !
L'article seul
RFC 9153: Requirements and Terminology for the Drone Remote Identification Protocol (DRIP)
Date de publication du RFC : Février 2022
Auteur(s) du RFC : S. Card, A. Wiethuechter (AX Enterprize), R. Moskowitz (HTT Consulting), A. Gurtov (Linköping University)
Pour information
Réalisé dans le cadre du groupe de travail IETF drip
Première rédaction de cet article le 11 février 2022
Il y a aujourd'hui beaucoup plus de drones que d'avions pilotés. Ces drones, qui se déplacent dans un espace partagé, soulèvent un certain nombre de questions de sécurité, ce qui justifie des mécanismes obligatoires d'immatriculation et d'identification. Dans tous les pays, des règles imposent aux drones ou au moins à certains d'entre eux de diffuser leur identité. Mais, ensuite, une fois que l'observateur du drone a cette identité, qu'en fait-on ? Le but du projet DRIP à l'IETF est de mettre au point des mécanismes pour utiliser cette identité. Ce RFC est le premier du projet, dédié à établir les exigences pour les futurs protocoles. Ce n'est pas gagné, vu qu'il y a beaucoup de grosses organisations sur le chemin qui vont privilégier des solutions fermées.
Pour aider à comprendre le problème, imaginons le scénario suivant. Un gardien fait sa ronde autour d'une centrale nucléaire. Un drone approche. Sa présence ici est-elle normale ? Est-il encore sous contrôle ou bien a-t-il échappé à son propriétaire ? Peut-on contacter son propriétaire pour vérifier ? S'il s'agissait d'un avion piloté traditionnel, les règles de circulation aérienne imposeraient tout un tas de contraintes au pilote (par exemple d'enregistrement de son vol à l'avance), qui permettraient d'éviter des incertitudes. On ne peut pas imposer des procédures aussi lourdes à un simple drone de loisirs. Mais on ne peut pas laisser non plus l'espace partagé qu'est l'air sans règles minimales. Prenons un autre scénario : un drone se promène au-dessus de votre jardin. Il a sans doute une caméra, comme la plupart des drones. Comment faire en sorte qu'il déguerpisse au lieu de vous filmer tranquillement en train de bronzer ? Peut-on lui tirer dessus, comme ça se fait aux États-Unis (« get off my lawn »), s'il ne répond pas ? Faut-il faire des sommations, et comment ? Comme l'analyse correctement la Quadrature du Net, le danger des drones ne vient pas que d'individus malveillants, une utilisation de ces engins par l'État crée également de nombreux risques.
Depuis quelques années, de nombreuses règles ont été édictées dans divers pays. Ainsi, en France, l'arrêté du 29 décembre 2019 impose la signalisation électronique des appareils pour tous les drones de plus de 800 grammes (cet article du Monde résume les obligations). Le drone doit être enregistré sur le site officiel AlphaTango (uniquement le drone, pas chaque vol, contrairement aux obligations des avions). Aux États-Unis, il existe des règles similaires . La plupart du temps, l'obligation minimale est que le drone diffuse son identité, de la même façon qu'une voiture a une plaque d'immatriculation. Mais cette règle est très insuffisante pour répondre à tous les scénarios. Le drone peut facilement mentir sur son identité. Et puis à quoi sert cette identité si elle ne fournit pas de moyen de retrouver le propriétaire ? Et ne serait-ce pas souhaitable d'avoir un moyen de contacter celui-ci en temps réel ? Ces questions ne sont pas évidentes et, comme toutes les questions liées à la sécurité, soulèvent d'innombrables problèmes politiques, juridiques et techniques. L'IETF se concentre sur une partie limitée de ces problèmes : ne pouvons-nous pas utiliser notre expérience en matière de protocoles réseau pour développer des mécanismes permettant de retrouver des données sur le drone à partir de son identité et, pourquoi pas, permettant de communiquer avec lui ? Voyons d'abord en détail le problème, les exigences de notre RFC pour les futurs protocoles ne seront présentées qu'à la fin de cet article.
Ah, si vous voyez ce drone, c'est le mien : 
La section 1 de notre RFC détaille pourquoi les drones posent des problèmes. Il existe plusieurs types de drones (à aile fixe, à aile tournante, capables de décollage vertical ou non, avec un ou plusieurs moteurs…). Le type le plus répandu et le plus connu, notamment grâce aux petits drones de loisir, est le multi-moteur à ailes tournantes (multicoptère). Disposant de systèmes de stabilisation automatiques, ils peuvent être pilotés par des amateurs, contrairement aux avions et hélicoptères. Mais il existe aussi des drones dont la taille et le prix rappelle davantage un avion. Être pilotés à distance par un humain tenant un joystick n'est pas la seule possibilité : doté d'un récepteur GPS, certains drones sont partiellement autonomes et, dans le futur, seront totalement autonomes.
Un petit drone, comme celui que vous achetez pour quelques dizaines d'euros en magasin, a des propriétés importantes pour la sécurité de l'espace aérien :
- ils sont nombreux,
- il est difficilement détectable par les radars,
- s'il est bruyant, voire insupportable, à courte distance, il est en général indétectable au bout de quelques centaines de mètres, alors qu'il peut couvrir cette distance rapidement ; un drone grand public peut faire 500 mètres en 13 secondes,
- il vole à très basse altitude,
- il est souvent piloté par un amateur sans vraie formation,
- très manœuvrant, il peut passer sous les arbres, rentrer dans un immeuble, etc.
Un drone peut donc être très utile pour l'espionnage, voire l'attaque. Il peut porter une caméra pour surveiller, et des explosifs pour attaquer (cf. l'attentat contre le premier ministre irakien en novembre 2021). Même sans explosifs, le drone peut jouer un rôle de projectile, involontaire ou volontaire. Un article de Kaspersky donne une bonne idée des dangers possibles (mais notez qu'il est publié par une entreprise qui vend des solutions et peut donc être soupçonnée de dramatiser).
Il n'y a évidemment pas de solution magique à ces risques mais la plupart des approches nécessitent a priori qu'on découvre un identificateur du drone, qu'on ait une solution RID (Remote IDentification and tracking). Dans le scénario typique de RID, un ou plusieurs drones volent dans un espace restreint, et des observateurs, certains ayant un rôle particulier (policiers, par exemple) et d'autres étant du grand public, veulent obtenir un identificateur, qui va être le point de départ de leurs actions (s'informer sur ce drone, peut-être le contacter). Il est donc prévu un ou plusieurs registres d'identificateurs, et des informations associées. Il existe déjà des normes pour cela, comme la F3411-19, développée par le comité F38 de l'ASTM. Elle coûte 91 dollars étatsuniens. Comme beaucoup de normes développées par des organismes privés, elle n'est pas librement et gratuitement disponible, mais on peut apparemment trouver des brouillons en ligne. F3411-19 est la référence dans ce domaine, normalisant les messages que le drone doit envoyer pour annoncer son identifiateur mais, pour l'instant, c'est à peu près tout, on ne peut pas forcément faire grand'chose de cet identificateur. Elle ne précise pas comment l'observateur se renseigne sur les personnes ou organisations derrière un identificateur. Elle ne traite pas la communication entre drones ou avec l'observateur. Elle n'a pas de mécanisme d'authentification de l'identificateur. Le RFC, étant surtout développé par des Étatsuniens, est très inspiré par le travail de l'ASTM, qui ne s'applique pas forcément partout dans le monde. En Europe, ASD-STAN, associée à CEN, publie une norme DIN EN 4709-002:2021-02 (également chère et pas libre). Un résumé est disponible en ligne. Cette norme décrit un système de DRI (Drone Remote Identification) où le drone diffuse par radio :
- le numéro d'identification de l'opérateur du drone (qui doit donc s'enregistrer),
- celui du drone (en suivant CTA2063A - aussi désignée ANSI/CTA/2063-A, enfin une norme gratuitement disponible mais attention, il faut laisser plein de données personnelles pour l'obtenir).
- l'heure qu'il est, la position du drone (en trois dimensions),
- la vitesse et le cap du drone,
- la position du pilote ou, à défaut, la position d'où le drone a décollé.
Un exemple d'identificateur de drone (celui donné par la norme) est
MFR1C123456789ABC. (Le C en cinquième position
est l'encodage de la longueur du numéro de série, ici 123456789ABC).
Même avec ces normes, de nombreux problème subsistent. Si trois drones sont proches, chacun diffusant son identité, et qu'un seul des trois a un comportement inquiétant, comment distinguer les trois identités ? Et puis les informations envoyées peuvent être erronnées (les drones bon marché n'incluent pas du matériel de mesure perfectionné) voire mensongères, notamment si le drone est malveillant.
Notez aussi que les groupes techniques comme DRIP ne peuvent qu'établir des normes techniques. Définir des règles politiques est une autre affaire. Et les faire respecter sera largement l'affaire des CAA.
Autre problème, comme le drone diffuse des informations en clair, tout le monde peut les capter et certaines informations (comme l'identificateur de l'opérateur) sont des données personnelles, ce qui soulève des questions de vie privée. On a là un beau débat politique en perspective, entre intimité et transparence.
Le RFC note qu'un déploiement massif d'un système de RID (Remote IDentification and Tracking) est à la fois urgent et important. Le déploiement doit être massif car, comme le dit le RFC, « quel serait l'intérêt des plaques minéralogiques si seulement 90 % des voitures en avaient ? ».
Un autre défi des systèmes d'identification réside dans le caractère capricieux des ondes radio. Elles peuvent être bloquées par des bâtiments ou du feuillage. Si le drone émet avec davantage de puissance, il va épuiser rapidement sa batterie. Et il aggravera la congestion dans cet espace partagé (d'autant plus que le drone émet dans des fréquences où une licence n'est pas nécessaire). Bref, d'une manière générale, la liaison radio sera lente et non fiable.
En parlant de batterie, il faut noter que le drone est typiquement un objet contraint (au sens du RFC 8352). Son « budget » en énergie, puissance de calcul et poids (ce qu'on désigne en général par le sigle CSWaP, Cost, Size, Weight, and Power, parfois écrit $SWaP) est très limité. Cela impose des protocoles de communication simples et frugaux, ce qui va rendre difficile l'utilisation de la cryptographie. Actuellement, il y a zéro authentification : un drone mensonger peut annoncer l'identificateur qu'il veut, sans qu'on puisse vérifier. (Dans des réunions, j'ai entendu des affirmations ridicules, comme de confondre la somme de contrôle avec un mécanisme d'authentification. Comme souvent en cybersécurité, on entend beaucoup de n'importe quoi dans les réunions.)
Et il n'y a pas que le drone, il y a aussi la machine de l'observateur. Dans des zones reculées, on ne peut pas compter sur une connectivité Internet permanente, et c'est une des raisons du choix du Broadcast RID (le drone diffuse son identificateur, également appelé Direct ID) plutôt que du Network ID (l'observateur obtient l'identificateur via un réseau public, typiquement l'Internet). Mais si vous voulez en savoir plus sur ce débat Network ID vs. Broadcast ID, voyez l'article « Why Did the FAA Go with Broadcast Remote ID for Drones Over Network? ».
Bref, les mécanismes actuellement normalisés et déployés sont très insuffisants. Le projet DRIP de l'IETF vise, non pas à remplacer les normes existantes, mais à les compléter pour traiter les manques. Ce RFC est le cahier des charges du projet.
Le monde des drones utilise une grande quantité d'acronymes. La section 2 du RFC en donne une liste complète, mais il faut au moins connaitre :
- CAA (Civil Aviation Authority), l'autorité de régulation de l'aviation comme la DGAC en France ou la FAA aux États-Unis. Le milieu aérien, partagé et complexe, est très régulé dans tous les pays.
- DRI (Direct Remote Identification), la possibilité d'obtenir l'identificateur d'un drone (le cœur du système).
- LOS (Line Of Sight), la ligne qui va mener au drone pour le contrôler. Ce n'est pas forcément un lien visuel (voir « VLOS »), le pilote peut obtenir l'information sur le drone par d'autres moyens. Lorsque le drone n'est pas sur la LOS, il est incontrôlable (sauf s'il peut agir de manière autonome).
- RID Remote IDentification ou UAS RID, le système qui permet aux observateurs d'obtenir l'identificateur du drone et, par extension, l'identificateur du drone.
- UA (Unmanned Aircraft), un drone.
- UAS (Unmanned Aircraft System), le drone, et tout ce qui lui permet de voler et d'être piloté (la télécommande, par exemple).
- UAS ID (Unmanned Aircraft System IDentifier), l'identificateur de l'UAS (en fait, en pratique, c'est plutôt celui de l'UA).
- VLOS (Visual Line Of Sight), lorsque le pilote voit son drone. Dans certains pays, la reglémentation peut imposer que le vol du drone se fasse en permanence à vue, et que le pilote ait donc une VLOS avec son engin, ce qui interdit par exemple de le faire voler derrière un bâtiment.
Pour les RID, les identificateurs des drones, il existe plusieurs textes normatifs. Le plus répandu est F3411-19, déjà mentionné, qui décrit les notions de Network RID et Broadcast RID. Pour le premier, l'observateur va récolter l'information via le réseau (le drone s'étant au préalable enregistré, on est dans le publish-subscribe), alors que dans le cas du second, il va écouter directement ce que diffuse le drone par ondes radio. Comme l'observateur, le pilote du drone et surtout le drone lui-même n'ont pas forcément d'accès à l'Internet, c'est le Broadcast RID qui est privilégié. Il fonctionne donc indépendamment de l'Internet.
Le Broadcast RID soulève de nombreux problèmes techniques, notamment en raison des caractéristiques physiques des ondes radio. Si on utilise Bluetooth, on a de sérieuses contraintes de taille des données, au cas où on veuille transmettre, en sus de l'identificateur, des informations de position, de vitesse et de route. En outre, les normes existantes ne standardisent pas les couches basses (Bluetooth 4, 5, Wifi NAN, Wifi Beacon…), donc il sera difficile de capter tous les drones, et surtout pas avec n'importe quel ordiphone, le drone émettant peut-être avec une technologie que l'ordiphone ne connait pas. En outre, sur beaucoup d'ordiphones, on n'a pas accès direct à Bluetooth (cf. les problèmes de l'application TousAntiCovid) et/ou pas accès aux paquets bruts, ce qui va compliquer la vie des développeurs. (Le projet AltBeacon vise à traiter ce problème.)
Comment est attribué le RID ? F3411-19 propose plusieurs méthodes :
- Un identificateur statique attribué par le fabricant du drone, comme prévu par la norme ANSI/CTA-2063-A,
- Un identificateur statique attribué par une CAA, comme cela se fait aujourd'hui pour les avions,
- Un UUID (RFC 9562), statique ou dynamique, attribué par un système spécifique aux drones (une nouvelle autorité ?),
- Un identificateur dynamique spécifique au vol.
Actuellement, l'Union Européenne impose le premier type, les États-Unis le premier ou le troisième. La situation est compliquée, et le choix fait a des implications évidentes en terme de vie privée (un identificateur statique permet de suivre à la trace un drone). C'est d'autant plus important que cette information, étant diffusée unilatéralement, ne peut pas être chiffrée, les protocoles de type défi-réponse étant inutilisables. Pour prendre un exemple, Amazon ne serait sans doute pas ravi qu'un concurrent puisse suivre précisement leurs drones de livraison.
La simple diffusion du RID est donc déjà un problème compliqué. Mais d'autres organismes que l'IETF s'en occupent. Par contre, cette diffusion laisse entier un autre problème : une fois qu'on a récupéré le RID, qu'en fait-on ? Comment, par exemple, communiquer avec le pilote du drone ? Si le message contenait, en sus de l'identificateur, la position du pilote, on peut toujours s'y rendre. Cela peut être lent, voire infaisable si le pilote est, par exemple, de l'autre côté d'une voie ferrée. Dans l'hypothèse où il existe un registre des identificateurs, associé à des informations de contact (comme on fait pour les noms de domaine), on pourrait imaginer que l'observateur regarde dans le registre (avec des protocoles comme RDAP ou whois) et appelle au téléphone le pilote. Reste à savoir si c'est une bonne idée que le pilote réponde alors que son attention devrait être concentrée sur le pilotage…
L'IETF, via son groupe DRIP, va donc tenter de développer des solutions pour :
- authentifier l'identificateur de drone,
- permettre l'interrogation d'un registre de ces identificateurs,
- faciliter la coordination entre observateurs pour qu'ils puissent vérifier collectivement ce que fait un drone,
- contacter le pilote.
Le but est évidemment que ces solutions reposent sur des normes ouvertes et accessibles. (Un certain nombre d'organisations font déjà du lobbying pour pousser au déploiement et à l'obligation légale de solutions privées et fermées, leur assurant le contrôle, et les revenus associés.)
Les normes existantes comme F3411-19 ne permettent pas cela, d'où ce cahier des charges du projet DRIP, dont les exigences forment la section 4 de notre RFC. Chacune est identifiée par trois lettres indiquant sa catégorie, puis un numéro. Ainsi, la première exigence est dans la catégorie des généralités et se nomme GEN-1 : « DRIP doit permettre d'authentifier les affirmations du drone » (puisque, actuellement, un drone peut raconter ce qu'il veut). Je ne vais pas vous lister toutes les exigences, seulement de quoi vous donner une idée du projet. Ainsi, GEN-2 suit GEN-1 en demandant qu'en outre, tous les messages du drone puissent être reliés à ceux qui prouvent l'identité du drone (et pas uniquement parce que les messages sont émis depuis la même adresse MAC). GEN-3 impose qu'il existe un moyen de vérifier l'enregistrement du drone dans un registre, même en l'absence de connexion Internet (par exemple le drone pourrait diffuser un certificat signé par le registre). GEN-6 concerne la prise de contact, il faut qu'il existe un moyen de contacter le pilote. (Attention, comme tout ce cahier des charges, il s'agit d'une exigence technique, pas politique. L'IETF n'a pas l'autorité pour édicter des règles disant, par exemple, que le pilote doit accepter les communications entrantes. Elle dit juste qu'un moyen technique doit exister, mais son utlisation pourra, par exemple, être restreinte à des appelants identifiés et autorisés.) Un protocole envisagé pour cette communication est HIP.
GEN-8 demande que tout cela fonctionne même si le drone (évidemment), son pilote et l'observateur sont en déplacement, GEN-9 veut un mode multicast, et GEN-10 un moyen de superviser le bon fonctionnement du système (notamment pour le Network RID).
La catégorie suivante concerne plus spécifiquement les identificateurs. ID-1 met une taille maximale à 19 octets (c'est une limite de F3411-19, sauf erreur). ID-2 dit que sur ces 19 octets au maximum, il faut placer un identificateur du registre. ID-4 exige que l'identificateur soit unique (ce qui est du simple bon sens) et ID-5, reprenant GEN-1, demande que le drone ne puisse pas mentir sur son identificateur. ID-6 veut qu'on puisse empêcher de suivre un drone ou son propriétaire à la trace (et il faut donc permettre des identificateurs qui ne soient pas statiques sur le long teme). Là encore, rappelez-vous l'avertissement de la catégorie précédente : DRIP ne définit pas une politique, l'activation ou non de la technique demandée par ID-6 n'est pas une question purement technique.
En parlant de gêner la surveillance, la troisième catégorie concerne la vie privée (voir aussi la section 7). PRIV-1 rappelle l'importance de protéger les données privées (par exemple en ne distribuant pas le nom et l'adresse du pilote publiquement) et PRIV-4 demande pour cela que le système d'enregistrement sépare ce qui est public et ce qui ne l'est pas (données personnelles, par exemple).
Et les registres ? Sur l'Internet, il existe de nombreux types de registres, comme les registres de noms de domaine ou les RIR. Certains problèmes, comme l'arbitrage entre les exigences opérationnelles (où on voudrait obtenir facilement beaucoup d'informations sur les titulaires des noms de domaine) et celles de vie privée, sont bien connues depuis longtemps (le « problème whois » de l'ICANN, par exemple). J'ai pris plusieurs exemples tirés des registres de noms de domaines car c'est là où je travaille. La quatrième et dernière catégorie d'exigences DRIP concerne précisément les futurs registres de drones. En raison des limites de taille très strictes sur ce que le drone peut diffuser, il est essentiel de disposer de registres permettant l'accès à davantage d'informations. REG-1 commence par demander qu'il existe un moyen d'interroger le registre (la solution évidente étant RDAP, RFC 9082). Ce moyen doit (exigence REG-2), contrairement à whois (RFC 3912), permettre l'accès différencié (davantage d'informations pour certains clients). REG-3 réclame qu'on puisse ajouter, retirer et modifier de l'information dans le registre (là, la solution évidente est EPP, RFC 5730). Notez qu'une présentation sur l'utilisation de registres avait été faite lors d'une réunion professionnelle des acteurs du monde des registres : les supports.
Enfin, la section 6 du RFC concerne l'analyse de sécurité du futur système. Quelles que soient les solutions adoptées, il faudra faire attention aux attaques Sybil, aux attaques par déni de service utilisant, par exemple, de nombreux messages incorrectement signés, aux attaques de l'Homme du Milieu, etc. On pourra voir aussi des attaques plus subtiles comme, suggère le RFC, un drone de petite taille, a priori pas très effrayant, et qui s'authentifiera proprement, mais derrière lequel surgira le vrai attaquant.
Pour les curieuses et les curieux, je recommande également l'annexe A du RFC, qui discute les choix effectués dans ce RFC et leurs raisons. Par exemple, l'analogie avec les plaques d'immatriculation des voitures, souvent utilisée dans les débats sur l'identification des drones a ses limites. Dans certains pays, par exemple des États des USA, n'importe qui peut accéder, parfois même gratuitement, aux données du registre, et donc aux informations personnelles sur les propriétaires de véhicules. Faut-il faire pareil pour les drones ? Même en Europe, si le registre n'est pas accessible, en revanche, les voitures ont un identificateur statique stable, qui peut faciliter certaines formes de surveillance. Veut-on cela pour les drones ?
Les avions (civils) pilotés et les bateaux ont l'habitude depuis longtemps de diffuser leur identité à qui veut écouter (le transpondeur pour les avions). D'excellentes et utiles applications comme OpenSky et Flightradar24 exploitent cette information. Souhaite-t-on un même fonctionnement pour les drones ? Outre les questions politiques, cela peut poser des problèmes techniques, par exemple parce que le nombre de codes utilisables est limité et qu'il y a beaucoup plus de drones que d'avions. Avec les 24 bits typiquement utilisés, on ne pourrait traiter que seize millions de drones, ce qui est loin des nombres envisagés.
Les drones qui diffusent leur identité le font en Wi-Fi ou en Bluetooth. Ces techniques ont l'avantage d'être très répandues, aussi bien du côté des drones que des observateurs (tous ont un ordiphone), peu chères, libres d'usage, et elles permettent la diffusion. Par contre, leur portée est faible. Il pourrait être intéressant de travailler sur des technologies conçues pour les grandes distances (comme WiMAX), ou pour les réseaux de capteurs (comme LoRA).
Voilà, le groupe DRIP est évidemment au travail pour mettre au point des protocoles correspondant à ces exigences. Le problème posé par les drones ne peut que devenir de plus en plus sérieux, notamment parce que leur discrétion augmentera. Dans les romans de la série Harry Potter (par J. K. Rowling), une journaliste-sorcière sans scrupule peut se transformer en insecte pour aller espionner les gens chez eux. Un drone suffisamment petit pour être quasiment indétectable serait un cauchemar pour la vie privée…
Pour en savoir plus, quelques ressources utiles :
- Pour développer des solutions ouvertes, le projet OpenDroneID.
- Autre projet analogue, Paparazzi UAV.
- La vidéo de l'atelier drones de CEN et CENELEC du 9 février 2021.. Les organisateurs sont deux organisations de normalisation traditionnelles.
- Un résumé de la situation européenne, par ASD-STAN (une organisation de normalisation spécialisée dans l'aéronautique).
- Un intéressant projet d'étudiants de l'université de Linköping sur DRIP et sur l'utilisation de HIP pour contacter le drone.
- La chaire de recherche sur les drones à l'ENAC. Et la volière de l'ENAC (une volière étant un endroit fermé où on peut faire des expérimentations avec les drones).
- Et enfin, divers dispositifs de réalité augmentée pour aider à piloter les drones.
L'article seul
RFC 9172: Bundle Protocol Security (BPSec)
Date de publication du RFC : Janvier 2022
Auteur(s) du RFC : E. Birrane, K. McKeever (JHU/APL)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dtn
Première rédaction de cet article le 1 février 2022
Le protocole Bundle, normalisé dans le RFC 9171, permet la communication entre des machines dont la connectivité est faible et/ou intermittente, par exemple dans le domaine spatial. L'absence de synchronicité interdit beaucoup de solutions de sécurité couramment utilisées sur l'Internet. Ce nouveau RFC présente donc un mécanisme spécifique pour assurer la sécurité (confidentialité et intégrité) des communications faites avec Bundle : ce mécanisme se nomme BPsec (Bundle Protocol security). Notez que le mécanisme est très général, et laisse de côté de nombreux détails.
BPsec peut assurer une sécurité de bout en bout. Ce n'est pas évident dans le contexte d'utilisation de Bundle (RFC 4838), les DTN (Delay Tolerant Networks). Bundle est un protocole qui fonctionne en « enregistre et fais suivre » (store and forward), sans liaisons directes entre émetteur et récepteur, et avec des réseaux lents, imprévisibles, à fort taux de perte de paquets. On ne peut donc pas garantir, par exemple, qu'émetteur et récepteur pourront communiquer à la demande avec un tiers de confiance, genre autorité de certification. On ne peut même pas supposer que toutes les liaisons seront bidirectionnelles, ce qui veut dire, entre autres, qu'un échange de clés Diffie-Hellman ne sera pas possible. Le protocole suppose évidemment que ledit réseau n'est pas de confiance : des méchants peuvent regarder et modifier les bits qui circulent. Cette supposition est classique en sécurité.
BPsec ne va pas essayer de garantir une authentification de chaque étape intermédiaire. D'abord, on ne sait pas si le nœud suivant est réellement adjacent dans l'espace physique (il peut y avoir des intermédiaires « invisibles ») et puis les différents nœuds par lequel le message va passer peuvent avoir des choix de sécurité incompatibles, les réseaux DTN pouvant, comme l'Internet, être composés de nœuds gérés par des organisations différentes.
Si les logiciels sont tous bien programmés, et que les clés privées utilisées n'ont pas été compromises, BPsec va garantir l'intégrité et la confidentialité des messages. BPsec est la continuation du cadre défini dans le RFC 6257, en le simplifiant et en le rendant plus réaliste.
Un peu de terminologie pour suivre ce RFC : d'abord, un rappel qu'un bundle est composé de blocs (RFC 9171, section 4.3). Ensuite :
- Bloc de sécurité (security block) : un bloc d'extension dans un bundle, une unité de données.
- Security acceptor : un nœud qui traite un bloc de sécurité, et le supprime ensuite. Ce n'est pas forcément le destinataire final (sauf évidemment pour les services de sécurité de bout en bout).
- Service de sécurité (security service) : un service particulier, par exemple la confidentialité.
- Source de sécurité (security source) : un nœud qui ajoute un bloc de sécurité. Ce n'est pas forcément l'émetteur initial.
- Vérificateur de sécurité (security verifier) : un nœud qui lit et vérifie un bloc de sécurité mais qui ne le supprime pas.
La section 2 du RFC résume les points importants de la conception de BPsec :
- Sécurité au niveau du bloc, pas du bundle entier.
- Plusieurs sources ont pu mettre des blocs de sécurité dans le bundle.
- Les différents nœuds ont des politiques de sécurité différentes.
- BPsec a une notion de contexte de sécurité (qui définit les techniques admissibles, par exemple les algorithmes de cryptographie), notion détaillée dans la section 9.
- Traitement déterministe des différents blocs de sécurité, notamment de l'ordre de traitement.
Il existe deux sortes de blocs de sécurité (les types de bloc figurent dans un registre IANA, défini dans le RFC 6255), les BIB (Block Integrity Block) et les BCB (Block Confidentiality Block). Les sources de sécurité ajoutent ces blocs et les acceptors les traitent. Dans le cas d'un chiffrement de bout en bout, par exemple, l'émetteur met un BCB que le destinataire déchiffrera. Dans un autre cas, on peut voir un nœud de départ ne mettre aucun bloc de sécurité (peut-être parce que ce nœud est un objet contraint, avec trop peu de ressources de calcul) mais un nœud intermédiaire ajouter un BIB pour protéger le contenu avant un voyage sur un lien qu'on sait dangereux. Ces blocs sont encodés comme spécifié dans le RFC 9171. L'ajout d'un BIB ne modifie pas le contenu du bundle mais celui d'un BCB va le faire, puisque les données seront chiffrées.
Le bloc contient notamment l'identificateur du nœud qui l'a ajouté.
Le bloc doit être mis sous forme canonique de CBOR (RFC 8949, section 4.2). Comme toujours en cryptographie, pour que les signatures soient vérififiables, il faut que les données soient sous une forme canonique.
La section 5 du RFC décrit le traitement des blocs de sécurité. Le nœud peut les passer tels quels, sans les interpréter, s'il n'est qu'un intermédiaire. Ou bien, s'il veut les valider, il va alors vérifier leurs signatures, déchiffrer, etc. En cas d'erreur, notre RFC ajoute cinq codes supplémentaires pour les signaler.
Pas de cryptographie sans clés et la gestion des clés est souvent le point difficile. La section 6 rappelle le problème. Comme les réseaux de type DTN seront très variés, avec des caractéristiques bien différentes, notre RFC ne décrit pas une méthode unique de gestion de clés. Disons que cette gestion est repoussée aux mises en œuvre ultérieures.
Enfin, la section 7 du RFC décrit les différentes politiques possibles, et la section 8 analyse en détail les caractéristiques de sécurité de ce système, face aux différentes menaces. Parmi les points amusants, le RFC note qu'avec les DTN, on peut s'attendre à ce que des bundles restent dans le réseau très longtemps, peut-être même des années (!) et que la cryptographie (choix des algorithmes, par exemple) doit donc être pensée pour durer.
Ce mécanisme de sécurité est mis en œuvre dans le logiciel libre ION.
L'article seul
RFC 9171: Bundle Protocol Version 7
Date de publication du RFC : Janvier 2022
Auteur(s) du RFC : S. Burleigh (JPL, Calif. Inst. Of Technology), K. Fall (Roland Computing Services), E. Birrane (APL, Johns Hopkins University)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dtn
Première rédaction de cet article le 1 février 2022
Après plusieurs itérations, le protocole Bundle, qui sert à transmettre des messages dans des situations où la connectivité est intermittente et la latence importante (par exemple dans l'espace), a atteint sa version 7, la première qui soit officiellement norme de l'Internet. Ce nouveau RFC décrit cette version 7, assez modifiée par rapport à la version 6 qui faisait l'objet du RFC 5050. Les deux versions n'interopèrent pas.
« Dans l'espace, personne ne vous entend crier », disait l'annonce du film Alien. Peut-être, mais on veut quand même communiquer, échanger des messages et des fichiers. Les particularités de cet environnement (et de quelques autres analogues comme par exemple des étendues peu connectées sur Terre ou bien des situations post-catastrophe) ont suscité la création du groupe DTN (Delay-Tolerant Networking), qui travaille à normaliser des techniques pour envoyer une photo de chat à un autre vaisseau spatial. La version 6 du protocole Bundle, spécifié dans le RFC 5050, avait été programmée dans de nombreux langages, et l'expérience acquise avec Bundle v6 a mené cette version 7. Dans les environnements concernés, avec leur latence élevée (et parfois très variable), leur taux de pertes de paquets souvent important, et leur connectivité intermittente, les protocoles de transport comme TCP et les protocoles applicatifs qui les accompagnent ne conviennent pas. Il n'est pas possible de faire du synchrone (on ne peut pas rester à attendre l'autre pendant on ne sait pas combien de temps). D'où la nécessité de protocoles spécifiques, architecturés autour de l'idée de « enregistre et fais suivre » (store and forward), où chaque machine intermédiaire va stocker les messages en attendant une occasion de les livrer. (Oui, ça ressemble à UUCP et c'est logique, les cahiers des charges étant analogues.) Notre RFC résume ce qu'on attend d'un tel protocole :
- Capacité à utiliser des déplacements physiques des données (en gros, la clé USB dans un camion, mécanisme dont on sait qu'il a une latence désastreuse mais une énorme capacité ; cf. l'anecdote amusante de l'Allemand et son cheval, ou bien l'offre SnowMobile d'Amazon).
- Capacité d'un envoyeur à oublier, une fois qu'il a transmis le message au nœud suivant (alors que TCP doit garder les données, en attendant l'accusé de réception de la destination finale).
- Capacité à gérer les connectivités intermittentes, voire les cas où émetteur et récepteur ne sont jamais joignables en même temps.
- Capacité à utiliser les cas où la connectivité arrive à un moment prédit à l'avance, aussi bien que ceux où il faut être opportuniste, utilisant la connectivité quand elle arrive.
Des détails sur ce cahier des charges sont dans les RFC 4838 et dans l'article de K. Fall à SIGCOMM « A delay-tolerant network architecture for challenged internets ».
La section 3 du RFC rappelle les termes utilisés, notamment :
- Bundle (j'ai été trop paresseux pour traduire ce terme mais Bertand Petit suggère « ballot ») : une unité de données transmises. Un message (tel que compris par l'utilisateur humain) va être découpé en bundles qui seront transmis sur le réseau.
- BPA (Bundle Protocol Agent) : le logiciel qui, sur un nœud, met en œuvre le protocole décrit dans ce RFC.
- CLA (Convergence Layer Adapter) : la partie du protocole qui parle aux couches basses, pour effectuer l'envoi et la réception. Cela peut, par exemple, être TCP (RFC 9174).
- Nœud (node) : une machine qui peut
envoyer et recevoir des bundles mais aussi
relayer les bundles des autres. Chaque nœud a
un identificateur, le node ID, qui est un
URI
(RFC 3986), en général de plan
dtn(commedtn://example.com/foobar) ou, de plus bas niveau et de signification seulement locale,ipn, qui avait été créé par le RFC 6260 (commeipn:9.37). Les plans utilisés ont été mis dans le registre IANA. - Transmission (Forwarding) : faire suivre le message au nœud suivant (tout ce protocole est « saut par saut », avec des nœuds qui se refilent les bundles).
- Terminal (endpoint) : un ou plusieurs nœuds qui mettent en œuvre un service. Une sorte de nœud virtuel, quoi. Comme les nœuds, ils ont un identificateur qui est un URI.
La section 4 du RFC décrit le format des bundles. Ce sera du CBOR (RFC 8949). Un bundle comprend un certain nombre de booléens qui indiquent si le récepteur doit accuser réception de l'arrivée du bundle, de la transmission au nœud suivant, etc. (Leur liste figure dans un registre IANA.) Il indique également la destination (sous le forme d'un endpoint ID) et la source (facultative).
Un bundle est en fait composé de blocs, chaque bloc étant un tableau CBOR. Le premier bloc porte les métadonnées indispensables pour les nœuds qui relaieront le bundle (comme l'identificateur de destination) ou comme la durée de vie du bundle (analogue au TTL d'IP). Chaque bloc contient un type et des données. La charge utile du bundle est dans un bloc de type 1, les autres types servant à divers détails (qui, dans IP, seraient mis dans les options du paquet en IPv4 et dans un en-tête d'extension en IPv6). Par exemple, un bloc de type 7 sert à transporter l'âge du bundle, alors qu'un bloc de type 10 à indiquer le nombre de sauts maximum et le nombre déjà effectués. Les différents types figurent dans un registre IANA.
La section 5 du RFC précise comment on traite les bundles. Lors de la réception d'un bundle, le nœud qui n'est pas destination (dont l'identificateur n'apparait pas dans le champ de destination) doit décider s'il transmet le bundle ou pas. S'il décide de le transmettre, il doit ensuite regarder s'il « connait » le nœud de destination (s'il sait le joindre directement) ou bien s'il doit le transmettre à un nœud mieux placé. Comment trouve-t-on ces nœuds mieux placés ? De même que le RFC sur IP ne décrit pas les protocoles de routage, le Bundle Protocol ne précise pas. Cela est fait par des protocoles externes comme SABR.
Une fois prise la décision d'envoyer le bundle à un autre nœud, on sélectionne un CLA adapté à cet autre nœud et on lui transmet. (Puis on le supprime du stockage local.) Bref, tout cela ressemble beaucoup au traitement d'un paquet IP par un routeur IP classique, avec le CLA jouant le rôle de la couche 2. La plus grosse différence est sans doute que le nœud peut garder le paquet pendant un temps assez long, s'il ne peut pas le transmettre tout de suite. La gestion des files d'attentes et des retransmissions sera donc assez différente de celle d'un routeur IP.
En cas d'échec, le nœud peut décider de renvoyer le bundle à l'expéditeur ou de le jeter. Si le bundle a expiré (durée de vie dépassée), il est jeté.
À la réception d'un bundle, le nœud regarde aussi si ce bundle nécessitait un accusé de réception et, si nécessaire, il en envoie. Si le bundle a une destination locale, il est livré à la machine. (Le bundle a pu être fragmenté et, dans ce cas, il faudra attendre que tous les fragments soient là, pour le réassemblage, cf. section 5.8).
La section 6 du RFC couvre le cas des enregistrements administratifs, des messages (envoyés évidemment sous forme de bundles) qui servent à gérer le bon fonctionnement du protocole (un peu comme ICMP pour IP). Ces enregistrements sont un tableau CBOR de deux entrées, un type (un nombre) et les données, un seul type d'enregistrement administratif existe actuellement, de type 1, le rapport d'état, qui va servir à indiquer ce que le message est devenu. Son format et son contenu sont détaillés dans la section 6.1.1. Il dispose d'une liste de codes, comme 1 pour « durée de vie dépassée » ou 5 pour « je n'arrive pas à joindre la destination ».
On a vu que BP, le Bundle Protocol, dépend d'un CLA (Convergence Layer Adapter) pour parler aux couches basses. La section 7 précise ce qu'on attend de ce convergence layer :
- Il doit évidemment permettre d'envoyer un bundle d'un nœud à l'autre,
- il doit rendre des comptes au BP, lui disant s'il a pu transmettre le bundle ou pas,
- il doit pouvoir recevoir des bundles et les livrer localement.
- Certaines extensions peuvent ajouter des exigences au CLA.
Le CLA doit faire tout cela tout en respectant le réseau sous-jacent, par exemple en évitant la congestion. Notez que dans la plupart des cas d'usage de BP, la latence est telle qu'on ne peut pas compter sur les réactions du récepteur, et il faut donc se débrouiller autrement. Un exemple d'un CLA est celui avec TCP du RFC 9174 (mais dans la plupart des scénarios envisagés pour le Bundle Protocol, TCP ne sera pas utilisable).
Il y a actuellement pas moins de sept mises en œuvres différentes de ce BP (Bundle Protocol) :
- µPCN. Écrit en C, pour le système d'exploitation FreeRTOS. Libre. Il semble que ce soit la première mise en œuvre de BP qui intègre la version de notre RFC, la 7.
- µD3TN. Écrit en Python. Licence libre.
- PyDTN (développé par X-works). Écrit en Python. Il ne semble pas publiquement disponible.
- LibDTN/Terra, bibliothèque et applications. En Java.
- dtn7-go est écrit en Go. Licence libre. Met en œuvre la version 7 de BP.
- dtn7-rs est en Rust, également sous une licence libre, et gère également la version 7. Il vise les machines contraintes.
- Bien sûr, vu le plus spectaculaire cas d'usage du DTN, l'espace, la NASA a également développé du logiciel. À propos de la NASA, notez qu'ils produisent beaucoup de documentation sur le DTN.
Notez que deux mises en œuvre de BP ne peuvent interopérer que si elles utilisent le même CLA.
Par défaut, BP n'offre aucune sécurité (cf. section 8). Un attaquant peut suivre le trafic, le modifier, etc. Certes, notre RFC recommande un CLA « sûr » mais cela ne suffit pas. La sécurité doit être fournie par des extensions, comme celle du RFC 9172. Notons aussi que le protocole utilise à plusieurs endroits des estampilles temporelles, donc sa sécurité dépend de celle de son horloge.
L'annexe A détaille les changements depuis le RFC 5050, qui normalisait la version 6 du protocole. Outre le changemente de statut (BP est désormais une norme et plus une « expérience »), les changements techniques sont importants à tel point qu'il n'y a pas d'interopérabilité entre les deux versions. Entre autres, les concepts de node ID et endpoint ID sont désormais séparés, le premier bloc d'un bundle est désormais immuable, de nouveaux types de blocs ont été créés, l'encodage abandonne l'ancien SDNV (RFC 6256) pour CBOR, etc. (Notez qu'il existe un registre IANA des versions de BP.)
Un des avantages de CBOR est l'existence du langage de
description CDDL (RFC 8610), ce qui permet de
donner une description formelle des bundles dans
l'annexe B. Par exemple, voici la description du premier bloc de
chaque bundle, en CDDL (eid
étant l'Endpoint ID) :
primary-block = [
version: 7,
bundle-control-flags,
crc-type,
destination: eid,
source-node: eid,
report-to: eid,
creation-timestamp,
lifetime: uint,
...
? crc-value,
]
Avec un cahier des charges présentant beaucoup de ressemblances avec celui du BP, notez l'existence du système NNCP, qui est également de type « enregistre et fais suivre ». Ça semble très intéressant mais je ne l'ai jamais testé.
L'article seul
Quelques remarques sur des discours à propos du Bitcoin
Première rédaction de cet article le 29 janvier 2022
Depuis deux mois, le cours du Bitcoin en monnaies fiat comme l'Euro baisse. On lit beaucoup de discours réjouis, parlant d'effondrement du Bitcoin, de chute vertigineuse, et clamant « je l'avais bien dit ». Il est intéressant de regarder de plus près ces discours et les erreurs de raisonnement qu'ils contiennent.
Un avertissement de taille d'abord : cet article ne contient pas de conseils de placement financier. Je ne prétends à nulle expertise dans ce domaine et puis c'est votre argent, pas le mien. Que vous décidiez d'acheter des bitcoins ou pas, ne prétendez pas que c'est sur mes conseils.
Donc, les faits, d'abord. Cette courbe (tirée de https://www.xe.com/currencycharts/?from=XBT&to=EUR
La tendance est nettement à la baisse (mais attention, l'axe des
ordonnées ne part pas de zéro, un piège classique qui exagère la baisse), et le
décrochage brusque autour du 20 janvier a suscité beaucoup de
messages sur les médias sociaux, autour par
exemple du mot-croisillon
#cryptocrash. Je ne vais pas essayer
d'expliquer les raisons de cette baisse : comme toujours en
économie, on trouvera plein d'experts pour
l'expliquer (sans qu'aucun d'entre eux ne soit capable de prévoir
les fluctuations à venir ; par contre, ils savent toujours expliquer
celles du passé).
Notons que le cours du Bitcoin en monnaies fiat (les monnaies étatiques) n'est pas forcément la seule ou la meilleure métrique pour évaluer le Bitcoin. Après tout, s'il s'agissait d'une monnaie massivement utilisée pour les échanges, sa relation avec les autres monnaies ne serait pas essentielle. Mais c'est une métrique simple, spectaculaire, et c'est celle qui intéresse les gens qui spéculent avec du Bitcoin, donc c'est la métrique favorite de beaucoup.
Alors, en quoi est-ce que le discours « ah, ah, je vous l'avais
bien dit, le Bitcoin s'effondre » est-il erroné ? Essentiellement
parce qu'il manque de perspective. Le cours du Bitcoin par rapport
à l'Euro baisse, c'est certain. Mais, au point le plus bas de cette
baisse, le 24 janvier, il avait juste reculé au cours qu'il avait à
la fin du mois de juillet 2021, il y a seulement quelques mois. Le
graphique du cours du Bitcoin relativise donc le discours
catastrophiste :
On le voit, la plupart des personnes qui ont commenté la baisse
du Bitcoin bruyamment ont une mémoire de poisson rouge et ne
regardent que les phénomènes récents. Sur une très longue période,
la tendance reste à la hausse. Bien sûr, si vous êtes un spéculateur
pressé qui voudrait gagner plein d'argent tout de suite, cela ne
vous consolera pas (mais, rappelez-vous ma remarque au début : je ne
donne pas de conseils financiers). Mais si vous évitez de regarder
le cours du Bitcoin toutes les cinq minutes (ce qui serait un bon
moyen d'avoir une crise cardiaque, vu sa volatilité), il n'y a pas
spécialement de raison de paniquer. Voici la courbe sur les dix
dernières années : 
Les personnes qui crient très fort à la fin du Bitcoin sur les médias sociaux disent souvent qu'ils avaient annoncé cette fin, inéluctable selon eux. Le problème est que la plupart de ces personnes disent la même chose en boucle depuis dix ans. Si on annonce tout le temps qu'il va pleuvoir, on n'aura pas de mal à dire qu'on avait bien raison dès qu'il pleuvra. Le meilleur signe du parti pris de beaucoup de ces commentateurs, est qu'ils annoncent avec joie les baisses du cours du Bitcoin en Euro, mais jamais les hausses… (Certaines personnes du camp opposé font l'inverse, ne citant que les hausses.)
On notera que le Bitcoin a toujours fait l'objet d'annonces de sa mort imminente. Il existe même un amusant site Web qui liste tous les articles en ce sens.
L'article seul
Derrière d'ennuyeuses normes techniques, des enjeux stratégiques
Première rédaction de cet article le 28 janvier 2022
Le 26 janvier 2022, à l'École de Guerre Économique, j'ai fait une conférence au sujet de la normalisation technique sur l'Internet, notamment en s'appuyant sur l'exemple de l'IETF.
Voici les supports présentés à cette occasion :
- La version PDF,
- et le source en LaTeX/Beamer.
Les RFC mentionnés pendant cette conférence étaient les RFC 8446 (sur TLS 1.3), RFC 8484 (sur DoH), RFC 9000 (sur QUIC) et l'image était celle du RFC 9156. Le groupe de travail DRIP (sur les drones) a sa charte ici et ses documents ici, et l'Internet-Draft montré (sur HTTP) est visible ici. Et, si vous vous intéressez à la normalisation, je vous recommande le livre The box. Il y a d'autres évènements par les mêmes organisateurs dont notamment un autre sur la normalisation.
L'article seul
RFC 9184: BGP Extended Community Registries Update
Date de publication du RFC : Janvier 2022
Auteur(s) du RFC : C. Loibl (next layer Telekom)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF idr
Première rédaction de cet article le 21 janvier 2022
Les « communautés étendues » de BGP, des attributs d'une annonce de route avec BGP, sont enregistrées dans des registres IANA, décrits par le RFC 7153. Notre nouveau RFC 9184 met légèrement à jour les procédures d'enregistrement dans ces registres.
Le principal changement est simple : les types 0x80, 0x81 et 0x82 du registre des communautés étendues transitives sont désormais utilisables selon une politique d'enregistrement « premier arrivé, premier servi » (cf. RFC 8126 sur ces politiques d'enregistrement à l'IANA). Ils sont en effet utilisés par le RFC 8955 alors qu'ils étaient dans une plage prévue pour les expérimentations. L'erreur est donc désormais rectifiée.
L'article seul
Amusant problème DNS Orange/Oléane/Google
Première rédaction de cet article le 19 janvier 2022
Les résolveurs DNS utilisés
entre autres par Orange Business Services renvoient l'adresse locale
localhost (127.0.0.1) pour des noms chez Google.
Cela ne concerne apparemment que les résolveurs
194.2.0.20
et 194.2.0.50, qui ne
semblent pas utilisés par tout le monde chez Orange (comme l'indique
leur nom, ce sont des
anciennes machines d'Oléane, société rachetée
par Orange). Vu avec les sondes RIPE Atlas :
% blaeu-resolve -r 100 --as 3215 --nameserver 194.2.0.20 --type A www.google.com Nameserver 194.2.0.20 [142.250.179.68] : 20 occurrences [216.58.213.164] : 14 occurrences [127.0.0.1] : 13 occurrences [216.58.214.164] : 6 occurrences [216.58.206.228] : 11 occurrences [216.58.213.68] : 11 occurrences [142.250.179.100] : 11 occurrences [216.58.213.132] : 5 occurrences [172.217.18.196] : 8 occurrences Test #34858799 done at 2022-01-19T14:07:44Z
La ligne importante est celle avec
127.0.0.1. Notez donc que ce résolveur ne
répond pas toujours avec cette adresse. Un problème analogue existe
en IPv6 :
% blaeu-resolve -r 100 --as 3215 --nameserver 194.2.0.20 --type AAAA www.google.com Nameserver 194.2.0.20 [2a00:1450:4007:80e::2004] : 12 occurrences [2a00:1450:4007:813::2004] : 29 occurrences [2a00:1450:4007:811::2004] : 11 occurrences [2a00:1450:4007:810::2004] : 11 occurrences [2a00:1450:4007:806::2004] : 14 occurrences [::1] : 11 occurrences [2a00:1450:4007:817::2004] : 11 occurrences Test #34858911 done at 2022-01-19T14:35:32Z
Pourquoi est-ce que la même adresse IP,
194.2.0.20, donne des résultats différents aux
sondes, le tout dans un intervalle de temps très court ?
Probablement parce que derrière cette adresse, il y a plusieurs
machines physiques, avec des configurations différentes.
Plusieurs personnes ont signalé ce problème par exemple sur
Twitter (ici
ou là),
sans réponse d'Orange. Le problème est bien du côté de ces résolveurs, pas des serveurs faisant
autorité pour google.com. (Notez
qu'aucun autre domaine ne semble avoir été touché, par exemple
google.fr n'a pas eu de problème.) En dehors de
ces résolveurs, on ne voit pas de problème :
% blaeu-resolve -c FR -r 100 - -type A alt2.gmail-smtp-in.l.google.com. [142.250.150.27] : 53 occurrences [74.125.200.27] : 1 occurrences [142.250.150.26] : 43 occurrences [74.125.200.26] : 2 occurrences [173.194.202.27] : 1 occurrences Test #34858791 done at 2022-01-19T14:05:34Z
Les signalements à DownDetector sont réels mais
trompeurs, Google n'y étant apparemment pour rien :
Quelques heures plus tard, le problème était apparemment réparé :
% blaeu-resolve -r 100 --as 3215 --nameserver 194.2.0.20 --type A www.google.com Nameserver 194.2.0.20 [216.58.206.228] : 17 occurrences [216.58.213.164] : 30 occurrences [142.250.179.68] : 24 occurrences [142.250.74.228] : 12 occurrences [142.250.186.36] : 1 occurrences [216.58.214.164] : 16 occurrences Test #34861409 done at 2022-01-19T20:08:59Z
La réponse d'Orange à ses clients : « ORANGE INFO INCIDENT xxxxxx Il y avait un problème de résolution sur le service Cache DNS. Nous avons fait un changement au niveau de nos serveurs. Le service est rétabli depuis hier soir 18H . Nous passons à la cloture du ticket. »
Quelle est la cause de la panne ? On l'ignore et il est certain qu'Orange ne communiquera rien. Rappelons juste que le DNS est un service critique de l'Internet et qu'il est donc essentiel de ne pas vouloir le bricoler à des fins, par exemple, de censure. (La panne est peut-être due à une erreur dans la configuration d'un résolveur menteur. Tout bricolage augmente les risques de panne, comme on l'a déjà vu chez Orange et comme le rapport du Conseil Scientifique de l'Afnic avait déjà alerté à ce sujet.)
L'article seul
Fiche de lecture : Vivre libre au 21e siècle
Auteur(s) du livre : Thierry Bayoud, Léa
Deneuville
Éditeur : Xérographes
978-2-917717-56-1
Publié en 2021
Première rédaction de cet article le 18 janvier 2022
Ce petit livre a comme sous-titre « Le leurre du progrès technologique ». Mais il ne parle pas que du progrès technique, il explore les absurdités et les problèmes de la société actuelle.
Ce livre examine une grande variété de sujets : le logiciel libre, la publicité, la consommation, la langue, le travail, l'argent, la mondialisation et d'autres encore. Le regard est critique : notre société a vraiment beaucoup de problèmes. Bien des chapitres sont justes mais pas forcément originaux (sa critique de la publicité est tout à fait correcte mais ne me semble pas apporter de nouveaux arguments). Moins communs, son plaidoyer pour une « monnaie libre » (il conseille Ğ1, tout en notant ses limites) ou sa défense bien argumentée de la langue française (sujet rarement abordé dans son camp politique). De même, le chapitre sur le numérique ne cède pas, contrairement à tant de livres qui critiquent notre société, à l'anti-numérisme primaire. Et l'auteur (les auteurs) proposent de nombreuses pistes d'amélioration.
Le livre est bien écrit, clair et sans jargon. Si vous avez déjà lu beaucoup de livres critiquant la société capitaliste, vous n'y lirez sans doute pas beaucoup de nouveautés. Mais ce livre peut être utilisé avec profit pour un début de réflexion.
Petite déclaration de conflit d'intérêts : j'ai reçu un exemplaire gratuit de ce livre.
Il y a eu une recension plus détaillée sur LinuxFr.
L'article seul
RFC 9124: A Manifest Information Model for Firmware Updates in Internet of Things (IoT) Devices
Date de publication du RFC : Janvier 2022
Auteur(s) du RFC : B. Moran, H. Tschofenig (Arm Limited), H. Birkholz (Fraunhofer SIT)
Pour information
Réalisé dans le cadre du groupe de travail IETF suit
Première rédaction de cet article le 15 janvier 2022
On le sait, la sécurité des gadgets nommés « objets connectés » est abyssalement basse. Une de raisons (mais pas la seule, loin de là !) est l'absence d'un mécanisme de mise à jour du logiciel, mécanisme qui pourrait permettre de corriger les inévitables failles de sécurité. Le problème de la mise à jour de ces machins, souvent contraints en ressources, est très vaste et complexe. Le groupe de travail SUIT de l'IETF se focalise sur un point bien particulier : un format de manifeste permettant de décrire une mise à jour. Ce RFC décrit le modèle de données des informations qui seront placées dans ce manifeste.
Donc, que faut-il indiquer pour permettre une mise à jour du logiciel (et des réglages) d'un objet connecté ? Le groupe de travail est parti des expériences concrètes, de scénarios et de menaces, pour arriver à la liste que contient ce RFC. Certes, cette liste n'est pas exhaustive (cela serait impossible) mais donne quand même un bon point de départ. Attention, ce RFC décrit le modèle d'information (cf. RFC 3444), pas le format du manifeste (qui sera en CBOR, et fera l'objet d'un futur RFC).
Pour suivre le contenu de ce RFC, il vaut mieux avoir déjà lu le premier RFC du groupe de travail, le RFC 9019, qui explique l'architecture générale du système, ainsi que le RFC 8240, qui était le compte-rendu d'un atelier de réflexion sur cette histoire de mise à jour des objets connectés..
La (longue) section 3 du RFC est consacrée à énumérer tous les éléments à mettre dans le manifeste. Je ne vais pas reproduire toute la liste, juste quelques éléments intéressants. Notez que pour chaque élément, le RFC précise s'il doit être présent dans le manifeste ou bien s'il est facultatif. Le premier élément listé est l'obligatoire identificateur de version de la structure du manifeste, qui permettra de savoir à quel modèle ce manifeste se réfère.
Autre élément obligatoire, un numéro de séquence, croissant de façon monotone, et qui permettra d'éviter les reculs accidentels (« mise à jour » avec une version plus ancienne que celle installée). On peut utiliser pour cela une estampille temporelle (si on a une horloge sûre).
Ensuite, le RFC recommande (mais, contrairement aux deux précédents éléments, ce n'est pas obligatoire) de placer dans le manifeste un identificateur du fournisseur de la mise à jour. Il n'est pas prévu pour d'autres comparaisons que la simple égalité. Le format recommandé pour cet identificateur est un UUID (RFC 9562) de « version 5 », c'est-à-dire formé à partir d'un nom de domaine, qui est forcément unique. L'avantage des UUID (surtout par rapport au texte libre) est leur taille fixe, qui simplifie analyse et comparaison. Si on veut un identificateur de fournisseur qui soit lisible par des humains, il faut le placer dans un autre élément.
L'identificateur de la classe (class ID), indique un type de machines, les machines d'une même classe acceptant le même logiciel (cette acceptation dépend du matériel mais aussi d'autres facteurs comme la version du microcode). Il doit être unique par identificateur de fournisseur (et, en cas de vente en marque blanche, il doit être fourni par le vrai fournisseur, pas par le vendeur). Là aussi, un UUID de « version 5 » est recommandé. Il ne doit pas dépendre juste du nom commercial, un même nom commercial pouvant recouvrir des produits qui n'acceptent pas les mêmes mises à jour. Si un objet peut recevoir des mises à jour indépendantes, pour différents composants de l'objet, il faut des identificateurs de classe différents (surtout si certains objets du fournisseur utilisent une partie des mêmes composants, mais pas tous ; l'identificateur doit identifier le composant, pas l'objet).
Le manifeste contient aussi (mais ce n'est pas obligatoire), une date d'expiration, indiquant à partir de quand il cesse d'être valable.
Le manifeste peut (mais ce n'est pas obligatoire) contenir directement l'image utilisée pour la mise à jour du logiciel de l'objet. Cela peut être utile pour les images de petite taille ; plus besoin d'une étape supplémentaire de téléchargement.
Par contre, l'indication du format de l'image, qu'elle soit directement incluse ou non, est obligatoire, ainsi que celle de la taille de la dite image.
Question sécurité, le RFC impose également la présence d'une signature du manifeste. Le manifeste peut aussi contenir des éléments qui vont servir à établir si on a une délégation sûre depuis une autorité reconnue : des Web Tokens en CBOR (RFC 8392), avec peut-être des preuves du RFC 8747.
La sécurité est au cœur des problèmes que traite ce RFC. Après cette liste d'élements facultatifs ou obligatoires dans un manifeste, la section 4 de notre RFC expose le modèle des menaces auxquelles il s'agit de faire face. Le RFC rappelle que la mise à jour elle-même peut être une menace : après tout, mettre à jour du logiciel, c'est exécuter du code distant. Juste répéter « il faut mettre à jour le logiciel de sa brosse à dents connectée » ne suffit pas, si le mécanisme de mise à jour permet d'insérer du code malveillant. (Et encore, le RFC est gentil, tendance bisounours, il ne rappelle pas que l'attaquant peut être le fournisseur, envoyant du code nouveau pour désactiver certaines fonctions ou pour espionner l'utilisateur, voir les exemples de Hewlett-Packard et de Sony. Sans même parler de la possibilité d'une attaque contre la chaine de développement comme celle contre SolarWinds.)
L'analyse part du modèle STRIDE. Je ne vais pas citer toutes les menaces possibles (il y en a beaucoup !), lisez le RFC pour avoir une vue complète. Notez que les attaques physiques contre les objets (ouvrir la boite et bricoler à l'intérieur) ne sont pas incluses.
Évidemment, la première menace est celle d'une mise à jour qui serait modifiée par un attaquant. Le code correspondant serait exécuté, avec les conséquences qu'on imagine. La signature prévient cette attaque.
Ensuite, le cas d'une vieille mise à jour, qui était honnête et signée, mais n'est plus d'actualité. Si elle a une faiblesse connue, un attaquant pourrait essayer de faire réaliser une « mise à jour » vers cette vieille version. Le numéro de séquence dans le manifeste, qui est strictement croissant, est là pour protéger de cette attaque.
Autre risque, celui d'une mise à jour signée mais qui concerne en fait un autre type d'appareil. Appliquer cette mise à jour pourrait mener à un déni de service. La protection contre ce risque est assurée par l'identificateur du type d'objet.
Le RFC liste la menace d'une rétro-ingénierie de l'image. Outre que cela ne s'applique qu'au logiciel privateur, du point de vue de la sécurité, cela n'est pas crucial, puisqu'on ne compte pas sur la STO. Si on y tient quand même, le chiffrement de l'image (qui n'est pas obligatoire) pare ce risque.
Sinon la section 4.4 contient des scénarios typiques d'utilisation, où une histoire décrit les acteurs, les menaces, les solutions possibles, rendant ainsi plus vivants et plus concrets les problèmes de sécurité étudiés dans ce RFC.
L'article seul
Fiche de lecture : The orphan tsunami of 1700
Auteur(s) du livre : Brian Atwater, Musumi-Rokkaku
Satoko, Satake Kenji, Tsuji
Yoshinobu, Ueda Kazue, David
Yamaguchi
Éditeur : US Geological Survey / University of Washington
Press
978-0-295-99808-4
Publié en 2015
Première rédaction de cet article le 12 janvier 2022
Le 26 janvier 1700, un tsunami a frappé le Japon et a été dûment enregistré dans les textes de l'époque. Mais ceux-ci se sont également étonnés de l'absence de tremblement de terre qui normalement précède les tsunamis (d'où le titre du livre, « Le tsunami orphelin »). Ce livre raconte l'enquête, et ses résultats ; on sait désormais d'où venait le tsunami.
Le principal intérêt du livre est qu'il plonge vraiment profondément dans les détails techniques : ce n'est pas écrit comme un roman, mais comme une étude détaillée de tous les aspects de l'enquête. De nombreuses illustrations, avec leurs légendes, des textes japonais de l'époque, des graphiques, des photos et des dessins, de quoi étudier pendant des heures. Il y a même une discussion des problèmes de calendrier, toujours difficiles pour les historiens quand il faut identifier une date du passé (les textes japonais de l'époque ne disaient pas « 26 janvier 1700 »…).
Un rapport de l'époque, avec son analyse : 
Donc, à gauche du Pacifique, un tsunami orphelin. Pourrait-il venir d'un tremblement de terre lointain ? A-t-on des candidats ? Je vous le divulgâche tout de suite (mais c'est sur la couverture du livre), oui, des tremblements de terre de l'autre côté du Pacifique peuvent provoquer un tsunami au Japon et cela s'est produit, par exemple, lors du plus gros tremblement de terre connu, souvent mentionné dans le livre, car bien étudié. Mais à l'époque, dans la région du supposé tremblement de terre, on ne prenait pas de notes écrites. (Alors qu'au Japon de la période Edo, tout était noté et archivé, la bureaucratie était florissante.) Il faut donc faire parler les sols et les arbres, puis les dater pour être sûr qu'on a trouvé le coupable. Et le livre fait même de l'ethnologie, en interrogeant les traditions orales des Makahs.
Explication de ce qui arrive aux arbres : 
Un livre collectif qui couvre plein d'aspects : une telle enquête est un travail d'équipe. Il est rare d'avoir une enquête aussi totale sur un phénomène naturel.
Notez que le livre est vendu sous forme papier, mais qu'il est aussi en ligne, et dans le domaine public, comme toutes les publications des organismes du gouvernement fédéral étatsunien. Sinon, ce livre a été longuement présenté dans l'excellente émission de radio « Sur les épaules de Darwin ».
L'article seul
Fiche de lecture : Internet aussi, c'est la vraie vie
Auteur(s) du livre : Lucie Ronfaut-Hazard, Mirion
Malle
Éditeur : La ville brûle
978-2-36012-134-2
Publié en 2022
Première rédaction de cet article le 11 janvier 2022
Ce livre explique l'Internet (bon, en pratique, plutôt les usages de l'Internet que le réseau lui-même) à un lectorat jeune.
Ce n'est pas une tâche facile : il faut être pédagogique sans être simplificateur, il faut être exact techniquement tout en étant compréhensible, il faut donner des conseils aux jeunes sans les prendre pour des imbéciles… Je trouve le résultat réussi et c'est un livre qu'on peut recommander à un public adolescent (ceci dit, je ne prétends pas bien connaitre ce public, donc prenez mon avis avec prudence).
Le titre résume bien le livre : contrairement à un discours conservateur courant, il n'y a pas « la vraie vie » d'un côté et le monde numérique de l'autre. Communiquer en étant physiquement proches et en se parlant, ou bien via une lettre en papier, ou bien via un logiciel de messagerie instantanée, c'est toujours communiquer, et ça a des conséquences, bonnes ou mauvaises. Les activités humaines se faisant très souvent via l'Internet, considérer qu'il ne serait pas de « la vraie vie » serait stupide. Donc, Internet, c'est la vraie vie. Mais, justement à cause de cela, il faut l'utiliser intelligemment. L'auteure et l'illustratrice vont parler successivement des GAFA, des données personnelles, des algorithmes de recommandation, du mensonge en ligne, de harcèlement, d'écologie, du Bitcoin, du sexisme, etc. (J'ai été étonné de la mention des cryptomonnaies : dans le public visé par ce livre, il y a des adolescent·es tenté·es par le Bitcoin ?)
L'auteure réussit bien à parler des sujets « à la mode » sans pour autant reprendre forcément tel quel le discours dominant. Par exemple, la section sur les mensonges en ligne (ce que les médias appelent fake news pour essayer de faire croire que c'est un phénomène spécifique au Web) traite ce sujet compliqué avec nuance. Et celle sur l'écologie essaie d'aller plus loin que les stupides recommandations « envoyez moins de messages » pour analyser plus en détail l'empreinte environnementale de nos usages du numérique. (Les caricatures qui illustrent le livre sont nettement plus… caricaturales que le texte.)
Par contre, en matière de harcèlement, il est à noter que les exemples citent de nombreux cas (le phénomène étant hélas répandu) mais ne mentionnent jamais les islamistes (comme dans le cas des attaques contre Mila), comme s'il y avait des bons harceleurs et des mauvais harceleurs. C'est d'autant plus ennuyeux que le dessin p. 39 semble un appel direct au harcèlement (oui, des méchants, mais c'est quand même glaçant, surtout que le texte met au contraire en garde contre les comportements de meute).
Le livre est court (probablement pour ne pas effrayer les lecteurs et lectrices potentiel·les avec un gros pavé) et ne peut donc pas tout traiter. Mais il est prévu pour des débutants, qui n'ont eu comme éducation au numérique que de vagues « c'est dangereux ». Parmi les points qui auraient pu être ajoutés (mais je comprends bien que le livre, vu son cahier des charges, se focalise sur ce qui existe aujourd'hui), on peut noter tout ce qui concerne la possibilité d'« alternatives » aux usages dominants. Par exemple, les algorithmes de recommandation sont discutés, mais sans remettre en cause l'existence même de ces algorithmes.
L'article seul
Portable Tuxedo Pulse 14
Première rédaction de cet article le 10 janvier 2022
Dernière mise à jour le 22 mai 2023
Je viens d'acheter un nouvel ordinateur portable, et ce court article est là pour raconter deux ou trois choses.
Un des éléments de mon cahier des charges était la nécessité que ce PC fonctionne avec du logiciel libre, notamment pour le système d'exploitation. Cela ne va pas de soi car un certain nombre de fabricants d'ordinateurs mettent des composants (carte graphique, ACPI, UEFI) qui ne marchent qu'avec Windows et, si cela arrive, aucune chance de pouvoir obtenir de l'aide du vendeur (en dépit du discours traditionnel comme quoi « avec un produit qu'on achète, on a du support »). C'est scandaleux, mais fréquent, surtout avec les ordinateurs portables. Pour limiter les risques, j'ai donc acheté la machine chez Tuxedo, qui vend des PC pré-installés avec un système libre. Ainsi, normalement, tout fonctionne sans devoir bricoler et passer un temps fou sur des forums divers. J'ai choisi un Tuxedo Pulse 14 - Gen1. C'est un peu plus cher, à matériel équivalent, mais il est bon d'encourager ce genre de fournisseurs.
La machine à l'arrivée :  (Image en grand)
(Image en grand)
{kind=link}
Un des intérêts de ce vendeur est que les machines ont un système d'exploitation pré-installé (un dérivé d'Ubuntu et vous avez bien sûr la possibilité de commander une machine nue et d'installer ce que vous voulez). Mais, vous allez me dire, comment ça marche si on veut un disque dur chiffré, ce qui est clairement indispensable pour un portable ? L'astuce est que le PC arrive avec un tel disque, et le mot de passe sur un papier inclus. Ce mot de passe n'est utilisé qu'une fois (et attention, au moment du démarrage, le clavier est encore en QWERTY, ce qui ne facilite pas sa saisie), on le remplace par un mot de passe que vous choisissez. (Les paranoïaques réinstalleront tout, de toute façon. Comme le fait remarquer FuraxFox, le risque le plus réaliste n'est pas celui de Tuxedo gardant les clés privées, mais celui d'une bogue dans le processus d'avitaillement qui mène à utiliser la même clé pour plusieurs machines.)
L'installation :  (Image en grand)
(Image en grand)
{kind=link}
L'environnement graphique par défaut est GNOME, avec le bureau Budgie. Pour l'instant, j'ai quelques petits problèmes de ce côté-là (pas de clic droit avec le pavé tactile - il faut taper avec deux doigts sur le pavé pour avoir le même effet, pas trouvé comment modifier la barre en bas du bureau, couleurs très saturées quand j'envoie les vidéos sur un écran externe en HDMI, etc). Les joies d'un environnement nouveau… Il va falloir chercher un peu. (Il ne semble pas exister de forum des utilisateurs de Tuxedo, il faut aller sur Reddit.)
Les logiciels spécifiques à Tuxedo sont pré-installés et leur source est disponible sur GitHub, avec les rapports de bogue>.
Une des caractéristiques les plus importantes d'un portable est évidemment sa robustesse mais je ne peux pas encore en juger. Pour l'instant, tout va bien, tout le matériel marche. Les deux plus gros problèmes sont :
- Le clavier est très dur, si on n'appuie pas avec insistance, on rate beaucoup de caractères,
- L'ACPI n'est pas fiable, il est fréquent qu'au retour du someil, le PC reste dans un mode économique d'une lenteur épouvantable, et que la seule solution soit de redémarrer (discussion sur Reddit).
Sinon, si le principe d'un PC déjà équipé avec un système d'exploitation libre vous plait, il y a aussi PCW (vendeur de Clevo) et, une liste de possibilités.
L'article seul
Tester les performances d'un service REST
Première rédaction de cet article le 5 janvier 2022
J'ai eu récemment à tester un service REST, pour ses performances mais aussi pour sa robustesse, et ça a été l'occasion de faire un rapide tour des outils libres existants. Voici quelques notes.
Précisons bien le cahier des charges : le service à tester était du REST. Certes, il tournait sur HTTP mais ce n'était pas un site Web avec plein de traqueurs, de JavaScript, de vidéos ou de fenêtres polichinelles à faire disparaitre avant de voir quelque chose. Il n'utilisait que HTTP 1.1, je n'ai donc pas regardé ce que ces outils donnaient avec HTTP/2. Et je voulais des outils libres, fonctionnant autant que possible en ligne de commande.
On peut tester les performances d'un serveur HTTP simplement avec
curl (et sa très pratique option
--write-out) mais on voudrait ici des tests
répétés, qui matraquent le serveur.
J'ai trouvé six outils différents, et voici mon expérience. Mais d'abord quelques notes générales si vous n'avez pas l'habitude de ce genre d'outils de test :
- Les résultats dépendent évidemment du réseau entre le client (le logiciel de test) et le serveur testé. On obtient évidemment des meilleures performances lorsqu'ils sont sur la même machine, mais c'est moins réaliste. Dans mon cas, le testeur était chez Free et le testé sur Nua.ge, ce qui veut dire entre autres que je ne maitrisais pas complètement les fluctations du réseau. (Mais j'ai aussi fait des tests en local.)
- Le parallélisme compte : une machine même lente peut saturer un serveur HTTP si elle fait de nombreuses requêtes en parallèle. Typiquement, le nombre de requêtes par seconde augmente lorsqu'on augmente le parallélisme, puis diminue au-delà d'un certain seuil.
- Pour atteindre un bon niveau de parallélisme, le client de
test doit ouvrir beaucoup de fichiers (en fait, de descripteurs de
fichiers), et des erreurs comme « socket: Too many open
files (24) » seront fréquentes. Sur
Unix, vous pouvez augmenter la limite du
nombre de descripteurs ouverts avec
limit descriptors 65535(mais attention, cela va dépendre de plusieurs choses, options du noyau, être root ou pas, etc). Comme le dit un message du logiciel Locust « It's [la limite] not high enough for load testing, and the OS didn't allow locust to increase it by itself. ». Les différents logiciels de test ont souvent une section entière de leurs documentation dédiée à ce problème (voir par exemple celle de Locust ou bien celle de Gatling). - Le goulet d'étranglement qui empêche d'avoir davantage de requêtes par seconde peut parfaitement être dans la machine de test, trop lente ou mal connectée. (C'est pour cela qu'il est sans doute préférable que les programmes de test soient écrits dans un langage de bas niveau.)
- Même avec la plus rapide des machines et le meilleur programme de test, une seule machine peut être insuffisante pour tester une charge importante du serveur. Plusieurs logiciels de test ont un mécanisme pour répartir le programme de test sur plusieurs machines (voir par exemple dans la documentation de Locust).
- Enfin, d'une manière générale, la mesure de performances est un art difficile et il y a plein de pièges. Au minimum, quand vous publiez des résultats, indiquez bien comment ils ont été obtenus (dire « le serveur X peut traiter N requêtes/seconde » sans autre détail n'a aucune valeur).
Maintenant, les différents outils. On commence par le vénérable ApacheBench (alias ab). Largement disponible, son utilisation de base est :
ab -n 5000 -c 100 http://tested.example.org/
Le -n permet de spécifier le nombre de requêtes
à faire et le -c le nombre de requêtes en
parallèle. ApacheBench produit un rapport détaillé :
Time taken for tests: 8.536 seconds
Complete requests: 5000
Failed requests: 0
Requests per second: 585.74 [#/sec] (mean)
Time per request: 170.724 [ms] (mean)
Time per request: 1.707 [ms] (mean, across all concurrent requests)
Connection Times (ms)
min mean[+/-sd] median max
Connect: 5 93 278.9 39 3106
Processing: 5 65 120.1 43 1808
Waiting: 4 64 120.2 43 1808
Total: 14 158 307.9 87 3454
Percentage of the requests served within a certain time (ms)
50% 87
66% 104
75% 123
80% 130
90% 247
95% 1027
98% 1122
99% 1321
100% 3454 (longest request)
Le serveur a bien tenu, aucune connexion n'a échoué. D'autre part,
on voit une forte dispersion des temps de réponse (on passe par
l'Internet, ça va et ça vient ; en local - sur la même machine, la
dispersion est bien plus faible). Le taux de requêtes obtenu (586
requêtes par seconde) dépend fortement du parallélisme. Avec
-c 1, on n'atteint que 81 requêtes/seconde.
ab affiche des messages d'erreur dès que le serveur HTTP en face se comporte mal, par exemple en fermant la connexion tout de suite (« apr_socket_recv: Connection reset by peer (104) » ou bien « apr_pollset_poll: The timeout specified has expired (70007) » et, dans ces cas, n'affiche pas du tout les statistiques. Ce manque de robustesse est regrettable pour un logiciel qui doit justement pousser les serveurs à leurs limites.
Par défaut, ab ne réutilise pas les connexions HTTP. Si on veut
des connexions persistentes, il existe une option
-k.
Deuxième logiciel testé, Siege (j'en profite pour placer le mot de poliorcétique, que j'adore) :
% siege -c 100 -r 50 http://tested.example.org/ Transactions: 5000 hits Availability: 100.00 % Elapsed time: 5.09 secs Response time: 0.07 secs Transaction rate: 982.32 trans/sec Concurrency: 66.82 Successful transactions: 5000 Failed transactions: 0 Longest transaction: 3.05 Shortest transaction: 0.00
(Le nombre de requêtes, donné avec -r est par
fil d'exécution et non pas global comme avec ab. Ici, 50*100 nous
redonne 5 000 comme dans le test avec ab.) On voit qu'on a même pu
obtenir un taux de requêtes plus élevé qu'avec ab alors que, comme
lui, il crée par défaut une nouvelle connexion HTTP par requête. En
éditant le fichier de configuration pour mettre connection
= keep-alive (pas trouvé d'option sur la ligne de
commande pour cela), on obtient cinq fois mieux :
Transactions: 5000 hits Availability: 100.00 % Elapsed time: 0.92 secs Response time: 0.02 secs Transaction rate: 5434.78 trans/sec Concurrency: 85.12 Successful transactions: 5000 Failed transactions: 0 Longest transaction: 0.46 Shortest transaction: 0.00
Si vous augmentez le niveau de parallélisme, vous aurez peut-être le message d'erreur :
WARNING: The number of users is capped at 255. To increase this
limit, search your .siegerc file for 'limit' and change
its value. Make sure you read the instructions there...
Il faut alors éditer le fichier de configuration (qui ne s'appelle
pas .siegerc, sur ma machine, c'était
~/.siege/siege.conf) et changer la
valeur. (Rappelez-vous l'avertissement au début sur les limites
imposées par le système d'exploitation.)
Siege a aussi des problèmes de robustesse et vous sort des messages comme « [alert] socket: select and discovered it's not ready sock.c:351: Connection timed out » ou « [alert] socket: read check timed out(30) sock.c:240: Connection timed out ».
Notons que Siege permet d'analyser le HTML reçu et de lancer des requêtes pour les objets qu'il contient, comme le CSS, mais je n'ai pas essayé (rappelez-vous, je testais un service REST, pas un site Web).
Troisième logiciel testé, JMeter. Contrairement à ApacheBench et Siege où tout était sur la ligne de commande et où on pouvait démarrer tout de suite, JMeter nécessite de d'abord définir un Test Plan, listant les requêtes qui seront faites. Cela permet de tester Et, apparemment, on ne peut écrire ce plan qu'avec l'outil graphique de JMeter (« GUI mode should only be used for creating the test script, CLI mode (NON GUI) must be used for load testing »). J'étais de mauvaise humeur, je ne suis pas allé plus loin.
Quatrième logiciel, Cassowary. Contrairement aux trois précédents, il n'était pas en paquetage tout fait pour mon système d'exploitation (Debian), donc place à la compilation. Cassowary est écrit en Go et la documentation disait qu'il fallait au moins la version 1.15 du compilateur mais, apparemment, ça marche avec la 1.13.8 que j'avais :
git clone https://github.com/rogerwelin/cassowary.git cd cassowary go build ./cmd/cassowary
Et on y va :
% ./cassowary run -u http://tested.example.org/ -n 5000 -c 100 TCP Connect.....................: Avg/mean=17.39ms Median=16.00ms p(95)=36.00ms Server Processing...............: Avg/mean=15.27ms Median=13.00ms p(95)=22.00ms Content Transfer................: Avg/mean=0.02ms Median=0.00ms p(95)=0.00ms Summary: Total Req.......................: 5000 Failed Req......................: 0 DNS Lookup......................: 8.00ms Req/s...........................: 5903.26
Par défaut, Cassowary réutilise les connexions HTTP, d'où le taux de
requêtes élevé (on peut changer ce comportement avec
--disable-keep-alive). Lui aussi affiche de
vilains messages d'erreur (« net/http: request canceled
(Client.Timeout exceeded while awaiting headers) ») si le
serveur HTTP, ayant du mal à répondre, laisse tomber certaines
requêtes. Et, ce qui est plus grave, Cassowary n'affiche pas les
statistiques s'il y a eu ne serait-ce qu'une erreur.
Cinquième logiciel utilisé, k6. Également écrit en Go, je n'ai pas réussi à le compiler :
% go get go.k6.io/k6 package hash/maphash: unrecognized import path "hash/maphash" (import path does not begin with hostname) package embed: unrecognized import path "embed" (import path does not begin with hostname)
Les deux derniers logiciels sont, je crois, les plus riches et
aussi les plus complexes. D'abord, le sixième que j'ai testé, Gatling. On le télécharge, on unzip
gatling-charts-highcharts-bundle-3.7.3-bundle.zip et on
va dans le répertoire ainsi créé.
On doit d'abord enregistrer les tests à faire. Pour cela, on lance
l'enregistreur de Gatling. L'interface principale est graphique (je n'ai pas vu s'il
y avait une interface en ligne de commande) :
% ./bin/recorder.sh
Il fait tourner un relais HTTP qu'on doit ensuite utiliser depuis son client HTTP. Par exemple, si j'utilise curl :
% export http_proxy=http://localhost:8000/ % curl http://tested.example.org/
Et Gatling enregistrera une requête HTTP vers
http://tested.example.org/. Le plan est
écrit sous forme d'un programme Scala
(d'autres langages sont possibles) que Gatling
exécutera. Il se lance avec :
% ./bin/gatling.sh
Et on a une jolie page HTML de résultats. Après, les choses se compliquent, Gatling est très riche, mais il faut écrire du code, même pour une tâche aussi simple que de répéter une opération N fois.
Enfin, le septième et dernier, Locust. (Après le champ lexical de
la guerre, avec Siege et Gatling, celui d'une plaie
d'Égypte…) Locust est écrit en Python et il a été simple à installer avec
pip3 install locust. Il dispose d'une documentation
détaillée. Comme JMeter, il faut écrire un plan de test mais,
contrairement à JMeter, on peut le faire avec un éditeur
ordinaire. Ce plan est écrit lui-même en Python et voici un exemple
très simple où le test sollicitera deux chemins sur le serveur :
from locust import HttpUser, task
import requests
class HelloWorldUser(HttpUser):
@task
def hello_world(self):
self.client.get("/")
self.client.get("/hello")
Une fois le plan écrit, on peut lancer Locust en ligne de commande :
% locust --host http://tested.example.org --headless --users 100 --spawn 10
On ne peut pas indiquer le nombre maximal de requêtes (seulement le temps maximal), il faut interrompre le programme au bout d'un moment. Il affiche alors :
Name # reqs # fails | Avg Min Max Median | req/s failures/s ------------------------------------------------------------------------------------------------------------------------------------------------ GET / 20666 0(0.00%) | 87 7 541 94 | 736.70 0.00
On voit que le nombre de requêtes par seconde est faible. Une des raisons est que Locust est très consommateur de temps de processeur : celui-ci est occupé à 100 % pendant l'exécution, et est le facteur limitant. Locust avertit, d'ailleurs, « CPU usage above 90%! This may constrain your throughput and may even give inconsistent response time measurements! ». Bref, il ne pousse pas le serveur à ses limites. Locust réutilise les connexions HTTP, et je n'ai pas trouvé comment faire si on voulait tester sans cela. Cette réponse sur StackOverflow ne marche pas pour moi, les requêtes sont bien faites, mais pas comptées dans les statistiques.
Mais l'intérêt de Locust est de lancer un serveur Web qui permet
d'obtenir de jolis graphes : 
On peut aussi utiliser cette interface Web pour piloter les tests.
En conclusion ? Je ne crois pas qu'il y ait un de ces logiciels qui fasse tout ce que je voulais et comme je voulais. Donc, j'en garde plusieurs.
L'article seul
Fiche de lecture : Le Minitel
Auteur(s) du livre : Valérie Schafer, Benjamin
Thierry
Éditeur : Cigref - Nuvis
978-2-36367-014-4
Publié en 2012
Première rédaction de cet article le 3 janvier 2022
Ah, le Minitel… Disparu complètement juste avant la parution de ce livre, il continue à susciter des discussions, des nostalgies et à servir de référence (positive ou négative) pour beaucoup de discussions autour des réseaux informatiques. Ce livre raconte l'histoire du Minitel, de ses débuts à sa fin. Une lecture nécessaire que l'on soit « pro » ou « anti », vu l'importance qu'a joué et joue encore le Minitel dans les réflexions.
C'est que l'histoire du Minitel a été longue et que certaines réflexions sur le Minitel oublient de prendre en compte cette durée. Ainsi, à la fin des années 1990, il est exact que le Minitel était très en retard sur les ordinateurs de l'époque. Mais ce n'était pas le cas au moment de sa création, où il avait des caractéristiques matérielles qu'on juge ridicules aujourd'hui, mais qui étaient raisonnables pour l'époque.
Ce livre peut aider à traiter des questions délicates comme « le Minitel fut-il un échec ? » La réponse dépend évidemment de l'angle choisi. Techniquement, beaucoup de choix erronés ont été faits. (Mais il ne faut pas faire d'anachronisme : des erreurs qui sont évidentes aujourd'hui, étaient bien plus difficiles à détecter à la fin des années 1970, au moment de sa conception.) Le réseau Transpac sous-jacent avait aussi de bonnes idées mais avait fait aussi plusieurs erreurs fondamentales, comme de rejeter le datagramme. Économiquement, l'idée très originale du Minitel était la distribution gratuite du terminal. Cela avait permis de casser le cercle vicieux « pas de services car pas de clients → pas de clients car pas de services » en amorçant la pompe. (Les auteurs rappellent toutefois qu'il n'y a jamais eu qu'une minorité de la population française à avoir un Minitel à la maison.) Et le Minitel a rapporté énormément d'argent à l'État, et a été à l'origine de certaines fortunes comme celle de Xavier Niel. (Par contre, je trouve que le livre passe trop vite sur le scandale qu'était la « pompe à fric » des tarifications à la durée, avec ses factures surprenantes, même s'ils rappellent que certains serveurs étaient délibérement mal conçus pour que la session dure plus longtemps.) Stratégiquement, le Minitel a permis à la France de partir plus vite dans les réseaux informatiques, puis l'a empêché d'aller plus loin. Politiquement, le Minitel est resté le symbole d'un système centralisé (cf. la fameuse conférence de Benjamin Bayart « Internet libre ou Minitel 2.0 »). Mais la situation est plus complexe que cela. Si l'asymétrie du Minitel n'est pas, sauf erreur, mentionnée dans le livre (1 200 b/s du serveur vers le client et 75 b/s, oui, SOIXANTE-QUINZE BITS PAR SECONDE, du client vers le serveur), le Minitel avait quand même généré une activité plus symétrique, par exemple avec les fameuses « messageries ». Enfin, artistiquement, le Minitel a quand même été l'inspiration d'une belle chanson.
Si vous voulez mon avis, je pense que le Minitel était utile au début, mais ensuite, assis sur le tas d'or que rapportait la tarification à la durée, piloté par des aveugles volontaires qui avaient nié jusqu'au bout l'intérêt de l'Internet, et qui étaient enfermés dans leur auto-satisfaction (« on est les meilleurs »), il a trop duré. Le Minitel aurait laissé un bien meilleur souvenir si son arrêt avait été engagé dès le début des années 1990.
Au fait, si vous lisez ce livre (ce que je recommande), vous pouvez sauter sans mal la préface de Pascal Griset et surtout, surtout, la ridicule postface de Dominique Wolton, caricaturalement nostalgique, chauvine (la France patrie de la culture, opposée au « libéralisme », comme si la France n'était pas un pays capitaliste comme les autres) et présentant le Minitel comme fondé sur une logique égalitaire, « éducative et d'émancipation » ! Il présente même le Minitel comme opposé au marché, ce qui va faire rire jaune tous ceux qui se souviennent de leur facture 3615.
Le livre rappelle tout un ensemble de faits peu connus ou oubliés sur le Minitel. Ainsi, ce qu'on appelait à l'époque « ergonomie » et qu'on dirait aujourd'hui UX, avait fait l'objet de nombreuses réflexions, et d'essais avec des vrais utilisateurs et utilisatrices. Alors que la conception globale du projet était très technocratique de haut en bas, l'UX avait été travaillée sur un mode bien plus interactif. Parmi les idées amusantes, celle d'un clavier alphabétique (ABCDEF au lieu d'AZERTY), supposé plus « intuitif ». Bien sûr, l'idée était mauvaise (et a été vite abandonnée) mais elle rappelle que très peu de gens avaient tapé sur un clavier d'ordinateur à l'époque (mais beaucoup plus avaient tapé sur un clavier de machine à écrire, ce qui explique la victoire finale du clavier Azerty).
Comme avec tout livre d'histoire, on est étonné de trouver des débats du passé qui sont toujours d'actualité. Les auteurs rappellent qu'une bonne partie de la presse s'était vigoureusement opposée au Minitel, l'accusant de détourner le marché de la publicité (la presse ne vit pas de ses lecteurs…).
Ce livre ne considère pas non plus que le phénomène était purement français (contrairement à un certain discours chauvin pro-Minitel). Prestel et le Bildschirmtext sont ainsi discutés en détail. (Tous les deux avaient en commun qu'il fallait un investissement initial de l'utilisateur, précisément le cercle vicieux que le Minitel a cassé avec sa distribution gratuite, une leçon importante pour l'innovation.)
L'article seul
RFC 9170: Long-term Viability of Protocol Extension Mechanisms
Date de publication du RFC : Décembre 2021
Auteur(s) du RFC : M. Thomson (Mozilla), T. Pauly (Apple)
Pour information
Première rédaction de cet article le 1 janvier 2022
Après des années de déploiement d'un protocole sur l'Internet, lorsqu'on essaie d'utiliser des fonctions du protocole parfaitement standards et légales, mais qui avaient été inutilisées jusqu'à présent, on découvre souvent que cela ne passe pas : des programmes bogués, notamment dans les middleboxes, plantent de manière malpropre lorsqu'ils rencontrent ces (toutes relatives) nouveautés. C'est ce qu'on nomme l'ossification de l'Internet. Ce RFC de l'IAB fait le point sur le problème et sur les solutions proposées, par exemple le graissage, l'utilisation délibérée et précoce de variations, pour ne pas laisser d'options inutilisées.
Lorsqu'un protocole a du succès (cf. RFC 5218, sur cette notion de succès), on va vouloir le modifier pour traiter des cas nouveaux. Cela n'est pas toujours facile, comme le note le RFC 8170. Tout protocole a des degrés de liberté (extension points) où on pourra l'étendre. Par exemple, le DNS permet de définir de nouveaux types de données (contrairement à ce qu'on lit souvent, le DNS ne sert pas qu'à « trouver des adresses IP à partir de noms ») et IPv6 permet de définir de nouvelles options pour la destination du paquet, voire de nouveaux en-têtes d'extension. En théorie, cela permet d'étendre le protocole. Mais en pratique, utiliser ces degrés de liberté peut amener des résultats imprévus, par exemple, pour le cas du DNS, un pare-feu programmé avec les pieds qui bloque les paquets utilisant un type de données que le pare-feu ne connait pas. Ce RFC se focalise sur des couches relativement hautes, où tout fonctionne de bout en bout (et où, en théorie, les intermédiaires doivent laisser passer ce qu'ils ne comprennent pas). Les couches basses impliquent davantage de participants et sont donc plus problématiques. Ainsi, pour IPv6, l'en-tête « options pour la destination » doit normalement être ignoré et relayé aveuglément par les routeurs alors que l'en-tête « options pour chaque saut » doit (enfin, devait, avant le RFC 8200) être compris et analysé par tous les routeurs du chemin, ce qui complique sérieusement son utilisation.
Notre RFC a été développé par l'IAB dans le cadre du programme « Evolvability, Deployability, & Maintainability (EDM) ».
Déployer une nouvelle version d'un protocole, ou simplement utiliser des options qui n'avaient pas été pratiquées avant, peut donc être très frustrant. Prenons le cas imaginaire mais très proche de cas réels d'un protocole qui a un champ de huit bits inutilisé et donc le RFC d'origine dit que l'émetteur du paquet doit mettre tous ces bits à zéro, et le récepteur du paquet, en application du principe de robustesse, doit ignorer ces bits. Un jour, un nouveau RFC sort, avec une description du protocole où ces bits ont désormais une utilité. Les premiers logiciels qui vont mettre en œuvre cette nouvelle version, et mettre certains bits à un, vont fonctionner lors de tests puis, une fois le déploiement sur l'Internet fait, vont avoir des problèmes dans certains cas. Un pare-feu programmé par des incompétents va jeter ces paquets. Dans son code, il y a un test que le champ vaut zéro partout, car le programmeur n'a jamais lu le RFC et il a juste observé que ce champ était toujours nul. Cette observation a été mise dans le code et bonne chance pour la corriger. (Les DSI qui déploient ce pare-feu n'ont pas regardé s'il était programmé correctement, ils ont juste lu la brochure commerciale.) À partir de là, les programmeurs qui mettent en œuvre le protocole en question ont le choix de foncer et d'ignorer les mines, acceptant que leur programme ne marche pas si les paquets ont le malheur de passer par un des pare-feux bogués (et seront donc perdus), ou bien de revenir à l'ancienne version, ce second choix étant l'ossification : on n'ose plus rien changer de peur que ça casse quelque chose quelque part. Comme les utilisateurs ignorants attribueraient sans doute les problèmes de timeout à l'application, et pas au pare-feu mal écrit, le choix des programmeurs est vite fait : on ne déploie pas la nouvelle version. C'est d'autant plus vrai si le protocole est particulièrement critique pour le bon fonctionnement de l'Internet (BGP, DNS…) ou bien s'il y a de nombreux acteurs non coordonnés (cf. section 2.3). Bien sûr, le blocage de certains paquets peut être volontaire mais, bien souvent, il résulte de la négligence et de l'incompétence des auteurs de middleboxes (cf. section 5).
Les exemples de tels problèmes sont innombrables (l'annexe A du
RFC en fournit plusieurs). Ainsi, TLS a eu bien des ennuis avec des nouvelles
valeurs de l'extension
signature_algorithms.
Si le protocole en question était conçu de nos jours, il est probable que ses concepteurs prendraient la précaution de réserver quelques valeurs non nulles pour le champ en question, et de demander aux programmes d'utiliser de temps en temps ces valeurs, pour être sûr qu'elles sont effectivement ignorées. C'est ce qu'on nomme le graissage et c'est une technique puissante (mais pas parfaite) pour éviter la rouille, l'ossification. (Notez que les valeurs utilisées pour le graissage ne doivent pas être consécutives, pour limiter les risques qu'un programmeur de middlebox paresseux ne les teste facilement. Et qu'il faut les réserver pour que, plus tard, l'utilisation de vraies valeurs pour ce champ ne soit pas empêchée par les valeurs de graissage.) Le graissage ne résout pas tous les problèmes puisqu'il y a toujours le risque que les valeurs utilisées pour graisser finissent par bénéficier d'un traitement de faveur, et soient acceptées, alors que les valeurs réelles poseront des problèmes.
On pourrait penser qu'une meilleure conception des protocoles éviterait l'ossification. (C'est le discours des inventeurs géniaux et méconnus qui prétendent que leur solution magique n'a aucun inconvénient et devrait remplacer tout l'Internet demain.) Après tout, le RFC 6709 contient beaucoup d'excellents conseils sur la meilleure façon de concevoir des protocoles pour qu'ils puissent évoluer. Par exemple, il insiste sur le fait que le mécanisme de négociation qui permet aux deux parties de se mettre d'accord sur une option ou une version doit être simple, pour qu'il y ait davantage de chances qu'il soit mis en œuvre correctement dans tous les programmes. En effet, en l'absence de graissage, ce mécanisme ne sera testé en vrai que lorsqu'on introduira une nouvelle version ou une nouvelle option et, alors, il sera trop tard pour modifier les programmes qui n'arrivent pas à négocier ces nouveaux cas, car leur code de négociation est bogué. Le RFC 6709 reconnait ce problème (tant qu'on n'a pas utilisé un mécanisme, on ne sait pas vraiment s'il marche) et reconnait que le conseil d'un mécanisme simple n'est pas suffisant.
Notre RFC 9170 contient d'ailleurs une petite pique contre QUIC en regrettant qu'on repousse parfois à plus tard le mécanisme de négociation de version, pour arriver à publier la norme décrivant le protocole (exactement ce qui est arrivé à QUIC, qui n'a pas de mécanisme de négociation des futures versions). Le problème est que, une fois la norme publiée et le protocole déployé, il sera trop tard…
Bref, l'analyse du RFC (section 3) est qu'il faut utiliser tôt et souvent les mécanismes d'extension. Une option ou un moyen de négocier de nouvelles options qui n'a jamais été utilisé depuis des années est probablement ossifié et ne peut plus être utilisé. C'est très joli de dire dans le premier RFC d'un protocole « cet octet est toujours à zéro dans cette version mais les récepteurs doivent ignorer son contenu car il pourra servir dans une future version » mais l'expérience prouve largement qu'une telle phrase est souvent ignorée et que bien des logiciels planteront, parfois de façon brutale, le jour où on commencer à utiliser des valeurs non nulles. Il faut donc utiliser les mécanismes ou bien ils rouillent. Par exemple, si vous concevez un mécanisme d'extension dans votre protocole, il est bon que, dès le premier jour, au moins une fonction soit mise en œuvre via ce mécanisme, pour forcer les programmeurs à en tenir compte, au lieu de simplement sauter cette section du RFC. Les protocoles qui ajoutent fréquemment des options ou des extensions ont moins de problèmes que ceux qui attendent des années avant d'exploiter leurs mécanismes d'extension. Et plus on attend, plus c'est pire. C'est pour cela que, par exemple, il faut féliciter le RIPE NCC d'avoir tenté l'annonce de l'attribut BGP 99, même si cela a cassé des choses, car si on ne l'avait pas fait (comme l'avaient demandé certaines personnes qui ne comprenaient pas les enjeux), le déploiement de nouveaux attributs dans BGP serait resté quasi-impossible.
Tester tôt est d'autant plus important qu'il peut être crucial, pour la sécurité, qu'on puisse étendre un protocole (par exemple pour l'agilité cryptographique, cf. RFC 7696). L'article de S. Bellovin et E. Rescorla, « Deploying a New Hash Algorithm » montre clairement que les choses ne se passent pas aussi bien qu'elles le devraient.
Comme dit plus haut, la meilleure façon de s'assurer qu'un
mécanisme est utilisable est de l'utiliser effectivement. Et pour
cela que ce mécanisme soit indispensable au fonctionnement normal du
protocole, qu'on ne puisse pas l'ignorer. Le RFC cite l'exemple de
SMTP :
le principal mécanisme d'extension de SMTP est d'ajouter de nouveaux
en-têtes (comme le Archived-At: dans le RFC 5064) or, SMTP dépend d'un traitement de ces
en-têtes pour des fonctions mêmes élémentaires. Un MTA ne peut pas se permettre
d'ignorer les en-têtes. Ainsi, on est sûr que toute mise en œuvre de
SMTP sait analyser les en-têtes. Et, comme des en-têtes nouveaux
sont assez fréquemment ajoutés, on sait que des en-têtes inconnus
des vieux logiciels ne perturbent pas SMTP. Ce cas est idéal : au
lieu d'un mécanisme d'extension qui serait certes spécifié dans le
RFC mais pas encore utilisé, on a un mécanisme d'extension dont
dépendent des fonctions de base du protocole.
Le RFC cite également le cas de SIP, qui est moins favorable : les relais ne transmettent en général pas les en-têtes inconnus, ce qui ne casse pas la communication, mais empêche de déployer de nouveaux services tant que tous les relais n'ont pas été mis à jour.
Bien sûr, aucune solution n'est parfaite. Si SMTP n'avait pas ajouté de nombreux en-têtes depuis sa création, on aurait peut-être des programmes qui certes savent analyser les en-têtes mais plantent lorsque ces en-têtes ne sont pas dans une liste limitée. D'où l'importance de changer souvent (ici, en ajoutant des en-têtes).
Souvent, les protocoles prévoient un mécanisme de négociation de la version utilisée. On parle de version différente lorsque le protocole a suffisamment changé pour qu'on ne puisse pas interagir avec un vieux logiciel. Un client SMTP récent peut toujours parler à un vieux serveur (au pire, le serveur ignorera les en-têtes trop récents) mais une machine TLS 1.2 ne peut pas parler à une machine TLS 1.3. Dans le cas le plus fréquent, la machine récente doit pouvoir parler les deux versions, et la négociation de version sert justement à savoir quelle version utiliser. Le problème de cette approche est que, quand la version 1 est publiée en RFC, avec son beau mécanisme de négociation de version, il n'y a pas encore de version 2 pour tester que cette négociation se passera bien. Celle-ci ne sortira parfois que des années plus tard et on s'apercevra peut-être à ce moment que certains programmes ont mal mis en œuvre la négociation de version, voire ont tout simplement négligé cette section du RFC…
Première solution à ce problème, utiliser un mécanisme de négociation de version située dans une couche plus basse. Ainsi, IP a un mécanisme de négociation de version dans l'en-tête IP lui-même (les quatre premiers bits indiquent le numéro de version, cf. RFC 8200, section 3) mais ce mécanisme n'a jamais marché en pratique. Ce qui marche, et qui est utilisé, c'est de se servir du mécanisme de la couche 2. Par exemple, pour Ethernet (RFC 2464), c'est l'utilisation du type de protocole (EtherType), 0x800 pour IPv4 et 0x86DD pour IPv6. Un autre exemple est l'utilisation d'ALPN (RFC 7301) pour les protocoles au-dessus de TLS. (Le RFC cite aussi la négociation de contenu de HTTP.)
Une solution récente au problème de l'ossification est le graissage, présenté en section 3.3. Décrit à l'origine pour TLS, dans le RFC 8701, il est désormais utilisé dans d'autres protocoles comme QUIC. Son principe est de réserver un certain nombre de valeurs utilisant des extensions du protocole et de s'en servir, de façon à forcer les différents logiciels, intermédiaires ou terminaux, à lire tout le RFC et à gérer tous les cas. Dans l'exemple cité plus haut d'un protocole qui aurait un champ de huit bits « cet octet est toujours à zéro dans cette version mais les récepteurs doivent ignorer son contenu car il pourra servir dans une future version », on peut réserver les valeurs 3, 21, 90 et 174 comme valeurs de graissage et l'émetteur les mettra de temps en temps dans le champ en question. Dans le cas de TLS, où le client propose des options et le serveur accepte celles qu'il choisit dans ce lot (oui, je sais, TLS est plus compliqué que cela, par exemple lorsque le serveur demande une authentification), le client annonce au hasard des valeurs de graissage. Ainsi, une middlebox qui couperait les connexions TLS serait vite détectée et, on peut l'espérer, rejetée par le marché. Le principe du graissage est donc « les extensions à un protocole s'usent quand on ne s'en sert pas ». Cela évoque les tests de fuzzing qu'on fait en sécurité, où on va essayer plein de valeurs inhabituelles prises au hasard, pour s'assurer que le logiciel ne se laisse pas surprendre. On voit aussi un risque du graissage : si les programmes bogués sont nombreux, le premier qui déploie un mécanisme de graissage va essuyer les plâtres et se faire parfois rejeter. Il est donc préférable que le graissage soit utilisé dès le début, par exemple dans un nouveau protocole.
Évidemment, la solution n'est pas parfaite. On peut imaginer un logiciel mal fait qui reconnait les valeurs utilisées pour le graissage (et les ignore) mais rejette quand même les autres valeurs pourtant légitimes. (La plupart du temps, les valeurs réservées pour le graissage ne sont pas continues, comme dans les valeurs 3, 21, 90 et 174 citées plus haut, pour rendre plus difficile un traitement spécifique au graissage.)
Bien sûr, même sans valeurs réservées au graissage, un programme pourrait toujours faire à peu près l'équivalent, en utilisant les valeurs réservées pour des expérimentations ou bien des usages privés. Mais le risque est alors qu'elles soient acceptées par l'autre partie, ce qui n'est pas le but.
Tous les protocoles n'ont pas le même style d'interaction que TLS, et le graissage n'est donc pas systématiquement possible. Et puis il ne teste qu'une partie des capacités du protocole, donc il ne couvre pas tous les cas possibles. Le graissage est donc utile mais ne résout pas complètement le problème.
Parfois, des protocoles qui ne permettaient pas facilement l'extensibilité ont été assez sérieusement modifiés pour la rendre possible. Ce fut le cas du DNS avec EDNS (RFC 6891). Son déploiement n'a pas été un long fleuve tranquille et, pendant longtemps, les réactions erronées de certains serveurs aux requêtes utilisant EDNS nécessitaient un mécanisme de repli (re-essayer sans EDNS). Il a ensuite fallu supprimer ce mécanisme de repli pour être sûr que les derniers systèmes erronés soient retirés du service, le tout s'étalant sur de nombreuses années. Un gros effort collectif a été nécessaire pour parvenir à ce résultat, facilité, dans le cas du DNS, par le relativement petit nombre d'acteurs et leur étroite collaboration.
La section 4 du RFC cite d'autres techniques qui peuvent être utilisées pour lutter contre l'ossification. D'abord, ne pas avoir trop de possibilités d'étendre le protocole car, dans ce cas, certaines possibilités seront fatalement moins testées que d'autres et donc plus fragiles si on veut s'en servir un jour.
Le RFC suggère aussi l'utilisation d'invariants. Un invariant est une promesse des auteurs du protocole, assurant que cette partie du protocole ne bougera pas (et, au contraire, que tout le reste peut bouger et qu'il ne faut pas compter dessus). Si les auteurs de logiciels lisent les RFC (une supposition audacieuse, notamment pour les auteurs de middleboxes), cela devrait éviter les problèmes avec les évolutions futures. (Il est donc toujours utile de graisser les parties du protocole qui ne sont pas des invariants.) Le RFC 5704, dans sa section 2.2, définit plus rigoureusement ce que sont les invariants. Deux exemples d'utilisation de ce concept sont le RFC 8999 (décrivant les invariants de QUIC) et la section 9.3 du RFC 9846 sur TLS. Notre RFC conseille aussi de préciser explicitement ce qui n'est pas invariant (comme le fait l'annexe A du RFC 8999), ce que je trouve contestable (il y a un risque que cette liste d'exemples de non-invariants soit interprétée comme limitative, alors que ce ne sont que des exemples).
Une autre bonne technique, que recommande notre RFC, est de prendre des mesures techniques pour empêcher les intermédiaires de tripoter la communication. Moins il y a d'entités qui analysent et interprètent les paquets, moins il y aura de programmes à vérifier et éventuellement à modifier en cas d'extension du protocole. Un bon exemple de ces mesures techniques est évidemment la cryptographie. Ainsi, chiffrer le fonctionnement du protocole, comme le fait QUIC, ne sert pas qu'à préserver la vie privée de l'utilisateur, cela sert aussi à tenir à l'écart les intermédiaires, ce qui limite l'ossification. Le RFC 8558 est une bonne lecture à ce sujet.
Bien sûr, si bien conçu que soit le protocole, il y aura des
problèmes. Le RFC suggère donc aussi qu'on crée des mécanismes de
retour, permettant d'être informés des problèmes. Prenons par
exemple un serveur TLS qui refuserait des clients corrects, mais qui
utilisent des extensions que le serveur ne gère pas correctement. Si
le serveur ne journalise pas ces problèmes, ou
bien que l'administrateur système ne lit pas
ces journaux, le problème pourra trainer très longtemps. Idéalement,
ces retours seront récoltés et traités automatiquement, et envoyés à
celles et ceux qui sont en mesure d'agir. C'est plus facile à dire
qu'à faire, et cela dépend évidemment du protocole utilisé. Des
exemples de protocoles ayant un tel mécanisme sont
DMARC (RFC 9989, avec
son étiquette rua, section 7), et SMTP (avec le
TLSRPT du RFC 8460).
Enfin, pour terminer, l'annexe A du RFC présente quelques
exemples de protocoles et comment ils ont géré ce problème. Elle
commence par le DNS
(RFC 1034 et RFC 1035). Le DNS a une mauvaise expérience avec le
déploiement de nouveaux types d'enregistrement qui, par exemple,
provoquaient des rejets violents des requêtes DNS par certains
équipements. C'est l'une des raisons pour lesquelles SPF (RFC 7208) a finalement renoncé à utiliser son propre type
d'enregistrement, SPF (cf. RFC 6686) et pour lesquelles tout le monde se sert de
TXT. Le problème s'est heureusement amélioré
depuis la parution du RFC 3597, qui normalise
le traitement des types inconnus. (Mais il reste d'autres obstacles
au déploiement de nouveaux types, comme la mise à jour des
interfaces « conviviales » d'avitaillement d'une zone DNS,
interfaces qui mettent de nombreuses années à intégrer les nouveaux
types.)
HTTP, lui, a plutôt bien marché, question extensibilité mais il a certains mécanismes d'extension que personne n'ose utiliser et qui ne marcheraient probablement pas, comme les extensions des chunks (RFC 7230, section 4.1.1) ou bien comme l'utilisation d'autres unités que les octets dans les requêtes avec intervalles (RFC 7233, section 2.2).
Et IP lui-même ?
Par exemple, IP avait un mécanisme pour permettre aux équipements
réseau de reconnaitre la version utilisée, permettant donc de faire
coexister plusieurs versions d'IP, le champ Version (les quatre
premiers bits du paquet). Mais il n'a jamais réellement fonctionné,
les équipements utilisant à la place les indications données par la
couche inférieure (l'« ethertype », dans le cas
d'Ethernet, cf. RFC 2464). D'autres problèmes sont arrivés avec IP, par
exemple l'ancienne « classe E ». Le préfixe
224.0.0.0/3 avait été réservé par le RFC 791, section 3.2, mais sans précisions
(« The extended addressing mode is undefined. Both of
these features are reserved for future use. »). Le RFC 988 avait ensuite pris
224.0.0.0/4 pour le
multicast (qui n'a jamais
été réellement déployé sur l'Internet), créant la « classe D », le
reste devenant la « classe E », 240.0.0.0/4 dont on
ne sait plus quoi faire aujourd'hui, même si certains voudraient la
récupérer pour prolonger l'agonie d'IPv4. Son
traitement spécial par de nombreux logiciels empêche de l'affecter
réellement. Une solution souvent utilisée pour changer la
signification de tel ou tel champ dans l'en-tête est la négociation
entre les deux parties qui communiquent, mais cela ne marche pas
pour les adresses (la communication peut être
unidirectionnelle).
SNMP n'a pas eu trop de problèmes avec le déploiement de ses versions 2 et 3. La norme de la version 1 précisait clairement (RFC 1157) que les paquets des versions supérieures à ce qu'on savait gérer devaient être ignorés silencieusement, et cela était vraiment fait en pratique. Il a donc été possible de commencer à envoyer des paquets des versions 2, puis 3, sans casser les vieux logiciels qui écoutaient sur le même port.
TCP, par contre, a eu bien des problèmes avec son mécanisme d'extension. (Lire l'article de Honda, M., Nishida, Y., Raiciu, C., Greenhalgh, A., Handley, M., et H. Tokuda, « Is it still possible to extend TCP? ».) En effet, de nombreuses middleboxes se permettaient de regarder l'en-tête TCP sans avoir lu et compris le RFC, jetant des paquets qui leur semblaient anormaux, alors qu'ils avaient juste des options nouvelles. Ainsi, le multipath TCP (RFC 6824) a été difficile à déployer (cf. l'article de Raiciu, C., Paasch, C., Barre, S., Ford, A., Honda, M., Duchêne, F., Bonaventure, O., et M. Handley, « How Hard Can It Be? Designing and Implementing a Deployable Multipath TCP »). TCP Fast Open (RFC 7413) a eu moins de problèmes sur le chemin, mais davantage avec les machines terminales, qui ne comprenaient pas ce qu'on leur demandait. Comme le but de TCP Fast Open était d'ouvrir une connexion rapidement, ce problème était fatal : on ne peut pas entamer une négociation lorsqu'on veut aller vite.
Et enfin, dernier protocole étudié dans cette annexe A, TLS. Là, la conclusion du RFC est que le mécanisme de négociation et donc d'extension de TLS était correct, mais que la quantité de programmes mal écrits et qui réagissaient mal à ce mécanisme l'a, en pratique, rendu inutilisable. Pour choisir une version de TLS commune aux deux parties qui veulent communiquer de manière sécurisée, la solution était de chercher la plus haute valeur de version commune (HMSV pour highest mutually supported version, cf. RFC 6709, section 4.1). Mais les innombrables bogues dans les terminaux, et dans les middleboxes (qui peuvent accéder à la négociation TLS puisqu'elle est en clair, avant tout chiffrement) ont fait qu'il était difficile d'annoncer une version supérieure sans que les paquets soient rejetés. (Voir l'expérience racontée dans ce message.)
TLS 1.3 (RFC 9846) a donc dû abandonner
complètement le mécanisme HMSV et se présenter comme étant du 1.2,
pour calmer les middleboxes intolérantes,
dissimulant ensuite dans le ClientHello des
informations qui permettent aux serveurs 1.3 de reconnaitre un
client qui veut faire du 1.3 (ici, vu avec tshark) :
TLSv1 Record Layer: Handshake Protocol: Client Hello
Content Type: Handshake (22)
Version: TLS 1.0 (0x0301)
Length: 665
Handshake Protocol: Client Hello
Handshake Type: Client Hello (1)
Length: 661
Version: TLS 1.2 (0x0303)
[Ce champ Version n'est là que pour satisfaire les middleboxes.]
Extension: supported_versions (len=9)
Type: supported_versions (43)
Length: 9
Supported Versions length: 8
Supported Version: TLS 1.3 (0x0304)
Supported Version: TLS 1.2 (0x0303)
Supported Version: TLS 1.1 (0x0302)
Supported Version: TLS 1.0 (0x0301)
[La vraie liste des versions acceptées était dans cette extension.]
Toujours à propos de TLS, SNI (Server Name
Indication, cf. RFC 6066, section 3)
est un autre exemple où la conception était bonne mais le manque
d'utilisation de certains options a mené à l'ossification et ces
options ne sont plus, en pratique, utilisables. Ainsi, SNI
permettait de désigner le serveur par son nom de domaine (host_name
dans SNI) mais aussi en utilisant d'autres types d'identificateurs
(champ name_type) sauf que, en pratique, ces
autres types n'ont jamais été utilisés et ne marcheraient
probablement pas. (Voir l'article de A. Langley, « Accepting
that other SNI name types will never work ».)
L'article seul
Articles des différentes années : 2026 2025 2024 2023 2022 2021 2020 Précédentes années
Syndication : Flux Atom avec seulement les résumés et Flux Atom avec tout le contenu.
{kind=link}