
Ce blog n'a d'autre prétention que de me permettre de mettre à la disposition de tous des petits textes que j'écris. On y parle surtout d'informatique mais d'autres sujets apparaissent parfois.
RFC 9154: Extensible Provisioning Protocol (EPP) Secure Authorization Information for Transfer
Date de publication du RFC : Décembre 2021
Auteur(s) du RFC : J. Gould, R. Wilhelm (VeriSign)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 31 décembre 2021
Le protocole EPP d'avitaillement des noms de domaine permet, entre autres opérations, de transférer un domaine d'un client (typiquement un BE) à un autre. Cette opération ouvre de sérieux problèmes de sécurité, le transfert pouvant être utilisé pour détourner un nom de domaine. En général, la sécurisation de ce transfert est faite par un mot de passe stocké en clair. Notre RFC décrit une méthode pour gérer ces mots de passe qui évite ce stockage, et qui gêne sérieusement les transferts malveillants.
EPP est normalisé dans le RFC 5730 et c'est ce document qui décrit le cadre général
d'autorisation d'un transfert de domaines. La forme exacte que prend
l'autorisation dépend du type d'objets qu'on gère avec EPP. Pour les
domaines (RFC 5731), c'est un élément
<authInfo>, qui peut contenir divers
types de sous-élements mais le plus fréquent est un simple
mot de passe (parfois appelé « code de
transfert » ou « code d'autorisation », ou simplement « authinfo »),
comme dans cet exemple, une réponse à une commande EPP
<info>, où le mot de passe est
« 2fooBAR » :
<domain:infData>
<domain:name>example.com</domain:name>
...
<domain:crDate>1999-04-03T22:00:00.0Z</domain:crDate>
...
<domain:authInfo>
<domain:pw>2fooBAR</domain:pw>
</domain:authInfo>
</domain:infData>
L'utilisation typique de ce mot de passe est que le client (en
général un BE)
le crée, le stocke en clair, l'envoie au serveur, qui le
stocke. Lors d'un transfert légitime, le BE gagnant recevra ce mot
de passe (typiquement via le titulaire de l'objet, ici un nom de
domaine) et le transmettra au registre (RFC 5731, section 3.2.4). Ici, le BE gagnant demande à son
client le code d'autorisation qu'il a normalement obtenu via le BE
perdant (si le client est vraiment le titulaire légitime) : 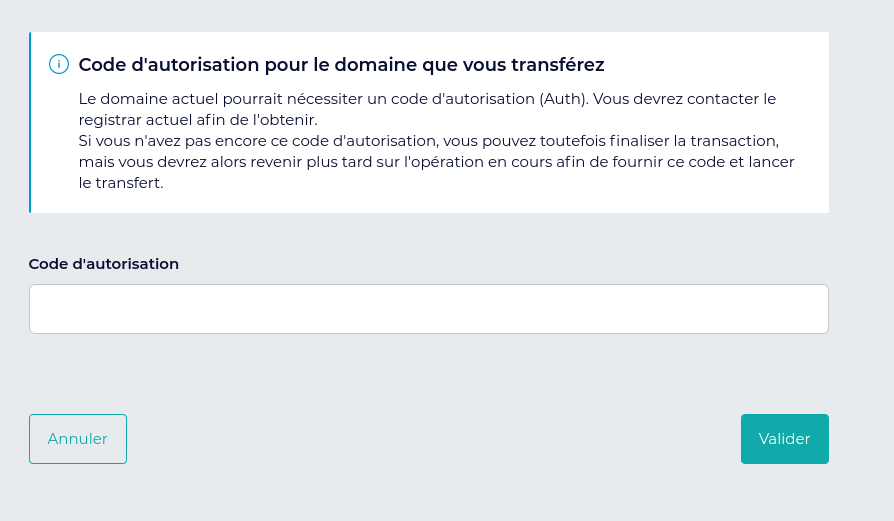 Et ici le BE perdant indique à
son client le code d'autorisation :
Et ici le BE perdant indique à
son client le code d'autorisation : 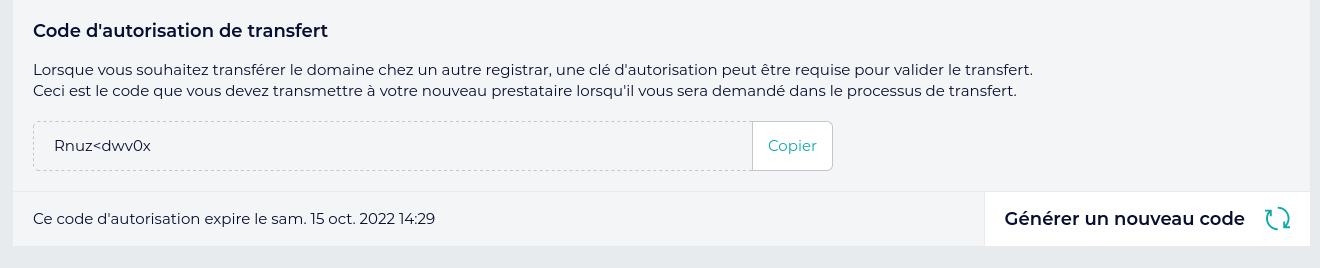 (registar = BE)
(registar = BE)
Notez que la façon d'autoriser les transferts, et d'accéder aux informations d'autorisation, dépend de la politique du registre. Les RFC sur EPP normalisent la technique mais pas la politique. Par exemple, lorsqu'un BE demande un transfert sans fournir d'information d'autorisation, certains registres refusent immédiatement le transfert, tandis que d'autres le mettent en attente d'une acceptation ou d'un refus explicite. De même, certains registres permettent de récupérer l'information d'autorisation, comme dans l'exemple ci-dessus, alors que d'autres (comme CentralNic) refusent.
Même chose pour d'autres types d'objets comme les contacts (RFC 5733) même si en pratique la pratique du transfert est plus rare pour ces types. Le mot de passe étant typiquement stocké en clair chez le client, pour pouvoir être donné en cas de transfert, on voit les risques que cela pose en cas d'accès à la base du BE. Aujourd'hui, stocker un mot de passe en clair est nettement considéré comme une mauvaise pratique de sécurité.
À la place, notre RFC décrit, non pas une modification du protocole EPP, mais une nouvelle procédure, une façon créative de se servir du protocole existant pour gérer ces informations d'autorisation de manière plus sérieuse : l'objet (par exemple le nom de domaine) est créé sans information d'autorisation, le serveur EPP (par exemple le registre de noms de domaine) doit refuser le transfert si cette information est manquante. Lors d'un transfert légitime, le client (par exemple un BE) perdant va générer un mot de passe, le transmettre au registre et à son client (typiquement le titulaire du nom de domaine) et ne pas le stocker. Le registre stockera le mot de passe uniquement sous forme condensée et, lorsqu'il recevra la demande de transfert accompagnée d'un mot de passe, il pourra condenser ce mot et vérifier qu'il correspond bien à celui stocké. Le mot ne servira qu'une fois et l'information d'autorisation est détruite après le succès du transfert. Tout ceci ne nécessite pas de modification du protocole, mais, dans certains cas, une modification des pratiques des différents acteurs (par exemple, le serveur EPP doit accepter qu'un objet soit créé sans information d'autorisation, et doit considérer que cela vaut refus de tout transfert).
Le RFC note que la norme EPP ne décrit, logiquement, que le protocole, c'est-à-dire l'interaction entre les deux machines, mais pas ce que fait chaque machine de son côté. Ainsi, la nécessité de stocker les mots de passe de manière sécurisée n'est pas imposée par EPP (mais est néanmoins une bonne pratique).
D'autre part, EPP ne prévoit pas explicitement de durée de vie pour les mots de passe (mais n'interdit pas non plus de les supprimer au bout d'un temps donné, ce qui va être justement la technique de notre RFC).
Petite révision sur les acteurs de l'avitaillement de noms de domaine en section 2 du RFC. La norme EPP parle de client et de serveur, notions techniques, mais du point de vue business, il y a trois acteurs (cf. la terminologie dans le RFC 8499), le registre (qui gère le serveur EPP), le bureau d'enregistrement (BE, qui gère le client EPP) et le titulaire (qui se connecte à son BE via une interface Web ou une API). Dans beaucoup de domaines d'enregistrement, il n'y a aucun lien direct entre le titulaire et le registre, tout devant passer par le BE.
Maintenant, place à la description de la nouvelle manière de faire
des transferts. Bien qu'elle ne change pas le protocole, qu'elle ne
soit qu'une nouvelle façon d'utiliser ce qui existe déjà dans EPP,
elle doit se signaler lors de la connexion EPP, avec
l'espace de noms
urn:ietf:params:xml:ns:epp:secure-authinfo-transfer-1.0
(enregistré
à l'IANA). En effet, la nouvelle manière a besoin que le
serveur accepte des choses qui sont autorisées par EPP mais pas
obligatoires, notamment :
- une information d'autorisation vide (représentée par exemple
par le
NULLdans une base SQL), - la possibilité de supprimer l'information d'autorisation
avec la commande EPP
<update>, - la possibilité de valider l'information d'autorisation
avec la commande EPP
<info>, - le refus de tout transfert si l'information d'autorisation est vide,
- la remise à zéro de l'information d'autorisation lorsque le transfert a été réalisé (mot de passe à usage unique).
Le serveur, lui, en recevant
urn:ietf:params:xml:ns:epp:secure-authinfo-transfer-1.0,
peut compter que le client EPP saura :
- générer une information d'autorisation forte (aléatoire, par exemple),
- ne le faire que lorsqu'un transfert est demandé.
L'autorisation d'information dans l'élement XML
<domain:pw> (RFC 5731, section 3.2.4) est un mot de passe qui doit être
difficile à deviner par un attaquant. Idéalement, il doit être
aléatoire ou équivalent (RFC 4086). Le RFC
calcule que pour avoir 128 bits d'entropie, avec uniquement les
caractères ASCII imprimables, il faut environ 20
caractères.
Pour compenser l'absence de la notion de durée de vie de l'information d'autorisation dans EPP, le client ne doit définir une information d'autorisation que lorsqu'un transfert est demandé, et supprimer cette information ensuite. La plupart du temps, le domaine n'aura pas d'information d'autorisation, et les transferts seront donc refusés.
L'information d'autorisation, comme tout mot de passe, ne doit plus être stockée en clair, mais sous forme d'un condensat. Le BE perdant ne doit pas la stocker (il la génère, la passe au titulaire et l'oublie ensuite). Le BE gagnant ne doit la stocker que le temps de finaliser le transfert. Évidemment, toute la communication EPP doit être chiffrée (RFC 5734). Lors d'une demande de transfert, le registre va vérifier qu'un condensat de l'information d'autorisation transmise par le BE gagnant correspond à ce que le BE perdant avait envoyé. L'information vide est un cas particulier, le registre ne doit pas tester l'égalité mais rejeter le transfert.
La section 4 explique en détail le processus de transfert avec cette nouvelle méthode :
- Quand le domaine est créé, l'information d'autorisation est vide (pas de « authinfo »),
- quand le titulaire veut transférer le nom à un nouveau BE, il demande au BE perdant l'information d'autorisation,
- le BE perdant génère un mot de passe, qu'il transmet au titulaire et au registre (qui peut répondre avec le code d'erreur EPP 2202 si ce mot de passe ne lui semble pas assez fort), puis qu'il oublie aussitôt,
- le titulaire donne le mot de passe au BE gagnant,
- le BE gagnant demande le transfert au registre, en fournissant le mot de passe, ce qui permet au transfert d'être accepté immédiatement,
- le registre (ou bien le BE perdant), efface le mot de passe.
Voici en EPP quelques messages pour réaliser ces différentes opérations. D'abord, la création d'un nom (notez le mot de passe vide) :
<create>
<domain:create
xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
<domain:name>example.test</domain:name>
<domain:authInfo>
<domain:pw/>
</domain:authInfo>
</domain:create>
</create>
Ici, la mise à jour de l'information d'autorisation par le BE
perdant, lorsque le titulaire lui a annoncé le départ du domaine ;
le mot de passe est
LuQ7Bu@w9?%+_HK3cayg$55$LSft3MPP (le RFC
rappelle fortement l'importance de générer un mot de passe fort, par
exemple en utilisant des sources bien aléatoires, comme documenté
dans le RFC 4086) :
<update>
<domain:update
xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
<domain:name>example.test</domain:name>
<domain:chg>
<domain:authInfo>
<domain:pw>LuQ7Bu@w9?%+_HK3cayg$55$LSft3MPP</domain:pw>
</domain:authInfo>
</domain:chg>
</domain:update>
</update>
Le BE perdant devra peut-être également supprimer l'état
clientTransferProhibited, si le domaine était
protégé contre les transferts.
Le BE gagnant peut également vérifier l'information
d'autorisation sans déclencher un transfert, avec une requête
<info>, qui lui renverra l'information
d'autorisation. Pour plusieurs exemples par la suite, j'ai utilisé le
logiciel Cocca. Cocca,
par défaut, ne stocke pas l'autorisation d'information en clair et
ne peut donc pas la renvoyer.
Ou bien le client EPP peut envoyer une commande
<info> en indiquant l'information
d'autorisation. S'il obtient une erreur EPP 2202 (RFC 5730, section 3), c'est que cette
information n'était pas correcte. Ici, la
réponse EPP de Cocca lorsqu'on lui envoie un
<info> avec information d'autorisation correcte :
Client : <info xmlns="urn:ietf:params:xml:ns:epp-1.0"><info xmlns="urn:ietf:params:xml:ns:domain-1.0"><name>foobar.test</name><authInfo xmlns="urn:ietf:params:xml:ns:domain-1.0"><pw xmlns="urn:ietf:params:xml:ns:domain-1.0">tropfort1298</pw></authInfo></info></info> Serveur : ... <ns1:authInfo><ns1:pw>Authinfo Correct</ns1:pw></ns1:authInfo> ...
Et si cette information est incorrecte :
Serveur : ... <ns1:authInfo><ns1:pw>Authinfo Incorrect</ns1:pw></ns1:authInfo>
(Mais Cocca répond quand même avec un code EPP 1000, ce qui n'est pas correct.)
Et enfin, bien sûr, voici la demande de transfert elle-même :
<transfer op="request">
<domain:transfer
xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
<domain:name>example1.com</domain:name>
<domain:authInfo>
<domain:pw>LuQ7Bu@w9?%+_HK3cayg$55$LSft3MPP</domain:pw>
</domain:authInfo>
</domain:transfer>
</transfer>
Et si c'est bon :
<ns0:response xmlns:ns0="urn:ietf:params:xml:ns:epp-1.0" xmlns:ns1="urn:ietf:params:xml:ns:domain-1.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"><ns0:result code="1000"><ns0:msg>Command completed successfully</ns0:msg></ns0:result><ns0:msgQ count="2" id="3" />
<ns1:trStatus>serverApproved</ns1:trStatus> ...
Et avec une mauvaise information d'autorisation :
<ns0:response xmlns:ns0="urn:ietf:params:xml:ns:epp-1.0"><ns0:result code="2202"><ns0:msg>Invalid authorization information; (T07) Auth Info Password incorrect</ns0:msg></ns0:result>...
La section 6 du RFC décrit le problème de la transition depuis
l'ancien modèle d'autorisation vers le nouveau. Notez que certains
registres peuvent avoir une partie du nouveau système déjà en
place. Le registre qui désire transitionner doit d'abord s'assurer
que l'information d'autorisation absente ou vide équivaut à un
rejet. Il doit ensuite permettre aux BE de mettre une information
d'autorisation vide, permettre que la commande
<info> puisse tester une information
d'autorisation, s'assurer que l'acceptation d'un transfert supprime
l'information d'autorisation, etc.
L'extension à EPP décrite dans ce RFC a été enregistrée dans le registre des extensions EPP. Quelles sont les mises en œuvre de ce RFC ? Cocca, déjà cité, le fait partiellement (par exemple en ne stockant pas les mots de passe en clair). Je n'ai pas testé avec ce logiciel ce qui se passait avec une information d'autorisation vide. Sinon, CentralNic a déjà ce mécanisme en production. Et Verisign l'a mis dans son SDK.
L'article seul
RFC 9167: Registry Maintenance Notification for the Extensible Provisioning Protocol (EPP)
Date de publication du RFC : Décembre 2021
Auteur(s) du RFC : T. Sattler, R. Carney, J. Kolker (GoDaddy)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 26 décembre 2021
Un registre, par exemple un registre de noms de domaine, utilise parfois le protocole EPP pour la communication avec ses clients. Ce RFC décrit comment utiliser ce protocole pour informer les clients des périodes d'indisponibilité du registre, par exemple lors d'une opération de maintenance.
Aujourd'hui, un registre prévient de ses periodes
d'indisponibilité prévues par divers moyens : courriers aux BE, messages sur des
réseaux sociaux, page Web dédiée comme : 
Chaque registre le fait de façon différente, il n'existe pas de règles communes, et le côté non-structuré de ces annonces fait qu'il faut une interventon humaine pour les analyser et les mettre dans un agenda. Et un BE peut devoir interagir avec de nombreux registres ! Notre RFC propose d'utiliser EPP (RFC 5730) pour ces annonces.
Donc, premier principe, puisqu'on va souvent manipuler des dates,
les dates et heures seront toutes représentées en UTC et dans le format
du RFC 3339. Ensuite, les annonces seront dans
un élément XML <item>, de
l'espace de noms
urn:ietf:params:xml:ns:epp:maintenance-1.0
(enregistré
à l'IANA). Parmi les sous-éléments de cet élément :
id, un identificateur de l'évènement,systems, qui permettra de désigner les systèmes affectés,environment, pour dire si l'évènement concerne la production ou bien un banc de test,startetend, qui indiquent le début et la fin (prévue…) de l'évènement,- et plusieurs autres éléments.
Un exemple d'évènement, une intervention sur le serveur EPP
epp.registry.example de production, peut être :
<maint:item>
<maint:id>2e6df9b0-4092-4491-bcc8-9fb2166dcee6</maint:id>
<maint:systems>
<maint:system>
<maint:name>EPP</maint:name>
<maint:host>epp.registry.example</maint:host>
<maint:impact>full</maint:impact>
</maint:system>
</maint:systems>
<maint:environment type="production"/>
<maint:start>2021-12-30T06:00:00Z</maint:start>
<maint:end>2021-12-30T07:00:00Z</maint:end>
<maint:reason>planned</maint:reason>
<maint:detail>
https://www.registry.example/notice?123
</maint:detail>
<maint:tlds>
<maint:tld>example</maint:tld>
<maint:tld>test</maint:tld>
</maint:tlds>
</maint:item>
On voit que le serveur EPP sera arrêté pendant une heure
(<impact>full</impact> indiquant
une indisponibilité totale) et que cela affectera les TLD
.example et .test. Une
telle information, étant sous une forme structurée, peut être
analysée par un programme et automatiquement insérée dans un agenda,
ou un système de supervision.
Les commandes EPP exactes, maintenant (section 4 du RFC). La
commande <info> peut renvoyer maintenant
un élément <maint:info> qui contient
l'information de maintenance. Voici l'exemple du RFC. D'abord, la
question du client, qui veut de l'information sur l'évènement
2e6df9b0-4092-4491-bcc8-9fb2166dcee6 :
<info>
<maint:info
xmlns:maint="urn:ietf:params:xml:ns:epp:maintenance-1.0">
<maint:id>2e6df9b0-4092-4491-bcc8-9fb2166dcee6</maint:id>
</maint:info>
</info>
Puis la réponse du serveur :
<response>
<result code="1000">
<msg>Command completed successfully</msg>
</result>
<resData>
<maint:infData
xmlns:maint="urn:ietf:params:xml:ns:epp:maintenance-1.0">
<maint:item>
<maint:id>2e6df9b0-4092-4491-bcc8-9fb2166dcee6
</maint:id>
<maint:type lang="en">Routine Maintenance</maint:type>
<maint:systems>
<maint:system>
<maint:name>EPP</maint:name>
<maint:host>epp.registry.example
</maint:host>
<maint:impact>full</maint:impact>
</maint:system>
</maint:systems>
<maint:environment type="production"/>
<maint:start>2021-12-30T06:00:00Z</maint:start>
<maint:end>2021-12-30T07:00:00Z</maint:end>
<maint:reason>planned</maint:reason>
<maint:detail>
https://www.registry.example/notice?123
</maint:detail>
<maint:description lang="en">free-text
</maint:description>
<maint:description lang="de">Freitext
</maint:description>
<maint:tlds>
<maint:tld>example</maint:tld>
<maint:tld>test</maint:tld>
</maint:tlds>
<maint:intervention>
<maint:connection>false</maint:connection>
<maint:implementation>false</maint:implementation>
</maint:intervention>
<maint:crDate>2021-11-08T22:10:00Z</maint:crDate>
</maint:item>
</maint:infData>
</resData>
...
Ici, le client connaissait l'identificateur d'une opération de maintenance particulière. S'il ne le connait pas et veut récupérer une liste d'événements :
<info>
<maint:info
xmlns:maint="urn:ietf:params:xml:ns:epp:maintenance-1.0">
<maint:list/>
</maint:info>
</info>
Il récupérera alors une <maint:list>, une
liste d'opérations de maintenance.
Le client EPP peut
également être prévenu des maintenances par la commande
<poll>, qui dote EPP d'un système de
messagerie (RFC 5730, section 2.9.2.3). Ainsi,
un message dans la boite aux lettres du client pourra être :
<response>
<result code="1301">
<msg>Command completed successfully; ack to dequeue</msg>
</result>
<msgQ count="1" id="12345">
<qDate>2021-11-08T22:10:00Z</qDate>
<msg lang="en">Registry Maintenance Notification</msg>
</msgQ>
<resData>
<maint:infData
xmlns:maint="urn:ietf:params:xml:ns:epp:maintenance-1.0">
<maint:item>
<maint:id>2e6df9b0-4092-4491-bcc8-9fb2166dcee6</maint:id>
<maint:pollType>create</maint:pollType>
<maint:systems>
<maint:system>
<maint:name>EPP</maint:name>
<maint:host>epp.registry.example
</maint:host>
<maint:impact>full</maint:impact>
...
La section 5 du RFC décrit la syntaxe formelle de cette extension (en XML Schema). Elle est dans le registre IANA des extensions à EPP.
Et question mises en œuvre ? Apparemment, les registres gérés par GoDaddy et Tango envoient déjà ces informations de maintenance.
L'article seul
Clé PGP inutilisable ?
Première rédaction de cet article le 25 décembre 2021
Décembre 2021, des correspondants m'informent que ma clé PGP n'est plus utilisable pour m'envoyer des messages chiffrés. Unusable public key ou autres messages peu parlants. Alors que ça marchait avant.
% gpg --encrypt --recipient CCC66677 toto.txt
gpg: CCC66677: skipped: Unusable public key
gpg: toto.txt: encryption failed: Unusable public key
C'était un simple oubli idiot de ma part : la clé a plusieurs sous-clés, ayant des rôles différents (chiffrement, signature…). Lors de la précédente expiration de la clé, j'avais bien re-signé mais en oubliant une des sous-clés, celle de chiffrement (une grosse bêtise). Au lieu d'un message clair du genre « cette clé a expiré » (ce qui se produit quand toutes les clés sont expirées), le logiciel, ne voyant que la clé de signature, n'arrivait pas à produire un message d'erreur intelligent. (Au passage, le format de clés PGP ou, plus exactement, OpenPGP, est normalisé dans le RFC 4880).
La clé et ses sous-clés, dont une (tout à la fin) était expirée :
sec rsa4096/555F5B15CCC66677
created: 2014-02-08 expires: 2023-12-21 usage: SC
trust: unknown validity: undefined
ssb rsa4096/3FA836C996A4A254
created: 2014-02-09 expires: 2023-12-21 usage: S
ssb* rsa4096/9045E02757F02AA1
created: 2014-02-09 expired: 2021-12-19 usage: E
(Usage: E = encryption - chiffrement, alors que Usage: S désigne la possibilité de signer.)
Une fois tout re-signé proprement :
sec rsa4096/555F5B15CCC66677
created: 2014-02-08 expires: 2023-12-25 usage: SC
trust: unknown validity: undefined
ssb* rsa4096/3FA836C996A4A254
created: 2014-02-09 expires: 2023-12-25 usage: S
ssb* rsa4096/9045E02757F02AA1
created: 2014-02-09 expires: 2023-12-25 usage: E
Vous pouvez récupérer ma clé publique sur les serveurs de clés PGP habituels, ou bien directement sur ce site Web. Les raisons pour lesquelles j'ai mis une date d'expiration à ma clé (ce n'est pas obligatoire et, vous avez vu, ça peut entrainer des problèmes), sont détaillées dans un autre article.
Merci à André Sintzoff pour le signalement et à Kim Minh Kaplan pour la solution.
L'article seul
RFC 9165: Additional Control Operators for Concise Data Definition Language (CDDL)
Date de publication du RFC : Décembre 2021
Auteur(s) du RFC : C. Bormann (Universität Bremen TZI)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF cbor
Première rédaction de cet article le 25 décembre 2021
Le langage CDDL (Concise Data Definition Language) est un langage de description de schémas de données, notamment pour le format CBOR. Ce nouveau RFC étend CDDL avec de nouveaux opérateurs, permettant entre autres l'addition d'entiers et la concaténation de chaines de caractères.
CDDL est normalisé dans le RFC 8610 (et le format CBOR dans le RFC 8949). Il permet l'ajout de nouveaux opérateurs pour étendre le langage, possibilité utilisée par notre nouveau RFC. Notez que, comme les modèles de données de JSON et CBOR sont très proches, les schémas CDDL peuvent également être utilisés pour JSON, ce que je fais ici pour les exemples car le JSON est plus facile à lire et à écrire.
D'abord, l'opérateur .plus. Il permet par
exemple, dans la spécification d'un schéma, de faire dépendre
certains nombres d'autres nombres. L'exemple ci-dessous
définit un type « intervalle » où la borne supérieure doit être
supérieure de 5 à la borne inférieure :
top = interval<3>
interval<BASE> = BASE .. (BASE .plus 5)
Avec un tel schéma, la valeur 4 sera acceptée mais 9 sera refusée :
% cddl tmp.cddl validate tmp.json CDDL validation failure (nil for 9): [9, [:range, 3..8, Integer], ""]
Deuxième opérateur, la
concaténation, avec le nouvel opérateur
.cat :
s = "foo" .cat "bar"
Dans cet exemple, évidemment, .cat n'est pas
très utile, on aurait pu écrire la chaine complète directement. Mais
.cat est plus pertinent quand on veut manipuler
des chaines contenants des sauts de ligne :
s = "foo" .cat ' bar baz '
Ce schéma acceptera la chaine de caractère "foo\n bar\n
baz\n".
Dans l'exemple ci-dessus, bar et
baz seront précédés des espaces qui
apparaissaient dans le code source. Souvent, on souhaite mettre ces
espaces en début de ligne dans le code source, pour
l'indenter joliment, mais les supprimer dans
le résultat final. Cela peut se faire avec l'opérateur pour lequel
notre RFC invente le joli mot de détentation
(dedending), .det, qui
fonctionne comme .cat mais « dédente » les
lignes :
s = "foo" .det ' bar baz '
Cette fois, le schéma n'acceptera que la chaine
"foo\nbar\nbaz\n".
Le RFC note que, comme .det est l'abréviation
de dedending cat, on aurait pu l'appeler
.dedcat mais cela aurait chagriné les amis des
chats.
CDDL est souvent utilisé dans les normes techniques de l'Internet
et celles-ci contiennent souvent des
grammaires en ABNF (RFC 5234). Pour permettre de réutiliser les règles ABNF dans
CDDL, et donc se dispenser d'une ennuyeuse traduction, un nouvel
opérateur fait son apparition, .abnf. Le RFC
donne l'exemple de la grammaire du RFC 3339,
qui normalise les formats de date : abnf-rfc3339.cddl. Avec ce fichier, on peut accepter des
chaines comme "2021-12-15" ou
"2021-12-15T15:52:00Z". Notons qu'il reste
quelques difficultés car les règles d'ABNF ne sont pas parfaitement
compatibles avec celles de CDDL. Si .abnf va
traiter l'ABNF comme de l'Unicode encodé en
UTF-8, un autre opérateur,
.abnfb, va le traiter comme une bête suite
d'octets. D'autre part, comme ABNF exige souvent des sauts de ligne,
les opérateurs .cat et
.det vont être très utiles.
Quatrième et dernier opérateur introduit par ce RFC,
.feature. À quoi sert-il ? Comme le langage
CDDL peut ếtre étendu au-delà de ce qui existait dans le RFC 8610, on court toujours le risque de traiter
un schéma CDDL avec une mise en œuvre de CDDL qui ne connait pas
toutes les fonctions utilisées dans le schéma. Cela produit en
général un message d'erreur peu clair et, surtout, cela mènerait à
considérer des données comme invalides alors qu'elles sont
parfaitement acceptables pour le reste du
schéma. .feature sert donc à marquer les
extensions qu'on utilise. Le programme qui met en œuvre CDDL pourra
ainsi afficher de l'information claire. Par exemple, si on définit
une personne :
person = {
? name: text
? organization: text
}
puis qu'on veut rajouter son groupe sanguin :
{"name": "Jean", "bloodgroup": "O+"}
Cet objet sera rejeté, en raison du champ
bloodgroup. On va faire un schéma plus ouvert, avec
.feature :
person = {
? name: text
? organization: text
* (text .feature "further-person-extension") => any
}
Et, cette fois, l'objet est accepté avec un message d'avertissement clair :
% cddl person-new-feature.cddl validate tmp.json ** Features potentially used (tmp.json): further-person-extension: ["bloodgroup"]
Comme le schéma est assez ouvert, la fonction de génération de fichiers d'exemple de l'outil donne des résultats amusants :
% cddl person-new-feature.cddl generate
{"name": "plain", "dependency's": "Kathryn's", "marvelous": "cleavers"}
Les nouveaux opérateurs ont été placés dans le registre
IANA. Ils sont mis en œuvre dans l'outil de référence de CDDL
(le cddl utilisé ici). Écrit en
Ruby, on peut l'installer avec la méthode Ruby
classique :
% gem install cddl
Il existe une autre mise en œuvre de CDDL (qui porte malheureusement le même nom). Elle est en Rust et peut donc s'installer avec :
% cargo install cddl
Elle n'inclut pas encore les opérateurs de ce RFC :
% /home/stephane/.cargo/bin/cddl validate --cddl plus.cddl plus.json Validation of "plus.json" failed error parsing CDDL: error: lexer error ┌─ input:8:12 │ 8 │ (BASE .plus 1) => int ; upper bound │ ^^^^^ invalid control operator
L'article seul
RFC 0810: DoD Internet host table specification
Date de publication du RFC : Mars 1982
Auteur(s) du RFC : Elizabeth Feinler, Ken Harrenstien, Zaw-Sing Su, Vic White (SRI International, Network Information Center)
Statut inconnu, probablement trop ancien
Première rédaction de cet article le 22 décembre 2021
Un peu d'histoire, avec ce RFC 810, qui mettait à jour le format du fichier géant qui, à l'époque, contenait la liste de toutes les machines de l'Internet. Il remplaçait le RFC 608.
Par rapport à son prédécesseur, ce RFC marquait le début de la fin de ce fichier
géant : ses limites étaient désormais bien comprises, et le
DNS était en cours
d'élaboration, quoique encore dans le futur. En attendant ce système
décentralisé et réparti, notre RFC mettait à jour la syntaxe du
fichier HOSTS.TXT, aussi appelé
« hosts » ou « host
table ». Il s'appliquait à
l'Internet mais aussi à son prédécesseur
Arpanet qui, à l'époque, vivait encore, une
vie séparée. Le fichier était ensuite distribué par un serveur
centralisé, décrit dans le RFC 811. Si vous
vouliez le fichier entier, notre RFC rappelait les instructions, à
l'époque où les URL n'existaient pas encore : « Connectez-vous
à 10.0.0.73 en FTP, en utilisant le compte
ANONYMOUS et le mot de passe
GUEST, puis utilisez la commande
get pour le fichier
<NETFINFO>HOSTS.TXT ». (On notera qu'à
l'époque, le FTP anonyme était réellement
anonyme, la convention d'utiliser son adresse comme mot de passe n'existait pas
encore.)
Bon, quelle était la syntaxe de ce fichier ? Les noms étaient
composés de lettres ASCII, de chiffres, de
traits d'union et de
points, en 24 caractères maximum. Ils étaient
insensibles à la casse. Il existait des
conventions de nommage : un routeur devait
avoir un nom se terminant en -GATEWAY ou
-GW. Un TAC devait se nommer
quelquechose-TAC. (Le RFC ne prend pas la peine
d'expliquer ce qu'est un TAC. Un TAC,
Terminal Access Controller était un ordinateur
spécialisé dans le service de terminaux, qui n'avait pas de compte
local et ne servait qu'à se connecter à des ordinateurs
distants.)
Le RFC décrit ensuite le format des adresses. Loin des débuts de l'Arpanet, elles étaient déjà sur 32 bits à l'époque (cela avait été normalisé par le RFC 796 en 1981). La longueur du préfixe dépendait de la valeur des premiers bits de l'adresse (le système des classes, qui a été abandonné en 1993).
Le fichier contenait aussi les noms des réseaux. Pour les machines, le fichier ne contenait pas que noms et adresses. À cette époque sans Web et sans moteur de recherche, il servait aussi à publier les services disponibles sur chaque machine. Et il indiquait aussi le système d'exploitation des machines, information utile quand on voulait se connecter avec telnet. (D'autres protocoles nécessitaient de connaitre ce système d'exploitation. L'utilisation de FTP en dépendait, sans compter les problèmes d'encodage des caractères, dans un monde sans Unicode.) Voici quelques exemples de machines, datant de 1983 :
HOST : 10.0.0.4, 192.5.12.21 : UTAH-CS : VAX-11/750 : UNIX : TCP/TELNET,TCP/FTP,TCP/SMTP : HOST : 10.0.0.6 : MIT-MULTICS,MULTICS : HONEYWELL-DPS-8/70M : MULTICS : TCP/TELNET,TCP/SMTP,TCP/FTP,TCP/FINGER,TCP/ECHO,TCP/DISCARD,ICMP : HOST : 10.0.0.9 : HARV-10,ACL : DEC-10 : TOPS10 :: HOST : 32.2.0.42 : UCL-TAC,LONDON-TAC : H-316 : TAC : TCP : HOST : 26.4.0.73 : SRI-F4 : FOONLY-F4 : TENEX :: HOST : 10.0.0.51, 26.0.0.73 : SRI-NIC,NIC : DEC-2060 : TOPS20 : TCP/TELNET,TCP/SMTP,TCP/TIME,TCP/FTP,TCP/ECHO,ICMP :
Vous noterez que l'université d'Utah
utilise toujours, en 2021, le même préfixe
192.5.12.0/24… Par contre, le
MIT n'a plus de service ECHO… (Ce service
était normalisé dans le RFC 862.) La machine de
l'UCL était une des rares étrangères aux
USA. Le Foonly qu'on voit au
SRI était une machine connue pour avoir fait
les CGI des films Tron
et, come le note John Shaft, Looker :
« première fois qu'il était possible de voir de la
3D avec ombrage dans un film, de mémoire. Un
corps humain de surcroît. ». Quant à la machine
SRI-NIC, c'est elle qui distribuait ce fichier
(son adresse avait changé depuis la publication du RFC).
L'internet était encore assez centralisé à l'époque, et il était possible de décider d'un « jour J », où on fait changer tout le monde en même temps : ce RFC fixait la date au 1er mai 1982, où tout le monde devait utiliser le nouveau format, l'ancien, celui du RFC 608, étant abandonné.
Une copie du fichier de 1983 est en ligne (merci à Patrick Mevzek pour l'avoir trouvée) et j'en ai fait une copie locale.
L'article seul
RFC 9155: Deprecating MD5 and SHA-1 signature hashes in (D)TLS 1.2
Date de publication du RFC : Décembre 2021
Auteur(s) du RFC : L.V. Velvindron (cyberstorm.mu), K.M. Moriarty (CIS), A.G. Ghedini (Cloudflare)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 20 décembre 2021
Vous le savez certainement déjà, car toutes les lectrices et tous les lecteurs de ce blog sont très attentif·ves et informé·es, mais les algorithmes de condensation MD5 et SHA-1 ont des failles connues et ne doivent pas être utilisés dans le cadre de signatures. Vous le savez, mais tout le monde ne le sait pas, ou bien certain·es ont besoin d'un document « officiel » pour agir donc, le voici : notre RFC dit qu'on ne doit plus utiliser MD5 et SHA-1 dans TLS.
Si vous voulez savoir pourquoi ces algorithmes sont mauvais, le RFC 6151 vous renseignera (et la section 1 de notre RFC 9155 vous donnera une bibliographie récente).
La section 2 à 5 sont le cœur du RFC et elle est sont très simples : pas de MD5, ni de SHA-1 pour les signatures. Dans le registre IANA, ces algorithmes sont désormais marqués comme déconseillés.
Les fanas de cryptographie noteront qu'on peut toujours utiliser SHA-1 pour HMAC (où ses faiblesses connues n'ont pas de conséquences).
L'article seul
Log4Shell, et le financement du logiciel libre
Première rédaction de cet article le 14 décembre 2021
Vous avez sans doute suivi l'affaire de la faille de sécurité Log4Shell. Elle a souvent été utilisée comme point de départ pour des discussions à propos du financement du logiciel libre, en mode « de nombreuses grosses entreprises utilisent tel logiciel libre et en dépendent mais ne contribuent pas à son financement ». Ce point de vue mérite d'être nuancé.
La faille concerne le logiciel Log4j, très utilisé (ce qui explique en partie l'intérêt porté à la faille Log4Shell). Comme beaucoup de logiciels libres très utilisés, il ne bénéficie pas d'une équipe de développeurs payés à temps plein pour le maintenir. Je cite tout de suite le dessin de XKCD que tout le monde mentionne tout le temps. Face à cela, on lit souvent des affirmations comme quoi les grosses entreprises (par exemple les GAFA) devraient financer ces logiciels cruciaux. Je pense que c'est plus compliqué que cela, et je voudrais présenter ici deux faits et une opinion.
Premier fait, un ou une développeureuse de logiciel libre n'est pas forcément bénévole. Le logiciel libre n'est pas synonyme de gratuité et, de toute façon, la gratuité du logiciel ne veut pas dire que les développeureuses n'ont pas été payé·es. Il y a beaucoup de logiciels libres cruciaux qui sont maintenus par des salarié·es. (Dans le domaine du DNS, c'est le cas de tous les serveurs libres, comme BIND ou NSD, maintenus par les employé·es de l'ISC, de NLnet Labs, de PowerDNS, etc.) D'affirmer comme je l'ai lu souvent qu'il faut s'inquiéter des logiciels libres car leurs développereuses sont bénévoles est donc absurde. La question du financement du logiciel libre est une question très intéressante (il est parfaitement normal que les programmeureuses soient payé·es pour leur travail) mais elle a de nombreuses réponses.
Deuxième fait, si le logiciel est libre, par définition, personne n'est obligé de payer pour l'utiliser. Du point de vue moral, on peut trouver que ce n'est pas beau qu'Amazon ou Google ne dépensent pas un centime pour des logiciels qu'ils utilisent mais c'est le principe du logiciel libre. Un·e auteur·e de logiciel peut toujours mettre son logiciel sous une licence non-libre, imposant par exemple un paiement pour un usage commercial (ce qui est en général une mauvaise idée) mais ce n'est plus du logiciel libre.
Enfin, mon opinion. À défaut d'imposer un paiement, ce qui n'est pas possible pour un logiciel libre, ne faudrait-il pas au moins exercer une pression morale pour que les entreprises qui gagnent de l'argent avec une infrastructure composée en (bonne) partie de logiciel libre mettent la main sur l'interface Web de leur banque et envoient de l'argent ?
Ce point soulève de nombreuses questions. D'abord, si la programmeuse ou le programmeur a choisi le logiciel libre (et donc de ne pas forcément toucher de l'argent des utilisateurs), c'est qu'il y a une raison. Souvent, c'était pour être elle-même ou lui-même plus libre, pour ne pas dépendre de product owners, de commerciaux ou de décideurs qui lui diraient qu'ils veulent telle ou telle jolie fonction dans l'interface. Si le financement des logiciels libres est assuré par des grosses entreprises, elles exigeront sans doute du reporting, des process formalisés, elles demanderont un pouvoir de décision, et tou·tes les auteur·es de logiciel libre n'ont pas envie de travailler dans un tel cadre. Même si Amazon voulait payer, tout le monde ne le voudrait pas. (En outre, se faire payer pour développer du logiciel libre est parfois compliqué, du point de vue administratif, même si quelqu'un veut le faire.)
C'est d'autant plus vrai que ces grosses entreprises ont souvent un rôle très néfaste dans l'Internet. Je me souviens d'une discussion il y a quelques années avec la responsable d'un gros projet libre, financé en grande partie par des contrats avec des entreprises de l'Internet qui payaient pour que telle ou telle fonction soit développée. Je lui suggérai des améliorations pour préserver la vie privée des utilisateurices. Elle m'avait répondu « Stéphane, tu nous demandes toujours des trucs pour mieux protéger la vie privée, mais les clients qui paient nous paient pour, au contraire, trouver des moyens de récolter davantage de données. »
Bien sûr, une solution possible serait d'isoler les programmeuses ou programmeurs des financeurs via, par exemple, une fondation qui recevrait l'argent et le distribuerait (un certain nombre de gros logiciels libres fonctionnent ainsi, et c'est d'ailleurs le cas de Log4j). Mais cela ne convient pas non plus à tout le monde. (Ces fondations ne sont pas forcément innocentes.)
Et la sécurité n'y gagnerait pas forcément. Dans le cas de Log4Shell, les auteurs ont commis une bogue, c'est sûr. Mais tous les logiciels peuvent avoir des bogues, que leurs auteurs soient payés ou pas. Et, une fois la bogue signalée, tout semble indiquer que les auteurs de Log4j ont réagi vite et bien. Tout n'est pas une question de financement, et, en matière de sécurité, la conscience professionnelle et la réactivité comptent davantage. Rajouter des règles, des procédures et de la bureaucratie, sous couvert d'avoir des dévelopements logiciels « plus sérieux » ne serait pas un progrès en sécurité, probablement plutôt le contraire. (Sans compter que les grosses entreprises sont les premières à réclamer davantage de fonctions, donc davantage de failles de sécurité, et à prioriser l'apparence sur la qualité.)
[Ne me faites pas dire ce que je n'ai pas dit ; je n'ai pas proposé que les développeur·ses de logiciels soient forcément pauvres et grelottant de froid dans une mansarde non chauffée. Qu'ielles soient payé·es est normal. Mais, vu l'actuel marché de l'emploi dans la programmation, celles et ceux qui ne s'intéressent qu'à l'argent n'ont en général pas de problème. La question du financement et de la maintenance des logiciels essentiels est importante, mais elle ne se résoudra pas en demandant simplement aux GAFA de mettre la main à la poche.]
Quelques lectures sur ce sujet délicat :
- Un appel à financer les développeurs dont on utilise le travail (appel qui n'est pas destiné qu'aux « grosses entreprises »).
- Un rappel de la situation dans Next Inpact.
- Un avis d'un employé de Google, qui pointe entre autres les contraintes liées aux grandes entreprises, et qui illustre parfaitement les dangers dont je parle plus haut (en disant explicitement que de payer les développeureuses permettra de leur donner des ordres).
- Un article de Numérama décrit bien l'opinion dominante (« il faut faire payer les grosses entreprises »).
- Au contraire, cet article pointe les dangers du financement par les grosses entreprises.
- Un excellent article de Daniel Stenberg sur le sujet, pointant entre autres les difficultés paperassières à toucher de l'argent, même quand une entreprise ou l'État veut vous en donner, et également le fait que ce n'est pas un hasard si les logiciels touchés sont souvent des logiciels d'infrastructure, sans jolie interface que les décideurs peuvent admirer.
- Un développeur qui pointe la paperasserie nécessaire pour se faire payer.
- Dans le débat, des gens disent souvent open source au lieu de logiciel libre, par snobisme, parce que c'est mieux en anglais (ou bien parce qu'ils ne comprennent pas le sujet). C'est pareil.
L'article seul
RFC 9164: Concise Binary Object Representation (CBOR) Tags for IPv4 and IPv6 Addresses
Date de publication du RFC : Décembre 2021
Auteur(s) du RFC : M. Richardson (Sandelman Software Works), C. Bormann (Universität Bremen TZI)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF cbor
Première rédaction de cet article le 14 décembre 2021
Ce nouveau RFC normalise deux étiquettes CBOR pour représenter des adresses IP et des préfixes d'adresses.
Le format de données CBOR, normalisé dans le RFC 8949, a une liste de types prédéfinis mais on peut en créer d'autres, en étiquetant la donnée avec un entier qui permettre de savoir comment interpréter la donnée en question. Notre RFC introduit les étiquettes 52 (pour les adresses IPv4) et 54 (pour les adresses IPv6). Ah, pourquoi 52 et 54 ? Je vous laisse chercher, la solution est à la fin de l'article
La section 3 de notre RFC décrit le format. Pour chaque famille (IPv4 ou IPv6), il y a trois formats (tous avec la même étiquette) :
- Les adresses à proprement parler, représentées sous forme d'une byte string CBOR (suite d'octets, cf. RFC 8949, section 3.1, type majeur 2) et donc pas sous la forme textuelle (celle avec les points pour IPv4 et les deux-points pour IPv6),
- Les préfixes, représentés par un tableau de deux éléments, un entier pour la longueur du préfixe et une suite d'octets pour le préfixe lui-même (les octets nuls à la fin doivent être omis),
- L'interface, sous forme d'un tableau de deux ou trois
éléments, qui comporte une adresse IP, la longueur du préfixe sur
cette interface et éventuellement un identificateur d'interface
(genre
eth0sur Linux, voir la section 6 du RFC 4007 pour IPv6, et les RFC 4001 et RFC 6991 pour IPv4, mais cela peut aussi être un entier), identificateur qui est local à la machine.
La section 5 du RFC contient une description en CDDL (RFC 8610) de ces données.
J'ai écrit une mise en œuvre en Python de ce RFC, qui renvoie à un client
HTTP son
adresse IP, et le préfixe annoncé dans la DFZ en BGP (en utilisant pour cela les
données du RIS,
via le programme WhichASN). Le
service est accessible à l'adresse
https://www.bortzmeyer.org/apps/addresses-in-cbor,
par exemple :
% curl -s https://www.bortzmeyer.org/apps/addresses-in-cbor > tmp.cbor
Le CBOR est du binaire, on peut regarde avec le programme read-cbor :
% read-cbor tmp.cbor Array of 3 items String of length 165: Your IP address in CBOR [...] Tag 54 Byte string of length 16 Tag 54 Array of 2 items Unsigned integer 32 Byte string of length 4
On voit que le service renvoie un tableau CBOR de trois entrées :
- Une chaine de caractères de documentation,
- l'adresse IP (ici, de l'IPv6, d'où l'étiquette 54 et les 16 octets),
- le préfixe routé, sous la forme d'une longueur (ici, 32 bits) et des octets non nuls dudit préfixe (ici, au nombre de 4).
Vu avec le programme cbor2diag, le même fichier :
% cbor2diag.rb tmp.cbor
["Your IP address in CBOR, done with Python 3.9.2 [...]",
54(h'200141D0030222000000000000000180'),
54([32, h'200141D0'])]
(Le préfixe du client HTTP était en effet bien
2001:41d0::/32.) Le code source de service est
dans les sources du moteur de ce
blog, plus précisement en
wsgis/dispatcher.py.
Sinon, la raison du choix des étiquettes est que, en ASCII, 52 est le chiffre 4 et 54 est 6. Les deux étiquettes sont désormais dans le registre IANA. À noter que la représentation des adresses IP en CBOR avait été faite initialement avec les étiquettes 260 et 261, en utilisant un encodage complètement différent. 260 désignait les adresses (v4 et v6), 261, les préfixes. (Ces deux étiquettes sont marquées comme abandonnées, dans le registre IANA.) Au contraire, dans notre nouveau RFC, l'étiquette identifie la version d'IP, la distinction entre adresse et préfixe se faisant par un éventuel entier initial pour indiquer la longueur.
L'article seul
RFC 9162: Certificate Transparency Version 2.0
Date de publication du RFC : Décembre 2021
Auteur(s) du RFC : B. Laurie, A. Langley, E. Kasper, E. Messeri (Google), R. Stradling (Sectigo)
Expérimental
Réalisé dans le cadre du groupe de travail IETF trans
Première rédaction de cet article le 10 décembre 2021
Le système de gestion de certificats PKIX (dérivé des certificats X.509) a une énorme faiblesse. N'importe quelle AC peut émettre un certificat pour n'importe quel nom de domaine. Il ne suffit donc pas de bien choisir son AC, votre sécurité dépend de toutes les AC. Ce RFC propose une approche pour combler cette faille de sécurité : encourager/obliger les AC à publier « au grand jour » les certificats qu'elles émettent. Un titulaire d'un certificat qui craint qu'une AC n'émette un certificat à son nom sans son autorisation n'a alors qu'à surveiller ces publications. (Il peut aussi découvrir à cette occasion que sa propre AC s'est fait pirater ou bien est devenue méchante et émet des certificats qu'on ne lui a pas demandés. L'idée est aussi d'empêcher l'émission « discrète » de vrais/faux certificats qui seraient ensuite utilisés uniquement à certains endroits.) Ce système, dit « Certificate Transparency » (CT) avait initialement été normalisé dans le RFC 6962, que notre RFC remplace, le protocole passant à une nouvelle version, la v2 (toujours considérée comme expérimentale).
Le principe est donc de créer des journaux des certificats émis. Le journal doit être public, pour que n'importe qui puisse l'auditer (section 4 du RFC). Il doit être en mode « ajout seulement » pour éviter qu'on puisse réécrire l'histoire. Les certificats sont déjà signés mais le journal a ses propres signatures, pour prouver son intégrité. Conceptuellement, ce journal est une liste de certificats dans l'ordre de leur création. Toute AC peut y ajouter des certificats (la liste ne peut pas être ouverte en écriture à tous, de crainte qu'elle ne soit remplie rapidement de certificats bidons). En pratique, le RFC estime que la liste des AC autorisées à écrire dans le journal sera l'union des listes des AC acceptées dans les principaux navigateurs Web (voir aussi les sections 4.2 et 5.7, chaque journal est responsable de ce qu'il accepte ou pas comme soumissions).
À chaque insertion, le journal renvoie à l'AC une estampille
temporelle signéee (SCT, pour Signed Certificate
Timestamp), permettant à l'AC de prouver qu'elle a bien
enregistré le certificat. Si on a cette signature mais que le
certificat est absent du journal, l'observateur aura la preuve que
le journal ne marche pas correctement. Le format exact de cette
estampille temporelle est décrit en section 4.8. Idéalement, elle
devra être envoyée au client par les serveurs TLS, dans l'extension
TLS transparency_info (désormais enregistrée
à l'IANA), comme preuve de la bonne foi de l'AC (cf. section
6 et notamment 6.5, car c'est plus compliqué que cela). Bien sûr,
cette validation de l'insertion dans un journal ne dispense pas de
la validation normale du certificat (un certificat peut être
journalisé et mensonger à la fois). Notez aussi que, si le serveur
TLS n'envoie pas toutes les données au client, celui-ci peut les
demander au journal (opérations /get-proof-by-hash et
get-all-by-hash) mais, ce faisant, il informe
le journal des certificats qui l'intéressent et donc, par exemple,
des sites Web qu'il visite.
De même, une extension à OCSP (RFC 6960) peut être utilisée pour appuyer les réponses OCSP. On peut même inclure les preuves d'inclusion dans le journal dans le certificat lui-même, ce qui permet d'utiliser des serveurs TLS non modifiés.
Les titulaires de certificats importants, comme Google, mais aussi des chercheurs, des agences de sécurité, etc, pourront alors suivre l'activité de ces journaux publics (section 8.2 du RFC). Ce qu'ils feront en cas de détection d'un certificat anormal (portant sur leur nom de domaine, mais qu'ils n'ont pas demandé) n'est pas spécifié dans le RFC : cela dépend de la politique de l'organisation concernée. Ce RFC fournit un mécanisme, son usage n'est pas de son ressort. Ce journal n'empêchera donc pas l'émission de vrais/faux certificats, ni leur usage, mais il les rendra visibles plus facilement et sans doute plus vite.
Notons que les certificats client, eux, ne sont typiquement pas journalisés (rappelez-vous que les journaux sont publics et que les certificats client peuvent contenir des données personnelles). Le serveur TLS ne peut donc pas utiliser Certificate Transparency pour vérifier le certificat du client. (Le RFC estime que le principal risque, de toute façon, est celui d'usurpation du serveur, pas du client.)
Pour que cela fonctionne, il faudra que les clients TLS vérifient que le certificat présenté est bien dans le journal (autrement, le méchant n'aurait qu'à ne pas enregistrer son vrai/faux certificat, cf. section 8.3 du RFC).
En pratique, la réalisation de ce journal utilise un arbre de Merkle, une structure de données qui permet de mettre en œuvre un système où l'ajout de certificats est possible, mais pas leur retrait, puisque chaque nœud est un condensat de ses enfants (voir aussi le RFC 8391). La section 2 du RFC détaille l'utilisation de ces arbres et la cryptographie utilisée. (Et les exemples en section 2.1.5 aident bien à comprendre comment ces arbres de Merkle sont utilisés.)
Le protocole utilisé entre les AC et le journal, comme celui
utilisé entre les clients TLS et le journal, est HTTP et le format des
données du JSON (section 5, qui décrit l'API). Ainsi, pour
ajouter un certificat nouvellement émis au journal géré sur
sunlight-log.example.net, l'AC fera :
POST https://sunlight-log.example.net/ct/v2/submit-entry
et le corps de la requête HTTP sera un tableau JSON de certificats encodés en Base64. La réponse contiendra notamment l'estampille temporelle (SCT pour Signed Certificate Timestamp). S'il y a un problème, le client recevra une des erreurs enregistrées. Pour récupérer des certificats, le programme de surveillance fera par exemple :
GET https://sunlight-log.example.net/ct/v2/get-entries
D'autres URL permettront de récupérer les condensats cryptographiques contenus dans l'arbre de Merkle, pour s'assurer qu'il est cohérent.
Comme il n'existe (en octobre 2021) aucune mise en œuvre de la
version 2 du protocole, voici quelques exemples, utilisant des
journaux réels, et la version 1 du protocole (notez le
v1 dans l'URL). Pour trouver les coordonnées
des journaux, j'ai utilisé la liste
« officielle » du projet. Notez que tous les journaux qui y figurent ne fonctionnent pas
correctement. Notez aussi que, comme pour les AC ou les serveurs de clés PGP, il n'y a
pas de « journal de référence », c'est à chacun de choisir les
journaux où il va écrire, et qu'il va lire. Le script test-ct-logs-v1.py teste la liste, et trouve :
50 logs are OK, 54 are currently broken
Si vous vous demandez pourquoi un même opérateur a plusieurs
journaux, c'est en partie parce qu'il n'est pas possible de faire
évoluer les algorithmes cryptographiques au sein d'un même journal
(cf. section 9 du RFC) et qu'il faut donc de temps en temps créer un
nouveau journal. Un journal est identifié par son URL, sa clé publique et
(en v2) par son OID. Par exemple, le journal
« Nimbus 2021 » de Cloudflare est en
https://ct.cloudflare.com/logs/nimbus2021/ et a
la clé
MFkwEwYHKoZIzj0CAQYIKoZIzj0DAQcDQgAExpon7ipsqehIeU1bmpog9TFo4Pk8+9oN8OYHl1Q2JGVXnkVFnuuvPgSo2Ep+6vLffNLcmEbxOucz03sFiematg==
(je ne donne pas l'OID, il n'existe pas encore de journaux qui
utilisent la version 2 du protocole). Voici un exemple d'utilisation
(le STH est le Signed Tree Head, la valeur de la
racine de l'arbre de Merkle, cf. section 4.2.10) :
% curl -s https://ct.cloudflare.com/logs/nimbus2021/ct/v1/get-sth | jq .
{
"tree_size": 408013312,
"timestamp": 1634739692384,
"sha256_root_hash": "7GnGjI7L6O5fn8kQKTdJG2riShNTTbcjRP2WbLoZrvQ=",
"tree_head_signature": "BAMARjBEAiAQ0gb6udc9e28ykUGUzl0HV8U5NlJhPVSTUF4JtXGSeQIgcSbZ9kRgttGzpFETFem4eCv7GgUYPUUnl7lTGGFZSHM="
}
Plus de quatre cents millions de certificats, fichtre. Si on veut récupérer les deux premiers certificats journalisés :
% curl -s https://ct.cloudflare.com/logs/nimbus2021/ct/v1/get-entries\?start=0\&end=1 | jq .
{
"entries": [
{
"leaf_input":
[L'exemple est fait avec un journal v1, l'objet JSON renvoyé est
différent en v2.]
Mais vous pouvez aussi utiliser Certificate
Transparency (CT) sans aller regarder du JSON. Un service en
ligne comme https://crt.sh
On a vu que plusieurs acteurs intervenaient, le gérant du
journal, les AC, les gens qui regardent le journal, par exemple pour
l'auditer, etc. Une utilisation courante de CT est pour surveiller
l'émission de certificats au nom de son entreprise ou de son
organisation, pour repérer les AC qui créent des certificats
incorrects. Pour éviter de programmer tout cela de zéro en partant
du RFC, on peut utiliser le service Certstream, qui sert
d'intermédiaire avec plusieurs journaux, et sa bibliothèque
Python. Ainsi, le petit script test-certstream.py permet de détecter tous les certificats
émis pour les noms de domaine en
.fr :
% pip3 install certstream % ./test-certstream.py ... [2021-10-23T13:21:46] pimpmydrone.fr (SAN: www.pimpmydrone.fr) [2021-10-23T13:21:51] pascal-goldbach.fr (SAN: www.pascal-goldbach.fr) [2021-10-23T13:21:52] leginkobiloba.fr (SAN: www.leginkobiloba.fr) [2021-10-23T13:21:52] promabat-distribution.fr (SAN: www.promabat-distribution.fr) [2021-10-23T13:21:53] maevakaliciak.fr (SAN: mail.maevakaliciak.fr, www.maevakaliciak.fr) [2021-10-23T13:21:55] pascal-goldbach.fr (SAN: www.pascal-goldbach.fr) [2021-10-23T13:21:56] maevakaliciak.fr (SAN: mail.maevakaliciak.fr, www.maevakaliciak.fr) [2021-10-23T13:21:57] blog.nicolas-buffart.itval.fr (SAN: euromillions-generator.itval.fr, itval.fr, loto-generator.itval.fr, password-generator.itval.fr, www.blog.nicolas-buffart.itval.fr, www.euromillions-generator.itval.fr, www.itval.fr, www.loto-generator.itval.fr, www.password-generator.itval.fr) ...
Bien sûr, cela fait beaucoup (regardez les intervalles entre deux messages). En pratique, on modifierait sans doute ce script pour ne regarder que les noms de son organisation. Ainsi, vous pouvez détecter les certificats et chercher ensuite s'ils sont légitimes (ce qui, dans certaines organisations très cloisonnées n'ira pas de soi…).
À part Certstream, Samuel Bizien Filippi me suggère CertSpotter mais qui me semble uniquement payant. Il a une API. Elle peut être utilisée par le programme check_ct_logs, qui peut être utilisé comme script de test pour les programmes de supervision comme Icinga.
Le projet « Certificate Transparency » (largement impulsé par Google) a un site officiel (lecture recommandée) et, une liste de diffusion (sans compter le groupe de travail IETF TRANS, mais qui se limitait à la normalisation, il ne parle pas des aspects opérationnels, et il a de toute façon été clos en août 2021). Questions logiciels, si vous voulez créer votre propre journal, il y a le programme de Google.
Aujourd'hui, on peut dire que « Certificate Transparency » est un grand succès. La plupart (voire toutes ?) des AC y participent, il existe de nombreux journaux publics, et ils sont fréquemment utilisés pour l'investigation numérique (voire pour le renseignement, puisqu'on peut savoir, via les journaux, les noms de domaine pas encore annoncés, ce qui a parfois été cité comme une objection contre CT). Un bon exemple est celui de l'attaque « moyen-orientale » de 2018 (mais il y a aussi l'affaire du certificat révoqué de la Poste). Par contre, un client TLS ne peut pas encore être certain que tous les certificats seront dans ces journaux, et ne peut donc pas encore refuser les serveurs qui ne signalent pas la journalisation du certificat. Et le navigateur Firefox ne teste pas encore la présence des certificats dans le sjournaux.
Un point amusant : le concept de « Certificate Transparency » montre qu'il est parfaitement possible d'avoir un livre des opérations publiquement vérifiable sans chaine de blocs. La chaine de blocs reste nécessaire quand on veut autoriser l'écriture (et pas juste la lecture) au public.
La section 1.3 du RFC résume les principaux changements entre les versions 1 (RFC 6962) et 2 du protocole :
- Les algorithmes cryptographiques utilisés sont désormais dans des registres IANA,
- certains échanges utilisent désormais le format CMS (RFC 5652),
- les journaux qui étaient auparavant idenfiés par un condensat de leur clé publique le sont désormais par un OID, enregistrés à l'IANA (aucun n'est encore attribué),
- nouvelle fonction
get-all-by-hashdans l'API, - remplacement de l'ancienne extension TLS
signed_certificate_timestamp(valeur 18) partransparency_info(valeur 52, et voir aussi le nouvel en-tête HTTPExpect-CT:du RFC 9163, - et d'autres changements, dans les structures de données utilisées.
CT ne change pas de statut avec la version 2 : il est toujours classé par l'IETF comme « Expérimental » (bien que largement déployé). La sortie de cette v2 n'est pas allée sans mal (le premier document étant sorti en février 2014), avec par exemple aucune activité du groupe pendant la deuxième moitié de 2020.
Une des plus chaudes discussions pour cette v2 avait été la
proposition de changer l'API pour que les requêtes, au lieu d'aller
à <BASE-URL>/ct/v2/ partent du chemin
/.well-known/ du RFC 8615. Cette idée a finalement été rejetée, malgré le RFC 8820, qui s'oppose à cette idée de chemins
d'URL en dur.
L'article seul
Saisie de noms de domaine par Microsoft
Première rédaction de cet article le 9 décembre 2021
Il y a quelques jours, la justice étatsunienne a saisi, sur demande de Microsoft, un certain nombre de domaines, et les a transférés à cette société. Quelques informations techniques concrètes suivent pour celles et ceux qui seraient intéressé·es.
D'abord, le jugement du 2 décembre (trouvé par Rayna
Stamboliyska, merci beaucoup) : une
copie en ligne. En gros, Microsoft a
identifié des noms de
domaine utilisés par un groupe de délinquants nommé
Nickel (apparemment entre autres pour contrôler des botnets composés de machines
Microsoft Windows). La société a donc demandé à la justice de saisir ces
noms. Cela marche car ces domaines étaient dans les TLD
.com et
.org, TLD gérés par des
registres étatsuniens (alors que beaucoup de
gens croient qu'ils ont un statut « international »). La justice a
donné raison à Microsoft et ordonné le transfert des
noms. Techniquement, c'est l'équivalent d'un détournement de nom de
domaine ; Microsoft, ayant désormais le contrôle du nom, peut
changer les informations associées et, par exemple, envoyer le
trafic vers un serveur qu'ils contrôlent. La liste de ces noms
figure dans l'annexe A du jugement.
Prenons un de ces noms au hasard,
optonlinepress.com. Une requête
whois nous montre le nouveau titulaire (on
admire la célérité de l'opération, effectuée le lendemain du
jugement) :
% whois optonlinepress.com ... Updated Date: 2021-12-03T21:42:26Z ... Registrant Name: Digital Crimes Unit Digital Crimes Unit Registrant Organization: Microsoft Corporation Registrant Street: One Microsoft Way, Registrant City: Redmond Registrant State/Province: WA Registrant Postal Code: 98052 Registrant Country: US ...
(Attention, .com est un registre mince, et les
informations au registre peuvent être
différentes de celles au BE, notamment si l'injonction
judiciaire a visé le registre sans prévenir le BE. Mais, ici, tout
est cohérent.)
Le domaine est désormais délégué aux serveurs DNS faisant autorité de Microsoft (ici, avec l'outil check-soa) :
% check-soa optonlinepress.com NS104A.microsoftinternetsafety.net. 13.107.222.41: OK: 1 NS104B.microsoftinternetsafety.net. 13.107.206.41: OK: 1 ns001.microsoftinternetsafety.net. 13.107.222.41: OK: 1 ns002.microsoftinternetsafety.net. 13.107.206.41: OK: 1
(On notera que la liste des serveurs n'est pas la même dans la zone
parente, .com et dans la zone
optonlinepress.com. C'est une erreur de
configuration fréquente et Zonemaster proteste à juste
titre. Ici, encore plus rigolo, les serveurs supplémentaires
ont la même adresse
IP.)
DNSDB nous montre l'ancienne configuration :
;; bailiwick: com. ;; count: 136 ;; first seen: 2020-06-17 19:04:12 -0000 ;; last seen: 2021-12-01 16:37:44 -0000 optonlinepress.com. IN NS ns67.domaincontrol.com. optonlinepress.com. IN NS ns68.domaincontrol.com.
La nouvelle étant :
;; bailiwick: com. ;; count: 4 ;; first seen in zone file: 2021-12-04 22:50:22 -0000 ;; last seen in zone file: 2021-12-07 22:50:26 -0000 optonlinepress.com. IN NS ns104a.microsoftinternetsafety.net. optonlinepress.com. IN NS ns104b.microsoftinternetsafety.net.
L'adresse IP pour le nom optonlinepress.com est
désormais 40.83.198.93 (chez Microsoft) alors
qu'elle était auparavant 172.105.98.76 (chez le
gros hébergeur Linode), qui ne répond plus
aujourd'hui. D'ailleurs, les anciens serveurs faisant autorité répondent
toujours pour ce nom (ce qui est courant en cas de saisie
judiciaire, l'ancien hébergeur n'ayant pas été prévenu) :
% dig +norecurse @ns67.domaincontrol.com. ANY optonlinepress.com ; <<>> DiG 9.16.22-Debian <<>> +norecurse @ns67.domaincontrol.com. ANY optonlinepress.com ; (2 servers found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 1600 ;; flags: qr aa; QUERY: 1, ANSWER: 4, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 1472 ;; QUESTION SECTION: ;optonlinepress.com. IN ANY ;; ANSWER SECTION: optonlinepress.com. 600 IN A 172.105.98.76 optonlinepress.com. 3600 IN NS ns67.domaincontrol.com. optonlinepress.com. 3600 IN NS ns68.domaincontrol.com. optonlinepress.com. 3600 IN SOA ns67.domaincontrol.com. dns.jomax.net. ( 2020111802 ; serial 28800 ; refresh (8 hours) 7200 ; retry (2 hours) 604800 ; expire (1 week) 600 ; minimum (10 minutes) ) ;; Query time: 12 msec ;; SERVER: 2603:5:2174::2c#53(2603:5:2174::2c) ;; WHEN: Thu Dec 09 10:53:43 CET 2021 ;; MSG SIZE rcvd: 164
L'affaire a fait l'objet d'un article sur ArsTechnica qui semble essentiellement reprendre l'article officiel de Microsoft, qui est très médiocre (utilisant au hasard des termes comme server et website, et mélangeant tout).
L'article seul
RFC 9138: Design Considerations for Name Resolution Service in Information-Centric Networking (ICN)
Date de publication du RFC : Novembre 2021
Auteur(s) du RFC : J. Hong, T. You (ETRI, L. Dong, C. Westphal (Futurewei Technologies), B. Ohlman (Ericsson)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF icnrg
Première rédaction de cet article le 1 décembre 2021
L'ICN est l'idée (très contestable) qu'un réseau informatique sert à accéder à du « contenu » et que le réseau doit donc être architecturé autour de cette idée de contenu. Les noms identifient ainsi un contenu donné. Mais il faut bien ensuite trouver le contenu donc résoudre ces noms en quelque chose de plus concret. Ce RFC est le cahier des charges d'un tel système de résolution de noms pour les projets ICN. Comme beaucoup de cahier des charges, il est très « liste au Père Noël », accumulant des desiderata sans se demander s'ils sont réalistes (et compatibles entre eux !).
Comme avec beaucoup de documents qui promeuvent l'ICN, ce RFC donne une description erronée du nommage et de l'adressage dans l'Internet d'aujourd'hui. Passons, et voyons ce que l'ICN propose. L'idée est que le contenu est stocké dans des NDO (Named Data Objects) et que toute activité dans le réseau coniste à récupérer des NDO. Les NDO sont identifiés par un nom. Il ne s'agit pas seulement d'un identificateur mis au-dessus d'un réseau architecturé sur d'autres concepts (comme le sont les URI) mais du concept de base du réseau ; les routeurs ne routent plus selon des adresses mais selon les noms des NDO. Le problème est évidemment qu'il faudra bien, à la fin, trouver l'objet désiré. Cela nécessite (cf. RFC 7927) :
- Un mécanisme de résolution des noms en de l'information plus concrète (une localisation, un autre nom, etc),
- un mécanisme de routage vers l'endroit où se trouve le NDO,
- un mécanisme de récupération du NDO.
Ce RFC se focalise sur le premier point, le NRS (Name Resolution Service), et en est le cahier des charges. Le RFC 9236 a depuis décrit l'architecture envisagée. Si vous voulez apprendre des choses sur les ICN en général et la résolution de noms en particulier, voir par exemple « A Survey of Information-Centric Networking » ou « A Survey of Information-Centric Networking Research ».
Si on compare avec l'Internet actuel, le NRS aura un rôle analogue à celui de BGP (plutôt que du DNS, car le NRS sera au cœur du réseau, et complètement inséparable). Bon, ceci dit, c'est plus compliqué que cela car, derrière l'étiquette « ICN », il y a des tas de propositions différentes. Par exemple, certaines ressemblent plutôt à l'Internet actuel, avec une résolution de noms en localisateurs qui servent ensuite pour le routage (comme dans IDnet, cf. « IDNet: Beyond All-IP Network), alors que d'autres versions du concept d'ICN utilisent les noms pour le routage (comme le NDN ou le CCNx du RFC 8569). La section 2.4 du RFC compare ces approches.
La section 3 du RFC est ensuite le cahier des charges proprement dit. Malheureusement, elle plane au-dessus des réalités quand elle affirme par exemple qu'il faut un NRS qui fonctionnera de la même façon que l'espace de nommage soit plat ou hiérarchique. C'est très irréaliste, il n'y a pas de nette séparation entre la structure de l'espace de nommage et le mécanisme de résolution. Ainsi, ce mécanisme, dans le cas du DNS, est très lié à la structure des noms. Si on la change, tout le DNS serait à refaire (et sans doute en moins efficace). Parmi les systèmes d'ICN qui utilisent un nommage hiérarchique (et réintroduisent donc une forme de « localisation » dans les noms), on trouve NDN et CCNx.
Certains des mécanismes de résolution discutés ont déjà un RFC, par exemple le NI du RFC 6920, utilisé dans NetInf (cf. « Network of Information (NetInf) - An information-centric networking architecture »).
Bref, les principes du NRS :
- Fonctionner avec des structures d'espaces de noms différentes (cf. ma critique ci-dessus),
- accepter la mobilité des contenus,
- passer à l'échelle (ce qui est trivial avec des noms hiérarchiques, beaucoup moins avec des noms plats),
- permettre la mémorisation (caching),
- accepter que les objets soient identifiés par un nom choisi ou par un condensat du contenu (ce que le RFC nomme les « objets sans nom », ce qui me semble accroitre encore la confusion),
- permettre enfin de récupérer des métadonnées et pas seulement le localisateur.
Et le cahier des charges à proprement parler est en section 4. Je ne cite pas tout mais la liste au Père Noël comprend :
- Des réponses rapides (« en un temps raisonnable »),
- des réponses correctes (on voit bien le ridicule de l'approche par cahier des charges, quand il faut préciser explicitement des points aussi évidents), et à jour (là encore, « raisonnablement »),
- des réponses justes, respectant un principe de neutralité (pas de censure ? L'ARCOM n'aimerait pas),
- un fonctionnement satisfaisant sur des réseaux de grande taille (le RFC mentionne au moins 10^21 objets),
- un système gérable (pouvant s'adapter avec par exemple l'ajout et le retrait de nœuds),
- la capacité à être réellement déployé (là encore, on a envie de dire « encore heureux »),
- la résistance aux pannes (la panne d'une machine ne doit pas arrêter le NRS), et aux attaques par déni de service,
- la confidentialité des requêtes (un problème pour le DNS, cf. RFC 7626), mais aussi des données (le RFC mentionne des ACL sur les noms, chose qui n'existe pas vraiment dans le DNS)
- l'authentification des serveurs, des producteurs de noms (par exemple pour que seule l'entité qui a enregistré un nom puisse modifier les données associées), et des données elle-mêmes (ce que DNSSEC fournit au DNS),
Une conclusion ? Les projets regroupés sous le nom d'ICN sont assez anciens, n'ont rien fait de vraiment nouveau récemment, et il y a peu de chances que ce RFC soit suivi de réalisations concrètes.
L'article seul
RFC 9157: Revised IANA Considerations for DNSSEC
Date de publication du RFC : Novembre 2021
Auteur(s) du RFC : P. Hoffman (ICANN)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 1 décembre 2021
Rien de très grave dans ce nouveau RFC, qui règle un problème surtout bureaucratique, le fait que les politiques d'inclusion dans les registres IANA pour certains algorithmes utilisés par DNSSEC n'étaient pas parfaitement alignées.
En effet, le RFC 6014 avait modifié la politique d'enregistrement des algorithmes cryptographiques de « Action de normalisation » à la plus laxiste « RFC nécessaire » (rappelez-vous que tous les RFC ne sont pas des normes, voir le RFC 8126 qui décrit ces politiques possibles). Mais cette « libéralisation » laissait de côté certains algorithmes, ceux utilisés pour les enregistrements DS (RFC 4034), et ceux utilisés pour NSEC3 (RFC 5155), qui restaient en « Action de normalisation ». Notre nouveau RFC aligne les politiques d'enregistrement des algorithmes utilisés pour les DS et pour NSEC3 pour qu'ils soient eux aussi « RFC nécessaire ».
Il modifie également le RFC 8624 pour préciser que les algorithmes normalisés dans des RFC qui ne sont pas sur le chemin des normes sont également couverts par les règles du RFC 8624 ; en gros, ils sont facultatifs (MAY dans le langage du RFC 2119).
Les registres concernés sur celui sur NSEC3 et celui sur DS. Ils portent désormais la mention RFC Required.
Comme l'enregistrement d'algorithmes va, du fait de ce RFC, être plus léger, cela facilitera l'enregistrement de bons algorithmes, mais aussi de mauvais. Le programmeur qui met en œuvre DNSSEC, ou l'administratrice système qui le déploie, ne doit donc pas considérer que la présence dans un registre IANA vaut forcément approbation de la solidité cryptographique de l'algorithme. Il faut consulter la littérature technique avant d'utiliser ces algorithmes.
L'article seul
Fiche de lecture : Digital roots
Auteur(s) du livre : Gabriele Balbi, Nelson
Ribeiro, Valérie Schafer, Christian
Schwarzenegger
Éditeur : De Gruyter Oldenbourg
978-3-11-073988-6
Publié en 2021
Première rédaction de cet article le 29 novembre 2021
Dans le débat public au sujet de l'Internet et du Web, il y a beaucoup de concepts qui sont discutés comme s'ils étaient nouveaux alors qu'ils ont en fait des racines anciennes (gouvernance, bulle de filtre, authenticité, participation d'amateurs…). Cet ouvrage collectif (en anglais) réunit plusieurs contributions qui analysent l'histoire d'un concept et ses origines, souvent bien antérieures au monde numérique.
Le livre a impliqué de nombreuses contributrices et de nombreux contributeurs (celles et ceux cité·es au début de cet article sont « juste » les coordinateurices). Chacun·e s'est attaqué à un concept particulier, montrant son historicité. Mon exemple favori a toujours été les soi-disant fake news, présentées comme une nouveauté du Web alors que le mensonge est aussi ancien que la communication. (Mais, en mettant le terme en anglais, on peut faire croire que c'est quelque chose de nouveau.) La version papier du livre est coûteuse mais il est sous une licence Creative Commons et peut être téléchargé.
Bien sûr, en insistant sur l'ancienneté d'un concept, et des débats qui l'ont toujours accompagné, il ne s'agit pas de dire que rien n'est nouveau, que tout existait déjà dans l'Antiquité. Mais juste de rappeler que la pression médiatico-commerciale a tendance à gommer le passé et à mettre en avant tous les mois un truc présenté comme nouveau.
Le livre commence logiquement par le concept de réseau, qui existait avant les réseaux informatiques, comme le réseau routier de l'empire romain (en étoile, « tous les chemins mènent à Rome », ce qui matérialisait la position dominante de la capitale), ou, plus récemment, le réseau télégraphique. Ces anciens réseaux ont déjà fait l'objet d'innombrables études et réflexions, rappelées par Massimo Rospocher et Gabriele Balbi. Certaines de ces études et réflexions s'appliquent toujours à l'ère de l'Internet. Le concept de multimédia fait l'objet d'un passionnant article de Katie Day Good, qui évoque les espoirs qu'avaient fait naitre les nouveaux médias, par exemple dans le domaine de l'éducation. Les commerciaux des entreprises liées à la radio annonçaient sans rire que radio et autres médias nouveaux à l'époque allaient révolutionner l'enseignement. On retrouve dans les textes de la première moitié du XXe siècle bien des illusions technosolutionnistes d'aujourd'hui. Toujours dans la technique, l'intelligence artificielle est bien sûr à l'honneur, tant le concept est ancien mais ressort régulièrement comme solution miracle à tous les problèmes (article de Paolo Bory, Simone Natale et Dominique Trudel).
Après la technique, la politique. « Gouvernance » est également un concept présenté comme nouveau alors que la politique (arriver à prendre des décisions quand tout le monde n'a pas les mêmes intérêts et les mêmes opinions) est étudiée depuis pas mal de siècles. Comme le rappellent Francesca Musiani et Valérie Schafer, la politique sur l'Internet a des particularités nouvelles, mais les questions politiques liées à l'émergence d'un nouveau réseau ne sont pas, elles, une nouveauté. On se posait des questions de gouvernance bien avant l'Internet, par exemple avec le télégraphe. De même, l'usage de données pour gouverner (la « dataification »), analysée par Eric Koenen, Christian Schwarzenegger et Juraj Kittler, remonte à longtemps, par exemple aux efforts de Jean-Baptiste Colbert en France pour que tout ce qui se passe en France lui soit transmis. On fichait déjà tout, avant que l'arrivée des ordinateurs n'accélère considérablement la quantité de données récoltées, et on en espérait déjà, avant qu'on parle de big data un gouvernement plus efficace. Évidemment, le concept de fake news a droit à son article, et Monika Hanley et Allen Munoriyarwa font un intéressant historique de l'histoire de la tromperie et de la propagande mensongère, remontant au second triumvirat de Rome, en 43 avant l'ère commune, et passant par le XIXe siècle, où l'extension de la littératie et la diffusion massive des journaux allait pouvoir faire décoller cette activité (un fait que les médias d'aujourd'hui oublient quand ils critiquent les fake news diffusées sur le Web). Même regard critique de Maria Löblich et Niklas Venema sur les « bulles de filtre », qui ne sont pas apparues avec les « algorithmes » des réseaux sociaux.
Une autre section traite des utilisateurs et de leurs pratiques. Jérôme Bourdon traite le cas de la présence et de la distance. Quand on communique « en présentiel » et pas par courrier électronique, est-ce qu'on communique « en vrai » ? Des gens avec qui on n'interagit qu'en ligne sont-ils de « vrais » ami·es ? Et, pour prendre un exemple récent, une réunion en ligne est-elle une vraie réunion ? Cicéron et Madame de Sévigné sont cités pour leurs réflexions à ce sujet, montrant qu'à chaque époque, des gens s'inquiétaient de savoir ce qu'était la présence. Dans son article sur la solitude, Edward Brennan poursuit le même genre de réflexions, ce qui permet de relativiser certaines inquiétudes sur « l'adolescent dans sa chambre qui n'interagit qu'en ligne ». Autre phénomène social étudié, les fans et leurs pratiques (j'en profite pour vous recommander le livre de Mélanie Bourdaa sur ce sujet des fans). Eleonora Benecchi et Erika Ningxin Wang décrivent le phénomène du fandom. Par contre, il est curieux qu'elles commencent par brandir des étiquettes raciales et prétendent avoir une approche « décoloniale » quand les seuls exemples non-« occidentaux » cités sont ceux de pays qui n'ont pas été colonisés (Chine et Japon). Et puis commencer par dire que la Chine est différente de l'Occident pour donner ensuite comme exemple que les fans, en Chine, ont une relation affective avec le personnage de fiction qu'ils aiment… Comme si ce n'était pas le cas de tous les fans… C'est l'avantage et l'inconvénient des ouvrages collectifs, il n'y a pas d'unité. Mais la quasi-totalité des articles sont excellents (je ne les ai pas tous cités ici).
Ce livre est écrit par des universitaires pour un public déterminé à s'accrocher un peu. Mais cela vaut la peine, j'y ai appris beaucoup de choses et j'ai bien perçu la profondeur de ces questions, qui agitent l'humanité depuis longtemps.
L'article seul
Les RFC les plus cités sur ce blog
Première rédaction de cet article le 28 novembre 2021
Une statistique tout à fait inutile mais, bon, on est dimanche soir. Quels sont les RFC les plus cités sur ce blog ?
Je mentionne en effet très souvent des RFC et je pointe vers l'article de résumé que j'ai écrit. La façon dont ce blog est écrit permet facilement d'écrire un petit programme pour voir quels RFC sont les plus fréquemment utilisés ici, un critère de tri qui en vaut bien d'autres :
% ./most-cited-rfcs.py RFC 1918: 66 times RFC 5246: 66 times RFC 1035: 63 times ...
On trouve donc dans l'ordre décroissant des citations sur ce blog :
- Le RFC 1918, sur les adresses IPv4 privées, souvent cité car, tant que tout le monde ne se sera pas décidé à déployer IPv6, il reste indispensable, vu la pénurie des adresses IPv4.
- Le RFC 5246, sur l'ancienne version du protocole de cryptographie TLS, la version 1.2. Depuis, la version 1.3 a été normalisée (dans le RFC 8446) et ce nombre de citations ne devrait donc pas augmenter.
- Le RFC 1035, sur le DNS, qui normalise le format des enregistrements DNS et les détails concrets du protocole. Il est logique qu'un RFC sur le DNS apparaisse dans cette liste en bonne position, le DNS étant à la fois mon activité professionnelle et un sujet que je connais bien et dont je parle souvent.
- Le RFC 4271, sur BGP. Avec le DNS, c'est l'autre grand protocole d'infrastructure sur l'Internet, ce qui explique sa présence.
- Le RFC 5226, sur les règles d'enregistrement dans les registres IANA. Ce RFC ne décrit donc pas un protocole, mais remplit un rôle plus politico-bureaucratique. Là aussi, il a été remplacé par un RFC plus récent, le RFC 8126, et devrait donc logiquement reculer dans le classement.
- Le RFC 1034, également sur le DNS. C'est le deuxième RFC de la norme originale (qui n'a pas été remplacée par des RFC plus récents), consacré aux concepts.
- Le RFC 3986, qui normalise les URI. Ces identificateurs sont une invention géniale, et un des trois piliers du Web, avec HTTP et HTML. Ils sont même utilisés en dehors du Web, par exemple pour Gemini.
- Le RFC 4862, sur l'auto-configuration sans état (SLAAC, StateLess Address AutoConfiguration) d'IPv6, une des nouveautés d'IPv6 qui n'a pas vraiment d'équivalent dans IPv4 (alors que la plupart des concepts sont communs aux deux versions d'IP).
- Le RFC 8415 décrit un autre moyen en IPv6 d'attribuer une adresse IP à une machine, DHCP.
- Le RFC 5322, est le RFC sur l'IMF
(Internet Message Format), le format des
messages de courrier électronique (vous
savez, les
From:,Date:,Subject:…). L'importance du courrier électronique explique sa bonne position dans cette liste. À noter que beaucoup de gens citent encore le RFC 822, qui n'est plus la norme de l'IMF depuis bien longtemps. - Le RFC 793 est toujours aujourd'hui le RFC sur TCP, le protocole de transport qui, malgré la concurrence récente de QUIC, fait passer l'essentiel des octets qui circulent sur l'Internet. Il n'a pas été remplacé mais bien d'autres RFC sont aujourd'hui nécessaires pour comprendre TCP, je vous recommande la liste du RFC 7414.
- Et le RFC 7231, un des RFC sur HTTP 1, qui normalise notamment la sémantique des messages. Là aussi, sa présence est logique, vu l'importance de HTTP dans l'Internet d'aujourd'hui.
Évidemment, cette liste reflète surtout les choix éditoriaux de l'auteur et n'indique donc pas une quelconque « importance » de tel ou tel RFC.
L'article seul
RFC 9156: DNS Query Name Minimisation to Improve Privacy
Date de publication du RFC : Novembre 2021
Auteur(s) du RFC : S. Bortzmeyer (AFNIC), R. Dolmans (NLnet Labs), P. Hoffman (ICANN)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 19 novembre 2021
Protéger la vie privée sur l'Internet nécessite au moins deux techniques : chiffrer les données en transit pour éviter leur lecture par des tiers et minimiser les données qu'on envoie, pour éviter les abus par les récepteurs des données. Ce deuxième point, pourtant bien mis en avant dans la loi Informatique & Libertés ou dans le RGPD est souvent oublié. Ce RFC applique ce principe au DNS : il ne faut pas envoyer aux serveurs faisant autorité le nom de domaine complet mais seulement la partie du nom de domaine qui lui est strictement nécessaire pour répondre, le minimum. Cette norme succède au RFC 7816, qui était purement expérimental alors que cette minimisation de la requête (QNAME minimisation) est désormais une norme. Le principal changement est la recommandation d'utiliser le type de données A (adresse IPv4) et plus NS (serveurs de noms).
Ce principe de minimisation, qui devrait être central dans toute
approche de la protection de la vie privée
est également exposé dans le RFC 6973, section
6.1. Le DNS violait
ce principe puisque, traditionnellement, un résolveur DNS qui recevait une demande
d'information sur www.foobar.example
transmettait aux serveurs
faisant autorité la question complète, alors que, par
exemple, les serveurs faisant autorité pour la
racine ne connaissent que les TLD et que leur demander simplement
des informations sur le TLD .example aurait
suffi. (Voir le RFC 7626 pour une analyse
complète des relations entre le DNS et la vie privée.) Cette
tradition (qui ne s'appuyait sur aucune norme technique) est remise
en cause par la QNAME minimisation qui demande au
contraire qu'on n'envoie aux serveurs faisant autorité que le nom
minimal (example à la racine,
foobar.example aux serveurs du TLD
.example, etc).
Cette minimisation est unilatérale, elle ne nécessite qu'un changement des résolveurs, sans toucher aux serveurs faisant autorité puisqu'elle ne change pas le protocole DNS. Depuis la sortie du RFC 7816, en 2016, elle a été largement déployée (si le résolveur que vous utilisez ne le fait pas, réclamez-le à votre service informatique !).
Le précédent RFC sur cette technique, le RFC 7816 avait le statut d'expérimentation alors que notre RFC 9156 est désormais une norme. En effet, une expérience considérable a été accumulée depuis le RFC 7816, qui a été mis en œuvre dans pratiquement tous les résolveurs, et souvent activé. Le FUD souvent entendu comme quoi la QNAME minimisation allait tuer Internet et des chatons a été largement réfuté. Les leçons tirées sont documentées dans « DNSThought QNAME minimisation results. Using Atlas probes », « Maximizing Qname Minimization: A New Chapter in DNS Protocol Evolution », « Measuring Query Name Minimization » et « A First Look at QNAME Minimization in the Domain Name System ».
Maintenant, la pratique, comment fait-on de la QNAME
minimisation ? La question envoyée par le résolveur au
serveur faisant autorité comprend un QNAME (Query
Name, le nom demandé) et un QTYPE (Query
Type, le type de données, par exemple serveur de courrier,
adresse IP, texte libre, etc). Avec la QNAME
minimisation, le nom doit être le nom le plus court
possible. Quand le résolveur interroge un serveur
racine, il n'envoie comme QNAME que le TLD, par
exemple. Trouver « le plus court possible » n'est pas forcément
trivial en raison des coupures de zone. Dans un nom comme
miaou.foo.bar.example,
foo.bar.example et
bar.example font peut-être partie de la même
zone (et ont donc les mêmes serveurs faisant autorité) et peut-être
pas. Rien dans la syntaxe du nom ne l'indique. Contrairement à une
idée fausse et répandue, il n'y a pas forcément une coupure de zone
pour chaque point dans le nom. Trouver les
coupures de zone est expliqué dans le RFC 2181, section 6. Un résolveur qui valide avec DNSSEC
doit savoir trouver ces coupures, pour savoir à qui demander les
enregistrements de type DS. Les autres (mais quelle idée, en 2021,
d'avoir un résolveur qui ne valide pas) doivent s'y mettre. Si, par
exemple, foo.bar.example et
bar.example sont dans la même zone, le
résolveur qui veut trouver des données associées à
miaou.foo.bar.example va envoyer le QNAME
example à la racine, puis
bar.example au serveur du TLD, puis
miaou.foo.bar.example au serveur de
bar.example. (Avant la QNAME
minimisation, il aurait envoyé le QNAME
miaou.foo.bar.example à tout le monde.)
Cela, c'était pour le QNAME. Et le QTYPE ? On peut choisir celui qu'on veut (à l'exception de ceux qui ne sont pas dans la zone, comme le DS), puisque les délégations de zones ne dépendent pas du type. Mais, et c'est un sérieux changement depuis le RFC 7816, notre RFC recommande le type A (ou AAAA), celui des adresses IP, et plus le type NS (les serveurs de noms), que recommandait le RFC 7816. Deux raisons à ce changement :
- Certaines middleboxes boguées jettent les questions DNS portant sur des types qu'elles ne connaissent pas. Le type A passe à coup sûr.
- Le but de la QNAME minimisation étant la protection de la vie privée, il vaut mieux ne pas se distinguer et, notamment, ne pas dire franchement qu'on fait de la QNAME minimisation (les requêtes explicites pour le type NS étaient rares). Un serveur faisant autorité, ou un surveillant qui espionne le trafic, ne peut donc pas déterminer facilement si un client fait de la QNAME minimisation.
Vous voyez ici le schéma de la résolution DNS sans la
QNAME minimisation puis avec :
Dans certains cas, la QNAME minimisation peut
augmenter le nombre de requêtes DNS envoyées par le résolveur. Si un
nom comporte dix composants (ce qui arrive dans des domaines
ip6.arpa), il faudra dans certains cas dix
requêtes au lieu de deux ou trois. Les RFC 8020 et RFC 8198
peuvent aider à diminuer ce nombre, en permettant la synthèse de
réponses par le résolveur. Une autre solution est de ne pas ajouter
un composant après l'autre en cherchant le serveur faisant autorité
mais d'en mettre plusieurs d'un coup, surtout après les quatre
premiers composants.
Un algorithme complet pour gérer la QNAME
minimisation figure dans la section 3 du RFC.
Notez que, si vous voulez voir si votre résolveur fait de la QNAME minimisation, vous pouvez utiliser tcpdump pour voir les questions qu'il pose mais il y a une solution plus simple, la page Web de l'OARC (dans les DNS features).
Un test avec les sondes RIPE Atlas semble indiquer que la QNAME minimisation est aujourd'hui largement répandue (les deux tiers des résolveurs utilisés par ces sondes) :
% blaeu-resolve --requested 1000 --type TXT qnamemintest.internet.nl
["hooray - qname minimisation is enabled on your resolver :)!"] : 651 occurrences
["no - qname minimisation is not enabled on your resolver :("] : 343 occurrences
Test #33178767 done at 2021-11-05T14:41:02Z
Il existe aussi une étude récente sur la QNAME minimization en République Tchèque.
Comme son prédécesseur, ce RFC utilise (prétend Verisign) un brevet. Comme la plupart des brevets logiciels, il n'est pas fondé sur une réelle invention (la QNAME minimisation était connue bien avant le brevet).
Ah, et vous noterez que le développement de ce RFC, par trois auteurs, a été fait sur FramaGit.
L'article seul
RFC 9141: Updating References to the IETF FTP Service
Date de publication du RFC : Novembre 2021
Auteur(s) du RFC : R. Danyliw (Software Engineering Institute)
Chemin des normes
Première rédaction de cet article le 19 novembre 2021
L'IETF distribuait un certain nombre de documents
en FTP anonyme. Ce service,
ftp.ietf.org, va être interrompu. Mais un
certain nombre de RFC continuent à le citer comme source. Comme
on ne peut pas modifier un RFC après publication, notre RFC 9141 fait la liste des mises à jour à lire pour corriger ces
RFC et indiquer la nouvelle source des documents.
FTP, qui avait été le premier protocole de transfert de fichiers de l'Internet, avant même l'adoption de TCP/IP, a été pendant longtemps le principal moyen de copier des fichiers à travers le réseau. Une de ces fonctions, le FTP anonyme (qui n'était en fait pas anonyme du tout) permettait d'accéder aux fichiers, lorsque le serveur le voulait bien, sans avoir de compte sur le serveur. D'immenses archives de logiciels, de documents, d'images, ont été ainsi distribuées pendant des années. Aujourd'hui, FTP n'est guère plus utilisé (entre autres parce qu'il fonctionne en clair, cf. la section 4 sur la sécurité) et maintenir un service FTP anonyme n'a plus guère de sens. D'où la décision de l'IETF en 2020 de fermer le sien (cf. l'annonce). Le plan élaboré à cette occasion (une lecture recommandée sur les détails de cette décision, par exemple les statistiques d'utilisation) notait qu'il y avait trente RFC qui référençaient ce service, le dernier, le RFC 7241, datant de 2014. Tous ces RFC sont donc formellement mis à jour par notre RFC 9141. (Comme le note GuB, « C'est pire que légifrance cette histoire ».)
Par exemple, le RFC 2077 dit « Copies of RFCs are available on:
ftp://ftp.isi.edu/in-notes/ » alors qu'il
faudra désormais lire « Copies of RFCs are available
on: https://www.rfc-editor.org/rfc/ ».
Voici par exemple, pour la nostalgie, le fonctionnement du serveur
en novembre 2021, avant sa fermeture. On cherche les archives
indiquées par le RFC 5098, et qui sont désormais en https://www.ietf.org/ietf-ftp/ietf-mail-archive/ipcdn/
% ncftp ftp.ietf.org NcFTP 3.2.5 (Feb 02, 2011) by Mike Gleason (http://www.NcFTP.com/contact/). Copyright (c) 1992-2011 by Mike Gleason. All rights reserved. Connecting to 4.31.198.44... FTP server ready Logging in... Anonymous access granted, restrictions apply Logged in to ftp.ietf.org. ncftp / > ls charter/ ietf/ internet-drafts/ slides/ concluded-wg-ietf-mail-archive/ ietf-mail-archive/ review/ status-changes/ conflict-reviews/ ietf-online-proceedings/ rfc/ yang/ ncftp / > ncftp / > cd ietf-mail-archive/ipcdn ncftp /ietf-mail-archive/ipcdn > ls ... 1996-12 1999-07.mail 2001-09.mail 2003-11.mail 2006-01.mail 2008-03.mail 1997-01 1999-08.mail 2001-10.mail 2003-12.mail 2006-02.mail 2008-04.mail 1997-02 1999-09.mail 2001-11.mail 2004-01.mail 2006-03.mail 2008-05.mail 1997-03 1999-10.mail 2001-12.mail 2004-02.mail 2006-04.mail 2008-06.mail ...
L'article seul
L'offre d'hébergement nua.ge
Première rédaction de cet article le 16 novembre 2021
Je viens de tester un peu l'offre d'hébergement de serveurs Internet Nua.ge de la société Oxeva. Voici quelques retours d'expérience.
(J'ai bénéficié sans frais d'une offre gratuite de lancement mais notez que,
pour en profiter, il faut laisser son adresse de
courrier et son numéro de carte de
crédit. Ceci dit, une panne de la Banque
postale à ce moment fait que la carte ne semble pas
avoir été enregistrée mais le compte Nua.ge a été créé quand
même.) 
Le site Web de gestion est en nua.ge. Il est
curieux qu'une entreprise qui communique beaucoup sur son caractère
français ait choisi le TLD de la Géorgie. (La
même société détient également nuage.fr mais ne
l'utilise pas, ce domaine est vide.) Le domaine a deux serveurs de
noms, dont l'un est apparemment dans le réseau de la
société :
% check-soa -i nua.ge ns1.reagi.com. 195.60.188.254: OK: 2021111501 (1 ms) ns2.reagi.com. 87.98.186.69: OK: 2021111501 (5 ms)
On notera qu'aucun des deux n'a IPv6 (on ne trouve d'IPv6 nulle part sur ce réseau).
La création du compte est classique (on laisse plein de données personnelles, on reçoit un courrier avec un cookie, on visite le lien indiqué et on a son compte). Il ne semble pas y avoir d'authentification à deux facteurs disponible dans l'onglet « Sécurité » ce qui, pour une offre IaaS, est vraiment problématique.
J'ai ensuite créé une machine virtuelle, utilisant Debian. (Il ne semble pas y avoir de miroir Debian local à l'hébergeur, la machine est configurée pour aller chercher ses paquets sur le serveur Debian par défaut.) Cela n'a pas marché du premier coup (time out d'abord, puis refus d'authentification SSH avec la clé que j'avais donné). Il a fallu contacter le support (par un service de clavardage sur leur site Web) qui a rapidement réagi, détruit la machine et reconstruit une autre, sur laquelle je pouvais me connecter. (Le problème est admis mais pas encore corrigé.)
Ma
machine actuelle a l'adresse
185.189.156.205. Et en
IPv6 ? Comme dit plus haut, il n'y a d'IPv6
nulle part. En 2021, c'est incroyable (tous les fournisseurs
français d'IaaS ont de l'IPv6 depuis longtemps), et rien que pour cela, je ne
prolongerai pas l'essai au-delà de la période de test gratuite.
Autre problème, 185.189.156.205 n'est pas la
vraie adresse IP de la machine. Les paquets
entrants sont NATés vers une adresse privée
(RFC 1918). Non seulement cela fait que la
machine ne connait pas sa propre adresse IP, mais cela limite les
protocoles utilisables à ceux reconnus par le routeur NAT
(TCP,
UDP et
ICMP). Si vous voulez faire du SCTP ou
autre protocole de transport, tant pis pour
vous. Autant dire qu'on est très loin d'un vrai service IaaS. Voici
la liste des protocoles acceptés :
Ajoutez des instances à ce groupe uniquement si votre application nécessite des ouvertures particulières. Règles Protocol Ports IP Range Autorise UDP 0 - 0 0.0.0.0/0 Autorise TCP 0 - 0 0.0.0.0/0 Autorise ICMP 0 - 0 0.0.0.0/0
Question sécurité, tout est bloqué par défaut (ce qui n'est pas logique pour un serveur Internet) et il faut mettre la machine dans le groupe de sécurité « Autoriser tout le trafic entrant (non recommandé) » pour qu'on puisse superviser la machine et utiliser ping. Voici avec les sondes RIPE Atlas :
% blaeu-reach -r 200 185.189.156.205 198 probes reported Test #33426048 done at 2021-11-16T12:53:50Z Tests: 593 successful tests (100.0 %), 0 errors (0.0 %), 0 timeouts (0.0 %), average RTT: 67 ms
Cette supervision automatique a été très utile, elle a permis de détecter une bogue dans Nua.ge, qui coupe les instances de temps en temps pour deux à trois minutes. (Problème signalé et admis mais pas encore corrigé.)
Pour voir, j'ai mis sur cette machine
perruche.bortzmeyer.org un très simple serveur
HTTP qui ne répond qu'à /hello et
/date :
% curl http://perruche.bortzmeyer.org/date The time is 20:43:09.579900
Question DNS, on note que les machines reçoivent par défaut comme résolveur… celui du géant étatsunien Cloudflare ce qui, là encore, fait très bizarre pour une offre supposée « souveraine » :
% cat /etc/resolv.conf # Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8) # DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN # 127.0.0.53 is the systemd-resolved stub resolver. # run "resolvectl status" to see details about the actual nameservers. nameserver 1.1.1.1 nameserver 1.0.0.1 search int.nua.ge
Enfin, au moins, comme ça, on a DNSSEC, ce qui n'est pas le cas de tous les résolveurs français.
Je n'ai pas trouvé de moyen de configurer l'enregistrement DNS de
type PTR (dans in-addr.arpa), qui m'aurait
permis d'avoir un plus
joli nom. Ce manque est ennuyeux si on veut héberger un
serveur de
messagerie.
Je n'ai pas lu les conditions d'utilisation et de gestion des données personnelles mais Aeris l'a fait, donc je vous renvoie à son récit.
Je n'ai pas trop suivi le mécanisme de facturation. Voici
l'interface permettant de suivre sa consommation :
Je n'ai pas non plus regardé s'il y avait des API disponibles.
Pour résumer : le service fonctionne, mais ne correspond pas à ce que j'attends d'un service IaaS, surtout que le marché français dans ce domaine est très riche et offre bien d'autres solutions. On ne voit pas ce que Nua.ge apporte de nouveau.
Autres articles sur ce service :
- Étude détaillée par DamyR.
- Long (trop long, et trop descriptif, mais avec de bonnes observations) article d'Olivier Poncet.
- Article de David Legrand dans Inpact Hardware (abonnés seulement).
L'article seul
Fiche de lecture : Les Fans
Auteur(s) du livre : Mélanie Bourdaa
Éditeur : C&F Éditions
978-2-37662-029-7
Publié en 2021
Première rédaction de cet article le 15 novembre 2021
Ce livre est consacré à l'étude des fans, notamment de série télé. Souvent présentés comme un peu bizarres, monomaniaques, fanatiques (cf. l'étymologie de « fan »), sans « vraie vie » et vivant dans l'imaginaire, les fans sont au contraire des sujets d'études dignes d'intérêt.
J'ai découvert dans ce livre qu'il existait même une catégorie de SHS sur la question, les fan studies. Les fans ne sont pas une nouveauté de l'Internet, l'auteure cite les regroupements de fans de Sherlock Holmes dès le 19e siècle. La thèse de l'auteure est que les fans ne sont pas des abrutis qui suivent passivement une série mais qu'ils interagissent, qu'ils critiquent, qu'ils utilisent la série dans tel ou tel but, par exemple politique (le sous-titre du livre est « publics actifs et engagés »). Le livre parle du militantisme autour des séries (des féministes utilisant Wonder Woman ou Leia comme référence), de création à partir de séries (fanfiction), etc.
J'ai eu du mal avec les références, toutes étatsuniennes. Par exemple, la dernière étude de cas couvre une série dont j'ignorais même l'existence, Wynonna Earp, qui a apparemment un club de fans particulièrement motivé·es et organisé·es. Il est parfois difficile de suivre le livre si on ne connait pas ces séries.
Les fans sont, par définition, passionnés par leur sujet et cela peut mener à des comportements négatifs, par exemple contre les fans d'autres séries, ou contre les fans de la même série, mais qui préfèrent tel personnage plutôt que tel autre. L'auteur parle assez peu de ces aspects néfastes, qu'on peut facilement observer sur Twitter dans l'univers de la téléréalité, avec les insultes et menaces des fans de tel ou tel personnage.
Les fans peuvent aussi s'estimer en droit d'influencer la série et ses futurs épisodes, menant des campagnes, par exemple pour qu'on donne une place plus importante à tel personnage particulièrement apprécié (parfois pour des raisons politiques). Je trouve personnellement que le livre est un peu court sur l'analyse critique de ce phénomène, par exemple lorsqu'il cite des acteurs et actrices de séries qui tiennent publiquement des discours en accord avec celui de leur personnage dans la série : sincérité ou marketing ? Ce n'est pas étudié.
Les fans, on l'a dit, ne sont pas des spectateurs passifs. Une des parties les plus intéressantes du livre est consacrée au travail que font certains fans autour de leur série favorite, par exemple en construisant des formidables encyclopédies en ligne comme le Wiki of Ice and Fire (non cité dans le livre, je crois) ou le Battlestar Galactica Museum. Un tel travail, avec ce qu'il implique, non seulement de temps passé, mais également de coordination dans le groupe, et de mentorat des nouveaux, est bien loin de l'image du fan asocial claquemuré dans sa chambre et s'adonnant au binge-watching. Bref si, comme moi, vous ne connaissez pas tellement ce monde des fans, vous apprendrez plein de choses dans ce livre.
Autre article, plus détaillé, sur ce livre, celui de Christine Hébert. Et un intéressant interview vidéo de l'auteure.
L'article seul
Combinaison d'analyseurs syntaxiques en Elixir avec NimbleParsec
Première rédaction de cet article le 11 novembre 2021
On a souvent besoin en programmation de faire de l'analyse syntaxique, pour vérifier qu'un texte est correct et pour y trouver les éléments qui nous intéressent. (Je ne considère ici que les textes écrits dans un langage formel, l'analyse de la langue naturelle étant une autre histoire.) Une des techniques que je trouve les plus agréables est celle des combinaisons d'analyseurs. Voici un exemple en Elixir, avec le module NimbleParsec.
L'idée de base est simple : on écrit l'analyseur en combinant des analyseurs simples, puis en combinant les combinaisons. Cela se fait par exemple en Haskell avec le module Parsec dont j'ai déjà parlé ici. En Elixir, cela peut se faire avec l'excellent module NimbleParsec qui est plutôt bien documenté.
Commençons par un exemple trivial, des textes composés d'un seul
mot, qui ne doit comporter que des lettres ASCII. L'analyseur consistera en un seul
analyseur primitif, ascii_string, fourni par
NimbleParsec, et qui prend deux arguments, un pour restreindre la
liste des caractères autorisés, et l'autre pour indiquer des options
comme, ici, le nombre minimal de caractères :
verb = ascii_string([], min: 1) defparsec :test, verb
(Le code complet est en nimbleparsec-1.exs.) On peut
alors analyser des chaînes de caractères et voir le résultat. Si je
mets dans le code :
IO.inspect Test1.test("foobar")
IO.inspect Test1.test("")
La première chaine sera acceptée (on n'a guère mis de restrictions à
ascii_string), la seconde refusée (en raison du
min: 1) :
{:ok, ["foobar"], "", %{}, {1, 0}, 6}
{:error, "expected ASCII character", "", %{}, {1, 0}, 0}
La valeur retournée par l'analyseur est un
tuple commençant par un mot qui indique si
tout s'est bien passé (:ok ou
:error), une liste
donnant les termes acceptés (ici, il n'y en a qu'un) si tout s'est
bien passé.
On peut utiliser ces résultats dans du code Elixir classique, avec pattern matching :
def print_result(r) do
case r do
{:ok, list, _, _, _, _} -> IO.inspect("Tout va bien et j'ai récupéré #{list}")
{:error, message, _, _, _, _} -> IO.inspect("C'est raté, à cause de #{message}")
end
end
Ah, si vous ne connaissez pas bien Elixir, la méthode « normale » pour utiliser NimbleParsec dans un projet serait de le déclarer en dépendance et d'utiliser Mix pour gérer ces dépendances mais, ici, on va simplifier, on installe NimbleParsec avec Hex et on lance mix avec les bonnes options pour exécuter le code :
% mix archive.install hex NimbleParsec % mix run --no-mix-exs nimbleparsec-2.exs "Tout va bien et j'ai récupéré foobar" "C'est raté, à cause de expected ASCII character"
Contrairement à ce que son nom pourrait faire croire,
ascii_string n'accepte pas que des caractères
ASCII, mais tout caractère codé sur huit
bits. Dans l'exemple ci-dessus, il accepterait des chaines comme
« café au lait » (avec le caractère composé et les
espaces). Restreignons un peu :
verb = ascii_string([?a..?z], min: 1)
Cette fois, seuls les caractères entre le petit a et le petit z seront acceptés. Testons :
% mix run --no-mix-exs nimbleparsec-3.exs
{:ok, ["foobar"], "", %{}, {1, 0}, 6}
{:error, "expected ASCII character in the range 'a' to 'z'", "", %{}, {1, 0}, 0}
{:ok, ["caf"], "é au lait", %{}, {1, 0}, 3}
« café au lait » a quand même été accepté car NimbleParsec s'arrête
avec succès dès qu'il est satisfait. Deux solutions : tester le
troisième membre du tuple (les caractères restants) pour vérifier
qu'il est vide ou bien combiner
ascii_string avec l'analyseur
eos qui indique la fin de la chaine :
verb = ascii_string([?a..?z], min: 1) defparsec :test, verb |> eos
La combinaison se fait avec l'opérateur classique de séquencement en
Elixir, |>.
Cette fois, ça marche :
% mix run --no-mix-exs nimbleparsec-3.exs
{:ok, ["foobar"], "", %{}, {1, 0}, 6}
{:error, "expected ASCII character in the range 'a' to 'z'", "", %{}, {1, 0}, 0}
{:error, "expected end of string", "é au lait", %{}, {1, 0}, 3}
Maintenant qu'on sait faire des combinaisons, allons plus loin. On voudrait analyser des chaînes du type « foo{bar} » avec un verbe suivi d'une valeur entre accolades :
verb = ascii_string([not: ?\{], min: 1)
value = ascii_string([not: ?\}], min: 1)
body = ignore(string("{")) |> concat(value) |> ignore(string("}"))
defparsec :test, verb |> concat(body) |> eos
Décortiquons un peu : verb est défini comme une
chaine ne comportant pas l'accolade ouvrante
(sinon, l'analyseur, qui est gourmand, ira jusqu'au bout et avalera
tout, y compris l'accolade ouvrante). De même,
value ne comporte pas l'accolade
fermante. body est la composition des deux
accolades et de la valeur. Les deux accolades ne servent que de
délimiteurs, on ne veut pas récupérer leur valeur, donc on ignore
leur résultat (alors que celui de value nous
sera retourné, c'est le rôle de
concat). Essayons avec ce code :
# Correct
IO.inspect Test4.test("foobar{ga}")
# Tous les autres sont incorrects
IO.inspect Test4.test("foobar")
IO.inspect Test4.test("foobar{ga")
IO.inspect Test4.test("foobar{}")
IO.inspect Test4.test("{ga}")
IO.inspect Test4.test("foobar{ga}extra")
Et ça donne :
% mix run --no-mix-exs nimbleparsec-4.exs
{:ok, ["foobar", "ga"], "", %{}, {1, 0}, 10}
{:error, "expected string \"{\"", "", %{}, {1, 0}, 6}
{:error, "expected string \"}\", followed by end of string", "", %{}, {1, 0}, 9}
{:error, "expected ASCII character, and not equal to '}'", "}", %{}, {1, 0}, 7}
{:error, "expected ASCII character, and not equal to '{'", "{ga}", %{}, {1, 0}, 0}
{:error, "expected string \"}\", followed by end of string", "}extra", %{}, {1, 0}, 9}
C'est parfait, « foobar{ga} » a été accepté, les autres sont refusés.
Maintenant, il est temps d'introduire un outil très utile de
NimbleParsec, la fonction generate. Elle permet
de générer des chaines de caractères conformes à la
grammaire qu'on a décrite en combinant les
analyseurs (lisez quand même la documentation, il y a des pièges). Voici un exemple (en nimbleparsec-5.exs) :
% mix run --no-mix-exs nimbleparsec-5.exs <<125, 40, 252, 204, 123, 151, 153, 125>>
Que signifie cette réponse incompréhensible ? C'est parce que
ascii_string, en dépit de son nom, n'accepte
pas que des caractères ASCII mais aussi tous les caractères sur huit
bits, qu'Elixir refuse ensuite prudemment d'imprimer. On va donc
restreindre les caractères autorisés (avec l'intervalle
?a..?z, déjà vu) et cette fois, ça marche :
% mix run --no-mix-exs nimbleparsec-6.exs
"gavi{xt}"
% mix run --no-mix-exs nimbleparsec-6.exs
"y{ltww}"
% mix run --no-mix-exs nimbleparsec-6.exs
"ha{yxsy}"
% mix run --no-mix-exs nimbleparsec-6.exs
"q{yx}"
Nous générons bien désormais des chaines conformes à la
grammaire. generate est vraiment un outil très
pratique (j'avais travaillé sur un projet ayant des points communs,
Eustathius, mais qui
n'est plus maintenu).
Voyons maintenant quelques autres combinateurs possibles (je vous
rappelle que NimbleParsec a une bonne
documentation). repeat permet de répéter
un analyseur :
# Permettra "foo{bar}{baz}"
lang = verb |> repeat(body)
Tandis qu'optional permettra de rendre un
analyseur facultatif :
# Permettra "foo{bar}{baz}" mais aussi "foo"
lang = verb |> optional(repeat(body))
Autres trucs utiles, le premier argument
d'ascii_string permet de donner une liste
d'intervalles de caractères acceptés. Le programme nimbleparsec-6.exs impose ainsi une lettre majuscule au
début, puis permet des tirets :
verb = ascii_char([?A..?Z]) |> concat(ascii_string([?a..?z, ?-], min: 1))
value = ascii_string([?a..?z, ?-], min: 1)
body = ignore(string("{")) |> concat(value) |> ignore(string("}"))
parser = verb |> optional(repeat((body))) |> eos
Voici le résultat :
% mix run --no-mix-exs nimbleparsec-6.exs
"Yga{-c--}{yt}{--}"
% mix run --no-mix-exs nimbleparsec-6.exs
"H--n{-r-v}{-}{j--h}"
% mix run --no-mix-exs nimbleparsec-6.exs
"L-x{-bj}{-}"
% mix run --no-mix-exs nimbleparsec-6.exs
"Upi"
Comme exercice, je vous laisse déterminer comment interdire deux tirets consécutifs.
ascii_string va chercher des caractères ou
plus exactement des octets. Si le texte est de
l'Unicode, il sera probablement encodé en
UTF-8 et on aura peut-être plutôt envie
d'utiliser utf8_string :
verb = utf8_string([], min: 1)
...
IO.inspect Test7.test("café-au-lait")
Qui donnera :
{:ok, ["café-au-lait"], "", %{}, {1, 0}, 13}
Mais une sérieuse limite apparait : tous les caractères Unicode
seront acceptés. On peut en éliminer certains (ici, l'espace - que
vous ne voyez pas - et le
point) avec
not :
verb = utf8_string([not: ? , not: ?.], min: 1)
Mais les intervalles (comme ?a..?z que vous
avez vu plus haut) n'ont guère d'intérêt en Unicode, où les
caractères qui vous intéressent ne sont probablement pas
consécutifs. Il faudrait pouvoir utiliser les catégories
Unicode, mais je ne trouve pas de moyen de le faire avec
NimbleParsec.
Des limites ou des défauts de cette solution ? Les deux principaux me semblent :
- Les messages d'erreur retournés par défaut ne me semblent pas idéaux et il est difficile d'insérer son propre traitement d'erreur.
- Il ne semble pas y avoir de moyen de faire de l'analyse incrémentale (« streaming ») ce qui est notamment génant pour l'analyse de protocoles réseau. De même, on ne peut pas facilement modifier la grammaire en fonction des données lues.
Bref, cette solution a l'avantage d'être très simple à mettre en œuvre pour un besoin ponctuel ou personnel, mais n'est pas forcément bien adaptée pour un analyseur « de production ».
Si vous voulez approfondir, je répète une dernière fois que la doc est très complète, mais il y a aussi l'article de Gints Dreimanis et celui de Drew Olson. Et, sur Elixir lui-même, je compte beaucoup sur le livre de Dave Thomas.
L'article seul
Mesurer l'efficacité du pare-feu national chinois
Première rédaction de cet article le 10 novembre 2021
L'Internet en Chine est censuré par un dispositif souvent décrit sous le nom de GFW (Great FireWall). C'est sans doute le dispositif de censure le plus perfectionné au monde. Il a donc été assez étudié mais rarement autant en détail que dans l'excellent article « How Great is the Great Firewall? Measuring China's DNS Censorship », dont les auteurs ont surveillé le GFW sur une longue période.
Le GFW n'a pas une technique unique de censure. Une de ses forces est de combiner plusieurs techniques. L'une d'elles est la génération, par le réseau lui-même (et pas par un résolveur menteur), de fausses réponses DNS. Vous demandez un nom censuré et paf vous recevez une réponse donnant une adresse IP qui n'a rien à voir avec la question posée. Dans la plupart des pays qui censurent avec le DNS, la réponse mensongère est un NXDOMAIN - code indiquant que le nom n'existe pas - ou bien l'adresse d'un site Web qui affichera un message explicatif. Au contraire, les censeurs chinois sont soucieux de brouiller les pistes et renvoient une adresse réelle, ce qui rendra plus difficile de comprendre ce qui se passe.
Voici un exemple. J'interroge l'adresse IP
113.113.113.113, qui est en Chine, sur le
réseau de China Telecom. Autant que j'en sache, aucune machine ne
répond à cette adresse (testé avec nmap). Si
je l'interroge sur un nom de domaine, je n'ai, logiquement, pas de
réponse :
% dig @113.113.113.113 A mit.edu ... ;; connection timed out; no servers could be reached
Mais si je l'interroge sur un nom censuré, là, le réseau génère une réponse mensongère :
% dig @113.113.113.113 A scratch.mit.edu ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 56267 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ... ;; ANSWER SECTION: scratch.mit.edu. 248 IN A 157.240.6.18 ;; Query time: 210 msec ;; SERVER: 113.113.113.113#53(113.113.113.113) ;; WHEN: Tue Nov 09 08:35:29 UTC 2021 ;; MSG SIZE rcvd: 60
L'adresse IP 157.240.6.18 appartient à
Facebook (normalement,
scratch.mit.edu est chez
Fastly), exemple typique des mensonges
générés par le GFW.
Pour étudier en détail ce mécanisme, les auteurs de l'article « How Great is the Great Firewall? » ont développé le logiciel GFWatch qui permet de faire des études du GFW sur une longue période, entre autres sur les adresses IP renvoyées par le GFWatch.
GFWatch utilise des listes de noms de domaine dans des TLD importants comme
.com, augmentées de noms
dont on a appris qu'ils étaint censurés
(scratch.mit.edu est censuré - cf. exemple plus
haut - mais mit.edu ne l'est pas, donc utiliser
les listes de noms sous les TLD comme
.edu ne suffit pas). Il
interroge ensuite des adresses IP en Chine, adresses qui ne
répondent pas aux questions DNS (rappelez-vous que les réponses
mensongères sont fabriquées par des middleboxes et
qu'il n'y a donc même pas besoin que l'adresse IP en question
réponde, comme dans le cas de
113.113.113.113). Toute réponse est donc
forcément une action de censure. Le logiciel GFWatch stocke alors
les réponses. L'article utilise des données de 2020, collectées
pendant neuf mois. (On peut voir les domaines
censurés.)
Les résultats ? Sur 534 millions de domaines testés, 311 000 ont
déclenché une réponse mensongère du GFW. Les censeurs chinois n'ont
pas peur des faux positifs et, par exemple,
mentorproject.org est censuré, probablement
uniquement parce qu'il contient la chaine de caractères
torproject.org, censurée parce que les censeurs
n'aiment pas Tor.
GFWatch peut ainsi obtenir une longue liste de domaines censurés, et essayer de les classer, ce qui permet d'obtenir une idée de la politique suivie par les censeurs (inutile de dire que les gérants du GFW ne publient pas de rapports d'activité détaillant ce qu'ils font…). On trouve par exemple des domaines liés à la pandémie de Covid-19 (les autorités chinoises ne veulent pas laisser l'information sur la maladie circuler librement).
Une des particularités du GFW est le renvoi d'adresses IP sans lien avec le nom demandé (comme, plus haut, une adresse de Facebook renvoyée à la place de celle du MIT). Quelles sont ces adresses IP ? Combien sont-elles ? Comment sont-elles choisies ? C'est l'un des gros intérêts d'un système comme GFWatch, de pouvoir répondre à ces questions. L'adresse retournée n'est clairement pas prise au hasard dans tout l'espace d'adressage IPv4. Seules 1 781 adresses IPv4 ont été vues par GFWatch, presque la moitié étant des adresses Facebook. Le GFW renvoie aussi des adresses IPv6 :
% dig @113.113.113.113 AAAA scratch.mit.edu ... ;; ANSWER SECTION: scratch.mit.edu. 84 IN AAAA 2001::4a75:b6b7
Et toutes appartiennent au préfixe réservé pour Teredo (RFC 4380), une technologie désormais abandonnée.
Quant aux adresses IPv4, leur nombre varie dans le temps (de nouvelles adresses apparaissent de temps en temps), et le choix ne semble pas aléatoire, certaines adresses apparaissant davantage que les autres.
Du fait que les réponses mensongères sont générées par le réseau
(plus exactement par une middlebox), et pas par un
serveur, le GFW brouille parfois les réponses de serveurs
légitimes. Plusieurs cas sont cités par l'article, mais je vais
plutôt mentionner un cas très récent, le brouillage des réponses du
serveur racine
k.root-servers.net car le résolveur d'un
FAI
mexicain a eu le malheur d'interroger l'instance pékinoise de
k.root-servers.net et le GFW a donc envoyé ses
réponses mensongères. Le point a été discuté
sur la liste dns-operations de l'OARC en novembre 2021 et il
semble que l'annonce BGP de l'instance pékinoise ait été transmise
bien au delà de sa portée voulue (un problème relativement fréquent
avec les serveurs anycastés).
L'article montre d'ailleurs que certains résolveurs DNS publics ont reçu des réponses générées par le GFW et les ont mémorisées. Les réponses de cette mémoire ainsi empoisonnée ont ensuite été servies à d'innocents utiisateurs. Bref, on ne répétera jamais assez qu'il faut utiliser DNSSEC (signer les zones, et vérifier les signatures ; les gros résolveurs publics vérifient tous les signatures mais cela ne marche que si la zone est signée).
Comment lutter contre cette censure ? Déjà, l'article note que le
GFW est en général « sur le côté » et pas « sur le chemin ». Il
injecte un mensonge mais ne bloque pas la vraie réponse. Parfois,
celle-ci arrive même avant le mensonge, si le GFW a été lent à
réagir. Une solution possible serait donc d'attendre un peu voir si
on ne reçoit pas une autre réponse, plus vraie. Certains motifs dans
la réponse mensongère (comme l'utilisation du préfixe
2001::/32, normalement inutilisé, pour les
requêtes AAAA) pourraient permettre d'ignorer les réponses de la
censure. (Vous pouvez voir les adresses retournées par les menteurs
sur le site de
GFWatch.) Mais, comme dit plus haut, la solution est
évidemment DNSSEC, avec un lien sécurisé vers le
résolveur validant (par exemple avec DoT ou
DoH). Ne vous fiez pas
à ce que raconte l'article sur des soi-disant « problèmes de
compatibilité », qui ne sont pas détaillés. Mais attention, cela ne
résout que la censure du DNS ; le GFW emploie une combinaison de
techniques et y échapper n'est pas facile (et peut, si vous êtes en
Chine, attirer l'attention de gens assez désagréables et en
uniforme).
Vous pouvez aussi regarder la censure chinoise avec un résolveur
situé en Chine et accessible via le fédivers,
ResolverCN@mastodon.xyz, par exemple voici ce
qu'il voyait pour Scratch. Mais ce n'est même pas nécessaire,
comme on l'a vu plus haut, donc vous pouvez aussi vous servir du
DNS Looking Glass, par exemple en
https://dns.bortzmeyer.org/facebook.com?server=113.113.113.113162.125.32.5
appartient à Dropbox, pas Facebook :
L'article seul
RFC 9097: Metrics and Methods for One-Way IP Capacity
Date de publication du RFC : Novembre 2021
Auteur(s) du RFC : A. Morton (AT&T Labs), R. Geib (Deutsche Telekom), L. Ciavattone (AT&T Labs)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF ippm
Première rédaction de cet article le 10 novembre 2021
Ce RFC
revisite la notion de capacité du RFC 5136 et spécifie une nouvelle métrique,
Type-P-One-way-Max-IP-Capacity.
Il y a déjà plusieurs RFC qui spécifient rigoureusement des métriques pour déterminer la capacité réseau. (Attention, les publicités des FAI et les articles dans les médias parlent souvent à tort de débit pour désigner ce qui est en fait la capacité, c'est-à-dire le débit maximum.) Une définition rigoureuse est en effet nécessaire car il peut y avoir, pour une même connexion et un même chemin, des capacités différentes selon ce qu'on mesure. Par exemple, est-ce qu'on compte les bits/s à la couche 3 ou à la couche 7 ? Compte-tenu de l'encapsulation et des retransmissions, la seconde est forcément plus basse. Les définitions actuelles sont surtout dans le RFC 5136 et le RFC 3148 mais le travail n'est jamais terminé et ce nouveau RFC vient donc compléter le RFC 5136. Vu l'importance de cette notion de capacité dans les publicités (« Nouveau : accès Premium Gold Plus à 10 Gb/s ! »), il est crucial que des associations de consommateurs ou des régulateurs puissent mesurer et vérifier les annonces.
Une des raisons pour lesquelles le travail sur la définition des métriques ne cesse jamais est que l'Internet évolue. Ainsi, note le RFC, depuis quelques années :
Première métrique défnie dans notre RFC (section 5), et venant
s'ajouter à celles du RFC 5136,
Type-P-One-way-IP-Capacity. C'est le nombre de
bits par seconde, mesurés en couche 3 et au-dessus (donc incluant
l'en-tête IP, par exemple). Le Type-P est là
pour rappeler que cette métrique n'a de sens que pour un certain
type de trafic, car des équipements réseau « intelligents » peuvent
faire que, par exemple, les paquets vers le port 22 passent plus vite que ceux pour un
autre port. Type-P est donc la description
complète des paquets utilisés. À noter que le RFC recommande
d'indiquer la valeur de cette métrique en mégabits par seconde (et
pas en mébibits, on
utilise plutôt les préfixes des télécoms que ceux de
l'informatique).
Deuxième métrique (section 6),
Type-P-One-way-Max-IP-Capacity, qui indique la
capacité maximum (la différence avec la métrique précédente vient du
fait que certains réseaux peuvent avoir une capacité variable, par
exemple les réseaux radio, oui, je sais, c'est compliqué).
Troisième métrique (section 7),
Type-P-IP-Sender-Bit-Rate. Elle désigne la
capacité de l'émetteur à envoyer des bits. En effet, lors d'une
mesure, le goulet d'étranglement peut être l'expéditeur et on croit
alors que le réseau a une capacité inférieure à ce qu'elle est
réellement.
La section 8 se penche sur la mesure effective de ces valeurs. Il faut une mesure active (envoi de bits sur le réseau uniquement pour faire la mesure), et elle possiblement très perturbatrice puisqu'on va chercher à remplir les tuyaux le plus possible. Le RFC inclut un algorithme d'ajustement du trafic mais qui n'est pas un vrai algorithme de contrôle de congestion. Le pseudo-code de cet algorithme est dans l'annexe A.
La mesure est bidirectionnelle (envoyeur et récepteur doivent
coopérer) même si la métrique est unidirectionnelle (le
One-Way dans le nom). Le RFC recommande de la
faire sur UDP
(attention au RFC 8085, UDP n'ayant pas de
contrôle de congestion propre, c'est à l'application de mesure de
faire attention à ne pas écrouler le réseau).
Jouons maintenant un peu avec une mise en œuvre de ce RFC, le
programme udpst, sur
deux machines Arch Linux (un
Raspberry Pi 1, donc avec un réseau très
lent) et Debian, sur le même
commutateur. On l'installe :
% git clone https://github.com/BroadbandForum/obudpst.git % cd obudpst % cmake . % make
On peut alors lancer le serveur :
% ./udpst UDP Speed Test Software Ver: 7.2.1, Protocol Ver: 8, Built: Sep 28 2021 15:46:40 Mode: Server, Jumbo Datagrams: Enabled, Authentication: Available, sendmmsg syscall: Available
Et le client, le Raspberry Pi :
% ./udpst -u 2001:db8:fafa:35::1
UDP Speed Test
Software Ver: 7.2.1, Protocol Ver: 8, Built: Sep 28 2021 18:25:23
Mode: Client, Jumbo Datagrams: Enabled, Authentication: Available, sendmmsg syscall: Available
Upstream Test Interval(sec): 10, DelayVar Thresholds(ms): 30-90 [RTT], Trial Interval(ms): 50, Ignore OoO/Dup: Disabled,
SendingRate Index: <Auto>, Congestion Threshold: 3, High-Speed Delta: 10, SeqError Threshold: 10, IPv6 TClass: 0
...
Sub-Interval[10](sec): 10, Delivered(%): 100.00, Loss/OoO/Dup: 0/0/0, OWDVar(ms): 2/8/18, RTTVar(ms): 2-16, Mbps(L3/IP): 65.73
Upstream Summary Delivered(%): 100.00, Loss/OoO/Dup: 0/0/0, OWDVar(ms): 0/3/23, RTTVar(ms): 0-16, Mbps(L3/IP): 49.87
Upstream Minimum One-Way Delay(ms): 2 [w/clock difference], Round-Trip Time(ms): 1
Upstream Maximum Mbps(L3/IP): 67.29, Mbps(L2/Eth): 67.45, Mbps(L1/Eth): 67.63, Mbps(L1/Eth+VLAN): 67.67
En sens inverse, avec l'option -d, où le
Raspberry Pi va envoyer des données :
Downstream Summary Delivered(%): 84.90, Loss/OoO/Dup: 8576/0/0, OWDVar(ms): 0/641/956, RTTVar(ms): 0-39, Mbps(L3/IP): 38.86 Downstream Minimum One-Way Delay(ms): -927 [w/clock difference], Round-Trip Time(ms): 1 Downstream Maximum Mbps(L3/IP): 46.98, Mbps(L2/Eth): 47.68, Mbps(L1/Eth): 48.46, Mbps(L1/Eth+VLAN): 48.62
(Notez le taux de pertes élevé, la pauvre machine n'arrive pas à suivre.)
L'article seul
Fiche de lecture : L'École sans école
Auteur(s) du livre : Stéphane Bortzmeyer, Gilles
Braun, Éric Bruillard, Goundo
Diawara, Olivier Ertzscheid, Camille
Fée, Pierre-Yves Gosset, Hélène
Mulot, Hélène Paumier, Serge
Pouts-Lajus, Delphine
Riccio, Élisabeth Schneider, Céline
Thiery, Stéphanie de Vanssay, les
élèves Lola, Ilyès et Shana
Éditeur : C&F Éditions
978-2-37662-025-9
Publié en 2021
Première rédaction de cet article le 1 novembre 2021
Vous l'avez remarqué, la France a été confinée en mars 2020 et cela a entre autres concerné l'École, qui était fermée ou, plus exactement, sortie de l'école (avec un petit é) pour se faire à distance depuis la maison. D'un tel bouleversement, décidé dans l'urgence, il y a forcément des leçons à tirer. C'est le but de ce petit livre collectif qui réunit un certain nombre d'analyses sur cette « période spéciale ».
À ma connaissance, le ministère n'a pas produit de texte officiel de bilan de cette « expérience ». (Sauf si on considère que le livre du ministre en tient lieu.) Pourtant, il y en a des choses à dire, un grand nombre de gens, des enseignants, élèves, parents, employés non enseignants de l'École ont dû s'adapter dans l'urgence, et ont souvent brillamment innové. Le livre alterne des témoignages du terrain, et des analyses plus générales. Goundo Diawara raconte ce qu'une CPE dans un établissement difficile (REP+) pouvait faire pour maintenir le moral des élèves et de leurs familles (comme pour beaucoup de choses, confinement et travail à la maison sont plus agréables quand on est riche que quand on est pauvre). Stéphanie de Vanssay rappelle que se focaliser sur le numérique, vu parfois comme danger, et parfois comme solution à tout pendant le confinement, est insuffisant. Ainsi, les inégalités ne relèvent pas uniquement de la « fracture numérique ». Serge Pouts-Lajus décrit ce que faisait le personnel non-enseignant, par exemple en préparant des repas et en les apportant aux élèves. Hélène Mulot parle du travail qu'elle a fait avec les élèves autour des masques. Et Pierre-Yves Gosset fait le bilan des relations de l'École avec le numérique, et notamment de sa capitulation, bien antérieure au confinement, devant Microsoft et autres entreprises. (Mais le confinement a aggravé les choses ; « nous avons tous émigré aux États-Unis » en matière d'outils numériques.)
J'espère que ce livre servira à ce que cette « expérience » ne soit pas oubliée et que les leçons du confinement serviront à quelque chose, et permettront de faire évoluer l'École (oui, je suis optimiste). Vous connaissez d'autres livres (à part celui du ministre) qui ont fait le bilan de ce confinement dans le milieu scolaire ?
Sur ce livre, il y a aussi une présentation d'une heure en vidéo et un article de Bruno Devauchelle dans le Café Pédagogique.
L'article seul
RFC 9120: Nameservers for the Address and Routing Parameter Area ("arpa") Domain
Date de publication du RFC : Octobre 2021
Auteur(s) du RFC : K. Davies (IANA), J. Arkko (Ericsson)
Pour information
Première rédaction de cet article le 30 octobre 2021
Dernière mise à jour le 4 mai 2022
Le TLD
.arpa sert pour
différentes fonctions techniques et est géré directement par
l'IAB. Ce
RFC décrit un
changement dans ses serveurs de noms.
Ce TLD
est décrit dans le RFC 3172. Le nom de
.arpa fait référence à
l'ancien nom de la DARPA, l'agence qui avait
financé le développement de l'Internet. Mais,
aujourd'hui, il veut dire « Address and Routing Parameter
Area » et le TLD sert à diverses fonctions techniques comme
la résolution d'adresses IP
en noms de domaine via
des sous-domaines comme ip6.arpa. Par exemple,
l'adresse IP du serveur Web de l'IAB a pour nom correspondant :
% dig -x 2001:1900:3001:11::2c ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 53150 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ... ;; ANSWER SECTION: c.2.0.0.0.0.0.0.0.0.0.0.0.0.0.0.1.1.0.0.1.0.0.3.0.0.9.1.1.0.0.2.ip6.arpa. 3600 IN PTR mail.ietf.org.
Comme vous le voyez, dig a inversé l'adresse IP et ajouté
ip6.arpa à la
fin. .arpa sert
également à d'autres fonctions comme le
home.arpa du RFC 8375.
Traditionnellement, le domaine .arpa était
hébergé sur une partie des serveurs de noms de la
racine. Le 22 octobre 2021, voici quels étaient les
serveurs faisant
autorité pour .arpa :
% dig +nodnssec NS arpa ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 43670 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 12, AUTHORITY: 0, ADDITIONAL: 1 ... ;; ANSWER SECTION: arpa. 15910 IN NS b.root-servers.net. arpa. 15910 IN NS f.root-servers.net. arpa. 15910 IN NS d.root-servers.net. arpa. 15910 IN NS l.root-servers.net. arpa. 15910 IN NS e.root-servers.net. arpa. 15910 IN NS a.root-servers.net. arpa. 15910 IN NS c.root-servers.net. arpa. 15910 IN NS i.root-servers.net. arpa. 15910 IN NS h.root-servers.net. arpa. 15910 IN NS g.root-servers.net. arpa. 15910 IN NS k.root-servers.net. arpa. 15910 IN NS m.root-servers.net. ;; Query time: 0 msec ;; SERVER: ::1#53(::1) ;; WHEN: Fri Oct 22 20:35:36 CEST 2021 ;; MSG SIZE rcvd: 241
Comme vous pouvez le voir, c'était presque tous les serveurs de la
racine (si vous aimez les jeux : quel serveur de la racine n'hébergeait
pas .arpa ?). La raison pour cela est que
.arpa est critique et doit donc bénéficier d'un
hébergement solide. Profiter des serveurs de la racine était donc
intéressant. Mais le problème est que ça lie
.arpa à la racine. On pourrait avoir envie de
faire des changements dans les serveurs faisant autorité pour
.arpa sans toucher aux serveurs de la racine,
celle-ci étant encore plus critique (cf. RFC 7720). Le principe de base de notre nouveau RFC est donc : découpler les
serveurs DNS de .arpa de ceux de la racine (ce
qui avait été fait pour ip6.arpa il y a dix ans,
voir le RFC 5855).
Le changement ne concerne que l'hébergement DNS, pas la gestion
de .arpa (section 2 de notre RFC), qui reste un
TLD
critique, et soumis au RFC 3172. Le choix des sous-domaines
et de leur administration est inchangé (par exemple, pour
ip6.arpa, c'est décrit dans le RFC 5855).
La section 3 du RFC décrit le nouveau système. Le principe est de commencer par utiliser des
noms différents pour les serveurs, mais qui pointeront vers les
mêmes machines, au moins au début. Les nouveaux noms sont dans le
sous-domaine ns.arpa, on a donc
a.ns.arpa, b.ns.arpa,
etc. Aucune modification dans les serveurs ne sera nécessaire pour
cette première étape, qui n'affectera que la zone racine et la zone
.arpa. Comme tous les noms seront dans la zone qu'ils
servent, il faudra ajouter de la colle aux réponses DNS (ne pas
juste dire « le serveur est c.ns.arpa » mais
également indiquer son adresse
IP). Il n'y a désormais
plus de nom de serveur commun à la racine et à
.arpa, et il sera possible dans le futur de
migrer vers d'autres serveurs. (Toujours en respectant le RFC 3172.) Voici l'état actuel :
% dig +nodnssec NS arpa ; <<>> DiG 9.16.1-Ubuntu <<>> +nodnssec NS arpa ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 15962 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 12, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 1232 ;; QUESTION SECTION: ;arpa. IN NS ;; ANSWER SECTION: arpa. 517877 IN NS h.ns.arpa. arpa. 517877 IN NS i.ns.arpa. arpa. 517877 IN NS k.ns.arpa. arpa. 517877 IN NS l.ns.arpa. arpa. 517877 IN NS m.ns.arpa. arpa. 517877 IN NS a.ns.arpa. arpa. 517877 IN NS b.ns.arpa. arpa. 517877 IN NS c.ns.arpa. arpa. 517877 IN NS d.ns.arpa. arpa. 517877 IN NS e.ns.arpa. arpa. 517877 IN NS f.ns.arpa. arpa. 517877 IN NS g.ns.arpa. ;; Query time: 3 msec ;; SERVER: 192.168.2.254#53(192.168.2.254) ;; WHEN: Wed May 04 08:57:47 CEST 2022 ;; MSG SIZE rcvd: 228
Vous pouvez également voir cet état actuel de .arpa à l'IANA
ou bien
dans le DNS.
Notez enfin que certains des serveurs de
.arpa autorisent le transfert de zones. Voici une copie faite le 24 octobre 2021.
L'article seul
L'informatique doit-elle être rangée dans les sciences humaines et sociales ?
Première rédaction de cet article le 17 octobre 2021
L'informatique est en fait une SHS et devrait être rangée ainsi dans les universités. C'est par cette idée provocante (mais, je vous rassure tout de suite, que l'auteur estime irréaliste) que commence l'article de Randy Connolly « Why computing belongs within the social sciences ». Une thèse intéressante et bien exposée, qui s'appuie sur des éléments sérieux mais qui a aussi d'ennuyeuses faiblesses.
Comme je l'ai dit, l'auteur ne propose pas réellement de réorganiser les universités et le CNRS en déplaçant le département d'informatique au même étage que la sociologie et l'histoire. Son but est plutôt de faire réfléchir au statut de l'informatique : on la place toujours dans les sciences dures (ou sciences exactes), en général à côté de la mathématique mais ne faudrait-il pas reconsidérer cette habitude ? L'idée centrale de l'auteur est que, d'abord, l'informatique a un tel pouvoir aujourd'hui, un tel rôle dans nos sociétés, qu'elle n'appartient plus au monde de la pure science, et ensuite que les sciences humaines et sociales auraient beaucoup à lui apporter.
Un grand nombre des points soulevés par l'auteur sont parfaitement exacts. L'informatique n'est pas seulement une technique à succès, présente partout (comme le sont bien d'autres sciences, par exemple la physique) : elle est au cœur de toutes nos activités à l'heure actuelle. Elle interagit donc fortement avec la société. L'informatique a du pouvoir (c'est bien pour cela que c'est un métier qui paie bien et ne connait pas le chômage) et donc des responsabilités. Affirmer, comme le fait l'auteur, que le code est politique n'est pas nouveau, ni original, mais ce n'est pas forcément encore bien compris, ni même admis par tou·tes les informaticien·nes (« je code juste, je ne fais pas de politique »). Ce n'est donc pas une mauvaise idée de le répéter. Ensuite, il est certain que les autres sciences (pas seulement les SHS) ont des choses à apprendre à l'informatique. C'est encore une banalité (que serait la science qui prétendrait rester isolée et considérerait les autres sciences comme dénuées d'intérêt ?) mais qui n'est pas encore bien intégrée. On trouvera sans peine des informaticien·nes qui renâcleraient à l'idée d'introduire des cours de psychologie ou d'économie dans leur cursus, au nom de « ça ne sert à rien ».
(Au passage, l'auteur a une façon intéressante de décrire la différence entre sciences dures et sciences humaines : les sciences dures se caractérisent par la méthode unique, la bonne, les sciences humaines par le pluralisme des méthodes. En effet, en SHS, il n'y a jamais de consensus entre les chercheurs, même sur des choses de base. Ce critère semble plus utile qu'un critère souvent utilisé, celui de la réfutabilité. Il y a des sciences dures comme la paléontologie ou l'astrophysique où on ne peut pas facilement faire des expériences…)
L'auteur fait trois suggestions concrètes, admettre que les autres sciences ont quelque chose à apporter à l'informatique, des cours de SHS dans les filières informatiques (et pas juste un « cours d'éthique » perdu en fin de semestre et clairement marqué comme secondaire), et l'embauche dans les départements d'informatique de gens qui ne sont pas à proprement parler informaticien·nes. Les trois me semblent de bonnes idées.
J'ai apprécié l'appel à s'ouvrir, à aller voir dans les autres champs disciplinaires ce qu'ils peuvent nous apporter. L'auteur a raison de faire remarquer que certain·es informaticien·nes ont une fâcheuse tendance à croire que tous les problèmes du monde se règlent avec de l'informatique, une vision techno-solutionniste très présente, par exemple, dans le discours macroniste et sa startup nation. Or, si l'arrivée d'informaticien·nes dans un champ nouveau peut rafraichir ce champ, la plupart du temps, quelqu'un qui débarque dans un nouveau domaine sans faire l'effort de la comprendre a plus de chances d'être un arrogant débutant que d'être un génie qui va bouleverser le monde. Mais l'article a aussi des faiblesses importantes.
La première est que la politique est absente. À le lire, on a l'impression que les décisions d'une entreprise comme Facebook sont uniquement dues au fait que les ingénieurs ont une certaine mentalité, et que ce sont eux qui décident. Il montre ainsi une étonnante ignorance du monde de l'entreprise et de ses mécanismes de gouvernance. Zuckerberg ne prend pas ses décisions parce que, il y a longtemps, il était programmeur. Il les prend en fonction des profits pour son entreprise, comme le fait n'importe quel autre patron. Le remplacer par quelqu'un qui a fait des études de science politique ou de communication ne changerait probablement rien. (Pour citer un commentaire de Joseph Bedard, « les patrons des entreprises de la tech ne sont pas des informaticiens et, s'ils l'ont été autrefois, ils ne le sont plus ».) Mais il est vrai qu'aux États-Unis, critiquer le capitalisme est un sujet tabou. Socialement, il est bien plus admis de demander qu'on donne quelques cours d'anthropologie ou de linguistique aux décideurs.
Cette négligence de la politique mène l'auteur à de curieuses affirmations comme de prétendre qu'aujourd'hui, le pouvoir ne s'exercerait rarement que par la violence et plutôt via des algorithmes. S'il est vrai que presque toutes nos activités sont médiées par des logiciels (et que les gens qui développent et déploient ce logiciel ont donc une responsabilité), il n'en est pas moins vrai que l'utilisation de ces logiciels est imposée et n'est pas le résultat d'une diffusion douce. N'importe quel gilet jaune ayant manifesté à Paris pourrait dire au professeur d'université dans sa tour d'ivoire que, si, la violence du pouvoir est encore un moyen utile et utilisé.
Ensuite, si je comprends que l'auteur (qui publie dans une revue de l'ACM) s'adresse surtout à un public d'informaticien·nes, et donc passe l'essentiel de l'article à réhabiliter les SHS dans l'esprit de ses confrères et consœurs, il faut quand même noter que les SHS, comme l'informatique, ne résolvent pas tous les problèmes. L'auteur parle de champs de recherche « établis depuis longtemps » comme si c'était une garantie de sérieux ; le cas de l'astrologie ou bien de la pseudo-médecine qu'on a pratiqué jusqu'au XVIIIe siècle montre que l'ancienneté d'une discipline ne dit rien sur son bon fonctionnement.
L'auteur estime ainsi que la conception de l'Internet, faite sans trop se soucier des problèmes de sécurité (un cliché classique), aurait été différente si on avait impliqué dès le début des gens ayant, entre autres, « une meilleure connaissance de la psychologie humaine ». Cette affirmation est franchement nulle sur plusieurs points. D'abord, l'expérience des réseaux informatiques prouve largement que les systèmes conçus en fonction de la sécurité ne sont tout simplement jamais utilisés et jamais déployés (ce qui, il est vrai, résout pas mal de problèmes de sécurité…). Comme l'analyse très justement le RFC 5218, pour avoir du succès dans le monde réel, il faut être utilisable et agréable, donc ne pas trop embêter les utilisateurs avec la sécurité (même s'il faudra bien s'y atteler un jour). Ensuite, même aujourd'hui, avec l'expérience acquise et la compréhension de l'importance des questions de sécurité, on ne sait pas forcément toujours sécuriser l'Internet sans le stériliser complètement. Enfin, prétendre que les psychologues auraient prévu le problème (alors que les SHS ne sont pas spécialement connues pour leurs succès prédictifs…) car la nature humaine, les gens sont méchants, ça a toujours été comme ça et sera toujours comme ça, c'est du Café du Commerce, pas de la psychologie comme science.
(Les lecteur·trices averti·es noteront en outre que l'article ne différencie pas tout le temps l'informatique en tant que science et celle en tant que technique. Mais c'est un sujet complexe que je ne traite pas moi non plus.)
Ah, et pour finir, une vidéo où une informaticienne parle de sa passion pour la programmation, mais aussi, et à juste titre, du pouvoir qu'apporte cette technique.
L'article seul
Tempête solaire sur l'Internet ?
Première rédaction de cet article le 15 octobre 2021
L'Internet est vulnérable aux attaques, aux pannes du matériel, aux bogues des logiciels. Mais il peut aussi être vulnérable aux actions du Soleil, comme le montre l'étude « Solar superstorm: planning for an Internet apocalypse » qui, en dépit d'un titre putaclic, est une analyse sérieuse et détaillée des risques que courra l'Internet avec l'actuelle croissance de la violence du Soleil.
Le Soleil nous éclaire et nous donne parfois des coups de soleil. Mais il a aussi un autre effet, celui provoqué par les tempêtes solaires, notamment les éjections de masse coronale. Pendant ces tempêtes, le Soleil éjecte une grande quantité de particules dont l'arrivée sur Terre provoque divers phénomènes électromagnétiques, notamment la génération de courants induits dans les conducteurs. Les câbles qui relient les équipements des réseaux informatiques, comme l'Internet, peuvent donc être perturbés, voire endommagés. La plus connue de ces tempêtes est l'événement de Carrington, qui est survenu à une époque où l'électricité était une nouveauté peu employée et où le réseau principal était le télégraphe. Les éjections de masse coronale sont très directionnelles et, si elles ne se produisent pas en direction de la Terre, les conséquences sont minimes (comme par exemple pour l'éruption de juillet 2012).
L'activité solaire, et ces tempêtes, suivent des cycles. Le plus connu est le cycle de 11 ans, et nous en sommes actuellement au cycle n° 25. Mais il y a d'autres cycles, de période plus longue, comme le cycle de Gleissberg. Le hasard a fait que l'expansion de l'Internet a coïncidé avec un minimum de la plupart de ces cycles, donc une activité solaire relativement faible. Mais les choses changent, l'activité solaire augmente, et une tempête de grande intensité, perturbant sérieusement l'Internet (et d'autres constructions techniques) est une possibilité réelle dans les prochaines années. Une tempête de la taille de celle de Carrington aurait des conséquences autrement plus importante aujourd'hui.
(Notez que, si les fibres optiques ne sont pas conductrices, le câble d'alimentation des répéteurs qui les longe l'est, et qu'une fibre optique peut donc être mise hors de service par une tempête solaire.)
L'article « Solar superstorm: planning for an Internet apocalypse » cherche à quantifier le risque et à étudier comment le limiter. Un de ses angles d'attaque est de regarder la distribution géographique des équipements réseau. En effet, les conséquences de la tempête solaire sont plus intenses aux latitudes élevées, donc près des pôles. D'autre part, plus un conducteur est long, plus le courant induit est important. Les câbles sous-marins transocéaniques sont donc les plus vulnérables. L'auteur s'est donc plongé dans les données et a regardé où il y avait le plus de risques. (Il a stocké une copie des données en ligne, sauf celles pour lesquelles il n'avait pas l'autorisation, comme les données de l'UIT.) Par exemple, CAIDA publie des informations très utiles sur les routeurs.
Je vous résume quelques conclusions :
- Les câbles sous-marins transatlantiques sont très concentrés en un petit nombre de points sur la côte Est des États-Unis (les transpacifiques sont mieux répartis), et trop au Nord, ce qui augmente les risques. En cas de tempête solaire intense, tous ces câbles seraient mis hors d'usage, seuls ceux partant de Floride, à une latitude plus basse, seraient épargnés (et ils ne vont pas en Europe, donc la connectivité entre l'Europe et les États-Unis serait probablement interrompue).
- Rappelez-vous que la tempête a surtout des effets aux latitudes élevées ; l'auteur calcule que l'Alaska perdait toute sa connectivité sous-marine, mais Hawaï serait relativement épargné.
- Fait amusant, dans l'hypothèse d'une tempête intense, le Royaume-Uni perdait sa connectivité avec l'Amérique du Nord mais pas avec l'Europe ; un Brexit à l'envers.
- Les câbles terrestres, plus courts, seront nettement moins touchés.
- Et les centres de données ? La tendance étant de les mettre de plus en plus au Nord, pour faciliter leur refroidissement, notamment dans le contexte du réchauffement planétaire, ils pourraient également être affectés.
- Et les serveurs DNS de la racine ? L'auteur y a pensé aussi et considère que, vu leur répartition très variée à la surface du globe, ils ne seront probablement pas tous affectés à la fois.
Dans l'état actuel de la science, on ne sait pas prédire les
tempêtes solaires, uniquement déterminer des probabilités. On ne
peut donc pas se préparer longtemps à l'avance. Toutefois, en cas
de tempête solaire, comme la masse coronale éjectée voyage plus
lentement que la lumière, on voit la tempête plusieurs heures, voire
plusieurs jours, avant d'en ressentir les effets. Il existe des
services d'alarme utilisés, par exemple, par l'aviation. C'est le
cas du service de
SpaceWeatherLive, ou du Presto du SIDC. Un avertissement typique
(daté du 11 octobre 2021) dit « A halo coronal mass
ejection has been observed in the available SOHO/LASCO coronagraph
imagery at 07:24 on Oct 9. This halo coronal mass ejection is
associate with the M1.6-class flare peaking at 06:38 UTC on the same
day in the Catania sunspots group 58 (NOAA AR-2882), which was
located on the central meridian. The projected speed was measured
692 km/s by the software package CACTus. The true speed has been
estimated around 950 km/s. The transit time to Earth is estimated to
take about 62 hours, ant the arrival to Earth time would be on Oct
12, around 01:00 UTC. ». Dans ce cas, la masse éjectée
(CME = Coronal Mass Ejection) arrivera bien sur
Terre mais on a un peu d'avance pour se préparer. Notez que ce
service Presto est également
accessible via Gemini : 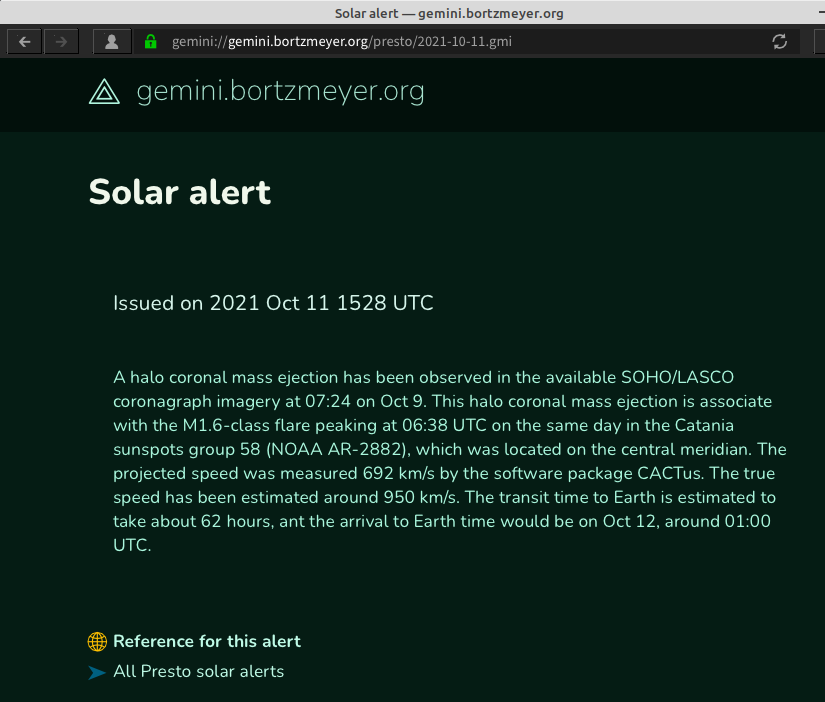
Que faire quand on reçoit l'avertissement ? Couper le courant peut aider mais ne suffit pas, le danger venant des courants induits par la réception sur Terre de la masse coronale éjectée. L'auteur recommande de travailler la diversité, avec davantage de câbles, et mieux répartis. La redondance (et l'absence de SPOF) reste la meilleure défense.
L'auteur se penche aussi sur la remise en fonctionnement après la panne et c'est sans doute la plus mauvaise partie de l'article, avec des « solutions » très stratosphériques comme SCION ou Loon.
Ah et, bien sûr, l'article rappelle que le plus gros problème sera peut-être le manque d'électricité, car le réseau électrique va déguster lui aussi (et son bon fonctionnement dépend peut-être en partie de l'Internet).
L'article seul
Panne de routage OVH d'octobre 2021
Première rédaction de cet article le 13 octobre 2021
Aujourd'hui le routage IPv4 chez OVH a été en panne pendant environ une heure. J'indique ici quelques observations effectuées puis j'en profite pour donner un avis sur la fiabilité de l'Internet, sur OVH et sur les yakafokons qui nous expliquent comment il aurait fallu faire. (Si vous n'êtes pas informaticien·ne, allez directement à la fin, la partie qui commence par « Maintenant, les leçons à en tirer. ».)
L'article complet
RFC 9137: Considerations for Cancellation of IETF Meetings
Date de publication du RFC : Octobre 2021
Auteur(s) du RFC : M. Duke (F5 Networks)
Réalisé dans le cadre du groupe de travail IETF shmoo
Première rédaction de cet article le 12 octobre 2021
Pour son travail de normalisation technique, l'IETF tient normalement trois réunions physiques par an. La pandémie de Covid-19 a évidemment changé tout cela. Les premières décisions d'annulation ont été prises selon un procédure ad hoc, mais ce nouveau RFC fournit des critères plus rigoureux pour les prochaines décisions d'annulation.
La dernière réunion physique de l'IETF a eu lieu à Singapour en novembre 2019. Depuis, les conditions sanitaires ont forcé à annuler toutes les réunions. Mais notre nouveau RFC ne se limite pas au cas de la Covid-19. Une réunion, après tout, peut devoir être annulée pour d'autres raisons, un problème de dernière minute dans le bâtiment où elle devait se tenir, une catastrophe naturelle dans le pays d'accueil, un brusque changement dans la politique de visa de ce pays, etc. (Le RFC cite même le cas d'une guerre civile, mais ce n'est encore jamais arrivé à une réunion IETF.) Dans ces cas, l'IETF LLC (la direction administrative de l'IETF) et l'IESG vont devoir décider si on maintient la réunion ou pas.
La section 3 du RFC expose les critères de décision. L'IETF LLC (cf. RFC 8711) détermine si la réunion peut se tenir, l'IESG si cela vaut la peine de la tenir. L'IETF LLC doit évidemment travailler en toute transparence, informant l'IETF de la situation, des décisions possibles et d'un éventuel « plan B ». Il n'est pas toujours possible de procéder proprement et démocratiquement si la situation est urgente (tremblement de terre trois jours avant la réunion…). Dans ce cas, l'IETF LLC doit déterminer seule si la réunion peut se tenir (ce qui implique certaines garanties de sécurité pour les participants, de la restauration mais également un accès Internet qui marche ; les participants à l'IETF n'ont pas juste besoin de dormir et de manger, il leur faut aussi du réseau). L'IETF LLC doit aussi intégrer des paramètres internes comme la disponibilité de ses employés et des bénévoles, et bien sûr les conséquences financières du maintien ou de l'annulation (si le lieu de la réunion considère qu'il n'y avait pas force majeure et ne veut pas rembourser…). La section 3 du RFC 8718 contient des indications utiles à cette évaluation.
L'IESG, lui, doit déterminer s'il y aura suffisamment de monde à la réunion pour que ça vaille la peine. Il ne serait pas malin de maintenir une réunion pour que personne ne vienne.
La section 4 du RFC couvre les alternatives. Si on annule, que peut-on proposer à la place ? Il faut évaluer ces alternatives en tenant compte de leur efficacité (une réunion en ligne est moins efficace) et de leur coût (changer les billets d'avion au dernier moment coûte cher). Ces alternatives peuvent être, dans l'ordre décroissant de préférence :
- Changer le lieu de la réunion. C'est ce qui dérange le moins le travail, surtout si le nouveau lieu est proche de l'ancien. Naturellement, le nouveau lieu doit correspondre aux critères des RFC 8718 et RFC 8719.
- Passer en ligne, à une réunion « virtuelle », ce qui a été fait pour toutes les réunions annulées en raison de la Covid-19.
- Repousser la réunion à plus tard. Ce n'est en général pas facilement faisable, puisque cela perturbe les agendas de tout le monde.
- Annuler complètement, sans alternative. Le RFC note que cela aura des conséquences, non seulement sur le travail de normalisation, mais également sur des processus politiques comme la détermination de qui peut siéger dans des comités comme le NomCom (comité de nomination, cf. RFC 8788 et RFC 8989).
La section 5 de notre RFC couvre les questions financières. En gros, l'IETF ne remboursera pas les dépenses engagées par les participants (avion, hôtel, etc), seulement les frais d'inscription à la réunion, en totalité s'il y a annulation complète et partiellement dans les autres cas.
L'article seul
RFC 9132: Distributed Denial-of-Service Open Threat Signaling (DOTS) Signal Channel Specification
Date de publication du RFC : Septembre 2021
Auteur(s) du RFC : M. Boucadair (Orange), J. Shallow, T. Reddy.K (Akamai)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dots
Première rédaction de cet article le 10 octobre 2021
Le protocole DOTS (Distributed Denial-of-Service Open Threat Signaling) vise à permettre au client d'un service anti-dDoS de demander au service de mettre en route des mesures contre une attaque. Ce RFC décrit le canal de signalisation de DOTS, celui par lequel passera la demande d'atténuation de l'attaque. Il remplace le RFC 8782, mais les changements sont mineurs.
Si vous voulez mieux comprendre DOTS, il est recommandé de lire le RFC 8612, qui décrit le cahier des charges de ce protocole, et le RFC 8811, qui décrit l'architecture générale. Ici, je vais résumer à l'extrême : un client DOTS, détectant qu'une attaque par déni de service est en cours contre lui, signale, par le canal normalisé dans ce RFC, à un serveur DOTS qu'il faudrait faire quelque chose. Le serveur DOTS est un service anti-dDoS qui va, par exemple, examiner le trafic, jeter ce qui appartient à l'attaque, et transmettre le reste à son client.
Ces attaques par déni de service sont une des plaies de l'Internet, et sont bien trop fréquentes aujourd'hui (cf. RFC 4987 ou RFC 4732 pour des exemples). Bien des réseaux n'ont pas les moyens de se défendre seuls et font donc appel à un service de protection (payant, en général, mais il existe aussi des services comme Deflect). Ce service fera la guerre à leur place, recevant le trafic (via des manips DNS ou BGP), l'analysant, le filtrant et envoyant ce qui reste au client. Typiquement, le client DOTS sera chez le réseau attaqué, par exemple en tant que composant d'un IDS ou d'un pare-feu, et le serveur DOTS sera chez le service de protection. Notez donc que client et serveur DOTS sont chez deux organisations différentes, communiquant via le canal de signalisation (signal channel), qui fait l'objet de ce RFC.
La section 3 de notre RFC expose les grands principes du
protocole utilisé sur ce canal de signalisation. Il repose sur
CoAP, un équivalent léger de HTTP, ayant beaucoup
de choses communes avec HTTP. Le choix d'un protocole différent de
HTTP s'explique par les spécificités de DOTS : on l'utilise quand ça
va mal, quand le réseau est attaqué, et il faut donc pouvoir
continuer à fonctionner même quand de nombreux paquets sont
perdus. CoAP a les caractéristiques utiles pour DOTS, il est conçu
pour des réseaux où il y aura des pertes, il tourne sur UDP, il permet des
messages avec ou sans accusé de réception, il utilise peu de
ressources, il peut être sécurisé par DTLS… TCP est également
utilisable mais UDP est préféré, pour éviter le head-of-line
blocking. CoAP est normalisé dans le RFC 7252. Parmi les choses à retenir, n'oubliez pas
que l'encodage du chemin dans l'URI est un peu spécial, avec une option
Uri-Path: par segment du chemin (RFC 7252, section 5.10.1). Par abus de langage,
j'écrirai « le client CoAP demande
/foo/bar/truc.cbor » alors qu'il y aura en fait
trois options Uri-Path: :
Uri-Path: "foo" Uri-Path: "bar" Uri-Path: "truc.cbor"
Par défaut, DOTS va utiliser le port 4646 (et non pas le port par
défaut de CoAP, 5684, pour éviter toute confusion avec d'autres
services tournant sur CoAP). Ce port a été choisi pour une bonne
raison, je vous laisse la chercher, la solution est à la fin de cet
article. Le plan d'URI sera coaps ou
coaps+tcp (RFC 7252,
section 6, et RFC 8323, section 8.2).
Le fonctionnement de base est simple : le client DOTS se connecte au serveur, divers paramètres sont négociés. Des battements de cœur peuvent être utilisés (par le client ou par le serveur) pour garder la session ouverte et vérifier son bon fonctionnement. En cas d'attaque, le client va demander une action d'atténuation. Pendant que celle-ci est active, le serveur envoie de temps en temps des messages donnant des nouvelles. L'action se terminera, soit à l'expiration d'un délai défini au début, soit sur demande explicite du client. Le serveur est connu du client par configuration manuelle, ou bien par des techniques de découverte comme celles du RFC 8973.
Les messages sont encodés en CBOR (RFC 8949). Rappelez-vous que le modèle de données de CBOR est
très proche de celui de JSON, et notre RFC spécifie donc les messages
avec une syntaxe JSON, même si ce n'est pas l'encodage utilisé sur
le câble. Pour une syntaxe formelle des messages, le RFC utilise
YANG (cf. RFC 7951). Le type
MIME des messages est application/dots+cbor.
La section 4 du RFC décrit les différents messages possibles plus
en détail. Je ne vais pas tout reprendre ici, juste donner quelques
exemples. Les URI commencent toujours par
/.well-known/dots
(.well-known est normalisé dans le RFC 8615, et dots est
désormais enregistré
à l'IANA). Les différentes actions ajouteront au chemin dans
l'URI /mitigate pour les demandes d'actions
d'atténuation, visant à protéger de l'attaque,
/hb pour les battements de cœur, etc.
Voici par exemple une demande de protection, effectuée avec la méthode CoAP PUT :
Header: PUT (Code=0.03)
Uri-Path: ".well-known"
Uri-Path: "dots"
Uri-Path: "mitigate"
Uri-Path: "cuid=dz6pHjaADkaFTbjr0JGBpw"
Uri-Path: "mid=123"
Content-Format: "application/dots+cbor"
{
... Données en CBOR (représentées en JSON dans le RFC et dans
cet article, pour la lisibilité).
}
L'URI, en notation traditionnelle, sera donc
/.well-known/dots/mitigate/cuid=dz6pHjaADkaFTbjr0JGBpw/mid=123. CUID
veut dire Client Unique IDentifier et sert à
identifier le client DOTS, MID est Mitigation
IDentifier et identifie une demande d'atténuation
particulière. Si ce client DOTS fait une autre demande de
palliation, le MID changera mais le CUID sera le même.
Que met-on dans le corps du message ? On a de nombreux champs définis pour indiquer ce qu'on veut protéger, et pour combien de temps. Par exemple, on pourrait avoir (je rappelle que c'est du CBOR, format binaire, en vrai) :
{
"ietf-dots-signal-channel:mitigation-scope": {
"scope": [
{
"target-prefix": [
"2001:db8:6401::1/128",
"2001:db8:6401::2/128"
],
"target-port-range": [
{
"lower-port": 80
},
{
"lower-port": 443
}
],
"target-protocol": [
6
],
"lifetime": 3600
}
]
}
}
Ici, le client demande qu'on protège
2001:db8:6401::1 et
2001:db8:6401::2 (target
veut dire qu'ils sont la cible d'une attaque, pas qu'on veut les
prendre pour cible), sur
les ports 80 et 443,
en TCP, pendant une heure. (lower-port seul,
sans upper-port indique un port unique, pas un
intervalle.)
Le serveur va alors répondre avec le code 2.01 (indiquant que la requête est acceptée et traitée) et des données :
{
"ietf-dots-signal-channel:mitigation-scope": {
"scope": [
{
"mid": 123,
"lifetime": 3600
}
]
}
}
La durée de l'action peut être plus petite que ce que le client a demandé, par exemple si le serveur n'accepte pas d'actions trop longues. Évidemment, si la requête n'est pas correcte, le serveur répondra 4.00 (format invalide), si le client n'a pas payé, 4.03, s'il y a un conflit avec une autre requête, 4.09, etc. Le serveur peut donner des détails, et la liste des réponses possibles figure dans des registres IANA, comme celui de l'état d'une atténuation, ou celui des conflits entre ce qui est demandé et d'autres actions en cours.
Le client DOTS peut ensuite récupérer des informations sur une action de palliation en cours, avec la méthode CoAP GET :
Header: GET (Code=0.01) Uri-Path: ".well-known" Uri-Path: "dots" Uri-Path: "mitigate" Uri-Path: "cuid=dz6pHjaADkaFTbjr0JGBpw" Uri-Path: "mid=123"
Ce GET
/.well-known/dots/mitigate/cuid=dz6pHjaADkaFTbjr0JGBpw/mid=123
va renvoyer de l'information sur l'action d'identificateur (MID)
123 :
{
"ietf-dots-signal-channel:mitigation-scope": {
"scope": [
{
"mid": 123,
"mitigation-start": "1507818393",
"target-prefix": [
"2001:db8:6401::1/128",
"2001:db8:6401::2/128"
],
"target-protocol": [
6
],
"lifetime": 1755,
"status": "attack-stopped",
"bytes-dropped": "0",
"bps-dropped": "0",
"pkts-dropped": "0",
"pps-dropped": "0"
}
]
}
}
Les différents champs de la réponse sont assez évidents. Par
exemple, pkts-dropped indique le nombre de
paquets qui ont été jetés par le protecteur.
Pour mettre fin aux actions du système de protection, le client utilise évidemment la méthode CoAP DELETE :
Header: DELETE (Code=0.04) Uri-Path: ".well-known" Uri-Path: "dots" Uri-Path: "mitigate" Uri-Path: "cuid=dz6pHjaADkaFTbjr0JGBpw" Uri-Path: "mid=123"
Le client DOTS peut se renseigner sur les capacités du serveur avec
un GET de /.well-known/dots/config.
Ce RFC décrit le canal de signalisation de DOTS. Le RFC 8783, lui, décrit le canal de données. Le canal de signalisation est prévu pour faire passer des messages de petite taille, dans un environnement hostile (attaque en cours). Le canal de données est prévu pour des données de plus grande taille, dans un environnement où les mécanismes de transport normaux, comme HTTPS, sont utilisables. Typiquement, le client DOTS utilise le canal de données avant l'attaque, pour tout configurer, et le canal de signalisation pendant l'attaque, pour déclencher et arrêter l'atténuation.
Les messages possibles sont modélisés en YANG. YANG est normalisé dans le RFC 7950. Notez que YANG avait été initialement créé pour décrire les commandes envoyées par NETCONF (RFC 6241) ou RESTCONF (RFC 8040) mais ce n'est pas le cas ici : DOTS n'utilise ni NETCONF, ni RESTCONF mais son propre protocole basé sur CoAP. La section 5 du RFC contient tous les modules YANG utilisés.
La mise en correspondance des modules YANG avec l'encodage
CBOR figure dans la section
6. (YANG permet une description abstraite d'un message mais ne dit
pas, à lui tout seul, comment le représenter en bits sur le réseau.)
Les clés CBOR sont toutes des entiers ; CBOR permet d'utiliser des
chaînes de caractères comme clés mais DOTS cherche à gagner de la
place. Ainsi, les tables de la section 6 nous apprennent que le
champ cuid (Client Unique
IDentifier) a la clé 4, suivie d'une chaîne de caractères
en CBOR. (Cette correspondance est désormais un
registre IANA.) D'autre part, DOTS introduit une étiquette
CBOR, 271 (enregistrée
à l'IANA, cf. RFC 8949, section 3.4)
pour marquer un document CBOR comme lié au protocole DOTS.
Évidemment, DOTS est critique en matière de sécurité. S'il ne fonctionne pas, on ne pourra pas réclamer une action de la part du service de protection. Et s'il est mal authentifié, on risque de voir le méchant envoyer de faux messages DOTS, par exemple en demandant l'arrêt de l'atténuation. La section 8 du RFC rappelle donc l'importance de sécuriser DOTS par TLS ou plutôt, la plupart du temps, par son équivalent pour UDP, DTLS (RFC 9147). Le RFC insiste sur l'authentification mutuelle du serveur et du client, chacun doit s'assurer de l'identité de l'autre, par les méthodes TLS habituelles (typiquement via un certificat). Le profil de DTLS recommandé (TLS est riche en options et il faut spécifier lesquelles sont nécessaires et lesquelles sont déconseillées) est en section 7. Par exemple, le chiffrement intègre est nécessaire.
La section 11 revient sur les questions de sécurité en ajoutant
d'autres avertissements. Par exemple, TLS ne protège pas contre
certaines attaques par déni de service, comme un paquet TCP RST
(ReSeT). On peut sécuriser la communication avec
TCP-AO (RFC 5925) mais c'est un vœu pieux, il
est très peu déployé à l'heure actuelle. Ah, et puis si les
ressources à protéger sont identifiées par un nom de domaine, et pas une adresse ou un
préfixe IP (target-fqdn au lieu de
target-prefix), le RFC dit qu'évidemment la
résolution doit être faite avec DNSSEC.
Question mises en œuvre, DOTS dispose d'au moins quatre implémentations, dont l'interopérabilité a été testée plusieurs fois lors de hackathons IETF (la première fois ayant été à Singapour, lors de l'IETF 100) :
Notez qu'il existe des serveurs de test DOTS
publics comme
coaps://dotsserver.ddos-secure.net:4646.
Ah, et la raison du choix du port 4646 ? C'est parce que 46 est le code ASCII pour le point (dot en anglais) donc deux 46 font deux points donc dots.
L'annexe A de notre RFC résume les principaux changements depuis le RFC 8782. Le principal changement touche les modules YANG, mis à jour pour réparer une erreur et pour tenir compte du RFC 8791. Il y a aussi une nouvelle section (la 9), qui détaille les codes d'erreur à renvoyer, et l'espace des valeurs des attributs a été réorganisé… Rien de bien crucial, donc.
L'article seul
Indiquer la consommation énergétique par requête a-t-il un sens ?
Première rédaction de cet article le 9 octobre 2021
Dernière mise à jour le 4 octobre 2022
Dans les débats sur l'empreinte environnementale du numérique, on voit souvent citer des coûts énergétiques par opération élémentaire, du genre « un message consomme X joules » ou bien « une recherche Google brûle autant de charbon que faire chauffer N tasses de café ». Ces chiffres sont trompeurs, et voici pourquoi.
Lorsqu'ils sont cités, ces chiffres sont souvent accompagnés d'injonctions à la sobriété. « N'envoyez pas ce courrier que vous étiez en train d'écrire et vous sauverez un arbre. » En effet, annoncer des coûts environnementaux par requête donne à penser que, si on s'abstient d'une action, le coût diminuera d'autant. Mais ce n'est pas ainsi que les choses se passent. Ces chiffres « par opération » sont obtenus (normalement…) en divisant la consommation énergétique totale par le nombre d'opérations. C'est classique, c'est le calcul de la moyenne. Si on connait la consommation d'essence de toutes les voitures en France, et le nombre de voitures, calculer la consommation moyenne de chaque voiture est simple. Certes, il faudrait tenir compte du fait qu'une petite voiture consomme moins qu'un SUV mais, en première approximation, cela a du sens de dire « chaque voiture dévore N litres d'essence par an ». Et il est raisonnable d'en déduire que de mettre des voitures supplémentaires sur la route augmentera cette consommation, de façon proportionnelle à l'augmentation du nombre de véhicules. La proportionnalité s'applique également à la consommation d'essence rapportée au nombre de kilomètres : la quantité de carburant brûlé est à peu près proportionnelle à ce nombre de kilomètres. Si je roule deux fois moins, je consomme deux fois moins d'essence, et ça diminuera le relâchement de gaz à effet de serre. Dans tous ces cas, la moyenne est un concept mathématique parfaitement valable.
Mais tout ne fonctionne pas ainsi : la consommation électrique des équipements réseau, par exemple, n'est pas linéaire, elle est même souvent constante (cela dépend des équipements ; il y un coût constant et un variable, ce dernier étant en général plus faible que le coût constant). Que le routeur passe des paquets ou pas, il consommera la même quantité d'énergie. Envoyer deux fois moins de courriers ne diminuera donc pas la consommation énergétique de votre box, ou du reste de l'Internet. Ainsi, le tweet de France Culture « Savez-vous que chaque mail envoyé, chaque vidéo regardée, émet des gaz à effet de serre ? » est faux et trompeur. Si vous renoncez à votre soirée devant Netflix, la consommation électrique des routeurs, serveurs et autres équipements ne changera pas forcément, et calculer une moyenne par film ou série visionné n'a donc pas beaucoup de sens. La moyenne n'est légitime que si la dépendance est à peu près linéaire.
Bon, OK mais, même si la moyenne n'a pas de sens et que les déclarations sensationnalistes « envoyer un courrier, c'est relâcher X grammes de dioxyde de carbone dans l'atmosphère » sont à côté de la plaque, il n'en reste pas moins que le numérique a une empreinte environnementale, non ? Oui, la construction et l'exploitation des réseaux informatiques a un coût (y compris environnemental). Ce n'est pas un coût à l'utilisation, d'accord. Mais si les gens augmentent leur activité en ligne, par exemple si ce blog double son nombre de visiteurs, il faudra déployer davantage de matériels (dont la construction est le principal facteur d'empreinte environnementale du numérique) et il y aura donc bien un résultat (néfaste…) sur l'environnement. (Le matériel nouveau sera plus efficace : un routeur capable de 100 Gb/s ne consommera pas dix fois plus qu'un routeur capable de 10 Gb/s. Mais sa fabrication, on l'a vu, a un fort coût environnemental.) Bref, chaque requête individuelle ne pèse rien, mais leur augmentation va mener à une empreinte accrue sur l'environnement. (En sens inverse, on pourrait se dire que, si les gens arrêtent de regarder Netflix, cette société va éteindre certains équipements et que cela diminuera la consommation d'électricité. Mais c'est moins certain et, rappelez-vous, c'est surtout la fabrication qui coûte. Une fois le serveur installé dans l'armoire, il a déjà imprimé l'essentiel de sa marque sur l'environnement.)
Ce raisonnement (comme quoi l'effet attendu de la sobriété n'est pas de diminuer la consommation énérgétique aujourd'hui, mais de limiter les dépenses de matériel demain) est correct et justifie donc qu'on porte attention aux conséquences écologiques du numérique. La frugalité est donc une bonne chose mais attention à ne pas la justifier par des arguments faux, comme ces coûts par requête.
Est-ce qu'à défaut d'être scientifiquement pertinent, les arguments fondés sur une moyenne sont au moins efficaces pour la communication, sensibilisant les utilisatrices et utilisateurs à l'importance de l'empreinte environnementale du numérique ? Même si c'était le cas, ce ne serait pas à mon avis (mon avis de rationaliste convaincu) une raison suffisante pour l'utiliser. Tromper les gens n'est pas une bonne idée. Mais, en plus, je ne suis même pas sûr que l'argument soit efficace : la plupart des gens le comprendront de travers, croyant que tel ou tel geste d'extinction va vraiment diminuer tout de suite l'empreinte environnementale.
J'emprunte à Pierre Beyssac une terminologie intéressante (cf. son fil Twitter originel) : il y a le modèle « conséquentiel » qui se focalise sur les conséquences d'un acte individuel. Je fais dix kilomètres en voiture, cela aura des conséquences environnementales, je renonce à prendre la voiture, il n'y aura pas de conséquences environnementales. Et le modèle « attributif » qui consiste à diviser une empreinte environnementale globale par le nombre d'utilisations, même s'il n'y a pas linéarité des causes et des effets. Le modèle conséquentiel est plus frappant (« si vous prenez votre voiture au lieu du vélo, vous relâcherez X grammes de gaz à effet de serre ») mais plus difficile (voire impossible) à calculer sérieusement dans le monde du numérique. On se sert donc plutôt en général de modèles attributifs, mais en les faisant passer pour des modèles conséquentiels, et en utilisant la « force de frappe » rhétorique de ces derniers, ce qui est intellectuellement malhonnête.
Le point essentiel de cet article était que la moyenne n'est pas forcément pertinente. Mais, sinon, que peut-on faire pour que l'empreinte environnementale cesse d'augmenter ou en tout cas que cette augmentation ralentisse ? Le discours médiatique dominant est plein de conseils absurdes et évite soigneusement de s'attaquer à des usages sacrés. On a vu ainsi un politicien qui dénonçait l'utilisation de l'Internet pour regarder du « porno dans l'ascenseur » mais qui se prenait en photo regardant un match de foot depuis sa voiture. (Le sport-spectacle est intouchable, quand on est un politicien ambitieux, pas question de le critiquer.)
Donc, voici ma liste de quelques « gisements d'économie énergétique » importants qui ne sont pas toujours mentionnés :
- La publicité est une source importante de dégâts environnementaux, par l'encouragement à la consommation mais aussi par un effet plus direct, l'importance des infrastructures qui sont dédiées à son fonctionnement en ligne. Il est grinçant de voir sur le Web des articles critiquant vertueusement l'« enfer numérique » mais qui contiennent des publicités. Pour l'utilisateur·rice final·e, installer un bloqueur de publicité est une bien meilleure action écologique que renoncer à envoyer un message. Mais les médias n'en parleront pas (la publicité est également sacrée).
- La surveillance de masse est également très coûteuse du point de vue environnemental, car elle aussi dépend d'infrastructures complexes et consommatrices (par exemple pour la vidéo-surveillance, et c'est encore pire avec la reconnaissance faciale). De même qu'on voit des articles anti-Internet (lui reprochant sa consommation électrique) qui sont hébergés sur des sites Web avec des publicités, il est fréquent de trouver des traqueurs comme ceux de Google Analytics sur ces sites. Lutter contre le capitalisme de surveillance est plus écologique que de ne pas envoyer le courrier que vous venez d'écrire.
- La fabrication du matériel est très coûteuse du point de vue environnemental. Changer moins souvent de matériel est donc également une action utile.
- Question frugalité, il est important de promouvoir les techniques qui imposent le moins de contraintes sur le réseau et sur les machines : LEDBAT (RFC 6297) comme algorithme de transport ou Gemini côté application.
- En moins disruptif, on peut noter que les applications et sites Web d'aujourd'hui sont loin d'être des modèles de frugalité. Leur consommation importante de ressources (notamment de temps de processeur) pousse rapidement les machines les plus anciennes dans la catégorie « vieux trucs à jeter ». Si vous êtes développeur ou développeuse, une des choses les plus importantes que vous pouvez faire pour le climat est de développer des applications et sites plus frugaux. (Et d'envoyer promener le marketeux qui dira « c'est moche, c'est trop austère, le client ne va pas aimer ».) C'est ce que prône par exemple le courant small Web ou slow Web. (On peut aussi citer l'intéressant Low-tech magazine, pour les bricoleur·ses.)
On trouve en ligne (ou sur papier…) plein de ressources sur l'empreinte environnementale du numérique. Toutes ne sont pas sérieuses, loin de là. En voici quelques-unes qui sont utiles (ce qui ne veut pas dire que je suis 100 % d'accord avec leurs auteurs) :
L'article seul
Plusieurs domaines de premier niveau en panne
Première rédaction de cet article le 7 octobre 2021
Le monde des noms de
domaine a vu aujourd'hui un incident rare : la panne
complète d'un TLD, .club, et même de
plusieurs autres.
Commençons par les faits : ce jeudi 7 octobre, vers 1035
UTC, plus
moyen de résoudre aucun nom de
domaine en .club. Tous les résolveurs renvoyaient le code de
retour SERVFAIL (SERver FAILure). Une telle panne
complète d'un TLD est rare (la dernière de
.com a eu lieu en 1997).
Pour le débogage, on peut regarder les jolies images de DNSviz, ou bien utiliser dig :
% dig NS club ; <<>> DiG 9.16.21 <<>> NS club ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 30784 ;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 1232 ;; QUESTION SECTION: ;club. IN NS ;; Query time: 2606 msec ;; SERVER: 127.0.0.1#53(127.0.0.1) ;; WHEN: Thu Oct 07 13:55:28 CEST 2021 ;; MSG SIZE rcvd: 33
Un test avec les sondes RIPE Atlas montrait que le problème n'était pas juste avec mon résolveur :
% blaeu-resolve --type SOA -r 100 club [ERROR: SERVFAIL] : 81 occurrences [ns1.dns.nic.club. admin.tldns.godaddy. 1633603168 1800 300 604800 1800] : 1 occurrences Test #32444898 done at 2021-10-07T11:55:21Z
La raison ? Les serveurs faisant
autorité pour .club répondaient tous
SERVFAIL :
dig @2610:a1:1076::d7 SOA club
; <<>> DiG 9.16.21 <<>> @2610:a1:1076::d7 SOA club
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 58363
;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 4096
;; QUESTION SECTION:
;club. IN SOA
;; Query time: 66 msec
;; SERVER: 2610:a1:1076::d7#53(2610:a1:1076::d7)
;; WHEN: Thu Oct 07 13:57:39 CEST 2021
;; MSG SIZE rcvd: 33
Contrairement à la récente panne de Facebook, il ne s'agissait donc pas d'un problème de routage ; les serveurs répondaient bien, mais mal. (Typiquement, quand un serveur faisant autorité répond SERVFAIL, c'est qu'il n'a pas pu charger les données de la zone, par exemple suite à une erreur de syntaxe dans le fichier de zone.)
Le TLD .hsbc (même opérateur technique de
registre et même hébergeur DNS) a été frappé de la même façon :
% blaeu-resolve --type SOA -r 100 hsbc [ERROR: SERVFAIL] : 90 occurrences [ns1.dns.nic.hsbc. admin.tldns.godaddy. 1633405738 1800 300 604800 1800] : 1 occurrences Test #32445325 done at 2021-10-07T12:23:28Z
La panne semble avoir été complètement résolue vers 1410 UTC :
% blaeu-resolve --type SOA -r 100 club [ns1.dns.nic.club. admin.tldns.godaddy. 1633615537 1800 300 604800 1800] : 90 occurrences [ns1.dns.nic.club. admin.tldns.godaddy. 1633613754 1800 300 604800 1800] : 1 occurrences [ns1.dns.nic.club. admin.tldns.godaddy. 1633615179 1800 300 604800 1800] : 4 occurrences Test #32446901 done at 2021-10-07T14:14:47Z
Quelques informations publiques :
- Le fil de l'incident, par l'hébergeur DNS UltraDNS/Neustar. Si la chronologie est correcte, on notera par contre que cette communication officielle parle de timeouts et de retards, ce qui n'est pas exact (comme on l'a vu plus haut, les serveurs répondaient, et vite). Autre fausseté : la panne affectait le monde entier, contrairement à ce que dit cette communication.
- Le tweet du registre et celui de son opérateur technique (très sommaires !).
- La panne vue par un des bureaux d'enregistrement de .club.
- Et vue par un utilisateur.
- Les opérateurs de gros résolveurs ont aussi vu le problème.
- Un article du site d'information sur les noms de domaine DomainIncite.
L'article seul
La panne Facebook du 4 octobre 2021
Première rédaction de cet article le 4 octobre 2021
Dernière mise à jour le 5 octobre 2021
Aujourd'hui, Facebook a connu une panne importante. Que s'est-il passé ? On sait désormais que la cause racine était un problème de configuration des routeurs BGP. A-t-on des détails ?
Le message d'erreur de beaucoup d'utilisateurs : 
Je vous le dis tout de suite, je n'ai pas d'informations internes à Facebook, et je n'ai pas fait une longue enquête. N'attendez donc pas de révélations extraordinaires. Commençons par les faits. Aujourd'hui, lundi 4 octobre vers 1550 UTC, les services de Facebook, y compris WhatsApp et Instagram étaient en panne. (La panne a duré environ 6 heures.) Les utilisateurs avaient typiquement un message faisant allusion au nom de domaine, qui ne marchait pas.
Arrivé là, il faut se rappeler que les noms de domaine et le protocole DNS sont critiques pour le fonctionnement de l'Internet. Quasiment toute activité sur l'Internet commence par une requête DNS. Si elle ne fonctionne pas, presque rien n'est possible. Mais il faut aussi se rappeler que ce DNS ne fonctionne pas sur un réseau parallèle : il utilise l'Internet lui aussi, les paquets DNS circulent dans des paquets IP et que donc un problème affectant IP va souvent se manifester comme un problème DNS (puisque c'est par le DNS qu'on commence une session).
Demandons aux sondes RIPE Atlas de
trouver les serveurs de noms de facebook.com :
% blaeu-resolve -r 200 --type NS facebook.com [a.ns.facebook.com. b.ns.facebook.com. c.ns.facebook.com. d.ns.facebook.com.] : 97 occurrences [ERROR: SERVFAIL] : 48 occurrences [] : 3 occurrences Test #32421708 done at 2021-10-04T16:16:14Z
Une partie y arrive, probablement parce que l'information était
encore dans la mémoire de leur résolveur. Mais ce n'est pas le cas de
toutes. En effet,
pendant la panne, les serveurs DNS faisant
autorité pour facebook.com ne répondaient pas. Voici la liste de ces serveurs, obtenue avec
dig en demandant à un serveur de la zone
parente, .com (on ne
pouvait pas faire un dig « normal » puisque le résolveur qu'il utilise aurait essayé de joindre
les serveurs en panne) :
% dig @a.gtld-servers.net. A a.ns.facebook.com. ; <<>> DiG 9.16.15-Debian <<>> @a.gtld-servers.net. A a.ns.facebook.com. ; (2 servers found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 4686 ;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 8, ADDITIONAL: 9 ... ;; AUTHORITY SECTION: facebook.com. 172800 IN NS a.ns.facebook.com. facebook.com. 172800 IN NS b.ns.facebook.com. facebook.com. 172800 IN NS c.ns.facebook.com. facebook.com. 172800 IN NS d.ns.facebook.com. ... ;; ADDITIONAL SECTION: a.ns.facebook.com. 172800 IN A 129.134.30.12 a.ns.facebook.com. 172800 IN AAAA 2a03:2880:f0fc:c:face:b00c:0:35 ... ;; Query time: 16 msec ;; SERVER: 2001:503:a83e::2:30#53(2001:503:a83e::2:30) ;; WHEN: Mon Oct 04 18:24:55 CEST 2021 ;; MSG SIZE rcvd: 833
Maintenant, demandons aux sondes RIPE Atlas
d'interroger
un de ces serveurs, a.ns.facebook.com :
% blaeu-resolve -r 200 --type NS --nameserver 129.134.30.12 --nsid facebook.com Nameserver 129.134.30.12 [] : 3 occurrences [TIMEOUT] : 189 occurrences Test #32421749 done at 2021-10-04T16:25:09Z
On le voit, l'échec est total. Un peu plus tard, ça marche un peu mieux :
% blaeu-resolve -r 200 --type NS --nameserver 129.134.30.12 --nsid facebook.com Nameserver 129.134.30.12 [TIMEOUT] : 192 occurrences [ERROR: SERVFAIL] : 3 occurrences [a.ns.facebook.com. b.ns.facebook.com. c.ns.facebook.com. d.ns.facebook.com.] : 1 occurrences Test #32421800 done at 2021-10-04T16:35:54Z
Donc, les choses sont claires : les serveurs DNS faisant autorité ne marchaient pas. Cela explique la panne vue par les utilisateurs. Maintenant, pourquoi ces quatre serveurs (et davantage de machines physiques, en raison de l'anycast) seraient-ils tous tombés en même temps ? Il y a plusieurs hypothèses, comme une erreur de configuration propagée automatiquement à toutes les machines (automatiser les configurations simplifie la vie mais les erreurs ont des conséquences plus graves). Mais on peut noter autre chose : tous ces serveurs sont dans le même AS, le 32934, l'AS de Facebook. Un problème de routage dans l'AS, empêchant les paquets d'arriver, peut également empêcher les serveurs DNS de répondre. Mettre tous ses œufs dans le même panier est décidément une mauvaise pratique. (Notez que ZoneMaster teste cette mauvaise pratique et vous alerte.) C'est un problème connu, déjà signalé par le RFC 2182, en 1997…
Creusons cette idée. Plusieurs observateurs ont noté que les préfixes IP de Facebook ont subitement disparu de la DFZ. Cela explique que les serveurs DNS soient devenus injoignables. Les sondes RIPE Atlas montrent que les traceroute ne vont pas très loin, les préfixes n'étant plus annoncés :
% blaeu-traceroute -r 10 --format 129.134.30.12 Measurement #32421753 Traceroute 129.134.30.12 uses 10 probes 9 probes reported Test #32421753 done at 2021-10-04T16:26:49Z From: 89.152.207.6 2860 NOS_COMUNICACOES, PT Source address: 89.152.207.6 Probe ID: 1001047 1 ['!', '!', '!'] 2 10.137.196.193 NA NA [10.743, 10.446, 6.726] 3 10.255.48.82 NA NA [12.727, 15.974, 14.397] 4 ['*', '*', '*'] 5 ['*', '*', '*'] 6 ['*', '*', '*'] 7 ['*', '*', '*'] 8 ['*', '*', '*'] 255 ['*', '*', '*'] From: 188.254.182.226 43205 BULSATCOM-BG-AS Sofia, BG Source address: 192.168.88.13 Probe ID: 15646 1 192.168.88.1 NA NA [0.66, 0.415, 0.4] 2 188.254.180.1 43205 BULSATCOM-BG-AS Sofia, BG [1.552, 1.614, 1.231] 3 46.40.64.1 43205 BULSATCOM-BG-AS Sofia, BG [2.223, '*', '*'] 4 ['*', '*', '*'] 5 ['*', '*', '*'] 6 ['*', '*', '*'] 7 ['*', '*', '*'] 8 ['*', '!', '!', '!', '!', '!', '!', '*', '*'] 255 ['*', '*', '*']
Des préfixes IP plus généraux sont parfois
restés. Ainsi, le 129.134.30.0/24 d'un des
serveurs a disparu mais un /17 plus générique est resté. On voit ici
(source:
RIPEstat, le retrait du /24 puis son rétablissement
(129.134.30.0/23,
129.134.31.0/24 et bien d'autres avaient subi
le même sort) : 
La panne DNS semble donc avoir été une conséquence d'une fausse
manœuvre BGP. Cela explique, par exemple, que le
service Tor de Facebook,
facebookwkhpilnemxj7asaniu7vnjjbiltxjqhye3mhbshg7kx5tfyd.onion,
ne marche pas non plus (il ne dépend pas du DNS,
.onion est spécial).
Le réseau social Instagram pendant la
panne. Bien que ses serveurs DNS répondaient parfaitement, le
serveur Web dépend de Facebook : 
Plusieurs personnes sur les réseaux sociaux ont également noté
que tous les serveurs faisant autorité pour
facebook.com étaient sous le même domaine
(ns.facebook.com). Ce n'est pas forcément une
mauvaise idée. Certes, cela oblige à publier des colles (les
adresses IP des serveurs), ce qui complique l'administration. Et, si
le domaine en question a un problème, par exemple administratif,
cela frappe tous les serveurs. D'un autre côté, cela évite de
dépendre de tiers, ce qui est pourquoi cette pratique est parfois
recommandée (par
exemple par l'ANSSI).
En revanche, il était tout à fait justifié de noter que les TTL de Facebook sont anormalement bas : 300 secondes. Cela veut dire que si la panne dure plus de 5 minutes, ce qui a été le cas, les mémoires des résolveurs ne servent plus à rien. La robustesse du DNS nécessite des TTL bien plus longs (supérieurs à la durée d'une panne typique).
Ah, et puis rappelez-vous que Facebook n'est pas tout l'Internet : tous les autres services fonctionnaient parfaitement (sauf ceux qui avaient choisi de dépendre de Facebook).
Articles dans les médias :
- Numérama
- Très bonnes explications, très pédagogiques, de Cécile Morange, sous forme d'un fil Twitter.
- Bon article de synthèse sur Numérama.
- Le communiqué officiel de Facebook (en anglais) ; la panne a été causée par un problème de configuration de leurs routeurs BGP. Facebook a ensuite considérablement détaillé dans un excellent article.
- Comme d'habitude, excellent article de Cloudflare (en anglais), avec plein de détails techniques concrets et des explications pédagogiques.
- Un autre article très détaillé, par Qrator (en anglais), notamment sur les observations BGP.
- ZDnet (en anglais)
L'article seul
RFC 9117: Revised Validation Procedure for BGP Flow Specifications
Date de publication du RFC : Août 2021
Auteur(s) du RFC : J. Uttaro (AT&T), J. Alcaide, C. Filsfils, D. Smith (Cisco), P. Mohapatra (Sproute Networks)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF idr
Première rédaction de cet article le 28 septembre 2021
Le RFC 8955 spécifie comment utiliser BGP pour diffuser des règles de filtrage (dites « FlowSpec ») aux routeurs. On voit facilement qu'une annonce de règles de filtrage maladroite ou malveillante pourrait faire bien des dégâts et c'est pour cela que le RFC 8955 insiste sur l'importance de valider ces annonces. Mais les règles de validation étaient trop strictes et ce nouveau RFC les adoucit légèrement.
Le changement ? Le RFC 8955 imposait que la machine qui annonce une règle de filtrage pour un préfixe de destination donné soit également le routeur suivant (next hop) pour le préfixe en question. Cela limitait l'annonce aux routeurs situés sur le trajet des données. En iBGP (BGP interne à un AS, où les routeurs qui annoncent ne sont pas toujours ceux qui transmettent les paquets), cette règle était trop restrictive. (Pensez par exemple à un réflecteur de routes interne, par exemple géré par le SOC, réflecteur qui n'est même pas forcément un routeur.)
La règle nouvelle, plus libérale, ne concerne que du iBGP, interne à un AS ou à une confédération d'AS (RFC 5065). Entre des AS gérés par des organisations différentes (par exemple un AS terminal informant son opérateur Internet de ses désirs de filtrage), la règle de validation reste inchangée.
Plus formellement, la section 6 du RFC 8955, sur la validation des annonces de filtrage, est modifiée, l'étape « l'annonceur doit être également l'annonceur de la meilleure route » devient « l'annonceur doit être l'annonceur de la meilleure route ou bien le chemin d'AS doit être vide (ou n'inclure que des AS de la confédération, s'il y en a une) ». Le RFC précise également que cette validation relâchée doit pouvoir être désactivée par l'administrateur réseaux (s'ielle sait qu'il n'y aura pas d'annonces de filtrage par un routeur qui n'est pas sur le chemin des paquets). Vous noterez plus bas que, pour l'instant, seul Huawei le permet.
Il y a également un léger changement des règles de validation du chemlin d'AS, pour les cas des serveurs de route (a priori, ils ne relaient pas ce genre d'annonces et peuvent donc les rejeter). Le RFC note que, même avec une validation stricte, certaines faiblesses de BGP permettent quand même dans certains cas à tort l'envoi de règles de filtrage. C'est un problème fondamental du RFC 8955, qui n'est donc pas nouveau.
Les nouvelles règles de ce RFC sont déjà largement mises en œuvre chez les routeurs.
L'article seul
Fiche de lecture : L'enfer numérique
Auteur(s) du livre : Guillaume Pitron
Éditeur : Les Liens qui Libèrent
979-10-209-0996-1
Publié en 2021
Première rédaction de cet article le 28 septembre 2021
Nous sommes désormais noyés sous les publications qui parlent de l'empreinte environnementale du numérique et notamment de l'Internet. Mais ce nouveau livre est plus approfondi que beaucoup de ces publications et contient des récits intéressants.
Au passage, je ne sais pas si quelqu'un a calculé l'empreinte environnementale des livres qui critiquent l'empreinte environnementale de l'Internet ☺. Plus sérieusement, une bonne partie de ces livres sont juste de l'anti-numérique primaire, par des auteurs nostalgiques d'un passé où seule une minorité d'experts pouvaient décider et s'exprimer, auteurs qui regrettent le bon vieux temps (ils critiquent le numérique mais jamais l'automobile). Ces défauts se retrouvent aussi dans le livre de Guillaume Pitron (par exemple quand il mentionne, même s'il n'insiste pas là-dessus, qu'il faudrait que des autorités décident des usages légitimes de l'Internet) mais heureusement cela ne fait pas la totalité du livre.
Donc, de quoi parle ce livre ? De beaucoup de choses mais surtout des conséquences environnementales et (à la fin) géopolitiques de l'usage de l'Internet. L'auteur insiste sur la matérialité du monde numérique : loin des discours marketing lénifiants sur le « virtuel » ou sur le « cloud », le monde numérique s'appuie sur la matière, des métaux rares, des centrales électriques fonctionnant au charbon ou au nucléaire, des centres de données énormes. Ce discours n'est pas très original, cet argument de la matérialité a été souvent cité ces dernières années mais le poids du discours commercial est tel que beaucoup d'utilisateurs du numérique n'ont pas encore conscience de cette matérialité. Et elle a des conséquences concrètes, notamment en matière environnementale. Le numérique consomme de l'énergie, ce qui a des conséquences (par exemple en matière de relâchement de gaz à effet de serre, qui contribuent au réchauffement planétaire) et des matériaux dont l'extraction se fait dans des conditions souvent terribles et pas seulement pour l'environnement, mais surtout pour les humains impliqués.
Quelle que soit la part réelle du numérique dans les atteintes à l'environnement (les chiffres qui circulent sont assez « doigt mouillé »), il n'y a pas de doute que, face à la gravité du changement climatique, tout le monde devra faire un effort, le numérique comme les autres. Des techniques frugales comme LEDBAT (RFC 6817) ou Gemini sont des briques utiles de cet effort (mais l'auteur ne les mentionne pas).
C'est après que les choses se compliquent. Qui doit agir, où et comment ? Le livre contient beaucoup d'informations intéressantes et de reportages variés et met en avant certaines initiatives utiles. C'est par exemple le cas du Fairphone, un ordiphone conçu pour limiter l'empreinte environnementale et sociale. Beaucoup de critiques ont été émises contre ce projet, notant que les objectifs n'étaient pas forcément atteints, mais je les trouve injustes : une petite société locale n'a pas les mêmes armes qu'un GAFA pour changer le monde, et ses efforts doivent être salués, il vaut mieux ne faire qu'une partie du chemin plutôt que de rester assis à critiquer. C'est à juste titre que le projet Fairphone est souvent cité dans le livre. (Sur ce projet, je recommande aussi l'interview d'Agnès Crepet dans la série audio « L'octet vert ».)
Ces reportages sont la partie la plus intéressante du livre et une bonne raison de recommander sa lecture. Il comprend également une partie géopolitique intéressante, détaillant notamment l'exploitation de plus en plus poussée de l'Arctique (à la fois rendue possible par le changement climatique, et l'aggravant) et les projets gigantesques et pas du tout bienveillants de la Chine. Même si beaucoup de projets (comme le câble Arctic Connect) se sont cassés la figure, bien d'autres projets leur succèdent.
Par contre, le livre ne tient pas les promesses de son sous-titre « Voyage au bout d'un like ». S'il explique rapidement que le simple fait de cliquer sur un bouton « J'aime » va mettre en action de nombreuses machines, parcourir un certain nombre de kilomètres, et écrire dans plusieurs bases de données, il ne détaille pas ce parcours et ne donne pas de chiffres précis. Il est vrai que ceux-ci sont très difficiles à obtenir, à la fois pour des raisons techniques (la plupart des équipements réseau ont une consommation électrique constante et donc déterminer « la consommation d'un Like » n'a donc guère de sens) et politiques (l'information n'est pas toujours disponible et le greenwashing contribue à brouiller les pistes). L'auteur oublie de rappeler la grande faiblesse méthodologique de la plupart des études sur la question, et des erreurs d'ordre de grandeur comme l'affirmation p. 157 que les États-Unis produisent… 640 tonnes de charbon par an n'aident pas à prendre aux sérieux les chiffres.
Mais le livre souffre surtout de deux problèmes : d'abord, il réduit l'utilisation de l'Internet au Like et aux vidéos de chat, souvent citées. D'accord, c'est amusant et, comme beaucoup d'utilisateurs, je plaisante moi-même souvent sur ce thème. Mais la réalité est différente : l'Internet sert à beaucoup d'activités, dont certaines sont cruciales, comme l'éducation, par exemple. L'auteur critique le surdimensionnement des infrastructures par les opérateurs, jugeant qu'il s'agit d'un gaspillage aux conséquences environnementales lourdes. Mais il oublie que ce surdimensionnement est au contraire indispensable à la robustesse de l'Internet, comme on l'a bien vu pendant le confinement, avec l'augmentation du trafic (voir le RFC 9075). Outre les pandémies, on pourrait également citer les attaques par déni de service (la cybersécurité est absente du livre), qui sont une excellente raison de surdimensionner les infrastructures.
Et le deuxième problème ? Parce que l'auteur pourrait répondre qu'il est bien conscient de la coexistence d'usages « utiles » et « futiles » de l'Internet et qu'il suggère de limiter les seconds. C'est là qu'est le deuxième problème : qui va décider ? Personnellement, je pense que le sport-spectacle (par exemple les scandaleux jeux olympiques de Paris, monstruosité environnementale) est à bannir des réseaux (et du reste du monde, d'ailleurs). Mais je ne serais probablement pas élu avec un tel programme. Personne n'est d'accord sur ce qui est sérieux et ce qui est futile. Qui va décider ? Des phrases du livre comme le fait d'ajouter « sacro-sainte » devant chaque mention de la neutralité de l'Internet ont de quoi inquiéter. J'avais déjà relevé ce problème dans ma critique du dernier livre de Ruffin. Une décision démocratique sur les usages, pourquoi pas ; mais je vois un risque sérieux de prise de pouvoir par des sages auto-proclamés qui décideraient depuis leurs hauteurs de ce qui est bon pour le peuple ou pas.
Je ne vais pas citer les articles publiés dans les médias sur ce livre, tous unanimement élogieux et sans jamais une seule critique. La corporation médiatique se serre les coudes, face à un Internet qui a écorné leur monopole de la parole. Mais, sinon, une autre critique de ce livre, sous un angle assez différent, celle de laem.
L'article seul
RFC 9115: An Automatic Certificate Management Environment (ACME) Profile for Generating Delegated Certificates
Date de publication du RFC : Septembre 2021
Auteur(s) du RFC : Y. Sheffer (Intuit), D. López, A. Pastor Perales (Telefonica I+D), T. Fossati (ARM)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF acme
Première rédaction de cet article le 21 septembre 2021
Ce nouveau RFC décrit un profil du protocole ACME d'obtention de certificat, profil qui permet de déléguer la demande à un tiers. C'est surtout utile pour le cas où vous sous-traitez l'hébergement de votre site Web (par exemple sur un CDN) : le sous-traitant peut alors demander un certificat, avec sa clé privée à lui, pour un nom de domaine que vous contrôlez et prouver qu'il héberge bien le serveur pour ce nom. Serveurs et clients TLS n'ont pas besoin d'être modifiés (seuls les serveurs et clients ACME le seront), et, bien entendu, le titulaire du nom de domaine garde un complet contrôle et peut, par exemple, révoquer les certificats obtenus par ses sous-traitants.
Ce profil utilise lui-même le profil STAR (Short-Term,
Automatically Renewed) décrit dans le RFC 8739 donc faites bien attention à avoir lu le RFC 8739 avant. Le cas typique d'utilisation de ce
mécanisme de délégation est le CDN. Un webmestre (l'IdO pour
Identifier Owner car il est titulaire du
nom de domaine, mettons
foobar.example) a un site Web et sous-traite
tout ou partie du service à un CDN, appelé ici NDC pour
Name Delegation Consumer (et la ressemblance
entre les sigles CDN et NDC est volontaire). Le CDN devra pouvoir
répondre aux requêtes HTTPS pour
www.foobar.example et donc présenter un
certificat au nom www.foobar.example. Avec
ACME, l'IdO peut
obtenir un tel certifiat mais il ne souhaite probablement pas
transmettre la clé
privée correspondante au NDC. La solution de notre RFC
est d'utiliser une extension à ACME, permettant la délégation du
nom. Le NDC pourra alors obtenir un certificat STAR (de courte durée
de vie, donc) pour www.foobar.example. Pas
besoin de partager une clé privée, ni de transmettre des secrets de
longue durée de vie (les délégations sont révocables, et les
certificats STAR ne durent pas longtemps, le NDC devra renouveller
souvent et ça cessera en cas de révocation). C'est l'utilisation
typique de la délégation mais d'autres sont possibles (par exemple
avec des certificats ordinaires, non-STAR). Le RFC note que la
solution de délégation ne modifie qu'ACME, et pas TLS, et qu'elle
marche donc avec les clients et serveurs TLS actuels (contrairement
à d'autres propositions qui sont étudiées).
Pour que la délégation fonctionne, l'IdO doit avoir un serveur ACME, auquel le NDC devra se connecter, et s'être mis d'accord avec le NDC sur les paramètres à utiliser. C'est donc une étape relativement nouvelle, l'utilisateur d'ACME typique n'ayant qu'un client ACME, seule l'AC a un serveur. Mais c'est quand même plus simple que de monter une AC. Le serveur ACME chez l'IdO ne signera pas de certificats, il relaiera simplement la requête. Quand le NDC aura besoin d'un certificat, il enverra une demande à l'IdO, qui la vérifiera et, devenant client ACME, l'IdO enverra une demande à l'AC. Si ça marche, l'IdO prévient le NDC, et celui-ci récupérera le certificat chez l'AC (par unauthenticated GET, RFC 8739, section 3.4).
Le protocole ACME gagne un nouveau type d'objet, les délégations, qui indiquent ce qu'on permet au NDC. Comme les autres objets ACME, elles sont représentées en JSON et voici un exemple :
{
"csr-template": {
"keyTypes": [
{
"PublicKeyType": "id-ecPublicKey",
"namedCurve": "secp256r1",
"SignatureType": "ecdsa-with-SHA256"
}
],
"subject": {
"country": "FR",
"stateOrProvince": "**",
"locality": "**"
},
"extensions": {
"subjectAltName": {
"DNS": [
"www.foobar.example"
]
},
"keyUsage": [
"digitalSignature"
],
"extendedKeyUsage": [
"serverAuth"
]
}
}
}
(Les champs des extensions comme keyUsage sont
dans un
nouveau registre IANA ; on peut ajouter des champs, selon la
politique « spécification nécessaire ».)
Ici, le NDC est autorisé à demander des certificats ECDSA
pour le nom www.foobar.example. Quand le NDC
enverra sa requête de certificat à l'IdO, il devra inclure cet objet
« délégation », que l'IdO pourra comparer avec ce qu'il a configuré
pour ce NDC. Voici un exemple partiel, envoyé lors d'un POST HTTPS
au serveur ACME de l'IdO :
{
"protected": base64url({
"alg": "ES256",
"kid": "https://acme.ido.example/acme/acct/evOfKhNU60wg",
"nonce": "Alc00Ap6Rt7GMkEl3L1JX5",
"url": "https://acme.ido.example/acme/new-order"
}),
"payload": base64url({
"identifiers": [
{
"type": "dns",
"value": "www.foobar.example"
}
],
"delegation":
"https://acme.ido.example/acme/delegation/gm0wfLYHBen"
}),
"signature": ...
(Le nouveau champ delegation a été placé dans
le
registre IANA.) Le NDC enverra ensuite le CSR, et l'IdO
relaiera la requête vers le serveur ACME de l'AC (moins l'indication
de délégation, qui ne regarde pas l'AC).
Quand on utilise un CDN, il est fréquent qu'on doive configurer un alias dans le DNS pour pointer vers un nom indiqué par l'opérateur du CDN. Voici par exemple celui de l'Élysée :
% dig CNAME www.elysee.fr ... ;; ANSWER SECTION: www.elysee.fr. 3600 IN CNAME 3cifmt6.x.incapdns.net. ...
L'extension au protocole ACME spécifiée dans notre RFC permet au NDC d'indiquer cet alias dans sa requête, l'IdO peut alors l'inclure dans sa zone DNS.
Tous les serveurs ACME ne seront pas forcément capables de gérer
des délégations, il faudra donc l'indiquer dans les capacités du
serveur, avec le champ delegation-enabled (mis
dans le
registre IANA).
Comme indiqué plus haut, l'IdO peut arrêter la délégation quand il veut, par exemple parce qu'il change de CDN. Cet arrêt se fait par une interruption explicite de la demande STAR (RFC 8739, section 3.1.2). Si les certificats ne sont pas des STAR, le mécanisme à utiliser est la révocation normale des certificats.
Après cet examen du protocole, la section 3 de notre RFC décrit le comportement de l'AC. Il n'y a pas grand'chose à faire pour l'AC (le protocole est entre le NDC et l'IdO) à part à être capable d'accepter des récupérations non authentifiées de certificats (car le NDC n'a pas de compte à l'AC).
On a parlé plus haut du CSR. Il doit se conformer à un certain gabarit, décidé par l'IdO. Ce gabarit est évidemment au format JSON, comme le reste d'ACME. La syntaxe exacte est décrite avec le langage CDDL (RFC 8610) et figure dans l'annexe A ou bien, si vous préférez, avec le langage JSON Schema, utilisé dans l'annexe B. Voici l'exemple de gabarit du RFC :
{
"keyTypes": [
{
"PublicKeyType": "rsaEncryption",
"PublicKeyLength": 2048,
"SignatureType": "sha256WithRSAEncryption"
},
{
"PublicKeyType": "id-ecPublicKey",
"namedCurve": "secp256r1",
"SignatureType": "ecdsa-with-SHA256"
}
],
"subject": {
"country": "CA",
"stateOrProvince": "**",
"locality": "**"
},
"extensions": {
"subjectAltName": {
"DNS": [
"abc.ido.example"
]
},
"keyUsage": [
"digitalSignature"
],
"extendedKeyUsage": [
"serverAuth",
"clientAuth"
]
}
}
Dans cet exemple, l'IdO impose au NDC un certificat RSA ou ECDSA et rend impérative (c'est le sens des deux astérisques) l'indication de la province et de la ville. L'IdO doit évidemment vérifier que le CSRT reçu se conforme bien à ce gabarit.
Le RFC présente (en section 5) quelques autres cas d'utilisation de cette délégation. Par exemple, un IdO peut déléguer à plusieurs CDN, afin d'éviter que la panne d'un CDN n'arrête tout. Avec la délégation, ça se fait tout seul, chacun des CDN est authentifié, et demande séparément son certificat.
Autre cas rigolo, celui où le CDN délègue une partie du service à un CDN plus petit. Le modèle de délégation ACME peut s'y adapter (le petit CDN demande un certificat au gros, qui relaie à l'IdO…), si les différentes parties sont d'accord.
Enfin, la section 7 du RFC revient sur les propriétés de sécurité de ces délégations. En gros, il faut avoir confiance en celui à qui on délègue car, pendant la durée de la délégation, il pourra faire ce qu'il veut avec le nom qu'on lui a délégué, y compris demander d'autres certificats en utilisant sa délégation du nom de domaine. Il existe quelques mesures techniques que l'IdO peut déployer pour empêcher le NDC de faire trop de bêtises. C'est le cas par exemple des enregistrements DNS CAA (RFC 8659) qui peuvent limiter le nombre d'AC autorisées (voir aussi le RFC 8657).
Je ne connais pas encore d'opérateur de CDN qui mette en œuvre cette solution.
L'article seul
RFC 9098: Operational Implications of IPv6 Packets with Extension Headers
Date de publication du RFC : Septembre 2021
Auteur(s) du RFC : F. Gont (SI6 Networks), N. Hilliard (INEX), G. Doering (SpaceNet AG), W. Kumari (Google), G. Huston (APNIC), W. Liu (Huawei Technologies)
Pour information
Réalisé dans le cadre du groupe de travail IETF v6ops
Première rédaction de cet article le 20 septembre 2021
IPv6 souffre de réseaux mal gérés qui se permettent de jeter les paquets ayant des caractéristiques normales, mais qui déplaisent à certains équipements réseau. C'est par exemple le cas des paquets utilisant les en-têtes d'extension. Pourquoi les paquets utilisant ces en-têtes sont-ils souvent jetés ?
Ces en-têtes d'extension (qui n'ont pas d'équivalent en IPv4) sont normalisés dans le RFC 8200, section 4. Ils servent à la fois à des fonctions de base d'IPv6 (comme la fragmentation) et à étendre le protocole si nécessaire. Mais, en pratique, on observe trop souvent que les paquets IPv6 utilisant ces en-têtes d'extension ne passent pas sur certains réseaux. Ce RFC vise à étudier pourquoi, et à expliquer les conséquences. Comme toujours quand on explique un phénomène (la délinquance, par exemple), des gens vont comprendre de travers et croire qu'on justifie le phénomène en question (« expliquer, c’est déjà vouloir un peu excuser », avait stupidement dit un ancien premier ministre français, à propos du terrorisme djihadiste). Le cas est d'autant plus fréquent qu'en français, « comprendre » est ambigu, car il peut désigner l'explication (qui est utile aussi bien aux partisans qu'aux adversaires d'un phénomène) que la justification. Bref, ce RFC explique pourquoi des paquets innocents sont détruits, il ne dit pas qu'il faut continuer à le faire !
La section 4 du RFC explique la différence entre l'en-tête d'un paquet IPv6 et celui d'un paquet de l'ancienne version. Dans les deux versions, le problème est de placer des options dans les en-têtes. Le gros changement est l'utilisation par IPv6 d'un en-tête de taille fixe (40 octets), suivi d'une liste chainée d'en-têtes d'extension permettant d'encoder ces options. Au contraire, IPv4 avait un en-tête de taille variable (entre 20 et 60 octets), avec un champ indiquant sa longueur, champ qu'il fallait lire avant d'accéder à l'en-tête. Le mécanisme d'IPv4 n'était ni pratique, ni rapide, mais celui d'IPv6 n'est pas plus satisfaisant : il faut lire toute la liste chainée (dont la longueur est quelconque et non limitée) si on veut accéder aux informations au-dessus de la couche 3. Ce n'est pas un problème pour les routeurs, à qui la couche 3 suffit (à part le cas de l'en-tête Hop-by-hop options), mais c'est ennuyeux pour les autres boitiers situés sur le chemin, comme les pare-feux. Les évolutions récentes d'IPv6 ont aidé, comme l'obligation que tous les en-têtes d'extension soient dans le premier fragment, si le datagramme est fragmenté (RFC 7112), ou comme l'imposition d'un format commun aux futurs en-têtes d'extension (dans le RFC 6564), mais l'analyse de la liste des en-têtes d'extension reste un travail pénible pour les machines.
Le problème est identifié depuis longtemps. Il est analysé dans
l'Internet-Draft
draft-taylor-v6ops-fragdrop,
dans draft-wkumari-long-headers,
dans draft-kampanakis-6man-ipv6-eh-parsing
mais aussi dans des RFC, le RFC 7113, le
RFC 8900 et le RFC 9288. Cela a mené à plusieurs changements
dans la norme, je vous renvoie aux RFC 5722,
RFC 7045, RFC 8021,
etc. Plusieurs changements ont été intégrés dans la dernière
révision du RFC principal de la norme, le RFC 8200. Ainsi, celui-ci dispense désormais les routeurs de
chercher un éventuel en-tête d'extension Hop-by-hop
options.
Parallèlement à ces analyses du protocole, diverses études ont porté sur le phénomène des paquets jetés s'ils contenaient des en-têtes d'extension. Cela a été documenté dans « Discovering Path MTU black holes on the Internet using RIPE Atlas », dans « IPv6 Extension Headers in the Real World v2.0 », également dans « Dealing with IPv6 fragmentation in the DNS » et « Measurement of IPv6 Extension Header Support » ainsi que dans le RFC 7872.
Comment est-ce que les équipements intermédiaires du réseau fonctionnent, et pourquoi est-ce que les en-têtes d'extension IPv6 peuvent parfois les défriser ? La section 6 du RFC rappelle l'architecture de ces machines. Un routeur de cœur de réseau est très différent de l'ordinateur de base, avec son processeur généraliste et sa mémoire de grande taille, ce qui le rend lent, mais souple. Au contraire, la transmission des paquets par le routeur est en général faite par du matériel spécialisé, ASIC ou NPU. (Vous pouvez consulter des explications dans l'exposé fait à l'IETF « Modern Router Architecture for Protocol Designers » et dans l'article « Modern router architecture and IPv6 ».) Avant de transmettre un paquet reçu sur l'interface de sortie, le routeur doit trouver quelle interface utiliser. Une méthode courante est de prendre les N premiers octets du paquet et de les traiter dans une TCAM ou une RLDRAM, où se fera la détermination du saut suivant (et donc de l'interface de sortie). Le choix du nombre N est crucial : plus il est petit, plus le routeur pourra traiter de paquets, mais moins il aura d'information sur le paquet. (En pratique, on observe des N allant de 192 à 384 octets.) Du fait qu'un routeur se limite normalement à la couche Réseau, et que l'en-tête IPv6 a une taille fixe, envoyer simplement les 40 octets de cet en-tête devrait suffire. Mais lisez plus loin : certains routeurs ou autres équipements intermédiaires sont configurés pour regarder au-delà, et voudraient des informations de la couche Transport, plus dure à atteindre.
Une solution, pour les routeurs qui ne lisent qu'un nombre limité d'octets avant de prendre une décision, est de lire les en-têtes d'extension un par un, et de réinjecter le reste du paquet dans le dispositif de traitement. Ça se nomme la recirculation, c'est plus lent, mais ça marche quelle que soit la longueur de la chaîne des en-têtes d'extension.
Comme le routeur comprend toujours un processeur généraliste (ne serait-ce que pour faire tourner les fonctions de contrôle comme SSH et les protocoles de routage), une autre solution serait d'envoyer à ce processeur les paquets « compliqués » (mais lire le RFC 6192 d'abord). L'énorme différence de performance entre le processeur généraliste et les circuits spécialisés fait que ce ne serait pas une solution réaliste sauf pour un trafic très modéré. (Le RFC note que certains routeurs ont trois dispositifs de traitement des paquets, et pas seulement deux comme présenté plus haut : outre le processeur généraliste, qui ne leur sert qu'aux fonctions de contrôle, et des circuits matériels spécialisés, ils ont un dispositif logiciel de transmission des paquets. Plus souple que les circuits spécialisés, il n'est pas forcément plus rapide que le processeur généraliste mais, au moins, il n'interfère pas avec les fonctions de contrôle.)
Bon, on l'a déjà dit, mais cela vaut la peine de le répéter : à part le cas (agaçant) de l'en-tête Hop-by-hop options, un routeur, équipement de couche 3 n'a normalement aucun besoin d'aller regarder tous les en-têtes d'extension (qui sont presque tous pour la machine terminale de destination uniquement). Encore moins de faire du DPI et d'aller chercher des informations dans les couches 4 à 7. Mais la section 7 du RFC explique pourquoi certains routeurs le font quand même (il s'agit d'une description de leurs pratiques, pas une approbation ; beaucoup des raisons données sont mauvaises).
D'abord, la répartition de charge et l'ECMP. Si un routeur peut faire passer un paquet via deux interfaces différentes, laquelle choisir ? Alterner (un coup à gauche, un coup à droite) augmenterait la probabilité d'une arrivée des paquets dans le désordre. On préfère la prédictabilité : tous les paquets d'un même flot doivent suivre le même chemin. Comment déterminer le « flot », notion parfois un peu floue ? En restant dans les couches basses, on peut utiliser uniquement les adresses IP de source et de destination mais elles ne sont pas assez discriminantes. En IPv6, on peut en théorie utiliser l'étiquette de flot (normalisé dans le RFC 6437, ainsi que les RFC 6438 et RFC 7098 pour son utilisation) mais elle n'est pas toujours présente, en partie (encore !) par la faute de middleboxes qui, ignorant ce concept d'étiquette de flot, jetaient les paquets qui en avaient une. (Voir les articles de I. Cunha, « IPv4 vs IPv6 load balancing in Internet routes » et J. Jaeggli, « IPv6 flow label: misuse in hashing ».) En pratique, les systèmes qui ont besoin d'identifier les flots utilisent plutôt une heuristique : le tuple à cinq élements {protocole de transport, adresse IP source, adresse IP destination, port source, port destination}. Ce n'est pas parfait mais, en pratique, cela marche à peu près. On voit que cela nécessite d'accéder à de l'information de la couche Transport, les ports. (Cette heuristique a d'autres limites : par exemple elle ne marche pas si une partie de la couche Transport est chiffrée, comme c'est le cas avec QUIC.)
Autre cas où un boitier intermédiaire ressent le besoin d'accéder aux informations des couches supérieures, les ACL. La plupart des pare-feux permettent d'utiliser comme critère de filtrage les numéros de ports, ce qui va nécessiter d'analyser la chaine des en-têtes d'extension IPv6 pour parvenir à la couche Transport. Entre les pare-feux mal faits qui cherchent les informations de la couche Transport immédiatement après l'en-tête fixe (car le programmeur a tout simplement sauté la partie du RFC qui parlait des en-têtes d'extension) et les difficultés posées par le fait, qu'avant le RFC 6564, les en-têtes d'extension inconnus étaient impossibles à analyser, on voit qu'arriver à la couche Transport n'est pas si facile que ça (le RFC dit qu'il est plus compliqué d'analyser IPv6 qu'IPv4, ce qui est très contestable ; mais ce n'est en effet pas plus facile). Cela peut avoir des conséquences en terme de sécurité, par exemple si un méchant ajoute des en-têtes d'extension dans l'espoir que ses paquets ne soient pas correctement identifiés (cf. RFC 7113).
Autre exemple, le réassemblage des paquets fragmentés nécessite un état (mémoriser les fragments en cours de réassemblage), ce qui peut être fatal à la mémoire du pare-feu, notamment en cas d'attaque. Pour les coûts de ce filtrage, voir l'article d'E. Zack « Firewall Security Assessment and Benchmarking IPv6 Firewall Load Tests ». Cette difficulté peut encourager les pare-feux à jeter les paquets ayant des en-têtes d'extension, surtout si un administrateur réseaux ignorant dit bien fort « ces en-têtes d'extension ne servent à rien de toute façon » (RFC 7872).
Un problème proche est celui de la protection contre les attaques par déni de service. Filtrer avec les adresses IP peut être fait rès efficacement (cf. RFC 5635) mais ne marche pas, par exemple si l'adresse IP source est usurpée. Une des méthodes utilisées alors est de repérer un motif récurrent dans les paquets envoyés par l'attaquant, et de filtrer sur ce motif (vous pouvez lire ici un exemple avec le DNS). Là encore, des informations au-delà de la couche Réseau sont nécessaires. Toujours en sécurité, les NIDS ont aussi besoin de plus d'informations que ce que fournit la couche Réseau.
Et, bien sûr, comme toute complexité, les en-têtes d'extension augmentent les risques de sécurité, d'autant plus qu'il y a un cercle vicieux : comme ils sont peu utilisés, le code qui les traite est peu testé, donc il y a des bogues, donc ils sont peu utilisés, etc.
Donc, un certain nombre de machines intermédiaires, qui assurent des fonctions allant au-delà de ce que fait un « simple » routeur, ont des problèmes avec les en-têtes d'extension IPv6 et choisissent souvent la solution de facilité, qui est de les jeter systématiquement.
L'article seul
Utiliser les « middleboxes » de censure pour des attaques par déni de service
Première rédaction de cet article le 17 septembre 2021
Une méthode courante pour réaliser une attaque par déni de service sur l'Internet est de trouver un réflecteur, une machine qui, sollicitée par l'attaquant, va envoyer des paquets vers la victime. Les bons (du point de vue de l'attaquant…) réflecteurs font en outre de l'amplification, émettant davantage de paquets et/ou d'octets qu'envoyés par l'attaquant. Un article à la conférence Usenix d'août 2021 expose un nouveau type de réflecteurs : les innombrables middleboxes placées pour censurer des communications sont tellement mal conçues qu'elles font d'excellents (du point de vue de l'attaquant…) réflecteurs.
Détaillons cet article, « Weaponizing Middleboxes for TCP Reflected Amplification ». Le but d'un attaquant est de trouver de nombreux réflecteurs (plus ils sont nombreux, plus l'attaque sera efficace) mais aussi de maximiser l'amplification (on parle de BAF - Bandwidth Amplification Factor - pour le gain en octets et de PAF - Packet Amplification Factor - pour le gain en paquets). On a ainsi vu des attaques exploitant l'amplification de protocoles utilisant UDP, comme par exemple le DNS ou bien NTP. Une des bases de l'attaque par réflexion étant de mentir sur son adresse IP, a priori, ces attaques ne sont pas possibles avec TCP, qui protège contre cette usurpation (RFC 5961). Mais, en fait, on sait déjà que des attaques par réflexion avec TCP sont possibles, et qu'elles ont parfois un bon BAF. C'est ce que développent les auteurs de l'article.
Comme réflecteurs, ils utilisent des
middleboxes, ces engins
installés en intermédiaires sur un grand nombre de chemins sur
l'Internet, qui examinent le trafic et agissent, souvent n'importe
comment. Une utilisation courante des middleboxes
est la censure, soit étatique (au niveau d'un
pays), soit au niveau
d'un réseau local. Par exemple, la middlebox va
examiner le trafic HTTP et, si l'adresse IP de destination est sur sa
liste de blocage, empêcher la communication. Une des façons de le
faire est de prétendre être le vrai serveur et de renvoyer une page
indiquant que la connexion est bloquée : 
Arrivé là, vous commencez à voir comment cela peut être exploité pour une attaque : l'attaquant envoie un paquet TCP d'ouverture de connexion (paquet SYN) vers une adresse IP censurée, en usurpant l'adresse IP de la victime, et le message de censure, avec l'image, sera envoyée à la victime, fournissant un BAF sérieux.
Mais, là, vous allez me dire que ça ne marchera pas, TCP ne fonctionne pas comme cela : la middlebox n'arrivera pas à établir une session TCP complète puisque la victime ne répondra pas aux accusés de réception, ou bien enverra un paquet de fin de session (paquet RST). Mais c'est là que l'article devient intéresssant : les auteurs ont découvert que de nombreuses middleboxes ne font pas du TCP correct : elles envoient le message de censure (une page Web complète, avec images), sans attendre qu'une session TCP soit établie.
Ce n'est pas uniquement de l'incompétence de la part des auteurs des logiciels qui tournent dans la middlebox. C'est aussi parce que, notamment dans le cas de la censure étatique, la middlebox ne voit pas forcément passer tous les paquets, le trafic Internet étant souvent asymétrique (si on a plusieurs liaisons avec l'extérieur). Et puis il faut aller vite et avoir le moins possible d'état à mémoriser. La middlebox ne se donne donc pas la peine de vérifier que la session TCP a été établie, elle crache ses données tout de suite, assomant la victime pour le compte de l'attaquant. L'amplification maximale observée (en octets, le BAF) a été de plus de 7 000… Et certains cas pathologiques permettaient de faire encore mieux.
Comment ont été trouvées les middleboxes
utilisables ? Comme l'attaque ne marche que si la
middlebox ne fait pas du TCP
correct, les conditions exactes du déclenchement de la réflexion ne
sont pas faciles à déterminer. Les auteurs ont donc envoyé une
variété de paquets TCP (avec ou sans PSH, ACK, etc) et utilisé le
système d'apprentissage Geneva pour
découvrir la solution la plus efficace. (Au passage, le meilleur
déclencheur de la censure semble être
www.youporn.com, largement bloqué un peu
partout.) En balayant tout l'Internet avec
ZMap, ils ont pu identifier un grand nombre
de réflecteurs. Ils ne les ont évidemment pas utilisé pour une vraie
attaque, mais des méchants auraient pu le faire, montrant ainsi le
danger que présente ces boitiers bogués et largement répandus (ils
sont très populaires auprès des décideurs), alors
qu'ils fournissent une armée de réflecteurs prêts à l'emploi.
Certains réflecteurs arrivent même à des facteurs d'amplification incroyables, voire infinis (une fois un paquet envoyé par l'attaquant, le tir de barrage du réflecteur ne cesse jamais). Les auteurs expliquent cela par des boucles de routage, faisant passer le paquet déclencheur plusieurs fois par la middlebox (et parfois sans diminuer le TTL), ainsi que par des réactions aux réactions de la victime (qui envoie des paquets RST).
Des bons réflecteurs d'attaque ont été identifiés à des nombreux endroits, comme l'université Brigham Young ou la municipalité de Jacksonville. Identifier les produits utilisés a été plus difficile mais on pu repérer le Dell SonicWALL NSA 220 ou un équipement Fortinet. D'un point de vue géopolitique, on notera que les réflecteurs sont situés un peu partout, avec évidemment davantage de présence dans les dictatures. Par contre, la Chine est assez peu représentée, leur système de censure étant (hélas) plus intelligement bâti.
L'article seul
Version 14 d'Unicode
Première rédaction de cet article le 16 septembre 2021
Le mardi 14 septembre est sortie la version 14 d'Unicode (retardée pour cause de Covid-19). Une description officielle des principaux changements est disponible mais voici ceux qui m'ont intéressé particulièrement. (Il n'y a pas de changement radical.)
Pour explorer plus facilement la grande base Unicode, j'utilise un programme qui la convertit en SQL et permet ensuite de faire des analyses variées. Faisons quelques requêtes SQL :
ucd=> SELECT count(*) AS Total FROM Characters; total -------- 144762
Combien de caractères sont arrivés avec la version 14 ?
ucd=> SELECT version,count(version) FROM Characters GROUP BY version ORDER BY version::float; ... 11.0 | 684 12.0 | 554 12.1 | 1 13.0 | 5930 14.0 | 838
838 nouveaux caractères, c'est une version calme (la version 13 apportait bien davantage de caractères). Quels sont ces nouveaux caractères ?
ucd=> SELECT To_U(codepoint) AS Code_point, name FROM Characters WHERE version='14.0' ORDER BY Codepoint; code_point | name -----------+---------------------------------------------------------------------------- ... U+870 | ARABIC LETTER ALEF WITH ATTACHED FATHA U+871 | ARABIC LETTER ALEF WITH ATTACHED TOP RIGHT FATHA U+872 | ARABIC LETTER ALEF WITH RIGHT MIDDLE STROKE U+873 | ARABIC LETTER ALEF WITH LEFT MIDDLE STROKE U+874 | ARABIC LETTER ALEF WITH ATTACHED KASRA ... U+12F90 | CYPRO-MINOAN SIGN CM001 U+12F91 | CYPRO-MINOAN SIGN CM002 U+12F92 | CYPRO-MINOAN SIGN CM004 U+12F93 | CYPRO-MINOAN SIGN CM005 ... U+1CF00 | ZNAMENNY COMBINING MARK GORAZDO NIZKO S KRYZHEM ON LEFT U+1CF01 | ZNAMENNY COMBINING MARK NIZKO S KRYZHEM ON LEFT U+1CF02 | ZNAMENNY COMBINING MARK TSATA ON LEFT ... U+1E290 | TOTO LETTER PA U+1E291 | TOTO LETTER BA U+1E292 | TOTO LETTER TA U+1E293 | TOTO LETTER DA ... U+1FAAC | HAMSA U+1FAB7 | LOTUS U+1FAB8 | CORAL U+1FAB9 | EMPTY NEST U+1FABA | NEST WITH EGGS ...
Cette version amène en effet plusieurs écritures nouvelles comme le toto, le chypro-minoen (toujours pas déchiffré, ce qui explique que ses caractères aient un numéro et pas un nom), le vieil ouïghour (écriture pour laquelle ont été fabriquées les plus anciens caractères mobiles connus), le vithkuqi, ou le tangsa. On trouve également beaucoup de nouveaux caractères de l'alphabet arabe pour écrire des langues non-arabes.
{kind=link}
Plus anecdotique, on trouve également la notation musicale Znamenny.
Si vous avez les bonnes polices de caractères, vous allez pouvoir voir quelques exemples (sinon, le lien mène vers Uniview). Un nouveau symbole apparait, le Som (⃀), pour la monnaie officielle du Kirghizistan. Et on a l'habituelle succession de nouveaux émojis, plus ou moins utiles. Les recruteurs aimeront l'index pointé 🫵, les royalistes seront contents de la tête couronnée 🫅, les nostalgiques d'Usenet auront le troll 🧌, les fanas de Dune frémiront en voyant l'eau qu'on verse 🫗, les geeks s'angoisseront de la batterie vide 🪫 et les partisans de la surveillance de la population noteront qu'on a un émoji « carte d'identité » 🪪. Les personnes transgenres remarqueront l'homme enceint (🫃, ainsi que la personne enceinte 🫄, la femme enceinte 🤰 était arrivée en Unicode version 9).
Tiens, d'ailleurs, combien de caractères Unicode sont des symboles (il n'y a pas que les emojis parmi eux, mais Unicode n'a pas de catégorie « emoji ») :
ucd=> SELECT count(*) FROM Characters WHERE category IN ('Sm', 'Sc', 'Sk', 'So');
count
-------
7741
Ou, en plus détaillé, et avec les noms longs des catégories :
ucd=> SELECT description,count(category) FROM Characters,Categories WHERE Categories.name = Characters.category AND category IN ('Sm', 'Sc', 'Sk', 'So') GROUP BY category, description;
description | count
-----------------+-------
Modifier_Symbol | 125
Other_Symbol | 6605
Math_Symbol | 948
Currency_Symbol | 63
L'article seul
RFC 9107: BGP Optimal Route Reflection (BGP ORR)
Date de publication du RFC : Août 2021
Auteur(s) du RFC : R. Raszuk (NTT Network Innovations), B. Decraene (Orange), C. Cassar, E. Aman, K. Wang (Juniper Networks)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF idr
Première rédaction de cet article le 13 septembre 2021
Les grands AS ont tellement de routeurs BGP qu'ils ne peuvent pas connecter chaque routeur à tous les autres. On utilise alors souvent des réflecteurs de route, un petit nombre de machines parlant BGP auxquelles tout le monde se connecte, et qui redistribuent les routes externes apprises. Mais une machine BGP ne redistribue que les routes qu'elle utiliserait elle-même. Or, le réflecteur risque de faire un choix en fonction de sa position dans le réseau, qui n'est pas la même que celle du routeur « client ». Les routeurs risquent donc d'apprendre du réflecteur des routes sous-optimales (la route optimale étant typiquement celle qui amène à la sortie le plus vite possible, en application de la méthode de la patate chaude). Ce RFC définit une extension de BGP qui va permettre de sélectionner des routes spécifiques à un client, ou à un groupe de clients.
Un petit rappel : un réflecteur de routes (route reflector) fonctionne sur iBGP (Internal BGP), à l'intérieur d'un AS, alors que les serveurs de routes (route server) font de l'eBGP (External BGP), par exemple sur un point d'échange. Ces réflecteurs sont décrits dans le RFC 4456. Ils ne sont pas la seule méthode pour distribuer l'information sur les routes externes à l'intérieur d'un grand AS, mais c'est quand même la solution la plus fréquente.
Le RFC 4456 notait déjà que, vu les coûts attribués aux liens internes à l'AS, le réflecteur ne choisirait pas forcément les mêmes routes que si on avait utilisé un maillage complet. Le routage « de la patate chaude » (qui consiste à essayer de faire sortir le paquet de son réseau le plus vite possible, pour que ce soit un autre qui l'achemine) risque donc de ne pas aussi bien marcher : le point de sortie lorsqu'on utilise le réflecteur sera peut-être plus éloigné que si on avait le maillage complet, surtout si le réflecteur est situé en dehors du chemin habituel des paquets et n'a donc pas la même vision que les routeurs « normaux ». Or, c'est un cas fréquent. Le réflecteur choisira alors des routes qui sont optimales pour lui, mais qui ne le sont pas pour ces routeurs « normaux ».
La solution ? Permettre à l'administrateur réseaux de définir une localisation virtuelle pour le réflecteur, à partir de laquelle il fera ses calculs et choisira ses routes, au lieu d'utiliser sa localisation physique. Cette localisation virtuelle sera une adresse IP. Le réflecteur peut avoir plusieurs de ces localisations virtuelles, adaptées à des publics différents. Bref, le texte du RFC 4271 qui concerne la sélection de la meilleure route (section 9.1.2.2 du RFC 4271) est modifié pour remplacer « en fonction du saut suivant » par « en fonction de l'adresse IP configurée dans le réflecteur ».
Pour que cela marche, il faut que le réflecteur ait une vue complète du réseau, pour pouvoir calculer des coûts à partir de n'importe quel point du réseau. C'est possible avec les IGP à état des liens comme OSPF, ou bien avec BGP-LS (RFC 9552).
Et si le réflecteur a plusieurs clients ayant des desiderata différents, par exemple parce qu'ils sont situés à des endroits différents ? Dans ce cas, il doit faire tourner plusieurs processus de décision, chacun configuré avec une localisation vituelle différente.
Les principales marques de routeurs mettent déjà en œuvre ce RFC, comme on peut le voir sur la liste des implémentations. Du côté des logiciels qui ne sont pas forcément installés sur des routeurs, il semble que BIRD ne sache pas encore faire comme décrit dans ce RFC.
L'article seul
RFC 9109: Network Time Protocol Version 4: Port Randomization
Date de publication du RFC : Août 2021
Auteur(s) du RFC : F. Gont, G. Gont (SI6 Networks), M. Lichvar (Red Hat)
Chemin des normes
Première rédaction de cet article le 13 septembre 2021
Le protocole NTP utilisait traditionnellement un port bien connu, 123, comme source et comme destination. Cela facilite certaines attaques en aveugle, lorsque l'attaquant ne peut pas regarder le trafic, mais sait au moins quels ports seront utilisés. Pour compliquer ces attaques, ce RFC demande que NTP utilise des numéros de ports aléatoires autant que possible.
NTP est un très vieux protocole (sa norme actuelle est le RFC 5905 mais sa première version date de 1985, dans le RFC 958). Dans son histoire, il a eu sa dose des failles de sécurité. Certaines des attaques ne nécessitaient pas d'être sur le chemin entre deux machines qui communiquent car elles pouvaient se faire en aveugle. Pour une telle attaque, il faut deviner un certain nombre de choses sur la communication, afin que les paquets de l'attaquant soient acceptés. Typiquement, il faut connaitre les adresses IP source et destination, ainsi que les ports source et destination et le key ID de NTP (RFC 5905, section 9.1). NTP a plusieurs modes de fonctionnement (RFC 5905, sections 2 et 3). Certains nécessitent d'accepter des paquets non sollicités et, dans ce cas, il faut bien écouter sur un port bien connu, en l'occurrence 123. Mais ce n'est pas nécessaire dans tous les cas et notre RFC demande donc qu'on n'utilise le port bien connu que si c'est nécessaire, au lieu de le faire systématiquement comme c'était le cas au début de NTP et comme cela se fait encore trop souvent (« Usage Analysis of the NIST Internet Time Service »). C'est une application à NTP d'un principe général sur l'Internet, documenté dans le RFC 6056 : n'utilisez pas de numéros de port statiques ou prévisibles. Si on suit ce conseil, un attaquant en aveugle aura une information de plus à deviner, ce qui gênera sa tâche. Le fait d'utiliser un port source fixe a valu à NTP un CVE, CVE-2019-11331.
La section 3 du RFC résume les considérations à prendre en compte. L'idée de choisir aléatoirement le port source pour faire face aux attaques en aveugle est présente dans bien d'autres RFC comme le RFC 5927 ou le RFC 4953. Elle est recommandée par le RFC 6056. Un inconvénient possible (mais mineur) est que la sélection du chemin en cas d'ECMP peut dépendre du port source (calcul d'un condensat sur le tuple à cinq éléments {protocole, adresse IP source, adresse IP destination, port source, port destination}, avant d'utiliser ce condensat pour choisir le chemin) et donc cela peut affecter les temps de réponse, troublant ainsi NTP, qui compte sur une certaine stabilité du RTT. D'autre part, le port source aléatoire peut gêner certaines stratégies de filtrage par les pare-feux : on ne peut plus reconnaitre un client NTP à son port source. Par contre, un avantage du port source aléatoire est que certains routeurs NAT sont suffisamment bogués pour ne pas traduire le port source s'il fait partie des ports « système » (inférieurs à 1 024), empêchant ainsi les clients NTP situés derrière ces routeurs de fonctionner. Le port source aléatoire résout le problème.
Assez de considérations, passons à la norme. Le RFC 5905, section 9.1, est modifié pour remplacer la supposition qui était faite d'un port source fixe par la recommandation d'un port source aléatoire.
Cela ne pose pas de problème particulier de mise en œuvre. Par
exemple, sur un système POSIX, ne
pas faire de bind() sur la
prise suffira à ce que les paquets associés
soient émis avec un port source aléatoirement sélectionné par le
système d'exploitation.
À propos de mise en œuvre, où en sont les logiciels actuels ? OpenNTPD n'a jamais utilisé le port source 123 et est donc déjà compatible avec la nouvelle règle. Même chose pour Chrony. Par contre, à ma connaissance, ntpd ne suit pas encore la nouvelle règle.
L'article seul
RFC 9103: DNS Zone Transfer over TLS
Date de publication du RFC : Août 2021
Auteur(s) du RFC : W. Toorop (NLnet Labs), S. Dickinson (Sinodun IT), S. Sahib (Brave Software), P. Aras, A. Mankin (Salesforce)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dprive
Première rédaction de cet article le 12 septembre 2021
Traditionnellement, le transfert d'une zone DNS depuis le serveur maitre vers ses esclaves se fait en clair. Si l'authentification et l'intégrité sont protégées, par exemple par TSIG, le transfert en clair ne fournit pas de confidentialité. Or on n'a pas forcément envie qu'un tiers puisse lire l'entièreté de la zone. Ce RFC normalise un transfert de zones sur TLS, XoT (zone transfer over TLS). Il en profite pour faire quelques ajustement dans l'utilisation de TCP pour les transferts de zone.
Le RFC fait quarante-deux pages mais le principe est très simple. Au lieu de faire le transfert de zones (aussi nommé AXFR, RFC 5936) directement sur TCP, on le fait sur du TLS, comme le fait DoT (RFC 7858). Le reste du RFC est consacré à des détails pratiques, mais le concept tient en une seule phrase.
Le DNS sur TLS est normalisé depuis cinq
ans, mais il ne couvre officiellement que la communication entre la
machine terminale et le résolveur. Bien que des essais aient
été faits pour communiquer en TLS avec des serveurs faisant
autorité, rien n'est encore normalisé. Mais, au fait, est-ce
que les transferts de zone ont vraiment besoin de confidentialité ?
Le RFC 9076 ne traite pas le problème, le
renvoyant aux RFC 5936 (la norme du transfert
de zones, qui parle de la possibilité de restreindre ce transfert à
des machines autorisées) et au RFC 5155 (qui
parle des risques d'énumération de tous les noms d'une
zone). Certes, le DNS étant public, tout le monde peut interroger
les serveurs faisant autorité, et connaitre ainsi les données
associées à un nom de
domaine, mais il faut pour cela connaitre les noms. Si
les petites zones n'ont rien de secret (elles ne contiennent que
l'apex et www), si certaines zones sont
publiques (la racine, par exemple), pour les autres zones, leur
responsable ne souhaite pas forcément qu'on ait accès à tous les
noms. Certains peuvent être le nom d'une personne
(le-pc-de-henri.zone.example), et donc être des
données personnelles, à protéger (le RFC note bien sûr que c'est une
mauvaise pratique, mais elle existe), certains noms peuvent
renseigner sur les activités et les projets d'une entreprise. Bref,
il peut être tout à fait raisonnable de ne pas vouloir transmettre
la zone en clair.
À noter qu'une surveillance du réseau pendant un transfert de zones fait en clair n'est pas la seule façon de trouver tous les noms. Une autre technique est l'énumération, utilisant par exemple les enregistrement NSEC de DNSSEC. Les enregistrement NSEC3 du RFC 5155 ont été conçus pour limiter ce risque (mais pas le supprimer ; le projet NSEC5 va essayer de résoudre le problème mais c'est loin d'être garanti).
Comment sécurise-t-on les transferts de zone aujourd'hui ? Les TSIG du RFC 8945 protègent l'intégrité mais pas la confidentialité. Vous pouvez trouver des détails pratiques sur la sécurisation des transferts de zone, combinant TSIG et ACL, dans un document du NIST en anglais et un document de l'ANSSI en français. On peut aussi en théorie utiliser IPsec entre maitre et esclaves mais cela semble irréaliste. D'où l'idée de base de ce nouveau RFC : mettre le transfert de zones sur TLS. Après tout, on utilise déjà TLS pour sécuriser la communication entre le client final et le résolveur : le protocole DoT, normalisé dans le RFC 7858.
Notre RFC introduit quelques nouveaux acronymes rigolos :
- XFR : couvre à la fois AXFR (RFC 5936) et IXFR (transferts incrémentaux, RFC 1995). Donc, XFR-over-TLS, c'est un transfert de zones, complet ou incrémental, sur TLS.
- XoT : acronyme pour XFR-over-TLS.
- AXoT : AXFR sur TLS.
- IXoT : IXFR sur TLS.
Pour la terminologie liée à la vie privée, voir le RFC 6973.
La section 3 du RFC spécifie le modèle de menace : on veut protéger le transfert de zones contre l'espionnage par un tiers, mais on n'essaie pas de cacher l'existence de la zone, ou le fait que telle machine soit serveur faisant autorité pour la zone. En effet, ces informations peuvent être obtenues facilement en interrogeant le DNS ou, dans le cas d'un maitre caché, en regardant le trafic réseau, sans même en décrypter le contenu.
Les principes de conception de XoT ? Fournir de la confidentialité et de l'authentification grâce à TLS, mais aussi en profiter pour améliorer les performances. Un certain nombre de programmes DNS ne peuvent pas, par exemple, utiliser la même connexion TCP pour plusieurs transferts de zone (même si le RFC 5936 le recommande). Il est difficile de résoudre ce problème sans casser les programmes existants et pas encore mis à jour. Par contre, XoT étant nouveau, il peut spécifier dès le début certains comportements qui améliorent les performances, comme l'utilisation d'une seule connexion pour plusieurs transferts.
Petit rappel de comment fonctionne le transfert de zones (RFC 5936, si vous voulez tous les détails). D'abord, le fonctionnement le plus courant : le serveur maitre (ou primaire) envoie un NOTIFY (RFC 1996) à ses esclaves (ou secondaires). Ceux-ci envoient une requête de type SOA au maitre puis, si le numéro de série récupéré est supérieur au leur, ils lancent l'AXFR sur TCP. Il y a des variations possibles : si le maitre n'envoie pas de NOTIFY ou bien s'ils sont perdus, les esclaves testent quand même de temps en temps le SOA (paramètre Refresh du SOA). Autre variante possible : les esclaves peuvent utiliser IXFR (RFC 1995) au lieu de AXFR pour ne transférer que la partie de la zone qui a changé. Et ils peuvent avoir à se rabattre en AXFR si le maitre ne gérait pas IXFR. Et les messages IXFR peuvent être sur UDP ou sur TCP (en pratique, BIND, NSD et bien d'autres font toujours l'IXFR sur TCP). Bref, il y a plusieurs cas. Les messages NOTIFY et SOA ne sont pas considérés comme sensibles du point de vue de la confidentialité et XoT ne les protège pas.
Maintenant, avec XoT, comment ça se passera (section 6 du RFC) ?
Une fois le transfert de zones décidé (via SOA, souvent précédé du
NOTIFY), le client (qui est donc le serveur secondaire) doit établir
une connexion TLS (1.3 minimum), en utilisant ALPN, avec
le nom dot (on notera que c'est donc le même
ALPN pour XoT et pour DoT, l'annexe A du RFC explique ce choix). Le
port est par défaut le classique 853 de
DoT. Le client authentifie le serveur via les techniques du RFC 8310. Le serveur vérifie le client, soit avec
des mécanismes TLS (plus sûrs mais plus compliqués à mettre en
œuvre), soit avec les classiques ACL. Le client TLS (le serveur DNS esclave) fait
ensuite de l'IXFR ou du AXFR classique sur ce canal TLS. Le serveur
doit être capable d'utiliser les codes d'erreur étendus du RFC 8914.
Voilà, c'est tout. Maintenant, quelques détails
pratiques. D'abord, rappelez-vous qu'il n'existe pas à l'heure
actuelle de norme pour du DoT entre résolveur et serveur faisant
autorité. Mais il y a des expériences en cours. Ici, par exemple, je
fais du DoT avec un serveur faisant autorité pour facebook.com :
% kdig +tls @a.ns.facebook.com. SOA facebook.com ;; TLS session (TLS1.3)-(ECDHE-X25519)-(RSA-PSS-RSAE-SHA256)-(AES-256-GCM) ... ;; ANSWER SECTION: facebook.com. 3600 IN SOA a.ns.facebook.com. dns.facebook.com. 1631273358 14400 1800 604800 300 ;; Received 86 B ;; Time 2021-09-10 13:35:44 CEST ;; From 2a03:2880:f0fc:c:face:b00c:0:35@853(TCP) in 199.0 ms
Mais on pourrait imaginer des serveurs faisant autorité qui ne fournissent pas ce service, pas encore normalisé, mais qui veulent faire du XoT. Est-ce possible de réserver TLS aux transferts de zone, mais sans l'utiliser pour les requêtes « normales » ? Oui, et dans ce cas le serveur doit répondre REFUSED à ces requêtes normales, avec le code d'erreur étendu 21 (Not supported). Ceci dit, il est difficile de dire comment réagiront les clients ; ils risquent d'ignorer le code d'erreur étendu et de recommencer bêtement (ou au contraire d'arrêter complètement d'utiliser le serveur).
Le but de XoT est de protéger le contenu de la zone contre les regards indiscrets. Mais comme vous le savez, TLS ne dissimule pas la taille des données qui passent entre ses mains et l'observation de cette taille peut donner des informations à un observateur, par exemple la taille des mises à jour en IXFR indique l'activité d'une zone. Le RFC suggère donc de remplir les données. Cela peut nécessiter d'envoyer des réponses vides, ce qui était interdit par les précédents RFC mais est maintenant autorisé.
Et les différentes formes de parallélisme des requêtes que permet le DNS sur TCP (et donc DoT) ? Elles sont décrites dans le RFC 7766. Si elles sont nécessaires pour exploiter le DNS de manière satisfaisante, elles ne sont pas forcément utiles pour XoT et notre RFC explique qu'on n'est pas forcé, par exemple, de permettre le pipelining (envoi d'une nouvelle requête quand la réponse à la précédente n'est pas encore arrivée) quand on fait du XoT. Par contre, comme avec tous les cas où on utilise du DNS sur TCP, il est recommandé de garder les connexions ouvertes un certain temps, par exemple en suivant le RFC 7828.
J'ai parlé plus haut de l'authentification dans une session XoT. La section 9 du RFC revient en détail sur cette question. Quels sont les mécanismes existants pour authentifier un transfert de zones ? Ils diffèrent par les services qu'ils rendent :
- Authentification de la source des données DNS.
- Authentification du correspondant (qui n'est pas forcément la source des données).
- Confidentialité.
Les mécanismes possibles sont :
- TSIG (RFC 8945) ; utiisant des clés partagées (ce qui n'est pas pratique), il permet d'authentifier la source des données.
- SIG(0) (RFC 2931) ; utilisant de la cryptographie asymétrique, il permet d'authentifier la source des données. Ceci dit, il n'est quasiment jamais mis en œuvre dans les programmes DNS.
- TLS en mode « opportuniste » (sans authentification) ; il ne garantit rien, sauf peut-être contre un observateur passif.
- TLS en mode strict (obligation d'authentification du serveur par le client, RFC 8310) ; cela permet l'authentification du correspondant, et la confidentialité (mais ne garantit pas que le correspondant est la vraie source des données).
- TLS mutuel ; le client s'authentifie également.
- ACL fondées sur l'adresse IP ; très répandu, ce mécanisme permet au serveur d'« authentifier » le client. Une faiblesse pour le cas de XoT : le serveur doit accepter l'établissement de la session TLS avant de savoir s'il s'agit de XoT ou de DNS ordinaire sur TLS.
- ZONEMD (RFC 8976) ; ce n'est pas vraiment une technique d'authentification mais elle peut être utile, en combinaison avec XoT.
Quelles sont les mises en œuvres actuelles de XoT ? Une liste existe. Actuellement, il n'y a guère que NSD qui permet le XoT mais le travail est en cours pour d'autres. Voyons comment faire du XoT avec NSD. On télécharge la dernière version (XoT est apparu en 4.3.7), on la compile (pas besoin d'options particulières) et on la configure, par exemple ainsi :
server:
port: 7053
...
tls-service-key: "server.key"
tls-service-pem: "server.pem"
# No TLS service if the port is not explicit in an interface definition
ip-address: 127.0.0.1@7153
tls-port: 7153
zone:
name: "fx"
zonefile: "fx"
# NSD 4.3.7 (september 2021) : not yet a way to restrict XoT
provide-xfr: 127.0.0.1 NOKEY
Ainsi configuré, NSD va écouter sur le port 7153 en TLS. Notons qu'il n'y a pas de moyen de configurer finement : il accepte forcément XoT et les requêtes « normales ». De même, on ne peut pas obliger un client DNS à n'utiliser que XoT. Testons avec kdig, un client DNS qui accepte TLS, d'abord une requête normale :
% kdig +tls @localhost -p 7153 SOA fx
;; TLS session (TLS1.3)-(ECDHE-SECP256R1)-(RSA-PSS-RSAE-SHA256)-(AES-256-GCM)
;; ->>HEADER<<- opcode: QUERY; status: NOERROR; id: 11413
...
;; ANSWER SECTION:
fx. 600 IN SOA ns1.fx. root.fx. 2021091201 604800 86400 2419200 86400
...
;; Time 2021-09-12 11:06:39 CEST
;; From 127.0.0.1@7153(TCP) in 0.2 ms
Parfait, tout marche. Et le transfert de zones ?
% kdig +tls @localhost -p 7153 AXFR fx ;; AXFR for fx. fx. 600 IN SOA ns1.fx. root.fx. 2021091201 604800 86400 2419200 86400 ... ;; Received 262 B (1 messages, 9 records) ;; Time 2021-09-12 11:07:25 CEST ;; From 127.0.0.1@7153(TCP) in 2.3 ms
Excellent, nous faisons du XoT. Wireshark nous le confirme :
% tshark -d tcp.port==7153,tls -i lo port 7153 ... 4 0.001200185 127.0.0.1 → 127.0.0.1 TLSv1 439 Client Hello ... 6 0.006305031 127.0.0.1 → 127.0.0.1 TLSv1.3 1372 Server Hello, Change Cipher Spec, Application Data, Application Data, Application Data, Application Data ... 10 0.007385823 127.0.0.1 → 127.0.0.1 TLSv1.3 140 Application Data
Dans ce cas, on utilisait NSD comme serveur primaire, recevant les clients XoT. Il peut aussi fonctionner comme serveur secondaire et il est alors client XoT. Je n'ai pas testé mais John Shaft l'a fait et en gros la configuration ressemble à :
tls-auth: name: un-nom-pour-identifier-ce-bloc auth-domain-name: nom-du-serveur-principal zone: ... request-xfr: AXFR 2001:db8::1 NOKEY un-nom-pour-identifier-ce-bloc
L'article seul
RFC 9108: YANG Types for DNS Classes and Resource Record Types
Date de publication du RFC : Septembre 2021
Auteur(s) du RFC : L. Lhotka (CZ.NIC), P. Spacek (ISC)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 9 septembre 2021
YANG est le langage standard à
l'IETF
pour décrire des modèles de données, afin de, par exemple, gérer
automatiquement des ressources. Ce RFC décrit le module YANG
iana-dns-class-rr-type, qui rassemble les
définitions des types d'enregistrements DNS.
YANG est normalisé dans le RFC 7950, et d'innombrables RFC décrivent des modules YANG pour de nombreux protocoles. YANG est utilisé par des protocoles de gestion à distance de ressources, comme RESTCONF (RFC 8040) ou NETCONF (RFC 6241). Mais ce RFC est le premier qui va utiliser YANG pour le DNS. L'un des objectifs (à long terme pour l'instant) est d'utiliser RESTCONF ou un équivalent pour gérer des serveurs DNS, résolveurs ou serveurs faisant autorité. (C'est un très vieux projet que cette gestion automatisée et normalisée des serveurs DNS.) Un mécanisme standard de gestion des serveurs nécessite un modèle de données commun, et c'est là que YANG est utile. Notre RFC est encore loin d'un modèle complet, il ne définit que le socle, le type des données que le DNS manipule. C'est la version YANG de deux registres IANA, celui des types d'enregistrements DNS et celui des classes (même si ce dernier concept est bien abandonné aujourd'hui).
Le registre IANA pour le DNS contient treize sous-registres. Le RFC n'en passe que deux en YANG, les classes et les types d'enregistrement. Les autres devront attendre un autre RFC. Les types d'enregistrement sont modélisés ainsi :
typedef rr-type-name {
type enumeration {
enum A {
value 1;
description
"a host address";
reference
"RFC 1035";
}
enum NS {
value 2;
description
"an authoritative name server";
...
Et les classes (mais, rappelez-vous, seule la classe
IN compte aujourd'hui) :
typedef dns-class-name {
type enumeration {
enum IN {
value 1;
description
"Internet (IN)";
reference
"RFC 1035";
}
enum CH {
value 3;
description
"Chaos (CH)";
reference
"D. Moon, 'Chaosnet', A.I. Memo 628, Massachusetts Institute of
Technology Artificial Intelligence Laboratory, June 1981.";
}
...
Le module YANG complet se retrouve dans le registre IANA (créé par le RFC 6020).
Le module YANG devra suivre l'actuel registre IANA, qui utilise un autre format. Pour faciliter la synchronisation, le RFC contient une feuille de style XSLT pour convertir l'actuel format, qui est la référence, vers le format YANG. La feuille de style est dans l'annexe A du RFC mais vous avez une copie ici. Voici comment produire et vérifier le module YANG :
% wget https://www.iana.org/assignments/dns-parameters/dns-parameters.xml % xsltproc iana-dns-class-rr-type.xsl dns-parameters.xml > iana-dns-class-rr-type.yang % pyang iana-dns-class-rr-type.yang
Le moteur XSLT xsltproc fait partie de la
libxslt. Le vérificateur YANG Pyang
est distribué via
GitHub mais on peut aussi l'installer avec pip (pip
install pyang).
L'article seul
RFC 9106: Argon2 Memory-Hard Function for Password Hashing and Proof-of-Work Applications
Date de publication du RFC : Septembre 2021
Auteur(s) du RFC : A. Biryukov, D. Dinu (University of Luxembourg), D. Khovratovich (ABDK Consulting), S. Josefsson (SJD AB)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF cfrg
Première rédaction de cet article le 8 septembre 2021
En général, en informatique, on essaie de diminuer la consommation de mémoire et de processeur des programmes, afin de les rendre plus efficaces. Mais il y a aussi des cas où on va tenter de réduire délibérement l'efficacité d'un programme. C'est le cas des fonctions de condensation qui sont utilisées en sécurité : on ne veut pas faciliter la tâche de l'attaquant. Ainsi, Argon2, spécifié dans ce RFC est volontairement très consommatrice de mémoire et d'accès à cette mémoire. Elle peut être utilisée pour condenser des mots de passe, ou pour des sytèmes à preuve de travail.
L'article original décrivant Argon2 est « Argon2: the memory-hard function for password hashing and other applications » et vous pouvez également lire « Argon2: New Generation of Memory-Hard Functions for Password Hashing and Other Applications ». Notre RFC reprend la description officielle, mais en s'orientant davantage vers les programmeurs et programmeuses qui devront mettre en œuvre cette fonction. Argon2 est conçu pour être memory-hard, c'est-à-dire faire souvent appel à la mémoire de la machine. Cela permet notamment aux ordinateurs classiques de tenir tête aux systèmes à base d'ASIC. (Par exemple, nombreuses sont les chaînes de blocs utilisant des preuves de travail. La fonction utilisée par Bitcoin, SHA-256, conçue pour être simple et rapide, n'est pas memory-hard et le résultat est qu'il y a belle lurette qu'un ordinateur, même rapide, n'a plus aucune chance dans le minage de Bitcoin. Seules les machines spécialisées peuvent rester en course, ce qui contribue à centraliser le minage dans peu de fermes de minage.) Argon2 est donc dur pour la mémoire, comme décrit dans l'article « High Parallel Complexity Graphs and Memory-Hard Functions ». À noter qu'Argon2 est très spécifique à l'architecture x86.
Argon2 se décline en trois variantes, Argon2id (celle qui est recommandée par le RFC), Argon2d et Argon2i. Argon2d a des accès mémoire qui dépendent des données, ce qui fait qu'il ne doit pas être employé si un attaquant peut examiner ces accès mémoire (attaque par canal auxiliaire). Il convient donc pour du minage de cryptomonnaie mais pas pour une carte à puce, que l'attaquant potentiel peut observer en fonctionnement. Argon2i n'a pas ce défaut mais est plus lent, ce qui ne gêne pas pour la condensation de mots de passe mais serait un problème pour le minage. Argon2id, la variante recommandée, combine les deux et est donc à la fois rapide et résistante aux attaques par canal auxiliaire. (Cf. « Tradeoff Cryptanalysis of Memory-Hard Functions », pour les compromis à faire en concevant ces fonctions dures pour la mémoire.) Si vous hésitez, prenez donc Argon2id. La section 4 du RFC décrit plus en détail les paramètres des variantes, et les choix recommandés.
Argon repose sur une fonction de condensation existante (qui n'est pas forcément dure pour la mémoire) et le RFC suggère Blake (RFC 7693).
La section 3 du RFC décrit l'algorithme mais je n'essaierai pas de vous le résumer, voyez le RFC.
La section 5 contient des vecteurs de test si vous voulez programmer Argon2 et vérifier les résultats de votre programme.
La section 7 du RFC revient en détail sur certaines questions de sécurité, notamment l'analyse de la résistance d'Argon2, par exemple aux attaques par force brute.
L'article seul
RFC 9096: Requirements for Customer Edge Routers to Mitigate IPv6 Renumbering Events
Date de publication du RFC : Août 2021
Auteur(s) du RFC : F. Gont (SI6 Networks), J. Zorz (6connect), R. Patterson (Sky UK), B. Volz (Cisco)
Réalisé dans le cadre du groupe de travail IETF v6ops
Première rédaction de cet article le 7 septembre 2021
Quand un FAI modifie la configuration de son réseau IPv6, les routeurs chez les clients finaux, les CPE, ne retransmettent pas toujours rapidement ce changement, ce qui mène parfois à des problèmes de connectivité. Ce RFC décrit ce que doivent faire ces CPE pour minimiser les conséquence négatives d'une rénumérotation d'un réseau.
Le problème est documenté dans le RFC 8978 : par exemple, lorsqu'un routeur chez M. Toutlemonde (une « box ») redémarre et « oublie » sa configuration réseau précédente, si elle a changé chez le FAI entretemps, les machines du réseau local de M. Toutlemonde risquent de continuer à utiliser pendant un certain une ancienne configuration, désormais invalide. Comment éviter cela ?
Notre RFC se penche surtout sur le cas où le routeur de M. Toutlemonde a appris son préfixe IPv6 depuis le FAI via la délégation de préfixe DHCP du RFC 9915, et qu'il retransmet l'information sur ce préfixe dans le réseau local avec le SLAAC du RFC 4862 (via les RA, Router Advertisements, RFC 4861) ou bien DHCP. Les machines terminales sur le réseau local peuvent aussi agir (ce sera dans un futur RFC) mais l'actuel RFC ne concerne que les routeurs. Il consiste en une série d'exigences auxquelles doivent se prêter les routeurs, exigences qui s'ajoutent à celles déjà présentes dans le RFC 7084 ou bien qui modifient des exigences de ce RFC 7084.
Beaucoup de ces exigences nécessitent un mécanisme de stockage d'informations sur le routeur, stockage qui doit survivre aux redémarrages, ce qui ne sera pas évident pour tous les routeurs. Ainsi, le RFC demande que, du côté WAN, le routeur utilise toujours le même identificateur (IAID, Identity Association IDentifier, RFC 9915, section 4.2) en DHCP (pour essayer de garder le même préfixe). Certains routeurs choisissent apparemment l'IAID au hasard à chaque démarrage, ce qui leur obtient un nouveau préfixe. Il vaut mieux le garder, mais cela nécessite qu'il puisse être stocké et mémorisé même en cas de redémarrage. Comme tous les routeurs n'ont pas de mécanisme de stockage stable, les exigences du RFC sont exprimées (dans le langage du RFC 2119) par un SHOULD et pas un MUST.
Autre exigence, qui relève du bon sens, le routeur ne doit pas, lorsqu'il utilise un préfixe du côté LAN (le réseau local), utiliser une durée de vie plus longue (options Preferred Lifetime et Valid Lifetime du message d'information sur le préfixe envoyé par le routeur, RFC 4861, section 4.6.2) que celle qu'il a lui-même appris en DHCP côté WAN. On ne doit pas promettre ce qu'on ne peut pas tenir, la durée du bail DHCP s'impose au routeur et aux annonces qu'il fait sur le réseau local.
Enfin, le routeur ne doit pas, au redémarrage, envoyer
systématiquement un abandon du préfixe appris en DHCP (message DHCP
RELEASE). Certains routeurs font apparemment
cela, ce qui risque de déclencher une renumérotation brutale (RFC 8978).
Lorsque le préfixe change, le routeur devrait aussi signaler cela sur le réseau local. Là encore, cela impose une mémoire, un stockage stable. Il doit se souvenir de ce qu'il a reçu, et annoncé, précédemment, pour pouvoir annoncer sur le réseau local que ces anciens préfixes ne doivent plus être utilisés (cela se fait en annonçant ces préfixes, mais avec une durée de vie nulle). Dans un monde idéal, le routeur sera prévenu des changements de préfixe parce que le FAI réduira la durée de vie de ses baux DHCP, permettant un remplacement ordonné d'un préfixe par un autre. Dans la réalité, on a parfois des renumérotations brutales, sans préavis (RFC 8978). Le routeur doit donc également gérer ces cas.
L'article seul
RFC 9099: Operational Security Considerations for IPv6 Networks
Date de publication du RFC : Août 2021
Auteur(s) du RFC : E. Vyncke (Cisco), K. Chittimaneni (Square), M. Kaeo (Double Shot Security), E. Rey (ERNW)
Pour information
Réalisé dans le cadre du groupe de travail IETF opsec
Première rédaction de cet article le 7 septembre 2021
Tous les gens qui gèrent des réseaux IPv4 savent comment les sécuriser (normalement…). Et pour IPv6 ? Si ce n'est pas un protocole radicalement différent, il a quand même quelques particularités de sécurité. Ce RFC donne des conseils pratiques et concrets sur la sécurisation de réseaux IPv6. (Je le répète, mais c'est juste une nouvelle version d'IP : l'essentiel du travail de sécurisation est le même en v4 et en v6.)
Les différences entre IPv4 et IPv6 sont subtiles (mais, en sécurité, la subtilité compte, des petits détails peuvent avoir de grandes conséquences). Ceci dit, le RFC a tendance à les exagérer. Par exemple, il explique que la résolution d'adresses de couche 3 en adresses de couche 2 ne se fait plus avec ARP (RFC 826) mais avec NDP (RFC 4861). C'est vrai, mais les deux protocoles fonctionnent de manière très proche et ont à peu près les mêmes propriétés de sécurité (en l'occurrence, aucune sécurité). Plus sérieusement, le remplacement d'un champ d'options de taille variable dans IPv4 par les en-têtes d'extension d'IPv6 a certainement des conséquences pour la sécurité. Le RFC cite aussi le cas du NAPT (Network Address and Port Translation, RFC 2663). Souvent appelée à tort NAT (car elle ne traduit pas que l'adresse mais également le port), cette technique est très utilisée en IPv4. En IPv6, on ne fait pas de traduction ou bien on fait du vrai NAT, plus précisement du NPT (Network Prefix Translation, RFC 6296) puisqu'on change le préfixe de l'adresse. La phrase souvent entendue « en IPv6, il n'y a pas de NAT » est doublement fausse : c'est en IPv4 qu'on n'utilise pas le NAT, mais le NAPT, et on peut faire de la traduction d'adresses en IPv6 si on veut. NAT, NAPT ou NPT ne sont évidemment pas des techniques de sécurité mais elles peuvent avoir des conséquences pour la sécurité. Par exemple, toute traduction d'adresse va complexifier le réseau, ce qui introduit des risques. Autre facteur nouveau lié à IPv6 : la plupart des réseaux vont devoir faire de l'IPv4 et de l'IPv6 et les différentes techniques de coexistence de ces deux versions peuvent avoir leur propre impact sur la sécurité (RFC 4942).
La section 2 du RFC est le gros morceau du RFC ; c'est une longue liste de points à garder en tête quand on s'occupe de la sécurité d'un réseau IPv6. Je ne vais pas tous les citer, mais en mentionner quelques-uns qui donnent une bonne idée du travail du ou de la responsable de la sécurité.
D'abord, l'adressage. Aux débuts d'IPv6, l'idée était que les spécificités d'IPv6 comme le SLAAC allaient rendre la renumérotation des réseaux tellement triviale qu'on pourrait changer les adresses souvent. En pratique, ce n'est pas tellement le cas (RFC 7010) et il faut donc prêter attention à la conception de son adressage : on aura du mal à en changer. Heureusement, c'est beaucoup plus facile qu'en IPv4 : l'abondance d'adresses dispense des astuces utilisées en IPv4 pour essayer d'économiser chaque adresse. Par exemple, on peut donner à tous ses sous-réseaux la même longueur de préfixe, quelle que soit leur taille, ce qui simplifie bien les choses (le RFC 6177 est une lecture instructive). Comme en IPv4, les adresses peuvent être liées au fournisseur d'accès (PA, Provider Allocated) ou bien obtenues indépendamment de ce fournisseur (PI, Provider Independent). Le RFC 7381 discute ce cas. Cela peut avoir des conséquences de sécurité. Par exemple, les adresses PA sont en dernier ressort gérées par l'opérateur à qui il faudra peut-être demander certaines actions. Et ces adresses PA peuvent pousser à utiliser la traduction d'adresses, qui augmente la complexité. (D'un autre côté, les adresses PI sont plus difficiles à obtenir, surtout pour une petite organisation.) Ah, et puis, pour les machines terminales, le RFC 7934 rappelle à juste titre qu'il faut autoriser ces machines à avoir plusieurs adresses (il n'y a pas de pénurie en IPv6). Une des raisons pour lesquelles une machine peut avoir besoin de plusieurs adresses est la protection de la vie privée (RFC 8981).
Les gens habitués à IPv4 demandent souvent quel est l'équivalent du RFC 1918 en IPv6. D'abord, de telles adresses privées ne sont pas nécessaires en IPv6, où on ne manque pas d'adresses. Mais si on veut, on peut utiliser les ULA (Unique Local Addresses) du RFC 4193. Par rapport aux adresses privées du RFC 1918, elles ont le gros avantage d'être uniques, et donc d'éviter toute collision, par exemple quand deux organisations fusionnent leurs réseaux locaux. Le RFC 4864 décrit comment ces ULA peuvent être utilisés pour la sécurité.
Au moment de concevoir l'adressage, un choix important est celui de donner ou non des adresses IP stables aux machines. (Ces adresses stables peuvent leur être transmises par une configuration statique, ou bien en DHCP.) Les adresses stables facilitent la gestion du réseau mais peuvent faciliter le balayage effectué par un attaquant pendant une reconnaissance préalable. Contrairement à ce qu'on lit parfois encore, ce balayage est tout à fait possible en IPv6, malgré la taille de l'espace d'adressage, même s'il est plus difficile qu'en IPv4. Le RFC 7707 explique les techniques de balayage IPv6 possibles. Même chose dans l'article « Mapping the Great Void ». Bref, on ne peut pas compter sur la STO et donc, adresses stables ou pas, les machines connectées à l'Internet peuvent être détectées, et doivent donc être défendues.
Cela n'empêche pas de protéger la vie privée des utilisateurs en utilisant des adresses temporaires pour contacter l'extérieur. L'ancien système de configuration des adresses par SLAAC était mauvais pour la vie privée puisqu'il utilisait comme partie locale de l'adresse (l'IID, Interface IDentifier) l'adresse MAC, ce qui permettait d'identifier une machine même après qu'elle ait changé de réseau. Ce système est abandonné depuis longtemps (RFC 8064) au profit d'adresses aléatoires (RFC 8981). Ceci dit, ces adresses aléatoires posent un autre problème : comme elles changent fréquemment, elles ne permettent pas à l'administrateur réseau de suivre les activités d'une machine (c'est bien leur but), et on ne peut plus utiliser de mécanismes comme les ACL. Une solution possible est d'utiliser des adresses qui sont stables pour un réseau donné mais qui ne permettent pas de suivre une machine quand elle change de réseau, les adresses du RFC 7217. C'est dans beaucoup de cas le meilleur compromis. (Le RFC 7721 contient des détails sur les questions de sécurité liées aux adresses IP.)
On peut aussi couper SLAAC (cela peut se faire à distance avec des annonces RA portant le bit M) et n'utiliser que DHCP mais toutes les machines terminales n'ont pas un client DHCP.
En parlant de DHCP, lui aussi pose des problèmes de vie privée (décrits dans le RFC 7824) et si on veut être discret, il est recommandé d'utiliser le profil restreint défini dans le RFC 7844.
Après les adresses, la question des en-têtes d'extension, un concept nouveau d'IPv6. En IPv4, les options sont placées dans l'en-tête, qui a une longueur variable, ce qui complique et ralentit son analyse. En IPv6, l'en-tête a une longueur fixe (40 octets) mais il peut être suivi d'un nombre quelconque d'en-têtes d'extension (RFC 8200, section 4). Si on veut accéder à l'information de couche 4, par exemple pour trouver le port TCP, il faut suivre toute la chaîne d'en-têtes. Ce système était conçu pour être plus facile et plus rapide à analyser que celui d'IPv4, mais à l'usage, ce n'est pas le cas (le RFC estime même que le système d'IPv6 est pire). En partie pour cette raison, certains nœuds intermédiaires jettent tous les paquets IPv6 contenant des en-têtes d'extension (RFC 7872, RFC 9288). D'autres croient que la couche Transport suit immédiatement l'en-tête, sans tenir compte de la possibilité qu'il y ait un en-tête d'extension, ce qui fausse leur analyse. L'en-tête d'extension Hop-by-hop options était particulièrement problématique, car devant être traité par tous les routeurs (le RFC 8200 a adouci cette règle).
Pour faciliter la tâche des pare-feux, plusieurs règles ont été ajoutées aux en-têtes d'extension depuis les débuts d'IPv6 : par exemple le premier fragment d'un datagramme doit contenir la totalité des en-têtes d'extension.
À l'interface
d'IPv6 et de la couche 2, on
trouve quelques problèmes supplémentaires. D'abord, concernant la
résolution d'adresses IP en adresses
MAC, pour laquelle IPv6 utilise le protocole NDP
(Neighbor Discovery Protocol, RFC 4861). NDP partage avec ARP un problème fondamental :
n'importe quelle machine du réseau local peut répondre ce qu'elle
veut. Par exemple, si une machine demande « qui est
2001:db8:1::23:42:61 ? », toutes les machines
locales peuvent techniquement répondre « c'est moi » et donner leur
adresse MAC. Ce problème et quelques autres analogues sont
documentés dans les RFC 3756 et RFC 6583. DHCP pose le même genre de problèmes,
toute machine peut se prétendre serveur DHCP et répondre aux
requêtes DHCP à la place du serveur légitime. Pour se prémunir
contre les attaques faites par des machines envoyant de faux
RA, on peut aussi isoler les machines, par
exemple en donnant un /64 à chacune, ou bien en configurant
commutateurs ou points d'accès Wifi pour bloquer les communications
de machine terminale à machine terminale (celles qui qui ne sont pas
destinées au routeur). Le RFC recommande le RA
guard du RFC 6105.
Et sur les mobiles ? Un lien 3GPP est un lien point-à-point, l'ordiphone qui est à un bout ne peut donc pas parler aux autres ordiphones, même utilisant la même base. On ne peut parler qu'au routeur (GGSN - GPRS Gateway Support Node, ou bien PGW - Packet GateWay). Pour la même raison, il n'y a pas de résolution des adresses IP et donc pas de risque liés à cette résolution. Ce mécanisme empêche un grand nombre des attaques liées à NDP. Si vous voulez en apprendre plus à ce sujet, il faut lire le RFC 6459.
Le
multicast peut être
dangereux sur un réseau local, puisqu'il permet d'écrire à des
machines qui n'ont rien demandé. Certains réseaux WiFi bloquent le
multicast. En IPv6, cela empêche des actions
néfastes comme de pinguer
ff01::1 (l'adresse multicast
qui désigne toutes les machines du réseau local), mais cela bloque
aussi des protocoles légitimes comme mDNS
(RFC 6762).
Compte-tenu de la vulnérabilité du réseau local, et des risques associés, il a souvent été proposé de sécuriser l'accès à celui-ci et IPv6 dispose d'un protocole pour cela, SEND, normalisé dans le RFC 3971, combiné avec les CGA du RFC 3972. Très difficile à configurer, SEND n'a connu aucun succès, à part dans quelques environnements ultra-sécurisés. On ne peut clairement pas compter dessus.
Voyons maintenant la sécurité du plan de contrôle : les routeurs et le routage (RFC 6192). Les problèmes de sécurité sont quasiment les mêmes en IPv4 et en IPv6, la principale différence étant le mécanisme d'authentification pour OSPF. Un routeur moderne typique sépare nettement le plan de contrôle (là où on fait tourner les protocoles comme OSPF, mais aussi les protocoles de gestion comme SSH qui sert à configurer le routeur) et le plan de transmission, là où se fait la transmission effective des paquets. Le second doit être très rapide, car il fonctionne en temps réel. Il utilise en général du matériel spécialisé, alors que le plan de contrôle est la plupart du temps mis en œuvre avec un processeur généraliste, et un système d'exploitation plus classique. Pas toujours très rapide, il peut être submergé par un envoi massif de paquets. Le plan de contrôle ne gère que les paquets, relativement peu nombreux, qui viennent du routeur ou bien qui y arrivent, le plan de transmission gérant les innombrables paquets que le routeur transmet, sans les garder pour lui. Chaque paquet entrant est reçu sur l'interface d'entrée, le routeur consulte une table qui lui dit quel est le routeur suivant pour ce préfixe IP, puis il envoie ce paquet sur l'interface de sortie. Et le tout très vite.
Notre RFC conseille donc de protéger le plan de contrôle en bloquant le plus tôt possible les paquets anormaux, comme des paquets OSPF qui ne viendraient pas d'une adresse locale au lien, ou les paquets BGP qui ne viennent pas d'un voisin connu. (Mais, bien sûr, il faut laisser passer l'ICMP, essentiel au débogage et à bien d'autres fonctions.) Pour les protocoles de gestion, il est prudent de jeter les paquets qui ne viennent pas du réseau d'administration. (Tout ceci est commun à IPv4 et IPv6.)
Protéger le plan de contrôle, c'est bien, mais il faut aussi protéger le protocole de routage. Pour BGP, c'est pareil qu'en IPv4 (lisez le RFC 7454). Mais OSPF est une autre histoire. La norme OSPFv3 (RFC 4552) comptait à l'origine exclusivement sur IPsec, dont on espérait qu'il serait largement mis en œuvre et déployé. Cela n'a pas été le cas (le RFC 8504 a d'ailleurs supprimé cette obligation d'IPsec dans IPv6, obligation qui était purement théorique). Le RFC 7166 a pris acte de l'échec d'IPsec en créant un mécanisme d'authentification pour OSPFv3. Notre RFC recommande évidemment de l'utiliser.
Sinon, les pratiques classiques de sécurité du routage tiennent toujours. Ne pas accepter les routes « bogons » (conseil qui n'est plus valable en IPv4, où tout l'espace d'adressage a été alloué), celles pour des adresses réservées (RFC 8190), etc.
Pas de sécurité sans surveillance (c'est beau comme du Ciotti, ça) et journalisation. En IPv6 comme en IPv4, des techniques comme IPFIX (RFC 7011), SNMP (RFC 4293), etc sont indispensables. Comme en IPv4, on demande à son pare-feu, son serveur RADIUS (RFC 2866) et à d'autres équipements de journaliser les évènements intéressants. À juste titre, et même si ça va chagriner les partisans de la surveillance massive, le RFC rappelle que, bien que tout cela soit très utile pour la sécurité, c'est dangereux pour la vie privée, et que c'est souvent, et heureusement, encadré par des lois comme le RGPD. Administrateur réseaux, ne journalise pas tout, pense à tes responsabilités morales et légales !
Bon, mais cela, c'est commun à IPv4 et IPv6. Qu'est-ce qui est spécifique à IPv6 ? Il y a le format textuel canonique des adresses, normalisé dans le RFC 5952, qui permet de chercher une adresse sans ambiguité. Et la mémoire des correspondances adresses IP adresses MAC dans les routeurs ? Elle est très utile à enregistrer, elle existe aussi en IPv4, mais en IPv6 elle est plus dynamique, surtout si on utilise les adresses favorables à la vie privée du RFC 8981. Le RFC recommande de la récupérer sur le routeur au moins une fois toutes les 30 secondes. Et le journal du serveur DHCP ? Attention, en IPv6, du fait de l'existence de trois mécanismes d'allocation d'adresses (DHCP, SLAAC et statique) au lieu de deux en IPv4, le journal du serveur DHCP ne suffit pas. Et puis il ne contiendra pas l'adresse MAC mais un identificateur choisi par le client, qui peut ne rien vous dire. (Ceci dit, avec les machines qui changent leur adresse MAC, DHCPv4 a un problème du même genre.) En résumé, associer une adresse IP à une machine risque d'être plus difficile qu'en IPv4.
Une autre spécificité d'IPv6 est l'existence de nombreuses technologies de transition entre les deux protocoles, technologies qui apportent leurs propres problèmes de sécurité (RFC 4942). Normalement, elles n'auraient dû être que temporaires, le temps que tout le monde soit passé à IPv6 mais, comme vous le savez, la lenteur du déploiement fait qu'on va devoir les supporter longtemps, les réseaux purement IPv6 et qui ne communiquent qu'avec d'autres réseaux IPv6 étant une petite minorité. La technique de coexistence la plus fréquente est la double pile, où chaque machine a à la fois IPv4 et IPv6. C'est la plus simple et la plus propre, le trafic de chaque version du protocole IP étant natif (pas de tunnel). Avec la double pile, l'arrivée d'IPv6 n'affecte pas du tout IPv4. D'un autre côté, il faut donc gérer deux versions du protocole. (Anecdote personnelle : quand j'ai commencé dans le métier, IP était très loin de la domination mondiale, et il était normal, sur un réseau local, de devoir gérer cinq ou six protocoles très différents. Prétendre que ce serait une tâche insurmontable de gérer deux versions du même protocole, c'est considérer les administrateurs réseaux comme très paresseux ou très incompétents.) L'important est que les politiques soient cohérentes, afin d'éviter, par exemple, que le port 443 soit autorisé en IPv4 mais bloqué en IPv6, ou le contraire. (C'est parfois assez difficile à réaliser sans une stricte discipline : beaucoup de pare-feux n'ont pas de mécanisme simple pour indiquer une politique indépendante de la version du protocole IP.)
Notez que certains réseaux peuvent être « double-pile » sans que l'administrateur réseaux l'ait choisi, ou en soit conscient, si certaines machines ont IPv6 activé par défaut (ce qui est fréquent et justifié). Des attaques peuvent donc être menées via l'adresse locale au lien même si aucun routeur du réseau ne route IPv6.
Mais les plus gros problèmes de sécurité liés aux techniques de coexistence/transition viennent des tunnels. Le RFC 6169 détaille les conséquences des tunnels pour la sécurité. Sauf s'ils sont protégés par IPsec ou une technique équivalente, les tunnels permettent bien des choses qui facilitent le contournement des mesures de sécurité. Pendant longtemps, l'interconnexion entre réseaux IPv6 isolés se faisait via des tunnels, et cela a contribué aux légendes comme quoi IPv6 posait des problèmes de sécurité. Aujourd'hui, ces tunnels sont moins nécessaires (sauf si un réseau IPv6 n'est connecté que par des opérateurs archaïques qui n'ont qu'IPv4).
Les tunnels les plus dangereux (mais aussi les plus pratiques) sont les tunnels automatiques, montés sans configuration explicite. Le RFC suggère donc de les filtrer sur le pare-feu du réseau, en bloquant le protocole IP 41 (ISATAP - RFC 5214, 6to4 - RFC 3056, mais aussi 6rd - RFC 5969 - qui, lui, ne rentre pas vraiment dans la catégorie « automatique »), le protocole IP 47 (ce qui bloque GRE, qui n'est pas non plus un protocole « automatique ») et le port UDP 3544, pour neutraliser Teredo - RFC 4380. D'ailleurs, le RFC rappelle plus loin que les tunnels statiques (RFC 2529), utilisant par exemple GRE (RFC 2784), sont plus sûrs (mais IPsec ou équivalent reste recommandé). 6to4 et Teredo sont de toute façon très déconseillés aujourd'hui (RFC 7526 et RFC 3964).
Et les mécanismes de traduction d'adresses ? On peut en effet traduire des adresses IPv4 en IPv4 (le traditionnel NAT, qui est plutôt du NAPT en pratique, puisqu'il traduit aussi le port), ce qui est parfois présenté à tort comme une fonction de sécurité, mais on peut aussi traduire de l'IPv4 en IPv6 ou bien de l'IPv6 en IPv6. Le partage d'adresses que permettent certains usages de la traduction (par exemple le CGNAT) ouvre des problèmes de sécurité bien connus. Les techniques de traduction d'IPv4 en IPv6 comme NAT64 - RFC 6146 ou 464XLAT - RFC 6877 apportent également quelques problèmes, décrits dans leurs RFC.
J'ai parlé plus haut du fait que les systèmes d'exploitation modernes ont IPv6 et l'activent par défaut. Cela implique de sécuriser les machines contre les accès non voulus faits avec IPv6. Du classique, rien de spécifique à IPv6 à part le fait que certains administrateurs système risqueraient de sécuriser les accès via IPv4 (avec un pare-feu intégré au système d'exploitation, par exemple) en oubliant de le faire également en IPv6.
Tous les conseils donnés jusqu'à présent dans cette section 2 du RFC étaient communs à tous les réseaux IPv6. Les sections suivantes s'attaquent à des types de réseau spécifiques à certaines catégories d'utilisateurs. D'abord (section 3), les « entreprises » (en fait, toutes les organisations - RFC 7381, pas uniquement les entreprises capitalistes privées, comme le terme étatsunien enterprise pourrait le faire penser). Le RFC contient quelques conseils de sécurité, proches de ce qui se fait en IPv4, du genre « bloquer les services qu'on n'utilise pas ». (Et il y a aussi le conseil plus évident : bloquer les paquets entrants qui ont une adresses IP source interne et les paquets sortants qui ont une adresse IP source externe.)
Et pour les divers opérateurs (section 4 du RFC) ? C'est plus délicat car ils ne peuvent pas, contrairement aux organisations, bloquer ce qu'ils ne veulent pas (sauf à violer la neutralité, ce qui est mal). Le RFC donne des conseils de sécurisation BGP (identiques à ceux d'IPv4) et RTBH (RFC 5635). Il contient également une section sur l'« interception légale » (le terme politiquement correct pour les écoutes et la surveillance). Légalement, les exigences (et les problèmes qu'elles posent) sont les mêmes en IPv4 et en IPv6. En IPv4, le partage d'adresses, pratique très répandue, complique sérieusement la tâche des opérateurs quand ils reçoivent un ordre d'identifier le titulaire de telle ou telle adresse IP (RFC 6269). En IPv6, en théorie, la situation est meilleure pour la surveillance, une adresse IP n'étant pas partagée. Par contre, l'utilisateur peut souvent faire varier son adresse au sein d'un préfixe /64.
Quand au réseau de l'utilisateur final, il fait l'objet de la section 5. Il n'y a pas actuellement de RFC définitif sur la délicate question de la sécurité de la maison de M. Michu. Notamment, les RFC 6092 et RFC 7084 ne prennent pas position sur la question très sensible de savoir si les routeurs/pare-feux d'entrée de ce réseau devraient bloquer par défaut les connexions entrantes. La sécurité plaiderait en ce sens mais ça casserait le principe de bout en bout.
Voilà, nous avons terminé cette revue du long RFC. Je résumerai mon opinion personnelle en disant : pour la plupart des questions de sécurité, les ressemblances entre IPv4 et IPv6 l'emportent sur les différences. La sécurité n'est donc pas une bonne raison de retarder la migration si nécessaire vers IPv6. J'ai développé cette idée dans divers exposés et articles.
L'article seul
RFC 9051: Internet Message Access Protocol (IMAP) - Version 4rev2
Date de publication du RFC : Août 2021
Auteur(s) du RFC : A. Melnikov (Isode), B. Leiba (Futurewei Technologies)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF extra
Première rédaction de cet article le 3 septembre 2021
IMAP, protocole d'accès distant à des boites aux lettres n'est pas juste un protocole, c'est tout un écosystème, décrit dans de nombreux RFC. Celui-ci est le socle de la version actuelle d'IMAP, la « 4rev2 ». Elle remplace la précédente version, « 4rev1 » (normalisée dans le RFC 3501). Le principal changement est sans doute une internationalisation plus poussée pour les noms de boites aux lettres et les en-têtes des messages.
Les protocoles traditionnels du courrier électronique, notamment SMTP ne permettaient que d'acheminer le courrier jusqu'à destination. Pour le lire, la solution la plus courante aujourd'hui est en mode client/serveur, avec IMAP, qui fait l'objet de notre RFC. IMAP ne permet pas d'envoyer du courrier, pour cela, il faut utiliser le RFC 6409. IMAP fonctionne sur un modèle où les messages ont plutôt vocation à rester sur le serveur, et où les clients peuvent, non seulement les récupérer mais aussi les classer, les détruire, les marquer comme lus, etc. IMAP permet de tout faire à distance.
Pour apprendre IMAP, il vaut mieux ne pas commencer par le RFC,
qui est très riche. (La lecture du RFC 2683 est recommandée
aux implémenteurs.) Pourtant, le principe de base est simple. IMAP
est client/serveur. Le
client se connecte en TCP au serveur, sur le
port 143, et envoie des commandes sous forme
de texte, comme avec SMTP. Il s'authentifie avec la commande
LOGIN, choisit une boite aux lettres avec la
commande SELECT, récupère un message avec la
commande FETCH. IMAP peut aussi utiliser du
TLS
implicite, sur le port 993. Voici un exemple de session. Notons tout
de suite, c'est un point très important du protocole IMAP, que
chaque commande est précédée d'une étiquette
(tag, voir les sections 2.2.1 et 5.5 du RFC)
arbitraire qui change à chaque commande et qui permet d'associer une
réponse à une commande, IMAP permettant d'envoyer plusieurs
commandes sans attendre de réponse. Les réponses portent
l'étiquette correspondante, ou bien un
astérisque s'il s'agit d'un message du
serveur non sollicité. Ici, le serveur utilise le logiciel Archiveopteryx :
% telnet imap.example.org imap Trying 192.0.2.23... Connected to imap.example.org. Escape character is '^]'. * OK [CAPABILITY IMAP4rev1 AUTH=CRAM-MD5 AUTH=DIGEST-MD5 AUTH=PLAIN COMPRESS=DEFLATE ID LITERAL+ STARTTLS] imap.example.org Archiveopteryx IMAP Server com1 LOGIN stephane vraimentsecret com1 OK [CAPABILITY IMAP4rev1 ACL ANNOTATE BINARY CATENATE CHILDREN COMPRESS=DEFLATE CONDSTORE ESEARCH ID IDLE LITERAL+ NAMESPACE RIGHTS=ekntx STARTTLS UIDPLUS UNSELECT URLAUTH] done com2 SELECT INBOX * 189 EXISTS * 12 RECENT * OK [UIDNEXT 1594] next uid * OK [UIDVALIDITY 1] uid validity * FLAGS (\Deleted \Answered \Flagged \Draft \Seen) * OK [PERMANENTFLAGS (\Deleted \Answered \Flagged \Draft \Seen \*)] permanent flags com2 OK [READ-WRITE] done
Le serveur préfixe ses réponses par OK si tout va bien, NO s'il ne pas réussi à faire ce qu'on lui demande et BAD si la demande était erronnée (commande inconnue, par exemple). Ici, avec l'étiquette A2 et un Dovecot :
A2 CAVAPAS A2 BAD Error in IMAP command CAVAPAS: Unknown command (0.001 + 0.000 secs).
Si le serveur n'est accessible qu'en TLS implicite (TLS démarrant
automatiquement au début, sans STARTTLS), on
peut utiliser un client TLS en ligne de commande, comme celui de
GnuTLS :
% gnutls-cli -p 993 imap.maison.example
- Certificate[0] info:
- subject `CN=imap.maison.example', issuer `CN=CAcert Class 3 Root,OU=http://www.CAcert.org,O=CAcert Inc.', serial 0x02e9bf, RSA key 2048 bits, signed using RSA-SHA512, activated `2020-12-14 14:47:42 UTC', expires `2022-12-14 14:47:42 UTC', pin-sha256="X21ApSVQ/Qcb5Q8kgL/YqlH2XuEco/Rs2X2EgkvDEdI="
...
- Status: The certificate is trusted.
- Description: (TLS1.3)-(ECDHE-SECP256R1)-(RSA-PSS-RSAE-SHA256)-(AES-256-GCM)
[À partir d'ici, on fait de l'IMAP]
* OK [CAPABILITY IMAP4rev1 SASL-IR LOGIN-REFERRALS ID ENABLE IDLE LITERAL+ AUTH=PLAIN] Dovecot (Debian) ready.
A1 LOGIN stephane vraimenttropsecret
A1 OK [CAPABILITY IMAP4rev1 SASL-IR LOGIN-REFERRALS ID ENABLE IDLE SORT SORT=DISPLAY THREAD=REFERENCES THREAD=REFS THREAD=ORDEREDSUBJECT MULTIAPPEND URL-PARTIAL CATENATE UNSELECT CHILDREN NAMESPACE UIDPLUS LIST-EXTENDED I18NLEVEL=1 CONDSTORE QRESYNC ESEARCH ESORT SEARCHRES WITHIN CONTEXT=SEARCH LIST-STATUS BINARY MOVE SNIPPET=FUZZY PREVIEW=FUZZY STATUS=SIZE SAVEDATE LITERAL+ NOTIFY SPECIAL-USE] Logged in
A2 SELECT INBOX
...
* 0 EXISTS
* 0 RECENT
A2 OK [READ-WRITE] Select completed (0.002 + 0.000 + 0.001 secs).
...
A14 FETCH 1 (BODY.PEEK[HEADER.FIELDS (SUBJECT)])
* 1 FETCH (BODY[HEADER.FIELDS (SUBJECT)] {17}
Subject: Test
)
A14 OK Fetch completed (0.007 + 0.000 + 0.006 secs).
Les commandes IMAP, comme FETCH dans l'exemple
ci-dessus, sont décrites dans la section 6 du RFC.
Pour tester son serveur IMAP, on peut aussi utiliser fetchmail et
lui demander d'afficher toute la session avec -v
-v :
% fetchmail -v -v -u MYLOGIN imap.1and1.fr Enter password for MYLOGIN@imap.1and1.fr: fetchmail: 6.3.6 querying imap.1and1.fr (protocol auto) at Tue Apr 15 12:00:27 2008: poll started fetchmail: 6.3.6 querying imap.1and1.fr (protocol IMAP) at Tue Apr 15 12:00:27 2008: poll started Trying to connect to 212.227.15.141/143...connected. fetchmail: IMAP< * OK IMAP server ready H mimap3 65564 fetchmail: IMAP> A0001 CAPABILITY fetchmail: IMAP< * CAPABILITY IMAP4rev1 LITERAL+ ID STARTTLS CHILDREN QUOTA IDLE NAMESPACE UIDPLUS UNSELECT SORT AUTH=LOGIN AUTH=PLAIN fetchmail: IMAP< A0001 OK CAPABILITY finished. fetchmail: Protocol identified as IMAP4 rev 1 fetchmail: IMAP> A0002 STARTTLS fetchmail: IMAP< A0002 OK Begin TLS negotiation. fetchmail: Issuer Organization: Thawte Consulting cc fetchmail: Issuer CommonName: Thawte Premium Server CA fetchmail: Server CommonName: imap.1and1.fr fetchmail: imap.1and1.fr key fingerprint: 93:13:99:6A:3F:23:73:C3:00:37:4A:39:EE:22:93:AB fetchmail: IMAP> A0003 CAPABILITY fetchmail: IMAP< * CAPABILITY IMAP4rev1 LITERAL+ ID CHILDREN QUOTA IDLE NAMESPACE UIDPLUS UNSELECT SORT AUTH=LOGIN AUTH=PLAIN fetchmail: IMAP< A0003 OK CAPABILITY finished. fetchmail: Protocol identified as IMAP4 rev 1 fetchmail: imap.1and1.fr: upgrade to TLS succeeded. fetchmail: IMAP> A0004 LOGIN "m39041005-1" * fetchmail: IMAP< A0004 OK LOGIN finished. fetchmail: selecting or re-polling default folder fetchmail: IMAP> A0005 SELECT "INBOX"
En IMAP, un message peut être identifié par un UID
(Unique Identifier) ou par un numéro. Le numéro
n'est pas global, il n'a de sens que pour une boite donnée, et il
peut changer, par exemple si on détruit des messages. L'UID, lui,
est stable, au moins pour une session (et de préférence pour
toutes). Les messages ont également des attributs
(flags). Ceux qui commencent par une
barre oblique inverse comme
\Seen (indique que le message a été lu),
\Answered (on y a répondu), etc, sont
obligatoires, et il existe également des attributs optionnels
commençant par un dollar comme
$Junk (spam). Les
fonctions de recherche d'IMAP pourront utiliser ces attributs comme
critères de recherche. Les attributs optionnels
(keywords) sont listés dans un
registre IANA, et on peut en ajouter (le RFC 5788
explique comment).
IMAP a des fonctions plus riches, notamment la possibilité de chercher dans les messages (section 6.4.4 du RFC), ici, on extrait les messages de mai 2007, puis on récupère le sujet du premier message, par son numéro :
com10 SEARCH since 1-May-2007 before 31-May-2007
* SEARCH 12
com10 OK done
com11 FETCH 1 (BODY.PEEK[HEADER.FIELDS (SUBJECT)])
* 1 FETCH (BODY[HEADER.FIELDS (Subject)] {17}
Subject: Rapport sur les fonctions de vue dans Archiveopteryx
)
com11 OK done
IMAP 4rev2 est complètement internationalisé et, par exemple, peut gérer des en-têtes en UTF-8, comme décrits dans le RFC 6532, ce qui est une des améliorations par rapport à 4rev1.
Vous noterez dans les réponses CAPABILITY
montrées plus haut, que le serveur indique la ou les versions d'IMAP
qu'il sait gérer. Il peut donc annoncer 4rev1 et 4rev2, s'il est
prêt à gérer les deux. Le client devra utiliser la commande
ENABLE pour choisir. S'il choisit 4rev2, le
serveur pourra utiliser les nouveautés de 4rev2, notamment dans le
domaine de l'internationalisation (noms de boites en UTF-8, alors
que 4rev1 savait tout juste utiliser un bricolage basé sur
UTF-7).
IMAP 4rev2 est compatible avec 4rev1 (un logiciel de la précédente norme peut interagir avec un logiciel de la nouvelle). Il peut même interagir avec l'IMAP 2 du RFC 1776 (IMAP 3 n'a jamais été publié), cf. RFC 2061.
L'annexe E résume les principaux changements depuis le RFC 3501, qui normalisait IMAP 4rev1 :
- Messages plus grands (taille stockée sur 63 bits et plus seulement 32). Un serveur qui accepte les messages de plus de quatre gigoctets devra donc les masquer aux clients 4rev1 (ou bien trouver une autre stratégie).
- UTF-8 pour les noms de boites et les sujets des messages.
- Incorporation de nombreuses extensions précédemment
séparées, trop nombreuses pour que je les cite toutes. Il y a par
exemple le
BINARYdu RFC 3516 ou leLIST-EXTENDEDdu RFC 5258. - Beaucoup de clarifications du texte.
- Abandon de certaines choses, aussi, comme le code de réponse
UNSEENde la commandeSELECT. - Application des progrès de la cryptanalyse, donc remplacement de MD5 par SHA-256.
- Suppression de la convention du préfixe « X- », en application du RFC 6648.
La réalisation d'un client ou d'un serveur IMAP soulève plein de problèmes pratiques, que la section 5 de notre RFC traite. Par exemple, les noms des boites aux lettres peuvent être en Unicode, plus précisément le sous-ensemble d'Unicode du RFC 5198 (cela n'était pas possible en 4rev1). Un logiciel doit donc s'attendre à rencontrer de tels noms.
IMAP est mis en œuvre dans de nombreux serveurs comme Dovecot, Courier, ou Archiveopteryx, déjà cité (mais qui semble abandonné). Mais, comme vous l'avez vu dans les exemples de session IMAP cités plus haut, la version de notre RFC, « 4rev2 » n'a pas encore forcément atteint tous les logiciels.
Côté client, on trouve du IMAP dans beaucoup de logiciels, des webmails, des MUA classiques comme mutt, des MUA en ligne de commande comme fetchmail, très pratique pour récupérer son courrier. (Si vous écrivez un logiciel IMAP à partir de zéro, ce RFC recommande la lecture préalable du RFC 2683.)
Il existe également des bibliothèques toutes faites pour programmer son client IMAP à son goût comme imaplib pour Python. Voici un exemple d'un court programme Python qui se connecte à un serveur IMAP, sélectionne tous les messages et les récupère. On note que la bibliothèque a choisi de rester très proche du vocabulaire du RFC :
import imaplib
# Unlike what the documentation says, "host" has no proper default.
connection = imaplib.IMAP4_SSL(host='localhost')
connection.login("stephane", "thisissecret")
connection.select() # Select the default mailbox
typee, data = connection.search(None, "ALL")
for num in data[0].split():
# Fetches the whole message
# "RFC822" est le terme traditionnel mais le format des messages
# est désormais dans le RFC 5322.
typ, data = connection.fetch(num, '(RFC822)')
print('Message %s\n%s\n' % (num, data[0][1]))
connection.close()
connection.logout()
L'article seul
Le registre Afrinic attaqué
Première rédaction de cet article le 31 août 2021
Le registre d'adresses IP Afrinic est actuellement l'objet d'une attaque juridique dans un conflit qui l'oppose à un revendeur d'adresses IP. L'affaire est complexe et vous ne trouverez pas ici d'opinions fermes sur « qui a raison » mais je voudrais expliquer de quoi il retourne et surtout signaler un problème grave : la justice a gelé les comptes bancaires d'Afrinic, menaçant à terme l'Internet africain. Il ne s'agit donc pas d'une affaire purement privée entre deux organisations en conflit.
D'abord, qu'est-ce qu'un RIR, un registre
d'adresses IP ? C'est l'organisme qui attribue les adresses IP, afin d'en garantir
l'unicité. Les informations sur ces allocations sont ensuite
publiquement accessibles via whois ou
RDAP. Il y a cinq RIR dans le monde,
Afrinic couvrant le continent
africain. Contrairement aux noms de domaine,
dont la gestion suscite toujours passions et controverses (l'une des
facettes de la « gouvernance de
l'Internet »), celle des adresses IP soulève nettement
moins d'intérêt. C'est en partie dû au fait qu'on se moque d'avoir
telle ou telle adresse IP (à quelques exceptions près comme certains résolveurs DNS publics avec leurs adresses
facilement mémorisables comme 1.1.1.1). Et puis les adresses IP,
c'est purement virtuel, le registre peut en « fabriquer » autant
qu'il veut, non ? Il ne devrait pas y avoir de problème de pénurie,
n'est-ce pas ?
Mais cela n'est vrai que pour l'actuelle version du protocole IP, la version 6. Avec l'ancienne version, IPv4, toujours utilisée à certains endroits, les adresses ne sont codées que sur 32 bits, ce qui ne permet qu'environ quatre milliards d'adresses (un peu moins en pratique, certaines adresses étant réservées pour des usages spécifiques). Si ce chiffre semble important, il est très insuffisant par rapport aux besoins de l'Internet mondial. Il y a donc bel et bien pénurie d'adresses IPv4 et, comme le disait ma grand-mère, « quand le foin manque dans l'écurie, les chevaux se battent ». Les tensions sur le stock d'adresses IPv4 imposent donc que les RIR aient une politique d'allocation de ces adresses, les réservant à ceux qui en ont besoin. On se doute bien que l'élaboration de telles politiques ne se fasse pas sans douleur, et les cinq RIR ont d'ailleurs des politiques différentes. En outre, et pour son malheur, Afrinic a eu pendant longtemps un stock d'adresses IPv4 important, ce qui a aggravé les tentations. (Le pillage des ressources de l'Afrique n'est pas une invention nouvelle.)
Et c'est la source du conflit actuel entre Afrinic et la société Cloud Innovation (chinoise, mais enregistrée dans un paradis fiscal africain). Cette société obtient des adresses IPv4 par différents moyens, et les loue ensuite à ses clients, notamment en Chine. Ce n'est pas forcément illégal, l'achat, la vente et la location d'adresses IP peuvent être acceptées par le système légal, et par les politiques des RIR (les détails sont complexes, je vous les épargne). On peut trouver ce business répugnant mais il existe et n'est pas interdit. Ceci dit, les organisations qui obtiennent des adresses IP sont censées respecter les règles d'allocation du RIR auquel elles se sont adressées. Ici, Afrinic reproche à Cloud Innovation d'avoir obtenu de nombreuses adresses IP en violation des règles, et menace cette société de reprendre les adresses, argumentant notamment sur le fait qu'elles ne sont pas utilisées en Afrique. Comme la question est complexe (j'ai déjà du mal à retenir les règles du RIR de ma région), je ne vais pas trancher en désignant un bon et un méchant.
Le vrai problème se situe ensuite : Cloud Innovation a obtenu de la justice qu'elle interdise à Afrinic de reprendre les adresses en question mais surtout à obtenu le gel des comptes bancaires d'Afrinic, ce qui menace le fonctionnement même du registre et, à terme, de l'Internet en Afrique.
Mais quelle justice au fait ? Afrinic est enregistré à Maurice et c'est donc la justice de ce pays qui est compétente. Je ne formulerai pas d'opinion sur la qualité de la justice mauricienne, je ne la connais pas, mais je trouve quand même que le blocage des comptes, empêchant l'une des parties au procès de fonctionner et même de payer ses juristes, est anormale, notamment compte-tenu de ses conséquences pour l'Internet. D'ailleurs, pourquoi Maurice ? C'est parce que, bien que chaque RIR serve un continent entier, l'organisation doit bien être enregistrée quelque part. Elle ne peut pas planer au-dessus des lois nationales. Pour avoir un statut international, il faudrait un traité intergouvernemental (comme pour l'Union africaine) et, outre la difficulté à négocier un tel traité, cela aurait d'autres conséquences de gouvernance, notamment sur le rôle des gouvernements. Il fallait donc un pays particulier et Maurice semblait un choix raisonnable. (Les Européens noteront que c'est pour la même raison que leur RIR est à Amsterdam et que l'Internet européen dépend donc de la justice néerlandaise.)
À court terme, l'Internet continue à fonctionner en Afrique : les RIR ne sont pas impliqués dans l'activité quotidienne, les paquets ne passent pas par eux, les opérateurs Internet font fonctionner les réseaux que le RIR fonctionne ou pas. Mais à moyen terme, le « gel » d'Afrinic pourrait paralyser beaucoup d'activités indispensables, notamment la tenue du registre des adresses IP. D'où l'urgence d'une solution.
Des personnes plus pressées ont suggéré d'attaquer l'attaquant et, par exemple, de ne plus router les préfixes IP de Cloud Innovation. La question est évidemment très délicate, car si je comprends l'exaspération de certains, des actions unilatérales de ce genre ne sont pas non plus un procédé satisfaisant pour résoudre les conflits. Il vaudrait mieux que la justice mauricienne débloque les comptes d'Afrinic, en attendant un jugement au fond.
(Un autre point dont j'aurais préféré ne pas parler ; le problème expliqué dans cet article a une origine extérieure à Afrinic. Il n'est pas lié à un autre problème, qui avait été abondemment discuté en 2019-2020, d'un employé d'Afrinic vendant discrètement des adresses IP, problème qui fait également l'objet d'actions en justice. Voir entre autres ma conférence à Coriin 2020.)
Et revenons à IPv6. Son déploiement est actuellement insuffisant, en raison de la lenteur anormale mise par beaucoup d'acteurs à effectuer la migration. Il y a des raisons à cela mais il faut noter que ces décisions de trainer la patte, en fonction des intérêts de ces acteurs, ont des conséquences globales, celles d'accentuer la pression sur les rares adresses IPv4, menant à ce genre de crises.
Quelles lectures pour finir :
- Le registre d'Amérique du Nord a fait une déclaration de soutien à Afrinic.
- Il y a une cagnotte en ligne d'aide à Afrinic.
- Un intéressant article du spécialiste de la gouvernance de l'Internet Milton Mueller, mais je ne suis pas forcément d'accord avec son renvoi des deux parties dos à dos.
- Le conflit est également un conflit de communication. Soyez donc informé·es que l'organisation nommée « Larus Foundation » est apparemment une vitrine de communication pour Cloud Innovation.
- En français, il y a un bon article de Digital Business Africa et cet article de Jeune Afrique (non public).
- Une vidéo de présentation d'Afrinic en français.
L'article seul
RFC 9079: Source-Specific Routing in Babel
Date de publication du RFC : Août 2021
Auteur(s) du RFC : M. Boutier, J. Chroboczek (IRIF, University of Paris)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF babel
Première rédaction de cet article le 29 août 2021
Traditionnellement, le routage dans l'Internet se fait sur la base de l'adresse IP de destination. Mais on peut aussi envisager un routage où l'adresse IP source est prise en compte. Ce nouveau RFC étend le protocole de routage Babel en lui ajoutant cette possibilité.
Babel, normalisé dans le RFC 8966 est un protocole de routage à vecteur de
distance. Il est prévu par défaut pour du routage
IP traditionnel, où
le protocole de routage construit une table de transmission qui
associe aux préfixes IP de destination le routeur suivant
(next hop). Un paquet
arrive dans un routeur ? Le routeur regarde
dans sa table le préfixe le plus spécifique qui correspond à
l'adresse IP de destination (utilisant pour cela une structure de
données comme, par exemple, le Patricia trie)
et, lorsqu'il le trouve, la table contient les coordonnées du
routeur suivant. Par exemple, si une entrée de la table dit que
2001:db8:1:fada::/64 a pour routeur suivant
fe80::f816:3eff:fef2:47db%eth0, un paquet
destiné à 2001:db8:1:fada::bad:1234 sera
transmis à ce fe80::f816:3eff:fef2:47db, sur
l'interface réseau eth0. Cette transmission
classique a de nombreux avantages : elle est simple et rapide, et
marche dans la plupart des cas.
Mais ce mécanisme a des limites. On peut vouloir prendre en compte d'autres critères que l'adresse de destination pour la transmission d'un paquet. Un exemple où un tel critère serait utile est le multihoming. Soit un réseau IP qui est connecté à plusieurs opérateurs, afin d'assurer son indépendance et pour faire face à un éventuel problème (technique ou commercial) chez l'un des opérateurs. La méthode officielle pour cela est d'acquérir des adresses indépendantes du fournisseur et de faire router ces adresses par les opérateurs auxquels on est connectés (par exemple en leur parlant en BGP). Mais avoir de ces adresses PI (Provider-Independent) est souvent difficile. Quand on est passionnée, on y arrive mais ce n'est pas vraiment accessible à tout le monde. On se retrouve donc en général avec des adresses dépendant du fournisseur. C'est par exemple le cas de loin le plus courant pour le particulier, la petite association ou la PME. Dans ce cas, le multihoming est compliqué. Mettons que les deux fournisseurs d'accès se nomment A et B et que chacun nous fournisse un préfixe d'adresses IP. Si une machine interne a deux adresses IP, chacune tirée d'un des préfixes, et qu'elle envoie vers l'extérieur un paquet ayant comme adresse source une adresse de B, que se passe-t-il ? Si le paquet est envoyé via le fournisseur B, tout va bien. Mais s'il est envoyé via le fournisseur A, il sera probablement jeté par le premier routeur de A, puisque son adresse IP source ne sera pas une adresse du fournisseur (RFC 3704 et RFC 8704). Pour éviter cela, il faudrait pouvoir router selon l'adresse IP source, envoyant les paquets d'adresse source A vers le fournisseur A et ceux ayant une adresse source B vers B. En gros, soit l'information de routage influe sur le choix de l'adresse source, soit c'est le choix de l'adresse source qui influe sur le routage. On ne peut pas faire les deux, ou alors on risque une boucle de rétroaction. Ce RFC choisit la deuxième solution.
La première solution serait que la machine émettrice choisisse l'adresse IP source selon que les adresses de destination soient routées vers A ou vers B. Le RFC 3484 explique comment le faire en séquentiel et le RFC 8305 le fait en parallèle (algorithme dit des « globes oculaires heureux »). Mais les systèmes actuels ne savent typiquement pas le faire et, de toute façon, cela ne réglerait pas le cas où le routage change pendant la vie d'une connexion TCP. TCP, contrairement à QUIC ou SCTP, ne supporte pas qu'une adresse IP change en cours de route, sauf à utiliser les extensions du RFC 8684. Une dernière solution serait de laisser les applications gérer cela (cf. RFC 8445) mais on ne peut pas compter que toutes les applications le fassent. Bref, le routage tenant compte de la source reste souvent la meilleure solution.
À part le cas du multihoming, d'autres usages peuvent tirer profit d'un routage selon la source. Ce routage peut simplifier la configuration des tunnels. Il peut aussi être utile dans le cas de l'anycast. Lorsqu'on utilise du routage classique, fondé uniquement sur la destination, il est difficile de prédire quels clients du groupe anycast seront servis par quelle instance du groupe. Cela rend la répartition de charge compliquée (il faut jouer avec les paramètres des annonces BGP, par exemple) et cela pose des problèmes aux protocoles avec état, comme TCP, où un même client doit rester sur la même instance du groupe anycast. (Des utilisations de l'anycast pour des services sans état, comme le DNS sur UDP, n'ont pas ce problème.) Au contraire, avec du routage fait selon la source, chaque instance anycast peut annoncer sa route avec le ou les préfixes IP qu'on veut que cette instance serve.
D'ailleurs, si vous voulez en savoir plus sur le routage selon la source (ou SADR Source-Address Dependent Routing, également appelé SSR pour Source-Specific Routing), vous pouvez lire l'article détaillé des auteurs du RFC, « Source-Specific Routing ». On peut aussi noter que ce routage dépendant de la source n'est pas la même chose qu'un routage décidé par la source (source routing), qui indiquerait une liste de routeurs par où passer. Ici, chaque routeur reste maitre du saut suivant (sur le routage décidé par la source, voir RFC 8354, et un exemple dans le RFC 6554).
Bon, le routage tenant compte de la source est intéressant,
OK. Mais, avant de s'y lancer, il faut faire attention à un petit
problème, la spécificité des routes. Lorsqu'on route uniquement
selon la destination, et que plusieurs routes sont possibles, la
règle classique d'IP est celle de la spécificité. La route avec le
préfixe le plus spécifique (le plus long) gagne. Mais que se passe
t-il si on ajoute l'adresse source comme critère ? Imaginons qu'on
ait deux routes, une pour la destination
2001:db8:0:1::/64 et s'appliquant à toutes les
sources et une autre route pour toutes les destinations (route par
défaut), ne s'appliquant qu'à la source
2001:db8:0:2::/64. On va noter ces deux routes
sous forme d'un tuple (destination, source) donc, ici,
(2001:db8:0:1::/64, ::/0)
et (::/0,
2001:db8:0:2::/64). Pour un paquet venant de
2001:db8:0:2::1 et allant en
2001:db8:0:1::1, quelle est la route la plus
spécifique ? Si on considère la spécificité de la destination
d'abord, la route choisie sera la
(2001:db8:0:1::/64,
::/0). Mais si on regarde la spécificité de la
source en premier, ce sera l'autre route, la (::/0,
2001:db8:0:2::/64) qui sera adoptée. Doit-on
laisser chaque machine libre de faire du destination d'abord ou du
source d'abord ? Non, car tous les routeurs du domaine doivent
suivre la même règle, autrement des boucles pourraient se former, un
paquet faisant du ping-pong éternel entre un routeur « destination
d'abord » et un routeur « source d'abord ». Babel impose donc une
règle : pour déterminer la spécificité d'une route, on regarde la
destination d'abord. Le choix n'est pas arbitraire, il correspond à
des topologies réseau typique, avec des réseaux locaux pour
lesquelles on a une route spécifique, et une route par défaut pour
tout le reste.
Un autre point important est celui du système de transmission des paquets. Il faut en effet rappeler que le terme « routage » est souvent utilisé pour désigner deux choses très différentes. La première est le routage à proprement parler (routing en anglais), c'est-à-dire la construction des tables de transmission, soit statiquement, soit avec des protocoles de routage comme Babel. La seconde est la transmission effective des paquets qui passent par le routeur (forwarding en anglais). Si on prend un routeur qui tourne sur Unix avec le logiciel babeld, ce dernier assure bien le routage au sens strict (construire les tables de routage grâce aux messages échangés avec les autres routeurs) mais c'est le noyau Unix qui s'occupe de la transmission. Donc, si on veut ajouter des fonctions de routage tenant compte de la source, il ne suffit pas de le faire dans le programme qui fait du Babel, il faut aussi s'assurer que le système de transmission en est capable, et avec la bonne sémantique (notamment l'utilisation de la destination d'abord pour trouver la route la plus spécifique). Si Babel, avec les extensions de ce RFC, tourne sur un système qui ne permet pas cela, il faut se résigner à ignorer les annonces spécifiques à une source. (Pour des systèmes comme Linux, qui permet le routage selon la source mais avec une mauvaise sémantique, puisqu'il utilise la source d'abord pour trouver la route la plus spécifique, la section V-B de l'article des auteurs cité plus haut fournit un algorithme permettant de créer des tables de transmission correctes.)
Le passage du routage classique au routage tenant compte de la
source nécessite de modifier les structures de données du protocole
de routage, ici Babel (section 3 du RFC). Les différentes structures
de données utilisées par une mise en œuvre de Babel doivent être
modifiées pour ajouter le préfixe de la source, et plusieurs des
TLV dans les messages que s'échangent les
routeurs Babel doivent être étendus avec un sous-TLV (RFC 8966, section 4.4) qui contient un préfixe
source. La section 5 du RFC détaille les modifications nécessaires
du protocole Babel. Les trois types de TLV
qui indiquent un préfixe de destination, Updates,
Route Requests et Seqno,
doivent désormais transporter en plus un sous-TLV indiquant le
préfixe source, marqué comme obligatoire (RFC 8966, section 4.4), de façon à ce qu'une version de Babel
ne connaissant pas le routage selon la source n'accepte pas des
annonces incomplètes. Si une annonce ne dépend pas de l'adresse IP
source, il ne faut pas envoyer un sous-TLV avec le préfixe
::/0 mais au contraire ne pas mettre de
sous-TLV (les autres versions de Babel accepteront alors
l'annonce).
Ainsi, des versions de Babel gérant les extensions de notre RFC 9079 et d'autres qui ne les gèrent pas (fidèles au RFC 8966) pourront coexister sur le même réseau, sans que des boucles de routage ne se forment. En revanche, comme la notion de sous-TLV obligatoire n'est apparue qu'avec le RFC 8966, les vieilles versions de Babel, qui suivent l'ancien RFC 6126, ne doivent pas être sur le même réseau que les routeurs à routage dépendant de la source.
Le nouveau sous-TLV Source Prefix a le type 128 et sa valeur comporte un préfixe d'adresses IP, encodé en {longueur, préfixe}.
Notez que si les routeurs qui font du routage selon la source n'annoncent que des routes ayant le sous-TLV indiquant un préfixe source, les routeurs qui ne gèrent pas ce routage selon la source, et qui ignorent donc cette annonce, souffriront de famine : il n'y aura pas de routes vers certaines destinations, conduisant le routeur à jeter les paquets. Il peut donc être prudent, par exemple, d'avoir une route par défaut sans condition liée à la source, pour ces routeurs qui ignorent cette extension.
Question sécurité, il faut signaler (section 9 du RFC), que cette extension au routage apporte davantage de souplesse, et que cela peut nécessiter une révision des règles de sécurité, si celles-ci supposaient que tous les paquets vers une destination donnée suivaient le même chemin. Ainsi, le filtrage des routes (RFC 8966, annexe C) pourra être inutile si des routes spécifiques à une source sont présentes. Autre supposition qui peut être désormais fausse : une route spécifique à une machine de destination (host route, c'est-à-dire un préfixe /128) n'est plus forcément obligatoire, une autre route pour certaines sources peut prendre le dessus.
Au moins deux mises en œuvre de cette extension existent, dans babeld depuis la version 1.6 (en IPv6 seulement), et dans BIRD depuis la 2.0.2.
Merci à Juliusz Chroboczek pour sa relecture, et pour ses bonnes remarques sur le choix entre le routage selon la source et les autres solutions.
L'article seul
RFC 9043: FFV1 Video Coding Format Version 0, 1, and 3
Date de publication du RFC : Août 2021
Auteur(s) du RFC : M. Niedermayer, D. Rice, J. Martinez
Pour information
Réalisé dans le cadre du groupe de travail IETF cellar
Première rédaction de cet article le 24 août 2021
Ce RFC décrit FFV1, un encodage de flux vidéo sans pertes, et sans piège connu, par exemple de brevet.
Certains encodages vidéo font perdre de l'information, c'est-à-dire que, après décompression, on ne retrouve pas tout le flux original. Ces encodages avec pertes tirent profit des limites de l'œil humain (on n'encode pas ce qui ne se voit pas) mais peut poser des problèmes dans certains cas. Par exemple, si on veut stocker une vidéo sur le long terme, il est certainement préférable qu'elle soit aussi « authentique » que possible, et donc encodée sans pertes. Les organisations qui font de l'archivage sur le long terme (comme l'INA) ont tout intérêt à privilégier un format sans pertes et libre, qui sera encore utilisable dans 50 ans, plutôt que de choisir les derniers gadgets à la mode. Si on souhaite faire analyser cette vidéo par autre chose qu'un œil humain, par exemple un programme qui souhaite avoir la totalité des informations, là encore, le « sans perte » est nécessaire. FFV1 est sans perte, pour le plus grand bénéfice de l'archivage et de la science. C'est le premier codec sans perte documenté par l'IETF.
FFV1 ne date pas d'aujourd'hui, et le RFC traite d'un coup trois versions de FFV1 (section 4.2.1) :
- La version 0, qui date de 2006,
- la version 1, de 2009,
- la version 2 qui n'était qu'expérimentale et n'a pas été officiellement utilisée,
- la version 3, la dernière, en 2013.
Le nom FFV1 veut dire « FF Video 1 » et FF est une référence à FFmpeg, le programme de référence (qui a largement précédé la spécification officielle) dont le nom venait de Fast Forward (avance rapide).
Je ne vais pas vous décrire les algorithmes de FFV1, ça dépasse largement mes compétences. Comme le note le RFC, il faut d'abord connaitre le codage par intervalle, et le modèle YCbCr. Je vous renvoie donc à l'article en français d'un des auteurs et bien sûr au RFC lui-même. FFV1 utilise souvent des techniques un peu anciennes, pour éviter les problèmes de brevet.
Le RFC utilise du pseudo-code pour décrire l'encodage FFV1. Ce pseudo-code particulier est assez proche de C. Vous verrez donc du pseudo-code du genre :
for (i = 0; i < quant_table_set_count; i++) {
states_coded
if (states_coded) {
for (j = 0; j < context_count[ i ]; j++) {
for (k = 0; k < CONTEXT_SIZE; k++) {
initial_state_delta[ i ][ j ][ k ]
}
}
}
}
Le type de média video/FFV1
a été enregistré
à l'IANA pour les flux encodés en FFV1.
FFV1 décrit un encodage d'un flux vidéo, pas un format de conteneur. Le flux en question doit donc être inclus dans un conteneur, par exemple aux formats AVI, NUT ou Matroska (section 4.3.3 pour les détails de l'inclusion dans chaque format).
Comme pour tout codec utilisé sur le grand méchant Internet, un programme qui lit du FFV1 doit être paranoïaque et ne doit pas supposer que le flux vidéo est forcément correct. Même si le contenu du fichier est délibérement malveillant, le décodeur ne doit pas allouer de la mémoire à l'infini ou boucler sans fin (ou, pire encore, exécuter du code arbitraire par exemple parce qu'il y aura eu un débordement de pile ; FFV1 lui-même ne contient pas de code exécutable). Le RFC (section 6) donne l'exemple d'un calcul de taille d'une image où on multiplie la largeur par la hauteur, sans plus de précautions. Si cela provoque un dépassement d'entier, des tas de choses vilaines peuvent arriver. Un exemple de précaution : FFmpeg a été soumis à des flux FFV1 corrects et à des données aléatoires, tout en étant examiné par Valgrind et le vérificateur de Clang et aucun accès mémoire anormal n'a été détecté.
Question mises en œuvre, FFV1 est suffisamment ancien pour que de nombreux programmes sachent le décoder. L'implémentation de référence est FFmpeg (qui sait aussi encoder en FFV1). Il y a également un décodeur en Go, développé en même temps que la spécification et il y a aussi MediaConch dont le développement a permis de détecter des incohérences entre le projet de spécification et certains programmes. La spécification elle-même a été développée sur GitHub si vous voulez suivre son histoire, et son futur (une version 4 est prévue).
Comme exemple d'une vidéo encodée en FFV1, j'ai pris les 20
premières secondes de mon
exposé au FOSDEM 2021. Le fichier (pour 20 secondes de
vidéo !) fait 60 mégaoctets : la
compression sans perte est évidemment moins efficace que si on
accepte les pertes. Le fichier a été produit par FFmpeg
(ffmpeg -i retro_gemini.webm -vcodec ffv1 -level 3 -to
00:00:20 retro_gemini.mkv, notez que, si FFV1 lui-même
est sans perte, si vous encodez en FFV1 à partir d'un fichier déjà
comprimé avec perte, vous ne recupérez évidemment pas ce qui a été
perdu). mediainfo vous montre son contenu :
% mediainfo retro_gemini.mkv General ... Format : Matroska Movie name : Gemini, a modern protocol that looks retro ... DATE : 2021-02-07 EVENT : FOSDEM 2021 SPEAKERS : Stéphane Bortzmeyer Video ID : 1 Format : FFV1 Format version : Version 3.4 Codec ID : V_MS/VFW/FOURCC / FFV1 Duration : 20 s 0 ms Bit rate mode : Variable Bit rate : 25.7 Mb/s Width : 1 280 pixels Height : 720 pixels Frame rate mode : Constant Frame rate : 25.000 FPS Color space : YUV Compression mode : Lossless ...
Ou bien avec ffprobe :
% fprobe -show_format -show_streams retro_gemini.mkv
...
Input #0, matroska,webm, from 'retro_gemini.mkv':
Metadata:
title : Gemini, a modern protocol that looks retro
DATE : 2021-02-07
...
[STREAM]
index=0
codec_name=ffv1
codec_long_name=FFmpeg video codec #1
codec_type=video
codec_time_base=1/25
codec_tag_string=FFV1
width=1280
height=720
...
Merci à Jérôme Martinez pour sa relecture attentive.
L'article seul
RFC 9102: TLS DNSSEC Chain Extension
Date de publication du RFC : Août 2021
Auteur(s) du RFC : V. Dukhovni (Two Sigma), S. Huque (Salesforce), W. Toorop (NLnet Labs), P. Wouters (Aiven), M. Shore (Fastly)
Expérimental
Première rédaction de cet article le 12 août 2021
Lorsqu'on authentifie un serveur TLS (par exemple un serveur
DoT) avec DANE, le client TLS
doit utiliser un résolveur DNS
validant et tenir compte de son résultat
(données validées ou pas), ce qui n'est pas toujours facile, ni même
possible dans certains environnements. Ce RFC propose une solution pour cela : une
extension à TLS, dnssec_chain, qui permet au
serveur TLS d'envoyer l'ensemble des enregistrements DNS pertinents
au client, le dispensant ainsi de solliciter un résolveur
validant. Toute la cuisine de vérification peut ainsi se faire sans
autre canal que TLS.
TLS
(normalisé dans les RFC 5246 et RFC 9846) fournit un canal de communication
sécurisé, si on a authentifié le serveur situé en face. La plupart
du temps, on authentifie via un certificat
PKIX (RFC 5280). Dans certains
cas, ce n'est pas facile d'utiliser PKIX. Par exemple, pour
DoT (RFC 7858), le
résolveur DoT n'est typiquement connu que par une adresse IP, alors que le
certificat ne contient en général qu'un nom
(oui, le RFC 8738 existe, mais n'est pas
toujours activé par les autorités de
certification). Les serveurs DoT sont souvent
authentifiables par DANE (RFC 6698 et
RFC 7671). Par exemple, mon résolveur DoT
public, dot.bortzmeyer.fr, est authentifiable
avec DANE (regardez les données TLSA de
_853._tcp.dot.bortzmeyer.fr). Mais DANE dépend
de la disponibilité d'un résolveur DNS
validant. Diverses raisons font que le
client TLS peut avoir du mal à utiliser un résolveur validant, et à
récupérer l'état de la validation (toutes les API de résolution de
noms ne donnent pas accès à cet état). L'article « Discovery
method for a DNSSEC validating stub resolver »
donne des informations sur ces difficultés. Bref, devoir récupérer
ces enregistrements DANE de manière sécurisée peut être un
problème. Et puis utiliser le DNS pour récupérer des données
permettant d'authentifier un résolveur DNS pose un
problème d'œuf et de poule.
D'où l'idée centrale de ce RFC : le client TLS demande au serveur de lui envoyer ces enregistrements. Le client n'a plus « que » à les valider à partir d'une clé de confiance DNSSEC (typiquement celle de la racine, commune à tout le monde). Le serveur peut aussi, s'il n'utilise pas DANE, renvoyer la preuve de non-existence de ces enregistrements, le client saura alors, de manière certaine, qu'il peut se rabattre sur un autre mécanisme d'authentification. L'extension TLS de notre RFC peut servir à authentifier un certificat complet, ou bien une clé brute (RFC 7250). Dans ce dernier cas, cette extension protège en outre contre les attaques dites « Unknown Key-Share ».
Notez le statut de ce RFC : cette spécification est pour l'instant expérimentale, elle n'a pas vraiment réuni de consensus à l'IETF, mais elle fait partie des solutions proposées pour sécuriser DoT, dans le RFC 8310 (section 8.2.2).
Bon, maintenant, l'extension elle-même (section 2). C'est une
extension TLS (ces extensions sont spécifiées dans la section 4.3 du
RFC 9846), elle est nommée
dnssec_chain et enregistrée
dans le registre IANA, avec le code 59. Son champ de données
(extension_data) vaut, dans le
ClientHello, le port de
connexion et, dans le ServerHello, un ensemble
d'enregistrements DNS au format binaire du DNS (pour TLS 1.2 ; en
1.3, cet ensemble est attaché au certificat du serveur). Dans le
langage de description des données TLS, cela donne, du client vers
le serveur :
struct {
uint16 PortNumber;
} DnssecChainExtension;
Et du serveur vers le client :
struct {
uint16 ExtSupportLifetime;
opaque AuthenticationChain<1..2^16-1>
} DnssecChainExtension;
(Le ExtSupportLifetime indique que le serveur
s'engage à continuer à gérer cette extension pendant au moins ce
temps - en heures. Si ce n'est plus le cas avant l'expiration du
délai, cela peut indiquer une usurpation par un faux serveur.)
Cette extension est donc une forme, assez spéciale, de « DNS sur
TLS ». Le client ne doit pas oublier d'envoyer un SNI (RFC 6066), pour que le serveur sache quel nom va
être authentifié et donc quels enregistrements DNS renvoyer. Quant
au serveur, s'il ne gère pas cette extension, il répond au client
avec un ServerHello n'ayant pas l'extension
dnssec_chain. Même chose si le serveur accepte
l'extension mais, pour une raison ou pour une autre, n'a pas pu
rassembler tous les enregistrements DNS.
Et pourquoi le client doit-il indiquer le port auquel il voulait se connecter ? Le serveur le connait, non ? Mais ce n'est pas forcément le cas, soit parce qu'il y a eu traduction de port quelque part sur le chemin, soit parce que le client a été redirigé, par exemple via le type d'enregistrement SVCB (RFC 9460). Le port indiqué par le client doit être le port original, avant toute traduction ou redirection.
Revenons à la « chaine », l'ensemble d'enregistrements DNS qui va
permettre la validation DANE. Le format est le format binaire
habituel du DNS, décrit dans le RFC 1035,
section 3.2.1. L'utilisation de ce format, quoiqu'il soit inhabituel
dans le monde TLS, permet, entre autres avantages, l'utilisation des
bibliothèques logicielles DNS existantes. Le RFC recommande
d'inclure dans l'ensemble d'enregistrements une chaine complète, y
compris la racine et incluant donc les clés DNSSEC de celle-ci
(enregistrements DNSKEY), même si le client les connait probablement
déjà. Cela donne par exemple la chaine suivante, pour le serveur
www.example.com écoutant sur le port 443. Notez
qu'on inclut les signatures (RRSIG) :
_443._tcp.www.example.comTLSA- RRSIG(
_443._tcp.www.example.comTLSA) example.com. DNSKEY- RRSIG(
example.comDNSKEY) example.comDS- RRSIG(
example.comDS) comDNSKEY- RRSIG(
comDNSKEY) comDS- RRSIG(
comDS) .DNSKEY- RRSIG(
.DNSKEY)
(L'exemple suppose que
_443._tcp.www.example.com et
example.com sont dans la même zone.) Voilà,
avec tous ces enregistrements, le client peut, sans faire appel à un
résolveur DNS validant, vérifier (s'il a confiance dans la clé de la
racine) l'authenticité de l'enregistrement DANE (type TLSA) et donc
le certificat du serveur. De la même façon, si on n'a pas
d'enregistrement TLSA, le serveur peut envoyer les preuves de
non-existence (enregistrements NSEC ou NSEC3). Bon, évidemment, dans
ce cas, c'est moins utile, autant ne pas gérer l'extension
dnssec_chain… Face à ce déni, le client TLS
n'aurait plus qu'à se rabattre sur une autre méthode
d'authentification.
Le serveur TLS construit la chaine des enregistrements comme il veut, mais pour l'aider, la section 3 du RFC fournit une procédure possible, à partir d'interrogations du résolveur de ce serveur. Une autre possibilité, plus simple pour le serveur, serait d'utiliser les requêtes chainées du RFC 7901 (mais qui n'ont pas l'air très souvent déployées aujourd'hui).
Comme tous les enregistrements DNS, ceux inclus dans l'extension
TLS dnssec_chain ont une durée de vie. Et les signatures DNSSEC ont
une période de validité (en général plus longue que la durée de
vie). Le serveur TLS qui construit l'ensemble d'enregistrements qu'il
va renvoyer peut donc mémoriser cet ensemble, dans la limite du
TTL et de l'expiration
des signatures DNSSEC. Le client TLS peut lui aussi mémoriser ces
informations, dans les mêmes conditions.
On a vu plus haut que les données de l'extension TLS incluaient
un ExtSupportLifetime qui indiquait combien de
temps le client pouvait s'attendre à ce que le serveur TLS continue
à gérer cette extension. Car le client peut épingler
(pinning) cette information. Cela permet de
détecter certaines attaques (« ce serveur gérait l'extension
dnssec_chain et ce n'est maintenant plus le
cas ; je soupçonne un détournement vers un serveur pirate »). Cet
engagement du serveur est analogue au HSTS de HTTPS (RFC 6797) ; dans les deux cas, le serveur s'engage à rester
« sécurisé » pendant un temps minimum (mais pas infini, car on doit
toujours pouvoir changer de politique). À noter que « gérer
l'extension dnssec_chain » n'est pas la même
chose que « avoir un enregistrement TLSA », on peut accepter
l'extension mais ne pas avoir de données à envoyer (il faudra alors
envoyer la preuve de non-existence mentionnée plus haut). Bien sûr,
le client TLS est libre de sa politique. Il peut aussi décider
d'exiger systématiquement l'acceptation de l'extension TLS
dnssec_chain (ce qui, aujourd'hui, n'est
réaliste que si on ne parle qu'à un petit nombre de serveurs).
Si un serveur gérait l'extension
dnssec_chain mais souhaite arrêter, il doit
bien calculer son coup : d'abord réduire
ExtSupportLifetime à zéro puis attendre que
la durée annoncée dans le précédent
ExtSupportLifetime soit écoulée, afin que tous
les clients aient arrêté de l'épingler comme serveur à
dnssec_chain. Il peut alors proprement stopper
l'extension (cf. section 10 du RFC).
Un petit problème se pose si on fait héberger le serveur TLS chez
un tiers. Par exemple, imaginons que le titulaire du domaine
boulanger.example ait un serveur chez la
société JVL (Je Vous Loge) et que
server.boulanger.example soit un alias
(enregistrement de type CNAME) vers
clients.jvl.example. Le client TLS va envoyer
server.boulanger.example comme SNI. Il ne sera
pas pratique du tout pour JVL de coordonner la chaine
d'enregistrements DNS et le certificat. Il est donc conseillé que
l'enregistrement TLSA du client soit lui aussi un alias vers un
enregistrement TLSA de l'hébergeur. Cela pourrait donner (sans les
signatures, pour simplifier la liste) :
server.boulanger.exampleCNAME (versclients.jvl.example)_443._tcp.server.boulanger.exampleCNAME (vers_dane443.node1.jvl.example)clients.jvl.exampleAAAA_dane443.node1.jvl.exampleTLSA
Les deux premiers enregistrements sont gérés par l'hébergé, les deux
derniers par l'hébergeur. (La section 9 du RFC explique pourquoi
l'enregistrement TLSA de l'hébergeur n'est pas en
_443._tcp…)
Comme dit plus haut, le client TLS est maitre de sa politique : il peut exiger l'extension TLS, il peut l'accepter si elle existe, il peut l'ignorer. Si l'authentification par DANE échoue mais que celle par PKIX réussit, ou le contraire, c'est au client TLS de décider, en fonction de sa politique, ce qu'il fait.
Est-ce que le serveur TLS qui gère cette extension doit envoyer la chaine complète de certificats ? S'il veut pouvoir également être identifié avec PKIX, oui. Si non, s'il se contente de DANE et plus précisément de DANE-EE ou DANE-TA (ces deux termes sont définis dans le RFC 7218), il peut envoyer uniquement le certificat du serveur (pour DANE-EE).
Question mise en œuvre, l'excellente bibliothèque ldns a (je n'ai pas testé…) tout ce qu'il faut pour générer et tester ces chaines d'enregistrements DNS. Si vous voulez développer du code pour gérer cette extension, l'annexe A du RFC contient des vecteurs de test qui vous seront probablement bien utiles.
L'article seul
RFC 9078: Reaction: Indicating Summary Reaction to a Message
Date de publication du RFC : Août 2021
Auteur(s) du RFC : D. Crocker (Brandenburg InternetWorking), R. Signes (Fastmail), N. Freed (Oracle)
Expérimental
Première rédaction de cet article le 5 août 2021
Vous trouvez que le courrier électronique, c'est vieux et ringard, et que les réseaux sociaux avec leurs possibilités de réaction (« J'aime ! », « Je partage ! », « Je rigole ! »), c'est mieux ? Et bien, vous n'êtes pas le seul ou la seule. Ce nouveau RFC normalise un mécanisme pour mettre des réactions courtes et impulsives dans le courrier électronique.
L'idée de base est que, si ce RFC plait et est mis en œuvre par les auteurs de MUA, on verra près du message qu'on lit un menu avec des émojis, et on cliquera dessus, et l'émetteur du message verra sur son propre MUA le message qu'il a envoyé accompagné de ces réactions. (Le RFC ne normalise pas une apparence particulière à ces réactions, cf. section 5.2 pour des idées qui ne sont que des suggestions.)
Bien sûr, on peut déjà répondre à un message avec des émojis dans le corps de la réponse. Mais l'idée est de structurer cette réaction pour permettre une utilisation plus proche de celle des réseaux sociaux, au lieu que la réaction soit affichée comme un message comme les autres. Liée au message originel, cette structuration permettra, par exemple, au MUA de l'émetteur originel de voir le nombre de Likes de son message… (Quant à savoir si c'est utile, c'est une autre histoire…)
Techniquement, cela fonctionnera avec la combinaison des en-têtes
Content-Disposition: et
In-Reply-To:. Voici un exemple montrant le
format d'une réaction (négative…) à un message (le
12345@example.com) :
To: author@example.com
From: recipient@example.org
Date: Today, 29 February 2021 00:00:10 -800
Message-id: 56789@example.org
In-Reply-To: 12345@example.com
Subject: Re: Meeting
Mime-Version: 1.0
Content-Type: text/plain; charset=utf-8
Content-Disposition: Reaction
👎
(Si vous n'avez pas les bons émojis sur votre système, le caractère
en question était le pouce vers le
bas.) Recevant cette réponse, le MUA de l'auteur
(author@example.com) peut rechercher le message
12345@example.com et afficher que
recipient@example.org n'est pas enthousiaste.
Le paramètre Reaction pour l'en-tête
Content-Disposition: (RFC 2183) a été ajouté
au registre IANA.
Le texte dans la partie MIME qui a l'en-tête
Content-Disposition: Reaction est une ligne
d'émojis. On
peut utiliser les séquences
d'émojis. Tous les émojis sont utilisables mais le RFC en
liste cinq qui sont particulièrement importants car considérés comme
la base, le minimum que devrait reconnaitre tout MUA :
Notez que le concept de séquence d'émojis n'est pas simple. Ce concept permet d'éviter de normaliser des quantités astronomiques d'émojis, en autorisation la combinaison d'émojis. Il est utilisé entre autres pour les drapeaux nationaux, ainsi le drapeau libanais sera 🇱🇧 (U+1F1F1 qui indique le L du code pays ISO 3166 et U+1F1E7 qui indique le B). Le RFC rappelle qu'écrire du code dans son application pour gérer ces séquences n'est pas raisonnable et qu'il vaut mieux utiliser une bibliothèque Unicode existante.
Les sections 4 et 5 du RFC donnent quelques idées aux auteurs de MUA sur la gestion de ces réactions. Normalement, l'IETF normalise des protocoles, pas des interfaces utilisateur. Mais cela n'interdit pas de parler un peu d'UX dans le RFC, comme indiqué plus haut. En outre, l'interface utilisateur vers le courrier est typiquement assez différente de celle des réseaux sociaux où ce concept de réaction existe. Ainsi, le RFC ne tranche pas sur la question de savoir s'il faut envoyer la réaction uniquement à l'auteur original du message, ou bien à tous les destinataires. Ou bien s'il faut envoyer un message contenant juste la partie Réaction ou si on peut la combiner avec un autre contenu. Et que faire si, depuis la même adresse, on reçoit plusieurs réactions, éventuellement contradictoires ? Ne garder que la dernière (attention, le courrier électronique ne conserve pas l'ordre d'envoi) ? Les additionner ?
Toujours en UX, le RFC note que la réception d'une image dépend beaucoup du récepteur. (Et, contrairement à ce que laisse entendre le RFC, ce n'est pas juste une question de « culture », des personnes de la même « culture » peuvent comprendre différemment la même image.) Il faut donc faire attention aux réactions, qui peuvent être mal comprises. (Ceci dit, c'est exactement pareil avec le texte seul.) Et, comme toujours sur l'Internet, cette possibilité pourra ouvrir de nouveaux problèmes de sécurité (utilisation pour l'hameçonnage ?).
L'article seul
RFC 9095: Extensible Provisioning Protocol (EPP) Domain Name Mapping Extension for Strict Bundling Registration
Date de publication du RFC : Juillet 2021
Auteur(s) du RFC : J. Yao, L. Zhou, H. Li (CNNIC), N. Kong (Consultant), W. Tan (Cloud Registry), J. Xie
Pour information
Première rédaction de cet article le 30 juillet 2021
Le bundling est le rassemblement de plusieurs noms de domaine dans un seul lot (bundle) qui va être traité comme un nom unique pour des opérations comme l'enregistrement du nom ou son transfert à un autre titulaire. Il est surtout pratiqué par les registres qui ont beaucoup de noms en écriture chinoise. Ce RFC décrit une extension au protocole d'avitaillement EPP pour pouvoir traiter ces lots.
Le problème n'existe pas qu'en chinois mais ce sont surtout les
sinophones qui se sont manifestés à ce sujet, en raison de la
possibilité d'écrire le même mot en écriture
traditionnelle ou en écriture
simplifiée (on parle de variantes :
l'ensemble des variantes forme le lot). Pour prendre un exemple
non-chinois, PIR avait décidé qu'un nom dans
.ngo et dans .ong devaient
être dans le même lot. Un registre qui décide que ces deux termes
sont équivalents et doivent être gérés ensemble (par exemple,
appartenir au même titulaire) les regroupent dans un lot
(bundle, ou parfois
package). C'est la politique suggérée dans les
RFC 3743 et RFC 4290, et
le RFC 6927 décrit les pratiques
existantes. Par exemple, certains registres peuvent n'autoriser
qu'une variante par lot, et bloquer les autres (empêcher leur
enregistrement), tandis que d'autres enregistreront tous les noms
ensemble. Sans compter bien sûr les registres qui n'ont pas de
système de lot du tout. Notre nouveau RFC 9095 ne prend pas
position sur ce sujet délicat, il décrit juste un moyen technique de
manipuler ces lots avec EPP (RFC 5731).
Les variantes dans un même lot n'ont pas forcément tout en commun. Un registre peut par exemple décider que l'enregistrement des variantes doit être fait par le même titulaire mais qu'un nom du lot peut ensuite être transféré à un autre titulaire. Notre RFC se limite au cas strict où les membres du lot ont presque tous leurs attributs (titulaires, contacts, date d'expiration, peut-être serveurs de noms et, pourquoi pas, clés DNSSEC) en commun.
La
lecture du RFC nécessite un peu de terminologie spécifique, décrite
dans sa section 2. Par exemple, le RDN (Registered Domain
Name) est celui qui a été demandé par le titulaire lors de
l'enregistrement, et le BDN (Bundled Domain Name)
est un nom qui a été inclus dans le lot, en fonction des règles du
registre. Par exemple, si un registre décidait que tout nom avec des
traits d'union était équivalent au même nom
sans traits d'union, et qu'un titulaire enregistre
tarte-poireaux.example (le RDN), alors
tartepoireaux.example et
tarte-poi-reaux.example seraient des BDN,
membres du même lot que le RDN. Dans le modèle de notre RFC, les
métadonnées comme la date d'expiration ou comme l'état du domaine
sont attachées au RDN, les BDN du lot partageant ces
métadonnées.
Notons aussi que le RFC n'envisage que le cas de lots assez
petits (par exemple le nom en écriture chinoise traditionnelle et
celui en écriture chinoise simplifiée). L'exemple que je donnais
avec le trait d'union ne rentre pas tellement dans le cadre de ce
RFC car le nombre de BDN est alors beaucoup plus élevé et serait
difficile à gérer. (Amusez-vous à calculer combien de variantes de
tartepoireaux.example existeraient si un
décidait que le trait d'union n'est pas significatif.)
Dans l'extension EPP décrite dans ce RFC, le RDN
est représenté (section 5 du RFC) en Unicode
(le « U-label ») ou bien en ASCII (le « A-label »,
la forme « punycodée »). L'élement XML est
<b-dn:rdn> (où b-dn
est un préfixe possible pour l'espace de noms
XML de notre RFC, urn:ietf:params:xml:ns:epp:b-dn). Si le RDN est représenté en ASCII, un attribut XML
uLabel permet d'indiquer la version Unicode du
nom. Cela donnerait, par exemple, <b-dn:rdn
uLabel="实例.example">xn--fsq270a.example</b-dn:rdn>.
Enfin, la section 6 décrit les commandes et réponses EPP pour
notre extension. La commande <check>
n'est pas modifiée dans sa syntaxe mais le RFC impose que, si un nom
qui fait partie d'un lot est envoyé dans la question, la réponse
doit contenir le RDN et le BDN. Pour un RDN en
sinogrammes, on aurait ainsi la version en
écriture traditionnelle et en écriture simplifiée (ici, le nom est
disponible à l'enregistrement) :
<response>
<result code="1000">
<msg>Command completed successfully</msg>
</result>
<resData>
<domain:chkData
xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
<domain:cd>
<domain:name avail="1">
xn--fsq270a.example</domain:name>
</domain:cd>
<domain:cd>
<domain:name avail="1">
xn--fsqz41a.example
</domain:name>
<domain:reason>This associated domain name is
a produced name based on bundle name policy.
</domain:reason>
</domain:cd>
</domain:chkData>
...
La commande <info> n'est pas non plus
modifiée mais sa réponse l'est, par l'ajout d'un élément
<bundle> qui décrit le lot :
<response>
<result code="1000">
<msg>Command completed successfully</msg>
</result>
<resData>
<domain:infData
xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
<domain:name>xn--fsq270a.example</domain:name>
<domain:roid>58812678-domain</domain:roid>
<domain:status s="ok"/>
...
</domain:infData>
</resData>
<extension>
<b-dn:infData
xmlns:b-dn="urn:ietf:params:xml:ns:epp:b-dn">
<b-dn:bundle>
<b-dn:rdn uLabel="实例.example">
xn--fsq270a.example
</b-dn:rdn>
<b-dn:bdn uLabel="實例.example">
xn--fsqz41a.example
</b-dn:bdn>
</b-dn:bundle>
</b-dn:infData>
</extension>
Quand on crée un domaine qui fait partie d'un lot, la commande
<create> doit inclure une extension
indiquant que le client EPP connait la gestion de lots, et la
réponse à <create> lui donnera le
BDN. D'une manière analogue, la commande
<delete> détruira tout le lot et
l'indiquera dans la réponse. La commande
<update> fonctionne sur le même
principe : elle modifie le RDN et indique dans sa réponse le BDN
affecté. La syntaxe complète de cette extension EPP figure dans la
section 7 du RFC, sous forme d'un schéma
W3C. Par ailleurs, cette extension est enregistrée dans
le
registre des extensions EPP (celui créé par le RFC 7451).
Un petit mot sur la sécurité, car de nombreux adversaires de l'internationalisation, notamment anglophones, ont critiqué les noms de domaine en Unicode, les accusant de tous les maux : les auteurs du RFC notent que des noms en chinois sont enregistrés depuis plus de quinze ans, et qu'aucun problème particulier n'a été signalé.
Questions mises en œuvre de ce RFC, les registres chinois (comme
.cn ou
.tw) suivent les
principes de ce RFC (l'enregistrement d'un lot) depuis
longtemps. CNNIC déploie cette extension
EPP. En dehors de la sinophonie, PIR utilise
les lots pour .ngo et
.ong. Et cette extension EPP est mise en œuvre
dans Net::DRI.
Et, comme souvent, il y a un brevet de Verisign sur la technique décrite dans ce RFC. Je ne l'ai pas lu mais il y a des chances qu'il soit sans mérite, comme beaucoup de brevets logiciels.
L'article seul
RFC 9077: NSEC and NSEC3: TTLs and Aggressive Use
Date de publication du RFC : Juillet 2021
Auteur(s) du RFC : P. van Dijk (PowerDNS)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 25 juillet 2021
Ce nouveau RFC corrige une légère bavure. Lorsqu'on utilise la mémorisation énergique du RFC 8198 pour synthétiser des réponses DNS en utilisant les informations DNSSEC, les normes existantes permettaient une mémorisation pendant une durée bien trop longue. Cette erreur (peu grave en pratique) est désormais corrigée.
Rappelons que le principe du RFC 8198 est
d'autoriser un résolveur DNS à synthétiser
des informations qu'il n'a normalement pas dans sa mémoire,
notamment à partir des enregistrements NSEC de
DNSSEC (RFC 4034,
section 4). Si un résolveur interroge la racine du DNS :
% dig @a.root-servers.net A foobar
...
;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 37332
...
foo. 86400 IN NSEC food. NS DS RRSIG NSEC
La réponse est négative (NXDOMAIN)
et un enregistrement NSEC annonce au client DNS
qu'il n'y a pas de nom dans la racine entre
.foo et .food. Si le
résolveur mémorise cette information et qu'on lui demande par la
suite un nom en .foocat, il n'aura pas besoin
de contacter la racine, il sait, en raison de l'enregistrement NSEC
que ce nom ne peut pas exister.
Bon, mais combien de temps le résolveur peut-il mémoriser cette
non-existence ? Le RFC 2308 disait qu'une
réponse négative (NXDOMAIN) pouvait être
mémorisée pendant une durée indiquée par le
minimum du champ Minimum
de l'enregistrement SOA et du TTL de ce même enregistrement
SOA. Mais le RFC 4034, normalisant DNSSEC,
disait que l'enregistrement NSEC devait avoir un TTL égal au champ
Minimum du SOA. Dans l'exemple de la racine du
DNS, à l'heure actuelle, cela ne change rien, ces durées sont toutes
égales. Mais elles pourraient être différentes. Si un enregistrement
SOA a un Minimum à une journée mais un TTL
d'une heure, le RFC 2308 impose une heure de
mémorisation au maximum, le RFC 4034
permettait une journée… Ça pourrait même être exploité pour une
attaque en faisant des requêtes qui retournent des enregistrements
NSEC, afin de nier l'existence d'un nom pendant plus longtemps que
prévu. [Bon, dans le monde réel, je trouve que
c'est un problème assez marginal mais ce n'est pas une raison pour ne
pas le corriger.]
Le RFC 8198 avait déjà tenté de corriger le
problème mais sans y réussir. Notre nouveau RFC impose désormais
clairement que, contrairement à ce que dit le RFC 4034 (et deux ou trois autres RFC sur DNSSEC), la durée
maximale de mémorisation est bien le minimum du
champ Minimum de l'enregistrement
SOA et du TTL
de ce même enregistrement SOA.
Si les logiciels que vous utilisez pour signer les zones ne
peuvent pas être corrigées immédiatement, le RFC demande que vous
changiez le contenu de la zone pour mettre la même valeur au champ
Minimum de l'enregistrement
SOA et au TTL
de ce même enregistrement SOA.
En pratique, les signeurs suivants ont déjà été corrigés :
- PowerDNS (par l'auteur du RFC) dans la version 4.3.0 (voir cette note dans la documentation).
- BIND dans la version 9.16 (voyez la correction, qui est très courte).
- Knot DNS dans la 3.1 (apparemment pas encore publiée, mais la correction a déjà été incluse).
- ldns dans une correction pas encore intégrée ?
- Pour les autres logiciels, une liste est en ligne.
L'article seul
RFC 9076: DNS Privacy Considerations
Date de publication du RFC : Juillet 2021
Auteur(s) du RFC : T. Wicinski
Pour information
Réalisé dans le cadre du groupe de travail IETF dprive
Première rédaction de cet article le 24 juillet 2021
La surveillance généralisée sur l'Internet est un gros problème pour la vie privée. L'IETF s'active donc à améliorer la protection de la vie privée contre cette surveillance (RFC 7258). Un protocole qui avait souvent été négligé dans ce travail est le DNS. Ce RFC décrit les problèmes de vie privée liés au DNS. Il remplace le RFC 7626, avec deux changements important, l'intégration des techniques de protection développées et déployées depuis l'ancien RFC et, malheureusement, beaucoup de propagande anti-chiffrement imposée par les acteurs traditionnels des résolveurs DNS qui ne veulent pas se priver de leurs possibilités de contrôle et de surveillance.
Ce RFC est en fait à la croisée de deux activités. L'une d'elles consiste à documenter les problèmes de vie privée, souvent ignorés jusqu'à présent dans les RFC. Cette activité est symbolisée par le RFC 6973, dont la section 8 contient une excellente analyse de ces problèmes, pour un service particulier (la présence en ligne). L'idée est que, même si on ne peut pas résoudre complètement le problème, on peut au moins le documenter, pour que les utilisateurs soient conscients des risques. Et la seconde activité qui a donné naissance à ce RFC est le projet d'améliorer effectivement la protection de la vie privée des utilisateurs du DNS, en marchant sur deux jambes : minimiser les données envoyées et les rendre plus résistantes à l'écoute, via le chiffrement. L'objectif de diminution des données a débouché sur la QNAME minimization spécifiée dans le RFC 9156 et le chiffrement a donné DoT (RFC 7858) et DoH (RFC 8484).
Donc, pourquoi un RFC sur les questions de vie privée dans le
DNS ? Ce dernier est un très ancien protocole, dont l'une des
particularités est d'être mal spécifié : aux deux RFC originaux, les
RFC 1034 et RFC 1035, il
faut ajouter dix ou vingt autres RFC dont la lecture est nécessaire
pour tout comprendre du DNS. Et aucun travail de consolidation n'a
jamais été fait, contrairement à ce qui a eu lieu pour XMPP,
HTTP ou
SMTP. Or, le DNS est crucial, car quasiment
toutes les transactions Internet mettent en jeu au moins une requête
DNS (ne me dites pas des bêtises du genre « moi, je télécharge avec
BitTorrent, je
n'utilise pas le DNS » : comment allez-vous sur
thepiratebay.am ?) Mais, alors que les
questions de vie privée liées à HTTP ont fait l'objet d'innombrables articles
et études, celles liées au DNS ont été largement ignorées pendant
longtemps (voir la bibliographie du RFC pour un état de
l'art). Pourtant, on peut découvrir bien des choses sur votre
activité Internet uniquement en regardant le trafic DNS.
Une des raisons du manque d'intérêt pour le thème « DNS et vie privée » est le peu de compétences concernant le DNS : le protocole est souvent ignoré ou mal compris. C'est pourquoi le RFC doit commencer par un rappel (section 1) du fonctionnement du DNS.
Je ne vais pas reprendre tout le RFC ici. Juste quelques rappels
des points essentiels du DNS : il existe deux sortes de serveurs
DNS, qui n'ont pratiquement aucun rapport. Il y a les
serveurs
faisant autorité et les résolveurs. Les premiers
sont ceux qui connaissent de première main l'information pour une
zone DNS donnée (comme fr ou
wikipedia.org). Ils sont gérés par le titulaire
de la zone ou bien sous-traités à un hébergeur DNS. Les seconds, les
résolveurs, ne connaissent rien (à part l'adresse IP des serveurs de la racine). Ils
interrogent donc les serveurs faisant autorité, en partant de la
racine. Les résolveurs sont gérés par le FAI ou le service
informatique qui s'occupe du réseau local de l'organisation. Ils
peuvent aussi être individuels, ou bien au
contraire être de gros serveurs publics comme Google Public DNS, gros fournisseur de la
NSA. Pour
prendre un exemple concret (et en simplifiant un peu), si M. Michu
veut visiter le site Web
http://thepiratebay.am/, son navigateur va
utiliser les services du système d'exploitation sous-jacent pour
demander l'adresse IP de
thepiratebay.am. Le système d'exploitation va
envoyer une requête DNS au résolveur (sur
Unix, les adresses IP des résolveurs sont
dans /etc/resolv.conf). Celui-ci va demander
aux serveurs de la racine s'ils connaissent
thepiratebay.am, il se fera rediriger vers les
serveurs faisant autorité pour am, puis vers ceux faisant
autorité pour thepiratebay.am. Le résolveur
aura alors une réponse qu'il pourra transmettre au navigateur de
M. Michu.
Principal point où j'ai simplifié : le DNS s'appuie beaucoup sur
la mise en cache des données, c'est-à-dire sur
leur mémorisation pour gagner du temps la fois suivante. Ainsi, si
le même M. Michu, cinq minutes après, veut aller en
http://armenpress.am/, son résolveur ne
demandera rien aux serveurs de la racine : il sait déjà quels sont
les serveurs faisant autorité pour am.
Le trafic DNS est un trafic IP ordinaire, typiquement porté par UDP. Mais il peut aussi fonctionner sur TCP et bientôt sur QUIC. Il peut être écouté, et comme il n'est pas toujours chiffré, un indiscret peut tout suivre. Voici un exemple pris avec tcpdump sur un serveur racine (pas la racine officielle, mais, techniquement, cela ne change rien) :
15:29:24.409283 IP6 2001:67c:1348:8002::7:107.10127 > \
2001:4b98:dc2:45:216:3eff:fe4b:8c5b.53: 32715+ [1au] \
AAAA? www.armenpress.am. (46)
On y voit que le client
2001:67c:1348:8002::7:107 a demandé l'adresse
IPv6 de
www.armenpress.am.
Pour compléter le tableau, on peut aussi noter que les logiciels
génèrent un grand nombre de requêtes DNS, bien supérieur à ce que
voit l'utilisateur. Ainsi, lors de la visite d'une page Web, le
résolveur va envoyer la requête primaire (le
nom du site visité, comme thepiratebay.am), des
requêtes secondaires dues aux objets contenus
dans la page Web (JavaScript, CSS, divers
traqueurs et autres outils de cyberflicage ou de cyberpub) et même
des requêtes tertiaires, lorsque le
fonctionnement du DNS lui-même nécessitera des requêtes. Par
exemple, si abc.xyz est hébergé sur des
serveurs dans google.com, une visite de
http://abc.xyz/ nécessitera de résoudre les
noms comme ns1.google.com, donc de faire des
requêtes DNS vers les serveurs de
google.com.
Bien sûr, pour un espion qui veut analyser tout cela, le trafic DNS représente beaucoup de données, souvent incomplètes en raison de la mise en cache, et dont l'interprétation peut être difficile (comme dans l'exemple ci-dessus). Mais les organisations qui pratiquent l'espionnage massif, comme la NSA, s'y connaissent en matière de big data et savent trouver les aiguilles dans les bottes de foin.
Les sections 3 à 7 du RFC détaille les risques pour la vie privée
dans les différents composants du DNS. Notez que la confidentialité
du contenu du DNS n'est pas prise en compte (elle l'est dans les
RFC 5936 et RFC 5155). Il est important de noter qu'il y a une énorme
différence entre la confidentialité du contenu
et la confidentialité des requêtes. L'adresse
IP de www.charliehebdo.fr
n'est pas un secret : les données DNS sont publiques, dès qu'on
connait le nom de domaine, et tout le monde peut faire une requête
DNS pour la connaitre. Mais le fait que vous fassiez une requête
pour ce nom ne devrait pas être public. Vous n'avez pas forcément
envie que tout le monde le sache. (On peut quand même nuancer un peu
le côté « public » des données DNS : on peut avoir des noms de
domaine purement internes à une organisation. Mais ces noms
« fuitent » souvent, par la marche sur la zone décrite dans le RFC 4470, ou via des systèmes de « passive DNS).
Pour comprendre les risques, il faut aussi revenir un peu au protocole DNS. Les deux informations les plus sensibles dans une requête DNS sont l'adresse IP source et le nom de domaine demandé (qname, pour Query Name, cf. RFC 1034, section 3.7.1). L'adresse IP source est celle de votre machine, lorsque vous parlez au résolveur, et celle du résolveur lorsqu'il parle aux serveurs faisant autorité. Elle peut indiquer d'où vient la demande. Lorsque on utilise un gros résolveur, celui-ci vous masque vis-à-vis des serveurs faisant autorité (par contre, ce gros résolveur va avoir davantage d'informations). Ceci dit, l'utilisation d'ECS (RFC 7871) peut trahir votre adresse IP, ou au moins votre préfixe. (Cf. cette analyse d'ECS. D'autre part, certains opérateurs se permettent d'insérer des informations comme l'adresse MAC dans des options EDNS de la requête.)
Quant au qname, il peut être très révélateur :
il indique les sites Web que vous visitez, voire, dans certains cas,
les logiciels utilisés. Au moins un client
BitTorrent fait des requêtes DNS pour
_bittorrent-tracker._tcp.domain.example,
indiquant ainsi à beaucoup de monde que vous utilisez un protocole
qui ne plait pas aux ayant-droits. Et si vous utilisez le RFC 4255, pas mal de serveurs verront à quelles
machines vous vous connectez en SSH...
Donc où un méchant qui veut écouter votre trafic DNS peut-il se placer ? D'abord, évidemment, il suffit qu'il écoute le trafic réseau. On l'a dit, le trafic DNS aujourd'hui est souvent en clair donc tout sniffer peut le décoder. Même si vous utilisez HTTPS pour vous connecter à un site Web, le trafic DNS, lui, ne sera pas chiffré. (Les experts pointus de TLS noteront qu'il existe d'autres faiblesses de confidentialité, comme le SNI du RFC 6066, qui n'est pas encore protégé, cf. RFC 8744.) À noter une particularité du DNS : le trafic DNS peut passer par un autre endroit que le trafic applicatif. Alice peut naïvement croire que, lorsqu'elle se connecte au serveur de Bob, seul un attaquant situé physiquement entre sa machine et celle de Bob représente une menace. Alors que son trafic DNS peut être propagé très loin, et accessible à d'autres acteurs. Si vous utilisez, par exemple, le résolveur DNS public de FDN, toute la portion de l'Internet entre vous et FDN peut facilement lire votre trafic DNS.
Donc, l'éventuel espion peut être près du câble, à écouter. Mais il peut être aussi dans les serveurs. Bercé par la musique du cloud, on oublie souvent cet aspect de la sécurité : les serveurs DNS voient passer le trafic et peuvent le copier. Pour reprendre les termes du RFC 6973, ces serveurs sont des assistants : ils ne sont pas directement entre Alice et Bob mais ils peuvent néanmoins apprendre des choses à propos de leur conversation. Et l'observation est très instructive. Elle est utilisée à de justes fins dans des systèmes comme DNSDB (section 6 du RFC) mais il n'est pas difficile d'imaginer des usages moins sympathiques comme dans le cas du programme NSA MORECOWBELL.
Les résolveurs voient tout le trafic puisqu'il y a peu de mise en cache en amont de ces serveurs. Il faut donc réfléchir à deux fois avant de choisir d'utiliser tel ou tel résolveur ! Il est déplorable qu'à chaque problème DNS (ou supposé tel), des ignorants bondissent sur les réseaux sociaux pour dire « zyva, mets 8.8.8.8 [Google Public DNS] comme serveur DNS et ça ira plus vite » sans penser à toutes les données qu'ils envoient à la NSA ainsi.
Les serveurs faisant autorité voient passer moins de trafic (à cause des caches des résolveurs) mais, contrairement aux résolveurs, ils n'ont pas été choisis délibérement par l'utilisateur. Celui-ci peut ne pas être conscient que ses requêtes DNS seront envoyées à plusieurs acteurs du monde du DNS, à commencer par la racine. Le problème est d'autant plus sérieux que, comme le montre une étude, la concentration dans l'hébergement DNS est élevée : dix gros hébergeurs hébergent le tiers des domaines des 100 000 sites Web les plus fréquentés (listés par Alexa).
Au passage, le lecteur attentif aura noté qu'un résolveur personnel (sur sa machine ou dans son réseau local) a l'avantage de ne pas envoyer vos requêtes à un résolveur peut-être indiscret mais l'inconvénient de vous démasquer vis-à-vis des serveurs faisant autorité, puisque ceux-ci voient alors votre adresse IP. Une bonne solution (qui serait également la plus économe des ressources de l'Internet) serait d'avoir son résolveur local et de faire suivre les requêtes non résolues au résolveur du FAI. Du point de vue de la vie privée, ce serait sans doute la meilleure solution mais cela ne résout hélas pas un autre problème, celui des DNS menteurs, contre lesquels la seule protection est d'utiliser uniquement un résolveur de confiance. On peut résoudre ce problème en ayant son propre résolveur mais qui fait suivre à un résolveur public de confiance. Notez que la taille compte : plus un résolveur est petit, moins il protège puisque ses requêtes sortantes ne seront dues qu'à un petit nombre d'utilisateurs.
Enfin, il y a aussi les serveurs DNS « pirates » (installés, par
exemple, via un serveur DHCP lui-même pirate) qui détournent le trafic
DNS, par exemple à des fins de surveillance. Voir par exemple
l'exposé de Karrenberg à JCSA
2012 disponible
en ligne (transparents 27 et 28, Unknown
et Other qui montrent l'existence de clones
pirates du serveur racine
K.root-servers.net).
Pour mes lecteurs en France férus de droit, une question intéressante : le trafic DNS est-il une « donnée personnelle » au sens de la loi Informatique & Libertés ? Je vous laisse plancher sur la question, qui a été peu étudiée.
Les changements depuis le RFC 7626 sont résumés dans l'annexe A. Outre des retours d'expérience basés sur le déploiement de solutions minimisant et/ou chiffrant les données, ils consistent essentiellement en remarques négatives sur le chiffrement, défendant le mécanisme traditionnel de résolution DNS. Il n'y avait d'ailleurs pas forcément d'urgence à sortir un nouveau RFC. Comme le demandait Alissa Cooper, l'auteure du RFC 6973, « Why not wait to see how QUIC, DOH, ADD, ODNS, etc. shake out in the next few years and take this up then? ». C'est en raison de ces changements négatifs que je ne suis pas cité comme auteur du RFC (contraitement à son prédécesseur). Sara Dickinson, qui avait géré l'essentiel du travail pour les débuts de ce nouveau RFC, s'est également retirée, en raison de la dureté des polémiques qui ont déchiré l'IETF sur ce document.
Depuis la sortie du RFC 7626, il y a eu un certain nombre de déploiement de techniques améliorant la protection de la vie privée dans le cas du DNS, notamment la minimisation des données (RFC 9156) et le chiffrement (DoT, RFC 7858, DoH, RFC 8484, et le futur DoQ). Cela permet des retours d'expérience. Par exemple, sur l'ampleur du déploiement de la minimisation, ou sur les performances du chiffrement (voir « An End-to-End, Large-Scale Measurement of DNS-over-Encryption »). Il y a eu également des discussions politiques à propos de ces techniques et de leur déploiement, souvent malhonnêtes ou confuses (et ce RFC en contient plusieurs) comme l'accusation de « centralisation », qui sert surtout à protéger l'état actuel, où l'opérateur de votre réseau d'accès à l'Internet peut à la fois vous surveiller et contrôler ce que vous voyez, via sa gestion de la résolution DNS. Mais il est vrai que rien n'est simple en matière de sécurité et que DoH (mais pas DoT) est trop bavard, puisqu'il hérite des défauts de HTTP, en envoyant trop d'informations au serveur.
Le RFC essaie de décourager les utilisateurs d'utiliser le chiffrement (dans l'esprit du RFC 8404) en notant que ce n'est pas une technologie parfaite (par exemple, l'observation des métadonnées peut donner des indications ou, autre exemple, une mauvaise authentification du résolveur peut vous faire envoyer vos requêtes à un méchant). C'est vrai mais c'est le cas de toutes les solutions de sécurité et on ne trouve pas de tels avertissements dans d'autres RFC qui parlent de chiffrement. L'insistance des opérateurs pour placer ces messages anti-chiffrement dans ce RFC montre bien, justement, l'importance de se protéger contre la curiosité des opérateurs.
Le RFC remarque également qu'il n'existe pas actuellement de moyen de découvrir automatiquement le résolveur DoT ou DoH. Mais c'est normal : un résolveur DoT ou DoH annoncé par le réseau d'accès, par exemple via DHCP, n'aurait guère d'intérêt, il aurait les mêmes défauts (et les mêmes qualités) que le résolveur traditionnel. DoT et DoH n'ont de sens qu'avec un résolveur configuré statiquement. Le RFC cite des déploiements de résolveurs DNS avec chiffrement faits par plusieurs FAI (aucun en France, notons-le). Cela montre une grosse incompréhension du problème : on ne chiffre pas pour le plaisir de chiffrer, mais parce que cela permet d'aller de manière sécurisée vers un autre résolveur. Chiffrer la communication avec le résolveur habituel ne fait pas de mal mais on ne gagne pas grand'chose puisque ce résolveur a les mêmes capacités de surveillance et de modification des réponses qu'avant. Notons que le RFC, inspiré par la propagande des telcos, raconte que le risque de surveillance est minimisé par le chiffrement du lien radio dans les réseaux 4G et après. Cela oublie le fait que la surveillance peut justement venir de l'opérateur.
Plus compliqué est le problème de l'endroit où se fait cette configuration. Traditionnellement, la configuration du résolveur à utiliser était faite globalement par le système d'exploitation. Ce n'est pas du tout une règle du protocole DNS (les RFC normalisant le DNS ne contrôlent que ce qui circule sur le câble, pas les choix locaux de chaque machine) et il serait donc absurde d'invoquer un soi-disant principe comme quoi le DNS serait forcément géré au niveau du système. Certains déploiements de DoH (celui de Firefox, par exemple), mettent le réglage dans l'application (en l'occurrence le navigateur Web). La question est discutable et discutée mais, de toute façon, elle ne relève pas de l'IETF (qui normalise ce qui passe sur le réseau) et il est anormal que le RFC en parle.
Le temps passé depuis le RFC 7626 a également permis la mise en service d'un plus grand nombre de résolveurs publics, comme Quad9 ou comme celui de Cloudflare. Mais il n'y a pas que les grosses boîtes états-uniennes qui gèrent des résolveurs DNS publics. Ainsi, je gère moi-même un modeste résolveur public. Le très intéressant RFC 8932 explique le rôle des politiques de vie privée dans ces résolveurs publics et comment en écrire une bonne. Bien sûr, comme toujours en sécurité, la lutte de l'épée contre la cuirasse est éternelle et des nouvelles actions contre la vie privée et la liberté de choix apparaissent, par exemple des réseaux qui bloquent l'accès à DoT (en bloquant son port 853) ou aux résolveurs DoH connus (DoH a été développé en partie pour être justement plus difficile à bloquer).
L'article seul
RFC 9075: Report from the IAB COVID-19 Network Impacts Workshop 2020
Date de publication du RFC : Juillet 2021
Auteur(s) du RFC : J. Arkko (Ericsson), S. Farrell (Trinity College Dublin), M. Kühlewind (Ericsson), C. Perkins (University of Glasgow)
Pour information
Première rédaction de cet article le 23 juillet 2021
La pandémie de Covid-19 en 2020 a affecté de nombreux aspects de notre vie. Concernant plus spécifiquement l'Internet, elle a accru l'utilisation d'outils de communication informatiques. Quels ont été les effets de ces changements sur l'Internet ? Un atelier de l'IAB fait le point sur ces effets et en tire des leçons. Je vous le dis tout de suite : contrairement à certains discours sensationnalistes, l'Internet n'a pas subi de conséquences sérieuses.
De janvier à mars 2020, de nombreux pays ont imposé un confinement plus ou moins strict. Des activités comme le travail ou l'éducation devaient se faire à distance, en utilisant les outils numériques. Certains politiciens ont tenu des discours dramatisants, prétendant que, si on ne renonçait pas à regarder ses vidéos favorites, l'Internet allait s'écrouler. Même si aucun professionnel des réseaux n'a repris ce discours, cela ne veut pas dire qu'il ne s'est rien passé. L'IAB a donc organisé en novembre 2020 un atelier (évidemment tenu en ligne car il n'y avait pas le choix) pour étudier les effets de ces confinements sur l'Internet, comprendre ce qui est arrivé et peut-être formuler des recommandations.
Donc, pendant le confinement et l'augmentation du télétravail qui en a résulté, le trafic Internet a changé. Il n'a pas toujours augmenté (les travailleurs utilisaient également Internet quand ils étaient au bureau, et les gens regardaient déjà Netflix avant la pandémie) mais il s'est déplacé : trafic de type différent, à des heures différentes, etc. Et, dans la plupart des pays, c'est arrivé assez soudainement, laissant peu de temps pour l'adaptation. La sécurité a été également très affectée, les mesures de sécurité conçues sur la base d'un lieu physique n'ayant plus de sens. Tout à coup, il a fallu autoriser beaucoup d'accès distants, avec tous les risques que cela impliquait. L'atelier lui-même a été différent des précédents ateliers de l'IAB, qui étaient fondés sur une participation physique pendant deux jours continus. Cette fois, l'atelier s'est fait en trois sessions à distance, avec respiration et réflexion entre les sessions.
Qu'ont observé les acteurs de l'Internet ? À l'atelier, certains
FAI ou
gérants de points d'échange Internet ont
signalé des accroissements de 20 % du trafic. C'est à la fois
beaucoup et peu. C'est beaucoup car c'est survenu soudainement, sans
être étalé sur une période permettant le déploiement de nouvelles
ressources, et c'est peu, car la croissance de l'utilisation des
réseaux est un phénomène permanent : il faut toujours augmenter la
capacité (20 % représente une
augmentation annuelle typique, mais qui fut concentrée en quelques
semaines). On voit ici le trafic sur le point d'échange
Internet de Francfort (la source
est ici). S'il y a bien une brusque montée début 2020 avec le
démarrage du confinement, il faut noter qu'elle s'inscrit dans une
augmentation du trafic Internet sur le long terme :
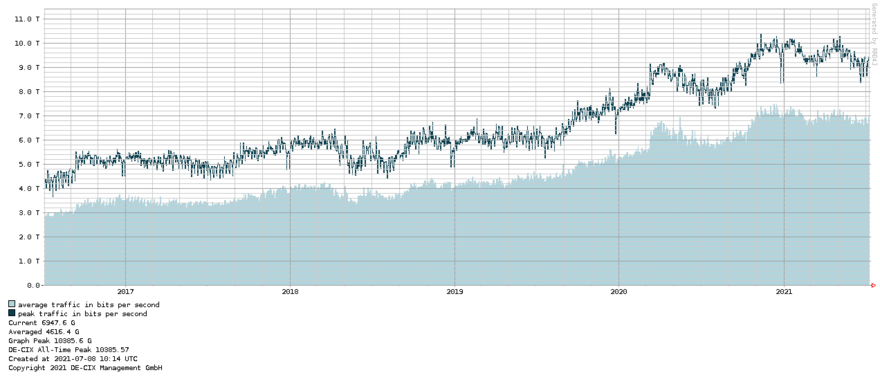
Cette montée du trafic lors du confinement est également
relativisée sur les statistiques de trafic au point
d'échange parisien (la source est ici) :
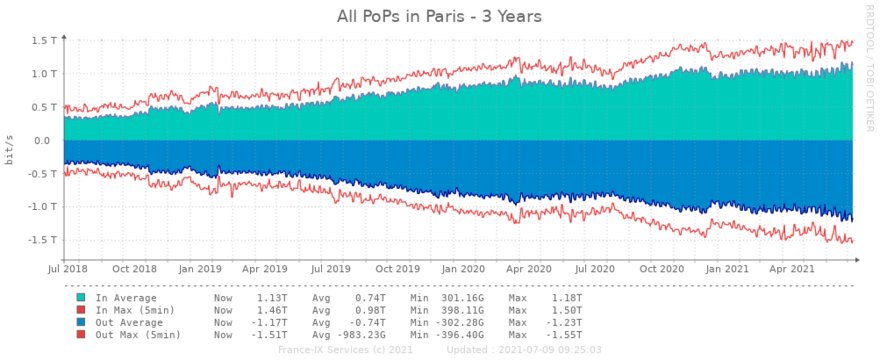
De même, l'article « Measurement of congestion on ISP interconnection links » mesure des moments de congestion limités aux États-Unis en mars. Cette croissance était très inégalement répartie selon les services. Vous ne serez pas surpris d'apprendre que certains opérateurs de services de vidéo-conférence ont vu leur activité tripler, voire décupler. Une intéressante conclusion est que, contrairement à ce que certains discours sensationnalistes comme ceux de Thierry Breton prétendaient, l'Internet n'a pas connu de problème généralisé. Comme toujours dans ce réseau mondial, les problèmes sont restés localisés, ralentissements à certains endroits, baisse automatique de la qualité des vidéos à d'autres, mais pas de problème systémique. Ce bon résultat n'a pas été obtenu uniquement par la capacité du réseau existant à encaisser la montée en charge. Il y a eu également de nombreuses actions prises par les différents acteurs du réseau, qui ne sont pas restés les bras croisés face au risque. Bref, vu du point de vue scientifique, c'était une expérience intéressante, qui montre que l'Internet peut résister à des crises, ce qui permet de penser que les problèmes futurs ne seront pas forcément fatals.
[L'atelier portait bien sur l'Internet, sur l'infrastructure, pas sur les services hébergés. Il est important de faire la distinction car certains services (comme ceux de l'Éducation Nationale en France) ont été incapables de résister à la charge et se sont vite écroulés. Mais ce n'était pas une défaillance de l'Internet, et renoncer à regarder des vidéos n'aurait pas protégé le CNED contre ces problèmes. Notons qu'il n'y avait pas de fatalité à ces problèmes des services : Wikipédia et Pornhub, deux services très différents dans leur utilisation et leur gestion, ont continué à fonctionner correctement.]
Voyons maintenant les détails, dans la section 3 du RFC. On commence avec la sous-section 3.1, les mesures. Que s'est-il passé ? Comme on pouvait s'y attendre, le trafic résidentiel a augmenté (en raison du travail à la maison), tandis que celui des réseaux mobiles chutait (on se déplaçait moins). Le trafic vers les opérateurs de services de vidéo-conférence (comme Zoom) a augmenté, ainsi que celui des services de distraction (VoD) pendant la journée. Mais il y a eu surtout un gros déplacement des pics d'activité. En semaine, l'activité Internet était très liée au rythme de la journée, avec des trafics très différents dans la journée et le soir. Pendant les confinements, on a vu au contraire une activité plus étalée dans le temps chez les FAI résidentiels, et une activité de la semaine qui ressemble à celle des week-ends. Là encore, pas de conséquences graves, bien que certains FAI aient signalé des ralentissements notamment en mars 2020. Bref, l'Internet sait bien résister aux sautes de trafic qui, il est vrai, font partie de son quotidien depuis sa création.
Parmi les articles soumis pour l'atelier, je vous recommande, sur
la question des mesures, le très détaillé « A
view of Internet Traffic Shifts at ISP and IXPs during the COVID-19
Pandemic ». Les auteurs ont observé le trafic chez
plusieurs opérateurs et points d'échange (le
seul nommé est le réseau académique de
Madrid). Par exemple, en utilisant diverses
heuristiques (le port seul ne suffit plus,
tout le monde étant sur 443),
les auteurs ont des chiffres concernant diverses applications
(vidéo-conférence, vidéo à la demande, jeux en ligne, etc). Moins
détaillé, il y a le « IAB
COVID-19 Workshop: Interconnection Changes in the United
States » (à l'origine publié dans un
Internet-Draft,
draft-feamster-livingood-iab-covid19-workshop).
Un exemple de changement du trafic est donné par le Politecnico de Turin qui a vu son trafic sortant multiplié par 2,5, en raison de la diffusion de ses 600 cours en ligne par jour, alors que le trafic entrant était divisé par 10. Dans les universités, le trafic entrant est typiquement bien plus gros que le sortant (les étudiants et enseignants sont sur le campus et accèdent à des ressources distantes) mais cela a changé pendant le confinement, les ressources externes étant accédées depuis la maison. (Une entreprise aurait pu voir des effets différents, si les employés accèdent à ces ressources externes via le VPN de l'entreprise.) Le REN REDIMadrid a vu également de gros changements dans son trafic. Effet imprévu, les communications avec les AS d'Amérique latine a augmenté, probablement parce que les étudiants hispanophones américains profitaient des possibilités de cours à distance pour suivre les activités des universités de l'ex-métropole.
Comme dit plus haut, les réseaux mobiles, 4G et autres, ont vu leur activité baisser. L'article « A Characterization of the COVID-19 Pandemic Impact on a Mobile Network Operator Traffic » note une mobilité divisée par deux en Grande-Bretagne et un trafic diminué d'un quart. (Certaines personnes ne sont plus mobiles mais utilisent la 4G à la maison, et il y a bien d'autres phénomènes qui rendent compliquée l'analyse.) L'observation des signaux envoyés par les téléphones (le réseau mobile sait où vous êtes…) a également permis de mesurer l'ampleur de la fuite hors des grandes villes (10 % des Londoniens).
Et dans la connexion des FAI avec les services sur le cloud ? Les liens d'interconnexion entre FAI et fournisseurs de services ont-ils tenu ? Pas de congestion persistante mais des moments de tension, par exemple aux États-Unis vers les petits FAI, qui n'avaient pas toujours une interconnexion suffisante pour encaisser tout le trafic accru. Comme toujours sur l'Internet, malgré le caractère mondial de la pandémie, il y a peu d'observations valables partout et tout le temps, vu la variété des capacités des liaisons. Malgré l'observation générale « globalement, ça a tenu », il y a toujours des endroits où ça rame à certains moments.
En effet, le bon fonctionnement de l'Internet mondial ne signifiait pas que tous les MM. Toutlemonde de la Terre avaient une bonne qualité de connexion. L'article « The Impact of COVID-19 on Last-mile Latency » (plus de détails sur le blog de l'auteur) rend compte de mesures faites avec les sondes RIPE Atlas, qui trouvent une congestion plus fréquente sur le « premier kilomètre » (le lien entre la maison de M. Toutlemonde et le premier POP de son FAI) pendant le confinement. Cela dépend évidemment beaucoup du FAI et du pays, le Japon ayant été particulièrement touché. La situation s'est toutefois améliorée au fur et à mesure, notamment en raison des déploiements de capacité supplémentaire par les opérateurs (et, au Japon, des investissements qui étaient prévus pour les Jeux Olympiques). L'Internet se retrouve donc plus robuste qu'avant. Le RFC cite même Nietzsche « Ce qui ne me tue pas me rend plus fort ».
On l'a dit, le trafic n'a pas seulement changé quantitativement mais aussi qualitativement. La vidéo-conférence a, fort logiquement, crû. Le trafic très asymétrique de certains FAI grand public (beaucoup plus de trafic entrant vers les consommateurs que de trafic sortant) s'est un peu égalisé, en raison des flux vidéos sortants. NCTA et Comcast signalent plus de 30 % de hausse de ce trafic sortant, Vodafone 100 %. Un rapport d'Ericsson sur les utilisateurs signale :
- Une augmentation de l'utilisation de l'Internet par 9 utilisateurs sur 10 (le dixième était peut-être déjà connecté tout le temps ?) et des usages nouveaux par 1 utilisateur sur 5 (des gens comme moi qui se mettent à la vidéo-conférence alors qu'ils détestaient cela avant).
- Peu de plaintes concernant les performances.
- Évidemment un changement dans les applications utilisées, les applications de vidéo-conférence voient leur usage s'accroitre, celles liées à la location d'hôtels ou de restaurants (ou, note le RFC, celles permettant la recherche d'une place de parking) le voient diminuer.
Ces changements sont-ils permanents ? Resteront-ils dans le « monde d'après » ? Le RFC estime que le télétravail s'est désormais installé et restera ; on peut donc prévoir que l'utilisation intensive d'outils de réunion à distance persistera (cf. le rapport « Work-At-Home After Covid-19—Our Forecast »).
Après ces observations, la section 3 du RFC continue avec des considérations sur les problèmes opérationnels constatés. D'abord, un point de fracture numérique. Aux États-Unis, et probablement dans bien d'autres pays, le débit entrant chez les utilisateurs est corrélé au niveau de vie. Mais on a constaté pendant la pandémie une réduction de l'écart entre riches et pauvres (l'étude ne portait pas sur des foyers individuels mais sur des zones géographiques identifiées par leur code postal, un bon indicateur de niveau de vie, au moins aux USA). Cette réduction de l'écart n'était pas forcément liée à un changement de comportement des utilisateurs mais l'était peut-être au fait que certains FAI comme Comcast ont étendu la capacité liée à des abonnements bon marché, par souci de RSE pendant la crise. L'écart entre riches et pauvres était donc peut-être dû à une différence dans les abonnements souscrits, pas à une différence d'utilisation de l'Internet.
Les applications vedettes des confinements ont évidemment été les outils de réunion en ligne, gros services privateurs et capteurs de données personnelles comme Microsoft Teams ou Zoom, ou bien services reposant sur des logiciels libres comme BigBlueButton (dont le RFC, qui reflète un point de vue surtout étatsunien, ne parle pas). D'autres outils de distribution de vidéo, comme YouTube ont vu également leur trafic augmenter soudainement. Certains acteurs, comme justement YouTube, ont délibérement réduit la qualité des vidéos pour diminuer la charge sur le réseau, mais il n'est pas évident que cela ait eu un effet majeur. Autre catégorie d'applications qui a vu son utilisation augmenter, les jeux en ligne. Souvent très consommateurs de ressources, ils ont la particularité de demander à la fois une forte capacité (en raisons des contenus multimédias riches à télécharger) et une faible latence (quand on tire sur le zombie, il doit tomber tout de suite). La mise à jour d'un jeu très populaire a un effet très net sur le réseau des FAI ! Mais il faut noter que ce n'est pas un phénomène spécifique au confinement. Les opérateurs ont déjà dû faire face à des évènements soudains, comme une nouvelle version d'un logiciel très utilisé ou comme une nouvelle mode, par exemple une application qui connait un succès rapide, ce qui est assez fréquent sur l'Internet. Outre ces « effets Slashdot », il y a aussi les attaques par déni de service, qui nécessitent de suravitailler (mettre davantage de capacité que strictement nécessaire). Les opérateurs ont donc déjà de l'expérience dans ce domaine mais, note le RFC, cette expérience n'est pas toujours partagée.
Une discussion lors de l'atelier a porté sur la possibilité de gérer ce genre de problèmes par des mesures discriminatoires, de type qualité de service (un terme propagandiste, il faut le noter : si on discrimine, certains auront une meilleure qualité et d'autres une moins bonne). Marquer le trafic « pas essentiel » (qui décidera de ce qui n'est pas essentiel ?) avec DSCP pour le faire passer par les chemins les plus lents aurait-il aidé ? Compte-tenu du caractère très brûlant de ce débat, il n'est pas étonnant qu'aucun consensus n'est émergé de l'atelier. Le RFC se réjouit qu'au moins les engueulades ont été moins graves que d'habitude.
Une bonne partie de cet atelier était consacré à l'étude de faits : qu'ont vu les opérateurs ? Or, ils n'ont pas vu la même chose. Cela reflète les différences de situation mais aussi les différences dans les outils d'observation. La métrologie n'est pas une chose facile ! Par exemple, les applications de vidéo-conférence ou de distribution de vidéo à la demande ont des mécanismes de correction d'erreur et de gestion de la pénurie très élaborés. L'application s'adapte en permanence aux caractéristiques du réseau, par exemple en ajustant son taux de compression. C'est très bien pour l'utilisateur, cela permet de lui dissimuler une grande partie des problèmes, mais cela complique l'observation. Et quand il y a un problème, il est difficile à analyser. L'autre jour, sans que cela ait de rapport avec un confinement, je regardais une vidéo sur Netflix et la qualité de l'image était vraiment médiocre, gâchant le plaisir. Mais où était le problème ? Mon PC était trop lent ? Le Wifi était pourri ? Le réseau de Free surchargé ? L'interconnexion entre Free et Netflix était-elle encombrée ? Les serveurs de Netflix ramaient-ils ? C'est très difficile à dire, et cela dépend de beaucoup de choses (par exemple, deux utilisateurs de Netflix ne tombent pas forcément sur le même serveur chez Netflix et peuvent donc avoir des vécus différents). Et puis, globalement, on manque de capacités d'observation sur l'Internet. Le client ne voit pas ce qui se passe sur le serveur, le serveur ne sait pas grand'chose sur le client, et peut-être qu'aucun des deux n'a pas visibilité sur l'interconnexion. Chacun connait bien son réseau, mais personne ne connait l'Internet dans son ensemble. Le RFC note que, paradoxalement, la Covid-19 a amélioré les choses, en augmentant le niveau de coopération entre les acteurs de l'Internet.
Et la sécurité ? Elle a aussi été discutée à l'atelier car le passage brusque de tant de gens au télétravail a changé le paysage de la sécurité. On ne pouvait plus compter sur le pare-feu corporate et sur les machines du bureau soigneusement verrouillées par la DSI. Au lieu de cela, tout le monde utilisait des VPN pas toujours bien maitrisés (cf. l'article « IAB COVID-19 Network Impacts »). Et la pandémie a été l'occasion de nombreuses escroqueries (décrites dans le même article). À propos de sécurité, le RFC en profite pour vanter les résolveurs DNS menteurs et critiquer DoH (qui n'est pour rien dans ces escroqueries).
En conclusion, le RFC note que le bon fonctionnement de l'Internet pendant la pandémie n'était pas dû uniquement à ses qualités intrinsèques, mais aussi à l'action de nombreux acteurs. Comme d'autres professions, les techniciens et techniciennes de l'Internet étaient une des lignes de défense face à l'épidémie et cette ligne était très motivée, et a tenu. Ces techniciennes et techniciens méritent donc de chaudes félicitations. Mais on peut quand même améliorer les choses :
- En continuant à étudier le fonctionnement de l'Internet. Le caractère critique de l'Internet pour tant d'activités humaines justifie qu'on continue à analyser ses caractéristiques et ses faiblesses.
- Le partage d'informations et la communication sont essentiels et doivent être accrus.
- La lutte contre la fracture numérique doit se poursuivre, puisqu'en période de confinement, être coupé du réseau, ou y accéder dans de mauvaises conditions (accès lent, matériel inadapté, manque de littératie numérique), aggrave encore l'isolement.
Et le RFC se conclut par un bilan de cet atelier qui, contrairement aux ateliers précédents de l'IAB, a été fait entièrement en ligne. Les participants ont été plutôt contents, notamment du fait que le travail à distance a permis de changer le format : au lieu de deux jours complets de discussions, l'atelier a pu se tenir en alternant des moments de discussion et du travail chez soi, pour approfondir et critiquer les discussions. Toutefois, le RFC note que cela a bien marché car la quasi-totalité des présents se connaissaient bien, étant des participants de longue date à l'IETF. Il n'est pas du tout évident que cela aurait aussi bien marché avec des gens nouveaux, le présentiel étant crucial pour créer des liens informels.
L'ensemble des articles écrits par les participants à l'atelier (pour participer, il fallait avoir écrit un texte) est disponible en ligne (en bas de la page).
L'article seul
Les problèmes gris dans les réseaux informatiques
Première rédaction de cet article le 21 juillet 2021
Une passionnante discussion sur la liste NANOG vient de porter sur les « problèmes gris ». Qu'est-ce qu'un problème gris en matière de réseaux informatiques ?
Les réseaux ne sont pas fiables, toute personne qui a déjà vu un message « Connection time out » peut en témoigner. De l'erreur de configuration chez un opérateur à l'attaque d'une pelleteuse sur une fibre, en passant par une bogue dans les routeurs, les causes de panne ne manquent pas. Ces pannes sont typiquement binaires : soit toutes les communications passent, soit aucune ne passe. À défaut d'être faciles à prévenir, ou même à réparer, ces pannes sont triviales à détecter : la supervision couine et les utilisateurs râlent. Mais il y a aussi des pannes « grises ». C'est quand ça déconne mais pas de manière binaire : la grande majorité du trafic passe (et on peut donc ne s'apercevoir de rien) mais le problème gris frappe une petite minorité des paquets, selon des critères qui ne sont pas évidents à première vue. Par exemple, le réseau laisse passer tous les paquets, sauf ceux qui ont telle combinaison d'options. Ou bien il laisse passer 99,99 % des paquets mais jette les autres (en dehors du cas de congestion, où il est normal de jeter les paquets). Dans la discussion sur NANOG, un ingénieur citait un cas qu'il avait rencontré où une line card défaillante jetait tous les paquets IPv6 où le 65e bit de l'adresse de destination était à 1 (ce qui est apparemment assez rare). Le terme a été utilisé dans d'autres contextes que le réseau (par exemple cette étude de Microsoft).
La discussion sur la liste NANOG avait été lancée dans le contexte d'une étude de l'École polytechnique de Zurich, étude qui commençait par un sondage auprès des opérateurs pour leur demander s'ils géraient les problèmes gris et comment.
D'abord, une constatation peu originale mais qu'il est important de rappeler. Même en dehors de la congestion, aucun réseau ne transporte 100 % des paquets. Il y a toujours des problèmes, les réseaux étant des objets physiques, soumis aux lois de la physique et aux perturbations diverses (comme les rayons cosmiques). Aucune machine n'est idéale, l'électronique n'est pas virtuelle et est donc imparfaite, la mémoire d'un routeur ne garde pas forcément intact ce qu'on lui a confié. Et, non, FCS et ECC ne détectent pas tous les problèmes. Comme le notait un observateur : « De ma longue expérience, j'en ai tiré une analyse (très pertinente) : en informatique il y a entre 1 % et 2 % de magie. C'est faux, mais ça soulage parfois de se dire qu'on est peut être la cible d'un sortilège vaudou ou sous la coupe d'une bonne fée. » Si un opérateur prétendait sincèrement ne pas avoir de problèmes gris, cela indiquerait une absence de recherche plutôt qu'une absence de problème. Fermer les yeux permet de dormir mieux :-)
Les problèmes gris sont très difficiles à détecter. Supposons que, comme tout bon ingénieur, vous avez un système de supervision automatique qui fonctionne, mettons, en envoyant des messages ICMP de type Echo et en attendant une réponse. Si vous envoyez trois paquets par test, et que le réseau jette 1 % des paquets (un chiffre très élevé) au hasard, vous n'avez qu'une chance sur un demi-million de détecter le problème. Bien sûr, on ne se contente pas de ce genre de tests. On regarde par exemple les compteurs attachés aux interfaces des routeurs et on regarde si les compteurs d'erreur grimpent. Mais si c'est l'électronique des routeurs qui est défaillante, les compteurs ne seront pas fiables.
Les problèmes gris sont parfois déterministes (comme dans l'exemple du bit 65 plus haut) mais pas toujours et, s'ils ne sont pas reproductibles, le problème est encore pire. Même s'ils sont déterministes, l'algorithme n'est pas forcément évident. Si les paquets sont aiguillés à l'intérieur d'un équipement selon des critères complexes, et qu'un seul des circuits est défaillant, vous ne trouverez pas forcément tout de suite pourquoi, des fois, ça passe et, des fois, ça ne passe pas.
Est-ce grave pour l'opérateur ? Dans la discussion sur NANOG, un participant a dit franchement que les problèmes gris étaient fréquents mais tellement difficiles à traiter (par exemple parce qu'ils impliquent souvent de longues et difficiles négociations avec les vendeurs de matériel) qu'il valait mieux les ignorer, sauf si un client râlait. Mais, justement, le client ne râle pas toujours si le problème est rare, et difficile à pointer du doigt avec précision. Et puis les systèmes modernes comportent tellement de couches superposées que le client a le plus grand mal à trouver l'origine d'un problème. Ainsi, dans le cas d'un problème spécifique à IPv6, comme celui cité plus haut, le fait que le navigateur Web typique se rabatte automatiquement et rapidement en IPv4 n'aide pas au diagnostic (même si c'est certainement mieux pour le bonheur de l'utilisateur).
Pour donner une idée de la subtilité des problèmes gris, un participant à NANOG citait un cas d'un commutateur qui perdait 0,00012 % des paquets, un nombre difficile à repérer au milieu des erreurs de mesure. Le problème avait été détecté lors du remplacement des anciens tests (genre les trois messages ICMP cités plus haut) par des tests plus violents.
Bref, quand vous (enfin, votre navigateur Web) avez récupéré cet article, peut-être un problème gris a-t-il perturbé cette récupération. Peut-être n'a-t-il même pas été détecté et le texte que vous lisez n'est pas le bon…
L'article seul
RFC 8984: JSCalendar: A JSON Representation of Calendar Data
Date de publication du RFC : Juillet 2021
Auteur(s) du RFC : N. Jenkins, R. Stepanek (Fastmail)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF calext
Première rédaction de cet article le 20 juillet 2021
Beaucoup d'applications gèrent des agendas, avec des réunions à ne pas oublier, des évènements récurrents, des rendez-vous précis. Le format traditionnel d'échange de ces applications est iCalendar, normalisé dans le RFC 5545 (ou, dans sa déclinaison en JSON, jCal, dans le RFC 7265). Ce RFC propose une syntaxe JSON mais, surtout, un modèle de données très différent, JSCalendar. Le but est de remplacer iCalendar.
Les principes de base ? Simplicité (au moins dans les cas simples, car les calendriers sont des bêtes compliquées…), uniformité (autant que possible, une seule façon de représenter un évènement), tout en essayant de permettre des conversions depuis iCalendar (RFC 5545 et RFC 7986), donc en ayant un modèle de données compatible. JSCalendar, comme son nom l'indique, utilise JSON, plus exactement le sous-ensemble i-JSON, normalisé dans le RFC 7493.
Bon, mais pourquoi ne pas avoir gardé iCalendar ? Parce qu'il est trop complexe avec plusieurs formats de date, parce que ses règles de récurrence sont ambigües et difficiles à comprendre, parce que sa syntaxe est mal définie. jCal n'a pas ce dernier problème mais il garde tous les autres. On voit même des logiciels utiliser leur propre représentation en JSON des données iCalendar au lieu d'utiliser jCal. Bref, JSCalendar préfère repartir, sinon de zéro, du moins d'assez loin.
Voici un exemple très simple et très minimal de représentation d'un évènement en JSCalendar :
{
"@type": "Event",
"uid": "a8df6573-0474-496d-8496-033ad45d7fea",
"updated": "2020-01-02T18:23:04Z",
"title": "Some event",
"start": "2020-01-15T13:00:00",
"timeZone": "America/New_York",
"duration": "PT1H"
}
Comme avec iCalendar, les données JSCalendar peuvent être échangées par courrier ou avec n'importe quel autre protocole de son choix comme JMAP ou WebDAV.
Avant d'attaquer ce format JSCalendar, rappelez-vous qu'il utilise JSON et que la terminologie est celle de JSON. Ainsi, on nomme « objet » ce qui, selon le langage utilisé, serait un dictionnaire ou un tableau associatif. Ensuite, outre les types de base de JSON, JSCalendar a des types supplémentaires (section 1), notamment :
Id, un identificateur, pour que les objets aient un nom simple et unique (c'est une chaîne de caractères JSON). On peut par exemple utiliser un UUID (RFC 9562). Dans l'exemple ci-dessus, le membreuidde l'objet est unId.UTCDateTime, une date-et-heure (un instant dans le temps) au format du RFC 3339 dans une chaîne de caractères JSON, est obligatoirement en UTC. Un tel type est intéressant pour les évènements internationaux comme une vidéoconférence. Dans l'exemple ci-dessus, le membreupdatedest de ce type.LocalDateTime, une date-et-heure selon le fuseau horaire local. Un tel type est utile pour les évènements locaux, comme un pique-nique. Dans l'exemple ci-dessus, qui concerne une réunion en présentiel,startest de ce type. On a besoin des deux types, à la fois parce que les évènements en distanciel et en présentiel n'ont pas les mêmes besoins, et aussi parce que le décalage entre les deux peut varier. Les calendriers, c'est compliqué et le RFC cite l'exemple de laLocalDateTime2020-10-04T02:30:00qui n'existe pas à Melbourne car le passage à l'heure d'été fait qu'on saute de 2h à 3h, mais qui peut apparaitre dans les calculs (start+ une durée) ou bien si les règles de l'heure d'été changent.Durationest une durée, exprimée comme en iCalendar (PT1Hpour « une heure » dans l'exemple ci-dessus, ce seraitP1Ypour une année). Gag : une journée (P1D) ne fait pas forcément 24 heures, par exemple si on passe à l'heure d'été pendant cette journée.SignedDuration, une durée qui peut être négative.TimeZoneId, un identifiant pour un fuseau horaire, pris dans la base de l'IANA, par exempleEurope/Paris.PatchObjectest un pointeur JSON (ces pointeurs sont normalisés dans le RFC 6901) qui permet de désigner un objet à modifier.Relationest un objet, et plus un simple type scalaire comme les précédents. Il permet d'indiquer une relation entre deux objets, notamment vers un objet parent ou enfant..Linkest également une relation et donc un objet, mais vers le monde extérieur. Il a des propriétés commehref(dont la valeur est, comme vous vous en doutez, un URI) oucidqui identifie le contenu vers lequel on pointe, dans la syntaxe du RFC 2392.
Les types de JSCalendar figurent dans un registre IANA, qu'on peut remplir avec la procédure « Examen par un expert » du RFC 8126.
Bien, maintenant que nous avons tous nos types, construisons des objets. Il y en a de trois types (section 2) :
Event(l'exemple ci-dessus, regardez sa propriété@type) est un évènement ponctuel, par exemple une réunion professionnelle ou une manifestation de rue. Il a une date-et-heure de départ, et une durée.Taskest une tâche à accomplir, elle peut avoir une date-et-heure limite et peut avoir une durée estimée.Groupest un groupe d'évènements JSCalendar.
JSCalendar n'a pas de règles de canonicalisation (normalisation)
générales, car cela dépend trop de considérations sémantiques que le
format ne peut pas connaitre. Par exemple, JSON permet des
tableaux, et JSCalendar utilise cette
possibilité mais, quand on veut décider si deux tableaux sont
équivalents, doit-on tenir compte de l'ordre des éléments
([1, 2] == [2, 1]) ? Cela dépend de
l'application et JSCalendar ne fixe donc pas de règles pour ce
cas. (Un cas rigolo et encore pire est celui des valeurs qui sont
des URI
puisque la canonicalisation des URI dépend du plan -
scheme.)
Quelles sont les propriétés typiques des objets JSCalendar (section 4) ? On trouve notamment, communs aux trois types d'objets (évènement, tâche et groupe) :
@type, le type d'objet (Eventdans l'exemple ci-dessus, un des trois types possibles).uid(a8df6573-0474-496d-8496-033ad45d7feadans l'exemple), l'identificateur de l'objet (il est recommandé que ce soit un des UUID du RFC 9562).prodID, un identificateur du logiciel utilisé, un peu comme leUser-Agent:de HTTP. Le RFC suggère d'utiliser un FPI.updated, une date-et-heure de typeUTCDateTime.titleetdescription, des chaînes de caractères utiles.locations(notez le S) qui désigne les lieux physiques de l'évènement. C'est compliqué. Chaque lieu est un objet de typeLocationqui a comme propriétés possibles un type (tiré du registre des types de lieux créé par le RFC 4589), et une localisation sous forme de latitude et longitude (RFC 5870).- Tous les évènements ne sont pas dans le monde physique,
certains se produisent en ligne, d'où le
virtualLocations, qui indique des informations comme l'URI (via la propriété du même nom). Ainsi, une conférence en ligne organisée par l'assocation Parinux via BigBlueButton aura commevirtualLocations{"@type": "VirtualLocation", "uri": "https://bbb.parinux.org/b/ca--xgc-4r3-n8z", …}. colorpermet de suggérer au logiciel une couleur à utiliser pour l'affichage, qui est une valeur RGB en hexadécimal ou bien un nom de couleur CSS.
Et je suis loin d'avoir cité toutes les propriétés possibles, sans compter celles spécifiques à un type d'objet.
Pour le cas de locations, le RFC fournit un
exemple de vol international (quand il était encore possible de prendre
l'avion) :
{
"...": "",
"title": "Flight XY51 to Tokyo",
"start": "2020-04-01T09:00:00",
"timeZone": "Europe/Berlin",
"duration": "PT10H30M",
"locations": {
"418d0b9b-b656-4b3c-909f-5b149ca779c9": {
"@type": "Location",
"rel": "start",
"name": "Frankfurt Airport (FRA)"
},
"c2c7ac67-dc13-411e-a7d4-0780fb61fb08": {
"@type": "Location",
"rel": "end",
"name": "Narita International Airport (NRT)",
"timeZone": "Asia/Tokyo"
}
}
}
Notez les UUID pour identifier les lieux, et le changement de fuseau horaire entre le départ et l'arrivée. Si l'évènement a lieu à la fois en présentiel et en distanciel (ici, le concert est dans un lieu physique identifié par ses coordonnées géographiques, mais aussi diffusé en ligne), cela peut donner :
{
"...": "",
"title": "Live from Music Bowl: The Band",
"description": "Go see the biggest music event ever!",
"locale": "en",
"start": "2020-07-04T17:00:00",
"timeZone": "America/New_York",
"duration": "PT3H",
"locations": {
"c0503d30-8c50-4372-87b5-7657e8e0fedd": {
"@type": "Location",
"name": "The Music Bowl",
"description": "Music Bowl, Central Park, New York",
"coordinates": "geo:40.7829,-73.9654"
}
},
"virtualLocations": {
"1": {
"@type": "VirtualLocation",
"name": "Free live Stream from Music Bowl",
"uri": "https://stream.example.com/the_band_2020"
}
},
...
Les fournisseurs de logiciel peuvent ajouter des propriétés
définies par eux. Dans ce cas, le RFC recommande fortement qu'ils
les nomment en les faisant précéder d'un nom de domaine identifiant le fournisseur. Si
celui-ci a example.com et veut une propriété
toto, il la nommera
example.com:toto. C'est évidemment une solution
temporaire, les fournisseurs ont tout intérêt à enregistrer ces
propriétés pour qu'elles puissent servir à tout le monde. Le
mécanisme d'enregistrement de nouvelles propriétés est « Examen par
un expert » (RFC 8126) et les propriétés sont
dans un
registre IANA.
Passons maintenant à un aspect compliqué mais indispensable des
calendriers : les règles de récurrence, comme « Réunion de service
tous les premiers lundis du mois à 10 h, sauf jour férié ». Il est
important de maintenir ces évènements récurrents sous forme de
règles, et de ne pas de les instancier immédiatement, car
l'application des règles peut donner des résultats différents dans
le futur. JSCalendar permet une propriété
recurrenceRules qui décrit ces règles de
récurrence et évidemment une
excludedRecurrenceRules car s'il n'y a pas
d'exceptions, ce n'est pas drôle. Exprimer les règles n'est pas
facile. L'idée est de spécifier la récurrence sous forme d'une série
de règles, chacune indiquant une fréquence (annuelle, mensuelle, etc), à
chaque fois à partir de la propriété start, le
calendrier utilisé (qui doit être un des calendriers disponibles
dans CLDR), la marche à suivre quand une règle
produit une date invalide dans ce calendrier (annuler l'évènement,
le mettre avant, le mettre après), et plein d'autres propriétés
optionnelles comme le jour du mois (« réunion tous les 6 du mois »),
de la semaine (« tous les mercredis »), etc. Il faut ensuite
plusieurs pages au RFC pour expliquer la façon subtile dont les
règles sont appliquées, et se combinent. Les exceptions de la
excludedRecurrenceRules fonctionnent de la même
façon, et sont ensuite soustraites des dates-et-heures sélectionnées
par les règles.
Le RFC fournit cet exemple de récurrence : le premier
avril arrive tous les ans (et dure une journée, notez le
duration) :
{
"...": "",
"title": "April Fool's Day",
"showWithoutTime": true,
"start": "1900-04-01T00:00:00",
"duration": "P1D",
"recurrenceRules": [{
"@type": "RecurrenceRule",
"frequency": "yearly"
}]
}
Alors qu'ici, on fait du yoga une demi-heure chaque jour à 7 h du matin :
{
"...": "",
"title": "Yoga",
"start": "2020-01-01T07:00:00",
"duration": "PT30M",
"recurrenceRules": [{
"@type": "RecurrenceRule",
"frequency": "daily"
}]
}
Bon, ensuite, quelques détails pour aider le logiciel à classer
et présenter les évènements. Un évènement peut avoir des propriétés
comme priority (s'il y a deux réunions en même
temps, laquelle choisir ?), freeBusyStatus
(est-ce que cet évènement fait que je doive être considéré comme
occupé ou est-il compatible avec autre chose ?),
privacy (cet évènement peut-il être affiché
publiquement ?), participationStatus (je
viendrai, je ne viendrai pas, je ne sais pas encore…), et plein
d'autres encore.
Il y a aussi des propriétés concernant d'autres sujets, par
exemple l'adaptation locale. Ainsi, la propriété
localizations indique la ou les langues à utiliser (leur valeur est une
étiquette de langue du RFC 5646).
Toutes les propriétés vues jusqu'à présent étaient possibles pour tous les types d'objets JSCalendar (évènement, tâche et groupe). D'autres propriétés sont spécifiques à un ou deux types :
- Les évènements (
Event) peuvent avoir entre autres unstart(unLocalDateTimequi indique le début de l'évènement) et unduration(la durée de l'évènement). - Les tâches (
Task) peuvent avoir unstartmais aussi unduequi indique la date où elles doivent être terminées, et unpercentComplete(pour les chefs de projet…). - Les groupes (
Group) ont, par exemple,entries, qui indique les objets qui sont membres du groupe.
Les fichiers à ce format JSCalendar sont servis sur l'Internet
avec le type
application/jscalendar+json.
Pour terminer, voyons un peu la sécurité de JSCalendar (section 7). Évidemment, toutes les informations stockées dans un calendrier sont sensibles : rares sont les personnes qui accepteraient de voir la totalité de leur agenda être publiée ! Celui-ci permet en effet de connaitre le graphe social (les gens qu'on connait), les lieux où passe la personne, ses habitudes et horaires, bref, que des choses personnelles. Toute application qui manipule des données JSCalendar doit donc soigneusement veiller à la confidentialité de ces données, et doit les protéger.
Le risque d'accès en lecture n'est pas le seul, la modification non autorisée de l'agenda serait également un problème, elle pourrait permettre, par exemple, de faire déplacer une personne en un lieu donné. D'autres conséquences d'une modification pourraient toucher la facturation (location d'une salle pendant une certaine durée) ou d'autres questions de sécurité (activer ou désactiver une alarme à certains moments). L'application qui manie du JSCalendar doit donc également empêcher ces changements non autorisés.
Notez que ces problèmes de sécurité ne concernent pas le format à proprement parler, mais les applications qui utilisent ce format. Rien dans JSCalendar, dans ce RFC, ne le rend particulièrement vulnérable ou au contraire protégé, tout est dans l'application.
Les règles de récurrence sont complexes et, comme tout programme, elles peuvent entrainer des conséquences imprévues, avec consommation de ressources informatiques associées. Un exemple aussi simple que la session de yoga quotidienne citée plus haut pourrait générer une infinité d'évènements, si elle était mise en œuvre par une répétition systématique, jusqu'à la fin des temps. Les programmes doivent donc faire attention lorsqu'ils évaluent les règles de récurrence.
L'un des buts d'un format standard d'évènements est évidemment l'échange de données. Il est donc normal et attendu qu'une application de gestion d'agenda reçoive des objets JSCalendar de l'extérieur, notamment via l'Internet. On voit souvent du iCalendar en pièce jointe d'un courrier, par exemple. Il ne faut pas faire une confiance aveugle à ces données venues d'on ne sait où, et ne pas tout intégrer dans le calendrier du propriétaire. L'authentification du courrier (par exemple avec DKIM, RFC 6376) aide un peu, mais n'est pas suffisante.
Les fuseaux horaires sont une source de confusion sans fin. Un utilisateur qui n'est pas attentif, lorsqu'on lui dit qu'un évènement a lieu à 10h30 (UTC-5) peut croire que c'est 10h30 de son fuseau horaire à lui. (Et encore, ici, j'ai indiqué le fuseau horaire de manière lisible, contrairement à ce que font la plupart des Étatsuniens, qui utilisent leurs sigles à eux comme PST, ou ce que font les Français qui n'indiquent pas le fuseau horaire, persuadés qu'ils sont que le monde entier est à l'heure de Paris.) Cette confusion peut être exploitée par des méchants qui utiliseraient les fuseaux horaires de manière délibérement peu claire pour tromper quelqu'un sur l'heure d'un évènement. (Dans la série Mad Men, les hommes qui ne supportent pas l'arrivée d'une femme dans le groupe lui donnent des informations trompeuses sur les heures de réunion, pour qu'elle manque ces évènements.)
Où trouve-t-on du JSCalendar à l'heure actuelle ? Mobilizon ne l'a pas encore (l'action « Ajouter à mon agenda » exporte du iCalendar). Fastmail annonce qu'ils gèrent JSCalendar (mais apparemment seulement dans les échanges JMAP, pas avec l'import/export normal). Cyrus l'a aussi (si vous avez des détails, ça m'intéresse). Pour le cas des récurrences, vous avez une intéressante mise en œuvre en Python. Attention, il y a aussi plein de logiciels qui s'appellent « jscalendar » (notamment des widgets JavaScript pour afficher un calendrier dans un formulaire Web) mais qui n'ont aucun rapport avec ce RFC.
L'article seul
RFC 9065: Considerations around Transport Header Confidentiality, Network Operations, and the Evolution of Internet Transport Protocols
Date de publication du RFC : Juillet 2021
Auteur(s) du RFC : G. Fairhurst (University of Aberdeen), C. Perkins (University of Glasgow)
Pour information
Réalisé dans le cadre du groupe de travail IETF tsvwg
Première rédaction de cet article le 20 juillet 2021
La couche Transport n'est pas celle qui suscite le plus de passions dans l'Internet. Mais la récente normalisation du protocole QUIC a mis cette couche en avant et l'usage du chiffrement par QUIC a relancé le débat : quelles sont les conséquences d'un chiffrement de plus en plus poussé de la couche Transport ?
Traditionnellement, la couche Transport ne faisait pas de chiffrement (cf. RFC 8095 et RFC 8922). On chiffrait en-dessous (IPsec) ou au-dessus (TLS, SSH). IPsec ayant été peu déployé, l'essentiel du chiffrement aujourd'hui sur l'Internet est fait par TLS. Toute la mécanique TCP est donc visible aux routeurs sur le réseau. Ils peuvent ainsi mesurer le RTT, découvrir début et fin d'une connexion, et interférer avec celle-ci, par exemple en envoyant des paquets RST (ReSeT) pour mettre fin à la session. Cela permet de violer la vie privée (RFC 6973), par exemple en identifiant une personne à partir de son activité en ligne. Et cette visibilité de la couche Transport pousse à l'ossification : de nombreux intermédiaires examinent TCP et, si des options inhabituelles sont utilisées, bloquent les paquets. Pour éviter cela, QUIC chiffre une grande partie de la couche 4, pour éviter les interférences par les intermédiaires et pour défendre le principe de bout en bout et la neutralité du réseau. Comme souvent en sécurité, cette bonne mesure de protection a aussi des inconvénients, que ce RFC examine. Notons tout de suite que ce qui est un inconvénient pour les uns ne l'est pas forcément pour les autres : pour un FAI, ne pas pouvoir couper les connexions TCP de BitTorrent avec RST est un inconvénient mais, pour l'utilisateur, c'est un avantage, cela le protège contre certaines attaques par déni de service.
On ne peut pas sérieusement aujourd'hui utiliser des communications non-chiffrées (RFC 7258). Personne n'ose dire publiquement le contraire. Par contre, on entend souvent un discours « je suis pour le chiffrement, mais » et, comme toujours avec ce genre de phrase, c'est ce qui est après le « mais » qui compte. Ce RFC essaie de documenter les avantages et les inconvénients du chiffrement de la couche Transport, mais, en pratique, est plus détaillé sur les inconvénients, ce qui était déjà le cas du RFC 8404.
La section 2 du RFC explique quel usage peut être fait des informations de la couche Transport par les équipements intermédiaires. En théorie, dans un modèle en couches idéal, il n'y en aurait aucun : la couche Transport est de bout en bout, les routeurs et autres équipements intermédiaires ne regardent rien au-dessus de la couche Réseau. Mais en pratique, ce n'est pas le cas, comme l'explique cette section. (Question pour mes lecteurices au passage : vous semble-t-il légitime de parler de DPI quand un routeur regarde le contenu de la couche Transport, dont il n'a en théorie pas besoin, ou bien doit-on réserver ce terme aux cas où il regarde dans la couche Application ?)
Première utilisation de la couche Transport par des intermédiaires : identifier des flots de données (une suite d'octets qui « vont ensemble »). Pourquoi en a-t-on besoin ? Il y a plusieurs raisons possibles, par exemple pour la répartition de charge, où on veut envoyer tous les paquets d'un flot donné au même serveur. Cela se fait souvent en prenant un tuple d'informations dans le paquet (tuple qui peut inclure une partie de la couche Transport, comme les ports source et destination) et en le condensant pour avoir un identificateur du flot. Si la couche Transport est partiellement ou totalement chiffrée, on ne pourra pas distinguer deux flots différents entre deux machines. En IPv6, l'étiquette de flot (RFC 6437) est une solution possible (RFC 6438, RFC 7098), mais je n'ai pas l'impression qu'elle soit très utilisée.
Maintenant, passons à la question de l'identification d'un flot. Était-ce un transfert de fichiers, de la vidéo, une session interactive ? Il faut déduire cette identification à partir des informations de la couche Transport (voir le RFC 8558). Mais pourquoi identifier ces flots alors que l'opérateur doit tous les traiter pareil, en application du principe de neutralité ? Cela peut être dans l'intérêt de l'utilisateur (mais le RFC ne donne pas d'exemple…) ou bien contre lui, par exemple à des fins de surveillance, ou bien pour discriminer certains usages (comme le réclament régulièrement certains politiciens et certains opérateurs), voire pour les bloquer complètement. Autrefois, on pouvait souvent identifier un service uniquement avec le numéro de port (43 pour whois, 25 pour le courrier, etc, cf. RFC 7605) mais cela n'a jamais marché parfaitement, plusieurs services pouvant utiliser le même port et un même service pouvant utiliser divers ports. De toute façon, cette identification par le numéro de port est maintenant finie, en partie justement en raison de cette discrimination selon les usages, qui pousse tout le monde à tout faire passer sur le port 443. Certains services ont un moyen simple d'être identifié, par exemple par un nombre magique, volontairement placé dans les données pour permettre l'identification, ou bien simple conséquence d'une donnée fixe à un endroit connu (RFC 3261, RFC 8837, RFC 7983…). Lors de la normalisation de QUIC, un débat avait eu lieu sur la pertinence d'un nombre magique permettant d'identifier du QUIC, idée finalement abandonnée.
Si les équipements intermédiaires indiscrets n'arrivent pas à déterminer le service utilisé, le flot va être considéré comme inconnu et le RFC reconnait que certains opérateurs, en violation de la neutralité de l'Internet, ralentissent ces flots inconnus.
L'étape suivante pour ceux qui veulent identifier à quoi servent les données qu'ils voient passer est d'utiliser des heuristiques. Ainsi, une visio-conférence à deux fera sans doute passer à peu près autant d'octets dans chaque sens, alors que regarder de la vidéo à la demande créera un trafic très asymétrique. Des petits paquets UDP régulièrement espacés permettent de soupçonner du trafic audio, même si on n'a pas pu lire l'information SDP (RFC 4566). Des heuristiques plus subtiles peuvent permettre d'en savoir plus. Donc, il faut se rappeler que le chiffrement ne dissimule pas tout, il reste une vue qui peut être plus ou moins précise (le RFC 8546 décrit en détail cette notion de vue depuis le réseau).
Autre motivation pour analyser la couche Transport, l'amélioration des performances. Inutile de dire que le FAI typique ne va pas se pencher sur les problèmes de performance d'un abonné individuel (si ça rame avec Netflix, appeler le support de son FAI ne déclenche pas de recherches sérieuses). Mais cela peut être fait pour des analyse globales. Là encore, les conséquences peuvent être dans l'intérêt de l'utilisateur, ou bien contre lui. Le RFC note que les mesures de performance peuvent amener à une discrimination de certains services (« QoS », qualité de service, c'est-à-dire dégradation de certains services). Que peut-on mesurer ainsi, qui a un impact sur les performances ? Il y a la perte de paquets, qu'on peut déduire, en TCP, des retransmissions. Dans l'Internet, il y a de nombreuses causes de pertes de paquets, du parasite sur un lien radio à l'abandon délibéré par un routeur surchargé (RFC 7567) en passant par des choix politiques de défavoriser certains paquets (RFC 2475). L'étude de ces pertes peut permettre dans certains cas de remonter aux causes.
On peut aussi mesurer le débit. Bon, c'est facile, sans la couche Transport, uniquement en regardant le nombre d'octets qui passent par les interfaces réseaux. Mais l'accès aux données de la couche Transport permet de séparer le débit total du débit utile (goodput, en anglais, pour le différencier du débit brut, le throughput, cf. section 2.5 du RFC 7928, et le RFC 5166). Pour connaitre ce débit utile, il faut pouvoir reconnaitre les retransmissions (si un paquet est émis trois fois avant enfin d'atteindre le destinataire, il ne contribue qu'une fois au débit utile). Une retransmission peut se voir en observant les numéros de séquence en TCP (ou dans d'autres protocoles comme RTP).
La couche Transport peut aussi nous dire quelle est la latence. Cette information est cruciale pour évaluer la qualité des sessions interactives, par exemple. Et elle influe beaucoup sur les calculs du protocole de couche 4. (Voir l'article « Internet Latency: A Survey of Techniques and their Merits ».) Comment mesure-t-on la latence ? Le plus simple est de regarder les accusés de réception TCP et d'en déduire le RTT. Cela impose d'avoir accès aux numéros de séquence. Dans TCP, ils sont en clair, mais QUIC les chiffre (d'où l'ajout du spin bit).
D'autres métriques sont accessibles à un observateur qui regarde la couche Transport. C'est le cas de la gigue, qui se déduit des observations de la latence, ou du réordonnancement des paquets (un paquet qui part après un autre, mais arrive avant). L'interprétation de toutes ces mesures dépend évidemment du type de lien. Un lien radio (RFC 8462) a un comportement différent d'un lien filaire (par exemple, une perte de paquets n'est pas forcément due à la congestion, elle peut venir de parasites).
Le RFC note que la couche Réseau, que les équipements intermédiaires ont tout à fait le droit de lire, c'est son rôle, porte parfois des informations qui peuvent être utiles. En IPv4, ce sont les options dans l'en-tête (malheureusement souvent jetées par des pare-feux trop fascistes, cf. RFC 7126), en IPv6, les options sont après l'en-tête de réseau, et une option, Hop-by-hop option est explicitement prévue pour être examinée par tous les routeurs intermédiaires.
Outre les statistiques, l'analyse des données de la couche Transport peut aussi servir pour les opérations (voir aussi le RFC 8517), pour localiser un problème, pour planifier l'avitaillement de nouvelles ressources réseau, pour vérifier qu'il n'y a pas de tricheurs qui essaient de grapiller une part plus importante de la capacité, au risque d'aggraver la congestion (RFC 2914). En effet, le bon fonctionnement de l'Internet dépend de chaque machine terminale. En cas de perte de paquets, signal probable de congestion, les machines terminales sont censées réémettre les paquets avec prudence, puisque les ressources réseau sont partagées. Mais une machine égoïste pourrait avoir plus que sa part de la capacité. Il peut donc être utile de surveiller ce qui se passe, afin d'attraper d'éventuels tricheurs, par exemple une mise en œuvre de TCP qui ne suivrait pas les règles habituelles. (Si on utilise UDP, l'application doit faire cela elle-même, cf. RFC 8085. Ainsi, pour RTP, comme pour TCP, un observateur extérieur peut savoir si les machines se comportent normalement ou bien essaient de tricher.)
Autre utilisation de l'observation de la couche Transport pour l'opérationnel, la sécurité, par exemple la lutte contre les attaques par déni de service, l'IDS et autres fonctions. Le RFC note que cela peut se faire en coopération avec les machines terminales, si c'est fait dans l'intérêt de l'utilisateur. Puisqu'on parle de machines terminales, puisque le chiffrement d'une partie de la couche Transport est susceptible d'affecter toutes les activités citées plus haut, le RFC rappelle la solution évidente : demander la coopération des machines terminales. Il y a en effet deux cas : soit les activités d'observation de la couche Transport sont dans l'intérêt des utilisateurs, et faites avec leur consentement, et dans ce cas la machine de l'utilisateur peut certainement coopérer, soit ces activités se font contre l'utilisateur (discrimination contre une application qu'il utilise, par exemple), et dans ce cas le chiffrement est une réponse logique à cette attaque. Bien sûr, c'est la théorie ; en pratique, certaines applications ne fournissent guère d'informations et de moyens de débogage. Les protocoles de transport qui chiffrent une bonne partie de leur fonctionnement peuvent aussi aider, en exposant délibérement des informations. C'est par exemple ce que fait QUIC avec son spin bit déjà cité, ou avec ses invariants documentés dans le RFC 8999.
Autre cas où le chiffrement de la couche Transport peut interférer avec certains usages, les réseaux d'objets contraints, disposant de peu de ressources (faible processeur, batterie qu'il ne faut pas vider trop vite, etc). Il arrive dans ce cas d'utiliser des relais qui interceptent la communication, bricolent dans la couche Transport puis retransmettent les données. Un exemple d'un tel bricolage est la compression des en-têtes, courante sur les liens à très faible capacité (cf. RFC 2507, RFC 2508, le ROHC du RFC 5795, RFC 6846, le SCHC du RFC 8724, etc). Le chiffrement rend évidemment cela difficile, les relais n'ayant plus accès à l'information. C'est par exemple pour cela que le RTP sécurisé du RFC 3711 authentifie l'en-tête mais ne le chiffre pas. (Je suis un peu sceptique sur cet argument : d'une part, les objets contraints ne vont pas forcément utiliser des protocoles de transport chiffrés, qui peuvent être coûteux, d'autre part un sous-produit du chiffrement est souvent la compression, ce qui rend inutile le travail des relais.)
Un dernier cas cité par le RFC où l'observation du fonctionnement de la couche Transport par les machines intermédiaires est utile est celui de la vérification de SLA. Si un contrat ou un texte légal prévoit certaines caractéristiques pour le réseau, l'observation de la couche 4 (retransmission, RTT…) est un moyen d'observer sans avoir besoin d'impliquer les machines terminales. (Personnellement, je pense justement que ces vérifications devraient plutôt se faire depuis les machines terminales, par exemple avec les sondes RIPE Atlas, les SamKnows, etc.)
La section 3 du RFC décrit un autre secteur qui est intéressé par l'accès aux données de transport, la recherche. Par exemple, concevoir de nouveaux protocoles doit s'appuyer sur des mesures faites sur les protocoles existants, pour comprendre leurs forces et leurs faiblesses. C'est possible avec un protocole comme TCP, où l'observation passive permet, via notamment les numéros de séquence, de découvrir le RTT et le taux de perte de paquets. (Passive : sans injecter de paquets dans le réseau. Voir le RFC 7799.) Mais ces mêmes informations peuvent aussi servir contre l'utilisateur. Même s'il n'y a pas d'intention néfaste (par exemple de discrimination contre certains usages), toute information qui est exposée peut conduire à l'ossification, l'impossibilité de changer le protocole dans le futur. Une des motivations des protocoles chiffrés comme QUIC est en effet d'éviter l'ossification : une middlebox ne pourra pas prendre de décisions sur la base d'informations qu'elle n'a pas. QUIC affiche des données au réseau seulement s'il le veut (c'est le cas du spin bit). D'où également le choix délibéré de graisser, c'est-à-dire de faire varier certaines informations pour éviter que des programmeurs de middleboxes incompétents et/ou paresseux n'en déduisent que cette information ne change jamais (le graissage est décrit dans le RFC 8701).
La bonne solution pour récolter des données sans sacrifier la vie
privée est, comme dit plus haut, de faire participer les extrémités,
les machines terminales, ce qu'on nomme en anglais le
endpoint-based logging. Actuellement,
malheureusement, les mécanismes de débogage ou de récolte
d'information sur ces machines terminales sont trop réduits, mais
des efforts sont en cours. Par exemple, pour QUIC, c'est la
normalisation du format « qlog » d'enregistrement des informations
vues par la couche Transport
(Internet-Draft
draft-ietf-quic-qlog-main-schem)
ou bien le format Quic-Trace. Mais
le RFC note que la participation des machines terminales ne suffit
pas toujours, notamment si on veut déterminer
où, dans le réseau, se produit un problème.
Après qu'on ait vu les utilisations qui sont faites de l'analyse de la couche Trnsport par les équipements intermédiaires, la section 4 du RFC revient ensuite sur les motivations du chiffrement de cette couche. Pourquoi ne pas se contenter de ce que font TLS et SSH, qui chiffrent uniquement la couche Application ? L'une des premières raisons est d'empêcher l'ossification, ce phénomène qui fait qu'on ne peut plus faire évoluer la couche Transport car de stupides équipements intermédiaires, programmés avec les pieds par des ignorants qui ne lisent pas les RFC, rejettent les paquets légaux mais qui ne correspondent pas à ce que ces équipements attendaient. Ainsi, si un protocole de transport permet l'utilisation d'un octet dans l'en-tête, mais que cet octet est à zéro la plupart du temps, on risque de voir des middleboxes qui jettent les paquets où certains bits de ce champ sont à un car « ce n'est pas normal ». Tout ce qui est observable risque de devenir ossifié, ne pouvant plus être modifié par la suite. Chiffrer permet de garantir que les équipements intermédiaires ne vont pas regarder ce qui ne les regarde pas. Le RFC donne plusieurs exemples édifiants des incroyables comportements de ces logiciels écrits par des gens qui ne comprenaient qu'une partie d'un protocole :
- Pendant le développement de TLS 1.3 (qui mènera au RFC 8446), il a fallu concevoir 1.3 de manière à ce qu'il ressemble à 1.2, car certaines middleboxes rejettaient du TLS légal, mais différent de ce qu'elles attendaient.
- MPTCP (RFC 8684) a également dû être modifié pour tenir compte de boitiers intermédiaires qui observaient le fonctionnement de la fenêtre TCP et se permettaient de couper les connexions qui leur semblaient anormales.
- D'une manière générale, tout protocole qui permet des options est confronté à des middleboxes qui interfèrent dès qu'on utilise des options nouvelles. C'est le cas par exemple de TCP Fast Open (RFC 7413).
- Encore pire, si c'est possible, on a vu des équipements intermédiaires qui changeaient les numéros de séquence TCP, ce qui cassait les accusés de réception SACK (RFC 2018).
Il n'est donc pas étonnant que les concepteurs de protocole cherchent désormais à chiffrer au maximum, pour éviter ces interférences. Le RFC 8546 rappelle ainsi que c'est la vue depuis le réseau (wire image), c'est-à-dire ce que les équipements intermédiaires peuvent observer, pas la spécification écrite du protocole, qui détermine, dans le monde réel, ce qu'un intermédiaire peut observer et modifier. Il faut donc réduire cette vue au strict minimum ; tout ce qui n'est pas chiffré risque fortement d'être ossifié, figé. Et le RFC 8558 affirme lui qu'on ne doit montrer au réseau que ce qui doit être utilisé par le réseau, le reste, qui ne le regarde pas, doit être dissimulé.
Une autre motivation du chiffrement de la couche Transport est évidemment de mieux protéger la vie privée (RFC 6973). L'ampleur de la surveillance massive (RFC 7624) est telle qu'il est crucial de gêner cette surveillance le plus possible. Le RFC note qu'il n'y a pas que la surveillance passive, il y a aussi l'ajout de données dans le trafic, pour faciliter la surveillance. Du fait de cet « enrichissement », il peut être utile, quand un champ doit être observable (l'adresse IP de destination est un bon exemple), d'utiliser quand même la cryptographie pour empêcher ses modifications, via un mécanisme d'authentification. C'est ce que fait TCP-AO (RFC 5925, mais qui semble peu déployé), et bien sûr le service AH d'IPsec (RFC 4302).
Comme on le voit, il y a une tension, voire une lutte, entre les opérateurs réseau et les utilisateurs. On pourrait se dire que c'est dommage, qu'il vaudrait mieux que tout le monde travaille ensemble. Cela a été discuté à l'IETF, avec des expressions comme « un traité de paix entre machines terminales et boitiers intermédiaires ». Pour l'instant, cela n'a pas débouché sur des résultats concrets, en partie parce qu'il n'existe pas d'organisations représentatives qui pourraient négocier, signer et faire respecter un tel traité de paix. On en reste donc aux mesures unilatérales. Les machines terminales doivent chiffrer de plus en plus pour maintenir le principe de bout en bout. Comme dans tout conflit, il y a des dégâts collatéraux (le RFC 8922 en décrit certains). Le problème n'étant pas technique mais politique, il est probable qu'il va encore durer. La tendance va donc rester à chiffrer de plus en plus de choses.
À noter qu'une autre méthode que le chiffrement existe pour taper sur les doigts des boitiers intermédiaires pénibles, qui se mêlent de ce qui ne les regarde pas, et s'en mêlent mal : c'est le graissage. Son principe est d'utiliser délibérément toutes les options possibles du protocole, pour habituer les middleboxes à voir ces variations. Le RFC 8701 en donne un exemple, pour le cas de TLS.
Déterminer ce qu'il faut chiffrer, ce qu'il faut authentifier, et ce qu'il vaut mieux laisser sans protection, autorisant l'observation et les modifications, n'est pas une tâche facile. Autrefois, tout était exposé parce qu'on avait moins de problèmes avec les boitiers intermédiaires et que les solutions, comme le chiffrement, semblaient trop lourdes. Aujourd'hui qu'on a des solutions réalistes, on doit donc choisir ce qu'on montre ou pas. Le choix est donc désormais explicite (cf. RFC 8558).
Au passage, une façon possible d'exposer des informations qui peuvent être utiles aux engins intermédiaires est via un en-tête d'extension. Par exemple en IPv6, l'en-tête Hop-by-hop (RFC 8200, section 4.3) est justement fait pour cela (voir un exemple dans le RFC 8250, quoiqu'avec un autre type d'en-tête). Toutefois, cet en-tête Hop-by-hop est clairement un échec : beaucoup de routeurs jettent les paquets qui le portent (RFC 7872), ou bien les traitent plus lentement que les paquets sans cette information. C'est encore pire si cet en-tête porte des nouvelles options, inconnues de certaines middleboxes, et c'est pour cela que le RFC 8200 déconseille (dans sa section 4.8) la création de nouvelles options Hop-by-hop.
Mais, bon, le plus important est de décider quoi montrer, pas juste comment. Le RFC rappelle qu'il serait sympa d'exposer explicitement des informations comme le RTT ou le taux de pertes vu par les machines terminales, plutôt que de laisser les machines intermédiaires le calculer (ce qu'elles ne peuvent de toute façon plus faire en cas de chiffrement). Cela permettrait de découpler l'information de haut niveau des détails du format d'un protocole de transport. Pourquoi une machine terminale ferait-elle cela, au risque d'exposer des informations qu'on peut considérer comme privées ? Le RFC cite la possibilité d'obtenir un meilleur service, sans trop préciser s'il s'agit de laisser les opérateurs offrir un traitement préférentiel aux paquets portant cette information, ou bien si c'est dans l'espoir que l'information exposée serve à l'opérateur pour améliorer son réseau. (Comme le note le RFC 8558, il y a aussi le risque que la machine terminale mente au réseau. Au moins, avec le chiffrement, les choses sont claires : « je refuse de donner cette information » est honnête.)
Dernière note, cet ajout d'informations utiles pour l'OAM peut être faite par la machine terminale mais aussi (section 6 du RFC) par certains équipements intermédiaires.
En conclusion ? La section 7 du RFC reprend et résume les points importants :
- Le chiffrement et l'authentification dans la couche de Transport sont une bonne chose. Personne n'ose dire ouvertement qu'il faudrait rester à des protocoles de transport non sécurisés. C'est un point sur lequel le document a beaucoup évolué. Dans les versions antérieures, comme le notait Christian Huitema, « Much of the draft reads like a lamentation of the horrible consequences of encrypting transport headers », reflétant unilatéralement le point de vue des opérateurs réseau, et des vendeurs de middleboxes. Une relecture par Christopher Wood au début du projet avait déjà pointé ce problème, notant que le document était très anti-chiffrement. Cette question a, fort logiquement, été le principal point de discussion à l'IETF.
- Le RFC, officiellement, ne tranche pas sur la pertinence et l'éthique des pratiques qu'il décrit, il explique juste ce qui se fait. (Le même argument, que je trouve un peu hypocrite, avait été utilisé pour le très contestable RFC 8404.)
- Comme souvent en sécurité, il n'y a pas de solution idéale, il faudra trouver un compromis, par exemple entre la vie privée et l'OAM. Le RFC cite le spin bit de QUIC, qui avait été très chaudement discuté, comme un exemple de compromis, en tout cas par le sérieux de l'analyse de ses coûts et de ses bénéfices.
- Le RFC reconnait que tout ce qui est exposé au réseau s'ossifiera et deviendra une spécification de fait, qu'on ne pourra plus changer. Qu'un protocole choisisse d'exposer beaucoup ou au contraire très peu, il doit de toute façon faire ce choix explicitement.
- Même le chiffrement de la couche Transport ne cache pas tout, et les couches inférieures exposent toujours des métadonnées. Un surveillant déterminé n'est donc pas désarmé. (Même si des organisations comme Interpol prétendent que le chiffrement rend la police « aveugle ».)
- Les opérationnels se sont habitués depuis longtemps à disposer de certaines informations, que le chiffrement de la couche Transport peut rendre inutilisables. Il faudra donc changer certaines pratiques et certains outils, par exemple avec davantage de coopération des machines terminales (sinon, les opérations seront affectées).
- Le RFC rappelle aussi qu'il existe différents types de réseaux, et qui n'ont pas forcément les mêmes contraintes et les mêmes buts. Entre le réseau d'une entreprise qui veut contrôler tout ce que font les employés et le réseau d'un FAI qui doit respecter (en théorie…) le principe de neutralité, il n'est pas du tout sûr qu'on puisse trouver des solutions qui plaisent à tout le monde. (A priori, l'IETF travaille et normalise pour l'Internet ouvert, pas forcément pour chaque réseau connecté à l'Internet avec ses règles spécifiques.)
- L'Internet est un réseau partagé et son bon fonctionnement dépend donc du respect de certaines règles par tous. Par exemple, un protocole de transport doit penser aux autres, en ne noyant pas le réseau sous les paquets de retransmission. Si un fournisseur de logiciels était tenté de développer un protocole de transport égoïste, qui tente d'obtenir plus que sa part de la capacité du réseau, la tricherie pourrait se détecter en observant le fonctionnement de ce protocole. Le chiffrement de la couche Transport rend évidemment la vérification plus complexe.
- Le bon fonctionnement de l'Internet sur le long terme dépend également d'une activité de recherche et développement, qui s'appuie sur des mesures, que le chiffrement de la couche Transport peut gêner. (C'est bien, de se préoccuper des chercheurs.)
L'article seul
RFC 9063: Host Identity Protocol Architecture
Date de publication du RFC : Juillet 2021
Auteur(s) du RFC : R. Moskowitz (HTT Consulting), M. Komu (Ericsson)
Pour information
Réalisé dans le cadre du groupe de travail IETF hip
Première rédaction de cet article le 15 juillet 2021
Ce RFC propose d'aborder l'architecture de l'Internet en utilisant un nouveau type d'identificateur, le Host Identifier (HI), pour beaucoup d'usages qui sont actuellement ceux des adresses IP. Il remplace le RFC 4423, qui était la description originale du protocole HIP, mais il n'y a pas de changements fondamentaux. HIP était un projet très ambitieux mais, malgré ses qualités, la disponibilité de plusieurs mises en œuvre, et des années d'expérimentation, il n'a pas percé.
Une adresse IP sert actuellement à deux choses : désigner une machine (l'adresse IP sert par exemple à distinguer plusieurs connexions en cours) et indiquer comment la joindre (routabilité). Dans le premier rôle, il est souhaitable que l'adresse soit relativement permanente, y compris en cas de changement de FAI ou de mobilité (actuellement, si une machine se déplace et change d'adresse IP, les connexions TCP en cours sont cassées). Dans le second cas, on souhaite au contraire une adresse qui soit le plus « physique » possible, le plus dépendante de la topologie. Ces deux demandes sont contradictoires.
HIP résout le problème en séparant les deux fonctions. Avec HIP, l'adresse IP ne serait plus qu'un identifiant « technique », ne servant qu'à joindre la machine, largement invisible à l'utilisateur et aux applications (un peu comme une adresse MAC aujourd'hui). Chaque machine aurait un HI (Host Identifier) unique. Contrairement aux adresses IP, il n'y a qu'un HI par machine multi-homée mais on peut avoir plusieurs HI pour une machine si cela correspond à des usages différents, par exemple une identité publique, et une « anonyme ».
Pour pouvoir être vérifié, le nouvel identificateur, le HI sera (dans la plupart des cas) une clé publique cryptographique, qui sera peut-être allouée hiérarchiquement par PKI ou plutôt de manière répartie par tirage au sort (comme le sont les clés SSH ou PGP aujourd'hui, ce qui serait préférable, question vie privée). Ces identificateurs fondés sur la cryptographie permettent l'authentification réciproque des machines (contrairement à IP, où il est trivial de mentir sur son adresse), et d'utiliser ensuite IPsec (RFC 7402) pour chiffrer la communication (HIP n'impose pas IPsec, plusieurs encapsulations des données sont possibles, et négociées dynamiquement, mais, en pratique, la plupart des usages prévus reposent sur IPsec).
L'authentification permet d'être sûr du HI de la machine avec qui on parle et, si le HI était connu préalablement à partir d'une source de confiance, d'être sûr qu'on parle bien à l'interlocuteur souhaité. (Si on ne connait pas le HI à l'avance, on dit que HIP est en mode « opportuniste ».)
Cette séparation de l'identificateur et du localisateur est un sujet de recherche commun et d'autres propositions que HIP existent, comme LISP (RFC 9300) ou ILNP (RFC 6740). Dans tous les cas, les couches supérieures (comme TCP) ne verront que l'identificateur, permettant au localisateur de changer sans casser les sessions de transport en cours. (Un mécanisme ressemblant est le Back to My Mac du RFC 6281.) L'annexe A.1 de notre RFC rappelle les avantages de cette approche. Et l'annexe A.2, lecture très recommandée, note également ses défauts, l'indirection supplémentaire ajoutée n'est pas gratuite, et entraine des nouveaux problèmes. Notamment, il faut créer un système de correspondance - mapping - entre les deux, système qui complexifie le projet. Il y a aussi la latence supplémentaire due au protocole d'échange initial, qui est plus riche. Comparez cette honnêteté avec les propositions plus ou moins pipeau de « refaire l'Internet en partant de zéro », qui ne listent jamais les limites et les problèmes de leurs solutions miracle.
Ce HI (Host Identifier) pourra être stocké dans des annuaires publics, comme le DNS (RFC 8005), ou une DHT (RFC 6537), pour permettre le rendez-vous (RFC 8004) entre les machines.
Notez que ce n'est pas directement le Host Identifier, qui peut être très long, qui sera utilisé dans les paquets IP, mais un condensat, le HIT (Host Identity Tag).
HIP intègre les leçons de l'expérience avec IP, notamment de l'importance d'authentifier la machine avec qui on parle. C'est ce qui est fait dans l'échange initial qui permet à un initiateur et un répondeur de se mettre à communiquer. Notamment, il y a obligation de résoudre un puzzle cryptographique, pour rendre plus difficile certaines attaques par déni de service. Voir à ce sujet « DOS-Resistant Authentication with Client Puzzles » de Tuomas Aura, Pekka Nikander et Jussipekka Leiwo, « Deamplification of DoS Attacks via Puzzles » de Jacob Beal et Tim Shepard ou encore « Examining the DOS Resistance of HIP » de Tritilanunt, Suratose, Boyd, Colin A., Foo, Ernest, et Nieto, Juan Gonzalez.
La sécurité est un aspect important de HIP. Les points à garder en tête sont :
- Protection contre certaines attaques par déni de service via le puzzle cryptographique à résoudre.
- Protection contre les attaques de l'homme du milieu si le HI a été obtenu par un mécanisme sûr. Cela ne marche évidemment pas en mode opportuniste, où l'initiateur ne connait pas le HI de son correspondant, et le découvre une fois la connexion faite.
- Le mode opportuniste peut être renforcé, question sécurité, par le TOFU (RFC 7435).
- Tout mécanisme de séparation de l'identificateur et du localisateur ouvre de nouveaux problèmes : que se passe-t-il si le correspondant ment sur son localisateur ? Est-ce que cela permet des attaques par réflexion ? C'est pour éviter cela que les systèmes à séparation de l'identificateur et du localisateur prévoient, comme HIP, un test de l'existence d'une voie de retour (Cf. RFC 4225).
- Enfin, on peut évidemment mettre des ACL sur des HI mais leur structure « plate » fait qu'il n'y a pas d'agrégation possible de ces ACL (il faut une ACL par machine avec qui on correspond).
Au sujet du TOFU, le RFC cite « Leap-of-faith security is enough for IP mobility » de Miika Kari Tapio Komu et Janne Lindqvist, « Security Analysis of Leap-of-Faith Protocols » de Viet Pham et Tuomas Aura et « Enterprise Network Packet Filtering for Mobile Cryptographic Identities » de Janne Lindqvist, Essi Vehmersalo, Miika Komu et Jukka Manner.
Notre RFC ne décrit qu'une architecture générale, il est complété par les RFC 7401, qui décrit le protocole, RFC 7402, RFC 8003, RFC 8004, RFC 8005, RFC 8046 et RFC 5207. Si des implémentations expérimentales existent déjà et que des serveurs publics utilisent HIP, aucun déploiement significatif n'a eu lieu (cf. l'article « Adoption barriers of network layer protocols: The case of host identity protocol de T. Leva, M. Komu, A. Keranen et S. Luukkainen). Comme le disait un des relecteurs du RFC, « There's a lot of valuable protocol design and deployment experience packed into this architecture and the associated protocol RFCs. At the same time, actual adoption and deployment of HIP so far appears to have been scarce. I don't find this surprising. The existing Internet network/transport/application protocol stack has already become sufficiently complicated that considerable expertise is required to manage it in all but the simplest of cases. Teams of skilled engineers routinely spend hours or days troubleshooting operational problems that crop up within or between the existing layers, and the collection of extensions, workarounds, identifiers, knobs, and failure cases continues to grow. Adding a major new layer--and a fairly complicated one at that--right in the middle of the existing stack seems likely to explode the already heavily-strained operational complexity budget of production deployments. ». L'annexe A.3 décrit les questions pratiques liées au déploiement. Elle rappelle le compte-rendu d'expérience chez Boeing de Richard Paine dans son livre « Beyond HIP: The End to Hacking As We Know It ». Elle tord le cou à certaines légendes répandues (que HIP ne fonctionne pas à travers les routeurs NAT, ou bien qu'il faut le mettre en œuvre uniquement dans le noyau.)
Ah, question implémentations (RFC 6538), on a au moins HIP for Linux et OpenHIP qui ont été adaptés aux dernières versions de HIP, et des protocoles associés.
Les changements depuis le RFC 4423 sont résumés en section 14. Il n'y en a pas beaucoup, à part l'intégration de l'expérience, acquise dans les treize dernières années (et résumée dans le RFC 6538) et des améliorations du texte. La nouvelle annexe A rassemble plein d'informations concrètes, notamment que les questions pratiques de déploiement de HIP, et sa lecture est très recommandée à tous ceux et toutes celles qui s'intéressent à la conception de protocoles. La question de l'agilité cryptographique (RFC 7696) a également été détaillée.
L'article seul
Récupérer la date d'expiration d'un domaine en RDAP
Première rédaction de cet article le 4 juillet 2021
Dernière mise à jour le 7 octobre 2022
C'est dimanche, il ne fait pas beau, pas question de pique-nique, on va donc faire un peu de JSON. Un des problèmes les plus courants avec les noms de domaine est l'expiration accidentelle du nom. « Nous avons oublié de le renouveler » et paf plus rien ne marche. Pourtant, la date à laquelle le domaine expire est publiquement annoncée, via des protocoles comme whois ou RDAP. Comment utiliser RDAP pour récupérer cette date dans un programme, par exemple un programme d'alerte qui préviendra si l'expiration approche ?
Un peu de contexte d'abord ; un certain nombre (mais pas tous) de
registres de noms de domaine exigent un renouvellement
périodique du nom, avec paiement et parfois acceptation de
nouvelles conditions. L'oubli de ce renouvellement est un gag très
fréquent. On ne paie pas, et, à la date d'expiration, le domaine
disparait ou bien est mis en attente, plus publié dans le DNS, ce qui fait que tous les
services associés cessent de fonctionner. Dans le premier cas, le
pire, le domaine a été supprimé, et un autre peut l'enregistrer
rapidement. Il est donc crucial de ne pas laisser le domaine
expirer. Un des outils indispensables quand on gère un domaine
important est donc une supervision
automatique de l'approche de l'expiration. L'information est
diffusée par le registre, via plusieurs protocoles. Le traditionnel
whois, normalisé dans le RFC 3912 a plusieurs inconvénients notamment le fait que le
format de sortie n'est pas normalisé. Il est donc difficile d'écrire
un programme qui analyse l'information retournée (il existe quand
même des solutions comme, en Perl, Net::DRI). Au
contraire, le plus moderne RDAP a un format
de sortie normalisé (dans le RFC 9083). Utilisons-le, en prenant comme exemple le domaine
de ce blog, bortzmeyer.org.
RDAP utilise HTTPS et produit du JSON (RFC 8259). D'autre part, pour interroger le bon serveur RDAP
(celui du registre), il faut connaitre son nom, ce qui se trouve
dans un registre
IANA qui associe le TLD à son serveur RDAP. On apprend ainsi que les
informations concernant
.org sont à demander à
https://rdap.publicinterestregistry.org/rdap/. Utilisant
le RFC 9082 pour former une requête RDAP
correcte, on va utiliser curl
pour poser la question sur bortzmeyer.org :
% curl -s https://rdap.publicinterestregistry.org/rdap/domain/bortzmeyer.org
On récupère un gros JSON compliqué, que je ne vous montre pas ici. On veut juste la date d'expiration du domaine. On va se servir pour cela de l'excellent outil jq :
% curl -s https://rdap.publicinterestregistry.org/rdap/domain/bortzmeyer.org | \
jq '.events | map(select(.eventAction == "expiration"))[0] | .eventDate'
"2021-08-29T09:32:04.304Z"
OK, j'ai triché, ça m'a pris plus de quelques secondes pour écrire le programme jq qui extrait cette information, et j'ai dû vérifier dans le RFC 9083. Expliquons donc.
Partons du haut de l'objet JSON retourné. Il contient un membre
nommé events (RFC 9083,
section 4.5) qui indique les évènements passés ou futurs pertinents,
comme la création du domaine ou comme sa future expiration. On doit
donc commencer par demander au programme jq de filtrer sur ce
membre, d'où le .events au début. Ensuite, on
veut ne garder, parmi les évènements, que l'expiration. On applique
donc (map) un test (.eventAction ==
"expiration") à chaque élement du tableau
events et on ne garde
(select) que celui qui nous intéresse. Oui,
« celui » et pas « ceux » car il n'y a normalement qu'un évènement
d'expiration, donc on ne garde que le premier élement
([0]) du tableau produit. Ce premier élément,
comme tous ceux qui composent le tableau events
est un évènement (RFC 9083, section 4.5), un
objet qui a ici deux membres, eventAction, son
type (celui sur lequel on filtre, avec .eventAction ==
"expiration" et eventDate,
l'information qu'on recherche. On termine donc par un filtre du seul
eventDate, date qui est au format du RFC 3339. Et voilà. On peut ensuite traiter cette
date comme on veut. Par exemple, le programme GNU date peut vous
traduire cette date en secondes écoulées depuis l'epoch :
% date --date=$(curl -s https://rdap.publicinterestregistry.org/rdap/domain/bortzmeyer.org | \
jq -r '.events | map(select(.eventAction== "expiration"))[0] | .eventDate') \
+%s
1630229524
Abandonnons maintenant curl et jq pour un programme écrit en Python. On utilise la bibliothèque Requests pour faire du HTTPS et les bibliothèques standard incluses dans Python pour faire du JSON, du calcul sur les dates, etc. Récupérer le JSON est simple :
response = requests.get("%s/%s" % (SERVER, domain))
if response.status_code != 200:
raise Exception("Invalid RDAP return code: %s" % response.status_code)
Le transformer en un dictionnaire Python également :
rdap = json.loads(response.content)
On va ensuite y chercher la date d'expiration, qu'on transforme en une belle date-et-heure Python sur laquelle il sera facile de faire des calculs :
for event in rdap["events"]:
if event["eventAction"] == "expiration":
expiration = datetime.datetime.strptime(event["eventDate"], RFC3339)
now = datetime.datetime.utcnow()
rest = expiration-now
Et on peut ensuite mettre les traitements qu'on veut, ici prévenir si l'expiration approche :
if rest < CRITICAL:
print("CRITICAL: domain %s expires in %s, HURRY UP!!!" % (domain, rest))
sys.exit(2)
elif rest < WARNING:
print("WARNING: domain %s expires in %s, renew now" % (domain, rest))
sys.exit(1)
else:
print("OK: domain %s expires in %s" % (domain, rest))
sys.exit(0)
Le code complet est disponible (il faut aussi ce module). Notez qu'il n'est pas
tellement robuste, il faudrait prévoir davantage de traitement
d'erreur. Python fait toutefois en sorte que la plupart des erreurs
soient détectées automatiquement (par exemple s'il n'existe pas de
membre events dans le résultat) donc, au moins,
vous n'aurez pas de résultats erronés. Et puis, par rapport au
programme curl+jq plus haut, un grand avantage de ce programme
Python est qu'il utilise le registre IANA des serveurs (décrit dans le RFC 9224) et qu'il trouve donc tout seul le serveur
RDAP :
% ./expiration-rdap.py bortzmeyer.org OK: domain bortzmeyer.org expires in 55 days, 18:54:01.281920 % ./expiration-rdap.py quimper.bzh WARNING: domain quimper.bzh expires in 6 days, 18:17:25.919080, renew now
Une version plus élaborée de ce programme Python, utilisable depuis des logiciels de supervision automatique comme Nagios, Icinga ou Zabbix est disponible.
Notez qu'un tel outil n'est qu'un élément parmi tout ce qu'il faut faire pour bien gérer l'éventuelle expiration de votre domaine. Il faut aussi mettre les dates de renouvellement dans votre agenda, il est recommandé d'activer l'auto-renouvellement ou, mieux, chez les registres qui le permettent, de louer pour plusieurs années. Je vous recommande également la lecture du « Guide du Titulaire Afnic » ou des « Bonnes pratiques pour l'acquisition et l'exploitation de noms de domaine de l'ANSSI ».
L'article seul
RFC 9039: Uniform Resource Names for Device Identifiers
Date de publication du RFC : Juin 2021
Auteur(s) du RFC : J. Arkko (Ericsson), C. Jennings (Cisco), Z. Shelby (ARM)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF core
Première rédaction de cet article le 1 juillet 2021
Voici un nouvel espace de noms pour des URN, dev, afin de
stocker des identificateurs pour des équipements matériels, par
exemple pour les inventaires.
Les URN, un
sous-ensemble des URI, et des cousins des URL, sont normalisés
dans le RFC 8141. On peut placer des URN
partout où on peut mettre des URI, par exemple comme noms dans
SenML (RFC 8428). Pour
des objets contraints, les URN risquent d'être un peu longs par
rapport à, par exemple, une adresse IPv4,
mais ils sont plus souples. Un URN commence par le plan
urn:, suivie d'un espace de noms. Ces espaces
sont stockés
dans un registre IANA. Ce nouveau RFC crée un nouvel espace de noms,
dev. On pourra donc désormais avec des URN
comme urn:dev:os:32473-123456 (qui identifie la
machine 123456 de l'organisation 32473). Ces identificateurs de
machines pourront être utilisés toutes les fois où on a besoin de
désigner une machine, dans les données du RFC 8428, dans
des inventaires, etc.
Passons au concret maintenant, avec la section 3 du RFC, qui
donne la définition formelle de l'espace de noms
dev. Ces URN sont évidemment conformes à la
norme des URN, le RFC 8141. Comme tous les
URN, ceux sous urn:dev: ne sont pas prévus pour
être résolus automatiquement. Contrairement aux URL, ils ne
fournissent pas de moyen d'accès à une ressource. Bien sûr, si on
les met dans une base de données, d'inventaire de ses machines, par
exemple, on pourra retrouver l'information, mais ce RFC ne spécifie
aucun mécanisme de résolution standard (section 3.6 du RFC).
Après le urn:dev:, ces URN prennent
un composant supplémentaire, qui identifie le type d'identificateur
dont dérive l'URN. Cela peut être :
mac, où l'identificateur est une adresse MAC, enregistrée selon les procédures IEEE, au format EUI-64. C'est par exempleurn:dev:mac:acde48234567019f(pour l'adresse MACac:de:48:23:45:67:01:9f). Si vous faites varier l'adresse MAC, par exemple pour protéger votre vie privée, l'URN n'est plus un identifiant stable.ow, qui s'appuie sur 1-Wire, un système privateur.org, avec des identificateurs spécifiques à une organisation, identifiée par son PEN (les PEN sont normalisés dans le RFC 2578). Les PEN sont enregistrés à l'IANA. Prenons comme exemple celui d'une entreprise dont j'étais un co-fondateur, 9319. Si cette entreprise utilise des noms pour ses machines, la machinemarxaurait comme URNurn:dev:org:9319-marx.os, comme lesorgmais plutôt prévus pour des numéros de série. Si cette entreprise numérote toutes ses machines en partant de 1, un URN seraiturn:dev:os:9319-1. (Notez que des versions précédentes des URNdevutilisaientospour les identificateurs LwM2M.) Ainsi, le RIPE-NCC qui a le PEN 15854 pourrait nommer ses sondes Atlas d'après leur numéro unique et donc la sonde 6593 pourrait être désignée parurn:dev:os:15854-6593. Notez qu'on pourrait avoir ici une intéressante discussion sur l'intérêt respectif des URN (urn:dev:os:15854-6593) et des URL (https://atlas.ripe.net/probes/6593/).ops, qui ressemble à l'os, mais avec un identificateur de produit entre le PEN et le numéro de série, par exempleurn:dev:ops:9319-coffeemachine-2pour la deuxième machine à café de l'organisation. (Commeos, il avait été utilisé pour l'Open Mobile Alliance.)- Un autre type, qui sera défini dans le futur (cf. section 7
du RFC). En attendant, on peut utiliser
examplepour des exemples, commeurn:dev:example:1234.
Enfin, une machine identifiée par un de ces URN peut avoir une
partie particulière de la machine désignée par une chaine de
caractères après un tiret bas. Ainsi,
urn:dev:os:9319-1_alimentation serait
l'alimentation de la machine
urn:dev:os:9319-1.
Notez que l'équivalence de deux URN est sensible à la casse donc attention, par exemple, à la façon dont vous écrivez les adresses MAC. Le RFC recommande de tout mettre en minuscules.
Idéalement, on veut bien sûr qu'un URN dev
identifie une machine et une seule. Mais, en pratique, cela peut
dépendre du type d'identificateurs utilisé. Ainsi, les adresses MAC
ne sont pas forcément uniques, entre autres parce que certains
fabricants ont déjà réutilisé des adresses.
Petit avertissement sur la vie privée : les identificateurs décrits dans ce RFC sont prévus pour être très stables sur le long terme (évidemment, puisque leur but est de garder trace d'une machine) et leur utilisation imprudente (par exemple si on envoie un de ces URN avec les données d'un utilisateur anonyme) peut permettre une surveillance accrue (sections 3.4 et 6.1 du RFC). Le RFC 7721 détaille les risques de ces identificateurs à longue durée de vie.
Le RFC note (section 1) qu'il existe d'autres catégories
d'identificateurs qui, selon le cas, pourraient concurrencer nos URN
de l'espace de noms dev. C'est le cas par
exemple des condensats du RFC 6920, des
IMEI du RFC 7254, des
MEID du RFC 8464 et
bien sûr des UUID du RFC 9562. Tous peuvent se
représenter sous forme d'URI, et parfois d'URN. Ils ont leurs
avantages et leurs inconvénients, le choix est vaste.
Pour les gens qui utiisent le SGBD
PostgreSQL, notez qu'il n'a pas de type de
données « URI » donc, si on veut stocker les URN de
notre RFC dans PostgreSQL, il faut utiliser le type
TEXT, ou bien installer une extension comme
pguri. Selon ce
qu'on veut faire de ces URN, on peut aussi prendre une solution plus
simple qui ne nécessite pas d'installer d'extension, ici pour une
organisation qui met toutes ces machines en
urn:dev:os:9319-… :
CREATE DOMAIN urndev AS text CHECK (VALUE ~ '^urn:dev:os:9319-[0-9]+(_[a-z0-9]+)?$');
COMMENT ON DOMAIN urndev IS 'URN DEV (RFC 9039) for our devices';
CREATE TABLE Devices (id SERIAL, urn urndev UNIQUE NOT NULL, comments TEXT);
INSERT INTO Devices (urn, comments) VALUES ('urn:dev:os:9319-2', 'No comment');
INSERT INTO Devices (urn) VALUES ('urn:dev:os:9319-1_alimentation');
INSERT INTO Devices (urn, comments) VALUES ('urn:dev:os:9319-666', 'Beast');
L'article seul
Une « monnaie numérique de banque centrale », c'est quoi ?
Première rédaction de cet article le 27 juin 2021
Dès qu'il s'agit de monnaie, on lit n'importe quoi dans les médias, et on entend n'importe quoi aux tribunes des colloques. Songeons par exemple à tous les gens qui ont péroré sur le Bitcoin ou sur les cryptomonnaies sans rien y connaitre. De même quand on parle de « monnaie numérique de banque centrale », la confusion règne. Notons donc un excellent article d'analyse écrit pour la banque centrale suisse (mais qui n'exprime pas la politique officielle de cette institution) expliquant à quoi pourrait ressembler une MNBC (monnaie numérique de banque centrale) et proposant une solution spécifique.
Lorsqu'on parle de « monnaie électronique » (ou numérique), la confusion règne. Parfois, le terme désigne toute monnaie qui n'est pas en pièces ou en billets (à ce compte, toutes les monnaies sont électroniques depuis longtemps). Parfois, on ne le dit que pour les cryptomonnaies ou que pour celles qui tournent sur une chaine de blocs. Ici, on va utiliser le terme pour une monnaie qui a certaines propriétés de l'argent liquide (notamment une certaine protection de la vie privée) tout en étant entièrement numérique. Ainsi, la carte Visa n'entre pas dans cette définition, car elle n'offre aucune vie privée.
L'article dont je parlais au début est « Comment émettre une monnaie numérique de banque centrale ». Oui, l'avantage des études faites pour un organisme officiel suisse, c'est qu'il y a une traduction de qualité en français. Ses auteurs sont David Chaum (celui de DigiCash), Christian Grothoff (celui de GNUnet) et Thomas Moser, des gens qui connaissent leur sujet, donc.
Pour résumer leur article (mais je vous en recommande la lecture complète), leur cahier des charges est celui d'une monnaie émise et gérée par une banque centrale (un cahier des charges, donc, très différent de celui du Bitcoin, qui vise à se passer de banque centrale), garantissant un minimum d'anonymat pour ceux qui paient avec cette monnaie (« la préservation d’une propriété clé de la monnaie physique: la confidentialité des transactions »), mais pas pour ceux qui la reçoivent. Les revenus des commerçants ne sont donc pas dissimulés, ce qui permet de lutter contre la fraude fiscale. La définition même de monnaie ne fait pas consensus mais les auteurs se focalisent sur un rôle, le moyen d'échange (il y en a d'autres rôles à la monnaie, par exemple unité de mesure ou stockage de valeur). De plus, les auteurs veulent appliquer les principes de KYC (connaissance du client), d'AML (lutte contre le blanchiment) et de CFT (lutte contre le financement du terrorisme), oui, il y en a, des sigles, dans le secteur bancaire. On voit que les objectifs mis en avant sont distincts de ceux de Bitcoin et, a fortiori, de Zcash puisque que, comme le note l'article, « La détection de fraude requiert cependant une capacité d’identification du payeur et le traçage des clients, ce qui est incompatible avec le respect de la confidentialité de la transaction. ». Le fait d'avoir un cahier des charges clair est un des intérêts de cette étude. Par exemple, d'innombrables articles ont été écrits sur des projets comme Diem ou le « yuan électronique » alors que leur cahier des charges reste vague. Le problème est d'autant plus grave qu'il y a souvent de la mauvaise foi dans certains discours. Ainsi, les projets de numérisation ont souvent pour but réel d'en finir avec l'argent liquide pour avoir une traçabilité complète des transactions et une surveillance permanente des acheteurs.
Comment les auteurs de l'article voient-ils leur système de MNBC (monnaie numérique de banque centrale) ? Étant donné qu'il n'y a qu'un émetteur, nul besoin d'une chaine de blocs. (La quasi-totalité des projets de « chaine de blocs privée » ou de « chaine de blocs à permission » n'ont aucun sens : comme le dit l'article « La DLT est une architecture intéressante lorsqu’il n’existe pas d’acteur central ou si les parties prenantes ne souhaitent pas s’accorder sur un acteur central de confiance. Ce qui n’est cependant pratiquement jamais le cas pour une monnaie numérique de détail émise par une banque centrale. [...] Recourir à un registre distribué [réparti, plutôt] ne fait qu’augmenter les coûts de transaction; cela n’apporte aucun avantage dans une mise en place par une banque centrale »). Leur système repose à la place sur GNU Taler (développé par un des auteurs) et les signatures en aveugle de Chaum. La sécurité du système dépend donc de ces techniques logicielles. (D'autres propositions font appel à des systèmes physiques spécifiques, mais « les fonctions physiques non clonables ne peuvent pas s’échanger sur Internet (éliminant de fait l’usage principal de la MNBC » et « les tentatives précédentes de verrous matériels pour empêcher la copie ont été compromises de façon répétée », voir les DRM.) Comme la monnaie numérique de banque centrale envisagée dans cet article a beaucoup de propriétés communes avec l'argent physique (le liquide), elle a également une sécurité proche : possession fait loi, ce qui veut dire que, si l'appareil sur lequel vous gardez vos pièces est détruit, vous perdez votre argent. Cette solution, comme l'argent liquide, n'est raisonnable que pour des sommes relativement faibles. Si l'acheteur n'est pas identifiable, le vendeur l'est car il ne peut pas réutiliser directement les « pièces », il doit les remettre à la banque. C'est nécessaire au mécanisme de protection contre la double dépense. Autre nécessité, la banque centrale doit être connectée en permanence, ce qui impose des exigences nouvelles pour les banques centrales (« La détection de doubles dépenses en ligne élimine ce risque mais rend donc les transactions impossibles si la connexion Internet de la banque centrale est indisponible. ») Je ne vous détaille pas les protocoles cryptographiques ici, je n'ai pas le niveau, lisez l'article. Notez qu'ils sont assez complexes, ce qui peut être un obstacle à l'adoption : la plupart des utilisateurs ne peuvent pas comprendre cette solution, ils devront faire confiance à la minorité qui a compris et vérifié. (Ceci dit, dès aujourd'hui, peu de gens comprennent le système monétaire.)
Quelles sont les chances qu'une banque centrale, avec ses messieurs sérieux en costume-cravate, reprenne cette idée et se lance dans un projet de monnaie numérique protégeant la vie privée ? Personnellement, je dirais qu'elles sont à peu près nulles. Les auteurs notent à juste titre que « une MNBC de détail devrait être basée sur un logiciel libre ou ouvert. Imposer une solution propriétaire qui entraînerait une dépendance à un fournisseur spécifique pourrait vraisemblablement constituer dès le départ un obstacle à son adoption. » Mais cette condition suffirait à faire rejeter le projet par toute banque centrale (déjà, le mot « libre »…). Tous ces dirigeants politiques et financiers passent du temps à critiquer le Bitcoin « qui permet la fraude fiscale et le financement du terrorisme » mais ils ne font aucun effort pour développer des alternatives. Le projet décrit dans cet article est sympathique mais n'a aucune chance. Il essaie de plaire aux banques centrales mais celles-ci n'en voudront jamais, attachées qu'elles sont à des solutions fermées, privatrices, et facilitant la surveillance.
L'article seul
RFC 9057: Email Author Header Field
Date de publication du RFC : Juin 2021
Auteur(s) du RFC : D. Crocker (Brandenburg InternetWorking)
Expérimental
Première rédaction de cet article le 23 juin 2021
Qui est l'auteur d'un message reçu par courrier
électronique ? La réponse semblait autrefois simple,
c'est forcément la personne ou l'organisation indiquée dans le champ
From:. Sauf que des changements récents (et pas
forcément bien inspirés) dans le traitement des messages ont amené à
ce que le From: soit parfois modifié, par
exemple par certaines listes de diffusion. Il
ne reflète donc plus le vrai auteur. D'où ce RFC qui crée un nouvel
en-tête, Author:, qui identifie le vrai
émetteur.
La norme pertinente est le RFC 5322, qui
définit des en-têtes comme From: (auteur d'un
message) ou Sender: (personne ou entité qui n'a
pas écrit le message mais réalise l'envoi, par exemple parce que
l'auteur n'avait pas le temps, ou bien parce que le message a été
relayé par un intermédiaire). Les amateurs d'archéologie noteront
que le courrier électronique est très ancien,
plus ancien que l'Internet, cette ancienneté étant la preuve de son
efficacité et de sa robustesse. Le premier RFC avec la notion formelle d'auteur d'un
message était le RFC 733.
Une particularité du courrier électronique est que le message ne
va pas toujours directement de la machine de l'auteure à celle du
lecteur (cf. le RFC 5598, sur l'architecture
du courrier). Il y a souvent des intermédiaires
(mediators) comme les gestionnaires de
listes de diffusion, qui prennent un message
et le redistribuent aux abonnées. En raison du problème du
spam, plusieurs mécanismes de protection ont
été développés, qui peuvent poser des problèmes pour ces
intermédiaires. SPF (RFC 7208),
contrairement à une légende tenace, n'affecte pas les listes de
diffusion. (C'est en raison de la distinction entre enveloppe et
en-tête d'un message. Si vous entendez quelqu'un pontifier sur SPF
et la messagerie, et qu'il ne connait pas la différence entre
l'émetteur indiqué dans l'enveloppe et celui marqué dans l'en-tête,
vous pouvez être sûre que cette personne est ignorante.) En
revanche, DKIM (RFC 6376), surtout
combiné avec DMARC (RFC 9989), peut poser des problèmes dans certains cas (le
RFC 6377 les détaille). Pour gérer ces
problèmes, certaines listes de diffusion choisissent de carrément
changer le From: du message et d'y mettre, par
exemple (ici tiré de l'utile liste
outages, informant des pannes Internet) :
From: Erik Sundberg via Outages <outages@outages.org>
Alors que le message avait en fait été écrit par « Erik Sundberg
<ESundberg@nitelusa.com> ». C'est une
mauvaise idée, mais elle est commune. Dans ce cas, la liste s'est
« approprié » le message et on a perdu le vrai auteur, privant ainsi
la lectrice d'une information utile (dans le cas de la liste
Outages, il a toutefois été préservé dans le
champ Reply-To:). [Personnellement, il me semble
que l'idéal serait de ne pas modifier le message, préservant ainsi
les signatures DKIM, et donc les vérifications DMARC. Dans les cas
où le message est modifié, DMARC s'obstine à vérifier le
From: et pas le Sender:,
ce qui serait pourtant bien plus logique.]
Maintenant, la solution (section 3 du RFC) : un nouvel en-tête,
Author:, dont la syntaxe est la même que celle
de From:. Par exemple :
Author: Dave Crocker <dcrocker@bbiw.net>
Cet en-tête peut être mis au départ, par le MUA, ou bien ajouté par un intermédiaire
qui massacre le champ From: mais veut garder
une trace de sa valeur originale en la recopiant dans le champ
Author:. Cela n'est possible que s'il n'y a pas
déjà un champ Author:. S'il existe, il est
strictement interdit de le modifier ou de le supprimer.
À la lecture, par le MUA de réception, le RFC conseille
d'utiliser le champ Author:, s'il est présent,
plutôt que le From:, pour afficher ou trier sur
le nom de l'expéditrice.
Comme dans le cas du champ From:, un
malhonnête peut évidemment mettre n'importe quoi dans le champ
Author: et il faut donc faire attention à ne
pas lui accorder une confiance aveugle.
Author: a été ajouté au registre
des en-têtes.
On notera qu'une tentative précédente de préservation de
l'en-tête From: original avait été faite dans
le RFC 5703, qui créait un
Original-From: mais uniquement pour les
intermédiaires, pas pour les MUA.
L'article seul
Traiter des options EDNS nouvelles dans un programme
Première rédaction de cet article le 18 juin 2021
Le protocole DNS permet d'attacher des métadonnées aux questions ou aux réponses par le biais de l'extension EDNS, normalisée dans le RFC 6891. Un certain nombre d'options sont déjà normalisées et peuvent être manipulées depuis un programme, via une bibliothèque DNS. Mais s'il s'agit d'une option EDNS nouvelle, pas encore traitée par la bibliothèque ?
On va voir cela avec l'option « RRSERIAL » actuellement en cours
de discussion à l'IETF, dans le
draft draft-ietf-dnsop-rrserial. (Elle
a depuis été renommée ZONEVERSION et normalisée dans le RFC 9660, avec une syntaxe différente.)
Son
but est de récupérer le numéro de série de la zone correspondant à
une réponse. Elle est très simple, la valeur associée étant vide
dans la question, et uniquement un entier sur 32 bits dans la
réponse. Un serveur expérimental existe utilisant cette option,
200.1.122.30.
Déjà, on peut tester sans programmer avec dig, et son option
+ednsopt. Les options EDNS ont un code, enregistré
à l'IANA. RRSERIAL n'en a pas encore, donc le serveur de test
utilise le code temporaire 65024 :
% dig +ednsopt=65024 @200.1.122.30 dateserial.example.com
...
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 4096
; OPT=65024: 78 49 7a 79 ("xIzy")
Ça marche, on a obtenu une réponse. dig ne sait pas la formater
proprement (« xIzy » est la représentation de 78 49 7a 79 interprété
comme de l'ASCII, alors qu'il s'agit d'un entier, le nombre 2018081401), mais c'est déjà
ça. (Le draft précise que l'option RRSERIAL a une
valeur nulle dans la requête, seule sa présence compte. S'il avait
fallu donner une valeur, dig permet de le faire avec
+ednsopt=CODE:VALEUR.) Donc, le serveur
fonctionne bien. Maintenant, on voudrait faire mieux et donc
utiliser un client DNS adapté (d'autant plus qu'il y a des cas à
traiter comme la réponse NXDOMAIN, où le numéro de série de la zone
est dans un enregistrement SOA, pas dans
l'option EDNS). On va donc programmer.
Commençons en Python avec la bibliothèque dnspython. On peut fabriquer
l'option dans la requête avec la classe
GenericOption :
opts = [dns.edns.GenericOption(dns.edns.RRSERIAL, b'')] ... message = dns.message.make_query(qname, qtype, options=opts)
(Le b'' indique une valeur binaire vide.) Pour
lire l'option dans la réponse :
for opt in response.options:
if opt.otype == dns.edns.RRSERIAL:
print("Serial of the answer is %s" % struct.unpack(">I", opt.data)[0])
On a donc juste à convertir la valeur binaire en chaine (le
>I signifie un entier
gros-boutien). Le code Python complet est en
test-rrserial.py
Pour Go, on va
utiliser la bibliothèque godns. Créer l'option et
l'ajouter à la requête DNS (m dans le code) se
fait ainsi :
m.Question = make([]dns.Question, 1)
// Tout pseudo-enregistrement EDNS a pour nom "." (la racine)
o.Hdr.Name = "."
o.Hdr.Rrtype = dns.TypeOPT
o.SetUDPSize(4096)
// Option EDNS générique
e := new(dns.EDNS0_LOCAL)
e.Code = otype
// Requête vide
e.Data = []byte{}
o.Option = append(o.Option, e)
// Extra est la section Additionnelle
m.Extra = append(m.Extra, o)
Et pour lire le résultat :
opt := msg.IsEdns0()
for _, v := range opt.Option {
// Merci à Tom Thorogood pour le rappel qu'il faut forcer le type
// et donc avoir une nouvelle variable v (le ':=').
switch v := v.(type) {
case *dns.EDNS0_LOCAL:
if v.Option() == otype {
serial := binary.BigEndian.Uint32(v.Data)
fmt.Printf("EDNS rrserial found, \"%d\"\n", serial)
...
Le code Go complet est en test-rrserial.go
L'article seul
RFC 9083: JSON Responses for the Registration Data Access Protocol (RDAP)
Date de publication du RFC : Juin 2021
Auteur(s) du RFC : S. Hollenbeck (Verisign Labs), A. Newton (AWS)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 16 juin 2021
Dans l'ensemble des normes sur le protocole RDAP, ce RFC est destiné à décrire le format de sortie, celui des réponses envoyées par le serveur d'information RDAP. Ce format est basé sur JSON et, pour utiliser RDAP en remplacement de whois, il faudra donc se munir de quelques outils pour traiter le JSON. Ce RFC remplace le RFC 7483 mais il y a très peu de changements.
JSON est normalisé dans le RFC 8259 et représente aujourd'hui le format de choix pour les données structurées c'est-à-dire analysables par un programme. (L'annexe E de notre RFC explique en détail le pourquoi du choix de JSON.) Une des caractéristiques importantes de whois est en effet que son format de sortie n'a aucune structure, c'est du texte libre, ce qui est pénible pour les programmeurs qui essaient de le traiter (mais, d'un autre côté, cela ralentit certains usages déplorables, comme la récolte d'adresses de courrier à des fins de spam, jouant ainsi un rôle de semantic firewall). L'utilisation typique de RDAP est en HTTP (RFC 7480) avec les requêtes exprimées dans la syntaxe des URL du RFC 9082. Voici tout de suite un exemple réel, avec la réponse JSON :
% curl https://rdap.afilias.net/rdap/info/domain/kornog-computing.info
...
{
"entities": [
...
"objectClassName": "entity",
"roles": [
"technical",
"billing",
"administrative"
],
"vcardArray": [
"vcard",
[
[
"version",
{},
"text",
"4.0"
],
[
"fn",
{},
"text",
"KORNOG computing"
],
[
"adr",
{
"cc": "FR"
},
"text",
{}
]
...
"events": [
{
"eventAction": "registration",
"eventDate": "2007-08-14T17:02:33Z"
},
{
"eventAction": "last changed",
"eventDate": "2014-08-14T01:54:07Z"
},
{
"eventAction": "expiration",
"eventDate": "2015-08-14T17:02:33Z"
}
],
"handle": "D19378523-LRMS",
"lang": "en",
"ldhName": "kornog-computing.info",
...
"nameservers": [
{
"ldhName": "ns1.kornog-computing.net",
"objectClassName": "nameserver",
"remarks": [
{
"description": [
"Summary data only. For complete data, send a specific query for the object."
],
"title": "Incomplete Data",
"type": "object truncated due to unexplainable reasons"
}
]
},
{
"ldhName": "ns2.kornog-computing.net",
"objectClassName": "nameserver",
"remarks": [
{
"description": [
"Summary data only. For complete data, send a specific query for the object."
],
"title": "Incomplete Data",
"type": "object truncated due to unexplainable reasons"
}
]
}
],
"notices": [
{
"description": [
"Access to AFILIAS WHOIS information is provided to assist persons in determining the contents of a domain name registration record in the Afilias registry database. The data in this record is provided by Afilias Limited for informational purposes only, and Afilias does not guarantee its accuracy. [...]"
],
"title": "TERMS OF USE"
}
],
"objectClassName": "domain",
...
"rdapConformance": [
"rdap_level_0"
],
"secureDNS": {
"zoneSigned": false
},
"status": [
"clientDeleteProhibited -- http://www.icann.org/epp#clientDeleteProhibited",
"clientTransferProhibited -- http://www.icann.org/epp#clientTransferProhibited"
]
}
La section 1.2 présente le modèle de données de RDAP. Dans les réponses, on trouve des types simples (comme des chaînes de caractères), des tableaux JSON, et des objets JSON qui décrivent les trucs sur lesquels on veut de l'information (noms de domaine, adresses IP, etc). Ces objets peuvent comporter des tableaux ou d'autres objets et, lorsqu'une réponse renvoie plusieurs objets (cas des recherches ouvertes, cf. RFC 9082, section 3.2), peuvent eux-même être regroupés en tableaux. Il existe plusieurs classes de ces objets. D'abord, les classes communes aux registres de noms de domaine et aux RIR (registres d'adresses IP) :
- Domaines (oui, même pour les RIR, pensez à
in-addr.arpaetip6.arpa), - Serveurs de noms,
- Entités diverses, comme les handles, les
identificateurs des contacts, genre
GR283-FRNIC.
Deux classes sont spécifiques aux RIR :
- Réseaux IP, identifiés par leur préfixe,
- Systèmes autonomes.
On verra peut-être apparaître d'autres classes avec le temps, si l'usage de RDAP se répand.
La section 2 de notre RFC décrit comment JSON est utilisé. Le
type MIME renvoyé est
application/rdap+json. La section 2 commence
par un rappel que le client RDAP doit ignorer
les membres inconnus dans les objets JSON, afin de préserver la
future extensibilité. (Cette règle ne s'applique pas au jCard
- cf. RFC 7095 - embarqué.) Si un serveur veut
ajouter des membres qui lui sont spécifiques, il est recommandé
qu'il préfixe leur nom avec un identificateur court suivi d'un
tiret bas. Ainsi, cet objet
RDAP standard :
{
"handle" : "ABC123",
"remarks" :
[
{
"description" :
[
"She sells sea shells down by the sea shore.",
"Originally written by Terry Sullivan."
]
}
]
}
S'il est servi par le « registre de la Lune » (registre imaginaire
qui fournit les exemples de ce RFC), celui-ci, lorsqu'il voudra
ajouter des membres, les précédera de
lunarNIC_ :
{
"handle" : "ABC123",
"lunarNic_beforeOneSmallStep" : "TRUE THAT!",
"remarks" :
[
{
"description" :
[
"She sells sea shells down by the sea shore.",
"Originally written by Terry Sullivan."
]
}
],
"lunarNic_harshMistressNotes" :
[
"In space,",
"nobody can hear you scream."
]
}
(Je vous laisse décoder les références geeks dans l'exemple.)
La section 3 s'occupe des types de données de base. On utilise du
JSON normal, tel que spécifié dans le RFC 8259, avec ses chaînes de caractères, ses booléens, son
null... Un handle
(l'identifiant unique - par registre - d'un contact, parfois nommé
NIC handle ou registry ID) est
une chaîne. Les adresses IP se représentent également par une chaîne
de caractères (ne pas oublier le RFC 5952 pour
IPv6). Les pays sont identifiés par le code à
deux lettres de ISO 3166. Les noms de
domaines peuvent être sous une forme ASCII ou bien en
Unicode. Les dates et heures suivent le RFC 3339, et les URI le RFC 3986.
Les informations plus complexes (comme les détails sur un contact) utilisent jCard, normalisé dans le RFC 7095.
Que trouve-t-on dans les objets JSON renvoyés par un serveur RDAP ? Une indication de la version de la norme :
"rdapConformance" :
[
"rdap_level_0"
]
(Éventuellement avec d'autres identificateurs pour les extensions locales.) Et des liens vers des ressources situées ailleurs, suivant le cadre du RFC 8288 :
"links": [
{
"href": "http://rdg.afilias.info/rdap/entity/ovh53ec16bekre5",
"rel": "self",
"type": "application/rdap+json",
"value": "http://rdg.afilias.info/rdap/entity/ovh53ec16bekre5"
}
On peut aussi avoir du texte libre, comme dans l'exemple plus haut
avec le membre remarks. Ce membre sert aux
textes décrivant la classe, alors que notices
est utilisé pour le service RDAP. Un exemple :
"notices": [
{
"description": [
"Access to AFILIAS WHOIS information is provided to assist persons in determining the contents of a domain name registration record in the Afilias registry database. The data in this record is provided by Afilias Limited for informational purposes only, and Afilias does not guarantee its accuracy. [...]"
],
"title": "TERMS OF USE"
}
],
Contrairement à whois, RDAP permet l'internationalisation sous tous ses aspects. Par exemple, on peut indiquer la langue des textes avec une étiquette de langue (RFC 5646) :
"lang": "en",
Enfin, la classe (le type) de l'objet renvoyé par RDAP est
indiquée par un membre objectClassName :
"objectClassName": "domain",
Ces classes, justement. La section 5 les décrit. Il y a d'abord
la classe Entity qui correspond aux requêtes
/entity du RFC 9082. Elle
sert à décrire les personnes et les organisations. Parmi les membres
importants pour les objets de cette classe,
handle qui est un identificateur de l'instance
de la classe, et roles qui indique la relation
de cette instance avec l'objet qui la contient (par exemple
"roles": ["technical"] indiquera que cette
Entity est le contact technique de
l'objet). L'information de contact sur une
Entity se fait avec le format
vCard du RFC 7095, dans
un membre vcardArray. Voici un exemple avec le
titulaire du domaine uba.ar :
% curl https://rdap.nic.ar/entity/30546666561
...
"objectClassName": "entity",
"vcardArray": [
"vcard",
[
[
"version",
{},
"text",
"4.0"
],
[
"fn",
{},
"text",
"UNIVERSIDAD DE BUENOS AIRES"
]
]
],
...
(jCard permet de mentionner plein d'autres choses qui ne sont a priori pas utiles pour RDAP, comme la date de naissance ou le genre.)
La classe Nameserver correspond aux requêtes
/nameserver du RFC 9082. Notez qu'un registre peut gérer les serveurs de noms
de deux façons : ils peuvent être vus comme des objets autonomes,
enregistrés tels quel dans le registre (par exemple via le RFC 5732), ayant des attributs par exemple des
contacts, et interrogeables directement par whois ou RDAP (c'est le
modèle de .com, on dit
alors que les serveurs de noms sont des « objets de première
classe »). Ou bien ils peuvent être simplement des attributs des
domaines, accessibles via le domaine. Le principal attribut d'un
objet Nameserver est son adresse IP, pour
pouvoir générer des colles dans le DNS (enregistrement DNS d'une
adresse IP, pour le cas où le serveur de noms est lui-même dans la
zone qu'il sert). Voici un exemple avec un des serveurs de noms de
la zone afilias-nst.info :
% curl https://rdap.afilias.net/rdap/info/nameserver/b0.dig.afilias-nst.info
...
"ipAddresses": {
"v4": [
"65.22.7.1"
],
"v6": [
"2a01:8840:7::1"
]
},
...
Notez que l'adresse IP est un tableau, un serveur pouvant avoir plusieurs adresses.
La classe Domain correspond aux requêtes
/domain du RFC 9082. Un
objet de cette classe a des membres indiquant les serveurs de noms,
si la zone est signée avec DNSSEC ou pas, l'enregistrement DS si elle est signée, le
statut (actif ou non, bloqué ou non), les contacts, etc. Voici un
exemple :
% curl http://rdg.afilias.info/rdap/domain/afilias-nst.info
...
"nameservers": [
{
"ldhName": "a0.dig.afilias-nst.info",
...
"secureDNS": {
"delegationSigned": false
},
...
"status": [
"client transfer prohibited",
"server delete prohibited",
"server transfer prohibited",
"server update prohibited"
],
...
La classe IP network rassemble les objets
qu'on trouve dans les réponses aux requêtes /ip
du RFC 9082. Un objet de cette classe ne
désigne en général pas une seule adresse IP mais un préfixe, dont on
indique la première (startAddress) et la
dernière adresse (endAddress). Personnellement,
je trouve cela très laid et j'aurai préféré qu'on utilise une
notation préfixe/longueur. Voici un exemple :
% curl https://rdap.db.ripe.net/ip/131.111.150.25
...
{
"handle" : "131.111.0.0 - 131.111.255.255",
"startAddress" : "131.111.0.0/32",
"endAddress" : "131.111.255.255/32",
"ipVersion" : "v4",
"name" : "CAM-AC-UK",
"type" : "LEGACY",
"country" : "GB",
...
La dernière classe normalisée à ce stade est
autnum (les AS), en réponse aux requêtes
/autnum du RFC 9082. Elle
indique notamment les contacts de l'AS. Pour l'instant, il n'y a pas
de format pour indiquer la politique de routage (RFC 4012). Un exemple d'un objet de cette classe :
% curl https://rdap.db.ripe.net/autnum/20766
{
"handle" : "AS20766",
"name" : "GITOYEN-MAIN-AS",
"type" : "DIRECT ALLOCATION",
...
"handle" : "GI1036-RIPE",
"vcardArray" : [ "vcard", [ [ "version", { }, "text", "4.0" ], [ "fn", { }, "text", "NOC Gitoyen" ], [ "kind", { }, "text", "group" ], [ "adr", {
"label" : "Gitoyen\n21 ter rue Voltaire\n75011 Paris\nFrance"
}, "text", null ], [ "email", { }, "text", "noc@gitoyen.net" ] ] ],
...
Comme, dans la vie, il y a parfois des problèmes, une section de
notre RFC, la section 6, est dédiée aux formats des erreurs que
peuvent indiquer les serveurs RDAP. Le code de retour HTTP fournit
déjà des indications (404 = cet objet n'existe pas ici, 403 = vous
n'avez pas le droit de le savoir, etc) mais on peut aussi ajouter un
objet JSON pour en indiquer davantage, objet ayant un membre
errorCode (qui reprend le code HTTP), un membre
title et un membre
description. Voici un exemple sur le serveur
RDAP de l'ARIN :
% curl -v http://rdap.arin.net/registry/autnum/99999
< HTTP/1.0 404 Not Found
< Mon, 10 May 2021 09:07:52 GMT
< Server: Apache/2.4.6 (CentOS) OpenSSL/1.0.2k-fips
...
{
...
"errorCode" : 404,
"title" : "AUTNUM NOT FOUND",
"description" : [ "The autnum you are seeking as '99999' is/are not here." ]
Plus positive, la possibilité de demander de l'aide à un serveur
RDAP, en se renseignant sur ses capacités, avec la requête
/help. Son résultat est décrit dans la section
7 mais tous les serveurs RDAP actuels n'utilisent pas
cette possibilité. En voici un où ça marche, à
l'ARIN :
% curl -s https://rdap.arin.net/registry/help
{
"rdapConformance" : [ "rdap_level_0" ],
"notices" : [ {
"title" : "Terms of Service",
"description" : [ "By using the ARIN RDAP/Whois service, you are agreeing to the RDAP/Whois Terms of Use" ],
"links" : [ {
"value" : "https://rdap.arin.net/registry/help",
"rel" : "about",
"type" : "text/html",
"href" : "https://www.arin.net/resources/registry/whois/tou/"
} ]
}, {
"title" : "Whois Inaccuracy Reporting",
"description" : [ "If you see inaccuracies in the results, please visit: " ],
"links" : [ {
"value" : "https://rdap.arin.net/registry/help",
"rel" : "about",
"type" : "text/html",
"href" : "https://www.arin.net/resources/registry/whois/inaccuracy_reporting/"
} ]
}, {
"title" : "Copyright Notice",
"description" : [ "Copyright 1997-2021, American Registry for Internet Numbers, Ltd." ]
} ]
}
Et les résultats des recherches ouvertes (section 3.2 du RFC 9082), qui peuvent renvoyer plusieurs objets ?
Ce sont des tableaux JSON, dans des membres dont le nom se termine
par Results. Par exemple, en cherchant les noms
de domaines commençant par ra (ce test a été
fait sur un serveur expérimental qui ne marche plus depuis) :
% curl http://rdg.afilias.info/rdap/domains\?name=ra\*|more
"domainSearchResults": [
{
"ldhName": "RAINSTRAGE.INFO",
...
"objectClassName": "domain",
"remarks": [
{
"description": [
"Summary data only. For complete data, send a specific query for the object."
],
"title": "Incomplete Data",
"type": "object truncated due to unexplainable reasons"
}
...
"ldhName": "RADONREMOVAL.INFO",
...
"ldhName": "RANCONDI.INFO",
...
Les vrais serveurs RDAP en production ne répondent pas forcément à ces requêtes trop coûteuses et qui peuvent trop facilement être utilisées pour le renseignement économique :
% curl https://rdap.afilias.net/rdap/info/domains\?name=ra\*
...
"errorCode": 422,
"title": "Error in processing the request",
"description": [
"WildCard search is not supported on sub-zone or tld"
]
Vous avez peut-être noté dans le tout premier exemple le membre
events (section 4.5 du RFC). Ces événements
comme created ou
last-changed donnent accès à l'histoire d'un
objet enregistré. Ici, nous apprenons que le domaine
kornog-computing.info a été enregistré en
2007.
Certaines valeurs qui apparaissent dans les résultats sont des
chaînes de caractères fixes, stockées dans un nouveau registre
IANA. Elles sont conçues pour être utilisées dans les
notices, remarks,
status, roles et quelques
autres. Parmi les remarques, on trouvera le cas où une réponse a été
tronquée (section 9 du RFC), comme dans l'exemple ci-dessus avec la
mention Incomplete Data. Parmi les statuts, on
trouvera, par exemple validated (pour un objet
vérifié, par exemple un nom de domaine dont on a vérifié les
coordonnées du titulaire), locked (pour un
objet verrouillé), obscured (qui n'est pas un
statut dans le base du données du registre mais simplement la
mention du fait que le serveur RDAP a délibérement modifié certaines
informations qu'il affiche, par exemple pour protéger la vie
privée), etc. Pour les rôles, on trouvera
registrant (titulaire),
technical (contact technique), etc.
Pour ceux qu'intéressent les questions d'internationalisation, la section 12 contient d'utiles mentions. L'encodage des données JSON doit être de l'UTF-8. Et, comme indiqué plus haut, les IDN peuvent être sous la forme Punycode ou bien directement en UTF-8.
Et la vie privée, un problème permanent
avec whois, où il faut toujours choisir entre la distribution de
données utiles pour contacter quelqu'un et les risques pour sa vie
privée ? La section 13 revient sur
cette question. Un point important : RDAP est un protocole, pas une
politique. Il ne définit pas quelles règles suivre (c'est de la
responsabilité des divers registres) mais il fournit les outils pour
mettre en œuvre ces règles. Notamment, RDAP permet de marquer des
parties de la réponse comme étant connues du registre, mais n'ayant
délibérement pas été envoyées (avec les codes
private et removed) ou
bien comme ayant été volontairement rendues peu ou pas lisibles
(code obscured).
Vous avez vu dans les exemples précédents que les réponses d'un serveur RDAP sont souvent longues et, a priori, moins lisibles que celles d'un serveur whois. Il faudra souvent les traiter avec un logiciel qui comprend le JSON. Un exemple très simple et que j'apprécie est jq. Il peut servir à présenter le résultat de manière plus jolie :
% curl -s https://rdap.centralnic.com/pw/domain/centralnic.pw | jq .
...
{
"objectClassName": "domain",
"handle": "D956082-CNIC",
"ldhName": "centralnic.pw",
"nameservers": [
{
"objectClassName": "nameserver",
"ldhName": "ns0.centralnic-dns.com",
...
(Essayez ce même serveur RDAP sans jq !)
Mais on peut aussi se servir de jq pour extraire un champ particulier, ici le pays :
% curl -s https://rdap.db.ripe.net/ip/131.111.150.25 | jq ".country" "GB" % curl -s https://rdap.db.ripe.net/ip/192.134.1.1 | jq ".country" "FR"
Il y a évidemment d'autres logiciels que jq sur ce créneau, comme
JSONpath,
jpath
ou, pour les programmeurs Python, python -m
json.tool.
Un dernier mot, sur le choix de JSON pour le format de sortie, alors que le protocole standard d'avitaillement des objets dans les bases Internet, EPP (RFC 5730) est en XML. L'annexe E de notre RFC, qui discute ce choix, donne comme principaux arguments que JSON est désormais plus répandu que XML (cf. l'article « The Stealthy Ascendancy of JSON ») et que c'est surtout vrai chez les utilisateurs (EPP étant utilisé par une population de professionnels bien plus réduite).
Quels changements depuis le RFC 7483 ? La
plupart sont mineurs et sont de l'ordre de la
clarification. D'autres sont des corrections
d'erreurs, par exemple une coquille
qui avait mis registrant là où il aurait fallu
dire registrar (la proximité des mots en anglais
entraine souvent des erreurs, même chez les professionnels). Il y a
une certaine tendance au durcissement des règles, des éléments qui
étaient optionnels dans le RFC 7483 sont
devenus obligatoires comme, par exemple,
rdapConformance (dont le statut optionnel avait
causé des
problèmes).
Et question logiciels qui mettent en œuvre RDAP ? Beaucoup de logiciels de gestion de registre le font aujourd'hui, notamment ceux sous contrat avec l'ICANN, puisqu'ils n'ont pas le choix. Mais les logiciels ne sont pas forcément publiquement disponibles. Parmi ceux qui le sont, il y a RedDog, Fred, celui de l'APNIC…
L'article seul
RFC 9082: Registration Data Access Protocol (RDAP) Query Format
Date de publication du RFC : Juin 2021
Auteur(s) du RFC : S. Hollenbeck (Verisign Labs), A. Newton (AWS)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 16 juin 2021
Le protocole d'information RDAP, qui vise à remplacer whois, est décrit dans un ensemble de RFC. Celui présenté ici normalise la façon de former les requêtes RDAP. Celles-ci ont la forme d'une URL, puisque RDAP repose sur l'architecture REST. Ce RFC remplace l'ancienne norme sur les requêtes RDAP, qui était dans le RFC 7482, mais il n'y a pas de changement significatif.
RDAP peut être utilisé pour beaucoup de sortes d'entités différentes mais ce RFC ne couvre que ce qui correspond aux usages actuels de whois, les préfixes d'adresses IP, les AS, les noms de domaine, etc. Bien sûr, un serveur RDAP donné ne gère pas forcément tous ces types d'entités, et il doit renvoyer le code HTTP 501 (Not implemented) s'il ne sait pas gérer une demande donnée. Ce RFC ne spécifie que l'URL de la requête, le format de la réponse est variable (JSON, XML...) et le seul actuellement normalisé, au-dessus de JSON, est décrit dans le RFC 9083. Quant au protocole de transport, le seul actuellement normalisé pour RDAP (dans le RFC 7480) est HTTP. D'autre part, ces RFC RDAP ne décrivent que le protocole entre le client RDAP et le serveur, pas « l'arrière-cuisine », c'est-à-dire l'avitaillement (création, modification et suppression) des entités enregistrées. RDAP est en lecture seule et ne modifie pas le contenu des bases de données qu'il interroge.
Passons aux choses concrètes. Une requête RDAP est un
URL (RFC 3986). Celui-ci est obtenu en ajoutant un chemin
spécifique à une base. La base (par exemple
https://rdap.example.net/) va être obtenue par
des mécanismes divers, comme celui du RFC 7484, qui spécifie un registre que vous pouvez
trouver en ligne. On met ensuite un chemin qui dépend du type
d'entité sur laquelle on veut se renseigner, et qui indique
l'identificateur de l'entité. Par exemple, avec la base ci-dessus,
et une recherche du nom de domaine
internautique.fr, on construirait un URL
complet
https://rdap.example.net/domain/internautique.fr. Il
y a cinq types d'entités possibles :
ip: les préfixes IP (notez qu'on peut chercher un préfixe en donnant juste une des adresses IP couvertes par ce préfixe),autnum: les numéros de systèmes autonomes,domain: un nom de domaine (notez que cela peut être un domaine dansin-addr.arpaouipv6.arpa),nameserver: un serveur de noms,entity: une entité quelconque, comme un bureau d'enregistrement, ou un contact identifié par un handle.
La requête est effectuée avec la méthode HTTP
GET (les méthodes permettant de modifier le
contenu du registre n'ont pas de sens ici, les modifications dans le
registre sont plutôt faites avec EPP). Pour juste savoir si un
objet existe, on peut aussi utiliser la méthode
HEAD. Si on n'obtient pas de code 404, c'est
que l'objet existe.
Pour ip, le chemin dans l'URL est
/ip/XXX où XXX peut être
une adresse IPv4 ou
IPv6 sous forme texte. Il peut aussi y avoir
une longueur de préfixe à la fin donc
/ip/2001:db8:1:a::/64 est un chemin
valable. Ainsi, sur le service RDAP du RIPE-NCC,
https://rdap.db.ripe.net/ip/2001:4b98:dc0:41::
est un URL possible. Testons-le avec curl (le format de sortie, en JSON, est décrit dans
le RFC 9083, vous aurez peut-être
besoin de passer le résultat à travers jq
pour l'afficher joliment) :
% curl https://rdap.db.ripe.net/ip/2001:4b98:dc0:41::
{
"handle" : "2001:4b98:dc0::/48",
"startAddress" : "2001:4b98:dc0::/128",
"endAddress" : "2001:4b98:dc0:ffff:ffff:ffff:ffff:ffff/128",
"ipVersion" : "v6",
"name" : "GANDI-HOSTING-DC0",
"type" : "ASSIGNED",
"country" : "FR",
"rdapConformance" : [ "rdap_level_0" ],
"entities" : [ {
"handle" : "GAD42-RIPE",
"vcardArray" : [ "vcard", [ [ "version", { }, "text", "4.0" ], [ "fn", { }, "text", "Gandi Abuse Department" ], [ "kind", { }, "text", "group" ], [ "adr", {
"label" : "63-65 Boulevard Massena\n75013 Paris\nFrance"
...
J'ai utilisé curl mais, notamment pour formater plus joliment la
sortie de RDAP, les vrais utilisateurs se serviront plutôt d'un
client RDAP dédié comme RDAPBrowser sur
Android, ou nicinfo. Voici
une vue de RDAPbrowser: 
Pour autnum, on met le numéro de
l'AS après
/autnum/ (au format
« asplain » du RFC 5396). Toujours dans l'exemple RIPE-NCC,
https://rdap.db.ripe.net/autnum/208069 permet de
chercher de l'information sur l'AS
208069 :
% curl https://rdap.db.ripe.net/autnum/208069
{
"handle" : "AS208069",
"name" : "ATAXYA",
"type" : "DIRECT ALLOCATION",
"entities" : [ {
"handle" : "mc40833-RIPE",
"roles" : [ "administrative", "technical" ],
"objectClassName" : "entity"
}, {
...
Pour les noms de domaines, on met le nom après
/domain/. Ainsi, sur le serveur RDAP d'Afilias,
https://rdap.afilias.net/rdap/info/domain/rmll.info
nous donnera de l'information sur le domaine
rmll.info. On peut mettre un nom en
Unicode donc
https://rdap.example.net/domain/potamochère.fr
est valable, mais il devra être encodé comme l'explique la section
6.1, plus loin (en gros, UTF-8 en
NFC). Si on ne veut pas lire cette
information sur l'encodage, on peut aussi utiliser la forme
Punycode, donc chercher avec
https://rdap.example.net/domain/xn--potamochre-66a.fr. Un
exemple réel, en Russie :
% curl https://api.rdap.nic.рус/domain/валфекс.рус
...
{
"eventAction": "registration",
"eventDate": "2018-12-26T07:53:41.776927Z"
},
...
"adr",
{
"type": "Registrar Contact"
},
"text",
[
"",
"",
"125476, g. Moskva, ul. Vasilya Petushkova, dom 3, str. 1",
"",
"",
"",
"RU"
]
]
...
(Attention, le certificat ne sera accepté par curl que si curl a été compilé avec l'option « IDN ».)
On peut aussi se servir de RDAP pour les noms de domaines qui servent à traduire une adresse IP en nom :
% curl https://rdap.db.ripe.net/domain/1.8.a.4.1.0.0.0.0.d.1.4.1.0.0.2.ip6.arpa
{
"handle" : "0.d.1.4.1.0.0.2.ip6.arpa",
"ldhName" : "0.d.1.4.1.0.0.2.ip6.arpa",
"nameServers" : [ {
"ldhName" : "dns15.ovh.net"
}, {
"ldhName" : "ns15.ovh.net"
} ],
"rdapConformance" : [ "rdap_level_0" ],
"entities" : [ {
"handle" : "OK217-RIPE",
"roles" : [ "administrative" ]
}, {
"handle" : "OTC2-RIPE",
"roles" : [ "zone", "technical" ]
}, {
"handle" : "OVH-MNT",
"roles" : [ "registrant" ]
} ],
"remarks" : [ {
"description" : [ "OVH IPv6 reverse delegation" ]
} ],
...
Pour un serveur de noms, on met son nom après
/nameserver donc, chez Afilias :
% curl https://rdap.afilias.net/rdap/info/nameserver/rmll1.rmll.info
{
...
"ipAddresses": {
"v4": [
"80.67.169.65"
]
},
"lang": "en",
"ldhName": "rmll1.rmll.info",
...
Pour entity, on indique juste un
identificateur. Voici un exemple :
% curl http://rdg.afilias.info/rdap/entity/81
{
"handle": "81",
"lang": "en",
...
"roles": [
"registrar"
],
"vcardArray": [
"vcard",
[
[
"version",
{},
"text",
"4.0"
],
[
"fn",
{},
"text",
"Gandi SAS"
],
[
"adr",
{},
"text",
[
"",
"",
"63-65 boulevard Massena",
"Paris",
"",
"F-75013",
"FR"
]
...
Certains registres, qui stockent d'autres types d'objets,
pourront ajouter leurs propres requêtes, en prenant soin
d'enregistrer les préfixes de ces requêtes dans le
registre IANA. Par exemple, le logiciel de gestion de
registres FRED permet
d'interroger le registre sur les clés DNSSEC avec les requêtes
/fred_keyset
(la syntaxe des requêtes locales est identificateur du préfixe +
tiret bas + type cherché).
Dernière possibilité, un chemin spécial indique qu'on veut
récupérer de l'aide sur ce serveur RDAP particulier. En envoyant
help (par exemple
https://rdap.example.net/help), on obtient un
document décrivant les capacités de ce serveur, ses conditions
d'utilisation, sa politique vis-à-vis de la vie
privée, ses possibilités d'authentification (via les
mécanismes de HTTP), l'adresse
où contacter les responsables, etc. C'est l'équivalent de la
fonction d'aide qu'offrent certains serveurs whois, ici celui de
l'AFNIC :
% whois -h whois.nic.fr -- -h ... %% Option Function %% ------- ------------------------------------- %% -r turn off recursive lookups %% -n AFNIC output format %% -o old fashioned output format (Default) %% -7 force 7bits ASCII output format %% -v verbose mode for templates and help options %% (may be use for reverse query) %% -T type return only objects of specified type %% -P don't return individual objects in case of contact search %% -h informations about server features %% -l lang choice of a language for informations (you can specify US|EN|UK for %% english or FR for french) %% ...
Pour RDAP, voyez par exemple https://rdap.nic.bzh/helphttp://rdap.apnic.net/helphttps://rdap.nic.cz/help
Toutes les recherches jusque-là ont été des recherches exactes
(pas complètement pour les adresses IP, où on pouvait chercher un
réseau par une seule des adresses contenues dans le réseau). Mais on
peut aussi faire des recherches plus ouvertes, sur une partie de
l'identificateur. Cela se fait en ajoutant une requête (la partie
après le point
d'interrogation) dans l'URL et en ajoutant un
astérisque (cf. section 4.1). Ainsi,
https://rdap.example.net/domains?name=foo*
cherchera tous les domaines dont le nom commence par la chaîne de
caractères foo. (Vous avez noté que c'est
/domains, au pluriel, et non plus
/domain ?) Voici un exemple d'utilisation :
% curl https://rdap.afilias.net/rdap/info/domains\?name=rm\*
...
"errorCode": 422,
"title": "Error in processing the request",
"description": [
"WildCard search is not supported on sub-zone or tld"
]
...
Eh oui, les requêtes ouvertes comme celle-ci posent à la fois des problèmes techniques (la charge du serveur) et politico-juridiques (la capacité à extraire de grandes quantités de la base de données). Elles sont donc typiquement utilisables seulement après une authentification.
On peut aussi chercher un domaine d'après ses serveurs de noms,
par exemple
https://rdap.example.net/domains?nsLdhName=ns1.example.com
chercherait tous les domaines délégués au serveur DNS
ns1.example.com. Une telle fonction peut être
jugée très indiscrète et le serveur RDAP est toujours libre de
répondre ou pas mais, ici, cela marche, on trouve bien le domaine
qui a ce serveur de noms :
% curl https://rdap.afilias.net/rdap/info/domains\?nsLdhName=ns0.abul.org
...
"domainSearchResults": [
{
"objectClassName": "domain",
"handle": "D10775367-LRMS",
"ldhName": "rmll.info",
...
Deux autres types permettent ces recherches ouvertes,
/nameservers (comme dans
https://rdap.example.net/nameservers?ip=2001:db8:42::1:53,
mais notez qu'on peut aussi chercher un serveur par son nom) et
/entities (comme dans
https://rdap.example.net/entities?fn=Jean%20Dupon*) :
% curl http://rdg.afilias.info/rdap/entities\?fn=go\*
{
"entitySearchResults": [
{
"fn": "Go China Domains, Inc.",
...
"fn": "Gotnames.ca Inc.",
...
Notez que ce type de recherche peut représenter un sérieux danger pour la vie privée (comme noté dans le RFC, par exemple en section 4.2) puisqu'elle permet, par exemple de trouver tous les titulaires prénommés Jean. Elle est donc parfois uniquement accessible à des clients authentifiés, et de confiance.
La section 4 détaille le traitement des requêtes. N'oubliez pas qu'on travaille ici sur HTTP et que, par défaut, les codes de retour RDAP suivent la sémantique HTTP (404 pour un objet non trouvé, par exemple). Il y a aussi quelques cas où le code à retourner est moins évident. Ainsi, si un serveur ne veut pas faire une recherche ouverte, il va répondre 422 (Unprocessable Entity).
Vous avez noté plus haut, mais la section 6 le rappelle aux
distraits, que le nom de domaine peut être exprimé en
Unicode ou en ASCII. Donc,
https://rdap.example.net/domain/potamochère.fr
et
https://rdap.example.net/domain/xn--potamochre-66a.fr
sont deux requêtes acceptables.
Enfin, la section 8 rappelle quelques règles de sécurité comme :
- Les requêtes ouvertes peuvent mener à une forte consommation de ressources sur le serveur. Le serveur qui ne vaut pas se faire DoSer doit donc faire attention avant de les accepter.
- Les requêtes RDAP, et surtout les requêtes ouvertes, peuvent soulever des questions liées à la vie privée. Les serveurs RDAP doivent donc réfléchir avant de renvoyer de l'information. Rappelez-vous que RDAP, contrairement à whois, peut avoir un mécanisme d'authentification, donc peut envoyer des réponses différentes selon le client.
- Et, corollaire du précédent point, les gérants de serveurs RDAP doivent définir une politique d'autorisation : qu'est-ce que je renvoie, et à qui ?
Les changements depuis le RFC 7482 sont peu nombreux et sont surtout de clarification.
L'article seul
QUIC et le suivi des utilisateurs par le serveur
Première rédaction de cet article le 12 juin 2021
Suite à mes articles sur le protocole QUIC, on a parfois attiré mon attention sur un problème potentiel de vie privée : certes, QUIC protège bien contre la surveillance exercée par un acteur extérieur à la communication, grâce à son chiffrement systématique. Mais qu'en est-il de la surveillance exercée par le serveur sur lequel on se connecte ? Penchons-nous sur la complexité de la conception des protocoles Internet, quand on est soucieux de vie privée.
Au contraire du cas de la surveillance par un tiers, très longuement traité dans les RFC sur QUIC (voir par exemple le RFC 9000, section 9.5), le cas du suivi d'un utilisateur par le serveur auquel il se connecte est absent. Et ce alors que les grosses entreprises capitalistes qui forment un partie très visible du Web d'aujourd'hui sont connues pour pratiquer la surveillance de masse. Mais qu'en est-il exactement ?
Voyons d'abord le principe de l'éventuel problème de suivi d'un
utilisateur par le serveur. Les connexions QUIC peuvent être
longues, peut-être plusieurs heures, voire jours, et elles survivent
même aux changements d'adresses IP, QUIC permettant la migration
d'une adresse à une autre. Le serveur peut donc facilement
déterminer que la demande de /truc.html à 9 h
est faite par le même utilisateur que la demande de
/machin.html à 16 h, puisque c'est la même
connexion QUIC. Indiscutablement, ce problème de suivi de
l'utilisateur existe. Mais est-ce spécifique à QUIC et est-ce un vrai
problème en pratique ?
D'abord, le problème est ancien. Si le vieil HTTP original n'envoyait qu'une requête par connexion, cette limitation a disparu il y a longtemps. Ainsi, HTTP/2 (RFC 7540) privilégiait déjà les connexions de longue durée, posant les mêmes problèmes. Toutefois, QUIC, avec sa capacité de survivre aux changements d'adresse IP, étend encore la durée de ces connexions, ce qui peut être vu comme aggravant le problème. (Des techniques assez rares, comme multipath TCP, RFC 8684, fonctionnaient également à travers les changements d'adresses IP.)
Mais surtout, dans l'utilisation typique du Web aujourd'hui, il existe bien d'autres méthodes de suivi de l'utilisateur par le serveur. Il y a évidemment les cookies du RFC 6265. Même si on n'est pas connecté à un service comme YouTube, des cookies sont placés. Et ces cookies, contrairement à la connexion de longue durée de QUIC, permettent un suivi inter-serveurs, via Google Analytics et les boutons de partage des GAFA que tant de webmestres mettent sur leurs pages sans réfléchir. Et il n'y a pas que les cookies, le fingerprinting du navigateur peut également permettre d'identifier un visiteur unique, par toutes les informations que le très bavard HTTP transmet, comme le montre bien le test de l'EFF. Bref, à l'heure actuelle, le serveur indiscret qui veut pister ses utilisateurs a bien des moyens plus puissants à sa disposition.
En revanche, si on utilise un système tout orienté vie privée, tel le Tor Browser, qui débraye beaucoup de services du Web trop indiscrets, et fait tout passer par Tor, alors, la durée des connexions QUIC pourrait devenir le maillon faible de la vie privée.
Pour Tor, le problème est à l'heure actuelle purement théorique puisque Tor ne transmet que TCP et que QUIC utilise UDP. Mais il pourrait se poser dans le futur, le projet Tor a d'ailleurs déjà réfléchi à cela dans le contexte de HTTP/2 (qui s'appelait SPDY à ses débuts).
Un client QUIC soucieux de ne pas être suivi à la trace peut donc, une fois qu'il a géré les problèmes bien plus énormes que posent les cookies et le fingerprinting, envisager des solutions comme de ne pas laisser les connexions QUIC durer trop longtemps et surtout ne pas utiliser la migration (qui permet de maintenir la connexion lorsque l'adresse IP change). Cela peut se faire en raccrochant délibérement la connexion, ou simplement en ne prévoyant pas de réserve de connection IDs (RFC 9000, section 5.1.1). Ceci dit, c'est plus facile à dire qu'à faire car une application n'est pas forcément informée rapidement d'un changement d'adresse IP de la machine. Et, évidemment, cela aura un impact négatif sur les performances totales.
La longue durée des connexions QUIC n'est pas le seul mécanisme par lequel un serveur pourrait suivre à la trace un client. QUIC permet à un client de mémoriser des informations qui lui permettront de se reconnecter au serveur plus vite (ce qu'on nomme le « 0-RTT »). Ces informations (qui fonctionnent exactement comme un cookie HTTP) permettent évidemment également au serveur de reconnaitre un client passé. Cette possibilité et ses conséquences parfois néfastes sont détaillées dans le RFC 9001, sections 4.5 et 9.1. Notez que cela existe également avec juste TLS (ce qu'on nomme le session resumption, RFC 9846, section 2.2) et avec le TCP Fast Open (RFC 7413), avec les mêmes conséquences sur la possibilité de suivi d'un client par le serveur. Le client QUIC qui voudrait protéger sa vie privée doit donc faire attention, quand il démarre une nouvelle connexion, à ne pas utiliser ces possibilités, qui le trahiraient (mais qui diminuent la latence ; toujours le compromis).
Comme souvent en sécurité, on est donc face à un compromis. Si on ne pensait qu'à la vie privée, on utiliserait Tor tout le temps… Les navigateurs Web, par exemple, optimisent clairement pour la vitesse, pas pour la vie privée.
L'article seul
L'Internet était-il en panne aujourd'hui ?
Première rédaction de cet article le 8 juin 2021
Aujourd'hui, entre 1015 et 1110 UTC, le CDN Fastly était en panne, provoquant des dysfonctionnements divers sur quelques sites Web connus. Je ne sais pas ce qui s'est passé, donc je ne vais pas vous l'expliquer mais je voudrais revenir sur la façon dont cet incident a été présenté dans les médias.
Car les titres sensationnalistes n'ont pas manqué, annonçant une
panne massive du Web, voire de tout l'Internet ou au moins d'une
grande partie. Des gens ont ricané en reprenant la légende comme quoi
l'Internet avait été conçu pour résister à une attaque nucléaire ou
déploré que l'Internet soit trop centralisé, ce qu'il n'est
justement pas. La tonalité générale dans les médias était qu'il
s'agissait d'une panne majeure de ce réseau informatique dont tant
de choses dépendent. La réalité est très différente : l'Internet a
très bien tenu, l'écrasante majorité des sites Web marchaient,
quelques gros sites Web commerciaux avaient une drôle
d'allure. Voici par exemple celui du Monde :
L'Internet est le réseau informatique sous-jacent à toutes nos activités en ligne. Si des pannes partielles et localisées l'affectent souvent, il n'a jamais connu de panne généralisée, ou visible à l'échelle mondiale. Pendant l'incident avec Fastly, le courrier électronique passait comme d'habitude, les nœuds Bitcoin se tenaient au courant des transactions financières, les téléchargements BitTorrent se poursuivaient, les informaticiens se connectaient en SSH, les gens continuaient à bavarder sur Signal ou Matrix, et les utilisateurs de Gemini regardaient du contenu en ligne.
Et le Web ? Si
l'Internet est l'infrastructure sous-jacente, le Web est
l'application la plus connue, et même la seule connue de la plupart
des gens qui ont le monopole de l'accès aux médias officiels. En
tout cas, le Web marchait comme d'habitude. Des millions de sites
Web (comme celui que vous visitez en ce moment) n'ont eu aucun
problème. Une infime minorité, ceux qui avaient du contenu sur le
CDN
Fastly était, soit inaccessible, soit
affichait une apparence curieuse car, si le code HTML était bien chargé
par le navigateur, les
feuilles de
style ou le JavaScript ne
suivaient pas. C'est pour cela que la page d'accueil de
GitHub était bizarre : 
D'accord, ces gros sites Web commerciaux étaient souvent des sites visibles et connus. Mais même comme cela, Fastly n'est pas le seul fournisseur de CDN et beaucoup d'autres sites continuaient à fonctionner. Il faut arrêter cette présentation erronée comme quoi une poignée de sites Web connus sont « l'Internet » comme cela a souvent été dit.
Des gens ont reproché à ces sites de n'avoir pas de redondance, de dépendre entièrement d'un seul CDN. Mais c'est un détail. Le point important est que les pannes arrivent. On ne peut pas les empêcher toutes. Ce qu'il faut, c'est éviter qu'elles aient des conséquences trop étendues. Il ne faut pas se poser la question de la robustesse de GitHub, il faut au contraire faire en sorte que toute l'activité de programmation mondiale ne cesse pas quand GitHub est en panne. Il faut des milliers de GitLab ou de Gitea, un système réellement décentralisé, où il n'y aura aucun site qui concentrera toute une activité.
Le lendemain, Fastly a publié une explication (sommaire) sur la panne. Notons qu'en attendant cette explication, les médias n'ont pas hésité à avancer des théories fumeuses comme France Inter qui a mis en cause « les serveurs DNS » alors qu'il n'y avait jamais eu aucune indication en ce sens.
Pour se détendre, Natouille avait lancé sur le fédivers (tiens, encore un système décentralisé et qui n'a donc pas eu de problème global) le mot-croisillon « #ExpliqueLaPanneInternet ». Vous pouvez consulter les très amusantes « explications » de la panne sur n'importe quelle instance du fédivers.
L'article seul
Fiche de lecture : Cosmogonies
Auteur(s) du livre : Julien d'Huy
Éditeur : La Découverte
978-2-348-05966-7
Publié en 2020
Première rédaction de cet article le 3 juin 2021
Il y a longtemps que les folkloristes et les ethnologues ont remarqué des ressemblances troublantes entre des contes et des mythes chez des peuples très lointains. De nombreuses explications ont été proposées. L'auteur, dans ce gros livre très technique, détaille une de ces explications : les mythes ont une origine commune, remontant parfois à des milliers d'années. Il explique ensuite comment étayer cette explication avec des méthodes proches de celles de la phylogénie.
Un exemple frappant est donné par le récit que vous connaissez peut-être grâce à l'Odyssée. Le cyclope Polyphème garde des troupeaux d'animaux. Ulysse et ses compagnons sont capturés par lui et dévorés un à un. Ulysse réussit à aveugler le cyclope en lui brûlant son œil puis s'échappe de la grotte où il était prisonnier en se cachant sous un mouton. Des récits très proches se trouvent chez des peuples qui n'ont aucun lien avec les Grecs de l'Antiquité, notamment chez des Amérindiens, complètement séparés des Européens bien avant Homère. On peut penser à une coïncidence mais de telles ressemblances sont quand même bien fréquentes. On peut aussi se dire que l'unicité physique de l'espèce humaine se traduit par une mentalité identique, et donc une unité des mythes. Mais si les ressemblances sont fréquentes, il y a aussi des différences. Par exemple, lorsqu'on fait des catalogues de mythes, l'Afrique est souvent à part. Si on a un peu bu, on peut aussi imaginer que des extra-terrestres ou bien un être surnaturel ont raconté les mêmes mythes à tous les humains. L'auteur part d'une autre hypothèse : les mythes actuels sont le résultat de l'évolution de mythes très anciens, qui ont divergé à partir d'une souche commune.
La théorie elle-même est ancienne. Mais comment l'étayer ? On peut remarquer que, pour les différentes versions d'un même mythe, des sous-groupes semblent se dessiner. par exemple, dans le mythe de Polyphème, les variantes américaines sont proches les unes des autres, et assez distinctes des variantes eurasiatiques (par exemple, en Amérique, le cyclope est remplacé par un corbeau). Cela évoque fortement un arbre évolutif.
À partir de là, l'auteur utilise une méthode proche de la phylogénie. Les mythes sont découpés en éléments, un peu comme les gènes qu'on utilise en biologie, et on utilise les outils de la phylogénie pour établir des arbres phylogénétiques, dont on étudie ensuite la vraisemblance. Par exemple, les grands mouvements migratoires se retrouvent bien dans cette analyse, avec des mythes amérindiens qui forment un groupe distinct, mais néanmoins souvent rattaché à des mythes qu'on trouve en Asie. De même, les variations génétiques de l'espèce humaine se retrouvent souvent dans les arbres des mythes, non pas évidemment parce que tel ou tel gène dicterait les mythes qu'on raconte, mais parce que les humains font souvent de l'endogamie et que gènes et mythes se transmettent ensemble, au sein des mêmes groupes humains. La place particulière de l'Afrique s'expliquerait par l'ancienneté : Homo sapiens est sorti d'Afrique il y a longtemps et les mythes qu'il avait à ce moment ont tellement évolué qu'on ne les reconnait plus aujourd'hui. Bien, sûr, je schématise beaucoup. Comme souvent en sciences humaines, la situation est plus compliquée que cela, et vous devrez lire le livre pour en apprécier les nuances. D'autant plus que les sujets ethnologiques sont toujours politiquement sensibles, par exemple lorsque l'auteur explique le mythe assez commun du matriarcat originel par un mythe commun, pas par une réalité historique (les mythes ne disent pas la vérité, ils racontent une histoire…).
Un autre exemple de mythe courant est celui de la femme-oiseau. En gros, un homme (un mâle) surprend, souvent au bain, une femme-animal (souvent un oiseau), et cache sa part animale (son manteau de plumes, par exemple). Il peut ainsi la garder près de lui, jusqu'au jour où elle remet la main sur son plumage et peut ainsi se sauver. Là encore, on peut isoler ses élements (les « gènes »), les abstraire (femme-animal au lieu de femme-oiseau car, dans certaines variantes, l'animal est une chèvre ou un éléphant) et les mettre dans le logiciel de phylogénie qui va alors sortir un arbre. Comme toujours, en phylogénie, beaucoup dépend de certaines hypothèses (les paramètres donnés au logiciel) et il est donc important de regarder ensuite les résultats de la reconstruction phylogénétique à la lumière de la génétique, de la connaissance qu'on a des migrations humaines, et des découvertes archéologiques. Dans certains cas, on peut même retrouver la racine de l'arbre, c'est-à-dire le mythe originel.
Le livre n'est pas toujours facile à lire, à pas mal d'endroits, c'est davantage une exposition de résultats de recherche récents qu'un ouvrage de vulgarisation. Avoir fait de la bio-informatique et notamment de la phylogénie, et/ou des statistiques peut aider. Mais les mythes eux-mêmes sont fascinants puisque chacun est un moyen de plonger dans l'esprit de peuples lointains ou même disparus.
(J'ai reçu un message détaillant des critiques sévères à propos de ce livre. Je précise donc que je ne suis moi-même ni folkloriste, ni ethnologue, et que je ne faisais que rendre compte de ce que j'avais compris du livre lu. De toute façon, en sciences humaines, il est rare qu'il existe des consensus, même sur les choses les plus basiques. Je n'ai donc pas modifié mon article.)
L'article seul
RFC 8903: Use cases for DDoS Open Threat Signaling
Date de publication du RFC : Mai 2021
Auteur(s) du RFC : R. Dobbins (Arbor Networks), D. Migault (Ericsson), R. Moskowitz (HTT Consulting), N. Teague (Iron Mountain Data Centers), L. Xia (Huawei), K. Nishizuka (NTT Communications)
Pour information
Réalisé dans le cadre du groupe de travail IETF dots
Première rédaction de cet article le 31 mai 2021
Le travail autour de DOTS (DDoS Open Threat Signaling) vise à permettre la communication, pendant une attaque par déni de service, entre la victime et une organisation qui peut aider à atténuer l'attaque. Ce nouveau RFC décrit quelques scénarios d'utilisation de DOTS. Autrement, DOTS est normalisé dans les RFC 8811 et ses copains.
Si vous voulez un rappel du paysage des attaque par déni de service, et du rôle de DOTS (DDoS Open Threat Signaling) là-dedans, je vous recommande mon article sur le RFC 8612. Notre RFC 8903 ne fait que raconter les scénarios typiques qui motivent le projet DOTS.
Par exemple, pour commencer, un cas simple où le fournisseur d'accès Internet d'une organisation est également capable de fournir des solutions d'atténuation d'une attaque. Ce fournisseur (ITP dans le RFC, pour Internet Transit Provider) est sur le chemin de tous les paquets IP qui vont vers l'organisation victime, y compris ceux de l'attaque. Et il a déjà une relation contractuelle avec l'utilisateur. Ce fournisseur est donc bien placé, techniquement et juridiquement, pour atténuer une éventuelle attaque. Il peut déclencher le système d'atténuation, soit à la demande de son client qui subit une attaque, soit au contraire contre son client si celui-ci semble une source (peut-être involontaire) d'attaque. (Le RFC appelle le système d'atténuation DMS pour DDoS Mitigation Service ; certains opérateurs ont des noms plus amusants pour le DMS comme OVH qui parle d'« aspirateur ».)
Dans le cas d'une demande du client, victime d'une attaque et qui souhaite l'atténuer, le scénario typique sera qu'une machine chez le client (un pare-feu perfectionné, par exemple), établira une session DOTS avec le serveur DOTS inclus dans le DMS du fournisseur d'accès. Lorsqu'une attaque est détectée (cela peut être automatique, avec un seuil pré-défini, ou bien manuel), la machine du client demandera l'atténuation. Pendant l'atténuation, le client pourra obtenir des informations de la part du DMS du fournisseur. Si l'attaque se termine, le client pourra décider de demander l'arrêt de l'atténuation. Notez que la communication entre le client DOTS (chez la victime) et le serveur DOTS (chez le fournisseur d'accès) peut se faire sur le réseau « normal » (celui qui est attaqué) ou via un lien spécial, par exemple en 4G, ce qui sera plus cher et plus compliqué mais aura l'avantage de fonctionner même si l'attaque sature le lien normal.
Ce scénario simple peut aussi couvrir le cas du réseau domestique. On peut imaginer une box disposant de fonctions de détection d'attaques (peut-être en communiquant avec d'autres, comme le fait la Turris Omnia) et d'un client DOTS, pouvant activer automatiquement l'atténuation en contactant le serveur DOTS du FAI.
Le second cas envisagé est celui où le fournisseur d'accès n'a pas de service d'atténuation mais où le client (mettons qu'il s'agisse d'un hébergeur Web), craignant une attaque, a souscrit un contrat avec un atténuateur spécialisé (de nombreuses organisations ont aujourd'hui ce genre de services, y compris sans but lucratif). Dans ce cas, il faudra « détourner » le trafic vers cet atténuateur, avec des trucs DNS ou BGP, qui sont sans doute hors de portée de la petite ou moyenne organisation. L'accord avec l'atténuateur doit prévoir la technique à utiliser en cas d'attaque. Si c'est le DNS, la victime va changer ses enregistrements DNS pour pointer vers les adresses IP de l'atténuateur (attention au TTL). Si c'est BGP, ce sera à l'atténuateur de commencer à annoncer le préfixe du client (attention aux règles de sécurité BGP, pensez IRR et ROA), et au client d'arrêter son annonce. Le reste se passe comme dans le scénario précédent.
L'article seul
RFC 9038: Extensible Provisioning Protocol (EPP) Unhandled Namespaces
Date de publication du RFC : Mai 2021
Auteur(s) du RFC : J. Gould (VeriSign), M. Casanova (SWITCH)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 30 mai 2021
Le protocole EPP, qui sert notamment lors de la communication entre un registre (par exemple de noms de domaine) et son client, est extensible : on peut rajouter de nouveaux types d'objets et de nouvelles informations. Normalement, le serveur EPP n'envoie au client ces nouveautés que si le client a annoncé, lors de la connexion, qu'il savait les gérer. Et s'il ne l'a pas fait, que faire de ces données, ces unhandled namespaces ? Ce nouveau RFC propose de les envoyer quand même, mais dans un élément XML prévu pour des informations supplémentaires, et qui ne devrait donc rien casser chez le client.
Le but est de rester compatible avec l'EPP standard,
tel que normalisé dans le RFC 5730. Prenons
l'exemple de l'extension pour DNSSEC du RFC 5910. Comme toutes les extensions EPP, elle utilise les
espaces de noms XML. Cette extension
particulière est identifiée par l'espace de noms
urn:ietf:params:xml:ns:secDNS-1.1. À
l'établissement de la connexion, le serveur annonce les extensions
connues :
<greeting
<svcMenu>
...
<svcExtension>
<extURI>urn:ietf:params:xml:ns:secDNS-1.1</ns0:extURI>
Et le client annonce ce qu'il sait gérer :
<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
<command>
<login>
...
<svcs>
<svcExtension><extURI>urn:ietf:params:xml:ns:secDNS-1.1</extURI></svcExtension>
...
(<svcExtension> est décrit dans le RFC 5730, sections 2.4 et 2.9.1.1). Ici, le serveur
a annoncé l'extension DNSSEC et le client l'a acceptée. Tout le
monde va donc pouvoir envoyer et recevoir des messages spécifiques à
cette extension, comme l'ajout d'une clé :
<extension>
<update xmlns="urn:ietf:params:xml:ns:secDNS-1.1">
<add xmlns="urn:ietf:params:xml:ns:secDNS-1.1">
<dsData xmlns="urn:ietf:params:xml:ns:secDNS-1.1">
...
<digest xmlns="urn:ietf:params:xml:ns:secDNS-1.1">076CF6DA3692EFE72434EA1322177A7F07023400E4D1A1F617B1885CF328C8AA</digest>
...
Mais, si le client ne gère pas une extension (et ne l'a donc pas
indiquée dans son <login>), que peut
faire le serveur s'il a quand même besoin d'envoyer des messages
spécifiques à cette extension inconnue du client, ce
unhandled namespace ? C'est particulièrement
important pour la messagerie EPP (commande
<poll>) puisque le serveur peut, par
exemple, mettre un message dans la boite sans connaitre les
capacités du client, mais cela peut affecter également d'autres
activités.
La solution de notre RFC est d'utiliser un élément EPP déjà
normalisé (RFC 5730, secton 2.6),
<extValue>, qui permet d'ajouter des
informations que le client ne pourra pas analyser automatiquement,
comme par exemple un message d'erreur lorsque le serveur n'a pas pu
exécuter l'opération demandée. Notre RFC étend cet
<extValue> au cas des espaces de noms non
gérés. Le sous-élément <value> contiendra
l'élément XML appartenant à l'espace de noms que le client ne sait
pas gérer, et le sous-élément <reason>
aura comme contenu un message d'information dont la forme
recommandée est NAMESPACE-URI not in login
services où NAMESPACE-URI est le
unhandled namespace. Par exemple, le RFC cite un
cas où le registre ne gère pas l'extension DNSSEC du RFC 5910 et répond :
<response>
...
<extValue>
<value>
<secDNS:infData
xmlns:secDNS="urn:ietf:params:xml:ns:secDNS-1.1">
<secDNS:dsData>
...
<secDNS:digest>49FD46E6C4B45C55D4AC</secDNS:digest>
</secDNS:dsData>
</secDNS:infData>
</value>
<reason>
urn:ietf:params:xml:ns:secDNS-1.1 not in login services
</reason>
</extValue>
(Le RFC a aussi un autre exemple, avec l'extension de rédemption du RFC 3915.)
Ce RFC ne change pas le protocole EPP : il ne fait que décrire
une pratique, compatible avec les clients actuels, pour leur donner
le plus d'informations possible. Toutefois, pour informer tout le
monde, cette pratique fait l'objet elle-même d'une extension,
urn:ietf:params:xml:ns:epp:unhandled-namespaces-1.0,
que le serveur va inclure dans son
<greeting> et que le client mettra dans
sa liste d'extensions acceptées. (Cet espace de nom a été mis
dans le registre IANA créé par le RFC 3688. L'extension a été ajoutée au registre
des extensions EPP introduit par le RFC 7451.) De toute façon, le client a tout intérêt à inclure
dans sa liste toutes les extensions qu'il gère
et à regarder s'il y a des
<extValue> dans les réponses qu'il reçoit
(même si la commande EPP a été un succès) ; cela peut donner des
idées aux développeurs sur des extensions supplémentaires qu'il
serait bon de gérer. Quant au serveur, il est bon que son
administrateur regarde s'il y a eu des réponses pour des
unhandled namespaces et prenne ensuite contact
avec l'administrateur du client pour lui signaler ce manque.
Notez que ce RFC s'applique aux extensions portant sur les objets manipulés en EPP (par exemple les noms de domaine) et à celles portant sur les séquences de commandes et de réponses EPP, mais pas aux extensions portant sur le protocole lui-même (cf. RFC 3735).
Question mises en œuvre de ce RFC, le SDK de Verisign
inclut
le code nécessaire (dans le fichier
gen/java/com/verisign/epp/codec/gen/EPPFullExtValuePollMessageFilter.java). D'autre
part, le registre du .ch
utilise ce concept d'espaces de noms inconnus pour indiquer au
BE les
changements d'un domaine provoqués par l'utilisation du CDS du RFC 7344, puisque ces changements ne sont pas
passés par EPP.
L'article seul
RFC 9022: Domain Name Registration Data (DNRD) Objects Mapping
Date de publication du RFC : Mai 2021
Auteur(s) du RFC : G. Lozano (ICANN), J. Gould, C. Thippeswamy (VeriSign)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 30 mai 2021
Le RFC 8909 normalisait un format générique pour les séquestres d'objets enregistrés dans un registre. Ce nouveau RFC 9022 précise ce format pour le cas spécifique des registres de noms de domaine (dont les objets enregistrés sont les noms de domaine, les contacts, les serveurs de noms, etc).
Rappelons que le but d'un séquestre est de permettre à un tiers de reprendre les opérations d'un registre (par exemple un registre de noms de domaine) en cas de défaillance complète de celui-ci. Pas juste une panne matérielle qui fait perdre des données, non, une défaillance grave, par exemple une faillite, qui fait que plus rien ne marche. Le registre doit donc envoyer régulièrement des données à l'opérateur de séquestre qui, au cas où la catastrophe survient, enverra ces données au nouveau registre, qui sera en mesure (en théorie…) de charger les données dans une nouvelle base et de reprendre les opérations. Sous quel format sont envoyées ces données ? Car il faut évidemment un format ouvert et documenté, pour que le nouveau registre ait pu développer un programme d'importation des données. C'est le but du RFC 8909 et de notre nouveau RFC 9022. Ils spécifient un format à base de XML (avec possibilité de CSV).
Par rapport au format générique du RFC 8909, notre RFC ajoute les objets spécifiques de l'industrie des noms de domaine (il est recommandé de réviser la terminologie du RFC 8499) :
- Les noms de domaine, tels que manipulés en EPP selon le RFC 5731.
- Les serveurs de noms (pour les registres où ils sont enregistrés comme objets séparés, ce qui n'est pas obligatoire), tels que gérés via EPP selon le RFC 5732.
- Les contacts (le titulaire du nom de domaine, le contact technique avec qui on verra les problèmes DNS, etc), selon le modèle utilisé en EPP par le RFC 5733.
- Les BE (Bureaux d'Enregistrement). Le cas est un peu différent car ils ne sont typiquement pas gérés via EPP puisque les sessions EPP sont justement établies par un BE, qui a donc dû être créé par un autre moyen.
- Les noms spéciaux, qui sont des noms de domaine qui ne sont pas des noms de domaines habituels mais, par exemple, des gros mots dont l'enregistrement est interdit. En anglais, le sigle officiel est NNDN, qui veut récursivement dire NNDN's Not a Domain Name.
- Les tables liées à IDN, pour les registres qui maintiennent des informations restreignant l'usage de ces noms de domaine en Unicode (cf. RFC 6927).
- Certains paramètres de configuration des serveurs EPP du registre.
- Des compteurs du nombre d'objets enregistrés.
- Des objets qui sont importants pour le registre mais pas assez répandus pour avoir fait l'objet d'une normalisation.
Le format concret du séquestre se décline en deux « modèles », un en XML et un en CSV (RFC 4180), mais j'ai l'impression que le XML est nettement plus utilisé. Dans tous les cas :
- Les dates sont au format du RFC 3339.
- Les noms des pays sont les identificateurs à deux lettres de ISO 3166.
- Les numéros de téléphone sont au format E.164.
- Les adresses IP doivent suivre le format du RFC 5952. Pour IPv4, le RFC est vague, car il n'y a pas de format standard (vous ne verrez pas une seule adresse IP dans le RFC 791, que cite notre RFC…).
Pour CSV, chaque fichier CSV représente une table (les noms de
domaine, les contacts, les serveurs de noms…) et chaque ligne du
fichier un objet. Le modèle de données est décrit plus précisément
en section 4.6. Voici un exemple d'une ligne extraite du fichier des
noms de domaine, décrivant le domaine
domain1.example, créé le 3 avril 2009, et dont
le titulaire a pour identificateur (handle)
registrantid :
domain1.example,Ddomain2-TEST,,,registrantid,registrarX,registrarX,clientY,2009-04-03T22:00:00.0Z,registrarX,clientY,2009-12-03T09:05:00.0Z,2025-04-03T22:00:00.0Z
Les contacts seraient mis dans un autre fichier CSV, avec un fichier de jointure pour faire le lien entre domaines et contacts.
Et pour XML ? Il s'inspire beaucoup des éléments XML échangés
avec EPP, par exemple pour la liste des états
possibles pour un domaine. Voici un exemple (RDE = Registry
Data Escrow, et l'espace de noms
correspondant rdeDom est
urn:ietf:params:xml:ns:rdeDomain-1.0) :
<rdeDom:domain>
<rdeDom:name>jdoe.example</rdeDom:name>
<rdeDom:roid>DOM03-EXAMPLE</rdeDom:roid>
<rdeDom:status s="ok"/>
<rdeDom:registrant>IZT01</rdeDom:registrant>
<rdeDom:contact type="tech">IZT01</rdeDom:contact>
<rdeDom:contact type="billing">IZT01</rdeDom:contact>
<rdeDom:contact type="admin">IZT01</rdeDom:contact>
<rdeDom:ns>
<domain:hostObj>ns.jdoe.example</domain:hostObj>
</rdeDom:ns>
<rdeDom:clID>RAR03</rdeDom:clID>
<rdeDom:crRr>RAR03</rdeDom:crRr>
<rdeDom:crDate>2019-12-26T14:18:40.65647Z</rdeDom:crDate>
<rdeDom:exDate>2020-12-26T14:18:40.509742Z</rdeDom:exDate>
</rdeDom:domain>
On voit que cela ressemble en effet beaucoup à ce qui avait été envoyé en EPP pour créer le domaine (cf. RFC 5731). Si vous voulez un exemple complet et réaliste, regardez les sections 14 et 15 du RFC.
Et voici un exemple de contact (RFC 5733) :
<rdeContact:contact>
<rdeContact:id>IZT01</rdeContact:id>
<rdeContact:status s="ok"/>
<rdeContact:postalInfo type="loc">
<contact:name>John Doe</contact:name>
<contact:addr>
<contact:street>12 Rue de la Paix</contact:street>
<contact:city>Paris</contact:city>
<contact:pc>75002</contact:pc>
<contact:cc>FR</contact:cc>
</contact:addr>
</rdeContact:postalInfo>
<rdeContact:voice>+33.0353011234</rdeContact:voice>
<rdeContact:email>john.doe@foobar.example</rdeContact:email>
<rdeContact:clID>RAR03</rdeContact:clID>
<rdeContact:crRr>RAR03</rdeContact:crRr>
<rdeContact:crDate>2019-12-26T13:47:05.580392Z</rdeContact:crDate>
<rdeContact:disclose flag="0">
<contact:name type="loc"/>
<contact:addr type="loc"/>
<contact:voice/>
<contact:fax/>
<contact:email/>
</rdeContact:disclose>
</rdeContact:contact>
On notera l'élement <disclose> qui
indique qu'on ne doit pas diffuser le nom, l'adresse ou d'autres
éléments sur le contact (normal, il s'agit d'une personne physique,
et la loi Informatique & Libertés
s'applique, cf. section 14 du RFC). La jointure avec les domaines
dont il est contact (comme le jdoe.example plus
haut), se fait sur l'identificateur (élément
<id>, dit aussi
handle). L'information sur l'adresse a le type
loc, ce qui veut dire qu'elle peut utiliser
tout le jeu de caractères Unicode. Avec le
type int, elle serait restreinte à l'ASCII (une très ancienne erreur fait que
EPP appelle loc - local, ce
qui est internationalisé et int -
international ce qui est restreint aux lettres
utilisées en anglais).
Et enfin, un objet représentant un serveur de noms (RFC 5732) :
<rdeHost:host>
<rdeHost:name>ns1.foobar.example</rdeHost:name>
<rdeHost:status s="ok"/>
<rdeHost:addr ip="v6">2001:db8:cafe:fada::53</rdeHost:addr>
<rdeHost:clID>RAR02</rdeHost:clID>
<rdeHost:crRr>RAR02</rdeHost:crRr>
<rdeHost:crDate>2020-05-13T12:37:41.788684Z</rdeHost:crDate>
</rdeHost:host>
Ce format de séquestre permet aussi de représenter des objets qui n'ont pas d'équivalent en EPP, comme les bureaux d'enregistrement, qui ne peuvent pas être créés en EPP puisque la session EPP est liée au client du registre, donc au bureau d'enregistrement. Un exemple de BE (Bureau d'Enregistrement) :
<rdeRegistrar:registrar>
<rdeRegistrar:id>RAR21</rdeRegistrar:id>
<rdeRegistrar:name>Name Business</rdeRegistrar:name>
<rdeRegistrar:status>ok</rdeRegistrar:status>
<rdeRegistrar:postalInfo type="loc">
<rdeRegistrar:addr>
<rdeRegistrar:street>1 rue du Test</rdeRegistrar:street>
<rdeRegistrar:city>Champignac</rdeRegistrar:city>
<rdeRegistrar:cc>FR</rdeRegistrar:cc>
</rdeRegistrar:addr>
</rdeRegistrar:postalInfo>
<rdeRegistrar:voice>+33.0639981234</rdeRegistrar:voice>
<rdeRegistrar:fax>+33.0199001234</rdeRegistrar:fax>
<rdeRegistrar:email>master-of-domains@namebusiness.example</rdeRegistrar:email>
</rdeRegistrar:registrar>
On peut aussi mettre dans le séquestre des références vers ses tables IDN (que l'ICANN exige mais qui n'ont aucun intérêt). Plus intéressant, la possibilité de stocker dans le séquestre les listes de termes traités spécialement, par exemple interdits ou bien soumis à un examen manuel. Cela se nomme NNDN pour « NNDN's not domain name », oui, c'est récursif. Voici un exemple :
<rdeNNDN:NNDN>
<rdeNNDN:uName>gros-mot.example</rdeNNDN:uName>
<rdeNNDN:nameState>blocked</rdeNNDN:nameState>
<rdeNNDN:crDate>2005-04-23T11:49:00.0Z</rdeNNDN:crDate>
</rdeNNDN:NNDN>
Tous les registres n'ont pas les mêmes règles et le RFC décrit également les mécanismes qui permettent de spécifier dans le séquestre les contraintes d'intégrité spécifiques d'un registre. L'opérateur de séquestre, qui reçoit le fichier XML ou les fichiers CSV, est censé vérifier tout cela (autrement, il ne joue pas son rôle, s'il se contente de stocker aveuglément un fichier). La section 8 de notre RFC décrit plus en profondeur les vérifications recommandées, comme de vérifier que les contacts indiqués pour chaque domaine sont bien présents. Pour vérifier un séquestre, il faut importer beaucoup de schémas. Voici, la liste, sous forme d'une commande shell :
for schema in contact-1.0.xsd host-1.0.xsd rdeDomain-1.0.xsd rdeIDN-1.0.xsd rgp-1.0.xsd domain-1.0.xsd rde-1.0.xsd rdeEppParams-1.0.xsd rdeNNDN-1.0.xsd secDNS-1.1.xsd epp-1.0.xsd rdeContact-1.0.xsd rdeHeader-1.0.xsd rdePolicy-1.0.xsd eppcom-1.0.xsd rdeDnrdCommon-1.0.xsd rdeHost-1.0.xsd rdeRegistrar-1.0.xsd); do
wget https://www.iana.org/assignments/xml-registry/schema/${schema}
done
Ensuite, on importe (fichier escrow-wrapper.xsd) et
on utilise xmllint sur l'exemple de séquestre de la section 14 du
RFC (fichier escrow-example.xml) :
% xmllint --noout --schema wrapper.xsd escrow-example.xml escrow-example.xml validates
Ouf, tout va bien, le registre nous a envoyé un séquestre correct.
Enfin, la syntaxe formelle de ce format figure dans la section 9 du RFC, dans le langage XML Schema.
Ce format est mis en œuvre par tous les TLD qui sont liés par un contrat avec l'ICANN. 1 200 TLD envoient ainsi un séquestre une fois par semaine à l'ICANN.
Le concept de séquestre pose de sérieux problèmes de sécurité car le ou les fichiers transmis sont typiquement à la fois confidentiels, et cruciaux pour assurer la continuité de service. Lors du transfert du fichier, le registre et l'opérateur de séquestre doivent donc vérifier tous les deux l'authenticité du partenaire, et la confidentialité de la transmission. D'autant plus qu'une bonne partie du fichier est composée de données personnelles.
L'article seul
Le protocole QUIC désormais normalisé
Première rédaction de cet article le 28 mai 2021
Le protocole de transport QUIC vient d'être normalisé, sous la forme de plusieurs RFC. QUIC, déjà largement déployé, peut changer pas mal de choses sur le fonctionnement de l'Internet, en remplaçant, au moins partiellement, TCP.
Je vais décrire les RFC en question plus longuement dans des articles spécifiques à chacun mais cet article est consacré à une vision de plus haut niveau : c'est quoi, QUIC, et à quoi ça sert ?
QUIC n'est pas un protocole d'application comme peuvent l'être HTTP ou SSH. Les utilisateurs ordinaires ne verront pas la différence, ils se serviront des mêmes applications, via les mêmes protocoles applicatifs. QUIC est un protocole de transport, donc un concurrent de TCP, dont il vise à résoudre certaines limites, notamment dans le contexte du Web. Quelles limites ? Pour comprendre, il faut revenir à ce à quoi sert la couche de transport (couche 4 du traditionnel modèle en couches). Placée entre les datagrammes d'IP, qui peuvent arriver ou pas, dans l'ordre ou pas, et les applications, qui comptent en général sur un flux d'octets ordonnés, où rien ne manque, la couche transport est chargée de surveiller l'arrivée des paquets, de signaler à l'émetteur qu'il en manque, qu'il puisse réémettre, et de mettre dans le bon ordre les données. Dit comme ça, cela semble simple, mais cela soulève beaucoup de problèmes intéressants. Par exemple, il ne faut pas envoyer toutes les données sans réfléchir : le réseau n'est peut-être pas capable de les traiter, et un envoi trop brutal pourrait mener à la congestion. De même, en cas de pertes de paquet, il faut certes ré-émettre, mais aussi diminuer le rythme d'envoi, la perte pouvant être le signal que le réseau est saturé. C'est à la couche transport de gérer cette congestion, en essayant de ne pas la déclencher, ou en tout cas de ne pas l'aggraver. En pratique, la couche transport est donc très complexe, comme le montre le nombre de RFC sur TCP. La norme de base est le RFC 9293, mais d'autres RFC sont également à prendre en compte.
Maintenant que nous avons révisé les tâches de la couche transport, quelles sont ces limites de TCP dont je parlais, et qui justifient le développement de QUIC ? Notez d'abord qu'elles ont surtout été mentionnées dans le contexte du Web. Celui-ci pose en effet des problèmes particuliers, notamment le désir d'une faible latence (quand on clique, on veut une réponse tout de suite) et le fait que l'affichage d'une seule page nécessite le chargement de plusieurs ressources (images sans intérêt, vidéos agaçantes, code JavaScript pour faire bouger des trucs, CSS, etc). La combinaison de TCP et de TLS n'est pas satisfaisante question latence, puisqu'il faut d'abord établir la connexion TCP, avant de pouvoir commencer la négociation qui mènera à l'établissement de la session TLS (il existe des solutions partielles comme le TCP Fast Open du RFC 7413, mais qui n'est pas protégé par la cryptographie, ou la session resumption du RFC 9846, section 2.2). Ensuite, TCP souffre du manque de parallélisme : quand on veut récupérer plusieurs ressources, il faut soit ouvrir plusieurs connexions TCP, qui ne partageront alors plus d'information (RTT, taux de perte, etc) ou de calculs (cryptographie…), et consommeront potentiellement beaucoup de ports, soit multiplexer à l'intérieur d'une connexion TCP, ce que fait HTTP/2 (RFC 7540) mais, alors, on risque le head-of-line blocking, où la récupération d'une ressource bloque les suivantes, et le fait que la perte d'un seul paquet va faire ralentir tous les téléchargements. Cela ne veut pas dire que TCP est complètement dépassé : largement testé au feu depuis de nombreuses années, il déplace chaque jour d'innombrables octets, pour des connexions qui vont de la courte page HTML à des fichiers de plusieurs giga-octets.
Quels sont les concepts de base de QUIC ? QUIC gère des connexions entre machines, comme TCP. Par contre, contrairement à TCP, ces connexions portent ensuite des ruisseaux (streams) séparés, ayant leur propre contrôle de congestion, en plus du contrôle global à la connexion. Les ruisseaux peuvent être facilement et rapidement créés. Ce n'est pas par hasard que le concept ressemble à celui des ruisseaux de HTTP/2 (RFC 7540), dans les deux cas, le but était de s'adapter au désir des navigateurs Web de charger toutes les ressources d'une page en parallèle, sans pour autant « payer » l'établissement d'une connexion pour chaque ressource.
Avec QUIC, le chiffrement est obligatoire. Il n'y a pas de version de QUIC en clair. Non seulement les données applicatives sont chiffrées, comme avec TLS ou SSH mais une bonne partie de la couche transport l'est également. Pourquoi ?
- En raison de la prévalence de la surveillance massive sur l'Internet (RFC 7258) ; moins on expose de données, moins il y a de risques.
- Afin d'éviter que les middleboxes ne se croient capables d'analyser le fonctionnement de la couche transport, et ne se croient autorisées à y intervenir, ce qui mène à une ossification de l'Internet. Si tout est chiffré, on pourra faire évoluer le protocole sans craindre l'intervention de ces fichus intermédiaires.
- Certains FAI ont déjà exploité le caractère visible de TCP (RFC 8546) pour des attaques, par exemple en envoyant des paquets RST (ReSeT) pour couper le trafic BitTorrent. TLS et SSH ne protègent pas contre ce genre d'attaques. (Mais QUIC ne protège pas complètement ; le problème est difficile car il faut bien permettre aux machines terminales de réclamer une coupure de la connexion.)
- L'observation de la couche transport peut permettre d'identifier les services utilisés et d'en dé-prioritiser certains. Le chiffrement du transport peut donc aider à préserver la neutralité du réseau.
On peut prévoir que les habituels adversaires du chiffrement protesteront d'ailleurs contre QUIC, en l'accusant de gêner la visibilité (ce qui est bien le but). Voir par exemple le RFC 8404 et même le RFC 9065. On voit ainsi un fabricant de produits de sécurité qui conseille carrément de bloquer QUIC. Qu'est-ce que vont dire ces adversaires du chiffrement lorsqu'on aura des VPN sur QUIC, comme ce sur quoi travaille le bien nommé groupe MASQUE !
QUIC utilise le classique protocole TLS (RFC 9846) pour le chiffrement mais pas de la manière habituelle. Normalement, TLS fait la poignée de main initiale, l'échange des clés et le chiffrement des données. Avec QUIC, TLS ne fait que la poignée de main initiale et l'échange des clés. Une fois les clés obtenues, QUIC chiffrera tout seul comme un grand, en utilisant les clés fournies par TLS.
Puisqu'on a parlé des middleboxes : déployer un nouveau protocole de transport dans l'Internet d'aujourd'hui est très difficile, en raison du nombre d'équipements qui interfèrent avec le trafic (les routeurs NAT, par exemple). Conceptuellement, QUIC aurait pu tourner directement sur IP. Mais il aurait alors été bloqué dans beaucoup de réseaux. D'où le choix de ses concepteurs de le faire passer sur UDP. (Le protocole de transport SCTP avait eu ce problème et a dû se résigner à la même solution, cf. RFC 6951.) QUIC utilise UDP comme il utiliserait IP. On lit parfois que QUIC, ce serait « HTTP au-dessus d'UDP », mais c'est une grosse incompréhension. QUIC est une couche de transport complète, concurrente de TCP, dont le fonctionnement sur UDP n'est qu'un détail nécessaire au déploiement. QUIC n'a aucune des propriétés d'UDP. Par exemple, comme TCP, mais contrairement à UDP, QUIC teste la réversibilité du trafic, ce qui empêche l'usurpation d'adresses IP et toutes les attaques UDP qui reposent dessus.
QUIC est parfois présenté comme « tournant en mode utilisateur et pas dans le noyau (du système d'exploitation) ». En fait, ce n'est pas spécifique à QUIC. Tout protocole de transport peut être mis en œuvre en mode utilisateur ou noyau (et il existe des mises en œuvre de TCP qui fonctionnent en dehors du noyau). Mais il est exact qu'en pratique la plupart des mises en œuvre de QUIC ne sont pas dans le noyau du système, l'expérience prouvant que les mises à jour du système sont souvent trop lentes, par rapport au désir de faire évoluer en permanence la couche transport. Ceci dit, la norme ne l'impose pas et n'en parle même pas. (On peut ajouter aussi que, dans beaucoup de systèmes d'exploitation, il est plus facile à un programme utilisateur de tourner sur UDP que directement sur IP. Par exemple, sur Unix, tourner directement sur IP nécessite d'utiliser les prises brutes et donc d'être root.) Et puis, sur Windows, Google n'aime pas dépendre de Microsoft pour les performances de son navigateur.
Pour résumer les différences entre QUIC et TCP (rappelez-vous qu'ils assurent à peu près les mêmes fonctions) :
- QUIC est systématiquement chiffré,
- QUIC permet un vrai multiplexage ; la requête lente ne bloque pas la rapide, et la perte d'un paquet ne ralentit pas tous les ruisseaux multiplexés,
- QUIC fusionne transport et chiffrement, ce qui permet notamment de diminuer la latence à l'établissement de la connexion,
- QUIC permet la migration d'une connexion en cas de changement d'adresse IP (je n'en ai pas parlé ici, voir RFC 9000).
Les RFC normalisant QUIC sont :
- RFC 9000 est la norme principale, décrivant le socle de base de QUIC,
- RFC 9001 normalise l'utilisation de TLS avec QUIC,
- RFC 9002 spécifie les mécanismes de récupération de QUIC, quand des paquets sont perdus et qu'il faut ré-émettre, sans pour autant écrouler le réseau,
- RFC 8999 est consacré aux invariants de QUIC, aux points qui ne changeront pas dans les nouvelles versions de QUIC.
J'ai dit que QUIC, comme TCP, est un protocole de transport généraliste, et qu'on peut faire tourner plusieurs applications différentes dessus. En pratique, QUIC a été conçu essentiellement en pensant à HTTP mais dans le futur, d'autres protocoles pourront profiter de QUIC, notamment s'ils ont des problèmes qui ressemblent à ceux du Web (désir de faible latence, et de multiplexage).
Pour HTTP, la version de HTTP qui tourne sur QUIC se nomme
HTTP/3 et a été normalisée plus
tard, dans le RFC 9113. Comme HTTP/2 (RFC 7540),
HTTP/3 a un encodage binaire mais il ne fait plus de
multiplexage, celui-ci étant désormais assuré par QUIC. Pour
d'autres protocoles, les curieux pourront s'intéresser à
SMB (déjà géré
par Wireshark), au DNS (draft-ietf-dprive-dnsoquic)
ou SSH (draft-bider-ssh-quic). En
moins sérieux, il y a même eu des discussions pour mettre IRC sur
QUIC, mais ce n'est pas allé très loin.
QUIC a eu une histoire longue et compliquée. À l'origine, vers 2012, QUIC était un projet Google (documenté dans « QUIC: Multiplexed Transport Over UDP », article qui ne reflète pas le QUIC actuel). Si les motivations étaient les mêmes que celles du QUIC actuel, et que certains concepts étaient identiques, il y avait quand même deux importantes différences techniques : le QUIC de Google utilisait un protocole de cryptographie spécifique, au lieu de TLS, et il était beaucoup plus marqué pour son utilisation par HTTP uniquement. Et il y a aussi bien sûr une différence politique, QUIC était un protocole privé d'une entreprise particulière, il est maintenant une norme IETF. Le travail à l'IETF a commencé en 2016 à la réunion de Séoul. Les discussions à l'IETF ont été chaudes et prolongées, vu l'importance du projet. Après tout, il s'agit de remplacer, au moins partiellement, le principal protocole de transport de l'Internet. C'est ce qui explique qu'il se soit écoulé plus de quatre ans entre le premier projet IETF et ces RFC. Vous pouvez avoir une idée de ce travail en visitant le site Web du groupe de travail ou en admirant les milliers de tickets traités.
Questions mises en œuvre de QUIC (elles sont nombreuses), je vous renvoie à mon article sur le RFC 9000. Le déploiement de QUIC a commencé il y a longtemps puisque Google l'avait déjà mis dans Chrome et ses services. En 2017, Google annonçait que QUIC représentait déjà 7 % du trafic vers ses serveurs. Bon, c'était le QUIC de Google, on va voir ce que cela va donner pour celui de l'IETF, mais le point important est que le déploiement n'a pas attendu les RFC.
Quelques lectures sur QUIC :
- La référence est bien sûr le livre libre et gratuit de Daniel Stenberg (l'auteur de curl), HTTP/3 explained. En dépit de son nom, il couvre également QUIC. Il a une traduction en français.
- Mon exposé à Capitole du Libre en 2019 couvrait QUIC, avec un beau résumé en image, fait par Kevin Ottens.
- L'IETF a publié un résumé de QUIC sur son blog.
- Il n'y a pas à l'heure actuelle de page QUIC sur le Wikipédia francophone.
- Si vous aimez les détails techniques, outre les RFC cités plus haut, j'ai fait un article détaillant une session QUIC.
{kind=link}
L'article seul
Une courte session QUIC avec explications
Première rédaction de cet article le 28 mai 2021
On va voir ici quelques exemples QUIC, avec explications des paquets échangés. On saute directement dans les détails donc, si ce n'est pas déjà fait, je recommande de commencer par l'article d'introduction à QUIC.
Comme on ne peut pas facilement utiliser tcpdump ou Wireshark (mais lisez cet article jusqu'au bout, j'explique à la fin) pour analyser une communication QUIC (tout est systématiquement chiffré), on va se servir d'un client QUIC qui a la gentillesse d'afficher en détail ce qu'il fait, en l'occurrence picoquic. Pour le compiler :
# La bibliothèque picotls git clone https://github.com/h2o/picotls.git cd picotls git submodule init git submodule update cmake . make cd .. # picoquic git clone https://github.com/private-octopus/picoquic.git cd picoquic cmake . make
Puis on va utiliser le programme client
picoquicdemo pour se connecter en
HTTP/3 à un serveur public, mettons
f5quic.com :
% ./picoquicdemo -l /tmp/quic.txt f5quic.com 4433 '0:index.html'
La ligne de commande ci-dessus lance
picoquicdemo, enregistre les informations dans
le fichier /tmp/quic.txt, se connecte à
f5quic.com sur le port
4433 et récupère le fichier index.html (qui
n'existe pas mais peu importe, une réponse 404 nous suffit).
Parmi les messages affichés, vous verrez :
No token file present. Will create one as <demo_token_store.bin>.
Ces jetons (tokens) sont définis dans le RFC 9000, section 8.1.1. Générés par le serveur, ils servent à s'assurer que le client reçoit bien les réponses, donc qu'il n'a pas usurpé son adresse IP. Ce test de retournabilité permet de se protéger contre les imposteurs. Comme c'est la première fois que nous lançons le client, il est normal qu'il n'ait pas encore de jeton.
Le fichier de résultat est téléchargeable ici, quic-demo-0.txt
efed1e171949e7a6: Sending ALPN list (8): h3-32, hq-32, h3-31, hq-31, h3-29, hq-29, h3-30, hq-30
La chaîne de caractères efed1e171949e7a6 est le
Connection ID (RFC 9000, section 5.1). QUIC utilise ALPN (RFC 7301) pour indiquer l'application à lancer à
l'autre bout. h3-32 est HTTP/3, draft
version 32 (dans le RFC final, le RFC 9113, l'ALPN est h3).
efed1e171949e7a6: Sending transport parameter TLS extension (89 bytes):
Diverses extensions au protocole TLS comme Extension type: 9
(max_streams_uni), length 2, 4201 qui indique le nombre
maximum de ruisseaux QUIC dans la connexion. Rappelez-vous que QUIC
fusionne la traditionnelle couche
transport et le chiffrement. Les paramètres de transport
sont donc envoyés sous forme d'extensions TLS (RFC 9001, section 8.2). Ces
paramètres figurent dans un
registre IANA. Vous pouvez y vérifier que 9 est
initial_max_streams_uni.
efed1e171949e7a6: Sending packet type: 2 (initial), S0, Q1, Version ff000020,
Les choses sérieuses démarrent. Le client envoie un paquet de type
Initial marquant son désir d'ouvrir une
connexion QUIC. Les types de paquets ne sont
pas dans un registre IANA, leur liste limitative
figure dans le RFC 9000,
notamment dans la section 17.2. La version
de QUIC désirée est ff000020, ce qui était la
dernière version de développement. Aujourd'hui, ce serait
Version 1. (La liste des versions, pour
l'instant réduite, est dans un
registre IANA.)
efed1e171949e7a6: Crypto HS frame, offset 0, length 335: 0100014b030372b6... efed1e171949e7a6: padding, 867 bytes
Ce premier paquet contient une trame QUIC de type
CRYPTO (RFC 9000, section 19.6), avec les paramètres
cryptographiques, et du remplissage, pour
atteindre la taille miminum imposée de 1 200 octets (RFC 9000, section 8.1)
efed1e171949e7a6: Sending 1252 bytes to 40.112.191.60:4433 at T=0.002156 (5bc54cac22aa1) efed1e171949e7a6: Receiving 1200 bytes from 40.112.191.60:4433 at T=0.169086 (5bc54cac4b6b3)
Parfait, on a envoyé le paquet, et reçu une réponse. Petit rappel : l'information de base dans QUIC est transmise dans des trames, les trames voyagent dans un paquet, les paquets sont placés dans des datagrammes UDP. Il peut y avoir plusieurs paquets dans un datagramme et plusieurs trames dans un paquet. Déchiffrons maintenant la réponse :
efed1e171949e7a6: Receiving packet type: 2 (initial), S0, Q1, Version ff000020, efed1e171949e7a6: <b3efa80036784b1f>, <041eb19906b9ca99>, Seq: 0, pl: 149 ... efed1e171949e7a6: ACK (nb=0), 0 efed1e171949e7a6: Crypto HS frame, offset 0, length 123: 02000077030314b7...
Le serveur a répondu avec son propre paquet
Initial (cf. RFC 9000, section 7, figure 4). Ensuite, il nous
serre la main :
efed1e171949e7a6: Receiving packet type: 4 (handshake), S0, Q1, Version ff000020, efed1e171949e7a6: Crypto HS frame, offset 0, length 979: 0800006400620010... efed1e171949e7a6: Received transport parameter TLS extension (82 bytes): ...
On est d'accord, on envoie nous aussi un Handshake :
efed1e171949e7a6: Sending packet type: 4 (handshake), S0, Q0, Version ff000020,
(Il y a en fait plusieurs paquets Handshake.)
efed1e171949e7a6: Receiving packet type: 6 (1rtt protected), S0, Q0, ... efed1e171949e7a6: Sending packet type: 6 (1rtt protected), S1, Q0, efed1e171949e7a6: Prepared 1414 bytes efed1e171949e7a6: ping, 1 bytes efed1e171949e7a6: padding, 1413 bytes
Cette fois, la connexion est établie. On peut maintenant échanger
des paquets de type 1-RTT, le type de paquet
général, qui sert pour tout sauf au début de la
connexion. ping et padding
sont des types de trames (RFC 9000, section 19). Les différents types
de trames sont dans un
registre IANA. ping sert à déclencher
l'envoi d'un accusé de réception, qui montrera que l'autre machine
est bien vivante. padding fait du remplissage pour
gêner l'analyse de
trafic. Maintenant, c'est bon, le travail est fait, on
peut raccrocher :
efed1e171949e7a6: Sending packet type: 6 (1rtt protected), S0, Q0, efed1e171949e7a6: <041eb19906b9ca99>, Seq: 4 (4), Phi: 0, efed1e171949e7a6: Prepared 8 bytes efed1e171949e7a6: ACK (nb=0), 0-4 efed1e171949e7a6: application_close, Error 0x0000, Reason length 0 efed1e171949e7a6: Sending 34 bytes to 40.112.191.60:4433 at T=0.334640 (5bc54cac73d65) efed1e171949e7a6: Receiving 37 bytes from 40.112.191.60:4433 at T=0.489651 (5bc54cac99ae8) efed1e171949e7a6: Receiving packet type: 6 (1rtt protected), S0, Q1, efed1e171949e7a6: <b3efa80036784b1f>, Seq: 5 (5), Phi: 0, efed1e171949e7a6: Decrypted 11 bytes efed1e171949e7a6: application_close, Error 0x0000, Reason length 8 efed1e171949e7a6: Reason: No error
Tout va bien, on a envoyé un paquet de type 1-RTT
qui contient l'alerte TLS application_close, la
connexion est fermée.
Ici, on n'avait demandé qu'un seul fichier
(index.html). Mais l'usage normal du Web est de
demander plusieurs ressources, puisque l'affichage d'une page
nécessite en général de nombreuses ressources (CSS,
JavaScript, images…). Avec QUIC, ces
différentes demandes peuvent être faites sur des ruisseaux
différents, pour un maximum de parallélisme :
% ./picoquicdemo -l /tmp/quic.txt f5quic.com 4433 '0:index.html;100:foobar.html' ... Opening stream 0 to GET /index.html Opening stream 100 to GET /foobar.html ...
Et dans le fichier contenant les détails (quic-demo-1.txt
7f0a5c80d9f66dab: Sending packet type: 6 (1rtt protected), S0, Q1,
7f0a5c80d9f66dab: Stream 100, offset 0, length 32, fin = 1: 011e0000d1d7510c...
...
7f0a5c80d9f66dab: Receiving packet type: 6 (1rtt protected), S0, Q0,
7f0a5c80d9f66dab: Stream 100, offset 0, length 245, fin = 0: 013e0000db5f4d91...
...
On a vu que la première connexion n'avait pas de jeton. Stocker
un jeton reçu du serveur permet de faire du « zéro-RTT », c'est-à-dire
d'envoyer des données dès le premier paquet transmis. Si on
recommence la même commande picoquicdemo, le
programme va lire le jeton précédemment obtenu, et stocké dans le
fichier demo_token_store.bin, et s'en servir :
The session was properly resumed! Zero RTT data is accepted!
Vous pouvez voir le résultat dans le fichier complet
(quic-demo-2.txtInitial, au lieu d'un type
Handshake, on attaque directement avec un
paquet de type 0-RTT :
119d7339e68827df: Sending packet type: 5 (0rtt protected), S0, Q1, Version ff000020,
Et si on veut quand même utiliser l'excellent
Wireshark, dont les versions les plus
récentes savent décoder QUIC ? D'abord, sans truc particulier, on
peut voir la partie non chiffrée des paquets QUIC. D'abord avec
tshark, la version texte de Wireshark analysant un
pcap pris en communiquant avec le serveur
public de Microsoft (le pcap a été
enregistré avec un tcpdump -w /tmp/quic-microsoft.pcap
host msquic.net and udp and port 443 :
% tshark -r /tmp/quic-microsoft.pcap 1 0.000000 10.168.234.1 → 138.91.188.147 QUIC 1294 Initial, DCID=9b4dccfc42f8ab9c, SCID=cf4d6e8c2c7b43a2, PKN: 0, CRYPTO, PADDING 2 0.170410 138.91.188.147 → 10.168.234.1 QUIC 1294 Handshake, DCID=cf4d6e8c2c7b43a2, SCID=09fa3e7edeb3b621ae 3 0.170550 138.91.188.147 → 10.168.234.1 QUIC 1294 Handshake, DCID=cf4d6e8c2c7b43a2, SCID=09fa3e7edeb3b621ae 4 0.170558 138.91.188.147 → 10.168.234.1 QUIC 1108 Protected Payload (KP0), DCID=cf4d6e8c2c7b43a2 5 0.171689 10.168.234.1 → 138.91.188.147 QUIC 331 Protected Payload (KP0), DCID=09fa3e7edeb3b621ae 6 0.171765 10.168.234.1 → 138.91.188.147 QUIC 1514 Protected Payload (KP0), DCID=09fa3e7edeb3b621ae
On voit que les paquets d'établissement de la connexion,
Initial et Handshake ne
sont pas chiffrés (on n'a pas encore négocié les paramètres
cryptographiques). On voit même que le paquet
Initial contient deux trames,
CRYPTO et PADDING (pour
atteindre la taille minimale, imposée pour éviter les attaques avec
amplification). tshark affiche les connections ID
(DCID = destination et SCID = source). Une fois la cryptographie
configurée, on ne voit plus grand'chose, la taille des paquets, et
le connection ID de la destination (il s'agit de
paquets à en-tête court, qui n'incluent pas le connection
ID de la source). Même les paquets à la fin, qui terminent
la connexion, ne sont pas décodables.
Voyons cette partie non chiffrée plus en détail avec l'option
-V :
User Datagram Protocol, Src Port: 44873, Dst Port: 443
Source Port: 44873
Destination Port: 443
Length: 1260
UDP payload (1252 bytes)
QUIC IETF
QUIC Connection information
[Connection Number: 0]
[Packet Length: 1252]
1... .... = Header Form: Long Header (1)
.1.. .... = Fixed Bit: True
..00 .... = Packet Type: Initial (0)
.... 00.. = Reserved: 0
.... ..11 = Packet Number Length: 4 bytes (3)
Version: 1 (0x00000001)
Destination Connection ID Length: 8
Destination Connection ID: 9b4dccfc42f8ab9c
Source Connection ID Length: 8
Source Connection ID: cf4d6e8c2c7b43a2
Token Length: 0
Length: 1226
Packet Number: 0
Payload: 03c99cd0b086b40241f66768c1806ae00bcfa9f7db97593669e784fa326c83f89aac54d2…
TLSv1.3 Record Layer: Handshake Protocol: Client Hello
Frame Type: CRYPTO (0x0000000000000006)
Offset: 0
Length: 393
Crypto Data
Handshake Protocol: Client Hello
Handshake Type: Client Hello (1)
Length: 389
...
ALPN Next Protocol: h3
...
Extension: quic_transport_parameters (len=85)
Type: quic_transport_parameters (57)
...
Parameter: initial_max_data (len=4) 1048576
Type: initial_max_data (0x04)
Length: 4
Value: 80100000
initial_max_data: 1048576
...
Parameter: max_idle_timeout (len=4) 30000 ms
Type: max_idle_timeout (0x01)
Length: 4
Value: 80007530
max_idle_timeout: 30000
...
Il s'agit du paquet Initial, à en-tête long (le
premier bit), incluant un classique Client Hello
TLS, qui
comprend notamment une demande ALPN pour HTTP/3, et les paramètres de transport
spécifique à QUIC. La réponse du serveur inclut
deux paquets QUIC (n'oubliez pas qu'un
datagramme UDP peut transporter plusieurs paquets QUIC, chacun
pouvant transporter plusieurs trames, ce qui est le cas du premier
paquet, qui inclut une trame ACK et une trame
CRYPTO) :
User Datagram Protocol, Src Port: 443, Dst Port: 44873
Source Port: 443
Destination Port: 44873
Length: 1260
UDP payload (1252 bytes)
QUIC IETF
QUIC Connection information
[Connection Number: 0]
[Packet Length: 179]
1... .... = Header Form: Long Header (1)
.1.. .... = Fixed Bit: True
..00 .... = Packet Type: Initial (0)
.... 00.. = Reserved: 0
.... ..11 = Packet Number Length: 4 bytes (3)
Version: 1 (0x00000001)
Destination Connection ID Length: 8
Destination Connection ID: cf4d6e8c2c7b43a2
Source Connection ID Length: 9
Source Connection ID: 09fa3e7edeb3b621ae
Token Length: 0
Length: 152
Packet Number: 0
ACK
Frame Type: ACK (0x0000000000000002)
Largest Acknowledged: 0
ACK Delay: 16
ACK Range Count: 0
First ACK Range: 0
TLSv1.3 Record Layer: Handshake Protocol: Server Hello
Frame Type: CRYPTO (0x0000000000000006)
Offset: 0
Length: 123
Crypto Data
Handshake Protocol: Server Hello
...
QUIC IETF
[Packet Length: 1073]
1... .... = Header Form: Long Header (1)
.1.. .... = Fixed Bit: True
..10 .... = Packet Type: Handshake (2)
Version: 1 (0x00000001)
Destination Connection ID Length: 8
Destination Connection ID: cf4d6e8c2c7b43a2
Source Connection ID Length: 9
Source Connection ID: 09fa3e7edeb3b621ae
Length: 1047
[Expert Info (Warning/Decryption): Failed to create decryption context: Secrets are not available]
...
Le deuxième paquet, le Handshake est déjà chiffré.
Cette analyse peut aussi être faite avec l'interface graphique de
Wireshark : 
Maintenant, si on veut aller plus loin et fouiller dans la partie
chiffrée des paquets ? Il faut pour cela que l'application écrive
les clés utilisées pendant la connexion dans un fichier, et qu'on
dise à Wireshark d'utiliser ce fichier pour déchiffrer. Si
l'application utilise une bibliothèque qui permet d'inscrire les clés
de session dans un fichier, comme
OpenSSL ou picotls, on peut la convaincre d'écrire ces
clés en définissant la variable
d'environnement SSLKEYLOGFILE. Par
exemple :
% export SSLKEYLOGFILE=/tmp/quic.key % ./picoquicdemo msquic.net 443 '0:index.html' % cat /tmp/quic.key SERVER_HANDSHAKE_TRAFFIC_SECRET 0469b5f648c6aece6b78338f4453f38d39a1527a5564458631a8d221c0d10ffa dc21c8a9927bc196a48e670c4920b26a4b9bdba8bfc5d610c055def0bda3f3cdc8062a90992b228e1f02b659ddc0bfec CLIENT_HANDSHAKE_TRAFFIC_SECRET 0469b5f648c6aece6b78338f4453f38d39a1527a5564458631a8d221c0d10ffa 53b7105c924b3f5ae1e8cda70f0b5f20119a267ba462e027e645bf1b762f490f4ee2deef2cde93feace61cdd56c708a1 SERVER_TRAFFIC_SECRET_0 0469b5f648c6aece6b78338f4453f38d39a1527a5564458631a8d221c0d10ffa 683e037fb3e1d6451d1edce1d638fc4271859d32c164ee7c9c5b16e9761abfd97d2f91ea5c8141f4b8d7f2b9bdc36cc8 CLIENT_TRAFFIC_SECRET_0 0469b5f648c6aece6b78338f4453f38d39a1527a5564458631a8d221c0d10ffa 2ca521c138a9e7ad66817b583c9a3423d1d2d92a0a51a7290e08d3e4707cc6a407fc7f389dde74ba6faeba19033492b7
Il faut ensuite dire à Wireshark d'utiliser ces clés. Dans les menus
Edit Preferences Protocols TLS, on indique le nom du fichier dans
(Pre-)-Master-Secret log filename. (Ou bien on
édite le fichier de préférences de Wireshark, par exemple
~/.config/wireshark/preferences pour mettre
tls.keylog_file: /tmp/quic.key.)
Désormais, Wireshark sait déchiffrer :
% tshark -r /tmp/quic-microsoft.pcap | more 1 0.000000 10.168.234.1 → 138.91.188.147 QUIC 1294 Initial, DCID=345d144296b90cff, SCID=f50587894e0cd26c, PKN: 0, CRYPTO, PADDING 2 0.166722 138.91.188.147 → 10.168.234.1 HTTP3 1294 Protected Payload (KP0), DCID=f50587894e0cd26c, PKN: 2, STREAM(3), SETTINGS, STREAM(7), STREAM(11), PADDING 3 0.167897 10.168.234.1 → 138.91.188.147 QUIC 332 Protected Payload (KP0), DCID=d9e7940a80b4975407, PKN: 0, ACK, NCI, NCI, NCI, PADDING 4 0.167987 10.168.234.1 → 138.91.188.147 QUIC 1514 Protected Payload (KP0), DCID=d9e7940a80b4975407, PKN: 1, PING, PADDING 5 0.168550 10.168.234.1 → 138.91.188.147 HTTP3 225 Protected Payload (KP0), DCID=d9e7940a80b4975407, PKN: 2, STREAM(2), SETTINGS, STREAM(6 ), STREAM(10), STREAM(0), HEADERS, PADDING 6 0.332156 138.91.188.147 → 10.168.234.1 QUIC 1294 Protected Payload (KP0), DCID=f50587894e0cd26c, PKN: 3, ACK, DONE, NCI, NCI, PADDING 7 0.332361 138.91.188.147 → 10.168.234.1 QUIC 1482 Protected Payload (KP0), DCID=f50587894e0cd26c, PKN: 4, PING, PADDING 8 0.332372 138.91.188.147 → 10.168.234.1 HTTP3 1294 Protected Payload (KP0), DCID=f50587894e0cd26c, PKN: 5, ACK, STREAM(7), STREAM(0), HEADERS 9 0.332375 138.91.188.147 → 10.168.234.1 HTTP3 177 Protected Payload (KP0), DCID=f50587894e0cd26c, PKN: 6, STREAM(0), DATA 10 0.332841 10.168.234.1 → 138.91.188.147 QUIC 77 Protected Payload (KP0), DCID=d9e7940a80b4975407, PKN: 3, ACK, CC 11 0.487969 138.91.188.147 → 10.168.234.1 QUIC 80 Protected Payload (KP0), DCID=f50587894e0cd26c, PKN: 7, ACK, CC
On voit que la communication était utilisée pour
HTTP/3 et on peut suivre les détails, comme
les types de trame utilisés. Même chose avec l'option
-V, on voit la totalité des paquets, ici un
datagramme envoyé par le client :
User Datagram Protocol, Src Port: 56785, Dst Port: 443
Source Port: 56785
Destination Port: 443
Length: 191
UDP payload (183 bytes)
QUIC IETF
QUIC Connection information
[Connection Number: 0]
[Packet Length: 183]
QUIC Short Header DCID=d9e7940a80b4975407 PKN=2
0... .... = Header Form: Short Header (0)
.1.. .... = Fixed Bit: True
..1. .... = Spin Bit: True
...0 0... = Reserved: 0
.... .0.. = Key Phase Bit: False
.... ..00 = Packet Number Length: 1 bytes (0)
Destination Connection ID: d9e7940a80b4975407
Packet Number: 2
STREAM id=2 fin=0 off=0 len=7 uni=1
Frame Type: STREAM (0x000000000000000a)
.... ...0 = Fin: False
.... ..1. = Len(gth): True
.... .0.. = Off(set): False
Stream ID: 2
Length: 7
STREAM id=6 fin=0 off=0 len=1 uni=1
Frame Type: STREAM (0x000000000000000a)
.... ...0 = Fin: False
.... ..1. = Len(gth): True
.... .0.. = Off(set): False
Stream ID: 6
Length: 1
STREAM id=10 fin=0 off=0 len=1 uni=1
Frame Type: STREAM (0x000000000000000a)
.... ...0 = Fin: False
.... ..1. = Len(gth): True
.... .0.. = Off(set): False
Stream ID: 10
Length: 1
STREAM id=0 fin=1 off=0 len=31 uni=0
Frame Type: STREAM (0x000000000000000b)
.... ...1 = Fin: True
.... ..1. = Len(gth): True
.... .0.. = Off(set): False
Stream ID: 0
Length: 31
PADDING Length: 104
Frame Type: PADDING (0x0000000000000000)
[Padding Length: 104]
...
Hypertext Transfer Protocol Version 3
Type: HEADERS (0x0000000000000001)
Length: 29
Frame Payload: 0000d1d7510b2f696e6465782e68746d6c500a6d73717569632e6e6574
Le datagramme comprend un seul paquet, qui contient cinq trames,
quatre de données (type STREAM) et une de
remplissage (type PADDING). Dans les données se
trouve une requête HTTP/3.
Graphiquement, on voit aussi davantage de détails : 
Si vous voulez regarder vous-même avec Wireshark, et que vous
n'avez pas de client QUIC pour créer du trafic, les fichiers quic-microsoft.pcap et quic.key
sont disponibles.
L'article seul
Le spin bit de QUIC
Première rédaction de cet article le 28 mai 2021
Une bonne partie du travail à l'IETF sur le protocole QUIC avait tourné autour d'un seul bit de l'en-tête QUIC, le spin bit. Pourquoi ?
Ce bit intéressant apparait dans les paquets QUIC à en-tête court (cf. le RFC 9000), et a agité énormément d'électrons lors des discussions à l'IETF. Pour comprendre ces polémiques, il faut voir à quoi sert ce bit. Avec TCP, quelqu'un qui surveillait le réseau pouvait calculer un certain nombre de choses sur la connexion TCP, comme le RTT, par exemple, en observant le délai entre un octet et l'accusé de réception couvrant cet octet. Cela peut être utilisé pour régler le réseau de manière à améliorer les performances (mais ne rêvez pas : contrairement à ce qui a parfois été prétendu, aucun FAI ne va vous informer de la santé de vos connexions individuelles, ni vous aider à les optimiser). Mais c'est également un problème de vie privée (toute information que vous envoyez sur le réseau peut être utilisée à mauvais escient). L'une des idées fortes de QUIC est de réduire la vue présentée au réseau (RFC 8546) et donc de chiffrer au maximum ; avec QUIC, on ne peut plus trouver le RTT en examinant les paquets qui passent. Cela peut être un problème si on souhaite justement informer le réseau et les gens qui le gèrent. Le spin bit a donc pour but de donner un minimum d'informations explicitement (alors qu'avec TCP, on donne plein d'informations sans s'en rendre compte). Ce spin bit est public (il n'est pas dans la partie chiffrée du paquet) et est inversé par l'initiateur de la connexion à chaque aller-retour (section 17.4 du RFC). Cela permet donc d'estimer le RTT. Cette utilisation est par exemple mise en œuvre dans le programme spindump.
Ce spin bit est optionnel, puisqu'on a vu qu'il pouvait être mal utilisé. Le RFC précise qu'une mise en œuvre de QUIC doit permettre sa désactivation, globalement ou par connexion. Il ajoute que, même si le spin bit est activé, QUIC doit le débrayer pour au moins une connexion sur seize, choisie au hasard, pour que les gens qui veulent être discrets et donc coupent le spin bit ne soient pas trop séparables des autres. C'est un principe classique en protection de la vie privée : il ne faut pas se distinguer. Pendant une enquête de police, les gens qui ont éteint leur ordiphone peu avant les faits seront les premiers suspects…
Cet unique bit a suscité beaucoup de discussions pour sa petite
taille. Si vous voulez en apprendre d'avantage, vous pouvez
consulter l'Internet-Draft draft-andersdotter-rrm-for-rtt-in-quic
(une technique compliquée mais qui contient une bonne explication du
spin bit), ou bien le draft-martini-hrpc-quichr
qui, globalement, était très enthousiaste en faveur de QUIC mais
suggèrait la suppression du spin bit. Merci
d'ailleurs à leurs auteurs, pour leurs explications qui m'ont
beaucoup aidé. Il y a également l'article « Three
Bits Suffice: Explicit Support for Passive Measurement of Internet
Latency in QUIC and TCP » (la version finale du
spin bit est différente mais l'article explique
bien le principe).
L'article seul
RFC 8999: Version-Independent Properties of QUIC
Date de publication du RFC : Mai 2021
Auteur(s) du RFC : M. Thomson (Mozilla)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF quic
Première rédaction de cet article le 28 mai 2021
Ce RFC, qui fait partie de la première fournée sur QUIC, décrit les invariants du protocole QUIC, les choses qui ne changeront pas dans les futures versions de QUIC.
Comme tous les protocoles Internet, QUIC doit faire face à l'ossification, cette tendance à rendre les changements impossibles, en raison du nombre de composants du réseau qui refusent tout comportement qu'ils n'attendaient pas, même si c'était une évolution prévue ou en tout cas possible. Une des méthodes pour limiter cette ossification est la documentation d'invariants, des parties du protocole dont on promet qu'elles ne changeront pas dans les futures versions. Tout le reste peut bouger et les équipements comme les middleboxes peuvent donc s'appuyer sur ce RFC pour faire les choses proprement, en sachant ce qui durera longtemps, et ce qui est susceptible d'évoluer.
La section 15 du RFC 9000 explique le principe des versions de QUIC. QUIC est actuellement à la version 1. C'est la seule pour l'instant. Mais si une version 2 (puis 3, puis 4…) apparait un jour, il faudra négocier la version utilisée entre les deux parties (section 6 du RFC 9000). Ces nouvelles versions pourront améliorer le protocole, répondant à des phénomènes qui ne sont pas forcément prévisibles. Par exemple QUIC v1 utilise forcément TLS pour la sécurité (RFC 9001), mais les futures versions pourront peut-être utiliser un autre protocole cryptographique, plus sûr, ou plus rapide. L'expérience de nombreux protocoles IETF est qu'il est difficile de déployer une nouvelle version d'un protocole déjà en place, car il y a toujours des équipements dans le réseau qui faisaient des suppositions sur le protocole, qui ne sont plus vraies avec la nouvelle version (et, souvent même pas avec l'ancienne…) et qui pertuberont, voire couperont la communication. D'où cette idée de documenter les invariants, en indiquant donc clairement que tout ce qui n'est pas invariant… peut changer. Un exemple d'invariant est « A QUIC packet with a long header has the high bit of the first byte set to 1. All other bits in that byte are version specific. ». Actuellement (version 1), le deuxième bit vaut forcément 1 (RFC 9000, section 17.2), mais ce n'est pas un invariant : les autres versions feront peut-être différemmment.
Concevoir des invariants est tout un art. Trop d'invariants et QUIC ne peut plus évoluer. Pas assez d'invariants et ils ne servent plus à rien. Ainsi, il semble difficile de faire un répartiteur de charge qui marche avec toutes les futures versions de QUIC (pas assez d'invariants pour lui).
Et dans les paquets, qu'est-ce qui sera invariant ? (Petit rappel au passage, un datagramme UDP peut contenir plusieurs paquets QUIC.) Il y a deux sortes de paquets, les longs et les courts. (Plus rigoureusement, ceux à en-tête long et ceux à en-tête court.) On les distingue par le premier bit. Tous les autres bits du premier octet sont spécifiques d'une version particulière de QUIC, et ne sont donc pas invariants. Ce premier octet est suivi d'un numéro de version sur 32 bits (aujourd'hui, forcément 1, sauf en cas de négociation de version, non encore spécifiée), puis du connection ID de la destination (attention : longueur variable, dans les paquets longs, il est encodé sous forme longueur puis valeur, cela permettra d'avoir des identificateurs de connexion très longs dans le futur) puis, mais seulement pour les paquets longs, du connection ID de la source. Tout le reste du paquet dépend de la version de QUIC utilisée.
Notez que la longueur des paquets n'étant pas dans les invariants, on ne peut même pas trouver combien il y a de paquets QUIC dans un datagramme de manière indépendante de la version.
L'identificateur de connexion est une donnée opaque : la façon de le choisir pourra varier dans le futur.
Bien sûr, spécifier rigoureusement les invariants n'empêchera pas les middleboxes de tirer des fausses conclusions et, par exemple, de généraliser des comportements de la version 1 de QUIC à toutes les versions ultérieures (section 7 du RFC). L'annexe A donne une liste (sans doute incomplète) des suppositions qu'un observateur pourrait faire mais qui sont erronées. QUIC essaie de réduire ce qu'on peut observer, en chiffrant au maximum, afin de limiter ces suppositions erronées, mais il reste des choses visibles, qui ne sont pas forcément invariantes. Le RFC écrit ces suppositions de manière neutre, en notant qu'elles sont fausses. J'ai préféré rédiger en insistant sur leur fausseté. Donc, rappelez-vous que, notamment dans les futures versions de QUIC :
- QUIC n'utilise pas forcément TLS,
- les paquets longs peuvent apparaitre même après l'établissement de la connexion,
- il n'y aura pas toujours de phase de connexion au début,
- le dernier paquet avant une période de silence n'est pas forcément uniquement un accusé de réception,
- les numéros de paquet ne croissent pas forcément de un à chaque paquet,
- ce n'est pas toujours le client qui parle le premier,
- les connection ID peuvent changer très vite,
- le second bit du premier octet, parfois appelé à tort le « QUIC bit », n'est pas forcément à un, et il avait même été proposé de le faire varier (ce qu'on appelle le graissage, cf. RFC 8701),
- et plusieurs autres points.
À noter que le numéro de version n'apparait que dans les paquets longs. Un programme qui observe des paquets QUIC de versions différentes ne peut donc analyser les paquets courts que s'il a mémorisé les numéros de versions correspondant à chaque connection ID de destination qu'il voit.
Autre point important : il n'y a pas d'invariant qui identifie un paquet QUIC. Pas de nombre magique ou de chose équivalente. Donc, aucun moyen d'être raisonnablement sûr que ce qui passe est du QUIC. C'est bien sûr volontaire, pour augmenter les chances que la neutralité soit respectée. Mais cela peut amener des middleboxes agressives à essayer de deviner si c'est bien du QUIC ou pas, en se trompant. (Le « QUIC bit » n'est évidemment pas une preuve suffisante, il peut s'agir d'un autre protocole où ce bit vaut 1.)
L'article seul
RFC 9000: QUIC: A UDP-Based Multiplexed and Secure Transport
Date de publication du RFC : Mai 2021
Auteur(s) du RFC : J. Iyengar (Fastly), M. Thomson (Mozilla)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF quic
Première rédaction de cet article le 28 mai 2021
Le protocole de transport QUIC vient d'être normalisé, dans une série de quatre RFC. J'ai écrit un résumé synthétique de QUIC, cet article porte sur le principal RFC du groupe, celui qui normalise le cœur de QUIC, le mécanisme de transport des données. QUIC, comme TCP, fournit aux protocoles applicatifs un service de transport des données fiable, et en prime avec authentification et confidentialité.
L'un des buts principaux de QUIC est de réduire la latence. La capacité des réseaux informatiques augmente sans cesse, et va continuer de la faire, alors que la latence sera bien plus difficile à réduire. Or, elle est déterminante dans la perception de « vitesse » de l'utilisateur. Quels sont les problèmes que pose actuellement l'utilisation de TCP, le principal protocole de transport de l'Internet ?
- Head-of-line blocking, quand une ressource rapide est bloquée par une lente située avant elle dans la file, ou quand la perte d'un seul paquet TCP bloque toute la connexion en attendant que les données manquantes soient réémises. Si on multiplexe au-dessus de TCP, comme le fait HTTP/2 (RFC 9113), tous les ruisseaux d'une même connexion doivent attendre.
- Latence due à l'ouverture de la session TLS, d'autant plus que TCP et TLS étant découplés, TLS doit attendre que TCP ait fini pour commencer sa négociation.
Le cahier des charges de QUIC était à peu près :
- Déployable aujourd'hui, sans changement important de l'Internet. Compte-tenu du nombre de boitiers intermédiaires intrusifs (cf. RFC 7663), cela exclut le développement d'un nouveau protocole de transport reposant directement sur IP : il faut passer sur TCP ou UDP. Les solutions « révolutionnaires » ont donc été abandonnées immédiatement.
- Faible latence, notamment pour le démarrage de la session.
- Meilleure gestion de la mobilité (ne pas casser les sessions si on change de connectivité).
- Assurer la protection de la vie privée au moins aussi bien qu'avec TCP+TLS (donc, tout chiffrer). Le chiffrement ne sert d'ailleurs pas qu'à gêner la surveillance : il a aussi pour but d'empêcher les modifications que se permettent bien des FAI.
- Services aux applications à peu près semblables à ceux de TCP (distribution fiable et ordonnée des données).
- Coexistence heureuse avec TCP, aucun des deux ne doit prendre toute la capacité au détriment de l'autre (cf. RFC 5348). QUIC, comme TCP, contrôle la quantité de données envoyées, pour ne pas écrouler le réseau.
Certains de ces objectifs auraient pu être atteints en modifiant TCP. Mais TCP étant typiquement mis en œuvre dans le noyau du système d'exploitation, tout changement de TCP met un temps trop long à se diffuser. En outre, si les changements à TCP sont importants, ils peuvent être bloqués par les boitiers intermédiaires, comme si c'était un nouveau protocole.
QUIC peut donc, plutôt qu'à TCP, être comparé à SCTP tournant sur DTLS (RFC 8261), et on peut donc se demander pourquoi ne pas avoir utilisé ce système. C'est parce que :
- La latence pour établir une session est très élevée. SCTP et DTLS étant deux protocoles séparés, il faut d'abord se « connecter » avec DTLS, puis avec SCTP (RFC 8261, section 6.1).
- Cette séparation de SCTP et DTLS fait d'ailleurs que d'autres tâches sont accomplies deux fois (alors que dans QUIC, chiffrement et transport sont intégrés, cf. RFC 9001).
Pour une comparaison plus détaillée de SCTP et QUIC, voir
l'Internet-Draft draft-joseph-quic-comparison-quic-sctp.
(SCTP peut aussi tourner sur UDP - RFC 6951
mais j'ai plutôt utilisé SCTP sur DTLS comme point de comparaison,
pour avoir le chiffrement.) Notez que ces
middleboxes intrusives sont particulièrement
répandues dans les réseaux pour mobiles, type
4G (où elles sont parfois appelée
TCP proxies), puisque c'est un monde où on viole
bien plus facilement la neutralité du
réseau.
Faire mieux que TCP n'est pas évident. Ce seul RFC fait 207 pages, et il y a d'autres RFC à lire. Déjà, commençons par un peu de terminologie :
- Client et serveur ont le sens habituel, le client est l'initiateur de la connexion QUIC, le serveur est le répondeur,
- Un paquet QUIC n'est pas forcément un datagramme IP ; plusieurs paquets peuvent se trouver dans un même datagramme envoyé sur UDP,
- Certains paquets déclenchent l'émission d'un accusé de réception (ACK-eliciting packets) mais pas tous,
- Dans un paquet, il y a plusieurs unités de données, les
trames. Il existe plusieurs types de trames, par exemple
PINGsert uniquement à déclencher l'accusé de réception, alors queSTREAMcontient des données de l'application. - Une adresse est la combinaison d'une adresse IP, et d'un port. Elle sert à identifier une extrémité du chemin entre client et serveur mais pas à identifier une connexion.
- L'identifiant de connexion (CID, connection ID) joue ce rôle. Il permet à QUIC de gérer les cas où un routeur NAT change le port source, ou bien celui où on change de type de connexion.
- Un ruisseau (stream) est un canal de données à l'intérieur d'une connexion QUIC. QUIC multiplexe des ruisseaux. Par exemple, pour HTTP/3 (RFC 9113), chaque ressource (image, feuille de style, etc) voyagera dans un ruisseau différent.
Maintenant, plongeons dans le RFC. Rappelez-vous qu'il est long ! Commençons par les ruisseaux (section 2 du RFC). Ils ressemblent aux ruisseaux de HTTP/2 (RFC 9113), ce qui est logique, QUIC ayant été conçu surtout en pensant à HTTP. Chaque ruisseau est un flux ordonné d'octets. Dans une même connexion QUIC, il y a plusieurs ruisseaux. Les octets d'un ruisseau sont reçus dans l'ordre où ils ont été envoyés (plus exactement, QUIC doit fournir ce service mais peut aussi fournir un service dans le désordre), ce qui n'est pas forcément le cas pour les octets d'une même connexion. (Dans le cas de HTTP, cela sert à éviter qu'une ressource lente à se charger ne bloque tout le monde.) Comme avec TCP, les données sont un flot continu, même si elles sont réparties dans plusieurs trames. La création d'un ruisseau est très rapide, il suffit d'envoyer une trame avec l'identifiant d'un ruisseau et hop, il est créé. Les ruisseaux peuvent durer très longtemps, ou au contraire tenir dans une seule trame.
J'ai parlé de l'identifiant d'un ruisseau. Ce numéro, ce stream ID est pair pour les ruisseaux créés par le client, impair s'ils sont créés par le serveur. Cela permet à client et serveur de créer des ruisseaux sans se marcher sur les pieds. Un autre bit dans l'identifiant indique si le ruisseau est bidirectionnel ou unidirectionnel.
Une application typique va donc créer un ou plusieurs ruisseaux,
y envoyer des données, en recevoir, et fermer les ruisseaux,
gentiment (trame STREAM avec le bit
FIN) ou brutalement (trame
RESET_STREAM). La machine à états complète des
ruisseaux figure dans la section 3 du RFC.
Comme avec TCP, il ne s'agit pas d'envoyer des données au débit
maximum, sans se soucier des conséquences. Il faut se contrôler, à
la fois dans l'intérêt du réseau (éviter la
congestion) et dans celui du récepteur, qui a
peut-être du mal à traiter tout ce qu'on lui envoie. D'où, par
exemple, la trame STOP_SENDING qui dit à
l'émetteur de se calmer.
Plus fondamentalement, le système de contrôle de QUIC est décrit
dans la section 4. Il fonctionne aussi bien par ruisseau qu'au
niveau de toute la connexion. C'est le récepteur qui contrôle ce que
l'émetteur peut envoyer, en disant « j'accepte au total N
octets ». Il le fait à l'établissement de la connexion puis,
lorsqu'il peut à nouveau traiter des données, via les trames
MAX_DATA (pour l'ensemble de la connexion) et
MAX_STREAM_DATA (valables, elles, pour un seul
ruisseau). Normalement, les quantités d'octets que l'émetteur peut
envoyer sont toujours croissantes. Par exemple, à l'établissement de
la connexion, le récepteur annonce qu'il peut traiter 1 024
octets. Puis, une fois qu'il a des ressources disponibles, il
signalera qu'il peut traiter 2 048 octets. Si l'émetteur ne lui
avait transmis que 1 024, cette augmentation lui indiquera qu'il
peut reprendre l'émission. Si l'émetteur envoie plus de données
qu'autorisé, le récepteur ferme brutalement la connexion. À noter
que les trames de type CRYPTO ne sont pas
concernées car elles peuvent être nécessaires pour changer les
paramètres cryptographiques (RFC 9001, section 4.1.3).
J'ai parlé des connexions QUIC mais pas encore dit comment elles
étaient établies. La section 5 le détaille. Comme QUIC tourne sur
UDP, un certain
nombre de gens n'ont pas compris le rôle d'UDP et croient que QUIC
est sans connexion. Mais c'est faux, QUIC impose l'établissement
d'une connexion, c'est-à-dire d'un état partagé entre l'initiateur
(celui qui sollicite une connexion) et le répondeur. La négociation
initiale permettra entre autres de se mettre d'accord sur les
paramètres cryptographiques, mais aussi sur le protocole applicatif utilisé (par exemple
HTTP). QUIC permet d'envoyer des données dès le premier paquet (ce
qu'on nomme le « 0-RTT ») mais rappelez-vous que, dans ce cas, vous
n'êtes plus protégé contre les attaques par
rejeu. Ce n'est pas grave pour un
GET HTTP mais cela peut être gênant dans
d'autres cas.
Une fonction essentielle aux connexions QUIC est le
connection ID. Il s'agit d'un identificateur de
la connexion, qui lui permettra notamment de survivre aux
changements de connectivité (passage de 4G dehors en WiFi chez soi,
par exemple) ou aux fantaisies des routeurs NAT qui peuvent
subitement changer les ports utilisés. Quand
un paquet QUIC arrive sur une machine, c'est ce connection
ID qui sert à démultiplexer les paquets entrants, et à
trouver les paramètres cryptographiques à utiliser pour le
déchiffrer. Il n'y a pas qu'un connection ID
mais tout un jeu, car, comme il circule en clair, il pourrait être
utilisé pour suivre à la trace un utilisateur. Ainsi, quand une
machine change d'adresse IP, la bonne pratique est de se mettre à
utiliser un connection ID qui faisait partie du
jeu de départ, mais n'a pas encore été utilisé, afin d'éviter qu'un
surveillant ne fasse le rapprochement entre les deux adresses
IP. Notez que le jeu de connection ID négocié au
début peut ensuite être agrandi avec des trames
NEW_CONNECTION_ID.
Dans quel cas un port peut-il changer ? QUIC utilise UDP, pour maximiser les chances de passer à travers les pare-feux et les routeurs NAT. Cela pose des problèmes si le boitier intermédiaire fait des choses bizarres. Par exemple, si un routeur NAT décide de mettre fin à une connexion TCP qui n'a rien envoyé depuis longtemps, il peut génerer un message RST (ReSeT) pour couper la connexion. Rien de tel en UDP, où le routeur NAT va donc simplement supprimer de sa table de correspondance (entre adresses publiques et privées) une entrée. Après cela, les paquets envoyés par la machine externe seront jetés sans notification, ceux envoyés par la machine interne créeront une nouvelle correspondance, avec un port source différent et peut-être même une adresse IP source différente. La machine externe risque donc de ne pas les reconnaitre comme des paquets appartenant à la même connexion QUIC. En raison des systèmes de traduction d'adresses, l'adresse IP source et le port source vus par le pair peuvent changer pendant une même « session ». Pour permettre de reconnaitre une session en cours, QUIC utilise donc le connection ID, un nombre de longueur variable généré au début de la connexion (un dans chaque direction) et présent dans les paquets. (Le connection ID source n'est pas présent dans tous les paquets.)
Vous avez vu qu'une connexion QUIC peut parfaitement changer
d'adresse IP en cours de route. Cela aura certainement des
conséquences pour tous les systèmes qui enregistrent les adresses
IP comme identificateur d'un dialogue, du
journal d'un serveur HTTP (qu'est-ce que
Apache va mettre dans son
access_log ?) aux surveillances de la
HADOPI.
Pour limiter les risques qu'une correspondance dans un routeur
faisant de la traduction d'adresses n'expire, QUIC dispose de
plusieurs moyens de
keepalive comme les trames
de type PING.
Comment l'application qui utilise QUIC va-t-elle créer des connexions et les utiliser ? La norme QUIC, dans notre RFC, ne spécifie pas d'API. Elle expose juste les services que doit rendre QUIC aux applications, notamment :
- Ouvrir une connexion (si on est initiateur),
- Attendre des demandes de connexions (si on est répondeur),
- Activer les données early data, c'est-à-dire envoyées dès le premier paquet (rappelez-vous que le rejeu est possible donc l'application doit s'assurer que cette première requête est idempotente),
- Configurer certaines valeurs comme le nombre maximal de ruisseaux ou comme la quantité de données qu'on est prêt à recevoir,
- Envoyer des trames
PING, par exemple pour s'assurer que la connexion reste ouverte, - Fermer la connexion.
Le RFC ne le spécifie pas, mais il faudra évidemment que QUIC permette à l'application d'envoyer et de recevoir des données.
Il n'y a actuellement qu'une seule version de QUIC, la 1, normalisée dans notre RFC 9000 (cf. section 15). Dans le futur, d'autres versions apparaitront peut-être, et la section 6 du RFC explique comment se fera la future négociation de version (ce qui sera un point délicat car il faudra éviter les attaques par repli). Notez que toute version future devra se conformer aux invariants du RFC 8999, une garantie de ce qu'on trouvera toujours dans QUIC.
Un point important de QUIC est qu'il n'y a pas de mode « en
clair ». QUIC est forcément protégé par la
cryptographie. L'établissement de la
connexion impose donc la négociation de paramètres cryptographiques
(section 7). Ces paramètres sont mis dans une trame
CRYPTO qui fait partie du premier paquet
envoyé. QUIC version 1 utilise TLS (RFC 9001). Le serveur est toujours authentifié, le client peut
l'être. C'est aussi dans cette négociation cryptographique qu'est
choisie l'application, via ALPN (RFC 7301).
Dans le cas courant, quatre paquets sont échangés,
Initial par chacun des participants, puis
Handshake. Mais, si le 0-RTT est accepté, des
données peuvent être envoyées par l'initiateur dès le premier
paquet.
Puisqu'UDP,
comme IP, ne protège
pas contre l'usurpation
d'adresse IP, QUIC doit valider les adresses IP utilisées,
pour éviter, par exemple, les attaques par réflexion (section
8). Si un initiateur contacte un répondeur en disant « mon adresse
IP est 2001:db8:dada::1 », il ne faut pas le
croire sur parole, et lui envoyer plein de données sans
vérification. QUIC doit valider
l'adresse IP de son correspondant, et le revalider lorsqu'il
change d'adresse IP. À l'établissement de la connexion, c'est la
réception du paquet Handshake, proprement
chiffré, qui montre que le correspondant a bien reçu notre paquet
Initial et a donc bien l'adresse IP qu'il
prétend avoir. En cas de changement d'adresse IP, la validation
vient du fait que le correspondant utilise un des
connection ID qui avait été échangés précédemment
ou d'un test explicite de joignabilité avec les trames
PATH_CHALLENGE et
PATH_RESPONSE. Sur ces migrations, voir aussi
la section 9.
Pour les futures connexions, on utilisera un jeton qui avait été
transmis dans une trame NEW_TOKEN et qu'on a
stocké localement. (C'est ce qui permet le 0-RTT.) Le RFC ne
spécifie pas le format de ce jeton, seule la machine qui l'a créé et
qui l'envoie à sa partenaire a besoin de le comprendre (comme pour un
cookie). Le RFC conseille également de n'accepter
les jetons qu'une fois (et donc de mémoriser leur usage) pour
limiter le risques de rejeu.
Tant que la validation n'a pas été faite, une machine
QUIC ne doit pas envoyer plus de trois fois la quantité de données
reçue (pour éviter les attaques avec
amplification). C'est pour cela que le paquet
Initial est rempli de manière à atteindre une
taille (1 200 octets, exige le RFC) qui garantit que l'autre machine
pourra répondre, même si elle a beaucoup à dire.
Une fois qu'on est connectés, on peut s'échanger des données, qui
feront l'objet d'accusés de réception de la part du voisin (trames
de type ACK). Contrairement au TCP classique,
les accusés de réception ne sont pas forcément contigus, comme dans
l'extension SACK du RFC 2018. Si l'accusé de
réception n'est pas reçu, l'émetteur réémet, comme avec TCP.
Bon, une fois qu'on a ouvert la connexion, et échangé des
données, quand on n'a plus rien à dire, que fait-on ? On
raccroche. La section 10 du RFC explique comment se terminent les
connexions QUIC. Cela peut se produire suite à une inactivité
prolongée, suite à une fermeture explicite normale, ou bien avec le
cas particulier de la fermeture sans état. Chacun des partenaires
peut évidemment estimer que, s'il ne s'est rien passé depuis
longtemps, il peut partir. (Cette durée maximale d'attente peut être
spécifiée dans les paramètres à l'établissement de la connexion.)
Mais on peut aussi raccrocher explicitement à tout moment (par
exemple parce que le partenaire n'a pas respecté le protocole QUIC),
en envoyant une trame de type
CONNECTION_CLOSE. Cela fermera la connexion et,
bien sûr, tous ses ruisseaux.
Pour que la trame CONNECTION_CLOSE soit
acceptée par l'autre machine, il faut que son émetteur connaisse les
paramètres cryptographiques qui permettront de la chiffrer
proprement. Mais il y a un cas ennuyeux, celui où une des deux
machines a redémarré, tout oublié, et reçoit des paquets d'une
ancienne connexion. Comment dire à l'autre machine d'arrêter d'en
envoyer ? Avec TCP, on envoie un paquet RST
(ReSeT) et c'est bon. Mais cette simplicité est
dangereuse car elle permet également à un tiers de faire des
attaques par déni de service en envoyant des
« faux » paquets RST. Des censeurs ou des FAI voulant
bloquer du trafic pair-à-pair ont déjà
pratiqué ce genre d'attaque. La solution QUIC à ce double problème
est la fermeture sans état (stateless
reset). Cela repose sur l'envoi préalable d'un jeton (cela
peut se faire via un paramètre lors de l'établissement de la
connexion, ou via une trame
NEW_CONNECTION_ID). Pour pouvoir utiliser ces
jetons, il faudra donc les stocker, mais il ne sera pas nécessaire
d'avoir les paramètres cryptographiques : on ne chiffre pas le
paquet de fermeture sans état, il est juste authentifié (par le
jeton). Si la perte de mémoire est totale (jeton stocké en mémoire
non stable, et perdu), il ne reste plus que les délais de garde pour
mettre fin à la connexion. Évidemment, le jeton ne peut être utilisé
qu'une fois, puisqu'un surveillant a pu le copier. Notez que les
détails de ce paquet de fermeture sans état sont soigneusement
conçus pour que ce paquet soit indistinguable d'un paquet QUIC
« normal ».
Dans un monde idéal, tout fonctionnera comme écrit dans le
RFC. Mais, dans la réalité, des machines ne vont pas suivre le
protocole et vont faire des choses anormales. La section 11 du RFC
couvre la gestion d'erreurs dans QUIC. Le problème peut être dans la
couche de transport, ou dans l'application (et, dans ce cas, il peut
être limité à un seul ruisseau). Lorsque l'erreur est dans la couche
transport et qu'elle semble irrattrapable, on ferme la connexion
avec une trame CONNECTION_CLOSE. Si le problème
ne touche qu'un seul ruisseau, on peut se contenter d'une trame
RESET_STREAM, qui met fin juste à ce ruisseau.
On a parlé de paquets et de trames. La section 12 précise ces termes :
- Les deux machines s'envoient des datagrammes UDP,
- chaque datagramme contient un ou plusieurs paquets QUIC,
- chaque paquet QUIC peut contenir une ou plusieurs trames. Chacune d'elle a un type, la liste étant dans un registre IANA.
Parmi les paquets, il y a les paquets longs et les paquets
courts. Les paquets longs, qui contiennent tous les détails, sont
Initial, Handshake,
0-RTT et Retry. Ce sont
surtout ceux qui servent à établir la connexion. Les paquets courts
sont le 1-RTT, qui ne peut être utilisé
qu'après l'établissement complet de la connexion, y compris les
paramètres cryptographiques. Bref, les paquets longs (plus
exactement, à en-tête long) sont plus complets, les paquets courts
(à en-tête court) plus efficaces.
Les paquets sont protégés par la cryptographie. (QUIC n'a pas de
mode en clair.) Mais attention, elle ne protège pas la totalité du
paquet. Ainsi, le connection ID est en clair
puisque c'est lui qui sera utilisé à la destination pour trouver la
bonne connexion et donc les bons paramètres cryptographiques pour
déchiffrer. (Mais il est protégé en intégrité
donc ne peut pas être modifié par un attaquant sans que ce soit
détecté.) De même, les paquets Initial n'ont de
protection que contre la modification, pas contre l'espionnage. En
revanche, les paquets qui transportent les données
(0-RTT et 1-RTT) sont
complètement protégés. Les détails de ce qui est protégé et ce qui
ne l'est pas figurent dans le RFC 9001.
La coalescence de plusieurs paquets au sein d'un seul datagramme UDP vise à augmenter les performances en diminuant le nombre de datagrammes à traiter. (J'en profite pour rappeler que la métrique importante pour un chemin sur le réseau n'est pas toujours le nombre d'octets par seconde qui peuvent passer par ce chemin. Parfois, c'est le nombre de datagrammes par seconde qui compte.) Par contre, si un datagramme qui comprend plusieurs paquets, qui eux-mêmes contiennent des trames de données de ruisseaux différents, est perdu, cela va évidemment affecter tous ces ruisseaux.
Les paquets ont un numéro, calculé différemment dans chaque direction, et partant de zéro. Ce numéro est chiffré. Les réémissions d'un paquet perdu utilisent un autre numéro que celui du paquet original, ce qui permet, contrairement à TCP, de distinguer émission et réémission.
Avec QUIC, les datagrammes ne sont jamais fragmentés (en IPv4), on met le bit DF à 1 pour éviter cela. QUIC peut utiliser la PLPMTUD (RFC 8899) pour trouver la MTU du chemin.
Le format exact des paquets est spécifié en section 17. Un paquet
long (plus exactement, à en-tête long) se reconnait par son premier
bit mis à 1. Il comprend un type (la liste est dans le RFC, elle
n'est pas extensible, il n'y a pas de registre IANA), les
deux connection ID et les données, dont la
signification dépend du type. Les paquets de type
Initial comportent entre autres dans ces
données un jeton, qui pourra servir, par exemple pour les futurs
connexions 0-RTT. Les paquets de type Handshake
contiennent des trames de type CRYPTO, qui
indiquent les paramètres cryptographiques. Quant aux paquets courts,
leur premier bit est à 0, et ils contiennent moins d'information,
par exemple, seul le connection ID de destination
est présent, pas celui de la source.
Dans sa partie non chiffrée, le paquet a un bit qui a suscité bien des débats, le spin bit. Comme c'est un peu long à expliquer, ce bit a son propre article.
QUIC chiffre beaucoup plus de choses que TCP. Ainsi, pour les paquets à en-tête court, en dehors du connection ID et de quelques bits dont le spin bit, rien n'est exposé. Par exemple, les accusés de réception sont chiffrés et on ne peut donc pas les observer. Le but est bien de diminuer la vue offerte au réseau (RFC 8546), alors que TCP expose tout (les accusés de réception, les estampilles temporelles, etc). QUIC chiffre tellement qu'il n'existe aucun moyen fiable, en observant le trafic, de voir ce qui est du QUIC et ce qui n'en est pas. (Certaines personnes avaient réclamé, au nom de la nécessité de surveillance, que QUIC se signale explicitement .)
Les différents types de trames sont tous listés en section 19. Il y a notamment :
PADDINGqui permet de remplir les paquets pour rendre plus difficile la surveillance,PINGqui permet de garder une connexion ouverte, ou de vérifier que la machine distante répond (il n'y a pas dePONG, c'est l'accusé de réception de la trame qui en tiendra lieu),ACK, les accusés de réception, qui indiquent les intervalles de numéros de paquets reçus,CRYPTO, les paramètres cryptographiques de la connexion,STREAM, qui contiennent les données, et créent les ruisseaux ; envoyer une trame de typeSTREAMsuffit, s'il n'est pas déjà créé, à créer le ruisseau correspondant (ils sont identifiés par un numéro contenu dans cette trame),CONNECTION_CLOSE, pour mettre fin à la connexion.
Les types de trame figurent dans un registre IANA. On notera que l'encodage des trames n'est pas auto-descriptif : on ne peut comprendre une trame que si on connait son type. C'est plus rapide, mais moins souple et cela veut dire que, si on introduit de nouveaux types de trame, il faudra utiliser des paramètres au moment de l'ouverture de la connexion pour être sûr que l'autre machine comprenne ce type.
Bon, les codes d'erreur, désormais (section 20 du RFC). La liste
complète est dans un
registre IANA, je ne vais pas la reprendre ici. Notons quand
même le code d'erreur NO_ERROR qui signifie
qu'il n'y a pas eu de problème. Il est utilisé lorsqu'on ferme une
connexion sans que pour autant quelque chose de mal se soit
produit.
Si vous voulez une vision plus concrète de QUIC, vous pouvez regarder mon article d'analyse d'une connexion QUIC.
L'une des principales motivations de QUIC est la sécurité, et il est donc logique qu'il y ait une longue section 21 consacrée à l'analyse détaillée de la sécurité de QUIC. D'abord, quel est le modèle de menace ? C'est celui du RFC 3552. En deux mots : on ne fait pas confiance au réseau, tout intermédiaire entre deux machines qui communiquent peut être malveillant. Il y a trois sortes d'attaquants : les attaquants passifs (qui ne peuvent qu'écouter), les attaquants actifs situés sur le chemin (et qui peuvent donc écouter et écrire) et les attaquants actifs non situés sur le chemin, qui peuvent écrire mais en aveugle. Voyons maintenant les attaques possibles.
La poignée de mains initiale est protégée par TLS. La sécurité de QUIC dépend donc de celle de TLS.
Les attaques par réflexion, surtout dangereuses quand elles se combinent avec une amplification sont gênées, sinon complètement empêchées, par la validation des adresses IP. QUIC ne transmet pas plus de trois fois le volume de données à une adresse IP non validée. Ce point n'a pas forcément été compris par tous, et certains ont paniqué à la simple mention de l'utilisation d'UDP. C'est par exemple le cas de cet article, qui est surtout du FUD d'un vendeur.
Du fait du chiffrement, même un attaquant actif qui serait sur le chemin et pourrait donc observer les paquets, ne peut pas injecter de faux paquets ou, plus exactement, ne peut pas espérer qu'ils seront acceptés (puisque l'attaquant ne connait pas la clé de chiffrement). L'attaquant actif qui n'est pas sur le chemin, et doit donc opérer en aveugle, est évidemment encore plus impuissant. (Avec TCP, l'attaquant actif situé sur le chemin peut insérer des paquets qui seront acceptés. Des précautions décrites dans le RFC 5961 permettent à TCP de ne pas être trop vulnérable à l'attaquant aveugle.)
La possibilité de migration des connexions QUIC (changement de port et/ou d'adresse IP) apporte évidemment de nouveaux risques. La validation du chemin doit être refaite lors de ces changements, autrement, un méchant partenaire QUIC pourrait vous rediriger vers une machine innocente.
Bien sûr, les attaques par déni de service restent
possibles. Ainsi, un attaquant actif sur le chemin qui a la
possibilité de modifier les paquets peut tout simplement les
corrompre de façon à ce qu'ils soient rejetés. Mais il y a aussi des
attaques par déni de service plus subtiles. L'attaque dite
Slowloris vise ainsi à épuiser une autre
machine en ouvrant beaucoup de connexions qui ne seront pas
utilisées. Un serveur utilisant QUIC doit donc se méfier et, par
exemple, limiter le nombre de connexions par client. Le méchant
client peut aussi ouvrir, non pas un grand nombre de connexions mais
un grand nombre de ruisseaux. C'est d'autant plus facile que
d'ouvrir le ruisseau de numéro N (ce qui ne nécessite qu'une seule
trame de type STREAM) ouvre tous les ruisseaux
jusqu'à N, dans la limite indiquée dans les paramètres de
transport.
On a vu que dans certains cas, une machine QUIC n'a plus les paramètres qui lui permettent de fermer proprement une connexion (par exemple parce qu'elle a redémarré) et doit donc utiliser la fermeture sans état (stateless reset). Dans certains cas, un attaquant peut mettre la main sur un jeton qu'il utilisera ensuite pour fermer une connexion.
Le chiffrement, comme toute technique de sécurité, a ses
limites. Ainsi, il n'empêche pas l'analyse de
trafic (reconnaitre le fichier récupéré à sa taille, par
exemple). D'où les trames de type PADDING pour
gêner cette attaque.
QUIC a plusieurs registres à l'IANA. Si vous voulez ajouter des valeurs à ces registres, leur politique (cf. RFC 8126) est :
- Pour les ajouts provisoires, ce sera « Examen par un expert », et le RFC donne l'instruction d'être assez libéral,
- Pour les ajouts permanents, il faudra écrire une spécification (« Spécification nécessaire »). Là aussi, le RFC demande d'être assez libéral, les registres ne manquent pas de place. Par exemple, les paramètres de transport jouissent de 62 bits.
- Pour les types de trame, si la majorité de l'espace prévu suit cette politique « Spécification nécessaire », une petite partie est reservée pour enregistrement via une politique plus stricte, « Action de normalisation ».
L'annexe A de notre RFC contient du pseudo-code pour quelques algorithmes utiles à la mise en œuvre de QUIC. Par exemple, QUIC, contrairement à la plupart des protocoles IETF, a plusieurs champs de taille variable. Les encoder et décoder efficacement nécessite des algorithmes astucieux, suggérés dans cette annexe.
Il existe d'ores et déjà de nombreuses mises en œuvre de QUIC, l'écriture de ce RFC ayant été faite en parallèle avec d'innombrables hackathons et tests d'interopérabilité. Je vous renvoie à la page du groupe de travail, qui indique également des serveurs QUIC publics. Elles sont dans des langages de programmation très différents, par exemple celle de Cloudflare, Quiche, est en Rust. À ma connaissance, toutes tournent en espace utilisateur mais ce n'est pas obligatoire, QUIC pourrait parfaitement être intégré dans le noyau du système d'exploitation. Une autre bonne source pour la liste des mises en œuvre de QUIC est le Wikipédia anglophone. Notez que le navigateur Web libre Firefox a désormais QUIC.
Quelques lectures pour aller plus loin :
- Une très bonne explication de QUIC, avec des dessins très parlants à l'Université catholique de Louvain (en anglais).
- Autre très bon article d'introduction à QUIC et à ses choix principaux, celui de Cloudflare.
- Beaucoup d'articles sur QUIC ne mentionnent que ses avantages. Cet article très détaillé expose honnêtement les limites de QUIC et les problèmes qu'il pourrait rencontrer.
- QUIC soulève des problèmes politiques intéressants comme,
par exemple, « vu sa complexité, peut-on encore innover s'il faut
les moyens de Google ? » En effet, qui d'autre aurait pu
développer et surtout pousser QUIC et faire qu'il soit déployé ?
Ces problèmes stratégiques se posent à beaucoup d'endroits dans le
Web, vu son importance dans nos vies. Ils sont discutés (avec
d'autres) dans l'Internet-Draft
draft-martini-hrpc-quichr(dont je remercie d'ailleurs les auteurs, qui m'ont bien aidé à comprendre QUIC). - Sur l'histoire du développement de QUIC à l'IETF et notamment sur les différents choix effectués, les décisions prises, et leurs raisons, je recommande l'article de Fastly (par un des auteurs de ce RFC).
- Sur les performances, je recommande « Taking a long look at QUIC: an approach for rigorous evaluation of rapidly evolving transport protocols » de Arash Molavi Kakhki, Samuel Jero et David Choffnes , qui analysait la version Google de QUIC, avec plein de mesures concrètes (leur code est en ligne).
- Toujours question performance, Uber a ajouté QUIC dans son application et détaille les résultats obtenus.
- Sur la question de l'exposition de données aux machines intermédiaires situées sur le chemin (la « vue depuis le réseau » du RFC 8546), l'article « "A Path Layer for the Internet: Enabling Network Operations on Encrypted Protocols » explore le problème et propose des solutions, notamment dans le contexte de QUIC.
L'article seul
RFC 9002: QUIC Loss Detection and Congestion Control
Date de publication du RFC : Mai 2021
Auteur(s) du RFC : J. Iyengar (Fastly), I. Swett (Google)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF quic
Première rédaction de cet article le 28 mai 2021
Pour tout protocole de transport, détecter les pertes de paquets, et être capable d'émettre et de réémettre des paquets sans provoquer de congestion sont deux tâches essentielles. Ce RFC explique comment le protocole QUIC assure cette tâche.
Pour l'instant, TCP reste le principal protocole de transport sur l'Internet. Mais QUIC pourrait le dépasser. QUIC est normalisé dans une série de RFC et notre RFC 9002 se charge d'une tâche délicate et cruciale : expliquer comment détecter les pertes de paquets, et comment ne pas contribuer à la congestion. Voyons d'abord la conception générale (section 3 du RFC). Les messages QUIC sont mis dans des trames, une ou plusieurs trames sont regroupées dans un paquet (qui n'est pas un paquet IP) et un ou plusieurs paquets sont dans un datagramme UDP qu'on envoie à son correspondant. Les paquets ont un numéro (RFC 9000, section 12.3). Ces numéros ne sont pas des numéros des octets dans les données envoyées, notamment, un numéro de paquet ne se répète jamais dans une connexion. Alors qu'on peut envoyer les mêmes données plusieurs fois, s'il y a perte et réémission ; en cas de retransmission, les données sont renvoyées dans un nouveau paquet, avec un nouveau numéro, contrairement à TCP. Cela permet de savoir facilement si c'est une retransmission. (TCP, lui, essaie de déduire l'ordre de distribution du numéro de séquence, et ce n'est pas trivial.)
La plupart des paquets QUIC feront l'objet d'un accusé de réception mais attention. Il y a des trames dont le type exige un accusé de réception et d'autres non. Si un paquet ne contient que des trames n'exigeant pas d'accusé de réception, ce paquet ne sera confirmé par le récepteur qu'indirectement, lors de la réception d'un paquet ultérieur contenant au moins une trame exigeant un accusé de réception.
QUIC n'est pas TCP, cela vaut la peine de le rappeler. La très intéressante section 4 du RFC enfonce le clou en énumérant les différences entre les algorithmes de TCP et ceux de QUIC, pour assurer les mêmes fonctions. Ainsi, dans TCP, tous les octets sont numérotés selon un seul espace de numérotation (les numéros de séquence) alors que QUIC a plusieurs espaces, les paquets servant à établir la connexion ne partagent pas leurs numéros avec ceux des données. QUIC fonctionne ainsi car les premiers sont moins protégés par la cryptographie.
Pour TCP, le numéro de séquence indique à la fois l'ordre
d'émission et l'ordre de l'octet dans le flux de données. Le
problème de cette approche est que, en cas de retransmission, le
numéro de séquence n'indique plus l'ordre d'émission, rendant
difficile de distinguer une émission initiale et une retransmission
(ce qui serait pourtant bien utile pour estimer le RTT). Au contraire, dans
QUIC, le numéro de paquet n'identifie que l'ordre d'émission. La
retransmission a donc forcément un numéro supérieur à l'émission
initiale. Pour déterminer la place des octets dans le flux de
données, afin de s'assurer que l'application reçoive les données
dans l'ordre, QUIC utilise le champ Offset des
trames de type STREAM, celles qui transmettent
les données (RFC 9000, section
19.8). QUIC a ainsi moins d'ambiguités, par exemple quand il
faut mesurer le taux de pertes.
QUIC, comme TCP, doit estimer le temps optimum pour décider qu'un paquet est perdu (RTO, pour Retransmission TimeOut). QUIC est plus proche de l'algorithme du RFC 8985 que du TCP classique. La section 5 du RFC détaille l'estimation du RTT.
La section 6 porte sur le problème délicat de la détection des pertes de paquets. La plupart des paquets QUIC doivent faire l'objet d'un accusé de réception. S'il n'est pas arrivé avant un temps limite, le paquet est décrété perdu, et il faudra demander une réémission (RFC 9000, section 13.3). Plus précisement, le paquet est considéré comme perdu s'il avait été envoyé avant un paquet qui a fait l'objet d'un accusé de réception et s'il s'est écoulé N paquets depuis ou bien un temps suffisamment long. (TCP fait face à exactement le même défi, et la lecture des RFC 5681, RFC 5827, RFC 6675 et RFC 8985 est recommandée.) La valeur recommandée pour N est 3, pour être proche de TCP. Mais attention si le réseau fait que les paquets arrivent souvent dans le désordre, cela pourrait mener à des paquets considérés à tort comme perdus. Le problème existait déjà pour TCP mais il est pire avec QUIC puisque des équipements intermédiaires sur le réseau qui remettaient les paquets dans l'ordre ne peuvent plus fonctionner avec QUIC, qui chiffre le plus de choses possibles pour éviter ces interventions souvent maladroites. Et le délai avant lequel on déclare qu'un paquet est perdu ? Il doit tenir compte du RTT qu'on doit donc mesurer.
Une fois la ou les pertes détectées, on réémet les paquets. Simple, non ? Sauf qu'il faut éviter que cette réémission n'aggrave les problèmes et ne mène à la congestion (le réseau, trop chargé, perd des paquets, les émetteurs réémettent, chargeant le réseau, donc on perd davantage de paquets, donc les émetteurs réémettent encore plus…). L'algorithme actuellement spécifié pour QUIC (section 7 du RFC) est proche du NewReno de TCP (normalisé dans le RFC 6582). Mais le choix d'un algorithme de contrôle de l'émetteur est unilatéral, et une mise en œuvre de QUIC peut toujours en choisir un autre, comme Cubic (RFC 8312). Évidemment, pas question d'être le gros porc qui s'attribue toute la capacité réseau pour lui seul, et cet algorithme doit de toute façon respecter les principes du RFC 8085 (en résumé : ne soyez pas égoïste, et pensez aux autres, laissez-leur de la capacité).
Pour aider à cette lutte contre la congestion, QUIC, comme TCP, peut utiliser ECN (RFC 3168 et RFC 8311).
Comme TCP, QUIC doit démarrer une nouvelle session doucement (RFC 6928) et non partir bille en tête avec une fenêtre de grande taille.
La réaction aux pertes de paquets peut avoir des conséquences sur
la sécurité (section 8 du RFC). Par exemple, les « signaux »
utilisés par QUIC pour décider qu'il y a eu une perte (l'absence
d'un paquet, le RTT, ECN) ne sont pas protégés par la cryptographie,
contrairement aux données transportées et à certaines
métadonnées. Un attaquant actif peut fausser ces signaux et mener
QUIC à réduire son débit. Il n'y a pas vraiment de protection contre
cela. Autre risque de sécurité, alors que QUIC est normalement conçu
pour priver un observateur de beaucoup d'informations qui, avec TCP
étaient en clair, il n'atteint pas 100 % de succès dans ce
domaine. Par exemple les paquets ne contenant que des accusés de
réception (trames de type ACK) peuvent être
identifiés par leur taille (ils sont tout petits), et l'observateur
peut alors en déduire des informations sur les performances du
chemin. Si on veut éviter cela, il faut utiliser le
remplissage des accusés de réception.
Vous aimez lire des programmes ? L'annexe A du RFC contient du pseudo-code mettant en œuvre les mécanismes de récupération décrits dans le RFC.
L'article seul
RFC 9001: Using TLS to Secure QUIC
Date de publication du RFC : Mai 2021
Auteur(s) du RFC : M. Thomson (Mozilla), S. Turner (sn3rd)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF quic
Première rédaction de cet article le 28 mai 2021
Le protocole de transport QUIC est toujours sécurisé par la cryptographie. Il n'y a pas de communication en clair avec QUIC. Cette sécurisation se fait actuellement par TLS mais QUIC utilise TLS d'une manière un peu spéciale, documentée dans ce RFC.
Fini d'hésiter entre une version avec TLS ou une version sans. Avec QUIC, c'est forcément chiffré et, pour l'instant, avec TLS (dans le futur, QUIC pourra utiliser d'autres protocoles, mais ce n'est pas encore défini). QUIC impose en prime au minimum TLS 1.3 (RFC 9846), qui permet notamment de diminuer la latence, la communication pouvant s'établir dans certains cas dès le premier paquet. Petit rappel de TLS, pour commencer : TLS permet d'établir un canal sûr, fournissant authentification du serveur et confidentialité de la communication, au-dessus d'un media non-sûr (l'Internet). TLS est normalement constitué de deux couches, la couche des enregistrements (record layer) et celle de contenu (content layer), qui inclut notamment le mécanisme de salutation initial. On établit une session avec le protocole de salutation (handshake protocol), puis la couche des enregistrements chiffre les données (application data) avec les clés issues de cette salutation. Les clés ont pu être créées par un échange Diffie-Helman, ou bien être pré-partagées (PSK, pour Pre-Shared Key), ce dernier cas permettant de démarrer la session immédiatement (« 0-RTT »).
QUIC utilise TLS d'une façon un peu spéciale. Certains messages
TLS n'existent pas comme ChangeCipherSpec ou
KeyUpdate (QUIC ayant ses propres mécanismes
pour changer la cryptographie en route, cf. section 6), et, surtout,
la couche des enregistrements disparait, QUIC faisant le chiffrement
selon son format, mais avec les clés négociées par TLS.
La poignée de mains qui établit la session TLS peut donc se faire de deux façons :
- « 1-RTT » où le client et le serveur peuvent envoyer des données après un aller-retour (RTT). Rappelez-vous que c'est ce temps d'aller-retour qui détermine la latence, donc la « vitesse » perçue par l'utilisateur, au moins pour les transferts de faible taille (comme le sont beaucoup de ressources HTML).
- « 0-RTT », où le client peut envoyer des données dès le
premier datagramme transmis. Cette façon de
faire nécessite que client et serveur se soient parlés avant, et
que le client ait stocké un jeton généré par le serveur (sept
jours maximum, dit le RFC 9846), qui
permettra au serveur de trouver tout de suite le matériel
cryptographique nécessaire. Attention, le 0-RTT ne protège pas
contre le rejeu, mais ce n'est pas grave
pour des applications comme HTTP avec la méthode
GET, qui est idempotente. Et le 0-RTT pose également problème avec la PFS (la confidentialité même en cas de compromission ultérieure des clés).
La section 3 du RFC fait un tour d'horizon général du protocole
TLS tel qu'utilisé par QUIC. Comme vu plus haut, la couche des
enregistrements (record layer) telle qu'utilisée
avec TCP n'est plus présente, les messages TLS comme
Handshake et Alert sont
directement transportés sur QUIC (qui, contrairement à TCP, permet
d'assurer confidentialité et intégrité). Avec TCP, la mise en
couches était stricte, TLS
étant entièrement au-dessus de TCP, avec QUIC, l'intégration est
plus poussée, QUIC et TLS coopèrent, le premier chiffrant avec les
clés fournies par le second, et QUIC transportant les messages de
TLS. De même, quand on fait tourner un protocole applicatif sur QUIC, par exemple
HTTP/3 (RFC 9113), celui-ci
est directement placé sur QUIC, TLS s'effaçant complètement. Les
applications vont donc confier leurs données à QUIC, pas à TLS. En
simplifiant (beaucoup…), on pourrait dire que TLS ne sert qu'au
début de la connexion. Pour citer Radia
Perlman, « It is misleading to regard this as a
specification of running QUIC over TLS. It is related to TLS in the
same way that DTLS is related to TLS: it imports much of the syntax,
but there are many differences and its security must be evaluated
largely independently. My initial reaction to this spec was to
wonder why it did not simply run QUIC over DTLS . I believe the
answer is that careful integration improves the performance and is
necessary for some of the address agility/transition
design. ».
La section 4 explique plus en détail comment les messages TLS
sont échangés via QUIC. Les messages cryptographiques sont
transportés dans des trames de type CRYPTO. Par
exemple, le ClientHello TLS sera dans une trame
CRYPTO elle-même située dans un paquet QUIC de
type Initial. Les Alert
sont dans des trames CONNECTION_CLOSE dont le
code d'erreur est l'alerte TLS. Ce sont les seuls messages que QUIC
passera à TLS, il fait tout le reste lui-même.
On a vu que le principal travail de TLS est de fournir du matériel cryptographique à QUIC. Plus précisément, TLS fournit, après sa négociation avec son pair :
- Un secret, d'où la clé sera dérivée,
- une fonction de chiffrement intègre,
par exemple
AEAD_AES_128_GCM(AES avec GCM) ouAEAD_CHACHA20_POLY1305(ChaCha20, RFC 8439), - une fonction de dérivation des clés.
QUIC se servira de tout cela pour chiffrer.
QUIC impose une version minimale de TLS : la 1.3, normalisée dans le RFC 9846. Les versions ultérieures sont acceptées mais elles n'existent pas encore.
Ah et, comme toujours avec TLS, le client doit authentifier le
serveur, typiquement via son certificat. Le
serveur ne doit pas utiliser les possibilités TLS de
ré-authentification ultérieure (message
CertificateRequest) car le multiplexage utilisé
par QUIC empêcherait de corréler cette demande d'authentification
avec une requête précise du client.
Outre le « 0-RTT » de QUIC, qui permet au client d'envoyer des
données applicatives dès le premier paquet, QUIC+TLS fournit un
autre mécanisme pour gagner du temps à l'établissement de la
connexion, la reprise de session (session
resumption, RFC 9846, section
2.2). Si le client a enregistré les informations nécessaires depuis
une précédente session avec ce serveur, il peut attaquer directement
avec un NewSessionTicket dans une trame
CRYPTO et abréger ainsi l'établissement de
session TLS.
Les erreurs TLS, comme bad_certificate,
unexpected_message ou
unsupported_extension, sont définies dans le
RFC 9846, section 6. Dans QUIC, elles sont
transportées dans des trames de type
CONNECTION_CLOSE, et mises dans le champ
d'erreur (Error Code, RFC 9000, section 19.19). Notez que ces trames
mènent forcément à la coupure de toute la session QUIC, et il n'y a
donc pas moyen de transporter un simple avertissement TLS.
Bien, maintenant qu'on a vu le rôle de TLS, comment QUIC
va-t-il utiliser les clés pour protéger les paquets ? La section 5
répond à cette question. QUIC va utiliser les clés fournies par TLS
(je simplifie, car QUIC effectue quelques dérivations avant) comme
clés de chiffrement intègre (RFC 5116). Il utilisera l'algorithme de chiffrement
symétrique indiqué par TLS. Tous les paquets ne sont pas
protégés (par exemple ceux de négociation de version, inutiles pour
l'instant puisque QUIC n'a qu'une version, ne bénéficient pas de
protection puisqu'il faudrait connaitre la version pour choisir les
clés de protection). Le cas des paquets Initial
est un peu plus subtil puisqu'ils sont chiffrés, mais avec une clé
dérivée du connection ID, qui circule en
clair. Donc, en pratique, seule leur
intégrité est protégée, par leur
confidentialité (cf. section 7 pour les
conséquences).
J'ai dit que QUIC n'utilisait pas directement les clés fournies par TLS. Il applique en effet une fonction de dérivation, définie dans la section 7.1 du RFC 9846, elle-même définie à partir des fonctions du RFC 5869.
Il existe plein de pièges et de détails à prendre en compte quand
on met en œuvre QUIC+TLS. Par exemple, en raison du réordonnancement
des datagrammes dans le réseau, et des pertes de datagrammes, un
paquet chiffré peut arriver avant le matériel cryptographique qui
permettrait de le déchiffrer, ou bien avant que les affirmations du
pair aient été validées. La section 5.7 du RFC explique comment
gérer ce cas (en gros, jeter les paquets qui sont « en avance », ou
bien les garder pour déchiffrement ultérieur mais ne surtout pas
tenter de les traiter). Autre piège, QUIC ignore les paquets dont la
vérification d'intégrité a échoué, alors que TLS ferme la
connexion. Cela a pour conséquences qu'avec QUIC un attaquant peut
essayer plusieurs fois. Il faut donc compter les échecs et couper la
connexion quand un nombre maximal a été atteint (section 6.6). Bien
sûr, pour éviter de faciliter une attaque par déni de service (où
l'attaquant enverrait plein de mauvais paquets dans l'espoir de
fermer la connexion), ces limites doivent être assez hautes (2^23
paquets pour AEAD_AES_128_GCM), voir
« Limits on
Authenticated Encryption Use in TLS » ou
« Robust
Channels: Handling Unreliable Networks in the Record Layers of QUIC
and DTLS 1.3 », ainsi que l'annexe B du RFC.
Encore question détails subtils, la poignée de mains de TLS n'est
pas tout à fait la même quand elle est utilisée par QUIC (section
8). Ainsi, ALPN doit être utilisé et avec succès,
autrement on raccroche avec l'erreur
no_application_protocol.
Le but de TLS est de fournir de la sécurité, notamment confidentialité et authentification, donc il est recommandé de bien lire la section 9, qui traite de la sécurité de l'ensemble du RFC. Ainsi, si on utilise les tickets de session de TLS (RFC 9846, section 4.7.1), comme ils sont transmis en clair, ils peuvent permettre à un observateur de relier deux sessions, même si les adresses IP sont différentes.
Le « 0-RTT » est formidable pour diminuer la latence, mais il
diminue aussi la sécurité : il n'y a pas de protection contre le
rejeu. Si QUIC lui-même n'est pas vulnérable
au rejeu, l'application qui travaille au-dessus de QUIC peut
l'être. Prenez un protocole applicatif qui aurait des services
comme, en HTTP, « envoyez-moi une pizza » (sans doute
avec la méthode POST), on voit bien que le
rejeu serait problématique. Bref, les applications qui,
contrairement au protocole QUIC, ne sont pas
idempotentes, ont tout intérêt à désactiver
le 0-RTT.
QUIC tournant sur UDP, qui ne protège pas contre l'usurpation d'adresse IP, il
existe en théorie un risque d'attaque par réflexion, avec
amplification. Par exemple, la réponse à un
ClientHello peut être bien plus grande que le
ClientHello lui-même. Pour limiter les risques,
QUIC impose que le premier paquet du client ait une taille minimale
(pour réduire le facteur d'amplification), en utilisant le
remplissage, et que le serveur ne réponde pas
avec plus de trois fois la quantité de données envoyée par le
client, tant que l'adresse IP de celui-ci n'a pas été validée.
Plus sophistiquées sont les attaques par canal auxiliaire. Par exemple, si une mise en œuvre de QUIC jette trop vite les paquets invalides, un attaquant qui mesure les temps de réaction pourra en déduire des informations sur ce qui n'allait pas exactement dans son paquet. Il faut donc que toutes les opérations prennent un temps constant.
Et puis, bien sûr, comme tout protocole utilisant la cryptographie, QUIC+TLS a besoin d'un générateur de nombres aléatoires correct (cf. RFC 4086).
Question mise en œuvre, notez qu'on ne peut pas forcément utiliser une bibliothèque TLS quelconque. Il faut qu'elle permette de séparer signalisation et chiffrement et qu'elle permette d'utiliser QUIC comme transport. (Et il n'y a pas d'API standard pour cela.) C'est par exemple le cas de la bibliothèque picotls. Pour OpenSSL, il faut attendre (un patch existe) et cela bloque parfois l'intégration de certains logiciels.
Et question tests, à ma connaissance, on ne peut pas actuellement
utiliser openssl s_client ou
gnutls-cli avec un serveur QUIC. Même problème avec le fameux site de
test TLS https://ssllabs.com/
Pour terminer, voici l'analyse d'une communication QUIC+TLS,
analyse faite avec Wireshark. D'abord, le
premier paquet, de type QUIC Initial, qui
contient le ClientHello dans une trame de type
CRYPTO :
QUIC IETF
1... .... = Header Form: Long Header (1)
.1.. .... = Fixed Bit: True
..00 .... = Packet Type: Initial (0)
.... 00.. = Reserved: 0
.... ..11 = Packet Number Length: 4 bytes (3)
Version: 1 (0x00000001)
Destination Connection ID Length: 8
Destination Connection ID: 345d144296b90cff
...
Length: 1226
Packet Number: 0
TLSv1.3 Record Layer: Handshake Protocol: Client Hello
Frame Type: CRYPTO (0x0000000000000006)
Offset: 0
Length: 384
Crypto Data
Handshake Protocol: Client Hello
Handshake Type: Client Hello (1)
Length: 380
...
Extension: quic_transport_parameters (len=85)
Type: quic_transport_parameters (57)
Length: 85
Parameter: initial_max_stream_data_bidi_local (len=4) 2097152
Type: initial_max_stream_data_bidi_local (0x05)
Length: 4
Value: 80200000
initial_max_stream_data_bidi_local: 2097152
...
Dans les extensions TLS, notez l'extension spécifique à QUIC,
quic_transport_parameters. QUIC « abuse » de
TLS en s'en servant pour emballer ses propres paramètres. (La liste
de ces paramètres de transport figure dans un
registre IANA.)
La réponse à ce paquet Initial contiendra le
ServerHello TLS. La poignée de mains se
terminera avec les paquets QUIC de type
Handshake. TLS ne servira plus par la suite,
QUIC chiffrera tout seul.
L'article seul
RFC Origins of Domain Names
Première rédaction de cet article le 10 mai 2021
Qu'est-ce qu'un nom de domaine ? La question semble simple puisque les noms de domaine sont aujourd'hui partout, y compris sur les affiches publicitaires. Mais cette question apparemment simple soulève bien d'autres questions, que ce texte d'Edward Lewis étudie. Notamment, il est très difficile de trouver la définition originale de « nom de domaine ».
Par exemple, quelles sont les relations des noms de domaine avec le DNS ? Les noms de domaine
ont-ils été inventés par le DNS, ou bien est-ce que le DNS a été
créé pour fournir un nouveau protocole pour faire des résolutions de
noms de domaine ? La question n'est pas purement philosophique, elle s'est posée ces
dernières années à l'IETF lorsqu'il a fallu travailler sur des
protocoles de résolution de noms autres que le DNS, et utiliser les
noms de domaine dans de nouveaux contextes. Cela a été le cas, par
exemple, du .onion du
RFC 7686. Un nom comme
sjnrk23rmcl4ie5atmz664v7o7k5nkk4jh7mm6lor2n4hxz2tos3eyid.onion (qui pointe vers le blog
que vous êtes en train de consulter, si vous utilisez
Tor) est-il un nom de domaine, bien qu'il
n'utilise pas du tout le DNS ? Le débat est d'autant plus confus
que, en raison de l'immense succès du DNS, même ses opposants et
ceux qui prétendent offrir une solution
alternative appellent souvent n'importe quel protocole de
résolution de noms « DNS ».
D'autres RFC ont eu une genèse difficile car ils nécessitaient des définitions claires de certains termes et concepts, définitions qu'on ne trouvait pas dans les textes fondateurs. C'est ainsi que les RFC 4592 et RFC 5936 ont suscité beaucoup de débats terminologiques.
En outre, le problème n'est pas purement technique ; les noms de domaine sont des enjeux financiers et politiques importants, et les débats sont rudes au sujet de leur gouvernance (notez au passage que l'auteur du texte travaille à l'ICANN, mais son embauche est récente, et son document n'est pas du tout langue de bois). Ainsi, l'ICANN décide des politiques d'enregistrement dans les gTLD et, dans une certaine mesure, à la racine des noms de domaine, mais l'IETF a aussi son mécanisme d'enregistrement, spécifié dans le RFC 6761. La délimitation de leurs pouvoirs et rôles respectifs est formalisée dans le RFC 2860 et, comme tous les textes sacrés, chacun l'interprète d'une manière différente. Notamment, le terme « assignments of domain names for technical uses » (qui sont pour l'IETF) a suscité des trésors d'exégèse : qu'est-ce qu'une « utilisation technique » ?
Pour traiter cette difficile question, la démarche de ce texte est historique : plongeons-nous dans le passé, relisons les vieux RFC et voyons ce qu'ils nous racontent. Je vous révèle la vérité tout de suite : les RFC parlaient de noms de domaine avant que le DNS ne soit inventé. Mais, en même temps, le concept de nom de domaine a évolué. Le texte ne propose pas de solution, ou de « définition définitive », il décrit plutôt qu'il ne spécifie. À l'origine, il avait été écrit comme Internet-Draft, pour être publié sous forme de RFC mais ce projet n'a pas abouti.
Aujourd'hui, la norme de base du DNS est constituée des RFC 1034 et RFC 1035. Ces documents anciens, jamais mis à jour, sont complétés par un grand nombre de RFC plus récents, formant un cauchemar pour le programmeur qui veut écrire un serveur ou un client DNS. Et aucun des deux RFC de référence ne définit ce qu'est un nom de domaine… Ils citent des textes précédents (IEN-116, RFC 799, RFC 819, et RFC 830), sans donner de définition précise, même si les concepts essentiels (la nature hiérarchique des noms, le point comme séparateur des composants dans la représentation textuelle) sont mentionnés. Mais il est clair que le concept de nom de domaine existait avant le DNS : il était utilisé par SMTP. Le RFC 788 y fait déjà allusion, des années avant la création du DNS, même si c'est seulement avec le RFC 821 que SMTP utilisera officiellement ces noms, « Domains are a recently [en 1982] introduced concept in the ARPA Internet mail system ». Et avant le DNS, il y avait déjà des protocoles de nommage utilisant ces noms de domaines, par exemple dans les RFC 819 ou surtout le RFC 830. Donc, la question est tranchée : ce n'est pas le DNS qui définit les noms de domaine. Cela a pour conséquence, entre autre, qu'il est absurde de parler d'un « DNS sur la blockchain » ou d'un « DNS pair-à-pair », sous prétexte que tel ou tel protocole de nommage utilise des noms de domaine.
Bon, mais si ce n'est pas le DNS qui a créé le concept de nom de
domaine, c'est qui ? Le courrier
électronique, comme semble l'indiquer les RFC sur SMTP ?
Comme indiqué ci-dessus, la première occurrence du terme apparait
dans le RFC 788, en novembre
1981, mais sans définition (le concept était
encore en discussion). La première définition apparait dans le RFC 799 mais c'est encore très confus, le nom de
domaine n'est pas encore hiérarchique. (Traditionnellement,
« domaine » est utilisé pour désigner une entité administrative
unique, avec ses règles propres, et ce sens est encore utilisé dans
des documents comme le RFC 5598. Les gens du
routage utilisent le terme
« système autonome » là où ceux du courrier
se serviront plutôt de « domaine ». Les noms de domaine
d'aujourd'hui viennent de là. Un exemple est donné par IEN 19.) Puis
le RFC 805, en février 1982, saute le pas et
introduit pour la première fois explicitement la notion de nom de
domaine hiérarchique (le premier RFC sur le DNS ne sera publié qu'un
an plus tard, et le DNS ne sera pas adopté instantanément, loin de
là). Le RFC 819 précisera le concept, et
créera en même temps celui de TLD, avec le premier domaine de tête,
.arpa.
Le texte de Lewis note bien que cette histoire n'est que celle transcrite dans les RFC. La réalité n'est pas exactement ce qui a été écrit, les choses sont sans doute plus compliquées. Mais les points importants ne font pas de doute : les noms de domaine existaient avant le DNS, et ils ont été créés surtout pour une application spécifique, SMTP, pas pour servir de système d'identificateurs généralisé. Par exemple, le RFC sur FTP, RFC 959, bien que publié deux ans après les premiers RFC sur le DNS, ne mentionne pas une seule fois les noms de domaine.
Et le concept de résolution, central dans le DNS, d'où vient-il ? La première mention semble être dans le RFC 724, quasiment dans le sens actuel, celui de trouver une information (par exemple une adresse) à partir d'un nom. Selon les auteurs des premiers RFC, interrogés par Ed Lewis, le terme venait de la programmation (par exemple la résolution des noms en adresses lors de l'édition de liens).
Bien, maintenant qu'on a renoncé à trouver la source unique et originale du concept de nom de domaine, voyons les variantes. Car il existe plusieurs types de noms de domaine. Déjà, il y a ceux utilisés dans le DNS. Ce sont un sous-ensemble de tous les noms de domaine, avec des restrictions spécifiques, et des règles de correspondance particulières :
- La taille maximale d'un nom est de 255 octets (j'ai bien dit octets et pas caractères), celle d'un composant de 63 caractères.
- La correspondance est faite de manière insensible à la casse.
En revanche, la limitation aux caractères ASCII et l'interdiction des symboles comme + ou & est une légende : le DNS autorise tous les octets, comme le rappelle bien le RFC 2181 (section 11). Ces restrictions existent par contre dans d'autres variantes des noms de domaine. Notez bien que j'ai écrit que le protocole DNS autorise tous les octets. Les registres de noms de domaine, eux, peuvent imposer des restrictions supplémentaires, notamment parce que les gens qui réservent des noms de domaine le font souvent pour créer des noms de machine, présentés plus loin.
Le DNS introduit deux autres concepts importants : une séparation entre la représentation des noms aux humains, et leur encodage dans les paquets effectivement échangés. Sur le câble, les noms de domaine ne comportent pas de point, par exemple (RFC 1035, section 3.1). Et le second concept est la notion d'autorité, lié à une zone (un sous-arbre géré par les mêmes serveurs faisant autorité).
Autre sous-ensemble, les noms de machines (host names). Ce n'est pas la même chose qu'un nom de domaine. Ils sont soumis à une syntaxe plus restrictive, décrite dans le RFC 952, légèrement assouplie ensuite par le RFC 1123. Là, les caractères comme le * ou le _ sont vraiment interdits. Cette règle est souvent nommée LDH, pour Letters Digits Hyphen, puisque seuls les lettres (ASCII), les chiffres (arabes) et le tiret sont admis.
À propos des lettres ASCII, il faut aussi parler des noms en
Unicode, puisque la planète n'est pas peuplée
que de gens qui écrivent en ASCII. Ces noms internationalisés, les
IDN,
sont normalisés dans le RFC 5890. Pourquoi un RFC
supplémentaires puisque le DNS admet tous les octets, même
non-ASCII, dans un nom ? Parce que le DNS ne permet pas d'indiquer
l'encodage, et qu'en prime ses règles
d'insensibilité à la casse ne sont pas
celles, bien plus complexes, d'Unicode. Enfin, certaines vieilles
applications ou bibliothèques auraient pu mal réagir à la présence
des caractères non-ASCII. D'où la séparation des noms en deux : les
U-label, le nom normal, en Unicode, et le
A-label, une représentation en pur ASCII,
normalisée dans le RFC 3492, qui permettait de
minimiser les risques de mauvaises surprises. Ainsi, lorsque
potamochère.fr est le
U-label,x
xn--potamochre-66a.fr sera le
A-label.
Le système IDN est donc une chose de plus dans l'univers déjà riche des noms de domaine. Pour approfondir, vous pouvez aussi lire le RFC 6055, qui traite du cas des noms en Unicode en dehors du DNS, et le RFC 4290, qui parle de règles que peuvent suivre les registres de noms de domaines.
Et, justement, un protocole proche du DNS, le
Multicast DNS du RFC 6762, utilise des noms qui ne sont pas passés en
punycode (la forme
xn--…) mais utilisent un encodage plus
traditionnel d'Unicode, UTF-8, tel que décrit
dans le RFC 5198. (L'annexe F du RFC 6762 explique ce choix.)
Notez que le texte considère que les adresses IP sont une forme de nom de domaine, puisqu'on peut les utiliser, par exemple, dans les URL. (En théorie, on peut aussi dans les adresses de courrier électronique mais, en pratique, cela ne marche pas.)
Mettons maintenant notre
hoodie et nos gants, pour
ressembler au hacker dans les reportages de
BFM TV, et descendons dans les profondeurs du
darknet. Non, je plaisante, on va simplement
regarder les noms des services Tor, en
.onion. Ce blog, par
exemple, est accessible avec Tor en
sjnrk23rmcl4ie5atmz664v7o7k5nkk4jh7mm6lor2n4hxz2tos3eyid.onion. S'agit-il d'un nom de
domaine ? Oui, certainement. Sa syntaxe est définie
dans la documentation Tor, et est celle d'un nom de
domaine. (Notez que le TLD
.onion a été réservé par le RFC 7686.) Mais ce n'est pas du tout un nom DNS : ces noms ne
sont jamais résolus par le DNS, mais par un protocole spécifique à
Tor (cf. le protocole de
rendez-vous), utilisant le fait que le nom est une clé
cryptographique.
Et le fichier /etc/hosts ? Historiquement, il
servait à stocker des noms de machine et leurs adresses IP. Il
fonctionne encore aujourd'hui, et sur de nombreux systèmes
d'exploitation. La syntaxe des noms qu'il contient n'est pas définie
très rigoureusement. La section 6 du RFC 3493
parle de ce cas.
Bref, si on veut assurer l'interopérabilité, ce n'est pas
facile. Il n'y a pas une définition unique des
noms de domaine, mais plusieurs sous-ensembles plus ou moins bien
définis. La tâche des interfaces utilisateur qui permettent
d'indiquer des noms de domaine n'est pas facile ! Cela rend
compliquée l'addition de nouveautés. Ainsi, les IDN n'avaient pas été
normalisés sans mal. Le texte de Lewis cite un dernier exemple de
cette difficulté à déterminer ce qui est acceptable : un nom d'un
seul composant (comme dk) est-il
valable ? C'est clairement un nom de domaine légal pour le DNS. Il
peut avoir des adresses IP associées, comme dans l'exemple. Mais il
ne marchera pas pour
certaines applications, comme le courrier électronique.
Sinon, quelques autres articles sur le DNS sur ce blog :
- Pourquoi le DNS, pourquoi ne pas se contenter des adresses IP ? (Et, comme on dit dans les médias à sensation, « la réponse va vous surprendre ».)
- Parmi les alternatives au DNS relativement sérieuses, Namecoin.
- Les premières années du nommage dans l'Internet, vues par une participante.
- Résumé d'une série d'articles sur l'histoire du DNS.
- Le RFC 226, premier RFC sur les noms de machines.
- Le RFC 608, premier à décrire la mise en ligne des noms.
- Le RFC 6761 parle de noms de domaines
« spéciaux », comme
.onion. - Très récent, le RFC 8499 donne une définition officielle de « nom de domaine », quoique bien tardive. On note que cette définition (« un nom de domaine est une liste de composants ») ne fait pas référence au DNS, montrant bien que DNS et nom de domaine sont des concepts différents.
L'article seul
Un rapport de la RAND sur l'utilisation des cryptomonnaies par les terroristes
Première rédaction de cet article le 8 mai 2021
« Les cryptomonnaies, comme le Bitcoin, financent le terrorisme » est un cliché classique lors des discussions sur ces cryptomonnaies. Dans quel mesure est-ce vrai ? L'argent, c'est le nerf de la guerre et, sans argent, une organisation ne va pas bien loin. Comment font les terroristes ? Sans avoir besoin de risquer votre vie en allant enquêter sur le financement de Daech, ce rapport de la RAND « Terrorist Use of Cryptocurrencies » est une analyse intéressante.
(Pour celles et ceux qui ne connaissent pas, la RAND n'est pas Framasoft ou la Quadrature du Net. Politiquement, c'est d'un tout autre bord, et il faut lire leurs analyses en se rappelant que leur but est défendre l'impérialisme étatsunien. Mais cela n'empêche pas que ces études contiennent souvent des informations utiles.)
Évidemment, connaitre le fonctionnement financier d'une organisation clandestine est difficile. Il n'y a pas d'informations publiques fiables, et on rencontre par contre beaucoup de discours sensationnalistes, fondés sur l'ignorance ou bien la mauvaise foi. Annoncer que les terroristes utilisent les cryptomonnaies précède en général des discours appelant à interdire ou en tout cas à restreindre sérieusement l'utilisation de ces cryptomonnaies. Comme on manque de faits précis (mais la bibliographie contient beaucoup d'éléments), ce rapport repose plutôt sur l'analyse : quels sont les propriétés utiles d'un mécanisme financier pour un groupe terroriste, et en quoi les cryptomonnaires ont, ou pas, ces propriétés ? Le rapport est détaillé, largement sourcé, et manifestement écrit par des gens qui connaissent bien le monde des cryptomonnaies, contrairement à la grande majorité des déclarations ou articles sur le Bitcoin. Une lecture que je vous recommande, donc.
Je vous divulgue tout de suite les conclusions : il n'y a pas d'utilisation significative des cryptomonnaies par les organisations terroristes, mais ça pourrait changer dans le futur. Voyons ces deux points.
(Point de terminologie au passage : je sais bien que « terrorisme » est un terme très polysémique, et d'un usage délicat. J'ai choisi la solution de facilité en reprenant ce terme tel que l'utilise le rapport. Notez que la RAND se focalise sur le terrorisme au Moyen-Orient, notamment Daech, même si les narcos latino-américains sont brièvement mentionnés.)
Une organisation terroriste a plusieurs activités financières ; par exemple, la levée de fonds auprès de donateurs, le financement d'attaques, le financement de l'infrastructure, les trafics illégaux pour remplir les caisses, etc. Certaines de ces activités sont proches de celles d'autres entreprises ou associations, d'autres sont plus spécifiques au terrorisme. Une organisation terroriste importante doit s'attendre à avoir des adversaires redoutables et doit donc bien réfléchir aux outils et aux méthodes employées, pour diminuer les risques. Sécuriser son portefeuille Bitcoin ne pose pas les mêmes problèmes quand on est un particulier visé uniquement par des attaques opportunistes et quand on est un groupe terroriste en guerre ouverte contre un État puissant. Les auteurs du rapport listent ensuite une série de propriétés des cryptomonnaies, essayant de voir si elles sont importantes ou pas pour les activités financières citées plus haut. Ainsi, l'utilisabilité d'une cryptomonnaie (disponibilité de logiciels sûrs et simples d'utilisation) est importante pour les dons des sympathisants, beaucoup de donateurs renonceront s'ils n'arrivent pas à envoyer de l'argent, mais elle est nettement moins cruciale pour les trafics illégaux, où seuls quelques professionnels entrainés manipuleront les fonds.
Le rapport analyse ensuite les cryptomonnaies par rapport à ces propriétés. Ainsi, Bitcoin est jugé pas facile à utiliser, pas très répandu dans les pays où opèrent les groupes terroristes considérés, et pas très anonyme. D'autres cryptomonnaies comme Monero ou Zcash sont bien meilleures question anonymat mais encore pires que le Bitcoin question facilité d'utilisation et diffusion. La tonalité générale du rapport est plutôt pessimiste sur les cryptomonnaies, considérant qu'une organisation terroriste rationnelle et compétente n'a guère de raisons de les utiliser. Des membres de Daech ont pu faire des essais, mais on est loin d'une utilisation significative.
Le rapport ne s'arrête pas à cette situation actuelle, et essaie d'analyser ce qui peut arriver dans le futur. C'est évidemment une partie plus faible du rapport, car prédire l'avenir est délicat. Les auteurs notent à plusieurs reprises que des changements dans les cryptomonnaies (apparition d'une nouvelle cryptomonnaie vraiment anonyme, simple à utiliser, répandue, etc) pourrait changer sérieusement la donne. Même chose si la répression sur les flux financiers ne laissait pas d'autres choix aux terroristes. Mais c'est purement théorique, on n'a pas d'indication en ce sens. Le rapport conclut qu'on ne sait pas trop mais qu'il faut rester vigilant.
Merci à Éric Freyssinet pour avoir attiré mon attention sur cet intéressant rapport, suite à un petit déjeuner du FIC.
L'article seul
La vulnérabilité DNS tsuNAME
Première rédaction de cet article le 6 mai 2021
L'Internet est plein de failles de sécurité donc, aujourd'hui, pas de surprise qu'une nouvelle faille soit publiée : tsuNAME est une faille DNS permettant des attaques par déni de service en exploitant un cycle dans les dépendances des noms de domaine.
Le principe est simple : l'attaquant doit contrôler deux noms de
domaine, avec un parent qui est la victime visée. Mettons que le
méchant veuille attaquer le TLD .example, il a deux
noms, foo.example et
bar.example, il crée un cycle en faisant en
sorte que les serveurs de noms de foo.example
soient tous dans bar.example et
réciproquement. En syntaxe de fichier de zone :
foo IN NS ns.bar.example. bar IN NS ns.foo.example.
(C'est une présentation simplifiée : un attaquant peut faire des
cycles plus complexes.) Aucun nom en
foo.example ou bar.example
ne peut être résolu avec succès, en raison de ce cycle. Mais le but
de l'attaquant n'est pas là : lorsqu'un résolveur veut résoudre
www.foo.example, le serveur faisant autorité
pour .example le renvoie à
ns.bar.example. Pour résoudre ce nom, il
interroge à nouveau le pauvre serveur faisant autorité pour
.example, qui le renvoie à
ns.foo.example et ainsi de suite. (Si vous
aimez les vidéos, je vous renvoie à celle
de l'Afnic sur le fonctionnement du DNS.) Et, pire, certains
résolveurs ne se souviennent pas que la résolution a échoué et
recommencent donc la fois suivante. Un attaquant qui a configuré le
cycle (ou bien repéré un cycle existant) peut donc utiliser les
résolveurs auxquels il a accès (directement, ou bien via un
botnet qu'il contrôle) pour faire l'attaque à
sa place.
Normalement, les résolveurs limitent le nombre de requêtes
déclenchées par une requête originale. Ils le font surtout pour se
protéger eux-mêmes, par exemple contre les attaques
en récursion infinie. Mais la nouveauté de tsuNAME est de se
servir d'un éventuel manque de limites pour attaquer les serveurs faisant
autorité. En pratique, peu de résolveurs sont assez imprudents pour
être vraiment intéressants pour l'attaquant. La principale exception
était Google Public DNS, qui a ainsi
involontairement participé à une attaque contre le
.nz. (Il a été corrigé depuis.)
Une leçon pour les programmeurs de résolveurs DNS : ne vous laissez pas entrainer dans des cycles, pensez à jeter l'éponge rapidement, et à mémoriser cet échec pour la prochaine fois.
L'article seul
Fiche de lecture : L'homme préhistorique est aussi une femme
Auteur(s) du livre : Marylène Patou-Mathis
Éditeur : Allary
978-2370-733412
Publié en 2020
Première rédaction de cet article le 2 mai 2021
La représentation traditionnelle des humains de la préhistoire montre les hommes en train de chasser et les femmes en train de coudre, faire la cuisine ou s'occuper des enfants. Est-ce que cette représentation repose sur des données scientifiques sérieuses sur la répartition des tâches à la préhistoire ? Pas forcément, dit l'auteure.
Dans ce livre, Marylène Patou-Mathis examine ce que l'on sait de la répartition genrée des activités chez nos ancêtres. Je vous le dis tout de suite : il y a beaucoup de choses qu'on ne sait pas. On n'a pas de photos prises sur le vif des humains préhistoriques. On n'a que leurs squelettes, leurs outils et les produits de leur activité, par exemple les peintures pariétales ou les statuettes, produits qui ne sont pas faciles à interpréter. La représentation traditionnelle des rôles des deux genres reflétait davantage ce qui se faisait dans la société où vivait les auteurs de ces représentations que ce qui se faisait à la préhistoire. Souvent, on plaquait donc notre conception de la division du travail entre genres sur nos ancêtres. Ou bien on supposait qu'ils étaient forcément comme les peuples « primitifs », ou plutôt comme on voyait les peuples « primitifs » contemporains.
Bon, mais maintenant qu'on a progressé, est-ce que la science peut répondre à des questions comme « Les femmes chassaient-elles ? Autant que les hommes ? » Là, c'est plus délicat. L'auteure note que, pour la majorité des squelettes retrouvés, on n'est pas sûr de leur sexe. Et ce n'est pas mieux pour les dessins qu'on retrouve. Souvent, on suppose, justement en fonction de ce qu'on estime être la société du passé. Une tombe contient des armes ? On suppose que le défunt était un homme. (L'excellent chapitre 2 est une véritable « histoire de la misogynie chez les penseurs » et montre bien que les hommes, même scientifiques, étaient largement aveuglés par leurs préjugés sexistes.) Et, par un raisonnement circulaire, on en déduit que les hommes chassaient et faisaient la guerre. Lorsqu'on examine de plus près (comme dans le cas de la fameuse guerrière de Birka p. 169), on a parfois des surprises. Une fois qu'on a déterminé le sexe de la personne dont on retrouve le squelette, on peut étudier des choses comme les déformations liées à une activité physique répétée (le lancer de javelot semblait pratiqué par les hommes et par les femmes chez les Néandertal). Mais il est difficile, avec ce qu'on retrouve de nos ancêtres, de décrire avec précision comment les deux genres se répartissaient les tâches. L'ADN peut aider (cas de Birka), ou certaines caractéristiques du corps (la forme différente des mains entre les deux sexes montre que certaines images de mains sur les parois des grottes étaient faites par des femmes, p. 144) mais il n'y aura pas de certitude, d'autant plus que rien n'indique que toutes les sociétés préhistoriques étaient identiques.
L'article seul
RFC 9019: A Firmware Update Architecture for Internet of Things
Date de publication du RFC : Avril 2021
Auteur(s) du RFC : B. Moran, H. Tschofenig (Arm Limited), D. Brown (Linaro), M. Meriac (Consultant)
Pour information
Réalisé dans le cadre du groupe de travail IETF suit
Première rédaction de cet article le 1 mai 2021
On le sait, le « S » dans « IoT » veut dire « sécurité ». Cette plaisanterie traditionnelle rappelle une vérité importante sur les brosses à dents connectées, les télés connectées, les voitures connectées et les sextoys connectés : leur sécurité est catastrophique. Les vendeurs de ces objets ont vingt ou trente ans de retard en matière de sécurité et c'est tous les jours qu'un nouveau piratage spectaculaire d'un objet connecté est annoncé. Une partie des vulnérabilités pourrait être bouchée en mettant à jour plus fréquemment les objets connectés. Mais cela ne va pas sans mal. Ce RFC fait partie d'un projet qui vise à construire certaines briques qui seront utiles pour permettre cette mise à jour fréquente. Il définit l'architecture générale.
Une bonne analyse du problème est décrite dans le RFC 8240, qui faisait le compte-rendu d'un atelier de réflexion sur la question. L'atelier avait bien montré l'ampleur et la complexité du problème ! Notre nouveau RFC est issu du groupe de travail SUIT de l'IETF, créé suite à cet atelier. La mise à jour du logiciel des objets connectés compte beaucoup d'aspects, et l'IETF se focalise sur un format de manifeste (en CBOR) qui permettra de décrire les mises à jour. (Le modèle d'information a été publié dans le RFC 9124, le format effectif sera dans un futur RFC.)
Le problème est compliqué : idéalement, on voudrait que les mises à jour logicielles de ces objets connectés se passent automatiquement, et sans casse. Ces objets sont nombreux, et beaucoup d'objets connectés sont installés dans des endroits peu accessibles ou, en tout cas, ne sont pas forcément bien suivis. Et ils n'ont souvent pas d'interface utilisateur du tout. Une solution réaliste doit donc être automatique (on sait que les injonctions aux humains « mettez à jour vos brosses à dents connectées » ne seront pas suivies). D'un autre côté, cette exigence d'automaticité va mal avec celle de consentement de l'utilisateur, d'autant plus que des mises à jour peuvent éliminer certaines fonctions de l'objet, ou en ajouter des peu souhaitables (cf. RFC 8240). En moins grave, elles peuvent aussi annuler des réglages ou modifications faits par les utilisateurs.
Le format de manifeste sur lequel travaille le groupe SUIT vise à authentifier l'image (le code), par exemple en la signant. Un autre point du cahier des charges, mais qui n'est qu'optionnel [et que je trouve peu réaliste dans la plupart des environnements] est d'assurer la confidentialité de l'image, afin d'empêcher la rétro-ingénierie du code. Ce format de manifeste vise avant tout les objets de classe 1 (selon la terminologie du RFC 7228). Il est prévu pour du logiciel mais peut être utilisé pour décrire d'autres ressources, comme des clés cryptographiques.
On l'a dit, le travail du groupe SUIT se concentre sur le format du manifeste. Mais une solution complète de mise à jour nécessite évidemment bien plus que cela, le protocole de transfert de fichiers pour récupérer l'image, un protocole pour découvrir qu'il existe des mises à jour (cf. le status tracker en section 2.3), un pour trouver le serveur pertinent (par exemple avec DNS-SD, RFC 6763). Le protocole LwM2M (Lightweight M2M) peut par exemple être utilisé.
Et puis ce n'est pas tout de trouver la mise à jour, la récupérer, la vérifier cryptographiquement. Une solution complète doit aussi fournir :
- La garantie que la mise à jour ne va pas tout casser (si beaucoup d'utilisateurs débrayent les mises à jour automatiques, ce n'est pas par pure paranoïa), ce qui implique des mises à jour bien testées, et une stratégie de repli si la mise à jour échoue,
- des mises à jour rapides, puisque les failles de sécurité sont exploitées dès le premier jour, alors que les mises à jour nécessitent souvent un long processus d'approbation, parfois pour de bonnes raisons (les tests dont je parlais au paragraphe précédent), parfois pour des mauvaises (processus bureaucratiques), et qu'elles doivent souvent passer en cascade par plusieurs acteurs (bibliothèque intégrée dans un système d'exploitation intégré dans un composant matériel intégré dans un objet, tous les quatre par des acteurs différents),
- des mises à jour économes en énergie, l'objet pouvant être contraint dans ce domaine,
- des mises à jour qui fonctionnent même après que les actionnaires de l'entreprise aient décidé de mettre leur argent ailleurs et aient abandonné les objets vendus (on peut toujours rêver).
Bon, maintenant, après cette liste au Père Noël, au travail. Un peu de vocabulaire pour commencer :
- Image (ou firmware) : le code qui sera téléchargé sur l'objet et installé (je n'ai jamais compris pourquoi ça s'appelait « ROM » dans le monde Android). L'image peut être juste le système d'exploitation (ou une partie de celui-ci) ou bien un système de fichiers complet.
- Manifeste : les métadonnées sur l'image, par exemple date, numéro de version, signature, etc.
- Point de départ de la validation (trust anchor, RFC 5914 et RFC 6024) : la clé publique à partir de laquelle se feront les validations cryptographiques.
- REE (Rich Execution Environment) : un environnement logiciel général, pas forcément très sécurisé. Par exemple, Alpine Linux est un REE.
- TEE (Trusted Execution Environment) : un environnement logiciel sécurisé, typiquement plus petit que le REE et doté de moins de fonctions.
Le monde de ces objets connectés se traduit par une grande dispersion des parties prenantes. On y trouve par exemple :
- Les auteurs de logiciel, qui sont souvent très loin du déploiement et de la maintenance des objets,
- les fabricants de l'objet,
- les opérateurs des objets qui ne sont pas les propriétaires de l'objet : la plupart du temps, pour piloter votre objet, celui que vous avez acheté, vous devez passer par cet opérateur, en général le fabricant, s'il n'a pas fait faillite ou abandonné ces objets,
- les gestionnaires des clés (souvent le fabricant),
- et le pauvre utilisateur tout en bas.
[Résultat, on a des chaînes d'approvisionnement longues, compliquées, opaques et vulnérables. Une grande partie des problèmes de sécurité des objets connectés vient de là, et pas de la technique. Par exemple, il est fréquent que les auteurs des logiciels utilisés se moquent de la sécurité et ne fournissent pas de mise à jour pour combler les failles dans les programmes.]
La section 3 du RFC présente l'architecture générale de la solution. Elle doit évidemment reposer sur IP (ce RFC étant écrit par l'IETF, un choix contraire aurait été étonnant), et, comme les images sont souvent de taille significative (des dizaines, des centaines de kilo-octets, au minimum), il faut utiliser en prime un protocole qui assurera la fiabilité du transfert et qui ne déclenchera pas de congestion, par exemple TCP, soit directement, soit par l'intermédiaire d'un protocole applicatif comme MQTT ou CoAP. En dessous d'IP, on pourra utiliser tout ce qu'on veut, USB, BLE, etc. Outre IP et TCP (pas évident pour un objet contraint, cf. RFC 9006), l'objet devra avoir le moyen de consulter le status tracker pour savoir s'il y a du nouveau, la capacité de stocker la nouvelle image avant de l'installer (si la mise à jour échoue, il faut pouvoir revenir en arrière, donc stocker l'ancienne image et la nouvelle), la capacité de déballer, voire de déchiffrer l'image et bien sûr, puisque c'est le cœur du projet SUIT, la capacité de lire et de comprendre le manifeste. Comme le manifeste comprend de la cryptographie (typiquement une signature), il faudra que l'objet ait du logiciel pour des opérations cryptographiques typiques, et un magasin de clés cryptographiques. Notez que la sécurité étant assurée via le manifeste, et non pas via le mécanisme de transport (sécurité des données et pas du canal), le moyen de récupération de l'image utilisé n'a pas de conséquences pour la sécurité. Ce sera notamment pratique pour le multicast.
Le manifeste peut être inclus dans l'image ou bien séparé. Dans le second cas, l'objet peut décider de charger l'image ou pas, en fonction du manifeste.
La mise à jour du code d'un objet contraint pose des défis particuliers. Ainsi, ces objets ne peuvent souvent pas utiliser de code indépendant de sa position. La nouvelle image ne peut donc pas être mise n'importe où. Cela veut dire que, lorsque le code est exécuté directement à partir du moyen de stockage (et donc pas chargé en mémoire), il faut échanger l'ancienne et la nouvelle image, ce qui complique un éventuel retour en arrière, en cas de problème.
Avec tout ça, je n'ai pas encore tellement parlé du manifeste lui-même. C'est parce que notre RFC ne décrit que l'architecture, donc les généralités. Le format du manifeste sera dans deux RFC, un pour décrire le format exact (fondé sur CBOR, cf. RFC 8949) et un autre, le RFC 9124 pour le modèle d'information (en gros, la liste des éléments qui peuvent être mis dans le manifeste).
La section 7 de notre RFC fait la synthèse des questions de sécurité liées à la mise à jour. Si une mise à jour fréquente du logiciel est cruciale pour la sécurité, en permettant de fermer rapidement des failles découvertes dans le logiciel de l'objet, la mise à jour peut elle-même présenter des risques. Après tout, mettre à jour son logiciel, c'est exécuter du code récupéré via l'Internet… L'architecture présentée dans ce RFC fournit une sécurité de bout en bout, par exemple en permettant de vérifier l'authenticité de l'image récupérée (et, bien sûr, son intégrité). Pas question d'exécuter un code non authentifié, ce qui est pourtant couramment le cas aujourd'hui avec les mises à jour de beaucoup d'équipements informatiques.
Cette même section en profite pour noter que la cryptographie nécessite de pouvoir changer les algorithmes utilisés. Le RFC cite même l'importance de la cryptographie post-quantique. (C'est un des tous premiers RFC publiés à en parler, après le RFC 8773.) D'un côté, ce genre de préoccupations est assez décalée : la réalité de l'insécurité des objets connectés est tellement abyssale qu'on aura bien des problèmes avant que les calculateurs quantiques ne deviennent une menace réelle. De l'autre, certains objets connectés peuvent rester en service pendant longtemps. Qui sait quelles seront les menaces dans dix ans ? (Un article comme « Quantum Annealing for Prime Factorization » estimait que, dans le pire des cas, les algorithmes pré-quantiques commenceraient à être cassés vers 2030, mais il est très difficile d'estimer la fiabilité de ces prédictions, cf. mon exposé à Pas Sage En Seine.)
J'insiste, mais je vous recommande de lire le RFC 8240 pour bien comprendre tous les aspects du problème. D'autre part, vous serez peut-être intéressés par l'évaluation faite du projet SUIT sous l'angle des droits humains. Cette évaluation suggérait (ce qui n'a pas été retenu) que le chiffrement des images soit obligatoire.
L'article seul
La curieuse annonce des adresses IPv4 de l'armée états-unienne
Première rédaction de cet article le 26 avril 2021
Le 20 janvier 2021, l'armée des États-Unis a soudainement annoncé sur l'Internet des millions d'adresses IP qui n'avaient jamais été actives sur l'Internet. Les causes exactes ne sont pas connues (il y a des explications officielles mais qui ne répondent pas à toutes les questions). Comment a-t-on vu cela et quelles conclusions (forcément assez spéculatives) peut-on en tirer ?
Au début, cela ressemblait à un détournement BGP classique, provoqué soit par une erreur humaine (cas de l'accident malaisien), soit par une volonté délibérée de détourner du trafic (cas de l'attaque contre MyEtherWallet). Le protocole BGP permet à un routeur Internet d'annoncer les préfixes d'adresses IP qu'il sait joindre. S'il se trompe ou qu'il ment, ses pairs vont parfois accepter l'annonce et l'utiliser, envoyant alors le trafic vers les détourneurs. Le 20 janvier 2021, ce fut la première réaction, « quelqu'un annonce les adresses IP de l'armée ». Comment le voit-on ? Rappelez-vous que l'Internet est très transparent. Tout routeur de la DFZ va voir les annonces et, même si vous n'avez pas accès à un tel routeur, plusieurs services vous fournissent les données. Servons-nous du classique RouteViews. Vous pouvez récupérer toutes les annonces du 20 janvier 2021 et les analyser (ici, on convertit les données qui étaient au format MRT du RFC 6396, avec l'outil bgpdump) :
% wget http://archive.routeviews.org/bgpdata/2021.01/UPDATES/updates.20210120.1645.bz2 % bunzip2 updates.20210120.1645.bz2 % bgpdump updates.20210120.1645 > updates.20210120.1645.txt
On a alors un fichier texte avec les annonces BGP, qu'on peut regarder avec l'éditeur ou l'afficheur de son choix. Voici la première annonce bizarre (l'heure est évidemment UTC) :
TIME: 01/20/21 16:57:35.081428 TYPE: BGP4MP_ET/MESSAGE/Update FROM: 64.71.137.241 AS6939 TO: 128.223.51.102 AS6447 ORIGIN: IGP ASPATH: 6939 8003 NEXT_HOP: 64.71.137.241 ANNOUNCE 11.0.0.0/8
(La dernière annonce pour ce même préfixe, relayée par plusieurs routeurs avant d'atteindre RouteViews, a été vue à 17:04:19.316776, ce qui donne une idée de la rapidité de la propagation des routes dans l'Internet.)
En quoi est-ce que cette annonce était bizarre ? D'abord, le
préfixe 11.0.0.0/8, un préfixe comportant
beaucoup d'adresses (surtout depuis l'épuisement des adresses
IPv4) n'avait jamais été annoncé publiquement sur l'Internet
avant (comme on peut le voir sur
RIPEstat) ou, plus exactement, jamais été annoncé en dehors
de quelques détournements ponctuels. Mais qui, en 2021, a encore un
préfixe /8 non annoncé ? whois nous montre
que c'est le DoD :
% whois 11.0.0.0 ... NetRange: 11.0.0.0 - 11.255.255.255 CIDR: 11.0.0.0/8 NetName: DODIIS NetType: Direct Allocation OriginAS: Organization: DoD Network Information Center (DNIC) RegDate: 1984-01-19 Updated: 2007-08-22 ... OrgName: DoD Network Information Center
(Pour la petite histoire, ce préfixe a été alloué au DoD en 1985, dans le RFC 943 ; oui, à l'époque, les RFC servaient de registres d'adresses IP.)
Tout de suite, on pense à un détournement des adresses IP de l'armée
états-unienne par des Chinois/Russes/Cubains/Iraniens. D'autant plus
que la date est curieuse : 16:57:35.081428 UTC, c'est moins de trois
minutes avant la fin officielle du mandat de
Trump, fin de mandat qui avait été marquée
par plusieurs troubles graves. Et puis
l'AS qui a fait les
annonces, l'AS 8003, n'était pas tellement connu avant, appartenant
à une
entreprise très discrète et sur laquelle les investigations
n'ont pas révélé grand-chose, à part son association passée à des
activités bizarres. (whois AS8003 pour avoir
les informations sur cet AS.)
Dans les jours et les semaines suivants, d'autres préfixes
autrefois inutilisés ont été annoncés, par exemple le
7.0.0.0/8.
Finalement, le Pentagone (via son service DDS) a révélé que l'annonce était normale : il ne s'agit pas d'un détournement mais d'une opération légitime. Mais quels sont ses buts ? Pourquoi l'armée qui n'annonçait pas ses adresses IP depuis si longtemps (ce qui ne veut pas dire qu'elles n'étaient pas utilisées en interne) a-t-elle tout à coup changé sa politique ? Inutile de préciser qu'on ne saura de toute façon pas tout. Mais on peut toujours spéculer :
- Un tel volume d'adresses IP représente beaucoup d'argent en période de pénurie (le marché est entre 20 et 30 dollars par adresse),
- ou bien l'armée est en train de monter un pot de miel géant, pour attraper plein de trafic malveillant,
- certains administrateurs réseau ont été assez incompétents et imprudents pour utiliser ces préfixes d'adresses IP apparemment inutilisés pour numéroter leurs réseaux internes ; l'annoncer sur l'Internet permettrait de capter ce trafic interne (on dit que l'armée chinoise était dans ce cas),
- ou encore le but est vraiment de s'en servir, par exemple pour y héberger des services.
La possibilité d'une vente de ces adresses, et donc peut-être d'un test pour s'assurer qu'elles ne posaient pas de problèmes techniques, a été souvent mentionnée, vu le « trésor » d'adresses IP de l'armée. Mais relativisons : au cours actuel (mais qui baisserait si le DoD vendait d'un coup toutes ces adresses), cela ferait certes plusieurs centaines de millions de dollars mais c'est une goutte d'eau par rapport aux budgets militaires de ce pays. Et puis le GAO (la « Cour des Comptes ») avait noté dans un rapport de 2020 les difficultés, notamment légales, à vendre ces adresses IP. Un rapport parlementaire estimait que la vente d'adresses IP par le DoD soulevait de nombreux problèmes et n'était pas forcément une solution viable.
Autre hypothèse, celle du pot de miel. C'est nettement plus vraisemblable : tout préfixe important annoncé sur l'Internet reçoit un « rayonnement de fond », l'Internet Background Radiation (IBR), et les nouveaux préfixes annoncés vont certainement attirer beaucoup de trafic, permettant des études qui intéressent certainement les services de cyberguerre.
Et, en parlant de cyberguerre, qu'en est-il de l'hypothèse d'un détournement délibéré du trafic des réseaux qui ont été assez stupides pour utiliser ces préfixes d'adresses IP ? Là, je ne vous étonnerai pas en vous disant que mes contacts au Pentagone sont muets et ne m'ont pas tenu informé :-)
Enfin, s'agissant de l'hébergement de services, ça reste possible
mais l'annonce faite par une petite société inconnue et discrète ne
plaide pas en ce sens. Notez que le très utile
Shodan trouve déjà des machines connectées
dans le préfixe 11.0.0.0/8. (Attention si vous
essayez de les pirater : le propriétaire n'a pas le sens de
l'humour.) Ma préférée (mais rappelez-vous qu'il peut s'agir d'un
pot de miel) est un routeur Ubiquiti annonçant comme nom
HACKED-ROUTER-HELP-SOS-HAD-DUPE-PASSWORD.
Quelques lectures en plus :
- La meilleure source technique, qui a fait connaitre ce cas, l'article de Doug Madory,
- une autre analyse technique est celle de Geoff Huston,
- la dépêche Associated Press, avec notamment leurs recherches infructueuses concernant la société qui gère l'AS 8003, et ses possibles liens avec d'autres activités douteuses,
- l'article du Washington Post contient également des informations sur la société Global Resources System (notez qu'il y en a deux, ayant la même adresse, une créée en 2006 et une créée en 2020).
L'article seul
Fiche de lecture : Leur progrès et le nôtre
Auteur(s) du livre : François Ruffin
Éditeur : Seuil
978-2-02-147770-2
Publié en 2021
Première rédaction de cet article le 25 avril 2021
Le progrès technique est-il une bonne ou une mauvaise chose ? Avec tous les philosophes et militants politiques qui ont réfléchi à la question depuis je ne sais plus combien de siècles, on se doute bien qu'il n'y aura pas de réponse simple. Et puis, posé comme ça, c'est trop binaire. Dans ce court livre, François Ruffin estime que ça dépend, ça dépend de quel progrès, de qui le décide, de comment c'est déployé.
Nous voyons en ce moment beaucoup d'« injonctions au progrès », d'affirmations peu subtiles comme quoi le « progrès » (au sens du progrès technique) est à la fois forcément positif, inévitable et que de toute façon ceux et celles qui s'y opposent sont à coup sûr des amish attardés. Ce discours de la « startup nation », porté par exemple par Emmanuel Macron, est tellement idiot qu'il permet à Ruffin de se faire plaisir facilement, par exemple en dressant p. 20 la liste des cérémonies d'adoration des entreprises du numérique auxquelles a participé le président de la république, qui préfère se faire photographier en présence de patrons du numérique qu'avec des infirmières ou des éboueurs. L'auteur oublie d'ailleurs parfois son point de vue de classe par exemple en affirmant p. 23 que Macron aime s'entourer d'une « cour de geeks » comme s'il y avait le moindre rapport entre les patrons des grandes entreprises du numérique et le développeur de logiciel libre dans son garage. De même, taper sur Musk (p. 123) n'est pas difficile, tant le personnage prend soin d'être sa propre caricature.
Ruffin peut donc, vu le ridicule des propagandistes de « la Tech », facilement expliquer que tout progrès n'est pas bon à prendre. Le progrès technique n'est pas toujours un progrès social, et l'auteur liste de nombreux exemples où les techniques modernes, notamment autour du numérique, peuvent servir à opprimer, à surveiller, à contrôler et pas à augmenter le bonheur humain. D'où le titre, il y a ce qu'ils appellent le progrès, et ce que les lecteurs du livre considéreraient comme le vrai progrès (augmenter le salaire des enseignants plutôt que de chercher à tout prix à se faire voir serrant la main de Zuckerberg). Même sans parler de cas où le progrès technique a été un recul social (la surveillance généralisée est probablement le meilleur exemple), l'auteur cite aussi avec raison des cas où le progrès n'est pas linéaire et où ses effets peuvent s'épuiser. Un réfrigérateur dans la maison est un progrès, un deuxième n'apporte pas tellement d'avantages. (Comme le dit un des protagonistes de la série Mad Men à un débutant dans le monde de la publicité « notre rôle est de convaincre le consommateur d'acheter un objet alors qu'il en a déjà un qui sert à la même chose ».)
Cette partie où Ruffin explique que le progrès technique est un moyen, pas un but en soi, est la meilleure du livre. Il l'illustre de nombreux exemples. Après, les difficultés commencent : il ne faut pas avaler tout sous prétexte que ce serait « le progrès » mais comment décider ? L'auteur suggère quelques pistes, mais plutôt vagues. La démocratie, que le déploiement de telle ou telle technique, soit décidé par les citoyens, d'accord, mais les modalités pratiques ne vont pas aller sans mal. (C'est un des points que notait, à juste titre, le RFC 8890.) François Ruffin propose p. 139, une « Convention citoyenne permanente sur le numérique », l'idée me semble intéressante mais elle n'est pas développée, alors que cette suggestion fait surgir plein de questions. Une autre proposition, formulée par une personne interrogée par l'auteur (p. 140), serait que les ingénieurs décident « quelles applications autoriser », ce qui, cette fois, fait plutôt froid dans le dos.
Il faut dire qu'analyser les conséquences d'un progrès technique, surtout s'il n'a pas encore été déployé, est difficile. François Ruffin cite souvent la 5G, sujet à la mode. Heureusement, il ne reprend pas les délires complotistes entendus souvent (par exemple sur le « danger des ondes ») mais il traite le sujet de manière trop superficielle, par exemple en disant que la 5G n'a « pas d'utilité », ce qui est toujours une conclusion imprudente.
L'auteur dérape également un peu lorsqu'il brode p. 69 sur la légende comme quoi toutes les écoles de la Silicon Valley seraient sans ordinateurs car les cadres des entreprises du numérique voudraient mettre leurs enfants à l'abri de ce danger. Non seulement ce récit ne repose que sur quelques déclarations isolées de quelques personnages, mais il est amusant de constater que des gens qui critiquent, à juste titre, le manque de culture politique de pas mal d'acteurs du numérique, considèrent comme crédibles toutes les théories qu'ils peuvent émettre sur l'éducation. Pourquoi ne pas également les citer quand ils deviennent végétaliens ou bien se convertissent au bouddhisme, autres modes californiennes ?
Ce livre a le mérite de poser les bonnes questions : qui décide ? La 5G, l'Internet, l'infomatique, les ordiphones ne sont pas arrivés tout seuls. Des gens ont décidé, et ont mis les moyens nécessaires. Toute la question du progrès est de savoir qui va pouvoir prendre ces décisions, aujourd'hui confisquées par une minorité.
L'article seul
RFC 9011: Static Context Header Compression and Fragmentation (SCHC) over LoRaWAN
Date de publication du RFC : Avril 2021
Auteur(s) du RFC : O. Gimenez (Semtech), I. Petrov (Acklio)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF lpwan
Première rédaction de cet article le 23 avril 2021
Le RFC 8724 décrivait un mécanisme général de compression pour les réseaux LPWAN (réseaux contraints pour objets contraints). Ce nouveau RFC 9011 précise ce mécanisme pour le cas spécifique de LoRaWAN.
Ces « réseaux contraints pour objets contraints » sont décrits dans le RFC 8376. Ils ont des concepts communs mais aussi des différences, ce qui justifie la séparation de SCHC en un cadre générique (celui du RFC 8724) et des spécifications précises par réseau, comme ce que fait notre RFC pour LoRaWAN, la technique qui est utilisée dans divers réseaux déployés. Donc, rappelez-vous, LoRaWAN = la technologie, LoRa = un réseau déployé utilisant cette technologie (mais d'autres réseaux concurrents peuvent utiliser LoRaWAN). LoRaWAN est normalisé par l'alliance LoRa (cf. le texte de la norme) et les auteurs du RFC sont actifs dans cette alliance. Si vous voulez un exemple d'utilisation de LoRaWAN, je recommande cet article en français sur une Gateway LoRaWAN réalisée sur un Raspberry Pi.
La section 3 du RFC fait un rappel de SCHC : si vous n'avez pas le courage de lire le RFC 8724, apprenez que SCHC a deux parties, une de compression des en-têtes, et une de fragmentation, les liens des réseaux contraints ayant souvent une faible MTU. La section 4, elle, explique LoRaWAN (vous avez aussi le RFC 8376, notamment sa section 2.1). La terminologie de SCHC et celle de LoRaWAN ne coïncident pas parfaitement donc il faut se souvenir que Gateway dans LoRaWAN s'appelle plutôt RGW (Radio GateWay) dans SCHC, que le Network Server de LoRaWAN est le NGW (Network GateWay) de SCHC et que les utilisateurs de LoRaWAN doivent se souvenir que leur Application Server est nommé C/D (Compression/Décompression) ou F/R (Fragmentation/Réassemblage) chez SCHC. Les objets connectés par LoRaWAN sont très souvent contraints et LoRaWAN définit trois classes d'objets, de la classe A, la plus contrainte, à la C. Notamment, les objets de la classe A émettent sur le réseau mais n'ont pas de moment d'écoute dédié, ceux de la classe B écoutent parfois, et ceux de la classe C écoutent en permanence, ce qui consomme pas mal d'énergie. Autant dire que les objets de classe C sont en général alimentés en électricité en permanence.
La section 5 est le cœur du RFC, expliquant en détail comment on met en correspondance les concepts abstraits de SCHC avec les détails du protocole LoRaWAN. Ainsi, le RuleID de SCHC est mis sur huit bits, dans le port (Fport) LoRaWAN (norme LoRaWAN, version 1.04, section 4.3.2), juste avant la charge utile. L'annexe A du RFC donne des exemples d'encodage des paquets.
Merci à Laurent Toutain pour sa relecture.
L'article seul
Name:Wreck, vulnérabilité Internet du jour
Première rédaction de cet article le 14 avril 2021
Comme souvent, une vulnérabilité logicielle a reçu un nom commercial (« Name:Wreck », notez le deux-points) et a eu droit à des articles dans les médias. Plongeons-nous un peu dans cette vulnérabilité et ce qu'elle nous apprend.
Name:Wreck est décrite dans un rapport (en anglais) de la société Forescout dont je vous recommande la lecture, c'est bien expliqué et avec une dose relativement limitée de sensationnalisme et de marketing. Name:Wreck n'est pas, comme cela a parfois été dit, une « vulnérabilité DNS » ou une « faille DNS » mais une bogue dans des logiciels client DNS. La bogue exploite une fonction peu connue du DNS, la compression des données dans les réponses. Comme le même nom de domaine peut apparaitre plusieurs fois dans une réponse DNS, l'encodage des noms dans le paquet peut se faire en ne mettant qu'une fois le nom et, le reste du temps, en mettant un pointeur vers ce nom. J'ai simplifié, pour avoir tous les détails, il faut lire le RFC 1035, section 4.1.4. (Notez que le rapport mentionne d'autres vulnérabilités, qui n'ont pas grand'chose à voir avec les pointeurs de compression.)
Si vous êtes programmeuse ou programmeur, vous avez déjà senti le problème : que se passe-t-il, par exemple, si le pointeur pointe en dehors du paquet ? Eh bien vous avez gagné, ce genre de problèmes est fréquent, beaucoup de mises en œuvre du DNS analysent les paquets sans faire assez attention. La section 6 du rapport cité plus haut liste un certain nombre d'erreurs courantes dans l'analyse des paquets DNS. Ces erreurs sont encore plus graves si on programme en C, langage qui, par défaut, vous laissera écrire au-delà des bornes. J'ajoute que mon expérience personnelle d'analyse de paquets DNS réels montre que les paquets mal formés sont une réalité, soit par désir de malveillance, soit par erreur. Ainsi, comme le note la sous-section 6.5 du rapport, un client DNS qui ferait une boucle sur le nombre d'enregistrements dans une section DNS sans précautions découvrirait rapidement que les paquets annonçant des milliers d'enregistrements, mais de taille bien trop courte pour les contenir, existent en vrai dans l'Internet. La règle de base de l'analyse de paquets entrants « soyez paranoïaques » s'applique au DNS.
Donc, en envoyant un paquet soigneusement calculé, avec des pointeurs de compression incorrects, on peut déclencher une boucle sans fin chez le client, ou un plantage, ou, pire, une exécution de code. Notons que si tout programme, quel que soit le langage dans lequel il est écrit, peut être vulnérable aux deux premières conséquences, la possibilité qu'une bogue mène à une exécution de code est quand même assez spécifique à C. Cela pourrait être un argument pour prôner l'utilisation de langages supposés plus sûrs, comme Rust (après, comme je n'ai pas appris à programmer en Rust, je réserve mon opinion).
La vulnérabilité existe par exemple dans le client DNS du système d'exploitation Nucleus de Siemens, conçu pour les objets connectés (cf. l'avis de sécurité). Elle touche aussi le système d'exploitation FreeBSD (cf. l'avis). Un des mérites des auteurs de l'étude est en effet de ne pas s'être limités aux clients DNS classiques mais d'avoir regardé d'autres logiciels qui analysent des informations DNS. C'est le cas des clients DHCP, qui peuvent recevoir des informations DNS, comme la liste des domaines à ajouter aux noms cherchés (option 119 en DHCP v4). En l'occurrence, chez FreeBSD, c'est en effet le client dhclient qui était vulnérable. (Quoique certaines mesures de protection peuvent, si elles sont utilisées, limiter les conséquences de la faille.)
Bien, donc, la faille existe. Maintenant, soyons positifs, agissons. Quelles sont les actions possibles ? Évidemment, les auteurs des logiciels concernés ont patché. Mais cela ne concerne que le code d'origine, pas toutes ses utilisations, loin en aval. Ce n'est pas parce qu'un patch existe chez FreeBSD, ou même qu'une nouvelle version de ce système d'exploitation sort, que toutes les machines FreeBSD de la planète vont recevoir le nouveau code. En outre, FreeBSD est souvent utilisé indirectement, par des gens qui ne savent même pas que le joli boitier très cher qu'ils ont acheté (répartiteur de charge, pare-feu, etc) utilise en fait FreeBSD. Ces boitiers spécialisés utilisent souvent des versions très en retard des logiciels (libres ou privateurs) qu'ils intègrent. Des versions vulnérables continueront donc à être en production pendant longtemps.
Et c'est encore pire dans le monde merveilleux de l'« Internet des Objets ». Là, la règle est le n'importe quoi, des objets vendus sans aucune mise à jour, ou bien une mise à jour compliquée, et qui ne dure de toute façon pas éternellement. Là, on peut parier que les versions vulnérables dureront bien plus longtemps. Un bonne lecture à rappeler est le RFC 8240, le compte-rendu d'un atelier IAB sur cette question de la mise à jour des objets connectés. Au passage, ce problème a une composante technique (ce sur quoi travaille le groupe de travail IETF SUIT) et surtout une composante business. Rien n'oblige les vendeurs d'objets connectés à assurer une maintenance rapide et correcte de leurs logiciels sur le long terme.
Bon, alors que faire en attendant ? Le rapport suggère d'isoler et de segmenter, pour éviter que les objets vulnérables se trouvent directement exposés au grand méchant Internet. C'est par exemple l'argument de Paul Vixie quand il dit qu'il faut s'assurer que les objets en entreprise ne parlent pas directement à des serveurs DNS externes mais passent forcément par un résolveur interne (qui ne leur enverra que des paquets DNS correctement formés). Le problème est que cela suppose que l'entreprise ait un résolveur interne, correct, à jour, qui rende le service attendu… (Par exemple, beaucoup de ces résolveurs internes ne valident pas.) Autrement, pas mal d'objets (via une décision de leur programmeur, ou de leur utilisateur) vont essayer de court-circuiter le résolveur local.
Et à l'IETF, peut-on faire quelque chose ? Changer le
protocole DNS pour supprimer la compression n'est clairement pas
possible, mais on pourrait attirer l'attention des programmeuses et
des programmeurs sur ces dangers. C'est ce que propose un
Internet-Draft écrit par
les auteurs du rapport Name:Wreck, draft-dashevskyi-dnsrr-antipatterns.
Le rapport suggère également de modifier le RFC 5625, qui dit qu'un relais DNS peut
jeter les paquets mal formés. Le rapport suggère de dire qu'il le
doit. Le problème est que certains de ces
relais analysent la totalité des paquets (et peuvent donc les
« proprifier ») alors que d'autres passent juste des bits et ne
savent donc pas quels sont les paquets incorrects.
On peut quand même en tirer une leçon pour la conception de systèmes informatiques critiques : la compression dans le DNS est compliquée, mal spécifiée, et dangereuse. Comme la fragmentation/réassemblage dans IP, elle a déjà mené à pas mal de failles. On peut donc rappeler que la complexité est l'ennemie de la sécurité et que, pour gagner quelques octets, les auteurs du DNS ont créé une fonction dangereuse. Pensez-y la prochaine fois que vous entendrez quelqu'un dire que rajouter « juste une petite fonction simple » dans une spécification ou un code ne peut pas poser de problème.
L'article seul
Fiche de lecture : Cavanna, paléontologue !
Auteur(s) du livre : Pascal Tassy
Éditeur : Éditions Matériologiques
978-2-37361-252-3
Publié en 2020
Première rédaction de cet article le 7 avril 2021
Si, comme beaucoup de personnes (comme moi, par exemple), vous ignoriez que Cavanna était féru de paléontologie, vous allez l'apprendre dans ce court livre où l'auteur nous raconte ses échanges scientifiques avec le fondateur de Charlie Hebdo.
Cavanna avait de nombreuses cordes à son arc. Mais ce récit de Pascal Tassy se focalise sur une seule corde : la passion du « rital » pour l'étude des espèces disparues. Cavanna était curieux de sciences et aimait discuter avec les scientifiques. Son arrivée à la soutenance de thèse de l'auteur (thèse sur les mastodontes) avait sérieusement déstabilisé le bientôt docteur. Ils ont finalement parlé d'adaptation, de sélection naturelle, de cladistique, d'écologie… pendant de nombreuses années.
Si Cavanna et Pascal Tassy étaient d'accord sur beaucoup de choses (par exemple pour se moquer des créationnistes), il leur restait des sujets de controverses. J'ai ainsi appris que Cavanna, contrairement à son ami, était plutôt favorable au transhumanisme et tenté par l'idée d'immatérialisme.
Il était même prévu entre les deux amis d'écrire ensemble un livre… qui ne s'est finalement pas fait. À défaut, vous aurez dans ce récit quelques idées sur ce qu'aurait pu être ce livre.
Autre compte-rendu de ce livre, dans Charlie Hebdo.
L'article seul
RFC 9018: Interoperable Domain Name System (DNS) Server Cookies
Date de publication du RFC : Avril 2021
Auteur(s) du RFC : O. Sury (Internet Systems Consortium), W. Toorop (NLnet Labs), D. Eastlake 3rd (Futurewei Technologies), M. Andrews (Internet Systems Consortium)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 6 avril 2021
Le RFC 7873 normalisait un mécanisme, les cookies, pour qu'un serveur DNS authentifie raisonnablement l'adresse IP du client (ce qui, normalement, n'est pas le cas en UDP). Comme seul le serveur avait besoin de reconnaitre ses cookies, le RFC 7873 n'imposait pas un algorithme particulier pour les générer. Cela posait problème dans certains cas et notre nouveau RFC propose donc un mécanisme standard pour fabriquer ces cookies.
L'un des scénarios d'utilisation de ces « cookies standards » est le cas d'un serveur anycast dont on voudrait que toutes les instances génèrent des cookies standardisés, pour qu'une instance puisse reconnaitre les cookies d'une autre. Le RFC 7873, section 6, disait bien que toutes les instances avaient intérêt à partir du même secret mais ce n'était pas plus détaillé que cela. La situation actuelle, où chaque serveur peut faire différemment, est décrite dans le RFC par un mot en anglais que je ne connaissais pas, gallimaufry. D'où l'idée de spécifier cet algorithme, pour simplifier la vie des programmeuses et programmeurs avec un algorithme de génération de cookie bien étudié et documenté ; plus besoin d'en inventer un. Et cela permet de créer un service anycast avec des logiciels d'auteurs différents. S'ils utilisent cet algorithme, ils seront compatibles. Il ne s'agit que d'une possibilité : les serveurs peuvent utiliser cet algorithme mais ne sont pas obligés, le RFC 7873 reste d'actualité.
Comment, donc, construire un cookie ?
Commençons par celui du client (section 3). Rappel : le but est
d'authentifier un minimum donc, par exemple, le client doit choisir
un cookie différent par serveur (sinon, un
serveur pourrait se faire passer pour un autre, d'autant plus que le
cookie circule en clair), et, donc, il faut
utiliser quelque chose de spécifique au serveur dans l'algorithme,
par exemple son adresse IP. Par contre, pas besoin de le changer
souvent, il peut parfaitement durer des mois, sauf évidemment si un
élément entrant dans sa construction change, ou est
compromis. Autrefois, il était suggéré d'utiliser l'adresse IP du
client dans la construction du cookie client,
mais cette suggestion a été retirée car le logiciel ne connait
parfois son adresse IP que trop tard (ça dépend de l'API réseau utilisée
et, par exemple, avec l'API sockets de si on
a déjà fait un bind() et, de toute façon, si on
est derrière un routeur NAT, connaitre
l'adresse IP locale ne sert pas à grand'chose). Néanmoins, pour
éviter qu'un cookie ne permette à un observateur
de relier deux requêtes d'une même machine, le
cookie doit changer quand l'adresse IP change,
comme rappelé par la section 8.1. (C'est particulièrement important
si on utilise des techniques de protection de la vie privée comme
celle du RFC 8981.)
Voilà, c'est tout parce que ce qui est important dans notre RFC, c'est le cookie serveur (section 4), puisque c'est là qu'on voudrait un cookie identique pour toutes les instances du service. Les éléments utilisés pour le générer sont le cookie du client, l'adresse IP du serveur, quelques métadonnées et un secret (qu'il faudra donc partager au sein du service anycast). Le secret changera, par exemple une fois par mois. Une fois qu'on a tous ces éléments, on va ensuite condenser le tout, ici avec SipHash (cf. J. Aumasson, et D. J. Bernstein, « SipHash: A Fast Short- Input PRF »). (Parmi les critères de choix d'une fonction de condensation, il y a les performances, un serveur DNS actif pouvant avoir à faire ce calcul souvent, pour vérifier les cookies.) Le cookie comprendra un numéro de version, un champ réservé, une estampille temporelle et le condensat. L'algorithme de génération du condensat inclus dans le cookie est donc : Condensat = SipHash-2-4 ( Cookie client | Version | Réservé | Estampille | Client-IP, Secret ), avec :
- Le signe | indique la concaténation.
- Le champ Version vaut actuellement 1 (les futures versions seront dans un registre IANA).
- Le champ Réservé ne comporte pour l'instant que des zéros.
- L'estampille temporelle sert à éviter les attaques par rejeu et permet de donner une durée de validité aux cookies (le RFC recommande une heure, avec cinq minutes de battement pour tenir compte des horloges mal synchronisées).
On a vu qu'il fallait changer le secret connu du serveur de temps en temps (voire plus rapidement s'il est compromis). Pour que ça ne casse pas tout (un serveur ne reconnaissant pas les cookies qu'il avait lui-même émis avec l'ancien secret…), il faut une période de recouvrement où le serveur connait déjà le nouveau secret (et accepte les cookies ainsi générés, par exemple par les autres instances du service anycast), puis une période où le serveur génère les cookies avec le nouveau secret, mais continue à accepter les cookies anciens (par exemple gardés par des clients). La section 5 rappelle, comme on le fait pour les remplacements de clés DNSSEC, de tenir compte des TTL pour calculer les délais nécessaires.
Si vous voulez mettre en œuvre vous-même cet algorithme, notez que l'annexe A du RFC contient des vecteurs de test, permettant de vérifier si vous ne vous êtes pas trompé.
La section 2 de notre RFC décrit les changements depuis le RFC 7873. Les algorithmes données comme simples suggestions dans les annexes A.1 et B.1 sont trop faibles et ne doivent pas être utilisés. Celui de l'annexe B.2 ne pose pas de problèmes de sécurité mais celui de notre nouveau RFC est préféré.
Plusieurs mises en œuvre de ce nouvel algorithme ont été faites, et leur interopérabilité testée (notamment au cours du hackathon de la réunion IETF 104 à Prague). Au moins BIND, Knot et getdns ont déjà cet algorithme dans leurs versions publiées.
L'article seul
Faut-il forcément passer du temps à étudier les techniques qui semblent farfelues ?
Première rédaction de cet article le 29 mars 2021
J'ai vu récemment, mais ce n'était la première fois, une personne se prétendant « inventeur » affirmer que ceux qui riaient de ses prétentions fantaisistes n'avaient pas pris le temps d'examiner son travail et que leurs critiques n'étaient donc pas pertinentes. Le bon sens dit en effet qu'il ne faut pas critiquer sans connaitre, et que connaitre nécessite de passer un peu de temps sur l'objet de la critique. Est-ce que le bon sens a raison ?
Le cas précis auquel je fais allusion concernait la sécurité informatique et l'inventeur prétendait avoir trouvé une solution de sécurité universelle. J'ai rencontré ce cas plusieurs fois en informatique (les participants à l'IETF penseront bien sûr à « IPv10 »). Mais ce serait la même chose avec quelqu'un prétendant avoir trouvé un remède contre toutes les maladies, ou bien une personne affirmant avoir mis au point le mouvement perpétuel. (On trouve même ce syndrome de l'inventeur génial dans les sciences humaines, par exemple les gens annonçant avoir déchiffré le disque de Phaistos.) Dans tous ces cas, face aux première réactions négatives, l'inventeur génial se drape dans sa dignité et dit bien haut que ses opposants n'ont pas lu ses textes, n'ont pas étudié sa machine, et qu'on ne doit donc pas les croire puisqu'ils n'ont même pas fait l'effort minimal de chercher à comprendre.
Ce raisonnement semble s'appuyer sur un principe de base de la science et de la technique : comprendre une invention n'est pas facile, il faut y passer du temps, et, tant qu'on ne l'a pas fait, on doit rester prudent dans ses affirmations. Mais il faut poursuivre plus loin ce raisonnement : c'est justement parce qu'évaluer sérieusement une invention prend du temps qu'on ne peut pas le faire pour chaque type qui annonce à l'univers qu'il a inventé un truc extraordinaire. Toute personne connue dans son domaine voit passer de nombreuses annonces d'inventions géniales, et si elle consacrait à chacune le temps nécessaire pour être absolument sûre de sa vacuité, cette personne n'aurait pas le temps de faire du travail sérieux.
Est-ce injuste ? Peut-être. Mais c'est ainsi. Les journées n'ont que 24 heures et il faut bien dormir de temps en temps. Si vous êtes inventeur, ne croyez pas qu'un·e expert·e du domaine va consacrer gratuitement des heures ou des jours de son temps à analyser patiemment tout ce que vous racontez. Trépigner du pied en enjoignant les expert·es de se pencher sur vos élucubrations ne produira pas de succès.
Mais, alors, une invention disruptive, surprenante, remettant en cause des certitudes n'a aucune chance de percer ? On ne travaillera que sur des choses déjà connues, sans surprise ? Non, évidemment. Mais on sélectionnera. L'expert·e passera du temps sur les propositions dont ielle estime, à première vue, qu'elles offrent des chances sérieuses de ne pas être une perte d'efforts. Pour celles qui sont très surprenantes, inhabituelles, et qui remettent en cause des certitudes, l'expert·e va d'abord utiliser des « signaux d'alarme ». Ce sont des heuristiques (terme prétentieux pour dire qu'elles ne sont pas parfaites, mais quand même utiles). Si vous êtes inventeur génial et que vous voulez augmenter vos chances d'être écouté, ne déclenchez pas ces signaux d'alarme :
- Prétentions délirantes (« Ce mode de communication […] est insaisissable, intraçable, anonyme et totalement sécurisé »). Rappelez-vous que les annonces extraordinaires nécessitent des preuves extraordinaires. Plus vous vous vantez, plus vous aurez du mal à convaincre.
- Applicabilité excessive. Les vraies inventions marchent dans certains cas, résolvent certains problèmes, et pas d'autres. Affirmer que vous allez « stopper les cyberattaques, les demandes de rançons informatiques ou encore les usurpations d'identité » ou « il pourrait aussi s'avérer très utile pour l'armée, puisqu'il s'agit là d'un outil idéal pour transmettre des ordres, des plans » ne contribue pas à votre crédibilité. Au contraire, une preuve de sérieux est quand vous exposez clairement les limites de votre invention (toute technique a des limites).
- Ignorance complète des bases du domaine dans lequel vous prétendez avoir inventé quelque chose. Cette heuristique est d'un usage délicat car, parfois (« parfois » au sens de « une fois sur un zillion »), quelqu'un d'extérieur au domaine fait une percée, en partie justement car ielle n'était pas du domaine et pouvait donc penser « en dehors de la boite ». Mais c'est beaucoup plus rare que le cas où l'inventeur est simplement ignorant des difficultés du domaine. Un exemple est, en cryptographie, quelqu'un qui ne saurait pas ce qu'est une attaque de l'homme du milieu, ou qui ne comprendrait pas la différence entre cryptographie symétrique et asymétrique (« votre correspondant, une fois le message reçu, passe de la même façon sa carte, qui a la même clé de chiffrement que la vôtre »).
- Propos vagues. Annoncer des résultats mirobolants sans donner de détails précis va allumer un signal d'alarme. Prétendre que cette absence de détails est due à votre souci d'éviter que les Chinois vous copient n'arrange rien (voir le point suivant).
- Paranoïa. Un inventeur qui commence par « je suis génial mais le système / les puissants / les GAFA / Framasoft / les polytechniciens / les énarques conspirent pour me faire taire » allume également le plus puissant des signaux d'alarme. (J'en profite pour signaler que se comparer à Galilée n'aide pas. 1) Galilée n'a pas été rejeté par les autres scientifiques mais par les religieux, qui sont toujours opposés à la science 2) pour un Galilée, combien d'escrocs ?)
- Grands mots. Ajouter « blockchain », « quantique » ou « IA » n'ajoute pas de la crédibilité à votre discours, sauf si vous pouvez expliquer en détail ce que ces techniques apportent à votre œuvre.
- La forme compte aussi. Bien sûr, un inventeur génial peut avoir une orthographe catastrophique. Mais un texte bacler PLEIN D'AFFIRMATIONS EN MAJUSCULES et de ponctation !!! eksèssive car votre invantion est GÉNIALE !!! ne va pas vous aider. Respirez et prenez le temps de relire. (Au passage, n'avoir comme documentation que des vidéos convient si vous êtes influenceur beauté, pas si vous prétendez être inventeur.)
Tous les inventeurs ne déclenchent pas la totalité de ces signaux d'alarme. Mais ils en allument en général plusieurs. Comme toutes les heuristiques, elles ne sont pas parfaites. On ne connait pas de mécanisme parfait pour déterminer si une invention est géniale ou débile. Et les expert·es, comme tout le monde, peuvent se tromper. Mais, en raison de la finitude de la journée de travail, on doit utilise ces heuristiques, sinon on ne produirait jamais rien.
L'article seul
RFC 9006: TCP Usage Guidance in the Internet of Things (IoT)
Date de publication du RFC : Mars 2021
Auteur(s) du RFC : C. Gomez (UPC), J. Crowcroft (University of Cambridge), M. Scharf (Hochschule Esslingen)
Pour information
Réalisé dans le cadre du groupe de travail IETF lwig
Première rédaction de cet article le 28 mars 2021
À côté de machines disposant de ressources matérielles suffisantes (électricité, processeur, etc), qui peuvent faire tourner des protocoles comme TCP sans ajustements particuliers, il existe des machines dites contraintes, et des réseaux de machines contraintes, notamment dans le cadre de l'Internet des Objets. Ces machines, pauvres en énergie ou en capacités de calcul, doivent, si elles veulent participer à des communications sur l'Internet, adapter leur usage de TCP. Ce RFC documente les façons de faire du TCP « léger ».
Ces CNN (Constrained-Node Networks, réseaux contenant beaucoup d'objets contraints) sont décrits dans le RFC 7228. On parle bien d'objets contraints, soit en processeur, soit en énergie. Un Raspberry Pi ou une télévision connectée ne sont pas des objets contraints, ils peuvent utiliser les systèmes habituels, avec un TCP normal, au contraire des objets contraints, qui nécessitent des technologies adaptées. Le RFC 8352 explique ainsi les problèmes liés à la consommation électrique de certains protocoles. Des protocoles spéciaux ont été développés pour ces objets contraints, comme 6LoWPAN (RFC 4944, RFC 6282 et RFC 6775) ou comme le RPL du RFC 6550 ou, au niveau applicatif, le CoAP du RFC 7252.
Côté transport, on sait que les principaux protocoles de transport actuels sur l'Internet sont UDP et TCP. TCP a été parfois critiqué comme inadapté à l'Internet des Objets. Ces critiques n'étaient pas forcément justifiées mais il est sûr que le fait que TCP ait des en-têtes plutôt longs, pas de multicast et qu'il impose d'accuser réception de toutes les données peut ne pas être optimal pour ces réseaux d'objets contraints. D'autres reproches pouvaient être traités, comme expliqué dans l'article « TCP in the Internet of Things: from ostracism to prominence ». Notez que CoAP, à l'origine, tournait uniquement sur UDP mais que depuis il existe aussi sur TCP (RFC 8323). Les CNN (Constrained-Node Networks) utilisent parfois d'autres protocoles applicatifs tournant sur TCP comme HTTP/2 (RFC 9113) ou MQTT.
TCP est certes complexe si on veut utiliser toutes les optimisations qui ont été développées au fil du temps. Mais elles ne sont pas nécessaires pour l'interopérabilité. Un TCP minimum peut parfaitement communiquer avec des TCP optimisés, et notre RFC explique comment réduire l'empreinte de TCP, tout en restant évidemment parfaitement compatible avec les TCP existants. (Notez qu'il y avait déjà eu des travaux sur l'adaptation de TCP à certains environnements, voir par exemple le RFC 3481.)
Bon, maintenant, au travail. Quelles sont les propriétés des CNN (RFC 7228) qui posent problème avec TCP (section 2 du RFC) ? Ils manquent d'énergie et il ne peuvent donc pas émettre et recevoir en permanence (RFC 8352), ils manquent de processeur, ce qui limite la complexité des protocoles, et ils utilisent souvent des réseaux physiques qui ont beaucoup de pertes (voire qui corrompent souvent les paquets), pas vraiment les réseaux avec lesquels TCP est le plus à l'aise (RFC 3819).
La communication d'un objet contraint se fait parfois à l'intérieur du CNN, avec un autre objet contraint et parfois avec une machine « normale » sur l'Internet. Les types d'interaction peuvent aller de l'unidirectionnel (un capteur transmet une mesure qu'il a faite), à la requête/réponse en passant par des transferts de fichiers (mise à jour du logiciel de l'objet contraint, par exemple). Voyons maintenant comment TCP peut s'adapter (section 3 du RFC).
D'abord, la MTU. En IPv6, faire des paquets de plus de 1 280 octets, c'est prendre le risque de la fragmentation, qui n'est pas une bonne chose pour des objets contraints en mémoire (RFC 8900), qui n'ont en plus pas très envie de faire de la Path MTU discovery (RFC 8201). Donc, notre RFC conseille d'utiliser la MSS (Maximum Segment Size) de TCP pour limiter la taille des paquets. Attention, les CNN tournent parfois sur des réseaux physiques assez spéciaux, où la MTU est bien inférieure aux 1 280 octets dont IPv6 a besoin (RFC 8200, section 5). Par exemple, IEEE 802.15.4 a une MTU de 127 octets seulement. Dans ce cas, il faut prévoir une couche d'adaptation entre IPv6 et le réseau physique (ce que fait le RFC 4944 pour IEE 802.15.4, le RFC 7668 pour Bluetooth LE, le RFC 8105 pour DECT LE, etc). Heureusement, d'autres technologies de réseau physique utilisées dans le monde des CNN n'ont pas ces limites de MTU, c'est le cas par exemple de Master-Slave/Token-Passing (cf. RFC 8163), IEEE 802.11ah, etc.
Deuxième endroit où on peut optimiser, ECN (RFC 3168). ECN permet aux routeurs intermédiaires de marquer dans un paquet que la congestion est proche ; le destinataire peut alors prévenir l'émetteur de ralentir. Le RFC 8087 décrit les avantages de l'ECN. Permettant de détecter l'approche de la congestion avant qu'on ait perdu un seul paquet (et donc sans qu'on ait à dépenser des watts pour retransmettre), l'ECN est particulièrement intéressant pour les CNN. Le RFC 7567 donne des conseils pratiques pour son déploiement.
Un problème classique de TCP sur les liens radio est que TCP interprète une perte de paquet comme signal de congestion, le poussant à ralentir, alors que cette perte peut en fait être due à la corruption d'un paquet (suite à une perturbation radio-électrique, par exemple). Il serait donc intéressant de pouvoir signaler explicitement ce genre de perte (la question était déjà discutée dans le RFC 2757 mais aussi dans l'article « Explicit Transport Error Notification (ETEN) for Error-Prone Wireless and Satellite Networks »). Pour l'instant, il n'existe aucun mécanisme standard pour cela, ce qui est bien dommage.
Pour faire tourner TCP sur une machine contrainte, une technique parfois utilisée est de n'envoyer qu'un segment à la fois (et donc d'annoncer une fenêtre dont la taille est d'un MSS - Maximum Segment Size). Dans ce cas, pas besoin de mémoriser plus qu'un segment de données envoyé mais dont l'accusé de réception n'a pas encore été reçu. C'est très économique, mais ça se paie cher en performances puisqu'il faut attendre l'accusé de réception de chaque segment avant d'en envoyer un autre. La capacité effective du lien va chuter, d'autant plus que certaines optimisations de TCP comme le fast recovery dépendent d'une fenêtre plus grande qu'un seul segment. Au niveau applicatif, on voit la même technique avec CoAP, qui est par défaut purement requête/réponse.
Si on veut faire du TCP « un seul segment », le code peut être
simplifié, ce qui permet de gagner encore en octets, mais notre RFC
rappelle quand même que des options comme MSS (évidemment),
NoOp et EndOfOptions
restent nécessaires. En revanche, on peut réduire le code en ne
gérant pas les autres options comme
WindowScaling (RFC 7323),
Timestamps (RFC 7323) ou
SACK (RFC 2018). TCP a le droit d'ignorer ces options, qui,
en « un seul segment » sont parfois inutiles
(WindowScaling, SACK) et parfois moins
importantes (Timestamps). En tout cas, si la
machine a assez de mémoire, il est sûr que transmettre plusieurs
segments avant d'avoir eu l'accusé de réception du premier, et
utiliser des algorithmes comme le fast recovery
améliore certainement les performances. Même chose pour les accusés
de réception sélectifs, les SACK du RFC 2018.
La détermination du RTO (Retransmission TimeOut) est un des points cruciaux de TCP (RFC 6298). S'il est trop long, on attendra longtemps la retransmission, quand un paquet est perdu, s'il est trop court, on ré-émettra parfois pour rien, gâchant des ressources alors que le paquet était juste en retard. Bref, une mise en œuvre de TCP pour les CNN doit soigner ses algorithmes de choix du RTO (cf. RFC 8961).
Continuons avec des conseils sur TCP dans les réseaux d'objets contraints. Notre RFC rappelle que les accusés de réception retardés, utiles pour accuser réception d'une plus grande quantité de données et ainsi diminuer le nombre de ces accusés, peuvent améliorer les performances… ou pas. Cela dépend du type de trafic. Si, par exemple, le trafic est surtout dans une direction, avec des messages courts (ce sera typiquement le cas avec CoAP), retarder les accusés de réception n'est sans doute pas une bonne idée.
Les paramètres par défaut de TCP sont parfois inadaptés aux CNN. Ainsi, le RFC 5681 recommande une taille de fenêtre initiale d'environ quatre kilo-octets. Le RFC 6298 fait des recommandations qui peuvent aboutir à des tailles de fenêtre initiale encore plus grandes. C'est très bien pour un PC connecté via la fibre mais pas pour la plupart des objets contraints, qui demandent des paramètres adaptés. Bref, il ne faut pas lire le RFC 6298 trop littéralement, car il faut en général une taille de fenêtre initiale plus petite.
Il n'y a pas que TCP lui-même, il y a aussi les applications qui l'utilisent. C'est l'objet de la section 4 du RFC. En général, si un objet contraint communique avec un non-contraint, c'est le premier qui initie la connexion (cela lui permet de dormir, et donc d'économiser l'énergie, s'il n'a rien à dire). L'objet contraint a tout intérêt à minimiser le nombre de connexions TCP, pour économiser la mémoire. Certes, cela crée des problèmes de head-of-line blocking (une opération un peu lente bloque les opérations ultérieures qui passent sur la même connexion TCP) mais cela vaut souvent la peine.
Et combien de temps garder la connexion TCP ouverte ? Tant qu'on a des choses à dire, c'est évident, on continue. Mais lorsqu'on n'a plus rien à dire, l'application doit-elle fermer les connexions, qui consomment de la mémoire, sachant que rouvrir la connexion prendra du temps et des ressources (la triple poignée de mains…). C'est un peu le problème de l'automobiliste arrêté qui se demande s'il doit couper son moteur. S'il faut redémarrer tout de suite, il consommera davantage de carburant. D'un autre côté, s'il laisse son moteur tourner, ce sera également un gaspillage. Le problème est soluble si l'application sait exactement quand elle aura à nouveau besoin d'émettre, ou si l'automobiliste sait exactement combien de temps durera l'arrêt mais, en pratique, on ne le sait pas toujours. (Ceci dit, pour l'automobile, le système d'arrêt-démarrage automatique dispense désormais le conducteur du choix.)
Une autre raison pour laquelle il faut être prudent avec les connexions TCP inactives est le NAT. Si un routeur NAT estime que la connexion est finie, il va retirer de ses tables la correspondance entre l'adresse IP interne et l'externe et, lorsqu'on voudra recommencer à transmettre des paquets, ils seront perdus. Le RFC 5382 donne des durées minimales avant ce retrait (deux heures…) mais elles ne sont pas forcément respectées par les routeurs NAT. Ainsi, l'étude « An Experimental Study of Home Gateway Characteristics » trouve que la moitié des boitiers testés ne respectent pas la recommandation du RFC 5382, avec des délais parfois aussi courts que quelques minutes ! Une des façons d'empêcher ces coupures est d'utiliser le mécanisme keep-alive de TCP (RFC 1122, section 4.2.3.6), qui envoie régulièrement des paquets dont le seul but est d'empêcher le routeur NAT d'oublier la connexion. Une autre est d'avoir des « battements de cœur » réguliers dans les applications, comme le permet CoAP (RFC 8323). Et, si on coupe rapidement les connexions TCP inutilisées, avant qu'une stupide middlebox ne le fasse, comment reprendre rapidement ensuite, si le trafic repart ? TCP Fast open (RFC 7413) est une solution possible.
Enfin, la sécurité pose des problèmes particuliers dans les CNN, où les ressources de certaines machines peuvent être insuffisantes pour certaines solutions de sécurité. Ainsi, pour TCP, la solution d'authentification AO (RFC 5925) augmente la taille des paquets et nécessite des calculs supplémentaires.
Il existe un certain nombre de mises en œuvre de TCP qui visent les objets contraints mentionnés dans ce RFC. Une machine 32 bits alimentée en courant en permanence, comme un vieux Raspberry Pi, n'est pas concernée, elle fait tourner le TCP habituel de Linux. On parle ici de TCP pour objets vraiment contraints. C'est par exemple (annexe A du RFC) le cas de :
- uIP, qui vise les microcontrôleurs à 8 et 16 bits. Elle est utilisée dans Contiki et sur la carte d'extension Ethernet (shield) pour Arduino. En 5 ko, elle réussit à faire IP (dont IPv6 dans les dernières versions) et TCP. Elle fait partie de celles qui utilisent le « un segment à la fois », ce qui évite les calculs de fenêtres (qui nécessitent des calculs sur 32 bits, qui seraient lents sur ces processeurs). Et c'est à l'application de se souvenir de ce qu'elle a envoyé, TCP ne le fait pas pour elle. L'utiliser est donc difficile pour le programmeur.
- lwIP, qui vise le même genre de processeurs, mais dont l'empreinte mémoire est supérieure (entre 14 et 22 ko). Il faut dire qu'elle n'est pas limitée à envoyer un segment à la fois et que TCP mémorise les données envoyées, déchargeant l'application de ce travail. Et elle dispose de nombreuses optimisations comme SACK.
- RIOT a sa propre mise en œuvre de TCP, nommée GNRC TCP. Elle vise aussi les engins de classe 1 (cf. RFC 7228 pour cette terminologie). Elle est de type « un segment à la fois » mais c'est TCP, et pas l'application, qui se charge de mémoriser les données envoyées (et qu'il faudra peut-être retransmettre). Par défaut, une application ne peut avoir qu'une seule connexion et il faut recompiler si on veut changer cela. Par contre, RIOT dispose d'une interface sockets, familière à beaucoup de programmeurs.
- freeRTOS a aussi un TCP, pouvant envoyer plusieurs segments (mais une option à un seul segment est possible, pour économiser la mémoire). Il a même les accusés de réception retardés.
- uC/OS peut également faire du TCP avec plusieurs segments en vol.
Un tableau comparatif en annexe A.7 résume les principales propriétés de ces différentes mises en œuvre de TCP sur objets contraints.
L'article seul
RFC 8997: Deprecation of TLS 1.1 for Email Submission and Access
Date de publication du RFC : Mars 2021
Auteur(s) du RFC : L. Velvindron (cyberstorm.mu), S. Farrell (Trinity College Dublin)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF uta
Première rédaction de cet article le 24 mars 2021
Dans le cadre général de l'abandon des versions 1.0 et 1.1 du protocole TLS (cf. RFC 8996), ce RFC déclare que ces vieilles versions ne doivent plus être utilisées pour le courrier (mettant ainsi à jour le RFC 8314).
Ce RFC 8314 spécifiait l'usage de TLS pour la soumission et la récupération de courrier. Sa section 4.1 imposait une version minimale de TLS, la 1.1. Cette 1.1 étant officiellement abandonnée pour obsolescence dans le RFC 8996, la version minimale est maintenant la 1.2. C'est tout, ce RFC est simple et court.
L'article seul
RFC 8996: Deprecating TLSv1.0 and TLSv1.1
Date de publication du RFC : Mars 2021
Auteur(s) du RFC : K. Moriarty (Dell EMC), S. Farrell (Trinity College Dublin)
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 24 mars 2021
Dernière mise à jour le 25 mars 2021
Ce RFC est très court, car il s'agit juste de formaliser une évidence : les versions 1.0 et 1.1 du protocole de cryptographie TLS ne devraient plus être utilisées, elles souffrent de diverses failles, notamment de sécurité. Les seules versions de TLS à utiliser sont la 1.2 (recommandée depuis 2008 !) et la 1.3 (publiée en 2018). Ainsi, une bibliothèque TLS pourra retirer tout le code correspondant à ces versions abandonnées, ce qui diminuera les risques (moins de code, moins de bogues).
Que reproche-t-on exactement à ces vieux protocoles (section 1 du RFC) ?
- Ils utilisent des algorithmes de cryptographie dépassés et dangereux, par exemple TLS 1.0 impose de gérer Triple DES, et SHA-1 est utilisé à plusieurs endroits. Un des points les plus problématiques à propos des vieilles versions de TLS est en effet leur dépendance vis-à-vis de cet algorithme de condensation SHA-1. Celui-ci est connu comme vulnérable.
- Ils ne permettent pas d'utiliser les algorithmes modernes, notamment le chiffrement intègre.
- Indépendamment des défauts de ces vieux protocoles, le seul fait d'avoir quatre versions à gérer augmente les risques d'erreur, pouvant mener à des attaques par repli.
- Des développeurs de bibliothèques TLS ont manifesté leur souhait de retirer les vieilles versions de TLS, ce qui implique leur abandon officiel par l'IETF.
- Pour davantage de détails sur les faiblesses reprochées aux vieilles versions de TLS, regardez le rapport SP800-52r2 du NIST ou bien le RFC 7457. S'il existe bien des contournements connus pour certaines de ces vulnérabilités, il est quand même plus simple et plus sûr d'abandonner ces anciennes versions 1.0 et 1.1.
Désormais, la programmeuse ou le programmeur qui veut faire mincir son code en retirant TLS 1.0 et 1.1 peut, si des utilisateurs contestent, s'appuyer sur cette décision de l'IETF. Désormais, la règle est simple : le client ne doit pas proposer TLS 1.0 et 1.1, et s'il le fait le serveur ne doit pas l'accepter. Cela concerne de nombreux RFC, qui mentionnaient 1.0 et 1.1, et tous n'ont pas encore été mis à jour. Ainsi, le RFC 7562 est toujours d'actualité, simplement la mention qu'il fait de TLS 1.1 est réputée supprimée. De même, le RFC 7525, qui résume les bonnes pratiques d'utilisation de TLS doit désormais se lire en oubliant les quelques endroits où il cite encore TLS 1.1. D'autres RFC avaient déjà été abandonnés, comme par exemple le RFC 5101.
Donc, pour résumer les points pratiques de ce RFC (sections 4 et 5) :
- N'utilisez pas TLS 1.0. Le client TLS ne doit pas le
proposer dans son
ClientHello, le serveur TLS ne doit jamais l'accepter. - N'utilisez pas TLS 1.1. Le client TLS
ne doit pas le proposer dans son
ClientHello, le serveur TLS ne doit jamais l'accepter.
Si vous êtes programmeu·r·se, virez le code de TLS 1.0 et 1.1 de vos logiciels. (OpenSSL a prévu de le faire en 2022.) Notez que certains protocoles récents comme Gemini ou DoH (RFC 8484) imposaient déjà TLS 1.2 au minimum.
Comme le note la section 7 du RFC, suivre les recommandations de
sécurité exposées ici va affecter l'interopérabilité : on ne pourra
plus communiquer avec les vieilles machines. J'ai à la maison une
vieille tablette pour laquelle le
constructeur ne propose pas de mise à jour logicielle et qui,
limitée à TLS 1.0, ne peut d'ores et déjà plus se connecter à
beaucoup de sites Web en HTTPS. L'obsolescence
programmée en raison de la sécurité… Plus grave, des
organisations peuvent être coincées avec une vieille version de TLS
sur des équipements, par exemple de contrôle industriel, qu'on ne
peut pas mettre à jour. (Lors des discussions à l'IETF sur ce RFC,
des personnes avaient suggéré d'attendre que le niveau d'utilisation
de TLS 1.0 et 1.1 tombe en dessous d'une certaine valeur, avant
d'abandonner officiellement ces protocoles. L'IETF a finalement
choisi une approche plus volontariste. Mais pensez aux
établissements comme les hôpitaux, avec tous les systèmes contrôlés
par des vieux PC pas mettables à jour.) Comme toujours en sécurité,
il n'y a pas de solution parfaite, uniquement des compromis. Le site de test TLS https://www.ssllabs.com/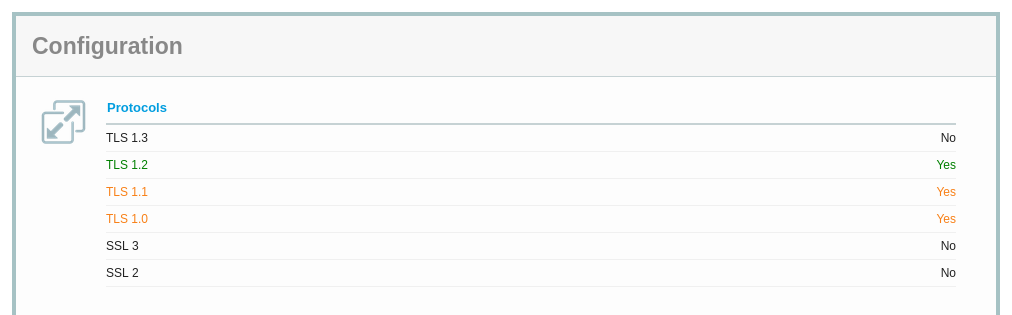
Au contraire, voici ce qu'affiche un
Firefox récent
quand on essaie de se connecter à un vieux site Web qui n'accepte
toujours pas TLS 1.2 : 
À noter que DTLS 1.0 (RFC 4347) est également abandonné. Cela laisse DTLS 1.2, le 1.1 n'ayant jamais été normalisé, et le 1.3 n'étant pas prêt à l'époque (il a depuis été publié dans le RFC 9147).
Les RFC 2246 (TLS 1.0) et RFC 4346 (TLS 1.1) ont été officiellement reclassifiés comme n'ayant plus qu'un intérêt historique. Le RFC 7507 est également déclassé, le mécanisme qu'il décrit n'étant utile qu'avec TLS 1.0 et 1.1.
L'article seul
RFC 9007: Handling Message Disposition Notification with the JSON Meta Application Protocol (JMAP)
Date de publication du RFC : Mars 2021
Auteur(s) du RFC : R. Ouazana (Linagora)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF jmap
Première rédaction de cet article le 23 mars 2021
Les avis de remise d'un message (MDN, Message Disposition Notification) sont normalisés dans le RFC 8098. Ce nouveau RFC normalise la façon de les gérer depuis le protocole d'accès au courrier JMAP (qui est, lui, dans les RFC 8620 et RFC 8621).
Un petit rappel sur JMAP : c'est un protocole générique pour accéder à des données distantes, qu'elles concernent la gestion d'un agenda ou celle du courrier. Il est normalisé dans le RFC 8620. Une extension spécifique, JMAP for Mail, décrit comment l'utiliser pour le cas du courrier (rôle pour lequel JMAP concurrence IMAP).
Quant à MDN (Message Disposition
Notifications), c'est un format qui décrit des accusés de
réception du courrier. Il a été spécifié dans le RFC 8098. Un MDN est un message structuré (en MIME, avec
une partie de type
message/disposition-notification) qui indique
ce qui est arrivé au message. On peut donc envoyer un MDN en
réponse à un message (c'est un accusé de réception, ou avis de
remise), on peut demander l'envoi d'un tel MDN lorsqu'on envoie un
message, on peut recevoir des MDN et vouloir les analyser, par
exemple pour les mettre en rapport avec un message qu'on a
envoyé.
Avant de manier les MDN, il faut les modéliser (section 2). Comme tout en JMAP, un MDN est un objet JSON comprenant entre autres les membres :
forEmailId: l'identifiant JMAP du message auquel se réfère ce MDN,originalMessageId, le Message ID du message auquel se réfère ce MDN, à ne pas confondre avec l'identifiant JMAP,includeOriginalMessage, qui indique qu'un envoyeur souhaite recevoir le message original dans les éventuels MDN,disposition: voir le RFC 8098, section 3.2.6, pour cette notion. Elle indique ce qui est arrivé au message, et les conditions dans lesquelles l'action d'émission du MDN a été prise, par exemple automatiquement, ou bien par une action explicite de l'utilisateur.
L'objet JSON MDN sert à modéliser les MDN reçus mais aussi les options envoyées, comme la demande de génération de MDN par le receveur.
Pour envoyer un MDN, notre RFC introduit une nouvelle
méthode JMAP, MDN/send. Pour analyser un MDN
entrant, la méthode se nomme MDN/parse. Voici
un exemple de MDN JMAP :
[[ "MDN/send", {
...
"send": {
...
"forEmailId": "Md45b47b4877521042cec0938",
"subject": "Read receipt for: World domination",
"textBody": "This receipt shows that the email has been
displayed on your recipient's computer. There is no
guaranty it has been read or understood.",
"reportingUA": "joes-pc.cs.example.com; Foomail 97.1",
"disposition": {
"actionMode": "manual-action",
"sendingMode": "mdn-sent-manually",
"type": "displayed"
},
...
On y voit l'identifiant du message concerné, et l'action qui a été entreprise : le destinataire a activé manuellement l'envoi du message, après avoir vu ledit message.
Et pour demander l'envoi d'un MDN lorsqu'on crée un message ?
C'est la méthode Email/set du RFC 8621 qui permet de créer le message. On doit juste ajouter
l'en-tête Disposition-Notification-To: du RFC 8098 :
[[ "Email/set", {
"accountId": "ue150411c",
"create": {
...
"header:Disposition-Notification-To:asText": "joe@example.com",
"subject": "World domination",
...
Comme un serveur JMAP annonce ses capacités lors de la connexion
(RFC 8620, section 2), notre RFC ajoute une
nouvelle capacité, urn:ietf:params:jmap:mdn, ce
qui permet à un serveur de dire qu'il sait gérer les MDN. Elle est
enregistrée
à l'IANA.
Question mise en œuvre de JMAP qui gère les MDN, il y a le serveur Cyrus, voir ce code, et aussi Apache James.
Merci à Raphaël Ouazana pour sa relecture.
L'article seul
Fiche de lecture : La fabuleuse histoire de l'invention de l'écriture
Auteur(s) du livre : Silvia Ferrara
Éditeur : Seuil
978-2-02-146412-2
Publié en 2021
Première rédaction de cet article le 22 mars 2021
L'écriture est un sujet passionnant, sur lequel beaucoup a déjà été écrit. Un livre de plus sur cette géniale invention et ses débuts ? Pas tout à fait, ce livre n'est pas un cours, ou un livre de vulgarisation, c'est une suite de réflexions de l'auteure sur la façon dont l'écriture a (peut-être) été inventée et sur le travail de ceux et celles qui essaient de jeter quelques lumières sur ce processus d'invention.
Comme vous le savez, il y a quatre (ou cinq ? ou six ? ou seulement trois ?) inventions indépendantes de l'écriture, en Égypte, en Mésopotamie, en Chine et en Méso-Amérique. Le processus est donc, sinon courant, du moins pas exceptionnel, et rentre donc tout à fait dans les capacités humaines. Mais comment en est-on arrivé là ? Quelles ont été les prémisses ? Typiquement, on part de petits dessins, puis on les abstrait de plus en plus et on finit par avoir une écriture. (Le cas de l'écriture chinoise est plus compliqué car on n'a pas retrouvé les étapes préalables.) L'excellent dessin p. 224 nous donne une idée de comment ça a pu se passer. Le processus étant continu, il est parfois difficile de dire à partir de quand on a affaire à une « vraie » écriture. C'est d'ailleurs un des obstacles qui se posent aux déchiffreurs d'écritures inconnues : cet ensemble d'émojis est-il une vraie écriture ? L'aveuglement des déchiffreurs, leur tendance à s'illusionner, peut les aider ou les freiner (comme dans le cas de l'écriture maya, longtemps tenue, à tort, pour « juste des dessins »).
L'auteure nous fait voyager, au rythme de sa fantaisie, de la Crète (sa spécialité scientifique) à l'île de Pâques en passant par le Mexique. Vous y trouverez les écritures inconnues les plus célèbres (le linéaire A ou l'IVS) et les Mystères Mystérieux comme évidemment le disque de Phaistos. L'auteure suggère d'ailleurs de ne pas passer trop de temps sur ce disque : vu le nombre réduit de caractères, elle estime qu'il n'y a aucune chance qu'on le déchiffre un jour. (Au fait, si vous voulez vous informer sur toutes les écritures connues, je vous recommande « The World's Writing Systems ».)
Mais la partie la plus intéressante concerne l'évolution des écritures, les mécanismes à l'œuvre, les tendances, les « lois » de l'évolution. Si certaines écritures sont très stables (à part à leur origine), d'autres ont changé, ont grandi, parfois ont disparu.
De même que M. Bidouille reçoit régulièrement des messages de gens qui ont découvert le mouvement perpétuel, de même que les chercheurs en réseaux informatiques sont agacés par les personnes qui ont trouvé la FUSSP, la solution au problème du spam, les chercheuses et chercheurs en écritures anciennes ont des lettres annonçant le déchiffrement du chypro-minoen ou celui du manuscrit de Voynich. L'auteure leur donne (p. 251) dix conseils très instructifs si vous voulez mieux comprendre comment s'analysent les écritures. Et le dixième conseil est « ne m'écrivez pas » (la quasi-totalité de ces annonces sont bidon).
L'article seul
Fiche de lecture : How the Internet really works
Auteur(s) du livre : Article 19, Catnip
Éditeur : No Starch Press
978-1-7185-0029-7
Publié en 2021
Première rédaction de cet article le 21 mars 2021
Dernière mise à jour le 19 août 2022
L'Internet, c'est important, toute notre vie et nos activités s'y passent, mais c'est compliqué. Tout le monde ne comprend pas comment ça marche. En fait, même les professionnels de l'informatique ne savent pas forcément. C'est ennuyeux car cette ignorance laisse les acteurs dominants dicter les règles et faire ce qu'ils veulent. Il serait préférable que les citoyen·nes puissent accéder à un minimum de compréhension de fonctionnement du réseau. C'est ce que propose ce livre.
D'abord, un point important : contrairement à la grande majorité des reportages, documentaires, livres, articles prétendant expliquer le fonctionnement de l'Internet, celui-ci est écrit par des gens qui connaissent et savent de quoi ils parlent. (Notez que deux des auteurs, Niels ten Oever et Corinne Cath, sont les auteurs du RFC 8280). Vous n'y trouverez pas d'erreur technique (ou pas beaucoup), d'explication bâclée ou de raccourcis journalistiques, genre « l'ICANN est le régulateur mondial d'Internet ».
Mais être correct ne suffit pas, il faut encore pouvoir expliquer des concepts complexes et un réseau dont le moins qu'on puisse dire est qu'il n'est pas évident à assimiler. Les auteur·es ont beaucoup travaillé l'aspect pédagogique. (Et, oui, il y a des dessins, et c'est un chat qui explique.) Le livre est relativement court, mais complet, et présente bien le sujet. Il sera très utile à tous les gens qui font de l'EMI, de la formation à la littératie numérique et autres activités d'éducation. Le livre couvre IP, TCP, DNS, BGP, HTTP, mais aussi le chiffrement, les points d'échange, l'allocation d'adresses IP, etc.
Je l'ai dit, les auteur·es sont impliqué·es dans les activités politiques de l'Internet (ce qu'on nomme « gouvernance de l'Internet », mais, bon, c'est juste de la politique sous un nouveau nom). Le livre insiste donc sur les aspects qui touchent aux droits humains fondamentaux comme le droit à la vie privée, la lutte contre la censure, et bien sûr les mécanismes de décision dans l'Internet : qui fait les choix ?
Sur cette question du pouvoir, le livre décrit également le fonctionnement d'organismes qui contribuent à façonner l'Internet tel qu'il est (comme l'IETF) et encourage la participation de tous et toutes à ces organismes, pour faire bouger les choses dans le bon sens.
Notez qu'il existe désormais une traduction en français, « Connaissez-vous vraiment Internet ? », qui est de bonne qualité.
L'article seul
Deux mots sur les NFT
Première rédaction de cet article le 13 mars 2021
Je suis la mode, tout le monde parle des NFT donc je m'y mets aussi. Comment ça marche et ça sert à quoi ?
L'idée de base s'inspire de l'humoriste Alphonse Allais. Un de ses personnages a déposé un brevet pour « enlever au caoutchouc cette élasticité qui le fait impropre à tant d'usages. Au besoin, il le rend fragile comme du verre. ». Les données numériques ont la propriété de pouvoir être copiées à un coût très bas, diffusées largement (grâce à l'Internet) et sans priver le détenteur originel de ces données. Les NFT visent à supprimer cette propriété et à faire des données numériques uniques et non copiables. Pourquoi donc, à part pour rendre hommage à Alphonse Allais ? Parce que cette rareté artificiellement créée permet de mettre en place un marché d'objets uniques, donc chers.
L'idée est que cela permettra des ventes d'objets numériques, ce qui intéresse particulièrement le marché de l'art. Ainsi, il y a deux jours, une vente d'une œuvre d'art (ou plutôt d'un NFT) a rapporté des millions d'euros. Mais l'idée est relativement ancienne, les premiers NFT populaires ayant été les CryptoKitties.
Mais comment peut-on transformer un fichier numérique en un truc unique et non copiable ? Je vous le dis tout de suite, on ne peut pas. C'est en fait le NFT dont on peut « prouver » le propriétaire (et l'unicité), pas l'œuvre d'art elle-même. Descendons un peu dans la technique. Fondamentalement, un NFT (Non-Fungible Token) est un certificat numérique, rassemblant un condensat cryptographique de l'œuvre d'art et une signature par une place de marché. Ce certificat est ensuite placé sur une chaîne de blocs (en général Ethereum) où un contrat automatique permettra de gérer les transactions sur ce certificat, et donc de déterminer de manière fiable le propriétaire. Sur cette idée de base, on peut ajouter diverses améliorations, comme le versement automatique d'un pourcentage des ventes successives au créateur de l'œuvre.
On le voit, le NFT est une idée simple mais qui ne garantit pas grand'chose : si la place de marché est sérieuse, et que le contrat automatique est correct, le NFT garantit uniquement :
- que la place de marché a certifié l'œuvre d'art,
- qu'il n'y a à un moment donné, qu'un seul propriétaire (la traçabilité est le point fort des chaînes de blocs).
C'est tout. Les places de marché peuvent générer n'importe quel NFT (il faut leur faire une confiance aveugle), le fichier original peut toujours être copié. Le cours d'un NFT, comme celui de toute monnaie ou bien, dépend uniquement de la valeur qu'on lui accorde. Comme l'argent, le NFT est « une illusion partagée ».
Pour les technicien·ne·s, fabriquons un NFT pour voir. Je prends une image de chat. Elle n'est pas de moi mais cela n'est pas un problème. Calculons un condensat cryptographique avec SHA-256 :
{kind=link}
% sha256sum Cat_November_2010-1a.jpg 59ec9bf12a5b63e0913e986b9566b96228c9f8921fda4fb87bf2a7f9acff3dd2 Cat_November_2010-1a.jpg
Puis ajoutons quelques métadonnées et signons le tout en OpenPGP (RFC 9580) :
% gpg --sign --armor > Cat_November_2010-1a.asc gpg: using "CCC66677" as default secret key for signing Je soussigné, Stéphane Bortzmeyer, certifie que cette image représente un chat. https://commons.wikimedia.org/wiki/File:Cat_November_2010-1a.jpg 59ec9bf12a5b63e0913e986b9566b96228c9f8921fda4fb87bf2a7f9acff3dd2 Cat_November_2010-1a.jpg
Le fichier Cat_November_2010-1a.asc va alors
contenir une signature, vérifiable :
% gpg --decrypt Cat_November_2010-1a.asc Je soussigné, Stéphane Bortzmeyer, certifie que cette image représente un chat. https://commons.wikimedia.org/wiki/File:Cat_November_2010-1a.jpg 59ec9bf12a5b63e0913e986b9566b96228c9f8921fda4fb87bf2a7f9acff3dd2 Cat_November_2010-1a.jpg gpg: Signature made Sat Mar 13 13:10:27 2021 CET gpg: using RSA key C760CAFC6387B0E8886C823B3FA836C996A4A254 gpg: Good signature from "Stéphane Bortzmeyer (Main key) <stephane@bortzmeyer.org>" [unknown] ...
En fait, vu la façon dont fonctionnent les signatures OpenPGP, j'aurais pu me passer de l'étape du calcul du condensat. C'était juste pour illustrer le principe des NFT.
Bref, un NFT est un pointeur vers l'œuvre, pas l'œuvre. Contrairement à l'adage bien connu, avec les NFT, quand on montre la lune, il faut regarder le doigt. Et j'emprunte à Framasky une blague de programmeur :
/* À vendre, pointeur, peu servi */ char *my_nft;
Du fait que le NFT n'est qu'un pointeur, il faut penser à stocker
l'œuvre originale proprement (avec sauvegardes). Voici un dessin
publié dans Charlie Hebdo qui illustre bien la question : 
Et un autre dessin, trouvé
sur Twitter : 
Il reste bien sûr à tout mettre sur une chaîne de blocs, sous le contrôle d'un contrat automatique qui se chargera entre autres des achats successifs. Je n'ai rien publié, pour éviter de payer des frais. (Prudence si vous entendez que les NFT permettront aux artistes de gagner enfin de l'argent. La seule certitude, avec les NFT, c'est que l'artiste va payer pour publier le NFT. Son NFT sera-t-il acheté ? Il n'y a évidemment aucune certitude. Tout le monde n'est pas Grimes ou Jack Dorsey.) Si j'avais publié les métadonnées signées plus haut, cela aurait été un vrai NFT. Je vous en aurais bien montré un vrai, mais la plupart des places de marché, tout en se réclamant bien fort de la « blockchain » ne font pas preuve de transparence et ne donnent pas beaucoup de détails sur, par exemple, l'adresse dans la chaîne où se trouve le NFT.
Notez qu'il n'existe pas
de normes sur les NFT, chaque place de marché a la sienne. Tout au
plus existe-t-il des normes sur l'interface des NFT (et d'autres
jetons), comme ERC-721, qui
standardise des opérations communes à tous les NFT, comme
ownerOf (renvoie le propriétaire actuel) ou
Transfer (vente par le propriétaire).
Il est tout à fait mensonger, comme on le lit souvent, de prétendre que le NFT garantit « l’authenticité ». N'importe qui, pas seulement l'auteur de l'œuvre, peut générer un NFT, et cela s'est déjà produit sans l'autorisation de l'auteur. (Pour celles et ceux qui ne connaissent pas, David Revoy est l'auteur de Pepper & Carrot, et il désapprouve ces pratiques.)
Quelle confiance faire à un NFT ? Pour la première étape, la génération du NFT, il faut faire confiance à la place de marché. Pour la seconde, les opérations de vente et de revente successives, on a les garanties qu'offre la chaine de blocs et le contrat automatique.
Est-ce une escroquerie ? S'il y a des prétentions malhonnêtes (comme l'authenticité de l'œuvre) dans le discours marketing sur les NFT, d'un autre côté, on peut dire que vendre du virtuel n'a rien de mal en soi, cela se fait tout le temps, entre autre dans le marché de l'art, qui est souvent du grand n'importe quoi (mon projet actuel est de laisser un fromage dehors, d'attendre qu'il se couvre de moisissure et de le vendre ensuite comme œuvre d'art). Si des gens achètent, et sont bien informés et conscients de ce qu'ils achètent, pourquoi pas ?
Quelques lectures en plus :
- Une bonnes synthèse en anglais sur Slate et une autre sur le même média,
- Un article de réflexion en français,
- Un artiste raconte son expérience dans le monde des NFT (il a dépensé 80 $ pour publier, l'acheteur a dépensé 20, et l'artiste a touché… 1 $),
- Une intéressante comparaison des NFT avec les DRM, une autre tentative de priver les utilisateurs des bénéfices du numérique et notamment de la copie facile et bon marché,
- Sur l'histoire d'Ethereum, je vous recommande le livre de Camila Russo ; à Pas Sage En Seine, j'avais expliqué comment faire un contrat automatique sur Ethereum (mais la technique a évolué depuis) ; j'ai fait plusieurs autres articles sur Ethereum.
- J'ai également parlé des NFT à Parinux. Il y en a une vidéo et les supports sont en ligne. Une excellente transcription de ma conférence a été faite par l'APRIL (version finale ici).
L'article seul
Un exemple de nom de domaine inhabituel (IDN et émojis)
Première rédaction de cet article le 12 mars 2021
C'est vendredi, bientôt le week-end, détendons-nous avec un nom de domaine rigolo, 📪.ws. Oui,
vous avez déjà vu des noms de domaines avec des
émojis. Mais celui-ci a une
particularité.
Un petit retour en arrière s'impose. D'abord, contrairement à une légende répandue, le DNS, le protocole qui résout les noms de domaine en informations concrètes, ce protocole n'est pas limité à l'ASCII, encore moins au sous-ensemble LDH (Letters-Digits-Hyphen) d'ASCII. On peut mettre n'importe quel octet dans un nom de domaine. Toutefois, le faire peut entrainer des surprises, parce qu'il n'existe pas d'encodage standard (si le DNS était créé aujourd'hui, UTF-8 serait l'encodage standard mais, à l'époque, ce n'était pas aussi clair) et surtout parce qu'il n'y a pas de règles de canonicalisation (depuis, le RFC 5198 fournirait certainement une solution mais, là encore, c'est trop tard). Et, surtout, pas mal d'applications (mais, répétons-le, pas le DNS lui-même) seraient surprises de recevoir des noms qui ne sont pas en ASCII. C'est pour ces raisons (que j'ai détaillées dans un autre article) que, si on veut de l'Unicode dans les noms de domaine (que l'on nommera alors IDN), on doit utiliser la norme décrite dans les RFC 5890 et suivants. Cette norme impose notamment :
- Une restriction des caractères autorisés, décrite dans le RFC 5892, en gros les lettres (toutes les lettres, pas uniquement celles d'ASCII), les chiffres et le tiret. Les symboles comme &, $ ou les émojis ne sont pas autorisés.
- Un encodage standard, Punycode,
normalisé dans le RFC 3492. C'est ainsi que
gémeaux.bortzmeyer.orgse retrouve encodé enxn--gmeaux-bva.bortzmeyer.orgetதளம்.பாராளுமன்றம்.இலங்கைest encodéxn--rlcuo9h.xn--wlcbmbhil0gb5a8kc.xn--xkc2al3hye2a.
Mais il y a les normes techniques (les RFC) et il y a la réalité. Il n'existe pas de
police de l'Internet qui ferait régner l'ordre normatif et
fusillerait les contrevenants qui violent les normes techniques. Si
l'ICANN impose ce respect des normes dans les
TLD qu'elle
contrôle, ce n'est pas le cas dans les autres TLD. Donc, on voit des
TLD (comme .ws)
autoriser des noms théoriquement invalides comme i❤️tacos.ws.
Mais revenons à notre 📪.ws. Si nous
essayons de résoudre ce nom en adresse
IP avec l'outil dig (il faut une version compilée avec la
gestion des IDN) :
% dig A 📪.ws dig: 'xn--gu8h.ws.' is not a legal IDNA2008 name (string contains a disallowed character), use +noidnout
dig a protesté, et à juste titre, la norme (IDNA2008 : norme
IDN in Applications, version 2008, c'est celle du
RFC 5890) ne permettant pas les émojis. Comme
dig nous le suggère, essayons avec l'option
+noidnout qui lui dit de ne pas afficher
d'Unicode en sortie :
% dig +noidnout A 📪.ws ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 10659 ;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 1 ... ;; QUESTION SECTION: ;xn--gu8h.ws. IN A
Cette fois, on a une réponse (status: NOERROR) mais pas de données (ANSWER: 0). C'est parce que dig, comme il l'affiche dans sa répétition de la question, a converti en Punycode, comme dicté par la norme, et qu'il n'y avait pas de données pour le nom en Punycode. Maintenant, débrayons complètement IDN et essayons le nom dans son encodage natif ce qui, sur ma machine, est UTF-8 :
% dig +noidnout +noidnin A 📪.ws ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 45985 ;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 9, ADDITIONAL: 7 ... ;; QUESTION SECTION: ;\240\159\147\170.ws. IN A ;; ANSWER SECTION: \240\159\147\170.ws. 300 IN A 64.70.19.203 ...
Cette fois, on a des données (et même deux, car il y a aussi la
signature DNSSEC), et on récupère une adresse
IP, 64.70.19.203. La question
(\240\159\147\170.ws) est le nom en UTF-8,
\240\159\147\170.ws étant bien la
représentation en UTF-8 du caractère Unicode
U+1F4EA, l'émoji « boite aux lettres ».
C'est donc un cas assez rare : un IDN qui a des données pour
l'encodage UTF-8 mais rien en Punycode. (J'ai trouvé des noms qui
avaient les deux.) À cause de cela, il est très probable que
l'URL
http://📪.ws/
John Shaft m'a mis sur la piste de l'explication de cette
étrangeté. Le domaine encodé en UTF-8 n'existe pas, donc les serveurs faisant
autorité pour .ws devraient répondre
NXDOMAIN (No Such
Domain). Mais .ws a un joker dans la zone
et répond donc pour tous les noms inexistants avec cette adresse IP,
64.70.19.203.
Merci à Sean Conner pour avoir attiré mon attention sur ce domaine, dans le cadre d'une discussion sur le projet Gemini. Victor Héry m'a appris ensuite que ce nom de domaine faisait partie du projet Mailoji, une pure escroquerie (car les noms vendus aux pigeons ne marcheront que dans un environnement fermé et contrôlé par le vendeur).
L'article seul
RFC 8978: Reaction of Stateless Address Autoconfiguration (SLAAC) to Flash-Renumbering Events
Date de publication du RFC : Mars 2021
Auteur(s) du RFC : F. Gont (SI6 Networks), J. Zorz (6connect), R. Patterson (Sky UK)
Pour information
Réalisé dans le cadre du groupe de travail IETF v6ops
Première rédaction de cet article le 11 mars 2021
Au moment où je commençais à écrire cet article, mon FAI a trouvé drôle de changer le préfixe IPv6 attribué à mon réseau à la maison. Cela a parfaitement illustré le problème que décrit ce RFC : comment réagissent les machines IPv6 qui ont obtenu une adresse dynamique lors d'une rénumérotation brutale et sans avertissement ? En résumé : ça ne se passe pas toujours bien.
Posons le problème. Notre RFC se concentre sur le cas des machines qui ont obtenu une adresse par le système SLAAC (StateLess Address AutoConfiguration), normalisé dans le RFC 4862. Le routeur émet des messages RA (Router Advertisement) qui indiquent quel est le préfixe d'adresses IP utilisé sur le réseau local. Les machines vont alors prendre une adresse dans ce préfixe, tester qu'elle n'est pas déjà utilisée et c'est parti. Le routeur n'a pas besoin de mémoriser quelles adresses sont utilisées, d'où le terme de « sans état ». L'information distribuée par ces RA a une durée de vie, qui peut être de plusieurs jours, voire davantage.
Maintenant, envisageons un changement du préfixe, quelle que soit sa raison. Si ce changement est planifié, le routeur va accepter les deux préfixes, il va annoncer le nouveau mais l'ancien marchera encore, pendant la durée de vie qui était annoncée, et tout le monde sera heureux et communiquera. Mais si le changement de préfixe n'est pas planifié ? Par exemple, si le routeur obtient lui-même le préfixe dynamiquement (par exemple par le DHCP-PD du RFC 9915) puis qu'il redémarre et qu'il n'avait pas noté le préfixe précédent ? Il ne pourra alors pas continuer à router l'ancien préfixe, que les machines du réseau local utiliseront encore pendant un certain temps, à leur grand dam.
C'est ce qui s'est passé le 19 janvier 2021 (et les jours suivants), lorsque Free a subitement renuméroté les préfixes IPv6 d'un bon nombre de clients. Free n'utilise pas DHCP-PD, je suppose que les Freebox étaient configurées par un autre procédé, en tout cas, les utilisateurs n'ont pas été prévenus. Sur le réseau local, les machines avaient acquis les deux préfixes, l'ancien, conservé en mémoire, et le nouveau. Et l'ancien préfixe ne marchait plus (n'était pas routé), entrainant plein de problèmes. (Notons que l'adresse IPv4 avait également été changée mais ce n'est pas le sujet ici.) Il a fallu redémarrer toutes les machines, pour qu'elles oublient l'ancien préfixe. Une illustration parfaite du problème qui a motivé ce RFC : SLAAC avait été prévu pour des préfixes qui changent rarement et de manière planifiée (avec réduction préalable de la durée de vie, pour que la transition soit rapide). Les surprises, qu'elles soient dues à un problème technique ou simplement au manque de planification, ne sont pas prises en compte.
À part le mode Yolo de Free, dans quelles conditions aura-t-on de ces renumérotages brutaux, ces flash-renumbering events ? Un exemple est celui où le RA qui doit annoncer la fin de l'ancien préfixe (avec une durée de vie nulle) s'est perdu (le multicast n'est pas toujours fiable). Mais, de toute façon, envoyer ce RA d'avertissement suppose de savoir qu'un nouveau préfixe a remplacé l'ancien. Or, cette information n'est pas toujours disponible. Un exemple est celui où il n'y a même pas de RA d'avertissement, car le CPE obtient son préfixe IPv6 par DHCP-PD (Prefix Delegation, RFC 9915, section 6.3), avant de le redistribuer sur le réseau local en SLAAC. Si ce CPE redémarre, et n'a pas de mémoire permanente, il va peut-être obtenir un autre préfixe via DHCP-PD, ce qui fera un flash-renumbering event sur le réseau local. (Il peut aussi y avoir désynchronisation entre la durée de vie des RA faits via SLAAC et la durée du bail DHCP. En théorie, c'est interdit, mais certains CPE où les deux protocoles sont gérés par des modules logiciels différents font cette erreur.)
La Freebox n'utilise apparemment pas DHCP-PD mais le même problème d'ignorance du préfixe précédent peut survenir si la mise à jour des box est faite par un autre moyen de synchronisation. Bref, des tas de choses peuvent aller mal, particulièrement si l'opérateur réseau est négligent (ce qui a été le cas de Free) mais même parfois s'il essaie de bien faire. À partir de là, si certaines machines du réseau local continuent à utiliser l'ancien préfixe, leurs paquets seront probablement jetés par le routeur et aucune communication ne sera possible.
Le RFC 4861 suggère, dans sa section 6.2.1, pour les durées de validité des préfixes annoncés, des valeurs très élevées (une semaine pour la durée préférée et un mois pour la durée maximale). En cas de renumérotation brutale, c'est beaucoup trop (voir aussi la section 2.2), une machine pourrait rester déconnectée pendant une semaine, voire davantage. Divers trucs permettent d'améliorer un peu les choses, mais avec d'autres inconvénients. Il n'y a pas de méthode propre pour nettoyer les machines du réseau local de la mauvaise information. Bien sûr, le mieux serait qu'il n'y ait pas de renumérotation brutale mais ne nous faisons pas d'illusions : cela arrivera et il faut des solutions pour réparer.
La section 2 du RFC analyse en détail certains aspects du problème. Ainsi, est-ce qu'on ne pourrait pas tout simplement attribuer des préfixes IP fixes aux clients ? Cela simplifierait certainement beaucoup de choses. Mais une étude récente indique qu'un tiers des FAI britanniques utilisent des préfixes dynamiques pour IPv6. C'est certainement pénible pour les clients qui veulent, par exemple, héberger un serveur. Mais c'est un état des choses qu'il va falloir traiter. Même si ces FAI changeaient leurs pratiques, des problèmes subsisteraient, par exemple avec des routeurs à la maison qui sous-alloueraient des préfixes plus spécifiques à une partie de la maison et le feraient de façon dynamique. D'autant plus que l'idéal serait que les clients aient le choix, les adresses fixes pouvant (RFC 7721) poser des problèmes de vie privée (le RFC 4941 ne fait varier que la partie de l'adresse IP spécifique à la machine). Ainsi, la DPA allemande suggère de ne pas les utiliser.
Le fond du problème est évidemment que le routeur qui émet des RA n'a aucun moyen de supprimer les préfixes anciens s'il ne les connait pas. S'ils les connaissait, cela serait trivial, en les annonçant avec une durée de vie de zéro mais attention, lisez plus loin. Dans les cas de redémarrage d'un routeur qui n'a pas de mémoire permanente, ce qui est oublié est oublié et le routeur ne peut pas dire « ce préfixe n'existe plus ». Mais même si le routeur connait les anciens préfixes, il y a un piège avec le point e) de la section 5.5.3 du RFC 4862 : on ne peut pas réduire la durée de vie en dessous de deux heures. C'est déjà mieux qu'une semaine mais c'est encore trop long. Autre piège, même une fois qu'un préfixe n'est plus utilisé pour de nouvelles communications, il peut encore servir pour répondre aux anciennes, donc est encore considéré comme valide pour ce réseau, ce qui fait qu'il n'est pas possible de communiquer avec le nouveau titulaire de ce préfixe (s'il y en a un).Par exemple ce patch Linux viole le RFC 4862 pour permettre une meilleure robustesse en cas de renumérotation.
Autre sujet sur lequel il faudrait peut-être améliorer les protocoles, l'interaction entre DHCP et SLAAC, qui reste peu spécifiée. Au minimum, le logiciel dans le routeur qui reçoit les préfixes par DHCP-PD devrait transmettre au logiciel qui envoie les RA quelles sont les durées de vie à utiliser pour qu'elles soient cohérentes avec la durée du bail DHCP.
Bon, et qu'est-ce qu'on peut faire aujourd'hui pour atténuer les conséquences du problème ? Comme dit plus haut, on pourrait n'utiliser que des préfixes fixes, mais cela ne semble pas réaliste. On pourrait surtout changer les paramètres SLAAC pour des valeurs plus réalistes, en mettant 45 minutes comme durée de vie préférée et 90 minutes comme durée maximale de validité. De telles valeurs conviendraient mieux à la grande majorité des réseaux que les valeurs du RFC 4861. En l'absence de mécanisme pour invalider rapidement les anciens préfixes, de courtes durées de vie sont préférables. Dans certains cas (si on est sûrs qu'il n'y aura pas de rénumérotation brutale et/ou si des machines sont longtemps déconnectées du réseau), des valeurs plus longues peuvent être préférables.
L'article seul
RFC 8998: ShangMi (SM) Cipher Suites for TLS 1.3
Date de publication du RFC : Mars 2021
Auteur(s) du RFC : P. Yang (Ant Group)
Pour information
Première rédaction de cet article le 11 mars 2021
La cryptographie est un outil essentiel pour la sécurité sur les réseaux numériques. N'avoir comme algorithmes de cryptographie que des algorithmes développés à l'étranger peut être jugé dangereux pour la sécurité nationale. Des pays comme la Russie et, bien sûr, les États-Unis, recommandent ou imposent des algorithmes « nationaux ». La Chine s'y met, avec les algorithmes de chiffrement ShangMi (« SM »), dont ce RFC décrit l'utilisation dans TLS.
Comme ces algorithmes sont obligatoires en Chine pour certaines applications (comme c'est le cas de l'algorithme russe Magma décrit dans le RFC 8891), il était nécessaire que TLS (RFC 9846) puisse les utiliser, indépendamment de l'opinion des cryptographes « occidentaux » à leur sujet. Ce RFC traite de deux algorithmes de chiffrement symétrique (« SM4 ») avec chiffrement intègre, une courbe elliptique (« curveSM2 «), un algorithme de condensation (« SM3 »), un algorithme de signature (« SM2 ») utilisant curveSM2 et SM3, et un d'échange de clés fondé sur ECDHE sur SM2. (Au passage, saviez-vous qu'il existe une courbe elliptique française officielle ?)
On notera que les Chinois n'ont pas poussé leurs algorithmes qu'à l'IETF, certains sont aussi normalisés à l'ISO (ISO/IEC 14888-3:2018, ISO/IEC 10118-3:2018 et ISO/IEC 18033-3:2010).
Le RFC ne décrit pas les algorithmes eux-mêmes, uniquement comment les utiliser dans le contexte de TLS 1.3 (RFC 9846). Si vous êtes curieux, les normes chinoises sont :
- Pour l'algorithme de condensation SM3 : Norme GBT.32905-2016.
- Pour l'algorithme de chiffrement symétrique SM4 : Norme GBT.32907-2016.
- Pour l'algorithme de signature SM2 : normes GBT.32918.2-2016 et GBT.32918.5-2016.
Les deux algorithmes de chiffrement symétrique sont désormais dans
le
registre IANA sous les noms de
TLS_SM4_GCM_SM3 et
TLS_SM4_CCM_SM3. L'algorithme de signature,
sm2sig_sm3 est dans le
registre approprié. La courbe elliptique
curveSM2 a été ajoutée
à un autre registre.
Je ne connais pas aujourd'hui de mise en œuvre de ces algorithmes dans les bibliothèques TLS habituelles mais OpenSSL va savoir les gérer à partir de sa version 4. Si vous avez d'autres informations… Mais Wireshark va bientôt savoir les afficher.
Ah, et si vous vous intéressez à l'Internet en Chine, je vous recommande le livre de Simone Pieranni, Red Mirror.
L'article seul
RFC 8981: Temporary Address Extensions for Stateless Address Autoconfiguration in IPv6
Date de publication du RFC : Février 2021
Auteur(s) du RFC : F. Gont (SI6 Networks), S. Krishnan (Kaloom), T. Narten, R. Draves (Microsoft Research)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF 6man
Première rédaction de cet article le 1 mars 2021
Une des particularités d'IPv6 est de disposer d'un mécanisme, l'autoconfiguration sans état qui permet à une machine de se fabriquer une adresse IP globale sans serveur DHCP. Autrefois, ce mécanisme créait souvent l'adresse IP à partir de l'adresse MAC de la machine et une même machine avait donc toujours le même identifiant (IID, Interface IDentifier, les 64 bits les plus à droite de l'adresse IPv6), même si elle changeait de réseau et donc de préfixe. Il était donc possible de « suivre à la trace » une machine, ce qui pouvait poser des problèmes de protection de la vie privée. Notre RFC, qui remplace le RFC 4941 fournit une solution, sous forme d'un mécanisme de création d'adresses temporaires, partiellement aléatoires (ou en tout cas imprévisibles). Les changements sont assez importants depuis le RFC 4941, qui traitait un peu les adresses IPv6 temporaires comme des citoyennes de deuxième classe. Désormais, elles sont au contraire le choix préféré.
L'autoconfiguration sans état (SLAAC, pour Stateless
Address Autoconfiguration), normalisée dans le RFC 4862, est souvent présentée comme un des gros
avantages d'IPv6. Sans nécessiter de serveur
central (contrairement à DHCP), ce mécanisme permet à chaque machine
d'obtenir une adresse globale (IPv4, via le
protocole du RFC 3927, ne permet que des
adresses purement locales) et unique. Cela se fait en concaténant un
préfixe (par exemple
2001:db8:32:aa12::), annoncé par le
routeur, à un identifiant
d'interface (par exemple
213:e8ff:fe69:590d, l'identifiant de mon PC
portable - les machines individuelles, non partagées, comme les
ordiphones sont particulièrement sensibles
puisque la connaissance de la machine implique celle de son maître),
typiquement dérivé de l'adresse MAC.
Partir de l'adresse MAC présente des avantages (quasiment toute
machine en a une, et, comme elle est relativement unique, l'unicité
de l'adresse IPv6 est obtenue facilement) mais aussi un
inconvénient : comme l'identifiant d'interface est toujours le même,
cela permet de reconnaître une machine, même lorsqu'elle change de
réseau. Dès qu'on voit une machine
XXXX:213:e8ff:fe69:590d (où XXXX est le
préfixe), on sait que c'est mon PC. Un tiers qui écoute le réseau
peut ainsi suivre « à la trace » une machine, et c'est pareil pour
les
machines avec lesquelles on correspond sur l'Internet.
Or, on ne peut pas cacher son adresse IP, il faut l'exposer pour
communiquer. Le RFC 7721 analyse le problème
plus en détail (voir aussi le RFC 7707).
Les sections 1.2 et 2 de notre RFC décrivent la question à résoudre. Elles notent entre autre que le problème n'est pas aussi crucial que l'avaient prétendu certains. En effet, il existe bien d'autres façons, parfois plus faciles, de suivre une machine à la trace, par exemple par les fameux petits gâteaux de HTTP (RFC 6265) mais aussi par des moyens de plus haute technologie comme les métadonnées de la communication (taille des paquets, écart entre les paquets) ou les caractéristiques matérielles de l'ordinateur, que l'on peut observer sur le réseau. Parmi les autres méthodes, notons aussi que si on utilise les adresses temporaires de notre RFC 8981 mais qu'on configure sa machine pour mettre dynamiquement à jour un serveur DNS avec cette adresse, le nom de domaine suffirait alors à suivre l'utilisateur à la trace !
La section 2.2 commence à discuter des solutions possibles. DHCPv6 (RFC 3315, notamment la section 12) serait évidemment une solution, mais qui nécessite l'administration d'un serveur. L'idéal serait une solution qui permette, puisque IPv6 facilite l'existence de plusieurs adresses IP par machine, d'avoir une adresse stable pour les connexions entrantes et une adresse temporaire, non liée à l'adresse MAC, pour les connexions sortantes, celles qui « trahissent » la machine. C'est ce que propose notre RFC, en générant les adresses temporaires selon un mécanisme pseudo-aléatoire (ou en tout cas imprévisible à un observateur extérieur).
Enfin, la section 3 décrit le mécanisme de protection lui-même. Deux algorithmes sont proposés mais il faut bien noter qu'une machine est toujours libre d'en ajouter un autre, le mécanisme est unilatéral et ne nécessite pas que les machines avec qui on correspond le comprennent. Il suffit que l'algorithme respecte ces principes :
- Les adresses IP temporaires sont utilisées pour les connexions sortantes (pour les entrantes, on a besoin d'un identificateur stable, un serveur n'a pas de vie privée),
- Elles sont… temporaires (typiquement quelques heures),
- Cette durée de vie limitée suit les durées de vie indiquées par SLAAC, et, en prime, on renouvelle les IID (identifiants d'interface) tout de suite lorsque la machine change de réseau, pour éviter toute corrélation,
- L'identifiant d'interface est bien sûr différent pour chaque interface, pour éviter qu'un observateur ne puisse détecter que l'adresse IP utilisée en 4G et celle utilisée en WiFi désignent la même machine,
- Ces adresses temporaires ne doivent pas avoir de sémantique visible (cf. RFC 7136) et ne pas être prévisibles par un observateur.
Le premier algorithme est détaillé dans la section 3.3.1 et nécessite l'usage d'une source aléatoire, selon le RFC 4086. On génère un identifiant d'interface avec cette source (attention, certains bits sont réservés, cf. RFC 7136), on vérifie qu'il ne fait pas partie des identifiants réservés du RFC 5453, puis on la préfixe avec le préfixe du réseau.
Second algorithme possible, en section 3.3.2, une génération à partir de l'algorithme du RFC 7217, ce qui permet d'utiliser le même algorithme pour ces deux catégories d'adresses, qui concernent des cas d'usage différents. Le principe est de passer les informations utilisées pour les adresses stables du RFC 7217 (dont un secret, pour éviter qu'un observateur ne puisse déterminer si deux adresses IP appartiennent à la même machine), en y ajoutant le temps (pour éviter la stabilité), à travers une PRF comme SHA-256. Plus besoin de générateur aléatoire dans ce cas.
Une fois l'adresse temporaire générée (les détails sont dans la section 3.4), et testée (DAD), il faut la renouveler de temps en temps (sections 3.5 et 3.6, cette dernière expliquant pourquoi renouveler une fois par jour est plus que suffisant). L'ancienne adresse peut rester active pour les connexions en cours mais plus pour de nouvelles connexions.
Notez que le RFC impose de fournir un moyen pour activer ou débrayer ces adresses temporaires, et que cela soit par préfixe IP, par exemple pour débrayer les adresses temporaires pour les adresses locales du RFC 4193.
Maintenant que l'algorithme est spécifié, la section 4 du RFC reprend de la hauteur et examine les conséquences de l'utilisation des adresses temporaires. C'est l'occasion de rappeler un principe de base de la sécurité : il n'y a pas de solution idéale, seulement des compromis. Si les adresses temporaires protègent davantage contre le « flicage », elles ont aussi des inconvénients comme de rendre le débogage des réseaux plus difficile. Par exemple, si on note un comportement bizarre associé à certaines adresses IP, il sera plus difficile de savoir s'il s'agit d'une seule machine ou de plusieurs. (Le RFC 7217 vise justement à traiter ce cas.)
Et puis les adresses temporaires de notre RFC ne concernent que l'identifiant d'interface, le préfixe IP reste, et il peut être révélateur, surtout s'il y a peu de machines dans le réseau. Si on veut vraiment éviter le traçage par adresse IP, il faut utiliser Tor ou une technique équivalente (cf. section 9).
L'utilisation des adresses temporaires peut également poser des problèmes avec certaines pratiques prétendument de sécurité comme le fait, pour un serveur, de refuser les connexions depuis une machine sans enregistrement DNS inverse (un nom correspondant à l'adresse, via un enregistrement PTR). Cette technique est assez ridicule mais néanmoins largement utilisée.
Un autre conflit se produira, note la section 8, si des mécanismes de validation des adresses IP source sont en place dans le réseau. Il peut en effet être difficile de distinguer une machine qui génère des adresses IP temporaires pour se protéger contre les indiscrets d'une machine qui se fabrique de fausses adresses IP source pour mener une attaque.
Quelles sont les différences entre le précédent RFC et celui-ci ? La section 5 du RFC résume les importants changements qu'il y a eu depuis le RFC 4941. Notamment :
- Abandon de MD5 (cf. RFC 6151),
- Autorisation de n'avoir que des adresses temporaires (le RFC 4941 imposait qu'une adresse stable reste présente),
- Autoriser les adresses temporaires à être utilisées par défaut, ce qui était déjà le cas en pratique sur la plupart des systèmes d'exploitation (depuis l'époque du RFC 4941, la gravité de la surveillance de masse est mieux perçue),
- Réduction de la durée de vie recommandée, et recommandation qu'elle soit partiellement choisie au hasard, pour éviter que toutes les adresses soient refaites en même temps,
- Un algorithme de génération des identifiants d'interface, reposant sur une mémoire stable de la machine, a été supprimé,
- Un autre a été ajouté, se fondant sur le RFC 7217,
- Intégration des analyses plus détaillées qui ont été faites de la sécurité d'IPv6 (RFC 7707, RFC 7721 et RFC 7217),
- Correction des bogues.
Passons maintenant aux mises en œuvre. L'ancienne norme, le RFC 4941, est appliqué par presque tous les
systèmes d'exploitation, souvent de manière plus protectrice de la
vie privée, par exemple en étant activé par défaut. Les
particularités de notre nouveau RFC ne sont pas toujours d'ores et
déjà présentes. Ainsi, il existe des patches
pour
FreeBSD et pour
Linux mais pas forcément intégrés aux versions
officielles. Sur
Linux, le paramètre sysctl qui contrôle ce protocole est
net.ipv6.conf.XXX.use_tempaddr où XXX est le
nom de l'interface réseau, par exemple eth0. En
mettant dans le fichier /etc/sysctl.conf :
# Adresses temporaires du RFC 8981 net.ipv6.conf.default.use_tempaddr = 2
On met en service les adresses temporaires, non « pistables » pour
toutes les interfaces (c'est le sens de la valeur
default). Pour s'assurer que les réglages soient bien pris en
compte, il vaut mieux faire en sorte que le module
ipv6 soit chargé tout de suite (sur
Debian, le mettre dans
/etc/modules) et que les interfaces fixes aient
leur propre réglage. Par exemple, sur Debian,
on peut mettre dans /etc/network/interfaces :
iface eth2 inet dhcp pre-up sysctl -w net.ipv6.conf.eth2.use_tempaddr=2
Ou alors il faut nommer explicitement ses interfaces :
net.ipv6.conf.eth0.use_tempaddr = 2
Notez aussi
qu'ifconfig n'affiche pas quelles
adresses sont les temporaires (mais ip addr
show le fait).
Notons que l'adresse « pistable » est toujours présente mais
vient s'y ajouter une adresse temporaire choisie au hasard. Selon
les règles du RFC 6724, rappelées dans la
section 3.1 de notre RFC, c'est cette adresse temporaire qui sera
choisie, en théorie, pour les connexions sortantes (voir aussi le
RFC 5014 pour une API permettant de contrôler ce
choix). Avec Linux, il faut pour cela que
use_tempaddr vale plus que un (sinon, l'adresse
temporaire est bien configurée mais pas utilisée par
défaut). ifconfig affichera donc :
wlan0 Link encap:Ethernet HWaddr 00:13:e8:69:59:0d
...
inet6 addr: 2001:db8:32:aa12:615a:c7ba:73fb:e2b7/64 Scope:Global
inet6 addr: 2001:db8:32:aa12:213:e8ff:fe69:590d/64 Scope:Global
puis, au démarrage suivant, l'adresse temporaire (la première ci-dessus) changera :
wlan0 Link encap:Ethernet HWaddr 00:13:e8:69:59:0d
...
inet6 addr: 2001:db8:32:aa12:48a9:bf44:5167:463e/64 Scope:Global
inet6 addr: 2001:db8:32:aa12:213:e8ff:fe69:590d/64 Scope:Global
Sur NetBSD, il n'y a qu'une seule variable
syscvtl pour toutes les interfaces. Il suffit donc de mettre dans
/etc/sysctl.conf :
net.inet6.ip6.use_tempaddr=1
Pour que l'adresse temporaire soit utilisée par défaut, c'est
net.inet6.ip6.prefer_tempaddr. Sur
FreeBSD, je n'ai pas essayé, mais je suppose
que les variables sysctl au nom bien parlant
net.inet6.ip6.use_tempaddr et
net.inet6.ip6.prefer_tempaddr sont là pour
cela.
L'article seul
RFC 8985: The RACK-TLP Loss Detection Algorithm for TCP
Date de publication du RFC : Février 2021
Auteur(s) du RFC : Y. Cheng, N. Cardwell, N. Dukkipati, P. Jha (Google)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tcpm
Première rédaction de cet article le 23 février 2021
Ce RFC normalise un nouvel algorithme pour la détection de paquets perdus dans TCP. Dans des cas comme celui où l'application n'a rien à envoyer (fin des données, ou attente d'une requête), RACK-TLP détecte les pertes plus rapidement, en utilisant des mesures fines du RTT, et en sollicitant des accusés de réception dans de nouveaux cas.
Pour comprendre cet algorithme et son intérêt, il faut revoir à quoi sert un protocole de transport comme TCP. Les données sont transmises sous forme de paquets (au format IP, dans le cas de l'Internet), paquets qui peuvent être perdus en route, par exemple si les files d'attente d'un routeur sont pleines. Le premier travail d'un protocole de transport est de réémettre les paquets perdus, de façon à ce que les applications reçoivent bien toutes les données (et dans l'ordre car, en prime, les paquets peuvent arriver dans le désordre, ce qu'on nomme un réordonnancement, qui peut être provoqué, par exemple, lorsque deux chemins sont utilisés pour les paquets). Un protocole de transport a donc besoin de détecter les pertes. Ce n'est pas si évident que cela. La méthode « on note quand on a émis un paquet et, si on n'a pas reçu d'accusé de réception au bout de N millisecondes, on le réémet » fonctionne, mais elle serait très inefficace. Notamment, le choix de N est difficile : trop court, et on déclarerait à tort des paquets comme perdus, réémettant pour rien, trop long et et ne détecterait la perte que trop tard, diminuant la capacité effective.
Le RFC original sur TCP, le RFC 793, expliquait déjà que N devait être calculé dynamiquement, en tenant compte du RTT attendu. En effet, si l'accusé de réception n'est pas arrivé au bout d'une durée égale au RTT, attendre davantage ne sert à rien. (Bien sûr, c'est plus compliqué que cela : le RTT peut être difficile à mesurer lorsque des paquets sont perdus, il varie dans le temps, puisque le réseau a pu changer, et il peut y avoir des temps de traitement qui s'ajoutent au RTT, il faut donc garder un peu de marge.) Armé de cette mesure dynamique du RTT, TCP peut calculer un RTO (Retransmission TimeOut, RFC 793, section 3.7) qui donne le temps d'attente. Le concept de RTO a été ensuite détaillé dans le RFC 6298 qui imposait un minimum d'une seconde (ce qui est beaucoup, par exemple à l'intérieur d'un même centre de données).
Mais d'autres difficultés surgissent ensuite. Par exemple, les accusés de réception de TCP indiquent le dernier octet reçu. Si on envoie trois paquets (plus rigoureusement trois segments, le terme utilisé par TCP) de cent octets, et qu'on reçoit un accusé de réception pour le centième octet indique que le premier paquet est arrivé mais ne dit rien du troisième. Peut-être est-il arrivé et que le second est perdu. Dans ce cas, la réémission du troisième paquet serait du gaspillage. Les accusés de réception cumulatifs de TCP ne permettent pas au récepteur de dire qu'il a reçu les premier et troisième paquets. Les SACK (Selective Acknowledgments) du RFC 2018 ont résolu ce problème. Dans l'exemple ci-dessus, SACK aurait permis au récepteur de dire « j'ai reçu les octets 0 - 100 et 200 - 300 [le second nombre de chaque bloc indique l'octet suivant le bloc] ».
Ensuite, on peut optimiser l'opération en n'attendant pas le RTO, dont on a vu qu'il était souvent trop long. L'idée de base est que, si le récepteur reçoit des données qui ne sont pas dans l'ordre attendu (le troisième paquet, alors qu'on n'a toujours pas vu le second), on renvoie un accusé de réception pour les données déjà reçues et déjà confirmées. Lorsque l'émetteur reçoit un accusé de réception qu'il a déjà vu (en fait, plusieurs), il comprend que des données manquent et il peut réémettre tout de suite, même si le RTO n'est pas écoulé. Ce mécanisme d'accusés de réception dupliqués (DUPACK, pour DUPlicate ACKnowledgment) a été décrit dans le RFC 5681, puis le RFC 6675. Une de ses faiblesses, que corrige notre RFC, est qu'il ne peut pas être utilisé à la fin d'une transmission, puisqu'il n'y a plus de données qui arrivent, empêchant le récepteur de détecter les pertes ou réordonnancements, et obligeant à attendre le RTO.
Et enfin, il faut se rappeler que le protocole de transport a une autre importante responsabilité : s'il doit s'assurer que toutes les données arrivent, et donc réémettre les paquets manquants, il doit aussi le faire en évitant la congestion (RFC 5681). Si des paquets se perdent, c'est peut-être que le réseau est saturé et réémettre trop brutalement pourrait encore aggraver la situation. Ceci dit, l'algorithme RACK-TLP décrit dans notre RFC ne traite que de la détection de pertes, les méthodes précédentes pour le contrôle de congestion restent valables. (C'est une des nouveautés de RACK-TLP : il sépare la détection de pertes du contrôle de congestion, pour lequel il existe plusieurs algorithmes comme le NewReno du RFC 6582 ou le CUBIC du RFC 8312. Ce découplage permet de faire évoluer séparement les algorithmes, et rend donc le système plus souple.)
Voici, désolé pour cette introduction un peu longue, on peut maintenant passer au sujet principal de ce RFC, RACK-TLP. Cet algorithme, ou plutôt ces deux algorithmes, vont être plus efficaces (détecter les pertes plus vite) que DUPACK, notamment à la fin d'une transmission, ou lorsqu'il y a des pertes des paquets retransmis, ou encore des réordonnancements fréquents des paquets (section 2.2 de notre RFC). RACK (Recent ACKnowledgment) va utiliser le RTT des accusés de réception pour détecter certaines pertes, alors que TLP (Tail Loss Probe) va émettre des paquets de données pour provoquer l'envoi d'accusés de réception par le récepteur.
La section 3 du RFC donne une vision générale des deux algorithmes. Commençons par RACK (Recent ACKnowledgment). Son but va être de détecter plus rapidement les pertes lorsque un paquet arrive au récepteur dans le désordre (paquet des octets 200 à 300 alors que le précédent était de 0 à 100, par exemple). Il va utiliser SACK (RFC 2018) pour cela, et RACK dépend donc du bon fonctionnement de SACK (section 4) et en outre, au lieu de ne regarder que les numéros de séquence contenus dans les ACK, comme le faisait DUPACK, il va également regarder le temps écoulé depuis l'émission d'un paquet. Les détails figurent en section 6 du RFC.
Quant à TLP (Tail Loss Probe), son rôle est de titiller le récepteur pour que celui-ci émette des accusés de récéption, même s'il n'en voyait pas la nécessité. Par exemple, si on arrive à la fin d'une session, l'émetteur a fini d'envoyer ses paquets, mais pas encore reçu les accusés de réception. Aucun envoi ne déclenchera donc DUPACK. Le principe de TLP est donc de solliciter un accusé de réception pour voir si on obtient un duplicata. RACK pourra alors utiliser cet accusé dupliqué. (Les deux algorithmes sont forcément utilisés ensemble, on n'utilise pas TLP sans RACK.) Les détails de TLP sont dans la section 7.
La résolution doit être meilleure qu'un quart du RTT. À l'intérieur d'un centre de données, cela implique de pouvoir compter les microsecondes, et, sur l'Internet public, les millisecondes.
La section 9 du RFC discute des avantages et inconvénients de RACK-TLP. Le gros avantage est que tout segment de données envoyé, même si c'est une retransmission, peut permettre de détecter des pertes. C'est surtout intéressant lorsqu'on est à la fin des données (et il n'y a donc plus rien à transmettre) ou lorsque des retransmissions sont perdues. Outre le cas de la fin du flot de données, les propriétés de RACK-TLP sont également utiles lorsque l'application garde la connexion ouverte mais n'a temporairement rien à transmettre (cas de sessions interactives, ou de protocoles requête/réponse comme EPP, où il ne se passe pas forcément quelque chose en permanence).
Mais comme la perfection n'existe pas en ce bas monde, RACK-TLP a aussi des inconvénients. Le principal est qu'il oblige à garder davantage d'état puisqu'il faut mémoriser l'heure de départ de chaque segment (contrairement à ce que proposait le RFC 6675), et avec une bonne résolution (un quart du RTT, demande le RFC). Une telle résolution n'est pas facile à obtenir dans un centre de données où les RTT sont très inférieurs à la milliseconde. Ceci dit, certaines mises en œuvre de TCP font déjà cela, même si, en théorie, elles pourraient se contenter de moins.
RACK-TLP coexiste avec d'autres algorithmes de détection de pertes, comme le classique RTO (RFC 6298) mais aussi avec ceux des RFC 7765, RFC 5682 et RFC 3522. De même, il coexiste avec divers algorithmes de contrôle de la congestion (RFC 5681, RFC 9937) puisqu'il se contente de détecter les pertes, il ne décide pas de comment on évite la congestion. En gros, RACK-TLP dit « ce segment est perdu » et la décision de réémission de celui-ci passera par l'algorithme de contrôle de la congestion, qui verra quand envoyer ces données à nouveau.
RACK-TLP est explicitement conçu pour TCP, mais il pourra aussi être utilisé dans le futur avec d'autres protocoles de transport, comme le futur QUIC.
RACK-TLP ne date pas d'aujourd'hui et il est déjà mis en œuvre dans Linux, FreeBSD et dans des systèmes d'exploitation moins connus comme Windows.
L'article seul
Fiche de lecture : Red Mirror
Auteur(s) du livre : Simone Pieranni
Éditeur : C&F Éditions
978-2-37662-021-1
Publié en 2021
Première rédaction de cet article le 23 février 2021
Autrefois, quand on voulait voir le futur, il fallait regarder ce qui se passe aux États-Unis, en se disant que cela allait arriver chez nous quelques années plus tard (que cela soit une bonne ou une mauvaise chose…) Aujourd'hui, faut-il plutôt regarder vers la Chine ? Ce livre explore l'état du numérique en Chine, et ce qu'il peut nous promettre comme futur plus ou moins positif.
Il est loin, le temps où la Chine était un pays pauvre où tout le monde passait son temps à cultiver du riz, en étant toujours au bord de la famine. Même le temps où la Chine était uniquement un atelier géant de construction de jouets en plastique parait bien éloigné. Aujourd'hui, la Chine est en avance sur bien des sujets, touchant notamment au numérique. Le film de propagande « La Bataille de la Montagne du Tigre » commence d'ailleurs, avant de raconter une bataille du passé, par montrer une Chine moderne, pleine de trains à grande vitesse et de gadgets électroniques. Est-ce que cette « avance » de la Chine est une bonne chose ? Plus « perfectionné » et plus « avancé » ne veut pas forcément dire « meilleur ». La Chine a souvent été citée pour le caractère dystopique de son utilisation du numérique, où les libertés individuelles et la protection des données personnelles n'existent pas. Le numérique y est souvent utilisé pour opprimer et pas pour libérer, d'où le titre de ce livre, jeu avec le titre d'une série télévisée connue.
Alors, la Chine est-elle le paradis du numérique comme le présentent certains techno-béats ou bien un enfer dystopique ? L'intérêt du livre de Simone Pieranni, expert de la Chine, est d'étudier la question plus en profondeur. Car la Chine est aussi un grand réservoir à fantasmes en Occident et fait l'objet de nombreux discours contradictoires et parfois peu informés. Il faut donc aller y voir de plus près. (« C'est comment, la Chine ? » « C'est comme vivre en Grande-Bretagne pendant la révolution industrielle. », commente l'auteur.)
Car le paysage est contrasté. Oui, les libertés individuelles et la protection des données personnelles sont complètement absentes. L'accès à l'Internet est largement censuré et très surveillé. L'État sait tout, d'autant plus que de nombreuses activités autrefois effectuées hors ligne sont passés sur l'Internet très récemment (ça bouge vite en Chine). Ainsi, l'application WeChat (qu'on connait en Occident uniquement comme une application de messagerie instantanée, concurrente de WhatsApp) est devenue la plate-forme d'accès à tout, une « super-app » sans laquelle rien n'est possible en Chine et notamment sans laquelle on ne peut rien acheter. Résultat, WeChat sait tout de tous les citoyens et, évidemment, l'État y a un accès complet, sans contrôle.
D'un autre côté, tout n'est pas aussi dystopique que c'est parfois présenté à l'étranger. Le fameux « crédit social », par exemple, n'est pas encore un système généralisé et centralisé de contrôle mais plutôt (pour l'instant), une série de projets locaux pas forcément coordonnés. Et l'auteur rappelle que certains systèmes chinois baptisés « crédit social » ne sont pas très éloignés de systèmes utilisés en Occident, par exemple par Uber où tout le monde note tout le monde (sans compter ce que font des horreurs comme Equifax). Il est amusant de voir l'auteur, p. 172, s'inquiéter des systèmes de vidéoconférence chinois qui surveillent l'attention portée par les utilisateurs à la réunion, alors que Zoom fait déjà cela.
Le gouvernement chinois ne veut pas s'arrêter là et il promeut fortement les idées les plus négatives comme la smart city de surveillance encore plus généralisée. Et il veut continuer à utiliser l'Internet pour assurer un contrôle politique des citoyens, par exemple via l'« armée des cinquante centimes » où on peut être payé pour noyer les rares critiques exprimées sur des forums sous des messages pro-gouvernementaux. Et les ambitions de la dictature chinoise ne s'arrêtent pas à son pays, le projet dit de « nouvelle route de la soie » sert de couverture à une promotion du contrôle à la chinoise dans d'autres pays. Bien des dictateurs, et même des dirigeants élus démocratiquement dans le monde, prêtent une oreille favorable à des discours promettant un meilleur contrôle du pays grâce à la technologie.
Le livre a quelques défauts. Par exemple, il ne mentionne pas les faiblesses techniques de la position chinoise. Si la Chine a rattrapé l'Occident sur certains points, et dépassé sur d'autres, elle n'est pas en position de force partout. Ainsi, comme l'a montré la crise entre Huawei et Google, provoquée par un refus du précédent gouvernement états-unien de laisser Google fournir un Android complet à Huawei, la Chine n'a pas encore un système d'exploitation pour ordiphone, tâche il est vrai difficile. Ces faiblesses sont d'autant plus importantes à analyser que le gouvernement chinois n'est pas avare de propagande présentant les résultats miraculeux obtenus en Chine, et qu'il faut garder la tête froide par rapport à des affirmations publicitaires. P. 70, l'auteur parle ainsi de la 5G en reprenant sans nuances le discours des techno-béats, chinois ou étrangers, discours qui mériterait d'être nuancé. De même, p. 160, il s'embrouille complètement sur les technologies quantiques, mélangeant QKD (sur laquelle la Chine a déjà fait des promesses exagérées, que l'auteur reprend à son compte sans aucune distance, surtout p. 163) et calculateurs quantiques.
Mais ce sont des détails. L'important est que ce livre analyse en détail ce qui se fait réellement et ce qui ne se fait pas (encore ?) en Chine, et permet de se faire une meilleure idée de ce qui nous attend si nous n'accompagnons pas le progrès technique d'une attention très serrée pour les questions de droits humains.
L'article seul
RFC 8980: Report from the IAB Workshop on Design Expectations vs. Deployment Reality in Protocol Development
Date de publication du RFC : Février 2021
Auteur(s) du RFC : J. Arkko, T. Hardie
Pour information
Première rédaction de cet article le 20 février 2021
L'atelier de l'IAB DEDR (Design Expectations vs. Deployment Reality) s'est tenu à Kirkkonummi en juin 2019 (oui, il faut du temps pour publier un RFC de compte-rendu). Son but était, par delà la constatation que le déploiement effectif des protocoles conçus par l'IETF ne suit pas toujours les attentes initiales, d'explorer pourquoi cela se passait comme cela et ce qu'on pouvait y changer.
Souvent, lors de la mise au point d'un nouveau protocole, les personnes qui y travaillent ont en tête un modèle de déploiement. Par exemple, pour le courrier électronique, l'idée dominante était qu'il y aurait souvent un serveur de messagerie par personne. On sait que ce n'est pas la situation actuelle. En raison de soucis de sécurité, de pressions économiques et/ou politiques, et d'autres facteurs, on a aujourd'hui un courrier nettement plus centralisé, avec un caractère oligopolistique marqué, dominé par une poignée d'acteurs qui dictent les règles. Cette centralisation n'est pas souhaitable (sauf pour les GAFA). Mais où est-ce que le dérapage a commencé ? Parfois, cela a été rapide, et parfois cela a pris beaucoup de temps.
Quelques exemples :
- Le courrier électronique, on l'a dit, était conçu autour de l'idée qu'il y aurait beaucoup de serveurs, gérés par des acteurs différents. (À une époque, dans le monde universitaire, il était courant que chaque station de travail ait un serveur de courrier, et ses propres adresses.) Aujourd'hui, il est assez centralisé, chez des monstres comme Gmail et Outlook.com. Un des facteurs de cette centralisation est le spam, contre lequel il est plus facile de se défendre si on est gros.
- Le DNS
avait été prévu pour une arborescence de noms assez profonde
(l'exemple traditionnel était l'ancien domaine de premier niveau
.usqui était découpé en entités géographiques de plus en plus spécifiques). Mais l'espace des noms est aujourd'hui plus plat que prévu. On voit même des organisations qui ont, mettons,example.comet qui, lançant un nouveau produit, mettonsfoobar, réserventfoobar.com, voirefoobar-example.comau lieu de tout simplement créerfoobar.example.com(ce qui serait en outre moins cher). Un autre exemple de centralisation est la tendance à abandonner les résolveurs locaux (qui, il est vrai, sont souvent mal gérés ou menteurs) pour des gros résolveurs publics comme Google Public DNS ou Quad9 (et cette centralisation, contrairement à ce qui est souvent prétendu, n'a rien à voir avec DoH). - Le Web est également un exemple de déviation des principes originels, vers davantage de centralisation. Le concept de base est très décentralisé. N'importe qui peut installer un serveur HTTP sur son Raspberry Pi et faire partie du World Wide Web. Mais cela laisse à la merci, par exemple, des dDoS ou, moins dramatiquement, de l'effet Slashdot (même si un site Web statique peut encaisser une charge importante). On constate que de plus en plus de sites Web dépendent donc de services centralisés, CDN ou gros relais comme Cloudflare.
- Et ça ne va pas forcément s'arranger avec de nouvelles technologies, par exemple l'apprentissage automatique, qui sont difficiles à décentraliser.
L'IAB avait produit un RFC sur la question « qu'est-ce qui fait qu'un protocole a du succès », le RFC 5218. Dans un autre document, le RFC 8170, l'IAB étudiait la question des transitions (passage d'un protocole à un autre, ou d'une version d'un protocole à une autre). L'atelier de Kirkkonummi avait pour but de poursuivre la réflexion, en se focalisant sur les cas où les suppositions de base n'ont pas tenu face à la réalité.
L'agenda de l'atelier était structuré en cinq sujets, le passé (qu'avons-nous appris), les principes (quelles sont les forces à l'œuvre et comment les contrer ou les utiliser), la centralisation (coûts et bénéfices), la sécurité et le futur (fera-t-on mieux à l'avenir et savons-nous comment). 21 articles ont été reçus (ils sont en ligne), et 30 personnes ont participé.
Sur le passé, l'atelier a étudié des exemples de déploiement de protocoles, comme PKIX, DNSSEC, le NAT, l'IoT, etc. Souvent, ce qui a été effectivement déployé ne correspondait pas à ce qui était prévu. Par exemple, un protocole très demandé n'a pas eu le succès attendu (c'est le cas de DNSSEC : tout le monde réclame de la sécurité, mais quand il faut travailler pour la déployer, c'est autre chose) ou bien il n'a pas été déployé comme prévu. C'est d'autant plus vrai que l'IETF n'a pas de pouvoir : elle produit des normes et, ensuite, d'autres acteurs décident ou pas de déployer, et de la manière qu'ils veulent (le « marché » sacré). Le RFC cite quelques leçons de l'expérience passée :
- Les retours du terrain arrivent toujours trop tard, bien après que la norme technique ait été bouclée. C'est particulièrement vrai pour les retours des utilisateurs individuels (ceux que, d'après le RFC 8890, nous devons prioriser).
- Les acteurs de l'Internet font des choses surprenantes.
- On constate la centralisation mais on ne peut pas forcément l'expliquer par les caractéristiques des protocoles. Rien dans HTTP ou dans SMTP n'impose la centralisation qu'on voit actuellement.
- En revanche, certaines forces qui poussent à la centralisation sont connues : cela rend certains déploiements plus faciles (c'est un argument donné pour refuser la décentralisation). Et les solutions centralisées ont nettement la faveur des gens au pouvoir, car ils préfèrent travailler avec un petit nombre d'acteurs bien identifiés. (C'est pour cela qu'en France, tous les hommes politiques disent du mal des GAFA tout en combattant les solutions décentralisées, qui seraient plus difficiles à contrôler.)
- On ne sait pas toujours si un nouveau protocole sera vraiment utile ou pas (cf. la 5G et le porno dans l'ascenseur).
- Il est facile de dire que l'IETF devrait davantage interagir avec tel ou tel groupe, mais certains groupes sont difficiles à toucher (le RFC 8890 détaille ce problème).
Sur les principes, on a quand même quelques conclusions solides. Par exemple, il est clair qu'un nouveau protocole qui dépend de plusieurs autres services qui ne sont pas encore déployés aura davantage de mal à s'imposer qu'un protocole qui peut s'installer unilatéralement sans dépendre de personne. Et puis bien sûr, il y a l'inertie. Quand quelque chose marche suffisamment bien, il est difficile de la remplacer. (Le RFC donne l'exemple de BGP, notamment de sa sécurité.) Et cette inertie génère le phénomène bien reconnu de la prime au premier arrivant. Si un protocole fournit un nouveau service, un remplaçant aura le plus grand mal à s'imposer, même s'il est meilleur, face au tenant du titre. Le monde du virtuel est lourd et ne bouge pas facilement. Quand un protocole a eu un succès fou (terme défini et discuté dans le RFC 5218), le remplacer devient presque impossible. Autre principe analysé : l'IETF ne devrait de toute façon pas avoir d'autorité sur la façon dont ses protocoles sont déployés. Ce n'est pas son rôle et elle n'a pas de légitimité pour cela. Et, on l'a dit, les usages sont durs à prévoir. L'atelier a aussi constaté que certains modèles de déploiement, qui s'appliquent à beaucoup de cas, n'avaient pas été prévus et planifiés. C'est le cas de l'extrême centralisation, bien sûr, mais également le cas de « tout via le Web » qui fait que tout nouveau service sur l'Internet tend à être accessible uniquement à distance, avec les protocoles et les formats du Web. Cela tend à créer des silos fermés, même s'ils utilisent des protocoles ouverts. (C'est en réponse à ce problème qu'a été créée la licence Affero.)
Concernant le troisième sujet, la centralisation, l'atelier a constaté que la tendance à la centralisation n'est pas toujours claire dès le début. Le RFC cite l'exemple (très mauvais, à mon avis) de DoH. Autre constatation, la sécurité, et notamment le risque d'attaques par déni de services réparties est un puissant facteur de centralisation. Si vous voulez gérer un site Web sur un sujet controversé, avec des opposants puissants et prêts à tout, vous êtes quasiment obligé de faire appel à un hébergement de grande taille (face aux dDoS, la taille compte). Ceci dit, l'atelier a aussi identifié des forces qui peuvent aller en sens contraire à la centralisation. Une fédération peut mieux résister aux attaques (qui ne sont pas forcément techniques, cela peut être aussi la censure) qu'un gros silo centralisé, le chiffrement peut permettre même aux petits de limiter la surveillance exercée par les gros, les navigateurs Web peuvent adopter de meilleures pratiques pour limiter les données envoyées à la grosse plate-forme à laquelle on accède (toute cette liste du RFC est d'un optimisme souvent injustifié…), l'interopérabilité peut permettre davantage de concurrence (cf. le bon rapport du Conseil National du Numérique), et certaines tendance lourdes peuvent être combattues également par des moyens non-techniques (le RFC cite la régulation, ce qui n'est pas facilement accepté par les libertariens, même si ceux-ci ne sont pas plus nombreux à l'IETF qu'ailleurs).
Quatrième sujet, la sécurité. Traditionnellement, le modèle de menace de l'Internet (RFC 3552 mais aussi RFC 7258) est que tout ce qui est entre les deux machines qui communiquent peut être un ennemi. Cela implique notamment le choix du chiffrement de bout en bout. Toutefois, ce modèle de menace ne marche pas si c'est l'autre pair qui vous trahit. Ainsi, utiliser TLS quand vous parlez à Facebook vous protège contre des tiers mais pas contre Facebook lui-même. À l'heure où tant de communications en ligne sont médiées par des GAFA, c'est un point à prendre en considération. (Attention à ne pas jeter le bébé avec l'eau du bain ; le chiffrement de bout en bout reste nécessaire, mais n'est pas suffisant. Certains FAI remettent en cause le modèle de menace traditionnel pour combattre ou restreindre le chiffrement, en faisant comme si les GAFA étaient les seuls à faire de la surveillance.) Les participants à l'atelier sont plutôt tombés d'accord sur la nécessité de faire évoluer le modèle de menace mais il faudra veiller à ce que ne soit pas un prétexte pour relativiser l'importance du chiffrement, qui reste indispensable. À noter une autre limite d'un modèle de menace qui ne mentionnerait que les tiers situés sur le trajet : non seulement la partie distante (par exemple Facebook) peut être une menace, mais votre propre machine peut vous trahir, par exemple si vous n'utilisez pas du logiciel libre.
Enfin, cinquième et dernier sujet, le futur. L'IETF n'a pas de pouvoir contraignant sur les auteurs de logiciels, sur les opérateurs ou sur les utilisateurs (et heureusement). Elle ne peut agir que via ses normes. Par exemple, pour l'Internet des Objets, le RFC 8520 permet davantage d'ouverture dans la description des utilisations qu'un objet fera du réseau. Outre la production de bonnes normes, l'IETF peut être disponible quand on a besoin d'elle, par exemple comme réserve de connaissance et d'expertise.
La conclusion du RFC (section 5) indique que le problème est complexe, notamment en raison de la variété des parties prenantes : tout le monde n'est pas d'accord sur les problèmes, et encore moins sur les solutions. (Il n'existe pas de « communauté Internet », à part dans des discours politiciens.) D'autre part, certains des problèmes n'ont pas de solution évidente. Le RFC cite ainsi les dDoS, ou le spam. Cette absence de solution satisfaisante peut mener à déployer des « solutions » qui ont un rôle négatif. Le RFC note ainsi à juste titre que l'absence d'une solution de paiement en ligne correcte (anonyme, simple, bon marché, reposant sur des normes ouvertes, etc) pousse à faire dépendre la rémunération des créateurs de la publicité, avec toutes ses conséquences néfastes. Et l'Internet fait face à de nombreux autres défis stratégiques, comme la non-participation des utilisateurs aux questions qui les concernent, ou comme la délégation de décisions à des logiciels, par exemple le navigateur Web.
On l'a dit, la conclusion est que l'IETF doit se focaliser sur ce qu'elle sait faire et bien faire, la production de normes. Cela implique :
- Travailler sur une mise à jour du modèle de menace cité plus haut,
- Réfléchir aux mesures qui peuvent être prises pour limiter la centralisation,
- Mieux documenter les principes architecturaux de l'Internet, notamment le principe de bout en bout,
- Travailler sur les systèmes de réputation (cf. RFC 7070),
- Etc.
Un autre compte-rendu de cet atelier, mais très personnel, avait été fait par Geoff Huston.
L'article seul
RFC 8976: Message Digest for DNS Zones
Date de publication du RFC : Février 2021
Auteur(s) du RFC : D. Wessels (Verisign), P. Barber (Verisign), M. Weinberg (Amazon), W. Kumari (Google), W. Hardaker (USC/ISI)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 10 février 2021
Ce nouveau RFC normalise un mécanisme pour ajouter aux zones DNS un condensat qui permet de vérifier leur intégrité. Pourquoi, alors qu'on a TSIG, TLS et SSH pour les transporter, et PGP et DNSSEC pour les signer ? Lisez jusqu'au bout, vous allez voir.
Le nouveau type d'enregistrement DNS créé par ce RFC se nomme ZONEMD et sa
valeur est un condensat de la zone. L'idée
est de permettre au destinataire d'une zone DNS de s'assurer qu'elle
n'a pas été modifiée en route. Elle est complémentaire des
différentes techniques de sécurité citées plus haut. Contrairement à
DNSSEC, elle protège une zone, pas un enregistrement.
Revenons un peu sur la terminologie. Une zone (RFC 8499, section 7) est un ensemble d'enregistrements servi par les mêmes serveurs. Ces serveurs reçoivent typiquement la zone depuis un maître, et utilisent souvent la technique AXFR (RFC 5936) pour cela. Ce transfert est souvent (mais pas toujours) protégé par le mécanisme TSIG (RFC 8945), qui permet de s'assurer que la zone est bien celle servie par le maître légitime. D'autres techniques de transfert peuvent être utilisées, avec leur propre mécanisme de sécurité. On peut par exemple utiliser rsync sur SSH. Les zones sont souvent stockées dans des fichiers de zone, du genre :
@ IN SOA ns4.bortzmeyer.org. hostmaster.bortzmeyer.org. (
2018110902
7200
3600
604800
43200 )
IN NS ns4.bortzmeyer.org.
IN NS ns2.bortzmeyer.org.
IN NS ns1.bortzmeyer.org.
IN NS puck.nether.net.
IN MX 0 mail.bortzmeyer.org.
IN TXT "v=spf1 mx -all"
IN A 92.243.4.211
IN AAAA 2001:4b98:dc0:41:216:3eff:fe27:3d3f
www IN CNAME ayla.bortzmeyer.org.
sub IN NS toto.example.
Donc, les motivations de notre RFC sont d'abord le désir de pouvoir vérifier une zone après son transfert, indépendamment de la façon dont elle a été transférée. Une zone candidate évidente est la racine du DNS (cf. section 1.4.1), publiquement disponible, et que plusieurs résolveurs copient chez eux (RFC 8806). Ensuite, l'idée est de disposer d'un contrôle minimum (une somme de contrôle) pour détecter les modifications accidentelles (le rayon cosmique qui passe). Un exemple de modification accidentelle serait une troncation de la fin de la zone, d'habitude difficile à détecter puisque les fichiers de zone n'ont pas de marques de fin (contrairement à, par exemple, un fichier JSON). Notez que la « vraie » vérification nécessite DNSSEC. Si la zone n'est pas signée, le mécanisme décrit dans ce RFC ne fournit que la somme de contrôle : c'est suffisant contre les accidents, pas contre les attaques délibérées. Mais, de toute façon, tous les gens sérieux utilisent DNSSEC, non ?
Il existe de nombreuses techniques qui fournissent un service qui ressemble plus ou moins à un des deux services mentionnés ci-dessus. L'un des plus utilisés est certainement TSIG (RFC 8945). Beaucoup de transferts de zone (cf. RFC 5936) sont ainsi protégés par TSIG. Il a l'inconvénient de nécessiter un secret partagé entre serveur maître et serveur esclave. SIG(0) (RFC 2931) n'a pas cet inconvénient mais n'est quasiment jamais mis en œuvre. Toujours dans la catégories des protections du canal, on a TLS et l'IETF travaille sur un mécanisme de protection des transferts par TLS, mais on peut aussi imaginer d'utiliser simplement DoT (RFC 7858).
Ceci dit, toutes ces techniques de protection du canal ont le même défaut : une fois le transfert fait, elles ne servent plus à rien. Pas moyen de vérifier si le fichier est bien le fichier authentique. Ainsi, un serveur faisant autorité qui charge une zone à partir d'un fichier sur le disque ne peut pas vérifier que ce fichier n'a pas été modifié. Bien sûr, les protections fournies par le système de fichiers offrent certaines garanties, mais pas parfaites, par exemple si un programme a planté et laissé le fichier dans un état invalide (oui, ça s'est déjà produit). Bref, on préférerait une protection des données et pas seulement du canal.
Alors, pourquoi ne pas simplement utiliser DNSSEC,
qui fournit effectivement cette sécurité des données ? Le problème
est que dans une zone, seules les informations faisant autorité sont
signées. Les délégations (vers un sous-domaine, comme
sub.bortzmeyer.org dans l'exemple plus haut) et
les colles (adresses IP des serveurs de noms qui sont dans la zone
qu'ils servent) ne sont pas signés. Pour une zone comme la racine,
où il n'y a quasiment que des délégations, ce serait un problème. Et
ce serait encore pire avec les zones qui utilisent NSEC3 (RFC 5155) avec opt-out puisqu'on
ne sait même plus si un nom non-signé existe ou pas. Donc, DNSSEC
est très bien, mais ne suffit pas pour notre cahier des charges.
On a d'autres outils pour la sécurité des données, le plus évident étant PGP (RFC 9580). D'ailleurs, ça tombe bien, la racine des noms de domaine est déjà distribuée avec une signature PGP :
% wget -q https://www.internic.net/domain/root.zone % wget -q https://www.internic.net/domain/root.zone.sig % gpg --verify root.zone.sig root.zone gpg: Signature made Wed Jan 13 08:22:50 2021 CET gpg: using DSA key 937BB869E3A238C5 gpg: Good signature from "Registry Administrator <nstld@verisign-grs.com>" [unknown] gpg: WARNING: This key is not certified with a trusted signature! gpg: There is no indication that the signature belongs to the owner. Primary key fingerprint: F0CB 1A32 6BDF 3F3E FA3A 01FA 937B B869 E3A2 38C5
Notez que Verisign utilise une signature détachée du fichier. Cela permet que le fichier reste un fichier de zone normal et chargeable, mais cela casse le lien entre la signature et le fichier. Bref, cela ne résout pas complètement le problème. (Les historiens et historiennes s'amuseront de noter qu'une autre solution, très proche de celle de notre RFC, figurait déjà dans le RFC 2065, mais qu'elle n'avait eu aucun succès.)
Bon, passons maintenant à la solution (section 1.3). On l'a dit,
le principe est d'avoir un enregistrement de type
ZONEMD qui contient un
condensat de la zone. Il est généré par le
responsable de la zone et quiconque a téléchargé la zone, par
quelque moyen que ce soit, peut vérifier qu'il correspond bien à la
zone. En prime, si la zone est signée avec DNSSEC, on peut
vérifier que ce ZONEMD est authentique.
Du fait que ce condensat couvre l'intégralité de la zone, il faut
le recalculer entièrement si la zone change, si peu que ce
soit. Cette solution ne convient donc pas aux grosses zones très
dynamiques (comme
.fr). Dans le futur, le
ZONEMD est suffisamment extensible pour que des
solutions à ce problème lui soient ajoutées. En attendant,
ZONEMD convient mieux pour des zones comme la
racine (rappel, elle est disponible en ligne),
ou comme la zone d'une organisation. La
racine est un cas particulièrement
intéressant car elle est servie par un grand nombre de serveurs,
gérés par des organisations différentes. Sans compter les gens qui
la récupèrement localement (RFC 8806). Le
contrôle de son intégrité est donc crucial. Il y a une discussion en
ce moment au sein du RZERC pour proposer l'ajout
de ZONEMD dans la racine.
Pour la zone d'une organisation, notre RFC rappelle qu'il est
recommandé d'avoir une diversité des serveurs de nom, afin d'éviter
les SPOF et que c'est donc une bonne idée
d'avoir des serveurs esclaves dans d'autres organisations. Comme
cette diversité peut entrainer des risques (le serveur esclave
est-il vraiment honnête ? le transfert s'est-il bien passé ?), là
aussi, la vérification de l'intégrité s'impose. Autre scénario
d'usage, les distributions de fichiers de zone, comme le fait
l'ICANN avec CZDS ou comme le fait le
registre du .ch (téléchargez
ici). D'une manière générale, ce contrôle supplémentaire ne
peut pas faire de mal.
Plongeons maintenant dans les détails techniques avec la section
2 du RFC, qui explique le type d'enregistrement
ZONEMD (code
63). Il se trouve forcément à l'apex
de la zone. Il comprend quatre champs :
- Numéro de série, il permet de s'assurer qu'il couvre bien la zone qu'on veut vérifier (dont le numéro de série est dans le SOA).
- Plan, la méthode utilisée pour génerer le condensat. Pour l'instant, un seul plan est normalisé, nommé Simple, il fonctionne par un calcul sur l'entièreté de la zone. On peut ajouter des plans au registre, selon la procédure « Spécification nécessaire ».
- Algorithme, est l'algorithme de condensation utilisé, SHA-384 ou SHA-512 à l'heure actuelle mais on pourra en ajouter d'autres au registre (« Spécification nécessaire », là encore).
- Et le condensat lui-même.
Question présentation dans les fichiers de zone, ça ressemble à :
example.com. 86400 IN ZONEMD 2018031500 1 1 (
FEBE3D4CE2EC2FFA4BA99D46CD69D6D29711E55217057BEE
7EB1A7B641A47BA7FED2DD5B97AE499FAFA4F22C6BD647DE )
Ici, le numéro de série est 2018031500, le plan 1 (Simple) et l'algorithme de condensation SHA-384.
Il peut y avoir plusieurs ZONEMD dans un
fichier, ils doivent avoir des couples {Plan, Algorithme}
différents. (Le but est de fournir plusieurs techniques de
vérification, et de permettre de passer en souplesse de l'une à
l'autre.)
Comment exactement se fait le calcul du condensat ? La section 3
le détaille. D'abord, on supprime de la zone les éventuels
ZONEMD existants, et on place un
ZONEMD bidon (il en faut un, en cas de
signature DNSSEC, pour éviter de casser la signature). Si on a
DNSSEC, on signe alors la zone (et il faudra re-faire le
RRSIG du ZONEMD après), on
canonicalise la zone (le condensat est calculé sur le format « sur
le câble » pas sur le format texte), et on calcule ensuite le
condensat sur la concaténation des enregistrements (à l'exclusion du
ZONEMD bidon, qui avait été mis pour DNSSEC, et
de sa signature). On génère ensuite le vrai ZONEMD, puis, si on a
DNSSEC, on recalcule sa signature. Autant dire que vous ne le ferez
pas à la main ! L'endroit logique pour faire ce calcul du
ZONEMD est dans le logiciel qui fait les
signatures DNSSEC. Notez que, contrairement à DNSSEC, tous les
enregistrements sont utilisés, y compris ceux qui ne font pas
autorité comme les délégations et les colles.
Un mot sur la canonicalisation. Tout calcul d'un condensat cryptographique doit se faire sur des données canonicalisées, c'est-à-dire mises sous une forme canonique, une forme unique et standardisée. Comme le changement d'un seul bit change complètement le condensat, il ne faut pas laisser des petites variations de détail (par exemple, pour le DNS, entre noms comprimés et non-comprimés) à l'imagination de chaque programmeur. Voilà pourquoi notre RFC spécifie rigoureusement une forme canonique (par exemple, les noms ne doivent pas être comprimés).
La vérification se fait de la même façon (section 4 du RFC). On
vérifie que le numéro de série est le même, on
canonicalise, on concatène, on condense et on vérifie qu'on trouve
bien ce qui était dans le ZONEMD. (S'il y a
plusieurs ZONEMD, le premier qui marche
suffit.) Le mieux est évidemment de tout valider avec DNSSEC, en
plus.
La section 6 de notre RFC revient sur la sécurité du
ZONEMD, ce qu'il garantit et ce qu'il ne
garantit pas. D'abord, le point le plus important : sans DNSSEC,
ZONEMD n'est qu'une somme de
contrôle, il garantit l'intégrité mais pas
l'authenticité, et il ne protège donc que contre les modifications
accidentelles (ce qui est déjà très bien !) Le bit flipping sera détecté mais pas
l'attaque délibérée et soignée. Ainsi, sans DNSSEC, un attaquant
n'aurait, par exemple, qu'à retirer l'enregistrement
ZONEMD de la zone avant de faire ses
modifications (une attaque par repli).
D'autre part, les algorithmes de cryptographie vieillissent (RFC 7696)
et
ZONEMD ne peut donc pas garantir de sécurité
sur le long terme. D'ailleurs, sur le long terme, on n'aurait
probablement plus les clés DNSSEC disponibles.
Plus drôle, ZONEMD permet, comme toute
technique de sécurité, de nouveaux modes de déni de service, comme
l'a déjà expérimenté tout utilisateur de la cryptographie. Comme le
condensat est strictement binaire (il colle aux données, ou pas du
tout), la zone entière peut être considérée comme invalide si un
problème modifie ne serait-ce qu'un seul bit. Le souci de
l'intégrité de la zone et celui de sa disponibilité sont ici
en conflit, et le responsable de la zone doit choisir.
Si vous aimez les comparatifs de performance, la section 7 du RFC
discute de chiffres. Par exemple, une zone de 300 000
enregistrements a été ZONEMDifiée en deux
secondes et demi sur un serveur ordinaire. C'est encore trop lent
pour être utilisable sur des zones comme
.com mais cela montre
que des grandes zones qui ne changent pas trop souvent peuvent être
protégées.
Et question mises en œuvre, ça se passe comment ? J'ai testé
l'excellente bibliothèque ldns. Le code avec
calcul de ZONEMD devrait être publié dans une
version officielle en 2021 mais, en attendant,
c'est déjà dans git, en https://github.com/NLnetLabs/ldnsZONEMD (ici, avec la zone d'exemple montrée
au début de cet article). On génère une clé, puis on signe, avec
calcul de ZONEMD :
% ./ldns-keygen -a ED25519 bortzmeyer.org Kbortzmeyer.org.+015+00990 % ./ldns-signzone -o bortzmeyer.org -z 1:1 bortzmeyer-org.zone Kbortzmeyer.org.+015+00990 % cat bortzmeyer-org.zone.signed ... bortzmeyer.org. 3600 IN ZONEMD 2018110902 1 1 b1af60c3c3e88502746cf831d2c64a5399c1e3c951136d79e63db2ea99898ba9f2c4f9b29e6208c09640aaa9deafe012 bortzmeyer.org. 3600 IN RRSIG ZONEMD 15 2 3600 20210215174229 20210118174229 990 bortzmeyer.org. FJ98//KDBF/iMl1bBkjGEBT3eeuH/rJDoGRDAoCBEocudLbA7F/38qwLpsPkr7oQcgbkLzhyHA7BXG/5fAwkAg==
(L'argument 1:1 signifie plan Simple et
algorithme SHA-384.) On peut ensuite vérifier la zone. Si elle a
un enregistrement ZONEMD, il est inclus dans
la vérification :
% ./ldns-verify-zone bortzmeyer-org.zone.signed Zone is verified and complete
Si je modifie une délégation (qui n'est pas protégée par DNSSEC mais
qui l'est par ZONEMD) :
% ./ldns-verify-zone bortzmeyer-org.zone.signed There were errors in the zone
Il y a aussi les dns-tools des gens
du .cl. Pour
BIND, c'est en
cours de réflexion. Apparemment,
Unbound y travaille également. Voir aussi
l'exposé
de Verisign à la réunion OARC de juillet 2022. Des tests sont en cours
(septembre 2022).
Depuis, un bon article de Jan-Piet Mens a expliqué le fonctionnement pratique de ZONEMD, et les outils utilisables.
L'article seul
RFC 8982: Registration Data Access Protocol (RDAP) Partial Response
Date de publication du RFC : Février 2021
Auteur(s) du RFC : M. Loffredo, M. Martinelli (IIT-CNR/Registro.it)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 10 février 2021
Le protocole de récupération d'informations auprès d'un registre RDAP peut parfois rapporter une grande quantité d'informations pour chaque objet récupéré (un nom de domaine, par exemple). Le RDAP originel ne permettait pas au serveur de ne renvoyer qu'une information partielle s'il trouvait que cela faisait trop. C'est désormais possible avec l'extension de ce RFC.
Le but est évidemment d'économiser les ressources du serveur, aussi bien que celles du client, en récupérant et en transférant moins de données. Avant notre RFC, la seule solution était de tout envoyer au client, même s'il n'en utiliserait pas la plus grande partie. (Si, au lieu de ne vouloir qu'une partie de chaque objet, on veut une partie des objets, il faut regarder le RFC 8977.)
Ce RFC étend donc le langage de requêtes de RDAP (normalisé dans
le RFC 9082), avec un paramètre
fieldSet (section 2 de notre RFC) qui permet de
sélectionner une partie des champs de la réponse. Voici un exemple
d'URL pour
une requête de tous les noms de domaine de
.com :
https://rdap.verisign.example/domains?name=*.com&fieldSet=afieldset
Et comment on connait les champs possibles ? Notre RFC introduit
un subsetting_metadata qui indique l'ensemble
de champs courant, et les ensembles possibles, chacun identifié par
un nom, et comportant les liens (RFC 8288) à
utiliser. (Vous aurez une erreur HTTP 400 si vous êtes assez
vilain·e pour faire une requête RDAP avec un ensemble inexistant.)
Et pour savoir si le serveur RDAP que vous interrogez accepte cette
nouvelle extension permettant d'avoir des réponses partielles,
regardez si subsetting apparait dans le tableau
rdapConformance de la réponse du serveur (cette
extension est désormais dans le
registre IANA). Voici l'exemple que donne le RFC :
{
"rdapConformance": [
"rdap_level_0",
"subsetting"
],
...
"subsetting_metadata": {
"currentFieldSet": "afieldset",
"availableFieldSets": [
{
"name": "anotherfieldset",
"description": "Contains some fields",
"default": false,
"links": [
{
"value": "https://example.com/rdap/domains?name=example*.com
&fieldSet=afieldset",
"rel": "alternate",
"href": "https://example.com/rdap/domains?name=example*.com
&fieldSet=anotherfieldset",
"title": "Result Subset Link",
"type": "application/rdap+json"
}
]
},
...
]
},
...
"domainSearchResults": [
...
]
}
Mais il y a encore plus simple que de regarder
subsetting_metadata : notre RFC décrit, dans sa
section 4, trois ensembles de champs standards qui, espérons-le,
seront présents sur la plupart des serveurs RDAP :
id, qui ne renvoie dans la réponse que les identificateurs des objets (handlepour les contacts,unicodeNamepour les noms de domaine, etc).brief, un peu plus bavard, qui renvoie l'information minimale (telle qu'estimée par le serveur) sur les objets.full, qui renvoie la réponse complète (actuellement, avant le déploiement de ce RFC 8982, c'est la valeur par défaut).
Un exemple de réponse avec l'ensemble id, où on
n'a que le nom (ASCII) des domaines :
{
"rdapConformance": [
"rdap_level_0",
"subsetting"
],
...
"domainSearchResults": [
{
"objectClassName": "domain",
"ldhName": "example1.com",
"links": [
{
"value": "https://example.com/rdap/domain/example1.com",
"rel": "self",
"href": "https://example.com/rdap/domain/example1.com",
"type": "application/rdap+json"
}
]
},
{
"objectClassName": "domain",
"ldhName": "example2.com",
"links": [
{
"value": "https://example.com/rdap/domain/example2.com",
"rel": "self",
"href": "https://example.com/rdap/domain/example2.com",
"type": "application/rdap+json"
}
]
},
...
]
}
Quelles mises en œuvre sont disponibles ? Il en existe une
chez
.it mais elle n'est
accessible sur leur serveur de test que si on est
authentifié.
Comme RDAP, contrairement à whois, permet l'authentification des clients (RFC 7481), on pourra imaginer des cas où l'ensemble complet de la réponse ne sera envoyé qu'à certains utilisateurs (section 8).
L'annexe A du RFC revient sur un choix sur lequel je suis passé rapidement : le fait que le client spécifie le nom d'un ensemble pré-défini de champs, plutôt que la liste des champs qui l'intéressent, ce qui serait plus souple. Mais cela aurait été compliqué pour les structures JSON profondes (il faudrait une syntaxe riche et peu lisible), et cela aurait compliqué les autorisations : que faire si un client demande deux champs et qu'il n'est autorisé que pour un seul ? Outre ces questions génériques de tout protocole utilisant JSON, il y avait des problèmes spécifiques à RDAP, comme le fait que le contenu sur une entité peut être réparti dans plusieurs structures JSON (ah, le jCard…) Des solutions existent, comme le langage de requêtes CQL, mais il a semblé trop coûteux pour un intérêt limité.
L'article seul
RFC 8941: Structured Field Values for HTTP
Date de publication du RFC : Février 2021
Auteur(s) du RFC : M. Nottingham (Fastly), P-H. Kamp (The Varnish Cache Project)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 9 février 2021
Plusieurs en-têtes HTTP sont structurés,
c'est-à-dire que le contenu n'est pas juste une suite de caractères
mais est composé d'éléments qu'un logiciel peut analyser. C'est par
exemple le cas de Accept-Language: ou de
Content-Disposition:. Mais chaque en-tête ainsi
structuré a sa propre syntaxe, sans rien en commun avec les autres
en-têtes structurés, ce qui en rend l'analyse pénible. Ce nouveau
RFC (depuis
remplacé par le RFC 9651) propose donc
des types de données et des algorithmes que les futurs en-têtes qui
seront définis pourront utiliser pour standardiser un peu l'analyse
d'en-têtes HTTP. Les en-têtes structurés existants ne seront pas
changés, pour préserver la compatibilité.
Imaginez : vous êtes un concepteur ou une conceptrice d'une extension au protocole HTTP qui va nécessiter la définition d'un nouvel en-tête. La norme HTTP, le RFC 7231, section 8.3.1, vous guide en expliquant ce à quoi il faut penser quand on conçoit un en-tête HTTP. Mais même avec ce guide, les pièges sont nombreux. Et, une fois votre en-tête spécifié, il vous faudra attendre que tous les logiciels, serveurs, clients, et autres (comme Varnish, pour lequel travaille un des auteurs du RFC) soient mis à jour, ce qui sera d'autant plus long que le nouvel en-tête aura sa syntaxe spécifique, avec ses amusantes particularités. Amusantes pour tout le monde, sauf pour le programmeur ou la programmeuse qui devra écrire l'analyse.
La solution est donc que les futurs en-têtes structurés réutilisent les éléments fournis par notre RFC, ainsi que son modèle abstrait, et la sérialisation proposée pour envoyer le résultat sur le réseau. Le RFC recommande d'appliquer strictement ces règles, le but étant de favoriser l'interopérabilité, au contraire du classique principe de robustesse, qui mène trop souvent à du code compliqué (et donc dangereux) car voulant traiter tous les cas et toutes les déviations. L'idée est que s'il y a la moindre erreur dans un en-tête structuré, celui-ci doit être ignoré complètement.
La syntaxe est spécifiée en ABNF (RFC 5234) mais le RFC fournit aussi des algorithmes d'analyse et, malheureusement, exige que, en cas de désaccord entre les algorithmes et la grammaire, ce soit les algorithmes qui l'emportent.
Voici un exemple fictif d'en-tête structuré très simple
(tellement simple que, si tous étaient comme lui, on n'aurait sans
doute pas eu besoin de ce RFC) :
Foo-Example: est défini comme ne prenant qu'un
élément comme valeur, un entier compris entre 0 et 10. Voici à quoi
il ressemblera en HTTP :
Foo-Example: 3
Il accepte des paramètres après un
point-virgule, un seul paramètre est défini,
foourl dont la valeur est un URI. Cela pourrait
donner :
Foo-Example: 2; foourl="https://foo.example.com/"
Donc, ces solutions pour les en-têtes structurés ne serviront que pour les futurs en-têtes, pas encore définis, et qui seront ajoutés au registre IANA. Imaginons donc que vous soyez en train de mettre au point une norme qui inclut, entre autres, un en-tête HTTP structuré. Que devez-vous mettre dans le texte de votre norme ? La section 2 de notre RFC vous le dit :
- Inclure une référence à ce RFC 8941.
- J'ai parlé jusqu'à présent d'en-tête structuré mais en fait ce RFC 8941 s'applique aussi aux pieds (trailers) (RFC 7230, sections 4.1.2 et 4.4 ; en dépit de leur nom, les pieds sont des en-têtes eux aussi). La norme devra préciser si elle s'applique seulement aux en-têtes classiques ou bien aussi aux pieds.
- Spécifier si la valeur sera une liste, un dictionnaire ou
juste un élément (ces termes sont définis en section 3). Dans
l'exemple ci-dessus
Foo-Example:, la valeur était un élément, de type entier. - Penser à définir la sémantique.
- Et ajouter les règles supplémentaires sur la valeur du
champ, s'il y en a. Ainsi, l'exemple avec
Foo-Example:imposait une valeur entière entre 0 et 10.
Une spécification d'un en-tête structuré ne peut que rajouter des contraintes à ce que prévoit ce RFC 8941. S'il en retirait, on ne pourrait plus utiliser du code générique pour analyser tous les en-têtes structurés.
Rappelez-vous que notre RFC est strict : si une erreur est présente
dans l'en-tête, il est ignoré. Ainsi, s'il était spécifié que la
valeur est un élément de type entier et qu'on trouve une chaîne de
caractères, on ignore l'en-tête. Idem dans l'exemple ci-dessus si on
reçoit Foo-Example: 42, la valeur excessive
mène au rejet de l'en-tête.
Les valeurs peuvent inclure des paramètres (comme le
foourl donné en exemple plus haut), et le RFC
recommande d'ignorer les paramètres inconnus, afin de permettre
d'étendre leur nombre sans tout casser.
On a vu qu'une des plaies du Web était le laxisme trop grand dans l'analyse des données reçues (c'est particulièrement net pour HTML). Mais on rencontre aussi des cas contraires, des systèmes (par exemple les pare-feux applicatifs) qui, trop fragiles, chouinent lorsqu'ils rencontrent des cas imprévus, parce que leurs auteurs avaient mal lu le RFC. Cela peut mener à l'ossification, l'impossibilité de faire évoluer l'Internet parce que des nouveautés, pourtant prévues dès l'origine, sont refusées. Une solution récente est le graissage, la variation délibérée des messages pour utiliser toutes les possibilités du protocole. (Un exemple pour TLS est décrit dans le RFC 8701.) Cette technique est recommandée par notre RFC.
La section 3 du RFC décrit ensuite les types qui sont les briques de base avec lesquelles on va pouvoir définir les en-têtes structurés. La valeur d'un en-tête peut être une liste, un dictionnaire ou un élément. Les listes et les dictionnaires peuvent à leur tour contenir des listes. Une liste est une suite de termes qui, dans le cas de HTTP, sont séparés par des virgules :
ListOfStrings-Example: "foo", "bar", "It was the best of times."
Et si les éléments d'une liste sont eux-mêmes des listes, on met ces listes internes entre parenthèses (et notez la liste vide à la fin) :
ListOfListsOfStrings-Example: ("foo" "bar"), ("baz"), ("bat" "one"), ()
Le cas des listes vides avait occupé une bonne partie des discussions à l'IETF (le vide, ça remplit…) Ainsi, un en-tête structuré dans la valeur est une liste a toujours une valeur, la liste vide, même si l'en-tête est absent.
Un dictionnaire est une suite de termes nom=valeur. En HTTP, cela donnera :
Dictionary-Example: en="Applepie", fr="Tarte aux pommes"
Et nous avons déjà vu les éléments simples dans le premier
exemple. Les éléments peuvent être de type
entier,
chaîne de
caractères, booléen,
identificateur, valeur binaire, et un dernier type plus exotique
(lisez le RFC pour en savoir plus). L'exemple avec
Foo-Example: utilisait un entier. Les exemples
avec listes et dictionnaires se servaient de chaînes de
caractères. Ces chaînes sont encadrées de
guillemets (pas
d'apostrophes). Compte-tenu des
analyseurs HTTP existants, les chaînes
doivent hélas être en ASCII (RFC 20). Si on veut envoyer de l'Unicode, il faudra utiliser
le type « contenu binaire » en précisant l'encodage (sans doute
UTF-8). Quant aux booléens, notez qu'il faut
écrire 1 et 0 (pas true et
false), et préfixé d'un point
d'interrogation.
Toutes ces valeurs peuvent prendre des paramètres, qui sont eux-mêmes une suite de couples clé=valeur, après un point-virgule qui les sépare de la valeur principale (ici, on a deux paramètres) :
ListOfParameters: abc;a=1;b=2
J'ai dit au début que ce RFC définit un modèle abstrait, et une sérialisation concrète pour HTTP. La section 4 du RFC spécifie cette sérialisation, et son inverse, l'analyse des en-têtes (pour les programmeu·r·se·s seulement).
Ah, et si vous êtes fana de formats structurés, ne manquez pas l'annexe A du RFC, qui répond à la question que vous vous posez certainement depuis plusieurs paragraphes : pourquoi ne pas avoir tout simplement décidé que les en-têtes structurés auraient des valeurs en JSON (RFC 8259), ce qui évitait d'écrire un nouveau RFC, et permettait de profiter du code JSON existant ? Le RFC estime que le fait que les chaînes de caractères JSON soient de l'Unicode est trop risqué, par exemple pour l'interopérabilité. Autre problème de JSON, les structures de données peuvent être emboîtées indéfiniment, ce qui nécessiterait des analyseurs dont la consommation mémoire ne peut pas être connue et limitée. (Notre RFC permet des listes dans les listes mais cela s'arrête là : on ne peut pas poursuivre l'emboîtement.)
Une partie des problèmes avec JSON pourrait se résoudre en se limitant à un profil restreint de JSON, par exemple en utilisant le RFC 7493 comme point de départ. Mais, dans ce cas, l'argument « on a déjà un format normalisé, et mis en œuvre partout » tomberait.
Enfin, l'annexe A note également qu'il y avait des considérations d'ordre plutôt esthétiques contre JSON dans les en-têtes HTTP.
Toujours pour les programmeu·r·se·s, l'annexe B du RFC donne quelques conseils pour les auteur·e·s de bibliothèques mettant en œuvre l'analyse d'en-têtes structurés. Pour les aider à suivre ces conseils, une suite de tests est disponible. Quant à une liste de mises en œuvre du RFC, vous pouvez regarder celle-ci.
Actuellement, il n'y a dans le registre
des en-têtes qu'un seul en-tête structuré, le
Accept-CH: du RFC 8942. Sa valeur est une liste d'identificateurs. Mais
plusieurs autres en-têtes structurés sont en préparation.
Si vous voulez un exposé synthétique sur ces en-têtes structuré, je vous recommande cet article par un des auteurs du RFC.
Voyons maintenant un peu de pratique avec une des mises en œuvre citées plus haut, http_sfv, une bibliothèque Python. Une fois installée :
% python3 >>> import http_sfv >>> my_item=http_sfv.Item() >>> my_item.parse(b"2") >>> print(my_item) 2
On a analysé la valeur « 2 » en déclarant que cette valeur devait être un élément et, pas de surprise, ça marche. Avec une valeur syntaxiquement incorrecte :
>>> my_item.parse(b"2, 3")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/stephane/.local/lib/python3.6/site-packages/http_sfv-0.9.1-py3.6.egg/http_sfv/util.py", line 57, in parse
ValueError: Trailing text after parsed value
Et avec un paramètre (il sera accessible après l'analyse, via le
dictionnaire Python params) :
>>> my_item.parse(b"2; foourl=\"https://foo.example.com/\"")
>>> print(my_item.params['foourl'])
https://foo.example.com/
Avec une liste :
>>> my_list.parse(b"\"foo\", \"bar\", \"It was the best of times.\"")
>>> print(my_list)
"foo", "bar", "It was the best of times."
Et avec un dictionnaire :
>>> my_dict.parse(b"en=\"Applepie\", fr=\"Tarte aux pommes\"")
>>> print(my_dict)
en="Applepie", fr="Tarte aux pommes"
>>> print(my_dict["fr"])
"Tarte aux pommes"
L'article seul
RFC 8942: HTTP Client Hints
Date de publication du RFC : Février 2021
Auteur(s) du RFC : I. Grigorik, Y. Weiss (Google)
Expérimental
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 9 février 2021
Aux débuts du Web,
il allait de soi que le contenu renvoyé à un client était identique
quel que soit le client. On demandait un article scientifique, le
même article était donné à tout le monde. La séparation du contenu
et de la présentation que permet HTML faisait en sorte que ce contenu
s'adaptait automatiquement aux différents clients et notamment à
leur taille. Mais petit à petit l'habitude s'est prise d'envoyer un
contenu différent selon le client. C'était parfois pour de bonnes
raisons (s'adapter à la langue de
l'utilisateur) et parfois pour des mauvaises (incompréhension de la
séparation du contenu et de la présentation, ignorance du Web par
des commerciaux qui voulaient contrôler l'apparence exacte de la
page). Cette adaptation au client peut se faire en tenant compte des
en-têtes envoyés par le
navigateur dans sa requête, notamment
l'affreux User-Agent:, très indiscret et en
général mensonger. Mais la tendance actuelle est de ne pas utiliser
systématiquement ces en-têtes, très dangereux pour la vie
privée et parfois inutiles : si le serveur HTTP n'adapte pas le
contenu en fonction des en-têtes, pourquoi les envoyer ? Ce nouveau
RFC propose une
solution : un en-tête Accept-CH: envoyé par le
serveur qui indique ce que le serveur va faire
des en-têtes d'indication envoyés par le client (client
hints) dans ses futures requêtes. Il s'agit d'un projet
Google, déjà mis en œuvre dans
Chrome mais, pour l'instant, seulement avec
le statut « Expérimental ».
Le Web a toujours été prévu pour être accédé par des machines très différentes, en terme de taille d'écran, de logiciels utilisés, de capacités de traitement. Sans compter les préférences propres à l'utilisateur, par exemple sa langue. C'est ainsi que, par exemple, les lignes de texte ne sont pas définies dans le source en HTML, elles seront calculées dynamiquement par le navigateur qui, lui, connait la largeur de la fenêtre. Mais il a été difficile de faire comprendre cela à des marketeux habitués de la page imprimée et qui insistaient pour contrôler tout au pixel près.
Bref, il y a longtemps que des gens qui ne connaissent pas le Web
font n'importe quoi, par exemple en regardant l'en-tête
User-Agent: (RFC 7231,
section 5.5.3) et en ajustant le contenu Web à cet en-tête, ce qui
nécessite une base de données de tous les
User-Agent: possibles puisque chaque nouvelle
version d'un navigateur peut changer les choses. (D'où ces
User-Agent: ridicules et mensongers qu'on voit
aujourd'hui, où chaque navigateur met le nom de tous les autres, par
exemple Edge annonce Mozilla/5.0
(Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/68.0.2704.79 Safari/537.36 Edge/18.014.) Ces
techniques sont évidemment très mauvaises : elles compliquent les
serveurs, elles ne permettent pas de gérer le cas d'un nouveau
navigateur (sauf à ce qu'il annonce les noms de ces prédécesseurs
dans User-Agent:, ce qui se fait couramment),
elles ne permettent pas facilement à l'utilisateur ou à son
navigateur de savoir quels critères ont été utilisés par le serveur
pour adapter le contenu. Et elles sont très indiscrètes, exposant
par défaut bien plus d'informations que ce qui est nécessaire au
serveur pour adapter son contenu. C'est ainsi que des
services comme Panopticlick ou
Am I
unique? peuvent fonctionner, démontrant la
possibilité d'identifier un utilisateur sans
biscuits, avec juste du
fingerprinting passif.
Un site Web peut aussi ajuster son contenu en fonction d'un utilisateur particulier, suivi, par exemple, par les biscuits du RFC 6265, ou via des paramètres dans l'URL mais cela complique les choses, par exemple en obligeant à mettre des informations dans l'URL de chaque ressource du site Web.
Une meilleure solution, au moins en théorie, est la négociation de contenu
HTTP (RFC 7231, section 3.4.1) :
le client utilise alors des en-têtes bien définis (comme
Accept-Language: pour la
langue) auxquels le serveur peut répondre par
un contenu spécifique. La négociation de contenu pose
toutefois un problème, note le RFC, c'est que les en-têtes sont
systématiquement envoyés par le client, qui ne sait pas si le
serveur en fera quelque chose. Cela peut notamment avoir des
conséquences en terme de vie
privée, un client pouvant être identifié par le jeu
complet des en-têtes qu'il envoie, même en l'absence de biscuits de
traçage. (En outre, pour le cas particulier de la langue, la
négociation de contenu n'aide guère car elle ne prend pas en compte
des questions comme la
notion de version originale.)
Au contraire, estime le RFC (avec pas mal d'optimisme), le mécanisme décrit ici peut potentiellement être davantage protecteur, en obligeant le serveur à annoncer quelles informations il va utiliser et en n'envoyant les informations permettant l'ajustement du contenu que lorsqu'elles sont explicitement demandées.
En quoi consiste ce mécanisme, justement ? La section 2 du RFC le
décrit. Un en-tête CH (Client Hint, indication
par le client) est un en-tête HTTP qui va envoyer des données
permettant au serveur de modifier le contenu. Les clients HTTP (les
navigateurs Web, par exemple) envoient les en-tête CH en fonction de
leur propre configuration, et des demandes du serveur, via l'en-tête
Accept-CH:. Le projet de spécification
« Client
Hints Infrastructure » discute de telles politiques
et donne un jeu minimal d'indications qui n'identifient pas trop le
client. Notre RFC ajoute que, par défaut, le client HTTP ne devrait
pas envoyer de données autres que celles contenues dans ce jeu
minimal. On verra bien si les navigateurs Web suivront cette
recommandation. En tout cas, le RFC insiste bien sur le risque
d'identification (fingerprinting), avec toute
technique où le client exprime des préférences. Notez qu'à l'heure
actuelle, les indications client ne sont pas encore spécifiées, mais
il existe des
propositions.
Si le client envoie des en-têtes CH (Client
Hint), le serveur peut alors ajuster son contenu. Comme
celui-ci dépend des en-têtes CH, le serveur doit penser à ajouter un
en-tête Vary: (RFC 7231,
section 7.1.4). Le serveur doit ignorer les indications qu'il ne
comprend pas (ce qui permettra d'en déployer des nouvelles sans tout
casser).
Comment est-ce que le serveur HTTP indique qu'il accepte le
système des indications client (client hints) ?
La section 3 de notre RFC décrit l'en-tête
Accept-CH: (Accept Client
Hints) qui sert à indiquer que le serveur connait bien ce
système. Il figure désormais dans le
registre des en-têtes. Accept-CH: est un
en-tête structuré (RFC 9651)
et sa valeur est une liste des indications qu'il accepte. Ainsi :
Accept-CH: CH-Example, CH-Example-again
indique que le serveur HTTP connait le système décrit dans notre RFC
et qu'il utilise deux indications client,
CH-Example et
CH-Example-again. (À l'heure actuelle, il
n'y a pas encore d'indications client normalisées, donc le RFC et
cet article utilisent des exemples bidons.)
Voici un exemple plus complet. Le serveur veut savoir quel logiciel utilise le client et sur quel système d'exploitation. Il envoie :
Accept-CH: Sec-CH-UA-Full-Version, Sec-CH-UA-Platform
(UA = User Agent, le client HTTP, il s'agit ici
de propositions
d'indications client ; Sec- et
CH- sont expliqués plus loin.) Le navigateur va
alors, dans ses requêtes suivantes, et s'il est d'accord, envoyer :
Sec-CH-UA: "Examplary Browser"; v="73" Sec-CH-UA-Full-Version: "73.3R8.2H.1" Sec-CH-UA-Platform: "Windows"
(Notez que cet exemple particulier suppose que
Sec-CH-UA: est envoyé systématiquement, même
non demandé, point qui est encore en discussion.)
Ce système des indications client pose évidemment des problèmes
de sécurité, analysés dans la section 4. D'abord, si les indications
client ont été conçues pour mieux respecter la vie privée, elles ne
sont pas non plus une solution magique. Un serveur malveillant peut
indiquer une liste très longue dans son
Accept-CH: espérant que les clients naïfs lui
enverront plein d'informations. (Notons que les chercheurs en
sécurité pourront analyser les réponses des serveurs HTTP et
compiler des listes de ceux qui abusent, contrairement au système
actuel où le serveur peut capter l'information de manière purement
passive.) Le client prudent ne doit envoyer au serveur que ce qui
est déjà accessible audit serveur par d'autres moyens (API
JavaScript par exemple). Et il doit tenir
compte des critères suivants :
- Entropie : il ne faut pas envoyer d'information rare, qui pourrait aider à identifier une machine. Indiquer qu'on tourne sur Windows n'est pas bien grave, cela n'est pas rare. Mais un client tournant sur Plan 9 ne devrait pas s'en vanter auprès du serveur.
- Sensibilité : les informations sensibles ne devraient pas être envoyées (le RFC ne donne pas d'exemple mais cela inclut certainement la localisation).
- Stabilité : les informations qui changent rapidement ne devraient pas être envoyées.
À noter que des indications apparemment utiles, comme la langue, peuvent être dangereuses ; s'il s'agit d'une langue rare, elle peut aider à l'identification d'un utilisateur, s'il s'agit de la langue d'une minorité persécutée, elle peut être une information sensible.
Le RFC recommande (reste à savoir si cela sera suivi) que les
clients HTTP devraient lier le Accept-CH: à une
origine (RFC 6454) et n'envoyer donc les informations qu'à
l'origine qui les demande. Ils devraient également être
configurables, permettant à l'utilisateur d'envoyer plus ou moins
d'informations selon son degré de méfiance. (Le RFC n'en parle pas,
mais j'ajoute que la valeur par défaut - très bavarde ou au
contraire très discrète - est un choix crucial, car peu
d'utilisateurs changeront ce réglage.) Et le RFC demande que tout
logiciel client permette également la discrétion totale, en
n'envoyant aucune indication client. (André Sintzoff me fait
remarquer à juste titre que « l'absence d'information est déjà une
information ». Signaler qu'on ne veut pas être suivi à la trace peut
vous signaler comme élement suspect, à surveiller.)
La liste des indications à envoyer pour chaque origine doit évidemment être remise à zéro lorsqu'on effectue des opérations de nettoyage, comme de supprimer les biscuits.
La même section 4 donne des conseils aux auteurs de futures
indications client. On a vu qu'à l'heure actuelle aucune n'était
encore normalisée mais des projets existent
déjà, notamment pour remplacer
User-Agent:. Un des choix cruciaux est de
décider si les indications peuvent être générées par une application
(typiquement du code JavaScript exécuté par
le navigateur Web) ou bien seulement par le client. Les secondes
sont évidemment plus sûres et c'est pour cela que leur nom est
préfixée par Sec- (pour
Secure). C'est une idée qui vient de la spécification
Fetch.
Toujours côté nommage des indications client, le RFC recommande
que le nom soit préfixé de CH- pour
Client Hints, ce qui peut permettre de les
distinguer facilement.
À l'heure actuelle, Chromium met déjà en œuvre ce système des indications client.
L'article seul
RFC 8989: Additional Criteria for Nominating Committee Eligibility
Date de publication du RFC : Février 2021
Auteur(s) du RFC : B.E. Carpenter (Univ. of Auckland), S. Farrell (Trinity College Dublin)
Expérimental
Première rédaction de cet article le 8 février 2021
L'épidémie de Covid-19 a remis en cause pas mal de choses dans nos sociétés, certaines fois très gravement. En moins dramatique, elle oblige l'IETF à adapter ses processus, étant donné qu'aucune réunion en présentiel n'a pu se tenir en 2020 et qu'on ne sait pas quand cela pourra reprendre. Or, la présence physique aux réunions était nécessaire pour se qualifier pour le NomCom, le comité de nomination. Ce RFC propose à titre expérimental de nouveaux critères de sélection. (Ces critères sont devenus officiels avec le RFC 9389.)
Ce NomCom a pour tâche, décrite dans le RFC 8713, de désigner des personnes nommées pour remplir certains rôles à l'IETF. Il est composé de volontaires qui, normalement, doivent avoir participé en présentiel à un minimum de réunions IETF. Aujourd'hui, comme vous le savez, les réunions physiques ne sont plus possibles (à l'heure où j'écris, la réunion de San Francisco est très incertaine). Ce RFC modifie donc les règles pour l'année 2021 (le RFC 8788 avait déjà traité le cas de 2020). Il est officiellement expérimental (cf. RFC 3933) ; si les vaccins tiennent leur promesse, l'idée pourra être abandonnée et on reviendra aux pratiques d'avant. Mais, à l'heure actuelle, personne ne peut faire de pronostics sérieux dans ce domaine… (En octobre 2021, l'« expérience » a été prolongée.) Peut-être faudra-t-il se résigner à une modification permanente du RFC 8713 (section 2 de notre RFC).
En attendant que le futur s'éclaircisse, les règles pour cette année sont donc modifiées (section 4). Au lieu du seul critère de présence physique aux réunions, on accepte désormais pour sièger au NomCom les gens qui ont participé aux réunions en ligne (qui nécessitent une inscription et un enregistrement de « présence »), ou bien ont été président d'un groupe de travail ou bien auteur d'au moins deux RFC dans les cinq dernières années. Comme pour le critère précédent de présence physique, le but (section 3) est de vérifier que les membres du NomCom connaissent bien l'IETF.
D'autres critères auraient été possibles, mais ont été rejetés (section 5), comme l'écriture d'Internet-Drafts ou l'envoi de messages sur les listes de diffusion de l'IETF. Notez que la qualité des contributions à l'IETF ne rentre pas en ligne de compte, car elle est subjective.
Pour déterminer la liste des critères, le RFC se fonde sur une analyse de données (annexe A). Les données de départ ne sont pas parfaites (si quelqu'un s'inscrit à une réunion sous le nom de John Smith et à la suivante en mettant J. A. Smith, il apparaitra comme deux personnes différentes) mais c'est mieux que rien. Les jolis diagrammes de Venn en art ASCII montrent que les nouveaux critères permettent en effet d'élargir l'ensemble des volontaires potentiels, et que les critères rejetés n'auraient de toute façon pas eu d'influence.
L'expérience a fait l'objet d'un rapport publié en septembre 2021.
L'article seul
RFC 8959: The "secret-token" URI Scheme
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : M. Nottingham
Pour information
Première rédaction de cet article le 30 janvier 2021
Enregistrer une clé
privée (ou tout autre secret) dans un dépôt public (par
exemple sur GitHub) est un gag courant. La
nature des VCS fait qu'il est souvent difficile de
retirer cette clé. Pour limiter un peu les dégâts, ce RFC enregistre
un nouveau plan d'URI, secret-token:, qui
permettra de marquer ces secrets, autorisant par exemple le VCS à
rejeter leur enregistrement.
Ce RFC se
focalise sur les secrets qui sont « au porteur » (bearer
tokens) c'est-à-dire que leur seule connaissance suffit à
les utiliser ; aucune autre vérification n'est faite. Ce peut être
un mot de passe, une clé d'API, etc. Voici un
exemple avec une clé GitLab (je vous rassure,
je l'ai révoquée depuis) : 
La révélation de ces secrets via un enregistrement accidentel,
par exemple dans un dépôt logiciel public, est un grand
classique. Lisez par exemple le témoignage « I
Published My AWS Secret Key to GitHub », ou une
aventure similaire, « Exposing
your AWS access keys on Github can be extremely costly. A personal
experience. », un avertissement
de Github à ses utilisateurs, ou enfin une étude
détaillée publiée à NDSS. Un git add de
trop (ou bien un secret mis dans le code source) et, au prochain
commit, le secret se
retrouve dans le dépôt, puis publié au premier git
push.
L'idée de ce RFC est de marquer clairement ces secrets pour que, par exemple, des audits du dépôt les repèrent plus facilement. Ou pour que les systèmes d'intégration continue puissent les rejeter automatiquement.
Le plan d'URI est simple (section 2 du RFC) :
la chaîne secret-token: suivie du secret. Un
exemple serait
secret-token:E92FB7EB-D882-47A4-A265-A0B6135DC842%20foo
(notez l'échappement du caractère
d'espacement). Par exemple avec les secrets au porteur
pour HTTP
du RFC 6750, cela donnerait un envoi au serveur :
GET /authenticated/stuff HTTP/1.1 Host: www.example.com Authorization: Bearer secret-token:E92FB7EB-D882-47A4-A265-A0B6135DC842%20foo
Le plan secret-token: est désormais dans le
registre IANA.
Je n'ai pas encore trouvé d'organisation qui distribue ces secrets au porteur en utilisant ce plan d'URI mais il semble que GitHub soit tenté.
L'article seul
RFC 8977: Registration Data Access Protocol (RDAP) Query Parameters for Result Sorting and Paging
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : M. Loffredo (IIT-CNR/Registro.it), M. Martinelli (IIT-CNR/Registro.it), S. Hollenbeck (Verisign Labs)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 24 janvier 2021
Le protocole RDAP, normalisé notamment dans les RFC 9082 et RFC 9083, permet de récupérer des informations structurées sur des trucs (oui, j'ai écrit « trucs ») enregistrés auprès d'un registre, par exemple des domaines auprès d'un registre de noms de domaine. Voici un RFC tout juste publié qui ajoute à RDAP la possibilité de trier les résultats et également de les afficher progressivement (paging). C'est évidemment surtout utile pour les requêtes de type « recherche », qui peuvent ramener beaucoup de résultats.
Avec des requêtes « exactes » (lookup dans le RFC 9082), le problème est moins grave. Ici, je cherche juste de l'information sur un nom de domaine et un seul :
% curl https://rdap.nic.bzh/domain/chouchen.bzh
...
"events" : [
{
"eventDate" : "2017-07-12T10:18:12Z",
"eventAction" : "registration"
},
{
"eventDate" : "2020-07-09T09:49:06Z",
"eventAction" : "last changed"
},
...
Mais si je me lançais dans une recherche plus ouverte
(search dit le RFC 9082),
avec par exemple la requête domains (notez le S
à la fin, cf. RFC 9082, section 3.2.1), le
nombre de résultats pourrait être énorme. Par exemple, si je
demandais tous les domaines en
.bzh avec
https://rdap.nic.bzh/rdap/domains?name=*.bzh,
j'aurais une réponse d'une taille conséquente. (Et je ne vous dis pas
pour .com…)
En pratique, cette requête ne fonctionnera pas car je ne connais aucun registre qui autorise les recherches RDAP aux utilisateurs anonymes. Ceux-ci ne peuvent faire que des requêtes exactes, à la fois pour épargner les ressources informatiques (cf. la section 7 du RFC sur la charge qu'impose les recherches), et pour éviter de distribuer trop d'informations à des inconnus pas toujours bien intentionnés. Pour effectuer ces recherches, il faut donc un compte et une autorisation. Autrement, vous récupérez un code 401, 403 ou bien carrément une liste vide.
Et si vous avez une telle autorisation, comment gérer une masse importante de résultats ? Avec le RDAP originel, vous récupérez la totalité des réponses, que vous devrez analyser, et ce sera à vous, client, de trier. (Si le serveur n'envoie qu'une partie des réponses, pour épargner le client et ses propres ressources, il n'a malheureusement aucun moyen de faire savoir au client qu'il a tronqué la liste.) C'est tout le but de notre RFC que de faire cela côté serveur. Des nouveaux paramètres dans la requête RDAP vont permettre de mieux contrôler les réponses, ce qui réduira les efforts du client RDAP, du serveur RDAP et du réseau, et permettra d'avoir des résultats plus pertinents.
La solution ? La section 2 de notre RFC décrit les nouveaux paramètres :
count: le client demande à être informé du nombre de trucs que contient la liste des réponses.sort: le client demande à trier les résultats.cursor: ce paramètre permet d'indiquer un endroit particulier de la liste (par exemple pour la récupérer progressivement, par itérations successives).
Par exemple,
https://example.com/rdap/domains?name=example*.com&count=true
va récupérer dans .com (si le registre de
.com acceptait cette requête…) tous les noms de
domaine dont le nom commence par example, et
indiquer leur nombre. Une réponse serait, par exemple :
"paging_metadata": {
"totalCount": 43
},
"domainSearchResults": [
...
]
(paging_metadata est expliqué plus loin.)
Pour le paramètre sort, le client peut
indiquer qu'il veut un tri, sur quel critère se fait le tri, et que
celui-ci doit être dans l'ordre croissant (a
pour ascending) ou décroissant
(d pour descending). Ainsi,
https://example.com/rdap/domains?name=*.com&sort=name
demande tous les noms en .com triés par
nom. https://example.com/rdap/domains?name=*.com&sort=registrationDate:d
demanderait tous les noms triés par date d'enregistrement, les plus
récents en premier.
L'ordre de tri dépend de la valeur JSON du résultat (comparaison
lexicographique
pour les chaînes de caractères et numérique pour les nombres), sauf
pour les adresses IP, qui
sont triées selon l'ordre des adresses et pour les dates qui sont
triées dans l'ordre chronologique. Ainsi, l'adresse
9.1.1.1 est inférieure à
10.1.1.1 (ce qui n'est pas le cas dans l'ordre
lexicographique). Le RFC fait remarquer que tous les SGBD
sérieux ont des fonctions pour traiter ce cas. Ainsi, dans
PostgreSQL, la comparaison des deux chaînes
de caractères donnera :
=> SELECT '10.1.1.1' < '9.1.1.1'; t
Alors que si les adresses IP sont mises dans une colonne ayant le
type correct (INET), on a le bon résultat :
=> SELECT '10.1.1.1'::INET < '9.1.1.1'::INET; f
Après le sort=, on trouve le nom de la
propriété sur laquelle on trie. C'est le nom d'un membre de l'objet
JSON de la réponse. Non, en fait, c'est plus compliqué que
cela. Certains membres de la réponse ne sont pas utilisables (comme
roles, qui est multi-valué) et des informations
importantes (comme registrationDate cité en
exemple plus haut) ne sont pas explicitement dans la réponse. Notre
RFC définit donc une liste de propriétés utilisables, et explique
comment on les calcule (par exempe,
registrationDate peut se déduire des
events). Plutôt que ces noms de propriétés, on
aurait tout pu faire en JSONpath ou JSON
Pointer (RFC 6901) mais ces deux syntaxes sont
complexes et longues
($.domainSearchResults[*].events[?(@.eventAction='registration')].eventDate
est le JSONPath pour registrationDate). La
mention en JSONPath du critère de tri est donc facultative.
Et, bien sûr, si le client envoie un nom de propriété qui n'existe pas, il récupérera une erreur HTTP 400 avec une explication en JSON :
{
"errorCode": 400,
"title": "Domain sorting property 'unknown' is not valid",
"description": [
"Supported domain sorting properties are:"
"'aproperty', 'anotherproperty'"
]
}
Et le troisième paramètre, cursor ? Ce RFC
fournit deux méthodes pour indiquer où on en est dans la liste des
résultats, la pagination par décalage (offset
pagination) et celle par clé (keyset
pagination, qu'on trouve parfois
citée sous le nom ambigu de cursor
pagination, qui désigne plutôt une méthode avec état sur
le serveur). Ces deux méthodes ont en commun de ne
pas nécessiter d'état du côté du serveur. La
pagination par décalage consiste à fournir un décalage depuis le
début de la liste et un nombre d'éléments désiré, par exemple
« donne-moi 3 éléments, commençant au numéro 10 ». Elle est simple à
mettre en œuvre, par exemple avec SQL :
SELECT truc FROM Machins ORDER BY chose LIMIT 3 OFFSET 9;
Mais elle n'est pas forcément robuste si la base est modifiée pendant ce temps : passer d'une page à l'autre peut faire rater des données si une insertion a eu lieu entretemps (cela dépend aussi de si la base est relue à chaque requête paginée) et elle peut être lente (surtout avec RDAP où la construction des réponses prend du temps, alors que celles situées avant le début de la page seront jetées). L'autre méthode est la pagination par clé où on indique une caractéristique du dernier objet vu. Si les données sont triées, il est facile de récupérer les N objets suivants. Par exemple en SQL :
SELECT truc FROM Machins WHERE chose > [la valeur] ORDER BY chose LIMIT 3;
Un inconvénient de cette méthode est qu'il faut un champ (ou un
ensemble de champs) ayant un ordre (et pas de duplicata). RDAP rend
cela plus difficile, en agrégeant des informations provenant de
différentes tables (cf. l'annexe B du RFC). (Voir des descriptions
de cette pagination par clé dans « Paginating
Real-Time Data with Keyset Pagination » ou
« Twitter
Ads API », pour Twitter.)
RDAP permet les deux méthodes, chacune ayant ses avantages et ses
inconvénients. L'annexe B du RFC explique plus en détail ces
méthodes et les choix faits. (Sinon, en dehors de RDAP, un bon
article sur le choix d'une méthode de pagination, avec leur mise en
œuvre dans PostgreSQL est « Five
ways to paginate in Postgres, from the basic to the
exotic ».) Pour RDAP, un
https://example.com/rdap/domains?name=*.com&cursor=offset:9,limit:3
récupérerait une page de trois éléments, commençant au dixième, et
https://example.com/rdap/domains?name=*.com&cursor=key:foobar.com
trouverait les noms qui suivent foobar.com.
Notez qu'en réalité, vous ne verrez pas directement le décalage, la
clé et la taille de la page dans l'URL : ils sont encodés pour
permettre d'utiliser des caractères quelconques (et aussi éviter que
le client ne les bricole, il est censé suivre les liens, pas
fabriquer les URL à la main). Les exemples du RFC utilisent
Base64 pour l'encodage, en notant qu'on peut
certainement faire mieux.
La capacité du serveur à mettre en œuvre le tri et la pagination
s'indiquent dans le tableau rdapConformance
avec les chaînes sorting et
paging (qui sont désormais dans le
registre IANA). Par exemple (pagination mais pas tri) :
"rdapConformance": [
"rdap_level_0",
"paging"
]
Il est recommandé que le serveur documente ces possibilités dans
deux nouveaux éléments qui peuvent être présents dans une réponse,
sorting_metadata et
paging_metadata. Cela suit les principes
d'auto-découverte de HATEOAS. Dans la
description sorting_metadata, on a
currentSort qui indique le critère de tri
utilisé, et availableSorts qui indique les
critères possibles. Chaque critère est indiqué avec un nom
(property), le fait qu'il soit le critère par
défaut ou pas, éventuellement une expression JSONPath
désignant le champ de la réponse utilisé et enfin une série de liens
(RFC 8288) qui vont nous indiquer les URL à
utiliser. Pour paging_metadata, on a
totalCount qui indique le nombre d'objets
sélectionnés, pageSize qui indique le nombre
récupérés à chaque itération, pageNumber qui
dit à quelle page on en est et là encore les liens à suivre. Ce
pourrait, par exemple, être :
"sorting_metadata": {
"currentSort": "name",
"availableSorts": [
{
"property": "registrationDate",
"jsonPath": "$.domainSearchResults[*].events[?(@.eventAction==\"registration\")].eventDate",
"default": false,
"links": [
{
"value": "https://example.com/rdap/domains?name=example*.com&sort=name",
"rel": "alternate",
"href": "https://example.com/rdap/domains?name=example*.com&sort=registrationDate",
"title": "Result Ascending Sort Link",
"type": "application/rdap+json"
},
{
"value": "https://example.com/rdap/domains?name=example*.com&sort=name",
"rel": "alternate",
"href": "https://example.com/rdap/domains?name=example*.com&sort=registrationDate:d",
"title": "Result Descending Sort Link",
"type": "application/rdap+json"
}
]
...
Ici, sorting_metadata nous indique que le tri
se fera sur la base du nom, mais nous donne les URL à utiliser pour
trier sur la date d'enregistrement. Quant à la pagination, voici un
exemple de réponse partielle, avec les liens permettant de récupérer
la suite :
"paging_metadata": {
"totalCount": 73,
"pageSize": 50,
"pageNumber": 1,
"links": [
{
"value": "https://example.com/rdap/domains?name=example*.com",
"rel": "next",
"href": "https://example.com/rdap/domains?name=example*.com&cursor=wJlCDLIl6KTWypN7T6vc6nWEmEYe99Hjf1XY1xmqV-M=",
"title": "Result Pagination Link",
"type": "application/rdap+json"
}
]
L'idée de permettre le contrôle des réponses via des nouveaux
paramètres (count, sort et
cursor, présentés ci-dessus), vient entre autre
du protocole OData. Une autre solution aurait
été d'utiliser des en-têtes HTTP (RFC 7231). Mais
ceux-ci ne sont pas contrôlables depuis le
navigateur, ce qui aurait réduit le nombre de
clients possibles. Et puis cela rend plus difficile
l'auto-découverte des extensions, qui est plus pratique via des
URL, cette
auto-découverte étant en général considérée comme une excellente
pratique REST.
Il existe à l'heure actuelle une seule mise en œuvre de ce RFC
dans le RDAP non public de .it.
La documentation est en ligne.
Notre RFC permet donc de ne récupérer qu'une partie des objets qui correspondent à la question posée. Si on veut plutôt récupérer une partie seulement de chaque objet, il faut utiliser le RFC 8982.
L'article seul
RFC 8963: Evaluation of a Sample of RFCs Produced in 2018
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : C. Huitema (Private Octopus)
Pour information
Première rédaction de cet article le 23 janvier 2021
On raconte souvent que la publication d'un RFC prend longtemps, très longtemps, trop longtemps, et on dit parfois que cela est dû à une bureaucratie excessive dans le processus de publication. Peut-on objectiver cette opinion ? Dans ce RFC, l'auteur étudie le trajet de plusieurs RFC (pris au hasard) publiés en 2018 et regarde où étaient les goulets d'étranglement, et ce qui a pris du temps. Les RFC étudiés ont mis en moyenne trois ans et quatre mois à être publiés, depuis le premier document écrit jusqu'à la publication finale. (Mais il y a de grandes variations.) La majorité du temps est passée dans le groupe de travail, ce ne sont donc pas forcément les étapes « bureaucratiques » qui retardent.
Heureusement pour cette étude, le DataTracker enregistre les différentes étapes de la vie d'un document et permet donc au chercheur de travailler sur des données solides. Mais attention, si les données sont fiables, leur interprétation est toujours délicate. Et, si une métrique devient un objectif, elle cesse d'être une bonne métrique. Si l'IETF ne cherchait qu'à raccourci le délai de publication, ce serait simple, il suffirait d'approuver sans discussion et immédiatement toutes les propositions, même mauvaises. (Ce qu'on nomme le rubber stamping en anglais.)
La section 2 expose la méthodologie suivie. D'abord, déterminer les dates importantes dans la vie d'un RFC. Tous les RFC ne suivent pas le même parcours, loin de là. Le cas typique est celui d'un document individuel, qui est ensuite adopté par un groupe de travail, approuvé par l'IESG, puis publié par le RFC Editor. Dans cette analyse, trois périodes sont prises en compte :
- Le temps de traitement dans le groupe de travail, qui part de la première publication et s'arrête au dernier appel à l'IETF,
- Le temps de traitement par l'IETF, qui part du dernier appel à l'IETF et se termine par l'approbation par l'IESG,
- Le temps de traitement par le RFC Editor, qui part de l'approbation par l'IESG et se termine par la publication en RFC.
Ainsi, pour le dernier RFC publié au moment où j'écris cet article (et qui n'est donc pas pris en compte dans l'analyse, qui couvre des RFC de 2018), pour ce RFC 9003, on voit sur le DataTracker qu'il a été documenté pour la première fois en décembre 2017, adopté par un groupe de travail en avril 2018, soumis à l'IESG en avril 2020, a eu un IETF Last Call en juin 2020, a été approuvé par l'IESG en novembre 2020 et enfin publié en RFC début janvier 2021. Mais beaucoup d'autres RFC suivent un autre parcours. Pour la voie indépendante (décrite dans le RFC 4846), l'analyse de ce RFC 8963 considère l'approbation par l'ISE (Independent Submission Editor) comme terminant la première période et l'envoi au RFC Editor comme terminant la deuxième.
Les vingt RFC qui sont utilisés dans l'étude ont été pris au hasard parmi ceux publiés en 2018. Le RFC reconnait que c'est un échantillon bien petit mais c'est parce que les données disponibles ne fournissaient pas toutes les informations nécessaires et qu'il fallait étudier « manuellement » chaque RFC, ce qui limitait forcément leur nombre. Je ne vais pas lister ici tous les RFC étudiés, juste en citer quelques uns que je trouve intéressant à un titre ou l'autre :
- Le RFC 8446 est un très gros morceau. C'est la nouvelle version d'un protocole absolument critique, TLS. Non seulement le RFC est gros et complexe, mais le souci de sécurité a entrainé des études particulièrement poussées. Et, pour couronner le tout, ce RFC a été au cœur de polémiques politiques, certains reprochant à cette version de TLS d'être trop efficace, d'empêcher d'accéder aux données. La phase finale chez le RFC Editor, dite « AUTH48 » (car elle se fait normalement en 48 heures…) n'a pas pris moins de deux mois ! C'est en partie dû à une nouveauté de l'époque, utiliser GitHub pour suivre les changements à apporter. Pour chaque RFC étudié, l'auteur note également son succès ou insuccès en terme de déploiement et TLS 1.3 est un succès massif, avec des dizaines de mises en œuvre différentes et une présence très forte sur l'Internet.
- Le RFC 8324 est un cas très différent. Consacré à une série d'opinions sur le DNS et ses évolutions récentes, il ne s'agit pas, contrairement au précédent, d'une norme IETF, mais d'une contribution individuelle. N'engageant que son auteur, elle ne nécessite pas le même niveau d'examen. C'est donc ce RFC qui est le titulaire du record dans l'étude : neuf mois seulement entre la première publication et le RFC.
- Le RFC 8429 avait pour but de documenter l'abandon de plusieurs protocoles de cryptographie désormais dépassés. A priori très simple et très consensuel, il a été retardé par une discussion plus bureaucratique à propos de ses conséquences exactes sur le RFC 4757, puis par un délai très long d'un des auteurs à répondre lors de la phase finale (« AUTH48 » a pris trois mois).
- Le RFC 8312 portait aussi sur un sujet consensuel, l'algorithme de lutte contre la congestion CUBIC étant aujourd'hui largement adopté. Mais il a quand même pris des années, en partie car, justement, CUBIC étant consensuel et largement déployé, il ne semblait pas crucial de le documenter. (Rappelez-vous que le travail à l'IETF est fait par des volontaires.)
- Le RFC 8492 a également pris longtemps car c'était un projet individuel, dont l'auteur n'avait pas le temps de s'occuper, ce qui explique des longs délais à certains points. En outre, il a été retardé par la nécessité d'attendre un changement de politique d'enrgistrements dans certains registres à l'IANA, changements qui dépendaient de TLS 1.3, qui prenait du temps.
- Un autre RFC qui a souffert du fait que même ses auteurs ne le considéraient pas comme urgent a été le RFC 8378, un projet très expérimental et dont la publication en RFC a pris plus de quatre ans.
- Un des buts de l'étude était de voir s'il y avait une corrélation entre le délai total et certaines caractéristiques du RFC, par exemple sa longueur. Mais le RFC 8472, quoique simple, a pris plus de trois ans, en partie pour un problème bureaucratique sur le meilleur groupe de travail à utiliser.
- En revanche, le RFC 8362 n'a pas de mal à expliquer le temps qu'il a pris : il modifie sérieusement le protocole OSPF et nécessite des mécanismes de transition depuis les anciennes versions, qui ont eux-même pris du temps.
Bien, après cette sélection d'un échantillon de RFC, qu'observe-t-on (section 4 de notre RFC) ? Le délai moyen entre le premier Internet Draft et la publication en RFC est de trois ans et trois mois. Mais les variations sont telles que cette moyenne n'a guère de sens (c'est souvent le cas avec la moyenne). Le plus malheureux est le RFC 8492, six ans et demi au total, mais ce cas n'est pas forcément généralisable. Pour les RFC de l'IETF, où le délai moyen est presque le même, le temps passé dans le groupe de travail est de deux ans et neuf mois, à l'IESG de trois à quatre mois et à peu près pareil chez le RFC Editor. Bref, 80 % du temps se passe en « vrai » travail, dans le groupe, les passages plus « bureaucratiques » n'occupent que 20 % du temps et ne sont donc pas les principaux responsables des délais.
L'étude regarde aussi des échantillons de RFC publiés en 2008 et en 1998 (en utilisant cette fois, à juste titre, des valeurs médianes) et note que le délai était à peu près le même en 2008 mais qu'il était trois à quatre fois plus court en 1998.
Et la partie purement éditoriale, chez le RFC Editor ? On a vu qu'elle prenait de trois à quatre mois. C'est quatre en moyenne mais si on exclut l'extrême RFC 8492, c'est plutôt trois mois, ce que je trouve plutôt court pour relire et préparer des documents longs et complexes, où une coquille peut être très gênante (ce ne sont pas des romans !) Quelles sont les caractéristiques des RFC que l'on pourrait corréler à ce délai chez le RFC Editor ? L'étude montre une corrélation entre le délai et la longueur du document, ce qui n'est pas surprenant. Même chose pour la corrélation entre le nombre de changements faits depuis l'approbation par l'IESG et la publication. (Une des tâches du RFC Editor est de faire en sorte que les RFC soient en bon anglais alors que beaucoup d'auteurs ne sont pas anglophones.) Plus étonnant, le nombre d'auteurs ne diminue pas le délai, au contraire, il l'augmente. Un nouveau cas de « quand on ajoute des gens au projet, le projet n'avance pas plus vite » ? Il ne faut pas oublier qu'il existe une zone grise entre « changement purement éditorial », où le RFC Editor devrait décider, et « changement qui a des conséquences techniques » et où l'approbation des auteurs est cruciale. Il n'est pas toujours facile de s'assurer de la nature d'un changement proposé par le RFC Editor. Et, si le changement a des conséquences techniques, il faut mettre les auteurs d'accord entre eux, ce qui est long (ils peuvent être dans des fuseaux horaires différents, avec des obligations professionnelles différentes) et peut soulever des désaccords de fond.
Et pour la voie indépendante ? Trois des RFC de l'échantillon étaient sur cette voie. Ils ont été publiés plus vite que sur la voie IETF, ce qui est logique puisqu'ils ne nécessitent pas le consensus de l'IETF (voir le RFC 8789). En revanche, le fait que la fonction d'ISE (Independant Stream Editor, cf. RFC 8730) soit une tâche assurée par un seul volontaire peut entrainer des retards ce qui a été le cas, ironiquement, de ce RFC 8963.
L'étude se penche aussi sur le nombre de citations dont bénéficie chaque RFC (section 5) car elle peut donner une idée sommaire de leur impact. Elle a utilisé l'API de Semantic Scholar. Par exemple, pour le RFC 8483, publié l'année de l'étude mais pas inclus dans l'échantillon :
% curl -s https://api.semanticscholar.org/v1/paper/10.17487/rfc8483\?include_unknown_references=true \ jq .
On voit qu'il est cité une fois, précisément par ce RFC. En revanche, le RFC 8446, sur TLS 1.3 est cité pas moins de 773 fois :
% curl -s https://api.semanticscholar.org/v1/paper/10.17487/rfc8446\?include_unknown_references=true | \ jq .citations\|length 773
C'est de très loin le plus « populaire » dans le corpus (l'échantillon étudié). C'est bien sûr en partie en raison de l'importance critique de TLS, mais c'est aussi parce que TLS 1.3 a été étudié par des chercheurs et fait l'objet d'une validation formelle, un sujet qui génère beaucoup d'articles dans le monde académique. C'est aussi le cas du RFC 8312, sur Cubic, car la congestion est également un sujet de recherche reconnu. Notez que le passage du temps est impitoyable : les RFC des échantillons de 2008 et 1998 ne sont quasiment plus cités (sauf le RFC 2267, qui résiste). Est-ce que le nombre de citations est corrélé à l'ampleur du déploiement ? Dans le cas des RFC 8446 et RFC 8312, on pourrait le croire, mais le RFC 8441 a également un très vaste déploiement, et quasiment aucune citation. À l'inverse, un RFC qui a un nombre de citations record, le RFC 5326, n'a quasiment pas eu de déploiement, mais a excité beaucoup de chercheurs académiques (et même médiatique, vu son sujet cool), ce qui explique le nombre de citations. Bref, le monde de la recherche et celui des réseaux n'ont pas des jugements identiques.
On avait noté que le RFC 2267 était beaucoup cité. Or, il n'est plus d'actualité, ayant officiellement été remplacé par le RFC 2827. Mais les citations privilégient la première occurrence, et ne reflètent donc pas l'état actuel de la normalisation.
Bon, on a vu que les citations dans le monde de la recherche ne reflétaient pas réellement l'« importance » d'un RFC. Et le nombre d'occurrences dans un moteur de recherche, c'est mieux ? L'auteur a donc compté le nombre de références aux RFC dans Google et Bing. Il y a quelques pièges. Par exemple, en cherchant « RFC8441 », Bing trouve beaucoup de références à ce RFC 8441, qui parle de WebSockets, mais c'est parce qu'il compte des numéros de téléphone se terminant par 8441, ou des adresses postales « 8441 Main Street ». Google n'a pas cette amusante bogue. Ceci dit, il est noyé par le nombre très élevé de miroirs des RFC, puisque l'IETF permet et encourage ces copies multiples (contrairement aux organisations de normalisation fermées comme l'AFNOR). Ceci dit, les RFC 8441 et RFC 8471 sont plus souvent cités, notamment car ils apparaissent fréquemment dans les commentaires du code source d'un logiciel qui les met en œuvre. Le « test Google » est donc assez pertinent pour évaluer le déploiement effectif.
Quelles conclusions en tirer (section 6 du RFC) ? D'abord, si on trouve le délai de publication trop long, il faut se focaliser sur le temps passé dans le groupe de travail, car c'est clairement le principal contributeur au délai. [En même temps, c'est logique, c'est là où a lieu le « vrai » travail.] Malheureusement, c'est là où le DataTracker contient le moins d'information alors que les phases « bureaucratiques » comme le temps passé à l'IESG bénéficient d'une traçabilité plus détaillée. Ainsi, on ne voit pas les derniers appels (Last Calls) internes aux groupes de travail. Bien sûr, on pourrait rajouter ces informations mais attention, cela ferait une charge de travail supplémentaire pour les présidents des groupes de travail (des volontaires). Récolter des données pour faire des études, c'est bien, mais cela ne doit pas mener à encore plus de bureaucratie.
Du fait que l'étude ne porte que sur des RFC effectivement publiés, elle pourrait être accusée de sensibilité au biais du survivant. Peut-être que les RFC qui n'ont pas été publiés auraient aussi des choses à nous dire ? L'abandon d'un projet de normalisation est fréquent (pensons par exemple à DBOUND ou RPZ) et parfaitement normal et souhaitable ; toutes les idées ne sont pas bonnes et le travail de tri est une bonne chose. Mais, en n'étudiant que les RFC publiés, on ne peut pas savoir si le tri n'a pas été trop violent et si de bonnes idées n'en ont pas été victimes. L'IETF ne documente pas les abandons et une étude de drafts sans successeur pourrait être intéressante.
Pour terminer, je me suis amusé à regarder ce qu'il en était des trois RFC que j'ai écrit :
- Le RFC 7626 a été publié moins de deux ans après le premier document ce qui, on l'a vu, est inférieur à la moyenne. Fortement poussé par l'engagement de l'IETF à agir après les révélations de Snowden, il n'a guère connu d'obstacles.
- Le RFC 7816 a pris deux ans. Il a passé à peine plus d'un mois chez le RFC Editor, ce qui est très peu. Comme le précédent, il faisait partie d'un projet porteur, visant à améliorer le respect de la vie privée dans le DNS. Il a connu des objections techniques mais son statut « Expérimental » ne nécessite pas une solution parfaite. Une partie du temps a été passée dans un problème dont le RFC 8963 ne parle pas : une histoire de brevets et de négociations juridico-politiques.
- Le RFC 8020 est le seul des trois à être sur le chemin des normes, en théorie bien plus exigeant. Mais il bat tous les records en n'ayant mis qu'un an à être publié. C'est en partie parce qu'il est simple, et relativement consensuel (il y a quand même eu des objections, par exemple sur le danger qu'il pouvait poser si la zone n'était pas signée avec DNSSEC).
L'article seul
RFC 8975: Network Coding for Satellite Systems
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : N. Kuhn (CNES), E. Lochin (ENAC)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF nwcrg
Première rédaction de cet article le 23 janvier 2021
Prenons de la hauteur (c'est le cas de le dire). Les communications via satellite posent des tas de problèmes techniques. L'envoi de chaque bit coûte cher, et dans certains cas d'usage, les pertes de paquets sont nombreuses, et on cherche donc à optimiser. Ce RFC explique comment on peut utiliser le network coding pour améliorer les performances de ces liaisons. Mais c'est encore un travail en cours.
Le network coding est un mécanisme d'encodage des données qui combine différentes données dans une même chaîne de bits, avant de les re-séparer à l'autre bout. Dans le cas le plus trivial on fait un XOR des données. Mais il y a d'autres moyens comme la convolution. Le network coding n'est pas un algorithme unique mais une classe de méthodes. Ces méthodes permettent de faire voyager davantage de données sur un même canal et/ou de diminuer le délai de transmission total, en ajoutant de la redondance. Le nom de network coding venait de l'encodage réalisé dans le réseau, pour tenir compte de sa topologie. Mais on peut utiliser des techniques du même genre de bout en bout (c'est le cas de FEC, dans le RFC 5052). (Je vous laisse en apprendre davantage sur Wikipédia). La question de l'encodage des données étant complexe, je vous renvoie également au RFC 8406 qui décrit le travail du groupe Network Coding de l'IRTF et définit les notions importantes.
Une idée de la latence dans une liaison satellite ? Le RFC observe que le RTT est typiquement de 0,7 secondes (deux passages par le satellite, la limite de la vitesse de la lumière, et le temps de traitement).
On peut se servir des satellites pour des tas de choses dans le domaine des télécommunications mais ce RFC se focalise sur l'accès à l'Internet par satellite, tel que normalisé par l'ETSI dans « Digital Video Broadcasting (DVB); Second Generation DVB Interactive Satellite System (DVB-RCS2); Part 2: Lower Layers for Satellite standard ». (Le RFC recommande également l'article de Ahmed, T., Dubois, E., Dupe, JB., Ferrus, R., Gelard, P., et N. Kuhn, « Software-defined satellite cloud RAN ».)
Le RFC décrit des scénarios où le network coding permet de gagner en capacité et en latence effective, en encodant plus efficacement les communications. Par exemple, en combinant le trafic de deux utilisateurs, on obtient parfois une quantité de données à transmettre qui est inférieure à celle de deux transmissions séparées, économisant ainsi de la capacité. Le RFC cite également l'exemple du multicast où, lorsqu'un des destinataires n'a pas reçu un paquet, on peut, pour éviter de faire attendre tout le monde, utiliser le network coding pour ré-envoyer les données en même temps que la suite du transfert. Là encore, la combinaison de toutes les données fait moins d'octets que lors de transmissions séparées. Cela pourrait s'adapter à des protocoles multicast comme NORM (RFC 5740) ou FLUTE (RFC 6726).
Le network coding permet également d'ajouter de la redondance aux données, sinon gratuitement, du moins à un « coût » raisonnable. Cela peut servir pour les cas de pertes de données comme le précédent. Un autre cas de perte est celui où la liaison satellite marche bien mais c'est tout près de l'utilisateur, par exemple dans son WiFi, que les paquets se perdent. Vu la latence très élevée des liaisons satellite, réémettre a des conséquences très désagréables sur la capacité effective (et sur le délai total). Une solution traditionnellement utilisée était le PEP (qui pose d'ailleurs souvent des problèmes de neutralité). Vous pouvez voir ici un exemple où le résultat est plutôt bon. Mais avec le chiffrement systématique, ces PEP deviennent moins efficaces. Cela redonne toute son importance au network coding.
Enfin, des pertes de paquets, avec leurs conséquences sur la latence car il faudra réémettre, se produisent également quand un équipement terminal passe d'une station de base à l'autre. Là encore, le network coding peut permettre d'éviter de bloquer le canal pendant la réémission.
Tout cela ne veut pas dire que le network coding peut être déployé immédiatement partout et va donner des résultats mirifiques. La section 4 du RFC décrit les défis qui restent à surmonter. Par exemple, les PEP (RFC 3135) ont toujours un rôle à jouer dans la communication satellitaire mais comment combiner leur rôle dans la lutte contre la congestion avec le network coding ? Faut-il réaliser cet encodage dans le PEP (RFC 9265) ? D'autre part, le network coding n'est pas complètement gratuit. Comme tout ajout de redondance, il va certes permettre de rattrapper certaines pertes de paquet, mais il occupe une partie du réseau. Et dans quelle couche ajouter cette fonction ? (Les couches hautes ont l'avantage de fenêtres - le nombre d'octets en transit - plus grandes, alors que les couches basses ne voient pas plus loin que le bout du paquet.)
Outre l'utilisation de satelittes pour la connectivité Internet des Terriens, il y a aussi une utilisation des communications spatiales pour échanger avec des vaisseaux lointains. La latence très élevée et l'indisponibilité fréquente de la liaison posent des défis particuliers. C'est ce qu'on nomme le DTN (Delay/Disruption Tolerant Network, décrit dans le RFC 4838). Le network coding peut aussi être utilisé ici, comme présenté dans l'article de Thai, T., Chaganti, V., Lochin, E., Lacan, J., Dubois, E., et P. Gelard, « Enabling E2E reliable communications with adaptive re-encoding over delay tolerant networks ».
Et, comme le rappelle la section 9 du RFC, il faut aussi tenir compte du chiffrement, qui est évidemment obligatoire puisque les liaisons avec les satellites peuvent trop facilement être écoutées.
Merci à Nicolas Kuhn et Emmanuel Lochin pour leur relecture attentive, sans laquelle il y aurait bien plus d'erreurs. (Je me suis aventuré très en dehors de mon domaine de compétence.) Les erreurs qui restent sont évidemment de mon fait.
L'article seul
RFC 8972: Simple Two-Way Active Measurement Protocol Optional Extensions
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : G. Mirsky, X. Min (ZTE Corp), H. Nydell (Accedian Networks), R. Foote (Nokia), A. Masputra (Apple), E. Ruffini (OutSys)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF ippm
Première rédaction de cet article le 22 janvier 2021
Le protocole STAMP, normalisé dans le RFC 8762, est un protocole pour piloter des mesures de performance vers un réflecteur qui renverra les paquets de test. Ce nouveau RFC étend STAMP pour ajouter un identificateur de session, et la possibilité d'ajouter des tas d'options sous forme de TLV.
Commençons par l'identificateur de session. Une session STAMP est normalement identifiée par le tuple classique {protocole (forcément UDP), adresse IP source, adresse IP destination, port source, port destination}. Ce n'est pas toujours pratique donc notre RFC ajoute un identificateur explicite, le SSID (STAMP Session Identifier). Il fait deux octets et est choisi par l'envoyeur. Mais où le mettre dans le paquet ? Le format original prévoyait qu'une partie du paquet STAMP soit composée de zéros, et c'est dans cette partie qu'on logera le SSID. Donc, si, après l'estimation de l'erreur de mesure, on trouve deux octets qui ne sont pas nuls, c'est le SSID.
La section 4 liste les TLV qui peuvent désormais être ajoutés aux paquets STAMP. Ces TLV sont situés à la fin du paquet STAMP. Ils commencent par une série de bits qui indiquent si le réflecteur connait le TLV en question, et si le réflecteur a détecté des problèmes par exemple un TLV à la syntaxe incorrecte (cf. le registre IANA). Les principaux TLV sont :
- Le type 1 permet de faire du remplissage, pour créer des paquets de la taille souhaitée,
- Le type 2 demande au réflecteur des informations sur son adresse MAC et autres identificateurs,
- Le type 3 demande une estampille temporelle (avec en prime indication de la méthode de synchronisation d'horloge utilisée, par exemple NTP),
- Le type 8 permet de vérifier l'intégrité du paquet par HMAC (voir la section 6 du RFC pour les détails),
- Etc.
Si cela ne suffit pas, d'autres types de TLV pourront être créés dans le futur et mis dans le registre IANA. La politique d'enregistrement (cf. RFC 8126) est « examen par l'IETF » pour la première moitié de la plage disponible et « premier arrivé, premier servi » ensuite.
L'article seul
RFC 8863: Interactive Connectivity Establishment Patiently Awaiting Connectivity (ICE PAC)
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : C. Holmberg (Ericsson), J. Uberti (Google)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF ice
Première rédaction de cet article le 19 janvier 2021
Le protocole ICE, normalisé dans le RFC 8445 permet de découvrir et de choisir, quand on est coincé derrière un routeur NAT, les adresses IP que vos correspondants verront. Parfois, au début du processus ICE, il n'y a pas d'adresses acceptables. Au lieu de renoncer tout de suite, ce nouveau RFC modifie le RFC 8445 pour demander qu'on patiente un peu : des adresses IP acceptables peuvent apparaitre par la suite.
Résumons le fonctionnement de base d'ICE. ICE sert lorsqu'une des deux machines qui correspondent a le malheur d'être derrière du NAT : le but est de choisir une paire d'adresses IP, pour les deux machines qui correspondent. ICE compte sur des protocoles comme STUN pour la découverte d'adresses possibles. Ensuite, il teste ces adresses et réussit lorsque la communication a pu s'établir avec l'autre machine. Un effet de bord de ce processus est qu'il « crée » parfois de nouvelles adresses IP possibles, qu'il faut donc ajouter à la liste et tester. Le problème que résout notre nouveau RFC est que ces nouvelles adresses peuvent être détectées trop tard, alors qu'ICE a déjà renoncé à trouver une paire qui marche. La solution ? Attendre un peu, même si la liste des paires candidates est vide, ou qu'aucune des paires d'adresses de la liste n'a marché.
La section 3 de notre RFC note que le problème n'est pas si fréquent en pratique car ICE est lent ; cela prend du temps d'établir la liste des paires d'adresses IP possibles, et de les tester, d'autant plus qu'on ne reçoit pas forcément tout de suite un rejet, il faut souvent attendre la fin du délai de garde. Bref, la plupart du temps, les nouvelles adresses apparaissant en cours de route auront le temps d'être intégrées à la liste des paires à tester. Il y a toutefois quelques cas où le risque d'échec complet existe. Par exemple, si une machine purement IPv6 essaie de contacter une machine purement IPv4, aucune paire d'adresses IP satisfaisante ne sera trouvée, menant ICE à renoncer tout de suite. Or, si le réseau local de la machine IPv6 avait NAT64, la connexion reste possible, il faut juste tester et apprendre ainsi qu'une solution existe. Cela demande un peu de patience.
La section 4 formalise la solution : un chronomètre global est créé, le PAC timer (PAC pour Patiently Awaiting Connectivity) et mis en route au tout début du processus ICE. ICE ne doit pas renoncer, même s'il croit ne plus avoir de solutions, avant que ce chronomètre n'ait mesuré au moins 39,5 secondes (cette durée vient du RFC 5389, section 7.2.1, mais peut être modifiée dans certains cas).
L'article seul
RFC 8831: WebRTC Data Channels
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : R. Jesup (Mozilla), S. Loreto (Ericsson), M. Tuexen (Muenster Univ. of Appl. Sciences)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF rtcweb
Première rédaction de cet article le 19 janvier 2021
Ce RFC décrit le canal de données (à l'exclusion de l'audio et de la vidéo) entre deux navigateurs Web se parlant avec WebRTC. Ce canal utilise le protocole de transport SCTP.
Le canal de données WebRTC est une modélisation d'un tuyau virtuel entre les deux parties qui communiquent, tuyau dans lequel circuleront les données. SCTP (RFC 9260) n'est pas utilisé pour les données « multimédia » comme la vidéo ou l'audio, mais seulement en cas de transfert d'autres données. On peut ainsi utiliser WebRTC pour se transmettre un fichier. (Je ne connais pas à l'heure actuelle de service WebRTC permettant cela. Vous avez un exemple ?) Le multimédia, lui, passe via SRTP, les données nécessitant une plus grande fiabilité passent par SCTP lui-même transporté sur DTLS (RFC 9147) lui même sur UDP. Du fait de cette encapsulation, vous ne verrez pas SCTP avec un logiciel comme Wireshark. La raison pour laquelle UDP est utilisé ? Permettre le passage des données même à travers le pire routeur NAT (cf. RFC 6951).
La section 3 de notre RFC décrit certains scénarios d'usage. Notons que dans certains, la fiabilité du canal de données n'est pas indispensable :
- Un jeu en ligne, où on est informé des mouvements des autres joueurs,
- Des notifications pendant une visioconférence du genre « Mamadou a coupé son micro »,
- Des transferts de fichiers (pour l'anecdote, ce n'est pas le point où les systèmes précédant WebRTC, comme IRC ou XMPP, se débrouillaient le mieux…),
- Le bavardage textuel entre les participants à une visioconférence.
La section 4, elle, décrit les exigences du canal de données. Notamment :
- Possibilité d'avoir plusieurs canaux simultanés,
- Transfert fiable des données (ce que la vidéo, par exemple, n'exige pas),
- Contrôle de congestion (cf. RFC 8085),
- Authentification et confidentialité (RFC 8826 et RFC 8827),
- Ne pas laisser fuiter d'informations, comme l'adresse IP locale.
La section 5 décrit une solution à ces exigences, l'utilisation de SCTP sur DTLS. SCTP (RFC 9260) fournit (entre autres) le contrôle de congestion (par contre, on n'utilise pas ses capacités de multihoming). Son encapsulation dans DTLS est décrite dans le RFC 8261. DTLS lui fournit authentification et confidentialité. L'utilisation d'ICE (RFC 8445) lui permet de passer à travers les routeurs NAT et certains pare-feux.
Petit détail : le fait de mettre SCTP sur DTLS (et non pas le
contraire comme dans le RFC 6083) fait que,
si DTLS est mis en œuvre dans l'espace
utilisateur du système
d'exploitation, SCTP devra l'être aussi. (Voir par exemple
third_party/usrsctp/usrsctplib dans le code
de Chromium, qui vient de https://github.com/sctplab/usrsctp
Quelques extensions de SCTP sont nécessaires (section 6) comme celles du RFC 6525, du RFC 5061 (enfin, une partie d'entre elles) et du RFC 3758.
La section 6 décrit les détails protocolaires de l'ouverture du canal de données, puis de son utilisation et enfin de sa fermeture.
Pour les programmeurs, cette bibliothèque WebRTC met en œuvre, entre autres, le canal de données.
L'article seul
RFC 8832: WebRTC Data Channel Establishment Protocol
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : R. Jesup (Mozilla), S. Loreto
(Ericsson), M. Tuexen (Muenster Univ. of
Appl. Sciences)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF rtcweb
Première rédaction de cet article le 19 janvier 2021
Ce RFC est un des composants de WebRTC. Il spécifie comment on établit le canal de communication des données entre deux pairs WebRTC.
WebRTC est résumé dans le RFC 8825 et la notion de « canal de communication de données » est dans le RFC 8831. Ces données sont protégées par DTLS et transportées en SCTP (RFC 8261).
Le principe est de connecter deux flux de données WebRTC, un entrant
et un sortant, pour faire un seul canal bi-directionnel. Le
protocole est simple, reposant sur seulement deux messages, un
DATA_CHANNEL_OPEN envoyé sur le flux sortant,
auquel le pair WebRTC répond par un
DATA_CHANNEL_ACK qui va arriver sur le flux
entrant. Pour éviter les ouvertures simultanées (un protocole à
deux messages n'est pas très robuste), le client DTLS
utilise des flux ayant un identificateur (stream
identifier) pair, et le serveur des flux à
identificateurs impairs. Le format de ces deux messages est décrit
dans la section 5 du RFC.
Les paquets SCTP contiennent un PPID (Payload Protocol IDentifier, RFC 9260, section 3.3.1 et 15.5) qui indique le protocole applicatif qui utilise SCTP. Dans le cas de notre protocole d'établissement de canal WebRTC, DCEP (Data Channel Establishement Protocol), le PPID vaut 50 (et figure dans le registre IANA sous le nom de WebRTC DCEP).
L'article seul
RFC 8825: Overview: Real Time Protocols for Browser-Based Applications
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : H. Alvestrand (Google)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF rtcweb
Première rédaction de cet article le 19 janvier 2021
WebRTC sert à faire communiquer en temps réel (avec audio et vidéo) deux navigateurs Web. Il est déjà largement déployé, ce RFC arrive bien après la bataille, et décrit les généralités sur WebRTC. Ce protocole est complexe et offre beaucoup de choix au concepteur d'applications.
En fait, WebRTC n'est pas vraiment un protocole. Deux applications utilisant WebRTC peuvent parfaitement être dans l'incapacité de communiquer. WebRTC est plutôt un cadre (framework) décrivant des composants, parmi lesquels le concepteur d'applications choisira. Vu cette complexité, ce RFC 8825 est un point de départ nécessaire, pour comprendre l'articulation des différents composants. D'ailleurs, il y a un abus de langage courant : WebRTC désigne normalement uniquement l'API JavaScript normalisée par le W3C. La communication sur le réseau se nomme rtcweb, et c'est le nom de l'ex-groupe de travail à l'IETF. Mais tout le monde fait cet abus de langage et moi aussi, j'utiliserai WebRTC pour désigner l'ensemble du système.
L'auteur du RFC est un « vieux de la vieille » et a vu passer beaucoup de protocoles. Il est donc logique qu'il commence par quelques rappels historiques en section 1. L'idée de faire passer de l'audio et de la vidéo sur l'Internet est aussi ancienne que l'Internet lui-même, malgré les prédictions pessimistes des telcos, qui avaient toujours prétendu que cela ne marcherait jamais. (La variante d'aujourd'hui est « si on ne nous laisse pas violer la neutralité du réseau, la vidéo ne marchera jamais ».)
Mais c'est vrai que les débuts ont été laborieux, la capacité du réseau étant très insuffisante, et les processeurs trop lents. Ça s'est amélioré par la suite. Mais si le matériel a progressé, les protocoles continuaient à manquer : il existe bien sûr des protocoles standards pour traiter certains aspects de la communication (comme SIP - RFC 3261 - pour la signalisation) mais, pour une communication complète, il faut un jeu de protocoles couvrant tous les aspects, de la signalisation à l'encodage du flux vidéo, en passant par les identificateurs à utiliser (comme les adresses de courrier électronique), et qu'on puisse compter sur ce jeu, de même qu'on peut compter sur la disponibilité de clients et serveurs HTTP, par exemple. Comme le note l'auteur, « la Solution Universelle s'est avérée difficile à développer ». (Cela a d'ailleurs laissé un boulevard à des entreprises privées, proposant un produit très fermé et complètement intégré comme le Skype de Microsoft.)
Depuis quelques années, la disponibilité très répandue de navigateurs Web ayant des possibilités très avancées a changé la donne. Plus besoin d'installer tel ou tel plugin, telle ou telle application, désormais, les possibilités qu'offre HTML5 sont largement répandues, et accessibles en JavaScript via une API standard. Un groupe de travail du W3C développe de nouvelles possibilités et WebRTC peut donc être vu comme un effort commun du W3C et de l'IETF. C'est sur ces nouvelles possibilités du navigateur que se fonde WebRTC (son cahier des charges figure dans le RFC 7478).
Notre RFC note que WebRTC change pas mal l'architecture des techniques de communication temps-réel et multimédia. Autant les solutions fondées sur SIP comptaient sur des éléments intermédiaires dans le réseau pour travailler (par exemple des ALG), autant WebRTC est nettement plus « bout en bout », et utilise la cryptographie pour faire respecter ce principe, bien menacé par les FAI.
Question histoire, WebRTC a lui-même eu une histoire compliquée. La première réunion du groupe à l'IETF a eu lieu en 2011, pour une fin prévue en 2012. En fait, il y a eu des retards, et même une longue période d'arrêt du travail. Ce RFC de survol de WebRTC, par exemple, a vu sa première version publiée il y a huit ans. Le premier RFC du projet n'a été publié qu'en 2015. Globalement, ce fut l'un des plus gros efforts de l'IETF, mais pas le plus efficace en terme de rapidité. Le groupe de travail rtcweb a finalement été clos en août 2019, le travail étant terminé.
La section 2 de notre RFC résume les principes de WebRTC : permettre une communication audio, vidéo et données la plus directe possible entre les deux participants. Ce RFC 8825 est la description générale, les protocoles effectifs figurent dans d'autres RFC comme le RFC 8832 pour le protocole de création du canal de données ou le RFC 8831 pour la communication via le canal de données. Techniquement, WebRTC a deux grandes parties :
- La spécification du protocole, faite à l'IETF, dans les RFC 8832 et RFC 8831.
- L'API JavaScript permettant le développement des clients tournant dans les navigateurs Web, API normalisée par le W3C dans « WebRTC 1.0: Real-time Communication Between Browsers » et « Media Capture and Streams ».
La section 2 décrit également le vocabulaire, si vous voulez réviser des concepts comme la notion de protocole ou de signalisation.
La section 3 de notre RFC présente l'architecture
générale. Chaque navigateur WebRTC se connecte à un serveur Web où
il récupère automatiquement un code
JavaScript qui appelle les fonctions
WebRTC, qui permettent d'accéder au canal de données, ouvert avec
l'autre navigateur, et aux services multimédia de son ordinateur
local (le micro, la caméra, etc). On y voit notamment (figure 2)
que les données (la voix, la vidéo, etc) passent directement
(enfin, presque, voir plus loin) entre les deux navigateurs, alors
que la signalisation se fait entre les deux serveurs Web. On note,
et c'est très important, que WebRTC ne gère que le canal de
données, pas celui de signalisation, qui peut utiliser SIP (RFC 3261), XMPP (RFC 6120) ou même un protocole privé. C'est entre autres
pour cette raison que deux services WebRTC différents ne peuvent
pas forcément interopérer. Voici un schéma de WebRTC lorsque les
deux parties se connectent au même site Web (la signalisation est
alors faite à l'intérieur de ce site) : 
Et ici une image d'une fédération, où les deux parties qui communiquent utilisent
des services différents, mais qui se sont mis d'accord sur un
protocole de signalisation : 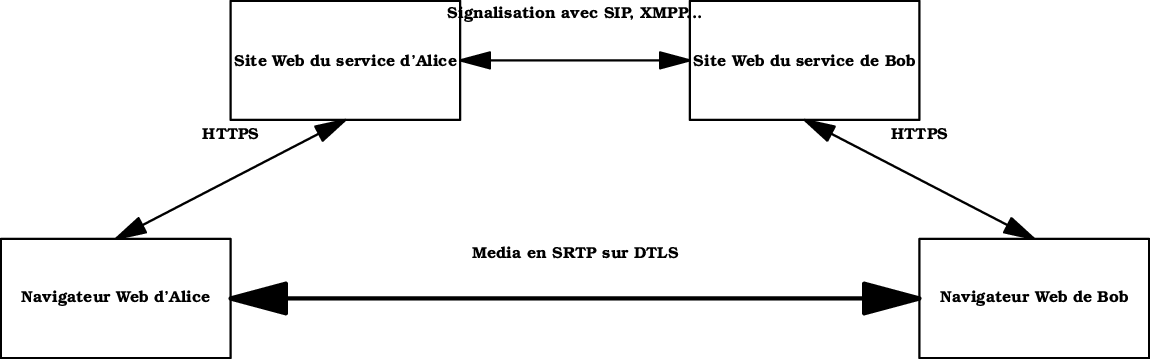
Le canal de données nécessite déjà beaucoup de spécifications, notamment le transport et l'encodage du contenu. Il est spécifié dans le RFC 8831.
Le transport, justement (section 4 du RFC). Il faut envoyer les données à l'autre navigateur, et assurer la retransmission des données perdues, le contrôle de congestion, etc. Tout cela est décrit dans le RFC 8835. Ce RFC spécifie, pour transporter les données multimédia, l'utilisation de SRTP sur DTLS, lui-même sur UDP (cf. RFC 8834). Des systèmes de relais comme TURN (RFC 5766) peuvent être nécessaires si les deux malheureux navigateurs Web soint coincés derrière des middleboxes méchantes, NAT ou pare-feu par exemple.
Ce n'est pas tout d'avoir un protocole de transport. Il faut aussi découper les données d'une manière compréhensible par l'autre bout (framing, section 5 de notre RFC). WebRTC utilise RTP (RFC 3550, et voir aussi le RFC 8083) et SRTP (RFC 3711 et RFC 5764). Le RFC 8834 détaille leur utilisation. La sécurité est, elle, couverte dans les RFC 8826 et RFC 8827. L'établissement du canal de données est normalisé dans le RFC 8832 et le canal de données lui-même dans le RFC 8831.
On le sait, les formats d'audio et de vidéo sont un problème compliqué, le domaine est pourri de brevets souvent futiles, et la variété des formats rend difficile l'interopérabilité. Notre RFC impose au minimum l'acceptation des codecs décrits dans le RFC 7874 pour l'audio (Opus est obligatoire) et RFC 7742 pour la vidéo (H.264 et VP8, après une longue lutte). D'autres codecs pourront s'y ajouter par la suite.
La section 7 mentionne la gestion des connexions, pour laquelle la solution officielle est le JSEP (JavaScript Session Establishment Protocol, RFC 8829).
La section 9 du RFC décrit les fonctions locales (l'accès par
le navigateur aux services de la machine qui l'héberge). Le RFC
rappelle que ces fonctions doivent inclure des choses comme la
suppression d'écho, la protection de la vie
privée (demander l'autorisation avant d'accéder à la caméra…) Le
RFC 7874 fournit des détails. Ici, un
exemple d'une demande d'autorisation par
Firefox : 
Parmi les logiciels qui permettent de faire du WebRTC, on peut
citer Jitsi, qui est derrière
le service Framatalk, mais
qui est également accessible via d'autres services comme
https://meet.jit.si/
Regarder du trafic WebRTC avec un logiciel comme Wireshark est frustrant, car tout est chiffré. Pour Jitsi, on voit beaucoup de STUN, pour contourner les problèmes posés par le NAT, puis du DTLS évidemment impossible à décrypter.
Il y a de nombreux autres logiciels avec WebRTC. C'est le cas par exemple de PeerTube mais attention, seul l'échange de vidéo entre pairs qui regardent au même moment utilise WebRTC (plus exactement WebTorrent, qui utilise WebRTC). La récupération de la vidéo depuis le serveur se fait en classique HTTPS.
Si vous voulez voir une session WebRTC, le mieux est d'utiliser
un service comme https://appr.tc/
Console (Webdeveloper tools) Firefox
9.569: Initializing; server= undefined.
Puis l'établissement des canaux nécessaires :
37.252: Opening signaling channel.
39.348: Joined the room.
39.586: Retrieved ICE server information.
39.927: Signaling channel opened.
39.930: Registering signaling channel.
39.932: Signaling channel registered.
Là, Firefox vous demande l'autorisation d'utiliser micro et caméra, que vous acceptez :
44.452: Got access to local media with mediaConstraints:
'{"audio":true,"video":true}'
44.453: User has granted access to local media.
Le navigateur peut alors utiliser ICE (RFC 8445) pour trouver le bon moyen de communiquer avec le pair (dans mon test, les deux pairs étaient sur le même réseau local, et s'en aperçoivent, ce qui permet une communication directe par la suite) :
44.579: Creating RTCPeerConnnection with:
config: '{"rtcpMuxPolicy":"require","bundlePolicy":"max-bundle","iceServers":[{"urls":["stun:74.125.140.127:19302","stun:[2a00:1450:400c:c08::7f]:19302"]},{"urls":["turn:74.125.140.127:19305?transport=udp","turn:[2a00:1450:400c:c08::7f]:19305?transport=udp","turn:74.125.140.127:19305?transport=tcp","turn:[2a00:1450:400c:c08::7f]:19305?transport=tcp"],"username":"CP/Bl+UXXXXXXX","credential":"XXXXXXXXXXX=","maxRateKbps":"8000"}],"certificates":[{}]}';
constraints: '{"optional":[]}'.
44.775: Created PeerConnectionClient
On peut alors négocier les codecs à utiliser (ici VP9) :
44.979: Set remote session description success.
44.980: Waiting for remote video.
44.993: No preference on audio receive codec.
44.993: Prefer video receive codec: VP9
Et, ici, on voit passer le descripteur de session (section 7 de notre RFC), au format SDP (RFC 4566 et RFC 3264, et notez la blague entre SDP et le film 300) :
44.997: C->WSS: {"sdp":"v=0\r\no=mozilla...THIS_IS_SDPARTA-60.5.1 6947646294855805442 0 IN IP4 0.0.0.0\r\ns=-\r\nt=0 0\r\na=fingerprint:sha-256 23:80:53:8A:DD:D7:BF:77:B5:C7:4E:0F:F4:6D:F2:FB:B8:EE:59:D1:91:6A:F5:21:11:22:C0:E3:E0:ED:54:39\r\na=group:BUNDLE 0 1\r\na=ice-options:trickle\r\na=msid-semantic:WMS *\r\nm=audio 9 UDP/TLS/RTP/SAVPF 111 126\r\nc=IN IP4 0.0.0.0\r\na=sendrecv\r\na=extmap:1 urn:ietf:params:rtp-hdrext:ssrc-audio-level\r\na=extmap:9 urn:ietf:params:rtp-hdrext:sdes:mid\r\na=fmtp:111 maxplaybackrate=48000;stereo=1;useinbandfec=1\r\na=fmtp:126 0-15\r\na=ice-pwd:bb7169d301496c0119c5ea3a69940a55\r\na=ice-ufrag:3d465335\r\na=mid:0\r\na=msid:{d926a161-3011-48af-9236-06e15377dfea} {a2597b07-7e80-47fe-8542-761dd93efb94}\r\na=rtcp-mux\r\na=rtpmap:111 opus/48000/2\r\na=rtpmap:126 telephone-event/8000/1\r\na=setup:active\r\na=ssrc:2096893919 cname:{e60fd6dc-6c2d-4132-bb6a-1178e1611d16}\r\nm=video 9 UDP/TLS/RTP/SAVPF 98\r\nc=IN IP4 0.0.0.0\r\na=recvonly\r\na=extmap:2 urn:ietf:params:rtp-hdrext:toffset\r\na=extmap:3 http://www.webrtc.org/experiments/rtp-hdrext/abs-send-time\r\na=extmap:9 urn:ietf:params:rtp-hdrext:sdes:mid\r\na=fmtp:98 max-fs=12288;max-fr=60\r\na=ice-pwd:bb7169d301496c0119c5ea3a69940a55\r\na=ice-ufrag:3d465335\r\na=mid:1\r\na=rtcp-fb:98 nack\r\na=rtcp-fb:98 nack pli\r\na=rtcp-fb:98 ccm fir\r\na=rtcp-fb:98 goog-remb\r\na=rtcp-mux\r\na=rtpmap:98 VP9/90000\r\na=setup:active\r\na=ssrc:4025254123 cname:{e60fd6dc-6c2d-4132-bb6a-1178e1611d16}\r\n","type":"answer"}
Et c'est bon, tout marche :
45.924: Call setup time: 1399ms.
Du fait de son caractère pair-à-pair (les données sont échangées, autant que le NAT le permet, directement entre les navigateurs), WebRTC soulève des questions de vie privée. Votre correspondant va voir votre adresse IP. Le point est discuté plus longuement dans le RFC 8826. (PeerTube met en bas un mot d'avertissement à ce sujet.)
WebRTC est présent depuis pas mal d'années dans tous les navigateurs graphiques comme Firefox, Chrome ou Edge. Côté bibliothèques, il existe de nombreuses mises en œuvre de WebRTC comme OpenWebRTC (abandonné depuis) ou comme l'implémentation de référence. Il y a également du WebRTC dans des serveurs comme Asterisk, WebEx ou MeetEcho (ce dernier étant utilisé par l'IETF pour ses réunions à distance). Mais rappelez-vous que WebRTC n'est pas un ensemble cohérent permettant l'interopérabilité. Vous pouvez avoir deux services WebRTC qui n'arrivent pas à interagir, et ce n'est pas une bogue, c'est un choix de conception.
Et, pour finir, quelques lectures et activités supplémentaires :
- Pour tester votre environnement (micro, caméra, etc) et
votre réseau (beaucoup de réseaux sont truffés de
middleboxes
hostiles), un bon site de test,
https://test.webrtc.org/ - Vous pouvez voir les statistiques d'activité WebRTC dans
votre navigateur, en
chrome://webrtc-internalsopera://webrtc-internalsabout:webrtc - Un bon tutoriel sur WebRTC, très détaillé, écrit plutôt du point de vue du programmeur JavaScript écrivant un client,
- Un bon résumé de WebRTC, plutôt du point de vue de « comment ça marche »,
- Le site « officiel » du projet,
- Le groupe de travail au W3C.
- L'annonce officielle de la publication des normes.
L'article seul
RFC 8827: WebRTC Security Architecture
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : E. Rescorla (RTFM)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF rtcweb
Première rédaction de cet article le 19 janvier 2021
Le système WebRTC permet des communications audio et vidéo entre deux navigateurs Web. Comme tout service Internet, il pose des problèmes de sécurité (RFC 8826), et ce RFC étudie l'architecture générale de WebRTC, du point de vue de la sécurité, et comment résoudre les problèmes.
D'abord, il faut réviser les généralités sur
WebRTC (RFC 8825). WebRTC a pour but de permettre à deux
utilisateurs ou utilisatrices de navigateurs
Web de s'appeler et de bavarder en audio et vidéo. Pas
besoin d'installer un logiciel de communication spécifique (comme
le Skype de
Microsoft, ou comme un
softphone tel que
Twinkle), il suffit d'un navigateur
ordinaire. Pour permettre cela, WebRTC repose sur une
API JavaScript
normalisée par le W3C et sur un ensemble de
protocoles normalisés par l'IETF, et
résumés dans le RFC 8825. Si on
prend l'exemple du service WebRTC
FramaTalk, Alice et Bob visitent
tous les deux https://framatalk.org/
Cela soulève plein de problèmes de sécurité amusants, étudiés dans le RFC 8826, et que notre RFC 8827 tente de résoudre.
Toute solution de sécurité dépend d'un modèle de confiance (section 3 de notre RFC). Si on ne fait confiance à rien ni personne, on ne peut résoudre aucun problème de sécurité. Pour WebRTC, la racine de toute confiance est le navigateur. C'est lui qui devra faire respecter un certain nombre de règles. (En conséquence de quoi, si le navigateur n'est pas de confiance, par exemple parce qu'il s'agit de logiciel non libre, ou bien parce que vous êtes sur une machine sur laquelle vous n'avez aucun contrôle, par exemple un cybercafé, tout est fichu.) Mais le navigateur ne suffit pas, il faut également faire confiance à des entités extérieures, comme le site Web où vous allez récupérer le code JavaScript. Certaines de ces entités peuvent être authentifiées par le navigateur, ce qui donne certaines garanties. Et d'autres, hélas, ne le peuvent pas. Dans la première catégorie, on trouve :
- Les sites Web où le navigateur vérifie un
certificat, dans une connexion
HTTPS. Vous vous connectez à
https://framatalk.org/https), vous êtes sûr que c'est bien Framasoft derrière. - Les pairs WebRTC authentifiés par une technique comme DTLS-SRTP.
Le reste des entités avec qui on communique est considéré comme potentiellement malveillant, et il faut donc se méfier (mais, évidemment, dans la vie, on ne communique pas qu'avec des gens qu'on connait bien et à qui on fait confiance : ce serait trop limité).
Pour revenir aux entités authentifiées, notez qu'on n'a parlé que d'authentification, pas de confiance. La cryptographie permet de vérifier qu'on parle bien au diable, pas que le diable est honnête !
La section 4 résume le fonctionnement général de WebRTC, afin
de pouvoir analyser sa sécurité, et définir une architecture de
sécurité. Notez que WebRTC permet pas mal de variantes et que le
schéma présenté ici est un cas « typique », pas forcément
identique partout dans tous ses détails. Donc, ici,
Alice et Bob veulent se parler. Tous les
deux utilisent un navigateur. Chacun va visiter le site Web du
service qu'ils utilisent, mettons
https://meet.example/ (en
HTTPS, donc, avec
authentification via un certificat). Ils récupèrent un code
JavaScript qui, appelant
l'API WebRTC, va
déclencher l'envoi d'audio et de vidéo, transportés sur
SRTP, lui-même sur
DTLS (les données en dehors du
« multimédia » passent sur du SCTP sur DTLS). Avant d'autoriser l'accès au micro et
à la caméra, chaque navigateur demandera l'autorisation à son
utilisat·eur·rice. Quant au fait que la machine en face accepte de
recevoir (en direct, en pair-à-pair) ce déluge de données
multimédia, la vérification sera faite par
ICE (cf. RFC 8826, section 4.2). ICE n'intervient qu'à la connexion
initiale, des messages périodiques seront nécessaires pendant la
communication pour s'assurer qu'il y a toujours consentement à recevoir. Pendant l'échange de données audio
et vidéo, le site Web
https://meet.example/ va assurer la
signalisation et, par exemple, si Alice part, indiquer à Bob qu'il
n'y a plus personne en face (notez que cet échange entre site Web
et utilisateur ne se fait pas avec un protocole normalisé). Notre RFC ajoute une possibilité :
qu'Alice et Bob utilisent un fournisseur d'identité, permettant à
chacun d'identifier et d'authentifier l'autre (par exemple via
OpenID Connect).
Ce cas où les deux participant·e·s partagent le même serveur
est le cas le plus courant aujourd'hui (c'est ce que vous verrez
si vous faites une visioconférence via
https://meet.jit.si/
Armés de ces informations, nous pouvons lire la section 6, qui plonge dans les détails techniques. D'abord, la securité de la connexion entre navigateur et site Web. Elle dépend de HTTPS (RFC 2818), de la vérification du certificat, bien sûr (RFC 6125 et RFC 5280) et de la vérification de l'origine (RFC 6454). La sécurité entre les pairs qui communiquent impose également l'usage de la cryptographie et il faut donc utiliser SRTP (RFC 3711) sur DTLS (RFC 9147 et RFC 5763). Pas question de faire du RTP en clair directement sur UDP ! Le niveau de sécurité (par exemple les paramètres TLS choisis) doivent être accessibles à l'utilisateur.
Ensuite, la securité de l'accès au micro et à la caméra. Le site Web qu'on visite peut être malveillant, et le navigateur ne permet évidemment pas à du code JavaScript de ce site d'ouvrir silencieusement la caméra. Il demande donc la permission à l'utilisateur, qui ne la donne que s'il était vraiment en train de passer un appel. De même, le navigateur doit afficher si micro et caméra sont utilisés, et ne doit pas permettre à du code JavaScript de supprimer cet affichage.
Dans WebRTC, l'échange des données audio et vidéo se fait en pair-à-pair, directement entre Alice et Bob. Il y a donc le risque qu'un méchant envoie plein de données vidéo à quelqu'un qui n'a rien demandé (la section 9.3 détaille le risque de déni de service). Il faut donc vérifier le consentement à recevoir. Comme indiqué plus haut, cela se fait avec ICE (RFC 8445). Comme le consentement initial n'est pas éternel, et comme on ne peut pas se fier aux accusés de réception, que DTLS n'envoie pas, ni aux réponses (il n'y en a pas forcément, par exemple si on regarde juste une vidéo), il faut envoyer de temps en temps des nouveaux messages ICE (cf. RFC 7675).
Parmi les questions de sécurité liées à WebRTC, il en est une qui a fait beaucoup de bruit, celle de la vie privée, notamment le problème de l'adresse IP qui est transmise au pair avec qui on communique. (Notez que le serveur du site Web où on se connecter initialement verra toujours, lui, cette adresse IP, sauf si on utilise une technique comme Tor.) Notre RFC impose donc, en cas d'appel entrant, de ne pas commencer la négociation ICE avant que l'utilisatrice n'ait décidé de répondre à l'appel, et que WebRTC permette de décider de n'utiliser que TURN, qui ne communique pas l'adresse IP au pair puisqu'on ne se parle plus directement, mais via le relais TURN. Évidemment, cela se fait au détriment des performances (les détails sont dans la section 9.2).
On a vu plus haut que les deux pairs qui communiquent peuvent désirer s'authentifier (sans se fier au site Web qu'ils utilisent pour la signalisation), par exemple via des fournisseurs d'identité externes (comme FranceConnect ?) C'est notamment indispensable pour une fédération puisque, dans ce cas, on n'a même plus de site Web commun. La section 7 de notre RFC détaille ce cas. WebRTC ne normalise pas une technique unique (comme OAuth) pour cela (WebRTC est un cadre, pas vraiment un protocole, encore moins un système complet), mais fixe quelques principes. Notamment, l'utilisateur s'authentifie auprès du fournisseur d'identité, pas auprès du site Web de signalisation. Le navigateur Web doit donc faire attention à tout faire lui-même et à ne pas laisser ce site Web interférer avec ce processus.
Enfin, il reste des problèmes de sécurité de WebRTC qui ne sont pas couverts par le RFC 8826 ni par les précédentes sections de notre RFC 8827. Ainsi, il est important que le code JavaScript téléchargé depuis le site Web du fournisseur de service WebRTC ne puisse pas directement fabriquer des messages chiffrés et signés pour DTLS, car il pourrait alors fabriquer de vraies/fausses signatures. Tout doit passer par le navigateur qui est le seul à pouvoir utiliser les clés de DTLS pour chiffrer et surtout signer.
Une bonne analyse de la sécurité de WebRTC se trouve en « A Study of WebRTC Security ».
L'article seul
RFC 8973: DDoS Open Threat Signaling (DOTS) Agent Discovery
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : M. Boucadair (Orange), T. Reddy (McAfee)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dots
Première rédaction de cet article le 13 janvier 2021
Le protocole DOTS, normalisé dans les RFC 8811, RFC 9132 et RFC 8783, sert à coordonner la réponse à une attaque par déni de service, entre la victime de l'attaque (le client DOTS) et un service d'atténuation de l'attaque (le serveur DOTS). Mais comment le client trouve-t-il son serveur ? Il peut y avoir une configuration manuelle, mais ce RFC propose aussi des moyens automatiques, basés sur un choix de plusieurs techniques, dont DHCP et NAPTR.
Attention, cela permet de trouver le serveur, mais pas le fournisseur du service d'atténuation. Car il faut un accord (souvent payant) avec ce fournisseur, et un échange de mécanismes d'authentification. Cette partie doit se faire manuellement. Le protocole de notre RFC prend ensuite le relais.
Notez aussi qu'il n'y a pas un seul moyen de découverte du serveur. La section 3 du RFC explique en effet que, vu la variété des cas d'utilisation de DOTS, on ne peut pas s'en tirer avec un seul mécanisme. Parfois le client a un CPE géré par le FAI, sur lequel on peut s'appuyer pour trouver le serveur DOTS, et parfois pas. Parfois, il faudra utiliser les résolveurs DNS d'un opérateur et parfois ce ne sera pas nécessaire. Parfois l'atténuateur est le FAI et parfois pas. Bref, il faut plusieurs solutions.
Voyons d'abord la procédure générale (section 4). Personnellement, je pense que le client DOTS doit donner la priorité aux configurations manuelles (DOTS est un système de sécurité, un strict contrôle de ce qui se passe est préférable). Mais le RFC ne décrit pas les choses ainsi. Il expose trois mécanismes, le premier, qualifié de configuration explicite, étant composé de deux techniques très différentes, la configuration manuelle ou bien DHCP. À noter au passage que la configuration manuelle peut indiquer le nom ou l'adresse IP mais, si elle indique l'adresse IP, le nom sera quand même obligatoire car il servira pour la vérification du certificat.
L'ordre des préférences entre ces mécanismes est imposé, pour que le résultat de la découverte soit prédictible. D'abord l'explicite (manuel ou DHCP, section 5), puis la résolution de service (section 6) puis la découverte de service (section 7).
Première technique automatique à utiliser, DHCP (section 5). Ce protocole va être utilisé pour récupérer le nom du serveur DOTS (le nom et pas seulement l'adresse IP car on en aura besoin pour authentifier la session TLS). Avec DHCPv6 (RFC 9915), l'option DHCP pour récupérer le nom est 141 en IPv6 et 147 pour IPv4. Une autre option permet de récupérer les adresses IP du serveur DOTS.
Deuxième technique, la résolution de service. Il faut partir d'un
nom, qui peut être configuré manuellement ou bien obtenu par
DHCP. Ce n'est pas le nom du serveur DOTS, contrairement au cas en
DHCP pur, mais celui du domaine dans lequel le client DOTS se
« trouve ». On va alors utiliser S-NAPTR (RFC 3958) sur ce
nom, pour obtenir les noms des serveurs. L'étiquette à utiliser est
DOTS pour le service (enregistré
à l'IANA) et signal (RFC 9132) ou data (RFC 8783) pour le protocole (également
à l'IANA). Par exemple si le client DOTS est dans le domaine
example.net, il va faire une requête DNS de type NAPTR. Si le
domaine comportait un enregistrement pour le service DOTS, il est
choisi, et on continue le processus (compliqué !) de NAPTR
ensuite. Si on cherche le serveur pour le protocole de
signalisation, on pourrait avoir successivement quatre requêtes
DNS :
example.net. IN NAPTR 100 10 "" DOTS:signal.udp "" signal.example.net. signal.example.net. IN NAPTR 100 10 "s" DOTS:signal.udp "" _dots-signal._udp.example.net. _dots-signal._udp.example.net. IN SRV 0 0 5000 a.example.net. a.example.net. IN AAAA 2001:db8::1
Troisième technique, la découverte de service (DNS-SD) du RFC 6763. On cherche alors un enregistrement de
type PTR dans _dots-signal.udp.example.net. Il
nous donnera un nom pour lequel on fera une requête
SRV.
DOTS servant en cas d'attaque, il faut prévoir la possibilité que l'attaquant tente de perturber ou de détourner ce mécanisme de découverte du serveur. Par exemple, on sait que DHCP n'est pas spécialement sécurisé (euphémisme !). D'autre part, DOTS impose TLS, il faut donc un nom à vérifier dans le certificat (oui, on peut mettre des adresses IP dans les certificats mais c'est rare). Quant aux techniques reposant sur le DNS, le RFC conseille d'utiliser DNSSEC, ce qui semble la moindre des choses pour une technique de sécurité. Il suggère également de faire la résolution DNS via un canal sûr par exemple avec DoT (RFC 7858) ou DoH (RFC 8484).
Apparemment, il existe au moins une mise en œuvre de DOTS qui inclut les procédures de découverte de notre RFC, mais j'ignore laquelle.
L'article seul
RFC 8965: Applicability of the Babel Routing Protocol
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : J. Chroboczek (IRIF, University of Paris-Diderot)
Pour information
Réalisé dans le cadre du groupe de travail IETF babel
Première rédaction de cet article le 12 janvier 2021
Comme tout bon protocole, le protocole de routage Babel, normalisé dans le RFC 8966 ne fait pas de miracles et ne marche pas dans tous les cas. Il est donc utile de savoir quels sont les cas où Babel est efficace et utile. Ce RFC s'applique à identifier et documenter les créneaux pour Babel.
C'est qu'il en existe beaucoup de protocoles de routage internes à un AS. Le RFC cite OSPF (RFC 5340) et IS-IS (RFC 1195), qui ont la faveur des grands réseaux gérés par des professionnels, mais je trouve que Babel se situe plutôt du côté de protocoles prévus pour des réseaux moins organisés, comme Batman ou RPL (RFC 6550). Je vous laisse lire le RFC 8966 pour voir comment fonctionne Babel. Disons juste que c'est un protocole à vecteur de distances (comme RIP - RFC 2453 - mais sans ses inconvénients) et qui considère la faisabilité de chaque route potentielle avant de l'ajouter, supprimant ainsi le risque de boucles. En refusant des routes qui pourraient peut-être créer une boucle, le risque est la famine, l'absence de route pour une destination, risque dont Babel se protège avec un mécanisme de numéro de séquence dans les annonces.
La section 2 de notre RFC explicite les caractéristiques de Babel, les bonnes et les mauvaises. D'abord, la simplicité. Babel est conceptuellement simple, ce qui facilite les analyses du protocole, et aussi sa mise en œuvre. Comme le note le RFC, Babel peut être expliqué en un micro-siècle. Et question programmation, le RFC cite une mise en œuvre de Babel réalisée en deux nuits (le RFC ne dit pas ce que le ou la programmeur·e faisait de jour…)
Ensuite, la résistance. Babel ne dépend que de quelques propriétés simples du réseau et peut donc fonctionner dans un large éventail de situations. Babel demande juste que les métriques soient strictement monotones croissantes (emprunter le chemin A puis le B, doit forcément coûter strictement plus cher que de juste prendre le chemin A, autrement des boucles pourraient se former) et distributives à gauche (cf. « Metarouting » de Griffin et Sobrinho). En revanche, Babel n'exige pas un transport fiable (les paquets ont le droit de se perdre, ou de doubler un autre paquet) et n'exige pas que la communication soit transitive (dans les liens radio, il peut arriver que A puisse joindre B et B puisse parler à C, sans que pour autant A puisse communiquer directement avec C). Des protocoles comme OSPF (RFC 5340) ou IS-IS sont bien plus exigeants de ce point de vue.
Babel est extensible : comme détaillé dans
l'annexe C du RFC 8966, le protocole
Babel peut être étendu. Cela a été fait, par exemple, pour permettre
du routage en fonction de la source (RFC 9079)
ou bien du routage en fonction du RTT (RFC 9616). Il y a aussi des
extensions qui n'ont pas (encore ?) été déployées comme du routage
en fonction des fréquences radio (draft-chroboczek-babel-diversity-routing)
ou en fonction du ToS (draft-chouasne-babel-tos-specific).
Mais Babel a aussi des défauts, notamment :
- Babel envoie périodiquement des messages, même quand il n'y a eu aucun changement. Cela permet de ne pas dépendre d'un transport fiable des paquets mais c'est du gaspillage lorsque le réseau est stable. Un grand réseau très stable et bien géré a donc plutôt intérêt à utiliser des protocoles comme OSPF, pour diminuer le trafic dû au routage. À l'autre extrémité, certains réseaux de machines contraintes (par exemple tournant uniquement sur batterie) n'auront pas intérêt à utiliser un protocole comme Babel, qui consomme de l'énergie même quand le réseau n'a pas changé.
- Avec Babel, chaque routeur connait toute la table de routage. Si des routeurs sont limités en mémoire, cela peut être un problème, et des protocoles comme AODV (RFC 3561), RPL (RFC 6550) ou LOADng sont peut-être plus adaptés.
- Babel peut être lent à récupérer lorsqu'il fait de l'agrégation de préfixes, et qu'une route plus spécifique est retirée.
Babel a connu plusieurs déploiements dans le monde réel (section 3). Certains de ces déploiements étaient dans des réseaux mixtes, mêlant des parties filaires, routant sur le préfixe, et des parties radio, avec du routage mesh sur les adresses IP. Babel a aussi été déployé dans des overlays, en utilisant l'extension tenant compte du RTT, citée plus haut. Il a aussi été utilisé dans des réseaux purement mesh. Voir à ce sujet les articles « An experimental comparison of routing protocols in multi hop ad hoc networks » et « Real-world performance of current proactive multi-hop mesh protocols ». Ces réseaux utilisent traditionnellement plutôt des protocoles comme OLSR (RFC 7181). Enfin, Babel a été déployé dans des petits réseaux non gérés (pas d'administrateur système).
Et la sécurité, pour finir (section 5). Comme tous les protocoles à vecteur de distance, Babel reçoit l'information de ses voisins. Il faut donc leur faire confiance, un voisin menteur peut annoncer ce qu'il veut. En prime, si le réseau sous-jacent n'est pas lui-même sécurisé (par exemple si c'est du WiFi sans WPA), il n'y a même pas besoin d'être routeur voisin, toute machine peut tripoter les paquets.
Pour empêcher cela, il y a deux solutions cryptographiques, dans les RFC 8967 (la solution la plus simple) et RFC 8968 (plus complexe mais plus sûre et qui fournit en prime de la confidentialité). La solution avec le MAC, normalisée dans le RFC 8967, est celle recommandée car elle convient mieux au caractère de la plupart des réseaux utilisant Babel. (Le RFC n'en parle apparamment pas, mais notez qu'authentifier le voisin ne résout pas complètement le problème. On peut être authentifié et mentir.)
Enfin, si on n'utilise pas de solution de confidentialité, un observateur peut déduire des messages Babel la position d'un routeur WiFi qui se déplacerait, ce qui peut être considéré comme un problème.
Sinon, pour creuser cette question de l'applicabilité de Babel, vous pouvez lire le texte, très vivant, « Babel does not care ».
L'article seul
RFC 8966: The Babel Routing Protocol
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : J. Chroboczek (IRIF, University of Paris-Diderot), D. Schinazi (Google LLC)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF babel
Première rédaction de cet article le 12 janvier 2021
Le travail sur les protocoles de routage ne désarme pas, motivé à la fois par les avancées de la science et par les nouvelles demandes (par exemple pour les réseaux ad hoc). Ainsi Babel est un protocole de routage, de la famille des protocoles à vecteur de distance, qui vise notammment à réduire drastiquement les probabilités de boucle. Il avait été décrit originellement dans le RFC 6126 ; ce nouveau RFC ne change pas fondamentalement le protocole Babel (quoique certains changements ne seront pas compris par les vieilles versions) mais il a désormais le statut de norme, et des solutions de sécurité plus riches. Ce manque de sécurité était la principale critique adressée à Babel.
Il y a deux familles de protocole de routage, ceux à vecteur de distance comme l'ancêtre RIP et ceux à états des liens comme OSPF (RFC 2328). Ce dernier est aujourd'hui bien plus utilisé que RIP, et à juste titre. Mais les problèmes de RIP n'ont pas forcément la même ampleur chez tous les membres de sa famille, et les protocoles à vecteurs de distance n'ont pas dit leur dernier mot.
Babel s'inspire de protocoles de routage plus récents comme DSDV. Il vise à être utilisable, à la fois sur les réseaux classiques, où le routage se fait sur la base du préfixe IP et sur les réseaux ad hoc, où il n'y a typiquement pas de regroupement par préfixe, où le routage se fait sur des adresses IP « à plat » (on peut dire que, dans un réseau ad hoc, chaque nœud est un routeur).
L'un des principaux inconvénients du bon vieux protocole RIP est sa capacité à former des boucles lorsque le réseau change de topologie. Ainsi, si un lien entre les routeurs A et B casse, A va envoyer les paquets à un autre routeur C, qui va probablement les renvoyer à A et ainsi de suite (le champ « TTL » pour IPv4 et « Hop limit » dans IPv6 a précisement pour but d'éviter qu'un paquet ne tourne sans fin). Babel, lui, évitera les boucles la plupart du temps mais, en revanche, il ne trouvera pas immédiatement la route optimale entre deux points. La section 1.1 du RFC spécifie plus rigoureusement les propriétés de Babel.
Babel peut fonctionner avec différentes métriques pour indiquer
les coûts de telle ou telle route, le protocole lui-même étant
indépendant de la métrique utilisée (cf. annexe A du RFC pour des
conseils sur les choix). D'ailleurs, je vous recommande la lecture
de l'Internet-Draft
draft-chroboczek-babel-doesnt-care,
pour mieux comprendre la philosophie de Babel.
Autre particularité de Babel, les associations entre deux machines pourront se faire même si elles utilisent des paramètres différents (par exemple pour la valeur de l'intervalle de temps entre deux « Hello » ; cf. l'annexe B pour une discussion du choix de ces paramètres, les compromis que ce choix implique entre intensité du trafic et détection rapide des changements, et les valeurs recommandées pour ces paramètres). Le RFC annonce ainsi que Babel est particulièrement adapté aux environnements « sans-fil » où certaines machines, devant économiser leur batterie, devront choisir des intervalles plus grands, ou bien aux environnements non gérés, où chaque machine est configurée indépendamment.
Je l'ai dit, rien n'est parfait en ce bas monde, et Babel a des limites, décrites en section 1.2. D'abord, Babel envoie périodiquement toutes les informations dont il dispose, ce qui, dans un réseau stable, mène à un trafic total plus important que, par exemple, OSPF (qui n'envoie que les changements). Ensuite, Babel a des mécanismes d'attente lorsqu'un préfixe disparait, qui s'appliquent aux préfixes plus généraux. Ainsi, lorsque deux préfixes deviennent agrégés, l'agrégat n'est pas joignable immédiatement.
Comment Babel atteint-il ses merveilleux objectifs ? La section 2 détaille les principes de base du protocole, la 3 l'échange de paquets et la 4 l'encodage d'iceux. Commençons par les principes. Babel est fondé sur le bon vieil algorithme de Bellman-Ford, tout comme RIP. Tout lien entre deux points A et B a un coût (qui n'est pas forcément un coût monétaire, c'est un nombre qui a la signification qu'on veut, cf. section 3.5.2). Le coût est additif (la somme des coûts d'un chemin complet faisant la métrique du chemin, section 2.1 et annexe A), ce qui veut dire que Métrique(A -> C) - pour une route passant par B >= Coût(A -> B) + Coût(B -> C). L'algorithme va essayer de calculer la route ayant la métrique le plus faible.
Un nœud Babel garde trace de ses voisins nœuds en
envoyant périodiquement des messages Hello et
en les prévenant qu'ils ont été entendus par des messages
IHU (I Heard You). Le
contenu des messages Hello et
IHU permet de déterminer le coût.
Pour chaque source (d'un préfixe, pas d'un paquet), le nœud garde trace de la métrique vers cette source (lorsqu'un paquet tentera d'atteindre le préfixe annoncé) et du routeur suivant (next hop). Au début, évidemment la métrique est infinie et le routeur suivant indéterminé. Le nœud envoie à ses voisins les routes qu'il connait. Si celle-ci est meilleure que celle que connait le voisin, ce dernier l'adopte (si la distance était infinie - route inconnue, toute route sera meilleure).
L'algorithme « naïf » ci-dessus est ensuite amélioré de plusieurs façons : envoi immédiat de nouvelles routes (sans attendre l'émission périodique), mémorisation, non seulement de la meilleure route mais aussi de routes alternatives, pour pouvoir réagir plus vite en cas de coupure, etc.
La section 2.3 rappelle un problème archi-connu de l'algorithme
de Bellman-Ford : la facilité avec laquelle des boucles se
forment. Dans le cas d'un réseau simple comme celui-ci A annonce une route de métrique 1 vers S,
B utilise donc A comme routeur suivant, avec une métrique de 2. Si
le lien entre S (S = source de l'annonce) et A casse
comme B continue à publier une route
de métrique 2 vers S, A se met à envoyer les paquets à B. Mais B les
renvoie à A, créant ainsi une boucle. Les annonces ultérieures ne
résolvent pas le problème : A annonce une route de métrique 3,
passant par B, B l'enregistre et annonce une route de métrique 4
passant par A, etc. RIP résout le problème en ayant une limite
arbitraire à la métrique, limite qui finit par être atteinte et
stoppe la boucle (méthode dite du « comptage à l'infini »).
Cette méthode oblige à avoir une limite très basse pour la métrique. Babel a une autre approche : les mises à jour ne sont pas forcément acceptées, Babel teste pour voir si elles créent une boucle (section 2.4). Toute annonce est donc examinée au regard d'une condition, dite « de faisabilité ». Plusieurs conditions sont possibles. Par exemple, BGP utilise la condition « Mon propre numéro d'AS n'apparaît pas dans l'annonce. ». (Cela n'empêche pas les micro-boucles, boucles de courte durée en cas de coupure, cf. RFC 5715.) Une autre condition, utilisée par DSDV et AODV (RFC 3561), repose sur l'observation qu'une boucle ne se forme que lorsqu'une annonce a une métrique moins bonne que la métrique de la route qui a été retirée. En n'acceptant que les annonces qui améliorent la métrique, on peut donc éviter les boucles. Babel utilise une règle un peu plus complexe, empruntée à EIGRP, qui tient compte de l'histoire des annonces faites par le routeur.
Comme il n'y a pas de miracles en routage, cette idée de ne pas accepter n'importe quelle annonce de route a une contrepartie : la famine. Celle-ci peut se produire lorsqu'il existe une route mais qu'aucun routeur ne l'accepte (section 2.5). EIGRP résout le problème en « rédémarrant » tout le réseau (resynchronisation globale des routeurs). Babel, lui, emprunte à DSDV une solution moins radicale, en numérotant les annonces, de manière strictement croissante, lorsqu'un routeur détecte un changement dans ses liens. Une route pourra alors être acceptée si elle est plus récente (si elle a un numéro de séquence plus élevé), et un routeur Babel peut demander explicitement aux autres routeurs d'incrémenter ce nombre, pour accélérer la convergence. Ce numéro n'est par contre pas utilisé pour sélectionner la meilleure route (seule la métrique compte pour cela), uniquement pour voir si une annonce est récente.
À noter que tout se complique s'il existe plusieurs routeurs qui annoncent originellement la même route (section 2.7 ; un exemple typique est la route par défaut, annoncée par tous les routeurs ayant une connexion extérieure). Babel gère ce problème en associant à chaque préfixe l'identité du routeur qui s'est annoncé comme origine et considère par la suite ces annonces comme distinctes, même si le préfixe est le même. Conséquence : Babel ne peut plus garantir qu'il n'y aura pas de boucle (Babel essaie de construire un graphe acyclique mais l'union de plusieurs graphes acycliques n'est pas forcément acyclique). Par contre, il pourra détecter ces boucles a posteriori et les éliminer plus rapidement qu'avec du comptage vers l'infini.
Notez aussi que chaque routeur Babel est libre de rejeter les
routes qui lui semblent déraisonnables, comme
127.0.0.1/32, sans affecter le fonctionnement
du protocole (le détail de cette question du filtrage des routes est
dans l'annexe C.)
Voilà pour les principes. Et le protocole ? La section 3 le décrit. Chaque routeur a une identité sur huit octets (le plus simple est de prendre l'adresse MAC d'une des interfaces). Les messages sont envoyés dans des paquets UDP et encodés en TLV. Le paquet peut être adressé à une destination unicast ou bien multicast. Les TLV peuvent contenir des sous-TLV dans leur partie Valeur.
Un routeur Babel doit se souvenir d'un certain nombre de choses (section 3.2), notamment :
- Le numéro de séquence, qui croît strictement,
- La liste des interfaces réseau où parler le protocole,
- La liste des voisins qu'on a entendus,
- La liste des sources (routeurs qui ont été à l'origine de l'annonce d'un préfixe). Elle sert pour calculer les critères d'acceptation (ou de rejet) d'une route. Babel consomme donc plus de mémoire que RIP, qui ne connait que son environnement immédiat, alors qu'un routeur Babel connaît tous les routeurs du réseau.
- Et bien sûr la table des routes, celle qui, au bout du compte, sera utilisée pour la transmission des paquets.
Les préfixes annoncés sont sans rapport avec la version du protocole IP utilisée pour transporter l'annonce. Un préfixe IPv4 peut donc être envoyé en IPv6. Le RFC recommande de faire tourner Babel sur IPv6, même si le réseau est en partie en IPv4.
Les messages Babel ne bénéficient pas d'une garantie de délivrance (c'est de l'UDP, après tout), mais un routeur Babel peut demander à ses voisins d'accuser réception (section 3.3). La décision de le demander ou pas découle de la politique locale de chaque routeur. Si un routeur ne demande pas d'accusé de réception, l'envoi périodique des routes permettra de s'assurer que, au bout d'un certain temps, tous les routeurs auront toute l'information. Les accusés de réception peuvent toutefois être utiles en cas de mises à jour urgentes dont on veut être sûr qu'elles ont été reçues.
Comment un nœud Babel trouve t-il ses voisins ? La section 3.4 décrit ce mécanisme. Les voisins sont détectés par les messages Hello qu'ils émettent. Les messages IHU (I Heard You) envoyés en sens inverse permettent notamment de s'assurer que le lien est bien bidirectionnel.
Les détails de la maintenance de la table de routage figurent en section 3.5. Chaque mise à jour envoyée par un nœud Babel est un quintuplet {préfixe IP, longueur du préfixe, ID du routeur, numéro de séquence, métrique}. Chacune de ces mises à jour est évaluée en regard des conditions de faisabilité : une distance de faisabilité est un doublet {numéro de séquence, métrique} et ces distances sont ordonnées en comparant d'abord le numéro de séquence (numéro plus élevée => distance de faisabilité meilleure) et ensuite la métrique (où le critère est inverse). Une mise à jour n'est acceptée que si sa distance de faisabilité est meilleure.
Si la table des routes contient plusieurs routes vers un préfixe donné, laquelle choisir et donc réannoncer aux voisins (section 3.6) ? La politique de sélection n'est pas partie intégrante de Babel. Plusieurs mises en œuvre de ce protocole pourraient faire des choix différents. Les seules contraintes à cette politique sont qu'il ne faut jamais réannoncer les routes avec une métrique infinie (ce sont les retraits, lorsqu'une route n'est plus accessible), ou les routes infaisables (selon le critère de faisabilité cité plus haut). Si les différents routeurs ont des politiques différentes, cela peut mener à des oscillations (routes changeant en permanence) mais il n'existe pas à l'heure actuelle de critères scientifiques pour choisir une bonne politique. On pourrait imaginer que le routeur ne garde que la route avec la métrique le plus faible, ou bien qu'il privilégie la stabilité en gardant la première route sélectionnée, ou encore qu'il prenne en compte des critères comme la stabilité du routeur voisin dans le temps. En attendant les recherches sur ce point, la stratégie conseillée est de privilégier la route de plus faible métrique, en ajoutant un petit délai pour éviter de changer trop souvent. Notez que la méthode de calcul des métriques n'est pas imposée par Babel : tant que cette méthode obéit à certains critères, notamment de monotonie, elle peut être utilisée.
Une fois le routeur décidé, il doit envoyer les mises à jour à ses voisins (section 3.7). Ces mises à jour sont transportées dans des paquets multicast (mais peuvent l'être en unicast). Les changements récents sont transmis immédiatement, mais un nœud Babel transmet de toute façon la totalité de ses routes à intervalles réguliers. Petite optimisation : les mises à jour ne sont pas transmises sur l'interface réseau d'où la route venait, mais uniquement si on est sûr que ladite interface mène à un réseau symétrique (un Ethernet filaire est symétrique mais un lien WiFi ad hoc ne l'est pas forcément).
Un routeur Babel peut toujours demander explicitement des annonces de routes à un voisin (section 3.8). Il peut aussi demander une incrémentation du numéro de séquence, au cas où il n'existe plus aucune route pour un préfixe donné (problème de la famine, section 3.8.2.1).
La section 4 spécifie l'encodage des messages Babel sur le
réseau. C'est un paquet UDP, envoyé à une adresse
multicast (ff02::1:6 ou
224.0.0.111) ou bien
unicast, avec un TTL de 1
(puisque les messages Babel n'ont jamais besoin d'être routés), et
un port source et
destination de
6696. En IPv6, les adresses IP de
source et de destination unicast sont locales au
lien et en IPv4 des adresses du réseau
local.
Les données envoyées dans le message sont typées et la section
4.1 liste les types possibles, par exemple
interval, un entier de 16 bits qui sert à
représenter des durées en centisecondes (rappelez-vous que, dans
Babel, un routeur informe ses voisins de ses paramètres temporels,
par exemple de la fréquence à laquelle il envoie des
Hello). Plus complexe est le type
address, puisque Babel permet d'encoder les
adresses par différents moyens (par exemple, pour une adresse IPv6
locale au lien, le préfixe
fe80::/64 peut être omis). Quant à l'ID du
routeur, cet identifiant est stocké sur huit octets.
Ensuite, ces données sont mises dans des TLV, eux-même placés derrière
l'en-tête Babel, qui indique un nombre magique (42...) pour
identifier un paquet Babel, un numéro de version (aujourd'hui 2) et
la longueur du message. (La fonction
babel_print_v2 dans le code de
tcpdump est un bon moyen de découvrir les
différents types et leur rôle.) Le message est suivi d'une remorque
qui n'est pas comptée pour le calcul de la longueur du message, et
qui sert notamment pour l'authentification
(cf. RFC 8967). La remorque, une
nouveauté qui n'existait pas explicitement dans le RFC 6126, est elle-même composée de TLV. Chaque TLV, comme son
nom l'indique, comprend un type (entier sur huit bits), une longueur
et une valeur, le corps, qui peut comprendre
plusieurs champs (dépendant du type). Parmi les types existants :
- 0 et 1, qui doivent être ignorés (ils servent si on a besoin d'aligner les TLV),
- 2, qui indique une demande d'accusé de réception, comme le Echo Request d'ICMP (celui qui est utilisé par la commande ping). Le récepteur doit répondre par un message contenant un TLV de type 3.
- 4, qui désigne un message
Hello. Le corps contient notamment le numéro de séquence actuel du routeur. Le type 5 désigne une réponse auHello, le IHU, et ajoute des informations comme le coût de la liaison entre les deux routeurs. - 6 sert pour transmettre l'ID du routeur.
- 7 et 8 servent pour les routes elles-mêmes. 7 désigne le
routeur suivant qui sera utilisé (next hop) pour
les routes portées dans les TLV de type 8. Chaque TLV
Update(type 8) contient notamment un préfixe (avec sa longueur), un numéro de séquence, et une métrique. - 9 est une demande explicite de route (lorsqu'un routeur n'a plus de route vers un préfixe donné ou simplement lorsqu'il est pressé et ne veut pas attendre le prochain message). 10 est la demande d'un nouveau numéro de séquence.
Les types de TLV sont stockés dans un registre IANA. On peut en ajouter à condition de fournir une spécification écrite (« Spécification nécessaire », cf. RFC 8126). Il y a aussi un registre des sous-TLV.
Quelle est la sécurité de Babel ? La section 6 dit franchement qu'elle est, par défaut, à peu près inexistante. Un méchant peut annoncer les préfixes qu'il veut, avec une bonne métrique pour être sûr d'être sélectionné, afin d'attirer tout le trafic.
En IPv6, une protection modérée est fournie par le fait que les adresses source et destination sont locales au lien. Comme les routeurs IPv6 ne sont pas censés faire suivre les paquets ayant ces adresses, cela garantit que le paquet vient bien du réseau local. Une raison de plus d'utiliser IPv6.
Ce manque de sécurité dans le Babel original du RFC 6126 avait suscité beaucoup de discussions à l'IETF lors de la mise de Babel sur le chemin des normes (voir par exemple cet examen de la direction de la sécurité). Normalement, l'IETF exige de tout protocole qu'il soit raisonnablement sécurisé (la règle figure dans le RFC 3365). Certaines personnes s'étaient donc vigoureusement opposées à la normalisation officielle de Babel tant qu'il n'avait pas de solution de sécurité disponible. D'autres faisaient remarquer que Babel était quand même déployable pour des réseaux fermés, « entre copains », même sans sécurité, mais les critiques pointaient le fait que tôt ou tard, tout réseau fermé risque de se retrouver ouvert. D'un autre côté, sécuriser des réseaux « ad hoc », par exemple un lot de machines mobiles qui se retrouvent ensemble pour un événement temporaire, est un problème non encore résolu.
Un grand changement de notre RFC est de permettre la signature des messages. Deux mécanismes existent, décrits dans les RFC 8967 (signature HMAC, pour authentifier, la solution la plus légère) et RFC 8968 (DTLS, qui fournit en plus la confidentialité). (Notons que, en matière de routage, la signature ne résout pas tout : c'est une chose d'authentifier un voisin, une autre de vérifier qu'il est autorisé à annoncer ce préfixe.)
J'ai parlé plus haut de la détermination des coûts des liens. L'annexe A du RFC contient des détails intéressants sur cette détermination. Ainsi, contrairement aux liens fixes, les liens radio ont en général une qualité variable, surtout en plein air. Déterminer cette qualité est indispensable pour router sur des liens radio, mais pas facile. L'algorithme ETX (décrit dans l'article de De Couto, D., Aguayo, D., Bicket, J., et R. Morris, « A high-throughput path metric for multi-hop wireless networks ») est recommandé pour cela.
L'annexe D est consacrée aux mécanismes d'extension du protocole, et reprend largement le RFC 7557, qu'elle remplace. Babel prévoyait des mécanismes d'extension en réservant certaines valeurs et en précisant le comportement d'un routeur Babel lors de la réception de valeurs inconnues. Ainsi :
- Un paquet Babel avec un numéro de version différent de 2 doit être ignoré, ce qui permet de déployer une nouvelle future version de Babel sans que ses paquets ne cassent les implémentations existantes,
- Un TLV de type inconnu doit être ignoré (section 4.3), ce qui permet d'introduire de nouveaux types de TLV en étant sûr qu'ils ne vont pas perturber les anciens routeurs,
- Les données contenues dans un TLV au-delà de sa longueur indiquée, ou bien les données présentes après le dernier TLV, devaient, disait le RFC 7557 qui reprenait le RFC 6126, également être silencieusement ignorées (au lieu de déclencher une erreur). Ainsi, une autre voie d'extension était possible, pour glisser des données supplémentaires. Cette voie est désormais utilisée par les solutions de signature comme celle du RFC 8966.
Quelles sont donc les possibilités d'extensions propres ? Cela commence par une nouvelle version du protocole (l'actuelle version est la 2), qui utiliserait des numéros 3, puis 4... Cela ne doit être utilisé que si la nouvelle version est incompatible avec les précédentes et ne peut pas interopérer sur le même réseau.
Moins radicale, une extension de la version 2 peut introduire de nouveaux TLV (qui seront ignorés par les mises en œuvre anciennes de la version 2). Ces nouveaux TLV doivent suivre le format de la section 4.3. De la même façon, on peut introduire de nouveaux sous-TLV (des TLV contenus dans d'autres TLV, décrits en section 4.4).
Si on veut ajouter des données dans un TLV existant, en
s'assurant qu'il restera correctement analysé par les anciennes
mises en œuvre, il faut jouer sur la différence entre la taille
explicite (explicit size) et la taille effective
(natural size) du TLV. La taille explicite est
celle qui est indiqué dans le champ Length
spécifié dans la section 4.3. La taille effective est celle déduite
d'une analyse des données (plus ou moins compliquée selon le type de
TLV). Comme les implémentations de Babel doivent ignorer les données
situées après la taille explicite, on peut s'en servir pour ajouter
des données. Elles doivent être encodées sous forme de sous-TLV,
chacun ayant type, longueur et valeur (leur format exact est décrit
en section 4.4).
Enfin, après le dernier TLV (Babel est transporté sur UDP, qui indique une longueur explicite), on peut encore ajouter des données, une « remorque ». C'est ce que fait le RFC 8966.
Bon, mais alors quel mécanisme d'extension choisir ? La section 4 fournit des pistes aux développeurs. Le choix de faire une nouvelle version est un choix drastique. Il ne devrait être fait que si la nouvelle version est réellement incompatible avec la précédente.
Un nouveau TLV, ou bien un nouveau sous-TLV d'un TLV existant est
la solution à la plupart des problèmes d'extension. Par exemple, si
on veut mettre de l'information supplémentaire aux mises à jour de
routes (TLV Update), on peut créer un nouveau
TLV « Update enrichi » ou bien un sous-TLV de
Update qui contiendra l'information
supplémentaire. Attention, les conséquences de l'un ou l'autre choix
ne seront pas les mêmes. Un TLV « Update
enrichi » serait totalement ignoré par un Babel ancien, alors qu'un
TLV Update avec un sous-TLV
d'« enrichissement » verrait la mise à jour des routes acceptée,
seule l'information supplémentaire serait perdue.
Il existe désormais, pour permettre le développement d'extensions, un registre IANA des types de TLV et un des sous-TLV (section 5 du RFC) et plusieurs extensions s'en servent déjà.
Enfin, l'annexe F du RFC résume les changements depuis le premier RFC, le RFC 6126, qui documentait la version 2 de Babel. On reste en version 2 car le protocole de notre RFC reste essentiellement compatible avec le précédent. Il y a toutefois trois fonctions de ce protocole qui pourraient créer des problèmes sur un réseau où certaines machines sont restées au RFC 6126 :
- Les messages de type
Helloen unicast sont une nouveauté. L'ancien RFC ne les mentionnait pas. Cela peut entrainer une mauvaise interprétation des numéros de séquence (qui sont distincts en unicast et multicast). - Les messages
Hellopeuvent désormais avoir un intervalle entre deux messages qui est nul, ce qui n'existait pas avant. - Les sous-TLV obligatoires (section 4.4) n'existaient pas avant et leur utilisation peut donc être mal interprétée par les vieilles mises en œuvre de Babel (le TLV englobant va être accepté alors qu'il devrait être rejeté).
Bref, si on veut déployer le Babel de ce RFC dans un réseau où il
reste de vieilles mises en œuvre, il faut prendre garde à ne pas
utiliser ces trois fonctions. Si on préfère mettre à jour les vieux
programmes, sans toutefois y intégrer tout ce que contient notre
RFC, il faut au minimum ignorer (ou bien gérer correctement) les
Hello en unicast, ou bien
avec un intervalle nul, et il faut ignorer un TLV qui contient un
sous-TLV obligatoire mais inconnu.
Il y a d'autres changements depuis le RFC 6126 mais qui ne sont pas de nature à affecter l'interopérabilité ; voyez le RFC pour les détails.
Vous pourrez trouver plus d'informations sur Babel en lisant le RFC, ou bien sur la page Web officielle. Si vous voulez approfondir la question des protocoles de routage, une excellente comparaison a été faite par David Murray, Michael Dixon et Terry Koziniec dans « An Experimental Comparison of Routing Protocols in Multi Hop Ad Hoc Networks » où ils comparent Babel (qui l'emporte largement), OLSR (RFC 7181) et Batman (ce dernier est dans le noyau Linux officiel). Notez aussi que l'IETF a un protocole standard pour ce problème, RPL, décrit dans le RFC 6550. Si vous aimez les vidéos, l'auteur de Babel explique le protocole en anglais.
Qu'en est-il des mises en œuvre de ce protocole ? Il existe une
implémentation
d'exemple, babeld, assez éprouvée
pour être disponible en paquetage dans plusieurs systèmes, comme babeld dans
Debian ou dans
OpenWrt, plateforme très souvent utilisée
pour des routeurs libres (cf. https://openwrt.org/docs/guide-user/services/babeld). babeld
ne met pas en œuvre les solutions de sécurité des RFC 8966 ou RFC 8967. Une
autre implémentation se trouve dans Bird. Si
vous voulez écrire votre implémentation, l'annexe E contient
plusieurs conseils utiles, accompagnés de calculs, par exemple sur
la consommation mémoire et réseau. Le RFC proclame que Babel est un
protocole relativement simple et, par exemple, l'implémentation de
référence contient environ 12 500 lignes de C.
Néanmoins, cela peut être trop, une fois compilé, pour des objets (le RFC cite les fours à micro-ondes...) et l'annexe E décrit donc des sous-ensembles raisonnables de Babel. Par exemple, une mise en œuvre passive pourrait apprendre des routes, sans rien annoncer. Plus utile, une mise en œuvre « parasite » n'annonce que la route vers elle-même et ne retransmet pas les routes apprises. Ne routant les paquets, elle ne risquerait pas de créer des boucles et pourrait donc omettre certaines données, comme la liste des sources. (Le RFC liste par contre ce que la mise en œuvre parasite doit faire.)
L'article seul
RFC 8967: Message Authentication Code (MAC) Authentication for the Babel Routing Protocol
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : C. Dô, W. Kołodziejak, J. Chroboczek (IRIF, University of Paris-Diderot)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF babel
Première rédaction de cet article le 12 janvier 2021
Le protocole de routage Babel, normalisé dans le RFC 8966, avait à l'origine zéro sécurité. N'importe quelle machine pouvait se dire routeur et annoncer ce qu'elle voulait. Le RFC 7298 avait introduit un mécanisme d'authentification. Ce nouveau RFC le remplace avec un nouveau mécanisme. Chaque paquet est authentifié par HMAC, et les routeurs doivent donc partager une clé secrète.
Comme, par défaut, Babel croit aveuglément ce que ses voisins lui racontent, un méchant peut facilement, par exemple, détourner du trafic (en annonçant une route de plus forte préférence). Le problème est bien connu mais n'a pas de solution simple. Par exemple, Babel permet à la fois de l'unicast et du multicast, le second étant plus difficile à protéger. Une solution de sécurité, DTLS, spécifiée pour Babel dans le RFC 8968, résout le problème en ne faisant que de l'unicast. Notre RFC choisit une autre solution, qui marche pour l'unicast et le multicast. Chaque paquet est authentifié par un MAC attaché au paquet, calculé entre autres à partir d'une clé partagée.
La solution décrite dans ce RFC implique que tous les routeurs connectés au réseau partagent la clé secrète, et que tous ces routeurs soient eux-mêmes de confiance (l'authentification n'implique pas l'honnêteté du routeur authentifié, point très souvent oublié quand on parle d'authentification…) En pratique, c'est un objectif difficile à atteindre, il nécessite un réseau relativement bien géré. Pour un rassemblement temporaire où tout le monde partage sa connectivité, faire circuler ce mot de passe partagé sera difficile.
Ce mécanisme a par contre l'avantage de ne pas nécessiter que les horloges soient correctes ou synchronisées, et ne nécessite pas de stockage de données permanent (ce qui serait contraignant pour, par exemple, certains objets connectés).
Pour que tout marche bien et qu'on soit heureux et en sécurité, ce mécanisme d'authentification compte sur deux pré-requis :
- Une fonction MAC sécurisée (évidemment), c'est-à-dire qu'on ne puisse pas fabriquer un MAC correct sans connaitre la clé secrète,
- Que les nœuds Babel arrivent à ne pas répéter certaines valeurs qu'ils transmettent. Cela peut se faire avec un générateur aléatoire correct (RFC 4086) mais il existe aussi d'autres solutions pour générer des valeurs uniques, non réutilisables.
En échange de ces garanties, le mécanisme de ce RFC garantit l'intégrité des paquets et le rejet des rejeux (dans certaines conditions, voir le RFC).
La section 2 du RFC résume très bien le protocole : quand un routeur Babel envoie un paquet sur une des interfaces où la protection MAC a été activée, il calcule le MAC et l'ajoute à la fin du paquet. Quand il reçoit un paquet sur une des interfaces où la protection MAC a été activée, il calcule le MAC et, s'il ne correspond pas à ce qu'il trouve à la fin du paquet, le paquet est jeté. Simple, non ? Mais c'est en fait un peu plus compliqué. Pour protéger contre les attaques par rejeu, la machine qui émet doit maintenir un compteur des paquets envoyés, le PC (Packet Counter). Il est inclus dans les paquets envoyés et protégé par le MAC.
Ce PC ne protège pas dans tous les cas. Par exemple, si un routeur Babel vient de démarrer, et n'a pas de stockage permanent, il ne connait pas les PC de ses voisins et ne sait donc pas à quoi s'attendre. Dans ce cas, il doit ignorer le paquet et mettre l'émetteur au défi de répondre à un numnique qu'il envoie. Le voisin répond en incluant le numnique et son nouveau PC, prouvant ainsi qu'il ne s'agit pas d'un rejeu.
Petite difficulté, en l'absence de stockage permanent, le PC peut revenir en arrière et un PC être réutilisé. Outre le PC, il faut donc un autre nombre, l'index. Celui-ci n'est, comme le numnique utilisé dans les défis, jamais réutilisé. En pratique, un générateur aléatoire est une solution raisonnable pour fabriquer numniques et index.
La section 3 du RFC décrit les structures de données qu'il faut utiliser pour mettre en œuvre ce protocole. La table des interfaces (RFC 8966, section 3.2.3), doit être enrichie avec une indication de l'activation de la protection MAC sur l'interface, et la liste des clés à utiliser (Babel permet d'avoir plusieurs clés, notamment pour permettre le remplacement d'une clé, et le récepteur doit donc les tester toutes). Il faut également ajouter à la table des interfaces l'index et le PC décrits plus haut.
Quant à la table des (routeurs) voisins (RFC 8966, section 3.2.4), il faut y ajouter l'index et le PC de chaque voisin, et le numnique.
Enfin la section 4 détaille le fonctionnement. Comment calculer le MAC (avec un pseudo-en-tête), où mettre le TLV qui indique le PC, et celui qui contient la ou les MAC (dans la remorque, c'est-à-dire la partie du paquet après la longueur explicite), etc. La section 6 fournit quant à elle le format exact des TLV utilisés : le MAC TLV qui stocke le MAC, le PC TLV qui indique le compteur, et les deux TLV qui permettent de lancer un défi et d'obtenir une réponse, pour se resynchroniser en cas d'oubli du compteur. Ils ont été ajoutés au registre IANA.
Les gens de l'opérationnel aimeront la section 5, qui décrit comment déployer initialement cette option, et comment effectuer un changement de clé. Pour le déploiement initial, il faut configurer les machines dans un mode où elles signent mais ne vérifient pas les paquets entrants (il faut donc que les implémentations aient un tel mode). Cela permet de déployer progressivement. Une fois tous les routeurs ainsi configurés, on peut activer le mode normal, avec signature et vérification. Pour le remplacement de clés, on ajoute d'abord la nouvelle clé aux routeurs, qui signent donc avec les deux clés, l'ancienne et la nouvelle, puis, une fois que tous les routeurs ont la nouvelle clé, on retire l'ancienne.
Un petit bilan de la sécurité de ce mécanisme, en section 7 : d'abord un rappel qu'il est simple et qu'il ne fournit que le minimum, l'authentification et l'intégrité des paquets. Si on veut d'avantage, il faut passer à DTLS, avec le RFC 8968. Ensuite, certaines valeurs utilisées doivent être générées sans que l'attaquant puisse les deviner, ce qui nécessite, par exemple, un générateur de nombres aléatoires sérieux. D'autant plus que la taille limitée de certaines valeurs peut permettre des attaques à la force brute. Si, par exemple, les clés dérivent d'une phrase de passe, il faut une bonne phrase de passe, plus une fonction de dérivation qui gêne ces attaques, comme PBKDF2 (RFC 2898), bcrypt ou scrypt (RFC 7914).
Et, comme toujours, il y a la lancinante menace des attaques par déni de service, par exemple en envoyant des paquets délibérement conçus pour faire faire des calculs cryptographiques inutiles aux victimes. C'est pour limiter leurs conséquences que, par exemple, Babel impose de limiter le rythme d'envoi des défis, pour éviter de s'épuiser à défier un attaquant.
Je n'ai pas vu quelles mises en œuvre de Babel avaient ce mécanisme. il ne semble pas dans la version officielle de babeld, en tout cas, même si il y a du code dans une branche séparée. Et ce n'est pas encore dans une version officielle de BIRD mais le code est déjà écrit.
Le RFC ne décrit pas les changements depuis le RFC 7298 car il s'agit en fait d'un protocole différent, et incompatible (ce ne sont pas les mêmes TLV, par exemple).
Merci à Juliusz Chroboczek pour sa relecture.
L'article seul
RFC 8968: Babel Routing Protocol over Datagram Transport Layer Security
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : A. Decimo (IRIF, University of Paris-Diderot), D. Schinazi (Google LLC), J. Chroboczek (IRIF, University of Paris-Diderot)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF babel
Première rédaction de cet article le 12 janvier 2021
Le protocole de routage Babel, normalisé dans le RFC 8966, n'offre par défaut aucune sécurité. Notamment, il n'y a aucun moyen d'authentifier un routeur voisin, ni de s'assurer que les messages suivants viennent bien de lui. Sans même parler de la confidentialité de ces messages. Si on veut ces services, ce RFC fournit un moyen : sécuriser les paquets Babel avec DTLS.
La sécurité est évidemment souhaitable pour un protocole de routage. Sans elle, par exemple, une méchante machine pourrait détourner le trafic. Cela ne veut pas dire qu'on va toujours employer une solution de sécurité. Babel (RFC 8966) est conçu entre autres pour des réseaux peu ou pas gérés, par exemple un événement temporaire où chacun apporte son PC et où la connectivité se fait de manière ad hoc. Dans un tel contexte, déployer de la sécurité ne serait pas facile. Mais, si on y tient, Babel fournit désormais deux mécanismes de sécurité (cf. RFC 8966, section 6), l'un, plutôt simple et ne fournissant pas de confidentialité, est décrit dans le RFC 8967, l'autre, bien plus complet, figure dans notre RFC et repose sur DTLS (qui est normalisé dans le RFC 9147). DTLS, version datagramme de TLS, fournit authentification, intégrité et confidentialité.
L'adaptation de DTLS à Babel est décrite dans la section 2 du
RFC. Parmi les problèmes, le fait que DTLS soit très asymétrique
(client-serveur) alors que Babel est pair-à-pair, et le fait que
DTLS ne marche qu'en unicast alors que Babel peut
utiliser unicast ou
multicast. Donc, chaque routeur Babel doit être
un serveur DTLS, écoutant sur le port 6699
(qui n'est pas le 6696 du Babel non sécurisé). Le routeur Babel
continue à écouter sur le port non chiffré, et, lorsqu'il entend un
nouveau routeur s'annoncer en multicast, il va
tenter de communiquer en DTLS avec lui. Puisque DTLS, comme TLS, est
client-serveur, il faut décider de qui sera le client et qui sera le
serveur : le routeur de plus faible adresse sera le client (par
exemple, fe80::1:2 est inférieure à
fe80::2:1. Le serveur différencie les sessions
DTLS par le port source ou par les connection
identifiers du RFC 9146. Comme avec
le Babel non chiffré, les adresses IPv6 utilisées doivent être des
adresses locales au lien. Client et serveur doivent s'authentifier,
en suivant les méthodes TLS habituelles (chacun doit donc avoir un
certificat).
Une fois que la session DTLS est en marche, les paquets Babel
unicast passent sur cette session et sont donc
intégralement (du premier au dernier octet) protégés par le
chiffrement. Pour que la sécurité fournie par DTLS soit ne soit pas
compromise, le routeur ne doit plus envoyer à son voisin de paquets
sur le port non chiffré, à part des paquets
Hello qui sont transmis en
multicast (pour lequel DTLS ne marche pas) et qui
permettent de découvrir d'éventuels nouveaux voisins (la règle
exacte est un peu plus compliquée, regardez le RFC). On ne peut donc
plus envoyer d'information en multicast (à part
les Hello). En réception, un nœud Babel
sécurisé doit ignorer les paquets non protégés par DTLS, sauf
l'information de type Hello.
Une stricte sécurité nécessite qu'un routeur Babel sécurisé
n'accepte plus de voisins qui ne gèrent pas DTLS, et ignore donc
tous leurs paquets sauf ceux qui contiennent un
TLV Hello. Autrement,
les communications non sécurisées ficheraient en l'air la
confidentialité de l'information. Si on veut
une sécurité plus relaxée, un nœud peut faire tourner les deux versions
du protocole, sécurisée et non sécurisée, mais
alors, exige le RFC, uniquement sur des interfaces réseau différentes.
Comme toutes les fois où on rajoute des données, on risque de dépasser la MTU. La section 3 du RFC nous rappelle qu'il faut éviter d'envoyer des paquets qui seront fragmentés et donc qu'il faut éviter de fabriquer des paquets qui, après chiffrement, seraient plus gros que la MTU.
Rien n'est parfait en ce bas monde et l'ajout de DTLS, s'il résout quelques problèmes de sécurité, ne fait pas tout, et même parfois ajoute des ennuis. La section 5 du RFC rappelle ainsi qu'un méchant pourrait tenter des négociations DTLS nombreuses avec une machine afin de la faire travailler pour rien (une variante de Slowloris). Limiter le nombre de connexions par client n'aiderait pas puisqu'il pourrait toujours mentir sur son adresse IP.
Même en faisant tourner Babel sur DTLS, les messages de type
Hello peuvent toujours être envoyés sans
protection, et donc manipulés à loisir. Un routeur Babel doit donc
toujours être capable d'utiliser des Hello
unicast et protégés.
Et puis bien sûr, limitation classique de TLS, authentifier un routeur voisin et sécuriser la communication avec lui ne signifie pas que ce voisin est honnête ; il peut toujours mentir, par exemple en annonçant des routes vers des préfixes qu'il ne sait en fait pas joindre.
À ma connaissance, il n'existe pas encore de mise en œuvre de ce RFC.
L'article seul
happyDomain, pour gérer ses noms de domaine facilement
Première rédaction de cet article le 11 janvier 2021
Le logiciel happyDomain (ou happyDNS) est une interface Web permettant de gérer ses noms de domaine. Pourquoi ? Comment ? Quand est-ce qu'on mange ?
Voyons le pourquoi d'abord. Avoir un nom de domaine à soi est crucial pour une
présence en ligne, qu'on soit une association, un particulier ou une
entreprise. Si on n'a pas son propre nom de domaine, par exemple
parce qu'on communique uniquement sur
Facebook, on est à la merci d'une société qui
peut changer ses algorithmes, voire vous virer du jour au
lendemain. Et, dans ce cas, une fois trouvé un autre hébergement, il
faudra prévenir tous vos visiteurs de la nouvelle adresse Web. Les noms de domaine permettent
au contraire la stabilité de l'adresse que vous communiquez. Mais
pour que ce nom de domaine fonctionne, il faut des serveurs
DNS qui répondent
aux requêtes des visiteurs, et il faut indiquer à ces serveurs DNS
les informations techniques indispensables comme
l'adresse IP de votre serveur Web. Une solution simple est de
confier toutes ces tâches à l'organisation (par exemple le
bureau d'enregistrement) où vous avez acheté
le nom de domaine. Certes, vous dépendez d'un seul acteur mais, si
l'intermédiaire est honnête, le nom de domaine est à vous et, si
vous changez d'intermédiaire, vous n'aurez pas à recommencer le
travail de communication sur votre adresse Web. À l'autre extrémité
du spectre des solutions est l'hébergement de vos propres serveurs
DNS, dans lesquels vous rentrez vous-même les informations
nécessaires. C'est ce que je fais pour le domaine
bortzmeyer.org où se trouve ce blog mais cela
nécessite quelques compétences techniques et surtout du temps. Même
si vous êtes un professionnel des serveurs Internet, vous n'avez pas
forcément le temps et l'envie de vous en occuper vous-même.
Il peut aussi y avoir des solutions intermédiaires entre « tout sous-traiter » et « tout faire soi-même ». C'est là que se situe le projet happyDomain (à l'origine happyDNS), le « Comment » de mon introduction. À terme, le projet veut couvrir plusieurs aspects de la gestion de noms de domaines mais, ici, je vais parler de ce qui est immédiatement disponible, à savoir une interface perfectionnée et agréable pour gérer les informations que les serveurs DNS distribueront au monde entier. (Mais rappelez-vous que d'autres possibilités sont prévues.) Une telle interface est souvent fournie par les hébergeurs DNS mais je trouve qu'elles sont souvent de médiocre qualité, par exemple parce qu'elles ne permettent pas d'indiquer tous les types d'information nécessaires. Et, souvent, ces interfaces sont soit trop complexes pour les utilisateurs, soit trop limitées en ne permettant pas de faire des choses non triviales. En outre, comme elles sont dépendantes de l'hébergeur DNS, changer d'hébergeur nécessite de tout réapprendre. happyDomain, au contraire, vous rend indépendant de l'hébergeur.
Le principe est le suivant : si votre hébergeur est dans la liste
des hébergeurs reconnus, vous configurez un accès à cet hébergeur
(typiquement via son API) et vous pouvez ensuite gérer le
contenu de votre domaine via happyDomain. Si vous changez
d'hébergeur, ou si vous en avez plusieurs, pas besoin de
réapprendre. 
Ici, je vais utiliser Gandi. Dans
l'interface de Gandi, le menu Paramètres puis Sécurité du compte
permet de configurer une clé d'API que l'on indiquera à
happyDomain : 
On voit alors dans happyDomain ses domaines et on peut les
importer dans la base de happyDomain. On peut ensuite les gérer,
ajouter des enregistrements, en retirer, etc. Il y a plein de bonnes
idées de présentation, par exemple les alias, les surnoms d'un nom
sont visualisés de manière claire et pas avec des termes techniques
très trompeurs comme « CNAME » : 
D'une manière générale, le but de happyDomain est de présenter une vision de plus haut niveau des modifications DNS, pour pouvoir se concentrer sur le contenu et pas sur des détails subtils de syntaxe. Ce n'est pas encore réalisé partout (ainsi, pour l'enregistrement SPF, il faut encore utiliser la syntaxe SPF qui est assez rébarbative) mais c'est un but sympa.
Les modifications qu'on veut faire sont bien représentées,
lorsqu'on valide :
J'apprécie également le fait qu'on dispose d'un historique de ses contenus DNS, et qu'on ait plusieurs présentations possibles du contenu.
Je m'aperçois que je n'ai pas encore parlé des auteurs d'happyDomain. Ce n'est pas moi, je n'ai participé que comme donneur de conseils (c'est moins fatigant), les félicitations vont donc à Pierre-Olivier et à toute l'équipe qui a travaillé. J'avais écrit un article sur l'hébergement DNS qui a été partiellement une source d'inspiration pour happyDomain, mais, pour l'instant, la partie « hébergement » n'est pas encore développée. Mais le projet démarre déjà très bien.
L'article seul
RFC 9003: Extended BGP Administrative Shutdown Communication
Date de publication du RFC : Janvier 2021
Auteur(s) du RFC : J. Snijders (NTT), J. Heitz (Cisco), J. Scudder (Juniper), A. Azimov (Yandex)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF idr
Première rédaction de cet article le 9 janvier 2021
Ce nouveau RFC normalise un mécanisme pour transmettre un texte en langue naturelle à un pair BGP afin de l'informer sur les raisons pour lesquelles on coupe la session. Il remplace le RFC 8203, notamment en augmentant la longueur maximale du message, afin de faciliter les messages en Unicode.
Le protocole de routage BGP offre un mécanisme
de coupure propre de la session, le message
NOTIFICATION avec le code
Cease (RFC 4271,
section 6.7). En prime, le RFC 4486
ajoutait à ce code des sous-codes permettant de préciser les
raisons de la coupure. Une coupure volontaire et manuelle aura
typiquement les sous-codes 2 (Administrative
Shutdown), 3 (Peer De-configured) ou
4 (Administrative Reset). (Ces sous-codes sont
enregistrés
à l'IANA.) Et enfin le RFC 8203,
déjà cité, ajoutait à ces sous-codes du texte libre, où on pouvait
exprimer ce qu'on voulait, par exemple « [#56554] Coupure de toutes les
sessions BGP au DE-CIX pour mise à jour
logicielle, retour dans trente minutes ». Notre RFC ne modifie que
légèrement cette possibilité introduite par le RFC 8203,
en augmentant la taille maximale du texte envoyé.
Bien sûr, la raison de la coupure peut être connue par d'autres moyens. Cela a pu être, par exemple, pour une session au travers d'un point d'échange, un message envoyé sur la liste du point d'échange, annonçant la date (en UTC, j'espère !) et la raison de la coupure. De tels message se voient régulièrement sur les listes, ici au France-IX :
Date: Wed, 16 Dec 2020 11:54:21 +0000
From: Jean Bon <jbon@operator.example>
To: <paris@members.franceix.net>
Subject: [FranceIX members] [Paris] AS64530 [REF056255] Temporary shut FranceIX sessions
Hi France-IX members,
This mail is to inform you that we are going to shut down all our
sessions on France-IX' Paris POP on 2021-01-05 08:00:00 UTC for 30
minutes, in order to upgrade the router.
Please use the ticket number [REF056255] for every correspondance about
this action.
Mais quand la coupure effective se produit, on a parfois oublié le message d'avertissement, ou bien on a du mal à le retrouver. D'où l'importance de pouvoir rappeler les informations importantes dans le message de coupure, qui, espérons-le, sera affiché quelque part chez le pair, ou bien journalisé par syslog.
La section 2 décrit le format exact de ce mécanisme. La chaîne
de caractères envoyée dans le message BGP
NOTIFICATION doit être en
UTF-8. Sa taille maximale est de 255
octets (ce qui ne fait pas 255 caractères, attention). À part ces
exigences techniques, son contenu est laissé à l'appréciation de
l'envoyeur.
La section 3 de notre RFC ajoute quelques conseils opérationnels. Par exemple, si vous utilisez un système de tickets pour suivre vos tâches, mettez le numéro du ticket correspondant à l'intervention de maintenance dans le message. Vos pairs pourront ainsi plus facilement vous signaler à quoi ils font référence.
Attention à ne pas agir aveuglément sur la seule base d'un message envoyé par BGP, notamment parce que, si la session BGP n'était pas sécurisée par, par exemple, IPsec, le message a pu être modifié en route.
L'annexe B du RFC résume les principaux changements depuis le RFC 8203. Le plus important est que la longueur maximale du message passe de 128 à 255 octets, notamment pour ne pas défavoriser les messages qui ne sont pas en ASCII. Comme l'avait fait remarquer lors de la discussion un opérateur du MSK-IX, si la phrase « Planned work to add switch to stack. Completion time - 30 minutes » fait 65 octets, sa traduction en russe aurait fait 119 octets.
L'article seul
Échec de RPZ à l'IETF
Première rédaction de cet article le 5 janvier 2021
RPZ (Response Policy Zones) est une technologie permettant de configurer les mensonges d'un résolveur DNS. Il était prévu de la normaliser à l'IETF mais le projet a finalement échoué. Pourquoi ?
Un résolveur DNS est censé transmettre fidèlement les réponses envoyées par les serveurs faisant autorité. S'il ne le fait pas, on parle de résolveur menteur ou, pour employer le terme plus corporate du RFC 8499, de « résolveur politique ». De tels résolveurs menteurs sont utilisés pour de nombreux usages, du blocage de la publicité (par exemple avec Pi-hole) à la censure étatique ou privée. L'administrateur d'un tel résolveur menteur peut configurer la liste des domaines où un mensonge sera fait à la main. Mais c'est évidemment un long travail que de suivre les changements d'une telle liste. Il peut être préférable de sous-traiter ce travail. RPZ (Response Policy Zones) est conçu pour faciliter cette sous-traitance.
Pour les principes techniques de RPZ, je vous laisse lire mon article technique, ou bien regarder le site « officiel ». RPZ est mis en œuvre dans plusieurs logiciels résolveurs comme BIND, Unbound (depuis la version 1.10, cf. cet article) ou Knot.
Comme RPZ est là pour permettre la communication entre le
fournisseur de listes de mensonges et le résolveur, il serait
intéressant techniquement qu'il soit
normalisé. Un effort a donc été fait à
l'IETF
pour cela. Sur l'excellent DataTracker de
l'IETF, vous pouvez suivre l'histoire
de ce projet depuis 2016 : d'abord une contribution
individuelle, draft-vixie-dns-rpz, puis après
adoption par un groupe de travail de l'IETF, une version de groupe
(qu'on reconnait à son nom commençant par
draft-ietf-NOMDUGROUPE),
draft-ietf-dnsop-dns-rpz puis, après une
interruption d'une année, à nouveau un retour à la contribution
individuelle, draft-vixie-dnsop-dns-rpz,
finalement abandonnée depuis aujourd'hui plus de deux ans.
Pourquoi cet échec ? Notez d'abord que l'IETF ne documente pas explicitement les échecs. Il n'y a pas eu de décision officielle « on laisse tomber », avec un texte expliquant pourquoi. Il s'agit plutôt d'un document qui a eu à faire face à tellement de problèmes que plus personne n'avait envie de travailler dessus.
Quels étaient ces problèmes ? Commençons par le plus gros, le problème politique. Beaucoup de gens ne sont pas d'accord avec la censure faite via le DNS et craignaient que RPZ n'aide les méchants davantage que les gentils. À ce problème politique (tout le monde n'étant pas d'accord sur la légitimité de la censure) s'ajoutait un problème classique lors des débats politico-techniques, celui de la neutralité de la technique (j'en ai parlé dans mon livre, p. 148 et suivantes de l'édition papier). Le débat est récurrent à l'IETF et peut se simplifier en deux positions opposées :
- Nous normalisons juste des techniques, les gens peuvent ensuite les utiliser pour le bien ou pour le mal et, de toute façon, si l'IETF ne normalise pas cette technique dans un RFC, elle sera utilisée quand même, et peut-être normalisée par des organismes moins scrupuleux comme l'UIT.
- Nous ne pouvons pas nier les conséquences des décisions que nous prenons (RFC 8890), tout est politique (RFC 8280), et un RFC sera interprété comme une approbation ou quasi-approbation par l'IETF.
Pris entre ces deux positions, le document a ainsi été adopté par le groupe de travail DNSOP, puis abandonné, après de longues et parfois vigoureuses discussions.
Une autre raison de la non-normalisation de RPZ est peut-être le
fait qu'en pratique, ce protocole n'a été adopté que par des acteurs
commerciaux. Je n'ai pas trouvé de flux RPZ librement accessible,
par exemple avec une liste de domaines liés à la publicité (ce
serait bien pratique pour les bloquer). Peut-être https://block.energized.pro/
Un problème supplémentaire est également survenu dans la discussion : le contrôle du changement. Normalement, une fois un protocole publié par l'IETF, c'est l'IETF qui gouverne les évolutions futures. Or, ici, les auteurs originaux de RPZ avaient écrit dans le document qu'ils gardaient le contrôle et pouvaient donc empêcher telle ou telle évolution de la norme. En contradiction avec les règles de l'IETF, cette mention a contribué à l'échec de RPZ dans le groupe de travail. Il aurait quand même pu être publié en RFC non-IETF mais le projet est finalement mort d'épuisement.
L'article seul
RFC 8956: Dissemination of Flow Specification Rules for IPv6
Date de publication du RFC : Décembre 2020
Auteur(s) du RFC : C. Loibl (next layer Telekom GmbH), R. Raszuk (NTT Network Innovations), S. Hares (Huawei)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF idr
Première rédaction de cet article le 1 janvier 2021
Il existe un mécanisme de diffusion des règles de filtrage IP, FlowSpec, normalisé dans le RFC 8955. Ce mécanisme permet d'utiliser BGP pour envoyer à tous les routeurs d'un AS les mêmes règles, ce qui est très pratique, par exemple pour bloquer une attaque sur tous les routeurs d'entrée du domaine. Le FlowSpec original ne gérait qu'IPv4, voici son adaptation à IPv6.
En fait, il n'y avait pas grand'chose à faire. Après tout, IPv6 n'est pas un nouveau protocole, juste une nouvelle version du même protocole IP. Des concepts cruciaux, comme la définition d'un préfixe en préfixe/longueur, ou comme la règle du préfixe le plus spécifique restent les mêmes. Ce RFC est donc assez simple. Il ne reprend pas l'essentiel du RFC 8955, il ajoute juste ce qui est spécifique à IPv6. (À l'IETF, il avait été proposé de fusionner les deux documents mais, finalement, il y a un RFC générique + IPv4, le RFC 8955, et un spécifique à IPv6, notre RFC 8956.)
Petit rappel sur FlowSpec : les règles de filtrage sont transportées en BGP, les deux routeurs doivent annoncer la capacité « multi-protocole » (les capacités sont définies dans le RFC 5492) définie dans le RFC 4760, la famille de l'adresse (AFI pour Address Family Identifier) est 2 (qui indique IPv6) et le SAFI (Subsequent Address Family Identifier) est le même qu'en IPv4, 133.
Le gros de notre RFC (section 3) est l'énumération des différents
types d'identifiant d'un trafic à filtrer. Ce sont les mêmes
qu'en IPv4 mais avec quelques adaptations. Ainsi, le type 1,
« préfixe de destination » permet par exemple de dire à ses routeurs
« jette à la poubelle tout ce qui est destiné à
2001:db:96b:1::/64 ». Son encodage ressemble
beaucoup à celui en IPv4 mais avec un truc en plus, le décalage
(offset) depuis le début de l'adresse. Avec un
décalage de 0, on est dans le classique préfixe/longueur mais on
peut aussi ignorer des bits au début de l'adresse avec un décalage
non-nul.
Le type 3, « protocole de niveau supérieur » est l'un de ceux dont la définition IPv6 est la plus différente de celle d'IPv4. En effet, IPv6 a les en-têtes d'extension (RFC 8200, section 4), une spécificité de cette version. Le champ « Next header » d'IPv6 (RFC 8200, section 3) n'a pas la même sémantique que le champ « Protocole » d'IPv4 puisqu'il peut y avoir plusieurs en-têtes avant celui qui indique le protocole de couche 4 (qui sera typiquement TCP ou UDP). Le choix de FlowSpec est que le type 3 désigne le dernier champ « Next header », celui qui identifie le protocole de transport, ce qui est logique, c'est bien là-dessus qu'on veut filtrer, en général. Rappelez-vous au passage que d'analyser les en-têtes d'extension IPv6 pour arriver au protocole de transport n'est hélas pas trivial. Et il y a d'autres pièges, expliqués dans les RFC 7112 et RFC 8883.
Autre type d'identifiant qui est différent en IPv6, le type 7, ICMP. Si le protocole est très proche, les types et les codes ne sont en effet pas les mêmes. Ainsi, l'un des types les plus célèbres, Echo Request, utilisé par ping, vaut 8 en IPv4 et 138 en IPv6.
Les autres types se comportent en IPv6 exactement comme en IPv4. Par exemple, si vous voulez dire à vos routeurs de filtrer sur le port, les types 4, 5 et 6, dédiés à cet usage, ont le même encodage et la même sémantique qu'en IPv4 (ce qui est logique, puisque le port est un concept de couche 4).
FlowSpec est aujourd'hui largement mis en œuvre dans les logiciels de routage, y compris en IPv6. Vous pouvez consulter à ce sujet le rapport de mise en œuvre. Si vous voulez jouer avec FlowSpec, le code Python d'exemple de l'annexe A est disponible en ligne.
L'article seul
RFC 8955: Dissemination of Flow Specification Rules
Date de publication du RFC : Décembre 2020
Auteur(s) du RFC : C. Loibl (next layer Telekom GmbH), S. Hares (Huawei), R. Raszuk (Bloomberg LP), D. McPherson (Verisign), M. Bacher (T-Mobile Austria)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF idr
Première rédaction de cet article le 1 janvier 2021
Lorsqu'on a un grand réseau compliqué, diffuser à tous les routeurs des règles de filtrage, par exemple pour faire face à une attaque par déni de service, peut être complexe. Il existe des logiciels permettant de gérer ses routeurs collectivement mais ne serait-il pas plus simple de réutiliser pour cette tâche les protocoles existants et notamment BGP ? Après tout, des règles de filtrage sont une forme de route. On profiterait ainsi des configurations existantes et de l'expérience disponible. C'est ce que se sont dit les auteurs de ce RFC. « FlowSpec » (nom officieux de cette technique) consiste à diffuser des règles de traitement du trafic en BGP, notamment à des fins de filtrage. Ce RFC remplace le RFC FlowSpec original, le RFC 5575, le texte ayant sérieusement changé (mais le protocole est presque le même).
Les routeurs modernes disposent en effet de nombreuses capacités de traitement du trafic. Outre leur tâche de base de faire suivre les paquets, ils peuvent les classifier, limiter leur débit, jeter certains paquets, etc. La décision peut être prise en fonction de critères tels que les adresses IP source et destination ou les ports source et destination. Un flot (flow) est donc défini comme un tuple rassemblant les critères d'acceptation d'un paquet IP. Notre RFC 8955 encode ces critères dans un attribut NLRI (Network Layer Reachability Information est décrit dans la section 4.3 du RFC 4271) BGP, de manière à ce qu'ils puissent être transportés par BGP jusqu'à tous les routeurs concernés. Sans FlowSpec, il aurait fallu qu'un humain ou un programme se connecte sur tous les routeurs et y rentre l'ACL concernée.
Pour reconnaitre les paquets FlowSpec, ils sont marqués avec le SAFI (concept introduit dans le RFC 4760) 133 pour les règles IPv4 (et IPv6 grâce au RFC 8956) et 134 pour celles des VPN.
La section 4 du RFC donne l'encodage du NLRI. Un message
UPDATE de BGP est utilisé, avec les attributs
MP_REACH_NLRI et
MP_UNREACH_NLRI du RFC 4760 et un NLRI FlowSpec. Celui-ci compte plusieurs
couples {type, valeur} où l'interprétation de la valeur dépend du
type (le type est codé sur un octet). Voici les principaux types :
- Type 1 : préfixe de la destination, représenté par un octet
pour la longueur, puis le préfixe, encodé comme traditionnellement
en BGP (section 4.3 du RFC 4271). Ainsi, le
préfixe
10.0.1.0/24sera encodé (noté en hexadécimal)01 18 0a 00 01(type 1, longueur 24 - 18 en hexa - puis le préfixe dont vous noterez que seuls les trois premiers octets sont indiqués, le dernier n'étant pas pertinent ici). - Type 2 : préfixe de la source (lors d'une attaque DoS, il est essentiel de pouvoir filtrer aussi sur la source).
- Type 3 : protocole (TCP, UDP, etc).
- Types 4, 5 et 6 : port (source ou destination ou les deux). Là encore, c'est un critère très important lors du filtrage d'une attaque DoS. Attention, cela suppose que le routeur soit capable de sauter les en-têtes IP (y compris des choses comme ESP) pour aller décoder TCP ou UDP. Tous les routeurs ne savent pas faire cela (en IPv6, c'est difficile).
- Type 9 : options activées de TCP, par exemple uniquement les
paquets
RST.
Tous les types de composants sont enregistrés à l'IANA.
Une fois qu'on a cet arsenal, à quoi peut-on l'utiliser ? La section 5 détaille le cas du filtrage. Autrefois, les règles de filtrage étaient assez statiques (je me souviens de l'époque où tous les réseaux en France avaient une ACL, installée manuellement, pour filtrer le réseau de l'EPITA). Aujourd'hui, avec les nombreuses DoS qui vont et viennent, il faut un mécanisme bien plus dynamique. La première solution apparue a été de publier via le protocole de routage des préfixes de destination à refuser. Cela permet même à un opérateur de laisser un de ses clients contrôler le filtrage, en envoyant en BGP à l'opérateur les préfixes, marqués d'une communauté qui va déclencher le filtrage (à ma connaissance, aucun opérateur n'a utilisé cette possibilité, en raison du risque qu'une erreur du client ne se propage). De toute façon, c'est très limité en cas de DoS (par exemple, on souhaite plus souvent filtrer sur la source que sur la destination). Au contraire, le mécanisme FlowSpec de ce RFC donne bien plus de critères de filtrage.
Cela peut d'ailleurs s'avérer dangereux : une annonce FlowSpec trop générale et on bloque du trafic légitime. C'est particulièrement vrai si un opérateur accepte du FlowSpec de ses clients : il ne faut pas permettre à un client de filtrer les autres. D'où la procédure suggérée par la section 6, qui demande de n'accepter les NLRI FlowSpec que s'ils contiennent un préfixe de destination, et que ce préfixe de destination est routé vers le même client qui envoie le NLRI (notez que cette règle a été assouplie par le RFC 9117). Ainsi, un client ne peut pas déclencher le filtrage d'un autre puisqu'il ne peut influencer que le filtrage des paquets qui lui sont destinés.
Au fait, en section 5, on a juste vu comment indiquer les
critères de classification du trafic qu'on voulait filtrer. Mais
comment indiquer le traitement qu'on veut voir appliqué aux paquets
ainsi classés ? (Ce n'est pas forcément les jeter : on peut vouloir
être plus subtil.) FlowSpec utilise les communautés étendues du RFC 4360. La valeur sans doute la plus importante
est 0x8006, traffic-rate, qui permet de
spécifier un débit maximal pour les paquets qui correspondent aux
critères mis dans le NLRI. Le débit est en octets/seconde. En
mettant zéro, on demande à ce que tous les paquets classés soient
jetés. (Mais on peut aussi indiquer des paquets/seconde, c'est une
nouveauté de ce RFC.) Les autres valeurs possibles permettent des
actions comme de modifier les bits DSCP du trafic classé.
Comme toutes les armes, celle-ci peut être dangereuse pour celui qui la manipule. La section 12 est donc la bienvenue, pour avertir de ces risques. Par exemple, comme indiqué plus haut, si on permet aux messages FlowSpec de franchir les frontières entre AS, un AS maladroit ou méchant risque de déclencher un filtrage chez son voisin. D'où l'importance de la validation, n'accepter des règles FlowSpec que pour les préfixes de l'AS qui annonce ces règles.
Ensuite, comme tous les systèmes de commande des routeurs à distance, FlowSpec permet de déclencher un filtrage sur tous les routeurs qui l'accepteront. Si ce filtrage est subtil (par exemple, filtrer tous les paquets plus grands que 900 octets), les problèmes qui en résultent seront difficiles à diagnostiquer.
FlowSpec a joué un rôle important dans la panne Level 3 / CenturyLink d'août 2020. Et, avant cela, dans la panne CloudFlare du 3 mars 2013, où des critères incorrects (une taille de paquet supérieure au maximum permis par IP) avaient été envoyés à tous les routeurs. Ce n'est pas une bogue de FlowSpec : tout mécanisme de diffusion automatique de l'information à N machines différentes a le même problème potentiel. Si l'information était fausse, le mécanisme de diffusion transmet l'erreur à tous... (Dans le monde des serveurs Unix, le même problème peut se produire avec des logiciels comme Chef ou Puppet. Lisez un cas rigolo avec Ansible.) Comme le prévient notre RFC : « When automated systems are used, care should be taken to ensure the correctness of the automated system. » Toutefois, contrairement à ce que laisse entendre le RFC, il n'y a pas que les processus automatiques qui injectent des erreurs : les humains le font aussi.
Si vous voulez en apprendre plus sur FlowSpec :
- Excellent exposé très détaillé (en anglais) de Frédéric Gabut-Deloraine à une réunion FRnOG,
- Excellent exposé général (en anglais) sur le BGP concret, par Thomas Mangin, avec quelques transparents sur FlowSpec à la fin,
- Un article en français sur LinuxFr, avec exemples de configuration d'ExaBGP,
- Exposé (en anglais) de Jean-Marc Uzé, détaillant le cas des attaques par déni de service,
- Le projet du projet Cymru d'un serveur FlowSpec public (mais je ne sais pas ce qu'il est devenu depuis 2011),
- Un exposé sur l'utilisation de FlowSpec à Cloudflare (écrit avant la panne).
Si vous vous intéressez à l'utilisation de BGP lors d'attaques par déni de service, vous pouvez aussi consulter les RFC 3882 et RFC 5635.
Les changements depuis la norme originale, le RFC 5575, sont résumés dans l'annexe B. Parmi les principaux :
- Le RFC 7674 a été intégré ici, et n'est donc plus d'actualité,
- Les comparaisons entre les valeurs indiquées dans les règles FlowSpec et les paquets qu'on voit passer sont désormais spécifiées plus strictement, avec du code d'exemple (en Python) dans l'annexe A,
- Les actions fondées sur le trafic peuvent désormais s'exprimer en nombre de paquets et plus seulement en nombre d'octets (certaines attaques par déni de service sont dangereuses par leur nombre de paquets, même si ces paquets sont petits).
FlowSpec est utilisé depuis dix ans et de nombreuses mises en œuvre existent (cf. la liste). Sur les Juniper, on peut consulter leur documentation en ligne.
L'article seul
Articles des différentes années : 2026 2025 2024 2023 2022 2021 2020 Précédentes années
Syndication : Flux Atom avec seulement les résumés et Flux Atom avec tout le contenu.
{kind=link}