
Ce blog n'a d'autre prétention que de me permettre de mettre à la disposition de tous des petits textes que j'écris. On y parle surtout d'informatique mais d'autres sujets apparaissent parfois.
Developing and running an Internet crawler
First publication of this article on 23 December 2020
I've just developed and now runs an Internet crawler. Yes, the sort of bots that goes around and gather content. But not a Web crawler. This is for Gemini. Here are a few lessons learned.
If you don't know Gemini, there is no Wikipedia page yet, so you have to go to the official site. Basically, Gemini is born from a disenchantment: the Web is technically too complicated, it is now impossible to write a browser from scratch and because of that the competition is very limited. This technical complexity does not even serve the interests of the users: it creates distractions (such as videos automatically starting), it encourages Web sites authors to focus on the look, not on the content, and it adds a lot of opportunities for surveillance. Gemini relies on a simpler protocol, with no extensions, and a simpler format.
Today, the "geminispace" is quite small. This makes easy and
reasonable to write a crawler to explore it completely. This is what
I did with the Lupa program,
which is now live on one of my machines. The goal of this crawler is
not to be used for a search engine (unlike
the crawler used in the Gemini search engine
gus.guru) but to do statistics and to survey
the geminispace. You can see the results on Gemini at the URI
gemini://gemini.bortzmeyer.org/software/lupa/stats.gmi. If
you don't have a Gemini
client yet, here is what it looks like, seen with the Lagrange client :
Now, what is the current state of the geminispace?
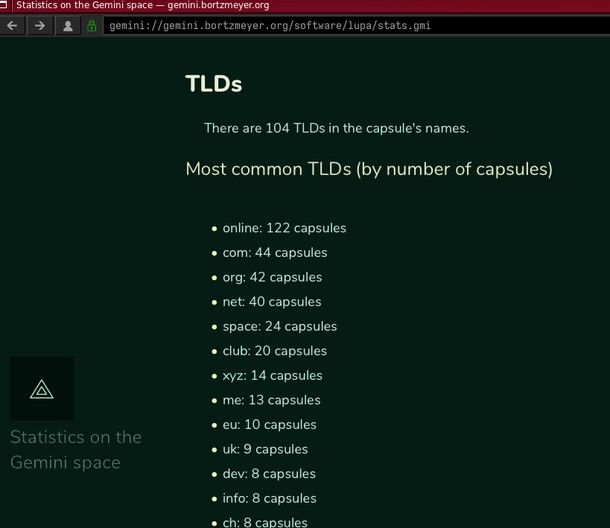
- 506 capsules (a Gemini capsule is a single host, a bit like a Web site) are known but Lupa could reach only 415 of them. (Gemini is quite experimental and many capsules are short-lived. Also, some links are examples and point to non-existing capsules.)
- The biggest capsule, both by the number of URIs it hosts and
by the number of bytes it contains, is
gemini.spam.works. Its content is mostly old files, some distributed on Usenet a long time ago. The second capsule by the number of bytes is my owngemini.bortzmeyer.orgbecause it contains a mirror of RFCs. - The question of certificates is touchy. Gemini suggests the use of self-signed certificates, augmented with TOFU, but not everyone agrees. Today, 17 % of the known capsules use a certificate issued by Let's Encrypt, the rest being probably self-signed.
- As it is for the Web, a same machine, with one IP address can host several "virtual hosts", several capsules. We observed 371 different IP addresses, among which 17 % use a modern protocol, IPv6. The IP address with the greatest number of "virtual hosts" is at Linode and is used for public hosting of Gemini capsules, hence its huge number of virtual hosts.
- Each capsule is identified by a domain name. Which TLD are used for these names? The most popular
is
.onlinebut this is because the same very common Gemini hosting service hosts many capsules under its name in.online, which skews the results. After that, the most popular TLDs are.com,.org,.netand.space. - 64,000 URIs are known but we got only 50,000 of them. Lupa follows the robots.txt exclusion system (more on that later) which means that some capsules or some parts of capsules cannot be crawled. Also, Lupa has a limit on how many URIs to get from a single capsule.
- The most common media types (60 % of
the total) is of course
text/geminialias "gemtext", the reference format for Gemini. Plain text comes after, with 30 %. Remember that Gemini is young and a lot of content has been produced by mirroring existing content, which is often in plain text. There are even 2 % of the URIs which are in HTML, which is surprising. Only 0.3 % are in Markdown, which should be more in the Gemini spirit than HTML. - The Gemini protocol allows servers to tag the resources with the language they're written in. The vast majority of the resources does not use this feature, maybe because they're written in English and assume it is the world's default? Among the tagged resources, the most common language is English, then French, then (but far after) Spanish.
Keep in mind that no crawler could explore everything. If there are capsules out here which are not linked from the capsules we know, they won't be retrieved.
What are the issues when running a crawler on the geminispace?
Since bots can create a serious load on some servers, a well-behaved
bot is supposed to limit itself, and to follow the preferences
expressed by the server. Unfortunately, there is no proper standard
to express these preferences. The Web uses
robots.txt but it is not really
standardized. The original
specification is very simple (may be too simple), and many
robots.txt files use one or another form of
extensions, such as the Allow: directive or
globbing. (IETF is currently trying to
standardize
robots.txt.) Because of that, you can never be sure that your
robots.txt will be interpreted as you
want. This is even worse in the geminispace where it is not clear or
specified if robots.txt apply and, if so, which
variant.
Another big problem when running a bot is the variety of network
problems you can encounter. The simplest case is when a server
replies with some Gemini error code (51 for "resource not found",
the equivalent of the famous HTTP 404) or when it rejects Gemini
connections right away (TCP RST for
instance). But many servers react in much stranger ways: timeout
when connecting (no response, not even a rejection), accepting the
TCP connection but no response to the start of the TLS negotiation,
accepting the TLS session but no response afterwards to the Gemini
request, etc. A lot of network operations can leave your bot stuck
forever, or make it run in an endless loop (for instance
never-ending redirections). It is very important to use defensive
programming and to plan for the worst. And to set a limit to
everything (size of the resources, number of resources per capsule,
etc). It is a general rule of programming that a simple
implementation which does 90 % of the job will be done quickly (may
be 10 % of the total time of the project), but a real implementation
able to handle 100 % of the job will take much longer. This is even
more so when managing a crawler.
L'article seul
RFC 8970: IMAP4 Extension: Message Preview Generation
Date de publication du RFC : Décembre 2020
Auteur(s) du RFC : M. Slusarz (Open-Xchange)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF extra
Première rédaction de cet article le 19 décembre 2020
Le protocole IMAP d'accès aux boites aux lettres (RFC 3501) continue à évoluer et reçoit de nouvelles extensions. Celle normalisée dans ce RFC permet au client IMAP, le MUA, de ne récupérer qu'une partie du message, afin d'afficher un avant-gout de celui-ci à l'utilisateur humain, qui pourra ainsi mieux choisir s'il veut lire ce message ou pas.
Il y a déjà des clients de
messagerie qui présentent le début du message mais, sans
l'extension de ce RFC, cela nécessite de tout récupérer (un
FETCH BODYSTRUCTURE pour savoir quelle partie
MIME récupérer, suivi d'un FETCH
BODY, et sans possibilité de les exécuter en parallèle)
avant de ne sélectionner qu'une partie. Au contraire, avec
l'extension PREVIEW (« avant-gout »), c'est le
serveur IMAP qui va sélectionner cet avant-gout. Avantages : une
présélection qui est identique sur tous les clients, moins de
travail pour le client et surtout moins de données
transmises. Avant, le client était forcé de récupérer beaucoup de
choses car il ne pouvait pas savoir à l'avance combien d'octets
récolter avant de générer l'avant-gout. Si le message était du
texte brut, OK, mais si c'était de
l'HTML, il
pouvait être nécessaire de ramasser beaucoup d'octets de formatage
et de gadgets avant d'en arriver au vrai contenu. (Ou bien, il
fallait procéder progressivement, récupérant une partie du message,
puis, si nécessaire, une autre, ce qui augmentait la latence.)
Donc, concrètement, comment ça se passe ? La section 3 de notre
RFC décrit l'extension en détail. Elle a la forme d'un attribut
PREVIEW qui suit la commande
FETCH (RFC 3501, section
6.4.5). Voici un exemple, la commande étant étiquetée
MYTAG01 :
Client : MYTAG01 FETCH 1 (PREVIEW) Serveur : * 1 FETCH (PREVIEW "Bonjour, voulez-vous gagner plein d'argent rapidement ?") MYTAG01 OK FETCH complete.
Idéalement, le serveur renvoie toujours le même avant-gout pour un message donné (mais le RFC ne l'impose pas car cela peut être difficile dans certains cas, par exemple en cas de mise à jour du logiciel du serveur, qui change l'algorithme de génération des avant-gouts).
La syntaxe formelle
de l'attribut PREVIEW est
en section 6 du RFC.
Le format de l'avant-gout est forcément du texte brut, encodé en UTF-8, et ne doit pas avoir subi d'encodages baroques comme Quoted-Printable. Sa longueur est limitée à 256 caractères (caractères Unicode, pas octets, attention si vous programmez un client et que votre tampon est trop petit).
Le contenu de l'avant-gout est typiquement composé des premiers caractères du message. Cela implique qu'il peut contenir des informations privées et il ne doit donc être montré qu'aux clients qui sont autorisés à voir le message complet.
Parfois, le serveur ne peut pas générer un avant-gout, par exemple si le message est chiffré avec OpenPGP (RFC 4880) ou bien si le message est entièrement binaire, par exemple du PNG. Dans ces cas, le serveur est autorisé à renvoyer une chaîne de caractères vide.
Si le serveur génère un avant-gout lui-même (du genre « Image de
600x600 pixels, prise le 18 décembre 2020 », en utilisant les
métadonnées de l'image), il est recommandé
qu'il choisisse la langue indiquée par
l'extension LANGUAGE (RFC 5255).
Comme l'avant-gout n'est pas forcément indispensable pour l'utilisateur, le RFC suggère (section 4) de le charger en arrière-plan, en affichant la liste des messages sans attendre tous ces avant-gouts.
Le serveur IMAP qui sait générer ces avant-gouts l'annonce via la
capacité PREVIEW, qui est notée dans le
registre des capacités. Voici un exemple :
Client :
MYTAG01 CAPABILITY
Serveur :
* CAPABILITY IMAP4rev1 PREVIEW
MYTAG01 OK Capability command completed.
Client :
MYTAG02 FETCH 1 (RFC822.SIZE PREVIEW)
Serveur :
* 1 FETCH (RFC822.SIZE 5647 PREVIEW {200}
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
Curabitur aliquam turpis et ante dictum, et pulvinar dui congue.
ligula nullam
)
MYTAG02 OK FETCH complete.
Attention si vous mettez en œuvre cette extension, elle nécessite davantage de travail du serveur, donc un client méchant pourrait surcharger ledit serveur. Veillez bien à authentifier les clients, pour retrouver le méchant (section 7 du RFC).
L'article seul
RFC 8953: Coordinating Attack Response at Internet Scale 2 (CARIS2) Workshop Report
Date de publication du RFC : Décembre 2020
Auteur(s) du RFC : K. Moriarty (Dell Technologies)
Pour information
Première rédaction de cet article le 17 décembre 2020
Voici le compte-rendu de la deuxième édition de l'atelier CARIS (Coordinating Attack Response at Internet Scale), un atelier de l'ISOC consacré à la défense de l'Internet contre les différentes attaques possibles, par exemple les dDoS. Cet atelier s'est tenu à Cambridge en mars 2019. Par rapport au premier CARIS, documenté dans le RFC 8073, on note l'accent mis sur les conséquences du chiffrement, désormais largement répandu.
Les problèmes de sécurité sur l'Internet sont bien connus. C'est tous les jours qu'on entend parler d'une attaque plus ou moins réussie contre des infrastructures du réseau. Ainsi, Google a été victime d'une grosse attaque en 2017 (mais qui n'a été révélée que des années après). Mais, pour l'instant, nous n'avons pas de solution miracle. L'idée de base des ateliers CARIS est de rassembler aussi bien des opérateurs de réseau, qui sont « sur le front » tous les jours, que des chercheurs, des fournisseurs de solutions de défense, et des CSIRT, pour voir ensemble ce qu'on pouvait améliorer. Pour participer, il fallait avoir soumis un article, et seules les personnes dont un article était accepté pouvait venir, garantissant un bon niveau de qualité aux débats, et permettant de limiter le nombre de participants, afin d'éviter que l'atelier ne soit juste une juxtaposition de discours.
La section 2 du RFC présente les quatorze papiers qui ont été acceptés. On les trouve en ligne.
Le but de l'atelier était d'identifier les points sur lesquels des progrès pourraient être faits. Par exemple, tout le monde est d'accord pour dire qu'on manque de professionnel·le·s compétent·e·s en cybersécurité mais il ne faut pas espérer de miracles : selon une étude, il manque trois millions de personnes dans ce domaine et il n'y a simplement aucune chance qu'on puisse les trouver à court terme. Plus réaliste, l'atelier s'est focalisé sur le déploiement du chiffrement (TLS 1.3, normalisé dans le RFC 9846, le futur - à l'époque - QUIC, et pourquoi pas le TCPcrypt du RFC 8548), déploiement qui peut parfois gêner la détection de problèmes, et sur les mécanismes de détection et de prévention. Une importance particulière était donnée au passage à l'échelle (on ne peut plus traiter chaque attaque individuellement et manuellement, il y en a trop).
Bon, maintenant, les conclusions de l'atelier (section 4). Première session, sur l'adoption des normes. C'est une banalité à l'IETF que de constater que ce n'est pas parce qu'on a normalisé une technique de sécurité qu'elle va être déployée. Beaucoup de gens aiment râler contre l'insécurité de l'Internet mais, dès qu'il s'agit de dépenser de l'argent ou du temps pour déployer les solutions de sécurité, il y a moins d'enthousiasme. (J'écris cet article au moment de la publication de la faille de sécurité SadDNS. Cela fait plus de dix ans qu'on a une solution opérationnelle contre la famille d'attaques dont SadDNS fait partie, DNSSEC et, pourtant, DNSSEC n'est toujours pas déployé sur la plupart des domaines.) Commençons par un point optimiste : certaines des technologies de sécurité de l'IETF ont été largement déployées, comme SSL (RFC 6101), remplacé il y a quinze ans par TLS (RFC 9846). L'impulsion initiale venait clairement du secteur du commerce électronique, qui voulait protéger les numéros des cartes de crédit. Lié à TLS, X.509 (RFC 5280) est aussi un succès. Cette fois, l'impulsion initiale est plutôt venue des États. (X.509 doit être une des très rares normes UIT survivantes sur l'Internet.)
Moins directement lié à la sécurité, SNMP (RFC 3410) est aussi un succès, même s'il est en cours de remplacement par les techniques autour de YANG comme RESTCONF. Toujours pour la gestion de réseaux, IPfix (RFC 7011) est également un succès, largement mis en œuvre sur beaucoup d'équipements réseau.
Par contre, il y a des semi-échecs et des échecs. Le format de
description d'incidents de sécurité IODEF
(RFC 7970) ne semble pas très répandu. (Il a
un concurrent en dehors de l'IETF, STIX - Structured Threat Information eXpression, qui
ne semble pas mieux réussir.) IODEF est utilisé par des CSIRT
mais souffre de son niveau de détail (beaucoup d'opérationnels
veulent des synthèses, pas des données brutes) et, comme toutes les
techniques d'échange d'information sur les questions de sécurité,
souffre également des problèmes de confiance qui grippent la
circulation de l'information. Autre technique de sécurité
excellente mais peu adoptée, DANE (RFC 7671). Malgré de nombreux efforts de promotion (comme
https://internet.nl
Un autre cas fameux de non-succès, même s'il n'est pas directement lié à la sécurité, est IPv6 (RFC 8200).
Deuxième session, les protocoles nouveaux. L'atelier s'est penché sur le format MUD (Manufacturer Usage Description, RFC 8520) qui pourrait aider à boucher une petite partie des trous de sécurité de l'Internet des objets. Il a également travaillé l'échange de données et les problèmes de confiance qu'il pose. Comme à CARIS 1, plusieurs participants ont noté que cet échange de données reste gouverné par des relations personnelles. La confiance ne passe pas facilement à l'échelle. L'échange porte souvent sur des IOC et un standard possible a émergé, MISP.
Une fois le problème détecté, il reste à coordonner la réaction, puisque l'attaque peut toucher plusieurs parties. C'est encore un domaine qui ne passe guère à l'échelle. L'Internet n'a pas de mécanisme (technique mais surtout humain) pour coordonner des centaines de victimes différentes. Des tas d'obstacles à la coordination ont été mentionnés, des outils trop difficiles à utiliser en passant par les obstacles frontaliers à l'échange, les obligations légales qui peuvent interdire l'échange de données, et bien sûr le problème récurrent de la confiance. Vous vous en doutez, pas plus qu'au premier atelier, il n'y aura eu de solution parfaite découverte pendant les sessions.
La session sur la surveillance a vu plusieurs discussions intéressantes. Ce fut le cas par exemple du problème de la réputation des adresses IP. Ces adresses sont souvent des IOC et on se les échange souvent, ce qui soulève des questions liées à la vie privée. (Un des papiers de l'atelier est « Measured Approaches to IPv6 Address Anonymization and Identity Association », de David Plonka et Arthur Berger , qui explique la difficulté de l'« anonymisation » des adresses IP si on veut qu'elles restent utiles pour les opérationnels.) L'exploitation correcte de ces adresses IP nécessite de connaitre les plans d'adressage utilisés (si une adresse IPv6 se comporte mal, faut-il bloquer tout le préfixe /64 ? Tout le /48 ?). Il n'y a pas de ressources publiquement disponibles à ce sujet, qui permettrait de connaitre, pour une adresse IP donnée, l'étendue du préfixe englobant. (Je ne parle évidemment pas du routage, pour lequel ces bases existents, mais de la responsabilité.) Une des suggestions était d'étendre les bases des RIR. Une autre était de créer une nouvelle base. Le problème est toujours le même : comment obtenir que ces bases soient peuplées, et correctement peuplées ?
Une des questions amusantes lorsqu'on essaie de déboguer un problème de communication entre deux applications est de savoir quoi faire si la communication est chiffrée. Il n'est évidemment pas question de réclamer une porte dérobée pour court-circuiter le chiffrement, cela créerait une énorme faille de sécurité. Mais alors comment faire pour savoir ce qui se dit ? On a besoin de la coopération de l'application. Mais toutes les applications ne permettent pas facilement de journaliser les informations importantes et, quand elles le font, ce n'est pas dans un format cohérent. D'où une suggestion lors de l'atelier de voir s'il ne serait pas envisageable de mettre cette fonction dans les compilateurs, pour avoir un mécanisme de journalisation partout disponibles.
Pendant qu'on parle de chiffrement, une autre question est celle de l'identification d'une machine ou d'un protocole par le fingerprinting, c'est-à-dire en observant des informations non chiffrées (taille des paquets, temps de réponse, variations permises par le protocole, etc). Le fingerprinting pose évidemment des gros risques pour la vie privée et beaucoup de travaux sur des protocoles récents (comme QUIC) visaient à limiter son efficacité.
Pour résumer l'atelier (section 6 du RFC), plusieurs projets ont été lancés pour travailler sur des points soulevés dans l'atelier. À suivre, donc.
L'article seul
RFC 8949: Concise Binary Object Representation (CBOR)
Date de publication du RFC : Décembre 2020
Auteur(s) du RFC : C. Bormann (Universität Bremen
TZI), P. Hoffman (ICANN)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF cbor
Première rédaction de cet article le 5 décembre 2020
Il existait un zillion de formats binaires d'échange de données ? Et bien ça en fera un zillion plus un. CBOR (Concise Binary Object Representation) est un format qui utilise un modèle de données très proche de celui de JSON, mais est encodé en binaire, avec comme but principal d'être simple à encoder et décoder, même par des machines ayant peu de ressources matérielles. Normalisé à l'origine dans le RFC 7049, il est désormais spécifié dans ce nouveau RFC. Si le texte de la norme a changé, le format reste le même.
Parmi les autres formats binaires courants, on connait ASN.1 (plus exactement BER ou DER, utilisés dans plusieurs protocoles IETF), EBML ou MessagePack mais ils avaient des cahiers des charges assez différents (l'annexe E du RFC contient une comparaison). CBOR se distingue d'abord par sa référence à JSON (RFC 8259), dont le modèle de données sert de point de départ à CBOR, puis par le choix de faciliter le travail des logiciels qui devront créer ou lire du CBOR. CBOR doit pouvoir tourner sur des machines très limitées (« classe 1 », en suivant la terminologie du RFC 7228). Par contre, la taille des données encodées n'est qu'une considération secondaire (section 1.1 du RFC pour une liste prioritisée des objectifs de CBOR). Quant au lien avec JSON, l'idée est d'avoir des modèles de données suffisamment proches pour qu'écrire des convertisseurs CBOR->JSON et JSON->CBOR soit assez facile, et pour que les protocoles qui utilisent actuellement JSON puissent être adaptés à CBOR sans douleur excessive. CBOR se veut sans schéma, ou, plus exactement, sans schéma obligatoire. Et le but est que les fichiers CBOR restent utilisables pendant des dizaines d'années, ce qui impose d'être simple et bien documenté.
La spécification complète de CBOR est en section 3 de ce RFC. Chaque élément contenu dans le flot de données commence par un octet dont les trois bits de plus fort poids indiquent le type majeur. Les cinq bits suivants donnent des détails. Ce mécanisme permet de programmeur un décodeur CBOR avec une table de seulement 256 entrées (l'annexe B fournit cette table et l'annexe C un décodeur en pseudo-code très proche de C). Pour un entier, si la valeur que codent ces cinq bits suivants est inférieure à 24, elle est utilisée telle quelle. Sinon, cela veut dire que les détails sont sur plusieurs octets et qu'il faut lire les suivants (la valeur des cinq bits codant la longueur à lire). Selon le type majeur, les données qui suivent le premier octet sont une valeur (c'est le cas des entiers, par exemple) ou bien un doublet {longueur, valeur} (les chaînes de caractères, par exemple). L'annexe A de notre RFC contient de nombreux exemples de valeurs CBOR avec leur encodage.
Quels sont les types majeurs possibles ? Si les trois premiers
bits sont à zéro, le type majeur, 0, est un entier non signé. Si les
cinq bits suivants sont inférieurs à 24, c'est la valeur de cet
entier. S'ils sont égaux à 24, c'est que l'entier se trouve dans
l'octet suivant l'octet initial, s'ils sont égaux à 25, que l'entier
se trouve dans les deux octets suivants, et ainsi de suite (31 est
réservé pour les tailles indéterminées, décrites plus
loin). L'entier 10 se représentera donc 00001010, l'entier 42 sera
00011000 00101010, etc. Presque pareil pour un type majeur de 1,
sauf que l'entier sera alors signé, et négatif. La valeur sera -1
moins la valeur encodée. Ainsi, -3 sera 00100010. Vous voulez
vérifier ? L'excellent terrain de jeu http://cbor.me
vous le permet, essayez par exemple http://cbor.me?diag=42.
Le type majeur 2 sera une chaîne d'octets (principal ajout par
rapport au modèle de données de JSON). La longueur est codée
d'abord, en suivant la même règle que pour les entiers. Puis
viennent les données. Le type 3 indique une chaîne de caractères et
non plus d'octets. Ce sont forcément des caractères
Unicode, encodés en
UTF-8 (RFC 3629). Le
champ longueur (codé comme un entier) indique le nombre d'octets de
l'encodage UTF-8, pas le nombre de caractères (pour connaître ce
dernier, il faut un décodeur UTF-8). Vous voulez des exemples ?
Connectez-vous à http://www.cbor.me/?diag=%22lait%22
et vous voyez que la chaîne « lait » est représentée par
646c616974 : 64 = 01100100, type majeur 3 puis une longueur de
4. Les codes ASCII suivent (rappelez-vous qu'ASCII est
un sous-ensemble d'UTF-8). Avec des caractères non-ASCII comme http://www.cbor.me/?diag=%22caf%C3%A9%22, on aurait
65636166c3a9 (même type majeur, longueur 5
octets, puis les caractères, avec c3a9 qui code
le é en UTF-8).
Le type majeur 4 indique un tableau. Rappelez-vous que CBOR utilise un modèle de données qui est très proche de celui de JSON. Les structures de données possibles sont donc les tableaux et les objets (que CBOR appelle les maps). Un tableau est encodé comme une chaîne d'octets, longueur (suivant les règles des entiers) puis les éléments du tableau, à la queue leu leu. La longueur est cette fois le nombre d'éléments, pas le nombre d'octets. Les éléments d'un tableau ne sont pas forcément tous du même type. Les tableaux (et d'autres types, cf. section 3.2) peuvent aussi être représentés sans indiquer explicitement la longueur ; le tableau est alors terminé par un élément spécial, le break code. Par défaut, un encodeur CBOR est libre de choisir la forme à longueur définie ou celle à longueur indéfinie, et le décodeur doit donc s'attendre à rencontrer les deux.
Le type majeur 5 indique une map (ce qu'on appelle objet en JSON et dictionnaire ou hash dans d'autres langages). Chaque élément d'une map est un doublet {clé, valeur}. L'encodage est le même que pour les tableaux, la longueur étant le nombre de doublets. Chaque doublet est encodé en mettant la clé, puis la valeur. Donc, le premier scalaire est la clé de la première entrée de la map, le deuxième la valeur de la première entrée, le troisième la clé de la deuxième entrée, etc.
Les clés doivent être uniques (une question problématique en JSON où les descriptions existantes de ce format ne sont ni claires ni cohérentes sur ce point).
Je passe sur le type majeur 6, voyez plus loin le paragraphe sur les étiquettes. Le type majeur 7 sert à coder les flottants (encodés ensuite en IEEE 754) et aussi d'autres types scalaires et le break code utilisé dans le paragraphe suivant. Les autres types scalaires, nommés « valeurs simples » (simple values) sont des valeurs spéciales comme 20 pour le booléen Faux, 21 pour le Vrai, et 22 pour le néant. Elles sont stockées dans un registre IANA.
Dans la description ci-dessus, les types vectoriels (tableaux,
chaînes, maps) commencent par la longueur du
vecteur. Pour un encodeur CBOR, cela veut dire qu'il faut connaître
cette longueur avant même d'écrire le premier élément. Cela peut
être contraignant, par exemple si on encode au fil de l'eau
(streaming) des données en cours de
production. CBOR permet donc d'avoir des longueurs
indéterminées. Pour cela, on met 31 comme « longueur » et cette
valeur spéciale indique que la longueur n'est pas encore connue. Le
flot des éléments devra donc avoir une fin explicite cette fois, le
break code. Celui-ci est représenté par un
élément de type majeur 7 et de détails 31, donc tous les bits de
l'octet à 1. Par exemple, http://cbor.me/?diag=%28_%20%22lait%22%29 nous montre que la
chaîne « lait » ainsi codée (le _ indique
qu'on veut un codage en longueur indéterminée) sera
7f646c616974ff. 7f est le type majeur 3, chaîne de caractères, avec
la longueur 31, indiquant qu'elle est indéterminée. Puis suit la
chaîne elle-même (les chaînes indéterminées en CBOR sont faites par
concaténation de châines de longueur déterminée), puis le
break code ff.
La même technique peut être utilisée pour les chaînes d'octets et de caractères, afin de ne pas avoir à spécifier leur longueur au début. Cette possibilité de listes de longueur indéterminée a été ajoutée pour faciliter la vie du streaming.
Revenons au type majeur 6. Il indique une étiquette (tag), qui sert à préciser la sémantique de l'élément qui suit (cf. section 3.4). Un exemple typique est pour indiquer qu'une chaîne de caractères est un fait une donnée structurée, par exemple une date ou un numéro de téléphone. Un décodeur n'a pas besoin de comprendre les étiquettes, il peut parfaitement les ignorer. Les valeurs possibles pour les étiquettes sont stockées dans un registre IANA, et on voit que beaucoup ont déjà été enregistrées, en plus de celles de ce RFC (par exemple par le RFC 8746 ou par le RFC 9132).
Quelques valeurs d'étiquette intéressantes ? La valeur 0 indique une date au format du RFC 3339 (une chaîne de caractères). La valeur 1 étiquette au contraire un entier, et indique une date comme un nombre de secondes depuis le 1er janvier 1970. Les valeurs négatives sont autorisées mais leur sémantique n'est pas normalisée (UTC n'est pas défini pour les dates avant l'epoch, surtout quand le calendrier a changé).
Les valeurs 2 et 3 étiquettent une chaîne d'octets et indiquent qu'on recommande de l'interpréter comme un grand entier (dont la valeur n'aurait pas tenu dans les types majeurs 0 ou 1). Les décodeurs qui ne gèrent pas les étiquettes se contenteront de passer à l'application cette chaîne d'octets, les autres passeront un grand entier.
Autre cas rigolos, les nombres décimaux non entiers. Certains ne peuvent pas être représentés de manière exacte sous forme d'un flottant. On peut alors les représenter par un couple [exposant, mantisse]. Par exemple, 273,15 est le couple [-2, 27315] (l'exposant est en base 10). On peut donc l'encoder en CBOR sous forme d'un tableau de deux éléments, et ajouter l'étiquette de valeur 4 pour préciser qu'on voulait un nombre unique.
D'autres étiquettes précisent le contenu d'une chaîne de caractères : l'étiquette 32 indique que la chaîne est un URI, la 34 que la chaîne est du Base64 (RFC 4648) et la 36 que cela va être un message MIME (RFC 2045). Comme l'interprétation des étiquettes est optionnelle, un décodeur CBOR qui n'a pas envie de s'embêter peut juste renvoyer à l'application cette chaîne.
Une astuce amusante pour finir les étiquettes, et la spécification du format : l'étiquette 55799 signifie juste que ce qui suit est du CBOR, sans modifier sa sémantique. Encodée, elle sera représentée par 0xd9d9f7 (type majeur 6 sur trois bits, puis détails 25 qui indiquent que le nombre est sur deux octets puis le nombre lui-même, d9f7 en hexa). Ce nombre 0xd9d9f7 peut donc servir de nombre magique. Si on le trouve au début d'un fichier, c'est probablement du CBOR (il ne peut jamais apparaître au début d'un fichier JSON, donc ce nombre est particulièrement utile quand on veut distinguer tout de suite si on a affaire à du CBOR ou à du JSON).
Maintenant que le format est défini rigoureusement, passons à son utilisation. CBOR est conçu pour des environnements où il ne sera souvent pas possible de négocier les détails du format entre les deux parties. Un décodeur CBOR générique peut décoder sans connaître le schéma utilisé en face. Mais, en pratique, lorsqu'un protocole utilise CBOR pour la communication, il est autorisé (section 5 du RFC) à mettre des restrictions, ou des informations supplémentaires, afin de faciliter la mise en œuvre de CBOR dans des environnements très contraints en ressources. Ainsi, on a parfaitement le droit de faire un décodeur CBOR qui ne gérera pas les nombres flottants, si un protocole donné n'en a pas besoin.
Un cas délicat est celui des maps (section 5.6). CBOR ne place guère de restrictions sur le type des clés et un protocole ou format qui utilise CBOR voudra souvent être plus restrictif. Par exemple, si on veut absolument être compatible avec JSON, restreindre les clés à des chaînes en UTF-8 est souhaitable. Si on tient à utiliser d'autres types pour les clés (voire des types différents pour les clés d'une même map !), il faut se demander comment on les traduira lorsqu'on enverra ces maps à une application. Par exemple, en JavaScript, la clé formée de l'entier 1 est indistinguable de celle formée de la chaîne de caractères "1". Une application en JavaScript ne pourra donc pas se servir d'une map qui aurait de telles clés, de types variés.
On a vu que certains éléments CBOR pouvaient être encodés de différentes manières, par exemple un tableau peut être représenté par {longueur, valeurs} ou bien par {valeurs, break code}. Cela facilite la tâche des encodeurs mais peut compliquer celle des décodeurs, surtout sur les machines contraintes en ressources, et cela peut rendre certaines opérations, comme la comparaison de deux fichiers, délicates. Existe-t-il une forme canonique de CBOR ? Pas à proprement parler mais la section 4.1 décrit la notion de sérialisation favorite, des décodeurs étant autorisés à ne connaitre qu'une sérialisation possible. Notamment, cela implique pour l'encodeur de :
- Mettre les entiers sous la forme la plus compacte possible. L'entier 2 peut être représenté par un octet (type majeur 0 puis détails égaux à 2) ou deux (type majeur 0, détails à 24 puis deux octets contenant la valeur 2), voire davantage. La forme recommandée est la première (un seul octet). Même règle pour les longueurs (qui, en CBOR, sont encodées comme les entiers).
- Autant que possible, mettre les tableaux et les chaînes sous la forme {longueur, valeurs}, et pas sous la forme où la longueur est indéfinie.
Tous les encodeurs CBOR qui suivent ces règles produiront, pour un même jeu de données, le même encodage.
Plus stricte est la notion de sérialisation déterministe de la section 4.2. Là encore, chacun est libre de la définir comme il veut (il n'y a pas de forme canonique officielle de CBOR, rappelez-vous) mais elle ajoute des règles minimales à la sérialisation favorite :
- Trier les clés d'une map de la plus petite à la plus grande. (Selon leur représentation en octets, pas selon l'ordre alphabétique.)
- Ne jamais utiliser la forme à longueur indéfinie des tableaux et chaînes.
- Ne pas utiliser les étiquettes si elles ne sont pas nécessaires.
Autre question pratique importante, le comportement en cas d'erreurs. Que doit faire un décodeur CBOR si deux clés sont identiques dans une map, ce qui est normalement interdit en CBOR ? Ou si un champ longueur indique qu'on va avoir un tableau de 5 éléments mais qu'on n'en rencontre que 4 avant la fin du fichier ? Ou si une chaîne de caractères, derrière son type majeur 3, n'est pas de l'UTF-8 correct ? D'abord, un point de terminologie important : un fichier CBOR est bien formé si sa syntaxe est bien celle de CBOR, il est valide s'il est bien formé et que les différents éléments sont conformes à leur sémantique (par exemple, la date après une étiquette de valeur 0 doit être au format du RFC 3339). Si le document n'est pas bien formé, ce n'est même pas du CBOR et doit être rejeté par un décodeur. S'il n'est pas valide, il peut quand même être utile, par exemple si l'application fait ses propres contrôles. Les sections 5.2 et 5.3 décrivent la question. CBOR n'est pas pédant : un décodeur a le droit d'ignorer certaines erreurs, de remplacer les valeurs par ce qui lui semble approprié. CBOR penche nettement du côté « être indulgent avec les données reçues » ; il faut dire qu'une application qui utilise CBOR peut toujours le renforcer en ajoutant l'obligation de rejeter ces données erronées. Un décodeur strict peut donc s'arrêter à la première erreur. Ainsi, un pare-feu qui analyse du CBOR à la recherche de contenu malveillant a tout intérêt à rejeter les données CBOR incorrectes (puisqu'il ne sait pas trop comment elles seront interprétées par la vraie application). Bref, la norme CBOR ne spécifie pas de traitement d'erreur unique. Je vous recommande la lecture de l'annexe C, qui donne en pseudo-code un décodeur CBOR minimum qui ne vérifie pas la validité, uniquement le fait que le fichier est bien formé, et l'annexe F, qui revient sur cette notion de « bien formé » et donne des exemples.
Comme CBOR a un modèle de données proche de celui de JSON, on aura souvent envie d'utiliser CBOR comme encodage efficace de JSON. Comment convertir du CBOR en JSON et vice-versa sans trop de surprises ? La section 6 du RFC se penche sur ce problème. Depuis CBOR vers JSON, il est recommandé de produire du I-JSON (RFC 7493). Les traductions suivantes sont suggérées :
- Les entiers deviennent évidemment des nombres JSON.
- Les chaînes d'octets sont encodées en Base64 et deviennent des chaînes de caractères JSON (JSON n'a pas d'autre moyen de transporter du binaire).
- Les chaînes de caractères deviennent des chaînes de caractères JSON (ce qui nécessite d'en échapper certains, RFC 8259, section 7).
- Les tableaux deviennent des tableaux JSON et les maps des objets JSON (ce qui impose de convertir les clés en chaînes UTF-8, si elles ne l'étaient pas déjà).
- Etc.
En sens inverse, de JSON vers CBOR, c'est plus simple, puisque JSON n'a pas de constructions qui seraient absentes de CBOR.
Pour les amateurs de futurisme, la section 7 discute des éventuelles évolutions de CBOR. Pour les faciliter, CBOR a réservé de la place dans certains espaces. Ainsi, le type majeur 7 permettra d'encoder encore quelques valeurs simples (cela nécessitera un RFC sur le chemin des normes, cf. RFC 8126 et la section 9.1 de notre RFC). Et on peut ajouter d'autres valeurs d'étiquettes (selon des règles qui dépendent de la valeur numérique : les valeurs les plus faibles nécessiteront une procédure plus complexe, cf. section 9.2).
CBOR est un format binaire. Cela veut dire, entre autres, qu'il n'est pas évident de montrer des valeurs CBOR dans, mettons, une documentation, contrairement à JSON. La section 8 décrit donc un format texte (volontairement non spécifié en détail) qui permettra de mettre des valeurs CBOR dans du texte. Nulle grammaire formelle pour ce format de diagnostic : il est prévu pour l'utilisation par un humain, pas par un analyseur syntaxique. Ce format ressemble à JSON avec quelques extensions pour les nouveautés de CBOR. Par exemple, les étiquettes sont représentées par un nombre suivi d'une valeur entre parenthèses. Ainsi, la date (une chaîne de caractères étiquetée par la valeur 0) sera notée :
0("2013-10-12T11:34:00Z")
Une map de deux éléments sera notée comme en JSON :
{"Fun": true, "Amt": -2}
Même chose pour les tableaux. Ici, avec étiquette sur deux chaînes de caractères :
[32("http://cbor.io/"), 34("SW5zw6lyZXogaWNpIHVuIMWTdWYgZGUgUMOicXVlcw==")]
L'annexe G du RFC 8610 ajoute quelques extensions utiles à ce format de diagnostic.
Lors de l'envoi de données encodées en CBOR, le type MIME à
utiliser sera application/cbor. Comme l'idée est d'avoir des formats
définis en utilisant la syntaxe CBOR et des règles sémantiques
spécifiques, on verra aussi sans doute des types MIME utilisant la
notation plus du RFC 6839, par exemple
application/monformat+cbor.
Voici par exemple un petit service Web qui envoie la date
courante en CBOR (avec deux étiquettes différentes, celle pour les
dates au format lisible et celle pour les dates en nombre de
secondes, et en prime celles du RFC 8943). Il a été réalisé avec la bibliothèque
flunn. Il utilise le type MIME
application/cbor :
% curl -s https://www.bortzmeyer.org/apps/date-in-cbor | read-cbor - ... Tag 0 String of length 20: 2020-11-16T15:02:24Z Tag 1 Unsigned integer 1605538944 ...
(Le programme read-cbor est présenté plus loin.)
Un petit mot sur la sécurité (section 10) : il est bien connu qu'un analyseur mal écrit est un gros risque de sécurité et d'innombrables attaques ont déjà été réalisées en envoyant à la victime un fichier délibérement incorrect, conçu pour déclencher une faille de l'analyseur. Ainsi, en CBOR, un décodeur qui lirait une longueur, puis chercherait le nombre d'éléments indiqué, sans vérifier qu'il est arrivé au bout du fichier, pourrait déclencher un débordement de tampon. Les auteurs de décodeurs CBOR sont donc priés de programmer de manière défensive, voire paranoïaque : ne faites pas confiance au contenu venu de l'extérieur.
Autre problème de sécurité, le risque d'une attaque par
déni de
service. Un attaquant taquin peut envoyer un fichier
CBOR où la longueur d'un tableau est un très grand nombre, dans
l'espoir qu'un analyseur naïf va juste faire
malloc(length) sans se demander si cela ne
consommera pas toute la mémoire.
Enfin, comme indiqué plus haut à propos du traitement d'erreur, comme CBOR ne spécifie pas de règles standard pour la gestion des données erronées, un attaquant peut exploiter cette propriété pour faire passer des données « dangereuses » en les encodant de telle façon que l'IDS n'y voit que du feu. Prenons par exemple cette map :
{"CodeToExecute": "OK",
"CodeToExecute": "DANGER"}
Imaginons qu'une application lise ensuite la donnée indexée par
CodeToExecute. Si, en cas de clés dupliquées,
elle lit la dernière valeur, elle exécutera le code dangereux. Si un
IDS lit la première valeur, il ne se sera pas inquiété. Voilà une
bonne raison de rejeter du CBOR invalide (les clés dupliquées sont
interdites) : il peut être interprété de plusieurs façons. Notez
quand même que ce problème des clés dupliquées, déjà présent en
JSON, a suscité des discussions passionnées à l'IETF, entre ceux
qui réclamaient une interdiction stricte et absolue et ceux qui
voulaient laisser davantage de latitude aux décodeurs. (La section
5.6 est une bonne lecture ici.)
Pour les amateurs d'alternatives, l'annexe E du RFC compare CBOR à des formats analogues. Attention, la comparaison se fait à la lumière du cahier des charges de CBOR, qui n'était pas forcément le cahier des charges de ces formats. Ainsi, ASN.1 (ou plutôt ses sérialisations comme BER ou DER, PER étant nettement moins courant puisqu'il nécessite de connaître le schéma des données) est utilisé par plusieurs protocoles IETF (comme LDAP) mais le décoder est une entreprise compliquée.
MessagePack est beaucoup plus proche de CBOR, dans ses objectifs et ses résultats, et a même été le point de départ du projet CBOR. Mais il souffre de l'absence d'extensibilité propre. Plusieurs propositions d'extensions sont restées bloquées à cause de cela.
BSON (connu surtout via son utilisation dans MongoDB) a le même problème. En outre, il est conçu pour le stockage d'objets JSON dans une base de données, pas pour la transmission sur le réseau (ce qui explique certains de ses choix). Enfin, MSDTP, spécifié dans le RFC 713, n'a jamais été réellement utilisé.
Rappelez-vous que CBOR prioritise la simplicité de l'encodeur et du décodeur plutôt que la taille des données encodées. Néanmoins, un tableau en annexe E.5 compare les tailles d'un même objet encodé avec tous ces protocoles : BSON est de loin le plus bavard (BER est le second), MessagePack et CBOR les plus compacts.
Une liste des implémentations est publiée en https://cbor.io/. Au moins quatre existent, en Python,
Ruby, JavaScript et
Java. J'avais moi-même
écrit un décodeur CBOR très limité (pour un besoin ponctuel) en Go. Il est disponible ici et son seul rôle est
d'afficher le CBOR sous forme arborescente, pour aider à déboguer un
producteur de CBOR. Cela donne quelque chose du genre :
% ./read-cbor test.cbor Array of 3 items String of length 5: C-DNS Map of 4 items Unsigned integer 0 => Unsigned integer 0 Unsigned integer 1 => Unsigned integer 5 Unsigned integer 4 => String of length 70: Experimental dnstap client, IETF 99 hackathon, data from unbound 1.6.4 Unsigned integer 5 => String of length 5: godin Array of indefinite number of items Map of 3 items Unsigned integer 0 => Map of 1 items Unsigned integer 1 => Array of 2 items Unsigned integer 1500204267 Unsigned integer 0 Unsigned integer 2 => Map of indefinite number of items Unsigned integer 0 => Array of 2 items Byte string of length 16 Byte string of length 16 ...
L'annexe G de notre RFC résume les changements depuis le RFC 7049. Le format reste le même, les fichiers CBOR d'avant sont toujours du CBOR. Il y a eu dans ce nouveau RFC des corrections d'erreurs (comme un premier exemple erroné, un autre, et encore un), un durcissement des conditions d'enregistrement des nouvelles étiquettes pour les valeurs les plus basses, une description plus détaillée du modèle de données (la section 2 est une nouveauté de notre RFC), un approfondissement des questions de représentation des nombres, etc. Notre RFC 8949 est également plus rigoureux sur les questions de sérialisation préférée et déterministe. L'étiquette 35, qui annonçait qu'on allait rencontrer une expression rationnelle a été retirée (le RFC note qu'il existe plusieurs normes pour ces expressions et que l'étiquette n'est pas définie de manière assez rigoureuse pour trancher).
L'article seul
Fiche de lecture : The trojan war
Auteur(s) du livre : Eric Cline
Éditeur : Oxford University Press
978-0-19-976027-5
Publié en 2013
Première rédaction de cet article le 4 décembre 2020
Vous voulez tout savoir sur la guerre de Troie mais n'avez pas envie de parcourir un livre d'universitaire de 800 pages, avec dix notes de bas de page par page ? Ce livre vous résume ce qu'on sait de cette guerre en 110 pages (écrites petit, il est vrai).
La guerre de Troie a-t-elle eu lieu ? Entre ceux qui prennent au pied de la lettre le récit d'Homère et ceux qui pensent que tout est inventé, il y a de la place pour de nombreuses nuances. Disons pour résumer qu'on a bien trouvé le site physique, qu'il y a bien des signes de guerre et de pillage, que les dates collent plus ou moins avec le bouquin, mais c'est à peu près tout. On n'est pas sûr de l'existence d'Achille, d'Hélène, ou même qu'un cheval ait été utilisé.
Ce livre fait partie de la collection VSI (Very Short Introduction), qui essaie de documenter en un livre court, écrit par un spécialiste, tout ce qu'on sait sur un sujet donné. La guerre de Troie n'est pas un sujet facile, car la légende prend beaucoup plus de place que la réalité. Le livre est en trois parties, chacune apportant un éclairage différent sur ce sujet :
L'histoire, d'abord. Contrairement à ce qu'on pourrait penser, l'Iliade ne contient qu'une petite partie du récit mythique. Il n'y a même pas l'histoire du cheval ! Ce sont d'autres textes (pas forcément écrits par Homère) qui nous content le reste (dont l'Odyssée, qui revient sur certaines évènements de la guerre). On peut donc dresser une version « officielle » à peu près cohérente.
Ensuite, l'analyse des textes, en se rappelant qu'on n'a pas en général le manuscrit original ! Déjà, la guerre est censée se passer bien avant la vie d'Homère. Est-ce cohérent avec le texte ? Oui, sur plusieurs points, Homère décrit des vétements, des armes ou des coutumes qui ne sont pas de son époque (il était plutôt âge du fer quand la guerre a eu lieu à l'âge du bronze). Donc, on ne sait pas si le récit est vrai, mais il est réaliste : Homère reprend bien une histoire qui était déjà ancienne pour lui. Il y a juste quelques erreurs et anachronismes mais rien qui indique que l'Iliade soit un récit complètement légendaire.
Évidemment, il reste des éléments invraisemblables comme les dieux. Et le fait que toute la Grèce soit venue au secours de Ménélas juste pour l'aider à reprendre sa femme ? Bien sûr, on ne ferait pas la guerre pour une seule personne, mais il est toujours possible qu'Hélène ait été un prétexte commode pour une guerre décidée pour d'autres raisons.
Mais il n'y a pas que les textes grecs ! Une des parties les plus intéressantes de l'analyse nous rappelle que nous avons aussi des textes hittites, et que Troie était sans doute une ville vassale ou alliée des Hittites. Est-ce qu'on peut retrouver la guerre de Troie dans ces récits hittites, vérifiant ainsi le récit homérique ? Ce n'est pas facile, déjà parce que les noms propres ne sont pas les mêmes. La ville de Wilusa, souvent citée dans ces textes hittites, est-elle vraiment Troie ? Son roi Alaksandu est-il Pâris, que les textes grecs nomment parfois Alexandre ? Les Ahhiyawa sont-ils bien les Grecs ? Ils ne sont pas vraiment décrits par les Hittites mais tous les autres peuples avec qui les Hittites étaient en contact ont bien été identifiés, il ne manque que les Grecs, qui doivent donc être ces Ahhiyawa, avec qui les Hittites étaient en contact, pas toujours pacifique, sur la côte de l'Anatolie.
Bon, et après s'être pris la tête sur des vieux textes pas très lisibles, et sans index, est-ce qu'on ne peut pas tout simplement creuser et voir si on retrouve bien la cité détruite ? Ça laisse des traces, une bataille ! C'est la troisième partie du livre, sur l'archéologie. On a trouvé un site qui colle mais mais mais il y a plusieurs villes successives, empilées, chaque ville bâtie au-dessus de la précédente, brûlée ou abandonnée. Laquelle de ces couches correspond à la Troie de l'Iliade ? Le niveau VI a le bon âge et pourrait correspondre à la description de la ville par Homère mais rien n'indique une destruction par la guerre. Le niveau VIIa, lui, a bien vu une armée ennemie tout détruire (beaucoup de pointes de flèches ont été découvertes, par exemple) mais sur d'autres points, il ne correspond pas au récit.
En conclusion, non, on ne sait pas, la guerre de Troie a peut-être eu lieu, peut-être à peu près comme Homère l'a raconté, mais on ne peut pas être sûr. Ce n'est pas grave, on peut apprécier le mythe sans certitude de son existence historique.
Et si après avoir lu ce livre, vous cherchez d'autres ressources sur la guerre de Troie, je recommande, de manière tout à fait subjective :
- La série Les grands mythes d'Arte, avec un excellent mélange d'un dessin animé au style très spécial, et d'œuvres d'art inspirées de ces mythes.
- L'opéra La Belle Hélène (qui se passe avant la guerre), très drôle et très vivant. (Voyez l'un des airs les plus fameux, Au mont Ida.)
L'article seul
RFC 8958: Updated Registration Rules for URI.ARPA
Date de publication du RFC : Décembre 2020
Auteur(s) du RFC : T. Hardie
Première rédaction de cet article le 3 décembre 2020
Le domaine uri.arpa a été créé par le RFC 3405 pour stocker dans le DNS des règles gouvernant la
résolution d'URI via des enregistrements NAPTR. Ce
nouveau RFC
introduit un très léger changement des procédures d'enregistrement
dans ce domaine uri.arpa.
À titre d'exemple de ces règles, vous pouvez regarder la règle pour les URN.
En effet, le RFC 3405 parlait d'un IETF tree qui avait été créé par le RFC 2717 (dans sa section 2.2) mais supprimé par le RFC 4395. Notre RFC 8958 prend simplement acte de cette suppression et retire les mentions IETF tree du RFC 3405.
L'article seul
RFC 8947: Link-Layer Addresses Assignment Mechanism for DHCPv6
Date de publication du RFC : Décembre 2020
Auteur(s) du RFC : B. Volz (Cisco), T. Mrugalski (ISC), CJ. Bernardos (UC3M)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dhc
Première rédaction de cet article le 2 décembre 2020
L'utilisation de DHCP pour attribuer des adresses IP est bien connue. Ce nouveau RFC spécifie comment utiliser DHCP pour attribuer des adresses MAC.
Dans quels cas est-ce utile ? La principale motivation vient des environnements virtualisés où on crée des quantités industrielles de machines virtuelles. C'est le cas chez les gros hébergeurs, par exemple, ou bien dans les organisations qui ont d'immenses fermes de machines. Si les adresses MAC de ces machines sont attribuées au hasard, le risque de collision est important, d'autant plus qu'il n'y a pas de protocole de détection de ces collisions. (Sur le risque de collision, notamment en raison du paradoxe de l'anniversaire, voir le RFC 4429, annexe A.1.) Bien sûr, les adresses MAC n'ont pas besoin d'être uniques au niveau mondial, mais la taille de certains réseaux L2 fait que la collision est un réel problème. Un autre scénario est celui des objets connectés (RFC 7228), où leur nombre pourrait menacer l'espace d'adressage OUI. L'idée est donc de récupérer ces adresses MAC auprès d'un serveur DHCP, ce qui évitera les collisions.
En effet, le protocole DHCP, normalisé pour sa version IPv6 dans le RFC 9915, ne sert pas qu'à attribuer des adresses IP. On peut s'en servir pour n'importe quel type de ressources. Et il offre toutes les fonctions nécessaires pour gérer ces ressources, et de nombreuses mises en œuvre déjà bien testées. Notre RFC va donc s'appuyer dessus pour les adresses MAC de 48 bits (EUI-48) d'IEEE 802 (et peut-être dans le futur pour d'autres types d'adresses).
Dans ces adresses de 48 bits, un bit nous intéresse particulièrement, le U/L. Comme son nom l'indique (U = universal, L = local), il indique si l'adresse suit le mécanisme d'allocation de l'IEEE (et est donc a priori unique au niveau mondial) ou bien si l'adresse est gérée selon des règles locales. Les adresses allouées via DHCP seront en général des adresses à gestion locale. Étant purement locales (aucune garantie quant à leur unicité), elles ne doivent pas être utilisées pour fabriquer le DUID - DHCP Unique Identifier - de DHCP (cf. RFC 9915, section 11). Notez aussi que la norme IEEE 802c découpe l'espace local en quatre parties (détails dans l'annexe A du RFC ou, pour les courageuses et les courageux, dans la norme 802c). Pendant qu'on parle de l'IEEE, leur norme 802 1CQ prévoit un mécanisme d'affectation des adresses MAC, qui peut être un concurrent de celui de ce RFC. Le RFC 8948 fournit un moyen de choisir l'un de ces quadrants.
Un peu de terminologie est nécessaire pour suivre ce RFC (section 3). Un bloc d'adresses est une suite consécutive d'adresses MAC. IA_LL désigne une Identity Association for Link-Layer Address et c'est une option DHCP (code 138) qui va beaucoup servir. Autre option DHCP, LLADDR (code 139) qui est l'option qui va servir à transporter les adresses MAC.
La section 4 du RFC présente les principes de déploiement de la solution. Il y a notamment deux scénarios envisagés :
- Le mode relais, où le client DHCP ne sera pas le destinataire final des adresses MAC. Par exemple, dans le cas de la virtualisation, le client DHCP sera l'hyperviseur qui demandera un bloc d'adresses qu'il attribuera ensuite aux machines virtuelles qu'il crée. Le serveur DHCP verra donc un client très gourmand, demandant de plus en plus d'adresses MAC.
- Le mode direct, où le client DHCP sera la machine utilisatrice de l'adresse MAC. C'est notamment le mode envisagé pour l'IoT, chaque objet demandant son adresse MAC. Comme il faudra bien une adresse MAC pour faire du DHCP afin de demander une adresse MAC, les objets utiliseront les adresses temporaires normalisées dans IEEE 802.11. Comme l'adresse MAC changera une fois allouée, il faut veiller à ne pas utiliser des commutateurs méchants qui bloquent le port en cas de changement d'adresse.
Bon, sinon, le fonctionnement de l'allocation d'adresses MAC
marche à peu près comme celui de l'allocation d'adresses IP. Le
client DHCP envoie un message Solicit incluant
une option IA_LL qui contient elle-même une option LLADDR qui
indique le type d'adresse souhaitée et peut aussi inclure une
suggestion, si le client a une idée de l'adresse qu'il voudrait. Le
serveur répond avec Advertise contenant
l'adresse ou le bloc d'adresses alloué (qui ne sont pas forcément
ceux suggérés par le client, comme toujours avec DHCP). Si
nécessaire, il y aura ensuite l'échange habituel
Request puis Reply. Bref,
du DHCPv6 classique. Le client devra renouveler l'allocation au
bout du temps indiqué dans le bail (le serveur peut toujours donner
l'adresse sans limite de temps, cf. RFC 9915,
section 7.7). Le client peut explicitement abandonner l'adresse,
avec un message Release. On l'a dit, ça se
passe comme pour les adresses IP.
Les fanas du placement exact des bits liront la section 10, où
est décrit l'encodage de l'option IA_LL et de la « sous-option »
LLADDR. C'est là qu'on trouvera l'indication des blocs d'adresses
MAC, encodés par la première adresse puis la taille du bloc
(-1). Ainsi, 02:04:06:08:0a / 3 indique un bloc
qui va de 02:04:06:08:0a à
02:04:06:08:0d. Pendant qu'on parle de bits,
notez que les bits indiquant diverses caractéristiques de l'adresse
MAC figurent dans le premier octet, et que la transmission se fait
en commençant par le bit le moins significatif (IEEE 802 est
petit-boutien pour les bits). Ainsi,
l'adresse citée plus haut, 02:04:06:08:0a a un
premier octet qui vaut 2, soit 00000010 en binaire, ce qui sera
transmis comme 01000000. Le premier bit est le M, qui indique ici
qu'il s'agit d'une adresse
unicast, le second est
U/L, indiquant ici que c'est bien une adresse locale, les deux bits
suivants sont une nouveauté de IEEE
802c et indiquent le quadrant des adresses (cf. annexe A du
RFC, puis le RFC 8948).
Quelques conseils pour les administrateurs des serveurs DHCP qui feront cette allocation d'adresses MAC figurent en section 11 du RFC. Par exemple, il ne faut allouer que des adresses locales (bit U/L à 1).
Les deux nouvelles options, IA_LL et LLADDR ont été mises dans le registre IANA.
Pour finir, l'annexe A du RFC résume la norme IEEE 802c. Dans la norme IEEE 802 originale, il y avait, comme indiqué plus haut, un bit U/L qui disait si l'adresse était gérée selon des règles locales (et n'était donc pas forcément unique au niveau mondial). 802c ajoute à ces adresses locales la notion de quadrant, découpant l'espace local en quatre. Après le bit M (unicast ou groupe) et le bit U/L (local ou pas). deux bits indiquent dans quel quadrant se trouve l'adresse :
- 01 est Extended Local, des adresses qui comportent un identifiant de l'organisation, le CID (Company ID), et qui sont donc apparemment garanties uniques à l'échelle de la planète,
- 11 est Standard Assigned, elles sont affectées par le protocole IEEE concurrent de celui du RFC,
- 00 est Administratively Assigned, ce sont
les « vraies » adresses locales, attribuées comme on veut (comme
l'était la totalité de l'espace des adresses locales autrefois,
les adresses d'exemple plus haut
(
02:04:06:08:0aet suivantes sont dans ce quadrant), - 10 est réservé pour un usage futur.
Un mécanisme de sélection du quadrant est normalisé dans le RFC 8948.
Pour l'instant, je ne connais pas de mise en œuvre de ce RFC que ce soit côté client ou serveur.
L'article seul
RFC 8948: Structured Local Address Plan (SLAP) Quadrant Selection Option for DHCPv6
Date de publication du RFC : Décembre 2020
Auteur(s) du RFC : CJ. Bernardos (UC3M), A. Mourad (InterDigital)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dhc
Première rédaction de cet article le 2 décembre 2020
Les adresses MAC sur 48
bits, normalisées par l'IEEE, ont un bit qui indique si
l'adresse découle d'un plan mondial et est donc globalement unique,
ou bien si elle a été allouée via une méthode locale. Plus
récemment, l'IEEE a découpé l'espace local en quatre quadrants, pouvant avoir
des poltiques différentes. Depuis qu'on peut allouer ces adresses
MAC locales par DHCP (RFC 8947), il serait intéressant de choisir son
quadrant. C'est ce que permet la nouvelle option DHCP
QUAD normalisée dans ce nouveau RFC.
Tout·e étudiant·e en réseaux informatiques a appris le découpage des adresses MAC de 48 bits via le bit U/L (Universal/Local). Les adresses avec ce bit à 1 sont gérées localement (et donc pas forcément uniques au niveau mondial). En 2017, l'IEEE a ajouté un nouveau concept, le SLAP (Structured Local Address Plan). L'espace des adresses locales est découpé en quadrants, identifiés par deux bits (troisième et quatrième position dans l'adresse) :
- 01 Extended Local Identifier où l'adresse commence par le CID (Company ID), qui identifie l'organisation,
- 11 Standard Assigned Identifier où l'adresse est allouée en suivant un protocole normalisé par l'IEEE (qui, à ma connaissance, n'est pas encore publié, il se nommera IEEE P802.1CQ: Multicast and Local Address Assignment),
- 00 Administratively Assigned Identifier où l'adresse est entièrement gérée localement, sans préfixe ou protocole standard (avant SLAP, toutes les adresses locales étaient gérées ainsi),
- 10 est réservé pour des idées futures.
De son côté, l'IETF a, dans le RFC 8947, normalisé une option de DHCPv6 qui permet d'obtenir des adresses MAC par DHCP.
Or, dans certains cas, une machine pourrait vouloir choisir le quadrant dans lequel son adresse MAC se situe. Le RFC cite l'exemple d'objets connectés qui voudraient une adresse dans le quadrant ELI (Extended Local Identifier) pour avoir l'identifiant du fabricant au début de l'adresse, sans pour autant que le fabricant ne soit obligé d'allouer à la fabrication une adresse unique à chaque objet. Par contre, des systèmes qui changeraient leur adresse MAC pour éviter la traçabilité préféreraient sans doute un adresse dans le quadrant AAI (Administratively Assigned Identifier). L'annexe A du RFC est très intéressante de ce point de vue, décrivant plusieurs scénarios et les raisons du choix de tel ou tel quadrant.
Notre nouveau RFC ajoute donc une option au protocole DHCP
que normalisait le RFC 9915. Elle se nomme
QUAD et repose sur l'option
LLADDR du RFC 8947. Le
client met cette option QUAD dans la requête
DHCP, pour indiquer son quadrant favori. Le serveur ne l'utilise pas
dans la réponse. Soit il est d'accord pour allouer une adresse MAC
dans ce quadrant et il le fait, soit il propose une autre
adresse. (Rappelez-vous qu'en DHCP, le client propose, et le serveur
décide.) Le client regarde l'adresse renvoyée et sait ainsi si sa
préférence pour un quadrant particulier a été satisfaite ou pas.
La section 4 décrit les détails de l'option
QUAD. Elle permet d'exprimer une liste de
quadrants, avec des préférences associées. L'option est désormais
enregistrée
à l'IANA (code 140).
Pour l'instant, je ne connais pas de mise en œuvre de ce RFC que ce soit côté client ou serveur.
L'article seul
RFC 8945: Secret Key Transaction Authentication for DNS (TSIG)
Date de publication du RFC : Novembre 2020
Auteur(s) du RFC : F. Dupont (ISC), S. Morris (ISC), P. Vixie (Farsight), D. Eastlake 3rd (Futurewei), O. Gudmundsson (Cloudflare), B. Wellington (Akamai)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 1 décembre 2020
Le DNS a des vulnérabilités à plusieurs endroits, notamment des risques d'usurpation, qui permettent de glisser une réponse mensongère à la place de la bonne. Il existe plusieurs solutions pour ces problèmes, se différenciant notamment par leur degré de complexité et leur facilité à être déployées. TSIG (Transaction SIGnature), normalisé dans ce RFC (qui remplace le RFC 2845), est une solution de vérification de l'intégrité du canal, permettant à deux machines parlant DNS de s'assurer de l'identité de l'interlocuteur. TSIG est surtout utilisé entre serveurs DNS maîtres et esclaves, pour sécuriser les transferts de zone (aujourd'hui, presque tous les transferts entre serveurs faisant autorité sont protégés par TSIG).
TSIG repose sur l'existence d'une clé secrète, partagée entre les deux serveurs, qui sert à générer un HMAC permettant de s'assurer que le dialogue DNS a bien lieu avec la machine attendue, et que les données n'ont pas été modifiées en route. L'obligation de partager une clé secrète le rend difficilement utilisable, en pratique, pour communiquer avec un grand nombre de clients. Mais, entre deux serveurs faisant autorité pour la même zone, ce n'est pas un problème (section 1.1 du RFC). On peut gérer ces secrets partagés manuellement. Même chose entre un serveur maître et un client qui met à jour les données par dynamic update (RFC 2136).
Bien sûr, si tout le monde utilisait DNSSEC partout, le problème de sécuriser le transfert de zones entre serveurs faisant autorité serait moins grave (mais attention, DNSSEC ne signe pas les délégations et les colles, cf. la section 10.2 de notre RFC). En attendant un futur lointain « tout-DNSSEC », TSIG fournit une solution simple et légère pour éviter qu'un méchant ne se glisse dans la conversation entre maître et esclave (par exemple grâce à une attaque BGP) et ne donne à l'esclave de fausses informations. (Il existe aussi des solutions non-DNS comme de transférer la zone avec rsync au dessus de SSH. Notez d'autre part que TSIG peut servir à d'autres choses que le transfert de zones, comme l'exemple des mises à jour dynamiques cité plus haut. Par contre, pour sécuriser la communication entre le client final et le résolveur, il vaut mieux utiliser DoT - RFC 7858 - ou DoH - RFC 8484.)
Comment fonctionne TSIG ? Les sections 4 et 5 décrivent le protocole. Le principe est de calculer, avec la clé secrète, un HMAC des données transmises, et de mettre ce HMAC (cette « signature ») dans un pseudo-enregistrement TSIG qui sera joint aux données, dans la section additionnelle. À la réception, l'enregistrement TSIG (obligatoirement le dernier de la section additionnelle) sera extrait, le HMAC calculé et vérifié.
Pour éviter des attaques par rejeu, les données sur lesquelles portent le HMAC incluent l'heure. C'est une des causes les plus fréquentes de problèmes avec TSIG : les deux machines doivent avoir des horloges très proches (section 10, qui recommande une tolérance - champ Fudge - de cinq minutes).
Le format exact des enregistrements TSIG est décrit en section 4. L'enregistrement est donc le dernier, et est mis dans la section additionnelle (voir des exemples plus loin avec dig et tshark). Le type de TSIG est 250 et, évidemment, ces pseudo-enregistrements ne doivent pas être gardés dans les caches. Plusieurs algorithmes de HMAC sont possibles. Un est obligatoire et recommandé, celui fondé sur SHA-256 (que j'utilise dans les exemples par la suite). On peut toujours utiliser SHA-1 et MD5 (avant que vous ne râliez : oui, SHA-1 et MD5 ont de gros problèmes mais cela n'affecte pas forcément leur utilisation en HMAC, cf. RFC 6151). Un registre IANA contient les algorithmes actuellement possibles (cf. aussi section 6 du RFC).
Le nom dans l'enregistrement TSIG est le nom de la clé (une
raison pour bien le choisir, il inclut typiquement le nom des deux
machines qui communiquent), la classe est
ANY, le TTL nul et les données contiennent
le nom de l'algorithme utilisé, le moment de la signature, et bien
sûr la signature elle-même.
Le fait que la clé soit secrète implique des pratiques de
sécurité sérieuses, qui font l'objet de la section 8. Par
exemple, l'outil de génération de clés de BIND crée des fichiers en
mode 0600, ce qui veut dire lisibles uniquement
par leur créateur, ce qui est la moindre des choses. Encore faut-il
assurer la sécurité de la machine qui stocke ces fichiers. (Voir
aussi le RFC 2104).
Voyons maintenant des exemples concrets où
polly (192.168.2.27) est
un serveur DNS maître pour la zone example.test
et jadis (192.168.2.29)
un serveur esclave. Pour utiliser TSIG afin d'authentifier un
transfert de zone entre deux machines, commençons avec BIND. Il faut
d'abord générer une clé. Le programme
tsig-keygen, livré avec BIND, génère de
nombreux types de clés (d'où ses nombreuses options). Pour TSIG, on
veut du SHA-256 (mais tsig-keygen connait
d'autres algorithmes) :
% tsig-keygen -a HMAC-SHA256 polly-jadis
key "polly-jadis" {
algorithm hmac-sha256;
secret "LnDomTT+IRf0daLYqxkstFpTpmFfcOvyxtRaq2VhHSI=";
};
(Avant BIND 9.13, le programme à utiliser était
dnssec-keygen, qui ne fait désormais plus que
du DNSSEC.) On a donné à la clé le nom des
deux machines entre lesquelles se fera la communication (le nom est
affiché dans le journal lors d'un transfert réussi, et à plusieurs
autres endroits, donc il vaut mieux le choisir long et descriptif),
plus un chiffre pour distinguer d'éventuelles autres clés. La clé
est partagée entre ces deux machines. On met alors la clé dans la
configuration de BIND, sur les deux machines
(tsig-keygen produit directement de la
configuration BIND). Naturellement, il faut transférer la clé de
manière sécurisée entre les deux machines, pas par courrier
électronique ordinaire, par exemple. Sur le serveur maître, on
précise que seuls ceux qui connaissent la clé peuvent transférer la
zone :
zone "example.test" {
type master;
file "/etc/bind/example.test";
allow-transfer { key polly-jadis; };
};
Les autres clients seront rejetés :
Apr 6 17:45:15 polly daemon.err named[27960]: client @0x159c250 192.168.2.29#51962 (example.test): zone transfer 'example.test/AXFR/IN' denied
Mais, si on connait la clé, le transfert est possible (ici, un test avec dig) :
% dig -y hmac-sha256:polly-jadis:LnDomTT+IRf0daLYqxkstFpTpmFfcOvyxtRaq2VhHSI= @polly.sources.org AXFR example.test ; <<>> DiG 9.16.1-Debian <<>> -y hmac-sha256 @polly.sources.org AXFR example.test ; (1 server found) ;; global options: +cmd example.test. 86400 IN SOA polly.sources.org. hostmaster.sources.org. 2020040600 7200 3600 604800 43200 example.test. 86400 IN NS polly.sources.org. example.test. 86400 IN SOA polly.sources.org. hostmaster.sources.org. 2020040600 7200 3600 604800 43200 polly-jadis. 0 ANY TSIG hmac-sha256. 1586195193 300 32 pJciUWLOkg1lc6J+msC+dzYotVSOr8PSXgE6fFU3UwE= 25875 NOERROR 0 ;; Query time: 10 msec ;; SERVER: 192.168.2.27#53(192.168.2.27) ;; WHEN: Mon Apr 06 17:46:33 UTC 2020 ;; XFR size: 3 records (messages 1, bytes 267)
On voit que dig affiche fidèlement tous les enregistrements, y
compris le pseudo-enregistrement de type TSIG qui contient la
signature. Un point de sécurité, toutefois (merci à Jan-Piet Mens
pour sa vigilance) : avec ce -y, quiconque a un
compte sur la même machine Unix peut voir la clé avec
ps. Il peut être préférable de la mettre dans un
fichier et de dire à dig d'utiliser ce fichier (dig -k
polly-jadis.key …).
Maintenant que le test marche, configurons le serveur BIND esclave :
// To avoid copy-and-paste errors, you can also redirect tsig-keygen's
// output to a file and then include it in named.conf with 'include
// polly-jadis.key'.
key "polly-jadis" {
algorithm hmac-sha256;
secret "LnDomTT+IRf0daLYqxkstFpTpmFfcOvyxtRaq2VhHSI=";
};
zone "example.test" {
type slave;
masters {192.168.2.27;};
file "example.test";
};
server 192.168.2.27 {
keys {
polly-jadis;
};
};
et c'est tout : l'esclave va désormais utiliser TSIG pour les transferts de zone. Le programme tshark va d'ailleurs nous afficher les enregistrements TSIG :
Queries
example.test: type AXFR, class IN
Name: example.test
[Name Length: 12]
[Label Count: 2]
Type: AXFR (transfer of an entire zone) (252)
Class: IN (0x0001)
Additional records
polly-jadis: type TSIG, class ANY
Name: polly-jadis
Type: TSIG (Transaction Signature) (250)
Class: ANY (0x00ff)
Time to live: 0
Data length: 61
Algorithm Name: hmac-sha256
Time Signed: Apr 6, 2020 19:51:36.000000000 CEST
Fudge: 300
MAC Size: 32
MAC
[Expert Info (Warning/Undecoded): No dissector for algorithm:hmac-sha256]
[No dissector for algorithm:hmac-sha256]
[Severity level: Warning]
[Group: Undecoded]
Original Id: 37862
Error: No error (0)
Other Len: 0
Et si l'esclave est un nsd et pas un BIND ? C'est le même principe. On configure l'esclave :
key:
name: polly-jadis
algorithm: hmac-sha256
secret: "LnDomTT+IRf0daLYqxkstFpTpmFfcOvyxtRaq2VhHSI="
zone:
name: "example.test"
zonefile: "example.test"
allow-notify: 192.168.2.27 NOKEY
request-xfr: 192.168.2.27 polly-jadis
Et le prochain nsd-control transfer example.test (ou bien la
réception de la notification) déclenchera un transfert, qui sera
ainsi enregistré :
Apr 07 06:46:48 jadis nsd[30577]: notify for example.test. from 192.168.2.27 serial 2020040700 Apr 07 06:46:48 jadis nsd[30577]: [2020-04-07 06:46:48.831] nsd[30577]: info: notify for example.test. from 192.168.2.27 serial 2020040700 Apr 07 06:46:48 jadis nsd[30565]: xfrd: zone example.test written received XFR packet from 192.168.2.27 with serial 2020040700 to disk Apr 07 06:46:48 jadis nsd[30565]: [2020-04-07 06:46:48.837] nsd[30565]: info: xfrd: zone example.test written received XFR packet from 192.168.2.27 with serial 2020040700 to disk
Pour générer des clés sans utiliser BIND, on peut consulter mon autre article sur TSIG.
On l'a vu, TSIG nécessite des horloges synchronisées. Une des
erreurs les plus fréquentes est d'oublier ce point. Si une machine
n'est pas à l'heure, on va trouver dans le journal des échecs TSIG
comme (section 5.2.3 du RFC), renvoyés avec le code de retour DNS
NOTAUTH (code 9) et un code
BADTIME dans l'enregistrement TSIG joint :
Mar 24 22:14:53 ludwig named[30611]: client 192.168.2.7#65495: \
request has invalid signature: TSIG golgoth-ludwig-1: tsig verify failure (BADTIME)
Ce nouveau RFC ne change pas le protocole du RFC 2845. Un ancien client peut interopérer avec un nouveau serveur, et réciproquement. Seule change vraiment la procédure de vérification, qui est unilatérale. Une des motivations pour la production de ce nouveau RFC venait de failles de sécurité de 2016-2017 (CVE-2017-3142, CVE-2017-3143 et CVE-2017-11104). Certes, elle concernaient des mises en œuvre, pas vraiment le protocole, mais elles ont poussé à produire un RFC plus complet et plus clair.
Le débat à l'IETF au début était « est-ce qu'on en profite pour réparer tout ce qui ne va pas dans le RFC 2845, ou bien est-ce qu'on se limite à réparer ce qui est clairement cassé ? » Il a été tranché en faveur d'une solution conservatrice : le protocole reste le même, il ne s'agit pas d'un « TSIG v2 ».
L'article seul
RFC 8952: Captive Portal Architecture
Date de publication du RFC : Novembre 2020
Auteur(s) du RFC : K. Larose (Agilicus), D. Dolson, H. Liu (Google)
Pour information
Réalisé dans le cadre du groupe de travail IETF capport
Première rédaction de cet article le 1 décembre 2020
Les portails captifs sont ces insupportables pages Web vers lesquels certains réseaux d'accès en WiFi vous détournent pour vous faire laisser des données personnelles avant d'avoir accès à l'Internet. Très répandus dans les hôtels et aéroports, ils utilisent pour ce détournement des techniques qui sont souvent celles des attaquants, et ils posent donc de graves problèmes de sécurité, sans parler de l'utilisabilité. Le groupe de travail CAPPORT de l'IETF travaille à définir des solutions techniques qui rendent ces portails captifs un peu moins pénibles. Ce RFC décrit l'architecture générale du système, d'autres RFC décrivant les solutions partielles.
Vu de l'utilisateurice, la connexion à
l'Internet sur pas mal de
hotspots se fait ainsi :
on accroche le réseau WiFi, on se rend à une page Web
quelconque et, au lieu de la page demandée, on est détourné vers une
page des gérants du hotspot, qui vous montre de
la publicité, exige des données personnelles (et parfois une
authentification) et l'acceptation de
conditions d'utilisation léonines, avant de continuer. Si la page
que vous vouliez visiter était en HTTPS, ce qui est le cas le
plus courant aujourd'hui, vous aurez probablement en outre un
avertissement de sécurité. Certains systèmes
d'exploitation, comme Android, ou
certains navigateurs,
comme Firefox,
détectent automatiquement la captivité, suspendent leurs autres
activités, et vous proposent d'aller directement à une page du
portail. Mais ça reste pénible, par exemple parce que c'est
difficile à automatiser. (Un exemple d'automatisation en
shell avec curl que j'ai récupéré
en ligne est hotel-wifi.sh
Techniquement, la mise en œuvre du concept de portail captif se fait en général actuellement en détournant le trafic HTTP (via un transparent proxy) ou avec un résolveur DNS menteur, qui donne l'adresse IP du portail en réponse à toute requête. L'annexe A du RFC résume les mises en œuvre actuelles de portails captifs, et les méthodes utilisées pour pouvoir se connecter le moins mal possible. La machine qui veut savoir si elle est derrière un portail captif va typiquement faire une requête HTTP vers un URL connu et contrôlé par le fournisseur de l'application ou du système d'explication. Cet URL est appelé le canari. (Au lieu ou en plus de HTTP, on peut faire un test DNS sur un nom de domaine où on connait le résultat, au cas où le portail captif fonctionne avec un résolveur menteur. Attention, DNS et HTTP peuvent donner des résultats différents, détournement DNS mais pas HTTP, ou bien le contraire.) Notez que toutes les techniques avec un canari peuvent mener à des faux négatifs si le canari est connu et que le gardien derrière le portail captif le laisse passer, via une règle spécifique.
Notre RFC choisit d'être positif et donne une liste des exigences auxquelles essaie de répondre les solutions développées dans le groupe de travail. Ces exigences peuvent aussi être lues comme une liste de tous les inconvénients des portails captifs actuels. Un échantillon de ces exigences :
- Ne pas détourner les protocoles standards de l'Internet comme HTTP, et, d'une manière générale, ne pas se comporter comme un attaquant (alors que les portails actuels violent systématiquement la sécurité en faisant des attaques de l'intermédiaire).
- Ne pas détourner non plus le DNS, puisque la solution doit être compatible avec DNSSEC, outil indispensable à la sécurité du DNS.
- Travailler au niveau IP (couche 3) et ne pas être dépendant d'une technologie d'accès particulière (cela ne doit pas marcher uniquement pour le WiFi).
- Les machines terminales doivent avoir un moyen simple et sûr
d'interroger leur réseau d'accès pour savoir si elles sont
captives, sans compter sur le détournement de protocoles Internet,
sans avoir besoin de « canaris »,
d'URI
spéciaux qu'on tester, comme le
detectportal.firefox.comde Firefox. - Les solutions déployées ne doivent pas exiger un navigateur Web, afin d'être utilisable, par exemple, par des machines sans utilisateur humain (les portails actuels plantent toutes les applications non-Web, comme la mise à jour automatique des logiciels). Ceci dit, le RFC se concentre surtout sur le cas où il y a un utilisateur humain.
L'architecture décrite ici repose sur :
- L'annonce aux machines clients d'un URI qui sera l'adresse de l'API à laquelle parler pour en savoir plus sur le portail captif. Cette annonce peut se faire en DHCP (RFC 8910) ou en RA (même RFC). Mais elle pourra aussi se faire avec RADIUS ou par une configuration statique.
- L'information donnée par le portail captif à la machine cliente, lui disant notamment si elle est en captivité ou pas.
Plus concrètement, le RFC liste les composants du problème et donc des solutions. D'abord, la machine qui se connecte (user equipment, dans le RFC). Pour l'instant, la description se limite aux machines qui ont un navigateur Web, même si elles sont loin d'être les seules, ou même les plus nombreuses. Pour que tout marche comme il faut, cette machine doit pouvoir récupérer l'URI de l'API du portail captif (par exemple, elle doit avoir un client DHCP), doit pouvoir gérer le fait que certaines de ses interfaces réseaux sont derrière un portail captif et pas les autres (RFC 7556), doit pouvoir notifier l'utilisateur qu'il y a un tel portail (et attention au hameçonnage !), et ce serait bien qu'il y a ait un moyen de dire aux applications « on est encore en captivité, n'essayez pas de vous connecter tout de suite ». Un exemple de cette dernière demande est fournie par Android où l'utilisation du réseau par défaut ne passe de la 4G au WiFi qu'une fois qu'Android a pu tester que l'accès WiFi n'était pas en captivité. Enfin, si la machine gère l'API des portails captifs, elle doit évidemment suivre toutes les règles de sécurité, notamment la validation du certificat.
Ensuite, deuxième composant, le système de distribution d'informations dans le réseau (provisioning service), DHCP ou RA. C'est lui qui va devoir envoyer l'URI de l'API à la machine qui se connecte, comme normalisé dans le RFC 8910.
Troisième composant, le serveur derrière l'API. Il permet de se
passer des « canaris », des tests du genre « est-ce que j'arrive à
me connecter à
https://detectportal.example ? », il y a juste
à interroger l'API. Cette API (RFC 8908) doit
permettre au minimum de connaitre l'état de la connexion (en
captivité ou pas), et d'apprendre l'URI que l'humain devra visiter
pour sortir de captivité (« j'ai lu les 200 pages de textes
juridiques des conditions d'utilisation, les 100 pages du code de
conduite et je les accepte inconditionnellement »). Elle doit
utiliser HTTPS.
Enfin, il y a le composant « gardien » (enforcement) qui s'assure qu'une machine en captivité ne puisse effectivement pas sortir ou en tout cas, ne puisse pas aller en dehors des services autorisés (qui doivent évidemment inclure le portail où on accepte les conditions). Il est typiquement placé dans le premier routeur. L'architecture présentée dans ce RFC ne change pas ce composant (contrairement aux trois premiers, qui devront être créés ou modifiés).
Parmi ces différents composants qui interagissent, l'un d'eux mérite une section entière, la section 3, dédiée à la machine qui se connecte (user equipment) et notamment à la question de son identité. Car il faut pouvoir identifier cette machine, et que les autres composants soient d'accord sur cette identification. Par exemple, une fois que le portail captif aura accepté la connexion, il faudra que le système « gardien » laisse désormais passer les paquets. Pour cette identification, plusieurs identificateurs sont possibles, soit présents explicitement dans les paquets, soit déduits d'autres informations. On peut imaginer, par exemple, utiliser l'adresse MAC ou l'adresse IP. Ou bien, pour les identificateurs qui ne sont pas dans le paquet, l'interface physique de connexion. Le RFC liste leurs propriétés souhaitables :
- Unicité,
- Difficulté à être usurpé par un attaquant (sur ce point, les adresses MAC ou IP ne sont pas satisfaisantes, alors que l'interface physique est parfaite ; diverses techniques existent pour limiter la triche sur l'adresse IP comme le test de réversibilité),
- Visibilité pour le serveur derrière l'API (selon la technique de développement utilisée, l'adresse MAC peut être difficile ou impossible à récupérer par ce serveur ; idem pour l'interface physique),
- Visibilité pour le gardien.
Notons que l'adresse IP a l'avantage d'être un identificateur qui n'est pas local au premier segment de réseau, ce qui peut permettre, par exemple, d'avoir un gardien qui soit situé un peu plus loin.
Armé de tous ces éléments, il est possible de présenter le traitement complet (section 4). Donc, dans l'ordre des évènements, dans le monde futur où ces différents RFC auront été déployés :
- La machine de l'utilisateur se connecte au réseau, et obtient des informations en DHCP ou RA,
- Parmi ces informations, l'URI de l'API du portail captif (options du RFC 8910),
- La machine parle à cette API en suivant le RFC 8908, ce qui lui permet d'apprendre l'URI de la page du portail captif prévue pour les humains,
- L'utilisateur humain lit les CGU (ah, ah) et les accepte,
- Le gardien est prévenu de cette acceptation et laisse désormais passer les paquets,
- L'utilisateur peut enfin regarder Joséphine, ange gardien sur Salto.
Si tout le monde joue le jeu, et que les techniques conformes à l'architecture décrite dans ce RFC sont déployées, les portails captifs, quoique toujours pénibles, devraient devenir plus gérables. Hélas, il est probable que beaucoup de déploiements ne soient jamais changé, notamment dans les environnements où le client est… captif (hôtels, aéroports) et où il n'y a donc aucune motivation commerciale pour améliorer les choses. Les logiciels vont donc devoir continuer à utiliser des heuristiques de type canari pendant une très longue période, car ils ne pourront pas compter sur des portails captifs propres.
Tout cela laisse ouvert quelques problèmes de sécurité, que la section 6 étudie. D'abord, fondamentalement, il faut faire confiance au réseau d'accès. Via DHCP et RA, il peut vous conduire n'importe où. (Le RFC 7556 discute de cette difficulté à authentifier le réseau d'accès.) Des protections comme l'authentification du serveur en TLS limitent un peu les dégâts mais ne résolvent pas tout. Ceci dit, c'est pour cela que notre RFC impose l'utilisation de HTTPS pour accéder à l'API. Mais, d'une manière générale, le réseau d'accès, et le portail captif qu'il utilise, a tous les pouvoirs. Il peut par exemple vous bloquer l'accès à tout ou partie de l'Internet, même après que vous ayez accepté les conditions d'utilisation.
Il y a aussi des questions de vie privée. L'identificateur de la machine qui se connecte peut être détourné de son usage pour servir à surveiller un utilisateur, par exemple. Les bases de données utilisées par les différents composants de cette architecture de portail captif doivent donc être considérées comme contenant des données personnelles. L'utilisateur peut changer ces identificateurs (pour l'adresse MAC, avec un logiciel comme macchanger) mais cela peut casser son accès Internet, si le gardien utilise justement cet identificateur.
L'article seul
Expliquer le fonctionnement de l'Internet en quarante minutes
Première rédaction de cet article le 30 novembre 2020
Le 26 novembre 2020, j'ai participé à une formation à l'UTC où il fallait expliquer le fonctionnement de l'Internet à des étudiants en développement Web. Pas facile.
Si vous voulez voir si j'ai réussi, la vidéo est en ligne. (L'interruption vers 12:24 est due à une coupure accidentelle de courant chez moi pendant l'installation d'une nouvelle chaudière.) Il y en a aussi une copie sur PeerTube (mais qui a un problème avec les supports). Et voici la présentation de cette formation, celle de ce cours, et mes supports de présentation :
Merci à Stéphane Crozat pour l'invitation et l'organisation.
L'article seul
Le protocole Gemini, revenir à du simple et sûr pour distribuer l'information en ligne ?
Première rédaction de cet article le 29 novembre 2020
Dernière mise à jour le 2 décembre 2020
Comme beaucoup de gens, je trouve que le Web, tout en étant un immense succès, souffre de plusieurs défauts. Tous ne proviennent pas de la technique, mais certains peuvent quand même être reliés à des choix lors de la conception des protocoles et formats. C'est par exemple le cas des problèmes de vie privée, car HTTP et HTML fournissent trop de moyens de pister les utilisateurs, et des problèmes stratégiques autour des navigateurs : aujourd'hui, écrire un navigateur Web complet, disons l'équivalent de Firefox, est une tâche colossale, réservée à de très grosses équipes très pointues. Cela limite la concurrence : seuls trois ou quatre navigateurs vraiment différents existent et encore moins de moteurs de rendu. (Et je n'ai pas encore mentionné le désir de davantage de sobriété numérique et d'empreinte environnementale réduite.) Le projet Gemini s'attaque à ce problème en définissant un nouveau protocole et un nouveau format, délibérement très simples et non extensibles, afin de rendre plus difficile l'apparition des mêmes problèmes que dans le Web.
Gemini est donc très simple. Il utilise :
- Un protocole à lui, qui ressemble un peu à la version 0.9 de HTTP (en mieux, quand même),
- Un format à lui, une sorte de version simplifiée et uniformisée de Markdown,
- Les URL que nous connaissons,
- Le TLS que nous connaissons.
Un point important et délibéré de Gemini est son absence d'extensibilité. Le but est d'éviter ce qui est arrivé au Web, où un protocole simple et sûr du début a évolué en un gros machin compliqué et dangereux. Ainsi, Gemini n'a pas d'en-têtes de requêtes ou de réponses. Y ajouter un outil de flicage comme les cookies sera donc difficile et c'est exprès.
Si vous êtes intéressé par ce projet, consultez le site Web pour avoir une première idée. Si vous avez des questions (notamment si vous en êtes au stade « ah, les cons, pourquoi ils n'ont pas tout simplement utilisé X et/ou fait comme Y ? »), il est probable que la FAQ très détaillée y répondra. Si vous êtes d'humeur à lire l'actuelle spécification, elle est aussi sur le Web. Mais beaucoup d'autres ressources à propos de Gemini ne sont évidemment pas sur le Web, mais dans le « geminispace ».
Comme ce « geminispace » ne peut pas se
visiter avec un navigateur Web classique, il
va falloir un client Gemini. Il en existe beaucoup. La plupart sont
assez sommaires mais les lectrices et lecteurs de mon blog sont des
gens avertis et qui savent qu'il ne faut pas juger un système de
publication à ses interfaces actuelles. Déjà, je vais commencer par
supposer que vous ne voulez pas installer un Nième logiciel sur
votre machine mais que vous voudriez quand même jeter un coup
d'œil. Ça tombe bien, plusieurs clients Gemini sont disponible sur
un serveur SSH
public. Connectez-vous en SSH à
kiosk@gemini.circumlunar.space et essayez le
client de votre choix. Personnellement, j'utilise Amfora. Vous
pouvez visiter les liens de la page d'accueil en tapant espace puis
leur numéro. À la place d'un numéro, vous pouvez aussi indiquer un
URL Gemini comme
gemini://gemini.bortzmeyer.org/. Si vous voulez
tester plus loin, vous pouvez installer Amfora
ou bien un
des autres clients. Sur Arch Linux,
c'est aussi simple que de taper pacman -S
amfora. Comme vous vous en doutez, il n'y a pas encore
beaucoup de contenu disponible mais ça grossit tous les jours.
Comme dit plus haut, il y a de nombreux autres
clients Gemini. Par exemple, les fans
d'Emacs vont apprécier Elpher, un client
Gopher et Gemini pour Emacs. Voici son
apparence :
Et, ici, avec le client graphique Lagrange : 
En plus sommaire, et si on aime la ligne de commande, récupérer un fichier avec Gemini est aussi simple que :
% echo -n "gemini://purexo.mom/\r\n" | gnutls-cli -p 1965 purexo.mom
(gnutls-cli fait partie de GnuTLS.)
Et si vous voulez un serveur, pour distribuer vos idées géniales
au monde entier ? Il existe plusieurs serveurs en logiciel libre, mais pas de page
Web pour les présenter, il faut aller dans le
geminispace en
gemini://gemini.circumlunar.space/software/. J'ai
choisi de commencer avec Agate. Agate est
écrit en Rust donc on l'installe en général par la
méthode Rust habituelle, cargo install
agate. Ensuite, il nous faut un
certificat car Gemini impose
TLS (notez qu'il semble que pas mal de
serveurs Gemini n'aient qu'un certificat auto-signé). Demandons à
Let's Encrypt :
# certbot certonly -n --standalone --domain gemini.bortzmeyer.org
Et je copie certificat et clé privée dans un répertoire à moi, pour ne pas exécuter Agate en étant root. (Pour le renouvellement du certificat, dans trois mois, il faudra que je trouve une solution plus pérenne.) Ensuite, je lance le serveur :
% ~/.cargo/bin/agate gemini.bortzmeyer.org:1965 /var/gemini fullchain.pem privkey.pem gemini.bortzmeyer.org
(Pourquoi le port 1965 est-il le port par défaut ? Je vous laisse chercher un peu.)
Mais il reste à ajouter du contenu, dans le répertoire
/var/gemini qu'on a indiqué au serveur. Ce
contenu est dans un format spécifique à Gemini, qui ressemble à
Markdown, en plus limité. Je vous le dis tout
de suite : il n'y a pas d'images ! Finies, les photos de chats
mignons ! Voici le source de la page d'accueil de mon serveur :
% cat index.gmi # First Gemini test No actual content yet => https://www.afnic.fr/ AFNIC Web site
Vous noterez :
- Le titre (équivalent du
<h1>de HTML) s'écrit comme en Markdown. - Le texte s'écrit sans marques particulières.
- Les liens sont forcément sur une ligne. On ne peut pas faire d'hypertexte. (En prime, j'ai mis un lien Web, ce qui n'est pas très géministe et ne marchera pas avec les clients Gemini non-Web.)
Voilà, je vais essayer de mettre un peu plus de contenu que ce premier exemple mais ne comptez pas sur une publication de mon blog en Gemini : l'absence d'hypertexte nécessiterait de réécrire sérieusement les articles.
Je reviens un peu au choix des serveurs. On a vu qu'il y avait
une liste en
gemini://gemini.circumlunar.space/software/
mais elle n'est pas éditée, c'est juste un vrac tous les serveurs
possibles, alors que certains sont très sommaires, voire déjà
abandonnés. Voici donc une liste personnelle de ceux que j'ai testés, en commençant (oui,
c'est subjectif), par ceux que je trouve les plus « prêts pour la
prod' » (avec des liens Web à chaque fois, pour faciliter la vie de
celles et ceux qui n'ont pas encore de client Gemini) :
- Molly-brown : le serveur de référence. Parfait en tout, mais n'a pas de virtual hosts.
- Gemserv : très bon serveur également, et il dispose de virtual hosts.
- Agate : simple mais marche bien.
- Twins : sans doute le plus riche en fonctions.
- geminid : écrit en C, donc seulement si vous n'avez pas peur des débordements. Mais il marche bien.
- Net-gemini : pas très documenté, mais j'ai l'impression que c'est plutôt une bibliothèque pour développer des serveurs adaptés à un usage particulier, par exemple la génération de pages dynamiques.
- Northstar : même remarque.
- GeGoBi : plutôt pour les gens qui ont déjà du contenu Gopher et veulent le servir rapidement sur Gemini.
- Pollux : très limité, il sert un seul fichier, et ne semble plus développé.
- Shavit : pour l'instant, il ne peut communiquer qu'avec des clients locaux à la machine.
- Blizanci : aucun développement depuis six mois.
Conclusion ? Ne me demandez pas si Gemini sera un succès ou pas, je suis mauvais pour les pronostics. Je dis juste que je suis content de voir que des gens ne se résignent pas à déplorer les problèmes du Web mais qu'ils essaient de les résoudre.
Autres articles en français sur Gemini :
L'article seul
Fiche de lecture : Paris démasqué
Auteur(s) du livre : Quentin Gérard, Louis
Moulin
Éditeur : Arkhê
978-29-18682-592
Publié en 2019
Première rédaction de cet article le 28 novembre 2020
Le citadin arrogant peut imaginer que les légendes, les monstres, les histoires irrationnelles ne naissent qu'à la campagne, chez des ruraux mal dégrossis, les seuls à croire à ces récits fantastiques. Mais les villes ont aussi leurs contes fabuleux, leurs angoisses et leurs mythes. Les auteurs s'attaquent ici à quelques histoires étonnantes qui prennent place à Paris, et en profitent pour analyser l'inconscient des concentrations urbaines.
Ce livre cite vingt mythes très différents. Mythes car, quoi qu'un bon nombre parte d'évènements et de personnages réels, ce qui intéresse les auteurs, c'est ce qu'en a fait la psychologie collective. Prenons quelques exemples.
Il y a des histoires inspirées par les crimes et la répression de ces crimes, répression souvent aussi horrible que le crime lui-même. Un chapitre du livre rappelle ainsi l'histoire du gibet de Montfaucon, à l'époque où on assassinait légalement (« nous fûmes occis par justice », dit François Villon) aux quatre coins de Paris, là où on ne trouve aujourd'hui que des gentilles boulangeries bio. Montfaucon était conçu pour être visible et pour faire peur et le gibet, scène d'horreur, a en effet marqué les imaginations pour de nombreux siècles.
Un autre chapitre est consacré aux grands drames collectifs qui ont frappé la ville. Il y a par exemple l'angoisse des rats (vous connaissiez le terme de musophobie, qui n'est même pas dans le Wiktionnaire ?) Cette angoisse se base sur des faits réels (le rôle des rats dans des maladies comme la peste) mais a souvent dérivé vers l'irrationnel, voire le racisme. Les auteurs citent le « les rats sont coupables, les rastas ne sont pas innocents » [dans la presse de l'époque, « rasta » est un étranger oriental], du journaliste d'extrême-droite José Germain, qui rappelle que les temps d'épidémie sont propices aux délires et aux mensonges.
Il y a bien sûr aussi un chapitre sur les récits politiques. La sainte patronne de Paris, sainte Geneviève, est un personnage historique réel. Mais elle a fait l'objet d'un gros travail de mythification. C'était une aristocrate, dirigeante politique habile dans des temps très troublés, mais on en a fait une humble bergère, avant de la considérer comme un symbole de la monarchie et de l'Église pendant la Révolution, où ses restes ont été détruits. Puis de nos jours on met davantage en avant son intelligence politique, plutôt que sa piété. Chaque époque met Geneviève à sa sauce.
En parlant de politique, le chapitre sur les « spectres et maléfices » évoque entre autres les pétroleuses. Là encore, il s'agit d'un phénomène historique réel (la participation des femmes à la Commune, pas les incendiaires se promenant avec leur bidon de pétrole) mais qui a été transformé par la presse versaillaise : les pétroleuses n'étaient pas simplement dépeintes comme des adversaires politiques mais comme des monstres inhumains. (Et c'est l'occasion de rappeler que, en deux mille et quelques années d'une histoire souvent troublée, le plus grand massacre qui ait jamais eu lieu à Paris a été commis par l'armée française.)
Paris n'est pas isolée, il y a la banlieue tout autour. Ah, la banlieue, comme objet de fantasmes et de peurs… Cela ne date pas d'aujourd'hui : la forêt de Bondy a ainsi droit à une place, car pendant longtemps, c'était le coupe-gorge qui faisait peur à tous les Parisiens. Dans les mythes, le danger est toujours à l'extérieur…
Je ne vais pas résumer toutes les histoires que contient ce livre. Juste terminer en disant que j'ai été très ému, par le rappel dans le chapitre sur les épreuves collectives subies par la ville, des attentats djihadistes de janvier et novembre 2015. Le récit se termine par un message d'espoir : Paris n'a pas cédé.
L'article seul
Le service MySocket, pour donner un accès Internet à ses développements locaux
Première rédaction de cet article le 25 novembre 2020
Le service MySocket vient d'être lancé. À quoi ça sert ? À plusieurs choses mais le scénario d'utilisation le plus évident est le cas où vous avez un service TCP/IP sur une machine de développement et vous voudriez que des gens dans le vaste monde l'essaient. Mais, pour des raisons diverses, cette machine de développement n'est pas accessible depuis l'Internet. MySocket est un relais qui va prendre les connexions des gens extérieurs et les apporter à votre service.
Il y a beaucoup de cas où la machine sur laquelle vous êtes en train de travailler ne peut pas être contactée par des clients situés sur l'Internet. Le plus évident est celui où vous êtes coincé sur un réseau attardé qui n'a pas IPv6 (ou bien que vos clients n'ont pas IPv6) et que le NAT empêche ces connexions entrantes. (Ou, encore pire, le service est dans un conteneur Docker double-NATé…) MySocket va agir comme un mini-Cloudflare, il va fournir une prise réseau à laquelle vos clients se connecteront et, derrière, cela viendra chez vous. C'est très pratique pour des essais, du développement, etc.
MySocket a été présenté dans cet article. Mais vous avez une documentation complète en ligne. Pratiquer est un bon moyen de voir en quoi ce service consiste concrètement, donc allons-y.
MySocket se pilote via son API. Il ne semble pas y avoir d'interface
Web pour les utilisateurs en ce moment. Pour parler à l'API, vous
pouvez écrire votre propre programme ou, plus simple, utiliser le
client mysocketctl développé par MySocket. (Son
source est
disponible.) C'est un script Python donc on l'installe de manière
pythonienne :
% pip3 install --user mysocketctl ... Successfully installed mysocketctl-0.3
La connexion entre MySocket et votre service se fera forcément en SSH. Donc, il faut une clé SSH. Ici, je vais en créer une dédiée à ce service MySocket :
% ssh-keygen -t ed25519 -f ~/.ssh/id_mysocket ... Your public key has been saved in /home/stephane/.ssh/id_mysocket.pub. % ssh-add ~/.ssh/id_mysocket
On peut maintenant se créer un compte sur le service MySocket (je me répète mais il n'y a pas d'interface Web pour cela) :
% mysocketctl account create \
--name "Stéphane Bortzmeyer" \
--email "foobar@example.com" \
--password "Plein de caractères" \
--sshkey "$(cat ~/.ssh/id_mysocket.pub)"
Congratulation! your account has been created. A confirmation email has been sent to foobar@example.com
Please complete the account registration by following the confirmation link in your email.
...
Une fois reçu le message de confirmation envoyé par courrier, vous
suivez le lien et votre adresse est confirmée. Note amusante : la
réponse du serveur Web sera en JSON (oui, oui, avec le type
application/json), et composée de la chaîne
"You have confirmed your account. Thanks!".
Les opérations de gestion des prises réseau nécessiteront un
jeton d'authentification que l'on crée avec
la commande login, et qui est valable quelques
heures (après, vous aurez un Login failed) :
% mysocketctl login \
--email "foobar@example.com" \
--password "Plein de caractères"
Logged in! Token stored in /home/stephane/.mysocketio_token
(À l'heure actuelle, ce fichier
.mysocketio_token est créé avec les permissions
par défaut. Vous aurez peut-être besoin de durcir ses permissions.)
Voilà, à ce stade, vous avez un compte, vous avez un jeton
d'authentification, on peut créer une
prise. mysocketctl permet de le faire de
manière simple, ou de manière plus compliquée mais permettant
davantage de choses. Commençons par la manière simple :
% mysocketctl connect \
--port 8080 \
--name "Youpi"
+--------------------------------------+--------------------------------+-------+
| socket_id | dns_name | name |
+--------------------------------------+--------------------------------+-------+
| 3d66b504-677f-4e68-85a7-bb63da251007 | shy-bush-6765.edge.mysocket.io | Youpi |
+--------------------------------------+--------------------------------+-------+
Connecting to Server: ssh.mysocket.io
...
Youpi - https://shy-bush-6765.edge.mysocket.io
...
(Si vous récupérez un Permission denied
(publickey), vérifier que la clé SSH a bien été chargée
dans l'agent avec ssh-add.) Et voilà, une
prise a été créée et elle est accessible du monde extérieur via le
nom shy-bush-6765.edge.mysocket.io. Par défaut,
c'est une prise HTTPS et les clients sont donc censés s'y
connecter avec l'URL indiqué
https://shy-bush-6765.edge.mysocket.io. Notez
bien que vous ne choisissez pas le nom de domaine, il est attribué par MySocket et
vous êtes donc dépendant d'eux, y compris dans le nom publié. On l'a
déjà dit : MySocket est surtout conçu pour du développement, du
temporaire, pas pour le site e-commerce de votre entreprise.
Maintenant, un client, par exemple un navigateur Web, va essayer
de se connecter à cet URL. Et paf, on a un 502 Bad
Gateway. Qu'est-ce que cela veut dire ? Tout simplement
qu'on a créé la prise, qu'on l'a connectée au
port 8080 de notre machine mais que rien
n'écoute sur ce port (d'où l'erreur 502, RFC 7231, section 6.6.3). Il nous faut développer un petit service. Ici,
on va utiliser le module http.server
de Python :
#!/usr/bin/env python3
import http.server
server_address = ('', 8080)
httpd = http.server.HTTPServer(server_address,
http.server.SimpleHTTPRequestHandler)
httpd.serve_forever()
Simple, non ? Cela crée un serveur HTTP (rappelez-vous que par défaut
mysocketctl crée une prise HTTP), écoutant sur
le port 8080 et traitant les requêtes avec la classe
SimpleHTTPRequestHandler. Cette classe contient
du code pour les méthodes HTTP comme GET et,
par défaut, elle crée un petit serveur de fichier qui sert les
fichiers locaux. Exécutons ce serveur :
% ./test-mysocket.py ... 127.0.0.1 - - [25/Nov/2020 18:13:06] "GET / HTTP/1.0" 200 -
Ça marche, le client HTTP reçoit cette fois le code de retour 200
indiquant que tout va bien, et il voit la liste des fichiers
locaux. La ligne commençant par 127.0.0.1 est
le journal qu'affiche par défaut le module
http.server. Le premier champ est l'adresse IP
du client, ici 127.0.0.1, l'adresse de la
machine locale, car c'est le client MySocket, lancé par
mysocketctl qui s'est connecté à ce service. Si
on veut voir la vraie adresse du client, il faut regarder le journal
de mysocketctl :
192.0.2.106 - - [25/Nov/2020:17:13:06 +0000] "GET / HTTP/1.1" 200 432 "-" "curl/7.64.0" response_time="0.032 secs"
C'est pratique, on a la vraie adresse IP du client. Elle est
également disponible dans les en-têtes de la requête HTTP, champs
X-Real-IP: et
X-Forwarded-For: (mais hélas pas avec l'en-tête
standard du RFC 7239).
Pendant que tout marche et que le bonheur coule à flot, regardons
d'un peu plus près le service que fournit MySocket. Je crée une
prise, et on m'obtient le nom
purple-surf-7070.edge.mysocket.io. Ce nom a une
adresse IP (IPv4 seul, hélas) :
% dig A purple-surf-7070.edge.mysocket.io ... ;; ANSWER SECTION: purple-surf-7070.edge.mysocket.io. 300 IN A 75.2.104.207
Mais cette adresse IP ne correspond pas à une seule machine : MySocket utilise l'anycast pour que cette adresse IP soit toujours proche de vous. (Évidemment, seul MySocket est anycasté, votre service ne tourne toujours que sur une seule machine.) Pour réaliser cela, MySocket tourne sur un service d'AWS (Global Accelerator) qui n'a hélas pas IPv6. Testons l'adresse IP avec les sondes RIPE Atlas :
% blaeu-reach -r 200 75.2.104.207 197 probes reported Test #28277168 done at 2020-11-25T17:23:21Z Tests: 584 successful tests (98.8 %), 0 errors (0.0 %), 7 timeouts (1.2 %), average RTT: 19 ms
On voit un RTT moyen très court, montrant bien l'intérêt de l'anycast.
Je n'ai pas utilisé cette possibilité, mais notez que MySocket
permet également de créer des prises protégées (avec l'option
--protected). Pour HTTP, ce sera avec
l'authentification simple du RFC 7235. mysocketctl connect --help si
vous voulez des détails, je n'ai personnellement pas testé.
J'ai dit qu'il y avait deux manières de gérer les prises, une
simple et une plus compliquée. On vient de tester la simple, avec
mysocketctl connect qui crée la prise, y
connecte votre service, et nettoie lorsqu'il se termine. Maintenant,
on va procéder en deux temps, d'abord en créant la prise, sans y
connecter notre service :
% mysocketctl socket create --name "Youpi" +--------------------------------------+-----------------------------------+---------+------+-------+ | socket_id | dns_name | port(s) | type | name | +--------------------------------------+-----------------------------------+---------+------+-------+ | c5d771fe-1ae8-4254-a8bd-fb8b1f4c293e | lively-rain-9509.edge.mysocket.io | 80 443 | http | Youpi | +--------------------------------------+-----------------------------------+---------+------+-------+
On dispose désormais d'une prise « permanente » (qui ne disparait
pas quand on a cessé de se connecter). mysocketctl socket
ls me donnera la liste de ces prises. Pour utiliser la
prise, il faut créer un tunnel :
% mysocketctl tunnel create --socket_id c5d771fe-1ae8-4254-a8bd-fb8b1f4c293e +--------------------------------------+--------------------------------------+---------------+------------+ | socket_id | tunnel_id | tunnel_server | relay_port | +--------------------------------------+--------------------------------------+---------------+------------+ | c5d771fe-1ae8-4254-a8bd-fb8b1f4c293e | ace4b7bf-78f5-4373-992c-e7854b917b45 | | 6150 | +--------------------------------------+--------------------------------------+---------------+------------+
Puis on se connecte à MySocket :
% mysocketctl tunnel connect \
--socket_id c5d771fe-1ae8-4254-a8bd-fb8b1f4c293e \
--tunnel_id ace4b7bf-78f5-4373-992c-e7854b917b45 --port 8080
Connecting to Server: ssh.mysocket.io
...
Youpi - https://lively-rain-9509.edge.mysocket.io
Et on peut s'en servir, à l'URL indiqué.
Quelques petits points divers, avant de montrer deux services actuellements disponibles via MySocket :
- Je n'ai pas creusé la question du modèle d'affaires de MySocket. Pour l'instant, tout est gratuit, fonctionnant au mieux (sans garantie). Je suppose qu'il y aura un service payant avec davantage de possibilités et de garanties, mais je n'en sais rien. Notez que le créateur de MySocket est Andree Tonk, créateur de BGPmon, donc a priori, c'est sérieux.
- Ceci dit, MySocket est une solution cloud, c'est-à-dire tournant sur d'autres ordinateurs que le vôtre. Si la communication entre votre service et MySocket est chiffrée avec SSH, et que celle entre le client et MySocket l'est en général avec TLS, le trafic est en clair sur les serveurs de MySocket (qui sont des machines Amazon). Donc, attention si vous manipulez des données importantes.
- Pensez aussi à la sécurité de votre
service. MySocket permet à tout l'Internet (sauf si vous utilisez
le mode protégé, avec
--protected) d'appeler un service qui tourne sur votre machine. Un serveur mal écrit et des tas de choses ennuyeuses peuvent se passer. Il est recommandé d'utiliser un langage de programmation sûr (Python plutôt que C…) et de faire tourner le service dans un bac à sable, par exemple un conteneur. - Un des avantages de MySocket est que votre service apparaitra aux yeux du monde comme sécurisé avec TLS, sans que vous ayiez le moindre effort de programmation ou de configuration à faire, ce qui est très sympa. (Le certificat de MySocket est un Let's Encrypt.)
Et pour finir, voici deux services qui tournent actuellement via
MySocket. Tous les deux sont hébergés sur un Raspberry
Pi 1 (oui, le premier modèle). Ces deux services sont
évidemment sans garantie de fiabilité ou de pérennité, c'est juste
pour vous montrer et que vous puissiez tester. Le premier utilise une
prise de
type HTTPS, comme dans les exemples plus haut. Il indique la
température du Raspberry Pi et le nombre de paquets et d'octets
passés sur son interface Ethernet. Il est accessible en
https://frosty-butterfly-737.edge.mysocket.io/. Le
source du service est disponible.
Le second utilise un autre type de prise, TLS, ce qui permet de
faire tourner des protocoles non-HTTP. Pour créer une telle prise,
on utilise l'option --type TLS. À noter qu'un
port est alloué pour ce service, pensez à le noter, les clients
devront utiliser ce port. Ce service compte simplement le nombre
d'octets dans la chaîne de caractères que vous lui envoyer. Il est
en
misty-violet-3591.edge.mysocket.io:41106. Comme
c'est du TLS, on ne peut pas utiliser telnet
ou netcat comme client, donc on va se servir
de gnutls-cli :
% gnutls-cli -p 41106 misty-violet-3591.edge.mysocket.io ... - Status: The certificate is trusted. - Description: (TLS1.2)-(ECDHE-SECP256R1)-(RSA-SHA256)-(AES-256-GCM) ... - Simple Client Mode: toto 4 bytes
Et mysocketctl va montrer la connexion :
192.0.2.106 [25/Nov/2020:19:19:50 +0000] TCP 200 bytes_sent:8 bytes_received:5 session_time: 1.899
Le source du service est disponible.
Comme la demande pour un tel service est forte, il y a d'autres solutions possibles (je ne les ai pas testées) :
- Ngrok (très riche en services, accès gratuit limité, payant ensuite),
- Le service Argo
(apparemment désormais "Cloudflare Tunnels")
via l'outil
cloudflaredde Cloudflare, - Expose.
L'article seul
RFC 8961: Requirements for Time-Based Loss Detection
Date de publication du RFC : Novembre 2020
Auteur(s) du RFC : M. Allman (ICSI)
Réalisé dans le cadre du groupe de travail IETF tcpm
Première rédaction de cet article le 24 novembre 2020
Vous savez certainement que l'Internet fait circuler les données sous forme de paquets indépendants, et qu'un paquet peut toujours être perdu, par exemple parce qu'un rayon cosmique agressif est passé à ce moment-là ou, moins spectaculaire, parce que les files d'un routeur étaient pleines et qu'il a dû se résigner à laisser tomber le paquet. Des protocoles existent donc pour gérer ces pertes de paquets, ce qui implique de les détecter. Et comment sait-on qu'un paquet a été perdu ? C'est plus complexe que ça n'en a l'air, et ce RFC tente d'établir un cadre générique pour la détection de pertes.
Ne tournons pas autour du pot : la seule façon fiable de savoir
si un paquet a été perdu, c'est d'attendre qu'il arrive (ce que le
RFC nomme, dans son titre, time-based loss
detection) et, s'il n'arrive pas, de le déclarer
perdu. Plus précisément, pour l'émetteur (car le récepteur ne sait
pas forcément qu'on lui a envoyé un paquet), on émet un paquet et on
attend une confirmation qu'il a été reçu (avec TCP, cette
confirmation sera le ACK, avec le DNS sur UDP, ce sera la réponse DNS). Si la
confirmation n'a pas été reçue, s'il y a timeout,
c'est qu'un paquet (la demande, ou bien l'accusé de réception) n'est
pas arrivé. Mais attendre combien de temps ? Si on attend peu de
temps (mettons 100 millisecondes), on risque de considérer le paquet
comme perdu, alors que le voyage était simplement un peu long (en
100 ms, vous ne pouvez même pas faire un aller-retour entre la
France et les
Philippines, ne serait-ce qu'à cause de la
limite de la vitesse de la lumière). Et si on attend longtemps
(mettons 5 secondes), on ne pourra pas réagir rapidement aux pertes,
et la latence perçue par l'utilisateur
sera insupportable (la sensation de « vitesse » pour l'utilisateur
dépend davantage de la latence que de la capacité). Il faut donc faire un compromis
entre réactivité et justesse.
Il existe d'autres méthodes que l'attente pour détecter des pertes, par exemple TCP et SCTP utilisent aussi les accusés de réception sélectifs (RFC 2018, RFC 9260 dans sa section 3.3.4 et RFC 6675) mais aucune de ces autres méthodes ne détecte toutes les pertes, et la détection par absence de réponse reste donc indispensable.
L'Internet, vous le savez, est un ensemble compliqué de réseaux, reliés par des câbles très variés (et quelques liens radio), avec des débits bien différents et changeant d'un moment à l'autre. Tout chemin d'une machine à l'autre va avoir un certain nombre de propriétés (qui varient dans le temps) telles que la latence ou la capacité. Et le taux de perte de paquets, qui nous intéresse ici. (Voir aussi le RFC 7680.)
Notre RFC suppose que la perte de paquets est une indication de congestion (RFC 5681). Ce n'est pas vrai à 100 %, surtout sur les liens radio, où des paquets peuvent être détruits par des perturbations électro-magnétiques sans qu'il y ait congestion, mais c'est quand même proche de la vérité.
Et, au fait, pourquoi détecter la perte de paquets ? Pourquoi ne pas tout simplement ignorer le problème ? Deux raisons :
- Pour pouvoir envoyer des données de manière fiable, il faut détecter les paquets manquants, afin de pouvoir demander leur retransmission. C'est ce que fait TCP, par exemple, sans quoi on ne pourrait pas transmettre un fichier en étant sûr qu'il arrive complet.
- Puisque la perte de paquets signale en général qu'il y a congestion, détecter cette perte permet de ralentir l'envoi de données et donc de lutter contre la congestion.
Résultat, beaucoup de protocoles ont un mécanisme de détection de pertes : TCP (RFC 6298), bien sûr, mais aussi SCTP (RFC 9260), SIP (RFC 3261), etc.
Le RFC cite souvent l'article de Allman, M. et Paxson V, « On Estimating End-to-End Network Path Properties » donc vous avez le droit d'interrompre votre lecture ici pour lire cet article avant de continuer.
Reprenons, avec la section 2 du RFC, qui explique les buts et non-buts de ce RFC :
- Ce RFC ne change aucun protocole existant, les RFC restent les mêmes, vous n'avez pas à réapprendre TCP,
- Ce RFC vise surtout les RFC futurs, qui auraient intérêt à se conformer aux principes énoncés ici (c'est par exemple le cas si vous développez un nouveau protocole au-dessus d'UDP et que vous devez donc mettre en œuvre la détection de pertes),
- Ce RFC n'impose pas des règles absolues, il donne des principes qui marchent dans la plupart des cas, c'est tout.
Nous arrivons maintenant à la section 4 du RFC, qui liste les exigences auxquelles doivent obéir les mécanismes de détection de pertes. (En pratique, les mécanismes existants collent déjà à ces exigences mais elles n'avaient pas été formalisées.) Un petit retour sur la notion de latence, d'abord. On veut savoir combien de temps attendre avant de déclarer un paquet perdu. Cette durée se nomme RTO (Retransmission TimeOut). Les latences dans l'Internet étant extrêmement variables, il serait intéressant de faire dépendre le RTO de la latence. Mais quelle latence ? Le temps d'aller-retour entre deux machines est le temps qu'il faut à un paquet IP pour aller de la machine A à la machine B plus le temps qu'il faut à un paquet IP pour aller de B à A. On ne peut pas mesurer directement ce temps, car le temps de traitement dans la machine B n'est pas forcément connu. Dans le cas de l'ICMP Echo utilisé par ping, ce temps est considéré comme négligeable, ce qui est assez correct si l'amer est une machine Unix dont le noyau traite l'ICMP Echo. Cela l'est moins si l'amer est un routeur qui traite les réponses ICMP à sa plus basse priorité. Et cela l'est encore moins si un client DNS essaie d'estimer la latence vers un résolveur. Si le résolveur avait la réponse dans sa mémoire, le temps de traitement est faible. S'il devait demander aux serveurs faisant autorité, ce temps peut être bien supérieur à la latence. Le RFC distingue donc RTT (Round-Trip Time), la vraie latence, et FT (Feedback Time) qui est ce qu'affichent ping, dig et autres outils. La machine qui veut savoir combien de temps attendre une réaction de la machine en face, avant de déclarer qu'un paquet est perdu, a tout intérêt à avoir une idée du FT.
Certaines des exigences du RFC sont quantitatives. Ainsi, tant qu'on n'a pas mesuré le FT (au début de la session), le RFC requiert que le RTO soit d'au moins une seconde, pour ne pas surcharger le réseau avec des réémissions, et parce que la perte étant interprétée comme un signe de congestion, un RTO trop faible amènerait à réduire la quantité de données qu'on peut envoyer, diminuant ainsi la capacité effective. Sans compter le problème de l'ambiguïté. Si on a réémis un paquet, et qu'une réponse revient, était-elle pour le paquet initial ou pour la réémission ? Dans le doute, il ne faut pas utiliser le temps mesuré pour changer son estimation du RTO. Et c'est une des raisons pour lesquelles il faut prendre son temps pour les premières mesures. Ah, au fait, pourquoi une seconde et pas 0,75 ou 1,25 ? Cela vient d'une analyse quantitative des RTT typiques de l'Internet, exposée dans l'annexe A du RFC 6298.
Après plusieurs mesures, on connait mieux le FT et on peut abaisser le RTO. Il n'y a pas de durée minimale, donc on peut s'approcher de zéro tant qu'on veut.
Le RFC dit aussi que le RTO (Retransmission TimeOut, le délai d'attente) doit se mesurer à partir de plusieurs observations du FT, pour éviter une mesure faussée par un cas extrême. Et il faut refaire ces observations souvent car le réseau change ; les vieilles mesures n'ont pas d'intérêt. C'est ce que fait TCP avec son smoothed RTT, utilisant la moyenne mobile exponentielle (RFC 6298).
L'Internet étant ce qu'il est, il est recommandé de s'assurer qu'un méchant ne puisse pas facilement fausser cette mesure en injectant des faux paquets. Pour TCP, cette assurance est donnée par le caractère imprévisible du numéro de séquence initial, si l'attaquant n'est pas sur le chemin (RFC 5961). Si on veut une protection contre un attaquant situé sur le chemin, il faut de la cryptographie.
Le RFC recommande de refaire l'évaluation du RTO au moins une fois par RTT et, de préference, aussi souvent que des données sont échangées. TCP le fait une fois par RTT et, si on utilise le RFC 7323, à chaque accusé de réception.
Le RFC rappelle qu'en l'absence d'indication du contraire, une perte de paquets doit être considérée comme un indicateur de congestion, et qu'il faut donc ralentir (RFC 5681, pour le cas de TCP).
Et, dernière exigence, en cas de perte de paquets, le RTO doit croitre exponentiellement, pour s'ajuster rapidement à la charge du réseau. On pourra réduire le RTO lorsqu'on aura la preuve que les paquets passent et qu'on reçoit des accusés de réception et/ou des réponses. Dans tous les cas, le RFC limite le RTO à 60 secondes, ce qui est déjà énorme (je n'ai jamais vu une réponse revenir après une durée aussi longue).
Enfin, la section 5 discute des exigences posées et de leurs limites. La tension entre le désir de réactivité (un RTO faible) et celui de mesures correctes (un RTO plus important, pour être raisonnablement sûr de ne pas conclure à tort qu'il y a eu une perte) est une tension fondamentale : on n'aura jamais de solution parfaite, juste des compromis. Il existe des techniques qui permettent de mieux détecter les pertes (l'algorithme Eifel - RFC 3522, le F-RTO du RFC 5682, DSACK - RFC 2883 et RFC 3708…) mais elles ne sont pas complètes et l'attente bornée par le RTO reste donc nécessaire en dernier recours.
Le noyau Linux a mis en œuvre plusieurs techniques non normalisées (par exemple des modifications du RFC 6298) sans que cela ne crée apparemment de problèmes. D'une manière générale, les algorithmes de détection de pertes de TCP, SCTP ou QUIC sont largement compatibles avec les exigences de ce RFC.
L'article seul
RFC 8943: Concise Binary Object Representation (CBOR) Tags for Date
Date de publication du RFC : Novembre 2020
Auteur(s) du RFC : M. Jones (Microsoft), A. Nadalin (Independent), J. Richter (pdv Financial Software GmbH)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF cbor
Première rédaction de cet article le 21 novembre 2020
Le format de données CBOR, normalisé dans le RFC 8949, possède un certain nombre de types de données de base, et un mécanisme d'extensions, les étiquettes (tags). Ce RFC spécifie deux nouvelles étiquettes, pour indiquer des dates.
Le RFC 8949 déclarait déjà deux types pour les estampilles temporelles, l'étiquette 0 pour une chaîne de caractères dont le contenu est une estampille au format du RFC 3339 (avec la date et l'heure), et l'étiquette 1 pour une estampille sous la forme d'un nombre de secondes depuis l'epoch. Dans ce nouveau RFC sont ajoutées deux étiquettes, 100 pour un entier qui va stocker le nombre de jours depuis l'epoch, et 1004 pour une date seule (sans heure) au format du RFC 3339. L'epoch est celle de la norme Posix 1 / IEEE Standard 1003.1, le 1 janvier 1970. Dans les deux cas, comme on ne stocke pas l'heure, des considérations comme le fuseau horaire ou les secondes intercalaires sont inutiles. Quant au calendrier utilisé, c'est le grégorien.
Dans ce calendrier, John Lennon (je reprends l'exemple du RFC…) est né le 9 octobre 1940 et mort le 8 décembre 1980. (Les dates utilisées dans ce RFC n'incluent pas l'heure.) Pour la première étiquette, 100, qui indique le nombre de jours depuis l'epoch, l'auteur d'I Am the Walrus est né le -10676. C'est un nombre négatif puisque l'epoch utilisée est le 1 janvier 1970, après sa naissance. Lennon est mort le 3994. Pour le cas de la deuxième étiquette, 1004, il est né le 1940-10-09 et mort le 1980-12-08, suivant le format du RFC 3339. Le jour (lundi, mardi, mercredi…) est explicitement non mentionné, si on en a besoin, il faut le recalculer.
Les deux formats, en nombre de jours depuis l'epoch, et en RFC 3339 ont l'avantage que les comparaisons de date sont triviales, une simple comparaison d'entiers dans le premier cas, de chaînes de caractères dans le suivant, suffit.
Petit piège des dates indiquées sans l'heure, un même événement peut survenir à deux dates différentes selon le fuseau horaire. Ainsi, une vidéoconférence qui a lieu, à Tokyo, le 12 octobre à 10h00 sera considérée par les habitants d'Honolulu comme se tenant le 11 octobre à 15h00.
Les deux étiquettes ont été enregistrées à l'IANA. La valeur 100 pour la première a été choisie car 100 est le code ASCII de 'd' (pour date).
Si vous voulez un fichier CBOR utilisant ces deux étiquettes,
vous pouvez appeler le service
https://www.bortzmeyer.org/apps/date-in-cbor
qui vous renvoie un tableau avec les quatre façons de servir une
date en CBOR, les deux standards du RFC 8949,
et les deux de notre RFC. Ici, on utilise le programmme read-cbor pour afficher
plus joliment :
% wget -q -O - https://www.bortzmeyer.org/apps/date-in-cbor | ./read-cbor -
Array of 5 items
...
Tag 0
String of length 20: 2020-11-21T06:44:33Z
Tag 1
Unsigned integer 1605941073
Tag 100
Unsigned integer 18587
Tag 1004
String of length 10: 2020-11-21
L'article seul
RFC 8726: How Requests for IANA Action Will be Handled on the Independent Stream
Date de publication du RFC : Novembre 2020
Auteur(s) du RFC : A. Farrel (Independent Submissions Editor)
Pour information
Première rédaction de cet article le 20 novembre 2020
Tous les RFC ne viennent pas de l'IETF. Certains sont publiés sur la voie indépendante, sous la responsabilité de l'ISE (Independent Submissions Editor). Certains de ces RFC « indépendants » créent ou modifient des registres IANA. Comment traiter ces demandes à l'IANA ?
Ce travail de l'ISE (Independent Submissions
Editor, actuellement Adrian Farrel, l'auteur de ce RFC, et
également des contes « Tales from the wood ») est
documenté dans le RFC 4846. Cet ancien RFC (il
date d'avant la création de l'ISE, qui avait été faite par le RFC 5620, puis précisée par le RFC 6548 puis enfin le RFC 8730) ne donne que peu de détails sur les relations avec
l'IANA, nécessaires si le RFC « indépendant »
demande la création d'un nouveau registre, ou la modification d'un
registre existant. Ces registres IANA sont en https://www.iana.org/protocols
Pour les registres existants (section 2 du RFC), l'ISE est évidemment tenu par ce RFC 8126. Si un RFC de la voie indépendante ajoute une entrée à un registre IANA, il doit suivre la politique qui avait été définie pour ce registre. Cela va de soi. D'autre part, un RFC « indépendant » ne représente pas, par définition, l'IETF, et ne peut donc pas créer d'entrées dans un registre dont la politique est « Examen par l'IETF » ou « Action de normalisation ». Pour la même raison, un RFC de la voie indépendante ne peut pas changer la politique d'un registre qui n'avait pas été créé par un RFC de la voie indépendante (section 3).
Et la création de nouveaux registres (section 4 de notre RFC) ? En général, un RFC « indépendant » ne devrait pas le faire, puisqu'il s'agit de documents qui n'ont pas bénéficié du même examen que les RFC de la voie IETF. La seule exception est la possibilité de créer un sous-registre s'il existe un registre à la politique « ouverte » (« Spécification nécessaire », « Examen par un expert », « RFC nécessaire » ou « Premier Arrivé, Premier Servi ») et que le sous-registre correspond à une entrée ajoutée par le RFC indépendant. L'une des raisons de ce choix est d'éviter de donner trop de travail à l'IANA, en multipliant les registres.
Certaines politiques d'allocation dans un registre IANA nécessitent un expert. La section 5 de notre RFC précise que la voie indépendante ne nommera pas d'expert et que donc aucun des sous-registres éventuellement créés n'aura la politique « Examen par un expert ».
Enfin, la section 6 traite le cas du transfert du contrôle d'un registre. Il n'y aura jamais de transfert depuis la voie IETF vers la voie indépendante (une fois qu'un registre est « officiel », il le reste) mais l'inverse peut arriver, par exemple si un protocole initialement décrit dans un RFC « indépendant » passe finalement sur le chemin des normes.
L'article seul
RFC 8950: Advertising IPv4 Network Layer Reachability Information (NLRI) with an IPv6 Next Hop
Date de publication du RFC : Novembre 2020
Auteur(s) du RFC : S. Litkowski, S. Agrawal, K. Ananthamurthy (Cisco), K. Patel (Arrcus)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF bess
Première rédaction de cet article le 20 novembre 2020
Le protocole de routage BGP annonce des préfixes qu'on sait joindre, avec l'adresse IP du premier routeur à qui envoyer les paquets pour ce préfixe. (Ce routeur est appelé le next hop.) BGP a une extension, BGP multi-protocoles (RFC 4760) où les préfixes annoncés (NLRI pour Network Layer Reachability Information) ne sont plus forcément de la même famille que les adresses utilisées dans la session BGP. On peut donc annoncer des préfixes IPv6 sur une session BGP établie en IPv4 et réciproquement. Notre RFC, qui succède au RFC 5549 avec quelques petits changements, étend encore cette possibilité en permettant que le next hop ait une adresse de version différente de celle du préfixe.
Normalement, BGP multi-protocoles (RFC 4760) impose la version (IPv4 ou IPv6) du next hop via l'AFI (Address Family Identifier) et le SAFI (Subsequent Address Family Identifier) indiqués dans l'annonce (cf. la liste actuelle des AFI possible et celle des SAFI). Ainsi, un AFI de 1 (IPv4) couplé avec un SAFI valant 1 (unicast), lors de l'annonce d'un préfixe IPv4, impose que l'adresse du routeur suivant soit en IPv4. Désormais, cette règle est plus libérale, le routeur suivant peut avoir une adresse IPv6. Cela peut faciliter, par exemple, la vie des opérateurs qui, en interne, connectent des ilots IPv4 au-dessus d'un cœur de réseau IPv6 (cf. RFC 4925). Notez que cela ne règle que la question de l'annonce BGP. Il reste encore à router un préfixe IPv4 via une adresse IPv6 mais ce n'est plus l'affaire de BGP.
Il y avait déjà des exceptions à la règle comme quoi le préfixe
et l'adresse du routeur suivant étaient de la même famille. Ainsi,
le RFC 6074 permettait cela pour le couple AFI 25
(L2VPN) / SAFI 65
(VPLS). Mais le couple AFI 2 / SAFI 1 (IPv6 /
unicast) ne permet pas de telles exceptions (RFC 2545). Une astuce (RFC 4798 et RFC 4659) permet de s'en
tirer en encodant l'adresse IPv4 du next hop dans
une adresse IPv6. (Oui, ::192.0.2.66 est une
adresse IPv4 encodée dans les seize octets d'IPv6, cf. RFC 4291, section 2.5.5.2.) Quant au cas inverse
(AFI IPv4, routeur suivant en IPv6), elle fait l'objet de notre RFC.
Lorsque l'adresse du next hop n'est pas de la famille du préfixe, il faut trouver la famille, ce qui peut se faire par la taille de l'adresse du next hop (quatre octets, c'est de l'IPv4, seize octets, de l'IPv6). C'est ce que propose le RFC 4684.
L'extension permettant la liberté d'avoir des next hop dans une famille différente du préfixe est spécifiée complètement en section 4. Elle liste les couples AFI / SAFI pour lesquels on est autorisé à avoir un next hop IPv6 alors que le préfixe est en IPv4. Le routeur BGP qui reçoit ces annonces doit utiliser la longueur de l'adresse pour trouver tout seul si le next hop est IPv4 ou IPv6 (la méthode des RFC 4684 et RFC 6074).
L'utilisation de cette liberté nécessite de l'annoncer à son pair BGP, pour ne pas surprendre des routeurs BGP anciens. Cela se fait avec les capacités du RFC 5492. La capacité se nomme Extended Next Hop Encoding et a le code 5. Cette capacité est restreinte à certains couples AFI / SAFI, listés dans l'annonce de la capacité. Par exemple, le routeur qui veut annoncer une adresse IPv6 comme next hop pour de l'unicast IPv4 va indiquer dans le champ Valeur de la capacité 1 / 1 (le couple AFI /SAFI) et le next hop AFI 2.
La section 2 du RFC résume les changements depuis le RFC 5549, que notre RFC remplace. L'encodage de l'adresse du next hop change dans le cas des VPN, et, pour les VPN MPLS, extension de l'exception au multicast. Bref, rien de bien crucial.
Et pour la mise en œuvre concrète, je vous conseille cet excellent article d'Anurag Bhatia.
L'article seul
À propos de l'enseignement de l'arabe et du pouvoir des langues
Première rédaction de cet article le 18 novembre 2020
Il y a un débat récurrent en France sur l'enseignement de la langue arabe à l'école. Ce débat a resurgi début octobre avec un discours d'Emmanuel Macron promettant de promouvoir cet enseignement. L'un des arguments serait l'influence de la langue sur la pensée. Creusons un peu.
Comme à chaque fois qu'on propose de développer l'enseignement de l'arabe en France, la droite extrême et l'extrême-droite protestent avec des arguments amalgamant langue arabe et islamisme, voire langue arabe et djihadisme. Selon leurs arguments, enseigner l'arabe reviendrait à promouvoir ces idéologies. (Ces arguments reposent en partie sur des ignorances répandues en France, comme de confondre arabe et musulman.) Les partisans de l'enseignement de l'arabe répliquent en général en niant le lien entre langue et idéologie, en notant que l'apprentissage de l'anglais ne fait pas de vous un loyal sujet d'Élisabeth II. Ou bien, si on n'a pas peur du point Godwin, en notant qu'apprendre l'allemand ne vous transforme pas en nazi.
Je suis bien convaincu que les arguments de type « apprendre l'arabe va encourager l'islamisme » sont faux, et certainement de mauvaise foi. Mais dire exactement le contraire, prétendre que la langue n'a aucune influence sur la pensée, est trop simpliste. Depuis que la linguistique existe, les linguistes débattent de cette influence de la langue sur la pensée. Dans sa forme extrême, celle qu'on appelle l'hypothèse de Sapir-Whorf, cette influence est supposée forte. Mais d'autres sont plus prudents (cf. le livre de Deutscher, « Through the language glass ») et estiment qu'il y a certes un rôle joué par la langue dans les pensées mais qu'il est complexe et certainement pas grossièrement déterministe du genre « dès qu'on apprend le nahuatl, on va essayer de reconstruire l'empire aztèque ».
Comme le dit Barbara Cassin (interview dans le numéro de novembre 2020 de la Recherche) « Chaque langue est une manière de dire le monde ». La langue qu'on utilise n'est pas neutre (et Cassin en tire argument pour prôner le multilinguisme, pour avoir plusieurs perspectives).
C'est justement parce que la langue n'est pas neutre que la France dépense baucoup d'argent pour promouvoir la francophonie, ou que la Chine a son réseau des instituts Confucius. Et les États-Unis utilisent également leur langue comme outil de soft power, par exemple via leur domination culturelle. Donc, oui, la langue compte.
Est-ce que cela veut dire qu'il ne faut pas enseigner l'arabe ? Évidemment non. C'est une langue importante, par le nombre de locuteurs et par la quantité de textes existants. Cette langue doit donc être proposée à l'école, comme le russe ou le chinois. Elle doit évidemment être proposée à toutes et tous, pas uniquement à des enfants qui seraient assignés à perpétuité « issu de l'immigration ». Mais il faut faire attention à certains arguments utilisés en faveur de cet enseignement : ils ne sont pas toujours solides.
Trois points pour terminer. Décider d'enseigner l'arabe va forcément amener à la question « lequel ? », vu la grande variété des langues qu'on regroupe sous ce terme. Je ne vais pas trancher ici, c'est un débat compliqué. Ensuite il faut parler des moyens matériels car, en France, on aime bien les grandes postures idéologiques, déconnectées des problèmes pratiques. Or, la promotion de toute matière à l'école suppose 1) des choix, car le nombre d'heures n'est pas extensible 2) de l'argent pour recruter des enseignants. Ce deuxième point a souvent été oublié dans les débats après le discours de Macron. Et le troisième et dernier point concerne l'amalgame souvent fait entre langue arabe et immigration. Je vous recommande l'article de Tassadit Yacine, Pierre Vermeren et Omar Hamourit, « La langue maternelle des immigrés n’est pas l’arabe ». La langue arabe doit être proposée à l'école pour son intérêt propre, pas parce qu'on pense à tort qu'elle est celle des immigrés.
L'article seul
RFC 8909: Registry Data Escrow Specification
Date de publication du RFC : Novembre 2020
Auteur(s) du RFC : G. Lozano (ICANN)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 14 novembre 2020
Prenons un registre, par exemple un registre de noms de domaine. Des tas de gens comptent sur lui. Si ce registre disparait en emportant sa base de données, ce serait une catastrophe. Il est donc nécessaire de garder les données à part, ce qu'on nomme un séquestre (escrow). Ce RFC décrit un format standard pour les données de séquestre, indépendant du type de registre (même si la demande prioritaire est pour les registres de noms de domaine). Il s'agit d'un format générique, qui sera complété par des spécifications pour les différents types de registre, par exemple le RFC 9022 pour les registres de noms de domaine.
L'idée (section 1 du RFC) est donc que le registre dépose à intervalles réguliers une copie de sa base de données auprès de l'opérateur de séquestre. Il ne s'agit pas d'une sauvegarde. La sauvegarde est conçue pour faire face à des accidents comme un incendie. Le séquestre, lui, est conçu pour faire face à une disparition complète du registre, par exemple une faillite si le registre est une entreprise commerciale. Ou bien une redélégation complète du domaine à un autre registre. Les sauvegardes, non standardisées et liées à un système d'information particulier, ne peuvent pas être utilisées dans ces cas. D'où l'importance d'un format standard pour un séquestre, précisément ce que normalise notre RFC. Lors d'une défaillance complète de l'ancien registre, l'opérateur de séquestre transmettra les données de séquestre au nouveau registre, qui pourra l'importer dans son système d'information, qui sera alors prêt à prendre le relais. Pour un registre de noms de domaine, le dépôt des données de séquestre devra comprendre la liste des noms, les titulaires et contacts pour chacun des noms, les serveurs de noms, les enregistrements DS (utilisés pour DNSSEC), etc. Par contre, certaines informations ne pourront pas être incluses, comme les parties privées des clés utilisées pour DNSSEC (qui sont peut-être enfermées dans un HSM) et le nouveau registre aura donc quand même un peu de travail de réparation.
Ainsi, la
convention entre l'État et l'AFNIC
pour la gestion du .fr
prévoit dans sa section 5 que « L'Office
d'enregistrement [sic] s'engage à mettre en place et à maintenir sur
le sol français un séquestre de données quotidien ». Même
chose pour les TLD sous contrat avec l'ICANN. Le Base
Registry Agreement impose un séquestre dans sa
spécification 2 « DATA ESCROW
REQUIREMENTS ». Elle dit « Deposit’s
Format. Registry objects, such as domains, contacts, name servers,
registrars, etc. will be compiled into a file constructed as
described in draft-arias-noguchi-registry-data-escrow, see Part A,
Section 9, reference 1 of this Specification and
draft-arias-noguchi-dnrd-objects-mapping, see Part A, Section 9,
reference 2 of this Specification (collectively, the “DNDE
Specification”). ». [Le document
draft-arias-noguchi-registry-data-escrow est
devenu ce RFC 8909.] L'ICANN reçoit actuellement 1 200
séquestres, pour chaque TLD qu'elle régule, les dépôts ayant lieu
une fois par semaine.
Ces exigences sont tout à fait normales : la disparition d'un
registre de noms de domaine, s'il n'y avait pas de séquestre,
entrainerait la disparition de tous les noms, sans moyen pour les
titulaires de faire valoir leurs droits. Si
.org disparaissait sans
séquestre,
bortzmeyer.org n'existerait plus, et si un
registre prenait le relais avec une base de données vide, rien ne me
garantit d'obtenir ce nom, l'adresse de ce blog devrait donc
changer. Cette question de continuité de
l'activité de registre, même si des organisations disparaissent, est
la motivation pour ce RFC (section 3).
Un exemple de service de « registre de secours » (third-party beneficiary, dans la section 2 du RFC, on pourrait dire aussi backup registry) est l'EBERO (Emergency Back-End Registry Operator) de l'ICANN, décrit dans les « Registry Transition Processes ».
Ce RFC ne spécifie qu'un format de données. Il ne règle pas les questions politiques (faut-il faire un séquestre, à quel rythme, qui doit être l'opérateur de séquestre, qui va désigner un registre de secours, etc).
Passons donc à la technique (section 5). Le format est du
XML.
L'élément racine est <deposit>
(dépôt). Un attribut type indique si ce dépôt
est complet (la totalité des données) ou bien incrémental
(différence avec le dépôt précédent). L'espace de
noms est
urn:ietf:params:xml:ns:rde-1.0, enregistré
à l'IANA (voir la section 8). RDE signifie Registry
Data Escrow. Parmi les éléments obligatoires sous
<deposit>, il y a :
<watermark>qui indique le moment où ce dépôt a été fait, au format du RFC 3339 (section 4). On peut traduire watermark par jalon, point de synchronisation, point d'étape ou marque.<rdeMenu>, diverses métadonnées.<contents>contient les données (rappelez-vous que ce RFC est générique, le format exact des données, qui dépend du type de registre, sera dans un autre RFC).<deletes>ne sert que pour les dépôts incrémentaux, et indique les objets qui ont été détruits depuis la dernière fois.- Eh non, il n'y a pas d'élément
<adds>; dans un dépôt incrémental, les éléments ajoutés sont sous<contents>.
Voici un exemple très partiel d'un dépôt complet :
<?xml version="1.0" encoding="UTF-8"?>
<d:deposit xmlns:d="urn:ietf:params:xml:ns:rde-1.0"
xmlns:myobj="urn:example:my-objects-1.0"
type="FULL" id="20201006" resend="0">
<d:watermark>2020-10-06T13:12:15Z</d:watermark>
<d:rdeMenu>
<d:version>1.0</d:version>
<d:objURI>urn:example:my-objects-1.0</d:objURI>
</d:rdeMenu>
<d:contents>
<myobj:object>
<myobj:value>42</myobj:value>
</myobj:object>
</d:contents>
</d:deposit>
Dans cet exemple, le fichier XML contient un dépôt complet, fait le
6 octobre 2020, et dont le contenu est un seul élément, de valeur
42. (Pour un vrai dépôt lors d'un séquestre d'un registre de noms
de domaine, on aurait, au lieu de
<myobj:object>, les domaines, leurs
titulaires, etc.) Vous avez des exemples un peu plus réalistes dans
les sections 11 à 13 du RFC.
Attention si vous utilisez des dépôts incrémentaux, l'ordre des
<contents> et
<deletes> compte : il faut mettre les
<deletes> en premier.
La syntaxe complète est décrite dans la section 6 du RFC, en XML Schema. Du fait de l'utilisation de XML, l'internationalisation est automatique, on peut par exemple mettre les noms des contacts en Unicode (section 7).
Le format décrit dans ce RFC est seulement un format. Des tas de
questions subsistent si on veut un système de séquestre complet, il
faut par exemple spécifier un mécanisme de transport des données
entre le registre et l'opérateur de séquestre (par exemple avec
SSH, ou bien un
POST HTTPS). Pour l'ICANN, c'est spécifié
dans l'Internet-Draft
draft-lozano-icann-registry-interfaces.
Il faut également se préoccuper de tout ce qui concerne la sécurité. La section 9 du RFC rappelle que, si on veut que les données de séquestre soient confidentielles (pour un registre de noms de domaine, les coordonnées des titulaires et contacts sont certainement en bonne partie des données personnelles, cf. section 10), il faut chiffrer la communication entre le registre et l'opérateur de séquestre. Et il faut bien sûr tout authentifier. L'opérateur de séquestre doit vérifier que le dépôt vient bien du registre et n'est pas un dépôt injecté par un pirate, le registre doit vérifier qu'il envoie bien le dépôt à l'opérateur de séquestre et pas à un tiers. Comme exemple des techniques qui peuvent être utilisées pour atteindre ce but, l'ICANN cite OpenPGP (RFC 9580, désormais) : « Files processed for compression and encryption will be in the binary OpenPGP format as per OpenPGP Message Format - RFC 4880, see Part A, Section 9, reference 3 of this Specification. Acceptable algorithms for Public-key cryptography, Symmetric-key cryptography, Hash and Compression are those enumerated in RFC 4880, not marked as deprecated in OpenPGP IANA Registry, see Part A, Section 9, reference 4 of this Specification, that are also royalty-free. ».
Comme le séquestre ne servirait qu'en cas de terminaison complète du registre, on peut penser que le registre actuel n'est pas très motivé pour assurer ce service (et c'est pour cela qu'il doit être imposé). Il y a un risque de négligence (voire de malhonnêté) dans le production des dépôts. Voici pourquoi l'opérateur de séquestre doit tester que les dépôts qu'il reçoit sont corrects. Au minimum, il doit vérifier leur syntaxe. Ici, on va se servir de xmllint pour cela. D'abord, on utilise un schéma pour les données spécifiques de notre type de registre. Ici, il est très simple, uniquement des données bidon :
% cat myobj.xsd
<?xml version="1.0" encoding="utf-8"?>
<schema targetNamespace="urn:example:my-objects-1.0"
xmlns:myobj="urn:example:my-objects-1.0"
xmlns:rde="urn:ietf:params:xml:ns:rde-1.0"
xmlns="http://www.w3.org/2001/XMLSchema"
elementFormDefault="qualified">
<annotation>
<documentation>
Test
</documentation>
</annotation>
<element name="object" type="myobj:objectType" substitutionGroup="rde:content"/>
<complexType name="objectType">
<complexContent>
<extension base="rde:contentType">
<sequence>
<element name="value" type="integer"/>
</sequence>
</extension>
</complexContent>
</complexType>
</schema>
Ensuite, on écrit un petit schéma qui va importer les deux schémas, le nôtre (ci-dessus), spécifique à un type de registre, et le schéma du RFC, générique :
% cat wrapper.xsd <?xml version="1.0" encoding="utf-8"?> <schema targetNamespace="urn:example:tmp-1.0" xmlns="http://www.w3.org/2001/XMLSchema"> <import namespace="urn:ietf:params:xml:ns:rde-1.0" schemaLocation="rde.xsd"/> <import namespace="urn:example:my-objects-1.0" schemaLocation="myobj.xsd"/> </schema>
Ensuite, on produit le dépôt :
% cat test.xml
<?xml version="1.0" encoding="UTF-8"?>
<d:deposit xmlns:d="urn:ietf:params:xml:ns:rde-1.0"
xmlns:myobj="urn:example:my-objects-1.0"
type="FULL" id="20201006" resend="0">
<d:watermark>2020-10-06T13:12:15Z</d:watermark>
<d:rdeMenu>
<d:version>1.0</d:version>
<d:objURI>urn:example:my-objects-1.0</d:objURI>
</d:rdeMenu>
<d:contents>
<myobj:object>
<myobj:value>42</myobj:value>
</myobj:object>
</d:contents>
</d:deposit>
Et on n'a plus qu'à valider ce dépôt :
% xmllint --noout --schema wrapper.xsd test.xml
test.xml validates
Si les données étaient incorrectes (dépôt mal fait), xmllint nous préviendrait :
% xmllint --noout --schema wrapper.xsd test.xml
test.xml:12: element value: Schemas validity error : Element '{urn:example:my-objects-1.0}value': 'toto' is not a valid value of the atomic type 'xs:integer'.
test.xml fails to validate
Idéalement, il faudrait même que l'opérateur de séquestre teste un chargement complet des données dans un autre logiciel de gestion de registre (oui, je sais, c'est beaucoup demander). Bon, s'il vérifie la syntaxe, c'est déjà ça.
L'article seul
Quand les gens déconnent, faut-il déréférencer leurs œuvres passées ?
Première rédaction de cet article le 13 novembre 2020
Dernière mise à jour le 14 novembre 2020
J'ai parlé plusieurs fois positivement, sur ce blog, des livres des Pinçon-Charlot. Maintenant que Monique Pinçon-Charlot a tenu des propos délirants dans le documentaire complotiste « Hold-up », que faire ?
Je donne tout de suite la réponse : rien. Je ne vais pas changer les articles en question. Pas seulement parce qu'il serait irréaliste (et peut-être néfaste) de tenir à jour tous les articles passés. Mais surtout parce que les gens évoluent. Ce n'est pas parce que quelqu'un dit des choses fausses ou parce qu'il a changé d'idées que sa production passée est automatiquement à jeter.
Sur les faits : si vous ne voulez pas vous taper les deux heures quarante du documentaire, l'extrait avec Monique Pinçon-Charlot est en ligne. Et on peut trouver aussi une bonne analyse de Daniel Schneidermann.
Il est triste que Pinçon-Charlot ait ainsi déconné. Et insupportable que la droite extrême complotiste l'utilise comme caution de gauche dans son documentaire. Mais cela ne change pas ce qu'elle a écrit de bien autrefois. Comme le dit Denis Colombi, « il serait faux de juger le jour en fonction du soir ». Je sépare donc la femme d'aujourd'hui de la chercheuse du passé, et je continue à recommander les livres des Pinçon-Charlot.
Une mise à jour du lendemain : sur le compte Twitter officiel des Pinçon-Charlot (je ne sais pas qui le gère), une série de tweets exprimait le regret d'avoir participé à ce documentaire. Personnellement, je trouve l'analyse du problème bienvenue, mais insuffisante, par exemple parce ce qu'elle mélange la défiance (justifiée) vis-à-vis des autorités avec la croyance aveugle dans les complots les plus délirants. Et l'argument « on m'avait dit que je pourrais visionner le documentaire avant » a ses limites. Les auteurs du documentaire sont des complotistes connus, et leur faire confiance montrait une certaine naïveté, qu'on peut pardonner au gilet jaune de base, mais pas à une intellectuelle qui a l'habitude des médias (aurait-elle donné un interview à Valeurs actuelles si ce journal avait « promis » qu'elle pourrait vérifier avant publication ?).
L'article seul
Fiche de lecture : Une nuit @thecallcenter
Auteur(s) du livre : Chetan Bhagat
Éditeur : Stock
978-2-234-06023-4
Publié en 2007
Première rédaction de cet article le 12 novembre 2020
Un roman de Chetan Bhagat très drôle et très vivant, mais sur un sujet pas forcément amusant, celui des travailleurs de l'ombre du call center en Inde.
Les héros travaillent dans une de ces entreprises, désormais bien connues (cf. le film Slumdog Millionaire) qui répondent en permanence à des appels d'utilisateurs perdus, qui ne savent pas faire fonctionner un des équipements compliqués qu'on nous vend. En l'occurrence, pour les personnages du roman, l'électroménager, d'où, par exemple, une client qui a démonté le four électrique pour faire rentrer la dinde de Thanksgiving et qui se plaint d'avoir reçu une décharge électrique.
On suit tous les problèmes de bureau, le chef incompétent et ses idées idiotes, la vision qu'ont les Indiens du reste du monde, la collègue avec qui le héros a une liaison, les conseils du formateur, les clients (« il y a dix mecs intelligents aux États-Unis ; les autres nous appellent ») et, une nuit, pendant une panne du système téléphonique, un appel inhabituel qui va tout changer. Je ne vous raconte pas, mais je vous recommande la lecture. C'est à la fois plein d'humour, et ça parle pourtant de choses sérieuses.
(J'ai lu la traduction française, l'original, écrit en anglais, était One night @ the call center, avec des espaces.)
L'article seul
RFC 8927: JSON Type Definition
Date de publication du RFC : Novembre 2020
Auteur(s) du RFC : U. Carion (Segment)
Expérimental
Première rédaction de cet article le 7 novembre 2020
Il existe plusieurs langages pour décrire la structure d'un document JSON. Aucun ne fait l'objet d'un clair consensus. Sans compter les nombreux programmeurs qui ne veulent pas entendre parler d'un schéma formel. Ce nouveau RFC décrit un de ces langages, JTD, JSON Type Definition. Une de ses particularités est que le schéma est lui-même écrit en JSON. Son cahier des charges est de faciliter la génération automatique de code à partir du schéma. JTD est plus limité que certains langages de schéma, afin de faciliter l'écriture d'outils JTD.
On l'a dit, il n'existe pas d'accord dans le monde JSON en faveur d'un langage de schéma particulier. La culture de ce monde JSON est même souvent opposée au principe d'un schéma. Beaucoup de programmeurs qui utilisent JSON préfèrent l'agilité, au sens « on envoie ce qu'on veut et le client se débrouille pour le comprendre ». Les mêmes désaccords existent à l'IETF, et c'est pour cela que ce RFC n'est pas sur le chemin des normes, mais a juste l'état « Expérimental ».
JSON est normalisé dans le RFC 8259. D'innombrables fichiers de données sont disponibles au format JSON, et de très nombreuses API prennent du JSON en entrée et en rendent en sortie. La description des structures de ces requêtes et réponses est typiquement faite en langage informel. C'est par exemple le cas de beaucoup de RFC qui normalisent un format utilisant JSON comme le RFC 9083, les RFC 8620 et RFC 8621, le RFC 7033, etc. Une des raisons pour lesquelles il est difficile de remplacer ces descriptions en langue naturelle par un schéma formel (comme on le fait couramment pour XML, par exemple avec Relax NG) est qu'il n'y a pas d'accord sur le cahier des charges du langage de schéma. JTD (JSON Type Definition) a des exigences bien précises (section 1 du RFC). Avant de comparer JTD à ses concurrents (cf. par exemple l'annexe B), il faut bien comprendre ces exigences, qui influent évidemment sur le langage :
- Description sans ambiguïté de la structure du document JSON (d'accord, cette exigence est assez banale, pour un langage de schéma…),
- Possibilité de décrire toutes les constructions qu'on trouve dans un document JSON typique,
- Une syntaxe qui doit être facile à lire et à écrire, aussi bien pour les humains que pour les programmes,
- Et, comme indiqué plus haut, tout faire pour faciliter la génération de code à partir du schéma, la principale exigence de JTD ; l'idée est que, si un format utilise JTD, un programme qui analyse ce format soit en bonne partie générable uniquement à partir de la description JTD.
Ainsi, JTD a des entiers sur 8, 16 et 32
bits, qu'un générateur de code peut traduire directement en (le RFC
utilise des exemples C++)
int8_t, int16_t, etc, mais
pas d'entiers de 64 bits, pourtant admis en JSON mais peu portables
(cf. annexe A.1). JTD permet de décrire les propriétés d'un objet
(« objet », en JSON, désigne un dictionnaire)
qu'on peut traduire en struct ou
std::map C++.
Les fans de théorie des langages et de langages formels noteront que JTD n'est pas lui-même spécifié en JTD. Le choix ayant été fait d'un format simple, JTD n'a pas le pouvoir de se décrire lui-même et c'est pour cela que la description de JTD est faite en CDDL (Concise Data Definition Language, RFC 8610).
La syntaxe exacte est spécifiée en section 2, une fois que vous avez (re)lu le RFC 8610. Ainsi, la description de base, en CDDL, d'un membre d'un objet JSON est :
properties = (with-properties // with-optional-properties)
with-properties = (
properties: { * tstr => { schema }},
? optionalProperties: { * tstr => { schema }},
? additionalProperties: bool,
shared,
)
Ce qui veut dire en langage naturel que le schéma JTD peut avoir un
membre properties, lui-même ayant des membres
composés d'un nom et d'un schéma. Le schéma peut être, entre autres,
un type, ce qui est le cas dans l'exemple ci-dessous. Voici un
schéma JTD trivial, en JSON comme il se doit :
{
"properties": {
"name": {
"type": "string"
},
"ok": {
"type": "boolean",
"nullable": true
},
"level": {
"type": "int32"
}
}
}
Ce schéma accepte le document JSON :
{
"name": "Foobar",
"ok": false,
"level": 1
}
Ou bien ce document :
{
"name": "Durand",
"ok": null,
"level": 42
}
(L'élément nullable peut valoir
null ; si on veut pouvoir omettre complètement
un membre, il faut le déclarer dans
optionalProperties, pas properties.) Par contre, cet autre document n'est pas
valide :
{
"name": "Zig",
"ok": true,
"level": 0,
"extra": true
}
Car il y a un membre de trop, extra. Par
défaut, JTD ne le permet pas mais un schéma peut comporter
additionalProperties: true ce qui les
autorisera.
Ce document JSON ne sera pas accepté non plus :
{
"name": "Invalid",
"ok": true
}
Car la propriété level ne peut pas être absente.
Un exemple plus détaillé, et pour un cas réel, figure dans l'annexe C du RFC, en utilisant le langage du RFC 7071.
JTD ne permet pas de vrai mécanisme d'extension mais on peut
toujours ajouter un membre metadata dont la
valeur est un objet JSON quelconque, et qui sert à définir des
« extensions » non portables.
Jouons d'ailleurs un peu avec une mise en œuvre de JTD. Vous en trouverez plusieurs ici, pour divers langages de programmation. Essayons avec celui en Python. D'abord, installer le paquetage :
% git clone https://github.com/jsontypedef/json-typedef-python.git % cd json-typedef-python % python setup.py build % python setup.py install --user
(Oui, on aurait pu utiliser pip install jtd à
la place.)
Le paquetage n'est pas livré avec un script exécutable, on en crée
un en suivant la
documentation. Il est simple :
#!/usr/bin/env python3
import sys
import json
import jtd
if len(sys.argv) != 3:
raise Exception("Usage: %s schema json-file" % sys.argv[0])
textSchema = open(sys.argv[1], 'r').read()
textJsonData = open(sys.argv[2], 'r').read()
schema = jtd.Schema.from_dict(json.loads(textSchema))
jsonData = json.loads(textJsonData)
result = jtd.validate(schema=schema, instance=jsonData)
print(result)
Si le fichier JSON correspond au schéma, il affichera un tableau vide, sinon un tableau contenant la liste des erreurs :
% ./jtd.py myschema.json mydoc1.json []
(myschema.json contient le schéma d'exemple
plus haut et mydoc1.json est le premier exemple
JSON.) Si, par contre, le fichier JSON est invalide :
% ./jtd.py myschema.json mydoc3.json [ValidationError(instance_path=['extra'], schema_path=[])]
(mydoc3.json était l'exemple avec le membre
supplémentaire, extra.)
Une particularité de JTD est de normaliser le mécanisme de
signalement d'erreurs. Les erreurs doivent être formatées en JSON
(évidemment…) avec un membre instancePath qui
est un pointeur JSON (RFC 6901) indiquant la partie invalide du document, et un
membre schemaPath, également un pointeur, qui
indique la partie du schéma qui invalidait cette partie du document
(cf. le message d'erreur ci-dessus, peu convivial mais
normalisé).
JTD est spécifié en CDDL donc on peut tester ses schémas avec les outils CDDL, ici un outil en Ruby :
% gem install cddl --user
Ensuite, on peut valider ses schémas :
% cddl jtd.cddl validate myschema.json %
Si le schéma a une erreur (ici, j'ai utilisé le type
char, qui n'existe pas) :
% cddl jtd.cddl validate wrongschema.json
CDDL validation failure (nil for {"properties"=>{"name"=>{"type"=>"char"}, "ok"=>{"type"=>"boolean", "nullable"=>true}, "level"=>{"type"=>"int32"}}}):
["char", [:text, "timestamp"], nil]
["char", [:text, "timestamp"], null]
(Oui, les messages d'erreur de l'outil cddl
sont horribles.)
Et avec l'exemple de l'annexe C, le reputon du RFC 7071 :
% cddl jtd.cddl validate reputon.json %
C'est parfait, le schéma du RFC est correct, validons le fichier JSON tiré de la section 6.4 du RFC 7071 :
% ./jtd.py reputon.json r1.json []
Si jamais il y a une erreur (ici, on a enlevé le membre
rating) :
% ./jtd.py reputon.json r1.json [ValidationError(instance_path=['reputons', '0'], schema_path=['properties', 'reputons', 'elements', 'properties', 'rating'])]
Une intéressante annexe B fait une comparaison de JTD avec CDDL. Par exemple, le schéma CDDL :
root = "PENDING" / "DONE" / "CANCELED"
accepterait les mêmes documents que le schéma JTD :
{ "enum": ["PENDING", "DONE", "CANCELED"]}
Et celui-ci, en CDDL (où le point d'interrogation indique un terme facultatif) :
root = { a: bool, b: number, ? c: tstr, ? d: tdate }
reviendrait à ce schéma JTD :
{
"properties": {
"a": {
"type": "boolean"
},
"b": {
"type": "float32"
}
},
"optionalProperties": {
"c": {
"type": "string"
},
"d": {
"type": "timestamp"
}
}
}
Merci à Ulysse Carion pour sa relecture.
L'article seul
Fiche de lecture : The weather machine
Auteur(s) du livre : Andrew Blum
Éditeur : Vintage
978-1-784-70098-0
Publié en 2019
Première rédaction de cet article le 6 novembre 2020
C'est vrai, ça, comment on prédit le temps ? On va sur le site Web de son choix qui présente la météo des jours suivants, on bien on a une application qui récupère ça et affiche dans un coin de votre écran soleil ou nuages. Mais, derrière, que se passe-t-il ? Andrew Blum a consacré un livre à la question de cette « machine du temps ». Comment fonctionne-t-elle ?
Bob Dylan chantait « vous n'avez pas besoin d'un météorologiste pour savoir dans quel sens le vent souffle ». Mais pour prévoir comment il va souffler dans deux, quatre ou six jours, là, vous avez besoin de météorologistes. Et d'observateurs, et d'ordinateurs et de théoriciens qui bossent sur les modèles. Andrew Blum, l'auteur de Tubes, où il explorait la matérialité de l'Internet, va cette fois se pencher sur la météo. Car c'est une machine complexe que celle qui sert à prédire le temps. Déjà, il faut des observations. Ensuite, il faut les transmettre assez vite pour qu'elles soient encore utiles. La météo n'a donc vraiment commencé qu'avec le télégraphe. Ensuite, il faut faire quelque chose de ces observations (faites d'abord à terre, puis, de nos jours, via des satellites), ensuite soit on a des experts qui regardent ces données et en déduisent le temps qu'il fera, soit, aujourd'hui, on a des ordinateurs qui calculent sur la base de modèles. Et il faut partager les observations, y compris entre pays qui ne s'aiment pas, car la météo ignore les frontières. Cela a nécessité quelques conférences internationales, et pas mal de réunions. (En parlant de géopolitique, j'ai appris dans ce livre que la météo avait été la raison de l'unique débarquement nazi en Amérique pendant la Seconde Guerre mondiale).
Comme dans Tubes, l'auteur va sur le terrain et nous raconte ses visites. (Mais le livre est plus mince que Tubes et je suis un peu resté sur ma faim.) On visite donc la station d'observaton d'Utsira, les bureaux d'EUMETSAT et l'ECMWF. Une bonne occasion de regarder tout ce qui se passe « derrière », tout ce qui fait qu'on sait à l'avance s'il fera beau ou pas.
L'article seul
RFC 8905: The 'payto' URI scheme for payments
Date de publication du RFC : Octobre 2020
Auteur(s) du RFC : F. Dold (Taler Systems SA), C. Grothoff (BFH)
Pour information
Première rédaction de cet article le 26 octobre 2020
Le paiement de services ou de biens est un problème crucial sur
l'Internet. En l'absence de mécanisme simple, léger et respectant la
vie privée, on n'a aujourd'hui que des solutions centralisées dans
des gros monstres, comme Amazon pour vendre
des objets physiques, ou YouTube pour
monétiser ses vidéos. Ce RFC ne propose pas de solution magique mais il
spécifie au moins une syntaxe pour indiquer un mécanisme de
paiement : le plan d'URI payto:, qui
permettra peut-être un jour de faciliter les paiements.
Le paysage d'aujourd'hui est le suivant. Si vous êtes un créateur (d'articles, de vidéos, de dessins, peu importe) et que vous voulez être payé pour vos créations (ce qui est tout à fait légitime), vous n'avez comme solutions que de faire appel à du financement participatif (style Liberapay ou Ulule) ou bien de passer par une grosse plate-forme comme YouTube, qui imposera ses règles, comme la captation de données personnelles. Sans compter le contrôle du contenu, qui fait qu'une vidéo parlant de sujets sensibles sera démonétisée. (Voyez par exemple cette vidéo de Charlie Danger où, à partir de 10:45 et surtout 11:45, elle explique comment YouTube n'a pas aimé sa vidéo sur l'IVG et ce qui en est résulté.) Mais cette solution d'hébergement sur un GAFA est sans doute la plus simple pour le créateur, et elle ne dépend pas de la bonne volonté des lecteurs/spectacteurs. Lorsqu'on discute avec un·e vidéaste de son hébergement chez Google et qu'on lui propose d'utiliser plutôt un service libre et décentralisé fait avec PeerTube, la réponse la plus fréquente est « mais je perdrais la monétisation, et je ne peux pas vivre seulement d'amour et d'eau fraîche ». Je l'ai dit, il n'existe pas encore de solution parfaite à ce problème. Pour un cas plus modeste, celui de ce blog, j'ai tenté Flattr et Bitcoin mais avec très peu de succès.
Ce nouveau RFC
ne propose pas une solution de paiement, juste un moyen de faire des
URI qu'on
pourra mettre dans ces pages Web pour pointer vers un mécanisme de
paiement. Par exemple, payto://bitcoin/1HtNJ6ZFUc9yu9u2qAwB4tGdGwPQasQGax?amount=BITCOIN:0.01&message="Ce%20blog%20est%20super"payto: (ce
qu'aucun ne fait à l'heure actuelle), que vous cliquez puis
confirmez, je recevrai 0,01 bitcoin. (Notez qu'il existe une syntaxe
spécifique à Bitcoin, pour un paiement, décrite dans le BIP 0021, et qui
ressemble beaucoup à celle du RFC.)
Un peu de technique maintenant : les plans d'URI
(scheme) sont définis dans le RFC 3986, section 3.1. Vous connaissez certainement des plans
comme http: ou mailto:. Le
plan payto: est désormais dans le
registre IANA des plans. Après le plan et les deux
barres se trouve l'autorité. Ici, elle
indique le type de paiement. Notre RFC en décrit certains (comme
bitcoin montré dans l'exemple) et on pourra en
enregistrer d'autres. L'idée est de pouvoir présenter à
l'utilisateur un mécanisme uniforme de paiement, quel que soit le
type de paiement. (À l'heure actuelle, si vous acceptez les
paiements par Flattr et
PayPal, vous devez mettre deux boutons
différents sur votre site Web, et qui déclencheront deux expériences
utilisateur très différentes. Sans compter les traqueurs qu'il y a
probablement derrière le bouton de Paypal.)
Question interface utilisateur, le RFC recommande que le navigateur permette ensuite à l'utilisateur de choisir le compte à utiliser, s'il en a plusieurs et, bien sûr, lui demande clairement une confirmation claire. Pas question qu'un simple clic déclenche le paiement ! (Cf. section 8 du RFC, qui pointe entre autres le risque de clickjacking.) Notez aussi que le RFC met en garde contre le fait d'envoyer trop d'informations (par exemple l'émetteur) dans le paiement, ce qui serait au détriment de la vie privée.
On peut ajouter des options à l'URI (section 5 du RFC). Par
exemple la quantité à verser (amount,
cf. l'exemple Bitcoin plus haut, le code de la monnaie, s'il a trois
lettres, devant être
conforme à ISO 4217, le
Bitcoin n'ayant pas de code officiel, j'ai utilisé un nom plus long),
receiver-name et
sender-name, message (pour
le destinataire) et
instruction, ce dernier servant à préciser le
traitement à faire par l'organisme de paiement.
Voici un autre exemple d'URI payto:, après
Bitcoin, IBAN (ISO
20022) : payto://iban/DE75512108001245126199?amount=EUR:200.0&message=helloiban,
l'option message correspond à ce que
SEPA appelle unstructured remittance
information et instruction au
end to end identifier.
Puisqu'il y a une option permettant d'envoyer un message, la section 6 du RFC note qu'il n'y a pas de vrai mécanisme d'internationalisation, entre autres parce qu'on ne peut pas garantir de manière générale comment ce sera traité par les établissements de paiement.
Outre Bitcoin et IBAN, déjà vus, notre RFC enregistre plusieurs
autres types de mécanismes de paiement. ACH, BIC/Swift et UPI appartiennent au
monde bancaire classique. Le type ilp vient,
lui, du monde Internet, comme Bitcoin, est pour les paiements via
InterLedger, s'appuyant sur les adresses
InterLedger. Et il y a aussi un type
void, qui indique que le paiement se fera en
dehors du Web, par exemple en liquide.
Cette liste n'est pas fermée, mais est stockée dans un registre évolutif, registre peuplé selon la politique « Premier arrivé, premier servi ». Vous noterez que ce registre n'est pas géré par l'IANA mais par GANA.
La section 7 indique les critères
d'enregistrement souhaitables d'un nouveau type (les enregistrements
existants peuvent servir d'exemple) : fournir des références
précises, trouver un nom descriptif, préférer un nom neutre à celui
d'un organisme particulier, etc. J'ai regardé ces critères pour le
cas de PayPal, mécanisme de paiement très
répandu sur l'Internet, mais ce n'était pas évident. Même si on
spécifie des URI du genre
payto://paypal/smith@example.com, il ne serait
pas évident pour le navigateur de les traduire en une requête PayPal
(PayPal privilégie l'installation de son propre bouton actif, ou
bien le système PayPal.me). Bref, je n'ai pas continué mais si
quelqu'un de plus courageux veut enregistrer le type
paypal, il n'est pas nécessaire d'être
représentant officiel de PayPal, et ce n'est pas trop
difficile. Idem pour d'autres systèmes de paiement par encore
spécifiés comme Liberapay. Notez que le
système conçu par les auteurs du RFC, Taler,
n'est pas encore enregistré non plus.
L'article seul
RFC 8932: Recommendations for DNS Privacy Service Operators
Date de publication du RFC : Octobre 2020
Auteur(s) du RFC : S. Dickinson (Sinodun IT), B. Overeinder (NLnet Labs), R. van Rijswijk-Deij (NLnet Labs), A. Mankin (Salesforce)
Réalisé dans le cadre du groupe de travail IETF dprive
Première rédaction de cet article le 25 octobre 2020
Vous gérez un résolveur DNS qui promet de protéger la vie privée des utilisateurs et utilisatrices ? Alors, vous serez certainement intéressé par ce nouveau RFC qui rassemble les bonnes pratiques en matière de gestion d'un tel résolveur, et explique comment documenter la politique du résolveur, les choix effectués. On y trouve une bonne analyse des questions de sécurité, une discussion de ce qui doit être dans une politique, une analyse comparée des politiques, et même un exemple de politique.
Depuis la publication du RFC 7626, les
risques pour la vie privée
posés par l'utilisation du DNS sont bien connus. Par exemple, un de ces
risques est que le trafic DNS entre une machine terminale et le
résolveur est en clair et peut
donc trivialement être écouté, ce qui est d'autant plus gênant que
ce trafic inclut toutes les informations (il n'y a pas de
minimisation possible de la question, par exemple). Un autre risque
est que le gérant du résolveur voit forcément tout le trafic, même
si on chiffre le trafic
entre la machine terminale et lui. Il peut abuser de cette confiance
qu'on lui fait. Une des solutions possibles face à ces risques est
d'utiliser, non pas le résolveur annoncé par le réseau d'accès à
l'Internet mais un résolveur extérieur, à qui vous faites confiance,
et avec qui vous communiquez de manière chiffrée. De tels résolveurs
existent. Certains sont publics (accessibles à tous), gérés par des
GAFA comme Cloudflare
(avec son résolveur 1.1.1.1) ou gérés par des
associations ou bien des individus (vous trouverez une liste
partielle à la fin
du README de ce logiciel). D'autres de ces résolveurs sont
réservés à tel ou tel groupe ou organisation.
Le problème pour l'utilisateur est celui du choix : lequel prendre ? Pour cela, il faut déjà que ceux et celles qui gèrent le résolveur aient documenté leurs pratiques et qu'on leur fasse confiance pour respecter leurs promesses. C'est l'un des buts de ce RFC : fournir un cadre général de description des pratiques d'un résolveur « vie privée », pour faciliter la tâche des rédacteurs et rédactrices de ces documents, dans l'esprit du RFC 6841, qui faisait la même chose pour DNSSEC. Notre RFC n'impose pas une politique particulière, il décrit juste les choix possibles, et ce qu'il ne faut pas oublier de mettre dans son RPS, son Recursive operator Privacy Statement.
Optimiste, notre RFC estime que des promesses formelles de strict préservation de la vie privée des utilisateurs seraient même un avantage pour les résolveurs ayant de tels engagements, leur apportant davantage d'utilisateurs. L'expérience du Web avec le succès des GAFA, entreprises capitalistes captatrices de données personnelles, même lorsqu'une alternative libre et respectueuse de la vie privée existe, me fait douter de ce pronostic.
Notez que la question du choix d'un résolveur est une question complexe. Le RFC cite par exemple le fait qu'avoir un résolveur stable, utilisé pour toutes les connexions d'une machine mobile, peut permettre à ce résolveur de vous suivre, lorsque vous changez de réseau d'accès.
La section 2 décrit le domaine d'applicabilité de ce document : il vise les gérants de résolveurs DNS, pas les utilisateurs finaux, ni les gérants de serveurs faisant autorité. Suivant les principes des RFC 6973 et RFC 7626, il va se pencher sur ce qui arrive aux données en transit sur l'Internet, aux données au repos sur un des serveurs (journaux, par exemple) et aux données transmises pour effectuer le travail (requêtes envoyées par un résolveur aux serveurs faisant autorité, lorsque la réponse n'est pas déjà dans la mémoire du résolveur).
La section 5 est le cœur de notre RFC, elle décrit les
recommandations concrètes. Pour illustrer ces recommandations, je
dirai à chaque fois comment elles ont été mises en œuvre sur le
résolveur sécurisé que je gère,
dot.bortzmeyer.fr &
https://doh.bortzmeyer.fr/. Non pas qu'il soit
le meilleur, le plus rapide, le plus sûr ou quoi que ce soit
d'autre. Mais parce qu'il met en œuvre les recommandations de ce
RFC, et que je sais qu'il respecte sa politique
affichée. Ces notes sur mon résolveur apparaitront entre
crochets.
D'abord, en transit, les communications faites en clair peuvent être écoutées par un surveillant passif et, pire, modifiées par un attaquant actif (section 5.1 du RFC). La première recommandation va de soi, il faut chiffrer. Un résolveur DNS public qui n'aurait pas de chiffrement (comme ceux actuellement proposés par certaines associations) n'a guère d'intérêt du point de vue de la vie privée. Pour ce chiffrement, deux techniques normalisées, DoT (DNS sur TLS, RFC 7858 et RFC 8310) et DoH (DNS sur HTTPS, RFC 8484). [Mon résolveur les déploie toutes les deux.] Il existe aussi un DNS sur DTLS (RFC 8094) mais qui n'a eu aucun succès, et des techniques non normalisées comme DNSCrypt, ou une forme ou l'autre de VPN vers le résolveur. Le RFC note que le chiffrement protège le canal, pas les données, et qu'il ne dispense donc pas de DNSSEC (cf. section 5.1.4). [Évidemment mon résolveur valide avec DNSSEC.] Un avantage des canaux sécurisés créés avec DoT ou DoH est qu'il y a beaucoup moins de risque que DNSSEC soit bloqué (cf. RFC 8027).
[Beaucoup de techniciens ont tendance à limiter la protection de la vie privée au chiffrement. C'est un exemple de fascination pour une technique complexe, au détriment d'autres mesures moins geek, qui sont présentées plus loin. Le chiffrement est nécessaire mais certainement pas suffisant.]
Chiffrer n'est pas très utile si on n'a pas authentifié celui avec qui on communique. Un attaquant actif peut toujours tenter de se faire passer pour le serveur qu'on essaie de joindre, par exemple par des attaques BGP ou tout simplement en injectant dans son réseau les routes nécessaires (comme le cas turc). Il faut donc authentifier le résolveur. DoT ne présentait guère de solutions satisfaisantes à l'origine, mais ça s'est amélioré avec le RFC 8310. Un résolveur DoT doit donc présenter un certificat qui permette son authentification ou bien publier sa clé publique (SPKI Subject Public Key Info, mais son utilisation est aujourd'hui déconseillée, car elle rend difficile le changement de clé). Le certificat peut contenir un nom ou une adresse IP. S'il contient un nom, il faut que le client connaisse ce nom, pour l'authentifier (un résolveur DNS traditionnel n'était connu que par son adresse IP). Ainsi, le certificat du résolveur Quad9 contient nom(s) et adresse(s) IP :
% openssl s_client -showcerts -connect 9.9.9.9:853 | openssl x509 -text
...
Subject: C = US, ST = California, L = Berkeley, O = Quad9, CN = *.quad9.net
...
X509v3 Subject Alternative Name:
DNS:*.quad9.net, DNS:quad9.net, IP Address:9.9.9.9, IP Address:9.9.9.10, IP Address:9.9.9.11, IP Address:9.9.9.12, IP Address:9.9.9.13, IP Address:9.9.9.14, IP Address:9.9.9.15, IP Address:149.112.112.9, IP Address:149.112.112.10, IP Address:149.112.112.11, IP Address:149.112.112.12, IP Address:149.112.112.13, IP Address:149.112.112.14, IP Address:149.112.112.15, IP Address:149.112.112.112, IP Address:2620:FE:0:0:0:0:0:9, IP Address:2620:FE:0:0:0:0:0:10, IP Address:2620:FE:0:0:0:0:0:11, IP Address:2620:FE:0:0:0:0:0:12, IP Address:2620:FE:0:0:0:0:0:13, IP Address:2620:FE:0:0:0:0:0:14, IP Address:2620:FE:0:0:0:0:0:15, IP Address:2620:FE:0:0:0:0:0:FE, IP Address:2620:FE:0:0:0:0:FE:9, IP Address:2620:FE:0:0:0:0:FE:10, IP Address:2620:FE:0:0:0:0:FE:11, IP Address:2620:FE:0:0:0:0:FE:12, IP Address:2620:FE:0:0:0:0:FE:13, IP Address:2620:FE:0:0:0:0:FE:14, IP Address:2620:FE:0:0:0:0:FE:15
...
[Mon résolveur, lui, utilise Let's Encrypt,
qui ne permet pas encore (cf. RFC 8738) de mettre
une adresse IP dans le certificat. Il n'y a donc que le nom. On peut
aussi l'authentifier avec sa clé publique (SPKI), qui vaut
eHAFsxc9HJW8QlJB6kDlR0tkTwD97X/TXYc1AzFkTFY=.]
Puisqu'on parle de certificats : le RFC note à juste
titre que les opérateurs de serveurs DNS ne sont pas forcément
experts en la matière, sauf à demander de l'aide à leurs collègues
HTTP qui
gèrent ces certificats depuis longtemps. Le RFC recommande donc
d'automatiser (par exemple avec ACME, cf. RFC 8555),
et de superviser les
certificats (c'est le B A BA, mais combien d'administrateurs
système ne le font toujours pas ?).
Le RFC a également des recommandations techniques sur les protocoles utilisés. En effet :
- TLS ne protège pas contre toutes les attaques (cf. RFC 7457),
- L'analyse de trafic reste notamment possible (cf. l'article de Haya Shulman « Pretty Bad Privacy: Pitfalls of DNS Encryption », et celui de Silby, S., Juarez, M., Vallina-Rodriguez, N., et C. Troncosol, « DNS Privacy not so private: the traffic analysis perspective »).
Il est donc conseillé de suivre les recommandations TLS du RFC 7525, de n'utiliser que des versions récentes
de TLS. Un rappel, d'ailleurs : les services comme SSLabs.com peuvent
parfaitement tester votre résolveur DoH. [J'ai une bonne note.]
Il est également conseillé de faire du remplissage (RFC 7830 et RFC 8467 ou bien, pour DoH, avec le remplissage HTTP/2), et de ne pas imposer des fonctions qui sont dangereuses pour la vie privée comme la reprise de session TLS (RFC 5077), ou comme les cookies (DNS, RFC 7873 ou HTTP, RFC 6265). [Le logiciel que j'utilise pour mon résolveur, dnsdist, semble faire du remplissage DNS, mais je n'ai pas testé.]
Question non plus de sécurité mais de performance, le RFC recommande de gérer les requêtes en parallèle, y compris de pouvoir donner des réponses dans le désordre (RFC 7766) et de maintenir les sessions TLS ouvertes (RFC 7766 et RFC 7828, voire RFC 8490). [Le logiciel utilisé sur mon résolveur, dnsdist, ne sait pas encore générer des réponses dans un ordre différent de celui d'arrivée.]
Le résolveur DNS est un composant crucial de l'utilisation de l'Internet. S'il est en panne, c'est comme si tout l'Internet est en panne. La disponibilité du résolveur est donc une question cruciale. Si les pannes sont trop fréquentes, les utilisateurs risquent de se rabattre sur des solutions qui ne respectent pas leur vie privée, voire sur des solutions non sécurisées. Le risque est d'autant plus élevé qu'il y a des attaques par déni de service visant les résolveurs DNS (cf. cet article de l'AFNIC). Le RFC recommande donc de tout faire pour assurer cette disponibilité. [Mon propre résolveur, étant un projet personnel, et installé sur un VPS ordinaire, n'est certainement pas bien placé de ce point de vue.]
Bien sûr, il faut fournir aux utilisateurs des services qui protègent la vie privée les mêmes options qu'aux autres visiteurs : résolveur non menteur, validation DNSSEC, etc. (Il existe des services où les choix sont exclusifs et où, par exemple, choisir un résolveur non menteur prive de DNSSEC.)
La protection de la vie privée ne plait pas à tout le monde. Les partisans de la surveillance ont défendu leur point de vue dans le RFC 8404 en réclamant de la visibilité sur le trafic, justement ce que le chiffrement veut empêcher. Ce RFC 8932 essaie de ménager la chèvre et le chou en signalant aux opérateurs de résolveurs chiffrants qu'ils ont toujours accès au trafic en clair, en prenant les données après leur déchiffrement, sur le résolveur. C'est ce que permet, par exemple, la technologie dnstap. Après tout, TLS ne protège qu'en transit, une fois arrivé sur le résolveur, les données sont en clair. [Mon résolveur ne copie pas le trafic en clair, qui n'est jamais examiné. Le logiciel utilisé est capable de faire du dnstap, mais a été compilé sans cette option.] Notez que ce RFC 8932 reprend hélas sans nuances les affirmations du RFC 8404 comme quoi il est légitime d'avoir accès aux données de trafic.
Une technique courante pour mettre en œuvre un résolveur avec TLS est de prendre un résolveur ordinaire, comme BIND, et de le placer derrière un relais qui terminera la session TLS avant de faire suivre au vrai résolveur, typiquement situé sur la même machine pour des raisons de sécurité. Des logiciels comme stunnel, haproxy ou nginx permettent de faire cela facilement, et fournissent des fonctions utiles, par exemple de limitation du trafic. Mais cela ne va pas sans limites. Notamment, avec cette méthode, le vrai résolveur ne voit pas l'adresse IP du client, mais celle du relais. Cela interdit d'utiliser des solutions de sécurité comme les ACL ou comme RRL (Response Rate Limiting). [Mon résolveur utilise un relais, mais avec un logiciel spécialisé dans le DNS, dnsdist. dnsdist peut résoudre le problème de la mauvaise adresse IP en utilisant le PROXY protocol mais je n'utilise pas cette possibilité.]
Nous avons vu jusqu'à présent le cas des données en transit, entre le client et le résolveur DNS. La réponse principale aux problèmes de vie privée était le chiffrement. Passons maintenant au cas des données « au repos », stockées sur le résolveur, par exemple dans des journaux, ou dans des pcap (ou équivalent) qui contiennent le trafic enregistré (section 5.2). Évidemment, pour qu'un service puisse se prétendre « protecteur de la vie privée », il faut qu'une telle rétention de données soit très limitée, notamment dans le temps (c'est un des principes du RGPD, par exemple). Si on garde de telles données pour des raisons légitimes (statistiques, par exemple), il est recommandé de les agréger afin de fournir un peu d'anonymisation. (La lecture recommandée sur ce point est le RFC 6973.) Pour des problèmes à court terme (analyser et comprendre une attaque par déni de service en cours, par exemple), le mieux est de ne pas stocker les données sur un support pérenne, mais de les garder uniquement en mémoire. [Mon résolveur n'enregistre rien sur disque. Des statistiques fortement agrégées sont possibles mais, à l'heure actuelle, ce n'est pas fait.]
Si le chiffrement est le principal outil technique dont on dispose pour protéger les données lorsqu'elles se déplacent d'une machine à l'autre, il est moins utile lorsque des données sont enregistrées sur le serveur. Ici, l'outil technique essentiel est la minimisation des données. C'est le deuxième pilier d'une vraie protection de la vie privée, avec le chiffrement, mais elle est très souvent oubliée, bien que des textes juridiques comme le RGPD insistent sur son importance. Mais attention, minimiser des données n'est pas facile. On a fait de gros progrès ces dernières années en matière de ré-identification de personnes à partir de données qui semblaient minimisées. Comme le note le RFC, il n'y a pas de solution générale, largement acceptée, qui permette de minimiser les données tout en gardant leur utilité. C'est pour cela que quand un décideur sérieux et sûr de lui affirme bien fort « Ne vous inquiétez pas de cette base de données, tout est anonymisé », vous pouvez être raisonnablement sûr qu'il est soit malhonnête, soit incompétent ; réellement anonymiser est très difficile.
Cela fait pourtant quinze ou vingt ans qu'il y a des recherches actives en « anonymisation », motivées entre autre par la volonté de partager des données à des fins de recherches scientifiques. Mais le problème résiste. Et les discussions sont difficiles, car les discoureurs utilisent souvent une terminologie floue, voire incorrecte (par mauvaise foi, ou par ignorance). Notre RFC rappelle donc des points de terminologie (déjà abordés dans le RFC 6973) :
- Anonymiser, c'est faire en sorte qu'on ne puisse plus distinguer un individu d'un autre individu. C'est une propriété très forte, difficile à atteindre, puisqu'il s'agit de supprimer toute traçabilité entre différentes actions. En général, il faut supprimer ou tronquer une bonne partie des données pour y arriver.
- Pseudonymiser, c'est remplacer un identificateur par un autre. (Le RFC parle de remplacer la « vraie » identité par une autre mais il n'existe pas d'identité qui soit plus vraie qu'une autre.) Ainsi, remplacer une adresse IP par son condensat SHA-256 est une pseudonymisation. Avec beaucoup de schémas de pseudonymisation, remonter à l'identité précédente est possible. Ici, par exemple, retrouver l'adresse IP originale est assez facile (en tout cas en IPv4).
Quand un politicien ou un autre Monsieur Sérieux parle d'anonymisation, il confond presque toujours avec la simple pseudonymisation. Mais la distinction entre les deux n'est pas toujours binaire.
Dans les données d'un résolveur DNS, l'une des principales
sources d'information sur l'identité de l'utilisateur est l'adresse
IP source (cf. RFC 7626, section 2.2). De
telles adresses sont
clairement des données personnelles et il serait donc
intéressant de les « anonymiser ». De nombreuses techniques, de
qualité très variable, existent pour cela, et le RFC les présente
dans son annexe B, que je décris à la fin de cet article. Aucune de
ces techniques ne s'impose comme solution idéale marchant dans tous
les cas. (À part, évidemment, supprimer complètement l'adresse IP.)
Notez qu'il existe d'autres sources d'information sur le client que
son adresse IP, comme la question posée (s'il demande
security.debian.org, c'est une machine
Debian) ou comme le
fingerprinting des caractéristiques techniques de
sa session. Le problème est évidemment pire avec DoH, en raison des
innombrables en-têtes HTTP très révélateurs que les navigateurs
s'obstinent à envoyer (User-Agent:, par
exemple). Dans certains cas, on voit même des équipements comme la
box ajouter
des informations précises sur le client.
Ces données stockées sur le résolveur peuvent parfois rester uniquement dans l'organisation qui gère le résolveur, mais elles sont parfois partagées avec d'autres. (Méfiez-vous des petites lettres : quand on vous promet que « nous ne vendrons jamais vos données », cela ne veut pas dire qu'elles ne seront pas partagées, juste que le partageur ne recevra pas directement d'argent pour ce partage.) Le partage peut être utile pour la science (envoi des données à des chercheurs qui feront ensuite d'intéressants articles sur le DNS), mais il est dangereux pour la vie privée. Comme exemple d'organisation qui partage avec les universités, voir SURFnet et leur politique de partage. [Mon résolveur ne partage avec personne.]
Après les données qui circulent entre le client et le résolveur, puis le cas des données stockées sur le résolveur, voyons le cas des données envoyées par le résolveur, pour obtenir la réponse à ses questions (section 5.3 du RFC). Bien sûr, cela serait très bien si le résolveur chiffrait ses communications avec les serveurs faisant autorité, mais il n'existe actuellement pas de norme pour cela (des propositions ont été faites, et des tests menés, mais sans résultat pour l'instant).
Et, de toute façon, cela ne protègerait que contre un tiers, pas
contre les serveurs faisant autorité qui enregistrent les questions
posées. Face à ce risque, la principale recommandation du RFC
est d'utiliser la QNAME minimisation (RFC 9156) pour réduire ces données, en application
du principe général « ne pas envoyer plus que ce qui est
nécessaire ». [Mon résolveur DoT/DoH fait appel à un résolveur qui fait
cela.] Seconde recommandation, respecter les consignes ECS
(RFC 7871) : si le client demande à ce que les
données ECS soient réduites ou supprimées, il faut lui
obéir. [Mon résolveur débraye ECS avec la directive dnsdist
useClientSubnet=false.] (Notez
que, par défaut, cela permet toujours au résolveur de transmettre
aux serveurs faisant autorité l'adresse de son client…)
Deux autres façons, pour le résolveur, de limiter les données qu'il envoie aux serveurs faisant autorité :
- Générer des réponses à partir de sa mémoire (RFC 8020 et RFC 8198),
- avoir une copie locale de la racine, privant les serveurs racine d'informations (RFC 8806).
[Sur mon résolveur DoH/DoT, le vrai résolveur qui tourne derrière,
un Unbound, a les options
harden-below-nxdomain et
aggressive-nsec, qui mettent à peu près en
œuvre les RFC 8020 et RFC 8198.] On peut aussi imaginer un résolveur qui envoie des
requêtes bidon, pour brouiller les informations connues du serveur
faisant autorité, ou, moins méchamment, qui demande en avance (avant
l'expiration du TTL) des données
qui sont dans sa mémoire, sans attendre une requête explicite d'un
de ses clients, pour casser la corrélation entre un client et une
requête. Pour l'instant, il n'existe pas de recommandations
consensuelles sur ces techniques. Enfin, un résolveur peut aussi
faire suivre toutes ses requêtes à un résolveur plus gros
(forwarder), au-dessus d'un lien sécurisé. Cela a
l'avantage que le gros résolveur, ayant une mémoire plus importante,
enverra moins de données aux serveurs faisant autorité, et que sa
base de clients plus large rendra plus difficile la
corrélation. Évidemment, dans ce cas, le danger peut venir du gros
résolveur à qui on fait tout suivre, et le choix final n'est donc
pas évident du tout. [Mon résolveur ne fait pas suivre à un gros
résolveur public, aucun ne me semblant satisfaisant. Comme il a peu
de clients, cela veut dire que les données envoyées aux serveurs
faisant autorité peuvent être un problème, question vie privée.]
Une fois que cette section 5 du RFC a exposé tous les risques et
les solutions possibles, la section 6 parle de la RPS,
Recursive operator Privacy Statement, la
déclaration officielle des gérants d'un résolveur à ses clients,
exposant ce qu'ils ou elles font, et ce qu'elles ou ils ne font pas
avec les données. (Au début du développement de ce RFC, la RPS se
nommait DROP - DNS Recursive Operator Privacy
statement, ce qui était plus drôle.) Notre RFC recommande
très fortement que les opérateurs d'un résolveur DNS publient une
RPS, l'exposition de leur politique. Le but étant de permettre aux
utilisateurs humains de choisir en toute connaissance de cause un
résolveur ayant une politique qu'ils acceptent. Évidemment, il y a
des limites à cette idée. D'abord, les utilisateurs ne lisent pas
forcément les conditions d'utilisation / codes de conduite et autres
textes longs et incompréhensibles. (Le RFC propose des
recommandations sur la rédaction des RPS, justement pour diminuer ce
problème, en facilitant les comparaisons.) [Mon résolveur a une RPS
publique, accessible en https://doh.bortzmeyer.fr/policy
Le RFC propose un plan pour la RPS. Rien n'est évidemment obligatoire dans ce plan, mais c'est une utile liste pour vérifier qu'on n'a rien oublié. Le but est de faire une RPS utilisable, et lisible, et le plan ne couvre pas donc d'éventuelles questions financières (si le service est payant), et ne prétend pas être un document juridique rigoureux, puisqu'elle doit pouvoir être lue et comprise.
Parmi les points à considérer quand on écrit une RPS :
- Le statut des adresses IP : bien préciser qu'elles sont des données personnelles,
- le devenir des données : collectées ou non, si elles sont collectées, partagées ou non, gardées combien de temps,
- si les données sont « anonymisées », une description détaillée du processus d'anonymisation (on a vu que la seule proclamation « les données sont anonymisées », sans détail, était un signal d'alarme, indiquant que l'opérateur se moque de vous),
- les exceptions, car toute règle doit permettre des exceptions, par exemple face à une attaque en cours, qui peut nécessiter de scruter avec tcpdump, même si on se l'interdit normalement,
- les détails sur l'organisation qui gère le résolveur, ses partenaires et ses sources de financement,
- et l'éventuel filtrage des résultats (« DNS menteur ») : a-t-il lieu, motifs de filtrage (noms utilisés pour la distribution de logiciel malveillant, par exemple), loi applicable (« nous sommes enregistrés en France donc nous sommes obligés de suivre les lois françaises »), mécanismes de décision internes (« nous utilisons les sources X et Y de noms à bloquer »)…
L'opérateur du résolveur qui veut bien faire doit également communiquer à ses utilisateurs :
- Les écarts par rapport à la politique affichée, s'il a fallu en urgence dévier des principes,
- les détails techniques de la connexion (est-ce qu'on accepte seulement DoH, seulement DoT, ou les deux, par exemple), et des services (est-ce qu'on valide avec DNSSEC ?),
- les détails de l'authentification du résolveur : nom à valider, clé publique le cas échéant.
Un autre problème avec ces RPS est évidemment le risque de
mensonge. « Votre vie privée est importante », « Nous nous engageons
à ne jamais transmettre vos données à qui que ce soit », il serait
très naïf de prendre ces déclarations pour argent comptant. Le RFC
est réaliste et sa section 6.2 du RFC parle des mécanismes qui
peuvent permettre, dans le cas idéal, d'augmenter légèrement les
chances que la politique affichée soit respectée. Par exemple, on
peut produire des transparency reports où on
documente ce qu'on a été forcés de faire (« en raison d'une
injonction judiciaire, j'ai dû ajouter une règle pour bloquer
machin.example »). Des vérifications techniques
peuvent être faites de l'extérieur, comme
l'uptime, le remplissage
ou la minimisation des requêtes. De tels outils existent pour la
qualité TLS des serveurs, comme SSLlabs.com, déjà
cité, ou Internet.nl. [Opinion
personnelle : beaucoup de tests d'Internet.nl ne sont pas pertinents
pour DoH.] Plus fort, on peut recourir à des audits externes, qui augmentent normalement
la confiance qu'on accorde à la RPS, puisqu'un auditeur indépendant
aura vérifié sa mise en œuvre. [Mon avis est que c'est d'une
fiabilité limitée, puisque l'auditeur est choisi et payé par
l'organisation qui se fait auditer… Et puis, même si vous êtes
root sur les machines de l'organisation
auditée, ce qui n'arrive jamais, s'assurer que, par exemple, les
données sont bien détruites au bout du temps prescrit est
non-trivial.] Cloudflare est ainsi audité
(par KPMG) et vous pouvez lire le
premier rapport (très court et sans aucun détail sur le
processus de vérification).
L'annexe A du RFC liste les documents, notamment les RFC, qui sont pertinents pour les opérateurs de résolveurs promettant le respect de la vie privée. On y trouve les normes techniques sur les solutions améliorant la protection de l'intimité, mais aussi celles décrivant les solutions qui peuvent diminuer la vie privée, comme ECS (RFC 7871), les cookies DNS (RFC 7873), la reprise de sessions TLS (RFC 5077, un format pour stocker des données sur le trafic DNS (RFC 8618, mais il y a aussi le traditionnel pcap), le passive DNS (RFC 8499), etc.
L'annexe C du RFC cite une intéressante comparaison, faite en 2019, de diverses RPS (Recursive operator Privacy Statement, les politiques des gérants de résolveurs). Comme ces RPS sont très différentes par la forme, une comparaison est difficile. Certaines font plusieurs pages, ce qui les rend longues à analyser. Aujourd'hui, en l'absence de cadres et d'outils pour éplucher ces RPS, une comparaison sérieuse par les utilisateurs n'est pas réaliste. Quelques exemples réels : la RPS de mon résolveur (la seule en français), celle de PowerDNS, celle de Quad9, celle de Cloudflare… Mozilla a développé, pour son programme TRR (Trusted Recursive Resolve), une liste de critères que les résolveurs qui veulent rejoindre le programme doivent respecter. Une sorte de méta-RPS. [Apparemment, le seul truc qui me manque est le transparency report annuel.]
L'annexe D du RFC contient un exemple de RPS. Elle ne prétend pas être parfaite, et il ne faudrait surtout pas la copier/coller directement dans une vraie RPS mais elle peut servir de source d'inspiration. Notez également qu'elle est écrite en anglais, ce qui ne conviendra pas forcément à un service non-étatsunien. Parmi les points que j'ai notés dans cette RPS (rappelez-vous qu'il s'agit juste d'un exemple et vous n'avez pas à l'utiliser telle quelle) :
- L'engagement à ne pas conserver les données en mémoire stable utilise un terme technique (does not have data logged to disk) pour parler d'un type de support stable particulier, ce qui peut encourager des trucs comme d'enregistrer sur un support stable qui ne soit pas un disque.
- Cette déclaration liste la totalité des champs de la requête DNS qui sont enregistrés. L'adresse IP n'y est pas (remplacée par des données plus générales comme le préfixe annoncé dans BGP au moment de l'analyse).
- La RPS s'engage à ne pas partager ces données. Mais des extraits ou des agrégations des données peuvent l'être.
- Des exceptions sont prévues, permettant aux administrateurs de regarder les données de plus près en cas de suspicion de comportement malveillant.
- Le résolveur est un résolveur menteur, bloquant la résolution des noms utilisés pour des activités malveillantes (C&C d'un botnet, par exemple). Hypocritement, la RPS d'exemple affirme ensuite ne pas faire de censure.
- La RPS promet que l'ECS ne sera pas envoyé aux serveurs faisant autorité.
On a dit plus haut que l'« anonymisation » d'adresses IP était un art très difficile. L'annexe B de notre RFC fait le point sur les techniques existantes, leurs avantages et inconvénients. C'est une lecture très recommandée pour ceux et celles qui veulent réellement « anonymiser », pas juste en parler. Un tableau résume ces techniques, leurs forces et leurs faiblesses. Le problème est de dégrader les données suffisamment pour qu'on ne puisse plus identifier l'utilisateur, tout en gardant assez d'informations pour réaliser des analyses. À bien des égards, c'est la quadrature du cercle.
Pour mettre de l'ordre dans les techniques d'« anonymisation », le RFC commence par lister les propriétés possibles des techniques (cf. RFC 6235). Il y a entre autres :
- Maintien du format : la donnée « anonymisée » a la même
syntaxe que la donnée originale. Ainsi, ne garder que les 64
premiers bits d'une adresse IP et mettre les autres à zéro
préserve le format
(
2001:db8:1:cafe:fafa:42:1:b53devient2001:db8:1:cafe::, qui est toujours une adresse IP). Par contre, condenser ne garde pas le format (le condensat SHA-256 de cette adresse deviendrait98a09452f58ffeba29e7ca06978b3d65e104308a7a7f48b0399d6e33c391f663). - Maintien du préfixe : l'adresse « anonymisée » garde un préfixe (qui n'est pas forcément le préfixe original, mais qui est cohérent pour toutes les adresses partageant ce préfixe). Cela peut être utile pour les adresses IP mais aussi pour les adresses MAC, où le préfixe identifie le fabricant.
Pour atteindre nos objectifs, on a beaucoup de solutions (pas forcément incompatibles) :
- Généralisation : sans doute l'une des méthodes les plus efficaces, car elle réduit réellement la quantité d'information disponible. C'est réduire la précision d'une estampille temporelle (par exemple ne garder que l'heure et oublier minutes et secondes), approximer une position (en ne gardant qu'un carré de N kilomètres de côté), remplacer tous les ports TCP et UDP par un booléen indiquant simplement s'ils sont supérieurs ou inférieurs à 1 024, etc.
- Permutation : remplacer chaque identificateur par un autre, par exemple via un condensat cryptographique.
- Filtrage : supprimer une partie des données, par exemple, dans une requête DNS, ne garder que le nom demandé.
- Et bien d'autres encore.
L'annexe B rentre ensuite dans les détails en examinant plusieurs techniques documentées (rappelez-vous que les responsables des données sont souvent très vagues, se contentant d'agiter les mains en disant « c'est anonymisé avec des techniques très avancées »). Par exemple, Google Analytics permet aux webmestres de demander à généraliser les adresses IP en mettant à zéro une partie des bits. Comme le note le RFC, cette méthode est très contestable, car elle garde bien trop de bits (24 en IPv4 et 48 en IPv6).
Plusieurs des techniques listées ont une mise en œuvre dans du logiciel publiquement accessible, mais je n'ai pas toujours réussi à tester. Pour dnswasher, il faut apparemment compiler tout PowerDNS. Une fois que c'est fait, dnswasher nous dit ce qu'il sait faire :
% ./dnswasher -h Syntax: dnswasher INFILE1 [INFILE2..] OUTFILE Allowed options: -h [ --help ] produce help message --version show version number -k [ --key ] arg base64 encoded 128 bit key for ipcipher -p [ --passphrase ] arg passphrase for ipcipher (will be used to derive key) -d [ --decrypt ] decrypt IP addresses with ipcipher
dnswasher remplace chaque adresse IP dans un fichier pcap par une autre adresse, attribuée dans l'ordre. C'est de la pseudonymisation (chaque adresse correspond à un pseudonyme et un seul), le trafic d'une adresse suffit en général à l'identifier, par ses centres d'intérêt. Traitons un pcap de requêtes DNS avec ce logiciel :
% ./dnswasher ~/tmp/dns.pcap ~/tmp/anon.pcap Saw 18 correct packets, 1 runts, 0 oversize, 0 unknown encaps % tcpdump -n -r ~/tmp/anon.pcap 15:28:49.674322 IP 1.0.0.0.41041 > 213.251.128.136.53: 51257 [1au] SOA? toto.fr. (36)
L'adresse 1.0.0.0 n'est pas la vraie, c'est le
résultat du remplacement fait par dnswasher. En revanche,
213.251.128.136 est la vraie adresse. dnswasher
ne remplace pas les adresses quand le port
est 53, considérant que les serveurs n'ont pas de vie privée,
contrairement aux clients.
Dans l'exemple ci-dessus, on n'avait pas utilisé de clé de
chiffrement, et dnswasher remplace les adresses IP avec
1.0.0.0, 1.0.0.1, etc. En
rajoutant l'option -p toto où toto est notre clé
(simpliste) :
15:28:49.674322 IP 248.71.56.220.41041 > 213.251.128.136.53: 51257 [1au] SOA? toto.fr. (36)
L'adresse est remplacée par une adresse imprévisible, ici
248.71.56.220. Cela
marche aussi en IPv6 :
15:28:49.672925 IP6 b4a:7e80:52fe:4003:6116:fcb8:4e5a:b334.52346 > 2001:41d0:209::1.53: 37568 [1au] SOA? toto.fr. (36)
(Une adresse comme
b4a:7e80:52fe:4003:6116:fcb8:4e5a:b334.52346 ne
figure pas encore dans les plages d'adresses attribuées.)
TCPdpriv, lui, préserve le préfixe des adresses IP. À noter qu'il n'est pas déterministe : les valeurs de remplacement seront différentes à chaque exécution.
On peut aussi chiffrer l'adresse IP, en utilisant une clé qu'on garde secrète. Cela a l'avantage qu'un attaquant ne peut pas simplement faire tourner l'algorithme sur toutes les adresses IP possibles, comme il le peut si on utilise une simple condensation. C'est ce que fait Crypto-PAn.
Comme chaque logiciel a sa propre façon de remplacer les adresses IP, cela peut rendre difficile l'échange de données et le travail en commun. D'où le projet ipcipher. Ce n'est pas du code, mais une spécification (avec des pointeurs vers des logiciels qui mettent en œuvre cette spécification). Au passage, je vous recommande cet article à ce sujet. La spécification ipcipher peut être mise en œuvre, par exemple, avec le programme ipcrypt, qui traite des fichiers texte au format CSV :
% cat test2.csv foo,127.0.0.1 bar,9.9.9.9 baz,204.62.14.153 sha,9.9.9.9 % ./ipcrypt test2.csv 1 e foo,118.234.188.6 bar,142.118.72.81 baz,235.237.54.9 sha,142.118.72.81
Notez le déterminisme : 9.9.9.9 est toujours
remplacé par la même adresse IP.
Enfin, des structures de données rigolotes peuvent fournir d'autres services. C'est ainsi que les filtres de Bloom peuvent permettre de savoir si une requête a été faite, mais sans pouvoir trouver la liste des requêtes. Un exemple d'application aux données DNS est l'article « Privacy-Conscious Threat Intelligence Using DNSBLOOM ».
L'article seul
RFC 8884: Research Directions for Using Information-Centric Networking (ICN) in Disaster Scenarios
Date de publication du RFC : Octobre 2020
Auteur(s) du RFC : J. Seedorf (HFT Stuttgart - Univ. of Applied Sciences), M. Arumaithurai (University of Goettingen), A. Tagami (KDDI Research), K. Ramakrishnan (University of California), N. Blefari Melazzi (University Tor Vergata)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF icnrg
Première rédaction de cet article le 24 octobre 2020
Si vous aimez les films catastrophe, voici un RFC pour vous ; il explore l'utilisation de l'ICN lors de grands désastres. N'espérez pas trouver de solutions, c'est un travail purement théorique. (Comme beaucoup de choses qui touchent à l'ICN.)
L'ICN (Information Centric Networking) ? C'est quoi ? Il s'agit d'une approche des réseaux informatiques où tout est vu comme du contenu, auquel les clients veulent accéder. Les routeurs ICN vont donc se charger de récupérer l'information, sans se soucier d'où elle vient. L'ICN est décrit dans des documents comme le RFC 7476 et le RFC 7927.
Parmi tous les RFC, il n'y a pas que l'ICN qui peut apporter des idées neuves en matière de robustesse lors de grandes catastrophes. Le DTN (RFC 9171), réseau acceptant les déconnexions fréquentes, est également une bonne approche. En effet, en cas de désastre, il est sûr que le réseau sera affecté, et le concept « stocke et réessaie » de DTN est donc un outil utile. Mais ICN offre des possibilités supplémentaires. D'ailleurs, le RFC 7476 (section 2.7.2) citait déjà cette possibilité d'utiliser l'ICN en cas de catastrophe. L'idée est que la couche réseau peut aider à partiellement contourner les problèmes post-catastrophe. Les applications ont leur rôle à jouer également, bien sûr, mais ce n'est pas l'objet de ce RFC.
La section 2 du RFC liste des cas d'usage. Comme déjà le RFC 7476, on commence par le tremblement de terre de Tohoku, qui avait détruit une partie importante de l'infrastructure, notamment en ce qui concerne la fourniture d'électricité. Or, après une telle catastrophe, il y a une grosse demande de communication. Les autorités veulent envoyer des messages (par exemple par diffusion sur les réseaux de téléphonie mobile), transmettre des informations, distribuer des consignes. Les habitants veulent donner des nouvelles à leurs proches, ou bien en recevoir. Les victimes veulent savoir où se trouvent les secours, les points de ravitaillement, etc.
Les gens de l'ICN étant toujours à la recherche de subventions, ils citent fréquemment les thèmes à la mode, qui promettent l'attention des pouvoirs publics. C'est ainsi que la liste des cas d'usage inclus évidemment le terrorisme (pourquoi pas la cyberguerre, tant qu'on y est ?). Dans ce cas, des difficultés supplémentaires surviennent : les attaquants peuvent effectuer des attaques par déni de service pour empêcher l'utilisation du réseau, si l'attaque elle-même ne l'a pas arrêté, ils peuvent surveiller l'utilisation du réseau pour, par exemple, découvrir des cibles intéressantes pour une nouvelle attaque, ils peuvent envoyer des messages mensongers pour créer une panique, etc. Le problème est donc plus difficile que celui d'une catastrophe naturelle.
Aujourd'hui, les réseaux existants ne permettent pas forcément de traiter les cas de catastrophes, même « simplement » naturelles. La section 3 du RFC liste les principaux défis qu'il faudrait traiter pour cela :
- On s'attend à ce que le réseau soit fragmenté par la catastrophe. Certains composants seront alors inaccessibles. Pensez à l'accès aux serveurs DNS racine si on est dans un îlot où il n'existe aucune instance de ces serveurs. Tous les systèmes centralisés seront inutilisables si on est du mauvais côté de la coupure. Par exemple, les systèmes de téléphonie mobile existants dépendent souvent de composants centraux comme le HLR. Un réseau utilisable pendant les catastrophes doit donc pouvoir fonctionner même en cas de fragmentation.
- Un service qui est très souvent centralisé est celui de l'authentification. Même quand le système peut marcher en pair-à-pair, la possibilité de l'utiliser dépend souvent d'une authentification centrale. Même quand il y a décentralisation, comme avec une PKI, il peut être nécessaire de passer d'abord par une ou plusieurs racines, qui peuvent être injoignables pendant la catastrophe. Créer un système d'authentification décentralisé est un sacré défi. Le RFC note que la chaîne de blocs n'est pas une solution, puisque celle-ci ne fonctionne plus s'il y a fragmentation (ou, plus exactement, chaque groupe de participants risque de voir sa portion de la chaîne invalidée lorsque le réseau sera à nouveau complètement connecté).
- En cas de catastrophe, il sera peut-être nécessaire de donner une priorité à certains messages, ceux liés à la coordination des secours, par exemple. C'est d'autant plus important à réaliser que la capacité du réseau sera réduite et que les arbitrages seront donc difficiles.
- Dans un réseau sérieusement endommagé, où la connectivité risque fort d'être intermittente, il ne sera pas toujours possible d'établir une liaison de bout en bout. Il faudra, beaucoup plus qu'avec l'Internet actuel, compter sur le relayage de machine en machine, avec stockage temporaire lorsque la machine suivante n'est pas joignable. C'est justement là où DTN est utile.
- Enfin, dans la situation difficile où se trouveront tous les participants, l'énergie sera un gros problème ; peu ou pas de courant électrique, pas assez de fuel pour les groupes électrogènes, et des batteries qui se vident vite (comme dans le film Tunnel, où le héros doit surveiller en permanence la batterie de son ordiphone, et économiser chaque joule).
Bon, ça, ce sont les problèmes. Maintenant, en quoi est-ce que l'ICN peut aider ? Plusieurs arguments sont avancés par le RFC (dont certains, à mon avis, plus faibles que d'autres) :
- L'ICN, c'est une de ses principales caractéristiques, route en fonction du nom du contenu convoité, pas en fonction d'une adresse IP. Cela peut permettre, dit le RFC, de survivre lorsque le réseau est coupé. (L'argument me semble douteux : il suppose qu'en cas de fragmentation, le contenu sera présent des deux côtés de la coupure. Mais on peut en dire autant des adresses IP. Contrairement à ce que racontent toujours les promoteurs de l'ICN, il y a bien longtemps que les adresses IP n'ont plus de rapport avec un lieu physique). C'est d'autant plus vrai si le système de résolution des noms est complètement décentralisé. (Là encore, ICN et système classique sont à égalité : l'un et l'autre peuvent utiliser un système centralisé, un système décentralisé, ou un système pair-à-pair pour la résolution de noms).
- Un point fort de l'ICN est que l'authentification et l'intégrité ne sont pas assurés par la confiance dans le serveur d'où on a obtenu le contenu, mais par une certification portée par l'objet (typiquement une signature). Certains mécanismes de nommage mettent même l'intégrité dans le nom (cf. RFC 6920). Cela permet de récupérer du contenu n'importe où, ce qui est utile si le serveur d'origine est injoignable mais que des copies circulent. On peut ainsi vérifier l'authenticité de ces copies.
- ICN utilise beaucoup les caches, les mémoires dans lesquelles sont stockées les objets. Avec l'ICN, chaque routeur peut être un cache. Là aussi, cela peut aider beaucoup si le serveur d'origine n'est plus joignable.
- Et ICN est bien adapté aux techniques à base de DTN (cf. par exemple RFC 9171), où il n'y a pas besoin de connectivité permanente : on transmet simplement le contenu en mode « stocke et fais suivre ».
En parlant de DTN, notons que DTN seul manque de certaines fonctions que pourrait fournir l'ICN. C'est le cas par exemple du publish/subscribe. Dans certains cas, ces fonctions pourraient être ajoutées au DTN, comme présenté dans « Efficient publish/ subscribe-based multicast for opportunistic networking with self-organized resource utilization » (par Greifenberg, J. et D. Kutscher) ou bien « A Socio-Aware Overlay for Publish/Subscribe Communication in Delay Tolerant Networks » (par Yoneki, E., Hui, P., Chan, S., et J. Crowcroft).
La section 4 du RFC précise ensuite les scénarios d'usage, et les exigences qui en découlent. Par exemple, pour le scénario « diffuser de l'information aux gens », la question de l'authentification est cruciale, de fausses informations diffusées par un malveillant ou par un plaisantin pourraient avoir des conséquences graves.
Est-ce que l'ICN peut assurer ces missions, là, aujourd'hui ? Clairement non, et la section 5 du RFC décrit tout ce qu'il reste à faire (rappelez-vous que l'ICN, c'est de la recherche fondamentale). Par exemple, dans le contexte envisagé, celui d'une vraie catastrophe, il est possible que les données doivent être transportées par des « mules », des porteurs physiques (on peut penser au RFC 1149 mais aussi, plus sérieusement, à UUCP où les messages étaient parfois transportés ainsi, notamment dans les pays du Sud). Cette proposition est envisagée dans l'article de Tagami, A., Yagyu, T., Sugiyama, K., Arumaithurai, M., Nakamura, K., Hasegawa, T., Asami, T., et K. Ramakrishnan, « Name-based Push/Pull Message Dissemination for Disaster Message Board ».
Enfin, la section 5 du RFC décrit ce qui reste à faire (l'ICN est aujourd'hui incapable d'assurer les missions décrites au début de ce RFC). La première chose serait d'évaluer en vrai les solutions ICN existantes. Un test à la prochaine catastrophe ?
À noter que le travail ayant mené à ce RFC a été fait en partie dans le cadre du projet GreenICN.
L'article seul
RFC 8914: Extended DNS Errors
Date de publication du RFC : Octobre 2020
Auteur(s) du RFC : W. Kumari (Google), E. Hunt
(ISC), R. Arends (ICANN), W. Hardaker
(USC/ISI), D. Lawrence (Oracle +
Dyn)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 24 octobre 2020
Un problème classique du DNS est qu'il n'y a pas assez de choix pour le
code de retour renvoyé par un serveur DNS. Contrairement à la richesse des codes de retour HTTP, le
DNS est très limité. Ainsi, le code de retour
SERVFAIL (SERver FAILure)
sert à peu près à tout, et indique des erreurs très différentes
entre elles. D'où ce nouveau RFC qui normalise un mécanisme permettant des
codes d'erreur étendus, les EDE, ce qui facilitera le diagnostic des
problèmes DNS.
Ces codes de retour DNS (RCODE, pour Response
CODE) sont décrits dans le RFC 1035,
section 4.1.1. Voici un exemple de requête faite avec dig. Le code de
retour est indiqué par l'étiquette status:. Ici,
c'est REFUSED, indiquant que le serveur faisant autorité pour
google.com ne veut pas répondre aux requêtes
pour mon .org :
% dig @ns1.google.com AAAA www.bortzmeyer.org ; <<>> DiG 9.11.3-1ubuntu1.12-Ubuntu <<>> @ns1.google.com AAAA www.bortzmeyer.org ; (2 servers found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: REFUSED, id: 4181 ;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1 ;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 512 ;; QUESTION SECTION: ;www.bortzmeyer.org. IN AAAA ;; Query time: 7 msec ;; SERVER: 2001:4860:4802:32::a#53(2001:4860:4802:32::a) ;; WHEN: Sat Jun 20 11:07:13 CEST 2020 ;; MSG SIZE rcvd: 47
Codés sur seulement quatre bits, ces codes de retour ne peuvent
pas être très nombreux. Le RFC 1035 en
normalisait six, et quelques
autres ont été ajoutés par la suite, mais sont rarement vus
sur le terrain. En pratique, les plus fréquents sont
NOERROR (pas de problème),
NXDOMAIN (ce nom de domaine n'existe pas) et
SERVFAIL (la plupart des autres erreurs). Notez
que le RFC 1034 n'utilisait pas ces sigles à
l'origine ils ont été introduits après.
On l'a dit, ces codes de retour sont insuffisants. Lorsqu'un
client DNS reçoit SERVFAIL, il doit essayer de
deviner ce que cela voulait dire. Lorsqu'on parle à un résolveur, le
SERVFAIL indique-t-il un problème de validation
DNSSEC ? Ou bien que les serveurs faisant autorité sont
injoignables ? Lorsqu'on parle à un serveur faisant
autorité, le SERVFAIL indiquait-il que
ce serveur n'avait pas pu charger sa zone (peut-être parce que le
serveur maître était injoignable) ? Ou bien un autre problème ?
L'un des scénarios de débogage les plus communs est celui de
DNSSEC. Au moins, il existe un truc simple :
refaire la requête avec le bit CD
(Checking Disabled). Si ça marche
(NOERROR), alors on est raisonnablement sûr que
le problème était un problème DNSSEC. Mais cela ne nous dit pas
lequel (signatures expirées ? clés ne correspondant pas à la
délégation ?). DNSSEC est donc un des principaux demandeurs d'erreurs
plus détaillées.
Alors, après cette introduction (section 1 du RFC), la solution
(section 2). Les erreurs étendues (EDE, pour Extended DNS Errors) sont transportées via une option
EDNS (RFC 6891) dans la
réponse. Cette option comporte un type (numéro 15)
et une longueur (comme toutes les options EDNS) suivis d'un code
d'information (sur deux octets) et de texte libre, non structuré (en
UTF-8, cf. RFC 5198, et
attention à ne pas le faire trop long, pour éviter la troncation
DNS). Les codes d'information possibles sont dans un
registre à l'IANA. En ajouter est simple, par la procédure
« Premier Arrivé, Premier Servi » du RFC 8126.
Cette option EDNS peut être envoyée par le serveur DNS, quel que
soit le code de retour (y compris donc
NOERROR). Il peut y avoir plusieurs de ces options. La seule condition
est que la requête indiquait qu'EDNS est accepté par le client. Le
client n'a pas à demander explicitement des erreurs étendues et ne
peut pas forcer l'envoi d'une erreur étendue, cela dépend uniquement
du serveur.
Les codes d'information initiaux figurent en section 4 du RFC. Le RFC ne précise pas avec quels codes de retour les utiliser (ce fut une grosse discussion à l'IETF…) mais, évidemment, certains codes d'erreur étendus n'ont de sens qu'avec certains codes de retour, je les indiquerai ici. Voici quelques codes d'erreur étendus :
- 0 indique un cas non prévu, le texte qui l'accompagne donnera des explications.
- 1 signale que le domaine était signé, mais avec uniquement
des algorithmes inconnus du résolveur. Il est typiquement en
accompagnement d'un
NOERRORpour expliquer pourquoi on n'a pas validé (en DNSSEC, un domaine signé avec des algorithmes inconnus est considéré comme non signé). - 3 (ou 19, pour le
NXDOMAIN) indique une réponse rassise (RFC 8767). Voir aussi le 22, plus loin. - 4 est une réponse fabriquée de toutes pièces par un
résolveur menteur. Notez qu'il existe
d'autres codes, plus loin, de 15 à 17,
permettant de détailler les cas de filtrage. 4 est typiquement en
accompagnement d'un
NOERRORpuisqu'il y a une réponse. - 6 vient avec les
SERVFAILpour indiquer que la validation DNSSEC a déterminé un problème (signature invalide ou absente). Plusieurs autres codes traitent des problèmes DNSSEC plus spécifiques. - 7 vient également avec
SERVFAILpour le cas des signatures expirées (sans doute un des problèmes DNSSEC les plus fréquents). - Trois codes viennent pour les cas où le résolveur refuse de répondre pour ce domaine, et le dit (au lieu, ou en plus, de fabriquer une réponse mensongère). Ce sont 15 (réponse bloquée par une décision de l'administrateur du résolveur), 16 (réponse bloquée par une décision extérieure, typiquement l'État, et il ne sert donc à rien de se plaindre à l'administrateur du résolveur, c'est de la censure) et 17 (réponse bloquée car le client a demandé qu'on filtre pour lui, par exemple parce qu'il a choisi de bloquer les domaines liés à la publicité, cf. l'exemple plus loin). 16 est donc à peu près l'équivalent du 451 de HTTP, normalisé dans le RFC 7725. Gageons que les résolveurs menteurs en France se garderont bien de l'utiliser…
- 18 accompagne en général
REFUSEDet indique au client qu'il n'est pas le bienvenu (par exemple une requête à un résolveur venue de l'extérieur du réseau local). - 22 indique qu'un résolveur n'a pu joindre aucun des
serveurs faisant autorité. Ce code peut accompagner une réponse
rassise ou bien un
SERVFAIL. J'en profite pour vous rappeler que, si vous gérez une zone DNS, attention à sa robustesse : évitez les SPOF. Ayez plusieurs serveurs faisant autorité, et dans des lieux séparés (et de préférence dans des AS distincts).
Voici un exemple où un résolveur se présentant comme « pour les
familles » ment sur la réponse à une requête pour
pornhub.com et ajoute l'EDE 17, puisque c'est
l'utilisateur qui, en choisissant ce résolveur public, a demandé ce
filtrage :
% dig @1.1.1.3 pornhub.com ; <<>> DiG 9.18.28-0ubuntu0.24.04.1-Ubuntu <<>> @1.1.1.3 pornhub.com ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 34585 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 1232 ; EDE: 17 (Filtered) ;; QUESTION SECTION: ;pornhub.com. IN A ;; ANSWER SECTION: pornhub.com. 60 IN A 0.0.0.0 ;; Query time: 9 msec ;; SERVER: 1.1.1.3#53(1.1.1.3) (UDP) ;; WHEN: Wed Sep 25 14:48:50 CEST 2024 ;; MSG SIZE rcvd: 62
Le client DNS qui reçoit un code d'erreur étendu est libre de l'utiliser comme il le souhaite (les précédentes versions de ce mécanisme prévoyaient des suggestions faites au client mais ce n'est plus le cas). Le but principal de cette technique est de fournir des informations utiles pour le diagnostic. (Une discussion à l'IETF avait porté sur des codes indiquant précisément si le problème était local - et devait donc être soumis à son administrateur système - ou distant, auquel cas il n'y avait plus qu'à pleurer, mais cela n'a pas été retenu. Notez que la différence entre les codes 15 et 16 vient de là, du souci d'indiquer à qui se plaindre.)
Attention à la section 6 du RFC, sur la sécurité. Elle note
d'abord que certains clients, quand ils reçoivent un
SERVFAIL, essaient un autre résolveur (ce qui
n'est pas une bonne idée si le SERVFAIL était
dû à un problème DNSSEC). Ensuite, les codes d'erreur étendus ne
sont pas authentifiés (comme, d'ailleurs, les
codes de retour DNS habituels), sauf si on utilise, pour parler au
serveur, un canal sécurisé comme DoT (RFC 7858) ou DoH (RFC 8484). Il ne faut
donc pas s'y fier trop aveuglément. Enfin, ces codes étendus vont
fuiter de l'information à un éventuel observateur (sauf si on
utilise un canal chiffré, comme avec DoT ou DoH) ; par exemple, 18
permet de savoir que vous n'êtes pas le bienvenu sur le serveur.
Et, désolé, je ne connais pas de mise en œuvre de cette option à l'heure actuelle. J'avais développé le code nécessaire pour Knot lors du hackathon de l'IETF à Prague en mars 2019 (le format a changé depuis donc ce code ne peut pas être utilisé tel quel). La principale difficulté n'était pas dans le formatage de la réponse, qui est trivial, mais dans le transport de l'information, depuis les entrailles du résolveur où le problème était détecté, jusqu'au code qui fabriquait la réponse. Il fallait de nouvelles structures de données, plus riches.
Sinon, le RFC mentionne le groupe Infected Mushroom. Si vous voulez voir leurs clips…
L'article seul
Usages de la 5G : est-ce le problème ?
Première rédaction de cet article le 23 octobre 2020
Dans les débats, souvent confus, sur la 5G, on a souvent cité l'argument des usages. D'un côté, on vend du rêve « la 5G va permettre la télémédecine et les voitures connectées, ainsi que la protection des gentilles brebis contre les loups », de l'autre du scepticisme, voire de la négation, « la 5G ne sert à rien, on n'a pas besoin d'une telle capacité, ça ne servira qu'au porno dans l'ascenseur ». A priori, parler des usages plutôt que de la technologie est raisonnable. On déploie une nouvelle infrastructure pour ses usages, pas pour faire plaisir aux techniciens, non ? Cela semble de bon sens mais cela oublie un gros problème : prévoir les usages d'une technologie d'infrastructure n'est pas facile.
En effet, la 5G est une technologie d'infrastructure. L'infrastructure, c'est ce qu'on ne voit pas, ce qui est loin de l'utilisatrice ou de l'utilisateur. Cela peut servir à plusieurs usages très différents. Ainsi, l'infrastructure routière peut servir à aller travailler le matin. (D'accord, pour la biosphère, il vaudrait mieux prendre les transports en commun. Mais ils ont souvent été supprimés dans les régions. Et ne me parlez pas de télétravail, vous croyez qu'un infirmier ou une ouvrière du BTP peuvent télétravailler ?) Mais la même infrastructure peut aussi servir à partir en vacances. Quel que soit le jugement de valeur (« les vacances, ce n'est pas vraiment utile ») qu'on ait sur ces usages, il est important de se rappeler que l'infrastructure ne se limite pas à tel ou tel usage.
Un point important avec l'infrastructure est que, quand on commence à la déployer, on ne connait pas réellement ses usages. Quand on a conçu l'Internet, personne n'envisageait le Web. Quand on a conçu le Web, personne n'envisageait Facebook, Gmail et Wikipédia. Les usages sont peu prévisibles et il ne faut pas forcément compter sur eux pour trancher en faveur ou en défaveur d'une technique d'infrastructure. L'argument de gros bon sens « avant d'investir dans un déploiement d'une infrastructure, il faut se demander si c'est vraiment utile » est trop court, car l'infrastructure (si elle est bien conçue) n'impose pas un usage unique. Faisons une expérience de pensée. Imaginons que, comme certains le proposent pour la 5G, un comité, une commission ou une agence ait été chargée, avant le déploiement de l'Internet, de peser ses usages et de décider si le jeu en valait la chandelle. Ce comité n'aurait pas connu le bon (Wikipédia, Sci-Hub, les appels vocaux à très bas prix entre continents) ou le mauvais (la surveillance massive) de l'Internet. Comment aurait-il pu prendre une bonne décision ?
Et est-il à craindre qu'il n'y ait tout simplement pas ou peu d'usage, que la nouvelle technologie qui a coûté si cher à déployer ne serve finalement à rien ? S'agissant d'une technologie de communication, comme l'Internet, il n'y a pas de risque : l'être humain est très communiquant, et toutes les technologies de communication, depuis l'aube de l'humanité, ont été des grands succès. On pouvait donc parier sans risque de l'Internet en serait un.
Autrefois, certains opérateurs ont pourtant essayé de contrôler les usages. À une époque lointaine, les opérateurs téléphoniques (AT&T et France Télécom, par exemple), avaient essayé d'interdire les modems, considérés comme un détournement du réseau téléphonique. Le même France Télécom, lorsque le RNIS est apparu en France, avait essayé de promouvoir des applications spécifiques au RNIS. (Voyez un exemple d'application liée au réseau dans cet amusant article de 2004.) Et ceci alors que l'Internet promouvait au contraire l'idée d'un réseau neutre, sur lequel de nombreuses applications, pas forcément développées ou encouragées par l'opérateur, seraient possibles. (Notez que les opérateurs issus de la téléphonie classique n'ont jamais vraiment renoncé à ce contrôle. Les ordiphones sont ainsi beaucoup plus fermés que les PC.) Comme le dit Joël Mau « Les infrastructures ne doivent pas être un frein mais un facilitateur ».
Ce « détournement » ou tout simplement, pour parler comme Zittrain, cette générativité, sont des qualités qu'on retrouve dans de nombreuses technologies, et qui permettent l'innovation. Après tout, lorsque Gutenberg a inventé sa presse, il n'avait pas non plus imaginé tous les usages. Et lorsque le Minitel a été conçu, personne ne pensait aux messageries, son grand usage. Ce phénomène est connue en sociologie de l'innovation d'assez longue date : les utilisatrices et utilisateurs ne sont pas des consommateurs passifs d'« usages » décidés d'en haut, elles et ils développent des usages surprenants, qui peuvent influer sur l'innovation. On peut lire par exemple « Les utilisateurs, acteurs de l’innovation », de Madeleine Akrich, qui contient beaucoup d'exemples amusants. Notez que très peu des exemples de cet article concernent le numérique, ce qui indique que cette générativité des techniques, et cette initiative des utilisateurs, ne sont pas une spécificité du monde numérique. (En anglais, on peut aussi citer les travaux d'Eric von Hippel.)
Revenons aux usages et à leur utilisation dans le cadre de controverses socio-techniques. Outre la difficulté à prédire les usages effectifs d'une technologie nouvelle, un des problèmes du « pilotage par les usages » est la question des opinions. Reprenons l'exemple du « porno dans l'ascenseur » cité plus haut. La pornographie est légale en France. Le politicien puritain qui a utilisé cet exemple voulait manifestement pointer que le porno était un « mauvais usage », pas digne qu'on investisse pour lui. On peut imaginer que les défenseurs de l'usage de la pornographie ne vont pas se mettre en avant et l'argument était donc bien calculé pour ne pas être contestable. (Pourtant, on peut noter qu'en période de confinement et de couvre-feu, la frustration sexuelle est un vrai problème, même si le porno n'est pas forcément la solution.) Mais passons du porno à d'autres usages. La diffusion de matches de football en haute définition est-elle utile ? Comme je ne m'intéresse pas du tout au football, ma réponse serait non. D'autres personnes auront un autre avis. On voit bien là l'un des problèmes fondamentaux du « pilotage par les usages » : comment déterminer les usages « légitimes » et selon quels critères ?
En conclusion, et notamment dans le cadre du débat sur la 5G, je pense qu'il faut manier l'argument des usages avec prudence. Lorsque j'entends cet argument, j'ai tout de suite envie de creuser la question avec celui qui le présente :
- Comment allez-vous prévoir les usages futurs ?
- Qui va décider de quels usages sont légitimes ou pas ?
[Article réalisé avec la participation de Francesca Musiani].
L'article seul
RFC 8922: A Survey of the Interaction Between Security Protocols and Transport Services
Date de publication du RFC : Octobre 2020
Auteur(s) du RFC : T. Enghardt (TU Berlin), T. Pauly (Apple), C. Perkins (University of Glasgow), K. Rose (Akamai Technologies), C.A. Wood (Cloudflare)
Pour information
Réalisé dans le cadre du groupe de travail IETF taps
Première rédaction de cet article le 22 octobre 2020
Quels sont les services de sécurité fournis par les protocoles de transport existants ? Ce nouveau RFC fait le point et examine ces services de sécurité pour un certain nombre de ces protocoles, comme TLS, QUIC, WireGuard, etc. Cela intéressera tous les gens qui travaillent sur la sécurité de l'Internet.
Ce RFC est issu du groupe de travail IETF TAPS, dont le projet est d'abstraire les services que rend la couche Transport pour permettre davantage d'indépendance entre les applications et les différents protocoles de transport. Vous pouvez en apprendre plus dans les RFC 8095 et RFC 8303.
Parmi les services que fournit la couche Transport aux applications, il y a la sécurité. Ainsi, TCP (si le RFC 5961 a bien été mis en œuvre et si l'attaquant n'est pas sur le chemin) protège assez bien contre les usurpations d'adresses IP. Notez que le RFC utilise le terme de « protocole de transport » pour tout ce qui est en dessous de l'application, et utilisé par elle. Ainsi, TLS est vu comme un protocole de transport, du point de vue de l'application, il fonctionne de la même façon (ouvrir une connexion, envoyer des données, lire des réponses, fermer la connexion), avec en prime les services permis par la cryptographie, comme la confidentialité. TLS est donc vu, à juste titre, comme un protocole d'infrastructure, et qui fait donc partie de ceux étudiés dans le cadre du projet TAPS.
La section 1 du RFC explique d'ailleurs quels protocoles ont été intégrés dans l'étude et pourquoi. L'idée était d'étudier des cas assez différents les uns des autres. Des protocoles très répandus comme SSH (RFC 4251), GRE (avec ses extensions de sécurité du RFC 2890) ou L2TP (RFC 5641) ont ainsi été écartés, pas parce qu'ils sont mauvais mais parce qu'ils fournissent à peu près les mêmes services que des protocoles étudiés (par exemple SSH vs. TLS) et ne nécessitaient donc pas d'étude séparée. Plus animée, au sein du groupe de travail TAPS, avait été la discussion sur des protocoles non-IETF comme WireGuard ou MinimaLT. Ils ne sont pas normalisés (et, souvent, même pas décrits dans une spécification stable), mais ils sont utilisés dans l'Internet, et présentent des particularités suffisamment importantes pour qu'ils soient étudiés ici. En revanche, les protocoles qui ne fournissent que de l'authentification, comme AO (RFC 5925) n'ont pas été pris en compte.
Comme c'est le cas en général dans le projet TAPS, le but est de découvrir et de documenter ce que les protocoles de transport ont en commun, pour faciliter leur choix et leur utilisation par l'application. Par contre, contrairement à d'autres cas d'usage de TAPS, il n'est pas prévu de permettre le choix automatique d'un protocole de sécurité. Pour les autres services, un tel choix automatique se justifie (RFC 8095). Si une application demande juste le service « transport d'octets fiable, j'ai des fichiers à envoyer », lui fournir TCP ou SCTP revient au même, et l'application se moque probablement du protocole choisi. Mais la sécurité est plus compliquée, avec davantage de pièges et de différences subtiles, et il est donc sans doute préférable que l'application choisisse explicitement le protocole.
La section 2 du RFC permet de réviser la terminologie, je vous renvoie à mon article sur le RFC 8303 pour la différence entre fonction (Transport Feature) et service (Transport Service).
Et la section 3 s'attaque aux protocoles eux-mêmes. Elle les classe selon qu'ils protègent n'importe quelle application, une application spécifique, l'application et le transport, ou bien carrément tout le paquet IP. Le RFC note qu'aucune classification n'est parfaite. Notamment, plusieurs protocoles sont séparés en deux parties, un protocole de connexion, permettant par exemple l'échange des clés de session, protocole utilisé essentiellement, voire uniquement, à l'ouverture et à la fermeture de la session, et le protocole de chiffrement qui traite les données transmises. Ces deux protocoles sont plus ou moins intégrés, de la fusion complète (tcpcrypt, RFC 8548) à la séparation complète (IPsec, où ESP, décrit dans le RFC 4303, ne fait que chiffrer, les clés pouvant être fournies par IKE, spécifié dans le RFC 7296, ou par une autre méthode). Par exemple, TLS décrit ces deux protocoles séparement (RFC 9846) mais on les considérait comme liés… jusqu'à ce que QUIC décide de n'utiliser qu'un seul des deux.
Bon, assez d'avertissements, passons à la première catégorie, les protocoles qui fournissent une protection générique aux applications. Ils ne protègent donc pas contre des attaques affectant la couche 4 comme les faux paquets RST. Le plus connu de ces protocoles est évidemment TLS (RFC 9846). Mais il y a aussi DTLS (RFC 9147).
Ensuite, il y a les protocoles spécifiques à une application. C'est par exemple le cas de SRTP (RFC 3711), extension sécurisée de RTP qui s'appuie sur DTLS.
Puis il y a la catégorie des protocoles qui protègent le transport ce qui, par exemple, protège contre les faux RST (ReSeT), et empêche un observateur de voir certains aspects de la connexion. C'est le cas notamment de QUIC, normalisé depuis. QUIC utilise TLS pour obtenir les clés, qui sont ensuite utilisées par un protocole sans lien avec TLS, et qui chiffre y compris la couche Transport. Notons que le prédécesseur de QUIC, développé par Google sous le même nom (le RFC nomme cet ancien protocole gQUIC pour le distinguer du QUIC normalisé), n'utilisait pas TLS.
Toujours dans la catégorie des protocoles qui protègent les couches Transport et Application, tcpcrypt (RFC 8548). Il fait du chiffrement « opportuniste » (au sens de « sans authentification ») et est donc vulnérable aux attaques actives. Mais il a l'avantage de chiffrer sans participation de l'application, contrairement à TLS. Bon, en pratique, il n'a connu quasiment aucun déploiement.
Il y a aussi MinimaLT, qui intègre l'équivalent de TCP et l'équivalent de TLS (comme le fait QUIC).
Le RFC mentionne également CurveCP, qui fusionne également transport et chiffrement. Comme QUIC ou MinimaLT, il ne permet pas de connexions non-sécurisées.
Et enfin il y a les protocoles qui protègent tout, même IP. Le plus connu est évidemment IPsec (RFC 4303 et aussi RFC 7296, pour l'échange de clés, qui est un protocole complètement séparé). Mais il y a aussi WireGuard qui est nettement moins riche (pas d'agilité cryptographique, par exemple, ni même de négociation des paramètres cryptographiques ; ce n'est pas un problème pour des tunnels statiques mais c'est ennuyeux pour un usage plus général sur l'Internet). Et il y a OpenVPN, qui est sans doute le plus répandu chez les utilisateurs ordinaires, pour sa simplicité de mise en œuvre. On trouve par exemple OpenVPN dans tous des systèmes comme OpenWrt et donc dans tous les routeurs qui l'utilisent.
Une fois cette liste de protocoles « intéressants » établie, notre RFC va se mettre à les classer, selon divers critères. Le premier (section 4 du RFC) : est-ce que le protocole dépend d'un transport sous-jacent, qui fournit des propriétés de fiabilité et d'ordre des données (si oui, ce transport sera en général TCP) ? C'est le cas de TLS, bien sûr, mais aussi, d'une certaine façon, de tcpcrypt (qui dépend de TCP et surtout de son option ENO, normalisée dans le RFC 8547). Tous les autres protocoles peuvent fonctionner directement sur IP mais, en général, ils s'appuient plutôt sur UDP, pour réussir à passer les différentes middleboxes qui bloquent les protocoles de transport « alternatifs ».
Et l'interface avec les applications ? Comment ces différents protocoles se présentent-ils aux applications qui les utilisent ? (Depuis, voir le RFC 9622.) Il y a ici beaucoup à dire (le RFC fournit un tableau synthétique de quelles possibilités et quels choix chaque protocole fournit aux applications). L'analyse est découpée en plusieurs parties (les services liés à l'établissement de la connexion, ceux accessibles pendant la session et ceux liés à la terminaison de la connexion), chaque partie listant plusieurs services. Pour chaque service, le RFC dresse la liste des différents protocoles qui le fournissent. Ainsi, la partie sur l'établissement de connexion indique entre autres le service « Extensions au protocole de base accessibles à l'application ». Ce service est fourni par TLS (via ALPN, RFC 7301) ou QUIC mais pas par IPsec ou CurveCP. De même le service « Délégation de l'authentification » peut être fourni par IPsec (par exemple via EAP, RFC 3748) ou tcpcrypt mais pas par les autres.
La section 7 rappelle que ce RFC ne fait qu'analyser les protocoles existants, il ne propose pas de changement. D'autre part, cette section note que certaines attaques ont été laissées de côté (comme celle par canal secondaire ou comme l'analyse de trafic).
La section 8 sur la vie privée rappelle ces faiblesses ; même si l'un des buts principaux du chiffrement est d'assurer la confidentialité, la plupart des protocoles présentés laissent encore fuiter une certaine quantité d'information, par exemple les certificats en clair de TLS (avant la version 1.3).
L'article seul
RFC 8923: A Minimal Set of Transport Services for End Systems
Date de publication du RFC : Octobre 2020
Auteur(s) du RFC : M. Welzl, S. Gjessing (University of Oslo)
Pour information
Réalisé dans le cadre du groupe de travail IETF taps
Première rédaction de cet article le 22 octobre 2020
Ce nouveau RFC s'incrit dans le travail en cours à l'IETF pour formaliser un peu plus les services que la couche transport offre aux applications. Le RFC 8095 décrivait tous les services possibles. Ce nouveau RFC 8923 liste les services minimums, ceux à offrir dans presque tous les cas.
Comme le note le RFC 8095, les applications tournant sur la famille de protocoles TCP/IP ne peuvent en général pas aujourd'hui exprimer les services attendus de la couche transport. Elles doivent choisir un protocole de transport (comme TCP ou UDP), même si ce protocole ne convient pas tout à fait. Toute l'idée derrière le travail du groupe TAPS de l'IETF est de permettre au contraire aux applications d'indiquer des services (« je veux un envoi de données fiable et dans l'ordre, avec confidentialité et intégrité ») et que le système d'exploitation choisisse alors la solution la plus adaptée (ici, cela pourrait être TCP ou SCTP avec TLS par dessus, ou bien le futur QUIC). De la même façon qu'un langage de programmation de haut niveau utilise des concepts plus abstraits qu'un langage de bas niveau, on pourrait ainsi avoir une interface de programmation réseau de plus haut niveau que les traditionnelles prises normalisées par Posix. Ce RFC ne normalise pas une telle API, il décrit seulement les services attendus. La liste des services possibles est dans le RFC 8095, et les protocoles qui les fournissent sont documentés dans le RFC 8303 et RFC 8304. Le cœur de notre nouveau RFC 8923 est la section 6, qui liste les services minimum attendus (je vous en dévoile l'essentiel tout de suite : établissement de connexion, fin de connexion, envoi de données, réception de données).
À noter que les services minimums exposés ici peuvent être mis en œuvre sur TCP, et, dans certains cas, sur UDP. TCP offre un ensemble de services qui est quasiment un sur-ensemble de celui d'UDP, donc, sur le seul critère des services, on pourrait n'utiliser que TCP. (Exercice : quelle(s) exception(s) trouvez-vous ?) Comme il s'agit de services de la couche transport aux applications, l'implémentation peut être faite d'un seul côté (il n'est pas nécessaire que les deux partenaires qui communiquent le fassent).
Et, si vous lisez le RFC, faites attention à la section 2 sur la terminologie, section qui reprend le RFC 8303 : une fonction (Transport Feature) est une fonction particulière que le protocole de transport va effectuer, par exemple la confidentialité, la fiabilité de la distribution des données, le découpage des données en messages, etc, un service (Transport Service) est un ensemble cohérent de fonctions, demandé par l'application, et un protocole (Transport Protocol) est une réalisation concrète d'un ou plusieurs services.
Comment définir un jeu minimal de services (section 3 du RFC) ? D'abord, il faut définir les services « sémantiques » (functional features) que l'application doit connaitre. Par exemple, l'application doit savoir si le service « distribution des données dans l'ordre » est disponible ou pas. Et il y a les services qui sont plutôt des optimisations comme l'activation ou la désactivation de DSCP ou comme l'algorithme de Nagle. Si l'application ignore ces services, ce n'est pas trop grave, elle fonctionnera quand même, même si c'est avec des performances sous-optimales.
La méthode utilisée par les auteurs du RFC pour construire la liste des services minimums est donc :
- Catégorisation des services du RFC 8303 (sémantique, optimisation…) ; le résultat de cette catégorisation figure dans l'annexe A de notre RFC,
- Réduction aux services qui peuvent être mis en œuvre sur les protocoles de transport qui peuvent passer presque partout, TCP et UDP,
- Puis établissement de la liste des services minimum.
Ainsi (section 4 du RFC), le service « établir une connexion » peut être mis en œuvre sur TCP de manière triviale, mais aussi sur UDP, en refaisant un équivalent de la triple poignée de mains. Le service « envoyer un message » peut être mis en œuvre sur UDP et TCP (TCP, en prime, assurera sa distribution à l'autre bout, mais ce n'est pas nécessaire). En revanche, le service « envoyer un message avec garantie qu'il soit distribué ou qu'on soit notifié », s'il est simple à faire en TCP, ne l'est pas en UDP (il faudrait refaire tout TCP au dessus d'UDP).
La section 5 du RFC discute de divers problèmes quand on essaie de définir un ensemble minimal de services. Par exemple, TCP ne met pas de délimiteur dans le flot d'octets qui circulent. Contrairement à UDP, on ne peut pas « recevoir un message », seulement recevoir des données. Certains protocoles applicatifs (comme DNS ou EPP) ajoutent une longueur devant chaque message qu'ils envoient, pour avoir une sémantique de message et plus de flot d'octets. TCP n'est donc pas un strict sur-ensemble d'UDP.
Pour contourner cette limitation, notre RFC définit (section 5.1) la notion de « flot d'octets découpé en messages par l'application » (Application-Framed Bytestream). Dans un tel flot, le protocole applicatif indique les frontières de message, par exemple en précédant chaque message d'une longueur, comme le fait le DNS.
Autre problème amusant, certains services peuvent être d'assez bas niveau par rapport aux demandes des applications. Ainsi, le RFC 8303 identifie des services comme « couper Nagle », « configurer DSCP » ou encore « utiliser LEDBAT ». Il serait sans doute plus simple, pour un protocole applicatif, d'avoir une configuration de plus haut niveau. Par exemple, « latence minimale » désactiverait Nagle et mettrait les bits qui vont bien en DSCP.
Nous arrivons finalement au résultat principal de ce RFC, la section 6, qui contient l'ensemble minimal de services. Chaque service est configurable via un ensemble de paramètres. Il est implémentable uniquement avec TCP, et d'un seul côté de la connexion. Dans certains cas, TCP fournira plus que ce qui est demandé, mais ce n'est pas un problème. Je ne vais pas lister tout cet ensemble minimal ici, juste énumérer quelques-uns de ses membres :
- Créer une connexion, avec des paramètres comme la fiabilité demandée,
- Mettre fin à la connexion,
- Envoyer des données, sans indication de fin de message (cf. la discussion plus haut),
- Recevoir des données.
Pour l'envoi de données, les paramètres sont, entre autres :
- Fiabilité (les données sont reçues à l'autre bout ou, en tout cas, l'émetteur est prévenu si cela n'a pas été possible) ou non,
- Contrôle de congestion ou non, sachant que si l'application ne demande pas de contrôle de congestion au protocole de transport, elle doit faire ce contrôle elle-même (RFC 8085),
- Idempotence,
- Etc.
Pour la réception de données, le service est juste la réception d'octets, un protocole applicatif qui veut des messages doit utiliser les « flots d'octets découpés par l'application » décrits en section 5.1.
On notera que la sécurité est un service, également, ou plutôt un ensemble de services (section 8 du RFC). Dans les protocoles IETF, la sécurité est souvent fournie par une couche intermédiaire entre la couche de transport et la couche application à proprement parler. C'est ainsi que fonctionne TLS, par exemple. Mais la tendance va peut-être aller vers l'intégration, avec QUIC.
L'article seul
Fiche de lecture : Histoire de la Mésopotamie
Auteur(s) du livre : Véronique Grandpierre
Éditeur : Gallimard
978-2-07-039605-4
Publié en 2010
Première rédaction de cet article le 21 octobre 2020
Voici un livre utile pour les gens qui, comme moi, ne connaissent de la Mésopotamie que le démon Pazuzu dans les aventures d'Adèle Blanc-Sec. Une histoire complète de la région où est née la civilisation, région qui a vu beaucoup de cultures différentes, et sur une longue période. De quoi faire rêver (royaumes disparus, mythologie passionnante, épopées héroïques, travaux intellectuels…)
La perception de la Mésopotamie en Europe occidentale est ambigüe. D'un côté, c'est le Croissant fertile, où la civilisation a commencé. De l'autre, l'influence des Hébreux, via la Bible, en a fait l'empire du mal, notamment via la figure de Babylone, accusée de tous les vices, de la sexualité débridée à l'orgueil en passant par l'oppression et l'esclavage. On connait sans doute mieux l'Égypte antique que la Mésopotamie. L'auteure va s'occuper à corriger cela, à expliquer que la Mésopotamie, c'est vaste, avec des royaumes bien distincts, et que les nombreux siècles (en très gros, de -3500 à -500) pendant lesquels on parle de « Mésopotamie » ont vu d'innombrables changements. D'où la taille du livre (417 pages dans l'édition de poche, parue en 2019, sans les annexes).
L'auteure nous parle donc des rois, des villes (c'est en Mésopotamie que sont apparues les premières villes), de la famille (l'inégalité n'était pas qu'entre rois et sujets, elle était aussi présente dans la famille), de l'écriture (également inventée en Mésopotamie), des sciences, de la religion (et on rencontre Pazuzu, chef des démons).
Ah, et comme dans tous les livres qui parlent d'archéologie en Mésopotamie, on croise Agatha Christie, qui a son entrée dans l'index. Sinon, si vous aimez les images, Wikimedia Commons a beaucoup de photos sur la Mésopotamie. Je vous mets d'ailleurs une image (source) de l'épopée de Gilgameš, l'une des plus anciennes légendes écrites (en cunéiforme…) Si vous avez la bonne configuration technique, le héros se nomme 𒄑𒂆𒈦.
{kind=link}
La tablette : 
L'article seul
Fiche de lecture : Digging up Armageddon
Auteur(s) du livre : Eric Cline
Éditeur : Princeton University Press
978-0-691-16632-2
Publié en 2020
Première rédaction de cet article le 18 octobre 2020
Ceux et celles qui ont lu la Bible savent qu'Armaguédon est le lieu du combat final entre le Bien et le Mal. Mais c'est aussi une ville réelle où plusieurs batailles historiques ont eu lieu, et où l'architecture a laissé beaucoup de témoignages. C'est donc un endroit parfait pour des fouilles, et ce livre nous raconte de manière détaillée la campagne de fouilles de l'université de Chicago qui a eu lieu pendant l'entre-deux-guerres.
Vous n'y apprendrez pas forcément beaucoup de choses sur les civilisations qui se sont succédé ici. Ce livre, qui se fonde notamment sur les lettres et les rapports des membres de la longue expédition, privilégie le récit des fouilles, les personnages qui s'y sont illustrés, leurs succès et leurs affrontements. Car l'archéologie n'est pas une discipline désincarnée menée par des êtres parfaits. Les tiraillements, voire les conflits ouverts ont été nombreux. Les fouilles de cette époque étaient financés par Rockfeller et le directeur distant, Breasted, doit toujours prendre soin de garder les faveurs du financier, en apportant régulièrement des résultats spectaculaires. Toute fouille en terre biblique doit forcément rapporter des artefacts mentionnés dans le livre sacré. Cette culture du résultat entraine évidemment des tensions et cela se reflète dans le recrutement et les licenciements brutaux des équipes sur le terrain, qui se renouvellent rapidement. D'autant plus que, sur place, les difficiles conditions matérielles et les difficultés du travail aggravent les tensions, et les appels à la direction à Chicago pour qu'elle tranche des conflits de personne. (Sans compter les lettres anonymes !)
Ces tensions ont au moins un avantage : elles tiennent l'équipe à l'écart de tout ce qui se passe dans le pays où ils travaillent. La lutte contre le colonialisme britannique, les pogroms, et les affrontements avec les sionistes ne semblent pas marquer le quotidien des archéologues, tout occupés à fouiller et à s'engueuler. Cette isolement des troubles est d'autant plus fort que, pour éviter que les ouvriers du chantier ne sympathisent avec d'éventuels mouvements locaux, tous ces ouvriers sont amenés d'Égypte…
Les archéologues ont pourtant des opinions. Reflet d'une autre époque, elles sont souvent racistes. Alors même qu'ils mettent en avant les réalisations de rois juifs qu'ils extraient du sol, certains tiennent des propos contre les juifs. Le directeur des fouilles a épousé une juive, et ses subordonnés ne manquent pas de le critiquer pour cela. On imagine que cela n'améliore pas l'ambiance. Et on s'étonne qu'un chercheur puisse faire preuve d'un racisme aussi crasse alors qu'il fait l'éloge des réalisations de Salomon… On voit ainsi un archéologue nouvellement arrivé écrire à ses parents, moins de 24 h après être venu en Palestine, pour y décrire doctement comment tout est de la faute des juifs. D'autres archéologues préfèrent accuser les Arabes, décrits comme attardés, barbares, sales, et autres clichés. Bref, la science n'empêche pas d'être un imbécile ou un salaud, on le savait déjà. Ce livre ne dissimule pas les défauts de ses personnages.
Mais il montre aussi leurs succès : cette longue campagne de fouilles a permis d'innombrables découvertes spectaculaires, sur un terrain qui est occupé par les humains depuis très longtemps. Si les interprétations des découvertes ont parfois été marqués par le sensationnalisme (le soldat tué en défendant l'aqueduc, qui était en fait enterré dans une tombe civile, plus tard percée par le creusement de l'aqueduc…) elles n'en sont pas moins remarquables. Le film « The human adventure » tourné en partie à Armaguédon durant ces fouilles est aujourd'hui visible sur YouTube. S'il a sérieusement vieilli, sur la forme comme sur le fond, il reste un intéressant témoignage des fouilles de l'époque, y compris l'usage du ballon à cette époque où on n'avait pas de drone. (La partie sur la Palestine commence vers 29'05'' et celle sur Meggido vers 30'25''.) La scène qui commence vers 47'06'' (sur un autre site) donne une bonne idée des relations entre les chefs et les travailleurs locaux…
Eric Cline est également l'auteur de « 1177 b.c. the year the civilization collapsed ».
L'article seul
RFC 8925: IPv6-Only-Preferred Option for DHCPv4
Date de publication du RFC : Octobre 2020
Auteur(s) du RFC : L. Colitti, J. Linkova (Google), M. Richardson (Sandelman), T. Mrugalski (ISC)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dhc
Première rédaction de cet article le 17 octobre 2020
Si une machine a IPv6 et est ravie de n'utiliser que ce protocole, pas la peine pour un serveur DHCP de lui envoyer une des rares adresses IPv4 restantes. Ce nouveau RFC décrit une option de DHCP-IPv4 qui permet au client de dire au serveur « je n'ai pas vraiment besoin d'IPv4 donc, s'il y a IPv6 sur ce réseau, tu peux garder les adresses IPv4 pour les nécessiteux ».
Idéalement, l'administrateur réseaux qui configure un nouveau réseau voudrait le faire en IPv6 seulement, ce qui simplifierait son travail. Mais, en pratique, c'est difficile (le RFC 6586 décrit une telle configuration). En effet, beaucoup de machines ne sont pas encore entrées dans le XXIe siècle, et ne gèrent qu'IPv4 ou, plus exactement, ont besoin d'IPv4 pour au moins certaines fonctions (comme des versions de Windows qui avaient IPv6 mais ne pouvaient parler à leur résolveur DNS qu'au-dessus d'IPv4). Il faut donc se résigner à gérer IPv4 pour ces machines anciennes. Mais, vu la pénurie d'adresses IPv4, il est également souhaitable de ne pas allouer d'adresses IPv4 aux machines qui n'en ont pas besoin.
La solution la plus courante à l'heure actuelle est de mettre les machines antédiluviennes et les machines modernes dans des réseaux séparés (VLAN ou SSID différents, par exemple, comme c'est fait aux réunions IETF ou RIPE), le réseau pour les ancêtres étant le seul à avoir un serveur DHCPv4 (RFC 2131). Cela a plusieurs inconvénients :
- Cela complique le réseau et son administration,
- Le risque d'erreur est élevé (utilisateur sélectionnant le mauvais SSID dans le menu des réseaux Wi-Fi accessibles, par exemple).
L'idéal serait de n'avoir qu'un réseau, accueillant aussi bien des machines IPv6 que des machines IPv4, sans que les machines IPv6 n'obtiennent d'adresse IPv4, dont elles n'ont pas besoin. On ne peut pas demander aux utilisateurs de débrayer complètement IPv4, car les machines mobiles peuvent en avoir besoin sur des réseaux purement IPv4 (ce qui existe encore). La machine IPv6 ne sachant pas, a priori, si le réseau où elle se connecte est seulement IPv4, seulement IPv6 ou accepte les deux, elle va donc, logiquement, demander une adresse IPv4 en DHCP, et bloquer ainsi une précieuse adresse IPv4. Retarder cette demande pour voir si IPv6 ne suffirait pas se traduirait par un délai peu acceptable lorsque le réseau n'a pas IPv6.
Notre RFC résout ce problème en créant une nouvelle option pour les requêtes et réponses DHCP v4 : dans la requête, cette option indique que le client n'a pas absolument besoin d'une adresse IPv4, qu'il peut se passer de ce vieux protocole, si le réseau a de l'IPv6 bien configuré et, dans la réponse, cette option indique que le réseau fonctionne bien en « IPv6 seulement ». Et comment fait-on si on veut joindre un service IPv4 depuis un tel réseau ? Il existe des techniques pour cela, la plus répandue étant le NAT64 du RFC 6146, et la réponse du serveur DHCP indique également qu'une de ces techniques est présente.
La section 1.2 précise quelques termes importants pour comprendre les choix à effectuer pour le client et pour le serveur DHCP :
- Capable de faire de l'IPv6 seule (IPv6-only capable host) : une machine terminale qui peut se débrouiller sans problème sans adresse IPv4,
- Nécessite IPv4 (IPv4-requiring host) : le contraire,
- IPv4 à la demande (IPv4-on-demand) : le scénario, rendu possible par ce RFC, où le même réseau accueille des machines capables de faire de l'IPv6 seul, et des machines qui nécessitent IPv4 ; ce réseau se nomme « Essentiellement IPv6 » (IPv6-mostly network), et fournit NAT64 (RFC 6146) ou une technique équivalente,
- En mode seulement IPv6 (IPv6-only mode) : état d'une machine capable de faire de l'IPv6 seule et qui n'a pas reçu d'adresse IPv4,
- Réseau seulement en IPv6 (IPv6-only network) : un réseau qui ne fournit pas du tout d'IPv4 et ne peut donc pas accueillir les machines qui nécessitent IPv4 (c'est un tel réseau qui sert de base à l'expérience du RFC 6586),
- Notez que le cas d'un réseau qui non seulement serait seulement en IPv6 mais en outre ne fournirait pas de technique comme celle de NAT64 (RFC 6146) n'apparait pas dans le RFC. Un tel réseau ne permettrait pas aux machines terminales de joindre les services qui sont restées en IPv4 seulement comme MicrosoftHub ou l'Élysée.
La section 2 du RFC résume ensuite les bonnes raisons qu'il y a pour signaler au réseau, via l'option DHCP, qu'on se débrouille très bien avec IPv6 seul :
- Il semble logique que la nouvelle option, qui veut dire « je n'ai pas réellement besoin d'IPv4 » soit envoyée via le protocole qui sert à demander les adresses IPv4,
- Tout le monde a déjà DHCP v4 et, surtout, utiliser le protocole existant n'introduit pas de nouvelles vulnérabilités (permettre à un nouveau protocole de couper IPv4 sur les machines terminales serait un risque de sécurité important),
- Comme il faut ajouter explicitement l'option aux requêtes et aux réponses, IPv4 ne sera coupé que si le client et le serveur DHCP sont tous les deux d'accord pour cela,
- Ce système n'ajoute aucun retard à la configuration via DHCP, le client qui envoie l'option alors que le réseau ne permet pas IPv6 seul, aura son adresse IPv4 aussi vite qu'avant (pas d'aller-retours de négociation),
- DHCP permet des résultats qui dépendent du client, donc, sur un même réseau, le serveur DHCP pourra économiser les adresses IPv4 en en n'envoyant pas aux machines qui peuvent s'en passer, tout en continuant à en distribuer aux autres.
La section 3 du RFC présente l'option elle-même. Elle contient le code 108 (IPv6-only Preferred), enregistré à l'IANA (cf. section 5), la taille de l'option (toujours quatre, mais précisée car c'est l'encodage habituel des options DHCP, cf. RFC 2132) et la valeur, qui est, dans la réponse, le nombre de secondes que le client peut mémoriser cette information, avant de redemander au serveur DHCP.
Le logiciel client DHCP doit donc offrir un moyen à son administrateur pour activer « je me débrouille très bien en IPv6 », et cela doit être par interface réseau. Dans ce cas, le client DHCP doit envoyer l'option décrite dans notre RFC. La décision d'activer le mode « IPv6 seul » peut aussi être prise automatiquement par le système d'exploitation, par exemple parce qu'il détecte que 464XLAT (RFC 6877) fonctionne. De même, des objets connectés qui ne parlent qu'à des services accessibles en IPv6 pourraient être livrés avec l'option « IPv6 seul » déjà activée.
Outre le côté « je suis un bon citoyen, je ne gaspille pas des ressources rares » qu'il y a à ne pas demander d'adresse IPv4, cette option permet de couper un protocole réseau inutile, diminuant la surface d'attaque de la machine.
Côté serveur DHCP, il faut un moyen de configurer, pour chaque réseau, si on accepte l'option « IPv6 me suffit ». Si elle est activée, le serveur, lorsqu'il recevra cette option dans une requête (et uniquement dans ce cas), la mettra dans sa réponse, et n'attribuera pas d'adresse IPv4. On voit donc que les vieux clients DHCP, qui ne connaissent pas cette option et ne l'inclueront donc pas dans leurs requêtes, ne verront pas de changement, ils continueront à avoir des adresses IPv4 comme avant (s'il en reste…).
A priori (section 4 du RFC), l'administrateurice du serveur DHCP ne va pas activer cette option si son réseau ne fournit pas un mécanisme permettant aux machines purement IPv6 de joindre des services purement IPv4 (par exemple le mécanisme NAT64 du RFC 6146). En effet, on ne peut pas s'attendre, à court terme, à ce que tous les services Internet soient accessibles en IPv6. Activer l'option « IPv6 seul » sans avoir un mécanisme de traduction comme NAT64 n'est réaliste que sur des réseaux non-connectés à l'Internet public.
Un petit mot sur la sécurité, juste pour rappeler que DHCP n'est pas vraiment sécurisé et que l'option « v6 seul » a pu être mise, retirée ou modifiée suite aux actions d'un attaquant. Cela n'a rien de spécifique à cette option, c'est un problème général de DHCP, contre lequel il faut déployer des protections comme le DHCP snooping.
Au moment de la sortie du RFC, je ne connaissais pas encore de mise en œuvre de cette option. Mais elle n'est pas trop dure à ajouter, elle n'a rien de très nouveau ou d'extraordinaire et, en 2022, Android et iOS l'envoyaient, comme le montre une étude faite pendant une réunion RIPE.
Un dernier mot : le RFC 2563 prévoyait une option pour couper l'auto-configuration des adresses IPv4. Elle peut être utilisée en même temps que l'option de notre RFC, qu'elle complète assez bien.
L'article seul
RFC 8937: Randomness Improvements for Security Protocols
Date de publication du RFC : Octobre 2020
Auteur(s) du RFC : C. Cremers (CISPA Helmholtz Center for Information Security), L. Garratt (Cisco Meraki), S. Smyshlyaev (CryptoPro), N. Sullivan, C. Wood (Cloudflare)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF cfrg
Première rédaction de cet article le 17 octobre 2020
Tout le monde sait désormais que la génération de nombres aléatoires (ou, plus rigoureusement, de nombres imprévisibles, pseudo-aléatoires) est un composant crucial des solutions de sécurité à base de cryptographie, comme TLS. Les failles des générateurs de nombres pseudo-aléatoires, ou bien les attaques exploitant une faiblesse de ces générateurs sont les problèmes les plus fréquents en cryptographie. Idéalement, il faut utiliser un générateur sans défauts. Mais, parfois, on n'a pas le choix et on doit se contenter d'un générateur moins satisfaisant. Ce nouveau RFC décrit un mécanisme qui permet d'améliorer la sécurité de ces générateurs imparfaits, en les nourrissant avec des clés privées.
Un générateur de nombres pseudo-aléatoires cryptographique (CSPRNG, pour Cryptographically-Strong PseudoRandom Number Generator) produit une séquence de bits qui est indistinguable d'une séquence aléatoire. Un attaquant qui observe la séquence ne peut pas prédire les bits suivants.
On les nomme générateur pseudo-aléatoires car un générateur réellement aléatoire devrait être fondé sur un phénomène physique aléatoire. Un exemple classique d'un tel phénomène, dont la théorie nous dit qu'il est réellement aléatoire, est la désintégration radioactive. Des exemples plus pratiques sont par exemple des diodes forcées de produire un bruit blanc (comme dans le Cryptech). (Ou alors un chat marchant sur le clavier ?) Mais, en pratique, les ordinateurs se servent de générateurs pseudo-aléatoires, ce qui suffit s'ils sont imprévisibles à un observateur extérieur.
Beaucoup de solutions de sécurité,
même en l'absence de cryptographie, dépendent de cette propriété
d'imprévisibilité. Ainsi, TCP, pour protéger contre un attaquant aveugle
(situé en dehors du chemin du paquet), a besoin de numéros de
séquence initiaux qui soient imprévisibles (RFC 5961). Et la cryptographie consomme
énormément de ces nombres pseudo-aléatoires. Ainsi, TLS (RFC 9846) se sert de tels nombres à de nombreux endroits, par
exemple les numniques utilisés dans le
ClientHello, sans compter les nombres
pseudo-aléatoires utilisés lors de la génération des clés de
session. La plupart des autres protocoles de
chiffrement dépendent de tels nombres que
l'attaquant ne peut pas prévoir.
Réaliser un générateur pseudo-aléatoire sur une machine aussi déterministe qu'un ordinateur n'est pas facile, en l'absence de source quantique comme un composant radioactif. (Cf. RFC 4086.) La solution adoptée la plus simple est d'utiliser une fonction qui calcule une séquence de nombres pseudo-aléatoires d'une manière que, même en observant la séquence, on ne puisse pas deviner le nombre suivant (la mathématique fournit plusieurs fonctions pour cela). Comme l'algorithme est en général connu, et que l'ordinateur est déterministe, s'il connait le premier nombre, la graine, un observateur pourrait calculer toute la séquence. La graine ne doit donc pas être connue des observateurs extérieurs. Elle est par exemple calculée à partir d'éléments qu'un tel observateur ne connait pas, comme des mouvements physiques à l'intérieur de l'ordinateur, ou bien provoqués par l'utilisateur.
De tels générateurs pseudo-aléatoires sont très difficiles à réaliser correctement et, en cryptographie, il y a eu bien plus de failles de sécurité dues à un générateur pseudo-aléatoire que dues aux failles des algorithmes de cryptographie eux-mêmes. L'exemple le plus fameux était la bogue Debian, où une erreur de programmation avait réduit drastiquement le nombre de graines possibles (l'entropie). Un autre exemple amusant est le cas du générateur cubain qui oubliait le chiffre 9.
Mais le générateur pseudo-aléatoire peut aussi être affaibli délibérement, pour faciliter la surveillance, comme l'avait fait le NIST, sur ordre de la NSA, en normalisant le générateur Dual-EC avec une faille connue.
Obtenir une graine de qualité est très difficile, surtout sur des appareils ayant peu de pièces mobiles, donc peu de mouvements physiques qui pourraient fournir des données aléatoires. Un truc avait déjà été proposé : combiner la graine avec la clé privée utilisée pour la communication (par exemple en prenant un condensat de la concaténation de la graine avec la clé privée, pour faire une graine de meilleure qualité), puisque la clé privée est secrète. L'idée vient du projet Naxos. (Cela suppose bien sûr que la clé privée n'ait pas été créée par la source qu'on essaie d'améliorer. Elle peut par exemple avoir été produite sur un autre appareil, ayant davantage d'entropie.) Le problème de cette approche avec la clé privée, est que les clés privées sont parfois enfermées dans un HSM, qui ne les laisse pas sortir.
La solution proposée par notre RFC est de ne pas utiliser directement la clé secrète, mais une signature de la graine. C'est une valeur qui est imprévisible par un observateur, puisqu'elle dépend de la clé privée, que l'attaquant ne connait pas. Ainsi, on peut obtenir une séquence de nombres pseudo-aléatoires que l'observateur ne pourra pas distinguer d'une séquence réellement aléatoire, même si la graine initiale n'était pas terrible.
L'algorithme exact est formulé dans la section 3 du RFC. Le Nième nombre pseudo-aléatoire est l'expansion (RFC 5869, section 2.3) de l'extraction (RFC 5869, section 2.2) d'un condensat de la signature d'une valeur qui ne change pas à chaque itération de la séquence, ce qui fait que cet algorithme reste rapide. (J'ai simplifié, il y a d'autres paramètres, notamment la valeur « normale » de la séquence, initiée à partir de la graine.) La signature doit évidemment être secrète (sinon, on retombe dans le générateur pseudo-aléatoire d'avant ce RFC). La fonction de signature doit être déterministe (exemple dans le RFC 6979). La « valeur qui ne change pas à chaque itération » peut, par exemple (section 4 du RFC) être l'adresse MAC de la machine mais attention aux cas de collisions (entre VM, par exemple). Une autre valeur constante est utilisée par l'algorithme et peut, par exemple, être un compteur, ou bien l'heure de démarrage. Ces deux valeurs n'ont pas besoin d'être secrètes.
Une analyse de sécurité de ce mécanisme a été faite dans l'article « Limiting the impact of unreliable randomness in deployed security protocols ». Parmi les points à surveiller (section 9), la nécessité de bien garder secrète la signature, ce qui n'est pas toujours évident notamment en cas d'attaque par canal auxiliaire.
À propos de générateurs pseudo-aléatoires, je vous recommande cet article très détaillé en français sur la mise en œuvre de ces générateurs sur Linux.
Merci à Kim Minh Kaplan pour une bonne relecture.
L'article seul
Fiche de lecture : Le mandat
Auteur(s) du livre : Ousmane Sembène
Éditeur : Présence africaine
978-2-7087-0170-0
Publié en 1966
Première rédaction de cet article le 14 octobre 2020
Ce petit livre rassemble deux longues nouvelles de Sembène, « Le mandat » et « Véhi-Ciosane », toutes les deux situées dans le Sénégal des années 1960.
Dans « Le mandat », le héros, qui est pauvre, reçoit de l'argent et tout de suite, plein de parasites essaient d'en obtenir une part. La nouvelle fait défiler toute une galerie de personnages de Dakar et voit le héros se confronter à la difficulté de toucher un mandat quand on n'est pas déjà bancarisé. De nombreux rebondissements tragi-comiques ponctuent l'histoire.
La nouvelle « Véhi-Ciosane » (« Blanche Genèse ») se passe par contre à la campagne et est un portrait assez cruel de certaines mœurs.
L'auteur a dû ajouter une préface d'explication parce que certains lui reprochaient de donner une mauvaise image de l'Afrique. En Afrique comme ailleurs, il y a des gens qui ne comprennent pas que, parce qu'un personnage de roman est négatif, cela ne veut pas dire que l'auteur déteste tout son pays ou tout son continent. Reprocher à Sembène Ousmane de donner une mauvaise image des Africains serait tout aussi absurde que de reprocher à Maupassant (le monde de « Véhi-Ciosane » me fait beaucoup penser à Maupassant) de donner une mauvaise image des Français !
Les deux nouvelles ont été adaptées au cinéma par l'auteur, « Véhi-Ciosane » sous le titre de « Niaye » et « Le mandat » sous le même titre, mais je n'ai pas eu l'occasion de voir ces films.
L'article seul
Fiche de lecture : The infinite machine
Auteur(s) du livre : Camila Russo
Éditeur : Harper Collins
978-0-06-288614-9
Publié en 2020
Première rédaction de cet article le 7 octobre 2020
Ce livre est une passionnante histoire d'Ethereum, la plus importante chaîne de blocs en nombre de nœuds (oui, devant Bitcoin, qui est plus concentré). Ethereum permet non seulement la circulation de monnaie, mais également l'exécution de programmes (d'où le titre du livre). La journaliste Camila Russo, qui a écrit de nombreux articles sur les cryptomonnaies, connait bien le monde Ethereum qu'elle suit depuis longtemps, et était donc toute désignée pour ce premier livre d'histoire d'Ethereum, une histoire toute récente puisque la plupart des événements cités se sont déroulés entre 2014 et 2018.
Il se trouve que je possède moi-même quelques ethers (la monnaie d'Ethereum) et que j'ai suivi de près certaines étapes du développement d'Ethereum (comme l'attaque contre The DAO), donc j'ai pu comparer certaines parties du livres avec ce que j'avais vu passer. Même si le ton journalistique est parfois un peu agaçant, le livre est bien documenté, l'auteure connait son sujet et je recommande donc le livre. On y croise plein de personnages pittoresques, à commencer par l'étonnant Vitalik Buterin, le principal concepteur d'Ethereum. On pense forcément au film The Social Network (ah, les descriptions people de la maison à Zoug où tout le monde travaillait ensemble en fumant des joints…). Le livre parlera surtout à tous les gens intéressés par l'innovation technologique et ses conséquences sociales.
Car, dès qu'il s'agit de cryptomonnaies, il est difficile de séparer la technique et la politique. Si toute technologie a des conséquences politiques, dans le cas des cryptomonnaies, la politique est souvent explicite. L'auteure a des sympathies claires pour le capitalisme (elle a travaillé chez Bloomberg, média d'information orienté business) et, parlant des crises économiques en Argentine, elle répète que c'est à cause de politiques « populistes », c'est-à-dire sociales. Mais, indépendamment des opinions politiques de l'auteure, le livre est l'occasion de réfléchir sur la monnaie et l'État. Les acteurs d'Ethereum sont très divisés, de ceux qui veulent plutôt changer le monde à ceux qui veulent juste gagner de l'argent, et, parmi les premiers, il ne manque pas de diversité. L'auteure les estime moins à droite que les acteurs du monde Bitcoin (« dans les réunions Bitcoin, c'est plutôt carnivore, dans celles d'Ethereum, davantage végétarien ») mais c'est compliqué. Une partie du développement d'Ethereum a été fait dans des squats anarchistes, une autre partie dans les garages chers aux startupeurs. Il serait bien difficile de classer politiquement tout le monde Ethereum (et l'auteure n'aide pas toujours en confondant parfois anarchiste et libertarien).
Comme beaucoup de projets sur la chaîne de blocs, ou d'ailleurs comme beaucoup de projets innovants, Ethereum a connu des hauts très hauts et des bas très bas, passant de moments d'euphorie où de nombreux développeurs géniaux étaient prêts à travailler gratuitement sans limite de temps, à des moments de déprime où les discours négatifs semblaient prendre le dessus. Le sommet avait sans doute été les nombreuses ICO de 2016-2018 où l'argent coulait à flot vers Ethereum, alors que certaines de ces ICO étaient des pures escroqueries, et que beaucoup d'autres étaient complètement irréalistes dans leurs prévisions. Aujourd'hui, Ethereum tourne toujours, a des projets, et suscite moins d'intérêt ce qui peut être vu comme un avantage : on bosse mieux sans pression. Le livre se termine donc sur une non-conclusion.
J'ai parlé d'Ethereum dans plusieurs articles, en voici la liste.
L'article seul
RFC 8886: Secure Device Install
Date de publication du RFC : Septembre 2020
Auteur(s) du RFC : W. Kumari (Google), C. Doyle
(Juniper Networks)
Pour information
Réalisé dans le cadre du groupe de travail IETF opsawg
Première rédaction de cet article le 6 octobre 2020
Quand vous êtes opérateur réseau et que vous avez à installer une nouvelle machine, par exemple un routeur, dans un centre de données lointain, vous avez deux solutions : envoyer un employé faire l'installation sur place, ce qui peut être coûteux, ou bien demander à la société qui gère le centre de données de le faire pour vous, ce qui n'est pas forcément génial question sécurité, puisque, selon la façon dont c'est fait, ils auront peut-être la possibilité de regarder ou de bricoler la configuration de la machine. Ce nouveau RFC propose un moyen simple d'améliorer la sécurité dans le deuxième cas, en chiffrant un fichier de configuration avec la clé publique de la machine. Celle-ci pourra le déchiffrer après téléchargement, en utilisant sa clé privée. (Cette solution nécessitera donc un changement des équipements pour que chacun ait une paire clé publique / clé privée.)
Précisons la question à résoudre. Ce problème est une variante d'un problème bien classique en informatique, celui du bootstrap. Par exemple, si la nouvelle machine est protégée par un mot de passe, il faut bien rentrer ce mot de passe la première fois. Si c'est un employé du centre de données qui le fait, il connaitra le mot de passe. Et si on le change juste après ? Rien ne dit qu'il n'aura pas laissé une porte dérobée. Il n'y a pas de solution générale et simple à ce problème. Notre RFC se contente d'une solution partielle, qui améliore la sécurité.
On va donc s'imaginer à la place de la société Machin, un gros opérateur réseau dont l'essentiel des équipes est à Charleville-Mézières (pourquoi pas ?). La société a des POP dans beaucoup d'endroits, et la plupart du temps dans ces centres de données qu'elle ne contrôle pas, où elle loue juste de l'espace. Comme les équipements réseau tombent parfois en panne, ou, tout simplement, ne parviennent plus à gérer le trafic toujours croissant, la société doit de temps en temps installer de nouveaux matériels, routeurs, commutateurs, etc. Si le centre de données où il faut installer est proche de Charleville-Mézières, tout va bien : un employé de l'opérateur Machin se rend sur place, le fabricant du routeur a déjà livré la nouvelle machine, il n'y a plus qu'à la racker et à la configurer (« Enter the password for the administrative account ») ou, en tout cas, faire une configuration minimale qui permettra de faire ensuite le reste via SSH, RESTCONF (RFC 8040) ou une autre technique d'administration à distance.
Mais supposons que la machine à installer, mettons que ce soit un gros routeur, doive être placé chez un centre de données éloigné, mettons Singapour (exemple choisi parce que c'est vraiment loin). Même avant la pandémie de Covid-19, un voyage à Singapour n'était guère raisonnable, du point de vue du temps passé, et du point de vue financier. Mais les centres de données ont tous un service d'action à distance (remote hands) où un employé de la société qui gère le centre peut appuyer sur des boutons et taper des commandes, non ? C'est en effet très pratique, mais ce service est limité à des cas simples (redémarrer…) et pas à une configuration complète. Celle-ci poserait de toute façon un problème de sécurité car l'employé en question aurait le contrôle complet de la machine pendant un moment.
(Une autre solution, apparemment non mentionnée dans le RFC, est que le fabricant du routeur livre à Charleville-Mézières l'appareil, qui soit alors configuré puis envoyé à Singapour. Mais cela impose deux voyages.)
Bon, et une solution automatique ? La machine démarre, acquiert une adresse IP, par exemple par DHCP (RFC 2131 et RFC 9915), et charge sa configuration sous forme d'un fichier récupéré, par exemple avec TFTP (RFC 1350). Mais cette configuration peut contenir des informations sensibles, par exemple des secrets RADIUS (RFC 2865). TFTP n'offre aucune sécurité et ce n'est pas très rassurant que de laisser ces secrets se promener en clair dans le centre de données singapourien. Il existe des contournements variés et divers pour traiter ces cas, mais aucun n'est complètement satisfaisant.
Bref, le cahier des charges de notre RFC est un désir de confidentialité des configurations du nouveau routeur. (Il y a une autre question de sécurité importante, l'authenticité de cette configuration, mais elle n'est pas traitée dans ce RFC. Des solutions, un peu complexes, existent, comme SZTP - RFC 8572 ou BRSKI - RFC 8995.) La solution présentées dans notre RFC n'est pas complète. Elle améliore les procédures d'installation (voir par exemple la documentation de celle de Cisco) mais ne prétend pas résoudre tout le problème.
Ce RFC ne spécifie pas un protocole, mais décrit une méthode, que chaque constructeur d'équipements réseau devra adapter à ses machines et à leurs particularités. Cette méthode est conçue pour ces équipements (routeurs et commutateurs, notamment), mais pourrait être adaptée à des engins comme les serveurs. Mais en attendant, ce RFC se focalise sur le matériel réseau.
La section 2 du RFC résume la solution. Elle nécessite que la machine à configurer ait un mécanisme de démarrage automatique de l'installation (autoinstall ou autoboot dans les documentations), permettant d'obtenir une adresse IP (typiquement avec DHCP) puis de récupérer un fichier de configuration (typiquement avec TFTP mais cela peut être HTTP ou un autre protocole de transfert de fichiers, les options DHCP 66 - Server-Name - ou 150 - TFTP server address pouvant être utilisées pour indiquer le serveur). Le nom du fichier est par exemple issue de l'option DHCP 67 - Bootfile-Name.
La méthode nécessite un identificateur, comme le numéro de série ou bien l'adresse MAC de l'équipement réseau qui est en cours d'installation. (Rien n'interdit d'utiliser un autre identificateur, par exemple un UUID - RFC 9562, mais l'avantage du numéro de série est qu'il est en général marqué sur la machine et facilement accessible, donc la personne dans le centre de données à Singapour peut le lire et le transmettre à la société Machin.)
Le RFC donne un exemple concret. La société Machin commande un nouveau routeur à un fabricant de routeur, mettons Truc, en indiquant l'adresse de livraison à Singapour. Truc doit indiquer à Machin le numéro de série de l'engin. Et il faut qu'une paire clé publique / clé privée spécifique à cet engin soit générée, la clé publique étant communiquée à l'acheteur (Machin). [Cette étape est l'une des deux seules que ne font pas les routeurs actuels.] Pendant que le routeur voyage vers Singapour, un employé de Machin prépare la configuration du routeur, et la chiffre avec la clé publique de ce routeur particulier. Puis il la place sur le serveur de fichiers, indexée par le numéro de série. Les employés du centre de données mettent le routeur dans l'armoire et le câblent. Le routeur démarre et voit qu'il n'a pas encore été configuré. Il récupère une adresse IP puis contacte le serveur de fichiers. Il récupère la configuration, la déchiffre [deuxième étape qui n'est pas encore mise en œuvre dans un routeur typique d'aujourd'hui] et l'installe. Désormais, le routeur est autonome. Les équipes de l'opérateur Machin peuvent le contacter par les moyens habituels (SSH, par exemple). Un éventuel attaquant pourra regarder le trafic ou, plus simplement, demander le fichier de configuration au serveur de fichiers, mais il ne pourra pas le déchiffrer.
Cette solution ne nécessite que peu de changements aux mécanismes d'aujourd'hui. La section 3 du RFC décrit ce que les fabricants de routeurs devront faire, pour qu'elle soit disponible. Le routeur devra disposer d'une paire clé publique / clé privée, générée lors de sa fabrication. Et le fabricant doit pouvoir accéder à cette clé facilement (les clés cryptographiques ne peuvent typiquement pas être affichées sur un petit écran LCD…), afin de la communiquer à l'acheteur. (On peut aussi envisager le RFC 7030 ou bien le RFC 8894.) Le fabricant de routeurs doit avoir un mécanisme de communication de ces clés au client. (Comme il s'agit de clés publiques, il n'est pas indispensable que ce soit un mécanisme confidentiel, mais il faut évidemment qu'un tiers ne puisse pas y ajouter des clés de son choix.) Le RFC recommande X.509 (RFC 5280) comme format pour ces clés, même s'il n'y a pas forcément besoin des méta-données de X.509 comme la date d'expiration.
Et le client, l'acheteur du routeur ? La section 4 décrit ce qu'il doit faire. Il faut réceptionner et transmettre le numéro de série du routeur (typiquement, cela veut dire une communication entre le service Achats et les Opérations, ce qui n'est pas toujours facile), puis récupérer la clé publique. Et enfin, il faut chiffrer la configuration (le RFC suggère S/MIME - RFC 5751).
Quelques détails supplémentaires figurent en section 5. Par exemple, si le routeur le permet (il faut du haut de gamme…), la clé privée peut être stockée dans un TPM. (Le RFC suggère également de jeter un œil à la Secure Device Identity de la norme IEEE Std 802-1AR.)
Et la section 7 du RFC revient sur la sécurité de ce mécanisme. Il sera de toute façon toujours préférable à la solution actuelle, qui est de transmettre la configuration en clair. Mais cela ne veut pas dire que tout soit parfait. Ainsi, un attaquant qui a un accès physique à la machine pendant son trajet, ou bien une fois qu'elle est arrivée dans le centre de données, peut extraire la clé privée (sauf si elle est stockée dans un TPM) et déchiffrer à loisir.
On a dit au début que le but de ce RFC n'était pas de trouver un moyen d'authentifier la configuration. (Une signature ne serait pas réaliste, car il y a peu de chances que le fabricant mette les clés publiques de chaque opérateur dans le routeur.) Un attaquant qui contrôle, par exemple, le réseau sur lequel se trouve l'équipement réseau qui se configure, peut donc diriger les requêtes TFTP vers un serveur de son choix et envoyer une configuration « pirate » à cet équipement. (Il peut même la chiffrer puisque la clé publique de l'équipement sera sans doute facilement accessible publiquement, pour faciliter la tâche du client.)
Et, bien sûr, rien ne protège contre un vendeur malhonnête. Si le fabricant du routeur ou du commutateur est malveillant (ou piraté par un de ses employés, ou par un pirate extérieur), il peut tout faire. C'est le problème de la supply chain en sécurité, et il est très difficile à résoudre. (Cf. les craintes concernant les pratiques de Huawei mais il serait naïf de penser que seuls les fabricants chinois soient malhonnêtes. Voyez aussi mon article sur les portes dérobées dans les routeurs.)
Si vous aimez le concret, l'annexe A du RFC donne les commandes
OpenSSL pour effectuer les différentes
manipulations décrites par ce RFC. (J'ai modifié les commandes du
RFC, qui ne marchaient pas pour moi.) Le fabricant du routeur va
d'abord générer la paire de clés sur le routeur, la clé publique
étant ensuite emballée dans un certificat
(SN19842256 étant le numéro de série du
routeur), et auto-signer :
% openssl req -new -nodes -newkey rsa:2048 -keyout key.pem -out SN19842256.csr ... Common Name (e.g. server FQDN or YOUR name) []:SN19842256 ... % openssl req -x509 -days 36500 -key key.pem -in SN19842256.csr -out SN19842256.crt
L'opérateur réseau va fabriquer un fichier de configuration (ici, trivial) :
% echo 'Test: true' > SN19842256.cfg
Ensuite, récupérer la clé (SN19842256.crt) et
chiffrer la configuration :
% openssl smime -encrypt -aes-256-cbc -in SN19842256.cfg -out SN19842256.enc -outform PEM SN19842256.crt % cat SN19842256.enc -----BEGIN PKCS7----- MIIB5gYJKoZIhvcNAQcDoIIB1zCCAdMCAQAxggGOMIIBigIBADByMFoxCzAJBgNV BAYTAkFVMRMwEQYDVQQIDApTb21lLVN0YXRlMSEwHwYDVQQKDBhJbnRlcm5ldCBX ...
On copie ensuite la configuration chiffrée sur le serveur de fichiers.
Lorsque le routeur démarre, il charge ce fichier et exécute une commande de déchiffrement :
% openssl smime -decrypt -in SN19842256.enc -inform PEM -out config.cfg -inkey key.pem % cat config.cfg Test: true
Pour l'instant, aucun fabricant de routeur ne semble avoir annoncé une mise en œuvre de ce RFC. Comme le RFC décrit un mécanisme générique, et pas un protocole précis, les détails dépendront sans doute du vendeur.
L'article seul
La question de la 5G mérite-t-elle autant de passions ?
Première rédaction de cet article le 1 octobre 2020
Dans une société démocratique, les controverses ne manquent pas. Dans l'espace public, on discute de plein de sujets, et chacun a son opinion, qui est légitime par définition, dans une démocratie. Cette variété d'opinions sur un même sujet a souvent été remarquée, analysée et discutée. Mais il y a eu moins de temps consacré à analyser pourquoi, sur certains sujets de controverse socio-technique, la machine politico-médiatique se met en marche, en accentuant et en caricaturant à la fois le sujet et les arguments déployés, alors que pour d'autres sujets, tout aussi importants, et où les positions ne sont pas moins diverses et reposant sur des arguments variés, cette machine se met peu ou pas en marche et le sujet reste l'apanage de cercles spécifiques d'acteurs.
Pourtant, on sait bien que, parfois, ce ne sont pas les réponses proposées (et divergentes) qui sont vraiment importantes, mais les questions. Ainsi, avoir des controverses sur « l'immigration » plutôt que, par exemple, sur « le chômage » n'est pas neutre. Quelles que soient les réponses données à ces questions, le fait d'avoir posé le débat sur un de ces terrains plutôt que sur l'autre est déjà un choix politique. Ce « choix » n'est pas forcément délibéré, il peut être le résultat de dynamiques que les acteurs eux-mêmes ne maitrisent pas. Mais il a des conséquences pratiques : en matière de temps disponible, bien sûr, d'autant plus que les sujets complexes nécessitent de passer du temps à lire, à réfléchir, à discuter. Si un sujet est mis en avant, cela fera forcément moins de temps pour décider démocratiquement des autres. Et il y a aussi des conséquences en matière de visibilité. Si un citoyen ou une citoyenne ne sait pas trop quels sont les sujets importants du jour, il considérera forcément les « grands sujets », âprement débattus publiquement, comme étant les seuls qui valent la peine. Enfin, la seule mise en avant d'un sujet de controverse a déjà des conséquences idéologiques, en avalisant les présupposés derrière ce sujet (par exemple, sur l'immigration, le fait que les immigrés soient un problème).
Ce raisonnement peut aussi s'appliquer au débat actuel sur l'ensemble des techniques de réseau mobile connues sous le nom de « 5G ». Ne discutons pas ici de savoir si le déploiement de la 5G est une bonne ou une mauvaise chose. Intéressons-nous plutôt à « pourquoi ce débat ? » Pourquoi est-ce que la machine de la « grande controverse » s'est mise en route pour la 5G ?
Pas question de considérer ce débat comme inutile ou néfaste parce qu'il a une forte composante technique. Cet aspect technique crucial nécessite certes que les participantes et participants fassent un effort d'éducation et de compréhension du problème. Mais il n'élimine pas la légitimité de tous et toutes à y participer : les techniques jouent un rôle crucial dans l'infrastructure de notre société, et ont certainement vocation à être débattues publiquement et démocratiquement. Mais on pourrait dire la même chose de plein d'autres techniques qui jouent un rôle crucial aujourd'hui. Alors, pourquoi la 5G ?
Certains pourraient dire que c'est parce que c'est une technique révolutionnaire, qui va changer en profondeur de nombreux aspects de notre société. Cet argument du caractère profondément disruptif de la 5G est souvent mis en avant par ses promoteurs commerciaux et, curieusement, souvent accepté sans critique par les détracteurs de la 5G. La vérité est que la 5G ne va pas être une révolution. C'est juste une technique d'accès au réseau, les applications sont les mêmes (regarder Netflix, lire Wikipédia, y contribuer…). Ainsi, les performances supérieures (en latence et en capacité) ne se traduiront pas forcément par un gain pour les usages, puisque le goulet d'étranglement n'est pas forcément l'accès radio. Toute personne étant passé de la 3G à la 4G (ou de l'ADSL à la fibre) a pu constater que le gain dans le réseau d'accès n'est pas forcément très visible lorsqu'on interagit avec des services Internet lointains et/ou lents.
Ainsi, beaucoup d'arguments entendus contre la 5G n'ont en fait rien de spécifique à la 5G :
- les risques pour la vie privée ne changent pas : qu'on accède à Facebook en 4G ou en 5G, cette entreprise récoltera autant de données,
- les caméras de vidéosurveillance existent déjà, sans avoir besoin de la 5G,
- les objets connectés, qui envoient massivement à leur fabricant des données personnelles sur les utilisateurs, existent également depuis un certain temps, la 5G ne va pas les multiplier,
- quant aux risques écologiques et environnementaux, on ne peut hélas pas dire qu'ils sont apparus avec la 5G.
Mais peut-être un changement quantitatif (performances supérieures, même si elles ne le seront pas autant que ce que raconte le marketing) va-t-il déclencher un changement qualitatif en rendant trivial et/ou facile ce qui était difficile avant ? Peut-être. De tels sauts se sont déjà produits dans l'histoire des systèmes socio-techniques. Mais souvent, également, la montagne a accouché d'une souris. Les tendances lourdes de l'Internet, bonnes ou mauvaises, n'ont pas été bouleversées par le déploiement de la fibre optique, par exemple.
Il est curieux, par contre, de constater que les vraies nouveautés de la 5G sont en général absentes du débat. Ainsi, le « network slicing », qui permet d'offrir plusieurs réseaux virtuels sur un accès physique, est un changement important. Ses conséquences peuvent être sérieuses, notamment parce qu'il peut faciliter des violations de la neutralité de l'Internet, avec une offre de base, vraiment minimale, et des offres « améliorées » mais plus chères. Mais ce point ne semble jamais mentionné dans les débats sur la 5G, alors que la neutralité du réseau est à la fois un élément crucial pour le citoyen utilisateur de l'Internet, et qu'elle est menacée en permanence.
Bien sûr, chacun est libre de trouver que tel sujet est plus important que tel autre. De même qu'il ne peut pas y avoir d'unanimité sur les réponses, il n'y aura pas d'unanimité sur les questions. Néanmoins, il est frappant de constater que certains sujets semblent plus porteurs, sans qu'on puisse trouver une base objective à l'importance qu'ils ont dans le débat public. Tout homme (ou femme) politique en France aujourd'hui se sent obligé d'avoir un avis sur la 5G, qu'il ou elle ait étudié le sujet ou pas. On voit l'argument de la vie privée être avancé, alors que la 5G ne change pas grand'chose à cette question, par des personnes qui ne s'étaient pas signalées jusqu'à présent par une grande sensibilité à cette question, pourtant cruciale sur l'Internet.
Alors, pourquoi est-ce que le thème de la 5G est un tel succès ? Si on était d'humeur complotiste, on pourrait penser que c'est parce qu'il est bien pratique pour éviter des débats gênants sur la neutralité de l'Internet, la vie privée sur le Web, la surveillance et l'érosion des libertés. Mais on pourrait aussi mettre l'accent sur des facteurs liés au récit : « les ondes » font peur, la propagande pro-5G, par son côté ridicule et exagéré (les opposants assimilés aux Amish…), a braqué beaucoup de monde, la tentation de simplifier les problèmes complexes à une seule cause (la 5G cause le cancer, le réchauffement planétaire, et fait disparaitre la vie privée) est toujours forte. Ce sont probablement des raisons de ce genre qui expliquent le « succès » de la controverse sur la 5G. La 4G avait suscité le même genre de controverses, bien oubliées aujourd'hui, et sans doute pour les mêmes raisons.
D'autres sujets ont vu des controverses animées, mais pas forcément aussi spectaculaires. Si la technologie de la chaîne de blocs a connu un certain succès médiatique, c'était en bonne partie à cause de la réputation sulfureuse du Bitcoin, réputation soigneusement entretenue par les médias. On n'a toutefois pas vu, contrairement au cas de la 5G, de manifestations de rue ou de déclarations de députés sur la chaîne de blocs.
Encore moins de succès pour des sujets pourtant cruciaux comme la domination de certains acteurs privés du logiciel sur des services publics essentiels. C'est ainsi que les différents accords étatiques avec Microsoft, pour l'éducation, la santé ou pour les armées n'ont suscité que l'intérêt d'une poignée de militants libristes alors que ces accords structurent le fonctionnement de l'État. Mais ces controverses sont moins spectaculaires et permettent moins de postures « humanistes ».
[Article réalisé avec la participation de Francesca Musiani].
L'article seul
RFC 8915: Network Time Security for the Network Time Protocol
Date de publication du RFC : Septembre 2020
Auteur(s) du RFC : D. Franke (Akamai), D. Sibold, K. Teichel (PTB), M. Dansarie, R. Sundblad (Netnod)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF ntp
Première rédaction de cet article le 1 octobre 2020
Ce nouveau RFC spécifie un mécanisme de sécurité pour le protocole de synchronisation d'horloges NTP. Une heure incorrecte peut empêcher, par exemple, de valider des certificats cryptographiques. Ou fausser les informations enregistrées dans les journaux. Ce mécanisme de sécurité NTS (Network Time Security) permettra de sécuriser le mode client-serveur de NTP, en utilisant TLS pour négocier les clés cryptographiques qui serviront à chiffrer le trafic NTP ultérieur..
La sécurité n'était pas jugée trop importante au début de NTP : après tout, l'heure qu'il est n'est pas un secret. Et il n'y avait pas d'application cruciale dépendant de l'heure. Aujourd'hui, les choses sont différentes. NTP est un protocole critique pour la sécurité de l'Internet. NTP a quand même un mécanisme de sécurité, fondé sur des clés secrètes partagées entre les deux pairs qui communiquent. Comme tout mécanisme à clé partagée, il ne passe pas à l'échelle, d'où le développement du mécanisme « Autokey » dans le RFC 5906. Ce mécanisme n'a pas été un grand succès et un RFC a été écrit pour préciser le cahier des charges d'une meilleure solution, le RFC 7384. La sécurité de l'Internet repose de plus en plus que l'exactitude de l'horloge de la machine. Plusieurs systèmes de sécurité, comme DNSSEC ou X.509 doivent vérifier des dates et doivent donc pouvoir se fier à l'horloge de la machine. Même criticité de l'horloge quand on veut coordonner une smart grid, ou tout autre processus industriel, analyser des journaux après une attaque, assurer la traçabilité d'opérations financières soumises à régulation, etc. Or, comme l'explique bien le RFC 7384, les protocoles de synchronisation d'horloge existants, comme NTP sont peu ou pas sécurisés. (On consultera également avec profit le RFC 8633 qui parle entre autre de sécurité.)
Sécuriser la synchronisation d'horloge est donc crucial aujourd'hui. Cela peut se faire par un protocole extérieur au service de synchronisation, comme IPsec, ou bien par des mesures dans le service de synchronisation. Les deux services les plus populaires sont NTP (RFC 5905) et PTP. Aucun des deux n'offre actuellement toutes les fonctions de sécurité souhaitées par le RFC 7384. Mais les protocoles externes ont un inconvénient : ils peuvent affecter le service de synchronisation. Par exemple, si l'envoi d'un paquet NTP est retardé car IKE cherche des clés, les mesures temporelles vont être faussées. Le paquet arrivera intact mais n'aura pas la même utilité.
Les menaces contre les protocoles de synchronisation d'horloge sont décrites dans le RFC 7384. Les objectifs de notre RFC sont d'y répondre, notamment :
- Permettre à un client d'authentifier son maître, via X.509 tel que l'utilise TLS,
- Protéger ensuite l'intégrité des paquets (via un MAC).
- En prime, mais optionnel, assurer la confidentialité du contenu des paquets.
- Empêcher la traçabilité entre les requêtes d'un même client (si un client NTP change d'adresse IP, un observateur passif ne doit pas pouvoir s'apercevoir qu'il s'agit du même client).
- Et le tout sans permettre les attaques par réflexion qui ont souvent été un problème avec NTP.
- Passage à l'échelle car un serveur peut avoir de très nombreux clients,
- Et enfin performances (RFC 7384, section 5.7).
Rappelons que NTP dispose de plusieurs modes de fonctionnement
(RFC 5905, section 3). Le plus connu et sans
doute le plus utilisé est le mode client-serveur (si vous faites sur
Unix un ntpdate
ntp.nic.fr, c'est ce mode que vous utilisez). Mais il y
aussi un mode symétrique, un mode à diffusion et le « mode » de contrôle
(dont beaucoup de fonctions ne sont pas normalisées). Le mode
symétrique est sans doute celui qui a le plus d'exigences de
sécurité (les modes symétriques et de contrôle de NTP nécessitent
notamment une protection réciproque contre le
rejeu, qui nécessite de maintenir un état de
chaque côté) mais le mode client-serveur est plus répandu, et pose
des difficultés particulières (un serveur peut avoir beaucoup de
clients, et ne pas souhaiter maintenir un état par client). Notre
RFC ne couvre que le mode client-serveur. Pour ce mode, la solution
décrite dans notre RFC 8915 est d'utiliser TLS afin que
le client authentifie le serveur, puis d'utiliser cette session TLS
pour générer la clé qui servira à sécuriser du NTP classique, sur
UDP. Les serveurs
NTP devront donc désormais également écouter en TCP, ce qu'ils ne
font pas en général pas actuellement. La partie TLS de NTS
(Network Time Security, normalisé dans ce RFC) se
nomme NTS-KE (pour Network Time Security - Key
Exchange). La solution à deux protocoles peut sembler
compliquée mais elle permet d'avoir les avantages de TLS (protocole
éprouvé) et d'UDP (protocole rapide).
Une fois qu'on a la clé (et d'autres informations utiles, dont les cookies), on ferme la session TLS, et on va utiliser la cryptographie pour sécuriser les paquets. Les clés sont dérivées à partir de la session TLS, suivant l'algorithme du RFC 5705. Quatre nouveaux champs NTP sont utilisés pour les paquets suivants (ils sont présentés en section 5), non TLS. Dans ces paquets se trouve un cookie qui va permettre au serveur de vérifier le client, et de récupérer la bonne clé. Les cookies envoyés du client vers le serveur et en sens inverse sont changés à chaque fois, pour éviter toute traçabilité, car ils ne sont pas dans la partie chiffrée du paquet. Notez que le format des cookies n'est pas spécifié par ce RFC (bien qu'un format soit suggéré en section 6). Pour le client, le cookie est opaque : on le traite comme une chaîne de bits, sans structure interne.
On a dit que NTS (Network Time Security) utilisait TLS. En fait, il se restreint à un profil spécifique de TLS, décrit en section 3. Comme NTS est un protocole récent, il n'y a pas besoin d'interagir avec les vieilles versions de TLS et notre RFC impose donc TLS 1.3 (RFC 9846) au minimum, ALPN (RFC 7301), les bonnes pratiques TLS du RFC 7525, et les règles des RFC 5280 et RFC 6125 pour l'authentification du serveur.
Passons ensuite au détail du protocole NTS-KE (Network
Time Security - Key Establishment) qui va permettre, en
utilisant TLS, d'obtenir les clés qui serviront au
chiffrement symétrique ultérieur. Il est
spécifié dans la section 4 du RFC. Le serveur doit écouter sur le
port ntske
(4460 par défaut). Le client utilise
ALPN (RFC 7301) pour
annoncer qu'il veut l'application ntske/1. On établit la session TLS, on échange des
messages et on raccroche (l'idée est
de ne pas obliger le serveur à garder une session TLS ouverte pour
chacun de ses clients, qui peuvent être nombreux).
Le format de ces messages est composé d'un champ indiquant le type du message, de la longueur du message, des données du message, et d'un bit indiquant la criticité du type de message. Si ce bit est à 1 et que le récepteur ne connait pas ce type, il raccroche. Les types de message actuels sont notamment :
- Next Protocol Negotiation (valeur 1) qui indique les protocoles acceptés (il n'y en a qu'un à l'heure actuelle, NTP, mais peut-être d'autres protocoles comme PTP suivront, la liste est dans un registre IANA),
- Error (valeur 2) qui indique… une erreur (encore un registre IANA de ces codes d'erreur, qui seront sans doute moins connus que ceux de HTTP),
- AEAD Algorithm Negotiation (valeur 3) ; NTS impose l'utilisation du chiffrement intègre (AEAD pour Authenticated Encryption with Associated Data) et ce type de message permet de choisir un algorithme de chiffrement intègre parmi ceux enregistrés,
- New Cookie (valeur 5), miam, le serveur envoie un cookie, que le client devra renvoyer (sans chercher à la comprendre), ce qui permettra au serveur de reconnaitre un client légitime ; le RFC recommande d'envoyer plusieurs messages de ce type, pour que le client ait une provision de cookies suffisante,
- Server Negotiation (valeur 6) (et Port Negotiation, valeur 7), pour indiquer le serveur NTP avec lequel parler de façon sécurisée, serveur qui n'est pas forcément le serveur NTS-KE.
D'autres types de message pourront venir dans le futur, cf. le registre.
Une fois la négociation faite avec le protocole NTS-KE, tournant sur TLS, on peut passer au NTP normal, avec le serveur indiqué. Comme indiqué plus haut, quatre champs supplémentaires ont été ajoutés à NTP pour gérer la sécurité. Ils sont présentés dans la section 5 de notre RFC. Les clés cryptographiques sont obtenues par la fonction de dérivation (HKDF) du RFC 9846, section 7.5 (voir aussi le RFC 5705). Les clés du client vers le serveur sont différentes de celles du serveur vers le client (ce sont les clés c2s et s2c dans l'exemple avec ntsclient montré plus loin).
Les paquets NTP échangés ensuite, et sécurisés avec NTS, comporteront l'en-tête NTP classique (RFC 5905, section 7.3), qui ne sera pas chiffré (mais sera authentifié), et le paquet original chiffré dans un champ d'extension (cf. RFC 5905, section 7.5, et RFC 7822). Les quatre nouveaux champs seront :
- L'identifiant du paquet (qui sert à détecter le rejeu), il sera indiqué (cf. section 5.7) dans la réponse du serveur, permetant au client de détecter des attaques menées en aveugle par des malfaisants qui ne sont pas situés sur le chemin (certaines mises en œuvre de NTP utilisaient les estampilles temporelles pour cela, mais elles sont courtes, et en partie prévisibles),
- Le cookie,
- La demande de cookies supplémentaires,
- Et le principal, le champ contenant le contenu chiffré du paquet NTP original.
On a vu que le format des cookies n'était pas imposé. Cela n'affecte pas l'interopérabilité puisque, de toute façon, le client n'est pas censé comprendre les cookies qu'il reçoit, il doit juste les renvoyer tels quels. La section 6 décrit quand même un format suggéré. Elle rappelle que les cookies de NTS sont utilisés à peu près comme les cookies de session de TLS (RFC 5077). Comme le serveur doit pouvoir reconnaitre les bons cookies des mauvais, et comme il est préférable qu'il ne conserve pas un état différent par client, le format suggéré permet au serveur de fabriquer des cookies qu'il pourra reconnaitre, sans qu'un attaquant n'arrive à en fabriquer. Le serveur part pour cela d'une clé secrète, changée de temps en temps. Pour le cas un peu plus compliqué où un ou plusieurs serveurs NTP assureraient le service avec des cookies distribués par un serveur NTS-KE séparé, le RFC recommande que les clés suivantes soient dérivées de la première, par un cliquet et la fonction de dérivation HKDF du RFC 5869.
Quelles sont les mises en œuvre de NTS à l'heure actuelle ? La
principale est dans chrony (mais dans le
dépôt git seulement, la version 3.5 n'a pas
encore NTS). chrony est
écrit en C et comprend un
client et un serveur. NTS est compilé par défaut (cela peut être
débrayé avec l'option --disable-nts du script
./configure), si et seulement si les
bibliothèques sur lesquelles s'appuie chrony (comme la bibliothèque
cryptographique nettle) ont tout ce qu'il
faut. Ainsi, sur une Ubuntu stable,
./configure n'active pas l'option NTS alors que
ça marche sur une Debian instable (sur cette
plate-forme, pensez à installer les paquetages
bison et asciidoctor,
./configure ne vérifie pas leur présence). Cela
se voit dans cette ligne émise par ./configure
(le +NTS) :
% ./configure ... Checking for SIV in nettle : No Checking for SIV in gnutls : Yes Features : +CMDMON +NTP +REFCLOCK +RTC -PRIVDROP -SCFILTER -SIGND +ASYNCDNS +NTS +READLINE +SECHASH +IPV6 -DEBUG
Autre serveur ayant NTS, NTPsec. (Développement sur Github.) Écrit en
C. C'est ce code qui est
utilisé pour deux serveurs NTS publics,
ntp1.glypnod.com:123 et
ntp2.glypnod.com:123 (exemples plus loin).
Il y a également une
mise en œuvre de NTS en FPGA (sur Github). La même organisation gère deux
serveurs NTP publics, nts.sth1.ntp.se:4460 et
nts.sth2.ntp.se:4460. Elle a publié une
bonne synthèse de ses travaux et un article
plus détaillé.
Dernier serveur public ayant NTS, celui de
Cloudflare, time.cloudflare.com. Il
utilise sans doute nts-rust, écrit par
Cloudflare (en Rust).
Les autres mises en œuvre de NTS semblent assez expérimentales, plutôt de la preuve de concept pas très maintenue. Il y a :
https://gitlab.com/MLanger/nts/https://github.com/Netnod/nts-poc-pythonhttps://gitlab.com/hacklunch/ntsclient
Voici un exemple avec ntsclient et les serveurs publics mentionnés plus haut. Vérifiez que vous avez un compilateur Go puis :
% git clone https://gitlab.com/hacklunch/ntsclient.git % make % ./ntsclient --server=ntp1.glypnod.com:123 -n Network time on ntp1.glypnod.com:123 2020-07-14 09:01:08.684729607 +0000 UTC. Local clock off by -73.844479ms.
(Le serveur devrait migrer bientôt vers le port 4460.)
Si on veut voir plus de détails et toute la machinerie NTS (le
type
de message 4 est AEAD, le type 5 le
cookie, l'algorithme
15 est AEAD_AES_SIV_CMAC_256) :
% ./ntsclient --server=ntp1.glypnod.com:123 -n --debug
Conf: &main.Config{Server:"ntp1.glypnod.com:123", CACert:"", Interval:1000}
Connecting to KE server ntp1.glypnod.com:123
Record type 1
Critical set
Record type 4
Record type 5
Record type 5
Record type 5
Record type 5
Record type 5
Record type 5
Record type 5
Record type 5
Record type 0
Critical set
NTSKE exchange yielded:
c2s: ece2b86a7e86611e6431313b1e45b02a8665f732ad9813087f7fc773bd7f2ff9
s2c: 818effb93856caaf17e296656a900a9b17229e2f79e69f43f9834d3c08194c06
server: ntp1.glypnod.com
port: 123
algo: 15
8 cookies:
[puis les cookies]
Notez que les messages de type 5 ont été répétés huit fois, car, conformément aux recommandations du RFC, le serveur envoie huit cookies. Notez aussi que si vous voulez analyser avec Wireshark, il va par défaut interpréter ce trafic sur le port 123 comme étant du NTP et donc afficher n'importe quoi. Il faut lui dire explicitement de l'interpréter comme du TLS (Decode as...). On voit le trafic NTS-KE en TCP puis du trafic NTP plus classique en UDP.
Enfin, la section 8 du RFC détaille quelques points de sécurité qui avaient pu être traités un peu rapidement auparavant. D'abord, le risque de dDoS. NTS, décrit dans notre RFC, apporte une nouveauté dans le monde NTP, la cryptographie asymétrique. Nécessaire pour l'authentification du serveur, elle est bien plus lente que la symétrique et, donc, potentiellement, un botnet pourrait écrouler le serveur sous la charge, en le forçant à faire beaucoup d'opérations de cryptographie asymétrique. Pour se protéger, NTS sépare conceptuellement l'authentification (faite par NTS-KE) et le service NTP à proprement parler. Ils peuvent même être assurés par des serveurs différents, limitant ainsi le risque qu'une attaque ne perturbe le service NTP.
Lorsqu'on parle de NTP et d'attaques par déni de service, on pense aussi à l'utilisation de NTP dans les attaques par réflexion et amplification. Notez qu'elles utilisent en général des fonctions non-standard des serveurs NTP. Le protocole lui-même n'a pas forcément de défauts. En tout cas, NTS a été conçu pour ne pas ajouter de nouvelles possibilités d'amplification. Tous les champs envoyés par le serveur ont une taille qui est au maximum celle des champs correspondants dans la requête du client. C'est par exemple pour cela que le client doit envoyer un champ de demande de cookie, rempli avec des zéros, pour chaque cookie supplémentaire qu'il réclame. Cela peut sembler inutile, mais c'est pour décourager toute tentative d'amplification.
Cette section 8 discute également la vérification du
certificat du serveur. Bon, on suit les
règles des RFC 5280 et RFC 6125, d'accord. Mais cela laisse un problème amusant : la
date d'expiration du certificat. Regardons celui des serveurs
publics cités plus haut, avec gnutls-cli :
% gnutls-cli ntp1.glypnod.com:123 Processed 126 CA certificate(s). Resolving 'ntp1.glypnod.com:123'... Connecting to '104.131.155.175:123'... - Certificate type: X.509 - Got a certificate list of 2 certificates. - Certificate[0] info: - subject `CN=ntp1.glypnod.com', issuer `CN=Let's Encrypt Authority X3,O=Let's Encrypt,C=US', serial 0x04f305691067ef030d19eb53bbb392588d07, RSA key 2048 bits, signed using RSA-SHA256, activated `2020-05-20 02:12:34 UTC', expires `2020-08-18 02:12:34 UTC', pin-sha256="lLj5QsLH8M8PjLSWe6SNlXv4fxVAyI6Uep99RWskvOU=" Public Key ID: sha1:726426063ea3c388ebcc23f913b41a15d4ef38b0 sha256:94b8f942c2c7f0cf0f8cb4967ba48d957bf87f1540c88e947a9f7d456b24bce5 Public Key PIN: pin-sha256:lLj5QsLH8M8PjLSWe6SNlXv4fxVAyI6Uep99RWskvOU= - Certificate[1] info: - subject `CN=Let's Encrypt Authority X3,O=Let's Encrypt,C=US', issuer `CN=DST Root CA X3,O=Digital Signature Trust Co.', serial 0x0a0141420000015385736a0b85eca708, RSA key 2048 bits, signed using RSA-SHA256, activated `2016-03-17 16:40:46 UTC', expires `2021-03-17 16:40:46 UTC', pin-sha256="YLh1dUR9y6Kja30RrAn7JKnbQG/uEtLMkBgFF2Fuihg=" - Status: The certificate is trusted. - Description: (TLS1.3-X.509)-(ECDHE-SECP256R1)-(RSA-PSS-RSAE-SHA256)-(AES-256-GCM) - Options: - Handshake was completed
On a un classique certificat Let's Encrypt, qui expire le 18 août 2020. Cette date figure dans les certificats pour éviter qu'un malveillant qui aurait mis la main sur la clé privée correspondant à un certificat puisse profiter de son forfait éternellement. Même si la révocation du certificat ne marche pas, le malveillant n'aura qu'un temps limité pour utiliser le certificat. Sauf que la vérification que cette date d'expiration n'est pas atteinte dépend de l'horloge de la machine. Et que le but de NTP est justement de mettre cette horloge à l'heure… On a donc un problème d'œuf et de poule : faire du NTP sécurisé nécessite NTS, or utiliser NTS nécessite de vérifier un certificat, mais vérifier un certificat nécessite une horloge à l'heure, donc que NTP fonctionne. Il n'y a pas de solution idéale à ce problème. Notre RFC suggère quelques trucs utiles, comme :
- Prendre un risque délibéré en ne vérifiant pas la date d'expiration du certificat,
- Chercher à savoir si l'horloge est correcte ou pas ; sur un
système d'exploitation qui dispose de
fonctions comme
ntp_adjtime, le résultat de cette fonction (dans ce cas, une valeur autre queTIME_ERROR) permet de savoir si l'horloge est correcte, - Permettre à l'administrateur système de configurer la validation des dates des certificats ; s'il sait que la machine a une horloge matérielle sauvegardée, par exemple via une pile, il peut demander une validation stricte,
- Utiliser plusieurs serveurs NTP et les comparer, dans l'espoir qu'ils ne soient pas tous compromis (cf. RFC 5905, section 11.2.1).
Comme toujours avec la cryptographie, lorsqu'il existe une version non sécurisée d'un protocole (ici, le NTP traditionnel), il y a le risque d'une attaque par repli, qui consiste à faire croire à une des deux parties que l'autre partie ne sait pas faire de la sécurité (ici, du NTS). Ce NTP stripping est possible si, par exemple, le client NTP se rabat en NTP classique en cas de problème de connexion au serveur NTS-KE. Le RFC recommande donc que le repli ne se fasse pas par défaut, mais uniquement si le logiciel a été explicitement configuré pour prendre ce risque.
Enfin, si on veut faire de la synchronisation d'horloges
sécurisée, un des problèmes les plus difficiles est l'attaque par
retard (section 11.5 du RFC). Le MAC empêche un attaquant actif de
modifier les messages mais il peut les retarder, donnant ainsi au
client une fausse idée de l'heure qu'il est réellement (RFC 7384, section 3.2.6 et Mizrahi, T.,
« A game theoretic analysis of delay attacks against time
synchronization protocols », dans les Proceedings
of Precision Clock Synchronization for Measurement Control and
Communication à ISPCS 2012). Ce dernier article n'est pas
en ligne mais, heureusement, il y a Sci-Hub
(DOI 10.1109/ISPCS.2012.6336612).
Les contre-mesures possibles ? Utiliser plusieurs serveurs, ce que fait déjà NTP. Faire attention à ce qu'ils soient joignables par des chemins différents (l'attaquant devra alors contrôler plusieurs chemins). Tout chiffrer avec IPsec, ce qui n'empêche pas l'attaque mais rend plus difficile l'identification des seuls paquets de synchronisation.
Revenons au mode symétrique de NTP, qui n'est pas traité par notre RFC. Vous vous demandez peut-être comment le sécuriser. Lors des discussions à l'IETF sur NTS, il avait été envisagé d'encapsuler tous les paquets dans DTLS mais cette option n'a finalement pas été retenue. Donc, pour le symétrique, la méthode recommandée est d'utiliser le MAC des RFC 5905 (section 7.3) et RFC 8573. Et le mode à diffusion ? Il n'y a pas pour l'instant de solution à ce difficile problème.
Et la vie privée (section 9) ? Il y a d'abord la question de la non-traçabilité. On ne veut pas qu'un observateur puisse savoir que deux requêtes NTP sont dues au même client. D'où l'idée d'envoyer plusieurs cookies (et de les renouveler), puisque, autrement, ces identificateurs envoyés en clair trahiraient le client, même s'il a changé d'adresse IP.
Et la confidentialité ? Le chiffrement de l'essentiel du paquet NTP fournit ce service, les en-têtes qui restent en clair, comme le cookie, ne posent pas de problèmes de confidentialité particuliers.
Un petit mot maintenant sur l'historique de ce RFC. Le projet
initial était plus ambitieux
(cf. l'Internet-Draft
draft-ietf-ntp-network-time-security). Il
s'agissait de développer un mécanisme abstrait, commun à NTP et
PTP/IEEE 1588 (alors que ce RFC 8915 est spécifique à NTP). Un autre groupe de travail
IETF TICTOC continue
de son côté mais ne fait plus de sécurité.
Si vous voulez des bonnes lectures sur NTS, autres que le RFC, il y a un article sur la sécurité NTP à la conférence ISPCS 17, « New Security Mechanisms for Network Time Synchronization Protocols ») (un des auteurs de l'article est un des auteurs du RFC). C'est un exposé général des techniques de sécurité donc il inclut PTP mais la partie NTP est presque à jour, à part la suggestion de DTLS pour les autres modes, qui n'a finalement pas été retenue). Les supports du même article à la conférence sont sur Slideshare. Et cet article est résumé dans l'IETF journal de novembre 2017, volume 13 issue 2. Il y a aussi l'article de l'ISOC, qui résume bien les enjeux.
L'article seul
Fiche de lecture : Mikrodystopies
Auteur(s) du livre : François Houste
Éditeur : C&F Éditions
9-782376-620112
Publié en 2020
Première rédaction de cet article le 30 septembre 2020
Beaucoup de gens sur Twitter ont déjà lu les Mikrodystopies, ces très courtes histoires d'un futur techniquement avancé mais pas forcément très heureux. Les voici réunies dans un livre, le premier livre de fiction publié chez C&F Éditions.
Des exemples de Mikrodystopies ? « Le robot de la bibliothèque municipale aurait été l'assistant idéal s'il n'avait pas pris l'initiative de censurer certains ouvrages de science-fiction qu'il jugeait offensants. » Ou bien « La licence du logicielle était claire : pour chaque faute d'orthographe corrigée, le romancier devait reverser une partie de ses droits d'auteur à la société qui avait créé ce traitement de texte. » Ou encore, en temps de pandémie, « Les robots de l'entreprise firent valoir leur droit de retrait, invoquant les pare-feu insuffisants du réseau informatique. ». Oui, je l'avais dit, ce sont des courtes histoires, qui se tiennent dans les limites du nombre de caractères que permet Twitter, mais je trouve chacune d'elles pertinente, et mettant bien en évidence un problème de notre société et de son rapport avec la technique.
Fallait-il publier ces histoires que tout le monde peut lire sur Twitter ? Je vous laisse en juger mais, moi, cela m'a beaucoup plu de les découvrir ou de les redécouvrir sur mon canapé. Et en plus le livre est beau comme l'explique Nicolas Taffin.
L'article seul
Fiche de lecture : Technologies partout, démocratie nulle part
Auteur(s) du livre : Irénée Régnauld, Yaël
Benayoun
Éditeur : FYP Éditions
978-2-36405-202-4
Publié en 2020
Première rédaction de cet article le 27 septembre 2020
La question de la démocratie face aux choix techniques est une question cruciale pour nos sociétés où la technique joue un rôle si important. À une extrémité, il y a des gens qui défendent l'idée que le peuple est vraiment trop con et qu'il faudrait le priver de tous les choix techniques. À une autre, des archaïques qui sont contre toute nouveauté par principe. Et le tout dans une grande confusion où les débats ayant une forte composante technique sont noyés dans des affirmations non étayées, voire franchement fausses, ou même carrément ridicules. Faut-il jeter l'éponge et en déduire qu'il ne pourra jamais y avoir de vrai débat démocratique sur un sujet technique ? Les auteurs de ce livre ne sont pas de cet avis et estiment qu'il est possible de traiter démocratiquement ces sujets. Reste à savoir comment, exactement.
Il y a trois parties importantes dans ce livre : une dénonciation d'une certaine propagande « pro-progrès » qui essaie de saturer l'espace de débat en répétant en boucle qu'on ne peut pas s'opposer au progrès technique, puis une analyse critique des solutions qui sont souvent proposées pour gérer de manière démocratique les débats liés aux sujets techniques, et enfin une exploration des solutions possibles dans le futur. Commençons par la première partie, c'est la plus facile et celle avec laquelle je suis le plus d'accord. En effet, les technolâtres ou techno-béats pratiquent une propagande tellement grossière qu'il serait difficile d'être en sympathie avec eux. Cette propagande avait été magnifiquement illustrée par la sortie raciste d'un président de la république qui avait estimé que tout opposant était forcément un Amish. (Et puis ce n'est pas risqué de s'en prendre à eux : les Amish ne feront pas de fatwa contre ceux qui critiquent leur religion.) Le livre donne plusieurs exemples amusants de ce discours non seulement anti-démocratique, mais également anti-politique puisqu'il prétend qu'il n'y a pas le choix, que le déploiement de telle ou telle technologie n'est tout simplement pas discutable. Les cas de tel discours « on n'arrête pas le progrès » sont innombrables, parfois matinés de « il faut rattraper notre retard » (qui semble indiquer qu'on peut arrêter le progrès, après tout, ce qu'ont hélas bien réussi les ayant-tous-les-droits avec le pair-à-pair).
En pratique, quel que soit le discours des technolâtres, il y a toujours eu des oppositions et des critiques. Mais, attention, les auteurs du livre mettent un peu tout dans le même sac. Quand des salariés travaillant dans les entrepôts d'Amazon protestent contre leurs conditions de travail, cela n'a pas grand'chose à voir avec la technique, l'Internet ou le Web : ce sont des travailleurs qui luttent contre l'exploitation, point. Le fait que leur entreprise soit considérée comme étant de la « tech » n'y change rien. De même les luddites ne luttaient pas tant contre « la machine » que contre le chômage et la misère qui allaient les frapper (le progrès technique n'étant pas toujours synonyme de progrès social). Assimiler les anti-Linky et les chauffeurs d'Uber qui demandent à être reconnus comme salariés (ce qu'ils sont, de facto), c'est mettre sous un même parapluie « anti-tech » des mouvements très différents.
À noter aussi que, paradoxalement, les auteurs traitent parfois la technique comme un être autonome, en affirmant que telle ou telle technique va avoir telles conséquences. La relation d'une technique avec la société où elle va être déployée est plus complexe que cela. La société crée telle ou telle technique, et elle va ensuite l'utiliser d'une certaine façon. La technique a sa propre logique (on ne pourra pas faire des centrales nucléaires en circuit court et gérées localement…) mais personnaliser une technique en disant qu'elle va avoir telle ou telle conséquence est dangereux car cela peut dépolitiser le débat. La voiture ne s'est pas déployée toute seule, ce sont des humains qui ont décidé, par exemple, de démanteler les lignes de chemin de fer au profit du tout-voiture.
Dans une deuxième partie, les auteurs examinent les réponses qui sont souvent données face aux critiques de la technologie. Par exemple, on entend souvent dire qu'il faut « une tech éthique ». L'adjectif « éthique » est un de ces termes flous et vagues qui sont mis à toutes les sauces. Toutes les entreprises, même les plus ignobles dans leurs pratiques, se réclament de l'éthique et ont des « chartes éthiques », des séminaires sur l'éthique, etc. Et, souvent, les discussions « éthiques » servent de rideau de fumée : on discute sans fin d'un détail « éthique » en faisant comme si tout le reste du projet ne pose aucun problème. Les auteurs citent l'exemple des panneaux publicitaires actifs qui captent les données personnelles des gens qui passent devant. Certes, il y a eu un débat sur l'éthique de ce flicage, et sur sa compatibilité avec les différentes lois qui protègent les données personnelles, mais cela a servi à esquiver le débat de fond : ces panneaux, avec leur consommation énergétique, et leur attirance qui capte l'attention de passants qui n'ont rien demandé sont-ils une bonne idée ? (Sans compter, bien sûr, l'utilité de la publicité dans son ensemble.)
Un autre exemple d'un débat éthique qui sert de distraction est celui des décisions de la voiture autonome au cas où elle doive choisir, dans la fraction de seconde précédant un accident, quelle vie mettre en danger s'il n'y a pas de solution parfaite. Les auteurs tombent d'ailleurs dans le piège, en accordant à ce problème du tramway, bien plus d'attention qu'il n'en mérite. Déjà, le problème n'existe pas pour les humains qui n'ont, en général, pas asez d'informations fiables pour peser le pour et le contre de manière rationnelle dans les instants avant l'accident. Pour cela, le problème du tramway n'est qu'une distraction de philosophe qui va le discuter gravement en prétendant qu'il réfléchit à des problèmes importants. (Comme le dit un T-shirt « I got 99 problems and the trolley problem ain't one ».) Même pour la voiture, qui a sans doute davantage d'informations que le conducteur, et peut réfléchir vite et calmement avant l'accident, dans quel cas aura-t-on vraiment un dilemme moral aussi simple et bien posé ? Discuter longuement et gravement de ce problème artificiel et irréaliste ne sert qu'à distraire des questions posées par l'utilisation de la voiture. (Je vous recommande l'excellente partie du roman « First Among Sequels » (dans la série des aventures de Thursday Next), où l'héroïne est à bord du bateau nommé « Moral Dilemma ».)
C'est également dans cette partie que les auteurs discutent le plus longuement du cas de la 5G, tarte à la crème des débats politico-techniques du moment. Je regrette que cette partie ne discute pas sérieusement les arguments présentés (à part celui de la santé, écarté à juste titre), et reprenne l'idée que la 5G va être « un sujet majeur qui engage toute la société », point de vue partagé par les partisans et les adversaires de la 5G, mais qui est contestable.
Enfin, une dernière partie du livre est consacrée aux solutions, et aux pistes pour dépasser l'injonction à déployer tout changement présenté comme « le progrès ». C'est à la fois la plus intéressante du livre et la plus délicate. Car si beaucoup de gens (comme moi) trouvent ridicule la propagande technobéate à base de blockchain digitale avec de l'IA et des startups, il y aura moins de consensus pour les solutions. D'autant plus qu'il ne s'agit pas de retourner au Moyen-Âge mais au contraire d'inventer du nouveau, sans pouvoir s'appuyer sur un passé (souvent mythifié, en prime). D'abord, les auteurs plaident pour une reprise de la confiance en soi : face à la saturation brutale du discours politique par des fausses évidences martelées en boucle (« il n'y a pas le choix », « on ne va pas retourner à la bougie quand même », « les citoyens sont trop cons pour décider »), les auteurs plaident pour une réaffirmation de l'importance mais aussi de la possibilité de la démocratie. Changer le monde est possible, la preuve, c'est déjà arrivé avant. (Un rappel que j'aime bien : la Sécurité sociale a été instaurée en France dans un pays ruiné par la guerre. Et aujourd'hui, alors que la guerre est loin et qu'on a fait d'innombrables progrès techniques depuis, elle ne serait plus réaliste ?).
Ensuite, il faut débattre des technologies et de leur intérêt. Il ne s'agit pas de tout refuser par principe (ce qui serait intellectuellement plus simple) mais de pouvoir utiliser son intelligence à dire « ça, OK, ça, j'hésite et ça je n'en veux pas ». Les auteurs estiment qu'il faut évaluer si une nouvelle technologie, par exemple, va favoriser les tendances autoritaires ou au contraire la démocratie.
Et, là, c'est un problème. Car les conséquences du déploiement d'une technologie sont souvent surprenantes, y compris pour leurs auteurs. Et elles varient dans le temps. Il n'est pas sûr du tout que des débats effectués avant le déploiement de l'Internet, par exemple, aient prévu ce qui allait se produire, d'autant plus que rien n'est écrit d'avance : le Facebook d'aujourd'hui, par exemple, n'était pas en germe dans l'Internet des années 1980.
Les auteurs mettent en avant l'expériences des « conférences citoyennes », où on rassemble un certain nombre de citoyens autour d'une thématique précise. Dans certains cas, ces citoyens sont tirés au sort. Si ce principe peut faire ricaner bêtement, il a l'avantage que les personnes choisies ont la possibilité d'apprendre sur le sujet traité.
En effet, je pense qu'une des principales limites de la démocratie représentative est le fait qu'il y a le même droit de vote pour la personne qui a pris le temps de se renseigner sur un sujet, de discuter et d'apprendre, que pour la personne qui n'a même pas vu une vidéo YouTube sur le sujet. Cette limite est particulièrement gênante dans le cas des questions ayant une forte composante technique. C'est pour cela que des sondages comme « pensez-vous que la chloroquine soit efficace contre la Covid-19 ? » (un tel sondage a bien eu lieu…) sont absurdes, pas tant parce que les sondés ne sont pas médecins que parce qu'on n'avait aucune information sur les efforts qu'ils avaient fait pour apprendre. Une décision, ou même simplement une discussion, sur un sujet technique, nécessite en effet, pas forcément d'être professionnel du métier (ce serait verser dans la technocratie) mais au moins qu'on a acquis des connaissances sur le sujet. Il me semble que cette exigence de savoir, très importante, est absente de ce livre. Ce manque de connaissances de base se paie lourdement, par exemple dans les débats sur la 5G, où on lit vraiment n'importe quoi (dans les deux camps, d'ailleurs). Je précise d'ailleurs qu'à mon avis, ce n'est pas seulement un problème chez les citoyens, c'est aussi le cas chez les professionnels de la politique. Notons que pour le cas particulier des protocoles Internet, le RFC 8890 couvre en détail cette question. Il faut évidemment que les citoyens décident, mais comment ?
Cette partie sur les propositions concrètes se termine avec cinq intéressants récits d'expériences réelles de participation de citoyens et de citoyennes à la délibération sur des sujets techniques. De quoi montrer que le futur n'est pas décidé d'avance et qu'il dépend de nous.
L'article seul
Fiche de lecture : La guerre des Russes blancs
Auteur(s) du livre : Jean-Jacques Marie
Éditeur : Tallandier
979-10-2102280-5
Publié en 2017
Première rédaction de cet article le 26 septembre 2020
Une étude détaillée d'un des camps de la Guerre civile russe, les blancs. Qui étaient-ils, qu'ont-ils fait, et pourquoi ont-ils perdu ?
Après la révolution bolchevique, qui a vu relativement peu de violences, une guerre civile impitoyable démarre entre les Rouges (les bolcheviques) et les Blancs (les tsaristes). Évidemment, c'est plus compliqué que cela : il y a plus que deux camps, et tous les camps sont eux-mêmes divisés. Le terme « les Blancs » regroupe des organisations, des individus et des idéologies différentes, sans compter les groupes difficiles à classer comme celui de Makhno ou comme les Verts (qui n'ont rien à voir avec les écologistes d'aujourd'hui). Le livre est donc épais, car l'auteur a beaucoup à dire.
Les Blancs avaient dès le début un problème politique considérable : fallait-il affirmer qu'on luttait pour la démocratie, voire la république, ou au contraire assumer ses origines tsaristes et motiver ses troupes par des références au passé ? Les Blancs n'ont jamais vraiment réussi à trancher nettement. Leurs soutiens impérialistes comme la France insistaient pour que les chefs blancs tiennent un discours moderniste, rejetant la restauration pur et simple du tsarisme, et prétendant vouloir construire démocratie et élections libres. Et les paysans russes refusaient le retour des grands propriétaires terriens et, pour les gagner à la cause blanche, il ne fallait pas tenir de discours trop rétrograde. Des chefs blancs comme Dénikine tenaient en public un discours raisonnablement progressiste et présentaient des programmes tout à fait acceptables. Sincérité ou tactique ? Car, d'un autre coté, l'écrasante majorité des officiers blancs étaient très réactionnaires et ne voulaient que le retour intégral au système politique d'avant la révolution de février. Et de toute façon, beaucoup de chefs blancs étaient des aventuriers indisciplinés, qui voulaient juste de la baston et du pillage, et ne tenaient aucun compte de ce que pouvaient dire Dénikine ou Wrangel. Les Blancs n'ont donc jamais eu une politique claire et cohérente. Une même impossibilité de trancher est apparue au sujet des questions nationales, comme l'indépendance de la Finlande ; pris entre le désir d'avoir un maximum d'alliés, et leur nostalgie d'une Russie impériale « prison des peuples », les Blancs n'ont pas su utiliser les sentiments nationaux qui auraient pu être dirigés contre les Rouges.
Et puis il n'y avait pas un parti et une armée unique. Chaque groupe blanc avait son chef, ses troupes, ses sources de financement jalousement gardées. Comme dans le roman « La garde blanche » de Mikhaïl Boulgakov ou dans la BD « Corto Maltese en Sibérie » d'Hugo Pratt, les Blancs ont passé plus de temps à se déchirer, voire à se combattre, qu'à lutter contre les Rouges.
Rapidement, les pays impérialistes qui soutenaient les Blancs ont compris qu'il n'y avait pas d'espoir qu'ils triomphent, et ont petit à petit abandonné leurs alliés. Churchill, dont le rôle pendant la Seconde Guerre mondiale ne doit pas faire oublier que dans le reste de sa carrière politique, il a toujours été ultra-réactionnaire, et a commis d'innombrables erreurs graves de jugement, insiste pour que la Grande-Bretagne continue à s'obstiner à aider les Blancs, mais sans résultat. (J'ai appris dans ce livre que plusieurs officiers blancs, devenus « soldats de fortune », encadreront l'armée paraguayenne dans la guerre du Chaco.) La défaite des Blancs étant sans doute inévitable. Ce livre vous expliquera pourquoi, dans un excellent chapitre final de synthèse. (Les divisions des Blancs et leur manque de programme cohérent ne sont pas les seules explications.)
L'article seul
RFC 8883: ICMPv6 Errors for Discarding packets Due to Processing Limits
Date de publication du RFC : Septembre 2020
Auteur(s) du RFC : T. Herbert (Intel)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF 6man
Première rédaction de cet article le 25 septembre 2020
Dans l'Internet, un routeur est toujours autorisé à jeter un paquet quand il ne peut pas le traiter, parce que ses files d'attente sont pleines, par exemple. Après tout, à l'impossible, nul n'est tenu, et les protocoles de transport et d'application savent à quoi s'attendre, et qu'ils devront peut-être gérer ces paquets perdus. Mais un routeur peut aussi jeter un paquet parce que des caractéristiques du paquet rendent impossible le traitement. Dans ce cas, il serait sympa de prévenir l'émetteur du paquet, pour qu'il puisse savoir que ses paquets, quoique légaux, ne peuvent pas être traités par certains routeurs. Notre nouveau RFC crée donc plusieurs nouveaux messages ICMP pour signaler à l'émetteur d'un paquet IPv6 qu'il en demande trop au routeur, par les en-têtes d'extension IPv6 qu'il ajoute.
La section 1 du RFC commence par lister les cas où un routeur peut légitimement jeter des paquets IPv6, même si les ressources matérielles du routeur ne sont pas épuisées :
- Voyons d'abord le cas des en-têtes d'extension pris individuellement. IPv6 permet d'ajouter aux paquets une chaîne d'en-têtes successifs (RFC 8200, section 4). Ces en-têtes peuvent être de taille variable (c'est le cas de Destination Options, qui peut contenir plusieurs options). Il n'y a pas de limite absolue à leur nombre, uniquement la contrainte qu'ils doivent tenir dans un datagramme, donc la taille de cette chaîne doit être inférieure à la MTU du chemin. Normalement, les routeurs ne regardent pas ces en-têtes (sauf Hop by Hop Options) mais certains équipements réseau le font (cf. RFC 7045). Si, par exemple, l'équipement a, dans son code, une limite du genre « maximum 100 octets par en-tête et au plus trois options dans les en-têtes à options », alors, il jettera les paquets excédant ces limites. (S'il n'a pas de limites, cela peut augmenter sa vulnérabilité à certaines attaques par déni de service.)
- Il peut aussi y avoir une limite portant sur la taille totale de la chaîne, pour les mêmes raisons, et avec les mêmes conséquences.
- Dans certains cas, les routeurs qui jettent le paquet ont tort, mais cela ne change rien en pratique : comme ils vont continuer à le faire, autant qu'ils puissent signaler qu'ils l'ont fait, ce qui est le but de ce RFC.
La section 2 du RFC définit donc six nouveaux codes pour indiquer les problèmes, à utiliser avec le type ICMP 4 (Parameter Problem, cf. RFC 4443, section 3.4). Petit rappel : les messages ICMP ont un type (ici, 4) et les messages d'erreur d'un même type sont différenciés par un code qui apporte des précisions. Ainsi, le type 1, Destination Unreachable, peut servir par exemple pour des messages d'erreur ICMP de code 1 (filtrage par décision délibérée), 4 (port injoignable), etc. Les codes de notre RFC sont dans le registre IANA. Les voici :
- 5, en-tête suivant inconnu (Unrecognized Next Header type encountered by intermediate node) : normalement, les routeurs ne doivent pas rejeter les en-têtes inconnus, juste les passer tel quels mais, s'ils le font, qu'au moins ils l'indiquent, avec ce code. (On a vu que l'approche de ce RFC est pragmatique.)
- 6, en-tête trop gros (Extension header too big).
- 7, chaîne d'en-têtes trop longue (Extension header chain too long).
- 8, trop d'en-têtes (Too many extension headers).
- 9, trop d'options dans un en-tête (Too many options in extension header) : à envoyer si le nombre d'options dans, par exemple, l'en-tête Hop-by-hop options, est trop élevé. Petit rappel : certains en-têtes (Destination Options et Hop-by-hop Options) sont composites : ils comportent une liste d'une ou plusieurs options.
- 10, option trop grosse (Option too big) : à envoyer si on rencontre une option de taille trop importante dans un en-tête comme Destination options.
Et la section 3 définit un nouveau code pour le type d'erreur Destination Unreachable, le code 8, en-têtes trop longs (Headers too long). Il a également été mis dans le registre IANA. Les messages utilisant ce code suivent le format du RFC 4884.
Et que fait-on quand on envoie ou reçoit des erreurs ICMP liées au traitement des en-têtes ? La section 4 du RFC rappelle les règles. D'abord, il faut évidemment suivre le RFC 4443, par exemple la limitation du rythme d'envoi des erreurs (RFC 4443, section 2.4f). Et, à la réception d'un message d'erreur ICMP, il est crucial de le valider (n'importe quelle machine sur l'Internet a pu générer ce message, en mentant sur son adresse IP source). Pour cela, on peut utiliser la portion du paquet original qui a été incluse dans le message d'erreur : il faut vérifier qu'elle correspond à une conversation en cours (connexion TCP existante, par exemple). Ensuite, il y a des règles spécifiques aux erreurs de ce RFC :
- On n'envoie qu'une erreur ICMP, même si plusieurs problèmes étaient survenus pendant le traitement d'un paquet (par exemple trop d'en-têtes et un total trop long). La section 4.1 donne la priorité à suivre pour savoir quelle erreur privilégier.
- À la réception, on peut ajuster son comportement en fonction de l'erreur signalée, par exemple envoyer moins d'en-têtes si l'erreur était le code 8, Too many extension headers. Si les en-têtes IPv6 ont été gérés par l'application, il faut la prévenir, qu'elle puisse éventuellement changer son comportement. Et s'ils ont été ajouté par le noyau, c'est à celui-ci d'agir différemment.
La section 5 rappelle un point d'ICMP qu'il vaut mieux garder en tête. ICMP n'est pas fiable. Les messages d'erreur ICMP peuvent se perdre, soit, comme tout paquet IP, parce qu'un routeur n'arrivait pas à suivre le rythme, soit parce qu'une middlebox sur le trajet jette tous les paquets ICMP (une erreur de configuration fréquente quand les amateurs configurent un pare-feu cf. RFC 8504). Bref, il ne faut pas compter que vous recevrez forcément les messages indiqués dans ce RFC, si vos paquets avec en-têtes d'extension ne sont pas transmis.
La même section 5 explique les motivations pour ce RFC : on constate une tendance à augmenter le nombre et la taille des en-têtes d'extension IPv6. Cela peut être pour faire du routage influencé par la source, pour de l'OAM (RFC 9486), ou pour d'autres innovations récentes.
Comme indiqué au début, cette augmentation peut se heurter aux limites des routeurs. La section 5.2.3 donne des exemples concrets. Les routeurs ne sont pas du pur logiciel, beaucoup de fonctions sont mises dans du matériel spécialisé. Ainsi, les circuits de traitement des paquets peuvent ne pas avoir de notion de boucle. Pour traiter les en-têtes d'extension ou les options dans un en-tête, la solution évidente qu'est la boucle n'est pas disponible, et on fait donc un petit nombre de tests suivis d'un saut. Le nombre maximal de tests est donc limité.
Enfin, la section 6 de notre RFC discute des questions de sécurité. Il y a le problème du filtrage par les pare-feux (voir le RFC 4890) mais aussi le risque (assez lointain, je trouve) que l'observation de la génération de ces nouveaux messages d'erreur donnent des indications à un observateur sur le logiciel utilisé. C'est un problème commun à tous les choix optionnels. En tout cas, le RFC recommande que l'envoi de ces messages d'erreur soit configurable.
Actuellement, il ne semble pas qu'il existe déjà de mise en œuvre de ce RFC.
L'article seul
RFC 8901: Multi-Signer DNSSEC Models
Date de publication du RFC : Septembre 2020
Auteur(s) du RFC : S. Huque, P. Aras (Salesforce), J. Dickinson (Sinodun), J. Vcelak (NS1), D. Blacka (Verisign)
Pour information
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 25 septembre 2020
Aujourd'hui, il est courant de confier l'hébergement de ses serveurs DNS faisant autorité à un sous-traitant. Mais si vous avez, comme c'est recommandé, plusieurs sous-traitants et qu'en prime votre zone, comme c'est recommandé, est signée avec DNSSEC ? Comment s'assurer que tous les sous-traitants ont bien l'information nécessaire ? S'ils utilisent le protocole standard du DNS pour transférer la zone, tout va bien. Mais hélas beaucoup d'hébergeurs ne permettent pas l'utilisation de cette norme. Que faire dans ce cas ? Ce nouveau RFC explique les pistes menant à des solutions possibles.
Pourquoi est-ce que des hébergeurs DNS ne permettent pas d'utiliser la solution normalisée et correcte, les transferts de zone du RFC 5936 ? Il peut y avoir de mauvaises raisons (la volonté d'enfermer l'utilisateur dans un silo, en lui rendant plus difficile d'aller voir la concurrence) mais aussi des (plus ou moins) bonnes raisons :
- Si l'hébergeur signe dynamiquement les données DNS,
- Si l'hébergeur produit dynamiquement des données DNS (ce qui implique de les signer en ligne),
- Si l'hébergeur utilise des trucs non-standards, par exemple pour mettre un CNAME à l'apex d'une zone.
Dans ces cas, le transfert de zones classique n'est pas une solution, puisqu'il ne permet pas de transmettre, par exemple, les instructions pour la génération dynamique de données.
Résultat, bien des titulaires de noms de domaine se limitent donc à un seul hébergeur, ce qui réduit la robustesse de leur zone face aux pannes… ou face aux conflits commerciaux avec leur hébergeur.
La section 2 de notre RFC décrit les modèles possibles pour avoir à
la fois DNSSEC et plusieurs
hébergeurs. Si aucune des trois raisons citées plus haut ne
s'applique, le cas est simple : un hébergeur (qui peut être le
titulaire lui-même, par exemple avec un serveur maître caché) signe
la zone, et elle est transférée ensuite, avec clés et signatures,
vers les autres. C'est tout simple. (Pour information, c'est par
exemple ainsi que fonctionne
.fr, qui a plusieurs
hébergeurs en plus de l'AFNIC : les serveurs dont le nom comprend
un « ext » sont sous-traités.)
Mais si une ou davantage des trois (plus ou moins bonnes) raisons citées plus haut s'applique ? Là, pas de AXFR (RFC 5936), il faut trouver d'autres modèles. (Et je vous préviens tout de suite : aucun de ces modèles n'est géré par les logiciels existants, il va falloir faire du devops.) Celui présenté dans le RFC est celui des signeurs multiples. Chaque hébergeur reçoit les données non-signées par un mécanime quelconque (par exemple son API) et les signe lui-même avec ses clés, plus exactement avec sa ZSK (Zone Signing Key). Pour que tous les résolveurs validants puissent valider ces signatures, il faut que l'ensemble des clés, le DNSKEY de la zone, inclus les ZSK de tous les hébergeurs de la zone. (Un résolveur peut obtenir les signatures d'un hébergeur et les clés d'un autre.) Comment faire en sorte que tous les hébergeurs reçoivent les clés de tous les autres, pour les inclure dans le DNSKEY qu'ils servent ? Il n'existe pas de protocole pour cela, et le problème n'est pas purement technique, il est également que ces hébergeurs n'ont pas de relation entre eux. C'est donc au titulaire de la zone d'assurer cette synchronisation. (Un peu de Python ou de Perl avec les API des hébergeurs…)
Il y a deux variantes de ce modèle : KSK unique (Key Signing Key) et partagée, ou bien KSK différente par hébergeur. Voyons d'abord la première variante, avec une seule KSK. Elle est typiquement gérée par le titulaire de la zone, qui est responsable de la gestion de la clé privée, et d'envoyer l'enregistrement DS à la zone parente. Par contre, chaque hébergeur a sa ZSK et signe les données. Le titulaire récupère ces ZSK (par exemple via une API de l'hébergeur) et crée l'ensemble DNSKEY, qu'il signe. (Le RFC note qu'il y a un cas particulier intéressant de ce modèle, celui où il n'y a qu'un seul hébergeur, par exemple parce que le titulaire veut garder le contrôle de la KSK mais pas gérer les serveurs de noms.)
Deuxième variante du modèle : chaque hébergeur a sa KSK (et sa ZSK). Il ouvre son API aux autres hébergeurs pour que chacun connaisse les ZSK des autres et puisse les inclure dans l'ensemble DNSKEY. Le titulaire doit récolter toutes les KSK, pour envoyer les DS correspondants à la zone parente. Le remplacement d'une KSK (rollover) nécessite une bonne coordination.
Dans ces deux modèles, chaque serveur faisant autorité connait toutes les ZSK utilisées, et un résolveur validant récupérera forcément la clé permettant la validation, quel que soit le serveur faisant autorité interrogé, et quelle que soit la signature que le résolveur avait obtenue (section 3 du RFC). À noter qu'il faut que tous les hébergeurs utilisent le même algorithme de signature (section 4 du RFC) puisque la section 2.2 du RFC 4035 impose de signer avec tous les algorithmes présents dans l'ensemble DNSKEY.
En revanche, les hébergeurs ne sont pas forcés d'utiliser le même mécanisme de déni d'existence (NSEC ou NSEC3, cf. RFC 7129). Chacun peut faire comme il veut (section 5 de notre RFC) puisqu'une réponse négative est toujours accompagnée de ses NSEC (ou NSEC3). Évidemment, si un hébergeur utilise NSEC et un autre NSEC3, le gain en sécurité de NSEC3 sera inutile.
Comme signalé plus haut, le remplacement (rollover) des clés, déjà une opération compliquée en temps normal, va être délicat. La section 6 du RFC détaille les procédures que l'on peut suivre dans les cas « une seule KSK » et « une KSK par hébergeur ».
La discussion plus haut supposait qu'il y avait deux clés, la KSK et la ZSK, ce qui est le mode le plus fréquent d'organisation des clés. Mais ce n'est pas obligatoire : on peut avec n'avoir qu'une seule clé (baptisée alors CSK, pour Common Signing Key). Dans ce cas, il n'y a qu'un seul modèle possible, chaque hébergeur a sa CSK. Cela ressemble au modèle « une KSK par hébergeur » : le titulaire de la zone doit récolter toutes les CSK et envoyer les DS correspondants à la zone parente (section 7 du RFC).
Cette configuration DNSSEC à plusieurs signeurs peut fonctionner avec les enregistrements CDS et CDNSKEY des RFC 7344 et RFC 8078 (section 8 de notre RFC). Dans le premier modèle « une seule KSK », le titulaire de la zone crée CDS et/ou CDNSKEY qu'il envoie à tous les hébergeurs avec les autres données. Dans le deuxième modèle « une KSK par hébergeur », il faut échanger les CDS et/ou CDNSKEY pour que chaque hébergeur ait les enregistrements des autres.
On voit que dans cette configuration, il est nécessaire de communiquer, au moins entre le titulaire de la zone et ses hébergeurs. Ces hébergeurs doivent fournir une API, typiquement de type REST. Notre RFC ne normalise pas une telle API mais sa section 9 indique les fonctions minimum qu'elle doit fournir :
- Permettre de récupérer les enregistrements DNSKEY (pour obtenir la ZSK),
- Pour le premier modèle (une seule KSK), permettre d'indiquer l'ensemble DNSKEY complet et signé,
- Pour le deuxième modèle, permettre d'indiquer les ZSK des autres hébergeurs,
- Et idem pour les CDS et CDNSKEY.
Autre problème pratique avec la co-existence de plusieurs hébergeurs DNS, qui signent eux-mêmes la zone, la taille des réponses. Comme il faut inclure toutes les ZSK dans l'ensemble DNSKEY, les réponses aux requêtes DNSKEY vont forcément être d'assez grande taille (section 10). Le RFC fait remarquer que les algorithmes cryptographiques utilisant les courbes elliptiques ont des clés plus courtes et que cela peut aider.
Enfin, dans la section 12, dédiée aux questions de sécurité restantes, le RFC note que ces mécanismes à plusieurs signeurs nécessitent d'avoir confiance dans chacun des signeurs. Au contraire, le système où le maître signe tout et transfère ensuite aux serveurs esclaves ne demande aucune confiance dans les hébergeurs.
Allez, un joli dessin pour terminer (trouvé
ici) :  .
.
L'article seul
RFC 8877: Guidelines for Defining Packet Timestamps
Date de publication du RFC : Septembre 2020
Auteur(s) du RFC : T. Mizrahi (Huawei Smart Platforms iLab), J. Fabini (TU Wien), A. Morton (AT&T Labs
Pour information
Réalisé dans le cadre du groupe de travail IETF idr
Première rédaction de cet article le 24 septembre 2020
De nombreux protocoles Internet contiennent un champ où se trouve une estampille temporelle (timestamp en anglais), une indication de date et d'heure. Mais chaque protocole a défini le format de cette estampille de son côté, il n'y a pas de format standard. Ce nouveau RFC essaie de mettre un peu d'ordre là-dedans en proposant aux concepteurs de futurs protocoles :
- Trois formats standards, parmi lesquels choisir, pour avoir un format tout fait,
- Des conseils pour les cas où un protocole définirait (ce qui est sans doute une mauvaise idée) un nouveau format.
Dans quels cas des protocoles contiennent dans leurs données une estampille temporelle ? Cela peut être bien sûr parce que le protocole est voué à distribuer de l'information temporelle, comme NTP (RFC 5905). Mais cela peut être aussi parce que le protocole a besoin d'indiquer le moment d'un événement, par exemple pour mesurer une latence (OWAMP, RFC 4656 ou les extensions à TCP du RFC 7323). La section 6 du RFC présente une liste non exhaustive de protocoles qui utilisent des estampilles temporelles, ce qui fournit d'autres exemples comme MPLS (RFC 6374), IPFIX (RFC 7011), TRILL (RFC 7456), etc. Il serait souhaitable que les formats de ces estampilles soient normalisés. Ainsi, utiliser le format de NTP dans un autre protocole permettrait facilement d'utiliser le temps NTP, sans perte de précision. Et la standardisation des formats permettait de les mettre en œuvre dans du matériel, comme les horloges. Bref, si vous concevez des protocoles réseau et qu'ils intègrent une information temporelle, lisez ce RFC.
Pour suivre la suite du RFC, il faut un peu de vocabulaire, rappelé en section 2. Notamment :
- Erreur sur l'estampille : la différence entre une estampille et une horloge de référence. Elle est de zéro quand tout est parfaitement à l'heure, ce qui n'arrive évidemment jamais dans le monde réel.
- Exactitude de l'estampille : la moyenne des erreurs.
- Précision de l'estampille : l'écart-type des erreurs.
- Résolution temporelle de l'estampille : le temps minimal qu'un format permet de représenter. Si on a un format texte HH:MM:SS (heures:minutes:secondes), la résolution sera de une seconde.
- Période de bouclage : le temps au bout duquel on reviendra à la valeur de départ. C'est la fameuse bogue de l'an 2000 : si on stocke les années sur deux chiffres, la période de bouclage vaut cent ans. Si on stocke les estampilles sous forme d'un entier de 32 bits signé, et que la résolution est d'une seconde, cette période de bouclage est de 68 ans.
Les formats recommandés par le RFC sont décrits en section 4. Pourquoi trois formats plutôt qu'un seul ? Parce que tous les protocoles réseau n'ont pas forcément les mêmes contraintes en terme de taille du champ, de résolution temporelle, ou d'intégration avec d'autres protocoles (sur un système d'exploitation conçu pour des PC connectés à l'Internet, utiliser le format de NTP est sans doute le plus raisonnable, mais pour du matériel de métrologie complexe, celui de PTP peut être une meilleure idée).
D'abord, le grand classique, le format de NTP (RFC 5905, section 6). Il est très répandu sur l'Internet, et utilisé dans de nombreux protocoles (RFC 6374, RFC 4656, RFC 5357, et bien d'autres). Il stocke l'estampille sous forme d'un entier de 32 bits pour les secondes depuis l'epoch 1900, et d'un autre entier de 32 bits pour les fractions de seconde. Sa taille totale est de 64 bits, sa résolution de 2 puissance -32 seconde, soit 0,2 milliardièmes de seconde. Et sa période de bouclage est de 136 ans.
NTP a un autre format, sur seulement 32 bits, pour les cas où la taille compte, par exemple des objets contraints. Dans ce cas, le nombre de secondes et la fraction de seconde sont sur 16 bits chacun. Cela lui donne une période de bouclage très courte, seulement 18 heures.
Et le troisième format standard proposé est celui de PTP, dans sa version « tronquée » à 64 bits. Ce format est utilisé dans les RFC 6374, RFC 7456 ou RFC 8186. Il est surtout intéressant lorsqu'il faut interagir avec de l'instrumentation utilisant PTP. Sa résolution est d'une nanoseconde, sa période de bouclage est la même que celle de NTP mais comme son epoch est en 1970, cela remet le prochain bouclage à 2106.
(Vous noterez que notre RFC ne parle que des formats binaires
pour représenter les estampilles temporelles. Il existe également
des formats texte, notamment celui du RFC 3339, utilisé par exemple dans les RFC 5424, RFC 5646, RFC 6991, ou RFC 7493. Les formats de
HTTP
- en-têtes Date: et
Last-Modified: - ainsi que
l'Internet Message Format - IMF, RFC 5322 -
n'utilisent hélas pas le RFC 3339.)
Deux exemples d'utilisation de ces formats binaires standards sont donnés dans notre RFC, aux sections 6.1 et 6.2, si vous êtes un ou une concepteur(trice) de protocoles qui veut inclure une estampille temporelle.
Mais, si, malgré les sages conseils du RFC, vous êtes l'auteur(e) d'un protocole et vous voulez quand même créer votre propre format binaire pour indiquer date et heure, y a-t-il des règles à suivre ? (À part la règle « ne le faites pas ».) Oui, la section 3 du RFC donne des indications (la plupart sont assez évidentes) :
- Bien documenter les raisons pour lesquelles vous tenez absolument à votre format à vous,
- indiquer évidemment la taille de chaque champ et la boutianité (ce sera du gros boutien par défaut),
- indiquer les unités utilisées, et l'epoch,
- documenter le moment du bouclage, et les solutions prévues pour quand il sera atteint,
- et ne pas oublier de gérer les secondes intercalaires.
À propos de secondes intercalaires, que vous utilisiez un format à vous, ou bien la méthode recommandée d'un format existant, pensez aux aspects liés à la synchronisation des horloges entre elles (section 5 du RFC), sauf pour les cas d'horloges complètement isolées (mais les RFC sont écrits pour l'Internet, donc il est prévu de communiquer). Quel(s) protocole(s) utiliser, quelle référence de temps (UTC ? TAI ?), et comment gérer ces fameuses secondes intercalaires. Que faut-il faire si l'horloge recule, faut-il faire un changement brusque ou bien du smearing (cf. RFC 8633), etc.
Un avant-dernier détail : parfois, le format de l'estampille temporelle, et ses propriétés, sont décrits dans le protocole, ou dans un modèle formel, par exemple en YANG. C'est ce que fait OWAMP (RFC 4656) avec le champ donnant une estimation de l'erreur de mesure (section 4.1.2 du RFC 4656). Notre RFC nomme ces « méta » champs « champs de contrôle » et donne quelques règles à suivre quand on les utilise : extensibilité (on aura toujours besoin d'autre chose), taille (assez gros mais pas trop…), importance (obligatoire ou optionnel), catégorie (statique ou dynamique).
Enfin, il y a évidemment la question de la sécurité (section 9). Il est bien sûr obligatoire dans la description d'un protocole de fournir une analyse de sa sécurité (RFC 3552). Cela doit inclure les conséquences des estampilles temporelles sur la sécurité. Par exemple, de telles estampilles, si elles sont transmises en clair, peuvent renseigner un observateur sur les performances d'un réseau. Et, si elle ne sont pas protégées contre les modifications non autorisées (ce qui peut se faire, par exemple, avec un MAC), un attaquant peut fausser sérieusement le fonctionnement d'un protocole en changeant la valeur des estampilles.
Autre problème de sécurité, un attaquant actif qui retarderait délibérement les messages. Cela perturberait évidemment tout protocole qui utilise le temps. Et, contrairement à la modification des estampilles, cela ne peut pas se résoudre avec de la cryptographie. Enfin, la synchronisation des horloges est elle-même exposée à des attaques (RFC 7384). Si on déploie NTP sans précautions particulières, un attaquant peut vous injecter une heure incorrecte.
L'article seul
RFC 8906: A Common Operational Problem in DNS Servers: Failure To Communicate
Date de publication du RFC : Septembre 2020
Auteur(s) du RFC : M. Andrews (ISC), R. Bellis (ISC)
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 23 septembre 2020
Normalement, le protocole DNS est très simple : le client écrit au serveur, posant une question, et le serveur répond. Il peut répondre qu'il ne veut pas ou ne sait pas répondre, mais il le dit explicitement. Cela, c'est la théorie. En pratique, beaucoup de serveurs DNS bogués (ou, plus fréquemment, situés derrière une middlebox boguée) ne répondent pas du tout, laissant le client perplexe se demander s'il doit réeessayer différemment ou pas. Ce nouveau RFC documente le problème et ses conséquences. Il concerne surtout la question des serveurs faisant autorité.
(Cette absence de réponse est en général due, non pas aux serveurs DNS eux-même, qui sont la plupart du temps corrects de ce point de vue, mais plutôt à ces middleboxes codées avec les pieds et mal configurées, que certains managers s'obstinent à placer devant des serveurs DNS qui marcheraient parfaitement sans cela. Ainsi, on voit des pare-feux inutiles mis parce que « il faut un pare-feu, a dit l'auditeur » et qui bloquent tout ce qu'ils ne comprennent pas. Ainsi, par exemple, le pare-feu laissera passer les requêtes de type A mais pas celles de type NS, menant à une expiration du délai de garde. La section 4 de notre RFC détaille ces erreurs communes des middleboxes.)
Voici un exemple d'un service DNS bogué. Le domaine
mabanque.bnpparibas est délégué à deux serveurs
mal configurés (ou placés derrière une middlebox
mal faite), sns6.bnpparibas.fr et
sns5.bnpparibas.net :
% dig @sns6.bnpparibas.fr A mabanque.bnpparibas ; <<>> DiG 9.11.5-P4-5.1-Debian <<>> @sns6.bnpparibas.fr A mabanque.bnpparibas ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 57381 ;; flags: qr aa rd ad; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0 ;; WARNING: recursion requested but not available ;; QUESTION SECTION: ;mabanque.bnpparibas. IN A ;; ANSWER SECTION: mabanque.bnpparibas. 30 IN A 159.50.187.79 ;; Query time: 24 msec ;; SERVER: 159.50.105.65#53(159.50.105.65) ;; WHEN: Wed Jun 17 08:21:07 CEST 2020 ;; MSG SIZE rcvd: 53 % dig @sns6.bnpparibas.fr NS mabanque.bnpparibas ; <<>> DiG 9.11.5-P4-5.1-Debian <<>> @sns6.bnpparibas.fr NS mabanque.bnpparibas ; (1 server found) ;; global options: +cmd ;; connection timed out; no servers could be reached
Face à un service aussi mal fait, le client DNS est très désarmé. Est-ce que le serveur a ignoré la requête ? Est-ce que le paquet a été perdu (c'est l'Internet, rien n'est garanti) ? Dans le deuxième cas, il faut réessayer, dans le premier, cela ne servirait à rien, qu'à perdre du temps, et à en faire perdre à l'utilisateur. Le client peut aussi supposer que l'absence de réponse est due à telle ou telle nouveauté du protocole DNS qu'il a utilisé, et se dire qu'il faudrait réessayer sans cette nouveauté, voire ne jamais l'utiliser. On voit que ces services grossiers, qui ne répondent pas aux requêtes, imposent un coût conséquent au reste de l'Internet, en délais, en trafic réseau, et en hésitation à déployer les nouvelles normes techniques.
Il n'y a aucune raison valable pour une absence de réponse ?
Notre RFC en note
une : une attaque par déni de service en
cours. Dans ce cas, l'absence de réponse est légitime (et, de toute
façon, le serveur peut ne pas avoir le choix). En dehors d'une telle
attaque, le serveur doit répondre, en utilisant
un des codes de retour DNS existants, qui couvrent tous les cas
possibles (de NOERROR, quand tout va bien, à
REFUSED, le refus délibéré, en passant par
SERVFAIL, l'impossibilité de produire une
réponse sensée). Ici, un cas où je demande à un serveur de
.fr des informations sur
un .com, qu'il n'a
évidemment pas, d'où le refus explicite (cf. le champ
status:) :
% dig @d.nic.fr A www.microsofthub.com ; <<>> DiG 9.11.5-P4-5.1-Debian <<>> @d.nic.fr A www.microsofthub.com ; (2 servers found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: REFUSED, id: 4212 ;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1 ;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 1432 ; COOKIE: 452269774eb7b7c574c779de5ee9b8e6efe0f777274b2b17 (good) ;; QUESTION SECTION: ;www.microsofthub.com. IN A ;; Query time: 4 msec ;; SERVER: 2001:678:c::1#53(2001:678:c::1) ;; WHEN: Wed Jun 17 08:32:06 CEST 2020 ;; MSG SIZE rcvd: 77
Le RFC note qu'il n'y a pas que l'absence de réponse, il y a aussi parfois des réponses incorrectes. Ainsi, certains serveurs (ou, là encore, la middlebox placée devant eux) copient le bit AD de la requête dans la réponse au lieu de déterminer par eux-mêmes si ce bit - qui signifie Authentic Data - doit être mis dans la réponse.
Donc, ne pas répondre, c'est mal, et égoïste. Mais quelles sont les conséquences exactes de cette absence de réponse ? Parmi elles :
- Pendant longtemps, les résolveurs DNS, face à une absence de réponse, réessayaient sans EDNS, ce qui résolvait parfois le problème, mais a sérieusement gêné le déploiement d'EDNS.
- Même problème avec les nouvelles utilisations d'EDNS.
- Un comportement fréquent des pare-feux est de bloquer les requêtes demandant des types de données qu'ils ne connaissent pas. La liste connue de ces pare-feux est toujours très réduite par rapport à la liste officielle, ce qui se traduit par une grande difficulté à déployer de nouveaux types de données DNS. C'est une des raisons derrière l'échec du type SPF (cf. RFC 6686). Cela encourage l'usage de types de données fourre-tout comme TXT.
- Même problème pour le déploiement de DANE et de son type TLSA.
- Le RFC ne cite pas ce cas, mais ne pas répondre peut aussi dans certains cas faciliter des attaques par empoisonnement d'un résolveur, cf. l'attaque SLIP.
Quels sont les cas où il est particulièrement fréquent qu'il n'y ait pas de réponse, ou bien une réponse erronée ? La section 3 en décrit un certain nombre (et le RFC vient avec un script qui utilise dig pour tester une grande partie de ces cas). Elle rappelle également les réponses correctes attendues. Par exemple, une requête de type SOA (Start Of Authority) à un serveur faisant autorité pour une zone doit renvoyer une réponse (contrairement aux serveurs de BNP Paribas cités plus haut, qui ne répondent pas). Même si le type de données demandé est inconnu du serveur, il doit répondre (probablement NOERROR s'il n'a tout simplement pas de données du type en question).
On voit parfois également des serveurs (ou plutôt des combinaisons serveur / middlebox boguée située devant le serveur) qui achoppent sur les requêtes utilisant des options (flags) DNS spécifiques. Ici, l'option Z fait que le serveur de la RATP ne répond plus :
% dig @193.104.162.15 +noedns +noad +norec +zflag soa ratp.fr ; <<>> DiG 9.11.5-P4-5.1-Debian <<>> @193.104.162.15 +noedns +noad +norec +zflag soa ratp.fr ; (1 server found) ;; global options: +cmd ;; connection timed out; no servers could be reached
Alors qu'il marche parfaitement sans cette option :
% dig @193.104.162.15 +noedns +noad +norec soa ratp.fr ; <<>> DiG 9.11.5-P4-5.1-Debian <<>> @193.104.162.15 +noedns +noad +norec soa ratp.fr ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 30635 ;; flags: qr aa; QUERY: 1, ANSWER: 1, AUTHORITY: 4, ADDITIONAL: 2 ;; QUESTION SECTION: ;ratp.fr. IN SOA ;; ANSWER SECTION: ratp.fr. 3600 IN SOA ns0.ratp.fr. hostmaster.ratp.fr. 2020051201 21600 3600 4204800 300 ... ;; ADDITIONAL SECTION: ns0.ratp.fr. 3600 IN A 193.104.162.15 ns1.ratp.fr. 3600 IN A 193.104.162.14 ;; Query time: 6 msec ;; SERVER: 193.104.162.15#53(193.104.162.15) ;; WHEN: Mon May 18 17:42:33 CEST 2020 ;; MSG SIZE rcvd: 213
Autre exemple, l'option AD (Authentic Data) dans la requête, qui indique que le client espère une validation DNSSEC, déclenche parfois des bogues, comme de ne pas répondre ou bien de répondre en copiant aveuglément le bit AD dans la réponse. La section 6 du RFC détaille un cas similaire, celui des serveurs qui réutilisent une réponse déjà mémorisée, mais pour des options différentes dans la requête.
Et les opérations (opcodes) inconnus ? Des
opérations comme NOTIFY ou
UPDATE n'existaient pas au début du DNS et
d'autres seront encore ajoutées dans le futur. Si le serveur ne
connait pas une opération, il doit répondre
NOTIMP (Not
Implemented). Ici, avec l'opération 1
(IQUERY, ancienne mais abandonnée par le RFC 3425) :
% dig @d.nic.fr +opcode=1 toto.fr ; <<>> DiG 9.11.5-P4-5.1+deb10u1-Debian <<>> @d.nic.fr +opcode=1 toto.fr ; (2 servers found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: IQUERY, status: NOTIMP, id: 20180 ;; flags: qr; QUERY: 0, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 1432 ; COOKIE: 71f9ced2f29076a65d34f3ed5ef2f718bab037034bb82106 (good) ;; Query time: 4 msec ;; SERVER: 2001:678:c::1#53(2001:678:c::1) ;; WHEN: Wed Jun 24 08:47:52 CEST 2020 ;; MSG SIZE rcvd: 51
Au contraire, voici un serveur qui répond incorrectement
(REFUSED au lieu de
NOTIMP) :
% dig @ns3-205.azure-dns.org. +noedns +noad +opcode=15 +norec microsoft.com ; <<>> DiG 9.11.5-P4-5.1+deb10u1-Debian <<>> @ns3-205.azure-dns.org. +noedns +noad +opcode=15 +norec microsoft.com ; (2 servers found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: RESERVED15, status: REFUSED, id: 41518 ;; flags: qr; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 0 ;; QUESTION SECTION: ;microsoft.com. IN A ;; Query time: 22 msec ;; SERVER: 2a01:111:4000::cd#53(2a01:111:4000::cd) ;; WHEN: Wed Jun 24 09:16:19 CEST 2020 ;; MSG SIZE rcvd: 31
Soyons positifs : c'était bien pire il y a encore seulement cinq ou
dix ans, malgré des tests techniques obligatoires dans certains
registres comme
Zonecheck pour
.fr. Des efforts comme
le DNS Flag
Day ont permis d'arranger sérieusement les choses.
Bien sûr, les serveurs DNS doivent accepter les requêtes venant sur TCP et pas seulement sur UDP. Cela a toujours été le cas, mais le RFC 7766 rend cette exigence encore plus stricte. Il y a fort longtemps, l'outil de test Zonecheck de l'AFNIC testait ce fonctionnement sur TCP, et avait attrapé beaucoup d'erreurs de configuration, suscitant parfois des incompréhensions de la part d'administrateurs système ignorants qui prétendaient que le DNS n'utilisait pas TCP.
Et il y a bien sûr EDNS (RFC 6891). Introduit après la norme originale du DNS, mais
quand même ancienne de plus de vingt ans, EDNS est toujours mal
compris par certains programmeurs, et bien des
middleboxes déconnent toujours sur des
particularités d'EDNS. Déjà, un serveur doit répondre aux requêtes
EDNS (même si lui-même ne connait pas EDNS, il doit au moins
répondre FORMERR). Ensuite, s'il connait EDNS,
il doit gérer les numéros de version d'EDNS (attention, la version
actuelle est la 0, il n'y a pas encore eu de version 1 mais, pour
qu'elle puisse être déployée un jour, il ne faut pas que les
serveurs plantent sur les versions supérieures à zéro). EDNS permet
d'indiquer des options (la liste complète est dans un
registre IANA) et les options inconnues doivent être ignorées
(autrement, on ne pourrait jamais déployer une nouvelle option).
Pour tester si vos serveurs gèrent correctement tous ces cas, le
RFC (section 8) vient avec une série de commandes utilisant
dig, dont
il faudra analyser le résultat manuellement en suivant le RFC. J'en
ai fait un script de test, check-dns-respond-rfc8906.sh. Si vous testez vos serveurs avec ce script, faites-le depuis
l'extérieur (pour intégrer dans le test les éventuelles
middleboxes, cf. section 4). Un exemple
d'exécution du test :
% ./check-dns-respond-rfc8906.sh cyberstructure.fr 2001:4b98:dc0:41:216:3eff:fe27:3d3f >& /tmp/mytest.txt
Et il vous reste à lire le fichier des résultats et à comparer avec les résultats attendus.
L'article seul
RFC 8908: Captive Portal API
Date de publication du RFC : Septembre 2020
Auteur(s) du RFC : T. Pauly (Apple), D. Thakore (CableLabs)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF capport
Première rédaction de cet article le 22 septembre 2020
Un des nombreux problèmes posés par les portails captifs est l'interaction avec le portail, par exemple pour accepter les CGU et continuer. Ces portails ne sont en général prévus que pour une interaction avec un humain. Ce RFC décrit une API ultra-simple qui permet à des programmes, au moins de savoir s'il y a un portail, quelles sont ses caractéristiques et comment sortir de captivité.
L'API suit les principes du RFC 8952. Elle permet donc de récupérer l'état de la captivité (est-ce que j'ai un accès à l'Internet ou pas), et l'URI de la page Web avec laquelle l'humain devra interagir.
Comment est-ce que la machine qui tente de se connecter a appris l'existence de l'API et son URI d'entrée ? Typiquement via les options de DHCP ou de RA décrites dans le RFC 8910. On accède ensuite à l'API avec HTTPS (RFC 2818). Il faudra naturellement authentifier le serveur, ce qui peut poser des problèmes tant qu'on n'a pas un accès à l'Internet complet (par exemple à OCSP, RFC 6960, et à NTP, RFC 5905, pour mettre l'horloge à l'heure et ainsi vérifier que le certificat n'a pas encore expiré). De même, des certificats intermédiaires qu'il faut récupérer sur l'Internet via Authority Information Access (AIA, section 5.2.7 du RFC 5280) peuvent poser des problèmes et il vaut mieux les éviter.
L'API elle-même est présentée en section 5 du RFC. Le contenu est
évidement en JSON (RFC 8259), et
servi avec le type application/captive+json. Dans
les réponses du serveur, l'objet JSON a obligatoirement un membre
captive dont la valeur est un booléen et qui
indique si on on est en captivité ou pas. Les autres membres
possibles sont :
user-portal-uriindique une page Web pour humains, avec laquelle l'utilisateur peut interagir,venue-info-urlest une page Web d'information,can-extend-session, un booléen qui indique si on peut prolonger la session, ce qui veut dire que cela peut être une bonne idée de ramener l'humain vers la page Webuser-portal-urilorsque la session va expirer,seconds-remaining, le nombre de secondes restant pour cette session, après quoi il faudra se reconnecter (sican-extend-sessionest à Vrai),bytes-remaining, la même chose mais pour des sessions limitées en quantité de données et plus en temps.
Ces réponses de l'API peuvent contenir des données spécifiques au
client, et donc privées. Auquel cas, le serveur doit penser à
utiliser Cache-control: private (RFC 9111) ou un mécanisme
équivalent, pour éviter que ces données se retrouvent dans des
caches.
Un exemple complet figure en section 6 du RFC. On suppose que le
client a découvert l'URL
https://example.org/captive-portal/api/X54PD39JV
via un des mécanismes du RFC 8910. Il
envoie alors une requête HTTP :
GET /captive-portal/api/X54PD39JV HTTP/1.1 Host: example.org Accept: application/captive+json
Et reçoit une réponse :
HTTP/1.1 200 OK
Cache-Control: private
Date: Mon, 02 Mar 2020 05:07:35 GMT
Content-Type: application/captive+json
{
"captive": true,
"user-portal-url": "https://example.org/portal.html"
}
Il sait alors qu'il est en captivité, et que l'utilisateur doit
aller en https://example.org/portal.html pour
accepter des CGU léonines, s'authentifier,
etc. Une fois que c'est fait, il peut continuer à faire des requêtes
à l'API et avoir, par exemple :
{
"captive": false,
"user-portal-url": "https://example.org/portal.html",
"venue-info-url": "https://flight.example.com/entertainment",
"seconds-remaining": 326,
"can-extend-session": true
}
D'autres membres de l'objet JSON pourront apparaitre, selon la procédure « Spécification nécessaire » (RFC 8126), un registre IANA a été créé pour les stocker.
Un peu de sécurité pour finir (section 7 du RFC). Le protocole de notre RFC impose l'utilisation de HTTPS (donc de TLS) ce qui règle pas mal de problèmes, notamment de confidentialité et d'authentification. À noter donc (mais cela en vaut la peine) que cela complique un peu les choses pour l'administrateur du portail captif, qui ne peut pas se contenter de HTTP en clair, et qui doit avoir un certificat valide. (Cet argument de la complexité avait été mentionné lors des discussions à l'IETF, où certains trouvaient notre RFC trop exigeant.) Combien de fois ai-je vu des portails captifs avec un certificat auto-signé et/ou expiré !
Mais attention, TLS va seulement sécuriser le fait qu'on se connecte bien au serveur indiqué via les méthodes du RFC 8910. Or, comme ces méthodes ne sont pas elle-mêmes très sûres, la sécurité du portail captif ne doit jamais être surestimée.
Le protocole décrit dans le RFC 8910 et dans ce RFC a été testé lors de réunions IETF, sur le grand réseau de ces réunions. En dehors de cela, il n'y a pas encore de déploiement. Je crains que, vu la nullité technique de la plupart des points d'accès WiFi, vite installés, mal configurés et plus maintenus après, il ne faille attendre longtemps un déploiement significatif.
L'article seul
RFC 8910: Captive-Portal Identification in DHCP and Router Advertisements (RAs)
Date de publication du RFC : Septembre 2020
Auteur(s) du RFC : W. Kumari (Google), E. Kline (Loon)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF capport
Première rédaction de cet article le 22 septembre 2020
Les portails captifs sont une des plaies de l'accès à l'Internet. À défaut de pouvoir les supprimer, ce nouveau RFC propose des options aux protocoles DHCP et RA pour permettre de signaler la présence d'un portail captif, au lieu que la malheureuse machine ne doive le détecter elle-même. Il remplace le RFC 7710, le premier à traiter ce sujet. Il y a peu de changements de fond mais quand même deux modifications importantes. D'abord, il a fallu changer le code qui identifiait l'option DHCP en IPv4 (du code 160 au 114). Et ensuite l'URI annoncé sur le réseau est désormais celui de l'API et pas une page Web conçue pour un humain.
On trouve de tels portails captifs en de nombreux endroits où de l'accès Internet est fourni, par exemple dans des hôtels, des trains ou des cafés. Tant que l'utilisateur ne s'est pas authentifié auprès du portail captif, ses capacités d'accès à l'Internet sont très limitées. Quels sont les problèmes que pose un portail captif ?
- Le plus important est qu'il détourne le trafic normal : en cela, le portail captif est une attaque de l'Homme du Milieu et a donc de graves conséquences en terme de sécurité. Il éduque les utilisateurs à trouver normal le fait de ne pas arriver sur l'objectif désiré, et facilite donc le hameçonnage. Au fur et à mesure que les exigences de sécurité augmentent, ces portails captifs seront, on peut l'espérer, de plus en plus mal vus.
- Le portail captif ne marche pas ou mal si la première connexion est en HTTPS, ce qui est, à juste titre, de plus en plus fréquent. Là encore, il éduque les utilisateurs à trouver normaux les avertissements de sécurité (« mauvais certificat, voulez-vous continuer ? »).
- Le portail captif n'est pas authentifié, lui, et l'utilisateur est donc invité à donner ses informations de créance à un inconnu.
- En Wifi, comme l'accès n'est pas protégé par WPA, le trafic peut être espionné par les autres utilisateurs.
- Spécifique au Web, le portail captif ne marche pas avec les activités non-Web (comme XMPP). Même les clients HTTP non-interactifs (comme une mise à jour du logiciel via HTTP) sont affectés.
Pourquoi est-ce que ces hôtels et cafés s'obstinent à imposer le passage par un portail captif ? On lit parfois que c'est pour authentifier l'utilisateur mais c'est faux. D'abord, certains portails captifs ne demandent pas d'authentification, juste une acceptation des conditions d'utilisation. Ensuite, il existe une bien meilleure solution pour authentifier, qui n'a pas les défauts indiqués plus haut. C'est 802.1X, utilisé entre autres dans eduroam (voir RFC 7593). La vraie raison est plutôt une combinaison d'ignorance (les autres possibilités comme 802.1X ne sont pas connues) et de désir de contrôle (« je veux qu'ils voient mes publicités et mes CGU »).
L'IETF travaille à développer un protocole complet d'interaction avec les portails captifs, pour limiter leurs conséquences. En attendant que ce travail soit complètement terminé, ce RFC propose une option qui permet au moins au réseau local de signaler « attention, un portail captif est là, ne lance pas de tâches - comme Windows Update - avant la visite du portail ». Cette option peut être annoncée par le serveur DHCP (RFC 2131 et RFC 9915) ou par le routeur qui envoie des RA (RFC 4861).
Cette option (section 2 du RFC) annonce au client qu'il est derrière un portail captif et lui fournit l'URI de l'API à laquelle accéder (ce qui évite d'être détourné, ce qui est grave quand on utilise HTTPS). Les interactions avec l'API de ce serveur sont spécifiées dans le RFC 8908.
Les sections 2.1, 2.2 et 2.3 de notre RFC donnent le format de l'option en DHCP v4, DHCP v6 et en RA. Le code DHCP v4 est 114 (un changement de notre RFC), le DHCP v6 est 103 et le type RA est 37. Pour la création d'options DHCPv6 avec des URI, voir le RFC 7227, section 5.7.
Un URI spécial,
urn:ietf:params:capport:unrestricted est
utilisé pour le cas où il n'y a pas de portail
captif. (Cet URI spécial est enregistré
à l'IANA, avec les autres suffixes du RFC 3553.)
Bien que la première version de ce RFC date de plus de quatre
ans, la grande majorité des réseaux d'accès avec portail captif
n'annoncent toujours pas la présence de ce portail et il faudra
encore, pendant de nombreuses années, que les machines terminales
« sondent » et essaient de détecter par elles-même s'il y a un
portail captif ou pas. Elles font cela, par exemple, en essayant de
se connecter à une page Web connue (comme http://detectportal.firefox.com/
% curl http://detectportal.firefox.com/ success
Et ici lorsqu'il y a un portail captif qui détourne le trafic :
% curl -v http://detectportal.firefox.com/ > GET / HTTP/1.1 > Host: detectportal.firefox.com > User-Agent: curl/7.58.0 > Accept: */* > < HTTP/1.1 302 Moved Temporarily < Server: nginx < Date: Mon, 27 Jul 2020 18:29:52 GMT ... < Location: https://wifi.free.fr/?url=http://detectportal.firefox.com/ < <html> <head><title>302 Found</title></head> <body bgcolor="white"> <center><h1>302 Found</h1></center> <hr><center>nginx</center> </body> </html>
La section 5 de notre RFC étudie les conséquences de cette option pour la sécurité. Elle rappelle que DHCP et RA ne sont pas sécurisés, de toute façon. Donc, un méchant peut envoyer une fausse option « il y a un portail captif, allez à cet URI pour vous authentifier » mais le même méchant peut aussi bien annoncer un faux routeur et ainsi recevoir tout le trafic... Si on n'utilise pas des précautions comme le RA Guard (RFC 6105) ou le DHCP shield (RFC 7610), on ne peut de toute façon pas se fier à ce qu'on a obtenu en DHCP ou RA.
Il est même possible que cette option nouvelle améliore la sécurité, en n'encourageant pas les utilisateurs à couper les mécanismes de validation comme la vérification des certificats, contrairement à ce que font les portails captifs actuels, qui se livrent à une véritable attaque de l'Homme du Milieu.
Pour DHCP, la plupart des serveurs permettent de servir une option quelconque, en mettant ses valeurs manuellement et une future mise à jour ne servira donc qu'à rendre l'usage de cette option plus simple. (Pour RA, c'est plus complexe, cf. l'expérience lors d'une réunion IETF.) Autrement, je ne connais pas encore de mise en œuvre côté clients DHCP ou RA, mais il semble (je n'ai pas testé personnellement) que ça marche sur iOS à partir de la version 14.
L'annexe B de notre RFC cite les changements depuis le RFC 7710. Les principaux :
- L'ajout de l'URN
urn:ietf:params:capport:unrestrictedpour le cas où il n'y a pas de portail captif, - le changement de l'option DHCP en IPv4, suite à la collision avec les produits Polycom,
- l'URI envoyée désigne désormais une API et plus una page Web ordinaire (contrairement à ce que dit l'annexe B de notre RFC, il ne s'agit pas d'une clarification mais d'un vrai changement),
- les noms (et plus seulement les adresses IP) sont acceptés dans l'URI,
- et plusieurs éclaircissements et précisions.
L'article seul
Mesurer la consommation d'électricité de ses appareils à la maison
Première rédaction de cet article le 19 septembre 2020
On parle beaucoup, en ce moment, de la consommation électrique du secteur du numérique. C'est à juste titre, vu les dangers qui nous attendent. Malheureusement ces débats ne sont pas toujours appuyés sur des arguments solides. Pour discuter, il faut savoir, et pour savoir, il faut mesurer. Je présente donc ici l'usage d'un simple wattmètre pour mesurer la consommation électrique de ses appareils.
Quelques petits rappels simples, pour commencer. La consommation électrique instantanée (à un instant T), la puissance, se mesure en watts (notés W). La consommation sur une période donnée, l'énergie, se mesure en joules (notés J) mais, en pratique, on l'exprime plus souvent en kilowattheures (notés kWh). Un kWh vaut 3,6 MJ joules (millions de joules).
La consommation électrique d'un appareil est souvent écrite dessus, sur son alimentation électrique, ou dans sa fiche technique mais attention, c'est en général sa consommation maximale (en théorie).
L'appareil qui mesure cette consommation électrique est donc un
wattmètre. Les wattmètres
bas de gamme sont peu coûteux et disponibles facilement. J'ai
utilisé le Chacon 54365
(disponible sur
Amazon, et, si vous n'aimez pas Amazon, on peut trouver cet
appareil sur
le site du fabricant - je n'ai pas testé leurs livraisons -, ou
dans d'autres boutiques comme
Cdiscount). Il m'a coûté 19 € mais je vois que le prix a augmenté
depuis. Il se branche dans une prise électrique, et on branche
ensuite l'appareil ou l'ensemble d'appareils à mesurer dessus. Sur
cette photo, le wattmètre est en haut, son écran à gauche :  (Image agrandie.)
(Image agrandie.)
{kind=link}
Pourquoi ai-je choisi ce modèle ? La principale raison est son écran séparé. Le wattmètre doit souvent être installé dans des endroits peu accessibles (derrière le frigo, par exemple) et un écran qui peut se placer loin de la prise est vraiment important. Second avantage : ce wattmètre ne dépend pas de piles (ce qui est apparemment le cas de certains modèles). Un tel engin bon marché est évidemment assez grossier, et il ne faut pas en attendre une parfaite précision. (Déjà, si on était sérieux, on l'étalonnerait avec un appareil de puissance connue.)
Autre considération méthodologique : si vous voulez vous faire une idée du coût énergétique de votre usage du numérique, attention, mesurer chez soi ne suffit pas. Si, comme la plupart des gens, votre usage du numérique fait un fort appel aux réseaux, plus spécialement à l'Internet, il faudra aussi tenir compte de la consommation de tout le matériel en dehors de chez vous. Sur la consommation énergétique de ce matériel, il est difficile d'obtenir des informations fiables et sourcées. Des chiffres sont parfois publiés mais leur crédibilité me semble faible. En attendant, mesurons ce qui est sous notre contrôle immédiat.
Commençons avec un engin simple, un PC. Le premier testé, tournant sous Windows, consomme environ 45 W. Cela passe à 52 si on allume l'imprimante/numériseur. Cette consommation dépend de l'activité du PC (les chiffres ici sont pour une machine au repos). Un PC portable, lui, prend 30 W quand son capot est fermé et qu'il se charge, 45 W quand il est allumé et jusqu'à 60 lorsqu'il travaille (affichage d'un film). On voit que, contrairement aux routeurs et serveurs de l'Internet, la consommation dépend de l'usage. (Mais pas du stockage et c'est pour cela que le conseil souvent lu « supprimez vos emails pour diminuer l'empreinte carbone » est absurde.) Un autre PC, tournant sous Debian (mais ce n'est pas le même matériel, donc une comparaison directe n'est pas possible) prend 72 W lorsqu'il est inactif, et 92 lorsqu'il travaille (mais cela tombe à 47 quand son écran se met en veille ; les écrans, ça consomme).
Un engin, très différent, un Raspberry Pi (modèle 1, donc très ancien), consomme, lui, moins de 3 W (mais il ne rend évidemment pas les mêmes services).
J'ai dit plus haut qu'il ne fallait pas regarder que la consommation des machines terminales mais aussi celle du reste de l'Internet. À la maison, je note qu'un adaptateur CPL et un commutateur Ethernet bas de gamme sifflent 8 W. Quant à l'armoire où se trouvent la box, le routeur Turris Omnia, le Raspberry Pi et la base DECT, elle prend 33 W. C'est moins que n'importe quel PC, mais ces équipements, eux, restent allumés bien plus longtemps donc l'énergie totale consommée peut être plus grande. (La box est une Freebox, la mesure a été faite avec le Server allumé et le Player éteint.)
En effet, rappelez-vous de la différence entre puissance (consommation instantanée) et énergie (consommation sur une certaine période). Un équipement qui consomme 3 W en permanence aura avalé 2,2 kWh en un mois alors qu'un équipement qui nécessite une puissance de 70 W mais qui n'est branché qu'une heure par jour avalera un peu moins (2,1 kWh) en un mois. Le wattmètre Chacon 54365 permet de mesurer l'énergie consommée mais c'est très limité : il accumule les mesures mais on ne peut pas lui demander « combien d'énergie depuis la dernière remise à zéro ? », juste la consommation énergétique de la dernière semaine, du dernier mois, et de la dernière année, ce qui manque de souplesse. (Le manuel en français est téléchargeable, si vous voulez essayer.)
Par exemple, pour mon poste de travail (un PC, un commutateur, les enceintes audio), après un mois de télétravail, j'ai consommé 14 kWh.
Revenons aux écrans. Si j'allume la deuxième boîte fournie par Free, le Freebox Player, et la télévision, avec son bel écran, cela fait 95 W de plus. La télé, ça consomme !
Et si on quitte le monde du numérique ? 10 W pour un halogène, 620 W pour l'aspirateur. Le nettoyage consomme mais rappelez-vous la différence entre puissance et énergie : on ne laisse pas l'aspirateur fonctionner pendant des heures. Plus difficile à mesurer, le réfrigérateur. Il fonctionne par cycles, gardant le froid grâce à son isolation entre deux périodes d'activité. Sa consommation est quasiment nulle la plupart du temps (mais elle passe à 13 W si j'ouvre la porte, ce qui allume la lumière) et est d'environ 92 W quand le moteur tourne. Le frigo est donc typiquement un appareil pour lequel il faut mieux faire des mesures sur une certaine période, pas des mesures instantanées (17 kWh en un mois, ce qui me semble beaucoup).
Quelles leçons en tirer ? D'abord, si vous êtes soucieux d'écologie, il est clairement intéressant d'éteindre les machines quand on peut. Comme on n'y pense pas toujours, les dispositifs qui le font automatiquement sont très utiles (on a vu qu'éteindre automatiquement l'écran inutilisé diminuait sérieusement la puissance requise). Ensuite, on note qu'il n'est pas forcément nécessaire d'utiliser des engins très consommateurs pour toutes les fonctions. Un simple Raspberry Pi ou équivalent, avec sa faible consommation, est recommandé s'il faut laisser une machine allumée en permanence (par exemple pour la supervision). Enfin, n'oubliez pas que la difficulté est de bien prendre en compte toutes les sources de « coût » écologique, pas uniquement celles qui sont bien visibles. Ainsi, dans le numérique, une source importante est la fabrication des machines. Il vaut souvent plus la peine de garder les machines longtemps, évitant leur remplacement, que de les éteindre un peu plus souvent. Le Raspberry Pi 1 cité plus haut fonctionne depuis 2012…
Et pour finir, si vous aimez les calculs et les détails, je vous recommande l'article de Pierre Beyssac.
L'article seul
RFC 8904: DNS Whitelist (DNSWL) Email Authentication Method Extension
Date de publication du RFC : Septembre 2020
Auteur(s) du RFC : A. Vesely
Pour information
Première rédaction de cet article le 18 septembre 2020
Le RFC 8601 décrit un en-tête pour le
courrier qui
indique le résultat d'une tentative
d'authentification. Cet en-tête Authentication-Results: permet
plusieurs méthodes d'authentification, telles que SPF ou DKIM. Notre nouveau
RFC 8904 ajoute une nouvelle méthode,
dnswl (pour DNS White List), qui indique le
résultat d'une lecture dans une liste blanche, ou liste
d'autorisation via le DNS. Ainsi, si le client SMTP avait son
adresse IP dans cette liste, un en-tête Authentication-Results: d'authentification
positive sera ajouté.
Accéder via le DNS à des listes blanches (autorisation) ou des
listes noires (rejet) de MTA est une pratique courante dans la gestion du
courrier. Elle
est décrite en détail dans le RFC 5782. Typiquement, le serveur SMTP qui voit une connexion entrante
forme un nom de domaine à partir de l'adresse IP du client SMTP et fait une requête DNS
pour ce nom et le type de données A (adresse IP). S'il obtient une
réponse non-nulle, c'est que l'adresse IP figurait dans la liste
(blanche ou noire). On peut aussi faire une requête de type TXT pour
avoir du texte d'information. Ensuite, c'est au serveur SMTP de
décider ce qu'il fait de l'information. La liste (noire ou blanche)
lui donne une information, c'est ensuite sa responsabilité de
décider s'il accepte ou rejette la connexion. La décision n'est pas
forcément binaire, le serveur peut décider d'utiliser cette
information comme entrée dans un algorithme de calcul de la
confiance (« il est listé dans bl.example, 20
points en moins dans le calcul »).
Les plus connues des listes sont les listes noires (liste de
clients SMTP mauvais) mais il existe aussi des listes blanches
(liste de clients SMTP qu'on connait et à qui on fait confiance), et
elles font l'objet de ce RFC. Il crée une nouvelle méthode pour
l'en-tête Authentication-Results:, permettant ainsi d'enregistrer, dans un message, le
fait qu'il ait été « authentifié » positivement via une liste
blanche. On peut après se servir de cette « authentification » pour,
par exemple, vérifier que le nom de
domaine annoncé dans l'enregistrement TXT correspondant
soit celui attendu (dans l'esprit de DMARC
- RFC 9989 - ce qui est d'ailleurs très
casse-gueule mais c'est une autre histoire).
Et le RFC fait un rappel utile : se servir d'une liste (noire ou blanche) gérée à l'extérieur, c'est sous-traiter. Cela peut être pratique mais cela peut aussi avoir des conséquences néfastes si la liste est mal gérée (comme le sont la plupart des listes noires, adeptes du « on tire d'abord et on négocie après »). Comme le dit le RFC, « vous épousez la politique du gérant de la liste ». Lisez aussi le RFC 6471, au sujet de la maintenance de ces listes.
La nouvelle méthode d'authentification
(dnswl, section 2 de notre RFC) figure
désormais dans le
registre IANA des méthodes d'authentification, spécifié dans
le RFC 8601 (notamment section 2.7). Notre
RFC 8904 décrit également les propriétés (RFC 8601, section 2.3 et RFC 7410) associées à cette authentification.
La méthode dnswl peut renvoyer
pass (cf. le RFC 8601
pour ces valeurs renvoyées), qui indique que l'adresse IP du client
est dans la liste blanche interrogée, none
(client absent de la liste), ou bien une erreur (si la résolution
DNS échoue). Contrairement à d'autres méthodes, il n'y a pas de
résultat fail, ce qui est logique pour une
liste blanche (qui liste les gentils et ne connait pas les
méchants). Les principales propriétés possibles sont :
dns.zone: le nom de domaine de la liste blanche,policy.ip: l'adresse IP renvoyée par la liste blanche, elle indique de manière codée les raisons pour lesquelles cette adresse est dans la liste,policy.txt: l'enregistrement TXT optionnel, peut indiquer le nom de domaine associé à ce client SMTP,dns.sec: indique si la requête DNS a été validée avec DNSSEC (yessi c'est le cas,nosi la zone n'est pas signée,nasi le résolveur ne sait pas valider).
Le type dns pour les propriétés est une
nouveauté de ce RFC, désormais enregistrée
à l'IANA.
La section 3 de notre RFC décrit l'enregistrement de type TXT qui donne des explications sur la raison pour laquelle l'adresse IP est dans la liste blanche (cf. RFC 5782, sections 2.1 et 2.2). Par exemple, il permet d'indiquer le domaine concerné (ADMD, ADministrative Management Domain, cf. RFC 8601 pour ce concept).
Tiré de l'annexe A du RFC, voici un exemple d'un message qui a
reçu un Authentication-Results:, qui contient les quatre propriétés indiquées plus haut :
Authentication-Results: mta.example.org;
dnswl=pass dns.zone=list.dnswl.example dns.sec=na
policy.ip=127.0.10.1
policy.txt="fwd.example https://dnswl.example/?d=fwd.example"
Il se lit ainsi : le MTA
mta.example.org estime son client authentifié
par la méthode dnswl (DNS White
List) de ce RFC. La liste blanche a renvoyé la valeur
127.0.10.1 (sa signification exacte dépend de
la liste blanche) et le TXT associé disait que le client SMTP
appartenait au domaine fwd.example.
Dans l'exemple plus détaillé du RFC, le message avait été
retransmis d'une manière qui cassait SPF et n'aurait donc pas été accepté sans la
liste blanche, qui certifie que fwd.example est
un retransmetteur connu et légitime.
Enfin, la section 5 du RFC traite de sécurité. Notamment, elle insiste sur le fait que le DNS n'est pas, par défaut, protégé contre diverses manipulations et qu'il est donc recommandé d'utiliser DNSSEC (ce que ne fait pas la liste blanche d'exemple citée plus loin).
Voyons maintenant des exemples avec une liste blanche réelle,
https://www.dnswl.org/2001:67c:2218:2::4:12. On inverse l'adresse
(par exemple, avec ipv6calc -a 2001:67c:2218:2::4:12) et
on fait une requête sous list.dnswl.org :
% dig A 2.1.0.0.4.0.0.0.0.0.0.0.0.0.0.0.2.0.0.0.8.1.2.2.c.7.6.0.1.0.0.2.list.dnswl.org ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 1634 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 8, ADDITIONAL: 11 ... ;; ANSWER SECTION: 2.1.0.0.4.0.0.0.0.0.0.0.0.0.0.0.2.0.0.0.8.1.2.2.c.7.6.0.1.0.0.2.list.dnswl.org. 7588 IN A 127.0.9.1 ... ;; Query time: 0 msec ;; SERVER: 127.0.0.1#53(127.0.0.1) ;; WHEN: Sat Jul 04 09:16:37 CEST 2020 ;; MSG SIZE rcvd: 555
Que veut dire la valeur retournée, 127.0.9.1 ?
On consulte la
documentation de la liste et on voit que 9 veut dire
Media and Tech companies (ce qui est exact) et 1
low trustworthiness. Il s'agit de la confiance
dans le classement, pas dans le serveur. Pour le même serveur, la
confiance est plus grande en IPv4 (3 au lieu de 1) :
% dig A 12.4.134.192.list.dnswl.org
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 266
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
...
;; ANSWER SECTION:
12.4.134.192.list.dnswl.org. 10788 IN A 127.0.9.3
...
;; Query time: 0 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: Sat Jun 20 12:31:57 CEST 2020
;; MSG SIZE rcvd: 72
Et les enregistrements TXT ? Ici, il valent :
% dig TXT 2.1.0.0.4.0.0.0.0.0.0.0.0.0.0.0.2.0.0.0.8.1.2.2.c.7.6.0.1.0.0.2.list.dnswl.org ... ;; ANSWER SECTION: 2.1.0.0.4.0.0.0.0.0.0.0.0.0.0.0.2.0.0.0.8.1.2.2.c.7.6.0.1.0.0.2.list.dnswl.org. 8427 IN TXT "nic.fr https://dnswl.org/s/?s=8580"
En visant l'URL
indiquée, on peut avoir tous les détails que la liste blanche
connait de ce serveur. (Je n'ai pas investigué en détail mais j'ai
l'impression que certains serveurs faisant autorité pour le domaine
dnswl.org renvoient des NXDOMAIN à tort, par
exemple sur les ENT - Empty Non-Terminals - ce
qui pose problème si votre résolveur utilise une QNAME
minimisation - RFC 9156 - stricte.)
Pour utiliser cette liste blanche depuis votre MTA favori, vous pouvez regarder la documentation de dnswl.org. par exemple, pour Courier, ce sera :
-allow=list.dnswl.org
(Tous les détails dans la documentation de
Courier). Pour Postfix, voyez la section dédiée
dans la documentation de
dnswl.org. SpamAssassin, quant à lui,
utilise dnswl.org par défaut.
L'article seul
RFC 8808: A YANG Data Model for Factory Default Settings
Date de publication du RFC : Août 2020
Auteur(s) du RFC : Q. Wu (Huawei), B. Lengyel
(Ericsson), Y. Niu (Huawei)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF netmod
Première rédaction de cet article le 17 septembre 2020
Ce RFC décrit un modèle YANG pour permettre la « remise aux réglages d'usine » d'un équipement, quand celui-ci est trop bizarrement configuré pour qu'il y ait une autre solution que l'effacement radical.
YANG (RFC 6020) est un langage de description des équipements réseau et de leurs capacités, afin de permettre de la gestion automatisée de ces équipements via des protocoles comme NETCONF (RFC 6241) ou RESTCONF (RFC 8040).
Ce RFC définit
un nouveau RPC,
factory-reset, qui va remettre tous les
réglages de la machine aux réglages qu'elle avait à la sortie
d'usine. C'est l'équivalent YANG de manipulations physiques comme
« appuyez sur les boutons Power et VolumeDown simultanément pendant
cinq secondes » ou bien « insérez un trombone dans ce petit trou ».
La section 2 du RFC décrit plus précisément ce que veut dire
« retourner aux réglages d'usine ». Les entrepôts
(datastore, cf. RFC 6020,
RFC 7950 et RFC 8342)
comme <running> reprennent les valeurs
qu'ils contenaient lorsque l'équipement a quitté l'usine. Toutes les
données générées depuis sont jetées. Cela inclut (le RFC utilise des
exemples de répertoires Unix, que je reprends
ici, mais ce sont juste des exemples, l'équipement n'utilise pas
forcément Unix) les certificats
(/etc/ssl), les journaux
(/var/log), les fichiers temporaires
(/tmp), etc. Par contre, il faut garder des
informations qui étaient spécifiques à cet engin particulier (et
différent des autres du même modèle) mais qui ont été fixés avant le
premier démarrage, par exemple des identificateurs uniques ou des
clés privées (RFC 8995) ou mots
de passe générées automatiquement au début du cycle de vie. Les
données sensibles doivent être effacées de manière sûre, par exemple
en écrivant plusieurs fois sur leur emplacement (cf. section 6). À
noter que cette remise au début peut couper la communication avec la
machine de gestion : l'équipement se comportera comme s'il sortait
du carton, ce qui peut nécessiter une configuration nouvelle.
Notre RFC normalise également un nouvel entrepôt
(datastore),
factory-default, qui contient ces réglages
d'usine et permet donc à un client NETCONF ou RESTCONF de savoir en
quoi ils consistent. Appeler factory-reset
revient donc à appliquer factory-default. Cet
entrepôt suit les principes du RFC 8342,
annexe A, et est en lecture seule.
La section 4 présente le module complet, qui est disponible en
ietf-factory-default.yang. Il s'appuie sur le module du RFC 8342 et
sur celui du RFC 8341.
L'URN de ce
RFC,
urn:ietf:params:xml:ns:yang:ietf-factory-default
a été enregistré à
l'IANA (registre du RFC 3688), et le
module ietf-factory-default dans le registre
des modules.
Quelques mots sur la sécurité pour terminer. Comme le but de ce
module est de permettre à des clients NETCONF ou RESTCONF d'appeler
ce RPC
factory-reset, et que ce RPC a des
conséquences… sérieuses pour l'équipement, il faut comme d'habitude
veiller à ce que les accès NETCONF et RESTCONF soient bien sécurisés
(par exemple via SSH,
cf. RFC 6242 et via les contrôles d'accès du
RFC 8341).
L'article seul
RFC 8891: GOST R 34.12-2015: Block Cipher "Magma"
Date de publication du RFC : Septembre 2020
Auteur(s) du RFC : V. Dolmatov (JSC "NPK Kryptonite"), D. Baryshkov (Auriga)
Pour information
Première rédaction de cet article le 15 septembre 2020
Ce RFC décrit un algorithme russe de chiffrement symétrique, « GOST R 34.12-2015 », surnommé Magma. N'attendez pas de ma part des conseils sur l'utilisation ou non de cet algorithme, je résume juste le RFC.
GOST est le nom des normes de l'organisme de normalisation officiel en Russie (et, par abus de langage, leurs algorithmes sont souvent cités sous le nom de « GOST » tout court). Cet organisme a normalisé plusieurs algorithmes de chiffrement symétrique dont Kuznyechik (décrit dans le RFC 7801) et l'ancien « GOST 28147-89 » (RFC 5830). Ce dernier est remplacé par « GOST R 34.12-2015 », qui fait l'objet de ce RFC. (La norme russe officielle est disponible en ligne mais, de toute façon, le russe plus la cryptographie, ce serait trop pour moi). Comme d'autres algorithmes de cryptographie normalisés par GOST, Magma a été développé en partie par le secteur public (Service des communications spéciales et d'information du Service fédéral de protection de la Fédération de Russie) et par le secteur privé (InfoTeCS). Le décret n° 749 du 19 juin 2015, pris par l'Agence fédérale pour la régulation technique et la métrologie en a fait un algorithme russe officiel.
Du fait de ce caractère officiel, si vous vendez des produits ou des prestations de sécurité en Russie, vous serez probablement obligés d'inclure les algorithmes GOST.
Je vous laisse lire le RFC pour la description de l'algorithme (ou l'original russe, si vous lisez le russe). Notez que, contrairement à son prédécesseur (cf. RFC 5830, sections 5 à 7), il ne décrit pas les modes utilisables, chacun choisit celui qui lui semble adapté.
Question mises en œuvre, il y en a une compatible avec WebCrypto, ou bien une pour OpenSSL.
L'article seul
RFC 8900: IP Fragmentation Considered Fragile
Date de publication du RFC : Septembre 2020
Auteur(s) du RFC : R. Bonica (Juniper Networks), F. Baker, G. Huston (APNIC), R. Hinden (Check Point Software), O. Troan (Cisco), F. Gont (SI6 Networks)
Réalisé dans le cadre du groupe de travail IETF intarea
Première rédaction de cet article le 12 septembre 2020
Un concept important d'IP est la fragmentation, le découpage d'un paquet trop gros en plusieurs fragments, chacun acheminé dans un datagramme différent. Excellente idée sur le papier, la fragmentation est handicapée, dans l'Internet actuel, par les nombreuses erreurs de configuration de diverses middleboxes. Ce nouveau RFC constate la triste réalité : en pratique, la fragmentation marche mal, et les machines qui émettent les paquets devraient essayer de faire en sorte qu'elle ne soit pas utilisée.
Rappelons d'abord ce qu'est la fragmentation, dans IP. Tout lien entre deux machines a une MTU, la taille maximale des datagrammes qui peuvent passer. C'est par exemple 1 500 octets pour l'Ethernet classique. Si le paquet IP est plus grand, il faudra le fragmenter, c'est-à-dire le découper en plusieurs fragments, chacun de taille inférieure à la MTU. En IPv4, n'importe quel routeur sur le trajet peut fragmenter un paquet (sauf si le bit DF - Don't Fragment - est mis à un dans l'en-tête IP), en IPv6, seule la machine émettrice peut fragmenter (tout ce passe comme si DF était systématiquement présent).
Ces fragments seront ensuite réassemblés en un paquet à la destination. Chacun étant transporté dans un datagramme IP différent, ils auront pu arriver dans le désordre, certains fragments ont même pu être perdus, le réassemblage est donc une opération non-triviale. Historiquement, certaines bogues dans le code de réassemblage ont même pu mener à des failles de sécurité.
Une légende urbaine s'est constituée petit à petit, racontant que les fragments, en eux-mêmes, posaient un problème de sécurité. C'est faux, mais ce genre de légendes a la vie dure, et a mené un certain nombre d'administrateurs de pare-feux à bloquer les fragments. Le RFC 7872 faisait déjà le constat que les fragments, souvent, n'arrivaient pas à destination. Outre ce RFC, on peut citer une étude très ancienne, qui montre que le problème ne date pas d'aujourd'hui, « "Fragmentation Considered Harmful (SIGCOMM '87 Workshop on Frontiers in Computer Communications Technology) ou, pour le cas spécifique du DNS, la plus récente « IPv6, Large UDP Packets and the DNS ».
La section 2 de notre RFC explique en grand détail la fragmentation IP. Notez par exemple qu'IPv4 impose (RFC 791, section 3.2) une MTU minimale de 68 octets mais, en pratique, on a toujours au moins 576 octets (ou, sinon, une autre fragmentation/réassemblage, dans la couche 2). IPv6, lui, impose (RFC 8200), 1 280 octets. Il a même été suggéré de ne jamais envoyer de paquets plus grands, pour éviter la fragmentation. Un Ethernet typique offre une MTU de 1 500 octets, mais elle peut être réduite par la suite en cas d'utilisation de tunnels.
Chaque lien a sa MTU mais ce qui est important, pour le paquet, c'est la MTU du chemin (Path MTU), c'est-à-dire la plus petite des MTU rencontrées sur le chemin entre le départ et l'arrivée. C'est cette MTU du chemin qui déterminera si on fragmentera ou pas. (Attention, le routage étant dynamique, cette MTU du chemin peut changer dans le temps.) Il est donc intéressant, pour la machine émettrice d'un paquet, de déterminer cette MTU du chemin. Cela peut se faire en envoyant des paquets avec le bit DF (Don't Fragment, qui est implicite en IPv6) et en regardant les paquets ICMP renvoyés par les routeurs, indiquant que la MTU est trop faible pour ce paquet (et, depuis le RFC 1191, le message ICMP indique la MTU du lien suivant, ce qui évite de la deviner par essais/erreurs successifs.) Cette procédure est décrite dans les RFC 1191 et RFC 8201. Mais (et c'est un gros mais), cela suppose que les erreurs ICMP « Packet Too Big » arrivent bien à l'émetteur et, hélas, beaucoup de pare-feux configurés par des ignorants bloquent ces messages ICMP. D'autre part, les messages ICMP ne sont pas authentifiés (RFC 5927) et un attaquant peut générer de fausses erreurs ICMP pour faire croire à une diminution de la MTU du chemin, affectant indirectement les performances. (Une MTU plus faible implique des paquets plus petits, donc davantage de paquets.)
Quand une machine fragmente un paquet (en IPv4, cette machine peut être l'émetteur ou un routeur intermédiaire, en IPv6, c'est forcément l'émetteur), elle crée plusieurs fragments, dont seul le premier porte les informations des couches supérieures, comme le fait qu'on utilise UDP ou TCP, ou bien le numéro de port. La description détaillée figure dans le RFC 791 pour IPv4 et dans le RFC 8200 (notamment la section 4.5) pour IPv6.
Voici un exemple où la fragmentation a eu lieu, vu par
tcpdump (vous pouvez récupérer le
pcap complet en dns-frag-md.pcap2605:4500:2:245b::bad:dcaf a fait une requête
DNS à 2607:5300:201:3100::2f69, qui est un des
serveurs faisant autorité pour le TLD
.md. La réponse a dû
être fragmentée en deux :
% tcpdump -e -n -r dns-frag-md.pcap 16:53:07.968917 length 105: 2605:4500:2:245b::bad:dcaf.44104 > 2607:5300:201:3100::2f69.53: 65002+ [1au] ANY? md. (43) 16:53:07.994555 length 1510: 2607:5300:201:3100::2f69 > 2605:4500:2:245b::bad:dcaf: frag (0|1448) 53 > 44104: 65002*- 15/0/16 SOA, RRSIG, Type51, RRSIG, RRSIG, DNSKEY, DNSKEY, RRSIG, NS dns-md.rotld.ro., NS nsfr.dns.md., NS nsb.dns.md., NS ns-ext.isc.org., NS nsca.dns.md., NS ns-int.dns.md., RRSIG (1440) 16:53:07.994585 length 321: 2607:5300:201:3100::2f69 > 2605:4500:2:245b::bad:dcaf: frag (1448|259)
Le premier paquet est la requête, le second est le premier fragment de la réponse (qui va des octets 0 à 1447), le troisième paquet est le second fragment de cette même réponse (octets 1448 à la fin). Regardez les longueur des paquets IP, et le fait que seul le premier fragment, qui porte l'en-tête UDP, a pu être interprété comme étant du DNS.
Notez que certaines versions de traceroute
ont une option qui permet d'afficher la MTU du lien (par exemple
traceroute -n --mtu IP-ADDRESS.)
Les couches supérieures (par exemple UDP ou TCP) peuvent ignorer ces questions et juste envoyer leurs paquets, comptant qu'IP fera son travail, ou bien elles peuvent tenir compte de la MTU du chemin, par exemple pour optimiser le débit, en n'envoyant que des paquets assez petits pour ne pas être fragmentés. Cela veut dire qu'elles ont accès au mécanisme de découverte de la MTU du chemin, ou bien qu'elles font leur propre découverte, via la procédure PLPMTUD (Packetization Layer Path MTU Discovery) du RFC 4821 (qui a l'avantage de ne pas dépendre de la bonne réception des paquets ICMP).
Bon, maintenant qu'on a vu la framentation, voyons les difficultés qui surviennent dans l'Internet d'aujourd'hui (section 3 du RFC). D'abord, chez les pare-feux et, d'une manière générale, tous les équipements intermédiaires qui prennent des décisions en fonction de critères au-dessus de la couche 3, par exemple un répartiteur de charge, ou un routeur qui enverrait les paquets à destination du port 443 vers un autre chemin que le reste des paquets. Ces décisions dépendent d'informations qui ne sont que dans le premier fragment d'un datagramme fragmenté. Décider du sort des fragments suivants n'est pas évident, surtout si on veut le faire sans maintenir d'état. Un pare-feu sans état peut toujours essayer d'accepter tous les fragments ultérieurs (ce qui pourrait potentiellement autoriser certaines attaques) ou bien tous les bloquer (ce qui arrêterait du trafic légitime fragmenté). Et les pare-feux avec état ne sont pas une solution idéale, puisque stocker et maintenir cet état est un gros travail, qui plante souvent, notamment en cas d'attaque par déni de service.
Certains types de NAT ont également des problèmes avec la fragmentation. Ainsi, les techniques A+P (RFC 6346) et CGN (RFC 6888) nécessitent toutes les deux que les fragments soient réassemblés en un seul paquet, avant de traduire.
Qui dit fragmentation dit réassemblage à un moment. C'est une opération délicate, et plusieurs programmeurs se sont déjà plantés en réassemblant sans prendre de précautions. Mais il y a aussi un problème de performance. Et il y a les limites d'IPv4. L'identificateur d'un fragment ne fait que 16 bits et cela peut mener rapidement à des réutilisations de cet identificateur, et donc à des réassemblages incorrects (les sommes de contrôle de TCP et UDP ne sont pas toujours suffisantes pour détecter ces erreurs, cf. RFC 4693). IPv6, heureusement, n'a pas ce problème, l'identificateur de fragment faisant 32 bits.
On l'a dit plus haut, la fragmentation, et surtout le réassemblage, ont une longue histoire de failles de sécurité liées à une lecture trop rapide du RFC par le programmeur qui a écrit le code de réassemblage. Ainsi, les fragments recouvrants sont un grand classique, décrits dans les RFC 1858, RFC 3128 et RFC 5722. Normalement, le récepteur doit être paranoïaque, et ne pas faire une confiance aveugle aux décalages (offset) indiqués dans les paquets entrants, mais tous les programmeurs ne sont pas prudents. Il y a aussi le risque d'épuisement des ressources, puisque le récepteur doit garder en mémoire (le réassemblage implique le maintien d'un état) les fragments pas encore réassemblés. Un attaquant peut donc épuiser la mémoire en envoyant des fragments d'un datagramme qui ne sera jamais complet. Et il y a des identificateurs de fragment non-aléatoires, qui permettent d'autres attaques, documentées dans le RFC 7739 ou dans des articles comme « Fragmentation Considered Poisonous de Herzberg et Shulman (cf. aussi mon résumé). Enfin, la fragmentation peut aider à échapper au regard des IDS (cf. « Insertion, Evasion and Denial of Service: Eluding Network Intrusion Detection »).
Un autre problème très fréquent avec la fragmentation est causé par la configuration erronée de pare-feux. Souvent, des administrateurs réseau incompétents bloquent les messages ICMP Packet Too Big, nécessaires pour la découverte de la MTU du chemin. C'est de leur part une grosse erreur (expliquée dans le RFC 4890) mais cela arrive trop souvent. Résultat, si la MTU du chemin est inférieure à la MTU du premier lien, la machine émettrice envoie des paquets trop gros, et ne sait pas que ces paquets n'ont pas pu passer. On a donc créé un trou noir (les paquets disparaissent sans laisser de trace).
Ce bloquage injustifié des messages ICMP peut également être dû à des causes plus subtiles. Par exemple, si un pare-feu laisse sortir tous les paquets mais, en entrée, n'autorise que les paquets dont l'adresse IP source a été utilisée comme destination récemment, alors, les erreurs ICMP, émises par des routeurs intermédiaires et ayant donc une adresse IP source jamais vue, seront jetées. Notre RFC note que cette bogue dans les pare-feux est apparemment assez fréquente dans les boxes.
Toujours côté mauvaise configuration, le RFC cite aussi le problème des routeurs qui jettent les paquets ayant options ou extensions qu'ils ne connaissent pas, ce qui peut inclure les fragments. L'analyse du RFC 7872, ou celle dans l'article de Huston « IPv6, Large UDP Packets and the DNS », montre bien que ce problème est fréquent, trop fréquent. Ainsi, même si la découverte de la MTU du chemin se passe bien, les fragments n'arriveront pas à destination. Pourquoi cette mauvaise configuration ? C'est évidemment difficile à dire, cela peut aller de logiciels bogués jusqu'à un choix délibéré d'un administrateur réseau ignorant qui a vaguement entendu une légende urbaine du genre « les fragments sont un risque de sécurité ».
Dans les cas précédents, la perte du message ICMP Packet Too Big était clairement de la faute d'un humain, l'administrateur du pare-feu. Mais il peut y avoir des obstacles plus fondamentaux au bon fonctionnement de la découverte de la MTU du chemin. Par exemple, si un serveur DNS anycasté envoie un paquet trop gros, et qu'un routeur intermédiaire envoie le message Packet Too Big, ledit message ira vers l'adresse anycast du serveur, et atterrira peut-être vers une autre instance du serveur DNS, si le routeur qui a signalé le problème n'est pas dans le même bassin d'attraction que le client original. Le message ICMP ne sera donc pas reçu par l'instance qui aurait eu besoin de l'information. Le problème est d'autant plus génant que le DNS est le plus gros utilisateur d'UDP, et est donc particulièrement sensible aux problèmes de fragmentation (TCP gère mieux ces problèmes, avec la négociation de MSS).
Une variante du problème anycast survient lorsque le routage est unidirectionnel. Si l'émetteur n'est pas joignable, il ne recevra pas les messages ICMP. (Le cas est cité par le RFC mais me semble peu convaincant ; il y a peu de protocoles où l'émetteur peut se passer de recevoir des réponses. Et beaucoup de routeurs jettent les paquets pour lesquels ils n'ont pas de voie de retour, cf. RFC 3704.)
Maintenant qu'on a présenté en détail les problèmes liés à la fragmentation IP dans l'Internet actuel, quelles sont les approches possibles pour traiter ce problème ? La section 4 du RFC les présente. D'abord, les solutions situées dans la couche Transport. Comme indiqué plus haut, TCP peut éviter la fragmentation en découpant les données en segments dont chacun a une taille inférieure à la MTU du chemin (paramètre MSS, Maximum Segment Size). Cela suppose que la MSS soit réglée à une telle valeur (cf. mon article). Cela peut être manuel (si on sait qu'on va toujours passer par un tunnel avec faible MTU, on peut toujours configurer sa machine pour réduire la MSS), cela peut utiliser la procédure classique de découverte de la MTU du chemin ou bien cela peut utiliser la découverte de MTU sans ICMP du RFC 4821. D'autres protocoles que TCP peuvent fonctionner ainsi, comme DCCP (RFC 4340) ou SCTP (RFC 9260). À noter qu'UDP, lui, n'a pas de tel mécanisme, même si des travaux sont en cours pour cela (ils ont débouché sur le RFC 9869).
Pour TCP, la méthode manuelle se nomme TCP clamping et peut se faire, par exemple avec Netfilter en mettant sur le routeur :
% iptables -t mangle -A FORWARD -p tcp -m tcp --tcp-flags SYN,RST SYN \
-j TCPMSS --clamp-mss-to-pmtu
La méthode avec ICMP, on l'a vu, est fragile car les messages ICMP peuvent être bloqués. La méthode sans ICMP consiste pour TCP, en cas de détection de perte de paquets, à envoyer des paquets plus petits pour essayer de s'ajuster à la MTU du chemin. (Bien sûr, des paquets peuvent se perdre pour d'autres raisons que la MTU trop basse, et la mise en œuvre de cette technique est donc délicate.)
Autre solution, plutôt que d'impliquer la couche Transport, faire appel à la couche Application. Le RFC 8085 conseille aux applications qui font de l'UDP d'essayer d'éviter la fragmentation. Par exemple, si vous gérez un serveur DNS avec NSD, cela peut se faire en mettant dans le fichier de configuration :
ipv4-edns-size: 1432 ipv6-edns-size: 1432
Vous pouvez voir le résultat sur, par exemple, un des serveurs
faisant autorité pour .bostik :
% dig +ignore @d.nic.fr DNSKEY bostik
; <<>> DiG 9.11.5-P4-5.1-Debian <<>> +ignore @d.nic.fr DNSKEY bostik
; (2 servers found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 12029
;; flags: qr aa tc rd; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags: do; udp: 1432
; COOKIE: ef8669d08e2d9b26bb1a8ab85e21830a8931f9ab23403def (good)
;; QUESTION SECTION:
;bostik. IN DNSKEY
;; Query time: 2 msec
;; SERVER: 2001:678:c::1#53(2001:678:c::1)
;; WHEN: Fri Jan 17 10:48:58 CET 2020
;; MSG SIZE rcvd: 63
Vous voyez que le serveur n'envoie pas de réponses de taille
supérieure à 1 432 octets (la OPT
PSEUDOSECTION). Au moment du test, la réponse faisait
1 461 octets, d'où le flag
tc (TRuncated). Normalement,
un client DNS, voyant que la réponse a été tronquée, réessaie en TCP
(j'ai mis l'option +ignore à dig pour empêcher
cela et illustrer le fonctionnement du DNS.)
En parlant du DNS, la section 5 du RFC liste des applications pour lesquelles la fragmentation joue un rôle important :
- Le DNS utilise encore largement UDP (malgré le RFC 7766) et, notamment avec DNSSEC, les réponses peuvent nettement excéder la MTU typique. C'est en général le premier protocole qui souffre, quand la fragmentation ne marche pas, d'autant plus que la grande majorité des échanges sur l'Internet commence par des requêtes DNS. Le client DNS peut limiter la taille des données envoyées, via EDNS (RFC 6891) et le serveur peut également avoir sa propre limite. Le serveur qui n'a pas la place de tout mettre dans la réponse peut, dans certains cas, limiter les données envoyées (en omettant les adresses de colle, par exemple) et si ça ne suffit pas, indiquer que la réponse est tronquée, ce qui doit mener le client à réessayer avec TCP (que tout le monde devrait gérer mais certains clients et certains serveurs, ou plutôt leurs réseaux, ont des problèmes avec TCP, comme illustré dans « Measuring ATR »). L'importance de la fragmentation pour le DNS fait que le DNS Flag Day de 2020 est consacré à ce sujet.
- Le protocole de routage OSPF utilise également UDP mais le problème est moins grave, car c'est un protocole interne, pas utilisé sur l'Internet public, l'administrateur réseau peut donc en général s'assurer que la fragmentation se passera bien. Et, de toute façon, la plupart des mises en œuvre d'OSPF limitent la taille de leurs messages pour être sûr de rester en dessous de la MTU.
- L'encapsulation des paquets IP (pas vraiment la couche Application mais quand même un usage répandu) peut également créer des problèmes avec la fragmentation (cf. RFC 4459.) Cela concerne des protocoles comme IP-in-IP (RFC 2003), GRE (RFC 2784 et RFC 8086), et d'autres. Le RFC 7588 décrit une stratégie générale pour ces protocoles.
- Le RFC note que certains protocoles, pour des raisons de performance, assument tout à fait d'envoyer de très grands paquets et donc de compter sur une fragmentation qui marche. Ce sont notamment des protocoles qui sont conçus pour des milieux très particuliers, comme LTP (RFC 5326) qui doit fonctionner en présence d'énormes latences.
Compte-tenu de tout ceci, quelles recommandations concrètes donner ? Cela dépend évidemment du public cible. La section 6 de notre RFC donne des conseils pour les concepteurs et conceptrices de protocoles et pour les différents types de développeurs et développeuses qui vont programmer des parties différentes du système. D'abord, les protocoles, sujet principal pour l'IETF. Compte-tenu des importants problèmes pratiques que pose la fragmentation dans l'Internet actuel, le RFC prend une décision douloureuse : plutôt que de chercher à réparer l'Internet, on jette l'éponge et on ne conçoit plus de protocoles qui dépendent de la fragmentation. De tels protocoles ne seraient raisonnables que dans des environnements fermés et contrôlés. Comme souvent à l'IETF, le choix était difficile car il faut choisir entre les principes (la fragmentation fait partie d'IP, les composants de l'Internet ne doivent pas l'empêcher) et la réalité d'un monde de middleboxes mal programmées et mal gérées. Comme pour la décision de faire passer beaucoup de nouveaux protocoles sur HTTPS, le choix ici a été de prendre acte de l'ossification de l'Internet, et de s'y résigner.
Pour ne pas dépendre de la fragmentation, les nouveaux protocoles peuvent utiliser une MTU suffisamment petite pour passer partout, ou bien utiliser un système de découverte de la MTU du chemin suffisamment fiable, comme celui du RFC 4821. Pour UDP, le RFC renvoie aux recommandations de la section 3.2 du RFC 8085.
Ensuite, les conseils aux programmeurs et programmeuses. D'abord, dans les systèmes d'exploitation. Le RFC demande que la PLPMTUD (RFC 8899) soit disponible dans les bibliothèques proposées aux applications.
Ensuite, pour ceux et celles qui programment les middleboxes, le RFC rappelle quand même qu'elles doivent respecter les RFC sur IPv4 (RFC 791) et IPv6 (RFC 8200). Pour beaucoup de fonctions assurées par ces boitiers (comme le filtrage), cela implique de réassembler les paquets fragmentés, et donc de maintenir un état. Les systèmes avec état sont plus compliqués et plus chers (il faut davantage de mémoire) ce qui motive parfois à préférer les systèmes sans état. Ceux-là n'ont que deux choix pour gérer la fragmentation : violer les RFC ou bien jeter tous les fragments. Évidemment, aucune de ces deux options n'est acceptable. Le RFC demande qu'au minimum, si on massacre le protocole IP, cela soit documenté. (Ces middleboxes sont souvent traitées comme des boites noires, installées sans les comprendre et sans pouvoir déboguer les conséquences.)
Enfin, les opérateurs des réseaux doivent s'assurer que la PMTUD fonctionne, donc émettre des Packet Too Big si le paquet est plus gros que la MTU, et ne pas bloquer les paquets ICMP. Notre RFC permet toutefois de limiter leur rythme (RFC 1812 et RFC 4443). En tout cas, comme le rappelle le RFC 4890, filtrer les paquets ICMP Packet Too Big est mal !
De la même façon, le RFC rappelle aux opérateurs réseau qu'on ne doit pas filtrer les fragments. Ils sont utiles et légitimes.
Notez que les recommandations de ce RFC peuvent sembler contradictoires : on reconnait que la fragmentation marche mal et qu'il ne faut donc pas compter dessus mais, en même temps, on rappelle qu'il faut se battre pour qu'elle marche mieux. En fait, il n'y a pas de contradiction, juste du réalisme. L'Internet n'ayant pas de Chef Suprême qui coordonne tout, on ne peut pas espérer qu'une recommandation de l'IETF soit déployée immédiatement partout. On se bat donc pour améliorer les choses (ne pas bloquer les fragments, ne pas bloquer les messages ICMP Packet Too Big) tout en étant conscient que ça ne marchera pas à 100 % et que les administrateurs système et réseau doivent en être conscients.
L'article seul
RFC 8899: Packetization Layer Path MTU Discovery for Datagram Transports
Date de publication du RFC : Septembre 2020
Auteur(s) du RFC : G. Fairhurst, T. Jones (University of Aberdeen), M. Tuexen, I. Ruengeler, T. Voelker (Muenster University of Applied Sciences)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tsvwg
Première rédaction de cet article le 12 septembre 2020
Ce RFC qui vient d'être publié décrit une méthode pour découvrir la MTU d'un chemin sur l'Internet (Path MTU, la découverte de la MTU du chemin se nommant PMTUD pour Path MTU Discovery). Il existe d'autres méthodes pour cette découverte, comme celle des RFC 1191 et RFC 8201, qui utilisent ICMP. Ici, la méthode ne dépend pas d'ICMP, et se fait avec les datagrammes normaux de la couche 4 (ou PL, pour Packetization Layer). Elle étend la technique du RFC 4821 à d'autres protocoles de transport que TCP (et SCTP).
Mais, d'abord, pourquoi est-ce important de découvrir la MTU maximale du chemin ? Parce que, si on émet des paquets qui sont plus gros que cette MTU du chemin, ces paquets seront jetés, au grand dam de la communication. En théorie, le routeur qui prend cette décision devrait fragmenter le paquet (IPv4 seulement), ou bien envoyer à l'expéditeur un message ICMP Packet Too Big mais ces fragments, et ces messages ICMP sont souvent bloqués par de stupides pare-feux mal gérés (ce qu'on nomme un trou noir). On ne peut donc pas compter dessus, et ce problème est connu depuis longtemps (RFC 2923, il y a vingt ans, ce qui est une durée insuffisante pour que les administrateurs de pare-feux apprennent leur métier, malgré le RFC 4890). La seule solution fiable est de découvrir la MTU du chemin, en envoyant des paquets de plus en plus gros, jusqu'à ce que ça ne passe plus, montrant ainsi qu'on a découvert la MTU.
Le RFC donne aussi quelques raisons plus subtiles pour lesquelles la découverte classique de la MTU du chemin ne marche pas toujours. Par exemple, s'il y a un tunnel sur le trajet, c'est le point d'entrée du tunnel qui recevra le message ICMP Packet Too Big, et il peut faillir à sa tâche de le faire suivre à l'émetteur du paquet. Ou bien, en cas de routage asymétrique, le message ICMP peut être jeté car il n'y a pas de route de retour.
Et ce n'est pas tout que le message ICMP revienne à l'émetteur, encore faut-il que celui-ci l'accepte. Les messages ICMP n'étant pas authentifiés, une machine prudente va essayer de les valider, en examinant le paquet originel contenu dans le message ICMP, et en essayant de voir s'il correspond à du trafic en cours. Si le routeur qui émet le message ICMP n'inclut pas assez du paquet original (malgré ce que demande le RFC 1812) pour que cette validation soit possible, le message ICMP « Vous avez un problème de taille » sera jeté par l'émetteur du paquet original. Et il peut y avoir d'autres problèmes, par exemple avec le NAT (cf. RFC 5508). Autant de raisons supplémentaires qui font que la découverte de la MTU du chemin ne peut pas compter sur les messages ICMP.
Notre RFC utilise le terme de couche de découpage en paquets (Packetization Layer, PL). Il désigne la couche où les données sont séparées en paquets qui seront soumis à IP. C'est en général la couche de transport (protocoles TCP, DCCP, SCTP, etc) mais cela peut aussi être fait au-dessus de celle-ci. Ce sigle PL donne naissance au sigle PLPMTUD, Packetization Layer Path MTU Discovery. Contrairement à la classique PMTUD (Path MTU Discovery) des RFC 1191 et RFC 8201, la PLPMTUD ne dépend pas des messages ICMP. C'est la PL, la couche de découpage en paquets qui se charge de trouver la bonne taille, en envoyant des données et en regardant lesquelles arrivent. La PLPMTUD est plus solide que la traditionnelle PMTUD, qui est handicapée par le blocage fréquent d'ICMP (cf. RFC 4821, qui a introduit ce terme de PLPMTUD, et RFC 8085).
La découverte de la MTU du chemin par le PL est ancienne pour TCP (RFC 4821). Et pour les autres protocoles de transport ? C'est l'objet de notre RFC. Pour UDP, le RFC 8085 (section 3.2) recommande d'utiliser une telle procédure (sauf si les couches inférieures fournissent l'information). Et, pour SCTP, la section 10.2 du RFC 4821 le recommandait également mais sans donner de détails, désormais fournis par notre nouveau RFC.
Un peu de vocabulaire avant de continuer la lecture du RFC (section 2) : un trou noir est un endroit du réseau d'où des paquets ne peuvent pas sortir. Par exemple, parce que les paquets trop gros sont jetés, sans émission de messages ICMP, ou bien avec des messages ICMP filtrés. Un paquet-sonde est un paquet dont l'un des buts est de tester la MTU du chemin. Il est donc de grande taille, et, en IPv4, a le bit DF (Don't Fragment), qui empêchera la fragmentation par les routeurs intermédiaires. Ceci étant défini, attaquons-nous au cahier des charges (section 3 du RFC). Le RFC 4821 était très lié à TCP, mais la généralisation de la PLPMTUD qui est dans notre nouveau RFC va nécessiter quelques fonctions supplémentaires :
- Il faut évidemment qu'on puisse envoyer des paquets-sonde, donc mettre le bit DF à 1 (en IPv4).
- Surtout, il faut un mécanisme de notification de la bonne
arrivée du paquet. En TCP (ou SCTP, ou
QUIC), il est inclus dans le protocole, ce
sont les accusés de réception (
ACK). Mais pour UDP et des protocoles similaires, il faut ajouter ce mécanisme de notification, ce qui implique en général une coopération avec l'application (par exemple, pour le DNS, le client DNS peut notifier le PL qu'il a reçu une réponse à sa question, prouvant ainsi que le datagramme est passé). - Les paquets-sonde peuvent se perdre pour d'autres raisons que la MTU, la congestion, par exemple. La méthode de PLPMTUD doit donc savoir traiter ces cas, par exemple en réessayant. (D'autant plus que le paquet-sonde ne sert pas forcément qu'à la PLPMTUD, il peut aussi porter des données utiles.)
- Et, même si la PLPMTUD ne dépend pas d'ICMP, il est quand même recommandé d'utiliser les messages PTB (Packet Too Big) si on en reçoit (cf. section 4.6). Attention toutefois à faire des efforts pour les valider : rien n'est plus facile pour un attaquant que d'envoyer de faux PTB pour réduire la MTU et donc les performances. Une solution sûre est de ne pas changer la MTU en recevant un PTB, mais d'utiliser ce PTB comme indication qu'il faut re-tester la MTU du chemin tout de suite.
En parlant de validation, cela vaut aussi pour les paquets-sonde (section 9 du RFC) : il faut empêcher un attaquant situé hors du chemin d'injecter de faux paquets. Cela peut se faire par exemple en faisant varier le port source (cf. section 5.1 du RFC 8085), comme le fait le DNS.
La section 4 du RFC passe ensuite aux mécanismes concrets à utiliser. D'abord, les paquets-sonde. Que doit-on mettre dedans, sachant qu'ils doivent être de grande taille, le but étant d'explorer les limites du chemin ? On peut utiliser des données utiles (mais on n'en a pas forcément assez, par exemple les requêtes DNS sont toujours de petite taille), on peut utiliser uniquement des octets bidons, du remplissage (mais c'est ennuyeux pour les protocoles qui doivent avoir une faible latence, comme le DNS, qui n'ont pas envie d'attendre pour envoyer les vraies données), ou bien on peut combiner les deux (des vraies données, plus du remplissage). Et, si on utilise des données réelles, il faut gérer le risque de perte, et pouvoir réémettre. Le RFC ne donne pas de consigne particulière aux mises en œuvre de PLPMTUD, les trois stratégies sont autorisées.
Ensuite, il faut évidemment un mécanisme permettant de savoir si le paquet-sonde est bien arrivé, si le protocole de transport ne le fournit pas, ce qui est le cas d'UDP, ce qui nécessite une collaboration avec l'application.
Dans le cas où le paquet-sonde n'arrive pas, il faut détecter la perte. C'est relativement facile si on a reçu un message ICMP PTB mais on ne veut pas dépendre uniquement de ces messages, vu les problèmes d'ICMP dans l'Internet actuel. Le PL doit garder trace des tailles des paquets envoyés et des pertes (cf. le paragraphe précédent) pour détecter qu'un trou noir avale les paquets de taille supérieure à une certaine valeur. Il n'est pas facile de déterminer les seuils de détection. Si on réduit la MTU du chemin au premier paquet perdu, on risque de la réduire trop, alors que le paquet avait peut-être été perdu pour une tout autre raison. Si on attend d'avoir perdu plusieurs paquets, on risque au contraire de ne pas réagir assez vite à un changement de la MTU du chemin (changement en général dû à une modification de la route suivie).
(J'ai parlé de MTU du chemin mais PLMTUD détecte en fait une valeur plus petite que la MTU, puisqu'il y a les en-têtes IP.)
Si vous aimez les détails des protocoles, les machines à état et la liste de toutes les variables nécessaires, la section 5 du RFC est pour vous, elle spécifie complètement la PLMTUD pour des protocoles utilisant des datagrammes. Cette section 5 est générique, et la section 6 décrit les détails spécifiques à un protocole de transport donné.
Ainsi, pour UDP (RFC 768) et UDP-Lite (RFC 3828), le protocole de transport n'a tout simplement pas les mécanismes qu'il faut pour faire de la PLPMTUD ; cette découverte de la MTU du chemin doit être faite par l'application, dans l'esprit du RFC 8085. L'idéal serait que cette PLPMTUD soit mise en œuvre dans une bibliothèque partagée, pour éviter que chaque application ne la réinvente mal. Mais je ne connais pas actuellement de telle bibliothèque.
Le RFC insiste sur le fait que l'application doit, pour effectuer cette tâche, pouvoir se souvenir de quels paquets ont été envoyés, donc mettre dans chaque paquet un identificateur, comme le Query ID du DNS.
Pour SCTP (RFC 9260), c'est un peu plus facile, puisque SCTP, comme TCP, a un système d'accusé de réception. Et les chunks de SCTP fournissent un moyen propre d'ajouter des octets au paquet-sonde pour atteindre la taille souhaitée (cf. RFC 4820), sans se mélanger avec les données des applications.
Pour le protocole QUIC, la façon de faire de la PLMTUD est spécifiée dans le RFC 9000. DCCP, lui, n'est pas spécifiquement cité dans cette section.
Ah, et quelles mises en œuvre de protocoles font déjà comme décrit dans ce RFC ? À part divers tests, il parait (mais je n'ai pas vérifié personnellement) que c'est le cas pour SCTP dans FreeBSD, et dans certains navigateurs Web pour WebRTC (WebRTC tourne sur UDP et rappelez-vous qu'en UDP, il faut une sérieuse coopération par l'application pour faire de la PLPMTUD). Côté QUIC, il y a lsquic, qui gère les techniques de notre RFC.
L'article seul
Exposé sur les RFC au FGI Bénin
Première rédaction de cet article le 10 septembre 2020
Le 9 septembre, dans le cadre du Forum de la Gouvernance de l'Internet au Bénin, j'ai fait (en ligne, bien sûr) un exposé sur les RFC. C'est quoi, ça sert à quoi, qui les écrit ?
L'évènement « École de la gouvernance de l'Internet » était organisé par le FGI Bénin. Merci à Muriel Alapini pour l'organisation. Plusieurs autres exposés très intéressants étaient présentés, afin de fournir à ceux et celles qui participent aux discussions sur la gouvernance de l'Internet les bases nécessaires pour comprendre l'Internet. Par exemple, félicitations à Yazid Akanho pour son exposé très complet et très bien expliqué sur le système de serveurs de noms de la racine.
Voici les supports de mon exposé :
- Version adaptée à l'écran,
- Version adaptée à l'impression sur des arbres morts.
L'article seul
Outils pour obtenir des informations BGP publiques
Première rédaction de cet article le 4 septembre 2020
Dernière mise à jour le 19 mai 2022
Cette page (que j'espère maintenir à jour) rassemble les outils existants pour obtenir de l'information sur les annonces BGP, même si on n'a pas d'accès à des routeurs BGP.
Le protocole de routage BGP est sans doute le système le plus crucial pour le bon fonctionnement de l'Internet. Contrairement à des protocoles applicatifs comme HTTP, il n'est pas prévu que tout le monde puisse parler BGP : seule une partie des routeurs le fait et, sauf si vous travaillez chez un acteur important de l'Internet, vous n'avez probablement pas accès à un routeur BGP, encore moins un routeur de la DFZ. D'où l'intérêt de divers outils et services qui permettent d'obtenir des informations BGP sans avoir cet accès privilégié.
D'ailleurs, même si vous avez accès à un ou plusieurs routeurs BGP, cela n'est pas forcément suffisant. Vu la façon dont fonctionne BGP, tous les routeurs ne voient pas la même chose (même les routeurs de la DFZ) et de tels outils sont donc utiles même pour les professionnels du réseau. Attention, certains de ces outils sont simples à utiliser, d'autres plus complexes mais dans tous les cas, comprendre ce qu'ils affichent nécessitent des compétences dans le fonctionnement de l'Internet, et dans le protocole BGP.
Cet article regroupe les outils que
j'utilise. Vous pouvez m'en suggérer d'autres
(ou bien corriger des erreurs) mais cette liste est forcément
incomplète et subjective. Alors, commençons tout de suite par le
principal outil dont je me sers, RIPEstat. RIPEstat est une
interface Web notamment vers les données récoltées par le RIS (Routing Information
Service), un ensemble de centaines de machines parlant BGP
et qui s'appairent avec tout le monde pour
récolter le plus d'informations BGP possibles. En échange d'une
adresse IP, d'un préfixe ou d'un AS, vous pouvez obtenir plein d'informations. On
va se concentrer sur celles liées au routage. Prenons par exemple le
préfixe 2a01:e30::/28, utilisé pour les clients
de Free. (Si vous ne connaissez pas le
préfixe, entrez l'adresse IP, RIPEstat trouvera le préfixe englobant
le plus spécifique.) Voici ce qu'affiche l'onglet « Routage » de
RIPEstat, en https://stat.ripe.net/2a01%3Ae34%3A%3A%2F28#tabId=routing
(Une minorité de routeurs du RIS voit ce préfixe ; il n'est
sans doute pas annoncé à tout le monde, et il existe un /26 plus
générique. Rappelez-vous ce que j'ai dit que tout les routeurs BGP
ne voient pas la même chose.) Ce Routing status
n'est qu'un des widgets disponible, plus bas dans
la page vous trouverez de nombreuses autres informations. J'aime
bien le widget historique qui permet de voir
comment a été annoncé ce préfixe dans le passé : 
Et aussi le rythme des mises à jour, souvent indicatifs d'un
problème. Ici, par exemple, le widget
BGP update activity montre la panne de
Level 3/CenturyLink du 30 août 2020. On a donné comme
ressource à voir l'AS 3356 (celui de Level 3)
et zoomé pour n'avoir que la partie intéressante. On voit alors le
gros surcroit d'activité BGP engendré par le problème chez
Level 3. C'est toujours visitable aujourd'hui, grâce aux URL intégrant la date :
https://stat.ripe.net/widget/bgp-update-activity#w.starttime=2020-08-19T09%3A00%3A00&w.endtime=2020-09-02T09%3A00%3A00&w.resource=AS3356
Du fait qu'il existe un URL stable pour les informations de RIPEstat, on peut facilement embarquer du RIPEstat dans ses pages Web, ses outils de supervision, etc.
RIPEstat est très gourmand en ressources, vu son utilisation
massive de plein de JavaScript. Vous avez
intérêt à avoir une machine riche en RAM et,
même ainsi, vous verrez souvent l'avertissement (ici de
Firefox) comme quoi un script ralentit la
machine : 
Le RIS, le réseau derrière RIPE stat peut aussi être interrogé en
ligne de commande. C'est ce RIS qui alimente mon service
bgp.bortzmeyer.org :
% curl -s https://bgp.bortzmeyer.org/2a03:2880:f0fc:c:face:b00c:0:35 2a03:2880:f0fc::/48 32934
Cette petite fonction shell peut vous faciliter la vie :
bgprouteris () {
if [ -z "$1" ]
then
echo "Usage: bgprouteris IP-address"
return 1
fi
curl -s https://bgp.bortzmeyer.org/$1
echo ""
}
Il est de toute façon bon de ne pas dépendre d'un seul service, même géré par une organisation sans but lucratif et fondée sur un projet commun comme l'est le RIPE-NCC. Tout service peut disparaitre ou tomber en panne précisement au moment où on en a besoin (si on veut investiguer un problème en cours, par exemple). Une alternative intéressante est bgp.tools. C'est plus léger que RIPEstat (mais moins riche) et cela se concentre sur des informations essentielles, donc cela peut être pratique pour des utilisateurs moins familiers de BGP. (Je ne trouve pas sur quelles données ils s'appuient pour afficher leurs informations : rappelez-vous que les informations BGP ne sont pas les mêmes partout, d'où l'importance d'avoir un grand nombre de routeurs situés un peu partout, comme le RIS. Je ne connais pas la représentativité des collecteurs d'informations de bgp.tools.)
Voici par exemple ce que voit bgp.tools sur le préfixe
2a01:e30::/28 cité plus haut (URL
https://bgp.tools/prefix/2a01:e30::/28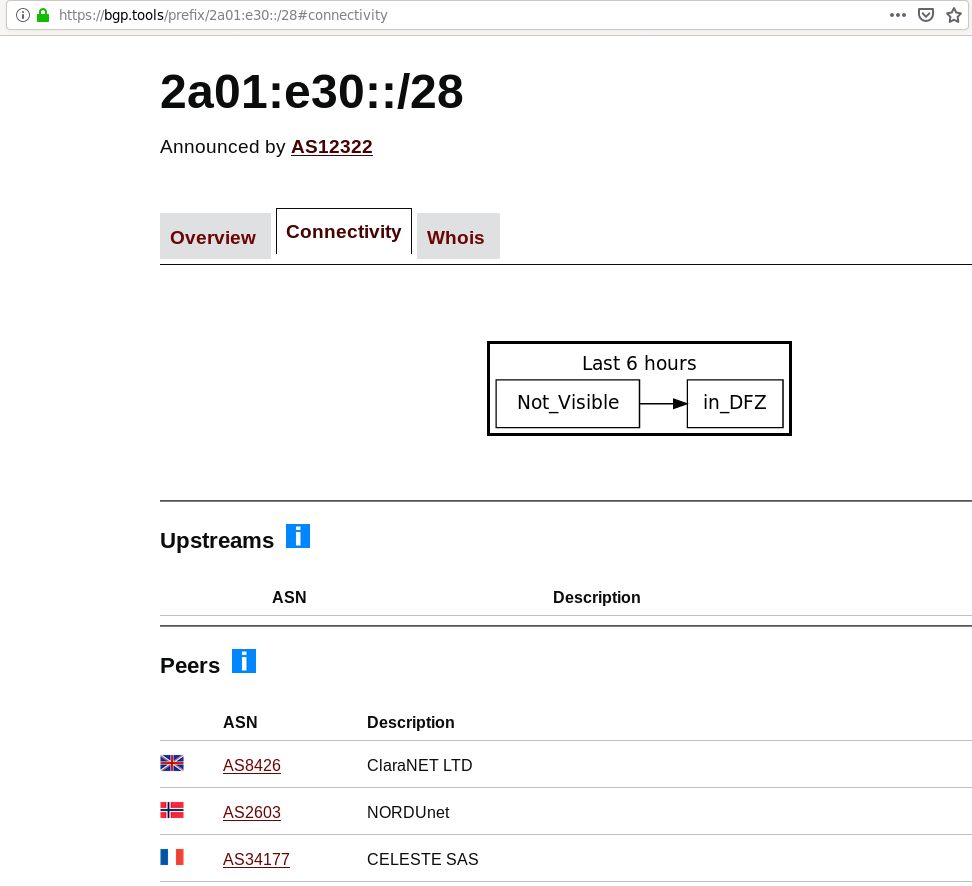
Et sur l'AS associé :
Vous avez noté que dans les informations sur le préfixe, la
rubrique Upstreams (transitaires) était
vide. bgp.tools ne l'affiche pas lorsqu'il y a un préfixe plus
général et visible plus globalement, ce qui est le cas ici
(rappelez-vous que le 2a01:e30::/28 n'est pas
annoncé partout). Avec le préfixe général, on a bien l'information :
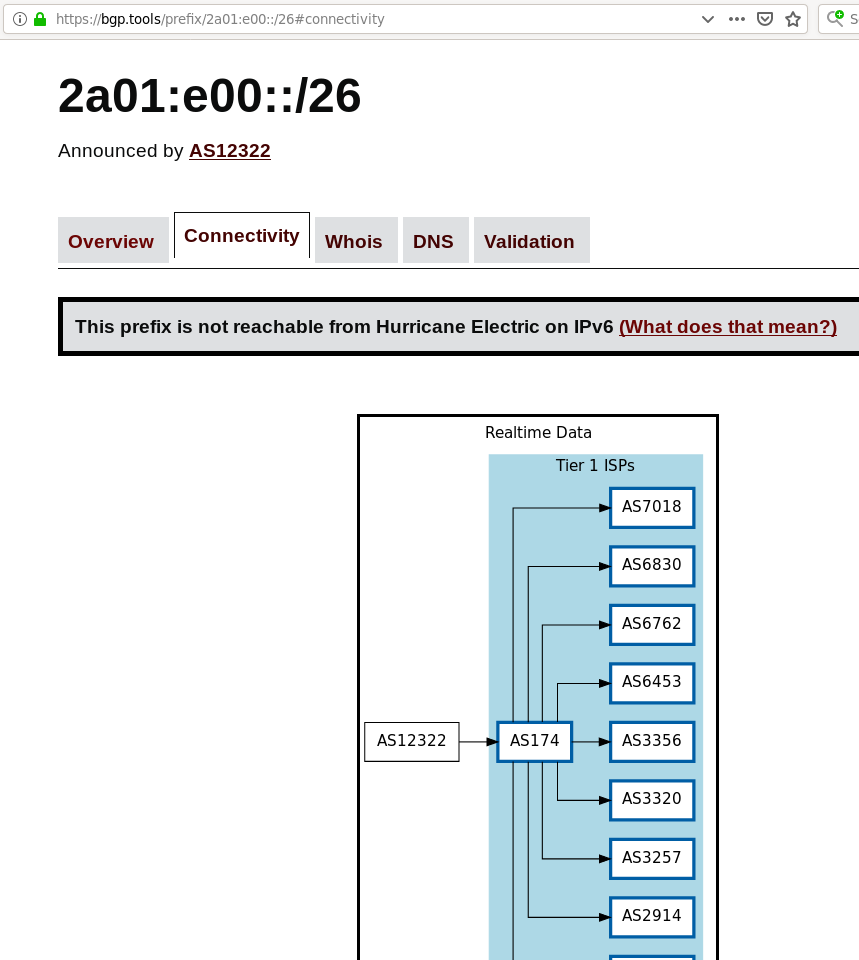
En prime, bgp.tools nous prévient que Free n'a qu'un seul transitaire en IPv6, Cogent et que celui-ci refuse de s'appairer avec Hurricane Electric, ce qui prive les abonnés Free d'une partie de l'Internet.
Dans la série « sites Web pour récupérer des informations BGP »,
beaucoup de gens utilisent https://bgp.he.net/
Pour les amateurs de ligne de commande, il y a aussi
bgpstuff.net :
% curl -s https://bgpstuff.net/route/185.89.219.12 Route is 185.89.219.0/24 for 185.89.219.12
Et si on veut le numéro d'AS, pas juste les préfixes :
% curl https://bgpstuff.net/origin/185.89.219.12 The origin AS for 185.89.219.12 is AS32934
Jusqu'ici, je n'ai listé que des outils Web (ou en tout cas HTTP). Et si on n'aime pas le Web ? Les mêmes informations sont souvent disponibles par d'autres protocoles, par exemple whois. (RIPEstat a également une API, que je n'utilise personnellement pas.) Le RIS est ainsi interrogeable par whois :
% whois -h riswhois.ripe.net 2a01:e30::/28 ... route6: 2a01:e30::/28 origin: AS12322 descr: PROXAD Free SAS, FR lastupd-frst: 2020-04-13 01:00Z 2001:7f8:20:101::208:223@rrc13 lastupd-last: 2020-09-02 07:37Z 2001:7f8:20:101::209:93@rrc13 seen-at: rrc00,rrc01,rrc03,rrc04,rrc05,rrc07,rrc10,rrc11,rrc12,rrc13,rrc15,rrc20,rrc21,rrc23 num-rispeers: 156 source: RISWHOIS
Il y a évidemment moins d'information que par le Web mais cela peut suffire. Si on veut juste une correspondance entre une adresse IP et l'AS qui l'annonce, Team Cymru propose plusieurs outils comme whois :
% whois -h whois.cymru.com 80.67.169.12 AS | IP | AS Name 20766 | 80.67.169.12 | GITOYEN-MAIN-AS The main Autonomous System of Gitoyen (Paris, France)., FR
Autre serveur whois, chez bgp.tools :
% whois -h bgp.tools 2a00:e00:0:5::2 AS | IP | BGP Prefix | CC | Registry | Allocated | AS Name 8304 | 2a00:e00:0:5::2 | 2a00:e00::/32 | FR | RIPE | 2008-11-07 | Ecritel SASU
Team Cymru a aussi une passerelle DNS. Celle-ci nécessite d'inverser les
différents composants de l'adresse IP. Par exemple, pour
204.62.14.153, il faudra interroger
153.14.62.204.origin.asn.cymru.com. Ça peut
s'automatiser avec awk :
% dig +short TXT $(echo 204.62.14.153 | awk -F. '{print $4 "." $3 "." $2 "." $1 ".origin.asn.cymru.com" }')
"46636 | 204.62.12.0/22 | US | arin | 2008-12-24"
Pour IPv6, cette inversion peut se faire avec le programme ipv6calc. On peut créer une fonction shell pour se faciliter la vie :
% which bgproutednscymru
bgproutednscymru () {
address=$1
if echo $address | fgrep -q : -; then
domain=$(echo $1 | ipv6calc --addr2ip6_arpa | sed 's/ip6\.arpa\.$/origin6.asn.cymru.com./')
else
domain=$(echo $1 | awk -F. '{print $4 "." $3 "." $2 "." $1 ".origin.asn.cymru.com" }')
fi
dig +short TXT $domain
}
% bgproutednscymru 80.67.169.12
"20766 | 80.67.160.0/19 | FR | ripencc | 2001-05-21"
% bgproutednscymru 2001:910:800::12
"20766 | 2001:910::/32 | FR | ripencc | 2002-09-24"
Le service RouteViews a également
une passerelle DNS, mais uniquement pour IPv4, avec le domaine
aspath.routeviews.org. Elle indique le chemin
d'AS (vers le collecteur de RouteViews), pas uniquement
l'origine. Avec une fonction analogue à celle ci-dessus, on obtient :
% which bgproutednsrouteviews
...
dig +short TXT `echo $1 | awk -F. '{print $4 "." $3 "." $2 "." $1 ".aspath.routeviews.org" }'` | \
awk -F\" '{print "AS path: " $2 "\nRoute: " $4 "/" $6}'
}
% bgproutednsrouteviews 80.67.169.12
AS path: 53767 3257 1299 20766
Route: 80.67.160.0/19
Un exemple de son utilisation figure dans mon article sur un opérateur nord-coréen.
Les nombreux outils de Team Cymru sont documentés en ligne.
Autre outil DNS, celui d'ipasn.net :
% dig +short www.ietf.org.aaaa.dns.ipasn.net TXT "2606:4700:0:0:0:0:6810:2c63|IPv6|ADVERTISED|2606:4700::/44|13335|Cloudflare,_Inc.|US|United_States_of_America|arin|2606:4700::/32|assigned|2011-11-01|VLD|2606:4700::/44|44|13335|ARIN"
Il a plein d'autres possibilités, lisez la documentation.
Plus original, il existe un bot sur le
fédivers (documenté ici) pour récupérer l'AS
d'origine d'une adresse IP :  .
.
J'ai parlé d'API à propos de RIPEstat. Personnellement, j'utilise l'API de QRator. Il faut s'enregistrer sur le site (la plupart des services présentés ici ne nécessitent pas d'enregistrement) pour obtenir une clé d'API puis lire la documentation (l'API produit évidemment du JSON). J'ai fait une fonction shell pour me faciliter la vie :
bgpqrator () {
if [ -z "$1" ]; then
echo "Usage: bgpqrator IP-address"
return 1
fi
curl -s -X GET "https://api.radar.qrator.net/v1/lookup/ip?query=$1" \
-H "accept: application/json" -H "QRADAR-API-KEY: $(cat ~/.qrator)" | \
jq .
}
Et cela me permet de faire :
% bgpqrator 2a01:e30::/28
{
"meta": {
"status": "success",
"code": 200
},
"data": [
{
"id": "12322",
"name": "PROXAD",
"short_descr": "Free SAS",
"prefix": "2a01:e00::/26",
"as_num": "12322",
"found_ips": "{2a01:e30::/28}"
},
{
"id": "12322",
"name": "PROXAD",
"short_descr": "Free SAS",
"prefix": "2a01:e30::/28",
"as_num": "12322",
"found_ips": "{2a01:e30::/28}"
}
]
}
Un point important de BGP aujourd'hui est la possibilité de
signer les
informations pour améliorer la sécurité, avec l'infrastructure
nommée RPKI. Pour vérifier ces signatures, on
peut installer son
propre validateur comme Routinator
(après tout, toutes les données de la RPKI sont publiques) mais
c'est un peu compliqué à faire et surtout à maintenir, donc il peut
être plus intéressant d'utiliser des services en ligne. Par exemple,
https://bgp.he.net
Autre excellent outil de vérification de la cohérence entre ce qui est annoncé et les bases de données (IRR) et la RPKI, IRRexplorer (c'est un logiciel libre, vous pouvez aussi l'installer chez vous).
Notez que je ne connais pas encore de moyen simple de récupérer
les ROA sur un site Web. Les services
ci-dessus indiquent juste le résultat de la validation, pas le ROA
d'origine. La seule méthode pour l'instant semble être de récupérer
tout le contenu de la RPKI connu d'un point de publication (pour le
RIPE-NCC, c'est avec rsync en
rsync://rpki.ripe.net/repository) puis de le
lire avec des outils comme OpenSSL (pour un
certificat, openssl x509 -inform DER -text -in NOMDUFICHIER.cer).
Jusqu'à présent, on a vu des techniques qui indiquaient une vue
« globale », supposant qu'on avait à peu près le même résultat sur
tous les routeurs BGP. En pratique, on sait que ce n'est pas vrai,
les différents routeurs ne voient pas exactement la même chose, et
il est souvent utile de regarder ce que voit un routeur
particulier. C'est le rôle des Looking
Glasses. Il en existe beaucoup, mais pas
toujours là où on voudrait. (Pour un
problème récent, je cherchais un looking
glass chez Algérie Télécom, sans en
trouver.) Bref, il faut utiliser les annuaires comme http://www.traceroute.org/#Looking%20Glass
Aux joies du Web moderne avec tous ses gadgets et son interactivité graphique, et même aux outils plus techniques qu'on vient de voir, on peut souhaiter préférer l'analyse qu'on fait soi-même à partir de données brutes. On télécharge des fichiers rassemblant les données BGP (soit l'état de la RIB du routeur, soit les annonces BGP) et on les analyse avec le programme de son choix. Un format standard existe même pour ces fichiers, MRT, normalisé dans le RFC 6396. Un exemple d'utilisation de ces fichiers figure dans mon article sur une panne à Saint-Pierre-et-Miquelon.
Où peut-on trouver de tels fichiers ? RouteViews en fournit, une
archive qui
remonte à 2001… Chose amusante, la seule taille de ces fichiers peut
indiquer un problème car les perturbations de l'Internet se
traduisent en général par une augmentation importante des mises à
jour BGP. Ainsi, la panne de
Level 3/CenturyLink du 30 août 2020 se voit très bien (à
partir de 10:00 h UTC) :
On peut aussi avoir de telles données via le RIS, cf. la documentation. C'est sur ces fichiers issus du RIS que s'appuie le bot fédivers cité plus haut.
L'article seul
RFC 8880: Special Use Domain Name 'ipv4only.arpa'
Date de publication du RFC : Août 2020
Auteur(s) du RFC : S. Cheshire (Apple), D. Schinazi (Google)
Chemin des normes
Première rédaction de cet article le 1 septembre 2020
La technique NAT64 pour permettre à des
machines d'un réseau purement IPv6
d'accéder à des services toujours uniquement en
IPv4 repose sur un préfixe IPv6 spécial,
utilisé pour donner l'impression aux machines IPv6 que le service
archaïque a de l'IPv6. Dans certains cas, il est pratique que
toutes les machines du réseau connaissent ce préfixe. Une
technique possible a été proposée dans le RFC 7050, utilisant un nom de domaine prévu à cet effet,
ipv4only.arpa. Mais ce nom de domaine n'avait
pas été documenté rigoureusement comme nom de domaine spécial. C'est
désormais fait, avec ce nouveau RFC.
Le NAT64 est normalisé dans le RFC 6146, et la découverte, par une machine, du
préfixe IPv6 utilisé, est dans le RFC 7050. Ce dernier RFC
avait créé le nom de
domaine ipv4only.arpa, mais sans
préciser clairement son statut, et notamment sans demander son
insertion dans le registre
des noms de domaine spéciaux. (Cette bavure bureaucratique
est d'ailleurs mentionnée dans le RFC 8244.)
Le but de notre nouveau RFC 8880 est de réparer cet
oubli et de documenter proprement le nom de domaine spécial
ipv4only.arpa.
Un petit rappel si vous n'avez pas le courage de lire le RFC 7050 : le problème qu'on cherche à résoudre
est celui d'une machine qui voudrait bénéficier de
NAT64 mais sans utiliser systématiquement
le résolveur DNS64 (RFC 6147). Pour cela, elle émet une requête DNS de type AAAA (adresse
IPv6) pour le nom ipv4only.arpa. Comme son
nom l'indique, ce nom n'a que des données de type A (adresses
IPv4). Si on récupère des adresses IPv6, c'est que le résolveur
DNS faisait du DNS64, et on peut déduire le préfixe IPv6 utilisé
de la réponse. Sans DNS64, on aura une réponse normale, rien sur
IPv6, et deux adresses stables en IPv4 :
% dig AAAA ipv4only.arpa
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 18633
;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 1
...
;; AUTHORITY SECTION:
ipv4only.arpa. 3600 IN SOA sns.dns.icann.org. noc.dns.icann.org. (
2020040300 ; serial
7200 ; refresh (2 hours)
3600 ; retry (1 hour)
604800 ; expire (1 week)
3600 ; minimum (1 hour)
)
;; Query time: 95 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: Thu May 07 15:22:20 CEST 2020
;; MSG SIZE rcvd: 127
% dig A ipv4only.arpa
...
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 2328
;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 14, ADDITIONAL: 27
...
;; ANSWER SECTION:
ipv4only.arpa. 86400 IN A 192.0.0.170
ipv4only.arpa. 86400 IN A 192.0.0.171
...
;; Query time: 238 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: Thu May 07 14:24:19 CEST 2020
;; MSG SIZE rcvd: 1171
En quoi est-ce que ce nom ipv4only.arpa
est « spécial » (section 2 du RFC) ? D'abord, il n'y a aucune
raison de le visiter en temps normal, il n'a aucune ressource
utile, et ses deux adresses IP sont stables et bien
connues. Paradoxalement, si on l'interroge, c'est qu'on espère un
mensonge, l'apparition d'adresses IPv6 qui ne sont pas dans la
zone originale. Ce nom de domaine permet en fait une communication
de la machine terminale vers un intermédiaire (le résolveur DNS),
pour savoir ce qu'il fait. C'est en cela que
ipv4only.arpa est spécial.
Mais, rappelez-vous, le RFC 7050 avait
oublié de déclarer ipv4only.arpa comme étant
spécial. Résultat, les différents logiciels qui traitent des noms
de domaine le traitent de la manière normale et, comme le note la
section 3 de notre RFC, cela a quelques conséquences ennuyeuses :
- Si la machine NAT64 utilise un résolveur DNS différent de celui du
réseau local, par exemple un résolveur public,
ipv4only.arpapeut ne pas donner le résultat attendu, - Les résolveurs DNS64 doivent faire une résolution normale
ipv4only.arpaalors qu'ils devraient avoir le droit de tout gérer localement et de fabriquer des réponses directement.
Bref, il fallait compléter le RFC 7050, en suivant le cadre du RFC 6761. Ce RFC 6761 impose de lister, pour chaque catégorie de logiciel, en quoi le nom de domaine est spécial. C'est fait dans la section 7 de notre RFC, qui indique que :
- Pour les utilisateurs finaux, pour les applications, pour
les serveurs faisant autorité, et
pour les résolveurs qui ne font que faire suivre à un résolveur
plus gros (ce qui est typiquement le cas de celui des
boxes),
rien de particulier, ils et elles peuvent traiter
ipv4only.arpacomme un domaine normal. Si elles le désirent, les applications peuvent résoudre ce nomipv4only.arpaet apprendre ainsi si un résolveur DNS64 est sur le trajet, mais ce n'est pas obligatoire. - Les bibliothèques qui gèrent la résolution de noms (comme
la libc sur Unix)
doivent par contre considérer
ipv4only.arpacomme spécial. Notamment, elles doivent utiliser le résolveur configuré par le réseau (par exemple via DHCP) pour résoudre ce nom. Le demander à un résolveur public n'aurait en effet pas de sens. - Les résolveurs qui ne font pas de DNS64 traitent
ipv4only.arpacomme normal, et leurs clients apprendront donc ainsi que leur résolveur ne fait pas de DNS64. - Les résolveurs DNS64 vont synthétiser des adresses IPv6 en
réponse aux requêtes de type AAAA pour
ipv4only.arpa, et leurs clients apprendront donc ainsi que leur résolveur fait du DNS64, et sauront quel préfixe IPv6 est utilisé. Ils n'ont pas besoin de consulter les serveurs faisant autorité, qui ne pourraient rien leur apprendre qui n'est pas déjà dans le RFC. L'annexe A du RFC donne un exemple de configuration pour BIND pour attendre cet objectif.
À noter qu'outre ipv4only.arpa, notre RFC
réserve deux autres noms spéciaux,
170.0.0.192.in-addr.arpa et
171.0.0.192.in-addr.arpa, pour permettre la
« résolution inverse ». Contrairement à
ipv4only.arpa, ils ne sont pas actuellement
délégués, et un résolveur normal, qui ne connait pas DNS64,
répondra donc NXDOMAIN (ce nom n'existe pas).
Sinon, la section 5 de notre RFC est dédiée à la sécurité et
note notamment que les noms synthétisés ne peuvent évidemment pas
être validés avec DNSSEC. C'est pour cela que la délégation
de ipv4only.arpa n'est même pas
signée. (C'est un changement depuis le RFC 7050, qui demandait au contraire une zone signée, ce
que ipv4only.arpa avait été au début.)
Vu par les sondes RIPE Atlas, voici les réponses de résolveurs à ce domaine spécial :
% blaeu-resolve -r 1000 -q AAAA ipv4only.arpa
[] : 986 occurrences
[64:ff9b::c000:aa 64:ff9b::c000:ab] : 4 occurrences
[2a01:9820:0:1:0:1:c000:aa 2a01:9820:0:1:0:1:c000:ab] : 1 occurrences
[2a0a:e5c0:0:1::c000:aa 2a0a:e5c0:0:1::c000:ab] : 1 occurrences
Test #24069173 done at 2020-02-24T14:49:43Z
Sur mille sondes Atlas, la grande majorité ne trouve pas d'adresse
IPv6 pour ipv4only.arpa ce qui, comme le nom
de domaine l'indique, est le comportement par défaut. Quelques
sondes sont derrière un résolveur DNS64, utilisant en général le
préfixe bien connu du RFC 7050 (les réponses
64:ff9b::…), mais parfois d'autres préfixes
(NSP - Network-Specific Prefix - dans la
terminologie du RFC 7050).
L'article seul
RFC 8875: Working Group GitHub Administration
Date de publication du RFC : Août 2020
Auteur(s) du RFC : A. Cooper (Cisco), P. Hoffman (ICANN)
Pour information
Réalisé dans le cadre du groupe de travail IETF github
Première rédaction de cet article le 29 août 2020
Certains groupes de travail IETF, ou bien certains participant·e·s à la normalisation au sein de cette organisation, utilisent le service GitHub de Microsoft pour gérer le processus de production des normes. Ce RFC donne des conseils pratiques aux groupes de travail qui utilisent GitHub. Il suit les principes généraux énoncés dans le RFC 8874, en étant plus concret, davantage orienté « tâches ».
Il s'agit cependant juste de conseils : des groupes peuvent parfaitement faire différemment, des individus peuvent utiliser GitHub (ou un service libre équivalent, ce que le RFC ne mentionne guère) en suivant d'autres méthodes. Le RFC concerne surtout les groupes de travail qui se disent que GitHub pourrait être intéressant pour eux, mais qui ne sont pas sûr de la meilleure manière de faire. Les groupes plus expérimentés qui utilisent GitHub parfois depuis des années savent déjà.
La section 2 du RFC décrit le processus recommandé pour le cycle de vie du groupe de travail. Ce processus peut s'automatiser, GitHub ayant une API documentée. Je ne sais pas si à l'heure actuelle cette automatisation est réellement utilisée par l'IETF Secretariat, mais le RFC suggère l'usage d'outils comme ietf-gh-scripts ou comme i-d-template.
Le RFC demande que l'interface utilisée par les directeurs de
zones IETF et les présidents des groupes de travail dans le
DataTracker
permette de créer une organisation GitHub. Elle doit être nommée
ietf-wf-NOMDUGROUPE (en pratique, cette
convention semble rarement suivie), les directeurs de la zone doivent
en être les propriétaires et les présidents du groupe doivent avoir
le statut d'administrateur (voyez par exemple les membre du groupe GitHub
QUIC). Elle est ensuite indiquée depuis le
DataTracker (cf. par exemple pour le groupe
capport). Il n'est pas possible actuellement d'associer
clairement les identités GitHub aux identités IETF (ça a été
demandé mais l'identité sur l'Internet est un sujet
complexe).
De même qu'il faudrait pouvoir créer facilement une organisation
dans GitHub, il serait bien de pouvoir créer facilement un nouveau
dépôt, et de le peupler avec les fichiers minimaux
(LICENSE - en suivant ces
principes, README,
CONTRIBUTING - en s'inspirant de ces
exemples, etc). L'outil i-d-template
fait justement cela.
Une fois organisation et dépôt(s) créés, le groupe peut se mettre
à travailler (section 3 du RFC). Un des points importants est la
sauvegarde. Il est crucial de sauvegarder
tout ce qui est mis dans GitHub au cas où, par exemple, Microsoft
déciderait tout à coup de limiter l'accès ou de le rendre
payant. Les listes de diffusion de l'IETF sont archivées via MailArchive, mais tout ce
qui se passe sur GitHub doit l'être également. Pour les documents,
c'est facile, git est un VCS décentralisé,
avoir une copie complète (avec l'historique) du dépôt est le
comportement par défaut. L'IETF n'a donc qu'à faire un git
fetch toutes les heures pour stocker une copie.
Il reste les tickets et les pull requests. Ils (elles ?) ne sont pas gérés par git. Il faut alors utiliser l'API de GitHub pour les sauvegarder.
Ce risque de pertes, si on ne fait pas de sauvegarde, fait d'ailleurs partie des risques mentionnés dans la section 4, sur la sécurité. Par contre, ce RFC ne mentionne pas les risques plus stratégiques liés à la dépendance vis-à-vis d'un système centralisé. C'est pour cela que certains documents sont développés en dehors de GitHub, par exemple le RFC 9156, successeur du RFC 7816 était sur un GitLab, FramaGit.
L'article seul
RFC 8874: Working Group GitHub Usage Guidance
Date de publication du RFC : Août 2020
Auteur(s) du RFC : M. Thomson (Mozilla), B. Stark (AT&T)
Pour information
Réalisé dans le cadre du groupe de travail IETF git
Première rédaction de cet article le 29 août 2020
De nombreux groupes de travail de l'IETF utilisent GitHub pour coordonner leur travail dans cet organisme de normalisation. Ce nouveau RFC donne des règles et des conseils à suivre dans ce cas. Personnellement, je déplore qu'il ne contienne pas de mise en garde contre l'utilisation d'un service centralisé extérieur à l'IETF.
L'IETF développe des normes pour l'Internet, notamment la plupart des RFC. Ce travail met en jeu des documents, les brouillons de futurs RFC, des discussions, des problèmes à résoudre. Les discussions sont assez complexes, durent souvent des mois, et nécessitent de suivre pas mal de problèmes, avec beaucoup d'éléments à garder en tête. Bref, des outils informatiques peuvent aider. Mais attention, l'IETF a des particularités (cf. RFC 2418). D'abord, tout doit être public, le but étant que le développement des normes soit aussi transparent que possible. Et il ne s'agit pas que de regarder, il faut que tous les participants (l'IETF est ouverte) puissent intervenir. Ensuite, tout doit être archivé, car il faudra pouvoir rendre compte au public, même des années après, et montrer comment l'IETF est parvenue à une décision. (D'autres SDO, comme l'AFNOR, sont bien plus fermées, et n'ont pas ces exigences d'ouverture et de traçabilité.)
Traditionnellement, l'IETF n'avait que peu d'outils de travail en
groupe et chacun se débrouillait de son côté pour suivre le travail
tant bien que mal. Mais les choses ont changé et l'IETF a désormais
une importante série d'outils, aussi bien les « officiels »,
maintenus par un prestataire extérieur, AMSL,
que des officieux, disponibles sur https://tools.ietf.org/
- Le service d'accès et de recherche dans les archives des listes de diffusion, MailArchive.
- Le service de suivi des documents DataTracker (regardez par exemple où en est HTTP/3).
Il n'y a pas par contre de VCS (dans les outils officieux, il y a un
service Subversion) ou de mécanisme de
suivi de tickets (il y a un
Trac officieux en https://trac.ietf.org/
Un VCS est pourtant un outil très utile, et pas seulement pour les programmeurs. Travaillant en général sur des fichiers texte quelconques, il permet de coordonner le travail de plusieurs personnes sur un document, que celui-ci soit du code source ou bien un Internet-Draft. C'est le cas par exemple du VCS décentralisé git, très utilisé aujourd'hui.
On peut utiliser git tout seul, d'autant plus que le fait qu'il doit décentralisé ne nécessite pas d'autorité de coordination (c'est ainsi qu'est développé le noyau Linux, par exemple). Mais beaucoup de programmeurs (ou d'auteurs d'Internet Drafts) utilisent une forge complète, intégrant un VCS mais aussi un système de gestion de rapports, un wiki et d'autres fonctions. La plus connue de ces forges est GitHub, propriété de Microsoft. Comme souvent avec les réseaux sociaux (GitHub est le Facebook du geek), la taille compte : plus il y a de gens sur le réseau social, plus il est utile. C'est pour cela qu'il y a des fortes pressions à la centralisation, et une difficulté, en pratique, à partir, sauf à perdre les possibilités de coopération (c'est pour cela que prétendre qu'il y a consentement des utilisateurs aux pratiques déplorables des réseaux sociaux centralisés est une farce : on n'a pas le choix). L'utilisation de GitHub n'est évidemment pas obligatoire à l'IETF mais elle est répandue. Regardez par exemple le groupe de travail QUIC, celui sur HTTP, ou celui sur les portails captifs. GitHub est également utilisé en dehors des groupes de travail, par exemple pour les résultats et présentations des hackathons. Le but de ce RFC est de fournir quelques règles utiles (mais facultatives) pour les groupes qui travailleront sur GitHub. Un autre RFC, le RFC 8875, est plus concret, donnant des règles précises de configuration de GitHub pour un groupe de travail.
L'introduction du RFC rappelle juste en passant qu'il existe d'autres forges comme Bitbucket et du logiciel libre qui permet d'installer diverses forges locales. Ainsi, le logiciel de GitLab permet d'installer des forges indépendantes comme FramaGit. (J'ai récemment migré tous mes dépôts vers un GitLab.) C'est FramaGit qui est utilisé pour le développement de la norme sur la QNAME minimisation, le RFC 9156, qui a remplacé le RFC 7816. Mais GitHub est de loin le plus utilisé et, par exemple, pour le successeur du RFC 7816, quasiment tous les contributeurs avaient été obligés de se créer un compte sur FramaGit, ils n'en avaient pas avant. Le RFC ne rappelle même pas les dangers qu'il y a à utiliser un service centralisé, géré par une entreprise privée. Si GitLab est mentionné dans le RFC, la possibilité d'une instance IETF (gérée par l'actuel prestataire qui administre les ressources IETF, AMSL) n'apparait pas. Simple question d'argent ou problème plus fondamental ?
Bon, au boulot, maintenant, quelles sont les règles listées par ce RFC ? (Rappel : ce RFC reste à un haut niveau, les instructions précises sont dans le RFC 8875.) D'abord, comment décider d'utiliser (ou non) GitHub (section 3 du RFC) ? Fondamentalement, ce sont les présidents du groupe qui décident, après consultation avec les directeurs de la zone (une zone regroupe plusieurs groupes de travail). Ils vont également définir les conditions d'utilisation (par exemple, décider d'utiliser le système de rapports - issues - ou pas). Notez que, même si le groupe en tant que tel n'utilise pas GitHub, certains contributeurs peuvent évidemment s'en servir pour leurs besoins propres. D'une manière générale, le travail fait sur GitHub n'a pas d'autorité particulière, c'est juste un élément parmi d'autres pour le groupe. Ainsi, ce n'est pas parce qu'un ticket est fermé sur GitHub que le groupe de travail est lié par cette fermeture et ne peut plus discuter le point en question.
Le groupe peut ensuite créer un dépôt par document, ce qui est recommandé (c'est ce que fait le groupe capport) ou bien, s'il préfère, un seul dépôt pour tous les documents du groupe (sans aller jusque là, le groupe QUIC met tous les documents de base du protocole dans le même dépôt).
Les documents sont a priori en XML, format standard des documents IETF (cf. RFC 7991) mais on a le droit d'utiliser Markdown (cf. RFC 7328). Par contre, les formats doivent être du texte, pas de binaire comme avec LibreOffice, binaire qui passerait mal avec git (pas moyen de voir les différences d'une version à l'autre).
Ensuite, un peu de paperasserie (section 2 du RFC), avec les
règles administratives. Le RFC recommande de créer une organisation
dans GitHub pour chaque groupe de travail qui utilise GitHub (il n'y
a pas d'organisation « IETF »). Les propriétaires de cette
organisation doivent être les directeurs de la zone dont fait partie
le groupe, et les présidents ou présidentes du groupe. Les auteurs
des documents doivent évidemment avoir un accès en écriture. Les
dépôts du groupe de travail sur GitHub doivent être clairement
documentés, indiquant la charte du groupe, sa politique, sa gestion
des contributeurs (fichier CONTRIBUTING, que
GitHub met en avant), etc. Et il faut évidemment pointer sur la
politique générale de l'IETF, le Note
Well (qui est tout le temps cité dans les réunions
physiques, mais qui doit également être connu des gens qui
n'interagissent que via GitHub). En sens inverse, le dépôt GitHub
doit être clairement indiqué sur les pages du groupe sur le site de
l'IETF, et sur les Internet-Drafts produits.
Un des intérêts d'une forge comme GitHub est qu'on dispose de plusieurs moyens de contribuer à un projet. Lesquels utiliser pour des documents IETF (section 4 du RFC) ? Il y a d'abord le système de suivi des questions. Il permet de noter les questions en cours et les décisions prises peuvent être inscrites dans le ticket, avant de le fermer. D'un coup d'œil, on peut voir facilement le travail en cours, et ce qui reste à faire. Dans chaque ticket, on peut voir l'ensemble des éléments liés à une question. Le système de suivi de questions (issue tracker) de GitHub permet bien d'autres choses, comme l'affectation d'un ticket à une personne. Un service très utile est l'étiquetage des questions (« rédaction » pour un texte mal écrit, « technique » pour un problème technique, etc). Comme dans la plupart des cas, le RFC n'impose pas une politique de gestion des étiquettes, seulement le fait qu'il y ait une politique et qu'elle soit communiquée aux participants. Même chose pour la politique de fermeture des tickets (un sujet parfois sensible).
Une fonction qui a beaucoup contribué à la popularité du GitHub est la possibilité de pull request (qui a une bonne traduction en français ? Alexis La Goutte suggère « demande d'intégration »), c'est-à-dire d'enregistrer une série de modifications qui sont collectivement soumises à l'approbation ou au rejet d'un responsable. Cela permet de proposer une contribution sans avoir l'autorisation d'écriture dans le dépôt, tout en permettant une grande traçabilité des contributions. C'est la méthode conseillée par le RFC pour soumettre des contributions significatives, notamment en raison de cette traçabilité. Par contre, il n'est pas conseillé de discuter de questions complexes dans les commentaires de la pull request ; comme la requête peut être modifiée, les commentaires risquent de devenir décalés par rapport au dernier état de la pull request.
GitHub permet d'avoir un flux de syndication pour les dépôts. C'est ce que j'utilise personnellement pour suivre les activités des dépôts qui m'intéressent. Mais il existe d'autres méthodes comme l'outil github-notify-ml, très utilisé à l'IETF.
J'ai dit plusieurs fois que ce RFC n'imposait pas une façon d'utiliser GitHub pour un groupe de travail IETF. Il y a plusieurs politiques possibles, chaque groupe de travail peut faire différemment, l'important étant que les participants au groupe soient au courant. Pour faciliter le choix, la section 5 du RFC propose un jeu de politiques typiques, parmi lesquelles on peut choisir. Elles sont classées de la plus élémentaire, à celle qui utilise le plus les possibilités de GitHub :
- Dans le cas le plus simple, le groupe travaille comme avant, il ne se sert que GitHub que pour stocker les documents, notamment les Internet-Drafts et leur historique.
- Plus élaborée, une politique avec utilisation du système de suivi des questions, mais où les discussions ont toujours lieu ailleurs que sur GitHub, les tickets ne stockant que les questions en cours et leur résolution. (Comme le note le RFC, c'est difficile à garantir, les discussions s'invitent souvent sur les tickets.)
- Encore plus githubienne, la politique où cette fois la discussion a officiellement lieu sur les tickets GitHub. La liste de diffusion (le principal outil officiel des groupes de travail IETF) a le dernier mot mais le gros du travail a été fait sur le système de gestion de tickets. Attention : cela veut dire qu'une bonne partie des explications et justifications à un RFC vont rester sur une plate-forme privée, qui peut changer sa politique à sa guise, ce qui pourrait faire perdre à l'IETF une partie de son histoire (la section 10 du RFC revient sur cette question). Le RFC ne contient pas de mise en garde à ce sujet, alors que le problème s'est déjà produit.
La section 5 discute également des politiques de nommage pour les étiquettes. Au minimum, il faut des étiquettes pour différencier les détails (« coquille dans le deuxième paragraphe ») des questions de fond. Ensuite, les étiquettes peuvent être utilisées pour :
- L'état d'un ticket (« en discussion », « consensus approximatif », « repoussé à une future version du protocole »).
- La partie du protocole concernée.
- Ou d'autres cas comme par exemple le marquage des tickets considérés comme complètement hors-sujet.
Une notion importante à l'IETF est celle de consensus. L'IETF ne vote pas (dans une organisation sans adhésion explicite, qui aurait le droit de vote ?) et prend normalement ses décisions par consensus (cf. RFC 2418). Pour estimer s'il y a consensus ou pas, les présidents du groupe de travail peuvent utiliser tous les moyens à leur disposition (section 7 du RFC) dont GitHub, mais doivent s'assurer, sur la liste de diffusion officielle du groupe, qu'il s'agit bien d'un consensus. (Certains participants ou participantes peuvent ne pas utiliser GitHub, et il faut quand même tenir compte de leur avis.)
Le RFC note aussi (section 8) que, parmi les fonctions de GitHub, l'intégration continue peut être très utile. Par exemple, si les documents rédigés comportent des extraits dans un langage formel (comme YANG ou Relax NG), mettre en place un système d'intégration continue permet de détecter les erreurs rapidement, et de présenter automatiquement la dernière version, automatiquement vérifiée, des documents.
La section 9 du RFC donne quelque conseils aux auteurs (editors dans le RFC car le concept d'auteur est délicat, pour des documents collectifs). Avec GitHub, il y aura sans doute davantage de contributions extérieures (par exemple sous forme de pull requests), puisque le processus de soumission est plus facile pour les gens qui ne sont pas à l'IETF depuis dix ans. C'est bien l'un des buts de l'utilisation d'une forge publique. Mais cela entraine aussi des difficultés. Des tickets vont être dupliqués, des pull requests être plus ou moins à côté de la plaque, etc. Les auteurs doivent donc se préparer à un travail de tri important.
Enfin, la section 10, consacrée à la sécurité, détaille plusieurs des problèmes que pose l'utilisation de GitHub. D'abord, il y a la dépendance vis-à-vis d'une plate-forme extérieure à l'IETF ; si GitHub est en panne, perturbant le fonctionnement d'un ou plusieurs groupes de travail, l'IETF ne peut rien faire. (Le caractère décentralisé de git limite un peu l'ampleur du problème.) Ensuite, il y a la nécessité de faire des sauvegardes, y compris des tickets (qui ne sont pas, eux, gérés de manière décentralisée). Le RFC 8875 donne des consignes plus précises à ce sujet. Et il y a le risque de modifications non souhaitées, si un participant ayant droit d'écriture se fait pirater son compte. Le fait que tout soit public à l'IETF, et que git permette assez facilement de revenir en arrière sur des modifications, limitent l'importance de cette menace mais, quand même, il est recommandé que les auteurs sécurisent leur compte (par exemple en activant la MFA). En revanche, un autre risque n'est pas mentionné dans le RFC, celui du blocage par GitHub des méchants pays. GitHub bloque ou limite l'accès à certains pays et ne s'en cache d'ailleurs pas.
Dernier problème avec GitHub, non mentionné dans le RFC (merci à Alexis La Goutte pour l'observation) : l'IETF travaille de nombreuses années à développer et promouvoir IPv6 et GitHub n'a toujours que les adresses de la version du siècle précédent.
L'article seul
RFC 8890: The Internet is for End Users
Date de publication du RFC : Août 2020
Auteur(s) du RFC : M. Nottingham
Pour information
Première rédaction de cet article le 28 août 2020
Ah, mais c'est une excellente question, ça. L'Internet est pour qui ? Qui sont les « parties prenantes » et, parmi elles, quelles sont les plus importantes ? Plus concrètement, la question pour l'IETF est « pour qui bossons-nous ? » Quels sont les « clients » de notre activité ? Ce RFC de l'IAB met les pieds dans le plat et affirme bien haut que ce sont les intérêts des utilisateurs finaux qu'il faut considérer avant tout. Et explique aussi comment prendre en compte ces intérêts, en pratique. C'est donc un RFC 100 % politique.
Il y a encore quelques personnes à l'IETF qui ne veulent pas voir les conséquences de leur travail (« la technique est neutre ») ou, pire, qui ne veulent en retenir que les conséquences positives. Mais les activités de l'IETF, comme la production des RFC, est en fait politique, affirme ce document. Car l'Internet est aujourd'hui un outil crucial pour toute la vie sociale, il a permis des changements importants, il a enrichi certains et en a appauvri d'autres, il a permis l'accès à un savoir colossal librement accessible, et il a facilité le déploiement de mécanismes de surveillance dont Big Brother n'aurait jamais osé rêver. Et toute décision apparemment « purement technique » va avoir des conséquences en termes de ce qui est possible, impossible, facile, ou difficile sur le réseau. Compte-tenu de leur impact, on ne peut pas dire que ces décisions ne sont pas politiques (section 1 du RFC).
Une fois qu'on reconnait que ce qu'on fait est politique, se pose la question : pour qui travaille-t-on ? Dresser la liste des « parties prenantes », les intéressé·e·s, les organisations ou individus qui seront affectés par les changements dans l'Internet est une tâche impossible ; c'est quasiment tout le monde. Le RFC donne une liste non limitative : les utilisateurs finaux, les opérateurs réseau, les écoles, les vendeurs de matériel, les syndicats, les auteurs de normes (c'est nous, à l'IETF), les programmeurs qui vont mettre en œuvre les normes en question, les ayant-droits, les États, les ONG, les mouvements sociaux en ligne, les patrons, la police, les parents de jeunes enfants… Tous et toutes sont affectés et tous et toutes peuvent légitimement réclamer que leurs intérêts soient pris en compte. Ce n'est pas forcément au détriment des autres : un changement technique peut être bénéfique à tout le monde (ou, en tout cas, être bénéfique à certains sans avoir d'inconvénients pour les autres). Mais ce n'est pas toujours le cas. Pour prendre un exemple classique (mais qui n'est pas cité dans ce RFC), voyons le chiffrement : l'écriture du RFC 8446, qui normalisait la version 1.3 de TLS, a remué beaucoup de monde à l'IETF car le gain en sécurité pour les utilisateurs finaux se « payait » par de moindres possibilités de surveillance pour les États et les patrons. Ici, pas question de s'en tirer en disant que tout le monde serait heureux : il fallait accepter de faire des mécontents.
Bon, là, c'étaient les grands principes, maintenant, il faut devenir un peu concret. D'abord, qui sont ces « utilisateurs finaux » ? Si on veut donner la priorité à leurs intérêts, il faudrait les définir un peu plus précisément. La section 2 explique : ce sont les humains pour qui l'Internet rend un service. Cela n'inclut donc pas les professionnels qui font marcher le réseau : les utilisateurs finaux du protocole BGP ne sont pas les administrateurs réseau, qui configurent les routeurs BGP, mais les gens à qui le réseau en question permet de communiquer.
Le RFC note que ces utilisateurs finaux ne forment donc pas un groupe homogène. Ils ont des intérêts différents et des opinions différentes. (Je suis personnellement très agacé par les gens qui, dans les réunions de « gouvernance Internet », plastronnent qu'ils représentent « les utilisateurs ». Comme la mythique « société civile », les utilisateurs ne sont pas d'accord entre eux.) Parfois, le désaccord est au sein du même individu, lorsqu'il occupe plusieurs rôles. Même dans un seul rôle, l'utilisateur final peut être le siège de tensions, par exemple entre la protection de sa vie privée et la facilité d'utilisation du réseau, deux objectifs honorables mais qui sont parfois difficiles à concilier.
Le RFC note aussi que l'utilisateur final peut… ne pas être un utilisateur, ou en tout cas pas directement. Si on prend une photo de moi et qu'on la met sur le Web avec un commentaire, je suis concerné, même si je n'utilise pas du tout l'Internet. Même chose si j'entre dans un magasin truffé de capteurs qui détectent mes mouvements et les signalent. Les utilisateurs finaux, au sens de ce RFC, peuvent donc être des utilisateurs indirects.
Une fois qu'on sait qui sont les utilisateurs finaux, pourquoi faudrait-il prioriser leurs intérêts ? La section 3 rappelle d'abord que l'IETF a une longue histoire d'affirmation de cette priorité. Le tout premier RFC, le RFC 1, disait déjà « One of our goals must be to stimulate the immediate and easy use by a wide class of users. » (Bon, le RFC 1 parlait d'accessibilité et de facilité d'usage plutôt que de politique, mais c'est une jolie référence.) La charte de l'IETF, dans le RFC 3935, est plus précise : « The IETF community wants the Internet to succeed because we believe that the existence of the Internet, and its influence on economics, communication, and education, will help us to build a better human society. ». Et, encore plus explicite, « We embrace technical concepts such as decentralized control, edge-user empowerment and sharing of resources, because those concepts resonate with the core values of the IETF community. These concepts have little to do with the technology that's possible, and much to do with the technology that we choose to create. ». Bref, le but est le bonheur de l'humanité, et celle-ci est composée des utilisateurs finaux.
(Pour ne fâcher personne, le RFC oublie de signaler l'existence d'autres RFC qui au contraire donnent explicitement la priorité à d'autres parties prenantes, par exemple les gérants du réseau dans le RFC 8404.)
Le RFC note que le progrès quantitatif (davantage de machines connectées, une capacité réseau plus importante, une latence plus faible) n'est pas un but en soi car l'Internet peut être utilisé pour des mauvaises causes (surveiller les utilisateurs, exercer un pouvoir sur eux). La technique pouvant être utilisée pour le bien comme pour le mal, les améliorations techniques (comme présentées en couleur rose par les techno-béats, par exemple les promoteurs de la 5G) ne doivent pas être considérées comme forcément positives.
Après ces arguments humanistes, le RFC mentionne aussi des arguments plus internes au réseau. D'abord, d'un point de vue égoïste, l'IETF a tout intérêt à garder la confiance de ces utilisateurs finaux, car l'IETF perdrait sa pertinence et son rôle si elle se mettait, par exemple, uniquement à la remorque des vendeurs de matériel ou de logiciel. (Ou même si elle était simplement vue comme se mettant à cette remorque.)
On pourrait même voir les utilisateurs se détourner massivement, non seulement du travail de l'IETF, mais aussi de l'Internet en général, si leurs intérêts ne sont pas mis en premier. Prioriser les utilisateurs finaux aide aussi à lutter contre certaine formes de technophobie.
Maintenant, on a défini les utilisateurs finaux, affirmé qu'il fallait penser à eux et elles en premier, et expliqué pourquoi. Il reste le comment. C'est bien joli de dire, dans une grande envolée « nous pensons avant tout à M. et Mme Toutlemonde » mais, concrètement, cela veut dire quoi ? La section 4 du RFC décortique les conséquences pratiques du choix politique.
D'abord, déterminer ce qui est bon pour les utilisateurs n'est pas évident. Paradoxalement, le fait que les participants à l'IETF connaissent et comprennent très bien le fonctionnement de l'Internet n'aide pas, au contraire ; cela rend plus difficile de se mettre à la place des utilisateurs finaux. Pourtant, on l'a vu, l'IETF se réclame depuis longtemps d'une vague « Internet community » mais sans trop savoir qui elle est. Une solution évidente au problème « quels sont les intérêts des utilisateurs finaux ? » serait de leur demander. C'est plus facile à dire qu'à faire, mais c'est en effet la première chose à envisager : se rapprocher des utilisateurs.
Cela ne va pas de soi. Déjà, le travail de l'IETF est très pointu techniquement, et nécessite une forte expertise, sans compter la nécessité de se familiariser avec la culture spécifique de l'IETF. les utilisateurs finaux qu'on veut prioriser ne sont pas des experts techniques. Pire, les connaissances qu'ils ont sur l'Internet ne sont pas seulement insuffisantes, elles sont souvent fausses. Bref, inviter M. ou Mme Toutlemonde sur les listes de diffusion de l'IETF n'est pas la bonne approche.
Les États sont prompts à dire « pas de problème, les utilisateurs ont une représentation, et c'est nous ». Il suffirait donc que les envoyés de ces États participent à l'IETF et on aurait donc automatiquement accès à « la voix des utilisateurs ». Il y a déjà de ces envoyés qui participent à l'IETF. (À chaque réunion, il y a au moins une personne avec un badge NSA, sans compter ceux qui n'ont pas le badge, mais ont le même employeur.) La question de leur représentativité (l'envoyé du gouvernement français est-il vraiment le porte-parole des soixante millions d'utilisateurs français ?) a été une des questions essentielles lors des discussions menant à ce RFC. Chaque gouvernement prétend qu'il est représentatif. C'est clairement faux pour les dictatures mais cela ne veut pas dire que les démocraties sont parfaites, sans compter la difficulté de classer les pays dans l'une ou l'autre catégorie. Bref, personne n'a envie de transformer l'IETF en un organisme multi-gouvernemental paralytique, comme l'ONU. (Les experts en « gouvernance Internet » noteront que l'ICANN a le même genre de problèmes, et son GAC - Governmental Advisory Committee - ne satisfait personne.)
À ce sujet, bien que cela ne soit pas mentionné explicitement dans le RFC, il faut aussi dire que les envoyés des États sont en général contraints par un processus de décision interne très rigide, et ne peuvent pas s'exprimer librement. Cela ne colle évidemment pas avec le mécanisme de discussion très ouvert et très vif de l'IETF. Je me souviens d'une réunion où deux personnes portant la mention FBI sur leur badge étaient venus me parler de problèmes avec un des documents sur lesquels je travaillais. Lorsque je leur ai fait remarquer que leurs analyses, assez pertinentes, devraient être faites dans la réunion officielle du groupe de travail et pas juste dans les couloirs, ils m'avaient répondu que leurs supérieurs ne les y autorisaient pas. Difficile d'envisager une participation effective des États dans ces conditions.
Bon, si on ne fait pas appel aux États, à qui ? Le RFC mentionne la classique « société civile » dont personne ne sait trop en quoi elle consiste, mais à qui tout le monde rend hommage. Selon l'interlocuteur, « société civile » peut vouloir dire « tout le monde sauf l'État » (incluant, par exemple, le MEDEF), ou bien « tous les individus » ou encore « tous les individus organisés (associations, syndicats, etc) » sans compter ceux qui disent « société civile » pour « les gens qui sont d'accord avec moi ». (Disons franchement les choses : l'un des problèmes de fond de la « gouvernance de l'Internet » est qu'il n'y a que peu ou pas de représentation des utilisateurs. Tout le monde parle pour eux et elles, mais ielles n'ont pas de voix propre. Ce syndrome « tout le monde se réclame de l'utilisateur final » avait été très net, par exemple, lors des débats sur DoH, mais aussi dans d'autres questions de gouvernance.)
Mais le RFC note à juste titre qu'il existe des organisations qui ont sérieusement travaillé les sujets politiques liés à l'Internet, et qui connaissent donc bien les problèmes, et les conséquences des choix techniques. (En France, ce serait par exemple La Quadrature du Net, Framasoft et certainement plusieurs autres.) Bien que rien ne garantisse leur représentativité, note le RFC, ces organisations sont sans doute le premier canal à utiliser pour essayer de comprendre les intérêts des utilisateurs finaux. La recommandation est donc d'essayer d'identifier ces groupes et de travailler avec eux.
L'accent est mis sur la nécessité d'aller les voir, de ne pas juste leur dire « venez participer à l'IETF » (ils n'ont pas forcément le temps ou les moyens, et pas forcément envie de se lancer dans ce processus). Outre ses réunions formelles et ses listes de diffusion, l'IETF a quelques canaux de communication plus adaptés mais certainement très peu connus (« venez à la Bar BoF, on en parlera autour d'une bière »). Idéalement, c'est l'IETF qui devrait prendre l'initiative, et essayer d'aller vers les groupes organisés d'utilisateurs, par exemple en profitant des réunions existantes. Le RFC recommande de faire davantage d'efforts de sensibilisation, faire connaitre le travail de l'IETF, ses enjeux, etc. (Mon expérience est qu'il est très difficile de faire s'intéresser les gens à l'infrastructure de l'Internet, certes moins sexy qu'une page d'accueil colorée d'un site Web. Après tout, on ne peut pas faire boire un âne qui n'a pas soif.)
Le RFC donne un exemple d'un atelier ayant réuni des participants à l'IETF, et des gens qui n'ont pas l'habitude d'aller à l'IETF, sur un sujet assez chaud politiquement, la réunion ESCAPE, documentée dans le RFC 8752.
On peut aussi penser que cette tâche de sensibilisation à l'importance de la normalisation, et à ses conséquences politiques, ne devrait pas revenir entièrement à l'IETF, qui n'est pas forcément bien préparée à cela. Le RFC cite à juste titre l'Internet Society, qui fait en effet un important travail dans ce domaine.
Le RFC continue avec une section sur le concept de systèmes
centrés sur l'utilisateur. Il part de l'exemple du Web, certainement un des plus gros
succès de l'Internet. Dans le Web, l'IETF normalise le protocole
HTTP (le
W3C faisant
le reste). La norme HTTP, le RFC 7230 décrit
explicitement le rôle du client HTTP, appelé user
agent dans la norme (et c'est de là que vient l'en-tête
HTTP User-Agent:). À noter que le RFC mélange
client HTTP et navigateur Web : le client
d'un serveur HTTP n'est pas forcément un navigateur. Quoi qu'il en
soit, la discussion continue sur le navigateur : celui-ci sert
d'intermédiaire entre l'utilisateur et le serveur Web. Au lieu d'un
client spécifique d'un service, et qui a accès à toute la machine de
l'utilisateur pour faire sa tâche, le passage par cet intermédiaire
qu'est le navigateur permet de créer un bac à sable. Quelles que
soient les demandes faites par le serveur Web, il ne sera pas
possible de sortir du bac à sable et, par exemple, de lire et
d'écrire arbitrairement des fichiers sur la machine de
l'utilisateur.
Au contraire, les services sur le Web qui exigent l'installation d'un client local demandent à l'utilisateur une confiance aveugle : ces clients peuvent faire des choses que le navigateur bloquerait normalement. Ce n'est pas par hasard que les sites des médias demandent si souvent l'installation de leur « app » quand on navigue depuis un ordiphone : ces clients locaux ont bien plus de possibilité, notamment de pistage et de surveillance que ce qui est possible via le navigateur.
(Le RFC ne mentionne pas un autre moyen de créer la confiance : le logiciel libre. La totalité de ces « apps » sont du logiciel privateur. Si le logiciel est sous une licence libre, il y a nettement moins de craintes à avoir lorsqu'on l'installe.)
Le RFC estime que le fait d'avoir défini explicitement le user agent et ses propriétés a facilité le succès du Web, en permettant la création de cet intermédiaire de confiance qu'est le navigateur Web, un exemple de système « centré sur l'utilisateur ». Bien sûr, cette vision est très contestable. Le RFC note par exemple que, à vouloir tout faire passer par le Web, on aboutit à des navigateurs qui sont devenus très complexes, ce qui se paie en sécurité et en performances. En outre, cette complexité diminue la concurrence : il n'y a que très peu de navigateurs et beaucoup de composants cruciaux, comme WebKit sont communs à plusieurs navigateurs, diminuant la diversité et le choix. Aujourd'hui, créer un nouveau navigateur en partant de zéro semble impossible, ce qui a de lourdes conséquences sur la distribution du pouvoir dans le Web.
Mais le RFC estime que c'est quand même une meilleure approche que celle, par exemple, de l'Internet des objets, où il n'y a pas de norme d'interaction entre l'utilisateur et le système, pas de « système centré sur l'utilisateur », ce qui fait que l'utilisateur doit faire une confiance aveugle à des systèmes opaques, dont la mauvaise qualité (notamment en sécurité) et la mauvaise éthique ont déjà été largement montrées.
On a dit plus haut que, dans le meilleur des cas, le travail de l'IETF menait à des solutions qui étaient positives pour tout le monde. L'IETF peut alors laisser les différentes parties prenantes interagir (cf. l'article « Luttes dans l'Internet », même si, aujourd'hui, je traduirais tussle par un terme moins violent que lutte). Mais ce cas idéal n'est pas systématique. Parfois, les solutions techniques normalisées dans les RFC ne sont positives que pour certains, et neutres pour d'autres (ne leur apportent aucun avantage). Et parfois, c'est pire, les solutions sont négatives pour certains. Dans le monde réel, fait de différences d'opinion et d'intérêts (et de lutte des classes, ajouterait un marxiste), il ne faut pas être naïf : on ne va pas plaire à tout le monde. Conformément aux principes établis plus haut, le RFC affirme que, si une solution envisagée a forcément des conséquences négatives, il faut faire en sorte que ces conséquences négatives ne soient pas supportées par les utilisateurs finaux, mais par d'autres parties prenantes.
L'IETF a déjà été confrontée à de tels choix, et a documenté cette décision, par exemple dans les RFC 7754 (sur le filtrage), RFC 7258 et RFC 7624 (sur la surveillance), RFC 7288 (sur les pare-feux des machines terminales) et enfin RFC 6973 (sur la vie privée).
Le RFC note aussi que certaines décisions politiques de l'IETF peuvent être correctes mais insuffisantes. Ainsi, le RFC 3724 insiste sur l'importance du modèle de bout en bout. Mais cela ne suffit pas si c'est la machine avec qui on communique qui trahit. Chiffrer grâce à HTTPS quand on parle avec un GAFA n'est une protection que contre les tiers, pas contre le GAFA.
Au sujet des GAFA, le RFC note que la concentration des services dans les mains d'un petit groupe de sociétés est un problème pour les utilisateurs. Il affirme aussi que cela peut être encouragé par des propriétés du protocole IETF. (C'est nettement plus contestable : quelles sont les caractéristiques de SMTP qui expliquent la concentration du courrier chez Gmail et Outlook.com ? Cet argument semble plutôt une allusion maladroite aux débats sur DoH.)
Comme indiqué au début, les utilisateurs finaux ne forment pas un groupe homogène. Ils n'ont ni les mêmes intérêts, ni les mêmes opinions. Cela peut entrainer des difficultés pour l'application du principe « les utilisateurs d'abord ». Par exemple, dans un cas hypothétique où une solution technique entrainerait des conséquences positives pour les utilisateurs d'un pays et négatives dans un autre pays, que faire ? Le RFC suggère de privilégier l'évitement des conséquences négatives. Dans certains cas, il ne sera pas possible de les éviter complètement, et il faudra vraiment faire des compromis. Mais, au moins, il ne faudra pas cacher le problème sous le tapis, et bien documenter ce compromis.
Le principe « les utilisateurs d'abord » s'applique aussi à l'IETF elle-même. Le RFC se termine en affirmant qu'il ne faut pas que l'IETF privilégie ses propres besoins. Ainsi, s'il faut compliquer la tâche des auteurs de RFC pour mieux préserver les intérêts de l'utilisateur, eh bien il faut le faire. De même, dit le RFC, la beauté de l'architecture technique n'est pas un but en soi, elle doit passer après les intérêts des utilisateurs finaux.
En anglais, vous pouvez aussi lire la synthèse qu'avait publié l'auteur du RFC, où il s'exprime plus librement que dans le RFC, par exemple sur DoH. Un article de synthèse, allant plus loin que le RFC a été écrit par Vesna Manojlovic. D'autre part, la norme HTML (du W3C) a une mention qui va dans le même esprit que ce RFC : « In case of conflict, consider users over authors over implementors over specifiers over theoretical purity. » (les mauvaises langues pourront faire remarquer que ce mépris de la « theoretical purity » explique le b...l technique qu'est le Web). Ou, en sens opposé, un article qui s'était vigoureusement opposé à cet empouvoirement des utilisateurs.
L'article seul
Fiche de lecture : Un trou dans la toile
Auteur(s) du livre : Luc Chomarat
Éditeur : Payot / Rivages
9-782743-636319
Publié en 2016
Première rédaction de cet article le 19 août 2020
Un peu de lecture de vacances ? Ce livre n'est pas vraiment (malgré la collection où il est publié) un roman policier. C'est plutôt une satire de notre société, de sa dépendance aux outils numériques mais pas uniquement.
Le seul lien avec un polar, c'est qu'il y a un mystère, un inconnu qu'on recherche. Sans divulgâcher, je peux vous dire tout de suite que ce n'est pas cet inconnu qui est important, il est juste un prétexte pour dénoncer l'absurdité du monde, la « communication » érigée en valeur suprême, la perte de sens et la dissimulation de la dureté de l'entreprise capitaliste derrière les mots à la mode. Le livre suit un héros qui est à la fois bien intégré dans la société (il est « créatif » dans une agence de publicité) et décalé (il n'utilise pas les réseaux sociaux et, d'une manière générale, ne comprend pas trop la société dans laquelle il vit).
Le monde du numérique n'occupe en fait qu'une partie du roman, malgré le titre, et malgré la couverture ridicule, avec 0 et 1 qui défilent et hacker à capuche. Pas de piratage ou de cyberconneries dans ce livre (juste un ou deux clichés idiots, par exemple sur le darknet). Mais beaucoup d'humour, pas mal de désespoir aussi (« nous sommes des hommes du siècle dernier, nous essayons de nous adapter, mais nous n'en avons pas vraiment envie »). Contrairement aux milliers de livres réacs publiés sur le thème « l'Internet, c'est la fin de la civilisation, à cause des réseaux sociaux, les gens ne se parlent plus en vrai », ce roman ne met pas tout sur le dos du numérique, et considère que le problème vient de notre société.
Je recommande sa lecture. Si vous êtes comme moi, vous allez souvent rire, et parfois réfléchir.
L'article seul
RFC 8811: DDoS Open Threat Signaling (DOTS) Architecture
Date de publication du RFC : Août 2020
Auteur(s) du RFC : A. Mortensen (Forcepoint), T. Reddy (McAfee), F. Andreasen (Cisco), N. Teague (Iron Mountain), R. Compton (Charter)
Pour information
Réalisé dans le cadre du groupe de travail IETF dots
Première rédaction de cet article le 18 août 2020
Ce nouveau RFC décrit l'architecture du système DOTS (Distributed-Denial-of-Service Open Threat Signaling), un ensemble de mécanismes pour permettre aux victimes d'attaques par déni de service de se coordonner avec les fournisseurs de solution d'atténuation. C'est juste l'architecture, les protocoles concrets sont dans d'autres RFC, comme le RFC 9132.
Il n'y a pas besoin d'expliquer que les attaques par déni de service sont une plaie. Tout le monde en a déjà vécu. Une des approches pour atténuer l'effet d'une de ces attaques est de sous-traiter votre trafic à un tiers, l'atténuateur (« Victor, atténuateur ») qui va recevoir les données, les classer, et jeter ce qui est envoyé par l'attaquant. Cette approche nécessite de la communication entre la victime et l'atténuateur, communication qui se fait actuellement de manière informelle (téléphone…) ou via des protocoles privés. L'idée de DOTS (Distributed-Denial-of-Service Open Threat Signaling) est d'avoir des protocoles normalisés pour ces fonctions de communication. Les scénarios typiques d'utilisation de DOTS sont décrits dans le RFC 8903.
Dans le cas le plus fréquent, DOTS sera utilisé entre des organisations différentes (la victime, et le fournisseur de solutions anti-dDoS). A priori, ils auront une relation contractuelle (du genre contrat, et paiement) mais cette question ne fait pas l'objet du RFC, qui mentionne seulement l'architecture technique. Mais en tout cas, ce caractère multi-organisations va nécessiter des mécanismes d'authentification sérieux (le cahier des charges complet de DOTS est le RFC 8612).
La section 1 de notre RFC rappelle également que DOTS, par définition, sera utilisé dans des moments difficiles, pendant une attaque (RFC 4732), et qu'il est donc conçu en pensant à des cas où les ressources sont insuffisantes (les paquets ont du mal à passer, par exemple). Parfois, il y aura un lien intact entre le client DOTS et le serveur, ou bien un réseau dédié pour cette communication, ou encore une qualité de service garantie pour les échanges DOTS, mais on ne pourra pas toujours compter dessus. DOTS doit fonctionner sur l'Internet normal, possiblement affecté par l'attaque. C'est un élément à systématiquement garder en tête lorsqu'on examine le protocole DOTS, et qui explique bien des choix, comme UDP pour le protocole de signalisation du RFC 9132.
D'autre part, les RFC sur DOTS décrivent des techniques, pas des politiques. Comment on définit une attaque DoS, à partir de quand on déclenche l'atténuation, comment on choisit un atténuateur, toutes ces questions dépendent de la victime, chacun peut faire des choix différents.
Ceci étant posé, place à la description de haut niveau de DOTS, en section 2. Dans le cas le plus simple, il y a :
- La victime, qui héberge un client DOTS,
- L'atténuateur, qui héberge un serveur DOTS.
Et client et serveur DOTS communiquent avec les deux protocoles DOTS, celui de signalisation (RFC 9132) et celui de données (RFC 8783). Il y a donc deux canaux de communication. DOTS permet également des schémas plus complexes, par exemple avec plusieurs serveurs, à qui le client demande des choses différentes, ou bien avec des serveurs différents pour la signalisation et pour les données. Notez bien que DOTS est uniquement un protocole de communication entre la victime et l'atténuateur qui va essayer de la protéger. Comment est-ce que l'atténuateur filtre, ou comment est-ce qu'on lui envoie le trafic à protéger, n'est pas normalisé. De même, DOTS ne spécifie pas comment le serveur répond aux demandes du client. Le serveur peut refuser d'aider, par exemple parce que le client n'a pas payé. (Pour l'envoi du trafic à protéger, il y a deux grandes techniques, fondées sur BGP ou sur DNS. Le trafic une fois filtré est ensuite renvoyé à la victime. Une autre solution est d'avoir le mitigateur dans le chemin en permanence.)
On a vu qu'il y avait deux canaux de communication. Celui de signalisation, normalisé dans le RFC 9132 sert surtout à demander à l'atténuateur une action de protection, et à voir quelles réponses l'atténuateur donne. C'est ce canal qui devra fonctionner au plus fort de l'attaque, ce qui lui impose des contraintes et des solutions particulières. Le canal de données, spécifié dans le RFC 8783, n'est pas en toute rigueur indispensable à DOTS, mais il est quand même pratique : il sert à envoyer des informations de configuration, permettant au client de spécifier plus précisement ce qu'il veut protéger et contre qui. Par exemple, il va permettre de donner des noms à des ressources (une ressource peut être, par exemple, un ensemble de préfixes IP), envoyer une liste noire d'adresses d'attaquants à bloquer inconditionnellement, une liste blanche de partenaires à ne surtout pas bloquer, à définir des ACL, etc. En général, ce canal de données s'utilise avant l'attaque, et utilise des protocoles habituels, puisqu'il n'aura pas à fonctionner pendant la crise.
Le RFC note aussi que DOTS n'a de sens qu'entre partenaires qui ont une relation pré-existante (par exemple client / fournisseur payant). Il n'y a pas de serveur DOTS public. L'authentification réciproque du client et du serveur est donc nécessaire, d'autant plus qu'on utilise DOTS pour faire face à des attaques et que l'attaquant peut donc chercher à subvertir DOTS.
Le serveur DOTS doit non seulement authentifier le client mais aussi l'autoriser à demander une mitigation pour telle ou telle ressource (préfixe IP ou nom de domaine). Par exemple, le serveur DOTS peut utiliser les IRR pour déterminer si son client est vraiment légitime pour demander une intervention sur telle ressource. Mais il pourrait aussi utiliser ACME (RFC 8738).
Typiquement, le client établit une session de signalisation avec le serveur, qu'il va garder pendant l'attaque. Il n'y a pas actuellement de norme sur comment le client trouve le serveur DOTS. On peut supposer qu'une fois l'accord avec le serveur fait, le gérant du serveur communique au client le nom ou l'adresse du serveur à utiliser.
La section 3 du RFC détaille certains points utiles. À lire si vous voulez comprendre toute l'architecture de DOTS, notamment les configurations plus complexes, que j'ai omises ici.
Et si vous vous intéressez aux mises en œuvre de DOTS, elles sont citées à la fin de mon article sur le RFC 9132.
L'article seul
RFC 8810: Revision to Capability Codes Registration Procedures
Date de publication du RFC : Août 2020
Auteur(s) du RFC : J. Scudder (Juniper Networks)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF idr
Première rédaction de cet article le 18 août 2020
Un petit RFC purement bureaucratique : un léger changement, dans le sens de la libéralisation, des procédures d'enregistrement d'une capacité BGP dans le registre IANA de ces capacités.
Les routeurs BGP ont des capacités optionnelles que ne partagent pas forcément leurs pairs, comme par exemple la gestion du redémarrage en douceur (RFC 4724) ou bien la configuration du filtrage sortant (RFC 5291). Il est donc utile de pouvoir annoncer formellement ce qu'on sait faire et ce qu'on ne sait pas faire. L'annonce des capacités BGP est normalisée dans le RFC 5492. Elle se fait en envoyant un code numérique, d'un octet. La liste des codes possibles figure dans un registre IANA. Une partie des codes, allant de 128 à 255, était réservée pour l'utilisation locale. Cette plage est désormais éclatée en trois, en utilisant la terminologie de politiques d'enregistrement du RFC 8126 :
- De 128 à 238 : « Premier Arrivé, Premier Servi », la politique d'enregistrement la plus libérale qui soit,
- De 239 à 254 : « Utilisation à des fins expérimentales », ce qui est proche de l'ancien « Utilisation privée » mais en insistant sur le côté temporaire de l'utilisation,
- 255 : réservé pour un usage futur, par exemple pour indiquer une indirection vers un code étendu, si on a un jour besoin de plus de 255 capacités BGP (un octet, c'est peu, mais il n'y a actuellement que 25 capacités enregistrées).
Les deux autres plages, de 1 à 63 (« Examen par l'IETF ») et de 64 à 127 (« Premier Arrivé, Premier Servi ») ne changent pas depuis le RFC 5492.
Lorsqu'on change une politique d'enregistrement, il faut se demander quoi faire des utilisations précédentes. Puisque la plage considérée était utilisable en privé, des gens ont pu légitimement s'en servir et annoncer des codes de capacité. En 2015, les auteurs de ce RFC avaient cherché les utilisations de cette plage et trouvé une liste (pas forcément complète), souvent composée de codes qui ont reçu un « vrai » numéro après, liste qui est présentée dans le RFC, et ajoutée au registre IANA. Et, bien sûr, comme avec tout registre, il y a toujours le risque de squatteurs s'appropriant tel ou tel code sans suivre les procédures (cf. RFC 8093).
L'article seul
L'Internet, ça ne marche pas de partout
Première rédaction de cet article le 13 août 2020
Dernière mise à jour le 16 août 2020
Lorsqu'une panne survient et empêche l'accès à une ressource sur
l'Internet, il y a parfois discussion car
certaines personnes disent « mais non, pour moi, ça marche », alors
que la victime originelle insiste « je te dis que c'est cassé ». Les
deux peuvent avoir simultanément raison. Les pannes peuvent dépendre
d'où vous vous trouvez, mais elles dépendent surtout de votre réseau
d'accès à l'Internet. Voyons un exemple concret avec une panne
affectant Algérie
Télécom et qui empêche, par exemple, les abonnés
d'Orange en
France d'accéder à http://cetic.dz/
Avant de tester depuis plusieurs endroits, il faut s'assurer
qu'on dispose d'un moyen fiable de tester. Beaucoup de gens font une
confiance aveugle à la commande ping mais ils ont tort : les paquets ICMP de type Echo qu'elle
utilise peuvent être bloqués par un pare-feu hargneux, sans que les autres
services soient affectés. Dans le cas de
cetic.dz, le signalement initial portait sur un
problème DNS et on
aurait donc pu tester avec des requêtes DNS mais, ici, ce n'est pas
la peine : les machines en cause,
193.251.169.83 et
193.251.169.84 répondent en ICMP Echo :
% ping -c 3 193.251.169.83 PING 193.251.169.83 (193.251.169.83) 56(84) bytes of data. 64 bytes from 193.251.169.83: icmp_seq=1 ttl=50 time=81.2 ms 64 bytes from 193.251.169.83: icmp_seq=2 ttl=50 time=79.2 ms 64 bytes from 193.251.169.83: icmp_seq=3 ttl=50 time=79.3 ms --- 193.251.169.83 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 4ms rtt min/avg/max/mdev = 79.184/79.875/81.183/0.953 ms
Depuis un réseau où ça ne marche pas :
% ping -c 3 193.251.169.83 PING 193.251.169.83 (193.251.169.83) 56(84) bytes of data. --- 193.251.169.83 ping statistics --- 3 packets transmitted, 0 received, 100% packet loss, time 2052ms
Bon, nous avons un problème variable : à certains endroits, ça marche, à d'autres pas. Dans des cas comme cela, lorsque les gens discutent sur un forum quelconque du problème, ceux et celles qui ont compris que le problème dépendait du point de mesure précisent souvent leur expérience en indiquant leur ville (« depuis Marseille, ça marche »). C'est une erreur car ce n'est en général pas la localisation géographique qui compte mais plus souvent le réseau d'accès, donc le FAI ou plus exactement l'AS. Il est curieux que même sur une liste de diffusion de professionnels du réseau comme NANOG, les gens qui signalent une panne indiquent plus souvent leur ville que leur AS… Pour M. Toutlemonde, comme il ne connait pas en général son AS, indiquer le FAI est plus utile.
Donc, ici, on a une panne qui dépend de l'endroit. Comment la
tester ? J'ai utilisé des comptes sur deux machines différentes,
connectées à des opérateurs différents. Mais si on n'a pas des
comptes partout, on fait comment ? Eh bien le plus simple est
d'utiliser les sondes RIPE
Atlas, ces petits boitiers installés par des volontaires un
peu partout et qui peuvent effectuer des mesures actives, créés par
exemple via le
logiciel Blaeu. Demandons à cent sondes Atlas de pinguer
193.251.169.84 :
% blaeu-reach --requested 100 193.251.169.84 98 probes reported Test #26682471 done at 2020-08-13T12:10:32Z Tests: 245 successful tests (83.6 %), 0 errors (0.0 %), 48 timeouts (16.4 %), average RTT: 111 ms
On aurait dû avoir à peu près 100 % de succès mais on n'a que 84 %. Et, surtout, cela dépend du réseau. Si on essaie depuis Orange (AS 3215) :
% blaeu-reach --requested 100 --as 3215 193.251.169.84 96 probes reported Test #26682501 done at 2020-08-13T12:12:04Z Tests: 3 successful tests (1.0 %), 0 errors (0.0 %), 285 timeouts (99.0 %), average RTT: 139 ms
On a cette fois quasiment uniquement des échecs. Depuis un autre opérateur (ici, Free), tout marche :
% blaeu-reach --requested 100 --as 12322 193.251.169.84 98 probes reported Test #26683832 done at 2020-08-13T14:08:11Z Tests: 293 successful tests (99.7 %), 0 errors (0.0 %), 1 timeouts (0.3 %), average RTT: 52 ms
Mais pourquoi est-ce que ça marche depuis Free et pas depuis
Orange ? La première tentation est de suspecter un problème
BGP, le
protocole qui distribue les routes sur
l'Internet. Le service RIPE Stat nous permet de voir
le
routage du préfixe concerné et, pour citer RIPE Stat,
« At 2020-08-13 00:00:00 UTC, 193.251.169.0/24 was 100%
visible (by 321 of 321 RIS full peers). ». Bref, le
préfixe 193.251.169.0/24 est visible partout,
et ne semble pas massivement filtré.
Mais attention, le RIS,
réseau de routeurs sur lequel se base RIPE Stat n'est pas présent
partout. Et, notamment, il ne semble pas présent chez OpenTransit,
transitaire d'Orange et membre du même groupe. On notera en effet
qu'un préfixe IP plus général,
193.251.160.0/20, est annoncé par la société
OpenTransit. Et, en regardant le looking glass
d'OpenTransit on ne voit que ce préfixe
plus général, pas le /24. 
Il semble donc bien qu'OpenTransit n'accepte pas l'annonce BGP
d'Algérie Télécom pour 193.251.169.0/24 et
n'ait pas de route pour ce préfixe.
La faute à qui dans cette embrouille ? C'est évidemment difficile
à dire. Le préfixe 193.251.160.0/20 est bien à
Orange, comme on le voit avec whois :
% whois 193.251.160.0/20 ... inetnum: 193.248.0.0 - 193.253.255.255 netname: FR-TELECOM-248-253 org: ORG-FT2-RIPE ... organisation: ORG-FT2-RIPE org-name: Orange S.A.
Mais le préfixe plus spécifique
193.251.169.0/24 a bien été délégué proprement
à Algérie Télécom :
% whois 193.251.169.0/24 ... inetnum: 193.251.169.0 - 193.251.169.255 netname: Djaweb-Algerie-Telecom descr: Internet Service Provider of Algerie Telecom country: DZ
Il n'y a par contre pas d'objet « route » dans les
IRR pour
193.251.169.0/24, on ne voit que la route du
plus général /20 :
% whois -T route 193.251.169.0/24 ... route: 193.251.160.0/20 descr: France Telecom descr: OPENTRANSIT origin: AS5511
Mais le préfixe 193.251.169.0/24 a un ROA
(Route Origin Authorizations, une signature des
ressources Internet pour garantir leur authenticité, cf. RFC 6482 :
% whois -h whois.bgpmon.net 193.251.169.0/24 ... Prefix: 193.251.169.0/24 Origin AS: 36947 Origin AS Name: ALGTEL-AS, DZ RPKI status: ROA validation successful ...
Il n'aurait pas pu avoir ce ROA sans l'autorisation du titulaire du préfixe plus général (Orange). Donc, il se pourrait qu'il s'agisse d'un problème interne à Orange, une délégation d'un préfixe incomplètement faite.
Ah, et pour revenir au problème original, on m'avait signalé
l'injoignabilité de cetic.dz en suspectant un
problème DNS. En
effet, le domaine cetic.dz ne fonctionne pas du
tout depuis Orange. Mais c'est parce que ce domaine n'a que deux
adresses IP pour ses serveurs de noms, les
193.251.169.83 et
193.251.169.84 cités plus haut, et que ces deux
adresses sont injoignables depuis Orange. Le problème n'était donc
pas de la faute des résolveurs
d'Orange mais du routage.
J'en profite pour rappeler les bonnes pratiques de robustesse
DNS : attention aux SPOF, ne faites pas comme
cetic.dz, ne mettez pas tous vos serveurs DNS faisant
autorité dans le même /29… Voici les serveurs de
cetic.dz vus par check-soa. On pourrait croire qu'ils
sont trois mais il n'y a en fait que deux adresses IP :
% check-soa cetic.dz dns.cetic.dz. 193.251.169.83: OK: 2020070604 193.251.169.83: OK: 2020070604 ftp.cetic.dz. 193.251.169.84: OK: 2020070604 raqdns.cetic.dz. 193.251.169.83: OK: 2020070604
Sur ces bonnes pratiques de gestion de serveurs DNS, on fera bien de consulter le guide de l'AFNIC et celui de l'ANSSI.
Voilà, j'espère vous avoir convaincu que le débogage de problèmes Internet n'est pas toujours simple et que, quand on signale un problème, il faut donner le maximum de détails. Merci au signaleur du problème, ce fut une recherche intéressante. Et merci à Pierre Emeriaud, Pavel Polyakov et Radu-Adrian Feurdean pour leurs observations pertinentes.
L'article seul
RFC 8807: Login Security Extension for the Extensible Provisioning Protocol (EPP)
Date de publication du RFC : Août 2020
Auteur(s) du RFC : J. Gould, M. Pozun (VeriSign)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 8 août 2020
Le protocole EPP d'avitaillement de ressources (par exemple de noms de domaine) a un mécanisme de sécurité très simple, à base de mots de passe indiqués lors de la connexion. Ce mécanisme avait plein de limitations ennuyeuses, dans le RFC original, et ce nouveau RFC vise à les réduire.
L'authentification dans EPP est décrite
dans le RFC 5730, section 2.9.1.1 (voir
aussi sa section 7). Le client EPP envoie un mot de passe, qui doit
faire entre 6 et 16 caractères (cf. le type
pwType dans le schéma
XSD du RFC 5730, section 4.1). Le
client peut changer son mot de passe en indiquant un nouveau mot via le
protocole
EPP, sans avoir à passer par un autre service. En outre, la session EPP est typiquement portée sur TLS, ce qui assure la
confidentialité du mot de passe, et la
possibilité d'ajouter une authentification par le biais d'un
certificat client. Mais c'est tout. Le RFC 5730 ne permet pas de mot de passe plus long,
ne permet pas au client de savoir combien de tentatives erronées
ont eu lieu, ne permet pas d'indiquer l'expiration d'un mot de passe
(si ceux-ci ont une durée de vie limitée) et ne permet pas au
serveur EPP d'indiquer, s'il refuse un nouveau mot de passe,
pourquoi il le juge inacceptable.
Cette extension à EPP figure désormais dans le registre des extensions, créé par le RFC 7451.
Notre RFC
ajoute donc plusieurs nouveaux éléments XML qui peuvent apparaitre en EPP
(section 3). D'abord, la notion d'évènement. Un évènement permet
d'indiquer, dans un élément <event> :
- l'expiration d'un mot de passe,
- l'expiration du certificat client,
- la faiblesse d'un algorithme cryptographique,
- la version de TLS, par exemple pour rejeter une version trop basse,
- les raisons du rejet d'un nouveau mot de passe (« le mot de passe doit comporter au moins une majuscule, une minuscule, un chiffre arabe, un chiffre romain, une rune et un hiéroglyphe », et autres règles absurdes mais fréquentes),
- des statistiques de sécurité, comme le nombre de connexions refusées suite à un mot de passe incorrect.
En utilisant loginSec comme abréviation pour
l'espace de noms de l'extension EPP de ce
RFC, urn:ietf:params:xml:ns:epp:loginSec-1.0,
voici un exemple d'évènement, indiquant qu'il faudra bientôt changer
de mot de passe :
<loginSec:event
type="password"
level="warning"
exDate="2020-04-01T22:00:00.0Z"
lang="fr">
Le mot de passe va bientôt expirer.
</loginSec:event>
On pourrait voir aussi cet évènement indiquant le nombre de connexions ratées, ce qui peut alerter sur une tentative de découverte du mot de passe par force brute :
<loginSec:event
type="stat"
name="failedLogins"
level="warning"
value="100"
duration="P1D"
lang="fr">
Trop de connexions ratées.
</loginSec:event>
Si on utilise des mots de passe qui suivent les nouvelles règles,
il faut l'indiquer en mettant dans l'ancien élément
<pw> la valeur
[LOGIN-SECURITY]. Si elle est présente, c'est
qu'il faut aller chercher le mot de passe dans le nouvel élément
<loginSec:pw> (idem pour un changement de
mot de passe).
La section 4 du RFC donne les changements pour les différentes
commandes EPP. Seule <login> est
concernée. Ainsi, <login> gagne un
élément <loginSec:userAgent> qui permet
d'indiquer le type de logiciel utilisé côté client. Mais le
principal ajout est évidemment
<loginSec:pw>, qui permet d'utiliser les
mots de passe aux nouvelles règles (mots de passe plus longs, par
exemple). Il y a aussi un
<loginSec:newPw> pour indiquer le nouveau
mot de passe à utiliser. Notez que, si le mot de passe comprend des
caractères Unicode, il est recommandé qu'ils
se conforment au RFC 8265 (profil
OpaqueString).
Voici un exemple d'une commande
<login> nouveau style :
<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
<command>
<login>
<clID>ClientX</clID>
<pw>[LOGIN-SECURITY]</pw>
...
</login>
<extension>
<loginSec:loginSec
xmlns:loginSec=
"urn:ietf:params:xml:ns:epp:loginSec-1.0">
<loginSec:userAgent>
<loginSec:app>EPP SDK 1.0.0</loginSec:app>
<loginSec:tech>Vendor Java 11.0.6</loginSec:tech>
<loginSec:os>x86_64 Mac OS X 10.15.2</loginSec:os>
</loginSec:userAgent>
<loginSec:pw>this is a long password not accepted before</loginSec:pw>
</loginSec:loginSec>
</extension>
...
</command>
</epp>
Et une réponse positive du serveur EPP à cette connexion, mais qui avertit que le mot de passe va expirer le 1er juillet :
<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
<response>
<result code="1000">
<msg>Command completed successfully</msg>
</result>
<extension>
<loginSec:loginSecData
xmlns:loginSec=
"urn:ietf:params:xml:ns:epp:loginSec-1.0">
<loginSec:event
type="password"
level="warning"
exDate="2020-07-01T22:00:00.0Z"
lang="en">
Password expiring in a week
</loginSec:event>
</loginSec:loginSecData>
</extension>
...
</response>
</epp>
Et, ici, lorsqu'un client a voulu changer son mot de passe expiré,
avec <loginSec:newPw>, mais que le nouveau
mot de passe était trop simple (cf. les recommandations
de l'ANSSI) :
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
<response>
<result code="2200">
<msg>Authentication error</msg>
</result>
<extension>
<loginSec:loginSecData
xmlns:loginSec=
"urn:ietf:params:xml:ns:epp:loginSec-1.0">
<loginSec:event
type="password"
level="error"
exDate="2020-03-24T22:00:00.0Z">
Password has expired
</loginSec:event>
<loginSec:event
type="newPW"
level="error"
lang="fr">
Mot de passe vraiment trop trivial.
</loginSec:event>
</loginSec:loginSecData>
</extension>
...
</response>
</epp>
Le schéma complet figure dans la section 5 du RFC.
Un changement plus radical aurait été de passer à un cadre d'authentification plus général comme SASL (RFC 4422) mais l'IETF a choisi une évolution plus en douceur.
À l'heure actuelle, je ne connais que deux mises en œuvre de ce
RFC, dans le SDK
de Verisign, en https://www.verisign.com/en_US/channel-resources/domain-registry-products/epp-sdks
L'article seul
RFC 4253: The Secure Shell (SSH) Transport Layer Protocol
Date de publication du RFC : Janvier 2006
Auteur(s) du RFC : T. Ylonen (SSH Communications Security Corp, C. Lonvick (Cisco Systems)
Chemin des normes
Première rédaction de cet article le 2 août 2020
Le protocole SSH de sécurité est composé de plusieurs parties, spécifiées dans des RFC différents. Ici, il s'agit de la couche basse de SSH, située juste au-dessus de TCP, et en dessous de protocoles qui permettent, par exemple, la connexion à distance. Cette couche basse fournit l'authentification (de la machine, pas de l'utilisateur) et la confidentialité, via de la cryptographie.
Le principe général de cette partie de SSH est classique, et proche de celui d'autres protocoles de cryptographie comme TLS (RFC 4251 pour une vue générale de l'architecture de SSH). Le client établit une connexion TCP avec le serveur puis chaque partie envoie une liste des algorithmes utilisés pour l'authentification, l'échange de clés et le chiffrement ultérieur. Une fois un accord trouvé, le serveur est authentifié, typiquement par de la cryptographie asymétrique, comme ECDSA. Un mécanisme d'échange de clés comme Diffie-Hellman permet de choisir des clés partagées qui serviront pour les opérations de chiffrement symétrique (par exemple avec AES) qui chiffreront tout le reste de la communication. Ce processus de négociation fournit l'agilité cryptographique (RFC 7696). Du fait de cette agilité, la liste des algorithmes utilisables n'est pas figée dans les RFC. Démarrée par le RFC 4250, sa version à jour et faisant autorité est à l'IANA.
Notez que j'ai simplifié le mécanisme de négociation : il y a d'autres choix à faire dans la négociation, comme celui de l'algorithme de MAC. Les autres fonctions de SSH, comme l'authentification du client, prennent place ensuite, une fois la session de transport établie selon les procédures définies dans notre RFC 4253.
L'établissement de connexion est normalisé dans la section 4 du
RFC. SSH suppose qu'il dispose d'un transport propre, acheminant des
octets sans les modifier et sans les interpréter. (TCP répond à cette
exigence, qui est très banale.) Le port par défaut est 22 (et il est enregistré
à l'IANA, lisez donc le récit de
cet enregistrement). En pratique, il est fréquent que SSH
utilise d'autres ports, par exemple pour ralentir certaines attaques par force
brute (OpenSSH rend cela très simple,
en indiquant dans son ~/.ssh/config le port du
serveur où on se connecte). Une fois la connexion TCP établie,
chaque machine envoie une bannière qui indique sa version de SSH,
ici la version 2 du protocole (la seule
survivante aujourd'hui) et la version 7.6 de sa mise en œuvre
OpenSSH :
% telnet localhost 22 ... SSH-2.0-OpenSSH_7.6p1 Ubuntu-4ubuntu0.3
Un établissement de session complet comprend :
- Connexion TCP,
- envoi des bannières (qui peut être fait simultanément par le serveur et le client, pas besoin d'attendre l'autre),
- début de la procédure d'échange de clés (KEX, pour
Key EXchange) avec les messages
SSH_MSG_KEXINIT(qui peuvent aussi être envoyés simultanément), - échange de clés proprement dit, par exemple avec des messages Diffie-Hellman.
Comme certains messages peuvent être envoyés en parallèle (sans attendre l'autre partie), il est difficile de compter combien d'aller-retours cela fait. (Optimiste, le RFC dit que deux aller-retours suffisent dans la plupart des cas.)
Le protocole décrit dans ce RFC peut être utilisé pour divers services (cf. RFC 4252 et RFC 4254). Une des utilisations les plus fréquentes est celle de sessions interactives à distance, où SSH avait rapidement remplacé telnet. À l'époque, certaines personnes s'étaient inquiétées de l'augmentation de taille des paquets due à la cryptographie (nouveaux en-têtes, et MAC). Le débat est bien dépassé aujourd'hui mais une section 5.3 du RFC discute toujours la question. SSH ajoute au moins 28 octets à chaque paquet. Pour un transfert de fichiers, où les paquets ont la taille de la MTU, cette augmentation n'est pas importante. Pour les sessions interactives, où il n'y a souvent qu'un seul octet de données dans un paquet, c'est plus significatif, mais il faut aussi prendre en compte le reste des en-têtes. Ainsi, IP et TCP ajoutent déjà 32 octets au minimum (en IPv4). Donc l'augmentation due à SSH n'est pas de 2800 % mais de seulement 55 %. Et c'est sans même prendre en compte les en-têtes Ethernet. En parlant d'Ethernet, il faut aussi noter que la taille minimale d'une trame Ethernet est de 46 octets (cf. RFC 894), de toute façon et que donc, sans SSH, il faudrait de toute façon remplir la trame… Bref, le problème n'est guère important. (Le RFC donne un autre exemple, avec des modems lents, qui n'est probablement plus d'actualité aujourd'hui.)
La section 6 du RFC décrit ensuite le format des en-têtes SSH, un
format binaire, comme le DNS ou BGP, mais pas comme SMTP ou HTTP version 1. Le
tout est évidemment chiffré (même la longueur du paquet, qu'on ne
peut donc pas connaitre avant de déchiffrer). Le chiffrement se fait
avec l'algorithme sélectionné dans la phase de négociation. Si vous
utilisez OpenSSH, l'option
-v affichera l'algorithme, ici
ChaCha20 :
% ssh -v $ADDRESS ... debug1: kex: server->client cipher: chacha20-poly1305@openssh.com MAC: <implicit> compression: none debug1: kex: client->server cipher: chacha20-poly1305@openssh.com MAC: <implicit> compression: none
ChaCha20 n'existait pas à l'époque du RFC 4253. Il n'est
toujours pas enregistré
à l'IANA. C'est ce qui explique que le nom d'algorithme
inclut un arobase suivi d'un nom de domaine, c'est la marque
des algorithmes locaux (ici, local à
OpenSSH), non enregistrés officiellement. Un
article
du programmeur décrit l'intégration de ChaCha20 dans
OpenSSH. Il
y avait eu une tentative de normalisation (dans
l'Internet-Draft draft-josefsson-ssh-chacha20-poly1305-openssh)
mais elle a été abandonnée. C'était peut-être simplement par manque
de temps et d'intérêt, car ChaCha20 est utilisé dans d'autres
protocoles cryptographiques de l'IETF comme TLS (cf. RFC 7905 et, pour une vision plus générale, RFC 8439). OpenSSH permet d'afficher la liste des algorithmes
de chiffrement symétriques qu'il connait avec l'option -Q
cipher :
% ssh -Q cipher 3des-cbc aes128-cbc aes192-cbc aes256-cbc rijndael-cbc@lysator.liu.se aes128-ctr aes192-ctr aes256-ctr aes128-gcm@openssh.com aes256-gcm@openssh.com chacha20-poly1305@openssh.com
À l'inverse, le RFC 4253 listait des algorithmes qui ont
été abandonnés depuis comme RC4 (nommé
arcfour dans le RFC pour des raisons
juridiques), retiré par le RFC 8758. La liste
comprend également l'algorithme none (pas de
chiffrement) qui avait été inclus pour des raisons douteuses de
performance et dont l'usage est évidemment déconseillé (section 6.3
de notre RFC).
Le paquet inclut également un MAC pour assurer son intégrité. Il est calculé avant le chiffrement. Pour le MAC aussi, la liste des algorithmes a changé depuis la parution du RFC 4253. On peut afficher ceux qu'OpenSSH connait (les officiels sont dans un registre IANA) :
% ssh -Q mac hmac-sha1 hmac-sha1-96 hmac-sha2-256 hmac-sha2-512 hmac-md5 hmac-md5-96 umac-64@openssh.com umac-128@openssh.com hmac-sha1-etm@openssh.com hmac-sha1-96-etm@openssh.com hmac-sha2-256-etm@openssh.com hmac-sha2-512-etm@openssh.com hmac-md5-etm@openssh.com hmac-md5-96-etm@openssh.com umac-64-etm@openssh.com umac-128-etm@openssh.com
Bon, mais les algorithmes de chiffrement symétrique comme ChaCha20 nécessitent une clé secrète et partagée entre les deux parties. Comment est-elle négociée ? Un algorithme comme par exemple Diffie-Hellman sert à choisir un secret, d'où sera dérivée la clé.
Le format binaire des messages est décrit en section 6 en
utilisant des types définis dans le RFC 4251,
section 5, comme byte[n] pour une suite
d'octets ou uint32 pour un entier non signé sur
32 bits. Ainsi, un certificat ou une clé
publique sera :
string certificate or public key format identifier
byte[n] key/certificate data
Un paquet SSH a la structure (après le point-virgule, un commentaire) :
uint32 packet_length byte padding_length byte[n1] payload; n1 = packet_length - padding_length - 1 byte[n2] random padding; n2 = padding_length byte[m] mac (Message Authentication Code - MAC); m = mac_length
La charge utile (payload) a un format qui
dépend du type de messages. Par exemple, le message d'échange de
clés initial, où chacun indique les algorithmes qu'il connait :
byte SSH_MSG_KEXINIT
byte[16] cookie (random bytes)
name-list kex_algorithms
name-list server_host_key_algorithms
name-list encryption_algorithms_client_to_server
name-list encryption_algorithms_server_to_client
name-list mac_algorithms_client_to_server
name-list mac_algorithms_server_to_client
name-list compression_algorithms_client_to_server
name-list compression_algorithms_server_to_client
name-list languages_client_to_server
name-list languages_server_to_client
boolean first_kex_packet_follows
uint32 0 (reserved for future extension)
Les types de message (message ID ou
message numbers) possibles sont listés dans un
registre IANA. Par exemple l'exemple ci-dessus est un
message de type SSH_MSG_KEXINIT, type qui est
défini en section 12 et dans le RFC 4250,
section 4.1.2. Il a la valeur 20.
Affiché par Wireshark, voici quelques
messages que SSH transmet en clair, avant le début du chiffrement.
Après l'échange des bannières, il y aura le
KEXINIT en clair, Wireshark suit les termes du
RFC donc vous pouvez facilement comparer ce message réel à la
description abstraite du RFC, ci-dessus :
SSH Protocol
SSH Version 2 (encryption:chacha20-poly1305@openssh.com mac:<implicit> compression:none)
Packet Length: 1388
Padding Length: 4
Key Exchange
Message Code: Key Exchange Init (20)
Algorithms
kex_algorithms length: 269
kex_algorithms string [truncated]: curve25519-sha256,curve25519-sha256@libssh.org,ecdh-sha2-nistp256,ecdh-sha2-nistp384,ecdh-sha2-nistp521,diffie-hellman-group-exchange-sha256,diffie-hellman-group16-sha512,diffie-hellman-group18-sha512,di
server_host_key_algorithms length: 358
server_host_key_algorithms string [truncated]: ecdsa-sha2-nistp256-cert-v01@openssh.com,ecdsa-sha2-nistp384-cert-v01@openssh.com,ecdsa-sha2-nistp521-cert-v01@openssh.com,ecdsa-sha2-nistp256,ecdsa-sha2-nistp384,ecdsa-sha2-nistp521,ssh-ed25
encryption_algorithms_client_to_server length: 108
encryption_algorithms_client_to_server string: chacha20-poly1305@openssh.com,aes128-ctr,aes192-ctr,aes256-ctr,aes128-gcm@openssh.com,aes256-gcm@openssh.com
encryption_algorithms_server_to_client length: 108
encryption_algorithms_server_to_client string: chacha20-poly1305@openssh.com,aes128-ctr,aes192-ctr,aes256-ctr,aes128-gcm@openssh.com,aes256-gcm@openssh.com
mac_algorithms_client_to_server length: 213
mac_algorithms_client_to_server string [truncated]: umac-64-etm@openssh.com,umac-128-etm@openssh.com,hmac-sha2-256-etm@openssh.com,hmac-sha2-512-etm@openssh.com,hmac-sha1-etm@openssh.com,umac-64@openssh.com,umac-128@openssh.com,hmac-sha2-
mac_algorithms_server_to_client length: 213
mac_algorithms_server_to_client string [truncated]: umac-64-etm@openssh.com,umac-128-etm@openssh.com,hmac-sha2-256-etm@openssh.com,hmac-sha2-512-etm@openssh.com,hmac-sha1-etm@openssh.com,umac-64@openssh.com,umac-128@openssh.com,hmac-sha2-
compression_algorithms_client_to_server length: 26
compression_algorithms_client_to_server string: none,zlib@openssh.com,zlib
compression_algorithms_server_to_client length: 26
compression_algorithms_server_to_client string: none,zlib@openssh.com,zlib
Notez qu'un seul message SSH contient tous les algorithmes, aussi bien ceux servant à l'authentification qu'à l'échange de clés, ou qu'au chiffrement symétrique. Le premier algorithme listé est le préféré. Si les deux parties ont le même algorithme préféré, il est choisi. Autrement, on boucle sur les algorithmes listés par le client, dans l'ordre, en sélectionnant le premier qui est accepté par le serveur. Voici maintenant le lancement de l'échange de clés :
SSH Protocol
SSH Version 2 (encryption:chacha20-poly1305@openssh.com mac:<implicit> compression:none)
Packet Length: 44
Padding Length: 6
Key Exchange
Message Code: Diffie-Hellman Key Exchange Init (30)
Multi Precision Integer Length: 32
DH client e: c834ef50c9ce27fa5ab43886aec2161a3692dd5e3267b567...
Padding String: 000000000000
Et la réponse en face :
SSH Protocol
SSH Version 2 (encryption:chacha20-poly1305@openssh.com mac:<implicit> compression:none)
Packet Length: 260
Padding Length: 9
Key Exchange
Message Code: Diffie-Hellman Key Exchange Reply (31)
KEX host key (type: ecdsa-sha2-nistp256)
Multi Precision Integer Length: 32
DH server f: 2e34deb08146063fdba1d8800cf853a3a6830a3b8549ee5b...
KEX H signature length: 101
KEX H signature: 0000001365636473612d736861322d6e6973747032353600...
Padding String: 000000000000000000
SSH Version 2 (encryption:chacha20-poly1305@openssh.com mac:<implicit> compression:none)
Packet Length: 12
Padding Length: 10
Key Exchange
Message Code: New Keys (21)
Padding String: 00000000000000000000
À partir de là, tout est chiffré et Wireshark ne peut plus afficher que du binaire sans le comprendre :
SSH Protocol
SSH Version 2 (encryption:chacha20-poly1305@openssh.com mac:<implicit> compression:none)
Packet Length (encrypted): 44cdc717
Encrypted Packet: ea98dbf6cc50af65ba4186bdb5bf02aa9e8366aaa4c1153f
MAC: e7a6a5a222fcdba71e834f3bb76c2282
OpenSSH avec son option -v permet d'afficher
cette négociation :
debug1: SSH2_MSG_KEXINIT sent
debug1: SSH2_MSG_KEXINIT received
debug1: kex: algorithm: curve25519-sha256
debug1: kex: host key algorithm: ecdsa-sha2-nistp256
debug1: kex: server->client cipher: chacha20-poly1305@openssh.com MAC: <implicit> compression: none
debug1: kex: client->server cipher: chacha20-poly1305@openssh.com MAC: <implicit> compression: none
Et les algorithmes acceptés pour l'échange de clés :
% ssh -Q kex diffie-hellman-group1-sha1 diffie-hellman-group14-sha1 diffie-hellman-group14-sha256 diffie-hellman-group16-sha512 diffie-hellman-group18-sha512 diffie-hellman-group-exchange-sha1 diffie-hellman-group-exchange-sha256 ecdh-sha2-nistp256 ecdh-sha2-nistp384 ecdh-sha2-nistp521 curve25519-sha256 curve25519-sha256@libssh.org
(Ceux à courbes elliptiques comme
curve25519-sha256 n'existaient pas à l'époque.
curve25519-sha256 a été ajouté dans le RFC 8731.)
On trouve aussi les algorithmes acceptés pour l'authentification du serveur via sa
clé publique :
% ssh -Q key ssh-ed25519 ssh-ed25519-cert-v01@openssh.com ssh-rsa ssh-dss ecdsa-sha2-nistp256 ecdsa-sha2-nistp384 ecdsa-sha2-nistp521 ssh-rsa-cert-v01@openssh.com ssh-dss-cert-v01@openssh.com ecdsa-sha2-nistp256-cert-v01@openssh.com ecdsa-sha2-nistp384-cert-v01@openssh.com ecdsa-sha2-nistp521-cert-v01@openssh.com
Ce RFC 4253 ne décrit que la couche basse de
SSH. Au-dessus se trouvent plusieurs services qui tirent profit de
la sécurité fournie par cette couche basse. Une fois la session
chiffrée établie, le protocole SSH permet de lancer d'autres
services. Ils ne sont que deux depuis le début, mais d'autres
pourront se rajouter dans le registre
IANA. Actuellement, il y a ssh-userauth
(authentifier l'utilisateur, par mot de passe ou par clé publique, RFC 4252)
et ssh-connection (connexion à distance, et
services qui en dépendent, cf. RFC 4254).
Nous avons vu plus haut le type de messages
SSH_MSG_KEXINIT (code numérique 20). Il y a de
nombreux autres types, présentés dans la section 11 du RFC. Par
exemple SSH_MSG_DISCONNECT (type 1 dans le
registre IANA) est défini ainsi :
byte SSH_MSG_DISCONNECT uint32 reason code string description in ISO-10646 UTF-8 encoding [RFC3629] string language tag [RFC3066]
Il indique la fin de la session SSH (l'étiquette de
langue pour indiquer la raison est désormais normalisée
dans le RFC 5646, et plus le RFC 3066). Autre exemple, SSH_MSG_IGNORE
(code 2) pour faire du remplissage afin de
diminuer les risques d'analyse du
trafic. Pour une vision complète des risques de sécurité
de SSH, (re)lisez la très détaillée section 9 du RFC 4251.
Notez qu'il avait existé une version 1 du protocole SSH, qui n'a
pas fait l'objet d'une normalisation formelle. La section 5 de notre
RFC traite de la compatibilité entre la version actuelle, la 2, et
cette vieille version 1, aujourd'hui complètement abandonnée. Ça,
c'est le passé. Et le futur ? Le cœur de SSH n'a pas bougé depuis
les RFC de la série du RFC 4250 au RFC 4254. Mais
il existe un projet (pour l'instant individuel, non accepté par
l'IETF
de remplacer ce RFC 4253 par QUIC,
en faisant tourner le reste de SSH sur QUIC (lisez draft-bider-ssh-quic).
L'article seul
RFC 8801: Discovering Provisioning Domain Names and Data
Date de publication du RFC : Juillet 2020
Auteur(s) du RFC : P. Pfister, E. Vyncke (Cisco), T. Pauly (Apple), D. Schinazi (Google), W. Shao (Cisco)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF intarea
Première rédaction de cet article le 29 juillet 2020
Vous vous demandez certainement, chère lectrice et cher lecteur, ce qu'est un PvD (ProVisioning Domain). Cette notion n'est pas nouvelle, mais elle n'avait été formalisée rigoureusement qu'avec le RFC 7556. Un PvD est un domaine de l'Internet où des règles cohérentes de configuration du réseau s'appliquent. Au sein, d'un PvD, il y a un résolveur DNS à utiliser, des adresses IP spécifiques, des règles de routage et de sécurité que n'ont pas forcément les autres PvD. Ce nouveau RFC décrit une option IPv6 qui permet au PvD de signaler explicitement son existence, via un RA (Router Advertisement.)
La notion de PvD (ProVisioning Domain) est utile pour les machines qui ont plusieurs connexions, à des réseaux (et donc peut-être des PvD) différents, par exemple un ordinateur connecté à la fois à un FAI grand public et au VPN de l'entreprise. Il y a des PvD implicites : une machine qui connait le concept de PvD affecte un PvD implicite à chaque réseau et, par défaut, ne considère pas que le résolveur DNS de l'un convient pour les autres. Et il y a des PvD explicites, et c'est à eux qu'est consacré ce RFC. Un PvD explicite a un identificateur, qui a la syntaxe d'un FQDN. Attention, même si l'identificateur est un nom de domaine, le terme de « domaine » (le D de PvD) ne doit pas être confondu avec le sens qu'il a dans le DNS. L'intérêt d'un PvD explicite est qu'il permet d'avoir plusieurs domaines distincts sur la même interface réseau, et qu'on peut y associer des informations supplémentaires, récupérées sur le réseau ou bien préconfigurées.
On l'a vu, le concept de PvD avait été décrit dans le RFC 7556. Ce que notre nouveau RFC 8801 rajoute, c'est :
- Une option aux RA (Router Advertisement, RFC 4861) pour indiquer aux machines IPv6 du réseau le PvD explicite,
- Un mécanisme pour récupérer, en HTTPS, de l'information de configuration du réseau, pour les cas où cette information ne tiendrait pas dans le message RA. Elle est évidemment codée en JSON.
Le RA va donc indiquer le ou les identificateurs du ou des PvD du réseau. Notez qu'on peut avoir aussi le même PvD sur plusieurs réseaux, par exemple le Wi-Fi et le filaire chez moi font partie du même PvD et ont les mêmes règles et la même configuration.
Dans un monde idéal, l'utilisatrice dont
l'ordiphone a à la fois une connexion
4G, une connexion Wi-Fi et un VPN par dessus, aurait un
PvD pour chacun de ces trois réseaux différentes, et pourrait donc
décider intelligemment quelle interface utiliser pour quel type de
trafic. Par exemple, une requête DNS pour
wiki.private.example.com (le
wiki interne de l'entreprise) sera envoyée
uniquement via le VPN, puisque les résolveurs des réseaux publics ne
connaissent pas ce domaine. Autre exemple, l'information envoyée
pour chaque PvD pourrait permettre aux applications de faire passer
le trafic important (la vidéo en haute définition, par exemple),
uniquement sur le réseau à tarification forfaitaire.
Bon, assez de considérations sur les PvD, passons aux nouvelles normes décrites dans ce RFC. D'abord, l'option RA. Elle est décrite dans la section 3. C'est très simple : une nouvelle option RA est créée, la 21, « PvD ID Router Advertisement Option », suivant le format classique des options RA, TLV (Type-Longueur-Valeur). Elle contient, entre autres :
- Un bit nommé H qui indique que le client peut récupérer des informations supplémentaires en HTTP (c'est détaillé en section 4 du RFC),
- Un bit nommé L qui indique que ce PvD est également valable pour IPv4,
- Un bit nommé R qui indique que le RA contient un autre RA (détails en section 5),
- Et bien sûr l'identificateur (PvD ID) lui-même, sous la forme d'un FQDN.
Si jamais il y a plusieurs PvD sur le réseau, le routeur doit envoyer des RA différents, il n'est pas autorisé à mettre plusieurs options PvD dans un même RA.
Que va faire la machine qui reçoit une telle option dans un RA ?
Elle doit marquer toutes les informations de configuration qui
étaient dans le RA comme étant spécifiques à ce PvD. Par exemple, si
la machine a deux interfaces, et reçoit un RA sur chacune, ayant des
PvD différents, et donnant chacun l'adresses d'un résolveur DNS
(RFC 8106), alors ce résolveur ne doit être
utilisé que pour le réseau où il a été annoncé (et avec une adresse
IP source de ce réseau). Rappelez-vous que différents résolveurs DNS
peuvent donner des résultats différents, par exemple un des réseaux
peut avoir un Pi-hole qui donne des réponses
mensongères, afin de bloquer la publicité. (En parlant du DNS, des
détails sur cette question complexe figurent dans la section 5.2.1
du RFC 7556.) Autre exemple, si on utilise un
VPN vers son
employeur, les requêtes DNS pour les ressources internes
(congés.rh.example.com…) doivent être envoyées
au résolveur de l'employeur, un résolveur extérieur peut ne pas être
capable de les résoudre. En fait, tous les cas où la réponse DNS
n'est pas valable publiquement nécessitent d'utiliser le bon
résolveur DNS. C'est aussi ce qui se passe avec
NAT64 (RFC 6147).
Idem pour d'autres informations de configuration comme le routeur par défaut : elles doivent être associées au PvD. Une machine qui connait les PvD ne peut donc pas se contenter d'une table simple listant le résolveur DNS, le routeur par défaut, etc. Elle doit avoir une table par PvD.
Si la machine récupère par ailleurs des informations de configuration avec DHCP, elle doit également les associer à un PvD, par exemple en utilisant comme PvD implicite celui de l'interface réseau utilisée.
Et pour IPv4, si le bit L est à un ? Dans ce cas, l'information IPv4 reçue sur la même interface doit être associée à ce PvD. (Notez que si plusieurs PvD sur la même interface ont le bit L, on ne peut rien décider, à part que quelqu'un s'est trompé.)
Les machines qui partagent leur connexion (tethering), ce qui est fréquent pour les connexions mobiles comme la 4G (RFC 7278), doivent relayer le RA contenant l'option PvD vers le réseau avec qui elles partagent (comme elles relaient d'autres messages similaires, cf. RFC 4389). Cela permettra à des techniques qui facilitent le partage, comme la délégation de préfixe du RFC 9915, de bien fonctionner. Même si la machine partageuse ne reçoit pas d'option PvD, il est recommandé qu'elle en ajoute une pour le bénéfice des engins avec qui elle partage sa connectivité.
Tout cela, c'était pour une machine PvD-aware, une machine qui sait ce qu'est un PvD et qui sait le gérer. Mais avec du vieux logiciel, écrit avant le concept de PvD, que se passe-t-il ? Une machine munie de ce logiciel va évidemment ignorer l'option PvD du RA et donc utiliser un seul résolveur DNS, un seul routeur par défaut pour tous les cas. Elle aura sans doute beaucoup de problèmes si plusieurs interfaces réseau sont actives et, en pratique, il vaudra mieux n'avoir qu'une seule interface à un moment donné.
Nous avons vu plus haut que, si le bit H dans l'option PvD est à
1, la machine peut obtenir davantage d'informations (PvD
Additional Information) en HTTP. Cette information sera encodée
en I-JSON (RFC 7493.)
Pourquoi ne pas avoir mis ces informations dans le RA ? Parce
qu'elles sont trop grosses ou, tout simplement, pas critiques, et
pouvant être ignorées. Et on les récupère où, ces informations ? Si
le PvD est radio.example.com, l'URL à utiliser est
https://radio.example.com/.well-known/pvd
(préfixe .well-known désormais enregistré.)
Attention, on ne doit tenter d'accéder à cet URL que si le bit H
était à 1. C'est du HTTPS (RFC 2818) et il
faut donc vérifier le certificat (cf. RFC 6125.) Vous voyez qu'on ne peut pas choisir un
PvD au hasard : il faut qu'il soit un nom de domaine qu'on contrôle, et pour lequel
on peut obtenir un certificat. Si on configure un des ces affreux
portails captifs, il
faut s'assurer que les clients auront le droit de se connecter au
serveur HTTP indiqué.
Les données auront le type application/pvd+json. Elles
contiennent obligatoirement :
- Le PvD,
- une date d'expiration, au format RFC 3339,
- les préfixes IP du PvD.
Ainsi que, si on veut :
- les domaines où chercher les noms qui ne sont pas des FQDN,
- une indication que ce PvD n'a pas de connexion à l'Internet.
D'autres membres peuvent être présents, un registre IANA existe et, pour y ajouter des termes, c'est la procédure « Examen par un expert » du RFC 8126.
Voici un exemple, avec le PvD smart.mpvd.io
(qui a servi à un hackathon
IETF) :
% curl https://smart.mpvd.io/.well-known/pvd
{
"name": "PvD for smart people",
"prefixes": ["2001:67c:1230:101::/64", "2001:67c:1230:111::/64"],
"noInternet": false,
"metered": false,
"captivePortalURL" : "https://smart.mpvd.io/captive.php"
}
On notera que le membre expires manque, ce qui
n'est pas bien, et que le membre identifier, qui devrait
indiquer le PvD, est également absent, ce qui est encore plus mal. On voit qu'il
s'agissait d'une expérimentation. Voici ce qu'aurait dû être l'objet
JSON :
{
"identifier": "smart.mpvd.io",
"expires": "2020-04-08T15:30:00Z",
"prefixes": ["2001:67c:1230:101::/64", "2001:67c:1230:111::/64"],
"noInternet": false,
"name": "PvD for smart people",
"metered": false,
"captivePortalURL" : "https://smart.mpvd.io/captive.php"
}
Si vous connaissez d'autres serveurs d'information PvD, indiquez-les moi. Mais il est probable que la plupart ne seront accessibles que depuis un réseau interne.
Voilà, vous savez l'essentiel désormais. La section 5 du RFC ajoute quelques considérations pratiques. D'abord, le bit R qui permettait à une option PvD d'inclure un RA. À quoi ça sert ? L'idée est que, pendant longtemps, la plupart des réseaux accueilleront un mélange de machines qui connaissent les PvD, et de machines qui ne sont pas conscientes de ce concept. Le bit R sert à envoyer des informations qui ne seront comprises que des premières. Par exemple, on met un préfixe dans le RA et, dans l'option PvD, un autre RA qui contient un autre préfixe. Les machines qui connaissent les PvD verront et utiliseront les deux préfixes, celles qui ne connaissent pas les PvD ignoreront l'option et n'auront que le premier préfixe. On peut également envoyer deux RA, un ne contenant pas d'option PvD, et un en contenant une (plus le « vrai » RA).
Un peu de sécurité, pour finir (section 6). D'abord, il faut bien se rappeler que les RA, envoyés en clair et non authentifiés, n'offrent aucune sécurité. Il est trivial, pour un méchant connecté au réseau, d'envoyer de faux RA et donc de fausses options PvD. En théorie, des protocoles comme IPsec ou SEND (RFC 3971) peuvent sécuriser les RA mais, en pratique, on ne peut guère compter dessus. Les seules solutions de sécurisation effectivement déployées sont au niveau 2, par exemple 802.1X combiné avec le RFC 6105. Ce n'est pas un problème spécifique à l'option PvD, c'est la sécurité (ou plutôt l'insécurité) des RA.
Ah, et un petit mot sur la vie
privée (section 7 du RFC). La connexion au serveur HTTP
va évidemment laisser des traces, et il est donc recommandé de la
faire depuis une adresse source temporaire (RFC 8981), et sans envoyer User-Agent: ou
cookies.
Question mise en œuvre, il y a eu du code libre pour des tests (incluant une modification du noyau Linux, et un dissecteur pour Wireshark) mais je ne sais pas ce que c'est devenu et où en sont les systèmes d'exploitation actuels.
L'article seul
RFC 8744: Issues and Requirements for Server Name Identification (SNI) Encryption in TLS
Date de publication du RFC : Juillet 2020
Auteur(s) du RFC : C. Huitema (Private
Octopus)
Pour information
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 29 juillet 2020
Le but du protocole de cryptographie TLS est de protéger une session contre l'écoute par un indiscret, et contre une modification par un tiers non autorisé. Pour cela, TLS chiffre toute la session. Toute la session ? Non, certaines informations circulent en clair, car elles sont nécessaires pour la négociation des paramètres de chiffrement. Par exemple, le SNI (Server Name Indication) donne le nom du serveur qu'on veut contacter. Il est nécessaire de le donner en clair car la façon dont vont se faire le chiffrement et l'authentification dépendent de ce nom. Mais cela ouvre des possibilités aux surveillants (savoir quel serveur on contacte, parmi tous ceux qui écoutent sur la même adresse IP) et aux censeurs (couper sélectivement les connexions vers certains serveurs). Il est donc nécessaire de protéger ce SNI, ce qui n'est pas facile. Ce nouveau RFC décrit les objectifs, mais pas encore la solution. Celle-ci reposera sans doute sur la séparation entre un frontal général qui acceptera les connexions TLS, et le « vrai » service caché derrière.
C'est que le problème est difficile puisqu'on est face à un dilemme de l'œuf et de la poule. On a besoin du SNI pour chiffrer alors qu'on voudrait chiffrer le SNI. Le RFC note qu'il n'y aura sans doute pas de solution parfaite.
Cela fait longtemps que le SNI (normalisé il y a longtemps, dans
le RFC 3546, et aujourd'hui dans le RFC 6066) est connu pour les risques qu'il pose
pour la vie privée. Les autres canaux de
fuite d'information sont fermés petit à petit (par exemple le
DNS, avec les RFC 9156, RFC 7858 et RFC 8484), souvent en utilisant TLS (RFC 8446). Même l'adresse
IP de destination, qu'on ne peut pas cacher, perd de sa
signification lorsque de nombreux services sont hébergés derrière la
même adresse IP (c'est particulièrement vrai pour les gros
CDN). Mais
ces services comptent sur le SNI (Server Name
Indication), transporté en clair dans le message TLS
ClientHello, pour le démultiplexage des
requêtes entrantes, et ce SNI tend donc à devenir le maillon faible
de la vie privée, l'information la plus significative qui reste en
clair. Voici, vu par tshark,
un exemple de ClientHello, avec un SNI
(server_name, affiche tshark) :
...
Secure Sockets Layer
TLSv1 Record Layer: Handshake Protocol: Client Hello
Content Type: Handshake (22)
Version: TLS 1.0 (0x0301)
Length: 233
Handshake Protocol: Client Hello
Handshake Type: Client Hello (1)
Length: 229
Version: TLS 1.2 (0x0303)
...
Extension: server_name (len=22)
Type: server_name (0)
Length: 22
Server Name Indication extension
Server Name list length: 20
Server Name Type: host_name (0)
Server Name length: 17
Server Name: doh.bortzmeyer.fr
Résultat, le SNI est souvent utilisé de manière intrusive, le RFC 8404 donnant de nombreux exemples. Par exemple,
il permet de censurer finement (si le SNI indique
site-interdit.example, on jette les paquets,
s'il indique site-commercial.example, on laisse
passer). Il permet de
shaper le trafic vers
certains sites, en violation de la neutralité du réseau. Il permet aussi de
laisser passer certains sites, lorsqu'on fait une attaque
de l'homme du milieu, par exemple une entreprise qui
fait de l'inspection HTTPS
systématique peut utiliser le SNI pour en exempter certaines sites
sensibles, comme ceux des banques ou des plate-formes médicales. Et,
bien sûr, le SNI peut être passivement observé à des fins de
surveillance (RFC 7258).
On peut s'amuser à noter que ces risques pour la vie privée
n'avaient pas été notés dans la section « Sécurité » des RFC de
normalisation de SNI, comme le RFC 6066. C'est
peut-être parce qu'à l'époque, les éventuels attaquants avaient des
moyens plus simples à leur disposition. (Je me souviens de
discussions à l'IETF « à quoi bon masquer le SNI puisque le
DNS révèle
tout ? » ; c'était avant le RFC 7626.) Il
restait un endroit où le nom du service était en clair, c'était le
certificat renvoyé par le serveur TLS
(subjectAltName) mais, depuis TLS 1.3 (RFC 8446), lui aussi est chiffré. Aujourd'hui, les
progrès de la sécurité font que le moyen le plus simple de savoir à
quel service un internaute se connecte devient souvent le SNI.
Notez toutefois que tout le monde n'est pas d'accord sur la nécessité de chiffrer le SNI. Certains craignent que cette nécessité débouche sur une solution compliquée et fragile. D'autres ne veulent tout simplement pas priver surveillants et censeurs d'un mécanisme si pratique. En réponse à cette dernière objection (cf. RFC 8404), le RFC note que la méthode recommandée (section 2.3 du RFC), si on peut surveiller et filtrer, est de le faire dans les machines terminales. Après tout, si l'organisation contrôle ces machines terminales, elle peut les configurer (par exemple avec le certificat de l'intercepteur) et si elle ne les contrôle pas, elle n'a sans doute pas le droit d'intercepter les communications.
La solution est évidente, chiffrer le SNI. Ce ne sont pas les propositions qui ont manqué, depuis des années. Mais toutes avaient des inconvénients sérieux, liés en général à la difficulté du bootstrap. Avec quelle clé le chiffrer puisque c'est justement le SNI qui aide le serveur à choisir la bonne clé ?
La section 3 de notre RFC énumère les exigences auxquelles va devoir répondre la solution qui sera adoptée. (Rappelez-vous qu'il s'agit d'un travail en cours.) C'est que beaucoup de solutions ont déjà été proposées, mais toutes avaient de sérieux problèmes. Petit exercice avant de lire la suite : essayez de concevoir un protocole de chiffrement du SNI (par exemple « le SNI est chiffré avec la clé publique du serveur, récupérée via DANE » ou bien « le SNI est chiffré par une clé symétrique qui est le condensat du nom du serveur [vous pouvez ajouter du sel si vous voulez, mais n'oubliez pas d'indiquer où le trouver] ») et voyez ensuite si cette solution répond aux exigences suivantes.
Par exemple, pensez à la possibilité d'attaque par rejeu. Si le SNI est juste chiffré avec une clé publique du serveur, l'attaquant n'a qu'à observer l'échange, puis faire à son tour une connexion au serveur en rejouant le SNI chiffré et paf, dans la réponse du serveur, l'attaquant découvrira quel avait été le service utilisé. La solution choisie doit empêcher cela.
Évidemment, la solution ne doit pas imposer d'utiliser un secret partagé (entre le serveur et tous ses clients), un tel secret ne resterait pas caché longtemps.
Il faut aussi faire attention au risque d'attaque par déni de service, avec un méchant qui générerait plein de SNI soi-disant chiffrés pour forcer des déchiffrements inutiles. Certes, TLS permet déjà ce genre d'attaques mais le SNI peut être traité par une machine frontale n'ayant pas forcément les mêmes ressources que le vrai serveur.
Autre chose importante quand on parle de protéger la
vie privée : il ne faut pas se distinguer
(Do not stick out). Porter un masque du
Joker dans la rue pour protéger son anonymat
serait sans doute une mauvaise idée, risquant au contraire d'attirer
l'attention. La solution choisie ne doit donc pas permettre à, par
exemple, un état policier, de repérer facilement les gens qui sont
soucieux de leur vie privée. Une extension spécifique du
ClientHello serait dangereuse, car triviale à
analyser automatiquement par un système de surveillance massive.
Il est évidemment souhaitable d'avoir une confidentialité persistante, c'est-à-dire que la compromission d'une clé privée ne doit pas permettre de découvrir, a posteriori, les serveurs auxquels le client s'était connecté. Simplement chiffrer le SNI avec la clé publique du serveur ne convient donc pas.
L'hébergement Web d'aujourd'hui est souvent compliqué, on peut avoir un frontal géré par une société d'hébergement, et des machines gérées par le client de l'hébergeur derrière, par exemple. Ou bien plusieurs clients de l'hébergeur sur la même machine physique, voire sur la même machine virtuelle avec certaines hébergements mutualisés. Cela peut être utile pour certaines solutions, par exemple le fronting où une machine frontale reçoit une demande de connexion TLS pour elle puis, une fois TLS démarré, reçoit le nom du vrai serveur, et relaie vers lui. Si la machine frontale relaie pour beaucoup de serveurs, cela fournit une assez bonne intimité. Mais cela nécessite de faire confiance à la machine frontale, et le risque d'attaque de l'homme du milieu (qui nous dit que ce frontal est le frontal légitime choisi par le serveur TLS ?) augmente. Or, plus la machine frontale protège des serveurs, plus elle est un objectif tentant pour la police ou les pirates.
Ah, et j'ai parlé du Web mais la solution doit évidemment fonctionner avec d'autres protocoles que HTTPS. Par exemple, le DNS sur TLS du RFC 7858 ou bien IMAP (RFC 8314) doivent fonctionner. Même pour HTTP, certaines particularités de HTTP peuvent poser problème, et il est donc important que la future solution de chiffrement de SNI soit agnostique, pour marcher avec tous les protocoles. Et elle doit également fonctionner avec tous les protocoles de transport, pas seulement TCP, mais aussi DTLS ou QUIC.
Le RFC note aussi qu'il serait bon d'avoir une solution de chiffrement de la négociation ALPN (RFC 7301). ALPN est moins indiscret que SNI mais il renseigne sur l'application utilisée.
Puisque j'ai parlé plus haut du fronting, cela
vaut la peine de parler du fronting HTTP car
c'est une technique courante, aussi bien pour échapper à la censure
que pour protéger la vie privée. La section 4 du RFC lui est
consacrée. Elle est décrite dans l'article de Fifield, D., Lan, C.,
Hynes, R., Wegmann, P., et V. Paxson, « Blocking-resistant
communication through domain fronting ». Le
principe est que le client TLS établit une connexion avec le système
de fronting puis, une fois le chiffrement TLS en
marche, le client demande la connexion avec le vrai serveur. Un
surveillant ne pourra voir que l'utilisation d'un service de
fronting, pas le nom du vrai service (le SNI en
clair dira, par exemple,
fronting.example.net). En pratique, cela marche
bien avec HTTPS si le serveur de fronting et le
vrai serveur sont sur le même système : il suffit alors d'indiquer
le domaine du fronting dans le SNI et le vrai
domaine dans les en-têtes Host: de HTTP. Cela
ne nécessite aucune modification du protocole TLS.
Le fronting a quelques limites :
- Le client doit trouver un service acceptant de faire du fronting. (Ce qui n'est pas évident.)
- Le client doit configurer son logiciel pour utiliser un service de fronting.
- Il faut évidemment faire confiance au service de fronting, qui est, d'une certaine façon, un homme du milieu. (Ceci dit, si serveur de fronting et vrai serveur sont au même endroit, cela n'implique pas de faire confiance à un nouvel acteur.) Le problème est d'autant plus crucial qu'il n'existe pas de moyen standard, pour un serveur, d'authentifier publiquement le service de fronting par lequel on peut y accéder. Des variantes du fronting existent, qui limitent ce problème, par exemple en faisant du HTTPS dans HTTPS, si le serveur de fronting l'accepte.
- Cela ne marche qu'avec HTTP, puisque cela utilise le fait que les requêtes HTTP indiquent le vrai serveur de destination. (C'est d'ailleurs une des raisons pour lesquelles a été développé DoH, spécifié dans le RFC 8484.)
À noter que les trames ORIGIN du RFC 8336 peuvent être utiles en cas de
fronting, pour indiquer le contenu venant du
« vrai » serveur.
Voilà, vous connaissez maintenant le problème, l'IETF est en train de travailler aux solutions, ce sera finalement publié dans le RFC 9849, en 2026.
L'article seul
Panne du site Web de la Poste, et la révocation des certificats
Première rédaction de cet article le 23 juillet 2020
Dernière mise à jour le 24 juillet 2020
Ce matin, les visiteurs du site Web de La
Poste ont la désagréable surprise de voir leur
navigateur afficher une alerte de sécurité
qui les empêche d'aller sur le site https://www.laposte.fr/
Voyons d'abord les symptômes vus par l'utilisateur ou
l'utilisatrice normale : 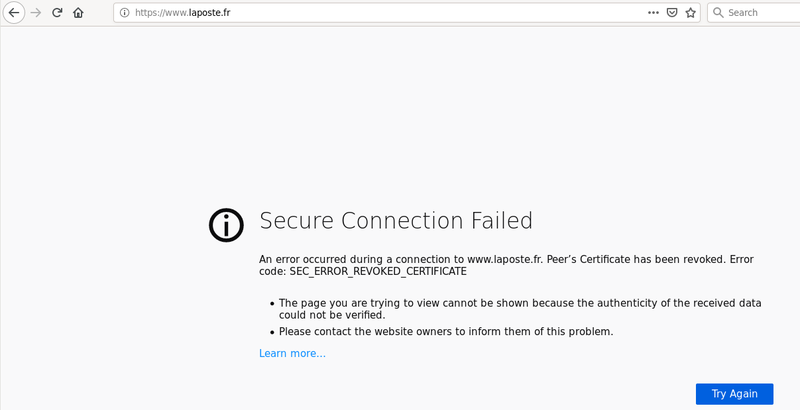
Le certificat a donc été révoqué, ce qui veut dire que l'organisme qui l'a émis, l'Autorité de Certification, a signé un message disant que ce certificat ne devait plus être utilisé (cela peut être, par exemple, car la clé privée correspondante a été compromise).
Et voyons maintenant les détails techniques. D'abord, quel est le numéro de série du certificat ?
% gnutls-cli www.laposte.fr
... - subject `CN=laposte.fr,serialNumber=35600000000048,O=La Poste
S.A.,street=Quai André
citroën\,7-11,L=Paris,ST=Île-de-France,C=FR,postalCode=75015,
businessCategory=Business
Entity,jurisdictionOfIncorporationLocalityName=Paris,
jurisdictionOfIncorporationStateOrProvinceName=Île-de-France,
jurisdictionOfIncorporationCountryName=FR', issuer `CN=CA de
Certificados SSL EV,OU=BZ Ziurtagiri publikoa - Certificado publico
EV,O=IZENPE S.A.,C=ES',
serial 0x279dad0bbf3d7a5e5b63f8aae70fa366,
RSA key 4096 bits, signed using RSA-SHA256, activated `2018-08-03 06:39:37 UTC', expires `2020-08-03 06:39:31 UTC', pin-sha256="fICfTOyzreCYOYqWfcbL3yJzdWGVPAhmDv3+IDBjrRo="
...
(J'aime bien les informations en basque mises
par l'AC,
Izenpe.)
OK, le certificat final est 279dad0bbf3d7a5e5b63f8aae70fa366 (c'est
bien celui qui est révoqué, autrement, il aurait également fallu
tester les autres certificats de la chaîne). Cherchons-le dans les
journaux Certificate
Transparency (normalisés par le RFC 6962). On les trouve en https://crt.sh/?serial=279dad0bbf3d7a5e5b63f8aae70fa366
Le service crt.sh ne nous donne pas
la raison de la révocation. Regardons donc la
CRL :
% openssl s_client -connect www.laposte.fr:443 -showcerts | openssl x509 -text
...
X509v3 CRL Distribution Points:
Full Name:
URI:http://crl.izenpe.com/cgi-bin/crlsslev2
...
% wget http://crl.izenpe.com/cgi-bin/crlsslev2
% openssl crl -inform DER -text -noout -in crlsslev2
...
Serial Number: 279DAD0BBF3D7A5E5B63F8AAE70FA366
Revocation Date: Jul 22 07:35:53 2020 GMT
CRL entry extensions:
X509v3 CRL Reason Code:
Unspecified
Et nous avons désormais la révocation de ce certificat 279DAD0BBF3D7A5E5B63F8AAE70FA366 , sa date (il y a plus de vingt-quatre heures, mais notez que la CRL n'est pas forcément publiée immédiatement après l'opération de révocation) et la raison (enfin, si on peut dire).
Sinon, dans un cas comme cela, il peut être prudent de vérifier que le problème n'est pas local et qu'il ne s'agit pas, par exemple, d'un détournement vers un serveur pirate. On va donc utiliser cent sondes RIPE Atlas en France pour demander le certificat :
% blaeu-cert --requested 100 --country FR --serial -4 www.laposte.fr 99 probes reported [279dad0bbf3d7a5e5b63f8aae70fa366] : 99 occurrences Test #26427062 done at 2020-07-23T08:50:57Z
OK, toutes les sondes voient le même numéro de série donc ce n'est sans doute pas un détournement local.
Suite de l'affaire : vers 1100 UTC, le 23 juillet, le certificat
révoqué a enfin été remplacé, par un Let's Encrypt. On peut le voir dans le
journal. Un autre certificat, fait par Global Sign, a
été émis et a remplacé le Let's Encrypt quelques heures après. Notez
qu'il ne s'agit que du site Web public,
www.laposte.fr. Le 24 juillet au matin, le
service api.laposte.fr
(API du système de suivi de colis) avait
toujours un
certificat révoqué de l'ancienne AC.
Sinon, il y a cet article du Monde Informatique, qui n'apprend rien de plus, et un autre du Figaro, où la Poste raconte que l'ancien certificat a été révoqué avant l'installation du nouveau.
L'article seul
RFC 8799: Limited Domains and Internet Protocols
Date de publication du RFC : Juillet 2020
Auteur(s) du RFC : B. E. Carpenter (Univ. of Auckland), B. Liu (Huawei)
Pour information
Première rédaction de cet article le 15 juillet 2020
Il y a depuis longtemps un débat sur l'architecture de l'Internet : dans quelle mesure faut-il un Internet uniforme, où tout est pareil partout, et dans quelle mesure faut-il au contraire des particularités qui ne s'appliquent que dans telle ou telle partie de l'Internet ? Bien sûr, la réponse n'est pas simple, et ce nouveau RFC explore la question et discute ses conséquences, par exemple pour le développement des normes.
Sur le long terme, la tendance est plutôt au développement de règles locales, et de services qui ne sont accessibles que d'une partie de l'Internet. Le NAS avec les photos de famille accessible uniquement depuis la maison, le site Web permettant aux employés d'indiquer leurs demandes de congés, qu'on ne peut voir que depuis le réseau de l'entreprise, parce qu'on y est présent physiquement, ou bien via le VPN, les lois d'un pays qu'il essaie, avec plus ou moins de succès, d'appliquer sur son territoire… Mais, d'abord, une précision : le terme « local » ne signifie pas forcément une région géographique précise. « Local » peut, par exemple, désigner le réseau d'une organisation spécifique, qui y applique ses règles. « Local » peut être un bâtiment, un véhicule, un pays ou bien un réseau s'étendant au monde entier.
À noter que certains ont poussé cette tendance très loin en estimant que l'Internet allait se fragmenter en réseaux distincts, ne communiquant plus, voire que cela avait déjà été fait. C'est clairement faux, aujourd'hui, comme l'explique bien, par exemple, le RFC 7754, ou bien Milton Mueller dans son livre « Will The Internet Fragment? ». On peut toujours visiter ce blog depuis tous les réseaux connectés à l'Internet…
Un petit point de terminologie : le RFC utilise le terme « domaine » pour désigner une région de l'Internet ayant des règles spécifiques. Ce terme ne doit pas être confondu avec celui de « nom de domaine » qui désigne quelque chose de tout à fait différent. « Domaine », dans ce RFC, est plutôt utilisé dans le même sens que dans les RFC 6398 et RFC 8085, pour indiquer un « domaine administratif ». C'est un environnement contrôlé, géré par une entité (entreprise, association, individu) et qui peut définir des règles locales et les appliquer.
Aujourd'hui, le concept de « domaine local » ou « domaine limité » n'est pas vraiment formalisé dans l'Internet. Des RFC comme le RFC 2775 ou le RFC 4924 ont plutôt défendu l'inverse, la nécessité de maintenir un Internet unifié, insistant sur le problème des middleboxes intrusives (RFC 3234, RFC 7663 et RFC 8517). Actuellement, il y a déjà une fragmentation de l'Internet en ilots séparés, puisque certaines fonctions ne marchent pas toujours, et qu'on ne peut donc pas compter dessus. C'est le cas par exemple des en-têtes d'extension IPv6 (RFC 7872), de la découverte de la MTU du chemin (RFC 4821) ou de la fragmentation (RFC 8900). Sans compter le filtrage par les pare-feux. Bref, tous ces problèmes font que, de facto, l'Internet n'est plus transparent, et que des communications peuvent échouer, non pas en raison d'une panne ou d'une bogue, mais en raison de règles décidées par tel ou tel acteur sur le trajet. Donc, en pratique, on a des « domaines limités » mais sans que cela soit explicite, et cela joue un rôle important dans l'utilisation du réseau.
Si on avait des « domaines limités » ou « domaines locaux » explicites, quel serait le cahier des charges de ce concept ? La section 3 du RFC donne quelques idées à ce sujet. Par exemple, ces scénarios sont envisagés :
- Un cas d'usage évident est le réseau de la maison, où des politiques spécifiques à ce logement sont tout à fait légitimes (par exemple, utilisation de Pi-hole pour bloquer les publicités). Typiquement non géré par des professionnels (voire pas géré du tout…), il doit marcher « à la sortie de la boîte ». Le RFC 7368 donne davantage de détails sur cette notion de réseau à la maison.
- Le réseau interne d'une petite entreprise est souvent proche du réseau de la maison : politique locale (donc « domaine limité ») mais personne de compétent pour s'en occuper. Par contre, il est parfois installé par des professionels (mais attention, « professionnel » ≠ « compétent »).
- Sujet à la mode, le réseau dans un véhicule. À l'intérieur du véhicule, il y a des exigences spécifiques, liées à la sécurité, et qui justifient des règles locales.
- Les réseaux SCADA ont également d'excellentes raisons d'avoir une politique locale, notamment en sécurité (cf. RFC 8578).
- Toujours dans le domaine industriel, il y a aussi les réseaux de capteurs et, plus généralement, l'IoT. Ils demandent également des règles locales spécifiques et, en prime, posent parfois des problèmes techniques ardus. C'est encore pire si les objets sont contraints en ressources matérielles (RFC 7228).
- Plus science-fiction, un autre scénario où on ne peut pas suivre les règles de l'Internet public et où il faut des règles locales, les DTN (RFC 4838).
- Les grands réseaux internes d'une organisation, répartie sur plusieurs sites physiques, peuvent également être concernées par le concept de politique locale. Notez qu'un seul RFC parle d'eux, à propos d'IPv6, le RFC 7381.
- Il y a aussi le cas du réseau semi-fermé d'un opérateur. Le réseau est utilisé par des clients de cet opérateur, et celui-ci a une offre réservée à certains, qui propose des garanties de service (avec des techniques comme EVPN ou VPLS). (Le RFC n'en parle pas, mais attention, ici, on commence à s'approcher de la question de la neutralité de l'Internet.)
- Et enfin (mais je n'ai pas recopié toute la liste du RFC), il y a les centres de données où, là encore, une organisation souhaite avoir une politique locale.
Bref, le cas est fréquent. On se dit, en regardant tous ces scénarios où un réseau, quoique connecté à l'Internet, a de très bonnes raisons d'avoir des règles locales spécifiques, qu'il serait bon qu'une organisation de normalisation, comme l'IETF, trouve une solution générale. Le problème est que, justement, chaque politique locale est différente. Néanmoins, les auteurs du RFC suggèrent de réfléchir à une nouvelle façon d'analyser les propositions à l'IETF, en ne considérant pas simplement leur usage sur l'Internet public (le vrai Internet, dirais-je) mais aussi ce qui se passera sur ces domaines limités.
Le RFC cite aussi le cas de protocoles qu'on avait cru pouvoir déployer sur l'Internet public mais qui en fait n'ont marché que dans des environnements fermés. Ce fut le cas bien sûr de RSVP (RFC 2205). Ses auteurs avaient pensé qu'un protocole de réservation de ressources pourrait marcher sur un réseau public, oubliant que, dans ce cas, chaque égoïste allait évidemment se réserver le plus de ressources possibles. (Ce n'est pas un problème spécifique à RSVP : aucun mécanisme de qualité de service ne peut marcher sur un réseau public décentralisé. Imaginez un bit « trafic très important, à ne jamais jeter » ; tout le monde le mettrait à 1 !)
Bon, maintenant qu'on a décrit les scénarios d'usage, quelle(s) solution(s) ? La section 4 du RFC liste quelques exemples de techniques conçues spécialement pour des domaines limités. Notons que le RFC parle des techniques en couche 3, la couche 2 étant évidemment toujours pour un domaine local (encore que, avec TRILL - RFC 6325, la couche 2 peut aller loin). Par exemple :
- DiffServ (RFC 2464), puisque la signification des bits utilisés est purement locale.
- RSVP, déjà cité.
- La virtualisation de réseaux, qui permet de créer un domaine local au-dessus de réseaux physiques divers. Idem pour celle dans les centres de données (RFC 8151).
- Le SFC du RFC 7665, qui permet d'attacher des instructions particulières aux paquets (encodées selon le RFC 8300), instructions qui n'ont évidemment de sens que dans un domaine local.
- Dans un genre analogue, il y a aussi le routage par les segments (RFC 8402).
- L'IETF a une série d'adaptations des protocoles Internet spécialement conçues pour le cas de la maison, collectivement nommées Homenet (RFC 7368, RFC 7788).
- Avec IPv6, d'autres possibilités amusantes existent. L'étiquette de flot (RFC 6294) peut permettre de marquer tel ou tel flot de données, pour ensuite lui appliquer une politique spécifique. Les en-têtes d'extension permettent de déployer des techniques comme le routage via des segments, cité plus haut. (Le fait que ces en-têtes passent mal sur l'Internet public - cf. RFC 7045 et RFC 7872 n'est pas un problème dans un domaine limité.) Et la grande taille des adresses IPv6 permet d'encoder dans l'adresse des informations qui seront ensuite utilisées par les machines du domaine.
- Et enfin je vais citer les PvD (ProVisioning Domain) du RFC 7556, qui formalisent cette notion de domaine local, et lui donnent un cadre.
La section 5 du RFC conclut qu'il peut être souhaitable d'avoir des protocoles explicitement réservés à des domaines limités, et pour qui les règles pourraient être différentes de celles des protocoles conçus pour le grand Internet ouvert. Le RFC donne un exemple : si faire ajouter des en-têtes d'extension à un paquet IPv6 par le réseau qu'il traverse serait une abominable violation de la neutralité, en revanche, dans un domaine local, pourquoi ne pas se dire que ce serait possible, et peut-être intéressant dans certains cas ? Pour de tels protocoles, on ne pourrait pas garantir leur interopérabilité sur l'Internet, mais ils pourraient former une intéressante addition au socle de base du travail de l'IETF, qui sont les protocoles de l'Internet public.
Une fois posée l'opinion que les protocoles « à usage local » sont intéressants (et qu'ils existent déjà), comment les améliorer ? Actuellement, comme le concept de « domaine limité » n'est pas explicitement défini, le domaine est créé par la configuration des machines, des pare-feux, des résolveurs DNS, des ACL, du VPN… Un processus compliqué et où il est facile de se tromper, surtout avec le BYOD, le télétravail… Imaginez un serveur HTTP privé, qui ne sert que le domaine. Comment le configurer pour cela ? Compter sur les pare-feux ? Mettre des ACL sur le serveur (ce qui nécessite de connaître la liste, évolutive, des préfixes IP du domaine) ? Définir un domaine nécessite d'avoir un intérieur et un extérieur, et que chaque machine, chaque application, sache bien de quel côté elle est (ou à l'interface entre les deux, si elle sert de garde-frontière). Et, quand on est à l'intérieur, et qu'on envoie ou reçoit un message, il est important de savoir si on l'envoie à l'extérieur ou pas, si on le reçoit de l'intérieur ou pas. Bref, actuellement, il n'y a pas de solution propre permettant de répondre à cette question.
Le RFC définit alors un cahier des charges pour qu'on puisse définir des règles locales et que ça marche. Notamment :
- Comme tout truc sur l'Internet, le domaine devrait avoir un identificateur. Le RFC suggère que ce soit une clé publique cryptographique, pour permettre les authentifications ultérieures. (Le RFC 7556, sur les PvD, propose plutôt que ce soit un simple FQDN.)
- Il serait bien sympa de pouvoir emboîter les domaines (un domaine limité dans un autre domaine limité).
- Les machines devraient pouvoir être dans plusieurs domaines.
- Idéalement, les machines devraient pouvoir être informées des domaines qu'elles peuvent rejoindre, pour pouvoir choisir.
- Évidemment, tout cela devrait être sécurisé. (Par exemple avec un mécanisme d'authentification de la machine.)
- Il faudrait un mécanisme de retrait. (Une machine quitte le domaine.)
- Ce serait bien de pouvoir savoir facilement si telle machine avec qui on envisage de communiquer est dans le même domaine que nous.
- Et enfin on voudrait pouvoir accéder facilement aux informations sur la politique du domaine, par exemple sur ses règles de filtrage. (Exemple : un domaine limité de l'employeur interdisant de contacter tel ou tel service.)
À l'heure actuelle, tout ceci relève du vœu pieux.
Une motivation fréquente des domaines locaux (ou limités) est la sécurité. La section 7 de notre RFC, dédiée à ce sujet, fait remarquer qu'on voit souvent des gens qui croient que, dans un domaine limité, on peut réduire la sécurité car « on est entre nous ». Cela oublie, non seulement le fait que la plupart des menaces sont internes (par une malhonnêteté ou par une infection), mais aussi celui qu'un protocole qu'on croyait purement interne se retrouve parfois utilisé en extérieur. Un exemple classique est le site Web « interne » pour lequel on se dit que HTTPS n'est pas nécessaire. Si, suite à un problème de routage ou de pare-feu, il se retrouve exposé à l'extérieur, il n'y aura pas de seconde chance.
Enfin, l'annexe B du RFC propose une taxonomie des domaines limités : utile si vous voulez creuser la question.
L'article seul
Le rapport du CNNum sur l'interopérabilité pour les GAFA
Première rédaction de cet article le 6 juillet 2020
Aujourd'hui 6 juillet, le Conseil National du Numérique a publié son étude de cas sur l’interopérabilité des réseaux sociaux. Un petit résumé.
Si vous avez déjà essayé de convaincre un utilisateur ou une utilisatrice de Facebook ou d'un autre réseau social centralisé de quitter cet environnement néfaste et d'utiliser des réseaux sociaux libres et décentralisés comme le fédivers, vous savez que c'est très difficile, notamment en raison de l'argument choc « mais tous mes amis / clients / électeurs / camarades y sont, je dois y être aussi, quelles que soient mes opinions personnelles, je ne peux pas me permettre de me déconnecter d'eux ». (Très peu de gens justifieront leur choix en disant que le GAFA est de meilleure qualité que les alternatives.) Effectivement, ce verrouillage des utilisateurs est la grande force des GAFA : en pratique, on ne peut pas partir, sauf à se résigner à mener une vie peu sociale en compagnie de trois libristes dans un garage.
Le problème est connu depuis longtemps. Quelles sont les solutions ? On peut être optimiste et continuer à essayer de convaincre utilisatrices et utilisateurs. Cela prend du temps et le succès n'est pas garanti. On peut aussi se résigner, et n'utiliser que les réseaux sociaux des GAFA. Ou bien on peut essayer d'ouvrir une brèche dans le monopole de ces réseaux sociaux en leur imposant l'interopérabilité.
De quoi s'agit-il ? L'idée est très banale et déjà très répandue sur l'Internet : il s'agit de permettre à des serveurs gérés par des organisations différentes, et réalisés par des programmeurs différents, de communiquer. C'est banal car c'est exactement ainsi que fonctionne, depuis ses débuts (antérieurs aux débuts de l'Internet…) le courrier électronique. On peut échanger des messages avec des gens qui ne sont pas chez le même hébergeur de courrier que soi, et encore heureux. Comme le notait la rapporteuse de l'étude, Myriam El Andaloussi, « L'interopérabilité a déjà fait ses preuves. » L'interopérabilité est en général assurée par une norme technique rédigée : si tout le monde la suit, on pourra communiquer. (Si vous êtes informaticien·ne, vous savez que l'interopérabilité, en pratique, ne se fait pas forcément toute seule, mais je simplifie.) En fait, l'Internet lui-même est un exemple parfait que l'interopérabilité fonctionne : des machines de fournisseurs différents, gérées par des organisations différentes, communiquent entre elles tous les jours.
Mais le monde des réseaux sociaux, sous la pression des GAFA, ne fonctionne pas comme cela : la règle n'est pas l'interopérabilité, mais le silo isolé. Si vous n'êtes pas utilisateur de Facebook, vous ne pouvez pas envoyer de message à un utilisateur Facebook et réciproquement. Les GAFA pourraient techniquement utiliser des solutions interopérables pour communiquer avec l'extérieur, c'est banal, ce n'est pas très compliqué techniquement (d'autant plus qu'on parle de très grosses entreprises ayant des ressources humaines considérables, en qualité et en quantité). Mais ce n'est clairement pas leur intérêt. Si cela l'était, ils auraient pu le faire depuis longtemps.
Le travail du Conseil National du Numérique (CNN) était de regarder la possibilité d'imposer cette interopérabilité. Compte tenu du poids de ces réseaux sociaux centralisés, il serait anormal qu'ils puissent continuer à utiliser leur position dominante pour verrouiller le « marché » et empêcher toute communication entre eux et l'extérieur. Le CNN a donc consulté beaucoup de monde et produit l'étude qui en résulte. Elle fait donc le tour de la question, et est très exhaustive. Tous les aspects, techniques, politiques, juridiques, sont examinés, et tous les points de vue sont exposés.
C'est d'ailleurs la limite de ce travail : le CNN ne tranche pas vraiment, il ménage la chèvre et le chou, montre des pistes, liste les avantages et les inconvénients mais ne fait pas vraiment de recommandation concrète. Il déblaie le terrain mais ce ne sera pas suffisant face aux GAFA qui, pendant ce temps, consolident toujours plus leur position. Pour échapper à leur domination, il faudrait des mesures immédiates, poussées par une forte volonté politique. L'inertie joue en faveur des GAFA. Discuter sans fin de tel ou tel détail pratique de mise en œuvre de l'interopérabilité ne ferait que pérenniser leur domination.
Le 6 juillet, la sortie du rapport avait été suivi d'une présentation en ligne, puis d'un panel de discussion. En fait, comme beaucoup de panels, il s'était résumé à une juxtaposition de discours, sans interactivité. Il n'est pas étonnant que le représentant de Snapchat se soit déclaré opposé à toute « réglementation contraignante » (comme si le but d'une réglementation n'était pas justement d'obtenir ce que le libre jeu du marché ne produisait pas) et que celle de Facebook ait esquivé comme « trop technique » la seule question du public, sur l'abandon par Messenger du protocole XMPP qui assurait, à une époque, l'interopérabilité de Messenger.
Quelques lectures utiles sur ce sujet de l'interopérabilité des réseaux sociaux :
- La lettre de 75 organisations qui appelait à l'interopérabilité,
- Au Sénat, la proposition de loi sur l'interopérabiité (c'est le chapitre II de ce texte),
- Mon explication de l'interopérabilité.
- Je crois qu'un des premiers textes sur cette importance d'imposer l'interopérabilité aux GAFA était l'interview de Lionel Maurel.
- J'ai raconté la présentation de l'étude sur un réseau social décentralisé et pratiquant l'interopérabilité, le fédivers (qui fonctionne grâce à la norme ActivityPub).
- Aux États-Unis, une proposition de loi, l'ACCESS Act, vise au même but d'interopérabilité. L'EFF a fait un article très détaillé sur l'importance de l'interopérabilité.
L'article seul
RFC 8792: Handling Long Lines in Content of Internet-Drafts and RFCs
Date de publication du RFC : Juin 2020
Auteur(s) du RFC : K. Watsen (Watsen Networks), E. Auerswald, A. Farrel (Old Dog Consulting), Q. Wu (Huawei Technologies)
Pour information
Réalisé dans le cadre du groupe de travail IETF netmod
Première rédaction de cet article le 3 juillet 2020
Le sujet peut sembler un point de détail sans importance mais, dans un RFC, tout compte. Que serait une norme si les exemples de code et les descriptions en langage formel avaient la moindre ambiguïté ? C'est le cas par exemple des lignes trop longues : comment les couper pour qu'on comprenne bien ce qui s'est passé ? Ce RFC propose deux méthodes.
Le cas principal est celui des modules YANG (RFC 7950) et c'est pour cela que ce RFC sort du groupe de travail netmod. Mais le problème concerne en fait tous les cas où on veut mettre dans un RFC du texte dans un langage formel et que les lignes dépassent ce qui est généralement considéré comme acceptable. Notre RFC formalise deux solutions, toutes les deux traditionnelles et déjà souvent utilisées, mettre une barre inverse après les lignes coupées, ou bien mettre cette barre inverse et une autre au début de la ligne suivante. Donc, dans le premier cas, le texte :
Il n'est pas vraiment très long, mais c'est un exemple.
Ce texte, coupé à quarante-cinq caractères, donnerait :
Il n'est pas vraiment très long, mais c'est \ un exemple.
Ou bien :
Il n'est pas vraiment très long, mais c'est \
un exemple.
Et, avec la seconde solution :
Il n'est pas vraiment très long, mais c'est \ \un exemple.
Si la forme officielle des RFC n'est plus le texte brut depuis le RFC 7990, il y a toujours une version en texte brut produite, suivant le format décrit dans le RFC 7994. Il impose notamment des lignes de moins de 72 caractères. Or, les exemples de code, ou les textes décrits en un langage formel (modules YANG, ABNF, ou ASN.1, par exemple), dépassent facilement cette limite. Les outils actuels comme xml2rfc ne gèrent pas vraiment ce cas, se contentant d'afficher un avertissement, et laissant l'auteur corriger lui-même, d'une manière non officiellement standardisée.
Désormais, c'est fait, il existe un tel standard, ce nouveau RFC,
standard qui
permettra notamment de bien traiter les textes contenus dans
l'élement <sourcecode> (RFC 7991, section 2.48) du source du RFC. Naturellement, rien
n'interdit d'utiliser cette norme pour autre chose que des RFC
(section 2 du RFC).
Les deux stratégies possibles, très proches, sont « une seule barre inverse » et « deux barres inverses ». Dans les deux cas, un en-tête spécial est mis au début, indiquant quelle stratégie a été utilisée, pour qu'il soit possible de reconstituer le fichier original.
Dans le premier cas, la stratégie à une seule barre inverse (section 7 du RFC), une ligne est considérée pliée si elle se termine par une barre inverse. La ligne suivante (moins les éventuels espaces en début de ligne) est sa suite. Dans le deuxième cas, la stratégie à deux barres inverses (section 8), une autre barre inverse apparait au début des lignes de continuation.
Différence pratique entre les deux stratégies ? Avec la première
(une seule barre inverse), le résultat est plus lisible, moins
encombré de caractères supplémentaires. Par contre, comme les
espaces au début de la ligne de continuation sont ignorés, cette
stratégie va échouer pour des textes comportant beaucoup d'espaces
consécutifs. La deuxième est plus robuste. La recommandation du RFC
est donc d'essayer d'abord la première stratégie, qui produit des
résultats plus jolis, puis, si elle échoue, la deuxième. L'outil
rfcfold, présenté plus loin, fait exactement
cela par défaut.
La section 4 rappellait le cahier des charges des solutions adoptées :
- Repli des lignes automatisable (cf. le script
rfcfoldprésenté à la fin), notamment pour le cas où un RFC ou autre document est automatiquement produit à partir de sources extérieures, - Reconstruction automatisable du fichier original, pour qu'on puisse réutiliser ce qu'on a trouvé dans un RFC en texte brut, ce qui est déjà utilisé par les outils de soumission d'Internet-Drafts, qui extraient le YANG automatiquement et le valident, pratique qui pourrait être étendu à XML et JSON, et qui assure une meilleure qualité des documents, dès la soumission.
En revanche, la section 5 liste les « non-buts » : il n'est pas prévu que les solutions fonctionnent pour l'art ASCII. Et il n'est pas prévu de gérer les coupures spécifiques à un format de fichier. Les stratégies décrites dans ce RFC sont génériques. Au contraire, des outils comme pyang ou yanglint connaissent la syntaxe de YANG et peuvent plier les lignes d'un module YANG plus intelligemment (cf. aussi RFC 8340).
L'annexe A du RFC contient un script bash
qui met en œuvre les deux stratégies (le script rfcfold.bash
% ./rfcfold.bash -s 1 -i /tmp/i.txt -o /tmp/t.txt && cat /tmp/t.txt
========== NOTE: '\' line wrapping per RFC 8792 ===========
[{"af":6,"avg":23.4686283333,"dst_addr":"2001:67c:2218:e::51:41","ds\
t_name":"2001:67c:2218:e::51:41","dup":0,"from":"2a01:4240:5f52:bbc4\
::ba3","fw":5020,"group_id":26102101,"lts":30,"max":23.639063,"min":\
23.285885,"msm_id":26102101,"msm_name":"Ping","mver":"2.2.1","prb_id\
":1000276,"proto":"ICMP","rcvd":3,"result":[{"rtt":23.480937},{"rtt"\
:23.639063},{"rtt":23.285885}],"sent":3,"size":64,"src_addr":"2a01:4\
240:5f52:bbc4::ba3","step":null,"stored_timestamp":1593694541,"times\
tamp":1593694538,"ttl":52,"type":"ping"},{"af":6,"avg":65.9926666667\
...
Et avec la deuxième stratégie :
% ./rfcfold.bash -s 2 -i /tmp/i.txt -o /tmp/t.txt && cat /tmp/t.txt|more
========== NOTE: '\\' line wrapping per RFC 8792 ==========
[{"af":6,"avg":23.4686283333,"dst_addr":"2001:67c:2218:e::51:41","ds\
\t_name":"2001:67c:2218:e::51:41","dup":0,"from":"2a01:4240:5f52:bbc\
\4::ba3","fw":5020,"group_id":26102101,"lts":30,"max":23.639063,"min\
\":23.285885,"msm_id":26102101,"msm_name":"Ping","mver":"2.2.1","prb\
\_id":1000276,"proto":"ICMP","rcvd":3,"result":[{"rtt":23.480937},{"\
\rtt":23.639063},{"rtt":23.285885}],"sent":3,"size":64,"src_addr":"2\
\a01:4240:5f52:bbc4::ba3","step":null,"stored_timestamp":1593694541,\
\"timestamp":1593694538,"ttl":52,"type":"ping"},{"af":6,"avg":65.992\
L'option -r du script permet d'inverser,
c'està-dire de reconstituer le fichier original à partir du fichier
aux lignes pliées.
L'outil rfcfold n'a pas de connaissance des
formats de fichiers et coupe donc brutalement, y compris au milieu
d'un nom de variable. Un outil plus intelligent (section 9.3)
pourrait couper au bon endroit, par exemple, pour XML, juste avant le
début d'un élément XML.
L'article seul
RFC 8820: URI Design and Ownership
Date de publication du RFC : Juin 2020
Auteur(s) du RFC : M. Nottingham
Première rédaction de cet article le 1 juillet 2020
Ah, les URI... Comme ces identificateurs sont très
souvent vus et manipulés par un grand nombre d'utilisateurs, ils
suscitent forcément des passions et des discussions sans fin. Ce
RFC de bonne
pratique s'attaque à un problème fréquent : les applications ou
extensions qui imposent des contraintes sur l'URI, sans que cela
soit justifié par le format de ces URI. Par exemple, on voit des
CMS
imposer, au moment de l'installation, que le CMS soit accessible par
un URI commençant par le nom du logiciel. S'il s'appelle Foobar, on
voit parfois des logiciels qui ne marchent que si l'URI commence par
http://www.example.org/Foobar/. Pourquoi est-ce
une mauvaise idée et que faudrait-il faire à la place ? (Ce document
remplace le RFC 7320, dans le sens d'un plus
grand libéralisme : moins de directives et davantage de
suggestions.)
Ce RFC est destiné aux concepteurs d'application (par exemple les API REST) et aux auteurs de protocoles qui étendent les protocoles existants.
D'abord, l'argument d'autorité qui tue : la norme des URI, le RFC 3986, dit clairement que la structure d'un URI
est déterminé par son plan
(scheme en anglais) et que donc l'application n'a
pas le droit d'imposer des règles supplémentaires. Les deux seuls
« propriétaires » sont la norme décrivant le plan (qui impose une
syntaxe, et certains éléments, par exemple le nom du serveur avec le
plan http://) et l'organisation qui contrôle
cet URI particulier (par exemple, toujours pour
http://, l'organisation qui contrôle le
domaine dans
l'URI). Imposer des règles, pour une application ou une extension,
c'est violer ce principe de propriété. (Il est formalisé dans une
recommandation du W3C, section 2.2.2.1.)
Un exemple de structure dans les URI est l'interprétation du
chemin (path en anglais) comme étant un endroit
du système de fichiers. Ainsi, bien des
serveurs HTTP, en voyant l'URI
http://www.example.org/foo/bar/toto.html,
chercheront le fichier en
$DOCUMENT_ROOT/foo/bar/toto.html. C'est une
particularité de la mise en œuvre de ce serveur, pas une obligation
du plan d'URI http://. Un autre exemple est
l'utilisation de l'extension du nom de fichier comme moyen de
trouver le type de média de
la ressource. (« Ça se termine en .png ? On
envoie le type image/png. ») Ces deux cas ne
violent pas forcément le principe de propriété des URI car
l'utilisateur, après tout, choisit son serveur.
Mais, dans certains cas, l'imposition d'une structure (autre que celle déjà imposée par la norme du plan d'URI) a des conséquences néfastes :
- Risque de collisions entre deux conventions différentes.
- Risque d'instabilité si on met trop d'informations dans l'URI (voir la section 3.5.1 du document « Architecture of the World Wide Web, Volume One », cité plus haut). Pour reprendre l'exemple de l'extension du fichier, si on change le format de l'image de PNG en JPEG, l'URI changera, ce qui est néfaste.
- Rigidité accrue. Si un logiciel impose d'être installé en
/Foobarcomme dans l'exemple au début, il contraint les choix pour l'administrateur système (et si je veux des URI avec un chemin vide, genrehttp://foobar.example.org/, je fais quoi ?) - Risque que le client fasse des suppositions injustifiées. Si
une spécification décrit le paramètre
sigcomme étant forcément une signature cryptographique, il y a une possibilité qu'un logiciel client croit, dès qu'il voit un paramètre de ce nom, que c'est une signature.
Donc, pour toutes ces raisons, notre RFC déconseille fortement de rajouter des règles de structure dans les URI. Ces règles diminuent la liberté du propriétaire de l'URI.
Qui risque de violer ce principe ? Les auteurs d'applications,
comme dans l'exemple Foobar plus haut, mais aussi des gens qui font
des extensions aux URI, par le biais de nouvelles spécifications
(par exemple pour mettre des signatures ou autres métadonnées dans
l'URI). En revanche, ce principe ne s'applique pas au propriétaire
lui-même, qui a évidemment le droit de définir ses règles pour la
gestion de ses URI (exemple : le webmestre
qui crée un schéma de nommage des URI de son site
Web). Et cela ne s'applique pas non plus au cas où le
propriétaire de l'URI reçoit lui-même une délégation pour gérer ce
site (par exemple, un RFC qui crée un registre IANA et
spécifie la structure des URI sous
https://www.iana.org/ est dans son droit,
l'IANA agissant sur délégation de l'IETF). Le principe ? On
n'interdit pas de mettre de la structure dans les URI, on dit juste
qui a le droit de le faire.
La partie normative de notre RFC est la section 2. Elle explicite
le principe. D'abord, éviter de contraindre l'usage d'un plan
particulier. Par exemple, imposer http:// peut
être trop contraignant, certaines applications ou extensions
pourraient marcher avec d'autres plans d'URI comme par exemple
file:// (RFC 8089).
D'autre part, si on veut une structure dans les URI d'un plan
particulier, cela doit être spécifié dans le document qui définit le
plan (RFC 7230 pour
http://, RFC 6920 pour
ni:, etc) pas dans une extension faite par
d'autres (« touche pas à mon plan »).
Les URI comprennent un champ « autorité » juste après le
plan. Les extensions ou applications ne doivent
pas imposer de contraintes particulières sur ce
champ. Ainsi, pour http://, l'autorité est un
nom de domaine et notre
RFC ne permet pas qu'on lui mette des contraintes (du genre « le
premier composant du nom de domaine doit commencer par
foobar-, comme dans
foobar-www.example.org »).
Même chose pour le champ « chemin », qui vient après
l'autorité. Pas question de lui ajouter des contraintes (comme dans
l'exemple du CMS qui imposerait /Foobar comme
préfixe d'installation). La seule exception est la définition des
URI bien connus du RFC 8615 (ceux dont le
chemin commence par /.well-known). Le RFC 6415 donne un exemple d'URI bien connus, avec
une structure imposée.
Autre conséquence du principe « bas les pattes » et qui est, il
me semble, plus souvent violée en pratique, le champ « requête »
(query). Optionnel, il se trouve après le
point d'interrogation dans l'URI. Notre RFC
interdit aux applications d'imposer l'usage des requêtes, car cela
empêcherait le déploiement de l'application dans d'autres contextes
où, par exemple, on veut utiliser des URI sans requête (je dois dire
que mes propres applications Web violent souvent ce principe). Quant
aux extensions, elles ne doivent pas contraindre le format des
requêtes. L'exemple cité plus haut, d'une extension hypothétique,
qui fonctionnerait par l'ajout d'un paramètre
sig aux requêtes pour indiquer une signature
est donc une mauvaise idée. Une telle extension causerait des
collisions (applications ou autres extensions qui voudraient un
paramètre de requête nommé sig) et des risques
de suppositions injustifié (un logiciel qui se dirait « tiens, un
paramètre sig, je vais vérifier la signature,
ah, elle est invalide, cet URI est erroné »). Au passage, les
préfixes n'aident pas. Supposons qu'une extension, voulant limiter
le risque de collisions, décide que tous les paramètres qu'elle
définit commencent par myapp_ (donc, la
signature serait myapp_sig). Cela ne supprime
pas le risque de collisions puisque le préfixe lui-même ne serait
pas enregistré.
(Sauf erreur, Dotclear gère bien cela, en
permettant, via les « méthodes de lecture »
PATH_INFO ou QUERY_STRING
d'avoir les deux types d'URI, sans requête ou bien avec.)
Pourtant, HTML lui-même fait cela, dans la norme 4.01, en restreignant la syntaxe lors de la soumission d'un formulaire. Mais c'était une mauvaise idée et les futures normes ne devraient pas l'imiter.
Comme précédemment, les URI bien connus ont, eux, droit à changer
la syntaxe ou contraindre les paramètres puisque, d'une certaine
façon, l'espace sous .well-known est délégué à
l'IETF et n'est plus « propriété » de l'autorité.
Dernier champ de l'URI à étudier, l'identificateur de fragment (ce qui est après le croisillon). Les définitions d'un type de média (RFC 6838) ont le droit de spécifier la syntaxe d'un identificateur de fragment spécifique à ce type de média (comme ceux du texte brut, dans le RFC 5147). Les autres extensions doivent s'en abstenir sauf si elles normalisent une syntaxe pour de futurs types de médias (comme le fait le RFC 6901).
Bon, assez de négativité et d'interdiction. Après les « faites pas ci » et les « faites pas ça », la section 3 de notre RFC expose les alternatives, les bonnes pratiques pour remplacer celles qui sont interdites ici. D'abord, si le but est de faire des liens, il faut se rappeler qu'il existe un cadre complet pour cela, décrit dans le RFC 8288. Une application peut utiliser ce cadre pour donner la sémantique qu'elle veut à des liens. Autre technique rigolote et peu connue, les gabarits du RFC 6570, qui permettent de gérer facilement le cas de données spécifiques à l'application dans un URI.
Et, comme cité plusieurs fois, les URI bien connus du RFC 8615 sont un moyen de déclarer sa propre structure sur des URI. Par contre, ils sont censés avoir un usage limité (accéder à des métadonnées avant de récupérer une ressource) et ne sont pas un moyen générique d'échapper aux règles qui nous dérangent !
Les changements depuis le premier RFC qui avait décrit ces règles
(RFC 7320) sont résumés dans l'annexe A. En
gros, moins d'interdictions, et davantage de conseils. Par exemple,
la règle comme quoi une application ne devrait pas empêcher
l'utilisation de futurs plans (comme file: en
plus de http:) n'utilise maintenant plus le
vocabulaire normatif du RFC 2119 et est donc
désormais davantage un avis. De même, pour le composant « requête »
de l'URI, l'interdiction de spécifier sa syntaxe dans les
applications n'est désormais plus une règle absolue. Autre cas, le
RFC 7320 parlait négativement, non seulement
du préfixe de chemin d'URI fixe (le /Foobar
dans mes exemples) mais même d'une partie fixe du chemin, y compris
si elle n'était pas au début du chemin. Cela avait suscité
des débats houleux dans la discussion du RFC 9162 (successeur du RFC 6962) et cette restriction a donc été
supprimée.
L'article seul
RFC 8785: JSON Canonicalization Scheme (JCS)
Date de publication du RFC : Juin 2020
Auteur(s) du RFC : A. Rundgren, B. Jordan (Broadcom), S. Erdtman (Spotify AB)
Pour information
Première rédaction de cet article le 29 juin 2020
Des opérations cryptographiques comme la signature sont nettement plus simples lorsqu'il existe une forme canonique des données, une représentation normalisée qui fait que toutes les données identiques auront la même représentation. Le format de données JSON n'a pas de forme canonique standard, ce RFC documente une des canonicalisations possibles, JCS (JSON Canonicalization Scheme).
Pourquoi canonicaliser ? Parce que deux documents JSON dont le contenu est identique peuvent avoir des représentations texte différentes. Par exemple :
{"foo": 1, "bar": 3}
et
{
"foo": 1,
"bar": 3
}
représentent exactement le même objet JSON. Mais la signature de ces deux formes textuelles ne donnera pas le même résultat. Pour les mécanismes de signature de JSON (comme JWS, décrit dans le RFC 7515), il serait préférable d'avoir un moyen de garantir qu'il existe une représentation canonique de l'objet JSON. Ce RFC en propose une. Je vous le dis tout de suite, la forme canonique de l'objet ci-dessus sera :
{"bar":3,"foo":1}
JSON est normalisé dans le RFC 8259. Il n'a pas de canonicalisation standard. Comme c'est une demande fréquente, plusieurs définitions d'une forme canonique de JSON ont été faites (cf. annexe H du RFC), comme Canonical JSON ou comme JSON Canonical Form. Mais aucune n'est encore la référence. (Vous noterez que ce RFC n'est pas une norme.) Cette situation est assez embêtante, alors que XML, lui, a une telle norme (cf. XML Signature).
Notez que la solution décrite dans ce RFC se nomme JCS, mais qu'il y a aussi un autre JCS, JSON Cleartext Signature.
Parmi les concepts importants de la proposition de ce RFC, JCS :
La section 3 du RFC décrit les opérations qui, ensemble, forment la canonicalisation JCS. À partir de données en mémoire (obtenues soit en lisant un fichier JSON, ce que je fais dans les exemples à la fin, soit en utilisant des données du programme), on émet du JSON avec :
- Pas d'espaces entre les éléments
lexicaux (
"foo":1et pas"foo": 1), - Représentation des nombres en suivant les règles de
sérialisation « ES6 » citées plus haut
(
3000000au lieu de3E6, c'est la section 7.12.2.1 de ES6, si vous avez le courage, les puissances de 10 où l'exposant est inférieur à 21 sont développées), - Membres des objets (rappel : un objet JSON est un
dictionnaire) triés
(
{"a":true,"b":false}et non pas{"b:"false,"a":true}), - Chaînes de caractères en UTF-8.
Concernant le tri, André Sintzoff me fait remarquer que les règles de tri de JSON sont parfois complexes. Évidentes pour les caractères ASCII, elles sont plus déroutantes en dehors du BMP.
Plusieurs annexes complètent ce RFC. Ainsi, l'annexe B fournit des exemples de canonicalisation des nombres.
Et pour les travaux pratiques, on utilise quoi ? L'annexe A du
RFC contient une mise en œuvre en JavaScript,
et l'annexe G une liste d'autres mises en œuvre (que vous
pouvez aussi trouver en
ligne). Ainsi, en npm, il y a
https://www.npmjs.com/package/canonicalizehttps://github.com/erdtman/java-json-canonicalization
Commençons avec Python, et https://github.com/cyberphone/json-canonicalization/tree/master/python3
{
"numbers": [333333333.33333329, 1E30, 4.50,
2e-3, 0.000000000000000000000000001],
"string": "\u20ac$\u000F\u000aA'\u0042\u0022\u005c\\\"\/",
"literals": [null, true, false]
}
Et ce programme :
from org.webpki.json.Canonicalize import canonicalize import json import sys raw = open(sys.argv[1]).read() data = canonicalize(json.loads(raw)) print(data.decode())
On obtient :
% git clone https://github.com/cyberphone/json-canonicalization.git
% export PYTHONPATH=json-canonicalization/python3/src
% ./canonicalize.py test.json
{"literals":[null,true,false],"numbers":[333333333.3333333,1e+30,4.5,0.002,1e-27],"string":"€$\u000f\nA'B\"\\\\\"/"}
Et en Go ? Avec le même fichier JSON de départ, et ce programme :
package main
import ("flag";
"fmt";
"os";)
import "webpki.org/jsoncanonicalizer"
func main() {
flag.Parse()
file, err := os.Open(flag.Arg(0))
if err != nil {
panic(err)
}
data := make([]byte, 1000000)
count, err := file.Read(data)
if err != nil {
panic(err)
}
result, err := jsoncanonicalizer.Transform(data[0:count])
if err != nil {
panic(err);
} else {
fmt.Printf("%s", result);
}
}
On arrive au même résultat (ce qui est bien le but de la canonicalisation) :
% export GOPATH=$(pwd)/json-canonicalization/go
% go build canonicalize.go
% ./canonicalize.py test.json
{"literals":[null,true,false],"numbers":[333333333.3333333,1e+30,4.5,0.002,1e-27],"string":"€$\u000f\nA'B\"\\\\\"/"}
Comme notre RFC contraint le JSON à suivre le sous-ensemble I-JSON (RFC 7493), si le texte d'entrée ne l'est pas, il va y avoir un problème. Ici, avec un texte JSON qui n'est pas du I-JSON (deux membres de l'objet principal ont le même nom) :
% cat test3.json
{
"foo": 1,
"bar": 3,
"foo": 42
}
% ./canonicalize test3.json
panic: Duplicate key: foo
(Un autre code en Go est en https://github.com/ucarion/jcs
L'excellent programme jq n'a pas d'option
explicite pour canonicaliser, mais Sébastien Lecacheur me fait
remarquer que les options -c et
-S donnent apparemment le même résultat (y
compris sur les nombres, ce qui ne semble pas documenté) :
% cat example.json
{
"foo": 1,
"bar": 3000000000000000000000000000000,
"baz": true
}
% jq -cS . example.json
{"bar":3e+30,"baz":true,"foo":1}
Par contre, je n'ai rien trouvé sur ce formateur en ligne.
Comme il y a un brevet pour tout, notez qu'apparemment VMware prétend avoir inventé la canonicalisation JSON (cf. ce signalement, et le commentaire « The patent is effectively a JSON based "remake" of XML's "enveloped" signature scheme which in the submitter's opinion makes it invalid. »).
L'article seul
RFC 8765: DNS Push Notifications
Date de publication du RFC : Juin 2020
Auteur(s) du RFC : T. Pusateri, S. Cheshire
(Apple)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnssd
Première rédaction de cet article le 23 juin 2020
Lorsqu'une donnée DNS change dans les serveurs faisant autorité, les clients ne seront prévenus que lorsqu'ils reviendront demander, et cela peut être long s'ils ont mémorisé l'ancienne valeur. Ce RFC propose une autre approche, où les données DNS sont poussées vers les clients au lieu d'attendre qu'ils tirent.
Qu'est-ce qui fait que des données DNS changent ? Cela peut être l'administrateur système qui a changé la zone et rechargé le serveur faisant autorité. Ou bien il y a pu y avoir mise à jour dynamique (RFC 2136). Ou encore d'autres mécanismes. Dans tous les cas, certains clients DNS (par exemple pour la découverte de services du RFC 6763) aimeraient bien être prévenus tout de suite (et voir la nouvelle imprimante du réseau local apparaitre dans la liste). Le DNS est purement pull et ces clients voudraient un peu de push.
Cette idée de protocoles push, où on envoie les données vers les clients au lieu d'attendre qu'il les réclame, est nouvelle pour le DNS mais ancienne dans l'Internet (modèle publish/subscribe ou design pattern Observateur). Parmi les protocoles IETF, XMPP peut fonctionner ainsi (cf. XEP0060).
Il y a quand même un peu de push dans une variante du DNS, mDNS (RFC 6762, section 5.2), où les changements peuvent être poussés vers une adresse IP multicast. Mais des protocoles comme la découverte de services du RFC 6763 peuvent aussi fonctionner sans multicast et cette solution ne leur convient donc pas. Il existait une solution non-standard, LLQ (Long-Lived Queries), décrite dans le RFC 8764 et mise en œuvre dans les produits Apple (cf. RFC 6281). Utilisant UDP, elle ne convient guère au DNS moderne.
Il existe aujourd'hui un mécanisme plus pratique pour déployer des fonctions comme le push : DSO (DNS Stateful Operations, RFC 8490), qui repose sur des connexions de longue durée, sur TCP (et TLS pour la sécurité). La solution push est donc bâtie sur DSO, et il est donc bon d'avoir lu le RFC 8490 avant celui-ci.
La section 3 de notre RFC présente le protocole DNS
push. Un client s'abonne à un service de notification et,
une fois abonné, il reçoit les nouveautés. Quand il n'a plus besoin
des données, le client se déconnecte. L'abonnement est valable pour
un certain couple {nom de
domaine, type de données}. Client et serveur utilisent
le mécanisme DSO du RFC 8490. Comment le
client trouve-t-il le serveur ? Ce n'est pas forcément un des
serveurs listés comme faisant autorité pour la zone. Il peut être
trouvé en demandant à son résolveur normal (s'il accepte DSO, le
client peut tenter sa chance) dans le DNS, puis, si ça ne marche
pas, via une requête SRV pour le nom
_dns-push-tls._tcp.LA-ZONE (cf. section 6, et
son enregistrement
à l'IANA). Rappelez-vous que, si un serveur DNS accepte DSO
mais pas DNS push, il répondra avec un code
de retour DNS DSOTYPENI (RFC 8490, section 5.1.1).
Pour éviter de trop charger le serveur, le client ne doit s'abonner que s'il a une bonne raison, par exemple parce qu'une fenêtre de sélection d'une imprimante est ouverte, et qu'il veut la rafraichir en permanence. Lorsque le client va s'endormir ou estomper son écran pour économiser sa batterie, il devrait se désabonner d'abord. En tout cas, le mécanisme DNS push ne devrait pas être utilisé 24x7, ce n'est pas son but. (Et c'est inutile, le mécanisme est suffisamment rapide pour pouvoir être invoqué seulement quand on en a besoin.)
De toute façon, le serveur n'est pas obligé d'accepter tous les clients qui se présentent. Il peut rejeter les abonnements s'il manque de ressources (section 4 du RFC).
Comment est-ce que le client demande du DNS
push ? En s'abonnant, une fois la session DSO établie. Il
envoie une requête
de type DSO SUBSCRIBE (la syntaxe des
TLV DSO est dans le RFC 8490, section 5.4.4). Dans les données de la requête se
trouvent le nom de domaine et le type de données qui intéressent le
client. Le serveur répond alors NOERROR (ou
bien un code DNS d'erreur s'il y a un problème, par exemple
REFUSED si le serveur ne veut pas) et envoie
une réponse de type SUBSCRIBE (même type que la
requête, c'est le bit QR de l'en-tête DNS qui permet de différencier
requête et réponse). Il est parfaitement légitime pour un client de
s'abonner à un nom de domaine qui n'existe pas encore, et le serveur
ne doit donc jamais répondre NXDOMAIN.
Une fois l'abonnement accepté, le client attend tranquillement
et, lorsqu'un changement survient, le serveur envoie des messages de
type DSO PUSH (code 0x0041). Les
données contenues dans ce message sont formatées comme les messages
DNS habituels, avec une exception : un TTL valant 0xFFFFFFFF signifie que l'ensemble
d'enregistrements concerné a été supprimé.
À la fin, quand le client n'est plus intéressé, il envoie un
message DSO UNSUBSCRIBE (code 0x0042). Encore
plus radical, le client peut mettre fin à la session DSO, annulant
ainsi tous ses abonnements.
Et la sécurité de ce DNS push (section 7 du RFC) ? DNS push impose l'utilisation de TLS (donc on a du DSO sur TLS sur TCP). Le client doit authentifier le serveur selon le profil strict du RFC 8310. Ensuite, DNSSEC est recommandé pour la découverte du serveur DNS push, lorsqu'on utilise les requêtes SRV, puis DANE pour vérifier le serveur auquel on se connecte (RFC 7673).
Ensuite, DNS push permet d'utiliser les données précoces du RFC 8446 (section 2.3), ce qui permet de diminuer la latence. Mais elles posent quelques problèmes de sécurité : plus de confidentialité persistante, et risque de duplication des messages. D'autre part, si on utilise la reprise de session du RFC 8446 (section 2.2), il faut noter que, si elle permet de ne pas recommencer toute la session TLS, en revanche, elle ne garde pas les abonnements DNS push, que le client devra donc renouveler.
Désolé, mais je ne connais pas encore de mise en œuvre de ce RFC, à part dans le monde Apple.
L'article seul
Risques pour la vie privée liés aux personnes proches
Première rédaction de cet article le 22 juin 2020
De nombreux articles ont été écrits sur la vie privée, et sur sa défense dans le monde numérique. Beaucoup de techniques ont été développées pour faire face aux menaces contre la vie privée, notamment autour du chiffrement. Mais ces techniques, quoique indispensables pour vous protéger d'un attaquant extérieur à votre entourage, ne sont pas forcément efficaces face à un proche. Or, les attaques contre la vie privée peuvent parfaitement être le fait de personnes proches, par exemple dans le cas d'un espionnage d'une épouse par un mari jaloux. Dans un article en anglais publié dans le Journal of Cybersecurity, Karen Levy et Bruce Schneier argumentent qu'il est urgent de traiter le cas des attaquants proches.
Un attaquant proche, cela peut être un ou une conjoint·e, les parents (ou les enfants !), un ou une colocataire. Beaucoup de mesures de sécurité sont fondées sur des suppositions sur l'attaquant, suppositions qui ne sont plus vraies dans le cas d'attaquants proches. Un exemple typique est celui des questions de sécurité « quel était le nom de jeune fille de votre mère », questions auxquelles un attaquant proche peut facilement répondre. Or, alors que la littérature technique et scientifique sur la sécurité informatique est pleine d'articles sur les attaquants, leurs motivations, leurs capacités, les meilleurs moyens de s'en protéger, il y a assez peu de publications sur la classe des attaquants proches (intimate threats). Mes lecteurs et lectrices orientés vers la technique peuvent se demander en quoi ces attaques par des proches sont si spéciales et si différentes des attaques plus connues. Patience, vous allez avoir des exemples.
Ces attaques par des proches sont difficiles à quantifier, mais semblent fréquentes : dans un sondage, 31 % des personnes interrogées ont admis avoir fouillé dans un ordiphone sans autorisation. (La grande majorité des exemples cités dans l'articles concernent les États-Unis, mais il n'y a pas de raison de penser que cela soit très différent ailleurs.) Parmi les gens hébergés dans des abris pour victimes de violences conjugales, les trois quarts ont été victimes de surveillance exercée par leur agresseur via des outils numériques. Et les attaques contre la vie privée sont souvent le préalable à des attaques plus dramatiques, par exemple des féminicides.
L'article classe dans les attaques de proches la surveillance exercée par les parents sur leurs enfants mineurs. Même si elle est bien intentionnée, elle n'est pas forcément une bonne idée, et elle contribue à banaliser la surveillance.
D'abord, les auteurs notent bien que la surveillance est inévitable dans une relation entre personnes proches. Quand on vit dans le même appartement, on sait quand l'autre rentre et sort, par exemple, une information typiquement considérée comme privée. On entend l'autre ou les autres parler au téléphone, on connait ses problèmes de santé, dans un couple, on a souvent un compte joint, on partage souvent le même PC, sans séparation entre plusieurs comptes sur la machine, etc (l'article donne plusieurs références d'études concernant le niveau de partage dans les couples). On pourrait en déduire qu'il n'y a pas de vie privée quand on vit ensemble mais ce n'est évidemment pas vrai. On ne veut pas que son conjoint, son colocataire, ou ses amis savent absolument tout de vous. Et c'est évidemment encore plus vrai si on a, par exemple, un conjoint violent. Mais le problème est compliqué : le partage d'informations n'est pas un mal en soi, et le niveau de partage dépend de goûts personnels et de normes sociales, tous les deux très variables. Et il peut être vu comme une preuve de confiance (« si on s'aime, on ne dissimule pas son mot de passe »).
Parfois, la question même de savoir si l'accès aux données des autres est légitime ou pas est compliquée. S'il n'y a aucun doute qu'on ne doit pas intercepter les messages échangés par un voisin dans le train, la question est moins claire dans le cas familial. Les parents doivent évidemment suivre ce qui arrive aux enfants mineurs (d'autant plus que certains problèmes, par exemple de harcèlement, ne seront pas toujours signalés spontanément). Et même entre adultes, chercher à savoir pourquoi son conjoint ou sa conjointe semble déprimé·e ou anxieu·x·se n'est-il pas souhaitable ? L'approche classique de la sécurité informatique, avec des règles simples (« dans une communication entre Alice et Bob, toute personne qui n'est pas Alice ou Bob est un attaquant »), ne marche pas forcément ici.
Cette difficulté à différencier ce qui est une communication normale et ce qui est de la surveillance est encore plus sérieuse sur le terrain juridique : porter plainte pour de l'espionnage par un proche est difficile, la justice pouvant hésiter à trancher la question de savoir ce qu'il est normal de partager au sein du couple. C'est encore plus compliqué dans les cas où la loi donne explicitement au mari le droit de surveiller sa femme, comme en Arabie saoudite, où l'État gère même un site Web permettant aux hommes de demander à être notifiés des déplacements de leur femme.
Notez que, dans des pays supposés plus civilisés, on voit également des horreurs, comme des applications de surveillance qui disent explicitement dans leur publicité que le but est de fliquer sa femme. Le pire étant sans doute cette société qui vend un matelas connecté permettant de détecter les mouvements suspects dans le lit, en votre absence (mais l'article contient d'autres exemples affreux ; aux États-Unis, les sociétés commerciales n'hésitent pas à faire ouvertement de la publicité pour des usages amoraux ; en Europe, on est plus hypocrites). Même quand la publicité ne dit pas explicitement que le but est de surveiller, beaucoup des gadgets connectés permettent de le faire facilement, et sont souvent utilisés en ce sens.
Un cas bien plus compliqué que celui du macho fliquant sa femme est celui, déjà mentionné, des parents surveillant leurs enfants. « Surveillance » n'est pas forcément un terme négatif, ici. Évidemment que les parents doivent surveiller leurs enfants mineurs, pour éviter qu'ils ne se mettent en danger, ou mettent en danger les autres. Mais le marketing exagère les dangers, pour vendre du matériel et des applications de surveillance. Cela va jusqu'à des bracelets connectés, comme ceux imposés aux prisonniers. (L'URL donné dans l'article ne marche plus, quoique la société soit toujours là, peut-être a-t-elle eu honte de son produit.) Dans le cas particulier des États-Unis, notez qu'il existe une énorme pression sociale contre tout ce qui apparait comme une négligence par les parents dans ce domaine. Policiers et même simple voisins se sentent autorisés à harceler les parents qui laissent ne serait-ce qu'un tout petit peu de liberté à leurs enfants. D'où le mouvement Free-range, qui plaide pour qu'on desserre la surveillance des enfants. Notez que ce soupçon contre les parents, et cette pression pour qu'ils resserrent la vis, est surtout dirigée contre les parents des classes populaires.
Quant à l'activité en ligne, aux États-Unis, la surveillance de l'activité des enfants par les parents est très répandue. (Et les parents qui ne le font pas ne sont pas forcément motivés par le désir de laisser de la liberté à leurs enfants, ils peuvent simplement être incompétents techniquement.) Le but n'est d'ailleurs pas uniquement d'assurer la sécurité de l'enfant, au moins une application prévient les parents quand… l'enfant utilise des gros mots en ligne.
L'article note aussi que le problème peut être inverse : dans les familles où la personne la plus à l'aise avec les outils numériques est un des enfants, les enfants peuvent violer la vie privée de leurs parents, et accéder à de l'information personnelle. Même la biométrie ne les arrête pas : comme les enfants ressemblent à leurs parents, ils peuvent parfois tromper la reconnaissance faciale.
Parmi les attaquants proches possibles, l'article note aussi le cas des personnes âgées. Comme pour le cas des enfants, une certaine surveillance peut être bien intentionnée. (Ce qui ne veut pas dire acceptable : les personnes âgées ne sont pas des mineures.) Le problème est que les visions de la personne âgée et de celle qui décide pour elle peuvent diverger, comme dans ce sondage du journal The gerontologist, cité dans l'article, où les surveillés avaient systématiquement une moins bonne opinion de la surveillance que les surveillants.
Enfin, parmi les personnes proches qui peuvent poser des problèmes en matière de vie privée, il y a les amis qui, sans partager autant de choses avec vous qu'un conjoint ou un ascendant, connaissent quand même pas mal de choses. Le problème est particulièrement net pour les jeunes, où les relations d'amitié peuvent être de courte durée. Les secrets confiés pendant la période d'amitié peuvent être dangereux ensuite.
Quels sont les points communs aux attaques contre la vie privée menées par des personnes proches, points qui méritent d'être pris en considération dans la recherche de solutions de protection ? D'abord, les auteurs notent que les attaquants ne sont pas toujours rationnels. Dans une attaque traditionnelle, le défenseur compte sur la rationalité de l'attaquant. Si celui-ci vise un gain financier, il ne dépensera pas d'avantage d'argent pour l'attaque que celle-ci lui aurait rapporté. Ce calcul devient faux dans le cas d'atteintes à la vie privée menées par des personnes proches, qui peuvent être motivées par des émotions irrationnelles comme la jalousie. L'un des auteurs se souvient d'avoir, enfant, occupé une journée d'oisiveté à essayer les 10 000 combinaisons possibles d'un cadenas, sans espoir d'un gain particulier, juste parce qu'il s'ennuyait. Un cambrioleur classique n'aurait pas fait cela.
Ensuite, les attaquants proches habitent souvent dans la même maison que les victimes. Cette coprésence complique sérieusement les questions de sécurité informatique où, souvent, le concepteur des solutions suppose que les différentes parties en cause sont physiquement séparées. Par exemple, regarder par dessus l'épaule pour apprendre un mot de passe est bien plus facile quand on vit ensemble. Même chose pour l'installation d'un logiciel malveillant sur l'ordinateur ou l'ordiphone de sa cible. Ou encore les systèmes d'exploitation d'ordiphone qui affichent tout ou partie d'un message entrant, même quand le téléphone est verrouillé. Un exemple plus amusant est celui de cette femme jalouse qui avait déverrouillé l'ordiphone de son mari en profitant d'une sieste pour placer son doigt sur le lecteur d'empreintes digitales.
Moins amusant, mais hélas fréquent dans le cas d'attaques par un proche, le risque de menaces ou de violences physiques. Le meilleur mot de passe du monde ne sert à rien si un mari violent menace de tabasser sa femme pour avoir accès à son ordinateur. Ce risque de pression physique est rarement pris en compte dans les analyses de sécurité.
Dans les analyses de sécurité classiques, on suppose que l'attaquant est un étranger complet, qui n'a pas de pouvoir particulier sur la victime. Dans les cas des attaques par les proches, ce n'est plus le cas : même sans menace physique explicite, l'attaquant peut exercer un certain pouvoir, par exemple dans les cas où la femme est (légalement, ou de facto) soumise au mari. Cette autorité (qui peut être en place pour d'excellentes raisons, cf. l'autorité des parents sur les enfants) complique encore les choses. Il y a également une « autorité implicite » : dans le foyer, il y a en général une personne qui pilote le système informatique et qui, via ses compétences techniques et sa mainmise sur ledit système, a un pouvoir supérieur. Et cette autorité implicite est souvent genrée : dans le couple, c'est souvent l'homme qui est l'administrateur système.
Enfin, les proches connaissent évidemment beaucoup de choses sur vous, ce qui est normal, mais peut rendre certaines attaques plus faciles.
Bon, ce n'est pas tout de décrire le problème. Et les solutions ? Évidemment, il n'est pas question d'arrêter de vivre en couple, ou d'avoir des amis, de même qu'on ne cesse pas d'avoir des relations sexuelles parce que les MST existent. La première étape est que les concepteurs de systèmes de sécurité devraient reconnaitre le problème des attaques par les proches, problème qui semble sous-estimé aujourd'hui. (J'ai écrit « les concepteurs », comme s'ils étaient tous des hommes, mais ce n'est pas parce que je ne connais pas l'écriture inclusive. L'auteure et l'auteur de l'article font remarquer que les victimes des attaques par les proches sont plus souvent des femmes, alors que les concepteurs des systèmes de sécurité sont plus souvent des hommes, et que cela peut expliquer le retard dans la prise en compte de ces attaques par les proches.)
Déjà, il n'y a pas que des solutions techniques. Il est par exemple anormal que les entreprises qui vendent des solutions de harcèlement restent impunies. La justice devrait les poursuivre, les antivirus devraient les détecter et les bloquer. Pour les systèmes à usages multiples, et qui ne sont donc pas de purs systèmes d'espionnage, c'est plus compliqué, mais l'article fournit plusieurs pistes. (L'article ne mentionne pas une autre piste de solution, celle de changements sociaux, par exemple de changement des relations entre hommes et femmes, avec moins d'indulgence pour la violence conjugale. Ces changements sont également une approche importante.)
Déjà, comme indiqué plus haut, il est temps de reconnaitre que le problème existe, et aussi d'admettre qu'il n'a pas de solution simple (personne ne propose une étanchéité complète dans les relations personnelles).
Plus concrètement, il faut que les concepteurs de systèmes informatiques cessent de considérer que l'attaquant est forcément lointain et fassent, entre autres, attention à ce qu'un système informatique affiche : l'attaquant peut être en train de regarder. C'est bien pour cela qu'on remplace les caractères d'un mot de passe par des puces, mais il faut pousser le raisonnement plus loin par exemple en se méfiant des notifications spontanées (« Vous avez reçu un message de Paul » « C'est qui, ce Paul qui t'écrit ? »). D'autre part, certaines indications visuelles peuvent poser problème. Firefox a un mode « navigation privée » (en général très mal compris et dont il y a beaucoup à dire mais ce n'est pas le sujet) et, au début, il était signalé par une barre violette très visible. Cette indication pouvait facilement être vue et attirer la suspicion (« pourquoi tu es en navigation privée ? Tu ne me fais pas confiance ? Tu as quelque chose à cacher ? ») Elle est depuis devenue plus discrète.
Ce cas contre-intuitif se rencontre également avec certaines options de sécurité bien intentionnées mais qui préviennent l'attaquant potentiel qu'on se méfie de lui. Par exemple, iOS affiche explicitement « Unetelle a cessé de partager sa localisation physique avec vous », ce qui est certainement un bon moyen de provoquer des réactions agressives chez un conjoint jaloux. Les auteurs de l'article estiment qu'il serait préférable de pouvoir « faire semblant », en évitant de montrer un téléphone vide ou un « vous n'avez pas l'autorisation de voir ces messages », qui risque au contraire de susciter des suspicions.
Les options sélectionnées par défaut sont toujours une question cruciale en informatique, car beaucoup d'utilisateurs ne les changent pas. Ils ne savent pas comment les changer, ou n'osent même pas imaginer que cela soit possible. Mais cette importance des choix par défaut est encore plus vraie dans le cas des attaques par les proches, car une fois que le mal est fait, il peut être difficile à rattraper (je ne vous donne pas l'URL vers l'article de TechCrunch en raison de la scandaleuse interface d'acceptation du fliquage du groupe Verizon Media/Oath ; c'est d'ailleurs intéressant de voir un média qui donne des leçons aux autres en matière de vie privée se comporter ainsi ; bref, vous avez l'URL dans l'article).
Autre problème lié aux attaques par les proches : les relations évoluent. À un moment, tout va bien, on se fait une confiance totale et aveugle, puis les choses changent et on doit commencer à prendre des précautions. Il est donc important que les systèmes informatiques prennent en compte ce caractère dynamique. Un exemple ? Il faudrait que le système vous rappelle de temps en temps vos réglages et vous demande s'ils sont toujours d'actualité (« Machin est autorisé à voir vos messages privés. Souhaitez-vous continuer ? »)
Dernier point sur les pistes de solutions, mais très important : arrêter de considérer que le foyer est forcément une unité où tout le monde partage tout. L'acheteur d'un produit n'est pas forcément son seul utilisateur (même s'il est la seule personne qui compte, pour les entreprises du numérique) et il est important de permettre que les utilisateurs aient chacun leur « espace ». Si Netflix permet plusieurs profils pour un compte, ils ne bénéficient d'aucune vie privée, chacun peut voir ce que les autres ont regardé. (YouTube TV est mieux fait de ce point de vue.) Idem avec les machines partagées : si vous avez un iPhone à vous, et qu'il y a un iPad partagé dans la maison, la synchronisation des données risque de montrer à tout utilisateur de l'iPad ce qu'a reçu l'iPhone.
Au minimum, les accès des autres personnes de la maison à vos données ne devraient pas être discrets mais au contraire, il est important que chacun soit prévenu. Dans le monde physique, la surveillance est à la fois très commune (comme je l'avais signalé au début, les personnes qui habitent avec vous savent forcément plein de choses sur vous, et ce n'est pas un problème) et très visible. Tout le monde, sans être un expert en sécurité, sait ce que les proches savent de nous. Le monde numérique est différent : beaucoup de personnes ne se rendent pas compte de ce que ces systèmes informatiques permettent de connaitre, d'autant plus que la littératie numérique est très loin d'être équitablement partagée (par exemple entre hommes et femmes). Une fois n'est pas commune, je vais dire du bien de Facebook : leur système interne permet à des collègues d'accéder à des informations sur vous, mais vous en êtes prévenu·e, par une alerte spirituellement nommée Sauron.
En conclusion, les auteurs de l'article (en anglais) nous préviennent que le problème va malheureusement sans doute s'aggraver dans le futur, avec la prolifération de gadgets connectés. Quelques efforts de protection de la vie privée sont faits, mais pas encore intégrés dans une vision globale de ce risque d'attaque par les proches.
Pour des conseils pratiques dans le cas du couple, je vous recommande l'article d'Éric, « Chacun ses comptes ».
L'article seul
RFC 8806: Running a Root Server Local to a Resolver
Date de publication du RFC : Juin 2020
Auteur(s) du RFC : W. Kumari (Google), P. Hoffman (ICANN)
Pour information
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 19 juin 2020
Toute résolution DNS commence par la racine (de l'arbre des noms de domaine). Bien sûr, la mémorisation (la mise en cache) des réponses fait qu'on n'a pas besoin tout le temps de contacter un serveur racine. Mais c'est quand même fréquent et les performances de la racine sont donc cruciales. L'idée documentée dans ce RFC est donc d'avoir en local un serveur esclave de la racine, copiant celle-ci et permettant donc de répondre localement aux requêtes. Ce RFC remplace le premier RFC qui avait documenté l'idée, le RFC 7706, avec des changements significatifs, notamment vers davantage de liberté (le précédent RFC restreignait sérieusement les possibilités).
Le problème est particulièrement important pour les noms qui
n'existent pas. Si les TLD existants comme
.com ou
.fr vont vite se
retrouver dans la mémoire (le cache) du résolveur DNS, les fautes de
frappe ou autres cas où un TLD n'existe pas vont nécessiter la
plupart du temps un aller-retour jusqu'au serveur racine le plus
proche. Les réponses négatives seront également mémorisées mais 1)
il y a davantage de noms non existants que de noms existants 2) le
TTL est plus court
(actuellement deux fois plus court). Ces noms non existants
représentent ainsi la majorité du trafic de la racine.
Bien qu'il existe aujourd'hui des centaines de sites dans le monde où se trouve une instance d'un serveur racine, ce nombre reste faible par rapport au nombre total de réseaux connectés à l'Internet. Dans certains endroits de la planète, le serveur racine le plus proche est assez lointain. Voici les RTT en millisecondes avec les serveurs racine observés depuis un réseau tunisien (notez les deux serveurs qui répondent bien plus vite que les autres, car ils ont une instance à Tunis) :
% check-soa -4 -i .
a.root-servers.net.
198.41.0.4: OK: 2015112501 (54 ms)
b.root-servers.net.
192.228.79.201: OK: 2015112501 (236 ms)
c.root-servers.net.
192.33.4.12: OK: 2015112501 (62 ms)
d.root-servers.net.
199.7.91.13: OK: 2015112501 (23 ms)
e.root-servers.net.
192.203.230.10: OK: 2015112501 (18 ms)
f.root-servers.net.
192.5.5.241: OK: 2015112501 (69 ms)
g.root-servers.net.
192.112.36.4: OK: 2015112501 (62 ms)
h.root-servers.net.
128.63.2.53: OK: 2015112501 (153 ms)
i.root-servers.net.
192.36.148.17: OK: 2015112501 (67 ms)
j.root-servers.net.
192.58.128.30: OK: 2015112501 (55 ms)
k.root-servers.net.
193.0.14.129: OK: 2015112501 (72 ms)
l.root-servers.net.
199.7.83.42: ERROR: Timeout
m.root-servers.net.
202.12.27.33: OK: 2015112501 (79 ms)
Ces délais peuvent sembler courts mais ils ne forment qu'une partie du travail de résolution, il est donc légitime de vouloir les réduire encore.
En outre, ces requêtes à la racine peuvent être observées, que ce soit par les opérateurs de serveurs racine, ou par des tiers sur le projet, ce qui n'est pas forcément souhaitable, question vie privée (cf. RFC 7626).
Donc, l'idée de base de ce RFC est de :
- Mettre un serveur esclave de la racine sur sa machine, configuré pour ne répondre qu'aux requêtes de cette machine,
- Configurer le résolveur pour interroger d'abord ce serveur.
Cette idée est documentée dans ce RFC mais n'est pas encouragée (c'est un très vieux débat, dont j'avais déjà parlé). En effet, cela ajoute un composant à la résolution (le serveur local faisant autorité pour la racine), composant peu ou pas géré et qui peut défaillir, entrainant ainsi des problèmes graves et difficiles à déboguer. Mais pourquoi documenter une idée qui n'est pas une bonne idée ? Parce que des gens le font déjà et qu'il vaut mieux documenter cette pratique, et en limiter les plus mauvais effets. C'est pour cela, par exemple, que notre RFC demande que le serveur racine local ne réponde qu'à la même machine, pour limiter les conséquences d'une éventuelle défaillance à une seule machine.
Pas découragé ? Vous voulez encore le faire ? Alors, les détails
pratiques. D'abord (section 2 du RFC), les pré-requis. DNSSEC est
indispensable (pour éviter de se faire refiler un faux fichier de
zone par de faux serveurs racine). Ensuite (section 3), vous mettez
un serveur faisant autorité (par exemple NSD ou Knot) qui écoute sur une des adresses
locales (en 127.0.0.0/8,
IPv6 est moins pratique car il ne fournit
paradoxalement qu'une seule adresse locale à la machine) et qui est
esclave des serveurs racine. À noter que votre serveur, n'étant pas
connu des serveurs racine, ne recevra pas les notifications (RFC 1996) et sera donc parfois un peu en retard sur
la vraie racine (ce qui n'est pas très grave, elle bouge peu).
Il est important de lister plusieurs serveurs maîtres dans sa configuration. En effet, si la mise à jour de la racine dans votre serveur esclave échoue, ce sera catastrophique (signatures DNSSEC expirées, etc) et cette configuration locale, contrairement à la « vraie » racine, n'a aucune redondance. (Une autre raison pour laquelle ce n'est pas une idée géniale.) Quels serveurs maîtres indiquer ? Certains serveurs racine permettent le transfert de zone (RFC 5936) mais ce n'est jamais officiel, ils peuvent cesser à tout moment (l'annexe A du RFC donne une liste et discute de ce choix). Une raison de plus de se méfier.
Il est donc important d'avoir un mécanisme de supervision, pour être prévenu si quelque chose échoue. On peut par exemple interroger le numéro de série dans l'enregistrement SOA de la racine et vérifier qu'il change.
Ensuite, une fois ce serveur faisant autorité configuré, il ne reste qu'à indiquer à un résolveur (comme Unbound) de l'utiliser (toujours section 3 du RFC).
Voici un exemple testé. J'ai choisi NSD et Unbound. Le RFC, dans son annexe B, donne plusieurs autres exemples, tous utilisant le même serveur comme résolveur et comme serveur faisant autorité. C'est en général une mauvaise idée mais, pour le cas particulier de ce RFC, cela peut se défendre.
D'abord, la configuration de NSD (notez la longue liste de
maîtres, pour maximiser les chances que l'un d'eux fonctionne ;
notez aussi l'adresse IP choisie,
127.12.12.12) :
# RFC 8806
server:
ip-address: 127.12.12.12
zone:
name: "."
request-xfr: 199.9.14.201 NOKEY # b.root-servers.net
request-xfr: 192.33.4.12 NOKEY # c.root-servers.net
request-xfr: 192.5.5.241 NOKEY # f.root-servers.net
request-xfr: 192.112.36.4 NOKEY # g.root-servers.net
request-xfr: 193.0.14.129 NOKEY # k.root-servers.net
request-xfr: 192.0.47.132 NOKEY # xfr.cjr.dns.icann.org
request-xfr: 192.0.32.132 NOKEY # xfr.lax.dns.icann.org
request-xfr: 2001:500:200::b NOKEY # b.root-servers.net
request-xfr: 2001:500:2f::f NOKEY # f.root-servers.net
request-xfr: 2001:7fd::1 NOKEY # k.root-servers.net
request-xfr: 2620:0:2830:202::132 NOKEY # xfr.cjr.dns.icann.org
request-xfr: 2620:0:2d0:202::132 NOKEY # xfr.lax.dns.icann.org
Le démarrage de NSD (notez qu'il faut patienter un peu la première fois, le temps que le premier transfert de zone se passe) :
[2020-05-04 17:51:05.496] nsd[25649]: notice: nsd starting (NSD 4.3.1) [2020-05-04 17:51:05.496] nsd[25649]: notice: listen on ip-address 127.12.12.12@53 (udp) with server(s): * [2020-05-04 17:51:05.496] nsd[25649]: notice: listen on ip-address 127.12.12.12@53 (tcp) with server(s): * [2020-05-04 17:51:05.600] nsd[25650]: notice: nsd started (NSD 4.3.1), pid 25649 [2020-05-04 17:51:08.380] nsd[25649]: info: zone . serial 0 is updated to 2020050400
C'est bon, on a transféré la zone. Testons (notez le bit AA - Authoritative Answer - dans la réponse) :
% dig @127.12.12.12 SOA . ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 24290 ;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 13, ADDITIONAL: 27 ... ;; ANSWER SECTION: . 86400 IN SOA a.root-servers.net. nstld.verisign-grs.com. 2020050400 1800 900 604800 86400 ... ;; Query time: 3 msec ;; SERVER: 127.12.12.12#53(127.12.12.12) ;; WHEN: Mon May 04 17:51:51 CEST 2020 ;; MSG SIZE rcvd: 868
C'est bon.
Maintenant, la configuration d'Unbound (différente de celle du RFC, qui utilise Unbound à la fois comme résolveur et comme serveur faisant autorité) :
server:
# RFC 8806
do-not-query-localhost: no
# Requires a slave auth. running (normally, nsd)
stub-zone:
name: "."
stub-prime: no
stub-addr: 127.12.12.12
(John Shaft me fait remarquer que la directive
stub-first devrait permettre d'utiliser le
mécanisme de résolution classique si la requête échoue, ce qui
apporterait une petite sécurité en cas de panne du serveur local
faisant autorité pour la racine.) Et le test :
% dig www.cnam.fr ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 30881 ;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1 ;; ANSWER SECTION: www.cnam.fr. 86400 IN CNAME kaurip.cnam.fr. kaurip.cnam.fr. 3600 IN A 163.173.128.40 ...
Ça a marché. Avec tcpdump, on voit le trafic (faible, en raison du cache) vers le serveur racine local :
18:01:09.865224 IP 127.0.0.1.54939 > 127.12.12.12.53: 55598% [1au] A? tn. (31) 18:01:09.865359 IP 127.12.12.12.53 > 127.0.0.1.54939: 55598- 0/8/13 (768)
Pour BIND, et d'autres logiciels, consultez l'annexe B du RFC.
À noter qu'il existe un brevet futile (comme tous les brevets...) de Verisign sur cette technique : déclaration #2539 à l'IETF. Il portait sur l'ancien RFC mais il est peut-être aussi valable (ou aussi ridicule) avec le nouveau.
La section 1.1 de notre RFC documente les changements depuis le
RFC 7606. Le principal est que le serveur
racine local n'a plus l'obligation d'être sur une adresse IP locale
à la machine (comme ::1). Les autres
changements, qui reflètent l'expérience pratique avec cette
technique, après plus de quatre ans écoulés, vont en général dans le
sens de la « libéralisation ». Il y a moins de restrictions que dans
le RFC 7706.
L'article seul
RFC 8789: IETF Stream Documents Require IETF Rough Consensus
Date de publication du RFC : Juin 2020
Auteur(s) du RFC : J. M. Halpern (Ericsson), E. K. Rescorla (Mozilla)
Première rédaction de cet article le 18 juin 2020
Un très court RFC pour une décision de clarification : les RFC publiés par l'IETF (qui ne sont pas la totalité des RFC) doivent recueillir l'accord (le consensus) de l'IETF.
Oui, cela parait assez évident, mais ce n'était pas écrit (le RFC 2026 n'était pas clair à ce sujet). Il existe plusieurs voies (streams) pour les RFC et l'une des voies est nommée IETF stream. Pour être ainsi publié, le RFC doit avoir recueilli le fameux consensus approximatif de l'IETF. Les autres voies, comme la voie indépendante, n'ont pas cette obligation.
Notez que cette obligation de consensus approximatif existait pour les RFC sur le chemin des normes mais pas pour ceux pour information ou expérimentaux. La nouvelle règle tient en une phrase : sur la voie IETF, l'IESG doit veiller à ce que tout RFC, même expérimental, recueille un consensus approximatif. Les documents qui ne réunissent pas un tel consensus peuvent toujours être publiées en RFC via d'autres voies comme la voie indépendante (cf. RFC 8730), ou celle de l'IRTF (cf. RFC 7418).
Certaines décisions précédentes (comme celle de l'IESG en 2007) se posaient déjà la question, mais sans interdire de telles publications.
Notez que le RFC ne rappelle pas comment on vérifie ce consensus approximatif. Un des moyens est via un dernier appel lancé sur la liste de diffusion de l'IETF avant l'approbation. (Voici un exemple récent, notez le Stream: IETF dans l'outil de suivi.)
L'article seul
RFC 8793: Information-Centric Networking (ICN): Content-Centric Networking (CCNx) and Named Data Networking (NDN) Terminology
Date de publication du RFC : Juin 2020
Auteur(s) du RFC : B. Wissingh (TNO), C. Wood (University of California Irvine), A. Afanasyev (Florida International University), L. Zhang (UCLA), D. Oran (Network Systems Research & Design, C. Tschudin (University of Basel)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF icnrg
Première rédaction de cet article le 18 juin 2020
Le terme d'ICN (Information-Centric Networking) désigne un paradigme de communication où tout est du contenu : plus d'adresses IP ou de noms de domaine, on désigne chaque ressource par un nom. Il en existe plusieurs déclinaisons comme le NDN (Named Data Networking) ou le CCNx (Content-Centric Networking). Ce nouveau RFC décrit le vocabulaire de ces deux déclinaisons.
La section 1 du RFC résume les concepts essentiels de l'ICN. Il s'agit d'une architecture de réseaux où le composant de base est un contenu auquel on veut accéder. Pour récupérer, mettons, une image de chaton, on donnerait le nom de cette image et elle arriverait sur votre écran. Dans cette architecture, la notion de machine disparait, il n'y a que du contenu. En théorie, cela permettra de faire du multicast, et de la mémorisation (caching) de contenu par les éléments du réseau, transformant chaque routeur en serveur miroir.
Le concept se décline ensuite en plusieurs architectures, utilisant des terminologies très variables, et peu normalisées. Toutes ne sont pas couvertes dans ce RFC, qui se focalise sur les sujets sur lesquels l'IRTF a le plus travaillé, NDN et CCNx (RFC 8569.)
La section 2 de notre RFC contient une description générale de l'ICN. Il y a un demandeur (requestor), également appelé consommateur, qui voudrait du contenu, mettons une photo de Scarlett Johansson. Il va manifester un intérêt (Interest) qui est un message demandant du contenu. Un ou plusieurs nœuds du réseau (l'équivalent des routeurs, mais la principale différence est qu'ils peuvent stocker du contenu) vont alors faire suivre cet intérêt jusqu'à une machine qui se trouve avoir le contenu en question, soit parce qu'elle en est la source (le producteur), soit parce qu'elle en a une copie. La machine répondra alors avec des données (Data) qui seront relayées en sens inverse, jusqu'au demandeur. Il y a donc deux types de messages, qui pourraient s'appeler requête et réponse mais que, dans le monde ICN, on nomme Intérêt et Données. Le message d'Intérêt contient le nom du contenu convoité. Chaque protocole particulier d'ICN a une façon différente de construire ces noms. Comme le message de Données arrive via plusieurs relais, l'authentification de ce message ne peut pas être déduit de sa source. Il faut qu'il soit signé, ou bien que le nom soit auto-certificateur, par exemple parce que le nom est un condensat du contenu. (Attention, l'authentification n'est pas la même chose que la confiance. Si un message est signé de la porte-parole du gouvernement, cela prouve qu'il vient bien d'elle, pas qu'elle dit la vérité. Voir la section 6 du RFC.)
Pour faire son travail, le nœud ICN va avoir besoin de trois base de données :
- La FIB (Forwarding Interest Base), les moyens de joindre les données,
- La PIT (Pending Interest Table), les requêtes en cours,
- Le stockage (Content Store), puisque tout nœud ICN peut stocker les données qu'il voit passer, pour les transmettre la fois d'après.
Parfois, les données sont de grande taille. En ICN, on dit qu'on va segmenter ces données en plusieurs messages. Le RFC utilise le terme de paquet pour une unité de données après la segmentation. Ces paquets sont potentiellement plus gros que la MTU et on parle de trame (frame) pour l'unité qui passe sur le réseau, après le découpage du paquet.
Une fois qu'on a ce résumé en tête, on peut passer aux termes utilisés dans l'ICN. C'est la section 3 du RFC, le gros morceau. Je ne vais pas les lister tous ici, je fais un choix arbitraire. Attention, comme il s'agit d'un domaine de recherche, et peu stabilisé, il y a beaucoup de synonymes. On a :
- ICN (Information-Centric Networking) ; c'est un concept dont le CCNx du RFC 8569 est une des déclinaisons possibles.
- L'immuabilité est une notion importante en ICN ; si le nom d'un contenu est un condensat du contenu, l'objet est immuable, tout changement serait un nouvel objet, avec un nouveau nom.
- Le contenu est produit par des producteurs et récupéré par des consommateurs. Il sera relayé par des transmetteurs (forwarders, un peu l'équivalent des routeurs.) Si le transmetteur stocke les données, pour accélérer les accès ultérieurs, on l'appelle une mule. La transmission est dite vers l'amont (upstream) quand il s'agit des Intérêts et vers l'aval (downstream) pour les Données et les rejets (lorsqu'un Intérêt ne correspond à aucune donnée connue).
- Un transmetteur peut être à état, ce qui signifie qu'il se souvient des Intérêts qu'il a transmis (dans sa PIT), et qu'il utilisera ce souvenir pour transmettre les Données qui seront envoyées en réponse.
- Un Intérêt peut ne pas être satisfait si on ne trouve aucune Donnée qui lui correspond (zut, pas de photo de Scarlet Johansson). Un rejet (Interest NACK) est alors renvoyé au demandeur. Notez que beaucoup de schémas d'ICN ont des noms hiérarchiques et que, dans ce cas, la correspondance dans la FIB entre un Intérêt et une interface se fait sur le préfixe le plus long.
- Un des points importants de l'ICN est la possibilité pour les nœuds intermédiaires de mémoriser les données, pour faciliter leur distribution (stockage dans le réseau, ou In-network storage). Cette mémorisation ne se fait en général pas systématiquement mais uniquement quand l'occasion se présente (opportunistic caching). Cela améliore la distribution de contenus très populaires mais cela soulève des gros problèmes de vie privée, puisque tous les nœuds intermédiaires, les transmetteurs, doivent pouvoir voir ce qui vous intéresse. (Une photo de Scarlet Johansson, ça va. mais certains contenus peuvent être plus sensibles.)
- Comme IP, ICN sépare le routage (construire les bases comme la FIB) et la transmission (envoyer des messages en utilisant ces bases).
- Un lien est un paquet de données qui contient le nom d'un autre contenu. Une indirection, donc.
- Et le nom, au fait, concept central de l'ICN ? Il est typiquement hiérarchique (plusieurs composants, parfois également appelés segments, je vous avais prévenu qu'il y avait beaucoup de synonymes) pour faciliter la transmission. Le début d'un nom se nomme un préfixe. Le nom peut indiquer la localisation d'un contenu ou bien peut être sémantique (indiquant le contenu). Dans ICN, on utilise en général le terme d'identificateur (packet ID) pour les identificateurs cryptographiques, calculés par condensation. Si le nom est l'identificateur, on parle de nommage à plat. (Et, évidemment, cela sera plus dur à router, il faudra sans doute une DHT.)
- L'ICN a une notion de version. Dans le cas de noms hiérarchiques, la version d'un contenu peut être mise dans le nom.
- Avec ICN, les propriétés de sécurité du contenu ne peuvent pas être garanties par le serveur où on l'a récupéré. Il faut donc une sécurité des données et pas seulement du canal. L'intégrité est vérifiée par la cryptographie, l'authenticité par une signature et la confidentialité par le chiffrement. Tout cela est classique. Plus délicate est la question de la confidentialité des noms, puisqu'elle empêcherait le nœuds intermédiaires de savoir ce qui est demandé, et donc de faire leur travail.
L'article seul
Des émojis pour les codes de retour HTTP
Première rédaction de cet article le 13 juin 2020
(C'est un article du week-end : n'attendez pas de savantes analyses, c'est plutôt pour la distraction.)
Le protocole HTTP prévoit que les réponses à une requête commencent par un code de retour sur trois chiffres, le premier chiffre identifiant une catégorie (2 = tout va bien, 4 = vous avez fait une erreur, 5 = j'ai fait une erreur, etc). Certains de ces codes sont très célèbres comme 404 pour « ressource non trouvée ». Ils sont normalisés dans le RFC 7231, section 6. Mais ces codes sont un peu arides, d'où la suggestion de francesc d'associer à chaque code HTTP un émoji. Par exemple le 404 pourrait être accompagné de 🤷 (U+1F937 en notation Unicode), un personnage qui lève les mains en signe d'impuissance (l'exemple de francesc est légèrement différent, voyez plus loin).
En partant du tweet
original, et en ajoutant les suggestions qui ont fait suite à
ce tweet, voici une liste possible. Notez que chaque émoji est un
caractère Unicode (et pas une image,
contrairement au tweet original) et est aussi un
hyperlien vers l'excellent service d'exploration
d'Unicode, Uniview. Et si vous voulez la signification de
chaque code de retour HTTP, voyez le registre IANA
de ces codes (ou, peut-être plus lisible, https://httpstatuses.com/
- 100 : 👂
- 102 : 🖥
- 200 : 👍 ou bien ✅
- 201 : 🆕 ou bien 👶
- 202 : 👌 (il pourrait aussi servir au 200…)
- 203 : 🤔
- 204 : 😶 (pas facile de représenter quelque chose qui n'existe pas…)
- 206 : 🥴
- 226 : 📲
- 301 : 👉
- 302 : 🤏
- 303 : 👀
- 400 : 👎
- 401 : 🔒
- 402 : 💰
- 403 : 🚫
- 404 : 🤷 (si vous regardez avec un logiciel qui gère toutes les possibilités d'Unicode, l'auteur utilisait quatre caractères Unicode combinés pour être sûr que le personnage soit mâle, ce qui donne 🤷♂️ ; regardez ce que ça donne sur mon Firefox)
- 405 : 👮 ou ❌
- 406 : 🙅
- 408 : ⌛
- 409 : ⚔ ou bien 🤼 (si vous regardez avec un logiciel qui gère toutes les possibilités d'Unicode, l'auteur utilise également des caractères combinés, ce qui donne 🤼♂️)
- 410 : 💨 ou bien 🦖
- 413 : 😵
- 415 : 🧐
- 418 : 🍵 ou bien 🫖 (notez que vous ne trouverez pas ce code dans le registre IANA, il a été décrit dans un RFC du premier avril, le RFC 2324 ; d'autre part, si vous ne voyez pas le deuxième émoji, la théière, c'est peut-être car c'est un des rares émojis cités ici qui n'ait été introduit qu'en version 13 d'Unicode, la plus récente)
- 422 : 🤦
- 426 : 🦕
- 429 : 😱 ou 🐇 (le lapin est l'idée que je préfère)
- 451 : 🔥, 🚔, 👮 ou bien 📛
- 500 : 💩, 💥, 🥴 ou bien 🤯
- 503 : 😓 ou 🤬 ou bien 🤯
- 504 : ⌛ ou ⏳
- 508 : ♾
{kind=link}
Pour vous amuser avec les codes de retour HTTP, il y a aussi des photos de chat et des explications à partir de films tamouls.
L'article seul
Fiche de lecture : Les nouvelles lois de l'amour
Auteur(s) du livre : Marie Bergström
Éditeur : La Découverte
978-2-7071-9894-5
Publié en 2019
Première rédaction de cet article le 8 juin 2020
« Sexualité, couple et rencontres au temps du numérique. » Une part très importante des activités humaines se passe désormais sur l'Internet. C'est donc logiquement également le cas de la drague et de toutes ses variantes. Mais comment se passent exactement les rencontres sur l'Internet, au-delà des discours faciles ? Une sociologue s'est penchée sur la question, a parlé avec utilisateurs et concepteurs de sites de rencontre, a eu accès à la base de données d'un gros site, pour des études quantitatives, et publie. Un livre qui parle d'amour, sous toutes ses formes.
C'est qu'il y a beaucoup d'idées fausses qui circulent sur les rencontres sexuelles et/ou amoureuses effectuées par le truchement d'un site Web. Il n'y aurait plus de couple stable, plus que des rencontres éphémères, celles-ci seraient égalitaires, sans considération de classe sociale, le passage par une entreprise commerciale tuerait tout romantisme, etc.
J'ai découvert ce livre lors des excellentes rencontres
« Aux sources du numérique ». Vos pouvez lire l'entretien
avec l'auteure fait à cette occasion. 
L'auteure remet les sites de rencontre modernes dans l'histoire (et c'est un des chapitres les plus intéressants du livre). L'action d'intermédiaires dans la formation des couples est ancienne, et leurs arguments sont parfois très stables (cf. la délicieuse mise côte-à-côte d'une publicité du journal d'annonces matrimoniales « Les mariages honnêtes » en 1907 et d'une publicité de Tinder de 2017). On trouvera entre autre dans ce chapitre historique le Minitel rose, qui avait été un des facteurs de décollage de ce succès technico-industriel français, et la source de quelques fortunes, y compris de celle du fondateur d'un gros FAI français. (Et, j'ajoute, la source d'inspiration d'une jolie chanson sur le numérique, Goodbye, Marylou.) Mal vus à l'époque, les « sites de rencontre » sont mieux perçus aujourd'hui. Comme le note l'auteure, un des intérêts des sites de rencontre, est qu'on ne drague pas en public, contrairement aux rencontres sur le lieu de travail ou en boite. C'est particulièrement important pour les femmes, qui sont critiquées si elles expérimentent beaucoup. Les femmes de 18-25 ans sont le groupe qui utilisent le plus ces sites.
Autre étude intéressante, les discussions avec les concepteurs des sites de rencontre. Alors que les agences matrimoniales du passé se vantaient de leurs compétences en matière de rencontres, ceux qui réalisent Meetic et les autres clament bien fort qu'ils sont juste des techniciens, qu'ils mettent les gens en rapport, qu'ils n'essaient pas d'être des « marieurs ». Les créateurs des sites de rencontre nient l'influence du site, de son organisation, de ses algorithmes. On ne sait pas si cette insistance sur la neutralité est une coquetterie d'informaticien (« la technique est neutre ») ou bien un moyen d'éviter de faire des promesses imprudentes (« satisfaction garantie »).
Et l'homogamie ? Est-ce que l'Internet tient sa promesse d'être égalitaire, et d'effacer les barrières ? Est-ce que, grâce aux applications de rencontre, les bergères peuvent enfin épouser des princes ? Malheureusement, non. Bourdieu reste le plus fort. Comme dans les rencontres hors-ligne, l'homogamie reste forte. Si la sélection sur le physique ne doit pas trop se dire, celle sur l'orthographe est assumée par les interlocuteurs de l'auteure, et on sait que l'orthographe est un fort marqueur social. (L'auteure, qui est d'origine suédoise, critique la langue française pour son manque de cohérence entre l'oral et l'écrit. Mais toute langue est difficile quand ce n'est pas sa langue maternelle.) Plus étonnant, cette importance donnée à l'orthographe reste très forte même quand on cherche des rencontres « légères », « sans lendemain ». Il n'y a pas de simple « plan cul ». « Nos goûts sexuels et romantiques sont sociaux. », dit l'auteure. Même si c'est juste pour le sexe, il faut une bonne orthographe. Ce choix contribue d'autant plus à la sélection sociale que le seul canal, au début, est l'écrit : on ne peut pas compenser par son apparence physique.
Autre idée importante du livre : le cliché traditionnel comme quoi les hommes chercheraient du sexe et les femmes un mari n'est pas corroboré par les données. Il y a bien des attentes différentes des hommes et femmes vers 30 ans, où les femmes veulent déjà se mettre en couple, mais les hommes pas encore. Mais, avant et après les visions classiques sont fausses (les femmes jeunes aussi veulent du sexe, les hommes mûrs aussi de la conjugalité).
Et à propos de sexe, est-ce que, sur les sites de rencontre, on ne s'intéresse qu'à la relation sexuelle et pas à la mise en couple stable ? Pas vraiment. Tout juste peut-on observer que les rencontres en ligne deviennent plus vite sexuelles (un peu comme celles en vacances, et sans doute pour les mêmes raisons, « les histoires en ligne ne font pas d'histoires »). Et puis, les deux parties savent dès le début pourquoi ielles sont là : il n'y a pas l'ambiguité qu'il peut y avoir, par exemple lors de rencontres au bureau.
Notez que le livre se limite à l'hétérosexualité, l'auteure notant que les homosexuels ont des pratiques très différentes. Un prochain livre ?
L'article seul
Mon fichier a-t-il été modifié pendant son voyage ?
Première rédaction de cet article le 7 juin 2020
Une très intéressante discussion à l'IETF a lieu en ce moment sur la modification des données lorsqu'elles circulent sur l'Internet : les mécanismes de protection contre ces modifications suffisent-ils ? Ou bien est-ce que nous recevons de temps en temps des données modifiées, sans nous en rendre compte ?
Le problème a été posé par Craig Partridge dans un message récent. Pour le comprendre, il faut partir du fait que, lorsque des données circulent sur l'Internet, les bits n'arrivent pas toujours comme ils sont partis. Contrairement à ce qu'essaie de faire croire le discours commercial sur « le virtuel » ou « le nuage », l'Internet repose sur le monde physique, et sur la physique. Un bit, ce n'est qu'une information stockée dans un dispositif physique. Un rayon cosmique passe, un composant électronique défaille et paf, un zéro devient un ou le contraire. Notez aussi que le problème n'est pas uniquement sur le réseau : les équipements intermédiaires (les routeurs) et terminaux n'ont pas des mémoires parfaites (on n'utilise pas toujours ECC). Dans un monde physique, la perfection n'existe pas : il y aura toujours de la corruption de données. (J'ai déjà parlé de ce problème dans mon article sur le bitsquatting.)
Le problème s'aggrave évidemment avec la taille des données et il est donc plus aigu aujourd'hui. Si vous transférez un film en haute définition (mettons un fichier de 60 Go), et qu'un bit a une probabilité de 10^-12 (une chance sur mille milliards, les réseaux réels sont souvent bien moins fiables) d'être modifié, vous avez une chance - ou plutôt une malchance - sur deux que le fichier arrive corrompu.
Est-ce grave ? Dans le cas de ce film, il est probable que la modidication d'un seul bit ne soit pas détectable par le spectateur. De même que le changement d'un bit dans la phrase précédant celle-ci vous a sans doute échappé (merci à Brian Carpenter pour l'idée), d'autant plus qu'elle affectait un mot assez long pour qu'il reste compréhensible. Mais les couches basses de la communication ne savent pas ce qui est vital ou pas. Elles doivent donc essayer d'assurer une fiabilité, sinon totale (ce serait utopique), du moins raisonnable en pratique.
C'est pour cela que dans la plupart des couches, il y a des sommes de contrôle qui résument les données en une somme : si elle ne correspond pas entre le départ et l'arrivée, les données sont jetées et on recommence. Ethernet a une telle somme de contrôle, et, dans le domaine de l'IETF, TCP (RFC 793, section 3.1) et UDP (RFC 768) l'ont aussi. C'est le même algorithme, la « somme de contrôle de l'Internet », décrit dans le RFC 1071. (IPv4 a aussi une somme de contrôle, supprimée en IPv6 car redondante entre celles de la couche 2 et de la couche 4.) Si un paquet TCP arrive et que la somme de contrôle ne correspond pas, le récepteur n'envoie pas d'accusé de réception, l'émetteur note que le paquet est perdu (ce qui n'est pas faux) et réémet.
Est-ce que ces sommes de contrôle suffisent ? Non. Une somme de contrôle ne peut pas détecter tous les problèmes, notamment parce que Shannon ne veut pas : la somme de contrôle étant plus petite que les données, plusieurs paquets ont la même somme et certains changements dans les bits d'un paquet ne modifieront donc pas la somme de contrôle. (Notez que beaucoup de calculs sur la probabilité de corruption considèrent que les changements des bits sont indépendants, ce qui n'est pas forcément le cas. En général, quand un bit est changé, ses voisins ont une probabilité plus forte de l'être également, parce qu'ils sont dans la même barrette mémoire, ou bien parce qu'ils ont été victimes du même rayon cosmique.)
Bon, donc, l'application peut recevoir des données corrompues bien qu'on apprenne en cours d'informatique que TCP fournit un « canal fiable ». Que va-t-elle faire alors ? Parfois rien, elle accepte béatement les données corrompues. Dans le cas du film cité plus haut, ce n'est pas forcément idiot. Un léger changement d'une image ne se verra pas. Dans d'autres cas, le problème est plus sérieux et certaines applications calculent leur propre somme de contrôle une fois le transfert de données terminé, parfois avec des algorithmes meilleurs que la « somme de contrôle de l'Internet », comme SHA-2. (Les algorithmes de condensation comme SHA-2 fournissent en plus d'autres propriétés de sécurité, mais ils peuvent être utilisés comme de simples sommes de contrôle.) Le problème, dans ce cas, est d'efficacité : si on détecte un problème, il faut tout recommencer et, pour des données de grande taille, cela fait beaucoup. C'est pour cela que certaines applications, comme BitTorrent, ont leur propre découpage des données, comme le fait TCP, pour éviter de devoir retransmettre la totalité d'un fichier. (On peut faire la même chose avec HTTP et ses range requests, cf. RFC 7233 mais toutes les applications ne gèrent pas cela.)
Est-ce que ce problème arrive ? Combien de fois les applications acceptent des fichiers corrompus ? Et, pour les applications qui testent une somme de contrôle applicative, est-ce que la réémission est fréquente ? En fait, on ne le sait pas tellement et c'était le but originel de l'article de Craig Partridge : annoncer un projet de recherche visant à récolter des données sur ce phénomène.
Arrivé à ce stade, mes lectrices et mes lecteurs, qui sont toutes et tous de grands connaisseurs de l'Internet, pensent depuis longtemps « mais, aujourd'hui, toutes les communications sont chiffrées et, dans ce cas, c'est le mécanisme de cryptographie qui détecte la corruption ; au fur et à mesure que le chiffrement s'étend, ce problème de corruption devrait disparaitre ». D'abord, c'est plus compliqué que cela. Certains algorithmes de chiffrement ne détectent pas la corruption et, quand elle a lieu, produisent des données en clair qui sont elle-même corrompues. Le chiffrement intègre a justement pour but de résoudre ce problème, en détectant la corruption avant de perdre son temps à déchiffrer. Il est donc logique que ce chiffrement intègre soit de plus en plus répandu (il est même obligatoire en TLS 1.3, cf. RFC 9846). D'autre part, les protocoles qui utilisent le cryptographie ont souvent leur propre mécanisme de détection de la corruption, au-dessus du protocole de transport mais en dessous de celui d' application. Par contre, ces mécanismes ne sont pas forcément bien intégrés au transport. Ainsi, TLS peut détecter des erreurs que la somme de contrôle de TCP n'a pas vues mais n'a aucun moyen de demander la retransmission, il ne peut qu'avorter la communication (ou bien prévenir l'application). SSH a la même limite (ce qui est logique, tous les deux supposent une couche Transport fiable). Des études semblent indiquer que les gros transferts de fichiers sur TLS ou SSH échouent souvent pour cette raison, et doivent être relancés au niveau applicatif. QUIC devrait améliorer les choses sur ce point. Bref, le chiffrement aide (et on peut donc espérer qu'il continuera à se répandre) mais n'est pas une solution magique.
Bon, et quelles sont les solutions envisagées ? La faiblesse de la somme de contrôle de l'Internet, qui échoue à détecter un certain nombre d'erreurs, est connue depuis longtemps, et l'augmentation de la quantité de données transférées ne fait qu'aggraver les choses. Une première solution serait de la remplacer par une somme de contrôle plus forte (mettons SHA-256 pour donner une idée, mais MD5 suffirait, il s'agit de se protéger contre des accidents, pas des attaques) mais aussi plus lente à calculer (mais la vitesse des processeurs a augmenté plus vite que celle des réseaux). Un problème amusant est « comment déployer cette nouvelle somme de contrôle » dans l'Internet ossifié et pourri de middleboxes que nous avons aujourd'hui. En théorie, le protocole de transport est de bout en bout et les équipements intermédiaires ne devraient pas poser de problèmes, ils passent juste les paquets sans les comprendre. En pratique, ce n'est pas le cas. Le RFC 1146 fournit un mécanisme de changement de la somme de contrôle standard mais il est certain qu'il n'est pas massivement déployé et, si on essayait aujourd'hui, on peut être sûr que la majorité des middleboxes, intrusives et programmées avec les pieds, réagirait mal. Et UDP ? C'est encore pire, il n'a pas de mécanisme standard pour changer l'algorithme de somme de contrôle (un travail à ce sujet est en cours à l'IETF).
Bref, un remplacement de TCP par QUIC serait peut-être la meilleure solution…
Quelques lectures sur ce sujet, rassemblées par Craig Partridge :
- L'article classique, de 2000 : « When the CRC and TCP checksum disagree ».
- Un article inquiétant de 2018 montrant l'importance de la corruption de données dans le monde réel, « Cross-geography scientific data transferring trends and behavior ».
- Un autre article, de 2017 (écrit dans le contexte de l'ICN, cf. RFC 7476) montre également beaucoup trop de problèmes, « Request Aggregation, Caching, and Forwarding Strategies for Improving Large Climate Data Distribution with NDN: A Case Study ».
- Et une dernière étude, « Transferring a petabyte in a day ».
L'article seul
Fiche de lecture : Le bug humain
Auteur(s) du livre : Sébastien Bohler
Éditeur : Robert Laffont
9782221240106
Publié en 2019
Première rédaction de cet article le 1 juin 2020
Dans cet essai, Sébastien Bohler explique et défend une thèse comme quoi une grande partie de nos comportements humains seraient dus à des règles très profondément enfouies dans notre cerveau et qui se résumeraient à « plus de tout, et tout de suite ». Selon lui, changer les choses, par exemple diminuer notre empreinte carbone, nécessite de prendre conscience de ces règles, avant de pouvoir les surmonter.
Après des romans comme « Les soldats de l'or gris », l'auteur passe à l'essai avec « Le bug humain ». Tout le monde peut constater, notamment à travers la destruction toujours plus poussée de l'environnement, que l'humanité, collectivement, n'est pas raisonnable. Pourquoi est-ce qu'on continue cette destruction alors qu'il est clair qu'il faudrait, au lieu de vouloir « relancer la croissance » et autres délires productivistes, diminuer la consommation de tout ? Depuis des siècles, des tas de gens ont réfléchi à ce problème, et ont proposé plein d'explications (qui ne sont pas forcément incompatibles entre elles). Ici, Sébastien Bohler a une théorie : l'essentiel du problème vient du striatum. Cet organe peu connu du cerveau est responsable de la motivation : c'est lui qui, via la dopamine qu'il secrète, pousse à consommer (de la nourriture, de l'information ou du sexe) et toujours davantage. En effet, lorsque l'évolution a façonné cet organe, on ne pouvait jamais consommer trop. On n'avait jamais assez à manger, par exemple et, même si c'était le cas temporairement, manger avec excès et accumuler des graisses était une bonne stratégie ; on perdrait ces graisses sans effort à la prochaine pénurie. De même, faire des enfants en quantité était raisonnable quand la plupart d'entre eux mourraient jeunes. Mais, aujourd'hui, cela mène à la surpopulation.
Aujourd'hui où la production de masse permet de consommer trop, le striatum est devenu dangereux ; il pousse à ne jamais s'arrêter, même au-delà du raisonnable. Et l'évolution naturelle, trop lente, ne va pas changer ce comportement avant qu'il ne soit trop tard et que toutes les ressources naturelles aient été détruites.
Est-ce une fatalité ? L'auteur estime que, si le striatum pousse à des comportements qui sont souvent négatifs dans notre société, il ne représente pas tout notre cerveau. D'autres parties, comme le cortex préfrontal, sont capables d'inhiber les instincts immédiats, et donc potentiellement de nous amener à un meilleur équilibre entre les désirs primaires et la réalité.
Le livre est très bien écrit, très convaincant. Vous apprendrez beaucoup de choses sur votre cerveau en le lisant. Mais je reste un peu sceptique car il résume un problème très vaste à une cause principale. Dans le cadre écologique, par exemple, les décisions individuelles poussées par le striatum ne sont pas tout. Il y a aussi la difficulté à parvenir à une décision commune lorsque le changement de mode de vie serait dans l'intérêt de tous mais heurtent les intérêts de certains (comme l'analyse bien Diamond dans « Effondrement »). Le pouvoir du striatum peut expliquer pourquoi, même quand on est déjà en surpoids, on reprend du dessert, mais peut-il vraiment expliquer l'avidité d'actionnaires qui, dans un bureau climatisé, sans qu'ils aient faim ou froid, prennent des décisions catastrophiques pour la biosphère ? Et, même quand tout le monde a les mêmes intérêts et en est conscient, une décision commune n'est pas facile, si chacun craint d'être le seul à faire des efforts.
L'article seul
RFC 8782: Distributed Denial-of-Service Open Threat Signaling (DOTS) Signal Channel Specification
Date de publication du RFC : Mai 2020
Auteur(s) du RFC : T. Reddy (McAfee), M. Boucadair (Orange), P. Patil (Cisco), A. Mortensen (Arbor Networks), N. Teague (Iron Mountain Data Centers)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dots
Première rédaction de cet article le 31 mai 2020
Le protocole DOTS (Distributed Denial-of-Service Open Threat Signaling) vise à permettre au client d'un service anti-dDoS de demander au service de mettre en route des mesures contre une attaque. Ce RFC décrit le canal de signalisation de DOTS, celui par lequel passera la demande d'atténuation de l'attaque. Suite à un petit problème YANG, ce RFC a été remplacé depuis par le RFC 9132.
Si vous voulez mieux comprendre DOTS, il est recommandé de lire le RFC 8612, qui décrit le cahier des charges de ce protocole, et le RFC 8811, qui décrit l'architecture générale. Ici, je vais résumer à l'extrême : un client DOTS, détectant qu'une attaque par déni de service est en cours contre lui, signale, par le canal normalisé dans ce RFC, à un serveur DOTS qu'il faudrait faire quelque chose. Le serveur DOTS est un service anti-dDoS qui va, par exemple, examiner le trafic, jeter ce qui appartient à l'attaque, et transmettre le reste à son client.
Ces attaques par déni de service sont une des plaies de l'Internet, et sont bien trop fréquentes aujourd'hui (cf. RFC 4987 ou RFC 4732 pour des exemples). Bien des réseaux n'ont pas les moyens de se défendre seuls et font donc appel à un service de protection (payant, en général, mais il existe aussi des services comme Deflect). Ce service fera la guerre à leur place, recevant le trafic (via des manips DNS ou BGP), l'analysant, le filtrant et envoyant ce qui reste au client. Typiquement, le client DOTS sera chez le réseau attaqué, par exemple en tant que composant d'un IDS ou d'un pare-feu, et le serveur DOTS sera chez le service de protection. Notez donc que client et serveur DOTS sont chez deux organisations différentes, communiquant via le canal de signalisation (signal channel), qui fait l'objet de ce RFC.
La section 3 de notre RFC expose les grands principes du
protocole utilisé sur ce canal de signalisation. Il repose sur
CoAP, un équivalent léger de HTTP, ayant beaucoup
de choses communes avec HTTP. Le choix d'un protocole différent de
HTTP s'explique par les spécificités de DOTS : on l'utilise quand ça
va mal, quand le réseau est attaqué, et il faut donc pouvoir
continuer à fonctionner même quand de nombreux paquets sont
perdus. CoAP a les caractéristiques utiles pour DOTS, il est conçu
pour des réseaux où il y aura des pertes, il tourne sur UDP, il permet des
messages avec ou sans accusé de réception, il utilise peu de
ressources, il peut être sécurisé par DTLS… TCP est également
utilisable mais UDP est préféré, pour éviter le
head-of-line
blocking. CoAP est normalisé dans le RFC 7252. Parmi les choses à retenir, n'oubliez pas
que l'encodage du chemin dans l'URI est un peu spécial, avec une option
Uri-Path: par segment du chemin (RFC 7252, section 5.10.1). Par abus de langage,
j'écrirai « le client CoAP demande
/foo/bar/truc.cbor » alors qu'il y aura en fait
trois options Uri-Path: :
Uri-Path: "foo" Uri-Path: "bar" Uri-Path: "truc.cbor"
Par défaut, DOTS va utiliser le port 4646 (et non pas le port par
défaut de CoAP, 5684, pour éviter toute confusion avec d'autres
services tournant sur CoAP). Ce port a été choisi pour une bonne
raison, je vous laisse la chercher, la solution est à la fin de cet
article. Le plan d'URI sera coaps ou
coaps+tcp (RFC 7252,
section 6, et RFC 8323, section 8.2).
Le fonctionnement de base est simple : le client DOTS se connecte au serveur, divers paramètres sont négociés. Des battements de cœur peuvent être utilisés (par le client ou par le serveur) pour garder la session ouverte et vérifier son bon fonctionnement. En cas d'attaque, le client va demander une action d'atténuation. Pendant que celle-ci est active, le serveur envoie de temps en temps des messages donnant des nouvelles. L'action se terminera, soit à l'expiration d'un délai défini au début, soit sur demande explicite du client. Le serveur est connu du client par configuration manuelle, ou bien par des techniques de découverte comme celles du RFC 8973.
Les messages sont encodés en CBOR (RFC 8949). Rappelez-vous que le modèle de données
de CBOR est très proche de celui de JSON, et notre RFC spécifie donc les
messages avec une syntaxe JSON, même si ce n'est pas l'encodage
utilisé sur le câble. Pour une syntaxe formelle des messages, le RFC
utilise YANG (cf. RFC 7951). Le type MIME des messages
est application/dots+cbor.
La section 4 du RFC décrit les différents messages possibles plus
en détail. Je ne vais pas tout reprendre ici, juste donner quelques
exemples. Les URI commencent toujours par
/.well-known/dots
(.well-known est normalisé dans le RFC 8615, et dots est
désormais enregistré
à l'IANA). Les différentes actions ajouteront au chemin dans
l'URI /mitigate pour les demandes d'actions
d'atténuation, visant à protéger de l'attaque,
/hb pour les battements de cœur, etc.
Voici par exemple une demande de protection, effectuée avec la méthode CoAP PUT :
Header: PUT (Code=0.03)
Uri-Path: ".well-known"
Uri-Path: "dots"
Uri-Path: "mitigate"
Uri-Path: "cuid=dz6pHjaADkaFTbjr0JGBpw"
Uri-Path: "mid=123"
Content-Format: "application/dots+cbor"
{
... Données en CBOR (représentées en JSON dans le RFC et dans
cet article, pour la lisibilité).
}
L'URI, en notation traditionnelle, sera donc
/.well-known/dots/mitigate/cuid=dz6pHjaADkaFTbjr0JGBpw/mid=123. CUID
veut dire Client Unique IDentifier et sert à
identifier le client DOTS, MID est Mitigation
IDentifier et identifie une demande d'atténuation
particulière. Si ce client DOTS fait une autre demande de
palliation, le MID changera mais le CUID sera le même.
Que met-on dans le corps du message ? On a de nombreux champs définis pour indiquer ce qu'on veut protéger, et pour combien de temps. Par exemple, on pourrait avoir (je rappelle que c'est du CBOR, format binaire, en vrai) :
{
"ietf-dots-signal-channel:mitigation-scope": {
"scope": [
{
"target-prefix": [
"2001:db8:6401::1/128",
"2001:db8:6401::2/128"
],
"target-port-range": [
{
"lower-port": 80
},
{
"lower-port": 443
}
],
"target-protocol": [
6
],
"lifetime": 3600
}
]
}
}
Ici, le client demande qu'on protège
2001:db8:6401::1 et
2001:db8:6401::2 (target
veut dire qu'ils sont la cible d'une attaque, pas qu'on veut les
prendre pour cible), sur
les ports 80 et 443,
en TCP, pendant une heure. (lower-port seul,
sans upper-port indique un port unique, pas un
intervalle.)
Le serveur va alors répondre avec le code 2.01 (indiquant que la requête est acceptée et traitée) et des données :
{
"ietf-dots-signal-channel:mitigation-scope": {
"scope": [
{
"mid": 123,
"lifetime": 3600
}
]
}
}
La durée de l'action peut être plus petite que ce que le client a demandé, par exemple si le serveur n'accepte pas d'actions trop longues. Évidemment, si la requête n'est pas correcte, le serveur répondra 4.00 (format invalide), si le client n'a pas payé, 4.03, s'il y a un conflit avec une autre requête, 4.09, etc. Le serveur peut donner des détails, et la liste des réponses possibles figure dans des registres IANA, comme celui de l'état d'une atténuation, ou celui des conflits entre ce qui est demandé et d'autres actions en cours.
Le client DOTS peut ensuite récupérer des informations sur une action de palliation en cours, avec la méthode CoAP GET :
Header: GET (Code=0.01) Uri-Path: ".well-known" Uri-Path: "dots" Uri-Path: "mitigate" Uri-Path: "cuid=dz6pHjaADkaFTbjr0JGBpw" Uri-Path: "mid=123"
Ce GET
/.well-known/dots/mitigate/cuid=dz6pHjaADkaFTbjr0JGBpw/mid=123
va renvoyer de l'information sur l'action d'identificateur (MID)
123 :
{
"ietf-dots-signal-channel:mitigation-scope": {
"scope": [
{
"mid": 123,
"mitigation-start": "1507818393",
"target-prefix": [
"2001:db8:6401::1/128",
"2001:db8:6401::2/128"
],
"target-protocol": [
6
],
"lifetime": 1755,
"status": "attack-stopped",
"bytes-dropped": "0",
"bps-dropped": "0",
"pkts-dropped": "0",
"pps-dropped": "0"
}
]
}
}
Les différents champs de la réponse sont assez évidents. Par
exemple, pkts-dropped indique le nombre de
paquets qui ont été jetés par le protecteur.
Pour mettre fin aux actions du système de protection, le client utilise évidemment la méthode CoAP DELETE :
Header: DELETE (Code=0.04) Uri-Path: ".well-known" Uri-Path: "dots" Uri-Path: "mitigate" Uri-Path: "cuid=dz6pHjaADkaFTbjr0JGBpw" Uri-Path: "mid=123"
Le client DOTS peut se renseigner sur les capacités du serveur avec
un GET de /.well-known/dots/config.
Ce RFC décrit le canal de signalisation de DOTS. Le RFC 8783, lui, décrit le canal de données. Le canal de signalisation est prévu pour faire passer des messages de petite taille, dans un environnement hostile (attaque en cours). Le canal de données est prévu pour des données de plus grande taille, dans un environnement où les mécanismes de transport normaux, comme HTTPS, sont utilisables. Typiquement, le client DOTS utilise le canal de données avant l'attaque, pour tout configurer, et le canal de signalisation pendant l'attaque, pour déclencher et arrêter l'atténuation.
Les messages possibles sont modélisés en YANG. YANG est normalisé dans le RFC 7950. Notez que YANG avait été initialement créé pour décrire les commandes envoyées par NETCONF (RFC 6241) ou RESTCONF (RFC 8040) mais ce n'est pas le cas ici : DOTS n'utilise ni NETCONF, ni RESTCONF mais son propre protocole basé sur CoAP. La section 5 du RFC contient tous les modules YANG utilisés.
La mise en correspondance des modules YANG avec l'encodage
CBOR figure dans la section 6. (YANG permet
une description abstraite d'un message mais ne dit pas, à lui tout
seul, comment le représenter en bits sur le réseau.) Les clés CBOR
sont toutes des entiers ; CBOR permet d'utiliser des chaînes de
caractères comme clés mais DOTS cherche à gagner de la place. Ainsi,
les tables de la section 6 nous apprennent que le champ
cuid (Client Unique
IDentifier) a la clé 4, suivie d'une chaîne de caractères
en CBOR. (Cette correspondance est désormais un
registre IANA.) D'autre part, DOTS introduit une étiquette
CBOR, 271 (enregistrée
à l'IANA, cf. RFC 8949, section 3.4)
pour marquer un document CBOR comme lié au protocole DOTS.
Évidemment, DOTS est critique en matière de sécurité. S'il ne fonctionne pas, on ne pourra pas réclamer une action de la part du service de protection. Et s'il est mal authentifié, on risque de voir le méchant envoyer de faux messages DOTS, par exemple en demandant l'arrêt de l'atténuation. La section 8 du RFC rappelle donc l'importance de sécuriser DOTS par TLS ou plutôt, la plupart du temps, par son équivalent pour UDP, DTLS (RFC 9147). Le RFC insiste sur l'authentification mutuelle du serveur et du client, chacun doit s'assurer de l'identité de l'autre, par les méthodes TLS habituelles (typiquement via un certificat). Le profil de DTLS recommandé (TLS est riche en options et il faut spécifier lesquelles sont nécessaires et lesquelles sont déconseillées) est en section 7. Par exemple, le chiffrement intègre est nécessaire.
La section 10 revient sur les questions de sécurité en ajoutant
d'autres avertissements. Par exemple, TLS ne protège pas contre
certaines attaques par déni de service, comme un paquet TCP RST
(ReSeT). On peut sécuriser la communication avec
TCP-AO (RFC 5925) mais c'est un vœu pieux, il
est très peu déployé à l'heure actuelle. Ah, et puis si les
ressources à protéger sont identifiées par un nom de domaine, et pas une adresse ou un
préfixe IP (target-fqdn au lieu de
target-prefix), le RFC dit qu'évidemment la
résolution doit être faite avec DNSSEC.
Question mises en œuvre, DOTS dispose d'au moins quatre implémentations, dont l'interopérabilité a été testée plusieurs fois lors de hackathons IETF (la première fois ayant été à Singapour, lors de l'IETF 100) :
Notez qu'il existe des serveurs de test DOTS
publics comme
coaps://dotsserver.ddos-secure.net:4646.
Ah, et la raison du choix du port 4646 ? C'est parce que 46 est le code ASCII pour le point (dot en anglais) donc deux 46 font deux points donc dots.
L'article seul
RFC 8783: Distributed Denial-of-Service Open Threat Signaling (DOTS) Data Channel Specification
Date de publication du RFC : Mai 2020
Auteur(s) du RFC : M. Boucadair (Orange), T. Reddy (McAfee)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dots
Première rédaction de cet article le 31 mai 2020
Le système DOTS (Distributed Denial-of-Service Open Threat Signaling) est conçu pour permettre la coordination des défenseurs pendant une attaque par déni de service (cf. RFC 8612). Pour cela, DOTS a deux protocoles, le protocole de signalisation, à utiliser en cas de crise, et le protocole de données, pour les temps plus calmes. Ce dernier fait l'objet de ce RFC.
Pourquoi deux protocoles ? Parce qu'il y a deux sortes de données : celles urgentes, de petite taille, transmises dans le feu de l'attaque, au moment où le réseau marche mal, c'est le domaine du protocole « signalisation », du RFC 9132. Et les données de grande taille, moins urgentes, mais qui doivent être transmises de manière fiable. Et c'est le but de notre RFC. Il y a donc deux canaux entre le client DOTS, qui demande de l'aide, et le serveur DOTS qui fournit des mécanismes d'atténuation des attaques : le canal « signalisation » du RFC 9132, et le canal « données », de notre RFC. Ce canal de données va servir, par exemple, à transporter :
- La liste des préfixes IP qu'il faudra protéger. (Notez que le serveur ne va pas forcément les accepter, il peut faire des vérifications),
- Des règles de filtrage, que le serveur appliquera en cas de crise (par exemple « laisse passer uniquement ce qui va vers le port 53 » ou bien « jette tout ce qui est à destination du port 666 », ou encore « voici une liste des préfixes vraiment importants, les seuls qu'il faudra accepter en cas de DDoS »).
Pour lire le reste du RFC, ne ratez pas la section 2, sur le vocabulaire à utiliser. Notamment, le terme d'ACL est utilisé dans un sens plus général que celui du RFC 8519.
Bon, le protocole, maintenant (section 3). Comme il n'a pas
besoin de fonctionner en permanence, même dans les cas d'attaque,
contrairement au protocole de signalisation, et comme il a par
contre besoin de fiabilité, il va utiliser des technologies
classiques : RESTCONF (RFC 8040) au-dessus de TLS (et donc au-dessus de TCP). RESTCONF
utilise HTTP donc on aura les méthodes classiques,
GET, DELETE, etc. Par
exemple, le client DOTS qui veut récupérer des informations sur la
configuration commence par faire un GET. Les données
sont encodées en JSON (RFC 8259). Elles
sont spécifiées dans un module YANG (RFC 7950) et on passe du modèle YANG à l'encodage
concret en suivant les règles du RFC 7951.
La connexion entre le client DOTS et le serveur peut être
intermittente (on se connecte juste le temps de faire un
GET, par exemple) ou bien permanente, ce qui
est pratique si le client faite des requêtes régulières, ou bien si
le serveur pousse des notifications (section 6.3 du RFC 8040).
Ah, et j'ai parlé de client et de serveur DOTS. Comment est-ce que le client trouve le serveur ? Cela peut être fait manuellement, ou bien via la procédure de découverte du RFC 8973.
Les détails sur ce qu'on peut récupérer en DOTS ? Ils sont dans
la section 4, sous forme d'un module YANG,
nommé ietf-dots-data-channel (désormais dans
le
registre IANA). Par exemple, dans ce module, les ACL permettent d'indiquer les
adresses IP et les protocoles de transport concernés, ainsi que les actions à
entreprendre (laisser passer le paquet, jeter le paquet, etc), comme
avec n'importe quel pare-feu. Le serveur DOTS agit donc
comme un pare-feu distant. Si le serveur l'accepte, on peut aussi
mettre des ACL portant sur les protocoles de la couche 4, par exemple pour filtrer sur
le port.
Bon, passons maintenant à la pratique. Nous allons utiliser le
serveur public de test
dotsserver.ddos-secure.net. Comme le protocole
de données de DOTS repose sur RESTCONF (RFC 8040) qui
repose lui-même sur HTTP, nous allons utiliser curl comme client. Ce serveur public exige
un certificat client, que nous récupérons
en ligne. Ensuite, je crée un alias
pour simplifier les commandes ultérieures :
% alias dotsdata='curl --cacert ./ca-cert.pem --cert ./client-cert.pem --key ./client-key.pem --header "Content-type: application/yang-data+json" --write-out "\n%{http_code}\n"'
Et enregistrons-nous, pour indiquer un identificateur de client DOTS :
% cat register.json
{
"ietf-dots-data-channel:dots-client": [
{
"cuid": "s-bortzmeyer"
}
]
}
% dotsdata --request POST --data @register.json https://dotsserver.ddos-secure.net/v1/restconf/data/ietf-dots-data-channel:dots-data/
201
Voilà, l'utilisateur s-bortzmeyer est
enregistré (201 est le code de retour HTTP
Created ; si cet identificateur avait déjà
existé, on aurait récupéré un 409 - Conflict).
Quand on aura fini, on pourra le détruire :
% dotsdata --request DELETE https://dotsserver.ddos-secure.net/v1/restconf/data/ietf-dots-data-channel:dots-data/dots-client=MONIDENTIFICATEUR 204
Suivant la logique REST de RESTCONF, l'identité du client figure dans l'URL.
Maintenant, créons un alias pour le préfixe
2001:db8::/32 :
% cat create-alias.json
{
"ietf-dots-data-channel:aliases": {
"alias": [
{
"name": "TEST-ALIAS",
"target-prefix": [
"2001:cafe::/32"
]
}
]
}
}
% dotsdata --request POST --data @create-alias.json https://dotsserver.ddos-secure.net/v1/restconf/data/ietf-dots-data-channel:dots-data/dots-client=s-bortzmeyer
{"ietf-restconf:errors":{"error":{"error-type":"application","error-tag":"invalid-value","error-message":"alias: post failed: dots r_alias: TEST-ALIAS: target_prefix \"2001:cafe::/32\" is not supported within Portal ex-portal1 (1.1.1.69,1.1.1.71,1.1.2.0/24,2001:db8:6401::/96)"}}}
400
Aïe, ça a raté (400 = Bad request). C'est parce que, comme nous le dit le message d'erreur, un vrai serveur DOTS n'accepte pas qu'un client joue avec n'importe quelle adresse IP, pour d'évidentes raisons de sécurité. Il faut prouver (par un moyen non spécifié dans le RFC) quels préfixes on contrôle, et ce seront les seuls où on pourra définir des alias et des ACL. Ici, le serveur de test n'autorise que trois préfixes, indiqués dans sa documentation et dans le message d'erreur. Reprenons :
% cat create-alias.json
{
"ietf-dots-data-channel:aliases": {
"alias": [
{
"name": "TEST-ALIAS",
"target-prefix": [
"2001:db8:6401::f00/128"
]
}
]
}
}
% dotsdata --request POST --data @create-alias.json https://dotsserver.ddos-secure.net/v1/restconf/data/ietf-dots-data-channel:dots-data/dots-client=s-bortzmeyer
201
Ouf, c'est bon, vérifions que l'alias a bien été créé :
% dotsdata --request GET --data @create-alias.json https://dotsserver.ddos-secure.net/v1/restconf/data/ietf-dots-data-channel:dots-data/dots-client=s-bortzmeyer/aliases
{"ietf-dots-data-channel:aliases":{"alias":[{"name":"TEST-ALIAS","pending-lifetime":10078,"target-prefix":["2001:db8:6401::f00/128"]}]}}
200
C'est parfait, on va essayer de demander du filtrage, maintenant. D'abord, les capacités du serveur dans ce domaine :
% dotsdata --request GET --data @create-alias.json https://dotsserver.ddos-secure.net/v1/restconf/data/ietf-dots-data-channel:dots-data/capabilities | jq .
...
"ipv6": {
"length": true,
"protocol": true,
"destination-prefix": true,
"source-prefix": true,
"fragment": true
},
"tcp": {
"flags": true,
"flags-bitmask": true,
"source-port": true,
"destination-port": true,
"port-range": true
},
Bien, le serveur sait filtrer sur la longueur des paquets, sur les
adresses IP source et destination, et il sait traiter spécifiquement
les fragments. Et il sait filtrer le TCP sur divers critères, comme
les ports source et destination. On va lui demander de filtrer tout
ce qui vient de 2001:db8:dead::/48 :
% cat install-acl.json
{
"ietf-dots-data-channel:acls": {
"acl": [
{
"name": "TEST-ACL",
"type": "ipv6-acl-type",
"activation-type": "activate-when-mitigating",
"aces": {
"ace": [
{
"name": "TEST-RULE",
"matches": {
"ipv6": {
"source-ipv6-network": "2001:db8:dead::/48"
}
},
"actions": {
"forwarding": "drop"
}
}
]
}
}
]
}
}
% dotsdata --request POST --data @install-acl.json https://dotsserver.ddos-secure.net/v1/restconf/data/ietf-dots-data-channel:dots-data/dots-client=s-bortzmeyer
201
Parfait, le serveur a accepté notre ACL. Le paramètre
activation-type indiquait de ne pas filtrer
tout de suite mais seulement lorsqu'une atténuation serait activée
(activate-when-mitigating). Vous avez vu les
fonctions les plus importantes du protocole de données de DOTS. En
cas d'attaque, il ne vous reste plus qu'à utiliser le protocole de
signalisation (RFC 9132) pour utiliser alias
et ACLs.
Quelques considérations de sécurité, maintenant, en section 10 du RFC. La sécurité est évidemment cruciale pour DOTS puisque, si on l'utilise, c'est qu'on a des ennemis et qu'ils nous attaquent. Les préfixes IP qu'on veut protéger ou au contraire qu'on veut filtrer sont par exemple une information confidentielle (elle pourrait aider l'attaquant). Le RFC impose donc la cryptographie pour protéger les communications, en utilisant TLS, et avec chiffrement intègre. Même avec TLS et ce chiffrement intègre, comme la couche transport n'est pas protégée, un attaquant actif pourrait perturber la communication, par exemple en injectant des paquets TCP RST (qui coupent la connexion). Il existe un mécanisme de protection, AO, normalisé dans le RFC 5925, mais il est très peu déployé en pratique.
La cryptographie ne protège pas contre un client DOTS malveillant, ou simplement mal configuré. Le serveur doit donc vérifier que le client a le droit de protéger tel ou tel préfixe IP. Autrement, un client DOTS pourrait demander le filtrage du préfixe d'un de ses ennemis. Le RFC ne spécifie pas quel mécanisme utiliser pour cette vérification, mais cela peut être, par exemple, l'utilisation des registres des RIR, qui indiquent qui est le titulaire légitime d'un préfixe.
Le protocole de ce RFC peut utiliser des noms de domaine pour configurer les ACL. Dans ce cas, le serveur doit veiller à sécuriser la résolution DNS, à la fois contre des manipulations, grâce à DNSSEC, et contre la surveillance, en utilisant du DNS chiffré comme dans le RFC 7858.
Pour les mises en œuvre de ce protocole, voyez mon article sur le RFC 9132. Mais le protocole de notre RFC étant fondé sur HTTPS, on peut dans une certaine mesure utiliser des outils existants comme, vous l'avez vu, curl.
L'article seul
RFC 8788: Eligibility for the 2020-2021 Nominating Committee
Date de publication du RFC : Mai 2020
Auteur(s) du RFC : B. Leiba (FutureWei Technologies)
Première rédaction de cet article le 28 mai 2020
Un très court RFC sorti dans l'urgence pour résoudre un petit problème politique. Les membres du NomCom (Nominating Committee) de l'IETF sont normalement choisis parmi des gens qui étaient à au moins trois des cinq précédentes réunions physiques de l'IETF. Que faire lorsqu'elles ont été annulées pour cause de COVID-19 ? (Ces critères sont ensuite devenus officiels avec le RFC 9389.)
Déjà deux réunions physiques ont été annulées, IETF 107 qui devait se tenir à Vancouver et IETF 108, qui devait se tenir à Madrid. Elles ont été remplacées par des réunions en ligne.
Le NomCom est un groupe qui désigne les membres de certaines instances de l'IETF. Les règles pour faire partie du NomCom sont exprimées dans le RFC 8713. Sa section 4.14 mentionne qu'un de ces critères est la présence à trois des cinq précédentes réunions physiques. Or, deux des réunions physiques de 2020 ont été annulées en raison de l'épidémie. Faut-il alors ne pas les compter dans « les cinq précédentes réunions » ? Ou bien compter la participation aux réunions en ligne comme équivalente à une réunion physique ?
La section 3 du RFC expose le choix fait : les réunions annulées ne comptent pas et le critère d'éligibilité au NomCom se fonde donc sur la participation à trois des cinq dernières réunions physiques qui se sont effectivement tenues. Cette interprétation n'a pas suscité d'objections particulières.
La même section 3 insiste sur le fait qu'il s'agit d'une décision exceptionnelle, ne s'appliquant que pour cette année, et qu'elle ne crée pas de nouvelles règles pour le futur.
L'article seul
Fiche de lecture : Obfuscation; A User's Guide for Privacy and Protest
Auteur(s) du livre : Finn Brunton, Helen
Nissenbaum
Éditeur : MIT Press
978-0-262-02973-5
Publié en 2015
Première rédaction de cet article le 17 mai 2020
Beaucoup d'efforts sont aujourd'hui dépensés pour protéger la vie privée sur l'Internet. En effet, le déploiement des réseaux informatiques a permis une extension considérable de la surveillance, privée comme étatique. Il est donc logique que des informaticiens cherchent à développer des moyens techniques pour gêner cette surveillance, moyens dont le plus connu est le chiffrement. Mais aucun moyen technique ne résout tous les problèmes à lui seul. Il faut donc développer une boîte à outils de techniques pour limiter la surveillance. Ce court livre est consacré à un de ces outils : le brouillage (obfuscation en anglais). Le principe est simple : le meilleur endroit pour cacher un arbre est au milieu d'une forêt.
Le principe du brouillage est en effet simple : introduire de fausses informations parmi lesquelles les vraies seront difficiles à trouver. Cette technique est surtout intéresssante quand on ne peut pas se dissimuler complètement. Par exemple, le logiciel TrackMeNot (dont une des développeuses est une des auteures du livre) envoie des recherches aléatoires aux moteurs de recherche. On ne peut pas empêcher ces moteurs de recherche de connaître nos centres d'intérêt, puisqu'il faut bien leur envoyer la question. Le chiffrement n'aide pas ici, puisque, s'il peut protéger la question sur le trajet, il s'arrête au serveur à l'autre extrémité. Mais on peut noyer ces serveurs sous d'autres requêtes, qu'ils ne pourront pas distinguer des vraies, brouillant ainsi l'image qu'ils se font de l'utilisateur.
À ma connaissance, il n'existe pas de traduction idéale du terme anglais obfuscation, qui est le titre de ce livre. Wikipédia propose offuscation, ce qui me fait plutôt penser à « s'offusquer ». À propos de français, notez qu'il existe une traduction de ce livre, « Obfuscation ; La vie privée, mode d'emploi » (avec préface de Laurent Chemla), chez C&F Éditions, mais je n'ai personnellement lu que la version originale.
Les techniciens ont facilement tendance à considérer comme
technique de protection de la vie privée le seul
chiffrement. Celui-ci est évidemment
indispensable mais il ne protège pas dans tous les cas. Deux
exemples où le chiffrement ne suffit pas sont l'analyse de trafic,
et le cas des GAFA. D'abord, l'analyse de
trafic. C'est une technique couramment utilisée par les
surveillants lorsqu'ils n'ont pas accès au contenu des
communications mais seulement aux
métadonnées. Par exemple, si on sait que A
appelle B, et que, dès que ça s'est produit, B appelle C, D et E, on
a identifié un réseau de personnes, même si on ne sait pas ce
qu'elles racontent. Et un autre cas est celui des
GAFA. Si la communication avec, par exemple,
Gmail, est chiffrée (le
https:// dans l'URL, qui indique que tout se passe en
HTTPS, donc chiffré), cela ne protège que contre
un tiers qui essaierait d'écouter la communication, mais pas contre
Google lui-même, qui voit évidemment tout en clair. Bref, le
chiffrement n'est pas une solution miracle. Dans ce second cas, une
autre solution pourrait être de dire « n'utilisez pas ces outils du
capitalisme de surveillance, n'utilisez que des services libres et
sans captation des données personnelles ». À long terme, c'est en
effet l'objectif. Mais à court terme, les auteurs du livre estiment
(et je suis d'accord avec eux) qu'il n'est pas réaliste de demander
cette « déGAFAisation
individuelle ». Comme le notent les auteurs p. 59
« Martyrdom is rarely a productive choice in a political
calculus ».
Le livre contient plein d'exemples de brouillage, car la technique est ancienne. Quand on ne peut pas cacher, on brouille. Des paillettes qui font croire à la défense anti-aérienne qu'il y a plein d'avions supplémentaires, au génial film de Spike Lee, Inside Man (non, je ne vais pas divulgâcher, regardez le film), les exemples ne manquent pas. Cette technique a été largement utilisée en informatique, et le livre comprend une passionnante description de l'opération Vula, où il ne fallait pas simplement dissimuler le contenu de la communication, mais également le fait qu'elle avait lieu, ce qui est bien plus difficile. Et les auteurs savent de quoi il parle puisqu'Helen Nissenbaum a également travaillé sur Ad Nauseam, un logiciel qui clique sur toutes les publicités, pour empêcher la surveillance (dont la publicité est à la fois l'un des moteurs importants et l'une des armes favorites) de savoir si les publicités sont efficaces ou pas.
Outre cette très intéressante partie sur les exemples réels (dans le monde de l'informatique, et en dehors), l'intéret du livre est une discussion détaillée de la légitimité du brouillage. Est-ce bien ou mal de « cliquer » sur les publicités, privant ainsi une profession honorable des informations sur la vie privée des utilisateurs (pardon, les pubards les appellent les « cibles ») ? Les auteurs insistent que le brouillage est l'arme du faible. Les riches et les puissants peuvent se cacher, ou échapper à la surveillance, le brouillage est pour ceux et celles qui ne peuvent pas se cacher. C'est cette asymétrie qui est le principal argument en faveur de la légitimité du brouillage (p. 78).
Et le problème écologique ? Le brouillage consomme davantage de ressources, c'est sûr. La question est suffisamment sérieuse pour faire l'objet d'un traitement en détail dans le livre (p. 65), je vous laisse découvrir la discussion dans le livre.
Ceci dit, de même que le chiffrement n'est pas la seule technique à utiliser dans la lutte pour préserver sa vie privée (p. 62), de la même façon, il ne faut pas penser qu'aux solutions techniques. Ne pourrait-on pas compter sur la bonne volonté des entreprises privées, pour qu'elles arrêtent la surveillance ? (p. 60, les auteurs expliquent pourquoi ils n'y croient pas.) Et, sinon, sur les États pour arrêter cette surveillance par la loi ? (p. 61, les auteurs sont pessimistes à ce sujet.)
Enfin, le livre compte aussi d'autres discussions passionnantes, mais je vous laisse les découvrir. Bonne lecture ! (Et, après, il y a une grosse bibliographie, si vous voulez approfondir.)
L'article seul
Supervision répartie sur plusieurs sites avec Icinga
Première rédaction de cet article le 16 mai 2020
De nos jours, quand on est un ou une ingénieur système responsable d'un service Internet un peu sérieux, on a une supervision automatique du service, pour être prévenu des pannes avant de se faire engueuler sur Twitter. C'est classique et cela va se soi, d'autant plus qu'il existe de très nombreux logiciels libres pour cette tâche (j'utilise Icinga). Mais, souvent, les tests sont faits depuis un seul point, en général dans les locaux de l'organisation qui gère le service. C'est insuffisant car, l'Internet étant ce qu'il est, les problèmes peuvent dépendre du point de mesure. Il existe plusieurs solutions pour faire de la supervision répartie sur plusieurs points, je vais parler ici du système maîtres/satellites/agents d'Icinga.
Pour illustrer cette histoire de supervision depuis plusieurs points, je prendrai comme exemple le système de répartition d'Icinga. Ce système est souvent présenté uniquement comme un moyen de répartir la charge entre plusieurs machines. Mais il a une bien plus grande utilité : permettre de voir la connectivité ou les données depuis plusieurs points de l'Internet. En effet, bien des choses dépendent d'où on est dans l'Internet. Un problème de routage ne va frapper que certains AS. Un « trou noir » annoncé à tort ne va capter qu'une partie du trafic. L'anycast va vous diriger vers un serveur différent (et potentiellement à problèmes) selon votre point de départ. Pour toutes ces raisons, il est crucial aujourd'hui d'avoir une supervision largement répartie. (Une autre utilité est la possibilité de superviser des choses purement locales à la machine, comme l'occupation de l'espace disque, comme on faisait autrefois avec NRPE.)
Commençons par la documentation d'Icinga, très détaillée. Elle n'est pas d'un abord facile, car il existe plusieurs façons de configurer sa supervision répartie. Personnellement, j'ai choisi un mode simple, avec une seule machine maîtresse (Master), plusieurs machines agentes (Agent), et pas de satellite. J'ai configuré de façon à ce que ce soit toujours le maître qui contacte les agents (ce qui simplifie les configurations des pare-feux), mais Icinga permet également la connexion en sens opposé (ce qui peut être utile si c'est le maître qui est un serveur public, et l'agent qui est coincé derrière du NAT), voire dans les deux sens. Et j'ai choisi de centraliser la configuration sur le maître, les agents n'ont aucune initiative, ils ne font qu'exécuter ce qu'a décidé le maitre. (Mais rappelez-vous qu'Icinga offre de nombreuses autres possibilités, et c'est une des raisons pour lesquelles la documentation est assez touffue.)
Il faut installer Icinga sur chaque machine, maître ou agent. Il n'y a pas de logiciels séparés pour les deux rôles (contrairement avec ce qui se fait chez, par exemple, Zabbix), c'est le même Icinga.
La configuration initiale peut se faire très simplement avec le Icinga 2 Setup Wizard (je donne un exemple plus loin) mais je vais d'abord montrer comment le faire à la main. Un petit mot sur la sécurité, d'abord : la communication entre les machines Icinga est protégée par TLS et il nous faut donc un certificat valable sur chaque machine. Comme certaines ne sont pas visibles depuis l'Internet, utiliser Let's Encrypt n'aurait pas forcément été pratique (oui, il y a des solutions, je sais, mais que je trouvais compliquées, dans mon cas). J'ai donc choisi de faire gérer tous les certificats par CAcert. Comme il ne s'agit que de machines que je contrôle, l'obligation d'ajouter le certificat de CAcert au magasin d'AC n'est pas un problème.
Une note sur le nom des fichiers de configuration. Icinga permet
d'inclure depuis le fichier de configuration principal d'autres
fichiers, et cela peut même être récursif
(include_recursive "conf.d"). Vous pouvez donc
choisir l'organisation que vous voulez pour vos fichiers de
configuration. Ici, j'ai choisi celle qu'a par défaut le
paquetage
Debian. Quant aux noms de domaine, j'ai tout mis sous
foobar.example, la zone du maître étant
icinga-master.foobar.example.
Bon, d'abord la configuration du maître. Il faut un fichier de
configuration zones.conf où on déclare les
agents à contacter (rappelez-vous que j'ai choisi une configuration
où c'est toujours le maître qui contacte l'agent) :
const NodeName = "icinga-master.foobar.example"
const ZoneName = "icinga-master.foobar.example"
// Dans le cas le plus simple, il y a une zone par machine.
object Zone ZoneName {
endpoints = [ NodeName ]
}
// La machine maîtresse
object Endpoint NodeName {
}
// Un des agents
object Endpoint "bellovese.foobar.example" {
host = "bellovese.foobar.example" // Nécessaire pour pouvoir le
// contacter, ça pourrait être une adresse IP.
}
// L'agent fait confiance à la machine maîtresse (la directive "parent")
object Zone "bellovese.foobar.example" {
endpoints = [ "bellovese.foobar.example" ]
parent = ZoneName
}
// La configuration qui sera poussée vers les agents
object Zone "global-templates" {
global = true
}
On crée ensuite un répertoire zones.d où on va
placer ce qui concerne la configuration des agents. Il y aura les
gabarits communs à tous les agents. Ici, la partie qui permettra de
faire des ping à distance :
% cat zones.d/global-templates/templates.conf
template Host "remote-host" {
vars.ping_wrta = 300
vars.ping_crta = 600
...
}
...
Avec cette configuration, qui sera poussée vers les agents, tous testeront avec les mêmes paramètres. Autre cas dans ce fichier des gabarits communs, la supervision du démon OpenDNSSEC, qui n'est pas accessible de l'extérieur :
% cat zones.d/global-templates/templates.conf
...
object CheckCommand "opendnssec" {
command = [ PluginContribDir + "/check_opendnssec" ]
arguments = {
"-e" = "$opendnssec_enforcer_expect$",
"-s" = "$opendnssec_signer_expect$"
}
}
apply Service "remote-opendnssec" {
import "generic-service"
check_command = "opendnssec"
assign where host.vars.opendnssec
}
Avec cela, toute machine où la variable
opendnssec a été définie sera testée (on va vérifier
que le démon tourne bien).
Ça, c'était la configuration globale, commune à tous les
agents. Ensuite, pour chaque agent, on va mettre une configuration
spécifique, sous, par exemple,
zones.d/nom-de-l-agent.conf, avec des choses
comme :
object Host "test-bellovese" {
import "remote-host"
address = "bellovese.foobar.example"
address6 = "bellovese.foobar.example"
}
qui fera que l'agent testera la machine
bellovese.foobar.example avec le gabarit
remote-host commun.
Il reste à créer un certificat :
[Choisir éventuellement des options OpenSSL] % openssl req -new -nodes [Répondre aux questions d'OpenSSL, notamment :] Server name []:icinga-master.foobar.example
et à le faire signer par l'AC. Puis on concatène les deux certificats de l'AC :
# cat /usr/share/ca-certificates/CAcert/root.crt /usr/share/ca-certificates/CAcert/class3.crt > /var/lib/icinga2/certs/ca.crt
Et on
met les certificats en
/var/lib/icinga2/certs, aussi bien celui de la
machine maître que celui de l'AC (ici,
CAcert) ;
# ls -l /var/lib/icinga2/certs total 16 -rw-rw---- 1 nagios nagios 5179 Jun 7 2018 ca.crt -rw-rw---- 1 nagios nagios 1875 Jan 7 09:44 icinga-master.foobar.example.crt -rw-rw---- 1 nagios nagios 1704 Jun 7 2018 icinga-master.foobar.example.key
On peut maintenant tester la configuration, avant de redémarrer Icinga :
# icinga2 daemon -C ... [2020-05-15 12:49:18 +0000] information/cli: Finished validating the configuration file(s).
C'est parfait, on redémarre le maître avec sa nouvelle configuration :
# systemctl restart icinga2
Mais les agents, eux, ne sont pas encore configurés et ne vont pas répondre aux demandes du maître. Configurons donc le premier agent. D'abord, activer l'API (on ne le fait pas sur le maître puisqu'on a choisi une configuration où c'est toujours le maître qui se connecte aux agents, jamais le contraire) :
# icinga2 feature enable api
Et n'oublions pas d'ajouter dans
features-available/api.conf :
object ApiListener "api" {
...
accept_config = true
accept_commands = true
Et dans le zones.conf de l'agent, on va
indiquer qui est le maître et donc à qui faire confiance
(l'authentification sera faite via les certificats, dans la session TLS) :
// Moi (l'agent)
object Endpoint NodeName {
host = NodeName
}
object Zone ZoneName {
endpoints = [ NodeName ]
parent = "icinga-master.foobar.example"
}
// Mon maître
object Endpoint "icinga-master.foobar.example" {
}
object Zone "icinga-master.foobar.example" {
endpoints = [ "icinga-master.foobar.example" ]
}
object Zone "global-templates" {
global = true
}
Ensuite, on crée des certificats pour l'agent, on les fait signer par l'AC CAcert et on les installe.
Comme avec le maître, on teste la configuration avec
icinga2 daemon -C et on redémarre Icinga. Comme
l'API a été activée, on doit voir Icinga écouter sur le réseau :
# lsof -i:5665 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME icinga2 21041 nagios 14u IPv4 261751305 0t0 TCP *:5665 (LISTEN)
Pour tester qu'Icinga écoute bien, et en TLS, essayons depuis le maître :
% gnutls-cli bellovese.foobar.example:5665 ... - Server has requested a certificate. ... - Certificate[0] info: - subject `CN=bellovese.foobar.example', issuer `CN=CAcert Class 3 Root,OU=http://www.CAcert.org,O=CAcert Inc.', serial 0x52cf13, RSA key 2048 bits, signed using RSA-SHA512, activated `2020-02-12 14:00:50 UTC', expires `2022-02-11 14:00:50 UTC', pin-sha256="sAA...=" ... - Status: The certificate is trusted. - Description: (TLS1.3)-(ECDHE-SECP256R1)-(RSA-PSS-RSAE-SHA256)-(AES-256-GCM)
Si cette connexion TCP plus TLS ne fonctionne pas, c'est peut-être un problème de réseau et/ou de pare-feu. À vous de déboguer !
Maintenant que l'agent fonctionne, on dit au maitre de s'y
connecter. Dans le zones.conf du maître :
object Zone "bellovese.foobar.example" {
endpoints = [ "bellovese.foobar.example" ]
parent = ZoneName
}
Et, toujours sur le maître, dans le fichier qui sert à configurer ce qu'on supervise sur cette machine :
object Host "bellovese" {
...
vars.client_endpoint = "bellovese.foobar.example"
zone = "icinga-master.foobar.example"
Et on crée sur le maitre un fichier
zones.d/bellovese.conf pour indiquer
ce qu'on veut faire faire à l'agent. Par exemple :
object Host "test-segovese" {
vars.outside = true
import "remote-host"
address = "segovese.foobar.example"
address6 = "segovese.foobar.example"
}
object Host "bellovese-opendnssec" {
import "generic-host"
check_command = "remote_always_true"
vars.opendnssec = true
vars.opendnssec_signer_expect="There are 7 zones configured"
vars.opendnssec_enforcer_expect="bortzmeyer\\.org"
}
La première directive object Host dit à l'agent
de tester la machine segovese.foobar.example (ce qui
donnera un point de vue différent du maître, si l'agent est situé
dans un autre réseau). La deuxième directive dit
que bellovese est un site
OpenDNSSEC et qu'on veut donc surveiller que
les deux démons OpenDNSSEC tournent bien (ils
ne sont pas accessibles de l'extérieur, il faut donc un agent Icinga
sur cette machine).
Maintenant que maître et agent sont prêts, la connexion devrait se faire, ce qu'on peut voir dans le journal, ici celui du maître :
May 15 13:52:48 ambigat icinga2[31436]: [2020-05-15 13:52:48 +0000] information/ApiListener: Finished syncing runtime objects to endpoint 'bellovese.foobar.example'.
On aurait aussi pu faire la configuration avec le wizard. Voici un exemple où on configure le maître :
# icinga2 node wizard
Welcome to the Icinga 2 Setup Wizard!
...
Please specify if this is a satellite setup ('n' installs a master setup) [Y/n]: n
Starting the Master setup routine...
Please specify the common name (CN) [ambigat]: icinga-master.foobar.example
...
information/cli: Dumping config items to file '/etc/icinga2/zones.conf'.
...
information/cli: Updating constants.conf.
...
Done.
Now restart your Icinga 2 daemon to finish the installation!
Et pour configurer un agent :
# icinga2 node wizard
Welcome to the Icinga 2 Setup Wizard!
...
Please specify if this is a satellite setup ('n' installs a master setup) [Y/n]: y
Starting the Node setup routine...
Please specify the common name (CN) [sumarios]: sumarios.foobar.example
Please specify the master endpoint(s) this node should connect to:
Master Common Name (CN from your master setup): icinga-master.foobar.example
Do you want to establish a connection to the master from this node? [Y/n]: n
...
Connection setup skipped. Please configure your master to connect to this node.
...
Bon, si tout va bien, les tests sont maintenant exécutés par
les agents et vous pouvez voir les résultats dans l'interface Web
ou en ligne de commande via l'API. Mais si
ça ne marche pas ? On a vu que la configuration d'Icinga était
complexe, et la documentation pas toujours d'un abord
facile. Alors, voyons maintenant le débogage des
problèmes. D'abord, et avant tout, si ça ne marche pas, il faut
évidemment regarder le journal
(journalctl -t icinga2 -f -n avec systemd). Par
exemple, ici, on voit que le maître ne peut pas se connecter à
l'agent, car le certificat de ce dernier a expiré :
Feb 12 14:00:41 ambigat icinga2[31333]: [2020-02-12 14:00:41 +0000] warning/ApiListener: Certificate validation failed for endpoint 'comrunos.foobar.example': code 10: certificate has expired
De la même façon, si vous voyez des tests qui restent
désespérément affichés dans l'état pending sur
le maître, le journal de l'agent pourra vous renseigner sur ce
qui se passe. Il peut, par exemple, manquer une commande externe (execvpe(/usr/local/lib/nagios/plugins/check_whichasn) failed: No such file or directory).
La panne peut être aussi due à une mauvaise configuration dans le
zones.conf de l'agent, par exemple l'oubli de
la directive parent. Autre cas, si vous
trouvez des messages comme :
warning/ApiListener: Ignoring config update. 'api' does not accept config.
c'est que vous avez oublié accept_config =
true dans
features-available/api.conf.
Si le journal par défaut n'est pas suffisant, vous pouvez
aussi rendre Icinga bien plus bavard. Vérifiez que
debuglog est bien activé :
# icinga2 feature list
Disabled features: compatlog elasticsearch gelf graphite icingastatus influxdb livestatus opentsdb perfdata statusdata syslog
Enabled features: api checker command debuglog ido-pgsql mainlog notification
Ou, s'il ne l'est pas, activez-le avec icinga2 feature
enable debuglog et configurez dans
features-available/debuglog.conf. Par
exemple, cette configuration :
object FileLogger "debug-file" {
severity = "debug"
path = LogDir + "/debug.log"
}
Va vous produire un debug.log très bavard.
L'article seul
StopCovid : une « éthique de la responsabilité ? »
Première rédaction de cet article le 12 mai 2020
Dans le dernier numéro du magazine « La Recherche », Jean-Gabriel Ganascia, président du comité d'éthique du CNRS, parle des applications de suivi de contacts en estimant que « la surveillance de la pandémie demande une éthique de responsabilité ».
Dans chaque numéro de ce mensuel, Jean-Gabriel Ganascia tient une chronique sur l'éthique. Dans le numéro 559 de mai 2020, il parle des applications de suivi de contacts comme l'hypothétique StopCovid, qui a suscité pas mal de discussions, sur divers points. Ici, un seul point est discuté : les risques que fait peser StopCovid sur la vie privée. (Sur le même thème, il a également donné un interview à France Info. Notez que StopCovid pose bien d'autres questions que la vie privée.)
L'argument principal de Jean-Gabriel Ganascia est présenté sous un angle philosophique. Il rappelle qu'il y a deux grands courants en éthique, qu'il nomme « éthique de conviction » et « éthique de responsabilité ». L'éthique de conviction fait passer le respect des principes avant tout. Mentir, c'est mal, donc on ne ment pas, même pour, par exemple, sauver une vie. L'éthique de responsabilité, également appelée « conséquentialisme », s'attache surtout aux conséquences des actes, pour juger s'ils étaient éthiques ou pas. Envahir un pays pour en chasser un dictateur brutal peut être considéré comme éthique, même si on juge la guerre mauvaise. Évidemment, ces deux courants sont ici présentés sous leur forme extrême. On pourrait les caricaturer (par exemple en disant que l'éthique de responsabilité mène au « qui veut la fin veut les moyens ») mais, en pratique, la plupart des gens sont situés quelque part entre les deux. Ici, Jean-Gabriel Ganascia présente les gens qui s'opposent à StopCovid au nom de la défense de la vie privée comme partisans d'une éthique de conviction extrême (« dogmatique »), et il les accuse de « [risquer] une nouvelle flambée de l'épidémie qui causerait des dizaines, voire des centaines de milliers de morts ». Il prône donc une éthique de la responsabilité, qui ferait passer la vie privée après, au nom des conséquences positives du suivi des contacts. (« Ces craintes [...] doivent, dans la période actuelle, être mises en regard des autres enjeux ».)
Le principal problème que je vois avec cette prise de position n'est pas sur le principe : je ne suis pas un moraliste pur, qui voudrait que les principes comme la défense de la vie privée aient le pas sur tout (il parait que Kant, lui, était comme ça). Il est sur le fait que, curieusement, Jean-Gabriel Ganascia défend le conséquentialisme en oubliant un de ses principes de base : l'efficacité. Si on défend des mesures mauvaises au nom de leurs résultats positifs, c'est la moindre des choses que d'évaluer quelle chance on a d'atteindre ces résultats. Or, il n'y a rien de tel dans l'article :
- Aucun mot sur les tests, actuellement en nombre très insuffisant alors que, justement, une application de suivi de contacts n'a de sens que si on teste les personnes, pour pouvoir ensuite prévenir leurs contacts qu'ils se sont approchés d'une personne contaminée.
- Aucune estimation de l'efficacité de l'application prévue. Jean-Gabriel Ganascia dit simplement qu'iil faut faire quelque chose donc que StopCovid est une bonne solution, sans étudier ses forces et ses faiblesses, qui ont pourtant été largement discutées publiquement.
Bref, il n'est pas un conséquentaliste conséquent. Il défend les applications de suivi de contacts au nom de l'éthique de responsabilité. Si on le suit, cela veut dire que ces applications peuvent être éthiques, même si elles violent la vie privée. (Notez que d'autres défenseurs de ces applications ont un autre angle d'attaque, affirmant bien haut qu'elles ne violent en rien la vie privée. La communication autour de StopCovid a changé dans le temps.) Mais cela n'implique pas forcément que ces applications soient éthiques, il leur reste encore à prouver leur efficacité. La fin justifie les moyens, peut-être mais des moyens non éthiques et qui ne permettent pas d'atteindre la fin auraient quelle légitimité ?
L'article seul
Serveur DNS faisant autorité : définition
Première rédaction de cet article le 11 mai 2020
Ce court article explique ce qu'est un serveur DNS faisant autorité. Il existe plein de ressources en ligne sur le DNS mais très peu expliquent la différence cruciale entre un résolveur et un serveur faisant autorité.
Il y a en effet deux catégories de serveurs DNS. Ils sont tellement différents que c'est en général une mauvaise idée de dire « serveur DNS » tout court. Le serveur faisant autorité est le serveur qui stocke les données, qui seront récupérées via le protocole DNS. C'est pour cela qu'on dit qu'il « fait autorité » : par définition, ce qu'il dit est la vérité. Il n'est jamais interrogé par les machines des utilisateurs, mais il est questionné indirectement, par les serveurs de l'autre catégorie, les résolveurs.
Les serveurs faisant autorité, et leur rôle dans la résolution
DNS :
Un serveur faisant autorité ne fait pas autorité pour tous les noms de domaine, puisque le DNS est décentralisé. Il fait autorité pour une partie de l'arbre des noms de domaine. Par exemple :
- Les serveurs de l'AFNIC,
l'organisation qui gère le TLD
.frfont autorité pour.fr. - Les serveurs faisant autorité pour les domaines du CNAM sont gérés par le service informatique du CNAM.
- Je gère moi-même la plupart des serveurs qui font autorité
pour le domaine de ce blog,
bortzmeyer.org. - Les serveurs faisant autorité pour le Ministère des Armées français sont sous-traités à la société Orange (via la marque Oleane).
À noter qu'un serveur faisant autorité se dit en anglais authoritative server, ce qu'on voit parfois bêtement traduit par « serveur autoritaire ». Non. Un adjudant est autoritaire, un serveur DNS fait autorité.
Si un serveur DNS faisant autorité est en panne, les autres serveurs faisant autorité pour la même zone (sous-arbre de l'arbre des noms de domaine) restent disponibles. Pour qu'une zone ne marche plus, il faut une panne de tous les serveurs faisant autorité (cf. la fameuse attaque contre Dyn, ou bien cette panne chez Microsoft). Mais cela n'affectera que les domaines hébergés sur ces serveurs, pas le reste du DNS.
Si vous êtes informaticien ou simplement intéressé par l'informatique, et que vous voulez monter des serveurs faisant autorité, il existe de nombreux logiciels libres pour cela, comme NSD ou Knot.
Notez que certains logiciels DNS permettent d'assurer les fonctions de résolveur et de serveur faisant autorité dans le même serveur. C'est en général une mauvaise idée.
Où les serveurs faisant autorité trouvent-ils leurs données, celles qu'ils vont servir à tout les résolveurs de la planète ? Cela dépend du serveur, c'est une décision locale. Il est courant de stocker les données dans un fichier de zone, dont la syntaxe absconse et pleine de pièges a souvent créé des problèmes :
$TTL 86400
@ IN SOA ns4.bortzmeyer.org. hostmaster.bortzmeyer.org. (
2020043001
7200
3600
604800
43200 )
IN NS ns4.bortzmeyer.org.
IN NS ns1.bortzmeyer.org.
...
IN MX 0 mail.bortzmeyer.org.
IN TXT "v=spf1 mx ?all"
IN TXT "My personal domain - Domaine personnel"
IN CAA 0 issue "cacert.org"
IN CAA 0 issuewild ";"
IN CAA 0 issue "letsencrypt.org"
www IN AAAA 2001:4b98:dc0:41:216:3eff:fe27:3d3f
www IN AAAA 2605:4500:2:245b::42
mercredifiction IN CNAME ayla
_443._tcp.mercredifiction IN TLSA 1 1 1 928dde55df4cd94cdcf998c55085fbb5228b561cc237a122d950260029c5b8c9
...
Mais d'autres méthodes existent, par exemple l'utilisation d'un SGBD.
Et si on veut continuer dans la technique et regarder les données
d'un serveur faisant autorité ? Normalement, ils ne sont pas
interrogés directement mais via les résolveurs. Ceci dit, les
serveurs faisant autorité sont publics, et on peut, sur
Unix, utiliser dig pour les interroger, en
mettant le nom ou l'adresse IP du serveur après le signe @. Ici, on
interroge un serveur de l'AFNIC sur le
domaine sante.gouv.fr :
% dig @d.nic.fr A sante.gouv.fr ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 38097 ;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 6, ADDITIONAL: 6 ;; WARNING: recursion requested but not available ... ;; AUTHORITY SECTION: sante.gouv.fr. 172800 IN NS ns3.nameshield.net. sante.gouv.fr. 172800 IN NS ns2.observatoiredesmarques.fr. sante.gouv.fr. 172800 IN NS ns1.travail.gouv.fr. sante.gouv.fr. 172800 IN NS ns1.sante.gouv.fr. sante.gouv.fr. 172800 IN NS ns2.sante.gouv.fr. sante.gouv.fr. 172800 IN NS a.ns.developpement-durable.gouv.fr. ... ;; Query time: 3 msec ;; SERVER: 2001:678:c::1#53(2001:678:c::1) ;; WHEN: Fri May 08 17:25:44 CEST 2020 ;; MSG SIZE rcvd: 326
La question posée au serveur d.nic.fr, qui fait
autorité pour .fr était « quelle est l'adresse
IPv4 de
sante.gouv.fr ? » Nous n'avons pas eu de
réponse directe, car d.nic.fr fait autorité
pour .fr mais pas pour
sante.gouv.fr (rappelez-vous que le DNS est
décentralisé). On a donc une délégation,
d.nic.fr nous renvoie à six serveurs qui font
autorité pour sante.gouv.fr. L'avertissement
« recursion requested but not available » est
normal, s'agissant d'un serveur faisant autorité, pas d'un résolveur
(les résolveurs sont également appelés serveurs récursifs).
Au passage, cela me permet d'expliquer comment on trouve les
serveurs faisant autorité pour une zone donnée : le DNS utilise le
DNS pour son propre fonctionnement. Une requête de type NS
(Name Servers) permet de trouver les serveurs,
ici, ceux faisant autorité pour
.fi (j'ai pensé à ce
TLD car je
venais de lire des récits
de randonnée en Finlande) :
% dig NS fi ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 7282 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 9, AUTHORITY: 0, ADDITIONAL: 1 ... ;; ANSWER SECTION: fi. 86400 IN NS e.fi. fi. 86400 IN NS b.fi. fi. 86400 IN NS a.fi. fi. 86400 IN NS h.fi. fi. 86400 IN NS i.fi. fi. 86400 IN NS f.fi. fi. 86400 IN NS d.fi. fi. 86400 IN NS g.fi. fi. 86400 IN NS c.fi. ;; Query time: 176 msec ;; SERVER: ::1#53(::1) ;; WHEN: Fri May 08 18:42:25 CEST 2020 ;; MSG SIZE rcvd: 175
On a vu plus haut que demander des informations sur
sante.gouv.fr à un serveur qui fait autorité
pour .fr renvoie une délégation. Si on suit
cette délégation et qu'on pose la même question à un serveur qui
fait autorité pour sante.gouv.fr, on a notre réponse :
% dig @a.ns.developpement-durable.gouv.fr. A sante.gouv.fr ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 15886 ;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 6, ADDITIONAL: 5 ;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ;; QUESTION SECTION: ;sante.gouv.fr. IN A ;; ANSWER SECTION: sante.gouv.fr. 600 IN A 213.162.60.164 ... ;; Query time: 25 msec ;; SERVER: 194.5.172.19#53(194.5.172.19) ;; WHEN: Fri May 08 17:26:21 CEST 2020 ;; MSG SIZE rcvd: 298
On voit qu'on parle à un serveur faisant autorité, et non pas à un résolveur, à deux détails :
- Dans les flags, il y a le bit AA (Authoritative Answer), qui serait absent sur un résolveur, qui aurait plutôt le bit RA.
- Le TTL est un chiffre rond.
Notez que la motivation originelle pour cet article était le désir de pouvoir parler de « serveur faisant autorité » dans les articles de ce blog sans devoir l'expliquer à chaque fois, uniquement en mettant un lien. D'habitude, je résous le problème en mettant un lien vers Wikipédia mais, ici, il n'existe pas de bon article Wikipédia sur la question. Je n'ai pas le courage de l'écrire, et surtout de le gérer par la suite, surtout face aux « corrections » erronnées. Mais, ce blog étant sous une licence libre, et compatible avec celle de Wikipédia, si vous souhaitez le faire, n'hésitez pas à copier/coller du texte.
L'article seul
Résolveur DNS : définition
Première rédaction de cet article le 11 mai 2020
Ce court article explique ce qu'est un résolveur DNS. Il existe plein de ressources en ligne sur le DNS mais très peu expliquent la différence cruciale entre un résolveur et un serveur faisant autorité.
Il y a en effet deux catégories de serveurs DNS. Ils sont tellement différents que c'est en général une mauvaise idée de dire « serveur DNS » tout court. Le résolveur est le serveur qu'interrogent directement les machines terminales (comme celle que vous touchez en ce moment, lorsque vous consultez cet article). Ces machines terminales ne parlent jamais directement aux serveurs faisant autorité, l'autre catégorie de serveurs DNS.
Comme c'est le serveur contacté pour toute résolution DNS, il est absolument critique : s'il tombe en panne, ce sera, pour la très grande majorité des activités, comme si on n'avait plus d'Internet du tout. S'il ment, il pourra emmener l'utilisateur où il veut. Et s'il capture des données, il peut avoir accès à énormément d'informations sur votre activité (cf. RFC 7626).
Notez que le résolveur est parfois appelé « serveur récursif » ou « serveur cache ».
Des exemples de résolveurs :
- Le cas le plus courant est celui où vous utilisez le résolveur fourni par votre FAI ou par le service informatique qui gère votre réseau d'accès à l'Internet.
- Mais il existe aussi des résolveurs DNS publics, dont les plus célèbres sont ceux des GAFA Google et Cloudflare. Les utiliser n'est pas forcément une bonne idée.
- Vous pouvez parfaitement avoir votre propre résolveur DNS, pour un maximum de contrôle ; c'est ce qui arrive avec le Pi-hole mais cela peut se faire avec beaucoup d'autres logiciels libres comme Unbound ou Knot. Notez toutefois qu'aucune solution n'est parfaite.
Comment la machine terminale connait le résolveur à utiliser ?
L'adresse IP du résolveur
est apprise via des protocoles comme DHCP, mais peut aussi avoir été
configurée statiquement, dans une base comme le fichier de
configuration /etc/resolv.conf sur
Unix. En pratique, ce n'est pas toujours trivial.
Le résolveur ne connait quasiment aucune donnée au démarrage, il apprend petit à petit en contactant les serveurs faisant autorité.
Le résolveur, au milieu de la résolution DNS :
Notez que certains logiciels DNS permettent d'assurer les fonctions de résolveur et de serveur faisant autorité dans le même serveur. C'est en général une mauvaise idée.
Et si vous êtes branché·e technique, et que vous voulez interroger un
résolveur directement, pour voir ce qu'il raconte ? Sur
Unix, le logiciel dig permet de le faire. Si on
n'indique pas explicitement un serveur, il interroge le résolveur
par défaut de la machine, ici il a l'adresse IP
::1 (la ligne SERVER) :
% dig AAAA cyberstructure.fr ... ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 50365 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1 ... ;; ANSWER SECTION: cyberstructure.fr. 82347 IN AAAA 2001:4b98:dc0:41:216:3eff:fe27:3d3f ... ;; Query time: 137 msec ;; SERVER: ::1#53(::1) ;; WHEN: Fri May 08 17:23:54 CEST 2020 ;; MSG SIZE rcvd: 251
On voit qu'on parle à un résolveur, et non pas à un serveur faisant autorité à deux détails :
- Dans les flags, il y a le bit RA (Recursion Available), qui serait absent sur un serveur faisant autorité, qui aurait plutôt le bit AA.
- Le TTL n'est pas un chiffre rond, ce qui arrive lorsque la donnée était déjà dans la mémoire du résolveur.
Notez que la motivation originelle pour cet article était le désir de pouvoir parler de « résolveur » dans les articles de ce blog sans devoir l'expliquer à chaque fois, uniquement en mettant un lien. D'habitude, je résous le problème en mettant un lien vers Wikipédia mais, ici, il n'existe pas de bon article Wikipédia sur la question. Je n'ai pas le courage de l'écrire, et surtout de le gérer par la suite, surtout face aux « corrections » erronnées. Mais, ce blog étant sous une licence libre, et compatible avec celle de Wikipédia, si vous souhaitez le faire, n'hésitez pas à copier/coller du texte.
L'article seul
Qui contrôle votre ordiphone et qui devrait avoir ce pouvoir ?
Première rédaction de cet article le 10 mai 2020
Le débat sur le contrôle des ordiphones est ancien mais a récemment repris de l'importance en France lors de la discussion sur une éventuelle application de suivi des contacts pour l'épidémie de COVID-19. En effet, les systèmes d'exploitation les plus répandus sur ordiphone ne permettent pas certaines fonctions qu'un projet d'application voulait utiliser. D'où la discussion « qui doit décider d'autoriser ou pas telle fonction de l'appareil ? »
Dans ce cas précis, le problème portait sur le Bluetooth et plus précisément sur son activation permanente par une application, même quand elle est en arrière-plan sur l'ordiphone. Le système d'exploitation d'Apple, iOS (mais, apparemment, également son concurrent Android) ne permet pas cela. Bluetooth est en effet très dangereux pour la sécurité, permettant à tout appareil proche de parler avec le vôtre, et surtout pour la vie privée. Compte tenu de l'attitude des commerçants vis-à-vis de la vie privée, des scénarios de type « Black Mirror » seraient possibles, si les applications pouvaient laisser le Bluetooth fonctionner discrètement, par exemple de la surveillance de clients dans un magasin, pour identifier les acheteurs potentiels. Il est donc tout à fait normal qu'iOS ne permette pas cela. C'est aussi pour cela que l'ANSSI recommande, à juste titre, « Les interfaces sans-fil (Bluetooth et WiFi) ou sans contact (NFC par exemple) doivent être désactivées lorsqu’elles ne sont pas utilisées ».
OK, dans ce cas bien précis, Apple a raison. Mais généralisons un peu le problème : qu'ils aient raison ou pas, est-ce normal qu'une entreprise privée étatsunienne prenne ce genre de décisions ? Et, si ce n'est pas Apple ou Google (qui gère Android), alors qui ?
La question est importante : la technique n'est pas neutre, les auteurs de logiciel (ici, Google et Apple) ont un pouvoir. En effet, une très grande partie des activités humaines passe par des équipements informatiques. Ces équipements déterminent ce qu'on peut faire ou ne pas faire, particulièrement sur les ordiphones, des engins beaucoup plus fermés et contrôlés par les auteurs de logiciel que les traditionnels ordinateurs. Même quand le logiciel n'impose pas et n'interdit pas, il facilite, ou au contraire il décourage telle ou telle utilisation, exerçant ainsi un réel pouvoir, même s'il n'est pas toujours très apparent. Mais, justement, dans le cas de l'application de suivi de contacts, ce pouvoir se manifeste plus nettement. On peut taper du poing sur la table, crier que c'est intolérable, si Apple et Google ne bougent pas, on ne peut rien faire. Notez que c'est une simple constatation que je fais ici : Apple et Google ont du pouvoir, indépendamment de si on pense qu'ils exercent ce pouvoir correctement ou pas. (Ici, j'ai déjà dit qu'Apple avait tout à fait raison et que leur demander de diminuer la sécurité de leur système - déjà basse - était une mauvaise idée.) Je ne vais pas développer davantage cette question de la neutralité de la technique, et du pouvoir des auteurs du logiciel, j'en ai déjà parlé dans mon livre (p. 148 et 97 de l'édition papier, respectivement).
Le problème du pouvoir d'Apple et Google sur ces machines, je l'ai dit au début, est perçu depuis un certain temps. L'ARCEP en a fait le thème d'une campagne sur la nécessaire « neutralité des terminaux », terme malheureux car un logiciel n'est jamais neutre, il fait des choix (ou, plus exactement, l'organisation qui écrit le logiciel fait des choix). L'ARCEP semble d'ailleurs depuis préférer une meilleure terminologie, parlant par exemple d'ouverture des terminaux. Une autre raison qui fait que le concept de « neutralité des terminaux » est contestable est qu'il est un peu trop évident qu'il s'agit de faire référence à la neutralité de l'Internet, une question assez différente. En effet, il est normalement bien plus facile de changer de machine et de logiciel que de FAI. Vraiment ? C'est que d'un autre côté, le choix est parfois plus théorique que réel. Ainsi, pour les ordiphones, le matériel impose souvent le choix d'un et d'un seul système d'exploitation, avec différents moyens techniques de rendre difficile le changement de ce système, ce qui est une entrave anormale à la liberté de l'utilisateur. J'y reviendrai.
Mais, d'abord, revenons à la souveraineté. Faut-il une solution « souveraine », par exemple un système d'exploitation français sur ces ordiphones, qui suivrait alors les ordres du gouvernement français ? Avant de considérer si ce serait une bonne idée ou pas, est-ce réaliste ? Clairement non, mais j'ai déjà détaillé cette question dans mon article sur le défunt projet « OS souverain ». À défaut de développer un système souverain, serait-il possible, en remuant suffisamment d'air, de contraindre Google et Apple à obtempérer ? Ces entreprises n'ont pas de morale, leur but est de gagner de l'argent et leur décision finale dépendrait simplement de si elles estiment préférable, pour leur cours en Bourse, d'obéir ou au contraire de jouer les vertueux résistants. Disons que cela va dépendre de l'importance du gouvernement qui demande…
Mais, outre, cette question de réalisme, il y a un problème politique bien plus fondamental : la souveraineté de qui ? La souveraineté n'est pas un but en soi, c'est normalement le moyen de prendre des décisions qui correspondent à nos intérêts et pas à ceux de Google et d'Apple. Mais qui est le « nous » ? L'État ? Le citoyen ? (Notez au passage que tous les citoyens ne sont pas d'accord entre eux…) L'entreprise nationale ? Un système d'exploitation contrôlé par Orange et Thales serait-il meilleur que s'il était contrôlé par Google et Apple ? J'en doute. Et c'est pour cela que je ne suis pas très enthousiaste en lisant les discours souverainistes, qui ne parlent en général jamais des décisions qui seront prises, uniquement du fait qu'elles seront « souveraines ».
Bon, maintenant, assez râlé, qu'est-ce que je propose ? Certainement pas de lancer le Nième grand projet national de développement d'un système souverain, projet qui finira soit en échec gaspilleur soit, pire, en un autre système fermé ne laissant aucune souveraineté aux citoyens et citoyennes. L'important est au contraire d'ouvrir le choix. Il ne s'agit pas de n'avoir le choix qu'entre deux systèmes privateurs mais au contraire de faire en sorte que les utilisateurs et utilisatrices d'ordiphones (et d'ordinateurs tout court, d'ailleurs) aient accès à plusieurs choix possibles. Un monopole de Capgemini ne serait pas meilleur qu'un monopole de Google ! Le pluralisme est en effet la meilleure garantie contre les abus du pouvoir. Si les auteurs d'un système d'exploitation tentent d'abuser de leur pouvoir, on peut espérer que les autres suivront un chemin différent. Notez que le fait d'avoir des systèmes d'exploitation différents est une condition nécessaire mais pas suffisante. Il faut aussi :
- Que les systèmes offrent un réel choix. Actuellement, le duopole Apple+Google leur permet trop facilement de s'entendre sur tel ou tel choix.
- Que le matériel permette de changer réellement de système d'exploitation, au contraire de la plupart des ordiphones d'aujourd'hui, verrouillés contre toute installation d'un système alternatif. Le problème n'est pas seulement Apple+Google : les fabricants de matériel, ainsi que les opérateurs téléphoniques qui distribuent des ordiphones, ont également une part de responsabilité.
- Que les systèmes d'exploitation en question soient du logiciel libre, autrement, l'utilisateur n'aurait pas davantage de souveraineté qu'aujourd'hui, quelle que soit l'organisation qui a développé ce système.
Sinon, d'autre(s) article(s) sur le même sujet :
- L'article « Souveraineté numérique » d'Elisabeth.
- Le dossier de l'ARCEP sur « les terminaux ». Il fait plusieurs propositions concrètes, assez modestes, mais qui vont dans le bon sens. Par exemple, le rapport demande « de permettre aux utilisateurs de supprimer des applications préinstallées » mais ne parle pas de leur permettre d'installer un système d'exploitation alternatif.
- L'étude sous l'angle juridique de la fermeture des ordiphones et de leurs systèmes d'exploitation, par Emmanuel Netter.
L'article seul
Afficher une page de ce blog prise au hasard
Première rédaction de cet article le 9 mai 2020
Sur une suggestion d'un fidèle lecteur, j'ai installé un p'tit script qui permet de voir une page au hasard de ce blog.
Quel intérêt ? Pas beaucoup, c'est surtout amusant, et cela peut
permettre de découvrir des articles peu lus sur ce
blog. L'URL
est https://www.bortzmeyer.org/apps/random
Notez que cela peut faire ressortir de vieux articles, pas du tout à jour. En effet, je ne m'engage pas à ce que tous les articles soient maintenus, cela ne me laisserait plus le temps d'en faire de nouveaux. Au moins, je mets systématiquement la date, ce qui permet de vérifier si l'article est récent ou pas.
Les amateurs de programmation noteront que le code source de ce service, en Python, est très simple :
def randomfile(start_response, environ):
global generator
files = glob.glob("%s/*.xml" % path)
file = re.sub(path, '', re.sub('\.xml$', '.html', generator.choice(files)))
url = "%s%s" % (prefix, file)
status = '307 Redirect'
output = """
<html><head><title>Redirect at random</title></head>
<body>
<h1>Redirect at random</h1>
<p>Go <a href="%s">to this article</a>.</p>
</body>
</html>""" % url
response_headers = [('Location', url),
('Content-type', 'text/html'),
('Content-Length', str(len(output)))]
start_response(status, response_headers)
return [output.encode()]
L'article seul
Fiche de lecture : The island of lost maps
Auteur(s) du livre : Miles Harvey
Éditeur : Broadway Books
0-7679-0826-0
Publié en 2000
Première rédaction de cet article le 7 mai 2020
Ce n'est pas un roman : ce livre raconte la triste histoire d'un salaud, Gilbert Bland, qui a écumé les bibliothèques des États-Unis pendant des années, découpant des livres anciens pour voler des cartes et les revendre. L'auteur raconte l'histoire de ces vols, les réactions des bibliothèques (souvent trop pauvres pour pouvoir protéger efficacement les trésors qu'elles contiennent) et le discret monde des vendeurs d'antiquités, où l'éthique est assez basse, et où d'autres salauds achètent sans discuter des œuvres manifestement volées.
L'enquête est très approfondie mais cela n'a pas été facile. Les bibliothèques ont pendant longtemps préféré se taire, en partie pour ne pas attirer l'attention sur la quantité d'objets précieux qu'elles stockent, en partie parce que les universités aux États-Unis dépendent beaucoup du financement privé et qu'il ne faut pas effrayer les riches donateurs. Le monde du commerce d'antiquités est discret, d'autant plus qu'ils savent bien qu'une bonne partie des transactions est fondé sur le vol. Mais Miles Harvey y a passé du temps, et a été le premier à exposer le business de Bland, dans une série d'articles dont il a ensuite tiré ce livre, plein de personnages mystérieux, de rendez-vous dans des lieux luxueux, de trésors antiques en péril.
Bland n'était pas le premier voleur de cartes, bien sûr. Le livre refait vivre une bonne partie de l'histoire de la cartographie ; les cartes sont précieuses, parfois secrètes, et dans de nombreux cas, des espions étaient prêts à prendre des risques énormes pour arriver à mettre la main sur les cartes utilisées pour les voyages lointains. Ce livre passionnant ne se limite pas aux actions d'un minable voleur du XXe siècle, il parle aussi de voyages, de comment on fait les cartes, comment on répare les vieux livres et de plein d'autres sujets qui font rêver.
Les vols dans les bibliothèques, hélas, continuent. (Vous pouvez voir la vidéo de Charlie Danger sur le pillage des œuvres d'art.) Et il n'y a pas que les vols, il y a aussi que la destruction d'ouvrages achetés légalement. Donc, un conseil pratique pour terminer : n'achetez jamais de planches et autres illustrations anciennes originales (cartes, illustrations de flore, de faune, d'outils médicaux, etc) chez les bouquinistes, elles ont souvent été découpées de livres anciens, dépecés car la vente à la page est plus facile et plus rémunératrice que celle du livre entier. Mieux vaut acheter une reproduction qui, au moins, n'est pas toujours issue de la destruction de l'ouvrage d'origine.
L'article seul
Fiche de lecture : Super-héros ; une histoire politique
Auteur(s) du livre : William Blanc
Éditeur : Libertalia
978-2377-290444
Publié en 2018
Première rédaction de cet article le 5 mai 2020
Les super-héros étatsuniens ne sont pas juste une bande de types bizarres en collants colorés et qui chassent des méchants en sautant d'un immeuble à l'autre. Ils résument et illustrent des valeurs et des opinions, ils sont donc politiques, comme les autres personnages de fiction. Dans cet excellent livre, William Blanc analyse cette politique des super-héros, depuis les débuts jusqu'à aujourd'hui, et comment ils reflètent les mythes, les espoirs et les préjugés de chaque époque.
Depuis toujours, il y a des histoires avec des héros. Mais quand on parle spécifiquement des « super-héros », on fait allusion à un courant purement étatsunien (et qui, logiquement dans ce pays, est une marque déposée). Ce courant est né en 1938, date de la parution du premier Superman. Le caractère bon marché des comics, et leur immense succès populaire ont paradoxalement retardé le moment où les thèmes politiques sous-jacents ont été sérieusement étudiés. Mais cette époque-là est révolue et, désormais, on ne compte plus les travaux érudits analysant les X-Men, Batman ou les Avengers. Ces super-héros sont-ils de gauche ou de droite ? Orientés vers le progrès ou vers le retour au passé ? Cela dépend du personnage et des époques. Les super-héros, qui semblent dotés d'une force invincible sont en fait très vulnérables à l'air du temps, et évoluent régulièrement en fonction des attentes du marché, pardon, de la société. Et comme la demande est vaste, l'offre s'adapte. Les super-héros sont trop machos ? On crée Wonder Woman, car il y a suffisamment de lectrices (ou de lecteurs intéressés par un personnage féminin fort) pour que ça se vende. Les Noirs revendiquent leurs droits ? Black Panther apparait (il y a aussi le moins connu Power Man, que j'ai découvert dans ce livre). Les super-héros ont ainsi épousé tous les changements de la société étatsunienne au cours du XXe siècle.
Si certains des super-héros ont des opinions politiques explicites, comme Green Arrow, d'autres sont plus difficiles à décoder. C'est ainsi que le chapitre sur le Punisher, personnage favori de l'extrême-droite, ne tranche pas complètement : ce super-héros est plus complexe que ce que croient ses supporters habituels.
Ah, et l'étude très fouillée des super-héros va jusqu'à étudier leurs pratiques sportives. Je vous laisse deviner quel est le sport le plus pratiqué par les super-héros.
Note personnelle : je n'aime pas les comics traditionnels, et j'absorbe avec modération les films modernes de super-héros. Donc, je ne suis peut-être pas le cœur du cible idéal pour ce livre. L'auteur, William Blanc, a écrit sur d'autres mythes qui me touchent plus, comme le roi Arthur ou comme Charles Martel (oui, c'est un personnage historique, mais on sait peu de choses sur lui, et c'est surtout le mythe qu'analyse l'auteur dans son livre).
L'article seul
RFC 8752: Report from the IAB Workshop on Exploring Synergy between Content Aggregation and the Publisher Ecosystem (ESCAPE)
Date de publication du RFC : Mars 2020
Auteur(s) du RFC : M. Thomson, M. Nottingham
Pour information
Première rédaction de cet article le 1 mai 2020
Ce RFC est le compte-rendu d'un atelier de l'IAB qui s'est tenu en juillet 2019 au sujet du Web Packaging, une proposition technique permettant de regrouper un ensemble de pages Web en un seul fichier, pouvant être distribué par des moyens non-Web, tout en étant authentifié. Web Packaging (ou WebPackage) est un concentré de pas mal d'enjeux technico-politiques actuels.
Pour en savoir plus sur ce projet, vous pouvez consulter l'actuel dépôt du projet, géré par le WICG. (Il y avait un projet W3C à un moment mais qui a été abandonné). Vous pouvez commencer par ce document. (Il y a aussi un brouillon à l'IETF, et un nouveau groupe de travail, wpack.) Le projet avait été lancé à l'origine par Google.
La proposition a suscité pas mal de discussions, voire de contestations. N'est-ce pas encore un plan diabolique de Google pour entuber les webmestres ? L'IAB a donc organisé un atelier, joliment nommé ESCAPE (Exploring Synergy between Content Aggregation and the Publisher Ecosystem) au sujet du Web Packaging. Cela permettait notamment de faire venir des gens qui sont plutôt du côté « création de contenus » (entreprises de presse, par exemple), et qui viennent rarement au W3C et jamais à l'IETF. Cet atelier s'est tenu à Herndon en juillet 2019. Il n'avait pas pour but de prendre des décisions, juste de discuter. Vous pouvez trouver les documents soumis par les participants sur la page de l'atelier. Je vous recommande la lecture de ces soumissions.
Le principe de base de Web Packaging est de séparer l'écriture du contenu et sa distribution, tout en permettant de valider l'origine du contenu (l'annexe B du RFC décrit Web Packaging plus en détail). Ainsi, un des scénarios d'usage (section 2 du RFC) serait que le crawler de Google ramasse un paquetage de pages et de ressources sur un site Web, l'indexe, et puisse ensuite servir directement ce paquetage de pages et autres ressources au client qui a utilisé le moteur de recherche, sans renvoyer au site original. Et tout cela avec des garanties d'origine et d'authenticité, et en faisant afficher par le navigateur dans sa barre d'adresses l'URL original. Un autre usage possible serait la distribution de sites Web censurés, par des techniques pair-à-pair, tout en ayant des garanties sur l'origine (sur ce point particulier, voir aussi la section 3.3 du RFC). Notez que ces techniques font que le site original ne connait pas les téléchargements, ce qui peut être vu comme une bonne chose (vie privée) ou une mauvaise (statistiques pour le marketing). Et puis les inquiétudes vis-à-vis de Web Packaging ne viennent pas uniquement des problèmes pour avoir des statistiques. Des éditeurs ont dit lors de l'atelier qu'il étaient tout simplement inquiets des « copies incontrôlées ». En outre, l'argument de vie privée est à double tranchant : le site d'origine du contenu ne voit pas les téléchargements, mais un autre acteur, celui qui envoie le Web Packaging le voit.
Séparer création de contenu et distribution permet également la consultation hors-ligne, puisque un paquetage Web Packaging peut être auto-suffisant. Cela serait très pratique, par exemple pour Wikipédia. Actuellement, il existe des trucs plus ou moins pratiques (HTTrack…) mais le Web Packaging rendrait cette activité plus agréable. Notez que les participants à l'atelier ne se sont pas mis d'accord sur le caractère indispensable ou pas de la signature dans ce cas.
Potentiellement, un système comme Web Packaging pourrait également changer le monde du livre électronique : tout site Web pourrait être facilement « ebookisé ». Une amusante discussion à l'atelier a eu lieu sur l'intérêt des signatures. Comme souvent en cryptographie, les signatures ont une durée de validité limitée. Sept jours est proposé, par défaut, mais Moby Dick a été écrit il y a 61 000 jours.
Dernier scénario d'usage envisagé, l'archivage du Web. Ce n'est pas trivial, car il ne suffit pas de copier la page HTML, il faut garder toutes les ressources auxiliaires, d'où l'intérêt de Web Packaging. Et la signature serait utile là aussi, pour vérifier que l'archive est sincère. (Voir aussi le RFC 7089).
La section 3 du RFC discute ensuite la difficile question de la relation entre les producteurs de contenu et les intermédiaires comme Google. Par exemple, si un producteur de contenu sous-traite la distribution du contenu à un CDN, il doit lui faire confiance pour ne pas modifier le contenu. Web Packaging, avec son système de signature, résoudrait le problème. D'un autre côté, ça fait encore un format de plus dans lequel il faut distribuer le contenu, un coût pas forcément négligeable, et qui frappera de manière disproportionnée les petits producteurs, ou les moins pointus techniquement. Certains participants en ont profité pour râler contre AMP.
Comme toute nouvelle technique, Web Packaging pourrait mener à des déplacements de pouvoir dans l'écosystème du Web. Mais il est très difficile de prévoir ces effets (cf. RFC 5218). Est-ce que Web Packaging va favoriser les producteurs de contenu, les intermédiaires, les utilisateurs ? La section 4 du RFC explore la question. Par exemple, un des risques est la consolidation du pouvoir des gros intermédiaires. Si Facebook peut directement servir des paquetages Web, sans passer par le site original, les performances seront bien meilleures pour les paquetages déjà chargés par Facebook, qui gagnera donc en pouvoir. D'un autre côté, Web Packaging pourrait mener au résultat inverse : l'authentification des paquetages rendrait la confiance en l'intermédiaire inutile. (Personnellement, j'apprécie dans l'idée de Web Packaging que cela pourrait encourager le pair-à-pair, dont le RFC ne parle quasiment pas, en supprimant l'inquiétude quant à l'authenticité du contenu.)
La section 4 couvre d'autres questions soulevées par le concept de Web Packaging. Par exemple, il ne permet pas facilement d'adapter le contenu à l'utilisateur puisque, au moment de fabriquer le paquetage, on ne sait pas qui le lira. Une solution possible serait, pour un même site Web, de produire plusieurs paquetages et de laisser l'utilisateur choisir, mais elle complexifie encore le travail des producteurs. (Personnellement, je pense que beaucoup de ces adaptations sont mauvaises, par exemple l'adaptation au navigateur Web dans l'espoir de contrôler plus étroitement l'apparence, et cela ne me chagrine donc pas trop si elles seraient plus difficiles.)
Et la sécurité ? Un mécanisme de distribution par paquetages Web signés envoyés par divers moyens serait un changement profond du mécanisme de sécurité du Web. Actuellement, ce mécanisme repose essentiellement sur TLS, via HTTPS (RFC 2818). Mais c'est très insuffisant ; TLS ne protège que le canal, pas les données. Si un site Web a des miroirs, HTTPS ne va pas protéger contre des miroirs malveillants ou piratés. Et, comme noté plus haut, si un contenu Web est archivé, et distribué, par exemple, par Internet Archive, comment s'assurer de son authenticité ? L'absence d'un mécanisme d'authentification des données (Object-based security) est une des plus grosses faiblesses du Web (malgré des essais anciens mais jamais déployés comme celui du RFC 2660), et Web Packaging, qui sépare la validation du contenu de sa distribution, pourrait contribuer à traiter le problème. Ceci dit, l'expérience de la sécurité sur l'Internet montre aussi que tout nouveau système amène de nouvelles vulnérabilités et il faudra donc être prudent.
Et la vie privée ? De toute façon, quand on récupère un contenu, qu'il soit sous forme de paquetages ou de pages Web classiques, on donne au serveur des informations (et HTTP est terriblement bavard, il n'y a pas que l'adresse IP qui est transmise). Il semble qu'au moins, Web Packaging n'aggrave pas les nombreux problèmes du Web. (Personnellement, je pense qu'il pourrait même les limiter mais l'analyse exacte est compliquée. À l'heure actuelle, si vous suivez un lien depuis Facebook, le site Web d'origine et Facebook sont au courant. Avec Web Packaging seul Facebook le saurait. Est-ce un progrès ?)
La technologie AMP, très controversée a souvent été mentionnée pendant l'atelier. Elle n'a pas de rapport direct avec Web Packaging mais elle sort de la même société, et est souvent présentée comme faisant partie d'un même groupe de technologies modernes. La section 5 du RFC discute donc des problèmes spécifiques à AMP.
Je n'ai pas regardé les outils existants pour faire du Web Packaging donc ce site n'est pas encore sous forme de paquetage.
L'article seul
Fiche de lecture : À l'école du partage
Auteur(s) du livre : Marion Carbillet, Hélène
Mulot
Éditeur : C&F Éditions
978-2-915825-93-0
Publié en 2019
Première rédaction de cet article le 30 avril 2020
Ce livre rassemble l'expérience de deux enseignantes sur l'utilisation de ressources libres à l'école. Au lieu de n'enseigner qu'avec des documents fermés et réservés, utilisons les Communs à l'école !
Chaque chapitre contient un recueil d'expérience (les auteures sont professeures documentalistes) et des idées pour un aspect particulier du monde numérique ; l'utilisation du Web pour la recherche d'information, la question de la copie et du partage des documents numériques, le travail en commun… Aux débuts du déploiement de l'Internet en France, le système scolaire avait globalement mal réagi, rejettant ce qui était nouveau, et créant un grand fossé entre les pratiques des élèves, qui étaient diabolisées (« n'utilisez pas Wikipédia, c'est gratuit, donc ça ne vaut rien ») et celles de l'Éducation Nationale. Heureusement, les choses changent.
Parmi les ressources en commun utilisables, les auteures citent évidemment Wikimedia Commons, mais aussi (page 110) les archives municipales de Toulouse, qui ont été les premières en France à mettre leur fond à la libre disposition du public (cf. l'excellent exposé de Vincent Privat au Capitole du Libre 2018). Les auteures citent de nombreux projets réalisés avec les élèves (par exemple p. 147), les sensibilisant à la fois à l'importance du partage, et à la nécessité de faire attention aux licences et aux conditions de réutilisation.
Bref, un livre qui, je crois, sera utile aux enseignants et enseignantes qui se demandent comment former les élèves à l'utilisation des Communs numériques. Notez que Stéphanie de Vanssay a fait un article plus détaillé sur ce livre.
Notez enfin que le site officiel du livre contient également des articles récents sur les mêmes sujets, par exemple « En période de confinement, quelles activités proposer aux élèves ? ».
L'article seul
RFC 8758: Deprecating RC4 in Secure Shell (SSH)
Date de publication du RFC : Avril 2020
Auteur(s) du RFC : L. Camara, L. Velvindron (cyberstorm.mu)
Réalisé dans le cadre du groupe de travail IETF curdle
Première rédaction de cet article le 29 avril 2020
L'algorithme de chiffrement symétrique RC4, trop fragile, est abandonné depuis longtemps. Ce nouveau RFC le retire officiellement de SSH. Notre RFC remplace donc le RFC 4345, dont le statut devient « Intérêt historique seulement ».
L'utilisation de RC4 dans SSH avait été enregistrée dans le RFC 4253, et précisée dans ce RFC 4345, désormais abandonné. Les faiblesses de RC4 sont connues depuis longtemps, et ont été documentées dans le RFC 7465. Résultat, RC4 est retiré peu à peu des protocoles Internet (cf. par exemple le RFC 8429.) Désormais, RC4 disparait également de SSH, et le registre IANA des algorithmes a été mis à jour en ce sens.
OpenSSH a retiré RC4 il y a longtemps :
% ssh -V OpenSSH_7.6p1 Ubuntu-4ubuntu0.3, OpenSSL 1.0.2n 7 Dec 2017 % ssh -Q cipher 3des-cbc aes128-cbc aes192-cbc aes256-cbc rijndael-cbc@lysator.liu.se aes128-ctr aes192-ctr aes256-ctr aes128-gcm@openssh.com aes256-gcm@openssh.com chacha20-poly1305@openssh.com
(RC4 apparaissait comme arcfour, pour des
raisons légales.)
L'article seul
RFC 8781: Discovering PREF64 in Router Advertisements
Date de publication du RFC : Avril 2020
Auteur(s) du RFC : L. Colitti, J. Linkova (Google)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF 6man
Première rédaction de cet article le 25 avril 2020
Lors qu'on utilise le système NAT64, pour permettre à des machines situées sur un réseau purement IPv6 de parler avec des machines restées en seulement IPv4, il faut utiliser un résolveur DNS spécial ou bien connaitre le préfixe utilisé pour la synthèse des adresses IPv6. Ce nouveau RFC décrit une option RA (Router Advertisement) pour informer les machines du préfixe en question.
NAT64 est normalisé dans le RFC 6146 et son copain DNS64 dans le RFC 6147. Il permet à des machines situées dans un
réseau n'ayant qu'IPv6 de parler à des
machines restées uniquement sur le protocole du siècle dernier,
IPv4. Le principe est que, pour parler à la
machine d'adresse 192.0.2.1, la machine
purement IPv6 va écrire à 64:ff9b::192.0.2.1
(soit 64:ff9b::c000:201.) C'est le routeur
NAT64 qui changera ensuite le paquet IPv6 allant vers
64:ff9b::192.0.2.1 en un paquet IPv4 allant
vers 192.0.2.1. NAT64 est, par exemple,
largement utilisé dans les grandes réunions internationales comme
l'IETF
ou le FOSDEM, où le réseau WiFi par
défaut est souvent purement IPv6. Mais pour que la machine émettrice
pense à écrire à 64:ff9b::192.0.2.1, il faut
qu'elle connaisse le préfixe à mettre devant les adresses IPv4
(64:ff9b::/96 n'est que le préfixe par défaut.)
La solution la plus courante, DNS64, est que le résolveur DNS mente, en fabriquant des
adresses IPv6 pour les machines n'en ayant pas, dispensant ainsi les
machines du réseau local IPv6 de tout effort. Mais si l'émetteur
veut faire sa résolution DNS lui-même, ou bien utiliser un autre
résolveur, qui ne fabrique pas les adresses v6 ? Une alternative est
donc que cet émetteur fasse lui-même la synthèse. Pour cela, il faut
lui fournir le préfixe IPv6 du routeur NAT64.
Cela résoudra le problème de la machine qui ne veut pas utiliser le résolveur DNS64 :
- Car elle veut faire la validation DNSSEC toute seule comme une grande,
- ou car elle veut se servir d'un résolveur extérieur, accessible via DoT (RFC 7858) ou DoH (RFC 8484),
- ou bien que l'administrateur du réseau local ne fournit tout simplement pas de résolveur DNS64,
- ou encore car elle veut pouvoir utiliser des adresses IPv4
littérales, par exemple parce qu'on lui a passé
l'URL
http://192.0.2.13/, dans lequel il n'y a pas de nom à résoudre, - ou enfin parce qu'elle utilise 464XLAT (RFC 6877) pour lequel la connaissance du préfixe IPv6 est nécessaire.
Pourquoi envoyer cette information avec les RA (Router Advertisements) du RFC 4861 plutôt que par un autre mécanisme ? La section 3 du RFC explique que c'est pour être sûr que le sort est partagé ; si le routeur qui émet les RA tombe en panne, on ne recevra plus l'information, ce qui est cohérent, alors qu'avec un protocole séparé (par exemple le PCP du RFC 7225), on risquait de continuer à annoncer un préfixe NAT64 désormais inutilisable. En outre, cela diminue le nombre de paquets à envoyer (l'information sur le préfixe NAT64 peut être une option d'un paquet RA qu'on aurait envoyé de toute façon.) Et, en cas de changement du préfixe, le protocole du RFC 4861 permet de mettre à jour toutes les machines facilement, en envoyant un RA non sollicité.
Enfin, l'utilisation des RA simplifie le déploiement, puisque toute machine IPv6 sait déjà traiter les RA.
L'option elle-même est spécifiée dans la section 4 du RFC. Outre les classiques champs Type (valeur 38) et Longueur (16 octets), elle comporte une indication de la durée de validité du préfixe, un code qui indique la longueur du préfixe (le mécanisme classique préfixe/longueur n'est pas utilisé, car toutes les longueurs ne sont pas acceptables), et le préfixe lui-même.
La section 5 explique comment les machines doivent utiliser cette option. Elle s'applique à tous les préfixes IPv4 connus. Si on veut router certains préfixes IPv4 vers un routeur NAT64 et d'autres préfixes vers un autre routeur, il faut quand même que les adresses IPv6 soient dans le même préfixe, et router ensuite sur les sous-préfixes de ce préfixe. Un autre problème découlant de ce choix d'avoir un préfixe IPv6 unique pour tout est celui des préfixes IPv4 qu'on ne veut pas traduire, par exemple des préfixes IPv4 purement internes. Il n'y a pas à l'heure actuelle de solution. De toute façon, l'option décrite dans notre RFC est surtout conçu pour des réseaux purement IPv6, et qui n'auront donc pas ce problème.
Attention, le préfixe IPv6 reçu est spécifique à une interface réseau. La machine réceptrice devrait donc le limiter à cette interface. Si elle a plusieurs interfaces (pensez par exemple à un ordiphone avec WiFi et 4G), elle peut recevoir plusieurs préfixes pour le NAT64, chacun ne devant être utilisé que sur l'interface où il a été reçu (cf. RFC 7556.)
Un petit mot sur la sécurité pour terminer. Comme toutes les annonces RA, celle du préfixe NAT64 peut être mensongère (cf. le RFC 6104 au sujet de ces « RAcailles ».) La solution est la même qu'avec les autres options RA, utiliser des techniques « RA guard » (RFC 6105.)
À noter qu'une annonce mensongère d'un préfixe IPv6 prévue pour le NAT64 affectera évidemment les adresses IPv4 qu'on tente de joindre (parfois au point de les rendre injoignables) mais pas les adresses IPv6, qui ne sont pas traduites et donc non touchées par cet éventuel RA tricheur. Comme une machine qui arrive à émettre et à faire accepter des RAcailles peut déjà facilement réaliser un déni de service, on voit que l'option de ce nouveau RFC n'aggrave pas les choses, en pratique.
Le RFC conclut que la procédure de validation des préfixes de la section 3.1 du RFC 7050 n'est pas nécessaire, si on a ce RA Guard.
À l'heure actuelle, il ne semble pas que cette option soit souvent mise en œuvre, que ce soit dans les émetteurs ou dans les récepteurs. Mais Wireshark sait déjà le décoder.
L'article seul
Deux ou trois choses sur les applications de suivi de contacts pendant l'épidémie
Première rédaction de cet article le 19 avril 2020
Deux ou trois personnes m'ayant demandé si j'avais une opinion sur les applications de suivi de contacts, dans le contexte de l'épidémie de COVID-19, je publie ici quelques notes, et pas mal d'hyperliens, pour vous donner de la lecture pendant le confinement.
D'abord, des avertissements :
- Je ne suis pas épidémiologiste. Même si je l'étais, il y a encore beaucoup de choses que la science ignore au sujet des infections par le SARS-CoV2, comme les durées exactes des phases où on est contagieux.
- Je ne suis pas non plus un spécialiste de la conception et de l'analyse de protocoles de suivi de contacts. Mais ce n'est pas très grave, pour les raisons que j'exposerai rapidement par la suite.
- Vous ne trouverez pas ici d'analyse de l'application annoncée par le gouvernement français, StopCovid, pour la bonne et simple raison qu'elle n'existe pas. Il y a eu des promesses sous la forme de quelques mots (« anonyme », « sur la base du volontariat ») mais aucun détail technique n'a été publié. À l'heure actuelle, il n'est donc pas possible de dire quoi que ce soit de sérieux sur cette application spécifique.
- D'une manière générale, la situation évolue vite, et il est très possible que, dans une ou deux semaines, cet article ne vale plus rien.
Maintenant, rentrons dans le vif du sujet. Dans la description et l'analyse des protocoles comme PACT, DP3T ou ROBERT ? Non, car, pour moi, c'est une question très secondaire. Voyons les problèmes par ordre décroissant d'importance.
D'abord, il faut se demander si une telle application de suivi des contacts est utile et, surtout, si elle justifie les efforts qu'on y consacre, par rapport à des sujets moins high-tech, moins prestigieux, moins startup-nation, qui motivent moins les informaticiens mais qui ont plus d'importance pour la santé publique, comme la production et la distribution de masques, ou comme la revalorisation des rémunérations et des conditions de travail du personnel de santé. Je ne vais pas insister sur ce point, c'est certes le plus important mais la Quadrature du Net en a déjà parlé, et mieux que moi.
Bref, ce projet d'application de suivi des contacts semble davantage motivé par le désir d'agir, de faire quelque chose, même inutile, désir qui est commun en temps de crise, plutôt que par un vrai problème à résoudre. (C'est ce que les anglophones nomment la maladie du do-something-itis.) Il y a également des enjeux commerciaux, qui expliquent que certaines entreprises se font de la publicité en affirmant travailler sur le sujet (sans tenir compte des travaux existants).
Mais surtout, une application n'a de sens que si on teste les gens, pour savoir qui est contaminé. Comme on peut apparemment être contagieux et pourtant asymptomatique (pas de maladie visible), il faut tester ces personnes asymptomatiques (qui sont sans doute celles qui risquent de contaminer le plus de gens puisque, ignorantes de leur état, elles sortent). Or, Macron a bien précisé dans son discours du 13 avril qu'on ne testerait pas les personnes asymptomatiques (probablement car il n'y a pas de tests disponibles). Cela suffit à rendre inutile toute application, indépendamment des techniques astucieuses qu'elle utilise, car l'application elle-même ne peut pas déterminer qui est malade ou contagieux.
Ensuite, le protocole est une chose, la mise en œuvre dans une application réelle en est une autre. Le diable est dans les détails. Comme indiqué plus haut, on ne sait encore rien sur l'application officielle, à part son nom, StopCovid. Pour formuler un avis intelligent, il ne faudra pas se contenter de généralités, il faudra regarder son code, les détails, les traqueurs embarqués (une plaie classique des applications sur ordiphone, cf. le projet ExodusPrivacy et également leur article sur le COVID-19), etc. Il faudra aussi se pencher sur le rôle du système d'exploitation (surtout s'il y a utilisation de l'API proposée par Google et Apple). Le fait que l'application soit en logiciel libre est évidemment un impératif, mais ce n'est pas suffisant.
Si vous n'êtes pas informaticienne ou informaticien, mais que vous voulez vous renseigner sur les applications de suivi de contacts et ce qu'il y a derrière, souvenez-vous qu'il y a plusieurs composants, chacun devant être étudié :
- L'application elle-même, celle que vous téléchargez sur le magasin, qui est la partie visible (mais pas forcément la plus importante).
- Le protocole qui est l'ensemble des règles que suit l'application, notamment dans la communication avec le reste du monde (autres ordiphones, serveur central…). Avec le même protocole, on peut créer plusieurs applications assez différentes.
- Le système d'exploitation qui, après tout, a un complet contrôle de la machine et peut passer outre les décisions des applications. C'est un sujet d'autant plus sensible que, sur les ordiphones, ce système est étroitement contrôlé par deux entreprises à but lucratif, Apple et Google.
- Le serveur central (la grande majorité des protocoles proposés nécessite un tel serveur) qui peut être piraté ou, tout simplement, géré par des gens qui ne tiennent pas leurs promesses.
Parmi les bonnes lectures accessible à un large public :
- L'excellente bande dessinée de Gee.
- Un article de Martin Untersinger.
- Le texte de Paula Forteza et Elliot Alderson.
- Le message de Pierre-Yves Gosset (Framasoft).
- En anglais, Privacy International a une analyse très détaillée.
Voilà, on peut maintenant passer aux questions qui passionnent mes lecteurs et lectrices passionnés d'informatique, les protocoles eux-mêmes. Il en existe de nombreux. J'ai une préférence pour PACT, dont je vous recommande la lecture de la spécification, très claire. La proposition DP3T est très proche (lisez donc son livre blanc).
Ces deux propositions sont très proches : l'ordiphone émet en Bluetooth des identifiants temporaires, générés aléatoirement et non reliables entre eux. Les autres ordiphones proches les captent et les stockent. Ces identifiants se nomment chirps dans PACT (qu'on pourrait traduire par « cui-cui ») et EphID (pour Ephemeral ID) dans DP3T. Lorsqu'on est testé (rappel : il n'y a pas assez de tests en France, on ne peut même pas tester tous les malades, ce qui est un problème bien plus grave que le fait d'utiliser tel algorithme ou pas), et détecté contaminé, on envoie les données à un serveur central, qui distribue la liste. En téléchargeant et en examinant cette liste, on peut savoir si on a été proche de gens contaminés.
C'est évidemment une présentation très sommaire, il y a plein de détails à traiter, et je vous recommande de ne pas vous lancer dans de longues discussions sur Twitter au sujet de ces protocoles, avant d'avoir lu les spécifications complètes. Les deux propositions ont été soigneusement pensées par des gens compétents et le Café du Commerce devrait lire avant de commenter.
PACT et DP3T ont assez peu de différences. Les principales portent sur le mécanisme de génération des identifiants, PACT déduit une série d'identifiants d'une graine renouvellée aléatoirement (on stocke les graines, pas réellement les identifiants), alors que DP3T déduit chaque graine de la précédente, des choses comme ça.
La proposition ROBERT est assez différente. La liste des identifiants des contaminés n'est plus publique, elle est gardée par le serveur central, que les applications doivent interroger. Globalement, le serveur central a bien plus de pouvoir et de connaissances, dans ROBERT. La question est souvent discutée de manière binaire, avec centralisé vs. décentralisé mais le choix est en fait plus compliqué que cela. (Paradoxalement, un protocole complètement décentralisé pourrait être moins bon pour la vie privée.) Au passage, j'ai déjà discuté de cette utilisation très chargée de termes comme « centralisé » dans un article à JRES. Autre avantage de ROBERT, la discussion sur le protocole se déroule au grand jour, via les tickets de GitHub (cf. leur liste mais lisez bien la spécification avant de commenter, pas juste les images). Par contre, son analyse de sécurité est très insuffisante, comme le balayage de tous les problèmes liés au serveur central en affirmant qu'il sera « honnête et sécurisé ». Et puis la communication autour de cette proposition est parfois scientiste (« Ce sont des analyses scientifiques qui permettent de le démontrer, pas des considérations idéologiques [comme si c'était mal d'avoir des idées, et des idées différentes des autres] ou des a priori sémantiques. ») et il y a une tendance à l'exagération dans les promesses.
Enfin, un peu en vrac :
- Le Wikipédia anglophone a un bon guide des applications de suivi.
- La proposition Apple/Google, détaillé ici ainsi que sur cette page. Il ne s'agit à proprement parler pas d'un protocole de suivi de contacts mais d'un ensemble de services dans les systèmes d'exploitation (iOS pour Apple et Android pour Google), pour aider les applications de suivi.
- Une critique détaillée du protocole ROBERT.
- Je n'ai pas cité les autres protocoles, NTK et TCN.
- La question de la protection de la vie privée, avec de telles applications, a suscité bien des discussions (et à juste titre). L'Union européenne a produit une série de recommandations à ce sujet, et le CCC une autre série d'exigences à satisfaire.
- L'avis du Conseil National du Numérique est une lecture intéressante.
- Une analyse par divers chercheurs montre bien en quoi suivi et anonymat sont deux notions difficilement conciliables, quelles que soient les promesses officielles.
- La mise en correspondance de deux ensembles de données (les identifiants des gens avec qui il y a eu contact, et les identifiants des gens contaminés) est un problème très difficile à résoudre si on veut respecter un peu la vie privée. Mais il n'est pas insoluble, voir par exemple la solution de Signal.
- Un bon article de Ross Anderson, qui prend de la hauteur sur le sujet.
L'article seul
RFC 8763: Deployment Considerations for Information-Centric Networking (ICN)
Date de publication du RFC : Avril 2020
Auteur(s) du RFC : A. Rahman (InterDigital Communications), D. Trossen (InterDigital Europe), D. Kutscher (University of Applied Sciences Emden/Leer), R. Ravindran (Futurewei)
Pour information
Réalisé dans le cadre du groupe de recherche IRTF icnrg
Première rédaction de cet article le 17 avril 2020
Ce nouveau RFC annonce [mais c'est très prématuré] que l'ICN est désormais une technologie mûre et qu'il est temps de se pencher sur les problèmes pratiques de déploiement. Il documente ces problèmes, et des solutions possibles. Il décrit aussi des expériences de déploiement (très limitées et qui ont souvent disparu.)
Si vous voulez réviser le concept d'ICN, lisez le RFC 8793. Il y a plusieurs façons (section 4 du RFC) d'envisager le déploiement des techniques « fondées sur le contenu » (ICN) :
- Une table rase, où on remplace complètement l'Internet existant par une solution à base d'ICN. Cela implique que les actuels routeurs soient tous changés, pour des machines faisant tourner un logiciel comme NFD. (Inutile de dire que c'est complètement irréaliste.)
- Un déploiement de l'ICN comme réseau de base, avec une couche TCP/IP au-dessus, pour continuer à faire tourner l'Internet classique. Cela pose les mêmes problèmes que la table rase.
- Un déploiement de l'ICN au-dessus de l'Internet existant, un réseau virtuel, quoi, comme on faisait pour IPv6 au début. C'est le seul déploiement effectif qu'ait connu l'ICN pour l'instant, avec des idées comme CCNx sur UDP. Cela permet l'expérimentation et le déploiement progressif.
- De l'ICN « sur les côtés » du réseau. On peut envisager une
épine dorsale qui reste en TCP/IP, avec des réseaux extérieurs en
ICN, et des passerelles entre les deux. Ces réseaux extérieurs en
ICN pourraient concerner, par exemple,
l'IoT (cf.
draft-irtf-icnrg-icniot), et les passerelles transformeraient du CoAP (RFC 7252) en ICN et réciproquement. - Les technologies qui permettent de découper un réseau physique en plusieurs tranches, chacune abritant un réseau virtuel, comme la 5G, pourraient permettre de faire cohabiter harmonieusement ICN et TCP/IP sur la même infrastructure physique.
- Enfin, on peut imaginer, tant qu'on y est, des déploiements mixtes, mêlant les différentes approches citées ci-dessus.
La section 5 du RFC décrit de manière plus détaillées des chemins de migration possibles. Et la section 6 décrit quelques expériences qui ont effectivement eu lieu (on peut aussi lire le RFC 7945) :
- Le projet FP7 PURSUIT (documenté dans un article IEEE non public) se positionnait comme une approche de table rase mais, en pratique, a été déployé par dessus l'Internet existant. Il a compté jusqu'à 70 nœuds. Comme tous les projets ICN, il a été abandonné à la fin des subventions. (Pour s'amuser, regardez ce qu'est devenu le site Web du projet.)
- Le projet NDN de la NSF a également effectué un déploiement (environ 100 nœuds) sur l'Internet existant.
- Le projet ICN 2020 a produit des rapports sur ses réalisations au-dessus de TCP/IP, avec 37 nœuds ICN.
- Le projet UMOBILE a été déployé entre autre sur le réseau communautaire Guifi, avec dix Raspberry Pi. C'est raconté dans « Information-Centric Multi-Access Edge Computing Platform for Community Mesh Networks ».
Ces projets tournaient sur l'Internet d'aujourd'hui. Mais il y avait aussi d'autres projets qui se situaient plus bas dans le modèle en couches :
- POINT et RIPE ont également utilisé Guifi mais cette fois en étant directement sur le WiFi, avec TCP/IP par dessus. l'ICN.
- Un autre projet concret a connecté 60 nœuds en 6LoWPAN, en utilisant RIOT, et est documenté dans « Information Centric Networking in the IoT: Experiments with NDN in the Wild ».
- Signalons enfin (mais le RFC en liste d'autres) le projet Doctor, sur lequel a été testé le transport de trafic HTTP réel.
Le RFC note qu'aucun de ces déploiements n'a dépassé mille utilisateurs. Pour moi, il s'agissait clairement d'expérimentation et appeler ça « déploiement » est trompeur.
La section 7 du RFC discute des points qui manquent pour des déploiements significatifs, notamment question normalisation. La liste est longue. Le RFC note entre autres :
- Le problème des applications ; un navigateur Web existant n'a aucun moyen de savoir s'il doit récupérer un contenu en ICN ou par des moyens classiques. Aucune API ne permet au programmeur de contrôler ce choix. De même, aucune API vaguement standard n'existe pour utiliser les capacités de l'ICN.
- Le nommage des objets dans l'ICN n'est pas normalisé, quoique il existe des tentatives comme celle du RFC 6920 (voir aussi les RFC 8569 et RFC 8609.)
- Et il y a tous les autres problèmes pratiques, comme l'OAM…
- La sécurité a droit à sa propre section, la 10. (Voir aussi le RFC 7945.) Elle n'a guère été testée en vrai pour l'instant, à part peut-être dans le projet Doctor (voir « Content Poisoning in Named Data Networking: Comprehensive Characterization of real Deployment », une étude détaillée de l'attaque par empoisonnement du contenu, où un méchant producteur essaie d'envoyer du contenu malveillant aux clients, ou bien « A Security Monitoring Plane for Named Data Networking Deployment », les deux articles se sont spécialement concentrés sur NFD.) Compte-tenu de l'expérience de l'Internet, cela sera pourtant un point crucial.
L'article seul
RFC 8761: Video Codec Requirements and Evaluation Methodology
Date de publication du RFC : Avril 2020
Auteur(s) du RFC : A. Filippov (Huawei), A. Norkin (Netflix), J.R. Alvarez (Huawei)
Pour information
Réalisé dans le cadre du groupe de travail IETF netvc
Première rédaction de cet article le 17 avril 2020
Si vous passez toutes vos soirées avachi·e devant un écran à regarder des séries sur Netflix, ce RFC est pour vous. Il est le cahier des charges d'un futur codec vidéo libre pour l'Internet. Ce codec devra gérer beaucoup de cas d'usage différents.
Concevoir un codec vidéo n'est jamais facile. Il y a beaucoup d'exigences contradictoires, par exemple minimiser le débit en comprimant, tout en n'exigeant pas de la part du processeur trop de calculs. Ce RFC, le premier du groupe de travail netvc de l'IETF, se limite au cas d'un codec utilisé au-dessus de l'Internet, mais cela fait encore plein d'usages différents, du streaming à la vidéoconférence en passant par la vidéosurveillance (celle que les politiciens hypocrites appellent la vidéoprotection, mais le RFC est plus sincère et utilise le bon terme.)
Le problème est d'autant plus difficile que plein de choses peuvent aller mal sur l'Internet, les paquets peuvent être perdus, les bits modifiés en route, etc. En pratique, tous ces incidents n'ont pas la même probabilité : les pertes sont bien plus fréquentes que les corruptions, par exemple. Si on n'est pas trop pressés (cas du téléchargement), TCP ou d'autres protocoles de transport similaires fournissent une bonne solution. Si on a des exigences temporelles plus fortes (diffusion en direct, « temps réel »), il faut parfois renoncer à TCP et, soit utiliser des réseaux idéaux (managed networks, dit le RFC, qui reprend le terme marketing de certains opérateurs qui tentent de nous faire croire qu'il existerait des réseaux sans pertes), soit trouver d'autres moyens de rattraper les pertes et les erreurs.
Depuis qu'on fait de la vidéo sur l'Internet, c'est-à-dire depuis très longtemps (malgré les prédictions des opérateurs de télécommunications traditionnels qui étaient unanimes, dans les années 1990, pour dire que cela ne serait jamais possible), toute une terminologie a été développée pour communiquer sur ce sujet. La section 2 de notre RFC rappelle les sigles importants, et quelques termes à garder en tête. Ainsi, la « compression visuellement sans perte » désigne les méthodes de compression avec perte, mais dont on ne voit pas d'effet secondaire à l'œil nu.
La section 3 de notre RFC fait ensuite le tour des applications de la vidéo sur l'Internet, pour cerner de plus près leurs caractéristiques et leurs exigences propres. (Le cahier des charges proprement dit sera en section 4.) Chaque cas d'usage est accompagné d'un tableau indiquant la résolution et la fréquence des trames souhaitées. On commence évidemment par le streaming (un des auteurs du RFC travaille chez Netflix.) Pouvoir regarder Le Messie via l'Internet est un objectif crucial. Comme les clients sont variés, et que les conditions de leur accès Internet varient en permanence (surtout s'il y a des liens radio), le codec doit tout le temps s'adapter, et pour cela tenir compte des caractéristiques de la perception humaine. L'encodage est typiquement fait une fois et une seule, lorsque la vidéo est chargée sur les serveurs. Pour cet usage :
- On peut accepter un encodeur complexe et coûteux en ressources, puisque l'encodage sera fait sur de grosses machines, et une seule fois,
- Le décodeur, par contre, doit être simple, car beaucoup de monde devra faire le décodage, et pas forcément sur des machines performantes,
- En entrée, il faut pouvoir accepter beaucoup de formats, et de types de contenus, parfois avec des particularités (le grain d'un film peut être délibéré, l'encodage ne doit pas le supprimer).
Proche du streaming mais quand même différent, il y a le partage de vidéos, usage popularisé par YouTube mais également accessible en utilisant du logiciel libre et décentralisé, comme PeerTube. C'est le monde de l'UGC : M. Michu filme des violences policières avec son petit ordiphone (ou avec sa GoPro), et les diffuse au monde entier grâce aux services de partage de vidéos.
Après le streaming et le partage de vidéos, la télévision sur IP. Il s'agit de distribuer de la télévision traditionnelle sur IP, pour permettre de se réduire le cerveau en regardant Hanouna. Cet usage se décompose en deux groupes : l'unicast, où on envoie l'émission à un seul destinataire, c'est la VoD, et le multicast où on diffuse à un grand nombre d'utilisateurs simultanément. Ce dernier est sans doute de moins en moins utilisé, à part pour les événements sportifs et les cérémonies. Le RFC se concentre sur la distribution de télévision au-desus d'un réseau « géré » (comme si les autres ne l'étaient pas…) où on peut garantir une certaine QoS. C'est par exemple le cas d'un FAI qui envoie les chaînes de télévision aux boxes des abonnés. Si on diffuse un match de foot, on souhaite que le but qui décide du sort du match atteigne les ordinateurs sans trop de retard sur les hurlements bestiaux de supporters utilisant la diffusion hertzienne, hurlements qu'on entendra dehors. Pour compliquer un peu les choses, on souhaite que l'utilisateur puisse mettre en pause, reprendre, etc.
Et la vidéoconférence ? Là aussi, le délai d'acheminement est crucial, pour qu'on n'ait pas l'impression de parler avec un astronaute perdu sur Mars. (Le RFC suggère 320 millisecondes au grand maximum, et de préférence moins de 100 ms.)
Il y a aussi le partage d'écran, où on choisit de partager l'écran de son ordinateur avec une autre personne. Comme pour la vidéoconférence, il faut du temps réel, encoder au fur et à mesure avec le plus petit retard possible.
Et les jeux vidéo, alors ? Les jeux ont souvent un contenu riche (beaucoup de vidéos). Dans certains cas, le moteur de jeu est quelque part sur l'Internet et, à partir d'un modèle 3D, génère des vidéos qu'il faut envoyer aux joueurs. Là encore, il faut être rapide : si un joueur flingue un zombie, les autres participants au jeu doivent le voir « tout de suite ». (Nombreux détails et exemples, comme GeForce Grid ou Twitch, dans le document N36771 « Game streaming requirement for Future Video Coding », de l'ISO/IEC JTC 1/SC 29/WG 11.)
Enfin, le RFC termine la liste des applications avec la vidéosurveillance. Dans le roman « 1984 », George Orwell ne donne aucun détail technique sur le fonctionnement du télécran, et notamment sur la connexion qui permet au Parti de savoir ce qui se passe chez Winston. Ici, l'idée est de connecter les caméras de vidéosurveillance à l'Internet et de faire remonter les flux vidéo à un central où on les regarde et où on les analyse. Comme l'État peut souhaiter disposer de très nombreuses caméras, le coût matériel est un critère important.
Après cet examen des cas d'usage possibles, la section 4 du RFC est le cahier des charges à proprement parler. D'abord, les exigences générales, qui concernent toutes les applications. Évidemment, le futur codec vidéo de l'Internet doit encoder efficacement, donc, dit le RFC, mieux que les codecs existants, H.265 ou VP9. Évidemment encore, l'interopérabilité entre les différentes mises en œuvre du codec est cruciale, et cela dépend en partie de l'IETF, qui devra écrire une norme claire et cohérente. Cette norme se déclinera en profils, qui limiteront certains aspects du codec, pour des cas d'usages spécifiques.
Le RFC exige également qu'il soit possible de gérer des extensions au format, pour les questions futures, tout en maintenant la compatibilité (un nouveau décodeur doit pouvoir décoder les vieilles vidéos). Le format doit permettre huit bits de couleur (par couleur) au minimum, et de préférence douze, gérer le YCbCr, permettre des résolutions quelconques, autoriser l'accès direct à un point donné de la vidéo, et bien d'autres choses encore. Et le tout doit pouvoir marcher en temps réel (aussi bien l'encodage que le décodage.) Par contre, pour l'encodage de haute qualité, le RFC autorise les encodeurs à être jusqu'à dix fois plus complexes que pour les formats existants : les ressources des ordinateurs croissent plus vite que la capacité des réseaux, et il est donc raisonnable de faire davantage d'efforts pour encoder.
Les réseaux sont imparfaits, et il faut donc gérer les erreurs. Outre les mécanismes présents dans la couche transport, le RFC demande que des mécanismes spécifiques à la vidéo soient également inclus dans le format. En parlant de couche transport, comme le but est de faire un codec vidéo pour l'Internet, le RFC rappelle l'importance de prévoir comment encapsuler le futur format dans les protocoles de transport existants.
Les exigences ci-dessus étaient impératives. Il y en a également des facultatives, par exemple un nombre de bits pour coder chaque couleur allant jusqu'à 16, la gestion du RGB, celle du transparence… Toujours dans les demandes facultatives, le RFC note qu'il serait bon que le format choisi n'empêche pas le parallélisme dans le traitement des vidéos, ce qui implique, par exemple, qu'on ne soit pas obligé de traiter toutes les images précédant une image pour encoder celle-ci. Et qu'on puisse utiliser des algorithmes qui soient acceptables pour les SIMD/GPU.
Ce n'est pas tout de faire une liste au Père Noël avec toutes les jolies choses qu'on voudrait voir dans le nouveau format, encore faut-il une bonne méthodologie pour évaluer les futures propositions. La section 5 décrit les tests à effectuer, avec plusieurs débits différents. Ces tests seront ensuite faits en comparant un codec de référence (HEVC ou VP9) aux codecs candidats pour répondre à ce cahier des charges. Comme le codec utilisera certainement des techniques dépendant de la perception humaine, ces tests « objectifs » ne suffisent pas forcément, et le RFC prévoit également des tests subjectifs, avec la procédure MOS (cf. le document ISO/IEC « PDTR 29170-1 », première partie.)
Et un petit point de sécurité pour finir : le RFC rappelle qu'encodeur et surtout décodeur doivent être paranoïaques, afin d'éviter qu'une vidéo un peu inhabituelle ne mène à des consommations de ressources déraisonnables, voire épuisant la machine.
Pour l'instant, le candidat sérieux pour répondre à ce cahier des charges est le codec AV1, notamment poussé par l'Alliance for Open Media. Mais il ne semble pas tellement se rapprocher de la normalisation formelle. Le groupe de travail ne semble plus très actif.
L'article seul
RFC 8724: SCHC: Generic Framework for Static Context Header Compression and Fragmentation
Date de publication du RFC : Avril 2020
Auteur(s) du RFC : A. Minaburo (Acklio), L. Toutain (IMT-Atlantique), C. Gomez (Universitat Politecnica de Catalunya), D. Barthel (Orange Labs), JC. Zuniga (SIGFOX)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF lpwan
Première rédaction de cet article le 16 avril 2020
Ce nouveau RFC décrit un mécanisme de compression des données, et de fragmentation des paquets, optimisé pour le cas des réseaux à longue distance lents connectant des objets contraints en ressources, ce qu'on nomme les LPWAN (Low-Power Wide Area Network, par exemple LoRaWAN.) L'un des buts est de permettre l'utilisation des protocoles Internet normaux (UDP et IPv6) sur ces LPWAN. SCHC utilise un contexte de compression et décompression statique : il n'évolue pas en fonction des données envoyées.
Le LPWAN (RFC 8376) pose en effet des défis particuliers. Il a une faible capacité, donc chaque bit compte. Il relie des objets ayant peu de ressources matérielles (par exemple un processeur très lent). Et la batterie n'a jamais assez de réserves, et émettre sur un lien radio coûte cher en énergie (1 bit reçu ou transmis = 1-1000 microjoules, alors qu'exécuter une instruction dans le processeur = 1-100 nanojoules.) . Le but de l'IETF est de pouvoir utiliser IPv6 sur ces LPWAN et la seule taille de l'en-tête IPv6 est un problème : 40 octets, dont plusieurs champs « inutiles » ou redondants, et qui auraient donc tout intérêt à être comprimés.
Trois choses importantes à retenir sur SCHC (Static Context Header Compression) :
- N'essayez pas de prononcer le sigle « èsse cé hache cé » : on dit « chic » en français, et « sheek » en anglais.
- Comme tout algorithme de compression, SCHC repose sur un contexte commun au compresseur et au décompresseur, contexte qui regroupe l'ensemble des règles suivies pour la compression et la décompression. Mais, contrairement aux mécanismes où le contexte est dynamiquement modifié en fonction des données transmises, ici le contexte est statique ; il n'évolue pas avec les données. Cela élimine notamment tout risque de désynchronisation entre émetteur et récepteur. (Contrairement à des protocoles comme ROHC, décrit dans le RFC 5795.)
- SCHC n'est pas un protocole précis, c'est un cadre générique, qui devra être incarné dans un protocole pour chaque type de LPWAN. Cela nous promet de nouveaux RFC dans le futur. L'annexe D liste les informations qu'il faudra spécifier dans ces RFC.
Si les LPWAN posent des problèmes particuliers, vu le manque de ressources disponibles, ils ont en revanche deux propriétés qui facilitent les choses :
- Topologie simple, avec garantie que les paquets passent au même endroit à l'aller et au retour,
- Jeu d'applications limité, et connu à l'avance, contrairement à ce qui arrive, par exemple, avec un ordiphone.
La section 5 de notre RFC expose le fonctionnement général de SCHC. SCHC est situé entre la couche 3 (qui sera typiquement IPv6) et la couche 2, qui sera une technologie LPWAN particulière, par exemple LoRaWAN (pour qui SCHC a déjà été mis en œuvre, et décrit dans le RFC 9011). Après compression, le paquet SCHC sera composé de l'identificateur de la règle (RuleID), du résultat de la compression de l'en-tête, puis de la charge utile du paquet. Compresseur et décompresseur doivent partager le même ensemble de règles, le contexte. Le contexte est défini de chaque côté (émetteur et récepteur) par des mécanismes non spécifiés, par exemple manuellement, ou bien par un protocole d'avitaillement privé. Chaque règle est identifiée par son RuleID (section 6 du RFC), identificateur dont la syntaxe exacte dépend d'un profil de SCHC donc en pratique du type de LPWAN. (Rappelez-vous que SCHC est un mécanisme générique, les détails concrets de syntaxe sont spécifiés dans le profil, pas dans SCHC lui-même. Par exemple, pour LoRaWAN, c'est dans le RFC 9011.)
Les règles sont expliquées dans la section 7. Chaque règle comporte plusieurs descriptions. Chaque description comprend notamment :
- L'identificateur du champ concerné (SCHC ne traite pas l'en-tête globalement, mais champ par champ), par exemple « port de destination UDP ».
- Longueur et position du champ.
- Valeur cible (TV, Target Value), qui est la valeur à laquelle on va comparer le champ.
- Opérateur de comparaison (MO, pour Matching Operator), l'égalité complète, par exemple, ou bien l'égalité de seulement les N bits de plus fort poids.
- Action (CDA, Compression Decompression Action), qui indique quoi faire si le contenu du champ correspond à la valeur cible. Par exemple, ne pas transmettre le champ (si sa valeur est une valeur connue), ou bien (pour le décompresseur) recalculer la valeur à partir des données. La liste des actions possibles figure dans un tableau en section 7.4. (Elle est fixée une fois pour toutes, il n'est pas prévu de procédure d'enregistrement de nouvelles possibilités.)
L'algorithme est donc : pour chaque description dans une règle, voir si elle correspond au champ visé, en utilisant l'opérateur de comparaison et la valeur cible. Si toutes les descriptions collent, appliquer les actions, et envoyer les données comprimées, précédées de l'identificateur de la règle. Un RuleID spécial est utilisé pour attraper tout le reste, les paquets qui ne seront pas comprimés car aucune règle ne correspondait.
Prenons un exemple : la règle de RuleID 1 a
deux descriptions, qui disent
que les champs X et Y de l'en-tête ont une valeur connue (indiquée
dans la valeur cible), mettons respectivement 42 et « foobar ». Dans
ce cas, les actions de compression (CDA, Compression
Decompression Action) peuvent être simplement « omets ces
champs » (not-sent). Le décompresseur, à
l'autre bout, a la même règle (rappelez-vous que le contexte,
l'ensemble des règles, est statique). Lorsque qu'il voit passer un
paquet comprimé avec la règle 1, il crée simplement les deux champs,
avec les valeurs définies dans la règle (valeurs TV, Target
Value.)
Un exemple figure en section 10 du RFC, avec des règles pour
comprimer et décomprimer les en-têtes IPv6 et UDP. Ainsi, le champ
Version d'IPv6 vaut forcément 6. On met donc la valeur cible (TV) à
6, l'opérateur de comparaison (MO) à « ignorer » (on ne teste pas
l'égalité, on est sûr d'avoir 6, si le paquet est correct), et
l'action (CDA) à not-sent (ne pas envoyer). Le
champ Longueur, par contre, n'a pas de valeur cible, l'opérateur de
comparaison est « ignorer », et l'action est
compute (recalculer à partir des données).
Pour UDP, on peut également omettre les ports source et destination si, connaissant l'application, on sait qu'ils sont fixes et connus, et on peut également recalculer le champ Longueur, ce qui évite de le transmettre. La somme de contrôle est un peu plus compliquée. IPv6 en impose une (RFC 8200, section 8.1) mais autorise des exceptions. Ne pas l'envoyer peut exposer à des risques de corruption de données, donc il faut bien lire le RFC 6936 et le RFC 6282 avant de décider d'ignorer la somme de contrôle. Les règles complètes pour UDP et IPv6 sont rassemblées dans l'annexe A du RFC.
Outre la compression, SCHC permet également la fragmentation (section 8 du RFC). La norme IPv6 (RFC 8200) dit que tout lien qui fait passer de l'IPv6 doit pouvoir transmettre 1 280 octets. C'est énorme pour du LPWAN, où la MTU n'est parfois que de quelques dizaines d'octets. Il faut donc effectuer fragmentation et réassemblage dans la couche 2, ce que fait SCHC (mais, désolé, je n'ai pas creusé cette partie, pourtant certainement intéressante .)
La section 12 de notre RFC décrit les conséquences de SCHC sur la sécurité. Par exemple, un attaquant peut envoyer un paquet avec des données incorrectes, dans l'espoir de tromper le décompresseur, et, par exemple, de lui faire faire de longs calculs, ou bien de générer des paquets de grande taille, pour une attaque avec amplification. Comme toujours, le décompresseur doit donc se méfier et, entre autres, ne pas générer de paquets plus grands qu'une certaine taille. Question sécurité, on peut aussi noter que SCHC n'est pas vulnérable aux attaques comme CRIME ou BREACH, car il traite les différents champs de l'en-tête séparément.
La fragmentation et le réassemblage amènent leurs propres risques, qui sont bien connus sur l'Internet (d'innombrables failles ont déjà été trouvées dans les codes de réassemblage de paquets fragmentés.) Par exemple, une attaque par déni de service est possible en envoyant plein de fragments, sans jamais en envoyer la totalité, forçant le récepteur à consommer de la mémoire pour stocker les fragments en attente de réassemblage. Là encore, le récepteur doit être prudent, voire paranoïaque, dans son code. Par contre, les attaques utilisant la fragmentation pour se dissimuler d'un IDS ne marcheront sans doute pas, puisque SCHC n'est utilisé qu'entre machines directement connectées, avec probablement aucun IDS sur le lien.
Merci à Laurent Toutain pour avoir attrapé une sérieuse erreur dans cet article et à Dominique Barthel pour sa relecture très attentive.
L'article seul
RFC 8753: Internationalized Domain Names for Applications (IDNA) Review for New Unicode Versions
Date de publication du RFC : Avril 2020
Auteur(s) du RFC : J. Klensin, P. Faltstrom (Netnod)
Chemin des normes
Première rédaction de cet article le 16 avril 2020
La norme IDN, qui permet depuis 2003 les noms de domaine en Unicode était autrefois liée à une version particulière d'Unicode. La révision de cette norme en 2010 a libérédélivré IDN d'une version spécifique. La liste des caractères autorisés n'est plus statique, elle est obtenue par l'application d'un algorithme sur les tables Unicode. Tout va donc bien, et, à chaque nouvelle version d'Unicode, il suffit de refaire tourner l'algorithme ? Hélas non. Car, parfois, un caractère Unicode change d'une manière qui casse la compatibilité d'IDN et qui, par exemple, rend invalide un nom qui était valide auparavant. La norme IDN prévoit donc un examen manuel de chaque nouvelle version d'Unicode pour repérer ces problèmes, et décider de comment les traiter, en ajoutant une exception spécifique, pour continuer à utiliser ce caractère, ou au contraire en décidant d'accepter l'incompatibilité. Ce nouveau RFC ne change pas ce principe, mais il en clarifie l'application, ce qui est d'autant plus nécessaire que les examens prévus n'ont pas toujours été faits, et ont pris anormalement longtemps, entre autre en raison de l'absence de consensus sur la question.
Le RFC à lire avant celui-ci, pour réviser, est le RFC 5892. Il définit l'algorithme qui va décider, pour chaque caractère Unicode, s'il est autorisé dans les noms de domaine ou pas. À chaque version d'Unicode (la dernière est la 13.0), on refait tourner l'algorithme. Bien qu'Unicode soit très stable, cela peut faire changer un caractère de statut. Si un caractère auparavant interdit devient autorisé, ce n'est pas grave. Mais si l'inverse survient ? Des noms qui étaient légaux cessent de l'être, ne laissant le choix qu'entre deux solutions insatisfaisantes, supprimer le nom, ou bien ajouter une exception manuelle (procédure qui n'est pas parfaitement définie dans le RFC 5892, qui sera faite, si tout va bien, par de nouveaux RFC.)
[Notez que ce RFC affirme que les registres sont responsables des noms qu'ils autorisent, point de vue politique et non technique, contestable et d'ailleurs contesté.]
En quoi consiste donc le nouveau modèle d'examen qui accompagne la sortie d'une nouvelle version d'Unicode ? La section 3 du RFC l'expose. D'abord faire tourner l'algorithme du RFC 5892, puis noter les caractères qui ont changé de statut. Cela doit être fait par un expert nommé par l'IESG (DE, pour Designated Expert, actuellement Patrik Fältström, un des auteurs du RFC.) Puis réunir un groupe d'experts (il faut un groupe car personne n'est compétent dans tous les aspects d'IDN à la fois, ni dans toutes les écritures normalisées, cf. annexe B ; si l'IETF n'a pas de problèmes à trouver des experts en routage, elle doit par contre ramer pour avoir des experts en écritures humaines.) La recommandation pour ce groupe est d'essayer de préserver le statut des caractères et donc, si nécessaire, de les ajouter à une table d'exceptions (le RFC 6452 avait pris la décision opposée.) Le fait d'avoir des experts explicitement nommés va peut-être permettre d'éviter le syndrome du « il faudrait que quelqu'un s'en occupe » qui avait prévalu jusqu'à présent.
La promesse de publier les tables résultant de l'algorithme du RFC 5892 n'ayant pas été tenue (ce qui a fait râler), le RFC espère que cette fois, le travail sera fait. (Elle a finalement été faite deux ans plus tard dans le RFC 9233.)
L'annexe A résume les changements depuis le RFC 5892 (qui n'est pas remplacé, juste modifié légèrement) :
- Séparer explicitement l'examen des nouvelles versions d'Unicode en deux, la partie algorithmique et la partie plus politique,
- Désigner un groupe d'experts pour cette deuxième partie,
- Et quelques autres détails pratico-bureaucratiques sur l'organisation du travail.
La section 2 du RFC rappelle l'histoire d'IDN. La norme originale, le RFC 3490 définissait l'acceptabilité de chaque caractère dans un nom de domaine. Lorsqu'une nouvelle version d'Unicode sortait, il n'y avait pas de mécanisme pour décider d'accepter ou non les nouveaux caractères. Il aurait fallu refaire un nouveau RFC pour chaque version d'Unicode (il y en a environ une par an.) La version 2 d'IDN, dans le RFC 5890, a changé cela, en décidant de normaliser l'algorithme et non plus la liste des caractères. L'algorithme, décrit en détail dans le RFC 5892, utilise les propriétés indiquées dans la base de données Unicode (cf. la norme, sections 4 et 3.5) pour décider du sort de chaque caractère. Dans un monde idéal, ce sort ne change pas d'une version d'Unicode à l'autre. Si les propriétés Unicode des caractères sont stables, le statut (accepté ou refusé) restera le même, l'algorithme ne servant vraiment que pour les nouveaux caractères introduits par la nouvelle version d'Unicode. Mais, bien qu'Unicode fasse certaines promesses de stabilité, elles ne sont pas totales : un caractère peut donc se retrouver accepté une fois, puis refusé. Le RFC 5892 prévoyait donc, à juste titre, un examen manuel, et le RFC 5892 décrivait une table d'exceptions permettant de maintenir la compatibilité (section 2.7). Cette table aurait pu être remplie au fur et à mesure, pour conserver une certaine stabilité. Mais un tel examen n'a été fait qu'une fois, pour Unicode 6, dans le RFC 6452, suite à quoi il a été décidé de ne pas ajouter d'exceptions (et donc de laisser des noms devenir invalides.) En 2015, l'IAB avait demandé que les mises à jour soient suspendues, suite au « problème » (dont tout le monde n'est pas convaincu) du caractère arabe bāʾ avec hamza (ࢡ, U+08A1). Puis, en 2018, avait insisté sur l'importance de terminer ce travail. Deux ans après, ce n'est toujours pas fait. Donc, en pratique, IDNA version 2 n'a pas encore tenu sa promesse de pouvoir être mis à jour « presque » automatiquement.
À noter un autre problème avec la nouvelle version d'IDN : le fait qu'un caractère soit autorisé ou pas dépend d'un algorithme, et non plus d'une table statique. Mais, pour faciliter la vie des utilisateurs, l'IANA avait produit des tables en appliquant l'algorithme aux données Unicode. Il a toujours été prévu que ces tables soient juste une aide, qu'elles ne fassent pas autorité mais, malheureusement, certaines personnes les ont compris comme étant la référence, ce qui n'était pas prévu. Comme ces tables IANA n'ont pas été mises à jour au fur et à mesure des versions d'Unicode, le problème devient sérieux. Le RFC demande à l'IANA de modifier la description des tables pour insister sur leur caractère non-normatif (« It should be stressed that these are not normative in that, in principle, an application can do its own calculations and these tables can change as IETF understanding evolves. ».)
J'ai écrit que tout le monde n'était pas convaincu de la nature du problème. Il y a en effet un désaccord de fond au sujet d'Unicode, entre ceux qui considèrent que toutes les lettres se valent, que toutes les écritures doivent avoir le même statut et, ceux, souvent des utilisateurs de l'alphabet latin, que la diversité dérange et qui voudraient mieux contrôler les caractères « dangereux », en utilisant des arguments de sécurité contestables. La question est d'autant plus sérieuse que les retards de mise à jour d'IDN (qui est toujours en version 6 alors qu'Unicode est en version 13) handicape surtout les utilisateurs des écritures les plus récemment ajoutées dans Unicode, en général des peuples minoritaires et peu présents dans le business international. Le retard n'est donc pas forcément gênant de la même manière pour tout le monde…
L'article seul
RFC 8770: Host Router Support for OSPFv2
Date de publication du RFC : Avril 2020
Auteur(s) du RFC : K. Patel (Arrcus), P. Pillay-Esnault
(PPE
Consulting), M. Bhardwaj, S. Bayraktar
(Cisco)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF ospf
Première rédaction de cet article le 13 avril 2020
Le protocole de routage OSPF, dans sa version 2, a une particularité amusante : dès qu'une machine participe au protocole, et échange des messages avec les autres, elle va être considérée comme un routeur, à qui on peut envoyer du trafic à faire suivre. Or, on peut souhaiter observer le routage sans être soi-même routeur. D'où ce RFC, qui prévoit un moyen de mettre dans les messages : « je suis juste un observateur, ne m'envoie pas de paquets à router ».
Dans quels cas trouve-t-on ces machines qui participent à un protocole de routage mais ne veulent pas transmettre les paquets des autres ? La section 1 du RFC cite plusieurs cas, dont :
- Un routeur en train de redémarrer et qui n'est pas encore prêt à transmettre des paquets,
- Un routeur surchargé de travail et qui souhaite demander qu'on arrête de l'utiliser (mais qui a besoin de continuer à connaitre les routes existantes),
- Des réflecteurs de route.
La solution proposée dans ce RFC est d'ajouter aux messages OSPF un bit, le bit H (Host bit). Lors du calcul des routes avec SPF (section 16.1 du RFC 2328, qui normalise OSPF version 2), les routeurs ayant le bit H seront exclus. Ce bit utilise un des bits inutilisés du LSA (Link State Advertisement) de routeur (RFC 2328, section A.4.2), et il est enregistré à l'IANA.
Difficulté classique quand on modifie un protocole, surtout ancien et très répandu, comme OSPF, la cohabitation entre anciens et récents logiciels. Que se passe-t-il si un réseau mêle des routeurs qui envoient le bit H et d'autres qui ne connaissent pas ce bit ? La section 5 explique la solution : en utilisant les extensions du RFC 7770, un LSA Router Information est envoyé, indiquant qu'on sait gérer le bit H (capacité Host Router, cf. le registre IANA.) Les routeurs connaissant notre RFC ne tiendront compte du bit H que si tous les routeurs de la zone OSPF ont annoncé cette capacité.
L'article seul
Fiche de lecture : Les furtifs
Auteur(s) du livre : Alain Damasio
Éditeur : La volte
978-2370-490742
Publié en 2019
Première rédaction de cet article le 7 avril 2020
J'ai aimé le dernier roman d'Alain Damasio, « Les furtifs », autant que « La horde du contrevent », ce qui n'est pas peu dire.
Mais, cette fois, le roman ne se passe plus dans une planète lointaine et bizarre mais chez nous. Enfin, un peu dans le futur, quand même. Il s'agit d'une dystopie où le pays est contrôlé par un gouvernement autoritaire, où tout est privatisé et ne fonctionne que pour le profit, et où les inégalités entre « premiers de cordée » et la masse sont ouvertement assumées ; par exemple, certaines rues de la ville sont réservées aux citoyens favorisés (il n'y a de toute façon plus guère d'espace public). Les activités non lucratives sont réprimées (l'un des personnages est « proferrante », ce qui veut dire qu'elle donne des cours clandestins, enfreignant le monopole des compagnies privées.)
Tout cela est évidemment compliqué à gérer mais, cette fois, il y a le numérique : tout est surveillé et fiché, et le citoyen sait exactement où il a le droit d'aller, et les systèmes de surveillance et de répression savent où est chacun. Comme toutes les dystopies, c'est exagéré mais… pas si exagéré que cela. On se dit qu'il ne manque pas grand'chose aux sociétés modernes pour arriver à ce stade. Pas une dictature totale et brutale comme dans « 1984 », non, simplement un monde bien contrôlé, une smart city totale.
Bien sûr, tout le monde n'est pas d'accord. Dans les interstices du système, il y a des protestations, des tentatives d'élargir les rares espaces de liberté, voire des franches rébellions. Et puis il y a des choses (choses ?) mystérieuses, les Furtifs, dont on ne sait pas grand'chose mais que l'armée traque, dans le doute. Et c'est au sein même de l'unité d'élite anti-Furtifs que vont naître les questions.
Je ne vais pas essayer de résumer le reste du livre, d'abord pour vous laisser le plaisir de la découverte et ensuite parce que le livre est riche, très riche, et part dans tous les sens. Il faut du temps pour y entrer et pour l'explorer dans tous les sens.
Comme dans « La horde du contrevent », le récit est fait par plusieurs des personnages, avec des jolis signes typographiques pour indiquer qui parle. Ne perdez donc pas de vue le rabat qui les résume.
L'article seul
Fiche de lecture : Culture numérique
Auteur(s) du livre : Dominique Cardon
Éditeur : Les presses de SciencesPo
978-2-7246-2365-9
Publié en 2019
Première rédaction de cet article le 3 avril 2020
Elle est loin, l'époque où l'Internet et le numérique en général, était ignoré des enseignants et des chercheurs en SHS. Désormais, il y a plein de livres étudiant tel ou tel aspect du réseau. Mais tous ne sont pas bien informés. Ici, au contraire, Dominique Cardon connait parfaitement son sujet, et a publié une version papier de son cours sur l'Internet à SciencesPo. Un ouvrage très utile si vous avez à enseigner l'Internet à des non-informaticiens.
Le plan est classique : histoire de l'Internet, gouvernance de l'Internet (bien expliquée, et sans les innombrables erreurs que contiennent la majorité des articles destinés au grand public), rôle des cultures « californiennes » (comme Burning Man), histoire du Web, les réseaux sociaux, la régulation du contenu, la pratique de la politique sur les réseaux, la publicité en ligne… Mais l'auteur parle également de sujets moins mentionnés dans les publications mainstream comme le rôle de la pensée des Communs (et celui du logiciel libre), avec l'exemple, toujours classique mais justifié, de Wikipédia. Les lecteurs de mon blog connaissent certainement déjà tout cela mais rappelez-vous que ce cours est destiné à un tout autre public, qui n'est normalement exposé qu'au discours mi-marketing (cloud, digital, etc), mi-catastrophiste (Internet, c'est que des fake news, et tout ça.)
Globalement, le livre se penche surtout sur les applications et sur les usages, pas tellement sur l'infrastructure sous-jacente. L'auteur a réussi à garder l'esprit d'un cours, accessible à un large public, tout en le réécrivant suffisamment pour que le livre ne soit pas juste une copie d'un support de cours. Cet ouvrage est utilisable pour le curieux ou la curieuse qui veut une introduction correcte à l'Internet, ou par l'enseignante ou l'enseignant qui veut l'utiliser comme base pour son cours.
Ah, et il y a plein de références bibliographiques : utile si vous vous ennuyez pendant le confinement. Vous aurez de quoi lire.
L'article seul
RFC 8767: Serving Stale Data to Improve DNS Resiliency
Date de publication du RFC : Mars 2020
Auteur(s) du RFC : D. Lawrence (Oracle), W. Kumari (Google),
P. Sood (Google)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 1 avril 2020
Ce nouveau RFC autorise les résolveurs DNS à servir des « vieilles » informations aux clients (« vieilles » parce que le TTL est dépassé), si et seulement si les serveurs faisant autorité ne sont pas joignables (par exemple parce qu'ils sont victimes d'une attaque par déni de service.) Cela devrait rendre le DNS plus robuste en cas de problèmes. Le principe est donc désormais « mieux vaut du pain rassis que pas de pain du tout ».
Normalement, avant ce RFC, le DNS fonctionne ainsi : le client interroge un résolveur. Ce résolveur :
- Soit possède l'information dans sa mémoire (dans son cache), et le TTL de cette information, TTL originellement choisi par le serveur faisant autorité, n'est pas encore dépassé ; le résolveur peut alors renvoyer cette information au client.
- Soit n'a pas l'information (ou bien le TTL est dépassé) et le résolveur doit alors demander aux serveurs faisant autorité, avant de transmettre le résultat au client.
C'est ce que décrit le RFC 1035, notamment sa section 3.2.1. Ici, faite avec dig, une interrogation DNS, les données étant déjà dans le cache (la mémoire), ce qui se voit au TTL qui n'est pas un chiffre rond :
% dig NS assemblee-nationale.fr ... ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 57234 ;; flags: qr rd ra; QUERY: 1, ANSWER: 3, AUTHORITY: 0, ADDITIONAL: 1 ... ;; ANSWER SECTION: assemblee-nationale.fr. 292 IN NS ns2.fr.claradns.net. assemblee-nationale.fr. 292 IN NS ns1.fr.claradns.net. assemblee-nationale.fr. 292 IN NS ns0.fr.claradns.net. ;; Query time: 0 msec ;; SERVER: 127.0.0.1#53(127.0.0.1) ;; WHEN: Thu Feb 20 11:09:57 CET 2020 ;; MSG SIZE rcvd: 120
Mais que se passe-t-il si le résolveur a des données, que le
TTL est expiré, mais que
les serveurs faisant autorité sont en panne (cas d'autant plus
fréquent que beaucoup de domaines ont trop peu de serveurs, et qu'il
y a souvent des SPOF), injoignables (par exemple suite à un
problème de routage) ou bien victimes d'une
DoS, comme
cela arrive trop souvent ? Dans ce cas, le résolveur ne peut pas
vérifier que les données sont à jour (alors que ce sera souvent le
cas) et doit renvoyer une réponse SERVFAIL (Server
Failure) qui empêchera le client d'avoir les informations
qu'il demande. Dommage : après tout, peut-être que le client voulait
se connecter au serveur imap.example.net qui,
lui, marchait, même si les serveurs DNS faisant autorité pour
example.net étaient en panne. C'est l'une des
motivations pour cette idées des données rassises. Comme le note
Tony Finch, cela rendra plus facile le débogage des problèmes
réseau. Au lieu d'un problème DNS mystérieux, qui masque le problème
sous-jacent, les opérateurs verront bien mieux ce qui se
passe. (Quasiment toutes les opérations sur l'Internet commencent
par une requête DNS, et les problèmes réseau sont donc souvent
perçus comme des problèmes DNS, même si ce n'est pas le cas.)
De tels problèmes sont relativement fréquents, et le RFC et moi vous recommandons l'excellent article « When the Dike Breaks: Dissecting DNS Defenses During DDoS ».
C'est pour cela que notre RFC prévoit, dans des cas exceptionnels, d'autoriser le résolveur à outrepasser le TTL et à renvoyer des données « rassises ». En temps normal, rien ne change au fonctionnement du DNS mais, si les circonstances l'exigent, le client recevra des réponses, certes peut-être dépassées, mais qui seront mieux que rien. Le compromis habituel entre fraîcheur et robustesse est donc déplacé un peu en faveur de la robustesse.
Bref, depuis la sortie de notre RFC, un résolveur est autorisé à servir des données rassises, si les serveurs faisant autorité ne répondent pas, ou bien s'ils répondent SERVFAIL (Server Failure.) Il doit dans ce cas (section 4 du RFC) mettre un TTL strictement positif, la valeur 30 (secondes) étant recommandée, pour éviter que ses clients ne le harcèlent, et aussi parce qu'un TTL de zéro (ne pas mémoriser du tout) est parfois mal compris par certains clients DNS bogués (cf. section 6).
La section 5 donne un exemple de comment cela peut être mis en œuvre. Elle suggère d'utiliser quatre délais :
- Le temps maximal pendant lequel faire patienter le client, 1,8 secondes étant la durée recommandée (par défaut, dig patiente 5 secondes, ce qui est très long),
- Le temps maximal pour avoir une réponse, typiquement entre 10 et 30 secondes (le résolveur va donc continuer à chercher une réponse, même s'il a déjà répondu au client car le précédent temps maximal était dépassé),
- L'intervalle entre deux essais quand on n'a pas réussi à obtenir une réponse, 30 secondes est le minimum recommandé, pour éviter de rajouter à une éventuelle DDoS en demandant sans cesse aux serveurs faisant autorité,
- L'âge maximal des données rassises, avant qu'on décide qu'elles sont vraiment trop vieilles. Le RFC suggère de mettre entre 1 et 3 journées.
Si le résolveur n'a pas eu de réponse avant que le temps maximal pendant lequel faire patienter le client soit écoulé, il cherche dans sa mémoire s'il n'a pas des données rassises et, si oui, il les envoie au client. (C'est la nouveauté de ce RFC.)
La section 6 donne quelques autres conseils pratiques. Par exemple, quel âge maximal des données rassises choisir ? Une durée trop courte diminuera l'intérêt de ce RFC, une durée trop longue augmentera la consommation mémoire du résolveur. Une demi-journée permet d'encaisser la grande majorité des attaques par déni de service. Une semaine permet d'être raisonnablement sûr qu'on a eu le temps de trouver les personnes responsables (c'est souvent beaucoup plus dur qu'on ne le croit !) et qu'elles résolvent le problème. D'où la recommandation du RFC, entre 1 et 3 jours.
Pour la consommation de mémoire, il faut aussi noter que, si la limite du résolveur a été atteinte, on peut prioriser les données rassises lorsqu'on fait de la place, et les sacrifier en premier. On peut aussi tenir compte de la « popularité » des noms, en supprimant en premier les noms les moins demandés. Attention, un tel choix pourrait pousser certains à faire des requêtes en boucle pour les noms qu'ils trouvent importants, de manière à les faire considérer comme populaires.
Beaucoup de résolveurs ont deux mémoires séparées, une pour les
données demandées par les clients, et une pour les données obtenues
lors du processus de résolution lui-même. Ainsi, lorsqu'un client
demande le MX de
foobar.example, et que les serveurs faisant
autorité pour foobar.example seront
ns0.op.example et
ns1.op.example, le résolveur devra à un moment
découvrir l'adresse IP de ns0 et
ns1.op.example (une « requête tertiaire », pour
reprendre la terminologie du RFC 7626.) Cette
adresse IP sera mémorisée, mais pas dans la même mémoire que le MX
de foobar.example, car ces données n'ont pas
forcément le même niveau de confiance (il peut s'agir de colles, par
exemple, et pas de données issues d'un serveur faisant autorité). Le
RFC autorise également à utiliser des données rassises pour cette
seconde mémoire, donc pour la cuisine interne du processus de
résolution. Ainsi, si un TLD est injoignable (comme c'était arrivé au
.tr en décembre
2015, suite à une attaque par déni de service), les serveurs
de noms sous ce TLD resteront peut-être utilisables, pour des
nouvelles requêtes.
Notez que le client du résolveur n'a aucun moyen de dire s'il accepte des données rassises, ou bien s'il veut uniquement du frais. Il avait été discuté à l'IETF une option EDNS permettant au client de signaler son acceptation de vieilles données, mais cette option n'a pas été retenue (section 9), le but étant de fournir une technique qui marche avec les clients actuels, afin de renforcer la robustesse du DNS dès maintenant. Ce point est sans doute celui qui avait suscité les plus chaudes discussions.
La section 10 discute de quelques problèmes de sécurité liés au fait de servir des données rassises. Par exemple, une attaque existante contre le DNS est celle des « domaines fantômes » où un attaquant continue à utiliser un domaine supprimé (par exemple parce qu'il servait à distribuer du logiciel malveillant) en comptant sur les mémoires des résolveurs. (Voir à ce sujet l'artricle « Cloud Strife: Mitigating the Security Risks of Domain-Validated Certificates ».) Le fait de servir des données rassises pourrait rendre l'attaque un peu plus facile, mais pas plus : après tout, la réponse NXDOMAIN (ce domaine n'existe pas) de la zone parente supprime toutes les entrées de ce domaine dans la mémoire. D'autre part, un attaquant pourrait mettre hors d'état de service les serveurs faisant autorité pour une zone afin de forcer l'utilisation de données anciennes. Ceci dit, sans ce RFC, un attaquant ayant ce pouvoir peut faire des dégâts plus graves, en bloquant tout service.
À noter que notre RFC change également les normes précédentes sur un autre point, l'interprétation des TTL lorsque le bit de plus fort poids est à un (section 4). Le RFC 2181 disait (dans sa section 8) « Implementations should treat TTL values received with the most significant bit set as if the entire value received was zero. ». C'était pour éviter les problèmes d'ambiguité entre entiers signés et non signés. Le RFC 8767 change cette règle dit désormais clairement que le TTL est un entier non signé et que ces valeurs avec le bit de plus fort poids à un sont des valeurs positives. Il ajoute qu'elles sont tellement grandes (plus de 68 ans…) qu'elles n'ont pas d'intérêt pratique et doivent donc être tronquées (un TTL de plus d'une semaine n'a pas de sens et les résolveurs sont donc invités à imposer cette limite). Donc, en pratique, cela ne change rien.
Questions mises en œuvre, de nombreux résolveurs offrent un moyen de servir les données anciennes. L'idée est loin d'être nouvelle, elle existait avant le RFC, et était largement acceptée, quoique violant la norme technique. Bref, les données rassises existent déjà un peu partout. Ainsi, les logiciels privateurs Nomimum and Xerocole (utilisés par Akamai) peuvent le faire. Idem pour OpenDNS. Du côté des logiciels libres, BIND, Knot et Unbound ont tous cette possibilité, à des degrés divers.
Pour Unbound, les versions avant la 1.10 ne permettaient pas de suivre rigoureusement notre RFC 8767. Les options étaient (je cite le fichier de configuration d'exemple) :
# Serve expired responses from cache, with TTL 0 in the response, # and then attempt to fetch the data afresh. # serve-expired: no # # Limit serving of expired responses to configured seconds after # expiration. 0 disables the limit. # serve-expired-ttl: 0 # # Set the TTL of expired records to the serve-expired-ttl value after a # failed attempt to retrieve the record from upstream. This makes sure # that the expired records will be served as long as there are queries # for it. # serve-expired-ttl-reset: no
Notez donc qu'avec serve-expired, Unbound
servait des données rassises avant même de vérifier si les serveurs
faisant autorité étaient joignables. À partir de la version 1.10,
cette configuration fonctionne et colle au RFC :
# Enable serve-expired serve-expired: yes # Time to keep serving expired records. serve-expired-ttl: 86400 # One day # Do not reset the TTL above on failed lookups serve-expired-ttl-reset: no # default # TTL to reply with expired entries serve-expired-reply-ttl: 30 # default # Time to wait before replying with expired data serve-expired-client-timeout: 1800
Si on met serve-expired-client-timeout à zéro
(c'est la valeur par défaut), on garde l'ancien comportement (qui ne
respecte ni les anciens RFC, ni le nouveau.)
Pour BIND, la possibilité de se contenter de vieilles données a été introduite dans la version 9.12. Les options pertinentes sont :
stale-answer-enable: active le service d'envoi de données dépassées, uniquement si les serveurs faisant autorité sont injoignables, ce qui est la recommandation du RFC,max-stale-ttl: l'âge maximal des données rassises (une semaine par défaut),stale-answer-ttl: le TTL des valeurs retournées, une seconde par défaut (alors que le RFC suggère trente secondes).
Et sur Knot ? Knot est modulaire et la
possibilité de servir des données dépassées est dans un module
Lua séparé, serve_stale
(cf. modules/serve_stale/README.rst dans le
source). Il sert des données dépassées pendant au maximum une
journée. Il n'est apparemment configurable qu'en éditant le source Lua.
L'article seul
RFC 8773: TLS 1.3 Extension for Certificate-Based Authentication with an External Pre-Shared Key
Date de publication du RFC : Mars 2020
Auteur(s) du RFC : R. Housley (Vigil Security)
Expérimental
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 31 mars 2020
L'authentification dans TLS se fait typiquement, soit à partir d'un certificat, soit par une clé partagée à l'avance. Ce nouveau RFC spécifie une extension de TLS qui permet d'utiliser ces deux méthodes en même temps. Il a depuis été remplacé par le RFC 9973.
Rappelons d'abord qu'il y a deux sortes de clés partagées à l'avance (PSK, pour Pre-Shared Key) : celles qui ont été négociées dans une session précédentes (resumption PSK) et celles qui ont été négociées par un mécanisme extérieur (envoi par pigeon voyageur sécurisé…), les external PSK. Ce RFC ne concerne que les secondes. Les certificats et les clés partagées à l'avance ont des avantages et des inconvénients. Les certificats ne nécessitent pas d'arrangement préalable entre client et serveur, ce qui est pratique. Mais il faut se procurer un certificat auprès d'une AC. Et les certificats, comme ils reposent sur des algorithmes comme RSA ou ECDSA, sont vulnérables aux progrès de la cryptanalyse, par exemple en utilisant un (futur) ordinateur quantique. Utiliser une clé partagée à l'avance n'est pas forcément commode (par exemple quand on veut la changer) mais cela peut être plus sûr. Or, la norme TLS actuelle (RFC 8446) ne permet d'utiliser qu'une seule des deux méthodes d'authentification. Si on les combinait ? L'ajout d'une clé externe permettrait de rendre l'authentification plus solide.
Le principe est simple : notre RFC spécifie une extension à TLS,
tls_cert_with_extern_psk (valeur
33.) Le client TLS l'envoie dans son
ClientHello. Elle indique la volonté de
combiner certificat et PSK. Elle est accompagnée d'extensions
indiquant quelle est la clé partagée à utiliser. Si le serveur TLS
est d'accord, il met l'extension
tls_cert_with_extern_psk dans son message
ServerHello. (Le serveur ne peut pas décider
seul de l'utilisation de cette extension, il faut que le client ait
demandé d'abord.)
Les clés ont une identité, une série d'octets sur lesquels client
et serveur se sont mis d'accord avant (PSK = Pre-Shared
Key, clé partagée à l'avance.) C'est cette identité qui
est envoyée dans l'extension pre_shared_key, qui
accompagne tls_cert_with_extern_psk. La clé
elle-même est bien sûr un secret, connu seulement du client et du
serveur (et bien protégée : ne la mettez pas sur un fichier lisible
par tous.) Voyez la section 7 du RFC pour une discussion plus
détaillée de la gestion de la PSK.
Une fois que client et serveur sont d'accord pour utiliser l'extension, et ont bien une clé en commun, l'authentification se fait via le certificat (sections 4.4.2 et 4.4.3 du RFC 8446) et en utilisant ensuite, non pas seulement la clé générée (typiquement par Diffie-Hellman), mais la combinaison de la clé générée et de la PSK. L'entropie de la PSK s'ajoute donc à celle de la clé générée de manière traditionnelle.
Du point de vue de la sécurité, on note donc que cette technique de la PSK est un strict ajout à l'authentification actuelle, donc on peut garantir que son utilisation ne diminuera pas la sécurité.
Il n'y a apparemment pas encore de mise en œuvre de cette extension dans une bibliothèque TLS.
Notez qu'il s'agit apparemment du premier RFC à mentionner explicitement les calculateurs quantiques, et les risques qu'ils posent pour la cryptographie.
L'article seul
Fiche de lecture : Tales from the wood
Auteur(s) du livre : Adrian Farrel
Éditeur : FeedaRead.com Publishing
978-1-78610-092-4
Publié en 2015
Première rédaction de cet article le 28 mars 2020
Tales from the wood est un recueil de nouvelles, qui reprennent des thèmes de contes de fées, mais les adaptent, souvent dans un sens plus noir.
Notez que, pendant la durée du confinement, certaines des nouvelles sont gratuitement disponibles en ligne.
L'auteur est Adrian Farrel et, en dehors de l'écriture de nouvelles, il est Independent Stream Editor à l'IETF, chargé, donc, de veiller sur les RFC de la voie indépendante (cf. RFC 8730.) Aux réunions IETF, il est le seul (avec moi) à embêter les participants à placer ses livres :-).
Mais revenons aux nouvelles. L'inspiration vient clairement des contes de fées traditionnels, plutôt du monde occidental (avec quelques exceptions). Le style est merveilleux, un anglais un peu précieux, avec beaucoup de vocabulaire. Le fond est modernisé (les femmes y ont un rôle moins inutile que dans les contes classiques), et, en général, assez noir (encore que les contes de fées traditionnels soient souvent assez durs.) Sans divulgâcher, disons que le conte se termine souvent mal et, pourtant, on veut toujours lire le suivant. Et les trois recueils qui suivent…
Vous pouvez acheter les livres sous forme papier ou bien sur le site Web. Notez que les textes sont sous une licence Creative Commons, CC-BY-SA-NC (partage à l'identique, mais pas d'utilisation commerciale.)
L'article seul
RFC 8749: Moving DNSSEC Lookaside Validation (DLV) to Historic Status
Date de publication du RFC : Mars 2020
Auteur(s) du RFC : W. Mekking, D. Mahoney (ISC)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF dnsop
Première rédaction de cet article le 27 mars 2020
DLV (DNSSEC Lookaside Validation) était un mécanisme permettant de contourner le fait que plusieurs zones DNS importantes, dont la racine, n'étaient pas signées. Jamais très utilisé, et aujourd'hui inutile, DLV est ici officiellement abandonné, et les RFC le décrivant sont reclassés « intérêt historique seulement ».
Normalement, DNSSEC (RFC 4033 et
suivants) suit le modèle de confiance du DNS. La résolution DNS part de la racine,
puis descend vers les domaines de premier niveau, de deuxième
niveau, etc. De même, un résolveur validant avec DNSSEC connait la
clé publique
de la racine, s'en sert pour valider la clé du premier niveau, qui
sert ensuite pour valider la clé du deuxième niveau, etc. C'est
ainsi que DNSSEC était prévu, et qu'il fonctionne aujourd'hui. Mais
il y a eu une période de transition, pendant laquelle la racine, et
la plupart des TLD, n'étaient pas signés. Le résolveur validant
aurait donc dû gérer autant de clés publiques qu'il y avait de zones
signées. Pour éviter cela, DLV (DNSSEC Lookaside
Validation) avait été
créé. Le principe de DLV était de mettre les clés des zones signées
dans une zone spéciale (par exemple
dlv.operator.example) et que les résolveurs
cherchent les clés à cet endroit. Ainsi, le résolveur validant
n'avait besoin que de la clé de la zone DLV. DLV a bien rempli son
rôle, et a sérieusement aidé au déploiement de DNSSEC. Mais,
aujourd'hui, les choses sont différentes, la racine (depuis 2010) et tous les
TLD importants sont signés (1 389 TLD sur 1 531 sont signés,
.fr l'a également été en
2010), et DLV n'a donc plus de raison d'être.
Bien sûr, il reste encore des zones de délégation non signées et donc en théorie des gens qui pourraient avoir besoin de DLV. Mais le consensus était clair à l'IETF sur l'abandon de DLV, car (section 3 de notre RFC) :
- Le maintien de DLV risque de décourager les zones manquantes de signer (« pas la peine, les gens n'ont qu'à utiliser DLV »),
- Toute occasion de simplifier le code des résolveurs (plus besoin du cas spécial de DLV) est bonne à prendre, et améliore la sécurité,
- D'ailleurs, tous les résolveurs n'ont pas DLV et donc, de toute façon, il ne remplace pas un chemin de validation « normal ».
Il n'y avait en pratique d'une seule zone DLV sérieuse,
dlv.isc.org, et elle a
été arrêtée en 2017, il ne reste donc de toute façon plus
d'utilisateurs connus de DLV.
Donc (section 4 de notre RFC), les deux RFC qui décrivaient DLV, le RFC 4431 et le RFC 5074
passent du statut « Pour information » à celui de « Intérêt
historique seulement ». (Vous pouvez consulter les détails
du processus.) Même chose pour le type d'enregistrement DNS
DLV (code 32769), qui apparait désormais dans
le
registre IANA comme (OBSOLETE).
L'article seul
Un site Web multi-serveur multi-organisations sans trop de travail
Première rédaction de cet article le 22 mars 2020
Je viens de configurer un site Web qui est composé de plusieurs serveurs gérés par plusieurs personnes. Cet article est juste un partage d'expérience pour raconter quelques techniques utiles pour ce genre de service.
Le problème de départ était de distribuer certaines des ressources pédagogiques disponibles sur le site du CNED malgré la surcharge de leur serveur, qui était souvent inaccessible. Caroline De Haas avait copié les fichiers, il restait à les héberger. Il fallait aller vite (ces ressources étaient utiles aux parents d'élèves pendant la phase de confinement) et que cela ne soit pas trop cher puisque c'était fait par des volontaires. D'un autre côté, contrairement à ce qu'essaient de vous faire croire les ESN, simplement distribuer des fichiers statiques ne nécessite pas beaucoup de travail, et il n'y a pas besoin d'un serveur costaud. Pour des raisons aussi bien techniques (répartir la charge) que politiques (je trouve plus sympas les projets collectifs), le service devait être réparti sur plusieurs machines. On n'a évidemment pas manqué de volontaires et, rapidement, de nombreuses machines étaient disponibles. Reste à coordonner tout cela.
Le cahier des charges était que le service devait être disponible
pour des utilisateurs ordinaires. Donc, du Web classique, pas de
BitTorrent (qui aurait sans doute été mieux
adapté à ce travail) et encore moins d'IPFS
(très joli mais franchement difficile à gérer). Donc, juste un
URL à connaitre, http://ressources-pedagogiques.org/. Pour
réaliser un tel service, on peut faire passer toutes les requêtes
HTTP par
un répartiteur de
charge (facile à réaliser, par exemple avec
nginx) et envoyer ensuite aux différents
serveurs. Problèmes, le répartiteur de charge est un
SPOF, et cela n'est pas forcément efficace de
rajouter systématiquement un intermédaire. Des solutions de plus
haute technologie étaient possibles, à base
d'anycast
BGP, par exemple, mais pas accessibles à un
groupe de volontaires sans moyens particuliers.
La solution choisie était donc de compter sur le DNS. On met les adresses de tous les serveurs dans le DNS et c'est le client DNS qui assure une répartition (plus ou moins raisonnable) du trafic. C'est loin d'être optimal mais c'est très simple, très robuste (presque aucun SPOF) et accessible à tous.
Le domaine
ressources-pedagogiques.org est installé sur
plusieurs
serveurs DNS. Chaque fois qu'un serveur est configuré, je le
teste et je l'ajoute à la zone. Le nom a actuellement 32
adresses IP. Si vous utilisez dig,
vous pouvez les afficher (ou bien se servir du DNS looking
glass, en suivant le lien précédent) :
% dig +bufsize=4096 AAAA ressources-pedagogiques.org
; <<>> DiG 9.11.3-1ubuntu1.11-Ubuntu <<>> AAAA ressources-pedagogiques.org
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 31490
;; flags: qr rd ra; QUERY: 1, ANSWER: 13, AUTHORITY: 0, ADDITIONAL: 1
...
;; ANSWER SECTION:
ressources-pedagogiques.org. 6168 IN AAAA 2a03:7220:8080:f00::1
ressources-pedagogiques.org. 6168 IN AAAA 2a01:cb19:815f:cb00:f6b5:20ff:fe1b:bec3
ressources-pedagogiques.org. 6168 IN AAAA 2a01:cb08:89a3:b900:21e:6ff:fe42:2565
ressources-pedagogiques.org. 6168 IN AAAA 2a01:4f9:4a:1fd8::26
ressources-pedagogiques.org. 6168 IN AAAA 2a01:4f8:1c1c:42c9::1
ressources-pedagogiques.org. 6168 IN AAAA 2605:4500:2:245b::42
ressources-pedagogiques.org. 6168 IN AAAA 2001:4b98:dc0:43:216:3eff:fec4:c1a7
ressources-pedagogiques.org. 6168 IN AAAA 2001:41d0:a:f4b4::1
ressources-pedagogiques.org. 6168 IN AAAA 2001:41d0:a:1370::1
ressources-pedagogiques.org. 6168 IN AAAA 2001:bc8:47b0:723::1
ressources-pedagogiques.org. 6168 IN AAAA 2001:bc8:4400:2400::5327
ressources-pedagogiques.org. 6168 IN AAAA 2001:67c:288:32::38
ressources-pedagogiques.org. 6168 IN AAAA 2001:470:1f13:2f:0:ff:fe01:500
;; Query time: 0 msec
;; SERVER: 127.0.0.53#53(127.0.0.53)
;; WHEN: Sun Mar 22 15:33:41 CET 2020
;; MSG SIZE rcvd: 443
(Et refaire la manipulation pour les adresses IPv4.)
Pour se synchroniser, les serveurs s'alimentent sur un site de
référence,
https://source.ressources-pedagogiques.org/ (ce
nom, lui, ne pointe que vers une seule machine), typiquement en
rsync (la documentation pour les gérants des
serveurs miroir est sur le
site.)
Voilà, c'est tout simple et ça marche. Mais il existe quelques
pièges. Le premier est celui de la vérification des miroirs. Dans un
tel service, géré par des personnes variées, il peut y avoir des
miroirs mal configurés, qui tombent en panne, ou bien qui ne se
synchronisent plus. Il est donc crucial de les tester, avant la mise
en service, puis de temps en temps. J'utilise pour cela un petit
script shell, check.sh, qui récupère les noms dans le
DNS et appelle curl pour tester :
% ./check.sh 2001:470:1f13:2f:0:ff:fe01:500 failed %
Ici, il y avait un problème de routage vers une adresse, et tous les
autres serveurs sont corrects. Si vous lisez le script, l'option la
plus intéressante de curl est
--connect-to, qui permet de tester
spécifiquement chaque serveur (il ne suffit pas de tester le service
général.) Notez que Marc Chantreux a développé une version améliorée
de ce script, rp-check-better.sh
Une version légèrement différente du script me permet de tester
un nouveau serveur lorsqu'on me le signale, rp-check-one.sh
...
Connected to 2605:4500:2:245b::42 (2605:4500:2:245b::42) port 80 (#0)
> GET /ressources/CP/5CPM9TEWB0016_CahierDeBord_Presentation.pdf HTTP/1.1
> Host: ressources-pedagogiques.org
> User-Agent: ressources-pedagogiques.org checker
...
< HTTP/1.1 200 OK
< Content-Length: 262219
< Content-Type: application/pdf
...
Tester que les serveurs marchent est une chose, il est également bon
de vérifier qu'ils sont à jour. Le script de mise à jour du serveur
de référence source.ressources-pedagogiques.org
met la date dans un fichier, qu'on peut récupérer pour voir si tous
les serveurs ont la même (ils lancent typiquement
rsync depuis cron) :
% ./updates.sh 2a03:7220:8080:f00::1 : 2020-03-20 13:47:37+00:00 2a01:cb19:815f:cb00:f6b5:20ff:fe1b:bec3 : 2020-03-20 13:47:37+00:00 2a01:cb08:89a3:b900:21e:6ff:fe42:2565 : 2020-03-20 13:47:37+00:00 2a01:4f9:4a:1fd8::26 : 2020-03-20 13:47:37+00:00 2a01:4f8:1c1c:42c9::1 : 2020-03-20 13:47:37+00:00 2605:4500:2:245b::42 : 2020-03-20 13:47:37+00:00 2001:4b98:dc0:43:216:3eff:fec4:c1a7 : 2020-03-20 13:47:37+00:00 2001:41d0:a:f4b4::1 : 2020-03-20 13:47:37+00:00 2001:41d0:a:1370::1 : 2020-03-20 13:47:37+00:00 2001:bc8:47b0:723::1 : 2020-03-20 13:47:37+00:00 2001:bc8:4400:2400::5327 : 2020-03-20 13:47:37+00:00 2001:67c:288:32::38 : 2020-03-20 13:47:37+00:00 2001:470:1f13:2f:0:ff:fe01:500 : ERROR 000 204.62.14.153 : 2020-03-20 13:47:37+00:00 195.154.172.222 : 2020-03-20 13:47:37+00:00 185.230.78.228 : 2020-03-20 13:47:37+00:00 185.34.32.38 : 2020-03-20 13:47:37+00:00 163.172.222.36 : 2020-03-20 13:47:37+00:00 163.172.175.248 : 2020-03-20 13:47:37+00:00 159.69.80.58 : 2020-03-20 13:47:37+00:00 95.217.83.231 : 2020-03-20 13:47:37+00:00 92.243.17.60 : 2020-03-20 13:47:37+00:00 91.224.149.235 : 2020-03-20 13:47:37+00:00 91.224.148.15 : 2020-03-20 13:47:37+00:00 86.250.18.250 : 2020-03-20 13:47:37+00:00 83.205.2.135 : 2020-03-20 13:47:37+00:00 62.210.124.111 : 2020-03-20 13:47:37+00:00 51.255.9.60 : 2020-03-20 13:47:37+00:00 51.15.229.92 : 2020-03-20 13:47:37+00:00 37.187.123.180 : 2020-03-20 13:47:37+00:00 37.187.19.112 : 2020-03-20 13:47:37+00:00 5.135.190.125 : 2020-03-20 13:47:37+00:00
Une telle configuration ne permet pas facilement de mettre du HTTPS sur le service : il faudrait distribuer la clé privée à tous les miroirs. À noter également que l'utilisation d'un nom de domaine unique permet à chaque gérant de miroir d'avoir une chance d'obtenir un certificat (et, en effet, j'ai vu dans le journal passer le vérificateur de Let's Encrypt.)
Autre sujet de réflexion : la vie privée. Personne n'a la main sur tous les serveurs du service, il faut donc faire confiance à chaque gérant de miroir pour respecter les principes de protection des données (pas trop de données dans le journal, et ne pas trop les garder.)
Pourrait-on ajouter des miroirs ? Il y a un léger problème technique avec des limites DNS. Il y a l'ancienne limite de 512 octets (qui n'est normalement plus d'actualité depuis longtemps ; notez qu'en IPv6, avec DNSSEC, on a déjà dépassé cette vieille limite.) Il y a la limite plus significative de 1 500 octets (la MTU d'Ethernet.) Mais, surtout, il est plus difficile d'assurer la qualité, notamment de la synchronisation, avec beaucoup de machines. Il faut tester, prendre contact avec les administrateurs des serveurs, relancer, etc.
L'article seul
Fiche de lecture : We have no idea
Auteur(s) du livre :
Jorge Cham, Daniel Whiteson
Éditeur : John Murray
976-1-473-66020-5
Publié en 2017
Première rédaction de cet article le 22 mars 2020
Les livres de vulgarisation scientifique se consacrent souvent à ce qu'on sait : ce qu'on a découvert, publié, et avec lequel on peut émerveiller les lecteurs « on va vous expliquer la quantique, on va vous dire tout ce que la neuroscience permet, etc ». Ici, l'angle est différent, ce livre est consacré à ce qu'on ne sait pas, en physique et astrophysique. C'est une banalité de dire qu'il y a beaucoup plus de choses qu'on ne connait pas que de choses qu'on connait. Mais quelles sont les choses dont on sait qu'on ne les connait pas ?
Évidemment, le livre commence par la matière noire et l'énergie noire. On a de bonnes raisons de penser qu'elles existent, mais on ne sait quasiment rien d'elles. (Personnellement, cela me fait penser à l'éther du début du 20e siècle, qui semblait certain, mais qui a fini par être abandonné.) Autre classique du « nous ne savons pas », la place de la gravité dans les différentes interactions possibles : pourquoi est-elle la seule interaction sans théorie quantique ? Et d'où viennent les rayons cosmiques ? Nous ne savons pas (enfin, pas pour tous.) Et pourquoi y a-t-il davantage de matière que d'antimatière ?
Le livre est drôle (j'ai bien aimé les dessins, même si le parti pris de tout prendre à la légère est parfois un peu agaçant), très bien expliqué, et, pour autant que je puisse en juger (mais je ne suis pas physicien), très correct. Un bon moyen de méditer sur la taille de l'univers et ce qu'il contient.
L'article seul
RFC 8762: Simple Two-way Active Measurement Protocol
Date de publication du RFC : Mars 2020
Auteur(s) du RFC : G. Mirsky (ZTE), G. Jun (ZTE), H. Nydell (Accedian Networks), R. Foote (Nokia)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF ippm
Première rédaction de cet article le 20 mars 2020
Ce nouveau RFC décrit un protocole simple pour piloter des mesures comme celle de la latence ou comme le taux de pertes de paquets entre deux points. Il fonctionne pour des mesures aller-simple (unidrectionnelles) et aller-retour (bidirectionnelles.)
Mais, vous allez me dire, il existe déjà un tel protocole, TWAMP, normalisé dans le RFC 5357, et dans quelques RFC suivants comme le RFC 6038. TWAMP est mis en œuvre dans plusieurs systèmes, et fonctionne. Le problème est que TWAMP est riche et complexe, et que sa simplifiation TWAMP Light (annexe 1 du RFC 5357) est apparemment insuffisamment spécifiée, menant à des problèmes d'interopérabilité. Voir par exemple le rapport « Performance Measurement from IP Edge to Customer Equipment using TWAMP Light ».
Les grandes lignes de STAMP (Simple Two-way Active Measurement Protocol) sont décrites dans la section 3 de notre RFC. Comme TWAMP, STAMP sépare les fonctions de contrôle du test, et le test lui-même. Contrairement à TWAMP, la norme STAMP ne décrit que le test (rappelez-vous que STAMP se veut plus simple que TWAMP). Le contrôle est fait de l'extérieur, par des programmes en ligne de commande, par Netconf ou par un autre moyen.
Avec STAMP, il y a deux acteurs, le Session-Sender qui envoie les paquets, et le Session-Reflector, qui répond. Les paquets sont de l'UDP vers le port 862, et contiennent un numéro de séquence qui permet d'associer requête et réponse. (La réponse contient davantage de données que la requête, mais la requête est remplie, pour avoir la même taille, afin d'éviter les attaques avec amplification.) STAMP a deux modes de fonctionnement (section 4 du RFC) :
- Sans état ; le Session-Reflector ne se souvient pas des numéros de séquence déjà vus, il se contente de répondre à chaque paquet, en recopiant le numéro dans la réponse.
- Avec état ; le Session-Reflector se souvient des numéros de séquence. Ce mode permet, par exemple, de calculer le taux de perte de paquets (en voyant les trous dans la séquence) dans chaque direction, alors que le mode sans état est limité au bidirectionnel (trajet aller/retour, sans pouvoir distinguer la contribution de l'aller et celle du retour.)
Le paquet STAMP inclus, outre le numéro de séquence déjà cité, une estampille temporelle, par défaut au format utilisé par NTP (cf. RFC 5905, section 6.) Un accord entre les deux parties (souvenez-vous que STAMP ne décrit pas comment l'envoyeur et le réflecteur sont coordonnés) permet d'utiliser d'autres formats comme celui de PTP (RFC 8186.)
L'authentification n'est pas indispensable et, si on ne l'utilise pas, le paquet peut être modifié par un attaquant actif qui cherche à fausser les mesures. STAMP a également une possibilité d'authentification, où le paquet contient en outre un HMAC (RFC 2104, et section 4.4 de notre RFC.)
Dans sa réponse, le Session-Reflector envoie un paquet qui indique son propre numéro de séquence, sa propre estampille temporelle, et les numéros de séquence et estampille temporelle du paquet reçu. (En outre, dans le mode avec état, le Session-Reflector enregistre les informations du paquet entrant.) Au retour, le Session-Sender peut donc calculer le RTT, la gigue et le taux de pertes. (Dans le mode avec état, le Session-Reflector peut lui aussi calculer ces informations, qui auront l'avantage de ne concerner qu'une seule direction des paquets.)
Notez que STAMP n'a aucune confidentialité. Si on veut empêcher un méchant de lire les informations, il faut emballer le tout, par exemple dans IPsec ou DTLS. Ce point est un de ceux qui avaient suscité les plus vives discussions à l'IETF, certains regrettant qu'il n'y ait pas de sécurité standard.
Notez également qu STAMP et TWAMP-Light peuvent partiellement interopérer, puisque le format de paquets et la sémantique sont les mêmes (en non authentifié, uniquement.)
Je n'ai pas trouvé de mise en œuvre de STAMP, ni en logiciel libre, ni en privateur. Je ne connais pas non plus de liste de serveurs STAMP publics.
L'article seul
RFC 2418: IETF Working Group Guidelines and Procedures
Date de publication du RFC : Septembre 1998
Auteur(s) du RFC : Scott Bradner (Harvard University)
Première rédaction de cet article le 19 mars 2020
Comment ça, ce RFC est vieux ? Oui, il l'est mais il est toujours d'actualité plus de vingt ans après, et fait toujours autorité. Il décrit le fonctionnement des groupes de travail de l'IETF.
Petit rappel : l'IETF est l'organisme qui normalise les protocoles de l'Internet, « de la couche réseau à la couche applications ». Le mécanisme de production des normes est spécifié dans le RFC 2026, et les structures utilisées sont dans le RFC 2028. Pour exécuter ce mécanisme, l'IETF est divisée en groupes de travail (Working Group) et ce RFC décrit comment ils sont censés fonctionner. Si vous êtes curieux ou curieuse, regardez la liste des groupes de travail actuels (ils sont 119 au moment où j'écris ces lignes, il y en avait déjà plus de 100 au moment de la rédaction du RFC.) Les groupes sont regroupés en zones (areas) et il y en sept à l'heure actuelle. Par exemple, le groupe de travail QUIC, qui normalise le protocole de même nom, fait partie de la zone Transport (Transport Area.) Si vous voulez savoir comment sont désignés les directeurs de chaque zone (AD, pour Area Director), lisez le RFC 7437. Ensemble, ces directeurs forment l'IESG, la direction technique de l'IETF.
L'IETF n'a pas de membres à proprement parler. Tout le monde peut participer (contrairement à la grande majorité des organisations de normalisation), ce qui se fait via les listes de diffusion et dans des réunions physiques, quand elles ne sont pas annulées pour cause d'épidémie.
Revenons aux groupes de travail. Contrairement à beaucoup d'organisations de normalisation, l'IETF a des groupes de travail qui sont, sauf exception, focalisés sur une tâche bien précise, et qui ont une durée de vie limitée. Un groupe qui réussit est un groupe qui sera fermé, ceux qui trainent des années et des années ne sont pas en général les plus efficaces.
D'abord, comment est-ce qu'on crée un groupe de travail ? La section 2 du RFC décrit la naissance d'un groupe. Le point de départ est en général un individu ou un groupe d'individus qui décident qu'un problème technique donné est à la fois important, et traitable par l'IETF. Rappelons qu'on ne fait pas un groupe juste pour bavarder. Il doit y avoir un but précis, et réaliste. Première étape, en parler aux directeurs de la zone concernée. (Note personnelle : je me souviens d'être passé par ces étapes pour le projet « DNS privacy », qui a donné naissance au groupe dprive.) C'est l'IESG qui décide ou non de créer le groupe. Les critères :
- Une bonne compréhension du problème (l'IETF n'est pas un organisme de recherche, et ne travaille pas sur des problèmes ouverts),
- Des objectifs réalistes et atteignables (« supprimer le spam » ou bien « rendre impossible les problèmes de sécurité » ne sont pas réalistes),
- Sujet non déjà traité dans un groupe existant,
- De claires indications que des gens vont effectivement travailler sur le problème ; il ne suffit pas que des gens aient dit « ce serait bien que », il faut des volontaires déterminés à écrire les futurs RFC, la normalisation, c'est du travail,
- Et que ces gens soient compétents sur le sujet, ce qui n'est pas toujours évident sur certains problèmes où les experts ne sont pas à l'IETF,
- Et que le projet ne vienne pas d'une seule personne, ou d'une seule entreprise (qui, dans ce cas, pourrait très bien se débrouiller seule) ; le RFC estime qu'il faut au moins quatre à cinq personnes actives, et une ou deux douzaines qui suivent de près, pour que le groupe ait un sens,
- L'IETF ne travaille pas pour l'amour de l'art, il faut aussi des indications comme quoi le résultat sera vraiment utilisé en vrai dans le vrai monde,
- Et le RFC suggère aussi de regarder si le travail ne serait pas mieux fait en dehors de l'IETF, citant l'exemple de clubs privés d'organisations (comme 3GPP) ; politiquement, cela me semble contestable qu'une organisation ouverte comme l'IETF envisage de laisser le champ libre à ces clubs privés,
- Que les questions de propriété intellectuelle liées à ce sujet soient bien comprises (vœu pieux, vu leur complexité),
- Que le projet implique une vraie action de l'IETF, pas juste un coup de tampon approbateur sur une technologie déjà développée complètement à l'extérieur (problème fréquent dans des organisations comme l'ISO ou l'ETSI.) Je mentionnais QUIC précédemment : l'IETF a beaucoup modifié la version originelle, proposée par Google.
Pour tester tous ces points, il y aura parfois une session relativement informelle, la BoF, avant la décision finale de créer le groupe (voir aussi la section 2.4 qui détaille ces BoF, et le RFC 5434, publié par la suite.)
Étape suivante, le groupe a besoin d'une charte qui définit son but (regardez par exemple celle du groupe quic.) Notez que les chartes indiquent des étapes, avec des dates, qui ne sont quasiment jamais respectées (celles du groupe quic viennent d'être prolongées.) La charte indique également :
- Le nom du groupe ; l'humour geek est souvent présent et on voit des groupes nommés clue, bier, kitten, tictoc…
- Les personnes responsables, les deux co-présidents du groupe, et le directeur de zone qui supervise ce groupe,
- La liste de diffusion du groupe, puisque c'est le principal outil de travail de l'IETF, pour assurer la traçabilité du travail, elles sont toutes archivées sur le service MailArchive (voici par exemple le travail de quic.)
Le dernier groupe créé, au moment de la publication de cet article, est le groupe webtrans.
Une fois créé, comment fonctionne le groupe ? Les groupes disposent d'une grande autonomie, l'IETF essaie de ne pas trop micro-gérer chaque détail (c'est pas complètement réussi.) L'idée de base est que le groupe doit être ouvert, et atteindre des décisions par le biais du « consensus approximatif » (approximatif pour éviter qu'un râleur isolé n'aie un droit de veto sur le groupe.) En pratique, c'est aux présidents du groupe de gérer ce fonctionnement. Les règles sont plutôt des guides que des lois formelles à respecter absolument. Donc, les règles :
- L'activité de l'IETF est publique (contrairement à des organismes comme l'ISO) donc les groupes également,
- L'essentiel de l'activité doit se faire en ligne (même en l'absence de confinement), pour éviter d'exclure ceux qui ne peuvent pas se déplacer, via une liste de diffusion (exemple, celle du groupe regext, qui normalise les interfaces des registres),
- Mais il y a quand même des réunions physiques, normalement trois fois par an, même si elles n'ont normalement pas de pouvoir de décision (toujours pour éviter d'exclure les gens qui n'ont pas pu venir, par exemple pour des raisons financières),
- (D'ailleurs, opinion personnelle, les réunions formelles des groupes de travail sont parfois assez guindées, avec peu de réel travail, celui-ci se faisant hors réunion, dans les couloirs ou bien en ligne),
- Le consensus approximatif est une notion difficile, qui n'est pas rigoureusement définie, pour éviter des règles trop rigides, le RFC note toutefois que 51 % des participants, ce n'est pas un consensus,
- Et comment estimer s'il y a consensus ? Dans la salle, on peut faire lever les mains, ou procéder au humming (procédure où on émet un son la bouche fermée, l'intensité du son permet de juger du soutien de telle ou telle position, cf. RFC 7282), qui a l'avantage d'un relatif anonymat, sur la liste de diffusion, c'est plus difficile, le RFC met en garde contre un simple comptage des messages, qui favorise les gens les plus prompts à écrire beaucoup ; là encore, ce sera aux présidents du groupe de déterminer le consensus.
Et une fois que le groupe a bien travaillé, et produit les documents promis ? On a vu que l'IETF n'aimait guère les groupes qui trainent dix ans sans buts précis, donc l'idéal est de mettre fin au groupe à un moment donné (section 4). Au moment de la rédaction de cet article, c'est ce qui vient d'arriver au groupe doh (qui avait normalisé le protocole du même nom, cf. l'annonce de la terminaison, et la page actuelle du groupe.)
Toute cette activité nécessite du monde, et il y a donc plusieurs postes importants à pourvoir (section 6 du RFC). D'abord, les président·e·s des groupes de travail. Il est important de comprendre que ce ne sont pas eux ou elles qui vont écrire les documents. Leur rôle est de faire en sorte que le groupe fonctionne, que les travaux avancent, mais pas de rédiger. C'est déjà pas mal de travail, entre les groupes où ça s'engueule, les trolls négatifs, ou bien les auteurs qui ne bossent pas et qui ne répondent pas aux sollicitations (je plaide coupable, ici, j'ai fait souffrir plusieurs présidents de groupe.) Les présidents sont responsables du résultat, il faut que les normes soient produites, et qu'elles soient de qualité. Cela implique une activité de modération de la liste (pas la censure, comme entend souvent aujourd'hui ce terme de « modération », mais des actions qui visent à calmer les discussions), l'organisation des sessions physiques, la production de compte-rendus de ces réunions, la distribution des tâches (il n'y a pas que l'écriture, il y a aussi la lecture, il faut s'assurer que les documents ont été attentivement relus par plusieurs personnes compétentes) et d'autres activités.
Et comme il faut bien que quelqu'un écrive, il faut également au groupe des rédacteurs. On les appelle parfois « auteurs », parfois « éditeurs », pour mettre en avant le fait que le vrai auteur est le groupe de travail. Quelque soit le terme, le travail est le même : rédiger, relire, intégrer les décisions du groupe de travail, etc. C'est un travail souvent ardu (je parle d'expérience.)
Une autre catégorie d'acteurs du groupe de travail est celle des design teams. Un design team est un sous-ensemble informel du groupe de travail, chargé de travailler à un projet lorsqu'il semble que le groupe entier serait trop gros pour cela. Les design teams ne sont pas forcément formalisés : deux personnes dans un couloir décident de travailler ensemble, et c'est un design team.
Le but final est de produire des documents. La section 7 du RFC décrit le processus d'écriture. Tout futur RFC commence sa vie comme Internet-Draft. (Le meilleur moyen d'accéder aux Internet-Drafts est sans doute le DataTracker.) Comme leur nom l'indique, les Internet-Draft sont des brouillons, pas des documents définitifs. N'importe qui peut écrire et soumettre (notez que les instructions dans le RFC ne sont plus d'actualité) un Internet-Draft, sa publication ne signifie aucune approbation par l'IETF. Si vous ressentez le désir d'en écrire un, notez que les instructions du RFC sur le format désormais dépassées, il faut plutôt lire le RFC 7990.
Une fois le document presque prêt, il va passer par l'étape du dernier appel au groupe (WGLC, pour Working Group Last Call.) Comme son nom l'indique, ce sera la dernière occasion pour le groupe d'indiquer si le document est considéré comme publiable. Après, il quittera le groupe et sera de la responsabilité de l'IETF toute entière, via l'IESG (section 8 de notre RFC.)
Ce RFC est ancien, je l'avais dit, et plusieurs mises à jour ont eu lieu depuis, sans le remplacer complètement. Cela a été le cas des RFC 3934 (lui-même remplacé par le RFC 9945), RFC 7475 et RFC 7776.
L'article seul
RFC 8748: Registry Fee Extension for the Extensible Provisioning Protocol (EPP)
Date de publication du RFC : Mars 2020
Auteur(s) du RFC : R. Carney (GoDaddy), G. Brown (CentralNic Group), J. Frakes
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF regext
Première rédaction de cet article le 15 mars 2020
Historiquement, le protocole EPP d'avitaillement des
ressources Internet (notamment les noms de domaine) n'indiquait pas le prix de
création ou de renouvellement d'un nom. Typiquement, tous les noms
coûtaient le même prix. Mais certains
registres préfèrent vendre plus cher
sex.example que
suitedelettressanstropdesignification.example. D'où
cette extension EPP qui permet d'indiquer le coût d'un nom de
domaine particulier, extension qui est aujourd'hui très
répandue.
Il y a donc deux logiques possibles, une purement technique (les noms de domaine ont tous le même coût pour le registre et devraient donc coûter pareil au client) et une logique business, où on essaie de faire payer le client plus cher pour les noms les plus demandés. Aux débuts d'EPP (ou de son prédécesseur RGP, dans le RFC 3915), il allait de soi qu'il n'y avait qu'un prix puisque les coûts réels sont les mêmes pour tous les domaines, mais ce n'est plus le cas aujourd'hui. Il faut donc pouvoir informer sur les prix, EPP n'étant pas juste un canal technique mais aussi un canal de vente. Comme cela avait été dit lors d'une discussion à l'IETF, « Arguably, in a situation where many TLDs are now offering domains at various pricing tiers (with no further policy requirements), general availability is no longer just a matter of "domain taken/reserved/valid?", but also of "how much is the registrant willing to pay?". »
L'ancien modèle était donc :
- Certaines opérations sur les objets avitaillés (cf. RFC 5730) sont
payantes, typiquement
<create>,<renew>et<transfer>, d'autres gratuites (par exemple<update>), - Le prix est le même pour tous les domaines,
- Ce prix n'est pas indiqué via le canal EPP, on le découvre dans la documentation fournie par le registre.
Le nouveau modèle, où le tarif est indiqué via le canal EPP, permet d'avoir des prix différents par domaine, mais permet également de découvrir automatiquement le tarif, sans se plonger dans la documentation.
La section 3 du RFC décrit ce qui se passe dans chaque commande
EPP facturable. L'extension utilise un espace de noms
XML qui vaut
urn:ietf:params:xml:ns:epp:fee-1.0 (abrégé à
fee: dans les exemples du RFC mais bien sûr,
comme toujours avec les espaces de noms XML, chacun choisit son
abréviation.)
Voici un exemple où le client vérifie la disponibilité d'un domaine
et son prix, avec <check> :
<?xml version="1.0" encoding="utf-8" standalone="no"?>
<epp xmlns="urn:ietf:params:xml:ns:epp-1.0">
<command>
<check>
<domain:check
xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
<domain:name>example.net</domain:name>
</domain:check>
</check>
<extension>
<fee:check xmlns:fee="urn:ietf:params:xml:ns:epp:fee-1.0">
<fee:currency>USD</fee:currency>
<fee:command name="create">
<fee:period unit="y">2</fee:period>
</fee:command>
</fee:check>
</extension>
</command>
</epp>
Le client a demandé quel était le prix en dollars étatsuniens pour
une réservation de deux ans. Ici, le serveur lui répond que le
domaine est libre (avail="1") :
...
<resData>
<domain:chkData
xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
<domain:cd>
<domain:name avail="1">example.net</domain:name>
</domain:cd>
</domain:chkData>
</resData>
<extension>
<fee:cd avail="1">
<fee:objID>example.net</fee:objID>
<fee:class>standard</fee:class>
<fee:command name="create" standard="1">
<fee:period unit="y">2</fee:period>
<fee:fee
description="Registration Fee"
refundable="1"
grace-period="P5D">10.00</fee:fee>
</fee:command>
...
Et qu'il en coûtera dix dollars. Notez que le prix dépend de la
commande (d'où le <fee:command
name="create"> chez le client, et dans la réponse) ;
un renouvellement peut coûter moins cher qu'une création, par
exemple. Notez aussi que le RFC ne spécifie pas comment le prix est
déterminé ; cela peut être configuré manuellement par le registre,
ou bien suivre un algorithme (prix plus élevé si le nom est dans un
dictionnaire, ou s'il fait moins de N caractères…)
Le serveur EPP aurait pu refuser, si les paramètres étaient inconciliables avec sa politique :
<fee:cd avail="0">
<fee:objID>example.net</fee:objID>
<fee:reason>Only 1 year registration periods are
valid.</fee:reason>
</fee:cd>
En quelle monnaie sont indiqués les coûts ? Un élément XML
<fee:currency> va permettre de
l'indiquer. Sa valeur est un code à trois lettres tiré de la norme ISO 4217, par exemple
EUR pour l'euro et
CNY pour le yuan. Si le
registre se fait payer, non pas dans une monnaie reconnue mais dans
une unité de compte privée (des « crédits » internes, par exemple),
il peut utiliser le code XXX. Le serveur ne
doit pas faire de conversion monétaire. S'il a
indiqué des coûts en dollars étatsuniens et
que le client indique ce qu'il paie en pesos
mexicains, le serveur doit rejeter la commande (ce qui
est logique, vu la volatilité des taux de conversion.)
Cette extension à EPP permet également d'indiquer des périodes pendant lesquelles les objets, par exemple les noms de domaine, sont enregistrés. L'unité de temps (mois ou année) est indiquée également.
L'extension permet également d'indiquer des actions commerciales comme une remise, un remboursement (par exemple en cas d'utilisation de la période de grâce du RFC 3915), etc.
Un mécanisme courant chez les registres est d'avoir un compte par client, où le client dépose une certaine somme, d'où les créations ultérieures de noms de domaine sont déduites. Cela donne au registre de la trésorerie, et cela simplifie la comptabilité. L'extension de ce RFC permet de consulter le montant restant (balance) et d'indiquer si l'épuisement de ce compte signifie un arrêt des opérations payantes, ou bien si le serveur fait crédit au client.
Les prix peuvent dépendre du nom de domaine
(hotels.example étant plus cher que
fzoigqskjjazw34.example) mais aussi de la phase
actuelle des enregistrements. Par exemple, une phase initiale, dite
de « lever de soleil » (RFC 8334) pour un
nouveau domaine d'enregistrement peut avoir des prix plus
élevés.
Le serveur peut exiger que le client marque son approbation en indiquant, dans ses requêtes, le prix à payer (section 4). Voilà ce que cela donnerait pour la commande de création :
...
<command>
<create>
<domain:create
xmlns:domain="urn:ietf:params:xml:ns:domain-1.0">
<domain:name>example.net</domain:name>
<domain:period unit="y">2</domain:period>
<domain:registrant>jd1234</domain:registrant>
...
</domain:create>
</create>
<extension>
<fee:create xmlns:fee="urn:ietf:params:xml:ns:epp:fee-1.0">
<fee:currency>USD</fee:currency>
<fee:fee>10.00</fee:fee>
</fee:create>
</extension>
</command>
Pour une demande de vérification de disponibilité
(<check>), le serveur peut répondre que
le domaine n'est pas libre si le client n'utilise pas l'extension de
coût. Le principe est que, si un <check>
indique qu'un domaine est libre, un
<create> avec les mêmes
extensions ou la même absence d'extension doit
réussir. « Libre » veut donc dire « libre, aux conditions que tu as
indiquées ».
Les détails de l'extension dans toutes les commandes EPP figurent en section 5, et le schéma en section 6.
L'extension décrite dans le RFC a été ajoutée au registre des extensions EPP, spécifié par le RFC 7451.
Cette extension EPP est déjà mise en œuvre par CentralNic et par d'autres registres mais attention, pas forcément avec la version du RFC, cela peut être des brouillons antérieurs.
L'article seul
RFC 8739: Support for Short-Term, Automatically-Renewed (STAR) Certificates in Automated Certificate Management Environment (ACME)
Date de publication du RFC : Mars 2020
Auteur(s) du RFC : Y. Sheffer
(Intuit), D. Lopez, O. Gonzalez de
Dios, A. Pastor Perales (Telefonica
I+D), T. Fossati (ARM)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF acme
Première rédaction de cet article le 12 mars 2020
Quand une Autorité de Certification (AC) émet un certificat numérique, une question de sécurité se pose : que se passe-t-il si un attaquant met la main sur la clé privée associée à ce certificat, et peut donc usurper l'identité du titulaire légitime ? La réponse traditionnelle était la révocation du certificat par l'AC dès qu'elle est prévenue. Pour diverses raisons, ce processus de révocation est peu fiable, ce qui laisse comme seule ligne de défense l'expiration du certificat. C'est le rôle du champ « Not After » dans un certificat. Pour la sécurité, on voudrait que la date d'expiration soit proche, pour ne pas laisser un éventuel attaquant profiter de son forfait trop longtemps. Mais ce n'est pas très pratique pour le titulaire que de renouveller son certificat très souvent, même avec un protocole comme ACME qui permet l'automatisation. Ce nouveau RFC propose une extension à ACME, qui autorise des certificats de très courte durée de vie (quelques jours seulement) mais renouvellés encore plus facilement qu'avec le ACME classique.
Petit rappel sur ACME : ce protocole, normalisé dans le RFC 8555, permet d'obtenir de manière automatique un certificat correspondant à une identité qui est, la plupart du temps, un nom de domaine. Comme ACME permet l'automatisation, il résout le problème de la révocation en utilisant des certificats dont la durée de vie se compte en mois et plus en années. Ainsi, l'AC Let's Encrypt émet des certificats qui durent trois mois. Mais même trois mois, ça peut être long, si quelqu'un a piqué votre clé privée et se sert de ce certificat. Si on souhaite des certificats durant quelques jours, peut-on utiliser ACME ? En théorie, oui, mais, en pratique, l'AC pourrait ne pas aimer cette charge supplémentaire, et puis que ferait le titulaire si l'AC était indisponible pendant 48 h et qu'on ne puisse pas renouveller le certificat ?
D'où l'idée des certificats STAR (Short-Term,
Automatically-Renewed), initialement décrits dans
l'article « Towards
Short-Lived Certificates », de Topalovic, E.,
Saeta, B., Huang, L., Jackson, C., et D. Boneh, puis dans
l'Internet-Draft
draft-nir-saag-star. Les
certificats seront de très courte durée de vie, et publiés un peu à
l'avance par l'AC, sans demande explicite du client. Celui-ci pourra
par contre demander l'interruption de la série de certificats, si sa
clé privée a été compromise.
La section 2 de notre RFC explique le déroulement des
opérations. Le client (IdO, pour Identifier
Owner) demande à l'AC une série de certificats STAR, l'AC,
aux intervalles indiqués, crée et publie les certificats, à tout
moment, l'IdO peut arrêter la série. Commençons par le commencement,
le démarrage de la série. C'est du ACME classique (RFC 8555), avec ses défis (par exemple, l'IdO doit prouver
qu'il contrôle bien le nom de
domaine qui sert d'identité). L'IdO doit envoyer
l'extension ACME nommée auto-renewal. L'AC
indique au client où seront publiés les certificats de la série.
Ensuite, la publication de la série. Tous les certificats de la série utilisent la même clé privée. (Par défaut, les clients ACME classiques créent une nouvelle clé pour chaque renouvellement du certificat.) Ces certificats sont publiés à l'URL annoncé à la fin de la phase précédente.
Lorsqu'il le souhaite, l'IdO peut demander à l'AC d'interrompre la publication de la série de certificats. Notez qu'on ne révoque jamais ces certificats STAR, puisque de toute façon ils expirent très vite.
Les détails du protocole figurent en section 3 du RFC. Ainsi,
l'objet auto-renewal (désormais dans le registre des champs de l'objet Order) a
plusieurs champs intéressants, comme start-date
(début de la série), end-date (fin de la série,
mais elle pourra se terminer plus tôt, en cas d'annulation
explicite), lifetime (durée de vie des
certificats, notez que la valeur réelle dépendra de la politique de
l'AC, cf. section 6.2). Voici un exemple de cet objet, à ajouter aux requêtes de
demande de certificat :
"auto-renewal": {
"start-date": "2019-01-10T00:00:00Z",
"end-date": "2019-01-20T00:00:00Z",
"lifetime": 345600, // 4 days
"lifetime-adjust": 259200 // 3 days
}
Les champs possibles dans un auto-renewal sont
listés dans un registre IANA. D'autres
champs pourront être ajoutés dans le futur, en suivant la politique
« Spécification nécessaire » (RFC 8126.)
L'objet Order
(section 7.1.6 du RFC 8555 sera en état
ready tant que la série des certificats
continuera.
L'AC annoncera sa capacité à faire du STAR (ici à la fin de son annonce) :
{
"new-nonce": "https://example.com/acme/new-nonce",
"new-account": "https://example.com/acme/new-account",
"new-order": "https://example.com/acme/new-order",
...
"meta": {
"terms-of-service": "https://example.com/acme/terms/2017-5-30",
...
"auto-renewal": {
"min-lifetime": 86400,
"max-duration": 31536000,
"allow-certificate-get": true
}
}
}
Pour arrêter la série avant end-date, le
client ACME mettra cet état à canceled :
POST /acme/order/ogfr8EcolOT HTTP/1.1
Host: example.org
Content-Type: application/jose+json
{
"protected": base64url({
"alg": "ES256",
"kid": "https://example.com/acme/acct/gw06UNhKfOve",
"nonce": "Alc00Ap6Rt7GMkEl3L1JX5",
"url": "https://example.com/acme/order/ogfr8EcolOT"
}),
"payload": base64url({
"status": "canceled"
}),
"signature": "g454e3hdBlkT4AEw...nKePnUyZTjGtXZ6H"
}
Le serveur ACME répondra alors 403 à toutes les requêtes de
récupération d'un certificat de la série annulée, de préférence en
ajoutant (RFC 7807)
urn:ietf:params:acme:error:autoRenewalCanceled. (Cette
erreur, et quelques autres, ont été ajoutées au registre des erreurs ACME.)
Comme vous avez vu, la théorie est simple. Maintenant, il y a un certain nombre de détails opérationnels sur lesquels il faut se pencher, détaillés en section 4. D'abord, le problème des horloges. Les certificats X.509 utilisent partout des temps (la date limite de validité, par exemple) et le respect de ces temps dépend de l'horloge de la machine. Si votre ordinateur a deux mois d'avance, il considérera les certificats comme expirés alors qu'ils ne devraient pas l'être. C'est un problème général de la cryptographie, comme montré par l'article « Where the Wild Warnings Are: Root Causes of Chrome HTTPS Certificate Errors », qui signale que des déviations de plusieurs jours chez les clients ne sont pas rares. Mais c'est évidemment plus grave avec des certificats à très courte durée de vie. Si on a des certificats Let's Encrypt classiques, qui durent trois mois et qu'on renouvelle une semaine avant leur expiration, même si l'horloge du client déconne de plusieurs jours, ça passera. En revanche, avec les certificats STAR, la désynchronisation des horloges aura des conséquences dans bien plus de cas.
La décision d'utiliser STAR ou pas, et le choix de la durée de vie des certificats, va dépendre de la population d'utilisateurs qu'on attend. Le RFC note que les problèmes d'horloge sont bien plus fréquents sur Windows que sur Android, par exemple.
Autre risque avec STAR, la charge supplémentaire pour les journaux Certificate Transparency (RFC 9162). Si STAR devenait le principal mode d'émission de certificats (c'est peu probable), leur trafic serait multiplié par cent. Avant la publication de ce RFC, de nombreuses discussions avec le groupe de travail IETF trans et avec les opérateurs des principaux journaux ont montré qu'il n'y avait a priori pas de risque, ces journaux peuvent encaisser la charge supplémentaire.
Questions mises en œuvre de STAR, il y a eu une scission (non publique ?) de Boulder, le serveur de Let's Encrypt et du client certbot pour y ajouter STAR. Il y a également un client et serveur avec STAR dans Lurk.
La section 6 de notre RFC revient sur les questions de sécurité
liées à STAR. Ainsi, comme l'expiration remplace la révocation, on
ne peut plus exiger la suppression immédiate d'un certificat. (Mais,
on l'a dit, la révocation marche tellement mal en pratique que ce
n'est pas une grande perte.) En cas de compromission de la clé
privée, on peut demander l'arrêt de l'émission des certificats mais
(et cela ne semble pas mentionné par le RFC), si on perd son compte
ACME, ou simplement le numnique ACME, on
ne peut plus annuler cette émission, et on doit attendre
l'expiration de la séquence (indiquée par
end-date.)
L'article seul
Version 13 d'Unicode
Première rédaction de cet article le 11 mars 2020
Ce mercredi 11 mars est sortie la version 13 d'Unicode. Une description officielle des principaux changements est disponible mais voici ceux qui m'ont intéressé particulièrement. (Il n'y a pas de changement radical.)
Pour explorer plus facilement la grande base Unicode, j'utilise un programme qui la convertit en SQL et permet ensuite de faire des analyses variées. Faisons quelques requêtes SQL :
ucd=> SELECT count(*) AS Total FROM Characters; total -------- 143924
Combien de caractères sont arrivés avec la version 13 ?
ucd=> SELECT version,count(version) FROM Characters GROUP BY version ORDER BY version::float; ... 10.0 | 8518 11.0 | 684 12.0 | 554 12.1 | 1 13.0 | 5930
5930 nouveaux, le rythme de création repart, après une version 12 qui était très modérée. Quels sont ces nouveaux caractères ?
ucd=> SELECT To_U(codepoint) AS Codepoint, name FROM Characters WHERE version='13.0'; codepoint | name -----------+---------------------------------------------------------------------------- ... U+1FAD5 | FONDUE ... U+10E80 | YEZIDI LETTER ELIF U+10E81 | YEZIDI LETTER BE U+10E82 | YEZIDI LETTER PE ... U+1F9A3 | MAMMOTH U+1F9A4 | DODO U+1F9AB | BEAVER ... U+1FBA0 | BOX DRAWINGS LIGHT DIAGONAL UPPER CENTRE TO MIDDLE LEFT U+1FBA1 | BOX DRAWINGS LIGHT DIAGONAL UPPER CENTRE TO MIDDLE RIGHT U+1FBA2 | BOX DRAWINGS LIGHT DIAGONAL MIDDLE LEFT TO LOWER CENTRE
On trouve donc le lot habituel de nouveaux émojis, comme la fondue ou le mammouth. Parmi ces nouveaux émojis, notons le drapeau trans. Comme souvent dans Unicode, pour limiter l'explosion du nombre d'émojis, le drapeau trans n'est pas en un seul caractère mais s'obtient par une combinaison, U+1F3F3 U+FE0F U+200D U+26A7 U+FE0F, où U+1F3F3 est le drapeau blanc et U+26A7 le signe transgenre. (Notons que tout le monde n'est pas d'accord sur cet ajout permanent d'émojis pour chaque groupe de plus en plus spécifique.) Toujours dans les émojis, on notera l'arrivée des symboles liés aux communs comme U+1F16D, le symbole des Creative Commons. Il avait été refusé pendant longtemps comme symbole politique, alors que le copyright a son U+A9 depuis la version 1 d'Unicode…
Tiens, d'ailleurs, combien de caractères Unicode sont des symboles (il n'y a pas que les emojis parmi eux, mais Unicode n'a pas de catégorie « emoji ») :
ucd=> SELECT count(*) FROM Characters WHERE category IN ('Sm', 'Sc', 'Sk', 'So');
count
-------
7564
Ou, en plus détaillé, et avec les noms longs des catégories :
ucd=> SELECT description,count(category) FROM Characters,Categories WHERE Categories.name = Characters.category AND category IN ('Sm', 'Sc', 'Sk', 'So') GROUP BY category, description;
description | count
-----------------+-------
Modifier_Symbol | 123
Other_Symbol | 6431
Math_Symbol | 948
Currency_Symbol | 62
Pour conclure sur les émojis, je vais citer Benjamin Bayart : « Alors, sans vouloir manquer de respects aux amateurices d'émojis, franchement, savoir si avec une série de caractères combinants on peut représenter une émoji "Courgette au curry qui fait du tambour avec un poireau bleu et un chapeau pointu", j'en comprend le côté amusant, mais c'est pas ça, le sens d'Unicode. Et ça m'exaspère qu'on laisse toujours le côté fantastique de cet outil [Unicode] dans l'ombre, pour montrer son côté le plus complètement inutile. »
Il y a surtout dans cette version 13 des nouvelles écritures comme le yezidi (qui renait, peut-être à cause de l'intérêt porté à leur lutte contre Daech), et plein de caractères pour faire de l'« art Unicode » en dessinant avec des caractères. Par contre, l'écriture maya n'est pas encore intégrée.
Si vous avez les bonnes polices de caractères, voici les caractères pris en exemple plus haut : 🫕, 𐺀, 𐺁, 𐺂, 🦣, 🦤, 🦫, 🮠, 🮡, 🮢, ⚧ (ce dernier étant dans Unicode depuis la version 4), 🅭… (Si vous n'avez pas les bonnes polices, chaque lettre est un lien vers Uniview.) Pour le drapeau trans, voici la combinaison qui est censée l'afficher, si vous avez logiciel et police récents : 🏳️⚧️.
L'article seul
Fiche de lecture : Déclic
Auteur(s) du livre : Maxime Guedj, Anne-Sophie Jacques
Éditeur : Les Arènes
978-2-7112-0197-6
Publié en 2020
Première rédaction de cet article le 10 mars 2020
Encore un livre pour parler du pouvoir excessif des GAFA et du capitalisme de surveillance ? Oui mais le sujet n'est pas encore épuisé et chaque livre a un angle différent. Celui-ci est clairement destiné aux utilisateurs et utilisatrices, pas informaticiens et pas biberonnés aux communiqués de la Quadrature du Net depuis des années. Comme je suppose que la plupart des lecteurs et lectrices de mon blog sont plutôt informés sur la surveillance de masse, je leur dis : faites circuler ce livre pour les personnes de votre entourage qui sont à la merci des GAFA.
Le livre est court, pour ne pas épuiser le lecteur, et comprend trois parties. 1) Expliquer le fonctionnement des GAFA et comment, loin d'être bienveillants, ils nous exploitent et nous fichent. (Si vous lisez ce blog, vous savez probablement tout ça. Mais pensez aux autres.) 2) Montrer qu'il y a des alternatives, que la situation est certes grave, mais que l'avenir dépend de nous, on peut le changer. 3) Donner une liste de ressources (documents, logiciels, services) pour « changer le monde, un octet à la fois » (slogan de Framasoft.)
La première partie s'attaque à une tâche difficile : expliquer à des non-informaticiens tout ce qui se passe derrière l'écran et qui abuse des données personnelles confiées. Si tout professionnel sait bien que la nature du numérique fait que collecter, traiter et analyser des données est facile et bon marché (après tout, l'informatique a justement été inventée pour cela), les utilisateurs ne sont pas forcément au courant et peuvent croire des discours du genre « ne vous inquiétez pas, tout est anonymisé, il n'y a aucun risque ». D'autant plus qu'avec le numérique, le pistage peut être discret. Sans Exodus Privacy, serait-on bien conscient de l'abondance de pisteurs dans les applications de notre ordiphone, y compris chez les services publics, et chez les médias qui critiquent vertueusement les GAFA ? Je trouve que ce livre se tire bien de cette tâche pédagogique. (Mais vous pouvez aussi lire l'excellent livre de Snowden, très pédagogique.)
La deuxième partie est tout aussi cruciale ; informer les utilisatrices et les utilisateurs des risques est bien sûr un pré-requis à toute action. Mais s'arrêter là serait dangereux : pour le cerveau humain, quand il n'y a pas de solution, il n'y a pas de problème. Si on se contente de dénoncer le danger, on risque davantage de générer de la résignation que de l'action. Il faut donc aussi, contrairement aux très nombreux livres qui encombrent les librairies avec des discours anxiogènes sur les vilains écrans et les méchants GAFA, proposer, sinon des solutions toutes faites, au moins des perspectives. C'est donc ici que les auteur·e·s exposent les CHATONS, le logiciel libre mais aussi des perspectives moins souvent présentées, comme les réseaux sociaux décentralisés. Là encore, ce livre est utile et bien fait.
Si plein de personnages connus sont félicités, à juste titre, dans ce livre (Aaron Swartz, Elinor Ostrom, Richard Stallman, Linus Torvalds…), une mention spéciale revient à Alexandra Elbakyan, la peu médiatique responsable de l'indispensable Sci-Hub. Au moment où l'épidémie de COVID-19 frappe la planète, c'est l'occasion de rappeler que la libre diffusion des articles scientifiques est un des enjeux essentiels d'aujourd'hui. Je me joins aux auteur·e·s du livre pour la congratuler chaudement.
[Et merci aussi à Hippase de Métaponte, qui, violant le ridicule secret imposé par Pythagore, avait décidé que les maths méritaient d'être connues de tous.]
La troisième partie était délicate, elle aussi. Il s'agit de présenter une liste de logiciels, de ressources et de services pour aider à la libération des utilisatrices et utilisateurs. De telles listes ne sont pas faciles à faire : il n'est pas toujours possibles de tout tester en détail, et ces listes se périment vite (même quand elles sont en ligne : l'Internet rend la distribution des mises à jour plus facile, mais il ne change rien au problème de maintenance d'une liste.) Personnellement, je ne vois pas de solution à ce problème : la liste du livre ne plaira probablement à personne à 100 %. Le débat lors du lancement du livre le 26 février 2020 avait montré que les solutions alternatives ne sont pas toujours équivalentes à celles des GAFA (« lorsque je veux planter un arbre, je vais sur Ecosia, lorsque je veux un résultat, je vais sur Google », avait dit un participant), et qu'il faudrait prévenir les utilisateurices qu'ielles auront parfois à faire des efforts.
En résumé, c'est un livre à lire si vous vous posez des questions sur le numérique et que vous voulez aller au-delà du « Facebook, c'est des fake news, faut réguler », ou bien si vous connaissez déjà tout cela mais que vous voulez aider les gens de votre entourage à « échapper au piège des géants du Web ».
Sinon, vous pouvez aussi écouter un podcast des auteur·e·s.
L'article seul
Se cacher de qui ? Chiffrement, sécurité informatique et modèle de menace
Première rédaction de cet article le 9 mars 2020
Depuis les révélations d'Edward Snowden, il est difficile d'ignorer le fait que des méchants nous espionnent via les outils numériques. Les solutions proposées se limitent fréquemment à la technique : chiffrement de bout en bout et vous êtes en sécurité. Mais c'est évidemment plus compliqué que cela, comme l'analysent bien Ksenia Ermoshina et Francesca Musiani dans leur article « Hiding from Whom? Threat-models and in-the-making encryption technologies ».
L'article repose sur beaucoup de travail de terrain, auprès de dissidents, lanceurs d'alerte et défenseurs des droits humains un peu partout dans le monde. Ils et elles ne sont pas en général informaticiens et ne maitrisent pas tous les détails techniques. Mais elles ou ils comprennent souvent le modèle de menace : on veut se protéger contre qui ? Ce n'est pas la même chose d'être un employé qui ne veut pas être surveillé par son patron, et d'être un agent secret infiltré dans un pays ennemi disposant de puissants moyens de surveillance. C'est en effet le point crucial souvent oublié des discours sur la sécurité informatique : qui est l'ennemi ?
Évidemment, s'il existait un outil de communication idéal, simple à utiliser, parfaitement sécurisé, ne nécessitant pas de faire confiance à tel ou tel acteur, et largement déployé, le problème serait simple. Il suffirait de dire « utilisez cet outil ». Mais comme il n'existe pas, il faut s'adapter. Et cela nécessite de bien comprendre les menaces. Par exemple, les interviews par les auteures de femmes au Moyen-Orient montrent une claire prise de conscience du fait que le risque, pour la femme, est à la maison (ce qui n'est évidemment pas limité au monde musulman.)
Comprendre les menaces est évidemment plus facile à dire qu'à faire. Les auteures dégagent deux axes de classification des utilisateurs, l'axe du risque (haut risque vs. faible risque) et l'axe compétences techniques (connaissances étendues vs. faibles connaissances.) Il y a des gens à faible risque et compétences élevées (l'informaticien spécialiste des questions de sécurité et vivant dans un pays calme et démocratique) et, malheureusement pour eux, des gens à risque élevé et compétences limitées (la militante écologiste dans un pays autoritaire.) Et il faut aussi compter avec le graphe social : dans beaucoup de circonstances, si on est à faible risque mais qu'on fréquente des gens à haut risque, on devient une cible.
Ah, et vous voulez encore compliquer les choses ? Notez alors que l'utilisation de l'application la plus efficace n'est pas forcément une bonne idée, si elle est peu répandue : l'ennemi peut considérer que la seule utilisation de cette application indique que vous êtes dangereux. Être trop différent peut être un délit et en rester à WhatsApp, malgré toutes ses faiblesses, peut être plus sûr…
Bref, la sécurité, c'est compliqué, vous vous en doutiez, il n'y a pas de solution magique. L'intérêt de cet article est d'élargir la perspective, surtout celle des informaticiens, et de comprendre la variété et la complexité des problèmes de sécurité.
Un résumé de l'étude avec interview des auteures a été publié sur le journal du CNRS.
L'article seul
Tests pour des programmes en ligne de commande
Première rédaction de cet article le 2 mars 2020
Tout développeur sait bien qu'il faut tester les programmes. Et il ou elle sait également qu'il doit s'agir de tests entièrement automatiques, pouvant être exécutés très souvent, idéalement à chaque changement du code ou de l'environnement. Il existe une quantité incroyable d'outils pour faciliter l'écriture de tels tests, pour tous les langages de programmation possibles. Souvent, ces outils sont même inclus dans la bibliothèque standard du langage, tellement les tests sont indispensables. Mais, lorsque j'ai eu besoin d'écrire un jeu de tests pour un programme en ligne de commande, je me suis aperçu qu'il n'existait pas beaucoup d'outils. Heureusement, Feth en a développé un, test_exe_matrix.
Les cadriciels existants
pour écrire des tests sont typiquement spécifiques d'un langage de
programmation donné. Le programme est structuré sous forme d'une ou
plusieurs bibliothèques, dont les fonctions sont appelées par le
programme de test, qui regarde si le résutat est celui attendu. Pour
prendre un exemple simple, le langage Python a à la fois un cadriciel standard,
unittest, et une alternative, que je trouve plus
agréable, pytest. Pour illustrer, écrivons
un test_add.py qui sera un jeu de tests de
l'opération d'addition :
#!/usr/bin/env python3
import random
import pytest
@pytest.fixture(scope="module")
def generator():
g = random.Random()
yield g
def test_trivial():
assert 2 + 2 == 4
def test_negative():
assert 42 + (-42) == 0
def test_zero(generator):
for i in range(0,10):
x = generator.randint(0, 100)
assert x + 0 == x
pytest va exécuter toutes les fonctions dont le nom commence par
test_. Si l'assertion
réussit, c'est bon, si elle échoue, pytest affiche le problème (en
utilisant l'introspection, c'est un de ses
avantages). Il suffit donc au développeur qui aurait modifié la mise
en œuvre de l'opérateur + de lancer pytest et il verra bien si le
code marche toujours ou pas. (Inutile de dire qu'un vrai jeu de test
pour l'opérateur d'addition serait bien plus détaillé.)
Tout cela, c'est bien connu. Mais si je veux tester du code qui n'est pas une bibliothèque mais un exécutable en ligne de commande ? Il peut y avoir plusieurs raisons pour cela :
- C'est un programme privateur dont je n'ai pas les sources,
- Je veux tester l'analyse des arguments,
- Le programme n'est pas structuré sous forme d'une bibliothèque, tout est dans l'exécutable.
Étant à la fois dans le deuxième et dans le troisième cas, j'ai cherché une solution pour le tester. Mon cahier des charges était :
- Permettre de tester des programmes en ligne de commande Unix.
- Il faut pouvoir spécifier les arguments et le code de retour attendu.
- Il faut pouvoir spécifier des chaînes de caractères qui doivent être sur la sortie standard et l'erreur standard.
Comme indiqué plus haut, Feth Arezki a développé un outil qui correspond à ce cahier des charges, test_exe_matrix. Il est bâti au dessus de pytest (ce qui est raisonnable, cela évite de tout refaire de zéro). Le principe est le suivant : on écrit un fichier en YAML décrivant les commandes à lancer et les résultats attendus. Puis on lance test_exe_matrix, et il indique si tout s'est bien passé ou pas, et en cas de problèmes, quels tests ont échoué. Voici un exemple de fichier de configuration avec un seul test, un test de la commande echo :
---
tests:
- exe: '/bin/echo'
name: "test echo stdout substring"
args:
- '-n'
- 'coincoin'
retcode: 0
partstdout: 'inco'
stderr: ''
La commande testée sera /bin/echo -n coincoin. Le paramètre retcode indique que le code de
retour attendu est 0 (un succès, dans le shell
Unix) et le paramètre partstdout
indique qu'on attend cette chaine de caractères
inco sur la sortie
standard. Si on avait utilisé stdout,
test_exe_matrix aurait exigé que l'entièreté de la sortie standard
soit égale à cette chaîne. Testons maintenant :
% test_exe_matrix tmp.yaml ========================================== test session starts =========================================== platform linux -- Python 3.6.9, pytest-5.3.1, py-1.8.1, pluggy-0.13.1 Tests from /home/stephane/src/Tests/CLI/test_exe_matrix/tmp.yaml rootdir: /home/stephane collected 2 items ../../../../.local/lib/python3.6/site-packages/test_exe_matrix/test_the_matrix.py .. [100%] =========================================== 2 passed in 0.12s ============================================
C'est parfait, tous les tests passent.
Un peu plus compliqué, avec la commande curl :
---
tests:
- exe: '/usr/bin/curl'
args:
- 'https://www.bortzmeyer.org/'
retcode: 0
partstdout: 'Blog Bortzmeyer'
timeout: 3 # Depuis Starbucks, c'est long
On a ajouté le paramètre timeout qui met une
limite au temps d'exécution. Comme précédement,
test_exe_matrix tmp.yaml va exécuter les tests
et montrer que tout va bien.
Comme tous les bons cadriciels de test, test_exe_matrix permet aussi de tester des choses qui sont censées échouer, ici avec un domaine qui n'existe pas :
---
tests:
- exe: '/usr/bin/curl'
args:
- 'https://www.doesnotexist.example/'
retcode: 6
On oublie souvent de tester que, non seulement le logiciel marche
bien dans les cas normaux, mais aussi qu'il échoue à juste titre
lorsque la situation l'exige. Ici, on vérifie que curl a bien
renvoyé le code de retour 6 et non pas 0. D'ailleurs, c'est
l'occasion de montrer ce que fait test_exe_matrix lorsqu'un test
échoue. Si je mets retcode: 0 dans le fichier
de configuration précédent :
% test_exe_matrix tmp.yaml
...
================================================ FAILURES ================================================
...
exetest = {'args': ['https://www.doesnotexist.example/'], 'exe': '/usr/bin/curl', 'retcode': 0, 'timeout': 1}
...
E AssertionError: expected retcode is 0, but process ended withcode 6
E assert 0 == 6
...
../../../../.local/lib/python3.6/site-packages/test_exe_matrix/test_the_matrix.py:127: AssertionError
====================================== 1 failed, 1 passed in 0.14s =======================================
En utilisant l'introspection, test_exe_matrix a pu montrer exactement quel test échouait.
À l'heure actuelle, test_exe_matrix est en plein développement, et l'installation est donc un peu rugueuse. Si vous n'avez pas déjà Poetry, il faut l'installer, par exemple avec (oui, c'est dangereux, je sais) :
% curl -sSL https://raw.githubusercontent.com/python-poetry/poetry/master/get-poetry.py | python3
Une fois que vous avez Poetry, vous pouvez installer test_exe_matrix, par exemple avec :
% poetry build % pip3 install dist/test_exe_matrix-0.0.18-py3-none-any.whl
Bien sûr, avant de suggérer le développement d'un nouveau logiciel, j'ai regardé ce qui existait, et ait été très surpris de ne rien trouver qui corresponde à mon cahier des charges, qui semblait pourtant modeste :
- Bats : il faut faire pas mal de shell bash pour l'utiliser.
- Btest est
proche de ce que je cherche mais le test du code de retour n'est que
binaire (0 ou pas 0), et on ne peut pas indiquer une chaîne qui doit
être présente dans la sortie. Mettre un
| grep <chaine>à la fin de la commande, ferait perdre le code de retour de la commande principale. (Dam_ned note qu'on peut peut-être s'en tirer avecset -o pipefailou utiliser le tableau$PIPESTATUS.) - Avec Lift, je ne vois pas comment indiquer des chaînes de caractères à tester dans la sortie standard.
- Roundup : lui aussi semble exiger d'écrire pas mal de code shell.
- Quant à Aruba, je n'ai tout simplement pas compris comment ça marchait.
- Testing-suite : très simple mais ne semble pas permettre de tester le code de retour.
L'article seul
RFC 8737: Automated Certificate Management Environment (ACME) TLS Application-Layer Protocol Negotiation (ALPN) Challenge Extension
Date de publication du RFC : Février 2020
Auteur(s) du RFC : R. Shoemaker (ISRG)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF acme
Première rédaction de cet article le 1 mars 2020
Ce court RFC normalise un mécanisme d'authentification lors d'une session ACME, permettant de prouver, via TLS et ALPN, qu'on contrôle effectivement le domaine pour lequel on demande un certificat.
Le protocole ACME
(RFC 8555) laisse le choix entre plusieurs
mécanismes d'authentification pour répondre aux défis du serveur
ACME « prouvez-moi que vous contrôlez réellement le domaine pour lequel vous me
demandez un certificat ! ». Le RFC 8555 propose un défi fondé sur HTTP
(http-01), dans sa section 8.3, et un défi
utilisant le DNS
(dns-01), dans sa section 8.4. Notez que le
défi HTTP est fait en clair, sans HTTPS. Or, outre la sécurité
de TLS,
certains utilisateurs d'ACME auraient bien voulu une solution
purement TLS, notamment pour les cas où la terminaison de TLS et
celle de HTTP sont faites par deux machines différentes (CDN, répartiteurs de charge TLS,
etc.)
D'où le nouveau défi normalisé par ce RFC, tls-alpn-01. Il
repose sur le mécanisme ALPN, qui avait été normalisé dans le RFC 7301. Déjà mis en œuvre dans des
AC comme Let's
Encrypt, il permet une vérification plus solide. Ce type
de défi figure maintenant dans le
registre des types de défis ACME. Notez qu'il existait déjà
un type utilisant TLS, tls-sni-01 / tls-sni-02,
mais qui avait des
failles, autorisant un utilisateur d'un serveur TLS à obtenir
des certificats pour d'autres domaines du même
serveur. tls-sni est aujourd'hui abandonné.
Les détails du mécanisme figurent dans la section 3 de notre
RFC. Le principe est que le serveur ACME se connectera en TLS au
nom de domaine indiqué
en envoyant l'extension ALPN avec le nom d'application
acme-tls/1 et vérifiera dans le
certificat la présence d'un
token, choisi aléatoirement par le serveur ACME,
token que le client ACME avait reçu sur le canal
ACME. (Ce nom d'application, acme-tls/1 est
désormais dans le
registre des applications ALPN.)
Bien sûr, c'est un peu plus compliqué que cela. Par exemple, comme le client ACME va devenir le serveur TLS lors du défi, il lui faut un certificat. La section 3 du RFC explique les règles auxquelles doit obéir ce certificat :
- Auto-signé, puisqu'on n'est pas encore authentifié auprès de l'AC,
- Un
subjectAlternativeName(RFC 5280) qui a comme valeur le nom de domaine à valider, - Une extension
acmeIdentifier(mise dans le registre des extensions aux certificats PKIX), qui doit être marquée comme critique, pour éviter que des clients TLS passant par là et n'ayant rien à voir avec ACME s'en servent, et dont la valeur est l'autorisation ACME (RFC 8555, section 8.1).
Le client ACME doit ensuite configurer ce qu'il faut sur son serveur
TLS pour que ce soit ce certificat qui soit retourné lors d'une
connexion TLS où le SNI vaut le domaine à valider et où ALPN
vaut acme-tls/1. Il annonce alors au serveur
ACME qu'il est prêt à répondre au défi. Le serveur ACME se connecte
au serveur TLS (créé par le client ACME) et fait les vérifications
nécessaires (nom de domaine dans le certificat, nom qui doit être un
A-label, donc en Punycode,
et extension du certificat acmeIdentifier
contenant la valeur indiquée par le serveur ACME lors du défi).
Une fois la vérification faite, le serveur ACME raccroche : ces
certificats ne sont pas conçus pour échanger de vraies données sur
la session TLS créée. D'ailleurs, les certificats auto-signés créés
pour le type de défi tls-alpn-01 ne permettent
pas d'authentification au sens du RFC 5280. Pour la même raison, le client TLS (créé par le
serveur ACME) n'est pas obligé d'aller jusqu'au bout de
l'établissement de la
session TLS.
La section 5 de notre RFC fait le point sur quelques suppositions
faites au sujet de la mise en œuvre de TLS, suppositions importantes
pour ACME. D'abord, si plusieurs organisations ou personnes
partagent la même adresse IP, ce qui est
courant en cas d'hébergement plus ou moins mutualisé, ACME compte
bien que leurs configurations TLS soient séparées, pour éviter
qu'une de ces entités puisse obtenir un certificat pour une autre,
hébergée au même endroit (cf. annexe A du RFC, qui décrit le
comportement surprenant de certains hébergeurs.) ACME espère
également que les serveurs TLS vont respecter le RFC 7301 en rejetant l'application
acme-tls/1 s'ils ne la connaissent
pas. (Certains programmeurs paresseux ont peut-être fait en sorte
que le serveur TLS accepte n'importe quelle application signalée en
ALPN.)
L'AC Let's Encrypt accepte déjà ce type de défi depuis juillet 2018. (Le RFC est en retard par rapport au déploiement effectif.) Le client ACME dehydrated permet d'utiliser le nouveau type de défi. Cet article utilise nginx côté serveur, avec son module SSL PreRead, qui permet d'aiguiller une requête en fonction de l'ALPN, mais, personnellement, je n'ai pas réussi (ça peut être un problème avec la gestion des modules dans le paquetage Debian de nginx, gestion quasiment pas documentée.)
Côté serveur, on a aussi ce qu'il faut dans Apache, avec le module
mod_md
(cf. plus précisement ce point
de la documentation.) Son utilisation est décrite
dans un article de Marc Framboisier (et sa
suite).
Côté client ACME, d'autres clients gèrent ce type de défi, mais pas encore certbot (cf. le ticket #6724 .)
L'article seul
RFC 8738: Automated Certificate Management Environment (ACME) IP Identifier Validation Extension
Date de publication du RFC : Février 2020
Auteur(s) du RFC : R. Shoemaker (ISRG)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF acme
Première rédaction de cet article le 1 mars 2020
Dernière mise à jour le 7 mars 2025
Le protocole ACME, surtout connu via son utilisation par l'AC Let's Encrypt, permet de prouver la « possession » d'un nom de domaine, pour avoir un certificat comprenant ce nom. Ce court RFC spécifie une extension à ACME qui permet de prouver la « possession » d'une adresse IP, ce qui permettra d'obtenir via ACME des certificats utilisant une adresse.
Le protocole ACME est normalisé dans le RFC 8555. Son principe est qu'on demande un certificat pour un identificateur (à l'heure actuelle, forcément un nom de domaine) et que le serveur ACME va alors vous défier de prouver que vous contrôlez bien ce nom, par exemple en publiant une chaîne de caractères choisie par le serveur dans un serveur HTTP accessible via ce nom de domaine. Or, les identificateurs dans les certificats PKIX ne sont pas forcément des noms de domaine. Les adresses IP, par exemple, sont prévues. Examinons les certificats du résolveur DNS public Quad9 :
% openssl s_client -connect 9.9.9.9:853 -showcerts | openssl x509 -text
...
X509v3 Subject Alternative Name:
DNS:*.quad9.net, DNS:quad9.net, IP Address:9.9.9.9, IP Address:9.9.9.10, IP Address:9.9.9.11, IP Address:9.9.9.12, IP Address:9.9.9.13, IP Address:9.9.9.14, IP Address:9.9.9.15, IP Address:149.112.112.9, IP Address:149.112.112.10, IP Address:149.112.112.11, IP Address:149.112.112.12, IP Address:149.112.112.13, IP Address:149.112.112.14, IP Address:149.112.112.15, IP Address:149.112.112.112, IP Address:2620:FE:0:0:0:0:0:9, IP Address:2620:FE:0:0:0:0:0:10, IP Address:2620:FE:0:0:0:0:0:11, IP Address:2620:FE:0:0:0:0:0:12, IP Address:2620:FE:0:0:0:0:0:13, IP Address:2620:FE:0:0:0:0:0:14, IP Address:2620:FE:0:0:0:0:0:15, IP Address:2620:FE:0:0:0:0:0:FE, IP Address:2620:FE:0:0:0:0:FE:9, IP Address:2620:FE:0:0:0:0:FE:10, IP Address:2620:FE:0:0:0:0:FE:11, IP Address:2620:FE:0:0:0:0:FE:12, IP Address:2620:FE:0:0:0:0:FE:13, IP Address:2620:FE:0:0:0:0:FE:14, IP Address:2620:FE:0:0:0:0:FE:15
...
On voit qu'outre des noms comme quad9.net, ce
certificat inclut aussi des adresses IP comme
9.9.9.9 et
2620:fe::9. Mais un tel certificat ne pouvait
pas s'obtenir automatiquement via ACME.
Notre RFC
résout ce problème en ajoutant un nouveau type d'identificateur
ACME, ip (section 3 du RFC). Les types
d'identificateurs ACME sont décrits dans la section 9.7.7 du RFC 8555. Le nouveau type ip a
été placé dans le
registre IANA des types d'identificateur. La valeur doit être
une adresse IP sous forme texte (normalisée très sommairement dans
la section 2.1 du RFC 1123 pour
IPv4, et dans la section 4 du RFC 5952 pour IPv6.)
Comme il s'agit d'authentifier des adresses IP, le défi ACME de
type dns-01 n'est pas pertinent et ne doit pas
être utilisé (section 7). Par contre, on peut (section 4 du RFC)
utiliser les défis http-01 (RFC 8555, section 8.3) et le récent
tls-alpn-01 (RFC 8737).
Pour le défi HTTP, le serveur ACME va se connecter en
HTTP à l'adresse IP indiquée, en mettant
cette adresse dans le champ Host:. Pour le défi
TLS avec ALPN, le certificat doit contenir un
subjectAltName de type
iPAddress. Un piège : contrairement au champ
Host: de HTTP, l'adresse IP nue ne peut pas
être utilisée dans le SNI (RFC 6066, « Currently, the only server names
supported are DNS hostnames »). Il faut donc utiliser un
nom dérivé de l'adresse, en in-addr.arpa ou
ip6.arpa. Par exemple, si on veut un certificat
pour 2001:db8::1, il faudra mettre
1.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.8.b.d.0.1.0.0.2.ip6.arpa
dans le SNI.
Un défi utilisant la « résolution inverse » (via une requête DNS
dans in-addr.arpa ou
ip6.arpa) avait été envisagé mais n'a pas été
retenu (les domaines de la « résolution inverse » sont en général
mal maintenus et il est difficile d'obtenir des entrées dans ces
domaines).
La section 9 de notre RFC étudie les conséquences de cette extension pour la sécurité. Le principal point à noter est que ce RFC ne spécifie qu'un mécanisme. L'AC a toute liberté pour définir une politique, elle peut par exemple refuser par principe les adresses IP dans les certificats, comme elle peut les accepter avec des restrictions ou des contrôles supplémentaires. Par exemple, il ne serait pas raisonnable d'allouer de tels certificats pour des adresses IP appartenant à des plages très dynamiques, pouvant changer d'utilisateur très souvent.
Côté mise en œuvre, pour le serveur Boulder (celui utilisé par Let's Encrypt), le code permettant de mettre en œuvre ce RFC a été inclus le 6 mars 2025 (la discussion est ici).
L'article seul
RFC 8731: Secure Shell (SSH) Key Exchange Method using Curve25519 and Curve448
Date de publication du RFC : Février 2020
Auteur(s) du RFC : A. Adamantiadis (libssh), S. Josefsson (SJD AB), M. Baushke (Juniper Networks)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF curdle
Première rédaction de cet article le 29 février 2020
Cela fait déjà pas mal de temps que des mises en œuvre du protocole SSH intègrent les courbes elliptiques « Bernstein », comme Curve25519. Ce RFC est donc juste une formalité, la normalisation officielle de cette utilisation.
SSH est normalisé dans le RFC 4251. C'est peut-être le protocole cryptographique de sécurisation d'un canal Internet le deuxième plus répandu, loin derrière TLS. Il permet de se connecter de manière sécurisée à une machine distante. En application du principe d'agilité cryptographique (RFC 7696), SSH n'est pas lié à un algorithme cryptographique particulier. Le protocole d'échange des clés, normalisé dans le RFC 4253, permet d'utiliser plusieurs algorithmes. Le RFC 5656 a étendu ces algorithmes aux courbes elliptiques.
Les courbes Curve25519 et
Curve448, créées par Daniel Bernstein, sont décrites dans le RFC 7748. Depuis des années, elles s'imposent
un peu partout, à la place des courbes
NIST comme P-256. La
libssh a ces courbes depuis des années,
sous l'ancien nom de
curve25519-sha256@libssh.org. Notre
RFC ne fait qu'officialiser ces
algorithmes, sous les nouveaux noms de
curve25519-sha256 et
curve448-sha512.
La section 3 du RFC décrit les détails de l'utilisation de ces algorithmes pour l'échange de clé. La méthode est proche de l'ECDH de la section 4 du RFC 5656.
Voici un exemple de session utilisant cet algorithme, avec OpenSSH 7.6 :
% ssh -v ...
...
debug1: SSH2_MSG_KEXINIT sent
debug1: SSH2_MSG_KEXINIT received
debug1: kex: algorithm: curve25519-sha256
L'article seul
RFC 8746: Concise Binary Object Representation (CBOR) Tags for Typed Arrays
Date de publication du RFC : Février 2020
Auteur(s) du RFC : C. Bormann (Universitaet Bremen TZI)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF cbor
Première rédaction de cet article le 29 février 2020
Ce nouveau RFC étend le format de fichiers CBOR (normalisé dans le RFC 8949) pour représenter des tableaux de données numériques, et des tableaux multidimensionnels.
Le format CBOR est en effet extensible par des étiquettes (tags) numériques qui indiquent le type de la donnée qui suit. Aux étiquettes définies dans la norme originale, le RFC 8949, ce nouveau RFC ajoute donc des étiquettes pour des types de tableaux plus avancés, en plus du type tableau de base de CBOR (qui a le type majeur 4, cf. RFC 8949, et dont les données ne sont pas forcément toutes de même type).
Le type de données « tableau de données numériques » est utile pour les calculs sur de grandes quantités de données numériques, et bénéficie de mises en œuvres adaptées puisque, opérant sur des données de même type, contrairement aux tableaux CBOR classiques, on peut optimiser la lecture des données. Pour comprendre l'utilité de ce type, on peut lire « TypedArray Objects » (la spécification de ces tableaux dans la norme ECMA de JavaScript, langage dont CBOR reprend le modèle de données) et « JavaScript typed arrays » (la mise en œuvre dans Firefox).
La section 2 spécifie ce type de tableaux dans CBOR. Un tableau typé (typed array) est composé de données numériques de même type. La représentation des nombres (par exemple entiers ou flottants) est indiquée par l'étiquette. En effet, il n'y a pas de représentation canonique des nombres dans un tableau typé (contrairement aux types numériques de CBOR, types majeurs 0, 1 et 7) puisque le but de ces tableaux est de permettre la lecture et l'écriture rapides de grandes quantités de données. En stockant les données sous diverses formes, on permet de se passer d'opérations de conversion.
Il n'y a pas moins de 24 étiquettes (désormais enregistrées dans
le
registre IANA des étiquettes CBOR) pour représenter toutes
les possibilités. (Ce nombre important, les étiquettes étant codées
en général sur un seul octet, a suscité des discussions dans le
groupe de travail, mais se justifie par le caractère très courant de
ces tableaux numériques. Voir la section 4 du RFC.) Par exemple,
l'étiquette 64 désigne un tableau typé d'octets (uint8),
l'étiquette 70 un tableau typé d'entiers de 32 bits non
signés et petit-boutiens
(uint32), l'étiquette 82 un tableau typé de
flottants IEEE 754 de 64 bits
gros-boutiens, etc. (CBOR est normalement gros-boutien, comme tous
les protocoles et formats Internet, cf. section 4 du RFC.) Les
étiquettes ne sont pas attribuées arbitrairement, chaque nombre
utilisé comme étiquette encode les différents choix possibles dans
les bits qui le composent. Par exemple, le quatrième bit de
l'étiquette indique si les nombres sont des entiers ou bien des
flottants (cf. section 2.1 du RFC pour les détails).
Le tableau typé est ensuite représenté par une simple chaîne d'octets CBOR (byte string, type majeur 2). Une mise en œuvre générique de CBOR peut ne pas connaitre ces nouvelles étiquettes, et considérera donc le tableau typé comme une bête suite d'octets.
La section 3 de notre RFC décrit ensuite les autres types de tableaux avancés. D'abord, les tableaux multidimensionnels (section 3.1). Ils sont représentés par un tableau qui contient deux tableaux unidimensionnels. Le premier indique les tailles des différentes dimensions du tableau multidimensionnel, le second contient les données. Deux étiquettes, 40 et 1040, sont réservées, pour différencier les tableaux en ligne d'abord ou en colonne d'abord. Par exemple, un tableau de deux lignes et trois colonnes, stocké en ligne d'abord, sera représenté par deux tableaux unidimensionnels, le premier comportant deux valeurs, 2 et 3, le second comportant les six valeurs, d'abord la première ligne, puis la seconde.
Les autres tableaux sont les tableaux homogènes (étiquette 41), en section 3.2. C'est le tableau unidimensionnel classique de CBOR, excepté que tous ses élements sont du même type, ce qui peut être pratique au décodage, pour les langages fortement typés. Mais attention : comme rappelé par la section 7 du RFC, consacrée à la sécurité, le décodeur doit être prudent avec des données inconnues, elles ont pu être produites par un programme malveillant ou bogué, et donc non conformes à la promesse d'homogénéité du tableau.
La section 5 de notre RFC donne les valeurs des nouvelles étiquettes dans le langage de schéma CDDL (RFC 8610).
L'article seul
RFC 8711: Structure of the IETF Administrative Support Activity, Version 2.0
Date de publication du RFC : Février 2020
Auteur(s) du RFC : B. Haberman (Johns Hopkins University), J. Hall (CDT), J. Livingood (Comcast)
Réalisé dans le cadre du groupe de travail IETF iasa2
Première rédaction de cet article le 28 février 2020
Le sigle IASA (IETF Administrative Support Activity) désigne les structures qui font le travail administratif, non-technique, pour l'IETF. L'actvité de l'IETF est de produire des normes (sous forme de RFC) et cette activité nécessite toute une organisation et des moyens concrets, des employés, des logiciels, des déclarations pour le fisc, des serveurs, des réunions, et c'est tout cela que gère l'IASA. Dans sa première version, qui avait été spécifiée dans le RFC 4071 en 2005, l'IASA était gérée par l'ISOC, et était surtout formée par l'IAOC (IETF Administrative Oversight Committee). Dans cette « version 2 » de l'IASA, l'IAOC disparait, et l'essentiel des tâches revient à un nouvel organisme, une LLC (Limited Liability Company). Ce nouveau RFC remplace le RFC 4071 et décrit cette IETF Administration LLC et ses relations avec l'IETF.
L'IETF était à l'origine une structure informelle, des ingénieurs qui se réunissaient, discutaient, et écrivaient des RFC. Petit à petit, elle a grossi et s'est structurée (certains diraient « bureaucratisée »). La précédente structure était encore assez légère, reposant largement sur l'ISOC. L'IETF ayant continué à grossir, les enjeux ont continué à devenir de plus en plus importants pour la société dans son ensemble, il a été nécessaire de créer une organisation propre, la LLC (Limited Liability Company). Le conseil d'administration de cette LLC assurera les tâches qui étaient auparavant celles de l'IAOC. Les différents RFC qui mentionnaient l'IAOC ont été mis à jour pour cela (d'où la publication, entre autres, des RFC 8721, RFC 8714 ou RFC 8716). De même, l'ancienne fonction d'IAD IETF Administrative Director, la personne qui dirigeait le travail de l'IASA, est supprimée et ses tâches passent au directeur de la LLC, avec le titre de IETF Executive Director. C'était auparavant Portia Wenze-Danley mais Jay Daley lui a succédé le 24 octobre 2019.
C'est donc désormais cette « IETF LLC » qui est la structure légale de l'IETF mais aussi de l'IRTF, de l'IAB et, partiellement, du RFC Editor.
Cette réorganisation très importante ne change pourtant rien au processus de production des normes, qui, lui, reste couvert par le RFC 2026 (et ses nombreuses mises à jour, comme le RFC 6410). Cette écriture des normes techniques n'est pas pilotée par l'IASA mais par l'IESG et l'IAB (cf. RFC 2850). Même chose pour le travail de l'IRTF (RFC 2014). Si vous ne vous intéressez qu'à la technique, vous pouvez donc sauter le reste de cet article, qui ne parlera que de gouvernance et de droit.
Aucun changement non plus pour les procédures d'appels en cas de désaccord, ou pour les nominations (RFC 8713).
Comme la LLC n'a pas beaucoup de moyens, et que l'activité de l'IETF se déroule dans un environnement parfois compliqué, notamment du point de vue juridique (risque de procès), l'IETF continue de s'appuyer sur l'Internet Society (ISOC). L'accord entre LLC et ISOC est disponible en ligne. Voir aussi le RFC 8712.
La section 4 de notre RFC définit un certain nombre de termes, et pose les principes qui régissent la LLC. Parmi les définitions :
- LLC (Limited Liability Company, le nom complet est IETF Administration LLC) : le nouvel organisme, créé par le projet « IASA [version] 2 », qui gérera la partie « administrative » de l'IETF ; c'est le représentant légal de l'IETF.
- Directeur (IETF LLC Executive Director) : la personne qui dirigera la LLC. Ce rôle remplace l'ancien IAD.
- Conseil d'Administration (IETF LLC Board) : le groupe de personnes qui supervise la LLC (le directeur s'occupant des opérations quotidiennes).
Le LLC va donc s'occuper :
- Des réunions physiques, un gros travail organisationnel,
- Des finances, et de la récolte de fonds,
- De la conformité aux lois et réglements divers. (La LLC est enregistrée aux États-Unis et doit donc suivre les lois de ce pays.)
Elle ne s'occupera pas du développement des normes (le travail central de l'IETF, qui ne relève pas de cette gestion administrative).
Les principes que lesquels va s'appuyer la LLC pour cela :
- Transparence (il faut rendre des comptes aux participants à l'IETF). Tout doit être public par défaut. C'est le cas, enre autres, des requêtes judiciaires reçues, des rapports et audits ou bien des réunions du conseil d'administration (comme son séminaire de janvier 2020.) Voir aussi le rapport de l'activité de la LLC présentée à la réunion IETF de novembre 2019, à Singapour.
- Réactivité face aux demandes des participants à l'IETF.
- Minimisation des risques, notamment financiers.
La section 5 du RFC expose la structure choisie pour mettre en pratique ces principes. Un directeur (aujourd'hui Jay Daley) pour les fonctions opérationnelles du quotidien, et plusieurs employés (traditionnellement, l'IETF fonctionnait avec une équipe très réduite, mais cela n'est plus possible aujourd'hui). Mais une spécificité de l'IETF est aussi son caractère associatif et fondé sur le volontariat. De nombreux participants à l'IETF donnent de leur temps pour effectuer des fonctions de support de l'IETF. C'est ainsi que, pendant longtemps, les outils logiciels de travail en groupe étaient tous développés et maintenus par des participants volontaires. De même, la gestion du réseau pendant les réunions, ou bien les activités de sensibilisation et d'éducation sont traditionnellement assurées en dehors des cadres organisés. Le but de la LLC n'est pas d'absorber tous ces efforts. Au contraire, le RFC insiste sur l'importance pour la LLC de travailler avec les volontaires, sans chercher à les remplacer.
Et qui est membre du conseil d'administration de la LLC ? La section 6 l'explique (cela avait été une des discussions les plus vives lors de la création de la LLC). Certains membres sont nommés par l'IESG, d'autres par l'ISOC. Vous pouvez voir sur le site Web de la LLC la liste des membres actuels.
L'argent étant une question évidemment cruciale, la section 7 discute le financement de la LLC. (Au fait, les informations financières sont elles aussi en ligne, pour la transparence. Et voici le plan pour le budget 2020.) Bien évidemment, le RFC précise que les éventuels dons, par exemple d'entreprises, ne donnent aucun droit particulier et ne permettent pas de donner des consignes à la LLC (du moins en théorie). L'argent ainsi récolté doit servir uniquement aux activités IETF, et proches (comme l'IRTF).
La LLC doit obéir à un certain nombre de règles, détaillées en section 8, et développées dans ses politiques publiques. Par exemple, la LLC doit avoir des politiques internes contre la corruption, ou en faveur de la protection des données personnelles. D'autre part, sa nature d'organisation officiellement enregistrée aux États-Unis l'oblige à appliquer certaines lois états-uniennes comme les sanctions contre ceux que le gouvernement de Washington va qualifier de terroristes. Pour l'instant, l'IETF n'a jamais pris de décision dans des domaines politiquement délicats comme celui-ci. Mais dans le futur ? Compte-tenu de l'actuelle crise entre le gouvernement Trump et Huawei, faudra-t-il un jour se demander si les employés de Huawei doivent être exclus des réunions ? Cela signifierait sans doute la fin de l'IETF.
Pour résumer les principaux changements entre l'« IASA 1 » (RFC 4071) et l'« IASA 2 » décrite par ce RFC : L'IAOC et l'IAD disparaissent, remplacés par la LLC, son conseil d'administration et son directeur.
L'article seul
RFC 8730: Independent Submission Editor Model
Date de publication du RFC : Février 2020
Auteur(s) du RFC : N. Brownlee (The University of Auckland), R. Hinden (Check Point Software)
Pour information
Réalisé dans le cadre du groupe de travail IETF iasa2
Première rédaction de cet article le 28 février 2020
Si vous n'aimez pas les RFC de procédure, et que vous ne voulez que de la technique, rassurez-vous, ce document est court : il spécifie le rôle et les qualités de l'ISE (Independent Submission Editor), celui (ou celle) qui supervise les RFC qui ne passent pas par l'IETF. Il remplace le RFC 6548, remplacement nécessaire compte tenu de la nouvelle structure adminstrative de l'IETF, introduite par le RFC 8711.
Comment, ça existe, des RFC non-IETF ? Tous les RFC ne naissent pas au sein d'un des nombreux groupes de travail de l'IETF ? Eh oui, c'est souvent oublié, mais c'est le cas, il existe une voie indépendante qui permet à des individus de publier un RFC, quel que soit l'avis de l'IETF. Cette voie est décrite dans le RFC 4846. Autrefois, il n'existait qu'un seul RFC Editor pour examiner et préparer tous les RFC. Mais cette tâche est désormais répartie entre plusieurs éditeurs spécialisés et l'ISE est en charge de la voie indépendante.
Ce mécanisme de répartition des tâches pour les RFC est décrit dans le RFC 8728 (modèle du RFC Editor, « v2 ») et ce RFC 8730.
La section 2.1 décrit les qualifications attendues de l'ISE. Ce doit être quelqu'un d'expérimenté (senior), compétent techniquement dans les sujets traités à l'IETF (ce qui fait beaucoup !), connu et reconnu de la communauté IETF, sachant écrire et corriger, connaissant très bien l'anglais, et capable de travailler dans le milieu souvent agité de l'IETF.
Sa tâche principale (section 2.2) est de maintenir la qualité des RFC de la voie indépendante, par la relecture et l'approbation des documents, avant transmission au Producteur des RFC (RFC Production Center). Mais il doit aussi traiter les errata pour les RFC de la voie indépendante, contribuer à définir les évolutions de cette voie, interagir avec les autres acteurs des RFC, et fournir des statistiques à l'IAB et l'IETF LLC (cf. RFC 8711). Il peut se faire assister par un conseil consultatif, dont il nomme les membres « at the pleasure of the ISE », dit le RFC dans une jolie formule. Il y a aussi un conseil éditorial, également nommé par l'ISE (section 3 du RFC).
Le site officiel des RFC contient une page consacrée à la voie indépendante, si cela vous tente d'y publier.
L'ISE est nommé par l'IAB. Aujourd'hui, c'est Adrian Farrel, qui joue ce rôle.
Il y a peu de changements depuis le RFC précédent, le RFC 6548, essentiellement le remplacement de l'ancienne structure administrative de l'IETF (l'IAOC) par la nouvelle (l'IETF LLC).
L'article seul
RFC 8722: Defining the Role and Function of IETF Protocol Parameter Registry Operators
Date de publication du RFC : Février 2020
Auteur(s) du RFC : D. McPherson, O. Kolkman (ISOC), J.C. Klensin, G. Huston (APNIC), Internet Architecture Board
Pour information
Réalisé dans le cadre du groupe de travail IETF iasa2
Première rédaction de cet article le 28 février 2020
Ce RFC officiel de l'IAB décrit le rôle de l'opérateur des registres des protocoles utilisé par l'IETF. Des tas de protocoles normalisés par cet organisme ont besoin de garder une trace des noms ou numéros réservés (par exemple les numéros de port de TCP ou UDP, les numéros d'options DHCP, etc.) C'est le rôle de l'opérateur du registre qui garde ces réservations (aujourd'hui, essentiellement l'IANA). Ce RFC remplace le RFC 6220, suite à la création de la nouvelle structure administrative de l'IETF, dans le RFC 8711.
L'IETF n'assure pas ce rôle d'opérateur du registre elle-même. Elle se focalise sur la production de normes (les RFC) et délègue la gestion du registre. Pourquoi les valeurs en question ne sont-elles pas directement mises dans les RFC ? Parce qu'elles évoluent plus vite que la norme elle-même. Ainsi, l'enregistrement d'un nouveau type d'enregistrement DNS est un processus bien plus souple que de modifier un RFC et la liste de tels types ne peut donc pas être figée dans un RFC (ceux-ci ne sont jamais modifiés, seulement remplacés, et cela n'arrive pas souvent).
Mais on ne peut pas non plus laisser chacun définir ses propres paramètres, car cela empêcherait toute interprétation commune. D'où cette idée d'un registre des paramètres. Les règles d'enregistrement dans ce registre, la politique suivie, sont décrites pour chaque norme dans la section IANA considerations du RFC, en utilisant le vocabulaire et les concepts du RFC 8126 (pour les types d'enregistrements DNS, cités plus haut, les détails sont dans le RFC 6895).
Plusieurs autres SDO suivent ce même principe de séparation entre la normalisation et l'enregistrement (en revanche, les groupes fermés d'industriels qui tentent d'imposer leur standard ne séparent pas en général ces deux fonctions). Par exemple, l'ISO définit, pour la plupart de ses normes, une Registration Authority ou bien une Maintenance Agency qui va tenir le registre. (Exemples : l'opérateur du registre de ISO 15924 est le consortium Unicode et celui du registre de ISO 639 est SIL. Contre-exemple : l'opérateur du registre de ISO 3166 est l'ISO elle-même.) Pourquoi cette séparation ? Les raisons sont multiples mais l'une des principales est la volonté de séparer la politique de base (définie dans la norme) et l'enregistrement effectif, pour gérer tout conflit d'intérêts éventuel. Un opérateur de registre séparé peut être plus indépendant, afin de ne pas retarder ou bloquer l'enregistrement d'un paramètre pour des raisons commerciales ou politiques. Notons aussi que bien d'autres fonctions liées à l'IETF sont également assurées à l'extérieur, comme la publication des RFC.
Contre-exemple, celui du W3C, qui utilise très peu de registres et
pas d'opérateur de registre officiel séparé. En pratique, c'est
l'IANA qui gère plusieurs registres Web, comme celui des
URI
bien
connus (RFC 8615), celui des types
de fichiers (comme application/pdf ou
image/png), celui des en-têtes
(utilisés notamment par HTTP), etc. En
dehors de l'IANA, le W3C a quelques registres gérés en interne
comme celui de
Xpointer. Pour le reste, la politique du W3C est plutôt
qu'un registre est un point de passage obligé et que de tels
points ne sont pas souhaitables.
Dans le cas de l'IETF, les documents existants sont le RFC 2026, qui décrit le processus de
normalisation mais pas celui d'enregistrement. Ce dernier est
traditionnellement connu sous le nom de « fonction IANA » (d'où la
section IANA considerations des RFC) même si,
en pratique, ce n'est pas toujours l'IANA qui l'effectue. (Les
registres de l'IANA sont en https://www.iana.org/protocols/.)
La section 2 du RFC expose donc le rôle et les responsabilités
du(des) opérateur(s) de registres de paramètres. Celui(ceux)-ci,
nommés avec majuscules IETF Protocol Parameter Registry
Operator, seront choisis par l'IETF LLC
(RFC 8711). J'ai mis le pluriel car
l'IANA n'assure pas actuellement la totalité
du rôle : il existe d'autres opérateurs de registres, en général
sur des tâches très secondaires comme par exemple le RIPE-NCC pour
l'enregistrement en
e164.arpa
(ENUM, cf. RFC 6116). Dans le futur, on pourrait imaginer un rôle
moins exclusif pour l'IANA.
La section 2.1 est la (longue) liste des devoirs qu'implique le rôle d'opérateur de registre. Il y a bien sûr le tenue du registre à proprement parler mais ce n'est pas tout. En voici une partie :
- Donner des avis sur les futurs RFC (concrètement, relire les sections IANA considerations à l'avance, pour voir si elles ne poseraient pas de problèmes insurmontables au registre).
- Suivre les RFC : l'opérateur du registre n'est pas censé déterminer la politique mais l'appliquer. Si un RFC dit que l'enregistrement dans tel registre se fait sans contrainte, l'opérateur du registre ne peut pas refuser un enregistrement, par exemple. Chaque registre a une politique d'enregistrement, expliquée dans le RFC correspondant (les règles générales figurent dans le RFC 8126).
- Bien indiquer dans chaque registre les références notamment le numéro du RFC qui normalise ce registre et pour chaque paramètre enregistré dans le registre, indiquer la source de ce paramètre et la date d'enregistrement.
- En cas de désaccord ou de problème, se tourner vers l'IESG, seule habilitée à trancher.
- Diffuser gratuitement les registres qui
sont tous publics par défaut (contrairement à ce qui se passe chez
l'ultra-dinosaure ISO). Un exemple est le registre de
DHCP, en
https://www.iana.org/assignments/bootp-dhcp-parameters/. - Maintenir les listes de diffusion spécifiées pour certains registres, par exemple lorsque l'enregistrement nécessite un examen par un expert, sous l'œil du public.
- Produire des rapports réguliers à destination de l'IAB, suivant le RFC 2860 mais aussi suivant l'accord supplémentaire qui l'a complété, et à destination de toute l'IETF. Aujourd'hui, cela se fait sous la forme de l'exposé IANA qu'il y a à chaque plénière de l'IETF. Ces rapports incluent des points comme les performances de l'opérateur du registre (délai de traitement, par exemple).
- Ne pas oublier que les droits de propriété intellectuelle sur ces registres sont gérés par l'IETF Trust (RFC 4371).
Après cette description des devoirs de l'opérateur du registre, la section 2 continue avec les devoirs des autres acteurs. En section 2.2, ceux de l'IAB, qui supervise l'opérateur du registre : l'IAB procède à la délégation formelle du registre, après que l'IETF LLC ait identifié les candidats. L'IAB décide, l'IETF LLC gère la relation avec l'opérateur.
En section 2.3, le rôle de l'IESG : celui-ci s'occupe de la partie technique, vérifier que les RFC comportent une bonne section IANA considerations, identifier les experts techniques si le RFC précise que l'enregistrement est précédé d'une évaluation technique (exemple : le RFC 5646, où l'enregistrement d'une langue dans le registre des langues est précédé d'une telle évaluation par un linguiste), répondre aux questions de l'opérateur du registre si celui-ci a un problème pratique.
En section 2.4, le rôle de l'IETF Trust (RFC 4371). Il gère la propriété intellectuelle de l'IETF donc est « propriétaire » du contenu des registres. Enfin, en section 2.5, le rôle de l'IETF LLC, bras administratif de l'IETF, qui est de gérer au quotidien les relations avec l'opérateur du registre. (C'est la principale nouveauté de ce RFC, par rapport au RFC 6220, que le remplacement de l'ancienne structure par cette IETF LLC.)
Voilà, l'essentiel était là mais la section 3 rajoute quelques détails.
L'article seul
RFC 8728: RFC Editor Model (Version 2)
Date de publication du RFC : Février 2020
Auteur(s) du RFC : O. Kolkman, J. Halpern (Ericsson), R. Hinden (Check Point Software)
Pour information
Réalisé dans le cadre du groupe de travail IETF iasa2
Première rédaction de cet article le 28 février 2020
L'articulation compliquée entre l'IETF qui produit les normes TCP/IP et le RFC Editor qui les publie, n'a jamais cessé de faire couler de l'encre (ou d'agiter des électrons). Dans ce document, l'IAB décrit un modèle pour le RFC Editor, modèle où les fonctions de ce dernier sont éclatées en plusieurs fonctions logiques. Elles peuvent ainsi être réparties entre plusieurs groupes. Ce RFC remplace le RFC 6635, avec peu de changements : c'est toujours le modèle « v2 » du modèle RFC Editor. Il a depuis été remplacé par une version 3, assez différente, décrite dans le RFC 9920.
Le document de référence actuel est le RFC 8729. Comme le rappelle la section 1, il décrit les tâches du RFC Editor de manière globale, comme si c'était forcément une seule entité (c'était, à l'origine, une seule personne, Jon Postel). La section 2 note que la tâche de RFC Editor est actuellement une partie de l'IASA (dont la récente réforme, décrite dans le RFC 8711, a nécessité ce nouveau RFC) et financée par son budget.
La même section 2 s'attaque à la définition du rôle du RFC Editor sous forme de fonctions séparées. Elles sont ici légèrement modifiées, compte-tenu de l'expérience et des problèmes de communication rencontrés, problèmes de communication qui n'existaient évidemment pas lorsque Postel faisait tout lui-même. Le terme de RFC Editor désigne collectivement toutes ces fonctions. L'IAB voit maintenant trois fonctions (voir aussi le dessin 1 de notre RFC) :
- Éditeur de la série des RFC,
- Producteur des RFC,
- Publieur des RFC,
- Enfin, l'éditeur des contributions indépendantes, décrit à part, dans le RFC 8730.
Chaque section va ensuite détailler ces tâches. Il y a également des rôles de supervision, tenus par l'IAB (RFC 2850) et l'IETF LLC (RFC 8711).
L'Éditeur de la série des RFC (RFC Series Editor, poste actuellement vacant depuis le départ d'Heather Flanagan) est décrit en premier, en section 2.1. Il ou elle est responsable du travail à long terme, il doit définir les principes qui assurent la pérennité des RFC, réfléchir à la stratégie, développer le RFC 7322, le guide de style des RFC, de la langue des RFC, etc. Il sert aussi de « visage » aux RFC, vis-à-vis, par exemple, des journalistes. L'Éditeur est censé travailler avec la communauté IETF pour les décisions politiques. Désigné par l'IAB, il ou elle sera formellement un employé de l'IETF LLC, la structure administrative de l'IETF.
Le RFC 8728 évalue la charge de travail à un mi-temps, ce qui me semble très peu. Notre RFC décrit les compétences nécessaires (section 2.1.6) pour le poste d'Éditeur de la série des RFC, compétences en anglais et en Internet, capacité à travailler dans l'environnement... spécial de l'IETF, expérience des RFC en tant qu'auteur souhaitée, etc.
Le travail quotidien est, lui, assuré par le Producteur des RFC (RFC Production Center) dont parle la section 2.2. C'est un travail moins stratégique. Le Producteur reçoit les documents bruts, les corrige, en discute avec les auteurs, s'arrange avec l'IANA pour l'allocation des numéros de protocoles, attribue le numéro au RFC, etc.
Les RFC n'étant publiés que sous forme numérique, il n'y a pas d'imprimeur mais le numérique a aussi ses exigences de publication et il faut donc un Publieur des RFC (RFC Publisher), détaillé en section 2.3. Celui-ci s'occupe de... publier, de mettre le RFC dans le dépôt où on les trouve tous, d'annoncer sa disponibilité, de gérer l'interface permettant de soumettre les errata, de garder à jour ces errata, et de s'assurer que les RFC restent disponibles, parfois pendant de nombreuses années.
Chacune de ces fonctions pourra faire l'objet d'une attribution spécifique (à l'heure actuelle, les fonctions de Producteur et de Publieur sont assurées par le même groupe à l'AMS). La liste à jour peut être vue sur le site officiel.
Un comité joue un rôle de supervision et de contrôle du RFC Editor : le RSOC (RFC Series Oversight Committee) est décrit en section 3.
Combien cela coûte et qui choisit les titulaires des différentes fonctions ? La section 4 décrit ce rôle, dévolu à l'IETF LLC ( IETF Administration Limited Liability Company, cf. RFC 8711). Le budget est publié en sur le site de l'IETF LLC et on y trouvera aussi les futures évaluations du RFC Editor. On peut aussi trouver cette information, ainsi que plein d'autres sur le fonctionnement du RFC Editor, via le site officiel).
Comme indiqué plus haut, il n'y a pas de grand changement depuis le RFC 6635, juste le remplacement de l'ancienne IAOC par l'IETF LLC. La version 3, dans le RFC 9920, a apporté davantage de changements.
L'article seul
RFC 8714: Update to the Process for Selection of Trustees for the IETF Trust
Date de publication du RFC : Février 2020
Auteur(s) du RFC : J. Arkko (Ericsson), T. Hardie
Réalisé dans le cadre du groupe de travail IETF iasa2
Première rédaction de cet article le 28 février 2020
Un RFC purement bureaucratique, faisant partie de la série des RFC sur la nouvelle structure administrative de l'IETF, décrite dans le RFC 8711. Celui-ci change légèrement la manière dont sont désignés les membres de l'IETF Trust, la structure qui gère la propriété intellectuelle de l'IETF.
Cet IETF Trust avait été créé pour s'occuper de toutes les questions liées aux marques, noms de domaine, droits sur les RFC, etc. C'était aussi la seule solution pour récupérer partiellement des droits qui avaient été détournés par CNRI. Il était spécifié dans le RFC 4371 que les membres de l'IAOC (IETF Administrative Oversight Committee) étaient automatiquemement membres de l'IETF trust.
La section 3 de notre RFC contient le changement important : comme la nouvelle structure administrative de l'IETF, décrite dans le RFC 8711 supprime l'ancienne IAOC, les membres de l'IETF trust ne seront plus issus de l'IAOC. Les cinq membres de l'IETF Trust sont désignés, pour trois d'entre eux par le comité de nomination de l'IETF (RFC 8713), pour l'un par l'IESG et pour le dernier par l'ISOC. Leur mandat est de trois ans mais le RFC prévoit des mandats plus courts pour certains, pour lisser la transition.
Un exemple du processus de sélection des trois membres « NomCom » (comité de nomination) se trouve en ligne. Regardez l'appel aux nominations (ou bien celui-ci). Comme vous le voyez avec le premier exemple, le processus de remplacement de l'ancien IETF trust a été fait bien avant la publication formelle de ce RFC.
Les raisons de ce changement sont décrites plus longuement dans le RFC 8715.
L'article seul
RFC 8713: IAB, IESG, IETF Trust and IETF LLC Selection, Confirmation, and Recall Process: Operation of the IETF Nominating and Recall Committees
Date de publication du RFC : Février 2020
Auteur(s) du RFC : M. Kucherawy, R. Hinden (Check Point Software), J. Livingood (Comcast)
Réalisé dans le cadre du groupe de travail IETF iasa2
Première rédaction de cet article le 28 février 2020
Voici un nouveau RFC « bureaucratique » autour des processus menant au choix et à la désignation des membres d'un certain nombre d'organismes de la galaxie IETF, comme l'IAB ou l'IESG. Ce RFC remplace le RFC 7437, mais il y a peu de changements ; les principaux portent sur les conséquences de la nouvelle structure administrative de l'IETF, « IASA 2 », décrite dans le RFC 8711.
Ce RFC concerne la désignation des membres de l'IAB, de l'IESG et de certains membres de la IETF LLC (voir la section 6.1 du RFC 8711) et de l'IETF Trust. Il ne concerne pas l'IRTF et ses comités propres. Il ne concerne pas non plus le fonctionnement quotidien de ces comités, juste la désignation de leurs membres.
Le processus tourne autour d'un comité nommé NomCom (pour Nominating Committee, comité de nomination).Comme expliqué en section 2, il faut bien différencier les nommés (nominee), les gens dont les noms ont été soumis au NomCom pour occuper un poste à l'IAB, l'IESG, à l'IETF LLC ou à l'IETF Trust, des candidats (candidate) qui sont les gens retenus par le NomCom. Le NomCom, comme son nom l'indique, n'a pas de pouvoir de désignation lui-même, celle-ci est décidée (on dit officiellement « confirmée ») par un organisme différent pour chaque comité (l'IAB pour l'IESG, l'ISOC pour l'IAB, l'IESG pour l'IETF Trust, etc). Une fois confirmé, le candidat devient... candidat confirmé (confirmed candidate). Et s'il n'est pas confirmé ? Dans ce cas, le NomCom doit se remettre au travail et proposer un ou une autre candidat·e.
La section 3 de notre RFC explique le processus général : il faut désigner le NomCom, le NomCom doit choisir les candidats, et ceux-ci doivent ensuite être confirmés. Cela peut sembler compliqué, mais le but est d'éviter qu'une seule personne ou une seule organisation puisse mettre la main sur l'IETF. Le processus oblige à travailler ensemble.
À première vue, on pourrait penser que le NomCom a un vaste pouvoir mais, en fait, au début du processus, il ne peut pas décider des postes vacants, et, à sa fin, il n'a pas le pouvoir de confirmation.
Un point important et souvent oublié est celui de la confidentialité (section 3.6 du RFC). En effet, l'IETF se vante souvent de sa transparence, tout doit être public afin que chacun puisse vérifier que tout le processus se déroule comme prévu. Mais le travail du NomCom fait exception. Toutes ses délibérations, toutes les informations qu'il manipule, sont confidentielles. Autrement, il serait difficile de demander aux personnes nommées de fournir des informations personnelles, et les personnes extérieures au NomCom qui sont interrogées hésiteraient à s'exprimer franchement sur tel ou tel candidat. Et la publicité des débats risquerait d'encourager des campagnes de soutien extérieures au NomCom, et du lobbying, toutes choses qui sont formellement interdites. La section 9, sur la sécurité, revient sur cette importance de la confidentialité : puisque le NomCom enquête littéralement sur les nommés, il peut récolter des informations sensibles et il doit donc faire attention à les garder pour lui.
Le résultat est annoncé publiquement. Voici, par exemple, l'annonce de la sélection des membres de l'IESG, début 2019.
Et le NomCom lui-même, comment est-il choisi (section 4) ? De ses quatorze membres, seuls dix ont le droit de vote. D'abord, les dix membres du NomCom votants doivent répondre à un certain nombre de critères (section 4.14) : ils doivent avoir été physiquement présents à trois des cinq précédentes réunions de l'IETF (c'est une des exceptions au principe comme quoi la participation à l'IETF n'impose pas de venir aux réunions physiques), et c'est vérifié par le secrétariat de l'IETF (chaque participant peut facilement voir sur sa page sur le Datatracker s'il est éligible ou pas.) Et ils doivent (évidemment), être très familiers avec les processus internes de l'IETF. Une fois qu'on a un ensemble (pool) de volontaires qui acceptent de participer au NomCom (voyez un appel à volontaires typique), comment choisit-on les dix membres de plein exercice ? Eh bien, c'est là que c'est amusant, ils sont choisis au hasard... Il n'existe en effet pas de critères consensuels sur la meilleure méthode de choix des membres du NomCom (rappelez-vous qu'à l'IETF, on ne peut pas voter, puisqu'il n'y a pas de notion de « membre » et donc pas de corps électoral rigoureusement défini). Le tirage au sort se fait selon la méthode, ouverte et publiquement vérifiable, spécifiée par le RFC 3797. Voici par exemple les sources de données aléatoires pour 2018 et un exemple de résultat.
Une fois sélectionnés, les membres du NomCom se mettent au travail (section 5 du RFC). Ils ne sont bien sûr pas éligibles pour les postes qu'il vont devoir pourvoir. Lorsqu'ils doivent prendre une décision, le NomCom vote (une procédure rare à l'IETF). Les nominations peuvent être faites par n'importe quel participant à l'IETF, y compris le nommé lui-même. La décision de retenir tel ou tel nommé comme candidat doit s'appuyer sur sa connaissance de l'IETF et ses qualifications pour le poste (qui ne sont pas forcément les mêmes pour tous les comités : par exemple, l'IETF LLC nécessite des compétences administratives qui sont moins importantes à l'IAB). L'IETF étant une organisation de grande taille, le NomCom ne connait pas forcément tout le monde, et peut donc aller à la « pêche aux informations » en consultant des gens extérieurs sur tel ou tel nommé.
Le « mandat » typique dure deux ans (trois à l'IETF LLC et au Trust). Il n'y a pas de limite au nombre de « mandats » mais le NomCom peut évidemment décider de donner la priorité aux nommés qui n'ont pas encore eu de mandat, ou pas encore effectué beaucoup de mandats.
Les informations récoltées par le NomCom, et ses discussions sont archivées (mais non publiques : voir plus haut au sujet de la confidentialité). Ces archives sont directement utiles s'il faut, par exemple, remplir un poste et qu'on ne veut pas recommencer le processus de zéro pour certains nommés.
Les humains étant ce qu'ils sont, il y aura des désaccords en interne. Comment le NomCom gère-t-il les contestations (section 6) ? Idéalement, le NomCom doit essayer de les régler tout seul (ne serait-ce que pour préserver la confidentialité déjà mentionnée). Si cela ne marche pas, le problème est transmis à l'ISOC, qui nomme un arbitre, dont les décisions sont définitives (pas d'appel).
J'ai parlé ici surtout de pourvoir des postes, mais il peut aussi y avoir révocation (recall, section 7) d'un membre d'un des comités concernés. Cette révocation peut être demandé par au moins vingt participants à l'IETF, qui doivent être éligibles au NomCom, à l'ISOC. Un Recall Committee est alors créé, et peut décider à la majorité des trois quarts d'une révocation, sur la base des griefs présentés par les signataires de la demande de révocation.
Bien des choses au sujet du NomCom ne sont pas écrites, et la tradition orale joue un rôle important dans son fonctionnement. L'annexe C rassemble plusieurs grains de sagesse issus de cette tradition. Par exemple, avoir été président d'un groupe de travail IETF est considéré comme une bonne préparation à l'IESG. Il y a aussi des considérations sur l'équilibre global entre les membres d'un comité. Il ne s'agit pas seulement que chaque membre soit individuellement bon, il faut aussi que le comité rassemble des gens de perspectives différentes (âge, expérience, région d'origine, monde académique vs. entreprises à but lucratif, etc). La tradition orale recommande aussi d'éviter qu'une même organisation n'occupe trop de postes dans un comité. Même si les gens de cette organisation ne forment pas un bloc, l'impression donnée serait mauvaise pour l'IETF.
L'annexe B de notre RFC contient les changements depuis le RFC 7437. Rien de crucial, mais on notera :
L'article seul
RFC 8716: Update to the IETF Anti-Harassment Procedures for the Replacement of the IETF Administrative Oversight Committee (IAOC) with the IETF Administration LLC
Date de publication du RFC : Février 2020
Auteur(s) du RFC : P. Resnick (Episteme Technology Consulting LLC), A. Farrel (Old Dog Consulting)
Réalisé dans le cadre du groupe de travail IETF iasa2
Première rédaction de cet article le 28 février 2020
Les procédures de l'IETF en cas de harcèlement lors des réunions physiques ou en ligne sont décrites dans le RFC 7776. Ce RFC 7776 reste d'actualité, il n'est modifié que sur un point : le remplacement de l'ancienne IAOC (IETF Administrative Oversight Committee) par les institutions du projet « IASA version 2 », décrit dans le RFC 8711.
On peut résumer notre nouveau RFC 8716 simplement : partout où, dans le RFC 7776, il y a écrit IAOC, remplacer par IETF LLC (IETF Administration Limited Liability Company, cf. RFC 8711), et partout où il y a écrit IAD (IETF Administrative Director), remplacer par IETF Executive Director. C'est tout.
L'article seul
RFC 8718: IETF Plenary Meeting Venue Selection Process
Date de publication du RFC : Février 2020
Auteur(s) du RFC : E. Lear (Cisco Systems)
Réalisé dans le cadre du groupe de travail IETF mtgvenue
Première rédaction de cet article le 28 février 2020
La question de la sélection du lieu pour les réunions physiques de l'IETF a toujours suscité des discussions passionnées, d'autant plus que chaque participant, et son chat, a un avis. Il y a de nombreux critères (coût, distance, agréments du lieu, goûts personnels…) Ce nouveau RFC décrit le nouveau mécanisme par lequel est sélectionné un lieu, et les critères à respecter.
En théorie, venir aux réunions physiques n'est pas indispensable. L'IETF, organisme de normalisation technique de l'Internet, travaille, étudie les propositions, les amende, les approuve ou les rejette entièrement en ligne (avec l'aide de quelques outils comme le DataTracker). Ceci dit, en pratique, venir aux trois réunions physiques par an aide certainement à faire avancer son sujet favori. Ces réunions rassemblent des centaines de participants IETF pendant une semaine et sont l'occasion de nombreuses discussions. À noter que, pendant la réunion, une liste de discussion permet également des bavardages généralisés, où les conseils sur les bons bars et restaurants rencontrent les avis sur la meilleure route vers l'aéroport, et des récriminations sur les ascenseurs, l'air conditionné, le manque de cookies, etc. Ce RFC sort d'ailleurs au moment exact où l'IETF se déchire sur l'opportunité ou non de maintenir la réunion de Vancouver malgré l'épidémie.
La reponsabilité du choix d'un lieu pour les réunions incombe à l'IASA (IETF Administrative Support Activity, RFC 8711). Ce RFC ne lui supprime pas cette responsabilité mais lui fournit des éléments à prendre en compte. L'IETF a trois rencontres physiques par an, s'inscrivant dans le cadre de ses missions, qui sont décrits dans le RFC 3935. (Notez que certains participants contestent ces rencontres physiques, considérant qu'une organisation de normalisation des protocoles Internet pourrait se « réunir » en ligne.) La section 2 du RFC décrit les principes fondamentaux à prendre en compte pour le choix du lieu de la réunion :
- Permettre la participation du plus grand nombre, quel que soit leur pays d'origine, ce qui implique que les pays ayant une politique de visa très restrictive, comme les États-Unis, sont déconseillés,
- Et cela implique également que l'IETF préfère se tenir à l'écart des pays qui discriminent selon le genre, la couleur de peau, l'orientation sexuelle, etc ; c'est d'ailleurs un tel cas, soulevé par Ted Hardie, qui avait été à l'origine de la création du groupe mtgvenue, lorsque le choix de se réunir à Singapour avait été contesté en raison des lois homophobes de ce pays,
- Un accès Internet de qualité est évidemment nécessaire, et non censuré ; cela avait donné lieu à de sévères discussions lors de la réunion (la seule jusqu'à ce jour) en Chine (le RFC note aussi, dans sa section 7, que la vie privée est importante et que les participants doivent être informés d'une éventuelle surveillance),
- Le but est de travailler, et cela implique un environnement qui s'y prête bien, par exemple la possibilité de réunions informelles dans les environs, et dans de bonnes conditions (RFC 6771),
- Le coût est un problème crucial, beaucoup de participants n'étant pas financés par une entreprise ou un gouvernement.
En revanche, la même section 2 cite des non-objectifs :
- À part les cas de discrimination cités plus haut, qui concernent directement les participants à l'IETF, le choix du lieu de la réunion n'a pas pour objectif de valider ou de critiquer la politique du gouvernement local, ou les mœurs locales,
- Avoir le maximum de participants n'est pas un but en soi, les réunions IETF n'ont pas un objectif commercial,
- Et, évidemment, il n'y aura pas de critères touristiques (ah, les réunions à Minneapolis en hiver…)
Compte-tenu de ces objectifs de haut niveau, la section 3 du RFC liste les critères. D'abord, ceux qui sont impératifs :
- L'endroit précis de la réunion (en général un grand hôtel, mais parfois un centre de conférences) doit fournir assez d'espace pour toutes les activités,
- Il doit être accessible aux handicapés en fauteuil roulant (d'autres formes de handicap sont mentionnées plus loin, avec des critères moins stricts),
- Il doit pouvoir être connecté à l'Internet dans de bonnes conditions (IPv4 et IPv6, pas de NAT, capacité suffisante, etc ; notez que, la plupart du temps, le lieu ne fournit pas cela par défaut et c'est à l'IETF de tout installer et configurer avant la réunion).
Il y a ensuite les critères importants. Évidemment, l'idéal serait de trouver un endroit qui satisfasse tous les critères mais, en général, ce n'est pas possible. Le choix sera toujours un compromis. Il faut donc déterminer quels critères on peut accepter de sacrifier, et c'est la raison pour laquelle il n'y a finalement que trois critères impératifs. Les critères importants mais non impératifs sont :
- Le lieu doit être raisonnablement accessible d'un grand nombre d'endroits (la réunion de Buenos Aires, la seule qui se soit tenue en Amérique latine, avait été très critiquée de ce point de vue, le coût total et le temps total de voyage avaient été très importants, par rapport à, disons, New York ou Singapour),
- Il doit être possible de trouver une organisation locale qui participe à l'organisation, et des sponsors qui acceptent de financer (les frais d'inscription, pourtant très élevés, ne couvrent pas tout le budget),
- Les barrières à l'entrée (typiquement les visas) doivent être le plus basses possibles (là encore, cela dépend du participant : pour aller en France, la barrière pour un Slovène est basse, la Slovénie étant dans Schengen, celle pour un Malien est bien plus haute ; c'est donc le « coût » total qu'il faut considérer),
- Le lieu doit offrir des conditions de sécurité acceptables (critère parfois subjectif, les États-uniens, par exemple, voient souvent le reste du monde comme une jungle, et des habitants de Chicago ou Los Angeles s'inquiètent parfois à l'idée d'aller à Yokohama…),
- Par ailleurs, il faut suivre les principes (assez généraux) du RFC 8719.
Il faut se rappeler que l'IETF est internationale, et que la notion de « lieu éloigné » dépend donc du participant, c'est le coût total de voyage qui compte, pas celui de telle ou telle personne, d'où la politique « 1-1-1 », une réunion en Amérique du Nord, puis une en Europe, puis une en Asie, politique qui vise à répartir les coûts sur les divers participants
Pour l'endroit exact de la réunion (en général un grand hôtel), il y a des critères supplémentaires :
- De la place pour les réunions informelles (couloirs, annexes, bars et cafétérias, etc) et des endroits où se rencontrer dans les environs, puisque, comme souvent dans les réunions formelles, le travail le plus important se fait en dehors des salles de réunion (on voit souvent des petits groupes écrire des Internet-Drafts assis dans les couloirs),
- Prix « conformes aux tarifs d'affaire habituels » (ce qui est déjà très cher, si on prend en compte les habitudes étatsuniennes).
Dans le cas typique, l'IETF se tient dans un grand hôtel pour hommes d'affaires riches. (La dernière (au moment de l'écriture de cet article) réunion, à Montréal, était au Fairmont.) Et les participants au budget voyage le plus important logent sur place. Il existe aussi des overflow hotels où logent les moins riches. Dans l'hôtel principal et, parfois, dans les overflow hotels, on dispose du réseau IETF même dans sa chambre. Ce réseau est installé par une équipe de volontaires de l'IETF avant la réunion (les réseaux des hôtels sont en général catastrophiques, pas d'IPv6, pas de DNSSEC, des ports filtrés, etc, une réunion à Paris avait battu les records). Beaucoup de participants vont chez Airbnb ou carrément en auberge de jeunesse et doivent alors se débrouiller pour le réseau.
Les ingénieurs et ingénieures sont des êtres humains et doivent donc manger. D'où des critères concernant nourriture et boisson :
- Disponibilité de ressources alimentaires proches, pour tous les goûts, toutes les bourses, tous les critères, par exemple de santé ; j'ai déjà vu des conférences dans des resorts isolés, où on était obligés de se contenter de l'offre locale, souvent très chère,
- Ces ressources doivent être disponibles sous forme de restaurants mais aussi de magasins pour ceux qui préfèrent ensuite aller manger dehors (il n'y a pas de repas servi, aux réunions IETF).
Enfin, il y a des critères sur des points variés :
- Il est préférable que tout soit au même endroit, pour éviter les déplacements,
- Il est préférable qu'on puisse revenir, et qu'il y ait des contrats pour plusieurs évenements, avec prix réduits.
Même si tous ces critères ne sont pas impératifs, mis ensemble, ils sont très exigeants. Des gens demandent parfois pourquoi, par exemple, il n'y a jamais eu de réunion de l'IETF en Inde, pays certainement important pour l'Internet. C'est entre autres en raison de spécificités locales, par exemple la difficulté d'obtention des visas. (Cf. cette discussion.)
On notera que les critères sont finalement peu nombreux. De très nombreuses autres propositions avaient été faites, qui risquaient de mener à un catalogue de critères, très épais et, de toute façon, impossibles à satisfaire simultanément. Le rapport « droits humains » notait que certains critères pouvaient être incompatibles entre eux (une personne aveugle voudrait pouvoir être accompagnée de son chien guide, et une autre personne est allergique aux chiens, voire en a une phobie.)
C'est ainsi que des critères comme la disponibilité d'une crèche ont été retirés (notez que le RIPE le fait et que l'IETF va tenter le coup), de même que la demande de toilettes non genrées, qui était dans certaines versions du projet de RFC.
Comme vous vous en doutez, la discussion à l'IETF sur ce RFC n'a pas été évidente. De toute façon, la décision sur le choix d'un lieu reviendra à l'IASA, sauf pour les critères impératifs, qui nécessiteront une discussion générale.
L'article seul
RFC 8729: The RFC Series and RFC Editor
Date de publication du RFC : Février 2020
Auteur(s) du RFC : R. Housley (Vigil Security), L. Daigle (Thinking Cat)
Pour information
Réalisé dans le cadre du groupe de travail IETF iasa2
Première rédaction de cet article le 28 février 2020
Les RFC, qui incluent notamment les normes techniques de l'Internet, sont en général réalisés par l'IETF mais sont publiés par une entitée séparée, le RFC editor. Ce RFC documente les RFC, et le rôle du RFC Editor. Il remplace le RFC 4844, avec assez peu de changements, essentiellement l'adaptation à la nouvelle structure administrative de l'IETF, décrite dans le RFC 8711.
Comme pour beaucoup de choses dans l'Internet, la définition exacte des rôles des différents acteurs n'avait pas été formalisée car personne n'en ressentait le besoin. Au fur et à mesure que l'Internet devient une infrastructure essentielle, cette absence de formalisation est mal ressentie et la politique actuelle est de mettre par écrit tout ce qui était implicite auparavant.
C'est le cas du rôle du RFC Editor. Autrefois le titre d'une seule personne, Jon Postel, ce nom désigne désormais une organisation plus complexe. Relire les RFC avant publication, les corriger, leur donner un numéro et assurer leur distribution, tels sont les principaux rôles du RFC Editor.
Notre RFC décrit le but des RFC (section 2) : « documenter les normes de l'Internet, et diverses contributions ». Puis, il explique le rôle du RFC Editor, sa place dans le processus de publication et les fonctions qu'il doit assurer (le cahier des charges de l'IETF avait été publié dans le RFC 4714). Pour plus de détails sur le travail, on peut consulter le site Web du RFC Editor.
Il faut noter (section 5 du RFC) que le RFC editor reçoit des textes candidats par plusieurs voies. Si la plus connue est celle de l'IETF, il peut aussi publier des RFC d'autres origines notamment ceux des soumissions indépendantes (RFC 4846). Il est supervisé par l'IAB et par la nouvelle IETF LLC (RFC 8711.) Le fonctionnement détaillé du RFC Editor et son organisation figurent dans le RFC 8728.
Le RFC editor a une mission difficile puisqu'il doit agir avec prudence, voire avec conservatisme, pour assurer la qualité et la disponibilité des RFC pendant de très longues périodes.
Il y a peu de changements depuis le RFC précédent sur ce sujet (le RFC 4844), essentiellement le remplacement de l'ancienne IAOC par l'IETF LLC décrite dans le RFC 8711.
L'article seul
RFC 8721: Advice to the Trustees of the IETF Trust on Rights to Be Granted in IETF Documents
Date de publication du RFC : Février 2020
Auteur(s) du RFC : J. Halpern (Ericsson)
Pour information
Réalisé dans le cadre du groupe de travail IETF iasa2
Première rédaction de cet article le 28 février 2020
Une fois les droits de publication, et de modification, offerts par le(s) auteur(s) d'un RFC à l'IETF trust, quels droits ce dernier va-t-il transmettre aux lecteurs et lectrices d'un RFC ? Le RFC 5378 spécifie les droits « entrants » à l'IETF trust, et notre RFC 8721 spécifie les droits sortants : que puis-je faire avec un RFC ? Ai-je le droit de le lire ? De le redistribuer ? De le traduire ? Ce RFC est une légère modification du RFC 5377, qu'il remplace. Le but de cette modification était de s'adapter à la nouvelle structure administrative de l'IETF, décrite dans le RFC 8711. Notamment, l'ancien IAOC (RFC 4071) disparait.
La section 1 du RFC rappelle un point important : c'est
l'IETF trust qui décide. Le RFC 8721, publié par l'IETF, n'est qu'indicatif et ne fixe que des
grands principes. Le texte exact de la licence des RFC est écrit
par l'IETF trust (http://trustee.ietf.org/license-info/ et il existe aussi
une FAQ sur
ces textes.) La section 2 revient d'ailleurs sur les raisons de ce
choix (pouvoir s'adapter aux changements légaux aux ÉUA, pays de
l'IETF trust et de l'ISOC).
On pourra trouver ce texte standard, ce boilerplate, sur le site du Trust dans la Trust Legal Provisions.
La section 2 du RFC décrit les buts que suit l'IETF en publiant des RFC (cf. RFC 3935). Clairement, l'élaboration d'une licence doit se faire en gardant ces buts à l'esprit : faire fonctionner l'Internet le mieux possible, notamment en assurant l'interopérabilité des mises en œuvres des protocoles TCP/IP.
La section 3 explique l'articulation de ce RFC avec le RFC 5378 : les droits sortants (ceux que l'IETF trust accorde aux utilisateurs) doivent être inférieurs ou égaux aux droits entrants (ceux que l'auteur a accordé à l'IETF trust). Autrement dit, l'IETF ne peut pas donner de droits qu'elle n'a pas. Si l'auteur d'un RFC interdit toute modification à son texte, le RFC publié ne permettra pas de modifications (et ne pourra d'ailleurs pas être publié sur le chemin des normes).
La section 4 s'attaque aux droits que l'IETF trust devrait donner aux utilisateurs :
- Droit de publier et de republier (section 4.1), une très ancienne politique de l'IETF,
- Droit (évidemment) d'implémenter la technique décrite dans le RFC (section 4.3). C'est ici qu'apparait la distinction entre code et texte. (Le code inclut également le XML, l'ASN.1, etc.) Par un mécanisme non spécifié dans le RFC (cela a été choisi par la suite comme une liste publiée par l'IETF trust), le code est marqué spécialement (entre <CODE BEGINS> et <CODE ENDS>, comme défini dans la Trust Legal Provisions) et l'implémenteur aura davantage de droits sur le code, notamment le droit de modification. Cela ne résout pas, et de loin, tous les problèmes. Par exemple, cela ne permet pas de modifier du texte d'un RFC qui est inclus dans la documentation d'un logiciel.
- Droit de modifier le texte ? Non, ce droit est exclu par la section 4.4, en tout cas pour le texte (le code inclus dans les RFC reste modifiable, pour permettre son intégration dans des logiciels libres.)
Comme indiqué plus haut, il n'y a pas de changements de fond depuis le RFC 5377, uniquement la suppression des références à l'ancien IAOC (IETF Administrative Oversight Committee).
L'article seul
RFC 8712: The IETF-ISOC Relationship
Date de publication du RFC : Février 2020
Auteur(s) du RFC : G. Camarillo (Ericsson), J. Livingood (Comcast)
Pour information
Réalisé dans le cadre du groupe de travail IETF iasa2
Première rédaction de cet article le 28 février 2020
L'IETF, l'organisme qui écrit les normes techniques de l'Internet fait partie de la galaxie des nombreuses organisations qui ont un rôle plus ou moins formel dans le fonctionnement du réseau. Ce nouveau RFC décrit les relations de l'IETF avec un autre de ces organismes, l'Internet Society (ISOC). Ce RFC remplace le RFC 2031, notamment pour s'adapter à la nouvelle structuration de l'IETF, dite « IASA 2 » (IASA veut dire IETF Administrative Support Activity).
Historiquement, l'IETF n'était qu'un sigle et une idée. Il n'y avait pas d'organisation formelle de l'IETF. Au début, cela marchait bien comme cela, mais des inquiétudes se sont fait jour. Si l'IETF n'existe pas juridiquement, qui est responsable des RFC ? Si une entreprise mécontente d'un RFC fait un procès, chose courante aux États-Unis, à qui va-t-elle le faire ? Aux individus auteurs du RFC ? C'est entre autres en raison de ce genre de risques que l'IETF s'est mise sous un parapluie juridique, celui de l'Internet Society (ISOC), organisation créée pour donner une structure à l'Internet, permettant par exemple d'avoir un budget, d'empêcher des escrocs de déposer la marque « Internet », pour faire du lobbying, etc. C'est donc l'ISOC qui est la représentation juridique de l'IETF, mais aussi de l'IAB et de l'IRTF. (Cela date de 1995, via un groupe de travail qui se nommait Poised, qui a lancé l'effort de formalisation des processus IETF.) Si une entreprise, motivée par des juristes aussi méchants que dans un roman de Grisham, veut faire un procès en raison d'un RFC, elle doit faire un procès à l'ISOC (qui a ses propres bataillons de juristes).
La relation exacte entre l'IETF et l'ISOC était spécifiée dans le RFC 2031. Depuis, a émergé le concept d'« IASA » (IASA veut dire IETF Administrative Support Activity), une structuration plus forte des activités non techniques de l'IETF. Encore depuis, la création de « IASA 2 », dans le RFC 8711, a changé les choses, nécessitant le remplacement du RFC 2031. L'IASA version 2 créé une nouvelle structure, l'IETF LLC (LLC veut dire Limited Liability Company), qui est une filiale de l'ISOC.
Assez d'histoire, voyons d'abord, les principes (section 2 de notre RFC). L'ISOC a dans ses missions d'encourager et d'aider le développement de normes techniques ouvertes, ce qui correspond au rôle de l'IETF. Le but est donc d'être efficace, et de produire des bonnes normes, librement accessibles, et via un processus ouvert.
La section 3 précise la répartition des rôles : à l'IETF le développement des normes, à l'ISOC la partie juridique et financière. L'ISOC ne doit pas intervenir dans les choix techniques.
Cela ne veut pas dire que l'ISOC se contente de regarder. La section 4 du RFC rappelle qu'elle contribue au choix des membres du NomCom (qui fait les nominations à certains postes, cf. RFC 8713), de l'IAB, et qu'elle sert d'appel ultime en cas de conflit. D'autre part, l'ISOC est membre de certaines organisations très formelles, comme l'UIT, et sert donc de relais pour l'IETF auprès de cette organisation (RFC 6756).
L'ISOC a aussi un rôle de popularisation des technologies Internet et de sensibilisation à certains enjeux. Par exemple, elle a créé le programme Deploy 360, qui promeut notamment DNSSEC et IPv6.
Et en sens inverse (section 5 du RFC), l'IETF a une représentation au conseil d'administration de l'ISOC (RFC 3677).
Du point de vue juridique, rappelons que l'IETF LLC est rattachée à l'ISOC comme décrit dans l'accord entre l'IETF et l'ISOC d'août 2018 (oui, il a fallu du temps pour publier ce RFC…) Notez que le RFC qualifie la LLC de disregarded (ignorée, négligée) mais c'est en fait le sens fiscal de disregarded qui compte : la LLC ne paie pas d'impôts, l'ISOC le fait pour elle.
L'IETF a une structure pour gérer sa propriété intellectuelle, l'IETF Trust, créée par le RFC 5378, puis mise à jour dans les RFC 8715 et RFC 8714. C'est l'IETF Trust qui gère les marques, le copyright, etc. C'est officiellement cet IETF Trust qui vous donne le droit de lire et de distribuer les RFC. La nouvelle structure ne change pas le rôle de l'IETF Trust.
Enfin, le fric (qui fait tourner le monde). La section 7 du RFC rappelle que c'est souvent l'ISOC qui finance les activités de l'IETF. Les détails financiers sont en ligne.
Voilà, cela fait déjà beaucoup de choses à savoir, et c'est bien sûr encore pire si on inclut tous les RFC de la nouvelle structuration IASA mais il faut se rappeler que cette complexité est en partie volontaire. D'abord, il faut éviter la domination d'une organisation unique qui contrôlerait tout, et ensuite certaines organisations nécessitent des compétences spécifiques (par exemple, à l'IETF, il faut être pointu sur les questions techniques).
L'article seul
RFC 8719: High-Level Guidance for the Meeting Policy of the IETF
Date de publication du RFC : Février 2020
Auteur(s) du RFC : S. Krishnan (Kaloom)
Réalisé dans le cadre du groupe de travail IETF mtgvenue
Première rédaction de cet article le 28 février 2020
Le groupe mtgvenue de l'IETF était chargé de définir une politique pour le choix des lieux pour les réunions physiques de l'IETF. Ce nouveau RFC pose le principe général d'une rotation entre divers continents. Le RFC 8718 décrit ensuite les détails.
L'IETF a trois réunions physiques par an. L'idée est d'avoir en moyenne (mais pas forcément pour chaque année) une réunion en Amérique du Nord, une en Europe et une en Asie (cf. cette présentation de la politique « 1-1-1 ».) Le but est de répartir les coûts et temps de voyage entre les différents participants. Cette politique était jusqu'à présent informelle, ce RFC la documente officiellement. Elle se base sur la répartition constatée des participants à l'IETF. Notez que les frontières exactes des continents sont volontairement laissées floues, pour ne pas se lier les mains dans certains cas (demandez-vous si le Mexique est en Amérique du Nord, ou si Chypre est en Europe ou en Asie…)
Certaines réunions, dites « exploratoires » peuvent se tenir dans d'autres continents. L'IETF a fait une fois une réunion à Buenos Aires, et une fois à Adelaide.
Sur la base de cette politique « 1-1-1 », les décisions effectives seront prises en suivant le RFC 8718. Et, bien sûr, la politique n'est pas 100 % rigide. L'Internet change, les participants à l'IETF également, et d'autres lieux deviendront envisageables.
L'article seul
RFC 8720: Principles for Operation of Internet Assigned Numbers Authority (IANA) Registries
Date de publication du RFC : Février 2020
Auteur(s) du RFC : R. Housley (Vigil Security), O. Kolkman (Internet Society)
Pour information
Première rédaction de cet article le 28 février 2020
Traditionnellement, le fonctionnement de la normalisation dans l'Internet sépare deux fonctions : l'IETF développe les normes techniques (qui sont publiées dans les RFC, documents immuables) et un opérateur de registres techniques, actuellement l'IANA, gère les nombreux registres qui stockent les paramètres des protocoles de l'IETF. Au contraire des RFC, ces registres changent tout le temps. Ce nouveau RFC décrit les principes de haut niveau sur lesquels repose le fonctionnement de ces registres. Il remplace le RFC 7500, sans changement crucial, juste en intégrant la nouvelle organisation administrative de l'IETF, qui voit le remplacement de l'IAOC par l'IETF LLC.
Ces registres sont cruciaux pour le bon fonctionnement de
l'Internet. Presque tous les protocoles Internet dépendent d'un ou
de plusieurs registres. Aujourd'hui, il existe plus de 2 000 registres à l'IANA (la liste complète est en https://www.iana.org/protocols). Les valeurs stockées
peuvent être des nombres, des chaînes de caractères, des adresses,
etc. Leur allocation peut être centralisée
(tout est à l'IANA) ou décentralisée, avec
l'IANA déléguant à des registres qui à leur tour délèguent, comme
c'est le cas pour les noms de
domaine et pour les adresses IP.
Notons aussi que, pendant longtemps, la gestion des registres et
la publication des RFC étaient assurés par le même homme, Jon Postel à l'ISI. Aujourd'hui, les deux opérations sont
complètement séparées, https://www.iana.org/ et https://www.rfc-editor.org/.
L'IANA n'a pas de pouvoirs de police : le respect des registres IANA dépend uniquement de la bonne volonté générale. Évidemment, la pression est forte pour respecter ces registres, puisque le bon fonctionnement de l'Internet en dépend. Ce RFC présente les principes sur lesquels ces registres reposent (sections 2 et 3 du RFC) :
- Unicité des identificateurs. C'est l'un des principaux buts
des registres, s'assurer que qu'il n'y a qu'un seul
.frou.org, ou que l'algorithme 13 de DNSSEC désigne bien ECDSA pour tout le monde. - Stabilité. Les registres doivent tenir plus longtemps que la page Web corporate moyenne. Leur contenu existant ne doit pas changer sauf s'il y a une très bonne raison.
- Prédictabilité. Le processus d'enregistrement doit être prévisible et ne pas comporter de soudaines surprises (« finalement, il faut tel papier en plus »). Parfois, un jugement humain est nécessaire (cf. RFC 8126) donc le processus n'a pas à être algorithmique, ni à être limité dans le temps, mais il ne doit pas soudainement ajouter des étapes non prévues.
- Publicité. Les registres doivent être publics (en pratique, le principal mode de distribution est via le Web). Ce n'est pas si évident que cela, les dinosaures attardés de la normalisation, comme l'AFNOR, l'ISO ou l'IEEE ne le font pas.
- Ouverture. Le processus qui détermine les politiques d'enregistrement doit être ouvert à tous ceux qui désirent participer. Dans presque tous les cas, c'est l'IETF qui détermine cette politique (les exceptions sont importantes comme la gestion de la racine des noms de domaine), via un RFC développé en effet dans un processus ouvert. Le RFC 8126 détaille les politiques IANA possibles. (Parmi elles, certaines nécessitent un examen par un expert, le jugement humain mentionné plus haut.)
- Transparence. La gestion des registres ne doit pas être opaque. On peut écrire à l'IANA, ou bien passer les voir Away From Keyboard pendant les réunions IETF, où l'IANA a toujours un stand.
- Redevabilité. L'IANA doit rendre compte de sa gestion. Selon le RFC 8722, la supervision de la fonction IANA incombe à l'IAB (RFC 2850). En outre, l'IETF LLC (RFC 8711) a un SLA avec l'actuel opérateur de la fonction IANA, l'ICANN. L'IAB et l'IETF LLC sont eux-même redevables devant une communauté plus large, via le processus NomCom (RFC 8713). Pour les adresses IP et les ressources associées, le RFC 7249 fait gérer la redevabilité par les RIR (RFC 7020). Ceux-ci sont des organisations ouvertes et eux-même redevables devant leurs membres. (Avez-vous noté quel registre n'était pas mentionné comme bon exemple par le RFC ?)
La section 5 décrit le changement depuis le prédécesseur, le RFC 7500. Il ne s'agit que d'un changement bureaucratique ; l'ancienne IAOC (IETF Administrative Oversight Committee) a été, dans le RFC 8711, remplacée par une nouvelle structure, l'IETF LLC (Limited Liability Company), nécessitant la mise à jour du RFC 7500.
L'article seul
RFC 8715: Discussion of the IASA 2.0 Changes as They Relate to the IETF Trust
Date de publication du RFC : Février 2020
Auteur(s) du RFC : J. Arkko (Ericsson)
Pour information
Réalisé dans le cadre du groupe de travail IETF iasa2
Première rédaction de cet article le 28 février 2020
Le passage de la structure administrative de l'IETF vers « IASA 2.0 » (IASA = IETF Administrative Support Activity, cf. RFC 8711) a nécessité des changements dans la manière dont les membres de l'IETF Trust sont désignés. Ces changements sont décrits dans le RFC 8714, et expliqués brièvement dans ce court RFC.
Petit rappel : l'IETF Trust gère la
propriété intellectuelle de l'IETF, comme la
marque ou comme le nom de domaine ietf.org et, bien sûr, comme les RFC, dont la licence dépend
formellement de cet IETF Trust. Cet IETF
Trust est enregistré
aux États-Unis. Au début, les membres de l'IAOC (IETF
Administrative Oversight Committee) étaient également
membres de l'IETF Trust. L'IAOC ayant été
supprimé par le RFC 8711, il fallait
donc changer les règles de désignation, ce qu'a fait le RFC 8714.
Lors des discussions sur la création de l'« IASA 2 » (IETF Administrative Support Activity, deuxième version), il avait été envisagé de fusionner l'IETF Trust avec la nouvelle structure, l'IETF LLC. Finalement, l'IETF Trust reste une organisation indépendante. Les raisons ? D'abord, une volonté de minimiser les changements liés au projet « IASA 2 », ensuite, l'observation du fait que le travail de l'IETF Trust est assez différent de celui de la IETF LLC (décrite dans le RFC 8711). L'IETF Trust a une activité calme, avec peu ou pas de problèmes urgents à résoudre, et les changements sont rares.
Mais comme il fallait bien tenir compte de la disparition de l'IAOC, le choix a été de réduire la taille de l'IETF Trust, plutôt que de créer un mécanisme alternatif à l'IAOC (puisque, comme indiqué plus haut, l'IETF Trust ne demande pas beaucoup de travail). Les cinq membres sont désignés par le comité de nomination de l'IETF (« NomCom »), par l'IESG et par l'ISOC. Pour ce dernier cas, le RFC note qu'on aurait pu utiliser l'IETF LLC et pas l'ISOC, mais que l'ISOC semblait plus adaptée, pour une tâche qui est assez politique (l'IETF LLC est normalement purement administrative).
Sinon, vous pouvez voir ici un appel à candidatures du NomCom pour l'IETF Trust.
L'article seul
RFC 8709: Ed25519 and Ed448 Public Key Algorithms for the Secure Shell (SSH) Protocol
Date de publication du RFC : Février 2020
Auteur(s) du RFC : B. Harris, L. Velvindron (cyberstorm.mu)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF curdle
Première rédaction de cet article le 26 février 2020
Un très court RFC, juste pour ajouter au protocole SSH les algorithmes de signature Ed25519 et Ed448. Ces algorithmes sont déjà disponibles dans OpenSSH.
Ce protocole SSH est normalisé dans le RFC 4251, et a de nombreuses mises en œuvre, par exemple dans le logiciel libre OpenSSH. Pour authentifier le serveur, SSH dispose de plusieurs algorithmes de signature. Ce nouveau RFC en ajoute deux, dont Ed25519, qui avait été normalisé dans le RFC 8032. (En toute rigueur, l'algorithme se nomme EdDSA et Ed25519 est une des courbes elliptiques possibles avec cet algorithme. Mais je reprends la terminologie du RFC.) À noter que les courbes elliptiques sous-jacentes peuvent également être utilisées pour l'échange de clés de chiffrement, ce que décrit le RFC 8731.
La section 3 de notre RFC donne les détails techniques, suivant
le RFC 4253. L'algorithme se nomme
ssh-ed25519. Son copain avec la courbe
elliptique Ed448 est ssh-ed448. Ils sont tous
les deux enregistrés à l'IANA.
Le format de la clé publique est la chaîne "ssh-ed25519" suivie
de la clé, telle que décrite dans le RFC 8032,
section 5.1.5 (et 5.2.5 pour Ed448). Avec OpenSSH, vous pouvez la
voir dans ~/.ssh/id_ed25519.pub. Les signatures
sont faites selon la technique du RFC 8032,
sections 5.1.6 et 5.2.6. Leur format est décrit en section 6, et la
vérification de ces signatures en section 7, en suivant la procédure
des sections 5.1.7 et 5.2.7 du RFC 8032.
La façon la plus courante de vérifier la clé publique du serveur SSH auquel on se connecte est le TOFU. Si on préfère une vérification plus sérieuse, on peut utiliser les clés SSH publiées dans le DNS, méthode décrite dans le RFC 4255, utilisant des enregistrements de type SSHFP. Cela fait longtemps que ces enregistrements peuvent utiliser Ed25519 (cf. RFC 7479) et notre RFC ajoute le cas de Ed448, par exemple :
example.net. IN SSHFP 6 2 ( a87f1b687ac0e57d2a081a2f282672334d90ed316d2b818ca9580ea384d924 01 )
(Il est enregistré à l'IANA.)
Ed25519 a été ajouté à OpenSSH en janvier 2014
(donc bien avant la publication de ce RFC.) C'est l'option
-t de ssh-keygen qui
permet de sélectionner cet algorithme :
% ssh-keygen -t ed25519 -f /tmp/ed25519 Generating public/private ed25519 key pair. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /tmp/ed25519. Your public key has been saved in /tmp/ed25519.pub. The key fingerprint is: SHA256:VEN6HVM0CXq+TIflAHWCOQ88tfR35WXQZ675mLIhIIs stephane@godin The key's randomart image is: +--[ED25519 256]--+ | o==O+*++| | oB* B.+*| | o o== oo=| | . . o.= .o| | . S + oo | | . o . o oo | | E . . + + | | ...o .| | .o | +----[SHA256]-----+
À noter que OpenSSH 7.6 n'a pas ed448. D'une manière générale, ed25519 a été beaucoup plus souvent mise en œuvre dans les clients et serveurs SSH.
L'article seul
RFC 8740: Using TLS 1.3 with HTTP/2
Date de publication du RFC : Février 2020
Auteur(s) du RFC : D. Benjamin (Google)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF httpbis
Première rédaction de cet article le 24 février 2020
Voici un très court RFC, pour résoudre un petit problème d'interaction entre TLS 1.3 et HTTP/2. (Mais ne le lisez pas, il a depuis été intégré au RFC 9113.)
Les anciennes versions du protocole de sécurité TLS avaient un mécanisme de renégociation des paramètres de la session, permettant de changer certains paramètres même après que la session ait démarré. C'était parfois utilisé pour l'authentification du client TLS, par exempe lorsqu'un serveur HTTP décide de demander ou pas un certificat client en fonction de la requête dudit client. Or, dans la version 2 de HTTP, HTTP/2, normalisée à l'origine dans le RFC 7540, il peut y avoir plusieurs requêtes HTTP en parallèle. On ne peut donc plus corréler une requête HTTP avec une demande de certificat. Le RFC 7540 (section 9.2.1) interdit donc d'utiliser la renégociation.
Mais la nouvelle version de TLS, la 1.3, spécifiée dans le RFC 9846, a supprimé complètement le mécanisme de renégociation. À la place, un mécanisme d'authentification spécifique a été normalisé (section 4.7.2 du RFC 9846.) Or, ce mécanisme pose les mêmes problèmes que la rénégociation avec le parallélisme que permet HTTP/2. Il fallait donc l'exclure aussi, ce qui n'avait pas été remarqué tout de suite. C'est ce que fait notre RFC. Pas d'authentification après la poignée de main initiale, elle est incompatible avec HTTP/2 (ou avec le futur HTTP/3, d'ailleurs, qui permet également des requêtes en parallèle) et elle doit déclencher une erreur.
À noter que la renégociation était également utilisée pour dissimuler le vrai certificat serveur, par exemple pour contourner certaines solutions de censure. Comme TLS 1.3 chiffre désormais le certificat serveur, la renégociation n'est plus utile pour ce scénario. En outre, la renégociation avait posé quelques problèmes de sécurité (cf. une faille fameuse, et le RFC 7457.)
Outre la renégociation, il y a d'autres messages qui peuvent
survenir après la poignée de main initiale. C'est le cas des
KeyUpdate (RFC 9846,
sections 4.7.3 et 7.2) mais ils concernent la session TLS entière,
pas juste une requête HTTP, donc ils sont compatibles avec le
parallélisme de HTTP/2. Quant aux
NewSessionTicket (RFC 9846, section 4.7.1), ils dépendent, eux, de la requête
HTTP, mais leur interaction avec HTTP/2 est prévue et documentée
dans le RFC 8470, et ils sont donc
acceptés. De toute façon, depuis, le problème a été réglé par le
remplacement du RFC 7540 par le RFC 9113.
L'article seul
RFC 8489: Session Traversal Utilities for NAT (STUN)
Date de publication du RFC : Février 2020
Auteur(s) du RFC : M. Petit-Huguenin (Impedance Mismatch), G. Salgueiro (Cisco), J. Rosenberg (Five9), D. Wing, R. Mahy, P. Matthews (Nokia)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tram
Première rédaction de cet article le 23 février 2020
Le NAT a toujours été une des plaies de l'Internet, entre autres parce qu'il perturbe les applications qui veulent transmettre une référence à leur adresse IP. STUN, décrit dans ce RFC, est un des protocoles qui permet de limiter les dégâts. (Il s'agit ici d'une mise à jour du RFC 5389.)
Pour plusieurs raisons, dont le manque d'adresses IPv4, de nombreuses machines sont connectées à l'Internet derrière un routeur qui fait du NAT. Leur adresse étant alors privée, elles ne peuvent pas la transmettre à l'extérieur, ce qui est une gêne considérable pour tous les protocoles qui reposent sur la référence à des adresses IP, comme SIP. SIP lui-même (RFC 3261) marche à travers le NAT mais les données audio ou vidéo transmises (typiquement par RTP) le sont à une adresse IP que l'appelant donne à l'appelé et, si cette adresse est privée, le flux multi-média n'arrivera jamais.
La bonne solution serait de déployer IPv6, qui fournit des adresses en quantité illimitée, ou à la rigueur de permettre un meilleur contrôle du routeur NAT avec PCP (RFC 6887) mais, en attendant, STUN est une solution simple et qui marche souvent.
STUN s'inscrit donc dans la catégorie des protocoles de « réparation » du NAT, catégorie décrite dans le RFC 3424.
STUN résout partiellement le problème des NAT de la manière
suivante : un serveur STUN doit être installé quelque part sur
l'Internet public (il existe des serveurs STUN
publics)
et reçoit des demandes envoyées en UDP (ou TCP, voir sections 6.2.2 et 6.2.3,
ou encore TLS ou DTLS) au port 3478. Le serveur STUN
peut alors connaitre l'adresse publique, celle mise par le routeur
NAT et, en répondant au client, il pourra informer celui-ci
« Voilà à quoi tes paquets ressemblent, vus de l'extérieur ».
Le nom du serveur STUN est typiquement configuré dans le client, puis le serveur recherché dans le DNS via les enregistrements SRV (RFC 2782), comme détaillé dans la section 8. (Le traditionnel client Unix en ligne de commande, montré plus loin, ne connait pas les SRV.)
Le principe est simple, mais le RFC est plus compliqué que cela, notamment en raison des problèmes de sécurité (la section 16 du RFC est très détaillée sur ce point). Par exemple, le client STUN peut avoir besoin de commencer par une connexion TCP pour obtenir un mot de passe temporaire. (D'autres méthodes d'authentification sont possibles.)
Lorsque STUN fonctionne sur UDP, ou bien sur DTLS, le client STUN doit également être préparé à rémettre les paquets qui seraient perdus (section 6.2.1).
Un autre problème est qu'il y a en fait plusieurs sortes de NAT (voir par exemple le RFC 2663). Par exemple, certains routeurs NAT (Symmetric NAT pour le RFC 3489) n'attribuent pas l'adresse externe uniquement en fonction de la source mais aussi en fonction de la destination. Ceux-ci ne fonctionnent pas avec STUN, qui a besoin de NAT cone, c'est-à-dire où les paquets d'une même machine auront toujours la même adresse IP externe.
Voici une démonstration d'un client STUN (assez ancien mais qui marche) qui, en se connectant à un serveur STUN public va apprendre son adresse IP publique, et le port, les deux ensemble formant l'adresse de transport (cf. section 4) :
% ifconfig -a hme0: [...] inet 172.19.1.2 (Adresse privée, probablement NATée...) % stun stun.1und1.de -v STUN client version 0.97 ... MappedAddress = 192.0.2.29:30189 SourceAddress = 212.227.67.33:3478 ChangedAddress = 212.227.67.34:3479 Unknown attribute: 32800 ServerName = Vovida.org 0.96 ... Primary: Independent Mapping, Port Dependent Filter, preserves ports, no hairpin ... (Mon adresse telle que vue de l'extérieur est donc 192.0.2.29, à noter que le terme MappedAddress n'est plus utilisé, le RFC parle de ReflexiveAddress.)
Une fois l'adresse extérieure détectée, tout n'est pas terminé car rien n'indique, par exemple, que les paquets vont effectivement passer. C'est pour cela que la section 13 insiste que STUN n'est qu'un outil, devant s'insérer dans une solution plus globale, comme ICE (RFC 8445). À lui seul, STUN ne permet pas la traversée de tous les NAT. La section 13 décrit en détail ce concept d'utilisation de STUN et les règles que doivent suivre les protocoles qui utilisent STUN.
La section 5 décrit le format des paquets. Un paquet STUN doit
comprendre l'indication d'une méthode, qui
indique le genre de services que désire le client. Notre RFC 8489 ne décrit qu'une seule méthode,
Binding, qui permet d'obtenir son adresse IP
extérieure mais TURN (RFC 8656), par exemple, en définit d'autres. Après la
méthode et un identificateur de transaction (qui sert au serveur
STUN à séparer ses clients), suivent les
attributs, encodés en TLV (la liste
des attributs figure en section 14). Les numéros des attributs
sont compris entre 0x0000 et 0x7FFF s'ils doivent être reconnus
par le serveur (autrement, la requête est rejetée) et entre 0x8000
et 0xFFFF si leur compréhension est facultative (cette notion
d'attributs obligatoires ou facultatifs facilite les évolutions
ultérieures du protocole). Il y a aussi un
magic cookie, une valeur fixe
(0x2112A442) qui sert à reconnaitre les
agents STUN conformes (il n'existait pas dans les vieilles
versions de STUN).
La section 19 de notre RFC résume les changements faits depuis le prédécesseur, le RFC 5389. Rien de bien crucial, d'autant plus que la plupart de ces changements sont l'intégration de RFC qui avaient étendu le protocole STUN après la parution du RFC 5389 :
- DTLS est désormais intégré (RFC 6347),
- L'algorithmes pour calculer le délai avant retransmission a été modifié suivant le RFC 6298,
- Les URI du RFC 7064 sont désormais inclus,
- SHA-256 et des nouveaux algorithmes pour TLS arrivent,
- Les identificateurs et mots de passe peuvent être en Unicode (RFC 8265),
- Possibilité d'anonymat pour les identificateurs (ce qui a nécessité des nouvelles règles dans le numnique envoyé par le serveur, pour éviter les attaques par repli),
- Ajout de l'attribut
ALTERNATE-DOMAIN, pour indiquer que le serveur proposé en alternative peut avoir un autre nom, - Et pour les programmeurs, des vecteurs de test en annexe B (venus du RFC 5769).
Il existe de nombreux logiciels clients et serveurs pour STUN (mais pas forcément déjà conforme aux légers changements de ce RFC). Le client est en général embarqué dans une application qui a besoin de contourner le NAT, par exemple un softphone, ou bien un navigateur Web qui fait du WebRTC. On peut citer :
- Le serveur coturn,
- Le serveur Restund,
- Le client et serveur stuntman,
- Le serveur turnserver.
Et si vous cherchez une liste de serveurs STUN publics, il y a celle-ci.
L'article seul
RFC 8656: Traversal Using Relays around NAT (TURN): Relay Extensions to Session Traversal Utilities for NAT (STUN)
Date de publication du RFC : Février 2020
Auteur(s) du RFC : T. Reddy (McAfee), A. Johnston (Villanova University), P. Matthews (Alcatel-Lucent, apparemment en fait Nokia, J. Rosenberg (jdrosen.net)
Chemin des normes
Réalisé dans le cadre du groupe de travail IETF tram
Première rédaction de cet article le 23 février 2020
Le protocole TURN, que décrit notre RFC, est le dernier recours des applications coincées derrière un routeur NAT et qui souhaitent communiquer avec une application dans la même situation (cf. RFC 5128). Avec TURN, le serveur STUN ne se contente pas d'informer sur l'existence du NAT et ses caractéristiques, il relaie chaque paquet de données. Ce nouveau RFC remplace la définition originelle de TURN (dans le RFC 5766), et inclut plusieurs changements qui étaient jusqu'à présent spécifiés dans des RFC séparés, comme IPv6 ou DTLS, et ajoute la possibilité de relayer les messages ICMP.
Être situé derrière un routeur NAT n'est jamais une situation enviable. De nombreuses applications fonctionnent mal ou pas du tout dans ce contexte, nécessitant des mécanismes spécifique de traversée des NAT. Le socle de tous ces mécanismes de traversée est STUN (RFC 8489), où le client STUN (notre machine bloquée par le NAT) communique avec un serveur STUN situé dans le monde libre pour apprendre sa propre adresse IP externe. Outre cette tâche de base, des extensions à STUN permettent d'aider davantage le client, c'est par exemple le cas de TURN que normalise notre RFC.
L'idée de base est que deux machines Héloïse et Abélard, chacune peut-être située derrière un NAT, vont utiliser STUN pour découvrir s'il y a un NAT entre elles (sinon, la communication peut se faire normalement) et, s'il y a un NAT, s'il se comporte « bien » (tel que défini dans les RFC 4787 et RFC 5382). Dans ce dernier cas, STUN seul peut suffire, en informant les machines de leur adresse extérieure et en ouvrant, par effet de bord, un petit trou dans le routeur pour permettre aux paquets entrants de passer.
Mais, parfois, le NAT ne se comporte pas bien, par exemple parce
qu'il a le comportement « address-dependent
mapping » (RFC 4787, section
4.1). Dans ce cas, il n'existe aucune solution permettant le
transport direct des données entre Héloïse et Abélard. La solution
utilisée par tous les systèmes pair-à-pair, par exemple en
téléphonie sur Internet, est de passer par un
relais. Normalement, le serveur STUN ne sert
qu'à un petit nombre de paquets, ceux de la
signalisation et les données elles-mêmes (ce
qui, en téléphonie ou en vidéo sur IP, peut représenter un très gros volume) vont
directement entre Héloïse et Abélard. Avec TURN, le serveur STUN
devient un relais, qui transmet les paquets de données.
TURN représente donc une charge beaucoup plus lourde pour le serveur, et c'est pour cela que cette option est restreinte au dernier recours, au cas où on ne peut pas faire autrement. Ainsi, un protocole comme ICE (RFC 8445) donnera systématiquement la préférence la plus basse à TURN. De même, le serveur TURN procédera toujours à une authentification de son client, car il ne peut pas accepter d'assurer un tel travail pour des inconnus (l'authentification - fondée sur celle de STUN, RFC 8489, section 9.2 - et ses raisons sont détaillées dans la section 5). Il n'y aura donc sans doute jamais de serveur TURN complètement public mais certains services sont quand même disponibles comme celui de Viagénie.
TURN est défini comme une extension de STUN, avec de nouvelles
méthodes et de nouveaux attributs (enregistrés à
l'IANA). Le client TURN envoie donc une requête STUN, avec
une méthode d'un type nouveau, Allocate, pour
demander au serveur de se tenir prêt à relayer (les détails du
mécanisme d'allocation figurent dans les sections 6 et 7). Le client
est enregistré par son adresse de transport
(adresse IP publique et port). Par exemple, si Héloise a pour
adresse de transport locale 10.1.1.2:17240
(adresse IP du RFC 1918 et port n° 17240), et
que le NAT réécrit cela en 192.0.2.1:7000, le
serveur TURN (mettons qu'il écoute en
192.0.2.15) va, en réponse à la requête
Allocate, lui allouer, par exemple,
192.0.2.15:9000 et c'est cette dernière adresse
qu'Héloïse va devoir transmettre à Abélard pour qu'il lui envoie des
paquets, par exemple RTP. Ces paquets arriveront donc au serveur
TURN, qui les renverra à 192.0.2.1:7000, le
routeur NAT les transmettant ensuite à
10.1.1.2:17240 (la transmission des données
fait l'objet des sections 11 et 12). Pour apprendre l'adresse
externe du pair, on utilise ICE ou bien un protocole de
« rendez-vous » spécifique (RFC 5128.) Un
exemple très détaillé d'une connexion faite avec TURN figure dans la
section 20 du RFC.
Ah, et comment le serveur TURN a-t-il choisi le port 9000 ? La section 7.2 détaille les pièges à éviter, notamment pour limiter le risque de collision avec un autre processus sur la même machine, et pour éviter d'utiliser des numéros de port prévisibles par un éventuel attaquant (cf. RFC 6056).
Et pour trouver le serveur TURN à utiliser ? Il peut être marqué
en dur dans l'application, mais il y a aussi la solution de
découverte du RFC 8155. Pour noter l'adresse d'un serveur TURN,
on peut utiliser les plans d'URI
turn: et turns: du RFC 7065.
TURN fonctionne sur IPv4 et IPv6. Lorsqu'IPv4 et IPv6 sont possibles, le serveur TURN doit utiliser l'algorithme du RFC 8305, pour trouver le plus rapidement possible un chemin qui fonctionne.
TURN peut relayer de l'UDP, du TCP (section 2.1), du TLS ou du DTLS, mais le serveur TURN enverra toujours de l'UDP en sortie (une extension existe pour utiliser TCP en sortie, RFC 6062) La section 3.1 explique aussi pourquoi accepter du TCP en entrée quand seul UDP peut être transmis : la principale raison est l'existence de pare-feux qui ne laisseraient sortir que TCP. La meilleure solution, recommandée par le RFC, serait quand même qu'on laisse passer l'UDP, notamment pour WebRTC (RFC 7478, section 2.3.5.1 et RFC 8827.)
Ah, et à propos d'UDP, notre RFC recommande d'éviter la fragmentation, et donc d'envoyer vers le pair qui reçoit les données des paquets UDP suffisamment petits pour ne pas avoir besoin de la fragmentation, celle-ci n'étant pas toujours bien gérée par les middleboxes.
Les données peuvent circuler dans des messages STUN classiques
(nommés Send et Data,
cf. section 11) ou bien dans des canaux virtuels
(channels, sortes de sous-connexions, section 12)
qui permettent d'éviter de transmettre les en-têtes STUN à chaque
envoi de données.
Enfin, la section 21, très détaillée, note également que TURN ne peut pas être utilisé pour contourner la politique de sécurité : l'allocation ne se fait que pour une adresse IP d'un correspondant particulier (Abélard), TURN ne permet pas à Héloïse de faire tourner un serveur. Ce point permet de rassurer les administrateurs de pare-feux et de leur demander de ne pas bloquer TURN.
Autre point important de cette section sur la sécurité : comme certains messages ne sont pas authentifiés, un méchant peut toujours envoyer au client des messages qui semblent venir du serveur et réciproquement. Le problème existe, mais c'est un problème plus général d'IP. TURN ne le résout pas mais ne l'aggrave pas (section 21.1.4). Pour le cas du multimédia, on peut par exemple utiliser SRTP (RFC 3711) pour empêcher cette attaque.
Comme TURN relaie les paquets, au lieu de simplement les router, l'adresse IP source va identifier le serveur TURN et pas le vrai expéditeur. Un méchant pourrait donc être tenté d'utiliser TURN pour se cacher. Il peut donc être utile que le serveur TURN enregistre les données comme l'adresse IP et le port de ses clients, pour permettre des analyses a posteriori.
Une question intéressante est celle du traitement des en-têtes IP (voir la 3.6). TURN travaille dans la couche 7, il n'est pas un « routeur virtuel » mais un relais applicatif. En conséquence, il ne préserve pas forcément des en-têtes comme ECN ou comme le TTL. D'ailleurs, un serveur TURN tournant comme une application sans privilèges particuliers n'a pas forcément accès aux valeurs de l'en-tête IP. Tout cela permet son déploiement sur des systèmes d'exploitation quelconque, où il n'est pas forcément facile de changer ces en-têtes. Pour la même raison, la découverte traditionnelle de MTU (RFC 1191) à travers TURN ne marche donc pas.
À propos d'implémentations, il existe plusieurs mises en œuvre libres de TURN, comme turnserver, CoTurn, Restund ou Pion.
Les changements depuis les RFC précédents, notamment le RFC 5766, sont résumés dans les sections 24 et 25 :
- Notre RFC intègre le RFC 6156, qui
ajoutait IPv6 à TURN. Le client peut
spécifier la version d'IP souhaitée, avec le nouvel attribut
REQUESTED-ADDRESS-FAMILYet il y a de nouveaux codes d'erreur comme 440 ou 443, - TURN peut maintenant accepter du DTLS en entrée,
- La découverte du serveur (RFC 8155)
et les plans d'URI
turn:etturns:(RFC 7065) ont été intégrés, - TURN relaie désormais l'ICMP.
L'article seul
À propos du débat sur la 5G
Première rédaction de cet article le 19 février 2020
Il y à en ce moment en France, et dans d'autres pays, un débat vigoureux sur le déploiement de la 5G. Je vous rassure, je ne vais pas donner un avis définitif sur tous les aspects de ce débat, mais il me semble que plusieurs points importants n'ont que peu ou pas été abordés.
5G est un terme qui regroupe un ensemble de techniques et de normes pour les télécommunications mobiles, techniques qui peuvent être déployées ensemble ou séparément. Les promoteurs de la 5G promettent des miracles, mais il y a des opposants.
D'abord, je voudrais dire que ce débat, cette friction, est une excellente chose. (Et c'est relativement récent.) Les techniques jouent un rôle crucial dans notre société, les techniques de communication sont partout et influencent fortement ce que nous pouvons faire ou ne pas faire, et il est donc très bien que les citoyens et citoyennes soient informés qu'un désaccord existe. Déployer ou pas la 5G est en effet un choix politique (politique au sens « concerne la vie de la société », évidemment pas au sens « qui sera ministre des Déclarations Ridicules à la Télé ».) Il n'y a pas de loi physique (ou sociale) qui ferait du déploiement de la 5G un événement inéluctable, comme la chute des pommes ou comme l'explosion de Bételgeuse. « On n'arrête pas le progrès » est une phrase idiote, d'abord parce que toute nouvelle technique n'est pas forcément un progrès (ce peut être une régression) et ensuite parce que, justement, le progrès se décide. C'est le cas pour l'invention (ce qui se fait dans les labos, et qui dépend des thèmes à la mode, et de leur financement) et encore plus pour l'innovation (le déploiement hors des labos, qui nécessite des investissements lourds et donc des décisions difficiles.)
Donc, le débat actuel sur la 5G est une bonne chose. Mais sur quoi porte-t-il ? Les partisans de la 5G mettent en avant :
- Les performances accrues, en capacité et surtout en latence,
- La possibilité de nouveaux services, par exemple pour les objets connectés, via des nouveautés comme une qualité de service garantie.
Les opposants critiquent (j'ai essayé de faire une liste exhaustive, mais il faut bien noter que tous les opposants ne partagent pas tous ces arguments) :
- Les risques d'espionnage liés au fait que les équipements 5G sont souvent fabriqués par des entreprises chinoises, notamment Huawei, qui fait en ce moment l'objet d'une campagne menée par le gouvernement des États-Unis,
- Plus généralement, le risque de perte de souveraineté lié à cette dépendance vis-à-vis d'un fournisseur chinois,
- Les problèmes de santé liés au rayonnement électromagnétique,
- Les problèmes écologiques liés à la consommation énergétique des nombreux équipements nécessaires (puisque la portée de la 5G est inférieure, il faudra davantage de stations de base),
- Lié au précédent, le problème philosophique du « progrès ». Voulons-nous de cette course à la communication toujours plus rapide ?
Ah et puis il parait que la 5G peut aussi poser des problèmes aux prévisions météo mais je n'ai pas creusé la question.
Je ne vais pas faire un dossier complet sur la 5G, sujet sur lequel je ne suis pas un expert. Mais je voudrais mettre en avant quelques points qui, il me semble, ont été un peu oubliés dans le débat. Je vais suivre l'ordre des arguments donnés ci-dessus, en commençant par les arguments « pour ».
Sur les performances, il est important de rappeler que le vécu d'un utilisateur ou d'une utilisatrice ne dépend pas que de la 5G. Quand M. Michu ou Mme Toutlemonde, dans la rue, regarde le site Web de Wikipédia, le résultat final, en terme de performances, dépend de toute une chaîne, les performances des deux ordinateurs aux extrémités, celles du réseau mobile, mais aussi celles de tous les liens Internet entre M. Michu et Wikipédia. Le goulet d'étranglement, le point le moins performant et qui limite la performance globale, n'est pas forcément le réseau mobile. Par exemple, les sites Web modernes nécessitent souvent des calculs complexes pour leur affichage, et la rapidité de chargement des fichiers n'y changera rien. Dire « la 5G permettra d'accélérer la visualisation des pages Web » est au mieux une simplification, au pire un mensonge publicitaire.
Et puis ces performances mirifiques sont très théoriques : elles reposent sur des comparaisons faites en laboratoire, or les ondes sont très sensibles à l'environnement extérieur, et la réalité ne sera donc jamais aussi belle que la théorie. Regardez simplement comment, aujoud'hui, vous n'avez pas la 4G partout et que votre ordiphone se rabat souvent en 3G voire moins.
Concernant les services nouveaux, on a entendu beaucoup d'arguments marketing. Le record étant sans doute la promesse de pouvoir faire de la téléchirurgie via la 5G car elle offrirait « des garanties de service ». La réalité est moins rose : aucune technique ne peut promettre qu'il n'y aura jamais de panne. Faire de la téléchirurgie sans avoir de solution de secours (par exemple un autre chirurgien sur place) serait criminel, 5G ou pas 5G.
Il faut aussi rajouter que ces nouveaux services ne sont pas forcément quelque chose de positif. Globalement, la 5G est surtout poussée par les opérateurs de télécommunications traditionnels, qui sont historiquement des adversaires de la neutralité du réseau. La 5G, par la virtualisation du réseau, permettrait plus facilement de faire des services différenciés, donc probablement de violer ladite neutralité.
Et les arguments des opposants, ou des gens critiques vis-à-vis de la 5G ? Commençons par le risque d'espionnage, souvent mentionné, et qui a mené à une guerre commerciale entre le gouvernement étatsunien et Huawei. Grosso-modo, disent les inquiets, si on laisse faire, une grande partie des équipements 5G installés seront fabriqués par Huawei (puisque ce sont les moins chers), et Huawei aura donc la possibilité technique d'espionner tout le trafic. Le problème de cet argument, c'est que ce n'est pas mieux avec les fournisseurs non-chinois. Il faudrait être naïf pour croire que seul Huawei a des portes dérobées. D'autre part, le modèle de menace de l'Internet a toujours été qu'on ne pouvait pas faire confiance au réseau, car on ne peut pas évaluer la totalité de la chaîne. Le RFC 3552 en déduit logiquement que la sécurité doit être de bout en bout, donc qu'il faut chiffrer la communication de bout en bout, 5G ou pas, Huawei ou pas. (Rappelez-vous que le lien 5G n'est qu'une partie de la chaîne qui connecte deux personnes qui communiquent et qu'analyser la sécurité en ne regardant que la 5G serait une sérieuse erreur.) Évidemment, ce point de vue comme quoi le chiffrement de bout en bout est indispensable n'est pas partagé par les opérateurs de télécommunications, qui voudraient bien continuer à surveiller le trafic (cf. RFC 8404.)
D'autre part, il n'y a pas que le fournisseur de matériel, il y a aussi les boites qui gèrent le réseau, et, là, la sous-traitance est fréquente, et la perte de compétence inquiétante, comme le démontre l'excellent article de Bert Hubert.
Si le chiffrement protège bien contre la surveillance, il ne protège pas contre les dénis de service. Que se passe-t-il si un ordre venu de Beijing bloque subitement toutes les commmunications ? Le problème est réel (mais bien moins cité que celui de confidentialité, pourtant plus facile à résoudre.) Pour ce problème, en effet, le choix du fournisseur des équipements 5G est crucial mais, comme on l'a dit, les Chinois n'ont pas le monopole des portes dérobées. La solution ici, nécessite au minimum de n'utiliser que du logiciel libre dans les équipements de communication, afin de pouvoir les évaluer, mais on en est loin.
Et les conséquences sur la santé ? La question est très difficile à analyser car on a peu d'études scientifiques sérieuses sur la question. (PS : si vous avez une bonne bibliographie sur ce sujet, n'hésitez pas à me la communiquer. Il y a entre autres cette étude de l'IARC et cette synthèse des Décodeurs du Monde ainsi que l'étude de l'ICNIRP.) Il ne fait aucun doute que les ondes électromagnétiques peuvent être dangereuses (exposez-vous au soleil au Sahara sans protection et vous constaterez douloureusement que les ondes font parfois mal.) La question est de savoir dans quelles conditions (fréquence, puissance, durée d'exposition, etc.) Si les ondes ont vraiment un effet sur la santé, cet effet dépend forcément de ces conditions, et les discours anti-ondes sont toujours muets sur ce point. La recherche en ce domaine est d'autant plus difficile qu'il est possible que les éventuels effets médicaux soient à long terme, surtout pour des doses faibles. Et le débat est brouillé par des « anti-ondes » qui racontent n'importe quoi sur le Web, parfois relayés par des médias peu rigoureux, et par des commerçants charlatans qui cherchent à placer des remèdes miracles. On est rarement dans la rationalité ici, les effets, pourtant, eux, bien connus, de la pollution due au trafic routier ne suscitent pas la même mobilisation que « les ondes ».
Voyons maintenant l'argument écologique. Les fréquences utilisées par la 5G portent moins loin, il va falloir davantage de stations de base (ce qui va poser d'intéressants problèmes de main d'œuvre), donc a priori davantage de consommation énergétique. Mais en contrepartie, la puissance dépensée par chaque base sera inférieure, donc les partisans de la 5G avancent qu'elle pourrait diminuer la facture énergétique. J'avoue ne pas connaitre les chiffres exacts. (Là encore, si vous avez des études sérieuses, je prends. Je connais déjà cet exposé détaillé de la Commission Européenne et l'étude de Jancovici souvent citée.) Je vais donc passer mon tour sur ce point. Notez que, comme souvent dans les débats techniques, on voit parfois passer des erreurs qui font douter de la qualité générale du texte. Par exemple dans ce document de la GSMA, on lit « can potentially increase cell energy consumption from 5-7 kW per 4G site per month to over 20 kW », mélangeant puissance (en watts) et énergie (en joules ou à la rigueur en watts*heures.)
Notez aussi qu'une conséquence du déploiement de la 5G serait sans doute le grand remplacement des terminaux (les ordiphones) et que cela a un coût (les équipements informatiques ont une empreinte écologique bien plus forte lors de la fabrication que lors de l'utilisation. Éteindre l'appareil qu'on n'utilise pas, c'est bien, ne pas le remplacer trop vite, c'est mieux.)
Il reste un dernier argument contre le déploiement de la 5G, l'argument qu'on pourrait appeler « philosophique ». En gros, en a-t-on besoin ? Le débat ne peut évidemment pas être tranché par la technique ou par les experts. D'un côté, on peut dire que l'augmentation des performances (dont on a vu qu'elle n'était pas garantie) est un but en soi. Après tout, chaque fois qu'on a augmenté les performances des ordinateurs et des réseaux, on a trouvé des usages (pas forcément souhaitables…) à cette augmentation. D'un autre côté, il n'y a pas de loi fondamentale disant que cela devrait continuer éternellement. Contrairement aux prévisions de la science-fiction, voitures volantes et avions à propulsion nucléaire ne se sont pas généralisés. Donc, le « progrès » n'est pas automatique. La question de fond est « qui va décider ? » Comment se font les choix qui impactent toute notre société ? Qui a décidé de déployer la 5G, et pour quels intérêts ?
Autres lectures pour s'informer :
- Jérôme Nicolle a fait un excellent fil Twitter, en français, et en anglais (la version en anglais étant un peu plus détaillée) faisant le tour de tous les arguments.
- Je n'ai guère parlé des aspects sécurité / vie privée / surveillance mais le Parlement s'en est préoccupé, craignant que la 5G ne rende plus difficile cette surveillance.
L'article seul
RFC 8701: Applying Generate Random Extensions And Sustain Extensibility (GREASE) to TLS Extensibility
Date de publication du RFC : Janvier 2020
Auteur(s) du RFC : D. Benjamin (Google)
Pour information
Réalisé dans le cadre du groupe de travail IETF tls
Première rédaction de cet article le 29 janvier 2020
Ce nouveau RFC s'attaque à un problème fréquent dans l'Internet : des programmeurs paresseux, incompétents ou pressés par les délais imposés mettent en œuvre un protocole normalisé (comme TLS) sans bien lire les normes, et notamment sans tenir compter des variations que la norme permet. Ils programment rapidement, testent avec une ou deux implémentations trouvées et, si ça marche, en déduisent que c'est bon. Mais dès qu'une autre implémentation introduit des variantes, par exemple un paramètre optionnel et qui n'était pas utilisé avant, la bogue se révèle. Le cas s'est produit de nombreuses fois. Notre RFC propose une solution disruptive : utiliser délibérément, et au hasard, plein de variantes d'un protocole, de façon à détecter rapidement les programmes écrits avec les pieds. C'est le principe de GREASE (Generate Random Extensions And Sustain Extensibility), la graisse qu'on va mettre dans les rouages de l'Internet pour que ça glisse mieux. Ce RFC 8701 commence par appliquer ce principe à TLS.
Le problème n'est évidemment pas spécifique à TLS, on l'a vu arriver aussi dans BGP lorsqu'on s'est aperçu que la simple annonce d'un attribut BGP inconnu pouvait planter les routeurs Cisco. Là aussi, le « graissage » (tester systématiquement des valeurs non allouées pour les différents paramètres, pour vérifier que cela ne plante rien) aurait bien aidé. D'où le projet « Use it or lose it », décrit dans le RFC 9170. dont GREASE est un cas particulier. Ce RFC analyse le problème des options non utilisées et recommande de les utiliser systématiquement, pour habituer les logiciels à voir ces options.
Le principe de GREASE (Generate Random Extensions And Sustain Extensibility) est donc de faire en sorte que clients et serveurs TLS (RFC 9846) annoncent, pour différents paramètres de la connexion, des valeurs qui ne correspondent à rien. Ainsi, les middleboxes boguées, installées au milieu de la communication parce que le commercial qui les vendait était convaincant, seront vite détectées, au lieu que le problème demeure dormant pendant des années et soit subitement révélé le jour où on essaie des valeurs légales mais nouvelles, comme dans le cas de l'attribut 99.
Qu'est-ce qui est variable dans TLS ? Beaucoup de choses, comme
la liste des algorithmes de cryptographie
ou comme les extensions. Dans TLS, le client annonce ce qu'il sait
faire, et le serveur sélectionne dans ce choix (RFC 9846, section 4.2.3). Voici un exemple vu par tshark, d'abord le message du client
(Client Hello), puis la réponse du serveur
(Server Hello) :
Secure Sockets Layer
TLSv1 Record Layer: Handshake Protocol: Client Hello
Content Type: Handshake (22)
Handshake Protocol: Client Hello
Version: TLS 1.2 (0x0303)
Cipher Suites (28 suites)
Cipher Suite: TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384 (0xc02c)
Cipher Suite: TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384 (0xc030)
...
Extension: ec_point_formats (len=4)
Type: ec_point_formats (11)
EC point formats Length: 3
Elliptic curves point formats (3)
EC point format: uncompressed (0)
...
Extension: SessionTicket TLS (len=0)
Type: SessionTicket TLS (35)
Extension: encrypt_then_mac (len=0)
Type: encrypt_then_mac (22)
Extension: signature_algorithms (len=48)
Type: signature_algorithms (13)
Signature Hash Algorithms (23 algorithms)
Signature Algorithm: ecdsa_secp256r1_sha256 (0x0403)
Signature Hash Algorithm Hash: SHA256 (4)
Signature Hash Algorithm Signature: ECDSA (3)
...
Secure Sockets Layer
TLSv1.2 Record Layer: Handshake Protocol: Server Hello
Content Type: Handshake (22)
Version: TLS 1.2 (0x0303)
Handshake Protocol: Server Hello
Cipher Suite: TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384 (0xc030)
Compression Method: null (0)
Extensions Length: 13
Extension: renegotiation_info (len=1)
Type: renegotiation_info (65281)
Length: 1
Renegotiation Info extension
Renegotiation info extension length: 0
Extension: ec_point_formats (len=4)
Type: ec_point_formats (11)
...
Le client propose de nombreux algorithmes de cryptographie, comme
TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384, et
plusieurs extensions comme le format pour les courbes
elliptiques (normalisé dans le RFC 8422), les tickets du RFC 5077, le chiffrement
avant le MAC du RFC 7366 et des
algorithmes de signature. Le serveur choisit l'algorithme de
chiffrement
TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384,
accepte l'extension sur le format des courbes elliptiques, et, puisque
le client était d'accord (via l'indication d'un algorithme de
chiffrement spécial), le serveur utilise l'extension de
renégociation.
Les valeurs inconnues (par exemple une nouvelle extension) doivent être ignorées (RFC 9846, section 4.2.2). Si ce n'était pas le cas, si une valeur inconnue plantait la partie située en face, il ne serait pas possible d'introduire de nouveaux algorithmes ou de nouvelles extensions, en raison des déploiements existants. Prenons les algorithmes de cryptographie, enregistrés à l'IANA. Si un nouvel algorithme apparait, et reçoit une valeur, comment vont réagir, non seulement les pairs avec qui on communique en TLS, mais également tous ces boitiers intermédiaires installés souvent sans raison sérieuse, et pour lesquels il n'existe pas de mécanisme pratique de remontée des problèmes ? Si leurs programmeurs avaient lu la norme, ils devraient ignorer ce nouvel algorithme, mais on constate qu'en pratique, ce n'est souvent pas le cas, ce qui rend difficile l'introduction de nouveaux algorithmes. Dans le pire des cas, le boitier intermédiaire jette les paquets portant les valeurs inconnues, sans aucun message, rendant le débogage très difficile.
D'où les métaphores mécaniques : dans l'Internet d'aujourd'hui, bien des équipements sur le réseau sont rouillés, et il faut les graisser, en faisant travailler les parties qui ne sont normalement pas testées. C'est le principe de GREASE que d'envoyer des valeurs inconnues pour certains paramètres, dans l'espoir de forcer les mises en œuvre de TLS, surtout celles dans les boitiers intermédiaires, à s'adapter. Une méthode darwinienne, en somme.
La section 2 de notre RFC indique les valeurs choisies pour ces annonces. C'est délibérement qu'elles ne sont pas contiguës, pour limiter le risque que des programmeurs paresseux ne testent simplement si une valeur est incluse dans tel intervalle. Il y a un jeu de valeurs pour les algorithmes de cryptographie et les identificateurs ALPN (RFC 7301), un pour les extensions, un pour les versions de TLS, etc. Toutes sont enregistrées à l'IANA, dans le registre respectif. Par exemple, pour les extensions TLS, (cf. leur liste), les valeurs, 2570, 6682, 10794 et plusieurs autres sont réservées pour le graissage. (Il fallait les réserver pour éviter qu'une future extension TLS ne reçoive le même numéro, ce qui aurait cassé la compatibilité avec les logiciels GREASE.)
Une fois ces valeurs réservées par notre RFC, le client TLS
peut, au hasard, ajouter ces valeurs dans, par exemple, la liste
des algorithmes de cryptographie qu'il gère, ou la liste des
extensions qu'il propose. Si jamais le serveur les accepte (dans
son ServerHello), le client doit rejeter la
connexion ; le but de ces valeurs était de tester les logiciels,
elles ne doivent jamais être sélectionnées. Notez que c'est le
comportement normal d'un client TLS d'aujourd'hui de refuser
proprement les valeurs inconnues. De même, un serveur normal
d'aujourd'hui va ignorer ces valeurs inconnues (et donc ne jamais
les sélectionner). Si tout le monde suit la norme, l'introduction
des valeurs GREASE ne va rien changer. Les règles de la section 3
ne sont qu'un rappel de règles TLS qui ont toujours existé.
La section 4 de notre RFC traite le cas un peu plus difficile
où le serveur propose et le client accepte. C'est par exemple ce
qui arrive quand le serveur demande au client de s'authentifier,
en envoyant un CertificateRequest. Le serveur
peut là aussi utiliser GREASE et indiquer des extensions ou des
algorithmes de signature inconnus, et le client doit les ignorer
(sinon, si le client sélectionne ces valeurs, le serveur doit
rejeter un tel choix).
La section 5 du RFC précise dans quels cas utiliser les valeurs GREASE et lesquelles. Le but étant de révéler les problèmes, le RFC recommande de choisir les valeurs aléatoirement. (Si un programme envoyait toujours la même valeur GREASE, il y aurait un risque que des programmes en face ignorent spécifiquement cette valeur, alors qu'il faut ignorer toutes les valeurs inconnues.) Par contre, pour un même partenaire TLS, il vaut mieux un certain déterminisme, sinon les problèmes seront difficiles à déboguer (parfois, ça marche, parfois, ça ne marche pas…)
Enfin, la section 7 du RFC discute des conséquences de l'absence de graissage sur la sécurité. Si certaines mises en œuvre de TLS résistent mal aux options inconnues, cela peut encourager le repli, c'est-à-dire à réessayer sans les options. Ainsi, un attaquant actif pourrait facilement forcer une machine à ne pas utiliser des options qui rendraient des attaques ultérieures plus compliquées. Les attaques par repli étant particulièrement dangereuses, il est important de ne pas se replier, et donc de s'assurer qu'on peut réellement utiliser toutes les possibilités du protocole. Cela veut dire entre autres que, si une machine TLS utilisant GREASE a du mal à se connecter, elle ne devrait pas essayer sans GREASE : cela annnulerait tous les bénéfices qu'on attend du graissage. Le principe de robustesse est mauvais pour la sécurité.
À noter que Chrome a déjà mis en œuvre ce principe, et que ça semble bien fonctionner. L'article « HTTPS : de SSL à TLS 1.3 », surtout consacré à la version 1.3 de TLS, montre à quoi ressemble les options GREASE pour Wireshark (« Unknown »).
À noter qu'un concept équivalent existe dans HTTP/3, Reserved Stream Types et Reserved Frame Types (RFC 9113, sections 6.2.3 et 7.2.9). Pour HTTP/2 (RFC 7540), où les trames de type inconnu devraient être ignorées, l'expérience a déjà prouvé qu'elles ne l'étaient pas toujours.
L'article seul
Google inverse les noms de domaines
Première rédaction de cet article le 16 janvier 2020
Dernière mise à jour le 20 janvier 2020
Le 16 janvier au matin, il y avait une bogue amusante (qui a duré quelques jours) dans le moteur de recherche Google. Les noms de domaine étaient dans certains cas inversés, plus exactement mélangés dans l'affichage.
Quand on cherche quelque chose dans ce moteur de recherche (sur une machine de bureau, car c'est différent sur les mobiles), Google affiche pour chaque résultat :
- L'endroit où a été trouvé le résultat, sous une forme vaguement inspirée des breadcrumbs (Google affichait autrefois un URL, ce qui était plus intelligent mais a sans doute été changé sur demande du marketing car « M. Michu ne comprend rien aux URL » et Google n'aime pas éduquer les utilisateurs),
- Le titre de la page, qui est un lien hypertexte (en promenant son pointeur dessus, on voit l'URL s'afficher en bas à gauche, ce qui est utile pour savoir où on va avant d'y foncer),
- La date et un résumé.
On voit ici un exemple :
L'endroit de la page est fabriqué à partir de l'URL mais n'est
pas un URL. Il commence par un nom
de domaine et se continue par un chemin dans le
site. Mais ce qui est amusant
est que cet affichage est bogué. Dans certains cas, le nom de
domaine est mélangé. L'exemple précédent est correct mais, si je
cherche le département de
physique de l'Université de Cambridge : 
Le vrai nom de domaine est www.phy.cam.ac.uk
mais Google affiche phy.www.cam.ac.uk. Autre
exemple, avec le gouverneur de Californie : 
Ici, le vrai nom était www.gov.ca.gov mais
Google affiche gov.www.ca.gov. L'URL vers
lequel pointe le résultat est néanmoins correct, comme on le voit
avec cet autre exemple (Firefox affiche l'URL de
destination en bas à gauche) :
Pourquoi cette bogue ? La raison fondamentale est sans doute une incompréhension des noms de domaine, notamment du fait que le nombre de composants d'un nom soit quelconque (contrairement à une légende répandue.) Vous noterez que les seuls noms ainsi massacrés sont des noms ayant plus de trois composants. Mais c'est curieux de la part de Google, dont les services ont d'habitude très peu de bogues.
Mais on peut aussi voir dans cette bogue le résultat d'une mentalité très fréquente dans le Web, et particulièrement chez Google, comme quoi les noms de domaine ne sont pas une information pertinente et peuvent être cachés, ou massacrés, sans problème.
Merci à Jean-Philippe Pick pour avoir noté le phénomène. Le problème a été réparé le 19 janvier, sans nouvelles de Google ou sans information publiée.
L'article seul
Fiche de lecture : Unix: A history and a Memoir
Auteur(s) du livre : Brian Kernighan
Éditeur : Kindle Direct Publishing
9781695978553
Publié en 2020
Première rédaction de cet article le 14 janvier 2020
Ce livre est une histoire du système d'exploitation Unix, par une des personnes qui ont suivi l'aventure d'Unix depuis le début, Brian Kernighan.
D'abord, Kernighan écrit très bien, il a un vrai talent pour tout expliquer, y compris les questions informatiques complexes (comme le fameux tube, une des inventions les plus marquantes dans Unix). Ensuite, il a lui-même travaillé au développement d'Unix (il a notamment participé à la création du langage C, dans lequel Unix a été rapidement réécrit, après ses débuts en langage d'assemblage.) Cela lui permet de faire revivre une époque aujourd'hui bien distante.
Il y a fort longtemps, dans un pays lointain, pas du tout dans la Silicon Valley mais à Murray Hill, un gentil roi, la compagnie AT&T avait installé son service de recherche et développement, les Bell Labs. Les Bell Labs (qui existent encore aujourd'hui sous ce nom mais ne sont plus que l'ombre de ce qu'ils étaient) sont devenus une légende de la physique, de la mathématique et de l'informatique, avec pas moins de neuf prix Nobel obtenus (non, l'invention d'Unix n'a pas été récompensée par un prix Nobel.)
C'est dans ce pays merveilleux que deux informaticiens, Ken Thompson et Dennis Ritchie, après le semi-échec du projet Multics, et le retrait des Bell Labs de ce travail, se sont attaqués à une de ces tâches où tous les gens raisonnables vous disent « c'est complèment irréaliste, jeune homme, vous n'êtes pas sérieux ». Ils ont écrit un système d'exploitation et Unix était né, prêt à conquérir le monde. Ce livre est l'histoire d'Unix. Elle est pleine de rebondissements, de crises, de discussions.
Pour rappeler l'importance d'Unix, il faut se souvenir que beaucoup de choses qui nous semblent aujourd'hui évidentes en informatique ne l'étaient pas à l'époque. Par exemple, la grande majorité des systèmes d'exploitation imposaient de fixer une taille maximale à un fichier avant sa création. Si elle était trop faible, on devait re-créer un autre fichier et copier les données. Si cette taille était trop élevée, on gaspillait de l'espace disque. Unix a mis fin à cela et, aujourd'hui, cela va de soi. De même Unix a unifié les différents types de fichiers. Avant Unix, plusieurs systèmes d'exploitation avaient des commandes différentes pour copier un fichier contenant un programme Cobol et un fichier de données !
L'atmosphère très spéciale des Bell Labs, informelle, avec peu de bureaucratie, un accent mis sur les compétences et pas sur les titres (une méritocratie, une vraie) a beaucoup aidé à développer un système d'exploitation à succès. Kernighan raconte beaucoup d'histoires amusantes, mais consacre également du temps à l'analyse des facteurs importants dans le succès des Bell Labs. Il insiste sur les facteurs physiques (« geography is destiny ») : tout le monde sur le même site, et un mélange de bureaux fermés (même les stagiaires avaient leur propre bureau fermé, loin de l'open space bruyant empêchant la concentration) et de pièces communes où on pouvait aller quand on voulait, discuter et interagir avec les autres. Les Bell Labs ont été un cas peut-être unique, où toutes les conditions étaient réunies au même endroit, pour produire une étonnante quantité d'inventions géniales. Le tout était aidé par un financement stable et un management qui laissait les chercheurs tranquilles. Il est curieux (et triste) de noter qu'une entreprise 100 % capitaliste comme AT&T donnait plus de liberté et de stabilité financière à ses chercheurs qu'une université publique d'aujourd'hui, où les chercheurs doivent passer tout leur temps en travail administratif, en évaluation, et en recherche d'argent.
Aux Bell Labs, il était fréquent pour un chercheur de travailler sur plusieurs sujets de front et le livre de Kernighan donne une petite idée de la variété des sujets. Anecdote personnelle : j'ai utilisé (très peu !) le système Ratfor que l'auteur avait écrit, quand je faisais du calcul numérique.
Une particularité d'Unix est en effet la profusion d'outils pour informaticiens qui ont été développés sur ce système. L'auteur consacre de nombreuses pages à ces outils en insistant sur le fait que le goupe Unix des Bell Labs maîtrisait toujours la théorie et la pratique. Chaque membre du groupe pouvait écrire une thèse en informatique théorique, et inventer puis programmer des outils utiles. Mais on oublie souvent que les premiers utilisateurs d'Unix n'étaient pas que des informaticiens. Le premier argument « de vente » d'Unix auprès de la direction des Bell Labs était ses capacités de… traitement de texte. Le service des brevets de Bell Labs déposait beaucoup de brevets, et leur préparation prenait un temps fou. En bons informaticiens, les auteurs d'Unix ont automatisé une grande partie des tâches, et les juristes se sont mis à préparer les demandes de brevets sur Unix…
De nos jours, on associe souvent Unix au logiciel libre, puisque Linux, FreeBSD et bien d'autres héritiers de l'Unix original sont libres. Mais à la grande époque des Bell Labs, ces considérations politiques étaient absentes. Kernighan n'en parle jamais et, au contraire, insiste sur le verrouillage de bien des innovations par des brevets. C'est en raison de la licence restrictive de l'Unix d'AT&T que des systèmes comme Linux ou FreeBSD n'ont plus une seule ligne du code original d'AT&T : il a fallu tout réécrire pour échapper aux avocats.
Kernighan ne fait pas que raconter des anecdotes édifiantes. Il corrige également quelques légendes. Par exemple, le fameux commentaire dans le code source d'Unix « You are not expected to understand this » ne veut pas du tout dire « lecteur, tu es stupide, laisse ce code aux pros » mais « il n'est pas nécessaire de comprendre ce bout de code pour comprendre le reste ».
Vous ne serez pas surpris d'apprendre que le livre a été composé sur Unix, avec groff et Ghostscript.
L'article seul
Rapport de la députée Forteza sur les technologies quantiques
Première rédaction de cet article le 12 janvier 2020
Le 9 janvier 2020, la députée Paula Forteza a rendu le rapport « Quantique : le virage technologique que la France ne ratera pas ». Quelques points sur ce rapport.
Le terme de « quantique » a un fort potentiel de hype pour les années à venir (surtout depuis l'annonce par Google de l'obtention de la suprématie quantique). Dans le contexte de la physique, il désigne quelque chose de clair (mais pas forcément de simple à comprendre !) Appliqué aux technologies, c'est plus compliqué. Et ce rapport couvre toutes les utilisations futures de la quantique, ce qui fait beaucoup. Globalement, le rapport est rigoureux sur la partie scientifique (il y a eu de bons conseillers, et ils ont été bien écoutés, donc des point délicats comme la différence entre qubits physiques et logiques, toujours oubliée par les marketeux, est bien décrite) mais plus contestable sur la partie politique. Je ne vais pas reprendre tous les points (lisez le rapport, vous ne vous ennuierez pas, et vous apprendrez des choses) mais seulement ceux qui me semblent particulièrement discutables.
Le point le plus curieux concerne la distribution quantique de clés (parfois appelée par abus de langage « cryptographique quantique »). La partie technique du rapport note à juste titre les nombreuses limitations (le rapport parle de « verrous ») de cette technique, que ses promoteurs présentent comme la solution magique à tous les problèmes de sécurité de l'Internet (ce qu'elle n'est pas). Mais la partie « propositions » du rapport oublie complètement ces limitations et assène qu'il faut mettre le paquet pour le développement de la QKD. On dirait vraiment que l'analyse de la technologie et les recommandations ont été écrites par des personnes différentes.
Le rapport est plus cohérent sur la question de la cryptographie post-quantique (cf. aussi mon exposé à pas Sage En Seine et le point de vue très différent de Renaud Lifchitz.) Encore que la partie résumée à l'attention des décideurs, comme souvent, présente le problème comme sans doute plus proche qu'il ne l'est (et propose de commencer à déployer les solutions en 2022 !) Le rapport semble pousser au déploiement immédiat d'algorithmes post-quantiques, alors qu'aucun n'est normalisé. (Et, puisqu'il s'agit d'un rapport officiel, on peut noter que le RGS, et notamment son annexe cryptographique, ne sont pas mentionnés.) Si vous voulez en savoir plus sur la cryptographie post-quantique, je vous recommande l'exposé de Magali Bardet lors de la JCSA de juillet 2019.
Ensuite, ce rapport reprend malheureusement le style de tant de rapports officiels précédents : pas d'autre proposition que de donner beaucoup d'argent à Atos ou Thales dans l'espoir que cela fera avancer les choses, meccano institutionnel (créer un comité machin), discours sur la grandeur de la France et sa maitrise de toutes les technologies et toutes les sciences, référence à la startup magique, croyance que la recherche fondamentale se pilote d'en haut (on annonce bien haut que la quantique est une priorité et paf, cela suffit à ce que les résultats arrivent), et surtout, aucune remise en cause des obstacles que rencontre actuellement la recherche. Par exemple, le rapport propose d'« encourager » (ça ne coûte rien…) les chercheurs à candidater à des programmes de financement européens mais sans se demander pourquoi il n'y a pas davantage de telles candidatures. (C'est en partie parce que les chercheurs passent déjà plus de temps dans la paperasserie et dans la chasse aux subventions que dans la recherche. Mais on ne pouvait pas attendre d'une députée du parti du gouvernement qu'elle critique l'organisation actuelle de la recherche.)
Le rapport propose de fournir un calculateur quantique accessible en ligne (pardon, le rapport dit « cloud », c'est plus poétique) pour faire du QCaaS (Quantum Computing as a Service). C'est déjà proposé par IBM et AliBaba. Cela ne veut pas dire qu'il soit inutile d'en créer d'autres, meilleurs et/ou différents mais cela ne montre pas une énorme ambition.
D'autre part, certaines propositions auraient mérité d'être développées, notamment sur les moyens à mettre en œuvre. Ainsi, la proposition de créer des enseignements d'algorithmique quantique dans vingt cycles d'enseignement supérieur est une très bonne idée mais pas un mot n'est dit sur le recrutement d'enseignants, alors que justement les compétences en ce domaine ne sont pas largement répandues.
Le rapport, je l'ai dit, est globalement rigoureux, mais dérape quand même parfois par exemple quand, à propos de programmation, il pointe l'importance de développer des langages de programmation adaptés, de haut niveau (ce qui est une très bonne idée) mais cite ensuite comme exemple Q#, qui est justement un langage de très bas niveau, où on manipule les portes logiques directement. Vous imaginez programmer un ordinateur classique ainsi ? Seule la syntaxe de Q# est « de haut niveau », les concepts manipulés ne le sont pas. Au passage, si vous êtes prorgrammeur ou programmeuse, le site de questions/réponses StackExchange a une déclinaison sur le calcul quantique.
Un point que j'ai apprécié, par contre, est l'insistance sur les « technologies habilitantes ». Il s'agit de toutes les techniques qui permettent de réaliser des dispositifs quantiques, notamment la cryogénie. C'est à juste titre que le rapport rappelle qu'un ordinateur quantique n'est pas seulement composé de qubits, c'est d'abord un gros réfrigérateur.
Sur la forme, je note l'abus de termes en anglais, qui n'aide pas à la compréhension.
Notez que l'IETF a un travail en cours sur la cryptographie post-quantique et un groupe de recherche sur les réseaux quantiques, qui a produit plusieurs documents intéressants (je vous recommande le RFC 9340, qui explique bien la quantique, avant d'expliquer ce que pourrait être un réseau quantique. Le RIPE-NCC a déjà organisé un hackathon sur ce sujet.)
L'article seul
Un système anti-censure qui évolue en autonomie : Geneva
Première rédaction de cet article le 10 janvier 2020
La lutte technique de la liberté d'expression contre la censure sur l'Internet n'est pas près de s'arrêter. Chaque fois que les censeurs conçoivent de nouvelles techniques, les défenseurs de la liberté mettent au point de meilleurs méthodes pour leur échapper, les censeurs améliorent alors leurs techniques, et ainsi de suite. La partie est donc difficile pour ceux et celles qui réalisent des dispositifs anti-censure, car il faut en permanence suivre et s'adapter. D'où l'idée d'un système qui évolue « tout seul ». Le génial Geneva utilise le concept des algorithmes génétiques, pour s'adapter à la censure et évoluer automatiquement en même temps qu'elle.
Geneva traite le cas des systèmes de censure Internet de type Homme du Côté. Dans ces systèmes (il en existe beaucoup d'autres ; les censeurs ont de l'imagination, et beaucoup plus d'argent et d'hommes que les défenseurs de la liberté), le censeur peut observer les paquets IP qui passent, et générer ses propres paquets, mais il ne peut pas modifier les paquets envoyés. (Dans les systèmes d'Homme du Milieu, par exemple le pare-feu d'une entreprise, l'attaquant peut modifier ou jeter les paquets, ces systèmes sont donc plus efficaces mais aussi plus coûteux, et parfois plus difficiles à intégrer dans l'infrastructure. Ils sont donc moins employés à l'échelle d'un pays, où le trafic est important. Mais rappelez-vous toujours que les censeurs utilisent plusieurs techniques, et souvent une combinaison de techniques, ajoutant par exemple les résolveurs DNS menteurs.) Un exemple d'attaque de l'Homme du Côté est un système qui observe le SNI dans les requêtes TLS (par exemple HTTPS) et, s'il voit un nom de domaine interdit (ou même simplement un mot censuré, par exemple Falun Gong en Chine), il génère un paquet TCP RST (ReSeT, RFC 793, section 3.1) vers l'émetteur ou le destinataire, coupant ainsi la connexion. TLS ne protège pas contre ces attaques, puisque, contrairement à QUIC, TLS ne chiffre pas la couche Transport. (Rappelez-vous également que l'Homme du Côté voit tous les paquets, il a donc la partie bien plus facile que l'attaquant aveugle des RFC 5927 ou RFC 5961.)
Contre de telles techniques de censure, la solution habituelle (et de nombreuses ont été développées) est de semer la confusion chez l'Homme du Côté, en envoyant des paquets qui seront interprétés différemment par le censeur et par le vrai destinataire. Par exemple, on envoie un paquet TCP RST avec un TTL qui lui permet d'atteindre la machine du censeur mais pas celle du destinataire. Le censeur croira alors que la connexion est finie, alors qu'en fait elle continuera. (Le censeur, dans le cas d'un État, a des moyens importants mais pas illimités. Il a donc intérêt à libérer de la mémoire en « oubliant » les connexions terminées, ce qui fait que le reste de la communication est ignoré.) L'inconvénient de ces stratégies est qu'il faut recommencer souvent, puisque les techniques de censure évoluent. Chaque fois que la censure se perfectionne, des contournements existants deviennent inefficaces et on est à nouveau censuré jusqu'au développement (lent et laborieux) d'un nouveau contournement. La lutte contre la censure est donc un combat éternel entre l'épée et la cuirasse.
Que peuvent apporter les algorithmes génétiques ici ? Un algorithme génétique est un algorithme qui reprend les grands concepts de la sélection naturelle. On choisit un ensemble de fonctions, on leur donne des règles de mutation, une fonction d'évaluation du résultat (qui joue le rôle de la survie du plus apte) et on laisse ensuite le système évoluer. On peut ainsi explorer un espace de solutions très large en bien moins de temps.
Portrait de Charles
Darwin par George Richmond. (
Source: Wikimedia Commons.) 
{kind=link}
Tout l'art du concepteur d'algorithmes génétiques est dans la liberté plus ou moins grande qu'il ou elle laisse aux mutations. Si on laisse les mutations se faire au hasard, l'écrasante majorité des stratégies produites seront non viables, et l'exploration de l'espace des solutions prendra des siècles. Mais si on contraint fortement les mutations possibles, l'algorithme n'ira jamais bien loin, il restera sur les sentiers battus et ne fera pas de découverte disruptive.
Geneva tourne sur la machine du client, celui ou celle qui veut accéder à des contenus censurés. Geneva définit les solutions contre les attaques de l'Homme du Côté en trois parties : un déclencheur (trigger) qui dit quand lancer la solution, des actions qui disent ce qu'on va faire (par exemple créer un nouveau paquet) et des arbres (action trees) qui coordonnent la succession des actions. Par exemple, la stratégie mentionnée plus haut (un paquet TCP RST avec un TTL conçu pour atteindre le censeur mais pas le destinataire) s'exprimerait, dans le DSL de Geneva :
[TCP:flags:A]-
duplicate(send,
tamper(TCP:flags:R)(
tamper(IP:TTL:replace:10)
(send)))
-| \/
Le terme [TCP:flags:A] est le déclencheur :
quand on envoie le TCP ACK (accusé de réception), on duplique ce
paquet et on envoie à la fois le vrai et une copie ayant le bit R
(RST) et un TTL diminué, pour n'atteindre que le censeur et lui
faire croire que la connexion est finie. Un autre exemple corrompt
délibérément la somme de contrôle TCP :
certains censeurs ignorent cette somme de contrôle, ce qui permet
d'envoyer un paquet (par exemple RST) qui ne sera lu que par l'Homme
du Côté.
Geneva commence avec un ensemble de solutions faites à la main, les individus sur lesquels va s'exercer l'évolution. Ensuite, les mutations se produisent, portant sur les déclencheurs, sur les actions, et sur les arbres (la succession des actions). Geneva teste ensuite les résultats des mutations en cherchant à se connecter à un site Web censuré. Le critère de sélection est donc la réussite dans le contournement de la censure. (Les règles exactes sont plus complexes, car il faut éviter de se laisser pièger dans des minima locaux ; ce n'est pas parce qu'une solution marche qu'elle est la meilleure. Et puis certains systèmes de censure ne sont pas déterministes ; soit suite à une bogue, soit délibérement pour compliquer l'analyse, ils ne bloquent pas toujours.)
Geneva a été mis en œuvre en Python, utilisant évidemment Scapy, et le NFqueue de Netfilter sur Linux pour accéder au réseau. Notons que certaines opérations nécessitent d'être root (modifier les en-têtes IP) mais pas toutes (changer le découpage des données en segments TCP), ce qui permet dans certains cas de faire tourner Geneva, ou du moins le script (la stratégie) sélectionné, sans être root. Le code pour exécuter les scripts (mais pas encore celui avec l'algorithme génétique) est disponible en ligne.
Quels sont les résultats ? Eh bien, Geneva fonctionne, et même très bien d'après ses auteurs. En seulement quelques heures, il trouve une stratégie de contournement de la censure. Geneva a été testé dans le laboratoire, face à des solutions de censure connues, mais aussi en vrai sur le terrain, en Chine face au GFW, en Inde et au Kazakhstan. Disons-le tout de suite, en matière de censure, le GFW est le seul système intéressant, les autres sont vraiment primitifs. Geneva n'a eu aucun problème à trouver une stratégie pour échapper aux censures indienne et kazakhstanaise (simplement mettre le SNI dans deux segments TCP différents suffit, au Kazakhstan) mais le GFW lui a donné plus de fil à retordre. Le script :
[TCP:flags:PA]-fragment{tcp:8:True}(send,send)-|
[TCP:flags:A]-tamper{TCP:seq:corrupt}(send)-| \/
a réussi à passer. J'ai également bien aimé la stratégie FRAPUN (ainsi nommée en raison des bits de l'en-tête TCP qu'elle met à 1.)
Un des avantages des algorithmes génétiques est qu'ils peuvent trouver des solutions auxquelles leurs auteurs n'ont pas pensé (mais qu'ils peuvent expliquer a posteriori). Plus drôle, Geneva a aussi trouvé une solution que les auteurs du programme n'ont pas pu expliquer, mais qui marche face au GFW :
[TCP:flags:PA]-
fragment{tcp:8:True}(send,
fragment{tcp:4:True}(send, send))-| \/
Ce très bon article se termine par une discussion sur l'avenir de la lutte anti-censure. Geneva ne va évidemment pas mettre un point final à la question, il est certain que les censeurs s'y adapteront (c'est un problème classique en sécurité informatique : les logiciels distribués publiquement peuvent être utilisés par les bons comme par les méchants.)
J'ai aussi apprécié que l'article n'utilise pas de buzzwords comme IA ou machine learning. Aujourd'hui, où les chercheurs doivent passer davantage de temps à chercher des subventions et de l'impact médiatique (l'un n'allant pas sans l'autre) plutôt qu'à chercher, c'est appréciable. Mais, hélas, le dépôt git du projet, lui, le fait.
Notez que l'article mentionne des considérations éthiques. Lancer Geneva sur une machine en Chine peut vous attirer des ennuis. (L'Inde est moins dangereuse, de ce point de vue.) Certes, Geneva n'est pas trop bavard en octets mais son comportement si particulier pourrait être remarqué par les systèmes de surveillance que déploient la plupart des pays. C'est un problème fréquent quand on étudie la censure. Il faut donc bien prévenir les utilisateurs (ce que rappelle bien la section Disclaimer dans la documentation d'installation du logiciel.)
L'article seul
Historique dans RDAP
Première rédaction de cet article le 9 janvier 2020
Le protocole RDAP permet d'obtenir des informations sur une ressource enregistrée dans un registre, par exemple un RIR. Une extension permet d'avoir accès à l'histoire d'une ressource.
RDAP est normalisé dans les RFC 7480, RFC 7481 et RFC 7482. L'extension n'a jamais été normalisée,
mais elle est déployée à l'APNIC. Voici un exemple
d'utilisation, pour avoir l'histoire de l'adresse
IP 2001:dc0:2001:11::194 :
% curl -s http://rdap.apnic.net/history/ip/2001:dc0:2001:11::194 ...
Bon, d'accord, le résultat est confus. C'est du JSON donc on utilise jq pour le formatter plus joliment :
% curl -s http://rdap.apnic.net/history/ip/2001:dc0:2001:11::194 | jq .
...
"applicableFrom": "2019-02-14T05:37:22Z",
"applicableUntil": "2019-07-29T03:31:05Z",
"content": {
"country": "AU",
"name": "APNIC-AP-V6-BNE",
"type": "ASSIGNED PORTABLE",
"startAddress": "2001:dc0:2000::",
"ipVersion": "v6",
"endAddress": "2001:dc0:3fff:ffff:ffff:ffff:ffff:ffff",
"objectClassName": "ip network",
"handle": "2001:0DC0:2000::/35",
...
On récupère un tableau d'enregistrements, chaque enregistrement
étant valable de applicableFrom à
applicableUntil. Pour voir combien de
changements a vu ce préfixe IP, on va utiliser les fonctions de
sélection de jq :
% curl -s http://rdap.apnic.net/history/ip/2001:dc0:2001:11::194 | \
jq ".records|.[].applicableFrom"
...
Ça fait 48 changements, comme on pourrait le compter avec jq :
% curl -s http://rdap.apnic.net/history/ip/2001:dc0:2001:11::194 | \
jq "[ .records|.[].applicableFrom ] | length"
49
Il avait été prévu à un moment de normaliser cette extension RDAP
à l'IETF
(Internet-Draft
draft-ellacott-historical-rdap). Mais
ça n'a pas suscité suffisamment d'intérêt. D'ailleurs, l'extension
n'est même pas dans le registre
des extensions RDAP. Une telle extension serait pratique pour
l'investigation, mais pose aussi des problèmes de vie
privée (plus de droit à
l'oubli).
L'article seul
50 ans
Première rédaction de cet article le 1 janvier 2020
Non, ce n'est pas mon âge. Mais, aujourd'hui, l'« epoch » d'Unix et de l'Internet a cinquante ans.
J'ai toujours été fasciné par les calendriers. C'est un intérêt courant chez les informaticiens, d'autant plus que la quasi-totalité des logiciels qui manipulent des dates sont bogués, en partie en raison de la complexité du problème.
Tous les calendriers commencent par une date spéciale. Cela peut-être la naissance d'un prophète, le début de sa prédication, une insurrection, une proclamation, un serment, une grande bataille, ou un autre événement important, réel ou imaginé. Il y a avant et puis après. Ainsi, le calendrier légal en France, comme dans la plupart des pays du monde, est fondé sur la date de naissance (supposée…) de Jésus-Christ. Pour le laïciser un peu, on parle désormais d'« ère commune » et nous sommes donc le 1 janvier 2020 de l'ère commune (en anglais, CE, pour « common era ».)
Cette date spéciale se nomme en anglais « epoch » et nous allons parler ici d'une « epoch » intéressante, le premier janvier 1970.
Car le choix de la date spéciale est crucial. Elle sépare l'histoire en deux, avant, âge de ténèbres, d'ignorance et d'oppression, et après, âge du bonheur et de la lumière. D'où le choix d'événements grandioses pour distinguer l'avant et l'après.
Mais les ordinateurs ne sont pas romantiques. Ils se moquent des grands sentiments et des passions humaines, ils sont gérés par la pure rationalité. Quand on a besoin de définir une « epoch », pour les ordinateurs, il n'est pas nécessaire d'utiliser une date émouvante. Et, comme on a rarement besoin, sauf si l'ordinateur est utilisé par un historien, de manipuler dans un programme informatique des dates très anciennes, autant prendre une « epoch » récente. Le premier janvier 1970, certains lecteurs et lectrices de ce texte étaient déjà nés, ainsi que l'auteur de ces lignes (mais je n'avais pas encore mon bac).
C'est ainsi que le système d'exploitation (logiciel de base de la machine) le plus utilisé dans le monde, Unix, utilise comme « epoch », comme date spéciale, le 1 janvier 1970, il y a juste cinquante ans. Cette date a été choisie simplement parce qu'elle était, au moment du choix, située dans un passé récent et qu'elle était facile à mémoriser.
Unix compte tous les temps en secondes écoulées depuis le 1 janvier 1970 à 0h0mn, temps universel. Évidemment, ce n'est que la représentation interne, dans la mémoire du système. Les applications destinées aux utilisateurs affichent la date d'une manière plus habituelle. La très forte prévalence d'Unix dans l'Internet (la quasi-totalité des serveurs, et la grande majorité des clients) fait que cette epoch est également, de facto, celle de l'Internet, qui a commencé à peu près au même moment. (Jérôme Mainaud, merci à lui, me fait remarquer que le protocole de synchronisation d'horloges NTP, très répandu sur l'Internet, a une autre epoch, le 1 janvier 1900.)
Si vous êtes en ce moment sur une machine Unix dotée d'un « shell », d'un interpréteur de commandes, et que vous avez le programme « GNU date » (sur des systèmes comme Ubuntu ou Mint, c'est le programme date par défaut), vous pouvez afficher le nombre de secondes écoulées depuis l'« epoch » en tapant :
date +%s
Le premier janvier 2020, à 0h0mn en temps universel, il affiche 1 577 836 800.
Une lecture recommandée : « Calendrical calculations », d'Edward Reingold et Nachum Dershowitz (Cambridge University Press).
Merci à Hervé Le Crosnier (C&F Éditions) pour l'inspiration pour cet article.
L'article seul
Articles des différentes années : 2026 2025 2024 2023 2022 2021 2020 Précédentes années
Syndication : Flux Atom avec seulement les résumés et Flux Atom avec tout le contenu.
{kind=link}